KR20210111254A - 차세대 분자 프로파일링 - Google Patents
차세대 분자 프로파일링 Download PDFInfo
- Publication number
- KR20210111254A KR20210111254A KR1020217020462A KR20217020462A KR20210111254A KR 20210111254 A KR20210111254 A KR 20210111254A KR 1020217020462 A KR1020217020462 A KR 1020217020462A KR 20217020462 A KR20217020462 A KR 20217020462A KR 20210111254 A KR20210111254 A KR 20210111254A
- Authority
- KR
- South Korea
- Prior art keywords
- cancer
- data
- machine learning
- treatment
- learning model
- Prior art date
Links
- 238000000034 method Methods 0.000 claims abstract description 391
- 238000011282 treatment Methods 0.000 claims abstract description 269
- 239000000090 biomarker Substances 0.000 claims abstract description 244
- 238000010801 machine learning Methods 0.000 claims abstract description 232
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims abstract description 224
- 201000010099 disease Diseases 0.000 claims abstract description 126
- 208000035475 disorder Diseases 0.000 claims abstract description 98
- 238000012545 processing Methods 0.000 claims abstract description 91
- 230000000694 effects Effects 0.000 claims abstract description 47
- 206010009944 Colon cancer Diseases 0.000 claims abstract description 25
- 208000001333 Colorectal Neoplasms Diseases 0.000 claims abstract description 23
- VVIAGPKUTFNRDU-UHFFFAOYSA-N 6S-folinic acid Natural products C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 VVIAGPKUTFNRDU-UHFFFAOYSA-N 0.000 claims abstract description 10
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 claims abstract description 10
- 229960002949 fluorouracil Drugs 0.000 claims abstract description 10
- 235000008191 folinic acid Nutrition 0.000 claims abstract description 10
- 239000011672 folinic acid Substances 0.000 claims abstract description 10
- VVIAGPKUTFNRDU-ABLWVSNPSA-N folinic acid Chemical compound C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 VVIAGPKUTFNRDU-ABLWVSNPSA-N 0.000 claims abstract description 10
- 229960001691 leucovorin Drugs 0.000 claims abstract description 10
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 claims abstract description 6
- 229960004768 irinotecan Drugs 0.000 claims abstract description 6
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 claims abstract description 6
- 229960001756 oxaliplatin Drugs 0.000 claims abstract description 6
- YXTKHLHCVFUPPT-YYFJYKOTSA-N (2s)-2-[[4-[(2-amino-5-formyl-4-oxo-1,6,7,8-tetrahydropteridin-6-yl)methylamino]benzoyl]amino]pentanedioic acid;(1r,2r)-1,2-dimethanidylcyclohexane;5-fluoro-1h-pyrimidine-2,4-dione;oxalic acid;platinum(2+) Chemical compound [Pt+2].OC(=O)C(O)=O.[CH2-][C@@H]1CCCC[C@H]1[CH2-].FC1=CNC(=O)NC1=O.C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 YXTKHLHCVFUPPT-YYFJYKOTSA-N 0.000 claims abstract 8
- 108090000623 proteins and genes Proteins 0.000 claims description 196
- 206010028980 Neoplasm Diseases 0.000 claims description 176
- 239000000523 sample Substances 0.000 claims description 140
- 150000007523 nucleic acids Chemical class 0.000 claims description 134
- 102000039446 nucleic acids Human genes 0.000 claims description 121
- 108020004707 nucleic acids Proteins 0.000 claims description 121
- 238000012549 training Methods 0.000 claims description 95
- 201000011510 cancer Diseases 0.000 claims description 90
- 210000004027 cell Anatomy 0.000 claims description 79
- 102000004169 proteins and genes Human genes 0.000 claims description 74
- 238000004458 analytical method Methods 0.000 claims description 68
- 238000012163 sequencing technique Methods 0.000 claims description 68
- 210000001519 tissue Anatomy 0.000 claims description 62
- 102000053602 DNA Human genes 0.000 claims description 56
- 108020004414 DNA Proteins 0.000 claims description 55
- 229920002477 rna polymer Polymers 0.000 claims description 52
- 230000015654 memory Effects 0.000 claims description 50
- 238000003199 nucleic acid amplification method Methods 0.000 claims description 44
- 230000003321 amplification Effects 0.000 claims description 42
- 238000002493 microarray Methods 0.000 claims description 41
- 230000008569 process Effects 0.000 claims description 40
- 238000003752 polymerase chain reaction Methods 0.000 claims description 37
- 239000012472 biological sample Substances 0.000 claims description 34
- 102100032481 B-cell CLL/lymphoma 9 protein Human genes 0.000 claims description 30
- 102100032610 Guanine nucleotide-binding protein G(s) subunit alpha isoforms XLas Human genes 0.000 claims description 30
- 101000798495 Homo sapiens B-cell CLL/lymphoma 9 protein Proteins 0.000 claims description 30
- 101001014590 Homo sapiens Guanine nucleotide-binding protein G(s) subunit alpha isoforms XLas Proteins 0.000 claims description 30
- 101001014594 Homo sapiens Guanine nucleotide-binding protein G(s) subunit alpha isoforms short Proteins 0.000 claims description 30
- 101001014610 Homo sapiens Neuroendocrine secretory protein 55 Proteins 0.000 claims description 30
- 101000610107 Homo sapiens Pre-B-cell leukemia transcription factor 1 Proteins 0.000 claims description 30
- 101000797903 Homo sapiens Protein ALEX Proteins 0.000 claims description 30
- 102100040171 Pre-B-cell leukemia transcription factor 1 Human genes 0.000 claims description 30
- 238000003556 assay Methods 0.000 claims description 30
- 238000009396 hybridization Methods 0.000 claims description 30
- 238000003860 storage Methods 0.000 claims description 30
- 239000012530 fluid Substances 0.000 claims description 29
- 102100025007 14-3-3 protein epsilon Human genes 0.000 claims description 24
- 102000004000 Aurora Kinase A Human genes 0.000 claims description 24
- 108090000461 Aurora Kinase A Proteins 0.000 claims description 24
- 101000760079 Homo sapiens 14-3-3 protein epsilon Proteins 0.000 claims description 24
- 101000981546 Homo sapiens LHFPL tetraspan subfamily member 6 protein Proteins 0.000 claims description 24
- 101001069727 Homo sapiens Paired mesoderm homeobox protein 1 Proteins 0.000 claims description 24
- 101000728236 Homo sapiens Polycomb group protein ASXL1 Proteins 0.000 claims description 24
- 102100027004 Inhibin beta A chain Human genes 0.000 claims description 24
- 102100024116 LHFPL tetraspan subfamily member 6 protein Human genes 0.000 claims description 24
- 102100033786 Paired mesoderm homeobox protein 1 Human genes 0.000 claims description 24
- 102100029799 Polycomb group protein ASXL1 Human genes 0.000 claims description 24
- 238000003364 immunohistochemistry Methods 0.000 claims description 24
- 108010019691 inhibin beta A subunit Proteins 0.000 claims description 24
- 238000007637 random forest analysis Methods 0.000 claims description 23
- 238000007481 next generation sequencing Methods 0.000 claims description 22
- 102100026548 Caspase-8 Human genes 0.000 claims description 20
- 102100038885 Histone acetyltransferase p300 Human genes 0.000 claims description 20
- 101000983528 Homo sapiens Caspase-8 Proteins 0.000 claims description 20
- 101000882390 Homo sapiens Histone acetyltransferase p300 Proteins 0.000 claims description 20
- 102100031513 Fc receptor-like protein 4 Human genes 0.000 claims description 18
- 101000846909 Homo sapiens Fc receptor-like protein 4 Proteins 0.000 claims description 18
- 210000001124 body fluid Anatomy 0.000 claims description 18
- 230000035772 mutation Effects 0.000 claims description 18
- 238000012217 deletion Methods 0.000 claims description 16
- 230000037430 deletion Effects 0.000 claims description 16
- 238000004422 calculation algorithm Methods 0.000 claims description 15
- 239000012634 fragment Substances 0.000 claims description 15
- 238000003780 insertion Methods 0.000 claims description 15
- 230000037431 insertion Effects 0.000 claims description 15
- 108700003785 Baculoviral IAP Repeat-Containing 3 Proteins 0.000 claims description 14
- 102100021662 Baculoviral IAP repeat-containing protein 3 Human genes 0.000 claims description 14
- 101150104237 Birc3 gene Proteins 0.000 claims description 14
- 102100030308 Homeobox protein Hox-A11 Human genes 0.000 claims description 14
- 101001083158 Homo sapiens Homeobox protein Hox-A11 Proteins 0.000 claims description 14
- 108010011536 PTEN Phosphohydrolase Proteins 0.000 claims description 14
- 102000014160 PTEN Phosphohydrolase Human genes 0.000 claims description 14
- 101100379220 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) API2 gene Proteins 0.000 claims description 14
- 238000007901 in situ hybridization Methods 0.000 claims description 14
- 230000004083 survival effect Effects 0.000 claims description 14
- 238000002560 therapeutic procedure Methods 0.000 claims description 14
- 238000012175 pyrosequencing Methods 0.000 claims description 13
- 238000006467 substitution reaction Methods 0.000 claims description 13
- 102100031456 Centriolin Human genes 0.000 claims description 12
- 102100029375 Crk-like protein Human genes 0.000 claims description 12
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 claims description 12
- 101000941711 Homo sapiens Centriolin Proteins 0.000 claims description 12
- 101000919315 Homo sapiens Crk-like protein Proteins 0.000 claims description 12
- 101001005667 Homo sapiens Mastermind-like protein 2 Proteins 0.000 claims description 12
- 101001030211 Homo sapiens Myc proto-oncogene protein Proteins 0.000 claims description 12
- 101001013158 Homo sapiens Myeloid leukemia factor 1 Proteins 0.000 claims description 12
- 101000808799 Homo sapiens Splicing factor U2AF 35 kDa subunit Proteins 0.000 claims description 12
- 102100025130 Mastermind-like protein 2 Human genes 0.000 claims description 12
- 102100038895 Myc proto-oncogene protein Human genes 0.000 claims description 12
- 102100029691 Myeloid leukemia factor 1 Human genes 0.000 claims description 12
- 102100038501 Splicing factor U2AF 35 kDa subunit Human genes 0.000 claims description 12
- -1 TERT Proteins 0.000 claims description 12
- 210000003169 central nervous system Anatomy 0.000 claims description 12
- 230000004927 fusion Effects 0.000 claims description 11
- 206010033128 Ovarian cancer Diseases 0.000 claims description 10
- 239000003550 marker Substances 0.000 claims description 10
- 238000013188 needle biopsy Methods 0.000 claims description 10
- 230000005945 translocation Effects 0.000 claims description 10
- 206010006187 Breast cancer Diseases 0.000 claims description 9
- 208000026310 Breast neoplasm Diseases 0.000 claims description 9
- 102100020903 Ezrin Human genes 0.000 claims description 9
- 230000004075 alteration Effects 0.000 claims description 9
- 238000013145 classification model Methods 0.000 claims description 9
- 230000003211 malignant effect Effects 0.000 claims description 9
- 230000001225 therapeutic effect Effects 0.000 claims description 9
- 102100037799 DNA-binding protein Ikaros Human genes 0.000 claims description 8
- 101000599038 Homo sapiens DNA-binding protein Ikaros Proteins 0.000 claims description 8
- 208000034578 Multiple myelomas Diseases 0.000 claims description 8
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 8
- 206010035226 Plasma cell myeloma Diseases 0.000 claims description 8
- 239000010839 body fluid Substances 0.000 claims description 8
- 238000003018 immunoassay Methods 0.000 claims description 8
- 230000010076 replication Effects 0.000 claims description 8
- 210000002966 serum Anatomy 0.000 claims description 8
- 108010083123 CDX2 Transcription Factor Proteins 0.000 claims description 7
- 101000854648 Homo sapiens Ezrin Proteins 0.000 claims description 7
- 101000804798 Homo sapiens Werner syndrome ATP-dependent helicase Proteins 0.000 claims description 7
- 102100035336 Werner syndrome ATP-dependent helicase Human genes 0.000 claims description 7
- 238000013528 artificial neural network Methods 0.000 claims description 7
- 102100038776 ADP-ribosylation factor-related protein 1 Human genes 0.000 claims description 6
- 102100034580 AT-rich interactive domain-containing protein 1A Human genes 0.000 claims description 6
- 102100022716 Atypical chemokine receptor 3 Human genes 0.000 claims description 6
- 102100033642 Bromodomain-containing protein 3 Human genes 0.000 claims description 6
- 201000009030 Carcinoma Diseases 0.000 claims description 6
- 102100026359 Cyclic AMP-responsive element-binding protein 1 Human genes 0.000 claims description 6
- 102100028202 Cytochrome c oxidase subunit 6C Human genes 0.000 claims description 6
- 102100023274 Dual specificity mitogen-activated protein kinase kinase 4 Human genes 0.000 claims description 6
- 102100034553 Fanconi anemia group J protein Human genes 0.000 claims description 6
- 102100031493 Growth arrest-specific protein 7 Human genes 0.000 claims description 6
- 102100029235 Histone-lysine N-methyltransferase NSD3 Human genes 0.000 claims description 6
- 101000809413 Homo sapiens ADP-ribosylation factor-related protein 1 Proteins 0.000 claims description 6
- 101000924266 Homo sapiens AT-rich interactive domain-containing protein 1A Proteins 0.000 claims description 6
- 101000678890 Homo sapiens Atypical chemokine receptor 3 Proteins 0.000 claims description 6
- 101000871851 Homo sapiens Bromodomain-containing protein 3 Proteins 0.000 claims description 6
- 101000855516 Homo sapiens Cyclic AMP-responsive element-binding protein 1 Proteins 0.000 claims description 6
- 101000861049 Homo sapiens Cytochrome c oxidase subunit 6C Proteins 0.000 claims description 6
- 101001115395 Homo sapiens Dual specificity mitogen-activated protein kinase kinase 4 Proteins 0.000 claims description 6
- 101000848171 Homo sapiens Fanconi anemia group J protein Proteins 0.000 claims description 6
- 101000923044 Homo sapiens Growth arrest-specific protein 7 Proteins 0.000 claims description 6
- 101000634046 Homo sapiens Histone-lysine N-methyltransferase NSD3 Proteins 0.000 claims description 6
- 101000581507 Homo sapiens Methyl-CpG-binding domain protein 1 Proteins 0.000 claims description 6
- 101000576323 Homo sapiens Motor neuron and pancreas homeobox protein 1 Proteins 0.000 claims description 6
- 101000961071 Homo sapiens NF-kappa-B inhibitor alpha Proteins 0.000 claims description 6
- 101000973211 Homo sapiens Nuclear factor 1 B-type Proteins 0.000 claims description 6
- 101000601661 Homo sapiens Paired box protein Pax-7 Proteins 0.000 claims description 6
- 101001134861 Homo sapiens Pericentriolar material 1 protein Proteins 0.000 claims description 6
- 101000579484 Homo sapiens Period circadian protein homolog 1 Proteins 0.000 claims description 6
- 101001126582 Homo sapiens Post-GPI attachment to proteins factor 3 Proteins 0.000 claims description 6
- 101000798015 Homo sapiens RAC-beta serine/threonine-protein kinase Proteins 0.000 claims description 6
- 101000798007 Homo sapiens RAC-gamma serine/threonine-protein kinase Proteins 0.000 claims description 6
- 101000591128 Homo sapiens RNA-binding protein Musashi homolog 2 Proteins 0.000 claims description 6
- 101100078258 Homo sapiens RUNX1T1 gene Proteins 0.000 claims description 6
- 101000932478 Homo sapiens Receptor-type tyrosine-protein kinase FLT3 Proteins 0.000 claims description 6
- 101000687474 Homo sapiens Rhombotin-1 Proteins 0.000 claims description 6
- 101000631899 Homo sapiens Ribosome maturation protein SBDS Proteins 0.000 claims description 6
- 101000654740 Homo sapiens Septin-5 Proteins 0.000 claims description 6
- 101000655119 Homo sapiens T-cell leukemia homeobox protein 3 Proteins 0.000 claims description 6
- 101000837401 Homo sapiens T-cell leukemia/lymphoma protein 1A Proteins 0.000 claims description 6
- 101000702545 Homo sapiens Transcription activator BRG1 Proteins 0.000 claims description 6
- 101000813738 Homo sapiens Transcription factor ETV6 Proteins 0.000 claims description 6
- 101000664703 Homo sapiens Transcription factor SOX-10 Proteins 0.000 claims description 6
- 101001051166 Homo sapiens Transcriptional activator MN1 Proteins 0.000 claims description 6
- 101000796673 Homo sapiens Transformation/transcription domain-associated protein Proteins 0.000 claims description 6
- 101000650162 Homo sapiens WW domain-containing transcription regulator protein 1 Proteins 0.000 claims description 6
- 101000782132 Homo sapiens Zinc finger protein 217 Proteins 0.000 claims description 6
- 102000000588 Interleukin-2 Human genes 0.000 claims description 6
- 108010002350 Interleukin-2 Proteins 0.000 claims description 6
- 102000004034 Kelch-Like ECH-Associated Protein 1 Human genes 0.000 claims description 6
- 108090000484 Kelch-Like ECH-Associated Protein 1 Proteins 0.000 claims description 6
- 102100027383 Methyl-CpG-binding domain protein 1 Human genes 0.000 claims description 6
- 102100025170 Motor neuron and pancreas homeobox protein 1 Human genes 0.000 claims description 6
- 208000003445 Mouth Neoplasms Diseases 0.000 claims description 6
- 102100039337 NF-kappa-B inhibitor alpha Human genes 0.000 claims description 6
- 102100022165 Nuclear factor 1 B-type Human genes 0.000 claims description 6
- 102100037503 Paired box protein Pax-7 Human genes 0.000 claims description 6
- 102100028293 Period circadian protein homolog 1 Human genes 0.000 claims description 6
- 102100040990 Platelet-derived growth factor subunit B Human genes 0.000 claims description 6
- 102100024952 Protein CBFA2T1 Human genes 0.000 claims description 6
- 108010019674 Proto-Oncogene Proteins c-sis Proteins 0.000 claims description 6
- 102100032315 RAC-beta serine/threonine-protein kinase Human genes 0.000 claims description 6
- 102100032314 RAC-gamma serine/threonine-protein kinase Human genes 0.000 claims description 6
- 102100034027 RNA-binding protein Musashi homolog 2 Human genes 0.000 claims description 6
- 108700040655 RUNX1 Translocation Partner 1 Proteins 0.000 claims description 6
- 102100020718 Receptor-type tyrosine-protein kinase FLT3 Human genes 0.000 claims description 6
- 102100024869 Rhombotin-1 Human genes 0.000 claims description 6
- 102100028750 Ribosome maturation protein SBDS Human genes 0.000 claims description 6
- 102100032744 Septin-5 Human genes 0.000 claims description 6
- 206010041067 Small cell lung cancer Diseases 0.000 claims description 6
- 102100032568 T-cell leukemia homeobox protein 3 Human genes 0.000 claims description 6
- 102100028676 T-cell leukemia/lymphoma protein 1A Human genes 0.000 claims description 6
- 102100031027 Transcription activator BRG1 Human genes 0.000 claims description 6
- 102100039580 Transcription factor ETV6 Human genes 0.000 claims description 6
- 102100038808 Transcription factor SOX-10 Human genes 0.000 claims description 6
- 102100024592 Transcriptional activator MN1 Human genes 0.000 claims description 6
- 102100032762 Transformation/transcription domain-associated protein Human genes 0.000 claims description 6
- 102100027548 WW domain-containing transcription regulator protein 1 Human genes 0.000 claims description 6
- 101100100541 Zea mays BX1 gene Proteins 0.000 claims description 6
- 102100036595 Zinc finger protein 217 Human genes 0.000 claims description 6
- 210000001185 bone marrow Anatomy 0.000 claims description 6
- 208000012987 lip and oral cavity carcinoma Diseases 0.000 claims description 6
- 230000036244 malformation Effects 0.000 claims description 6
- 208000002154 non-small cell lung carcinoma Diseases 0.000 claims description 6
- 208000000587 small cell lung carcinoma Diseases 0.000 claims description 6
- 238000012706 support-vector machine Methods 0.000 claims description 6
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 claims description 6
- 210000002700 urine Anatomy 0.000 claims description 6
- 108090000740 RNA-binding protein EWS Proteins 0.000 claims description 5
- 102000004229 RNA-binding protein EWS Human genes 0.000 claims description 5
- 210000001175 cerebrospinal fluid Anatomy 0.000 claims description 5
- 238000003776 cleavage reaction Methods 0.000 claims description 5
- 230000002496 gastric effect Effects 0.000 claims description 5
- 201000011243 gastrointestinal stromal tumor Diseases 0.000 claims description 5
- 238000007477 logistic regression Methods 0.000 claims description 5
- 230000036210 malignancy Effects 0.000 claims description 5
- 210000002381 plasma Anatomy 0.000 claims description 5
- 230000007017 scission Effects 0.000 claims description 5
- 208000031261 Acute myeloid leukaemia Diseases 0.000 claims description 4
- 102100022089 Acyl-[acyl-carrier-protein] hydrolase Human genes 0.000 claims description 4
- 206010003445 Ascites Diseases 0.000 claims description 4
- 206010003571 Astrocytoma Diseases 0.000 claims description 4
- 101000964894 Bos taurus 14-3-3 protein zeta/delta Proteins 0.000 claims description 4
- 208000003174 Brain Neoplasms Diseases 0.000 claims description 4
- 206010006143 Brain stem glioma Diseases 0.000 claims description 4
- 206010014967 Ependymoma Diseases 0.000 claims description 4
- 102100037858 G1/S-specific cyclin-E1 Human genes 0.000 claims description 4
- 101000824278 Homo sapiens Acyl-[acyl-carrier-protein] hydrolase Proteins 0.000 claims description 4
- 101000738568 Homo sapiens G1/S-specific cyclin-E1 Proteins 0.000 claims description 4
- 101000740519 Homo sapiens Syndecan-4 Proteins 0.000 claims description 4
- 101000611023 Homo sapiens Tumor necrosis factor receptor superfamily member 6 Proteins 0.000 claims description 4
- 101000851018 Homo sapiens Vascular endothelial growth factor receptor 1 Proteins 0.000 claims description 4
- 208000009164 Islet Cell Adenoma Diseases 0.000 claims description 4
- 208000008839 Kidney Neoplasms Diseases 0.000 claims description 4
- 206010023825 Laryngeal cancer Diseases 0.000 claims description 4
- 206010025323 Lymphomas Diseases 0.000 claims description 4
- 206010061269 Malignant peritoneal neoplasm Diseases 0.000 claims description 4
- 208000000172 Medulloblastoma Diseases 0.000 claims description 4
- 201000007224 Myeloproliferative neoplasm Diseases 0.000 claims description 4
- 208000034176 Neoplasms, Germ Cell and Embryonal Diseases 0.000 claims description 4
- 206010029260 Neuroblastoma Diseases 0.000 claims description 4
- 208000007571 Ovarian Epithelial Carcinoma Diseases 0.000 claims description 4
- 208000007913 Pituitary Neoplasms Diseases 0.000 claims description 4
- 206010038389 Renal cancer Diseases 0.000 claims description 4
- 206010039491 Sarcoma Diseases 0.000 claims description 4
- 102100037220 Syndecan-4 Human genes 0.000 claims description 4
- 208000024770 Thyroid neoplasm Diseases 0.000 claims description 4
- 201000005969 Uveal melanoma Diseases 0.000 claims description 4
- 102100033178 Vascular endothelial growth factor receptor 1 Human genes 0.000 claims description 4
- 206010047700 Vomiting Diseases 0.000 claims description 4
- 210000003567 ascitic fluid Anatomy 0.000 claims description 4
- 201000006612 cervical squamous cell carcinoma Diseases 0.000 claims description 4
- 208000006990 cholangiocarcinoma Diseases 0.000 claims description 4
- 210000004913 chyme Anatomy 0.000 claims description 4
- 208000010932 epithelial neoplasm Diseases 0.000 claims description 4
- 210000004392 genitalia Anatomy 0.000 claims description 4
- 201000010982 kidney cancer Diseases 0.000 claims description 4
- 206010023841 laryngeal neoplasm Diseases 0.000 claims description 4
- 208000032839 leukemia Diseases 0.000 claims description 4
- 201000007270 liver cancer Diseases 0.000 claims description 4
- 208000014018 liver neoplasm Diseases 0.000 claims description 4
- 208000037819 metastatic cancer Diseases 0.000 claims description 4
- 208000011575 metastatic malignant neoplasm Diseases 0.000 claims description 4
- 206010061289 metastatic neoplasm Diseases 0.000 claims description 4
- 201000005962 mycosis fungoides Diseases 0.000 claims description 4
- 230000009826 neoplastic cell growth Effects 0.000 claims description 4
- 201000002524 peritoneal carcinoma Diseases 0.000 claims description 4
- 210000004180 plasmocyte Anatomy 0.000 claims description 4
- 210000004910 pleural fluid Anatomy 0.000 claims description 4
- 210000002307 prostate Anatomy 0.000 claims description 4
- 201000009571 retroperitoneal cancer Diseases 0.000 claims description 4
- 201000004847 retroperitoneum carcinoma Diseases 0.000 claims description 4
- 201000009410 rhabdomyosarcoma Diseases 0.000 claims description 4
- 201000008261 skin carcinoma Diseases 0.000 claims description 4
- 201000002314 small intestine cancer Diseases 0.000 claims description 4
- 208000008732 thymoma Diseases 0.000 claims description 4
- 201000002510 thyroid cancer Diseases 0.000 claims description 4
- 230000008673 vomiting Effects 0.000 claims description 4
- 108091023037 Aptamer Proteins 0.000 claims description 3
- 102100024607 DNA topoisomerase 1 Human genes 0.000 claims description 3
- 101000830681 Homo sapiens DNA topoisomerase 1 Proteins 0.000 claims description 3
- 108091005461 Nucleic proteins Proteins 0.000 claims description 3
- 206010036790 Productive cough Diseases 0.000 claims description 3
- 206010060862 Prostate cancer Diseases 0.000 claims description 3
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 3
- 206010038111 Recurrent cancer Diseases 0.000 claims description 3
- 210000003608 fece Anatomy 0.000 claims description 3
- 238000000684 flow cytometry Methods 0.000 claims description 3
- 238000012165 high-throughput sequencing Methods 0.000 claims description 3
- 210000003734 kidney Anatomy 0.000 claims description 3
- 201000001441 melanoma Diseases 0.000 claims description 3
- 230000001394 metastastic effect Effects 0.000 claims description 3
- 230000001953 sensory effect Effects 0.000 claims description 3
- 210000003802 sputum Anatomy 0.000 claims description 3
- 208000024794 sputum Diseases 0.000 claims description 3
- 210000001138 tear Anatomy 0.000 claims description 3
- 101150106774 9 gene Proteins 0.000 claims description 2
- 208000030507 AIDS Diseases 0.000 claims description 2
- 208000002008 AIDS-Related Lymphoma Diseases 0.000 claims description 2
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 claims description 2
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 claims description 2
- 206010052747 Adenocarcinoma pancreas Diseases 0.000 claims description 2
- 206010061424 Anal cancer Diseases 0.000 claims description 2
- 208000007860 Anus Neoplasms Diseases 0.000 claims description 2
- 206010003011 Appendicitis Diseases 0.000 claims description 2
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 claims description 2
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 claims description 2
- 208000005440 Basal Cell Neoplasms Diseases 0.000 claims description 2
- 206010004146 Basal cell carcinoma Diseases 0.000 claims description 2
- 206010005003 Bladder cancer Diseases 0.000 claims description 2
- 206010005949 Bone cancer Diseases 0.000 claims description 2
- 208000018084 Bone neoplasm Diseases 0.000 claims description 2
- 208000011691 Burkitt lymphomas Diseases 0.000 claims description 2
- 206010050337 Cerumen impaction Diseases 0.000 claims description 2
- 206010008342 Cervix carcinoma Diseases 0.000 claims description 2
- 201000009047 Chordoma Diseases 0.000 claims description 2
- 208000010833 Chronic myeloid leukaemia Diseases 0.000 claims description 2
- 206010052360 Colorectal adenocarcinoma Diseases 0.000 claims description 2
- 208000009798 Craniopharyngioma Diseases 0.000 claims description 2
- 102100034157 DNA mismatch repair protein Msh2 Human genes 0.000 claims description 2
- 102100021147 DNA mismatch repair protein Msh6 Human genes 0.000 claims description 2
- 206010014733 Endometrial cancer Diseases 0.000 claims description 2
- 206010014759 Endometrial neoplasm Diseases 0.000 claims description 2
- 201000008228 Ependymoblastoma Diseases 0.000 claims description 2
- 206010014968 Ependymoma malignant Diseases 0.000 claims description 2
- 208000000461 Esophageal Neoplasms Diseases 0.000 claims description 2
- 208000006168 Ewing Sarcoma Diseases 0.000 claims description 2
- 208000022072 Gallbladder Neoplasms Diseases 0.000 claims description 2
- 201000003741 Gastrointestinal carcinoma Diseases 0.000 claims description 2
- 208000021309 Germ cell tumor Diseases 0.000 claims description 2
- 208000032612 Glial tumor Diseases 0.000 claims description 2
- 206010018338 Glioma Diseases 0.000 claims description 2
- 208000017604 Hodgkin disease Diseases 0.000 claims description 2
- 208000021519 Hodgkin lymphoma Diseases 0.000 claims description 2
- 208000010747 Hodgkins lymphoma Diseases 0.000 claims description 2
- 101001134036 Homo sapiens DNA mismatch repair protein Msh2 Proteins 0.000 claims description 2
- 101000968658 Homo sapiens DNA mismatch repair protein Msh6 Proteins 0.000 claims description 2
- 206010020675 Hypermetropia Diseases 0.000 claims description 2
- 206010021042 Hypopharyngeal cancer Diseases 0.000 claims description 2
- 206010056305 Hypopharyngeal neoplasm Diseases 0.000 claims description 2
- 206010061252 Intraocular melanoma Diseases 0.000 claims description 2
- 208000007766 Kaposi sarcoma Diseases 0.000 claims description 2
- 201000005099 Langerhans cell histiocytosis Diseases 0.000 claims description 2
- 208000031671 Large B-Cell Diffuse Lymphoma Diseases 0.000 claims description 2
- 206010062038 Lip neoplasm Diseases 0.000 claims description 2
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 claims description 2
- 206010025312 Lymphoma AIDS related Diseases 0.000 claims description 2
- 229910015837 MSH2 Inorganic materials 0.000 claims description 2
- 208000006644 Malignant Fibrous Histiocytoma Diseases 0.000 claims description 2
- 208000030070 Malignant epithelial tumor of ovary Diseases 0.000 claims description 2
- 206010073059 Malignant neoplasm of unknown primary site Diseases 0.000 claims description 2
- 208000032271 Malignant tumor of penis Diseases 0.000 claims description 2
- 208000002030 Merkel cell carcinoma Diseases 0.000 claims description 2
- 206010027406 Mesothelioma Diseases 0.000 claims description 2
- 102000008071 Mismatch Repair Endonuclease PMS2 Human genes 0.000 claims description 2
- 108010074346 Mismatch Repair Endonuclease PMS2 Proteins 0.000 claims description 2
- 102000013609 MutL Protein Homolog 1 Human genes 0.000 claims description 2
- 108010026664 MutL Protein Homolog 1 Proteins 0.000 claims description 2
- 201000003793 Myelodysplastic syndrome Diseases 0.000 claims description 2
- 208000033761 Myelogenous Chronic BCR-ABL Positive Leukemia Diseases 0.000 claims description 2
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 claims description 2
- 208000001894 Nasopharyngeal Neoplasms Diseases 0.000 claims description 2
- 206010061306 Nasopharyngeal cancer Diseases 0.000 claims description 2
- 208000008846 Neurocytoma Diseases 0.000 claims description 2
- 206010029266 Neuroendocrine carcinoma of the skin Diseases 0.000 claims description 2
- 206010052399 Neuroendocrine tumour Diseases 0.000 claims description 2
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 claims description 2
- 208000010505 Nose Neoplasms Diseases 0.000 claims description 2
- 206010030155 Oesophageal carcinoma Diseases 0.000 claims description 2
- 206010031096 Oropharyngeal cancer Diseases 0.000 claims description 2
- 206010057444 Oropharyngeal neoplasm Diseases 0.000 claims description 2
- 206010061328 Ovarian epithelial cancer Diseases 0.000 claims description 2
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 2
- 208000000821 Parathyroid Neoplasms Diseases 0.000 claims description 2
- 206010061336 Pelvic neoplasm Diseases 0.000 claims description 2
- 208000002471 Penile Neoplasms Diseases 0.000 claims description 2
- 206010034299 Penile cancer Diseases 0.000 claims description 2
- 208000005228 Pericardial Effusion Diseases 0.000 claims description 2
- 208000009565 Pharyngeal Neoplasms Diseases 0.000 claims description 2
- 206010034811 Pharyngeal cancer Diseases 0.000 claims description 2
- 208000007641 Pinealoma Diseases 0.000 claims description 2
- 201000007552 Pituitary carcinoma Diseases 0.000 claims description 2
- 201000008199 Pleuropulmonary blastoma Diseases 0.000 claims description 2
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 claims description 2
- 208000015634 Rectal Neoplasms Diseases 0.000 claims description 2
- 208000006265 Renal cell carcinoma Diseases 0.000 claims description 2
- 201000000582 Retinoblastoma Diseases 0.000 claims description 2
- 208000004337 Salivary Gland Neoplasms Diseases 0.000 claims description 2
- 206010061934 Salivary gland cancer Diseases 0.000 claims description 2
- 208000009359 Sezary Syndrome Diseases 0.000 claims description 2
- 206010068771 Soft tissue neoplasm Diseases 0.000 claims description 2
- 208000021712 Soft tissue sarcoma Diseases 0.000 claims description 2
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 2
- 208000031673 T-Cell Cutaneous Lymphoma Diseases 0.000 claims description 2
- 206010042971 T-cell lymphoma Diseases 0.000 claims description 2
- 208000027585 T-cell non-Hodgkin lymphoma Diseases 0.000 claims description 2
- 208000024313 Testicular Neoplasms Diseases 0.000 claims description 2
- 206010057644 Testis cancer Diseases 0.000 claims description 2
- 201000009365 Thymic carcinoma Diseases 0.000 claims description 2
- 208000000728 Thymus Neoplasms Diseases 0.000 claims description 2
- 208000015778 Undifferentiated pleomorphic sarcoma Diseases 0.000 claims description 2
- 208000023915 Ureteral Neoplasms Diseases 0.000 claims description 2
- 206010046392 Ureteric cancer Diseases 0.000 claims description 2
- 206010046431 Urethral cancer Diseases 0.000 claims description 2
- 206010046458 Urethral neoplasms Diseases 0.000 claims description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 claims description 2
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 claims description 2
- 208000002495 Uterine Neoplasms Diseases 0.000 claims description 2
- 206010047741 Vulval cancer Diseases 0.000 claims description 2
- 208000004354 Vulvar Neoplasms Diseases 0.000 claims description 2
- 208000033559 Waldenström macroglobulinemia Diseases 0.000 claims description 2
- 208000008383 Wilms tumor Diseases 0.000 claims description 2
- 230000009471 action Effects 0.000 claims description 2
- 208000009956 adenocarcinoma Diseases 0.000 claims description 2
- 208000020990 adrenal cortex carcinoma Diseases 0.000 claims description 2
- 208000007128 adrenocortical carcinoma Diseases 0.000 claims description 2
- 210000004381 amniotic fluid Anatomy 0.000 claims description 2
- 201000011165 anus cancer Diseases 0.000 claims description 2
- 210000001742 aqueous humor Anatomy 0.000 claims description 2
- 210000000941 bile Anatomy 0.000 claims description 2
- 210000002459 blastocyst Anatomy 0.000 claims description 2
- 210000004556 brain Anatomy 0.000 claims description 2
- 208000002458 carcinoid tumor Diseases 0.000 claims description 2
- 210000002939 cerumen Anatomy 0.000 claims description 2
- 201000010881 cervical cancer Diseases 0.000 claims description 2
- 210000003756 cervix mucus Anatomy 0.000 claims description 2
- 208000011654 childhood malignant neoplasm Diseases 0.000 claims description 2
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 claims description 2
- 238000007635 classification algorithm Methods 0.000 claims description 2
- 208000029742 colonic neoplasm Diseases 0.000 claims description 2
- 201000007241 cutaneous T cell lymphoma Diseases 0.000 claims description 2
- 208000017763 cutaneous neuroendocrine carcinoma Diseases 0.000 claims description 2
- 210000002726 cyst fluid Anatomy 0.000 claims description 2
- 230000004069 differentiation Effects 0.000 claims description 2
- 206010012818 diffuse large B-cell lymphoma Diseases 0.000 claims description 2
- 208000018554 digestive system carcinoma Diseases 0.000 claims description 2
- 230000002124 endocrine Effects 0.000 claims description 2
- 208000037828 epithelial carcinoma Diseases 0.000 claims description 2
- 201000004101 esophageal cancer Diseases 0.000 claims description 2
- 210000003722 extracellular fluid Anatomy 0.000 claims description 2
- 230000002550 fecal effect Effects 0.000 claims description 2
- 210000004700 fetal blood Anatomy 0.000 claims description 2
- 201000010175 gallbladder cancer Diseases 0.000 claims description 2
- 201000008361 ganglioneuroma Diseases 0.000 claims description 2
- 201000006585 gastric adenocarcinoma Diseases 0.000 claims description 2
- 206010017758 gastric cancer Diseases 0.000 claims description 2
- 201000006972 gastroesophageal adenocarcinoma Diseases 0.000 claims description 2
- 208000005017 glioblastoma Diseases 0.000 claims description 2
- 201000010536 head and neck cancer Diseases 0.000 claims description 2
- 201000003911 head and neck carcinoma Diseases 0.000 claims description 2
- 208000014829 head and neck neoplasm Diseases 0.000 claims description 2
- 201000010235 heart cancer Diseases 0.000 claims description 2
- 208000024348 heart neoplasm Diseases 0.000 claims description 2
- 206010073071 hepatocellular carcinoma Diseases 0.000 claims description 2
- 231100000844 hepatocellular carcinoma Toxicity 0.000 claims description 2
- 235000020256 human milk Nutrition 0.000 claims description 2
- 210000004251 human milk Anatomy 0.000 claims description 2
- 230000004305 hyperopia Effects 0.000 claims description 2
- 201000006318 hyperopia Diseases 0.000 claims description 2
- 201000006866 hypopharynx cancer Diseases 0.000 claims description 2
- 201000002529 islet cell tumor Diseases 0.000 claims description 2
- 201000006721 lip cancer Diseases 0.000 claims description 2
- 208000030173 low grade glioma Diseases 0.000 claims description 2
- 201000005296 lung carcinoma Diseases 0.000 claims description 2
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 2
- 208000026045 malignant tumor of parathyroid gland Diseases 0.000 claims description 2
- 230000005906 menstruation Effects 0.000 claims description 2
- 210000000716 merkel cell Anatomy 0.000 claims description 2
- 230000033607 mismatch repair Effects 0.000 claims description 2
- 206010051747 multiple endocrine neoplasia Diseases 0.000 claims description 2
- 208000037830 nasal cancer Diseases 0.000 claims description 2
- 208000016065 neuroendocrine neoplasm Diseases 0.000 claims description 2
- 201000011519 neuroendocrine tumor Diseases 0.000 claims description 2
- 201000002575 ocular melanoma Diseases 0.000 claims description 2
- 201000006958 oropharynx cancer Diseases 0.000 claims description 2
- 201000008968 osteosarcoma Diseases 0.000 claims description 2
- 230000002611 ovarian Effects 0.000 claims description 2
- 208000021284 ovarian germ cell tumor Diseases 0.000 claims description 2
- 201000002094 pancreatic adenocarcinoma Diseases 0.000 claims description 2
- 201000002528 pancreatic cancer Diseases 0.000 claims description 2
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 2
- 208000022102 pancreatic neuroendocrine neoplasm Diseases 0.000 claims description 2
- 208000003154 papilloma Diseases 0.000 claims description 2
- 208000029211 papillomatosis Diseases 0.000 claims description 2
- 210000004912 pericardial fluid Anatomy 0.000 claims description 2
- 210000005259 peripheral blood Anatomy 0.000 claims description 2
- 239000011886 peripheral blood Substances 0.000 claims description 2
- 208000024724 pineal body neoplasm Diseases 0.000 claims description 2
- 201000004119 pineal parenchymal tumor of intermediate differentiation Diseases 0.000 claims description 2
- 208000011866 pituitary adenocarcinoma Diseases 0.000 claims description 2
- 208000010916 pituitary tumor Diseases 0.000 claims description 2
- 208000025638 primary cutaneous T-cell non-Hodgkin lymphoma Diseases 0.000 claims description 2
- 208000029340 primitive neuroectodermal tumor Diseases 0.000 claims description 2
- 201000005825 prostate adenocarcinoma Diseases 0.000 claims description 2
- 206010038038 rectal cancer Diseases 0.000 claims description 2
- 201000001275 rectum cancer Diseases 0.000 claims description 2
- 208000015347 renal cell adenocarcinoma Diseases 0.000 claims description 2
- 208000010639 renal pelvis urothelial carcinoma Diseases 0.000 claims description 2
- 230000000241 respiratory effect Effects 0.000 claims description 2
- 210000003296 saliva Anatomy 0.000 claims description 2
- 210000002374 sebum Anatomy 0.000 claims description 2
- 210000000582 semen Anatomy 0.000 claims description 2
- 208000037968 sinus cancer Diseases 0.000 claims description 2
- 201000000849 skin cancer Diseases 0.000 claims description 2
- 206010062261 spinal cord neoplasm Diseases 0.000 claims description 2
- 206010041823 squamous cell carcinoma Diseases 0.000 claims description 2
- 210000002784 stomach Anatomy 0.000 claims description 2
- 201000011549 stomach cancer Diseases 0.000 claims description 2
- 210000002536 stromal cell Anatomy 0.000 claims description 2
- 201000008205 supratentorial primitive neuroectodermal tumor Diseases 0.000 claims description 2
- 210000004243 sweat Anatomy 0.000 claims description 2
- 210000001179 synovial fluid Anatomy 0.000 claims description 2
- 201000003120 testicular cancer Diseases 0.000 claims description 2
- 230000004797 therapeutic response Effects 0.000 claims description 2
- 201000009377 thymus cancer Diseases 0.000 claims description 2
- 206010044412 transitional cell carcinoma Diseases 0.000 claims description 2
- 208000029387 trophoblastic neoplasm Diseases 0.000 claims description 2
- 210000000626 ureter Anatomy 0.000 claims description 2
- 201000011294 ureter cancer Diseases 0.000 claims description 2
- 201000000334 ureter transitional cell carcinoma Diseases 0.000 claims description 2
- 201000005112 urinary bladder cancer Diseases 0.000 claims description 2
- 206010046766 uterine cancer Diseases 0.000 claims description 2
- 208000037965 uterine sarcoma Diseases 0.000 claims description 2
- 206010046885 vaginal cancer Diseases 0.000 claims description 2
- 208000013139 vaginal neoplasm Diseases 0.000 claims description 2
- 201000005102 vulva cancer Diseases 0.000 claims description 2
- 102100031671 Homeobox protein CDX-2 Human genes 0.000 claims 3
- 206010051066 Gastrointestinal stromal tumour Diseases 0.000 claims 2
- 210000000621 bronchi Anatomy 0.000 claims 1
- 210000004880 lymph fluid Anatomy 0.000 claims 1
- 210000003097 mucus Anatomy 0.000 claims 1
- 208000014653 solitary fibrous tumor Diseases 0.000 claims 1
- 230000004044 response Effects 0.000 abstract description 29
- 239000003814 drug Substances 0.000 abstract description 26
- 238000013459 approach Methods 0.000 abstract description 24
- 239000013610 patient sample Substances 0.000 abstract description 4
- 239000013598 vector Substances 0.000 description 112
- 239000002773 nucleotide Substances 0.000 description 93
- 125000003729 nucleotide group Chemical group 0.000 description 89
- 239000002679 microRNA Substances 0.000 description 62
- 108091070501 miRNA Proteins 0.000 description 61
- 230000014509 gene expression Effects 0.000 description 48
- 239000000047 product Substances 0.000 description 48
- 239000013615 primer Substances 0.000 description 36
- 238000001514 detection method Methods 0.000 description 35
- 238000004891 communication Methods 0.000 description 34
- 108020004999 messenger RNA Proteins 0.000 description 34
- 239000002585 base Substances 0.000 description 32
- 230000000875 corresponding effect Effects 0.000 description 30
- 239000002299 complementary DNA Substances 0.000 description 26
- 230000006870 function Effects 0.000 description 26
- 238000006243 chemical reaction Methods 0.000 description 25
- 239000000427 antigen Substances 0.000 description 23
- 230000011987 methylation Effects 0.000 description 23
- 238000007069 methylation reaction Methods 0.000 description 23
- 102000004190 Enzymes Human genes 0.000 description 22
- 108090000790 Enzymes Proteins 0.000 description 22
- 230000027455 binding Effects 0.000 description 22
- 238000010586 diagram Methods 0.000 description 22
- 229940088598 enzyme Drugs 0.000 description 22
- 238000003491 array Methods 0.000 description 21
- 108091007433 antigens Proteins 0.000 description 20
- 102000036639 antigens Human genes 0.000 description 20
- 108700011259 MicroRNAs Proteins 0.000 description 19
- 238000004590 computer program Methods 0.000 description 19
- 241000282414 Homo sapiens Species 0.000 description 18
- 238000003757 reverse transcription PCR Methods 0.000 description 18
- 239000000758 substrate Substances 0.000 description 18
- 108090000765 processed proteins & peptides Proteins 0.000 description 17
- 150000001413 amino acids Chemical class 0.000 description 16
- 239000011324 bead Substances 0.000 description 16
- 239000007787 solid Substances 0.000 description 16
- 239000000243 solution Substances 0.000 description 16
- 238000005516 engineering process Methods 0.000 description 15
- 238000012360 testing method Methods 0.000 description 15
- 108091034117 Oligonucleotide Proteins 0.000 description 14
- 238000001574 biopsy Methods 0.000 description 14
- 229940079593 drug Drugs 0.000 description 14
- 238000000605 extraction Methods 0.000 description 14
- 230000002068 genetic effect Effects 0.000 description 14
- 102000004196 processed proteins & peptides Human genes 0.000 description 13
- 239000000975 dye Substances 0.000 description 12
- 239000002243 precursor Substances 0.000 description 12
- 108091028043 Nucleic acid sequence Proteins 0.000 description 11
- 239000012528 membrane Substances 0.000 description 11
- 230000003287 optical effect Effects 0.000 description 11
- 210000004881 tumor cell Anatomy 0.000 description 11
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 10
- 230000000295 complement effect Effects 0.000 description 10
- 102000054766 genetic haplotypes Human genes 0.000 description 10
- 210000004379 membrane Anatomy 0.000 description 10
- 230000004048 modification Effects 0.000 description 10
- 238000012986 modification Methods 0.000 description 10
- 229920001184 polypeptide Polymers 0.000 description 10
- 108700028369 Alleles Proteins 0.000 description 9
- 238000011529 RT qPCR Methods 0.000 description 9
- 125000003275 alpha amino acid group Chemical group 0.000 description 9
- 102000040430 polynucleotide Human genes 0.000 description 9
- 108091033319 polynucleotide Proteins 0.000 description 9
- 239000002157 polynucleotide Substances 0.000 description 9
- 239000000126 substance Substances 0.000 description 9
- LSNNMFCWUKXFEE-UHFFFAOYSA-M Bisulfite Chemical compound OS([O-])=O LSNNMFCWUKXFEE-UHFFFAOYSA-M 0.000 description 8
- 230000008901 benefit Effects 0.000 description 8
- 210000000349 chromosome Anatomy 0.000 description 8
- 230000000670 limiting effect Effects 0.000 description 8
- 230000036961 partial effect Effects 0.000 description 8
- 229940124597 therapeutic agent Drugs 0.000 description 8
- 238000011269 treatment regimen Methods 0.000 description 8
- 210000004369 blood Anatomy 0.000 description 7
- 239000008280 blood Substances 0.000 description 7
- 230000008859 change Effects 0.000 description 7
- 150000001875 compounds Chemical class 0.000 description 7
- 210000001808 exosome Anatomy 0.000 description 7
- 238000002866 fluorescence resonance energy transfer Methods 0.000 description 7
- 238000002955 isolation Methods 0.000 description 7
- 238000003753 real-time PCR Methods 0.000 description 7
- 230000001105 regulatory effect Effects 0.000 description 7
- 241000894007 species Species 0.000 description 7
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 6
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 6
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 6
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- 229960002685 biotin Drugs 0.000 description 6
- 239000011616 biotin Substances 0.000 description 6
- 150000001720 carbohydrates Chemical group 0.000 description 6
- 230000001413 cellular effect Effects 0.000 description 6
- 238000012512 characterization method Methods 0.000 description 6
- 238000010195 expression analysis Methods 0.000 description 6
- 238000003205 genotyping method Methods 0.000 description 6
- 239000011521 glass Substances 0.000 description 6
- 238000007855 methylation-specific PCR Methods 0.000 description 6
- 239000012188 paraffin wax Substances 0.000 description 6
- 229920000642 polymer Polymers 0.000 description 6
- 238000011160 research Methods 0.000 description 6
- 238000003196 serial analysis of gene expression Methods 0.000 description 6
- 238000013518 transcription Methods 0.000 description 6
- 230000035897 transcription Effects 0.000 description 6
- 238000013519 translation Methods 0.000 description 6
- 108020004705 Codon Proteins 0.000 description 5
- 238000002965 ELISA Methods 0.000 description 5
- 102100031780 Endonuclease Human genes 0.000 description 5
- 108091030146 MiRBase Proteins 0.000 description 5
- 235000020958 biotin Nutrition 0.000 description 5
- 235000014633 carbohydrates Nutrition 0.000 description 5
- 239000003795 chemical substances by application Substances 0.000 description 5
- 238000012937 correction Methods 0.000 description 5
- 230000008995 epigenetic change Effects 0.000 description 5
- 230000001973 epigenetic effect Effects 0.000 description 5
- 239000007850 fluorescent dye Substances 0.000 description 5
- 230000010354 integration Effects 0.000 description 5
- 238000007726 management method Methods 0.000 description 5
- 230000007246 mechanism Effects 0.000 description 5
- 239000000203 mixture Substances 0.000 description 5
- 102000013415 peroxidase activity proteins Human genes 0.000 description 5
- 108040007629 peroxidase activity proteins Proteins 0.000 description 5
- 238000000746 purification Methods 0.000 description 5
- 238000012552 review Methods 0.000 description 5
- 239000007790 solid phase Substances 0.000 description 5
- 108091093088 Amplicon Proteins 0.000 description 4
- 102000006277 CDX2 Transcription Factor Human genes 0.000 description 4
- 108091035707 Consensus sequence Proteins 0.000 description 4
- 230000007067 DNA methylation Effects 0.000 description 4
- 101150029707 ERBB2 gene Proteins 0.000 description 4
- 241000196324 Embryophyta Species 0.000 description 4
- 101710163270 Nuclease Proteins 0.000 description 4
- 108091093037 Peptide nucleic acid Proteins 0.000 description 4
- 238000001190 Q-PCR Methods 0.000 description 4
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 4
- 108010006785 Taq Polymerase Proteins 0.000 description 4
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 4
- 230000033228 biological regulation Effects 0.000 description 4
- 238000010804 cDNA synthesis Methods 0.000 description 4
- 239000003153 chemical reaction reagent Substances 0.000 description 4
- 230000001419 dependent effect Effects 0.000 description 4
- 238000011161 development Methods 0.000 description 4
- 230000018109 developmental process Effects 0.000 description 4
- 238000003745 diagnosis Methods 0.000 description 4
- 238000007672 fourth generation sequencing Methods 0.000 description 4
- 230000037433 frameshift Effects 0.000 description 4
- 239000000499 gel Substances 0.000 description 4
- 230000030279 gene silencing Effects 0.000 description 4
- 230000003993 interaction Effects 0.000 description 4
- 210000000265 leukocyte Anatomy 0.000 description 4
- 239000003446 ligand Substances 0.000 description 4
- 238000012417 linear regression Methods 0.000 description 4
- 150000002632 lipids Chemical class 0.000 description 4
- 238000004519 manufacturing process Methods 0.000 description 4
- 239000000463 material Substances 0.000 description 4
- 238000012775 microarray technology Methods 0.000 description 4
- 239000011325 microbead Substances 0.000 description 4
- 238000000386 microscopy Methods 0.000 description 4
- 238000010369 molecular cloning Methods 0.000 description 4
- 239000003147 molecular marker Substances 0.000 description 4
- 230000002018 overexpression Effects 0.000 description 4
- 239000002245 particle Substances 0.000 description 4
- 239000012071 phase Substances 0.000 description 4
- 102000054765 polymorphisms of proteins Human genes 0.000 description 4
- 238000002360 preparation method Methods 0.000 description 4
- 239000002987 primer (paints) Substances 0.000 description 4
- 230000002829 reductive effect Effects 0.000 description 4
- 230000002441 reversible effect Effects 0.000 description 4
- 230000035945 sensitivity Effects 0.000 description 4
- 238000007841 sequencing by ligation Methods 0.000 description 4
- 238000011272 standard treatment Methods 0.000 description 4
- 238000003786 synthesis reaction Methods 0.000 description 4
- 230000000007 visual effect Effects 0.000 description 4
- 241000219198 Brassica Species 0.000 description 3
- 235000003351 Brassica cretica Nutrition 0.000 description 3
- 235000003343 Brassica rupestris Nutrition 0.000 description 3
- 241000282472 Canis lupus familiaris Species 0.000 description 3
- 108020004635 Complementary DNA Proteins 0.000 description 3
- 102000012410 DNA Ligases Human genes 0.000 description 3
- 108010061982 DNA Ligases Proteins 0.000 description 3
- 238000000018 DNA microarray Methods 0.000 description 3
- 230000004543 DNA replication Effects 0.000 description 3
- 238000001712 DNA sequencing Methods 0.000 description 3
- 102100033553 Delta-like protein 4 Human genes 0.000 description 3
- 206010061818 Disease progression Diseases 0.000 description 3
- 108700024394 Exon Proteins 0.000 description 3
- 208000032843 Hemorrhage Diseases 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- 101000872077 Homo sapiens Delta-like protein 4 Proteins 0.000 description 3
- 108091092878 Microsatellite Proteins 0.000 description 3
- 241000699666 Mus <mouse, genus> Species 0.000 description 3
- 241000220259 Raphanus Species 0.000 description 3
- 235000006140 Raphanus sativus var sativus Nutrition 0.000 description 3
- 108020004459 Small interfering RNA Proteins 0.000 description 3
- 108010090804 Streptavidin Proteins 0.000 description 3
- 208000007536 Thrombosis Diseases 0.000 description 3
- 150000001412 amines Chemical class 0.000 description 3
- 238000000540 analysis of variance Methods 0.000 description 3
- 230000005540 biological transmission Effects 0.000 description 3
- 229960000074 biopharmaceutical Drugs 0.000 description 3
- QKSKPIVNLNLAAV-UHFFFAOYSA-N bis(2-chloroethyl) sulfide Chemical compound ClCCSCCCl QKSKPIVNLNLAAV-UHFFFAOYSA-N 0.000 description 3
- 208000034158 bleeding Diseases 0.000 description 3
- 230000000740 bleeding effect Effects 0.000 description 3
- 210000000170 cell membrane Anatomy 0.000 description 3
- 230000002759 chromosomal effect Effects 0.000 description 3
- 210000001072 colon Anatomy 0.000 description 3
- 230000006835 compression Effects 0.000 description 3
- 238000007906 compression Methods 0.000 description 3
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical class NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 3
- 230000007423 decrease Effects 0.000 description 3
- BFMYDTVEBKDAKJ-UHFFFAOYSA-L disodium;(2',7'-dibromo-3',6'-dioxido-3-oxospiro[2-benzofuran-1,9'-xanthene]-4'-yl)mercury;hydrate Chemical compound O.[Na+].[Na+].O1C(=O)C2=CC=CC=C2C21C1=CC(Br)=C([O-])C([Hg])=C1OC1=C2C=C(Br)C([O-])=C1 BFMYDTVEBKDAKJ-UHFFFAOYSA-L 0.000 description 3
- 239000003596 drug target Substances 0.000 description 3
- 238000001493 electron microscopy Methods 0.000 description 3
- 210000003743 erythrocyte Anatomy 0.000 description 3
- 238000011156 evaluation Methods 0.000 description 3
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 3
- 238000011223 gene expression profiling Methods 0.000 description 3
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 3
- 229940022353 herceptin Drugs 0.000 description 3
- 230000006195 histone acetylation Effects 0.000 description 3
- 238000010348 incorporation Methods 0.000 description 3
- 230000002452 interceptive effect Effects 0.000 description 3
- 238000007834 ligase chain reaction Methods 0.000 description 3
- 238000004949 mass spectrometry Methods 0.000 description 3
- 235000010460 mustard Nutrition 0.000 description 3
- 238000001769 parametric statistical test Methods 0.000 description 3
- 238000004393 prognosis Methods 0.000 description 3
- 230000002285 radioactive effect Effects 0.000 description 3
- 238000010839 reverse transcription Methods 0.000 description 3
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 3
- 238000000926 separation method Methods 0.000 description 3
- 239000011780 sodium chloride Substances 0.000 description 3
- 239000001509 sodium citrate Substances 0.000 description 3
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 3
- 238000010186 staining Methods 0.000 description 3
- 238000000547 structure data Methods 0.000 description 3
- 238000001356 surgical procedure Methods 0.000 description 3
- 238000000204 total internal reflection microscopy Methods 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 2
- TZCPCKNHXULUIY-RGULYWFUSA-N 1,2-distearoyl-sn-glycero-3-phosphoserine Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@H](N)C(O)=O)OC(=O)CCCCCCCCCCCCCCCCC TZCPCKNHXULUIY-RGULYWFUSA-N 0.000 description 2
- 102100022900 Actin, cytoplasmic 1 Human genes 0.000 description 2
- 108010085238 Actins Proteins 0.000 description 2
- 241000972773 Aulopiformes Species 0.000 description 2
- 108091026890 Coding region Proteins 0.000 description 2
- 108091029523 CpG island Proteins 0.000 description 2
- IGXWBGJHJZYPQS-SSDOTTSWSA-N D-Luciferin Chemical compound OC(=O)[C@H]1CSC(C=2SC3=CC=C(O)C=C3N=2)=N1 IGXWBGJHJZYPQS-SSDOTTSWSA-N 0.000 description 2
- 108020003215 DNA Probes Proteins 0.000 description 2
- 230000004544 DNA amplification Effects 0.000 description 2
- 239000003298 DNA probe Substances 0.000 description 2
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 2
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 2
- CYCGRDQQIOGCKX-UHFFFAOYSA-N Dehydro-luciferin Natural products OC(=O)C1=CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 CYCGRDQQIOGCKX-UHFFFAOYSA-N 0.000 description 2
- 241000282326 Felis catus Species 0.000 description 2
- BJGNCJDXODQBOB-UHFFFAOYSA-N Fivefly Luciferin Natural products OC(=O)C1CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 BJGNCJDXODQBOB-UHFFFAOYSA-N 0.000 description 2
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 2
- ZWZWYGMENQVNFU-UHFFFAOYSA-N Glycerophosphorylserin Natural products OC(=O)C(N)COP(O)(=O)OCC(O)CO ZWZWYGMENQVNFU-UHFFFAOYSA-N 0.000 description 2
- 208000004044 Hypesthesia Diseases 0.000 description 2
- 239000000232 Lipid Bilayer Substances 0.000 description 2
- DDWFXDSYGUXRAY-UHFFFAOYSA-N Luciferin Natural products CCc1c(C)c(CC2NC(=O)C(=C2C=C)C)[nH]c1Cc3[nH]c4C(=C5/NC(CC(=O)O)C(C)C5CC(=O)O)CC(=O)c4c3C DDWFXDSYGUXRAY-UHFFFAOYSA-N 0.000 description 2
- 102000018697 Membrane Proteins Human genes 0.000 description 2
- 108010052285 Membrane Proteins Proteins 0.000 description 2
- 241001465754 Metazoa Species 0.000 description 2
- 238000000636 Northern blotting Methods 0.000 description 2
- 239000004677 Nylon Substances 0.000 description 2
- 208000002193 Pain Diseases 0.000 description 2
- 102000035195 Peptidases Human genes 0.000 description 2
- 108091005804 Peptidases Proteins 0.000 description 2
- 239000004743 Polypropylene Substances 0.000 description 2
- 239000004793 Polystyrene Substances 0.000 description 2
- 241000288906 Primates Species 0.000 description 2
- 102000007066 Prostate-Specific Antigen Human genes 0.000 description 2
- 108010072866 Prostate-Specific Antigen Proteins 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- 238000002123 RNA extraction Methods 0.000 description 2
- 108091028664 Ribonucleotide Proteins 0.000 description 2
- 241000283984 Rodentia Species 0.000 description 2
- BLRPTPMANUNPDV-UHFFFAOYSA-N Silane Chemical compound [SiH4] BLRPTPMANUNPDV-UHFFFAOYSA-N 0.000 description 2
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 2
- DWAQJAXMDSEUJJ-UHFFFAOYSA-M Sodium bisulfite Chemical compound [Na+].OS([O-])=O DWAQJAXMDSEUJJ-UHFFFAOYSA-M 0.000 description 2
- 102000004523 Sulfate Adenylyltransferase Human genes 0.000 description 2
- 108010022348 Sulfate adenylyltransferase Proteins 0.000 description 2
- 102000040945 Transcription factor Human genes 0.000 description 2
- 108091023040 Transcription factor Proteins 0.000 description 2
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 2
- 230000002159 abnormal effect Effects 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- IRLPACMLTUPBCL-FCIPNVEPSA-N adenosine-5'-phosphosulfate Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@@H](CO[P@](O)(=O)OS(O)(=O)=O)[C@H](O)[C@H]1O IRLPACMLTUPBCL-FCIPNVEPSA-N 0.000 description 2
- 230000006907 apoptotic process Effects 0.000 description 2
- 239000013060 biological fluid Substances 0.000 description 2
- 230000000903 blocking effect Effects 0.000 description 2
- 210000003855 cell nucleus Anatomy 0.000 description 2
- 108091092328 cellular RNA Proteins 0.000 description 2
- 239000005081 chemiluminescent agent Substances 0.000 description 2
- 208000037516 chromosome inversion disease Diseases 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 230000000052 comparative effect Effects 0.000 description 2
- 230000002596 correlated effect Effects 0.000 description 2
- 210000004748 cultured cell Anatomy 0.000 description 2
- 238000007405 data analysis Methods 0.000 description 2
- 238000013479 data entry Methods 0.000 description 2
- 238000013500 data storage Methods 0.000 description 2
- 238000001212 derivatisation Methods 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 229960000633 dextran sulfate Drugs 0.000 description 2
- 238000007847 digital PCR Methods 0.000 description 2
- XPPKVPWEQAFLFU-UHFFFAOYSA-J diphosphate(4-) Chemical compound [O-]P([O-])(=O)OP([O-])([O-])=O XPPKVPWEQAFLFU-UHFFFAOYSA-J 0.000 description 2
- 235000011180 diphosphates Nutrition 0.000 description 2
- 230000005750 disease progression Effects 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 230000003828 downregulation Effects 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 230000007613 environmental effect Effects 0.000 description 2
- 230000005281 excited state Effects 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 238000001917 fluorescence detection Methods 0.000 description 2
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 2
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 2
- 125000000524 functional group Chemical group 0.000 description 2
- 238000007429 general method Methods 0.000 description 2
- 230000007614 genetic variation Effects 0.000 description 2
- 238000013412 genome amplification Methods 0.000 description 2
- 102000006602 glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 2
- 208000034783 hypoesthesia Diseases 0.000 description 2
- 238000010166 immunofluorescence Methods 0.000 description 2
- 238000001114 immunoprecipitation Methods 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 150000002500 ions Chemical class 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 239000004973 liquid crystal related substance Substances 0.000 description 2
- 210000004072 lung Anatomy 0.000 description 2
- 238000012423 maintenance Methods 0.000 description 2
- 238000000816 matrix-assisted laser desorption--ionisation Methods 0.000 description 2
- 238000002844 melting Methods 0.000 description 2
- 230000008018 melting Effects 0.000 description 2
- 239000011859 microparticle Substances 0.000 description 2
- 230000000869 mutational effect Effects 0.000 description 2
- 230000006855 networking Effects 0.000 description 2
- 238000003062 neural network model Methods 0.000 description 2
- 108091027963 non-coding RNA Proteins 0.000 description 2
- 102000042567 non-coding RNA Human genes 0.000 description 2
- 238000010606 normalization Methods 0.000 description 2
- 238000007899 nucleic acid hybridization Methods 0.000 description 2
- 238000003203 nucleic acid sequencing method Methods 0.000 description 2
- 231100000862 numbness Toxicity 0.000 description 2
- 229920001778 nylon Polymers 0.000 description 2
- JMANVNJQNLATNU-UHFFFAOYSA-N oxalonitrile Chemical compound N#CC#N JMANVNJQNLATNU-UHFFFAOYSA-N 0.000 description 2
- 239000004033 plastic Substances 0.000 description 2
- 229920003023 plastic Polymers 0.000 description 2
- 229920002401 polyacrylamide Polymers 0.000 description 2
- 229920001155 polypropylene Polymers 0.000 description 2
- 229920002223 polystyrene Polymers 0.000 description 2
- 238000003498 protein array Methods 0.000 description 2
- 238000000734 protein sequencing Methods 0.000 description 2
- 238000011002 quantification Methods 0.000 description 2
- 238000004445 quantitative analysis Methods 0.000 description 2
- 238000003127 radioimmunoassay Methods 0.000 description 2
- 238000007894 restriction fragment length polymorphism technique Methods 0.000 description 2
- 239000002336 ribonucleotide Substances 0.000 description 2
- 235000019515 salmon Nutrition 0.000 description 2
- 210000004739 secretory vesicle Anatomy 0.000 description 2
- 229910000077 silane Inorganic materials 0.000 description 2
- 229940126586 small molecule drug Drugs 0.000 description 2
- 235000010267 sodium hydrogen sulphite Nutrition 0.000 description 2
- 239000001488 sodium phosphate Substances 0.000 description 2
- 229910000162 sodium phosphate Inorganic materials 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 230000006641 stabilisation Effects 0.000 description 2
- 238000011105 stabilization Methods 0.000 description 2
- 239000007858 starting material Substances 0.000 description 2
- 238000000528 statistical test Methods 0.000 description 2
- 235000000346 sugar Nutrition 0.000 description 2
- 208000024891 symptom Diseases 0.000 description 2
- 230000002194 synthesizing effect Effects 0.000 description 2
- 238000004885 tandem mass spectrometry Methods 0.000 description 2
- 125000003396 thiol group Chemical group [H]S* 0.000 description 2
- 238000001890 transfection Methods 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 2
- 239000000107 tumor biomarker Substances 0.000 description 2
- 230000009452 underexpressoin Effects 0.000 description 2
- 210000003932 urinary bladder Anatomy 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- 238000005406 washing Methods 0.000 description 2
- 238000001262 western blot Methods 0.000 description 2
- 238000012049 whole transcriptome sequencing Methods 0.000 description 2
- VGONTNSXDCQUGY-RRKCRQDMSA-N 2'-deoxyinosine Chemical group C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC2=O)=C2N=C1 VGONTNSXDCQUGY-RRKCRQDMSA-N 0.000 description 1
- 150000003923 2,5-pyrrolediones Chemical class 0.000 description 1
- 108020005345 3' Untranslated Regions Proteins 0.000 description 1
- LRSASMSXMSNRBT-UHFFFAOYSA-N 5-methylcytosine Chemical compound CC1=CNC(=O)N=C1N LRSASMSXMSNRBT-UHFFFAOYSA-N 0.000 description 1
- 208000004998 Abdominal Pain Diseases 0.000 description 1
- 240000005020 Acaciella glauca Species 0.000 description 1
- 108010013043 Acetylesterase Proteins 0.000 description 1
- 241000251468 Actinopterygii Species 0.000 description 1
- 239000012099 Alexa Fluor family Substances 0.000 description 1
- 201000004384 Alopecia Diseases 0.000 description 1
- 108010007730 Apyrase Proteins 0.000 description 1
- 102000007347 Apyrase Human genes 0.000 description 1
- 241000271566 Aves Species 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 108700012439 CA9 Proteins 0.000 description 1
- 102100025238 CD302 antigen Human genes 0.000 description 1
- 101100476924 Caenorhabditis elegans sdc-1 gene Proteins 0.000 description 1
- 102100024423 Carbonic anhydrase 9 Human genes 0.000 description 1
- 208000024172 Cardiovascular disease Diseases 0.000 description 1
- 241000700198 Cavia Species 0.000 description 1
- 206010008111 Cerebral haemorrhage Diseases 0.000 description 1
- 206010008479 Chest Pain Diseases 0.000 description 1
- 108010077544 Chromatin Proteins 0.000 description 1
- 206010052358 Colorectal cancer metastatic Diseases 0.000 description 1
- 206010010774 Constipation Diseases 0.000 description 1
- 208000034656 Contusions Diseases 0.000 description 1
- 206010010904 Convulsion Diseases 0.000 description 1
- 206010011224 Cough Diseases 0.000 description 1
- 108091029430 CpG site Proteins 0.000 description 1
- 241000938605 Crocodylia Species 0.000 description 1
- 239000003155 DNA primer Substances 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- 230000004568 DNA-binding Effects 0.000 description 1
- 206010011878 Deafness Diseases 0.000 description 1
- 206010012735 Diarrhoea Diseases 0.000 description 1
- 208000000059 Dyspnea Diseases 0.000 description 1
- 206010013975 Dyspnoeas Diseases 0.000 description 1
- 102000001301 EGF receptor Human genes 0.000 description 1
- 108060006698 EGF receptor Proteins 0.000 description 1
- 108010042407 Endonucleases Proteins 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 208000010201 Exanthema Diseases 0.000 description 1
- 206010016100 Faeces discoloured Diseases 0.000 description 1
- 238000001135 Friedman test Methods 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 208000018522 Gastrointestinal disease Diseases 0.000 description 1
- 206010071602 Genetic polymorphism Diseases 0.000 description 1
- 108010015776 Glucose oxidase Proteins 0.000 description 1
- 239000004366 Glucose oxidase Substances 0.000 description 1
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 1
- 229930186217 Glycolipid Natural products 0.000 description 1
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 1
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 1
- 206010019233 Headaches Diseases 0.000 description 1
- 208000000616 Hemoptysis Diseases 0.000 description 1
- 206010019909 Hernia Diseases 0.000 description 1
- 108091027305 Heteroduplex Proteins 0.000 description 1
- 102100039869 Histone H2B type F-S Human genes 0.000 description 1
- 101100273718 Homo sapiens CD302 gene Proteins 0.000 description 1
- 101001035372 Homo sapiens Histone H2B type F-S Proteins 0.000 description 1
- 108090000144 Human Proteins Proteins 0.000 description 1
- 102000003839 Human Proteins Human genes 0.000 description 1
- 206010020751 Hypersensitivity Diseases 0.000 description 1
- 101000829171 Hypocrea virens (strain Gv29-8 / FGSC 10586) Effector TSP1 Proteins 0.000 description 1
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 1
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 238000012313 Kruskal-Wallis test Methods 0.000 description 1
- 102000003960 Ligases Human genes 0.000 description 1
- 108090000364 Ligases Proteins 0.000 description 1
- 206010067125 Liver injury Diseases 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- 108091007780 MiR-122 Proteins 0.000 description 1
- 208000032818 Microsatellite Instability Diseases 0.000 description 1
- 241000713869 Moloney murine leukemia virus Species 0.000 description 1
- 241000699660 Mus musculus Species 0.000 description 1
- 101100496109 Mus musculus Clec2i gene Proteins 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- OVBPIULPVIDEAO-UHFFFAOYSA-N N-Pteroyl-L-glutaminsaeure Natural products C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-UHFFFAOYSA-N 0.000 description 1
- 206010028813 Nausea Diseases 0.000 description 1
- 108020004485 Nonsense Codon Proteins 0.000 description 1
- 201000010133 Oligodendroglioma Diseases 0.000 description 1
- 208000007117 Oral Ulcer Diseases 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 238000009004 PCR Kit Methods 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 241000282579 Pan Species 0.000 description 1
- 241000282376 Panthera tigris Species 0.000 description 1
- 206010034960 Photophobia Diseases 0.000 description 1
- 208000002664 Pleural Solitary Fibrous Tumor Diseases 0.000 description 1
- 102000001253 Protein Kinase Human genes 0.000 description 1
- 206010037660 Pyrexia Diseases 0.000 description 1
- 238000010802 RNA extraction kit Methods 0.000 description 1
- 238000003559 RNA-seq method Methods 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 1
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 1
- 206010070308 Refractory cancer Diseases 0.000 description 1
- 235000014548 Rubus moluccanus Nutrition 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- 206010040844 Skin exfoliation Diseases 0.000 description 1
- 238000002105 Southern blotting Methods 0.000 description 1
- 238000000692 Student's t-test Methods 0.000 description 1
- 206010051877 Testicular haemorrhage Diseases 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical class OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 1
- 101710120037 Toxin CcdB Proteins 0.000 description 1
- 108090001108 Troponin T Proteins 0.000 description 1
- 102000004987 Troponin T Human genes 0.000 description 1
- 108010020713 Tth polymerase Proteins 0.000 description 1
- 108091023045 Untranslated Region Proteins 0.000 description 1
- 208000024780 Urticaria Diseases 0.000 description 1
- 206010046788 Uterine haemorrhage Diseases 0.000 description 1
- 206010046910 Vaginal haemorrhage Diseases 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 206010047513 Vision blurred Diseases 0.000 description 1
- 229930003779 Vitamin B12 Natural products 0.000 description 1
- 208000021017 Weight Gain Diseases 0.000 description 1
- 238000001793 Wilcoxon signed-rank test Methods 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 238000001261 affinity purification Methods 0.000 description 1
- 238000007844 allele-specific PCR Methods 0.000 description 1
- 238000003016 alphascreen Methods 0.000 description 1
- 125000000539 amino acid group Chemical group 0.000 description 1
- 208000007502 anemia Diseases 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 230000009830 antibody antigen interaction Effects 0.000 description 1
- 230000001640 apoptogenic effect Effects 0.000 description 1
- 230000004596 appetite loss Effects 0.000 description 1
- 238000010420 art technique Methods 0.000 description 1
- 238000002820 assay format Methods 0.000 description 1
- 230000002567 autonomic effect Effects 0.000 description 1
- 238000011888 autopsy Methods 0.000 description 1
- 108091031690 bantam stem loop Proteins 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 238000003339 best practice Methods 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 239000012620 biological material Substances 0.000 description 1
- 210000000601 blood cell Anatomy 0.000 description 1
- 238000004820 blood count Methods 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 238000007707 calorimetry Methods 0.000 description 1
- 230000003683 cardiac damage Effects 0.000 description 1
- 230000000747 cardiac effect Effects 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 230000033077 cellular process Effects 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 239000007795 chemical reaction product Substances 0.000 description 1
- 238000002512 chemotherapy Methods 0.000 description 1
- 210000003483 chromatin Anatomy 0.000 description 1
- 239000003593 chromogenic compound Substances 0.000 description 1
- FDJOLVPMNUYSCM-WZHZPDAFSA-L cobalt(3+);[(2r,3s,4r,5s)-5-(5,6-dimethylbenzimidazol-1-yl)-4-hydroxy-2-(hydroxymethyl)oxolan-3-yl] [(2r)-1-[3-[(1r,2r,3r,4z,7s,9z,12s,13s,14z,17s,18s,19r)-2,13,18-tris(2-amino-2-oxoethyl)-7,12,17-tris(3-amino-3-oxopropyl)-3,5,8,8,13,15,18,19-octamethyl-2 Chemical compound [Co+3].N#[C-].N([C@@H]([C@]1(C)[N-]\C([C@H]([C@@]1(CC(N)=O)C)CCC(N)=O)=C(\C)/C1=N/C([C@H]([C@@]1(CC(N)=O)C)CCC(N)=O)=C\C1=N\C([C@H](C1(C)C)CCC(N)=O)=C/1C)[C@@H]2CC(N)=O)=C\1[C@]2(C)CCC(=O)NC[C@@H](C)OP([O-])(=O)O[C@H]1[C@@H](O)[C@@H](N2C3=CC(C)=C(C)C=C3N=C2)O[C@@H]1CO FDJOLVPMNUYSCM-WZHZPDAFSA-L 0.000 description 1
- 238000012875 competitive assay Methods 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 239000002521 compomer Substances 0.000 description 1
- 239000000306 component Substances 0.000 description 1
- 238000000205 computational method Methods 0.000 description 1
- 229920001940 conductive polymer Polymers 0.000 description 1
- 239000013068 control sample Substances 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 230000036461 convulsion Effects 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 238000004132 cross linking Methods 0.000 description 1
- 230000001186 cumulative effect Effects 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 239000000824 cytostatic agent Substances 0.000 description 1
- 230000001085 cytostatic effect Effects 0.000 description 1
- 238000013075 data extraction Methods 0.000 description 1
- 238000013523 data management Methods 0.000 description 1
- 238000013499 data model Methods 0.000 description 1
- 101150012655 dcl1 gene Proteins 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 231100000517 death Toxicity 0.000 description 1
- 238000003066 decision tree Methods 0.000 description 1
- 230000006837 decompression Effects 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 238000004925 denaturation Methods 0.000 description 1
- 230000036425 denaturation Effects 0.000 description 1
- 238000000432 density-gradient centrifugation Methods 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 230000008021 deposition Effects 0.000 description 1
- 239000000104 diagnostic biomarker Substances 0.000 description 1
- 238000001085 differential centrifugation Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 230000003467 diminishing effect Effects 0.000 description 1
- 230000008034 disappearance Effects 0.000 description 1
- 208000037765 diseases and disorders Diseases 0.000 description 1
- 238000006073 displacement reaction Methods 0.000 description 1
- 208000002173 dizziness Diseases 0.000 description 1
- 229940000406 drug candidate Drugs 0.000 description 1
- 238000002651 drug therapy Methods 0.000 description 1
- 230000008406 drug-drug interaction Effects 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 201000006549 dyspepsia Diseases 0.000 description 1
- 210000003981 ectoderm Anatomy 0.000 description 1
- 230000002900 effect on cell Effects 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 210000001900 endoderm Anatomy 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 230000007608 epigenetic mechanism Effects 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- 229960005542 ethidium bromide Drugs 0.000 description 1
- ZMMJGEGLRURXTF-UHFFFAOYSA-N ethidium bromide Chemical compound [Br-].C12=CC(N)=CC=C2C2=CC=C(N)C=C2[N+](CC)=C1C1=CC=CC=C1 ZMMJGEGLRURXTF-UHFFFAOYSA-N 0.000 description 1
- 238000000105 evaporative light scattering detection Methods 0.000 description 1
- 201000005884 exanthem Diseases 0.000 description 1
- 238000007387 excisional biopsy Methods 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 230000028023 exocytosis Effects 0.000 description 1
- 239000003777 experimental drug Substances 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 210000003414 extremity Anatomy 0.000 description 1
- 210000000416 exudates and transudate Anatomy 0.000 description 1
- 239000000835 fiber Substances 0.000 description 1
- 238000009093 first-line therapy Methods 0.000 description 1
- 235000019688 fish Nutrition 0.000 description 1
- 238000007667 floating Methods 0.000 description 1
- 238000002875 fluorescence polarization Methods 0.000 description 1
- 235000019152 folic acid Nutrition 0.000 description 1
- 239000011724 folic acid Substances 0.000 description 1
- 229960000304 folic acid Drugs 0.000 description 1
- 102000036215 folic acid binding proteins Human genes 0.000 description 1
- 108091011001 folic acid binding proteins Proteins 0.000 description 1
- 239000012520 frozen sample Substances 0.000 description 1
- 238000003500 gene array Methods 0.000 description 1
- 230000004545 gene duplication Effects 0.000 description 1
- 230000004547 gene signature Effects 0.000 description 1
- 238000010362 genome editing Methods 0.000 description 1
- 229940116332 glucose oxidase Drugs 0.000 description 1
- 235000019420 glucose oxidase Nutrition 0.000 description 1
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 1
- 239000005090 green fluorescent protein Substances 0.000 description 1
- 230000005283 ground state Effects 0.000 description 1
- 208000024963 hair loss Diseases 0.000 description 1
- 230000003676 hair loss Effects 0.000 description 1
- 229910052736 halogen Inorganic materials 0.000 description 1
- 231100000869 headache Toxicity 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 230000010370 hearing loss Effects 0.000 description 1
- 231100000888 hearing loss Toxicity 0.000 description 1
- 208000016354 hearing loss disease Diseases 0.000 description 1
- 208000024798 heartburn Diseases 0.000 description 1
- 231100000234 hepatic damage Toxicity 0.000 description 1
- 230000001744 histochemical effect Effects 0.000 description 1
- 230000006197 histone deacetylation Effects 0.000 description 1
- 238000001794 hormone therapy Methods 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 230000006607 hypermethylation Effects 0.000 description 1
- 238000005286 illumination Methods 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 230000003100 immobilizing effect Effects 0.000 description 1
- 238000003119 immunoblot Methods 0.000 description 1
- 230000000984 immunochemical effect Effects 0.000 description 1
- 238000003365 immunocytochemistry Methods 0.000 description 1
- 230000002055 immunohistochemical effect Effects 0.000 description 1
- 239000012133 immunoprecipitate Substances 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 238000011273 incision biopsy Methods 0.000 description 1
- 238000007386 incisional biopsy Methods 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 238000009830 intercalation Methods 0.000 description 1
- 230000000968 intestinal effect Effects 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 210000004020 intracellular membrane Anatomy 0.000 description 1
- 238000002032 lab-on-a-chip Methods 0.000 description 1
- 238000001499 laser induced fluorescence spectroscopy Methods 0.000 description 1
- 239000004816 latex Substances 0.000 description 1
- 229920000126 latex Polymers 0.000 description 1
- 108091023663 let-7 stem-loop Proteins 0.000 description 1
- 108091063478 let-7-1 stem-loop Proteins 0.000 description 1
- 108091049777 let-7-2 stem-loop Proteins 0.000 description 1
- 230000031700 light absorption Effects 0.000 description 1
- 208000013469 light sensitivity Diseases 0.000 description 1
- 108091053735 lin-4 stem-loop Proteins 0.000 description 1
- 108091032363 lin-4-1 stem-loop Proteins 0.000 description 1
- 108091028008 lin-4-2 stem-loop Proteins 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 230000008818 liver damage Effects 0.000 description 1
- 238000011068 loading method Methods 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 208000019017 loss of appetite Diseases 0.000 description 1
- 235000021266 loss of appetite Nutrition 0.000 description 1
- 238000000504 luminescence detection Methods 0.000 description 1
- 239000000891 luminescent agent Substances 0.000 description 1
- 210000002751 lymph Anatomy 0.000 description 1
- 210000001165 lymph node Anatomy 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 239000006166 lysate Substances 0.000 description 1
- 238000010841 mRNA extraction Methods 0.000 description 1
- 206010025482 malaise Diseases 0.000 description 1
- 238000001840 matrix-assisted laser desorption--ionisation time-of-flight mass spectrometry Methods 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 210000002780 melanosome Anatomy 0.000 description 1
- 210000003716 mesoderm Anatomy 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 239000002207 metabolite Substances 0.000 description 1
- 229910044991 metal oxide Inorganic materials 0.000 description 1
- 150000004706 metal oxides Chemical class 0.000 description 1
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical class CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 1
- 108091051828 miR-122 stem-loop Proteins 0.000 description 1
- 108091049773 miR-14 stem-loop Proteins 0.000 description 1
- 108091053008 miR-23 stem-loop Proteins 0.000 description 1
- 108091007426 microRNA precursor Proteins 0.000 description 1
- 238000010208 microarray analysis Methods 0.000 description 1
- 239000004005 microsphere Substances 0.000 description 1
- 230000009149 molecular binding Effects 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 239000003068 molecular probe Substances 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 210000004400 mucous membrane Anatomy 0.000 description 1
- 238000007838 multiplex ligation-dependent probe amplification Methods 0.000 description 1
- 231100000219 mutagenic Toxicity 0.000 description 1
- 230000003505 mutagenic effect Effects 0.000 description 1
- 239000011807 nanoball Substances 0.000 description 1
- 238000003058 natural language processing Methods 0.000 description 1
- 230000008693 nausea Effects 0.000 description 1
- 239000002547 new drug Substances 0.000 description 1
- 238000001151 non-parametric statistical test Methods 0.000 description 1
- 230000036963 noncompetitive effect Effects 0.000 description 1
- 230000037434 nonsense mutation Effects 0.000 description 1
- 238000003499 nucleic acid array Methods 0.000 description 1
- 230000005257 nucleotidylation Effects 0.000 description 1
- 210000004940 nucleus Anatomy 0.000 description 1
- 102000027450 oncoproteins Human genes 0.000 description 1
- 108091008819 oncoproteins Proteins 0.000 description 1
- 238000001543 one-way ANOVA Methods 0.000 description 1
- 238000011369 optimal treatment Methods 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 238000005192 partition Methods 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- KHIWWQKSHDUIBK-UHFFFAOYSA-N periodic acid Chemical compound OI(=O)(=O)=O KHIWWQKSHDUIBK-UHFFFAOYSA-N 0.000 description 1
- 230000002974 pharmacogenomic effect Effects 0.000 description 1
- 238000000819 phase cycle Methods 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 150000003904 phospholipids Chemical class 0.000 description 1
- 150000008298 phosphoramidates Chemical class 0.000 description 1
- 229920005597 polymer membrane Polymers 0.000 description 1
- 239000004800 polyvinyl chloride Substances 0.000 description 1
- 229920000915 polyvinyl chloride Polymers 0.000 description 1
- 238000010837 poor prognosis Methods 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000002335 preservative effect Effects 0.000 description 1
- 108091007428 primary miRNA Proteins 0.000 description 1
- 230000037452 priming Effects 0.000 description 1
- 230000004952 protein activity Effects 0.000 description 1
- 238000000159 protein binding assay Methods 0.000 description 1
- 108060006633 protein kinase Proteins 0.000 description 1
- 230000004850 protein–protein interaction Effects 0.000 description 1
- 230000002797 proteolythic effect Effects 0.000 description 1
- 239000002096 quantum dot Substances 0.000 description 1
- 238000010791 quenching Methods 0.000 description 1
- 230000000171 quenching effect Effects 0.000 description 1
- 238000000163 radioactive labelling Methods 0.000 description 1
- 206010037844 rash Diseases 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 102000005962 receptors Human genes 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 210000000664 rectum Anatomy 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 235000003499 redwood Nutrition 0.000 description 1
- 239000013074 reference sample Substances 0.000 description 1
- 208000016691 refractory malignant neoplasm Diseases 0.000 description 1
- 238000007634 remodeling Methods 0.000 description 1
- 238000002271 resection Methods 0.000 description 1
- 230000004043 responsiveness Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 238000004366 reverse phase liquid chromatography Methods 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 108010008790 ribosomal phosphoprotein P1 Proteins 0.000 description 1
- 238000009118 salvage therapy Methods 0.000 description 1
- 238000007480 sanger sequencing Methods 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 238000007789 sealing Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 230000035939 shock Effects 0.000 description 1
- 208000013220 shortness of breath Diseases 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- RMAQACBXLXPBSY-UHFFFAOYSA-N silicic acid Chemical compound O[Si](O)(O)O RMAQACBXLXPBSY-UHFFFAOYSA-N 0.000 description 1
- 239000000377 silicon dioxide Substances 0.000 description 1
- 235000012239 silicon dioxide Nutrition 0.000 description 1
- 238000001542 size-exclusion chromatography Methods 0.000 description 1
- 210000003491 skin Anatomy 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 239000000344 soap Substances 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- 150000003461 sulfonyl halides Chemical class 0.000 description 1
- 230000001502 supplementing effect Effects 0.000 description 1
- 230000008093 supporting effect Effects 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 230000009747 swallowing Effects 0.000 description 1
- 206010042772 syncope Diseases 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 230000009897 systematic effect Effects 0.000 description 1
- 238000009121 systemic therapy Methods 0.000 description 1
- 238000012353 t test Methods 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- MPLHNVLQVRSVEE-UHFFFAOYSA-N texas red Chemical compound [O-]S(=O)(=O)C1=CC(S(Cl)(=O)=O)=CC=C1C(C1=CC=2CCCN3CCCC(C=23)=C1O1)=C2C1=C(CCC1)C3=[N+]1CCCC3=C2 MPLHNVLQVRSVEE-UHFFFAOYSA-N 0.000 description 1
- 229940126585 therapeutic drug Drugs 0.000 description 1
- 230000025366 tissue development Effects 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 238000011222 transcriptome analysis Methods 0.000 description 1
- 229960000575 trastuzumab Drugs 0.000 description 1
- 238000007492 two-way ANOVA Methods 0.000 description 1
- 238000000108 ultra-filtration Methods 0.000 description 1
- 229940035893 uracil Drugs 0.000 description 1
- 238000010200 validation analysis Methods 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 108700026220 vif Genes Proteins 0.000 description 1
- 238000012800 visualization Methods 0.000 description 1
- 239000011715 vitamin B12 Substances 0.000 description 1
- 235000019163 vitamin B12 Nutrition 0.000 description 1
- 239000007762 w/o emulsion Substances 0.000 description 1
- 230000004584 weight gain Effects 0.000 description 1
- 235000019786 weight gain Nutrition 0.000 description 1
- 230000004580 weight loss Effects 0.000 description 1
- 208000016261 weight loss Diseases 0.000 description 1
- 238000007482 whole exome sequencing Methods 0.000 description 1
- 238000012070 whole genome sequencing analysis Methods 0.000 description 1
- 238000004383 yellowing Methods 0.000 description 1
Images
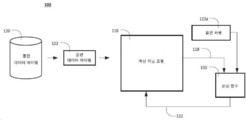

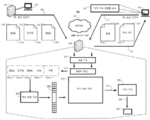



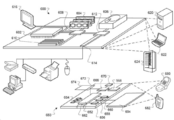



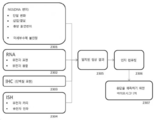























Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H10/00—ICT specially adapted for the handling or processing of patient-related medical or healthcare data
- G16H10/40—ICT specially adapted for the handling or processing of patient-related medical or healthcare data for data related to laboratory analysis, e.g. patient specimen analysis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B5/00—Measuring for diagnostic purposes; Identification of persons
- A61B5/48—Other medical applications
- A61B5/4836—Diagnosis combined with treatment in closed-loop systems or methods
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B5/00—Measuring for diagnostic purposes; Identification of persons
- A61B5/72—Signal processing specially adapted for physiological signals or for diagnostic purposes
- A61B5/7235—Details of waveform analysis
- A61B5/7264—Classification of physiological signals or data, e.g. using neural networks, statistical classifiers, expert systems or fuzzy systems
- A61B5/7267—Classification of physiological signals or data, e.g. using neural networks, statistical classifiers, expert systems or fuzzy systems involving training the classification device
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G06N20/10—Machine learning using kernel methods, e.g. support vector machines [SVM]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G06N20/20—Ensemble learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G06N5/003—
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/01—Dynamic search techniques; Heuristics; Dynamic trees; Branch-and-bound
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/10—Ploidy or copy number detection
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B40/00—ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H20/00—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance
- G16H20/10—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance relating to drugs or medications, e.g. for ensuring correct administration to patients
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H20/00—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance
- G16H20/40—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance relating to mechanical, radiation or invasive therapies, e.g. surgery, laser therapy, dialysis or acupuncture
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H20/00—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance
- G16H20/70—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance relating to mental therapies, e.g. psychological therapy or autogenous training
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H50/00—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics
- G16H50/20—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics for computer-aided diagnosis, e.g. based on medical expert systems
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02A—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE
- Y02A90/00—Technologies having an indirect contribution to adaptation to climate change
- Y02A90/10—Information and communication technologies [ICT] supporting adaptation to climate change, e.g. for weather forecasting or climate simulation
Abstract
포괄적인 분자 프로파일링은 환자 샘플의 분자 상태에 관한 풍부한 데이터를 제공한다. 이러한 데이터를 치료에 대한 환자의 반응과 비교하여 이러한 치료에 대한 반응 또는 무 반응을 예측하는 바이오마커 시그니처를 식별할 수 있다. 이 방식은 대장암 환자와 강한 상관 관계를 갖는 바이오마커 시그니처를 식별하기 위해 이 방식이 FOLFOX에 적용된다. 바이오마커의 특정 세트를 갖는 피험체의 질병 또는 장애에 대한 치료의 효과를 예측하기 위한 데이터 구조, 데이터 처리, 및 머신 러닝 모델, 및 정밀 의학, 가령, 분자 프로파일에 기초한 치료, 가령, 옥살리플라틴과 조합된 5-플루오로우라실/류코보린(FOLFOX) 또는 이리노테칸으로 조합된 것(FOLFIRI)의 투여를 포함하는 치료를 선택하기 위한 방법으로의 이러한 모델의 예시적 적용이 본 명세서에 기재된다.
Description
우선권 주장
본 출원은 2018년 11월 30일에 출원된 미국 가특허출원 번호 62/774,082, 2019년 01월 04월에 출원된 62/788,689, 및 2019년 01월 07일에 출원된 62/789,495의 우선권을 주장한다. 상기 출원의 전체 내용이 본 명세서에 참조로서 포함된다.
기술 분야
본 개시 내용은 데이터 구조, 데이터 처리, 및 머신 러닝 분야와 관련되며, 정밀 의료에서의 이들의 용도, 가령, 다양한 질병 및 장애, 비제한적 예를 들면, 암의 희생자를 위한 개인화된 치료 추천안을 유도하기 위한 분자 프로파일링의 사용과 관련된다.
암 환자를 위한 약물 요법은 오랫동안 도전과제였다. 전통적으로, 환자가 암 진단을 받으면 치료 의사는 일반적으로 암 유형 및 단계와 같은 환자의 관찰 가능한 임상 요인과 관련된 정의된 치료 옵션 리스트에서 선택한다. 결과적으로, 암 환자는 일반적으로 동일한 유형과 단계의 암을 가진 다른 사람들과 동일한 치료를 받았다. 동일한 유형과 단계의 암을 가진 환자가 동일한 치료에 대해 종종 다르게 반응하는 경우가 많기 때문에 이러한 치료의 효과는 시행 착오를 통해 결정될 것이다. 또한, 환자가 즉시 또는 이전에 성공한 치료가 실패하기 시작했을 때 이러한 "일률적인(one-size-fits-all)" 치료에 반응하지 못한 경우 의사의 치료 선택은 기껏해야 일화적인 증거를 기반으로 하는 경우가 많다.
2000년대 후반까지, 제한된 분자 검사가 의사가 환자의 암 유형, 이른바 "암 계통"과 관련된 기존 치료법의 리스트로부터 더 많은 정보성 선택을 하는 데 도움이 되었다. 예를 들어, Herceptin®을 포함한 기존 치료 옵션의 리스트를 제공 받은 유방암 환자가 있는 의사는 환자의 종양에서 HER2/neu 유전자의 과발현을 테스트했을 수 있다. HER2/neu는 그 당시 유방암 및 Herceptin®에 대한 반응성과 관련이 있는 것으로 알려졌다. 종양이 HER2/neu 유전자를 과발현하는 것으로 밝혀진 유방암 환자의 약 1/3은 Herceptin® 치료에 대한 초기 반응을 보였지만, 대부분은 1년 이내에 진행되기 시작했다. 예를 들어, Bartsch, R.et al, Trastuzumab in the management of early and advanced stage breast cancer, Biologics.2007 Mar; 1(1) : 19-31를 참조할 수 있다. 이러한 유형의 분자 검사는 특정 유형의 암에 대해 알려진 치료가 다른 유형보다 해당 유형의 암에 걸린 일부 환자를 치료하는 데 더 효과적인 이유를 설명하는 데 도움이 되었지만, 이 검사는 환자를 위한 추가 치료 옵션을 확인하거나 배제하지 않았다.
암 환자를 치료하는 일률적인 접근 방식에 불만족하고 많은 환자의 종양이 진행되어 결국 모든 기존 치료법을 고갈시키는 현실에 직면한 종양 학자 다니엘 폰 호프(Daniel Von Hoff) 박사는 자신의 환자를 위해 추가적인 비전통적 치료 옵션을 찾으려고 노력했다. 임상 관찰과 계통별 분자 검사의 한계를 기반으로 치료 결정을 내리는 한계를 인식하고 이러한 한계로 인해 효과적인 치료 옵션이 간과되었다고 믿고 폰 호프 박사와 동료들은 종양의 분자 특성에 대한 포괄적인 평가를 기반으로 한 암 치료 요법을 결정하기 위한 시스템과 방법을 개발했다. 이러한 "분자 프로파일링"에 대한 그들의 접근 방식은 다양한 검사 기술을 사용하여 환자의 종양에서 분자 정보를 수집하여 암 유형과 관계 없이 고유한 분자 프로파일을 생성했다. 그런 다음 의사는 분자 프로파일의 결과를 사용하여 암세포의 단계, 해부학적 위치 또는 해부학적 기원에 관계없이 환자에 대한 후보 치료법을 선택할 수 있다. Von Hoff DD, et al., Pilot study using molecular profiling of patients' tumors to find potential targets and select treatments for their refractory cancers. J Clin Oncol. 2010 Nov 20;28(33):4877-83을 참조할 수 있다. 이러한 분자 프로파일링 접근 방식은 치료 의사가 간과할 수 있는 치료법의 이점을 제시 할 수 있지만, 마찬가지로 특정 치료법의 이점이 없을 가능성이 있음을 암시하여 비효과적인 치료와 관련된 시간, 비용, 질병 진행 및 부작용을 피할 수 있다. 분자 프로파일링은 환자가 다중 치료 요법에 반응하지 않거나 내성을 나타내는 "구제 요법(salvage therapy)" 환경에서 특히 유용할 수 있다. 또한, 이러한 접근 방식은 일선 및 그 밖의 다른 표준 치료 요법에 대한 의사 결정을 안내하는 데 사용될 수도 있다.
대장암(CRC)은 여성에서 두 번째로 흔한 암이고 남성에서 세 번째로 흔한 암이며, 전세계적으로 2015년에 CRC로 인해 835,000명이 사망했다(Global Burden of Disease Cancer Collaboration, JAMA Oncol.2017;3(4):524 참조). 수술이 첫 번째 치료 방법이지만, 전신 요법, 가령, 5-플루오로우라실/류코보린을 옥살리플라틴(FOLFOX) 또는 이리노테칸(FOLFIRI)과 병용 투여하는 것이 일부 환자, 특히 원격 전이가 있는 대장암 환자에서 효과적인 것으로 나타났다(Mohelnikova-Duchonova et al., World J Gastroenterol.2014 Aug 14; 20(30): 10316-10330).
FOLFOX가 보조제 환경에서 전이성 CRC에 대한 표준 치료가 되었지만 환자의 약 절반 만이 치료에 반응한다. 또한 FOLFOX 환자의 20-100%가 탈모, 손바닥과 발바닥의 통증 또는 벗겨짐, 발진, 설사, 메스꺼움, 구토, 변비, 식욕 부진, 연하 곤란, 구강 궤양, 속쓰림, 낮은 백혈구 수로 인한 감염, 빈혈, 타박상 또는 출혈, 두통, 불쾌감, 무감각, 사지의 저림 또는 통증, 호흡 곤란, 기침 및 발열 중 적어도 하나를 경험할 것이며, 4-20%가 흉통, 비정상적인 심장 박동, 실신, 주입 부위에 대한 반응, 두드러기, 체중 증가, 체중 감소, 복통, 내부 출혈(가령, 검은 변, 구토 또는 소변의 혈액 포함, 각혈, 질 또는 고환 출혈, 뇌 출혈), 미각의 변화, 혈전, 간 손상, 눈과 피부의 황변, 알레르기 반응, 음성 변화, 혼란, 현기증, 쇠약, 시야 흐림, 빛 민감성, 틱 또는 경련, 운동 능력(걷기, 손 사용, 입 열기, 말하기, 균형 및 청각, 냄새 맡기, 먹기, 잠자기, 방광 비우기)의 곤란 및 난청 중 적어도 하나를 경험할 것이며, 최대 3%는 심장 손상 및 치료에 의한 다른 암의 발병 중 적어도 하나라는 심각한 부작용을 경험할 것이다.
머신 러닝 모델이 라벨링된 훈련 데이터를 분석한 후 훈련 데이터로부터 추론을 도출하도록 구성될 수 있다. 머신 러닝 모델이 훈련되면, 라벨링되지 않은 데이터의 세트가 입력으로서 머신 러닝 모델로 제공될 수 있다. 머신 러닝 모델은 입력 데이터, 가령, 분자 프로파일링 데이터를 처리하고, 훈련 동안 학습된 추론에 기초하여 입력에 대한 예측을 할 수 있다. 본 개시 내용은 단일 모델을 사용함으로써 달성되는 것보다 더 정확한 분류를 달성하기 위해 다수의 분류기 모델을 조합하는 "투표" 방법론을 제공한다.
포괄적인 분자 프로파일링은 환자 샘플의 분자 상태에 관한 풍부한 데이터를 제공한다. 우리는 사실상 모든 암 계통의 100,000명 이상의 종양 환자에 대해 이러한 프로파일링을 수행했으며 수천 명의 환자에서 환자 결과와 치료에 대한 반응을 추적했다. 예를 들어, 우리의 분자 프로파일링 데이터는 치료에 대한 환자의 효험 또는 효험 부재와 비교되고 머신 러닝 알고리즘, 가령, "투표" 방법론을 사용하여 처리되어, 다양한 치료의 효과를 예측하는 추가 바이오마커 시그니처를 식별할 수 있다. 여기서, 이 "차세대 프로파일링"(NGP) 접근 방식은 대장암 환자에서 FOLFOX 치료 요법의 효험을 예측하는 바이오마커 시그니처를 식별하기 위해 적용되었다.
포괄적인 분자 프로파일링은 환자 샘플의 분자 상태에 관한 풍부한 데이터를 제공한다. 이러한 데이터를 치료에 대한 환자의 반응과 비교하여 이러한 치료에 대한 반응 또는 무 반응을 예측하는 바이오마커 시그니처를 식별할 수 있다. 이 접근 방식은 대장암 환자에서 FOLFOX 치료 요법의 효험 또는 효험 부재와 상관되는 바이오마커 시그니처를 식별하기 위해 적용되었다.
특정 세트의 바이오마커를 갖는 피험체의 질병 또는 장애에 대한 치료의 효과를 예측하기 위해 머신 러닝 모델을 훈련시키는 방법이 본 명세서에 기재된다.
피험체에 대한 질병 또는 장애의 치료의 효과를 예측하기 위해 머신 러닝 모델을 훈련할 때 사용되기 위한 입력 데이터 구조를 생성하기 위한 데이터 처리 장치가 본 명세서에 제공되며, 상기 데이터 처리 장치는 하나 이상의 프로세서 및 하나 이상의 프로세서에 의해 실행될 때 상기 하나 이상의 프로세서로 하여금 동작을 수행하게 하는 명령을 저장하는 하나 이상의 저장 장치를 포함하고, 상기 동작은: 데이터 처리 장치에 의해 하나 이상의 바이오마커 데이터 구조 및 하나 이상의 결과 데이터 구조를 획득하는 것,데이터 처리 장치에 의해, 상기 하나 이상의 바이오마커 데이터 구조로부터 피험체와 연관된 하나 이상의 바이오마커를 나타내는 제1 데이터를 추출하고, 하나 이상의 결과 데이터 구조로부터 질병 또는 장애 및 치료를 나타내는 제2 데이터를 추출하며, 상기 질병 또는 장애에 대한 치료의 결과를 나타내는 제3 데이터를 추출하는 것, 데이터 처리 장치에 의해, 하나 이상의 바이오마커를 나타내는 제1 데이터 및 질병 또는 장애 및 치료를 나타내는 제2 데이터에 기초하여 머신 러닝 모델로의 입력을 위한, 데이터 구조를 생성하는 것, 데이터 처리 장치에 의해, 머신 러닝 모델로의 입력으로서 생성된 데이터 구조를 제공하는 것,데이터 처리 장치에 의해, 생성된 데이터 구조의 머신 러닝 모델의 처리에 기초하여 머신 러닝 모델에 의해 생성된 출력을 획득하는 것,데이터 처리 장치에 의해, 질병 또는 장애에 대한 치료의 결과를 나타내는 제3 데이터와 머신 러닝 모델에 의해 생성된 출력 간 차이를 결정하는 것, 및 데이터 처리 장치에 의해, 질병 또는 장애에 대한 치료의 결과를 나타내는 제3 데이터와 머신 러닝 모델에 의해 생성된 출력 간 차이에 기초하여 머신 러닝 모델의 하나 이상의 파라미터를 조절하는 것을 포함한다.
일부 구체예에서, 하나 이상의 바이오마커의 세트는 표 2-8 중 어느 하나에 나열된 하나 이상의 바이오마커를 포함한다. 일부 구체예에서, 하나 이상의 바이오마커의 세트는 표 2-8의 바이오마커 각각을 포함한다. 일부 구체예에서, 하나 이상의 바이오마커의 세트는 표 2-8의 바이오마커 중 적어도 하나를 포함하고, 선택적으로, 하나 이상의 바이오마커의 세트는 표 5, 표 6, 표 7, 표 8의 마커 또는 이들의 임의의 조합을 포함한다.
특정 치료에 대한 피험체의 치료 반응을 예측하기 위해 머신 러닝 모델을 훈련할 때 사용되기 위한 입력 데이터 구조를 생성하기 위한 데이터 처리 장치로서, 상기 데이터 처리 장치는 하나 이상의 프로세서 및 하나 이상의 프로세서에 의해 실행될 때 상기 하나 이상의 프로세서로 하여금 동작을 수행하게 하는 명령을 저장하는 하나 이상의 저장 장치를 포함하고, 상기 동작은: 데이터 처리 장치에 의해, 제1 분산 데이터 소스로부터 피험체와 연관된 하나 이상의 바이오마커의 세트를 나타내는 데이터를 구조화하는 제1 데이터 구조를 획득하는 것 - 제1 데이터 구조는 피험체를 식별하는 키 값을 포함함 - , 데이터 처리 장치에 의해, 하나 이상의 메모리 장치 내 제1 데이터 구조를 저장하는 것,데이터 처리 장치에 의해, 제2 분산 데이터 소스로부터 하나 이상의 바이오마커를 갖는 피험체에 대한 결과 데이터를 나타내는 데이터를 구조화하는 제2 데이터 구조를 획득하는 것 - 결과 데이터는 질병 또는 장애, 치료를 식별하는 데이터, 치료의 효과의 지시자를 포함하고, 제2 데이터 구조는 피험체를 식별하는 키 값을 더 포함함 - , 데이터 처리 장치에 의해, 하나 이상의 메모리 장치 내 제2 데이터 구조를 저장하는 것,데이터 처리 장치에 의해 메모리 디바이스 내에 저장되는 제1 데이터 구조 및 제2 데이터 구조를 이용해, (i) 하나 이상의 바이오마커의 세트, 질병 또는 장애, 및 치료를 나타내는 데이터, 및 (ii) 질병 또는 장애에 대한 치료의 효과의 지시자를 제공하는 라벨을 포함하는 라벨링된 훈련 데이터 구조를 생성하는 것 - 데이터 처리 장치에 의해 제1 데이터 구조 및 제2 데이터 구조를 생성하고 이용하는 것은, 데이터 처리 장치에 의해, 피험체와 연관된 하나 이상의 바이오마커의 세트를 나타내는 데이터를 구조화하는 제1 데이터 구조를 피험체를 식별하는 키 값에 기초하여 하나 이상의 바이오마커를 갖는 피험체에 대한 결과 데이터를 나타내는 제2 데이터 구조와 상관시키는 것을 포함함 - , 및 데이터 처리 장치에 의해, 생성된 라벨 훈련 데이터 구조를 이용해 머신 러닝 모델을 훈련시키는 것 - 생성된 라벨링된 훈련 데이터 구조를 이용해 머신 러닝 모델을 훈련하는 것은 데이터 처리 장치에 의해 머신 러닝 모델로, 생성된 라벨 훈련 데이터 구조를 머신 러닝 모델의 입력으로서 제공하는 것을 포함함 - 을 포함한다.
일부 구체예에서, 상기 동작은 데이터 처리 장치에 의해 머신 러닝 모델로부터, 생성된 라벨링된 훈련 데이터 구조의 머신 러닝 모델의 처리에 기초하여 머신 러닝 모델에 의해 생성되는 출력을 획득하는 것, 및 데이터 처리 장치에 의해, 머신 러닝 모델에 의해 생성되는 출력과 질병 또는 장애에 대한 치료의 효과의 지시자를 제공하는 라벨 간 차이를 결정하는 것을 더 포함한다.
일부 구체예에서, 동작은 데이터 처리 장치에 의해, 머신 러닝 모델에 의해 생성되는 출력과 질병 또는 장애에 대한 치료의 효과의 지시자를 제공하는 라벨 간 결정된 차이에 기초하여 머신 러닝 모델의 하나 이상의 파라미터를 조절하는 것을 더 포함한다.
일부 구체예에서, 하나 이상의 바이오마커의 세트는 표 2-8 중 어느 하나에 나열된 하나 이상의 바이오마커를 포함한다. 일부 구체예에서, 하나 이상의 바이오마커의 세트는 표 2-8의 바이오마커 각각을 포함한다. 일부 구체예에서, 하나 이상의 바이오마커의 세트는 표 2-8의 바이오마커 중 적어도 하나를 포함하고, 선택적으로, 하나 이상의 바이오마커의 세트는 표 5, 표 6, 표 7, 표 8의 마커 또는 이들의 임의의 조합을 포함한다.
이와 관련하여, 앞서 기재된 데이터 처리 장치의 동작 각각에 대응하는 단계를 포함하는 방법이 본 명세서에 제공된다. 또한 하나 이상의 컴퓨터 및 상기 하나 이상의 컴퓨터에 의해 실행될 때 상기 하나 이상의 컴퓨터로 하여금 앞서 기재된 데이터 처리 장치를 참조하여 기재된 동작 각각을 수행하게 하는 명령을 저장하는 하나 이상의 저장 매체를 포함하는 시스템이 본 명세서에 제공된다. 또한 하나 이상의 컴퓨터에 의해 실행되는 명령을 포함하는 소프트웨어를 저장하는 비일시적 컴퓨터 판독형 매체로서, 상기 명령은 실행 시 하나 이상의 컴퓨터로 하여금 앞서 기재된 데이터 처리 장치를 참조하여 기재된 동작을 수행하게 하는, 비일시적 컴퓨터 판독형 매체가 본 명세서에 제공된다.
또 다른 양태에서, 개체 분류 방법이 본 명세서에 제공되며, 상기 방법은 복수의 머신 러닝 모델의 각각의 특정 머신 러닝 모델에 대해:예측 또는 분류를 결정하도록 훈련된 특정 머신 러닝 모델로, 분류될 개체의 설명을 나타내는 입력 데이터를 제공하는 단계, 및 특정 머신 러닝 모델이 입력 데이터를 처리하는 것에 기초하여 특정 머신 러닝 모델에 의해 생성된, 복수의 후보 개체 분류 중 초기 개체 분류로의 개체 분류를 나타내는 출력 데이터를 획득하는 단계, 투표 유닛(voting unit)으로, 복수의 머신 러닝 모델의 각각의 머신 러닝 모델에 대해 획득된 출력 데이터를 제공하는 단계, 및 투표 유닛에 의해, 제공된 출력 데이터에 기초하여, 개체에 대한 실제 개체 분류를 결정하는 단계를 포함한다.
일부 구체예에서, 제공된 출력 데이터에 다수결 규칙을 적용함으로써, 개체에 대한 실제 개체 분류가 결정된다.
일부 구체예에서, 투표 유닛에 의해 제공된 출력 데이터에 기초하여 개체에 대한 실제 개체 분류를 결정하는 것은, 투표 유닛에 의해 복수의 후보 개체 분류 중 각각의 초기 개체 분류의 등장 횟수를 결정하는 것, 및 복수의 후보 개체 분류 중 가장 높은 등장 횟수를 가진 초기 개체 분류를 선택하는 것을 포함한다.
일부 구체예에서, 복수의 머신 러닝 모델의 각각의 머신 러닝 모델은 랜덤 포레스트 분류 알고리즘, 서포트 벡터 머신, 로지스틱 회귀, k-최근접 이웃 모델, 인공 신경망, 나이브 베이즈 모델, 2차 판별 분석, 또는 가우시안 프로세스 모델을 포함한다.
일부 구체예에서, 복수의 머신 러닝 모델의 각각의 머신 러닝 모델은 랜덤 포레스트 분류 알고리즘을 포함한다.
일부 구체예에서, 복수의 머신 러닝 모델은 동일한 유형의 분류 알고리즘의 복수의 표현을 포함한다.
일부 구체예에서, 입력 데이터는 (i) 개체 속성 및 (ii) 질병 또는 장애에 대한 치료법의 설명을 나타낸다.
일부 구체예에서, 복수의 후보 개체 분류는 반응 분류 또는 비반응 분류를 포함한다.
일부 구체예에서, 개체 속성은 개체에 대한 하나 이상의 바이오마커를 포함한다.
일부 구체예에서, 하나 이상의 바이오마커는 개체의 알려진 유전자의 일부인 유전자 패널을 포함한다.
일부 구체예에서, 하나 이상의 바이오마커는 개체의 알려진 유전자의 전부인 유전자 패널을 포함한다.
일부 구체예에서, 입력 데이터는 질병 또는 장애의 설명을 나타내는 데이터를 더 포함한다.
이와 관련하여, 하나 이상의 컴퓨터 및 상기 하나 이상의 컴퓨터에 의해 실행될 때 상기 하나 이상의 컴퓨터로 하여금 앞서 기재된 개체의 분류 방법을 참조하여 기재된 동작 각각을 수행하게 하는 명령을 저장하는 하나 이상의 저장 매체를 포함하는 시스템이 본 명세서에 제공된다. 또한, 하나 이상의 컴퓨터에 의해 실행되는 명령을 포함하는 소프트웨어를 저장하는 비일시적 컴퓨터 판독형 매체로서, 상기 명령은 실행 시 하나 이상의 컴퓨터로 하여금 앞서 기재된 데이터 처리 장치를 참조하여 기재된 동작을 수행하게 하는, 비일시적 컴퓨터 판독형 매체가 본 명세서에 제공된다.
또 다른 양태에서, 본 명세서에 방법이 제공되며, 상기 방법은 피험체의 암으로부터의 세포를 포함하는 생체 샘플을 획득하는 단계, 및 생체 샘플 내 적어도 하나의 바이오마커를 평가하기 위한 분석을 수행하는 단계 - 상기 바이오마커는 (a) MYC, EP300, U2AF1, ASXL1, MAML2, 및 CNTRL 중 1, 2, 3, 4, 5 또는 6개를 포함하는 그룹 1; (b) MYC, EP300, U2AF1, ASXL1, MAML2, CNTRL, WRN, 및 CDX2 중 1, 2, 3, 4, 5, 6, 7, 또는 8 개를 포함하는 그룹 2; (c) BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, HOXA11, AURKA, BIRC3, IKZF1, CASP8, 및 EP300 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 또는 14 개를 포함하는 그룹 3; (d) PBX1, BCL9, INHBA, PRRX1, YWHAE, GNAS, LHFPL6, FCRL4, AURKA, IKZF1, CASP8, PTEN, 및 EP300 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 또는 13 개를 포함하는 그룹 4; (e) BCL9, PBX1, PRRX1, INHBA, GNAS, YWHAE, LHFPL6, FCRL4, PTEN, HOXA11, AURKA, 및 BIRC3 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 또는 12개를 포함하는 그룹 5; (f) BCL9, PBX1, PRRX1, INHBA, 및 YWHAE 중 1, 2, 3, 4, 또는 5개를 포함하는 그룹 6; (g) BCL9, PBX1, GNAS, LHFPL6, CASP8, ASXL1, FH, CRKL, MLF1, TRRAP, AKT3, ACKR3, MSI2, PCM1, 및 MNX1 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 또는 15개를 포함하는 그룹 7; (h) BX1, GNAS, AURKA, CASP8, ASXL1, CRKL, MLF1, GAS7, MN1, SOX10, TCL1A, LMO1, BRD3, SMARCA4, PER1, PAX7, SBDS, SEPT5, PDGFB, AKT2, TERT, KEAP1, ETV6, TOP1, TLX3, COX6C, NFIB, ARFRP1, ARID1A, MAP2K4, NFKBIA, WWTR1, ZNF217, IL2, NSD3, CREB1, BRIP1, SDC4, EWSR1, FLT3, FLT1, FAS, CCNE1, RUNX1T1, 및 EZR 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44 또는 45개를 포함하는 그룹 8; 및 (i) BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, BIRC3, AURKA, 및 HOXA11 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 또는 11 개를 포함하는 그룹 9를 포함함 - 를 포함한다.
일부 구체예에서, 생체 샘플은 포르말린-고정 파라핀-포매(FFPE: formalin-fixed paraffin-embedded) 조직, 고정된 조직, 코어 바늘 생검, 미세 바늘 흡인물, 비염색 슬라이드, 신선 동결(FF: fresh frozen) 조직, 포르말린 샘플, 핵산 또는 단백질 분자를 보존하는 용액에 포함된 조직, 신선 샘플, 악성 유체, 체액, 종양 샘플, 조직 샘플, 또는 이들의 임의의 조합을 포함한다.
일부 구체예에서, 생체 샘플은 고형 종양으로부터의 세포를 포함한다.
일부 구체예에서, 생체 샘플은 체액을 포함한다.
일부 구체예에서, 체액은 악성 유체, 흉수, 복막액, 또는 이들의 임의의 조합을 포함한다.
일부 구체예에서, 체액은 말초 혈액, 혈청, 혈장, 복수, 소변, 뇌척수액(CSF), 가래, 타액, 골수, 활액, 안방수, 양수, 귀지, 모유, 기관지폐포 세척액, 정액, 전립선액, 소액, 사정전액, 여성의 사정액, 땀, 대변, 눈물, 낭종액, 흉막액, 복막액, 심낭액, 림프액, 유미즙, 유미, 담즙, 간질액, 월경, 고름, 피지, 구토, 질 분비물, 점막 분비물, 대변 물, 췌장액, 부비동강 세척액, 기관지폐 흡인물, 배반포강액 또는 제대혈을 포함한다.
일부 구체예에서, 평가는 각각의 바이오머커에 대한 단백질 또는 핵산의 존재여부, 레벨, 또는 상태를 결정하는 것을 포함하며, 선택적으로, 핵산은 DNA(deoxyribonucleic acid), RNA(ribonucleic acid), 또는 이들의 조합을 포함한다. 일부 구체예에서, (a) 단백질의 존재 여부, 레벨 또는 상태는 IHC(immunohistochemistry), 유세포 분석, 면역분석, 항체 또는 이의 기능 단편, 압타머, 또는 이의 임의의 조합을 이용해 결정되거나, 및/또는 (b) 핵산의 존재 여부, 레벨, 또는 상태는 PCR(polymerase chain reaction), 원위치 혼성화, 증폭, 혼성화, 마이크로어레이, 핵산 시퀀싱, 염료 종단 시퀀싱, 파이로시퀀싱, 차세대 시퀀싱(NGS, 고처리율 시퀀싱), 또는 이들의 임의의 조합을 이용해 결정된다.
일부 구체예에서, 핵산의 상태는 서열, 돌연변이, 다형성, 결실, 삽입, 치환, 전위, 융합, 절단, 복제, 증폭, 반복, 복제수, 복제수 변이(CNV; 복제수 변경; CNA), 또는 임의의 이들의 조합을 포함한다.
일부 구체예에서, 핵산의 상태는 복제수를 포함한다.
일부 구체예에서, 방법은 그룹 1의 모든 구성원(즉, MYC, EP300, U2AF1, ASXL1, MAML2, 및 CNTRL)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함한다.
일부 구체예에서, 방법은 그룹 2의 모든 구성원(즉, MYC, EP300, U2AF1, ASXL1, MAML2, CNTRL, WRN, 및 CDX2)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함한다.
일부 구체예에서, 방법은 그룹 3의 모든 구성원(즉, BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, HOXA11, AURKA, BIRC3, IKZF1, CASP8, 및 EP300)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함한다.
일부 구체예에서, 방법은 그룹 4의 모든 구성원(즉, PBX1, BCL9, INHBA, PRRX1, YWHAE, GNAS, LHFPL6, FCRL4, AURKA, IKZF1, CASP8, PTEN, 및 EP300)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함한다.
일부 구체예에서, 방법은 그룹 5의 모든 구성원(즉, BCL9, PBX1, PRRX1, INHBA, GNAS, YWHAE, LHFPL6, FCRL4, PTEN, HOXA11, AURKA, 및 BIRC3)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함한다.
일부 구체예에서, 방법은 그룹 6의 모든 구성원(즉, BCL9, PBX1, PRRX1, INHBA, 및 YWHAE)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함한다.
일부 구체예에서, 방법은 그룹 7의 모든 구성원(즉, BCL9, PBX1, GNAS, LHFPL6, CASP8, ASXL1, FH, CRKL, MLF1, TRRAP, AKT3, ACKR3, MSI2, PCM1, 및 MNX1)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함한다.
일부 구체예에서, 방법은 그룹 8의 모든 구성원(즉, BX1, GNAS, AURKA, CASP8, ASXL1, CRKL, MLF1, GAS7, MN1, SOX10, TCL1A, LMO1, BRD3, SMARCA4, PER1, PAX7, SBDS, SEPT5, PDGFB, AKT2, TERT, KEAP1, ETV6, TOP1, TLX3, COX6C, NFIB, ARFRP1, ARID1A, MAP2K4, NFKBIA, WWTR1, ZNF217, IL2, NSD3, CREB1, BRIP1, SDC4, EWSR1, FLT3, FLT1, FAS, CCNE1, RUNX1T1, 및 EZR)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함한다.
일부 구체예에서, 방법은 그룹 9의 모든 구성원(즉, BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, BIRC3, AURKA, 및 HOXA11)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함한다.
일부 구체예에서, 방법은 그룹 1 및 그룹 2의 적어도 하나 또는 모든 구성원, 또는 이의 근접 게놈 영역, 그룹 3의 적어도 하나 또는 모든 구성원, 또는 이의 근접 게놈 영역, 또는그룹 2, 그룹 6, 그룹 7, 그룹 8 및 그룹 9의 적어도 하나 또는 모든 구성원, 또는 이의 근접 게놈 영역의 복제수를 결정하기 위한 분석을 수행하는 단계를 포함한다.
일부 구체예에서, 방법은 바이오마커의 복제수를 참조 복제수(가령, 디플로이드)에 비교하는 단계, 및 복제수 변동(CNV)을 갖는 바이오마커를 식별하는 단계를 더 포함한다.
일부 구체예에서, 방법은 CNV를 갖는 유전자 또는 이의 근접 영역을 식별하는 분자 프로파일을 생성하는 단계를 더 포함한다.
일부 구체예에서, PTEN 단백질의 존재 여부 또는 레벨이 결정되며, 선택적으로, PTEN 단백질 존재 여부 또는 레벨이 IHC(immunohistochemistry)을 이용해 결정된다.
일부 구체예에서, 방법은 TOPO1 및 하나 이상의 불일치 리페어 단백질(가령, MLH1, MSH2, MSH6, 및 PMS2)을 포함하는 단백질의 레벨을 결정하는 단계를 더 포함하고, PTEN 단백질 존재 여부 또는 레벨은 IHC(immunohistochemistry)을 이용해 결정된다.
일부 구체예에서, 방법은 단백질의 레벨을 각각의 단백질에 대한 기준 레벨에 비교하는 단계를 더 포함한다.
일부 구체예에서, 방법은 기준 레벨과 상이한, 가령, 기준 레벨과 유의미하게 상이한 레벨을 갖는 단백질을 식별하는 분자 프로파일을 생성하는 단계를 더 포함한다.
일부 구체예에서, 방법은 평가된 바이오마커에 기초하여 효험 가능성이 있는 치료를 선택하는 단계를 더 포함하며, 치료는 옥살리플라틴과 조합된 5-플루오로우라실/류코보린(FOLFOX) 또는 이의 대안 치료를 포함하며, 선택적으로 대안 치료는 이리노테칸과 조합된 5-플루오우라실/류코보린(FOLFIRI)을 포함한다.
일부 구체예에서, 효험 가능한 치료를 선택하는 것은 (a) 앞서 기재된 그룹에 대해 결정된 복제수; 및/또는 (b) 앞서 기재된 바와 같이 결정된 분자 프로파일에 기초한다.
일부 구체예에서, 앞서 기재된 그룹에 대해 결정된 복제수에 기초하여 효험 가능성 있는 치료를 선택하는 것은 투표 모듈의 사용을 포함한다.
일부 실시예에서, 투표 모듈은 본 명세서에 제공된 바와 같다.
일부 실시예에서, 투표 모듈은 적어도 하나의 랜덤 포레스트 모델의 사용을 포함한다.
일부 실시예에서, 투표 모듈의 사용은 머신 러닝 분류 모델을 그룹 2, 그룹 6, 그룹 7, 그룹 8 및 그룹 9 각각에 대해 획득된 복제수에 적용하는 것을 포함하며, 선택적으로, 각각의 머신 러닝 분류 모델은 랜덤 포레스트 모델이며, 랜덤 포레스트 모델은 이하의 표 10에 기재되어 있다.
일부 구체예에서, 피험체는 효험 가능성 있는 치료로 치료된 적 없다.
일부 구체예에서, 암은 전이암, 재발암, 또는 이의 조합을 포함한다.
일부 구체예에서, 피험체는 이전에 암 치료를 받은 적이 없다.
일부 구체예에서, 방법은 피험체에 효험이 있을 가능성이 있는 치료를 투여하는 것을 더 포함한다.
일부 구체예에서, 투여에 의해 무진행 생존률(PFS), 무질병 생존률(DFS), 또는 수명이 연장된다.
암은 급성 림프모구성 백혈병; 급성 골수성 백혈병; 부신피질 암종; AIDS-관련 암; AIDS-관련 림프종; 항문암; 맹장암; 성상세포종; 비정형 기형/횡문형 종양; 기저 세포 암; 방광암; 뇌간 신경교종; 뇌종양, 뇌간 신경교종, 중추신경계 비정형 기형/횡문근 종양, 중추신경계 배아 종양, 성상세포종, 두개인두종, 뇌실막세포종, 뇌실막종, 수모세포종, 수상피종, 송과체 중간 분화의 실질 종양, 천막상피종, 원시 신경세포종 유방암; 기관지 종양; 버킷 림프종; 미지의 원발성 부위의 암(CUP); 카르시노이드 종양; 미지의 원발 부위의 암종; 중추신경계 비정형 기형/횡문형 종양; 중추신경계 배아 종양; 자궁 경부암; 소아암; 척색종; 만성 림프구성 백혈병; 만성 골수성 백혈병; 만성 골수증식성 장애; 대장 암; 결장직장암; 두개인두종; 피부 T 세포 림프종; 내분비 췌장 섬 세포 종양; 자궁내막암; 뇌실막모세포종; 뇌실막종; 식도암; 감각신경모세포종; 유잉 육종; 두개외 생식 세포 종양; 생식선외 생식 세포 종양; 간외 담관암; 담낭암; 위암; 위장관 유암종; 위장관 기질 세포 종양; 위장관 기질 종양(GIST); 임신성 융모성 종양; 신경교종; 모세포 백혈병; 두경부암; 심장암; 호지킨 림프종; 하인두암; 안내 흑색종; 섬 세포 종양; 카포시 육종; 신장암; 랑게르한스 세포 조직구증; 후두암; 입술암; 간암; 악성 섬유성 조직구종 골암; 수모세포종; 수질상피종; 흑색종; 메르켈 세포 암종; 메르켈 세포 피부 암종; 중피종; 잠재성 원발성을 동반한 전이성 편평 경부암; 구강암; 다발성 내분비 신생물 증후군; 다발성 골수종; 다발성 골수종/형질 세포 신생물; 균상 식육종; 골수이형성 증후군; 골수증식성 신생물; 비강암; 비인두암; 신경 모세포종; 비호지킨 림프종; 비흑색종 피부암; 비소세포폐암; 구강암; 구강암; 구인두암; 골육종; 기타 뇌 및 척수 종양; 난소 암; 난소 상피암; 난소 생식 세포 종양; 난소의 저악성 잠재성 종양; 췌장암; 유두종증; 부비동암; 부갑상선암; 골반암; 음경암; 인두암; 중간 분화의 송과체 실질 종양; 송과체종; 뇌하수체 종양; 형질 세포 신생물/다발성 골수종; 흉막폐모세포종; 원발성 중추신경계(CNS) 림프종; 원발성 간세포 간암; 전립선암; 직장암; 신장암; 신세포(신장)암; 신세포암; 호흡기 암; 망막모세포종; 횡문근육종; 침샘암; 세자리 증후군; 소세포 폐암; 소장암; 연조직 육종; 편평 세포 암종; 편평 경부암; 위(위)암; 천막상 원시 신경외배엽 종양; T 세포 림프종; 고환암; 후두암; 흉선 암종; 흉선종; 갑상선 암; 이행 세포암; 신우 및 요관의 이행 세포암; 영양막 종양; 요관암; 요도암; 자궁암; 자궁 육종; 질암; 외음부암; 발덴스트롬 마크로글로불린혈증; 또는 빌름스 종양을 포함한다.
일부 실시예에서, 암은 급성 골수성 백혈병(AML), 유방암, 담관암, 결장직장 선암, 간외 담관 선암, 여성 생식기 악성종양, 위 선암, 위식도 선암, 위장관 기질 종양(GIST), 교모세포종, 두경부 암종, 백혈병 간세포 암종, 저등급 신경교종, 폐 세기관지폐포암종(BAC), 비소세포폐암(NSCLC), 소세포폐암(SCLC), 림프종, 남성 생식기 악성종양, 흉막의 악성 단독 섬유성 종양(MSFT), 흑색종, 다발성 골수종, 신경내분비 종양, 결절 미만성 거대 B 세포 림프종, 비상피성 난소암(비-EOC), 난소 표면 상피 암종, 췌장 선암종, 뇌하수체 암종, 희소돌기아교종, 전립선 선암종, 후복막 또는 복막 암종, 후복막 또는 복막 암종 육종, 소장암, 연조직종양, 흉선암, 갑상선암, 또는 포도막 흑색종을 포함한다.
일부 구체예에서, 암은 대장암을 포함한다.
대장암을 가진 피험체에 대한 치료를 선택하는 방법이 더 제공되며, 상기 방법은 대장암으로부터의 세포를 포함하는 생체 세포를 획득하는 단계, MYC, EP300, U2AF1, ASXL1, MAML2, CNTRL, WRN, 및 CDX2 중 1, 2, 3, 4, 5, 6, 7, 또는 8개를 포함하는 그룹 2, BCL9, PBX1, PRRX1, INHBA, 및 YWHAE 중 1, 2, 3, 4, 또는 5를 포함하는 그룹 6,BCL9, PBX1, GNAS, LHFPL6, CASP8, ASXL1, FH, CRKL, MLF1, TRRAP, AKT3, ACKR3, MSI2, PCM1, 및 MNX1 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 또는 15개를 포함하는 그룹 7, BX1, GNAS, AURKA, CASP8, ASXL1, CRKL, MLF1, GAS7, MN1, SOX10, TCL1A, LMO1, BRD3, SMARCA4, PER1, PAX7, SBDS, SEPT5, PDGFB, AKT2, TERT, KEAP1, ETV6, TOP1, TLX3, COX6C, NFIB, ARFRP1, ARID1A, MAP2K4, NFKBIA, WWTR1, ZNF217, IL2, NSD3, CREB1, BRIP1, SDC4, EWSR1, FLT3, FLT1, FAS, CCNE1, RUNX1T1, 및 EZR 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44 또는 45개를 포함하는 그룹 8, BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, BIRC3, AURKA, 및 HOXA11 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 또는 11개를 포함하는 그룹 9의 유전자 그룹 또는 이의 근접 게놈 영역 각각에 대해 복제수를 결정하기 위해 생체 세포로부터의 게놈 DNA에 차세대 시퀀싱을 수행하는 단계, 머신 러닝 분류 모델을 그룹 2, 그룹 6, 그룹 7, 그룹 8 및 그룹 9 각각에 대해 획득된 복제수에 적용하는 단계 - 선택적으로, 각각의 머신 러닝 분류 모델은 랜덤 포레스트 모델이며, 랜덤 포레스트 모델은 표 10에 기재되어 있음 - ,피험체가 옥살리플라틴과 조합된 5-플루오로우라실/류코보린(FOLFOX) 치료에 효험이 있을 가능성이 있는 여부에 대한 지시자를 각각의 머신 러닝 분류 모델로부터 획득하는 단계, 및머신 러닝 부류 모델의 과반수가 피험체가 상기 치료에 효험이 있을 가능성이 있음을 나타내는 경우 FOLFOX를 선택하고, 머신 러닝 분류 모델의 과반수가 피험체가 FOLFOX에 효험이 있을 가능성이 없음을 나타내는 경우 FOLFOX의 대안 치료를 선택하는 단계 - 선택적으로, 대안 치료는 이리노테칸과 조합된 5-플루오로오라실/류코보린(FOLFIRI)임 - 를 포함한다. 일부 실시예에서, 상기 방법은 피험체에게 선택된 치료를 투여하는 것을 더 포함한다.
분자 프로파일링 리포트를 생성하는 방법이 본 명세서에 제공되며, 상기 방법은 앞서 기재된 방법을 수행하는 결과를 요약하는 리포트를 제작하는 단계를 포함한다. 일부 실시예에서, 리포트는 (a) 앞서 기재된 바와 같이 결정된 효험 가능성 있는 치료, 또는 (b) 앞서 개시된 바와 같이 결정된 선택된 치료를 포함한다. 일부 구체예에서, 리포트는 컴퓨터에 의해 생성되며, 인쇄 리포트 또는 컴퓨터 파일이거나, 웹 포털에 의해 액세스 가능하다.
이와 관련하여, 피험체의 암에 대한 치료법을 식별하기 위한 시스템으로서, 상기 시스템은 적어도 하나의 호스트 서버, 데이터를 액세스 및 입력하도록 적어도 하나의 호스트 서버를 액세스하기 위한 적어도 하나의 사용자 인터페이스, 입력된 데이터를 처리하기 위한 적어도 하나의 프로세서,처리된 데이터 및 명령을 저장하기 위한, 상기 프로세서에 연결된 적어도 하나의 메모리 - 상기 명령은 앞서 기재된 바에 따라 생체 샘플을 분석하는 결과를 액세스하기 위한 명령, 및 앞서 기재된 바에 따라 효험 가능성 있는 치료 또는 앞서 기재된 바에 따는 선택된 치료를 결정하기 위한 명령을 포함함 - , 및 암의 치료를 디스플레이하기 위한 적어도 하나의 디스플레이 - 상기 치료는 FOLFOX 또는 이의 대안, 가령, FOLFIRI임 - 를 포함한다.
일부 구체예에서, 적어도 하나의 디스플레이는 생체 샘플을 분석한 결과 및 암의 치료에 효험 가능성이 있거나 선택된 치료를 포함하는 리포트를 포함한다.
덧붙여, 연장된 무진행 생존율, 연장된 무질병 생존율, 연장된 전체 생존율, 또는 연장된 수명을 제공하기 위해, 암을 치료하기 위한 추천안을 제공하는 방법이 본 명세서에 제공되며, 상기 방법은 암이 진단된 개체로부터 핵산 및/또는 단백질을 포함하는 생체 샘플을 획득하는 단계, 표적 유전자의 세트의 핵산 서열 또는 그 일부, 표적 유전자 세트의 복제수 변동의 존재, 유전자 융합 또는 그 밖의 다른 게놈 변형의 존재, 단백질의 세트 중 하나 이상 및/또는 전사의 레벨, 및 또는 표적 유전자 세트의 후성유전학적 상태, 가령, 본 명세서에 기재된 바로 구성된 군 중에서 선택된 하나 이상의 분자 특성을 결정하기 위해 상기 생체 샘플에 분자 테스트를 수행하여, 암 유형에 대한 분자 프로파일을 형성하는 단계, 기준 분자 프로파일에 비교해서 차이, 가령, 유의미한 차이를 나타내는 분자 특성의 리스트를 생성하는 단계, 및 표적 유전자의 기준 서열 프로파일에 비교해서 차이를 나타내는 분자 특성의 리스트에 기초하여 개체에 대한 하나 이상의 치료 추천안의 리스트를 생성하는 단계를 포함한다.
일부 구체예에서, 분자 테스트는 NextGen 시퀀싱, Sanger 시퀀싱, ISH, 단편 분석, PCR, IHC 및 면역 분석 중 적어도 하나이다.
일부 구체예에서, 생체 샘플은 세포, 조직 샘플, 혈액 샘플 또는 이들의 조합을 포함한다.
일부 구체예에서, 분자 테스트는 돌연변이, 다형성, 결실, 삽입, 치환, 전위, 융합, 파손, 복제, 증폭 또는 반복 중 적어도 하나를 검출한다.
일부 구체예에서, 핵산 서열은 데옥시리보핵산 서열을 포함한다.
일부 구체예에서, 핵산 서열은 리보핵산 서열을 포함한다.
달리 정의되지 않는 한, 본 명세서에서 사용되는 모든 기술적 및 과학적 용어는 본 발명이 속하는 기술 분야에서 통상의 지식을 가진 자에 의해 일반적으로 이해되는 것과 동일한 의미를 갖는다. 본 발명에서 사용하기 위한 방법 및 물질이 본 명세서에 기술되어 있으며, 해당 업계에 공지 된 다른 적절한 방법 및 물질이 또한 사용될 수 있다. 재료, 방법 및 예는 예시일 뿐이며 제한하려는 의도가 없다. 본 명세서에 언급된 모든 간행물, 특허 출원, 특허, 서열, 데이터베이스 항목 및 기타 참고 문헌은 그 전체가 참고로 포함된다. 상충되는 경우, 정의를 포함하여 본 명세서가 우선시 될 것이다.
본 발명의 다른 특징 및 이점은 다음의 상세한 설명 및 도면, 그리고 청구 범위로부터 명백해질 것이다.
도 1a는 머신 러닝 모델을 훈련하기 위한 종래 기술 시스템의 예의 블록도이다.
도 1b는 특정 바이오마커 세트를 갖는 피험자의 질병 또는 장애에 대한 치료의 효과를 예측하기 위해 머신 러닝 모델을 훈련하기 위한 훈련 데이터 구조를 생성하는 시스템의 블록 다이어그램이다.
도 1c는 특정 바이오마커 세트를 갖는 피험자의 질병 또는 장애에 대한 치료의 효과를 예측하도록 훈련된 머신 러닝 모델을 사용하기 위한 시스템의 블록 다이어그램이다.
도 1d는 특정 바이오마커 세트를 갖는 피험체의 질병 또는 장애에 대한 치료의 효과를 예측하기 위해 머신 러닝 모델을 훈련하기 위한 훈련 데이터를 생성하는 프로세스의 흐름도이다.
도 1e는 특정 바이오마커 세트를 갖는 피험체의 질병 또는 장애에 대한 치료 효과를 예측하도록 훈련된 머신 러닝 모델을 사용하기 위한 프로세스의 흐름도이다.
도 1f는 다수의 머신 러닝 모델에 의해 생성된 출력을 해석하기 위해 투표 유닛을 사용함으로써 특정 바이오마커 세트를 갖는 피험체의 질병 또는 장애에 대한 치료의 효과를 예측하기 위한 시스템의 블록 다이어그램이다.
도 1g는 도 2-5의 시스템을 구현하는 데 사용될 수 있는 시스템 구성요소의 블록도이다.
도 1h는 환자의 생물학적 표본의 분자 프로파일링을 사용하는 암에 대한 개별화된 의료 개입을 결정하기 위한 시스템의 예시적인 구체예의 블록도를 도시한다.
도 2a-c는 (A) 환자의 생물학적 표본의 분자 프로파일링을 활용하는 암에 대한 개별화된 의료 개입을 결정하기 위한 방법, (B) 치료의 효험을 예측하는 데 사용될 수 있는 시그니처 또는 분자 프로파일을 식별하기 위한 방법, 및 (C) (B)의 대안 버전의 구체예의 흐름도이다.
도 3a-b는 FOLFOX (3A) 또는 FOLFIRI (3B)로 처리하기 위해 8개 마커의 CNV 프로파일링을 사용하여 모델 성능을 보여주는 한 쌍의 위험 비율 그래프(Hazard Ratio Graph)이다. CNA = 복제수 변경(copy number alteration). 8개의 마커는 MYC, EP300, U2AF1, ASXL1, MAML2, CNTRL, WRN 및 CDX2였다.
도 3c-d는 FOLFOX (3C) 또는 FOLFIRI (3D)로 치료하기 위해 6개 마커의 CNV 프로파일링을 사용하여 모델 성능을 보여주는 한 쌍의 위험 비율 그래프이다. 6개의 마커는 MYC, EP300, U2AF1, ASXL1, MAML2 및 CNTRL이었다.
도 3e는 도 3a-b에 도시된 8개의 마커 시그니처에 대한 예시적 랜덤 포레스트 결정 트리를 도시한다.
도 4a-o는 전이성 대장암 환자에서 FOLFOX 요법의 효험을 예측하기 위한 바이오시그니처의 형상을 나타낸다.
도 5a-c는 대장암 환자에서 FOLFOX 요법의 효험을 예측하기 위한 바이오시그니처의 형성을 도시한다.
도 1b는 특정 바이오마커 세트를 갖는 피험자의 질병 또는 장애에 대한 치료의 효과를 예측하기 위해 머신 러닝 모델을 훈련하기 위한 훈련 데이터 구조를 생성하는 시스템의 블록 다이어그램이다.
도 1c는 특정 바이오마커 세트를 갖는 피험자의 질병 또는 장애에 대한 치료의 효과를 예측하도록 훈련된 머신 러닝 모델을 사용하기 위한 시스템의 블록 다이어그램이다.
도 1d는 특정 바이오마커 세트를 갖는 피험체의 질병 또는 장애에 대한 치료의 효과를 예측하기 위해 머신 러닝 모델을 훈련하기 위한 훈련 데이터를 생성하는 프로세스의 흐름도이다.
도 1e는 특정 바이오마커 세트를 갖는 피험체의 질병 또는 장애에 대한 치료 효과를 예측하도록 훈련된 머신 러닝 모델을 사용하기 위한 프로세스의 흐름도이다.
도 1f는 다수의 머신 러닝 모델에 의해 생성된 출력을 해석하기 위해 투표 유닛을 사용함으로써 특정 바이오마커 세트를 갖는 피험체의 질병 또는 장애에 대한 치료의 효과를 예측하기 위한 시스템의 블록 다이어그램이다.
도 1g는 도 2-5의 시스템을 구현하는 데 사용될 수 있는 시스템 구성요소의 블록도이다.
도 1h는 환자의 생물학적 표본의 분자 프로파일링을 사용하는 암에 대한 개별화된 의료 개입을 결정하기 위한 시스템의 예시적인 구체예의 블록도를 도시한다.
도 2a-c는 (A) 환자의 생물학적 표본의 분자 프로파일링을 활용하는 암에 대한 개별화된 의료 개입을 결정하기 위한 방법, (B) 치료의 효험을 예측하는 데 사용될 수 있는 시그니처 또는 분자 프로파일을 식별하기 위한 방법, 및 (C) (B)의 대안 버전의 구체예의 흐름도이다.
도 3a-b는 FOLFOX (3A) 또는 FOLFIRI (3B)로 처리하기 위해 8개 마커의 CNV 프로파일링을 사용하여 모델 성능을 보여주는 한 쌍의 위험 비율 그래프(Hazard Ratio Graph)이다. CNA = 복제수 변경(copy number alteration). 8개의 마커는 MYC, EP300, U2AF1, ASXL1, MAML2, CNTRL, WRN 및 CDX2였다.
도 3c-d는 FOLFOX (3C) 또는 FOLFIRI (3D)로 치료하기 위해 6개 마커의 CNV 프로파일링을 사용하여 모델 성능을 보여주는 한 쌍의 위험 비율 그래프이다. 6개의 마커는 MYC, EP300, U2AF1, ASXL1, MAML2 및 CNTRL이었다.
도 3e는 도 3a-b에 도시된 8개의 마커 시그니처에 대한 예시적 랜덤 포레스트 결정 트리를 도시한다.
도 4a-o는 전이성 대장암 환자에서 FOLFOX 요법의 효험을 예측하기 위한 바이오시그니처의 형상을 나타낸다.
도 5a-c는 대장암 환자에서 FOLFOX 요법의 효험을 예측하기 위한 바이오시그니처의 형성을 도시한다.
분자 프로파일링을 이용함으로써 개별화된 토대로 치료에서 사용될 치료제를 식별하기 위한 방법 및 시스템, 예를 들어, 머신 러닝 모델을 훈련시킨 후 훈련된 머신 러닝 모델을 이용하여 피험체의 질병 또는 장애에 대한 치료의 효과를 예측하기 위한 시스템, 방법, 장치, 및 컴퓨터 프로그램이 본 명세서에 개시된다. 일부 구현예에서, 시스템은 가령, 본 명세서에 기재된 방법에서 사용되도록 구성된 하나 이상의 위치에 있는 하나 이상의 컴퓨터 상의 하나 이상의 컴퓨터 프로그램을 포함할 수 있다.
본 개시 내용의 양태는 생체 샘플의 표현형을 특징화하는 것과 같은 다양한 분류를 제공하기 위해 머신 러닝 모델을 훈련시키는 데 사용될 수 있는 하나 이상의 훈련 데이터 구조 세트를 생성하는 시스템과 관련된다. 표현형을 특징화하는 것은 진단, 예후, 치료 또는 그 밖의 다른 관련 분류를 제공하는 것을 포함할 수 있다. 예를 들어, 분류는 특정 바이오마커 세트를 갖는 피험체의 질병 또는 장애에 대한 질병 상태 또는 치료의 효과를 예측할 수 있다. 훈련되면, 훈련된 머신 러닝 모델이 사용되어 시스템에 의해 제공되는 입력 데이터를 처리하고 처리된 입력 데이터에 기초하여 예측을 수행할 수 있다. 입력 데이터는 하나 이상의 피험체 바이오마커를 나타내는 데이터 및 질병 또는 장애를 나타내는 데이터와 같은 피험체와 관련된 피처(feature)의 세트를 포함할 수 있다. 일부 구체예에서, 입력 데이터는 제안된 치료 유형을 나타내는 피처를 더 포함하고 피험체가 치료에 반응할 가능성을 설명하는 예측을 할 수 있다. 예측은 머신 러닝 모델에 대한 입력으로 제공된 특정 피처 세트의 머신 러닝 모델의 처리를 기반으로 머신 러닝 모델에 의해 출력되는 데이터를 포함할 수 있다. 데이터는 하나 이상의 피험체 바이오마커를 나타내는 데이터, 질병 또는 장애를 나타내는 데이터 및 필요에 따라 제안된 치료 유형을 나타내는 데이터를 포함할 수 있다.
본 개시 내용의 혁신적인 양태는 트레이닝 데이터 구조를 생성하는 데 사용되기 위한 인입 데이터 스트림으로부터 특정 데이터의 추출을 포함한다. 중요한 것은 훈련 데이터 구조에 포함되기 위한 하나 이상의 바이오마커의 특정 세트를 선택하는 것이다. 이는 특정 바이오마커의 존재, 부재 또는 상태가 원하는 분류를 나타낼 수 있기 때문이다. 예를 들어, 질병 또는 장애에 대한 치료가 효과적인지 여부를 결정하기 위해 특정 바이오마커가 선택될 수 있다. 예를 들어, 본 개시 내용에서, 출원인은 머신 러닝 모델을 훈련시키는 데 사용될 때, 다른 바이오마커 세트를 이용하는 것보다 더 정확히 치료 효과를 예측할 수 있는 훈련된 모델을 도출하는 특정 바이오마커 세트를 제시한다. 예 2-4를 참조할 수 있다.
시스템은 머신 러닝 모델의 데이터 처리를 기반으로 훈련된 머신 러닝 모델에 의해 생성된 출력 데이터를 얻도록 구성된다. 다양한 구체예에서, 데이터는 하나 이상의 바이오마커를 나타내는 생물학적 데이터, 질병 또는 장애를 나타내는 데이터, 및 치료 유형을 나타내는 데이터를 포함한다. 그 후 시스템은 특정 바이오마커 세트를 갖는 피험체에 대한 치료의 효과를 예측할 수 있다. 일부 구현예에서, 질병 또는 장애는 암의 유형을 포함할 수 있고, 피험체에 대한 치료는 하나 이상의 치료제, 예를 들어, 소분자 약물, 생물의약품(biologics) 및 이의 다양한 조합을 포함할 수 있다. 이 설정에서, 바이오마커 세트, 질병 또는 장애 및 치료 유형을 포함하는 입력 데이터의 훈련된 머신 러닝 처리에 기초하여 생성된 훈련된 머신 러닝 모델의 출력이 피험체가 질병 또는 장애에 대한 치료에 대한 반응의 레벨을 나타내는 데이터를 포함한다.
일부 구현예에서, 훈련된 머신 러닝 모델에 의해 생성된 출력 데이터는 원하는 분류의 확률을 포함할 수 있다. 예를 들어, 이러한 확률은 피험체가 질병 또는 장애에 대한 치료에 호의적으로 반응할 확률일 수 있다. 또 다른 구현에서, 출력 데이터는 훈련된 머신 러닝 모델의 입력 데이터 처리에 기초하여 훈련된 머신 러닝 모델에 의해 생성된 임의의 출력 데이터를 포함할 수 있다. 일부 구체예에서, 입력 데이터는 바이오마커 세트, 질병 또는 장애를 나타내는 데이터, 및 치료 유형을 나타내는 데이터를 포함한다.
일부 구현예에서, 본 개시 내용에 의해 생성된 훈련 데이터 구조는 특정 훈련 샘플에 대응하는 피처 벡터(feature vector)를 나타내는 필드를 각각 포함하는 복수의 훈련 데이터 구조를 포함할 수 있다. 피처 벡터는 훈련 샘플에서 파생된 피처의 집합을 포함한다. 훈련 샘플은 예를 들어, 피험체의 하나 이상의 바이오마커, 피험체의 질병 또는 장애 및 질병 또는 장애에 대한 제안된 치료를 포함할 수 있다. 훈련 데이터 구조는 각각의 훈련 데이터 구조가 피처 벡터의 각각의 피처를 나타내는 가중치가 할당될 수 있기 때문에 유연하다. 따라서, 복수의 훈련 데이터 구조의 각각의 훈련 데이터 구조는 특히 훈련 중에 머신 러닝 모델에 의해 특정 추론이 이루어지도록 구성될 수 있다.
모델이 질병 또는 장애에 대한 특정 치료의 가능한 효험을 예측하도록 훈련된 비제한적인 예를 고려할 수 있다. 결과적으로, 본 명세서에 따라 생성된 새로운 훈련 데이터 구조는 특정 바이오마커 세트를 갖는 피험체의 질병 또는 장애에 대한 치료의 효과를 예측하도록 머신 러닝 모델을 훈련시키는 데 사용될 수 있기 때문에 머신 러닝 모델의 성능을 개선하도록 설계된다. 예를 들어, 본 개시 내용에 의해 기재되는 훈련 데이터 구조, 시스템 및 동작을 이용해 훈련되기 전에 특정 바이오마커 세트를 갖는 피험체의 질병 또는 장애에 대한 치료의 효과에 대해 예측을 수행하지 않을 수 있는 머신 러닝 모델이, 본 개시 내용에 의해 기재된 훈련 데이터 구조, 시스템 및 동작을 이용해 훈련됨으로써, 피험체의 질병 또는 장애에 대한 치료의 효과에 대해 예측하도록 학습할 수 있다. 따라서, 이 프로세스는 범용 머신 러닝 모델을 취하며 범용 머신 러닝 모델을 특정 바이오마커 세트를 갖는 피험체의 질병 또는 장애에 대한 치료의 효과를 예측하는 것을 수행하는 특정 작업을 수행하기 위한 특정 컴퓨터로 변경한다.
도 1a는 머신 러닝 모델(110)을 훈련하기 위한 종래 기술 시스템(100)의 예의 블록도이다. 일부 구현예에서, 머신 러닝 모델은 예를 들어 서포트 벡터 머신(support vector machine)일 수 있다. 또는, 머신 러닝 모델은 신경망 모델, 선형 회귀 모델, 랜덤 포레스트 모델, 로지스틱 회귀 모델, 나이브 베이즈 모델, 2차 판별 분석 모델(quadratic discriminant analysis model), K-최근접 이웃 모델, 서포트 벡터 머신 등을 포함할 수 있다. 머신 러닝 모델 훈련 시스템(100)은 하나 이상의 위치에 있는 하나 이상의 컴퓨터 상의 컴퓨터 프로그램으로서 구현될 수 있으며, 여기서 이하에서 기재된 시스템, 구성요소, 및 기법이 구현될 수 있다. 머신 러닝 모델 훈련 시스템(100)은 훈련 데이터 항목의 데이터베이스(또는 데이터세트)(120)로부터 훈련 데이터 항목을 사용하여 머신 러닝 모델(110)을 훈련시킨다. 트레이닝 데이터 항목은 복수의 피처 벡터를 포함할 수 있다. 각각의 훈련 벡터는 훈련 벡터가 나타내는 훈련 샘플의 특정 피처에 각각 대응하는 복수의 값을 포함할 수 있다. 훈련 피처는 독립 변수로 지칭될 수 있다. 또한, 시스템(100)은 피처 벡터에 포함된 각각의 피처에 대한 각자의 가중치를 유지한다.
머신 러닝 모델(110)은 입력 훈련 데이터 항목(122)을 수신하고 입력 훈련 데이터 항목(122)을 처리하여 출력(118)을 생성하도록 구성된다. 입력 훈련 데이터 항목은 복수의 피처(또는 독립 변수 "X") 및 훈련 라벨(또는 종속 변수 "Y")을 포함할 수 있다. 머신 러닝 모델은 훈련 항목을 사용하여 훈련될 수 있으며, 훈련되면 X = f(Y)를 예측할 수 있다.
머신 러닝 모델(110)이 수신된 데이터 항목에 대한 정확한 출력을 생성할 수 있도록 하기 위해, 머신 러닝 모델 훈련 시스템(100)은 머신 러닝 모델(110)을 훈련시켜 머신 러닝 모델(110)의 파라미터의 값을 조절할 수 있다, 가령, 초기 값으로부터 파라미터의 훈련된 값을 결정할 수 있다. 훈련 단계로부터 유도된 이들 파라미터는 완전 훈련된 머신 러닝 모델(110)을 사용하여 예측 단계 동안 사용될 수 있는 가중치를 포함할 수 있다.
훈련에서, 머신 러닝 모델(110), 머신 러닝 모델 훈련 시스템(100)은 라벨링된 훈련 데이터 항목의 데이터베이스(데이터 세트)(120)에 저장된 훈련 데이터 항목을 사용한다. 데이터베이스(120)는 다수의 훈련 데이터 항목의 세트를 저장하고, 다수의 트레이닝 항목 세트의 각각의 트레이닝 데이터 항목은 각자의 라벨과 연관된다. 일반적으로, 훈련 데이터 항목에 대한 라벨은 훈련 데이터 항목에 대한 올바른 분류(또는 예측), 즉, 머신 러닝 모델(110)에 의해 생성된 출력 값에 의해 훈련 데이터 항목의 분류로 식별되어야 할 분류를 식별한다. 도 1a를 참조하면, 훈련 데이터 항목(122)은 훈련 라벨(122a)과 연관될 수 있다.
머신 러닝 모델 훈련 시스템(100)은 목적 함수를 최적화하기 위해 머신 러닝 모델(110)을 훈련시킨다. 목적 함수를 최적화하는 것은 예를 들어 손실 함수(130)를 최소화하는 것을 포함할 수 있다. 일반적으로, 손실 함수(130)는 (i) 주어진 훈련 데이터 항목(122)을 처리하여 머신 러닝 모델(110)에 의해 생성된 출력(118) 및 (ii) 훈련 데이터 아이템(122)에 대한 라벨(122a), 즉, 훈련 데이터 아이템(122)을 처리함으로써 머신 러닝 모델(110)이 생성했었어야 하는 목표 출력에 의존하는 함수이다.
종래의 머신 러닝 모델 훈련 시스템(100)은 데이터베이스(120)로부터 훈련 데이터 항목에 대해 종래의 머신 러닝 모델 훈련 기법, 예를 들어, 힌지 손실, 통계적 경사법, 역전파를 갖는 통계적 경사 하강법 등을 수행함으로써, (누적) 손실 함수(130)를 최소화하도록 머신 러닝 모델(110)을 훈련시켜, 머신 러닝 모델(110)의 파라미터의 값을 반복적으로 조절할 수 있다. 그런 다음 완전히 훈련된 머신 러닝 모델(110)은 라벨링되지 않은 입력 데이터에 기초하여 예측을 하는 데 사용될 수 있는 예측 모델로서 전개될 수 있다.
도 1b는 특정 바이오마커 세트를 갖는 피험체의 질병 또는 장애에 대한 치료의 효과를 예측하기 위해 머신 러닝 모델을 훈련하기 위한 훈련 데이터 구조를 생성하는 시스템(200)의 블록 다이어그램이다.
시스템(200)은 둘 이상의 분산 컴퓨터(210, 310), 네트워크(230) 및 애플리케이션 서버(240)를 포함한다. 애플리케이션 서버(240)는 추출 유닛(242), 메모리 유닛(244), 벡터 생성 유닛(250) 및 머신 러닝 모델(270)을 포함한다. 머신 러닝 모델(270)은 벡터 서포트 머신, 신경망 모델, 선형 회귀 모델, 랜덤 포레스트 모델, 로지스틱 회귀 모델, 나이브 베이즈 모델, 2차 판별 분석 모델(quadratic discriminant analysis model), K-최근접 이웃 모델, 서포트 벡터 머신 등 중 하나 이상을 포함할 수 있다. 각각의 분산 컴퓨터(210, 310)는 스마트폰, 태블릿 컴퓨터, 랩톱 컴퓨터 또는 데스크톱 컴퓨터 등을 포함할 수 있다. 대안으로, 분산 컴퓨터(210, 310)는 각각 하나 이상의 단말기(205, 305)에 의해 입력된 데이터를 수신하는 서버 컴퓨터를 포함할 수 있다. 단말 컴퓨터(205, 305)는 임의의 사용자 디바이스, 가령, 스마트폰, 태블릿 컴퓨터, 랩톱 컴퓨터, 데스크톱 컴퓨터 등을 포함할 수 있다. 네트워크(230)는 하나 이상의 네트워크(230), 가령, LAN, WAN, 유선 이더넷 네트워크, 무선 네트워크, 셀룰러 네트워크, 인터넷, 또는 이들의 임의의 조합을 포함할 수 있다.
애플리케이션 서버(240)는 네트워크(230)를 사용해 하나 이상의 분산 컴퓨터, 가령, 제1 분산 컴퓨터(210) 및 제2 분산 컴퓨터(310)에 의해 제공되는 데이터 레코드(220, 222, 224, 320)를 획득, 또는 그 밖의 다른 방식으로 수신하도록 구성된다. 일부 구현예에서, 각각의 분산 컴퓨터(210, 310)는 서로 다른 유형의 데이터 레코드(220, 222, 224, 320)를 제공할 수 있다. 예를 들어, 제1 분산 컴퓨터(210)는 피험체에 대한 바이오마커를 나타내는 바이오마커 데이터 레코드(220, 222, 224)를 제공할 수 있고, 제2 분산 컴퓨터(310)는 결과 데이터베이스(312)로부터 획득된 피험체에 대한 결과 데이터를 나타내는 결과 데이터(320)를 제공할 수 있다.
바이오마커 데이터 레코드(220, 222, 224)는 피험체의 생체 속성을 설명하는 임의의 유형의 바이오마커 데이터를 포함할 수 있다. 예를 들어, 도 1b의 예는 DNA 바이오마커(220), 단백질 바이오마커(222) 및 RNA 데이터 바이오마커(224)를 나타내는 데이터 레코드를 포함하는 바이오마커 데이터 레코드를 보여준다. 이들 바이오마커 데이터 레코드는 각각 피험체의 바이오마커, 가령, 피험체의 DNA 바이오마커(220a), 단백질 바이오마커(222a), 또는 RNA 바이오마커(224a)를 기술하는 구조 정보(220a, 222a, 224a) 필드를 갖는 데이터 구조를 포함할 수 있다. 그러나, 본 개시 내용은 이에 한정될 필요는 없다. 예를 들어, 바이오마커 데이터 레코드(220, 222, 224)는 차세대 시퀀싱 데이터, 가령, DNA 변경을 포함할 수 있다. 이러한 차세대 시퀀싱 데이터는 단일 변이체, 삽입 및 결실, 치환, 전위, 융합, 파손, 복제, 증폭, 손실, 복제수, 반복, 총 돌연변이 부담, 미세 위성 불안정성 등을 포함할 수 있다. 대안으로 또는 추가로, 바이오마커 데이터 레코드(220, 222, 224)은 또한 원위치 혼성화(in situ hybridization) 데이터, 가령, DNA 복제를 포함할 수 있다. 이러한 원위치 혼성화 데이터는 유전자 복제, 유전자 전위 등을 포함할 수 있다. 대안으로 또는 추가로, 바이오마커 데이터 레코드(220, 222, 224)는 RNA 데이터, 가려, 유전자 표현 또는 유전자 융합, 비제한적 예를 들면, 전체 전사체 시퀀싱을 포함할 수 있다. 대안으로 또는 추가로, 바이오마커 데이터 레코드(220, 222, 224)는 단백질 발현 데이터, 가령, 면역 조직 화학(IHC)을 사용하여 얻은 것을 포함할 수 있다. 대안으로 또는 추가로, 바이오마커 데이터 레코드(220, 222, 224)는 복합체와 같은 ADAPT 데이터를 포함할 수 있다.
일부 구현예에서, 하나 이상의 바이오마커의 세트는 표 2-8 중 어느 하나에 나열된 하나 이상의 바이오마커를 포함한다. 그러나, 본 개시 내용은 이에 한정될 필요는 없으며 그 밖의 다른 유형의 바이오마커가 대신 사용될 수 있다. 예를 들어, 바이오마커 데이터는 전체 엑솜 시퀀싱, 전체 전사체 시퀀싱, 또는 이들의 조합에 의해 획득될 수 있다.
결과 데이터 레코드(320)는 피험체에 대한 치료의 결과를 기술할 수 있다. 예를 들어, 결과 데이터베이스(312)로부터 획득된 결과 데이터 레코드(320)는 피험체의 데이터 속성을 구조화하는 필드, 가령, 질병 또는 장애(320a), 피험체가 질병 또는 장애에 대해 받은 치료(320a), 치료 결과(320a), 또는 이들의 조합을 갖는 하나 이상의 데이터 구조를 포함할 수 있다. 또한, 결과 데이터 레코드(320)는 치료의 세부사항 및 치료에 대한 피험체의 반응을 설명하는 데이터 속성을 구조화하는 필드를 포함할 수도 있다. 질병 또는 장애의 예는 예를 들어 암의 유형을 포함할 수 있다. 치료 유형은 예를 들어, 결과 데이터 레코드(320)에 포함된 질병 또는 장애에 대해 피험체가 받은 약물, 생물의약품 또는 그 밖의 다른 치료의 유형을 포함할 수 있다. 치료 결과에는 치료 요법에 대한 피험체의 결과, 효험 있음, 적당히 효험 있음, 효험 없음 등을 나타내는 데이터를 포함할 수 있다. 일부 구현예에서, 치료 결과는 치료 말기에서의 암성 종양의 설명, 가령, 종양이 감소된 양, 치료 후 종양의 전체 크기 등을 포함할 수 있다. 대안으로 또는 추가적으로, 치료 결과는 백혈구, 적혈구 등의 수 또는 비율을 포함할 수 있다. 치료의 세부 사항은 투여량, 가령, 복용된 약물의 양, 약물 요법, 놓친 투여 횟수 등을 포함할 수 있다. 따라서, 도 1b의 예가 결과 데이터가 질병 또는 장애, 치료 및 치료 결과를 포함할 수 있음을 보여주지만, 결과 데이터는 본 명세서에 기재된 다른 유형의 정보를 포함할 수 있다. 또한, 결과 데이터가 인간 "환자"로 제한되어야 한다는 요건은 없다. 대신, 결과 데이터 레코드(220, 222, 224) 및 생체 측정 데이터 레코드(320)가 임의의 비-인간 유기체를 포함하는 임의의 원하는 피험체와 연관될 수 있다.
일부 구현예에서, 각각의 데이터 레코드(220, 222, 224, 320)는 각각의 분산된 컴퓨터로부터의 데이터 레코드가 애플리케이션 서버(240)에 의해 상관될 수 있게 하는 키잉된 데이터(keyed data)를 포함할 수 있다. 키잉된 데이터는 예를 들어 피험체 식별자를 나타내는 데이터를 포함할 수 있다. 피험체 식별자는 피험체를 식별하고 피험체에 대한 바이오마커를 피험체에 대한 결과 데이터와 연관시킬 수 있는 모든 형태의 데이터를 포함할 수 있다.
제1 분산 컴퓨터(210)는 바이오마커 데이터 레코드(220, 222, 224)를 애플리케이션 서버(240)에 제공할 수 있다(208). 제2 분산 컴퓨팅(310)은 결과 데이터 레코드(320)를 애플리케이션 서버(240)에 제공할 수 있다. 애플리케이션 서버(240)는 바이오마커 데이터 레코드(220) 및 결과 데이터 레코드(220, 222, 224)를 추출 유닛(242)으로 제공할 수 있다.
추출 유닛(242)은 수신된 바이오마커 데이터(220, 222, 224) 및 결과 데이터 레코드(320)를 처리하여 머신 러닝 모델을 훈련시키는 데 사용될 수 있는 데이터(220a-1, 222a-1, 224a-1, 320a-1, 320a-2, 320a-3)를 추출할 수 있다. 예를 들어, 추출 유닛(242)은 생체 측정 데이터 레코드(220, 222, 224)의 데이터 구조의 필드에 의해 구조화된 데이터를 획득하거나, 결과 데이터 레코드(320)의 데이터 구조의 필드에 의해 구조화된 데이터를 획득하거나, 이들의 조합일 수 있다. 추출 유닛(242)은 하나 이상의 정보 추출 알고리즘, 가령, 키잉된 데이터 추출, 패턴 매칭, 자연어 처리 등을 수행하여, 생체 측정 데이터 레코드(220, 222, 224) 및 결과 데이터 레코드(320)로부터 각각 데이터(220a-1, 222a-1, 224a-1, 320a-1, 320a-2, 320a-3)를 식별 및 획득할 수 있다. 추출 유닛(242)은 추출된 데이터를 메모리 유닛(244)에 제공할 수 있다. 추출된 데이터 유닛은 메모리 유닛(244), 가령, (하드 디스크와 대비되는) 플래시 메모리에 저장되어, 데이터 액세스 시간을 개선하고 추출된 데이터를 액세스하는 레이턴시를 감소시켜 시스템 성능을 개선할 수 있다. 일부 구현예에서, 추출된 데이터는 인-메모리 데이터 그리드로서 메모리 유닛(244)에 저장될 수 있다.
구체적으로, 추출 유닛(242)은 생성된 입력 데이터 구조(260)에 대한 라벨로서 사용될 결과 데이터 레코드(320)의 부분으로부터 머신 러닝 모델(270)에 의한 처리를 위한 입력 데이터 구조(260)를 생성하는 데 사용될 바이오마커 데이터 레코드(220, 222, 224) 및 결과 데이터 레코드(320)의 일부를 필터링하도록 구성될 수 있다. 이러한 필터링은 추출 유닛(242)이 바이오마커 데이터와 치료 결과로부터의 질병 또는 장애, 치료, 치료 상세사항, 또는 이들의 조합을 포함하는 결과 데이터의 제1 부분을 분리하는 것을 포함한다. 애플리케이션 서버(240)는 이어서 바이오마커 데이터(220a-1, 222a-1, 224a-1, 320a-1, 320a-2) 및 질병 또는 장애(320a-1), 치료(320a-2), 치료 상세사항(도 1b에 도시되지 않음), 또는 이들의 조합을 포함하는 결과 데이타의 제1 부분을 이용해, 입력 데이터 구조(260)를 생성할 수 있다. 또한, 애플리케이션 서버(240)는 치료 결과(320a-3)를 설명하는 결과 데이터의 제2 부분을 생성된 데이터 구조에 대한 라벨로서 사용할 수 있다.
애플리케이션 서버(240)는 메모리 유닛(244)에 저장된 추출된 데이터를 처리할 수 있으며, 바이오마커 데이터 레코드(220, 222, 224)에서 추출된 바이오마커 데이터(220a-1, 222a-1, 224a-1)를 결과 데이터(320a-1, 320a-2)의 제1 부분과 연관시킬 수 있다. 이 상관 관계의 목적은 피험체에 대한 결과 데이터가 피험체에 대한 바이오마커 데이터와 클러스터링되도록 바이오마커 데이터를 결과 데이터와 클러스터링하는 것이다. 일부 구현예에서, 바이오마커 데이터와 결과 데이터의 제1 부분의 상관은 바이오마커 데이터 레코드(220, 222, 224) 및 결과 데이터 레코드(320) 각각과 연관된 키잉된 데이터에 기초할 수 있다. 예를 들어, 키잉된 데이터는 피험자 식별자를 포함할 수 있다.
애플리케이션 서버(240)는 추출된 바이오마커 데이터(220a-1, 222a-1, 224a-1) 및 결과 데이터(320a-1, 320a-2)의 추출된 제1 부분을 벡터 생성 유닛(250)으로의 입력으로서 제공한다. 벡터 생성 유닛(250)은 추출된 바이오마커 데이터(220a-1, 222a-1, 224a-1) 및 결과 데이터(320a-1, 320a-2)의 추출된 제1 부분에 기초하여 데이터 구조를 생성하는 데 사용된다. 생성된 데이터 구조는 추출된 바이오마커 데이터(220a-1, 222a-1, 224a-1) 및 결과 데이터(320a-1, 320a-2)의 추출된 제1 부분을 숫자로 나타내는 복수의 값을 포함하는 피처 벡터(260)이다. 피처 벡터(260)는 각각의 유형의 바이오마커 및 각각의 유형의 결과 데이터에 대한 필드를 포함할 수 있다. 예를 들어, 피처 벡터(260)는 (i) 하나 이상의 유형의 차세대 시퀀싱 데이터, 가령, 단일 변이체, 삽입 및 삭제, 치환, 전좌, 융합, 파손, 복제, 증폭, 손실, 복제수, 반복, 총 돌연변히 부담, 미세부수체 불완정성, (ii) 하나 이상의 유형의 원위치 혼성화 데이터, 가령, DNA 복제, 유전자 복제, 유전자 전좌, (iii) 하나 이상의 유형의 RNA 데이터, 가령, 유전자 발현 또는 유전자 융합, (iv) 하나 이상의 유형의 단백질 데이터, 가령, 면역 조직 화학을 사용하여 얻은 것, (v) 하나 이상의 유형의 ADAPT 데이터, 가령, 복합체, 및 (vi) 하나 이상의 유형의 결과 데이터, 가령, 질병 또는 장애, 치료 유형, 각각의 유형의 치료 세부사항 등에 대응하는 하나 이상의 필드를 포함할 수 있다.
벡터 생성 유닛(250)은 추출된 바이오마커 데이터(220a-1, 222a-1, 224a-1) 및 결과 데이터(320a-1, 320a-2)의 추출된 제1 부분이 각각의 필드에 의해 표현되는 데이터를 포함하는 범위를 나타내는 피처 벡터(260)의 각각의 필드에 가중치를 할당하도록 구성된다. 하나의 구현예에서, 예를 들어, 벡터 생성 유닛(250)은 추출된 바이오마커 데이터(220a-1, 222a-1, 224a-1) 및 결과 데이터(320a-1, 320a-2)의 추출된 제1 부분에서 발견된 피처에 대응하는 피처 벡터의 각각의 필드에 '1'을 할당할 수 있다. 이러한 구현예에서, 벡터 생성 유닛(250)은, 예를 들어 추출된 바이오마커 데이터(220a-1, 222a-1, 224a-1) 및 결과 데이터(320a-1, 320a-2)의 추출된 제1 부분에서 발견되지 않은 피처에 대응하는 피처 벡터의 각각의 필드에 '0'을 할당할 수도 있다. 벡터 생성 유닛(250)의 출력은 머신 러닝 모델(270)을 훈련시키는 데 사용될 수 있는 피처 벡터(260)와 같은 데이터 구조를 포함할 수 있다.
애플리케이션 서버(240)는 트레이닝 피처 벡터(260)를 라벨링할 수 있다. 구체적으로, 애플리케이션 서버는 환자 결과 데이터(320a-3)의 추출된 제2 부분을 사용하여 생성된 피처 벡터(260)를 치료 결과(320a-3)로 라벨링할 수 있다. 치료 결과(320a-3)에 기초하여 생성된 훈련 피처 벡터(260)의 라벨은 훈련 데이터 구조(260)에서 각각 기재된 특정 세트의 바이오마커(220a-1, 222a-1, 224a-1)에 의해 정의된 피험체의 질병 또는 장애(320a-1)에 대한 치료(320a-2)의 효과의 표시를 제공할 수 있다.
애플리케이션 서버(240)는 머신 러닝 모델(270)로의 입력으로서 피처 벡터(260)를 제공함으로써 머신 러닝 모델(270)을 훈련시킬 수 있다. 머신 러닝 모델(270)은 생성된 피처 벡터(260)를 처리하고 출력(272)을 생성할 수 있다. 애플리케이션 서버(240)는 손실 함수(280)를 사용하여 머신 러닝 모델(280)의 출력(272)과 치료 결과(320a-3)를 설명하는 추출된 환자 결과 데이터의 제2 부분에 기초하여 생성되는 훈련 라벨에 의해 특정된 값 사이의 오차 양을 결정할 수 있다. 손실 함수(280)의 출력(282)은 머신 러닝 모델(282)의 파라미터를 조정하는 데 사용될 수 있다.
일부 구현예에서, 머신 러닝 모델(270)의 파라미터를 조정하는 것은 머신 러닝 모델 파라미터의 수동 조정을 포함할 수 있다. 대안으로, 일부 구현예에서, 머신 러닝 모델(270)의 파라미터는 애플리케이션 서버(242)에 의해 실행되는 하나 이상의 알고리즘에 의해 자동으로 조정될 수 있다.
애플리케이션 서버(240)는 피험체에 대한 바이오마커 데이터의 세트에 대응하는 결과 데이터베이스에 저장된 각각의 결과 데이터 레코드(320)에 대해 도 1b를 참조하여 앞서 기재된 프로세스의 복수의 반복을 수행할 수 있다. 이는 결과 데이터베이스(312)에 저장되고 피험체에 대한 대응하는 바이오마커 데이터 세트를 갖는 결과 데이터 레코드(320) 각각이 고갈될 때까지, 또는 특정 오차 마진 내에서 머신 러닝 모델(270)이 훈련될 때까지, 또는 이 둘 모두의 조합으로, 수백 회의 반복, 수천 회의 반복, 수만 회의 반복, 수십만 회의 반복, 수백만 회의 반복, 또는 그 이상을 포함할 수 있다. 예를 들어 머신 러닝 모델(270)이 라벨링되지 않은 바이오마커 데이터 세트에 기초하여, 바이오마커 데이터를 갖는 피험체에 대한 질병 또는 장애 데이터, 치료 데이터, 치료 효과를 예측할 수 있을 때 머신 러닝 모델(270)은 특징 오차 마진 내에서 훈련된다. 효과는, 예를 들어, 치료가 성공인지 또는 실패인지의 확률, 일반적인 지시자 등을 포함할 수 있다.
도 1c는 특정 바이오마커 세트를 갖는 피험자의 질병 또는 장애에 대한 치료의 효과를 예측하도록 훈련된 머신 러닝 모델을 사용하기 위한 시스템의 블록 다이어그램이다.
머신 러닝 모델(370)은 도 1b의 시스템을 참조하여 기재된 프로세스를 사용하여 훈련된 머신 러닝 모델을 포함한다. 훈련된 머신 러닝 모델(370)은 하나 이상의 바이오마커 세트, 질병 또는 장애 및 치료를 나타내는 입력 피처 벡터에 기초하여, 상기 바이오마커를 갖는 피험체에 대한 질병 또는 장애를 치료하는 치료의 효과 레벨을 예측할 수 있다. 일부 구현예에서, "치료"는 약물, 치료 세부 사항(예를 들어, 투여량, 요법, 놓친 투여량 등) 또는 이들의 임의의 조합을 포함할 수 있다.
머신 러닝 모델(370)을 호스팅하는 애플리케이션 서버(240)는 라벨링되지 않는 바이오마커 데이터 레코드(320, 322, 324)를 수신하도록 구성된다. 바이오마커 데이터 레코드(320, 322, 324)는 하나 이상의 특정 바이오마커, 가령, DNA 바이오마커(320a), 단백질 바이오마커(322a), RNA 바이오마커(324a) 또는 이들의 임의의 조합을 나타내는 필드 구조 데이터를 갖는 하나 이상의 데이터 구조를 포함한다. 앞서 논의된 바와 같이, 수신된 바이오마커 데이터 레코드는 도 1c에 도시되지 않는 바이오마커의 유형, 가령, (i) 하나 이상의 유형의 차세대 시퀀싱 데이터, 가령, 단일 변이체, 삽입 및 삭제, 치환, 전좌, 융합, 파손, 복제, 증폭, 손실, 복제수, 반복, 총 돌연변히 부담, 미세부수체 불완정성, (ii) 하나 이상의 유형의 원위치 혼성화 데이터, 가령, DNA 복제, 유전자 복제, 유전자 전좌, (iii) 하나 이상의 유형의 RNA 데이터, 가령, 유전자 발현 또는 유전자 융합, (iv) 하나 이상의 유형의 단백질 데이터, 가령, 면역 조직 화학을 사용하여 얻은 것, 또는 (v) 하나 이상의 유형의 ADAPT 데이터, 가령, 복합체를 포함할 수 있다.
머신 러닝 모델(370)을 호스팅하는 애플리케이션 서버(240)는 또한 수신된 바이오마커 데이터 레코드(320, 322, 324)로 표현되는 바이오마커를 갖는 피험체의 질병 또는 장애 데이터(420a)에 의해 설명된 질병 또는 장애에 대해 제안된 치료 데이터(422a)를 나타내는 데이터를 수신하도록 구성된다. 질병 또는 장애(422a)에 대해 제안된 치료 데이터(422a)는 또한 라벨링되지 않으며 바이오마커 데이터 레코드(320, 322, 324)에 의해 표현되는 바이오마커를 갖는 피험체를 치료하기 위한 제안에 불과하다.
일부 구현예에서, 질병 또는 장애 데이터(420a) 및 제안된 치료(422a)는 네트워크(230)를 통해 단말기(405)에 의해 제공되고(305) 바이오마커 데이터는 제2 분산 컴퓨터(310)로부터 획득된다. 바이오마커 데이터는 다양한 검증을 수행하는 데 사용되는 실험실 기계로부터 얻어질 수 있다. 다른 구현에서, 질병 또는 장애 데이터(420a), 제안된 치료(422a) 및 바이오마커 데이터(320, 322, 324)는 각각 단말기(405)로부터 수신될 수 있다. 예를 들어, 단말기(405)는 의사, 의사 사무실에서 근무하는 직원, 의사의 에이전트, 또는 질병 또는 장애를 나타내는 데이터, 제안된 치료를 나타내는 데이터, 및 질병 또는 장애를 갖는 피험체에 대한 하나 이상의 바이오마커를 나타내는 데이터를 입력하는 그 밖의 다른 인간 개체의 사용자 장치일 수 있다. 일부 구현예에서, 치료 데이터(422)는 약물 이름에 의해 기술된 제안된 치료를 나타내는 데이터의 필드를 구조화하는 데이터 구조를 포함할 수 있다. 다른 구현예에서, 치료 데이터(422)는 더 복잡한 치료 데이터, 가령, 투여량, 약물 요법, 허용된 누락된 투여 횟수 등을 나타내는 데이터의 필드를 구조화하는 데이터 구조를 포함할 수 있다.
애플리케이션 서버(240)는 바이오마커 데이터 레코드(320, 322, 324), 질병 또는 장애 데이터(420), 및 치료 데이터(422)를 수신한다. 애플리케이션 서버(240)는 바이오마커 데이터 레코드(320, 322, 324), 질병 또는 장애 데이터(420), 및 치료 데이터(422)를 추출 유닛(242)으로 제공되며, 상기 추출 유닛은 (i) 특정 바이오마커 데이터, 가령, DNA 바이오마커 데이터(320a-1), 단백질 표현 데이터(322a-1, 324a-1), (ii) 질병 또는 장애 데이터(420a-1), 및 (iii) 바이오마커 데이터 레코드(320, 322, 324) 및 결과 데이터 레코드(420, 422)의 필드로부터 제안된 치료 데이터(420a-1)를 추출하도록 구성된다. 일부 구현예에서, 추출된 데이터는 버퍼, 캐시 등으로서의 메모리 유닛(244)에 저장되고, 그런 다음 벡터 생성 유닛(250)이 처리되기 위한 입력을 수신하기 위한 대역폭을 가질 때 벡터 생성 유닛(250)으로의 입력으로서 제공된다. 또 다른 구현에서, 추출된 데이터는 처리를 위해 벡터 생성 유닛(250)에 직접 제공된다. 예를 들어, 일부 구현예에서, 다수의 벡터 생성 유닛(250)은 입력의 병렬 처리를 가능하게 하여 지연을 감소시키기 위해 사용될 수 있다.
벡터 생성 유닛(250)은 데이터 구조, 가령, 복수의 필드를 포함하는 피처 벡터(360)를 생성하고 각각의 유형의 바이오마커에 대한 하나 이상의 필드 및 각각의 유형의 결과 데이터에 대한 하나의 필드를 포함할 수 있다. 예를 들어, 피처 벡터(360)의 각각의 필드는 (i) 바이오마커 데이터 레코드(320, 322, 324)로부터 추출될 수 있는 각각의 유형의 추출된 바이오마커 데이터, 가령, 각각의 유형의 차세대 시퀀싱 데이터, 각각의 유형의 원위치 혼성화 데이터, 각각의 유형의 RNA 데이터, 각각의 유형의 면역 조직 화학 데이터, 및 각각의 유형의 ADAPT 데이터 및 (ii) 결과 데이터 레코드(420, 422)로부터 추출될 수 있는 각각의 유형의결과 데이터, 가령, 각각의 유형의 질병 또는 장애, 각각의 유형의 치료, 및 각각의 유형의 치료 세부사항에 대응할 수 있다.
벡터 생성 유닛(250)은 추출된 바이오마커 데이터(320a-1, 322a-1, 324a-1), 추출된 질병 또는 장애(420a-1), 및 추출된 치료(422a-1)가 각각의 필드에 의해 나타내어지는 데이터를 포함하는 범위를 나타내는 피처 벡터(360)의 각각의 필드에 가중치를 할당하도록 구성된다. 하나의 구현예에서, 예를 들어 벡터 생성 유닛(250)는 추출된 바이오마커 데이터(320a-1, 322a-1, 324a-1), 추출된 질병 또는 장애(420a-1), 및 추출된 치료(422a-1)에서 발견된 피처에 대응하는 피처 벡터(360)의 각각의 필드에 '1'을 할당할 수 있다. 이러한 구현예에서, 벡터 생성 유닛(250)는, 예를 들어, 추출된 바이오마커 데이터(320a-1, 322a-1, 324a-1), 추출된 질병 또는 장애(420a-1), 및 추출된 치료(422a-1)에서 발견되지 않은 피처에 대응하는 피처 벡터의 각각의 필드에 '0'을 할당할 수 있다. 벡터 생성 유닛(250)의 출력은 훈련된 머신 러닝 모델(370)로의 입력으로서 제공될 수 있는 피처 벡터(360)와 같은 데이터 구조를 포함할 수 있다.
훈련된 머신 러닝 모델(370)은 훈련 단계 동안 결정되고 도 1을 참조하여 설명된 조정된 파라미터에 기초하여 생성된 피처 벡터(360)를 처리한다. 훈련된 머신 러닝 모델의 출력(272)은 바이오마커(320a-1, 322a-1, 324a-1)를 갖는 피험체에 대한 질병 또는 장애(420a-1)의 치료(422a-1)의 효과의 지시자를 제공한다. 일부 구현예에서, 출력(272)은 바이오마커(320a-1, 322a-1, 324a-1)를 갖는 피험체에 대한 질병 또는 장애(420a-1)의 치료(422a-1)의 효과를 나타내는 확률을 포함할 수 있다. 이러한 구현에서, 출력(272)은 네트워크(230)를 사용하여 단말기(405)에 제공될 수 있다(311). 그런 다음, 단말기(405)는 피처 벡터(360)에 의해 나타내어지는 바이오마커를 갖는 사람에 대한 질병 또는 장애의 치료의 효과의 예측 레벨을 나타내는 출력을 사용자 인터페이스(420) 상에 생성할 수 있다.
다른 구현에서, 출력(272)은 출력(272)의 의미를 해독하도록 구성된 예측 유닛(380)에 제공될 수 있다. 예를 들어, 예측 유닛(380)은 출력(272)을 하나 이상의 효과 카테고리에 매핑하도록 구성될 수 있다. 그런 다음, 예측 유닛(328)의 출력은 피험체, 피험체의 보호자, 간호사, 의사 등에 의해 검토되도록 네트워크(230)를 사용하여 단말기(305)에 제공(311)되는 메시지(390)의 일부로서 사용될 수 있다.
도 1d는 특정 바이오마커 세트를 갖는 피험자의 질병 또는 장애에 대한 치료의 효과를 예측하기 위해 머신 러닝 모델을 훈련하기 위한 훈련 데이터를 생성하는 프로세스(400)의 흐름도이다. 하나의 양태에서, 프로세서(400)는, 분산 데이터 소스로부터, 피험체와 연관된 하나 이상의 바이오마커의 세트를 나타내는 데이터를 구조화하는 필드를 포함하는 제1 데이터 구조를 획득하는 단계(410), 상기 제1 데이터 구조를 하나 이상의 메모리 디바이스에 저장하는 단계(420), 제2 분산 데이터 소스로부터, 하나 이상의 바이오마커를 갖는 피험체에 대한 결과 데이터를 나타내는 데이터를 구조화하는 필드를 포함하는 제2 데이터 구조를 획득하는 단계(430), 하나 이상의 메모리 디바이스에 제2 데이터 구조를 저장하는 단계(440), (i) 하나 이상의 바이오마커, (ii) 질병 또는 장애, (iii) 치료, 및 (iv) 제1 데이터 구조 및 제2 데이터 구조에 기초하는 질병 또는 장애에 대한 치료 효과를 나타내는 데이터를 포함하는 라벨링된 훈련 데이터 구조를 생성하는 단계(450), 및 생성된 라벨링된 훈련 데이터(460)를 이용해 머신 러닝 모델을 훈련하는 단계(460)를 포함할 수 있다.
도 1e는 특정 바이오마커 세트를 갖는 피험자의 질병 또는 장애에 대한 치료 효과를 예측하도록 훈련된 머신 러닝 모델을 사용하기 위한 프로세스의 흐름도(500)이다. 하나의 양태에서, 프로세스(500)는, 피험체와 연관된 하나 이상의 바이오마커의 세트를 나타내는 데이터 구조를 획득하는 단계(510), 피험체에 대한 질병 또는 장애를 나타내는 데이터를 획득하는 단계(520), 피험체에 대한 치료 유형을 나타내는 데이터를 획득하는 단계(530), (i) 하나 이상의 바이오마커, (ii) 질병 또는 장애, 및 (iii) 치료 유형(540)을 나타내는 머신 러닝 모델로의 입력을 위한 데이터 구조를 생성하는 단계(540), 생성된 데이터 구조를, 하나 이상의 획득된 바이오마커, 하나 이상의 치료 유형, 및 하나 이상의 질병 또는 장애를 나타내는 라벨링된 훈련 데이터를 이용해 훈련된 머신 러닝 모델로의 입력으로서 제공하는 단계(550), 및 제공된 데이터 구조의 머신 러닝 모델 처리에 기초하여 머신 러닝 모델에 의해 생성된 출력을 획득하는 단계(560), 및 머신 러닝 모델에 의해 생성된 획득된 출력에 기초하여 하나 이상의 바이오마커를 갖는 피험체에 대한 질병 또는 장애의 치료에 대한 예측 결과를 결정하는 단계(570)를 포함할 수 있다.
분류 성능을 향상시키기 위해 여러 머신 러닝 모델을 사용하는 방법이 본 명세서에서 제공된다. 종래 방식에서는, 원하는 예측/분류를 수행하기 위해 단일 모델이 선택된다. 예를 들어, 훈련 동안, 상이한 모델 파라미터 또는 유형의 모델, 가령, 랜덤 포레스트, 서포트 벡터 머신, 로지스틱 회귀, k- 최근 접 이웃, 인공 신경망, 나이브 베이즈, 2 차 판별 분석 또는 가우스 프로세스 모델이 비교되어, 최적의 원하는 성능을 갖는 모델을 식별할 수 있다. 출원인은 단일 모델을 선택하면 모든 설정에서 최적의 성능을 제공하지 못할 수 있음을 깨달았다. 대신, 복수의 모델이 훈련되어 예측/분류를 수행할 수 있고 공동 예측이 사용되어 분류를 할 수 있다. 이 시나리오에서 각각의 모델에 "투표(vote)"할 수 있으며 과반수 득표를 받은 분류가 승자로 간주된다.
본 명세서에 개시된 이 투표 스킴은 모델 빌딩(예를 들어, 훈련 데이터 사용하는 모델 빌딩) 및 나이브 샘플(na ve sample)을 분류하기 위한 애플리케이션을 포함한 임의의 머신 러닝 분류에 적용될 수 있다. 이러한 설정은 생물학, 금융, 커뮤니케이션, 미디어 및 엔터테인먼트 분야의 데이터를 비제한적으로 포함한다. 일부 바람직한 실시예에서, 데이터는 고차원의 "빅 데이터"이다. 일부 구체예에서, 데이터는 본 명세서에 기재된 바와 같은 분자 프로파일링을 통해 획득된 생물학적 데이터를 포함 하나 이에 제한되지 않는 생물학적 데이터를 포함한다. 예를 들어, 실시예 1을 참조할 수 있다. 분자 프로파일링 데이터는 예를 들어 특정 바이오마커 패널(예를 들어, 실시예 1 참조) 또는 전장 엑솜 및/또는 전장 전사체 데이터에 대한 고차원 차세대 시퀀싱 데이터를 제한없이 포함할 수 있다. 분류는 예를 들어 표현형을 특징화하기 위한 유용한 분류일 수 있다. 예를 들어, 분류는 진단(가령, 질병 또는 건강), 예후(가령, 더 나은 결과 또는 더 나쁜 결과 예측) 또는 치료법(가령, 치료 효능 또는 그 결여를 예측 또는 모니터링)을 제공할 수 있다. 투표 스킴의 적용은 본 명세서의 실시예 2-4에서 제공된다.
ve sample)을 분류하기 위한 애플리케이션을 포함한 임의의 머신 러닝 분류에 적용될 수 있다. 이러한 설정은 생물학, 금융, 커뮤니케이션, 미디어 및 엔터테인먼트 분야의 데이터를 비제한적으로 포함한다. 일부 바람직한 실시예에서, 데이터는 고차원의 "빅 데이터"이다. 일부 구체예에서, 데이터는 본 명세서에 기재된 바와 같은 분자 프로파일링을 통해 획득된 생물학적 데이터를 포함 하나 이에 제한되지 않는 생물학적 데이터를 포함한다. 예를 들어, 실시예 1을 참조할 수 있다. 분자 프로파일링 데이터는 예를 들어 특정 바이오마커 패널(예를 들어, 실시예 1 참조) 또는 전장 엑솜 및/또는 전장 전사체 데이터에 대한 고차원 차세대 시퀀싱 데이터를 제한없이 포함할 수 있다. 분류는 예를 들어 표현형을 특징화하기 위한 유용한 분류일 수 있다. 예를 들어, 분류는 진단(가령, 질병 또는 건강), 예후(가령, 더 나은 결과 또는 더 나쁜 결과 예측) 또는 치료법(가령, 치료 효능 또는 그 결여를 예측 또는 모니터링)을 제공할 수 있다. 투표 스킴의 적용은 본 명세서의 실시예 2-4에서 제공된다.
도 1f는 다중 머신 러닝 모델에 의해 생성된 출력을 해석하기 위해 투표 유닛을 사용하는 시스템(600)의 블록도이다. 시스템(600)은 도 1c의 시스템(300)과 유사하다. 그러나, 단일 머신 러닝 모델(370) 대신, 시스템(600)은 다중 머신 러닝 모델(370-0, 370-1, ..., 370-x)를 포함하며, 여기서 x는 1보다 큰 0이 아닌 정수이다. 또한, 시스템(600)은 투표 유닛(480)을 포함한다.
비제한적인 예로서, 시스템(600)은 특정 바이오마커 세트를 갖는 피험체의 질병 또는 장애에 대한 치료의 효과를 예측하기 위해 사용될 수 있다. 실시예 2-4를 참조할 수 있다.
각각의 머신 러닝 모델(370-0, 370-1, 370-x)은 특정 유형의 입력 데이터(320-0, 320-1 ...320-x)를 분류하도록 훈련된 머신 러닝 모델을 포함할 수 있으며, 여기서 x는 1보다 크고 머신 러닝 모델의 수 x와 같은 0이 아닌 정수이다. 일부 구현예에서, 각각의 머신 러닝 모델(370-0, 370-1, 370-x)은 동일한 유형일 수 있다. 예를 들어, 각각의 머신 러닝 모델(370-0, 370-1, 370-x)은 가령, 상이한 파라미터를 이용해 훈련된 랜덤 포레스트 분류 알고리즘일 수 있다. 다른 구현예에서, 머신 러닝 모델(370-0, 370-1, 370-x)은 다른 유형일 수 있다. 예를 들어, 하나 이상의 랜덤 포레스트 분류기, 하나 이상의 신경망, 하나 이상의 K- 최근접 이웃 분류기, 그 밖의 다른 유형의 머신 러닝 모델 또는 이들의 조합이 있을 수 있다.
입력 데이터, 가령, 입력 데이터-0(320-0), 입력 데이터-1(320-1), 입력 데이터-x(320-x)가 애플리케이션 서버(240)에 의해 획득될 수 있다. 일부 구현예에서, 입력 데이터(320-0, 320-1 , 320-x)는 하나 이상의 분산 컴퓨터(310, 405)로부터 네트워크(230)를 통해 획득된다. 예를 들어, 입력 데이터 항목(320-0, 320-1, 320-x) 중 하나 이상은 다수의 상이한 데이터 소스(210, 405)로부터의 데이터를 상관시킴으로써 생성될 수 있다. 이러한 구현에서, (i) 피험체에 대한 바이오마커를 설명하는 제1 데이터는 제1 분산 컴퓨터(310)로부터 획득될 수 있고 (ii) 질병 또는 장애 및 관련 치료를 설명하는 제2 데이터가 제2 컴퓨터(405)로부터 획득될 수 있다. 애플리케이션 서버(240)는 제1 데이터와 제2 데이터를 상관시켜 입력 데이타 구조, 가령, 입력 데이터 구조(320-0)를 생성할 수 있다. 이 프로세스는 도 1c에서 더 자세히 설명된다. 입력 데이터 항목(320-0, 320-1, 320-x)은 예를 들어 벡터 생성 유닛에 직렬로 한 번에 하나씩 각각의 입력으로 제공 될 수 있다. 벡터 생성 유닛은 각각의 입력 데이터(320-0, 320-1, 320-x)에 대응하는 입력 벡터(360-0, 360-1, 360-x)를 생성할 수 있다. 일부 구현예는 벡터(360-0, 360-1, 360-x)를 직렬로 생성할 수 있지만, 본 개시는 이에 제한될 필요는 없다.
대신, 일부 구현예에서, 벡터 생성 유닛(250)은 벡터 생성 프로세스를 병렬화할 수 있는 다수의 병렬 벡터 생성 유닛을 동작하도록 구성될 수 있다. 이러한 구현에서, 벡터 생성 유닛(250)은 입력 데이터(320-0, 320-1, 320-x)를 병렬로 수신하고, 입력 데이터(320-0, 320-1, 320-x)를 병렬로 처리하고, 입력 데이터(320-0, 320-1, 320-x) 중 하나에 병렬로 대응하는 각각의 벡터(360-0, 360-1, 360-x )를 생성 할 수 있다.
일부 구현예에서, 벡터(360-0, 360-1, 360-x)는 각각 입력 데이터(320-0, 320-1, 320-x)와 같은 대응하는 입력 데이터에 기초하여 생성될 수 있다. 즉, 벡터(360-0)는 입력 데이터(320-0)에 기초하여 생성되고 이를 나타낸다. 유사하게, 벡터(360-1)는 입력 데이터(320-1)에 기초하여 생성되고 이를 나타낸다. 유사하게, 벡터(360-x)는 입력 데이터(320-x)에 기초하여 생성되고 이를 나타낸다.
일부 구현예에서, 각각의 입력 데이터 구조(320-0, 320-1, 320-x)는 피험체의 바이오마커를 나타내는 데이터, 피험체와 관련된 질병 또는 장애를 설명하는 데이터, 피험체에 대해 제안 된 치료를 설명하는 데이터, 또는 임의의 이들의 조합을 포함할 수 있다. 피험체의 바이오마커를 나타내는 데이터에는 피험체의 특정 하위 집합 또는 유전자 패널을 설명하는 데이터가 포함될 수 있다. 대안으로, 일부 구현예에서, 피험체의 바이오마커를 나타내는 데이터는 피험체에 대해 알려진 유전자의 완전한 세트를 나타내는 데이터를 포함할 수 있다. 피험체에 대한 알려진 유전자의 완전한 세트는 피험체의 모든 유전자를 포함할 수 있다. 일부 구현예에서, 각각의 머신 러닝 모델(370-0, 370-1, 370-x)은 동일 유형의 머신 러닝 모델, 가령, 입력 데이터 벡터를, 머신 러닝 모델에 의해 처리된 벡터에 의해 연관된 식별된 치료에 반응을 나타낼 가능성이 높은 또는 반응을 나타내지 않을 가능성이 높은 대응하는 피험체로 분류하도록 훈련된 신경망이다. 이러한 구현예에서, 각각의 머신 러닝 모델(370-0, 370-1, 370-x)은 동일한 유형의 머신 러닝 모델이지만, 각각의 머신 러닝 모델(370-0, 370-1, 370-x)은 다양한 방법으로 훈련될 수 있다. 머신 러닝 모델(370-1, 370-1, 370-x)은 각각 입력 벡터(360-0, 360-1, 360-x)과 연관된 피험체가 입력 벡터(360-0, 360-1, 360-x)와 연관된 치료에 반응을 나타낼 가능성이 높은지 또는 반응을 나타내지 않을 가능성이 높은지 여부를 나타내는 출력 데이터(272-0, 272-1, 272-x)를 생성할 수 있다. 이 예에서, 입력 데이터 세트 및 이들의 해당 입력 벡터는 동일한데, 예를 들어 각각의 입력 데이터 세트는 동일한 바이오마커, 동일한 질병 또는 장애, 동일한 치료 또는 임의의 조합을 가진다. 그럼에도, 도 1f에 도시된 바와 같이 각각의 머신 러닝 모델(370-0, 370-1, 370-x)을 훈련하는 데 사용되는 상이한 훈련 방법이, 각각의 머신 러닝 모델(370-0, 370-1, 370-x)이 입력 벡터(360-0, 361-1, 361-x)를 처리하는 것에 기초하여, 상이한 출력(272-0, 272-1, 272-x)을 생성할 수 있는 것이 고려된다.
대안으로, 각각의 머신 러닝 모델(370-0, 370-1, 370-x)은 질병 또는 장애에 대한 치료에 반응할 가능성이 높거나 반응하지 않을 가능성이 높은 피험체를 나타내는 것으로 입력 데이터를 분류하도록 훈련 또는 그 밖의 다른 방식으로 구성된 상이한 유형의 머신 러닝 모델일 수 있다. 예를 들어, 제1 머신 러닝 모델(370-1)은 신경망을 포함할 수 있고, 머신 러닝 모델(370-1)은 랜덤 포레스트 분류 알고리즘을 포함할 수 있으며, 머신 러닝 모델(370-x)은 K-최근접 이웃 알고리즘을 포함할 수 있다. 이 예에서, 이러한 각기 다른 유형의 머신 러닝 모델(370-0, 370-1, 370-x)은 입력 벡터를 수신 및 처리하고 입력 벡터가 입력 벡터와 또한 연관된 치료에 반응할 가능성이 높거나 반응하지 않을 가능성이 높은 피험체와 연관되는지 여부를 결정하도록 훈련되거나 그 밖의 다른 방식으로 구성될 수 있다. 이 예에서, 입력 데이터 세트 및 이들의 해당 입력 벡터는 동일한데, 예를 들어 각각의 입력 데이터 세트는 동일한 바이오마커, 동일한 질병 또는 장애, 동일한 치료 또는 임의의 조합을 가진다. 따라서, 머신 러닝 모델(370-0)은 입력 벡터(360-0)를 처리하고 입력 벡터(360-0)와 연관된 피험체가 또한 상기 입력 벡터(360-0)와 연관된 치료에 반응을 할 가능성이 높은지 또는 반응하지 않을 가능성이 높은지를 나타내는 출력 데이터(272-0)를 생성하도록 훈련된 신경망일 수 있다. 또한, 머신 러닝 모델(370-1)은 입력 벡터(360-0)와 동일한 목적으로 입력 벡터(360-1)를 처리하고, 입력 벡터(360-1)와 연관된 피험체가 상기 입력 벡터(360-1)와 또한 연관된 치료에 반응할 가능성이 높은지 또는 반응하지 않을 가능성이 높은지 여부를 나타내는 출력 데이터(272-1)를 생성하도록 훈련된 랜덤 포레스트 분류 알고리즘일 수 있다. 이 입력 벡터 분석 방법은 x개의 입력, x개의 입력 벡터 및 x개의 머신 러닝 모델 각각에 대해 계속할 수 있다. 이 예시는 도 1f를 참조하여 계속되며, 머신 러닝 모델(370-x)는 입력 벡터(360-0 및 360-1)와 동일한 목적으로 입력 벡터(360-x)를 처리하고, 입력 벡터(360-x)와 연관된 피험체가 상기 입력 벡터(360-x)와 또한 연관된 치료에 반응할 가능성이 높은지 또는 반응하지 않을 가능성이 높은지 여부를 나타내는 출력 데이터(272-x)를 생성하도록 훈련된 랜덤 포레스트 분류 알고리즘일 수 있다.
대안으로, 각각의 머신 러닝 모델(370-0, 370-1, 370-x)은 동일한 유형의 머신 러닝 모델이거나 각각 상이한 입력을 수신하도록 구성된 다른 유형의 머신 러닝 모델 일 수 있다. 예를 들어, 제1 머신 러닝 모델(370-0)에 대한 입력은 피험체의 제1 유전자 부분집합 또는 패널을 나타내는 데이터를 포함하는 벡터(360-0)를 포함한 후, 벡터(360-0)의 머신 러닝 모델(370-0) 처리에 기초하여, 피험체가 치료에 반응할 가능성이 높은지 또는 반응하지 않을 가능성이 높은지 여부를 예측할 수 있다. 또한, 이 예에서, 제2 머신 러닝 모델(370-1)로의 입력은 제1 유전자 부분집합 또는 패널과 상이한 피험체의 제2 유전자 부분집합 또는 패널을 나타내는 데이터를 포함하는 벡터(360-1)를 포함할 수 있다. 그런 다음, 제2 머신 러닝 모델은 입력 벡터(360-1)와 연관된 피험체가 입력 벡터(360-2)와 연관된 치료에 반응할 가능성이 높은지 또는 반응하지 않을 가능성이 높은지 여부를 나타내는 제2 출력 데이터(272-1)를 생성할 수 있다. 이 입력 벡터 분석 방법은 x개의 입력, x개의 입력 벡터 및 x개의 머신 러닝 모델 각각에 대해 계속할 수 있다. 제x 머신 러닝 모델(370-x)에 대한 입력은 다른 x-1개의 입력 데이터 벡터(370-0 내지 370-x-1) 중 (i) 적어도 하나,(i) 둘 이상, 또는 (iii) 모두 각각과 상이한 피험체의 유전자의 제x 부분집합 또는 제x 패널을 나타내는 데이터를 포함하는 벡터(360-x)를 포함할 수 있다. 일부 구현예에서, x개의 입력 데이터 벡터 중 적어도 하나는 피험체로부터의 완전한 유전자 집합을 나타내는 데이터를 포함할 수 있다. 그런 다음, 제x 머신 러닝 모델(370-x)은 입력 벡터(360-x)와 연관된 피험체가 입력 벡터(360-x)와 연관된 치료에 반응할 가능성이 높은지 또는 반응하지 않을 가능성이 높은지 여부를 나타내는 제2 출력 데이터(272-x)를 생성할 수 있다.
앞서 기재된 시스템(400)의 다중 구현예는 제한하려는 의도가 아니며, 오히려 본 개시 내용을 이용하여 채용될 수 있는 다수의 머신 러닝 모델(370-0, 370-1, 370-x) 및 이들 각자의 입력의 구성의 예시에 불과하다. 이들 예를 참조하면, 피험체는 임의의 인간, 비-인간 동물, 식물 또는 그 밖의 다른 피험체일 수 있다. 앞서 언급한 바와 같이, 입력 데이터를 기반으로 입력 피처 벡터가 생성될 수 있으며 입력 데이터를 나타낼 수 있다. 따라서, 각각의 입력 벡터는 하나 이상의 바이오마커, 질병 또는 장애, 및 치료, 바이오마커를 갖는 피험체에 대한 질병 또는 장애를 치료하는 치료에 대한 효과 수준을 포함하는 데이터를 나타낼 수 있다. "치료"는 임의의 치료제, 예를 들어 소분자 약물 또는 생물학적 제제, 치료 세부사항(예를 들어, 투여량, 요법, 누락된 투여량 등) 또는 이들의 임의의 조합을 설명하는 데이터를 포함할 수 있다.
도 1f의 구현예에서, 출력 데이터(272-0, 272-1, 272-x)는 투표 유닛(480)을 사용하여 분석될 수 있다. 예를 들어, 출력 데이터(272-0, 272-1, 272-x)는 투표 유닛(480)으로 입력될 수 있다. 일부 구현예에서, 출력 데이터(272-0, 272-1, 272-x)는 머신 러닝 모델에 의해 처리된 입력 벡터와 연관된 피험체가 머신 러닝 모델에 의해 처리된 벡터와 연관된 치료에 반응할 가능성이 높은지 또는 반응하지 않을 가능성이 높은지를 나타내는 데이터일 수 있다. 피험체가 입력 벡터와 연관되는지 여부를 나타내고 각각의 머신 러닝 모델에 의해 생성된 데이터가 "0" 또는 "1"을 포함할 수 있다. 입력 벡터(360-0)에 대한 머신 러닝 모델(370-0)의 처리에 기초하여 러닝 모델(370-0)에 의해 생성된 "0"은 입력 벡터(360-0)와 연관된 피험체가 입력 벡터(360-0)와 연관된 치료에 반응하지 않을 가능성이 높음을 나타낼 수 있다. 마찬가지로, 입력 벡터(360-0)에 대한 머신 러닝 모델(370-0)의 처리를 기반으로 머신 러닝 모델(360-0)에 의해 생성된 "1"은 입력 벡터(360-0)와 연관된 피험체가 입력 벡터(360-0)와 연관된 치료에 반응할 가능성이 높음을 나타낼 수 있다. 이 예에서는 비반응으로 "0"을, 반응으로 "1"을 사용하지만, 본 개시는 이에 제한되지 않는다. 대신, 임의의 값이 "반응" 및 "비반응" 분류를 나타내도록 출력 데이터로서 생성될 수 있다. 예를 들어, 일부 구현예에서, "1"은 "반응 없음" 분류를 나타내고 "0"은 "반응" 분류를 나타내도록 사용될 수 있다. 또 다른 구현에서, 출력 데이터(272-0, 272-1, 272-x)는 머신 러닝 모델에 의해 처리된 입력 벡터와 연관된 피험체가 "반응" 또는 "비반응" 분류와 연관될 가능성을 나타내는 확률을 포함할 수 있다. 이러한 구현에서, 예를 들어, 생성된 확률은 임계값에 적용될 수 있고, 임계값이 충족되는 경우, 머신 러닝 모델에 의해 처리된 입력 벡터와 연관된 피험체가 "반응" 분류에 있는 것으로 결정될 수 있다.
투표 유닛(480)은 수신된 출력 데이터(270-0-0, 272-1, 272-x)를 평가하고 처리된 입력 벡터(360-0, 360-1, 360-x)와 연관된 피험체가 처리된 입력 벡터(360-0, 360-1, 360-x)와 연관된 치료에 반응할 가능성이 높은지 또는 반응하지 않을 가능성이 높은지 여부를 결정할 수 있다. 투표 유닛(480)은 수신된 출력 데이터(270-0, 272-1, 272-x)의 세트에 기초하여 입력 벡터(360-0, 360-1, 360-x)와 연관된 피험체가 입력 벡터(360-0, 360-2, 360-x)와 연관된 치료에 반응할 가능성이 높은지 여부를 결정할 수 있다. 일부 구현예에서, 투표 유닛(480)은 "다수결 규칙"을 적용할 수 있다. 다수결 규칙을 적용하면, 투표 유닛(480)은 출력(272-0, 272-1 및 272-x)을 집계하여 피험체가 반응하고 있음을 나타내고 (272-0, 272-1, 272-x)를 출력하여 피험체가 반응하지 않음을 나타낼 수 있다. 그런 다음, 다수결 예측 또는 투표를 갖는 분류 - 가령, 반응 또는 반응 없음 - 는 입력 벡터(360-0, 360-1, 360-x)와 연관된 피험체에 대한 적절한 분류로서 선택된다. 이 선택된 분류는 개체의 실제 분류라고 할 수 있으며, 머신 러닝 모델(370-0, 370-1, 370-x)에 의해 출력된 각각의 예측 또는 투표는 초기 개체 분류로 지칭된다.
따라서, 일부 구현예에서, 예측 또는 투표의 과반수를 결정하는 것이 각각의 초기 개체 분류에 대한 예측 또는 투표의 발생 횟수를 집계하는 투표 유닛(480)에 의해 달성될 수 있다. 예를 들어, 시스템(600)은 머신 러닝 모델(370-0, 370-1, 370-x)에 의해 각각의 초기 개체 분류가 예측되거나 투표된 횟수를 결정한 다음 가장 높은 양의 예측 또는 투표의 발생과 연관된 개체 분류를 선택할 수 있다.
일부 구현예에서, 투표 유닛(480)은 보다 미묘한 분석을 완료할 수 있다. 예를 들어, 일부 구현예에서, 투표 유닛(480)은 각각의 머신 러닝 모델(370-0, 370-1, 370-x)에 대한 신뢰도 점수를 저장할 수 있다. 각각의 머신 러닝 모델(370-0, 370-1, 370-x)에 대한 이 신뢰도 점수는 초기에 0, 1 등과 같은 기본값으로 설정될 수 있다. 그런 다음, 입력 벡터 처리의 각각의 라운드에서 투표 유닛(480) 또는 애플리케이션 서버(240)의 다른 모듈은 이전 반복 구간 동안 머신 러닝 모델이 투표 유닛(480)에 의해 선택된 피험체 분류를 정확히 예측했는지 여부에 기초하여, 머신 러닝 모델(370-0, 370-1, 370-x)에 대한 신뢰도 점수를 조정할 수 있다. 따라서, 각각의 머신 러닝 모델에 대해, 저장된 신뢰도 점수는 각각의 머신 러닝 모델에 대한 과거 정확도의 표시를 제공할 수 있다.
보다 미묘한 접근 방식에서, 투표 유닛(480)은 머신 러닝 모델에 대해 계산된 신뢰도 점수를 기반으로 각각의 머신 러닝 모델(370-0, 370-1, 370-x)에 의해 생성된 출력 데이터(272-0, 272-0, 272-x)를 조정할 수 있다. 따라서, 머신 러닝 모드가 역사적으로 정확함을 나타내는 신뢰도 점수가 사용되어 머신 러닝 모델에 의해 생성된 출력 데이터의 값을 높일 수 있다. 마찬가지로, 머신 러닝 모델이 역사적으로 부정확하다는 것을 나타내는 신뢰도 점수가 사용되어 머신 러닝 모델에 의해 생성된 출력 데이터의 값을 줄일 수 있다. 머신 러닝 모델에 의해 생성된 출력 데이터 값의 이러한 증가 또는 감소는 예를 들어 신뢰도 점수를 감소에 대해 1 미만, 증가에 대해 1 초과의 승수로 사용함으로써 달성될 수 있다. 출력 데이터의 값을 줄이기 위해 출력 데이터의 값에서 신뢰도 점수를 빼거나 값을 높이기 위해 출력 데이터의 값에 신뢰 점수를 더하는 등 출력 데이터의 값을 조정하는 데 다른 작업을 사용할 수도 있다. 머신 러닝 모델에 의해 생성된 출력 데이터의 값을 높이거나 낮추기 위해 신뢰도 점수를 사용하는 것은 피험체가 치료에 반응할지 또는 반응하지 않을지 여부를 결정하기 위해 하나 이상의 임계값에 적용될 확률을 출력하도록 구성될 때 특히 유용하다. 이는 신뢰도 점수를 사용하여 머신 러닝 모델의 출력을 조정하는 것이 사용되어 분류 임계값 초과 또는 미만으로 생성된 출력 값을 이동시켜, 과거 정확도에 기초하여 머신 러닝 모델에 의해 예측을 변경할 수 있다.
복수의 머신 러닝 모델 간 합의가 단일 머신 러닝 모델만의 출력 대신 평가될 수 있기 때문에, 이 복수의 머신 러닝 모델의 출력을 평가하기 위해 투표 유닛(480)을 사용하면 특정 피험체 바이오마커 세트에 대한 치료의 효과의 예측의 정확도를 더 높일 수 있다.
도 1g는 도 2 및 3의 시스템을 구현하도록 사용될 수 있는 시스템 구성요소의 블록도이다.
컴퓨팅 장치(600)는 디지털 컴퓨터, 가령, 랩톱, 데스크탑, 워크스테이션, 개인용 디지털 어시스턴트, 서버, 블레이드 서버, 메인프레임 및 그 밖의 다른 적절한 컴퓨터의 다양한 형태를 나타내도록 의도된다. 컴퓨팅 장치(650)는 다양한 형태의 모바일 장치, 가령, 개인 디지털 어시스턴트, 셀룰러 전화기, 스마트폰, 및 그 밖의 다른 유사한 컴퓨팅 장치를 나타내도록 의도된다. 또한, 컴퓨팅 장치(600 또는 650)는 범용 직렬 버스(USB) 플래시 드라이브를 포함할 수 있다. USB 플래시 드라이브는 운영 체제 및 기타 응용 프로그램을 저장할 수 있다. USB 플래시 드라이브는 다른 컴퓨팅 장치의 USB 포트에 삽입될 수 있는 무선 송신기 또는 USB 커넥터와 같은 입력/출력 구성요소가 포함될 수 있다. 여기에 표시된 구성요소, 이들의 연결 및 관계 및 기능은 예시일 뿐이며 이 문서에서 설명 및/또는 청구된 발명의 구현을 제한하려는 것이 아니다.
컴퓨팅 장치(600)는 프로세서(602), 메모리(604), 저장 장치(608), 메모리(604)에 연결된 고속 인터페이스(608) 및 고속 확장 포트(610), 및 저속 버스(614) 및 저장 장치(608)를 연결하는 저속 인터페이스(612)를 포함한다. 각각의 구성요소(602, 604, 608, 608, 610 및 612)는 다양한 버스를 사용하여 상호연결되며, 공통 마더 보드에 또는 적절한 다른 방식으로 장착될 수 있다. 프로세서(602)는 컴퓨팅 장치(600) 내에서 실행될 명령, 가령, 메모리(604) 내에 또는 저장 장치(608) 상에 저장된 명령을 처리하여, 외부 입/출력 장치 상의 GUI, 가령, 고속 인터페이스(608)에 연결된 디스플레이(616)에 대한 그래픽 정보를 디스플레이할 수 있다. 다른 구현에서, 다중 프로세서 및/또는 다중 버스가 다중 메모리 및 메모리 유형과 함께 적절하게 사용될 수 있다. 또한, 다수의 컴퓨팅 장치(600)는 예를 들어 서버 뱅크, 블레이드 서버 그룹, 또는 다중 프로세서 시스템과 같이 필요한 동작의 일부를 제공하는 각 장치와 연결될 수 있다.
메모리(604)는 컴퓨팅 장치(600) 내에 정보를 저장한다. 하나의 구현예에서, 메모리(604)는 휘발성 메모리 유닛 또는 유닛들이다. 다른 구현예에서, 메모리(604)는 비 휘발성 메모리 유닛(들)이다. 메모리(604)는 또한 자기 또는 광학 디스크와 같은 다른 형태의 컴퓨터 판독 가능 매체 일 수 있다.
저장 장치(608)는 컴퓨팅 장치(600)에 대용량 저장 장치를 제공할 수 있다. 하나의 구현예에서, 저장 장치(608)는 컴퓨터 판독형 매체, 가령, 플로피 디스크 장치, 하드 디스크 장치, 광 디스크 장치, 또는 테이프 장치, 플래시 메모리 또는 그 밖의 다른 유사한 솔리드 상태 메모리 장치, 또는 장치의 어레이, 가령, 저장 영역 네트워크 또는 그 밖의 다른 구성의 장치이거나 이를 포함할 수 있다. 컴퓨터 프로그램 프로덕트는 정보 매체에 유형적으로(tangibly) 구현될 수 있다. 컴퓨터 프로그램 프로덕트는 실행될 때 위에서 설명한 것과 같은 하나 이상의 방법을 수행하는 명령을 포함할 수도 있다. 정보 캐리어는 컴퓨터 또는 기계 판독형 매체, 가령, 메모리(604), 저장 장치(608) 또는 프로세서(602)이다.
고속 제어기(608)는 컴퓨팅 장치(600)에 대한 대역폭-집약적 동작을 관리하는 반면, 저속 제어기(612)는 낮은 대역폭 집약적 동작을 관리한다. 이러한 기능 할당은 예시에 불과하다. 하나의 구현예에서, 고속 제어기(608)는 예를 들어 그래픽 프로세서 또는 가속기를 통해 메모리(604), 디스플레이(616) 및 다양한 확장 카드(도시되지 않음)를 수용 할 수 있는 고속 확장 포트(610)에 결합된다. 구현예에서, 저속 제어기(612)는 저장 장치(608) 및 저속 확장 포트(614)에 결합된다. 다양한 통신 포트를 포함할 수 있는 저속 확장 포트, 가령, USB, 블루투스, 이더넷, 무선 이더넷이 하나 이상의 입/출력 장치, 가령, 키보드, 포인팅 장치, 마이크로폰/스피커 쌍, 스캐너, 또는 네트워킹 장치, 가령, 스위치 또는 라우터에, 가령, 네트워크 어댑터를 통해 연결될 수 있다. 컴퓨팅 장치(600)는 도면에 도시된 바와 같이 여러 다른 형태로 구현될 수 있다. 예를 들어, 표준 서버(620)로 구현되거나 이러한 서버 그룹에서 여러 번 구현될 수 있다. 이것은 또한 랙 서버 시스템(624)의 일부로서 구현될 수 있다. 또한, 랩톱 컴퓨터(622)와 같은 개인용 컴퓨터에서 구현될 수 있다. 대안으로, 컴퓨팅 장치(600)로부터의 구성요소는 모바일 장치(도시되지 않음), 가령, 장치(650) 내 다른 구성요소와 결합될 수 있다. 이러한 장치 각각은 컴퓨팅 장치(600, 650) 중 하나 이상을 포함할 수 있고, 전체 시스템은 서로 통신하는 다수의 컴퓨팅 장치(600, 650)로 구성될 수 있다.
컴퓨팅 장치(600)는 도면에 도시된 바와 같이 여러 다른 형태로 구현될 수 있다. 예를 들어, 표준 서버(620)로 구현되거나 이러한 서버 그룹에서 여러 번 구현될 수 있다. 이는 또한 랙 서버 시스템(624)의 일부로서 구현될 수 있다. 또한, 랩톱 컴퓨터(622)와 같은 개인용 컴퓨터에서 구현될 수 있다. 대안으로, 컴퓨팅 장치(600)로부터의 구성요소는 모바일 장치(도시되지 않음), 가령, 장치(650) 내 다른 구성요소와 결합될 수 있다. 이러한 장치 각각은 컴퓨팅 장치(600, 650) 중 하나 이상을 포함할 수 있고, 전체 시스템은 서로 통신하는 다수의 컴퓨팅 장치(600, 650)로 구성될 수 있다.
컴퓨팅 장치(650)는 프로세서(652), 메모리(664) 및 입/출력 장치, 가령, 디스플레이(654), 통신 인터페이스(666), 및 트랜시버(668) 등을 포함한다. 장치(650)는 또한 추가 저장을 제공하기 위해 마이크로-드라이브 또는 그 밖의 다른 장치와 같은 저장 장치와 함께 제공 될 수 있다. 각각의 구성요소(650, 652, 664, 654, 666 및 668)는 다양한 버스를 사용하여 상호 연결되며, 여러 구성요소는 공통 마더 보드에 또는 적절한 다른 방식으로 장착될 수 있다.
프로세서(652)는 메모리(664)에 저장된 명령어를 포함하여 컴퓨팅 장치(650) 내에서 명령어를 실행할 수 있다. 프로세서는 분리된 다중 아날로그 및 디지털 프로세서를 포함하는 칩의 칩셋으로서 구현 될 수 있다. 또한, 프로세서는 다수의 아키텍처를 사용하여 구현될 수 있다. 예를 들어, 프로세서(610)는 CISC(Complex Instruction Set Computers) 프로세서, RISC(Reduced Instruction Set Computer) 프로세서 또는 MISC(Minimal Instruction Set Computer) 프로세서일 수 있다. 프로세서는 예를 들어, 사용자 인터페이스의 제어, 장치(650)에 의해 실행되는 애플리케이션 및 장치(650)에 의한 무선 통신과 같은 장치(650)의 다른 구성요소의 조정을 제공할 수 있다.
프로세서(652)는 디스플레이(654)에 결합된 제어 인터페이스(658) 및 디스플레이 인터페이스(656)를 통해 사용자와 통신할 수 있다. 디스플레이(654)는 예를 들어 TFT(Thin-Film-Transistor Liquid Crystal Display) 디스플레이 또는 OLED(Organic Light Emitting Diode), 또는 그 밖의 다른 적절한 디스플레이 기술일 수 있다. 디스플레이 인터페이스(656)는 그래픽 및 기타 정보를 사용자에게 제공하기 위해 디스플레이(654)를 구동하기 위한 적절한 회로를 포함할 수 있다. 제어 인터페이스(658)는 사용자로부터 명령을 수신하고 이를 프로세서(652)에 제출하기 위해 변환할 수 있다. 또한, 외부 인터페이스(662)는 프로세서(652)와 통신하여 제공될 수 있어서, 다른 장치와 장치(650)의 근거리 통신을 가능하게 한다. 외부 인터페이스(662)는 예를 들어 일부 구현예에서 유선 통신을 위해, 또는 다른 구현에서 무선 통신을 위해 제공할 수 있으며, 다중 인터페이스가 또한 사용될 수 있다.
메모리(664)는 컴퓨팅 장치(650) 내에 정보를 저장한다. 메모리(664)는 컴퓨터 판독 가능 매체 또는 매체, 휘발성 메모리 유닛(들) 또는 비 휘발성 메모리 유닛(들) 중 하나 이상으로서 구현될 수 있다. 확장 메모리(674)는 또한 예를 들어 SIMM(Single In Line Memory Module) 카드 인터페이스를 포함할 수 있는 확장 인터페이스(672)를 통해 장치(650)에 제공되고 연결될 수 있다. 이러한 확장 메모리(674)는 장치(650)에 대한 추가 저장 공간을 제공할 수 있거나, 또한 장치(650)에 대한 애플리케이션 또는 기타 정보를 저장할 수 있다. 구체적으로, 확장 메모리(674)는 위에서 설명된 프로세스를 수행하거나 보충하기 위한 명령을 포함할 수 있고 보안 정보도 포함할 수 있다. 따라서, 예를 들어, 확장 메모리(674)는 장치(650)에 대한 보안 모듈로서 제공될 수 있고, 장치(650)의 안전한 사용을 허용하는 명령으로 프로그래밍 될 수 있다. 또한, 보안 애플리케이션은 추가 정보와 함께 SIMM 카드를 통해 제공될 수 있는데, 가령, 해킹 불가능한 방식으로 SIMM 상에 식별 정보를 위치시킬 수 있다.
메모리는 예를 들어 아래에서 논의되는 바와 같이 플래시 메모리 및/또는 NVRAM 메모리를 포함할 수 있다. 하나의 구현예에서, 컴퓨터 프로그램 제품은 정보 캐리어에 유형적으로 구현된다. 컴퓨터 프로그램 프로덕트는 실행될 때 위에서 설명한 것과 같은 하나 이상의 방법을 수행하는 명령을 포함할 수도 있다. 정보 캐리어는 컴퓨터 또는 기계 판독형 매체, 가령, 트랜시버(668) 또는 외부 인터페이스(662)를 통해 수신될 수 있는 메모리(664), 확장 메모리(674) 또는 프로세서 상 메모리(652)이다.
장치(650)는 필요한 경우 디지털 신호 처리 회로를 포함할 수 있는 통신 인터페이스(666)를 통해 무선으로 통신 할 수 있다. 통신 인터페이스(666)는 다양한 모드 또는 프로토콜, 가령, GSM 음성 호출, SMS, EMS 또는 MMS 메시징, CDMA, TDMA, PDC, WCDMA, CDMA2000 또는 GPRS 등에 따르는 통신을 제공할 수 있다. 그러한 통신은 예를 들어 무선-주파수 트랜시버(668)를 통해 발생할 수 있다. 또한, 단거리 통신, 가령, 블루투스, Wi-Fi 또는 그 밖의 다른 그러한 트랜시버(도시되지 않음)가 발생할 수 있다. 또한, GPS(Global Positioning System) 수신기 모듈(670)은 장치(650)에서 실행되는 애플리케이션에 의해 적절하게 사용될 수 있는 추가적인 내비게이션 및 위치 관련 무선 데이터를 장치(650)에 제공할 수 있다.
장치(650)는 또한 사용자로부터 음성 정보를 수신하고 이를 사용 가능한 디지털 정보로 변환할 수 있는 오디오 코덱(660)을 사용하여 청각적으로 통신할 수 있다. 오디오 코덱(660)은 마찬가지로 예를 들어 장치(650)의 핸드셋과 같은 스피커를 통해 사용자를위한 가청 사운드를 생성 할 수 있다. 이러한 사운드는 음성 전화 통화로부터의 사운드를 포함할 수 있고, 녹음된 사운드, 예를 들어 음성 메시지, 음악 파일 등을 포함할 수 있으며, 장치(650) 상에서 에서 동작하는 애플리케이션에 의해 생성된 사운드를 포함할 수 있다.
컴퓨팅 장치(650)는 도면에 도시된 바와 같이 여러 다른 형태로 구현될 수 있다. 예를 들어, 이는 셀룰러 전화기(680)로서 구현될 수 있다. 이는 또한 스마트폰(682), 개인 디지털 어시스턴트, 또는 그 밖의 다른 유사한 모바일 장치의 일부로서 구현될 수 있다.
본 명세서에 기재된 시스템 및 방법의 다양한 구현은 디지털 전자 회로, 집적 회로, 특별히 설계된 ASIC(애플리케이션 특정 집적 회로), 컴퓨터 하드웨어, 펌웨어, 소프트웨어 및/또는 이러한 구현의 조합에서 실현 될 수 있다. 이들 다양한 구현예는, 저장 시스템, 적어도 하나의 입력 장치, 및 적어도 하나의 출력 장치로 데이터 및 명령을 수신하고 송신하도록 연결된 특수 또는 범요일 수 있는 적어도 하나의 프로그램 가능 프로세서를 포함하는 프로그램 가능 시스템 상에서 실행 및/또는 해석 가능한 하나 이상의 컴퓨터 프로그램에서의 구현을 포함할 수 있다.
이들 컴퓨터 프로그램(프로그램, 소프트웨어, 소프트웨어 응용 프로그램 또는 코드라고도 함)에는 프로그래밍 가능한 프로세서에 대한 기계 명령이 포함되어 있으며 하이-레벨 절차 및/또는 객체 지향 프로그래밍 언어 및/또는 어셈블리/기계어에서 구현될 수 있다. 본 명세서에서 사용되는 "기계 판독형 매체" "컴퓨터 판독형 매체"라는 용어는 프로그램 가능 프로세서, 가령, 기계 명령을 기계-판독 신호로서 수신하는 기계-판독 매체로 기계 명령 및/또는 데이터를 제공하도록 사용된 임의의 컴퓨터 프로그램 프로덕트, 장치 및/또는 장치, 예를 들어, 자기 디스크, 광 디스크, 메모리, 프로그램 가능 논리 장치(PLD)를 의미한다. 용어 "기계 판독형 신호"는 기계 명령 및/또는 데이터를 프로그래밍 가능 프로세서에 제공하는 데 사용되는 모든 신호를 의미한다.
사용자와의 대화를 제공하기 위해 본 명세서에 설명된 시스템 및 기술은 사용자에게 정보를 표시하기 위한 CRT(음극선 관) 또는 LCD(액정 디스플레이) 모니터와 같은 디스플레이 장치 및 키보드 및 포인팅 장치, 예를 들어 사용자가 컴퓨터에 입력을 제공할 수 있는 마우스 또는 트랙볼이 있는 컴퓨터에서 구현 될 수 있다. 사용자와의 대화를 제공하기 위해 다른 종류의 장치를 사용할 수도 있는데, 예를 들어, 사용자에게 제공되는 피드백은 예를 들어 시각적 피드백, 청각 적 피드백 또는 촉각 적 피드백과 같은 모든 형태의 감각 피드백 일 수 있고 사용자로부터의 입력은 음향, 음성 또는 촉각 입력을 포함한 모든 형태로 수신될 수 있다.
본 명세서에 기재된 시스템 및 기법은 백 엔드 구성요소를 가령, 데이터 서버로서 포함하는, 또는 미들웨어 구성요소, 가령, 애플리케이션 서버를 포함하는, 또는 프론트 엔드 구성요소, 가령, 사용자가 본 명세서에 기재된 시스템 및 기법의 구현과 대화할 수 있게 하는 그래픽 사용자 인터페이스 또는 웹 브라우저를 갖는 클라이언트 컴퓨터를 포함하는, 또는 이러한 백엔드, 미들웨어, 또는 프론트 엔드 구성요소의 임의의 조합을 갖는 컴퓨팅 시스템에서 구현될 수 있다. 시스템의 구성요소는 디지털 데이터 통신의 모든 형태 또는 매체, 예를 들어 통신 네트워크에 의해 상호 연결될 수 있다. 통신 네트워크의 예로는 근거리 통신망("LAN"), 광역 통신망("WAN") 및 인터넷이 있다.
컴퓨팅 시스템은 클라이언트와 서버를 포함할 수 있다. 클라이언트와 서버는 일반적으로 서로 떨어져 있으며 일반적으로 통신 네트워크를 통해 대화한다. 클라이언트와 서버의 관계는 각각의 컴퓨터에서 실행되고 서로 클라이언트-서버 관계를 갖는 컴퓨터 프로그램으로 인해 발생한다.
컴퓨터 시스템
본 방법의 실행은 또한 컴퓨터 관련 소프트웨어 및 시스템을 사용할 수 있다. 본 명세서에 기재된 컴퓨터 소프트웨어 제품은 일반적으로 본 명세서에 기재된 방법의 논리 단계를 수행하기 위한 컴퓨터 실행 가능 명령을 갖는 컴퓨터 판독 가능 매체를 포함한다. 적절한 컴퓨터 판독 가능 매체는 플로피 디스크, CD-ROM/DVD/DVD-ROM, 하드 디스크 드라이브, 플래시 메모리, ROM/RAM, 자기 테이프 등을 포함한다. 컴퓨터 실행 가능 명령은 적절한 컴퓨터 언어 또는 여러 언어의 조합으로 작성될 수 있다. 기본적인 계산 생물학(computational biology) 방법은 예를 들어 Setubal and Meidanis et al., Introduction to Computational Biology Methods (PWS Publishing Company, Boston, 1997); Salzberg, Searles, Kasif, (Ed.), Computational Methods in Molecular Biology, (Elsevier, Amsterdam, 1998); Rashidi and Buehler, Bioinformatics Basics: Application in Biological Science and Medicine (CRC Press, London, 2000) and Ouelette and Bzevanis Bioinformatics: A Practical Guide for Analysis of Gene and Proteins (Wiley & Sons, Inc., 2.sup.nd ed., 2001)에 기재되어 있다. 미국 특허 번호 6,420,108를 참조할 수 있다.
본 방법은 또한 다양한 목적으로, 가령, 프로브 설계, 데이터 관리, 분석, 및 기구 동작을 위해 다양한 컴퓨터 프로그램 프로덕트 및 소프트웨어를 사용할 수 있다. 미국 특허 번호 5,593,839, 5,795,716, 5,733,729, 5,974,164, 6,066,454, 6,090,555, 6,185,561, 6,188,783, 6,223,127, 6,229,911 및 6,308,170를 참조할 수 있다.
추가로, 본원 방법은 미국 출원 번호 10/197,621, 10/063,559 (미국 공개 번호 20020183936), 10/065,856, 10/065,868, 10/328,818, 10/328,872, 10/423,403, 및 60/482,389에서 나타난, 네트워크, 가령, 인터넷을 통한 유전 정보를 제공하기 위한 방법을 포함하는 실시예와 관련된다. 예를 들어, 하나 이상의 분자 프로파일링 기술이 하나의 장소, 예를 들어 도시, 주, 국가 또는 대륙에서 수행될 수 있으며 결과는 다른 도시, 주, 국가 또는 대륙으로 전송될 수 있다. 그런 다음, 두 번째 장소에서 전체적으로 또는 부분적으로 치료 선택이 이뤄질 수 있다. 본 명세서에 기재된 방법은 상이한 위치들 간 정보의 전송을 포함한다.
종래의 데이터 네트워킹, 애플리케이션 개발 및 시스템의 다른 기능적 측면(및 시스템의 개별 운영 구성요소의 구성요소)은 본 명세서에서 상세히 기재되지 않을 수 있지만, 본 명세서에 기재된 것의 일부이다. 또한, 본 명세서에 포함된 다양한 도면에서 나타난 연결 선은 다양한 요소 사이의 예시적인 기능적 관계 및/또는 물리적 결합을 나타내기 위한 것이다. 실제 시스템에는 많은 대체 또는 추가 기능적 관계 또는 물리적 연결이 존재할 수 있다는 점에 유의해야 한다.
본 명세서에서 논의되는 다양한 시스템 구성요소는 다음 중 하나 이상을 포함할 수 있다: 디지털 데이터를 처리하기 위한 프로세서를 포함하는 호스트 서버 또는 그 밖의 다른 컴퓨팅 시스템; 디지털 데이터를 저장하기 위해 프로세서에 연결된 메모리; 디지털 데이터를 입력하기 위해 프로세서에 연결된 입력 디지타이저; 프로세서에 의한 디지털 데이터의 처리를 지시하기 위해 메모리에 저장되고 프로세서에 의해 액세스 가능한 애플리케이션 프로그램; 프로세서에 의해 처리된 디지털 데이터로부터 얻어진 정보를 디스플레이하기 위해 프로세서 및 메모리에 연결된 디스플레이 장치; 및 복수의 데이터베이스. 본 명세서에 사용되는 다양한 데이터베이스는 다음을 포함할 수 있다: 환자 데이터, 가령, 가족 내력, 인구통계적 및 환경적 데이터, 생체 샘플 데이터, 이전 치료 및 프로토콜 데이터, 환자 임상 데이터, 생체 샘플의 분자 프로파일링 데이터, 치료 약물제 및/또는 조사 약물에 대한 데이터, 유전자 라이브러리, 질병 라이브러리, 약물 라이브러리, 환자 추적 데이터, 파일 관리 데이터, 금융 관리 데이터, 청구 데이터 및/또는 시스템 운영에 유용한 그 밖의 다른 데이터. 해당 분야의 통상의 기술자라면 알다시피, 사용자 컴퓨터는 운영 체제(가령, Windows NT, 95/98/2000, OS2, UNIX, Linux, Solaris, MacOS 등)뿐만 아니라 일반적으로 컴퓨터와 연관된 다양한 기존 지원 소프트웨어 및 드라이버를 포함할 수 있다. 컴퓨터는 임의의 적합한 개인용 컴퓨터, 네트워크 컴퓨터, 워크스테이션, 미니컴퓨터, 메인프레임 등을 포함할 수 있다. 사용자 컴퓨터는 네트워크에 액세스할 수 있는 가정 또는 의료/비즈니스 환경에 있을 수 있다. 예시적인 구체예에서, 액세스는 상업적으로 이용 가능한 웹-브라우저 소프트웨어 패키지를 통해 네트워크 또는 인터넷을 통해 이루어진다.
본 명세서에서 사용될 때 "네트워크"라는 용어는 하드웨어 및 소프트웨어 구성요소를 모두 포함하는 전자 통신 수단을 포함한다. 당사자들 간의 통신은 임의의 적절한 통신 채널, 가령, 전화 네트워크, 엑스트라넷, 인트라넷, 인터넷, 상호 작용 지점 장치, 개인용 디지털 어시스턴트(가령, Palm Pilot®, Blackberry®), 셀룰러 폰, 키오스크 등, 온라인 통신, 위성 통신, 오프라인 통신, 무선 통신, 트랜스폰더 통신, 근거리 통신망(LAN), 광역 통신망(WAN), 네트워크 또는 연결된 장치, 키보드, 마우스 및/또는 임의의 적절한 통신 또는 데이터 입력 양식을 통해 이뤄질 수 있다. 또한, 시스템이 TCP/IP 통신 프로토콜로 구현되는 것으로 본 명세서에서 빈번하게 기재되지만, 시스템은 또한 IPX, Appletalk, IP-6, NetBIOS, OSI 또는 임의의 수의 기존 또는 미래 프로토콜을 사용하여 구현될 수 있다. 네트워크가 공개 네트워크, 가령, 인터넷의 속성을 갖는 경우, 네트워크가 안전하지 않고 도청자에게 열려 있다고 가정하는 것이 바람직할 수 있다. 인터넷과 관련하여 사용되는 프로토콜, 표준 및 애플리케이션 소프트웨어와 관련된 특정 정보는 일반적으로 해당 분야의 통상의 기술자에게 공지되어 있으므로 본 명세서에서 구체적으로 설명될 필요가 없다. 예를 들어, Dilip Naik, Internet Standards and Protocols (1998); Java 2 Complete, various authors, (Sybex 1999); Deborah Ray and Eric Ray, Mastering HTML 4.0 (1997); and Loshin, TCP/IP Clearly Explained (1997) and David Gourley and Brian Totty, HTTP, The Definitive Guide (2002)을 참조할 수 있으며, 이들 내용은 본 명세서에 참조로서 포함된다.
다양한 시스템 구성요소는 예를 들어, 표준 모뎀 통신, 케이블 모뎀, 디쉬 네트워크(Dish network), ISDN, DSL(Digital Subscriber Line), 또는 다양한 무선 통신 방법 - 가령, Gilbert Held, Understanding Data Communications (1996)을 참조할 수 있으며, 이의 내용은 본 명세서에 참조로서 포함됨 - 과 함께 일반적으로 사용될 때, 로컬 루프를 통해 ISP(Internet Service Provider)로의 연결을 포함하는 데이터 링크를 통해 네트워크로 독립적으로, 개별적으로 또는 집합적으로 적절하게 연결될 수 있다. 네트워크는 그 밖의 다른 유형의 네트워크, 가령, 대화형 텔레비전(ITV) 네트워크로서 구현될 수 있다. 또한, 시스템은 본 명세서에 기재된 유사한 기능을 갖는 임의의 네트워크를 통한 임의의 제화, 서비스 또는 정보의 사용, 판매 또는 배포를 고려한다.
본 명세서에서 사용될 때, "전송"은 네트워크 연결을 통해 하나의 시스템 구성요소에서 다른 구성요소로의 전자 데이터 전송을 포함할 수 있다. 추가로, 본 명세서에서 사용될 때 "데이터"는 저장되기 위한 정보, 가령, 커맨드, 질의, 파일, 데이터 등을 디지털 또는 그 밖의 다른 임의의 형태로 포함하는 것을 포함할 수 있다.
이 시스템은 웹 서비스, 유틸리티 컴퓨팅, 퍼베이시브 및 개별화된 컴퓨팅, 보안 및 식별 솔루션, 자율 컴퓨팅, 상품 컴퓨팅, 이동성 및 무선 솔루션, 오픈 소스, 생체 인식, 그리드 컴퓨팅 및/또는 메시 컴퓨팅과 관련된 사용을 고려한다.
본 명세서에서 논의되는 모든 데이터베이스는 관계형, 계층적, 그래픽 또는 객체 지향 구조 및/또는 기타 데이터베이스 구성을 포함할 수 있다. 데이터베이스를 구현하는 데 사용할 수 있는 일반적인 데이터베이스 제품에는 IBM(뉴욕 주, 화이트 플레인)의 DB2, Oracle Corporation(캘리포니아 주, 레드우드 쇼 어스)에서 제공하는 다양한 데이터베이스 제품, Microsoft Corporation(워싱턴 주, 레드몬드)의 Microsoft Access 또는 Microsoft SQL Server, 또는 그 밖의 다른 임의의 적절한 데이터베이스 제품이 포함될 수 있다. 또한, 데이터베이스는 예를 들어 데이터 테이블 또는 룩업 테이블과 같은 임의의 적절한 방식으로 구성될 수 있다. 각각의 레코드는 단일 파일, 일련의 파일, 연결된 일련의 데이터 필드 또는 기타 데이터 구조일 수 있다. 특정 데이터의 연관은 임의의 바람직한 데이터 연관 기법, 가령, 해당 업계에서 공지되어 있거나 사용되는 것을 통해 이뤄질 수 있다. 예를 들어, 연관은 수동 또는 자동으로 수행될 수 있다. 자동 연결 기술에는 예를 들어 데이터베이스 검색, 데이터베이스 병합, GREP, AGREP, SQL, 테이블의 키 필드를 사용하여 검색 속도 향상, 모든 테이블 및 파일을 통한 순차적 검색, 룩업을 단순화하기 위해 알려진 순서에 따라 파일 내 레코드를 정렬하는 것 등이 있을 수 있다. 연관 단계는 예를 들어 사전 선택된 데이터베이스 또는 데이터 섹터에서 "키 필드"를 사용하는 데이터베이스 병합 기능에 의해 수행될 수 있다.
더 구체적으로, "키 필드"는 키 필드에 의해 정의된 객체의 하이-레벨 분류에 따라 데이터베이스를 파티셔닝한다. 예를 들어, 특정 유형의 데이터는 복수의 관련 데이터 테이블에서 키 필드로서 지정될 수 있고, 그 후 데이터 테이블은 키 필드의 데이터 유형에 기초하여 링크될 수 있다. 링크된 데이터 테이블 각각에서의 키 필드에 대응하는 데이터는 바람직하게는 동일하거나 동일한 유형이다. 그러나, 키 필드 내 데이터가 동일하지는 않지만 유사한 데이터를 갖는 데이터 테이블도 예를 들어 AGREP를 사용하여 연결될 수 있다. 하나의 구체예에 따르면, 임의의 적절한 데이터 저장 기술이 표준 포맷 없이 데이터를 저장하는데 사용될 수 있다. 데이터 세트는 임의의 적절한 기술, 가령, ISO/IEC 7816-4 파일 구조를 이용해 개별 파일을 저장하는 것, 도메인을 구현하여, 하나 이상의 데이터 세트를 포함하는 하나 이상의 요소 파일을 노출시키는 전용 파일이 선택되게 하는 것, 계층 파일링 시스템을 이용해 개별 파일에 저장된 데이터 세트, (압축, SQL 액세스 가능, 제1 튜플에 의한 해싱된 하나 이상의 키, 숫자, 알파벳 등) 단일 파일 내 레코드로서 저장된 데이터 세트를 이용하는 것, 바이너리 라지 객체(BLOB), ISO/IEC 7816-6 데이터 요소를 이용해 인코딩된 언그룹화된 데이터 요소로서 저장된 것, ISO/IEC 8824 및 8825에서처럼 ISO/IEC ASN.1(Abstract Syntax Notation)을 이용해 인코딩된 언그룹화된 데이터 요소로서 저장된 것, 및/또는 프랙탈 압축 방법, 이미지 압축 방법 등을 포함할 수 있는 그 밖의 다른 사설 기법을 이용해 저장될 수 있다.
하나의 예시적인 구체예에서, 다양한 포맷으로 다양한 정보를 저장하는 능력은 정보를 BLOB로 저장함으로써 용이하게 된다. 따라서 모든 바이너리 정보는 데이터 세트와 관련된 저장 공간에 저장될 수 있다. BLOB 방법은 고정 스토리지 할당, 순환 큐 기술, 또는 메모리 관리와 관련한 모범 사례(가령, 가장 최근에 사용 된 페이징 메모리 등)를 사용하여 고정 메모리 오프셋을 통해 바이너리 블록으로 포맷된 그룹화되지 않은 데이터 요소로 데이터 세트를 저장할 수 있다. BLOB 방법을 사용함으로써, 상이한 포맷을 가진 다양한 데이터 세트를 저장하는 기능이 데이터 세트의 여러 소유자 및 관련 없는 소유자가 데이터를 쉽게 저장할 수 있게 한다. 예를 들어, 저장될 수 있는 제1 데이터 세트가 제1측에 의해 제공될 수 있고, 저장될 수 있는 제2 데이터 세트가 무관한 제2측에 의해 제공될 수 있으며, 저장될 수 있는 제3 데이터 세트가 제1측 및 제2측과 무관한 제3측에 의해 제공될 수 있다. 이들 3개의 예시적인 데이터 세트 각각은 상이한 데이터 저장 포맷 및/또는 기술을 사용하여 저장되는 상이한 정보를 포함할 수 있다. 또한, 각각의 데이터 세트는 타 서브세트와 구별될 수 있는 데이터 서브세트를 포함할 수 있다.
앞서 서술한 바와 같이, 다양한 구체예에서, 데이터는 공통 포맷에 관계없이 저장될 수 있다. 그러나, 하나의 예시적인 구체예에서, 데이터 세트(예를 들어, BLOB)는 데이터를 조작하기 위해 제공될 때 표준 방식으로 주석 첨가(annotate)될 수 있다. 주석은 다양한 데이터 세트를 관리하는 데 유용한 정보를 전달하도록 구성된 각각의 데이터 세트와 관련된 짧은 헤더, 트레일러 또는 그 밖의 다른 적절한 표시자를 포함할 수 있다. 예를 들어, 주석은 본 명세서에서 "조건 헤더", "헤더", "트레일러"또는 "상태"로 불릴 수 있으며, 데이터 세트의 상태의 지시자를 포함하거나 데이터의 특정 발행인 또는 소유주와 상관된 식별자를 포함할 수 있다. 예를 들어, 데이터의 후속 바이트가 사용되어 데이터의 발행자 또는 소유자의 신원, 사용자, 거래/회원 계정 식별자 등을 나타낼 수 있다. 이들 조건 주석 각각은 본 명세서에서 더 언급된다.
데이터 세트 주석은 그 밖의 다른 유형의 상태 정보 및 다양한 그 밖의 다른 목적으로도 사용될 수 있다. 예를 들어, 데이터 세트 주석은 액세스 레벨을 확립하는 보안 정보를 포함할 수 있다. 예를 들어 액세스 레벨은 특정 개인, 직원, 회사, 또는 그 밖의 다른 개체가 데이터 세트를 액세스할 수 있는 레벨만이 거래, 발행자 또는 데이터 소유자, 사용자 등에 기초하여 특정 데이터 세트로의 액세스를 허용하도록 구성될 수 있다. 또한, 보안 정보는 특정 동작, 가령, 데이터 세트를 액세스, 수정 및/또는 삭제하는 것만 제한/허용할 수 있다. 하나의 예에서, 데이터 세트 주석은 데이터 세트 소유자 또는 사용자만 데이터 세트를 삭제할 수 있고, 식별된 다양한 사용자는 읽을 수 있도록 데이터 세트에 액세스하는 것이 허용될 수 있으며, 그 밖의 다른 사용자는 데이터 세트를 액세스하지 못함을 나타낸다. 그러나, 그 밖의 다른 액세스 제한 파라미터가 또한 사용되어 다양한 개체가 적절하게 다양한 권한 레벨로 데이터 세트를 액세스할 수 있게 할 수 있다. 헤더 또는 트레일러를 포함하는 데이터는 헤더 또는 트레일러에 따라 데이터를 추가, 삭제, 수정 또는 증강시키도록 구성된 독립형 대화형 장치에 의해 수신될 수 있다.
해당 분야의 통상의 기술자는 또한 보안상의 이유로 임의의 데이터베이스, 시스템, 장치, 서버 또는 시스템의 다른 구성요소가 단일 위치 또는 여러 위치에서 이들의 임의의 조합으로 구성될 수 있음을 알 것이며, 각각의 데이터베이스 또는 시스템은 다양한 적절한 보안 기능, 가령, 방화벽, 액세스 코드, 암호화, 복호화, 압축, 압축 해제 등을 포함한다.
웹 클라이언트의 컴퓨팅 유닛은 표준 다이얼-업, 케이블, DSL 또는 해당 분야에 알려진 임의의 다른 인터넷 프로토콜에 연결된 인터넷 브라우저가 구비될 수 있다. 웹 클라이언트에서 시작된 트랜잭션은 다른 네트워크 사용자의 무단 액세스를 방지하기 위해 방화벽을 통과할 수 있다. 또한, 보안을 더욱 강화하기 위해 CMS의 다양한 구성요소들 사이에 추가 방화벽이 배치될 수 있다.
방화벽은 다른 네트워크의 사용자로부터 CMS 구성요소 및/또는 엔터프라이즈 컴퓨팅 자원을 보호하도록 적절하게 구성된 하드웨어 및/또는 소프트웨어를 포함할 수 있다. 또한, 웹 서버를 통해 연결하는 웹 클라이언트에 대한 방화벽 뒤의 다양한 시스템 및 구성요소에 대한 액세스를 제한하도록 방화벽을 구성할 수 있다. 방화벽은 다양한 구성, 가령, 상태 저장 검사, 프록시 기반 및 패킷 필터링 등에서 존재할 수 있다. 방화벽은 웹 서버 또는 그 밖의 다른 임의의 CMS 구성요소에 일체 구성되거나 별도의 개체로 추가될 수 있다.
본 명세서에 기재된 컴퓨터는 사용자에 의해 액세스될 수 있는 적절한 웹사이트 또는 그 밖의 다른 인터넷 기반 그래픽 사용자 인터페이스를 제공할 수 있다. 하나의 실시예에서, Microsoft Internet Information Server(IIS), Microsoft Transaction Server(MTS) 및 Microsoft SQL Server가 Microsoft 운영 체제, Microsoft NT 웹 서버 소프트웨어, Microsoft SQL Server 데이터베이스 시스템 및 Microsoft Commerce Server와 함께 사용된다. 또한, 구성요소, 가령, Access 또는 Microsoft SQL Server, Oracle, Sybase, Informix MySQL, Interbase 등이 ADO(Active Data Object) 호환 데이터베이스 관리 시스템을 제공하는 데 사용될 수 있다.
본 명세서에서 언급된 통신, 입력, 스토리지, 데이터베이스 또는 디스플레이가 웹 페이지가 있는 웹 사이트를 통해 용이화될 수 있다. 본 명세서에서 사용될 때 "웹 페이지"라는 용어는 사용자와 대화하는 데 사용될 수 있는 문서 및 애플리케이션의 유형을 제한하는 것을 의미하지 않는다. 예를 들어, 일반적인 웹사이트는, 표준 HTML 문서 외에도, 다양한 양식, Java 애플릿, JavaScript, ASP(Active Server Page), CGI(Common Gateway Interface Script), XML(Extensible Markup Language), 동적 HTML, CSS(cascading style sheet), 헬퍼 애플리케이션, 플러그-인 등을 포함할 수 있다. 서버는 웹 서버로부터 요청을 수신하는 웹 서비스를 포함할 수 있으며, 요청은 URL(http://yahoo.com/stockquotes/ge) 및 IP 주소(123.56.789.234)를 포함한다. 웹 서버는 적절한 웹 페이지를 불러오고 웹 페이지에 대한 데이터 또는 애플리케이션을 IP 주소로 전송한다. 웹 서비스는 통신 수단, 가령, 인터넷을 통해 타 애플리케이션과 대화할 수 있는 애플리케이션이다. 웹 서비스는 일반적으로 표준 또는 프로토콜, 가령, XML, XSLT, SOAP, WSDL 및 UDDI에 기초한다. 웹 서비스 방법은 해당 분야에서 잘 알려져 있고, 많은 표준 텍스트에서 다루어진다. 예를 들어, 본 명세서에서 참조로서 포함되는 Alex Nghiem, IT Web Services: A Roadmap for the Enterprise (2003)를 참조할 수 있다.
본 방법의 시스템 및 방법에 대한 웹-기반 임상 데이터베이스는 바람직하게는 네이티브 형식으로 임상 데이터 파일을 업로드하고 저장할 수 있는 기능을 가지며 임의의 임상 파라미터에서 검색할 수 있다. 데이터베이스는 또한 확장 가능하며 EAV 데이터 모델(메타데이터)을 사용하여 다른 연구와 쉽게 통합할 수 있도록 임의의 연구로부터 임상 주석을 입력할 수 있다. 또한 웹-기반 임상 데이터베이스는 유연하며 사용자 정의 질문을 동적으로 추가할 수 있도록 XML 및 XSLT를 사용할 수 있다. 또한, 데이터베이스는 CDISC ODM으로의 보내기 기능을 포함한다.
실무자들은 또한 브라우저-기반 문서 내에 데이터를 디스플레이하기 위한 방법이 많음을 알 것이다. 데이터는 표준 텍스트 또는 고정 리스트, 스크롤 가능 리스트, 드롭-다운 리스트, 편집 가능한 텍스트 필드, 고정 텍스트 필드, 팝-업 창 등으로 표현될 수 있다. 마찬가지로, 웹 페이지에서 데이터를 수정하는 데 사용 가능한 다수의 방법, 가령, 키보드를 이용한 자유 텍스트 입력, 메뉴 아이템 선택, 체크 박스, 옵션 박스 등이 존재한다.
시스템 및 방법은 기능 블록 구성요소, 스크린 샷, 선택적 선택 및 다양한 처리 단계와 관련하여 본 명세서에서 기재될 수 있다. 이러한 기능 블록은 특정된 기능을 수행하도록 구성된 임의의 개수의 하드웨어 및/또는 소프트웨어 구성요소에 의해 실현될 수 있음을 이해해야 한다. 예를 들어, 시스템은 하나 이상의 마이크로 프로세서 또는 그 밖의 다른 제어 장치의 제어 하에서 다양한 기능을 수행할 수 있는 다양한 집적 회로 구성요소, 가령,메모리 요소, 처리 요소, 논리 요소, 룩업 테이블 등과 같은 다양한 집적 회로 구성요소를 사용할 수 있다. 마찬가지로, 시스템의 소프트웨어 요소는 임의의 프로그래밍 또는 스크립팅 언어, 가령, C, C++, Macromedia Cold Fusion, Microsoft Active Server Pages, Java, COBOL, 어셈블러(assembler), PERL, Visual Basic, SQL Stored Procedures, XML(extensible markup language)로 구현될 수 있으며, 이때, 다양한 알고리즘이 데이터 구조, 객체, 프로세스, 루틴, 또는 그 밖의 다른 프로그래밍 요소의 임의의 조합으로 구현된다. 또한, 시스템은 데이터 전송, 시그널링, 데이터 처리, 네트워크 제어 등에 대해 임의의 수의 종래 기술을 사용할 수 있다는 점에 유의해야한다. 또한 시스템은 클라이언트-측 스크립팅 언어, 가령, JavaScript, VBScript 등을 이용해 보안 문제를 감지하거나 방지하는 데 사용될 수 있다. 암호학 및 네트워크 보안의 기본적인 소개를 위해, 다음 참고문헌 중 어느 것이든 참고할 수 있고, 이들 모두 참조로서 본 명세서에 포함된다: (1) "Applied Cryptography: Protocols, Algorithms, And Source Code In C," by Bruce Schneier, published by John Wiley & Sons (second edition, 1995); (2) "Java Cryptography" by Jonathan Knudson, published by O'Reilly & Associates (1998); (3) "Cryptography & Network Security: Principles & Practice" by William Stallings, published by Prentice Hall.
본 명세서에서 사용될 때, "최종 사용자", "소비자", "고객", "클라이언트", "치료 의사", "병원" 또는 "사업체"는 서로 바꿔서 사용할 수 있으며 각각은 임의의 사람, 개체, 머신, 하드웨어, 소프트웨어 또는 사업체를 의미할 것이다. 각각의 참가자는 시스템과 상호 대화하고 온라인 데이터 액세스 및 데이터 입력을 용이하게 하기 위해 컴퓨팅 장치를 갖추고 있다. 고객은 개인용 컴퓨터 형태의 컴퓨팅 유닛을 가지고 있지만, 랩탑, 노트북, 핸드 헬드 컴퓨터, 셋톱 박스, 셀룰러 전화, 터치 톤 전화 등을 포함한 다른 유형의 컴퓨팅 유닛이 사용될 수 있다. 본 방법의 시스템 및 방법의 소유자/운영자는 컴퓨터 서버의 형태로 구현된 컴퓨팅 유닛을 가지고 있지만, 다른 구현은 메인 프레임 컴퓨터, 미니-컴퓨터, PC 서버, 상이한 지리적 위치에 위치하는 컴퓨터의 컴퓨터 네트워크 등으로 나타나는 컴퓨팅 센터를 포함할 수 있다. 또한, 시스템은 본 명세서에 기재된 유사한 기능을 갖는 임의의 네트워크를 통한 임의의 제화, 서비스 또는 정보의 사용, 판매 또는 배포를 고려한다.
하나의 예시적인 실시예에서, 각각의 클라이언트 고객은 "계정" 또는 "계정 번호"를 발급받을 수 있다. 본 명세서에서 사용될 때, 계정 또는 계정 번호는 소비자가 시스템과 액세스, 대화, 또는 통신할 수 있도록 적절하게 구성된 임의의 장치, 코드, 번호, 문자, 기호, 디지털 인증서, 스마트 칩, 디지털 신호, 아날로그 신호, 생체 인식 또는 기타 식별자/인디시아(indicia)(예를 들어, 인증/액세스 코드, 개인 식별 번호(PIN), 인터넷 코드, 그 밖의 다른 식별 코드 등 중 하나 이상)를 포함할 수 있다. 계정 번호는 선택적으로 충전 카드, 신용 카드, 직불 카드, 선불 카드, 엠보싱 카드, 스마트 카드, 마그네틱 스트라이프 카드, 바코드 카드, 트랜스 폰더, 무선 주파수 카드 또는 관련 계정에 위치하거나 이와 관련될 수 있다. 시스템은 앞서 언급된 카드 또는 장치 중 임의의 것, 또는 포브(fob)와 RF 통신하는 트랜스 폰더 및 RFID 판독기를 갖는 포브를 초함하거나 이와 인터페이싱할 수 있다. 시스템이 포브 실시예를 포함할 수 있지만, 방법은 이에 한정되지 않는다. 실제로, 시스템은 RF 통신을 통해 RFID 판독기와 통신하도록 구성된 트랜스폰더를 갖는 임의의 장치를 포함할 수 있다. 전형적인 장치는 예를 들어 열쇠 고리, 태그, 카드, 휴대폰, 손목시계 또는 문의(interrogation)를 위해 제공될 수 있는 임의의 형태를 포함할 수 있다. 또한, 본 명세서에서 기재된 시스템, 컴퓨팅 유닛 또는 장치는 컴퓨팅 유닛이 내장된 전통적으로 컴퓨터화되지 않은 장치를 포함할 수 있는 "퍼베이시브 컴퓨팅 장치(pervasive computing device)"를 포함할 수 있다. 계정 번호는 데이터를 제2 장치로 전송 또는 다운로딩할 수 있는 플라스틱, 전자, 자기, 라디오 주파수, 무선, 오디오 및/또는 광학 장치의 형태로 배포 및 저장될 수 있다.
해당 분야의 통상의 기술자에 의해 이해되는 바와 같이, 시스템은 기존 시스템, 애드온 제품, 업그레이드된 소프트웨어, 독립형 시스템, 분산 시스템, 방법, 데이터 처리 시스템, 데이터 처리를 위한 장치, 및/또는 컴퓨터 프로그램 제품의 맞춤화로 구현될 수 있다. 따라서, 시스템은 전체 소프트웨어 실시예, 전체 하드웨어 실시예, 또는 소프트웨어와 하드웨어 양태를 결합한 실시예의 형태를 취할 수 있다. 또한, 시스템은 저장 매체에 구현된 컴퓨터 판독형 프로그램 코드 수단을 갖는 컴퓨터 판독형 저장 매체 상의 컴퓨터 프로그램 제품의 형태를 취할 수 있다. 하드 디스크, CD-ROM, 광학 저장 장치, 자기 저장 장치 등을 포함하는 임의의 적절한 컴퓨터 판독 가능 저장 매체가 사용될 수 있다.
다양한 실시예에 따라 방법, 장치(가령, 시스템), 및 컴퓨터 프로그램 제품의 스크린 샷, 블록도 및 흐름도를 참고하여 시스템 및 방법이 기재된다. 블록도 및 흐름도의 각각의 기능 블록 및 블록도 및 흐름도에서의 기능 블록의 조합 각각이 컴퓨터 프로그램 명령에 의해 구현될 수 있다.
이들 컴퓨터 프로그램 명령은 범용 컴퓨터, 특수 목적 컴퓨터 또는 기타 프로그래밍 가능한 데이터 처리 장치에 로드되어 컴퓨터 또는 기타 프로그래밍 가능한 데이터 처리 장치에서 실행되는 명령이 순서도 블록 또는 블록에서 지정된 기능을 구현하기 위한 수단을 생성하도록 할 수 있다. 이들 컴퓨터 프로그램 명령은 또한 컴퓨터 또는 다른 프로그램 가능한 데이터 처리 장치가 특정 방식으로 기능하도록 지시 할 수 있는 컴퓨터 판독 가능 메모리에 저장될 수 있으며, 컴퓨터 판독 가능 메모리에 저장된 명령은 흐름도에서 특정된 기능을 구현하는 명령 수단을 포함하는 제조 물품을 생성한다. 컴퓨터 프로그램 명령은 또한 컴퓨터 또는 그 밖의 다른 프로그램 가능한 데이터 처리 장치에 로드되어 일련의 동작 단계가 컴퓨터 또는 또 다른 프로그램 가능한 장치에서 수행되도록 하여 컴퓨터에서 실행되는 명령이 흐름도에서 특정된 기능을 구현하기 위한 단계를 제공하도록 컴퓨터에서 실행되도록 컴퓨터 구현 프로세스를 생성 할 수 있다.
따라서, 블록도 및 흐름도의 기능 블록은 지정된 기능을 수행하기 위한 수단, 지정된 기능을 수행하기 위한 단계의 조합 및 지정된 기능을 수행하기 위한 프로그램 명령 수단의 조합을 지원한다. 또한, 블록도 및 흐름도의 각각의 기능 블록, 그리고 블록도 및 흐름도의 기능 블록 조합은 특정된 기능 또는 단계, 또는 특수 하드웨어 및 컴퓨터 명령의 적절한 조합을 수행하는 특수 하드웨어 기반 컴퓨터 시스템에 의해 구현될 수 있다. 또한, 프로세스 흐름 및 이의 기술의 예시는 사용자 윈도, 웹 페이지, 웹사이트, 웹 서식, 프롬프트 등을 참조할 수 있다. 실무자는 본 명세서에 기재된 예시된 단계가 윈도, 웹 페이지, 웹 서식, 팝업 창, 프롬프트 등의 사용을 포함하는 임의의 개수의 구성을 포함할 수 있음을 알 것이다. 예시되고 설명된 다수의 단계는 단일 웹 페이지 및/또는 창으로 결합될 수 있지만 단순성을 위해 확장되었다는 것을 더 이해해야 한다. 다른 경우에, 단일 프로세스 단계로 예시되고 설명된 단계는 여러 웹 페이지 및/또는 창으로 분리 될 수 있지만 단순성을 위해 결합되었음을 알아야 한다.
분자 프로파일링
분자 프로파일링 접근법은 상태 또는 질병, 가령, 암이 있는 개인에 대해 임상 과정을 유리하게 변경할 수 있는 개인에 대한 후보 치료를 선택하기 위한 방법을 제공한다. 분자 프로파일링 접근법은 개인을 위한 임상적 인점, 가령, 더 긴 무진행 생존(PFS), 더 긴 무병 생존(DFS), 더 긴 전체 생존(OS) 또는 연장된 수명을 제공하는 치료 요법을 식별하는 것을 제공한다. 본 명세서에 기재된 방법 및 시스템은 최적 치료 요법을 식별할 수 있는 개인별 암의 분자 프로파일링과 관련된다. 분자 프로파일링은 암에 효험이 있을 가능성이 높은 후보 치료를 선택하는 개인화된 방식을 제공한다. 본 명세서에 기재된 분자 프로파일링 방법은 임의의 바람직한 세팅, 비제한적 예를 들면, 일선/표준 치료 세팅에서, 또는 좋지 않은 예후를 갖는 환자, 가령, 표준 일선 요법에서 전이성 질병 또는 암이 진전된 환자 또는 이전 화학요법 또는 호르몬 요법에서 암이 진전된 환자를 위해 치료를 안내하도록 사용될 수 있다.
본 발명의 시스템 및 방법은 환자를 다양한 치료에 대해 어느 정도 유익하거나 반응 할 가능성이있는 것으로 분류하는 데 사용될 수 있다. 달리 언급되지 않는 한, 본 명세서에서 사용된 용어 "반응" 또는 "비반응"은 치료가 환자에게 효험을 제공했다는 임의의 적절한 지시자( "반응군" 또는 "효험군") 또는 환자에게 효험이 없었다는 지시자("비반응군" 또는 "비효험군")를 지칭한다. 이러한 지시자는 허용된 임상 응답 기준, 가령, 표준 RECIST(Response Evaluation Criteria in Solid Tumor) 기준, 또는 또 다른 유용한 환자 응답 기준, 가령, PFS(progression free survival), TTP(time to progression), DFS(disease free survival), TNT, TTNT(time-to-next treatment), 종양 수축 또는 소멸 등을 이용해 결정될 수 있다. RECIST는 암 환자를 치료하는 동안 종양이 개선("반응"), 동일하게 유지("안정화") 또는 악화("진행")되는 때를 정의하는 국제 컨소시엄에서 발표한 일련의 규칙이다. 본 명세서에서 사용될 때 그리고 달리 언급되지 않는 한, 치료에 대한 환자 "효험"은 개선의 적절한 측정, 비제한적 예를 들면, RECIST 반응 또는 장기적인 PFS/TTP/DFS/TNT/TTNT을 지칭할 수 있으며, 치료에 대한 "효험 부재"는 치료 동안의 질병 악화의 적절한 측정을 지칭할 수 있다. 일반적으로 질병 안정화는 효험으로 간주되지만 특정 상황에서, 본 명세서에서 언급되는 경우, 안정화는 효험의 부족으로 간주될 수 있다. 효험 또는 효험 부재에 대한 허용 가능한 수준의 예측이 없는 경우 예측되거나 표시된 효험은 "미확정"으로 기재될 수 있다. 어떤 경우에는 필요한 데이터가 부족하여 계산될 수 없는 경우 효험이 미확정으로 간주될 수 있다.
약물유전학적 통찰에 기반한 개인화된 의학, 가령, 본 명세서에 기재된 바와 같은 분자 프로파일링에 의해 제공되는 것이 일부 실무자와 학계에서 점점 더 당연한 것으로 여겨지지만 개선된 암 치료에 대한 희망의 기초를 형성한다. 그러나, 본 명세서에 기재된 분자 프로파일링은 대부분의 경우 환자가 함께 그룹화되고 광학 현미경 및 질병 단계의 결과에 기반한 접근법으로 치료되는 종양 치료에 대한 전통적인 접근 방식에서 근본적인 출발을 나타낸다. 전통적으로, 특정 치료 전략에 대한 차별적 반응은 치료가 제공된 후, 즉, 사후에만 결정되었다. 질병 치료에 대한 "표준" 접근 방식은 주어진 암 진단에 대해 일반적으로 참인 것에 의존하며 치료 반응은 무작위 3상 임상 시험을 통해 검토되었으며 의료 행위에서 "표준 치료"를 형성한다. 이들 시험의 결과는 미국 종합 암 네트워크(National Comprehensive Cancer Network) 및 미국 임상 종양 학회(American Society of Clinical Oncology)와 같은 가이드 라인 기관에 의해 합의된 성명서에서 체계화되었다. NCCN Compendium™은 암 환자에서 약물 및 생물학적 제제의 적절한 사용에 대한 의사 결정을 지원하도록 설계된 권위 있고 과학적으로 파생된 정보를 포함한다. NCCN Compendium™은 CMS(Centers for Medicare and Medicaid Services)와 United Healthcare에서 종양 보장 정책에 대한 권위 있는 참고 자료로 인정 받았다. 개요서(compendium) 상의 치료는 이러한 가이드가 권장하는 치료법이다. 임상 시험 결과를 검증하는 데 사용되는 생물 통계 학적 방법은 환자 간의 차이를 최소화하는 데 의존하며 종양의 개인차가 아닌 광학 현미경 및 단계로만 정의된 환자 그룹에 대해 하나의 접근법이 다른 접근법보다 낫다는 오류 가능성을 선언하는 것을 기반으로 한다. 본 명세서에 기재된 분자 프로파일링 방법은 이러한 개인차를 활용한다. 방법은 환자를 치료하기 위해 의사에 의해 선택될 수 있는 후보 치료를 제공할 수 있다.
분자 프로파일링은 샘플의 생물학적 상태에 대한 포괄적인 보기를 제공하는 데 사용할 수 있다. 하나의 구체예에서, 분자 프로파일링은 전체 종양 프로파일링을 위해 사용된다. 따라서, 종양의 상태를 평가하기 위해 많은 분자 접근법이 사용된다. 전체 종양 프로파일링은 종양에 대한 후보 치료를 선택하는 데 사용될 수 있다. 분자 프로파일링은 질병의 임의의 단계에 대한 임의의 샘플에서 후보 치료제를 선택하는 데 사용될 수 있다. 구체예에서, 본 명세서에 기재된 방법은 새로 진단된 암을 프로파일링하는 데 사용되지 않는다. 분자 프로파일링에 의해 지시된 후보 치료법이 사용되어 새로 진단된 암 치료를 위한 치료법을 선택할 수 있다. 또 다른 구체예에서, 본 명세서에 기재된 방법은 예를 들어 하나 이상의 표준 치료 요법으로 이미 치료된 암을 프로파일링하는 데 사용된다. 구체예에서, 암은 이전 치료에 불응성이다. 예를 들어, 암은 암에 대한 표준 치료 치료에 불응할 수 있다. 암은 전이성 암 또는 기타 재발성 암일 수 있다. 치료법은 개요서 내에 있거나 개요서에 없는 치료법일 수 있다.
분자 프로파일링은 생체 샘플에서 분자를 검출하기 위한 알려진 수단으로 수행될 수 있다. 분자 프로파일링은 핵산 시퀀싱, 가령, DNA 시퀀싱 또는 RNA 시퀀싱, 면역 조직 화학(IHC); 원위치 혼성화(ISH); 형광 원위치 혼성화(FISH); 발색성 원위치 혼성화(CISH); PCR 증폭(가령, qPCR 또는 RT-PCR); 다양한 유형의 마이크로어레이(mRNA 발현 어레이, 저밀도 어레이, 단백질 어레이 등); 다양한 유형의 시퀀싱(생어(Sanger), 파이로시퀀싱(pyrosequencing) 등); 비교 게놈 혼성화(CGH); 높은 처리량 또는 차세대 시퀀싱(NGS); 노던 블랏; 서던 블랏; 면역분석; 및 관심 생물학적 분자의 존재 또는 양을 분석하기 위한 기타 적절한 기법을 포함하는 방법을 포함한다. 다양한 구체예에서, 임의의 하나 이상의 이들 방법은 본 명세서에 개시된 표적 유전자를 평가하기 위해 동시에 또는 서로 후속하여 사용될 수 있다.
개별 샘플의 분자 프로파일링은 예를 들어 주어진 암에 효과적일 수 있는 약물에 대한 표적을 식별함으로써 피험체의 장애에 대한 하나 이상의 후보 치료를 선택하는 데 사용된다. 예를 들어, 후보 치료제는 분자 프로파일링 기법에 의해 식별된 바와 같이 상이하게 유전자를 발현하는 세포에 효과를 가지는 것으로 알려진 치료법, 실험 약물, 정부 또는 법적 승인 약물 또는 생체 샘플이 획득되고 분자 프로파일링된 피험체의 지시자와 동일하거나 상이한 특정 지시자에 대해 연구 및 승인되었던 이러한 약물의 임의의 조합일 수 있다.
분자 프로파일링에 의해 표적 유전자를 평가함으로써 다중 바이오마커 표적이 밝혀지면, 개인별 치료를 위한 특정 치료제의 선택에 우선 순위를 부여하기 위해 하나 이상의 결정 규칙이 적용될 수 있다. 본 명세서에 기재된 규칙, 예를 들어, 분자 프로파일링의 직접적인 결과, 치료제의 예상 효능, 동일하거나 다른 치료에 대한 이전 이력, 예상되는 부작용, 치료제의 가용성, 치료제 비용, 약물-약물 상호 작용, 및 치료 의사가 고려하는 기타 요인은 치료의 우선 순위를 정하는 데 도움을 준다. 권장되고 우선화되는 치료제 목표에 따라 의사는 특정 개인에 대한 치료 과정을 결정할 수 있다. 따라서, 본 명세서에 기재된 분자 프로파일링 방법 및 시스템은, 질병, 특히, 암으로 고통 받는 사람을 치료하는 데 전통적으로 사용되는 전통적인 단일 크기 적합에 의존하는 것과는 반대로, 질병에 걸린 세포, 예를 들어 종양 세포 및 치료를 필요로 하는 피험체에서 다른 개인화된 인자의 개별적인 특성을 기반으로 후보 치료를 선택할 수 있다. 일부 경우, 권장되는 치료법은 피험체에게 영향을 주는 질병 또는 장애를 치료하는 데 일반적으로 사용되지 않는 치료법이다. 일부 경우, 표준 치료 요법이 더는 적절한 효능을 제공하지 못한 후에 권장 치료법이 사용된다.
치료 의사는 분자 프로파일링 방법의 결과를 사용하여 환자를 위한 치료 요법을 최적화할 수 있다. 본 명세서에 기재된 방법에 의해 식별된 후보 치료는 환자를 치료하는 데 사용될 수 있지만, 이러한 치료는 방법을 필요로 하지 않는다. 실제로, 분자 프로파일링 결과의 분석 및 이러한 결과에 기반한 후보 치료의 식별은 자동화될 수 있으며 의사의 개입이 필요하지 않는다.
생물학적 개체
핵산은 데옥시리보뉴클레오티드 또는 리보뉴클레오티드 및 이의 단일 가닥 또는 이중 가닥 형태의 중합체, 또는 이의 보체를 포함한다. 핵산은 합성, 자연 발생 및 비 자연 발생이며, 참조 핵산과 유사한 결합 특성을 가지며, 참조 뉴클레오티드와 유사한 방식으로 대사되는 알려진 뉴클레오티드 유사체 또는 변형된 백본 잔기 또는 연결을 포함할 수 있다. 이러한 유사체의 비제한적 예로는 포스포로티오에이트, 포스포라미데이트, 메틸포스포네이트, 키랄-메틸 포스포네이트, 2-O-메틸 리보뉴클레오티드, 펩티드-핵산(PNA)을 포함한다. 핵산 서열은 이의 보존적으로 변형된 변이(예를 들어, 축퇴성 코돈 치환)와 상보적 서열, 및 명시적으로 표시된 서열을 포함할 수 있다. 구체적으로, 축퇴성 코돈 치환은 하나 이상의 선택된(또는 모든) 코돈의 세 번째 위치가 혼합 염기 및/또는 데옥시이노신 잔기로 치환된 서열을 생성함으로써 달성 될 수 있다(Batzer et al., Nucleic Acid Res.19:5081 (1991); Ohtsuka et al., J.Biol.Chem.260:2605-2608 (1985); Rossolini et al., Mol.Cell Probes 8:91-98 (1994)). 용어 핵산은 유전자, cDNA, mRNA, 올리고뉴클레오티드 및 폴리뉴클레오티드와 상호 교환적으로 사용될 수 있다.
특정 핵산 서열은 특정 서열 및 "스플라이스 변이체"및 절단된 형태를 인코딩하는 핵산 서열을 암시적으로 포함할 수 있다. 마찬가지로, 핵산에 의해 코딩된 특정 단백질은 스플라이스 변이체에 의해 인코딩되거나 임의의 단백질 또는 그 핵산의 절단된 형태를 포함할 수 있다. 명칭에서 알 수 있듯이 "스플라이스 변이체"는 유전자의 대체 스플라이싱 산물이다. 전사 후, 초기 핵산 전사체는 상이한(대체) 핵산 스플라이스 산물이 상이한 폴리펩티드를 인코딩하도록 스 플라이싱될 수 있다. 스플라이스 변종 생산을 위한 메커니즘은 다양하지만 엑손의 대체 스플라이싱을 포함한다. 판독-통과 전사에 의해 동일한 핵산으로부터 유래된 대체 폴리펩티드도 이 정의에 포함된다. 스플라이싱 반응의 임의의 산물, 가령, 스플라이스 산물의 재조합 형태가 이 정의에 포함된다. 핵산은 5' 말단 또는 3' 말단에서 절단될 수 있다. 폴리펩티드는 N-말단 또는 C-말단에서 절단될 수 있다. 핵산 또는 폴리펩티드 서열의 절단된 버전은 자연적으로 발생하거나 재조합 기술을 사용하여 생성될 수 있다.
용어 "유전자 변이" 및 "뉴클레오티드 변이"는 본 명세서에서 사용될 때 특정 유전자 자리에서 참조 인간 유전자 또는 cDNA 서열에 대한 변경 또는 변화, 비제한적 예를 들면, 코딩 및 비-코딩 영역에서의 뉴클레오티드 염기 결실, 삽입, 역위, 및 치환을 지칭할 수 있다. 결실은 단일 뉴클레오티드 염기, 유전자의 뉴클레오티드 서열의 일부 또는 한 영역, 또는 전체 유전자 서열의 결실일 수 있다. 삽입은 하나 이상의 뉴클레오티드 염기의 삽입일 수 있다. 유전적 변이 또는 뉴클레오티드 변이는 전사 조절 영역, mRNA의 비해석 영역, 엑손, 인트론, 엑손/인트론 접합 등에서 발생할 수 있다. 유전자 변이 또는 뉴클레오티드 변이는 잠재적으로 정지 코돈, 프레임 이동, 아미노산의 결실, 변경된 유전자 전사 슬라이스 형태 또는 변경된 아미노산 서열을 초래할 수 있다.
대립유전자 또는 유전자 대립은 일반적으로 참조 서열을 갖는 자연 발생 유전자 또는 특정 뉴클레오티드 변이를 포함하는 유전자를 포함한다.
하플로타입(haplotype)은 mRNA 영역의 유전적(뉴클레오티드) 변이 또는 개체에서 발견되는 염색체의 게놈 DNA 조합을 의미한다. 따라서, 하플로타입은 일반적으로 하나의 단위로 함께 유전되는 다수의 유전적으로 연결된 다형성 변이를 포함한다.
본 명세서에서 사용될 때 용어 "아미노산 변이"는 참조 단백질을 인코딩하는 참조 인간 유전자에 대한 유전적 변이 또는 뉴클레오티드 변이로부터 발생하는 참조 인간 단백질 서열에 대한 아미노산 변화를 지칭하기 위해 사용된다. 용어 "아미노산 변이"는 단일 아미노산 치환뿐만 아니라 참조 단백질에서의 아미노산 결실, 삽입 및 아미노산 서열의 그 밖의 다른 유의미한 변화를 포함하는 것으로 의도된다.
본 명세서에서 사용될 때 용어 "유전형"은 유전자의 하나의 대립 유전자 또는 두 대립 유전자(또는 특정 염색체 영역)의 특정 뉴클레오티드 변이 마커(또는 유전자 자리)에서 뉴클레오티드 특성을 의미한다. 관심 유전자의 특정 뉴클레오티드 위치와 관련하여, 하나 또는 두 대립 유전자에서 그 유전자 자리의 뉴클레오티드(들) 또는 이의 동등물은 그 유전자 자리에서 유전자의 유전자형을 형성한다. 유전자형은 동형 접합 또는 이형 접합일 수 있다. 따라서, "유전형 분석"은 유전자형, 즉 특정 유전자 자리에서 뉴클레오티드(들)를 결정하는 것을 의미한다. 유전자형은 또한 상응하는 뉴클레오티드 변이체(들)를 추론하는 데 사용될 수 있는 단백질의 특정 위치에서 아미노산 변이체를 결정함으로써 수행될 수 있다.
용어 "자리"는 유전자 서열 또는 단백질의 특정 위치 또는 부위를 지칭한다. 따라서, 특정 유전자 자리에 하나 이상의 인접 뉴클레오티드가 있을 수 있거나 폴리펩티드의 특정 자리에 하나 이상의 아미노산이 있을 수 있다. 또한, 자리는 하나 이상의 뉴클레오티드가 결실, 삽입 또는 반전된 유전자의 특정 위치를 나타낼 수 있다.
달리 명시되거나 해당 분야의 통상의 기술자에 의해 이해되지 않는 한, 용어 "폴리펩티드", "단백질" 및 "펩티드"는 아미노산 잔기가 공유 펩티드 결합에 의해 연결된 아미노산 사슬을 지칭하기 위해 본 명세서에서 상호교환적으로 사용된다. 아미노산 사슬은 전장 단백질을 포함하여, 임의의 길이의 적어도 2개의 아미노산을 가질 수 있다. 달리 명시되지 않는 한, 폴리펩티드, 단백질 및 펩티드는 또한 글리코실화된 형태, 인산화된 형태 등을 포함하지만 이에 제한되지 않는 다양한 변형된 형태를 포함한다. 폴리펩티드, 단백질 또는 펩티드는 또한 유전자 산물로 지칭될 수 있다.
분자 프로파일링 기술에 의해 검정될 수 있는 유전자 및 유전자 산물의 리스트이 본 명세서에 제공된다. 유전자 리스트은 유전자 산물(가령, mRNA 또는 단백질)을 검출하는 분자 프로파일링 기술의 맥락에서 제공될 수 있다. 해당 분야의 통상의 기술자라면 이것이 나열된 유전자의 유전자 산물의 검출을 의미함을 이해할 것이다. 마찬가지로, 유전자 산물의 리스트은 유전자 서열 또는 복제수를 검출하는 분자 프로파일링 기술의 맥락에서 제시될 수 있다. 해당 분야의 통상의 기술자는 이것이 유전자 산물을 인코딩하는 DNA를 예로 포함하여 유전자 산물에 상응하는 유전자의 검출을 의미한다는 것을 이해할 것이다. 해당 분야의 통상의 기술자라면 알 듯이, "바이오마커" 또는 "마커"는 문맥에 따라 유전자 및/또는 유전자 산물을 포함한다.
용어 "라벨" 및 "검출 가능한 라벨"은 분광, 광화학, 생화학, 면역화학, 전기, 광학, 화학 또는 그 밖의 다른 유사한 방법에 의해 검출가능한 임의의 조성물을 지칭할 수 있다. 이러한 라벨은 라벨링된 스트렙타비딘 공액체로 염색하기 위한 비오틴, 자기 비드(가령, DYNABEADS™), 형광 염료(가령, 플루오레세인, 텍사스 레드, 로다민, 녹색 형광 단백질 등), 라디오라벨(가령, 3H, 125I, 35S, 14C, 또는 32P), 엔자임(가령, 겨자무 과산화효소, 알칼리성 포스파타제 및 ELISA에서 일반적으로 사용되는 그 밖의 다른 것) 및 열량측정 라벨, 가령, 콜로이드 금 또는 유색 유리 또는 플라스틱(가령, 폴리스티렌, 폴리프로파일렌, 라텍스 등) 비드를 포함한다. 이러한 라벨의 사용을 설명하는 특허로는 미국 특허 번호 3,817,837; 3,850,752; 3,939,350; 3,996,345; 4,277,437; 4,275,149; 및 4,366,241가 있다. 이러한 라벨을 검출하는 수단은 해당 분야의 통상의 기술자에게 잘 알려져있다. 따라서, 예를 들어, 라디오라벨(radiolabel)은 사진 필름 또는 섬광 카운터를 사용하여 검출될 수 있고, 형광 마커는 방출된 빛을 검출하기 위해 광검출기를 사용하여 검출될 수 있다. 효소 라벨은 일반적으로 효소에 기질을 제공하고 기질에 대한 효소의 작용에 의해 생성된 반응 산물을 검출함으로써 검출되며, 열량측정 라벨은 단순히 컬러 라벨을 시각화하여 검출된다. 라벨은 예를 들어 라벨링된 항체에 결합하는 리간드, 형광단, 화학발광제, 효소, 및 라벨링된 리간드에 대한 특정 결합 쌍 구성원으로 역할 할 수 있는 항체를 포함할 수 있다. 라벨, 라벨링 절차 및 라벨 검출에 대한 소개는 Polak and Van Noorden Introduction to Immunocytochemistry, 2nd ed., Springer Verlag, NY (1997); and in Haugland Handbook of Fluorescent Probes and Research Chemicals, a combined handbook and catalogue Published by Molecular Probes, Inc.(1996)에서 발견된다.
검출 가능한 라벨의 비제한적 예로는 뉴클레오티드(라벨링되거나 라벨링되지 않은 것), 컴포머, 당, 펩티드, 단백질, 항체, 화학 화합물, 전도성 폴리머, 결합 모이어 티, 가령, 비오틴, 질량 태그, 열량측정제, 발광제, 화학 발광제, 산광제, 형광 태그, 방사선 태그, 전하 태그(전기 또는 자기 전하), 휘발성 태그 및 소수성 태그, 생체 분자(가령, 결합 쌍 항체/항원, 항체/항체, 항체/항체 단편, 항체/항체 수용체, 항체/단백질 A 또는 단백질 G, 합텐/항-합텐, 비오틴/아비딘, 비오틴/스트렙타비딘, 엽산/엽산 결합 단백질, 비타민 B12/내인성 인자, 화학적 반응성 그룹/상보적 화학적 반응성 그룹(가령, 설프하이드릴/말레이미드, 설프하이드릴/할로아세틸 유도체, 아민/이소트리오시아네이트, 아민/숙신이미딜 에스테르 및 아민/설포닐 할라이드) 등이 있다.
용어 "프라이머", "프로브" 및 "올리고뉴클레오티드"는 비교적 짧은 핵산 단편 또는 서열을 지칭하기 위해 본 명세서 상호교환적으로 사용된다. 이들은 DNA, RNA 또는 이의 하이브리드, 또는 화학적으로 변형된 유사체 또는 이의 유도체를 포함할 수 있다. 일반적으로, 이들은 단일 가닥이다. 그러나 이들은 변성에 의해 분리될 수 있는 두 개의 보완 가닥을 갖는 이중 가닥일 수도 있다. 일반적으로, 프라이머, 프로브 및 올리고뉴클레오티드는 약 8개 뉴클레오티드 내지 약 200개 뉴클레오티드, 바람직하게는 약 12개 뉴클레오티드 내지 약 100개 뉴클레오티드, 더 바람직하게는 약 18개 내지 약 50개 뉴클레오티드의 길이를 가진다. 이들은 검출 가능한 마커로 라벨링되거나 다양한 분자 생물학적 적용을 위해 기존 방식을 사용하여 수정될 수 있다.
핵산(가령, 게놈 DNA, cDNA, mRNA 또는 이의 단편)과 관련하여 사용될 때 용어 "단리된"은 일반적으로 분자와 연관된 자연 발생 핵산으로부터 실질적으로 단리된 형태로 존재함을 의미한다. 자연적으로 존재하는 염색체(또는 이의 바이러스 등가물)가 긴 핵산 서열을 포함하기 때문에, 단리된 핵산은 염색체에 핵산 서열의 일부만 포함하고 동일한 염색체 상에 존재하는 하나 이상의 다른 부분을 포함하지 않는 핵산 분자일 수 있다. 더 구체적으로, 단리된 핵산은 자연 발생 염색체(또는 이의 바이러스 등가물)에서 핵산 옆에 있는 자연 발생 핵산 서열을 포함할 수 있다. 단리된 핵산은 동일한 유기체의 상이한 염색 상에 있는 다른 자연 발생 핵산과 실질적으로 분리될 수 있다. 단리된 핵산은 또한 특정된 핵산 분자가 전체 핵산의 조성의 적어도 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95%, 또는 적어도 99%을 구성하도록 상당히 농후화된 조성물일 수 있다.
단리된 핵산은 자연적으로 특정 핵산 옆에 있는 핵산이 아닌 하나 이상의 핵산 분자에 공액적으로 연결된 특정된 핵산 분자를 갖는 하이브리드 핵산일 수 있다. 예를 들어, 단리된 핵산은 매개체에 있을 수 있다. 또한, 특정된 핵산은 하나 이상의 돌연변이, 가령, 뉴클레오티드 치환, 결실/삽입, 반전 등을 갖는 자연 발생 핵산 또는 그의 변형된 형태 또는 뮤테인과 동일한 뉴클레오티드 서열을 가질 수 있다.
단리된 핵산은 재조합 숙주 세포(핵산이 재조합적으로 증폭 및/또는 발현된 것)로부터 제조될 수 있거나, 자연 발생 뉴클레오티드 서열을 갖는 화학적으로 합성된 핵산 또는 이의 인공적으로 변형된 형태일 수 있다.
핵산 혼성화와 관련하여 사용될 때 용어 "고 엄격성 혼성화 조건"은, 약 65°C에서 0.1ХSSC로 세정된 혼성화 필터를 이용해 50% 포름아미드, 5ХSSC(750 mM NaCl, 75 mM 소듐 시트레이트), 50 mM 소듐 포스페이트, pH 7.6, 5ХDenhardt 용액, 10% 덱스트란 설페이트, 및 20 마이크로그램/ml 변성 및 전단 연어 정자 DNA를 함유하는 용액에서 42°C에서 밤새 실시된 혼성화를 포함한다. 핵산 혼성화와 관련하여 사용될 때 용어 "중간 엄격성 혼성화 조건"은 약 50°C에서 1ХSSC로 세정된 혼성화 필터를 이용해, 50% 포름아미드, 5ХSSC(750 mM NaCl, 75 mM 소듐 시트레이트), 50 mM 소듐 포스페이트, pH 7.6, 5ХDenhardt 용액, 10% 덱스트란 설페이트, 및 20 마이크로그램/ml 변성 및 전단 연어 정자 DNA를 함유하는 용액에서 37°C에서 밤새 실시된 혼성화를 포함한다. 많은 다른 혼성화 방법, 용액 및 온도가 해당 분야의 통상의 기술자에게 자명할 바와 같이 유사한 엄격한 혼성화 조건을 달성하기 위해 사용될 수 있다는 점이 주목된다.
두 개의 상이한 핵산 또는 폴리펩티드 서열을 비교하기 위해, 하나의 서열(시험 서열)이 다른 서열(비교 서열)과 동일한 특정 비율이도록 기재될 수 있다. 동일성 퍼센티지는 Karlin and Altschul, Proc.Natl.Acad.Sci.USA, 90:5873-5877 (1993)의 알고리즘에 의해 결정될 수 있으며, 이는 다양한 BLAST 프로그램에 통합된다. 동일성 퍼센티지는 NCBI(National Center for Biotechnology Information) 웹 사이트에서 이용 가능한 "BLAST 2 시퀀스" 도구에 의해 결정될 수 있다. Tatusova and Madden, FEMS Microbiol.Lett., 174(2):247-250 (1999)를 참조할 수 있다. 쌍별 DNA-DNA 비교를 위해, BLASTN 프로그램은 디폴트 파라미터(가령, 일치: 1; 불일치: -2; 개방 간격: 5 페널티; 확장 간격: 2 페널티; 갭 x_dropoff: 50; 기대: 10; 및 워드 크기: 11, 필터 포함)와 함께 사용된다. 쌍별 단백질-단백질 서열 비교를 위해, BLASTP 프로그램은 디폴트 파라미터(가령, 모체: BLOSUM62; 간격 개방: 11; 간격 확장: 1; x_dropoff: 15; 기대: 10.0; 및 워크 크기: 3, 필터 포함)를 사용하여 사용될 수 있다. 두 서열의 동일성 퍼센트는 BLAST를 사용하여 테스트 서열을 비교 서열과 정렬하고, 정렬된 테스트 서열에서 비교 서열의 동일한 위치에 있는 아미노산 또는 뉴클레오티드와 동일한 아미노산 또는 뉴클레오티드의 수를 결정하며, 동일한 아미노산 또는 뉴클레오티드의 수를 비교 서열 내 아미노산 또는 뉴클레오티드의 수로 나눔으로써, 계산된다. BLAST가 사용되어 두 개의 서열을 비교할 때, 서열을 정렬하고 정의된 정렬 영역에 대한 동일성 퍼센트를 산출한다. 두 개의 서열이 전체 길이에 걸쳐 정렬된 경우 BLAST에 의해 산출된 동일성 퍼센트는 두 개의 서열의 동일성 퍼센트이다. BLAST가 전체 길이에 걸쳐 두 서열을 정렬하지 않는 경우, 테스트 서열과 비교 서열에서의 동일한 아미노산 또는 뉴클레오티드의 수가 0으로 간주되고 동일성 퍼센트가 정렬된 영역 내 동일한 아미노산 또는 뉴클레오티드의 수를 더하고 상기 수를 비교 시퀀스의 길이로 나눔으로써 계산된다. 다양한 버전의 BLAST 프로그램이 사용되어 서열을 비교할 수 있는데, 가령, BLAST 2.1.2 또는 BLAST+ 2.2.22가 있다.
피험체 또는 개인, 예를 들어 인간 및 비인간 포유 동물, 예컨대, 영장류, 설치류, 말, 개 및 고양이가 본 명세서에 기재된 방법으로부터 이익을 얻을 수 있는 임의의 동물일 수 있다. 피험체의 비제한적 예를 들면, 진핵 유기체, 가장 바람직하게는 포유동물, 가령, 영장류, 예를 들어 침팬지 또는 인간, 소, 개, 고양이; 설치류, 예를 들어 기니피그, 쥐, 생쥐, 토끼, 또는 새, 파충류, 또는 어류가 있다. 피험체는 또한 본 명세서에 기재된 방법을 이용한 치료에 특정하게 의도되며, 인간을 포함한다. 피험체는 또한 본 명세서에서 사람 또는 환자라고 지칭될 수 있다. 본원 방법에서 피험체는 대장암을 가질 수 있는데, 예를 들어 대장암을 진단 받았을 수 있다. 대장암에 걸린 피험체를 식별하는 방법은 해당 분야에 알려져 있으며, 가령, 생검을 이용하는 것이 있다. 예를 들어, Fleming et al., J Gastrointest Oncol.2012 Sep; 3(3): 153-173; Chang et al., Dis Colon Rectum.2012; 55(8):831-43를 참조할 수 있다.
본 명세서에 기재된 방법에 따른 질병 또는 개인의 치료는 임상 결과를 포함하는 유익하거나 원하는 의학적 결과를 얻기 위한 접근 방식이지만 반드시 치료는 아니다. 본 명세서에 기재된 방법의 목적을 위해, 효험이 있거나 바람직한 임상 결과는, 비제한적 예를 들어, 검출가능한지 여부에 무관하게, 하나 이상의 증상의 완화 또는 개선, 질병 정도의 감소, 질병의 안정된(즉, 악화되지 않는) 상태, 확산 방지, 질병 진행 지연 또는 둔화, 질병 상태의 개선 또는 완화, (부분적이든 전체적이든) 완화를 포함한다. 치료는 치료를 받지 않거나 다른 치료를 받는 경우 예상되는 생존과 비교하여 생존을 연장하는 것도 포함한다. 치료는 FOLFOX 또는 FOLFIRI 요법의 투여를 포함할 수 있다. 바이오마커는 일반적으로 유전자 또는 이의 산물, 핵산(가령, DNA, RNA), 단백질/펩티드/폴리펩티드, 탄수화물 구조, 지질, 당지질을 비제한적으로 포함하며, 이들의 특성은 조직 또는 세포에서 검출될 수 있어서, 후보 치료에 대한 민감성 또는 내성에 대한 예측, 진단, 예후 및/또는 치료적 정보를 제공할 수 있다.
생체 샘플
본 명세서에서 사용되는 샘플은 분자 프로파일링에 사용될 수 있는 모든 관련 생체 샘플, 예를 들어, 수술 또는 기타 절차 동안 제거된 조직 또는 조직 절편, 체액, 부검 샘플 및 조직 학적 목적을 위해 취한 냉동 절편을 포함한다. 이러한 샘플은 혈액 및 혈액 분획 또는 산물(가령, 혈청, 백혈구연층, 혈장, 혈소판, 적혈구 등), 객담, 악성 삼출액, 볼 세포 조직, 배양 세포(가령, 1차 배양, 외식편 및 형질 전환된 세포), 대변, 소변, 기타 생체 유체 또는 체액(가령, 전립선 액, 위액, 장액, 신장 액, 폐액, 뇌척수액 등) 등을 포함한다. 샘플은 신선 냉동 및 포르말린 고정 파라핀 임베디드(FFPE) 블록, 포르말린 고정 파라핀 임베디드 또는 RNA 보존제 + 포르말린 고정제 내에 있는 생체 물질을 포함할 수 있다. 각각의 환자에 대해 둘 이상의 유형의 둘 이상의 샘플이 사용될 수 있다. 바람직한 구체예에서, 샘플은 고정된 종양 샘플을 포함한다.
본 발명의 시스템 및 방법에서 사용되는 샘플은 포르말린 고정 파라핀 임베디드(FFPE) 샘플일 수 있다. FFPE 샘플은 고정 조직, 염색되지 않은 슬라이드, 골수 코어 또는 응고, 코어 바늘 생검, 악성 유체 및 미세 바늘 흡인물(FNA) 중 하나 이상일 수 있다. 하나의 구체예에서, 고정 조직은 수술 또는 생검으로부터 얻은 종양 포함 포르말린 고정 파라핀 임베디드(FFPE) 블록을 포함한다. 또 다른 구체예에서, 착색되지 않은 슬라이드는 파라핀 블록으로부터의 착색되지 않은, 대전된, 베이킹되지 않은 슬라이드를 포함한다. 또 다른 구체예에서, 골수 코어 또는 혈전은 석회화 제거된 코어를 포함한다. 포르말린 고정 코어 및/또는 혈전은 파라핀-임베디드일 수 있다. 또 다른 구체예에서, 코어 바늘 생검은 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개 이상, 예를 들어 3-4개의 파라핀 임베디드 생검 샘플을 포함한다. 18 게이지 바늘 생검이 사용될 수 있다. 악성 유체는 5x5x2mm 세포 펠릿을 생성하기에 충분한 양의 신선한 흉막/복수액을 포함할 수 있다. 유체는 파라핀 블록에 고정된 포르말린일 수 있다. 하나의 구체예에서, 코어 바늘 생검은 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개 이상, 예를 들어 4-6개의 파라핀 임베디드 흡인물을 포함한다.
샘플은 해당 분야의 통상의 기술자가 이해하는 기술에 따라 처리될 수 있다. 샘플은 신선, 냉동 또는 고정된 세포 또는 조직일 수 있으나, 이에 한정되지는 않는다. 일부 구체예에서, 샘플은 포르말린-고정 파라핀-임베디드(FFPE) 조직, 신선한 조직 또는 신선한 냉동(FF) 조직을 포함한다. 샘플은 피험체 샘플로부터 유래된 일차 또는 불멸화된 세포주를 포함하는 배양된 세포를 포함할 수 있다. 샘플은 피험체로부터의 샘플로부터 추출된 것을 지칭할 수 있다. 예를 들어, 샘플은 조직 또는 체액에서 추출한 DNA, RNA 또는 단백질을 포함할 수 있다. 이러한 목적을 위해 많은 기술과 상용 키트가 사용될 수 있다. 개인의 신선한 샘플은 추가 처리(가령, 세포 용해 및 추출) 전에 RNA를 보존하기 위해 작용제로 처리될 수 있다. 샘플은 다른 목적으로 수집된 냉동 샘플을 포함할 수 있다. 샘플은 관련 정보, 가령, 연령, 성별, 및 피험체에게 존재하는 임상 증상, 샘플의 출처, 및 샘플의 수집 및 저장 방법과 연관될 수 있다. 샘플은 일반적으로 피험체로부터 얻어진다.
생검은 진단 또는 예후 평가를 위해 조직 샘플을 제거하고 조직 표본 자체를 제거하는 과정으로 구성된다. 해당 분야의 통상의 기술자는 본 개시내용의 분자 프로파일링 방법에 적용될 수 있다. 적용되는 생검 기술은 평가될 조직 유형(가령, 결장, 전립선, 신장, 방광, 림프절, 간, 골수, 혈액 세포, 폐, 유방 등), 종양의 크기 및 유형(가령, 고체형인지 또는 부유형인지, 혈액인지 복수인지), 그 밖의 다른 요인에 따라 달라질 수 있다. 대표적인 생검 기술의 비제한적 예를 들면, 절제 생검, 절개 생검, 바늘 생검, 외과 생검 및 골수 생검이 있다. "절제 생검"은 종양을 둘러싼 정상 조직의 작은 마진과 함께 전체 종양 덩어리를 제거하는 것을 지칭한다. "절개 생검"은 종양의 단면 직경을 포함하는 조직의 웨지를 제거하는 것을 지칭한다. 분자 프로파일링은 종양 덩어리의 "코어-침 생검" 또는 일반적으로 종양 덩어리 내로부터 세포의 현탁액을 얻는 "세침 흡인 생검"을 사용할 수 있다. 예를 들어, 생검 기술은 Harrison 's Principles of Internal Medicine, Kasper, et al., eds., 16th ed., 2005, Chapter 70 및 Part V 전체에서 설명된다.
달리 언급되지 않는 한, 환자의 분자 프로파일링을 위해 본 명세서에서 언급되는 "샘플"은 둘 이상의 물리적 표본을 포함할 수 있다. 하나의 비제한적인 예로서, "샘플"은 종양으로부터의 다수의 섹션, 예를 들어 FFPE 블록의 다수의 섹션 또는 다중 코어-침 생검 섹션을 포함할 수 있다. 또 다른 비제한적인 예를 들어, "샘플"은 다수의 생검 표본, 예를 들어, 하나 이상의 외과용 생검 표본, 하나 이상의 코어-침 생검 표본, 하나 이상의 세침 흡인 생검 표본, 또는 이들의 임의의 유용한 조합을 포함할 수 있다. 또 다른 비제한적인 예로서, 고형 종양 표본 및 체액 표본을 포함하는 "샘플"을 사용하여 피험체에 대해 분자 프로파일이 생성될 수 있다. 일부 구체예에서, 샘플은 단일 샘플, 즉 단일 물리적 표본이다.
해당 분야에 알려져 있고 구체적으로 기재되지 않는 표준 분자 생물학 기법은 일반적으로, 본 명세서에서 참조로서 포함되는 Sambrook et al., Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory Press, New York (1989), 및 Ausubel et al., Current Protocols in Molecular Biology, John Wiley and Sons, Baltimore, Md.(1989) 및 Perbal, A Practical Guide to Molecular Cloning, John Wiley & Sons, New York (1988), 및 Watson et al., Recombinant DNA, Scientific American Books, New York and in Birren et al (eds) Genome Analysis: A Laboratory Manual Series, Vols.1-4 Cold Spring Harbor Laboratory Press, New York (1998) 및 미국 특허 번호 4,666,828; 4,683,202; 4,801,531; 5,192,659 및 5,272,057에 제공된 방법에 있는 바를 따른다. 중합효소 연쇄 반응(PCR)은 일반적으로 PCR Protocols: A Guide to Methods and Applications, Academic Press, San Diego, Calif.(1990)에 있는 바에 따라 수행될 수 있다.
소포
샘플은 소포를 포함할 수 있다. 본 명세서에 기재된 방법은 하나 이상의 소포를 평가하는 것, 가령, 소포 개체군을 평가하는 것을 포함할 수 있다. 본 명세서에서 사용될 때, 소포는 세포로부터 흘리는 막 소포이다. 소포 또는 막 소포는 순환 미세 소포(cMV), 미세소포, 엑소좀, 나노소포, 덱소좀, 수포, 물집, 프로스타좀, 미세입자, 내강 소포, 막 단편, 내강 엔도좀 소포, 엔도좀-유사 소포, 엑소시토시스 소포, 엔도좀 소포, 엔도조말 소포, 자멸소체, 다낭체, 분비 소포, 인지질 소포, 리포좀 소포, 아르고좀, 텍사좀, 시크레좀, 톨러로좀, 멜라노 좀, 온코좀, 또는 외세포성 소포를 포함하지만, 이에 한정되는 않는다. 또한, 소포는 상이한 세포 과정에 의해 생성될 수 있지만, 본 명세서에 기재된 방법은 그러한 소포가 생체 샘플 내에 존재하고 본 명세서에 개시된 방법에 의해 특징 화될 수 있는 한, 임의의 하나의 메커니즘에 제한되거나 이에 의존되지 않는다. 달리 특징되지 않는 한, 소포의 표본을 사용하는 방법은 그 밖의 다른 다른 유형의 소포에 적용될 수 있다. 소포는 때때로 페이로드라고 지칭되는, 가용성 성분을 포함할 수 있는 내부 구획을 둘러싸는 세포막과 유사한 지질 이중층을 갖는 구형 구조를 포함한다. 일부 구체예에서, 본 명세서에 기재된 방법은 직경이 약 40-100 nm 인 작은 분비 소포인 엑소좀을 사용한다. 유형 및 특징화를 포함한 막 소포를 검토하기 위해, Thery et al., Nat Rev Immunol.2009 Aug;9(8):581-93를 참조할 수 있다. 다양한 유형의 소포의 일부 특성은 표 1에 있는 특성을 포함한다:
표 1: 소포 속성

약어: 포스파티딜 세린(PPS: phosphatidylserine), 전자 현미경(EM: electron microscopy) 소포는 원형질막 또는 내부 막에서 유래된 흘리기 막 결합 입자 또는 "마이크로입자"를 포함한다. 소포는 세포로부터 세포외 환경으로 방출될 수 있다. 소포를 방출하는 세포는 외배엽, 내배엽 또는 중배엽으로부터 기원되거나 이로부터 유래된 세포를 포함하지만, 이에 한정되지는 않는다. 세포는 유전적, 환경적 및/또는 그 밖의 다른 임의의 변이 또는 변화를 겪었을 수 있다. 예를 들어, 세포는 종양 세포일 수 있다. 소포는 근원 세포의 모든 변화를 반영할 수 있으며, 이에 따라 기원 세포의 변화, 가령, 다양한 유전자 돌연변이를 가진 세포를 반영할 수 있다. 하나의 메커니즘에서, 소포는 세포막의 한 부분이 자발적으로 침투하여 궁극적으로 세포외 유출된다(가령, Keller et al., Immunol.Lett.107 (2): 102-8 (2006) 참조). 소포는 탈장(출포) 분리와 원형질막의 일부의 밀봉 모두로부터 또는 종양 기원의 다양한 막-연관단백질을 함유하는 임의의 세포내 막-경계 소포 구조의 내보내기로부터 발생하는 지질 이중층 막에 의해 결합된 세포-유래 구조, 가령, 소포 내강에 함유된 분자, 비제한적 예를 들면 종양-유래 마이크로RNA 또는 세포내 단백질과 함께 종양-유래 단백질에 선택적으로 결합된 숙주 순환으로부터 유래된 표면-결합 분자를 포함한다. 수포 및 출혈은 Charras et al., Nature Reviews Molecular and Cell Biology, Vol.9, No.11, p.730-736 (2008)에 더 기재되어 있다. 순환으로 흘러 나오는 소포 또는 종양 세포로부터의 체액이 나오는 것을 "순환하는 종양-유래 소포"라고 지칭될 수 있다. 이러한 소포가 엑소좀인 경우, 순환 종양 유래 엑소좀(CTE)이라고 지칭될 수 있다. 일부 사례에서 소포는 특정 기원 세포로부터 유래될 수 있다. 기원 세포 특정 소포와 마찬가지로, CTE는 일반적으로, 예를 들어, 체액으로부터 그리고 때로는 특정 방식으로 CTE 또는 기원 세포 특정 소포의 단리를 가능하게 하는 하나 이상의 고유한 바이오마커를 가진다. 예를 들어, 세포 또는 조직 특정 마커는 기원 세포를 식별하는 데 사용된다. 이러한 세포 또는 조직 특정 마커의 예가 본 명세서에 개시되어 있으며, bioinfo.wilmer.jhu.edu/tiger/에서 이용 가능한 Tissue-specific Gene Expression and Regulation (TiGER) Database; Liu et al.(2008) TiGER: a database for tissue-specific gene expression and regulation.BMC Bioinformatics.9:271; genome.dkfz-heidelberg.de/menu/tissue_db/index.html에서 이용 가능한 TissueDistributionDB에서 더 접근될 수 있다.
소포는 약 10nm, 20nm 또는 30nm보다 큰 직경을 가질 수 있다. 소포는 40nm, 50nm, 100nm, 200nm, 500nm, 1000nm 또는 10,000nm보다 큰 직경을 가질 수 있다. 소포는 약 30-1000 nm, 약 30-800 nm, 약 30-200 nm, 또는 약 30-100 nm의 직경을 가질 수 있다. 일부 구체예에서, 소포는 10,000nm, 1000nm, 800nm, 500nm, 200nm, 100nm, 50nm, 40nm, 30nm, 20nm 또는 10nm 미만의 직경을 가진다. 본 명세서에서 사용될 때, 수치 값와 관련된 용어 "약"은 수치 값의 10 % 이상 또는 미만의 변화가 특정 값에 속하는 범위 내에 있음을 의미한다. 다양한 유형의 소포에 대한 일반적인 크기가 표 1에 나타나 있다. 소포는 단일 소포의 직경 또는 임의의 수의 소포를 측정하기 위해 평가될 수 있다. 예를 들어, 소포 개체군의 직경 범위 또는 소포 개체군의 평균 직경이 결정될 수 있다. 소포 직경은 해당 분야에 알려진 방법을 이용해, 가령, 전자 현미경 같은 이미징 기법을 이용해 평가될 수 있다. 하나의 구체예에서, 하나 이상의 소포의 직경은 광학 입자 검출을 사용하여 결정된다. 예를 들어, 2010년 07월 06일에 발행된 미국 특허 번호 7,751,053, 발명의 명칭 "Optical Detection and Analysis of Particles" 및 2010년 07월 15일에 공개된 미국 특허 번호 7,399,600, 발명의 명칭 "Optical Detection and Analysis of Particles"을 참조할 수 있다.
일부 구체예에서, 소포는 생체 샘플로부터 사전 단리, 정제 또는 농축 없이 생체 샘플로부터 직접 분석된다. 예를 들어, 샘플 내 소포의 양은 그 자체로 진단, 예후 또는 치료적 결정을 제공하는 바이오시그니처를 제공할 수 있다. 대안으로, 샘플의 소포는 분석 전에 샘플로부터 단리, 포획, 정제 또는 농축될 수 있다. 언급한 바와 같이, 본 명세서에 사용될 때 포획 또는 정제는 샘플 내 다른 성분과 별도로 부분 단리, 부분 포획 또는 부분 정제를 포함한다. 소포 단리는 본 명세서에 기재된 또는 종래 기술에서 알려진 다양한 기법, 비제한적 예를 들면, 크기 배제 크로마토그래피, 밀도 구배 원심분리, 차등 원심분리, 나노 막 한외 여과, 면역 흡수성 포획, 친화성 정제, 친화성 포획, 면역 분석, 면역 침전, 미세 유체 분리, 유세포 분석 또는 이들의 조합을 이용해 수행될 수 있다.
소포 특성을 기준에 비교함으로써, 소포가 평가되어 표현형 특징화를 제공할 수 있다. 일부 구체예에서, 소포 상의 표면 항원이 평가된다. 특정 마커를 보유한 소포 또는 소포 개체군은 양성(바이오마커+) 소포 또는 소포 개체군이라고 지칭될 수 있다. 예를 들어, DLL4+ 개체군은 DLL4와 연관된 소포 개체군을 지칭한다. 반대로, DLL4- 개체군은 DLL4와 연관되지 않을 것이다. 표면 항원은 소포의 해부학적 기원 및/또는 세포의 표시자 및 기타 표현형 정보, 예를 들어 종양 상태를 제공할 수 있다. 예를 들어, 환자 샘플에서 발견된 소포는 결장 직장 기원 및 암의 존재를 나타내는 표면 항원에 대해 평가되어 대장암 세포와 연관된 소포를 식별할 수 있다. 표면 항원은 소포박 표면 상에서 검출될 수 있는 임의의 정보성 생체 개체, 비제한적 예를 들면, 표면 단백질, 지질, 탄수화물 및 그 밖의 다른 막 성분을 포함할 수 있다. 예를 들어, 종양 항원을 발현하는 결장 유래 소포의 양성 검출은 환자가 대장 암에 걸렸다는 것을 나타낼 수 있다. 이와 같이, 본 명세서에 기재된 방법은 예를 들어 피험체로부터 수득된 하나 이상의 소포의 질병 특이적 및 세포 특이적 바이오마커를 평가함으로써 해부학적 또는 세포 기원과 관련된 임의의 질병 또는 상태를 특징화하는 데 사용될 수 있다.
구체예에서, 표현형 특징화를 제공하기 위해 하나 이상의 소포 페이로드가 평가된다. 소포를 갖는 페이로드는 소포 내 캡슐화되는 것으로 검출될 수 있는 정보성 생체 개체, 비제한적 예를 들면, 단백질 및 핵산, 예를 들어 게놈 또는 cDNA, mRNA 또는 이의 기능적 단편, 뿐만 아니라 마이크로RNA(miR)를 포함한다. 또한, 본 명세서에 기재된 방법은 표현형 특징화를 제공하기 위해 (소포 페이로드에 추가로 또는 이를 대신하여) 소포 표면 항원을 검출하는 것과 관련된다. 예를 들어, 소포는 소포 표면 항원 특정적 결합제(예를 들어, 항체 또는 압타머)를 사용하여 특징화될 수 있으며, 결합된 소포는 본 명세서에 기재된 하나 이상의 페이로드 성분을 식별하도록 더 평가될 수 있다. 본 명세서에 기재된 바와 같이, 관심 표면 항원 또는 관심 페이로드를 갖는 소포의 레벨은 표현형을 특징화하기 위해 기준에 비교될 수 있다. 예를 들어, 암 관련 표면 항원 또는 소포 페이로드의 샘플, 예를 들어, 기준과 비교하여 종양 관련 mRNA 또는 microRNA의 과발현은 샘플에서의 암의 존재를 나타낼 수 있다. 평가된 바이오마커는 원하는 표적 샘플의 선택 및 원하는 참조 샘플에 대한 표적 샘플의 비교에 기초하여 존재 또는 부재, 증가 또는 감소될 수 있다. 표적 샘플의 비제한적인 예로는 질병; 치료됨/치료되지 않음; 상이한 시점, 가령, 종단 연구; 및 참조 샘플의 비 제한적 예: 비-질병; 표준; 상이한 시점; 및 후보 치료에 대한 민감성 또는 내성이 있다.
하나의 구체예에서, 본 명세서에 기재된 분자 프로파일링은 미세소포, 가령, 순환 미세소포의 분석을 포함한다.
MicroRNA
다양한 바이오마커 분자는 생체 샘플 또는 이러한 생체 샘플로부터 획득된 소포에서 평가될 수 있다. MicroRNA는 본 명세서에 기재된 방법을 통해 평가되는 하나의 부류 바이오마커를 포함한다. 본 명세서에서 miRNA 또는 miR로도 지칭되는 MicroRNA는 길이가 대략 21-23개 뉴클레오티드인 짧은 RNA가닥이다. MiRNA는 DNA에서 전사되지만 단백질로 번역되지 않는 유전자에 의해 인코딩되므로 비-코딩 RNA를 포함한다. miR은 pri-miRNA로 알려진 1차 전사체로부터 pre-miRNA라고 하는 짧은 줄기 루프 구조로, 그리고 마지막으로 생성된 단일 가닥 miRNA로 처리된다. pre-miRNA는 일반적으로 자기 상보적 영역에서 자체적으로 접히는 구조를 형성한다. 그런 다음 이들 구조는 동물의 뉴클레아제 다이서 또는 식물의 DCL1에 의해 처리된다. 성숙한 miRNA 분자는 하나 이상의 메신저 RNA(mRNA) 분자에 부분적으로 상보적이며 단백질의 번역을 조절하는 기능을 할 수 있다. 식별된 miRNA 서열은 공개적으로 이용 가능한 데이터베이스, 가령, www.microRNA.org, www.mirbase.org 또는 www.mirz.unibas.ch/cgi/miRNA.cgi에서 액세스될 수 있다.
miRNA는 일반적으로 "mir-[number]"라는 명명 규칙에 따라 번호가 지정된다. miRNA의 수는 이전에 식별된 miRNA 종과 관련된 발견 순서에 따라 할당된다. 예를 들어, 마지막으로 게시된 miRNA가 mir-121인 경우, 다음에 발견된 miRNA는 mir-122 등으로 명명될 것이다. 상이한 유기체의 알려진 miRNA와 동종인 miRNA가 발견될 때, 이름은 [유기체 식별자]-mir-[번호] 형식의 선택적 유기체 식별자를 부여 받을 수 있다. 식별자는 호모 사피엔스(Homo sapiens)의 경우 hsa, 무스 무스쿨루스(Mus Musculus)의 경우 mmu를 가진다. 예를 들어, mir-121에 대한 인간 동족체는 hsa-mir-121로 지칭될 수 있는 반면, 마우스 동족체는 mmu-mir-121로 지칭될 수 있다.
성숙한 microRNA는 일반적으로 접두사 "miR"로 지정되는 반면 유전자 또는 전구체 miRNA는 접두사 "mir"로 지정된다. 예를 들어, mir-121은 miR-121의 전구체다. 상이한 miRNA 유전자 또는 전구체가 동일한 성숙한 miRNA로 처리될 때 유전자/전구체는 번호가 붙은 접미사로 표시될 수 있다. 예를 들어, mir-121-1 및 mir-121-2는 miR-121로 처리되는 별개의 유전자 또는 전구체를 나타낼 수 있다. 문자 접미사는 밀접하게 관련된 성숙한 서열을 나타내는 데 사용된다. 예를 들어, mir-121a 및 mir-121b는 각각 밀접하게 관련된 miRNA 인 miR-121a 및 miR-121b로 처리될 수 있다. 본 개시 내용의 맥락에서, 접두사 mir- * 또는 miR- *로 본 명세서에 지정된 임의의 microRNA(miRNA 또는 miR)는 달리 명시 적으로 언급되지 않는 한 전구체 및/또는 성숙한 종을 모두 포함하는 것으로 이해된다.
때로는 두 개의 성숙한 miRNA 서열이 동일한 전구체에서 유래하는 것으로 관찰된다. 서열 중 하나가 다른 것보다 더 풍부할 경우, "*" 접미사가 사용되어 덜 일반적인 변형을 지정할 수 있다. 예를 들어, miR-121이 우세한 산물인 반면 miR-121 *은 전구체의 반대쪽 팔에서 발견되는 덜 일반적인 변형이다. 우세한 변형이 식별되지 않는 경우, miR은 전구체의 5' 팔로부터 나온 변형에 대한 접미사 "5p" 및 3' 팔로부터 변형에 대한 접미사 "3p"로 구분될 수 있다. 예를 들어, miR-121-5p는 전구체의 5' 팔에서 시작되는 반면 miR-121-3p는 3' 팔에서 기원한다. 덜 일반적으로, 5p 및 3p 변형은 각각 센스( "s") 및 안티-센스( "as") 형식이라고 지칭된다. 예를 들어, miR-121-5p는 miR-121-s로 지칭될 수 있는 반면 miR-121-3p는 miR-121-as로 지칭될 수 있다.
상기 명명 규칙은 시간이 지남에 따라 발전했으며 절대적인 규칙이 아닌 일반적인 지침이다. 예를 들어, miRNA의 let- 및 lin- 군은 이들 모니커(moniker)에 의해 계속 참조된다. 전구체/성숙한 형태에 대한 mir/miR 규약도 지침이며 어떤 형태를 참조할지 결정하기 위해 맥락을 고려해야 한다. MiR 명명 규칙의 추가 세부사항이 www.mirbase.org 또는 Ambros et al., A uniform system for microRNA annotation, RNA 9:277-279 (2003)에서 발견될 수 있다.
식물 miRNA는 Meyers et al., Plant Cell.2008 20(12):3186-3190에서 기재된 바와 같이 상이한 명명 규칙을 따른다.
많은 miRNA가 유전자 조절에 관여하며, miRNA는 현재 유전자 조절의 주요 계층으로 인식되고 있는 비-코딩 RNA의 성장하는 클래스의 일부이다. 일부 경우에, miRNA는 표적 mRNA의 3'-UTR에 내장된 조절 부위에 결합하여, 번역을 방해하여 번역을 억제할 수 있다. 표적 인식은 표적 부위와 miRNA의 시드 영역(miRNA의 5' 단부에서 2-8 위치)의 상보적인 염기 쌍을 포함하지만, 정확한 종자 상보성의 정도는 정확하게 결정되지 않고 3' 쌍으로 수정될 수 있다. 다른 경우에, miRNA는 작은 간섭 RNA(siRNA)처럼 기능하고 완벽하게 상보적인 mRNA 서열에 결합하여 표적 전사체를 파괴할 수 있다.
많은 miRNA의 특성화는 초기 발달, 세포 증식 및 세포 사멸, 세포 사멸 및 지방 대사를 포함한 다양한 과정에 영향을 미친다는 것을 나타낸다. 예를 들어, 일부 miRNA, 가령, lin-4, let-7, mir-14, mir-23 및 bantam은 세포 분화 및 조직 발달에 중요한 역할을 하는 것으로 나타났다. 다른 것들은 이들의 공간적 및 시간적 표현 패턴이 다르기 때문에 마찬가지로 중요한 역할을 한다고 여겨진다.
miRBase(www.mirbase.org)에서 제공되는 miRNA 데이터베이스는 게시된 miRNA 염기 서열 및 주석의 검색 가능한 데이터베이스를 포함한다. miRBase에 대한 추가 정보는 다음 논문에서 찾을 수 있으며, 각 논문은 그 전체가 본 명세어세 참조로서 포함된다: Griffiths-Jones et al., miRBase: tools for microRNA genomics.NAR 2008 36(Database Issue):D154-D158; Griffiths-Jones et al., miRBase: microRNA sequences, targets and gene nomenclature.NAR 2006 34(Database Issue):D140-D144; 및 Griffiths-Jones, S.The microRNA Registry.NAR 2004 32(Database Issue):D109-D111. miRBase의 버전 16에 포함된 대표적인 miRNA는 2010년 9월에 이용 가능해졌다.
본 명세서에 기재된 바와 같이, microRNA는 암 및 기타 질환에 관여하는 것으로 알려져 있으며 샘플에서 표현형을 특징화하기 위해 평가될 수 있다. 예를 들어, Ferracin et al., Micromarkers: miRNAs in cancer diagnosis and prognosis, Exp Rev Mol Diag, Apr 2010, Vol.10, No.3, Pages 297-308; Fabbri, miRNAs as molecular biomarkers of cancer, Exp Rev Mol Diag, May 2010, Vol.10, No.4, Pages 435-444를 참조할 수 있다.
하나의 구체예에서, 본 명세서에 기재된 분자 프로파일링은 microRNA의 분석을 포함한다.
소포 및 miR을 분리하고 특징화하는 기술은 해당 분야의 통상의 기술자에게 알려져 있다. 본 명세서에 제시된 방법에 추가로, 추가 방법이 본 명세서에서 참조로서 포함되는 다음 특허 문서에서 발견된다: 미국 특허 번호 7,888,035, 발명의 명칭 "METHODS FOR ASSESSING RNA PATTERNS" 2011년02월15일 공개; 및 7,897,356, 발명의 명칭 "METHODS AND SYSTEMS OF USING EXOSOMES FOR DETERMINING PHENOTYPES" 2011년 03월 01일 공개; 및 국제 특허 공개 번호 WO/2011/066589, 발명의 명칭 "METHODS AND SYSTEMS FOR ISOLATING, STORING, AND ANALYZING VESICLES" 2010년 11월 30일 출원; WO/2011/088226, 발명의 명칭 "DETECTION OF GASTROINTESTINAL DISORDERS" 2011년01월13일 출원; WO/2011/109440, 발명의 명칭 "BIOMARKERS FOR THERANOSTICS" 2011년03월01일 출원; 및 WO/2011/127219, 발명의 명칭 "CIRCULATING BIOMARKERS FOR DISEASE" 2011년 04월 06일 출원.
순환 바이오마커
순환 바이오마커는 체액, 가령, 혈액, 혈장, 혈청에서 검출 가능한 바이오마커를 포함한다. 순환 암 바이오마커의 예로는 심장 트로포닌 T(cTnT), 전립선 암에 대한 전립선 특이 항원(PSA) 및 난소 암에 대한 CA125가 있다. 본 개시 내용에 따른 순환 바이오마커는 체액에서 검출될 수 있는 임의의 적절한 바이오마커, 비제한적 예를 들면, 단백질, 핵산, 예를 들어 DNA, mRNA 및 microRNA, 지질, 탄수화물 및 대사 산물을 포함한다. 순환 바이오마커는 세포와 연관되지 않은 바이오마커, 예를 들어 막 연관된 것이거나, 막 단편에 포함되거나, 생물학적 복합체의 일부이거나, 용액에 없는 바이오마커를 포함할 수 있다. 하나의 구체예에서, 순환 바이오마커는 피험체의 생물학적 유체에 존재하는 하나 이상의 소포와 관련된 바이오마커이다.
순환 바이오마커는 암 검출과 같은 다양한 표현형의 특징화에 사용하기 위해 식별되었다. 예를 들어, Ahmed N, et al., Proteomic-based identification of haptoglobin-1 precursor as a novel circulating biomarker of ovarian cancer.Br.J.Cancer 2004; Mathelin et al., Circulating proteinic biomarkers and breast cancer, Gynecol Obstet Fertil.2006 Jul-Aug;34(7-8):638-46.Epub 2006 Jul 28; Ye et al., Recent technical strategies to identify diagnostic biomarkers for ovarian cancer.Expert Rev Proteomics.2007 Feb;4(1):121-31; Carney, Circulating oncoproteins HER2/neu, EGFR and CAIX (MN) as novel cancer biomarkers.Expert Rev Mol Diagn.2007 May;7(3):309-19; Gagnon, Discovery and application of protein biomarkers for ovarian cancer, Curr Opin Obstet Gynecol.2008 Feb;20(1):9-13; Pasterkamp et al., Immune regulatory cells: circulating biomarker factories in cardiovascular disease.Clin Sci (Lond).2008 Aug;115(4):129-31; Fabbri, miRNAs as molecular biomarkers of cancer, Exp Rev Mol Diag, May 2010, Vol.10, No.4, Pages 435-444; PCT 특허 공개 번호 WO/2007/088537; 미국 특허 번호 7,745,150 및 7,655,479; 미국 특허 공개 번호 20110008808, 20100330683, 20100248290, 20100222230, 20100203566, 20100173788, 20090291932, 20090239246, 20090226937, 20090111121, 20090004687, 20080261258, 20080213907, 20060003465, 20050124071, 및 20040096915를 참조할 수 있으며, 이들 각각은 그 전체가 본 명세서에 참조로서 포함된다. 하나의 구체예에서, 본 명세서에 기재된 바와 같은 분자 프로파일링은 순환 바이오마커의 분석을 포함한다.
유전자 발현 프로파일링
본 명세서에 기재된 방법 및 시스템은 본 명세서에 개시된 하나 이상의 표적 유전자의 차등 발현을 평가하는 것을 포함하는 발현 프로파일링을 포함한다. 차등 발현은 대조군(또는 참조)과 비교하여 생물학적 산물, 예를 들어 유전자, mRNA 또는 단백질의 과발현 및/또는 과소 발현을 포함할 수 있다. 대조군은 샘플과 유사한, 그러나 질병이 없는 세포(가령, 건강한 개인의 샘플에서 얻은 발현 프로파일)를 포함할 수 있다. 대조군은 특정 질병 및 특정 약물 표적과 관련된 약물 표적 효능을 나타내는 이전에 결정된 수준일 수 있다. 대조군은 동일한 환자, 예를 들어 질병에 걸린 세포와 동일한 장기의 정상적인 인접 부분에서 유래 할 수 있으며, 대조군은 특정 약물 표적에 반응하는 다른 환자의 건강한 조직 또는 질병 반응 여부를 나타내는 이전에 결정된 역치에서 유래 할 수 있다. 대조군은 동일한 샘플에서 발견되는 대조군, 가령, 세포유지 유전자 또는 그 산물(가령, mRNA 또는 단백질)일 수도 있다. 예를 들어, 대조군 핵산은 세포의 암성 또는 비-암성 상태에 따라 다르지 않는 것으로 알려진 것일 수 있다. 대조 핵산의 발현 수준은 검사 및 참조 개체군에서 신호 수준을 정규화하는 데 사용될 수 있다. 예시적인 대조군 유전자는 예를 들어, β-액틴, 글리세르알데히드 3-포스페이트 탈수소 효소 및 리보솜 단백질 P1을 포함하지만 이에 제한되지 않는다. 여러 대조군 또는 대조군 유형이 사용될 수 있다. 차등 발현의 원인은 달라질 수 있다. 예를 들어, 세포에서 유전자 복제수가 증가하여 유전자 발현이 증가 할 수 있다. 대안으로, 유전자의 전사는 예를 들어 염색질 리모델링, 차등 메틸화, 전사 인자의 차등 발현 또는 활성 등에 의해 변형될 수 있다. 번역은 또한 예를 들어 mRNA를 저하하는 인자의 차등 발현, mRNA 번역, 침묵 번역, 예를 들어, microRNA 또는 siRNA에 의해 변형될 수 있다. 일부 구체예에서, 차등 발현은 차등 활성을 포함한다. 예를 들어, 단백질은 단백질의 활성을 증가시키는 돌연 변이, 가령, 구조 활성화를 지닐 수 있어서, 질병 상태에 기여할 수 있다. 활성의 변화를 나타내는 분자 프로파일링이 사용되어 치료 선택이 안내될 수 있다.
유전자 발현 프로파일링 방법은 폴리 뉴클레오티드의 혼성화 분석에 기반한 방법과 폴리 뉴클레오티드의 시퀀싱에 기반한 방법을 포함한다. 샘플에서 mRNA 발현의 정량화를 위해 해당 분야의 통상의 기술자에게 알려진 일반적으로 사용되는 방법은 노던 블롯 및 현장 혼종화를 포함한다(Parker & Barnes (1999) Methods in Molecular Biology 106:247-283); RNAse protection assays (Hod (1992) Biotechniques 13:852-854); and reverse transcription polymerase chain reaction (RT-PCR) (Weis et al.(1992) Trends in Genetics 8:263-264). 대안으로, 특정 이중 나선, 가령, DNA 이중 나선, RNA 이중 나선 및 DNA-RNA 하이브리드 이중 나선 또는 DNA-단백질 이중 나선을 인식할 수 있는 항체가 사용될 수 있다. 시퀀싱-기반 유전자 발현 분석을 위한 대표적인 방법은 SAGE(Serial Analysis of Gene Expression), MPSS(massively parallel signature sequencing) 및/또는 차세대 시퀀싱에 의한 유전자 발현 분석을 포함한다.
RT-PCR
역전사 중합효소 연쇄 반응(RT-PCR: Reverse transcription polymerase chain reaction)은 중합효소 연쇄 반응(PCR)의 변형이다. 이 기법에 따르면, RNA 가닥은 효소 역전사 효소를 사용하여 DNA 보체(즉, 상보적 DNA 또는 cDNA)로 역전사되고 결과적인 cDNA는 PCR을 사용하여 증폭된다. 실시간 중합효소 연쇄 반응은 정량적 PCR, Q-PCR, qRT-PCR 또는 때로는 RT-PCR이라고도 하는 또 다른 PCR 변이체이다. 역전사 PCR 방법 또는 실시간 PCR 방법은 본 개시 내용에 따라 분자 프로파일링을 위해 사용될 수 있으며, RT-PCR은 달리 명시되지 않는 한 또는 해당 분야의 통상의 기술자에 의해 이해되는 바와 같이 지칭될 수 있다.
RT-PCR이 사용되어 본 명세서에 기재된 바와 같은 바이오마커의 RNA 수준, 예를 들어 mRNA 또는 miRNA 수준이 결정될 수 있다. RT-PCR은 약물 치료 유무에 관계없이 다양한 샘플 집단, 정상 및 종양 조직에서 본 명세서에 기재된 바이오마커의 이러한 RNA 수준을 비교하고, 유전자 발현 패턴을 특징화하고, 밀접하게 관련된 RNA를 구별하고, RNA 구조를 분석하는 데 사용될 수 있다.
첫 번째 단계는 샘플에서 RNA, 예를 들어 mRNA를 분리하는 것이다. 출발 물질은 각각 인간 종양 또는 종양 세포주 및 상응하는 정상 조직 또는 세포주로부터 분리된 총 RNA일 수 있다. 따라서 RNA는 샘플(가령, 종양 세포 또는 종양 세포주)에서 분리될 수 있으며 건강한 기증자의 풀링된 DNA와 비교할 수 있다. mRNA의 출처가 원발성 종양인 경우, mRNA는 예를 들어 냉동 또는 보관된 파라핀 내장 및 고정(가령, 포르말린 고정) 조직 샘플에서 추출될 수 있다.
mRNA 추출을 위한 일반적인 방법은 해당 분야에 잘 알려져 있고 분자 생물학의 표준 교과서, 가령, Ausubel et al.(1997) Current Protocols of Molecular Biology, John Wiley and Sons에 개시되어 있다. 파라핀 내장 조직으로부터 RNA를 추출하는 방법은 예를 들어 Rupp & Locker (1987) Lab Invest.56:A67, and De Andres et al., BioTechniques 18:42044 (1995)에 개시되어 있다. 특히, RNA 분리는 제조업체(QIAGEN Inc., 캘리포니아, 발렌시아)의 지시사항에 따라 정제 키트, 완충 세트, 및 상업적 제조업체, 가령, Qiagen로부터의 프로테아제를 이용해 수행될 수 있다. 예를 들어, Qiagen RNeasy 미니-컬럼을 사용하여 배양중인 세포의 총 RNA를 분리할 수 있다. 수많은 RNA 분리 키트가 상업적으로 이용 가능하며 본 명세서에 기재된 방법에 사용될 수 있다.
대안으로, 첫 번째 단계는 표적 샘플로부터 miRNA를 분리하는 것이다. 출발 물질은 각각 인간 종양 또는 종양 세포주 및 상응하는 정상 조직 또는 세포주로부터 분리된 총 RNA일 수 있다. 따라서 RNA는 다양한 원발성 종양 또는 종양 세포주에서 분리될 수 있으며 건강한 기증자로부터 수집된 DNA를 사용한다. miRNA의 출처가 원발성 종양인 경우, miRNA는 예를 들어 냉동 또는 보관된 파라핀 내장 및 고정(가령, 포르말린 고정) 조직 샘플에서 추출될 수 있다.
miRNA 추출을 위한 일반적인 방법은 해당 분야에 잘 알려져 있고 분자 생물학의 표준 교과서, 가령, Ausubel et al.(1997) Current Protocols of Molecular Biology, John Wiley and Sons에 개시되어 있다. 파라핀 내장 조직으로부터 RNA를 추출하는 방법은 예를 들어 Rupp & Locker (1987) Lab Invest.56:A67, and De Andres et al., BioTechniques 18:42044 (1995)에 개시되어 있다. 특히 RNA 분리는 제조업체의 지침에 따라 Qiagen과 같은 상용 제조업체의 정제 키트, 완충 세트 및 프로테아제를 사용하여 수행될 수 있다. 예를 들어, Qiagen RNeasy 미니-컬럼을 사용하여 배양중인 세포의 총 RNA를 분리할 수 있다. 수많은 miRNA 분리 키트가 상업적으로 이용 가능하며 본 명세서에 기재된 방법에 사용될 수 있다.
RNA가 mRNA, miRNA 또는 다른 유형의 RNA를 포함하는지 여부에 관계없이 RT-PCR에 의한 유전자 발현 프로파일링에는 RNA 템플릿을 cDNA로 역전사한 다음 PCR 반응에서 증폭하는 것이 포함될 수 있다. 일반적으로 사용되는 역전사 효소의 비제한적 예를 들면, 아빌로 골수모세포증 바이러스 역전사 효소(AMV-RT) 및 몰로니 쥐 백혈병 바이러스 역전사 효소(MMLV-RT)가 있다. 역전사 단계는 일반적으로 상황과 발현 프로파일링의 목표에 따라 특정 프라이머, 랜덤 6량체 또는 올리고-dT 프라이머를 사용하여 프라이밍된다. 예를 들어, 추출된 RNA는 제조업체의 지침에 따라 GeneAmp RNA PCR 키트(Perkin Elmer, 미국, 캘리포니아 소재)를 사용하여 역전사될 수 있다. 파생된 cDNA는 후속 PCR 반응에서 템플릿으로 사용될 수 있다.
PCR 단계는 다양한 열안정성 DNA-의존성 DNA 폴리머아제를 사용할 수 있지만 일반적으로 5'-3' 뉴클레아제 활성을 갖지만 3'-5' 교정 엔도뉴클레아제 활성이 없는 Taq DNA 중합 효소를 사용한다. TaqMan PCR은 일반적으로 Taq 또는 Tth 폴리머아제의 5'-뉴클레아제 활성을 사용하여 표적 앰플리콘에 결합된 혼성화 프로브를 가수 분해하지만 동등한 5' 뉴 클레아제 활성을 가진 모든 효소가 사용될 수 있다. PCR 반응의 전형적인 앰플리콘을 생성하기 위해 2개의 올리고 뉴클레오티드 프라이머가 사용된다. 세 번째 올리고뉴클레오티드 또는 프로브는 두 개의 PCR 프라이머 사이에 위치한 뉴클레오티드 서열을 검출하도록 설계되었다. 프로브는 Taq DNA 폴리머아제 효소에 의해 확장될 수 없으며, 리포터 형광 염료와 소광제 형광 염료로 라벨링된다. 리포터 염료(reporter dye)로부터 레이저로 유도된 방출은 두 염료가 프로브에 있을 때 서로 가까이 위치할 때 감소 염료(quenching dye)에 의해 감소된다. 증폭 반응 동안 Taq DNA 폴리머아제 효소는 템플릿-종속 방식으로 프로브를 절단한다. 결과적 프로브 단편은 용액에서 분리되고 방출된 리포터 염료로부터의 신호는 두 번째 형광단의 감소 효과가 없습니다. 합성된 각각의 새로운 분자에 대해 하나의 리포터 염료 분자가 해방되며, 감소되지 않은 리포터 염료의 검출은 데이터의 정량적 해석을 위한 기초를 제공한다.
TaqMan™ RT-PCR은 상용화된 장비, 가령, ABI PRISM 7700™ Sequence Detection System™ (Perkin-Elmer-Applied Biosystems, 미국, 캘리포니아, 포스터 시티 소재), 또는 LightCycler (Roche Molecular Biochemicals, 독일, 맨하임 소재)를 이용해 수행될 수 있다. 하나의 구체예에서, 5' 뉴클레아제 절차는 실시간 정량적 PCR 장치, 가령, ABI PRISM 7700 서열 검출 시스템 상에서 실행된다. 이 시스템은 열순환기, 레이저, CCD(charge-coupled device), 카메라 및 컴퓨터로 구성된다. 이 시스템은 열순환기에서 96-웰 포맷으로 샘플을 증폭한다. 증폭 동안, 레이저-유도 형광 신호는 96개의 모든 웰에 대해 광섬유 케이블을 통해 실시간으로 수집되고 CCD에서 검출된다.시스템은 기기를 실행하고 데이터를 분석하기 위한 소프트웨어를 포함한다.
TaqMan 데이터는 처음에 Ct 또는 임계값 주기로 표시된다. 앞서 논의한 바와 같이, 형광 값은 모든 주기 동안 기록되며 증폭 반응에서 해당 지점까지 증폭된 산물의 양을 나타낸다. 형광 신호가 처음에 통계적으로 유의미한 것으로 기록되는 지점은 임계주기(Ct)이다.
오류와 샘플간 변동의 영향을 최소화하기 위해, RT-PCR은 일반적으로 내부 표준을 사용하여 수행된다. 이상적인 내부 표준은 상이한 조직간에 일정한 수준으로 표현되며 실험적 처리에 의해 영향을 받지 않는다. 유전자 발현 패턴을 정규화하는 데 가장 자주 사용되는 RNA는 세포유지 유전자 글리세랄데하이드-3-포스페이트-데하이드로게나제(GAPDH) 및 베타액틴( -actin)에 대한 mRNA이다.
-actin)에 대한 mRNA이다.
실시간 정량적 PCR(또한 정량적 실시간 폴리머아제 연쇄 반응, QRT-PCR 또는 Q-PCR)은 RT-PCR 기술의 최근 변형이다. Q-PCR은 이중-라벨링된 형광생성 프로브(즉, TaqMan 프로브)를 통해 PCR 산물 축적을 측정할 수 있다. 실시간 PCR은 각 표적 서열에 대한 내부 경쟁자가 정규화에 사용되는 정량적 경쟁 PCR과 샘플에 포함된 정규화 유전자 또는 RT-PCR을 위한 세포유지 유전자를 사용하는 정량적 비교 PCR과 모두 호환된다. 예를 들어 Held et al.(1996) Genome Research 6:986-994를 참조할 수 있다.
단백질-기반 검출 기술은 특히 뉴클레오티드 변이가 단백질 1차, 2차 또는 3차 구조에 영향을 미치는 아미노산 치환 또는 결실 또는 삽입 또는 프레임 이동을 유발할 때 분자 프로파일링에 유용하다. 아미노산 변이를 검출하기 위해 단백질 시퀀싱 기술이 사용될 수 있다. 예를 들어, 유전자에 해당하는 단백질 또는 이의 단편은 검사 대상 개체로부터 단리된 DNA 단편을 사용하여 재조합 발현에 의해 합성될 수 있다. 바람직하게는, 결정될 다형성 유전자 자리를 포함하는 100 내지 150개 이하의 염기쌍의 cDNA 단편이 사용된다. 그 후 펩티드의 아미노산 서열은 통상적인 단백질 서열 분석 방법에 의해 결정될 수 있다. 또는, HPLC-현미경 탠덤 질량 분석 기법이 사용되어 아미노산 서열 변이를 결정할 수 있다. 이 기법에서 단백질 분해 분해는 단백질에서 수행되고 생성된 펩타이드 혼합물은 역상 크로마토 그래피 분리에 의해 분리된다. 그런 다음 탠덤 질량 분석이 수행되고 수집된 데이터가 분석된다.Gatlin et al., Anal.Chem., 72:757-763 (2000)을 참조할 수 있다.
마이크로어레이
본 명세서에 기재된 바와 같은 바이오마커는 또한 마이크로어레이 기술을 사용하여 확인, 확인 및/또는 측정될 수 있다. 따라서 마이크로어레이 기술을 사용하여 암 샘플에서 발현 프로파일 바이오마커를 측정할 수 있다. 이 방법에서, 관심 폴리뉴클레오티드 서열은 마이크로칩 기질에 도금 또는 배열된다. 배열된 서열은 관심 세포 또는 조직의 특정 DNA 프로브와 혼성화된다. mRNA의 소스는 샘플, 예를 들어, 인간 종양 또는 종양 세포주 및 상응하는 정상 조직 또는 세포주로부터 단리된 총 RNA일 수 있다. 따라서 RNA는 다양한 원발성 종양 또는 종양 세포주로부터 단리될 수 있다. mRNA의 소스가 원발성 종양인 경우, mRNA는 예를 들어 냉동 또는 보관된 파라핀 내장 및 고정(가령, 포르말린 고정) 조직 샘플에서 추출될 수 있으며, 이는 일상 임상 실시에서 일상적으로 제조되고 보존된다.
바이오마커의 발현 프로파일은 마이크로어레이 기술을 사용하여 신선하거나 파라핀이 내장된 종양 조직 또는 체액에서 측정될 수 있다. 이 방법에서, 관심 폴리뉴클레오티드 서열은 마이크로칩 기질에 도금 또는 배열된다. 배열된 서열은 관심 세포 또는 조직의 특정 DNA 프로브와 혼성화된다. RT-PCR 방법과 마찬가지로, miRNA의 소스는 일반적으로 인간 종양 또는 종양 세포주, 가령, 체액, 가령, 혈청, 소변, 눈물 및 엑소좀 및 이에 대응하는 정상 조직 또는 세포주로부터 단리된다. 따라서 RNA는 다양한 소스로부터 단리될 수 있다. miRNA의 출처가 원발성 종양인 경우, 예를 들어, 일상적인 임상 실습에서 일상적으로 준비되고 보존되는 냉동 조직 샘플에서 miRNA이 추출될 수 있다.
바이오칩, DNA 칩 또는 유전자 어레이로도 알려진 cDNA 마이크로어레이 기술을 사용하면 생체 샘플에서 유전자 발현 수준을 식별할 수 있다. 각각 주어진 유전자를 나타내는 cDNA 또는 올리고뉴클레오티드는 기질(가령, 작은 칩, 비드 또는 나일론 막)에 고정되고 태그가 지정되고 관심 생체 샘플에서 발현되는지 여부를 나타내는 프로브 역할을 한다. 수천 개의 유전자의 동시 발현이 동시에 모니터링될 수 있다.
마이크로어레이 기법의 특정 구체예에서, cDNA 클론의 PCR 증폭된 삽입은 고밀도 어레이의 기질에 적용된다. 하나의 양태에서, 적어도 100, 200, 300, 400, 500, 600, 700, 800, 900, 1,000, 1,500, 2,000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10,000, 15,000, 20,000, 25,000, 30,000, 35,000, 40,000, 45,000 또는 적어도 50,000개의 뉴클레오티드 서열이 기질에 적용된다. 각각의 서열은 다른 유전자에 대응할 수 있거나, 유전자당 여러 서열이 배열될 수 있다. 마이크로 칩에 고정된 마이크로어레이 유전자는 엄격한 조건 하에서 혼성화에 적합하다. 형광 라벨링된 cDNA 프로브는 관심 조직으로부터 추출된 RNA의 역전사에 의한 형광 뉴클레오티드의 통합을 통해 생성될 수 있다. 칩에 적용된 라벨링된 cDNA 프로브는 어레이 상의 각 DNA 지점에 특이적으로 혼성화된다. 비특이적으로 결합된 프로브를 제거하기 위해 엄격한 세척 후 칩은 공초점 레이저 현미경 또는 CCD 카메라와 같은 다른 감지 방법으로 스캔된다. 배열된 각 요소의 혼성화를 정량화하면 해당 mRNA 풍부도를 평가할 수 있다. 이중 색상 형광을 사용하면, 두 RNA 소스로부터 생성된 개별적으로 라벨링된 cDNA 프로브가 어레이에 쌍으로 혼성화된다. 따라서 각 특정 유전자에 해당하는 두 소스로부터의 전 사체의 상대적 풍부도가 동시에 결정된다. 소형화된 규모의 혼성화는 다수의 유전자에 대한 발현 패턴의 편리하고 신속한 평가를 제공한다. 이러한 방법은 세포당 몇 개의 사본으로 발현되는 희귀 전 사체를 검출하고 발현 수준에서 적어도 약 2 배의 차이를 재현 가능하게 검출하는 데 필요한 감도를 갖는 것으로 나타났다(Schena et al.(1996) Proc.Natl.Acad.Sci.USA 93(2):106-149). 마이크로어레이 분석은 제조업체의 프로토콜, 비제한적 예를 들면, Affymetrix GeneChip technology (Affymetrix, 캘리포니아, 산타 클라라 소재), Agilent (Agilent Technologies, Inc., 캘리포니아, 산타 클라라 소재), 또는 Illumina (Illumina, Inc., 캘리포니아, 샌 디에고 소재)에 따르는 사용화된 장비에 의해 수행될 수 있다.
유전자 발현의 대규모 분석을 위한 마이크로어레이 방법의 개발은 다양한 종양 유형에서 암 분류 및 결과 예측의 분자 마커를 체계적으로 검색할 수 있게 한다.
일부 구체예에서에서, Agilent Whole Human Genome Microarray Kit (Agilent Technologies, Inc., 캘리포니아, 산타 클라라 소재)가 있다. 이 시스템은 공용 도메인 주석을 사용하여 41,000개 이상의 고유한 인간 유전자 및 전사체를 분석할 수 있다. 이 시스템은 제조업체의 지침에 따라 사용된다.
일부 구체예에서, Illumina Whole Genome DASL assay (Illumina Inc., 캘리포니아, 샌 디에고)가 사용된다. 이 시스템은 신선한 냉동(FF) 및 포르말린 고정 파라핀 내장(FFPE) 조직 소스에서 최소 RNA 입력으로부터 24,000개 이상의 전 사체를 높은 처리량 방식으로 동시에 프로파일링하는 방법을 제공한다.
마이크로어레이 발현 분석은 유전자 또는 유전자 산물이 기준에 비해 상향 조절되는지 또는 하향 조절되는지 확인하는 것을 포함한다. 식별은 관찰된 모든 차등 발현의 통계적 유의성을 결정하기 위해 통계 테스트를 사용하여 수행될 수 있다. 일부 구체예에서, 통계적 유의성은 모수적 통계 테스트를 사용하여 결정된다. 모수적 통계 검정은 예를 들어 부분 요인 설계, 분산 분석(ANOVA), t-검정, 최소 제곱, 피어슨 상관, 단순 선형 회귀, 비선형 회귀, 다중 선형 회귀 또는 다중 비선형 회귀를 포함할 수 있다. 또는, 모수적 통계 테스트는 일원 분산 분석, 양방향 분산 분석 또는 반복 측정 분산 분석을 포함할 수 있다. 또 다른 구체예에서, 통계적 유의성은 비모수적 통계 테스트를 사용하여 결정된다. 예로는 윌콕슨(Wilcoxon) 부호 순위 검정, 맨-휘트니(Mann-Whitney) 검정, 크루스컬-월리스(Kruskal-Wallis) 검정, 프리드먼(Friedman) 검정, 스피어맨(Spearman) 순위 순서 상관 계수, 켄달 타우(Kendall Tau) 분석 및 비모수 회귀 검정이 있다. 일부 구체예에서, 통계적 유의성은 약 0.05, 0.01, 0.005, 0.001, 0.0005, 또는 0.0001 미만의 p-값에서 결정된다. 본 명세서에 기재된 방법에 사용 된 마이크로어레이 시스템이 수천 개의 전 사체를 분석 할 수 있지만, 데이터 분석은 관심있는 전 사체에 대해서만 수행하면되므로 다중 통계 테스트를 수행하는 데 내재 된 다중 비교 문제를 줄일 수 있다. P-값은 또한 예를 들어 본페로니(Bonferroni) 보정, 이의 수정 또는 해당 분야에 알려진 다른 기술(가령, 호흐베르크(Hochberg) 보정, 홈-본페로니(Holm-Bonferroni) 보정, 시닥(??idαk) 보정 또는 더넷(Dunnett) 보정)을 사용하여 다중 비교를 위해 보정될 수 있다.. 차등 발현의 정도가 또한 고려될 수 있다. 예를 들어, 유전자는 대조군 수준에 비해 발현의 배 변화가 샘플 대 대조군에서 최소 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0, 2.2, 2.5, 2.7, 3.0, 4, 5, 6, 7, 8, 9 또는 10-배 차이가 있다. 차등 발현은 과발현과 과소 발현을 모두 고려한다. 유전자 또는 유전자 산물은 차동 발현이 통계적 임계 값, 폴드-변경 임계 값 또는 둘 다를 충족하는 경우 상향 또는 하향 조절된 것으로 간주 될 수 있다. 예를 들어, 차별적 발현을 식별하는 기준은 p- 값 0.001과 최소 1.5 배(위 또는 아래)의 폴드 변화를 모두 포함할 수 있다. 해당 분야의 통상의 기술자는 이러한 통계 및 역치 측정이 본 명세서에 개시된 임의의 분자 프로파일링 기술에 의해 차별적 발현을 결정하도록 적용될 수 있음을 이해할 것이다.
본 명세서에 기재된 다양한 방법은 샘플에서 생물학적 개체의 존재 및 잠재적으로 양을 검출하는 다양한 유형의 마이크로어레이를 사용한다. 어레이는 일반적으로 예를 들어 결합 이벤트를 통해 샘플에서 개체의 존재를 감지 할 수 있는 어드레싱 가능한 모이어티를 포함한다. 마이크로어레이는 cDNA 마이크로어레이, 올리고 뉴클레오티드 마이크로어레이 및 SNP 마이크로어레이, microRNA 어레이, 단백질 마이크로어레이, 항체 마이크로어레이, 조직 마이크로어레이, 세포 마이크로어레이(트랜스펙션 마이크로어레이라고도 함), 화학적 화합물 마이크로어레이 및 탄수화물 어레이(글리코 어레이)와 같은 DNA 마이크로어레이를 제한없이 포함한다. DNA 어레이는 일반적으로 샘플에 존재하는 서열에 결합 할 수 있는 주소 지정 가능한 뉴클레오티드 서열을 포함한다. MicroRNA 어레이, 예를 들어 University of Louisville의 MMChips 어레이 또는 Agilent의 상용 시스템을 사용하여 microRNA를 검출 할 수 있다. 단백질 마이크로어레이는 단백질 키나제의 기질 식별, 전사 인자 단백질 활성화를 포함하되 이에 국한되지 않는 단백질-단백질 상호 작용을 식별하거나 생물학적으로 활성 인 작은 분자의 표적을 식별하는 데 사용할 수 있다. 단백질 어레이는 관심 단백질에 결합하는 상이한 단백질 분자, 일반적으로 항체 또는 뉴클레오티드 서열의 어레이를 포함할 수 있다. 항체 마이크로어레이는 샘플, 예를 들어 세포 또는 조직 용 해물 용액에서 단백질 또는 기타 생물학적 물질을 검출하기 위해 포획 분자로 사용되는 단백질 칩에 스팟 팅 된 항체를 포함한다. 예를 들어, 항체 어레이는 진단 적용을 위해 체액, 예를 들어 혈청 또는 소변에서 바이오마커를 검출하는 데 사용될 수 있다. 조직 마이크로어레이는 다중 조직 학적 분석을 허용하기 위해 어레이 방식으로 조립 된 별도의 조직 코어로 구성된다. 형질 감염 마이크로어레이라고도 하는 세포 마이크로어레이는 항체, 단백질 또는 지질과 같은 다양한 포획 제를 포함하며, 세포와 상호 작용하여 주소 지정 가능한 위치에서 포획을 용이하게 할 수 있다. 화학적 화합물 마이크로어레이는 화학적 화합물의 어레이를 포함하며 화합물을 결합하는 단백질 또는 기타 생물학적 물질을 검출하는 데 사용할 수 있다. 탄수화물 어레이(글리코 어레이)는 탄수화물 어레이를 포함하고 예를 들어 당 모이어티에 결합하는 단백질을 검출 할 수 있다. 해당 분야의 통상의 기술자는 본 명세서에 설명 된 방법에 따라 유사한 기술 또는 개선이 사용될 수 있음을 이해할 것이다.
현재 방법의 특정 구체예는 다중 웰 플레이트 또는 다중 챔버 미세 유체 장치를 포함 하나 이에 제한되지 않는 다중 웰 반응 용기를 포함하며, 여기서 다수의 증폭 반응 및 일부 구체예에서 검출은 전형적으로 병렬로 수행된다. 특정 구체예에서, 앰플리콘을 생성하기 위한 하나 이상의 다중 반응은 96-웰, 384-웰, 1536-웰 플레이트 등, 또는 미세유체 장치, 비제한적 예를 들면, TaqMan™ 저밀도 어레이(Applied Biosystems, 캘리포니아, 포스터 시티 소재)과 같은 다중-웰 플레이트를 포함 하나 이에 제한되지 않는 동일한 반응 용기에서 수행된다. 일부 구체예에서, 대규모 병렬 증폭 단계는 다중 반응 웰을 포함하는 플레이트, 예를 들어 24-웰 플레이트, 96-웰 플레이트, 384-웰 플레이트, 또는 1536-웰 플레이트; 또는 다중 챔버 미세 유체 장치, 예를 들어 저밀도 어레이에 제한되지 않고 각 챔버 또는 웰은 적절한 프라이머, 프라이머 세트 및/또는 리포터 프로브를 적절하게 포함한다. 일반적으로 이러한 증폭 단계는 일련의 병렬 단일 플렉스(plex), 2 플렉스, 3 플렉스, 4 플렉스, 5 플렉스 또는 6 플렉스 반응에서 발생하지만 더 높은 수준의 병렬 멀티플렉싱도 의도된 범위 내에 있다. 이들 방법은 관심 핵산 분자를 증폭 및/또는 검출하기 위해 각각의 웰 또는 챔버에서 RT-PCR과 같은 PCR 방법론을 포함할 수 있다.
저밀도 어레이에는 수 천개의 분자가 아닌 수십 개 또는 수백 개의 분자를 감지하는 어레이가 포함될 수 있다. 이들 어레이는 고밀도 어레이보다 더 민감할 수 있다. 구현예에서, 저 밀도 어레이, 가령, TaqMan™ 저밀도 어레이가 사용되어 WO2018175501의 표 5-12 중 어느 하나에서 하나 이상의 유전자 또는 유전자 산물을 검출할 수 있다. 예를 들어, 저밀도 어레이는 WO2018175501의 표 5-12 중 어느 것으로부터 선택된 적어도 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 40, 50, 60, 70, 80, 90 또는 100 유전자 또는 유전자 산물을 검출하도록 사용될 수 있다.
일부 구체예에서, 개시된 방법은 미세 유체 장치, "랩 온 칩" 또는 마이크로 토탈 분석 시스템(pTAS)을 포함한다. 일부 구체예에서, 샘플 준비는 미세 유체 장치를 사용하여 수행된다. 일부 구체예에서, 증폭 반응은 미세 유체 장치를 사용하여 수행된다. 일부 구체예에서, 시퀀싱 또는 PCR 반응은 미세 유체 장치를 사용하여 수행된다. 일부 구체예에서, 증폭된 산물의 적어도 일부의 뉴클레오티드 서열은 미세 유체 장치를 사용하여 수득된다. 일부 구체예에서, 검출은 미세 유체 장치, 비제한적 예를 들면 TaqMan ™ 저밀도 어레이와 같은 저밀도 어레이를 포함한다. 예시적인 미세 유체 장치의 설명은 예를 들어 공개 PCT 출원 번호 WO/0185341 및 WO 04/011666, Kartalov and Quake, Nucl.Acids Res.32:2873-79, 2004; 및 Fiorini and Chiu, Bio Techniques 38:429-46, 2005에 개시되어 있다.
임의의 적절한 미세 유체 장치가 본 명세서에 기재된 방법에서 사용될 수 있다. 분자 프로파일링과 함께 사용되도록 사용되거나 구성될 수 있는 미세 유체 장치의 예는 비제한적 예를 들어, 미국 특허 번호 7,591,936, 7,581,429, 7,579,136, 7,575,722, 7,568,399, 7,552,741, 7,544,506, 7,541,578, 7,518,726, 7,488,596, 7,485,214, 7,467,928, 7,452,713, 7,452,509, 7,449,096, 7,431,887, 7,422,725, 7,422,669, 7,419,822, 7,419,639, 7,413,709, 7,411,184, 7,402,229, 7,390,463, 7,381,471, 7,357,864, 7,351,592, 7,351,380, 7,338,637, 7,329,391, 7,323,140, 7,261,824, 7,258,837, 7,253,003, 7,238,324, 7,238,255, 7,233,865, 7,229,538, 7,201,881, 7,195,986, 7,189,581, 7,189,580, 7,189,368, 7,141,978, 7,138,062, 7,135,147, 7,125,711, 7,118,910, 7,118,661, 7,640,947, 7,666,361, 7,704,735; 미국 특허 출원 공개 번호 20060035243; 및 국제 특허 공개 번호 WO 2010/072410가 있으며, 이들 각각은 그 전체가 본 명세서에 참조로서 포함된다. 본 명세서에 개시된 방법과 함께 사용되기 위한 또 다른 예시가 Chen et al., "Microfluidic isolation and transcriptome analysis of serum vesicles," Lab on a Chip, Dec.8, 2009 DOI: 10.1039/b916199f에 기재되어 있다.
대량 병렬 시그니처 시퀀싱(MPSS: Massively Parallel Signature Sequencing)에 의한 유전자 발현 분석
Brenner et al.(2000) Nature Biotechnology 18:630-634에 의해 기재되어 있는 이 방법은 개별 마이크로비즈 상의 수십억 개의 템플릿의 체외 복제와 비-겔-기반 시그니처 시퀀싱을 조합하는 시퀀싱 방식이다. 첫째, DNA 템플릿의 마이크로비즈 라이브러리는 체외 복제에 의해 구축된다. 그 후 고밀도에서 플로우 셀에서 템플릿이 포함된 마이크로 비드의 평면의 어레이가 뒤 따른다. DNA 단편 분리가 필요 없는 형광 기반 시그니처 시퀀싱 방법을 사용하여 각 마이크로비즈에서 복제된 템플릿의 자유 단부가 동시에 분석된다. 이 방법은 cDNA 라이브러리에서 수십만 개의 유전자 서명 서열을 단일 작업으로 동시에 정확하게 제공하는 것으로 나타났다.
MPSS 데이터에는 많은 용도가 있다. 거의 모든 전사체의 발현 수준은 정량적으로 결정될 수 있다, 풍부한 시그니처는 분석된 조직에서 유전자의 발현 수준을 나타낸다. 태그 빈도 분석 및 라이브러리 간의 차이 감지를위한 정량적 방법이 게시되어 SAGE™ 데이터에 대한 공용 데이터베이스에 통합되었으며 MPSS 데이터에 적용할 수 있다. 완전한 게놈 서열의 가용성은 게놈 서열에 대한 서명의 직접 비교를 허용하고 MPSS 데이터의 유용성을 더욱 확장한다. MPSS 분석 대상이 (마이크로어레이에서와 같이) 미리 선택되지 않았기 때문에 MPSS 데이터는 전 사체의 전체 복잡성을 특징화 할 수 있다. 이는 수백만 개의 EST를 한 번에 시퀀싱하는 것과 유사하며, 게놈 서열 데이터를 사용하여 MPSS 서명의 소스를 계산 수단으로 쉽게 식별할 수 있다.
유전자 발현의 연속 분석(SAGE: Serial Analysis of Gene Expression)
SAGE(Serial Analysis of Gene Expression)는 각각의 전사체에 대해 개별 혼성화 프로브를 제공 할 필요없이 다수의 유전자 전 사체를 동시에 정량적으로 분석할 수 있는 방법이다. 먼저, 각각의 전사체 내의 고유한 위치에서 태그를 얻는 경우 전 사체를 고유하게 식별하는 데 충분한 정보를 포함하는 짧은 서열 태그(가령, 약 10-14bp)가 생성된다. 그런 다음, 많은 전사체가 서로 연결되어 긴 연속 분자를 형성하며, 이는 시퀀싱될 수 있으며 동시에 여러 태그의 정체성을 드러낸다. 모든 전사체 집단의 발현 패턴은 개별 태그의 풍부도를 결정하고 각각의 태그에 해당하는 유전자를 식별하여 정량적으로 평가할 수 있다. 예를 들어 Velculescu et al.(1995) Science 270:484-487; and Velculescu et al.(1997) Cell 88:243-51를 참조할 수 있다.
DNA 복제수 프로파일링
특정 샘플의 DNA 복제수 프로파일을 결정할 수 있는 임의의 방법은 해상도가 본 명세서에 기재된 바이오마커에서 복제수 변이를 확인하기에 충분하다면 본 명세서에 기재된 방법에 따라 분자 프로파일링에 사용될 수 있다. 해당 분야의 통상의 기술자는 본 명세서에 기술 된 방법의 하나 이상의 바이오마커의 복제수를 확인하기에 충분한 해상도로 전체 게놈 복제수 변화를 평가하기위한 다수의 상이한 플랫폼을 인지하고 사용할 수 있다. 플랫폼 및 기술 중 일부는 아래의 실시예에서 설명된다. 본 명세서에 기술 된 일부 구체예에서, 본 명세서에 기술되거나 해당 업계에 공지된 차세대 시퀀싱 또는 ISH 기술은 복제수/유전자 증폭을 결정하기 위해 사용된다.
일부 구체예에서, 복제수 프로파일 분석은 전체 게놈 증폭 방법에 의한 전체 게놈 DNA의 증폭을 포함한다. 전체 게놈 증폭 방법은 가닥 치환 폴리머아제와 랜덤 프라이머를 사용할 수 있다.
이들 구체예의 일부 측면에서, 복제수 프로파일 분석은 전체 게놈 증폭 DNA와 고밀도 어레이의 혼성화를 포함한다. 더 구체적인 측면에서 고밀도 어레이는 5,000개 이상의 서로 다른 프로브를 가진다. 또 다른 특정 측면에서, 고밀도 어레이는 5,000, 10,000, 20,000, 50,000, 100,000, 200,000, 300,000, 400,000, 500,000, 600,000, 700,000, 800,000, 900,000, 또는 1,000,000 이상의 상이한 프로브를 가진다. 또 다른 특정 측면에서, 어레이 상의 상이한 프로브 각각은 약 15 내지 200개의 염기 길이를 갖는 올리고뉴클레오티드이다. 또 다른 특정 양태에서, 어레이상의 상이한 프로브 각각은 약 15 내지 200, 15 내지 150, 15 내지 100, 15 내지 75, 15 내지 60, 또는 20 내지 55 개의 염기 길이를 갖는 올리고뉴클레오티드이다.
일부 구체예에서, 샘플, 예를 들어 종양 유래 세포에 대한 복제수 프로파일을 결정하는 데 도움을주기 위해 마이크로어레이가 사용된다. 마이크로어레이는 전형적으로 어레이 패턴으로 기판(예를 들어, 유리 지지체) 상에 합성되거나 침착된 복수의 올리고머(예를 들어, DNA 또는 RNA 폴리 뉴클레오티드 또는 올리고 뉴클레오티드, 또는 다른 중합체)를 포함한다. 지지체 결합 올리고머는 혼성화 실험에서 샘플 물질(예를 들어, 종양 샘플에서 제조되거나 얻은 핵산)과 혼성화 또는 결합하는 기능을하는 "프로브"이다. 반대 상황도 적용될 수 있다: 샘플은 마이크로어레이 기판에 결합될 수 있고 올리고머 프로브는 혼종화를 위해 용액 내에 있다. 사용시, 어레이 표면은 하나 이상의 프로브에 대한 표적의 특이 적 고친 화성 결합을 촉진하는 조건 하에서 하나 이상의 표적과 접촉된다. 일부 구성에서 샘플 핵산은 형광 태그와 같은 검출 가능한 라벨로 라벨링되어 혼성화 된 샘플 및 프로브를 스캐닝 장비로 검출 할 수 있다. DNA 어레이 기술은 DNA 복제수 프로파일을 분석하기 위해 많은(가령, 수십만 개의) 올리고 뉴클레오티드를 사용할 수 있는 잠재력을 제공한다. 일부 구체예에서, 어레이에 사용되는 기질은 표면-유도체 화 된 유리 또는 실리카, 또는 중합체 막 표면이다(가령, in Z.Guo, et al., Nucleic Acids Res, 22, 5456-65 (1994); U.Maskos, E.M.Southern, Nucleic Acids Res, 20, 1679-84 (1992), and E.M.Southern, et al., Nucleic Acids Res, 22, 1368-73 (1994)를 참조할 수 있으며, 각각은 본 명세서에 참조로서 포함된다). 어레이 기판의 표면 수정은 많은 기술로 수행될 수 있다. 예를 들어, 규산 또는 금속 산화물 표면은 이작용성 실란, 즉 표면에 공유 결합을 가능하게하는 제1 작용기(가령, --SiCl3 또는--Si(OCH3) 3에서와 같은 Si- 할로겐 또는 Si-알콕시 기)으로 유도체화 될 수 있고 생물학적 프로브 어레이를위한 리간드 및/또는 중합체 또는 단량체를 공유 또는 비공유적으로 부착하기 위해 표면에 원하는 화학적 및/또는 물리적 변형을 부여 할 수 있는 제 2 작용기를 갖는 실란일 수 있다. 해당 분야에 알려진 실릴화된 유도체화 및 그 밖의 다른 표면 유도체화(Sundberg의 미국 특허 번호 5,624,711, Willis의 미국 특허 번호 5,266,222, 및 Farnsworth의 미국 특허 번호 5,137,765).어레이를 제조하는 그 밖의 다른 프로세스가 현장 합성 방법에 의해 생성된 DNA 어레이를 개시하는 Agilent Corp에게 양도된 미국 특허 번호 6,649,348에 기재되어 있다.
중합체 어레이 합성은 또한 그 전체가 본 명세서에 참조로서 포함되는 다음의 문헌에 광범위하게 기술되어있다: WO00/58516, 미국 특허 번호 5,143,854, 5,242,974, 5,252,743, 5,324,633, 5,384,261, 5,405,783, 5,424,186, 5,451,683, 5,482,867, 5,491,074, 5,527,681, 5,550,215, 5,571,639, 5,578,832, 5,593,839, 5,599,695, 5,624,711, 5,631,734, 5,795,716, 5,831,070, 5,837,832, 5,856,101, 5,858,659, 5,936,324, 5,968,740, 5,974,164, 5,981,185, 5,981,956, 6,025,601, 6,033,860, 6,040,193, 6,090,555, 6,136,269, 6,269,846 and 6,428,752, 5,412,087, 6,147,205, 6,262,216, 6,310,189, 5,889,165, 및 5,959,098, PCT 출원 번호 PCT/US99/00730 (국제 공개 번호 WO 99/36760) 및 PCT/US01/04285 (국제 공개 번호 WO 01/58593).
본 개시 내용에 유용한 핵산 어레이는 브랜드 명 GeneChip™으로 Affymetrix(캘리포니아 주 산타 클라라)로부터 상업적으로 입수 가능한 것들을 포함하지만 이에 제한되지 않는다. 예제 어레이는 affymetrix.com 웹 사이트에 나와 있다. 또 다른 마이크로어레이 공급 업체는 캘리포니아 샌디에고에 소재하는 Illumina, Inc.이며, 자사 웹 사이트 illumina.com에 예제 어레이가 나와 있다.
일부 구체예에서, 본 발명의 방법은 샘플 제조를 제공한다. 수행될 마이크로어레이 및 실험에 따라, 샘플 핵산은 숙련된 기술자에게 알려진 방법에 의해 다양한 방법으로 제조될 수 있다. 본 명세서에 기재된 일부 측면에서, 유전형 분석(복제수 프로파일 분석) 이전에 또는 이와 동시에, 샘플은 임의의 수의 메커니즘으로 증폭될 수 있다. 사용되는 가장 일반적인 증폭 절차로는 PCR이 있다. 예를 들어, PCR Technology: Principles and Applications for DNA Amplification (Ed.H.A.Erlich, Freeman Press, NY, N.Y., 1992); PCR Protocols: A Guide to Methods and Applications (Eds.Innis, et al., Academic Press, San Diego, Calif., 1990); Mattila et al., Nucleic Acids Res.19, 4967 (1991); Eckert et al., PCR Methods and Applications 1, 17 (1991); PCR (Eds.McPherson et al., IRL Press, Oxford); 및 미국 특허 번호 4,683,202, 4,683,195, 4,800,159 4,965,188, 및 5,333,675를 참조할 수 있으며, 이들 각각은 본 명세서에서 참조로서 포함된다. 일부 구체예에서, 샘플은 어레이상에서 증폭될 수 있다(예를 들어, 본 명세서에 참조로 포함되는 미국 특허 번호 6,300,070를 참조).
또 다른 적절한 증폭 방법은 리가제 연쇄 반응(LCR: ligase chain reaction)(예를 들어, Wu and Wallace, Genomics 4, 560 (1989), Landegren et al., Science 241, 1077 (1988) and Barringer et al.Gene 89:117 (1990)), transcription amplification (Kwoh et al., Proc.Natl.Acad.Sci.USA 86, 1173 (1989) 및 WO88/10315), 자가-지속 서열 복제(Guatelli et al., Proc.Nat.Acad.Sci.USA, 87, 1874 (1990) 및 WO90/06995), 표적 폴리뉴클레오티드 서열의 선택적 증폭(미국 특허 번호 6,410,276), 컨센서스 서열 프라이밍 중합 효소 연쇄 반응(CP-PCR: consensus sequence primed polymerase chain reaction)(미국 특허 번호 4,437,975) , 임의 프라이밍된 폴리머아제 연쇄 반응(AP-PCR: arbitrarily primed polymerase chain reaction)(미국 특허 번호 5,413,909, 5,861,245) 및 핵산 기반 서열 증폭(NABSA: nucleic acid based sequence amplification)(미국 특허 번호 5,409,818, 5,554,517 및 6,063,603 참조, 이들 각각은 본 명세서에 참조로 포함됨)을 포함한다. 사용될 수 있는 다른 증폭 방법은 미국 특허 번호 5,242,794, 5,494,810, 4,988,617 및 미국 특허 출원 번호 09/854,317에 기재된 바가 있으며, 이들 각각은 본 명세서에 참조로 포함된다.
샘플 준비의 추가 방법 및 핵산 샘플의 복잡성을 감소시키기 위한 기법은 Dong et al., Genome Research 11, 1418 (2001), 미국 특허 번호 6,361,947, 6,391,592 및 미국 특허 출원 번호 09/916,135, 09/920,491 (미국 특허 출원 공개 번호 20030096235), 09/910,292 (미국 특허 출원 공개 번호 20030082543), 및 10/013,598에 기재되어 있다.
폴리 뉴클레오티드 혼성화 분석을 수행하는 방법은 해당 업계에서 잘 개발되어있다. 본 명세서에 기재된 방법에 사용되는 혼성화 검정 절차 및 조건은 응용 분야에 따라 달라질 수 있으며 다음과 같은 공지된 일반적인 결합 방법에 따라 선택된다: Maniatis et al.Molecular Cloning: A Laboratory Manual (2.sup.nd Ed.Cold Spring Harbor, N.Y., 1989); Berger and Kimmel Methods in Enzymology, Vol.152, Guide to Molecular Cloning Techniques (Academic Press, Inc., San Diego, Calif., 1987); Young and Davism, P.N.A.S, 80: 1194 (1983). 반복 및 제어된 혼성화 반응을 수행하기 위한 방법 및 장치는 미국 특허 번호 5,871,928, 5,874,219, 6,045,996 및 6,386,749, 6,391,623에 기재되어 있으며, 이들 각각은 참조로서 포함된다.
본 명세서에 기재된 방법은 또한 혼성화 후(및/또는 도중)에서 리간드 간 혼성화의 신호 검출을 포함할 수 있다. 미국 특허 번호 5,143,854, 5,578,832; 5,631,734; 5,834,758; 5,936,324; 5,981,956; 6,025,601; 6,141,096; 6,185,030; 6,201,639; 6,218,803; 및 6,225,625, 미국 특허 출원 번호 10/389,194 및 PCT 출원 PCT/US99/06097 (공개 번호 WO99/47964)를 참조할 수 있으며, 이들 각각은 본 명세서에 참조로서 포함된다.
신호 검출 및 강도 데이터 처리를 위한 방법 및 장치는 예를 들어, 미국 특허 5,143,854, 5,547,839, 5,578,832, 5,631,734, 5,800,992, 5,834,758; 5,856,092, 5,902,723, 5,936,324, 5,981,956, 6,025,601, 6,090,555, 6,141,096, 6,185,030, 6,201,639; 6,218,803; 및 6,225,625, 미국 특허 출원 번호 10/389,194, 60/493,495 및 PCT 출원 번호 PCT/US99/06097(공개 번호 WO99/47964)에 개시되어 있으며, 이들 각각은 본 명세서에 참조로서 포함된다.
면역-기반 검정
단백질-기반 검출 분자 프로파일링 기술은 본 방법에 따라 돌연변이 유전자 코딩된 단백질과 선택적으로 면역 반응하는 항체에 기초한 면역 친화성 검정을 포함한다. 이들 기술은 제한 없이 면역 침전, 웨스턴 블롯 분석, 분자 결합 분석, 효소 결합 면역 흡착 분석(ELISA), 효소 결합 면역 여과 분석(ELIFA), 형광 활성화 세포 분류(FACS) 등을 포함한다. 예를 들어, 샘플에서 바이오마커의 발현을 검출하는 선택적인 방법은 샘플을 바이오마커에 대한 항체, 또는 항체의 면역 반응성 단편, 또는 항체의 항원 결합 영역을 포함하는 재조합 단백질과 접촉시키는 단계, 또는 샘플 내 바이오마커의 결합을 검출하는 단계를 포함한다. 이러한 항체를 생산하는 방법은 해당 업계에 공지되어있다. 항체는 용액 샘플에서 특정 단백질을 면역 침전시키거나 예를 들어 폴리아크릴아미드 겔로 분리된 단백질을 면역 블롯하는 데 사용될 수 있다. 면역 세포 화학적 방법은 조직이나 세포에서 특정 단백질 다형성을 검출하는 데에도 사용할 수 있다. 예를 들어, ELISA, 방사성 면역 분석(RIA), 면역 방사성 분석(IRMA) 및 면역 효소 분석(IEMA), 가령 단클론 또는 다클론 항체를 사용한 샌드위치 검정을 포함하는 다른 잘 알려진 항체 기반 기술이 또한 사용될 수 있다. 예를 들어, 미국 특허 번호 4,376,110 및 4,486,530를 참조할 수 있으며, 이들 각각은 참조로서 포함된다.
대안적인 방법에서, 샘플은 항체-바이오마커 복합체가 형성하기에 충분한 조건 하에서 바이오마커에 특이적인 항체와 접촉한 다음 상기 복합체를 검출 할 수 있다. 바이오마커의 존재는 혈장 또는 혈청을 포함한 다양한 조직 및 샘플을 검정하기 위한 웨스턴 블롯팅 및 ELISA 절차와 같은 다양한 방법으로 검출될 수 있다. 이러한 분석 형식을 사용하는 광범위한 면역 분석 기술은 가령, 4,016,043, 4,424,279 및 4,018,653에서 이용 가능하다. 여기에는 비경쟁 유형의 1-사이트 및 2-사이트 또는 "샌드위치" 검정뿐만 아니라 전통적인 경쟁 결합 분석이 포함된다. 이들 검정은 라벨링된 항체가 표적 바이오마커에 직접 결합하는 것을 포함한다.
샌드위치 분석 기술의 많은 변형이 존재하며, 모두 본 방법에 포함되도록 의도된다. 간단히 말하면, 전형적인 순방향 분석에서, 라벨링되지 않은 항체는 고체 기질에 고정되고 테스트 할 샘플은 결합된 분자와 접촉하게 된다. 적절한 배양 기간 후, 항체-항원 복합체의 형성을 허용하기에 충분한 시간 동안 검출 가능한 신호를 생성할 수 있는 리포터 분자로 라벨링된 항원에 특이적인 2차 항체를 첨가하고 배양하여 시간이 허용된다. 반응하지 않은 물질은 씻어 내고 항원의 존재는 리포터 분자에 의해 생성 된 신호를 관찰하여 결정된다. 결과는 가시적 신호를 간단히 관찰하여 정성 적이거나 알려진 양의 바이오마커를 포함하는 대조 샘플과 비교하여 정량화할 수 있다.
순방향 분석의 변형에는 샘플과 라벨링된 항체가 결합된 항체에 동시에 추가되는 동시 분석이 포함된다. 이들 기법은 용이하게 명백한 임의의 사소한 변형을 포함하여 해당 분야의 통상의 기술자에게 잘 알려져있다. 전형적인 포워드 샌드위치 검정에서 바이오마커에 대한 특이성을 갖는 첫 번째 항체는 고체 표면에 공유 또는 수동적으로 결합된다. 고체 표면은 일반적으로 유리 또는 폴리머이며 가장 일반적으로 사용되는 폴리머는 셀룰로오스, 폴리 아크릴 아미드, 나일론, 폴리스티렌, 폴리 염화 비닐 또는 폴리 프로파일렌이다. 고체 지지체는 튜브, 비드, 마이크로 플레이트 디스크, 또는 면역 분석을 수행하기에 적합한 다른 표면의 형태일 수 있다. 결합 공정은 해당 업계에 잘 알려져 있으며 일반적으로 가교 결합 또는 물리적 흡착으로 구성되며, 중합체-항체 복합체는 시험 샘플을 위한 준비에서 세척된다. 그런 다음 검사될 샘플의 분취량을 고체상태 복합체에 첨가하고 충분한 시간(가령, 2-40분 또는 더 편리하게는 밤새) 동안 적절한 조건(가령, 실온에서 40 까지, 가령, 25
까지, 가령, 25 내지 32
내지 32 경계값 포함))에서 배양하여, 항체에 존재하는 임의의 서브유닛의 결합을 허용한다. 배양 기간 후, 항체 서브유닛 고체상은 세척 및 건조되고 바이오마커의 일부에 특이적인 제2 항체와 함께 배양된다. 제2 항체는 분자 마커에 대한 제2 항체의 결합을 나타내는 데 사용되는 리포터 분자에 연결된다.
경계값 포함))에서 배양하여, 항체에 존재하는 임의의 서브유닛의 결합을 허용한다. 배양 기간 후, 항체 서브유닛 고체상은 세척 및 건조되고 바이오마커의 일부에 특이적인 제2 항체와 함께 배양된다. 제2 항체는 분자 마커에 대한 제2 항체의 결합을 나타내는 데 사용되는 리포터 분자에 연결된다.
대안적인 방법은 샘플에서 표적 바이오마커를 고정시킨 다음 고정된 표적을 리포터 분자로 라벨링되거나 라벨링되지 않을 수 있는 특정 항체에 노출시키는 것을 포함한다. 표적의 양과 리포터 분자 신호의 강도에 따라, 결합된 표적은 항체로 직접 라벨링하여 검출될 수 있다. 대안으로, 제1 항체에 특이적인 제2 라벨링된 항체는 표적-제1 항체 복합체에 노출되어 표적-제1 항체-제2 항체 삼원 복합체를 형성할 수 있다. 이 복합체는 리포터 분자에 의해 방출되는 신호에 의해 검출된다. 본 명세서에서 사용되는 "리포터 분자"는 화학적 성질에 의해 항원 결합 항체의 검출을 허용하는 분석적으로 식별 가능한 신호를 제공하는 분자를 의미한다. 이 유형의 분석에서 가장 일반적으로 사용되는 리포터 분자는 효소, 형광단 또는 방사성 핵종 함유 분자(즉, 방사성 동위 원소) 및 화학 발광 분자이다.
효소 면역 검정의 경우, 효소는 일반적으로 글루타르알데히드 또는 과아이오딘산염에 의해 제2 항체에 공액결합된다. 그러나 쉽게 인식되는 바와 같이, 숙련된 기술자가 쉽게 이용할 수 있는 매우 다양한 상이한 접합 기술이 존재한다. 일반적으로 사용되는 효소에는 겨자무 페록시다제, 포도당 옥시다제, β-갈락토시다제 및 알칼리성 포스파타제가 포함된다. 특정 효소와 함께 사용될 기질은 일반적으로, 대응하는 효소에 의한 가수 분해 시, 검출 가능한 색상 변화의 생산을 위해 선택된다. 적합한 효소의 예로는 알칼리성 포스파타제 및 페록시다제를 포함한다. 앞서 언급된 발색 기질보다는 형광 산물을 생성하는 형광 기질을 사용하는 것이 가능하다. 모든 경우에, 효소-라벨링된 항체는 제1 항체-분자 마커 복합체에 추가되고 결합이 허용된 다음 여분의 시약이 세척된다. 그런 다음 적절한 기질을 포함하는 용액을 항체-항원-항체 복합체에 첨가된다. 기질은 제2 항체에 연결된 효소와 반응하여 정성적인 시각 신호를 제공하며, 이는 샘플에 존재하는 바이오마커의 양을 표시하기 위해 일반적으로 분광 광도계로 추가 정량화될 수 있다. 대안으로, 형광 화합물, 가령, 플루오레세인 및 로다민이 결합 능력을 변경하지 않고 항체에 화학적으로 결합될 수 있다. 특정 파장의 광으로의 조명에 의해 활성화될 때, 형광색소-라벨링된 항체가 광 에너지를 흡수하여, 분자의 여기 상태를 유도하고, 광학 현미경으로 시각적으로 검출 가능한 특성 색상에서 광의 발산이 뒤 따를 수 있다. EIA에서와 같이, 형광 라벨링된 항체는 제1 항체-분자 마커 복합체로 결합될 수 있다. 결합되지 않은 시약을 세척한 후, 나머지 3원 복합체를 적절한 파장의 광에 노출시키고 관찰된 형광은 관심 분자 마커의 존재를 나타낸다. 면역형광 및 EIA 기법은 모두 해당 분야에서 매우 잘 확립되어 있다. 그러나, 그 밖의 다른 리포터 분자, 가령, 방사성 동위 원소, 화학 발광 또는 생물 발광 분자도 사용될 수 있다.
면역 조직 화학(IHC: Immunohistochemistry)
IHC는 조직의 항원에 특이적으로 결합하는 항체의 세포에서 항원(가령, 단백질)을 국소화하는 과정이다. 항원-결합 항체는 예를 들어 시각화를 통해 검출을 허용하는 태그에 접합되거나 융합될 수 있다. 일부 구체예에서, 태그는 발색 반응을 촉진시킬 수 있는 효소, 가령, 알칼리성 포스파타제 또는 겨자무 페록시다제이다. 효소는 예를 들어 비오틴-아바딘 시스템을 이용해, 항체에 융합되거나 비공유 결합될 수 있다. 대안으로, 항체는 형광단, 가령, 플루오레세인, 로다민, DyLight Fluor 또는 Alexa Fluor으로 태깅될 수 있다. 항원-결합 항체는 직접 태그가 지정되거나 태그를 포함하는 검출 항체에 의해 자체적으로 인식될 수 있다. IHC를 사용하여 하나 이상의 단백질이 검출될 수 있다. 유전자 산물의 발현은 대조군 수준과 비교하여 염색 강도와 관련이 있을 수 있다. 일부 구체예에서, 유전자 산물은 이의 염색이 샘플과 대조군에서 적어도 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0, 2.2, 2.5, 2.7, 3.0, 4, 5, 6, 7, 8, 9 또는 10-배로 변하는 경우 차등적으로 발현되는 것으로 간주된다.
IHC는 항원-항체 상호 작용을 조직 화학적 기술에 적용하는 것을 포함한다. 예를 들면, 조직 섹션은 슬라이드에 장착되고 항원에 특이적인 항체(다 클론 또는 단일 클론)와 함께 배양된다(1 차 반응). 그런 다음 항원-항체 신호는 페록시다제(PAP), 아비딘-비오틴-페록시다제(ABC) 또는 아비딘-비오틴 알칼리 포스파타제의 복합체에 공액결합된 제2 항체를 사용하여 증폭된다. 기질과 발색원의 존재하에 효소는 항체-항원 결합 부위에 컬러링된 침착물을 형성한다. 면역형광(immunofluorescence)은 항원을 시각화하는 대체 접근 방식이다. 이 기술에서 1차 항원-항체 신호는 형광 색소에 공액 연결된 제2 항체를 사용하여 증폭된다. UV 광 흡수에서 형광 색소는 더 긴 파장(형광)에서 자체 빛을 방출하므로 항체-항원 복합체의 국소화가 가능하다.
후성적 상태(Epigenetic Status)
본 개시 내용에 따른 분자 프로파일링 방법은 또한 후성적 변화, 즉 메틸화 상태 또는 히스톤 아세틸 화의 변화와 같은 후성적 메커니즘에 의해 야기되는 유전자의 변형을 측정하는 것을 포함한다. 종종, 후성 유전학적 변화는 후성 유전적 변화의 지표로서 (적절한 RNA 또는 단백질 수준에서) 검출될 수 있는 유전자 발현 수준의 변화를 초래할 것이다. 종종, 후성 유전적 변화는 "후성 유전적 침묵"이라고하는 유전자의 침묵 또는 하향 조절을 초래한다. 본 명세서에 기재된 방법에서 가장 빈번하게 조사되는 후성 유전적 변화는 유전자의 DNA 메틸화 상태를 결정하는 것을 포함하며, 여기서 메틸화 수준의 증가는 (유전자 발현의 하향 조절을 유발할 수 있기 때문에) 일반적으로 관련 암과 관련이 있다. 유전자 또는 유전자의 과메틸화라고도 할 수 있는 비정상적인 메틸화가 검출될 수 있다. 전형적으로, 메틸화 상태는 유전자(들)의 프로모터 영역에서 종종 발견되는 적합한 CpG 섬에서 결정된다. 용어 "메틸화", "메틸화 상태" 또는 "메틸화 상태"는 DNA 서열 내의 하나 또는 복수의 CpG 디뉴클레오티드에서 5-메틸시토신의 존재 또는 부재를 지칭할 수 있다. CpG 디뉴클레오티드는 일반적으로 인간 유전자의 프로모터 영역 및 엑손에 집중되어 있다.
감소된 유전자 발현은 DNA 메틸화 상태 또는 유전자의 메틸화 상태에 의해 결정된 발현 수준의 관점에서 평가될 수 있다. 후성 유전적 침묵을 검출하는 한 가지 방법은 정상 세포에서 발현되는 유전자가 종양 세포에서 덜 발현되는지 또는 발현되지 않는지 확인하는 것이다. 따라서, 본 개시 내용은 후성적 침묵을 검출하는 것을 포함하는 분자 프로파일링 방법을 제공한다.
메틸화를 직접 검출하기 위한 다양한 분석 절차가 당 업계에 공지되어 있으며, 본 방법과 함께 사용될 수 있다. 이러한 분석은 바이설파이트(bisulphite) 변환 기반 방식과 비-바이설파이트(non-bisulphite) 기반 방식의 두 가지 개별 방식을 이용한다. DNA 메틸화 분석을 위한 비-바이설파이트 기반 방법은 메틸화 민감성 효소가 제한에서 메틸화 시토신을 절단할 수 없음을 이용한다. 바이설파이트 변환은 비메틸화 시토신을 우라실로 변환하는 나트륨 바이설파이트로 DNA 샘플을 처리하는 데 의존하며, 메틸화 시토신은 유지된다(Furuichi Y, Wataya Y, Hayatsu H, Ukita T.Biochem Biophys Res Commun.1970 Dec 9;41(5):1185-91). 이 변환으로 인해 원래 DNA의 서열이 변경된다. 이러한 변화를 검출하기 위한 방법은 MS AP-PCR (Methylation-Sensitive Arbitrarily-Primed Polymerase Chain Reaction), Gonzalgo et al., Cancer Research 57:594-599, 1997에 기재된 CpG 디뉴클레오티드를 함유할 가능성이 가장 높은 영역에 포커싱하는 CG-농후 프라이머를 이용한 게놈의 전역 스캔을 가능하게 하는 기법; Eads et al., Cancer Res.59:2302-2306, 1999에 기재된 형광-기반 실시간 PCR 기법으로 지칭되는 MethyLight™; 본 명세서에서, 사이의 CpG 위치를 커버하거나 증폭 프라이머에 의해 커버되는 메틸화 특이 차단 프로브(블로커라고도 지칭됨)이 핵산 샘플의 메틸화 특이 선택 증폭을 활성화한는 분석으로 구현되는 HeavyMethyl™ 분석, MethyLight™ 분석이 증폭 프라이머들 간 CpG 위치를 커버하는 메틸화 특이 차단 프로브와 결합된 MethyLight™ 분석의 변형인 HeavyMethyl™MethyLight™, Gonzalgo & Jones, Nucleic Acids Res.25:2529-2531, 1997에 기재된 분석인 Ms-SNuPE (Methylation-sensitive Single Nucleotide Primer Extension), Herman et al.Proc.Natl.Acad.Sci.USA 93:9821-9826, 1996, 및 U.S.Pat.No.5,786,146에 기재된메틸화 분석인 MSP (Methylation-specific PCR); Xiong & Laird, Nucleic Acids Res.25:2532-2534, 1997에 기재된 메틸화 분석인 COBRA (Combined Bisulfite Restriction Analysis), Toyota et al., Cancer Res.59:2307-12, 1999, 및 WO 00/26401A1에 기재된 메틸화 분석인 MCA (Methylated CpG Island Amplification)를 포함한다.
DNA 메틸화 분석을 위한 또 다른 기법으로는 시퀀싱, MS-PCR(methylation-specific PCR), McMS-PCR(melting curve methylation-specific PCR), 바이설파이트 처리를 동반하거나 동반하지 않는 MLPA, QAMA, MSRE-PCR, MethyLight, ConLight-MSP, BS-MSP(bisulfite conversion-specific methylation-specific PCR), COBRA (소듐 바이설파이트-처리 DNA의 PCR 생산에서 메틸화 종속 서열 차이를 드러내도록 제한 효소를 사용하는 것을 이용함), MS-SNuPE(methylation-sensitive single-nucleotide primer extension conformation), MS-SSCA(methylation-sensitive single-strand conformation analysis), McCOBRA(Melting curve combined bisulfite restriction analysis), PyroMethA, HeavyMethyl, MALDI-TOF, MassARRAY, QAMA(Quantitative analysis of methylated alleles), ERMA(enzymatic regional methylation assay), QBSUPT, MethylQuant, 정량적 PCR 시퀀싱 및 올리고뉴클레오티드-기반 마이크로어레이 시스템, 파이로시퀀싱, Meth-DOP-PCR이 있다. 일부 유용한 기술에 대한 리뷰가 본 명세서에서 그 전체가 참조로서 포함되는 Nucleic acids research, 1998, Vol.26, No.10, 2255-2264; Nature Reviews, 2003, Vol.3, 253-266; Oral Oncology, 2006, Vol.42, 5-13에 제공되어 있다. 이들 기술 중 임의의 것이 본 방법에 따라 적절하게 사용될 수 있다. 그 밖의 다른 기술은 미국 특허 공개 20100144836; 및 20100184027에 기재되어 있으며, 이들 출원은 그 전체가 참조로서 본 명세서에 포함된다.
다양한 아세틸라제와 탈 아세틸라제의 활성을 통해 히스톤 단백질의 DNA 결합 기능이 엄격하게 조절된다. 또한, 히스톤 아세틸화 및 히스톤 탈 아세틸화가 악성 진행과 관련이 있다. Nature, 429: 457-63, 2004를 참조할 수 있다. 히스톤 아세틸화를 분석하는 방법은 미국 특허 공개 번호 20100144543 및 20100151468에 기재되어 있으며,이 출원은 그 전체가 본 명세서에 참조로 포함된다.
서열 분석
본 개시 내용에 따른 분자 프로파일링은 개체가 하나 이상의 유전자 또는 유전자 산물에 하나 이상의 뉴클레오티드 변이체(또는 아미노산 변이체)를 갖는지 여부를 결정함으로써 하나 이상의 바이오마커를 유전형화하는 방법을 포함한다. 일부 구체예에서 본 명세서에 기재된 방법에 따라 하나 이상의 유전자를 유전형화하는 것은 치료 선택에 대한 더 많은 증거를 제공 할 수 있다.
본 명세서에 기재된 바와 같은 바이오마커는 핵산 또는 이들이 코딩하는 단백질의 변경을 결정하는 데 유용한 임의의 방법에 의해 분석될 수 있다. 한 실시 양태에 따르면, 해당 분야의 통상의 기술자는 결실 돌연변이, 삽입 돌연변이, 프레임 이동 돌연변이, 넌센스 돌연변이, 미스센스 돌연변이 및 스플라이스 돌연변이를 포함하는 돌연변이에 대한 하나 이상의 유전자를 분석할 수 있다.
하나 이상의 유전자 분석에 사용되는 핵산은 표준 방법론에 따라 샘플의 세포에서 분리할 수 있다(Sambrook et al., 1989). 예를 들어, 핵산은 게놈 DNA 또는 분획화되거나 전체 세포 RNA, 또는 엑소좀 또는 세포 표면으로부터 획득된 miRNA일 수 있다. RNA가 사용되는 경우, RNA를 상보적인 DNA로 변환하는 것이 바람직할 수 있다. 한 구체예에서, RNA는 전체 세포 RNA이고, 또 다른 예에서, 폴리-A RNA이며, 또 다른 예에서, 엑소좀 RNA이다. 일반적으로, 핵산이 증폭된다. 하나 이상의 유전자를 분석하기 위한 분석의 형식에 따라, 관심 특정 핵산은 증폭을 사용하여 직접 또는 증폭 후 두 번째 알려진 핵산을 사용하여 샘플에서 식별된다. 다음으로, 식별된 산물이 검출된다. 특정 적용예에서, 검출은 시각적 수단(예를 들어, 겔의 에티듐 브로마이드 염색)에 의해 수행될 수 있다. 대안으로, 검출은 화학 발광, 라디오라벨 또는 형광 라벨의 방사성 신티그라피를 통한 제품의 간접 식별을 포함하거나 심지어 전기 또는 열 충격 신호를 사용하는 시스템을 통해 포함될 수 있다(Affymax Technology; Bellus, 1994).
본 명세서에 기재된 바와 같이 다양한 유형의 결함이 바이오마커에서 발생하는 것으로 알려져있다. 변경에는 삭제, 삽입, 점 돌연변이 및 복제가 포함되며, 이에 제한되지는 않는다. 점 돌연변이는 침묵하거나 중지 코돈, 프레임 이동 돌연변이 또는 아미노산 치환을 초래할 수 있다. 하나 이상의 유전자의 코딩 영역 내부 및 외부의 돌연변이가 발생할 수 있으며 본 명세서에 기재된 방법에 따라 분석될 수 있다. 관심 핵산의 표적 부위는 서열이 변하는 영역을 포함할 수 있다. 예에는 상이한 형태로 존재하는 다형성, 가령, 단일 뉴클레오티드 변이, 뉴클레오티드 반복, 다중 염기 결실(컨센서스 서열에서 삭제된 둘 이상의 뉴클레오티드), 다중 염기 삽입(컨센서스 서열에서 삽입 된 둘 이상의 뉴클레오티드), 미세 위성 반복(전형적인 5-1000 반복 단위를 가진 적은 수의 뉴클레오티드 반복), 디-뉴클레오티드 반복, 트리-뉴클레오티드 반복, 서열 재배열(전위 및 복제 포함), 키메라 서열(상이한 유전자 기원으로부터의 두 서열이 함께 융합됨) 등이 있으며, 이에 한정되지는 않는다. 서열 다형성 중, 인간 게놈에서 가장 빈번한 동질이상은 단일-염기 변이이며, 또한 단일-뉴클레오티드 다형성(SNP: single-nucleotide polymorphism)이라고도 한다. SNP는 풍부하고, 안정적이며, 게놈 전체에 널리 분포되어 있다.
분자 프로파일링은 하나 이상의 유전자를 하플로타이핑하는 방법을 포함한다. 하플로타입은 단일 염색체에 위치한 일련의 유전적 결정 인자이며 일반적으로 염색체 영역에 대립 유전자의 특정 조합(유전자의 모든 대체 서열)을 포함한다. 즉, 하플로타입은 개별 염색체에 대한 위상 시퀀스 정보이다. 염색체의 단계적 SNP는 하플로타입을 정의하는 것이 매우 흔하다. 염색체의 하플로타입의 조합은 세포의 유전적 프로파일을 결정할 수 있다. 특정 유전 표지와 질병 돌연변이 사이의 연관성을 결정하는 것은 하플로타입이다. 하플로타입은 해당 분야에 알려진 임의의 방법에 의해 수행될 수 있다. SNP를 채점하는 일반적인 방법은 Landgren et al., Genome Research, 8:769-776, 1998에서 검토된 혼성화 마이크로어레이 또는 직접 겔 시퀀싱이 포함된다. 예를 들어, 하나 이상의 유전자의 사본 하나만 개인으로부터 단리될 수 있으며 각각의 변이 위치에서 뉴클레오티드가 결정된다. 대안으로, 대립 유전자 특이적 PCR 또는 유사한 방법을 사용하여 개체에서 하나 이상의 유전자의 하나의 복제만을 증폭시킬 수 있으며, 본 개시 내용의 변이 위치에서의 SNP가 결정된다. 해당 분야에서 알려진 Clark 방법은 또한 일배 체형화를 위해 사용될 수 있다. 고 처리량 분자 하플로타이핑 방법은 또한 본 명세서에 참조로서 포함된 Tost et al., Nucleic Acids Res., 30(19):e96 (2002)에 개시되어있다.
따라서, 본 개시 내용의 변이 및/또는 하플로타입과 연관 불균형에있는 추가 변이체(들)는 유전학 및 하플로타이핑 분야의 숙련된 기술자에게 명백한 바와 같이 해당 업계에 공지된 하플로타이핑 방법에 의해 식별될 수 있다. 본 개시 내용의 변이체 또는 하플로타입과 연관 불균형에있는 추가 변이체는 또한 아래에 기재된 바와 같이 다양한 적용에서 유용 할 수 있다.
유전형 분석 및 하플로타이핑을 위해, 게놈 DNA와 mRNA/cDNA가 모두 사용될 수 있으며, 둘 다 본 명세서에서 일반적으로 "유전자"로 지칭된다.
뉴클레오티드 변이체를 검출하기 위한 수많은 기술이 해당 업계에 공지되어 있으며 모두 본 개시 내용의 방법에 사용될 수 있다. 기술은 단백질 기반 또는 핵산 기반일 수 있다. 어느 경우라도, 사용되는 기술이 작은 뉴클레오티드 또는 아미노산 변이를 정확하게 감지 할 수 있도록 충분히 민감해야 한다. 검출 가능한 마커로 라벨링된 프로브가 매우 일반적으로 사용된다. 하기 기재된 특정 기술에서 달리 명시되지 않는 한, 방사성 동위 원소, 형광 화합물, 스트렙타비딘을 사용하여 검출 할 수 있는 비오틴, 효소(가령, 알칼리성 포스파타제), 효소, 리간드 및 항체 등의 해당 분야에 알려진 임의의 적절한 마커가 사용될 수 있다. Jablonski et al., Nucleic Acids Res., 14:6115-6128 (1986); Nguyen et al., Biotechniques, 13:116-123 (1992); Rigby et al., J.Mol.Biol., 113:237-251 (1977)를 참조할 수 있다.
핵산 기반 검출 방법에서 표적 DNA 샘플, 즉 하나 이상의 유전자에 해당하는 게놈 DNA, cDNA, mRNA 및/또는 miRNA를 포함하는 샘플이 검사 대상 개체로부터 얻어져야 한다. 하나 이상의 유전자에 대응하는 게놈 DNA, miRNA, mRNA 및/또는 cDNA(또는 이의 일부)를 포함하는 임의의 조직 또는 세포 샘플이 사용될 수 있다. 이를 위해 세포핵과 게놈 DNA를 포함하는 조직 샘플을 개체로부터 얻을 수 있다. 백혈구와 다른 림프구에만 세포핵이 있는 반면 적혈구에는 핵이 없고 mRNA 또는 miRNA 만 포함한다는 점을 제외하면 혈액 샘플도 유용 할 수 있다. 그럼에도 불구하고, miRNA와 mRNA는 또한 그 서열에서 뉴클레오티드 변이체의 존재를 분석하거나 cDNA 합성을 위한 템플릿으로 사용할 수 있기 때문에 유용하다. 조직 또는 세포 샘플은 많은 처리없이 직접 분석될 수 있다. 대안으로, 표적 서열을 포함하는 핵산은 아래에서 논의되는 다양한 검출 절차를 거치기 전에 추출, 정제 및/또는 증폭될 수 있다. 조직 또는 세포 샘플 이외에, 검사 대상 개체로부터 얻은 조직 또는 세포 샘플을 사용하여 구축된 cDNA 또는 게놈 DNA 라이브러리의 cDNA 또는 게놈 DNA도 유용하다.
특정 뉴클레오티드 변이체의 존재 또는 부재를 결정하기 위해, 표적 게놈 DNA 또는 cDNA, 특히, 검출될 뉴클레오티드 변이체 자리를 포함하는 영역의 시퀀싱. 다양한 시퀀싱 기법이 일반적으로 알려져 있고 널리 사용되며, 예를 들어 Sanger 방법 및 Gilbert 화학 방법이 있다. 파이로시퀀싱(pyrosequencing) 방법은 발광 검출 시스템을 사용하여 실시간으로 DNA 합성을 모니터링한다. 파이로시퀀싱은 단일 뉴클레오티드 다형성과 같은 유전적 다형성을 분석하는 데 효과적인 것으로 나타났으며 본 방법에서도 사용할 수 있다. Nordstrom et al., Biotechnol.Appl.Biochem., 31(2):107-112 (2000); Ahmadian et al., Anal.Biochem., 280:103-110 (2000)을 참조할 수 있다.
핵산 변이체는 적절한 검출 과정을 통해 검출될 수 있다. 검출, 정량화, 시퀀싱 등의 방법의 비제한적 예를 들면 다음과 같다: 질량 변형 앰플리콘의 질량 검출(가령, MALDI(matrix-assisted laser desorption ionization) 질량분석계 및 ES(electrospray) 질량 분석계), 프라이머 확장 방법(가령, iPLEX™; Sequenom, Inc.), 미세시퀀싱 방법(가령, 수정된 프라이머 확장 방법), 리가제 서열 결정 방법(가령, 미국 특허 번호 5,679,524 및 5,952,174, 및 WO 01/27326), 불일치 서열 결정 방법(가령, 미국 특허 번호 5,851,770; 5,958,692; 6,110,684; 및 6,183,958), 직접 DNA 시퀀싱, FA(fragment analysis), RFLP(restriction fragment length polymorphism) 분석, ASO(allele specific oligonucleotide) 분석, MSPCR(methylation-specific PCR), 파이로시퀀싱 분석, 아시클로프라임 분석, 역 도트 블롯, GeneChip 마이크로어레이, DASH(Dynamic allele-specific hybridization), PNA(Peptide nucleic acid) 및 LNA(locked nucleic acids) 프로브, TaqMan, 분자 비컨, 인터칼레이팅 염료, FRET 프라이머, AlphaScreen, SNPstream, GBA(genetic bit analysis), 멀티플렉스 미니시퀀싱, SNaPshot, GOOD 분석, 마이크로어레이 미니시퀀싱, APEX(arrayed primer extension), 마이크로어레이 프라이머 확장(가령, 마이크로어레이 서열 결정 방법), 태그 어레이, 코딩된 미세구체, TDI(Template-directed incorporation), 형광 편광, 색채학적 OLA(oligonucleotide ligation assay), 서열-코딩된 OLA, 마이크로어레이 결찰, 리가제 연쇄 반응, 패들락 프로브(Padlock probe), 전화 분석, 혼종화 방법(가령, 적어도 하나의 프로브를 이용한 혼종화, 적어도 하나의 형광 라벨링된 프로브를 이용한 혼종화 등), 종래의 도트 블롯 분석, 단일 가닥 순응 다형성 분석(SSCP, 가령, U.S.Pat.Nos.5,891,625 and 6,013,499; Orita et al., Proc.Natl.Acad.Sci.U.S.A.86: 27776-2770 (1989)), 헤테로듀플렉스 분석, 불일치 클리비지 검출, 및 Sheffield et al., Proc.Natl.Acad.Sci.USA 49: 699-706 (1991), White et al., Genomics 12: 301-306 (1992), Grompe et al., Proc.Natl.Acad.Sci.USA 86: 5855-5892 (1989), and Grompe, Nature Genetics 5: 111-117 (1993)에 기재된 기법, 복제 및 시퀀싱, 전기영동법, 혼종화 프로브 및 QRT-PCR(quantitative real time polymerase chain reaction) 및 디지털 PCR, 나노포어 시퀀싱, 칩 및 이들의 조합. 대립유전자 또는 이원체의 검출 및 정량화가 2007년12월04일에 출원된 미국 특허 출원 번호 11/950,395에 기재된 "폐관" 방법을 이용해 수행될 수 있다. 일부 실시예에서, 질량 분석계, 프라이머 확장, 시퀀싱(가령, 임의의 적절한 방법, 가령, 나노포어 또는 파이로시퀀싱), 정량적 PCR(Q-PCR 또는 QRT-PCR), 디지털 PCR, 이들의 조합 등에 의해 핵산 종의 양이 결정된다.
본 명세서에 사용된 용어 "서열 분석"은 뉴클레오티드 서열, 예를 들어 증폭 생성물의 서열을 결정하는 것을 지칭한다. 예를 들어, DNA 또는 mRNA와 같은 폴리뉴클레오티드의 전체 서열 또는 부분 서열이 결정될 수 있고, 결정된 뉴클레오티드 서열은 "리드(read)" 또는 "서열 리드(read)"으로 지칭될 수 있다. 예를 들어, 선형 증폭 산물은 일부 구체예에서 추가 증폭없이 (예를 들어, 단일-분자 시퀀싱 방법을 사용하여) 직접 분석될 수 있다. 특정 구체예에서, 선형 증폭 산물은 추가 증폭을 거쳐 분석될 수 있다(예를 들어, 결찰 또는 파이로 시퀀싱 방법론에 의한 시퀀싱 사용). 리드(read)는 다양한 유형의 시퀀스 분석의 대상이 될 수 있다. 임의의 적합한 시퀀싱 방법을 사용하여 뉴클레오티드 서열 종, 증폭된 핵산 종, 또는 상기로부터 생성된 검출 가능한 산물의 양을 검출하고 결정할 수 있다. 특정 시퀀싱 방법의 예는 이하에서 기재된다.
서열 분석 장치 또는 서열 분석 구성요소(들)는 장치, 및 이러한 장치와 함께 사용되는 하나 이상의 구성요소를 포함하며, 이는 해당 분야의 통상의 기술자에 의해 본 명세서에 기재된 프로세스로부터 생성된 뉴클레오티드 서열을 결정하기 위해 사용될 수 있다(예를 들어, 선형 및/또는 지수 증폭 산물). 시퀀싱 플랫폼의 비제한적 예를 들면, 다음이 있다: 454 플랫폼 (Roche) (Margulies, M.et al.2005 Nature 437, 376-380), Illumina Genomic Analyzer (또는 Solexa 플랫폼) 또는 SOLID 시스템 (Applied Biosystems; see PCT 특허 출원 공개 번호 WO 06/084132 발명의 명칭 "Reagents, Methods, and Libraries For Bead-Based Sequencing" 및 WO07/121,489 발명의 명칭 "Reagents, Methods, and Libraries for Gel-Free Bead-Based Sequencing"), the Helicos True Single Molecule DNA sequencing technology (Harris TD et al.2008 Science, 320, 106-109), Pacific Biosciences의 단일 분자, 실시간 (SMRT™) 기술, 및 나노포어 시퀀싱 (Soni G V and Meller A.2007 Clin Chem 53: 1996-2001), 이온 반도체 시퀀싱(Ion Torrent Systems, Inc, 캘리포니아, 샌 프란시스코 소재), 또는 DNA 나노볼 시퀀싱(Complete Genomics, 캘리포니아, 마운틴 뷰 소재), VisiGen Biotechnologies approach (Invitrogen) 및 폴로니 시퀀싱. 이러한 플랫폼은 고차 멀티플렉싱에서 표본으로부터 단리된 많은 핵산 분자의 시퀀싱을 병렬 방식으로 가능하게 한다(Dear Brief Funct Genomic Proteomic 2003; 1: 397-416; Haimovich, Methods, challenges, and promise of next-generation sequencing in cancer biology.Yale J Biol Med.2011 Dec;84(4):439-46). 이들 비-Sanger-계열 시퀀싱 기술은 때때로 NextGen 시퀀싱, NGS, 차세대 시퀀싱, 차세대 시퀀싱, 및 이들의 변형으로 지칭된다. 일반적으로 이들은 전통적인 Sanger 접근 방식보다 훨씬 높은 처리량을 가능하게 한다. Schuster, Next-generation sequencing transforms today's biology, Nature Methods 5:16-18 (2008); Metzker, Sequencing technologies - the next generation.Nat Rev Genet.2010 Jan;11(1):31-46; Levy and Myers, Advancements in Next-Generation Sequencing.Annu Rev Genomics Hum Genet.2016 Aug 31;17:95-115를 참조할 수 있다. 이들 플랫폼은 핵산 단편의 클론 확장 또는 비-증폭 단일 분자의 시퀀싱을 가능하게 할 수 있다. 특정 플랫폼에는 예를 들어 염료 변형 프로브의 연결에 의한 시퀀싱(순환 연결 및 절단 포함), 파이로 시퀀싱 및 단일 분자 시퀀싱이 포함된다. 뉴클레오티드 서열 종, 증폭 핵산 종 및 이로부터 생성된 검출 가능한 산물은 이러한 서열 분석 플랫폼에 의해 분석될 수 있다. 예를 들어, 적절하게 돌연변이, 복제수 또는 발현 수준을 결정하기 위해, 본 명세서에 기재된 바와 같은 방법에서 차세대 시퀀싱이 사용될 수 있다. 방법은 전체 게놈 시퀀싱 또는 관심 특정 서열, 가령, 관심 유전자 또는 이의 단편의 시퀀싱을 수행하는 데 사용될 수 있다.
결찰에 의한 시퀀싱은 염기 페어링 불일치에 대한 DNA 리가제의 민감도에 의존하는 핵산 시퀀싱 방법이다. DNA 리가제는 정확하게 염기쌍을 이루는 DNA의 끝을 연결한다. DNA 리가제가 올바르게 염기 쌍을 이룬 DNA 말단만 결합하는 기능을 형광 라벨링된 올리고 뉴클레오티드 또는 프라이머의 혼합 풀과 결합하면 형광 검출을 통해 서열을 결정할 수 있다. 더 긴 서열 리드는 라벨 식별 후 절단될 수 있는 절단 가능한 연결을 포함하는 프라이머를 포함하여 얻을 수 있다. 링커(linker)에서의 절단은 라벨을 제거하고 결찰된 프라이머의 끝에 있는 5' 인산염을 재생하여 또 다른 결찰 라운드를위한 프라이머를 준비한다. 일부 구체예에서 프라이머는 둘 이상의 형광 라벨, 예를 들어 적어도 1, 2, 3, 4 또는 5개의 형광 라벨로 라벨링될 수 있다.
결찰에 의한 시퀀싱에는 일반적으로 다음 단계가 포함된다. 클론 비드 개체군은 표적 핵산 템플릿 서열, 증폭 반응 성분, 비드 및 프라이머를 포함하는 에멀젼 마이크로 반응기에서 준비 될 수 있다. 증폭 후, 템플릿이 변성되고 비드 농축이 수행되어 확장 템플릿이있는 비드와 원하지 않는 비드(가령, 확장 템플릿이없는 비드)를 분리한다. 선택된 비드의 템플릿은 슬라이드에 공유 결합을 허용하기 위해 3' 변형을 거치고 변형된 비드는 유리 슬라이드에 증착될 수 있다. 증착 챔버는 비드 로딩 프로세스 동안 슬라이드를 1개, 4개 또는 8개의 챔버로 분할하는 기능을 제공한다. 서열 분석을 위해 프라이머는 어댑터 서열에 혼성화된다. 4가지 색상의 염료로 라벨링된 프로브 세트가 시퀀싱 프라이머에 대한 결찰을 위해 경쟁한다. 프로브 결찰의 특이성은 결찰 시리즈 동안 4번째 염기 마다 그리고 5번째 염기 마다 조사함으로써 달성된다. 5-7 라운드의 결찰, 감지 및 절단은 사용된 라이브러리 유형에 따라 결정된 라운드 수로 5번째 위치마다 색상을 기록한다. 각각의 라운드의 결찰 후, 5' 방향으로 하나의 염기만큼 오프셋된 새로운 보체 프라이머가 또 다른 일련의 결찰을 위해 배치된다. 프라이머 재설정 및 결찰 라운드(라운드 당 5-7 결찰 주기)를 순차적으로 5 회 반복하여 단일 태그에 대해 25-35 염기 쌍의 시퀀스를 생성한다. 메이트-쌍 시퀀싱을 사용하면, 두 번째 태그에 대해 이 프로세스가 반복된다.
파이로시퀀싱은 합성에 의한 시퀀싱에 기반한 핵산 시퀀싱 방법으로, 뉴클레오티드 통합시 방출되는 피로 포스페이트의 검출에 의존한다. 일반적으로, 합성에 의한 시퀀싱은 한 번에 하나의 뉴클레오티드를 합성하는 것을 포함하며, 그 서열을 찾는 가닥에 보체 DNA 가닥을 합성한다. 표적 핵산은 DNA 중합 효소, ATP 설퍼일라제, 루시퍼라제, 아피라제, 아데노신 5' 포스포설페이트 및 루시페린과 함께 배양된 시퀀싱 프라이머와 혼성화된 고체 지지체에 고정될 수 있다. 뉴클레오티드 솔루션은 순차적으로 추가 및 제거된다. 뉴클레오티드의 올바른 통합은 ATP 설퍼일라제와 상호 작용하고 아데노신 5' 포스포설페이트의 존재 하에 ATP를 생성하는 피로포스페이트를 방출하여 루시페린 반응을 촉진하여 서열 결정을 허용하는 화학 발광 신호를 생성한다. 생성되는 빛의 양은 추가된 염기의 수에 비례한다. 따라서, 시퀀싱 프라이머 하류의 서열이 결정될 수 있다. 파이로시퀀싱을 위한 예시적인 시스템은 다음 단계를 포함한다: 어댑터 핵산을 조사 대상 핵산에 묶고 생성된 핵산을 비드에 혼성화하는 단계; 에멀젼에서 뉴클레오티드 서열 증폭; 피코리터 멀티웰 고체 지지체를 사용한 비드 분류; 및 파이로시퀀싱 방법론(가령, Nakano et al., "Single-molecule PCR using water-in-oil emulsion;" Journal of Biotechnology 102: 117-124 (2003))에 의해 증폭된 뉴클레오티드 서열을 시퀀싱하는 단계.
특정 단일-분자 시퀀싱 실시예는 합성에 의한 시퀀싱의 원리를 기반으로하며, 성공적인 뉴클레오티드 통합의 결과로 광자가 방출되게 하는 메커니즘으로 단일-쌍 형광 공명 에너지 전달(단일 쌍 FRET)을 사용한다. 방출된 광자는 종종 내부 전반사 현미경(TIRM: total internal reflection microscopy)과 함께 강화 또는 고감도 냉각 전하 결합 장치를 사용하여 검출된다. 광자는 도입된 반응 용액이 시퀀싱 과정의 결과로 합성되는 성장하는 핵산 사슬에 통합하기위한 올바른 뉴클레오티드를 포함할 때만 방출된다. FRET 계열 단일 분자 시퀀싱에서 에너지는 장거리 쌍극자 상호 작용을 통해 두 개의 형광 염료, 때로는 폴리메틴시아닌 염료 Cy3 및 Cy5 간에 전달된다. 도너는 특정 여기 파장에서 여기되고 여기된 상태 에너지는 비방사 방식으로 수용체 염료로 전달되며, 이는 그 후 여기된다. 수용체 염료는 결국 광자의 복사 방출에 의해 바닥 상태로 돌아간다. 에너지 전달 과정에서 사용되는 두 개의 염료는 단일 쌍 FRET의 "단일 쌍"을 나타낸다. Cy3는 종종 도너 형광단으로 사용되며 종종 첫 번째 라벨링된 뉴클레오티드로 포함된다. Cy5는 종종 수용체 형광단으로 사용되며 첫 번째 Cy3 라벨링된 뉴클레오티드를 통합한 후 연속적인 뉴클레오티드 추가를 위한 뉴클레오티드 라벨로 사용된다. 형광단은 일반적으로 에너지 전달이 성공적으로 이루어지도록 각각 10 나노 미터 이내에 있다.
단일-분자 시퀀싱을 기반으로 사용될 수 있는 시스템의 예는 일반적으로 복합체를 생성하기 위해 프라이머를 표적 핵산 서열에 혼성화하는 것; 복합체를 고체상과 연관시키는 것; 형광 분자로 태그된 뉴클레오티드에 의해 프라이머를 반복적으로 확장하는 것; 및 각각의 반복 후에 형광 공명 에너지 전달 신호의 이미지를 캡처하는 것을 포함한다(예를 들어, U.S.Pat.No.7,169,314; Braslavsky et al., PNAS 100(7): 3960-3964 (2003)). 이러한 시스템은 본 명세서에 기재된 공정에 의해 생성된 증폭 산물(선형 또는 지수 증폭 산물)을 직접 시퀀싱하는 데 사용될 수 있다. 일부 구체예에서, 증폭 산물은 예를 들어 고체 지지체, 비드 또는 유리 슬라이드 상에 존재하는 고정화된 포획 서열에 보체 서열을 함유하는 프라이머에 혼성화될 수 있다. 고정된 포획 서열과 프라이머-증폭 생성물 복합체의 혼성화는 합성에 의한 단일 쌍 FRET 계열 시퀀싱을 위한 고체 지지체에 증폭 산물을 고정시킨다. 프라이머는 종종 형광성이어서, 고정된 핵산이있는 슬라이드 표면의 초기 참조 이미지를 생성할 수 있다. 초기 참조 이미지는 실제 뉴클레오티드 통합이 발생하는 위치를 결정하는 데 유용하다. "프라이머 전용" 참조 이미지에서 초기에 식별되지 않은 어레이 위치에서 검출된 형광 신호는 비특이적 형광으로서 폐기된다. 프라이머-증폭 산물 복합체의 고정화 후, 결합된 핵산은 종종 a) 하나의 형광 라벨링된 뉴클레오티드 존재 하에서 폴리머아제 확장, b) 적절한 현미경 검사법, 예를 들어 TIRM을 사용한 형광 검출, c) 형광 뉴클레오티드의 제거, 및 d) 상이한 형광 라벨링된 뉴클레오티드로 단계 a로 복귀?l 반복 단계에 의해 병렬로 시퀀싱된다.
일부 구체예에서, 뉴클레오티드 시퀀싱은 고체상 단일 뉴클레오티드 시퀀싱 방법 및 프로세스에 의해 이루어질 수 있다. 고체상 단일 뉴클레오티드 시퀀싱 방법은 단일 분자의 샘플 핵산이 고체 지지체의 단일 분자에 혼성화하는 조건 하에서 표적 핵산 및 고체 지지체를 접촉시키는 것을 포함한다. 이러한 조건은 "마이크로 반응기"에서 고체 지지체 분자 및 표적 핵산의 단일 분자를 제공하는 것을 포함할 수 있다. 이러한 조건은 또한 표적 핵산 분자가 고체 지지체상의 고체상 핵산에 혼성화할 수 있는 혼합물을 제공하는 것을 포함할 수 있다. 본 명세서에 기재된 실시 양태에서 유용한 단일 뉴클레오티드 서열 분석 방법은 2008년01월17일에 출원된 미국 가특허 출원 번호 61/021,871에 기재되어 있다.
특정 구체예에서, 나노포어 시퀀싱 검출 방법은 (a) 검출체(detector)가 실질적으로 염기 핵산의 실질적으로 보체 부분서열에 특정하게 혼종화되는 조건 하에서, 서열-특이적 검출체로 시퀀싱을 위한 표적 핵산("염기 핵산", 가령, 연결된 프로브 분자)을 접촉시키는 것, (b) 검출기로부터 신호를 검출하는 것, 및 (c) 검출된 신호에 따라 염기 핵산의 서열을 결정하는 것을 포함한다. 특정 구체예에서, 염기 핵산이 기공을 통과함에 따라 검출체가 나노포어 구조체와 간섭을 일으킬 때 염기 핵산으로 혼종화된 검출체가 염기 핵산으로부터 분리되고(가령, 서열적으로 분리되고) 염기 시퀀스로부터 분리된 검출체가 검출된다. 일부 구체예에서, 염기 핵산으로부터 분리된 검출체는 검출 가능한 신호를 발산하고, 염기 핵산에 혼성화된 검출체는 상이한 검출 가능한 신호를 발산하거나 어떠한 검출 가능한 신호도 발산하지 않는다. 특정 구체예에서, 핵산(예를 들어, 연결된 프로브 분자) 내 뉴클레오티드는 특정 뉴클레오티드("뉴클레오티드 대표")에 대응하는 특정 뉴클레오티드 서열로 치환되어 확장된 핵산을 발생시키고(가령, 미국 특허 번호 6,723,513 참조) 검출체는 염기 핵산 역할을 하는 확장된 핵산의 뉴클레오티드 대표에 혼성화된다. 이러한 구체예에서, 뉴클레오티드 대표는 이원 이상의 배열로 배열될 수 있다(예를 들어, Soni and Meller, Clinical Chemistry 53(11): 1996-2001 (2007)). 일부 구체예에서, 핵산은 확장되지 않고, 확장된 핵산을 생성하지 않으며, 염기 핵산을 직접 제공하며(예를 들어, 연결된 프로브 분자는 비-확장 염기 핵산으로 사용), 검출체는 직접 염기 핵산과 접촉한다. 예를 들어, 제1 검출체는 제1 부분 서열로 혼성화될 수 있고 제2 검출체는 제2 부분 서열로 혼성화될 수 있으며, 여기서 제1 검출체와 제2 검출체는 각각 서로 구별 될 수 있는 검출 가능한 라벨을 가지며, 여기서 제1 검출체 및 제2 검출체로부터의 신호는 검출체가 염기 핵산과 분리될 때 서로 구별될 수 있다. 특정 구체예에서, 검출체는 약 3개 내지 약 100개의 뉴클레오티드 길이(예를 들어, 약 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 25, 30, 35, 40, 50, 55, 60, 65, 70, 75, 80, 85, 90, 또는 95개의 뉴클레오티드 길이)일 수 있는 염기 핵산에 혼성화되는 영역(가령, 2개 영역)을 포함한다. 검출체는 또한 염기 핵산에 혼성화되지 않는 하나 이상의 뉴클레오티드 영역을 포함할 수 있다. 일부 구체예에서, 검출체는 분자 비콘(molecular beacon)이다. 검출체는 종종 본 명세서에 기재된 것들로부터 독립적으로 선택된 하나 이상의 검출 가능한 라벨을 포함한다. 각각의 검출 가능한 라벨은 각각의 라벨(가령, 자기, 전기, 화학, 광학 등)에 의해 생성된 신호를 검출할 수 있는 임의의 종래의 검출 프로세스에 의해 검출될 수 있다. 예를 들어, CD 카메라가 검출기에 연결된 하나 이상의 구별 가능한 양자점(quantum dot)에서 신호를 검출할 수 있다.
특정 서열 분석 구체예에서, 리드(read)는 더 큰 뉴클레오티드 서열을 구축하는 데 사용될 수 있으며, 이는 상이한 리드에서 중첩 서열을 식별하고 리드에서 식별 서열을 사용함으로써 용이해질 수 있다. 리드로부터 더 큰 서열을 구성하기 위한 이러한 서열 분석 방법 및 소프트웨어는 해당 분야의 통상의 기술자에게 공지되어있다(예를 들어, Venter et al., Science 291: 1304-1351 (2001)). 특정 리드, 부분 뉴클레오티드 서열 구축물 및 전체 뉴클레오티드 서열 구축물은 샘플 핵산 내의 뉴클레오티드 서열들 간에 비교될 수 있거나(즉, 내부 비교) 특정 서열 분석 구체예에서 참조 서열(즉, 참조 비교)과 비교될 수 있다. 내부 비교는 샘플 핵산이 여러 샘플 또는 서열 변이를 포함하는 단일 샘플 소스에서 준비되는 상황에서 수행될 수 있다. 참조 뉴클레오티드 서열이 알려져 있고 샘플 핵산이 참조 뉴클레오티드 서열과 실질적으로 유사하거나 동일하거나 상이한 뉴클레오티드 서열을 포함하는지 여부를 결정하는 것이 목적 일 때 참조 비교가 때때로 수행된다. 서열 분석은 앞서 기재된 서열 분석 장치 및 구성요소를 사용하여 촉진될 수 있다.
본 명세서에서 "마이크로시퀀싱" 방법으로도 지칭되는 프라이머 연장 다형성 검출 방법은 전형적으로 보체 올리고 뉴클레오티드를 다형성 부위를 운반하는 핵산에 혼성화시킴으로써 수행된다. 이들 방법에서, 올리고뉴클레오티드는 전형적으로 다형성 부위에 인접하여 혼성화한다. "마이크로 시퀀싱" 방법과 관련하여 사용된 용어 "인접한"은, 연장 올리고뉴클레오티드가 핵산에 혼종화될 때 연장 올리고뉴클레오티드의 3' 말단이 때때로 다형성 부위의 5' 말단으로부터 1개 뉴클레오티드, 종종 다형성 부위의 5' 말단으로부터 2 또는 3개, 그리고 때때로 4, 5, 6, 7, 8, 9, 또는 10개의 뉴클레오티드인 것을 지칭한다. 그런 다음 연장 올리고뉴클레오티드는 하나 이상의 뉴클레오티드, 종종 1, 2 또는 3개의 뉴클레오티드만큼 연장되고, 연장 올리고뉴클레오티드에 추가되는 뉴클레오티드의 수 및/또는 유형이 어떠한 하나 또는 복수의 다형성 변이체 또는 변이체가 존재하는지를 결정한다. 올리고뉴클레오티드 연장 방법은 예를 들어 U.S.Pat.Nos.4,656,127; 4,851,331; 5,679,524; 5,834,189; 5,876,934; 5,908,755; 5,912,118; 5,976,802; 5,981,186; 6,004,744; 6,013,431; 6,017,702; 6,046,005; 6,087,095; 6,210,891; 및 WO 01/20039에 개시되어 있다. 연장 산물은 임의의 방식으로, 가령, 형광 방법(가령, Chen & Kwok, Nucleic Acids Research 25: 347-353 (1997) and Chen et al., Proc.Natl.Acad.Sci.USA 94/20: 10756-10761 (1997)) 또는 질량 분광법(가령, MALDI-TOF 질량 분광법) 및 본 명세서에 기재된 그 밖의 다른 방법에 의해 검출될 수 있다. 질량 분석법을 사용하는 올리고뉴클레오티드 연장 방법은 예를 들어 미국 특허 번호 5,547,835; 5,605,798; 5,691,141; 5,849,542; 5,869,242; 5,928,906; 6,043,031; 6,194,144; 및 6,258,538에 기재되어 있다.
미세시퀀싱 검출 방법은 종종 연장 단계를 진행하는 증폭 과정을 포함한다. 증폭 과정은 일반적으로 다형성 부위를 포함하는 핵산 샘플로부터 영역을 증폭한다. 증폭은 앞서 기재된 방법을 사용하거나 예를 들어 중합 효소 연쇄 반응(PCR)에서 한 쌍의 올리고뉴클레오티드 프라이머를 사용하여 수행될 수 있으며, 여기서 하나의 올리고뉴클레오티드 프라이머는 일반적으로 다형성의 영역 3'에 보체이고 다른 하나는 일반적으로 다형성의 영역 5'에 보체이다. PCR 프라이머 쌍은 미국 특허 번호 4,683,195; 4,683,202, 4,965,188; 5,656,493; 5,998,143; 6,140,054; WO 01/27327; 및 WO 01/27329에 개시된 방법에서 사용될 수 있다. PCR 프라이머 쌍은 PCR을 수행하는 임의의 사용화된 기계, 가령, Applied Biosystems의 GeneAmp ™ 시스템들 중 임의의 것에서 사용될 수 있다.
그 밖의 다른 적절한 시퀀싱 방법은 부동화된 마이크로비드를 이용하는 멀티플렉싱 폴로니 시퀀싱(www.sciencexpress.org/4 Aug.2005/Page1/10.1126/science.1117389에서 이용 가능한 본 명세서에서 참조로서 포함되는 Shendure et al., Accurate Multiplex Polony Sequencing of an Evolved Bacterial Genome, Sciencexpress, Aug.4, 2005, pg 1에 기재된 것) 및 마이크로제조된 피코리터 반응기에서의 시퀀싱(www.nature.com/nature (published online 31 Jul.2005, doi:10.1038/nature03959에서 이용 가능한 본 명세서에서 참조로서 포함되는 Margulies et al., Genome Sequencing in Microfabricated High-Density Picolitre Reactors, Nature, August 2005에 기재된 것)을 포함한다.
일부 구체예에서, 전체 게놈 시퀀싱은 또한 RNA 전사체의 대립 유전자를 구별하기 위해 사용될 수 있다. 전체 게놈 시퀀싱 방법의 비제한적 예를 들면, 나노포어-기반 시퀀싱 방법, 합성에 의한 시퀀싱, 및 결찰에 의한 시퀀싱이 있다.
핵산 변이체는 표준 전기 영동 기술을 사용하여 검출될 수도 있다. 검출 단계는 때때로 증폭 단계가 선행될 수 있지만, 본 명세서에 기재된 실시예에서는 증폭이 요구되지는 않는다. 전기 영동 기술을 사용하여 핵산을 검출 및 정량화하는 방법의 예는 해당 업계에서 찾을 수 있다. 비 제한적인 예로는 아가로스 또는 폴리아크릴아미드 겔에 샘플(예를 들어, 모체 혈청으로부터 분리된 혼합 핵산 샘플, 또는 증폭 핵산 종)을 실행하는 것을 포함한다. 겔은 에티듐 브로미드로 라벨링(가령, 염색)될 수 있다(Sambrook and Russell, Molecular Cloning: A Laboratory Manual 3d ed., 2001 참조). 표준 대조군과 동일한 크기의 밴드의 존재는 표적 핵산 서열의 존재를 나타내는 것이며, 그 양은 밴드의 강도에 따라 대조군과 비교할 수 있으므로 관심 표적 서열을 검출하고 정량화할 수 있다. 일부 구체예에서, 모계 및 부계 대립 유전자를 구별할 수 있는 제한 효소를 사용하여 표적 핵산 종을 검출하고 정량화할 수 있다. 특정 구체예에서, 관심 표적 서열의 존재를 검출하기 위해 관심 서열에 특이적인 올리고 뉴클레오티드 프로브가 사용된다. 올리고뉴클레오티드는 또한 프로브에 의해 전달되는 신호의 강도에 기초하여 표준 대조군과 비교하여 표적 핵산 분자의 양을 나타내는 데 사용될 수 있다.
서열-특이적 프로브 혼성화는 다른 종의 핵산을 포함하는 혼합물 또는 혼합 집단에서 특정 핵산을 검출하는데 사용될 수 있다. 충분히 엄격한 혼성화 조건 하에서 프로브는 실질적으로 보체인 서열에만 특이적으로 혼성화된다. 혼성화 조건의 엄격함은 다양한 양의 서열 불일치를 허용하도록 완화될 수 있다. 용액상, 고체상 또는 혼합상 혼성화 분석을 포함하지만 이에 제한되지 않는 다수의 혼성화 형식이 해당 분야에 공지되어있다. 다음 문헌은 다양한 혼성화 분석 형식에 대한 개요를 제공한다: Singer et al., Biotechniques 4:230, 1986; Haase et al., Methods in Virology, pp.189-226, 1984; Wilkinson, In situ Hybridization, Wilkinson ed., IRL Press, Oxford University Press, Oxford; and Hames and Higgins eds., Nucleic Acid Hybridization: A Practical Approach, IRL Press, 1987.
혼성화 복합체는 해당 업계에 공지된 기술에 의해 검출될 수 있다. 표적 핵산(예를 들어, mRNA 또는 DNA)에 특이적으로 혼성화될 수 있는 핵산 프로브는 임의의 적합한 방법에 의해 라벨링될 수 있으며, 라벨링된 프로브는 혼성화 된 핵산의 존재를 검출하는 데 사용된다. 일반적으로 사용되는 검출 방법 중 하나는 3H, 125I, 35S, 14C, 32P, 33P 등으로 라벨링된 프로브를 사용하는 자동 방사선 촬영(autoradiography)이다. 방사성 동위 원소의 선택은 선택한 동위 원소의 합성 용이성, 안정성 및 반감기 때문에 연구 선호도에 따라 달라진다. 다른 라벨에는 형광단, 화학 발광제 및 효소로 라벨링된 항 리간드 또는 항체에 결합하는 화합물(가령, 비오틴 및 디곡시제닌)이 포함된다. 일부 구체예에서, 프로브는 형광단, 화학 발광제 또는 효소와 같은 라벨링과 직접 접합될 수 있다. 라벨 선택은 필요한 감도, 프로브와의 용이성, 안정성 요구 사항 및 사용 가능한 기기에 따라 달라진다.
구체예에서, 단편 분석(본 명세서에서 "FA"로 지칭됨) 방법이 분자 프로파일링에 사용된다. 단편 분석(FA)은 제한 단편 길이 다형성(RFLP) 및/또는(증폭 단편 길이 다형성)과 같은 기술을 포함한다. 하나 이상의 유전자에 해당하는 표적 DNA의 뉴클레오티드 변이가 제한 효소 인식 부위의 제거 또는 생성을 초래하는 경우, 특정 제한 효소로 표적 DNA를 소화하면 변경된 제한 단편 길이 패턴이 생성된다. 따라서 검출된 RFLP 또는 AFLP는 특정 뉴클레오티드 변이체의 존재를 나타낸다.
TRFLP(terminal restriction fragment length polymorphism)은 형광 태그로 라벨링된 프라이머 쌍을 사용하여 DNA의 PCR 증폭에 의해 작동한다. PCR 산물은 RFLP 효소를 사용하여 분해되고 결과 패턴은 DNA 시퀀서를 사용하여 시각화된다. 결과는 TRFLP 프로파일에서 밴드 또는 피크를 계산 및 비교하거나 데이터베이스에서 하나 이상의 TRFLP 실행의 밴드를 비교하여 분석된다.
RFLP와 직접 관련된 서열 변화는 PCR을 통해 더 빠르게 분석될 수도 있다. 증폭은 변경된 제한 부위 및 제한 효소로 분해 된 산물을 통해 지시될 수 있다. 이 방법을 CAPS(Cleaved Amplified Polymorphic Sequence)라고 한다. 대안으로, 증폭된 세그먼트는 ASO(Allele specific oligonucleotide) 프로브로 분석될 수 있으며, 이 과정은 때때로 도트 블롯을 사용하여 평가된다.
AFLP의 변이는 cDNA-AFLP이며 이는 유전자 발현 수준의 차이를 정량화하는 데 사용될 수 있다.
또 다른 유용한 접근법은 관심 뉴클레오티드 변이체에 걸쳐 있는 단일 가닥 표적 DNA의 변경된 이동성을 기반으로하는 SSCA(single-stranded conformation polymorphism assay)이다. 표적 서열의 단일 뉴클레오티드 변화는 상이한 분자 내 염기 쌍 패턴을 초래할 수 있으며, 따라서 비-변성 겔에서 검출 될 수 있는 단일 가닥 DNA의 상이한 2차 구조를 초래할 수 있다. Orita et al., Proc.Natl.Acad.Sci.USA, 86:2776-2770 (1989)를 참조할 수 있다. 변성 겔-계열 기법, 가령, CDGE(clamped denaturing gel electrophoresis) 및 DGGE(denaturing gradient gel electrophoresis)가 변성 겔의 야생형 서열과 비교하여 돌연변이 서열의 이동 속도 차이를 검출한다. Miller et al., Biotechniques, 5:1016-24 (1999); Sheffield et al., Am.J.Hum, Genet., 49:699-706 (1991); Wartell et al., Nucleic Acids Res., 18:2699-2705 (1990); and Sheffield et al., Proc.Natl.Acad.Sci.USA, 86:232-236 (1989)를 참조할 수 있다. 또한, DSCA(double-strand conformation analysis)도 본 방법에서 유용할 수 있다. Arguello et al., Nat.Genet., 18:192-194 (1998)를 참조할 수 있다.
개인의 하나 이상의 유전자에서 특정 유전자 자리에서 뉴클레오티드 변이의 존재 또는 부재는 또한 ARMS(amplification refractory mutation system) 기술을 사용하여 검출될 수 있다. 가령, European Patent No.0,332,435; Newton et al., Nucleic Acids Res., 17:2503-2515 (1989); Fox et al., Br.J.Cancer, 77:1267-1274 (1998); Robertson et al., Eur.Respir.J., 12:477-482 (1998)를 참조할 수 있다. ARMS 방법에서, 검사되는 자리에서의 뉴클레오티드에 대응하는 3'-말단 뉴클레오티드가 지정 뉴클레오티드인 것을 제외하고, 검사되는 자리로부터 바로 5' 상향에 있는 뉴클레오티드 서열과 일치하도록 프라이머가 합성된다. 예를 들어, 3'-말단 뉴클레오티드는 돌연변이된 유전자 자리에 있는 것과 동일할 수 있다. 프라이머는 이의 3'-말단 뉴클레오티드가 검사되는 자리에서의 뉴클레오티드와 일치될 때만 엄격한 조건 하에서 표적 DNA에 혼성화하는 한 임의의 적절한 길이를 가질 수 있다. 바람직하게는 프라이머는 적어도 12개의 뉴클레오티드, 더 바람직하게는 약 18 내지 50개의 뉴클레오티드를 가진다. 검사된 개체가 유전자 자리에 돌연변이를 갖고 그 안에 있는 뉴클레오티드가 프라이머의 3'-말단 뉴클레오티드와 일치하는 경우, 프라이머는 표적 DNA 템플릿에 혼성화될 때 추가로 연장될 수 있으며, 프라이머는 또 다른 적절한 PCR 프라이머와 함께 PCR 증폭 반응을 시작할 수 있다. 이와 달리, 유전자 자리의 뉴클레오티드가 야생형(wild type)이면 프라이머 연장을 달성할 수 없다. 지난 몇 년 동안 개발된 다양한 형태의 ARMS 기술이 사용될 수 있다. 예를 들어, Gibson et al., Clin.Chem.43:1336-1341 (1997)를 참조할 수 있다.
ARMS 기술과 유사한 것으로는 단일 뉴클레오티드의 통합을 기반으로 하는 미니 시퀀싱 또는 단일 뉴클레오티드 프라이머 연장 방법이 있다. 검사되는 유전자 자리에 바로 5' 뉴클레오티드 서열과 일치하는 올리고뉴클레오티드 프라이머는 라벨링된 디데옥시리보뉴클레오티드의 존재 하에 표적 DNA, mRNA 또는 miRNA에 혼성화된다. 라벨링된 뉴클레오티드는 디데옥시리보뉴클레오티드가 검출되는 변이 유전자 잘ㅣ의 뉴클레오티드와 일치하는 경우에만 프라이머에 통합되거나 연결된다. 따라서, 혼입된 디데옥시리보뉴클레오티드에 부착된 검출 라벨에 기초하여 변이 유전자 자리의 뉴클레오티드의 정체가 밝혀질 수 있다. See Syvanen et al., Genomics, 8:684-692 (1990); Shumaker et al., Hum.Mutat., 7:346-354 (1996); Chen et al., Genome Res., 10:549-547 (2000)를 참조할 수 있다.
본 방법에서 유용한 또 다른 기술 세트는 야생형 유전자 자리와 돌연변이 사이의 분화가 2개의 올리고뉴클레오티드가 표적 DNA 분자 상에서 서로 인접하여 어닐링하여 DNA 리가제에 의해 함께 접합되는 2개의 올리고뉴클레오티드를 허용하는 능력에 기초하는 소위 "올리고뉴클레오티드 결찰 분석(OLA)"이다. Landergren et al., Science, 241:1077-1080 (1988); Chen et al, Genome Res., 8:549-556 (1998); Iannone et al., Cytometry, 39:131-140 (2000)를 참조할 수 있다. 따라서, 예를 들어, 하나 이상의 유전자의 특정 유전자 자리에서 단일-뉴클레오티드 돌연변이를 검출하기 위해, 2개의 올리고 뉴클레오티드가 합성될 수 있는데, 하나는 유전자 자리에서 단지 5' 상류에 있는 서열을 가지며 그 3' 말단 뉴클레오티드는 특정 유전자의 변이 유전자 자리에 있는 뉴클레오티드와 동일하고, 다른 하나는 유전자의 유전자 자리에서 바로 3' 하류에 있는 서열과 일치하는 뉴클레오티드 서열을 가진다. 올리고 뉴클레오티드는 검출 목적으로 라벨링될 수 있다. 엄격한 조건 하에서 표적 유전자에 혼성화될 때, 2개의 올리고뉴클레오티드는 적절한 리가제의 존재하에 결찰된다. 2개의 올리고뉴클레오티드의 결찰은 표적 DNA가 검출되는 유전자 자리에 뉴클레오티드 변이가 있음을 나타낼 것이다.
작은 유전적 변이의 검출은 또한 다양한 혼성화 기반 접근법에 의해 달성될 수 있다. 대립 유전자 특이적 올리고뉴클레오티드가 가장 유용하다. Conner et al., Proc.Natl.Acad.Sci.USA, 80:278-282 (1983); Saiki et al, Proc.Natl.Acad.Sci.USA, 86:6230-6234 (1989)를 참조할 수 있다. 다른 대립 유전자가 아닌 특정 유전자 자리에 특정 유전자 변이를 갖는 유전자 대립 유전자에 특이적으로 혼성화(대립 유전자 특이적)되는 올리고뉴클레오티드 프로브는 해당 업계에 공지된 방법에 의해 설계될 수 있다. 프로브는 예를 들어 10 내지 약 50개의 뉴클레오티드 염기의 길이를 가질 수 있다. 표적 DNA와 올리고 뉴클레오티드 프로브는 혼성화의 유무에 따라 뉴클레오티드 변이체가 야생형 유전자와 구별될 수 있도록 충분히 엄격한 조건 하에서 서로 접촉할 수 있다. 검출 신호를 제공하기 위해 프로브가 라벨링될 수 있다. 대안으로, 대립 유전자 특이적 올리고뉴클레오티드 프로브는 "대립 유전자 특이적 PCR"에서 PCR 증폭 프라이머로 사용될 수 있고 예상 길이의 PCR 산물의 존재 또는 부재는 특정 뉴클레오티드 변이체의 존재 또는 부재를 나타낼 것이다.
그 밖의 다른 유용한 혼종화 기반 기법에 의해, 2개의 단일-가닥 핵산이 뉴클레오티드 치환, 삽입 또는 결실로 인한 불일치의 존재에서도 함께 어닐링되는 것이 가능하다. 그런 다음 다양한 기법에 의해 불일치가 검출될 수 있다. 예를 들어, 어닐된 듀플렉스가 전기영동의 대상이 될 수 있다. 불일치된 듀플렉스가 완벽하게 일치된 듀플렉스와 상이한 전기영동 이동도에 기초하여 검출될 수 있다. Cariello, Human Genetics, 42:726 (1988)를 참조할 수 있다. 대안으로, RNase 보호 분석에서, 검출될 뉴클레오티드 변이 사이트를 스패닝하고 검출 마커를 갖는 RNA 프로브가 준비될 수 있다. Giunta et al., Diagn.Mol.Path., 5:265-270 (1996); Finkelstein et al., Genomics, 7:167-172 (1990); Kinszler et al., Science 251:1366-1370 (1991)를 참조할 수 있다. RNA 프로브는 표적 DNA 또는 mRNA에 혼성화되어 이질듀플렉스를 형성한 다음 리보뉴클레아제 RNase A 분해의 대상이 될 수 있다. RNase A는 불일치의 사이트에서만 이질듀플렉스에서 RNA 프로브를 분해한다. 분해는 크기 변화에 따라 변성 전기영동 겔에서 결정될 수 있다. 또한, 불일치는 해당 업계에 공지된 화학적 절단 방법에 의해 검출될 수도 있다. 예를 들어, Roberts et al., Nucleic Acids Res., 25:3377-3378 (1997)를 참조할 수 있다.
MutS 분석에서, 변이 유전자 자리에서 지정된 뉴클레오티드가 사용되는 것을 제외하고, 변이의 존재 또는 부재가 검출될 유전자 자리 주위의 유전자 서열과 일치하는 프로브가 준비될 수 있다. 프로브를 표적 DNA에 어닐하여 듀플렉스를 형성할 때, E.coli mutS 단백질은 듀플렉스와 접촉된다. mutS 단백질은 뉴클레오티드 불일치를 포함하는 이질듀플렉스 서열에만 결합하기 때문에, mutS 단백질의 결합은 변이의 존재를 나타낼 것이다. Modrich et al., Ann.Rev.Genet., 25:229-253 (1991)를 참조할 수 있다.
본 방법에서 돌연변이 또는 뉴클레오티드 변이체를 검출하는 데 유용할 수 있는 앞서 기재된 기본 기술에 기초하여 당업계에서 매우 다양한 개선 및 변형이 개발되어 왔다. 예를 들어, "선라이즈 프로브" 또는 "분자 비컨"은 FRET(fluorescence resonance energy transfer) 특성을 사용하고 높은 감도를 제공한다. Wolf et al., Proc.Nat.Acad.Sci.USA, 85:8790-8794 (1988)를 참조할 수 있다. 일반적으로 검출될 뉴클레오티드 유전자 자리에 걸쳐 있는 프로브는 머리핀 모양의 구조로 설계되고 한쪽 끝에는 소광 형광단이 있고 다른 쪽 끝에는 리포터 형광단으로 라벨링된다. 자연 상태에서, 리포터 형광단의 형광은 하나의 형광단이 다른 형광단에 근접하기 때문에 소광 형광단에 의해 소멸된다. 프로브가 표적 DNA에 혼성화되면 5' 말단이 3' 말단으로부터 멀리 분리되어 형광 신호가 재생된다. Nazarenko et al., Nucleic Acids Res., 25:2516-2521 (1997); Rychlik et al., Nucleic Acids Res., 17:8543-8551 (1989); Sharkey et al., Bio/Technology 12:506-509 (1994); Tyagi et al., Nat.Biotechnol., 14:303-308 (1996); Tyagi et al., Nat.Biotechnol., 16:49-53 (1998)를 참조할 수 있다. HANDS(homo-tag assisted non-dimer system)는 분자 표지 방법과 함께 사용되어 프라이머-이량체 축적을 억제할 수 있다. Brownie et al., Nucleic Acids Res., 25:3235-3241 (1997)를 참조할 수 있다.
염료-라벨링된 올리고뉴클레오티드 결찰 분석이 OLA 분석과 PCR을 결합하는 FRET-기반 방법이다. Chen et al., Genome Res.8:549-556 (1998)를 참조할 수 있다. TaqMan은 뉴클레오티드 변이를 검출하기 위한 또 다른 FRET-기반 방법이다. TaqMan 프로브는 관심 있는 변이 유전자 자리에 걸친 유전자의 뉴클레오티드 서열을 갖고 다른 대립 유전자와 차별적으로 혼성화되도록 설계된 올리고뉴클레오티드일 수 있다. 프로브의 두 끝은 각각 소광 형광 단 및 리포터 형광 단으로 라벨링된다. TaqMan 프로브는 Taq 폴리머아제를 사용하여 관심 유전자 자리를 포함하는 표적 유전자 영역의 증폭을 위해 PCR 반응에 혼입된다. Taq 폴리머아제는 5'-3' 엑소뉴클레아제 활성을 나타내지만 3'-5' 엑소뉴클레아제 활성이 없기 때문에 TaqMan 프로브가 표적 DNA 템플릿에 어닐되는 경우, PCR 반응 동안 TaqMan 프로브의 5' 말단이 Taq 폴리머아제에 의해 분해되고, 따라서 리포트 형광 단을 소광 형광 단에서 분리하고 형광 신호를 방출할 수 있다. Holland et al., Proc.Natl.Acad.Sci.USA, 88:7276-7280 (1991); Kalinina et al., Nucleic Acids Res., 25:1999-2004 (1997); Whitcombe et al., Clin.Chem., 44:918-923 (1998)를 참조할 수 있다.
또한, 본 방법에서의 검출은 화학발광-기반 기술을 사용할 수도 있다. 예를 들어, 올리고 뉴클레오티드 프로브는 야생형 또는 변이 유전자 자리 중 하나에 혼성화하도록 설계될 수 있지만 둘 모두에 혼성화되지는 않는다. 프로브는 고도의 화학 발광 아크리디늄 에스테르로 라벨링된다. 아크리디늄 에스테르의 가수 분해는 화학 발광을 파괴한다. 프로브를 표적 DNA로 혼성화하는 것은 아크리디늄 에스테르의 가수 분해를 막는다. 따라서 표적 DNA에서의 특정 돌연변이의 유무는 화학 발광 변화를 측정하여 결정된다. Nelson et al., Nucleic Acids Res., 24:4998-5003 (1996)를 참조할 수 있다.
본 방법에 따른 유전자의 유전적 변이의 검출은 또한 BESS(base excision sequence scanning) 기법에 기초할 수 있다. BESS 방법은 PCR 기반 돌연변이 스캔 방법이다. 디데옥시 시퀀싱(dideoxy sequencing)의 T 및 G 래더와 유사한 BESS T-Scan 및 BESS G-Tracker가 생성된다. 돌연변이는 정상 DNA와 돌연변이 DNA의 서열을 비교함으로써 검출된다. 가령, Hawkins et al., Electrophoresis, 20:1171-1176 (1999)를 참조할 수 있다.
질량 분석법은 본 방법에 따라 분자 프로파일링에 사용될 수 있다. Graber et al., Curr.Opin.Biotechnol., 9:14-18 (1998)를 참조할 수 있다. 예를 들어, 프라이머 올리고 염기 연장(PROBE(primer oligo base extension)™) 방법에서 표적 핵산은 고체상 지지체에 고정된다. 프라이머는 분석될 유전자 자리로부터 바로 5' 상류의 표적에 어닐된다. 프라이머 연장은 데옥시리보뉴클레오티드와 디데옥시리보뉴클레오티드의 선택된 혼합물의 존재 하에 수행된다. 새로 연장된 프라이머의 결과 혼합물은 MALDI-TOF로 분석된다. 예를 들어, Monforte et al., Nat.Med., 3:360-362 (1997)를 참조할 수 있다.
또한, 마이크로칩 또는 마이크로어레이 기술이 본 방법의 검출 방법에도 적용 가능하다. 기본적으로, 마이크로칩에서, 다수의 상이한 올리고뉴클레오티드 프로브가 기판 또는 캐리어(가령, 실리콘 칩 또는 유리 슬라이드) 상에 어레이로 고정된다. 분석될 표적 핵산 서열은 마이크로칩 상의 고정된 올리고뉴클레오티드 프로브와 접촉될 수 있다. Lipshutz et al., Biotechniques, 19:442-447 (1995); Chee et al., Science, 274:610-614 (1996); Kozal et al., Nat.Med.2:753-759 (1996); Hacia et al., Nat.Genet., 14:441-447 (1996); Saiki et al., Proc.Natl.Acad.Sci.USA, 86:6230-6234 (1989); Gingeras et al., Genome Res., 8:435-448 (1998)를 참조할 수 있다. 대안으로, 연구될 다중 표적 핵산 서열은 기질에 고정되고 프로브 어레이는 고정된 표적 서열과 접촉된다. Drmanac et al., Nat.Biotechnol., 16:54-58 (1998)를 참조할 수 있다. 돌연 변이를 검출하기 위한 기재죔 기술 중 하나 이상을 통합하는 수 많은 마이크로 칩 기술이 개발되었다. 컴퓨터화된 분석 도구와 결합된 마이크로칩 기술은 대규모로 빠른 스크리닝을 가능하게 한다. 마이크로칩 기술을 본 방법에 적용하는 것은 본 개시 내용을 적용한 해당 분야의 통상의 기술자에게 명백할 것이다. 예를 들어, U.S.Pat.No.5,925,525 to Fodor et al; Wilgenbus et al., J.Mol.Med., 77:761-786 (1999); Graber et al., Curr.Opin.Biotechnol., 9:14-18 (1998); Hacia et al., Nat.Genet., 14:441-447 (1996); Shoemaker et al., Nat.Genet., 14:450-456 (1996); DeRisi et al., Nat.Genet., 14:457-460 (1996); Chee et al., Nat.Genet., 14:610-614 (1996); Lockhart et al., Nat.Genet., 14:675-680 (1996); Drobyshev et al., Gene, 188:45-52 (1997)를 참조할 수 있다.
적합한 검출 기술에 대한 상기 조사에서 명백한 바와 같이, 표적 DNA 분자의 수를 증가시키기 위해, 사용되는 감지 기술에 따라, 표적 DNA, 즉 유전자, cDNA, mRNA, miRNA 또는 이의 일부를 증폭하는 것이 필요하거나 필요하지 않을 수 있다. 예를 들어, 대부분의 PCR 기반 기술은 표적의 일부의 증폭과 돌연변이의 검출을 결합한다. PCR 증폭은 해당 분야에 잘 알려져 있으며 미국 특허 번호 4,683,195 및 4,800,159에 개시되어 있으며, 이들 모두는 참조로서 본 명세서에 포함된다. 비-PCR-기반 검출 기술의 경우, 필요에 따라, 증폭이 예를 들어 체내 플라스미드 증식 또는 다량의 조직 또는 세포 샘플에서 표적 DNA를 정제하여 달성될 수 있다. 일반적으로 Sambrook et al., Molecular Cloning: A Laboratory Manual, 2nd ed., Cold Spring Harbor Laboratory, Cold Spring Harbor, N.Y., 1989를 참조할 수 있다. 그러나, 희소한 샘플의 경우에도, 샘플에서 표적 DNA를 증폭하지 않고도 단일 염기 치환과 같은 작은 유전적 변이를 검출할 수 있는 많은 민감한 기술이 개발되었다. 예를 들어, 표적 DNA에 혼성화될 수 있는 분지형 DNA 또는 덴드리머(dendrimer)를 사용함으로써, 표적 DNA와 반대되는 신호를 증폭하는 기술이 개발되었다. 분지형 또는 덴드리머 DNA는 혼성화 프로브가 부착될 다중 혼성화 부위를 제공하여 검출 신호를 증폭한다. Detmer et al., J.Clin.Microbiol., 34:901-907 (1996); Collins et al., Nucleic Acids Res., 25:2979-2984 (1997); Horn et al., Nucleic Acids Res., 25:4835-4841 (1997); Horn et al., Nucleic Acids Res., 25:4842-4849 (1997); Nilsen et al., J.Theor.Biol., 187:273-284 (1997)를 참조할 수 있다.
Invader™ 분석은 방법에 따라 분자 프로파일링에 사용될 수 있는 단일 뉴클레오티드 변이를 검출하기 위한 또 다른 기술이다. Invader™ 분석은 일반적인 PCR DNA 염기 서열 분석에 필요한 긴 처리 시간을 개선하는 새로운 선형 신호 증폭 기술을 사용한다. Cooksey et al., Antimicrobial Agents and Chemotherapy 44:1296-1301 (2000)를 참조할 수 있다. 이 분석은 "플랩"을 형성하기 위해 관심 표적 서열에 혼성화하는 2개의 중첩 올리고뉴클레오티드 사이에 형성된 독특한 2차 구조의 절단을 기반으로 한다. 그런 다음 각각의 "플랩"은 시간당 수천 개의 신호를 생성한다. 따라서, 이 기술의 결과는 쉽게 판독될 수 있으며 방법은 DNA 표적의 지수 증폭이 필요하지 않는다. Invader™ 시스템은 DNA 표적에 혼성화된 두 개의 짧은 DNA 프로브를 사용한다. 혼성화 이벤트에 의해 형성된 구조는 프로브 중 하나를 절단하여 짧은 DNA "플랩"을 방출하는 특수 절단 효소에 의해 인식된다. 각각의 방출된 "플랩"은 형광 라벨링된 프로브에 결합하여 또 다른 절단 구조를 형성할 수 있다. 절단 효소가 라벨링된 프로브를 절단할 때, 프로브는 검출 가능한 형광 신호를 방출한다. 가령, Lyamichev et al., Nat.Biotechnol., 17:292-296 (1999)를 참조할 수 있다.
롤링 서클 방법은 지수 증폭을 피하는 또 다른 방법이다. Lizardi et al., Nature Genetics, 19:225-232 (1998)(본 명세서에 참조로서 포함됨). 예를 들어, 이 방법의 상업적 구현인 Sniper™는 특정 변이체의 정확한 형광 검출을 위해 설계된 민감하고 처리량이 높은 SNP 스코어링 시스템이다. 각각의 뉴클레오티드 변형에 대해, 두 개의 선형 대립 유전자 특이적 프로브가 설계되었다. 2개의 대립 유전자 특이적 프로브는 변이 부위를 보완하기 위해 변화하는 3' 염기를 제외하고는 동일하다. 분석의 첫 번째 단계에서 표적 DNA가 변성된 후 한 쌍의 단일 대립 유전자 특이적 개방형 올리고뉴클레오티드 프로브와 혼성화된다. 3' 염기가 표적 DNA를 정확히 보완할 때 프로브의 결찰이 우선적으로 발생할 것이다. 순환 올리고뉴클레오티드 프로브의 후속 검출은 롤링 서클 증폭에 의한 것이며, 증폭된 프로브 생성물은 형광에 의해 검출된다. Clark and Pickering, Life Science News 6, 2000, Amersham Pharmacia Biotech (2000)을 참조할 수 있다.
증폭을 모두 피하는 다른 많은 기술에는 예를 들어 SERRS(surface-enhanced resonance Raman scattering), 형광 상관 분광법 및 단일 분자 전기 영동이 포함된다. SERRS에서, 발색단-핵산 접합체는 콜로이드성 은에 흡수되고 발색단의 공명 주파수에서 레이저 광으로 조사된다. Graham et al., Anal.Chem., 69:4703-4707 (1997)을 참조할 수 있다. 형광 상관 분광법은 변동하는 광 신호와 전기장에 단일 분자를 포획하는 사이의 시공간 상관 관계를 기반으로 한다. Eigen et al., Proc.Natl.Acad.Sci.USA, 91:5740-5747 (1994)를 참조할 수 있다. 단일-분자 전기 영동에서, 형광 태깅된 핵산의 전기 영동 속도는 분자가 두 레이저 빔 간 지정 거리를 이동하는 데 필요한 시간을 측정함으로써 결정된다. Castro et al., Anal.Chem., 67:3181-3186 (1995)를 참조할 수 있다.
또한, 대립 유전자 특이적 올리고뉴클레오티드(ASO)는 조직 또는 세포를 샘플로 사용하는 원위치 혼성화도 사용할 수 있다. 야생형 유전자 서열 또는 돌연변이를 포함하는 유전자 서열과 차별적으로 혼성화할 수 있는 올리고뉴클레오티드 프로브는 방사성 동위 원소, 형광 또는 기타 검출 가능한 마커로 라벨링될 수 있다. 원위치 혼성화 기술은 해당 업계에 잘 알려져 있으며, 해당 분야의 통상의 기술자라면,이들을 본 방법에 적용하여 특정 개체의 하나 이상의 유전자에서 뉴클레오티드 변이체의 존재 또는 부재를 검출할 수 있음을 자명하게 알 것이다.
따라서, 개체에서 하나 이상의 유전자 뉴클레오티드 변이체 또는 아미노산 변이체의 존재 또는 부재는 상기 기재된 임의의 검출 방법을 사용하여 결정될 수 있다.
일반적으로, 하나 이상의 유전자 뉴클레오티드 변이 또는 아미노산 변이의 존재 또는 부재가 결정되면 의사나 유전 상담사, 환자 또는 다른 연구자에게 결과를 알릴 수 있다. 특히, 결과는 다른 연구자, 의사, 유전 상담사 또는 환자에게 통신되거나 전달될 수 있는 전달 가능한 형태로 캐스팅될 수 있다. 이러한 형식은 다양할 수 있으며 유형 또는 무형일 수 있다. 시험 대상 개체에서 본 방법의 뉴클레오티드 변이체의 존재 또는 부재와 관련된 결과는 설명문, 다이어그램, 사진, 차트, 이미지 또는 기타 시각적 형태로 구체화될 수 있다. 예를 들어, PCR 산물의 겔 전기 영동 이미지를 사용하여 결과가 설명될 수 있다. 개인의 유전자에서 변이가 발생하는 위치를 보여주는 다이어그램도 검사 결과를 나타내는 데 유용하다. 진술과 시각적 형식은 종이와 같은 유형의 매체, 플로피 디스크, 콤팩트 디스크 등과 같은 컴퓨터 판독 가능 매체 또는 무형 매체(가령, 이메일 형식의 전자 매체 또는 인터넷상의 웹 사이트)에 기록 될 수 있다. 또는, 검사되는 개체에서 뉴클레오티드 변이 또는 아미노산 변이의 존재 또는 부재와 관련된 결과가 소리 형식으로 기록될 수 있으며 임의의 적절한 매체, 가령, 아날로그 또는 디지털 케이블 선, 광섬유 케이블 등을 통해, 가령, 전화기, 팩시밀리, 무선 모바일 전화기, 인터넷 전화기 등을 통해 전송될 수 있다.
따라서 검사 결과에 대한 정보와 데이터는 세계 어디에서나 생성되어 다른 위치로 전송될 수 있다. 예를 들어, 유전형 분석이 해외에서 수행되는 경우, 검사 결과에 대한 정보 및 데이터가 생성되어 앞서 설명한 전송 가능한 형태로 캐스팅될 수 있다. 따라서 전송 가능한 형태로의 검사 결과가 U.S로 가져와질 수 있다. 따라서 본 발명은 개체로부터의 둘 이상의 의심되는 암 샘플의 유전자형에 대한 정보의 전송 가능한 형태를 생성하기 위한 방법을 더 포함한다. 이 방법은 (1) 본 방법의 방법에 따라 샘플로부터 DNA의 유전자형을 결정하는 단계, 및 (2) 결정 단계의 결과를 전송 가능한 형태로 구현하는 단계를 포함한다. 전송 가능한 형태는 생성 방법의 산물이다.
원위치 혼성화
원위치 혼성화에서 분석이 잘 알여져 있으며 일반적으로 Angerer et al., Methods Enzymol.152:649-660 (1987)에 기재되어 있다. 원위치 혼성화 분석에서, 예를 들어 생검으로부터 얻은 세포는 고체 지지체, 일반적으로 유리 슬라이드에 고정된다. DNA가 프로빙될 경우, 세포는 열이나 알칼리에 의해 변성된다. 그런 다음 세포를 적당한 온도에서 혼성화 용액과 접촉시켜 라벨링된 특정 프로브의 어닐을 허용한다. 프로브는 바람직하게는 예를 들어 방사성 동위 원소 또는 형광 리포터로 또는 효소적으로 라벨링된다. FISH(fluorescence in situ hybridization)는 높은 수준의 서열 유사성을 보이는 서열의 일부에만 결합하는 형광 프로브를 사용한다. CISH(chromogenic in situ hybridization)는 표준 명시야 현미경 하에서 시각화된 기존의 페르옥시다제 또는 알칼리성 포스파타제 반응을 사용한다.
원위치 혼성화는 뉴클레오티드 프로브의 상보적 가닥을 관심 서열에 혼성화함으로써 조직 절편 또는 세포 제제에서 특정 유전자 서열을 검출하는 데 사용될 수 있다. FISH(fluorescent in situ hybridization)는 형광 프로브를 사용하여 원위치 혼성화의 감도를 증가시킨다.
FISH는 세포에서 특정 폴리 뉴클레오티드 서열을 검출하고 국소화하는 데 사용되는 세포 유전학 기술이다. 예를 들어, FISH는 염색체에서 DNA 서열을 검출하는 데 사용될 수 있다. FISH는 또한 조직 샘플 내에서 특정 RNA(가령, mRNA)를 검출하고 국소화하는 데 사용될 수 있다. FISH에서는 높은 수준의 서열 유사성을 나타내는 특정 뉴클레오티드 서열에 결합하는 형광 프로브가 사용된다. 형광 현미경은 형광 프로브가 결합되었는지 여부와 위치를 확인하는 데 사용될 수 있다. 특정 뉴클레오티드 서열, 가령, 전좌, 융합, 파손, 복제 및 기타 염색체 이상을 검출하는 것 외에도 FISH는 세포 및 조직 내에서 특정 유전자 복제수 및/또는 유전자 발현의 공간-시간 패턴을 정의하는 데 도움을 줄 수 있다.
다양한 유형의 FISH 프로브가 사용되어 염색체 전위를 감지할 수 있다. 이중 색상, 단일 융합 프로브는 특정 염색체 전좌를 보유한 세포를 검출하는 데 유용할 수 있다. DNA 프로브 혼성화 표적은 두 유전적 중단점 각각의 한쪽에 있다. "추가 신호" 프로브는 정상 핵에서 프로브 신호의 무작위 공동 국소화로 인해 비정상적인 FISH 패턴을 나타내는 정상 세포의 빈도를 줄일 수 있다. 하나의 큰 프로브는 하나의 중단점에 걸쳐 있고 다른 프로브는 다른 유전자의 중단점 옆에 있다. 이중 색상, 분리 프로브는 알려진 유전적 중단점과 관련된 여러 전좌 파트너가 있을 수 있는 경우에 유용하다. 이 라벨링 체계는 하나의 유전자에서 중단점의 반대편에 있는 표적에 혼성화하는 두 개의 서로 다른 색상의 프로브를 특징으로 한다. 이중 색상, 이중 융합 프로브는 비정상적인 신호 패턴을 나타내는 정상 핵의 수를 줄일 수 있다. 이 프로브는 단순한 균형 전좌를 가진 낮은 수준의 핵을 검출하는 데 유리하다. 큰 프로브는 서로 다른 염색체의 두 중단점에 걸쳐 있다. 이러한 프로브는 일리노이 주, 애보트 파크에있는 애보트 연구소(Abbott Laboratories)의 비시스 프로브(Vysis probe)로서 이용 가능하다.
CISH, 또는 발색성 원위치 혼성화가 라벨링된 상보적 DNA 또는 RNA 가닥이 사용되어 조직 표본에서 특정 DNA 또는 RNA 서열을 국소화하는 과정입니다. CISH 방법론은 유전자 증폭, 유전자 결실, 염색체 전좌 및 염색체 수를 평가하는 데 사용할 수 있다. CISH는 표준 명시야 현미경으로 시각화된, 종래의 효소 검출 방법, 가령, 양겨자 페르옥시다제 또는 알칼리성 포스파타제 반응을 이용할 수 있다. 일반적인 구체예에서, 관심 서열을 인식하는 프로브는 샘플과 접촉된다. 예를 들어, 프로브에 의해 운반되는 라벨을 통해, 프로브를 인식하는 항체 또는 기타 결합제는 효소 검출 시스템을 프로브 부위에 표적화하는 데 사용될 수 있다. 일부 시스템에서, 항체는 FISH 프로브의 라벨을 인식할 수 있으므로 FISH 및 CISH 검출을 모두 사용하여 샘플을 분석할 수 있다. CISH는 여러 설정, 가령, 포르말린 고정, 파라핀 포매(FFPE) 조직, 혈액 또는 골수 도말, 중기 염색체 확산 및/또는 고정 세포에서 핵산을 평가하는 데 사용될 수 있다. 하나의 구체예에서, CISH는 Life Technologies(캘리포니아, 칼스배드)로부터 입수 가능한 SPoT-Light® HER2 CISH 키트 또는 Life Technologies로부터 입수 가능한 유사한 CISH 제품의 방법론에 따라 수행된다. SPoT-Light® HER2 CISH 키트 자체는 체외 진단용으로 FDA 승인을 받았으며 HER2의 분자 프로파일링에 사용할 수 있다. CISH는 FISH와 유사한 응용 프로그램에서 사용될 수 있다. 따라서, 해당 분야의 통상의 기술자는 본 명세서에서 FISH를 사용한 분자 프로파일링에 대한 언급이 달리 명시되지 않는 한 CISH를 사용하여 수행될 수 있음을 인식 할 것이다.
SISH(silver-enhanced in situ hybridization)은 CISH와 유사하지만 SISH를 사용하면 신호가 CISH의 발색체 침전물 대신 은 침전으로 인해 검은 색으로 나타난다.
방법에 따라 분자 프로파일링을 위해 변형된 원위치 혼성화를 사용할 수 있다. 이러한 변형은 예를 들어 복수의 표적의 동시 검출 , 가령, Dual ISH, Dual color CISH, BDISH(bright field double in situ hybridization)을 포함한다. 예를 들어, FDA 승인된 Ventana Medical Systems, Inc.(Tucson, AZ)의 INFORM HER2 Dual ISH DNA 프로브 칵테일 키트, Dako Denmark A/S(덴마크)에 의해 개발된 듀얼 컬러 CISH 키트를 참조할 수 있다.
CGH(Comparative Genomic Hybridization)는 염색체 및 아염색체 수준에서 복제수 변화에 대한 특징적인 패턴을 보여주는 유전적 변화에 대해 종양 샘플을 스크리닝하는 분자 세포 유전 학적 방법을 포함한다. 패턴의 변화는 DNA 증가와 손실로 분류될 수 있다. CGH는 한 샘플에서 다른 DNA 또는 RNA 서열의 복제수 또는 한 샘플에서 다른 DNA 또는 RNA 서열의 복제수를 다른 샘플에서 실질적으로 동일한 서열의 복제수와 비교하기 위해 원위치 혼성화 역학을 사용한다. CGH의 많은 유용한 응용에서, DNA 또는 RNA는 대상 세포 또는 세포 개체군으로부터 분리된다. 비교는 질적 또는 양적일 수 있다. 절대 복제수가 하나 또는 여러 서열에 대해 알려지거나 결정되는 경우 세포 또는 세포 집단의 게놈 전체에 걸쳐 DNA 서열의 절대 복제수를 결정하는 절차가 설명된다. 상이한 서열은 참조 게놈, 일반적으로 중기 염색체에 혼성화될 때 결합 부위의 상이한 위치에 의해 서로 구별되지만 특정 경우에는 간기 핵이다. 복제수 정보는 참조 게놈의 서로 다른 위치 간의 혼성화 신호 강도 비교에서 비롯된다. CGH의 방법, 기술 및 응용은 미국 특허 번호 6,335,167, 및 60/804,818에서 알려져 있으며, 이들의 관련 부분이 본 명세서에 참조로서 포함된다.
하나의 구체예에서, CGH는 질병이있는 조직과 건강한 조직 사이의 핵산을 비교하는 데 사용된다. 이 방법은 질병 조직(예를 들어, 종양) 및 기준 조직(예를 들어, 건강한 조직)에서 DNA를 분리하고 각각 다른 "색상" 또는 형광으로 라벨링하는 것을 포함한다. 두 샘플은 혼합되어 정상 중기 염색체에 혼성화된다. 어레이 또는 매트릭스 CGH의 경우, 혼성화 혼합은 수천 개의 DNA 프로브가 있는 슬라이드 상에서 수행된다. 기본적으로 염색체를 따라 색상 비율을 결정하는 다양한 검출 시스템을 사용하여 참조와 비교하여 질병에 걸린 샘플에서 얻거나 잃을 수 있는 DNA 영역을 결정할 수 있다.
분자 프로파일링 방법
도 1g는 환자의 생물학적 표본의 분자 프로파일링을 사용하는 특정 질병 상태에 대한 개별화된 의료 개입을 결정하기 위한 시스템(10)의 예시적인 실시예의 블록도를 예시한다. 시스템(10)은 사용자 인터페이스(12), 데이터 처리를 위한 프로세서(16)를 포함하는 호스트 서버(14), 프로세서에 결합된 메모리(18), 메모리(18)에 저장되고 데이터 처리를 지시하기 위해 프로세서(16)에 의해 액세스 가능한 애플리케이션 프로그램(20), 복수의 내부 데이터베이스(22) 및 외부 데이터베이스(24), 및 유선 또는 무선 통신 네트워크(26)(가령, 인터넷)와의 인터페이스를 포함한다. 시스템(10)은 또한 사용자 인터페이스(12)로부터 수신된 데이터로부터 디지털 데이터를 입력하기 위해 프로세서(16)에 연결된 입력 디지타이저(28)를 포함할 수 있다.
사용자 인터페이스(12)는 시스템(10)에 데이터를 입력하고 프로세서(16)에 의해 처리된 데이터로부터 유도된 정보를 표시하기위한 입력 장치(30) 및 디스플레이(32)를 포함한다. 사용자 인터페이스(12)는 또한 프로세서(16)에 의해 처리된 데이터로부터 유도된 정보, 가령, 표적에 대한 검사 결과 및 검사 결과에 기초하는 제안 약물 요법을 포함할 수 있는 환자 리포트를 인쇄하기 위한 프린터(34)를 포함할 수 있다.
내부 데이터베이스(22)는 환자 생체 샘플/표본 정보 및 추적, 임상 데이터, 환자 데이터, 환자 추적, 파일 관리, 연구 프로토콜, 분자 프로파일링으로부터의 환자 검사 결과, 및 청구 정보 및 추적을 포함할 수 있지만 이에 제한되지는 않는다. 외부 데이터베이스는 약물 라이브러리, 유전자 라이브러리, 질병 라이브러리 및 공개 및 사설 데이터베이스, 가령, UniGene, OMIM, GO, TIGR, GenBank, KEGG 및 Biocarta를 포함할 수 있지만, 이에 한정되지는 않는다.
다양한 방법이 시스템(10)에 따라 사용될 수 있다. 도 2는 질병 특이적이 아닌 환자의 생물학적 표본의 분자 프로파일링을 사용하는 특정 질병 상태에 대한 개별화된 의료 개입을 결정하기 위한 방법의 예시적인 실시예의 블록도를 예시한다. 질병 계통 진단에 독립적인 분자 프로파일링(즉, 단일 질병 제한 없음)을 사용하는 특정 질병 상태에 대한 의학적 개입을 결정하기 위해 질병 있는 환자의 생체 샘플에 대해 적어도 하나의 분자 검사가 수행된다. 종양 생검을 취하고, 어떠한 최신 종양도 가능하지 않은 경우 최소 침습적 수술을 실시하며, 환자의 혈액 샘플, 또는 그 밖의 다른 임의의 생체 유체의 샘플, 비제한적 예를 들면, 세포 추출물, 핵 추출물, 세포 용해물 또는 생체 산물 또는 생체 기원의 물질, 가령, 배설물, 혈액, 혈청, 혈장, 소변, 가래, 눈물, 대벽, 타액, 막 추출물 등을 획득함으로써, 질병 있는 환자로부터 생체 샘플이 획득된다.
표적은 분자 검사로부터 획득될 수 있는 임의의 분자 발견으로 정의된다. 예를 들어, 표적은 하나 이상의 유전자 또는 단백질을 포함할 수 있다. 예를 들어, 유전자의 복제수 변이의 존재가 결정될 수 있다. 도 2에 도시된 바와 같이, 이러한 표적을 찾기 위한 검사의 비제한적 예를 들면, NGS, IHC, FISH(fluorescent in-situ hybridization), ISH(in-situ hybridization) 및 그 밖의 다른 분자 검사를 포함할 수 있다.
또한, 본 명세서에 개시된 방법은 또한 둘 이상의 표적을 프로파일링하는 것을 포함한다. 예를 들어, 복수의 유전자의 복제수 또는 CNV의 존재가 식별될 수 있다. 또한, 샘플에서 복수의 표적의 식별은 하나의 방법 또는 다양한 수단에 의해 이루어질 수 있다. 예를 들어, 제1 유전자의 CNV의 존재는 하나의 방법으로 결정될 수 있고 제2 유전자의 CNV의 존재는 다른 방법으로 결정될 수 있다. 대안으로, 동일한 방법이 사용되어여 첫 번째 및 두 번째 유전자 모두에서 CNV의 존재를 감지할 수 있다.
따라서, 다음 중 하나 이상이 수행될 수 있다: CNV 분석, IHC 분석, 미세분석 및 해당 분야의 통상의 기술자에게 알려진 그 밖의 다른 분자 검사.
그런 다음 테스트 결과들이 합쳐져 암의 개별 특성을 결정할 수 있다. 암의 특성을 결정한 후 치료 요법이 식별된다.
마지막으로, 다양한 표적에 대한 환자의 검사 결과와 이러한 결과를 기반으로 제안된 치료법이 포함된 환자 프로파일 리포트가 제공될 수 있다.
본 명세서에 기재된 시스템은 암을 평가하기 위해 분자 프로파일을 확인하는 단계를 자동화하는 데 사용될 수 있다. 하나의 양태에서, 본 방법은 분자 프로파일을 포함하는 리포트를 생성하는 데 사용될 수 있다. 방법은 다음을 포함할 수 있다: 복수의 암 바이오마커의 각각의 바이오마커의 CNV의 복제수 또는 존재여부를 분석하기 위해 피험체로부터의 샘플에 대해 분자 프로파일링을 수행하는 단계, 및 분석된 특성을 포함하는 리포트를 하나의 리스트로 편집하여, 샘플에 대한 분자 프로파일을 식별하는 리포트를 생성하는 단계. 리포트는 평가된 복제수에 기초하여 복수의 치료 옵션의 예상 이익을 설명하는 리스트을 추가로 포함할 수 있으며, 이에 따라 피험자에 대한 후보 치료 옵션을 식별 할 수 있다.
치료 선택을 위한 분자 프로파일링
본 명세서에 기재된 방법은 이를 필요로 하는 피험체에 대한 후보 치료 선택을 제공한다. 분자 프로파일링은 본 명세서에 개시된 하나 이상의 바이오마커가 치료를 위한 표적인 질환을 앓고 있는 개체에 대한 하나 이상의 후보 치료를 식별하기 위해 사용될 수 있다. 예를 들어, 방법은 암에 대한 하나 이상의 화학 요법 치료를 식별할 수 있다. 하나의 양태에서, 방법은 하나 이상의 바이오마커에 대해 하나 이상의 분자 프로파일링 기술을 수행하는 단계를 포함하는 방법을 제공한다. 임의의 관련 바이오마커는 본 명세서에 기술되거나 해당 업계에 공지된 하나 이상의 분자 프로파일링 기술을 사용하여 평가될 수 있다. 마커는 유용할 치료와 직접 또는 간접적으로 연관될 필요가 있다. 본 명세서에 개시된 것과 같은 모든 관련 분자 프로파일링 기술을 수행할 수 있다. 여기에는 단백질 및 핵산 분석 기술이 제한 없이 포함될 수 있다. 단백질 분석 기술은 비제한적인 예로서, 면역 분석, 면역 조직 화학 및 질량 분석을 포함한다. 핵산 분석 기술의 비 제한적인 예로는, 증폭, 폴리머아제 연쇄 증폭, 혼성화, 마이크로어레이, 원위치 혼성화, 시퀀싱, 염료-종결자 시퀀싱, 차세대 시퀀싱, 파이로 시퀀싱 및 제한 단편 분석이 있다.
분자 프로파일링은 수행되는 각각의 분석 기술에 대한 하나 이상의 유전자(또는 유전자 산물)의 프로파일링을 포함할 수 있다. 상이한 수의 유전자가 상이한 기법에 의해 분석될 수 있다. 표적 치료제와 직접 또는 간접적으로 관련된 본 명세서에 개시된 임의의 마커가 평가될 수 있다. 예를 들어, 소분자 또는 항체와 같은 결합제와 같은 치료제로 조절될 수 있는 표적을 포함하는 임의의 "투약 가능 표적(druggable target)"은 본 명세서에 기재된 바와 같은 분자 프로파일링 방법에 포함될 후보이다. 표적은 또한 연관된 약물에 의해 영향을 받는 생물학적 경로의 구성요소와 같이 간접적으로 약물과 연관될 수 있다. 분자 프로파일링은 유전자(가령, DNA 서열) 및/또는 유전자 산물(가령, mRNA 또는 단백질)을 기반으로 할 수 있다. 이러한 핵산 및/또는 폴리펩티드는 존재 또는 부재, 수준 또는 양, 활성, 돌연변이, 서열, 하플로타입, 재 배열, 복제수 또는 기타 측정 가능한 특성에 대해 적용 가능한 것으로 프로파일링될 수 있다. 일부 구체예에서, 단일 유전자 및/또는 하나 이상의 대응하는 유전자 산물은 둘 이상의 분자 프로파일링 기술에 의해 분석된다. 유전자 또는 유전자 산물(본 명세서에서 "마커" 또는 "바이오마커"라고도 함), 예를 들어 mRNA 또는 단백질은 적용 가능한 기술(가령, DNA, RNA, 단백질을 평가하기 위해), 비제한적 예를 들어, ISH, 유전자 발현, IHC, 시퀀싱 또는 면역분석을 사용하여 평가됩니다. 따라서, 본 명세서에 개시된 임의의 마커는 단일 분자 프로파일링 기술 또는 본 명세서에 개시된 다중 방법에 의해 분석될 수 있다(예를 들어, 단일 마커는 IHC, ISH, 시퀀싱, 마이크로어레이 등 중 하나 이상에 의해 프로파일링됨). 일부 구체예에서, 적어도 약1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95 또는 적어도 약 100개의 유전자 또는 유전자 산물은 적어도 하나의 기술에 의해, 복수의 기술에 의해 또는 ISH, IHC, 유전자 발현, 유전자 복제 및 시퀀싱의 임의의 원하는 조합을 사용하여 프로파일링된다. 일부 구체예에서, 적어도 약 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10,000, 11,000, 12,000, 13,000, 14,000, 15,000, 16,000, 17,000, 18,000, 19,000, 20,000, 21,000, 22,000, 23,000, 24,000, 25,000, 26,000, 27,000, 28,000, 29,000, 30,000, 31,000, 32,000, 33,000, 34,000, 35,000, 36,000, 37,000, 38,000, 39,000, 40,000, 41,000, 42,000, 43,000, 44,000, 45,000, 46,000, 47,000, 48,000, 49,000 또는 적어도 50,000개의 유전자 또는 유전자 산물이 다양한 기술을 사용하여 프로파일링된다. 분석된 마커의 수는 사용되는 기술에 따라 달라질 수 있다. 예를 들어, 마이크로어레이 및 대규모 병렬 시퀀싱은 높은 처리량 분석에 적합하다. 분자 프로파일링은 종양 자체의 분자 특성을 쿼리하기 때문에 이 접근 방식은 종양의 계통에 따라 고려되지 않을 수 있는 치료법에 대한 정보를 제공한다.
일부 구체예에서, 이를 필요로 하는 피험체로부터의 샘플은 다음 중 하나 이상에 대해 IHC 분석, 유전자 발현 분석, ISH 분석 및/또는 서열 분석(예를 들어, PCR, RT-PCR, 파이로시퀀싱, NGS)을 포함하는 방법을 이용해 프로파일링된다: ABCC1, ABCG2, ACE2, ADA, ADH1C, ADH4, AGT, AR, AREG, ASNS, BCL2, BCRP, BDCA1, 베타 III 튜불린, BIRC5, B-RAF, BRCA1, BRCA2, CA2, 카베올린, CD20, CD25, CD33, CD52, CDA, CDKN2A, CDKN1A, CDKN1B, CDK2, CDW52, CES2, CK 14, CK 17, CK 5/6, c-KIT, c-Met, c-Myc, COX-2, 사이클린 D1, DCK, DHFR, DNMT1, DNMT3A, DNMT3B, E-카드헤린, ECGF1, EGFR, EML4-ALK fusion, EPHA2, 에피레귤린, ER, ERBR2, ERCC1, ERCC3, EREG, ESR1, FLT1, 엽산 수용체, FOLR1, FOLR2, FSHB, FSHPRH1, FSHR, FYN, GART, GNA11, GNAQ, GNRH1, GNRHR1, GSTP1, HCK, HDAC1, hENT-1, Her2/Neu, HGF, HIF1A, HIG1, HSP90, HSP90AA1, HSPCA, IGF-1R, IGFRBP, IGFRBP3, IGFRBP4, IGFRBP5, IL13RA1, IL2RA, KDR, Ki67, KIT, K-RAS, LCK, LTB, 림포톡신 베타 수용체, LYN, MET, MGMT, MLH1, MMR, MRP1, MS4A1, MSH2, MSH5, Myc, NFKB1, NFKB2, NFKBIA, NRAS, ODC1, OGFR, p16, p21, p27, p53, p95, PARP-1, PDGFC, PDGFR, PDGFRA, PDGFRB, PGP, PGR, PI3K, POLA, POLA1, PPARG, PPARGC1, PR, PTEN, PTGS2, PTPN12, RAF1, RARA, ROS1, RRM1, RRM2, RRM2B, RXRB, RXRG, SIK2, SPARC, SRC, SSTR1, SSTR2, SSTR3, SSTR4, SSTR5, 서비빈(Survivin), TK1, TLE3, TNF, TOP1, TOP2A, TOP2B, TS, TUBB3, TXN, TXNRD1, TYMS, VDR, VEGF, VEGFA, VEGFC, VHL, YES1, ZAP70.
해당 분야의 통상의 기술자에 의해 이해되는 바와 같이, 유전자 및 단백질은 과학 문헌에서 다수의 대체 명칭을 발전시켰다. 본 명세서에서 사용되는 유전자 별칭 및 설명 리스트은 다양한 온라인 데이터베이스, 가령, GeneCards® (www.genecards.org), HUGO Gene Nomenclature (www.genenames.org), Entrez Gene (www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=gene), UniProtKB/Swiss-Prot (www.uniprot.org), UniProtKB/TrEMBL (www.uniprot.org), OMIM (www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=OMIM), GeneLoc (genecards.weizmann.ac.il/geneloc/), 및 Ensembl (www.ensembl.org)를 이용해 발견될 수 있다. 예를 들어, 본 명세서에서 사용된 유전자 기호 및 이름은 HUGO에 의해 승인된 것에 대응할 수 있고 단백질 이름은 UniProtKB/Swiss-Prot에 의해 권장되는 것일 수 있다. 본 명세서에서, 단백질 이름이 전구체를 나타내는 경우 성숙 단백질도 함축된다. 애플리케이션 전체에서, 유전자 및 단백질 기호는 상호교환적으로 사용될 수 있으며 의미는 문맥으로부터 파생될 수 있다, 예를 들어 ISH 또는 NGS는 핵산을 분석하기 위해 사용될 수 있는 반면에 IHC는 단백질 분석에 사용된다.
본 명세서에 기재된 분자 프로파일을 제공하기 위해 평가될 유전자 및 유전자 산물의 선택은 새로운 치료법 및 새로운 약물 표적이 식별됨에 따라 시간이 지남에 따라 업데이트 될 수 있다. 예를 들어, 바이오마커의 발현 또는 돌연변이가 치료 옵션과 상관되면 분자 프로파일링에 의해 평가될 수 있다. 해당 분야의 통상의 기술자는 이러한 분자 프로파일링이 본 명세서에 개시된 기술에 제한되지 않고 핵산 또는 단백질 수준, 서열 정보 또는 둘 모두를 평가하기 위한 통상적인 방법론을 포함한다는 것을 이해할 것이다. 본 명세서에 기재된 방법은 또한 현재 방법 또는 미래에 개발된 새로운 분자 프로파일링 기술에 대한 임의의 개선을 이용할 수 있다. 일부 구체예에서, 유전자 또는 유전자 산물은 단일 분자 프로파일링 기술에 의해 평가된다. 다른 구체예에서, 유전자 및/또는 유전자 산물은 다중 분자 프로파일링 기술에 의해 평가된다. 비 제한적인 예에서, 유전자 서열은 NGS, ISH 및 파이로시퀀싱 분석 중 하나 이상에 의해 분석될 수 있으며, mRNA 유전자 산물은 NGS, RT-PCR 및 마이크로어레이 중 하나 이상에 의해 분석될 수 있고, IHC 및 면역 분석 중 하나 이상에 의해 단백질 유전자 산물이 분석될 수 있다. 해당 분야의 통상의 기술자는 질병 치료에 도움이 될 바이오마커 및 분자 프로파일링 기술의 임의의 조합이 본 방법에 의해 고려된다는 것을 이해할 것이다.
암에서 역할을 하는 것으로 알려져 있고 본 명세서에 기재된 바와 같은 분자 프로파일링 기술 중 어느 것에 의해 분석될 수 있는 유전자 및 유전자 산물은 제한없이그 전체가 본 명세서에 참조로서 포함되는 2007년11월29일에 공개된 국제 특허 공개 번호 WO/2007/137187 (국제 출원 번호 PCT/US2007/069286); 2010년 04월 22일에 공개된 WO/2010/045318 (국제 출원 번호 PCT/US2009/060630), 2010년 08월 19일에 공개된 WO/2010/093465 (국제 출원 번호 PCT/US2010/000407), 2012년 12월 13일에 공개된 WO/2012/170715 (국제 출원 번호 PCT/US2012/041393), 2014년 06월 12일에 공개된 WO/2014/089241 (국제 출원 번호 PCT/US2013/073184), 2011년 05월 12일에 공개된 WO/2011/056688 (국제 출원 번호 PCT/US2010/054366), 2012년 07월 05일에 공개된 WO/2012/092336 (국제 출원 번호 PCT/US2011/067527), 2015년 08월 06일에 공개된 WO/2015/116868 (국제 출원 번호 PCT/US2015/013618), 2017년 03월 30일에 공개된 WO/2017/053915 (국제 출원 번호 PCT/US2016/053614), 2016년 09월 09일에 공개된 WO/2016/141169 (국제 출원 번호 PCT/US2016/020657), 및 2018년 09월 27일에 공개된 WO2018175501 (국제 출원 번호 PCT/US2018/023438) 중 임의의 것에 나열된 것일 수 있다.
돌연변이 프로파일링은 Sanger 시퀀싱, 어레이 시퀀싱, 파이로시퀀싱, NextGen 시퀀싱 등을 포함한 시퀀싱에 의해 결정될 수 있다. 서열 분석은 활성을 억제하는 약물이 치료를 위해 표시되도록 유전자에 활성화 돌연변이가 있음을 보여줄 수 있다. 대안으로, 서열 분석은 유전자가 활성을 억제하거나 제거하는 돌연변이를 가지고 있음을 나타내어 치료를 보상하기 위한 치료를 나타낸다. 일부 구체예에서, 서열 분석은 c-KIT의 엑손 9 및 11의 분석을 포함한다. 시퀀싱은 또한 EGFR-키나제 도메인 엑손 18, 19, 20 및 21에서 수행될 수 있다. EGFR 또는 그 가족 구성원의 돌연변이, 증폭 또는 잘못된 조절은 모든 상피암의 약 30 %와 관련이 있다. 시퀀싱은 PIK3CA 유전자에 의해 암호화된 PI3K에서도 수행될 수 있다. 이 유전자는 많은 암에서 돌연변이된 것으로 발견된다. 시퀀싱 분석은 또한 하나 이상의 ABCC1, ABCG2, ADA, AR, ASNS, BCL2, BIRC5, BRCA1, BRCA2, CD33, CD52, CDA, CES2, DCK, DHFR, DNMT1, DNMT3A, DNMT3B, ECGF1, EGFR, EPHA2, ERBB2, ERCC1, ERCC3, ESR1, FLT1, FOLR2, FYN, GART, GNRH1, GSTP1, HCK, HDAC1, HIF1A, HSP90AA1, IGFBP3, IGFBP4, IGFBP5, IL2RA, KDR, KIT, LCK, LYN, MET, MGMT, MLH1, MS4A1, MSH2, NFKB1, NFKB2, NFKBIA, NRAS, OGFR, PARP1, PDGFC, PDGFRA, PDGFRB, PGP, PGR, POLA1, PTEN, PTGS2, PTPN12, RAF1, RARA, RRM1, RRM2, RRM2B, RXRB, RXRG, SIK2, SPARC, SRC, SSTR1, SSTR2, SSTR3, SSTR4, SSTR5, TK1, TNF, TOP1, TOP2A, TOP2B, TXNRD1, TYMS, VDR, VEGFA, VHL, YES1, 및 ZAP70에서 돌인변이를 평가하는 것을 포함할 수 있다. 다음의 유전자 중 하나 이상이 서열 분석에 의해 평가될 수 있다: ALK, EML4, hENT-1, IGF-1R, HSP90AA1, MMR, p16, p21, p27, PARP-1, PI3K 및 TLE3. 돌연변이 또는 서열 분석에 사용되는 유전자 및/또는 유전자 산물은 WO2018175501의 표 4-12 중 임의의 것, 가령, WO2018175501의 표 5-10 중 임의의 것, 또는 WO2018175501의 표 7-10에서 나열된 유전자 및/또는 유전자 산물 중 적어도 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 40, 50, 60, 70, 80, 90, 100, 200, 300, 400, 500개 또는 전부일 수 있다.
구체예에서, 본 명세서에 기재된 방법은 유전자 융합, 가령, 다음의 국제특허출원 중 임의의 것에 나열된 것을 검출하기 위해 사용된다: 2007년11월29일에 공개된 국제 특허 공개 번호 WO/2007/137187 (국제 출원 번호 PCT/US2007/069286); 2010년 04월 22일에 공개된 WO/2010/045318 (국제 출원 번호 PCT/US2009/060630), 2010년 08월 19일에 공개된 WO/2010/093465 (국제 출원 번호 PCT/US2010/000407), 2012년 12월 13일에 공개된 WO/2012/170715 (국제 출원 번호 PCT/US2012/041393), 2014년 06월 12일에 공개된 WO/2014/089241 (국제 출원 번호 PCT/US2013/073184), 2011년 05월 12일에 공개된 WO/2011/056688 (국제 출원 번호 PCT/US2010/054366), 2012년 07월 05일에 공개된 WO/2012/092336 (국제 출원 번호 PCT/US2011/067527), 2015년 08월 06일에 공개된 WO/2015/116868 (국제 출원 번호 PCT/US2015/013618), 2017년 03월 30일에 공개된 WO/2017/053915 (국제 출원 번호 PCT/US2016/053614), 2016년 09월 09일에 공개된 WO/2016/141169 (국제 출원 번호 PCT/US2016/020657), 및 2018년 09월 27일에 공개된 WO2018175501 (국제 출원 번호 PCT/US2018/023438). 융합 유전자는 이전에 분리된 두 유전자의 병치에 의해 생성된 하이브리드 유전자이다. 이는 염색체 전위 또는 반전, 결실 또는 트랜스 스플라이싱을 통해 발생할 수 있다. 결과적 융합 유전자는 비정상적인 유전자의 시간적 및 공간적 발현을 유발하여 세포 성장 인자, 혈관 신생 인자, 종양 프로모터 또는 세포의 종양 변형 및 종양 생성에 기여하는 기타 인자의 비정상적인 발현을 유발할 수 있다. 예를 들어, 이러한 융합 유전자는 1) 세포 성장 인자의 코딩 영역 옆에있는 한 유전자의 강력한 프로모터 영역, 종양 프로모터 또는 증가된 유전자 발현을 유도하는 종양 발생을 촉진하는 다른 유전자의 병치, 또는 2) 두 개의 서로 다른 유전자의 코딩 영역이 융합되어 키메라 유전자와 비정상적인 활성을 가진 키메라 단백질의 생성으로 인해 발암성일 수 있다 융합 유전자는 많은 암의 특징이다. 치료적 개입이 융합과 연관되면, 모든 유형의 암에서 그 융합의 존재는 치료적 개입이 암 치료를 위한 후보 요법으로 식별된다.
융합 유전자의 존재는 치료 선택을 안내하는 데 사용될 수 있다. 예를 들어, BCR-ABL 유전자 융합은 만성 골수성 백혈병(CML)의 ~ 90 %와 급성 백혈병의 하위 집합에서 특징적인 분자 이상이다(Kurzrock et al., Annals of Internal Medicine 2003; 138:819-830). BCR-ABL은 일반적으로 필라델피아 염색체 또는 필라델피아 전위라고 하는 9번과 22번 염색체 사이의 전위로 인해 발생한다. 전위는 BCR 유전자의 5' 영역과 ABL1의 3' 영역을 결합하여 키메라 BCR-ABL1 유전자를 생성하며, 이는 구성적으로 활성인 티로신키나제 활성을 갖는 단백질을 인코딩한다(Mittleman et al., Nature Reviews Cancer 2007; 7:233-245). 비정상적인 티로신 키나제 활성은 조절 해제된 세포 신호 전달, 세포 성장 및 세포 생존, 세포 자멸사 저항성 및 성장 인자 독립성을 유발하며,이 모두는 백혈병의 병태 생리학에 기여한다(Kurzrock et al., Annals of Internal Medicine 2003; 138:819-830). 필라델피아 염색체를 가진 환자는 이마티닙 및 그 밖의 다른 표적 요법으로 치료된다. 이마티닙은 융합 단백질의 구성적 티로신 키나제 활성 부위에 결합하여 그 활성을 방지한다. 이마티닙 치료는 분자 반응(BCR-ABL + 혈액 세포의 소멸)을 이끌고 BCR-ABL + CML 환자의 무진행 생존을 개선했다(Kantarjian et al., Clinical Cancer Research 2007; 13:1089-1097).
또 다른 융합 유전자인 IGH-MYC는 버킷 림프종의 ~80%를 정의하는 특징이다(Ferry et al.Oncologist 2006; 11:375-83). 이에 대한 인과적 사건은 염색체 8과 14 사이의 전위로, c-Myc 종양 유전자를 면역 글로불린 중쇄 유전자의 강력한 프로모터에 인접하게 하여 c-myc 과발현을 유발한다(Mittleman et al., Nature Reviews Cancer 2007; 7:233-245). c-myc 재배열은 영구 증식 상태를 초래하기 때문에 림프종 발생에서 중추적인 사건이다. 이는 세포주기, 세포 분화, 세포 자멸사 및 세포 접착을 통한 진행에 광범위한 영향을 미친다(Ferry et al.Oncologist 2006; 11:375-83).
Mittleman 데이터베이스(cgap.nci.nih.gov/Chromosomes/Mitelman)에는 다수의 반복 융합 유전자가 분류되어 있다. 유전자 융합은 신생물 및 암을 특징화하고 본 명세서에 기재된 방법을 사용하여 요법을 안내하는 데 사용될 수 있다. 예를 들어, TMPRSS2-ERG, TMPRSS2-ETV 및 SLC45A3-ELK4 융합이 검출되어 전립선 암을 특징지을 수 있고, ETV6-NTRK3 및 ODZ4-NRG1이 유방암을 특징짓기 위해 사용될 수 있다. EML4-ALK, RLF-MYCL1, TGF-ALK, 또는 CD74-ROS1 융합이 폐암을 특징짓기 위해 사용될 수 있다. ACSL3-ETV1, C15ORF21-ETV1, FLJ35294-ETV1, HERV-ETV1, TMPRSS2-ERG, TMPRSS2-ETV1/4/5, TMPRSS2-ETV4/5, SLC5A3-ERG, SLC5A3-ETV1, SLC5A3-ETV5 또는 KLK2-ETV4 융합이 전립선암을 특징짓는 데 사용될 수 있다. GOPC-ROS1 융합은 뇌암을 특징짓도록 사용될 수 있다. CHCHD7-PLAG1, CTNNB1-PLAG1, FHIT-HMGA2, HMGA2-NFIB, LIFR-PLAG1, 또는 TCEA1-PLAG1 융합은 두경부암을 특징짓는데 사용될 수 있다. ALPHA-TFEB, NONO-TFE3, PRCC-TFE3, SFPQ-TFE3, CLTC-TFE3, 또는 MALAT1-TFEB 융합은 신장 세포 암종(RCC)을 특징 짓는 데 사용될 수 있다. AKAP9-BRAF, CCDC6-RET, ERC1-RETM, GOLGA5-RET, HOOK3-RET, HRH4-RET, KTN1-RET, NCOA4-RET, PCM1-RET, PRKARA1A-RET, RFG-RET, RFG9-RET, Ria-RET, TGF-NTRK1, TPM3-NTRK1, TPM3-TPR, TPR-MET, TPR-NTRK1, TRIM24-RET, TRIM27-RET 또는 TRIM33-RET 융합이 갑상선 암 및/또는 유두 갑상선 암종을 특징짓는 데 사용될 수 있으며, PAX8-PPARy 융합은 여포성 갑상선 암을 특징 짓기 위해 분석될 수 있다. 혈액 악성 종양과 연관된 융합의 비제한적 예를 들면, 급성 림프구성 백혈병(ALL)의 특징인 TTL-ETV6, CDK6-MLL, CDK6-TLX3, ETV6-FLT3, ETV6-RUNX1, ETV6-TTL, MLL-AFF1, MLL-AFF3, MLL-AFF4, MLL-GAS7, TCBA1-ETV6, TCF3-PBX1 또는 TCF3-TFPT; T 세포 급성 림프구성 백혈병(T-ALL)의 특징인 BCL11B-TLX3, IL2-TNFRFS17, NUP214-ABL1, NUP98-CCDC28A, TAL1-STIL, 또는 ETV6-ABL2; 역 형성 대세포 림프종(ALCL)의 특징인 ATIC-ALK, KIAA1618-ALK, MSN-ALK, MYH9-ALK, NPM1-ALK, TGF-ALK 또는 TPM3-ALK; 만성 골수성 백혈병(CML)의 특징인 BCR-ABL1, BCR-JAK2, ETV6-EVI1, ETV6-MN1 또는 ETV6-TCBA1; 급성 골수성 백혈병(AML)의 특징인 CBFB-MYH11, CHIC2-ETV6, ETV6-ABL1, ETV6-ABL2, ETV6-ARNT, ETV6-CDX2, ETV6-HLXB9, ETV6-PER1, MEF2D-DAZAP1, AML-AFF1, MLL-ARHGAP26, MLL-ARHGEF12, MLL-CASC5, MLL-CBL,MLL-CREBBP, MLL-DAB21P, MLL-ELL, MLL-EP300, MLL-EPS15, MLL-FNBP1, MLL-FOXO3A, MLL-GMPS, MLL-GPHN, MLL-MLLT1, MLL-MLLT11, MLL-MLLT3, MLL-MLLT6, MLL-MYO1F, MLL-PICALM, MLL-SEPT2, MLL-SEPT6, MLL-SORBS2, MYST3-SORBS2, MYST-CREBBP, NPM1-MLF1, NUP98-HOXA13, PRDM16-EVI1, RABEP1-PDGFRB, RUNX1-EVI1, RUNX1-MDS1, RUNX1-RPL22, RUNX1-RUNX1T1, RUNX1-SH3D19, RUNX1-USP42, RUNX1-YTHDF2, RUNX1-ZNF687, 또는 TAF15-ZNF-384; 만성 림프구성 백혈병(CLL)의 특징인 CCND1-FSTL3, which is characteristic of chronic lymphocytic leukemia (CLL); B-세포 만성 림프구성 백혈병(B-CLL)의 특징인 BCL3-MYC, MYC-BTG1, BCL7A-MYC, BRWD3-ARHGAP20 또는 BTG1-MYC; 미만성 거대 B 세포 림프종(DLBCL)의 특징인 CITTA-BCL6, CLTC-ALK, IL21R-BCL6, PIM1-BCL6, TFCR-BCL6, IKZF1-BCL6 또는 SEC31A-ALK; 과다 호산구 증가/만성 호산구 증가증의 특징인 FLIP1-PDGFRA, FLT3-ETV6, KIAA1509-PDGFRA, PDE4DIP-PDGFRB, NIN-PDGFRB, TP53BP1-PDGFRB, 또는 TPM3-PDGFRB; 및 버킷 림프종의 특징인 IGH-MYC 또는 LCP1-BCL6이 있다. 해당 분야의 통상의 기술자라면 아직까지 확인되지 않은 융합을 포함하여 추가 융합이 치료적 개입과 관련이있는 경우 치료를 안내하는 데 사용될 수 있음을 이해할 것이다.
융합 유전자 및 유전자 산물은 본 명세서에 기재된 하나 이상의 기술을 사용하여 검출될 수 있다. 일부 구체예에서, 유전자 서열 또는 상응하는 mRNA는 예를 들어 Sanger 시퀀싱, NGS, 파이로시퀀싱, DNA 마이크로어레이 등을 사용하여 결정된다. 염색체 이상은 무엇보다도 ISH, NGS 또는 PCR 기술을 사용하여 평가될 수 있다. 예를 들어, ALK 융합, 가령, EML4-ALK, KIF5B-ALK 및/또는 TFG-ALK의 ISH 검출을 위해 분리 프로브가 사용될 수 있다. 대안으로서, PCR이 사용되어 융합 산물을 증폭시킬 수 있으며, 여기서 증폭 또는 부족은 각각 융합의 존재 또는 부재를 나타낸다.예를 들어, 이러한 융합을 검출하기 위해 NGS를 사용하여 mRNA가 시퀀싱될 수 있다. 예를 들어, WO2018175501의 표 9 또는 표 12를 참조할 수 있다. 일부 구체예에서, 융합 단백질 융합이 검출된다. 단백질 분석을 위한 적절한 방법의 비제한적 예를 들면 질량 분광법, 전기 영동(가령, 2D 겔 전기 영동 또는 SDS-PAGE) 또는 면역 분석, 단백질 어레이 또는 면역 조직 화학을 포함한 항체 관련 기술을 포함한다. 기술들은 조합될 수 있다. 비제한적인 예로서, NGS에 의한 ALK 융합의 표시는 IHC를 사용한 ISH 또는 ALK 발현에 의해 확인될 수 있으며, 그 반대의 경우도 마찬가지이다.
치료 선택을 위한 분자 프로파일링 표적
본 명세서에 기재된 시스템 및 방법은 분자 프로파일링에 기초하여 예상되는 치료 효능을 갖는 하나 이상의 치료 요법의 확인을 허용한다. 치료 요법을 식별하기 위해 분자 프로파일링을 사용하는 예시적인 계획이 전체에 제공된다. 추가 계획은 그 전체가 본 명세서에 참조로서 포함되는 2007년11월29일에 공개된 국제 특허 공개 번호 WO/2007/137187 (국제 출원 번호 PCT/US2007/069286); 2010년 04월 22일에 공개된 WO/2010/045318 (국제 출원 번호 PCT/US2009/060630), 2010년 08월 19일에 공개된 WO/2010/093465 (국제 출원 번호 PCT/US2010/000407), 2012년 12월 13일에 공개된 WO/2012/170715 (국제 출원 번호 PCT/US2012/041393), 2014년 06월 12일에 공개된 WO/2014/089241 (국제 출원 번호 PCT/US2013/073184), 2011년 05월 12일에 공개된 WO/2011/056688 (국제 출원 번호 PCT/US2010/054366), 2012년 07월 05일에 공개된 WO/2012/092336 (국제 출원 번호 PCT/US2011/067527), 2015년 08월 06일에 공개된 WO/2015/116868 (국제 출원 번호 PCT/US2015/013618), 2017년 03월 30일에 공개된 WO/2017/053915 (국제 출원 번호 PCT/US2016/053614), 2016년 09월 09일에 공개된 WO/2016/141169 (국제 출원 번호 PCT/US2016/020657), 및 2018년 09월 27일에 공개된 WO2018175501 (국제 출원 번호 PCT/US2018/023438)에 기재되어 있다.
본 명세서에 기재된 방법은 치료 효험과의 연관성을 제안하기 위해 분자 프로파일링 결과를 사용하는 것을 포함한다. 일부 구체예에서, 규칙은 분자 프로파일링 테스트 결과에 기초하여 제안된 화학 요법 치료를 제공하기 위해 사용된다. 가장 간단한 규칙은 "바이오마커가 양성이면 치료 옵션 1, 그렇지 않으면 치료 옵션 2" 형식으로 구성된다. 치료 옵션에는 특정 약물로 치료하지 않거나 특정 요법(가령, FOLFOX 또는 FOLFIRI)을 사용한 치료가 포함된다. 일부 구체예에서, 둘 이상의 바이오마커의 상호 작용을 포함하는 더 복잡한 규칙이 구성된다. 마지막으로, 치료의 예상 효험과 바이오마커의 연관성을 기재하는 리포트가 생성될 수 있으며, 선택적으로 선택된 치료를 뒷받침하는 최상의 증거에 대한 요약 설명이 있다. 궁극적으로, 치료 의사는 최선의 치료 과정을 결정할 것이다.
개인에 대한 후보 치료의 선택은 기재된 방법 중 임의의 하나 이상의 분자 프로파일링 결과를 기반으로 할 수 있다.
본 명세서에 개시된 바와 같이, 분자 프로파일링은 샘플에 존재하는 하나 이상의 유전자의 복제수 또는 복제수 변이를 결정하기 위해 수행 될 수 있다. 유전자(들)의 CNV는 효능이 있을 것으로 예측되는 요법을 선택하는 데 사용된다. 방법은 또한 다른 유전자 및/또는 유전자 산물에서의 돌연변이, 삽입-결실, 융합 등의 검출을 더 포함할 수 있으며, 이는 예를 들어, 그 전체가 본 명세서에 참조로서 포함되는 2007년11월29일에 공개된 국제 특허 공개 번호 WO/2007/137187 (국제 출원 번호 PCT/US2007/069286); 2010년 04월 22일에 공개된 WO/2010/045318 (국제 출원 번호 PCT/US2009/060630), 2010년 08월 19일에 공개된 WO/2010/093465 (국제 출원 번호 PCT/US2010/000407), 2012년 12월 13일에 공개된 WO/2012/170715 (국제 출원 번호 PCT/US2012/041393), 2014년 06월 12일에 공개된 WO/2014/089241 (국제 출원 번호 PCT/US2013/073184), 2011년 05월 12일에 공개된 WO/2011/056688 (국제 출원 번호 PCT/US2010/054366), 2012년 07월 05일에 공개된 WO/2012/092336 (국제 출원 번호 PCT/US2011/067527), 2015년 08월 06일에 공개된 WO/2015/116868 (국제 출원 번호 PCT/US2015/013618), 2017년 03월 30일에 공개된 WO/2017/053915 (국제 출원 번호 PCT/US2016/053614), 2016년 09월 09일에 공개된 WO/2016/141169 (국제 출원 번호 PCT/US2016/020657), 및 2018년 09월 27일에 공개된 WO2018175501 (국제 출원 번호 PCT/US2018/023438)에 기재되어 있다.
본 명세서에 기재된 방법은 개인화된 치료를 제공함으로써 대장암에 걸린 피험체의 생존율을 연장하기 위해 사용된다. 일부 구체예에서, 피험체는 암을 치료하기 위해 하나 이상의 치료제로 이전에 치료를 받은 적이있다. 암은 예를 들어 약물 내성 돌연변이를 획득함으로써 이러한 작용제 중 하나에 불응성일 수 있다. 일부 구체예에서, 암은 전이성이다. 일부 구체예에서, 피험체는 방법에 의해 식별된 하나 이상의 치료제로 이전에 치료 된 적이 없다. 분자 프로파일링을 사용하면 암세포의 단계, 해부학적 위치 또는 해부학적 기원에 관계없이 후보 치료법을 선택할 수 있다.
본 개시 내용은 전술한 바와 같이 분자 프로파일링을 사용하여 병든 조직을 분석하기 위한 방법 및 시스템을 제공한다. 이 방법은 분석 중인 종양의 특성 분석에 의존하기 때문에,이 방법은 질병의 진행 단계 또는 원인을 알 수없는 전이성 종양과 같은 모든 종양 또는 질병 단계에 적용 할 수 있다. 본 명세서에 기술된 바와 같이, 종양 또는 암 샘플은 후보 치료 치료를 예측하거나 확인하기 위해 하나 이상의 바이오마커의 CNV의 복제수 또는 존재에 대해 분석된다.
본 방법은 원발성 또는 전이성 대장암의 치료를 선택하는 데 사용될 수 있다.
바이오마커 패턴 및/또는 바이오마커 시그니처 세트는 복수의 바이오마커를 포함할 수 있다. 또 다른 구체예에서, 바이오마커 패턴 또는 시그니처 세트는 적어도 6, 7, 8, 9 또는 10개의 바이오마커를 포함할 수 있다. 일부 구체예에서, 바이오마커 시그니처 세트 또는 바이오마커 패턴은 적어도 15, 20, 30, 40, 50 또는 60 개의 바이오마커를 포함할 수 있다. 일부 구체예에서, 바이오마커 시그니처 세트 또는 바이오마커 패턴은 적어도 70, 80, 90, 100 또는 200개의 바이오마커를 포함할 수 있다. 하나 이상의 바이오마커의 분석은 예를 들어, 본 명세서에 기재된 바와 같은 하나 이상의 방법에 의해 이루어질 수 있다.
본 명세서에 기재된 바와 같이, 하나 이상의 표적의 분자 프로파일링은 개인에 대한 치료제를 결정하거나 확인하는 데 사용될 수 있다. 예를 들어, 하나 이상의 바이오마커의 CNV의 복제수 또는 존재는 개인에 대한 치료제를 결정하거나 확인하는 데 사용될 수 있다. 본 명세서에 개시된 바와 같은 하나 이상의 바이오마커는 개인에 대한 치료제를 확인하는 데 사용되는 바이오마커 패턴 또는 바이오마커 시그니처 세트를 형성하는 데 사용될 수 있다. 일부 구체예에서, 식별된 치료법은 개인이 이전에 치료받은 적이 없는 치료법이다. 예를 들어, 특정 치료법에 대한 참조 바이오마커 패턴이 확립되어, 참조 바이오마커 패턴을 가진 개인이 해당 치료법에 반응할 것이다. 기준과 상이한 바이오마커 패턴을 가진 개체, 예를 들어 바이오마커 패턴에서 유전자의 발현이 기준의 것으로부터 변경되거나 상이한 경우, 그 치료법이 투여되지 않을 것이다. 또 다른 예에서, 기준과 동일하거나 실질적으로 동일한 바이오마커 패턴을 나타내는 개체는 해당 치료법으로 치료를 받는 것이 권장된다. 일부 구체예에서, 개체는 이전에 그 치료법으로 치료된 적 없고 따라서 상기 개체에 대해 새로운 치료법이 식별되었다.
예를 들어, IHC, ISH, 시퀀싱(가령, NGS) 및/또는 PCR(가령, qPCR)에 의해 분자 프로파일링에 사용되는 유전자는 WO2018175501, 예를 들어 표 5-10에 기재된 임의의 유전자로부터 선택 될 수 있다. 본 명세서에 개시된 하나 이상의 바이오마커를 평가하는 것은 암, 예를 들어 본 명세서에 개시된 바와 같은 대장암을 특징화하기 위해 사용될 수 있다.
피험체의 암은 피험체로부터 생체 샘플을 획득하고 샘플로부터의 하나 이상의 바이오마커를 분석함으로써 특징화될 수 있다. 예를 들어, 피험체 또는 개인에 대한 암을 특징화하는 것은 특정 질병, 상태, 질병 단계 및 상태 단계, 특히 질병 재발, 전이성 확산 또는 질병 재발의 예측 및 가능성 분석에 대한 적절한 치료 또는 치료 효능을 식별하는 것을 포함할 수 있다. 본 명세서에 기재된 제품 및 프로세스를 통해 개인별로 피험자를 평가할 수 있으므로 치료에 있어 보다 효율적이고 경제적인 결정의 이점을 얻을 수 있다.
한 측면에서, 암을 특징화하는 것은 피험체가 암에 대한 치료로부터 혜택을받을 가능성이 있는지 예측하는 것을 포함한다. 바이오마커는 피험체에서 분석될 수 있고 치료에 효험이 있다고 또는 없다고 알려진 이전 피험체의 바이오마커 프로파일에 비교될 수 있다. 피험체의 바이오마커 프로파일이 치료로부터 이익을 얻는 것으로 알려진 이전 피험체의 프로파일과 더 밀접하게 일치한다면, 피험체는 치료법에 효험이 있는 것으로 특징화되거나 예측될 수 있다. 유사하게, 피험체의 바이오마커 프로파일이 치료로부터 이익을 얻지 못한 이전 피험체의 프로파일과 더 밀접하게 일치한다면, 피험체는 치료법으로부터 효험이 없는 것으로 특징화되거나 예측될 수 있다. 암을 특징화하기 위해 사용되는 샘플은 본 명세서에 개시된 것들을 포함 하나 이에 제한되지 않는 임의의 유용한 샘플 일 수 있다.
방법은 피험체에게 선택된 치료를 투여하는 것을 추가로 포함할 수 있다. FOLFOX 및 FOLFIRI 요법은 해당 업계에 알려져 있다; 가령, nccn.org/professionals/physician_gls/pdf/colon.pdf를 참조할 수 있다.
본 개시 내용은 FOLFOX로부터 효험 또는 효험 부재를 예측하기 위해 임상적으로 관련된 바이오시그니처를 발견하기 위해 분자 프로파일링 데이터를 분석하기 위한 머신 러닝 접근법의 사용을 개시한다. 우리는 단계 III 및 단계 IV 대장암(CRC) 샘플에 대한 머신 러닝 분류 모델을 훈련했다. 실시예 2-4를 참조할 수 있다. 여기에서, 우리는 모든 모델을 결합하여 CRC 환자를 FOLFOX 화학 요법 치료 요법에 대한 반응군 또는 비반응군으로서 예측하기 위한 머신-러닝 접근법을 개발했다. 효험은 상대적인 용어이며 치료가 암 환자를 치료하는 데 긍정적인 영향을 미치지만 완전한 차도를 요구하지 않는다. 효험 있는 피험체는 효험군, 반응군 등으로 지칭될 수 있다. 마찬가지로, 효험을 있을 가능성이 없거나 효험이 없는 피험체는 비효험군, 비반응군 등으로 지칭될 수 있다.
실시예에 기재된 바와 같이, 본 명세서에 방법이 제공되며, 상기 방법은 피험체의 암으로부터의 세포를 포함하는 생체 샘플을 획득하는 단계, 및 생체 샘플 내 적어도 하나의 바이오마커를 평가하기 위한 분석을 수행하는 단계 - 상기 바이오마커는 (a) MYC, EP300, U2AF1, ASXL1, MAML2, 및 CNTRL 중 1, 2, 3, 4, 5 또는 6개를 포함하는 그룹 1; (b) MYC, EP300, U2AF1, ASXL1, MAML2, CNTRL, WRN, 및 CDX2 중 1, 2, 3, 4, 5, 6, 7, 또는 8 개를 포함하는 그룹 2; (c) BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, HOXA11, AURKA, BIRC3, IKZF1, CASP8, 및 EP300 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 또는 14 개를 포함하는 그룹 3; (d) PBX1, BCL9, INHBA, PRRX1, YWHAE, GNAS, LHFPL6, FCRL4, AURKA, IKZF1, CASP8, PTEN, 및 EP300 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 또는 13 개를 포함하는 그룹 4; (e) BCL9, PBX1, PRRX1, INHBA, GNAS, YWHAE, LHFPL6, FCRL4, PTEN, HOXA11, AURKA, 및 BIRC3 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 또는 12개를 포함하는 그룹 5; (f) BCL9, PBX1, PRRX1, INHBA, 및 YWHAE 중 1, 2, 3, 4, 또는 5개를 포함하는 그룹 6; (g) BCL9, PBX1, GNAS, LHFPL6, CASP8, ASXL1, FH, CRKL, MLF1, TRRAP, AKT3, ACKR3, MSI2, PCM1, 및 MNX1 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 또는 15개를 포함하는 그룹 7; (h) BX1, GNAS, AURKA, CASP8, ASXL1, CRKL, MLF1, GAS7, MN1, SOX10, TCL1A, LMO1, BRD3, SMARCA4, PER1, PAX7, SBDS, SEPT5, PDGFB, AKT2, TERT, KEAP1, ETV6, TOP1, TLX3, COX6C, NFIB, ARFRP1, ARID1A, MAP2K4, NFKBIA, WWTR1, ZNF217, IL2, NSD3, CREB1, BRIP1, SDC4, EWSR1, FLT3, FLT1, FAS, CCNE1, RUNX1T1, 및 EZR 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44 또는 45개를 포함하는 그룹 8; 및 (i) BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, BIRC3, AURKA, 및 HOXA11 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 또는 11 개를 포함하는 그룹 9를 포함함 - 를 포함한다. 이러한 유전자 식별자는 제출 당시 과학계에서 일반적으로 허용되는 것으로, 다양한 공지된 데이터베이스, 가령, HUGO Gene Nomenclature Committee (HNGC; genenames.org), NCBI's Gene database (www.ncbi.nlm.nih.gov/gene), GeneCards (genecards.org), Ensembl (ensembl.org), UniProt (uniprot.org)을 검색하는 데 사용될 수 있다. 방법은 예를 들어, 피험체에 대한 원하는 정보를 제공하도록 바이오마커 그룹의 유용한 조합을 평가할 수 있다.
생체 샘플은 피험체로부터의 임의의 유용한 생체 샘플, 가령, 본 명세서에 기재된 것, 비제한적 예를 들면, 포르말린-고정 파라핀-포매(FFPE: formalin-fixed paraffin-embedded) 조직, 고정된 조직, 코어 바늘 생검, 미세 바늘 흡인물, 비염색 슬라이드, 신선 동결(FF: fresh frozen) 조직, 포르말린 샘플, 핵산 또는 단백질 분자를 보존하는 용액에 포함된 조직, 신선 샘플, 악성 유체, 체액, 종양 샘플, 조직 샘플, 또는 이들의 임의의 조합일 수 있다. 바람직한 구체예에서, 생체 샘플은 고형 종양으로부터의 세포를 포함한다. 생체 샘플은 체액일 수 있으며, 체액은 순환 종양 세포(CTC)를 포함할 수 있다. 일부 구체예에서, 체액은 악성 유체, 흉수, 복막액, 또는 이들의 임의의 조합을 포함한다. 체액은 피험체로부터의 임의의 유용한 체액, 비제한적 예를 들면, 말초 혈액, 혈청, 혈장, 복수, 소변, 뇌척수액(CSF), 가래, 타액, 골수, 활액, 안방수, 양수, 귀지, 모유, 기관지폐포 세척액, 정액, 전립선액, 소액, 사정전액, 여성의 사정액, 땀, 대변, 눈물, 낭종액, 흉막액, 복막액, 심낭액, 림프액, 유미즙, 유미, 담즙, 간질액, 월경, 고름, 피지, 구토, 질 분비물, 점막 분비물, 대변 물, 췌장액, 부비동강 세척액, 기관지폐 흡인물, 배반포강액 또는 제대혈일 수 있다. 바람직한 구체예에서, 체액은 혈액 또는 혈액 유도체 또는 분획물, 가령, 혈장 또는 혈청을 포함한다.
바이오마커를 평가하는 데 사용되는 분석은 생체 샘플에서 바이오마커에 대한 원하는 수준의 정보를 제공하기 위해 선택 될 수 있다. 일부 구체예에서, 평가는 각 바이오마커에 대한 단백질 또는 핵산의 존재, 수준 또는 상태를 결정하는 것을 포함한다. 핵산은 DNA(deoxyribonucleic acid), RNA(ribonucleic acid), 또는 이들의 조합을 포함한다. 다양한 단백질의 존재 여부, 레벨 또는 상태는 방법, 가령, 본 명세서에 기재된 것을 이용해, 비제한적 예를 들면 IHC(immunohistochemistry), 유세포 분석, 면역분석, 항체 또는 기능 단편, 압타머, 또는 이들의 임의의 조합을 이용해 결정된다. 마찬가지로, 다양한 핵산의 존재 여부, 레벨, 또는 상태는 방법, 본 명세서에 기재된 바, 비제한적 예를 들면, PCR(polymerase chain reaction), 원위치 혼성화, 증폭, 혼성화, 마이크로어레이, 핵산 시퀀싱, 염료 종단 시퀀싱, 파이로시퀀싱, 차세대 시퀀싱(NGS, 고처리율 시퀀싱), 또는 이들의 임의의 조합을 이용해 결정될 수 있다. 핵산의 상태는 임의의 관련 상태, 비제한적 예를 들면, 서열, 돌연변이, 다형성, 결실, 삽입, 치환, 전위, 융합, 절단, 복제, 증폭, 반복, 복제수, 복제수 변이(CNV; 복제수 변경; CNA), 또는 임의의 이들의 조합을 포함한다. 상태는 야생형 또는 비-야생형일 수 있다. 일부 구체예에서, 차세대 시퀀싱(NGS)이 단일 분석에서 존재 여부, 레벨, 또는 상태를 평가할 수 있다. NGS는 바이오마커의 패널(가령, 실시예 1을 참조), 전체 엑솜, 전체 전사, 또는 이들의 임의의 조합을 평가하도록 사용될 수 있다.
대장암 환자에서 FOLFOX의 반응 또는 효험을 예측하기 위한 유용한 바이오마커 그룹은 본 명세서에 개시된 머신 러닝 모델링에 따라 식별되었다. 이러한 그룹은 실시예 1에 기재된 바와 같이 수집된 분자 프로파일링 데이터를 사용하여 암 환자로부터 수집된 데이터를 분석함으로써 실시예 2-4에 기재된 바와 같이 확인되었다. 이러한 유용한 그룹은 그룹 1 (즉, MYC, EP300, U2AF1, ASXL1, MAML2, 및 CNTRL), 그룹 2 (즉, MYC, EP300, U2AF1, ASXL1, MAML2, CNTRL, WRN, 및 CDX2), 그룹 3 (즉, BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, HOXA11, AURKA, BIRC3, IKZF1, CASP8, 및 EP300), 그룹 4 (즉, PBX1, BCL9, INHBA, PRRX1, YWHAE, GNAS, LHFPL6, FCRL4, AURKA, IKZF1, CASP8, PTEN, 및 EP300), 그룹 5 (즉, BCL9, PBX1, PRRX1, INHBA, GNAS, YWHAE, LHFPL6, FCRL4, PTEN, HOXA11, AURKA, 및 BIRC3), 그룹 6 (즉, BCL9, PBX1, PRRX1, INHBA, 및 YWHAE), 그룹 7 (즉, BCL9, PBX1, GNAS, LHFPL6, CASP8, ASXL1, FH, CRKL, MLF1, TRRAP, AKT3, ACKR3, MSI2, PCM1, 및 MNX1), 그룹 8 (즉, BX1, GNAS, AURKA, CASP8, ASXL1, CRKL, MLF1, GAS7, MN1, SOX10, TCL1A, LMO1, BRD3, SMARCA4, PER1, PAX7, SBDS, SEPT5, PDGFB, AKT2, TERT, KEAP1, ETV6, TOP1, TLX3, COX6C, NFIB, ARFRP1, ARID1A, MAP2K4, NFKBIA, WWTR1, ZNF217, IL2, NSD3, CREB1, BRIP1, SDC4, EWSR1, FLT3, FLT1, FAS, CCNE1, RUNX1T1, 및 EZR), 그룹 9 (즉, BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, BIRC3, AURKA, 및 HOXA11)을 포함한다. 달리 명시되지 않는 한, 머신 러닝 알고리즘은 특정 바이오마커의 관련 상태로 NGS에 의해 결정된 복제수를 선택한다.
세포는 일반적으로 각각의 유전자의 두 번의 복제를 갖는 디폴로이드이다. 그러나 암은 복제수를 변경할 수 있는 다양한 게놈 변경을 초래할 수 있다. 어떤 경우에는 유전자 복제가 증폭(게인)되는 반면 다른 경우에는 유전자 복제가 손실된다. 게놈 변경은 염색체의 다른 영역에 영향을 미칠 수 있다. 예를 들어, 유전자 내에서, 유전자 수준에서 또는 인접 유전자 그룹 내에서 이득 또는 손실이 발생할 수 있다. 세포 유전 학적 밴드 수준 또는 염색체 암의 더 큰 부분에서 또는 손실이 관찰 될 수 있다. 따라서 유전자에 대한 이러한 근접 영역의 분석은 유전자 자체에 유사하거나 심지어 동일한 정보를 제공 할 수 있다. 따라서, 본 명세서에 제공된 방법은 특정 유전자의 복제수를 결정하는 데 제한되지 않고, 또한 유전자에 대한 근접 영역의 분석을 명시 적으로 고려하며, 여기서 이러한 근접 영역은 유사하거나 동일한 수준의 정보를 제공합니다. 예를 들어, 표 11은 세포 유전 학적 밴드 수준에서 각 유전자의 위치를 나열합니다. 유전자 그룹은 밴드, 완 또는 염색체 수준에서 관찰 할 수 있다. 복수의 유전자가 등장하는 영역이 존재하는데, 비제한적 예를 들면, 1q(PAX7, BCL9, FCRL4, PBX1, PRRX1, FH, AKT3), 20q(ASXL1, TOP1, SDC4, AURKA, ZNF217, GNAS, ARFRP1) 및 22q(CRKL, SEPT5, MN1, EWSR1, PDGFB, SOX10, EP300)가 있다. 이것은 여러 유전자가 주어진 유전 적 지역에있을 때 우리의 방법이 감지하는 게놈 변경을 위한 염색체 "핫스팟"이 있음을 시사한다. 단지 예로서, 본 개시 내용은 1q, 20q 및 22q에서 대체 유전자의 분석이 본 명세서에 제공된 FOLFOX 바이오시그니처에서 사용될 수 있음을 고려한다. 그룹 1-9에 나열된 각 유전자의 유전자 자리에 대해 유사한 분석을 적용할 수 있다.
언급된 바와 같이, 본 명세서에 제공된 방법은 평가된 바이오마커에 기초하여 FOLFOX의 가능한 이점을 추가로 포함할 수 있다. 방법이 FOLFOX가 피험체에게 효험 가능성이 없다고 결정하는 경우, 대안 치료법, 가령, FOLFIRI이 선택될 수 있다. 일부 구체예에서, 방법은 (a) 그룹 1 및 그룹 2의 적어도 하나 또는 모든 구성원, 또는 이의 근접 게놈 영역(실시예 2 참조), (b) 그룹 3의 적어도 하나 또는 모든 구성원, 또는 이의 근접 게놈 영역(실시예 3 참조), 또는(c) 그룹 2, 그룹 6, 그룹 7, 그룹 8 및 그룹 9의 적어도 하나 또는 모든 구성원, 또는 이의 근접 게놈 영역(실시예 4 참조)의 복제수를 결정하기 위한 분석을 수행하는 단계를 포함한다. 관찰된 복제수에 기초하여, 투표 모듈을 사용하여 FOLFOX의 효험 가능성이 결정될 수 있다(도 1F 및 관련 텍스트 참조). 바람직한 실시예에서, 그러한 투표 모듈의 사용은 머신 러닝 분류 모델, 비제한적 예를 들어, 랜덤 포레스트 모델을 그룹 2, 그룹 6, 그룹 7, 그룹 8 및 그룹 9 각각에 대해 획득된 복제수에 적용하는 것을 포함한다. 랜덤 포레스트 모델은 표 10에 설명된 것과 같을 수 있다.
대장암을 가진 피험체에 대한 치료를 선택하는 방법이 더 제공되며, 상기 방법은 대장암으로부터의 세포를 포함하는 생체 세포를 획득하는 단계, MYC, EP300, U2AF1, ASXL1, MAML2, CNTRL, WRN, 및 CDX2 중 1, 2, 3, 4, 5, 6, 7, 또는 8개를 포함하는 그룹 2, BCL9, PBX1, PRRX1, INHBA, 및 YWHAE 중 1, 2, 3, 4, 또는 5를 포함하는 그룹 6,BCL9, PBX1, GNAS, LHFPL6, CASP8, ASXL1, FH, CRKL, MLF1, TRRAP, AKT3, ACKR3, MSI2, PCM1, 및 MNX1 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 또는 15개를 포함하는 그룹 7, BX1, GNAS, AURKA, CASP8, ASXL1, CRKL, MLF1, GAS7, MN1, SOX10, TCL1A, LMO1, BRD3, SMARCA4, PER1, PAX7, SBDS, SEPT5, PDGFB, AKT2, TERT, KEAP1, ETV6, TOP1, TLX3, COX6C, NFIB, ARFRP1, ARID1A, MAP2K4, NFKBIA, WWTR1, ZNF217, IL2, NSD3, CREB1, BRIP1, SDC4, EWSR1, FLT3, FLT1, FAS, CCNE1, RUNX1T1, 및 EZR 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44 또는 45개를 포함하는 그룹 8, BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, BIRC3, AURKA, 및 HOXA11 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 또는 11개를 포함하는 그룹 9의 유전자 그룹 또는 이의 근접 게놈 영역 각각에 대해 복제수를 결정하기 위해 생체 세포로부터의 게놈 DNA에 차세대 시퀀싱을 수행하는 단계, 머신 러닝 분류 모델을 그룹 2, 그룹 6, 그룹 7, 그룹 8 및 그룹 9 각각에 대해 획득된 복제수에 적용하는 단계 - 선택적으로, 각각의 머신 러닝 분류 모델은 랜덤 포레스트 모델이며, 랜덤 포레스트 모델은 표 10에 기재되어 있음 - ,피험체가 옥살리플라틴과 조합된 5-플루오로우라실/류코보린(FOLFOX) 치료에 효험이 있을 가능성이 있는 여부에 대한 지시자를 각각의 머신 러닝 분류 모델로부터 획득하는 단계, 및머신 러닝 부류 모델의 과반수가 피험체가 상기 치료에 효험이 있을 가능성이 있음을 나타내는 경우 FOLFOX를 선택하고, 머신 러닝 분류 모델의 과반수가 피험체가 FOLFOX에 효험이 있을 가능성이 없음을 나타내는 경우 FOLFOX의 대안 치료를 선택하는 단계 - 선택적으로, 대안 치료는 이리노테칸과 조합된 5-플루오로오라실/류코보린(FOLFIRI)임 - 를 포함한다. 일부 실시예에서, 상기 방법은 피험체에게 선택된 치료를 투여하는 것을 더 포함한다. 실시예 5를 참조할 수 있다.
리포트
하나의 구체예에서, 본 명세서에 기재된 방법은 분자 프로파일 리포트를 생성하는 것을 포함한다. 리포트는 암이 프로파일링된 피험체의 치료 의사 또는 다른 간병인에게 전달될 수 있다. 리포트는 다음을 포함하되 이에 국한되지 않는 관련 정보의 여러 섹션으로 구성될 수 있다: 1) 분자 프로파일 내 유전자의 리스트; 2) 피험체에 대해 결정된 유전자 및/또는 유전자 산물의 CNV의 복제수를 포함하는 분자 프로파일의 설명; 3) 분자 프로파일과 연관된 치료; 및 4) 각각의 치료가 환자에게 효험이 있을 가능성이 있는지, 가능성이 없는지, 또는 결정될 수 없는 지시자. 분자 프로파일의 유전자의 리스트가 본 명세서에 제공된 것일 수 있다. 피험체에 대해 결정된 유전자의 분자 프로파일에 대한 설명은 각각의 바이오마커(가령, RT-PCR, FISH/CISH, PCR, FA/RFLP, NGS 등)를 평가하는 데 사용되는 실험실 기술 및 각각의 기술에 점수를 매기는 데 사용되는 기준과 같은 정보를 포함할 수 있다. 예를 들어, CNV를 점수 매기기 위한 기준이 존재(즉, 암이 없는 피험체에 존재하는 또는 일반적인 개체군에 존재하는 것으로 통계적으로 식별된 "정상" 복제수, 일반적으로 디플로이드보다 크거나 작은 복제수) 또는 부재(즉, 암이 없는 피험체에 존재하는 또는 일반적인 개체군에 존재하는 것으로 통계적으로 식별된 "정상" 복제수, 일반적으로 디플로이드보다 크거나 작은 복제수와 동일한 복제수)일 수 있다. 분자 프로파일 내 유전자 및/또는 유전자 산물 중 하나 이상과 연관된 치료가, 가령, 그 전체가 본 명세서에 참조로서 포함되는 2007년11월29일에 공개된 국제 특허 공개 번호 WO/2007/137187 (국제 출원 번호 PCT/US2007/069286); 2010년 04월 22일에 공개된 WO/2010/045318 (국제 출원 번호 PCT/US2009/060630), 2010년 08월 19일에 공개된 WO/2010/093465 (국제 출원 번호 PCT/US2010/000407), 2012년 12월 13일에 공개된 WO/2012/170715 (국제 출원 번호 PCT/US2012/041393), 2014년 06월 12일에 공개된 WO/2014/089241 (국제 출원 번호 PCT/US2013/073184), 2011년 05월 12일에 공개된 WO/2011/056688 (국제 출원 번호 PCT/US2010/054366), 2012년 07월 05일에 공개된 WO/2012/092336 (국제 출원 번호 PCT/US2011/067527), 2015년 08월 06일에 공개된 WO/2015/116868 (국제 출원 번호 PCT/US2015/013618), 2017년 03월 30일에 공개된 WO/2017/053915 (국제 출원 번호 PCT/US2016/053614), 2016년 09월 09일에 공개된 WO/2016/141169 (국제 출원 번호 PCT/US2016/020657), 및 2018년 09월 27일에 공개된 WO2018175501 (국제 출원 번호 PCT/US2018/023438)의 바이오마커-약물 연관 규칙 세트를 이용해 결정될 수 있다. 각각의 치료가 환자에게 효험 가능성이 있는지, 또는 효험이 없는지, 또는 결정되지 않았는지 여부의 지시자가 가중화될 수 있다. 예를 들어, 잠재적 효험은 강력한 잠재적 효험 또는 더 적은 잠재적 효험일 수 있다. 이러한 가중화는 임의의 적절한 기준, 예를 들어 바이오마커-치료 연관성 증거의 강도 또는 프로파일링 결과, 예를 들어 과발현 또는 과소 발현 정도를 기반으로 할 수 있다.
원하는 대로 다양한 추가 구성요소를 리포트에 추가할 수 있다. 일부 구체예에서, 리포트는 분자 프로파일에서 하나 이상의 유전자의 복제수 또는 CNV가 진행중인 임상 시험과 관련이 있는지 여부를 나타내는 리스트를 포함한다. 리포트에는 예를 들어, 임상 시험에서 피험자의 잠재적 등록에 대한 치료 의사의 조사를 용이하게 하기 위해 임상 시험에 대한 식별자가 포함될 수 있다. 일부 구체예에서, 리포트는 분자 프로파일에서 CNV와 리포트된 치료의 연관성을 뒷받침하는 증거 리스트를 제공한다. 이 리스트에는 증거 문헌에 대한 인용 및/또는 특정 바이오마커-치료 연관성에 대한 증거의 강도 표시가 포함될 수 있다. 일부 구체예에서, 리포트는 분자 프로파일의 유전자에 대한 설명을 포함한다. 분자 프로파일에서 유전자의 설명은 제한없이 생물학적 기능 및/또는 다양한 치료 연관성을 포함할 수 있다.
분자 프로파일링 리포트는 피험자의 간병인, 예를 들어 종양 전문의 또는 기타 치료 의사에게 전달될 수 있다. 간병인은 리포트의 결과를 사용하여 피험자를위한 치료 요법을 안내할 수 있다. 예를 들어, 간병인은 환자를 치료하기 위해 리포트에서 유익한 것으로 표시된 하나 이상의 치료를 사용할 수 있다. 유사하게, 간병인은 리포트에서 효험이 없을 가능성이 있는 것으로 표시된 하나 이상의 치료로 환자를 치료하는 것을 피할 수 있다.
가능한 효험의 적어도 하나의 요법을 확인하는 방법의 일부 구체예에서, 피험체는 가능한 효험의 적어도 하나의 요법으로 이전에 치료 된 적이 없다. 암은 전이성 암, 재발성 암 또는 이들의 임의의 조합을 포함할 수 있다. 일부 경우에, 암은 이전 요법, 비제한적 예를 들면, 암의 최일선 또는 표준 치료에 대해 불응성이다. 일부 구체예에서, 암은 모든 공지된 표준 치료 요법에 불응성이다. 또 다른 구체예에서, 피험체는 이전에 암 치료를 받은 적이 없다. 상기 방법은 개체에 가능한 효험의 적어도 하나의 치료를 투여하는 것을 더 포함할 수 있다. 무진행 생존율(PFS), 무질병 생존율(DFS) 또는 수명은 투여에 의해 연장될 수 있다.
리포트는 컴퓨터로 생성될 수 있으며 인쇄된 리포트, 컴퓨터 파일 또는 둘 다일 수 있다. 리포트는 보안 웹 포털을 통해 액세스될 수 있다.
한 측면에서, 본 개시 내용은 상기 기재된 바와 같이 본 명세서에 기재된 방법을 수행하는데 시약의 사용을 제공한다. 관련 측면에서, 본 개시 내용은 본 명세서에 기재된 방법을 수행하기 위한 시약 또는 키트의 제조에있어서 시약을 제공한다. 또 다른 관련 측면에서, 본 개시 내용은 본 명세서에 기재된 방법을 수행하기 위한 시약을 포함하는 키트를 제공한다. 시약은 유용하고 원하는 시약일 수 있다. 바람직한 구체예에서, 시약은 샘플에서 핵산을 추출하기 위한 시약 및 차세대 시퀀싱을 수행하기위한 시약 중 적어도 하나를 포함한다.
하나의 양태에서, 본 개시 내용은 개체에서의 암과 연관된 적어도 하나의 치료법을 식별하기 위한 시스템을 제공하며, 상기 시스템은 (a) 적어도 하나의 호스트 서버, (b) 데이터를 액세스 및 입력하도록 적어도 하나의 호스트 서버를 액세스하기 위한 적어도 하나의 사용자 인터페이스, (c) 입력된 데이터를 처리하기 위한 적어도 하나의 프로세서, (d) 프로세서에 연결되고 처리된 데이터 및 명령을 저장하기 위한 적어도 하나의 메모리 - 상기 명령은 i) CNV 상태 (복제수 또는 CNV의 존재/부재)를 결정하는 명령, 및 (ii) CNV 상태에 기초하여, 암의 치료에 대한 가능한 효험을 갖는 적어도 하나의 치료법을 식별하는 명령을 포함함 - , 및 (e) 암의 치료에 가능한 효험이 있는 식별된 치료법을 디스플레이하기 위한 적어도 하나의 디스플레이를 포함한다. 일부 구체예에서, 시스템은 상기 방법에 따라 생성 된 분자 프로파일에 기초하여 암 치료에 잠재적 인 이점이있는 적어도 하나의 요법을 식별하기위한 명령 및 처리 된 데이터를 저장하기 위해 프로세서에 연결된 적어도 하나의 메모리 및 그 디스플레이를위한 적어도 하나의 디스플레이를 포함한다. 시스템은 다양한 바이오마커 상태에 대한 참조, 약물/바이오마커 연관에 대한 데이터, 또는 둘 다를 포함하는 적어도 하나의 데이터베이스를 추가로 포함할 수 있다. 적어도 하나의 디스플레이는 본 개시 내용에 의해 제공되는 리포트일 수 있다.
실시예
본 발명은 특허 청구 범위에 기재된 바와 같은 범위를 제한하지 않는하기 실시예에서 추가로 설명된다.
실시예 1: 차세대 프로파일링
포괄적인 분자 프로파일링은 환자 샘플의 분자 상태에 관한 풍부한 데이터를 제공한다. 우리는 예를 들어, 실시예 1에서 설명된 바와 같이 다양한 프로파일링 기술을 사용하여 사실상 모든 암 계통의 100,000명 이상의 종양 환자에 대해 이러한 프로파일링을 수행했다. 현재까지, 우리는 이러한 환자 중 20,000명 이상에서 치료의 효험 또는 효험 부재를 추적했다. 따라서 우리의 분자 프로파일링 데이터를 치료에 대한 환자 효험에 비교되어 추가 암 환자의 다양한 치료에 대한 효험을 예측하는 추가 바이오마커 시그니처를 식별 할 수 있다. 우리는 다양한 암 치료법에 대한 환자 효험(가령, 긍정적, 부정적 또는 불확실한 효험)과 상관된 바이오마커 시그니처를 식별하기 위해 이 "차세대 프로파일링"(NGP) 접근 방식을 적용했다.
NGP에 대한 일반적인 접근 방식은 다음과 같다. 수 년에 걸쳐 다양한 분자 프로파일링 기술을 사용하여 수만 명의 환자에 대한 포괄적인 분자 프로파일링을 수행했다. 도 2c에 추가로 나타나듯이, 이러한 기술의 비제한적 예를 들면, 다양한 속성을 평가하기 위한 DNA의 차세대 시퀀싱(NGS)(2301), RNA의 유전자 발현 및 유전자 융합 분석(2302), 단백질 발현의 IHC 분석(2303) 및 유전자 복제수 및 염색체 이상, 가령, 전좌를 평가하기 위한 ISH(2304)가 있다. 우리는 현재 다양한 암 계통의 20,000명 이상의 환자에 대한 환자 임상 결과 데이터(2305)와 매칭했다. 우리는 인지 컴퓨팅 방식(2306)을 사용하여 원하는 대로 다양한 치료에 대한 실제 환자 결과 데이터와 종합적인 분자 프로파일링 결과를 연관시켰다. 임상 결과는 치료 종료 시간(TOT) 또는 다음 치료까지의 시간(TTNT 또는 TNT)을 사용하여 결정될 수 있다. 가령, Roever L (2016) Endpoints in Clinical Trials: Advantages and Limitations.Evidence Based Medicine and Practice 1: e111.doi:10.4172/ebmp.1000e111를 참조할 수 있다. 결과는 바이오마커의 패널(2307)을 포함하는 바이오시그니처를 제공하며, 이때, 바이오시그니처는 검사 대상 치료에 대한 효험 또는 효험 없음을 나타낸다. 바이오시그니처는 적용 가능한 치료의 이점을 예측하고 치료 결정을 안내하기 위해 새로운 환자의 분자 프로파일링 결과에 적용 할 수 있다. 이러한 개인화된 안내는 효과적인 치료법의 선택을 개선할 수 있으며 임상적 이점이 적은 치료법을 피할 수 있다.
표 2는 지난 몇 년 동안 우리가 프로파일링한 수많은 바이오마커를 나열한다. 관련 분자 프로파일링 및 환자 결과가 이용 가능하고, 이들 바이오마커 중 일부 또는 전부가 관심 바이오시그니처를 개발하기 위해 인지 컴퓨팅 환경으로 입력되기 위한 피처로서 역할 할 수 있다. 표는 분자 프로파일링 기술과 이러한 기술을 사용하여 평가된 다양한 바이오마커를 보여준다. 리스트은 포괄적인 것이 아니며 나열된 모든 바이오마커에 대한 데이터가 모든 환자를 위해 가용한 것은 아닐 것이다. 다양한 바이오마커가 여러 방법을 사용하여 프로파일링되었음이 추가로 인식될 것이다. 비-제한적인 예로서, EGFR(Epidermal Growth Factor Receptor) 단백질을 발현하는 EGFR 유전자를 고려할 수 있다. 표 2에 나타난 바와 같이, EGFR 단백질의 발현은 IHC를 사용하여 검출되었고; EGFR 유전자 증폭, 유전자 재배열, 돌연변이 및 변경은 ISH, Sanger 시퀀싱, NGS, 단편 분석 및 PCR, 가령, qPCR로 검출되었고, EGFR RNA 발현은 PCR 기술, 예를 들어 qPCR 및 DNA 마이크로어레이를 사용하여 검출되었다. 비제한적인 추가 예로서, EGFR 변이체 III(EGFRvIII) 전사체의 존재에 대한 분자 프로파일링 결과는 단편 분석(가령, RFLP) 및 시퀀싱(가령, NGS)을 사용하여 수집되었다.
표 3은 다양한 종양 계통에 대한 예시적인 분자 프로파일을 보여준다. 이러한 분자 프로파일의 데이터는 관심 있는 하나 이상의 바이오시그니처를 식별하기 위해 NGP에 대한 입력으로 사용될 수 있다. 표에서, 암 혈통은 "계통" 열에 표시된다. 나머지 열은 표시된 방법론(즉, 면역조직화학(IHC), 현장 혼성화(ISH) 또는 그 밖의 다른 기술)을 사용하여 평가될 수 있는 다양한 바이오마커를 보여준다. 앞서 설명한 바와 같이, 바이오마커는 해당 분야의 통상의 기술자에게 알려진 기호를 사용하여 식별된다. IHC 열에서, "MMR"은 각각 IHC를 사용하여 개별적으로 평가되는 불일치 복구 단백질 MLH1, MSH2, MSH6 및 PMS2를 의미합니다. NGS 열 "DNA"에서 "CNA"는 본 명세서에서 복제수 변이(CNV)로도 지칭되는 복제수 변경을 지칭한다. 해당 분야의 통상의 기술자는 분자 프로파일링 기술이 원하는 대로 및/또는 상호 교환 될 수 있음을 인식 할 것이다. 예를 들어, IHC 대신에 다른 적합한 단백질 분석 방법(가령, 대체 면역 분석 형식)을 사용할 수 있고, ISH 대신에 다른 적합한 핵산 분석 방법(가령, 복제수 및/또는 재 배열, 전좌 등을 평가하는 것) 을 사용할 수 있고 기타 적합한 핵산 분석 방법이 단편 분석 대신 사용될 수 있다. 마찬가지로, FISH와 CISH는 일반적으로 상호 교환 가능하며 프로브 가용성 등에 따라 선택이 이루어질 수 있다. 표 4-8은 NGS(Next Generation Sequencing) 분석을 사용하여 평가된 게놈 분석 및 유전자 패널을 보여준다. 해당 분야의 통상의 기술자는 NGS 분석 대신에 다른 핵산 분석 방법, 예를 들어 다른 시퀀싱(가령, Sanger), 혼성화(가령, 마이크로어레이, 나노 스트링) 및/또는 증폭(가령, PCR 기반) 방법을 사용할 수 있음을 인식할 것이다.
유전자의 다양한 측면을 평가하기 위해 핵산 분석이 수행될 수 있다. 예를 들어, 핵산 분석은 돌연변이 분석, 융합 분석, 변이 분석, 스플 라이스 변이, SNP 분석 및 유전자 복제수/증폭을 포함할 수 있지만 이에 한정되지 않는다. 이러한 분석은 본 명세서에 기재되어 있거나 해당 분야에 잘 알려진 임의의 개수의 기법, 비제한적 예를 들면, 시퀀싱(가령, Sanger, 차세대(Next Generation), 파이로시퀀싱), PCR의 변형, 가령, RT-PCR, 단편 분석 등을 이용해 수행될 수 있다. NGS 기술은 단일 분석에서 다중 유전자의 돌연변이, 융합, 변이체 및 복제수를 검출하는 데 사용될 수 있다. 달리 언급되거나 문맥 상 명백하지 않는 한, 본 명세서에 사용 된 "돌연변이"는 야생형에 비교되는 유전자 또는 게놈의 임의의 변경, 가령, 돌연변이, 다형성, 결실, 삽입, 인델(즉, 삽입 또는 결실), 치환, 전좌, 융합, 단절, 복제, 증폭, 반복 또는 복제수 변이를 포함한다. 상이한 게놈 변경 및/또는 유전자 세트에 대해 상이한 분석이 가능할 수 있다. 예를 들어, 표 4는 NGS로 측정할 수 있는 게놈 안정성의 속성을 나열하고, 표 5는 점 돌연변이 및 인델에 대해 평가할 수 있는 다양한 유전자를 나열하고, 표 6은 점 돌연변이, 인델 및 복제수 변이에 대해 평가할 수 있는 다양한 유전자를 나열하며, 표 7은 RNA 분석을 통해 유전자 융합에 대해 평가 될 수 있는 다양한 유전자를 나열하고, 마찬가지로 표 8은 RNA를 통해 전사 변이체에 대해 평가할 수 있는 유전자를 나열한다. 추가 유전자에 대한 분자 프로파일링 결과는 이러한 데이터를 사용할 수 있으므로 NGP 바이오시그니처를 식별하는 데 사용할 수 있다.
표 2 - 분자 프로파일링 바이오마커



표 3 - 분자 프로파일링


표 4 - 게놈 안정성 검사(DNA)
표 5 - 점 돌연변이 및 삽입/결실 (DNA)


표 6 - 점 돌연변이, 삽입/결실 및 복제수 변이 (DNA)



표 7 - 유전자 융합 (RNA)

표 8 - 변이 전사
이 실시예 및 명세서 전반에 걸쳐 사용된 약어, 예를 들어 IHC: 면역 조직 화학(immunohistochemistry); ISH: 원위치 혼성화(in situ hybridization); CISH: 색상측정 원위치 혼성화(colorimetric in situ hybridization); FISH: 형광 현장 혼성화(fluorescent in situ hybridization); NGS: 차세대 시퀀싱(next generation sequencing); PCR: 폴리머아제 연쇄 반응(polymerase chain reaction); CNA: 복제수 변경(copy number alteration); CNV: 복제수 변이(copy number variation); MSI: 미세 위성 불안정성(microsatellite instability); TMB: 종양 돌연변이 부담(tumor mutational burden).
실시예 2: 대장암 치료 효능 예측을 위한 분자 프로파일링 분석
이 실시예에서, 본 명세서에 기재된 최신 머신 러닝 알고리즘의 상태(가령,도 1a-1g)가 포괄적인 분자 프로파일링 데이터(가령, 위의 실시예 1 참조; WO/2018/175501(2018.03.20에 출원한 국제 출원 번호 PCT/US2018/023438)의 표 5-12, WO/2015/116868(2015.01.29에 출원한 국제 출원 번호 PCT/US2015/013618), WO/2017/053915(2016년 9월 24일에 출원한 국제 출원 번호 PCT/US2016/053614) 및 WO/2016/141169(2016년 03월 03일에 출원된 국제 출원 번호 PCT/US2016/020657))를 통해, TNT 또는 TTNT(Time-to-Next-Treatment)가 결과 종점으로서 사용될 때 FOLFOX에 대해 효험이 있었거나 효험이 없었던 환자를 구별하는 바이오마커 시그니처를 식별할 수 있다. 환자 개체군에는 III기 또는 IV기 대장암 환자가 포함되었다. 평가된 바이오마커는 실시예 1에서와 같았다.
우리는 대장암(CRC) 환자에 대한 FOLFOX 치료의 효험 또는 효험 없음을 정확하게 예측하는 8개의 바이오마커(도 3a-b) 및 6개의 바이오마커(도 3c-d) 시그니처를 식별했다. 효험군 또는 비효험군의 수는 도 3a-d에서 식별된다. 이들 시그니처는 CRC 환자에서 FOLFOX의 효험을 예측하는 데 사용될 수 있다.
바이오마커 시그니처 식별
분자 프로파일링 파이프 라인에서 생성된 선택된 바이오마커의 숫자 연속 값은 랜덤 포레스트(Random Forest), 서포트 벡터 머신(Support Vector Machine), 로지틱스 회귀(Logistic Regression), K-최근접 이웃(K-Nearest Neighbor), 인공 신경망(Artificial Neural Network), 나이브 베이즈(Na ve Bayes), 2차 판별식(Quadratic Discriminant)으로 구성된 앙상블 분류기로 입력되는 피처로서 사용된다. 각각의 환자에 대한 바이오마커 값으로 구성된 훈련 데이터가 조합되고 환자의 TNT에 따라 효험군 또는 비효험군으로 라벨링된다. 앙상블의 각각의 모델은 학습 프로세스 중에 이 학습 데이터를 입력으로 사용하여 이전에 보지 못한 테스트 케이스를 예측할 수 있는 최종 학습 모델을 생성한다. 훈련 데이터에 없는 새로운 테스트 케이스는 앙상블의 훈련된 각각의 모델을 통해 제공되며, 이때 각각의 모델은 테스트 세트의 각각의 환자에 대한 효험 또는 효험 없음의 예측을 출력한다.
ve Bayes), 2차 판별식(Quadratic Discriminant)으로 구성된 앙상블 분류기로 입력되는 피처로서 사용된다. 각각의 환자에 대한 바이오마커 값으로 구성된 훈련 데이터가 조합되고 환자의 TNT에 따라 효험군 또는 비효험군으로 라벨링된다. 앙상블의 각각의 모델은 학습 프로세스 중에 이 학습 데이터를 입력으로 사용하여 이전에 보지 못한 테스트 케이스를 예측할 수 있는 최종 학습 모델을 생성한다. 훈련 데이터에 없는 새로운 테스트 케이스는 앙상블의 훈련된 각각의 모델을 통해 제공되며, 이때 각각의 모델은 테스트 세트의 각각의 환자에 대한 효험 또는 효험 없음의 예측을 출력한다.
이들 바이오마커 결과가 머신 러닝 알고리즘에서 사용되는 방식을 명확히 하기 위해, 램덤 포레스트(Random Forest) 알고리즘을 간략하게 기술한다. 랜덤 포레스트(Random Forest)는 여러 의사 결정 트리로 구성되며, 각각의 의사 결정 트리는 각각의 샘플에 대해 단일 효험/효험없음 예측을 생성한다. 의사 결정 트리는 순서도와 유사하게 노드와 에지로 구성된다. 의사 결정 트리의 각각의 노드에서, 의사 결정 트리를 통과하는 특정 테스트 케이스의 경로는 해당 테스트 케이스의 피처 값을, 훈련 프로세스 동안 결정된 각각의 노드에서의 임계 값과 비교함으로써 결정된다. 환자의 숫자 바이오마커 값이 주어진 임계값을 초과하는 경우, 흐름이 자식 노드들 중 첫 번째 자식 노드로 계속되고 그렇지 않은 경우 흐름이 자식 노드들 중 두 번째 자식 노드로 계속된다. 의사 결정 트리의 맨 아래 층에 있는 노드는 클래스 라벨로 구성되며, 이때 각각의 환자는 환자가 배치된 가장 아래 층 내 노드에 따라 분류된다.
랜덤 포레스트는 랜덤 포레스트에 포함된 각각의 의사 결정 트리의 과반수 투표를 통해 최종 예측을 얻는다. 각각의 의사 결정 트리의 구조는 일변량 접근법을 사용하여 가능한 것보다 더 정확한 예측을 가져 오는 바이오마커 값 간의 높은 비선형 및 상호작용 효과를 발견할 수 있게 한다. 랜덤 포레스트(Random Forest)와 알고리즘 및 수학적으로 다르지만, 앙상블의 나머지 모델은 모두 바이오마커 값을 입력으로 취하고 각 환자에 대한 효험 예측을 출력으로 반환한다.
각각의 모델에 대한 설명적 통계는 두 개체군 간의 위험 차이의 측정치인 위험 비율(HR)을 포함한다. HR이 1.0에서 멀수록, 하나의 개체군이 다른 개체군에 비해 경험하는 위험이 더 크다. 결과는 잘 알려진 카플란-마이어(Kaplan-Meier) 추정량 플롯을 사용하여 표시된다.Kaplan, E.L.; Meier, P.(1958)."Nonparametric estimation from incomplete observations." J.Amer.Statist.Assoc.53 (282): 457-481을 참조할 수 있다.
결과
도 3e는 8개의 마커 시그니처에 대한 예시적인 랜덤 포레스트 결정 트리를 도시한다(도 3a-b). 시그니처는 유전자 EP300, ASXL1, U2AF1, WRN, ASXL1, MAML2, MYC 및 CDX2를 포함한다. 유전자 식별자는 제출 당시 과학계에서 일반적으로 허용되는 것으로, 다양한 공지된 데이터베이스, 가령, HUGO Gene Nomenclature Committee (HNGC; genenames.org), NCBI's Gene database (www.ncbi.nlm.nih.gov/gene), GeneCards (genecards.org), Ensembl (ensembl.org), UniProt (uniprot.org)을 검색하는 데 사용될 수 있다. 각각의 상자의 번호는 NGS를 사용하여 검출된 정규화된 복제수에 대응한다. 8개 유전자 바이오시그니처의 구성원의 정규화된 복제수 변이가 결정 트리에 적용된다. 도면에서, WRN, ASXL1 및 MYC 아래의 수직 "??"은 U2AF1에 대응하는 상자 아래에 표시된 것과 동일한 방식으로 효험/효험 없음 예측이 이뤄짐을 나타낸다. 대장암 환자에 대해 트리의 논리가 평가된다. 효험군은 FOLFOX에 효험을 나타내는 것으로 예측되고, 따라서 검사가 이들 환자에게 FOLFOX 요법을 투여해야 함을 나타낸다. 다른 한편으로, FOLFOX에 대해 효험이 없는 것으로 예측되는 환자는 상이한 치료 요법, 가령, FOLFIRI을 투여 받을 수 있다.
실시예 3: 전이성 대장암에서의 치료 효험 예측을 위한 분자 프로파일링 분석
실시예 2에서, 우리는 대장암 치료 요법 FOLFOX로부터 효험을 예측하기 위한 바이오시그니처를 식별하기 위한 접근법을 제시했다. 우리는 이 샘플에서 동일한 접근법을 따라 IV기 전이성 대장암의 고도로 선별된 집합을 사용하여 FOLFOX의 바이오시그니처를 식별했다.
도 4a는 전이성 대장암에서 바이오마커 평가에 대한 현재 접근법을 보여준다. 1차 치료를 위해 종양 전문의는 FOLFOX(folinic acid(leucovorin), 5-fluorouracil(5FU) 및 oxaliplatin) 또는 FOLFIRI(folinic acid(leucovorin), 5-fluorouracil(5FU) 및 irinotecan)로 구성된 요법을 선택할 수 있다. 5FU는 DNA 합성을 중지하고 폴린산은 5FU의 효능을 증가시키는 뉴클레오티드 유사체이다. 옥살리플라틴은 또한 DNA 합성을 차단하는 것으로 여겨지는 반면 이리노테칸은 토포이소머라제 억제제이다. 치료는 또한 KRAS, NRAS, BRAF 및 마이크로위성 불안정성(MSI)으로 구성된 소형 바이오마커 패널("SP")의 사용을 이용할 수 있다. 야생형 KRAS는 베바시주맙, 혈관신생을 억제하고 FOLFOX 또는 FOLFIRI와 병용하여 투여될 수 있는 항-VEGFA 단일 클론 항체, 및 항-EGFR 치료, 가령, 세툭시맙 치료를 제안할 수 있다. BRAF의 돌연변이는 화학 요법과 MEK 억제제(MEKi) 및 EGFR 억제제(EGFRi)를 시사할 수 있다. 2차 치료는 종양 전문의가 대체 요법을 시도한다는 점을 제외하고 1차 치료와 유사할 수 있다. 또한 MSI의 존재는 면역 요법, 가령, 항-PD-L1의 유용성을 나타낼 수 있다. 이러한 접근법이 실패하면 3차 치료는 레고라페닙, 혈관 신생을 차단하는 다중-키나제 억제제, 또는 트리플루리딘, 뉴클레오시드 유사체, 및 티피라실, 티미딘 포스포리라제 억제제로 구성되는 병행 치료법 트리플루리딘/티피라실(상표명 Lonsurf)을 필요로 할 수 있다. 이러한 옵션이 실패하면 환자는 일반적으로 가능한 경우 실험적 치료를 시작한다.
현재는 어느 것이 1차 요법에 가장 적합한지가 명확하지 않다. 일부 환자는 FOLFOX에 더 잘 반응하는 반면 다른 환자는 FOLFIRI에 더 잘 반응한다.도 4b는 1차 요법으로서 FOLFOX를, 2 차 요법으로서 FOLFIRI를 투여받은, 또는 그 반대의 경우의 전이성 CRC 환자의 시간 경과에 따른 생존율을 나타낸다. Tournigand, C.et al., FOLFIRI followed by FOLFOX6 or the reverse sequence in advanced colorectal cancer: a randomized GERCOR study.J Clin Oncol.2004 Jan 15;22(2):229-37.Epub 2003 Dec 2를 참조할 수 있다. 그룹 간에 효능의 차이는 관찰되지 않았다. 유사한 결과가 KRAS 야생형 CRC의 대체 치료법에 대해 관찰된다. 도 4c는 1차 화학 요법과 베바시주맙 또는 세툭시맙이 제공된 진행성 또는 전이성 대장암 환자의 시간 경과에 따른 생존율을 보여준다. Venook AP et al., Effect of First-Line Chemotherapy Combined With Cetuximab or Bevacizumab on Overall Survival in Patients With KRAS Wild-Type Advanced or Metastatic Colorectal Cancer: A Randomized Clinical Trial.JAMA.2017 Jun 20;317(23):2392-2401을 참조할 수 있다. 도 4b-c에 도시된 바와 같이, 개별 환자가 다른 치료보다 특정 치료에 더 잘 반응하지만 전체 개체군을 볼 때 명확한 추세는 없다. 따라서 이러한 지침이 개별 환자에게 분명히 도움이 되더라도 현재 전이성 대장암 환자를 위한 1차 치료를 선택하는 지침은 거의 없다.
이 실시예에서, 우리는 본 명세서에 개시된 방법에 따라 데이터를 분자 프로파일링하는 것에 머신 러닝 접근법을 채용함으로써, 전이성 대장암의 1차 요법으로서 FOLFOX에 대한 효험 또는 효험 없음을 예측하기 위한 임상적으로 관련된 바이오시그니처를 발견할 수 있다. 도 4d는 이 목표에 대한 실시예 2의 접근 방식의 적용에 대한 개요를 제공한다. 먼저 의도된 용도에 따라 훈련 및 테스트를 위한 환자 코호트를 식별했다. 포함 기준은 환자가 1차 치료로 FOLFOX를 받았으며 적어도 한 번의 전체 치료주기를 가졌다는 것이다. 보조 요법을 포함하여 이전에 화학 요법을 받은 환자는 제외되었다. 훈련 단계를 위해 선택된 환자의 특성은 도 4e에 도시되어 있다. 바이오시그니처 발견을 위해, 우리는 먼저 환자 상태를 효험 또는 효험 없음으로 결정하기 위해 종말점을 검증했다. Tournigand 2004가 기록한 ~ 8.5 개월의 무진행 생존율(PFS)에 기초하여 270일의 TTNT가 선택되었다. 환자의 훈련 세트를 사용하여, 앞서 기재된 다양한 인지 컴퓨팅 알고리즘을 사용하여 바이오마커(피처) 선택의 프로세스가 수행되었다. 선택된 바이오마커 피처를 사용하여, 환자를 FOLFOX 효험군 또는 비효험군으로 식별하도록 알고리즘이 훈련되었다. 이러한 결정을 내리기 위하 바이오시그니처가 사용되는 방법의 예시에 대해 도 6 및 첨부 텍스트를 참조할 수 있다. 그런 다음 우리는 바이오시그니처의 분석 검증 및 특징화를 수행했다. 예를 들어, 우리는 성능을 평가하기 위해 교차 검증을 사용했다. 또한, 바이오시그니처가 단지 예후인지 여부도 검증했다. 마지막으로, 블라인드 테스트 세트에서 임상 검증이 수행됐다.
이 접근법은 14개의 바이오마커 특징을 포함하는 바이오시그니처를 발견했다. 피처는 BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, HOXA11, AURKA, BIRC3, IKZF1, CASP8, 및 EP300의 복제수이다. 이러한 유전자 식별자는 제출 당시 과학계에서 일반적으로 허용되는 것으로, 다양한 공지된 데이터베이스, 가령, HUGO Gene Nomenclature Committee (HNGC; genenames.org), NCBI's Gene database (www.ncbi.nlm.nih.gov/gene), GeneCards (genecards.org), Ensembl (ensembl.org), UniProt (uniprot.org)을 검색하는 데 사용될 수 있다.
도 4f-g는 5-배 교차 검증을 사용하여 얻은 결과를 보여준다. 최고 성능의 교차 검증이 도 4f에 나와 있다. 도면에서 보듯이, 위험 비(HR)는 0.315였고 HR의 95% 신뢰 구간은 0.167-0.595였다. 로그 순위 p-값은 <0.0001에서 매우 유의미했다. 마찬가지로, 중앙값 모델이 도 4g에 도시되어 있다. 0.407의 관찰된 HR은 이 모델이 개체군의 한 부분집합이 나머지 개체군에 비해 FOLFOX에 대한 효험 부재 리스크의 146% 증가를 겪음을 예측했음을 나타낸다. 146 % 계산은 공식 100 x (1 - 1/HR)%에 따라 수행되었지만(가령, Andreas Sashegy and David Ferry, On the Interpretation of the Hazard Ratio and Communication of Survival Benefit, Oncologist.2017 Apr; 22(4): 484-486), HR의 역이 반응군에 비해 비반응군을 식별하는 목표에 따르도록 리스트 감소 대신 리스크 증가를 발생시킨다.
우리는 다음으로 바이오시그니처가 FOLFOX의 효험에 대해 예측이 아니라 예후였는지를 물었다.즉, 우리는 바이오시그니처가 치료와 무관하게 더 나은 결과를 가진 환자를 식별할 뿐인지 알고자 했다. 따라서 바이오시그니처는 1차 치료로 FOLFIRI로 치료 받은 환자 코호트에 적용되었다. 결과는 도 4h에 도시되어 있다. 도면에서 볼 수 있듯이, 95% 신뢰 구간은 1.0의 HR과 겹쳤으며 분리에 대한 p-값은 0.379에서 통계적으로 유의미하지 않았다. 바이오시그니처가 FOLFIRI로부터의 효험을 예측할 수 없었기 때문에, 이들 결과는 FOLFOX로부터 효험을 예측할 수 있음을 보여준다.
마찬가지로, 우리는 좌/우 종양의 기원이 바이오시그니처 발견에서 교란변수였는지 여부를 조사했다. CRC는 결장의 왼쪽 또는 오른쪽에서 발생할 수 있으며 이 기원은 예후와 치료 모두에 영향을 미칠 수 있다. 예를 들어, 오른쪽 CRC 환자는 왼쪽 CRC 환자보다 더 나쁜 결과를 가진다. 전이성 대장암 환자에서 결장 내 원발성 종양의 좌우는 생존율뿐만 아니라 베바시주맙 및 세툭시맙과 같은 일반적으로 사용되는 생물학적 치료의 효과에도 영향을 미치는 것으로 보인다. Venook AP et al., Effect of First-Line Chemotherapy Combined With Cetuximab or Bevacizumab on Overall Survival in Patients With KRAS Wild-Type Advanced or Metastatic Colorectal Cancer: A Randomized Clinical Trial.JAMA.2017 Jun 20;317(23):2392-2401를 참조할 수 있고; 도 4a를 참조할 수 있다. 도 4i는 FOLFOX 효험/효험 없음을 검출하는 것에 대해 훈련되고, FOLFOX 효험/효험 없음, 좌/우 CRC 및 대조군으로서 치환된 좌/우에 대해 평가된 5-배 교차 검증에 의해 계산된 정확도의 히스토그램을 보여준다. 관찰된 바와 같이, 무작위로 치환된 좌/우 대조군의 정확도에 비해 좌/우 정확도가 약간만 증가되었다. 이는 FOLFOX 효험을 예측하기 위해 관찰된 높은 정확도와 대조된다. 이들 데이터는 바이오시그니처가 원발성 종양의 우/좌에 의해 교란되지 않음을 나타낸다.
마지막으로, 우리는 일선 전이성 대장암 환자의 독립적인 코호트를 사용하여 바이오시그니처에 대한 임상 검증을 수행했다. 결과는 도 4j에 도시되어 있다. 이용 가능한 비효험군 환자 수가 적음에도 불구하고, HR은 0.333이었으며, 이는 이 모델이 0.003의 높은 유의도의 p-값을 갖고, 개체군의 한 부분집합이 나머지 개체군에 비해 FOLFOX에 대한 효험 부재 리스크의 200% 증가를 겪음을 예측했음을 나타낸다. 우리는 또한 보조제 환경에서 독립적인 환자 코호트에 바이오시그니처를 적용했다. 도 4k는 III기 CRC 환자의 더 작은 코호트에서 얻은 결과를 보여준다. 이 설정에서, HR은 0.506이고 p-값은 0.080에서 그다지 유의미하지 않았다. 도 4l은 각각 도 4k 및 도 4l로부터의 도 3의 III기 및 IV기 환자를 조합한 결과를 보여준다. 이 설정에서, HR은 0.466이고 p-값은 0.003에서 유의미했다. 이러한 결과는 바이오시그니처가 IV기 전이성 CRC 환자에서 FOLFOX의 최적 예측을 제공하고 다른 설정, 예를 들어 III기 암 또는 기타에서도 유용할 수 있음을 시사할 수 있다.
위의 바이오시그니처를 식별하기 위해 사용된 복수의 알고리즘 접근법(예를 들어,도 4f-4l에서와 같이)에 추가로, 우리는 FOLFOX 응답의 바이오시그니처를 식별하기 위해 단일 모델 접근법을 사용했다. 이러한 3개의 랜덤 포레스트 분류기 모델은 파라미터 및 결과와 함께 표 9에 나타난다. 모델은 위의 훈련 샘플(도 4e 참조)에 대해 훈련되고 도 4j에서와 같이 샘플에 대해 테스트되었다. 모델에 대한 KM 플롯은 표 9의 "모델" 열에 표시된 것과 같다. 도면에서 나타난 바와 같이, 모델 1(도 4m, HR = 0.917, p-값 = 0.814)은 FOLFOX 효험군과 비효험군을 유의미하게 분류하지 않았고, 모델 2(도 4n, HR = 0.365, p-값 = 0.007) 및 모델 3(도 4o; HR = 0.465; p-값 = 0.047) 둘 모두 테스트 세트에서 FOLFOX 효험군과 비효험군을 유의미하게 분류했다.
표 9 - 랜덤 포레스트 분류자 모델


실시예 4: FOLFOX 화학 요법 치료법에 대한 반응군 또는 비반응군로서 대장암 환자의 다중 모델 예측
위의 실시예에서, 우리는 FOLFOX에 대한 효험 또는 효험 부재를 예측하기 위한 임상적으로 관련된 바이오시그니처를 발견하기 위해 본 명세서에 개시된 방법에 따라 분자 프로파일링 데이터를 분석하기 위한 머신 러닝 접근법의 사용을 기재한다. 모델은 III기 및 IV기 대장암(CRC) 샘플(실시예 2) 또는 IV기 CRC 샘플(실시예 3)에 대해 훈련되었다. 여기에서, 우리는 모든 모델을 결합하여 CRC 환자를 FOLFOX 화학 요법 치료 요법에 대한 반응군 또는 비반응군으로서 예측하기 위한 머신-러닝 접근법을 개발했다.
샘플 세트 및 훈련 방법은 앞서 기재된 바와 같다. 우리는 함께 최적의 반응 예측을 제공하는 5개의 랜덤 포레스트 모델을 식별했다. Python 언어 및 sklearn.ensemble.RandomForestClassifier 모듈을 사용하여 랜덤 포레스트를 생성했다. Pedregosa et al., Scikit-learn: Machine Learning in Python, JMLR 12, pp.2825-2830, 2011를 참조할 수 있다. 모델을 생성하는 데 사용되는 sklearn.ensemble.RandomForestClassifier 파라미터가 표 10에 나타나 있다. 모델 식별자는 "모델" 열에 나타나 있다. 각각의 모델은 표의 "바이오시그니처" 열에 표시된 대로 고유한 피처 리스트를 가진다. 유전자 식별자는 제출 당시 과학계에서 일반적으로 허용되는 것으로, 다양한 공지된 데이터베이스, 가령, HUGO Gene Nomenclature Committee (HNGC; genenames.org), NCBI's Gene database (www.ncbi.nlm.nih.gov/gene), GeneCards (genecards.org), Ensembl (ensembl.org), UniProt (uniprot.org)을 검색하는 데 사용될 수 있다. 예상되듯이, 몇 개의 피처가 복수의 모델에서 사용된다. 예를 들어, ASXL1은 아래에서 자세히 설명하는 것처럼 5개 모델 중 4개에서 사용된다. 바이오시그니처의 각각의 유전자 피처에 대한 데이터는 차세대 시퀀싱을 사용하여 결정된 복제수로 구성된다. 자세한 내용은 실시예 1을 참조할 수 있다.
표 10 - 랜덤 포레스트 분류자 모델




모델을 사용하여 만든 예측은 5,000개의 저장된 모델 인스턴스를 기반으로 한다. 5개의 모델 각각은 1,000번 훈련되었으며 각각의 특정 인스턴스는 약간 상이한 랜덤 포레스트를 생성하여 약간 상이한 랜덤 포레스트를 생성한다. 그러나 포레스트는 저장된 개체이며 고정된 입력이 주어지면 항상 동일한 출력을 생성할 것이다. 케이스에 대한 예측을 수행하기 위해 1,000개의 저장된 모델 인스턴스 각각을 통해 지정된 유전자 특징에 대한 케이스의 복제수 값을 운영한다. 각각의 개별 인스턴스는 케이스가 무반응군일 확률을 생성한다. 그런 다음 케이스는 모델 #1에 대해 확률 1,000개, 모델 #2에 대해 확률 1,000개 등이 있다. 모델당 확률 중앙값을 취하여 이러한 결과를 5개 확률로 집계한다(즉, 모델 1 확률 = 중앙값(model1.1, model1.2, ??, model1.1000 등). 이들 5개의 중앙값 확률의 중앙값, 즉, 표 10에 나열된 모델 당 하나의 확률이다. 5개의 모델이 있으므로 모델 중 3개 이상이 케이스가 비반응군이라고 예측하면 전체 예측은 비반응군이다. 훈련 세트에 대한 5-배 교차 검증을 사용한 이 접근법의 결과는 도 5a-b에 나타나 있다. 도 5a는 모든 모델을 사용한 결과를 보여준다. 도 5b는 하나의 모델을 사용한 대표적인 결과를 나타낸다.
공동 5 랜덤 포레스트 모델은 166개의 IV기 CRC 케이스에 대한 분자 프로파일링 및 결과 데이터를 이용해 검증되었다. 각각의 환자는 실시예 1에 기재된 바와 같이 이전에 프로파일링된 CRC 종양을 가졌지 만, 케이스는 본 명세서에 기술된 이전 FOLFOX 개발 노력에 사용되지 않았다. 공동 모델의 결과를 기반으로 한 FOLFOX에 대한 반응 예측이 도 5c에 도시되어 있다. 도면은 본 방법이 FOLFOX에 대한 반응 또는 반응 없음을 정확하게 예측한다는 것을 보여준다.공동 모델은 또한 검증 세트에 적용되고 앞서 기재된 실시예를 사용했고 유사한 결과를 획득했다. 데이터는 나타나 있지 않다. 종합적으로, 이들 데이터는 다양한 출처의 실제 환자 샘플을 사용하여 최전선 후기 CRC 환자에서 FOLFOX에 대한 반응을 예측하는 데 공동 5 랜덤 포레스트 모델을 사용할 수 있음을 나타낸다. 우리의 데이터는 FOLFOX에 대한 예측된 반응군인 환자의 치료를 제안하는 반면, 예측된 비반응군은 FOLFIRI로 치료할 수 있다.
표 11은 표 10에 나열된 유전자/피처에 대한 자세한 내용을 제공한다. 열 "Ensembl ID"는 Ensembl(ensembl.org)의 유전자 ID를 나열한다. "이름" 열은 출원 당시 일반적으로 허용되는 유전자에 대한 이름을 나열한다. 열 "R" 및 "NR"은 각각 반응군 케이스 및 비반응군 케이스에 대한 NGS 접근 방식을 사용하여 검출된 각각의 유전자에 대한 복제수를 보여준다. 세포는 디플로이드일 것으로 예상되므로 세포당 2개의 유전자 복제를 보유하므로 2 미만의 숫자는 손실을 시사하고, 반면에 2 초과의 숫자는 증가/증폭을 시사한다. 열 "# 모델"은 표 10의 5개의 모델에서 유전자가 등장하는 횟수를 나타낸다. 예를 들어 PAX7은 표 10의 한 모델, 즉 모델 2(ARF43)에 등장하고, PBX1은 5개 모델 중 4개의 모델, 즉, 모델 1(ARF2), 모델 2(ARF43), 모델 3(DRF13) 및 모델 4(DRF25)에서 등장한다. "사이토 밴드(Cyto Band)" 열은 표준 명명법에서 주어진 유전자의 자리이다(가령, 선행 번호는 염색체이고, "p"는 단완(short arm), "q"는 염색체의 장완(long arm), 후행 번호는 영역 및 밴드를 나타낸다).
표 11 - 랜덤 포레스트 분류자 모델




이론에 얽매이지 않고 표 11의 데이터에서 다양한 관찰을 할 수 있다. 예를 들어, 우리의 방법은 복제수의 변화에 매우 민감하다. 우리는 모델이 실제 샘플에서 강건할 것을 발견했지만, 표에 표시된 것처럼, 사본의 변경 사항은 기존 실험실 기술을 사용하여 검출될 차이보다 더 작을 경우가 많다. NGS를 사용하여 프로파일링하는 샘플은 일반적으로 미세 해부된 FFPE 종양 샘플이다. 따라서 우리의 방법은 샘플의 종양 세포들 간의 이질성을 고려할 때 강건하다. 또한, 복수의 유전자가 등장하는 영역이 존재하는데, 비제한적 예를 들면, 1q(PAX7, BCL9, FCRL4, PBX1, PRRX1, FH, AKT3), 20q(ASXL1, TOP1, SDC4, AURKA, ZNF217, GNAS, ARFRP1) 및 22q(CRKL, SEPT5, MN1, EWSR1, PDGFB, SOX10, EP300)가 있다. 이는 여러 유전자가 주어진 유전 영역에 있을 때 우리의 방법이 감지하는 게놈 변경을 위한 염색체 "핫스팟"이 있음을 시사한다. 예를 들어, Ashktorab H et al.Distinct genetic alterations in colorectal cancer.PLoS One.2010 Jan 26;5(1):e8879.doi: 10.1371/journal.pone.0008879를 참조할 수 있다. 또한, 많은 경우에 우리가 분석한 유전자의 인접 염색체 위치에 대한 평가는 유사한 결과를 제공할 것으로 예상 될 수 있다.
다중 랜덤 포레스트 모델이 동일한 분자 프로파일링 데이터(가령, 실시예 1 참조)는 아니지만 동일한 샘플 데이터(가령, 표 9 및 10 참조) 또는 다른 샘플 세트(비고.실시예 2 및 3)인 경우 유사하게 훈련되었다. 본질적으로 각각의 모델이 표를 받는 "투표" 방식을 사용하여 모델을 결합하면 개별 모델에 대해 우수한 결과를 제공한다. 비고.도 5a 및 5b. 이론에 얽매이지 않고, 각각의 모델은 서로 다른 특성을 가진 케이스에서 최적의 성능을 발휘할 수 있으며, 조합에서 투표 체계는 특정 하위 집합 또는 케이스 하위 집합에서 주어진 모델의 차선 성능을 설명한다.
종합하여, 우리는 FOLFOX 화학 요법 치료 요법에 대한 CRC 환자의 반응 또는 반응 없음을 예측하는 다중 모델을 구축하기 위해 고급 머신 러닝 알고리즘을 사용했다. 다중 모델은 각각 여기에 개시된 방법에 따라 "투표"가 허용되고 최다 득표자가 "선출"된다. 이 방법은 이질적이고 실제적인 샘플(즉, 실제 임상 샘플)에 걸쳐 강력한 결과를 제공하는 것으로 나타났으며, 단순한 예후가 아니며 측면성(sidedness)에 강건하다. 치료 의사는 FOLFOX 검사 결과를 사용하여 CRC 환자를 FOLFOX으로 또는 FOLFIRI와 같은 대체 요법으로 치료할지 여부를 결정할 수 있다.
실시예 3: 대장암 환자에 대한 치료 선택
대장암 환자를 치료하는 종양 전문의는 환자를 FOLFOX 또는 FOLFIRI로 치료할지 여부를 결정한다. 환자의 종양 세포를 포함하는 생체 샘플을 수집한다. 실시예 1에 따른 샘플에 대한 분자 프로파일이 생성된다. 표 10에 기재된 5개의 랜덤 포레스트 모델은 각각 FOLFOX에 대한 반응 가능성 또는 반응 없음 가능성을 나타내는 분자 프로파일을 분류하는 데 사용된다.대부분의 분류는 수행된 분자 프로파일링을 설명하는 리포트에 포함된다. 리포트는 종양 전문의에게 제공된다. 종양 전문의는 리포트의 분류를 사용하여 환자에 대한 치료 요법을 결정한다. 분류가 반응군인 경우 종양 전문의는 해당 환자를 FOLFOX로 치료한다. 분류가 반응군인 경우 종양 전문의는 해당 환자를 FOLFIRI로 치료한다.
그 밖의 다른 구체예
본 발명이 상세한 설명과 함께 설명되었지만, 상기의 설명은 첨부 된 청구 범위의 범위에 의해 정의되는 본 명세서에 설명된 범위를 제한하는 것이 아니라 예시하기위한 것임을 이해해야 한다. 또 다른 측면, 장점 및 수정은 다음의 청구 범위 내에 있다.
Claims (74)
- 피험체에 대한 질병 또는 장애의 치료의 효과를 예측하기 위해 머신 러닝 모델을 훈련할 때 사용되기 위한 입력 데이터 구조를 생성하기 위한 데이터 처리 장치로서, 상기 데이터 처리 장치는 하나 이상의 프로세서 및 하나 이상의 프로세서에 의해 실행될 때 상기 하나 이상의 프로세서로 하여금 동작을 수행하게 하는 명령을 저장하는 하나 이상의 저장 장치를 포함하고, 상기 동작은:
데이터 처리 장치에 의해 하나 이상의 바이오마커 데이터 구조 및 하나 이상의 결과 데이터 구조를 획득하는 것,
데이터 처리 장치에 의해, 상기 하나 이상의 바이오마커 데이터 구조로부터 피험체와 연관된 하나 이상의 바이오마커를 나타내는 제1 데이터를 추출하고, 하나 이상의 결과 데이터 구조로부터 질병 또는 장애 및 치료를 나타내는 제2 데이터를 추출하며, 상기 질병 또는 장애에 대한 치료의 결과를 나타내는 제3 데이터를 추출하는 것,
데이터 처리 장치에 의해, 하나 이상의 바이오마커를 나타내는 제1 데이터 및 질병 또는 장애 및 치료를 나타내는 제2 데이터에 기초하여 머신 러닝 모델로의 입력을 위한, 데이터 구조를 생성하는 것,
데이터 처리 장치에 의해, 머신 러닝 모델로의 입력으로서 생성된 데이터 구조를 제공하는 것,
데이터 처리 장치에 의해, 생성된 데이터 구조의 머신 러닝 모델의 처리에 기초하여 머신 러닝 모델에 의해 생성된 출력을 획득하는 것,
데이터 처리 장치에 의해, 질병 또는 장애에 대한 치료의 결과를 나타내는 제3 데이터와 머신 러닝 모델에 의해 생성된 출력 간 차이를 결정하는 것, 및
데이터 처리 장치에 의해, 질병 또는 장애에 대한 치료의 결과를 나타내는 제3 데이터와 머신 러닝 모델에 의해 생성된 출력 간 차이에 기초하여 머신 러닝 모델의 하나 이상의 파라미터를 조절하는 것을 포함하는, 데이터 처리 장치. - 제1항에 있어서, 하나 이상의 바이오마커의 세트는 표 2-8 중 임의의 하나에 나열된 하나 이상의 바이오마커를 포함하는, 데이터 처리 장치.
- 제1항에 있어서, 하나 이상의 바이오마커의 세트는 청구항 2의 바이오마커 각각을 포함하는, 데이터 처리 장치.
- 제1항에 있어서, 하나 이상의 바이오마커의 세트는 청구항 2의 바이오마커 중 적어도 하나를 포함하고, 선택적으로, 하나 이상의 바이오마커의 세트는 표 5, 표 6, 표 7, 표 8의 마커, 또는 이들의 임의의 조합을 포함하는, 데이터 처리 장치.
- 특정 치료에 대한 피험체의 치료 반응을 예측하기 위해 머신 러닝 모델을 훈련할 때 사용되기 위한 입력 데이터 구조를 생성하기 위한 데이터 처리 장치로서, 상기 데이터 처리 장치는 하나 이상의 프로세서 및 하나 이상의 프로세서에 의해 실행될 때 상기 하나 이상의 프로세서로 하여금 동작을 수행하게 하는 명령을 저장하는 하나 이상의 저장 장치를 포함하고, 상기 동작은:
데이터 처리 장치에 의해, 제1 분산 데이터 소스로부터 피험체와 연관된 하나 이상의 바이오마커의 세트를 나타내는 데이터를 구조화하는 제1 데이터 구조를 획득하는 것 - 제1 데이터 구조는 피험체를 식별하는 키 값을 포함함 - ,
데이터 처리 장치에 의해, 하나 이상의 메모리 장치 내 제1 데이터 구조를 저장하는 것,
데이터 처리 장치에 의해, 제2 분산 데이터 소스로부터 하나 이상의 바이오마커를 갖는 피험체에 대한 결과 데이터를 나타내는 데이터를 구조화하는 제2 데이터 구조를 획득하는 것 - 결과 데이터는 질병 또는 장애, 치료를 식별하는 데이터, 치료 효과의 지시자를 포함하고, 제2 데이터 구조는 피험체를 식별하는 키 값을 더 포함함 - ,
데이터 처리 장치에 의해, 하나 이상의 메모리 장치 내 제2 데이터 구조를 저장하는 것,
데이터 처리 장치에 의해 메모리 디바이스 내에 저장되는 제1 데이터 구조 및 제2 데이터 구조를 이용해, (i) 하나 이상의 바이오마커의 세트, 질병 또는 장애, 및 치료를 나타내는 데이터, 및 (ii) 질병 또는 장애에 대한 치료의 효과의 지시자를 제공하는 라벨을 포함하는 라벨링된 훈련 데이터 구조를 생성하는 것 - 데이터 처리 장치에 의해 제1 데이터 구조 및 제2 데이터 구조를 생성하고 이용하는 것은, 데이터 처리 장치에 의해, 피험체와 연관된 하나 이상의 바이오마커의 세트를 나타내는 데이터를 구조화하는 제1 데이터 구조를 피험체를 식별하는 키 값에 기초하여 하나 이상의 바이오마커를 갖는 피험체에 대한 결과 데이터를 나타내는 제2 데이터 구조와 상관시키는 것을 포함함 - , 및
데이터 처리 장치에 의해, 생성된 라벨 훈련 데이터 구조를 이용해 머신 러닝 모델을 훈련시키는 것 - 생성된 라벨링된 훈련 데이터 구조를 이용해 머신 러닝 모델을 훈련하는 것은 데이터 처리 장치에 의해 머신 러닝 모델로, 생성된 라벨 훈련 데이터 구조를 머신 러닝 모델의 입력으로서 제공하는 것을 포함함 - 을 포함하는, 데이터 처리 장치. - 제5항에 있어서, 상기 동작은
데이터 처리 장치에 의해 머신 러닝 모델로부터, 생성된 라벨링된 훈련 데이터 구조의 머신 러닝 모델의 처리에 기초하여 머신 러닝 모델에 의해 생성되는 출력을 획득하는 것, 및
데이터 처리 장치에 의해, 머신 러닝 모델에 의해 생성되는 출력과 질병 또는 장애에 대한 치료 효과의 지시자를 제공하는 라벨 간 차이를 결정하는 것을 더 포함하는, 데이터 처리 장치. - 제6항에 있어서, 동작은
데이터 처리 장치에 의해, 머신 러닝 모델에 의해 생성되는 출력과 질병 또는 장애에 대한 치료 효과의 지시자를 제공하는 라벨 간 결정된 차이에 기초하여 머신 러닝 모델의 하나 이상의 파라미터를 조절하는 것을 더 포함하는, 데이터 처리 장치. - 제5항에 있어서, 하나 이상의 바이오마커의 세트는 표 2-8 중 하나에 나열된 하나 이상의 바이오마커를 포함하며, 선택적으로, 하나 이상의 바이오마커의 세트는 표 5, 표 6, 표 7, 표 8의 마커, 또는 이들의 임의의 조합을 포함하는, 데이터 처리 장치.
- 제5항에 있어서, 하나 이상의 바이오마커의 세트는 청구항 8의 바이오마터 각각을 포함하는, 데이터 처리 장치.
- 제5항에 있어서, 하나 이상의 바이오마커의 세트는 청구항 8의 바이오마커 중 하나를 포함하는, 데이터 처리 장치.
- 청구항 제1항 내지 제10항 중 어느 한 항의 동작에 대응하는 단계를 포함하는 방법.
- 하나 이상의 컴퓨터 및 상기 하나 이상의 컴퓨터에 의해 실행될 때 상기 하나 이상의 컴퓨터로 하여금 청구항 제1항 내지 제10항 중 어느 한 항에 기재된 동작을 수행하게 하는 명령을 저장하는 하나 이상의 저장 매체를 포함하는 시스템.
- 하나 이상의 컴퓨터에 의해 실행되는 명령을 포함하는 소프트웨어를 저장하는 비일시적 컴퓨터 판독형 매체로서, 상기 명령은 실행 시 하나 이상의 컴퓨터로 하여금 청구항 제1항 내지 제10항 중 어느 한 항에 기재된 동작을 수행하게 하는, 비일시적 컴퓨터 판독형 매체.
- 개체 분류 방법으로서, 상기 방법은
복수의 머신 러닝 모델의 각각의 특정 머신 러닝 모델에 대해:
예측 또는 분류를 결정하도록 훈련된 특정 머신 러닝 모델로, 분류될 개체의 설명을 나타내는 입력 데이터를 제공하는 단계, 및
특정 머신 러닝 모델이 입력 데이터를 처리하는 것에 기초하여 특정 머신 러닝 모델에 의해 생성된, 복수의 후보 개체 분류 중 초기 개체 분류로의 개체 분류를 나타내는 출력 데이터를 획득하는 단계,
투표 유닛(voting unit)으로, 복수의 머신 러닝 모델의 각각의 머신 러닝 모델에 대해 획득된 출력 데이터를 제공하는 단계, 및
투표 유닛에 의해, 제공된 출력 데이터에 기초하여, 개체에 대한 실제 개체 분류를 결정하는 단계를 포함하는, 개체 분류 방법. - 제14항에 있어서, 제공된 출력 데이터에 다수결 규칙을 적용함으로써, 개체에 대한 실제 개체 분류가 결정되는, 개체 분류 방법.
- 제14항 또는 제15항에 있어서, 투표 유닛에 의해, 제공된 출력 데이터에 기초하여, 개체에 대한 실제 개체 분류를 결정하는 단계는
투표 유닛에 의해, 복수의 후보 분류의 각각의 초기 개체 분류의 발생 횟수를 결정하는 단계, 및
투표 유닛에 의해, 복수의 후보 개체 분류 중 가장 높은 등장 횟수를 가진 초기 개체 분류를 선택하는 단계를 포함하는, 개체 분류 방법. - 제14항 내지 제16항 중 어느 한 항에 있어서, 복수의 머신 러닝 모델의 각각의 머신 러닝 모델은 랜덤 포레스트 분류 알고리즘, 서포트 벡터 머신, 로지스틱 회귀, k-최근접 이웃 모델, 인공 신경망, 나이브 베이즈 모델, 2차 판별 분석, 또는 가우시안 프로세스 모델을 포함하는, 개체 분류 방법.
- 제14항 내지 제16항 중 어느 한 항에 있어서, 복수의 머신 러닝 모델의 각각의 머신 러닝 모델은 랜덤 포레스트 분류 알고리즘을 포함하는, 개체 분류 방법.
- 제14항 내지 제18항 중 어느 한 항에 있어서, 복수의 머신 러닝 모델은 동일한 유형의 분류 알고리즘의 복수의 표현을 포함하는, 개체 분류 방법.
- 제14항 내지 제18항 중 어느 한 항에 있어서, 입력 데이터는 (i) 개체 속성 및 (ii) 질병 또는 장애에 대한 치료법의 설명을 나타내는, 개체 분류 방법.
- 제20항에 있어서, 복수의 후보 개체 분류는 반응 분류 또는 비반응 분류를 포함하는, 개체 분류 방법.
- 제20항 또는 제21항에 있어서, 개체 속성은 개체에 대한 하나 이상의 바이오마커를 포함하는, 개체 분류 방법.
- 제22항에 있어서, 하나 이상의 바이오마커는 개체의 알려진 유전자의 일부인 유전자 패널을 포함하는, 개체 분류 방법.
- 제22항에 있어서, 하나 이상의 바이오마커는 개체의 알려진 유전자의 전부인 유전자 패널을 포함하는, 개체 분류 방법.
- 제20항 내지 제24항 중 어느 한 항에 있어서, 입력 데이터는 질병 또는 장애의 설명을 나타내는 데이터를 더 포함하는, 개체 분류 방법.
- 하나 이상의 컴퓨터 및 상기 하나 이상의 컴퓨터에 의해 실행될 때 상기 하나 이상의 컴퓨터로 하여금 청구항 제14항 내지 제25항 중 어느 한 항에 기재된 동작을 수행하게 하는 명령을 저장하는 하나 이상의 저장 매체를 포함하는 시스템.
- 하나 이상의 컴퓨터에 의해 실행되는 명령을 포함하는 소프트웨어를 저장하는 비일시적 컴퓨터 판독형 매체로서, 상기 명령은 실행 시 하나 이상의 컴퓨터로 하여금 청구항 제14항 내지 제25항 중 어느 한 항에 기재된 동작을 수행하게 하는, 비일시적 컴퓨터 판독형 매체.
- 방법으로서,
피험체의 암으로부터의 세포를 포함하는 생체 샘플을 획득하는 단계, 및
생체 샘플에서 적어도 하나의 바이오마커를 평가하기 위한 분석(assay)을 수행하는 단계 - 상기 바이오마커는 다음 중 적어도 하나를 포함함:
(a) MYC, EP300, U2AF1, ASXL1, MAML2, 및 CNTRL 중 1, 2, 3, 4, 5 또는 6개를 포함하는 그룹 1,
(b) MYC, EP300, U2AF1, ASXL1, MAML2, CNTRL, WRN, 및 CDX2 중 1, 2, 3, 4, 5, 6, 7, 또는 8개를 포함하는 그룹 2,
(c) BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, HOXA11, AURKA, BIRC3, IKZF1, CASP8, 및 EP300 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 또는 14개를 포함하는 그룹 3,
(d) PBX1, BCL9, INHBA, PRRX1, YWHAE, GNAS, LHFPL6, FCRL4, AURKA, IKZF1, CASP8, PTEN, 및 EP300 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 또는 13개를 포함하는 그룹 4,
(e) BCL9, PBX1, PRRX1, INHBA, GNAS, YWHAE, LHFPL6, FCRL4, PTEN, HOXA11, AURKA, 및 BIRC3 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 또는 12개를 포함하는 그룹 5,
(f) BCL9, PBX1, PRRX1, INHBA, 및 YWHAE 중 1, 2, 3, 4, 또는 5를 포함하는 그룹 6,
(g) BCL9, PBX1, GNAS, LHFPL6, CASP8, ASXL1, FH, CRKL, MLF1, TRRAP, AKT3, ACKR3, MSI2, PCM1, 및 MNX1 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 또는 15개를 포함하는 그룹 7,
(h) BX1, GNAS, AURKA, CASP8, ASXL1, CRKL, MLF1, GAS7, MN1, SOX10, TCL1A, LMO1, BRD3, SMARCA4, PER1, PAX7, SBDS, SEPT5, PDGFB, AKT2, TERT, KEAP1, ETV6, TOP1, TLX3, COX6C, NFIB, ARFRP1, ARID1A, MAP2K4, NFKBIA, WWTR1, ZNF217, IL2, NSD3, CREB1, BRIP1, SDC4, EWSR1, FLT3, FLT1, FAS, CCNE1, RUNX1T1, 및 EZR 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44 또는 45개를 포함하는 그룹 8,
(i) BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, BIRC3, AURKA, 및 HOXA11 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 또는 11개를 포함하는 그룹 9 - 를 포함하는, 방법. - 제28항에 있어서, 생체 샘플은 포르말린-고정 파라핀-포매(FFPE: formalin-fixed paraffin-embedded) 조직, 고정된 조직, 코어 바늘 생검, 미세 바늘 흡인물, 비염색 슬라이드, 신선 동결(FF: fresh frozen) 조직, 포르말린 샘플, 핵산 또는 단백질 분자를 보존하는 용액에 포함된 조직, 신선 샘플, 악성 유체, 체액, 종양 샘플, 조직 샘플, 또는 이들의 임의의 조합을 포함하는, 방법.
- 제28항 또는 제29항에 있어서, 생체 샘플은 고형 종양으로부터의 세포를 포함하는, 방법.
- 제28항 또는 제29항에 있어서, 생체 샘플은 체액을 포함하는, 방법.
- 제28항 내지 제31항 중 어느 한 항에 있어서, 체액은 악성 유체, 흉수, 복막액, 또는 이들의 임의의 조합을 포함하는, 방법.
- 제28항 내지 제32항 중 어느 한 항에 있어서, 체액은 말초 혈액, 혈청, 혈장, 복수, 소변, 뇌척수액(CSF), 가래, 타액, 골수, 활액, 안방수, 양수, 귀지, 모유, 기관지폐포 세척액, 정액, 전립선액, 소액, 사정전액, 여성의 사정액, 땀, 대변, 눈물, 낭종액, 흉막액, 복막액, 심낭액, 림프액, 유미즙, 유미, 담즙, 간질액, 월경, 고름, 피지, 구토, 질 분비물, 점막 분비물, 대변 물, 췌장액, 부비동강 세척액, 기관지폐 흡인물, 배반포강액 또는 제대혈을 포함하는, 방법.
- 제28항 내지 제33항 중 어느 한 항에 있어서, 평가는 각각의 바이오머커에 대한 단백질 또는 핵산의 존재여부, 레벨, 또는 상태를 결정하는 것을 포함하며, 선택적으로, 핵산은 DNA(deoxyribonucleic acid), RNA(ribonucleic acid), 또는 이들의 조합을 포함하는, 방법.
- 제34항에 있어서,
(a) 단백질의 존재 여부, 레벨 또는 상태는 IHC(immunohistochemistry), 유세포 분석, 면역분석, 항체 또는 기능 단편, 압타머, 또는 이들의 임의의 조합을 이용해 결정되며, 및/또는
(b) 핵산의 존재 여부, 레벨, 또는 상태는 PCR(polymerase chain reaction), 원위치 혼성화, 증폭, 혼성화, 마이크로어레이, 핵산 시퀀싱, 염료 종단 시퀀싱, 파이로시퀀싱, 차세대 시퀀싱(NGS, 고처리율 시퀀싱), 또는 이들의 임의의 조합을 이용해 결정되는, 방법. - 제35항에 있어서, 핵산의 상태는 서열, 돌연변이, 다형성, 결실, 삽입, 치환, 전위, 융합, 절단, 복제, 증폭, 반복, 복제수, 복제수 변이(CNV; 복제수 변경; CNA), 또는 임의의 이들의 조합을 포함하는, 방법.
- 제36항에 있어서, 핵산의 상태는 복제수를 포함하는, 방법.
- 제37항에 있어서, 그룹 1의 모든 구성원(즉, MYC, EP300, U2AF1, ASXL1, MAML2, 및 CNTRL)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함하는, 방법.
- 제37항에 있어서, 그룹 2의 모든 구성원(즉, MYC, EP300, U2AF1, ASXL1, MAML2, CNTRL, WRN, 및 CDX2)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함하는, 방법.
- 제37항에 있어서, 그룹 3의 모든 구성원(즉, BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, HOXA11, AURKA, BIRC3, IKZF1, CASP8, 및 EP300)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함하는, 방법.
- 제37항에 있어서, 그룹 4의 모든 구성원(즉, PBX1, BCL9, INHBA, PRRX1, YWHAE, GNAS, LHFPL6, FCRL4, AURKA, IKZF1, CASP8, PTEN, 및 EP300)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함하는, 방법.
- 제37항에 있어서, 그룹 5의 모든 구성원(즉, BCL9, PBX1, PRRX1, INHBA, GNAS, YWHAE, LHFPL6, FCRL4, PTEN, HOXA11, AURKA, 및 BIRC3)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함하는, 방법.
- 제37항에 있어서, 그룹 6의 모든 구성원(즉, BCL9, PBX1, PRRX1, INHBA, 및 YWHAE)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함하는, 방법.
- 제37항에 있어서, 그룹 7의 모든 구성원(즉, BCL9, PBX1, GNAS, LHFPL6, CASP8, ASXL1, FH, CRKL, MLF1, TRRAP, AKT3, ACKR3, MSI2, PCM1, 및 MNX1)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함하는, 방법.
- 제37항에 있어서, 그룹 8의 모든 구성원(즉, BX1, GNAS, AURKA, CASP8, ASXL1, CRKL, MLF1, GAS7, MN1, SOX10, TCL1A, LMO1, BRD3, SMARCA4, PER1, PAX7, SBDS, SEPT5, PDGFB, AKT2, TERT, KEAP1, ETV6, TOP1, TLX3, COX6C, NFIB, ARFRP1, ARID1A, MAP2K4, NFKBIA, WWTR1, ZNF217, IL2, NSD3, CREB1, BRIP1, SDC4, EWSR1, FLT3, FLT1, FAS, CCNE1, RUNX1T1, 및 EZR)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함하는, 방법.
- 제37항에 있어서, 그룹 9의 모든 구성원(즉, BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, BIRC3, AURKA, 및 HOXA11)의 복제수 및 이의 근접한 게놈 영역을 결정하도록 분석을 수행하는 단계를 포함하는, 방법.
- 제37항에 있어서,
(a) 그룹 1 및 그룹 2의 적어도 하나 또는 모든 구성원, 또는 이의 근접 게놈 영역,
(b) 그룹 3의 적어도 하나 또는 모든 구성원, 또는 이의 근접 게놈 영역, 또는
(c) 그룹 2, 그룹 6, 그룹 7, 그룹 8 및 그룹 9의 적어도 하나 또는 모든 구성원, 또는 이의 근접 게놈 영역의 복제수를 결정하기 위한 분석을 수행하는 단계를 포함하는, 방법. - 제37항 내지 제47항 중 어느 한 항에 있어서, 바이오마커의 복제수를 참조 복제수(가령, 디플로이드)에 비교하는 단계, 및 복제수 변동(CNV)을 갖는 바이오마커를 식별하는 단계를 더 포함하는, 방법.
- 제48항에 있어서, CNV를 갖는 유전자 또는 이의 근접 영역을 식별하는 분자 프로파일을 생성하는 단계를 더 포함하는, 방법.
- 제28항 내지 제49항 중 어느 한 항에 있어서, PTEN 단백질의 존재 여부 또는 레벨이 결정되며, 선택적으로, PTEN 단백질 존재 여부 또는 레벨이 IHC(immunohistochemistry)을 이용해 결정되는, 방법.
- 제28항 내지 제50항 중 어느 한 항에 있어서, TOPO1 및 하나 이상의 불일치 리페어 단백질(가령, MLH1, MSH2, MSH6, 및 PMS2)을 포함하는 단백질의 레벨을 결정하는 단계를 더 포함하고, PTEN 단백질 존재 여부 또는 레벨은 IHC(immunohistochemistry)을 이용해 결정되는, 방법.
- 제50항 또는 제51항에 있어서, 단백질의 레벨을 각각의 단백질에 대한 기준 레벨에 비교하는 단계를 더 포함하는, 방법.
- 제52항에 있어서, 기준 레벨과 상이한, 가령, 기준 레벨과 유의미하게 상이한 레벨을 갖는 단백질을 식별하는 분자 프로파일을 생성하는 단계를 더 포함하는, 방법.
- 제28항 내지 제53항 중 어느 한 항에 있어서, 평가된 바이오마커에 기초하여 효험 가능성이 있는 치료를 선택하는 단계를 더 포함하며, 치료는 옥살리플라틴과 조합된 5-플루오로우라실/류코보린(FOLFOX) 또는 이의 대안 치료를 포함하며, 선택적으로 대안 치료는 이리노테칸과 조합된 5-플루오우라실/류코보린(FOLFIRI)을 포함하는, 방법.
- 제54항에 있어서, 효험 가능성 있는 치료를 선택하는 단계는,
(a) 청구항 제37항 내지 제47항 중 어느 한 항에 따라 결정된 복제수, 및/또는
(b) 청구항 제49항 또는 제53항에 따르는 분자 프로파일에 기초하는, 방법. - 제55항에 있어서, 청구항 제37항 내지 제47항 중 어느 한 항에 따라 결정된 복제수에 기초하여 효험 가능성 있는 치료를 선택하는 것은 투표 모듈의 사용을 포함하는, 방법.
- 제56항에 있어서, 투표 모듈은 청구항 제14항 내지 제25항 중 어느 한 항에 따르는, 방법.
- 제56항 또는 제57항에 있어서, 투표 모듈은 적어도 하나의 랜덤 포레스트 모델의 사용을 포함하는, 방법.
- 제56항 내지 제58항 중 어느 한 항에 있어서, 투표 모듈의 사용은 머신 러닝 분류 모델을 그룹 2, 그룹 6, 그룹 7, 그룹 8 및 그룹 9 각각에 대해 획득된 복제수에 적용하는 것을 포함하며, 선택적으로, 각각의 머신 러닝 분류 모델은 랜덤 포레스트 모델이며, 랜덤 포레스트 모델은 표 10에 기재되어 었는 것인, 방법.
- 제54항 내지 제59항 중 어느 한 항에 있어서, 피험체는 효험 가능성 있는 치료법으로 치료된 적 없는, 방법.
- 제28항 내지 제60항 중 어느 한 항에 있어서, 암은 전이암, 재발암, 또는 이의 조합을 포함하는, 방법.
- 제28항 내지 제61항 중 어느 한 항에 있어서, 피험체는 암에 대해 치료 받은 적이 없는, 방법.
- 제54항 내지 제62항 중 어느 한 항에 있어서, 효험 가능성 있는 치료를 피험체에게 투여하는 단계를 더 포함하는, 방법.
- 제63항에 있어서, 투여에 의해 무진행 생존률(PFS), 무질병 생존률(DFS), 또는 수명이 연장되는, 방법.
- 제28항 내지 제64항 중 어느 한 항에 있어서, 암은 급성 림프모구성 백혈병; 급성 골수성 백혈병; 부신피질 암종; AIDS-관련 암; AIDS-관련 림프종; 항문암; 맹장암; 성상세포종; 비정형 기형/횡문형 종양; 기저 세포 암; 방광암; 뇌간 신경교종; 뇌종양, 뇌간 신경교종, 중추신경계 비정형 기형/횡문근 종양, 중추신경계 배아 종양, 성상세포종, 두개인두종, 뇌실막세포종, 뇌실막종, 수모세포종, 수상피종, 송과체 중간 분화의 실질 종양, 천막상피종, 원시 신경세포종 유방암; 기관지 종양; 버킷 림프종; 미지의 원발성 부위의 암(CUP); 카르시노이드 종양; 미지의 원발 부위의 암종; 중추신경계 비정형 기형/횡문형 종양; 중추신경계 배아 종양; 자궁 경부암; 소아암; 척색종; 만성 림프구성 백혈병; 만성 골수성 백혈병; 만성 골수증식성 장애; 대장 암; 결장직장암; 두개인두종; 피부 T 세포 림프종; 내분비 췌장 섬 세포 종양; 자궁내막암; 뇌실막모세포종; 뇌실막종; 식도암; 감각신경모세포종; 유잉 육종; 두개외 생식 세포 종양; 생식선외 생식 세포 종양; 간외 담관암; 담낭암; 위암; 위장관 유암종; 위장관 기질 세포 종양; 위장관 기질 종양(GIST); 임신성 융모성 종양; 신경교종; 모세포 백혈병; 두경부암; 심장암; 호지킨 림프종; 하인두암; 안내 흑색종; 섬 세포 종양; 카포시 육종; 신장암; 랑게르한스 세포 조직구증; 후두암; 입술암; 간암; 악성 섬유성 조직구종 골암; 수모세포종; 수질상피종; 흑색종; 메르켈 세포 암종; 메르켈 세포 피부 암종; 중피종; 잠재성 원발성을 동반한 전이성 편평 경부암; 구강암; 다발성 내분비 신생물 증후군; 다발성 골수종; 다발성 골수종/형질 세포 신생물; 균상 식육종; 골수이형성 증후군; 골수증식성 신생물; 비강암; 비인두암; 신경 모세포종; 비호지킨 림프종; 비흑색종 피부암; 비소세포폐암; 구강암; 구강암; 구인두암; 골육종; 기타 뇌 및 척수 종양; 난소 암; 난소 상피암; 난소 생식 세포 종양; 난소의 저악성 잠재성 종양; 췌장암; 유두종증; 부비동암; 부갑상선암; 골반암; 음경암; 인두암; 중간 분화의 송과체 실질 종양; 송과체종; 뇌하수체 종양; 형질 세포 신생물/다발성 골수종; 흉막폐모세포종; 원발성 중추신경계(CNS) 림프종; 원발성 간세포 간암; 전립선암; 직장암; 신장암; 신세포(신장)암; 신세포암; 호흡기 암; 망막모세포종; 횡문근육종; 침샘암; 세자리 증후군; 소세포 폐암; 소장암; 연조직 육종; 편평 세포 암종; 편평 경부암; 위(위)암; 천막상 원시 신경외배엽 종양; T 세포 림프종; 고환암; 후두암; 흉선 암종; 흉선종; 갑상선 암; 이행 세포암; 신우 및 요관의 이행 세포암; 영양막 종양; 요관암; 요도암; 자궁암; 자궁 육종; 질암; 외음부암; 발덴스트롬 마크로글로불린혈증; 또는 빌름스 종양을 포함하는, 방법.
- 제28항 내지 제64항 중 어느 한 항에 있어서, 암은 급성 골수성 백혈병(AML), 유방암, 담관암, 결장직장 선암, 간외 담관 선암, 여성 생식기 악성종양, 위 선암, 위식도 선암, 위장관 기질 종양(GIST), 교모세포종, 두경부 암종, 백혈병 간세포 암종, 저등급 신경교종, 폐 세기관지폐포암종(BAC), 비소세포폐암(NSCLC), 소세포폐암(SCLC), 림프종, 남성 생식기 악성종양, 흉막의 악성 단독 섬유성 종양(MSFT), 흑색종, 다발성 골수종, 신경내분비 종양, 결절 미만성 거대 B 세포 림프종, 비상피성 난소암(비-EOC), 난소 표면 상피 암종, 췌장 선암종, 뇌하수체 암종, 희소돌기아교종, 전립선 선암종, 후복막 또는 복막 암종, 후복막 또는 복막 암종 육종, 소장암, 연조직종양, 흉선암, 갑상선암, 또는 포도막 흑색종을 포함하는, 방법.
- 제28항 내지 제64항 중 어느 한 항에 있어서, 암은 대장암을 포함하는, 방법.
- 대장암을 가진 피험체에 대한 치료를 선택하는 방법으로서, 상기 방법은
대장암으로부터의 세포를 포함하는 생체 세포를 획득하는 단계,
(a) MYC, EP300, U2AF1, ASXL1, MAML2, CNTRL, WRN, 및 CDX2 중 1, 2, 3, 4, 5, 6, 7, 또는 8개를 포함하는 그룹 2,
(b) BCL9, PBX1, PRRX1, INHBA, 및 YWHAE 중 1, 2, 3, 4, 또는 5를 포함하는 그룹 6,
(c) BCL9, PBX1, GNAS, LHFPL6, CASP8, ASXL1, FH, CRKL, MLF1, TRRAP, AKT3, ACKR3, MSI2, PCM1, 및 MNX1 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 또는 15개를 포함하는 그룹 7,
(d) BX1, GNAS, AURKA, CASP8, ASXL1, CRKL, MLF1, GAS7, MN1, SOX10, TCL1A, LMO1, BRD3, SMARCA4, PER1, PAX7, SBDS, SEPT5, PDGFB, AKT2, TERT, KEAP1, ETV6, TOP1, TLX3, COX6C, NFIB, ARFRP1, ARID1A, MAP2K4, NFKBIA, WWTR1, ZNF217, IL2, NSD3, CREB1, BRIP1, SDC4, EWSR1, FLT3, FLT1, FAS, CCNE1, RUNX1T1, 및 EZR 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44 또는 45개를 포함하는 그룹 8,
(e) BCL9, PBX1, PRRX1, INHBA, YWHAE, GNAS, LHFPL6, FCRL4, BIRC3, AURKA, 및 HOXA11 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 또는 11개를 포함하는 그룹 9의 유전자 그룹 또는 이의 근접 게놈 영역 각각에 대해 복제수를 결정하기 위해 생체 세포로부터의 게놈 DNA에 차세대 시퀀싱을 수행하는 단계,
머신 러닝 분류 모델을 그룹 2, 그룹 6, 그룹 7, 그룹 8 및 그룹 9 각각에 대해 획득된 복제수에 적용하는 단계 - 선택적으로, 각각의 머신 러닝 분류 모델은 랜덤 포레스트 모델이며, 랜덤 포레스트 모델은 표 10에 기재되어 있음 - ,
피험체가 옥살리플라틴과 조합된 5-플루오로우라실/류코보린(FOLFOX) 치료에 효험이 있을 가능성이 있는 여부에 대한 지시자를 각각의 머신 러닝 분류 모델로부터 획득하는 단계, 및
머신 러닝 부류 모델의 과반수가 피험체가 상기 치료에 효험이 있을 가능성이 있음을 나타내는 경우 FOLFOX를 선택하고, 머신 러닝 분류 모델의 과반수가 피험체가 FOLFOX에 효험이 있을 가능성이 없음을 나타내는 경우 FOLFOX의 대안 치료를 선택하는 단계 - 선택적으로, 대안 치료는 이리노테칸과 조합된 5-플루오로오라실/류코보린(FOLFIRI)임 - 를 포함하는, 방법. - 제68항에 있어서, 피험체에 선택된 치료를 투여하는 단계를 더 포함하는, 방법.
- 분자 프로파일링 리포트를 생성하는 방법으로서, 상기 방법은 청구항 제28항 내지 제69항 중 어느 한 항에 따르는 방법을 수행하는 결과를 요약하는 리포트를 제작하는 단계를 포함하는, 방법.
- 제70항에 있어서, 상기 리포트는
(a) 청구항 제54항 내지 제59항 중 어느 한 항에 따라 효험 가능성이 있는 치료, 또는
(b) 청구항 제68항 또는 제69항에 따라 선택된 치료를 포함하는, 방법. - 제70항 또는 제71항에 있어서, 상기 리포트는 컴퓨터에 의해 생성되며, 인쇄 리포트 또는 컴퓨터 파일이거나, 웹 포털에 의해 액세스 가능한, 방법.
- 피험체의 암에 대한 치료법을 식별하기 위한 시스템으로서, 상기 시스템은
(a) 적어도 하나의 호스트 서버,
(b) 데이터를 액세스 및 입력하도록 적어도 하나의 호스트 서버를 액세스하기 위한 적어도 하나의 사용자 인터페이스,
(c) 입력된 데이터를 처리하기 위한 적어도 하나의 프로세서,
(d) 처리된 데이터 및 명령을 저장하기 위한, 상기 프로세서에 연결된 적어도 하나의 메모리 - 상기 명령은
(1) 청구항 제28항 내지 제69항 중 어느 한 항에 따라 생체 샘플을 분석하는 결과를 액세스하기 위한 명령, 및
(2) 청구항 제54항 내지 제59항 중 어느 한 항에 따라 효험 가능성 있는 치료 또는 청구항 제68항 또는 제69항에 따는 선택된 치료를 결정하기 위한 명령을 포함함 - , 및
(e) 암의 치료를 디스플레이하기 위한 적어도 하나의 디스플레이 - 상기 치료는 FOLFOX 또는 이의 대안, 가령, FOLFIRI임 - 를 포함하는, 시스템. - 제73항에 있어서, 적어도 하나의 디스플레이는 생체 샘플을 분석한 결과 및 암의 치료에 효험 가능성이 있거나 선택된 치료를 포함하는 리포트를 포함하는, 시스템.
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862774082P | 2018-11-30 | 2018-11-30 | |
| US62/774,082 | 2018-11-30 | ||
| US201962788689P | 2019-01-04 | 2019-01-04 | |
| US62/788,689 | 2019-01-04 | ||
| US201962789495P | 2019-01-07 | 2019-01-07 | |
| US62/789,495 | 2019-01-07 | ||
| PCT/US2019/064078 WO2020113237A1 (en) | 2018-11-30 | 2019-12-02 | Next-generation molecular profiling |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210111254A true KR20210111254A (ko) | 2021-09-10 |
Family
ID=70853593
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217020462A KR20210111254A (ko) | 2018-11-30 | 2019-12-02 | 차세대 분자 프로파일링 |
Country Status (9)
| Country | Link |
|---|---|
| US (2) | US11315673B2 (ko) |
| EP (1) | EP3888021B1 (ko) |
| JP (1) | JP7462632B2 (ko) |
| KR (1) | KR20210111254A (ko) |
| AU (1) | AU2019389175A1 (ko) |
| CA (1) | CA3121170A1 (ko) |
| IL (2) | IL283371B1 (ko) |
| MX (1) | MX2021006234A (ko) |
| WO (1) | WO2020113237A1 (ko) |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11942189B2 (en) * | 2019-01-16 | 2024-03-26 | International Business Machines Corporation | Drug efficacy prediction for treatment of genetic disease |
| WO2021112918A1 (en) * | 2019-12-02 | 2021-06-10 | Caris Mpi, Inc. | Pan-cancer platinum response predictor |
| BR112021018933A2 (pt) * | 2019-12-05 | 2022-06-21 | Illumina Inc | Detecção rápida de fusões genéticas |
| CN111767390A (zh) * | 2020-06-28 | 2020-10-13 | 北京百度网讯科技有限公司 | 技能词评估方法及装置、电子设备、计算机可读介质 |
| WO2022029488A1 (en) * | 2020-08-06 | 2022-02-10 | Agenda Nv | Systems and methods of assessing breast cancer |
| US11335443B1 (en) | 2020-09-07 | 2022-05-17 | OpenNano Pte. Ltd. | Phenotypic patient data derivation from economic data |
| US11954859B2 (en) | 2020-11-11 | 2024-04-09 | Agendia NV | Methods of assessing diseases using image classifiers |
| CN112768076B (zh) * | 2021-02-01 | 2023-11-21 | 华中科技大学同济医学院附属协和医院 | 一种食管癌化疗发生骨髓抑制的风险预测模型构建方法 |
| US11550580B2 (en) * | 2021-02-24 | 2023-01-10 | Northrop Grumman Systems Corporation | Systems and methods for emulating a processor |
| AU2022276734A1 (en) * | 2021-05-18 | 2024-01-04 | Venn Biosciences Corporation | Biomarkers for diagnosing ovarian cancer |
| WO2023092108A2 (en) * | 2021-11-19 | 2023-05-25 | Insitro, Inc. | Autonomous cell imaging and modeling system |
| WO2023164665A1 (en) * | 2022-02-25 | 2023-08-31 | Fred Hutchinson Cancer Center | Machine learning applications to predict biological outcomes and elucidate underlying biological mechanisms |
| WO2024006639A2 (en) * | 2022-06-27 | 2024-01-04 | Deep Rx Inc. | Machine-learning computer systems and methods for predicting efficacy of chemical and biological agents for treating diseases, such as gastrointestinal cancers |
| CN117916816A (zh) * | 2022-08-19 | 2024-04-19 | 优特心研究所股份有限公司 | 计算机心脏病数据库运用方法、计算机心脏病数据库运用程序、以及信息处理装置 |
| WO2024057316A1 (en) * | 2022-09-13 | 2024-03-21 | The Open University Of Israel | System and method of predicting a gene expression profile |
| CN115631849B (zh) * | 2022-10-19 | 2023-04-28 | 哈尔滨工业大学 | 基于深度神经网络的乳腺癌预后指示系统、存储介质及设备 |
Family Cites Families (261)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| NL154598B (nl) | 1970-11-10 | 1977-09-15 | Organon Nv | Werkwijze voor het aantonen en bepalen van laagmoleculire verbindingen en van eiwitten die deze verbindingen specifiek kunnen binden, alsmede testverpakking. |
| US3817837A (en) | 1971-05-14 | 1974-06-18 | Syva Corp | Enzyme amplification assay |
| US4018653A (en) | 1971-10-29 | 1977-04-19 | U.S. Packaging Corporation | Instrument for the detection of Neisseria gonorrhoeae without culture |
| US3939350A (en) | 1974-04-29 | 1976-02-17 | Board Of Trustees Of The Leland Stanford Junior University | Fluorescent immunoassay employing total reflection for activation |
| US3996345A (en) | 1974-08-12 | 1976-12-07 | Syva Company | Fluorescence quenching with immunological pairs in immunoassays |
| US4016043A (en) | 1975-09-04 | 1977-04-05 | Akzona Incorporated | Enzymatic immunological method for the determination of antigens and antibodies |
| US4437975A (en) | 1977-07-20 | 1984-03-20 | Mobil Oil Corporation | Manufacture of lube base stock oil |
| US4275149A (en) | 1978-11-24 | 1981-06-23 | Syva Company | Macromolecular environment control in specific receptor assays |
| US4277437A (en) | 1978-04-05 | 1981-07-07 | Syva Company | Kit for carrying out chemically induced fluorescence immunoassay |
| US4486530A (en) | 1980-08-04 | 1984-12-04 | Hybritech Incorporated | Immunometric assays using monoclonal antibodies |
| US4376110A (en) | 1980-08-04 | 1983-03-08 | Hybritech, Incorporated | Immunometric assays using monoclonal antibodies |
| US4366241A (en) | 1980-08-07 | 1982-12-28 | Syva Company | Concentrating zone method in heterogeneous immunoassays |
| US4424279A (en) | 1982-08-12 | 1984-01-03 | Quidel | Rapid plunger immunoassay method and apparatus |
| GB8311018D0 (en) | 1983-04-22 | 1983-05-25 | Amersham Int Plc | Detecting mutations in dna |
| US4666828A (en) | 1984-08-15 | 1987-05-19 | The General Hospital Corporation | Test for Huntington's disease |
| US5242794A (en) | 1984-12-13 | 1993-09-07 | Applied Biosystems, Inc. | Detection of specific sequences in nucleic acids |
| US4965188A (en) | 1986-08-22 | 1990-10-23 | Cetus Corporation | Process for amplifying, detecting, and/or cloning nucleic acid sequences using a thermostable enzyme |
| US5656493A (en) | 1985-03-28 | 1997-08-12 | The Perkin-Elmer Corporation | System for automated performance of the polymerase chain reaction |
| US5333675C1 (en) | 1986-02-25 | 2001-05-01 | Perkin Elmer Corp | Apparatus and method for performing automated amplification of nucleic acid sequences and assays using heating and cooling steps |
| US4683202A (en) | 1985-03-28 | 1987-07-28 | Cetus Corporation | Process for amplifying nucleic acid sequences |
| US4683195A (en) | 1986-01-30 | 1987-07-28 | Cetus Corporation | Process for amplifying, detecting, and/or-cloning nucleic acid sequences |
| US4801531A (en) | 1985-04-17 | 1989-01-31 | Biotechnology Research Partners, Ltd. | Apo AI/CIII genomic polymorphisms predictive of atherosclerosis |
| US4800159A (en) | 1986-02-07 | 1989-01-24 | Cetus Corporation | Process for amplifying, detecting, and/or cloning nucleic acid sequences |
| US4851331A (en) | 1986-05-16 | 1989-07-25 | Allied Corporation | Method and kit for polynucleotide assay including primer-dependant DNA polymerase |
| IL86724A (en) | 1987-06-19 | 1995-01-24 | Siska Diagnostics Inc | Methods and kits for amplification and testing of nucleic acid sequences |
| CA1340843C (en) | 1987-07-31 | 1999-12-07 | J. Lawrence Burg | Selective amplification of target polynucleotide sequences |
| JP2650159B2 (ja) | 1988-02-24 | 1997-09-03 | アクゾ・ノベル・エヌ・ベー | 核酸増幅方法 |
| CA1340807C (en) | 1988-02-24 | 1999-11-02 | Lawrence T. Malek | Nucleic acid amplification process |
| IE61148B1 (en) | 1988-03-10 | 1994-10-05 | Ici Plc | Method of detecting nucleotide sequences |
| US4988617A (en) | 1988-03-25 | 1991-01-29 | California Institute Of Technology | Method of detecting a nucleotide change in nucleic acids |
| US5137765A (en) | 1988-08-05 | 1992-08-11 | Porton Instruments, Inc. | Derivatized glass supports for peptide and protein sequencing |
| US5272057A (en) | 1988-10-14 | 1993-12-21 | Georgetown University | Method of detecting a predisposition to cancer by the use of restriction fragment length polymorphism of the gene for human poly (ADP-ribose) polymerase |
| AU4829690A (en) | 1988-12-16 | 1990-07-10 | Siska Diagnostics, Inc. | Self-sustained, sequence replication system |
| US5856092A (en) | 1989-02-13 | 1999-01-05 | Geneco Pty Ltd | Detection of a nucleic acid sequence or a change therein |
| US6346413B1 (en) | 1989-06-07 | 2002-02-12 | Affymetrix, Inc. | Polymer arrays |
| US5547839A (en) | 1989-06-07 | 1996-08-20 | Affymax Technologies N.V. | Sequencing of surface immobilized polymers utilizing microflourescence detection |
| US5527681A (en) | 1989-06-07 | 1996-06-18 | Affymax Technologies N.V. | Immobilized molecular synthesis of systematically substituted compounds |
| US5143854A (en) | 1989-06-07 | 1992-09-01 | Affymax Technologies N.V. | Large scale photolithographic solid phase synthesis of polypeptides and receptor binding screening thereof |
| US5925525A (en) | 1989-06-07 | 1999-07-20 | Affymetrix, Inc. | Method of identifying nucleotide differences |
| US5242974A (en) | 1991-11-22 | 1993-09-07 | Affymax Technologies N.V. | Polymer reversal on solid surfaces |
| US5744101A (en) | 1989-06-07 | 1998-04-28 | Affymax Technologies N.V. | Photolabile nucleoside protecting groups |
| US5871928A (en) | 1989-06-07 | 1999-02-16 | Fodor; Stephen P. A. | Methods for nucleic acid analysis |
| US5800992A (en) | 1989-06-07 | 1998-09-01 | Fodor; Stephen P.A. | Method of detecting nucleic acids |
| US5424186A (en) | 1989-06-07 | 1995-06-13 | Affymax Technologies N.V. | Very large scale immobilized polymer synthesis |
| US5192659A (en) | 1989-08-25 | 1993-03-09 | Genetype Ag | Intron sequence analysis method for detection of adjacent and remote locus alleles as haplotypes |
| US5252743A (en) | 1989-11-13 | 1993-10-12 | Affymax Technologies N.V. | Spatially-addressable immobilization of anti-ligands on surfaces |
| US6013431A (en) | 1990-02-16 | 2000-01-11 | Molecular Tool, Inc. | Method for determining specific nucleotide variations by primer extension in the presence of mixture of labeled nucleotides and terminators |
| US5494810A (en) | 1990-05-03 | 1996-02-27 | Cornell Research Foundation, Inc. | Thermostable ligase-mediated DNA amplifications system for the detection of genetic disease |
| US5266222A (en) | 1990-05-23 | 1993-11-30 | California Institute Of Technology | Durable low surface-energy surfaces |
| JPH06500471A (ja) | 1990-08-24 | 1994-01-20 | ザ・ユニバーシティ・オブ・テネシー・リサーチ・コーポレーション | Dna増幅フィンガープリント法 |
| WO1992007095A1 (en) | 1990-10-15 | 1992-04-30 | Stratagene | Arbitrarily primed polymerase chain reaction method for fingerprinting genomes |
| US6004744A (en) | 1991-03-05 | 1999-12-21 | Molecular Tool, Inc. | Method for determining nucleotide identity through extension of immobilized primer |
| DE4214112A1 (de) | 1991-08-02 | 1993-02-04 | Europ Lab Molekularbiolog | Neues verfahren zur sequenzierung von nukleinsaeuren |
| US5324633A (en) | 1991-11-22 | 1994-06-28 | Affymax Technologies N.V. | Method and apparatus for measuring binding affinity |
| US5384261A (en) | 1991-11-22 | 1995-01-24 | Affymax Technologies N.V. | Very large scale immobilized polymer synthesis using mechanically directed flow paths |
| US5412087A (en) | 1992-04-24 | 1995-05-02 | Affymax Technologies N.V. | Spatially-addressable immobilization of oligonucleotides and other biological polymers on surfaces |
| US5550215A (en) | 1991-11-22 | 1996-08-27 | Holmes; Christopher P. | Polymer reversal on solid surfaces |
| DE69233331T3 (de) | 1991-11-22 | 2007-08-30 | Affymetrix, Inc., Santa Clara | Kombinatorische Strategien zur Polymersynthese |
| US5965362A (en) | 1992-03-04 | 1999-10-12 | The Regents Of The University Of California | Comparative genomic hybridization (CGH) |
| GB9208733D0 (en) | 1992-04-22 | 1992-06-10 | Medical Res Council | Dna sequencing method |
| GB9211979D0 (en) | 1992-06-05 | 1992-07-15 | Buchard Ole | Uses of nucleic acid analogues |
| US5605798A (en) | 1993-01-07 | 1997-02-25 | Sequenom, Inc. | DNA diagnostic based on mass spectrometry |
| EP1262564A3 (en) | 1993-01-07 | 2004-03-31 | Sequenom, Inc. | Dna sequencing by mass spectrometry |
| US6194144B1 (en) | 1993-01-07 | 2001-02-27 | Sequenom, Inc. | DNA sequencing by mass spectrometry |
| US5491074A (en) | 1993-04-01 | 1996-02-13 | Affymax Technologies Nv | Association peptides |
| US5858659A (en) | 1995-11-29 | 1999-01-12 | Affymetrix, Inc. | Polymorphism detection |
| US5837832A (en) | 1993-06-25 | 1998-11-17 | Affymetrix, Inc. | Arrays of nucleic acid probes on biological chips |
| US6045996A (en) | 1993-10-26 | 2000-04-04 | Affymetrix, Inc. | Hybridization assays on oligonucleotide arrays |
| JPH09505397A (ja) | 1993-11-17 | 1997-05-27 | アマーシャム・インターナショナル・ピーエルシー | プライマー伸長質量分光分析による核酸配列決定法 |
| AU694187B2 (en) | 1994-02-07 | 1998-07-16 | Beckman Coulter, Inc. | Ligase/polymerase-mediated genetic bit analysis TM of single nucleotide polymorphisms and its use in genetic analysis |
| US5631734A (en) | 1994-02-10 | 1997-05-20 | Affymetrix, Inc. | Method and apparatus for detection of fluorescently labeled materials |
| US6090555A (en) | 1997-12-11 | 2000-07-18 | Affymetrix, Inc. | Scanned image alignment systems and methods |
| US5578832A (en) | 1994-09-02 | 1996-11-26 | Affymetrix, Inc. | Method and apparatus for imaging a sample on a device |
| US5851770A (en) | 1994-04-25 | 1998-12-22 | Variagenics, Inc. | Detection of mismatches by resolvase cleavage using a magnetic bead support |
| CA2188660C (en) | 1994-04-25 | 2005-01-18 | Richard G. H. Cotton | Detection of mutation by resolvase cleavage |
| DE69503126T2 (de) | 1994-05-05 | 1998-11-12 | Beckman Instruments Inc | Repetitive oligonukleotide matrix |
| US5571639A (en) | 1994-05-24 | 1996-11-05 | Affymax Technologies N.V. | Computer-aided engineering system for design of sequence arrays and lithographic masks |
| US5834189A (en) | 1994-07-08 | 1998-11-10 | Visible Genetics Inc. | Method for evaluation of polymorphic genetic sequences, and the use thereof in identification of HLA types |
| US5795716A (en) | 1994-10-21 | 1998-08-18 | Chee; Mark S. | Computer-aided visualization and analysis system for sequence evaluation |
| US5959098A (en) | 1996-04-17 | 1999-09-28 | Affymetrix, Inc. | Substrate preparation process |
| US5599695A (en) | 1995-02-27 | 1997-02-04 | Affymetrix, Inc. | Printing molecular library arrays using deprotection agents solely in the vapor phase |
| DE19515552A1 (de) | 1995-04-27 | 1996-10-31 | Europ Lab Molekularbiolog | Simultane Sequenzierung von Nukleinsäuren |
| US5624711A (en) | 1995-04-27 | 1997-04-29 | Affymax Technologies, N.V. | Derivatization of solid supports and methods for oligomer synthesis |
| US5545531A (en) | 1995-06-07 | 1996-08-13 | Affymax Technologies N.V. | Methods for making a device for concurrently processing multiple biological chip assays |
| US5981186A (en) | 1995-06-30 | 1999-11-09 | Visible Genetics, Inc. | Method and apparatus for DNA-sequencing using reduced number of sequencing mixtures |
| US5968740A (en) | 1995-07-24 | 1999-10-19 | Affymetrix, Inc. | Method of Identifying a Base in a Nucleic Acid |
| JP3193301B2 (ja) | 1995-09-14 | 2001-07-30 | 麒麟麦酒株式会社 | 生理活性タンパク質p160 |
| US5733729A (en) | 1995-09-14 | 1998-03-31 | Affymetrix, Inc. | Computer-aided probability base calling for arrays of nucleic acid probes on chips |
| US5869242A (en) | 1995-09-18 | 1999-02-09 | Myriad Genetics, Inc. | Mass spectrometry to assess DNA sequence polymorphisms |
| US6147205A (en) | 1995-12-15 | 2000-11-14 | Affymetrix, Inc. | Photocleavable protecting groups and methods for their use |
| US6114122A (en) | 1996-03-26 | 2000-09-05 | Affymetrix, Inc. | Fluidics station with a mounting system and method of using |
| US5928906A (en) | 1996-05-09 | 1999-07-27 | Sequenom, Inc. | Process for direct sequencing during template amplification |
| US5981956A (en) | 1996-05-16 | 1999-11-09 | Affymetrix, Inc. | Systems and methods for detection of labeled materials |
| US5786146A (en) | 1996-06-03 | 1998-07-28 | The Johns Hopkins University School Of Medicine | Method of detection of methylated nucleic acid using agents which modify unmethylated cytosine and distinguishing modified methylated and non-methylated nucleic acids |
| JP2000512498A (ja) | 1996-06-14 | 2000-09-26 | サルノフ コーポレーション | ポリヌクレオチドのシークエンス法 |
| GB9620209D0 (en) | 1996-09-27 | 1996-11-13 | Cemu Bioteknik Ab | Method of sequencing DNA |
| US6017702A (en) | 1996-12-05 | 2000-01-25 | The Perkin-Elmer Corporation | Chain-termination type nucleic acid sequencing method including 2'-deoxyuridine-5'-triphosphate |
| US5876934A (en) | 1996-12-18 | 1999-03-02 | Pharmacia Biotech Inc. | DNA sequencing method |
| US6046005A (en) | 1997-01-15 | 2000-04-04 | Incyte Pharmaceuticals, Inc. | Nucleic acid sequencing with solid phase capturable terminators comprising a cleavable linking group |
| US6586806B1 (en) | 1997-06-20 | 2003-07-01 | Cypress Semiconductor Corporation | Method and structure for a single-sided non-self-aligned transistor |
| US6420108B2 (en) | 1998-02-09 | 2002-07-16 | Affymetrix, Inc. | Computer-aided display for comparative gene expression |
| DE69823206T2 (de) | 1997-07-25 | 2004-08-19 | Affymetrix, Inc. (a Delaware Corp.), Santa Clara | Verfahren zur herstellung einer bio-informatik-datenbank |
| ATE280246T1 (de) | 1997-08-15 | 2004-11-15 | Affymetrix Inc | Polymorphismuserkennung mit hilfe cluster-analyse |
| AU1287799A (en) | 1997-10-31 | 1999-05-24 | Affymetrix, Inc. | Expression profiles in adult and fetal organs |
| US5998143A (en) | 1997-12-05 | 1999-12-07 | The Perkin-Elmer Corporation | Cycle sequencing thermal profiles |
| US6428752B1 (en) | 1998-05-14 | 2002-08-06 | Affymetrix, Inc. | Cleaning deposit devices that form microarrays and the like |
| US6201639B1 (en) | 1998-03-20 | 2001-03-13 | James W. Overbeck | Wide field of view and high speed scanning microscopy |
| US6269846B1 (en) | 1998-01-13 | 2001-08-07 | Genetic Microsystems, Inc. | Depositing fluid specimens on substrates, resulting ordered arrays, techniques for deposition of arrays |
| EP1053352B1 (en) | 1998-02-04 | 2002-09-18 | Variagenics, Inc. | Mismatch detection techniques |
| US6185030B1 (en) | 1998-03-20 | 2001-02-06 | James W. Overbeck | Wide field of view and high speed scanning microscopy |
| US5936324A (en) | 1998-03-30 | 1999-08-10 | Genetic Microsystems Inc. | Moving magnet scanner |
| US7805388B2 (en) * | 1998-05-01 | 2010-09-28 | Health Discovery Corporation | Method for feature selection in a support vector machine using feature ranking |
| US6183958B1 (en) | 1998-05-06 | 2001-02-06 | Variagenics, Inc. | Probes for variance detection |
| JP3565025B2 (ja) | 1998-07-07 | 2004-09-15 | 日産自動車株式会社 | 治具交換装置および治具交換方法 |
| US6185561B1 (en) | 1998-09-17 | 2001-02-06 | Affymetrix, Inc. | Method and apparatus for providing and expression data mining database |
| US6140054A (en) | 1998-09-30 | 2000-10-31 | University Of Utah Research Foundation | Multiplex genotyping using fluorescent hybridization probes |
| US6262216B1 (en) | 1998-10-13 | 2001-07-17 | Affymetrix, Inc. | Functionalized silicon compounds and methods for their synthesis and use |
| ATE316152T1 (de) | 1998-10-27 | 2006-02-15 | Affymetrix Inc | Komplexitätsmanagement und analyse genomischer dna |
| US7700324B1 (en) | 1998-11-03 | 2010-04-20 | The Johns Hopkins University School Of Medicine | Methylated CpG island amplification (MCA) |
| NO986133D0 (no) | 1998-12-23 | 1998-12-23 | Preben Lexow | FremgangsmÕte for DNA-sekvensering |
| EP1165839A2 (en) | 1999-03-26 | 2002-01-02 | Whitehead Institute For Biomedical Research | Universal arrays |
| US6300070B1 (en) | 1999-06-04 | 2001-10-09 | Mosaic Technologies, Inc. | Solid phase methods for amplifying multiple nucleic acids |
| US6218803B1 (en) | 1999-06-04 | 2001-04-17 | Genetic Microsystems, Inc. | Position sensing with variable capacitance transducers |
| US6811668B1 (en) | 1999-06-22 | 2004-11-02 | Caliper Life Sciences, Inc. | Apparatus for the operation of a microfluidic device |
| US7601270B1 (en) | 1999-06-28 | 2009-10-13 | California Institute Of Technology | Microfabricated elastomeric valve and pump systems |
| US6274320B1 (en) | 1999-09-16 | 2001-08-14 | Curagen Corporation | Method of sequencing a nucleic acid |
| US6297016B1 (en) | 1999-10-08 | 2001-10-02 | Applera Corporation | Template-dependent ligation with PNA-DNA chimeric probes |
| US6221600B1 (en) | 1999-10-08 | 2001-04-24 | Board Of Regents, The University Of Texas System | Combinatorial oligonucleotide PCR: a method for rapid, global expression analysis |
| EP1235932A2 (en) | 1999-10-08 | 2002-09-04 | Protogene Laboratories, Inc. | Method and apparatus for performing large numbers of reactions using array assembly |
| US7970718B2 (en) * | 2001-05-18 | 2011-06-28 | Health Discovery Corporation | Method for feature selection and for evaluating features identified as significant for classifying data |
| US6958225B2 (en) | 1999-10-27 | 2005-10-25 | Affymetrix, Inc. | Complexity management of genomic DNA |
| AU2001232805A1 (en) | 2000-01-12 | 2001-07-24 | Ut-Battelle, Llc | A microfluidic device and method for focusing, segmenting, and dispensing of a fluid stream |
| US7452713B2 (en) | 2000-02-29 | 2008-11-18 | Stmicroelectronics S.R.L. | Process for manufacturing a microfluidic device with buried channels |
| US7867763B2 (en) | 2004-01-25 | 2011-01-11 | Fluidigm Corporation | Integrated chip carriers with thermocycler interfaces and methods of using the same |
| SE0001768D0 (sv) | 2000-05-12 | 2000-05-12 | Helen Andersson | Mikrofluidisk flödescell för manipulering av partiklar |
| US6386749B1 (en) | 2000-06-26 | 2002-05-14 | Affymetrix, Inc. | Systems and methods for heating and mixing fluids |
| AU2001282786A1 (en) | 2000-08-23 | 2002-03-04 | Imego Ab | A sample preparing arrangement and a method |
| US20020048821A1 (en) | 2000-08-24 | 2002-04-25 | David Storek | Sample preparing arrangement and a method relating to such an arrangement |
| JP2004511810A (ja) | 2000-10-27 | 2004-04-15 | マウント・サイナイ・ホスピタル | 卵巣癌の検出方法 |
| AU2002241595A1 (en) | 2000-12-01 | 2002-07-24 | Protasis Corporation | Microfluidic device with multiple microcoil nmr detectors |
| US6391592B1 (en) | 2000-12-14 | 2002-05-21 | Affymetrix, Inc. | Blocker-aided target amplification of nucleic acids |
| US20020183936A1 (en) | 2001-01-24 | 2002-12-05 | Affymetrix, Inc. | Method, system, and computer software for providing a genomic web portal |
| US7323140B2 (en) | 2001-03-28 | 2008-01-29 | Handylab, Inc. | Moving microdroplets in a microfluidic device |
| US6802342B2 (en) | 2001-04-06 | 2004-10-12 | Fluidigm Corporation | Microfabricated fluidic circuit elements and applications |
| US6649348B2 (en) | 2001-06-29 | 2003-11-18 | Agilent Technologies Inc. | Methods for manufacturing arrays |
| US6585606B2 (en) | 2001-07-16 | 2003-07-01 | Thomas S. Penrose | Golf club accessory |
| US6632611B2 (en) | 2001-07-20 | 2003-10-14 | Affymetrix, Inc. | Method of target enrichment and amplification |
| US7390463B2 (en) | 2001-09-07 | 2008-06-24 | Corning Incorporated | Microcolumn-based, high-throughput microfluidic device |
| US7189368B2 (en) | 2001-09-17 | 2007-03-13 | Gyros Patent Ab | Functional unit enabling controlled flow in a microfluidic device |
| US7253003B2 (en) | 2001-10-19 | 2007-08-07 | Wisconsin Alumni Research Foundation | Method for monitoring the environment within a microfluidic device |
| US7189580B2 (en) | 2001-10-19 | 2007-03-13 | Wisconsin Alumni Research Foundation | Method of pumping fluid through a microfluidic device |
| EP1463796B1 (en) | 2001-11-30 | 2013-01-09 | Fluidigm Corporation | Microfluidic device and methods of using same |
| EP1461606A4 (en) | 2001-12-05 | 2005-06-29 | Univ Washington | MICROFLUIDIC DEVICE AND SURFACE DECORATION METHOD FOR SOLID PHASE AFFINITY BINDING ASSAYS |
| US7238255B2 (en) | 2001-12-31 | 2007-07-03 | Gyros Patent Ab | Microfluidic device and its manufacture |
| US6958119B2 (en) | 2002-02-26 | 2005-10-25 | Agilent Technologies, Inc. | Mobile phase gradient generation microfluidic device |
| US7195986B1 (en) | 2002-03-08 | 2007-03-27 | Caliper Life Sciences, Inc. | Microfluidic device with controlled substrate conductivity |
| GB2388189B (en) | 2002-04-29 | 2006-01-11 | Robert Jeffrey Geddes Carr | Optical detection and analysis of particles |
| US7189581B2 (en) | 2002-04-30 | 2007-03-13 | Wisconsin Alumni Research Foundation | Method of obtaining a sample concentration of a solution in a microfluidic device |
| DE60228685D1 (de) | 2002-05-16 | 2008-10-16 | Micronit Microfluidics Bv | Verfahren zur Herstellung eines mikrofluidischen Bauteiles |
| WO2004007582A2 (en) | 2002-07-15 | 2004-01-22 | University Of Virginia Patent Foundation | Hybrid polymers for functional tuning of microfluidic device surfaces |
| US7135147B2 (en) | 2002-07-26 | 2006-11-14 | Applera Corporation | Closing blade for deformable valve in a microfluidic device and method |
| US7201881B2 (en) | 2002-07-26 | 2007-04-10 | Applera Corporation | Actuator for deformable valves in a microfluidic device, and method |
| US20040132051A1 (en) | 2002-07-26 | 2004-07-08 | Andersen Mark R. | Mg-mediated hot start biochemical reactions |
| US7452509B2 (en) | 2002-07-26 | 2008-11-18 | Applied Biosystems Inc. | Microfluidic device including displaceable material trap, and system |
| KR100480338B1 (ko) | 2002-08-08 | 2005-03-30 | 한국전자통신연구원 | 극소량의 유체제어를 위한 미세 유체제어소자 |
| TW536524B (en) | 2002-09-17 | 2003-06-11 | Fan-Gen Tzeng | Network-type micro-channel device for micro-fluid |
| US7118661B2 (en) | 2002-09-30 | 2006-10-10 | The Regents Of The University Of California | Nanolaminate microfluidic device for mobility selection of particles |
| ES2588905T3 (es) | 2002-10-04 | 2016-11-07 | The Regents Of The University Of California | Dispositivo microfluídico de compartimentos múltiples para investigación en neurociencias |
| FR2848125B1 (fr) | 2002-12-04 | 2006-06-09 | Commissariat Energie Atomique | Dispositif microfluidique dans lequel l'interface liquide/fluide est stabilisee |
| US7467928B2 (en) | 2002-12-12 | 2008-12-23 | Board Of Trustees Of The University Of Arkansas | Microfluidic device utilizing magnetohydrodynamics and method for fabrication thereof |
| US7125711B2 (en) | 2002-12-19 | 2006-10-24 | Bayer Healthcare Llc | Method and apparatus for splitting of specimens into multiple channels of a microfluidic device |
| US7338637B2 (en) | 2003-01-31 | 2008-03-04 | Hewlett-Packard Development Company, L.P. | Microfluidic device with thin-film electronic devices |
| US7413709B2 (en) | 2003-02-12 | 2008-08-19 | Agilent Technologies, Inc. | PAEK-based microfluidic device with integrated electrospray emitter |
| JP3856763B2 (ja) | 2003-03-11 | 2006-12-13 | 財団法人川村理化学研究所 | マイクロ流体素子の製造方法 |
| AU2004228678A1 (en) | 2003-04-03 | 2004-10-21 | Fluidigm Corp. | Microfluidic devices and methods of using same |
| AU2004227018A1 (en) | 2003-04-08 | 2004-10-21 | Colotech A/S | A method for detection of colorectal cancer in human samples |
| US7422725B2 (en) | 2003-05-01 | 2008-09-09 | Enplas Corporation | Sample handling unit applicable to microchip, and microfluidic device having microchips |
| CN1812839A (zh) | 2003-06-06 | 2006-08-02 | 精密公司 | 在微流体装置上的加热、冷却和热循环的系统与方法 |
| US20050124071A1 (en) | 2003-09-30 | 2005-06-09 | Kraus Virginia B. | Methods and compositions for diagnosing musculoskeletal, arthritic and joint disorders by biomarker dating |
| FR2862007B1 (fr) | 2003-11-12 | 2005-12-23 | Commissariat Energie Atomique | Dispositif microfluidique muni d'un nez d'electronebulisation. |
| US7329391B2 (en) | 2003-12-08 | 2008-02-12 | Applera Corporation | Microfluidic device and material manipulating method using same |
| EP1547688A1 (en) | 2003-12-23 | 2005-06-29 | STMicroelectronics S.r.l. | Microfluidic device and method of locally concentrating electrically charged substances in a microfluidic device |
| US7099778B2 (en) | 2003-12-30 | 2006-08-29 | Caliper Life Sciences, Inc. | Method for determining diffusivity and molecular weight in a microfluidic device |
| US7351380B2 (en) | 2004-01-08 | 2008-04-01 | Sandia Corporation | Microfluidic structures and methods for integrating a functional component into a microfluidic device |
| EP1715954A1 (en) | 2004-02-18 | 2006-11-02 | Applera Corporation | Multi-step bioassays on modular microfluidic application platforms |
| US7402229B2 (en) | 2004-03-31 | 2008-07-22 | Intel Corporation | Fabrication and use of semipermeable membranes and gels for the control of electrolysis in a microfluidic device |
| EP1744986A2 (en) | 2004-04-02 | 2007-01-24 | Eksigent Technologies, LLC | Microfluidic device |
| US7419639B2 (en) | 2004-05-12 | 2008-09-02 | The Board Of Trustees Of The Leland Stanford Junior University | Multilayer microfluidic device |
| WO2006005065A2 (en) | 2004-06-30 | 2006-01-12 | University Of South Florida | Luminescence characterization of quantum dots conjugated with biomarkers for early cancer detection |
| WO2006085984A2 (en) | 2004-07-09 | 2006-08-17 | Amaox, Inc. | Immune cell biosensors and methods of using same |
| US7488596B2 (en) | 2004-12-17 | 2009-02-10 | Samsung Electronics Co., Ltd. | Microfluidic device comprising electrolysis device for cell lysis and method for electrochemically lysing cells using the same |
| AU2006210553A1 (en) | 2005-02-01 | 2006-08-10 | Ab Advanced Genetic Analysis Corporation | Reagents, methods and libraries for bead-based sequencing |
| EP1880197B1 (en) | 2005-04-12 | 2019-06-12 | Caliper Life Sciences, Inc. | Microfluidic device for use with a compact optical detection system |
| KR100590581B1 (ko) | 2005-05-10 | 2006-06-19 | 삼성전자주식회사 | 미세유동장치 및 그 제조방법 |
| JP4992201B2 (ja) | 2005-06-07 | 2012-08-08 | 富士ゼロックス株式会社 | マイクロ流体制御方法、マイクロ流体素子およびその製造方法 |
| US20100173788A1 (en) | 2005-06-21 | 2010-07-08 | Vermillion, Inc. | Biomarkers for breast cancer |
| JP2009513953A (ja) | 2005-10-14 | 2009-04-02 | インスティトュート デ カーディオロジー デ モントリオール | 生物試料の酸化ストレスのバイオマーカを検出する方法 |
| US7993859B2 (en) | 2005-10-14 | 2011-08-09 | Institut De Cardiologie De Montreal | Method for quantifying oxidative stress caused by different biological pathways |
| TWI274040B (en) | 2005-12-23 | 2007-02-21 | Ind Tech Res Inst | Microfluidic device and method of manufacturing the same |
| US7568399B2 (en) | 2006-01-05 | 2009-08-04 | Integrated Sensing Systems, Inc. | Microfluidic device |
| US7581429B2 (en) | 2006-01-06 | 2009-09-01 | Integrated Sensing Systems, Inc. | Microfluidic device and method of operation |
| PT1994410E (pt) | 2006-01-31 | 2011-01-10 | Medical Res Fund Of Tel Aviv Sourasky Medical Ct | Métodos e estojos para detecção precoce de cancro ou de predisposição a este |
| JP2009538123A (ja) | 2006-04-19 | 2009-11-05 | アプライド バイオシステムズ, エルエルシー | ゲル非含有ビーズベースの配列決定のための試薬、方法およびライブラリー |
| US8768629B2 (en) * | 2009-02-11 | 2014-07-01 | Caris Mpi, Inc. | Molecular profiling of tumors |
| IL282783B2 (en) | 2006-05-18 | 2023-09-01 | Caris Mpi Inc | A system and method for determining a personalized medical intervention for a disease stage |
| US20100184027A1 (en) | 2006-07-13 | 2010-07-22 | Epigenomics Ag | Methods and nucleic acids for analyses of cellular proliferative disorders |
| US8187889B2 (en) | 2006-07-27 | 2012-05-29 | Ludwig Institute For Cancer Research Ltd. | Protein markers for the diagnosis and prognosis of ovarian and breast cancer |
| ES2655564T3 (es) | 2006-09-07 | 2018-02-20 | Otago Innovation Limited | Biomarcador para la detección precoz de trastornos cardiacos agudos |
| GB0700374D0 (en) | 2007-01-09 | 2007-02-14 | Oncomethylome Sciences S A | NDRG family methylation markers |
| WO2008128043A2 (en) | 2007-04-11 | 2008-10-23 | The General Hospital Corporation | Diagnostic and prognostic methods for renal cell carcinoma |
| US20100151468A1 (en) | 2007-04-11 | 2010-06-17 | Manel Esteller | Epigenetic biomarkers for early detection, therapeutic effectiveness, and relapse monitoring of cancer |
| EP2637020A3 (en) | 2007-06-29 | 2014-01-08 | Correlogic Systems Inc. | Predictive markers for ovarian cancer |
| WO2009065230A1 (en) | 2007-11-23 | 2009-05-28 | British Columbia Cancer Agency Branch | Methods for detecting lung cancer and monitoring treatment response |
| CN101939009B (zh) | 2008-02-05 | 2013-07-17 | 哈博生物科学公司 | 药学固体形式 |
| EP2245568A4 (en) * | 2008-02-20 | 2012-12-05 | Univ Mcmaster | EXPERT SYSTEM FOR DETERMINING A PATIENT'S RESPONSE TO A TREATMENT |
| US7745150B2 (en) | 2008-03-07 | 2010-06-29 | The University Of Connecticut | Methods for the detection and monitoring of congestive heart failure |
| AU2009224114B2 (en) | 2008-03-12 | 2013-02-21 | Otago Innovation Limited | Biomarkers |
| WO2009134420A2 (en) | 2008-05-01 | 2009-11-05 | The Salk Institute For Biological Studies | Epigenetic silencing of tumor suppressor genes |
| CN106153918A (zh) | 2008-10-14 | 2016-11-23 | 卡里斯Mpi公司 | 描绘肿瘤类型生物标志模式和特征集的基因靶和基因表达的蛋白靶 |
| CN102308004A (zh) | 2008-10-30 | 2012-01-04 | 卡里斯生命科学卢森堡控股有限责任公司 | 评价rna图案的方法 |
| WO2010056337A2 (en) | 2008-11-12 | 2010-05-20 | Caris Mpi, Inc. | Methods and systems of using exosomes for determining phenotypes |
| EP2202522A1 (en) | 2008-12-23 | 2010-06-30 | Universiteit Leiden | Methods for immobilizing microvesicles, means and methods for detecting them, and uses thereof |
| EP3722810A3 (en) | 2009-02-11 | 2021-01-13 | Caris MPI, Inc. | Molecular profiling of tumors |
| CA2724331A1 (en) | 2009-06-19 | 2010-12-19 | John Wayne Cancer Institute | Use of methylation status of mint loci as a marker for rectal cancer |
| WO2011056688A2 (en) | 2009-10-27 | 2011-05-12 | Caris Life Sciences, Inc. | Molecular profiling for personalized medicine |
| US20130203061A1 (en) | 2009-11-30 | 2013-08-08 | Michael KLASS | Methods and systems for isolating, storing, and analyzing vesicles |
| US20140148348A1 (en) | 2010-01-13 | 2014-05-29 | Christine Kuslich | Dectection of gastrointestinal disorders |
| JP5808349B2 (ja) | 2010-03-01 | 2015-11-10 | カリス ライフ サイエンシズ スウィッツァーランド ホールディングスゲーエムベーハー | セラノーシスのためのバイオマーカー |
| BR112012025593A2 (pt) | 2010-04-06 | 2019-06-25 | Caris Life Sciences Luxembourg Holdings | biomarcadores em circulação para doença |
| CA2796272C (en) * | 2010-04-29 | 2019-10-01 | The Regents Of The University Of California | Pathway recognition algorithm using data integration on genomic models (paradigm) |
| EP2647708B1 (en) | 2010-12-03 | 2017-04-26 | Kabushiki Kaisha Yakult Honsha | Marker for determination of sensitivity to triplet combination anti-cancer agent |
| WO2012092336A2 (en) | 2010-12-28 | 2012-07-05 | Caris Mpi, Inc. | Molecular profiling for cancer |
| JP2014503222A (ja) | 2011-01-18 | 2014-02-13 | エバリスト ジェノミックス, インコーポレイテッド | 結腸直腸がん再発に関する予後のサイン |
| EP2702411A4 (en) * | 2011-04-29 | 2015-07-22 | Cancer Prevention & Cure Ltd | METHODS OF IDENTIFYING AND DIAGNOSING PULMONARY DISEASES USING CLASSIFICATION SYSTEMS AND THEIR KITS |
| WO2012170715A1 (en) | 2011-06-07 | 2012-12-13 | Caris Mpi, Inc. | Molecular profiling for cancer |
| GB201215944D0 (en) * | 2012-09-06 | 2012-10-24 | Univ Manchester | Image processing apparatus and method for fittng a deformable shape model to an image using random forests |
| US20150307947A1 (en) | 2012-12-04 | 2015-10-29 | Caris Mpi, Inc. | Molecular profiling for cancer |
| FR3016461B1 (fr) | 2014-01-10 | 2017-06-23 | Imabiotech | Procede de traitement de donnees d'imagerie moleculaire et serveur de donnees correspondant |
| AU2015210886A1 (en) | 2014-01-29 | 2016-09-01 | Caris Mpi, Inc. | Molecular profiling of immune modulators |
| US10504020B2 (en) * | 2014-06-10 | 2019-12-10 | Sightline Innovation Inc. | System and method for applying a deep learning neural network to data obtained from one or more sensors |
| WO2016046640A2 (en) * | 2014-09-26 | 2016-03-31 | Medical Prognosis Institute A/S | Methods for predicting drug responsiveness |
| WO2016094330A2 (en) * | 2014-12-08 | 2016-06-16 | 20/20 Genesystems, Inc | Methods and machine learning systems for predicting the liklihood or risk of having cancer |
| EP3265079A4 (en) | 2015-03-03 | 2019-01-02 | Caris MPI, Inc. | Molecular profiling for cancer |
| CN106252749B (zh) | 2015-06-04 | 2020-12-29 | 松下知识产权经营株式会社 | 蓄电池包的控制方法以及蓄电池包 |
| IL258309B2 (en) | 2015-09-24 | 2023-03-01 | Caris Science Inc | Method, device and product of computer software for analyzing biological data |
| US20170132362A1 (en) * | 2015-11-09 | 2017-05-11 | Washington State University | Novel machine learning approach for the identification of genomic features associated with epigenetic control regions and transgenerational inheritance of epimutations |
| WO2017176423A1 (en) * | 2016-04-08 | 2017-10-12 | Biodesix, Inc. | Classifier generation methods and predictive test for ovarian cancer patient prognosis under platinum chemotherapy |
| US10350280B2 (en) * | 2016-08-31 | 2019-07-16 | Medgenome Inc. | Methods to analyze genetic alterations in cancer to identify therapeutic peptide vaccines and kits therefore |
| US20180089373A1 (en) * | 2016-09-23 | 2018-03-29 | Driver, Inc. | Integrated systems and methods for automated processing and analysis of biological samples, clinical information processing and clinical trial matching |
| WO2018078142A1 (en) * | 2016-10-28 | 2018-05-03 | MAX-PLANCK-Gesellschaft zur Förderung der Wissenschaften e.V. | Means and methods for determining efficacy of fluorouracil (5-fu) in colorectal cancer (crc) therapy |
| WO2018146033A1 (en) | 2017-02-07 | 2018-08-16 | F. Hoffmann-La Roche Ag | Non-invasive test to predict recurrence of colorectal cancer |
| EP3580360A1 (en) | 2017-02-07 | 2019-12-18 | H. Hoffnabb-La Roche Ag | Non-invasive test to predict response to therapy in colorectal cancer patients |
| US11618926B2 (en) | 2017-02-28 | 2023-04-04 | Baylor Research Institute | Methods for diagnosing, prognosing, and treating colorectal cancer using biomarker expression |
| CA3056896A1 (en) | 2017-03-20 | 2018-09-27 | Caris Mpi, Inc. | Genomic stability profiling |
| US11392827B1 (en) * | 2017-07-19 | 2022-07-19 | United States Of America As Represented By The Secretary Of The Navy | Deeper learning from the real-time transformative correction of and reasoning from neural network outputs |
| US10679129B2 (en) * | 2017-09-28 | 2020-06-09 | D5Ai Llc | Stochastic categorical autoencoder network |
| US11708600B2 (en) * | 2017-10-05 | 2023-07-25 | Decode Health, Inc. | Long non-coding RNA gene expression signatures in disease diagnosis |
| US20190317079A1 (en) * | 2017-10-16 | 2019-10-17 | Sightline Innovation Inc. | System and method for volatile organic compound detection |
| US11250345B1 (en) * | 2018-06-08 | 2022-02-15 | Intuit Inc. | Methods for identifying transactions with user location information |
| US11120364B1 (en) * | 2018-06-14 | 2021-09-14 | Amazon Technologies, Inc. | Artificial intelligence system with customizable training progress visualization and automated recommendations for rapid interactive development of machine learning models |
| CA3210376A1 (en) * | 2021-03-31 | 2022-10-06 | Philip Ma | Multi-omic assessment |
-
2019
- 2019-12-02 KR KR1020217020462A patent/KR20210111254A/ko unknown
- 2019-12-02 JP JP2021530882A patent/JP7462632B2/ja active Active
- 2019-12-02 EP EP19888693.9A patent/EP3888021B1/en active Active
- 2019-12-02 CA CA3121170A patent/CA3121170A1/en active Pending
- 2019-12-02 IL IL283371A patent/IL283371B1/en unknown
- 2019-12-02 MX MX2021006234A patent/MX2021006234A/es unknown
- 2019-12-02 WO PCT/US2019/064078 patent/WO2020113237A1/en unknown
- 2019-12-02 IL IL311084A patent/IL311084A/en unknown
- 2019-12-02 AU AU2019389175A patent/AU2019389175A1/en active Pending
-
2021
- 2021-05-28 US US17/334,483 patent/US11315673B2/en active Active
-
2022
- 2022-04-22 US US17/727,681 patent/US20220262494A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| US20220262494A1 (en) | 2022-08-18 |
| EP3888021B1 (en) | 2024-02-21 |
| US20210295979A1 (en) | 2021-09-23 |
| CA3121170A1 (en) | 2020-06-04 |
| IL283371B1 (en) | 2024-04-01 |
| AU2019389175A1 (en) | 2021-06-10 |
| US11315673B2 (en) | 2022-04-26 |
| IL311084A (en) | 2024-04-01 |
| JP2022512080A (ja) | 2022-02-02 |
| MX2021006234A (es) | 2021-09-10 |
| JP7462632B2 (ja) | 2024-04-05 |
| IL283371A (en) | 2021-07-29 |
| EP3888021A1 (en) | 2021-10-06 |
| WO2020113237A1 (en) | 2020-06-04 |
| EP3888021A4 (en) | 2022-08-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7462632B2 (ja) | 次世代分子プロファイリング | |
| KR20220130108A (ko) | 범-암 백금 반응 예측기 | |
| CA3056896A1 (en) | Genomic stability profiling | |
| US20220093217A1 (en) | Genomic profiling similarity | |
| US20230178245A1 (en) | Immunotherapy Response Signature | |
| US20230113092A1 (en) | Panomic genomic prevalence score | |
| CA3167694A1 (en) | Panomic genomic prevalence score | |
| US20230368915A1 (en) | Metastasis predictor | |
| CA3198134A1 (en) | Immunotherapy response signature |