KR20220119026A - 구아니디노아세트산의 발효 생산 방법 - Google Patents
구아니디노아세트산의 발효 생산 방법 Download PDFInfo
- Publication number
- KR20220119026A KR20220119026A KR1020227020423A KR20227020423A KR20220119026A KR 20220119026 A KR20220119026 A KR 20220119026A KR 1020227020423 A KR1020227020423 A KR 1020227020423A KR 20227020423 A KR20227020423 A KR 20227020423A KR 20220119026 A KR20220119026 A KR 20220119026A
- Authority
- KR
- South Korea
- Prior art keywords
- glu
- leu
- ala
- val
- asp
- Prior art date
Links
- BPMFZUMJYQTVII-UHFFFAOYSA-N guanidinoacetic acid Chemical compound NC(=N)NCC(O)=O BPMFZUMJYQTVII-UHFFFAOYSA-N 0.000 title claims abstract description 193
- 238000004519 manufacturing process Methods 0.000 title claims description 47
- 238000000855 fermentation Methods 0.000 title claims description 19
- 230000004151 fermentation Effects 0.000 title claims description 18
- 244000005700 microbiome Species 0.000 claims abstract description 83
- CVSVTCORWBXHQV-UHFFFAOYSA-N creatine Chemical compound NC(=[NH2+])N(C)CC([O-])=O CVSVTCORWBXHQV-UHFFFAOYSA-N 0.000 claims abstract description 46
- 238000000034 method Methods 0.000 claims abstract description 34
- 229960003624 creatine Drugs 0.000 claims abstract description 23
- 239000006046 creatine Substances 0.000 claims abstract description 23
- 238000012262 fermentative production Methods 0.000 claims abstract description 9
- 108090000623 proteins and genes Proteins 0.000 claims description 118
- 108010073791 Glycine amidinotransferase Proteins 0.000 claims description 80
- 102100040870 Glycine amidinotransferase, mitochondrial Human genes 0.000 claims description 76
- ODKSFYDXXFIFQN-BYPYZUCNSA-N L-arginine Chemical compound OC(=O)[C@@H](N)CCCN=C(N)N ODKSFYDXXFIFQN-BYPYZUCNSA-N 0.000 claims description 69
- 229930064664 L-arginine Natural products 0.000 claims description 67
- 235000014852 L-arginine Nutrition 0.000 claims description 67
- 102000004190 Enzymes Human genes 0.000 claims description 58
- 108090000790 Enzymes Proteins 0.000 claims description 58
- 150000001413 amino acids Chemical group 0.000 claims description 44
- 230000000694 effects Effects 0.000 claims description 41
- 241000588724 Escherichia coli Species 0.000 claims description 40
- 241000186226 Corynebacterium glutamicum Species 0.000 claims description 38
- AHLPHDHHMVZTML-BYPYZUCNSA-N L-Ornithine Chemical compound NCCC[C@H](N)C(O)=O AHLPHDHHMVZTML-BYPYZUCNSA-N 0.000 claims description 35
- 241000589776 Pseudomonas putida Species 0.000 claims description 32
- 230000001965 increasing effect Effects 0.000 claims description 27
- 239000004475 Arginine Substances 0.000 claims description 25
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 claims description 25
- 235000009697 arginine Nutrition 0.000 claims description 25
- 102000004169 proteins and genes Human genes 0.000 claims description 21
- 235000018102 proteins Nutrition 0.000 claims description 20
- AHLPHDHHMVZTML-UHFFFAOYSA-N Orn-delta-NH2 Natural products NCCCC(N)C(O)=O AHLPHDHHMVZTML-UHFFFAOYSA-N 0.000 claims description 19
- 229960003104 ornithine Drugs 0.000 claims description 19
- 101710113083 Carbamoyl-phosphate synthase Proteins 0.000 claims description 12
- 230000002018 overexpression Effects 0.000 claims description 12
- 102000007981 Ornithine carbamoyltransferase Human genes 0.000 claims description 11
- 102000009042 Argininosuccinate Lyase Human genes 0.000 claims description 9
- 108010070742 Guanidinoacetate N-Methyltransferase Proteins 0.000 claims description 9
- 101710113020 Ornithine transcarbamylase, mitochondrial Proteins 0.000 claims description 9
- 101150089004 argR gene Proteins 0.000 claims description 9
- 102000053640 Argininosuccinate synthases Human genes 0.000 claims description 8
- 108700024106 Argininosuccinate synthases Proteins 0.000 claims description 8
- 238000012258 culturing Methods 0.000 claims description 8
- 230000035772 mutation Effects 0.000 claims description 8
- 101710191958 Amino-acid acetyltransferase Proteins 0.000 claims description 6
- 230000006696 biosynthetic metabolic pathway Effects 0.000 claims description 5
- 230000002255 enzymatic effect Effects 0.000 claims description 5
- 101000950981 Bacillus subtilis (strain 168) Catabolic NAD-specific glutamate dehydrogenase RocG Proteins 0.000 claims description 4
- 241000186216 Corynebacterium Species 0.000 claims description 4
- 102000016901 Glutamate dehydrogenase Human genes 0.000 claims description 4
- 241000589516 Pseudomonas Species 0.000 claims description 4
- 101710165738 Acetylornithine aminotransferase Proteins 0.000 claims description 3
- 102000009661 Repressor Proteins Human genes 0.000 claims description 3
- 108010034634 Repressor Proteins Proteins 0.000 claims description 3
- 101800001241 Acetylglutamate kinase Proteins 0.000 claims description 2
- 241000588921 Enterobacteriaceae Species 0.000 claims description 2
- 101150099894 GDHA gene Proteins 0.000 claims description 2
- 101100295959 Halobacterium salinarum (strain ATCC 700922 / JCM 11081 / NRC-1) arcB gene Proteins 0.000 claims description 2
- 108010072610 N-acetyl-gamma-glutamyl-phosphate reductase Proteins 0.000 claims description 2
- 102000001253 Protein Kinase Human genes 0.000 claims description 2
- 101100217185 Pseudomonas aeruginosa (strain ATCC 15692 / DSM 22644 / CIP 104116 / JCM 14847 / LMG 12228 / 1C / PRS 101 / PAO1) aruC gene Proteins 0.000 claims description 2
- 101100022072 Sulfolobus acidocaldarius (strain ATCC 33909 / DSM 639 / JCM 8929 / NBRC 15157 / NCIMB 11770) lysJ gene Proteins 0.000 claims description 2
- 101150008194 argB gene Proteins 0.000 claims description 2
- 101150070427 argC gene Proteins 0.000 claims description 2
- 101150089042 argC2 gene Proteins 0.000 claims description 2
- 101150050866 argD gene Proteins 0.000 claims description 2
- 101150029940 argJ gene Proteins 0.000 claims description 2
- 230000002238 attenuated effect Effects 0.000 claims description 2
- 238000001035 drying Methods 0.000 claims description 2
- 101150019455 gdh gene Proteins 0.000 claims description 2
- 108010050322 glutamate acetyltransferase Proteins 0.000 claims description 2
- 101150094164 lysY gene Proteins 0.000 claims description 2
- 101150039489 lysZ gene Proteins 0.000 claims description 2
- 102000005756 Guanidinoacetate N-methyltransferase Human genes 0.000 claims 2
- 108020004414 DNA Proteins 0.000 description 92
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 73
- 241000282326 Felis catus Species 0.000 description 61
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 61
- 239000013612 plasmid Substances 0.000 description 61
- 108010012581 phenylalanylglutamate Proteins 0.000 description 47
- 108010003700 lysyl aspartic acid Proteins 0.000 description 38
- 238000003752 polymerase chain reaction Methods 0.000 description 38
- 239000004471 Glycine Substances 0.000 description 35
- 108010077245 asparaginyl-proline Proteins 0.000 description 34
- 239000012634 fragment Substances 0.000 description 34
- 238000010367 cloning Methods 0.000 description 32
- 241000320117 Pseudomonas putida KT2440 Species 0.000 description 28
- 239000002609 medium Substances 0.000 description 28
- 108010005233 alanylglutamic acid Proteins 0.000 description 27
- 229920001817 Agar Polymers 0.000 description 25
- 239000008272 agar Substances 0.000 description 25
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 24
- ZLXKLMHAMDENIO-DCAQKATOSA-N Pro-Lys-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLXKLMHAMDENIO-DCAQKATOSA-N 0.000 description 24
- 238000006243 chemical reaction Methods 0.000 description 24
- 108010034529 leucyl-lysine Proteins 0.000 description 24
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 23
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 23
- 108010050848 glycylleucine Proteins 0.000 description 22
- FGGKGJHCVMYGCD-UKJIMTQDSA-N Glu-Val-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGGKGJHCVMYGCD-UKJIMTQDSA-N 0.000 description 21
- WZDCVAWMBUNDDY-KBIXCLLPSA-N Ile-Glu-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](C)C(=O)O)N WZDCVAWMBUNDDY-KBIXCLLPSA-N 0.000 description 21
- BDFHWFUAQLIMJO-KXNHARMFSA-N Lys-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N)O BDFHWFUAQLIMJO-KXNHARMFSA-N 0.000 description 21
- KXYLFJIQDIMURW-IHPCNDPISA-N Lys-Trp-Leu Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CCCCN)=CNC2=C1 KXYLFJIQDIMURW-IHPCNDPISA-N 0.000 description 21
- LDSOBEJVGGVWGD-DLOVCJGASA-N Phe-Asp-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 LDSOBEJVGGVWGD-DLOVCJGASA-N 0.000 description 21
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 21
- 230000014509 gene expression Effects 0.000 description 21
- 108010025306 histidylleucine Proteins 0.000 description 21
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 20
- 101150118463 argG gene Proteins 0.000 description 20
- 239000013587 production medium Substances 0.000 description 20
- VCBWXASUBZIFLQ-IHRRRGAJSA-N His-Pro-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O VCBWXASUBZIFLQ-IHRRRGAJSA-N 0.000 description 18
- 101150056313 argF gene Proteins 0.000 description 18
- KWKQGHSSNHPGOW-BQBZGAKWSA-N Arg-Ala-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)NCC(O)=O KWKQGHSSNHPGOW-BQBZGAKWSA-N 0.000 description 17
- SQIARYGNVQWOSB-BZSNNMDCSA-N Asp-Tyr-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQIARYGNVQWOSB-BZSNNMDCSA-N 0.000 description 17
- 101100096227 Bacteroides fragilis (strain 638R) argF' gene Proteins 0.000 description 17
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 17
- ZIMTWPHIKZEHSE-UWVGGRQHSA-N His-Arg-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O ZIMTWPHIKZEHSE-UWVGGRQHSA-N 0.000 description 17
- 101100354186 Mycoplasma capricolum subsp. capricolum (strain California kid / ATCC 27343 / NCTC 10154) ptcA gene Proteins 0.000 description 17
- 108010079364 N-glycylalanine Proteins 0.000 description 17
- AMRRYKHCILPAKD-FXQIFTODSA-N Ser-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CO)N AMRRYKHCILPAKD-FXQIFTODSA-N 0.000 description 17
- 101150054318 argH gene Proteins 0.000 description 17
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 17
- 230000015572 biosynthetic process Effects 0.000 description 17
- 229940041514 candida albicans extract Drugs 0.000 description 17
- 108010092114 histidylphenylalanine Proteins 0.000 description 17
- 239000012138 yeast extract Substances 0.000 description 17
- OVVUNXXROOFSIM-SDDRHHMPSA-N Arg-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O OVVUNXXROOFSIM-SDDRHHMPSA-N 0.000 description 16
- 108091034117 Oligonucleotide Proteins 0.000 description 16
- XWTNPSHCJMZAHQ-QMMMGPOBSA-N 2-[[2-[[2-[[(2s)-2-amino-4-methylpentanoyl]amino]acetyl]amino]acetyl]amino]acetic acid Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)NCC(=O)NCC(O)=O XWTNPSHCJMZAHQ-QMMMGPOBSA-N 0.000 description 15
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 15
- JGDGLDNAQJJGJI-AVGNSLFASA-N Arg-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N JGDGLDNAQJJGJI-AVGNSLFASA-N 0.000 description 15
- WTUZDHWWGUQEKN-SRVKXCTJSA-N Arg-Val-Met Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O WTUZDHWWGUQEKN-SRVKXCTJSA-N 0.000 description 15
- MVRGBQGZSDJBSM-GMOBBJLQSA-N Asp-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC(=O)O)N MVRGBQGZSDJBSM-GMOBBJLQSA-N 0.000 description 15
- 238000001712 DNA sequencing Methods 0.000 description 15
- VJVAQZYGLMJPTK-QEJZJMRPSA-N Glu-Trp-Asp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N VJVAQZYGLMJPTK-QEJZJMRPSA-N 0.000 description 15
- JXYMPBCYRKWJEE-BQBZGAKWSA-N Gly-Arg-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O JXYMPBCYRKWJEE-BQBZGAKWSA-N 0.000 description 15
- RNMNYMDTESKEAJ-KKUMJFAQSA-N His-Leu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 RNMNYMDTESKEAJ-KKUMJFAQSA-N 0.000 description 15
- TZCGZYWNIDZZMR-UHFFFAOYSA-N Ile-Arg-Ala Natural products CCC(C)C(N)C(=O)NC(C(=O)NC(C)C(O)=O)CCCN=C(N)N TZCGZYWNIDZZMR-UHFFFAOYSA-N 0.000 description 15
- ILJREDZFPHTUIE-GUBZILKMSA-N Leu-Asp-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ILJREDZFPHTUIE-GUBZILKMSA-N 0.000 description 15
- LVHHEVGYAZGXDE-KDXUFGMBSA-N Thr-Ala-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(=O)O)N)O LVHHEVGYAZGXDE-KDXUFGMBSA-N 0.000 description 15
- 108010093581 aspartyl-proline Proteins 0.000 description 15
- 108010073093 leucyl-glycyl-glycyl-glycine Proteins 0.000 description 15
- 239000000047 product Substances 0.000 description 15
- PDECQIHABNQRHN-GUBZILKMSA-N Asp-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(O)=O PDECQIHABNQRHN-GUBZILKMSA-N 0.000 description 14
- RGSOCXHDOPQREB-ZPFDUUQYSA-N Ile-Asp-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N RGSOCXHDOPQREB-ZPFDUUQYSA-N 0.000 description 14
- VMTYLUGCXIEDMV-QWRGUYRKSA-N Lys-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCCN VMTYLUGCXIEDMV-QWRGUYRKSA-N 0.000 description 14
- SKUOQDYMJFUMOE-ULQDDVLXSA-N Lys-Met-Phe Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCCCN)N SKUOQDYMJFUMOE-ULQDDVLXSA-N 0.000 description 14
- 239000008103 glucose Substances 0.000 description 14
- 108010018006 histidylserine Proteins 0.000 description 14
- 229930027917 kanamycin Natural products 0.000 description 14
- 229960000318 kanamycin Drugs 0.000 description 14
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 14
- 229930182823 kanamycin A Natural products 0.000 description 14
- 108010057821 leucylproline Proteins 0.000 description 14
- 108010009298 lysylglutamic acid Proteins 0.000 description 14
- GORKKVHIBWAQHM-GCJQMDKQSA-N Ala-Asn-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GORKKVHIBWAQHM-GCJQMDKQSA-N 0.000 description 13
- JSHVMZANPXCDTL-GMOBBJLQSA-N Arg-Asp-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JSHVMZANPXCDTL-GMOBBJLQSA-N 0.000 description 13
- MNBHKGYCLBUIBC-UFYCRDLUSA-N Arg-Phe-Phe Chemical compound C([C@H](NC(=O)[C@H](CCCNC(N)=N)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MNBHKGYCLBUIBC-UFYCRDLUSA-N 0.000 description 13
- VRTWYUYCJGNFES-CIUDSAMLSA-N Arg-Ser-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O VRTWYUYCJGNFES-CIUDSAMLSA-N 0.000 description 13
- MSBDSTRUMZFSEU-PEFMBERDSA-N Asn-Glu-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MSBDSTRUMZFSEU-PEFMBERDSA-N 0.000 description 13
- DMLSCRJBWUEALP-LAEOZQHASA-N Asn-Glu-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O DMLSCRJBWUEALP-LAEOZQHASA-N 0.000 description 13
- GQRDIVQPSMPQME-ZPFDUUQYSA-N Asn-Ile-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O GQRDIVQPSMPQME-ZPFDUUQYSA-N 0.000 description 13
- KVMPVNGOKHTUHZ-GCJQMDKQSA-N Asp-Ala-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KVMPVNGOKHTUHZ-GCJQMDKQSA-N 0.000 description 13
- MFMJRYHVLLEMQM-DCAQKATOSA-N Asp-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)O)N MFMJRYHVLLEMQM-DCAQKATOSA-N 0.000 description 13
- DBWYWXNMZZYIRY-LPEHRKFASA-N Asp-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)O)N)C(=O)O DBWYWXNMZZYIRY-LPEHRKFASA-N 0.000 description 13
- HOBNTSHITVVNBN-ZPFDUUQYSA-N Asp-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N HOBNTSHITVVNBN-ZPFDUUQYSA-N 0.000 description 13
- GWIJZUVQVDJHDI-AVGNSLFASA-N Asp-Phe-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O GWIJZUVQVDJHDI-AVGNSLFASA-N 0.000 description 13
- PCJOFZYFFMBZKC-PCBIJLKTSA-N Asp-Phe-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O PCJOFZYFFMBZKC-PCBIJLKTSA-N 0.000 description 13
- BWJZSLQJNBSUPM-FXQIFTODSA-N Asp-Pro-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O BWJZSLQJNBSUPM-FXQIFTODSA-N 0.000 description 13
- BOXNGMVEVOGXOJ-UBHSHLNASA-N Asp-Trp-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N BOXNGMVEVOGXOJ-UBHSHLNASA-N 0.000 description 13
- VTJLJQGUMBWHBP-GUBZILKMSA-N Cys-His-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CS)N VTJLJQGUMBWHBP-GUBZILKMSA-N 0.000 description 13
- QQAYIVHVRFJICE-AEJSXWLSSA-N Cys-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CS)N QQAYIVHVRFJICE-AEJSXWLSSA-N 0.000 description 13
- OFPWCBGRYAOLMU-AVGNSLFASA-N Gln-Asp-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N)O OFPWCBGRYAOLMU-AVGNSLFASA-N 0.000 description 13
- XSBGUANSZDGULP-IUCAKERBSA-N Gln-Gly-Lys Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CCCCN)C(O)=O XSBGUANSZDGULP-IUCAKERBSA-N 0.000 description 13
- AKJRHDMTEJXTPV-ACZMJKKPSA-N Glu-Asn-Ala Chemical compound C[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AKJRHDMTEJXTPV-ACZMJKKPSA-N 0.000 description 13
- IOUQWHIEQYQVFD-JYJNAYRXSA-N Glu-Leu-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IOUQWHIEQYQVFD-JYJNAYRXSA-N 0.000 description 13
- LGWUJBCIFGVBSJ-CIUDSAMLSA-N Glu-Met-Cys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N LGWUJBCIFGVBSJ-CIUDSAMLSA-N 0.000 description 13
- HLYCMRDRWGSTPZ-CIUDSAMLSA-N Glu-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CS)C(=O)O HLYCMRDRWGSTPZ-CIUDSAMLSA-N 0.000 description 13
- ZSIDREAPEPAPKL-XIRDDKMYSA-N Glu-Trp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N ZSIDREAPEPAPKL-XIRDDKMYSA-N 0.000 description 13
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 13
- AFMOTCMSEBITOE-YEPSODPASA-N Gly-Val-Thr Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O AFMOTCMSEBITOE-YEPSODPASA-N 0.000 description 13
- GQKSJYINYYWPMR-NGZCFLSTSA-N Ile-Gly-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N1CCC[C@@H]1C(=O)O)N GQKSJYINYYWPMR-NGZCFLSTSA-N 0.000 description 13
- CSQNHSGHAPRGPQ-YTFOTSKYSA-N Ile-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCCN)C(=O)O)N CSQNHSGHAPRGPQ-YTFOTSKYSA-N 0.000 description 13
- CCQLQKZTXZBXTN-NHCYSSNCSA-N Leu-Gly-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O CCQLQKZTXZBXTN-NHCYSSNCSA-N 0.000 description 13
- ONPJGOIVICHWBW-BZSNNMDCSA-N Leu-Lys-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 ONPJGOIVICHWBW-BZSNNMDCSA-N 0.000 description 13
- KZZCOWMDDXDKSS-CIUDSAMLSA-N Leu-Ser-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O KZZCOWMDDXDKSS-CIUDSAMLSA-N 0.000 description 13
- IRNSXVOWSXSULE-DCAQKATOSA-N Lys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN IRNSXVOWSXSULE-DCAQKATOSA-N 0.000 description 13
- MYZMQWHPDAYKIE-SRVKXCTJSA-N Lys-Leu-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O MYZMQWHPDAYKIE-SRVKXCTJSA-N 0.000 description 13
- LOGFVTREOLYCPF-RHYQMDGZSA-N Lys-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN LOGFVTREOLYCPF-RHYQMDGZSA-N 0.000 description 13
- BIWVMACFGZFIEB-VFAJRCTISA-N Lys-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCCCN)N)O BIWVMACFGZFIEB-VFAJRCTISA-N 0.000 description 13
- PHKBGZKVOJCIMZ-SRVKXCTJSA-N Met-Pro-Arg Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PHKBGZKVOJCIMZ-SRVKXCTJSA-N 0.000 description 13
- MIXPUVSPPOWTCR-FXQIFTODSA-N Met-Ser-Ser Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MIXPUVSPPOWTCR-FXQIFTODSA-N 0.000 description 13
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 13
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 13
- AJOKKVTWEMXZHC-DRZSPHRISA-N Phe-Ala-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 AJOKKVTWEMXZHC-DRZSPHRISA-N 0.000 description 13
- KIEPQOIQHFKQLK-PCBIJLKTSA-N Phe-Asn-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KIEPQOIQHFKQLK-PCBIJLKTSA-N 0.000 description 13
- HQCSLJFGZYOXHW-KKUMJFAQSA-N Phe-His-Cys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CS)C(=O)O)N HQCSLJFGZYOXHW-KKUMJFAQSA-N 0.000 description 13
- QUUCAHIYARMNBL-FHWLQOOXSA-N Phe-Tyr-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N QUUCAHIYARMNBL-FHWLQOOXSA-N 0.000 description 13
- MWQXFDIQXIXPMS-UNQGMJICSA-N Phe-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CC1=CC=CC=C1)N)O MWQXFDIQXIXPMS-UNQGMJICSA-N 0.000 description 13
- ILMLVTGTUJPQFP-FXQIFTODSA-N Pro-Asp-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ILMLVTGTUJPQFP-FXQIFTODSA-N 0.000 description 13
- BWCZJGJKOFUUCN-ZPFDUUQYSA-N Pro-Ile-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O BWCZJGJKOFUUCN-ZPFDUUQYSA-N 0.000 description 13
- HFNPOYOKIPGAEI-SRVKXCTJSA-N Pro-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 HFNPOYOKIPGAEI-SRVKXCTJSA-N 0.000 description 13
- HBBBLSVBQGZKOZ-GUBZILKMSA-N Pro-Met-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O HBBBLSVBQGZKOZ-GUBZILKMSA-N 0.000 description 13
- MZNUJZBYRWXWLQ-AVGNSLFASA-N Pro-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@@H]2CCCN2 MZNUJZBYRWXWLQ-AVGNSLFASA-N 0.000 description 13
- FIODMZKLZFLYQP-GUBZILKMSA-N Pro-Val-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FIODMZKLZFLYQP-GUBZILKMSA-N 0.000 description 13
- 241000169446 Promethis Species 0.000 description 13
- XVWDJUROVRQKAE-KKUMJFAQSA-N Ser-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CC1=CC=CC=C1 XVWDJUROVRQKAE-KKUMJFAQSA-N 0.000 description 13
- PQEQXWRVHQAAKS-SRVKXCTJSA-N Ser-Tyr-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CO)N)CC1=CC=C(O)C=C1 PQEQXWRVHQAAKS-SRVKXCTJSA-N 0.000 description 13
- JVTHIXKSVYEWNI-JRQIVUDYSA-N Thr-Asn-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JVTHIXKSVYEWNI-JRQIVUDYSA-N 0.000 description 13
- OQCXTUQTKQFDCX-HTUGSXCWSA-N Thr-Glu-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O OQCXTUQTKQFDCX-HTUGSXCWSA-N 0.000 description 13
- QQWNRERCGGZOKG-WEDXCCLWSA-N Thr-Gly-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O QQWNRERCGGZOKG-WEDXCCLWSA-N 0.000 description 13
- HOVLHEKTGVIKAP-WDCWCFNPSA-N Thr-Leu-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HOVLHEKTGVIKAP-WDCWCFNPSA-N 0.000 description 13
- NJNCVQYFNKZMAH-JYBASQMISA-N Trp-Thr-Cys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CS)C(O)=O)=CNC2=C1 NJNCVQYFNKZMAH-JYBASQMISA-N 0.000 description 13
- HSVPZJLMPLMPOX-BPNCWPANSA-N Tyr-Arg-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O HSVPZJLMPLMPOX-BPNCWPANSA-N 0.000 description 13
- IIJWXEUNETVJPV-IHRRRGAJSA-N Tyr-Arg-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)O)N)O IIJWXEUNETVJPV-IHRRRGAJSA-N 0.000 description 13
- QYSBJAUCUKHSLU-JYJNAYRXSA-N Tyr-Arg-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O QYSBJAUCUKHSLU-JYJNAYRXSA-N 0.000 description 13
- SLCSPPCQWUHPPO-JYJNAYRXSA-N Tyr-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SLCSPPCQWUHPPO-JYJNAYRXSA-N 0.000 description 13
- LYPKCSYAKLTBHJ-ILWGZMRPSA-N Tyr-Trp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CC4=CC=C(C=C4)O)N)C(=O)O LYPKCSYAKLTBHJ-ILWGZMRPSA-N 0.000 description 13
- ISERLACIZUGCDX-ZKWXMUAHSA-N Val-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N ISERLACIZUGCDX-ZKWXMUAHSA-N 0.000 description 13
- BZOSBRIDWSSTFN-AVGNSLFASA-N Val-Leu-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](C(C)C)N BZOSBRIDWSSTFN-AVGNSLFASA-N 0.000 description 13
- 108010047926 leucyl-lysyl-tyrosine Proteins 0.000 description 13
- 108010054155 lysyllysine Proteins 0.000 description 13
- 108010038320 lysylphenylalanine Proteins 0.000 description 13
- 239000000203 mixture Substances 0.000 description 13
- 108010025488 pinealon Proteins 0.000 description 13
- 108010061238 threonyl-glycine Proteins 0.000 description 13
- 239000013598 vector Substances 0.000 description 13
- GGNHBHYDMUDXQB-KBIXCLLPSA-N Ala-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)N GGNHBHYDMUDXQB-KBIXCLLPSA-N 0.000 description 12
- SIGTYDNEPYEXGK-ZANVPECISA-N Ala-Gly-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)CNC(=O)[C@@H](N)C)C(O)=O)=CNC2=C1 SIGTYDNEPYEXGK-ZANVPECISA-N 0.000 description 12
- SWLOHUMCUDRTCL-ZLUOBGJFSA-N Asn-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N SWLOHUMCUDRTCL-ZLUOBGJFSA-N 0.000 description 12
- OLISTMZJGQUOGS-GMOBBJLQSA-N Asn-Ile-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N OLISTMZJGQUOGS-GMOBBJLQSA-N 0.000 description 12
- GUOWMVFLAJNPDY-CIUDSAMLSA-N Glu-Ser-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O GUOWMVFLAJNPDY-CIUDSAMLSA-N 0.000 description 12
- 241000282414 Homo sapiens Species 0.000 description 12
- UDBPXJNOEWDBDF-XUXIUFHCSA-N Ile-Lys-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)O)N UDBPXJNOEWDBDF-XUXIUFHCSA-N 0.000 description 12
- WSGXUIQTEZDVHJ-GARJFASQSA-N Leu-Ala-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O WSGXUIQTEZDVHJ-GARJFASQSA-N 0.000 description 12
- VHGIWFGJIHTASW-FXQIFTODSA-N Met-Ala-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O VHGIWFGJIHTASW-FXQIFTODSA-N 0.000 description 12
- KYXDADPHSNFWQX-VEVYYDQMSA-N Met-Thr-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(O)=O KYXDADPHSNFWQX-VEVYYDQMSA-N 0.000 description 12
- 241001413575 Moorea Species 0.000 description 12
- XZFYRXDAULDNFX-UHFFFAOYSA-N N-L-cysteinyl-L-phenylalanine Natural products SCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XZFYRXDAULDNFX-UHFFFAOYSA-N 0.000 description 12
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 12
- PEFJUUYFEGBXFA-BZSNNMDCSA-N Phe-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=CC=C1 PEFJUUYFEGBXFA-BZSNNMDCSA-N 0.000 description 12
- 239000004098 Tetracycline Substances 0.000 description 12
- TWJDQTTXXZDJKV-BPUTZDHNSA-N Trp-Arg-Ser Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O TWJDQTTXXZDJKV-BPUTZDHNSA-N 0.000 description 12
- 229940024606 amino acid Drugs 0.000 description 12
- 235000001014 amino acid Nutrition 0.000 description 12
- 108010060199 cysteinylproline Proteins 0.000 description 12
- 108010049041 glutamylalanine Proteins 0.000 description 12
- 108010036413 histidylglycine Proteins 0.000 description 12
- 108010031719 prolyl-serine Proteins 0.000 description 12
- 238000000746 purification Methods 0.000 description 12
- 229930101283 tetracycline Natural products 0.000 description 12
- 229960002180 tetracycline Drugs 0.000 description 12
- 235000019364 tetracycline Nutrition 0.000 description 12
- 150000003522 tetracyclines Chemical class 0.000 description 12
- 241000131329 Carabidae Species 0.000 description 11
- KNKHAVVBVXKOGX-JXUBOQSCSA-N Lys-Ala-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KNKHAVVBVXKOGX-JXUBOQSCSA-N 0.000 description 11
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 11
- 108010092854 aspartyllysine Proteins 0.000 description 11
- 108091008146 restriction endonucleases Proteins 0.000 description 11
- 108010040956 Ala-Asp-Glu-Leu Proteins 0.000 description 10
- UDPSLLFHOLGXBY-FXQIFTODSA-N Cys-Glu-Glu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UDPSLLFHOLGXBY-FXQIFTODSA-N 0.000 description 10
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 10
- SWQALSGKVLYKDT-UHFFFAOYSA-N Gly-Ile-Ala Natural products NCC(=O)NC(C(C)CC)C(=O)NC(C)C(O)=O SWQALSGKVLYKDT-UHFFFAOYSA-N 0.000 description 10
- MLZVJIREOKTDAR-SIGLWIIPSA-N His-Ile-Ile Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MLZVJIREOKTDAR-SIGLWIIPSA-N 0.000 description 10
- UCXQIIIFOOGYEM-ULQDDVLXSA-N Leu-Pro-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCXQIIIFOOGYEM-ULQDDVLXSA-N 0.000 description 10
- 239000006142 Luria-Bertani Agar Substances 0.000 description 10
- FJLODLCIOJUDRG-PYJNHQTQSA-N Pro-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@@H]2CCCN2 FJLODLCIOJUDRG-PYJNHQTQSA-N 0.000 description 10
- RCYUBVHMVUHEBM-RCWTZXSCSA-N Pro-Pro-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O RCYUBVHMVUHEBM-RCWTZXSCSA-N 0.000 description 10
- BEBVVQPDSHHWQL-NRPADANISA-N Ser-Val-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O BEBVVQPDSHHWQL-NRPADANISA-N 0.000 description 10
- VYQQQIRHIFALGE-UWJYBYFXSA-N Tyr-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 VYQQQIRHIFALGE-UWJYBYFXSA-N 0.000 description 10
- BTWMICVCQLKKNR-DCAQKATOSA-N Val-Leu-Ser Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C([O-])=O BTWMICVCQLKKNR-DCAQKATOSA-N 0.000 description 10
- WUFHZIRMAZZWRS-OSUNSFLBSA-N Val-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C(C)C)N WUFHZIRMAZZWRS-OSUNSFLBSA-N 0.000 description 10
- PFMSJVIPEZMKSC-DZKIICNBSA-N Val-Tyr-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N PFMSJVIPEZMKSC-DZKIICNBSA-N 0.000 description 10
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 10
- 239000000243 solution Substances 0.000 description 10
- 108010073969 valyllysine Proteins 0.000 description 10
- GJLXVWOMRRWCIB-MERZOTPQSA-N (2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-acetamido-5-(diaminomethylideneamino)pentanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]-3-(1H-indol-3-yl)propanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanamide Chemical compound C([C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=C(O)C=C1 GJLXVWOMRRWCIB-MERZOTPQSA-N 0.000 description 9
- RHGKLRLOHDJJDR-BYPYZUCNSA-N L-citrulline Chemical compound NC(=O)NCCC[C@H]([NH3+])C([O-])=O RHGKLRLOHDJJDR-BYPYZUCNSA-N 0.000 description 9
- 108091028043 Nucleic acid sequence Proteins 0.000 description 9
- 108010060035 arginylproline Proteins 0.000 description 9
- 238000004520 electroporation Methods 0.000 description 9
- 239000013613 expression plasmid Substances 0.000 description 9
- 108010091871 leucylmethionine Proteins 0.000 description 9
- 239000000758 substrate Substances 0.000 description 9
- WQVYAWIMAWTGMW-ZLUOBGJFSA-N Ala-Asp-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N WQVYAWIMAWTGMW-ZLUOBGJFSA-N 0.000 description 8
- YHKANGMVQWRMAP-DCAQKATOSA-N Ala-Leu-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YHKANGMVQWRMAP-DCAQKATOSA-N 0.000 description 8
- CLICCYPMVFGUOF-IHRRRGAJSA-N Arg-Lys-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O CLICCYPMVFGUOF-IHRRRGAJSA-N 0.000 description 8
- YNDLOUMBVDVALC-ZLUOBGJFSA-N Asn-Ala-Ala Chemical compound C[C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CC(=O)N)N YNDLOUMBVDVALC-ZLUOBGJFSA-N 0.000 description 8
- GYOHQKJEQQJBOY-QEJZJMRPSA-N Asn-Glu-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)N)N GYOHQKJEQQJBOY-QEJZJMRPSA-N 0.000 description 8
- HYQYLOSCICEYTR-YUMQZZPRSA-N Asn-Gly-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O HYQYLOSCICEYTR-YUMQZZPRSA-N 0.000 description 8
- XHTUGJCAEYOZOR-UBHSHLNASA-N Asn-Ser-Trp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O XHTUGJCAEYOZOR-UBHSHLNASA-N 0.000 description 8
- DZQKLNLLWFQONU-LKXGYXEUSA-N Asp-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N)O DZQKLNLLWFQONU-LKXGYXEUSA-N 0.000 description 8
- LTXGDRFJRZSZAV-CIUDSAMLSA-N Asp-Glu-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)O)N LTXGDRFJRZSZAV-CIUDSAMLSA-N 0.000 description 8
- HHABWQIFXZPZCK-ACZMJKKPSA-N Cys-Gln-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N HHABWQIFXZPZCK-ACZMJKKPSA-N 0.000 description 8
- 241000205692 Galeopterus variegatus Species 0.000 description 8
- YLABFXCRQQMMHS-AVGNSLFASA-N Gln-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O YLABFXCRQQMMHS-AVGNSLFASA-N 0.000 description 8
- FYBSCGZLICNOBA-XQXXSGGOSA-N Glu-Ala-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FYBSCGZLICNOBA-XQXXSGGOSA-N 0.000 description 8
- LGYZYFFDELZWRS-DCAQKATOSA-N Glu-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O LGYZYFFDELZWRS-DCAQKATOSA-N 0.000 description 8
- OQXDUSZKISQQSS-GUBZILKMSA-N Glu-Lys-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OQXDUSZKISQQSS-GUBZILKMSA-N 0.000 description 8
- GMAGZGCAYLQBKF-NHCYSSNCSA-N Glu-Met-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O GMAGZGCAYLQBKF-NHCYSSNCSA-N 0.000 description 8
- WVWZIPOJECFDAG-AVGNSLFASA-N Glu-Phe-Cys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N WVWZIPOJECFDAG-AVGNSLFASA-N 0.000 description 8
- YRMZCZIRHYCNHX-RYUDHWBXSA-N Glu-Phe-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O YRMZCZIRHYCNHX-RYUDHWBXSA-N 0.000 description 8
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 8
- 102100040579 Guanidinoacetate N-methyltransferase Human genes 0.000 description 8
- WGVPDSNCHDEDBP-KKUMJFAQSA-N His-Asp-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WGVPDSNCHDEDBP-KKUMJFAQSA-N 0.000 description 8
- MRVZCDSYLJXKKX-ACRUOGEOSA-N His-Tyr-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CN=CN3)N MRVZCDSYLJXKKX-ACRUOGEOSA-N 0.000 description 8
- 108700039609 IRW peptide Proteins 0.000 description 8
- ZXJFURYTPZMUNY-VKOGCVSHSA-N Ile-Arg-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 ZXJFURYTPZMUNY-VKOGCVSHSA-N 0.000 description 8
- AXNGDPAKKCEKGY-QPHKQPEJSA-N Ile-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N AXNGDPAKKCEKGY-QPHKQPEJSA-N 0.000 description 8
- JNLSTRPWUXOORL-MMWGEVLESA-N Ile-Ser-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N JNLSTRPWUXOORL-MMWGEVLESA-N 0.000 description 8
- YHFPHRUWZMEOIX-CYDGBPFRSA-N Ile-Val-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)O)N YHFPHRUWZMEOIX-CYDGBPFRSA-N 0.000 description 8
- 241000880493 Leptailurus serval Species 0.000 description 8
- OGUUKPXUTHOIAV-SDDRHHMPSA-N Leu-Glu-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N OGUUKPXUTHOIAV-SDDRHHMPSA-N 0.000 description 8
- PWPBLZXWFXJFHE-RHYQMDGZSA-N Leu-Pro-Thr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O PWPBLZXWFXJFHE-RHYQMDGZSA-N 0.000 description 8
- HWROAFGWPQUPTE-OSUNSFLBSA-N Met-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CCSC)N HWROAFGWPQUPTE-OSUNSFLBSA-N 0.000 description 8
- PPHLBTXVBJNKOB-FDARSICLSA-N Met-Ile-Trp Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O PPHLBTXVBJNKOB-FDARSICLSA-N 0.000 description 8
- RFMMMVDNIPUKGG-YFKPBYRVSA-N N-acetyl-L-glutamic acid Chemical compound CC(=O)N[C@H](C(O)=O)CCC(O)=O RFMMMVDNIPUKGG-YFKPBYRVSA-N 0.000 description 8
- UAMFZRNCIFFMLE-FHWLQOOXSA-N Phe-Glu-Tyr Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N UAMFZRNCIFFMLE-FHWLQOOXSA-N 0.000 description 8
- LWPMGKSZPKFKJD-DZKIICNBSA-N Phe-Glu-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O LWPMGKSZPKFKJD-DZKIICNBSA-N 0.000 description 8
- WPTYDQPGBMDUBI-QWRGUYRKSA-N Phe-Gly-Asn Chemical compound N[C@@H](Cc1ccccc1)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O WPTYDQPGBMDUBI-QWRGUYRKSA-N 0.000 description 8
- MSSXKZBDKZAHCX-UNQGMJICSA-N Phe-Thr-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O MSSXKZBDKZAHCX-UNQGMJICSA-N 0.000 description 8
- YTGGLKWSVIRECD-JBACZVJFSA-N Phe-Trp-Glu Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 YTGGLKWSVIRECD-JBACZVJFSA-N 0.000 description 8
- VIIRRNQMMIHYHQ-XHSDSOJGSA-N Phe-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N VIIRRNQMMIHYHQ-XHSDSOJGSA-N 0.000 description 8
- SSSFPISOZOLQNP-GUBZILKMSA-N Pro-Arg-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSFPISOZOLQNP-GUBZILKMSA-N 0.000 description 8
- UUHXBJHVTVGSKM-BQBZGAKWSA-N Pro-Gly-Asn Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O UUHXBJHVTVGSKM-BQBZGAKWSA-N 0.000 description 8
- CLJLVCYFABNTHP-DCAQKATOSA-N Pro-Leu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O CLJLVCYFABNTHP-DCAQKATOSA-N 0.000 description 8
- ULWBBFKQBDNGOY-RWMBFGLXSA-N Pro-Lys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@@H]2C(=O)O ULWBBFKQBDNGOY-RWMBFGLXSA-N 0.000 description 8
- APIAILHCTSBGLU-JYJNAYRXSA-N Pro-Met-Phe Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@@H]2CCCN2 APIAILHCTSBGLU-JYJNAYRXSA-N 0.000 description 8
- LGMBKOAPPTYKLC-JYJNAYRXSA-N Pro-Phe-Arg Chemical compound C([C@@H](C(=O)N[C@@H](CCCNC(=N)N)C(O)=O)NC(=O)[C@H]1NCCC1)C1=CC=CC=C1 LGMBKOAPPTYKLC-JYJNAYRXSA-N 0.000 description 8
- OQSGBXGNAFQGGS-CYDGBPFRSA-N Pro-Val-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O OQSGBXGNAFQGGS-CYDGBPFRSA-N 0.000 description 8
- 108010079005 RDV peptide Proteins 0.000 description 8
- 241000700157 Rattus norvegicus Species 0.000 description 8
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 8
- QGMLKFGTGXWAHF-IHRRRGAJSA-N Ser-Arg-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QGMLKFGTGXWAHF-IHRRRGAJSA-N 0.000 description 8
- UGHCUDLCCVVIJR-VGDYDELISA-N Ser-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CO)N UGHCUDLCCVVIJR-VGDYDELISA-N 0.000 description 8
- ZVBCMFDJIMUELU-BZSNNMDCSA-N Ser-Tyr-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CO)N ZVBCMFDJIMUELU-BZSNNMDCSA-N 0.000 description 8
- AAZOYLQUEQRUMZ-GSSVUCPTSA-N Thr-Thr-Asn Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O AAZOYLQUEQRUMZ-GSSVUCPTSA-N 0.000 description 8
- PMDOQZFYGWZSTK-LSJOCFKGSA-N Val-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)C(C)C PMDOQZFYGWZSTK-LSJOCFKGSA-N 0.000 description 8
- 239000011543 agarose gel Substances 0.000 description 8
- 108010087924 alanylproline Proteins 0.000 description 8
- 238000004458 analytical method Methods 0.000 description 8
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 8
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 8
- 108010016616 cysteinylglycine Proteins 0.000 description 8
- 108010054813 diprotin B Proteins 0.000 description 8
- 238000001976 enzyme digestion Methods 0.000 description 8
- 108010084389 glycyltryptophan Proteins 0.000 description 8
- 108010085325 histidylproline Proteins 0.000 description 8
- 108010051673 leucyl-glycyl-phenylalanine Proteins 0.000 description 8
- 108010056582 methionylglutamic acid Proteins 0.000 description 8
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 8
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 8
- 108010004914 prolylarginine Proteins 0.000 description 8
- 239000000725 suspension Substances 0.000 description 8
- 238000011144 upstream manufacturing Methods 0.000 description 8
- AKKUDRZKFZWPBH-SRVKXCTJSA-N Asp-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N AKKUDRZKFZWPBH-SRVKXCTJSA-N 0.000 description 7
- 108700010070 Codon Usage Proteins 0.000 description 7
- YFXFOZPXVFPBDH-VZFHVOOUSA-N Cys-Ala-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)CS)C(O)=O YFXFOZPXVFPBDH-VZFHVOOUSA-N 0.000 description 7
- MWMJCGBSIORNCD-AVGNSLFASA-N Glu-Leu-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O MWMJCGBSIORNCD-AVGNSLFASA-N 0.000 description 7
- RQJUKVXWAKJDBW-SVSWQMSJSA-N Ile-Ser-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N RQJUKVXWAKJDBW-SVSWQMSJSA-N 0.000 description 7
- APQYGMBHIVXFML-OSUNSFLBSA-N Ile-Val-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N APQYGMBHIVXFML-OSUNSFLBSA-N 0.000 description 7
- RDFIVFHPOSOXMW-ACRUOGEOSA-N Leu-Tyr-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O RDFIVFHPOSOXMW-ACRUOGEOSA-N 0.000 description 7
- IQJMEDDVOGMTKT-SRVKXCTJSA-N Met-Val-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IQJMEDDVOGMTKT-SRVKXCTJSA-N 0.000 description 7
- NIOYDASGXWLHEZ-CIUDSAMLSA-N Ser-Met-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O NIOYDASGXWLHEZ-CIUDSAMLSA-N 0.000 description 7
- DVAAUUVLDFKTAQ-VHWLVUOQSA-N Trp-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N DVAAUUVLDFKTAQ-VHWLVUOQSA-N 0.000 description 7
- 108010047495 alanylglycine Proteins 0.000 description 7
- 101150014229 carA gene Proteins 0.000 description 7
- 101150070764 carB gene Proteins 0.000 description 7
- 238000003780 insertion Methods 0.000 description 7
- 230000037431 insertion Effects 0.000 description 7
- 230000009466 transformation Effects 0.000 description 7
- KIUYPHAMDKDICO-WHFBIAKZSA-N Ala-Asp-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KIUYPHAMDKDICO-WHFBIAKZSA-N 0.000 description 6
- PEEYDECOOVQKRZ-DLOVCJGASA-N Ala-Ser-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PEEYDECOOVQKRZ-DLOVCJGASA-N 0.000 description 6
- ZJLORAAXDAJLDC-CQDKDKBSSA-N Ala-Tyr-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O ZJLORAAXDAJLDC-CQDKDKBSSA-N 0.000 description 6
- BOKLLPVAQDSLHC-FXQIFTODSA-N Ala-Val-Cys Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(=O)O)N BOKLLPVAQDSLHC-FXQIFTODSA-N 0.000 description 6
- QGZKDVFQNNGYKY-UHFFFAOYSA-N Ammonia Chemical compound N QGZKDVFQNNGYKY-UHFFFAOYSA-N 0.000 description 6
- NKBQZKVMKJJDLX-SRVKXCTJSA-N Arg-Glu-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NKBQZKVMKJJDLX-SRVKXCTJSA-N 0.000 description 6
- OGUPCHKBOKJFMA-SRVKXCTJSA-N Arg-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N OGUPCHKBOKJFMA-SRVKXCTJSA-N 0.000 description 6
- JEOCWTUOMKEEMF-RHYQMDGZSA-N Arg-Leu-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEOCWTUOMKEEMF-RHYQMDGZSA-N 0.000 description 6
- 101710149879 Arginine repressor Proteins 0.000 description 6
- 101100163308 Clostridium perfringens (strain 13 / Type A) argR1 gene Proteins 0.000 description 6
- 108020004705 Codon Proteins 0.000 description 6
- 238000007702 DNA assembly Methods 0.000 description 6
- VPKBCVUDBNINAH-GARJFASQSA-N Glu-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)O)N)C(=O)O VPKBCVUDBNINAH-GARJFASQSA-N 0.000 description 6
- QXDXIXFSFHUYAX-MNXVOIDGSA-N Glu-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O QXDXIXFSFHUYAX-MNXVOIDGSA-N 0.000 description 6
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 6
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 6
- 108010065920 Insulin Lispro Proteins 0.000 description 6
- ZRLUISBDKUWAIZ-CIUDSAMLSA-N Leu-Ala-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O ZRLUISBDKUWAIZ-CIUDSAMLSA-N 0.000 description 6
- BQSLGJHIAGOZCD-CIUDSAMLSA-N Leu-Ala-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O BQSLGJHIAGOZCD-CIUDSAMLSA-N 0.000 description 6
- DLCOFDAHNMMQPP-SRVKXCTJSA-N Leu-Asp-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O DLCOFDAHNMMQPP-SRVKXCTJSA-N 0.000 description 6
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 6
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 6
- VDIARPPNADFEAV-WEDXCCLWSA-N Leu-Thr-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O VDIARPPNADFEAV-WEDXCCLWSA-N 0.000 description 6
- XZNJZXJZBMBGGS-NHCYSSNCSA-N Leu-Val-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O XZNJZXJZBMBGGS-NHCYSSNCSA-N 0.000 description 6
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 6
- HHCOOFPGNXKFGR-HJGDQZAQSA-N Met-Gln-Thr Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HHCOOFPGNXKFGR-HJGDQZAQSA-N 0.000 description 6
- RMLLCGYYVZKKRT-CIUDSAMLSA-N Met-Ser-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O RMLLCGYYVZKKRT-CIUDSAMLSA-N 0.000 description 6
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 6
- JARJPEMLQAWNBR-GUBZILKMSA-N Pro-Asp-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JARJPEMLQAWNBR-GUBZILKMSA-N 0.000 description 6
- LXLFEIHKWGHJJB-XUXIUFHCSA-N Pro-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 LXLFEIHKWGHJJB-XUXIUFHCSA-N 0.000 description 6
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 6
- XPNSAQMEAVSQRD-FBCQKBJTSA-N Thr-Gly-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)NCC(O)=O XPNSAQMEAVSQRD-FBCQKBJTSA-N 0.000 description 6
- ILTXFANLDMJWPR-SIUGBPQLSA-N Tyr-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N ILTXFANLDMJWPR-SIUGBPQLSA-N 0.000 description 6
- CVIXTAITYJQMPE-LAEOZQHASA-N Val-Glu-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CVIXTAITYJQMPE-LAEOZQHASA-N 0.000 description 6
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 6
- 108010044940 alanylglutamine Proteins 0.000 description 6
- 108010070944 alanylhistidine Proteins 0.000 description 6
- 108010013835 arginine glutamate Proteins 0.000 description 6
- 108010068380 arginylarginine Proteins 0.000 description 6
- 108010038633 aspartylglutamate Proteins 0.000 description 6
- 108010068265 aspartyltyrosine Proteins 0.000 description 6
- 230000001580 bacterial effect Effects 0.000 description 6
- 239000013604 expression vector Substances 0.000 description 6
- 108010078144 glutaminyl-glycine Proteins 0.000 description 6
- 108010085059 glutamyl-arginyl-proline Proteins 0.000 description 6
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 6
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 6
- 108010090894 prolylleucine Proteins 0.000 description 6
- 230000010076 replication Effects 0.000 description 6
- 230000009469 supplementation Effects 0.000 description 6
- 235000013619 trace mineral Nutrition 0.000 description 6
- 239000011573 trace mineral Substances 0.000 description 6
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 6
- OMMDTNGURYRDAC-NRPADANISA-N Ala-Glu-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OMMDTNGURYRDAC-NRPADANISA-N 0.000 description 5
- UZSQXCMNUPKLCC-FJXKBIBVSA-N Arg-Thr-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UZSQXCMNUPKLCC-FJXKBIBVSA-N 0.000 description 5
- 241001582517 Cylindrospermopsis raciborskii AWT205 Species 0.000 description 5
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 5
- SYWCGQOIIARSIX-SRVKXCTJSA-N Glu-Pro-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O SYWCGQOIIARSIX-SRVKXCTJSA-N 0.000 description 5
- COVXELOAORHTND-LSJOCFKGSA-N Gly-Ile-Val Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O COVXELOAORHTND-LSJOCFKGSA-N 0.000 description 5
- NURNJECQNNCRBK-FLBSBUHZSA-N Ile-Thr-Thr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NURNJECQNNCRBK-FLBSBUHZSA-N 0.000 description 5
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 5
- SHZGCJCMOBCMKK-JFNONXLTSA-N L-rhamnopyranose Chemical compound C[C@@H]1OC(O)[C@H](O)[C@H](O)[C@H]1O SHZGCJCMOBCMKK-JFNONXLTSA-N 0.000 description 5
- PNNNRSAQSRJVSB-UHFFFAOYSA-N L-rhamnose Natural products CC(O)C(O)C(O)C(O)C=O PNNNRSAQSRJVSB-UHFFFAOYSA-N 0.000 description 5
- HQVDJTYKCMIWJP-YUMQZZPRSA-N Lys-Asn-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O HQVDJTYKCMIWJP-YUMQZZPRSA-N 0.000 description 5
- VSRXPEHZMHSFKU-IUCAKERBSA-N Lys-Gln-Gly Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O VSRXPEHZMHSFKU-IUCAKERBSA-N 0.000 description 5
- QVTDVTONTRSQMF-WDCWCFNPSA-N Lys-Thr-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CCCCN QVTDVTONTRSQMF-WDCWCFNPSA-N 0.000 description 5
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 5
- LNOWDSPAYBWJOR-PEDHHIEDSA-N Pro-Ile-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LNOWDSPAYBWJOR-PEDHHIEDSA-N 0.000 description 5
- PLQWGQUNUPMNOD-KKUMJFAQSA-N Ser-Tyr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O PLQWGQUNUPMNOD-KKUMJFAQSA-N 0.000 description 5
- GVJUTBOZZBTBIG-AVGNSLFASA-N Val-Lys-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N GVJUTBOZZBTBIG-AVGNSLFASA-N 0.000 description 5
- 108010059459 arginyl-threonyl-phenylalanine Proteins 0.000 description 5
- 230000001851 biosynthetic effect Effects 0.000 description 5
- 229960002173 citrulline Drugs 0.000 description 5
- 230000029087 digestion Effects 0.000 description 5
- 108020001507 fusion proteins Proteins 0.000 description 5
- 102000037865 fusion proteins Human genes 0.000 description 5
- 238000009630 liquid culture Methods 0.000 description 5
- 239000000463 material Substances 0.000 description 5
- 239000013615 primer Substances 0.000 description 5
- 230000008929 regeneration Effects 0.000 description 5
- 238000011069 regeneration method Methods 0.000 description 5
- 238000003786 synthesis reaction Methods 0.000 description 5
- HHGYNJRJIINWAK-FXQIFTODSA-N Ala-Ala-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N HHGYNJRJIINWAK-FXQIFTODSA-N 0.000 description 4
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 4
- YWWATNIVMOCSAV-UBHSHLNASA-N Ala-Arg-Phe Chemical compound NC(=N)NCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 YWWATNIVMOCSAV-UBHSHLNASA-N 0.000 description 4
- NHCPCLJZRSIDHS-ZLUOBGJFSA-N Ala-Asp-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O NHCPCLJZRSIDHS-ZLUOBGJFSA-N 0.000 description 4
- KUDREHRZRIVKHS-UWJYBYFXSA-N Ala-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KUDREHRZRIVKHS-UWJYBYFXSA-N 0.000 description 4
- YIGLXQRFQVWFEY-NRPADANISA-N Ala-Gln-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O YIGLXQRFQVWFEY-NRPADANISA-N 0.000 description 4
- NHLAEBFGWPXFGI-WHFBIAKZSA-N Ala-Gly-Asn Chemical compound C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N NHLAEBFGWPXFGI-WHFBIAKZSA-N 0.000 description 4
- PCIFXPRIFWKWLK-YUMQZZPRSA-N Ala-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N PCIFXPRIFWKWLK-YUMQZZPRSA-N 0.000 description 4
- CKLDHDOIYBVUNP-KBIXCLLPSA-N Ala-Ile-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O CKLDHDOIYBVUNP-KBIXCLLPSA-N 0.000 description 4
- LDLSENBXQNDTPB-DCAQKATOSA-N Ala-Lys-Arg Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N LDLSENBXQNDTPB-DCAQKATOSA-N 0.000 description 4
- RAAWHFXHAACDFT-FXQIFTODSA-N Ala-Met-Asn Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CC(N)=O)C(O)=O RAAWHFXHAACDFT-FXQIFTODSA-N 0.000 description 4
- FVNAUOZKIPAYNA-BPNCWPANSA-N Ala-Met-Tyr Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FVNAUOZKIPAYNA-BPNCWPANSA-N 0.000 description 4
- 108010011667 Ala-Phe-Ala Proteins 0.000 description 4
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 4
- WNHNMKOFKCHKKD-BFHQHQDPSA-N Ala-Thr-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O WNHNMKOFKCHKKD-BFHQHQDPSA-N 0.000 description 4
- JNJHNBXBGNJESC-KKXDTOCCSA-N Ala-Tyr-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JNJHNBXBGNJESC-KKXDTOCCSA-N 0.000 description 4
- HJVGMOYJDDXLMI-AVGNSLFASA-N Arg-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCCNC(N)=N HJVGMOYJDDXLMI-AVGNSLFASA-N 0.000 description 4
- TTXYKSADPSNOIF-IHRRRGAJSA-N Arg-Asp-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O TTXYKSADPSNOIF-IHRRRGAJSA-N 0.000 description 4
- YSUVMPICYVWRBX-VEVYYDQMSA-N Arg-Asp-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YSUVMPICYVWRBX-VEVYYDQMSA-N 0.000 description 4
- XLWSGICNBZGYTA-CIUDSAMLSA-N Arg-Glu-Asp Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O XLWSGICNBZGYTA-CIUDSAMLSA-N 0.000 description 4
- HAVKMRGWNXMCDR-STQMWFEESA-N Arg-Gly-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HAVKMRGWNXMCDR-STQMWFEESA-N 0.000 description 4
- ZATRYQNPUHGXCU-DTWKUNHWSA-N Arg-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ZATRYQNPUHGXCU-DTWKUNHWSA-N 0.000 description 4
- LLUGJARLJCGLAR-CYDGBPFRSA-N Arg-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N LLUGJARLJCGLAR-CYDGBPFRSA-N 0.000 description 4
- INXWADWANGLMPJ-JYJNAYRXSA-N Arg-Phe-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)CC1=CC=CC=C1 INXWADWANGLMPJ-JYJNAYRXSA-N 0.000 description 4
- NIELFHOLFTUZME-HJWJTTGWSA-N Arg-Phe-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O NIELFHOLFTUZME-HJWJTTGWSA-N 0.000 description 4
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 4
- BSYKSCBTTQKOJG-GUBZILKMSA-N Arg-Pro-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O BSYKSCBTTQKOJG-GUBZILKMSA-N 0.000 description 4
- HGKHPCFTRQDHCU-IUCAKERBSA-N Arg-Pro-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HGKHPCFTRQDHCU-IUCAKERBSA-N 0.000 description 4
- VENMDXUVHSKEIN-GUBZILKMSA-N Arg-Ser-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VENMDXUVHSKEIN-GUBZILKMSA-N 0.000 description 4
- XEOXPCNONWHHSW-AVGNSLFASA-N Arg-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N XEOXPCNONWHHSW-AVGNSLFASA-N 0.000 description 4
- XXAOXVBAWLMTDR-ZLUOBGJFSA-N Asn-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)N)N XXAOXVBAWLMTDR-ZLUOBGJFSA-N 0.000 description 4
- PPCORQFLAZWUNO-QWRGUYRKSA-N Asn-Phe-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC(=O)N)N PPCORQFLAZWUNO-QWRGUYRKSA-N 0.000 description 4
- QXOPPIDJKPEKCW-GUBZILKMSA-N Asn-Pro-Arg Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)N)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O QXOPPIDJKPEKCW-GUBZILKMSA-N 0.000 description 4
- KSZHWTRZPOTIGY-AVGNSLFASA-N Asn-Tyr-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O KSZHWTRZPOTIGY-AVGNSLFASA-N 0.000 description 4
- XEGZSHSPQNDNRH-JRQIVUDYSA-N Asn-Tyr-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XEGZSHSPQNDNRH-JRQIVUDYSA-N 0.000 description 4
- KBQOUDLMWYWXNP-YDHLFZDLSA-N Asn-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KBQOUDLMWYWXNP-YDHLFZDLSA-N 0.000 description 4
- XBQSLMACWDXWLJ-GHCJXIJMSA-N Asp-Ala-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O XBQSLMACWDXWLJ-GHCJXIJMSA-N 0.000 description 4
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 4
- GWTLRDMPMJCNMH-WHFBIAKZSA-N Asp-Asn-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GWTLRDMPMJCNMH-WHFBIAKZSA-N 0.000 description 4
- CELPEWWLSXMVPH-CIUDSAMLSA-N Asp-Asp-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O CELPEWWLSXMVPH-CIUDSAMLSA-N 0.000 description 4
- VAWNQIGQPUOPQW-ACZMJKKPSA-N Asp-Glu-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VAWNQIGQPUOPQW-ACZMJKKPSA-N 0.000 description 4
- QCLHLXDWRKOHRR-GUBZILKMSA-N Asp-Glu-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)O)N QCLHLXDWRKOHRR-GUBZILKMSA-N 0.000 description 4
- JNNVNVRBYUJYGS-CIUDSAMLSA-N Asp-Leu-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O JNNVNVRBYUJYGS-CIUDSAMLSA-N 0.000 description 4
- RQHLMGCXCZUOGT-ZPFDUUQYSA-N Asp-Leu-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RQHLMGCXCZUOGT-ZPFDUUQYSA-N 0.000 description 4
- VWWAFGHMPWBKEP-GMOBBJLQSA-N Asp-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CC(=O)O)N VWWAFGHMPWBKEP-GMOBBJLQSA-N 0.000 description 4
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 4
- KESWRFKUZRUTAH-FXQIFTODSA-N Asp-Pro-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O KESWRFKUZRUTAH-FXQIFTODSA-N 0.000 description 4
- NWAHPBGBDIFUFD-KKUMJFAQSA-N Asp-Tyr-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O NWAHPBGBDIFUFD-KKUMJFAQSA-N 0.000 description 4
- 241001485655 Corynebacterium glutamicum ATCC 13032 Species 0.000 description 4
- 241001299747 Cylindrospermopsis raciborskii Species 0.000 description 4
- ZALVANCAZFPKIR-GUBZILKMSA-N Cys-Pro-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CS)N ZALVANCAZFPKIR-GUBZILKMSA-N 0.000 description 4
- KVCJEMHFLGVINV-ZLUOBGJFSA-N Cys-Ser-Asn Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(N)=O KVCJEMHFLGVINV-ZLUOBGJFSA-N 0.000 description 4
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 4
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 4
- 108700007698 Genetic Terminator Regions Proteins 0.000 description 4
- PRBLYKYHAJEABA-SRVKXCTJSA-N Gln-Arg-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O PRBLYKYHAJEABA-SRVKXCTJSA-N 0.000 description 4
- AAOBFSKXAVIORT-GUBZILKMSA-N Gln-Asn-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O AAOBFSKXAVIORT-GUBZILKMSA-N 0.000 description 4
- LLRJEFPKIIBGJP-DCAQKATOSA-N Gln-Glu-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N LLRJEFPKIIBGJP-DCAQKATOSA-N 0.000 description 4
- UWMDGPFFTKDUIY-HJGDQZAQSA-N Gln-Pro-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O UWMDGPFFTKDUIY-HJGDQZAQSA-N 0.000 description 4
- PAOHIZNRJNIXQY-XQXXSGGOSA-N Gln-Thr-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O PAOHIZNRJNIXQY-XQXXSGGOSA-N 0.000 description 4
- VLOLPWWCNKWRNB-LOKLDPHHSA-N Gln-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O VLOLPWWCNKWRNB-LOKLDPHHSA-N 0.000 description 4
- LTUVYLVIZHJCOQ-KKUMJFAQSA-N Glu-Arg-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LTUVYLVIZHJCOQ-KKUMJFAQSA-N 0.000 description 4
- CKRUHITYRFNUKW-WDSKDSINSA-N Glu-Asn-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O CKRUHITYRFNUKW-WDSKDSINSA-N 0.000 description 4
- NKLRYVLERDYDBI-FXQIFTODSA-N Glu-Glu-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKLRYVLERDYDBI-FXQIFTODSA-N 0.000 description 4
- AUTNXSQEVVHSJK-YVNDNENWSA-N Glu-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O AUTNXSQEVVHSJK-YVNDNENWSA-N 0.000 description 4
- GRHXUHCFENOCOS-ZPFDUUQYSA-N Glu-Ile-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CCC(=O)O)N GRHXUHCFENOCOS-ZPFDUUQYSA-N 0.000 description 4
- YGLCLCMAYUYZSG-AVGNSLFASA-N Glu-Lys-His Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 YGLCLCMAYUYZSG-AVGNSLFASA-N 0.000 description 4
- YKBUCXNNBYZYAY-MNXVOIDGSA-N Glu-Lys-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YKBUCXNNBYZYAY-MNXVOIDGSA-N 0.000 description 4
- MFNUFCFRAZPJFW-JYJNAYRXSA-N Glu-Lys-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFNUFCFRAZPJFW-JYJNAYRXSA-N 0.000 description 4
- PMSMKNYRZCKVMC-DRZSPHRISA-N Glu-Phe-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CCC(=O)O)N PMSMKNYRZCKVMC-DRZSPHRISA-N 0.000 description 4
- BFEZQZKEPRKKHV-SRVKXCTJSA-N Glu-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O BFEZQZKEPRKKHV-SRVKXCTJSA-N 0.000 description 4
- SWDNPSMMEWRNOH-HJGDQZAQSA-N Glu-Pro-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O SWDNPSMMEWRNOH-HJGDQZAQSA-N 0.000 description 4
- UUTGYDAKPISJAO-JYJNAYRXSA-N Glu-Tyr-Leu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 UUTGYDAKPISJAO-JYJNAYRXSA-N 0.000 description 4
- WGYHAAXZWPEBDQ-IFFSRLJSSA-N Glu-Val-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGYHAAXZWPEBDQ-IFFSRLJSSA-N 0.000 description 4
- MFVQGXGQRIXBPK-WDSKDSINSA-N Gly-Ala-Glu Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O MFVQGXGQRIXBPK-WDSKDSINSA-N 0.000 description 4
- CLODWIOAKCSBAN-BQBZGAKWSA-N Gly-Arg-Asp Chemical compound NC(N)=NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(O)=O)C(O)=O CLODWIOAKCSBAN-BQBZGAKWSA-N 0.000 description 4
- DTPOVRRYXPJJAZ-FJXKBIBVSA-N Gly-Arg-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N DTPOVRRYXPJJAZ-FJXKBIBVSA-N 0.000 description 4
- BIRKKBCSAIHDDF-WDSKDSINSA-N Gly-Glu-Cys Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(O)=O BIRKKBCSAIHDDF-WDSKDSINSA-N 0.000 description 4
- LLZXNUUIBOALNY-QWRGUYRKSA-N Gly-Leu-Lys Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN LLZXNUUIBOALNY-QWRGUYRKSA-N 0.000 description 4
- LOEANKRDMMVOGZ-YUMQZZPRSA-N Gly-Lys-Asp Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(O)=O)C(O)=O LOEANKRDMMVOGZ-YUMQZZPRSA-N 0.000 description 4
- YOBGUCWZPXJHTN-BQBZGAKWSA-N Gly-Ser-Arg Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YOBGUCWZPXJHTN-BQBZGAKWSA-N 0.000 description 4
- DKJWUIYLMLUBDX-XPUUQOCRSA-N Gly-Val-Cys Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(=O)O DKJWUIYLMLUBDX-XPUUQOCRSA-N 0.000 description 4
- FULZDMOZUZKGQU-ONGXEEELSA-N Gly-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN FULZDMOZUZKGQU-ONGXEEELSA-N 0.000 description 4
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 4
- RVKIPWVMZANZLI-UHFFFAOYSA-N H-Lys-Trp-OH Natural products C1=CC=C2C(CC(NC(=O)C(N)CCCCN)C(O)=O)=CNC2=C1 RVKIPWVMZANZLI-UHFFFAOYSA-N 0.000 description 4
- JFFAPRNXXLRINI-NHCYSSNCSA-N His-Asp-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O JFFAPRNXXLRINI-NHCYSSNCSA-N 0.000 description 4
- PGTISAJTWZPFGN-PEXQALLHSA-N His-Gly-Ile Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O PGTISAJTWZPFGN-PEXQALLHSA-N 0.000 description 4
- PGXZHYYGOPKYKM-IHRRRGAJSA-N His-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CN=CN2)N)C(=O)N[C@@H](CCCCN)C(=O)O PGXZHYYGOPKYKM-IHRRRGAJSA-N 0.000 description 4
- GGXUJBKENKVYNV-ULQDDVLXSA-N His-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N GGXUJBKENKVYNV-ULQDDVLXSA-N 0.000 description 4
- DRKZDEFADVYTLU-AVGNSLFASA-N His-Val-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O DRKZDEFADVYTLU-AVGNSLFASA-N 0.000 description 4
- 101000893303 Homo sapiens Glycine amidinotransferase, mitochondrial Proteins 0.000 description 4
- FVEWRQXNISSYFO-ZPFDUUQYSA-N Ile-Arg-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N FVEWRQXNISSYFO-ZPFDUUQYSA-N 0.000 description 4
- TVSPLSZTKTUYLV-ZPFDUUQYSA-N Ile-Glu-Met Chemical compound N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCSC)C(=O)O TVSPLSZTKTUYLV-ZPFDUUQYSA-N 0.000 description 4
- NZOCIWKZUVUNDW-ZKWXMUAHSA-N Ile-Gly-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O NZOCIWKZUVUNDW-ZKWXMUAHSA-N 0.000 description 4
- KFVUBLZRFSVDGO-BYULHYEWSA-N Ile-Gly-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O KFVUBLZRFSVDGO-BYULHYEWSA-N 0.000 description 4
- IGJWJGIHUFQANP-LAEOZQHASA-N Ile-Gly-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N IGJWJGIHUFQANP-LAEOZQHASA-N 0.000 description 4
- CDGLBYSAZFIIJO-RCOVLWMOSA-N Ile-Gly-Gly Chemical compound CC[C@H](C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O CDGLBYSAZFIIJO-RCOVLWMOSA-N 0.000 description 4
- CCYGNFBYUNHFSC-MGHWNKPDSA-N Ile-His-Phe Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O CCYGNFBYUNHFSC-MGHWNKPDSA-N 0.000 description 4
- KYLIZSDYWQQTFM-PEDHHIEDSA-N Ile-Ile-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CCCN=C(N)N KYLIZSDYWQQTFM-PEDHHIEDSA-N 0.000 description 4
- TVYWVSJGSHQWMT-AJNGGQMLSA-N Ile-Leu-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N TVYWVSJGSHQWMT-AJNGGQMLSA-N 0.000 description 4
- LRAUKBMYHHNADU-DKIMLUQUSA-N Ile-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)CC)CC1=CC=CC=C1 LRAUKBMYHHNADU-DKIMLUQUSA-N 0.000 description 4
- FHPZJWJWTWZKNA-LLLHUVSDSA-N Ile-Phe-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N FHPZJWJWTWZKNA-LLLHUVSDSA-N 0.000 description 4
- NAFIFZNBSPWYOO-RWRJDSDZSA-N Ile-Thr-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N NAFIFZNBSPWYOO-RWRJDSDZSA-N 0.000 description 4
- QHUREMVLLMNUAX-OSUNSFLBSA-N Ile-Thr-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)O)N QHUREMVLLMNUAX-OSUNSFLBSA-N 0.000 description 4
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 4
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 4
- SUPVSFFZWVOEOI-UHFFFAOYSA-N Leu-Ala-Tyr Natural products CC(C)CC(N)C(=O)NC(C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 SUPVSFFZWVOEOI-UHFFFAOYSA-N 0.000 description 4
- HBJZFCIVFIBNSV-DCAQKATOSA-N Leu-Arg-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(N)=O)C(O)=O HBJZFCIVFIBNSV-DCAQKATOSA-N 0.000 description 4
- REPPKAMYTOJTFC-DCAQKATOSA-N Leu-Arg-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O REPPKAMYTOJTFC-DCAQKATOSA-N 0.000 description 4
- HASRFYOMVPJRPU-SRVKXCTJSA-N Leu-Arg-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O HASRFYOMVPJRPU-SRVKXCTJSA-N 0.000 description 4
- KSZCCRIGNVSHFH-UWVGGRQHSA-N Leu-Arg-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O KSZCCRIGNVSHFH-UWVGGRQHSA-N 0.000 description 4
- YVKSMSDXKMSIRX-GUBZILKMSA-N Leu-Glu-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O YVKSMSDXKMSIRX-GUBZILKMSA-N 0.000 description 4
- KUIDCYNIEJBZBU-AJNGGQMLSA-N Leu-Ile-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O KUIDCYNIEJBZBU-AJNGGQMLSA-N 0.000 description 4
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 4
- RZXLZBIUTDQHJQ-SRVKXCTJSA-N Leu-Lys-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O RZXLZBIUTDQHJQ-SRVKXCTJSA-N 0.000 description 4
- WXDRGWBQZIMJDE-ULQDDVLXSA-N Leu-Phe-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(O)=O WXDRGWBQZIMJDE-ULQDDVLXSA-N 0.000 description 4
- SVBJIZVVYJYGLA-DCAQKATOSA-N Leu-Ser-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O SVBJIZVVYJYGLA-DCAQKATOSA-N 0.000 description 4
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 4
- KCXUCYYZNZFGLL-SRVKXCTJSA-N Lys-Ala-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O KCXUCYYZNZFGLL-SRVKXCTJSA-N 0.000 description 4
- BRSGXFITDXFMFF-IHRRRGAJSA-N Lys-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)N BRSGXFITDXFMFF-IHRRRGAJSA-N 0.000 description 4
- CKSXSQUVEYCDIW-AVGNSLFASA-N Lys-Arg-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)N CKSXSQUVEYCDIW-AVGNSLFASA-N 0.000 description 4
- DEFGUIIUYAUEDU-ZPFDUUQYSA-N Lys-Asn-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DEFGUIIUYAUEDU-ZPFDUUQYSA-N 0.000 description 4
- KPJJOZUXFOLGMQ-CIUDSAMLSA-N Lys-Asp-Asn Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N KPJJOZUXFOLGMQ-CIUDSAMLSA-N 0.000 description 4
- YEIYAQQKADPIBJ-GARJFASQSA-N Lys-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCCN)N)C(=O)O YEIYAQQKADPIBJ-GARJFASQSA-N 0.000 description 4
- QZONCCHVHCOBSK-YUMQZZPRSA-N Lys-Gly-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O QZONCCHVHCOBSK-YUMQZZPRSA-N 0.000 description 4
- WAIHHELKYSFIQN-XUXIUFHCSA-N Lys-Ile-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O WAIHHELKYSFIQN-XUXIUFHCSA-N 0.000 description 4
- NJNRBRKHOWSGMN-SRVKXCTJSA-N Lys-Leu-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O NJNRBRKHOWSGMN-SRVKXCTJSA-N 0.000 description 4
- PYFNONMJYNJENN-AVGNSLFASA-N Lys-Lys-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PYFNONMJYNJENN-AVGNSLFASA-N 0.000 description 4
- JQSIGLHQNSZZRL-KKUMJFAQSA-N Lys-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)N JQSIGLHQNSZZRL-KKUMJFAQSA-N 0.000 description 4
- QQPSCXKFDSORFT-IHRRRGAJSA-N Lys-Lys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN QQPSCXKFDSORFT-IHRRRGAJSA-N 0.000 description 4
- DRRXXZBXDMLGFC-IHRRRGAJSA-N Lys-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN DRRXXZBXDMLGFC-IHRRRGAJSA-N 0.000 description 4
- MYKLINMAGAIRPJ-CIUDSAMLSA-N Met-Gln-Asn Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O MYKLINMAGAIRPJ-CIUDSAMLSA-N 0.000 description 4
- HLYIDXAXQIJYIG-CIUDSAMLSA-N Met-Gln-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HLYIDXAXQIJYIG-CIUDSAMLSA-N 0.000 description 4
- PZUUMQPMHBJJKE-AVGNSLFASA-N Met-Leu-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCNC(N)=N PZUUMQPMHBJJKE-AVGNSLFASA-N 0.000 description 4
- WXXNVZMWHOLNRJ-AVGNSLFASA-N Met-Pro-Lys Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O WXXNVZMWHOLNRJ-AVGNSLFASA-N 0.000 description 4
- XPVCDCMPKCERFT-GUBZILKMSA-N Met-Ser-Arg Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O XPVCDCMPKCERFT-GUBZILKMSA-N 0.000 description 4
- DSZFTPCSFVWMKP-DCAQKATOSA-N Met-Ser-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN DSZFTPCSFVWMKP-DCAQKATOSA-N 0.000 description 4
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 4
- 108700026244 Open Reading Frames Proteins 0.000 description 4
- CUMXHKAOHNWRFQ-BZSNNMDCSA-N Phe-Asp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 CUMXHKAOHNWRFQ-BZSNNMDCSA-N 0.000 description 4
- RYQWALWYQWBUKN-FHWLQOOXSA-N Phe-Phe-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O RYQWALWYQWBUKN-FHWLQOOXSA-N 0.000 description 4
- WKLMCMXFMQEKCX-SLFFLAALSA-N Phe-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O WKLMCMXFMQEKCX-SLFFLAALSA-N 0.000 description 4
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 4
- KUSYCSMTTHSZOA-DZKIICNBSA-N Phe-Val-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N KUSYCSMTTHSZOA-DZKIICNBSA-N 0.000 description 4
- FZHBZMDRDASUHN-NAKRPEOUSA-N Pro-Ala-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1)C(O)=O FZHBZMDRDASUHN-NAKRPEOUSA-N 0.000 description 4
- AMBLXEMWFARNNQ-DCAQKATOSA-N Pro-Asn-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@@H]1CCCN1 AMBLXEMWFARNNQ-DCAQKATOSA-N 0.000 description 4
- HAEGAELAYWSUNC-WPRPVWTQSA-N Pro-Gly-Val Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HAEGAELAYWSUNC-WPRPVWTQSA-N 0.000 description 4
- TYMBHHITTMGGPI-NAKRPEOUSA-N Pro-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@@H]1CCCN1 TYMBHHITTMGGPI-NAKRPEOUSA-N 0.000 description 4
- FYPGHGXAOZTOBO-IHRRRGAJSA-N Pro-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@@H]2CCCN2 FYPGHGXAOZTOBO-IHRRRGAJSA-N 0.000 description 4
- RMODQFBNDDENCP-IHRRRGAJSA-N Pro-Lys-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O RMODQFBNDDENCP-IHRRRGAJSA-N 0.000 description 4
- ZVEQWRWMRFIVSD-HRCADAONSA-N Pro-Phe-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N3CCC[C@@H]3C(=O)O ZVEQWRWMRFIVSD-HRCADAONSA-N 0.000 description 4
- VEUACYMXJKXALX-IHRRRGAJSA-N Pro-Tyr-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VEUACYMXJKXALX-IHRRRGAJSA-N 0.000 description 4
- DGDCSVGVWWAJRS-AVGNSLFASA-N Pro-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@@H]2CCCN2 DGDCSVGVWWAJRS-AVGNSLFASA-N 0.000 description 4
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 4
- 238000012181 QIAquick gel extraction kit Methods 0.000 description 4
- 108020004511 Recombinant DNA Proteins 0.000 description 4
- KCFKKAQKRZBWJB-ZLUOBGJFSA-N Ser-Cys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O KCFKKAQKRZBWJB-ZLUOBGJFSA-N 0.000 description 4
- XWCYBVBLJRWOFR-WDSKDSINSA-N Ser-Gln-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O XWCYBVBLJRWOFR-WDSKDSINSA-N 0.000 description 4
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 4
- SFTZTYBXIXLRGQ-JBDRJPRFSA-N Ser-Ile-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O SFTZTYBXIXLRGQ-JBDRJPRFSA-N 0.000 description 4
- ZOPISOXXPQNOCO-SVSWQMSJSA-N Ser-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CO)N ZOPISOXXPQNOCO-SVSWQMSJSA-N 0.000 description 4
- IUXGJEIKJBYKOO-SRVKXCTJSA-N Ser-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CO)N IUXGJEIKJBYKOO-SRVKXCTJSA-N 0.000 description 4
- KCGIREHVWRXNDH-GARJFASQSA-N Ser-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N KCGIREHVWRXNDH-GARJFASQSA-N 0.000 description 4
- AXOHAHIUJHCLQR-IHRRRGAJSA-N Ser-Met-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CO)N AXOHAHIUJHCLQR-IHRRRGAJSA-N 0.000 description 4
- WOJYIMBIKTWKJO-KKUMJFAQSA-N Ser-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CO)N WOJYIMBIKTWKJO-KKUMJFAQSA-N 0.000 description 4
- RWDVVSKYZBNDCO-MELADBBJSA-N Ser-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CO)N)C(=O)O RWDVVSKYZBNDCO-MELADBBJSA-N 0.000 description 4
- WUXCHQZLUHBSDJ-LKXGYXEUSA-N Ser-Thr-Asp Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC(O)=O)C(O)=O WUXCHQZLUHBSDJ-LKXGYXEUSA-N 0.000 description 4
- 229930006000 Sucrose Natural products 0.000 description 4
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 4
- LXWZOMSOUAMOIA-JIOCBJNQSA-N Thr-Asn-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O LXWZOMSOUAMOIA-JIOCBJNQSA-N 0.000 description 4
- GNHRVXYZKWSJTF-HJGDQZAQSA-N Thr-Asp-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N)O GNHRVXYZKWSJTF-HJGDQZAQSA-N 0.000 description 4
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 4
- IUFQHOCOKQIOMC-XIRDDKMYSA-N Trp-Asn-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N IUFQHOCOKQIOMC-XIRDDKMYSA-N 0.000 description 4
- AFSYEUHJBVCPEL-JBACZVJFSA-N Trp-Gln-Phe Chemical compound C([C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(O)=O)C1=CC=CC=C1 AFSYEUHJBVCPEL-JBACZVJFSA-N 0.000 description 4
- YXONONCLMLHWJX-SZMVWBNQSA-N Trp-Glu-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O)=CNC2=C1 YXONONCLMLHWJX-SZMVWBNQSA-N 0.000 description 4
- HABYQJRYDKEVOI-IHPCNDPISA-N Trp-His-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CN=CN3)C(=O)N[C@@H](CCCCN)C(=O)O)N HABYQJRYDKEVOI-IHPCNDPISA-N 0.000 description 4
- HVHJYXDXRIWELT-RYUDHWBXSA-N Tyr-Glu-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O HVHJYXDXRIWELT-RYUDHWBXSA-N 0.000 description 4
- KOVXHANYYYMBRF-IRIUXVKKSA-N Tyr-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O KOVXHANYYYMBRF-IRIUXVKKSA-N 0.000 description 4
- LRHBBGDMBLFYGL-FHWLQOOXSA-N Tyr-Phe-Glu Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=C(O)C=C1 LRHBBGDMBLFYGL-FHWLQOOXSA-N 0.000 description 4
- CVIOOPXLWWMJDA-UHFFFAOYSA-N Tyr-Pro-Ile-Pro-Phe Natural products C1CCC(C(=O)NC(CC=2C=CC=CC=2)C(O)=O)N1C(=O)C(C(C)CC)NC(=O)C1CCCN1C(=O)C(N)CC1=CC=C(O)C=C1 CVIOOPXLWWMJDA-UHFFFAOYSA-N 0.000 description 4
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 4
- DDRBQONWVBDQOY-GUBZILKMSA-N Val-Ala-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O DDRBQONWVBDQOY-GUBZILKMSA-N 0.000 description 4
- UEOOXDLMQZBPFR-ZKWXMUAHSA-N Val-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N UEOOXDLMQZBPFR-ZKWXMUAHSA-N 0.000 description 4
- ZLFHAAGHGQBQQN-GUBZILKMSA-N Val-Ala-Pro Natural products CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O ZLFHAAGHGQBQQN-GUBZILKMSA-N 0.000 description 4
- SLLKXDSRVAOREO-KZVJFYERSA-N Val-Ala-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N)O SLLKXDSRVAOREO-KZVJFYERSA-N 0.000 description 4
- NMANTMWGQZASQN-QXEWZRGKSA-N Val-Arg-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N NMANTMWGQZASQN-QXEWZRGKSA-N 0.000 description 4
- JOQSQZFKFYJKKJ-GUBZILKMSA-N Val-Arg-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N JOQSQZFKFYJKKJ-GUBZILKMSA-N 0.000 description 4
- COYSIHFOCOMGCF-UHFFFAOYSA-N Val-Arg-Gly Natural products CC(C)C(N)C(=O)NC(C(=O)NCC(O)=O)CCCN=C(N)N COYSIHFOCOMGCF-UHFFFAOYSA-N 0.000 description 4
- WJVLTYSHNXRCLT-NHCYSSNCSA-N Val-His-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(=O)O)C(=O)O)N WJVLTYSHNXRCLT-NHCYSSNCSA-N 0.000 description 4
- JPPXDMBGXJBTIB-ULQDDVLXSA-N Val-His-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N JPPXDMBGXJBTIB-ULQDDVLXSA-N 0.000 description 4
- KDKLLPMFFGYQJD-CYDGBPFRSA-N Val-Ile-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N KDKLLPMFFGYQJD-CYDGBPFRSA-N 0.000 description 4
- VCIYTVOBLZHFSC-XHSDSOJGSA-N Val-Phe-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N VCIYTVOBLZHFSC-XHSDSOJGSA-N 0.000 description 4
- UQMPYVLTQCGRSK-IFFSRLJSSA-N Val-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N)O UQMPYVLTQCGRSK-IFFSRLJSSA-N 0.000 description 4
- RTJPAGFXOWEBAI-SRVKXCTJSA-N Val-Val-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RTJPAGFXOWEBAI-SRVKXCTJSA-N 0.000 description 4
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 4
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 4
- 230000003321 amplification Effects 0.000 description 4
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 4
- 108010043240 arginyl-leucyl-glycine Proteins 0.000 description 4
- 108010047857 aspartylglycine Proteins 0.000 description 4
- 238000003556 assay Methods 0.000 description 4
- 239000000872 buffer Substances 0.000 description 4
- FFQKYPRQEYGKAF-UHFFFAOYSA-N carbamoyl phosphate Chemical compound NC(=O)OP(O)(O)=O FFQKYPRQEYGKAF-UHFFFAOYSA-N 0.000 description 4
- 235000013681 dietary sucrose Nutrition 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 4
- 230000002708 enhancing effect Effects 0.000 description 4
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 4
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 4
- 108010089804 glycyl-threonine Proteins 0.000 description 4
- 108010087823 glycyltyrosine Proteins 0.000 description 4
- 238000011534 incubation Methods 0.000 description 4
- 108010027338 isoleucylcysteine Proteins 0.000 description 4
- 239000007788 liquid Substances 0.000 description 4
- 238000003199 nucleic acid amplification method Methods 0.000 description 4
- WWZKQHOCKIZLMA-UHFFFAOYSA-N octanoic acid Chemical compound CCCCCCCC(O)=O WWZKQHOCKIZLMA-UHFFFAOYSA-N 0.000 description 4
- 230000003287 optical effect Effects 0.000 description 4
- 108010064486 phenylalanyl-leucyl-valine Proteins 0.000 description 4
- 108010089198 phenylalanyl-prolyl-arginine Proteins 0.000 description 4
- 108010051242 phenylalanylserine Proteins 0.000 description 4
- 239000002243 precursor Substances 0.000 description 4
- 108010070643 prolylglutamic acid Proteins 0.000 description 4
- 108010029020 prolylglycine Proteins 0.000 description 4
- 108010015796 prolylisoleucine Proteins 0.000 description 4
- 108010015840 seryl-prolyl-lysyl-lysine Proteins 0.000 description 4
- 229960004793 sucrose Drugs 0.000 description 4
- 108010031491 threonyl-lysyl-glutamic acid Proteins 0.000 description 4
- 108010052768 tyrosyl-isoleucyl-glycyl-seryl-arginine Proteins 0.000 description 4
- 108010020532 tyrosyl-proline Proteins 0.000 description 4
- 108010027345 wheylin-1 peptide Proteins 0.000 description 4
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 3
- KXEVYGKATAMXJJ-ACZMJKKPSA-N Ala-Glu-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KXEVYGKATAMXJJ-ACZMJKKPSA-N 0.000 description 3
- FUKFQILQFQKHLE-DCAQKATOSA-N Ala-Lys-Met Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(O)=O FUKFQILQFQKHLE-DCAQKATOSA-N 0.000 description 3
- FQNILRVJOJBFFC-FXQIFTODSA-N Ala-Pro-Asp Chemical compound C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N FQNILRVJOJBFFC-FXQIFTODSA-N 0.000 description 3
- OEVCHROQUIVQFZ-YTLHQDLWSA-N Ala-Thr-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(O)=O OEVCHROQUIVQFZ-YTLHQDLWSA-N 0.000 description 3
- DCGLNNVKIZXQOJ-FXQIFTODSA-N Arg-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N DCGLNNVKIZXQOJ-FXQIFTODSA-N 0.000 description 3
- 108700040066 Argininosuccinate lyases Proteins 0.000 description 3
- YFGUZQQCSDZRBN-DCAQKATOSA-N Asp-Pro-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O YFGUZQQCSDZRBN-DCAQKATOSA-N 0.000 description 3
- 241000894006 Bacteria Species 0.000 description 3
- 229910021591 Copper(I) chloride Inorganic materials 0.000 description 3
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 3
- 239000003155 DNA primer Substances 0.000 description 3
- 241000644323 Escherichia coli C Species 0.000 description 3
- DTMLKCYOQKZXKZ-HJGDQZAQSA-N Gln-Arg-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DTMLKCYOQKZXKZ-HJGDQZAQSA-N 0.000 description 3
- ZKJZBRHRWKLVSJ-ZDLURKLDSA-N Gly-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN)O ZKJZBRHRWKLVSJ-ZDLURKLDSA-N 0.000 description 3
- SOFSRBYHDINIRG-QTKMDUPCSA-N His-Arg-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC1=CN=CN1)N)O SOFSRBYHDINIRG-QTKMDUPCSA-N 0.000 description 3
- IWXMHXYOACDSIA-PYJNHQTQSA-N His-Ile-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O IWXMHXYOACDSIA-PYJNHQTQSA-N 0.000 description 3
- QSPLUJGYOPZINY-ZPFDUUQYSA-N Ile-Asp-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N QSPLUJGYOPZINY-ZPFDUUQYSA-N 0.000 description 3
- HGCNKOLVKRAVHD-UHFFFAOYSA-N L-Met-L-Phe Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 HGCNKOLVKRAVHD-UHFFFAOYSA-N 0.000 description 3
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 3
- 125000002059 L-arginyl group Chemical group O=C([*])[C@](N([H])[H])([H])C([H])([H])C([H])([H])C([H])([H])N([H])C(=N[H])N([H])[H] 0.000 description 3
- VLMNBMFYRMGEMB-QWRGUYRKSA-N Lys-His-Gly Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CNC=N1 VLMNBMFYRMGEMB-QWRGUYRKSA-N 0.000 description 3
- ZCWWVXAXWUAEPZ-SRVKXCTJSA-N Lys-Met-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZCWWVXAXWUAEPZ-SRVKXCTJSA-N 0.000 description 3
- LMKSBGIUPVRHEH-FXQIFTODSA-N Met-Ala-Asn Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(N)=O LMKSBGIUPVRHEH-FXQIFTODSA-N 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- 241001413577 Moorea producens Species 0.000 description 3
- UTJLXEIPEHZYQJ-UHFFFAOYSA-N Ornithine Natural products OC(=O)C(C)CCCN UTJLXEIPEHZYQJ-UHFFFAOYSA-N 0.000 description 3
- OPEVYHFJXLCCRT-AVGNSLFASA-N Phe-Gln-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O OPEVYHFJXLCCRT-AVGNSLFASA-N 0.000 description 3
- RYJRPPUATSKNAY-STECZYCISA-N Pro-Ile-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@@H]2CCCN2 RYJRPPUATSKNAY-STECZYCISA-N 0.000 description 3
- GURGCNUWVSDYTP-SRVKXCTJSA-N Pro-Leu-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GURGCNUWVSDYTP-SRVKXCTJSA-N 0.000 description 3
- DWPXHLIBFQLKLK-CYDGBPFRSA-N Pro-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 DWPXHLIBFQLKLK-CYDGBPFRSA-N 0.000 description 3
- 108091081024 Start codon Proteins 0.000 description 3
- OYTNZCBFDXGQGE-XQXXSGGOSA-N Thr-Gln-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C)C(=O)O)N)O OYTNZCBFDXGQGE-XQXXSGGOSA-N 0.000 description 3
- KPMIQCXJDVKWKO-IFFSRLJSSA-N Thr-Val-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O KPMIQCXJDVKWKO-IFFSRLJSSA-N 0.000 description 3
- HOJPPPKZWFRTHJ-PJODQICGSA-N Trp-Arg-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N HOJPPPKZWFRTHJ-PJODQICGSA-N 0.000 description 3
- CNLKDWSAORJEMW-KWQFWETISA-N Tyr-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O CNLKDWSAORJEMW-KWQFWETISA-N 0.000 description 3
- 238000000246 agarose gel electrophoresis Methods 0.000 description 3
- 102000006614 amidinotransferase Human genes 0.000 description 3
- 108020004134 amidinotransferase Proteins 0.000 description 3
- 229910021529 ammonia Inorganic materials 0.000 description 3
- 239000003795 chemical substances by application Substances 0.000 description 3
- 230000002759 chromosomal effect Effects 0.000 description 3
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 3
- OXBLHERUFWYNTN-UHFFFAOYSA-M copper(I) chloride Chemical compound [Cu]Cl OXBLHERUFWYNTN-UHFFFAOYSA-M 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- DHNGCHLFKUPGPX-RMKNXTFCSA-N ethyl trans-p-methoxycinnamate Chemical compound CCOC(=O)\C=C\C1=CC=C(OC)C=C1 DHNGCHLFKUPGPX-RMKNXTFCSA-N 0.000 description 3
- 230000006698 induction Effects 0.000 description 3
- 238000011081 inoculation Methods 0.000 description 3
- 108010017391 lysylvaline Proteins 0.000 description 3
- 108010068488 methionylphenylalanine Proteins 0.000 description 3
- 230000000813 microbial effect Effects 0.000 description 3
- 239000012071 phase Substances 0.000 description 3
- 238000013492 plasmid preparation Methods 0.000 description 3
- 108090000765 processed proteins & peptides Proteins 0.000 description 3
- 108010020432 prolyl-prolylisoleucine Proteins 0.000 description 3
- 230000008439 repair process Effects 0.000 description 3
- 239000011780 sodium chloride Substances 0.000 description 3
- 239000000600 sorbitol Substances 0.000 description 3
- 241000894007 species Species 0.000 description 3
- 239000007858 starting material Substances 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- XDEYHXABZOKKDZ-YFKLLHAASA-N (2s)-2-[[2-(diaminomethylideneamino)acetyl]-hydroxyamino]-n-[[(2r,3s,4r,5s)-5-(2,4-dioxo-1h-pyrimidin-5-yl)-3,4-dihydroxyoxolan-2-yl]methyl]pentanediamide Chemical compound O[C@@H]1[C@H](O)[C@@H](CNC(=O)[C@@H](N(O)C(=O)CN=C(N)N)CCC(=O)N)O[C@H]1C1=CNC(=O)NC1=O XDEYHXABZOKKDZ-YFKLLHAASA-N 0.000 description 2
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 2
- 108010044087 AS-I toxin Proteins 0.000 description 2
- 229920000936 Agarose Polymers 0.000 description 2
- AAQGRPOPTAUUBM-ZLUOBGJFSA-N Ala-Ala-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O AAQGRPOPTAUUBM-ZLUOBGJFSA-N 0.000 description 2
- DKJPOZOEBONHFS-ZLUOBGJFSA-N Ala-Ala-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O DKJPOZOEBONHFS-ZLUOBGJFSA-N 0.000 description 2
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 2
- ODWSTKXGQGYHSH-FXQIFTODSA-N Ala-Arg-Ala Chemical compound C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O ODWSTKXGQGYHSH-FXQIFTODSA-N 0.000 description 2
- SVBXIUDNTRTKHE-CIUDSAMLSA-N Ala-Arg-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O SVBXIUDNTRTKHE-CIUDSAMLSA-N 0.000 description 2
- CVGNCMIULZNYES-WHFBIAKZSA-N Ala-Asn-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O CVGNCMIULZNYES-WHFBIAKZSA-N 0.000 description 2
- BTYTYHBSJKQBQA-GCJQMDKQSA-N Ala-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N)O BTYTYHBSJKQBQA-GCJQMDKQSA-N 0.000 description 2
- WCBVQNZTOKJWJS-ACZMJKKPSA-N Ala-Cys-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O WCBVQNZTOKJWJS-ACZMJKKPSA-N 0.000 description 2
- XAGIMRPOEJSYER-CIUDSAMLSA-N Ala-Cys-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N XAGIMRPOEJSYER-CIUDSAMLSA-N 0.000 description 2
- LGFCAXJBAZESCF-ACZMJKKPSA-N Ala-Gln-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O LGFCAXJBAZESCF-ACZMJKKPSA-N 0.000 description 2
- RXTBLQVXNIECFP-FXQIFTODSA-N Ala-Gln-Gln Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O RXTBLQVXNIECFP-FXQIFTODSA-N 0.000 description 2
- SFNFGFDRYJKZKN-XQXXSGGOSA-N Ala-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C)N)O SFNFGFDRYJKZKN-XQXXSGGOSA-N 0.000 description 2
- NWVVKQZOVSTDBQ-CIUDSAMLSA-N Ala-Glu-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NWVVKQZOVSTDBQ-CIUDSAMLSA-N 0.000 description 2
- HMRWQTHUDVXMGH-GUBZILKMSA-N Ala-Glu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN HMRWQTHUDVXMGH-GUBZILKMSA-N 0.000 description 2
- BEMGNWZECGIJOI-WDSKDSINSA-N Ala-Gly-Glu Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O BEMGNWZECGIJOI-WDSKDSINSA-N 0.000 description 2
- BLIMFWGRQKRCGT-YUMQZZPRSA-N Ala-Gly-Lys Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN BLIMFWGRQKRCGT-YUMQZZPRSA-N 0.000 description 2
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 2
- SMCGQGDVTPFXKB-XPUUQOCRSA-N Ala-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N SMCGQGDVTPFXKB-XPUUQOCRSA-N 0.000 description 2
- JDIQCVUDDFENPU-ZKWXMUAHSA-N Ala-His-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CNC=N1 JDIQCVUDDFENPU-ZKWXMUAHSA-N 0.000 description 2
- PNALXAODQKTNLV-JBDRJPRFSA-N Ala-Ile-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O PNALXAODQKTNLV-JBDRJPRFSA-N 0.000 description 2
- FOHXUHGZZKETFI-JBDRJPRFSA-N Ala-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C)N FOHXUHGZZKETFI-JBDRJPRFSA-N 0.000 description 2
- DVJSJDDYCYSMFR-ZKWXMUAHSA-N Ala-Ile-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O DVJSJDDYCYSMFR-ZKWXMUAHSA-N 0.000 description 2
- NMXKFWOEASXOGB-QSFUFRPTSA-N Ala-Ile-His Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 NMXKFWOEASXOGB-QSFUFRPTSA-N 0.000 description 2
- XCZXVTHYGSMQGH-NAKRPEOUSA-N Ala-Ile-Met Chemical compound C[C@H]([NH3+])C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCSC)C([O-])=O XCZXVTHYGSMQGH-NAKRPEOUSA-N 0.000 description 2
- QCTFKEJEIMPOLW-JURCDPSOSA-N Ala-Ile-Phe Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QCTFKEJEIMPOLW-JURCDPSOSA-N 0.000 description 2
- HHRAXZAYZFFRAM-CIUDSAMLSA-N Ala-Leu-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O HHRAXZAYZFFRAM-CIUDSAMLSA-N 0.000 description 2
- SUMYEVXWCAYLLJ-GUBZILKMSA-N Ala-Leu-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O SUMYEVXWCAYLLJ-GUBZILKMSA-N 0.000 description 2
- AWZKCUCQJNTBAD-SRVKXCTJSA-N Ala-Leu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN AWZKCUCQJNTBAD-SRVKXCTJSA-N 0.000 description 2
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 2
- PMQXMXAASGFUDX-SRVKXCTJSA-N Ala-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CCCCN PMQXMXAASGFUDX-SRVKXCTJSA-N 0.000 description 2
- BLTRAARCJYVJKV-QEJZJMRPSA-N Ala-Lys-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](Cc1ccccc1)C(O)=O BLTRAARCJYVJKV-QEJZJMRPSA-N 0.000 description 2
- NINQYGGNRIBFSC-CIUDSAMLSA-N Ala-Lys-Ser Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CO)C(O)=O NINQYGGNRIBFSC-CIUDSAMLSA-N 0.000 description 2
- MDNAVFBZPROEHO-DCAQKATOSA-N Ala-Lys-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O MDNAVFBZPROEHO-DCAQKATOSA-N 0.000 description 2
- MDNAVFBZPROEHO-UHFFFAOYSA-N Ala-Lys-Val Natural products CC(C)C(C(O)=O)NC(=O)C(NC(=O)C(C)N)CCCCN MDNAVFBZPROEHO-UHFFFAOYSA-N 0.000 description 2
- NLOMBWNGESDVJU-GUBZILKMSA-N Ala-Met-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NLOMBWNGESDVJU-GUBZILKMSA-N 0.000 description 2
- IHRGVZXPTIQNIP-NAKRPEOUSA-N Ala-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C)N IHRGVZXPTIQNIP-NAKRPEOUSA-N 0.000 description 2
- GKAZXNDATBWNBI-DCAQKATOSA-N Ala-Met-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)O)N GKAZXNDATBWNBI-DCAQKATOSA-N 0.000 description 2
- BFMIRJBURUXDRG-DLOVCJGASA-N Ala-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 BFMIRJBURUXDRG-DLOVCJGASA-N 0.000 description 2
- VJVQKGYHIZPSNS-FXQIFTODSA-N Ala-Ser-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N VJVQKGYHIZPSNS-FXQIFTODSA-N 0.000 description 2
- MSWSRLGNLKHDEI-ACZMJKKPSA-N Ala-Ser-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O MSWSRLGNLKHDEI-ACZMJKKPSA-N 0.000 description 2
- MMLHRUJLOUSRJX-CIUDSAMLSA-N Ala-Ser-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN MMLHRUJLOUSRJX-CIUDSAMLSA-N 0.000 description 2
- NZGRHTKZFSVPAN-BIIVOSGPSA-N Ala-Ser-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N NZGRHTKZFSVPAN-BIIVOSGPSA-N 0.000 description 2
- LSMDIAAALJJLRO-XQXXSGGOSA-N Ala-Thr-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O LSMDIAAALJJLRO-XQXXSGGOSA-N 0.000 description 2
- VNFSAYFQLXPHPY-CIQUZCHMSA-N Ala-Thr-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNFSAYFQLXPHPY-CIQUZCHMSA-N 0.000 description 2
- JJHBEVZAZXZREW-LFSVMHDDSA-N Ala-Thr-Phe Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](Cc1ccccc1)C(O)=O JJHBEVZAZXZREW-LFSVMHDDSA-N 0.000 description 2
- IETUUAHKCHOQHP-KZVJFYERSA-N Ala-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](C)N)[C@@H](C)O)C(O)=O IETUUAHKCHOQHP-KZVJFYERSA-N 0.000 description 2
- VQBULXOHAZSTQY-GKCIPKSASA-N Ala-Trp-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O VQBULXOHAZSTQY-GKCIPKSASA-N 0.000 description 2
- AOAKQKVICDWCLB-UWJYBYFXSA-N Ala-Tyr-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N AOAKQKVICDWCLB-UWJYBYFXSA-N 0.000 description 2
- QRIYOHQJRDHFKF-UWJYBYFXSA-N Ala-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=C(O)C=C1 QRIYOHQJRDHFKF-UWJYBYFXSA-N 0.000 description 2
- IYKVSFNGSWTTNZ-GUBZILKMSA-N Ala-Val-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IYKVSFNGSWTTNZ-GUBZILKMSA-N 0.000 description 2
- ZCUFMRIQCPNOHZ-NRPADANISA-N Ala-Val-Gln Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N ZCUFMRIQCPNOHZ-NRPADANISA-N 0.000 description 2
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 2
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 2
- 244000153158 Ammi visnaga Species 0.000 description 2
- 235000010585 Ammi visnaga Nutrition 0.000 description 2
- 108091093088 Amplicon Proteins 0.000 description 2
- VBFJESQBIWCWRL-DCAQKATOSA-N Arg-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCNC(N)=N VBFJESQBIWCWRL-DCAQKATOSA-N 0.000 description 2
- SBVJJNJLFWSJOV-UBHSHLNASA-N Arg-Ala-Phe Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SBVJJNJLFWSJOV-UBHSHLNASA-N 0.000 description 2
- RCAUJZASOAFTAJ-FXQIFTODSA-N Arg-Asp-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N)CN=C(N)N RCAUJZASOAFTAJ-FXQIFTODSA-N 0.000 description 2
- YFBGNGASPGRWEM-DCAQKATOSA-N Arg-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N YFBGNGASPGRWEM-DCAQKATOSA-N 0.000 description 2
- OTCJMMRQBVDQRK-DCAQKATOSA-N Arg-Asp-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O OTCJMMRQBVDQRK-DCAQKATOSA-N 0.000 description 2
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 description 2
- LLZXKVAAEWBUPB-KKUMJFAQSA-N Arg-Gln-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LLZXKVAAEWBUPB-KKUMJFAQSA-N 0.000 description 2
- HPKSHFSEXICTLI-CIUDSAMLSA-N Arg-Glu-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HPKSHFSEXICTLI-CIUDSAMLSA-N 0.000 description 2
- OHYQKYUTLIPFOX-ZPFDUUQYSA-N Arg-Glu-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O OHYQKYUTLIPFOX-ZPFDUUQYSA-N 0.000 description 2
- PPPXVIBMLFWNSK-BQBZGAKWSA-N Arg-Gly-Cys Chemical compound C(C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N)CN=C(N)N PPPXVIBMLFWNSK-BQBZGAKWSA-N 0.000 description 2
- NKNILFJYKKHBKE-WPRPVWTQSA-N Arg-Gly-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O NKNILFJYKKHBKE-WPRPVWTQSA-N 0.000 description 2
- MSILNNHVVMMTHZ-UWVGGRQHSA-N Arg-His-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CN=CN1 MSILNNHVVMMTHZ-UWVGGRQHSA-N 0.000 description 2
- RKQRHMKFNBYOTN-IHRRRGAJSA-N Arg-His-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N RKQRHMKFNBYOTN-IHRRRGAJSA-N 0.000 description 2
- IRRMIGDCPOPZJW-ULQDDVLXSA-N Arg-His-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O IRRMIGDCPOPZJW-ULQDDVLXSA-N 0.000 description 2
- OOIMKQRCPJBGPD-XUXIUFHCSA-N Arg-Ile-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O OOIMKQRCPJBGPD-XUXIUFHCSA-N 0.000 description 2
- GMFAGHNRXPSSJS-SRVKXCTJSA-N Arg-Leu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GMFAGHNRXPSSJS-SRVKXCTJSA-N 0.000 description 2
- UZGFHWIJWPUPOH-IHRRRGAJSA-N Arg-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UZGFHWIJWPUPOH-IHRRRGAJSA-N 0.000 description 2
- FSNVAJOPUDVQAR-AVGNSLFASA-N Arg-Lys-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FSNVAJOPUDVQAR-AVGNSLFASA-N 0.000 description 2
- NGTYEHIRESTSRX-UWVGGRQHSA-N Arg-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N NGTYEHIRESTSRX-UWVGGRQHSA-N 0.000 description 2
- VEAIMHJZTIDCIH-KKUMJFAQSA-N Arg-Phe-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O VEAIMHJZTIDCIH-KKUMJFAQSA-N 0.000 description 2
- PRLPSDIHSRITSF-UNQGMJICSA-N Arg-Phe-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PRLPSDIHSRITSF-UNQGMJICSA-N 0.000 description 2
- ISJWBVIYRBAXEB-CIUDSAMLSA-N Arg-Ser-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISJWBVIYRBAXEB-CIUDSAMLSA-N 0.000 description 2
- DNLQVHBBMPZUGJ-BQBZGAKWSA-N Arg-Ser-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O DNLQVHBBMPZUGJ-BQBZGAKWSA-N 0.000 description 2
- AIFHRTPABBBHKU-RCWTZXSCSA-N Arg-Thr-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O AIFHRTPABBBHKU-RCWTZXSCSA-N 0.000 description 2
- WCZXPVPHUMYLMS-VEVYYDQMSA-N Arg-Thr-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O WCZXPVPHUMYLMS-VEVYYDQMSA-N 0.000 description 2
- ZJBUILVYSXQNSW-YTWAJWBKSA-N Arg-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ZJBUILVYSXQNSW-YTWAJWBKSA-N 0.000 description 2
- PJOPLXOCKACMLK-KKUMJFAQSA-N Arg-Tyr-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O PJOPLXOCKACMLK-KKUMJFAQSA-N 0.000 description 2
- XMZZGVGKGXRIGJ-JYJNAYRXSA-N Arg-Tyr-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O XMZZGVGKGXRIGJ-JYJNAYRXSA-N 0.000 description 2
- PSUXEQYPYZLNER-QXEWZRGKSA-N Arg-Val-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O PSUXEQYPYZLNER-QXEWZRGKSA-N 0.000 description 2
- QTAIIXQCOPUNBQ-QXEWZRGKSA-N Arg-Val-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QTAIIXQCOPUNBQ-QXEWZRGKSA-N 0.000 description 2
- LLQIAIUAKGNOSE-NHCYSSNCSA-N Arg-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N LLQIAIUAKGNOSE-NHCYSSNCSA-N 0.000 description 2
- FMYQECOAIFGQGU-CYDGBPFRSA-N Arg-Val-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FMYQECOAIFGQGU-CYDGBPFRSA-N 0.000 description 2
- SUMJNGAMIQSNGX-TUAOUCFPSA-N Arg-Val-Pro Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCCNC(N)=N)C(=O)N1CCC[C@@H]1C(O)=O SUMJNGAMIQSNGX-TUAOUCFPSA-N 0.000 description 2
- UTSMXMABBPFVJP-SZMVWBNQSA-N Arg-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UTSMXMABBPFVJP-SZMVWBNQSA-N 0.000 description 2
- KDZOASGQNOPSCU-WDSKDSINSA-N Argininosuccinic acid Chemical compound OC(=O)[C@@H](N)CCC\N=C(/N)N[C@H](C(O)=O)CC(O)=O KDZOASGQNOPSCU-WDSKDSINSA-N 0.000 description 2
- RZVVKNIACROXRM-ZLUOBGJFSA-N Asn-Ala-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N RZVVKNIACROXRM-ZLUOBGJFSA-N 0.000 description 2
- XWGJDUSDTRPQRK-ZLUOBGJFSA-N Asn-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(N)=O XWGJDUSDTRPQRK-ZLUOBGJFSA-N 0.000 description 2
- JEPNYDRDYNSFIU-QXEWZRGKSA-N Asn-Arg-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(N)=O)C(O)=O JEPNYDRDYNSFIU-QXEWZRGKSA-N 0.000 description 2
- CUQUEHYSSFETRD-ACZMJKKPSA-N Asn-Asp-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N CUQUEHYSSFETRD-ACZMJKKPSA-N 0.000 description 2
- ZWASIOHRQWRWAS-UGYAYLCHSA-N Asn-Asp-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZWASIOHRQWRWAS-UGYAYLCHSA-N 0.000 description 2
- HLTLEIXYIJDFOY-ZLUOBGJFSA-N Asn-Cys-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(O)=O HLTLEIXYIJDFOY-ZLUOBGJFSA-N 0.000 description 2
- LUVODTFFSXVOAG-ACZMJKKPSA-N Asn-Cys-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)N)N LUVODTFFSXVOAG-ACZMJKKPSA-N 0.000 description 2
- IICZCLFBILYRCU-WHFBIAKZSA-N Asn-Gly-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O IICZCLFBILYRCU-WHFBIAKZSA-N 0.000 description 2
- PLVAAIPKSGUXDV-WHFBIAKZSA-N Asn-Gly-Cys Chemical compound C([C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N)C(=O)N PLVAAIPKSGUXDV-WHFBIAKZSA-N 0.000 description 2
- OOWSBIOUKIUWLO-RCOVLWMOSA-N Asn-Gly-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O OOWSBIOUKIUWLO-RCOVLWMOSA-N 0.000 description 2
- VXLBDJWTONZHJN-YUMQZZPRSA-N Asn-His-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC(=O)N)N VXLBDJWTONZHJN-YUMQZZPRSA-N 0.000 description 2
- GLWFAWNYGWBMOC-SRVKXCTJSA-N Asn-Leu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GLWFAWNYGWBMOC-SRVKXCTJSA-N 0.000 description 2
- GMUOCGCDOYYWPD-FXQIFTODSA-N Asn-Pro-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O GMUOCGCDOYYWPD-FXQIFTODSA-N 0.000 description 2
- WLVLIYYBPPONRJ-GCJQMDKQSA-N Asn-Thr-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O WLVLIYYBPPONRJ-GCJQMDKQSA-N 0.000 description 2
- QUMKPKWYDVMGNT-NUMRIWBASA-N Asn-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QUMKPKWYDVMGNT-NUMRIWBASA-N 0.000 description 2
- BCADFFUQHIMQAA-KKHAAJSZSA-N Asn-Thr-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O BCADFFUQHIMQAA-KKHAAJSZSA-N 0.000 description 2
- FLJVGAFLZVBBNG-BPUTZDHNSA-N Asn-Trp-Arg Chemical compound N[C@@H](CC(=O)N)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(=O)N[C@@H](CCCNC(=N)N)C(=O)O FLJVGAFLZVBBNG-BPUTZDHNSA-N 0.000 description 2
- XLDMSQYOYXINSZ-QXEWZRGKSA-N Asn-Val-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N XLDMSQYOYXINSZ-QXEWZRGKSA-N 0.000 description 2
- LTDGPJKGJDIBQD-LAEOZQHASA-N Asn-Val-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LTDGPJKGJDIBQD-LAEOZQHASA-N 0.000 description 2
- WQAOZCVOOYUWKG-LSJOCFKGSA-N Asn-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CC(=O)N)N WQAOZCVOOYUWKG-LSJOCFKGSA-N 0.000 description 2
- SLHOOKXYTYAJGQ-XVYDVKMFSA-N Asp-Ala-His Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CNC=N1 SLHOOKXYTYAJGQ-XVYDVKMFSA-N 0.000 description 2
- CXBOKJPLEYUPGB-FXQIFTODSA-N Asp-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(=O)O)N CXBOKJPLEYUPGB-FXQIFTODSA-N 0.000 description 2
- NECWUSYTYSIFNC-DLOVCJGASA-N Asp-Ala-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 NECWUSYTYSIFNC-DLOVCJGASA-N 0.000 description 2
- NJIKKGUVGUBICV-ZLUOBGJFSA-N Asp-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O NJIKKGUVGUBICV-ZLUOBGJFSA-N 0.000 description 2
- RGKKALNPOYURGE-ZKWXMUAHSA-N Asp-Ala-Val Chemical compound N[C@@H](CC(=O)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O RGKKALNPOYURGE-ZKWXMUAHSA-N 0.000 description 2
- OERMIMJQPQUIPK-FXQIFTODSA-N Asp-Arg-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O OERMIMJQPQUIPK-FXQIFTODSA-N 0.000 description 2
- WSOKZUVWBXVJHX-CIUDSAMLSA-N Asp-Arg-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O WSOKZUVWBXVJHX-CIUDSAMLSA-N 0.000 description 2
- HMQDRBKQMLRCCG-GMOBBJLQSA-N Asp-Arg-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HMQDRBKQMLRCCG-GMOBBJLQSA-N 0.000 description 2
- RSMIHCFQDCVVBR-CIUDSAMLSA-N Asp-Gln-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCNC(N)=N RSMIHCFQDCVVBR-CIUDSAMLSA-N 0.000 description 2
- ZSJFGGSPCCHMNE-LAEOZQHASA-N Asp-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N ZSJFGGSPCCHMNE-LAEOZQHASA-N 0.000 description 2
- VILLWIDTHYPSLC-PEFMBERDSA-N Asp-Glu-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VILLWIDTHYPSLC-PEFMBERDSA-N 0.000 description 2
- HAFCJCDJGIOYPW-WDSKDSINSA-N Asp-Gly-Gln Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O HAFCJCDJGIOYPW-WDSKDSINSA-N 0.000 description 2
- WSGVTKZFVJSJOG-RCOVLWMOSA-N Asp-Gly-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O WSGVTKZFVJSJOG-RCOVLWMOSA-N 0.000 description 2
- GBSUGIXJAAKZOW-GMOBBJLQSA-N Asp-Ile-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O GBSUGIXJAAKZOW-GMOBBJLQSA-N 0.000 description 2
- SEMWSADZTMJELF-BYULHYEWSA-N Asp-Ile-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O SEMWSADZTMJELF-BYULHYEWSA-N 0.000 description 2
- OEDJQRXNDRUGEU-SRVKXCTJSA-N Asp-Leu-His Chemical compound N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O OEDJQRXNDRUGEU-SRVKXCTJSA-N 0.000 description 2
- IVPNEDNYYYFAGI-GARJFASQSA-N Asp-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N IVPNEDNYYYFAGI-GARJFASQSA-N 0.000 description 2
- UZFHNLYQWMGUHU-DCAQKATOSA-N Asp-Lys-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UZFHNLYQWMGUHU-DCAQKATOSA-N 0.000 description 2
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 2
- UAXIKORUDGGIGA-DCAQKATOSA-N Asp-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O UAXIKORUDGGIGA-DCAQKATOSA-N 0.000 description 2
- FAUPLTGRUBTXNU-FXQIFTODSA-N Asp-Pro-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O FAUPLTGRUBTXNU-FXQIFTODSA-N 0.000 description 2
- NBKLEMWHDLAUEM-CIUDSAMLSA-N Asp-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N NBKLEMWHDLAUEM-CIUDSAMLSA-N 0.000 description 2
- HRVQDZOWMLFAOD-BIIVOSGPSA-N Asp-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N)C(=O)O HRVQDZOWMLFAOD-BIIVOSGPSA-N 0.000 description 2
- XYPJXLLXNSAWHZ-SRVKXCTJSA-N Asp-Ser-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XYPJXLLXNSAWHZ-SRVKXCTJSA-N 0.000 description 2
- JJQGZGOEDSSHTE-FOHZUACHSA-N Asp-Thr-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O JJQGZGOEDSSHTE-FOHZUACHSA-N 0.000 description 2
- KCOPOPKJRHVGPE-AQZXSJQPSA-N Asp-Thr-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O KCOPOPKJRHVGPE-AQZXSJQPSA-N 0.000 description 2
- JDDYEZGPYBBPBN-JRQIVUDYSA-N Asp-Thr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JDDYEZGPYBBPBN-JRQIVUDYSA-N 0.000 description 2
- WOKXEQLPBLLWHC-IHRRRGAJSA-N Asp-Tyr-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)CC1=CC=C(O)C=C1 WOKXEQLPBLLWHC-IHRRRGAJSA-N 0.000 description 2
- BYLPQJAWXJWUCJ-YDHLFZDLSA-N Asp-Tyr-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O BYLPQJAWXJWUCJ-YDHLFZDLSA-N 0.000 description 2
- XWKBWZXGNXTDKY-ZKWXMUAHSA-N Asp-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O XWKBWZXGNXTDKY-ZKWXMUAHSA-N 0.000 description 2
- WAEDSQFVZJUHLI-BYULHYEWSA-N Asp-Val-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O WAEDSQFVZJUHLI-BYULHYEWSA-N 0.000 description 2
- GIKOVDMXBAFXDF-NHCYSSNCSA-N Asp-Val-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GIKOVDMXBAFXDF-NHCYSSNCSA-N 0.000 description 2
- SFJUYBCDQBAYAJ-YDHLFZDLSA-N Asp-Val-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SFJUYBCDQBAYAJ-YDHLFZDLSA-N 0.000 description 2
- GYNUXDMCDILYIQ-QRTARXTBSA-N Asp-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N GYNUXDMCDILYIQ-QRTARXTBSA-N 0.000 description 2
- 102100021277 Beta-secretase 2 Human genes 0.000 description 2
- 101710150190 Beta-secretase 2 Proteins 0.000 description 2
- 102100026422 Carbamoyl-phosphate synthase [ammonia], mitochondrial Human genes 0.000 description 2
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 2
- 108091026890 Coding region Proteins 0.000 description 2
- TVYMKYUSZSVOAG-ZLUOBGJFSA-N Cys-Ala-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O TVYMKYUSZSVOAG-ZLUOBGJFSA-N 0.000 description 2
- CPTUXCUWQIBZIF-ZLUOBGJFSA-N Cys-Asn-Ser Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CPTUXCUWQIBZIF-ZLUOBGJFSA-N 0.000 description 2
- HNNGTYHNYDOSKV-FXQIFTODSA-N Cys-Cys-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CS)N HNNGTYHNYDOSKV-FXQIFTODSA-N 0.000 description 2
- YUZPQIQWXLRFBW-ACZMJKKPSA-N Cys-Glu-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O YUZPQIQWXLRFBW-ACZMJKKPSA-N 0.000 description 2
- LBOLGUYQEPZSKM-YUMQZZPRSA-N Cys-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CS)N LBOLGUYQEPZSKM-YUMQZZPRSA-N 0.000 description 2
- ZMWOJVAXTOUHAP-ZKWXMUAHSA-N Cys-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N ZMWOJVAXTOUHAP-ZKWXMUAHSA-N 0.000 description 2
- CUXIOFHFFXNUGG-HTFCKZLJSA-N Cys-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H](CS)N CUXIOFHFFXNUGG-HTFCKZLJSA-N 0.000 description 2
- IZUNQDRIAOLWCN-YUMQZZPRSA-N Cys-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N IZUNQDRIAOLWCN-YUMQZZPRSA-N 0.000 description 2
- CAXGCBSRJLADPD-FXQIFTODSA-N Cys-Pro-Asn Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O CAXGCBSRJLADPD-FXQIFTODSA-N 0.000 description 2
- NAPULYCVEVVFRB-HEIBUPTGSA-N Cys-Thr-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)CS NAPULYCVEVVFRB-HEIBUPTGSA-N 0.000 description 2
- 102000012410 DNA Ligases Human genes 0.000 description 2
- 108010061982 DNA Ligases Proteins 0.000 description 2
- 241001646716 Escherichia coli K-12 Species 0.000 description 2
- RZSLYUUFFVHFRQ-FXQIFTODSA-N Gln-Ala-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O RZSLYUUFFVHFRQ-FXQIFTODSA-N 0.000 description 2
- LKUWAWGNJYJODH-KBIXCLLPSA-N Gln-Ala-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LKUWAWGNJYJODH-KBIXCLLPSA-N 0.000 description 2
- XXLBHPPXDUWYAG-XQXXSGGOSA-N Gln-Ala-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XXLBHPPXDUWYAG-XQXXSGGOSA-N 0.000 description 2
- XEYMBRRKIFYQMF-GUBZILKMSA-N Gln-Asp-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O XEYMBRRKIFYQMF-GUBZILKMSA-N 0.000 description 2
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 2
- CGVWDTRDPLOMHZ-FXQIFTODSA-N Gln-Glu-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O CGVWDTRDPLOMHZ-FXQIFTODSA-N 0.000 description 2
- KQOPMGBHNQBCEL-HVTMNAMFSA-N Gln-His-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KQOPMGBHNQBCEL-HVTMNAMFSA-N 0.000 description 2
- HWEINOMSWQSJDC-SRVKXCTJSA-N Gln-Leu-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O HWEINOMSWQSJDC-SRVKXCTJSA-N 0.000 description 2
- XFAUJGNLHIGXET-AVGNSLFASA-N Gln-Leu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XFAUJGNLHIGXET-AVGNSLFASA-N 0.000 description 2
- QMVCEWKHIUHTSD-GUBZILKMSA-N Gln-Met-Glu Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N QMVCEWKHIUHTSD-GUBZILKMSA-N 0.000 description 2
- DOMHVQBSRJNNKD-ZPFDUUQYSA-N Gln-Met-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DOMHVQBSRJNNKD-ZPFDUUQYSA-N 0.000 description 2
- RWCBJYUPAUTWJD-NHCYSSNCSA-N Gln-Met-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O RWCBJYUPAUTWJD-NHCYSSNCSA-N 0.000 description 2
- SWDSRANUCKNBLA-AVGNSLFASA-N Gln-Phe-Asp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N SWDSRANUCKNBLA-AVGNSLFASA-N 0.000 description 2
- QBEWLBKBGXVVPD-RYUDHWBXSA-N Gln-Phe-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N QBEWLBKBGXVVPD-RYUDHWBXSA-N 0.000 description 2
- YPFFHGRJCUBXPX-NHCYSSNCSA-N Gln-Pro-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O)C(O)=O YPFFHGRJCUBXPX-NHCYSSNCSA-N 0.000 description 2
- HNAUFGBKJLTWQE-IFFSRLJSSA-N Gln-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCC(=O)N)N)O HNAUFGBKJLTWQE-IFFSRLJSSA-N 0.000 description 2
- RUFHOVYUYSNDNY-ACZMJKKPSA-N Glu-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O RUFHOVYUYSNDNY-ACZMJKKPSA-N 0.000 description 2
- SZXSSXUNOALWCH-ACZMJKKPSA-N Glu-Ala-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O SZXSSXUNOALWCH-ACZMJKKPSA-N 0.000 description 2
- UTKUTMJSWKKHEM-WDSKDSINSA-N Glu-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O UTKUTMJSWKKHEM-WDSKDSINSA-N 0.000 description 2
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 2
- ATRHMOJQJWPVBQ-DRZSPHRISA-N Glu-Ala-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ATRHMOJQJWPVBQ-DRZSPHRISA-N 0.000 description 2
- NCWOMXABNYEPLY-NRPADANISA-N Glu-Ala-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O NCWOMXABNYEPLY-NRPADANISA-N 0.000 description 2
- PBEQPAZRHDVJQI-SRVKXCTJSA-N Glu-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)O)N PBEQPAZRHDVJQI-SRVKXCTJSA-N 0.000 description 2
- KKCUFHUTMKQQCF-SRVKXCTJSA-N Glu-Arg-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O KKCUFHUTMKQQCF-SRVKXCTJSA-N 0.000 description 2
- FLLRAEJOLZPSMN-CIUDSAMLSA-N Glu-Asn-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N FLLRAEJOLZPSMN-CIUDSAMLSA-N 0.000 description 2
- RDPOETHPAQEGDP-ACZMJKKPSA-N Glu-Asp-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O RDPOETHPAQEGDP-ACZMJKKPSA-N 0.000 description 2
- DSPQRJXOIXHOHK-WDSKDSINSA-N Glu-Asp-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O DSPQRJXOIXHOHK-WDSKDSINSA-N 0.000 description 2
- WATXSTJXNBOHKD-LAEOZQHASA-N Glu-Asp-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O WATXSTJXNBOHKD-LAEOZQHASA-N 0.000 description 2
- OXEMJGCAJFFREE-FXQIFTODSA-N Glu-Gln-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O OXEMJGCAJFFREE-FXQIFTODSA-N 0.000 description 2
- CGOHAEBMDSEKFB-FXQIFTODSA-N Glu-Glu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O CGOHAEBMDSEKFB-FXQIFTODSA-N 0.000 description 2
- BUZMZDDKFCSKOT-CIUDSAMLSA-N Glu-Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BUZMZDDKFCSKOT-CIUDSAMLSA-N 0.000 description 2
- SJPMNHCEWPTRBR-BQBZGAKWSA-N Glu-Glu-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O SJPMNHCEWPTRBR-BQBZGAKWSA-N 0.000 description 2
- YLJHCWNDBKKOEB-IHRRRGAJSA-N Glu-Glu-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O YLJHCWNDBKKOEB-IHRRRGAJSA-N 0.000 description 2
- PHONAZGUEGIOEM-GLLZPBPUSA-N Glu-Glu-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PHONAZGUEGIOEM-GLLZPBPUSA-N 0.000 description 2
- ZCOJVESMNGBGLF-GRLWGSQLSA-N Glu-Ile-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZCOJVESMNGBGLF-GRLWGSQLSA-N 0.000 description 2
- ATVYZJGOZLVXDK-IUCAKERBSA-N Glu-Leu-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O ATVYZJGOZLVXDK-IUCAKERBSA-N 0.000 description 2
- IVGJYOOGJLFKQE-AVGNSLFASA-N Glu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N IVGJYOOGJLFKQE-AVGNSLFASA-N 0.000 description 2
- ILWHFUZZCFYSKT-AVGNSLFASA-N Glu-Lys-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O ILWHFUZZCFYSKT-AVGNSLFASA-N 0.000 description 2
- RBXSZQRSEGYDFG-GUBZILKMSA-N Glu-Lys-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O RBXSZQRSEGYDFG-GUBZILKMSA-N 0.000 description 2
- SUIAHERNFYRBDZ-GVXVVHGQSA-N Glu-Lys-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O SUIAHERNFYRBDZ-GVXVVHGQSA-N 0.000 description 2
- CBEUFCJRFNZMCU-SRVKXCTJSA-N Glu-Met-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O CBEUFCJRFNZMCU-SRVKXCTJSA-N 0.000 description 2
- SOEPMWQCTJITPZ-SRVKXCTJSA-N Glu-Met-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N SOEPMWQCTJITPZ-SRVKXCTJSA-N 0.000 description 2
- HQOGXFLBAKJUMH-CIUDSAMLSA-N Glu-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)O)N HQOGXFLBAKJUMH-CIUDSAMLSA-N 0.000 description 2
- KXTAGESXNQEZKB-DZKIICNBSA-N Glu-Phe-Val Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=CC=C1 KXTAGESXNQEZKB-DZKIICNBSA-N 0.000 description 2
- BIYNPVYAZOUVFQ-CIUDSAMLSA-N Glu-Pro-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O BIYNPVYAZOUVFQ-CIUDSAMLSA-N 0.000 description 2
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 2
- ZAPFAWQHBOHWLL-GUBZILKMSA-N Glu-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N ZAPFAWQHBOHWLL-GUBZILKMSA-N 0.000 description 2
- VNCNWQPIQYAMAK-ACZMJKKPSA-N Glu-Ser-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O VNCNWQPIQYAMAK-ACZMJKKPSA-N 0.000 description 2
- QCMVGXDELYMZET-GLLZPBPUSA-N Glu-Thr-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QCMVGXDELYMZET-GLLZPBPUSA-N 0.000 description 2
- GPSHCSTUYOQPAI-JHEQGTHGSA-N Glu-Thr-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O GPSHCSTUYOQPAI-JHEQGTHGSA-N 0.000 description 2
- RGJKYNUINKGPJN-RWRJDSDZSA-N Glu-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(=O)O)N RGJKYNUINKGPJN-RWRJDSDZSA-N 0.000 description 2
- QGAJQIGFFIQJJK-IHRRRGAJSA-N Glu-Tyr-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O QGAJQIGFFIQJJK-IHRRRGAJSA-N 0.000 description 2
- RXJFSLQVMGYQEL-IHRRRGAJSA-N Glu-Tyr-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCC(O)=O)C(O)=O)CC1=CC=C(O)C=C1 RXJFSLQVMGYQEL-IHRRRGAJSA-N 0.000 description 2
- KIEICAOUSNYOLM-NRPADANISA-N Glu-Val-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O KIEICAOUSNYOLM-NRPADANISA-N 0.000 description 2
- MLILEEIVMRUYBX-NHCYSSNCSA-N Glu-Val-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O MLILEEIVMRUYBX-NHCYSSNCSA-N 0.000 description 2
- SOYWRINXUSUWEQ-DLOVCJGASA-N Glu-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O SOYWRINXUSUWEQ-DLOVCJGASA-N 0.000 description 2
- BRFJMRSRMOMIMU-WHFBIAKZSA-N Gly-Ala-Asn Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O BRFJMRSRMOMIMU-WHFBIAKZSA-N 0.000 description 2
- GZUKEVBTYNNUQF-WDSKDSINSA-N Gly-Ala-Gln Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GZUKEVBTYNNUQF-WDSKDSINSA-N 0.000 description 2
- JBRBACJPBZNFMF-YUMQZZPRSA-N Gly-Ala-Lys Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN JBRBACJPBZNFMF-YUMQZZPRSA-N 0.000 description 2
- QIZJOTQTCAGKPU-KWQFWETISA-N Gly-Ala-Tyr Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CC1=CC=C(O)C=C1 QIZJOTQTCAGKPU-KWQFWETISA-N 0.000 description 2
- RQZGFWKQLPJOEQ-YUMQZZPRSA-N Gly-Arg-Gln Chemical compound C(C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)CN)CN=C(N)N RQZGFWKQLPJOEQ-YUMQZZPRSA-N 0.000 description 2
- KFMBRBPXHVMDFN-UWVGGRQHSA-N Gly-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCNC(N)=N KFMBRBPXHVMDFN-UWVGGRQHSA-N 0.000 description 2
- VXKCPBPQEKKERH-IUCAKERBSA-N Gly-Arg-Pro Chemical compound NC(N)=NCCC[C@H](NC(=O)CN)C(=O)N1CCC[C@H]1C(O)=O VXKCPBPQEKKERH-IUCAKERBSA-N 0.000 description 2
- KKBWDNZXYLGJEY-UHFFFAOYSA-N Gly-Arg-Pro Natural products NCC(=O)NC(CCNC(=N)N)C(=O)N1CCCC1C(=O)O KKBWDNZXYLGJEY-UHFFFAOYSA-N 0.000 description 2
- GWCRIHNSVMOBEQ-BQBZGAKWSA-N Gly-Arg-Ser Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O GWCRIHNSVMOBEQ-BQBZGAKWSA-N 0.000 description 2
- FMNHBTKMRFVGRO-FOHZUACHSA-N Gly-Asn-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)CN FMNHBTKMRFVGRO-FOHZUACHSA-N 0.000 description 2
- XQHSBNVACKQWAV-WHFBIAKZSA-N Gly-Asp-Asn Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O XQHSBNVACKQWAV-WHFBIAKZSA-N 0.000 description 2
- MHHUEAIBJZWDBH-YUMQZZPRSA-N Gly-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN MHHUEAIBJZWDBH-YUMQZZPRSA-N 0.000 description 2
- YZACQYVWLCQWBT-BQBZGAKWSA-N Gly-Cys-Arg Chemical compound [H]NCC(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O YZACQYVWLCQWBT-BQBZGAKWSA-N 0.000 description 2
- KTSZUNRRYXPZTK-BQBZGAKWSA-N Gly-Gln-Glu Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KTSZUNRRYXPZTK-BQBZGAKWSA-N 0.000 description 2
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 2
- MOJKRXIRAZPZLW-WDSKDSINSA-N Gly-Glu-Ala Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O MOJKRXIRAZPZLW-WDSKDSINSA-N 0.000 description 2
- SOEATRRYCIPEHA-BQBZGAKWSA-N Gly-Glu-Glu Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SOEATRRYCIPEHA-BQBZGAKWSA-N 0.000 description 2
- STVHDEHTKFXBJQ-LAEOZQHASA-N Gly-Glu-Ile Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O STVHDEHTKFXBJQ-LAEOZQHASA-N 0.000 description 2
- BEQGFMIBZFNROK-JGVFFNPUSA-N Gly-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)CN)C(=O)O BEQGFMIBZFNROK-JGVFFNPUSA-N 0.000 description 2
- JSNNHGHYGYMVCK-XVKPBYJWSA-N Gly-Glu-Val Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O JSNNHGHYGYMVCK-XVKPBYJWSA-N 0.000 description 2
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 2
- UFPXDFOYHVEIPI-BYPYZUCNSA-N Gly-Gly-Asp Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O UFPXDFOYHVEIPI-BYPYZUCNSA-N 0.000 description 2
- QPTNELDXWKRIFX-YFKPBYRVSA-N Gly-Gly-Gln Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O QPTNELDXWKRIFX-YFKPBYRVSA-N 0.000 description 2
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 2
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 2
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 2
- CQIIXEHDSZUSAG-QWRGUYRKSA-N Gly-His-His Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 CQIIXEHDSZUSAG-QWRGUYRKSA-N 0.000 description 2
- SWQALSGKVLYKDT-ZKWXMUAHSA-N Gly-Ile-Ala Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O SWQALSGKVLYKDT-ZKWXMUAHSA-N 0.000 description 2
- HKSNHPVETYYJBK-LAEOZQHASA-N Gly-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)CN HKSNHPVETYYJBK-LAEOZQHASA-N 0.000 description 2
- SCWYHUQOOFRVHP-MBLNEYKQSA-N Gly-Ile-Thr Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SCWYHUQOOFRVHP-MBLNEYKQSA-N 0.000 description 2
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 2
- UHPAZODVFFYEEL-QWRGUYRKSA-N Gly-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN UHPAZODVFFYEEL-QWRGUYRKSA-N 0.000 description 2
- YSDLIYZLOTZZNP-UWVGGRQHSA-N Gly-Leu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN YSDLIYZLOTZZNP-UWVGGRQHSA-N 0.000 description 2
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 2
- VBOBNHSVQKKTOT-YUMQZZPRSA-N Gly-Lys-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O VBOBNHSVQKKTOT-YUMQZZPRSA-N 0.000 description 2
- VEPBEGNDJYANCF-QWRGUYRKSA-N Gly-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN VEPBEGNDJYANCF-QWRGUYRKSA-N 0.000 description 2
- FXGRXIATVXUAHO-WEDXCCLWSA-N Gly-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN FXGRXIATVXUAHO-WEDXCCLWSA-N 0.000 description 2
- OJNZVYSGVYLQIN-BQBZGAKWSA-N Gly-Met-Asp Chemical compound [H]NCC(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O OJNZVYSGVYLQIN-BQBZGAKWSA-N 0.000 description 2
- ZWRDOVYMQAAISL-UWVGGRQHSA-N Gly-Met-Lys Chemical compound CSCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CCCCN ZWRDOVYMQAAISL-UWVGGRQHSA-N 0.000 description 2
- WZSHYFGOLPXPLL-RYUDHWBXSA-N Gly-Phe-Glu Chemical compound NCC(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CCC(O)=O)C(O)=O WZSHYFGOLPXPLL-RYUDHWBXSA-N 0.000 description 2
- IBYOLNARKHMLBG-WHOFXGATSA-N Gly-Phe-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 IBYOLNARKHMLBG-WHOFXGATSA-N 0.000 description 2
- IEGFSKKANYKBDU-QWHCGFSZSA-N Gly-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)CN)C(=O)O IEGFSKKANYKBDU-QWHCGFSZSA-N 0.000 description 2
- GGAPHLIUUTVYMX-QWRGUYRKSA-N Gly-Phe-Ser Chemical compound OC[C@@H](C([O-])=O)NC(=O)[C@@H](NC(=O)C[NH3+])CC1=CC=CC=C1 GGAPHLIUUTVYMX-QWRGUYRKSA-N 0.000 description 2
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 2
- GLACUWHUYFBSPJ-FJXKBIBVSA-N Gly-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN GLACUWHUYFBSPJ-FJXKBIBVSA-N 0.000 description 2
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 2
- VNNRLUNBJSWZPF-ZKWXMUAHSA-N Gly-Ser-Ile Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNNRLUNBJSWZPF-ZKWXMUAHSA-N 0.000 description 2
- WCORRBXVISTKQL-WHFBIAKZSA-N Gly-Ser-Ser Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WCORRBXVISTKQL-WHFBIAKZSA-N 0.000 description 2
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 2
- LKJCZEPXHOIAIW-HOTGVXAUSA-N Gly-Trp-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)CN LKJCZEPXHOIAIW-HOTGVXAUSA-N 0.000 description 2
- LYZYGGWCBLBDMC-QWHCGFSZSA-N Gly-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)CN)C(=O)O LYZYGGWCBLBDMC-QWHCGFSZSA-N 0.000 description 2
- DNVDEMWIYLVIQU-RCOVLWMOSA-N Gly-Val-Asp Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O DNVDEMWIYLVIQU-RCOVLWMOSA-N 0.000 description 2
- SYOJVRNQCXYEOV-XVKPBYJWSA-N Gly-Val-Glu Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SYOJVRNQCXYEOV-XVKPBYJWSA-N 0.000 description 2
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 2
- KSOBNUBCYHGUKH-UWVGGRQHSA-N Gly-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN KSOBNUBCYHGUKH-UWVGGRQHSA-N 0.000 description 2
- FRJIAZKQGSCKPQ-FSPLSTOPSA-N His-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CN=CN1 FRJIAZKQGSCKPQ-FSPLSTOPSA-N 0.000 description 2
- BIAKMWKJMQLZOJ-ZKWXMUAHSA-N His-Ala-Ala Chemical compound C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)Cc1cnc[nH]1)C(O)=O BIAKMWKJMQLZOJ-ZKWXMUAHSA-N 0.000 description 2
- QIVPRLJQQVXCIY-HGNGGELXSA-N His-Ala-Gln Chemical compound C[C@H](NC(=O)[C@@H](N)Cc1cnc[nH]1)C(=O)N[C@@H](CCC(N)=O)C(O)=O QIVPRLJQQVXCIY-HGNGGELXSA-N 0.000 description 2
- IPIVXQQRZXEUGW-UWJYBYFXSA-N His-Ala-His Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 IPIVXQQRZXEUGW-UWJYBYFXSA-N 0.000 description 2
- XINDHUAGVGCNSF-QSFUFRPTSA-N His-Ala-Ile Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O XINDHUAGVGCNSF-QSFUFRPTSA-N 0.000 description 2
- ZJSMFRTVYSLKQU-DJFWLOJKSA-N His-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC1=CN=CN1)N ZJSMFRTVYSLKQU-DJFWLOJKSA-N 0.000 description 2
- HQKADFMLECZIQJ-HVTMNAMFSA-N His-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC1=CN=CN1)N HQKADFMLECZIQJ-HVTMNAMFSA-N 0.000 description 2
- ORERHHPZDDEMSC-VGDYDELISA-N His-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N ORERHHPZDDEMSC-VGDYDELISA-N 0.000 description 2
- YAALVYQFVJNXIV-KKUMJFAQSA-N His-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 YAALVYQFVJNXIV-KKUMJFAQSA-N 0.000 description 2
- LVXFNTIIGOQBMD-SRVKXCTJSA-N His-Leu-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O LVXFNTIIGOQBMD-SRVKXCTJSA-N 0.000 description 2
- SVVULKPWDBIPCO-BZSNNMDCSA-N His-Phe-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O SVVULKPWDBIPCO-BZSNNMDCSA-N 0.000 description 2
- PYNPBMCLAKTHJL-SRVKXCTJSA-N His-Pro-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O PYNPBMCLAKTHJL-SRVKXCTJSA-N 0.000 description 2
- FLXCRBXJRJSDHX-AVGNSLFASA-N His-Pro-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O FLXCRBXJRJSDHX-AVGNSLFASA-N 0.000 description 2
- MDOBWSFNSNPENN-PMVVWTBXSA-N His-Thr-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O MDOBWSFNSNPENN-PMVVWTBXSA-N 0.000 description 2
- LQSBBHNVAVNZSX-GHCJXIJMSA-N Ile-Ala-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N LQSBBHNVAVNZSX-GHCJXIJMSA-N 0.000 description 2
- CISBRYJZMFWOHJ-JBDRJPRFSA-N Ile-Ala-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CS)C(=O)O)N CISBRYJZMFWOHJ-JBDRJPRFSA-N 0.000 description 2
- YPWHUFAAMNHMGS-QSFUFRPTSA-N Ile-Ala-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N YPWHUFAAMNHMGS-QSFUFRPTSA-N 0.000 description 2
- VAXBXNPRXPHGHG-BJDJZHNGSA-N Ile-Ala-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)O)N VAXBXNPRXPHGHG-BJDJZHNGSA-N 0.000 description 2
- TZCGZYWNIDZZMR-NAKRPEOUSA-N Ile-Arg-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](C)C(=O)O)N TZCGZYWNIDZZMR-NAKRPEOUSA-N 0.000 description 2
- DMHGKBGOUAJRHU-UHFFFAOYSA-N Ile-Arg-Pro Natural products CCC(C)C(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O DMHGKBGOUAJRHU-UHFFFAOYSA-N 0.000 description 2
- QTUSJASXLGLJSR-OSUNSFLBSA-N Ile-Arg-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N QTUSJASXLGLJSR-OSUNSFLBSA-N 0.000 description 2
- CCHSQWLCOOZREA-GMOBBJLQSA-N Ile-Asp-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCSC)C(=O)O)N CCHSQWLCOOZREA-GMOBBJLQSA-N 0.000 description 2
- GYAFMRQGWHXMII-IUKAMOBKSA-N Ile-Asp-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N GYAFMRQGWHXMII-IUKAMOBKSA-N 0.000 description 2
- KUHFPGIVBOCRMV-MNXVOIDGSA-N Ile-Gln-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(C)C)C(=O)O)N KUHFPGIVBOCRMV-MNXVOIDGSA-N 0.000 description 2
- JDAWAWXGAUZPNJ-ZPFDUUQYSA-N Ile-Glu-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N JDAWAWXGAUZPNJ-ZPFDUUQYSA-N 0.000 description 2
- BEWFWZRGBDVXRP-PEFMBERDSA-N Ile-Glu-Asn Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O BEWFWZRGBDVXRP-PEFMBERDSA-N 0.000 description 2
- LGMUPVWZEYYUMU-YVNDNENWSA-N Ile-Glu-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N LGMUPVWZEYYUMU-YVNDNENWSA-N 0.000 description 2
- WUKLZPHVWAMZQV-UKJIMTQDSA-N Ile-Glu-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N WUKLZPHVWAMZQV-UKJIMTQDSA-N 0.000 description 2
- NHJKZMDIMMTVCK-QXEWZRGKSA-N Ile-Gly-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N NHJKZMDIMMTVCK-QXEWZRGKSA-N 0.000 description 2
- SVBAHOMTJRFSIC-SXTJYALSSA-N Ile-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SVBAHOMTJRFSIC-SXTJYALSSA-N 0.000 description 2
- PWDSHAAAFXISLE-SXTJYALSSA-N Ile-Ile-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O PWDSHAAAFXISLE-SXTJYALSSA-N 0.000 description 2
- SJLVSMMIFYTSGY-GRLWGSQLSA-N Ile-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N SJLVSMMIFYTSGY-GRLWGSQLSA-N 0.000 description 2
- YNMQUIVKEFRCPH-QSFUFRPTSA-N Ile-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)O)N YNMQUIVKEFRCPH-QSFUFRPTSA-N 0.000 description 2
- KLBVGHCGHUNHEA-BJDJZHNGSA-N Ile-Leu-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)O)N KLBVGHCGHUNHEA-BJDJZHNGSA-N 0.000 description 2
- PKGGWLOLRLOPGK-XUXIUFHCSA-N Ile-Leu-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PKGGWLOLRLOPGK-XUXIUFHCSA-N 0.000 description 2
- GAZGFPOZOLEYAJ-YTFOTSKYSA-N Ile-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N GAZGFPOZOLEYAJ-YTFOTSKYSA-N 0.000 description 2
- PHRWFSFCNJPWRO-PPCPHDFISA-N Ile-Leu-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N PHRWFSFCNJPWRO-PPCPHDFISA-N 0.000 description 2
- GLYJPWIRLBAIJH-UHFFFAOYSA-N Ile-Lys-Pro Natural products CCC(C)C(N)C(=O)NC(CCCCN)C(=O)N1CCCC1C(O)=O GLYJPWIRLBAIJH-UHFFFAOYSA-N 0.000 description 2
- AKOYRLRUFBZOSP-BJDJZHNGSA-N Ile-Lys-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N AKOYRLRUFBZOSP-BJDJZHNGSA-N 0.000 description 2
- UFRXVQGGPNSJRY-CYDGBPFRSA-N Ile-Met-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@H](C(O)=O)CCCN=C(N)N UFRXVQGGPNSJRY-CYDGBPFRSA-N 0.000 description 2
- MSASLZGZQAXVFP-PEDHHIEDSA-N Ile-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N MSASLZGZQAXVFP-PEDHHIEDSA-N 0.000 description 2
- SNHYFFQZRFIRHO-CYDGBPFRSA-N Ile-Met-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(=O)O)N SNHYFFQZRFIRHO-CYDGBPFRSA-N 0.000 description 2
- OTSVBELRDMSPKY-PCBIJLKTSA-N Ile-Phe-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OTSVBELRDMSPKY-PCBIJLKTSA-N 0.000 description 2
- XLXPYSDGMXTTNQ-UHFFFAOYSA-N Ile-Phe-Leu Natural products CCC(C)C(N)C(=O)NC(C(=O)NC(CC(C)C)C(O)=O)CC1=CC=CC=C1 XLXPYSDGMXTTNQ-UHFFFAOYSA-N 0.000 description 2
- MLSUZXHSNRBDCI-CYDGBPFRSA-N Ile-Pro-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)O)N MLSUZXHSNRBDCI-CYDGBPFRSA-N 0.000 description 2
- ZNOBVZFCHNHKHA-KBIXCLLPSA-N Ile-Ser-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZNOBVZFCHNHKHA-KBIXCLLPSA-N 0.000 description 2
- PZWBBXHHUSIGKH-OSUNSFLBSA-N Ile-Thr-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PZWBBXHHUSIGKH-OSUNSFLBSA-N 0.000 description 2
- YCKPUHHMCFSUMD-IUKAMOBKSA-N Ile-Thr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCKPUHHMCFSUMD-IUKAMOBKSA-N 0.000 description 2
- MITYXXNZSZLHGG-OBAATPRFSA-N Ile-Trp-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N MITYXXNZSZLHGG-OBAATPRFSA-N 0.000 description 2
- WRDTXMBPHMBGIB-STECZYCISA-N Ile-Tyr-Val Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=C(O)C=C1 WRDTXMBPHMBGIB-STECZYCISA-N 0.000 description 2
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 2
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 2
- KFKWRHQBZQICHA-STQMWFEESA-N L-leucyl-L-phenylalanine Natural products CC(C)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KFKWRHQBZQICHA-STQMWFEESA-N 0.000 description 2
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 2
- PBCHMHROGNUXMK-DLOVCJGASA-N Leu-Ala-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 PBCHMHROGNUXMK-DLOVCJGASA-N 0.000 description 2
- KWTVLKBOQATPHJ-SRVKXCTJSA-N Leu-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N KWTVLKBOQATPHJ-SRVKXCTJSA-N 0.000 description 2
- YOZCKMXHBYKOMQ-IHRRRGAJSA-N Leu-Arg-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N YOZCKMXHBYKOMQ-IHRRRGAJSA-N 0.000 description 2
- IGUOAYLTQJLPPD-DCAQKATOSA-N Leu-Asn-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IGUOAYLTQJLPPD-DCAQKATOSA-N 0.000 description 2
- WGNOPSQMIQERPK-UHFFFAOYSA-N Leu-Asn-Pro Natural products CC(C)CC(N)C(=O)NC(CC(=O)N)C(=O)N1CCCC1C(=O)O WGNOPSQMIQERPK-UHFFFAOYSA-N 0.000 description 2
- YKNBJXOJTURHCU-DCAQKATOSA-N Leu-Asp-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YKNBJXOJTURHCU-DCAQKATOSA-N 0.000 description 2
- DLFAACQHIRSQGG-CIUDSAMLSA-N Leu-Asp-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O DLFAACQHIRSQGG-CIUDSAMLSA-N 0.000 description 2
- KTFHTMHHKXUYPW-ZPFDUUQYSA-N Leu-Asp-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KTFHTMHHKXUYPW-ZPFDUUQYSA-N 0.000 description 2
- JQSXWJXBASFONF-KKUMJFAQSA-N Leu-Asp-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JQSXWJXBASFONF-KKUMJFAQSA-N 0.000 description 2
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 2
- DPWGZWUMUUJQDT-IUCAKERBSA-N Leu-Gln-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O DPWGZWUMUUJQDT-IUCAKERBSA-N 0.000 description 2
- BOFAFKVZQUMTID-AVGNSLFASA-N Leu-Gln-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N BOFAFKVZQUMTID-AVGNSLFASA-N 0.000 description 2
- WMTOVWLLDGQGCV-GUBZILKMSA-N Leu-Glu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N WMTOVWLLDGQGCV-GUBZILKMSA-N 0.000 description 2
- WIDZHJTYKYBLSR-DCAQKATOSA-N Leu-Glu-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WIDZHJTYKYBLSR-DCAQKATOSA-N 0.000 description 2
- NEEOBPIXKWSBRF-IUCAKERBSA-N Leu-Glu-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O NEEOBPIXKWSBRF-IUCAKERBSA-N 0.000 description 2
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 2
- LAGPXKYZCCTSGQ-JYJNAYRXSA-N Leu-Glu-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LAGPXKYZCCTSGQ-JYJNAYRXSA-N 0.000 description 2
- HVJVUYQWFYMGJS-GVXVVHGQSA-N Leu-Glu-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVJVUYQWFYMGJS-GVXVVHGQSA-N 0.000 description 2
- OXRLYTYUXAQTHP-YUMQZZPRSA-N Leu-Gly-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(O)=O OXRLYTYUXAQTHP-YUMQZZPRSA-N 0.000 description 2
- BABSVXFGKFLIGW-UWVGGRQHSA-N Leu-Gly-Arg Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N BABSVXFGKFLIGW-UWVGGRQHSA-N 0.000 description 2
- KGCLIYGPQXUNLO-IUCAKERBSA-N Leu-Gly-Glu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O KGCLIYGPQXUNLO-IUCAKERBSA-N 0.000 description 2
- QPXBPQUGXHURGP-UWVGGRQHSA-N Leu-Gly-Met Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CCSC)C(=O)O)N QPXBPQUGXHURGP-UWVGGRQHSA-N 0.000 description 2
- KEVYYIMVELOXCT-KBPBESRZSA-N Leu-Gly-Phe Chemical compound CC(C)C[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KEVYYIMVELOXCT-KBPBESRZSA-N 0.000 description 2
- YFBBUHJJUXXZOF-UWVGGRQHSA-N Leu-Gly-Pro Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O YFBBUHJJUXXZOF-UWVGGRQHSA-N 0.000 description 2
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 2
- KOSWSHVQIVTVQF-ZPFDUUQYSA-N Leu-Ile-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O KOSWSHVQIVTVQF-ZPFDUUQYSA-N 0.000 description 2
- HGFGEMSVBMCFKK-MNXVOIDGSA-N Leu-Ile-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O HGFGEMSVBMCFKK-MNXVOIDGSA-N 0.000 description 2
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 2
- ZRHDPZAAWLXXIR-SRVKXCTJSA-N Leu-Lys-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O ZRHDPZAAWLXXIR-SRVKXCTJSA-N 0.000 description 2
- JLWZLIQRYCTYBD-IHRRRGAJSA-N Leu-Lys-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JLWZLIQRYCTYBD-IHRRRGAJSA-N 0.000 description 2
- BGZCJDGBBUUBHA-KKUMJFAQSA-N Leu-Lys-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O BGZCJDGBBUUBHA-KKUMJFAQSA-N 0.000 description 2
- OVZLLFONXILPDZ-VOAKCMCISA-N Leu-Lys-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OVZLLFONXILPDZ-VOAKCMCISA-N 0.000 description 2
- ZAVCJRJOQKIOJW-KKUMJFAQSA-N Leu-Phe-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(O)=O)C(O)=O)CC1=CC=CC=C1 ZAVCJRJOQKIOJW-KKUMJFAQSA-N 0.000 description 2
- AIRUUHAOKGVJAD-JYJNAYRXSA-N Leu-Phe-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIRUUHAOKGVJAD-JYJNAYRXSA-N 0.000 description 2
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 2
- QMKFDEUJGYNFMC-AVGNSLFASA-N Leu-Pro-Arg Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O QMKFDEUJGYNFMC-AVGNSLFASA-N 0.000 description 2
- UCBPDSYUVAAHCD-UWVGGRQHSA-N Leu-Pro-Gly Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UCBPDSYUVAAHCD-UWVGGRQHSA-N 0.000 description 2
- XXXXOVFBXRERQL-ULQDDVLXSA-N Leu-Pro-Phe Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XXXXOVFBXRERQL-ULQDDVLXSA-N 0.000 description 2
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 2
- IDGZVZJLYFTXSL-DCAQKATOSA-N Leu-Ser-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IDGZVZJLYFTXSL-DCAQKATOSA-N 0.000 description 2
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 2
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 2
- DAYQSYGBCUKVKT-VOAKCMCISA-N Leu-Thr-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O DAYQSYGBCUKVKT-VOAKCMCISA-N 0.000 description 2
- HGLKOTPFWOMPOB-MEYUZBJRSA-N Leu-Thr-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HGLKOTPFWOMPOB-MEYUZBJRSA-N 0.000 description 2
- UCRJTSIIAYHOHE-ULQDDVLXSA-N Leu-Tyr-Arg Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N UCRJTSIIAYHOHE-ULQDDVLXSA-N 0.000 description 2
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 2
- 239000006137 Luria-Bertani broth Substances 0.000 description 2
- MPOHDJKRBLVGCT-CIUDSAMLSA-N Lys-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N MPOHDJKRBLVGCT-CIUDSAMLSA-N 0.000 description 2
- MPGHETGWWWUHPY-CIUDSAMLSA-N Lys-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN MPGHETGWWWUHPY-CIUDSAMLSA-N 0.000 description 2
- JCFYLFOCALSNLQ-GUBZILKMSA-N Lys-Ala-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JCFYLFOCALSNLQ-GUBZILKMSA-N 0.000 description 2
- 108010062166 Lys-Asn-Asp Proteins 0.000 description 2
- BYPMOIFBQPEWOH-CIUDSAMLSA-N Lys-Asn-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N BYPMOIFBQPEWOH-CIUDSAMLSA-N 0.000 description 2
- SQXUUGUCGJSWCK-CIUDSAMLSA-N Lys-Asp-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N SQXUUGUCGJSWCK-CIUDSAMLSA-N 0.000 description 2
- GJJQCBVRWDGLMQ-GUBZILKMSA-N Lys-Glu-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O GJJQCBVRWDGLMQ-GUBZILKMSA-N 0.000 description 2
- PBIPLDMFHAICIP-DCAQKATOSA-N Lys-Glu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PBIPLDMFHAICIP-DCAQKATOSA-N 0.000 description 2
- LPAJOCKCPRZEAG-MNXVOIDGSA-N Lys-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCCCN LPAJOCKCPRZEAG-MNXVOIDGSA-N 0.000 description 2
- DCRWPTBMWMGADO-AVGNSLFASA-N Lys-Glu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O DCRWPTBMWMGADO-AVGNSLFASA-N 0.000 description 2
- PAMDBWYMLWOELY-SDDRHHMPSA-N Lys-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)C(=O)O PAMDBWYMLWOELY-SDDRHHMPSA-N 0.000 description 2
- SLQJJFAVWSZLBL-BJDJZHNGSA-N Lys-Ile-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN SLQJJFAVWSZLBL-BJDJZHNGSA-N 0.000 description 2
- XREQQOATSMMAJP-MGHWNKPDSA-N Lys-Ile-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XREQQOATSMMAJP-MGHWNKPDSA-N 0.000 description 2
- VUTWYNQUSJWBHO-BZSNNMDCSA-N Lys-Leu-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VUTWYNQUSJWBHO-BZSNNMDCSA-N 0.000 description 2
- RIJCHEVHFWMDKD-SRVKXCTJSA-N Lys-Lys-Asn Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O RIJCHEVHFWMDKD-SRVKXCTJSA-N 0.000 description 2
- WBSCNDJQPKSPII-KKUMJFAQSA-N Lys-Lys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O WBSCNDJQPKSPII-KKUMJFAQSA-N 0.000 description 2
- KJIXWRWPOCKYLD-IHRRRGAJSA-N Lys-Lys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)N KJIXWRWPOCKYLD-IHRRRGAJSA-N 0.000 description 2
- MSSJJDVQTFTLIF-KBPBESRZSA-N Lys-Phe-Gly Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](Cc1ccccc1)C(=O)NCC(O)=O MSSJJDVQTFTLIF-KBPBESRZSA-N 0.000 description 2
- LUTDBHBIHHREDC-IHRRRGAJSA-N Lys-Pro-Lys Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O LUTDBHBIHHREDC-IHRRRGAJSA-N 0.000 description 2
- MEQLGHAMAUPOSJ-DCAQKATOSA-N Lys-Ser-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O MEQLGHAMAUPOSJ-DCAQKATOSA-N 0.000 description 2
- RPWTZTBIFGENIA-VOAKCMCISA-N Lys-Thr-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O RPWTZTBIFGENIA-VOAKCMCISA-N 0.000 description 2
- OHXUUQDOBQKSNB-AVGNSLFASA-N Lys-Val-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O OHXUUQDOBQKSNB-AVGNSLFASA-N 0.000 description 2
- RPWQJSBMXJSCPD-XUXIUFHCSA-N Lys-Val-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCCCN)C(C)C)C(O)=O RPWQJSBMXJSCPD-XUXIUFHCSA-N 0.000 description 2
- QGQGAIBGTUJRBR-NAKRPEOUSA-N Met-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCSC QGQGAIBGTUJRBR-NAKRPEOUSA-N 0.000 description 2
- QEVRUYFHWJJUHZ-DCAQKATOSA-N Met-Ala-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(C)C QEVRUYFHWJJUHZ-DCAQKATOSA-N 0.000 description 2
- CTVJSFRHUOSCQQ-DCAQKATOSA-N Met-Arg-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O CTVJSFRHUOSCQQ-DCAQKATOSA-N 0.000 description 2
- ZEDVFJPQNNBMST-CYDGBPFRSA-N Met-Arg-Ile Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZEDVFJPQNNBMST-CYDGBPFRSA-N 0.000 description 2
- JMEWFDUAFKVAAT-WDSKDSINSA-N Met-Asn Chemical compound CSCC[C@H]([NH3+])C(=O)N[C@H](C([O-])=O)CC(N)=O JMEWFDUAFKVAAT-WDSKDSINSA-N 0.000 description 2
- UZVWDRPUTHXQAM-FXQIFTODSA-N Met-Asp-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O UZVWDRPUTHXQAM-FXQIFTODSA-N 0.000 description 2
- PNDCUTDWYVKBHX-IHRRRGAJSA-N Met-Asp-Tyr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PNDCUTDWYVKBHX-IHRRRGAJSA-N 0.000 description 2
- CHQWUYSNAOABIP-ZPFDUUQYSA-N Met-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCSC)N CHQWUYSNAOABIP-ZPFDUUQYSA-N 0.000 description 2
- OOSPRDCGTLQLBP-NHCYSSNCSA-N Met-Glu-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OOSPRDCGTLQLBP-NHCYSSNCSA-N 0.000 description 2
- IUYCGMNKIZDRQI-BQBZGAKWSA-N Met-Gly-Ala Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O IUYCGMNKIZDRQI-BQBZGAKWSA-N 0.000 description 2
- UZWMJZSOXGOVIN-LURJTMIESA-N Met-Gly-Gly Chemical compound CSCC[C@H](N)C(=O)NCC(=O)NCC(O)=O UZWMJZSOXGOVIN-LURJTMIESA-N 0.000 description 2
- XKJUFUPCHARJKX-UWVGGRQHSA-N Met-Gly-His Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CNC=N1 XKJUFUPCHARJKX-UWVGGRQHSA-N 0.000 description 2
- LRALLISKBZNSKN-BQBZGAKWSA-N Met-Gly-Ser Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LRALLISKBZNSKN-BQBZGAKWSA-N 0.000 description 2
- BMHIFARYXOJDLD-WPRPVWTQSA-N Met-Gly-Val Chemical compound [H]N[C@@H](CCSC)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O BMHIFARYXOJDLD-WPRPVWTQSA-N 0.000 description 2
- HOLJKDOBVJDHCA-DCAQKATOSA-N Met-His-Cys Chemical compound N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CS)C(O)=O HOLJKDOBVJDHCA-DCAQKATOSA-N 0.000 description 2
- ZIIMORLEZLVRIP-SRVKXCTJSA-N Met-Leu-Gln Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZIIMORLEZLVRIP-SRVKXCTJSA-N 0.000 description 2
- LNXGEYIEEUZGGH-JYJNAYRXSA-N Met-Phe-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CCSC)CC1=CC=CC=C1 LNXGEYIEEUZGGH-JYJNAYRXSA-N 0.000 description 2
- QEDGNYFHLXXIDC-DCAQKATOSA-N Met-Pro-Gln Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O QEDGNYFHLXXIDC-DCAQKATOSA-N 0.000 description 2
- YLDSJJOGQNEQJK-AVGNSLFASA-N Met-Pro-Leu Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O YLDSJJOGQNEQJK-AVGNSLFASA-N 0.000 description 2
- CIDICGYKRUTYLE-FXQIFTODSA-N Met-Ser-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O CIDICGYKRUTYLE-FXQIFTODSA-N 0.000 description 2
- CIIJWIAORKTXAH-FJXKBIBVSA-N Met-Thr-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O CIIJWIAORKTXAH-FJXKBIBVSA-N 0.000 description 2
- UZBQXELAFPCGRV-SZMVWBNQSA-N Met-Trp-Arg Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UZBQXELAFPCGRV-SZMVWBNQSA-N 0.000 description 2
- OVTOTTGZBWXLFU-QXEWZRGKSA-N Met-Val-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O OVTOTTGZBWXLFU-QXEWZRGKSA-N 0.000 description 2
- JRLGPAXAGHMNOL-LURJTMIESA-N N(2)-acetyl-L-ornithine Chemical compound CC(=O)N[C@H](C([O-])=O)CCC[NH3+] JRLGPAXAGHMNOL-LURJTMIESA-N 0.000 description 2
- WYBVBIHNJWOLCJ-UHFFFAOYSA-N N-L-arginyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCCN=C(N)N WYBVBIHNJWOLCJ-UHFFFAOYSA-N 0.000 description 2
- 108010087066 N2-tryptophyllysine Proteins 0.000 description 2
- 239000004677 Nylon Substances 0.000 description 2
- 108700006307 Ornithine carbamoyltransferases Proteins 0.000 description 2
- 238000012408 PCR amplification Methods 0.000 description 2
- 229910019142 PO4 Inorganic materials 0.000 description 2
- LBSARGIQACMGDF-WBAXXEDZSA-N Phe-Ala-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 LBSARGIQACMGDF-WBAXXEDZSA-N 0.000 description 2
- QMMRHASQEVCJGR-UBHSHLNASA-N Phe-Ala-Pro Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=CC=C1 QMMRHASQEVCJGR-UBHSHLNASA-N 0.000 description 2
- SEPNOAFMZLLCEW-UBHSHLNASA-N Phe-Ala-Val Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O SEPNOAFMZLLCEW-UBHSHLNASA-N 0.000 description 2
- LNIIRLODKOWQIY-IHRRRGAJSA-N Phe-Asn-Met Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O LNIIRLODKOWQIY-IHRRRGAJSA-N 0.000 description 2
- CSYVXYQDIVCQNU-QWRGUYRKSA-N Phe-Asp-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O CSYVXYQDIVCQNU-QWRGUYRKSA-N 0.000 description 2
- WIVCOAKLPICYGY-KKUMJFAQSA-N Phe-Asp-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N WIVCOAKLPICYGY-KKUMJFAQSA-N 0.000 description 2
- MQVFHOPCKNTHGT-MELADBBJSA-N Phe-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O MQVFHOPCKNTHGT-MELADBBJSA-N 0.000 description 2
- QPQDWBAJWOGAMJ-IHPCNDPISA-N Phe-Asp-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=CC=C1 QPQDWBAJWOGAMJ-IHPCNDPISA-N 0.000 description 2
- UEHNWRNADDPYNK-DLOVCJGASA-N Phe-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=CC=C1)N UEHNWRNADDPYNK-DLOVCJGASA-N 0.000 description 2
- PSBJZLMFFTULDX-IXOXFDKPSA-N Phe-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=CC=C1)N)O PSBJZLMFFTULDX-IXOXFDKPSA-N 0.000 description 2
- UNLYPPYNDXHGDG-IHRRRGAJSA-N Phe-Gln-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 UNLYPPYNDXHGDG-IHRRRGAJSA-N 0.000 description 2
- GDBOREPXIRKSEQ-FHWLQOOXSA-N Phe-Gln-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O GDBOREPXIRKSEQ-FHWLQOOXSA-N 0.000 description 2
- KJJROSNFBRWPHS-JYJNAYRXSA-N Phe-Glu-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O KJJROSNFBRWPHS-JYJNAYRXSA-N 0.000 description 2
- PSKRILMFHNIUAO-JYJNAYRXSA-N Phe-Glu-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N PSKRILMFHNIUAO-JYJNAYRXSA-N 0.000 description 2
- HGNGAMWHGGANAU-WHOFXGATSA-N Phe-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HGNGAMWHGGANAU-WHOFXGATSA-N 0.000 description 2
- CWFGECHCRMGPPT-MXAVVETBSA-N Phe-Ile-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O CWFGECHCRMGPPT-MXAVVETBSA-N 0.000 description 2
- YVXPUUOTMVBKDO-IHRRRGAJSA-N Phe-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)N)C(=O)N[C@@H](CS)C(=O)O YVXPUUOTMVBKDO-IHRRRGAJSA-N 0.000 description 2
- FZBGMXYQPACKNC-HJWJTTGWSA-N Phe-Pro-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FZBGMXYQPACKNC-HJWJTTGWSA-N 0.000 description 2
- ZLAKUZDMKVKFAI-JYJNAYRXSA-N Phe-Pro-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O ZLAKUZDMKVKFAI-JYJNAYRXSA-N 0.000 description 2
- XDMMOISUAHXXFD-SRVKXCTJSA-N Phe-Ser-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O XDMMOISUAHXXFD-SRVKXCTJSA-N 0.000 description 2
- GMWNQSGWWGKTSF-LFSVMHDDSA-N Phe-Thr-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O GMWNQSGWWGKTSF-LFSVMHDDSA-N 0.000 description 2
- BSTPNLNKHKBONJ-HTUGSXCWSA-N Phe-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N)O BSTPNLNKHKBONJ-HTUGSXCWSA-N 0.000 description 2
- YUPRIZTWANWWHK-DZKIICNBSA-N Phe-Val-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N YUPRIZTWANWWHK-DZKIICNBSA-N 0.000 description 2
- DRVIASBABBMZTF-GUBZILKMSA-N Pro-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@@H]1CCCN1 DRVIASBABBMZTF-GUBZILKMSA-N 0.000 description 2
- HFZNNDWPHBRNPV-KZVJFYERSA-N Pro-Ala-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HFZNNDWPHBRNPV-KZVJFYERSA-N 0.000 description 2
- LCRSGSIRKLXZMZ-BPNCWPANSA-N Pro-Ala-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LCRSGSIRKLXZMZ-BPNCWPANSA-N 0.000 description 2
- CYQQWUPHIZVCNY-GUBZILKMSA-N Pro-Arg-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O CYQQWUPHIZVCNY-GUBZILKMSA-N 0.000 description 2
- VPVHXWGPALPDGP-GUBZILKMSA-N Pro-Asn-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VPVHXWGPALPDGP-GUBZILKMSA-N 0.000 description 2
- VOHFZDSRPZLXLH-IHRRRGAJSA-N Pro-Asn-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O VOHFZDSRPZLXLH-IHRRRGAJSA-N 0.000 description 2
- SGCZFWSQERRKBD-BQBZGAKWSA-N Pro-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 SGCZFWSQERRKBD-BQBZGAKWSA-N 0.000 description 2
- XUSDDSLCRPUKLP-QXEWZRGKSA-N Pro-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 XUSDDSLCRPUKLP-QXEWZRGKSA-N 0.000 description 2
- QXNSKJLSLYCTMT-FXQIFTODSA-N Pro-Cys-Asp Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O QXNSKJLSLYCTMT-FXQIFTODSA-N 0.000 description 2
- DIZLUAZLNDFDPR-CIUDSAMLSA-N Pro-Cys-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H]1CCCN1 DIZLUAZLNDFDPR-CIUDSAMLSA-N 0.000 description 2
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 2
- KIPIKSXPPLABPN-CIUDSAMLSA-N Pro-Glu-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 KIPIKSXPPLABPN-CIUDSAMLSA-N 0.000 description 2
- NMELOOXSGDRBRU-YUMQZZPRSA-N Pro-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 NMELOOXSGDRBRU-YUMQZZPRSA-N 0.000 description 2
- NXEYSLRNNPWCRN-SRVKXCTJSA-N Pro-Glu-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NXEYSLRNNPWCRN-SRVKXCTJSA-N 0.000 description 2
- VOZIBWWZSBIXQN-SRVKXCTJSA-N Pro-Glu-Lys Chemical compound NCCCC[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1)C(O)=O VOZIBWWZSBIXQN-SRVKXCTJSA-N 0.000 description 2
- UEHYFUCOGHWASA-HJGDQZAQSA-N Pro-Glu-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 UEHYFUCOGHWASA-HJGDQZAQSA-N 0.000 description 2
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 2
- XQSREVQDGCPFRJ-STQMWFEESA-N Pro-Gly-Phe Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XQSREVQDGCPFRJ-STQMWFEESA-N 0.000 description 2
- BFXZQMWKTYWGCF-PYJNHQTQSA-N Pro-His-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BFXZQMWKTYWGCF-PYJNHQTQSA-N 0.000 description 2
- AQGUSRZKDZYGGV-GMOBBJLQSA-N Pro-Ile-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O AQGUSRZKDZYGGV-GMOBBJLQSA-N 0.000 description 2
- KWMUAKQOVYCQJQ-ZPFDUUQYSA-N Pro-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@@H]1CCCN1 KWMUAKQOVYCQJQ-ZPFDUUQYSA-N 0.000 description 2
- AUQGUYPHJSMAKI-CYDGBPFRSA-N Pro-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 AUQGUYPHJSMAKI-CYDGBPFRSA-N 0.000 description 2
- BRJGUPWVFXKBQI-XUXIUFHCSA-N Pro-Leu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRJGUPWVFXKBQI-XUXIUFHCSA-N 0.000 description 2
- MRYUJHGPZQNOAD-IHRRRGAJSA-N Pro-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 MRYUJHGPZQNOAD-IHRRRGAJSA-N 0.000 description 2
- MCWHYUWXVNRXFV-RWMBFGLXSA-N Pro-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 MCWHYUWXVNRXFV-RWMBFGLXSA-N 0.000 description 2
- ABSSTGUCBCDKMU-UWVGGRQHSA-N Pro-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H]1CCCN1 ABSSTGUCBCDKMU-UWVGGRQHSA-N 0.000 description 2
- GFHOSBYCLACKEK-GUBZILKMSA-N Pro-Pro-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O GFHOSBYCLACKEK-GUBZILKMSA-N 0.000 description 2
- QKDIHFHGHBYTKB-IHRRRGAJSA-N Pro-Ser-Phe Chemical compound N([C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C(=O)[C@@H]1CCCN1 QKDIHFHGHBYTKB-IHRRRGAJSA-N 0.000 description 2
- UGDMQJSXSSZUKL-IHRRRGAJSA-N Pro-Ser-Tyr Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O UGDMQJSXSSZUKL-IHRRRGAJSA-N 0.000 description 2
- CHYAYDLYYIJCKY-OSUNSFLBSA-N Pro-Thr-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CHYAYDLYYIJCKY-OSUNSFLBSA-N 0.000 description 2
- XNJVJEHDZPDPQL-BZSNNMDCSA-N Pro-Trp-Arg Chemical compound NC(=N)NCCC[C@H](NC(=O)[C@H](Cc1c[nH]c2ccccc12)NC(=O)[C@@H]1CCCN1)C(O)=O XNJVJEHDZPDPQL-BZSNNMDCSA-N 0.000 description 2
- 101100029566 Rattus norvegicus Rabggta gene Proteins 0.000 description 2
- MEFKEPWMEQBLKI-AIRLBKTGSA-N S-adenosyl-L-methioninate Chemical compound O[C@@H]1[C@H](O)[C@@H](C[S+](CC[C@H](N)C([O-])=O)C)O[C@H]1N1C2=NC=NC(N)=C2N=C1 MEFKEPWMEQBLKI-AIRLBKTGSA-N 0.000 description 2
- BKOKTRCZXRIQPX-ZLUOBGJFSA-N Ser-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N BKOKTRCZXRIQPX-ZLUOBGJFSA-N 0.000 description 2
- BTKUIVBNGBFTTP-WHFBIAKZSA-N Ser-Ala-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)NCC(O)=O BTKUIVBNGBFTTP-WHFBIAKZSA-N 0.000 description 2
- WTWGOQRNRFHFQD-JBDRJPRFSA-N Ser-Ala-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WTWGOQRNRFHFQD-JBDRJPRFSA-N 0.000 description 2
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 2
- IDQFQFVEWMWRQQ-DLOVCJGASA-N Ser-Ala-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O IDQFQFVEWMWRQQ-DLOVCJGASA-N 0.000 description 2
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 2
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 2
- DKKGAAJTDKHWOD-BIIVOSGPSA-N Ser-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N)C(=O)O DKKGAAJTDKHWOD-BIIVOSGPSA-N 0.000 description 2
- TYYBJUYSTWJHGO-ZKWXMUAHSA-N Ser-Asn-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O TYYBJUYSTWJHGO-ZKWXMUAHSA-N 0.000 description 2
- KNZQGAUEYZJUSQ-ZLUOBGJFSA-N Ser-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N KNZQGAUEYZJUSQ-ZLUOBGJFSA-N 0.000 description 2
- CNIIKZQXBBQHCX-FXQIFTODSA-N Ser-Asp-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O CNIIKZQXBBQHCX-FXQIFTODSA-N 0.000 description 2
- MESDJCNHLZBMEP-ZLUOBGJFSA-N Ser-Asp-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MESDJCNHLZBMEP-ZLUOBGJFSA-N 0.000 description 2
- VAIZFHMTBFYJIA-ACZMJKKPSA-N Ser-Asp-Gln Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(N)=O VAIZFHMTBFYJIA-ACZMJKKPSA-N 0.000 description 2
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 2
- OHKFXGKHSJKKAL-NRPADANISA-N Ser-Glu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OHKFXGKHSJKKAL-NRPADANISA-N 0.000 description 2
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 2
- AEGUWTFAQQWVLC-BQBZGAKWSA-N Ser-Gly-Arg Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O AEGUWTFAQQWVLC-BQBZGAKWSA-N 0.000 description 2
- MUARUIBTKQJKFY-WHFBIAKZSA-N Ser-Gly-Asp Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MUARUIBTKQJKFY-WHFBIAKZSA-N 0.000 description 2
- UAJAYRMZGNQILN-BQBZGAKWSA-N Ser-Gly-Met Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O UAJAYRMZGNQILN-BQBZGAKWSA-N 0.000 description 2
- QGAHMVHBORDHDC-YUMQZZPRSA-N Ser-His-Gly Chemical compound OC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CN=CN1 QGAHMVHBORDHDC-YUMQZZPRSA-N 0.000 description 2
- YIUWWXVTYLANCJ-NAKRPEOUSA-N Ser-Ile-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O YIUWWXVTYLANCJ-NAKRPEOUSA-N 0.000 description 2
- CJINPXGSKSZQNE-KBIXCLLPSA-N Ser-Ile-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O CJINPXGSKSZQNE-KBIXCLLPSA-N 0.000 description 2
- LWMQRHDTXHQQOV-MXAVVETBSA-N Ser-Ile-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LWMQRHDTXHQQOV-MXAVVETBSA-N 0.000 description 2
- NLOAIFSWUUFQFR-CIUDSAMLSA-N Ser-Leu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O NLOAIFSWUUFQFR-CIUDSAMLSA-N 0.000 description 2
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 2
- HEUVHBXOVZONPU-BJDJZHNGSA-N Ser-Leu-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HEUVHBXOVZONPU-BJDJZHNGSA-N 0.000 description 2
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 2
- VZQRNAYURWAEFE-KKUMJFAQSA-N Ser-Leu-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 VZQRNAYURWAEFE-KKUMJFAQSA-N 0.000 description 2
- GVMUJUPXFQFBBZ-GUBZILKMSA-N Ser-Lys-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GVMUJUPXFQFBBZ-GUBZILKMSA-N 0.000 description 2
- VIIJCAQMJBHSJH-FXQIFTODSA-N Ser-Met-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(O)=O VIIJCAQMJBHSJH-FXQIFTODSA-N 0.000 description 2
- FZEUTKVQGMVGHW-AVGNSLFASA-N Ser-Phe-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O FZEUTKVQGMVGHW-AVGNSLFASA-N 0.000 description 2
- XKFJENWJGHMDLI-QWRGUYRKSA-N Ser-Phe-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O XKFJENWJGHMDLI-QWRGUYRKSA-N 0.000 description 2
- BSXKBOUZDAZXHE-CIUDSAMLSA-N Ser-Pro-Glu Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O BSXKBOUZDAZXHE-CIUDSAMLSA-N 0.000 description 2
- FLONGDPORFIVQW-XGEHTFHBSA-N Ser-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FLONGDPORFIVQW-XGEHTFHBSA-N 0.000 description 2
- FZXOPYUEQGDGMS-ACZMJKKPSA-N Ser-Ser-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O FZXOPYUEQGDGMS-ACZMJKKPSA-N 0.000 description 2
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 2
- NADLKBTYNKUJEP-KATARQTJSA-N Ser-Thr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NADLKBTYNKUJEP-KATARQTJSA-N 0.000 description 2
- ZKOKTQPHFMRSJP-YJRXYDGGSA-N Ser-Thr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKOKTQPHFMRSJP-YJRXYDGGSA-N 0.000 description 2
- BCAVNDNYOGTQMQ-AAEUAGOBSA-N Ser-Trp-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(O)=O BCAVNDNYOGTQMQ-AAEUAGOBSA-N 0.000 description 2
- PCMZJFMUYWIERL-ZKWXMUAHSA-N Ser-Val-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O PCMZJFMUYWIERL-ZKWXMUAHSA-N 0.000 description 2
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 2
- LSHUNRICNSEEAN-BPUTZDHNSA-N Ser-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CO)N LSHUNRICNSEEAN-BPUTZDHNSA-N 0.000 description 2
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 2
- 239000008049 TAE buffer Substances 0.000 description 2
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 2
- CAJFZCICSVBOJK-SHGPDSBTSA-N Thr-Ala-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAJFZCICSVBOJK-SHGPDSBTSA-N 0.000 description 2
- GLQFKOVWXPPFTP-VEVYYDQMSA-N Thr-Arg-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O GLQFKOVWXPPFTP-VEVYYDQMSA-N 0.000 description 2
- TWLMXDWFVNEFFK-FJXKBIBVSA-N Thr-Arg-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O TWLMXDWFVNEFFK-FJXKBIBVSA-N 0.000 description 2
- IRKWVRSEQFTGGV-VEVYYDQMSA-N Thr-Asn-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IRKWVRSEQFTGGV-VEVYYDQMSA-N 0.000 description 2
- JHBHMCMKSPXRHV-NUMRIWBASA-N Thr-Asn-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O JHBHMCMKSPXRHV-NUMRIWBASA-N 0.000 description 2
- XDARBNMYXKUFOJ-GSSVUCPTSA-N Thr-Asp-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XDARBNMYXKUFOJ-GSSVUCPTSA-N 0.000 description 2
- YAAPRMFURSENOZ-KATARQTJSA-N Thr-Cys-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N)O YAAPRMFURSENOZ-KATARQTJSA-N 0.000 description 2
- MQUZMZBFKCHVOB-HJGDQZAQSA-N Thr-Gln-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O MQUZMZBFKCHVOB-HJGDQZAQSA-N 0.000 description 2
- WDFPMSHYMRBLKM-NKIYYHGXSA-N Thr-Glu-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N)O WDFPMSHYMRBLKM-NKIYYHGXSA-N 0.000 description 2
- HJOSVGCWOTYJFG-WDCWCFNPSA-N Thr-Glu-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N)O HJOSVGCWOTYJFG-WDCWCFNPSA-N 0.000 description 2
- KCRQEJSKXAIULJ-FJXKBIBVSA-N Thr-Gly-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O KCRQEJSKXAIULJ-FJXKBIBVSA-N 0.000 description 2
- NIEWSKWFURSECR-FOHZUACHSA-N Thr-Gly-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NIEWSKWFURSECR-FOHZUACHSA-N 0.000 description 2
- AQAMPXBRJJWPNI-JHEQGTHGSA-N Thr-Gly-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AQAMPXBRJJWPNI-JHEQGTHGSA-N 0.000 description 2
- MPUMPERGHHJGRP-WEDXCCLWSA-N Thr-Gly-Lys Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)O)N)O MPUMPERGHHJGRP-WEDXCCLWSA-N 0.000 description 2
- JQAWYCUUFIMTHE-WLTAIBSBSA-N Thr-Gly-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JQAWYCUUFIMTHE-WLTAIBSBSA-N 0.000 description 2
- AYCQVUUPIJHJTA-IXOXFDKPSA-N Thr-His-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O AYCQVUUPIJHJTA-IXOXFDKPSA-N 0.000 description 2
- XOWKUMFHEZLKLT-CIQUZCHMSA-N Thr-Ile-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O XOWKUMFHEZLKLT-CIQUZCHMSA-N 0.000 description 2
- ZBKDBZUTTXINIX-RWRJDSDZSA-N Thr-Ile-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZBKDBZUTTXINIX-RWRJDSDZSA-N 0.000 description 2
- LCCSEJSPBWKBNT-OSUNSFLBSA-N Thr-Ile-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N LCCSEJSPBWKBNT-OSUNSFLBSA-N 0.000 description 2
- VTVVYQOXJCZVEB-WDCWCFNPSA-N Thr-Leu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O VTVVYQOXJCZVEB-WDCWCFNPSA-N 0.000 description 2
- MECLEFZMPPOEAC-VOAKCMCISA-N Thr-Leu-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MECLEFZMPPOEAC-VOAKCMCISA-N 0.000 description 2
- FIFDDJFLNVAVMS-RHYQMDGZSA-N Thr-Leu-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O FIFDDJFLNVAVMS-RHYQMDGZSA-N 0.000 description 2
- SCSVNSNWUTYSFO-WDCWCFNPSA-N Thr-Lys-Glu Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O SCSVNSNWUTYSFO-WDCWCFNPSA-N 0.000 description 2
- QHUWWSQZTFLXPQ-FJXKBIBVSA-N Thr-Met-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O QHUWWSQZTFLXPQ-FJXKBIBVSA-N 0.000 description 2
- XNTVWRJTUIOGQO-RHYQMDGZSA-N Thr-Met-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O XNTVWRJTUIOGQO-RHYQMDGZSA-N 0.000 description 2
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 2
- FWTFAZKJORVTIR-VZFHVOOUSA-N Thr-Ser-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O FWTFAZKJORVTIR-VZFHVOOUSA-N 0.000 description 2
- DOBIBIXIHJKVJF-XKBZYTNZSA-N Thr-Ser-Gln Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O DOBIBIXIHJKVJF-XKBZYTNZSA-N 0.000 description 2
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 2
- XZUBGOYOGDRYFC-XGEHTFHBSA-N Thr-Ser-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O XZUBGOYOGDRYFC-XGEHTFHBSA-N 0.000 description 2
- VUXIQSUQQYNLJP-XAVMHZPKSA-N Thr-Ser-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N)O VUXIQSUQQYNLJP-XAVMHZPKSA-N 0.000 description 2
- IEZVHOULSUULHD-XGEHTFHBSA-N Thr-Ser-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O IEZVHOULSUULHD-XGEHTFHBSA-N 0.000 description 2
- YRJOLUDFVAUXLI-GSSVUCPTSA-N Thr-Thr-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(O)=O YRJOLUDFVAUXLI-GSSVUCPTSA-N 0.000 description 2
- VBMOVTMNHWPZJR-SUSMZKCASA-N Thr-Thr-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VBMOVTMNHWPZJR-SUSMZKCASA-N 0.000 description 2
- ZESGVALRVJIVLZ-VFCFLDTKSA-N Thr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O ZESGVALRVJIVLZ-VFCFLDTKSA-N 0.000 description 2
- GRIUMVXCJDKVPI-IZPVPAKOSA-N Thr-Thr-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GRIUMVXCJDKVPI-IZPVPAKOSA-N 0.000 description 2
- BEZTUFWTPVOROW-KJEVXHAQSA-N Thr-Tyr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O BEZTUFWTPVOROW-KJEVXHAQSA-N 0.000 description 2
- XGFYGMKZKFRGAI-RCWTZXSCSA-N Thr-Val-Arg Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N XGFYGMKZKFRGAI-RCWTZXSCSA-N 0.000 description 2
- AKHDFZHUPGVFEJ-YEPSODPASA-N Thr-Val-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AKHDFZHUPGVFEJ-YEPSODPASA-N 0.000 description 2
- PWONLXBUSVIZPH-RHYQMDGZSA-N Thr-Val-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O PWONLXBUSVIZPH-RHYQMDGZSA-N 0.000 description 2
- QNXZCKMXHPULME-ZNSHCXBVSA-N Thr-Val-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O QNXZCKMXHPULME-ZNSHCXBVSA-N 0.000 description 2
- VYVBSMCZNHOZGD-RCWTZXSCSA-N Thr-Val-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O VYVBSMCZNHOZGD-RCWTZXSCSA-N 0.000 description 2
- AWYXDHQQFPZJNE-QEJZJMRPSA-N Trp-Gln-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N AWYXDHQQFPZJNE-QEJZJMRPSA-N 0.000 description 2
- AIISTODACBDQLW-WDSOQIARSA-N Trp-Leu-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 AIISTODACBDQLW-WDSOQIARSA-N 0.000 description 2
- YVXIAOOYAKBAAI-SZMVWBNQSA-N Trp-Leu-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 YVXIAOOYAKBAAI-SZMVWBNQSA-N 0.000 description 2
- PWPJLBWYRTVYQS-PMVMPFDFSA-N Trp-Phe-Leu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O PWPJLBWYRTVYQS-PMVMPFDFSA-N 0.000 description 2
- GEGYPBOPIGNZIF-CWRNSKLLSA-N Trp-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)O GEGYPBOPIGNZIF-CWRNSKLLSA-N 0.000 description 2
- NSOMQRHZMJMZIE-GVARAGBVSA-N Tyr-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NSOMQRHZMJMZIE-GVARAGBVSA-N 0.000 description 2
- LGEYOIQBBIPHQN-UWJYBYFXSA-N Tyr-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 LGEYOIQBBIPHQN-UWJYBYFXSA-N 0.000 description 2
- CKKFTIQYURNSEI-IHRRRGAJSA-N Tyr-Asn-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 CKKFTIQYURNSEI-IHRRRGAJSA-N 0.000 description 2
- MBFJIHUHHCJBSN-AVGNSLFASA-N Tyr-Asn-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MBFJIHUHHCJBSN-AVGNSLFASA-N 0.000 description 2
- MNMYOSZWCKYEDI-JRQIVUDYSA-N Tyr-Asp-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MNMYOSZWCKYEDI-JRQIVUDYSA-N 0.000 description 2
- IYHNBRUWVBIVJR-IHRRRGAJSA-N Tyr-Gln-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 IYHNBRUWVBIVJR-IHRRRGAJSA-N 0.000 description 2
- XQYHLZNPOTXRMQ-KKUMJFAQSA-N Tyr-Glu-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O XQYHLZNPOTXRMQ-KKUMJFAQSA-N 0.000 description 2
- LHTGRUZSZOIAKM-SOUVJXGZSA-N Tyr-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O LHTGRUZSZOIAKM-SOUVJXGZSA-N 0.000 description 2
- HIINQLBHPIQYHN-JTQLQIEISA-N Tyr-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 HIINQLBHPIQYHN-JTQLQIEISA-N 0.000 description 2
- CTDPLKMBVALCGN-JSGCOSHPSA-N Tyr-Gly-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O CTDPLKMBVALCGN-JSGCOSHPSA-N 0.000 description 2
- KIJLSRYAUGGZIN-CFMVVWHZSA-N Tyr-Ile-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O KIJLSRYAUGGZIN-CFMVVWHZSA-N 0.000 description 2
- CDKZJGMPZHPAJC-ULQDDVLXSA-N Tyr-Leu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 CDKZJGMPZHPAJC-ULQDDVLXSA-N 0.000 description 2
- WOAQYWUEUYMVGK-ULQDDVLXSA-N Tyr-Lys-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WOAQYWUEUYMVGK-ULQDDVLXSA-N 0.000 description 2
- TYFLVOUZHQUBGM-IHRRRGAJSA-N Tyr-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 TYFLVOUZHQUBGM-IHRRRGAJSA-N 0.000 description 2
- PWKMJDQXKCENMF-MEYUZBJRSA-N Tyr-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O PWKMJDQXKCENMF-MEYUZBJRSA-N 0.000 description 2
- FZSPNKUFROZBSG-ZKWXMUAHSA-N Val-Ala-Asp Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O FZSPNKUFROZBSG-ZKWXMUAHSA-N 0.000 description 2
- LTFLDDDGWOVIHY-NAKRPEOUSA-N Val-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N LTFLDDDGWOVIHY-NAKRPEOUSA-N 0.000 description 2
- RUCNAYOMFXRIKJ-DCAQKATOSA-N Val-Ala-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN RUCNAYOMFXRIKJ-DCAQKATOSA-N 0.000 description 2
- SMKXLHVZIFKQRB-GUBZILKMSA-N Val-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](C(C)C)N SMKXLHVZIFKQRB-GUBZILKMSA-N 0.000 description 2
- ZLFHAAGHGQBQQN-AEJSXWLSSA-N Val-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZLFHAAGHGQBQQN-AEJSXWLSSA-N 0.000 description 2
- VJOWWOGRNXRQMF-UVBJJODRSA-N Val-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 VJOWWOGRNXRQMF-UVBJJODRSA-N 0.000 description 2
- COYSIHFOCOMGCF-WPRPVWTQSA-N Val-Arg-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N COYSIHFOCOMGCF-WPRPVWTQSA-N 0.000 description 2
- JYVKKBDANPZIAW-AVGNSLFASA-N Val-Arg-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](C(C)C)N JYVKKBDANPZIAW-AVGNSLFASA-N 0.000 description 2
- CVUDMNSZAIZFAE-UHFFFAOYSA-N Val-Arg-Pro Natural products NC(N)=NCCCC(NC(=O)C(N)C(C)C)C(=O)N1CCCC1C(O)=O CVUDMNSZAIZFAE-UHFFFAOYSA-N 0.000 description 2
- DBOXBUDEAJVKRE-LSJOCFKGSA-N Val-Asn-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N DBOXBUDEAJVKRE-LSJOCFKGSA-N 0.000 description 2
- KXUKIBHIVRYOIP-ZKWXMUAHSA-N Val-Asp-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N KXUKIBHIVRYOIP-ZKWXMUAHSA-N 0.000 description 2
- HHSILIQTHXABKM-YDHLFZDLSA-N Val-Asp-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](Cc1ccccc1)C(O)=O HHSILIQTHXABKM-YDHLFZDLSA-N 0.000 description 2
- OVLIFGQSBSNGHY-KKHAAJSZSA-N Val-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N)O OVLIFGQSBSNGHY-KKHAAJSZSA-N 0.000 description 2
- FRUYSSRPJXNRRB-GUBZILKMSA-N Val-Cys-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N FRUYSSRPJXNRRB-GUBZILKMSA-N 0.000 description 2
- HIZMLPKDJAXDRG-FXQIFTODSA-N Val-Cys-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N HIZMLPKDJAXDRG-FXQIFTODSA-N 0.000 description 2
- YCMXFKWYJFZFKS-LAEOZQHASA-N Val-Gln-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCMXFKWYJFZFKS-LAEOZQHASA-N 0.000 description 2
- UZDHNIJRRTUKKC-DLOVCJGASA-N Val-Gln-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N UZDHNIJRRTUKKC-DLOVCJGASA-N 0.000 description 2
- ZXAGTABZUOMUDO-GVXVVHGQSA-N Val-Glu-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N ZXAGTABZUOMUDO-GVXVVHGQSA-N 0.000 description 2
- MHAHQDBEIDPFQS-NHCYSSNCSA-N Val-Glu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C MHAHQDBEIDPFQS-NHCYSSNCSA-N 0.000 description 2
- WDIGUPHXPBMODF-UMNHJUIQSA-N Val-Glu-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N WDIGUPHXPBMODF-UMNHJUIQSA-N 0.000 description 2
- CELJCNRXKZPTCX-XPUUQOCRSA-N Val-Gly-Ala Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O CELJCNRXKZPTCX-XPUUQOCRSA-N 0.000 description 2
- DJEVQCWNMQOABE-RCOVLWMOSA-N Val-Gly-Asp Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)O)C(=O)O)N DJEVQCWNMQOABE-RCOVLWMOSA-N 0.000 description 2
- GMOLURHJBLOBFW-ONGXEEELSA-N Val-Gly-His Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N GMOLURHJBLOBFW-ONGXEEELSA-N 0.000 description 2
- BZMIYHIJVVJPCK-QSFUFRPTSA-N Val-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N BZMIYHIJVVJPCK-QSFUFRPTSA-N 0.000 description 2
- UKEVLVBHRKWECS-LSJOCFKGSA-N Val-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](C(C)C)N UKEVLVBHRKWECS-LSJOCFKGSA-N 0.000 description 2
- DJQIUOKSNRBTSV-CYDGBPFRSA-N Val-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](C(C)C)N DJQIUOKSNRBTSV-CYDGBPFRSA-N 0.000 description 2
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 2
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 2
- RFKJNTRMXGCKFE-FHWLQOOXSA-N Val-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC(C)C)C(O)=O)=CNC2=C1 RFKJNTRMXGCKFE-FHWLQOOXSA-N 0.000 description 2
- YMTOEGGOCHVGEH-IHRRRGAJSA-N Val-Lys-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O YMTOEGGOCHVGEH-IHRRRGAJSA-N 0.000 description 2
- UOUIMEGEPSBZIV-ULQDDVLXSA-N Val-Lys-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UOUIMEGEPSBZIV-ULQDDVLXSA-N 0.000 description 2
- JVGHIFMSFBZDHH-WPRPVWTQSA-N Val-Met-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)NCC(=O)O)N JVGHIFMSFBZDHH-WPRPVWTQSA-N 0.000 description 2
- MGVYZTPLGXPVQB-CYDGBPFRSA-N Val-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C(C)C)N MGVYZTPLGXPVQB-CYDGBPFRSA-N 0.000 description 2
- CKTMJBPRVQWPHU-JSGCOSHPSA-N Val-Phe-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)O)N CKTMJBPRVQWPHU-JSGCOSHPSA-N 0.000 description 2
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 2
- XBJKAZATRJBDCU-GUBZILKMSA-N Val-Pro-Ala Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O XBJKAZATRJBDCU-GUBZILKMSA-N 0.000 description 2
- QIVPZSWBBHRNBA-JYJNAYRXSA-N Val-Pro-Phe Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccccc1)C(O)=O QIVPZSWBBHRNBA-JYJNAYRXSA-N 0.000 description 2
- KSFXWENSJABBFI-ZKWXMUAHSA-N Val-Ser-Asn Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O KSFXWENSJABBFI-ZKWXMUAHSA-N 0.000 description 2
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 2
- QTPQHINADBYBNA-DCAQKATOSA-N Val-Ser-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN QTPQHINADBYBNA-DCAQKATOSA-N 0.000 description 2
- QZKVWWIUSQGWMY-IHRRRGAJSA-N Val-Ser-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QZKVWWIUSQGWMY-IHRRRGAJSA-N 0.000 description 2
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 2
- UJMCYJKPDFQLHX-XGEHTFHBSA-N Val-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N)O UJMCYJKPDFQLHX-XGEHTFHBSA-N 0.000 description 2
- UVHFONIHVHLDDQ-IFFSRLJSSA-N Val-Thr-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O UVHFONIHVHLDDQ-IFFSRLJSSA-N 0.000 description 2
- GVNLOVJNNDZUHS-RHYQMDGZSA-N Val-Thr-Lys Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O GVNLOVJNNDZUHS-RHYQMDGZSA-N 0.000 description 2
- PDDJTOSAVNRJRH-UNQGMJICSA-N Val-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](C(C)C)N)O PDDJTOSAVNRJRH-UNQGMJICSA-N 0.000 description 2
- UEXPMFIAZZHEAD-HSHDSVGOSA-N Val-Thr-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](C(C)C)N)O UEXPMFIAZZHEAD-HSHDSVGOSA-N 0.000 description 2
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 2
- ODUHAIXFXFACDY-SRVKXCTJSA-N Val-Val-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)C(C)C ODUHAIXFXFACDY-SRVKXCTJSA-N 0.000 description 2
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 2
- JVGDAEKKZKKZFO-RCWTZXSCSA-N Val-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N)O JVGDAEKKZKKZFO-RCWTZXSCSA-N 0.000 description 2
- 108010081404 acein-2 Proteins 0.000 description 2
- HGEVZDLYZYVYHD-UHFFFAOYSA-N acetic acid;2-amino-2-(hydroxymethyl)propane-1,3-diol;2-[2-[bis(carboxymethyl)amino]ethyl-(carboxymethyl)amino]acetic acid Chemical compound CC(O)=O.OCC(N)(CO)CO.OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O HGEVZDLYZYVYHD-UHFFFAOYSA-N 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 229960001570 ademetionine Drugs 0.000 description 2
- 108010045023 alanyl-prolyl-tyrosine Proteins 0.000 description 2
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 2
- 108010045350 alanyl-tyrosyl-alanine Proteins 0.000 description 2
- 108010041407 alanylaspartic acid Proteins 0.000 description 2
- OBETXYAYXDNJHR-UHFFFAOYSA-N alpha-ethylcaproic acid Natural products CCCCC(CC)C(O)=O OBETXYAYXDNJHR-UHFFFAOYSA-N 0.000 description 2
- VZTDIZULWFCMLS-UHFFFAOYSA-N ammonium formate Chemical compound [NH4+].[O-]C=O VZTDIZULWFCMLS-UHFFFAOYSA-N 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- 101150094408 argI gene Proteins 0.000 description 2
- 108010008355 arginyl-glutamine Proteins 0.000 description 2
- 108010001271 arginyl-glutamyl-arginine Proteins 0.000 description 2
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 2
- 108010018691 arginyl-threonyl-arginine Proteins 0.000 description 2
- 108010010430 asparagine-proline-alanine Proteins 0.000 description 2
- 239000007621 bhi medium Substances 0.000 description 2
- 210000004556 brain Anatomy 0.000 description 2
- 239000004202 carbamide Substances 0.000 description 2
- 229910052799 carbon Inorganic materials 0.000 description 2
- 238000012512 characterization method Methods 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 108010069495 cysteinyltyrosine Proteins 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 2
- 108010054812 diprotin A Proteins 0.000 description 2
- 238000010828 elution Methods 0.000 description 2
- 108010030074 endodeoxyribonuclease MluI Proteins 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 108010006664 gamma-glutamyl-glycyl-glycine Proteins 0.000 description 2
- 229960002989 glutamic acid Drugs 0.000 description 2
- 108010008237 glutamyl-valyl-glycine Proteins 0.000 description 2
- 108010073628 glutamyl-valyl-phenylalanine Proteins 0.000 description 2
- 108010079547 glutamylmethionine Proteins 0.000 description 2
- 108010090037 glycyl-alanyl-isoleucine Proteins 0.000 description 2
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 2
- 108010072405 glycyl-aspartyl-glycine Proteins 0.000 description 2
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 2
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 2
- 108010079413 glycyl-prolyl-glutamic acid Proteins 0.000 description 2
- 108010010147 glycylglutamine Proteins 0.000 description 2
- 108010020688 glycylhistidine Proteins 0.000 description 2
- 108010015792 glycyllysine Proteins 0.000 description 2
- 108010081551 glycylphenylalanine Proteins 0.000 description 2
- 238000004128 high performance liquid chromatography Methods 0.000 description 2
- 108010040030 histidinoalanine Proteins 0.000 description 2
- 108010050343 histidyl-alanyl-glutamine Proteins 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 230000010354 integration Effects 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 2
- 108010060857 isoleucyl-valyl-tyrosine Proteins 0.000 description 2
- 108010078274 isoleucylvaline Proteins 0.000 description 2
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 2
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 2
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 2
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 2
- 108010000761 leucylarginine Proteins 0.000 description 2
- 108010072591 lysyl-leucyl-alanyl-arginine Proteins 0.000 description 2
- 108010075702 lysyl-valyl-aspartyl-leucine Proteins 0.000 description 2
- 108010064235 lysylglycine Proteins 0.000 description 2
- 238000012269 metabolic engineering Methods 0.000 description 2
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 2
- 108010085203 methionylmethionine Proteins 0.000 description 2
- 108010034507 methionyltryptophan Proteins 0.000 description 2
- 108020004707 nucleic acids Proteins 0.000 description 2
- 102000039446 nucleic acids Human genes 0.000 description 2
- 150000007523 nucleic acids Chemical class 0.000 description 2
- 239000002773 nucleotide Substances 0.000 description 2
- 125000003729 nucleotide group Chemical group 0.000 description 2
- 229920001778 nylon Polymers 0.000 description 2
- 108010018625 phenylalanylarginine Proteins 0.000 description 2
- 235000021317 phosphate Nutrition 0.000 description 2
- 108091033319 polynucleotide Proteins 0.000 description 2
- 102000040430 polynucleotide Human genes 0.000 description 2
- 239000002157 polynucleotide Substances 0.000 description 2
- 102000004196 processed proteins & peptides Human genes 0.000 description 2
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 2
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 2
- 108010053725 prolylvaline Proteins 0.000 description 2
- 230000001915 proofreading effect Effects 0.000 description 2
- 238000011002 quantification Methods 0.000 description 2
- 230000006798 recombination Effects 0.000 description 2
- 238000005215 recombination Methods 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- 102000037983 regulatory factors Human genes 0.000 description 2
- 108091008025 regulatory factors Proteins 0.000 description 2
- 238000012163 sequencing technique Methods 0.000 description 2
- 108010071207 serylmethionine Proteins 0.000 description 2
- 239000001509 sodium citrate Substances 0.000 description 2
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 2
- 239000006228 supernatant Substances 0.000 description 2
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- HRXKRNGNAMMEHJ-UHFFFAOYSA-K trisodium citrate Chemical compound [Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O HRXKRNGNAMMEHJ-UHFFFAOYSA-K 0.000 description 2
- 229940038773 trisodium citrate Drugs 0.000 description 2
- 108010058119 tryptophyl-glycyl-glycine Proteins 0.000 description 2
- 108010029599 tyrosyl-glutamyl-tryptophan Proteins 0.000 description 2
- 108010017949 tyrosyl-glycyl-glycine Proteins 0.000 description 2
- 108010051110 tyrosyl-lysine Proteins 0.000 description 2
- XOYCLJDJUKHHHS-LHBOOPKSSA-N (2s,3s,4s,5r,6r)-6-[[(2s,3s,5r)-3-amino-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy]-3,4,5-trihydroxyoxane-2-carboxylic acid Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO[C@H]2[C@@H]([C@@H](O)[C@H](O)[C@H](O2)C(O)=O)O)[C@@H](N)C1 XOYCLJDJUKHHHS-LHBOOPKSSA-N 0.000 description 1
- OJJHFKVRJCQKLN-YFKPBYRVSA-N (4s)-4-acetamido-5-oxo-5-phosphonooxypentanoic acid Chemical compound OC(=O)CC[C@H](NC(=O)C)C(=O)OP(O)(O)=O OJJHFKVRJCQKLN-YFKPBYRVSA-N 0.000 description 1
- 108010052418 (N-(2-((4-((2-((4-(9-acridinylamino)phenyl)amino)-2-oxoethyl)amino)-4-oxobutyl)amino)-1-(1H-imidazol-4-ylmethyl)-1-oxoethyl)-6-(((-2-aminoethyl)amino)methyl)-2-pyridinecarboxamidato) iron(1+) Proteins 0.000 description 1
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 1
- 108700021045 Acetylglutamate kinase Proteins 0.000 description 1
- 108030006759 Acetylornithine deacetylases Proteins 0.000 description 1
- QQKKFVXSQXUHPI-NBVRZTHBSA-N Acidissiminol epoxide Chemical compound O1C(C)(C)C1CC(O)C(/C)=C/COC(C=C1)=CC=C1CCNC(=O)C1=CC=CC=C1 QQKKFVXSQXUHPI-NBVRZTHBSA-N 0.000 description 1
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 1
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 1
- LTTLSZVJTDSACD-OWLDWWDNSA-N Ala-Thr-Trp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O LTTLSZVJTDSACD-OWLDWWDNSA-N 0.000 description 1
- 108010032178 Amino-acid N-acetyltransferase Proteins 0.000 description 1
- 102000007610 Amino-acid N-acetyltransferase Human genes 0.000 description 1
- QGZKDVFQNNGYKY-UHFFFAOYSA-O Ammonium Chemical compound [NH4+] QGZKDVFQNNGYKY-UHFFFAOYSA-O 0.000 description 1
- 108010082340 Arginine deiminase Proteins 0.000 description 1
- MQLZLIYPFDIDMZ-HAFWLYHUSA-N Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](N)CC(N)=O MQLZLIYPFDIDMZ-HAFWLYHUSA-N 0.000 description 1
- KDFQZBWWPYQBEN-ZLUOBGJFSA-N Asp-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N KDFQZBWWPYQBEN-ZLUOBGJFSA-N 0.000 description 1
- MFTVXYMXSAQZNL-DJFWLOJKSA-N Asp-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)O)N MFTVXYMXSAQZNL-DJFWLOJKSA-N 0.000 description 1
- HKEZZWQWXWGASX-KKUMJFAQSA-N Asp-Leu-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 HKEZZWQWXWGASX-KKUMJFAQSA-N 0.000 description 1
- 241000186146 Brevibacterium Species 0.000 description 1
- 108010072454 CTGCAG-specific type II deoxyribonucleases Proteins 0.000 description 1
- 101100512078 Caenorhabditis elegans lys-1 gene Proteins 0.000 description 1
- 241000589877 Campylobacter coli Species 0.000 description 1
- 102000007132 Carboxyl and Carbamoyl Transferases Human genes 0.000 description 1
- 108010072957 Carboxyl and Carbamoyl Transferases Proteins 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- 241000192700 Cyanobacteria Species 0.000 description 1
- 241001057362 Cyra Species 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 108010076804 DNA Restriction Enzymes Proteins 0.000 description 1
- 238000007399 DNA isolation Methods 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- 102100034581 Dihydroorotase Human genes 0.000 description 1
- 108091000126 Dihydroorotase Proteins 0.000 description 1
- 241000588722 Escherichia Species 0.000 description 1
- OPINTGHFESTVAX-BQBZGAKWSA-N Gln-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@H](C(O)=O)CCCN=C(N)N OPINTGHFESTVAX-BQBZGAKWSA-N 0.000 description 1
- 108030000852 Glutamate N-acetyltransferases Proteins 0.000 description 1
- HAXARWKYFIIHKD-ZKWXMUAHSA-N Gly-Ile-Ser Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HAXARWKYFIIHKD-ZKWXMUAHSA-N 0.000 description 1
- UMBDRSMLCUYIRI-DVJZZOLTSA-N Gly-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)CN)O UMBDRSMLCUYIRI-DVJZZOLTSA-N 0.000 description 1
- 108010011689 Glycine transaminase Proteins 0.000 description 1
- 101000893897 Homo sapiens Guanidinoacetate N-methyltransferase Proteins 0.000 description 1
- 150000008575 L-amino acids Chemical class 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- FSBIGDSBMBYOPN-VKHMYHEASA-N L-canavanine Chemical compound OC(=O)[C@@H](N)CCONC(N)=N FSBIGDSBMBYOPN-VKHMYHEASA-N 0.000 description 1
- MYGQXVYRZMKRDB-SRVKXCTJSA-N Leu-Asp-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN MYGQXVYRZMKRDB-SRVKXCTJSA-N 0.000 description 1
- ZTLGVASZOIKNIX-DCAQKATOSA-N Leu-Gln-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZTLGVASZOIKNIX-DCAQKATOSA-N 0.000 description 1
- 102000003960 Ligases Human genes 0.000 description 1
- 108090000364 Ligases Proteins 0.000 description 1
- PNPYKQFJGRFYJE-GUBZILKMSA-N Lys-Ala-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNPYKQFJGRFYJE-GUBZILKMSA-N 0.000 description 1
- ATIPDCIQTUXABX-UWVGGRQHSA-N Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](N)CCCCN ATIPDCIQTUXABX-UWVGGRQHSA-N 0.000 description 1
- XOQMURBBIXRRCR-SRVKXCTJSA-N Lys-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN XOQMURBBIXRRCR-SRVKXCTJSA-N 0.000 description 1
- 239000007993 MOPS buffer Substances 0.000 description 1
- 101000859568 Methanobrevibacter smithii (strain ATCC 35061 / DSM 861 / OCM 144 / PS) Carbamoyl-phosphate synthase Proteins 0.000 description 1
- 125000003047 N-acetyl group Chemical group 0.000 description 1
- 108010002161 N-acetylornithine deacetylase Proteins 0.000 description 1
- RHGKLRLOHDJJDR-UHFFFAOYSA-N Ndelta-carbamoyl-DL-ornithine Natural products OC(=O)C(N)CCCNC(N)=O RHGKLRLOHDJJDR-UHFFFAOYSA-N 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- FSBIGDSBMBYOPN-UHFFFAOYSA-N O-guanidino-DL-homoserine Natural products OC(=O)C(N)CCON=C(N)N FSBIGDSBMBYOPN-UHFFFAOYSA-N 0.000 description 1
- 108090000854 Oxidoreductases Proteins 0.000 description 1
- 102000004316 Oxidoreductases Human genes 0.000 description 1
- 239000012807 PCR reagent Substances 0.000 description 1
- 239000001888 Peptone Substances 0.000 description 1
- 108010080698 Peptones Proteins 0.000 description 1
- HWMGTNOVUDIKRE-UWVGGRQHSA-N Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 HWMGTNOVUDIKRE-UWVGGRQHSA-N 0.000 description 1
- 239000004793 Polystyrene Substances 0.000 description 1
- DRKAXLDECUGLFE-ULQDDVLXSA-N Pro-Leu-Phe Chemical compound CC(C)C[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O DRKAXLDECUGLFE-ULQDDVLXSA-N 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- KQNDIKOYWZTZIX-FXQIFTODSA-N Ser-Ser-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQNDIKOYWZTZIX-FXQIFTODSA-N 0.000 description 1
- SZRNDHWMVSFPSP-XKBZYTNZSA-N Ser-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N)O SZRNDHWMVSFPSP-XKBZYTNZSA-N 0.000 description 1
- FCHAMFUEENBIDH-UHFFFAOYSA-N Severin Natural products CC1CCC2C(C)C3CCC4(O)C(CC5C4CC(O)C6CC(CCC56C)OC(=O)C)C3CN2C1 FCHAMFUEENBIDH-UHFFFAOYSA-N 0.000 description 1
- 108700014839 Streptococcus SAGP Proteins 0.000 description 1
- 241000187747 Streptomyces Species 0.000 description 1
- 241000187132 Streptomyces kanamyceticus Species 0.000 description 1
- 101000893300 Sus scrofa Glycine amidinotransferase, mitochondrial Proteins 0.000 description 1
- 108700005078 Synthetic Genes Proteins 0.000 description 1
- DHPPWTOLRWYIDS-XKBZYTNZSA-N Thr-Cys-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O DHPPWTOLRWYIDS-XKBZYTNZSA-N 0.000 description 1
- CRZNCABIJLRFKZ-IUKAMOBKSA-N Thr-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N CRZNCABIJLRFKZ-IUKAMOBKSA-N 0.000 description 1
- AHOLTQCAVBSUDP-PPCPHDFISA-N Thr-Ile-Lys Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)[C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O AHOLTQCAVBSUDP-PPCPHDFISA-N 0.000 description 1
- PZSDPRBZINDEJV-HTUGSXCWSA-N Thr-Phe-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PZSDPRBZINDEJV-HTUGSXCWSA-N 0.000 description 1
- ATJFFYVFTNAWJD-UHFFFAOYSA-N Tin Chemical compound [Sn] ATJFFYVFTNAWJD-UHFFFAOYSA-N 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- LIQJSDDOULTANC-QSFUFRPTSA-N Val-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N LIQJSDDOULTANC-QSFUFRPTSA-N 0.000 description 1
- 150000003863 ammonium salts Chemical class 0.000 description 1
- 235000019730 animal feed additive Nutrition 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- KDZOASGQNOPSCU-UHFFFAOYSA-N argininosuccinate Chemical compound OC(=O)C(N)CCCN=C(N)NC(C(O)=O)CC(O)=O KDZOASGQNOPSCU-UHFFFAOYSA-N 0.000 description 1
- KGBXLFKZBHKPEV-UHFFFAOYSA-N boric acid Chemical compound OB(O)O KGBXLFKZBHKPEV-UHFFFAOYSA-N 0.000 description 1
- 239000004327 boric acid Substances 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 238000005251 capillar electrophoresis Methods 0.000 description 1
- 230000001654 carbamoyl phosphate biosynthesis Effects 0.000 description 1
- 238000006555 catalytic reaction Methods 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 239000006285 cell suspension Substances 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 238000013375 chromatographic separation Methods 0.000 description 1
- 235000013477 citrulline Nutrition 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- LHJPHMKIGRLKDR-UHFFFAOYSA-N cylindrospermopsin Natural products C1C(N23)CC(OS(O)(=O)=O)C(C)C2CN=C3NC1C(O)C1=CC(=O)NC(=O)N1 LHJPHMKIGRLKDR-UHFFFAOYSA-N 0.000 description 1
- LHJPHMKIGRLKDR-VDPNAHCISA-N cylindrospermopsin zwitterion Chemical compound C1([C@H](O)[C@@H]2NC3=NC[C@@H]4[C@H]([C@H](C[C@H](C2)N43)OS(O)(=O)=O)C)=CC(=O)NC(=O)N1 LHJPHMKIGRLKDR-VDPNAHCISA-N 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000007865 diluting Methods 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- -1 for example Proteins 0.000 description 1
- 235000019253 formic acid Nutrition 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- JGBUYEVOKHLFID-UHFFFAOYSA-N gelred Chemical compound [I-].[I-].C=1C(N)=CC=C(C2=CC=C(N)C=C2[N+]=2CCCCCC(=O)NCCCOCCOCCOCCCNC(=O)CCCCC[N+]=3C4=CC(N)=CC=C4C4=CC=C(N)C=C4C=3C=3C=CC=CC=3)C=1C=2C1=CC=CC=C1 JGBUYEVOKHLFID-UHFFFAOYSA-N 0.000 description 1
- 108091008053 gene clusters Proteins 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 238000002013 hydrophilic interaction chromatography Methods 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 1
- 244000000010 microbial pathogen Species 0.000 description 1
- 230000002438 mitochondrial effect Effects 0.000 description 1
- 230000025608 mitochondrion localization Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- FEMOMIGRRWSMCU-UHFFFAOYSA-N ninhydrin Chemical compound C1=CC=C2C(=O)C(O)(O)C(=O)C2=C1 FEMOMIGRRWSMCU-UHFFFAOYSA-N 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 150000002894 organic compounds Chemical class 0.000 description 1
- 235000019319 peptone Nutrition 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 1
- 150000008300 phosphoramidites Chemical class 0.000 description 1
- 150000003013 phosphoric acid derivatives Chemical group 0.000 description 1
- 239000013600 plasmid vector Substances 0.000 description 1
- 238000007747 plating Methods 0.000 description 1
- 229920000768 polyamine Polymers 0.000 description 1
- 229920002223 polystyrene Polymers 0.000 description 1
- 238000001121 post-column derivatisation Methods 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- YQUVCSBJEUQKSH-UHFFFAOYSA-N protochatechuic acid Natural products OC(=O)C1=CC=C(O)C(O)=C1 YQUVCSBJEUQKSH-UHFFFAOYSA-N 0.000 description 1
- 238000002708 random mutagenesis Methods 0.000 description 1
- 239000011541 reaction mixture Substances 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 238000001953 recrystallisation Methods 0.000 description 1
- 238000004064 recycling Methods 0.000 description 1
- 238000007480 sanger sequencing Methods 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000012807 shake-flask culturing Methods 0.000 description 1
- 239000013605 shuttle vector Substances 0.000 description 1
- 239000000377 silicon dioxide Substances 0.000 description 1
- 239000007790 solid phase Substances 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 229960005322 streptomycin Drugs 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 239000013076 target substance Substances 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- WKOLLVMJNQIZCI-UHFFFAOYSA-N vanillic acid Chemical compound COC1=CC(C(O)=O)=CC=C1O WKOLLVMJNQIZCI-UHFFFAOYSA-N 0.000 description 1
- TUUBOHWZSQXCSW-UHFFFAOYSA-N vanillic acid Natural products COC1=CC(O)=CC(C(O)=O)=C1 TUUBOHWZSQXCSW-UHFFFAOYSA-N 0.000 description 1
- MWOOGOJBHIARFG-UHFFFAOYSA-N vanillin Chemical compound COC1=CC(C=O)=CC=C1O MWOOGOJBHIARFG-UHFFFAOYSA-N 0.000 description 1
- FGQOOHJZONJGDT-UHFFFAOYSA-N vanillin Natural products COC1=CC(O)=CC(C=O)=C1 FGQOOHJZONJGDT-UHFFFAOYSA-N 0.000 description 1
- 235000012141 vanillin Nutrition 0.000 description 1
- 239000003643 water by type Substances 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/93—Ligases (6)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/70—Vectors or expression systems specially adapted for E. coli
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/74—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora
- C12N15/77—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora for Corynebacterium; for Brevibacterium
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/74—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora
- C12N15/78—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora for Pseudomonas
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/1003—Transferases (2.) transferring one-carbon groups (2.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P13/00—Preparation of nitrogen-containing organic compounds
- C12P13/04—Alpha- or beta- amino acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P13/00—Preparation of nitrogen-containing organic compounds
- C12P13/04—Alpha- or beta- amino acids
- C12P13/10—Citrulline; Arginine; Ornithine
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/40—Preparation of oxygen-containing organic compounds containing a carboxyl group including Peroxycarboxylic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y603/00—Ligases forming carbon-nitrogen bonds (6.3)
- C12Y603/04—Other carbon-nitrogen ligases (6.3.4)
- C12Y603/04016—Carbamoyl-phosphate synthase (ammonia) (6.3.4.16)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y201/00—Transferases transferring one-carbon groups (2.1)
- C12Y201/01—Methyltransferases (2.1.1)
- C12Y201/01002—Guanidinoacetate N-methyltransferase (2.1.1.2)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y201/00—Transferases transferring one-carbon groups (2.1)
- C12Y201/03—Carboxy- and carbamoyltransferases (2.1.3)
- C12Y201/03003—Ornithine carbamoyltransferase (2.1.3.3)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y201/00—Transferases transferring one-carbon groups (2.1)
- C12Y201/04—Amidinotransferases (2.1.4)
- C12Y201/04001—Glycine amidinotransferase (2.1.4.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y403/00—Carbon-nitrogen lyases (4.3)
- C12Y403/02—Amidine-lyases (4.3.2)
- C12Y403/02001—Argininosuccinate lyase (4.3.2.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y603/00—Ligases forming carbon-nitrogen bonds (6.3)
- C12Y603/04—Other carbon-nitrogen ligases (6.3.4)
- C12Y603/04005—Argininosuccinate synthase (6.3.4.5)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y603/00—Ligases forming carbon-nitrogen bonds (6.3)
- C12Y603/05—Carbon-nitrogen ligases with glutamine as amido-N-donor (6.3.5)
- C12Y603/05005—Carbamoyl-phosphate synthase (glutamine-hydrolysing) (6.3.5.5)
Landscapes
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Biotechnology (AREA)
- Microbiology (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Medicinal Chemistry (AREA)
- Plant Pathology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Organic Low-Molecular-Weight Compounds And Preparation Thereof (AREA)
- Enzymes And Modification Thereof (AREA)
Abstract
본 발명은 구아니디노아세트산 (GAA) 을 생산할 수 있도록 형질전환된 미생물 및 상기 미생물을 이용하는 GAA 의 발효 생산 방법에 관한 것이다. 본 발명은 또한 크레아틴의 발효 생산 방법에 관한 것이다.
Description
본 발명은 구아니디노아세트산 (GAA) 을 생산할 수 있도록 형질전환된 미생물 및 상기 미생물을 이용하는 GAA 의 발효 생산 방법에 관한 것이다. 본 발명은 또한 크레아틴의 발효 생산 방법에 관한 것이다.
GAA 는 동물 사료 첨가제로서 사용되는 유기 화합물이다 (WO2005120246 A1/ US2011257075 A1). GAA 는 크레아틴의 천연 전구체이다 (예를 들어, Humm et al., Biochem. J. (1997) 322, 771-776). 따라서, GAA 의 보충은 유기체 내의 크레아틴의 최적의 공급을 허용한다.
본 발명은 출발 물질로서 산업용 공급 원료 (예를 들어, 암모니아, 암모늄 염 및 글루코스 또는 당 함유 기질) 를 사용하는 발효 공정에 의해 GAA 를 제조하는 방법에 관한 것이다. 생물학적 시스템에서, GAA 및 오르니틴은 L-아르기닌:글리신-아미디노트랜스퍼라제 (AGAT; EC 2.1.4.1) 의 촉매 작용에 의해 출발 물질로서 아르기닌 및 글리신으로부터 형성되며, 이는 크레아틴 생합성의 제 1 단계이다 (US 20060200870 A1):
L-아르기닌 + 글리신 AGAT > L-오르니틴 + GAA
Guthmiller et al. (J Biol Chem. 1994 Jul 1;269(26):17556-60) 은 E. 콜라이 (E. coli) 에서 효소를 클로닝하고 이종적으로 발현시킴으로써 래트 신장 AGAT 를 특징화하였다. Muenchhoff et al. (FEBS Journal 277 (2010) 3844-3860) 은 또한 E. 콜라이에서 효소를 클로닝하고 이종적으로 발현시킴으로써 원핵생물로부터 AGAT 의 제 1 특징화를 보고한다. Sosio et al. (Cell Chemical Biology 25, 540-549, May 17, 2018) 은 스트렙토마이세스 종에서 슈도우리디마이신에 대한 생합성 경로를 설명하였다. 이들은 PumN, L-아르기닌:글리신-아미디노트랜스퍼라제 (AGAT) 에 의해 촉매되는 글리신과 L-아르기닌의 반응에 의한 GAA 및 L-오르니틴의 형성을 중간 반응으로서 기술한다. Humm et al. 은 인간 AGAT 를 인코딩하는 재조합 유전자를 대장균에서 발현시키고, AGAT 의 활성 부위 잔기로서 시스테인-407 을 확인하였다 (Biochem. J. (1997) 322, 771-776).
Mijts et al. (WO 2018079687 A1) 은 미생물 중의 목적 물질, 예를 들어 바닐린 및 바닐산의 생산의 맥락에서 크레아틴이 L-아르기닌 및 글리신으로부터 생산될 수 있음을 개시하고 있다. 저자는 이것이 L-아르기닌 생합성 효소, 글리신 생합성 효소, 및 L-아르기닌 및 글리신의 크레아틴으로의 전환을 촉매하는 효소를 사용함으로써 달성될 수 있음을 추가로 제안한다. L-아르기닌 및 글리신은 AGAT (EC 2.1.4.1) 의 작용에 의해 구아니디노아세테이트 (GAA) 및 오르니틴을 생성하기 위해 조합될 수 있고, GAA 는 메틸 공여체로서 S-아데노실 메티오닌 (SAM) 을 사용하여 구아니디노아세테이트 N-메틸트랜스퍼라제 (GAMT, EC 2.1.1.2) 의 작용에 의해 크레아틴을 생성하기 위해 메틸화될 수 있다. 저자는 L-아르기닌 생합성 효소의 예인 폴리아민의 생산의 맥락에서 또한 공지된 L-오르니틴 생합성 효소뿐만 아니라 소위 L-오르니틴 사이클로부터 잘 공지된 효소, 즉 카르바모일 포스페이트 신타아제 (carAB), 오르니틴 카르바모일 트랜스퍼라제 (argF, argI), 아르기니노숙시네이트 신테타제 (argG), 아르기니노숙시네이트 리아제 (argH) 를 포함할 수 있다 (참조: Marc et al., Eur. J. Biochem. 267, 5217-5226, 200).
그러나, 미생물, 특히 박테리아에서, GAA 합성에서 출발 물질 중 하나, 즉 L-아르기닌의 생산을 증가시키기 위한 몇 가지 더 구체적인 접근법이 또한 문헌으로부터 공지되어 있다. L-아르기닌 생산을 위한 코리네박테리움 글루타미쿰 (C. glutamicum) 의 대사 공학에 대한 개요는 ark et al. (NATURE COMMUNICATIONS | DOI: 10.1038/ncomms5618) 에 의해 제공된다. 이들은 이미 L-아르기닌 생산 C. 글루타미쿰 균주의 L-아르기닌 생산자, 예를 들어 ATCC 21831 (Nakayama and Yoshida 1974, US3849250 A) 에 대한 랜덤 돌연변이유발 및 스크리닝을 제안하며, 대사의 시스템-와이드 분석에 기초한 단계적 합리적 대사 공학은 균주 공학 단계 전반에 걸쳐 L-아르기닌 생산의 점진적 증가를 초래한다. Yim et al. (J Ind Microbiol Biotechnol (2011) 38:1911-1920) 은 C. 글루타미쿰에서 염색체 argR 유전자를 파괴함으로써 L-아르기닌 생합성 경로를 제어하는 중심 리프레서 단백질 ArgR 을 코딩하는 유전자인 argR 의 불활성화가 아르기닌-생산 균주를 개선시킨다는 것을 보여줄 수 있었다. Ginesy et al. (Microbial Cell Factories (2015) 14:29) 은 아르기닌 생산 증대를 위한 E. 콜라이의 성공적인 공학을 보고한다. 그 중에서도, 그들은 argR 리프레서 유전자의 결실을 제안하였다.
Kurahashi et al. (EP1057893 A1) 은 재조합 DNA 기술을 이용하여 L-아르기닌 생합성 효소를 증진시킴으로써, 예를 들어 에스케리키아 속에 속하는 미생물로부터 유래된 아세틸오르니틴 데아세틸라제, N-아세틸글루탐산-γ-세미알데히드 데히드로게나제, N-아세틸 글루타모키나제 및 아르기니노숙신아제에 대한 유전자를 함유하는 DNA 단편 및 벡터 DNA 를 포함하는 재조합 DNA 를 갖도록 제조된 코리네박테리움 또는 브레비박테리움 속에 속하는 미생물을 이용함으로써 미생물의 L-아르기닌 생산 능력을 증가시키는 방법에 대한 보고한다. 개선된 L-아르기닌 생산을 위해, 상기 저자는 세포내 글루타메이트 디히드로게나제 (GDH) 의 활성이 향상되고, L-아르기닌 생산 능력이 있는 미생물을 추가로 제안하였다.
아르기닌-생합성 오페론인 argR 의 발현을 저해하는 유전자가 불활성화된 유전자 재조합 균주의 이용 방법이 Suga et al. (US7160705 B2) 에 의해 보고되었다. 특히, 아르기닌 오페론을 조절하는 argR 내 결실은 아르기닌 생산의 중요한 인자로서 여겨져 왔다.
코리네박테리움 미생물에서, 아르기닌 생합성에 관여하는 argCJBDFR 유전자는 오페론 형태로 구성되어 세포내 아르기닌에 의한 피드백 저해를 거침으로써 (Sakanyan et al., Microbiology, 142:9-108, 1996), 이의 높은 L-아르기닌 생산 수율에 대한 제한을 가하였다.
그러나, Bae et al. (EP3153573 A1) 은 C. 글루타미쿰에서 L-아르기닌의 생산 수율을 증가시키려는 시도로, 아르기닌 리프레서 (argR) 에서 어떠한 결실도 없이, 아르기닌 오페론 및 오르니틴 카르바모일트랜스퍼라제 (ArgF, ArgF2) 의 활성을 향상시킴으로써, 모체 L-아르기닌-생산 균주에 비해 L-아르기닌을 더 높은 수율로 생산할 수 있음을 발견하였다.
아르기닌 오페론은 L-아르기닌 생합성 기전에 관여하는 효소를 인코딩하는 유전자로 구성된 오페론으로, 특히 아르기닌 오페론은 L-아르기닌 생합성의 순환형 단계를 구성하는 효소를 인코딩하는 유전자로 구성된다. 구체적으로, 아르기닌 오페론은 N-아세틸글루타밀 포스페이트 리덕타제 (ArgC), 글루타메이트 N-아세틸트랜스퍼라제 (ArgJ), N-아세틸글루타메이트 키나제 (ArgB), 아세틸오르니틴 아미노트랜스퍼라제 (ArgD), 오르니틴 카르바모일트랜스퍼라제 (ArgF) 및 아르기닌 리프레서 (ArgR) 로 구성된다. 이들 효소는 L-아르기닌 생합성의 연속 효소 반응에 관여하며, argR 에 의해 인코딩된 아르기닌 리프레서에 의해 조절된다 (WO 2006/057450 A1).
Fan Wenchao 은 코리네박테리움 글루타미쿰과 같은 비병원성 미생물의 발효에 의한 크레아틴의 생산 방법을 개시한다 (CN106065411 A). 미생물은 다음의 바이오전환 기능을 갖는다: 글루코스의 L-글루탐산으로의 전환; L-글루탐산의 N-아세틸-L-글루탐산으로의 전환; N-아세틸-L-글루탐산의 N-아세틸-L-글루탐산 세미알데히드로의 전환; N-아세틸-L-글루탐산 세미알데히드의 N-아세틸-L-오르니틴으로의 전환; N-아세틸-L-오르니틴의 L-오르니틴으로의 전환; L-오르니틴의 L-시트룰린으로의 전환; L-시트룰린의 아르기니노-숙신산으로의 전환; 아르기니노-숙신산의 L-아르기닌으로의 전환; L-아르기닌의 구아니디노아세트산으로의 전환; 및 마지막으로 구아니디노아세트산의 크레아틴으로의 전환. Fan Wenchao 는 미생물이 N-아세틸글루타메이트-신타아제, N-아세틸오르니틴-δ-아미노트랜스퍼라제, N-아세틸오르니티나제, 오르니틴-카르바모일 트랜스퍼라제, 아르기니노숙시네이트 신테타제, 글리신 아미디노-트랜스퍼라제 (EC: 2.1. 4.1), 및 구아니디노아세테이트 N-메틸트랜스퍼라제 (EC: 2.1.1.2) 로 이루어진 군으로부터 선택된 하나 이상의 효소를 과발현한다고 제안한다. 미생물은 바람직하게는 글리신 아미노트랜스퍼라제 (L-아르기닌:글리신 아미디노트랜스퍼라제) 및 구아니디노아세테이트 N-메틸트랜스퍼라제를 과발현한다.
지금까지, 야생형 형태에 비해 증가된 GAA 생산에 적합한 미생물 및 이러한 미생물을 이용한 GAA 생산에 대한 각각의 방법은 보고되지 않았다.
따라서, 본 발명의 근본적인 과제는 구아니디노아세트산 (GAA) 을 생산할 수 있도록 형질전환된 미생물 및 상기 미생물을 이용하는 GAA 의 발효 생산 방법을 제공하는 것이다.
이 과제는 야생형 미생물에서 각각의 효소 활성에 비해 카르바모일포스페이트 신타아제 (EC 6.3.4.16) 의 기능을 갖는 효소의 증가된 활성을 포함하고, L-아르기닌:글리신 아미디노트랜스퍼라제 (AGAT) 의 기능을 갖는 단백질을 코딩하는 적어도 하나의 이종 유전자를 포함하는 미생물에 의해 해결된다.
이종 유전자는 유전자가 자연적으로 이 유전자를 갖지 않는 숙주 유기체 내에 삽입되었음을 의미한다. 숙주 내 이종 유전자의 삽입은 재조합 DNA 기술에 의해 수행된다. 재조합 DNA 기술을 거친 미생물은 형질전환, 유전자 변형 또는 재조합체로 불린다. 따라서, 본 발명에 따른 미생물은 재조합체이다.
카르바모일포스페이트 신타아제의 기능을 갖는 효소의 증가된 활성은 카르바모일포스페이트 신타아제의 기능을 갖는 효소를 코딩하는 유전자의 돌연변이 및/또는 과발현에 의해 달성될 수 있다.
L-아르기닌:글리신 아미디노트랜스퍼라제의 활성은 또한 L-아르기닌:글리신 아미디노트랜스퍼라제를 코딩하는 유전자의 돌연변이 및/또는 과발현에 의해 증가될 수 있다.
L-아르기닌:글리신 아미디노트랜스퍼라제 (AGAT) 의 기능을 갖는 단백질은 아미디노트랜스퍼라제 패밀리에 속한다. 아미디노트랜스퍼라제 패밀리는 각각 크레아틴 및 스트렙토마이신 생합성에 관여하는 효소인 글리신 (EC:2.1.4.1) 및 이노사민 (EC:2.1.4.2) 을 포함한다. 이 패밀리는 또한 아르기닌 데이미나제, EC:3.5.3.6 을 포함한다. 이들 효소는 반응을 촉매한다: 아르기닌 + H2O <=> 시트룰린 + NH3. 또한 이 패밀리에서 발견되는 것은 스트렙토코쿠스 항종양 당단백질이다. L-아르기닌:글리신-아미디노트랜스퍼라제 (AGAT) 활성을 갖는 효소 또는 단백질은 또한, 하기 간행물: Pissowotzki K et al., Mol Gen Genet 1991;231:113-123 (PUBMED:1661369 EPMC:1661369); D'Hooghe I et al., J Bacteriol 1997;179:7403-7409 (PUBMED:9393705 EPMC:9393705); Kanaoka M et al., Jpn J Cancer Res 1987;78:1409-1414 (PUBMED:3123442 EPMC:3123442) 에서 설명되는 바와 같은, PFAM 패밀리: Amidinotransf (PF02274) (: Marchler-Bauer A et al. (2017), "CDD/SPARCLE: functional classification of proteins via subfamily domain architectures.", Nucleic Acids Res. 45(D1):D200-D203.) 에 속하는 보존된 도메인을 갖는 것으로 기술된다. AGAT 의 특정 예는 무레아 프로듀센스 (Moorea producens), 호모 사피엔스 (Homo sapiens), 라투스 노르베지쿠스 (Rattus norvegicus), 갈레옵테루스 바리에가투스 (Galeopterus variegatus), 및 실린드로스페르모프시스 라시보르스키 (Cylindrospermopsis raciborskii) 의 것이다.
본 발명에 따른 미생물은 야생형 미생물의 능력에 비해 L-아르기닌 생산 능력이 이상적으로 개선된다. 이러한 특성은 천연 L-아르기닌 생산자인 미생물의 선별에 의해 달성될 수 있거나 돌연변이에 의해 L-아르기닌을 생산하는 능력을 취득할 수 있다.
본 발명에 따르고 야생형 미생물의 능력에 비해 L-아르기닌 생산 능력이 향상된 미생물은 야생형 미생물에서 각각의 효소 활성에 비해 아르기니노숙시네이트 리아제 (E.C. 4.3.2.1) 의 기능을 갖는 효소의 활성이 증가될 수 있다.
또한, 본 발명에 따른 미생물에서, 오르니틴 카르바모일트랜스퍼라제 (EC 2.1.3.3) 의 기능을 갖는 효소의 활성을 야생형 미생물에서의 각각의 효소 활성에 비해 증가시킬 수 있다.
본 발명에 따른 미생물에서, 아르기니노숙시네이트 신테타제 (E.C. 6.3.4.5) 의 기능을 갖는 효소의 활성을 야생형 미생물에서의 각각의 효소 활성에 비해 증가시킬 수 있다.
미생물에서 증가된 효소 활성은, 예를 들어, 상응하는 내인성 유전자의 돌연변이에 의해 달성될 수 있다. 효소 활성을 증가시키기 위한 추가 측정은 효소를 코딩하는 mRNA 를 안정화시키는 것일 수 있다.
상기 언급된 효소의 활성 증가는 각 효소를 코딩하는 유전자를 과발현시킴으로써 달성될 수도 있다. 다시 말해, 이 과제는 바람직하게는 야생형 유기체의 능력에 비해 L-아르기닌을 생산하는 능력이 개선된 및/또는 카르바모일포스페이트 신타아제 (EC 6.3.4.16) 의 기능을 갖는 단백질을 코딩하는 적어도 하나 이상의 과발현된 유전자 (예를 들어, carA, carB) 를 갖고, L-아르기닌:글리신 아미디노트랜스퍼라제 (AGAT, 예를 들어, EC 2.1.4.1) 의 기능을 갖는 단백질을 코딩하는 유전자를 추가로 포함하는 미생물에 의해 해결된다.
또한, 본 발명에 따른 미생물은 바람직하게는 오르니틴 카르바모일트랜스퍼라제의 기능 (EC 2.1.3.3) 을 갖는 단백질을 코딩하는 유전자 (예를 들어, argF/argF2/argI), 아르기니노숙시네이트 신테타제 (E.C. 6.3.4.5) 의 기능을 갖는 단백질을 코딩하는 유전자 (예를 들어, argG), 및 아르기니노숙시네이트 리아제 (E.C. 4.3.2.1) 의 기능을 갖는 단백질을 코딩하는 유전자 (예를 들어, argH) 로 이루어진 군으로부터 선택되는 적어도 하나 이상의 과발현된 유전자를 포함한다.
유전자의 과발현은 일반적으로 유전자의 카피수를 증가시킴으로써 및/또는 유전자를 강력한 프로모터와 기능적으로 연결시킴으로써 및/또는 리보솜 결합 부위를 향상시킴으로써 및/또는 개시 코돈 또는 전체 유전자의 코돈 사용 최적화 또는 상기 언급된 모든 방법의 선택을 포함하는 조합에 의해 달성된다.
본 발명의 문맥에서 L-아르기닌을 생산하는 능력이 향상된 미생물은 자신의 필요를 초과하여 L-아르기닌을 생산하는 미생물을 의미한다. 이러한 L-아르기닌 생산 미생물의 예는 예를 들어 C. 글루타미쿰 ATCC 21831 또는 Park et al. (NATURE COMMUNICATIONS | DOI: 10.1038/ncomms5618) 또는 Ginesy et al. (Microbial Cell Factories (2015) 14:29) 에 의해 개시된 것들이다.
본 발명에 따른 미생물의 일 구현예에서, 아르기닌 오페론 (argCJBDFR) 은 과발현될 수 있다.
대안적으로는, 본 발명에 따른 미생물에서 아르기닌 반응성 리프레서 단백질 ArgR 을 코딩하는 argR 유전자는 약독화되거나 결실될 수 있다.
본 발명의 추가의 구현예에서, 및 임의로 상기 언급된 변형에 더하여, 글루타메이트 디히드로게나제, 오르니틴 아세틸트랜스퍼라제, 아세틸글루타메이트 키나제, 아세틸글루타밀포스페이트 리덕타제 및 아세틸오르니틴 아미노트랜스퍼라제를 각각 코딩하는 gdh, argJ, argB, argC 및/또는 argD 를 포함하는, L-아르기닌의 생합성 경로의 효소를 코딩하는 적어도 하나 이상의 유전자가 본 발명에 따른 미생물에서 과발현된다.
표 1 은 상이한 종, 즉 E. 콜라이, C. 글루타미쿰 및 슈도모나스 푸티다 (P. putida) 에서 아르기닌 생합성에 관여하거나 이에 기여하는 효소의 상이한 명칭을 나타낸다.
본 발명의 미생물에 있어서, L-아르기닌:글리신 아미디노트랜스퍼라제 기능을 갖는 단백질을 코딩하는 유전자가 추가로 과발현될 수 있다. 유전자의 과발현은 일반적으로 유전자의 카피수를 증가시킴으로써 및/또는 유전자를 강력한 프로모터와 기능적으로 연결시킴으로써 및/또는 리보솜 결합 부위를 향상시킴으로써 및/또는 전체 유전자의 개시 코돈의 코돈 사용 최적화 또는 상기 언급된 모든 방법 또는 선택을 포함하는 조합에 의해 달성된다.
표 1: 효소의 명칭


본 발명의 미생물에서 L-아르기닌:글리신 아미디노트랜스퍼라제 (AGAT) 의 기능을 갖는 단백질은 SEQ ID NO: 2 또는 SEQ ID NO: 4 에 따른 아미노산 서열 (무레아 프로듀센스 (Moorea producens) 의 "AGAT_Mp") 에 대해 적어도 70% 상동, 바람직하게는 적어도 80% 또는 적어도 90% 상동인 아미노산 서열을 포함할 수 있다. 본 발명의 추가의 구현예에서, L-아르기닌:글리신 아미디노트랜스퍼라제의 아미노산 서열은 SEQ ID NO: 2 또는 SEQ ID NO: 4 에 따른 아미노산 서열과 동일하다 (참조: Database UniProt, 15 February 2017, "Glycine amidinotransferase", XP055706853, EBI 수탁 번호 UNIPROT: A0A1D8TKD3). 무레아 프로듀센스 AGAT 를 코딩하는 야생형 DNA 의 서열은 SEQ ID NO:1 이고, C. 글루타미쿰에 대해 코돈 최적화된 상응하는 DNA 서열은 SEQ ID NO:3 이다. P. 푸티다에 대해 코돈 최적화된 무레아 프로듀센스 AGAT 유전자에 대한 상응하는 DNA 서열은 SEQ ID NO: 33 이다.
본 발명의 미생물에서 L-아르기닌:글리신 아미디노트랜스퍼라제의 기능을 갖는 단백질은 SEQ ID NO: 16 또는 SEQ ID NO: 26 에 따른 아미노산 서열 (실린드로스페르모프시스 라시보르스키 (Cylindrospermopsis raciborskii) ATW205 의 "AGAT_cyrA") 에 대해 적어도 70% 상동, 바람직하게는 적어도 80% 또는 적어도 90% 상동인 아미노산 서열을 포함할 수 있다. 본 발명의 추가의 구현예에서, L-아르기닌:글리신 아미디노트랜스퍼라제의 아미노산 서열은 SEQ ID NO:16 또는 SEQ ID NO:26 에 따른 아미노산 서열과 동일하다. 실린드로스페르모프시스 라시보르스키 (Cylindrospermopsis raciborskii) AGAT 를 코딩하는 야생형 DNA 의 서열은 SEQ ID NO:15 이고, C. 글루타미쿰에 대해 코돈 최적화된 상응하는 DNA 서열은 SEQ ID NO:25 이다.
본 발명의 미생물에서 L-아르기닌:글리신 아미디노트랜스퍼라제의 기능을 갖는 단백질은 SEQ ID NO: 23 (갈레옵테루스 바리에가투스 (Galeopterus variegatus) 의 "AGAT_Gv"), 바람직하게는 SEQ ID NO: 24 또는 SEQ ID NO:32 에 따른 아미노산 서열에 대해 적어도 70% 상동, 바람직하게는 적어도 80% 또는 적어도 90% 상동인 아미노산 서열을 포함할 수 있다. 본 발명의 추가의 구현예에서, L-아르기닌:글리신 아미디노트랜스퍼라제의 아미노산 서열은 SEQ ID NO:24 또는 SEQ ID NO:32 에 따른 아미노산 서열과 동일하다. C. 글루타미쿰에 대해 코돈 최적화된 상응하는 갈레옵테루스 바리에가투스 AGAT DNA 의 서열은 SEQ ID NO: 31 이다.
본 발명의 미생물에서 L-아르기닌:글리신 아미디노트랜스퍼라제의 기능을 갖는 단백질은 SEQ ID NO:18 (호모 사피엔스 (Homo sapiens) 의 "AGAT_Hs"), 바람직하게는 SEQ ID NO: 20 또는 SEQ ID NO:28 에 따른 아미노산 서열, 예를 들어 SEQ ID NO: 21 또는 SEQ ID NO: 22 또는 SEQ ID NO:30 (라투스 노르베지쿠스 (Rattus norvegicus) 의 각 "AGAT Rn"; C. 글루타미쿰에 대해 코돈 최적화된, 상응하는 DNA 는 SEQ ID NO: 29 임) 에 따른 아미노산 서열에 대해 적어도 70% 상동, 바람직하게는 적어도 80% 또는 적어도 90% 상동인 아미노산 서열을 포함할 수 있다. 본 발명의 추가의 구현예에서, L-아르기닌:글리신 아미디노트랜스퍼라제의 아미노산 서열은 SEQ ID NO:18 에 따른 아미노산 서열과 동일하다. 호모 사피엔스 AGAT 를 코딩하는 야생형 DNA 의 서열은 SEQ ID NO:17 이고, C. 글루타미쿰에 대해 코돈 최적화된 상응하는 DNA 서열은 SEQ ID NO:27 이다.
본 발명의 미생물은 코리네박테리움 (Corynebacterium) 속, 바람직하게는 코리네박테리움 글루타미쿰 (Corynebacterium glutamicum (C. glutamicum)), 또는 엔테로박테리아세아에 (Enterobacteriaceae) 속, 바람직하게는 에스케리치아 콜라이 (Escherichia coli (E. coli)), 또는 슈도모나스 (Pseudomonas) 속, 바람직하게는 슈도모나스 푸티다 (Pseudomonas putida (P. putida)) 에 속할 수 있다.
일반적으로, 미생물에서 증가된 효소 활성은, 예를 들어, 상응하는 내인성 유전자의 돌연변이에 의해 달성될 수 있다. 또한 상응하는 유전자의 과발현에 의해 효소 활성이 향상될 수 있다.
일반적으로, 본 발명에 따른, 유전자의 과발현은 유전자의 카피수를 증가시킴으로써 및/또는 조절 인자의 향상에 의해, 예를 들어, 유전자를 강력한 프로모터와 기능적으로 연결시킴으로써 및/또는 리보솜 결합 부위를 향상시킴으로써 및/또는 개시 코돈 또는 전체 유전자의 코돈 사용 최적화에 의해 달성된다. 유전자 발현에 긍정적인 영향을 미치는 이러한 조절 인자의 향상은, 예를 들어, 프로모터의 유효성을 증가시키기 위해 구조 유전자의 업스트림의 프로모터 서열을 변형함으로써 또는 상기 프로모터를 보다 효과적이거나 소위 강한 프로모터로 완전히 대체함으로써 달성될 수 있다. 프로모터는 유전자의 업스트림에 위치한다. 프로모터는 약 40 내지 50 개의 염기쌍으로 이루어진 DNA 서열로서, RNA 중합효소 할로효소의 결합 부위 및 전사 시작 지점을 구성하며, 이에 의해 조절된 폴리뉴클레오티드 또는 유전자의 발현 강도가 영향을 받을 수 있다. 일반적으로, 강한 프로모터를 선택함으로써, 예를 들어, 본래의 프로모터를 강하고 천연적인 (본래 다른 유전자에 할당된) 프로모터로 대체함으로써, 또는 주어진 천연적인 프로모터의 특정 영역 (예를 들어, 소위 -10 및 -35 영역) 을, 예를 들어, C. 글루타미쿰의 경우 M. Patek et al. (Microbial Biotechnology 6 (2013), 103-117) 에 의해 교시된 바와 같이, 컨센서스 서열을 향해 변형시킴으로써, 박테리아에서 유전자의 과발현 또는 발현의 증가를 달성할 수 있다. "기능적 연결" 은 프로모터와 유전자의 순차적인 배열로, 이는 유전자의 전사를 초래하는 것을 의미하는 것으로 이해된다.
유전자 코드는 퇴보되는데, 이는 특정 아미노산이 다수의 상이한 트리플릿에 의해 인코딩될 수 있다는 것을 의미한다. 용어 코돈 사용은 특정 유기체가 전형적으로 동일한 빈도를 갖는 특정 아미노산에 대해 모든 가능한 코돈을 사용하지 않을 것이라는 관찰을 의미한다. 대신에, 유기체는 전형적으로 특정 코돈에 대한 특정 선호도를 나타낼 것이며, 이는 이들 코돈이 유기체의 전사된 유전자의 코딩 서열에서 더 빈번하게 발견됨을 의미한다. 미래의 숙주에 외래인, 즉 상이한 종으로부터 유래된 특정 유전자가 미래의 숙주 유기체에서 발현되어야 한다면, 상기 유전자의 코딩 서열은 상기 미래의 숙주 유기체의 코돈 사용에 대해 조정되어야 한다 (즉, 코돈 사용 최적화).
상기 언급된 과제는 또한, a) 상기 정의된 본 발명에 따른 미생물을 적합한 배지에서 적합한 조건 하에서 배양하는 단계, 및 b) 배지에 구아니디노 아세트산 (GAA) 을 축적하여 GAA 함유 발효 브로쓰를 형성하는 단계를 포함하는, 구아니디노 아세트산 (GAA) 의 발효 생산 방법에 의해 해결된다.
본 발명에 따른 방법은 배지에 글리신을 첨가하는 단계 및/또는 L-아르기닌을 첨가하는 단계 및/또는 L-오르니틴을 첨가하는 단계를 더 포함할 수 있다. 바람직하게는, 배지에 0.1 내지 300 g 글리신/l 배지, 바람직하게는 0.82 g 글리신/l 배지 범위의 농도의 글리신 및/또는 0.1 내지 200 g L-아르기닌/l 배지, 바람직하게는 1.9 g L-아르기닌/l 배지 범위의 농도를 얻도록 L-아르기닌을 보충한다.
본 발명의 방법은 발효 브로쓰로부터 GAA 를 단리하는 단계를 더 포함할 수 있다.
본 발명에 따른 방법은 GAA 함유 발효 브로쓰를 건조 및/또는 과립화하는 단계를 더 포함할 수 있다.
본 발명은 또한 구아니디노아세테이트 N-메틸트랜스퍼라제 (EC: 2.1.1.2) 의 활성을 갖는 효소를 코딩하는 유전자를 추가로 포함하는, 상기 정의된 미생물에 관한 것이다. 바람직하게는, 구아니디노아세테이트 N-메틸트랜스퍼라제의 활성을 갖는 효소를 코딩하는 유전자가 과발현된다.
또한, 본 발명은 a) 구아니디노아세테이트 N-메틸트랜스퍼라제의 활성을 갖는 효소를 코딩하는 유전자를 포함하는 본 발명에 따른 미생물을 적합한 배지에서 적합한 조건 하에 배양하는 단계, 및 b) 상기 배지 내에 크레아틴을 축적하여 크레아틴 함유 발효 브로쓰를 형성하는 단계를 포함하는, 크레아틴의 발효 생산 방법에 관한 것이다.
바람직하게는, 상기 방법은 크레아틴 함유 발효 브로쓰로부터 크레아틴을 단리하는 단계를 추가로 포함한다. 크레아틴은 등전점법 및/또는 이온 교환법에 의해 발효 브로쓰로부터 추출될 수 있다. 대안적으로, 크레아틴은 물 중에서 재결정화하는 방법에 의해 추가로 정제될 수 있다.
실험 부문
A) 재료 및 방법
화학물질
스트렙토마이세스 카나마이세티쿠스 (Streptomyces kanamyceticus) 로부터의 카나마이신 용액을 Sigma Aldrich (St. Louis, USA, Cat. no. K0254) 로부터 구입하였다. IPTG (이소프로필 β-D-1-티오갈락토피라노사이드) 를 Carl-Roth (Karlsruhe, Germany, Cat. no. 2316.4.) 로부터 구입하였다. 달리 언급되지 않는다면, 모든 다른 화학물질은 Merck (Darmstadt, Germany), Sigma Aldrich (St. Louis, USA) 또는 Carl-Roth (Karlsruhe, Germany) 로부터 분석적으로 순수하게 구입하였다.
세포 증식을 위한 배양
달리 언급되지 않는다면, 배양/인큐베이션 절차는 다음과 같이 수행하였다:
a. Merck (Darmstadt, Germany; Cat. no. 110285) 사의 LB 브로쓰 (MILLER) 를 액체 배지에서 E. 콜라이 균주를 배양하는데 사용하였다. 액체 배양물 (3 개의 배플이 있는 100 ml Erlenmeyer 플라스크 당 10 ml 액체 배지) 을 Infors GmbH (Bottmingen, Switzerland) 사의 Infors HT Multitron 표준 인큐베이터 진탕기에서 30℃ 및 200 rpm 으로 인큐베이션하였다.
b. Merck (Darmstadt, Germany; Cat. no. 110283) 사의 LB 브로쓰 (MILLER) 를 아가 플레이트 상에서 E. 콜라이 균주를 배양하는데 사용하였다. 아가 플레이트를 VWR (Radnor, USA) 사의 INCU-Line® 미니 인큐베이터에서 30℃ 에서 인큐베이션하였다.
c. Merck (Darmstadt, Germany; Cat. no. 110493) 사의 뇌 심장 인퓨전 브로쓰 (BHI) 를 액체 배지에서 C. 글루타미쿰 균주를 배양하는데 사용하였다. 액체 배양물 (3 개의 배플이 있는 100 ml Erlenmeyer 플라스크 당 10 ml 액체 배지) 을 Infors GmbH (Bottmingen, Switzerland) 사의 Infors HT Multitron 표준 인큐베이터 진탕기에서 30℃ 및 200 rpm 으로 인큐베이션하였다.
d. Merck (Darmstadt, Germany; Cat. no. 113825) 사의 뇌 심장 아가 (BHI-아가) 를 아가 플레이트 상에서 C. 글루타미쿰 균주의 배양에 사용하였다. 아가 플레이트를 Kelvitron® 온도 제어기 (Hanau, Germany) 가 있는 Heraeus Instruments 사의 인큐베이터에서 30℃ 에서 인큐베이션하였다.
e. 전기천공 후 C. 글루타미쿰을 배양하기 위하여, BHI-agar (Merck, Darmstadt, Germany, Cat. no. 113825) 에 134 g/l 소르비톨 (Carl Roth GmbH + Co. KG, Karlsruhe, Germany), 2.5 g/l 효모 추출물 (Oxoid/ThermoFisher Scientific, Waltham, USA, Cat. no. LP0021) 및 25 mg/l 카나마이신을 보충하였다. 아가 플레이트를 Kelvitron® 온도 제어기 (Hanau, Germany) 가 있는 Heraeus Instruments 사의 인큐베이터에서 30℃ 에서 인큐베이션하였다.
박테리아 현탁액의 광학 밀도 결정
a. 진탕 플라스크 배양물 중의 박테리아 현탁액의 광학 밀도를 Eppendorf AG (Hamburg, Germany) 사의 BioPhotometer 를 사용하여 600 nm (OD600) 에서 측정하였다.
b. Tecan Group AG (Maennedorf, Switzerland) 사의 GENios™ 플레이트 판독기를 사용하여 Wouter Duetz (WDS) 마이크로 발효 시스템 (24-웰 플레이트) 에서 생산된 박테리아 현탁액의 광학 밀도를 660 nm (OD660) 에서 측정하였다.
원심분리
a. 최대 부피가 2 ml 인 박테리아 현탁액을 Eppendorf 5417 R 벤치탑 원심분리 (13.000 rpm 에서 5 분) 를 사용하여 1.5 ml 또는 2 ml 반응 튜브 (예를 들어, Eppendorf Tubes® 3810X) 에서 원심분리하였다.
b. 최대 부피가 50 ml 인 박테리아 현탁액을 4.000 rpm 에서 10 분 동안 Eppendorf 5810 R 벤치탑 원심분리를 사용하여 15 ml 또는 50 ml 반응 튜브 (예를 들어, FalconTM 50 ml Conical Centrifuge Tubes) 에서 원심분리하였다.
DNA 단리
플라스미드 DNA 를 제조사의 지시에 따라 Qiagen (Hilden, Germany, Cat. No. 27106) 사의 QIAprep Spin Miniprep Kit 를 사용하여 E. 콜라이 세포로부터 단리하였다.
중합효소 연쇄 반응 (PCR)
프루프 리딩 (높은 충실도) 폴리머라제를 사용한 PCR 을 사용하여 생어 (Sanger) 서열분석 또는 DNA 어셈블리를 위해 원하는 DNA 분절을 증폭시켰다. 비-프루프-리딩 폴리머라제 키트를 E. 콜라이 또는 C. 글루타미쿰 콜로니로부터 직접 원하는 DNA 단편의 존재 또는 부재를 결정하기 위해 사용하였다.
a. New England BioLabs Inc. (Ipswich, USA, Cat. No. M0530) 사의 Phusion® High-Fidelity DNA Polymerase Kit (Phusion Kit) 를 제조자의 지시에 따라 선택된 DNA 영역의 주형-정확한 증폭에 사용하였다 (표 2 참조).
표 2: New England BioLabs Inc. 사의 Phusion® High-Fidelity DNA Polymerase Kit 를 이용한 PCR 을 위한 열순환 조건.

b. Qiagen (Hilden, Germany, Cat. No.201203) 사의 Taq PCR Core Kit (Taq Kit) 를 DNA 의 원하는 분절을 그의 존재를 확인하기 위해 증폭하는데 사용하였다. 키트는 제조사의 지시에 따라 사용하였다 (표 3 참조).
표 3: Qiagen 사의 Taq PCR Core Kit 를 이용한 PCR 을 위한 열순환 조건.

c. Takara Bio Inc (Takara Bio Europe S.A.S., Saint-Germain-en-Laye, France, Cat. No. RR350A/B) 사의 SapphireAmp® Fast PCR Master Mix (Sapphire Mix) 를 제조자의 지침에 따라 E. 콜라이 또는 C. 글루타미쿰으로부터 취한 세포에서 원하는 DNA 분절의 존재를 확인하기 위한 대안으로서 사용하였다 (표 4 참조).
표 4: Takara Bio Inc. 사의 SapphireAmp® Fast PCR Master Mix (Sapphire Mix) 를 사용한 PCR 을 위한 열순환 조건.

d. 모든 올리고뉴클레오티드 프라이머는 McBride and Caruthers (1983) 에 의해 기술된 포스포라미다이트 방법을 사용하여 Eurofins Genomics GmbH (Ebersberg, Germany) 에 의해 합성되었다.
e. PCR 주형으로서, 단리된 플라스미드 DNA 또는 액체 배양물로부터 단리된 총 DNA 의 적합하게 희석된 용액 또는 박테리아 콜로니에 함유된 총 DNA (콜로니 PCR) 를 사용하였다. 상기 콜로니 PCR 을 위해, 아가 플레이트 상의 콜로니로부터 이쑤시개로 세포 물질을 취하고, 세포 물질을 PCR 반응 튜브 내로 직접 위치시킴으로써 주형을 제조하였다. 세포 물질을 SEVERIN Elektrogeraete GmbH (Sundern, Germany) 사의 전자레인지 오븐 유형 Mikrowave & Grill 에서 800 W 에서 10 초 동안 가열한 다음, PCR 반응 튜브 내의 주형에 PCR 시약을 첨가하였다.
f. 모든 PCR 반응은 Eppendorf AG (Hamburg, Germany) 사의 PCR 사이클러 타입 Mastercycler 또는 Mastercycler nexus 구배에서 수행하였다.
DNA 의 제한효소 분해
제한 효소 분해에 대해서는 New England BioLabs Inc. (Ipswich, USA) 사의 "FastDigest restriction endonucleases (FD)" (ThermoFisher Scientific, Waltham, USA) 또는 제한 엔도뉴클레아제를 사용하였다. 반응은 제조사의 매뉴얼의 지시에 따라 수행되었다.
DNA 단편의 크기 결정
a. 작은 DNA 단편의 크기 (<1000 bps) 는 일반적으로 Qiagen (Hilden, Germany) 사의 QIAxcel 을 사용하는 자동 모세관 전기영동에 의해 결정되었다.
b. DNA 단편이 단리되어야 하는 경우 또는 DNA 단편이 1000 bps 초과인 경우, DNA 를 TAE 아가로스 겔 전기영동에 의해 분리하고, GelRed® Nucleic Acid Gel Stain (Biotium, Inc., Fremont, Canada) 으로 염색하였다. 염색된 DNA 는 302 nm 에서 눈에 보였다.
PCR 증폭물 및 제한 단편의 정제
PCR 증폭물 및 제한 단편을 제조자의 지침에 따라, Qiagen (Hilden, Germany; Cat. No. 28106) 사의 QIAquick PCR Purification Kit 를 사용하여 세정하였다. DNA 를 30 ㎕ 의 10 mM Tris*HCl (pH 8.5) 로 용리시켰다.
DNA 농도 결정
DNA 농도는 PEQLAB Biotechnologie GmbH, 2015 년부터 VWR brand (Erlangen, Germany) 사의 NanoDrop Spectrophotometer ND-1000 을 사용하여 측정하였다.
어셈블리 클로닝
플라스미드 벡터는 New England BioLabs Inc. (Ipswich, USA, Cat. No. E5520) 로부터 구입한 "NEBuilder HiFi DNA Assembly Cloning Kit"를 사용하여 어셈블리하였다. 선형 벡터 및 적어도 하나의 DNA 삽입물을 함유하는 반응 혼합물을 50℃ 에서 60 분 동안 인큐베이션하였다. 어셈블리 혼합물 0.5 ㎕ 를 각 형질전환 실험에 사용하였다.
E. 콜라이
의 화학적 형질전환
플라스미드 클로닝을 위해, 화학적으로 적격인 "NEB® Stable Competent E. coli (High Efficiency)" (New England BioLabs Inc., Ipswich, USA, Cat. No. C3040) 을 제조사의 프로토콜에 따라 형질전환시켰다. 성공적으로 형질전환된 세포를 25 mg/l 카나마이신이 보충된 LB 아가 상에서 선별하였다.
C. 글루타미쿰
의 형질전환
플라스미드-DNA 로의 C. 글루타미쿰의 형질전환은 Ruan et al. (2015) 에 의해 기술된 바와 같이 "Gene Pulser Xcell" (Bio-Rad Laboratories GmbH, Feldkirchen, Germany) 을 사용하는 전기천공을 통해 수행하였다. 전기천공은 1 mm 전기천공 큐벳 (Bio-Rad Laboratories GmbH, Feldkirchen, Germany) 에서 1.8 kV 및 5 ms 로 설정된 고정된 시간 상수로 수행하였다. 형질전환된 세포를 134 g/l 소르비톨, 2.5 g/l 효모 추출물 및 25 mg/l 카나마이신을 함유하는 BHI-아가 상에서 선별하였다.
뉴클레오티드 서열 결정
DNA 분자의 뉴클레오티드 서열은 Applied Biosystems® (Carlsbad, CA, USA) 3730xl DNA Analyzers 상에서, Sanger et al. (Proceedings of the National Academy of Sciences USA 74, 5463 - 5467, 1977) 의 디데옥시 사슬 종결 방법을 사용하여, 사이클 서열분석에 의해 Eurofins Genomics GmbH (Ebersberg, Germany) 에 의해 결정하였다. Scientific & Educational Software (Denver, USA) 사의 Clonemanager Professional 9 소프트웨어를 사용하여 서열을 시각화하고 평가하였다.
E.콜라이
및
C. 글루타미쿰
균주의 글리세롤 스톡
E.콜라이 및 C. 글루타미쿰 균주의 장기간 저장을 위해 글리세롤 스톡을 제조하였다. 선별된 E.콜라이 클론을 2 g/l 글루코스로 보충된 10 ml LB 배지에서 배양하였다. 선별된 C. 글루타미쿰 클론을 2 g/l 글루코스로 보충된 10 ml 2 배 농축 BHI 배지에서 배양하였다. 플라스미드 함유 E.콜라이 및 C. 글루타미쿰 균주의 배양물에 25 mg/l 카나마이신을 보충하였다. 3 개의 배플이 있는 100 ml Erlenmeyer 플라스크에 배지를 함유하였다. 이것을 콜로니로부터 취한 세포의 루프로 접종하였다. 배양물을 30℃ 및 200 rpm 에서 18 h 동안 인큐베이션하였다. 상기 인큐베이션 기간 후, 1.2 ml 85% (v/v) 멸균 글리세롤을 배양물에 첨가하였다. 얻어진 글리세롤 함유 세포 현탁액을 2 ml 분량으로 분취하여 -80℃ 에서 보관하였다.
밀리리터-규모 배양에서의 GAA 생산
Duetz (2007) 에 따른 밀리리터-규모 배양 시스템을 사용하여 균주의 GAA-생산을 평가하였다. 이를 위해, 웰 당 2.5 ml 배지로 충전된 EnzyScreen BV (Heemstede, Netherlands, Cat. no. CR1424) 사의 24-딥웰 마이크로플레이트 (24 웰 WDS 플레이트) 를 사용하였다.
균주의 예비배양은 10 ml 종자 배지 (SM) 에서 수행하였다. 3 개의 배플이 있는 100 ml Erlenmeyer 플라스크에 배지를 함유하였다. 이를 100 ㎕ 의 글리세롤 스톡 배양물로 접종하고, 배양물을 30℃ 및 200 rpm 에서 24 h 동안 인큐베이션하였다. 종자 배지 (SM) 의 조성은 표 5 에 제시한다.
표 5: 종자 배지 (SM)

상기 인큐베이션 기간 후, 예비배양물의 광학 밀도 OD600 을 결정하였다. 0.1 의 OD600 에 2.5 ml 의 생산 배지 (PM) 를 접종하는데 필요한 부피를 예비배양물로부터 샘플링하고, 원심분리 (8000 g 에서 1 분) 하고, 상청액을 폐기하였다. 그 후, 세포를 100 ㎕ 의 생산 배지에 재현탁시켰다.
주 배양은 24 웰 WDS-플레이트의 웰의 2.4 ml 생산 배지 (PM) 함유 웰에 예비배양물로부터의 재현탁된 세포 각각 100 ㎕ 를 접종함으로써 시작하였다. 생산 배지 (PM) 의 조성은 표 6 에 제시한다.
표 6: 생산 배지 (PM)

주 배양물을 글루코스의 완전한 소비까지 Infors GmbH (Bottmingen, Switzerland) 사의 Infors HT Multitron 표준 인큐베이터 진탕기에서 30℃ 및 300 rpm 에서 72 h 동안 인큐베이션하였다. 현탁액 중의 글루코오스 농도를 LifeScan (Johnson & Johnson Medical GmbH, Neuss, Germany) 사의 혈당계 OneTouch Vita® 로 분석하였다.
배양 후, 배양 현탁액을 딥 웰 마이크로플레이트로 옮겼다. 배양 현탁액의 일부를 적절히 희석하여 OD600 을 측정하였다. 배양물의 또다른 부분을 원심분리하고, 상층액 중의 GAA 의 농도를 하기 기재된 바와 같이 분석하였다.
효모 펩톤 FM902 중의 L-아르기닌 및 글리신 함량의 측정
효모 추출물 FM902 (Angel Yeast Co.,LTD, Hubei, P.R.China) 는 다양한 펩티드와 아미노산을 함유하므로, L-아르기닌과 글리신의 함량을 다음과 같이 측정하였다.
유리 아미노산을 측정하기 위해, 1 g 의 효모 추출물을 20 ml 의 물에 용해시켜 샘플을 제조하였다. 용액을 25 ml 의 총 부피까지 물로 채우고, 완전히 혼합하고, 0.2 μΜ 나일론 시린지 필터를 사용하여 여과하였다.
총 아미노산 (유리 아미노산 + 펩티드에 결합된 아미노산) 을 측정하기 위해, 1 g 효모 추출물을 10 ml 6M HCl 에 용해시키고, 이들을 110℃ 에서 24 h 동안 인큐베이션함으로써 샘플을 제조하였다. 그 후, 총 부피 25 ml 까지 물을 첨가하였다. 용액을 완전히 혼합하고, 0.2 μΜ 나일론 시린지 필터를 사용하여 여과하였다.
샘플 중의 L-아르기닌 및 글리신의 농도는 SYKAM Vertriebs GmbH (F rstenfeldbruck, Germany) 사의 SYKAM S433 아미노산 분석기를 사용하여 이온 교환 크로마토그래피에 의해 결정하였다. 고체상으로서, SYKAM 사의 구형의, 폴리스티렌-기반 양이온 교환기 (Peek LCA N04/Na, 치수 150 x 4.6 mm) 를 갖는 컬럼을 사용하였다. L-아미노산에 따라, 분리는 용리를 위한 완충액 A 및 B 의 혼합물을 사용하는 등용매 실행에서 또는 상기 완충액을 사용하는 구배 용리에 의해 일어난다. 완충액 A 로서 20 l 에 263 g 트리소듐 시트레이트, 120 g 시트르산, 1100 ml 메탄올, 100 ml 37% HCl 및 2 ml 옥탄산 (최종 pH 3.5) 을 함유하는 수용액을 사용하였다. 완충액 B 로서 20 l 에 392 g 트리소듐 시트레이트, 100 g 붕산 및 2 ml 옥탄산 (최종 pH 10.2) 을 함유하는 수용액을 사용하였다. 유리 아미노산을 포스트-컬럼 유도체화를 통해 닌히드린으로 착색하고 570 nm 에서 광도법으로 검출하였다.
rstenfeldbruck, Germany) 사의 SYKAM S433 아미노산 분석기를 사용하여 이온 교환 크로마토그래피에 의해 결정하였다. 고체상으로서, SYKAM 사의 구형의, 폴리스티렌-기반 양이온 교환기 (Peek LCA N04/Na, 치수 150 x 4.6 mm) 를 갖는 컬럼을 사용하였다. L-아미노산에 따라, 분리는 용리를 위한 완충액 A 및 B 의 혼합물을 사용하는 등용매 실행에서 또는 상기 완충액을 사용하는 구배 용리에 의해 일어난다. 완충액 A 로서 20 l 에 263 g 트리소듐 시트레이트, 120 g 시트르산, 1100 ml 메탄올, 100 ml 37% HCl 및 2 ml 옥탄산 (최종 pH 3.5) 을 함유하는 수용액을 사용하였다. 완충액 B 로서 20 l 에 392 g 트리소듐 시트레이트, 100 g 붕산 및 2 ml 옥탄산 (최종 pH 10.2) 을 함유하는 수용액을 사용하였다. 유리 아미노산을 포스트-컬럼 유도체화를 통해 닌히드린으로 착색하고 570 nm 에서 광도법으로 검출하였다.
표 7 은 효모 추출물 FM902 (Angel Yeast Co.,LTD, Hubei, P.R.China) 에서 결정된 유리 및 총 L-아르기닌 및 글리신의 함량 및 생성 배지 (PM) 에서의 결과량을 나타낸다.
표 7: 효모 추출물 (YE) FM902 중의 L-아르기닌 및 글리신의 함량 및 1.5 g/l YE 를 함유하는 생산 배지 (PM) 중의 생성된 농도.

GAA 의 정량화
샘플을 질량 분석기 "Triple Quad 6420" (Agilent Technologies Inc., Santa Clara, USA) 와 커플링된 HPLC "Infinity 1260" 으로 구성된 Agilent 사의 분석 시스템으로 분석하였다. 35℃ 에서 Atlantis HILIC Silica 컬럼, 4,6 X 250mm, 5 μm (Waters Corporation, Milford, USA) 상에서 크로마토그래피 분리를 수행하였다. 이동상 A 는 10 mM 암모늄 포르메이트 및 0.2% 포름산을 갖는 물이었다. 이동상 B 는 90% 아세토니트릴과 10% 물의 혼합물이었고, 10 mM 암모늄 포르메이트를 혼합물에 첨가하였다. HPLC 시스템은 100% B 로 시작한 후, 22 분 동안 선형 구배 및 0,6 mL/분의 일정한 유속으로 66% B 까지 이어졌다. 질량 분석기는 ESI 양성 이온화 모드로 작동되었다. GAA 의 검출을 위해, m/z 값을 MRM 단편화 [M+H] + 118 - 76 을 사용하여 모니터링하였다. GAA 에 대한 정량화 한계 (LOQ) 는 7 ppm 으로 고정되었다.
B) 실험 결과
실시예 1:
다양한 유기체로부터 L-아르기닌:글리신 아미디노트랜스퍼라제 (AGAT, EC 2.1.4.1) 를 코딩하는 유전자의 합성
무레아 프로듀센스 (Moorea producens) 는 사상성 시아노박테리아이다. 무레아 프로듀센스 균주 PAL-8-15-08-1 의 게놈은 Leao et al. 에 의해 공개되었다 (Leao T, Castel o G, Korobeynikov A, Monroe EA, Podell S, Glukhov E, Allen EE, Gerwick WH, Gerwick L, Proc Natl Acad Sci U S A. 2017 Mar 21;114(12):3198-3203. doi: 10.1073/pnas.1618556114; 수탁 번호 CP017599.1). 이는 L-아르기닌:글리신 아미디노트랜스퍼라제 (AGAT, EC 2.1.4.1, 수탁 번호 BJP34_00300, SEQ ID NO:1) 를 추정적으로 코딩하는 오픈 리딩 프레임을 함유한다. SEQ ID NO:2 및 SEQ ID NO: 4 는 AGAT_Mp 로서 지정된 유래된 아미노산 서열 (수탁 번호 WP_070390602) 을 나타낸다.
o G, Korobeynikov A, Monroe EA, Podell S, Glukhov E, Allen EE, Gerwick WH, Gerwick L, Proc Natl Acad Sci U S A. 2017 Mar 21;114(12):3198-3203. doi: 10.1073/pnas.1618556114; 수탁 번호 CP017599.1). 이는 L-아르기닌:글리신 아미디노트랜스퍼라제 (AGAT, EC 2.1.4.1, 수탁 번호 BJP34_00300, SEQ ID NO:1) 를 추정적으로 코딩하는 오픈 리딩 프레임을 함유한다. SEQ ID NO:2 및 SEQ ID NO: 4 는 AGAT_Mp 로서 지정된 유래된 아미노산 서열 (수탁 번호 WP_070390602) 을 나타낸다.
실린드로스페르몹시스 라시보르스키 (Cylindrospermopsis raciborskii) AWT205 (수탁 번호 EU140798.1) 로부터의 유전자 cyrA 는 L-아르기닌:글리신 아미디노트랜스퍼라제를 코딩한다 (Mihali TK, Kellmann R, Muenchhoff J, Barrow KD, Neilan BA (2008) "Characterization of the gene cluster responsible for cylindrospermopsin biosynthesis.", Appl Environ Microbiol., 74(3):716-22, doi: 10.1128/AEM.01988-07; SEQ ID NO:15). SEQ ID NO:16 및 SEQ ID NO: 26 은 AGAT_cyrA 로서 지정된 유래된 아미노산 서열 (수탁 번호 ABX60160) 을 나타낸다.
인간 L-아르기닌:글리신 아미디노트랜스퍼라제의 cDNA 서열은 Humm et al., 1994 에 의해 기술되었다 (Humm A, Huber R, Mann K (1994) "The amino acid sequences of human and pig l-arginine:glycine amidinotransferase.", FEBS Letters, Vol. 339 (1-2), 101-107, DOI: 10.1016/0014-5793(94)80394-3; 수탁 번호 NM_001482.3, SEQ ID NO:17). 유래된 아미노산 서열 (수탁번호 NP_001473.1, SEQ ID NO:18) 은 성숙 효소에 부재하는 미토콘드리아 전이 펩티드 (아미노산 1 내지 37) 로 시작한다. 아미노산 56 에서 시작하는, 절단된 효소는 E. 콜라이에서 발현될 때 활성인 것으로 밝혀졌다 (Humm A, Fritsche E, Mann K, Goehl M, Huber R (1997) "Recombinant expression and isolation of human L-arginine : glycine amidinotransferase and identification of its active-site cysteine residue." Biochem. J. 322, 771-776, DOI: 10.1042/bj3220771). 7 개 아미노산 태그 (SEQ ID NO:19) 의 N-말단 융합은 E. 콜라이에서 단백질 발현을 개선시키는 것으로 나타났다 (Hansted JG, Pietikaeinen L, Hoeg F, Sperling-Petersen HU, Mortensen KK (2011) "Expressivity tag: A novel tool for increased expression in Escherichia coli." Journal of Biotechnology 155 (2011) 275- 283, DOI:10.1016/j.jbiotec.2011.07.013). 따라서, 태그 및 절두된 AGAT 로 이루어진 융합 단백질을 설계하고, 이를 AGAT_Hs (SEQ ID NO:20 및 SEQ ID NO:28) 로 지정하였다.
라투스 노르베지쿠스 (Rattus norvegicus) 로부터의 L-아르기닌:글리신 아미디노트랜스퍼라제의 아미노산 서열 (수탁 번호 NP_112293.1, SEQ ID NO:21) 은 인간 효소와 매우 유사하다. 인간 효소에 대해 기재된 바와 같이, 상기 서열을 사용하여 N-말단 발현 태그 및 효소의 절단된 서열로 이루어진 융합 단백질을 설계하였다. 생성된 융합 단백질을 AGAT_Rn (SEQ ID NO:22 및 SEQ ID NO:30) 으로 지정하였다.
순다 날개여우원숭이 (sunda flying lemur) 갈레옵테루스 바리에가투스 (Galeopterus variegatus) 는 예측된 L-아르기닌:글리신 아미디노트랜스퍼라제 (수탁 번호 NP_112293.1, SEQ ID NO:23) 를 갖는다. 인간 효소에 대해 기재된 바와 같이, 이의 아미노산 서열을 사용하여 N-말단 발현 태그 및 효소의 절단된 서열로 이루어진 융합 단백질을 설계하였다. 생성된 융합 단백질을 AGAT_Gv (SEQ ID NO:24 및 SEQ ID NO:32) 으로 지정하였다.
소프트웨어 툴 "GeneOptimizer" (Geneart/ ThermoFisher Scientific, Waltham, USA) 를 사용하여, AGAT_Mp, AGAT_cyrA, AGAT_Hs, AGAT_Rn 및 AGAT_Gv 의 아미노산 서열을 DNA 서열로 다시 번역하고 C. 글루타미쿰의 코돈 사용에 최적화하였다. 이들의 말단은 어셈블리 클로닝을 위한 서열로 확장되었고, 샤인-달가노-서열 (Shine-Dalgarno-Sequence) 은 오픈 리딩 프레임의 업스트림에 추가되었다. 생성된 DNA 서열은 SEQ ID NO:3 (AGAT_Mp 를 코딩함), SEQ ID NO:25 (AGAT_cyrA 를 코딩함), SEQ ID NO:27 (AGAT_Hs 를 코딩함), SEQ ID NO: 29 (AGAT_Rn 을 코딩함) 및 SEQ ID NO:31 (AGAT_Gv 를 코딩함) 이다. 이들은 Invitrogen/Geneart (Thermo Fisher Scientific, Waltham, USA) 로부터 유전자 합성을 위해 주문하였다. 합성 유전자는 pMA-T_AGAT_Mp, pMA-T_AGAT_cyrA, pMA-T_AGAT_Hs, pMA-T_AGAT_Rn 및 pMA-T_AGAT_Gv 로서 지정된 클로닝 플라스미드의 일부로서 전달되었다.
실시예 2:
AGAT_Mp 의 발현 플라스미드 pEC-XK99E 내로의 클로닝
E. 콜라이-C. 글루타미쿰 셔틀 플라스미드 pEC-XK99E 를 제한 엔도뉴클레아제 SmaI 를 사용하여 소화시켰다. "FastAP Thermosensitive Alkaline Phosphatase" (Thermo Fisher Scientific, Waltham, USA) 를 사용하여 말단 포스페이트를 제거하였다. 이후, DNA 를 "QIAquick PCR Purification Kit" (Qiagen GmbH, Hilden, Germany) 로 정제하였다.
클로닝 플라스미드 pMA-T_AGAT_Mp 를 MluI + AatII 로 소화시키고, 생성된 단편을 "Fast DNA End Repair Kit" (Thermo Fisher Scientific, Waltham, USA) 를 사용하여 블런트화하였다. 이들을 아가로스 겔 전기영동 (TAE 완충액 중 0,8% 아가로스) 으로 분리하고, "AGAT_Mp" (1174 bp) 에 해당하는 밴드를 잘라냈다. 이의 DNA 를 "QIAquick Gel Extraction Kit" (Qiagen GmbH, Hilden, Germany) 를 사용하여 정제하였다.
AGAT_Mp 단편 및 선형화된 pEC-XK99E 를 "Ready-To-Go T4 DNA ligase" (GE Healthcare Europe GmbH, Freiburg, Germany) 를 사용하여 라이게이션하였다. 라이게이션 생성물을 "NEB Stable Competent E. coli (High Efficiency)" (New England Biolabs, Ipswich, USA) 내로 형질전환시키고, 세포를 25 mg/l 카나마이신을 함유하는 LB 아가 상에서 성장시켰다. 적절한 클론은 제한 효소 소화 및 DNA 서열분석에 의해 확인되었다. 생성된 플라스미드를 pEC-XK99E_AGAT_Mp 로 명명하였다.
실시예 2.1:
AGAT_Mp 및 AGAT_cyrA 의 발현 플라스미드 pEKEx2 내로의 클로닝
E. 콜라이-C. 글루타미쿰 셔틀 플라스미드 pEKEx2 (Eikmanns, 1991) 를 제한 엔도뉴클레아제 PstI 를 사용하여 소화시켰다. 생성된 단편을 "Fast DNA End Repair Kit" (Thermo Fisher Scientific) 를 사용하여 블런트화하고, 말단 포스페이트를 "FastAP Thermosensitive Alkaline Phosphatase" (Thermo Fisher Scientific, Waltham, USA) 로 제거하였다. 이후, DNA 를 "QIAquick PCR Purification Kit" (Qiagen GmbH, Hilden, Germany) 로 정제하였다.
클로닝 플라스미드 pMA-T_AGAT_Mp 및 pMA-T_AGAT_cyrA 를 MluI + AatII 로 소화시키고, 생성된 단편을 "Fast DNA End Repair Kit" (Thermo Fisher Scientific, Waltham, USA) 를 사용하여 블런트화하였다. 이들을 아가로스 겔 전기영동 (TAE 완충액 중 0,8% 아가로스) 으로 분리하고, AGAT_Mp (1174 bp) 및 AGAT_cyrA (1204 bp) 에 해당하는 밴드를 잘라냈다. DNA 를 "QIAquick Gel Extraction Kit" (Qiagen GmbH, Hilden, Germany) 를 사용하여 정제하였다.
각각의 AGAT 단편을 "Ready-To-Go T4 DNA ligase" (GE Healthcare Europe GmbH, Freiburg, Germany) 를 사용하여 선형화된 pEKEx2 로 라이게이션하였다. 라이게이션 생성물을 "NEB Stable Competent E. coli (High Efficiency)" (New England Biolabs, Ipswich, USA) 내로 형질전환시키고, 세포를 25 mg/l 카나마이신을 함유하는 LB 아가 상에서 성장시켰다. 적절한 클론은 제한 효소 소화 및 DNA 서열분석에 의해 확인되었다. 생성된 플라스미드를 pEKEx2_AGAT_Mp 및 pEKEx2_AGAT_cyrA 로 명명하였다.
실시예 2.2:
AGAT_Hs, AGAT_Rn 및 AGAT_Gv 의 발현 플라스미드 pEKEx2 내로의 클로닝
클로닝 플라스미드 pMA-T_AGAT_Hs, pMA-T_AGAT_Rn 및 pMA-T_AGAT_Gv 를 Eco31I 로 소화시키고, 생성물을 "QIAquick Gel Extraction Kit" (Qiagen GmbH, Hilden, Germany) 를 사용하여 정제하였다.
E. 콜라이-C. 글루타미쿰 셔틀 플라스미드 pEKEx2 (Eikmanns BJ, Kleinertz E, Liebl W, Sahm H (1991) "A family of Corynebacterium glutamicum/Escherichia coli shuttle vectors for cloning, controlled gene expression, and promoter probing.", Gene. 1991 Jun 15;102(1):93-8) 를 제한 엔도뉴클레아제 SbfI 및 BamHI 를 사용하여 소화시켰다. DNA 를 "QIAquick PCR Purification Kit" (Qiagen GmbH, Hilden, Germany) 로 정제하였다.
각각의 AGAT 단편은 "NEBuilder HiFi DNA Assembly Cloning Kit" (New England BioLabs Inc., Ipswich, USA, Cat. No. E5520) 를 사용하여 소화된 pEKEx2 와 어셈블리하였다. 어셈블리 생성물을 "NEB Stable Competent E. coli (High Efficiency)" (New England Biolabs, Ipswich, USA) 내로 형질전환시키고, 세포를 25 mg/l 카나마이신을 함유하는 LB 아가 상에서 성장시켰다. 적절한 클론은 제한 효소 소화 및 DNA 서열분석에 의해 확인되었다. 생성된 플라스미드를 각각 pEKEx2_AGAT_Hs, pEKEx2_AGAT_Rn 및 pEKEx2_AGAT_Gv 로 명명하였다.
실시예 3:
유전자 argF 의 플라스미드 pCR-Blunt II-TOPO 내로의 클로닝
argF 유전자를 C. 글루타미쿰 ATCC13032 의 게놈 DNA 와 올리고뉴클레오타이드 프라이머 argF_1.p (SEQ ID NO:5) 및 argF_2.p (SEQ ID NO:6) 를 사용하여 Phusion High-Fidelity DNA Polymerase Kit (New England BioLabs Inc., Ipswich, USA) 로 PCR 증폭하였다. 생성된 PCR 생성물을 플라스미드 pCR-Blunt II-TOPO (Thermo Fisher Scientific/Invitrogen, Waltham, USA) 내에 클로닝하고, 적절한 플라스미드 클론을 제한 효소 소화 및 DNA 서열분석에 의해 확인하였다. 이 플라스미드를 pCRII-argF 로 명명하였다.
실시예 4:
유전자
argG
및
argH
의 플라스미드 pCR-Blunt II-TOPO 내로의 클로닝
유전자 argG 및 argH 를 C. 글루타미쿰 ATCC13032 의 게놈 DNA 와 올리고뉴클레오타이드 프라이머 argG_1.p (SEQ ID NO:7) 및 argH_2.p (SEQ ID NO:8) 를 사용하여 Phusion High-Fidelity DNA Polymerase Kit (New England BioLabs Inc., Ipswich, USA) 로 PCR 증폭하였다. 생성된 PCR 생성물을 플라스미드 pCR-Blunt II-TOPO (Thermo Fisher Scientific/Invitrogen, Waltham, USA) 내에 클로닝하고, 적절한 플라스미드 클론을 제한 효소 소화 및 DNA 서열분석에 의해 확인하였다. 플라스미드를 pCRII-argGH 로 명명하였다.
실시예 5:
유전자
argG
및
argH
의 플라스미드 pCRII-argF 내로의 클로닝
pCRII-argGH 를 HpaI + AvrII 를 사용하여 절단하고, 2773 bps 의 제한 단편을 아가로스 겔로부터 단리하였다. pCRII-argF 를 SspI + AvrII 를 사용하여 절단하고, 4526 bps 의 제한 단편을 아가로스 겔로부터 단리하였다. 두 단편을 라이게이션한 후 E. 콜라이로 형질전환하였다. 적절한 플라스미드 클론은 제한 효소 소화 및 DNA 서열분석에 의해 확인되었다. 생성된 플라스미드를 pCRII-argFGH 로 명명하였다.
실시예 6:
유전자
argF
,
argG
및
argH
의 발현 플라스미드 pEC-XK99E 내로의 클로닝
pCRII-argFGH 를 HpaI + AvrII 를 사용하여 절단하고, 2773 bps 의 제한 단편을 아가로스 겔로부터 단리하였다. 플라스미드 pEC-XK99E 를 Ecl136II + XbaI 를 사용하여 절단하였다. 6999 bps 의 제한 단편을 아가로스 겔로부터 단리하였다. 두 단편을 라이게이션한 후 E. 콜라이로 형질전환하였다. 적절한 플라스미드 클론은 제한 소화 및 DNA 서열분석에 의해 확인되었다. 생성된 플라스미드 pEC-XK99E_argFGH 는 C. 글루타미쿰으로부터의 유전자 argF, argG 및 argH 를 함유한다.
실시예 7:
유전자
argF
,
argG
및
argH
의 발현 플라스미드 pEC-XK99E_AGAT_Mp 내로의 클로닝
pCRII-argFGH 를 XbaI + SpeI 를 사용하여 절단하고, 3868 bps 의 제한 단편을 아가로스 겔로부터 단리하였다. 플라스미드 pEC-XK99E_AGAT_Mp 를 XbaI 를 사용하여 절단하였다. 8188 bps 의 제한 단편을 아가로스 겔로부터 단리하였다. 두 단편을 라이게이션한 후 E. 콜라이로 형질전환하였다. 적절한 플라스미드 클론은 제한 소화 및 DNA 서열분석에 의해 확인되었다. 생성된 플라스미드 pEC-XK99E_AGAT_Mp_argFGH 는 AGAT_Mp 와 조합으로 C. 글루타미쿰으로부터의 유전자 argF, argG 및 argH 를 함유한다.
실시예 8:
유전자
argF
의 발현 플라스미드 pEC-XK99E_AGAT_Mp 내로의 클로닝
pCRII-argF 를 KpnI + XbaI + AseI 를 사용하여 절단하고, DNA 를 "QIAquick PCR Purification Kit" (Qiagen GmbH, Hilden, Germany) 로 정제하였다. 플라스미드 pEC-XK99E_AGAT_Mp 를 KpnI + XbaI 를 사용하여 절단하고, DNA 를 "QIAquick PCR Purification Kit" (Qiagen GmbH, Hilden, Germany) 로 정제하였다. 두 용리액을 혼합하고, DNA 단편을 라이게이션하고, 생성물을 사용하여 E. 콜라이를 형질전환시켰다. 적절한 플라스미드 클론은 제한 소화 및 DNA 서열분석에 의해 확인되었다. 생성된 플라스미드 pEC-XK99E_AGAT_Mp_argF 는 AGAT_Mp 와 조합으로 C. 글루타미쿰으로부터의 유전자 argF 를 함유한다.
실시예 9:
유전자
argG
의 발현 플라스미드 pEC-XK99E_AGAT_Mp 내로의 클로닝
pCRII-argGH 를 XbaI + SalI 를 사용하여 절단하고, 1798 bps 의 제한 단편을 아가로스 겔로부터 단리하였다. 플라스미드 pEC-XK99E_AGAT_Mp 를 XbaI + SalI 를 사용하여 절단하고, DNA 를 "QIAquick PCR Purification Kit" (Qiagen GmbH, Hilden, Germany) 로 정제하였다. DNA 단편을 라이게이션하고, 생성물을 사용하여 E. 콜라이를 형질전환시켰다. 적절한 플라스미드 클론은 제한 소화 및 DNA 서열분석에 의해 확인되었다. 생성된 플라스미드 pEC-XK99E_AGAT_Mp_argG 는 AGAT_Mp 와 조합으로 C. 글루타미쿰으로부터의 유전자 argG 를 함유한다.
실시예 10:
ATCC13032 내 carAB 오페론의 업스트림 sod 프로모터의 염색체 삽입
카르바모일 포스페이트 신테타제의 효소 활성은 ATCC13032 내 carAB 오페론의 업스트림 강한 sod-프로모터의 게놈 삽입에 의해 증가되었다. 따라서, 플라스미드 pK18mobsacB_Psod-carAB 는 다음과 같이 구성되었다. 플라스미드 pK18mobsacB 를 EcoRI + HindIII 를 사용하여 절단하고, 선형화된 벡터 DNA (5670 bps) 를 아가로스 겔로부터 절단하였다. DNA 를 "QIAquick Gel Extraction Kit" (QIAGEN GmbH, Hilden, Germany) 를 사용하여 추출하였다.
삽입체를 구성하기 위해, 3 개의 DNA 단편을 하기 프라이머 쌍 (주형으로서 ATCC13032 의 게놈 DNA) 을 사용하는 PCR 에 의해 생성하였다:
PsodcarAB-LA-F (SEQ ID NO:9) + PsodcarAB-LA-R (SEQ ID NO:10)
= 좌측 상동 암 (arm) (1025 bps)
PsodcarAB-F (SEQ ID NO:11) + PsodcarAB-R (SEQ ID NO:12)
= sod-프로모터 (250 bps)
PsodcarAB-RA-F SEQ ID NO:13) + PsodcarAB-RA-R (SEQ ID NO:14)
= 우측 상동 암 (944 bps)
생성물 DNA 를 "QIAquick PCR Purification Kit" (Qiagen GmbH, Hilden, Germany) 를 사용하여 정제하였다. 선형화된 플라스미드 및 PCR 생성물은 이후 "NEBuilder HiFi DNA Assembly Cloning Kit" (New England BioLabs Inc., Ipswich, USA, Cat. No. E5520) 를 사용하여 어셈블리하였다. 적절한 플라스미드 클론은 제한 소화 및 DNA 서열분석에 의해 확인되었다.
pK18mobsacB_Psod-carAB 를 사용하여 carAB 유전자의 업스트림 강한 sod-프로모터를 C. 글루타미쿰 ATCC13032 의 게놈 내로 통합하였다. 플라스미드를 전기천공에 의해 ATCC13032 내로 형질전환시켰다. 염색체 통합 (제 1 재조합 사건으로부터 초래됨) 을 134 g/l 소르비톨, 2.5 g/l 효모 추출물 및 25 mg/l 카나마이신이 보충된 BHI 아가 상에 플레이팅함으로써 선별하였다. 아가 플레이트를 33℃ 에서 48 시간 동안 인큐베이션한다.
개별 콜로니를 신선한 아가 플레이트 (카나마이신 25 mg/l 함유) 로 옮기고 33℃ 에서 24 시간 동안 인큐베이션하였다. 이들 클론의 액체 배양물을 3 개의 배플이 있는 100 ml Erlenmeyer 플라스크에 함유된 10 ml BHI 배지에서 24 시간 동안 33℃ 에서 배양하였다. 제 2 재조합 사건에 직면한 클론을 단리하기 위해, 각각의 액체 배양물로부터 분취물을 취하고, 적합하게 희석하고, 10% 사카로오스가 보충된 BHI 아가 상에 플레이팅하였다 (전형적으로 100 내지 200 ㎕). 이들 아가 플레이트를 33℃ 에서 48 시간 동안 인큐베이션하였다. 이어서, 사카로오스 함유 아가 플레이트 상에서 성장하는 콜로니를 카나마이신 민감성에 대해 검사하였다. 이를 위해, 이쑤시개를 사용하여 콜로니로부터 세포 물질을 제거하고, 이를 25 mg/l 카나마이신을 함유하는 BHI 아가 및 10% 사카로오스를 함유하는 BHI 아가 상에 전달하였다. 아가 플레이트를 60 시간 동안 33℃ 에서 인큐베이션하였다. 카나마이신에 민감하고 사카로오스에 내성인 것으로 입증된 클론을 sod 프로모터의 적절한 통합을 위해 PCR 및 DNA 서열분석에 의해 검사하였다. 생성된 균주를 ATCC13032_Psod-carAB 로 명명하였다.
표 8: 균주 목록

표 9: 플라스미드 목록

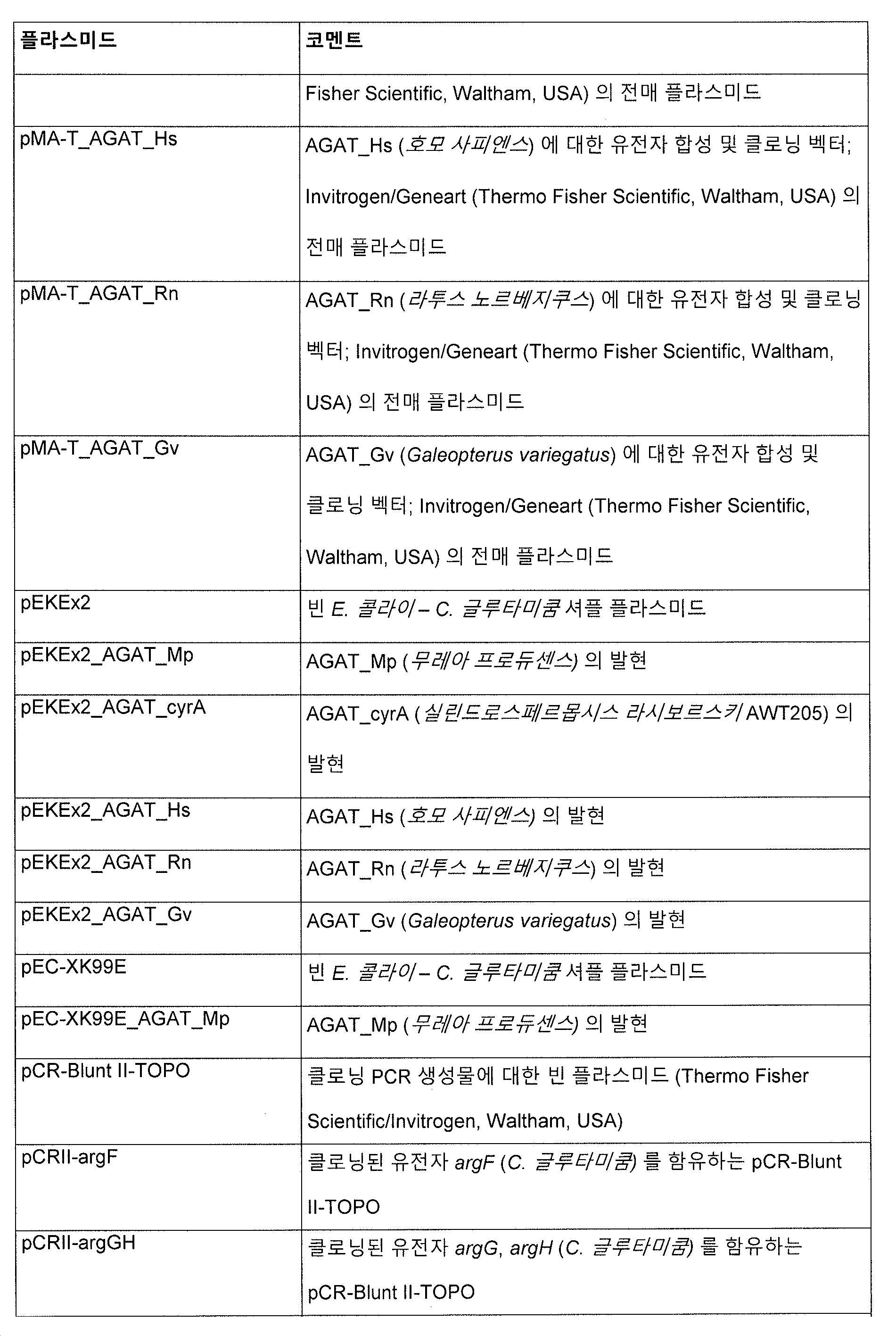

실시예 11:
다양한 발현 플라스미드로의
C. 글루타미쿰
균주의 형질전환
하기 C. 글루타미쿰 균주를 다양한 플라스미드로 형질전환시켰다:
·
C. 글루타미쿰 ATCC13032 ATCC13032 (Kinoshita et al., J. Gen. Appl. Microbiol. 1957; 3(3): 193-205) 가 통상 사용되는 야생형 균주이다.
·
C. 글루타미쿰 균주 ATCC21831 (Park et al., Nat Commun. 2014 Aug 5; 5:4618) 는 암모니아 및 글루코스와 같은 일차 기질로부터 L-아르기닌을 합성한다.
·
ATCC13032__Psod-carAB 는 carAB 유전자의 업스트림 강한 sod 프로모터를 갖는 ATCC13032 의 변이체이다.
균주를 다양한 플라스미드 (표 10 에 나타낸 바와 같음) 로 전기천공함으로써 형질전환시켰다. 플라스미드 함유 세포를 25 mg/l 카나마이신으로 선별하였다.
표 10: 플라스미드-함유 C. 글루타미쿰 균주 목록

실시예 12:
GAA 생산에 대한 AGAT 및 기질 이용능의 영향
균주 ATCC13032/pEC-XK99E_AGAT_Mp (무레아 프로듀센스로부터의 AGAT 효소에 대한 유전자를 보유함) 및 ATCC13032/pEC-XK99E (대조군을 위한 빈 벡터) 를 Wouter Duetz 의 시스템 (상기 기재됨) 을 사용하여 배치 배양에서 GAA 를 생산하는 능력에 대해 분석하였다. 생산 배지 (PM) 는 40 g/l D-글루코스를 주 탄소원으로 함유하였다. 일부 배치에는 지시된 바와 같이 L-아르기닌 및/또는 글리신을 보충하였다.
표 11: 균주 ATCC13032/pEC-XK99E 및 ATCC13032/pEC-XK99E_AGAT_Mp 에 의한 GAA 생산

표 11 에 나타낸 바와 같이, 대조군 균주 ATCC13032/pEC-XK99E 는 전구체 L-아르기닌 및 글리신을 제공하더라도 GAA 를 생산할 수 없었다. 본 발명자들은 그것이 본질적인 AGAT 활성을 가지지 않는다고 결론지었다. 균주 ATCC13032/pEC-XK99E_AGAT_Mp 는 무레아 프로듀센스로부터의 추정 AGAT 를 코딩하는 폴리뉴클레오티드를 함유한다. 이것은 보충되지 않은 PM 에서 25 mg/l GAA 를 생성하였다. 글리신의 보충은 31 mg/l GAA 로의 작은 증가를 초래하였다. 글리신 및 L-아르기닌의 보충은 GAA 생산을 124 mg/l 로 크게 증가시켰다.
실시예 13:
일차 기질로부터 GAA 의 생산
산업적 GAA 생산 공정에서, L-아르기닌의 보충은 암모니아, 우레아 및 글루코스와 같은 일차 기질과 비교할 때 오히려 비용이 많이 들 것이다. 따라서, 이러한 일차 기질로부터 직접 GAA 를 생성하는 것이 바람직할 것이다.
이를 위해, L-아르기닌 생산자 C. 글루타미쿰 ATCC21831 을:
·
pEKEx2 (대조군을 위한 빈 벡터),
·
pEKEx2_AGAT_Mp (무레아 프로듀센스 (Moorea producens) 로부터의 AGAT_Mp 유전자 함유),
·
pEKEx2_AGAT_Hs (호모 사피엔스 (Homo sapiens) 로부터의 AGAT_Hs 유전자 함유),
·
pEKEx2_AGAT_Rn (라투스 노르베지쿠스 (Rattus norvegicus) 로부터의 AGAT_Rn 유전자 함유),
·
pEKEx2_AGAT_Gv (갈레옵테루스 바리에가투스 (Galeopterus variegatus), 및 로부터의 AGAT_Gv 유전자 함유) 및
·
pEKEx2_AGAT_cyrA (실린드로스페르모프시스 라시보르스키 (Cylindrospermopsis raciborskii) 로부터의 AGAT_cyrA 유전자 함유)
로 형질전환시켰다.
ATCC21831 은 카나바닌 내성 돌연변이체로서 단리되었고, 이는 L-아르기닌을 생산하는 것으로 밝혀졌다. 이의 게놈은 Park et al. 에 의해 서열분석되었고 (Nat Commun. 2014 Aug 5;5:4618. doi: 10.1038/ncomms5618; accession number CP007722), 균주는 LGC 표준 (LGC Standards GmbH, Wesel, Germany) 으로부터 공개적으로 입수가능하다.
모든 형질전환된 ATCC21831 균주를 Wouter Duetz 의 시스템 (상기 기재됨) 을 사용하여 배치 배양에서 GAA 를 생산하는 그들의 능력에 대해 분석하였다. 생산 배지 (PM) 는 40 g/l D-글루코스를 주 탄소원으로 함유하였다. 일부 배치는 글리신 및/또는 L-아르기닌으로 보충되었다.
표 12: 1.5 g/l 효모 추출물을 갖는 CGAF 및 MOPS 배지에서 상이한 종으로부터의 AGAT 를 함유하는 pEKEx2 벡터로 형질전환된 ATCC21831 균주에 의한 GAA 생산


표 12 에 나타낸 바와 같이, ATCC21831/pEKEx2 는 심지어 전구체 L-아르기닌 및 글리신이 존재하는 경우에도, GAA 를 생산하지 않았다. 본 발명자들은 ATCC21831/ pEKEx2 가 본질적인 AGAT 활성을 가지지 않는다고 결론지었다. 형질전환된 균주 ATCC21831/ pEKEx2_AGAT_Mp, ATCC21831/pEKEx2_AGAT_Hs, ATCC21831/pEKEx2_AGAT_Rn, ATCC21831/pEKEx2_AGAT_Gv, 및 ATCC21831/pEKEx2_AGAT_cyrA 는 보충되지 않은 PM 에서 약 1 내지 26 mg/l GAA 를 생산하였다. 본 발명자들은 전구체 L-아르기닌 및 글리신이 일차 기질 D-글루코스, 암모늄 및 우레아로부터 합성되었다고 결론내렸다.
글리신을 첨가하였을 때, ATCC21831/pEKEx2_AGAT_Mp, ATCC21831/pEKEx2_AGAT_Hs, ATCC21831/pEKEx2_AGAT_Rn, ATCC21831/pEKEx2_AGAT_Gv, 및 ATCC21831/pEKEx2_AGAT_cyrA 의 GAA 생산은 보충되지 않은 실험에 비해 상당히 증가하였다. 균주 ATCC13032/pEC-XK99E_AGAT_Mp (표 10 참조) 와 비교할 때, AGAT 유전자를 갖는 L-아르기닌 생산자 ATCC21831 은 글리신이 제한되지 않을 때 훨씬 더 많은 GAA 를 축적한다. 본 발명자들은 L-아르기닌을 내부적으로 제공하는 능력이 GAA 생산을 향상시킨다고 결론지었다.
실시예 14: GAA 생산에 대한 L-아르기닌 재생의 영향
L-아르기닌 생산 균주 (예를 들어, ATCC21831) 에서, 중간체 L-오르니틴을 드 노보로 합성하고, 추가로 L-아르기닌으로 전환시킨다. 이러한 균주에 AGAT 가 제공되는 경우, 효소는 동일한 몰량의 GAA 및 L-오르니틴을 생성할 것이다. L-오르니틴의 형성은 상당한 양의 일차 C- 및 N-공급원을 소비하고, 따라서 GAA 의 수율을 저하시킨다.
본 발명자들은 L-오르니틴으로부터 L-아르기닌에 이르는 생합성 경로의 향상이, 아마도 L-오르니틴의 L-아르기닌으로의 재순환을 개선함으로써, GAA 생산을 개선한다는 것을 발견하였다.
ATCC13032 로부터 유래된 다양한 균주를 Wouter Duetz 시스템을 사용하여 배양한 다음, GAA 를 생산하는 이들의 능력에 대해 분석하였다 (표 13, 14 및 15).
표 13: 글리신 또는 L-아르기닌 보충 없이 YE 를 포함하는 PM 에서의 GAA 생산에 대한 개선된 L-아르기닌 재생의 영향

표 14: YE 가 없는 PM 에서의 GAA 생산에 대한 개선된 L-아르기닌 재생의 영향 모든 배양물은 0.82 g/l 글리신으로 보충되었다

표 15: YE 를 포함하는 PM 에서의 GAA 생산에 대한 개선된 L-아르기닌 재생의 영향 모든 배양물은 0.82 g/l 글리신 및/또는 1.9 g/l L-아르기닌으로 보충되었다.

표 13 내지 15 에 나타낸 바와 같이, AGAT 유전자가 결여된 균주는 검출가능한 양의 GAA 를 생산하지 않았다.
ATCC13032/pEC-XK99E_AGAT_Mp 에서 AGAT_Mp 의 발현은 124 mg/l GAA 를 생성하였다. argG (균주 ATCC13032/pEC-XK99E_AGAT_Mp_argG), argF (균주 ATCC13032/pEC-XK99E_AGAT_Mp_argF) 또는 argG+argH (균주 ATCC13032/pEC-XK99E_AGAT_Mp_argGH) 의 추가적인 증폭은 GAA 의 생산을 개선시켰다 (표 14 참조).
균주 ATCC13032/pEC-XK99E_AGAT_Mp_argFGH 에서, 유전자 argF (오르니틴 카르바모일트랜스퍼라제를 코딩함), argG (아르기니노숙시네이트 신테타제를 코딩함) 및 argH (아르기니노숙시네이트 리아제를 코딩함) 의 발현이 향상된다. 이는 GAA 의 생산을 154 mg/l 로 추가로 개선시켰다 (표 14 참조).
오르니틴 카르바모일트랜스퍼라제에 의해 촉매되는, L-오르니틴의 L-시트룰린으로의 전환은 공동-기질 카르바모일 포스페이트의 이용가능성에 의존한다. 카르바모일 포스페이트는 유전자 carA 및 carB 에 의해 인코딩되는 카르바모일 포스페이트 신타아제에 의해 생성된다. 균주 ATCC13032_Psod-carAB/pEC-XK99E_AGAT_Mp 에서, 강한 sod-프로모터의 게놈 삽입은 carA 및 carB 의 발현을 향상시킨다. ATCC13032/pEC-XK99E_AGAT_Mp 와 비교할 때, 이는 개선된 GAA 생산 (156 mg/l 대 124 mg/l) 을 초래하였다.
균주 ATCC13032_Psod-carAB/pEC-XK99E_AGAT_Mp_argFGH 에서, 개선된 L-오르니틴 전환 (argF, argG 및 argH 의 과발현) 을 개선된 카르바모일 포스페이트 생합성 (carA 및 carB 의 과발현) 과 조합하였다. 이러한 조합은 GAA 생산을 171 mg/l 로 추가로 개선시켰다.
실시예 15:
무레아 프로듀센스
유전자 AGAT_Mp 를 위한
P. 푸티다
발현 벡터의 구축
P. 푸티다 KT2440 에서 무레아 프로듀센스 (EC 2.1.4.1, SEQ ID NO:2 및 SEQ ID NO:4) 로부터의 AGAT 의 이종 발현을 위해, 플라스미드 pACYCATh-5{PRha}[agat_Mp(coPp)] 를 구축하였다. 코돈 최적화된 AGAT_Mp 유전자를 람노오스 유도성 프로모터 Prha 의 제어 하에 벡터 pACYATh-5 내로 클로닝하였다. AGAT_Mp 유전자의 다운스트림에 터미네이터 서열이 위치한다. AGAT_Mp 유전자를 Eurofins Genomics Germany GmbH (Ebersberg, Germany) 로부터 유전자 합성을 위해 주문하고, 유전자 단편의 DNA 서열을 P. 푸티다 KT2440 에서의 발현을 위해 코돈-최적화하였다 (SEQ ID NO:33). 오픈 리딩 프레임의 업스트림에는 샤인-달가노 서열이 추가되었다. PRha 프로모터 카세트 (SEQ ID NO:34) 및 터미네이터 서열 (SEQ ID NO:35) 을 E. 콜라이 K12 게놈 DNA 로부터 증폭시켰다. 벡터는 pACYC184 (New England BioLabs Inc., Ipswich, USA) 에 기초하며 E. 콜라이에 대한 p15A 복제 기원 및 P. 푸티다 KT2440 에서의 복제를 위한 pVS1 복제 기원을 가지고 있다. pVS1 기원은 슈도모나스 플라스미드 pVS1 (Itoh Y, Watson JM, Haas D, Leisinger T, Plasmid 1984, 11(3), 206-20) 로부터 유래한다. 다음 단계에서, AGAT_Mp 유전자 단편을 프라이머 MW_20_01_fw (SEQ ID NO:36) 및 MW_20_02_rv (SEQ ID NO:37) 를 사용하는 PCR 을 통해 증폭시키고, 제한 부위 ApaI/XhoI 및 NEBuilder® HiFi DNA Assembly Cloning Kit (New England BioLabs Inc., Ipswich, USA, Cat. No. E5520 사제) 를 사용하여 벡터 pACYCATh-5 내로 클로닝하였다. 어셈블리된 생성물을 10-베타 전기적격 E. 콜라이 세포 (New England BioLabs Inc., Ipswich, USA, Cat. No. C3020K) 내로 형질전환시켰다. PCR 정제, 클로닝 및 형질전환 절차는 제조사의 매뉴얼에 따라 수행하였다. 표적 유전자의 정확한 삽입을 제한 분석에 의해 확인하고, 도입된 DNA 단편의 진위를 DNA 서열분석에 의해 확인하였다. 생성된 발현 벡터를 pACYCATh-5{PRha}[agat_Mp(coPp)] (SEQ ID NO:38, 표 17 참조) 로 명명하였다.
P. 푸티다 균주 KT2440 을 플라스미드 pACYCATh-5{PRha}[agat_Mp(coPp)] 로 전기천공에 의해 형질전환하고, 테트라사이클린 (10 mg/l) 이 보충된 LB 아가 플레이트 상에 플레이팅하였다. 형질전환체를 플라스미드 제조 및 분석 제한 분석에 의해 정확한 플라스미드의 존재에 대해 체크하였다. 생성된 균주를 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp)] 로 명명하였다 (표 18 참조).
실시예 16:
무레아 프로듀센스
유전자 AGAT_Mp 및
P. 푸티다
유전자 argF, argG 및 argH 에 대한
P. 푸티다
발현 벡터의 구축
무레아 프로듀센스로부터의 AGAT_Mp 및 P. 푸티다 KT2440 로부터의 argF (SEQ ID NO:39), argG (SEQ ID NO:41), argH (SEQ ID NO:43) 의 이종 발현을 위해, 플라스미드 pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp] 를 구축하였다. L-아르기닌:글리신 아미디노트랜스퍼라제 (AGAT, EC 2.1.4.1, SEQ ID NO:2 및 SEQ ID NO:4) 를 인코딩하는 AGAT_Mp, 오르니틴 카르바모일트랜스퍼라제를 인코딩하는 argF (ArgF, EC 2.1.3.3, SEQ ID NO:40), 아르기니노숙시네이트 신타아제를 인코딩하는 argG (ArgG, E.C. 6.3.4.5, SEQ ID NO:42) 및 아르기니노숙시네이트 리아제를 인코딩하는 argH (ArgH, E.C. 4.3.2.1, SEQ ID NO:44) 로 각각 이루어진 합성 오페론을 람노오스 유도성 프로모터 Prha 의 제어 하에 벡터 pACYCATh-5 내로 클로닝하였다. 합성 오페론의 다운스트림에 터미네이터 서열이 위치한다. AGAT_Mp 유전자를 Eurofins Genomics Germany GmbH (Ebersberg, Germany) 로부터 유전자 합성을 위해 주문하고, 유전자 단편의 DNA 서열을 P. 푸티다 KT2440 에서의 발현을 위해 코돈-최적화하였다. 유전자 argFGH 는 또한 유전자 단편 argFGH (SEQ ID NO: 45) 로서 합성되었다. PRha 프로모터 카세트 (SEQ ID NO:34) 및 터미네이터 서열 (SEQ ID NO:35) 을 E. 콜라이 K12 게놈 DNA 로부터 증폭시켰다. 벡터는 pACYC184 (New England BioLabs Inc., Ipswich, USA) 에 기초하며 E. 콜라이에 대한 p15A 복제 기원 및 P. 푸티다 KT2440 에서의 복제를 위한 pVS1 복제 기원을 가지고 있다. pVS1 기원은 슈도모나스 플라스미드 pVS1 (Itoh Y, Watson JM, Haas D, Leisinger T, Plasmid 1984, 11(3), 206-20) 로부터 유래한다. 클로닝을 위해, AGAT_Mp 및 argFGH 를 PCR 을 통해 증폭시켰다. 클로닝에 사용된 프라이머가 표 16 에 열거되어 있다. 최적화된 오페론을 생성하기 위해 제한 부위 ApaI/XhoI 및 NEBuilder® HiFi DNA Assembly Cloning Kit (New England BioLabs Inc., Ipswich, USA, Cat. No. E5520 사제) 를 사용하여 PCR 생성물을 벡터 pACYCATh-5 내에 클로닝하였다. 증폭을 위해 New England Biolabs (Ipswich, USA ) 로부터의 PhusionTM High-Fidelity Master Mix 를 제조자의 매뉴얼에 따라 사용하였다. 어셈블리된 생성물을 10-베타 전기적격 E. 콜라이 세포 (New England BioLabs Inc., Ipswich, USA, Cat. No. C3020K) 내로 형질전환시켰다. PCR 정제, 클로닝 및 형질전환 절차는 제조사의 매뉴얼에 따라 수행하였다. 표적 유전자의 정확한 삽입을 제한 분석에 의해 확인하고, 도입된 DNA 단편의 진위를 DNA 서열분석에 의해 확인하였다. 생성된 발현 벡터를 pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp] (SEQ ID NO:49, 표 17 참조) 로 명명하였다.
P. 푸티다 균주 KT2440 을 플라스미드 pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp] 로 전기천공에 의해 형질전환하고, 테트라사이클린 (10 mg/l) 이 보충된 LB 아가 플레이트 상에 플레이팅하였다. 형질전환체를 플라스미드 제조 및 분석 제한 분석에 의해 정확한 플라스미드의 존재에 대해 체크하였다. 생성된 균주를 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp] 로 명명하였다 (표 18 참조).
표 16: AGAT_Mp 및 argFGH 의 pACYCATh-5 내로의 클로닝을 위해 사용된 프라이머.

실시예 17:
P. 푸티다
KT2440
으로부터 유전자
carAB
의 발현 벡터 pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp] 내로의 클로닝
무레아 프로듀센스로부터의 AGAT_Mp, P. 푸티다 KT2440 로부터의 argF (SEQ ID NO:39), argG (SEQ ID NO:41), argH (SEQ ID NO:43), carA (SEQ ID NO:50) 및 carB (SEQ ID NO:52) 의 이종 발현을 위해, 플라스미드 pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp]{carAB_Pp}[carAB_Pp][ter] 를 구축하였다. 카르바모일-포스페이트 신타아제 (CarAB, EC 6.3.5.5, SEQ ID NO:51 및 SEQ ID NO:53) 를 인코딩하는 carA (SEQ ID NO:50) 및 carB 유전자 (SEQ ID NO:52) 를 프라이머 MW_20_35_fw (SEQ ID NO:54) 및 MW_20_36_rv (SEQ ID NO:55) 를 사용하여 PCR 을 통해 carAB 오페론의 고유의 프로모터를 포함하는 P. 푸티다 KT2440 의 게놈 DNA 로부터 증폭시켰다. 증폭을 위해 New England Biolabs (Ipswich, USA ) 로부터의 PhusionTM High-Fidelity Master Mix 를 제조자의 매뉴얼에 따라 사용하였다. PCR 생성물 (SEQ ID NO:56) 을 NEBuilder® HiFi DNA Assembly Cloning Kit (New England BioLabs Inc., Ipswich, USA, Cat. No. E5520 사제) 를 사용하여 Bsu36I 로 절단된 pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp] 내에 클로닝하였다. 어셈블리된 생성물을 10-베타 전기적격 E. 콜라이 세포 (New England BioLabs Inc., Ipswich, USA, Cat. No. C3020K) 내로 형질전환시켰다. PCR 정제, 클로닝 및 형질전환 절차는 제조사의 매뉴얼에 따라 수행하였다. 표적 유전자의 정확한 삽입을 제한 분석에 의해 확인하고, 도입된 DNA 단편의 진위를 DNA 서열분석에 의해 확인하였다. 생성된 발현 벡터를 pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp]{carAB_Pp}[carAB_Pp][ter] (SEQ ID NO:57, 표 17 참조) 로 명명하였다.
P. 푸티다 균주 KT2440 을 플라스미드 pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp]{carAB_Pp}[carAB_Pp][ter] 로 전기천공에 의해 형질전환하고, 테트라사이클린 (10 mg/l) 이 보충된 LB 아가 플레이트 상에 플레이팅하였다. 형질전환체를 플라스미드 제조 및 분석 제한 분석에 의해 정확한 플라스미드의 존재에 대해 체크하였다. 생성된 균주를 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp]{carAB_Pp}[carAB_Pp][ter] 로 명명하였다 (표 18 참조).
표 17:
P. 푸티다
발현 플라스미드 목록

표 18: 플라스미드-함유 P. 푸티다 균주 목록

실시예 18:
P. 푸티다
KT2440 에서의 GAA 생산에 대한 AGAT 의 영향
M. 프로듀센스로부터의 AGAT 효소에 대한 유전자를 운반하는 균주 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp)] 및 P. 푸티다 KT2440/pACYCATh-5 (빈 벡터 대조군) 를 진탕 플라스크를 사용하여 배치 배양에서 GAA 를 생산하는 능력에 대해 분석하였다. 10 mg/l 테트라사이클린을 함유하는 LB 아가 플레이트 상에서, 상응하는 균주의 글리세롤 동결배양물의 접종 루프를 스트리킹하였다. 아가 플레이트를 30℃ 에서 24 시간 동안 인큐베이션한다. 10 mg/l 테트라사이클린이 있는, 15 ml 의 종자 배지 (오토클레이브됨: 4.4 g/L Na2HPO4 x 2 H2O, 1.5 g/L KH2PO4, 1 g/L NH4Cl, 10 g/L 효모 추출물, 각각 멸균됨: 20 g/L 글루코스, 0.2 g/L MgSO4 x 7 H2O, 0.006 g/L FeCl3, 0.015 g/L CaCl2, 1 ml/L 미량 원소 용액 SL6 (멸균-여과됨: 0.3 g/L H3BO3, 0.2 g/L CoCl2 x 6 H2O, 0.1 g/L ZnSO4 x 7 H2O, 0.03 g/L MnCl2 x 4H2O, 0.01 g/L CuCl2 x 2 H2O, 0.03 g/L Na2MoO4 x 2 H2O, 0.02 g/L NiCl2 x 6 H2O), pH 7) 를 함유하는 배플을 가진 100 ml 플라스크에 아가 플레이트의 단일 콜로니를 접종하고, 진탕 인큐베이터에서 18 시간 동안 30℃ 및 200 rpm 에서 인큐베이션하여, 예비배양물을 생산하였다. 예비배양물을 사용하여 10 mg/l 테트라사이클린, 3.48 g/l 아르기닌 및 1.5 g/l 글리신이 있는, 40 ml 의 M12 배지 (조성: (2.2 g/L (NH4)2SO4, 0.02 g/L NaCl, 0.4 g/L MgSO4 x 7H2O, 0.04 g/L CaCl2 x 2H2O, 각각 멸균됨: 2 g/L KH2PO4, 8.51 g/L Na2HPO4, 20 g/L 그루코스, 10 ml/l 미량 원소 용액 M12 (멸균-여과됨: 0.2 g/L ZnSO4 x 7 H2O, 0.1 g/L MnCl2 x 4H2O, 1.5 g/L Na3-시트레이트 x 2 H2O, 0.1 g/L CuSO4 x 5 H2O, 0.002 g/L NiCl2 x 6 H2O, 0.003 g/L Na2MoO4 x 2 H2O, 0.03 g/L H3BO3, 1 g/L FeSO4 x 7 H2O), pH 7.4) 에 접종하고 0.1 의 OD600 을 시작하였다. 균주를 48 시간 동안 배양하였다. 대략 0.5-0.8 의 OD600 에서, 0.2% (w/v) 람노스를 첨가함으로써 유전자 발현을 유도하였다. 유도 9 시간 및 24 시간 후 1.74 g/l 아르기닌 및 0.75 g/l 글리신이 스파이킹되었다. 배양 종료시, 생성된 GAA 의 농도를 결정하기 위해 샘플을 취하였다.
결과는 표 19 에 제시된다.
표 19: 균주 P. 푸티다 KT2440/pACYCATh-5 및 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp)] 에 의한 GAA 생산

표 19 에서 알 수 있는 바와 같이, M. 프로듀센스로부터의 AGAT_Mp 유전자가 장착된 균주 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp)] 는 약 81.5 mg/l GAA 를 생산할 수 있었다. 대조군 균주 P. 푸티다 KT2440/pACYCATh-5 는 어떠한 GAA 도 전혀 생산할 수 없었다.
실시예 19:
P. 푸티다
KT2440 에서 GAA 생산에 대한 AGAT 및 증가된 L-아르기닌 공급의 영향
M. 프로듀센스로부터의 AGAT 효소에 대한 유전자를 운반하는 균주 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp)] 및 아르기닌 생합성 유전자 argFGH 를 부가적으로 운반하는 균주 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp] 를 진탕 플라스크를 사용하여 배치 배양에서 GAA 를 생산하는 능력에 대해 분석하였다. 10 mg/l 테트라사이클린을 함유하는 LB 아가 플레이트 상에서, 상응하는 균주의 글리세롤 동결배양물의 접종 루프를 스트리킹하였다. 아가 플레이트를 30℃ 에서 24 시간 동안 인큐베이션한다. 10 mg/l 테트라사이클린이 있는, 15 ml 의 종자 배지 (오토클레이브됨: 4.4 g/L Na2HPO4 x 2 H2O, 1.5 g/L KH2PO4, 1 g/L NH4Cl, 10 g/L 효모 추출물, 각각 멸균됨: 20 g/L 글루코스, 0.2 g/L MgSO4 x 7 H2O, 0.006 g/L FeCl3, 0.015 g/L CaCl2, 1 ml/L 미량 원소 용액 SL6 (멸균-여과됨: 0.3 g/L H3BO3, 0.2 g/L CoCl2 x 6 H2O, 0.1 g/L ZnSO4 x 7 H2O, 0.03 g/L MnCl2 x 4H2O, 0.01 g/L CuCl2 x 2 H2O, 0.03 g/L Na2MoO4 x 2 H2O, 0.02 g/L NiCl2 x 6 H2O), pH 7) 를 함유하는 배플을 가진 100 ml 플라스크에 아가 플레이트의 단일 콜로니를 접종하고, 진탕 인큐베이터에서 18 시간 동안 30℃ 및 200 rpm 에서 인큐베이션하여, 예비배양물을 생산하였다. 예비배양물을 사용하여 10 mg/l 테트라사이클린, 3.48 g/l 아르기닌 및 1.5 g/l 글리신이 있는, 40 ml 의 M12 배지 (조성: (2.2 g/L (NH4)2SO4, 0.02 g/L NaCl, 0.4 g/L MgSO4 x 7H2O, 0.04 g/L CaCl2 x 2H2O, 각각 멸균됨: 2 g/L KH2PO4, 8.51 g/L Na2HPO4, 20 g/L 그루코스, 10 ml/l 미량 원소 용액 M12 (멸균-여과됨: 0.2 g/L ZnSO4 x 7 H2O, 0.1 g/L MnCl2 x 4H2O, 1.5 g/L Na3-시트레이트 x 2 H2O, 0.1 g/L CuSO4 x 5 H2O, 0.002 g/L NiCl2 x 6 H2O, 0.003 g/L Na2MoO4 x 2 H2O, 0.03 g/L H3BO3, 1 g/L FeSO4 x 7 H2O), pH 7.4) 에 접종하고 0.1 의 OD600 을 시작하였다. 균주를 48 시간 동안 배양하였다. 대략 0.5-0.8 의 OD600 에서, 0.2% (w/v) 람노스를 첨가함으로써 유전자 발현을 유도하였다. 유도 9 시간 및 24 시간 후 1.74 g/l 아르기닌 및 0.75 g/l 글리신이 스파이킹되었다. 배양 종료시, 생성된 GAA 의 농도를 결정하기 위해 샘플을 취하였다.
결과는 표 20 에 제시된다.
표 20: 균주 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp)] 및 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp] 에 의한 GAA 생산

표 20 에서 알 수 있는 바와 같이, M. 프로듀센스로부터의 AGAT_Mp 유전자가 장착된 균주 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp)] 는 약 81.5 mg/l GAA 를 생산할 수 있었다. 부가적으로 균주 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp] 에서 argF, argG 및 argH 의 구현은 GAA 생산을 169.5 mg/l 로 개선시켰다.
실시예 20:
P. 푸티다
KT2440 에서 GAA 생산에 대한 AGAT 및 L-아르기닌 재생의 영향
M. 프로듀센스로부터의 AGAT 효소에 대한 유전자를 운반하는 균주 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp)], 아르기닌 생합성 유전자 argFGH 를 부가적으로 운반하는 균주 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp argFGH_Pp] 및 카르바모일-포스페이트 신타아제 유전자 carAB 를 부가적으로 운반하는 균주 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp]{carAB_Pp}[carAB_Pp][ter] 를 진탕 플라스크를 사용하여 배치 배양에서 GAA 를 생산하는 능력에 대해 분석하였다. 오르니틴 카르바모일트랜스퍼라제에 의해 촉매되는, L-오르니틴의 L-시트룰린으로의 전환은 공동-기질 카르바모일 포스페이트의 이용가능성에 의존한다. 카르바모일 포스페이트는 유전자 carA 및 carB 에 의해 인코딩되는 카르바모일 포스페이트 신타아제에 의해 생성된다. 10 mg/l 테트라사이클린을 함유하는 LB 아가 플레이트 상에서, 상응하는 균주의 글리세롤 동결배양물의 접종 루프를 스트리킹하였다. 아가 플레이트를 30℃ 에서 24 시간 동안 인큐베이션한다. 10 mg/l 테트라사이클린이 있는, 15 ml 의 종자 배지 (오토클레이브됨: 4.4 g/L Na2HPO4 x 2 H2O, 1.5 g/L KH2PO4, 1 g/L NH4Cl, 10 g/L 효모 추출물, 각각 멸균됨: 20 g/L 글루코스, 0.2 g/L MgSO4 x 7 H2O, 0.006 g/L FeCl3, 0.015 g/L CaCl2, 1 ml/L 미량 원소 용액 SL6 (멸균-여과됨: 0.3 g/L H3BO3, 0.2 g/L CoCl2 x 6 H2O, 0.1 g/L ZnSO4 x 7 H2O, 0.03 g/L MnCl2 x 4H2O, 0.01 g/L CuCl2 x 2 H2O, 0.03 g/L Na2MoO4 x 2 H2O, 0.02 g/L NiCl2 x 6 H2O), pH 7) 를 함유하는 배플을 가진 100 ml 플라스크에 아가 플레이트의 단일 콜로니를 접종하고, 진탕 인큐베이터에서 18 시간 동안 30℃ 및 200 rpm 에서 인큐베이션하여, 예비배양물을 생산하였다. 예비배양물을 사용하여 10 mg/l 테트라사이클린, 3.48 g/l 아르기닌 및 1.5 g/l 글리신이 있는, 40 ml 의 M12 배지 (조성: (2.2 g/L (NH4)2SO4, 0.02 g/L NaCl, 0.4 g/L MgSO4 x 7H2O, 0.04 g/L CaCl2 x 2H2O, 각각 멸균됨: 2 g/L KH2PO4, 8.51 g/L Na2HPO4, 20 g/L 그루코스, 10 ml/l 미량 원소 용액 M12 (멸균-여과됨: 0.2 g/L ZnSO4 x 7 H2O, 0.1 g/L MnCl2 x 4H2O, 1.5 g/L Na3-시트레이트 x 2 H2O, 0.1 g/L CuSO4 x 5 H2O, 0.002 g/L NiCl2 x 6 H2O, 0.003 g/L Na2MoO4 x 2 H2O, 0.03 g/L H3BO3, 1 g/L FeSO4 x 7 H2O), pH 7.4) 에 접종하고 0.1 의 OD600 을 시작하였다. 균주를 48 시간 동안 배양하였다. 대략 0.5-0.8 의 OD600 에서, 0.2% (w/v) 람노스를 첨가함으로써 유전자 발현을 유도하였다. 유도 후 4 시간 / 18 시간 / 23 시간에, 6.97 g/l Arg/1.5 g/l Gly, 2.34 g/L Arg/0.75 g/L Gly 및 6.97 g/l Arg/1.5 g/l Gly 가 스파이킹되었다. 배양 종료시, 생성된 GAA 의 농도를 결정하기 위해 샘플을 취하였다.
결과는 표 21 에 제시된다.
표 21: 균주 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp)], P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp] 및 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp]{carAB_Pp}[carAB_Pp][ter] 에 의한 GAA 생산

표 21 에서 알 수 있는 바와 같이, M. 프로듀센스로부터의 AGAT_Mp 유전자 및 P. 푸티다로부터의 argFGH 유전자가 장착된 균주는 589 mg/l GAA 를 생산할 수 있었다. 부가적으로 균주 P. 푸티다 KT2440/pACYCATh-5{PRha}[agat_Mp(coPp) argFGH_Pp]{carAB_Pp}[carAB_Pp][ter] 에서 carAB 의 구현은 GAA 생산을 693 mg/l 로 개선시켰다.
SEQUENCE LISTING
<110> Evonik Operations GmbH
<120> Method for the fermentative production of guanidinoacetic acid
<130> 000
<160> 57
<170> PatentIn version 3.5
<210> 1
<211> 1146
<212> DNA
<213> Moorea producens strain PAL-8-15-08-1
<220>
<221> CDS
<222> (1)..(1143)
<223> Genbank accession Number WP_070390602
<400> 1
atg tcg gaa aaa att gtt aat tcc tgg aat gaa tgg gat gaa ttg gaa 48
Met Ser Glu Lys Ile Val Asn Ser Trp Asn Glu Trp Asp Glu Leu Glu
1 5 10 15
gaa atg gtg gta gga att gca gac tat gct agc ttt gaa cca aaa gaa 96
Glu Met Val Val Gly Ile Ala Asp Tyr Ala Ser Phe Glu Pro Lys Glu
20 25 30
cca ggg aat cat ccg aaa tta aga aat caa aat tta gcg gaa atc att 144
Pro Gly Asn His Pro Lys Leu Arg Asn Gln Asn Leu Ala Glu Ile Ile
35 40 45
cct ttc ccc agt gga cct aaa gac cct aaa gtc ctt gaa aaa gct aat 192
Pro Phe Pro Ser Gly Pro Lys Asp Pro Lys Val Leu Glu Lys Ala Asn
50 55 60
gaa gaa tta aat gga ctg gct tat tta tta aaa gac cac gat gtg ata 240
Glu Glu Leu Asn Gly Leu Ala Tyr Leu Leu Lys Asp His Asp Val Ile
65 70 75 80
gta aga aga ccc gaa aaa att gat ttt act aaa tct cta aaa aca cct 288
Val Arg Arg Pro Glu Lys Ile Asp Phe Thr Lys Ser Leu Lys Thr Pro
85 90 95
tac ttt gaa gtt gca aat caa tac tgt gga gtc tgt cct cgg gat gtc 336
Tyr Phe Glu Val Ala Asn Gln Tyr Cys Gly Val Cys Pro Arg Asp Val
100 105 110
atg att acc ttt ggg aat gaa atc atg gaa gcg act atg tcg aag aga 384
Met Ile Thr Phe Gly Asn Glu Ile Met Glu Ala Thr Met Ser Lys Arg
115 120 125
gct aga ttt ttt gaa tac tta cct tac cgg aaa ttg gtc tat gaa tat 432
Ala Arg Phe Phe Glu Tyr Leu Pro Tyr Arg Lys Leu Val Tyr Glu Tyr
130 135 140
tgg aat aaa gac gag cat atg att tgg aat gct gcg cct aaa ccg act 480
Trp Asn Lys Asp Glu His Met Ile Trp Asn Ala Ala Pro Lys Pro Thr
145 150 155 160
atg cag gat agt atg tat cta gag aat ttc tgg gag ctg tct tta gaa 528
Met Gln Asp Ser Met Tyr Leu Glu Asn Phe Trp Glu Leu Ser Leu Glu
165 170 175
gaa cga ttt aag cgt atg cat gat ttt gaa ttt tgt att aca caa gat 576
Glu Arg Phe Lys Arg Met His Asp Phe Glu Phe Cys Ile Thr Gln Asp
180 185 190
gaa gta att ttt gat gcg gct gac tgt agc aga tta gga aag gat ata 624
Glu Val Ile Phe Asp Ala Ala Asp Cys Ser Arg Leu Gly Lys Asp Ile
195 200 205
tta gtt cag gaa tcg atg aca aca aat aga aca gga att cgg tgg tta 672
Leu Val Gln Glu Ser Met Thr Thr Asn Arg Thr Gly Ile Arg Trp Leu
210 215 220
aaa aag cac cta gaa cca aga gga ttt cgg gtt cac cct gtt cat ttt 720
Lys Lys His Leu Glu Pro Arg Gly Phe Arg Val His Pro Val His Phe
225 230 235 240
ccc ctt gat ttt ttc ccc tca cac att gac tgt acg ttt gtt cct ttg 768
Pro Leu Asp Phe Phe Pro Ser His Ile Asp Cys Thr Phe Val Pro Leu
245 250 255
cga cca ggt ctt att ttg aca aac cct gaa aga cct ata cgg gaa gag 816
Arg Pro Gly Leu Ile Leu Thr Asn Pro Glu Arg Pro Ile Arg Glu Glu
260 265 270
gag gag aag att ttt aaa gag aat ggc tgg gag ttg atc aca gtt cct 864
Glu Glu Lys Ile Phe Lys Glu Asn Gly Trp Glu Leu Ile Thr Val Pro
275 280 285
caa ccg act tgc tcg aat gat gaa atg cca atg ttt tgc cag tcc agt 912
Gln Pro Thr Cys Ser Asn Asp Glu Met Pro Met Phe Cys Gln Ser Ser
290 295 300
aag tgg ttg tca atg aat gtt ctg agt ata tca ccg aca aag gtt atc 960
Lys Trp Leu Ser Met Asn Val Leu Ser Ile Ser Pro Thr Lys Val Ile
305 310 315 320
tgt gag gaa aga gaa aaa cct ctc caa gaa ttg ttg gat aag cat gga 1008
Cys Glu Glu Arg Glu Lys Pro Leu Gln Glu Leu Leu Asp Lys His Gly
325 330 335
ttt gag gtt ttt cct tta ccc ttt aga cat gtc ttt gaa ttt ggg ggg 1056
Phe Glu Val Phe Pro Leu Pro Phe Arg His Val Phe Glu Phe Gly Gly
340 345 350
tct ttt cat tgt gca act tgg gat att cgc cga aaa ggt gag tgt gaa 1104
Ser Phe His Cys Ala Thr Trp Asp Ile Arg Arg Lys Gly Glu Cys Glu
355 360 365
gat tat tta cca aat tta aac tat caa ccg att tgt ggt taa 1146
Asp Tyr Leu Pro Asn Leu Asn Tyr Gln Pro Ile Cys Gly
370 375 380
<210> 2
<211> 381
<212> PRT
<213> Moorea producens strain PAL-8-15-08-1
<400> 2
Met Ser Glu Lys Ile Val Asn Ser Trp Asn Glu Trp Asp Glu Leu Glu
1 5 10 15
Glu Met Val Val Gly Ile Ala Asp Tyr Ala Ser Phe Glu Pro Lys Glu
20 25 30
Pro Gly Asn His Pro Lys Leu Arg Asn Gln Asn Leu Ala Glu Ile Ile
35 40 45
Pro Phe Pro Ser Gly Pro Lys Asp Pro Lys Val Leu Glu Lys Ala Asn
50 55 60
Glu Glu Leu Asn Gly Leu Ala Tyr Leu Leu Lys Asp His Asp Val Ile
65 70 75 80
Val Arg Arg Pro Glu Lys Ile Asp Phe Thr Lys Ser Leu Lys Thr Pro
85 90 95
Tyr Phe Glu Val Ala Asn Gln Tyr Cys Gly Val Cys Pro Arg Asp Val
100 105 110
Met Ile Thr Phe Gly Asn Glu Ile Met Glu Ala Thr Met Ser Lys Arg
115 120 125
Ala Arg Phe Phe Glu Tyr Leu Pro Tyr Arg Lys Leu Val Tyr Glu Tyr
130 135 140
Trp Asn Lys Asp Glu His Met Ile Trp Asn Ala Ala Pro Lys Pro Thr
145 150 155 160
Met Gln Asp Ser Met Tyr Leu Glu Asn Phe Trp Glu Leu Ser Leu Glu
165 170 175
Glu Arg Phe Lys Arg Met His Asp Phe Glu Phe Cys Ile Thr Gln Asp
180 185 190
Glu Val Ile Phe Asp Ala Ala Asp Cys Ser Arg Leu Gly Lys Asp Ile
195 200 205
Leu Val Gln Glu Ser Met Thr Thr Asn Arg Thr Gly Ile Arg Trp Leu
210 215 220
Lys Lys His Leu Glu Pro Arg Gly Phe Arg Val His Pro Val His Phe
225 230 235 240
Pro Leu Asp Phe Phe Pro Ser His Ile Asp Cys Thr Phe Val Pro Leu
245 250 255
Arg Pro Gly Leu Ile Leu Thr Asn Pro Glu Arg Pro Ile Arg Glu Glu
260 265 270
Glu Glu Lys Ile Phe Lys Glu Asn Gly Trp Glu Leu Ile Thr Val Pro
275 280 285
Gln Pro Thr Cys Ser Asn Asp Glu Met Pro Met Phe Cys Gln Ser Ser
290 295 300
Lys Trp Leu Ser Met Asn Val Leu Ser Ile Ser Pro Thr Lys Val Ile
305 310 315 320
Cys Glu Glu Arg Glu Lys Pro Leu Gln Glu Leu Leu Asp Lys His Gly
325 330 335
Phe Glu Val Phe Pro Leu Pro Phe Arg His Val Phe Glu Phe Gly Gly
340 345 350
Ser Phe His Cys Ala Thr Trp Asp Ile Arg Arg Lys Gly Glu Cys Glu
355 360 365
Asp Tyr Leu Pro Asn Leu Asn Tyr Gln Pro Ile Cys Gly
370 375 380
<210> 3
<211> 1248
<212> DNA
<213> synthetic DNA
<220>
<221> RBS
<222> (49)..(52)
<223> Shine-Dalgarno Sequence AGGA
<220>
<221> CDS
<222> (58)..(1200)
<223> open reading frame of optimized AGAT_Mp; protein is identical to
genbank accession number WP_070390602
<400> 3
cgtctctgtg gataactgag cggataagtt cctagtacgc gtgcgagcag gaagaac 57
atg agc gag aaa att gtg aac agc tgg aat gaa tgg gat gaa ctg gaa 105
Met Ser Glu Lys Ile Val Asn Ser Trp Asn Glu Trp Asp Glu Leu Glu
1 5 10 15
gaa atg gtt gtt ggt att gca gat tat gca agc ttt gaa ccg aaa gaa 153
Glu Met Val Val Gly Ile Ala Asp Tyr Ala Ser Phe Glu Pro Lys Glu
20 25 30
ccg ggt aat cat ccg aaa ctg cgt aat cag aat ctg gca gaa att att 201
Pro Gly Asn His Pro Lys Leu Arg Asn Gln Asn Leu Ala Glu Ile Ile
35 40 45
ccg ttt ccg agc ggt ccg aaa gat ccg aaa gtt ctg gaa aaa gca aat 249
Pro Phe Pro Ser Gly Pro Lys Asp Pro Lys Val Leu Glu Lys Ala Asn
50 55 60
gaa gaa ctg aat ggt ctg gcc tat ctg ctg aaa gat cat gat gtt att 297
Glu Glu Leu Asn Gly Leu Ala Tyr Leu Leu Lys Asp His Asp Val Ile
65 70 75 80
gtt cgc cgt ccg gaa aaa atc gac ttt acc aaa agc ctg aaa acc ccg 345
Val Arg Arg Pro Glu Lys Ile Asp Phe Thr Lys Ser Leu Lys Thr Pro
85 90 95
tat ttc gaa gtt gcc aat cag tat tgt ggt gtt tgt ccg cgt gat gtt 393
Tyr Phe Glu Val Ala Asn Gln Tyr Cys Gly Val Cys Pro Arg Asp Val
100 105 110
atg att acc ttt ggc aac gaa att atg gaa gcc acc atg agc aaa cgt 441
Met Ile Thr Phe Gly Asn Glu Ile Met Glu Ala Thr Met Ser Lys Arg
115 120 125
gcc cgt ttt ttt gaa tat ctg ccg tat cgt aaa ctg gtg tat gag tat 489
Ala Arg Phe Phe Glu Tyr Leu Pro Tyr Arg Lys Leu Val Tyr Glu Tyr
130 135 140
tgg aac aaa gat gag cat atg atc tgg aat gca gca ccg aaa ccg acc 537
Trp Asn Lys Asp Glu His Met Ile Trp Asn Ala Ala Pro Lys Pro Thr
145 150 155 160
atg cag gat agc atg tat ctg gaa aac ttt tgg gaa ctg agc ctg gaa 585
Met Gln Asp Ser Met Tyr Leu Glu Asn Phe Trp Glu Leu Ser Leu Glu
165 170 175
gaa cgt ttt aaa cgt atg cac gat ttt gag ttt tgc atc acc cag gat 633
Glu Arg Phe Lys Arg Met His Asp Phe Glu Phe Cys Ile Thr Gln Asp
180 185 190
gaa gtg att ttt gat gca gca gat tgt agc cgt ctg ggt aaa gat att 681
Glu Val Ile Phe Asp Ala Ala Asp Cys Ser Arg Leu Gly Lys Asp Ile
195 200 205
ctg gtt caa gaa agc atg acc acc aat cgt acc ggt att cgt tgg ctg 729
Leu Val Gln Glu Ser Met Thr Thr Asn Arg Thr Gly Ile Arg Trp Leu
210 215 220
aaa aaa cat ctg gaa ccg cgt ggt ttt cgt gtt cat ccg gtt cat ttt 777
Lys Lys His Leu Glu Pro Arg Gly Phe Arg Val His Pro Val His Phe
225 230 235 240
ccg ctg gat ttt ttt ccg agc cat att gat tgt acc ttt gtt ccg ctg 825
Pro Leu Asp Phe Phe Pro Ser His Ile Asp Cys Thr Phe Val Pro Leu
245 250 255
cgt ccg ggt ctg att ctg acc aat ccg gaa cgt ccg att cgt gaa gaa 873
Arg Pro Gly Leu Ile Leu Thr Asn Pro Glu Arg Pro Ile Arg Glu Glu
260 265 270
gaa gag aaa atc ttc aaa gag aat ggc tgg gag ctg att acc gtt ccg 921
Glu Glu Lys Ile Phe Lys Glu Asn Gly Trp Glu Leu Ile Thr Val Pro
275 280 285
cag ccg acc tgt agc aat gat gaa atg ccg atg ttt tgt cag agc agc 969
Gln Pro Thr Cys Ser Asn Asp Glu Met Pro Met Phe Cys Gln Ser Ser
290 295 300
aaa tgg ctg agc atg aat gtt ctg agc att agc ccg acc aaa gtt att 1017
Lys Trp Leu Ser Met Asn Val Leu Ser Ile Ser Pro Thr Lys Val Ile
305 310 315 320
tgt gaa gaa cgt gaa aaa ccg ctg caa gaa ctg ctg gat aaa cat ggt 1065
Cys Glu Glu Arg Glu Lys Pro Leu Gln Glu Leu Leu Asp Lys His Gly
325 330 335
ttt gaa gtg ttt ccg ctg ccg ttt cgt cat gtt ttt gaa ttt ggt ggt 1113
Phe Glu Val Phe Pro Leu Pro Phe Arg His Val Phe Glu Phe Gly Gly
340 345 350
agc ttt cat tgt gcc acc tgg gat att cgt cgt aaa ggt gaa tgt gaa 1161
Ser Phe His Cys Ala Thr Trp Asp Ile Arg Arg Lys Gly Glu Cys Glu
355 360 365
gat tat ctg ccg aat ctg aat tat cag ccg att tgt ggt taataagacg 1210
Asp Tyr Leu Pro Asn Leu Asn Tyr Gln Pro Ile Cys Gly
370 375 380
tccgcgaggg ccgtgttgcc ggtttcttca gagagacg 1248
<210> 4
<211> 381
<212> PRT
<213> synthetic DNA
<400> 4
Met Ser Glu Lys Ile Val Asn Ser Trp Asn Glu Trp Asp Glu Leu Glu
1 5 10 15
Glu Met Val Val Gly Ile Ala Asp Tyr Ala Ser Phe Glu Pro Lys Glu
20 25 30
Pro Gly Asn His Pro Lys Leu Arg Asn Gln Asn Leu Ala Glu Ile Ile
35 40 45
Pro Phe Pro Ser Gly Pro Lys Asp Pro Lys Val Leu Glu Lys Ala Asn
50 55 60
Glu Glu Leu Asn Gly Leu Ala Tyr Leu Leu Lys Asp His Asp Val Ile
65 70 75 80
Val Arg Arg Pro Glu Lys Ile Asp Phe Thr Lys Ser Leu Lys Thr Pro
85 90 95
Tyr Phe Glu Val Ala Asn Gln Tyr Cys Gly Val Cys Pro Arg Asp Val
100 105 110
Met Ile Thr Phe Gly Asn Glu Ile Met Glu Ala Thr Met Ser Lys Arg
115 120 125
Ala Arg Phe Phe Glu Tyr Leu Pro Tyr Arg Lys Leu Val Tyr Glu Tyr
130 135 140
Trp Asn Lys Asp Glu His Met Ile Trp Asn Ala Ala Pro Lys Pro Thr
145 150 155 160
Met Gln Asp Ser Met Tyr Leu Glu Asn Phe Trp Glu Leu Ser Leu Glu
165 170 175
Glu Arg Phe Lys Arg Met His Asp Phe Glu Phe Cys Ile Thr Gln Asp
180 185 190
Glu Val Ile Phe Asp Ala Ala Asp Cys Ser Arg Leu Gly Lys Asp Ile
195 200 205
Leu Val Gln Glu Ser Met Thr Thr Asn Arg Thr Gly Ile Arg Trp Leu
210 215 220
Lys Lys His Leu Glu Pro Arg Gly Phe Arg Val His Pro Val His Phe
225 230 235 240
Pro Leu Asp Phe Phe Pro Ser His Ile Asp Cys Thr Phe Val Pro Leu
245 250 255
Arg Pro Gly Leu Ile Leu Thr Asn Pro Glu Arg Pro Ile Arg Glu Glu
260 265 270
Glu Glu Lys Ile Phe Lys Glu Asn Gly Trp Glu Leu Ile Thr Val Pro
275 280 285
Gln Pro Thr Cys Ser Asn Asp Glu Met Pro Met Phe Cys Gln Ser Ser
290 295 300
Lys Trp Leu Ser Met Asn Val Leu Ser Ile Ser Pro Thr Lys Val Ile
305 310 315 320
Cys Glu Glu Arg Glu Lys Pro Leu Gln Glu Leu Leu Asp Lys His Gly
325 330 335
Phe Glu Val Phe Pro Leu Pro Phe Arg His Val Phe Glu Phe Gly Gly
340 345 350
Ser Phe His Cys Ala Thr Trp Asp Ile Arg Arg Lys Gly Glu Cys Glu
355 360 365
Asp Tyr Leu Pro Asn Leu Asn Tyr Gln Pro Ile Cys Gly
370 375 380
<210> 5
<211> 30
<212> DNA
<213> synthetic oligonucleotide
<400> 5
ccgttaactg ccgagacaat cgcataaagg 30
<210> 6
<211> 34
<212> DNA
<213> synthetic oligonucleotide
<400> 6
ctcctaggct aatattctta cctcggctgg ttgg 34
<210> 7
<211> 27
<212> DNA
<213> synthetic oligonucleotide
<400> 7
ccgttaacac ggctggcaag gaactta 27
<210> 8
<211> 41
<212> DNA
<213> synthetic oligonucleotide
<400> 8
gccctaggtc aatattacag gccataaact aatgcttatc g 41
<210> 9
<211> 46
<212> DNA
<213> synthetic oligonucleotide
<400> 9
ggaaacagct atgacatgat tacgcggtta tcgcggaatc cgtatg 46
<210> 10
<211> 25
<212> DNA
<213> PsodcarAB-LA-R
<400> 10
ttaagcgttt tgtgcaactc cgtct 25
<210> 11
<211> 50
<212> DNA
<213> synthetic oligonucleotide
<400> 11
agacggagtt gcacaaaacg cttaaaccct acttagctgc caattattcc 50
<210> 12
<211> 50
<212> DNA
<213> synthetic oligonucleotide
<400> 12
ggtaggtggt ggtgtcttta ctcatgggta aaaaatcctt tcgtaggttt 50
<210> 13
<211> 25
<212> DNA
<213> synthetic oligonucleotide
<400> 13
atgagtaaag acaccaccac ctacc 25
<210> 14
<211> 46
<212> DNA
<213> synthetic oligonucleotide
<400> 14
gttgtaaaac gacggccagt gccaccggtg atgtggttct tcactg 46
<210> 15
<211> 1176
<212> DNA
<213> Cylindrospermopsis raciborskii AWT205
<220>
<221> CDS
<222> (1)..(1176)
<223> genbank accession number EU140798.1
<400> 15
atg caa aca aga att gta aat agc tgg aat gag tgg gat gaa cta aag 48
Met Gln Thr Arg Ile Val Asn Ser Trp Asn Glu Trp Asp Glu Leu Lys
1 5 10 15
gag atg gtt gtc ggg att gca gat ggt gct tat ttt gaa cca act gag 96
Glu Met Val Val Gly Ile Ala Asp Gly Ala Tyr Phe Glu Pro Thr Glu
20 25 30
cca ggt aac cgc cct gct tta cgc gat aag aac att gcc aaa atg ttc 144
Pro Gly Asn Arg Pro Ala Leu Arg Asp Lys Asn Ile Ala Lys Met Phe
35 40 45
tct ttt ccc agg ggt ccg aaa aag caa gag gta aca gag aaa gct aat 192
Ser Phe Pro Arg Gly Pro Lys Lys Gln Glu Val Thr Glu Lys Ala Asn
50 55 60
gag gag ttg aat ggg ctg gta gcg ctt cta gaa tca cag ggc gta act 240
Glu Glu Leu Asn Gly Leu Val Ala Leu Leu Glu Ser Gln Gly Val Thr
65 70 75 80
gta cgc cgc cca gag aaa cat aac ttt ggc ctg tct gtg aag aca cca 288
Val Arg Arg Pro Glu Lys His Asn Phe Gly Leu Ser Val Lys Thr Pro
85 90 95
ttc ttt gag gta gag aat caa tat tgt gcg gtc tgc cca cgt gat gtt 336
Phe Phe Glu Val Glu Asn Gln Tyr Cys Ala Val Cys Pro Arg Asp Val
100 105 110
atg atc acc ttt ggg aac gaa att ctc gaa gca act atg tca cgg cgg 384
Met Ile Thr Phe Gly Asn Glu Ile Leu Glu Ala Thr Met Ser Arg Arg
115 120 125
tca cgc ttc ttt gag tat tta ccc tat cgc aaa cta gtc tat gaa tat 432
Ser Arg Phe Phe Glu Tyr Leu Pro Tyr Arg Lys Leu Val Tyr Glu Tyr
130 135 140
tgg cat aaa gat cca gat atg atc tgg aat gct gcg cct aaa ccg act 480
Trp His Lys Asp Pro Asp Met Ile Trp Asn Ala Ala Pro Lys Pro Thr
145 150 155 160
atg caa aat gcc atg tac cgc gaa gat ttc tgg gag tgt ccg atg gaa 528
Met Gln Asn Ala Met Tyr Arg Glu Asp Phe Trp Glu Cys Pro Met Glu
165 170 175
gat cga ttt gag agt atg cat gat ttt gag ttc tgc gtc acc cag gat 576
Asp Arg Phe Glu Ser Met His Asp Phe Glu Phe Cys Val Thr Gln Asp
180 185 190
gag gtg att ttt gac gca gca gac tgt agc cgc ttt ggc cgt gat att 624
Glu Val Ile Phe Asp Ala Ala Asp Cys Ser Arg Phe Gly Arg Asp Ile
195 200 205
ttt gtg cag gag tca atg acg act aat cgt gca ggg att cgc tgg ctc 672
Phe Val Gln Glu Ser Met Thr Thr Asn Arg Ala Gly Ile Arg Trp Leu
210 215 220
aaa cgg cat tta gag ccg cgt cgc ttc cgc gtg cat gat att cac ttc 720
Lys Arg His Leu Glu Pro Arg Arg Phe Arg Val His Asp Ile His Phe
225 230 235 240
cca cta gat att ttc cca tcc cac att gat tgt act ttt gtc ccc tta 768
Pro Leu Asp Ile Phe Pro Ser His Ile Asp Cys Thr Phe Val Pro Leu
245 250 255
gca cct ggg gtt gtg tta gtg aat cca gat cgc ccc atc aaa gag ggt 816
Ala Pro Gly Val Val Leu Val Asn Pro Asp Arg Pro Ile Lys Glu Gly
260 265 270
gaa gag aaa ctc ttc atg gat aac ggt tgg caa ttc atc gaa gca ccc 864
Glu Glu Lys Leu Phe Met Asp Asn Gly Trp Gln Phe Ile Glu Ala Pro
275 280 285
ctc ccc act tcc acc gac gat gag atg cct atg ttc tgc cag tcc agt 912
Leu Pro Thr Ser Thr Asp Asp Glu Met Pro Met Phe Cys Gln Ser Ser
290 295 300
aag tgg ttg gcg atg aat gtg tta agc att tcc ccc aag aag gtc atc 960
Lys Trp Leu Ala Met Asn Val Leu Ser Ile Ser Pro Lys Lys Val Ile
305 310 315 320
tgt gaa gag caa gag cat ccg ctt cat gag ttg cta gat aaa cac ggc 1008
Cys Glu Glu Gln Glu His Pro Leu His Glu Leu Leu Asp Lys His Gly
325 330 335
ttt gag gtc tat cca att ccc ttt cgc aat gtc ttt gag ttt ggc ggt 1056
Phe Glu Val Tyr Pro Ile Pro Phe Arg Asn Val Phe Glu Phe Gly Gly
340 345 350
tcg ctc cat tgt gcc acc tgg gat atc cat cgc acg gga acc tgt gag 1104
Ser Leu His Cys Ala Thr Trp Asp Ile His Arg Thr Gly Thr Cys Glu
355 360 365
gat tac ttc cct aaa cta aac tat acg ccg gta act gca tca acc aat 1152
Asp Tyr Phe Pro Lys Leu Asn Tyr Thr Pro Val Thr Ala Ser Thr Asn
370 375 380
ggc gtt tct cgc ttc atc att tag 1176
Gly Val Ser Arg Phe Ile Ile
385 390
<210> 16
<211> 391
<212> PRT
<213> Cylindrospermopsis raciborskii AWT205
<400> 16
Met Gln Thr Arg Ile Val Asn Ser Trp Asn Glu Trp Asp Glu Leu Lys
1 5 10 15
Glu Met Val Val Gly Ile Ala Asp Gly Ala Tyr Phe Glu Pro Thr Glu
20 25 30
Pro Gly Asn Arg Pro Ala Leu Arg Asp Lys Asn Ile Ala Lys Met Phe
35 40 45
Ser Phe Pro Arg Gly Pro Lys Lys Gln Glu Val Thr Glu Lys Ala Asn
50 55 60
Glu Glu Leu Asn Gly Leu Val Ala Leu Leu Glu Ser Gln Gly Val Thr
65 70 75 80
Val Arg Arg Pro Glu Lys His Asn Phe Gly Leu Ser Val Lys Thr Pro
85 90 95
Phe Phe Glu Val Glu Asn Gln Tyr Cys Ala Val Cys Pro Arg Asp Val
100 105 110
Met Ile Thr Phe Gly Asn Glu Ile Leu Glu Ala Thr Met Ser Arg Arg
115 120 125
Ser Arg Phe Phe Glu Tyr Leu Pro Tyr Arg Lys Leu Val Tyr Glu Tyr
130 135 140
Trp His Lys Asp Pro Asp Met Ile Trp Asn Ala Ala Pro Lys Pro Thr
145 150 155 160
Met Gln Asn Ala Met Tyr Arg Glu Asp Phe Trp Glu Cys Pro Met Glu
165 170 175
Asp Arg Phe Glu Ser Met His Asp Phe Glu Phe Cys Val Thr Gln Asp
180 185 190
Glu Val Ile Phe Asp Ala Ala Asp Cys Ser Arg Phe Gly Arg Asp Ile
195 200 205
Phe Val Gln Glu Ser Met Thr Thr Asn Arg Ala Gly Ile Arg Trp Leu
210 215 220
Lys Arg His Leu Glu Pro Arg Arg Phe Arg Val His Asp Ile His Phe
225 230 235 240
Pro Leu Asp Ile Phe Pro Ser His Ile Asp Cys Thr Phe Val Pro Leu
245 250 255
Ala Pro Gly Val Val Leu Val Asn Pro Asp Arg Pro Ile Lys Glu Gly
260 265 270
Glu Glu Lys Leu Phe Met Asp Asn Gly Trp Gln Phe Ile Glu Ala Pro
275 280 285
Leu Pro Thr Ser Thr Asp Asp Glu Met Pro Met Phe Cys Gln Ser Ser
290 295 300
Lys Trp Leu Ala Met Asn Val Leu Ser Ile Ser Pro Lys Lys Val Ile
305 310 315 320
Cys Glu Glu Gln Glu His Pro Leu His Glu Leu Leu Asp Lys His Gly
325 330 335
Phe Glu Val Tyr Pro Ile Pro Phe Arg Asn Val Phe Glu Phe Gly Gly
340 345 350
Ser Leu His Cys Ala Thr Trp Asp Ile His Arg Thr Gly Thr Cys Glu
355 360 365
Asp Tyr Phe Pro Lys Leu Asn Tyr Thr Pro Val Thr Ala Ser Thr Asn
370 375 380
Gly Val Ser Arg Phe Ile Ile
385 390
<210> 17
<211> 1272
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (1)..(1272)
<223> codes for NP_001473.1
<220>
<221> transit_peptide
<222> (1)..(111)
<223> mitochondrial localisation signal peptide
<400> 17
atg ctg cgg gtg cgg tgt ctg cgc ggc ggg agc cgc ggc gcc gag gcg 48
Met Leu Arg Val Arg Cys Leu Arg Gly Gly Ser Arg Gly Ala Glu Ala
1 5 10 15
gtg cac tac atc gga tct cgg ctt gga cga acc ttg aca gga tgg gtg 96
Val His Tyr Ile Gly Ser Arg Leu Gly Arg Thr Leu Thr Gly Trp Val
20 25 30
cag cga act ttc cag agc acc cag gca gct acg gct tcc tcc cgg aac 144
Gln Arg Thr Phe Gln Ser Thr Gln Ala Ala Thr Ala Ser Ser Arg Asn
35 40 45
tcc tgt gca gct gac gac aaa gcc act gag cct ctg ccc aag gac tgc 192
Ser Cys Ala Ala Asp Asp Lys Ala Thr Glu Pro Leu Pro Lys Asp Cys
50 55 60
cct gtc tct tct tac aac gaa tgg gac ccc tta gag gaa gtg ata gtg 240
Pro Val Ser Ser Tyr Asn Glu Trp Asp Pro Leu Glu Glu Val Ile Val
65 70 75 80
ggc aga gca gaa aac gcc tgt gtt cca ccg ttc acc atc gag gtg aag 288
Gly Arg Ala Glu Asn Ala Cys Val Pro Pro Phe Thr Ile Glu Val Lys
85 90 95
gcc aac aca tat gaa aag tac tgg cca ttt tac cag aag caa gga ggg 336
Ala Asn Thr Tyr Glu Lys Tyr Trp Pro Phe Tyr Gln Lys Gln Gly Gly
100 105 110
cat tat ttt ccc aaa gat cat ttg aaa aag gct gtt gct gaa att gaa 384
His Tyr Phe Pro Lys Asp His Leu Lys Lys Ala Val Ala Glu Ile Glu
115 120 125
gaa atg tgc aat att tta aaa acg gaa gga gtg aca gta agg agg cct 432
Glu Met Cys Asn Ile Leu Lys Thr Glu Gly Val Thr Val Arg Arg Pro
130 135 140
gac ccc att gac tgg tca ttg aag tat aaa act cct gat ttt gag tct 480
Asp Pro Ile Asp Trp Ser Leu Lys Tyr Lys Thr Pro Asp Phe Glu Ser
145 150 155 160
acg ggt tta tac agt gca atg cct cga gac atc ctg ata gtt gtg ggc 528
Thr Gly Leu Tyr Ser Ala Met Pro Arg Asp Ile Leu Ile Val Val Gly
165 170 175
aat gag att atc gag gct ccc atg gca tgg cgt tca cgc ttc ttt gag 576
Asn Glu Ile Ile Glu Ala Pro Met Ala Trp Arg Ser Arg Phe Phe Glu
180 185 190
tac cga gcg tac agg tca att atc aaa gac tac ttc cac cgt ggc gcc 624
Tyr Arg Ala Tyr Arg Ser Ile Ile Lys Asp Tyr Phe His Arg Gly Ala
195 200 205
aag tgg aca aca gct cct aag ccc aca atg gct gat gag ctt tat aac 672
Lys Trp Thr Thr Ala Pro Lys Pro Thr Met Ala Asp Glu Leu Tyr Asn
210 215 220
cag gat tat ccc atc cac tct gta gaa gac aga cac aaa ttg gct gct 720
Gln Asp Tyr Pro Ile His Ser Val Glu Asp Arg His Lys Leu Ala Ala
225 230 235 240
cag gga aaa ttt gtg aca act gag ttt gag cca tgc ttt gat gct gct 768
Gln Gly Lys Phe Val Thr Thr Glu Phe Glu Pro Cys Phe Asp Ala Ala
245 250 255
gac ttc att cga gct gga aga gat att ttt gca cag aga agc cag gtt 816
Asp Phe Ile Arg Ala Gly Arg Asp Ile Phe Ala Gln Arg Ser Gln Val
260 265 270
aca aac tac cta ggc att gaa tgg atg cgt agg cat ctt gct cca gac 864
Thr Asn Tyr Leu Gly Ile Glu Trp Met Arg Arg His Leu Ala Pro Asp
275 280 285
tac aga gtg cat atc atc tcc ttt aaa gat ccc aat ccc atg cat att 912
Tyr Arg Val His Ile Ile Ser Phe Lys Asp Pro Asn Pro Met His Ile
290 295 300
gat gct acc ttc aac atc att gga cct ggt att gtg ctt tcc aac cct 960
Asp Ala Thr Phe Asn Ile Ile Gly Pro Gly Ile Val Leu Ser Asn Pro
305 310 315 320
gac cga cca tgt cac cag att gat ctt ttc aag aaa gca gga tgg act 1008
Asp Arg Pro Cys His Gln Ile Asp Leu Phe Lys Lys Ala Gly Trp Thr
325 330 335
atc att act cct cca aca cca atc atc cca gac gat cat cca ctc tgg 1056
Ile Ile Thr Pro Pro Thr Pro Ile Ile Pro Asp Asp His Pro Leu Trp
340 345 350
atg tca tcc aaa tgg ctt tcc atg aat gtc tta atg cta gat gaa aaa 1104
Met Ser Ser Lys Trp Leu Ser Met Asn Val Leu Met Leu Asp Glu Lys
355 360 365
cgt gtt atg gtg gat gcc aat gaa gtt cca att caa aag atg ttt gaa 1152
Arg Val Met Val Asp Ala Asn Glu Val Pro Ile Gln Lys Met Phe Glu
370 375 380
aag ctg ggt atc act acc att aaa gtt aac att cgt aat gcc aat tcc 1200
Lys Leu Gly Ile Thr Thr Ile Lys Val Asn Ile Arg Asn Ala Asn Ser
385 390 395 400
ctg gga gga ggc ttc cat tgc tgg acc tgc gat gtc cgg cgc cga ggc 1248
Leu Gly Gly Gly Phe His Cys Trp Thr Cys Asp Val Arg Arg Arg Gly
405 410 415
acc tta cag tcc tac ttg gac tga 1272
Thr Leu Gln Ser Tyr Leu Asp
420
<210> 18
<211> 423
<212> PRT
<213> Homo sapiens
<400> 18
Met Leu Arg Val Arg Cys Leu Arg Gly Gly Ser Arg Gly Ala Glu Ala
1 5 10 15
Val His Tyr Ile Gly Ser Arg Leu Gly Arg Thr Leu Thr Gly Trp Val
20 25 30
Gln Arg Thr Phe Gln Ser Thr Gln Ala Ala Thr Ala Ser Ser Arg Asn
35 40 45
Ser Cys Ala Ala Asp Asp Lys Ala Thr Glu Pro Leu Pro Lys Asp Cys
50 55 60
Pro Val Ser Ser Tyr Asn Glu Trp Asp Pro Leu Glu Glu Val Ile Val
65 70 75 80
Gly Arg Ala Glu Asn Ala Cys Val Pro Pro Phe Thr Ile Glu Val Lys
85 90 95
Ala Asn Thr Tyr Glu Lys Tyr Trp Pro Phe Tyr Gln Lys Gln Gly Gly
100 105 110
His Tyr Phe Pro Lys Asp His Leu Lys Lys Ala Val Ala Glu Ile Glu
115 120 125
Glu Met Cys Asn Ile Leu Lys Thr Glu Gly Val Thr Val Arg Arg Pro
130 135 140
Asp Pro Ile Asp Trp Ser Leu Lys Tyr Lys Thr Pro Asp Phe Glu Ser
145 150 155 160
Thr Gly Leu Tyr Ser Ala Met Pro Arg Asp Ile Leu Ile Val Val Gly
165 170 175
Asn Glu Ile Ile Glu Ala Pro Met Ala Trp Arg Ser Arg Phe Phe Glu
180 185 190
Tyr Arg Ala Tyr Arg Ser Ile Ile Lys Asp Tyr Phe His Arg Gly Ala
195 200 205
Lys Trp Thr Thr Ala Pro Lys Pro Thr Met Ala Asp Glu Leu Tyr Asn
210 215 220
Gln Asp Tyr Pro Ile His Ser Val Glu Asp Arg His Lys Leu Ala Ala
225 230 235 240
Gln Gly Lys Phe Val Thr Thr Glu Phe Glu Pro Cys Phe Asp Ala Ala
245 250 255
Asp Phe Ile Arg Ala Gly Arg Asp Ile Phe Ala Gln Arg Ser Gln Val
260 265 270
Thr Asn Tyr Leu Gly Ile Glu Trp Met Arg Arg His Leu Ala Pro Asp
275 280 285
Tyr Arg Val His Ile Ile Ser Phe Lys Asp Pro Asn Pro Met His Ile
290 295 300
Asp Ala Thr Phe Asn Ile Ile Gly Pro Gly Ile Val Leu Ser Asn Pro
305 310 315 320
Asp Arg Pro Cys His Gln Ile Asp Leu Phe Lys Lys Ala Gly Trp Thr
325 330 335
Ile Ile Thr Pro Pro Thr Pro Ile Ile Pro Asp Asp His Pro Leu Trp
340 345 350
Met Ser Ser Lys Trp Leu Ser Met Asn Val Leu Met Leu Asp Glu Lys
355 360 365
Arg Val Met Val Asp Ala Asn Glu Val Pro Ile Gln Lys Met Phe Glu
370 375 380
Lys Leu Gly Ile Thr Thr Ile Lys Val Asn Ile Arg Asn Ala Asn Ser
385 390 395 400
Leu Gly Gly Gly Phe His Cys Trp Thr Cys Asp Val Arg Arg Arg Gly
405 410 415
Thr Leu Gln Ser Tyr Leu Asp
420
<210> 19
<211> 7
<212> PRT
<213> Escherichia coli
<400> 19
Met Thr Asp Val Thr Ile Lys
1 5
<210> 20
<211> 375
<212> PRT
<213> Homo sapiens
<400> 20
Met Thr Asp Val Thr Ile Lys Ala Thr Glu Pro Leu Pro Lys Asp Cys
1 5 10 15
Pro Val Ser Ser Tyr Asn Glu Trp Asp Pro Leu Glu Glu Val Ile Val
20 25 30
Gly Arg Ala Glu Asn Ala Cys Val Pro Pro Phe Thr Ile Glu Val Lys
35 40 45
Ala Asn Thr Tyr Glu Lys Tyr Trp Pro Phe Tyr Gln Lys Gln Gly Gly
50 55 60
His Tyr Phe Pro Lys Asp His Leu Lys Lys Ala Val Ala Glu Ile Glu
65 70 75 80
Glu Met Cys Asn Ile Leu Lys Thr Glu Gly Val Thr Val Arg Arg Pro
85 90 95
Asp Pro Ile Asp Trp Ser Leu Lys Tyr Lys Thr Pro Asp Phe Glu Ser
100 105 110
Thr Gly Leu Tyr Ser Ala Met Pro Arg Asp Ile Leu Ile Val Val Gly
115 120 125
Asn Glu Ile Ile Glu Ala Pro Met Ala Trp Arg Ser Arg Phe Phe Glu
130 135 140
Tyr Arg Ala Tyr Arg Ser Ile Ile Lys Asp Tyr Phe His Arg Gly Ala
145 150 155 160
Lys Trp Thr Thr Ala Pro Lys Pro Thr Met Ala Asp Glu Leu Tyr Asn
165 170 175
Gln Asp Tyr Pro Ile His Ser Val Glu Asp Arg His Lys Leu Ala Ala
180 185 190
Gln Gly Lys Phe Val Thr Thr Glu Phe Glu Pro Cys Phe Asp Ala Ala
195 200 205
Asp Phe Ile Arg Ala Gly Arg Asp Ile Phe Ala Gln Arg Ser Gln Val
210 215 220
Thr Asn Tyr Leu Gly Ile Glu Trp Met Arg Arg His Leu Ala Pro Asp
225 230 235 240
Tyr Arg Val His Ile Ile Ser Phe Lys Asp Pro Asn Pro Met His Ile
245 250 255
Asp Ala Thr Phe Asn Ile Ile Gly Pro Gly Ile Val Leu Ser Asn Pro
260 265 270
Asp Arg Pro Cys His Gln Ile Asp Leu Phe Lys Lys Ala Gly Trp Thr
275 280 285
Ile Ile Thr Pro Pro Thr Pro Ile Ile Pro Asp Asp His Pro Leu Trp
290 295 300
Met Ser Ser Lys Trp Leu Ser Met Asn Val Leu Met Leu Asp Glu Lys
305 310 315 320
Arg Val Met Val Asp Ala Asn Glu Val Pro Ile Gln Lys Met Phe Glu
325 330 335
Lys Leu Gly Ile Thr Thr Ile Lys Val Asn Ile Arg Asn Ala Asn Ser
340 345 350
Leu Gly Gly Gly Phe His Cys Trp Thr Cys Asp Val Arg Arg Arg Gly
355 360 365
Thr Leu Gln Ser Tyr Leu Asp
370 375
<210> 21
<211> 423
<212> PRT
<213> Rattus norvegicus
<400> 21
Met Leu Arg Val Arg Cys Leu Arg Gly Gly Ser Arg Gly Ala Glu Ala
1 5 10 15
Val His Tyr Ile Gly Ser Arg Leu Gly Gly Ser Leu Thr Gly Trp Val
20 25 30
Gln Arg Thr Phe Gln Ser Thr Gln Ala Ala Thr Ala Ser Ser Gln Asn
35 40 45
Ser Cys Ala Ala Glu Asp Lys Ala Thr His Pro Leu Pro Lys Asp Cys
50 55 60
Pro Val Ser Ser Tyr Asn Glu Trp Asp Pro Leu Glu Glu Val Ile Val
65 70 75 80
Gly Arg Ala Glu Asn Ala Cys Val Pro Pro Phe Thr Val Glu Val Lys
85 90 95
Ala Asn Thr Tyr Glu Lys Tyr Trp Pro Phe Tyr Gln Lys Asn Gly Gly
100 105 110
Leu Tyr Phe Pro Lys Asp His Leu Lys Lys Ala Val Ala Glu Val Glu
115 120 125
Glu Met Cys Asn Ile Leu Ser Met Glu Gly Val Thr Val Lys Arg Pro
130 135 140
Asp Pro Ile Asp Trp Ser Leu Lys Tyr Lys Thr Pro Asp Phe Glu Ser
145 150 155 160
Thr Gly Leu Tyr Ser Ala Met Pro Arg Asp Ile Leu Met Val Val Gly
165 170 175
Asn Glu Ile Ile Glu Ala Pro Met Ala Trp Arg Ser Arg Phe Phe Glu
180 185 190
Tyr Arg Ala Tyr Arg Ser Ile Ile Lys Asp Tyr Phe His Arg Gly Ala
195 200 205
Lys Trp Thr Thr Ala Pro Lys Pro Thr Met Ala Asp Glu Leu Tyr Asp
210 215 220
Gln Asp Tyr Pro Ile His Ser Val Glu Asp Arg His Lys Leu Ala Ala
225 230 235 240
Gln Gly Lys Phe Val Thr Thr Glu Phe Glu Pro Cys Phe Asp Ala Ala
245 250 255
Asp Phe Ile Arg Ala Gly Arg Asp Ile Phe Ala Gln Arg Ser Gln Val
260 265 270
Thr Asn Tyr Leu Gly Ile Glu Trp Met Arg Arg His Leu Ala Pro Asp
275 280 285
Tyr Arg Val His Ile Ile Ser Phe Lys Asp Pro Asn Pro Met His Ile
290 295 300
Asp Ala Thr Phe Asn Ile Ile Gly Pro Gly Leu Val Leu Ser Asn Pro
305 310 315 320
Asp Arg Pro Cys His Gln Ile Asp Leu Phe Lys Lys Ala Gly Trp Thr
325 330 335
Ile Val Thr Pro Pro Thr Pro Val Ile Pro Asp Asp His Pro Leu Trp
340 345 350
Met Ser Ser Lys Trp Leu Ser Met Asn Val Leu Met Leu Asp Glu Lys
355 360 365
Arg Val Met Val Asp Ala Asn Glu Val Pro Ile Gln Lys Met Phe Glu
370 375 380
Lys Leu Gly Ile Ser Thr Ile Lys Val Asn Ile Arg Asn Ala Asn Ser
385 390 395 400
Leu Gly Gly Gly Phe His Cys Trp Thr Cys Asp Val Arg Arg Arg Gly
405 410 415
Thr Leu Gln Ser Tyr Phe Asp
420
<210> 22
<211> 375
<212> PRT
<213> Rattus norvegicus
<400> 22
Met Thr Asp Val Thr Ile Lys Ala Thr His Pro Leu Pro Lys Asp Cys
1 5 10 15
Pro Val Ser Ser Tyr Asn Glu Trp Asp Pro Leu Glu Glu Val Ile Val
20 25 30
Gly Arg Ala Glu Asn Ala Cys Val Pro Pro Phe Thr Val Glu Val Lys
35 40 45
Ala Asn Thr Tyr Glu Lys Tyr Trp Pro Phe Tyr Gln Lys Asn Gly Gly
50 55 60
Leu Tyr Phe Pro Lys Asp His Leu Lys Lys Ala Val Ala Glu Val Glu
65 70 75 80
Glu Met Cys Asn Ile Leu Ser Met Glu Gly Val Thr Val Lys Arg Pro
85 90 95
Asp Pro Ile Asp Trp Ser Leu Lys Tyr Lys Thr Pro Asp Phe Glu Ser
100 105 110
Thr Gly Leu Tyr Ser Ala Met Pro Arg Asp Ile Leu Met Val Val Gly
115 120 125
Asn Glu Ile Ile Glu Ala Pro Met Ala Trp Arg Ser Arg Phe Phe Glu
130 135 140
Tyr Arg Ala Tyr Arg Ser Ile Ile Lys Asp Tyr Phe His Arg Gly Ala
145 150 155 160
Lys Trp Thr Thr Ala Pro Lys Pro Thr Met Ala Asp Glu Leu Tyr Asp
165 170 175
Gln Asp Tyr Pro Ile His Ser Val Glu Asp Arg His Lys Leu Ala Ala
180 185 190
Gln Gly Lys Phe Val Thr Thr Glu Phe Glu Pro Cys Phe Asp Ala Ala
195 200 205
Asp Phe Ile Arg Ala Gly Arg Asp Ile Phe Ala Gln Arg Ser Gln Val
210 215 220
Thr Asn Tyr Leu Gly Ile Glu Trp Met Arg Arg His Leu Ala Pro Asp
225 230 235 240
Tyr Arg Val His Ile Ile Ser Phe Lys Asp Pro Asn Pro Met His Ile
245 250 255
Asp Ala Thr Phe Asn Ile Ile Gly Pro Gly Leu Val Leu Ser Asn Pro
260 265 270
Asp Arg Pro Cys His Gln Ile Asp Leu Phe Lys Lys Ala Gly Trp Thr
275 280 285
Ile Val Thr Pro Pro Thr Pro Val Ile Pro Asp Asp His Pro Leu Trp
290 295 300
Met Ser Ser Lys Trp Leu Ser Met Asn Val Leu Met Leu Asp Glu Lys
305 310 315 320
Arg Val Met Val Asp Ala Asn Glu Val Pro Ile Gln Lys Met Phe Glu
325 330 335
Lys Leu Gly Ile Ser Thr Ile Lys Val Asn Ile Arg Asn Ala Asn Ser
340 345 350
Leu Gly Gly Gly Phe His Cys Trp Thr Cys Asp Val Arg Arg Arg Gly
355 360 365
Thr Leu Gln Ser Tyr Phe Asp
370 375
<210> 23
<211> 423
<212> PRT
<213> Galeopterus variegatus
<400> 23
Met Leu Arg Val Arg Cys Leu Arg Gly Gly Ser Arg Gly Ala Glu Ala
1 5 10 15
Val His Tyr Ile Gly Ser Arg Leu Gly Gly Ser Leu Thr Gly Trp Val
20 25 30
Gln Arg Thr Phe Gln Ser Thr Gln Ala Ala Thr Ala Ser Ser Gln Asn
35 40 45
Ser Cys Ala Ala Glu Asp Lys Ala Thr His Pro Leu Pro Lys Asp Cys
50 55 60
Pro Val Ser Ser Tyr Asn Glu Trp Asp Pro Leu Glu Glu Val Ile Val
65 70 75 80
Gly Arg Ala Glu Asn Ala Cys Val Pro Pro Phe Thr Val Glu Val Lys
85 90 95
Ala Asn Thr Tyr Glu Lys Tyr Trp Pro Phe Tyr Gln Lys Asn Gly Gly
100 105 110
Leu Tyr Phe Pro Lys Asp His Leu Lys Lys Ala Val Ala Glu Val Glu
115 120 125
Glu Met Cys Asn Ile Leu Ser Met Glu Gly Val Thr Val Lys Arg Pro
130 135 140
Asp Pro Ile Asp Trp Ser Leu Lys Tyr Lys Thr Pro Asp Phe Glu Ser
145 150 155 160
Thr Gly Leu Tyr Ser Ala Met Pro Arg Asp Ile Leu Met Val Val Gly
165 170 175
Asn Glu Ile Ile Glu Ala Pro Met Ala Trp Arg Ser Arg Phe Phe Glu
180 185 190
Tyr Arg Ala Tyr Arg Ser Ile Ile Lys Asp Tyr Phe His Arg Gly Ala
195 200 205
Lys Trp Thr Thr Ala Pro Lys Pro Thr Met Ala Asp Glu Leu Tyr Asp
210 215 220
Gln Asp Tyr Pro Ile His Ser Val Glu Asp Arg His Lys Leu Ala Ala
225 230 235 240
Gln Gly Lys Phe Val Thr Thr Glu Phe Glu Pro Cys Phe Asp Ala Ala
245 250 255
Asp Phe Ile Arg Ala Gly Arg Asp Ile Phe Ala Gln Arg Ser Gln Val
260 265 270
Thr Asn Tyr Leu Gly Ile Glu Trp Met Arg Arg His Leu Ala Pro Asp
275 280 285
Tyr Arg Val His Ile Ile Ser Phe Lys Asp Pro Asn Pro Met His Ile
290 295 300
Asp Ala Thr Phe Asn Ile Ile Gly Pro Gly Leu Val Leu Ser Asn Pro
305 310 315 320
Asp Arg Pro Cys His Gln Ile Asp Leu Phe Lys Lys Ala Gly Trp Thr
325 330 335
Ile Val Thr Pro Pro Thr Pro Val Ile Pro Asp Asp His Pro Leu Trp
340 345 350
Met Ser Ser Lys Trp Leu Ser Met Asn Val Leu Met Leu Asp Glu Lys
355 360 365
Arg Val Met Val Asp Ala Asn Glu Val Pro Ile Gln Lys Met Phe Glu
370 375 380
Lys Leu Gly Ile Ser Thr Ile Lys Val Asn Ile Arg Asn Ala Asn Ser
385 390 395 400
Leu Gly Gly Gly Phe His Cys Trp Thr Cys Asp Val Arg Arg Arg Gly
405 410 415
Thr Leu Gln Ser Tyr Phe Asp
420
<210> 24
<211> 375
<212> PRT
<213> Galeopterus variegatus
<400> 24
Met Thr Asp Val Thr Ile Lys Ala Thr Asp Pro Leu Pro Lys Asp Cys
1 5 10 15
Pro Val Ser Ser Tyr Asn Glu Trp Asp Pro Leu Glu Glu Val Ile Val
20 25 30
Gly Arg Ala Glu Asn Ala Cys Val Pro Pro Phe Thr Val Glu Val Lys
35 40 45
Ala Asn Thr Tyr Glu Lys Tyr Trp Pro Phe Tyr Gln Lys His Gly Gly
50 55 60
His Tyr Phe Pro Lys Asp His Leu Lys Lys Ala Val Ala Glu Ile Glu
65 70 75 80
Glu Met Cys Asn Ile Leu Lys Met Glu Gly Val Thr Val Arg Arg Pro
85 90 95
Asp Pro Ile Asp Trp Ser Leu Lys Tyr Lys Thr Pro Asp Phe Glu Ser
100 105 110
Thr Gly Leu Tyr Gly Ala Met Pro Arg Asp Ile Leu Ile Val Val Gly
115 120 125
Asn Glu Ile Ile Glu Ala Pro Met Ala Trp Arg Ala Arg Phe Phe Glu
130 135 140
Tyr Arg Ala Tyr Arg Ser Ile Ile Lys Asp Tyr Phe His Arg Gly Ala
145 150 155 160
Lys Trp Thr Thr Ala Pro Lys Pro Thr Met Ala Asn Glu Leu Tyr Asp
165 170 175
Gln Asp Tyr Pro Ile Tyr Thr Val Glu Asp Arg His Lys Leu Ala Ala
180 185 190
Gln Gly Lys Phe Val Thr Thr Glu Phe Glu Pro Cys Phe Asp Ala Ala
195 200 205
Asp Phe Ile Arg Ala Gly Arg Asp Ile Phe Ala Gln Arg Ser Gln Val
210 215 220
Thr Asn Tyr Leu Gly Ile Glu Trp Met Arg Arg His Leu Ala Pro Asp
225 230 235 240
Tyr Arg Val His Ile Val Ser Phe Lys Asp Pro Asn Pro Met His Ile
245 250 255
Asp Ala Thr Phe Asn Ile Ile Gly Pro Gly Leu Val Leu Ser Asn Pro
260 265 270
Asp Arg Pro Cys His Gln Ile Asp Leu Phe Lys Lys Ala Gly Trp Thr
275 280 285
Ile Ile Thr Pro Pro Ile Pro Val Ile Pro Asp Asp His Pro Leu Trp
290 295 300
Met Ser Ser Lys Trp Leu Ser Met Asn Val Leu Met Leu Asp Glu Lys
305 310 315 320
Arg Val Met Val Asp Ala Asn Glu Val Pro Ile Gln Lys Met Phe Gly
325 330 335
Lys Leu Gly Ile Ser Thr Ile Lys Val Asn Ile Arg Asn Ala Asn Ser
340 345 350
Leu Gly Gly Gly Phe His Cys Trp Thr Cys Asp Val Arg Arg Arg Gly
355 360 365
Thr Leu Gln Ser Tyr Phe Asp
370 375
<210> 25
<211> 1278
<212> DNA
<213> Cylindrospermopsis raciborskii AWT205
<220>
<221> RBS
<222> (49)..(52)
<223> Shine-Dalgarno-Sequence
<220>
<221> CDS
<222> (58)..(1230)
<400> 25
cgtctctgtg gataactgag cggataagtt cctagtacgc gtgcgagcag gaagaac 57
atg cag acc cgt att gtt aat agc tgg aat gaa tgg gat gag ctg aaa 105
Met Gln Thr Arg Ile Val Asn Ser Trp Asn Glu Trp Asp Glu Leu Lys
1 5 10 15
gaa atg gtt gtt ggt att gca gat ggt gcc tat ttt gaa ccg acc gaa 153
Glu Met Val Val Gly Ile Ala Asp Gly Ala Tyr Phe Glu Pro Thr Glu
20 25 30
ccg ggt aat cgt ccg gca ctg cgt gat aaa aac att gca aaa atg ttt 201
Pro Gly Asn Arg Pro Ala Leu Arg Asp Lys Asn Ile Ala Lys Met Phe
35 40 45
agc ttt ccg cgt ggt ccg aaa aaa caa gaa gtt acc gaa aaa gcc aac 249
Ser Phe Pro Arg Gly Pro Lys Lys Gln Glu Val Thr Glu Lys Ala Asn
50 55 60
gaa gaa ctg aat ggt ctg gtt gca ctg ctg gaa agc cag ggt gtt acc 297
Glu Glu Leu Asn Gly Leu Val Ala Leu Leu Glu Ser Gln Gly Val Thr
65 70 75 80
gtt cgt cgt ccg gaa aaa cac aat ttt ggt ctg agc gtt aaa acc ccg 345
Val Arg Arg Pro Glu Lys His Asn Phe Gly Leu Ser Val Lys Thr Pro
85 90 95
ttt ttt gaa gtg gaa aat cag tat tgt gca gtg tgt ccg cgt gat gtt 393
Phe Phe Glu Val Glu Asn Gln Tyr Cys Ala Val Cys Pro Arg Asp Val
100 105 110
atg att acc ttt ggt aac gaa att ctg gaa gca acc atg agc cgt cgt 441
Met Ile Thr Phe Gly Asn Glu Ile Leu Glu Ala Thr Met Ser Arg Arg
115 120 125
agc cgt ttt ttt gaa tat ctg ccg tat cgt aaa ctg gtg tat gag tat 489
Ser Arg Phe Phe Glu Tyr Leu Pro Tyr Arg Lys Leu Val Tyr Glu Tyr
130 135 140
tgg cat aaa gat ccg gat atg att tgg aat gca gca ccg aaa ccg acc 537
Trp His Lys Asp Pro Asp Met Ile Trp Asn Ala Ala Pro Lys Pro Thr
145 150 155 160
atg cag aat gca atg tat cgt gaa gat ttt tgg gaa tgc ccg atg gaa 585
Met Gln Asn Ala Met Tyr Arg Glu Asp Phe Trp Glu Cys Pro Met Glu
165 170 175
gat cgt ttt gaa agc atg cac gat ttt gaa ttt tgc gtg acc cag gat 633
Asp Arg Phe Glu Ser Met His Asp Phe Glu Phe Cys Val Thr Gln Asp
180 185 190
gaa gtg att ttt gat gca gca gat tgc agc cgt ttt ggt cgt gat att 681
Glu Val Ile Phe Asp Ala Ala Asp Cys Ser Arg Phe Gly Arg Asp Ile
195 200 205
ttt gtt caa gaa agc atg acc acc aat cgt gca ggt att cgc tgg ctg 729
Phe Val Gln Glu Ser Met Thr Thr Asn Arg Ala Gly Ile Arg Trp Leu
210 215 220
aaa cgt cat ctg gaa ccg cgt cgt ttt cgt gtt cat gat att cat ttt 777
Lys Arg His Leu Glu Pro Arg Arg Phe Arg Val His Asp Ile His Phe
225 230 235 240
ccg ctg gat att ttt ccg agc cat att gat tgt acc ttt gtt ccg ctg 825
Pro Leu Asp Ile Phe Pro Ser His Ile Asp Cys Thr Phe Val Pro Leu
245 250 255
gca ccg ggt gtt gtt ctg gtt aat ccg gat cgt ccg att aaa gaa ggt 873
Ala Pro Gly Val Val Leu Val Asn Pro Asp Arg Pro Ile Lys Glu Gly
260 265 270
gaa gaa aaa ctg ttt atg gac aac ggc tgg cag ttt att gaa gca ccg 921
Glu Glu Lys Leu Phe Met Asp Asn Gly Trp Gln Phe Ile Glu Ala Pro
275 280 285
ctg ccg acc agc acc gat gat gaa atg ccg atg ttt tgt cag agc agc 969
Leu Pro Thr Ser Thr Asp Asp Glu Met Pro Met Phe Cys Gln Ser Ser
290 295 300
aaa tgg ctg gcc atg aat gtt ctg agc att agc ccg aaa aaa gtg atc 1017
Lys Trp Leu Ala Met Asn Val Leu Ser Ile Ser Pro Lys Lys Val Ile
305 310 315 320
tgt gaa gaa caa gaa cat ccg ctg cat gaa ctg ctg gat aaa cat ggt 1065
Cys Glu Glu Gln Glu His Pro Leu His Glu Leu Leu Asp Lys His Gly
325 330 335
ttt gag gtt tat ccg att ccg ttt cgc aac gtg ttt gaa ttt ggt ggt 1113
Phe Glu Val Tyr Pro Ile Pro Phe Arg Asn Val Phe Glu Phe Gly Gly
340 345 350
agc ctg cat tgt gca acc tgg gat att cat cgt acc ggc acc tgt gaa 1161
Ser Leu His Cys Ala Thr Trp Asp Ile His Arg Thr Gly Thr Cys Glu
355 360 365
gat tat ttt ccg aaa ctg aat tat aca ccg gtt acc gca agc acc aat 1209
Asp Tyr Phe Pro Lys Leu Asn Tyr Thr Pro Val Thr Ala Ser Thr Asn
370 375 380
ggt gtg agc cgt ttt atc att taataagacg tccgcgaggg ccgtgttgcc 1260
Gly Val Ser Arg Phe Ile Ile
385 390
ggtttcttca gagagacg 1278
<210> 26
<211> 391
<212> PRT
<213> Cylindrospermopsis raciborskii AWT205
<400> 26
Met Gln Thr Arg Ile Val Asn Ser Trp Asn Glu Trp Asp Glu Leu Lys
1 5 10 15
Glu Met Val Val Gly Ile Ala Asp Gly Ala Tyr Phe Glu Pro Thr Glu
20 25 30
Pro Gly Asn Arg Pro Ala Leu Arg Asp Lys Asn Ile Ala Lys Met Phe
35 40 45
Ser Phe Pro Arg Gly Pro Lys Lys Gln Glu Val Thr Glu Lys Ala Asn
50 55 60
Glu Glu Leu Asn Gly Leu Val Ala Leu Leu Glu Ser Gln Gly Val Thr
65 70 75 80
Val Arg Arg Pro Glu Lys His Asn Phe Gly Leu Ser Val Lys Thr Pro
85 90 95
Phe Phe Glu Val Glu Asn Gln Tyr Cys Ala Val Cys Pro Arg Asp Val
100 105 110
Met Ile Thr Phe Gly Asn Glu Ile Leu Glu Ala Thr Met Ser Arg Arg
115 120 125
Ser Arg Phe Phe Glu Tyr Leu Pro Tyr Arg Lys Leu Val Tyr Glu Tyr
130 135 140
Trp His Lys Asp Pro Asp Met Ile Trp Asn Ala Ala Pro Lys Pro Thr
145 150 155 160
Met Gln Asn Ala Met Tyr Arg Glu Asp Phe Trp Glu Cys Pro Met Glu
165 170 175
Asp Arg Phe Glu Ser Met His Asp Phe Glu Phe Cys Val Thr Gln Asp
180 185 190
Glu Val Ile Phe Asp Ala Ala Asp Cys Ser Arg Phe Gly Arg Asp Ile
195 200 205
Phe Val Gln Glu Ser Met Thr Thr Asn Arg Ala Gly Ile Arg Trp Leu
210 215 220
Lys Arg His Leu Glu Pro Arg Arg Phe Arg Val His Asp Ile His Phe
225 230 235 240
Pro Leu Asp Ile Phe Pro Ser His Ile Asp Cys Thr Phe Val Pro Leu
245 250 255
Ala Pro Gly Val Val Leu Val Asn Pro Asp Arg Pro Ile Lys Glu Gly
260 265 270
Glu Glu Lys Leu Phe Met Asp Asn Gly Trp Gln Phe Ile Glu Ala Pro
275 280 285
Leu Pro Thr Ser Thr Asp Asp Glu Met Pro Met Phe Cys Gln Ser Ser
290 295 300
Lys Trp Leu Ala Met Asn Val Leu Ser Ile Ser Pro Lys Lys Val Ile
305 310 315 320
Cys Glu Glu Gln Glu His Pro Leu His Glu Leu Leu Asp Lys His Gly
325 330 335
Phe Glu Val Tyr Pro Ile Pro Phe Arg Asn Val Phe Glu Phe Gly Gly
340 345 350
Ser Leu His Cys Ala Thr Trp Asp Ile His Arg Thr Gly Thr Cys Glu
355 360 365
Asp Tyr Phe Pro Lys Leu Asn Tyr Thr Pro Val Thr Ala Ser Thr Asn
370 375 380
Gly Val Ser Arg Phe Ile Ile
385 390
<210> 27
<211> 1313
<212> DNA
<213> Homo sapiens
<220>
<221> RBS
<222> (55)..(58)
<223> Shine-Dalgarno-Sequence
<220>
<221> CDS
<222> (62)..(1189)
<400> 27
ggtctcaaga tatgaccatg attacgccaa gcttgcatgc ctgcaggaaa ggagaggatt 60
g atg aca gat gta acg att aaa gcg acg gag ccg ctg ccg aag gat tgc 109
Met Thr Asp Val Thr Ile Lys Ala Thr Glu Pro Leu Pro Lys Asp Cys
1 5 10 15
ccg gtt agc tct tat aat gag tgg gat ccg ttg gag gag gtt atc gtg 157
Pro Val Ser Ser Tyr Asn Glu Trp Asp Pro Leu Glu Glu Val Ile Val
20 25 30
ggc cgc gcg gag aac gcc tgt gtt cct cca ttc act atc gag gtg aag 205
Gly Arg Ala Glu Asn Ala Cys Val Pro Pro Phe Thr Ile Glu Val Lys
35 40 45
gcc aac act tat gaa aag tac tgg ccg ttc tac cag aag caa gga ggt 253
Ala Asn Thr Tyr Glu Lys Tyr Trp Pro Phe Tyr Gln Lys Gln Gly Gly
50 55 60
cat tac ttc cct aag gat cat ctg aaa aaa gcg gta gcc gaa att gag 301
His Tyr Phe Pro Lys Asp His Leu Lys Lys Ala Val Ala Glu Ile Glu
65 70 75 80
gag atg tgc aac atc ctg aaa acg gaa ggc gtg acc gtc cgt cgc ccg 349
Glu Met Cys Asn Ile Leu Lys Thr Glu Gly Val Thr Val Arg Arg Pro
85 90 95
gat ccc att gac tgg tca ttg aag tat aaa acc ccg gac ttc gaa agc 397
Asp Pro Ile Asp Trp Ser Leu Lys Tyr Lys Thr Pro Asp Phe Glu Ser
100 105 110
acg ggt ctt tat tca gcc atg ccg cgt gat atc ctg atc gtt gtt ggt 445
Thr Gly Leu Tyr Ser Ala Met Pro Arg Asp Ile Leu Ile Val Val Gly
115 120 125
aat gaa att att gaa gcc cct atg gcc tgg cgg agc cgc ttc ttc gag 493
Asn Glu Ile Ile Glu Ala Pro Met Ala Trp Arg Ser Arg Phe Phe Glu
130 135 140
tac cgt gct tat cgg tct att atc aaa gat tac ttc cat cgt ggt gca 541
Tyr Arg Ala Tyr Arg Ser Ile Ile Lys Asp Tyr Phe His Arg Gly Ala
145 150 155 160
aaa tgg acg act gct cct aag cca acc atg gca gac gag ttg tac aac 589
Lys Trp Thr Thr Ala Pro Lys Pro Thr Met Ala Asp Glu Leu Tyr Asn
165 170 175
cag gat tac cct atc cat tca gtc gaa gac cgc cac aag ctg gca gca 637
Gln Asp Tyr Pro Ile His Ser Val Glu Asp Arg His Lys Leu Ala Ala
180 185 190
cag ggt aaa ttt gtc acg act gag ttc gaa ccc tgc ttc gat gct gcc 685
Gln Gly Lys Phe Val Thr Thr Glu Phe Glu Pro Cys Phe Asp Ala Ala
195 200 205
gac ttt att cgt gcc gga cgg gat att ttc gca caa cgc tcg caa gta 733
Asp Phe Ile Arg Ala Gly Arg Asp Ile Phe Ala Gln Arg Ser Gln Val
210 215 220
act aac tac ctc ggc att gag tgg atg cgt cgg cat ctg gcc cct gat 781
Thr Asn Tyr Leu Gly Ile Glu Trp Met Arg Arg His Leu Ala Pro Asp
225 230 235 240
tac cgt gtc cac atc att agc ttc aaa gac ccg aac ccg atg cac att 829
Tyr Arg Val His Ile Ile Ser Phe Lys Asp Pro Asn Pro Met His Ile
245 250 255
gac gcg act ttt aat atc atc gga ccc ggt att gtg ctg tcg aat cct 877
Asp Ala Thr Phe Asn Ile Ile Gly Pro Gly Ile Val Leu Ser Asn Pro
260 265 270
gac cgc ccg tgt cac cag att gac ctt ttt aag aaa gct gga tgg acg 925
Asp Arg Pro Cys His Gln Ile Asp Leu Phe Lys Lys Ala Gly Trp Thr
275 280 285
att atc acc cct cca act ccg att atc cct gat gac cac cca ctc tgg 973
Ile Ile Thr Pro Pro Thr Pro Ile Ile Pro Asp Asp His Pro Leu Trp
290 295 300
atg tcc tct aaa tgg ctt tcc atg aac gtt ctg atg ctt gac gag aag 1021
Met Ser Ser Lys Trp Leu Ser Met Asn Val Leu Met Leu Asp Glu Lys
305 310 315 320
cgg gtt atg gtt gac gcc aac gaa gtc ccc att cag aaa atg ttt gaa 1069
Arg Val Met Val Asp Ala Asn Glu Val Pro Ile Gln Lys Met Phe Glu
325 330 335
aag ctt ggc atc act acg att aag gtc aat atc cgt aac gcg aac agc 1117
Lys Leu Gly Ile Thr Thr Ile Lys Val Asn Ile Arg Asn Ala Asn Ser
340 345 350
ttg ggc ggt ggt ttt cat tgc tgg acg tgc gat gtg cgc cgc cgg gga 1165
Leu Gly Gly Gly Phe His Cys Trp Thr Cys Asp Val Arg Arg Arg Gly
355 360 365
acc ctt cag tcc tat ctc gac taa taagacgtct aaaaaaaaac cccgcccctg 1219
Thr Leu Gln Ser Tyr Leu Asp
370 375
acagggcggg gtttttttta gtcgactcta gaggatcccc gggtaccgag ctcgaattca 1279
ctggccgtcg ttttacagcc aagcttggga gacc 1313
<210> 28
<211> 375
<212> PRT
<213> Homo sapiens
<400> 28
Met Thr Asp Val Thr Ile Lys Ala Thr Glu Pro Leu Pro Lys Asp Cys
1 5 10 15
Pro Val Ser Ser Tyr Asn Glu Trp Asp Pro Leu Glu Glu Val Ile Val
20 25 30
Gly Arg Ala Glu Asn Ala Cys Val Pro Pro Phe Thr Ile Glu Val Lys
35 40 45
Ala Asn Thr Tyr Glu Lys Tyr Trp Pro Phe Tyr Gln Lys Gln Gly Gly
50 55 60
His Tyr Phe Pro Lys Asp His Leu Lys Lys Ala Val Ala Glu Ile Glu
65 70 75 80
Glu Met Cys Asn Ile Leu Lys Thr Glu Gly Val Thr Val Arg Arg Pro
85 90 95
Asp Pro Ile Asp Trp Ser Leu Lys Tyr Lys Thr Pro Asp Phe Glu Ser
100 105 110
Thr Gly Leu Tyr Ser Ala Met Pro Arg Asp Ile Leu Ile Val Val Gly
115 120 125
Asn Glu Ile Ile Glu Ala Pro Met Ala Trp Arg Ser Arg Phe Phe Glu
130 135 140
Tyr Arg Ala Tyr Arg Ser Ile Ile Lys Asp Tyr Phe His Arg Gly Ala
145 150 155 160
Lys Trp Thr Thr Ala Pro Lys Pro Thr Met Ala Asp Glu Leu Tyr Asn
165 170 175
Gln Asp Tyr Pro Ile His Ser Val Glu Asp Arg His Lys Leu Ala Ala
180 185 190
Gln Gly Lys Phe Val Thr Thr Glu Phe Glu Pro Cys Phe Asp Ala Ala
195 200 205
Asp Phe Ile Arg Ala Gly Arg Asp Ile Phe Ala Gln Arg Ser Gln Val
210 215 220
Thr Asn Tyr Leu Gly Ile Glu Trp Met Arg Arg His Leu Ala Pro Asp
225 230 235 240
Tyr Arg Val His Ile Ile Ser Phe Lys Asp Pro Asn Pro Met His Ile
245 250 255
Asp Ala Thr Phe Asn Ile Ile Gly Pro Gly Ile Val Leu Ser Asn Pro
260 265 270
Asp Arg Pro Cys His Gln Ile Asp Leu Phe Lys Lys Ala Gly Trp Thr
275 280 285
Ile Ile Thr Pro Pro Thr Pro Ile Ile Pro Asp Asp His Pro Leu Trp
290 295 300
Met Ser Ser Lys Trp Leu Ser Met Asn Val Leu Met Leu Asp Glu Lys
305 310 315 320
Arg Val Met Val Asp Ala Asn Glu Val Pro Ile Gln Lys Met Phe Glu
325 330 335
Lys Leu Gly Ile Thr Thr Ile Lys Val Asn Ile Arg Asn Ala Asn Ser
340 345 350
Leu Gly Gly Gly Phe His Cys Trp Thr Cys Asp Val Arg Arg Arg Gly
355 360 365
Thr Leu Gln Ser Tyr Leu Asp
370 375
<210> 29
<211> 1313
<212> DNA
<213> Rattus norvegicus
<220>
<221> RBS
<222> (55)..(58)
<220>
<221> CDS
<222> (62)..(1189)
<400> 29
ggtctcaaga tatgaccatg attacgccaa gcttgcatgc ctgcaggaaa ggagaggatt 60
g atg aca gat gta acg att aaa gct act cat ccg ctt cct aaa gat tgc 109
Met Thr Asp Val Thr Ile Lys Ala Thr His Pro Leu Pro Lys Asp Cys
1 5 10 15
cct gtg tca agc tat aac gaa tgg gac cct ttg gag gag gtg atc gtg 157
Pro Val Ser Ser Tyr Asn Glu Trp Asp Pro Leu Glu Glu Val Ile Val
20 25 30
ggc cgt gct gag aac gct tgt gta ccc ccc ttt act gtc gaa gta aaa 205
Gly Arg Ala Glu Asn Ala Cys Val Pro Pro Phe Thr Val Glu Val Lys
35 40 45
gcc aac act tac gag aag tac tgg ccg ttt tac cag aaa aat ggt ggc 253
Ala Asn Thr Tyr Glu Lys Tyr Trp Pro Phe Tyr Gln Lys Asn Gly Gly
50 55 60
ctt tat ttc ccc aaa gat cac ctg aag aaa gcc gtt gca gag gtc gaa 301
Leu Tyr Phe Pro Lys Asp His Leu Lys Lys Ala Val Ala Glu Val Glu
65 70 75 80
gag atg tgc aat att ctg agc atg gaa ggt gtg act gtg aaa cgc cca 349
Glu Met Cys Asn Ile Leu Ser Met Glu Gly Val Thr Val Lys Arg Pro
85 90 95
gat ccg att gac tgg tca ctt aag tat aag acg ccc gac ttt gag tcg 397
Asp Pro Ile Asp Trp Ser Leu Lys Tyr Lys Thr Pro Asp Phe Glu Ser
100 105 110
act gga ctt tac agc gcg atg ccg cgc gac att ctg atg gta gtg gga 445
Thr Gly Leu Tyr Ser Ala Met Pro Arg Asp Ile Leu Met Val Val Gly
115 120 125
aat gag atc att gag gcg ccc atg gcg tgg cgg tcc cgc ttt ttt gag 493
Asn Glu Ile Ile Glu Ala Pro Met Ala Trp Arg Ser Arg Phe Phe Glu
130 135 140
tat cgc gcg tac cgg tcg att atc aag gat tac ttt cac cgg ggc gcg 541
Tyr Arg Ala Tyr Arg Ser Ile Ile Lys Asp Tyr Phe His Arg Gly Ala
145 150 155 160
aag tgg acc acc gct cca aag cct acg atg gct gac gag ctt tac gat 589
Lys Trp Thr Thr Ala Pro Lys Pro Thr Met Ala Asp Glu Leu Tyr Asp
165 170 175
caa gat tac ccc att cat tcg gtt gaa gac cgt cac aaa ttg gcg gca 637
Gln Asp Tyr Pro Ile His Ser Val Glu Asp Arg His Lys Leu Ala Ala
180 185 190
caa gga aaa ttc gtt acg act gag ttc gag cct tgc ttt gac gcc gcc 685
Gln Gly Lys Phe Val Thr Thr Glu Phe Glu Pro Cys Phe Asp Ala Ala
195 200 205
gat ttt att cgg gct ggc cgc gac atc ttc gca cag cgt tca caa gta 733
Asp Phe Ile Arg Ala Gly Arg Asp Ile Phe Ala Gln Arg Ser Gln Val
210 215 220
acc aac tac ttg gga atc gag tgg atg cgt cgg cac ctt gcc cca gat 781
Thr Asn Tyr Leu Gly Ile Glu Trp Met Arg Arg His Leu Ala Pro Asp
225 230 235 240
tac cgg gtc cat atc att tca ttt aaa gat ccc aac ccg atg cac att 829
Tyr Arg Val His Ile Ile Ser Phe Lys Asp Pro Asn Pro Met His Ile
245 250 255
gac gct acc ttc aat att att gga cca gga ctg gta ctc tca aac cct 877
Asp Ala Thr Phe Asn Ile Ile Gly Pro Gly Leu Val Leu Ser Asn Pro
260 265 270
gat cgg ccc tgt cac cag att gat ctc ttc aag aag gct ggt tgg acg 925
Asp Arg Pro Cys His Gln Ile Asp Leu Phe Lys Lys Ala Gly Trp Thr
275 280 285
att gtc acg cca ccg act cct gta atc ccg gat gat cat ccc ctc tgg 973
Ile Val Thr Pro Pro Thr Pro Val Ile Pro Asp Asp His Pro Leu Trp
290 295 300
atg tct tcc aaa tgg ctc tct atg aac gta ctg atg ctc gat gaa aaa 1021
Met Ser Ser Lys Trp Leu Ser Met Asn Val Leu Met Leu Asp Glu Lys
305 310 315 320
cgc gtg atg gta gat gcg aat gag gtc cca att caa aaa atg ttc gag 1069
Arg Val Met Val Asp Ala Asn Glu Val Pro Ile Gln Lys Met Phe Glu
325 330 335
aag ctg ggc atc tct act att aag gtg aac att cgg aat gca aac tcg 1117
Lys Leu Gly Ile Ser Thr Ile Lys Val Asn Ile Arg Asn Ala Asn Ser
340 345 350
ctc gga gga ggt ttc cac tgt tgg act tgt gac gta cgg cgg cgt gga 1165
Leu Gly Gly Gly Phe His Cys Trp Thr Cys Asp Val Arg Arg Arg Gly
355 360 365
act ctc cag agc tac ttc gat taa taagacgtct aaaaaaaaac cccgcccctg 1219
Thr Leu Gln Ser Tyr Phe Asp
370 375
acagggcggg gtttttttta gtcgactcta gaggatcccc gggtaccgag ctcgaattca 1279
ctggccgtcg ttttacagcc aagcttggga gacc 1313
<210> 30
<211> 375
<212> PRT
<213> Rattus norvegicus
<400> 30
Met Thr Asp Val Thr Ile Lys Ala Thr His Pro Leu Pro Lys Asp Cys
1 5 10 15
Pro Val Ser Ser Tyr Asn Glu Trp Asp Pro Leu Glu Glu Val Ile Val
20 25 30
Gly Arg Ala Glu Asn Ala Cys Val Pro Pro Phe Thr Val Glu Val Lys
35 40 45
Ala Asn Thr Tyr Glu Lys Tyr Trp Pro Phe Tyr Gln Lys Asn Gly Gly
50 55 60
Leu Tyr Phe Pro Lys Asp His Leu Lys Lys Ala Val Ala Glu Val Glu
65 70 75 80
Glu Met Cys Asn Ile Leu Ser Met Glu Gly Val Thr Val Lys Arg Pro
85 90 95
Asp Pro Ile Asp Trp Ser Leu Lys Tyr Lys Thr Pro Asp Phe Glu Ser
100 105 110
Thr Gly Leu Tyr Ser Ala Met Pro Arg Asp Ile Leu Met Val Val Gly
115 120 125
Asn Glu Ile Ile Glu Ala Pro Met Ala Trp Arg Ser Arg Phe Phe Glu
130 135 140
Tyr Arg Ala Tyr Arg Ser Ile Ile Lys Asp Tyr Phe His Arg Gly Ala
145 150 155 160
Lys Trp Thr Thr Ala Pro Lys Pro Thr Met Ala Asp Glu Leu Tyr Asp
165 170 175
Gln Asp Tyr Pro Ile His Ser Val Glu Asp Arg His Lys Leu Ala Ala
180 185 190
Gln Gly Lys Phe Val Thr Thr Glu Phe Glu Pro Cys Phe Asp Ala Ala
195 200 205
Asp Phe Ile Arg Ala Gly Arg Asp Ile Phe Ala Gln Arg Ser Gln Val
210 215 220
Thr Asn Tyr Leu Gly Ile Glu Trp Met Arg Arg His Leu Ala Pro Asp
225 230 235 240
Tyr Arg Val His Ile Ile Ser Phe Lys Asp Pro Asn Pro Met His Ile
245 250 255
Asp Ala Thr Phe Asn Ile Ile Gly Pro Gly Leu Val Leu Ser Asn Pro
260 265 270
Asp Arg Pro Cys His Gln Ile Asp Leu Phe Lys Lys Ala Gly Trp Thr
275 280 285
Ile Val Thr Pro Pro Thr Pro Val Ile Pro Asp Asp His Pro Leu Trp
290 295 300
Met Ser Ser Lys Trp Leu Ser Met Asn Val Leu Met Leu Asp Glu Lys
305 310 315 320
Arg Val Met Val Asp Ala Asn Glu Val Pro Ile Gln Lys Met Phe Glu
325 330 335
Lys Leu Gly Ile Ser Thr Ile Lys Val Asn Ile Arg Asn Ala Asn Ser
340 345 350
Leu Gly Gly Gly Phe His Cys Trp Thr Cys Asp Val Arg Arg Arg Gly
355 360 365
Thr Leu Gln Ser Tyr Phe Asp
370 375
<210> 31
<211> 1313
<212> DNA
<213> Galeopterus variegatus
<220>
<221> RBS
<222> (55)..(58)
<220>
<221> CDS
<222> (62)..(1189)
<400> 31
ggtctcaaga tatgaccatg attacgccaa gcttgcatgc ctgcaggaaa ggagaggatt 60
g atg aca gat gta acg att aaa gcg acc gat cct ttg cct aaa gat tgc 109
Met Thr Asp Val Thr Ile Lys Ala Thr Asp Pro Leu Pro Lys Asp Cys
1 5 10 15
ccc gtg tcc tcg tat aat gaa tgg gac ccg ctc gag gag gta atc gtt 157
Pro Val Ser Ser Tyr Asn Glu Trp Asp Pro Leu Glu Glu Val Ile Val
20 25 30
ggt cgg gct gaa aat gcc tgc gtt ccg ccc ttc act gtt gaa gtc aaa 205
Gly Arg Ala Glu Asn Ala Cys Val Pro Pro Phe Thr Val Glu Val Lys
35 40 45
gcg aat act tat gaa aag tac tgg ccg ttc tat caa aaa cac ggt ggc 253
Ala Asn Thr Tyr Glu Lys Tyr Trp Pro Phe Tyr Gln Lys His Gly Gly
50 55 60
cac tat ttc ccg aaa gac cac ctg aaa aaa gct gtt gct gag att gaa 301
His Tyr Phe Pro Lys Asp His Leu Lys Lys Ala Val Ala Glu Ile Glu
65 70 75 80
gaa atg tgt aac atc ctg aag atg gaa ggc gtt acg gtt cgt cgg cca 349
Glu Met Cys Asn Ile Leu Lys Met Glu Gly Val Thr Val Arg Arg Pro
85 90 95
gac cca atc gat tgg tca ctg aag tac aag acc ccc gac ttt gag tcg 397
Asp Pro Ile Asp Trp Ser Leu Lys Tyr Lys Thr Pro Asp Phe Glu Ser
100 105 110
act gga ctc tac gga gct atg ccc cgt gat atc ctc atc gtt gtt ggc 445
Thr Gly Leu Tyr Gly Ala Met Pro Arg Asp Ile Leu Ile Val Val Gly
115 120 125
aat gaa atc atc gaa gcc cct atg gcc tgg cgg gca cgc ttc ttc gaa 493
Asn Glu Ile Ile Glu Ala Pro Met Ala Trp Arg Ala Arg Phe Phe Glu
130 135 140
tac cgg gct tat cgc agc atc atc aag gat tat ttt cac cgg gga gcc 541
Tyr Arg Ala Tyr Arg Ser Ile Ile Lys Asp Tyr Phe His Arg Gly Ala
145 150 155 160
aaa tgg acc acg gcc ccg aaa ccc act atg gct aac gag ttg tat gat 589
Lys Trp Thr Thr Ala Pro Lys Pro Thr Met Ala Asn Glu Leu Tyr Asp
165 170 175
caa gac tat ccg atc tat acg gtc gag gac cgg cat aaa ctt gca gcg 637
Gln Asp Tyr Pro Ile Tyr Thr Val Glu Asp Arg His Lys Leu Ala Ala
180 185 190
caa ggt aaa ttt gtg act acg gag ttc gaa cct tgt ttc gat gcc gct 685
Gln Gly Lys Phe Val Thr Thr Glu Phe Glu Pro Cys Phe Asp Ala Ala
195 200 205
gat ttt att cgt gca gga cgc gat atc ttt gcg caa cgg agc caa gta 733
Asp Phe Ile Arg Ala Gly Arg Asp Ile Phe Ala Gln Arg Ser Gln Val
210 215 220
act aat tac ctc ggt atc gag tgg atg cgg cgt cat ctg gca cca gat 781
Thr Asn Tyr Leu Gly Ile Glu Trp Met Arg Arg His Leu Ala Pro Asp
225 230 235 240
tac cgt gtt cac atc gtt tcg ttc aaa gat ccg aac ccg atg cac att 829
Tyr Arg Val His Ile Val Ser Phe Lys Asp Pro Asn Pro Met His Ile
245 250 255
gat gcc acc ttc aac atc att ggt ccc ggc ctc gtg ctc agc aat cca 877
Asp Ala Thr Phe Asn Ile Ile Gly Pro Gly Leu Val Leu Ser Asn Pro
260 265 270
gac cgg cct tgc cac caa att gac ttg ttc aaa aaa gct ggt tgg acc 925
Asp Arg Pro Cys His Gln Ile Asp Leu Phe Lys Lys Ala Gly Trp Thr
275 280 285
att att act cct cca att ccc gtg att cca gac gac cac ccg ctt tgg 973
Ile Ile Thr Pro Pro Ile Pro Val Ile Pro Asp Asp His Pro Leu Trp
290 295 300
atg agc tca aaa tgg ttg agc atg aat gtc ctt atg ctt gat gag aag 1021
Met Ser Ser Lys Trp Leu Ser Met Asn Val Leu Met Leu Asp Glu Lys
305 310 315 320
cgt gtc atg gtt gat gct aac gag gta cca atc caa aag atg ttc ggc 1069
Arg Val Met Val Asp Ala Asn Glu Val Pro Ile Gln Lys Met Phe Gly
325 330 335
aag ctg ggt att tca acg atc aaa gtc aac att cgg aac gcc aat tca 1117
Lys Leu Gly Ile Ser Thr Ile Lys Val Asn Ile Arg Asn Ala Asn Ser
340 345 350
ctg ggc ggt ggc ttt cac tgc tgg act tgt gat gtt cgt cgg cgg ggc 1165
Leu Gly Gly Gly Phe His Cys Trp Thr Cys Asp Val Arg Arg Arg Gly
355 360 365
acg ctt caa agc tat ttc gac taa taagacgtct aaaaaaaaac cccgcccctg 1219
Thr Leu Gln Ser Tyr Phe Asp
370 375
acagggcggg gtttttttta gtcgactcta gaggatcccc gggtaccgag ctcgaattca 1279
ctggccgtcg ttttacagcc aagcttggga gacc 1313
<210> 32
<211> 375
<212> PRT
<213> Galeopterus variegatus
<400> 32
Met Thr Asp Val Thr Ile Lys Ala Thr Asp Pro Leu Pro Lys Asp Cys
1 5 10 15
Pro Val Ser Ser Tyr Asn Glu Trp Asp Pro Leu Glu Glu Val Ile Val
20 25 30
Gly Arg Ala Glu Asn Ala Cys Val Pro Pro Phe Thr Val Glu Val Lys
35 40 45
Ala Asn Thr Tyr Glu Lys Tyr Trp Pro Phe Tyr Gln Lys His Gly Gly
50 55 60
His Tyr Phe Pro Lys Asp His Leu Lys Lys Ala Val Ala Glu Ile Glu
65 70 75 80
Glu Met Cys Asn Ile Leu Lys Met Glu Gly Val Thr Val Arg Arg Pro
85 90 95
Asp Pro Ile Asp Trp Ser Leu Lys Tyr Lys Thr Pro Asp Phe Glu Ser
100 105 110
Thr Gly Leu Tyr Gly Ala Met Pro Arg Asp Ile Leu Ile Val Val Gly
115 120 125
Asn Glu Ile Ile Glu Ala Pro Met Ala Trp Arg Ala Arg Phe Phe Glu
130 135 140
Tyr Arg Ala Tyr Arg Ser Ile Ile Lys Asp Tyr Phe His Arg Gly Ala
145 150 155 160
Lys Trp Thr Thr Ala Pro Lys Pro Thr Met Ala Asn Glu Leu Tyr Asp
165 170 175
Gln Asp Tyr Pro Ile Tyr Thr Val Glu Asp Arg His Lys Leu Ala Ala
180 185 190
Gln Gly Lys Phe Val Thr Thr Glu Phe Glu Pro Cys Phe Asp Ala Ala
195 200 205
Asp Phe Ile Arg Ala Gly Arg Asp Ile Phe Ala Gln Arg Ser Gln Val
210 215 220
Thr Asn Tyr Leu Gly Ile Glu Trp Met Arg Arg His Leu Ala Pro Asp
225 230 235 240
Tyr Arg Val His Ile Val Ser Phe Lys Asp Pro Asn Pro Met His Ile
245 250 255
Asp Ala Thr Phe Asn Ile Ile Gly Pro Gly Leu Val Leu Ser Asn Pro
260 265 270
Asp Arg Pro Cys His Gln Ile Asp Leu Phe Lys Lys Ala Gly Trp Thr
275 280 285
Ile Ile Thr Pro Pro Ile Pro Val Ile Pro Asp Asp His Pro Leu Trp
290 295 300
Met Ser Ser Lys Trp Leu Ser Met Asn Val Leu Met Leu Asp Glu Lys
305 310 315 320
Arg Val Met Val Asp Ala Asn Glu Val Pro Ile Gln Lys Met Phe Gly
325 330 335
Lys Leu Gly Ile Ser Thr Ile Lys Val Asn Ile Arg Asn Ala Asn Ser
340 345 350
Leu Gly Gly Gly Phe His Cys Trp Thr Cys Asp Val Arg Arg Arg Gly
355 360 365
Thr Leu Gln Ser Tyr Phe Asp
370 375
<210> 33
<211> 1211
<212> DNA
<213> Synthetic DNA
<400> 33
tctagagatc cgcgggggcc caggaggggg gatctggcat ttttgggagg tgtgaaatga 60
gtgagaagat cgtcaactcg tggaacgaat gggatgagct cgaggagatg gtggtcggca 120
ttgcggacta tgccagcttc gaaccgaaag agccaggcaa ccatcccaaa ctgcgcaacc 180
agaacctggc cgaaatcatc cccttcccaa gcggcccaaa ggacccgaag gtgctggaga 240
aagcgaacga agagctgaat gggctggctt acctgctgaa ggaccacgat gtgatcgtgc 300
gtcgtcccga gaagatcgac ttcaccaaga gcctgaaaac cccgtatttc gaggttgcca 360
accagtactg cggcgtttgt cctcgcgacg tgatgatcac gtttggcaac gaaatcatgg 420
aagcgaccat gtccaaacgt gcacgcttct tcgaatacct cccctatcgg aagctggtct 480
acgagtactg gaacaaggac gagcacatga tctggaacgc agccccgaaa ccgaccatgc 540
aggatagcat gtacctggaa aacttctggg agctctcgct ggaagaacgc ttcaagcgga 600
tgcacgactt cgaattctgc atcacccaag acgaggtgat cttcgatgcc gccgattgct 660
cccgcttggg taaggacatc ctggtgcagg aaagcatgac caccaatcgc actggcatcc 720
gctggctgaa gaagcatctc gaaccacgcg gctttcgcgt ccatccggtg cacttcccgt 780
tggacttctt ccctagccac atcgactgca cgttcgtacc gttgcgtccg ggtctgatcc 840
tgaccaatcc ggaacgcccg attcgcgagg aagaggagaa gatcttcaag gagaatggct 900
gggagctgat caccgtaccg cagcctacct gctcgaacga cgagatgccc atgttctgcc 960
agagctcgaa atggctgtcc atgaacgtcc tgagcattag tcccaccaag gtgatctgcg 1020
aagaacggga aaagccgctg caagaactgc tggacaagca cgggttcgaa gtctttccct 1080
tgcctttccg ccatgtgttt gagttcggtg gcagctttca ctgtgccacg tgggatattc 1140
gccgcaaggg cgagtgcgag gactacctgc cgaacctgaa ctaccagccg atttgcggct 1200
gacgcggatc c 1211
<210> 34
<211> 2028
<212> DNA
<213> Escherichia coli
<400> 34
ttaatctttc tgcgaattga gatgacgcca ctggctgggc gtcatcccgg tttcccgggt 60
aaacaccacc gaaaaatagt tactatcttc aaagccacat tcggtcgaaa tatcactgat 120
taacaggcgg ctatgctgga gaagatattg cgcatgacac actctgacct gtcgcagata 180
ttgattgatg gtcattccag tctgctggcg aaattgctga cgcaaaacgc gctcactgca 240
cgatgcctca tcacaaaatt tatccagcgc aaagggactt ttcaggctag ccgccagccg 300
ggtaatcagc ttatccagca acgtttcgct ggatgttggc ggcaacgaat cactggtgta 360
acgatggcga ttcagcaaca tcaccaactg cccgaacagc aactcagcca tttcgttagc 420
aaacggcaca tgctgactac tttcatgctc aagctgaccg ataacctgcc gcgcctgcgc 480
catccccatg ctacctaagc gccagtgtgg ttgccctgcg ctggcgttaa atcccggaat 540
cgccccctgc cagtcaagat tcagcttcag acgctccggg caataaataa tattctgcaa 600
aaccagatcg ttaacggaag cgtaggagtg tttatcgtca gcatgaatgt aaaagagatc 660
gccacgggta atgcgataag ggcgatcgtt gagtacatgc aggccattac cgcgccagac 720
aatcaccagc tcacaaaaat catgtgtatg ttcagcaaag acatcttgcg gataacggtc 780
agccacagcg actgcctgct ggtcgctggc aaaaaaatca tctttgagaa gttttaactg 840
atgcgccacc gtggctacct cggccagaga acgaagttga ttattcgcaa tatggcgtac 900
aaatacgttg agaagattcg cgttattgca gaaagccatc ccgtccctgg cgaatatcac 960
gcggtgacca gttaaactct cggcgaaaaa gcgtcgaaaa gtggttactg tcgctgaatc 1020
cacagcgata ggcgatgtca gtaacgctgg cctcgctgtg gcgtagcaga tgtcgggctt 1080
tcatcagtcg caggcggttc aggtatcgct gaggcgtcag tcccgtttgc tgcttaagct 1140
gccgatgtag cgtacgcagt gaaagagaaa attgatccgc cacggcatcc caattcacct 1200
catcggcaaa atggtcctcc agccaggcca gaagcaagtt gagacgtgat gcgctgtttt 1260
ccaggttctc ctgcaaactg cttttacgca gcaagagcag taattgcata aacaagatct 1320
cgcgactggc ggtcgagggt aaatcatttt ccccttcctg ctgttccatc tgtgcaacca 1380
gctgtcgcac ctgctgcaat acgctgtggt taacgcgcca gtgagacgga tactgcccat 1440
ccagctcttg tggcagcaac tgattcagcc cggcgagaaa ctgaaatcga tccggcgagc 1500
gatacagcac attggtcaga cacagattat cggtatgttc atacagatgc cgatcatgat 1560
cgcgtacgaa acagaccgtg ccaccggtga tggtataggg ctgcccatta aacacatgaa 1620
tacccgtgcc atgttcgaca atcacaattt catgaaaatc atgatgatgt tcaggaaaat 1680
ccgcctgcgg gagccggggt tctatcgcca cggacgcgtt accagacgga aaaaaatcca 1740
cactatgtaa tacggtcata ctggcctcct gatgtcgtca acacggcgaa atagtaatca 1800
cgaggtcagg ttcttacctt aaattttcga cggaaaacca cgtaaaaaac gtcgattttt 1860
caagatacag cgtgaatttt caggaaatgc ggtgagcatc acatcaccac aattcagcaa 1920
attgtgaaca tcatcacgtt catctttccc tggttgccaa tggcccattt tcctgtcagt 1980
aacgagaagg tcgcgaattc aggcgctttt tagactggtc gtaatgaa 2028
<210> 35
<211> 107
<212> DNA
<213> Escherichia coli
<400> 35
caaataaaac gaaaggctca gtcgaaagac tgggcctttc gttttatctg ttgtttgtcg 60
gtgaacgctc tcctgagtag gacaaatccg ccgggagcgg atttgaa 107
<210> 36
<211> 24
<212> DNA
<213> synthetic oligonucleotide
<400> 36
tctagagatc cgcgggggcc cagg 24
<210> 37
<211> 46
<212> DNA
<213> synthetic oligonucleotide
<400> 37
agttccctac tctcgcgtgc tcgagggatc cgcgtcagcc gcaaat 46
<210> 38
<211> 10235
<212> DNA
<213> various
<400> 38
tcaggcgggc aagaatgtga ataaaggccg gataaaactt gtgcttattt ttctttacgg 60
tctttaaaaa ggccgtaata tccagctgaa cggtctggtt ataggtacat tgagcaactg 120
actgaaatgc ctcaaaatgt tctttacgat gccattggga tatatcaacg gtggtatatc 180
cagtgatttt tttctccatt ttagcttcct tagctcctga aaatctcgat aactcaaaaa 240
atacgcccgg tagtgatctt atttcattat ggtgaaagtt ggaacctctt acgtgccgat 300
caacgtctca ttttcgccaa aagttggccc agggcttccc ggtatcaaca gggacaccag 360
gatttattta ttctgcgaag tgatcttccg tcacaggtat ttattcggcg caaagtgcgt 420
cgggtgatgc tgccaactta ctgatttagt gtatgatggt gtttttgagg tgctccagtg 480
gcttctgttt ctatcagctg tccctcctgt tcagctactg acggggtggt gcgtaacggc 540
aaaagcaccg ccggacatca gcgctagcgg agtgtatact ggcttactat gttggcactg 600
atgagggtgt cagtgaagtg cttcatgtgg caggagaaaa aaggctgcac cggtgcgtca 660
gcagaatatg tgatacagga tatattccgc ttcctcgctc actgactcgc tacgctcggt 720
cgttcgactg cggcgagcgg aaatggctta cgaacggggc ggagatttcc tggaagatgc 780
caggaagata cttaacaggg aagtgagagg gccgcggcaa agccgttttt ccataggctc 840
cgcccccctg acaagcatca cgaaatctga cgctcaaatc agtggtggcg aaacccgaca 900
ggactataaa gataccaggc gtttccccct ggcggctccc tcgtgcgctc tcctgttcct 960
gcctttcggt ttaccggtgt cattccgctg ttatggccgc gtttgtctca ttccacgcct 1020
gacactcagt tccgggtagg cagttcgctc caagctggac tgtatgcacg aaccccccgt 1080
tcagtccgac cgctgcgcct tatccggtaa ctatcgtctt gagtccaacc cggaaagaca 1140
tgcaaaagca ccactggcag cagccactgg taattgattt agaggagtta gtcttgaagt 1200
catgcgccgg ttaaggctaa actgaaagga caagttttgg tgactgcgct cctccaagcc 1260
agttacctcg gttcaaagag ttggtagctc agagaacctt cgaaaaaccg ccctgcaagg 1320
cggttttttc gttttcagag caagagatta cgcgcagacc aaaacgatct caagaagatc 1380
atcttattaa tcagataaaa tatttctaga tttcagtgca atttatctct tcaaatgtag 1440
cacctgaagt cagccccata cgatataagt tgtaattctc atgtttgaca gcttatcatc 1500
gataagcttt aatgcggtag tttatcacag ttaaattgct aacgcagtca ggcaccgtgt 1560
atgaaatcta acaatgcgct catcgtcatc ctcggcaccg tcaccctgga tgctgtaggc 1620
ataggcttgg ttatgccggt actgccgggc ctcttgcggg atatcgtcca ttccgacagc 1680
atcgccagtc actatggcgt gctgctagcg ctatatgcgt tgatgcaatt tctatgcgca 1740
cccgttctcg gagcactgtc cgaccgcttt ggccgccgcc cagtcctgct cgcttcgcta 1800
cttggagcca ctatcgacta cgcgatcatg gcgaccacac ccgtcctgtg gatcctctac 1860
gccggacgca tcgtggccgg catcaccggc gccacaggtg cggttgctgg cgcctatatc 1920
gccgacatca ccgatgggga agatcgggct cgccacttcg ggctcatgag cgcttgtttc 1980
ggcgtgggta tggtggcagg ccccgtggcc gggggactgt tgggcgccat ctccttgcat 2040
gcaccattcc ttgcggcggc ggtgctcaac ggcctcaacc tactactggg ctgcttccta 2100
atgcaggagt cgcataaggg agagcgtcga ccgatgccct tgagagcctt caacccagtc 2160
agctccttcc ggtgggcgcg gggcatgact atcgtcgccg cacttatgac tgtcttcttt 2220
atcatgcaac tcgtaggaca ggtgccggca gcgctctggg tcattttcgg cgaggaccgc 2280
tttcgctgga gcgcgacgat gatcggcctg tcgcttgcgg tattcggaat cttgcacgcc 2340
ctcgctcaag ccttcgtcac tggtcccgcc accaaacgtt tcggcgagaa gcaggccatt 2400
atcgccggca tggcggccga cgcgctgggc tacgtcttgc tggcgttcgc gacgcgaggc 2460
tggatggcct tccccattat gattcttctc gcttccggcg gcatcgggat gcccgcgttg 2520
caggccatgc tgtccaggca ggtagatgac gaccatcagg gacagcttca aggatcgctc 2580
gcggctctta ccagcctaac ttcgatcatt ggaccgctga tcgtcacggc gatttatgcc 2640
gcctcggcga gcacatggaa cgggttggca tggattgtag gcgccgccct ataccttgtc 2700
tgcctccccg cgttgcgtcg cggtgcatgg agccgggcca cctcgacctg aatggaagcc 2760
ggcggcacct cgctaacgga ttcaccactc caagaattgg agccaatcaa ttcttgcgga 2820
gaactgtgaa tgcgcaaacc aacccttggc agaacatatc catcgcgtcc gccatctcca 2880
gcagccgcac gcggcgcatc tcgggcagcg ttgggtcctg gccacgggtg cgcatgatcg 2940
tgctcctgtc gttgaggacc cggctaggct ggcggggttg ccttactggt tagcagaatg 3000
aatcaccgat acgcgagcga acgtgaagcg actgctgctg caaaacgtct gcgacctgag 3060
caacaacatg aatggtcttc ggtttccgtg tttcgtaaag tctggaaacg cggaagtccc 3120
ctacgtgctg ctgaagttgc ccgcaacaga gagtggaacc aaccggtgat accacgatac 3180
tatgactgag agtcaacgcc atgagcggcc tcatttctta ttctgagtta caacagtccg 3240
caccgctgtc cggtagctcc ttccggtggg cgcggggcat gactatcgtc gccgcactta 3300
tgactgtctt ctttatcatg caactcgtag gacaggtgcc ggcagcgccc aacagtcccc 3360
cggccacggg gcctgccacc atacccacgc cgaaacaagc gccctgcacc attatgttcc 3420
ggatctgcat cgcaggatgc tgctggctac cctgtggaac acctacatct gtattaacga 3480
agcgctaacc gtttttatca ggctctggga ggcagaataa atgatcatat cgtcaattat 3540
tacctccacg gggagagcct gagcaaactg gcctcaggca tttgagaagc acacggtcac 3600
actgcttccg gtagtcaata aaccggtaaa ccagcaatag acataagcgg ctatttaacg 3660
accctgccct gaaccgacga ccgggtcgaa tttgctttcg aatttctgcc attcatccgc 3720
ttattatcac ttattcaggc gtagcaccag gcgtttaagg gcaccaataa ctgccttaaa 3780
aaaattacgc cccgccctgc cactcatcgc agtactgttg taattcatta agcattctgc 3840
cgacatggaa gccatcacaa acggcatgat gaacctgaat cgccagcggc atcagcacct 3900
tgtcgccttg cgtataatat ttgcccatgg atttaaattt aatctttctg cgaattgaga 3960
tgacgccact ggctgggcgt catcccggtt tcccgggtaa acaccaccga aaaatagtta 4020
ctatcttcaa agccacattc ggtcgaaata tcactgatta acaggcggct atgctggaga 4080
agatattgcg catgacacac tctgacctgt cgcagatatt gattgatggt cattccagtc 4140
tgctggcgaa attgctgacg caaaacgcgc tcactgcacg atgcctcatc acaaaattta 4200
tccagcgcaa agggactttt caggctagcc gccagccggg taatcagctt atccagcaac 4260
gtttcgctgg atgttggcgg caacgaatca ctggtgtaac gatggcgatt cagcaacatc 4320
accaactgcc cgaacagcaa ctcagccatt tcgttagcaa acggcacatg ctgactactt 4380
tcatgctcaa gctgaccgat aacctgccgc gcctgcgcca tccccatgct acctaagcgc 4440
cagtgtggtt gccctgcgct ggcgttaaat cccggaatcg ccccctgcca gtcaagattc 4500
agcttcagac gctccgggca ataaataata ttctgcaaaa ccagatcgtt aacggaagcg 4560
taggagtgtt tatcgtcagc atgaatgtaa aagagatcgc cacgggtaat gcgataaggg 4620
cgatcgttga gtacatgcag gccattaccg cgccagacaa tcaccagctc acaaaaatca 4680
tgtgtatgtt cagcaaagac atcttgcgga taacggtcag ccacagcgac tgcctgctgg 4740
tcgctggcaa aaaaatcatc tttgagaagt tttaactgat gcgccaccgt ggctacctcg 4800
gccagagaac gaagttgatt attcgcaata tggcgtacaa atacgttgag aagattcgcg 4860
ttattgcaga aagccatccc gtccctggcg aatatcacgc ggtgaccagt taaactctcg 4920
gcgaaaaagc gtcgaaaagt ggttactgtc gctgaatcca cagcgatagg cgatgtcagt 4980
aacgctggcc tcgctgtggc gtagcagatg tcgggctttc atcagtcgca ggcggttcag 5040
gtatcgctga ggcgtcagtc ccgtttgctg cttaagctgc cgatgtagcg tacgcagtga 5100
aagagaaaat tgatccgcca cggcatccca attcacctca tcggcaaaat ggtcctccag 5160
ccaggccaga agcaagttga gacgtgatgc gctgttttcc aggttctcct gcaaactgct 5220
tttacgcagc aagagcagta attgcataaa caagatctcg cgactggcgg tcgagggtaa 5280
atcattttcc ccttcctgct gttccatctg tgcaaccagc tgtcgcacct gctgcaatac 5340
gctgtggtta acgcgccagt gagacggata ctgcccatcc agctcttgtg gcagcaactg 5400
attcagcccg gcgagaaact gaaatcgatc cggcgagcga tacagcacat tggtcagaca 5460
cagattatcg gtatgttcat acagatgccg atcatgatcg cgtacgaaac agaccgtgcc 5520
accggtgatg gtatagggct gcccattaaa cacatgaata cccgtgccat gttcgacaat 5580
cacaatttca tgaaaatcat gatgatgttc aggaaaatcc gcctgcggga gccggggttc 5640
tatcgccacg gacgcgttac cagacggaaa aaaatccaca ctatgtaata cggtcatact 5700
ggcctcctga tgtcgtcaac acggcgaaat agtaatcacg aggtcaggtt cttaccttaa 5760
attttcgacg gaaaaccacg taaaaaacgt cgatttttca agatacagcg tgaattttca 5820
ggaaatgcgg tgagcatcac atcaccacaa ttcagcaaat tgtgaacatc atcacgttca 5880
tctttccctg gttgccaatg gcccattttc ctgtcagtaa cgagaaggtc gcgaattcag 5940
gcgcttttta gactggtcgt aatgaacatt taaatgaatt cccttgggac tctagagatc 6000
cgcgggggcc caggaggggg gatctggcat ttttgggagg tgtgaaatga gtgagaagat 6060
cgtcaactcg tggaacgaat gggatgagct cgaggagatg gtggtcggca ttgcggacta 6120
tgccagcttc gaaccgaaag agccaggcaa ccatcccaaa ctgcgcaacc agaacctggc 6180
cgaaatcatc cccttcccaa gcggcccaaa ggacccgaag gtgctggaga aagcgaacga 6240
agagctgaat gggctggctt acctgctgaa ggaccacgat gtgatcgtgc gtcgtcccga 6300
gaagatcgac ttcaccaaga gcctgaaaac cccgtatttc gaggttgcca accagtactg 6360
cggcgtttgt cctcgcgacg tgatgatcac gtttggcaac gaaatcatgg aagcgaccat 6420
gtccaaacgt gcacgcttct tcgaatacct cccctatcgg aagctggtct acgagtactg 6480
gaacaaggac gagcacatga tctggaacgc agccccgaaa ccgaccatgc aggatagcat 6540
gtacctggaa aacttctggg agctctcgct ggaagaacgc ttcaagcgga tgcacgactt 6600
cgaattctgc atcacccaag acgaggtgat cttcgatgcc gccgattgct cccgcttggg 6660
taaggacatc ctggtgcagg aaagcatgac caccaatcgc actggcatcc gctggctgaa 6720
gaagcatctc gaaccacgcg gctttcgcgt ccatccggtg cacttcccgt tggacttctt 6780
ccctagccac atcgactgca cgttcgtacc gttgcgtccg ggtctgatcc tgaccaatcc 6840
ggaacgcccg attcgcgagg aagaggagaa gatcttcaag gagaatggct gggagctgat 6900
caccgtaccg cagcctacct gctcgaacga cgagatgccc atgttctgcc agagctcgaa 6960
atggctgtcc atgaacgtcc tgagcattag tcccaccaag gtgatctgcg aagaacggga 7020
aaagccgctg caagaactgc tggacaagca cgggttcgaa gtctttccct tgcctttccg 7080
ccatgtgttt gagttcggtg gcagctttca ctgtgccacg tgggatattc gccgcaaggg 7140
cgagtgcgag gactacctgc cgaacctgaa ctaccagccg atttgcggct gacgcggatc 7200
cctcgagcac gcgagagtag ggaactgcca ggcatcaaat aaaacgaaag gctcagtcga 7260
aagactgggc ctttcgtttt atctgttgtt tgtcggtgaa cgctctcctg agtaggacaa 7320
atccgccggg agcggatttg aacgatgata agctgtcaaa catgagaatt cttgaagacg 7380
aaagggcctc gtgtgtacaa acgttcgtca aaagggcgac acaaaattcc tgcaggggcc 7440
ggcccagcgc cggcggtcga gtggcgacgg cgcggcttgt ccgcgccctg gtagattgcc 7500
tggccgtagg ccagccattt ttgagcggcc agcggccgcg ataggccgac gcgaagcggc 7560
ggggcgtagg gagcgcagcg accgaagggt aggcgctttt tgcagctctt cggctgtgcg 7620
ctggccagac agttatgcac aggccaggcg ggttttaaga gttttaataa gttttaaaga 7680
gttttaggcg gaaaaatcgc cttttttctc ttttatatca gtcacttaca tgtgtgaccg 7740
gttcccaatg tacggctttg ggttcccaat gtacgggttc cggttcccaa tgtacggctt 7800
tgggttccca atgtacgtgc tatccacagg aaagagacct tttcgacctt tttcccctgc 7860
tagggcaatt tgccctagca tctgctccgt acattaggaa ccggcggatg cttcgccctc 7920
gatcaggttg cggtagcgca tgactaggat cgggccagcc tgccccgcct cctccttcaa 7980
atcgtactcc ggcaggtcat ttgacccgat cagcttgcgc acggtgaaac agaacttctt 8040
gaactctccg gcgctgccac tgcgttcgta gatcgtcttg aacaaccatc tggcttctgc 8100
cttgcctgcg gcgcggcgtg ccaggcggta gagaaaacgg ccgatgccgg gatcgatcaa 8160
aaagtaatcg gggtgaaccg tcagcacgtc cgggttcttg ccttctgtga tctcgcggta 8220
catccaatca actagctcga tctcgatgta ctccggccgc ccggtttcgc tctttacgat 8280
cttgtagcgg ctaatcaagg cttcaccctc ggataccgtc accaggcggc cgttcttggc 8340
cttcttcgta cgctgcatgg caacgtgcgt ggtgtttaac cgaatgcagg tttctaccag 8400
gtcgtctttc tgctttccgc catcggctcg ccggcagaac ttgagtacgt ccgcaacgtg 8460
tggacggaac acgcggccgg gcttgtctcc cttcccttcc cggtatcggt tcatggattc 8520
ggttagatgg gaaaccgcca tcagtaccag gtcgtaatcc cacacactgg ccatgccggc 8580
cggccctgcg gaaacctcta cgtgcccgtc tggaagctcg tagcggatca cctcgccagc 8640
tcgtcggtca cgcttcgaca gacggaaaac ggccacgtcc atgatgctgc gactatcgcg 8700
ggtgcccacg tcatagagca tcggaacgaa aaaatctggt tgctcgtcgc ccttgggcgg 8760
cttcctaatc gacggcgcac cggctgccgg cggttgccgg gattctttgc ggattcgatc 8820
agcggccgct tgccacgatt caccggggcg tgcttctgcc tcgatgcgtt gccgctgggc 8880
ggcctgcgcg gccttcaact tctccaccag gtcatcaccc agcgccgcgc cgatttgtac 8940
cgggccggat ggtttgcgac cgctcacgcc gattcctcgg gcttgggggt tccagtgcca 9000
ttgcagggcc ggcagacaac ccagccgctt acgcctggcc aaccgcccgt tcctccacac 9060
atggggcatt ccacggcgtc ggtgcctggt tgttcttgat tttccatgcc gcctccttta 9120
gccgctaaaa ttcatctact catttattca tttgctcatt tactctggta gctgcgcgat 9180
gtattcagat agcagctcgg taatggtctt gccttggcgt accgcgtaca tcttcagctt 9240
ggtgtgatcc tccgccggca actgaaagtt gacccgcttc atggctggcg tgtctgccag 9300
gctggccaac gttgcagcct tgctgctgcg tgcgctcgga cggccggcac ttagcgtgtt 9360
tgtgcttttg ctcattttct ctttacctca ttaactcaaa tgagttttga tttaatttca 9420
gcggccagcg cctggacctc gcgggcagcg tcgccctcgg gttctgattc aagaacggtt 9480
gtgccggcgg cggcagtgcc tgggtagctc acgcgctgcg tgatacggga ctcaagaatg 9540
ggcagctcgt acccggccag cgcctcggca acctcaccgc cgatgcgcgt gcctttgatc 9600
gcccgcgaca cgacaaaggc cgcttgtagc cttccatccg tgacctcaat gcgctgctta 9660
accagctcca ccaggtcggc ggtggcccat atgtcgtaag ggcttggctg caccggaatc 9720
agcacgaagt cggctgcctt gatcgcggac acagccaagt ccgccgcctg gggcgctccg 9780
tcgatcacta cgaagtcgcg ccggccgatg gccttcacgt cgcggtcaat cgtcgggcgg 9840
tcgatgccga caacggttag cggttgatct tcccgcacgg ccgcccaatc gcgggcactg 9900
ccctggggat cggaatcgac taacagaaca tcggccccgg cgagttgcag ggcgcgggct 9960
agatgggttg cgatggtcgt cttgcctgac ccgcctttct ggttaagtac agcgataacc 10020
ttcatgcgtt ccccttgcgt atttgtttat ttactcatcg catcatatac gcagcgaccg 10080
catgacgcaa gctgttttac tcaaatacac atcacctttt tagacggcgg cgctcggttt 10140
cttcagcggc caagctggcc ggccaggccg ccagcttggc atcagacaaa ccggccagga 10200
tttcatgcag ccgcacggtt ccggatgagc attca 10235
<210> 39
<211> 921
<212> DNA
<213> Pseudomonas putida
<220>
<221> CDS
<222> (1)..(921)
<400> 39
atg agc gct agg cac ttt ctc tcc ctg ctg gac ttc acc acc gac gaa 48
Met Ser Ala Arg His Phe Leu Ser Leu Leu Asp Phe Thr Thr Asp Glu
1 5 10 15
ttg ctc ggg gtg atc cgc cac ggc atc gag ctg aag gac ctg cgc aag 96
Leu Leu Gly Val Ile Arg His Gly Ile Glu Leu Lys Asp Leu Arg Lys
20 25 30
cga ggc gtg ctg ttc gaa ccg ctg aag aac cgt gtg cta ggc atg atc 144
Arg Gly Val Leu Phe Glu Pro Leu Lys Asn Arg Val Leu Gly Met Ile
35 40 45
ttc gaa aag tcc tcg acc cgt acc cgt gtg tcg ttc gag gcc ggc atg 192
Phe Glu Lys Ser Ser Thr Arg Thr Arg Val Ser Phe Glu Ala Gly Met
50 55 60
atc cag ctc ggc ggc cag gcc atc ttc ctg tcg ccc cgc gac acc cag 240
Ile Gln Leu Gly Gly Gln Ala Ile Phe Leu Ser Pro Arg Asp Thr Gln
65 70 75 80
ctg ggc cgc ggc gag cca att ggt gac agc gcc atc gtg ctg tcg agc 288
Leu Gly Arg Gly Glu Pro Ile Gly Asp Ser Ala Ile Val Leu Ser Ser
85 90 95
atg gtt gat gtg gtg atg atc cgg acc cac gcc cac agc acc ctg acc 336
Met Val Asp Val Val Met Ile Arg Thr His Ala His Ser Thr Leu Thr
100 105 110
gag ttc gcc gcc aag tcg cgt gtg ccc gtg atc aac ggc ctg tcc gac 384
Glu Phe Ala Ala Lys Ser Arg Val Pro Val Ile Asn Gly Leu Ser Asp
115 120 125
gaa tcg cac ccg tgc caa ctg ctg gcc gac atg cag acc ttc gtt gaa 432
Glu Ser His Pro Cys Gln Leu Leu Ala Asp Met Gln Thr Phe Val Glu
130 135 140
cac cgc ggc tcg att cag ggc aag acc gtg acc tgg atc ggc gat ggc 480
His Arg Gly Ser Ile Gln Gly Lys Thr Val Thr Trp Ile Gly Asp Gly
145 150 155 160
ttc aac atg tgc aac tcc tat atc gaa gcc gcc agg cag ttc gat ttc 528
Phe Asn Met Cys Asn Ser Tyr Ile Glu Ala Ala Arg Gln Phe Asp Phe
165 170 175
cag ctg cgc atc gcc tgc ccc gaa ggc tat gag ccg gat caa cgc ttc 576
Gln Leu Arg Ile Ala Cys Pro Glu Gly Tyr Glu Pro Asp Gln Arg Phe
180 185 190
atg gca ctg ggc ggc gac cgc gtg cag atc atc cgg gat gcc agg gaa 624
Met Ala Leu Gly Gly Asp Arg Val Gln Ile Ile Arg Asp Ala Arg Glu
195 200 205
gct gtg cgt gat gca cac ctg gtg gtc acc gat gtc tgg act tcc atg 672
Ala Val Arg Asp Ala His Leu Val Val Thr Asp Val Trp Thr Ser Met
210 215 220
ggt cag gag gag gaa act gca cgg cgc ctg gcg cat ttc gcg cct tac 720
Gly Gln Glu Glu Glu Thr Ala Arg Arg Leu Ala His Phe Ala Pro Tyr
225 230 235 240
cag gtc acc cgc gaa ctg ctc gac ctg gct gca ccc gat gtc ctc ttc 768
Gln Val Thr Arg Glu Leu Leu Asp Leu Ala Ala Pro Asp Val Leu Phe
245 250 255
atg cac tgc ctg ccc gcc cac cgt ggc gag gaa atc agc cag gac ctg 816
Met His Cys Leu Pro Ala His Arg Gly Glu Glu Ile Ser Gln Asp Leu
260 265 270
ctc gac gac cca cgt tcg gtc gcc tgg gac gag gct gaa aac cgc ctg 864
Leu Asp Asp Pro Arg Ser Val Ala Trp Asp Glu Ala Glu Asn Arg Leu
275 280 285
cat gca cag aag gcg ctt ctc gaa ttc ctt gta gaa ccg gct tac cac 912
His Ala Gln Lys Ala Leu Leu Glu Phe Leu Val Glu Pro Ala Tyr His
290 295 300
cac gca tga 921
His Ala
305
<210> 40
<211> 306
<212> PRT
<213> Pseudomonas putida
<400> 40
Met Ser Ala Arg His Phe Leu Ser Leu Leu Asp Phe Thr Thr Asp Glu
1 5 10 15
Leu Leu Gly Val Ile Arg His Gly Ile Glu Leu Lys Asp Leu Arg Lys
20 25 30
Arg Gly Val Leu Phe Glu Pro Leu Lys Asn Arg Val Leu Gly Met Ile
35 40 45
Phe Glu Lys Ser Ser Thr Arg Thr Arg Val Ser Phe Glu Ala Gly Met
50 55 60
Ile Gln Leu Gly Gly Gln Ala Ile Phe Leu Ser Pro Arg Asp Thr Gln
65 70 75 80
Leu Gly Arg Gly Glu Pro Ile Gly Asp Ser Ala Ile Val Leu Ser Ser
85 90 95
Met Val Asp Val Val Met Ile Arg Thr His Ala His Ser Thr Leu Thr
100 105 110
Glu Phe Ala Ala Lys Ser Arg Val Pro Val Ile Asn Gly Leu Ser Asp
115 120 125
Glu Ser His Pro Cys Gln Leu Leu Ala Asp Met Gln Thr Phe Val Glu
130 135 140
His Arg Gly Ser Ile Gln Gly Lys Thr Val Thr Trp Ile Gly Asp Gly
145 150 155 160
Phe Asn Met Cys Asn Ser Tyr Ile Glu Ala Ala Arg Gln Phe Asp Phe
165 170 175
Gln Leu Arg Ile Ala Cys Pro Glu Gly Tyr Glu Pro Asp Gln Arg Phe
180 185 190
Met Ala Leu Gly Gly Asp Arg Val Gln Ile Ile Arg Asp Ala Arg Glu
195 200 205
Ala Val Arg Asp Ala His Leu Val Val Thr Asp Val Trp Thr Ser Met
210 215 220
Gly Gln Glu Glu Glu Thr Ala Arg Arg Leu Ala His Phe Ala Pro Tyr
225 230 235 240
Gln Val Thr Arg Glu Leu Leu Asp Leu Ala Ala Pro Asp Val Leu Phe
245 250 255
Met His Cys Leu Pro Ala His Arg Gly Glu Glu Ile Ser Gln Asp Leu
260 265 270
Leu Asp Asp Pro Arg Ser Val Ala Trp Asp Glu Ala Glu Asn Arg Leu
275 280 285
His Ala Gln Lys Ala Leu Leu Glu Phe Leu Val Glu Pro Ala Tyr His
290 295 300
His Ala
305
<210> 41
<211> 1218
<212> DNA
<213> Pseudomonas putida
<220>
<221> CDS
<222> (1)..(1218)
<400> 41
atg gcg gac gta aaa aag gtc gta ctg gcg tat tcc ggc ggc ctt gat 48
Met Ala Asp Val Lys Lys Val Val Leu Ala Tyr Ser Gly Gly Leu Asp
1 5 10 15
act tcg gtg att ctc aag tgg ctg cag gat acc tac aac tgc gaa gtg 96
Thr Ser Val Ile Leu Lys Trp Leu Gln Asp Thr Tyr Asn Cys Glu Val
20 25 30
gtg acc ttc acc gct gac ctg ggg cag ggc gaa gag gtc gaa ccg gcc 144
Val Thr Phe Thr Ala Asp Leu Gly Gln Gly Glu Glu Val Glu Pro Ala
35 40 45
cgt gcc aag gcc cag gca atg ggc gtt aaa gag atc tac atc gac gac 192
Arg Ala Lys Ala Gln Ala Met Gly Val Lys Glu Ile Tyr Ile Asp Asp
50 55 60
ctg cgc gaa gaa ttc gtg cgt gat ttc gtg ttc ccg atg ttc cgc gcc 240
Leu Arg Glu Glu Phe Val Arg Asp Phe Val Phe Pro Met Phe Arg Ala
65 70 75 80
aac acc gtc tac gaa ggc gag tac ctg ctg ggt act tcc atc gcc cgt 288
Asn Thr Val Tyr Glu Gly Glu Tyr Leu Leu Gly Thr Ser Ile Ala Arg
85 90 95
ccg ctg atc gcc aag cgc ctg atc gaa atc gcc aac gaa acc ggc gct 336
Pro Leu Ile Ala Lys Arg Leu Ile Glu Ile Ala Asn Glu Thr Gly Ala
100 105 110
gac gcc att tcc cat ggc gcc acc ggc aag ggt aac gac cag gtg cgc 384
Asp Ala Ile Ser His Gly Ala Thr Gly Lys Gly Asn Asp Gln Val Arg
115 120 125
ttc gag ctg ggt gcc tat gcc ctg aag cca ggc gtc aag gtc atc gct 432
Phe Glu Leu Gly Ala Tyr Ala Leu Lys Pro Gly Val Lys Val Ile Ala
130 135 140
cca tgg cgc gag tgg gac ctg ctg tcc cgc gaa aag ctg atg gac tac 480
Pro Trp Arg Glu Trp Asp Leu Leu Ser Arg Glu Lys Leu Met Asp Tyr
145 150 155 160
gcc gag aag cac ggc atc ccg atc gag cgc cac ggc aag aag aag tcg 528
Ala Glu Lys His Gly Ile Pro Ile Glu Arg His Gly Lys Lys Lys Ser
165 170 175
ccg tac tcg atg gac gcc aac ctg ctg cac atc tcc tac gag ggc ggt 576
Pro Tyr Ser Met Asp Ala Asn Leu Leu His Ile Ser Tyr Glu Gly Gly
180 185 190
gtc ctg gaa gat acc tgg acc gag cac gaa gaa gac atg tgg cgc tgg 624
Val Leu Glu Asp Thr Trp Thr Glu His Glu Glu Asp Met Trp Arg Trp
195 200 205
agt gtc tcg cct gag aat gcc ccg gac cag gct acc tac atc gag ctg 672
Ser Val Ser Pro Glu Asn Ala Pro Asp Gln Ala Thr Tyr Ile Glu Leu
210 215 220
acc tac cgc aat ggt gac atc gtt gcc atc gac ggc gtc gag aaa tcc 720
Thr Tyr Arg Asn Gly Asp Ile Val Ala Ile Asp Gly Val Glu Lys Ser
225 230 235 240
ccg gcc acc gtc ctg gca gac ctg aac cgt atc ggt ggt gcc aac ggc 768
Pro Ala Thr Val Leu Ala Asp Leu Asn Arg Ile Gly Gly Ala Asn Gly
245 250 255
atc ggc cgt ctg gac atc gtc gaa aac cgt tac gtc ggc atg aag tcg 816
Ile Gly Arg Leu Asp Ile Val Glu Asn Arg Tyr Val Gly Met Lys Ser
260 265 270
cgc ggt tgc tac gaa acg cct ggc ggt acc atc atg ctc aag gca cac 864
Arg Gly Cys Tyr Glu Thr Pro Gly Gly Thr Ile Met Leu Lys Ala His
275 280 285
cgt gcc atc gag tcg atc acc ctg gac cgc gaa gtc gct cac ctg aaa 912
Arg Ala Ile Glu Ser Ile Thr Leu Asp Arg Glu Val Ala His Leu Lys
290 295 300
gat gag ctg atg cca aag tat gcc agc ctg atc tac acc ggc tac tgg 960
Asp Glu Leu Met Pro Lys Tyr Ala Ser Leu Ile Tyr Thr Gly Tyr Trp
305 310 315 320
tgg agc ccg gag cgt ctg atg ctg caa cag atg atc gat gct tcg cag 1008
Trp Ser Pro Glu Arg Leu Met Leu Gln Gln Met Ile Asp Ala Ser Gln
325 330 335
gtc aac gtg aat ggt gtg gtg cgc ctg aaa ctg tac aag ggc aac gtg 1056
Val Asn Val Asn Gly Val Val Arg Leu Lys Leu Tyr Lys Gly Asn Val
340 345 350
acc gtg gtt ggc cgc aag tcg gac gat tcg ctg ttc gat gcc aac atc 1104
Thr Val Val Gly Arg Lys Ser Asp Asp Ser Leu Phe Asp Ala Asn Ile
355 360 365
gcc acc ttt gaa gaa gat ggt ggt gcc tac aac cag gca gat gct gct 1152
Ala Thr Phe Glu Glu Asp Gly Gly Ala Tyr Asn Gln Ala Asp Ala Ala
370 375 380
ggc ttc atc aag ctc aat gca ctg cgt atg cgc att gcc gcc aac aag 1200
Gly Phe Ile Lys Leu Asn Ala Leu Arg Met Arg Ile Ala Ala Asn Lys
385 390 395 400
ggc cgt tcg ctg ctc tga 1218
Gly Arg Ser Leu Leu
405
<210> 42
<211> 405
<212> PRT
<213> Pseudomonas putida
<400> 42
Met Ala Asp Val Lys Lys Val Val Leu Ala Tyr Ser Gly Gly Leu Asp
1 5 10 15
Thr Ser Val Ile Leu Lys Trp Leu Gln Asp Thr Tyr Asn Cys Glu Val
20 25 30
Val Thr Phe Thr Ala Asp Leu Gly Gln Gly Glu Glu Val Glu Pro Ala
35 40 45
Arg Ala Lys Ala Gln Ala Met Gly Val Lys Glu Ile Tyr Ile Asp Asp
50 55 60
Leu Arg Glu Glu Phe Val Arg Asp Phe Val Phe Pro Met Phe Arg Ala
65 70 75 80
Asn Thr Val Tyr Glu Gly Glu Tyr Leu Leu Gly Thr Ser Ile Ala Arg
85 90 95
Pro Leu Ile Ala Lys Arg Leu Ile Glu Ile Ala Asn Glu Thr Gly Ala
100 105 110
Asp Ala Ile Ser His Gly Ala Thr Gly Lys Gly Asn Asp Gln Val Arg
115 120 125
Phe Glu Leu Gly Ala Tyr Ala Leu Lys Pro Gly Val Lys Val Ile Ala
130 135 140
Pro Trp Arg Glu Trp Asp Leu Leu Ser Arg Glu Lys Leu Met Asp Tyr
145 150 155 160
Ala Glu Lys His Gly Ile Pro Ile Glu Arg His Gly Lys Lys Lys Ser
165 170 175
Pro Tyr Ser Met Asp Ala Asn Leu Leu His Ile Ser Tyr Glu Gly Gly
180 185 190
Val Leu Glu Asp Thr Trp Thr Glu His Glu Glu Asp Met Trp Arg Trp
195 200 205
Ser Val Ser Pro Glu Asn Ala Pro Asp Gln Ala Thr Tyr Ile Glu Leu
210 215 220
Thr Tyr Arg Asn Gly Asp Ile Val Ala Ile Asp Gly Val Glu Lys Ser
225 230 235 240
Pro Ala Thr Val Leu Ala Asp Leu Asn Arg Ile Gly Gly Ala Asn Gly
245 250 255
Ile Gly Arg Leu Asp Ile Val Glu Asn Arg Tyr Val Gly Met Lys Ser
260 265 270
Arg Gly Cys Tyr Glu Thr Pro Gly Gly Thr Ile Met Leu Lys Ala His
275 280 285
Arg Ala Ile Glu Ser Ile Thr Leu Asp Arg Glu Val Ala His Leu Lys
290 295 300
Asp Glu Leu Met Pro Lys Tyr Ala Ser Leu Ile Tyr Thr Gly Tyr Trp
305 310 315 320
Trp Ser Pro Glu Arg Leu Met Leu Gln Gln Met Ile Asp Ala Ser Gln
325 330 335
Val Asn Val Asn Gly Val Val Arg Leu Lys Leu Tyr Lys Gly Asn Val
340 345 350
Thr Val Val Gly Arg Lys Ser Asp Asp Ser Leu Phe Asp Ala Asn Ile
355 360 365
Ala Thr Phe Glu Glu Asp Gly Gly Ala Tyr Asn Gln Ala Asp Ala Ala
370 375 380
Gly Phe Ile Lys Leu Asn Ala Leu Arg Met Arg Ile Ala Ala Asn Lys
385 390 395 400
Gly Arg Ser Leu Leu
405
<210> 43
<211> 1407
<212> DNA
<213> Pseudomonas putida
<220>
<221> CDS
<222> (1)..(1407)
<400> 43
atg agt gaa tcc atg agc acc gag aag acc aat cag tcc tgg ggc ggc 48
Met Ser Glu Ser Met Ser Thr Glu Lys Thr Asn Gln Ser Trp Gly Gly
1 5 10 15
cgc ttc agt gag ccc gtc gac gcc ttc gtc gcc cgt ttc acc gcc tcg 96
Arg Phe Ser Glu Pro Val Asp Ala Phe Val Ala Arg Phe Thr Ala Ser
20 25 30
gta gat ttc gac aag cgc ctg tac cgt cac gac atc atg ggt tcg att 144
Val Asp Phe Asp Lys Arg Leu Tyr Arg His Asp Ile Met Gly Ser Ile
35 40 45
gcc cat gcc acc atg ctg gcg cag gtc ggc gtg ctc agt gat gcc gag 192
Ala His Ala Thr Met Leu Ala Gln Val Gly Val Leu Ser Asp Ala Glu
50 55 60
cgc gac acc atc atc gat ggc ctg aaa acc atc cag ggc gag att gaa 240
Arg Asp Thr Ile Ile Asp Gly Leu Lys Thr Ile Gln Gly Glu Ile Glu
65 70 75 80
gcc ggc aac ttc gac tgg cgt gtc gac ctc gaa gac gtg cac atg aac 288
Ala Gly Asn Phe Asp Trp Arg Val Asp Leu Glu Asp Val His Met Asn
85 90 95
atc gaa gca cgc ctg acc gac cgc atc ggc atc acc ggc aag aag ctg 336
Ile Glu Ala Arg Leu Thr Asp Arg Ile Gly Ile Thr Gly Lys Lys Leu
100 105 110
cat act ggg cgt agc cgc aac gac cag gtg gcc acc gac atc cgc ctt 384
His Thr Gly Arg Ser Arg Asn Asp Gln Val Ala Thr Asp Ile Arg Leu
115 120 125
tgg ctg cgc gac gaa atc gac ctg atc ctg ggc gaa atc acc cgc ctg 432
Trp Leu Arg Asp Glu Ile Asp Leu Ile Leu Gly Glu Ile Thr Arg Leu
130 135 140
cag cag ggc ctg ctg gag cag gca gag cgt gaa gcc gaa acc atc atg 480
Gln Gln Gly Leu Leu Glu Gln Ala Glu Arg Glu Ala Glu Thr Ile Met
145 150 155 160
cct ggt ttc acc cac ctg cag acg gcg cag ccg gtc acc ttt ggc cac 528
Pro Gly Phe Thr His Leu Gln Thr Ala Gln Pro Val Thr Phe Gly His
165 170 175
cac ctg ctg gcg tgg ttc gaa atg ctc agc cgc gac tat gag cgc ctg 576
His Leu Leu Ala Trp Phe Glu Met Leu Ser Arg Asp Tyr Glu Arg Leu
180 185 190
gtc gac tgc cgc aag cgc acc aac cgc atg cca ctg ggc agc gcc gcg 624
Val Asp Cys Arg Lys Arg Thr Asn Arg Met Pro Leu Gly Ser Ala Ala
195 200 205
ctg gcc ggc acc acc tac ccg atc gac cgt gaa ctg acc tgc aag ctg 672
Leu Ala Gly Thr Thr Tyr Pro Ile Asp Arg Glu Leu Thr Cys Lys Leu
210 215 220
ctg ggc ttt gaa gcc gtg gcc ggc aac tcg ctg gat ggc gtg tcg gac 720
Leu Gly Phe Glu Ala Val Ala Gly Asn Ser Leu Asp Gly Val Ser Asp
225 230 235 240
cgt gat ttc gcc atc gaa ttc tgc gcc gct gcc agc gtg gcg atg atg 768
Arg Asp Phe Ala Ile Glu Phe Cys Ala Ala Ala Ser Val Ala Met Met
245 250 255
cac ctt tcg cgc ttc tcc gaa gag ctg gtg ctg tgg acc agc gcg cag 816
His Leu Ser Arg Phe Ser Glu Glu Leu Val Leu Trp Thr Ser Ala Gln
260 265 270
ttc cag ttc atc gac ctt ccg gac cgc ttc tgc act ggc agc tcg atc 864
Phe Gln Phe Ile Asp Leu Pro Asp Arg Phe Cys Thr Gly Ser Ser Ile
275 280 285
atg ccg cag aaa aag aac ccg gac gtg cca gag ctg gta cgt ggc aag 912
Met Pro Gln Lys Lys Asn Pro Asp Val Pro Glu Leu Val Arg Gly Lys
290 295 300
agc ggc cgc gtg ttc ggc gcc ctg acc ggc ctg ctg acc ctg atg aaa 960
Ser Gly Arg Val Phe Gly Ala Leu Thr Gly Leu Leu Thr Leu Met Lys
305 310 315 320
ggc caa ccg ctg gcc tac aac aag gac aac cag gaa gac aag gaa ccg 1008
Gly Gln Pro Leu Ala Tyr Asn Lys Asp Asn Gln Glu Asp Lys Glu Pro
325 330 335
ctg ttc gac gcc gcc gat acc ctg cgc gac tcg ctg cgg gcc ttc gct 1056
Leu Phe Asp Ala Ala Asp Thr Leu Arg Asp Ser Leu Arg Ala Phe Ala
340 345 350
gac atg atc ccg gcg atc aag ccc aag cac gcc atc atg cgt gaa gcg 1104
Asp Met Ile Pro Ala Ile Lys Pro Lys His Ala Ile Met Arg Glu Ala
355 360 365
gcc ctg cgc ggt ttc tcc acc gct acc gac ctg gct gac tat ctg gtt 1152
Ala Leu Arg Gly Phe Ser Thr Ala Thr Asp Leu Ala Asp Tyr Leu Val
370 375 380
cgc cgt ggc ctg ccg ttc cgt gac tgc cac gag atc gtt ggc cac gcg 1200
Arg Arg Gly Leu Pro Phe Arg Asp Cys His Glu Ile Val Gly His Ala
385 390 395 400
gtg aag tat ggt gtg gac act ggc aag gac ctg gcc gag atg agc ctg 1248
Val Lys Tyr Gly Val Asp Thr Gly Lys Asp Leu Ala Glu Met Ser Leu
405 410 415
gac gaa ctg cgc caa ttc agc gac cag atc gag cag gac gtg ttt gcc 1296
Asp Glu Leu Arg Gln Phe Ser Asp Gln Ile Glu Gln Asp Val Phe Ala
420 425 430
gtg ctg acg ctg gaa ggc tcg gtg aat gcg cgt gac cac att ggt ggt 1344
Val Leu Thr Leu Glu Gly Ser Val Asn Ala Arg Asp His Ile Gly Gly
435 440 445
acg gcg ccg gcg cag gtg cgt gct gcc gtc gtt cgt ggc aag gcc ctg 1392
Thr Ala Pro Ala Gln Val Arg Ala Ala Val Val Arg Gly Lys Ala Leu
450 455 460
ttg gcg tct cgc taa 1407
Leu Ala Ser Arg
465
<210> 44
<211> 468
<212> PRT
<213> Pseudomonas putida
<400> 44
Met Ser Glu Ser Met Ser Thr Glu Lys Thr Asn Gln Ser Trp Gly Gly
1 5 10 15
Arg Phe Ser Glu Pro Val Asp Ala Phe Val Ala Arg Phe Thr Ala Ser
20 25 30
Val Asp Phe Asp Lys Arg Leu Tyr Arg His Asp Ile Met Gly Ser Ile
35 40 45
Ala His Ala Thr Met Leu Ala Gln Val Gly Val Leu Ser Asp Ala Glu
50 55 60
Arg Asp Thr Ile Ile Asp Gly Leu Lys Thr Ile Gln Gly Glu Ile Glu
65 70 75 80
Ala Gly Asn Phe Asp Trp Arg Val Asp Leu Glu Asp Val His Met Asn
85 90 95
Ile Glu Ala Arg Leu Thr Asp Arg Ile Gly Ile Thr Gly Lys Lys Leu
100 105 110
His Thr Gly Arg Ser Arg Asn Asp Gln Val Ala Thr Asp Ile Arg Leu
115 120 125
Trp Leu Arg Asp Glu Ile Asp Leu Ile Leu Gly Glu Ile Thr Arg Leu
130 135 140
Gln Gln Gly Leu Leu Glu Gln Ala Glu Arg Glu Ala Glu Thr Ile Met
145 150 155 160
Pro Gly Phe Thr His Leu Gln Thr Ala Gln Pro Val Thr Phe Gly His
165 170 175
His Leu Leu Ala Trp Phe Glu Met Leu Ser Arg Asp Tyr Glu Arg Leu
180 185 190
Val Asp Cys Arg Lys Arg Thr Asn Arg Met Pro Leu Gly Ser Ala Ala
195 200 205
Leu Ala Gly Thr Thr Tyr Pro Ile Asp Arg Glu Leu Thr Cys Lys Leu
210 215 220
Leu Gly Phe Glu Ala Val Ala Gly Asn Ser Leu Asp Gly Val Ser Asp
225 230 235 240
Arg Asp Phe Ala Ile Glu Phe Cys Ala Ala Ala Ser Val Ala Met Met
245 250 255
His Leu Ser Arg Phe Ser Glu Glu Leu Val Leu Trp Thr Ser Ala Gln
260 265 270
Phe Gln Phe Ile Asp Leu Pro Asp Arg Phe Cys Thr Gly Ser Ser Ile
275 280 285
Met Pro Gln Lys Lys Asn Pro Asp Val Pro Glu Leu Val Arg Gly Lys
290 295 300
Ser Gly Arg Val Phe Gly Ala Leu Thr Gly Leu Leu Thr Leu Met Lys
305 310 315 320
Gly Gln Pro Leu Ala Tyr Asn Lys Asp Asn Gln Glu Asp Lys Glu Pro
325 330 335
Leu Phe Asp Ala Ala Asp Thr Leu Arg Asp Ser Leu Arg Ala Phe Ala
340 345 350
Asp Met Ile Pro Ala Ile Lys Pro Lys His Ala Ile Met Arg Glu Ala
355 360 365
Ala Leu Arg Gly Phe Ser Thr Ala Thr Asp Leu Ala Asp Tyr Leu Val
370 375 380
Arg Arg Gly Leu Pro Phe Arg Asp Cys His Glu Ile Val Gly His Ala
385 390 395 400
Val Lys Tyr Gly Val Asp Thr Gly Lys Asp Leu Ala Glu Met Ser Leu
405 410 415
Asp Glu Leu Arg Gln Phe Ser Asp Gln Ile Glu Gln Asp Val Phe Ala
420 425 430
Val Leu Thr Leu Glu Gly Ser Val Asn Ala Arg Asp His Ile Gly Gly
435 440 445
Thr Ala Pro Ala Gln Val Arg Ala Ala Val Val Arg Gly Lys Ala Leu
450 455 460
Leu Ala Ser Arg
465
<210> 45
<211> 3701
<212> DNA
<213> Pseudomonas putida
<400> 45
tctagagatc cgcgggggcc cgacctgcat accgttgcag ataaggtagt cactcatgag 60
cgctaggcac tttctctccc tgctggactt caccaccgac gaattgctcg gggtgatccg 120
ccacggcatc gagctgaagg acctgcgcaa gcgaggcgtg ctgttcgaac cgctgaagaa 180
ccgtgtgcta ggcatgatct tcgaaaagtc ctcgacccgt acccgtgtgt cgttcgaggc 240
cggcatgatc cagctcggcg gccaggccat cttcctgtcg ccccgcgaca cccagctggg 300
ccgcggcgag ccaattggtg acagcgccat cgtgctgtcg agcatggttg atgtggtgat 360
gatccggacc cacgcccaca gcaccctgac cgagttcgcc gccaagtcgc gtgtgcccgt 420
gatcaacggc ctgtccgacg aatcgcaccc gtgccaactg ctggccgaca tgcagacctt 480
cgttgaacac cgcggctcga ttcagggcaa gaccgtgacc tggatcggcg atggcttcaa 540
catgtgcaac tcctatatcg aagccgccag gcagttcgat ttccagctgc gcatcgcctg 600
ccccgaaggc tatgagccgg atcaacgctt catggcactg ggcggcgacc gcgtgcagat 660
catccgggat gccagggaag ctgtgcgtga tgcacacctg gtggtcaccg atgtctggac 720
ttccatgggt caggaggagg aaactgcacg gcgcctggcg catttcgcgc cttaccaggt 780
cacccgcgaa ctgctcgacc tggctgcacc cgatgtcctc ttcatgcact gcctgcccgc 840
ccaccgtggc gaggaaatca gccaggacct gctcgacgac ccacgttcgg tcgcctggga 900
cgaggctgaa aaccgcctgc atgcacagaa ggcgcttctc gaattccttg tagaaccggc 960
ttaccaccac gcatgagtca accgtacaac cccgtggagt gatggcatgg cggacgtaaa 1020
aaaggtcgta ctggcgtatt ccggcggcct tgatacttcg gtgattctca agtggctgca 1080
ggatacctac aactgcgaag tggtgacctt caccgctgac ctggggcagg gcgaagaggt 1140
cgaaccggcc cgtgccaagg cccaggcaat gggcgttaaa gagatctaca tcgacgacct 1200
gcgcgaagaa ttcgtgcgtg atttcgtgtt cccgatgttc cgcgccaaca ccgtctacga 1260
aggcgagtac ctgctgggta cttccatcgc ccgtccgctg atcgccaagc gcctgatcga 1320
aatcgccaac gaaaccggcg ctgacgccat ttcccatggc gccaccggca agggtaacga 1380
ccaggtgcgc ttcgagctgg gtgcctatgc cctgaagcca ggcgtcaagg tcatcgctcc 1440
atggcgcgag tgggacctgc tgtcccgcga aaagctgatg gactacgccg agaagcacgg 1500
catcccgatc gagcgccacg gcaagaagaa gtcgccgtac tcgatggacg ccaacctgct 1560
gcacatctcc tacgagggcg gtgtcctgga agatacctgg accgagcacg aagaagacat 1620
gtggcgctgg agtgtctcgc ctgagaatgc cccggaccag gctacctaca tcgagctgac 1680
ctaccgcaat ggtgacatcg ttgccatcga cggcgtcgag aaatccccgg ccaccgtcct 1740
ggcagacctg aaccgtatcg gtggtgccaa cggcatcggc cgtctggaca tcgtcgaaaa 1800
ccgttacgtc ggcatgaagt cgcgcggttg ctacgaaacg cctggcggta ccatcatgct 1860
caaggcacac cgtgccatcg agtcgatcac cctggaccgc gaagtcgctc acctgaaaga 1920
tgagctgatg ccaaagtatg ccagcctgat ctacaccggc tactggtgga gcccggagcg 1980
tctgatgctg caacagatga tcgatgcttc gcaggtcaac gtgaatggtg tggtgcgcct 2040
gaaactgtac aagggcaacg tgaccgtggt tggccgcaag tcggacgatt cgctgttcga 2100
tgccaacatc gccacctttg aagaagatgg tggtgcctac aaccaggcag atgctgctgg 2160
cttcatcaag ctcaatgcac tgcgtatgcg cattgccgcc aacaagggcc gttcgctgct 2220
ctgattgcta tcgacgccac tttttcgttc acgcctgcaa tgagtgaatc catgagcacc 2280
gagaagacca atcagtcctg gggcggccgc ttcagtgagc ccgtcgacgc cttcgtcgcc 2340
cgtttcaccg cctcggtaga tttcgacaag cgcctgtacc gtcacgacat catgggttcg 2400
attgcccatg ccaccatgct ggcgcaggtc ggcgtgctca gtgatgccga gcgcgacacc 2460
atcatcgatg gcctgaaaac catccagggc gagattgaag ccggcaactt cgactggcgt 2520
gtcgacctcg aagacgtgca catgaacatc gaagcacgcc tgaccgaccg catcggcatc 2580
accggcaaga agctgcatac tgggcgtagc cgcaacgacc aggtggccac cgacatccgc 2640
ctttggctgc gcgacgaaat cgacctgatc ctgggcgaaa tcacccgcct gcagcagggc 2700
ctgctggagc aggcagagcg tgaagccgaa accatcatgc ctggtttcac ccacctgcag 2760
acggcgcagc cggtcacctt tggccaccac ctgctggcgt ggttcgaaat gctcagccgc 2820
gactatgagc gcctggtcga ctgccgcaag cgcaccaacc gcatgccact gggcagcgcc 2880
gcgctggccg gcaccaccta cccgatcgac cgtgaactga cctgcaagct gctgggcttt 2940
gaagccgtgg ccggcaactc gctggatggc gtgtcggacc gtgatttcgc catcgaattc 3000
tgcgccgctg ccagcgtggc gatgatgcac ctttcgcgct tctccgaaga gctggtgctg 3060
tggaccagcg cgcagttcca gttcatcgac cttccggacc gcttctgcac tggcagctcg 3120
atcatgccgc agaaaaagaa cccggacgtg ccagagctgg tacgtggcaa gagcggccgc 3180
gtgttcggcg ccctgaccgg cctgctgacc ctgatgaaag gccaaccgct ggcctacaac 3240
aaggacaacc aggaagacaa ggaaccgctg ttcgacgccg ccgataccct gcgcgactcg 3300
ctgcgggcct tcgctgacat gatcccggcg atcaagccca agcacgccat catgcgtgaa 3360
gcggccctgc gcggtttctc caccgctacc gacctggctg actatctggt tcgccgtggc 3420
ctgccgttcc gtgactgcca cgagatcgtt ggccacgcgg tgaagtatgg tgtggacact 3480
ggcaaggacc tggccgagat gagcctggac gaactgcgcc aattcagcga ccagatcgag 3540
caggacgtgt ttgccgtgct gacgctggaa ggctcggtga atgcgcgtga ccacattggt 3600
ggtacggcgc cggcgcaggt gcgtgctgcc gtcgttcgtg gcaaggccct gttggcgtct 3660
cgctaatccc ccaaggctcg agcacgcgag agtagggaac t 3701
<210> 46
<211> 23
<212> DNA
<213> synthetic oligonucleotide
<400> 46
ggatccgcgt cagccgcaaa tcg 23
<210> 47
<211> 45
<212> DNA
<213> synthetic oligonucleotide
<400> 47
tttgcggctg acgcggatcc cgacctgcat accgttgcag ataag 45
<210> 48
<211> 22
<212> DNA
<213> synthetic oligonucleotide
<400> 48
agttccctac tctcgcgtgc tc 22
<210> 49
<211> 13891
<212> DNA
<213> various
<400> 49
tcaggcgggc aagaatgtga ataaaggccg gataaaactt gtgcttattt ttctttacgg 60
tctttaaaaa ggccgtaata tccagctgaa cggtctggtt ataggtacat tgagcaactg 120
actgaaatgc ctcaaaatgt tctttacgat gccattggga tatatcaacg gtggtatatc 180
cagtgatttt tttctccatt ttagcttcct tagctcctga aaatctcgat aactcaaaaa 240
atacgcccgg tagtgatctt atttcattat ggtgaaagtt ggaacctctt acgtgccgat 300
caacgtctca ttttcgccaa aagttggccc agggcttccc ggtatcaaca gggacaccag 360
gatttattta ttctgcgaag tgatcttccg tcacaggtat ttattcggcg caaagtgcgt 420
cgggtgatgc tgccaactta ctgatttagt gtatgatggt gtttttgagg tgctccagtg 480
gcttctgttt ctatcagctg tccctcctgt tcagctactg acggggtggt gcgtaacggc 540
aaaagcaccg ccggacatca gcgctagcgg agtgtatact ggcttactat gttggcactg 600
atgagggtgt cagtgaagtg cttcatgtgg caggagaaaa aaggctgcac cggtgcgtca 660
gcagaatatg tgatacagga tatattccgc ttcctcgctc actgactcgc tacgctcggt 720
cgttcgactg cggcgagcgg aaatggctta cgaacggggc ggagatttcc tggaagatgc 780
caggaagata cttaacaggg aagtgagagg gccgcggcaa agccgttttt ccataggctc 840
cgcccccctg acaagcatca cgaaatctga cgctcaaatc agtggtggcg aaacccgaca 900
ggactataaa gataccaggc gtttccccct ggcggctccc tcgtgcgctc tcctgttcct 960
gcctttcggt ttaccggtgt cattccgctg ttatggccgc gtttgtctca ttccacgcct 1020
gacactcagt tccgggtagg cagttcgctc caagctggac tgtatgcacg aaccccccgt 1080
tcagtccgac cgctgcgcct tatccggtaa ctatcgtctt gagtccaacc cggaaagaca 1140
tgcaaaagca ccactggcag cagccactgg taattgattt agaggagtta gtcttgaagt 1200
catgcgccgg ttaaggctaa actgaaagga caagttttgg tgactgcgct cctccaagcc 1260
agttacctcg gttcaaagag ttggtagctc agagaacctt cgaaaaaccg ccctgcaagg 1320
cggttttttc gttttcagag caagagatta cgcgcagacc aaaacgatct caagaagatc 1380
atcttattaa tcagataaaa tatttctaga tttcagtgca atttatctct tcaaatgtag 1440
cacctgaagt cagccccata cgatataagt tgtaattctc atgtttgaca gcttatcatc 1500
gataagcttt aatgcggtag tttatcacag ttaaattgct aacgcagtca ggcaccgtgt 1560
atgaaatcta acaatgcgct catcgtcatc ctcggcaccg tcaccctgga tgctgtaggc 1620
ataggcttgg ttatgccggt actgccgggc ctcttgcggg atatcgtcca ttccgacagc 1680
atcgccagtc actatggcgt gctgctagcg ctatatgcgt tgatgcaatt tctatgcgca 1740
cccgttctcg gagcactgtc cgaccgcttt ggccgccgcc cagtcctgct cgcttcgcta 1800
cttggagcca ctatcgacta cgcgatcatg gcgaccacac ccgtcctgtg gatcctctac 1860
gccggacgca tcgtggccgg catcaccggc gccacaggtg cggttgctgg cgcctatatc 1920
gccgacatca ccgatgggga agatcgggct cgccacttcg ggctcatgag cgcttgtttc 1980
ggcgtgggta tggtggcagg ccccgtggcc gggggactgt tgggcgccat ctccttgcat 2040
gcaccattcc ttgcggcggc ggtgctcaac ggcctcaacc tactactggg ctgcttccta 2100
atgcaggagt cgcataaggg agagcgtcga ccgatgccct tgagagcctt caacccagtc 2160
agctccttcc ggtgggcgcg gggcatgact atcgtcgccg cacttatgac tgtcttcttt 2220
atcatgcaac tcgtaggaca ggtgccggca gcgctctggg tcattttcgg cgaggaccgc 2280
tttcgctgga gcgcgacgat gatcggcctg tcgcttgcgg tattcggaat cttgcacgcc 2340
ctcgctcaag ccttcgtcac tggtcccgcc accaaacgtt tcggcgagaa gcaggccatt 2400
atcgccggca tggcggccga cgcgctgggc tacgtcttgc tggcgttcgc gacgcgaggc 2460
tggatggcct tccccattat gattcttctc gcttccggcg gcatcgggat gcccgcgttg 2520
caggccatgc tgtccaggca ggtagatgac gaccatcagg gacagcttca aggatcgctc 2580
gcggctctta ccagcctaac ttcgatcatt ggaccgctga tcgtcacggc gatttatgcc 2640
gcctcggcga gcacatggaa cgggttggca tggattgtag gcgccgccct ataccttgtc 2700
tgcctccccg cgttgcgtcg cggtgcatgg agccgggcca cctcgacctg aatggaagcc 2760
ggcggcacct cgctaacgga ttcaccactc caagaattgg agccaatcaa ttcttgcgga 2820
gaactgtgaa tgcgcaaacc aacccttggc agaacatatc catcgcgtcc gccatctcca 2880
gcagccgcac gcggcgcatc tcgggcagcg ttgggtcctg gccacgggtg cgcatgatcg 2940
tgctcctgtc gttgaggacc cggctaggct ggcggggttg ccttactggt tagcagaatg 3000
aatcaccgat acgcgagcga acgtgaagcg actgctgctg caaaacgtct gcgacctgag 3060
caacaacatg aatggtcttc ggtttccgtg tttcgtaaag tctggaaacg cggaagtccc 3120
ctacgtgctg ctgaagttgc ccgcaacaga gagtggaacc aaccggtgat accacgatac 3180
tatgactgag agtcaacgcc atgagcggcc tcatttctta ttctgagtta caacagtccg 3240
caccgctgtc cggtagctcc ttccggtggg cgcggggcat gactatcgtc gccgcactta 3300
tgactgtctt ctttatcatg caactcgtag gacaggtgcc ggcagcgccc aacagtcccc 3360
cggccacggg gcctgccacc atacccacgc cgaaacaagc gccctgcacc attatgttcc 3420
ggatctgcat cgcaggatgc tgctggctac cctgtggaac acctacatct gtattaacga 3480
agcgctaacc gtttttatca ggctctggga ggcagaataa atgatcatat cgtcaattat 3540
tacctccacg gggagagcct gagcaaactg gcctcaggca tttgagaagc acacggtcac 3600
actgcttccg gtagtcaata aaccggtaaa ccagcaatag acataagcgg ctatttaacg 3660
accctgccct gaaccgacga ccgggtcgaa tttgctttcg aatttctgcc attcatccgc 3720
ttattatcac ttattcaggc gtagcaccag gcgtttaagg gcaccaataa ctgccttaaa 3780
aaaattacgc cccgccctgc cactcatcgc agtactgttg taattcatta agcattctgc 3840
cgacatggaa gccatcacaa acggcatgat gaacctgaat cgccagcggc atcagcacct 3900
tgtcgccttg cgtataatat ttgcccatgg atttaaattt aatctttctg cgaattgaga 3960
tgacgccact ggctgggcgt catcccggtt tcccgggtaa acaccaccga aaaatagtta 4020
ctatcttcaa agccacattc ggtcgaaata tcactgatta acaggcggct atgctggaga 4080
agatattgcg catgacacac tctgacctgt cgcagatatt gattgatggt cattccagtc 4140
tgctggcgaa attgctgacg caaaacgcgc tcactgcacg atgcctcatc acaaaattta 4200
tccagcgcaa agggactttt caggctagcc gccagccggg taatcagctt atccagcaac 4260
gtttcgctgg atgttggcgg caacgaatca ctggtgtaac gatggcgatt cagcaacatc 4320
accaactgcc cgaacagcaa ctcagccatt tcgttagcaa acggcacatg ctgactactt 4380
tcatgctcaa gctgaccgat aacctgccgc gcctgcgcca tccccatgct acctaagcgc 4440
cagtgtggtt gccctgcgct ggcgttaaat cccggaatcg ccccctgcca gtcaagattc 4500
agcttcagac gctccgggca ataaataata ttctgcaaaa ccagatcgtt aacggaagcg 4560
taggagtgtt tatcgtcagc atgaatgtaa aagagatcgc cacgggtaat gcgataaggg 4620
cgatcgttga gtacatgcag gccattaccg cgccagacaa tcaccagctc acaaaaatca 4680
tgtgtatgtt cagcaaagac atcttgcgga taacggtcag ccacagcgac tgcctgctgg 4740
tcgctggcaa aaaaatcatc tttgagaagt tttaactgat gcgccaccgt ggctacctcg 4800
gccagagaac gaagttgatt attcgcaata tggcgtacaa atacgttgag aagattcgcg 4860
ttattgcaga aagccatccc gtccctggcg aatatcacgc ggtgaccagt taaactctcg 4920
gcgaaaaagc gtcgaaaagt ggttactgtc gctgaatcca cagcgatagg cgatgtcagt 4980
aacgctggcc tcgctgtggc gtagcagatg tcgggctttc atcagtcgca ggcggttcag 5040
gtatcgctga ggcgtcagtc ccgtttgctg cttaagctgc cgatgtagcg tacgcagtga 5100
aagagaaaat tgatccgcca cggcatccca attcacctca tcggcaaaat ggtcctccag 5160
ccaggccaga agcaagttga gacgtgatgc gctgttttcc aggttctcct gcaaactgct 5220
tttacgcagc aagagcagta attgcataaa caagatctcg cgactggcgg tcgagggtaa 5280
atcattttcc ccttcctgct gttccatctg tgcaaccagc tgtcgcacct gctgcaatac 5340
gctgtggtta acgcgccagt gagacggata ctgcccatcc agctcttgtg gcagcaactg 5400
attcagcccg gcgagaaact gaaatcgatc cggcgagcga tacagcacat tggtcagaca 5460
cagattatcg gtatgttcat acagatgccg atcatgatcg cgtacgaaac agaccgtgcc 5520
accggtgatg gtatagggct gcccattaaa cacatgaata cccgtgccat gttcgacaat 5580
cacaatttca tgaaaatcat gatgatgttc aggaaaatcc gcctgcggga gccggggttc 5640
tatcgccacg gacgcgttac cagacggaaa aaaatccaca ctatgtaata cggtcatact 5700
ggcctcctga tgtcgtcaac acggcgaaat agtaatcacg aggtcaggtt cttaccttaa 5760
attttcgacg gaaaaccacg taaaaaacgt cgatttttca agatacagcg tgaattttca 5820
ggaaatgcgg tgagcatcac atcaccacaa ttcagcaaat tgtgaacatc atcacgttca 5880
tctttccctg gttgccaatg gcccattttc ctgtcagtaa cgagaaggtc gcgaattcag 5940
gcgcttttta gactggtcgt aatgaacatt taaatgaatt cccttgggac tctagagatc 6000
cgcgggggcc caggaggggg gatctggcat ttttgggagg tgtgaaatga gtgagaagat 6060
cgtcaactcg tggaacgaat gggatgagct cgaggagatg gtggtcggca ttgcggacta 6120
tgccagcttc gaaccgaaag agccaggcaa ccatcccaaa ctgcgcaacc agaacctggc 6180
cgaaatcatc cccttcccaa gcggcccaaa ggacccgaag gtgctggaga aagcgaacga 6240
agagctgaat gggctggctt acctgctgaa ggaccacgat gtgatcgtgc gtcgtcccga 6300
gaagatcgac ttcaccaaga gcctgaaaac cccgtatttc gaggttgcca accagtactg 6360
cggcgtttgt cctcgcgacg tgatgatcac gtttggcaac gaaatcatgg aagcgaccat 6420
gtccaaacgt gcacgcttct tcgaatacct cccctatcgg aagctggtct acgagtactg 6480
gaacaaggac gagcacatga tctggaacgc agccccgaaa ccgaccatgc aggatagcat 6540
gtacctggaa aacttctggg agctctcgct ggaagaacgc ttcaagcgga tgcacgactt 6600
cgaattctgc atcacccaag acgaggtgat cttcgatgcc gccgattgct cccgcttggg 6660
taaggacatc ctggtgcagg aaagcatgac caccaatcgc actggcatcc gctggctgaa 6720
gaagcatctc gaaccacgcg gctttcgcgt ccatccggtg cacttcccgt tggacttctt 6780
ccctagccac atcgactgca cgttcgtacc gttgcgtccg ggtctgatcc tgaccaatcc 6840
ggaacgcccg attcgcgagg aagaggagaa gatcttcaag gagaatggct gggagctgat 6900
caccgtaccg cagcctacct gctcgaacga cgagatgccc atgttctgcc agagctcgaa 6960
atggctgtcc atgaacgtcc tgagcattag tcccaccaag gtgatctgcg aagaacggga 7020
aaagccgctg caagaactgc tggacaagca cgggttcgaa gtctttccct tgcctttccg 7080
ccatgtgttt gagttcggtg gcagctttca ctgtgccacg tgggatattc gccgcaaggg 7140
cgagtgcgag gactacctgc cgaacctgaa ctaccagccg atttgcggct gacgcggatc 7200
ccgacctgca taccgttgca gataaggtag tcactcatga gcgctaggca ctttctctcc 7260
ctgctggact tcaccaccga cgaattgctc ggggtgatcc gccacggcat cgagctgaag 7320
gacctgcgca agcgaggcgt gctgttcgaa ccgctgaaga accgtgtgct aggcatgatc 7380
ttcgaaaagt cctcgacccg tacccgtgtg tcgttcgagg ccggcatgat ccagctcggc 7440
ggccaggcca tcttcctgtc gccccgcgac acccagctgg gccgcggcga gccaattggt 7500
gacagcgcca tcgtgctgtc gagcatggtt gatgtggtga tgatccggac ccacgcccac 7560
agcaccctga ccgagttcgc cgccaagtcg cgtgtgcccg tgatcaacgg cctgtccgac 7620
gaatcgcacc cgtgccaact gctggccgac atgcagacct tcgttgaaca ccgcggctcg 7680
attcagggca agaccgtgac ctggatcggc gatggcttca acatgtgcaa ctcctatatc 7740
gaagccgcca ggcagttcga tttccagctg cgcatcgcct gccccgaagg ctatgagccg 7800
gatcaacgct tcatggcact gggcggcgac cgcgtgcaga tcatccggga tgccagggaa 7860
gctgtgcgtg atgcacacct ggtggtcacc gatgtctgga cttccatggg tcaggaggag 7920
gaaactgcac ggcgcctggc gcatttcgcg ccttaccagg tcacccgcga actgctcgac 7980
ctggctgcac ccgatgtcct cttcatgcac tgcctgcccg cccaccgtgg cgaggaaatc 8040
agccaggacc tgctcgacga cccacgttcg gtcgcctggg acgaggctga aaaccgcctg 8100
catgcacaga aggcgcttct cgaattcctt gtagaaccgg cttaccacca cgcatgagtc 8160
aaccgtacaa ccccgtggag tgatggcatg gcggacgtaa aaaaggtcgt actggcgtat 8220
tccggcggcc ttgatacttc ggtgattctc aagtggctgc aggataccta caactgcgaa 8280
gtggtgacct tcaccgctga cctggggcag ggcgaagagg tcgaaccggc ccgtgccaag 8340
gcccaggcaa tgggcgttaa agagatctac atcgacgacc tgcgcgaaga attcgtgcgt 8400
gatttcgtgt tcccgatgtt ccgcgccaac accgtctacg aaggcgagta cctgctgggt 8460
acttccatcg cccgtccgct gatcgccaag cgcctgatcg aaatcgccaa cgaaaccggc 8520
gctgacgcca tttcccatgg cgccaccggc aagggtaacg accaggtgcg cttcgagctg 8580
ggtgcctatg ccctgaagcc aggcgtcaag gtcatcgctc catggcgcga gtgggacctg 8640
ctgtcccgcg aaaagctgat ggactacgcc gagaagcacg gcatcccgat cgagcgccac 8700
ggcaagaaga agtcgccgta ctcgatggac gccaacctgc tgcacatctc ctacgagggc 8760
ggtgtcctgg aagatacctg gaccgagcac gaagaagaca tgtggcgctg gagtgtctcg 8820
cctgagaatg ccccggacca ggctacctac atcgagctga cctaccgcaa tggtgacatc 8880
gttgccatcg acggcgtcga gaaatccccg gccaccgtcc tggcagacct gaaccgtatc 8940
ggtggtgcca acggcatcgg ccgtctggac atcgtcgaaa accgttacgt cggcatgaag 9000
tcgcgcggtt gctacgaaac gcctggcggt accatcatgc tcaaggcaca ccgtgccatc 9060
gagtcgatca ccctggaccg cgaagtcgct cacctgaaag atgagctgat gccaaagtat 9120
gccagcctga tctacaccgg ctactggtgg agcccggagc gtctgatgct gcaacagatg 9180
atcgatgctt cgcaggtcaa cgtgaatggt gtggtgcgcc tgaaactgta caagggcaac 9240
gtgaccgtgg ttggccgcaa gtcggacgat tcgctgttcg atgccaacat cgccaccttt 9300
gaagaagatg gtggtgccta caaccaggca gatgctgctg gcttcatcaa gctcaatgca 9360
ctgcgtatgc gcattgccgc caacaagggc cgttcgctgc tctgattgct atcgacgcca 9420
ctttttcgtt cacgcctgca atgagtgaat ccatgagcac cgagaagacc aatcagtcct 9480
ggggcggccg cttcagtgag cccgtcgacg ccttcgtcgc ccgtttcacc gcctcggtag 9540
atttcgacaa gcgcctgtac cgtcacgaca tcatgggttc gattgcccat gccaccatgc 9600
tggcgcaggt cggcgtgctc agtgatgccg agcgcgacac catcatcgat ggcctgaaaa 9660
ccatccaggg cgagattgaa gccggcaact tcgactggcg tgtcgacctc gaagacgtgc 9720
acatgaacat cgaagcacgc ctgaccgacc gcatcggcat caccggcaag aagctgcata 9780
ctgggcgtag ccgcaacgac caggtggcca ccgacatccg cctttggctg cgcgacgaaa 9840
tcgacctgat cctgggcgaa atcacccgcc tgcagcaggg cctgctggag caggcagagc 9900
gtgaagccga aaccatcatg cctggtttca cccacctgca gacggcgcag ccggtcacct 9960
ttggccacca cctgctggcg tggttcgaaa tgctcagccg cgactatgag cgcctggtcg 10020
actgccgcaa gcgcaccaac cgcatgccac tgggcagcgc cgcgctggcc ggcaccacct 10080
acccgatcga ccgtgaactg acctgcaagc tgctgggctt tgaagccgtg gccggcaact 10140
cgctggatgg cgtgtcggac cgtgatttcg ccatcgaatt ctgcgccgct gccagcgtgg 10200
cgatgatgca cctttcgcgc ttctccgaag agctggtgct gtggaccagc gcgcagttcc 10260
agttcatcga ccttccggac cgcttctgca ctggcagctc gatcatgccg cagaaaaaga 10320
acccggacgt gccagagctg gtacgtggca agagcggccg cgtgttcggc gccctgaccg 10380
gcctgctgac cctgatgaaa ggccaaccgc tggcctacaa caaggacaac caggaagaca 10440
aggaaccgct gttcgacgcc gccgataccc tgcgcgactc gctgcgggcc ttcgctgaca 10500
tgatcccggc gatcaagccc aagcacgcca tcatgcgtga agcggccctg cgcggtttct 10560
ccaccgctac cgacctggct gactatctgg ttcgccgtgg cctgccgttc cgtgactgcc 10620
acgagatcgt tggccacgcg gtgaagtatg gtgtggacac tggcaaggac ctggccgaga 10680
tgagcctgga cgaactgcgc caattcagcg accagatcga gcaggacgtg tttgccgtgc 10740
tgacgctgga aggctcggtg aatgcgcgtg accacattgg tggtacggcg ccggcgcagg 10800
tgcgtgctgc cgtcgttcgt ggcaaggccc tgttggcgtc tcgctaatcc cccaaggctc 10860
gagcacgcga gagtagggaa ctgccaggca tcaaataaaa cgaaaggctc agtcgaaaga 10920
ctgggccttt cgttttatct gttgtttgtc ggtgaacgct ctcctgagta ggacaaatcc 10980
gccgggagcg gatttgaacg atgataagct gtcaaacatg agaattcttg aagacgaaag 11040
ggcctcgtgt gtacaaacgt tcgtcaaaag ggcgacacaa aattcctgca ggggccggcc 11100
cagcgccggc ggtcgagtgg cgacggcgcg gcttgtccgc gccctggtag attgcctggc 11160
cgtaggccag ccatttttga gcggccagcg gccgcgatag gccgacgcga agcggcgggg 11220
cgtagggagc gcagcgaccg aagggtaggc gctttttgca gctcttcggc tgtgcgctgg 11280
ccagacagtt atgcacaggc caggcgggtt ttaagagttt taataagttt taaagagttt 11340
taggcggaaa aatcgccttt tttctctttt atatcagtca cttacatgtg tgaccggttc 11400
ccaatgtacg gctttgggtt cccaatgtac gggttccggt tcccaatgta cggctttggg 11460
ttcccaatgt acgtgctatc cacaggaaag agaccttttc gacctttttc ccctgctagg 11520
gcaatttgcc ctagcatctg ctccgtacat taggaaccgg cggatgcttc gccctcgatc 11580
aggttgcggt agcgcatgac taggatcggg ccagcctgcc ccgcctcctc cttcaaatcg 11640
tactccggca ggtcatttga cccgatcagc ttgcgcacgg tgaaacagaa cttcttgaac 11700
tctccggcgc tgccactgcg ttcgtagatc gtcttgaaca accatctggc ttctgccttg 11760
cctgcggcgc ggcgtgccag gcggtagaga aaacggccga tgccgggatc gatcaaaaag 11820
taatcggggt gaaccgtcag cacgtccggg ttcttgcctt ctgtgatctc gcggtacatc 11880
caatcaacta gctcgatctc gatgtactcc ggccgcccgg tttcgctctt tacgatcttg 11940
tagcggctaa tcaaggcttc accctcggat accgtcacca ggcggccgtt cttggccttc 12000
ttcgtacgct gcatggcaac gtgcgtggtg tttaaccgaa tgcaggtttc taccaggtcg 12060
tctttctgct ttccgccatc ggctcgccgg cagaacttga gtacgtccgc aacgtgtgga 12120
cggaacacgc ggccgggctt gtctcccttc ccttcccggt atcggttcat ggattcggtt 12180
agatgggaaa ccgccatcag taccaggtcg taatcccaca cactggccat gccggccggc 12240
cctgcggaaa cctctacgtg cccgtctgga agctcgtagc ggatcacctc gccagctcgt 12300
cggtcacgct tcgacagacg gaaaacggcc acgtccatga tgctgcgact atcgcgggtg 12360
cccacgtcat agagcatcgg aacgaaaaaa tctggttgct cgtcgccctt gggcggcttc 12420
ctaatcgacg gcgcaccggc tgccggcggt tgccgggatt ctttgcggat tcgatcagcg 12480
gccgcttgcc acgattcacc ggggcgtgct tctgcctcga tgcgttgccg ctgggcggcc 12540
tgcgcggcct tcaacttctc caccaggtca tcacccagcg ccgcgccgat ttgtaccggg 12600
ccggatggtt tgcgaccgct cacgccgatt cctcgggctt gggggttcca gtgccattgc 12660
agggccggca gacaacccag ccgcttacgc ctggccaacc gcccgttcct ccacacatgg 12720
ggcattccac ggcgtcggtg cctggttgtt cttgattttc catgccgcct cctttagccg 12780
ctaaaattca tctactcatt tattcatttg ctcatttact ctggtagctg cgcgatgtat 12840
tcagatagca gctcggtaat ggtcttgcct tggcgtaccg cgtacatctt cagcttggtg 12900
tgatcctccg ccggcaactg aaagttgacc cgcttcatgg ctggcgtgtc tgccaggctg 12960
gccaacgttg cagccttgct gctgcgtgcg ctcggacggc cggcacttag cgtgtttgtg 13020
cttttgctca ttttctcttt acctcattaa ctcaaatgag ttttgattta atttcagcgg 13080
ccagcgcctg gacctcgcgg gcagcgtcgc cctcgggttc tgattcaaga acggttgtgc 13140
cggcggcggc agtgcctggg tagctcacgc gctgcgtgat acgggactca agaatgggca 13200
gctcgtaccc ggccagcgcc tcggcaacct caccgccgat gcgcgtgcct ttgatcgccc 13260
gcgacacgac aaaggccgct tgtagccttc catccgtgac ctcaatgcgc tgcttaacca 13320
gctccaccag gtcggcggtg gcccatatgt cgtaagggct tggctgcacc ggaatcagca 13380
cgaagtcggc tgccttgatc gcggacacag ccaagtccgc cgcctggggc gctccgtcga 13440
tcactacgaa gtcgcgccgg ccgatggcct tcacgtcgcg gtcaatcgtc gggcggtcga 13500
tgccgacaac ggttagcggt tgatcttccc gcacggccgc ccaatcgcgg gcactgccct 13560
ggggatcgga atcgactaac agaacatcgg ccccggcgag ttgcagggcg cgggctagat 13620
gggttgcgat ggtcgtcttg cctgacccgc ctttctggtt aagtacagcg ataaccttca 13680
tgcgttcccc ttgcgtattt gtttatttac tcatcgcatc atatacgcag cgaccgcatg 13740
acgcaagctg ttttactcaa atacacatca cctttttaga cggcggcgct cggtttcttc 13800
agcggccaag ctggccggcc aggccgccag cttggcatca gacaaaccgg ccaggatttc 13860
atgcagccgc acggttccgg atgagcattc a 13891
<210> 50
<211> 1137
<212> DNA
<213> Pseudomonas putida
<220>
<221> CDS
<222> (1)..(1137)
<400> 50
ttg aca aag cca gcc ata ctc gcc ctt gcc gac ggc agt att ttc cgc 48
Leu Thr Lys Pro Ala Ile Leu Ala Leu Ala Asp Gly Ser Ile Phe Arg
1 5 10 15
ggt gaa gcc atc ggt gcc gac ggt cag acc gtt ggt gag gtg gta ttc 96
Gly Glu Ala Ile Gly Ala Asp Gly Gln Thr Val Gly Glu Val Val Phe
20 25 30
aac acc gct atg acc ggc tac cag gaa atc ctt aca gac cct tcc tac 144
Asn Thr Ala Met Thr Gly Tyr Gln Glu Ile Leu Thr Asp Pro Ser Tyr
35 40 45
gcg cag caa atc gtt acc ctg acc tac ccg cac atc ggc aac acc ggt 192
Ala Gln Gln Ile Val Thr Leu Thr Tyr Pro His Ile Gly Asn Thr Gly
50 55 60
act acc ccg gaa gac gcc gag tcg agc cgc gtc tgg tcc gct ggc ctg 240
Thr Thr Pro Glu Asp Ala Glu Ser Ser Arg Val Trp Ser Ala Gly Leu
65 70 75 80
gtc atc cgt gac ctg ccg ctg ctg gcc agc aac tgg cgt aac acc cag 288
Val Ile Arg Asp Leu Pro Leu Leu Ala Ser Asn Trp Arg Asn Thr Gln
85 90 95
tcg ctg cct gag tac ctc aag gcc aac aac gtc gtc gcc atc gcc ggc 336
Ser Leu Pro Glu Tyr Leu Lys Ala Asn Asn Val Val Ala Ile Ala Gly
100 105 110
atc gac acc cgt cgc ctg acc cgt atc ctg cgt gaa aag ggc gcc cag 384
Ile Asp Thr Arg Arg Leu Thr Arg Ile Leu Arg Glu Lys Gly Ala Gln
115 120 125
aac ggc tgc att ctg gcg ggt gac aac atc agc gaa gaa gct gcc atc 432
Asn Gly Cys Ile Leu Ala Gly Asp Asn Ile Ser Glu Glu Ala Ala Ile
130 135 140
gct gct gcc cgc ggc ttc ccg ggc ctg aag ggc atg gac ctg gcc aag 480
Ala Ala Ala Arg Gly Phe Pro Gly Leu Lys Gly Met Asp Leu Ala Lys
145 150 155 160
gtc gtc tcc acc aag gaa cgt tac gag tgg cgc tcc agc gtg tgg gag 528
Val Val Ser Thr Lys Glu Arg Tyr Glu Trp Arg Ser Ser Val Trp Glu
165 170 175
ctg aaa acc gac agc cac ccg acc atc gac gct gcc gac ctg ccg tac 576
Leu Lys Thr Asp Ser His Pro Thr Ile Asp Ala Ala Asp Leu Pro Tyr
180 185 190
cac gtg gtt gcc ttc gac tat ggc gtc aag ctg aac atc ctg cgc atg 624
His Val Val Ala Phe Asp Tyr Gly Val Lys Leu Asn Ile Leu Arg Met
195 200 205
ctg gtg gcc cgc ggc tgc cgc gtg acc gtg gta cca gcc cag acc ccg 672
Leu Val Ala Arg Gly Cys Arg Val Thr Val Val Pro Ala Gln Thr Pro
210 215 220
gcc agc gaa gta ctg gca ctc aac ccg gac ggc gtg ttc ctg tcc aac 720
Ala Ser Glu Val Leu Ala Leu Asn Pro Asp Gly Val Phe Leu Ser Asn
225 230 235 240
ggc cct ggt gac cct gag ccg tgc gac tac gcg atc cag gcg atc aag 768
Gly Pro Gly Asp Pro Glu Pro Cys Asp Tyr Ala Ile Gln Ala Ile Lys
245 250 255
gaa atc ctc gaa acc gag atc ccg gta ttc ggc atc tgc ctc ggc cac 816
Glu Ile Leu Glu Thr Glu Ile Pro Val Phe Gly Ile Cys Leu Gly His
260 265 270
cag ctg ctg gcc ctg gcg tcc ggc gcc aag acc gtg aaa atg ggc cac 864
Gln Leu Leu Ala Leu Ala Ser Gly Ala Lys Thr Val Lys Met Gly His
275 280 285
ggc cac cac ggt gcc aac cac ccg gtc cag gac ctg gat act ggt gtg 912
Gly His His Gly Ala Asn His Pro Val Gln Asp Leu Asp Thr Gly Val
290 295 300
gtc atg atc acc agc cag aac cac ggt ttc gcc gtt gac gag gcg acc 960
Val Met Ile Thr Ser Gln Asn His Gly Phe Ala Val Asp Glu Ala Thr
305 310 315 320
ctg ccg ggc aac gtt cgc gcc att cac aag tcg ctg ttc gac ggc acc 1008
Leu Pro Gly Asn Val Arg Ala Ile His Lys Ser Leu Phe Asp Gly Thr
325 330 335
ctg cag ggt atc gag cgt acc gac aag agc gcg ttc agc ttc cag ggc 1056
Leu Gln Gly Ile Glu Arg Thr Asp Lys Ser Ala Phe Ser Phe Gln Gly
340 345 350
cac cct gaa gcg agc ccg ggc ccg acc gac gtc gcg cct ctg ttc gat 1104
His Pro Glu Ala Ser Pro Gly Pro Thr Asp Val Ala Pro Leu Phe Asp
355 360 365
cgt ttc acc gat gcc atg gcc aag cgc cgc tga 1137
Arg Phe Thr Asp Ala Met Ala Lys Arg Arg
370 375
<210> 51
<211> 378
<212> PRT
<213> Pseudomonas putida
<400> 51
Leu Thr Lys Pro Ala Ile Leu Ala Leu Ala Asp Gly Ser Ile Phe Arg
1 5 10 15
Gly Glu Ala Ile Gly Ala Asp Gly Gln Thr Val Gly Glu Val Val Phe
20 25 30
Asn Thr Ala Met Thr Gly Tyr Gln Glu Ile Leu Thr Asp Pro Ser Tyr
35 40 45
Ala Gln Gln Ile Val Thr Leu Thr Tyr Pro His Ile Gly Asn Thr Gly
50 55 60
Thr Thr Pro Glu Asp Ala Glu Ser Ser Arg Val Trp Ser Ala Gly Leu
65 70 75 80
Val Ile Arg Asp Leu Pro Leu Leu Ala Ser Asn Trp Arg Asn Thr Gln
85 90 95
Ser Leu Pro Glu Tyr Leu Lys Ala Asn Asn Val Val Ala Ile Ala Gly
100 105 110
Ile Asp Thr Arg Arg Leu Thr Arg Ile Leu Arg Glu Lys Gly Ala Gln
115 120 125
Asn Gly Cys Ile Leu Ala Gly Asp Asn Ile Ser Glu Glu Ala Ala Ile
130 135 140
Ala Ala Ala Arg Gly Phe Pro Gly Leu Lys Gly Met Asp Leu Ala Lys
145 150 155 160
Val Val Ser Thr Lys Glu Arg Tyr Glu Trp Arg Ser Ser Val Trp Glu
165 170 175
Leu Lys Thr Asp Ser His Pro Thr Ile Asp Ala Ala Asp Leu Pro Tyr
180 185 190
His Val Val Ala Phe Asp Tyr Gly Val Lys Leu Asn Ile Leu Arg Met
195 200 205
Leu Val Ala Arg Gly Cys Arg Val Thr Val Val Pro Ala Gln Thr Pro
210 215 220
Ala Ser Glu Val Leu Ala Leu Asn Pro Asp Gly Val Phe Leu Ser Asn
225 230 235 240
Gly Pro Gly Asp Pro Glu Pro Cys Asp Tyr Ala Ile Gln Ala Ile Lys
245 250 255
Glu Ile Leu Glu Thr Glu Ile Pro Val Phe Gly Ile Cys Leu Gly His
260 265 270
Gln Leu Leu Ala Leu Ala Ser Gly Ala Lys Thr Val Lys Met Gly His
275 280 285
Gly His His Gly Ala Asn His Pro Val Gln Asp Leu Asp Thr Gly Val
290 295 300
Val Met Ile Thr Ser Gln Asn His Gly Phe Ala Val Asp Glu Ala Thr
305 310 315 320
Leu Pro Gly Asn Val Arg Ala Ile His Lys Ser Leu Phe Asp Gly Thr
325 330 335
Leu Gln Gly Ile Glu Arg Thr Asp Lys Ser Ala Phe Ser Phe Gln Gly
340 345 350
His Pro Glu Ala Ser Pro Gly Pro Thr Asp Val Ala Pro Leu Phe Asp
355 360 365
Arg Phe Thr Asp Ala Met Ala Lys Arg Arg
370 375
<210> 52
<211> 3222
<212> DNA
<213> Pseudomonas putida
<220>
<221> CDS
<222> (1)..(3222)
<400> 52
atg cca aaa cgt aca gac atc aaa agc atc ctg att ctc ggc gct ggc 48
Met Pro Lys Arg Thr Asp Ile Lys Ser Ile Leu Ile Leu Gly Ala Gly
1 5 10 15
ccg atc gtg atc ggc cag gcc tgc gaa ttc gac tac tcc ggc gcc cag 96
Pro Ile Val Ile Gly Gln Ala Cys Glu Phe Asp Tyr Ser Gly Ala Gln
20 25 30
gcc tgt aaa gcc ctg cgc gag gaa ggt ttc cgc gtc atc ctg gtg aac 144
Ala Cys Lys Ala Leu Arg Glu Glu Gly Phe Arg Val Ile Leu Val Asn
35 40 45
tcc aac cca gcc acc atc atg acc gac ccg gcc atg gct gac gcc acc 192
Ser Asn Pro Ala Thr Ile Met Thr Asp Pro Ala Met Ala Asp Ala Thr
50 55 60
tac atc gag ccg atc aag tgg caa tcg gtg gcc aag atc atc gag aaa 240
Tyr Ile Glu Pro Ile Lys Trp Gln Ser Val Ala Lys Ile Ile Glu Lys
65 70 75 80
gag cgc ccg gac gcc gtc ctg ccg acc atg ggt ggc cag acc gcc ctg 288
Glu Arg Pro Asp Ala Val Leu Pro Thr Met Gly Gly Gln Thr Ala Leu
85 90 95
aac tgc gcc ctg gac ctg gag cgc cac ggc gtt ctg gag aag ttc ggc 336
Asn Cys Ala Leu Asp Leu Glu Arg His Gly Val Leu Glu Lys Phe Gly
100 105 110
gtg gag atg atc ggt gcc aac gct gac acc atc gac aag gcc gaa gac 384
Val Glu Met Ile Gly Ala Asn Ala Asp Thr Ile Asp Lys Ala Glu Asp
115 120 125
cgt tcg cgc ttc gac aag gcc atg aag gac atc ggc ctg gag tgc ccg 432
Arg Ser Arg Phe Asp Lys Ala Met Lys Asp Ile Gly Leu Glu Cys Pro
130 135 140
cgc tcc ggt atc gcc cac agc atg gaa gag gcc aat gcg gtc ctc gag 480
Arg Ser Gly Ile Ala His Ser Met Glu Glu Ala Asn Ala Val Leu Glu
145 150 155 160
aag ctc ggc ttc ccg tgc atc att cgc ccg tcg ttc acc atg ggc ggc 528
Lys Leu Gly Phe Pro Cys Ile Ile Arg Pro Ser Phe Thr Met Gly Gly
165 170 175
acc ggc ggc ggt atc gct tac aac cgt gaa gag ttc gaa gaa atc tgc 576
Thr Gly Gly Gly Ile Ala Tyr Asn Arg Glu Glu Phe Glu Glu Ile Cys
180 185 190
acc cgt ggt ctg gac ctg tcg ccg acc aaa gag ctg ctg atc gac gaa 624
Thr Arg Gly Leu Asp Leu Ser Pro Thr Lys Glu Leu Leu Ile Asp Glu
195 200 205
tcg ctg atc ggc tgg aag gaa tac gag atg gag gtg gtc cgc gac aag 672
Ser Leu Ile Gly Trp Lys Glu Tyr Glu Met Glu Val Val Arg Asp Lys
210 215 220
aag gac aac tgc atc atc gtc tgc tcg atc gag aac ttc gac ccg atg 720
Lys Asp Asn Cys Ile Ile Val Cys Ser Ile Glu Asn Phe Asp Pro Met
225 230 235 240
ggt gtg cac acc ggt gac tcg atc act gtt gcc ccg gca cag acc ctg 768
Gly Val His Thr Gly Asp Ser Ile Thr Val Ala Pro Ala Gln Thr Leu
245 250 255
acc gac aag gaa tac cag atc atg cgc aac gcc tcg ctg gcg gtg ctg 816
Thr Asp Lys Glu Tyr Gln Ile Met Arg Asn Ala Ser Leu Ala Val Leu
260 265 270
cgt gaa atc ggt gtg gaa acc ggc ggt tcc aac gtc cag ttc ggc att 864
Arg Glu Ile Gly Val Glu Thr Gly Gly Ser Asn Val Gln Phe Gly Ile
275 280 285
tgc ccg aac acc ggc cgc atg gtt gtc atc gag atg aac ccg cgc gtg 912
Cys Pro Asn Thr Gly Arg Met Val Val Ile Glu Met Asn Pro Arg Val
290 295 300
tcg cgt tcg tcc gcc ctg gcc tcc aag gcc acc ggc ttc ccg atc gcc 960
Ser Arg Ser Ser Ala Leu Ala Ser Lys Ala Thr Gly Phe Pro Ile Ala
305 310 315 320
aag atc gcc gcc aag ctg gcc att ggt tac acc ctc gac gag ctg cag 1008
Lys Ile Ala Ala Lys Leu Ala Ile Gly Tyr Thr Leu Asp Glu Leu Gln
325 330 335
aac gac atc act ggc ggt cgc acc cca gcg tcc ttc gaa cct tcg atc 1056
Asn Asp Ile Thr Gly Gly Arg Thr Pro Ala Ser Phe Glu Pro Ser Ile
340 345 350
gac tac gtc gtc acc aag ctg cca cgc ttc gcc ttc gag aaa ttc ccg 1104
Asp Tyr Val Val Thr Lys Leu Pro Arg Phe Ala Phe Glu Lys Phe Pro
355 360 365
aaa gcc gac gcc cgc ctg acc acc cag atg aaa tcc gtg ggt gaa gtc 1152
Lys Ala Asp Ala Arg Leu Thr Thr Gln Met Lys Ser Val Gly Glu Val
370 375 380
atg gcc atc ggc cgt act ttc cag gaa tcc ctg cag aaa gcc ctg cgc 1200
Met Ala Ile Gly Arg Thr Phe Gln Glu Ser Leu Gln Lys Ala Leu Arg
385 390 395 400
ggc ctg gaa gtc ggc gcc tgc ggc ctc gac ccg aaa gtc gac ctg gcc 1248
Gly Leu Glu Val Gly Ala Cys Gly Leu Asp Pro Lys Val Asp Leu Ala
405 410 415
agc ccg gaa gcc gcc agc atc ctc aag cgc gaa ctg acc gtg ccg ggt 1296
Ser Pro Glu Ala Ala Ser Ile Leu Lys Arg Glu Leu Thr Val Pro Gly
420 425 430
gcc gag cgt atc tgg tac gtg gct gac gcc atg cgt tcg ggc atg acc 1344
Ala Glu Arg Ile Trp Tyr Val Ala Asp Ala Met Arg Ser Gly Met Thr
435 440 445
tgc gaa gaa atc ttc aat ctg acc ggc atc gac atg tgg ttc ctg gtg 1392
Cys Glu Glu Ile Phe Asn Leu Thr Gly Ile Asp Met Trp Phe Leu Val
450 455 460
cag atg gaa gac ctg atc aag gaa gaa gag aag gtc aag acc ctg gcc 1440
Gln Met Glu Asp Leu Ile Lys Glu Glu Glu Lys Val Lys Thr Leu Ala
465 470 475 480
ctg tcg gca atc gac aag gac tac atg ctg cgc ctc aag cgc aag ggc 1488
Leu Ser Ala Ile Asp Lys Asp Tyr Met Leu Arg Leu Lys Arg Lys Gly
485 490 495
ttc tcg gac cag cgc ctg gca gta ctg ctg ggt atc acc gac aag aac 1536
Phe Ser Asp Gln Arg Leu Ala Val Leu Leu Gly Ile Thr Asp Lys Asn
500 505 510
ctg cgt cgc cac cgc cac aag ctg gaa gtg ttc ccg gtg tac aag cgc 1584
Leu Arg Arg His Arg His Lys Leu Glu Val Phe Pro Val Tyr Lys Arg
515 520 525
gtc gac acc tgc gcc gcc gag ttc gcc acc gac acc gcc tac ctg tac 1632
Val Asp Thr Cys Ala Ala Glu Phe Ala Thr Asp Thr Ala Tyr Leu Tyr
530 535 540
tcc acc tac gag gaa gag tgc gag gcc aac ccg tcg acc cgc gac aag 1680
Ser Thr Tyr Glu Glu Glu Cys Glu Ala Asn Pro Ser Thr Arg Asp Lys
545 550 555 560
atc atg atc ctg ggt ggc ggc ccg aac cgt atc ggc caa ggt atc gag 1728
Ile Met Ile Leu Gly Gly Gly Pro Asn Arg Ile Gly Gln Gly Ile Glu
565 570 575
ttc gac tac tgc tgc gta cac gcc gcc ctg gcg ctg cgt gaa gac ggt 1776
Phe Asp Tyr Cys Cys Val His Ala Ala Leu Ala Leu Arg Glu Asp Gly
580 585 590
tac gag acc atc atg gtc aac tgc aac ccg gaa acc gtc tcc acc gac 1824
Tyr Glu Thr Ile Met Val Asn Cys Asn Pro Glu Thr Val Ser Thr Asp
595 600 605
tac gac act tcc gac cgc ctg tac ttc gag ccg ctg acc ctg gaa gac 1872
Tyr Asp Thr Ser Asp Arg Leu Tyr Phe Glu Pro Leu Thr Leu Glu Asp
610 615 620
gtg ctg gaa gtc tgc cgc gtc gag aag ccg aag ggc gtg atc gtt cac 1920
Val Leu Glu Val Cys Arg Val Glu Lys Pro Lys Gly Val Ile Val His
625 630 635 640
tac ggc ggc cag acc ccg ctg aag ctg gcc cgc gct ctg gaa gag gct 1968
Tyr Gly Gly Gln Thr Pro Leu Lys Leu Ala Arg Ala Leu Glu Glu Ala
645 650 655
ggc gtg ccg atc atc ggt acc agc cct gac gcc atc gac cgc gcc gaa 2016
Gly Val Pro Ile Ile Gly Thr Ser Pro Asp Ala Ile Asp Arg Ala Glu
660 665 670
gac cgc gag cgc ttc cag cag atg gtt cag cgc ctg agc ctg ctg cag 2064
Asp Arg Glu Arg Phe Gln Gln Met Val Gln Arg Leu Ser Leu Leu Gln
675 680 685
ccg cca aac gcc acc gtg cgc agc gaa gaa gaa gcc atc cgt gct gcg 2112
Pro Pro Asn Ala Thr Val Arg Ser Glu Glu Glu Ala Ile Arg Ala Ala
690 695 700
ggc agc atc ggc tac ccg ctg gtc gtg cgt ccg tcc tac gta ctg ggc 2160
Gly Ser Ile Gly Tyr Pro Leu Val Val Arg Pro Ser Tyr Val Leu Gly
705 710 715 720
ggc cgt gcc atg gag atc gtc tac gag ctg gac gag ctc aag cgc tac 2208
Gly Arg Ala Met Glu Ile Val Tyr Glu Leu Asp Glu Leu Lys Arg Tyr
725 730 735
ctg cgt gaa gcg gta caa gtg tcg aac gac agc ccg gta ctg ctc gac 2256
Leu Arg Glu Ala Val Gln Val Ser Asn Asp Ser Pro Val Leu Leu Asp
740 745 750
cac ttc ctc aac tgc gcc atc gag atg gac gtg gat gcg gtg tgc gac 2304
His Phe Leu Asn Cys Ala Ile Glu Met Asp Val Asp Ala Val Cys Asp
755 760 765
ggc acc gac gtg gtc atc ggc gcg atc atg cag cac atc gag cag gcc 2352
Gly Thr Asp Val Val Ile Gly Ala Ile Met Gln His Ile Glu Gln Ala
770 775 780
ggc gta cac tcc ggc gac tcg gcg tgc tcg ctg cca cct tac tcg ctg 2400
Gly Val His Ser Gly Asp Ser Ala Cys Ser Leu Pro Pro Tyr Ser Leu
785 790 795 800
agc aag gaa gtg cag gac gaa gtc cgc gtt cag gtc aag aaa atg gcg 2448
Ser Lys Glu Val Gln Asp Glu Val Arg Val Gln Val Lys Lys Met Ala
805 810 815
ctg gag ctg ggt gta gtc ggc ctg atg aac gtg cag ctg gcc ctg cag 2496
Leu Glu Leu Gly Val Val Gly Leu Met Asn Val Gln Leu Ala Leu Gln
820 825 830
ggc gac aag atc tac gtg atc gaa gtc aac ccg cgt gcc tcg cgt acc 2544
Gly Asp Lys Ile Tyr Val Ile Glu Val Asn Pro Arg Ala Ser Arg Thr
835 840 845
gta ccg ttc gtg tcc aag tgc atc ggc acg tcc ctg gcg atg atc gca 2592
Val Pro Phe Val Ser Lys Cys Ile Gly Thr Ser Leu Ala Met Ile Ala
850 855 860
gcc cgt gtc atg gcg ggt aaa acc ctg aaa gag ctg ggc ttc acc cag 2640
Ala Arg Val Met Ala Gly Lys Thr Leu Lys Glu Leu Gly Phe Thr Gln
865 870 875 880
gaa atc atc ccg aac ttc tac agc gtg aag gaa gcc gtc ttc ccg ttc 2688
Glu Ile Ile Pro Asn Phe Tyr Ser Val Lys Glu Ala Val Phe Pro Phe
885 890 895
gcc aag ttc cca ggg gtt gac ccg atc ctc ggc cct gag atg aaa tcg 2736
Ala Lys Phe Pro Gly Val Asp Pro Ile Leu Gly Pro Glu Met Lys Ser
900 905 910
acc ggt gaa gtg atg ggt gtc ggt gac agc ttc ggt gaa gcc ttc gcc 2784
Thr Gly Glu Val Met Gly Val Gly Asp Ser Phe Gly Glu Ala Phe Ala
915 920 925
aaa gcc cag atg ggt gcc agc gaa gtg ctg ccg act ggc ggt acc gcg 2832
Lys Ala Gln Met Gly Ala Ser Glu Val Leu Pro Thr Gly Gly Thr Ala
930 935 940
ttc atc agc gtg cgc gac gac gac aag cca caa gtg gcc ggc gtt gcc 2880
Phe Ile Ser Val Arg Asp Asp Asp Lys Pro Gln Val Ala Gly Val Ala
945 950 955 960
cgc gac ctg atc gcc ctg ggc ttc gaa gtg gtt gcc act gcc ggc acc 2928
Arg Asp Leu Ile Ala Leu Gly Phe Glu Val Val Ala Thr Ala Gly Thr
965 970 975
gcc aag gtt atc gag gcg gct ggc ctg aaa gtg cgc cgt gtg aac aag 2976
Ala Lys Val Ile Glu Ala Ala Gly Leu Lys Val Arg Arg Val Asn Lys
980 985 990
gtg acc gaa ggt cgc cct cac gtg gtc gac atg atc aag aac gac gaa 3024
Val Thr Glu Gly Arg Pro His Val Val Asp Met Ile Lys Asn Asp Glu
995 1000 1005
gtg tcg ctg atc atc aac acc acc gaa ggt cgc cag tcg atc gcc 3069
Val Ser Leu Ile Ile Asn Thr Thr Glu Gly Arg Gln Ser Ile Ala
1010 1015 1020
gac tcc tac tcg att cgt cgc aat gcg ctg cag cac aag att tac 3114
Asp Ser Tyr Ser Ile Arg Arg Asn Ala Leu Gln His Lys Ile Tyr
1025 1030 1035
tgc acc act acc att gcg gct ggt gaa gcc atc tgc gaa gcg ctg 3159
Cys Thr Thr Thr Ile Ala Ala Gly Glu Ala Ile Cys Glu Ala Leu
1040 1045 1050
aaa ttc ggt ccg gaa aag acc gtt cgt cgc ttg cag gat ctg cat 3204
Lys Phe Gly Pro Glu Lys Thr Val Arg Arg Leu Gln Asp Leu His
1055 1060 1065
gca gga ctg aaa gca tga 3222
Ala Gly Leu Lys Ala
1070
<210> 53
<211> 1073
<212> PRT
<213> Pseudomonas putida
<400> 53
Met Pro Lys Arg Thr Asp Ile Lys Ser Ile Leu Ile Leu Gly Ala Gly
1 5 10 15
Pro Ile Val Ile Gly Gln Ala Cys Glu Phe Asp Tyr Ser Gly Ala Gln
20 25 30
Ala Cys Lys Ala Leu Arg Glu Glu Gly Phe Arg Val Ile Leu Val Asn
35 40 45
Ser Asn Pro Ala Thr Ile Met Thr Asp Pro Ala Met Ala Asp Ala Thr
50 55 60
Tyr Ile Glu Pro Ile Lys Trp Gln Ser Val Ala Lys Ile Ile Glu Lys
65 70 75 80
Glu Arg Pro Asp Ala Val Leu Pro Thr Met Gly Gly Gln Thr Ala Leu
85 90 95
Asn Cys Ala Leu Asp Leu Glu Arg His Gly Val Leu Glu Lys Phe Gly
100 105 110
Val Glu Met Ile Gly Ala Asn Ala Asp Thr Ile Asp Lys Ala Glu Asp
115 120 125
Arg Ser Arg Phe Asp Lys Ala Met Lys Asp Ile Gly Leu Glu Cys Pro
130 135 140
Arg Ser Gly Ile Ala His Ser Met Glu Glu Ala Asn Ala Val Leu Glu
145 150 155 160
Lys Leu Gly Phe Pro Cys Ile Ile Arg Pro Ser Phe Thr Met Gly Gly
165 170 175
Thr Gly Gly Gly Ile Ala Tyr Asn Arg Glu Glu Phe Glu Glu Ile Cys
180 185 190
Thr Arg Gly Leu Asp Leu Ser Pro Thr Lys Glu Leu Leu Ile Asp Glu
195 200 205
Ser Leu Ile Gly Trp Lys Glu Tyr Glu Met Glu Val Val Arg Asp Lys
210 215 220
Lys Asp Asn Cys Ile Ile Val Cys Ser Ile Glu Asn Phe Asp Pro Met
225 230 235 240
Gly Val His Thr Gly Asp Ser Ile Thr Val Ala Pro Ala Gln Thr Leu
245 250 255
Thr Asp Lys Glu Tyr Gln Ile Met Arg Asn Ala Ser Leu Ala Val Leu
260 265 270
Arg Glu Ile Gly Val Glu Thr Gly Gly Ser Asn Val Gln Phe Gly Ile
275 280 285
Cys Pro Asn Thr Gly Arg Met Val Val Ile Glu Met Asn Pro Arg Val
290 295 300
Ser Arg Ser Ser Ala Leu Ala Ser Lys Ala Thr Gly Phe Pro Ile Ala
305 310 315 320
Lys Ile Ala Ala Lys Leu Ala Ile Gly Tyr Thr Leu Asp Glu Leu Gln
325 330 335
Asn Asp Ile Thr Gly Gly Arg Thr Pro Ala Ser Phe Glu Pro Ser Ile
340 345 350
Asp Tyr Val Val Thr Lys Leu Pro Arg Phe Ala Phe Glu Lys Phe Pro
355 360 365
Lys Ala Asp Ala Arg Leu Thr Thr Gln Met Lys Ser Val Gly Glu Val
370 375 380
Met Ala Ile Gly Arg Thr Phe Gln Glu Ser Leu Gln Lys Ala Leu Arg
385 390 395 400
Gly Leu Glu Val Gly Ala Cys Gly Leu Asp Pro Lys Val Asp Leu Ala
405 410 415
Ser Pro Glu Ala Ala Ser Ile Leu Lys Arg Glu Leu Thr Val Pro Gly
420 425 430
Ala Glu Arg Ile Trp Tyr Val Ala Asp Ala Met Arg Ser Gly Met Thr
435 440 445
Cys Glu Glu Ile Phe Asn Leu Thr Gly Ile Asp Met Trp Phe Leu Val
450 455 460
Gln Met Glu Asp Leu Ile Lys Glu Glu Glu Lys Val Lys Thr Leu Ala
465 470 475 480
Leu Ser Ala Ile Asp Lys Asp Tyr Met Leu Arg Leu Lys Arg Lys Gly
485 490 495
Phe Ser Asp Gln Arg Leu Ala Val Leu Leu Gly Ile Thr Asp Lys Asn
500 505 510
Leu Arg Arg His Arg His Lys Leu Glu Val Phe Pro Val Tyr Lys Arg
515 520 525
Val Asp Thr Cys Ala Ala Glu Phe Ala Thr Asp Thr Ala Tyr Leu Tyr
530 535 540
Ser Thr Tyr Glu Glu Glu Cys Glu Ala Asn Pro Ser Thr Arg Asp Lys
545 550 555 560
Ile Met Ile Leu Gly Gly Gly Pro Asn Arg Ile Gly Gln Gly Ile Glu
565 570 575
Phe Asp Tyr Cys Cys Val His Ala Ala Leu Ala Leu Arg Glu Asp Gly
580 585 590
Tyr Glu Thr Ile Met Val Asn Cys Asn Pro Glu Thr Val Ser Thr Asp
595 600 605
Tyr Asp Thr Ser Asp Arg Leu Tyr Phe Glu Pro Leu Thr Leu Glu Asp
610 615 620
Val Leu Glu Val Cys Arg Val Glu Lys Pro Lys Gly Val Ile Val His
625 630 635 640
Tyr Gly Gly Gln Thr Pro Leu Lys Leu Ala Arg Ala Leu Glu Glu Ala
645 650 655
Gly Val Pro Ile Ile Gly Thr Ser Pro Asp Ala Ile Asp Arg Ala Glu
660 665 670
Asp Arg Glu Arg Phe Gln Gln Met Val Gln Arg Leu Ser Leu Leu Gln
675 680 685
Pro Pro Asn Ala Thr Val Arg Ser Glu Glu Glu Ala Ile Arg Ala Ala
690 695 700
Gly Ser Ile Gly Tyr Pro Leu Val Val Arg Pro Ser Tyr Val Leu Gly
705 710 715 720
Gly Arg Ala Met Glu Ile Val Tyr Glu Leu Asp Glu Leu Lys Arg Tyr
725 730 735
Leu Arg Glu Ala Val Gln Val Ser Asn Asp Ser Pro Val Leu Leu Asp
740 745 750
His Phe Leu Asn Cys Ala Ile Glu Met Asp Val Asp Ala Val Cys Asp
755 760 765
Gly Thr Asp Val Val Ile Gly Ala Ile Met Gln His Ile Glu Gln Ala
770 775 780
Gly Val His Ser Gly Asp Ser Ala Cys Ser Leu Pro Pro Tyr Ser Leu
785 790 795 800
Ser Lys Glu Val Gln Asp Glu Val Arg Val Gln Val Lys Lys Met Ala
805 810 815
Leu Glu Leu Gly Val Val Gly Leu Met Asn Val Gln Leu Ala Leu Gln
820 825 830
Gly Asp Lys Ile Tyr Val Ile Glu Val Asn Pro Arg Ala Ser Arg Thr
835 840 845
Val Pro Phe Val Ser Lys Cys Ile Gly Thr Ser Leu Ala Met Ile Ala
850 855 860
Ala Arg Val Met Ala Gly Lys Thr Leu Lys Glu Leu Gly Phe Thr Gln
865 870 875 880
Glu Ile Ile Pro Asn Phe Tyr Ser Val Lys Glu Ala Val Phe Pro Phe
885 890 895
Ala Lys Phe Pro Gly Val Asp Pro Ile Leu Gly Pro Glu Met Lys Ser
900 905 910
Thr Gly Glu Val Met Gly Val Gly Asp Ser Phe Gly Glu Ala Phe Ala
915 920 925
Lys Ala Gln Met Gly Ala Ser Glu Val Leu Pro Thr Gly Gly Thr Ala
930 935 940
Phe Ile Ser Val Arg Asp Asp Asp Lys Pro Gln Val Ala Gly Val Ala
945 950 955 960
Arg Asp Leu Ile Ala Leu Gly Phe Glu Val Val Ala Thr Ala Gly Thr
965 970 975
Ala Lys Val Ile Glu Ala Ala Gly Leu Lys Val Arg Arg Val Asn Lys
980 985 990
Val Thr Glu Gly Arg Pro His Val Val Asp Met Ile Lys Asn Asp Glu
995 1000 1005
Val Ser Leu Ile Ile Asn Thr Thr Glu Gly Arg Gln Ser Ile Ala
1010 1015 1020
Asp Ser Tyr Ser Ile Arg Arg Asn Ala Leu Gln His Lys Ile Tyr
1025 1030 1035
Cys Thr Thr Thr Ile Ala Ala Gly Glu Ala Ile Cys Glu Ala Leu
1040 1045 1050
Lys Phe Gly Pro Glu Lys Thr Val Arg Arg Leu Gln Asp Leu His
1055 1060 1065
Ala Gly Leu Lys Ala
1070
<210> 54
<211> 44
<212> DNA
<213> synthetic oligonucleotide
<400> 54
agagcctgag caaactggcc gactgatgtg gtgttggctt cttc 44
<210> 55
<211> 45
<212> DNA
<213> synthetic oligonucleotide
<400> 55
ccgtgtgctt ctcaaatgcc tatttggtaa tgctcatgct ttcag 45
<210> 56
<211> 4841
<212> DNA
<213> Pseudomonas putida
<400> 56
agagcctgag caaactggcc gactgatgtg gtgttggctt cttcgcgggc ttgcccgctc 60
ccacaggtgc ggcgttgctc ttgggctggt gcgatccctg tgggggcgca ccagcccgcg 120
cagaagccaa cacagatgtc agtctgtcgc attgatgtgt tttagagaca catccgcggt 180
agaccgaaaa cacacttttc tgtaagctac agctttagtg tgtccactaa aagcgcgcag 240
cgaattgaat tcagcacatg aaagcggggt gacgtgtcca tacgtcactc cgcttttttg 300
caacctgcga tcgccctttc atgcttgatt tacgggaggt cttcttgaca aagccagcca 360
tactcgccct tgccgacggc agtattttcc gcggtgaagc catcggtgcc gacggtcaga 420
ccgttggtga ggtggtattc aacaccgcta tgaccggcta ccaggaaatc cttacagacc 480
cttcctacgc gcagcaaatc gttaccctga cctacccgca catcggcaac accggtacta 540
ccccggaaga cgccgagtcg agccgcgtct ggtccgctgg cctggtcatc cgtgacctgc 600
cgctgctggc cagcaactgg cgtaacaccc agtcgctgcc tgagtacctc aaggccaaca 660
acgtcgtcgc catcgccggc atcgacaccc gtcgcctgac ccgtatcctg cgtgaaaagg 720
gcgcccagaa cggctgcatt ctggcgggtg acaacatcag cgaagaagct gccatcgctg 780
ctgcccgcgg cttcccgggc ctgaagggca tggacctggc caaggtcgtc tccaccaagg 840
aacgttacga gtggcgctcc agcgtgtggg agctgaaaac cgacagccac ccgaccatcg 900
acgctgccga cctgccgtac cacgtggttg ccttcgacta tggcgtcaag ctgaacatcc 960
tgcgcatgct ggtggcccgc ggctgccgcg tgaccgtggt accagcccag accccggcca 1020
gcgaagtact ggcactcaac ccggacggcg tgttcctgtc caacggccct ggtgaccctg 1080
agccgtgcga ctacgcgatc caggcgatca aggaaatcct cgaaaccgag atcccggtat 1140
tcggcatctg cctcggccac cagctgctgg ccctggcgtc cggcgccaag accgtgaaaa 1200
tgggccacgg ccaccacggt gccaaccacc cggtccagga cctggatact ggtgtggtca 1260
tgatcaccag ccagaaccac ggtttcgccg ttgacgaggc gaccctgccg ggcaacgttc 1320
gcgccattca caagtcgctg ttcgacggca ccctgcaggg tatcgagcgt accgacaaga 1380
gcgcgttcag cttccagggc caccctgaag cgagcccggg cccgaccgac gtcgcgcctc 1440
tgttcgatcg tttcaccgat gccatggcca agcgccgctg agcatcctgc ttcaaggccc 1500
cgggccggca cctgccgcgc ccggcagcgc ctgacccaga ttgttcaaag cggcttgccg 1560
actgaccccg gatttgagtg accaccatgc caaaacgtac agacatcaaa agcatcctga 1620
ttctcggcgc tggcccgatc gtgatcggcc aggcctgcga attcgactac tccggcgccc 1680
aggcctgtaa agccctgcgc gaggaaggtt tccgcgtcat cctggtgaac tccaacccag 1740
ccaccatcat gaccgacccg gccatggctg acgccaccta catcgagccg atcaagtggc 1800
aatcggtggc caagatcatc gagaaagagc gcccggacgc cgtcctgccg accatgggtg 1860
gccagaccgc cctgaactgc gccctggacc tggagcgcca cggcgttctg gagaagttcg 1920
gcgtggagat gatcggtgcc aacgctgaca ccatcgacaa ggccgaagac cgttcgcgct 1980
tcgacaaggc catgaaggac atcggcctgg agtgcccgcg ctccggtatc gcccacagca 2040
tggaagaggc caatgcggtc ctcgagaagc tcggcttccc gtgcatcatt cgcccgtcgt 2100
tcaccatggg cggcaccggc ggcggtatcg cttacaaccg tgaagagttc gaagaaatct 2160
gcacccgtgg tctggacctg tcgccgacca aagagctgct gatcgacgaa tcgctgatcg 2220
gctggaagga atacgagatg gaggtggtcc gcgacaagaa ggacaactgc atcatcgtct 2280
gctcgatcga gaacttcgac ccgatgggtg tgcacaccgg tgactcgatc actgttgccc 2340
cggcacagac cctgaccgac aaggaatacc agatcatgcg caacgcctcg ctggcggtgc 2400
tgcgtgaaat cggtgtggaa accggcggtt ccaacgtcca gttcggcatt tgcccgaaca 2460
ccggccgcat ggttgtcatc gagatgaacc cgcgcgtgtc gcgttcgtcc gccctggcct 2520
ccaaggccac cggcttcccg atcgccaaga tcgccgccaa gctggccatt ggttacaccc 2580
tcgacgagct gcagaacgac atcactggcg gtcgcacccc agcgtccttc gaaccttcga 2640
tcgactacgt cgtcaccaag ctgccacgct tcgccttcga gaaattcccg aaagccgacg 2700
cccgcctgac cacccagatg aaatccgtgg gtgaagtcat ggccatcggc cgtactttcc 2760
aggaatccct gcagaaagcc ctgcgcggcc tggaagtcgg cgcctgcggc ctcgacccga 2820
aagtcgacct ggccagcccg gaagccgcca gcatcctcaa gcgcgaactg accgtgccgg 2880
gtgccgagcg tatctggtac gtggctgacg ccatgcgttc gggcatgacc tgcgaagaaa 2940
tcttcaatct gaccggcatc gacatgtggt tcctggtgca gatggaagac ctgatcaagg 3000
aagaagagaa ggtcaagacc ctggccctgt cggcaatcga caaggactac atgctgcgcc 3060
tcaagcgcaa gggcttctcg gaccagcgcc tggcagtact gctgggtatc accgacaaga 3120
acctgcgtcg ccaccgccac aagctggaag tgttcccggt gtacaagcgc gtcgacacct 3180
gcgccgccga gttcgccacc gacaccgcct acctgtactc cacctacgag gaagagtgcg 3240
aggccaaccc gtcgacccgc gacaagatca tgatcctggg tggcggcccg aaccgtatcg 3300
gccaaggtat cgagttcgac tactgctgcg tacacgccgc cctggcgctg cgtgaagacg 3360
gttacgagac catcatggtc aactgcaacc cggaaaccgt ctccaccgac tacgacactt 3420
ccgaccgcct gtacttcgag ccgctgaccc tggaagacgt gctggaagtc tgccgcgtcg 3480
agaagccgaa gggcgtgatc gttcactacg gcggccagac cccgctgaag ctggcccgcg 3540
ctctggaaga ggctggcgtg ccgatcatcg gtaccagccc tgacgccatc gaccgcgccg 3600
aagaccgcga gcgcttccag cagatggttc agcgcctgag cctgctgcag ccgccaaacg 3660
ccaccgtgcg cagcgaagaa gaagccatcc gtgctgcggg cagcatcggc tacccgctgg 3720
tcgtgcgtcc gtcctacgta ctgggcggcc gtgccatgga gatcgtctac gagctggacg 3780
agctcaagcg ctacctgcgt gaagcggtac aagtgtcgaa cgacagcccg gtactgctcg 3840
accacttcct caactgcgcc atcgagatgg acgtggatgc ggtgtgcgac ggcaccgacg 3900
tggtcatcgg cgcgatcatg cagcacatcg agcaggccgg cgtacactcc ggcgactcgg 3960
cgtgctcgct gccaccttac tcgctgagca aggaagtgca ggacgaagtc cgcgttcagg 4020
tcaagaaaat ggcgctggag ctgggtgtag tcggcctgat gaacgtgcag ctggccctgc 4080
agggcgacaa gatctacgtg atcgaagtca acccgcgtgc ctcgcgtacc gtaccgttcg 4140
tgtccaagtg catcggcacg tccctggcga tgatcgcagc ccgtgtcatg gcgggtaaaa 4200
ccctgaaaga gctgggcttc acccaggaaa tcatcccgaa cttctacagc gtgaaggaag 4260
ccgtcttccc gttcgccaag ttcccagggg ttgacccgat cctcggccct gagatgaaat 4320
cgaccggtga agtgatgggt gtcggtgaca gcttcggtga agccttcgcc aaagcccaga 4380
tgggtgccag cgaagtgctg ccgactggcg gtaccgcgtt catcagcgtg cgcgacgacg 4440
acaagccaca agtggccggc gttgcccgcg acctgatcgc cctgggcttc gaagtggttg 4500
ccactgccgg caccgccaag gttatcgagg cggctggcct gaaagtgcgc cgtgtgaaca 4560
aggtgaccga aggtcgccct cacgtggtcg acatgatcaa gaacgacgaa gtgtcgctga 4620
tcatcaacac caccgaaggt cgccagtcga tcgccgactc ctactcgatt cgtcgcaatg 4680
cgctgcagca caagatttac tgcaccacta ccattgcggc tggtgaagcc atctgcgaag 4740
cgctgaaatt cggtccggaa aagaccgttc gtcgcttgca ggatctgcat gcaggactga 4800
aagcatgagc attaccaaat aggcatttga gaagcacacg g 4841
<210> 57
<211> 18689
<212> DNA
<213> various
<400> 57
tcaggcgggc aagaatgtga ataaaggccg gataaaactt gtgcttattt ttctttacgg 60
tctttaaaaa ggccgtaata tccagctgaa cggtctggtt ataggtacat tgagcaactg 120
actgaaatgc ctcaaaatgt tctttacgat gccattggga tatatcaacg gtggtatatc 180
cagtgatttt tttctccatt ttagcttcct tagctcctga aaatctcgat aactcaaaaa 240
atacgcccgg tagtgatctt atttcattat ggtgaaagtt ggaacctctt acgtgccgat 300
caacgtctca ttttcgccaa aagttggccc agggcttccc ggtatcaaca gggacaccag 360
gatttattta ttctgcgaag tgatcttccg tcacaggtat ttattcggcg caaagtgcgt 420
cgggtgatgc tgccaactta ctgatttagt gtatgatggt gtttttgagg tgctccagtg 480
gcttctgttt ctatcagctg tccctcctgt tcagctactg acggggtggt gcgtaacggc 540
aaaagcaccg ccggacatca gcgctagcgg agtgtatact ggcttactat gttggcactg 600
atgagggtgt cagtgaagtg cttcatgtgg caggagaaaa aaggctgcac cggtgcgtca 660
gcagaatatg tgatacagga tatattccgc ttcctcgctc actgactcgc tacgctcggt 720
cgttcgactg cggcgagcgg aaatggctta cgaacggggc ggagatttcc tggaagatgc 780
caggaagata cttaacaggg aagtgagagg gccgcggcaa agccgttttt ccataggctc 840
cgcccccctg acaagcatca cgaaatctga cgctcaaatc agtggtggcg aaacccgaca 900
ggactataaa gataccaggc gtttccccct ggcggctccc tcgtgcgctc tcctgttcct 960
gcctttcggt ttaccggtgt cattccgctg ttatggccgc gtttgtctca ttccacgcct 1020
gacactcagt tccgggtagg cagttcgctc caagctggac tgtatgcacg aaccccccgt 1080
tcagtccgac cgctgcgcct tatccggtaa ctatcgtctt gagtccaacc cggaaagaca 1140
tgcaaaagca ccactggcag cagccactgg taattgattt agaggagtta gtcttgaagt 1200
catgcgccgg ttaaggctaa actgaaagga caagttttgg tgactgcgct cctccaagcc 1260
agttacctcg gttcaaagag ttggtagctc agagaacctt cgaaaaaccg ccctgcaagg 1320
cggttttttc gttttcagag caagagatta cgcgcagacc aaaacgatct caagaagatc 1380
atcttattaa tcagataaaa tatttctaga tttcagtgca atttatctct tcaaatgtag 1440
cacctgaagt cagccccata cgatataagt tgtaattctc atgtttgaca gcttatcatc 1500
gataagcttt aatgcggtag tttatcacag ttaaattgct aacgcagtca ggcaccgtgt 1560
atgaaatcta acaatgcgct catcgtcatc ctcggcaccg tcaccctgga tgctgtaggc 1620
ataggcttgg ttatgccggt actgccgggc ctcttgcggg atatcgtcca ttccgacagc 1680
atcgccagtc actatggcgt gctgctagcg ctatatgcgt tgatgcaatt tctatgcgca 1740
cccgttctcg gagcactgtc cgaccgcttt ggccgccgcc cagtcctgct cgcttcgcta 1800
cttggagcca ctatcgacta cgcgatcatg gcgaccacac ccgtcctgtg gatcctctac 1860
gccggacgca tcgtggccgg catcaccggc gccacaggtg cggttgctgg cgcctatatc 1920
gccgacatca ccgatgggga agatcgggct cgccacttcg ggctcatgag cgcttgtttc 1980
ggcgtgggta tggtggcagg ccccgtggcc gggggactgt tgggcgccat ctccttgcat 2040
gcaccattcc ttgcggcggc ggtgctcaac ggcctcaacc tactactggg ctgcttccta 2100
atgcaggagt cgcataaggg agagcgtcga ccgatgccct tgagagcctt caacccagtc 2160
agctccttcc ggtgggcgcg gggcatgact atcgtcgccg cacttatgac tgtcttcttt 2220
atcatgcaac tcgtaggaca ggtgccggca gcgctctggg tcattttcgg cgaggaccgc 2280
tttcgctgga gcgcgacgat gatcggcctg tcgcttgcgg tattcggaat cttgcacgcc 2340
ctcgctcaag ccttcgtcac tggtcccgcc accaaacgtt tcggcgagaa gcaggccatt 2400
atcgccggca tggcggccga cgcgctgggc tacgtcttgc tggcgttcgc gacgcgaggc 2460
tggatggcct tccccattat gattcttctc gcttccggcg gcatcgggat gcccgcgttg 2520
caggccatgc tgtccaggca ggtagatgac gaccatcagg gacagcttca aggatcgctc 2580
gcggctctta ccagcctaac ttcgatcatt ggaccgctga tcgtcacggc gatttatgcc 2640
gcctcggcga gcacatggaa cgggttggca tggattgtag gcgccgccct ataccttgtc 2700
tgcctccccg cgttgcgtcg cggtgcatgg agccgggcca cctcgacctg aatggaagcc 2760
ggcggcacct cgctaacgga ttcaccactc caagaattgg agccaatcaa ttcttgcgga 2820
gaactgtgaa tgcgcaaacc aacccttggc agaacatatc catcgcgtcc gccatctcca 2880
gcagccgcac gcggcgcatc tcgggcagcg ttgggtcctg gccacgggtg cgcatgatcg 2940
tgctcctgtc gttgaggacc cggctaggct ggcggggttg ccttactggt tagcagaatg 3000
aatcaccgat acgcgagcga acgtgaagcg actgctgctg caaaacgtct gcgacctgag 3060
caacaacatg aatggtcttc ggtttccgtg tttcgtaaag tctggaaacg cggaagtccc 3120
ctacgtgctg ctgaagttgc ccgcaacaga gagtggaacc aaccggtgat accacgatac 3180
tatgactgag agtcaacgcc atgagcggcc tcatttctta ttctgagtta caacagtccg 3240
caccgctgtc cggtagctcc ttccggtggg cgcggggcat gactatcgtc gccgcactta 3300
tgactgtctt ctttatcatg caactcgtag gacaggtgcc ggcagcgccc aacagtcccc 3360
cggccacggg gcctgccacc atacccacgc cgaaacaagc gccctgcacc attatgttcc 3420
ggatctgcat cgcaggatgc tgctggctac cctgtggaac acctacatct gtattaacga 3480
agcgctaacc gtttttatca ggctctggga ggcagaataa atgatcatat cgtcaattat 3540
tacctccacg gggagagcct gagcaaactg gccgactgat gtggtgttgg cttcttcgcg 3600
ggcttgcccg ctcccacagg tgcggcgttg ctcttgggct ggtgcgatcc ctgtgggggc 3660
gcaccagccc gcgcagaagc caacacagat gtcagtctgt cgcattgatg tgttttagag 3720
acacatccgc ggtagaccga aaacacactt ttctgtaagc tacagcttta gtgtgtccac 3780
taaaagcgcg cagcgaattg aattcagcac atgaaagcgg ggtgacgtgt ccatacgtca 3840
ctccgctttt ttgcaacctg cgatcgccct ttcatgcttg atttacggga ggtcttcttg 3900
acaaagccag ccatactcgc ccttgccgac ggcagtattt tccgcggtga agccatcggt 3960
gccgacggtc agaccgttgg tgaggtggta ttcaacaccg ctatgaccgg ctaccaggaa 4020
atccttacag acccttccta cgcgcagcaa atcgttaccc tgacctaccc gcacatcggc 4080
aacaccggta ctaccccgga agacgccgag tcgagccgcg tctggtccgc tggcctggtc 4140
atccgtgacc tgccgctgct ggccagcaac tggcgtaaca cccagtcgct gcctgagtac 4200
ctcaaggcca acaacgtcgt cgccatcgcc ggcatcgaca cccgtcgcct gacccgtatc 4260
ctgcgtgaaa agggcgccca gaacggctgc attctggcgg gtgacaacat cagcgaagaa 4320
gctgccatcg ctgctgcccg cggcttcccg ggcctgaagg gcatggacct ggccaaggtc 4380
gtctccacca aggaacgtta cgagtggcgc tccagcgtgt gggagctgaa aaccgacagc 4440
cacccgacca tcgacgctgc cgacctgccg taccacgtgg ttgccttcga ctatggcgtc 4500
aagctgaaca tcctgcgcat gctggtggcc cgcggctgcc gcgtgaccgt ggtaccagcc 4560
cagaccccgg ccagcgaagt actggcactc aacccggacg gcgtgttcct gtccaacggc 4620
cctggtgacc ctgagccgtg cgactacgcg atccaggcga tcaaggaaat cctcgaaacc 4680
gagatcccgg tattcggcat ctgcctcggc caccagctgc tggccctggc gtccggcgcc 4740
aagaccgtga aaatgggcca cggccaccac ggtgccaacc acccggtcca ggacctggat 4800
actggtgtgg tcatgatcac cagccagaac cacggtttcg ccgttgacga ggcgaccctg 4860
ccgggcaacg ttcgcgccat tcacaagtcg ctgttcgacg gcaccctgca gggtatcgag 4920
cgtaccgaca agagcgcgtt cagcttccag ggccaccctg aagcgagccc gggcccgacc 4980
gacgtcgcgc ctctgttcga tcgtttcacc gatgccatgg ccaagcgccg ctgagcatcc 5040
tgcttcaagg ccccgggccg gcacctgccg cgcccggcag cgcctgaccc agattgttca 5100
aagcggcttg ccgactgacc ccggatttga gtgaccacca tgccaaaacg tacagacatc 5160
aaaagcatcc tgattctcgg cgctggcccg atcgtgatcg gccaggcctg cgaattcgac 5220
tactccggcg cccaggcctg taaagccctg cgcgaggaag gtttccgcgt catcctggtg 5280
aactccaacc cagccaccat catgaccgac ccggccatgg ctgacgccac ctacatcgag 5340
ccgatcaagt ggcaatcggt ggccaagatc atcgagaaag agcgcccgga cgccgtcctg 5400
ccgaccatgg gtggccagac cgccctgaac tgcgccctgg acctggagcg ccacggcgtt 5460
ctggagaagt tcggcgtgga gatgatcggt gccaacgctg acaccatcga caaggccgaa 5520
gaccgttcgc gcttcgacaa ggccatgaag gacatcggcc tggagtgccc gcgctccggt 5580
atcgcccaca gcatggaaga ggccaatgcg gtcctcgaga agctcggctt cccgtgcatc 5640
attcgcccgt cgttcaccat gggcggcacc ggcggcggta tcgcttacaa ccgtgaagag 5700
ttcgaagaaa tctgcacccg tggtctggac ctgtcgccga ccaaagagct gctgatcgac 5760
gaatcgctga tcggctggaa ggaatacgag atggaggtgg tccgcgacaa gaaggacaac 5820
tgcatcatcg tctgctcgat cgagaacttc gacccgatgg gtgtgcacac cggtgactcg 5880
atcactgttg ccccggcaca gaccctgacc gacaaggaat accagatcat gcgcaacgcc 5940
tcgctggcgg tgctgcgtga aatcggtgtg gaaaccggcg gttccaacgt ccagttcggc 6000
atttgcccga acaccggccg catggttgtc atcgagatga acccgcgcgt gtcgcgttcg 6060
tccgccctgg cctccaaggc caccggcttc ccgatcgcca agatcgccgc caagctggcc 6120
attggttaca ccctcgacga gctgcagaac gacatcactg gcggtcgcac cccagcgtcc 6180
ttcgaacctt cgatcgacta cgtcgtcacc aagctgccac gcttcgcctt cgagaaattc 6240
ccgaaagccg acgcccgcct gaccacccag atgaaatccg tgggtgaagt catggccatc 6300
ggccgtactt tccaggaatc cctgcagaaa gccctgcgcg gcctggaagt cggcgcctgc 6360
ggcctcgacc cgaaagtcga cctggccagc ccggaagccg ccagcatcct caagcgcgaa 6420
ctgaccgtgc cgggtgccga gcgtatctgg tacgtggctg acgccatgcg ttcgggcatg 6480
acctgcgaag aaatcttcaa tctgaccggc atcgacatgt ggttcctggt gcagatggaa 6540
gacctgatca aggaagaaga gaaggtcaag accctggccc tgtcggcaat cgacaaggac 6600
tacatgctgc gcctcaagcg caagggcttc tcggaccagc gcctggcagt actgctgggt 6660
atcaccgaca agaacctgcg tcgccaccgc cacaagctgg aagtgttccc ggtgtacaag 6720
cgcgtcgaca cctgcgccgc cgagttcgcc accgacaccg cctacctgta ctccacctac 6780
gaggaagagt gcgaggccaa cccgtcgacc cgcgacaaga tcatgatcct gggtggcggc 6840
ccgaaccgta tcggccaagg tatcgagttc gactactgct gcgtacacgc cgccctggcg 6900
ctgcgtgaag acggttacga gaccatcatg gtcaactgca acccggaaac cgtctccacc 6960
gactacgaca cttccgaccg cctgtacttc gagccgctga ccctggaaga cgtgctggaa 7020
gtctgccgcg tcgagaagcc gaagggcgtg atcgttcact acggcggcca gaccccgctg 7080
aagctggccc gcgctctgga agaggctggc gtgccgatca tcggtaccag ccctgacgcc 7140
atcgaccgcg ccgaagaccg cgagcgcttc cagcagatgg ttcagcgcct gagcctgctg 7200
cagccgccaa acgccaccgt gcgcagcgaa gaagaagcca tccgtgctgc gggcagcatc 7260
ggctacccgc tggtcgtgcg tccgtcctac gtactgggcg gccgtgccat ggagatcgtc 7320
tacgagctgg acgagctcaa gcgctacctg cgtgaagcgg tacaagtgtc gaacgacagc 7380
ccggtactgc tcgaccactt cctcaactgc gccatcgaga tggacgtgga tgcggtgtgc 7440
gacggcaccg acgtggtcat cggcgcgatc atgcagcaca tcgagcaggc cggcgtacac 7500
tccggcgact cggcgtgctc gctgccacct tactcgctga gcaaggaagt gcaggacgaa 7560
gtccgcgttc aggtcaagaa aatggcgctg gagctgggtg tagtcggcct gatgaacgtg 7620
cagctggccc tgcagggcga caagatctac gtgatcgaag tcaacccgcg tgcctcgcgt 7680
accgtaccgt tcgtgtccaa gtgcatcggc acgtccctgg cgatgatcgc agcccgtgtc 7740
atggcgggta aaaccctgaa agagctgggc ttcacccagg aaatcatccc gaacttctac 7800
agcgtgaagg aagccgtctt cccgttcgcc aagttcccag gggttgaccc gatcctcggc 7860
cctgagatga aatcgaccgg tgaagtgatg ggtgtcggtg acagcttcgg tgaagccttc 7920
gccaaagccc agatgggtgc cagcgaagtg ctgccgactg gcggtaccgc gttcatcagc 7980
gtgcgcgacg acgacaagcc acaagtggcc ggcgttgccc gcgacctgat cgccctgggc 8040
ttcgaagtgg ttgccactgc cggcaccgcc aaggttatcg aggcggctgg cctgaaagtg 8100
cgccgtgtga acaaggtgac cgaaggtcgc cctcacgtgg tcgacatgat caagaacgac 8160
gaagtgtcgc tgatcatcaa caccaccgaa ggtcgccagt cgatcgccga ctcctactcg 8220
attcgtcgca atgcgctgca gcacaagatt tactgcacca ctaccattgc ggctggtgaa 8280
gccatctgcg aagcgctgaa attcggtccg gaaaagaccg ttcgtcgctt gcaggatctg 8340
catgcaggac tgaaagcatg agcattacca aataggcatt tgagaagcac acggtcacac 8400
tgcttccggt agtcaataaa ccggtaaacc agcaatagac ataagcggct atttaacgac 8460
cctgccctga accgacgacc gggtcgaatt tgctttcgaa tttctgccat tcatccgctt 8520
attatcactt attcaggcgt agcaccaggc gtttaagggc accaataact gccttaaaaa 8580
aattacgccc cgccctgcca ctcatcgcag tactgttgta attcattaag cattctgccg 8640
acatggaagc catcacaaac ggcatgatga acctgaatcg ccagcggcat cagcaccttg 8700
tcgccttgcg tataatattt gcccatggat ttaaatttaa tctttctgcg aattgagatg 8760
acgccactgg ctgggcgtca tcccggtttc ccgggtaaac accaccgaaa aatagttact 8820
atcttcaaag ccacattcgg tcgaaatatc actgattaac aggcggctat gctggagaag 8880
atattgcgca tgacacactc tgacctgtcg cagatattga ttgatggtca ttccagtctg 8940
ctggcgaaat tgctgacgca aaacgcgctc actgcacgat gcctcatcac aaaatttatc 9000
cagcgcaaag ggacttttca ggctagccgc cagccgggta atcagcttat ccagcaacgt 9060
ttcgctggat gttggcggca acgaatcact ggtgtaacga tggcgattca gcaacatcac 9120
caactgcccg aacagcaact cagccatttc gttagcaaac ggcacatgct gactactttc 9180
atgctcaagc tgaccgataa cctgccgcgc ctgcgccatc cccatgctac ctaagcgcca 9240
gtgtggttgc cctgcgctgg cgttaaatcc cggaatcgcc ccctgccagt caagattcag 9300
cttcagacgc tccgggcaat aaataatatt ctgcaaaacc agatcgttaa cggaagcgta 9360
ggagtgttta tcgtcagcat gaatgtaaaa gagatcgcca cgggtaatgc gataagggcg 9420
atcgttgagt acatgcaggc cattaccgcg ccagacaatc accagctcac aaaaatcatg 9480
tgtatgttca gcaaagacat cttgcggata acggtcagcc acagcgactg cctgctggtc 9540
gctggcaaaa aaatcatctt tgagaagttt taactgatgc gccaccgtgg ctacctcggc 9600
cagagaacga agttgattat tcgcaatatg gcgtacaaat acgttgagaa gattcgcgtt 9660
attgcagaaa gccatcccgt ccctggcgaa tatcacgcgg tgaccagtta aactctcggc 9720
gaaaaagcgt cgaaaagtgg ttactgtcgc tgaatccaca gcgataggcg atgtcagtaa 9780
cgctggcctc gctgtggcgt agcagatgtc gggctttcat cagtcgcagg cggttcaggt 9840
atcgctgagg cgtcagtccc gtttgctgct taagctgccg atgtagcgta cgcagtgaaa 9900
gagaaaattg atccgccacg gcatcccaat tcacctcatc ggcaaaatgg tcctccagcc 9960
aggccagaag caagttgaga cgtgatgcgc tgttttccag gttctcctgc aaactgcttt 10020
tacgcagcaa gagcagtaat tgcataaaca agatctcgcg actggcggtc gagggtaaat 10080
cattttcccc ttcctgctgt tccatctgtg caaccagctg tcgcacctgc tgcaatacgc 10140
tgtggttaac gcgccagtga gacggatact gcccatccag ctcttgtggc agcaactgat 10200
tcagcccggc gagaaactga aatcgatccg gcgagcgata cagcacattg gtcagacaca 10260
gattatcggt atgttcatac agatgccgat catgatcgcg tacgaaacag accgtgccac 10320
cggtgatggt atagggctgc ccattaaaca catgaatacc cgtgccatgt tcgacaatca 10380
caatttcatg aaaatcatga tgatgttcag gaaaatccgc ctgcgggagc cggggttcta 10440
tcgccacgga cgcgttacca gacggaaaaa aatccacact atgtaatacg gtcatactgg 10500
cctcctgatg tcgtcaacac ggcgaaatag taatcacgag gtcaggttct taccttaaat 10560
tttcgacgga aaaccacgta aaaaacgtcg atttttcaag atacagcgtg aattttcagg 10620
aaatgcggtg agcatcacat caccacaatt cagcaaattg tgaacatcat cacgttcatc 10680
tttccctggt tgccaatggc ccattttcct gtcagtaacg agaaggtcgc gaattcaggc 10740
gctttttaga ctggtcgtaa tgaacattta aatgaattcc cttgggactc tagagatccg 10800
cgggggccca ggagggggga tctggcattt ttgggaggtg tgaaatgagt gagaagatcg 10860
tcaactcgtg gaacgaatgg gatgagctcg aggagatggt ggtcggcatt gcggactatg 10920
ccagcttcga accgaaagag ccaggcaacc atcccaaact gcgcaaccag aacctggccg 10980
aaatcatccc cttcccaagc ggcccaaagg acccgaaggt gctggagaaa gcgaacgaag 11040
agctgaatgg gctggcttac ctgctgaagg accacgatgt gatcgtgcgt cgtcccgaga 11100
agatcgactt caccaagagc ctgaaaaccc cgtatttcga ggttgccaac cagtactgcg 11160
gcgtttgtcc tcgcgacgtg atgatcacgt ttggcaacga aatcatggaa gcgaccatgt 11220
ccaaacgtgc acgcttcttc gaatacctcc cctatcggaa gctggtctac gagtactgga 11280
acaaggacga gcacatgatc tggaacgcag ccccgaaacc gaccatgcag gatagcatgt 11340
acctggaaaa cttctgggag ctctcgctgg aagaacgctt caagcggatg cacgacttcg 11400
aattctgcat cacccaagac gaggtgatct tcgatgccgc cgattgctcc cgcttgggta 11460
aggacatcct ggtgcaggaa agcatgacca ccaatcgcac tggcatccgc tggctgaaga 11520
agcatctcga accacgcggc tttcgcgtcc atccggtgca cttcccgttg gacttcttcc 11580
ctagccacat cgactgcacg ttcgtaccgt tgcgtccggg tctgatcctg accaatccgg 11640
aacgcccgat tcgcgaggaa gaggagaaga tcttcaagga gaatggctgg gagctgatca 11700
ccgtaccgca gcctacctgc tcgaacgacg agatgcccat gttctgccag agctcgaaat 11760
ggctgtccat gaacgtcctg agcattagtc ccaccaaggt gatctgcgaa gaacgggaaa 11820
agccgctgca agaactgctg gacaagcacg ggttcgaagt ctttcccttg cctttccgcc 11880
atgtgtttga gttcggtggc agctttcact gtgccacgtg ggatattcgc cgcaagggcg 11940
agtgcgagga ctacctgccg aacctgaact accagccgat ttgcggctga cgcggatccc 12000
gacctgcata ccgttgcaga taaggtagtc actcatgagc gctaggcact ttctctccct 12060
gctggacttc accaccgacg aattgctcgg ggtgatccgc cacggcatcg agctgaagga 12120
cctgcgcaag cgaggcgtgc tgttcgaacc gctgaagaac cgtgtgctag gcatgatctt 12180
cgaaaagtcc tcgacccgta cccgtgtgtc gttcgaggcc ggcatgatcc agctcggcgg 12240
ccaggccatc ttcctgtcgc cccgcgacac ccagctgggc cgcggcgagc caattggtga 12300
cagcgccatc gtgctgtcga gcatggttga tgtggtgatg atccggaccc acgcccacag 12360
caccctgacc gagttcgccg ccaagtcgcg tgtgcccgtg atcaacggcc tgtccgacga 12420
atcgcacccg tgccaactgc tggccgacat gcagaccttc gttgaacacc gcggctcgat 12480
tcagggcaag accgtgacct ggatcggcga tggcttcaac atgtgcaact cctatatcga 12540
agccgccagg cagttcgatt tccagctgcg catcgcctgc cccgaaggct atgagccgga 12600
tcaacgcttc atggcactgg gcggcgaccg cgtgcagatc atccgggatg ccagggaagc 12660
tgtgcgtgat gcacacctgg tggtcaccga tgtctggact tccatgggtc aggaggagga 12720
aactgcacgg cgcctggcgc atttcgcgcc ttaccaggtc acccgcgaac tgctcgacct 12780
ggctgcaccc gatgtcctct tcatgcactg cctgcccgcc caccgtggcg aggaaatcag 12840
ccaggacctg ctcgacgacc cacgttcggt cgcctgggac gaggctgaaa accgcctgca 12900
tgcacagaag gcgcttctcg aattccttgt agaaccggct taccaccacg catgagtcaa 12960
ccgtacaacc ccgtggagtg atggcatggc ggacgtaaaa aaggtcgtac tggcgtattc 13020
cggcggcctt gatacttcgg tgattctcaa gtggctgcag gatacctaca actgcgaagt 13080
ggtgaccttc accgctgacc tggggcaggg cgaagaggtc gaaccggccc gtgccaaggc 13140
ccaggcaatg ggcgttaaag agatctacat cgacgacctg cgcgaagaat tcgtgcgtga 13200
tttcgtgttc ccgatgttcc gcgccaacac cgtctacgaa ggcgagtacc tgctgggtac 13260
ttccatcgcc cgtccgctga tcgccaagcg cctgatcgaa atcgccaacg aaaccggcgc 13320
tgacgccatt tcccatggcg ccaccggcaa gggtaacgac caggtgcgct tcgagctggg 13380
tgcctatgcc ctgaagccag gcgtcaaggt catcgctcca tggcgcgagt gggacctgct 13440
gtcccgcgaa aagctgatgg actacgccga gaagcacggc atcccgatcg agcgccacgg 13500
caagaagaag tcgccgtact cgatggacgc caacctgctg cacatctcct acgagggcgg 13560
tgtcctggaa gatacctgga ccgagcacga agaagacatg tggcgctgga gtgtctcgcc 13620
tgagaatgcc ccggaccagg ctacctacat cgagctgacc taccgcaatg gtgacatcgt 13680
tgccatcgac ggcgtcgaga aatccccggc caccgtcctg gcagacctga accgtatcgg 13740
tggtgccaac ggcatcggcc gtctggacat cgtcgaaaac cgttacgtcg gcatgaagtc 13800
gcgcggttgc tacgaaacgc ctggcggtac catcatgctc aaggcacacc gtgccatcga 13860
gtcgatcacc ctggaccgcg aagtcgctca cctgaaagat gagctgatgc caaagtatgc 13920
cagcctgatc tacaccggct actggtggag cccggagcgt ctgatgctgc aacagatgat 13980
cgatgcttcg caggtcaacg tgaatggtgt ggtgcgcctg aaactgtaca agggcaacgt 14040
gaccgtggtt ggccgcaagt cggacgattc gctgttcgat gccaacatcg ccacctttga 14100
agaagatggt ggtgcctaca accaggcaga tgctgctggc ttcatcaagc tcaatgcact 14160
gcgtatgcgc attgccgcca acaagggccg ttcgctgctc tgattgctat cgacgccact 14220
ttttcgttca cgcctgcaat gagtgaatcc atgagcaccg agaagaccaa tcagtcctgg 14280
ggcggccgct tcagtgagcc cgtcgacgcc ttcgtcgccc gtttcaccgc ctcggtagat 14340
ttcgacaagc gcctgtaccg tcacgacatc atgggttcga ttgcccatgc caccatgctg 14400
gcgcaggtcg gcgtgctcag tgatgccgag cgcgacacca tcatcgatgg cctgaaaacc 14460
atccagggcg agattgaagc cggcaacttc gactggcgtg tcgacctcga agacgtgcac 14520
atgaacatcg aagcacgcct gaccgaccgc atcggcatca ccggcaagaa gctgcatact 14580
gggcgtagcc gcaacgacca ggtggccacc gacatccgcc tttggctgcg cgacgaaatc 14640
gacctgatcc tgggcgaaat cacccgcctg cagcagggcc tgctggagca ggcagagcgt 14700
gaagccgaaa ccatcatgcc tggtttcacc cacctgcaga cggcgcagcc ggtcaccttt 14760
ggccaccacc tgctggcgtg gttcgaaatg ctcagccgcg actatgagcg cctggtcgac 14820
tgccgcaagc gcaccaaccg catgccactg ggcagcgccg cgctggccgg caccacctac 14880
ccgatcgacc gtgaactgac ctgcaagctg ctgggctttg aagccgtggc cggcaactcg 14940
ctggatggcg tgtcggaccg tgatttcgcc atcgaattct gcgccgctgc cagcgtggcg 15000
atgatgcacc tttcgcgctt ctccgaagag ctggtgctgt ggaccagcgc gcagttccag 15060
ttcatcgacc ttccggaccg cttctgcact ggcagctcga tcatgccgca gaaaaagaac 15120
ccggacgtgc cagagctggt acgtggcaag agcggccgcg tgttcggcgc cctgaccggc 15180
ctgctgaccc tgatgaaagg ccaaccgctg gcctacaaca aggacaacca ggaagacaag 15240
gaaccgctgt tcgacgccgc cgataccctg cgcgactcgc tgcgggcctt cgctgacatg 15300
atcccggcga tcaagcccaa gcacgccatc atgcgtgaag cggccctgcg cggtttctcc 15360
accgctaccg acctggctga ctatctggtt cgccgtggcc tgccgttccg tgactgccac 15420
gagatcgttg gccacgcggt gaagtatggt gtggacactg gcaaggacct ggccgagatg 15480
agcctggacg aactgcgcca attcagcgac cagatcgagc aggacgtgtt tgccgtgctg 15540
acgctggaag gctcggtgaa tgcgcgtgac cacattggtg gtacggcgcc ggcgcaggtg 15600
cgtgctgccg tcgttcgtgg caaggccctg ttggcgtctc gctaatcccc caaggctcga 15660
gcacgcgaga gtagggaact gccaggcatc aaataaaacg aaaggctcag tcgaaagact 15720
gggcctttcg ttttatctgt tgtttgtcgg tgaacgctct cctgagtagg acaaatccgc 15780
cgggagcgga tttgaacgat gataagctgt caaacatgag aattcttgaa gacgaaaggg 15840
cctcgtgtgt acaaacgttc gtcaaaaggg cgacacaaaa ttcctgcagg ggccggccca 15900
gcgccggcgg tcgagtggcg acggcgcggc ttgtccgcgc cctggtagat tgcctggccg 15960
taggccagcc atttttgagc ggccagcggc cgcgataggc cgacgcgaag cggcggggcg 16020
tagggagcgc agcgaccgaa gggtaggcgc tttttgcagc tcttcggctg tgcgctggcc 16080
agacagttat gcacaggcca ggcgggtttt aagagtttta ataagtttta aagagtttta 16140
ggcggaaaaa tcgccttttt tctcttttat atcagtcact tacatgtgtg accggttccc 16200
aatgtacggc tttgggttcc caatgtacgg gttccggttc ccaatgtacg gctttgggtt 16260
cccaatgtac gtgctatcca caggaaagag accttttcga cctttttccc ctgctagggc 16320
aatttgccct agcatctgct ccgtacatta ggaaccggcg gatgcttcgc cctcgatcag 16380
gttgcggtag cgcatgacta ggatcgggcc agcctgcccc gcctcctcct tcaaatcgta 16440
ctccggcagg tcatttgacc cgatcagctt gcgcacggtg aaacagaact tcttgaactc 16500
tccggcgctg ccactgcgtt cgtagatcgt cttgaacaac catctggctt ctgccttgcc 16560
tgcggcgcgg cgtgccaggc ggtagagaaa acggccgatg ccgggatcga tcaaaaagta 16620
atcggggtga accgtcagca cgtccgggtt cttgccttct gtgatctcgc ggtacatcca 16680
atcaactagc tcgatctcga tgtactccgg ccgcccggtt tcgctcttta cgatcttgta 16740
gcggctaatc aaggcttcac cctcggatac cgtcaccagg cggccgttct tggccttctt 16800
cgtacgctgc atggcaacgt gcgtggtgtt taaccgaatg caggtttcta ccaggtcgtc 16860
tttctgcttt ccgccatcgg ctcgccggca gaacttgagt acgtccgcaa cgtgtggacg 16920
gaacacgcgg ccgggcttgt ctcccttccc ttcccggtat cggttcatgg attcggttag 16980
atgggaaacc gccatcagta ccaggtcgta atcccacaca ctggccatgc cggccggccc 17040
tgcggaaacc tctacgtgcc cgtctggaag ctcgtagcgg atcacctcgc cagctcgtcg 17100
gtcacgcttc gacagacgga aaacggccac gtccatgatg ctgcgactat cgcgggtgcc 17160
cacgtcatag agcatcggaa cgaaaaaatc tggttgctcg tcgcccttgg gcggcttcct 17220
aatcgacggc gcaccggctg ccggcggttg ccgggattct ttgcggattc gatcagcggc 17280
cgcttgccac gattcaccgg ggcgtgcttc tgcctcgatg cgttgccgct gggcggcctg 17340
cgcggccttc aacttctcca ccaggtcatc acccagcgcc gcgccgattt gtaccgggcc 17400
ggatggtttg cgaccgctca cgccgattcc tcgggcttgg gggttccagt gccattgcag 17460
ggccggcaga caacccagcc gcttacgcct ggccaaccgc ccgttcctcc acacatgggg 17520
cattccacgg cgtcggtgcc tggttgttct tgattttcca tgccgcctcc tttagccgct 17580
aaaattcatc tactcattta ttcatttgct catttactct ggtagctgcg cgatgtattc 17640
agatagcagc tcggtaatgg tcttgccttg gcgtaccgcg tacatcttca gcttggtgtg 17700
atcctccgcc ggcaactgaa agttgacccg cttcatggct ggcgtgtctg ccaggctggc 17760
caacgttgca gccttgctgc tgcgtgcgct cggacggccg gcacttagcg tgtttgtgct 17820
tttgctcatt ttctctttac ctcattaact caaatgagtt ttgatttaat ttcagcggcc 17880
agcgcctgga cctcgcgggc agcgtcgccc tcgggttctg attcaagaac ggttgtgccg 17940
gcggcggcag tgcctgggta gctcacgcgc tgcgtgatac gggactcaag aatgggcagc 18000
tcgtacccgg ccagcgcctc ggcaacctca ccgccgatgc gcgtgccttt gatcgcccgc 18060
gacacgacaa aggccgcttg tagccttcca tccgtgacct caatgcgctg cttaaccagc 18120
tccaccaggt cggcggtggc ccatatgtcg taagggcttg gctgcaccgg aatcagcacg 18180
aagtcggctg ccttgatcgc ggacacagcc aagtccgccg cctggggcgc tccgtcgatc 18240
actacgaagt cgcgccggcc gatggccttc acgtcgcggt caatcgtcgg gcggtcgatg 18300
ccgacaacgg ttagcggttg atcttcccgc acggccgccc aatcgcgggc actgccctgg 18360
ggatcggaat cgactaacag aacatcggcc ccggcgagtt gcagggcgcg ggctagatgg 18420
gttgcgatgg tcgtcttgcc tgacccgcct ttctggttaa gtacagcgat aaccttcatg 18480
cgttcccctt gcgtatttgt ttatttactc atcgcatcat atacgcagcg accgcatgac 18540
gcaagctgtt ttactcaaat acacatcacc tttttagacg gcggcgctcg gtttcttcag 18600
cggccaagct ggccggccag gccgccagct tggcatcaga caaaccggcc aggatttcat 18660
gcagccgcac ggttccggat gagcattca 18689
Claims (26)
- 야생형 미생물에서 각각의 효소 활성에 비해 카르바모일포스페이트 신타아제의 기능을 갖는 효소의 증가된 활성을 포함하고, L-아르기닌:글리신 아미디노트랜스퍼라제의 활성을 갖는 단백질을 코딩하는 적어도 하나의 이종 유전자를 포함하는 미생물.
- 제 1 항에 있어서, 카르바모일포스페이트 신타아제의 기능을 갖는 효소의 증가된 활성이 카르바모일포스페이트 신타아제의 기능을 갖는 효소를 코딩하는 유전자의 돌연변이 및/또는 과발현에 의해 달성되는 미생물.
- 제 1 항 또는 제 2 항에 있어서, L-아르기닌:글리신 아미디노트랜스퍼라제의 활성이 L-아르기닌:글리신 아미디노트랜스퍼라제를 코딩하는 유전자의 돌연변이 및/또는 과발현에 의해 증가되는 미생물.
- 제 1 항 내지 제 3 항 중 어느 한 항에 있어서, 야생형 미생물의 능력에 비해 L-아르기닌 생산 능력이 개선된 미생물.
- 제 4 항에 있어서, 아르기니노숙시네이트 리아제의 기능을 갖는 효소의 활성이 야생형 미생물에서의 각각의 효소 활성에 비해 증가되는 미생물.
- 제 4 항 또는 제 5 항에 있어서, 오르니틴 카르바모일트랜스퍼라제의 기능을 갖는 효소의 활성이 야생형 미생물에서의 각각의 효소 활성에 비해 증가되는 미생물.
- 제 4 항 내지 제 6 항 중 어느 한 항에 있어서, 아르기니노숙시네이트 신테타제의 기능을 갖는 효소의 활성이 야생형 미생물에서의 각각의 효소 활성에 비해 증가되는 미생물.
- 제 4 항 내지 제 7 항 중 어느 한 항에 있어서, 효소의 증가된 활성이 각각의 효소를 코딩하는 유전자의 돌연변이 및/또는 과발현에 의해 달성되는 미생물.
- 제 4 항 내지 제 8 항 중 어느 한 항에 있어서, 아르기닌 오페론 (argCJBDFR) 이 과발현되는 미생물.
- 제 4 항 내지 제 8 항 중 어느 한 항에 있어서, 아르기닌 반응성 리프레서 단백질 ArgR 을 코딩하는 argR 유전자가 약독화되거나 결실되는 미생물.
- 제 4 항 내지 제 8 항 또는 제 10 항 중 어느 한 항에 있어서, 글루타메이트 디히드로게나제, 오르니틴 아세틸트랜스퍼라제, 아세틸글루타메이트 키나제, 아세틸글루타밀포스페이트 리덕타제 및 아세틸오르니틴 아미노트랜스퍼라제를 각각 코딩하는 gdh, argJ, argB, argC 및/또는 argD 를 포함하는, L-오르니틴 및 L-아르기닌의 생합성 경로의 효소를 코딩하는 유전자 중 적어도 하나 이상이 과발현되는 미생물.
- 제 1 항 내지 제 11 항 중 어느 한 항에 있어서, L-아르기닌:글리신 아미디노트랜스퍼라제의 기능을 갖는 단백질이 SEQ ID NO: 2 에 따른 아미노산 서열과 적어도 70% 동일한 아미노산 서열을 포함하는 미생물.
- 제 1 항 내지 제 11 항 중 어느 한 항에 있어서, L-아르기닌:글리신 아미디노트랜스퍼라제의 기능을 갖는 단백질이 SEQ ID NO: 16 에 따른 아미노산 서열과 적어도 70% 동일한 아미노산 서열을 포함하는 미생물.
- 제 1 항 내지 제 11 항 중 어느 한 항에 있어서, L-아르기닌:글리신 아미디노트랜스퍼라제의 기능을 갖는 단백질이 SEQ ID NO: 24 에 따른 아미노산 서열과 적어도 70% 동일한 아미노산 서열을 포함하는 미생물.
- 제 1 항 내지 제 11 항 중 어느 한 항에 있어서, L-아르기닌:글리신 아미디노트랜스퍼라제의 기능을 갖는 단백질이 SEQ ID NO: 20 에 따른 아미노산 서열과 적어도 70% 동일한 아미노산 서열을 포함하는 미생물.
- 제 1 항 내지 제 15 항 중 어느 한 항에 있어서, 미생물이 코리네박테리움 (Corynebacterium) 속, 엔테로박테리아세아에 (Enterobacteriaceae) 속 또는 슈도모나스 (Pseudomonas) 속에 속하는 미생물.
- 제 16 항에 있어서, 미생물이 코리네박테리움 글루타미쿰 (Corynebacterium glutamicum) 인 미생물.
- 제 16 항에 있어서, 미생물이 에스케리치아 콜라이 (Escherichia coli) 인 미생물.
- 제 16 항에 있어서, 미생물이 슈도모나스 푸티다 (Pseudomonas putida) 인 미생물.
- a) 발효 배지에서 제 1 항 내지 제 19 항 중 어느 한 항에서 정의된 미생물을 배양하는 단계, 및 b) 배지에 구아니디노 아세트산 (GAA) 을 축적하여 GAA 함유 발효 브로쓰를 형성하는 단계를 포함하는, 구아니디노 아세트산 (GAA) 의 발효 생산 방법.
- 제 20 항에 있어서, GAA 함유 발효 브로쓰로부터 GAA 를 단리하는 단계를 추가로 포함하는 구아니디노 아세트산 (GAA) 의 발효 생산 방법.
- 제 20 항에 있어서, GAA 함유 발효 브로쓰를 건조 및/또는 과립화하는 단계를 추가로 포함하는 구아니디노 아세트산 (GAA) 의 발효 생산 방법.
- 제 1 항 내지 제 19 항 중 어느 한 항에 있어서, 구아니디노아세테이트 N-메틸트랜스퍼라제의 활성을 갖는 효소를 코딩하는 유전자를 추가로 포함하는 미생물.
- 제 23 항에 있어서, 구아니디노아세테이트 N-메틸트랜스퍼라제의 활성을 갖는 효소를 코딩하는 유전자가 과발현되는 미생물.
- a) 발효 배지에서 제 22 항 또는 제 24 항에서 정의된 미생물을 배양하는 단계, 및 b) 배지에 크레아틴을 축적하여 크레아틴 함유 발효 브로쓰를 형성하는 단계를 포함하는, 크레아틴의 발효 생산 방법.
- 제 25 항에 있어서, 크레아틴 함유 발효 브로쓰로부터 크레아틴을 단리하는 단계를 추가로 포함하는 크레아틴의 발효 생산 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP19218204.6 | 2019-12-19 | ||
| EP19218204.6A EP3839051A1 (en) | 2019-12-19 | 2019-12-19 | Method for the fermentative production of guanidinoacetic acid |
| PCT/EP2020/085882 WO2021122400A1 (en) | 2019-12-19 | 2020-12-14 | Method for the fermentative production of guanidinoacetic acid |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220119026A true KR20220119026A (ko) | 2022-08-26 |
Family
ID=69410969
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020227020423A KR20220119026A (ko) | 2019-12-19 | 2020-12-14 | 구아니디노아세트산의 발효 생산 방법 |
Country Status (13)
| Country | Link |
|---|---|
| EP (2) | EP3839051A1 (ko) |
| JP (1) | JP2023507482A (ko) |
| KR (1) | KR20220119026A (ko) |
| CN (1) | CN114867861A (ko) |
| AR (1) | AR120771A1 (ko) |
| AU (1) | AU2020410242A1 (ko) |
| BR (1) | BR112022010862A2 (ko) |
| DK (1) | DK4077695T3 (ko) |
| IL (1) | IL293952A (ko) |
| MX (1) | MX2022007250A (ko) |
| TW (1) | TW202136505A (ko) |
| WO (1) | WO2021122400A1 (ko) |
| ZA (1) | ZA202207792B (ko) |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3816247B1 (de) | 2019-10-28 | 2022-12-07 | Evonik Operations GmbH | Härtermischung |
| CN113481139B (zh) * | 2021-07-29 | 2022-11-08 | 江南大学 | 一种产胍基乙酸的重组枯草芽孢杆菌及其构建方法 |
| AU2023281826A1 (en) | 2022-06-03 | 2024-10-03 | Evonik Operations Gmbh | Improved biotechnological method for producing guanidino acetic acid (gaa) by using nadh-dependent dehydrogenases |
| WO2023232584A1 (en) | 2022-06-03 | 2023-12-07 | Evonik Operations Gmbh | Method for producing guanidino acetic acid (gaa) |
| WO2024094481A1 (en) | 2022-11-03 | 2024-05-10 | Evonik Operations Gmbh | Improved biotechnological process to produce guanidinoacetic acid (gaa) by targeted introduction or by increasing the activity of a transmembrane exporter protein |
| WO2024094483A1 (en) | 2022-11-03 | 2024-05-10 | Evonik Operations Gmbh | Improved biotechnological process to produce guanidinoacetic acid (gaa) by targeted introduction or by increasing the activity of a transmembrane transport protein belonging to the amino acid-polyamine-organocation superfamily |
| WO2024149617A1 (en) | 2023-01-09 | 2024-07-18 | Evonik Operations Gmbh | Fermentative production guanidinoacetic acid (gaa) from serine by attenuating l serine ammonia lyase activity in microorganisms |
| WO2024149616A1 (en) | 2023-01-09 | 2024-07-18 | Evonik Operations Gmbh | Fermentative production guanidinoacetic acid (gaa) from serine using a microorganism having an enhanced l-serine hydroxymethyltransferase activity |
| WO2024160790A1 (en) | 2023-02-01 | 2024-08-08 | Evonik Operations Gmbh | Method for the fermentative production of guanidinoacetic acid using a microorganism comprising a heterologous l-threonine aldolase gene |
| WO2024160791A1 (en) | 2023-02-01 | 2024-08-08 | Evonik Operations Gmbh | Method for the fermentative production of guanidinoacetic acid using a microorganism comprising a heterologous l-threonine 3-dehydrogenase gene (tdh) and a glycine c-acetyltransferase gene (kbl) |
| WO2024165344A1 (en) * | 2023-02-06 | 2024-08-15 | Evonik Operations Gmbh | Process for producing free-flowing particles comprising or consisting of an n-guanylamino acid |
| WO2024165348A1 (en) | 2023-02-06 | 2024-08-15 | Evonik Operations Gmbh | Process for preparing an n-guanylamino acid |
| CN116426497B (zh) * | 2023-03-20 | 2023-10-13 | 江南大学 | 一种l-精氨酸-甘氨酸脒基转移酶及其在生产胍基乙酸中的应用 |
| WO2024208621A1 (en) | 2023-04-03 | 2024-10-10 | Evonik Operations Gmbh | Composition comprising an n-guanylamino acid for drinking water application |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3849250A (en) | 1971-02-26 | 1974-11-19 | Kyowa Hakko Kogyo Kk | Process for producing l-arginine by fermentation |
| DE60034843T2 (de) | 1999-06-03 | 2008-01-17 | Ajinomoto Co., Inc. | Verfahren zur Herstellung von L-arginin |
| US7160705B2 (en) | 2000-04-28 | 2007-01-09 | Ajinomoto Co., Inc. | Arginine repressor deficient strain of coryneform bacterium and method for producing L-arginine |
| SI1758463T1 (sl) | 2004-06-09 | 2008-08-31 | Alzchem Trostberg Gmbh | Gvanidino ocetna kislina kot dodatek Ĺľivalski hrani |
| US20060200870A1 (en) * | 2004-11-24 | 2006-09-07 | Brian Tseng | Methods of treating muscular dystrophy |
| JP4595506B2 (ja) * | 2004-11-25 | 2010-12-08 | 味の素株式会社 | L−アミノ酸生産菌及びl−アミノ酸の製造方法 |
| KR101835935B1 (ko) | 2014-10-13 | 2018-03-12 | 씨제이제일제당 (주) | L-아르기닌을 생산하는 코리네박테리움 속 미생물 및 이를 이용한 l-아르기닌의 제조 방법 |
| CN106065411B (zh) | 2016-08-10 | 2021-12-07 | 洛阳华荣生物技术有限公司 | 发酵法生产肌酸 |
| JP2019531759A (ja) * | 2016-10-26 | 2019-11-07 | 味の素株式会社 | 目的物質の製造方法 |
-
2019
- 2019-12-19 EP EP19218204.6A patent/EP3839051A1/en not_active Withdrawn
-
2020
- 2020-12-14 DK DK20823810.5T patent/DK4077695T3/da active
- 2020-12-14 WO PCT/EP2020/085882 patent/WO2021122400A1/en unknown
- 2020-12-14 KR KR1020227020423A patent/KR20220119026A/ko unknown
- 2020-12-14 CN CN202080087505.XA patent/CN114867861A/zh active Pending
- 2020-12-14 EP EP20823810.5A patent/EP4077695B1/en active Active
- 2020-12-14 JP JP2022537864A patent/JP2023507482A/ja active Pending
- 2020-12-14 AU AU2020410242A patent/AU2020410242A1/en active Pending
- 2020-12-14 BR BR112022010862A patent/BR112022010862A2/pt unknown
- 2020-12-14 MX MX2022007250A patent/MX2022007250A/es unknown
- 2020-12-14 IL IL293952A patent/IL293952A/en unknown
- 2020-12-15 AR ARP200103498A patent/AR120771A1/es unknown
- 2020-12-16 TW TW109144374A patent/TW202136505A/zh unknown
-
2022
- 2022-07-13 ZA ZA2022/07792A patent/ZA202207792B/en unknown
Also Published As
| Publication number | Publication date |
|---|---|
| EP4077695B1 (en) | 2024-07-24 |
| ZA202207792B (en) | 2023-04-26 |
| MX2022007250A (es) | 2022-07-13 |
| JP2023507482A (ja) | 2023-02-22 |
| TW202136505A (zh) | 2021-10-01 |
| BR112022010862A2 (pt) | 2022-08-23 |
| DK4077695T3 (da) | 2024-10-14 |
| EP3839051A1 (en) | 2021-06-23 |
| EP4077695A1 (en) | 2022-10-26 |
| WO2021122400A1 (en) | 2021-06-24 |
| AR120771A1 (es) | 2022-03-16 |
| IL293952A (en) | 2022-08-01 |
| CN114867861A (zh) | 2022-08-05 |
| AU2020410242A1 (en) | 2022-08-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20220119026A (ko) | 구아니디노아세트산의 발효 생산 방법 | |
| RU2770464C1 (ru) | Новая аденилосукцинат-синтетаза и способ получения нуклеотидов пурина с ее использованием | |
| JP4841093B2 (ja) | 細胞性nadphの増加によるl−アミノ酸の生成方法 | |
| US12065677B2 (en) | Method for the fermentative production of guanidinoacetic acid | |
| US11999982B2 (en) | Method for the fermentative production of guanidinoacetic acid | |
| WO2022243116A1 (en) | Improved biotechnological method for producing guanidino acetic acid (gaa) by inactivation of an amino acid exporter | |
| JP2002520067A (ja) | グルコサミンを製造するためのプロセス及び物質 | |
| KR102149044B1 (ko) | 2-히드록시 감마 부티로락톤 또는 2,4-디히드록시-부티레이트 의 제조 방법 | |
| EP1147198A1 (en) | Pyruvate carboxylase from corynebacterium glutamicum | |
| CN110195088B (zh) | 一种精氨酸水解酶及其编码基因和应用 | |
| CN113166787A (zh) | 使用具有完全或部分缺失的whiB4基因的物种谷氨酸棒杆菌的L-赖氨酸分泌细菌发酵生产L-赖氨酸的方法 | |
| WO2023232583A1 (en) | Improved biotechnological method for producing guanidino acetic acid (gaa) by using nadh-dependent dehydrogenases | |
| WO2024094483A1 (en) | Improved biotechnological process to produce guanidinoacetic acid (gaa) by targeted introduction or by increasing the activity of a transmembrane transport protein belonging to the amino acid-polyamine-organocation superfamily | |
| CN117355537A (zh) | 改善的通过氨基酸输出蛋白失活来生产胍基乙酸(gaa)的生物技术方法 | |
| CN115028694A (zh) | 与l-谷氨酸产量相关的蛋白及其相关生物材料和应用 | |
| EP2930244A1 (en) | Microorganisms and methods for producing acrylate and other products from homoserine |