KR20210095874A - Epcam 항체, 활성화 가능한 항체 및 면역접합체, 그리고 이들의 용도 - Google Patents
Epcam 항체, 활성화 가능한 항체 및 면역접합체, 그리고 이들의 용도 Download PDFInfo
- Publication number
- KR20210095874A KR20210095874A KR1020217015710A KR20217015710A KR20210095874A KR 20210095874 A KR20210095874 A KR 20210095874A KR 1020217015710 A KR1020217015710 A KR 1020217015710A KR 20217015710 A KR20217015710 A KR 20217015710A KR 20210095874 A KR20210095874 A KR 20210095874A
- Authority
- KR
- South Korea
- Prior art keywords
- antibody
- seq
- epcam
- sequence
- binding
- Prior art date
Links
- 229940127121 immunoconjugate Drugs 0.000 title claims abstract description 112
- 101150084967 EPCAM gene Proteins 0.000 title description 2
- 101150057140 TACSTD1 gene Proteins 0.000 title description 2
- 102000012804 EPCAM Human genes 0.000 title 1
- 108010066687 Epithelial Cell Adhesion Molecule Proteins 0.000 claims abstract description 1032
- 102000008394 Immunoglobulin Fragments Human genes 0.000 claims abstract description 407
- 108010021625 Immunoglobulin Fragments Proteins 0.000 claims abstract description 407
- 238000000034 method Methods 0.000 claims abstract description 108
- 102000018651 Epithelial Cell Adhesion Molecule Human genes 0.000 claims abstract 101
- 230000027455 binding Effects 0.000 claims description 441
- 210000004027 cell Anatomy 0.000 claims description 144
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 109
- 206010028980 Neoplasm Diseases 0.000 claims description 86
- 201000011510 cancer Diseases 0.000 claims description 68
- 230000000873 masking effect Effects 0.000 claims description 65
- 108091005804 Peptidases Proteins 0.000 claims description 63
- 229910052757 nitrogen Inorganic materials 0.000 claims description 63
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 63
- 239000004365 Protease Substances 0.000 claims description 62
- 150000003839 salts Chemical class 0.000 claims description 61
- 229910052727 yttrium Inorganic materials 0.000 claims description 61
- 150000001875 compounds Chemical class 0.000 claims description 59
- -1 Va-Ala Chemical compound 0.000 claims description 51
- 239000000758 substrate Substances 0.000 claims description 51
- 229910052717 sulfur Inorganic materials 0.000 claims description 39
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 37
- 239000000427 antigen Substances 0.000 claims description 34
- 102000036639 antigens Human genes 0.000 claims description 34
- 108091007433 antigens Proteins 0.000 claims description 34
- 229920001184 polypeptide Polymers 0.000 claims description 34
- 229910052731 fluorine Inorganic materials 0.000 claims description 33
- 239000012634 fragment Substances 0.000 claims description 31
- 108091033319 polynucleotide Proteins 0.000 claims description 28
- 102000040430 polynucleotide Human genes 0.000 claims description 28
- 239000002157 polynucleotide Substances 0.000 claims description 28
- 229910052721 tungsten Inorganic materials 0.000 claims description 28
- 125000000539 amino acid group Chemical group 0.000 claims description 24
- 238000011282 treatment Methods 0.000 claims description 21
- 206010009944 Colon cancer Diseases 0.000 claims description 19
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 16
- 206010017758 gastric cancer Diseases 0.000 claims description 16
- 229910052739 hydrogen Inorganic materials 0.000 claims description 16
- 201000011549 stomach cancer Diseases 0.000 claims description 16
- 239000013598 vector Substances 0.000 claims description 15
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 14
- 239000003814 drug Substances 0.000 claims description 14
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Chemical compound NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 claims description 14
- 208000002154 non-small cell lung carcinoma Diseases 0.000 claims description 14
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 claims description 14
- 208000001333 Colorectal Neoplasms Diseases 0.000 claims description 13
- 206010033128 Ovarian cancer Diseases 0.000 claims description 13
- 108010056243 alanylalanine Proteins 0.000 claims description 13
- 229910052799 carbon Inorganic materials 0.000 claims description 12
- 239000000203 mixture Substances 0.000 claims description 12
- 201000009030 Carcinoma Diseases 0.000 claims description 10
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 10
- 208000002495 Uterine Neoplasms Diseases 0.000 claims description 10
- 229910052805 deuterium Inorganic materials 0.000 claims description 10
- 201000005202 lung cancer Diseases 0.000 claims description 10
- 208000020816 lung neoplasm Diseases 0.000 claims description 10
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 10
- 239000011734 sodium Substances 0.000 claims description 10
- 206010046766 uterine cancer Diseases 0.000 claims description 10
- 125000006273 (C1-C3) alkyl group Chemical group 0.000 claims description 9
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 9
- 239000008194 pharmaceutical composition Substances 0.000 claims description 9
- PVGATNRYUYNBHO-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-(2,5-dioxopyrrol-1-yl)butanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCN1C(=O)C=CC1=O PVGATNRYUYNBHO-UHFFFAOYSA-N 0.000 claims description 8
- 208000026310 Breast neoplasm Diseases 0.000 claims description 8
- 241001529936 Murinae Species 0.000 claims description 8
- 206010060862 Prostate cancer Diseases 0.000 claims description 8
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 8
- 150000001412 amines Chemical class 0.000 claims description 8
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 8
- 201000002528 pancreatic cancer Diseases 0.000 claims description 8
- LIWMQSWFLXEGMA-WDSKDSINSA-N Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)N LIWMQSWFLXEGMA-WDSKDSINSA-N 0.000 claims description 7
- DEFJQIDDEAULHB-QWWZWVQMSA-N D-alanyl-D-alanine Chemical compound C[C@@H]([NH3+])C(=O)N[C@H](C)C([O-])=O DEFJQIDDEAULHB-QWWZWVQMSA-N 0.000 claims description 7
- DEFJQIDDEAULHB-UHFFFAOYSA-N N-D-alanyl-D-alanine Natural products CC(N)C(=O)NC(C)C(O)=O DEFJQIDDEAULHB-UHFFFAOYSA-N 0.000 claims description 7
- 239000003153 chemical reaction reagent Substances 0.000 claims description 7
- 208000029742 colonic neoplasm Diseases 0.000 claims description 7
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 claims description 7
- 210000000130 stem cell Anatomy 0.000 claims description 7
- 125000001424 substituent group Chemical group 0.000 claims description 7
- 206010006187 Breast cancer Diseases 0.000 claims description 6
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical group C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 claims description 6
- DEFJQIDDEAULHB-IMJSIDKUSA-N L-alanyl-L-alanine Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(O)=O DEFJQIDDEAULHB-IMJSIDKUSA-N 0.000 claims description 6
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 claims description 6
- 229910052708 sodium Inorganic materials 0.000 claims description 6
- 208000000461 Esophageal Neoplasms Diseases 0.000 claims description 5
- 206010027476 Metastases Diseases 0.000 claims description 5
- 206010030155 Oesophageal carcinoma Diseases 0.000 claims description 5
- 208000015634 Rectal Neoplasms Diseases 0.000 claims description 5
- 201000004101 esophageal cancer Diseases 0.000 claims description 5
- 206010038038 rectal cancer Diseases 0.000 claims description 5
- 201000001275 rectum cancer Diseases 0.000 claims description 5
- ULARYIUTHAWJMU-UHFFFAOYSA-M sodium;1-[4-(2,5-dioxopyrrol-1-yl)butanoyloxy]-2,5-dioxopyrrolidine-3-sulfonate Chemical compound [Na+].O=C1C(S(=O)(=O)[O-])CC(=O)N1OC(=O)CCCN1C(=O)C=CC1=O ULARYIUTHAWJMU-UHFFFAOYSA-M 0.000 claims description 5
- 238000012258 culturing Methods 0.000 claims description 4
- 239000003937 drug carrier Substances 0.000 claims description 4
- XAEFZNCEHLXOMS-UHFFFAOYSA-M potassium benzoate Chemical compound [K+].[O-]C(=O)C1=CC=CC=C1 XAEFZNCEHLXOMS-UHFFFAOYSA-M 0.000 claims description 4
- KQRHTCDQWJLLME-XUXIUFHCSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-aminopropanoyl]amino]-4-methylpentanoyl]amino]propanoyl]amino]-4-methylpentanoic acid Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)N KQRHTCDQWJLLME-XUXIUFHCSA-N 0.000 claims description 3
- AGGWFDNPHKLBBV-YUMQZZPRSA-N (2s)-2-[[(2s)-2-amino-3-methylbutanoyl]amino]-5-(carbamoylamino)pentanoic acid Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(O)=O)CCCNC(N)=O AGGWFDNPHKLBBV-YUMQZZPRSA-N 0.000 claims description 3
- 125000004178 (C1-C4) alkyl group Chemical group 0.000 claims description 3
- 125000004169 (C1-C6) alkyl group Chemical group 0.000 claims description 3
- WEZDRVHTDXTVLT-GJZGRUSLSA-N 2-[[(2s)-2-[[(2s)-2-[(2-aminoacetyl)amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]acetic acid Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 WEZDRVHTDXTVLT-GJZGRUSLSA-N 0.000 claims description 3
- FSHURBQASBLAPO-WDSKDSINSA-N Ala-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](C)N FSHURBQASBLAPO-WDSKDSINSA-N 0.000 claims description 3
- OMLWNBVRVJYMBQ-YUMQZZPRSA-N Arg-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O OMLWNBVRVJYMBQ-YUMQZZPRSA-N 0.000 claims description 3
- DAQIJMOLTMGJLO-YUMQZZPRSA-N Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](N)CCCNC(N)=N DAQIJMOLTMGJLO-YUMQZZPRSA-N 0.000 claims description 3
- SJUXYGVRSGTPMC-IMJSIDKUSA-N Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](N)CC(N)=O SJUXYGVRSGTPMC-IMJSIDKUSA-N 0.000 claims description 3
- 206010005003 Bladder cancer Diseases 0.000 claims description 3
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 claims description 3
- FAQVCWVVIYYWRR-WHFBIAKZSA-N Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O FAQVCWVVIYYWRR-WHFBIAKZSA-N 0.000 claims description 3
- VHLZDSUANXBJHW-QWRGUYRKSA-N Gln-Phe Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 VHLZDSUANXBJHW-QWRGUYRKSA-N 0.000 claims description 3
- MRVYVEQPNDSWLH-XPUUQOCRSA-N Gln-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](N)CCC(N)=O MRVYVEQPNDSWLH-XPUUQOCRSA-N 0.000 claims description 3
- 108010009504 Gly-Phe-Leu-Gly Proteins 0.000 claims description 3
- YLEIWGJJBFBFHC-KBPBESRZSA-N Gly-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 YLEIWGJJBFBFHC-KBPBESRZSA-N 0.000 claims description 3
- VAXBXNPRXPHGHG-BJDJZHNGSA-N Ile-Ala-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)O)N VAXBXNPRXPHGHG-BJDJZHNGSA-N 0.000 claims description 3
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 claims description 3
- LSPYFSHXDAYVDI-SRVKXCTJSA-N Leu-Ala-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(C)C LSPYFSHXDAYVDI-SRVKXCTJSA-N 0.000 claims description 3
- NVGBPTNZLWRQSY-UWVGGRQHSA-N Lys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(O)=O)CCCCN NVGBPTNZLWRQSY-UWVGGRQHSA-N 0.000 claims description 3
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 claims description 3
- JHKXZYLNVJRAAJ-WDSKDSINSA-N Met-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(O)=O JHKXZYLNVJRAAJ-WDSKDSINSA-N 0.000 claims description 3
- MIDZLCFIAINOQN-WPRPVWTQSA-N Phe-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 MIDZLCFIAINOQN-WPRPVWTQSA-N 0.000 claims description 3
- RBRNEFJTEHPDSL-ACRUOGEOSA-N Phe-Phe-Lys Chemical compound C([C@@H](C(=O)N[C@@H](CCCCN)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 RBRNEFJTEHPDSL-ACRUOGEOSA-N 0.000 claims description 3
- 108010003723 Single-Domain Antibodies Proteins 0.000 claims description 3
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 claims description 3
- QRZVUAAKNRHEOP-GUBZILKMSA-N Val-Ala-Val Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O QRZVUAAKNRHEOP-GUBZILKMSA-N 0.000 claims description 3
- IBIDRSSEHFLGSD-YUMQZZPRSA-N Val-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-YUMQZZPRSA-N 0.000 claims description 3
- JKHXYJKMNSSFFL-IUCAKERBSA-N Val-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(O)=O)CCCCN JKHXYJKMNSSFFL-IUCAKERBSA-N 0.000 claims description 3
- 108010054982 alanyl-leucyl-alanyl-leucine Proteins 0.000 claims description 3
- 108010068380 arginylarginine Proteins 0.000 claims description 3
- 108010036533 arginylvaline Proteins 0.000 claims description 3
- 230000002147 killing effect Effects 0.000 claims description 3
- 108010054155 lysyllysine Proteins 0.000 claims description 3
- 108010024607 phenylalanylalanine Proteins 0.000 claims description 3
- 201000002314 small intestine cancer Diseases 0.000 claims description 3
- 206010044285 tracheal cancer Diseases 0.000 claims description 3
- 201000005112 urinary bladder cancer Diseases 0.000 claims description 3
- IBIDRSSEHFLGSD-UHFFFAOYSA-N valinyl-arginine Natural products CC(C)C(N)C(=O)NC(C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-UHFFFAOYSA-N 0.000 claims description 3
- 108010073969 valyllysine Proteins 0.000 claims description 3
- 208000036634 Metastases to small intestine Diseases 0.000 claims description 2
- 208000003721 Triple Negative Breast Neoplasms Diseases 0.000 claims description 2
- 238000004113 cell culture Methods 0.000 claims description 2
- 210000004978 chinese hamster ovary cell Anatomy 0.000 claims description 2
- 210000003527 eukaryotic cell Anatomy 0.000 claims description 2
- 239000012216 imaging agent Substances 0.000 claims description 2
- 235000012054 meals Nutrition 0.000 claims description 2
- 229910021645 metal ion Inorganic materials 0.000 claims description 2
- 208000022679 triple-negative breast carcinoma Diseases 0.000 claims description 2
- 102100037486 Reverse transcriptase/ribonuclease H Human genes 0.000 claims 3
- ALBODLTZUXKBGZ-JUUVMNCLSA-N (2s)-2-amino-3-phenylpropanoic acid;(2s)-2,6-diaminohexanoic acid Chemical compound NCCCC[C@H](N)C(O)=O.OC(=O)[C@@H](N)CC1=CC=CC=C1 ALBODLTZUXKBGZ-JUUVMNCLSA-N 0.000 claims 1
- RVLOMLVNNBWRSR-KNIFDHDWSA-N (2s)-2-aminopropanoic acid;(2s)-2,6-diaminohexanoic acid Chemical compound C[C@H](N)C(O)=O.NCCCC[C@H](N)C(O)=O RVLOMLVNNBWRSR-KNIFDHDWSA-N 0.000 claims 1
- 102100031940 Epithelial cell adhesion molecule Human genes 0.000 description 943
- 235000001014 amino acid Nutrition 0.000 description 92
- 229940024606 amino acid Drugs 0.000 description 63
- 238000006467 substitution reaction Methods 0.000 description 61
- 102000035195 Peptidases Human genes 0.000 description 60
- 150000001413 amino acids Chemical class 0.000 description 55
- 235000019419 proteases Nutrition 0.000 description 46
- 125000005647 linker group Chemical group 0.000 description 45
- 108090000435 Urokinase-type plasminogen activator Proteins 0.000 description 30
- 238000010494 dissociation reaction Methods 0.000 description 30
- 230000005593 dissociations Effects 0.000 description 30
- 102100031358 Urokinase-type plasminogen activator Human genes 0.000 description 29
- 108090000623 proteins and genes Proteins 0.000 description 28
- 239000012636 effector Substances 0.000 description 26
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 25
- 150000007523 nucleic acids Chemical group 0.000 description 25
- 102000004169 proteins and genes Human genes 0.000 description 25
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 24
- 230000002829 reductive effect Effects 0.000 description 24
- 239000003795 chemical substances by application Substances 0.000 description 23
- 108060003951 Immunoglobulin Proteins 0.000 description 22
- 102000018358 immunoglobulin Human genes 0.000 description 22
- 235000018102 proteins Nutrition 0.000 description 22
- 239000000562 conjugate Substances 0.000 description 20
- 101100285903 Drosophila melanogaster Hsc70-2 gene Proteins 0.000 description 19
- 229940127089 cytotoxic agent Drugs 0.000 description 19
- 108091028043 Nucleic acid sequence Proteins 0.000 description 18
- 239000002254 cytotoxic agent Substances 0.000 description 18
- 231100000599 cytotoxic agent Toxicity 0.000 description 18
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 18
- 125000003729 nucleotide group Chemical group 0.000 description 18
- 230000004048 modification Effects 0.000 description 16
- 238000012986 modification Methods 0.000 description 16
- 239000013612 plasmid Substances 0.000 description 16
- 210000001519 tissue Anatomy 0.000 description 16
- 230000000259 anti-tumor effect Effects 0.000 description 15
- 230000000875 corresponding effect Effects 0.000 description 15
- YUOCYTRGANSSRY-UHFFFAOYSA-N pyrrolo[2,3-i][1,2]benzodiazepine Chemical compound C1=CN=NC2=C3C=CN=C3C=CC2=C1 YUOCYTRGANSSRY-UHFFFAOYSA-N 0.000 description 15
- 239000011230 binding agent Substances 0.000 description 14
- 210000002919 epithelial cell Anatomy 0.000 description 14
- 239000002773 nucleotide Substances 0.000 description 14
- 125000000217 alkyl group Chemical group 0.000 description 13
- 150000001768 cations Chemical class 0.000 description 13
- 238000003776 cleavage reaction Methods 0.000 description 13
- 230000007017 scission Effects 0.000 description 13
- 230000009870 specific binding Effects 0.000 description 13
- 102100037942 Suppressor of tumorigenicity 14 protein Human genes 0.000 description 12
- 239000000611 antibody drug conjugate Substances 0.000 description 12
- 229940049595 antibody-drug conjugate Drugs 0.000 description 12
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 12
- 102000004190 Enzymes Human genes 0.000 description 11
- 108090000790 Enzymes Proteins 0.000 description 11
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 11
- 230000009471 action Effects 0.000 description 11
- 201000010099 disease Diseases 0.000 description 11
- 231100000673 dose–response relationship Toxicity 0.000 description 11
- 229940088598 enzyme Drugs 0.000 description 11
- 230000006870 function Effects 0.000 description 11
- 238000003780 insertion Methods 0.000 description 11
- 230000037431 insertion Effects 0.000 description 11
- 210000002966 serum Anatomy 0.000 description 11
- 102000005927 Cysteine Proteases Human genes 0.000 description 10
- 108010005843 Cysteine Proteases Proteins 0.000 description 10
- 230000001588 bifunctional effect Effects 0.000 description 10
- 230000000694 effects Effects 0.000 description 10
- 102000039446 nucleic acids Human genes 0.000 description 10
- 108020004707 nucleic acids Proteins 0.000 description 10
- 101000920667 Homo sapiens Epithelial cell adhesion molecule Proteins 0.000 description 9
- 108010091175 Matriptase Proteins 0.000 description 9
- 125000004432 carbon atom Chemical group C* 0.000 description 9
- 230000009467 reduction Effects 0.000 description 9
- 125000006850 spacer group Chemical group 0.000 description 9
- 229940124597 therapeutic agent Drugs 0.000 description 9
- 230000001225 therapeutic effect Effects 0.000 description 9
- KFZMGEQAYNKOFK-UHFFFAOYSA-N Isopropanol Chemical compound CC(C)O KFZMGEQAYNKOFK-UHFFFAOYSA-N 0.000 description 8
- 102100029205 Low affinity immunoglobulin gamma Fc region receptor II-b Human genes 0.000 description 8
- 102000012479 Serine Proteases Human genes 0.000 description 8
- 108010022999 Serine Proteases Proteins 0.000 description 8
- 108090000190 Thrombin Proteins 0.000 description 8
- 229920000642 polymer Polymers 0.000 description 8
- 102000005962 receptors Human genes 0.000 description 8
- 108020003175 receptors Proteins 0.000 description 8
- 229960004072 thrombin Drugs 0.000 description 8
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 7
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 7
- 108010028275 Leukocyte Elastase Proteins 0.000 description 7
- 102100029193 Low affinity immunoglobulin gamma Fc region receptor III-A Human genes 0.000 description 7
- 102100033174 Neutrophil elastase Human genes 0.000 description 7
- 239000002253 acid Substances 0.000 description 7
- 239000003431 cross linking reagent Substances 0.000 description 7
- 208000035475 disorder Diseases 0.000 description 7
- 125000004185 ester group Chemical group 0.000 description 7
- 235000000346 sugar Nutrition 0.000 description 7
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 6
- 238000002965 ELISA Methods 0.000 description 6
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 6
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 6
- 241000282567 Macaca fascicularis Species 0.000 description 6
- 241000124008 Mammalia Species 0.000 description 6
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 6
- 125000003277 amino group Chemical group 0.000 description 6
- 125000003310 benzodiazepinyl group Chemical class N1N=C(C=CC2=C1C=CC=C2)* 0.000 description 6
- 238000012217 deletion Methods 0.000 description 6
- 230000037430 deletion Effects 0.000 description 6
- 150000002148 esters Chemical class 0.000 description 6
- 230000014509 gene expression Effects 0.000 description 6
- 125000000879 imine group Chemical group 0.000 description 6
- 239000002207 metabolite Substances 0.000 description 6
- 125000006239 protecting group Chemical group 0.000 description 6
- 238000003127 radioimmunoassay Methods 0.000 description 6
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 5
- 102000005600 Cathepsins Human genes 0.000 description 5
- 108010084457 Cathepsins Proteins 0.000 description 5
- 108020004414 DNA Proteins 0.000 description 5
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 5
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 5
- 108010076504 Protein Sorting Signals Proteins 0.000 description 5
- 229910006069 SO3H Inorganic materials 0.000 description 5
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 5
- WPYMKLBDIGXBTP-UHFFFAOYSA-N benzoic acid Chemical compound OC(=O)C1=CC=CC=C1 WPYMKLBDIGXBTP-UHFFFAOYSA-N 0.000 description 5
- 230000004071 biological effect Effects 0.000 description 5
- 230000000903 blocking effect Effects 0.000 description 5
- 239000000872 buffer Substances 0.000 description 5
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 5
- 231100000433 cytotoxic Toxicity 0.000 description 5
- 230000001472 cytotoxic effect Effects 0.000 description 5
- 238000003745 diagnosis Methods 0.000 description 5
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 5
- 239000011159 matrix material Substances 0.000 description 5
- 230000035772 mutation Effects 0.000 description 5
- 239000012453 solvate Substances 0.000 description 5
- 102000011727 Caspases Human genes 0.000 description 4
- 108010076667 Caspases Proteins 0.000 description 4
- 102000003902 Cathepsin C Human genes 0.000 description 4
- 108090000267 Cathepsin C Proteins 0.000 description 4
- 102100024940 Cathepsin K Human genes 0.000 description 4
- 102100026540 Cathepsin L2 Human genes 0.000 description 4
- 239000004971 Cross linker Substances 0.000 description 4
- 102100031111 Disintegrin and metalloproteinase domain-containing protein 17 Human genes 0.000 description 4
- 108010021472 Fc gamma receptor IIB Proteins 0.000 description 4
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 4
- 101000917824 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-b Proteins 0.000 description 4
- 101000917839 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-B Proteins 0.000 description 4
- OAKJQQAXSVQMHS-UHFFFAOYSA-N Hydrazine Chemical compound NN OAKJQQAXSVQMHS-UHFFFAOYSA-N 0.000 description 4
- 102100029185 Low affinity immunoglobulin gamma Fc region receptor III-B Human genes 0.000 description 4
- 102000005741 Metalloproteases Human genes 0.000 description 4
- 108010006035 Metalloproteases Proteins 0.000 description 4
- AFVFQIVMOAPDHO-UHFFFAOYSA-N Methanesulfonic acid Chemical compound CS(O)(=O)=O AFVFQIVMOAPDHO-UHFFFAOYSA-N 0.000 description 4
- 108091034117 Oligonucleotide Proteins 0.000 description 4
- MUBZPKHOEPUJKR-UHFFFAOYSA-N Oxalic acid Chemical compound OC(=O)C(O)=O MUBZPKHOEPUJKR-UHFFFAOYSA-N 0.000 description 4
- 108010067372 Pancreatic elastase Proteins 0.000 description 4
- 102000016387 Pancreatic elastase Human genes 0.000 description 4
- 108090000284 Pepsin A Proteins 0.000 description 4
- 102000057297 Pepsin A Human genes 0.000 description 4
- 238000011579 SCID mouse model Methods 0.000 description 4
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 4
- 238000013459 approach Methods 0.000 description 4
- 125000003118 aryl group Chemical group 0.000 description 4
- 238000003556 assay Methods 0.000 description 4
- 229940049706 benzodiazepine Drugs 0.000 description 4
- 210000004899 c-terminal region Anatomy 0.000 description 4
- 230000015556 catabolic process Effects 0.000 description 4
- DDRJAANPRJIHGJ-UHFFFAOYSA-N creatinine Chemical compound CN1CC(=O)NC1=N DDRJAANPRJIHGJ-UHFFFAOYSA-N 0.000 description 4
- 230000002255 enzymatic effect Effects 0.000 description 4
- 238000000099 in vitro assay Methods 0.000 description 4
- 238000001727 in vivo Methods 0.000 description 4
- 230000001965 increasing effect Effects 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- 108091008042 inhibitory receptors Proteins 0.000 description 4
- 150000002500 ions Chemical class 0.000 description 4
- 229940111202 pepsin Drugs 0.000 description 4
- NMHMNPHRMNGLLB-UHFFFAOYSA-N phloretic acid Chemical compound OC(=O)CCC1=CC=C(O)C=C1 NMHMNPHRMNGLLB-UHFFFAOYSA-N 0.000 description 4
- 229940012957 plasmin Drugs 0.000 description 4
- 230000002062 proliferating effect Effects 0.000 description 4
- 239000012070 reactive reagent Substances 0.000 description 4
- 238000002864 sequence alignment Methods 0.000 description 4
- 241000894007 species Species 0.000 description 4
- 238000010561 standard procedure Methods 0.000 description 4
- 239000000126 substance Substances 0.000 description 4
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 4
- 238000003786 synthesis reaction Methods 0.000 description 4
- VZCYOOQTPOCHFL-UHFFFAOYSA-N trans-butenedioic acid Natural products OC(=O)C=CC(O)=O VZCYOOQTPOCHFL-UHFFFAOYSA-N 0.000 description 4
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 3
- CSCPPACGZOOCGX-UHFFFAOYSA-N Acetone Chemical compound CC(C)=O CSCPPACGZOOCGX-UHFFFAOYSA-N 0.000 description 3
- XEKOWRVHYACXOJ-UHFFFAOYSA-N Ethyl acetate Chemical compound CCOC(C)=O XEKOWRVHYACXOJ-UHFFFAOYSA-N 0.000 description 3
- 108010021468 Fc gamma receptor IIA Proteins 0.000 description 3
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 3
- VZCYOOQTPOCHFL-OWOJBTEDSA-N Fumaric acid Chemical compound OC(=O)\C=C\C(O)=O VZCYOOQTPOCHFL-OWOJBTEDSA-N 0.000 description 3
- 239000004471 Glycine Substances 0.000 description 3
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 3
- 101000661807 Homo sapiens Suppressor of tumorigenicity 14 protein Proteins 0.000 description 3
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 3
- 102000009786 Immunoglobulin Constant Regions Human genes 0.000 description 3
- 108010009817 Immunoglobulin Constant Regions Proteins 0.000 description 3
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 3
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 3
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 3
- 102100029204 Low affinity immunoglobulin gamma Fc region receptor II-a Human genes 0.000 description 3
- 101710099301 Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 3
- 102000002274 Matrix Metalloproteinases Human genes 0.000 description 3
- 108010000684 Matrix Metalloproteinases Proteins 0.000 description 3
- 102000004055 Matrix metalloproteinase-19 Human genes 0.000 description 3
- 108090000587 Matrix metalloproteinase-19 Proteins 0.000 description 3
- 241001465754 Metazoa Species 0.000 description 3
- 241000699666 Mus <mouse, genus> Species 0.000 description 3
- 101100501585 Mus musculus Epcam gene Proteins 0.000 description 3
- OFOBLEOULBTSOW-UHFFFAOYSA-N Propanedioic acid Natural products OC(=O)CC(O)=O OFOBLEOULBTSOW-UHFFFAOYSA-N 0.000 description 3
- 108090000412 Protein-Tyrosine Kinases Proteins 0.000 description 3
- 102000004022 Protein-Tyrosine Kinases Human genes 0.000 description 3
- 230000002159 abnormal effect Effects 0.000 description 3
- 230000003213 activating effect Effects 0.000 description 3
- 230000004913 activation Effects 0.000 description 3
- 125000003342 alkenyl group Chemical group 0.000 description 3
- 125000004429 atom Chemical group 0.000 description 3
- 239000002585 base Substances 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 150000004657 carbamic acid derivatives Chemical class 0.000 description 3
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 3
- 230000004663 cell proliferation Effects 0.000 description 3
- 235000018417 cysteine Nutrition 0.000 description 3
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 3
- 238000006731 degradation reaction Methods 0.000 description 3
- 230000001419 dependent effect Effects 0.000 description 3
- 238000010586 diagram Methods 0.000 description 3
- 230000029087 digestion Effects 0.000 description 3
- 239000013604 expression vector Substances 0.000 description 3
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 3
- 230000036541 health Effects 0.000 description 3
- 125000000623 heterocyclic group Chemical group 0.000 description 3
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 3
- 229960004592 isopropanol Drugs 0.000 description 3
- 239000003446 ligand Substances 0.000 description 3
- 230000003211 malignant effect Effects 0.000 description 3
- 229910052751 metal Inorganic materials 0.000 description 3
- 239000002184 metal Substances 0.000 description 3
- 150000002739 metals Chemical class 0.000 description 3
- 210000000440 neutrophil Anatomy 0.000 description 3
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 3
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 3
- BDERNNFJNOPAEC-UHFFFAOYSA-N propan-1-ol Chemical compound CCCO BDERNNFJNOPAEC-UHFFFAOYSA-N 0.000 description 3
- 238000010188 recombinant method Methods 0.000 description 3
- 239000002904 solvent Substances 0.000 description 3
- JJAHTWIKCUJRDK-UHFFFAOYSA-N succinimidyl 4-(N-maleimidomethyl)cyclohexane-1-carboxylate Chemical group C1CC(CN2C(C=CC2=O)=O)CCC1C(=O)ON1C(=O)CCC1=O JJAHTWIKCUJRDK-UHFFFAOYSA-N 0.000 description 3
- 150000008163 sugars Chemical class 0.000 description 3
- JOXIMZWYDAKGHI-UHFFFAOYSA-N toluene-4-sulfonic acid Chemical compound CC1=CC=C(S(O)(=O)=O)C=C1 JOXIMZWYDAKGHI-UHFFFAOYSA-N 0.000 description 3
- 210000004881 tumor cell Anatomy 0.000 description 3
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 3
- VRDGQQTWSGDXCU-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 2-iodoacetate Chemical compound ICC(=O)ON1C(=O)CCC1=O VRDGQQTWSGDXCU-UHFFFAOYSA-N 0.000 description 2
- WGMMKWFUXPMTRW-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-[(2-bromoacetyl)amino]propanoate Chemical compound BrCC(=O)NCCC(=O)ON1C(=O)CCC1=O WGMMKWFUXPMTRW-UHFFFAOYSA-N 0.000 description 2
- JSHOVKSMJRQOGY-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-(pyridin-2-yldisulfanyl)butanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCSSC1=CC=CC=N1 JSHOVKSMJRQOGY-UHFFFAOYSA-N 0.000 description 2
- GTBCXYYVWHFQRS-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-(pyridin-2-yldisulfanyl)pentanoate Chemical compound C=1C=CC=NC=1SSC(C)CCC(=O)ON1C(=O)CCC1=O GTBCXYYVWHFQRS-UHFFFAOYSA-N 0.000 description 2
- PMJWDPGOWBRILU-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-[4-(2,5-dioxopyrrol-1-yl)phenyl]butanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCC(C=C1)=CC=C1N1C(=O)C=CC1=O PMJWDPGOWBRILU-UHFFFAOYSA-N 0.000 description 2
- VHYRHFNOWKMCHQ-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-formylbenzoate Chemical compound C1=CC(C=O)=CC=C1C(=O)ON1C(=O)CCC1=O VHYRHFNOWKMCHQ-UHFFFAOYSA-N 0.000 description 2
- WCMOHMXWOOBVMZ-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 6-[3-(2,5-dioxopyrrol-1-yl)propanoylamino]hexanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCNC(=O)CCN1C(=O)C=CC1=O WCMOHMXWOOBVMZ-UHFFFAOYSA-N 0.000 description 2
- 125000003088 (fluoren-9-ylmethoxy)carbonyl group Chemical group 0.000 description 2
- RVRLFABOQXZUJX-UHFFFAOYSA-N 1-[1-(2,5-dioxopyrrol-1-yl)ethyl]pyrrole-2,5-dione Chemical compound O=C1C=CC(=O)N1C(C)N1C(=O)C=CC1=O RVRLFABOQXZUJX-UHFFFAOYSA-N 0.000 description 2
- SGVWDRVQIYUSRA-UHFFFAOYSA-N 1-[2-[2-(2,5-dioxopyrrol-1-yl)ethyldisulfanyl]ethyl]pyrrole-2,5-dione Chemical compound O=C1C=CC(=O)N1CCSSCCN1C(=O)C=CC1=O SGVWDRVQIYUSRA-UHFFFAOYSA-N 0.000 description 2
- DIYPCWKHSODVAP-UHFFFAOYSA-N 1-[3-(2,5-dioxopyrrol-1-yl)benzoyl]oxy-2,5-dioxopyrrolidine-3-sulfonic acid Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)C1=CC=CC(N2C(C=CC2=O)=O)=C1 DIYPCWKHSODVAP-UHFFFAOYSA-N 0.000 description 2
- FPKVOQKZMBDBKP-UHFFFAOYSA-N 1-[4-[(2,5-dioxopyrrol-1-yl)methyl]cyclohexanecarbonyl]oxy-2,5-dioxopyrrolidine-3-sulfonic acid Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)C1CCC(CN2C(C=CC2=O)=O)CC1 FPKVOQKZMBDBKP-UHFFFAOYSA-N 0.000 description 2
- VHYRLCJMMJQUBY-UHFFFAOYSA-N 1-[4-[4-(2,5-dioxopyrrol-1-yl)phenyl]butanoyloxy]-2,5-dioxopyrrolidine-3-sulfonic acid Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)CCCC1=CC=C(N2C(C=CC2=O)=O)C=C1 VHYRLCJMMJQUBY-UHFFFAOYSA-N 0.000 description 2
- WXTMDXOMEHJXQO-UHFFFAOYSA-N 2,5-dihydroxybenzoic acid Chemical compound OC(=O)C1=CC(O)=CC=C1O WXTMDXOMEHJXQO-UHFFFAOYSA-N 0.000 description 2
- ZMRMMAOBSFSXLN-UHFFFAOYSA-N 4-[4-(2,5-dioxopyrrol-1-yl)phenyl]butanehydrazide Chemical compound C1=CC(CCCC(=O)NN)=CC=C1N1C(=O)C=CC1=O ZMRMMAOBSFSXLN-UHFFFAOYSA-N 0.000 description 2
- 102100027400 A disintegrin and metalloproteinase with thrombospondin motifs 4 Human genes 0.000 description 2
- 102100026007 ADAM DEC1 Human genes 0.000 description 2
- 108091007504 ADAM10 Proteins 0.000 description 2
- 108091007507 ADAM12 Proteins 0.000 description 2
- 108091007505 ADAM17 Proteins 0.000 description 2
- 108091022879 ADAMTS Proteins 0.000 description 2
- 102000029750 ADAMTS Human genes 0.000 description 2
- 102000051388 ADAMTS1 Human genes 0.000 description 2
- 108091005660 ADAMTS1 Proteins 0.000 description 2
- 108091005664 ADAMTS4 Proteins 0.000 description 2
- 102000051389 ADAMTS5 Human genes 0.000 description 2
- 108091005663 ADAMTS5 Proteins 0.000 description 2
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 2
- QXRNAOYBCYVZCD-BQBZGAKWSA-N Ala-Lys Chemical compound C[C@H](N)C(=O)N[C@H](C(O)=O)CCCCN QXRNAOYBCYVZCD-BQBZGAKWSA-N 0.000 description 2
- QGZKDVFQNNGYKY-UHFFFAOYSA-N Ammonia Chemical compound N QGZKDVFQNNGYKY-UHFFFAOYSA-N 0.000 description 2
- 239000004382 Amylase Substances 0.000 description 2
- 102000013142 Amylases Human genes 0.000 description 2
- 108010065511 Amylases Proteins 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 2
- 102000030431 Asparaginyl endopeptidase Human genes 0.000 description 2
- 102100021257 Beta-secretase 1 Human genes 0.000 description 2
- 102000015081 Blood Coagulation Factors Human genes 0.000 description 2
- 108010039209 Blood Coagulation Factors Proteins 0.000 description 2
- 102000004152 Bone morphogenetic protein 1 Human genes 0.000 description 2
- 108090000654 Bone morphogenetic protein 1 Proteins 0.000 description 2
- 102100033620 Calponin-1 Human genes 0.000 description 2
- 101000898643 Candida albicans Vacuolar aspartic protease Proteins 0.000 description 2
- 101000898783 Candida tropicalis Candidapepsin Proteins 0.000 description 2
- 241000283707 Capra Species 0.000 description 2
- 102000004958 Caspase-14 Human genes 0.000 description 2
- 108090001132 Caspase-14 Proteins 0.000 description 2
- 108010059081 Cathepsin A Proteins 0.000 description 2
- 102000005572 Cathepsin A Human genes 0.000 description 2
- 108090000712 Cathepsin B Proteins 0.000 description 2
- 102000004225 Cathepsin B Human genes 0.000 description 2
- 102000003908 Cathepsin D Human genes 0.000 description 2
- 108090000258 Cathepsin D Proteins 0.000 description 2
- 102000004178 Cathepsin E Human genes 0.000 description 2
- 108090000611 Cathepsin E Proteins 0.000 description 2
- 108090000625 Cathepsin K Proteins 0.000 description 2
- 108090000624 Cathepsin L Proteins 0.000 description 2
- 101710169274 Cathepsin L2 Proteins 0.000 description 2
- 108090000613 Cathepsin S Proteins 0.000 description 2
- 102100035654 Cathepsin S Human genes 0.000 description 2
- 108010061117 Cathepsin Z Proteins 0.000 description 2
- 102100026657 Cathepsin Z Human genes 0.000 description 2
- KRKNYBCHXYNGOX-UHFFFAOYSA-K Citrate Chemical compound [O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O KRKNYBCHXYNGOX-UHFFFAOYSA-K 0.000 description 2
- 101000898784 Cryphonectria parasitica Endothiapepsin Proteins 0.000 description 2
- AEMOLEFTQBMNLQ-AQKNRBDQSA-N D-glucopyranuronic acid Chemical compound OC1O[C@H](C(O)=O)[C@@H](O)[C@H](O)[C@H]1O AEMOLEFTQBMNLQ-AQKNRBDQSA-N 0.000 description 2
- SRBFZHDQGSBBOR-IOVATXLUSA-N D-xylopyranose Chemical compound O[C@@H]1COC(O)[C@H](O)[C@H]1O SRBFZHDQGSBBOR-IOVATXLUSA-N 0.000 description 2
- RTZKZFJDLAIYFH-UHFFFAOYSA-N Diethyl ether Chemical compound CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 2
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 2
- 102100039673 Disintegrin and metalloproteinase domain-containing protein 10 Human genes 0.000 description 2
- 102100031112 Disintegrin and metalloproteinase domain-containing protein 12 Human genes 0.000 description 2
- 102100031113 Disintegrin and metalloproteinase domain-containing protein 15 Human genes 0.000 description 2
- 101710121363 Disintegrin and metalloproteinase domain-containing protein 15 Proteins 0.000 description 2
- 102100024364 Disintegrin and metalloproteinase domain-containing protein 8 Human genes 0.000 description 2
- 102100024361 Disintegrin and metalloproteinase domain-containing protein 9 Human genes 0.000 description 2
- 108090000371 Esterases Proteins 0.000 description 2
- JOYRKODLDBILNP-UHFFFAOYSA-N Ethyl urethane Chemical class CCOC(N)=O JOYRKODLDBILNP-UHFFFAOYSA-N 0.000 description 2
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 2
- 108010087819 Fc receptors Proteins 0.000 description 2
- 102000009109 Fc receptors Human genes 0.000 description 2
- IAJILQKETJEXLJ-UHFFFAOYSA-N Galacturonsaeure Natural products O=CC(O)C(O)C(O)C(O)C(O)=O IAJILQKETJEXLJ-UHFFFAOYSA-N 0.000 description 2
- 101710088083 Glomulin Proteins 0.000 description 2
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 description 2
- AEMRFAOFKBGASW-UHFFFAOYSA-N Glycolic acid Chemical compound OCC(O)=O AEMRFAOFKBGASW-UHFFFAOYSA-N 0.000 description 2
- 102000001398 Granzyme Human genes 0.000 description 2
- 108060005986 Granzyme Proteins 0.000 description 2
- 102000004989 Hepsin Human genes 0.000 description 2
- 108090001101 Hepsin Proteins 0.000 description 2
- 241000282412 Homo Species 0.000 description 2
- 101000719904 Homo sapiens ADAM DEC1 Proteins 0.000 description 2
- 101000894895 Homo sapiens Beta-secretase 1 Proteins 0.000 description 2
- 101000945318 Homo sapiens Calponin-1 Proteins 0.000 description 2
- 101000761509 Homo sapiens Cathepsin K Proteins 0.000 description 2
- 101000983577 Homo sapiens Cathepsin L2 Proteins 0.000 description 2
- 101000910979 Homo sapiens Cathepsin Z Proteins 0.000 description 2
- 101000777461 Homo sapiens Disintegrin and metalloproteinase domain-containing protein 17 Proteins 0.000 description 2
- 101000832767 Homo sapiens Disintegrin and metalloproteinase domain-containing protein 8 Proteins 0.000 description 2
- 101000832769 Homo sapiens Disintegrin and metalloproteinase domain-containing protein 9 Proteins 0.000 description 2
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 description 2
- 101001008919 Homo sapiens Kallikrein-10 Proteins 0.000 description 2
- 101001008922 Homo sapiens Kallikrein-11 Proteins 0.000 description 2
- 101000605520 Homo sapiens Kallikrein-14 Proteins 0.000 description 2
- 101001098833 Homo sapiens Proprotein convertase subtilisin/kexin type 6 Proteins 0.000 description 2
- 101001059454 Homo sapiens Serine/threonine-protein kinase MARK2 Proteins 0.000 description 2
- 101000652736 Homo sapiens Transgelin Proteins 0.000 description 2
- 101000637855 Homo sapiens Transmembrane protease serine 11E Proteins 0.000 description 2
- 108091006905 Human Serum Albumin Proteins 0.000 description 2
- 102000008100 Human Serum Albumin Human genes 0.000 description 2
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 2
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 2
- 206010061218 Inflammation Diseases 0.000 description 2
- XEEYBQQBJWHFJM-UHFFFAOYSA-N Iron Chemical compound [Fe] XEEYBQQBJWHFJM-UHFFFAOYSA-N 0.000 description 2
- 102100027613 Kallikrein-10 Human genes 0.000 description 2
- 102100027612 Kallikrein-11 Human genes 0.000 description 2
- 102100038298 Kallikrein-14 Human genes 0.000 description 2
- 208000008839 Kidney Neoplasms Diseases 0.000 description 2
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 2
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 2
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 2
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- 108010063045 Lactoferrin Proteins 0.000 description 2
- 102000010445 Lactoferrin Human genes 0.000 description 2
- 102000004882 Lipase Human genes 0.000 description 2
- 108090001060 Lipase Proteins 0.000 description 2
- 239000004367 Lipase Substances 0.000 description 2
- NPPQSCRMBWNHMW-UHFFFAOYSA-N Meprobamate Chemical compound NC(=O)OCC(C)(CCC)COC(N)=O NPPQSCRMBWNHMW-UHFFFAOYSA-N 0.000 description 2
- YNAVUWVOSKDBBP-UHFFFAOYSA-N Morpholine Chemical compound C1COCCN1 YNAVUWVOSKDBBP-UHFFFAOYSA-N 0.000 description 2
- 101100333157 Mus musculus Egfbp2 gene Proteins 0.000 description 2
- NQTADLQHYWFPDB-UHFFFAOYSA-N N-Hydroxysuccinimide Chemical group ON1C(=O)CCC1=O NQTADLQHYWFPDB-UHFFFAOYSA-N 0.000 description 2
- 102000003729 Neprilysin Human genes 0.000 description 2
- 108090000028 Neprilysin Proteins 0.000 description 2
- 241000283973 Oryctolagus cuniculus Species 0.000 description 2
- 229910019142 PO4 Inorganic materials 0.000 description 2
- FADYJNXDPBKVCA-STQMWFEESA-N Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 FADYJNXDPBKVCA-STQMWFEESA-N 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 2
- GLUUGHFHXGJENI-UHFFFAOYSA-N Piperazine Chemical compound C1CNCCN1 GLUUGHFHXGJENI-UHFFFAOYSA-N 0.000 description 2
- NQRYJNQNLNOLGT-UHFFFAOYSA-N Piperidine Chemical compound C1CCNCC1 NQRYJNQNLNOLGT-UHFFFAOYSA-N 0.000 description 2
- 102100026534 Procathepsin L Human genes 0.000 description 2
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 2
- 102100023832 Prolyl endopeptidase FAP Human genes 0.000 description 2
- 102100038946 Proprotein convertase subtilisin/kexin type 6 Human genes 0.000 description 2
- 101800004937 Protein C Proteins 0.000 description 2
- 102000017975 Protein C Human genes 0.000 description 2
- 102000001708 Protein Isoforms Human genes 0.000 description 2
- 108010029485 Protein Isoforms Proteins 0.000 description 2
- JUJWROOIHBZHMG-UHFFFAOYSA-N Pyridine Chemical compound C1=CC=NC=C1 JUJWROOIHBZHMG-UHFFFAOYSA-N 0.000 description 2
- LCTONWCANYUPML-UHFFFAOYSA-N Pyruvic acid Chemical compound CC(=O)C(O)=O LCTONWCANYUPML-UHFFFAOYSA-N 0.000 description 2
- 241000700159 Rattus Species 0.000 description 2
- 102100028255 Renin Human genes 0.000 description 2
- 108090000783 Renin Proteins 0.000 description 2
- 101000933133 Rhizopus niveus Rhizopuspepsin-1 Proteins 0.000 description 2
- 101000910082 Rhizopus niveus Rhizopuspepsin-2 Proteins 0.000 description 2
- 101000910079 Rhizopus niveus Rhizopuspepsin-3 Proteins 0.000 description 2
- 101000910086 Rhizopus niveus Rhizopuspepsin-4 Proteins 0.000 description 2
- 101000910088 Rhizopus niveus Rhizopuspepsin-5 Proteins 0.000 description 2
- 241000283984 Rodentia Species 0.000 description 2
- 101000898773 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) Saccharopepsin Proteins 0.000 description 2
- 101800001700 Saposin-D Proteins 0.000 description 2
- 102100028904 Serine/threonine-protein kinase MARK2 Human genes 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- 102100032001 Transmembrane protease serine 11E Human genes 0.000 description 2
- 102100032452 Transmembrane protease serine 6 Human genes 0.000 description 2
- 108060005989 Tryptase Proteins 0.000 description 2
- 102000001400 Tryptase Human genes 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- 102100025914 Ubiquitin thioesterase OTUB2 Human genes 0.000 description 2
- 108050001615 Ubiquitin thioesterase OTUB2 Proteins 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- HSRXSKHRSXRCFC-WDSKDSINSA-N Val-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(O)=O HSRXSKHRSXRCFC-WDSKDSINSA-N 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- PNNCWTXUWKENPE-UHFFFAOYSA-N [N].NC(N)=O Chemical compound [N].NC(N)=O PNNCWTXUWKENPE-UHFFFAOYSA-N 0.000 description 2
- 230000001594 aberrant effect Effects 0.000 description 2
- DZBUGLKDJFMEHC-UHFFFAOYSA-N acridine Chemical compound C1=CC=CC2=CC3=CC=CC=C3N=C21 DZBUGLKDJFMEHC-UHFFFAOYSA-N 0.000 description 2
- 229950009084 adecatumumab Drugs 0.000 description 2
- 230000001270 agonistic effect Effects 0.000 description 2
- 239000002168 alkylating agent Substances 0.000 description 2
- 229940100198 alkylating agent Drugs 0.000 description 2
- 125000000304 alkynyl group Chemical group 0.000 description 2
- 150000001408 amides Chemical class 0.000 description 2
- 235000019418 amylase Nutrition 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 230000000890 antigenic effect Effects 0.000 description 2
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 108010055066 asparaginylendopeptidase Proteins 0.000 description 2
- 235000003704 aspartic acid Nutrition 0.000 description 2
- 230000005784 autoimmunity Effects 0.000 description 2
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 2
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 2
- 239000003114 blood coagulation factor Substances 0.000 description 2
- 210000000481 breast Anatomy 0.000 description 2
- 235000013877 carbamide Nutrition 0.000 description 2
- 230000010261 cell growth Effects 0.000 description 2
- 230000012292 cell migration Effects 0.000 description 2
- BFPSDSIWYFKGBC-UHFFFAOYSA-N chlorotrianisene Chemical compound C1=CC(OC)=CC=C1C(Cl)=C(C=1C=CC(OC)=CC=1)C1=CC=C(OC)C=C1 BFPSDSIWYFKGBC-UHFFFAOYSA-N 0.000 description 2
- 208000006990 cholangiocarcinoma Diseases 0.000 description 2
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Natural products OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 2
- 210000001072 colon Anatomy 0.000 description 2
- 238000012875 competitive assay Methods 0.000 description 2
- 230000021615 conjugation Effects 0.000 description 2
- 229940109239 creatinine Drugs 0.000 description 2
- 108090000711 cruzipain Proteins 0.000 description 2
- 238000004925 denaturation Methods 0.000 description 2
- 230000036425 denaturation Effects 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 230000001627 detrimental effect Effects 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical compound [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 2
- 125000002228 disulfide group Chemical group 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 210000000981 epithelium Anatomy 0.000 description 2
- 238000005886 esterification reaction Methods 0.000 description 2
- CCIVGXIOQKPBKL-UHFFFAOYSA-M ethanesulfonate Chemical compound CCS([O-])(=O)=O CCIVGXIOQKPBKL-UHFFFAOYSA-M 0.000 description 2
- 208000021045 exocrine pancreatic carcinoma Diseases 0.000 description 2
- 238000000684 flow cytometry Methods 0.000 description 2
- 125000000524 functional group Chemical group 0.000 description 2
- 210000004602 germ cell Anatomy 0.000 description 2
- 235000013922 glutamic acid Nutrition 0.000 description 2
- 239000004220 glutamic acid Substances 0.000 description 2
- 108010022683 guanidinobenzoate esterase Proteins 0.000 description 2
- 125000005179 haloacetyl group Chemical group 0.000 description 2
- 208000014829 head and neck neoplasm Diseases 0.000 description 2
- 125000001072 heteroaryl group Chemical group 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 150000004677 hydrates Chemical class 0.000 description 2
- 150000002429 hydrazines Chemical class 0.000 description 2
- 150000002443 hydroxylamines Chemical class 0.000 description 2
- 150000002466 imines Chemical class 0.000 description 2
- 230000001900 immune effect Effects 0.000 description 2
- 229940072221 immunoglobulins Drugs 0.000 description 2
- 230000001976 improved effect Effects 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 238000005462 in vivo assay Methods 0.000 description 2
- 238000011065 in-situ storage Methods 0.000 description 2
- 230000004054 inflammatory process Effects 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- CSSYQJWUGATIHM-IKGCZBKSSA-N l-phenylalanyl-l-lysyl-l-cysteinyl-l-arginyl-l-arginyl-l-tryptophyl-l-glutaminyl-l-tryptophyl-l-arginyl-l-methionyl-l-lysyl-l-lysyl-l-leucylglycyl-l-alanyl-l-prolyl-l-seryl-l-isoleucyl-l-threonyl-l-cysteinyl-l-valyl-l-arginyl-l-arginyl-l-alanyl-l-phenylal Chemical compound C([C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 CSSYQJWUGATIHM-IKGCZBKSSA-N 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 229940078795 lactoferrin Drugs 0.000 description 2
- 235000021242 lactoferrin Nutrition 0.000 description 2
- 210000000265 leukocyte Anatomy 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 235000019421 lipase Nutrition 0.000 description 2
- VZCYOOQTPOCHFL-UPHRSURJSA-N maleic acid Chemical compound OC(=O)\C=C/C(O)=O VZCYOOQTPOCHFL-UPHRSURJSA-N 0.000 description 2
- 125000005439 maleimidyl group Chemical group C1(C=CC(N1*)=O)=O 0.000 description 2
- 108010047374 matriptase 2 Proteins 0.000 description 2
- 230000001404 mediated effect Effects 0.000 description 2
- 108091007169 meprins Proteins 0.000 description 2
- 230000009401 metastasis Effects 0.000 description 2
- 239000003607 modifier Substances 0.000 description 2
- 125000006501 nitrophenyl group Chemical group 0.000 description 2
- 231100001221 nontumorigenic Toxicity 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 230000002018 overexpression Effects 0.000 description 2
- 230000036961 partial effect Effects 0.000 description 2
- 230000001575 pathological effect Effects 0.000 description 2
- 125000000538 pentafluorophenyl group Chemical group FC1=C(F)C(F)=C(*)C(F)=C1F 0.000 description 2
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 2
- 239000010452 phosphate Substances 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 2
- 229920001481 poly(stearyl methacrylate) Polymers 0.000 description 2
- 239000000047 product Substances 0.000 description 2
- 238000004393 prognosis Methods 0.000 description 2
- 238000011321 prophylaxis Methods 0.000 description 2
- 210000002307 prostate Anatomy 0.000 description 2
- 235000019833 protease Nutrition 0.000 description 2
- 238000000159 protein binding assay Methods 0.000 description 2
- 229960000856 protein c Drugs 0.000 description 2
- ZCCUUQDIBDJBTK-UHFFFAOYSA-N psoralen Chemical compound C1=C2OC(=O)C=CC2=CC2=C1OC=C2 ZCCUUQDIBDJBTK-UHFFFAOYSA-N 0.000 description 2
- 230000005180 public health Effects 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 108091008598 receptor tyrosine kinases Proteins 0.000 description 2
- 102000027426 receptor tyrosine kinases Human genes 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- YGSDEFSMJLZEOE-UHFFFAOYSA-N salicylic acid Chemical compound OC(=O)C1=CC=CC=C1O YGSDEFSMJLZEOE-UHFFFAOYSA-N 0.000 description 2
- 239000000523 sample Substances 0.000 description 2
- LSNNMFCWUKXFEE-UHFFFAOYSA-L sulfite Chemical class [O-]S([O-])=O LSNNMFCWUKXFEE-UHFFFAOYSA-L 0.000 description 2
- DHCDFWKWKRSZHF-UHFFFAOYSA-N sulfurothioic S-acid Chemical compound OS(O)(=O)=S DHCDFWKWKRSZHF-UHFFFAOYSA-N 0.000 description 2
- 208000024891 symptom Diseases 0.000 description 2
- 230000008685 targeting Effects 0.000 description 2
- 150000003573 thiols Chemical group 0.000 description 2
- 230000014616 translation Effects 0.000 description 2
- 238000002054 transplantation Methods 0.000 description 2
- 230000004614 tumor growth Effects 0.000 description 2
- 231100000588 tumorigenic Toxicity 0.000 description 2
- 230000000381 tumorigenic effect Effects 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- 238000011179 visual inspection Methods 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- DOKWDOLZCMETIJ-ZAQUEYBZSA-N (12as)-9-[[3-[[(12as)-8-methoxy-6-oxo-11,12,12a,13-tetrahydroindolo[2,1-c][1,4]benzodiazepin-9-yl]oxymethyl]-5-[2-[2-(2-methoxyethoxy)ethoxy]ethyl-(2-methyl-2-sulfanylpropyl)amino]phenyl]methoxy]-8-methoxy-12a,13-dihydroindolo[2,1-c][1,4]benzodiazepin-6-o Chemical compound N1=C[C@@H]2CC3=CC=CC=C3N2C(=O)C(C=C2OC)=C1C=C2OCC1=CC(N(CC(C)(C)S)CCOCCOCCOC)=CC(COC=2C(=CC=3C(=O)N4C5=CC=CC=C5C[C@H]4CNC=3C=2)OC)=C1 DOKWDOLZCMETIJ-ZAQUEYBZSA-N 0.000 description 1
- LLXVXPPXELIDGQ-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(2,5-dioxopyrrol-1-yl)benzoate Chemical compound C=1C=CC(N2C(C=CC2=O)=O)=CC=1C(=O)ON1C(=O)CCC1=O LLXVXPPXELIDGQ-UHFFFAOYSA-N 0.000 description 1
- JKHVDAUOODACDU-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(2,5-dioxopyrrol-1-yl)propanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCN1C(=O)C=CC1=O JKHVDAUOODACDU-UHFFFAOYSA-N 0.000 description 1
- JWDFQMWEFLOOED-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(pyridin-2-yldisulfanyl)propanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCSSC1=CC=CC=N1 JWDFQMWEFLOOED-UHFFFAOYSA-N 0.000 description 1
- QBYIENPQHBMVBV-HFEGYEGKSA-N (2R)-2-hydroxy-2-phenylacetic acid Chemical compound O[C@@H](C(O)=O)c1ccccc1.O[C@@H](C(O)=O)c1ccccc1 QBYIENPQHBMVBV-HFEGYEGKSA-N 0.000 description 1
- KXJQNQWYMAXZEV-BXXZVTAOSA-N (2r,3r,4r)-2,3,4,5-tetrahydroxypentanoyl azide Chemical compound OC[C@@H](O)[C@@H](O)[C@@H](O)C(=O)N=[N+]=[N-] KXJQNQWYMAXZEV-BXXZVTAOSA-N 0.000 description 1
- GHOKWGTUZJEAQD-ZETCQYMHSA-N (D)-(+)-Pantothenic acid Chemical compound OCC(C)(C)[C@@H](O)C(=O)NCCC(O)=O GHOKWGTUZJEAQD-ZETCQYMHSA-N 0.000 description 1
- WBYWAXJHAXSJNI-VOTSOKGWSA-M .beta-Phenylacrylic acid Natural products [O-]C(=O)\C=C\C1=CC=CC=C1 WBYWAXJHAXSJNI-VOTSOKGWSA-M 0.000 description 1
- FUHCFUVCWLZEDQ-UHFFFAOYSA-N 1-(2,5-dioxopyrrolidin-1-yl)oxy-1-oxo-4-(pyridin-2-yldisulfanyl)butane-2-sulfonic acid Chemical compound O=C1CCC(=O)N1OC(=O)C(S(=O)(=O)O)CCSSC1=CC=CC=N1 FUHCFUVCWLZEDQ-UHFFFAOYSA-N 0.000 description 1
- VNJBTKQBKFMEHH-UHFFFAOYSA-N 1-[4-(2,5-dioxopyrrol-1-yl)-2,3-dihydroxybutyl]pyrrole-2,5-dione Chemical compound O=C1C=CC(=O)N1CC(O)C(O)CN1C(=O)C=CC1=O VNJBTKQBKFMEHH-UHFFFAOYSA-N 0.000 description 1
- WXXSHAKLDCERGU-UHFFFAOYSA-N 1-[4-(2,5-dioxopyrrol-1-yl)butyl]pyrrole-2,5-dione Chemical compound O=C1C=CC(=O)N1CCCCN1C(=O)C=CC1=O WXXSHAKLDCERGU-UHFFFAOYSA-N 0.000 description 1
- MVMSCBBUIHUTGJ-UHFFFAOYSA-N 10108-97-1 Natural products C1=2NC(N)=NC(=O)C=2N=CN1C(C(C1O)O)OC1COP(O)(=O)OP(O)(=O)OC1OC(CO)C(O)C(O)C1O MVMSCBBUIHUTGJ-UHFFFAOYSA-N 0.000 description 1
- SVUOLADPCWQTTE-UHFFFAOYSA-N 1h-1,2-benzodiazepine Chemical compound N1N=CC=CC2=CC=CC=C12 SVUOLADPCWQTTE-UHFFFAOYSA-N 0.000 description 1
- 125000001917 2,4-dinitrophenyl group Chemical group [H]C1=C([H])C(=C([H])C(=C1*)[N+]([O-])=O)[N+]([O-])=O 0.000 description 1
- YVJSYWFYCJWIKW-UHFFFAOYSA-N 2-(2,5-dioxopyrrolidin-1-yl)-2-(4-formylphenoxy)acetic acid Chemical compound O=C1CCC(=O)N1C(C(=O)O)OC1=CC=C(C=O)C=C1 YVJSYWFYCJWIKW-UHFFFAOYSA-N 0.000 description 1
- OWDQCSBZQVISPN-UHFFFAOYSA-N 2-[(2,5-dioxopyrrolidin-1-yl)amino]-4-(2-iodoacetyl)benzoic acid Chemical compound OC(=O)C1=CC=C(C(=O)CI)C=C1NN1C(=O)CCC1=O OWDQCSBZQVISPN-UHFFFAOYSA-N 0.000 description 1
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- SCVJRXQHFJXZFZ-KVQBGUIXSA-N 2-amino-9-[(2r,4s,5r)-4-hydroxy-5-(hydroxymethyl)oxolan-2-yl]-3h-purine-6-thione Chemical compound C1=2NC(N)=NC(=S)C=2N=CN1[C@H]1C[C@H](O)[C@@H](CO)O1 SCVJRXQHFJXZFZ-KVQBGUIXSA-N 0.000 description 1
- XHEYLBRFUKIQMM-UHFFFAOYSA-N 2-aminoethanol;dichloromethane Chemical compound ClCCl.NCCO XHEYLBRFUKIQMM-UHFFFAOYSA-N 0.000 description 1
- ASJSAQIRZKANQN-CRCLSJGQSA-N 2-deoxy-D-ribose Chemical class OC[C@@H](O)[C@@H](O)CC=O ASJSAQIRZKANQN-CRCLSJGQSA-N 0.000 description 1
- NEAQRZUHTPSBBM-UHFFFAOYSA-N 2-hydroxy-3,3-dimethyl-7-nitro-4h-isoquinolin-1-one Chemical class C1=C([N+]([O-])=O)C=C2C(=O)N(O)C(C)(C)CC2=C1 NEAQRZUHTPSBBM-UHFFFAOYSA-N 0.000 description 1
- 125000004398 2-methyl-2-butyl group Chemical group CC(C)(CC)* 0.000 description 1
- 125000004918 2-methyl-2-pentyl group Chemical group CC(C)(CCC)* 0.000 description 1
- 125000004922 2-methyl-3-pentyl group Chemical group CC(C)C(CC)* 0.000 description 1
- 125000004493 2-methylbut-1-yl group Chemical group CC(C*)CC 0.000 description 1
- BMYNFMYTOJXKLE-UHFFFAOYSA-N 3-azaniumyl-2-hydroxypropanoate Chemical compound NCC(O)C(O)=O BMYNFMYTOJXKLE-UHFFFAOYSA-N 0.000 description 1
- FEWJPZIEWOKRBE-UHFFFAOYSA-M 3-carboxy-2,3-dihydroxypropanoate Chemical compound OC(=O)C(O)C(O)C([O-])=O FEWJPZIEWOKRBE-UHFFFAOYSA-M 0.000 description 1
- 125000004917 3-methyl-2-butyl group Chemical group CC(C(C)*)C 0.000 description 1
- 125000004919 3-methyl-2-pentyl group Chemical group CC(C(C)*)CC 0.000 description 1
- 125000004921 3-methyl-3-pentyl group Chemical group CC(CC)(CC)* 0.000 description 1
- VXGRJERITKFWPL-UHFFFAOYSA-N 4',5'-Dihydropsoralen Natural products C1=C2OC(=O)C=CC2=CC2=C1OCC2 VXGRJERITKFWPL-UHFFFAOYSA-N 0.000 description 1
- QFVHZQCOUORWEI-UHFFFAOYSA-N 4-[(4-anilino-5-sulfonaphthalen-1-yl)diazenyl]-5-hydroxynaphthalene-2,7-disulfonic acid Chemical compound C=12C(O)=CC(S(O)(=O)=O)=CC2=CC(S(O)(=O)=O)=CC=1N=NC(C1=CC=CC(=C11)S(O)(=O)=O)=CC=C1NC1=CC=CC=C1 QFVHZQCOUORWEI-UHFFFAOYSA-N 0.000 description 1
- ALYNCZNDIQEVRV-UHFFFAOYSA-N 4-aminobenzoic acid Chemical compound NC1=CC=C(C(O)=O)C=C1 ALYNCZNDIQEVRV-UHFFFAOYSA-N 0.000 description 1
- 125000004920 4-methyl-2-pentyl group Chemical group CC(CC(C)*)C 0.000 description 1
- ACVAAFHNDGTZLL-UHFFFAOYSA-N 5-(2,5-dioxopyrrol-1-yl)pentanoic acid Chemical compound OC(=O)CCCCN1C(=O)C=CC1=O ACVAAFHNDGTZLL-UHFFFAOYSA-N 0.000 description 1
- PXRKCOCTEMYUEG-UHFFFAOYSA-N 5-aminoisoindole-1,3-dione Chemical compound NC1=CC=C2C(=O)NC(=O)C2=C1 PXRKCOCTEMYUEG-UHFFFAOYSA-N 0.000 description 1
- HBEDKBRARKFPIC-UHFFFAOYSA-N 6-(2,5-dioxopyrrol-1-yl)hexanoic acid;1-hydroxypyrrolidine-2,5-dione Chemical compound ON1C(=O)CCC1=O.OC(=O)CCCCCN1C(=O)C=CC1=O HBEDKBRARKFPIC-UHFFFAOYSA-N 0.000 description 1
- 208000035657 Abasia Diseases 0.000 description 1
- 108010066676 Abrin Proteins 0.000 description 1
- NIXOWILDQLNWCW-UHFFFAOYSA-N Acrylic acid Chemical class OC(=O)C=C NIXOWILDQLNWCW-UHFFFAOYSA-N 0.000 description 1
- 108010083359 Antigen Receptors Proteins 0.000 description 1
- 102000006306 Antigen Receptors Human genes 0.000 description 1
- 208000002109 Argyria Diseases 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- CKLJMWTZIZZHCS-UHFFFAOYSA-N Aspartic acid Chemical compound OC(=O)C(N)CC(O)=O CKLJMWTZIZZHCS-UHFFFAOYSA-N 0.000 description 1
- 206010004593 Bile duct cancer Diseases 0.000 description 1
- LSNNMFCWUKXFEE-UHFFFAOYSA-M Bisulfite Chemical compound OS([O-])=O LSNNMFCWUKXFEE-UHFFFAOYSA-M 0.000 description 1
- 102000004506 Blood Proteins Human genes 0.000 description 1
- 108010017384 Blood Proteins Proteins 0.000 description 1
- 108030001720 Bontoxilysin Proteins 0.000 description 1
- ZOXJGFHDIHLPTG-UHFFFAOYSA-N Boron Chemical compound [B] ZOXJGFHDIHLPTG-UHFFFAOYSA-N 0.000 description 1
- 208000003174 Brain Neoplasms Diseases 0.000 description 1
- CPELXLSAUQHCOX-UHFFFAOYSA-M Bromide Chemical compound [Br-] CPELXLSAUQHCOX-UHFFFAOYSA-M 0.000 description 1
- 208000011691 Burkitt lymphomas Diseases 0.000 description 1
- FERIUCNNQQJTOY-UHFFFAOYSA-N Butyric acid Natural products CCCC(O)=O FERIUCNNQQJTOY-UHFFFAOYSA-N 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 239000004215 Carbon black (E152) Substances 0.000 description 1
- BVKZGUZCCUSVTD-UHFFFAOYSA-L Carbonate Chemical compound [O-]C([O-])=O BVKZGUZCCUSVTD-UHFFFAOYSA-L 0.000 description 1
- 208000005623 Carcinogenesis Diseases 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 206010008342 Cervix carcinoma Diseases 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-M Chloride anion Chemical compound [Cl-] VEXZGXHMUGYJMC-UHFFFAOYSA-M 0.000 description 1
- WBYWAXJHAXSJNI-SREVYHEPSA-N Cinnamic acid Chemical compound OC(=O)\C=C/C1=CC=CC=C1 WBYWAXJHAXSJNI-SREVYHEPSA-N 0.000 description 1
- 108020004705 Codon Proteins 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 1
- 241000557626 Corvus corax Species 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- AEMOLEFTQBMNLQ-YMDCURPLSA-N D-galactopyranuronic acid Chemical compound OC1O[C@H](C(O)=O)[C@H](O)[C@H](O)[C@H]1O AEMOLEFTQBMNLQ-YMDCURPLSA-N 0.000 description 1
- DSLZVSRJTYRBFB-LLEIAEIESA-N D-glucaric acid Chemical compound OC(=O)[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C(O)=O DSLZVSRJTYRBFB-LLEIAEIESA-N 0.000 description 1
- RGHNJXZEOKUKBD-SQOUGZDYSA-M D-gluconate Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C([O-])=O RGHNJXZEOKUKBD-SQOUGZDYSA-M 0.000 description 1
- HAIWUXASLYEWLM-UHFFFAOYSA-N D-manno-Heptulose Natural products OCC1OC(O)(CO)C(O)C(O)C1O HAIWUXASLYEWLM-UHFFFAOYSA-N 0.000 description 1
- COLNVLDHVKWLRT-MRVPVSSYSA-N D-phenylalanine Chemical compound OC(=O)[C@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-MRVPVSSYSA-N 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- FEWJPZIEWOKRBE-JCYAYHJZSA-N Dextrotartaric acid Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O FEWJPZIEWOKRBE-JCYAYHJZSA-N 0.000 description 1
- 108010016626 Dipeptides Proteins 0.000 description 1
- 206010061818 Disease progression Diseases 0.000 description 1
- 238000012286 ELISA Assay Methods 0.000 description 1
- 206010014733 Endometrial cancer Diseases 0.000 description 1
- 206010014759 Endometrial neoplasm Diseases 0.000 description 1
- 101710147220 Ent-copalyl diphosphate synthase, chloroplastic Proteins 0.000 description 1
- 101001055311 Equus asinus Immunoglobulin heavy constant alpha Proteins 0.000 description 1
- 101710089384 Extracellular protease Proteins 0.000 description 1
- 108091006020 Fc-tagged proteins Proteins 0.000 description 1
- BDAGIHXWWSANSR-UHFFFAOYSA-M Formate Chemical compound [O-]C=O BDAGIHXWWSANSR-UHFFFAOYSA-M 0.000 description 1
- MVMSCBBUIHUTGJ-GDJBGNAASA-N GDP-alpha-D-mannose Chemical compound C([C@H]1O[C@H]([C@@H]([C@@H]1O)O)N1C=2N=C(NC(=O)C=2N=C1)N)OP(O)(=O)OP(O)(=O)O[C@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@@H]1O MVMSCBBUIHUTGJ-GDJBGNAASA-N 0.000 description 1
- 208000022072 Gallbladder Neoplasms Diseases 0.000 description 1
- BCCRXDTUTZHDEU-VKHMYHEASA-N Gly-Ser Chemical compound NCC(=O)N[C@@H](CO)C(O)=O BCCRXDTUTZHDEU-VKHMYHEASA-N 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 101100334515 Homo sapiens FCGR3A gene Proteins 0.000 description 1
- 101000840258 Homo sapiens Immunoglobulin J chain Proteins 0.000 description 1
- 101000998952 Homo sapiens Immunoglobulin heavy variable 1-3 Proteins 0.000 description 1
- 101001008325 Homo sapiens Immunoglobulin kappa variable 2D-29 Proteins 0.000 description 1
- 101001013150 Homo sapiens Interstitial collagenase Proteins 0.000 description 1
- 101000878605 Homo sapiens Low affinity immunoglobulin epsilon Fc receptor Proteins 0.000 description 1
- 101001011906 Homo sapiens Matrix metalloproteinase-14 Proteins 0.000 description 1
- 101001011896 Homo sapiens Matrix metalloproteinase-19 Proteins 0.000 description 1
- 101001013139 Homo sapiens Matrix metalloproteinase-20 Proteins 0.000 description 1
- 101000627858 Homo sapiens Matrix metalloproteinase-24 Proteins 0.000 description 1
- 101000627852 Homo sapiens Matrix metalloproteinase-25 Proteins 0.000 description 1
- 101000627854 Homo sapiens Matrix metalloproteinase-26 Proteins 0.000 description 1
- 101000627860 Homo sapiens Matrix metalloproteinase-27 Proteins 0.000 description 1
- 101000990902 Homo sapiens Matrix metalloproteinase-9 Proteins 0.000 description 1
- 101000990915 Homo sapiens Stromelysin-1 Proteins 0.000 description 1
- 101000577877 Homo sapiens Stromelysin-3 Proteins 0.000 description 1
- AVXURJPOCDRRFD-UHFFFAOYSA-N Hydroxylamine Chemical compound ON AVXURJPOCDRRFD-UHFFFAOYSA-N 0.000 description 1
- 102100026120 IgG receptor FcRn large subunit p51 Human genes 0.000 description 1
- 101710177940 IgG receptor FcRn large subunit p51 Proteins 0.000 description 1
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 1
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 1
- 102100029571 Immunoglobulin J chain Human genes 0.000 description 1
- 102100036886 Immunoglobulin heavy variable 1-3 Human genes 0.000 description 1
- 102100027458 Immunoglobulin kappa variable 2D-29 Human genes 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- HSNZZMHEPUFJNZ-UHFFFAOYSA-N L-galacto-2-Heptulose Natural products OCC(O)C(O)C(O)C(O)C(=O)CO HSNZZMHEPUFJNZ-UHFFFAOYSA-N 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- 125000000510 L-tryptophano group Chemical group [H]C1=C([H])C([H])=C2N([H])C([H])=C(C([H])([H])[C@@]([H])(C(O[H])=O)N([H])[*])C2=C1[H] 0.000 description 1
- JVTAAEKCZFNVCJ-UHFFFAOYSA-M Lactate Chemical compound CC(O)C([O-])=O JVTAAEKCZFNVCJ-UHFFFAOYSA-M 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- WHXSMMKQMYFTQS-UHFFFAOYSA-N Lithium Chemical compound [Li] WHXSMMKQMYFTQS-UHFFFAOYSA-N 0.000 description 1
- 102100038007 Low affinity immunoglobulin epsilon Fc receptor Human genes 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- FYYHWMGAXLPEAU-UHFFFAOYSA-N Magnesium Chemical compound [Mg] FYYHWMGAXLPEAU-UHFFFAOYSA-N 0.000 description 1
- 102000000380 Matrix Metalloproteinase 1 Human genes 0.000 description 1
- 102100030216 Matrix metalloproteinase-14 Human genes 0.000 description 1
- 102100030218 Matrix metalloproteinase-19 Human genes 0.000 description 1
- 102100024129 Matrix metalloproteinase-24 Human genes 0.000 description 1
- 102100024131 Matrix metalloproteinase-25 Human genes 0.000 description 1
- 102100024128 Matrix metalloproteinase-26 Human genes 0.000 description 1
- 102100024132 Matrix metalloproteinase-27 Human genes 0.000 description 1
- 102100030412 Matrix metalloproteinase-9 Human genes 0.000 description 1
- 101150073847 Mmp23 gene Proteins 0.000 description 1
- LMSMREVZQWXONY-UHFFFAOYSA-N N-(2,5-dioxopyrrolidin-1-yl)-6-hydrazinylpyridine-3-carboxamide propan-2-ylidenehydrazine Chemical compound CC(C)=NN.C1=NC(NN)=CC=C1C(=O)NN1C(=O)CCC1=O LMSMREVZQWXONY-UHFFFAOYSA-N 0.000 description 1
- 229910017852 NH2NH2 Inorganic materials 0.000 description 1
- 229910017912 NH2OH Inorganic materials 0.000 description 1
- 229910002651 NO3 Inorganic materials 0.000 description 1
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 1
- 108091061960 Naked DNA Proteins 0.000 description 1
- NHNBFGGVMKEFGY-UHFFFAOYSA-N Nitrate Chemical compound [O-][N+]([O-])=O NHNBFGGVMKEFGY-UHFFFAOYSA-N 0.000 description 1
- GRYLNZFGIOXLOG-UHFFFAOYSA-N Nitric acid Chemical compound O[N+]([O-])=O GRYLNZFGIOXLOG-UHFFFAOYSA-N 0.000 description 1
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 1
- 101710163270 Nuclease Proteins 0.000 description 1
- 229910018830 PO3H Inorganic materials 0.000 description 1
- 206010033645 Pancreatitis Diseases 0.000 description 1
- 206010033647 Pancreatitis acute Diseases 0.000 description 1
- 108090000526 Papain Proteins 0.000 description 1
- 206010057249 Phagocytosis Diseases 0.000 description 1
- ABLZXFCXXLZCGV-UHFFFAOYSA-N Phosphorous acid Chemical group OP(O)=O ABLZXFCXXLZCGV-UHFFFAOYSA-N 0.000 description 1
- 206010035226 Plasma cell myeloma Diseases 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- XBDQKXXYIPTUBI-UHFFFAOYSA-M Propionate Chemical compound CCC([O-])=O XBDQKXXYIPTUBI-UHFFFAOYSA-M 0.000 description 1
- 101000762949 Pseudomonas aeruginosa (strain ATCC 15692 / DSM 22644 / CIP 104116 / JCM 14847 / LMG 12228 / 1C / PRS 101 / PAO1) Exotoxin A Proteins 0.000 description 1
- IWYDHOAUDWTVEP-UHFFFAOYSA-N R-2-phenyl-2-hydroxyacetic acid Natural products OC(=O)C(O)C1=CC=CC=C1 IWYDHOAUDWTVEP-UHFFFAOYSA-N 0.000 description 1
- 239000012980 RPMI-1640 medium Substances 0.000 description 1
- 206010038389 Renal cancer Diseases 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 1
- 102220492414 Ribulose-phosphate 3-epimerase_H35A_mutation Human genes 0.000 description 1
- 108010039491 Ricin Proteins 0.000 description 1
- 208000004337 Salivary Gland Neoplasms Diseases 0.000 description 1
- 206010061934 Salivary gland cancer Diseases 0.000 description 1
- 108010084592 Saporins Proteins 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- 206010039509 Scab Diseases 0.000 description 1
- HAIWUXASLYEWLM-AZEWMMITSA-N Sedoheptulose Natural products OC[C@H]1[C@H](O)[C@H](O)[C@H](O)[C@@](O)(CO)O1 HAIWUXASLYEWLM-AZEWMMITSA-N 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 108010071390 Serum Albumin Proteins 0.000 description 1
- 102000007562 Serum Albumin Human genes 0.000 description 1
- 101710084578 Short neurotoxin 1 Proteins 0.000 description 1
- 208000000453 Skin Neoplasms Diseases 0.000 description 1
- DWAQJAXMDSEUJJ-UHFFFAOYSA-M Sodium bisulfite Chemical group [Na+].OS([O-])=O DWAQJAXMDSEUJJ-UHFFFAOYSA-M 0.000 description 1
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 1
- 208000000102 Squamous Cell Carcinoma of Head and Neck Diseases 0.000 description 1
- 102100030416 Stromelysin-1 Human genes 0.000 description 1
- 102100028847 Stromelysin-3 Human genes 0.000 description 1
- KDYFGRWQOYBRFD-UHFFFAOYSA-N Succinic acid Natural products OC(=O)CCC(O)=O KDYFGRWQOYBRFD-UHFFFAOYSA-N 0.000 description 1
- QAOWNCQODCNURD-UHFFFAOYSA-L Sulfate Chemical compound [O-]S([O-])(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-L 0.000 description 1
- LSNNMFCWUKXFEE-UHFFFAOYSA-N Sulfurous acid Chemical class OS(O)=O LSNNMFCWUKXFEE-UHFFFAOYSA-N 0.000 description 1
- FEWJPZIEWOKRBE-UHFFFAOYSA-N Tartaric acid Natural products [H+].[H+].[O-]C(=O)C(O)C(O)C([O-])=O FEWJPZIEWOKRBE-UHFFFAOYSA-N 0.000 description 1
- 208000024313 Testicular Neoplasms Diseases 0.000 description 1
- 206010057644 Testis cancer Diseases 0.000 description 1
- 101710182532 Toxin a Proteins 0.000 description 1
- 102100023935 Transmembrane glycoprotein NMB Human genes 0.000 description 1
- 102000003990 Urokinase-type plasminogen activator Human genes 0.000 description 1
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 1
- 125000002777 acetyl group Chemical group [H]C([H])([H])C(*)=O 0.000 description 1
- 230000021736 acetylation Effects 0.000 description 1
- 238000006640 acetylation reaction Methods 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 201000003229 acute pancreatitis Diseases 0.000 description 1
- 150000001266 acyl halides Chemical class 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 239000003513 alkali Substances 0.000 description 1
- 229910052783 alkali metal Inorganic materials 0.000 description 1
- 150000008044 alkali metal hydroxides Chemical class 0.000 description 1
- 150000001340 alkali metals Chemical class 0.000 description 1
- 229910052784 alkaline earth metal Inorganic materials 0.000 description 1
- 150000001342 alkaline earth metals Chemical class 0.000 description 1
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 1
- SRBFZHDQGSBBOR-STGXQOJASA-N alpha-D-lyxopyranose Chemical compound O[C@@H]1CO[C@H](O)[C@@H](O)[C@H]1O SRBFZHDQGSBBOR-STGXQOJASA-N 0.000 description 1
- 229910052782 aluminium Inorganic materials 0.000 description 1
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 1
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 1
- 229940059260 amidate Drugs 0.000 description 1
- 230000009435 amidation Effects 0.000 description 1
- 238000007112 amidation reaction Methods 0.000 description 1
- 238000010976 amide bond formation reaction Methods 0.000 description 1
- 125000006242 amine protecting group Chemical group 0.000 description 1
- BBLCQPWSRMSMGD-UHFFFAOYSA-N aminoazanium;pyridine-3-carboxylate;hydrochloride Chemical compound Cl.[NH3+]N.[O-]C(=O)C1=CC=CN=C1 BBLCQPWSRMSMGD-UHFFFAOYSA-N 0.000 description 1
- 229940064734 aminobenzoate Drugs 0.000 description 1
- 229910021529 ammonia Inorganic materials 0.000 description 1
- 150000003863 ammonium salts Chemical class 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 239000004037 angiogenesis inhibitor Substances 0.000 description 1
- 229940121369 angiogenesis inhibitor Drugs 0.000 description 1
- 150000008064 anhydrides Chemical class 0.000 description 1
- 238000000137 annealing Methods 0.000 description 1
- 230000008485 antagonism Effects 0.000 description 1
- 230000009830 antibody antigen interaction Effects 0.000 description 1
- 229940125644 antibody drug Drugs 0.000 description 1
- 108091000831 antigen binding proteins Proteins 0.000 description 1
- 239000003080 antimitotic agent Substances 0.000 description 1
- 239000002246 antineoplastic agent Substances 0.000 description 1
- PYMYPHUHKUWMLA-WDCZJNDASA-N arabinose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)C=O PYMYPHUHKUWMLA-WDCZJNDASA-N 0.000 description 1
- 229940072107 ascorbate Drugs 0.000 description 1
- 235000010323 ascorbic acid Nutrition 0.000 description 1
- 239000011668 ascorbic acid Substances 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 229940077388 benzenesulfonate Drugs 0.000 description 1
- SRSXLGNVWSONIS-UHFFFAOYSA-M benzenesulfonate Chemical compound [O-]S(=O)(=O)C1=CC=CC=C1 SRSXLGNVWSONIS-UHFFFAOYSA-M 0.000 description 1
- 229940053197 benzodiazepine derivative antiepileptics Drugs 0.000 description 1
- 235000010233 benzoic acid Nutrition 0.000 description 1
- 238000007068 beta-elimination reaction Methods 0.000 description 1
- 208000026900 bile duct neoplasm Diseases 0.000 description 1
- 239000003124 biologic agent Substances 0.000 description 1
- 230000008512 biological response Effects 0.000 description 1
- 239000012472 biological sample Substances 0.000 description 1
- 201000000053 blastoma Diseases 0.000 description 1
- 238000010504 bond cleavage reaction Methods 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- 210000000988 bone and bone Anatomy 0.000 description 1
- 229910052796 boron Inorganic materials 0.000 description 1
- 229940053031 botulinum toxin Drugs 0.000 description 1
- KDYFGRWQOYBRFD-NUQCWPJISA-N butanedioic acid Chemical compound O[14C](=O)CC[14C](O)=O KDYFGRWQOYBRFD-NUQCWPJISA-N 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 230000036952 cancer formation Effects 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 125000002837 carbocyclic group Chemical group 0.000 description 1
- 231100000504 carcinogenesis Toxicity 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 230000004709 cell invasion Effects 0.000 description 1
- 230000017455 cell-cell adhesion Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000005754 cellular signaling Effects 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 201000010881 cervical cancer Diseases 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 239000002738 chelating agent Substances 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 230000000973 chemotherapeutic effect Effects 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 description 1
- 235000013985 cinnamic acid Nutrition 0.000 description 1
- 229930016911 cinnamic acid Natural products 0.000 description 1
- 230000008045 co-localization Effects 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 201000001416 congenital diarrhea 5 with tufting enteropathy Diseases 0.000 description 1
- 230000030944 contact inhibition Effects 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 229910052802 copper Inorganic materials 0.000 description 1
- 239000010949 copper Substances 0.000 description 1
- 238000012866 crystallographic experiment Methods 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 125000000392 cycloalkenyl group Chemical group 0.000 description 1
- 125000000753 cycloalkyl group Chemical group 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 230000006240 deamidation Effects 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- KZNICNPSHKQLFF-UHFFFAOYSA-N dihydromaleimide Natural products O=C1CCC(=O)N1 KZNICNPSHKQLFF-UHFFFAOYSA-N 0.000 description 1
- HRKQOINLCJTGBK-UHFFFAOYSA-N dihydroxidosulfur Chemical class OSO HRKQOINLCJTGBK-UHFFFAOYSA-N 0.000 description 1
- 230000006806 disease prevention Effects 0.000 description 1
- 230000005750 disease progression Effects 0.000 description 1
- 208000037765 diseases and disorders Diseases 0.000 description 1
- 238000006073 displacement reaction Methods 0.000 description 1
- WBZKQQHYRPRKNJ-UHFFFAOYSA-N disulfurous acid Chemical class OS(=O)S(O)(=O)=O WBZKQQHYRPRKNJ-UHFFFAOYSA-N 0.000 description 1
- GRWZHXKQBITJKP-UHFFFAOYSA-L dithionite(2-) Chemical compound [O-]S(=O)S([O-])=O GRWZHXKQBITJKP-UHFFFAOYSA-L 0.000 description 1
- GRWZHXKQBITJKP-UHFFFAOYSA-N dithionous acid Chemical compound OS(=O)S(O)=O GRWZHXKQBITJKP-UHFFFAOYSA-N 0.000 description 1
- 125000005414 dithiopyridyl group Chemical group 0.000 description 1
- AFOSIXZFDONLBT-UHFFFAOYSA-N divinyl sulfone Chemical compound C=CS(=O)(=O)C=C AFOSIXZFDONLBT-UHFFFAOYSA-N 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 201000008184 embryoma Diseases 0.000 description 1
- 210000005175 epidermal keratinocyte Anatomy 0.000 description 1
- 210000004955 epithelial membrane Anatomy 0.000 description 1
- 230000032050 esterification Effects 0.000 description 1
- JOXWSDNHLSQKCC-UHFFFAOYSA-N ethenesulfonamide Chemical compound NS(=O)(=O)C=C JOXWSDNHLSQKCC-UHFFFAOYSA-N 0.000 description 1
- NPUKDXXFDDZOKR-LLVKDONJSA-N etomidate Chemical compound CCOC(=O)C1=CN=CN1[C@H](C)C1=CC=CC=C1 NPUKDXXFDDZOKR-LLVKDONJSA-N 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 229960000390 fludarabine Drugs 0.000 description 1
- GIUYCYHIANZCFB-FJFJXFQQSA-N fludarabine phosphate Chemical compound C1=NC=2C(N)=NC(F)=NC=2N1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@@H]1O GIUYCYHIANZCFB-FJFJXFQQSA-N 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 229940017705 formaldehyde sulfoxylate Drugs 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 239000012458 free base Substances 0.000 description 1
- 229940050411 fumarate Drugs 0.000 description 1
- 239000001530 fumaric acid Substances 0.000 description 1
- 150000002243 furanoses Chemical class 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 201000010175 gallbladder cancer Diseases 0.000 description 1
- 229940083124 ganglion-blocking antiadrenergic secondary and tertiary amines Drugs 0.000 description 1
- 201000006585 gastric adenocarcinoma Diseases 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- 201000007492 gastroesophageal junction adenocarcinoma Diseases 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 229940114119 gentisate Drugs 0.000 description 1
- 229940050410 gluconate Drugs 0.000 description 1
- 229940097042 glucuronate Drugs 0.000 description 1
- 229940097043 glucuronic acid Drugs 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 229960004275 glycolic acid Drugs 0.000 description 1
- 150000002337 glycosamines Chemical group 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 210000003128 head Anatomy 0.000 description 1
- 201000010536 head and neck cancer Diseases 0.000 description 1
- 201000000459 head and neck squamous cell carcinoma Diseases 0.000 description 1
- 210000003494 hepatocyte Anatomy 0.000 description 1
- 201000001599 hereditary nonpolyposis colorectal cancer type 8 Diseases 0.000 description 1
- KIWQWJKWBHZMDT-UHFFFAOYSA-N homocysteine thiolactone Chemical compound NC1CCSC1=O KIWQWJKWBHZMDT-UHFFFAOYSA-N 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 238000001794 hormone therapy Methods 0.000 description 1
- 210000004408 hybridoma Anatomy 0.000 description 1
- 230000036571 hydration Effects 0.000 description 1
- 238000006703 hydration reaction Methods 0.000 description 1
- 229930195733 hydrocarbon Natural products 0.000 description 1
- 150000003840 hydrochlorides Chemical class 0.000 description 1
- 125000004435 hydrogen atom Chemical group [H]* 0.000 description 1
- XMBWDFGMSWQBCA-UHFFFAOYSA-N hydrogen iodide Chemical compound I XMBWDFGMSWQBCA-UHFFFAOYSA-N 0.000 description 1
- QAOWNCQODCNURD-UHFFFAOYSA-M hydrogensulfate Chemical compound OS([O-])(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-M 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- 150000001261 hydroxy acids Chemical class 0.000 description 1
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 description 1
- 230000033444 hydroxylation Effects 0.000 description 1
- 238000005805 hydroxylation reaction Methods 0.000 description 1
- SBGKURINHGJRFN-UHFFFAOYSA-N hydroxymethanesulfinic acid Chemical compound OCS(O)=O SBGKURINHGJRFN-UHFFFAOYSA-N 0.000 description 1
- 150000002463 imidates Chemical class 0.000 description 1
- 230000028993 immune response Effects 0.000 description 1
- 238000002991 immunohistochemical analysis Methods 0.000 description 1
- 230000002637 immunotoxin Effects 0.000 description 1
- 229940051026 immunotoxin Drugs 0.000 description 1
- 239000002596 immunotoxin Substances 0.000 description 1
- 231100000608 immunotoxin Toxicity 0.000 description 1
- 229910052738 indium Inorganic materials 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 150000007529 inorganic bases Chemical class 0.000 description 1
- 229910017053 inorganic salt Inorganic materials 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 239000000138 intercalating agent Substances 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 229910052742 iron Inorganic materials 0.000 description 1
- 125000000959 isobutyl group Chemical group [H]C([H])([H])C([H])(C([H])([H])[H])C([H])([H])* 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- TWBYWOBDOCUKOW-UHFFFAOYSA-M isonicotinate Chemical compound [O-]C(=O)C1=CC=NC=C1 TWBYWOBDOCUKOW-UHFFFAOYSA-M 0.000 description 1
- 125000001972 isopentyl group Chemical group [H]C([H])([H])C([H])(C([H])([H])[H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 201000010982 kidney cancer Diseases 0.000 description 1
- 238000012004 kinetic exclusion assay Methods 0.000 description 1
- 230000003902 lesion Effects 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- 230000029226 lipidation Effects 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 229910052744 lithium Inorganic materials 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 201000007270 liver cancer Diseases 0.000 description 1
- 208000014018 liver neoplasm Diseases 0.000 description 1
- 244000144972 livestock Species 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 150000002680 magnesium Chemical class 0.000 description 1
- 229910052749 magnesium Inorganic materials 0.000 description 1
- 239000011777 magnesium Substances 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 239000011976 maleic acid Substances 0.000 description 1
- 230000036210 malignancy Effects 0.000 description 1
- 229960002510 mandelic acid Drugs 0.000 description 1
- WPBNNNQJVZRUHP-UHFFFAOYSA-L manganese(2+);methyl n-[[2-(methoxycarbonylcarbamothioylamino)phenyl]carbamothioyl]carbamate;n-[2-(sulfidocarbothioylamino)ethyl]carbamodithioate Chemical compound [Mn+2].[S-]C(=S)NCCNC([S-])=S.COC(=O)NC(=S)NC1=CC=CC=C1NC(=S)NC(=O)OC WPBNNNQJVZRUHP-UHFFFAOYSA-L 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 230000010534 mechanism of action Effects 0.000 description 1
- 201000001441 melanoma Diseases 0.000 description 1
- 210000004379 membrane Anatomy 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 229910000000 metal hydroxide Inorganic materials 0.000 description 1
- 150000004692 metal hydroxides Chemical class 0.000 description 1
- 230000001394 metastastic effect Effects 0.000 description 1
- 206010061289 metastatic neoplasm Diseases 0.000 description 1
- TWXDDNPPQUTEOV-FVGYRXGTSA-N methamphetamine hydrochloride Chemical compound Cl.CN[C@@H](C)CC1=CC=CC=C1 TWXDDNPPQUTEOV-FVGYRXGTSA-N 0.000 description 1
- 229940098779 methanesulfonic acid Drugs 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- WBYWAXJHAXSJNI-UHFFFAOYSA-N methyl p-hydroxycinnamate Natural products OC(=O)C=CC1=CC=CC=C1 WBYWAXJHAXSJNI-UHFFFAOYSA-N 0.000 description 1
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical compound CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 1
- 238000002493 microarray Methods 0.000 description 1
- 230000000813 microbial effect Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 150000007522 mineralic acids Chemical class 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 210000001616 monocyte Anatomy 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 201000000050 myeloid neoplasm Diseases 0.000 description 1
- 125000004108 n-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000001280 n-hexyl group Chemical group C(CCCCC)* 0.000 description 1
- 125000000740 n-pentyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000004123 n-propyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 210000003739 neck Anatomy 0.000 description 1
- 230000009826 neoplastic cell growth Effects 0.000 description 1
- 229910017604 nitric acid Inorganic materials 0.000 description 1
- 125000004433 nitrogen atom Chemical group N* 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 239000002777 nucleoside Substances 0.000 description 1
- 150000003833 nucleoside derivatives Chemical class 0.000 description 1
- 229940049964 oleate Drugs 0.000 description 1
- ZQPPMHVWECSIRJ-KTKRTIGZSA-N oleic acid Chemical compound CCCCCCCC\C=C/CCCCCCCC(O)=O ZQPPMHVWECSIRJ-KTKRTIGZSA-N 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 150000007530 organic bases Chemical class 0.000 description 1
- 230000002611 ovarian Effects 0.000 description 1
- 235000006408 oxalic acid Nutrition 0.000 description 1
- 229940116315 oxalic acid Drugs 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 230000001590 oxidative effect Effects 0.000 description 1
- 210000001711 oxyntic cell Anatomy 0.000 description 1
- 125000000636 p-nitrophenyl group Chemical group [H]C1=C([H])C(=C([H])C([H])=C1*)[N+]([O-])=O 0.000 description 1
- WLJNZVDCPSBLRP-UHFFFAOYSA-N pamoic acid Chemical compound C1=CC=C2C(CC=3C4=CC=CC=C4C=C(C=3O)C(=O)O)=C(O)C(C(O)=O)=CC2=C1 WLJNZVDCPSBLRP-UHFFFAOYSA-N 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 229940014662 pantothenate Drugs 0.000 description 1
- 235000019161 pantothenic acid Nutrition 0.000 description 1
- 239000011713 pantothenic acid Substances 0.000 description 1
- FJKROLUGYXJWQN-UHFFFAOYSA-N papa-hydroxy-benzoic acid Natural products OC(=O)C1=CC=C(O)C=C1 FJKROLUGYXJWQN-UHFFFAOYSA-N 0.000 description 1
- 229940055729 papain Drugs 0.000 description 1
- 235000019834 papain Nutrition 0.000 description 1
- 230000008506 pathogenesis Effects 0.000 description 1
- 230000007170 pathology Effects 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 230000008782 phagocytosis Effects 0.000 description 1
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 1
- 150000004713 phosphodiesters Chemical class 0.000 description 1
- UEZVMMHDMIWARA-UHFFFAOYSA-M phosphonate Chemical compound [O-]P(=O)=O UEZVMMHDMIWARA-UHFFFAOYSA-M 0.000 description 1
- 150000008298 phosphoramidates Chemical class 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 102000054765 polymorphisms of proteins Human genes 0.000 description 1
- 150000003109 potassium Chemical class 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 235000010259 potassium hydrogen sulphite Nutrition 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 150000003141 primary amines Chemical class 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 125000001436 propyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 201000001514 prostate carcinoma Diseases 0.000 description 1
- 108020001580 protein domains Proteins 0.000 description 1
- 230000009145 protein modification Effects 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 150000003214 pyranose derivatives Chemical class 0.000 description 1
- UMJSCPRVCHMLSP-UHFFFAOYSA-N pyridine Natural products COC1=CC=CN=C1 UMJSCPRVCHMLSP-UHFFFAOYSA-N 0.000 description 1
- 229940107700 pyruvic acid Drugs 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 238000006722 reduction reaction Methods 0.000 description 1
- 230000008844 regulatory mechanism Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 125000000548 ribosyl group Chemical class C1([C@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 1
- 229960001860 salicylate Drugs 0.000 description 1
- YGSDEFSMJLZEOE-UHFFFAOYSA-M salicylate Chemical compound OC1=CC=CC=C1C([O-])=O YGSDEFSMJLZEOE-UHFFFAOYSA-M 0.000 description 1
- 229960004889 salicylic acid Drugs 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 125000002914 sec-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 208000011581 secondary neoplasm Diseases 0.000 description 1
- HSNZZMHEPUFJNZ-SHUUEZRQSA-N sedoheptulose Chemical compound OC[C@@H](O)[C@@H](O)[C@@H](O)[C@H](O)C(=O)CO HSNZZMHEPUFJNZ-SHUUEZRQSA-N 0.000 description 1
- 238000004904 shortening Methods 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- 238000004513 sizing Methods 0.000 description 1
- 201000000849 skin cancer Diseases 0.000 description 1
- 235000010267 sodium hydrogen sulphite Nutrition 0.000 description 1
- 159000000000 sodium salts Chemical group 0.000 description 1
- MKNJJMHQBYVHRS-UHFFFAOYSA-M sodium;1-[11-(2,5-dioxopyrrol-1-yl)undecanoyloxy]-2,5-dioxopyrrolidine-3-sulfonate Chemical compound [Na+].O=C1C(S(=O)(=O)[O-])CC(=O)N1OC(=O)CCCCCCCCCCN1C(=O)C=CC1=O MKNJJMHQBYVHRS-UHFFFAOYSA-M 0.000 description 1
- 210000004872 soft tissue Anatomy 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 238000007614 solvation Methods 0.000 description 1
- 238000009987 spinning Methods 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- KDYFGRWQOYBRFD-UHFFFAOYSA-L succinate(2-) Chemical compound [O-]C(=O)CCC([O-])=O KDYFGRWQOYBRFD-UHFFFAOYSA-L 0.000 description 1
- 229960002317 succinimide Drugs 0.000 description 1
- 125000000020 sulfo group Chemical group O=S(=O)([*])O[H] 0.000 description 1
- 150000003461 sulfonyl halides Chemical class 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 239000011975 tartaric acid Substances 0.000 description 1
- 235000002906 tartaric acid Nutrition 0.000 description 1
- 150000003892 tartrate salts Chemical class 0.000 description 1
- 125000000999 tert-butyl group Chemical group [H]C([H])([H])C(*)(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 201000003120 testicular cancer Diseases 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 238000002560 therapeutic procedure Methods 0.000 description 1
- 150000007970 thio esters Chemical group 0.000 description 1
- 125000000101 thioether group Chemical group 0.000 description 1
- 150000003568 thioethers Chemical class 0.000 description 1
- 125000003396 thiol group Chemical group [H]S* 0.000 description 1
- CNHYKKNIIGEXAY-UHFFFAOYSA-N thiolan-2-imine Chemical compound N=C1CCCS1 CNHYKKNIIGEXAY-UHFFFAOYSA-N 0.000 description 1
- 150000003580 thiophosphoric acid esters Chemical class 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 108700012359 toxins Proteins 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 108091007466 transmembrane glycoproteins Proteins 0.000 description 1
- 125000004044 trifluoroacetyl group Chemical group FC(C(=O)*)(F)F 0.000 description 1
- 150000003668 tyrosines Chemical class 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 150000003672 ureas Chemical class 0.000 description 1
- 229960005356 urokinase Drugs 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 229910052725 zinc Inorganic materials 0.000 description 1
- 239000011701 zinc Substances 0.000 description 1
Images














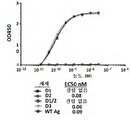






















Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/68033—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being a maytansine
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/68035—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being a pyrrolobenzodiazepine
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/6811—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being a protein or peptide, e.g. transferrin or bleomycin
- A61K47/6817—Toxins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6849—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a receptor, a cell surface antigen or a cell surface determinant
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6851—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a determinant of a tumour cell
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6851—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a determinant of a tumour cell
- A61K47/6857—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a determinant of a tumour cell the tumour determinant being from lung cancer cell
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6889—Conjugates wherein the antibody being the modifying agent and wherein the linker, binder or spacer confers particular properties to the conjugates, e.g. peptidic enzyme-labile linkers or acid-labile linkers, providing for an acid-labile immuno conjugate wherein the drug may be released from its antibody conjugated part in an acidic, e.g. tumoural or environment
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
Abstract
본 개시내용은 일반적으로 인간 EpCAM, EpCAM 활성화 가능한 항체, 및 이의 면역접합체에 특이적으로 결합하는 항체 및 항체 단편뿐만 아니라, 암과 같은 질환의 진단 및 치료를 위한 항체, 항체 단편, 활성화 가능한 항체 및 면역접합체의 제조 및 이용 방법에 관한 것이다.
Description
본 개시내용은 일반적으로 인간 EpCAM, EpCAM 활성화 가능한 항체, 및 이의 면역접합체에 특이적으로 결합하는 항체 및 항체 단편뿐만 아니라, 암과 같은 질환의 진단 및 치료를 위한 항체, 항체 단편, 활성화 가능한 항체, 및 면역접합체의 제조 및 이용 방법에 관한 것이다.
상피세포 부착 분자(EpCAM)는 세포외 도메인, 막관통 도메인 및 단일 세포내 도메인을 포함하는 I형 막관통 당단백질이다. 인간에서의 EpCAM 발현은 상피-특이적이다. 편평상피 및 일부 특정 상피세포 유형, 예컨대, 표피 각질형성세포, 간세포, 위벽세포 및 근상피세포를 제외한 대다수의 상피세포는 EpCAM을 발현시킨다(Balzar et al., J. Mol. Med. 77:699-712 (1999); Momburg et al., Cancer Res 47:2883-2891 (1987)).
EpCAM은 상이한 기관의 인간 암종 상에서 풍부하게 그리고 균질하게 발현된다(Went et al., Br. J. Cancer 94:128-35 (2006); Herlyn et al., Proc Natl. Acad. Sci. USA 76:1438-1442 (1979); Went et al., Hum. Pathol. 35:122-128 (2004)). EpCAM은, 예를 들어, 난소암, 결장암, 위암, 전립선암 및 폐암을 포함하는 대다수의 상피암에서 과발현된다. 또한, EpCAM은 위 및 위-식도 접합부 선암종(Martin, J. Clin. Pathol. 52:701-704 (1999)) 상의 그리고 결장직장, 췌장암종 및 유방 암종으로부터 유래된 세포주에서(Szala, Proc. Natl. Acad. Sci. USA 87:3542-3546 (1990), Packeisen, Hybridoma 18:37-40 (1999)) 대다수의 원발성, 전이성 및 파종성 NSCLC(비소세포 폐암) 상에서 발현되는 것으로 나타났다(Passlick, Int. J. Cancer 87:548-552 (2000)). 다른 연구에서, 2차 종양의 108개 샘플의 면역조직화학 분석은 4%만이 EpCAM 발현을 결여한다는 것을 발견하였다. EpCAM은 또한 결장, 유방, 췌장 및 전립선 암종으로부터 단리된 암-개시 또는 암 줄기 세포에서 과발현된다(O'Brien et al., Nature 445:106-110 (2007); Marhaba etal., Curr. Mol. Med. 8:784-804 (2008)).
정상 세포는 상피막의 기저측부 상에서 EpCAM을 발현시키는 반면, 암세포는 선단면 상에서 EpCAM을 과하게 발현시킨다. 정상 세포 EpCAM이 덜 두드러지며 덜 노출되었기 때문에 항체 기반 치료제는 EpCAM 발현의 이런 특징을 활용하도록 설계되었는데, 이는 건강한 세포라 치료적 항-EpCAM 항체에 의한 결합에 민감하지 않을 수도 있다는 것을 의미한다.
EpCAM에 대한 다수의 항체는 임상에서 사용되었지만, 다양한 이유로 실패되었다. 시험한 EpCAM 항체는 네이키드(naked) 항체, 면역독소 및 이중- 또는 삼중-특이성 항체를 포함하는 다수의 형식을 취한다(Baeuerle, Br. J. Cancer, 96:417-423 (2007)). 예를 들어, 아데카투무맙(adecatumumab)(MT201), 네이키드 항-EpCAM 항체는 결장직장, 전립선 및 유방암 치료의 임상 연구에서 시험되었다. 현재의 항-EpCAM 항체-기반 접근에 직면하는 안전성 문제는 전신 불내약성 및 급성 췌장염을 포함한다. 따라서, EpCAM에 대한 치료 항체를 개발하기 위한 몇몇 시도가 있었지만, 이전에 개발한 항체의 단점 및 제한을 극복하는 신규한 치료적 EpCAM 항체의 개발에 대한 유의한 필요가 있다.
본 개시내용은 인간 EpCAM에 특이적으로 결합하는 항체 및 항체 단편뿐만 아니라 EpCAM 활성화 가능한 항체, 및 항체, 항체 단편 및 활성화 가능한 항체를 포함하는 면역접합체를 제공한다. EpCAM 항체, EpCAM-결합 항체 단편 및 활성화 가능한 항체를 암호화하는 핵산 서열을 포함하는 폴리뉴클레오타이드가 또한 제공되며, 폴리뉴클레오타이드를 포함하는 벡터, 및 폴리뉴클레오타이드 및 벡터를 포함하는 세포가 제공된다. 본 개시내용은 또한 EpCAM 항체, EpCAM-결합 항체 단편 및 활성화 가능한 항체를 포함하는 약제학적 조성물과 같은 조성물이 제공된다. EpCAM 항체, EpCAM-결합 항체 단편, 활성화 가능한 항체, 및 조성물을 제조하고 이용하는 방법이 추가로 제공된다. 이러한 방법은 종양 성장을 저해하기 위해 항체, 항체 단편, 활성화 가능한 항체, 면역접합체 및 기타 조성물을 이용하는 것뿐만 아니라 암과 같은 질환의 진단 및 치료를 위한 항체, 항체 단편, 활성화 가능한 항체, 면역접합체, 및 조성물의 제조 및 이용 방법을 포함한다.
일부 실시형태에서, 본 개시내용은 하기를 제공한다:
[1]
EpCAM 항체 또는 EpCAM-결합 항체 단편으로서, 하기를 포함하는, 항체 또는 항체 단편:
(a) 서열 X1YX3X4H(여기서, X1은 N 및 S로부터 선택되며, X3은 Y, N, F, S, H, D, L, I 및 W로부터 선택되고, X4는 I 및 M으로부터 선택됨)(서열번호 5)를 포함하는 중쇄 CDR1(VH-CDR1);
(b) 서열 WX2X3PGX6VYIQYX12X13KFX17G(여기서, X2는 I 및 F로부터 선택되며, X3은 Y 및 N으로부터 선택되고, X6은 N 및 D로부터 선택되며, X12는 N 및 S로부터 선택되고, X13은 E 및 Q로부터 선택되며, X17은 K 및 Q로부터 선택됨)(서열번호 7)를 포함하는 중쇄 CDR2(VH-CDR2);
(c) 서열 X1GX3X4FAY(여기서, X1은 D 및 E로부터 선택되고, X3은 P, A, S, Y, F, G, T 및 V로부터 선택되며, X4는 Y 및 W로부터 선택됨)(서열번호 8)를 포함하는 중쇄 CDR3(VH-CDR3);
(d) 서열 RSSX4SLLHSX10GX12TY LX16(여기서, X4는 R 및 K로부터 선택되고, X10은 N 및 D로부터 선택되며, X12는 F 및 I로부터 선택되고, X16은 Y 및 S로부터 선택됨)(서열번호 10)을 포함하는 경쇄 CDR1(VL-CDR1);
(e) 서열 QTSNLAS(서열번호 40)를 포함하는 경쇄 CDR2(VL-CDR2): 및
(f) 서열 X1QX3LELPX8T(여기서, X1은 A, L 및 Q로부터 선택되고, X3은 S, G, Y 및 N으로부터 선택되며, X8은 N 및 W로부터 선택됨)(서열번호 11)를 포함하는 경쇄 CDR3(VL-CDR3);
[2]
[1]에 있어서, 상기 항체 또는 항체 단편은 하기를 포함하는, 항체 또는 항체 단편:
(a) 서열 NYX3IH(여기서, X3은 Y, N, F, S, H, D, L, I 및 W로부터 선택됨)(서열번호 6)를 포함하는 중쇄 CDR1(VH-CDR1);
(b) 서열 WX2X3PGX6VYIQYX12X13KFX17G(여기서, X2는 I 및 F로부터 선택되며, X3은 Y 및 N으로부터 선택되고, X6은 N 및 D로부터 선택되며, X12는 N 및 S로부터 선택되고, X13은 E 및 Q로부터 선택되며, X17은 K 및 Q로부터 선택됨)(서열번호 7)를 포함하는 중쇄 CDR2(VH-CDR2);
(c) 서열 DGPX4FAY(여기서, X4는 Y 및 W로부터 선택됨)(서열번호 9)를 포함하는 중쇄 CDR3(VH-CDR3);
(d) 서열 RSSX4SLLHSX10GX12TYLX16(여기서, X4는 R 및 K로부터 선택되고, X10은 N 및 D로부터 선택되며, X12는 F 및 I로부터 선택되고, X16은 Y 및 S로부터 선택됨)(서열번호 10)을 포함하는 경쇄 CDR1(VL-CDR1);
(e) 서열 QTSNLAS(서열번호 40)를 포함하는 경쇄 CDR2(VL-CDR2): 및
(f) 서열 AQX3LELPNT(여기서, X3은 S, G, Y 및 N으로부터 선택됨)(서열번호 12)를 포함하는 경쇄 CDR3(VL-CDR3);
[3]
[1] 또는 [2]에 있어서, 상기 항체 또는 항체 단편은 하기 군으로부터 선택된 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편:
(a) 각각 서열번호 13 내지 15, 42, 40 및 41;
(b) 각각 서열번호 13 내지 15, 및 39 내지 41;
(c) 각각 서열번호 13, 26, 15 및 39 내지 41; 및
(d) 각각 서열번호 13, 24, 15, 42, 40 및 41;
[4]
[1] 내지 [3] 중 어느 하나에 있어서, 상기 항체 또는 항체 단편은 인간 EpCAM과 사이노몰거스(cynomolgus) EpCAM 둘 다에 대해 3.0nM 이하의 KD로 결합하는, EpCAM 항체 또는 EpCAM-결합 항체 단편;
[5]
[4]에 있어서, 상기 항체 또는 항체 단편은 서열번호 2의 아미노산 서열을 갖는 인간 EpCAM의 세포외 도메인 내의 에피토프에 특이적으로 결합하는, EpCAM 항체 또는 EpCAM-결합 항체 단편;
[6]
[5]에 있어서, 상기 항체 또는 항체 단편은 하기를 포함하는, 항체 또는 항체 단편:
(a) 서열 NYYIH(서열번호 13)를 포함하는 VH-CDR1;
(b) 서열 WIYPGNVYIQYNEKFKG(서열번호 14)를 포함하는 VH-CDR2:
(c) 서열 DGPWFAY(서열번호 15)를 포함하는 VH-CDR3;
(d) 서열 RSSRSLLHSDGFTYLY(서열번호 42)를 포함하는 VL-CDR1;
(e) 서열 QTSNLAS(서열번호 40)를 포함하는 VL-CDR2: 및
(f) 및 서열 AQNLELPNT(서열번호 41)를 포함하는 VL-CDR3;
[7]
[4]에 있어서, 상기 항체 또는 항체 단편은 하기를 포함하는, 항체 또는 항체 단편:
(a) 서열 NYYIH(서열번호 13)를 포함하는 VH-CDR1;
(b) 서열 WIYPGNVYIQYNEKEKG(서열번호 14)를 포함하는 VH-CDR2;
(c) 서열 DGPWFAY(서열번호 15)를 포함하는 VH-CDR3:
(d) 서열 RSSKSLLHSDGFTYLY(서열번호 39)를 포함하는 VL-CDR1;
(e) 서열 QTSNLAS(서열번호 40)를 포함하는 VL-CDR2: 및
(f) 서열 AQNLELPNT(서열번호 41)를 포함하는 VL-CDR3;
[8]
[3]에 있어서, 상기 항체 또는 항체 단편은 하기로부터 선택된 VH 및 VL을 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편:
(a) 서열번호 54의 서열을 갖는 VH, 및 서열번호 89의 서열을 갖는 VL:
(b) 서열번호 54의 서열을 갖는 VH, 및 서열번호 87의 서열을 갖는 VL;
(c) 서열번호 55의 서열을 갖는 VH, 및 서열번호 87의 서열을 갖는 VL:
(d) 서열번호 56의 서열을 갖는 VH, 및 서열번호 88의 서열을 갖는 VL:
(e) 서열번호 55의 서열을 갖는 VH, 및 서열번호 89의 서열을 갖는 VL; 및
(f) 서열번호 56의 서열을 갖는 VH, 및 서열번호 89의 서열을 갖는 VL:
[9]
[8]에 있어서, 상기 항체 또는 항체 단편은 서열번호 54의 VH 및 서열번호 89의 VL을 포함하는, 항체 또는 항체 단편;
[10]
[8]에 있어서, 상기 항체 또는 항체 단편은 서열번호 54의 VH 및 서열번호 87의 VL을 포함하는, 항체 또는 항체 단편;
[11]
[8]에 있어서, 상기 항체 또는 항체 단편은,
(a) 서열번호 103의 서열을 갖는 HC, 및 서열번호 140의 서열을 갖는 LC;
(b) 서열번호 103의 서열을 갖는 HC, 및 서열번호 138의 서열을 갖는 LC;
(c) 서열번호 105의 서열을 갖는 HC, 및 서열번호 139의 서열을 갖는 LC;
(d) 서열번호 106의 서열을 갖는 HC, 및 서열번호 139의 서열을 갖는 LC;
(e) 서열번호 105의 서열을 갖는 HC, 및 서열번호 140의 서열을 갖는 LC; 및
(f) 서열번호 106의 서열을 갖는 HC, 및 서열번호 140의 서열을 갖는 LC
로부터 선택된 중쇄 및 경쇄를 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편;
[12]
[11]에 있어서, 상기 항체 또는 항체 단편은 서열번호 103의 HC 및 서열번호 140의 LC를 포함하는, 항체 또는 항체 단편;
[13]
[11]에 있어서, 상기 항체 또는 항체 단편은 서열번호 103의 HC 및 서열번호 138의 LC를 포함하는, 항체 또는 항체 단편;
[14]
[1] 또는 [2]에 있어서, 상기 항체 또는 항체 단편은 하기로 이루어진 군으로부터 선택된 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편:
(a) 각각 서열번호 22, 14, 15, 42, 40 및 41;
(b) 각각 서열번호 13, 14, 33, 42, 40 및 41;
(c) 각각 서열번호 23, 14, 15, 42, 40 및 41; 및
(d) 각각 서열번호 25, 14, 15, 42, 40 및 41;
[15]
[14]에 있어서, 상기 항체 또는 항체 단편은 하기를 포함하는, 항체 또는 항체 단편:
(a) 서열 NYHIH(서열번호 22)를 포함하는 VH-CDR1;
(b) 서열 WIYPGNVYIQYNEKFKG(서열번호 14)를 포함하는 VH-CDR2;
(c) 서열 DGPWFAY(서열번호 15)를 포함하는 VH-CDR3;
(d) 서열 RSSRSLLHSDGFTYLY(서열번호 42)를 포함하는 VL-CDR1;
(e) 서열 QTSNLAS(서열번호 40)를 포함하는 VL-CDR2: 및
(f) 서열 AQNLELPNT(서열번호 41)를 포함하는 VL-CDR3;
[16]
[14]에 있어서, 상기 항체 또는 항체 단편은 하기를 포함하는, 항체 또는 항체 단편:
(a) 서열 NYYIH(서열번호 13)를 포함하는 VH-CDR1;
(b) 서열 WIYPGNVYIQYNEKFKG(서열번호 14)를 포함하는 VH-CDR2;
(c) 서열 DGYWFAY(서열번호 33)를 포함하는 VH-CDR3;
(d) 서열 RSSRSLLHSDGFTYLY(서열번호 42)를 포함하는 VL-CDR1;
(e) 서열 QTSNLAS(서열번호 40)를 포함하는 VL-CDR2: 및
(f) 서열 AQNLELPNT(서열번호 41)를 포함하는 VL-CDR3;
[17]
[14]에 있어서, 상기 항체 또는 항체 단편은 하기로부터 선택된 VH 및 VL을 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편:
(a) 서열번호 75의 서열을 갖는 VH, 및 서열번호 89의 서열을 갖는 VL:
(b) 서열번호 77의 서열을 갖는 VH, 및 서열번호 89의 서열을 갖는 VL:
(c) 서열번호 76의 서열을 갖는 VH, 및 서열번호 89의 서열을 갖는 VL: 및
(d) 서열번호 84의 서열을 갖는 VH, 및 서열번호 89의 서열을 갖는 VL:
[18]
[17]에 있어서, 상기 항체 또는 항체 단편은 서열번호 75의 VH 및 서열번호 89의 VL을 포함하는, 항체 또는 항체 단편;
[19]
[17]에 있어서, 상기 항체 또는 항체 단편은 서열번호 77의 VH 및 서열번호 89의 VL을 포함하는, 항체 또는 항체 단편;
[20]
[17]에 있어서, 상기 항체 또는 항체 단편은,
(a) 서열번호 125의 서열을 갖는 HC, 및 서열번호 140의 서열을 갖는 LC;
(b) 서열번호 127의 서열을 갖는 HC, 및 서열번호 140의 서열을 갖는 LC;
(c) 서열번호 126의 서열을 갖는 HC, 및 서열번호 140의 서열을 갖는 LC; 및
(d) 서열번호 134의 서열을 갖는 HC, 및 서열번호 140의 서열을 갖는 LC
로부터 선택된 중쇄 및 경쇄를 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편;
[21]
[20]에 있어서, 상기 항체 또는 항체 단편은 서열번호 125의 HC 및 서열번호 140의 LC를 포함하는, 항체 또는 항체 단편;
[22]
[20]에 있어서, 상기 항체 또는 항체 단편은 서열번호 127의 HC 및 서열번호 140의 LC를 포함하는, 항체 또는 항체 단편;
[23]
[1] 내지 [22] 중 어느 하나에 있어서, 상기 항체 또는 항체 단편은 뮤린, 비-인간 포유류, 키메라, 인간화 또는 인간 항체인, 항체 또는 항체 단편;
[24]
[1] 내지 [23] 중 어느 하나에 있어서, 상기 항체는 전장 항체인, 항체 또는 항체 단편;
[25]
[24]에 있어서, 상기 항체는 인간 IgG1인, 전장 항체;
[26]
[1] 내지 [23] 중 어느 하나에 있어서, 항체 단편은 Fab, Fab', F(ab')2, Fd, 단일쇄 Fv 또는 scFv, 이황화 연결된 Fv, V-NAR 도메인, IgNar, 인트라바디, IgGΔCH2, 미니바디, F(ab')3, 테트라바디, 트라이어바디(triabody), 다이어바디(diabody), 단일-도메인 항체, DVD-Ig, Fcab, mAb2, (scFv)2 또는 scFv-Fc인, 항체 또는 이의 항체 단편;
[27]
[1] 내지 [26] 중 어느 하나에 있어서, 상기 활성화 가능한 항체는,
(a) 항체 또는 항체 단편에 결합된 절단 가능 모이어티로서, 프로테아제에 대한 기질로서 작용하는 폴리펩타이드인, 절단 가능 모이어티; 및
(b) 항체 또는 항체 단편에 결합된 마스킹 모이어티로서, 활성화 가능한 항체가 비절단 상태일 때 EpCAM에 대한 항체 또는 항체 단편의 결합을 저해하는, 마스킹 모이어티
를 더 포함하되,
비절단 상태의 활성화 가능한 항체는 N-말단으로부터 C-말단까지 다음과 같은 구조적 배열: (마스킹 모이어티)-(절단 가능 모이어티)-(항체 또는 항체 단편) 또는 (항체 또는 항체 단편)-(절단 가능 모이어티)-(마스킹 모이어티)
을 갖는, 항체 또는 항체 단편을 포함하는, 활성화 가능한 항체;
[28]
EpCAM 활성화 가능한 항체로서,
(a) 하기 (i) 내지 (iv)의 군으로부터 선택된 구성원의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편:
(i) 각각 서열번호 13 내지 15, 42, 40 및 41;
(ii) 각각 서열번호 13 내지 15, 및 39 내지 41;
(iii) 각각 서열번호 13, 26, 15 및 39 내지 41: 및
(iv) 각각 서열번호 13, 24, 15, 42, 40 및 41;
(b) EpCAM 항체 또는 EpCAM-결합 항체 단편에 결합된 마스킹 모이어티로서, 활성화 가능한 항체가 비절단 상태일 때 EpCAM에 대한 항체 또는 항체 단편의 결합을 저해하는, 마스킹 모이어티; 및
(c) EpCAM 항체 또는 EpCAM-결합 항체 단편에 결합된 절단 가능 모이어티로서, 프로테아제에 대한 기질로서 작용하는 폴리펩타이드인, 절단 가능 모이어티
를 포함하되,
비절단 상태의 활성화 가능한 항체는 N-말단으로부터 C-말단까지 다음과 같은 구조적 배열: (마스킹 모이어티)-(절단 가능 모이어티)-(항체 또는 항체 단편) 또는 (항체 또는 항체 단편)-(절단 가능 모이어티)-(마스킹 모이어티)
을 갖는, EpCAM 활성화 가능한 항체;
[29]
[28]에 있어서, 상기 활성화 가능한 항체는 각각 서열번호 13 내지 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체;
[30]
[29]에 있어서, 상기 활성화 가능한 항체는 서열번호 54의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체;
[31]
[30]에 있어서, 상기 활성화 가능한 항체는 서열번호 103의 서열을 갖는 중쇄 및 서열번호 140의 서열을 갖는 LC를 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체;
[32]
[29] 내지 [31] 중 어느 하나에 있어서, 상기 활성화 가능한 항체는 서열번호 151 내지 157로부터 선택된 아미노산 서열을 갖는 마스킹 모이어티를 포함하는, EpCAM 활성화 가능한 항체;
[33]
[32]에 있어서, 상기 활성화 가능한 항체는 서열번호 155의 아미노산 서열을 갖는 마스킹 모이어티를 포함하는, EpCAM 활성화 가능한 항체;
[34]
[29] 내지 [33] 중 어느 하나에 있어서, 상기 활성화 가능한 항체는 서열번호 168 또는 169의 아미노산 서열을 포함하는 절단 가능 모이어티를 포함하는, EpCAM 활성화 가능한 항체;
[35]
EpCAM 활성화 가능한 항체로서,
(a) 하기 (i) 내지 (iv)로 이루어진 군으로부터 선택된 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편:
(i) 각각 서열번호 22, 14, 15, 42, 40 및 41;
(ii) 각각 서열번호 13, 14, 33, 42, 40 및 41;
(iii) 각각 서열번호 23, 14, 15, 42, 40 및 41; 및
(iv) 각각 서열번호 25, 14, 15, 42, 40 및 41;
(b) EpCAM 항체 또는 EpCAM-결합 항체 단편에 결합된 마스킹 모이어티로서, 활성화 가능한 항체가 비절단 상태일 때 EpCAM에 대한 항체 또는 항체 단편의 결합을 저해하는, 마스킹 모이어티; 및
(c) EpCAM 항체 또는 EpCAM-결합 항체 단편에 결합된 절단 가능 모이어티로서, 프로테아제에 대한 기질로서 작용하는 폴리펩타이드인, 절단 가능 모이어티
를 포함하되,
비절단 상태의 활성화 가능한 항체는 N-말단으로부터 C-말단까지 다음과 같은 구조적 배열: (마스킹 모이어티)-(절단 가능 모이어티)-(항체 또는 항체 단편) 또는 (항체 또는 항체 단편)-(절단 가능 모이어티)-(마스킹 모이어티)
을 갖는, EpCAM 활성화 가능한 항체.
[36]
[35]에 있어서, 상기 활성화 가능한 항체는 각각 서열번호 22, 14, 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체;
[37]
[36]에 있어서, 상기 활성화 가능한 항체는 서열번호 75의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체;
[38]
[37]에 있어서, 상기 활성화 가능한 항체는 서열번호 125의 서열을 갖는 중쇄 및 서열번호 140의 서열을 갖는 경쇄를 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체;
[39]
[36] 내지 [38] 중 어느 하나에 있어서, 상기 활성화 가능한 항체는 서열번호 151 내지 157 및 162 내지 167로부터 선택된 아미노산 서열을 갖는 마스킹 모이어티를 포함하는, EpCAM 활성화 가능한 항체;
[40]
[39]에 있어서, 상기 활성화 가능한 항체는 서열번호 162 내지 167로부터 선택된 아미노산 서열을 갖는 마스킹 모이어티를 포함하는, EpCAM 활성화 가능한 항체;
[41]
[36] 내지 [40] 중 어느 하나에 있어서, 상기 활성화 가능한 항체는 서열번호 168 또는 169의 아미노산 서열을 포함하는 절단 가능 모이어티를 포함하는, EpCAM 활성화 가능한 항체;
[42]
[35]에 있어서, 상기 활성화 가능한 항체는 각각 서열번호 13, 14, 33, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체;
[43]
[42]에 있어서, 상기 활성화 가능한 항체는 서열번호 77의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체;
[44]
[43]에 있어서, 상기 활성화 가능한 항체는 서열번호 127의 서열을 갖는 중쇄 및 서열번호 140의 서열을 갖는 경쇄를 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체;
[45]
[42] 내지 [44] 중 어느 하나에 있어서, 상기 활성화 가능한 항체는 서열번호 151 내지 161로부터 선택된 아미노산 서열을 갖는 마스킹 모이어티를 포함하는, EpCAM 활성화 가능한 항체;
[46]
[45]에 있어서, 상기 활성화 가능한 항체는 서열번호 158 내지 161로부터 선택된 아미노산 서열을 갖는 마스킹 모이어티를 포함하는, EpCAM 활성화 가능한 항체;
[47]
[42] 내지 [46] 중 어느 하나에 있어서, 상기 활성화 가능한 항체는 서열번호 168 또는 169의 아미노산 서열을 포함하는 절단 가능 모이어티를 포함하는, EpCAM 활성화 가능한 항체;
[48]
[1] 내지 [26] 중 어느 하나의 항체 또는 EpCAM-결합 항체 단편 또는 [27] 내지 [47] 중 어느 하나의 활성화 가능한 항체를 생성하는 세포;
[49]
EpCAM 항체 또는 EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 생성하는 방법으로서,
(a) [48]의 세포를 배양시키는 단계; 및,
(b) 세포 또는 세포 배양물로부터 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 단리시키는 단계
를 포함하는, 방법;
[50]
[49]에 있어서, 세포는 진핵 세포인, 방법;
[51]
[50]에 있어서, 세포는 CHO 세포인, 방법;
[52]
[1] 내지 [26] 중 어느 하나의 항체 또는 항체 단편 또는 [27] 내지 [47] 중 어느 하나의 EpCAM 활성화 가능한 항체를 포함하는 진단 시약;
[53]
[52]에 있어서, 항체, 항체 단편, 또는 활성화 가능한 항체는 표지된, 진단 시약;
[54]
[53]에 있어서, 표지는 방사성표지, 형광단, 발색단, 영상화제 및 금속 이온으로부터 선택된, 진단 시약;
[55]
[1] 내지 [26] 중 어느 것의 항체 또는 항체 단편 또는 [27] 내지 [47] 중 어느 하나의 활성화 가능한 항체를 암호화하는 폴리뉴클레오타이드 또는 폴리뉴클레오타이드의 세트;
[56]
[55]의 폴리뉴클레오타이드를 포함하는 벡터 또는 벡터의 세트;
[57]
[55]의 폴리뉴클레오타이드 또는 폴리뉴클레오타이드의 세트 또는 [56]의 벡터를 포함하는, 숙주 세포;
[58]
다음의 식으로 표시되는 면역접합체:

식 중:
EpBA는 라이신 잔기를 통해 CyL1에 공유적으로 연결된, [1] 내지 [47] 중 어느 것에 따른 EpCAM 항체, EpCAM 항체 단편, 또는 EpCAM 활성화 가능한 항체이다;
WL은 1 내지 20의 정수이고; 그리고
CyL1은 다음의 식으로 표시되며:

또는 이의 약제학적으로 허용 가능한 염, 식 중:
N과 C 사이의 이중선  은 단일 결합 또는 이중 결합을 나타내며, 단, 이것이 이중 결합일 때, X는 존재하지 않고, Y는 -H 또는 (C1-C4)알킬이며; 이것이 단일 결합일 때, X는 -H 또는 아민 보호 모이어티이며, Y는 -OH 또는 -SO3H이고 또는 이의 약제학적으로 허용 가능한 염이고;
은 단일 결합 또는 이중 결합을 나타내며, 단, 이것이 이중 결합일 때, X는 존재하지 않고, Y는 -H 또는 (C1-C4)알킬이며; 이것이 단일 결합일 때, X는 -H 또는 아민 보호 모이어티이며, Y는 -OH 또는 -SO3H이고 또는 이의 약제학적으로 허용 가능한 염이고;
W'는 -NRe'이고,
Re'는 -(CH2-CH2-O)n-Rk이며;
n은 2 내지 6의 정수이고;
Rk는 -H 또는 -Me이며;
Rx3은 (C1-C6)알킬이고;
L'은 다음의 식으로 표시되며:

R5는 -H 또는 (C1-C3)알킬이고;
P는 아미노산 잔기 또는 2 내지 20개의 아미노산 잔기를 포함하는 펩타이드이며;
Ra 및 Rb는, 각각의 경우에 대해, 각각 독립적으로 -H, (C1-C3)알킬, 또는 하전된 치환체 또는 이온화 가능한 기 Q이고;
m은 1 내지 6의 정수이고; 그리고
Zs1은 하기 식 중 어느 하나로부터 선택되고:


식 중, q는 1 내지 5의 정수이며;
[59]
[58]에 있어서, Ra와 Rb는 둘 다 H이고; R5는 H 또는 Me인, 면역접합체;
[60]
[58] 또는 [59]에 있어서, P는 2 내지 5개의 아미노산 잔기를 포함하는 펩타이드인, 면역접합체;
[61]
[58] 내지 [60] 중 어느 하나에 있어서, P는 Gly-Gly-Gly, Ala-Val, Val-Ala, Val-Cit, Val-Lys, Phe-Lys, Lys-Lys, Ala-Lys, Phe-Cit, Leu-Cit, Ile-Cit, Trp, Cit, Phe-Ala, Phe-N9-토실-Arg, Phe-N9-나이트로-Arg, Phe-Phe-Lys, D-Phe-Phe-Lys, Gly- Phe-Lys, Leu-Ala-Leu, Ile-Ala-Leu, Val-Ala-Val, Ala-Leu-Ala-Leu(서열번호 215), β-Ala-Leu-Ala-Leu(서열번호 216), Gly-Phe-Leu-Gly(서열번호 217), Val-Arg, Arg-Val, Arg-Arg, Val-D-Cit, Val-D-Lys, Val-D-Arg, D-Val-Cit, D-Val-Lys, D-Val-Arg, D-Val-D-Cit, D-Val-D-Lys, D-Val-D-Arg, D-Arg-D-Arg, Ala-Ala, Ala-D-Ala, D-Ala-Ala, D-Ala-D-Ala, Ala-Met, Met-Ala, Gln-Val, Asn-Ala, Gln-Phe 및 Gln-Ala으로부터 선택된, 면역접합체. 더 구체적으로는, P는 Gly-Gly-Gly, Ala-Val, Ala-Ala, Ala-D-Ala, D-Ala-Ala, 또는 D-Ala-D-Ala인, 면역접합체;
[62]
[61]에 있어서, P는 Gly-Gly-Gly, Ala-Val, Ala-Ala, Ala-D-Ala, D-Ala-Ala, 또는 D-Ala-D-Ala인, 면역접합체;
[63][58] 내지 [62] 중 어느 하나에 있어서, Q는 -SO3H 또는 이의 약제학적으로 허용 가능한 염인, 면역접합체;
[64] [58]에 있어서, 상기 면역접합체는 하기 식으로 표시되는, 면역접합체 또는 이의 약제학적으로 허용 가능한 염:





식 중,
WL는 1 내지 10의 정수이고; N과 C 사이의 이중선  은 단일 결합 또는 이중 결합을 나타내며, 단, 이것이 이중 결합일 때, X는 존재하지 않고, Y는 -H이며; 이것이 단일 결합일 때, X는 -H이며, Y는 -OH 또는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이다;
은 단일 결합 또는 이중 결합을 나타내며, 단, 이것이 이중 결합일 때, X는 존재하지 않고, Y는 -H이며; 이것이 단일 결합일 때, X는 -H이며, Y는 -OH 또는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이다;
[65]
[58] 내지 [64] 중 어느 하나에 있어서, N과 C 사이의 이중선  은 이중 결합을 나타내고, X는 존재하지 않으며, Y는 -H인, 면역접합체;
은 이중 결합을 나타내고, X는 존재하지 않으며, Y는 -H인, 면역접합체;
[66]
[58] 내지 [64] 중 어느 하나에 있어서, N과 C 사이의 이중선 ~은 단일 결합을 나타내고, X는 -H이며, Y는 -SO3H 또는 이의 약제학적으로 허용 가능한 염인, 면역접합체;
[67]
[66]에 있어서, Y는 -SO3H, -SO3Na 또는 -SO3K인, 면역접합체;
[68]
[66]에 있어서, Y는 -SO3Na인, 면역접합체;
[69]
다음의 식으로 표시되는 면역접합체:

식 중:
EpBA는 라이신 잔기를 통해 CyL2에 공유적으로 연결된, [1] 내지 [47] 중 어느 것에 따른 EpCAM 항체, EpCAM 항체 단편, 또는 EpCAM 활성화 가능한 항체;
WL은 1 내지 20의 정수이고;
CyL2는 다음의 식으로 표시되며:

m'는 1 또는 2이고;
R1 및 R2는, 각각 독립적으로 H 또는 (C1-C3)알킬이며;
Zs1은 하기 식 중 어느 하나로부터 선택되고:

식 중, q는 1 내지 5의 정수이며;
[70]
[69]에 있어서, m'는 1이고, R1와 R2는 둘 다 H인, 면역접합체;
[71]
[69]에 있어서, m'는 2이고, R1와 R2는 둘 다 Me인, 면역접합체;
[72] [69]에 있어서, 상기 면역접합체는 하기 식으로 표시되는, 면역접합체 또는 이의 약제학적으로 허용 가능한 염:


식 중 WL은 1 내지 10의 정수이고;
[73][69]에 있어서, 상기 면역접합체는 하기 식으로 표시되는, 면역접합체 또는 이의 약제학적으로 허용 가능한 염:

[74]
다음의 식으로 표시되는 면역접합체 또는 이의 약제학적으로 허용 가능한 염:

식 중:
WL은 1 내지 10의 정수이고;
EpBA는 각각 서열번호 13 내지 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체, EpCAM 항체 단편, 또는 EpCAM 활성화 가능한 항체이다;
[75]
[74]에 있어서, 단리된 항체 또는 EpCAM-결합 항체 단편은 각각 서열번호 54 및 서열번호 89의 서열을 갖는 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하는, 면역접합체;
[76]
[74]에 있어서, 단리된 항체는 각각 서열번호 103 및 서열번호 140의 서열을 갖는 중쇄 및 경쇄를 포함하는, 면역접합체;
[77]
[74] 내지 [76] 중 어느 하나에 있어서, 면역접합체는 서열번호 151 내지 157로부터 선택된 아미노산 서열을 갖는 마스킹 모이어티를 포함하는 활성화 가능한 항체를 포함하는, 면역접합체;
[78]
[77]에 있어서, 마스킹 모이어티는 서열번호 155의 아미노산 서열을 갖는, 면역접합체;
[79]
[77] 또는 [78]에 있어서, 면역접합체는 서열번호 168 또는 서열번호 169의 절단 가능 모이어티를 더 포함하는 활성화 가능한 항체를 포함하는, 면역접합체;
[80]
γ-말레이미도뷰티르산 N-석신이미딜 에스터(GMBS) 또는 N-(γ-말레이미도뷰틸옥시)설포석신이미드 에스터(설포-GMBS 또는 sGMBS) 링커를 통해, 다음의 구조식으로 표시되는 메이탄시노이드 화합물 DM21L(LDL-DM으로도 지칭됨)에 결합된 EpBA를 포함하는 면역접합체:

식 중, EpBA는 [1] 내지 [47] 중 어느 것에 따른 pCAM 항체, EpCAM 항체 단편, 또는 EpCAM 활성화 가능한 항체이다;
[81]
[80]에 있어서, GMBS 및 설포-GMBS(또는 sGMBS) 링커는 하기 식으로 표시되는, 면역접합체:

[82]
[80] 또는 [81]에 있어서, 하기 식으로 표시되는, 면역접합체:

식 중:
EpBA는 Lys 아민기를 통해 메이탄시노이드 화합물에 연결되되, q는 1 내지 10의 정수이다;
[83]
[80] 내지 [82] 중 어느 하나에 있어서, EpBA는 각각 서열번호 13 내지 15, 42, 40 및 41의 서열을 포함하는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는, 면역접합체;
[84]
[83]에 있어서, EpBA는 각각 서열번호 54 및 서열번호 89의 서열을 갖는 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하는, 면역접합체;
[85]
[84]에 있어서, EpBA는 각각 서열번호 103 및 서열번호 140의 서열을 갖는 중쇄 및 경쇄를 포함하는, 면역접합체;
[86]
[83] 내지 [85] 중 어느 하나에 있어서, 면역접합체는 서열번호 151 내지 157로부터 선택된 아미노산 서열을 갖는 마스킹 모이어티를 포함하는 활성화 가능한 항체를 포함하는, 면역접합체;
[87]
[86]에 있어서, 마스킹 모이어티는 서열번호 155의 아미노산 서열을 갖는, 면역접합체;
[88]
[86] 또는 [87]에 있어서, 면역접합체는 서열번호 168 또는 서열번호 169의 절단 가능 모이어티를 더 포함하는 활성화 가능한 항체를 포함하는, 면역접합체;
[89]
[58] 내지 [88] 중 어느 하나에 있어서, 약제학적으로 허용 가능한 염은 나트륨 또는 칼륨염은, 면역접합체;
[90]
[1] 내지 [47] 중 어느 하나의 항체, 항원-결합 단편, 또는 활성화 가능한 항체 및 약제학적으로 허용 가능한 담체를 포함하는, 약제학적 조성물;
[91]
[58] 내지 [88] 중 어느 하나의 면역접합체 및 약제학적으로 허용 가능한 담체를 포함하는, 약제학적 조성물;
[92]
암세포를 유효량의 [1] 내지 [47] 중 어느 하나의 항체, 항원-결합 단편, 또는 활성화 가능한 항체, [58] 내지 [88] 중 어느 하나의 면역접합체, 또는 [90] 또는 [91]의 약제학적 조성물과 접촉시키는 단계를 포함하는, 암세포의 사멸 방법;
[93]
[92]에 있어서, 암세포는 상피 암세포, 유방 암세포, 폐 암세포, 위암세포, 결장직장암, 전립선 암세포, 난소암세포, 결장암세포, 직장암세포 또는 암 줄기 세포인, 방법;
[94]
[92]에 있어서, 암세포는 난소암세포, 자궁암세포, 위암세포, 췌장암세포, 또는 결장직장암세포인, 방법;
[95]
EpCAM을 발현시키는 암 치료 방법으로서, 치료적 유효량의 [1] 내지 [47] 중 어느 하나의 항체 또는 항원-결합 단편, [58] 내지 [88] 중 어느 하나의 면역접합체, 또는 [90] 또는 [91]의 약제학적 조성물을 암 치료가 필요한 대상체에게 투여하는 단계를 포함하는, 치료 방법.
[96]
[95]에 있어서, 암은 상피암인, 치료 방법;
[97]
[95]에 있어서, 암은 유방 암, 폐 암, 위암, 결장직장암, 전립선 암, 난소암, 결장암, 식도암, 기관암, 위암 방광암, 자궁암, 직장암, 소장암, 또는 이들의 전이인, 치료 방법;
[98]
[95]에 있어서, 암은 난소암, 자궁암, 위암, 췌장암, 결장직장암, 또는 이들의 전이인, 치료 방법;
[99]
[97]에 있어서, 암은 폐암인, 치료 방법;
[100]
[99]에 있어서, 폐암은 비소세포 폐암인, 치료 방법;
[101]
[100]에 있어서, 비소세포 폐암은 비-편평 비소세포 폐암인, 치료 방법;
[102]
[95]에 있어서, 암은 난소암인, 치료 방법;
[103]
[95]에 있어서, 암은 삼중 음성 유방암인, 치료 방법;
[104]
[95]에 있어서, 암은 결장직장암인, 치료 방법;
[105]
[95]에 있어서, 암은 식도암인, 치료 방법;
[106]
[95]에 있어서, 암은 위암인, 치료 방법;
[107]
[95]에 있어서, 암은 자궁암인, 치료 방법;
[108]
[95]에 있어서, 암은 췌장암인, 치료 방법;
[109]
(i) PTA-125343으로서 ATCC®에 기탁된 플라스미드에 의해 암호화된 중쇄의 아미노산 서열과 동일한 아미노산 서열을 포함하는 중쇄 및 (ii) PTA-125342로서 ATCC®에 기탁된 플라스미드에 의해 암호화된 경쇄 가변 영역의 아미노산 서열과 동일한 아미노산 서열을 포함하는 경쇄를 포함하는, EpCAM 항체, EpCAM-결합 항체 단편, 또는 이들의 면역접합체;
[110]
(i) PTA-125343으로서 ATCC®에 기탁된 플라스미드에 의해 암호화된 중쇄의 아미노산 서열과 동일한 아미노산 서열을 포함하는 중쇄 및 (ii) PTA-125344로서 ATCC®에 기탁된 플라스미드에 의해 암호화된 경쇄 가변 영역의 아미노산 서열과 동일한 아미노산 서열을 포함하는 경쇄를 포함하는, EpCAM 활성화 가능한 항체, EpCAM-결합 활성화 가능한 항체 단편, 또는 면역접합체; 및/또는
[111]
(i) PTA-125343으로서 ATCC®에 기탁된 플라스미드에 의해 암호화된 중쇄의 아미노산 서열과 동일한 아미노산 서열을 포함하는 중쇄 및 (ii) PTA-125345로서 ATCC®에 기탁된 플라스미드에 의해 암호화된 경쇄 가변 영역의 아미노산 서열과 동일한 아미노산 서열을 포함하는 경쇄를 포함하는, EpCAM 활성화 가능한 항체, EpCAM-결합 활성화 가능한 항체 단편, 또는 면역접합체.
도 1A 및 도 1B는 HSC2 세포(도 1A) 및 cyno 신장 상피세포(도 1B)에 대한 뮤린 EpCAM 항체 mEpCAM23의 결합 곡선을 도시한 도면.
도 2A 및 도 2B는 본래의 muEpCAM-23 경쇄 및 중쇄 서열의 가변 영역과 이들의 가장 가까운 인간 생식계열 매치 간의 서열 정렬을 도시한 도면. 정렬 결과에 기반하여, EpCAM-23 항체의 VL 및 VH 도메인에 대한 억셉터(수용자) 프레임워크로서 선택된 인간 생식계열 서열은 각각 IGKV2D- 29*02(도 2A) 및 IGHV1-3*01(도 2B)였다.
도 3A 내지 도 3F는 mEpCAM23의 다양한 인간화 항체의 결합 곡선을 도시한 도면. 특히, 도 3A는 HSC2 세포에 대한 mEpCAM23의 결합을 나타내고, 도 3B는 cyno 1차 신장 상피세포에 대한 mEpCAM23의 결합을 나타내며, 도 3C는 HSC2 세포에 대한 다양한 인간화 EpCAM23 항체의 결합을 나타내고, 도 3D는 cyno 1차 신장 상피세포에 대한 다양한 인간화 EpCAM23 항체의 결합을 나타낸다. 도 3E는 HSC2 세포에 대한 부위-특이적 변형 항체 huEpCAM23Gv4.2-C442의 결합을 도시하고, 도 3F는 cyno 1차 신장 상피세포에 대한 동일 항체의 결합을 도시한 도면.
도 4A 및 도 4B는 본래의 뮤린 EpCAM-23 항체, 접합 형태 Gv2.2, 및 접합 형태 Gv4.2의 가변 영역의 서열 정렬을 도시한 도면. 특히, 도 4A는 항체 경쇄의 가변 영역 정렬을 도시하며, 도 4B는 항체 중쇄의 가변 영역 정렬을 도시한 도면.
도 5A 내지 도 5N은 HSC2 세포 및 cyno 1차 신장 상피세포 상의 huEpCAM23Gv4.2의 다양한 친화도 변이체에 대한 결합 곡선을 도시한 도면. 특히, 도 5A는 huEpCAM-mFc에 대한 Gv4a.2, Gv4b.2 및 Gv4c.2의 결합을 도시하고; 도 5B는 cynoEpCAM-mFc에 대한 Gv4a.2, Gv4b.2 및 Gv4c.2의 결합을 도시하며; 도 5C는 huEpCAM-mFc에 대한 Gv4.2a, Gv4.2b, Gv4.2c 및 Gv4.2d의 결합을 도시하고; 도 5D는 cynoEpCAM-mFc에 대한 Gv4.2a, Gv4.2b, Gv4.2c 및 Gv4.2d의 결합을 도시하며; 도 5E는 HSC2 세포에 대한 Gv4a.2a, Gv4b.2a 및 Gv4c.2a의 결합을 도시하고; 도 5F는 cyno 1차 신장 상피세포에 대한 Gv4a.2a, Gv4b.2a 및 Gv4c.2a의 결합을 도시하며; 도 5G는 HSC2 세포에 대한 Gv4a.2b, Gv4a.2d, Gv4b.2b, Gv4b.2d, Gv4c.2b 및 Gv4c.2d의 결합을 도시하고; 그리고 도 5H는 cyno 1차 신장 상피세포에 대한 Gv4a.2b, Gv4a.2d, Gv4b.2b, Gv4b.2d, Gv4c.2b 및 Gv4c.2d의 결합을 도시한 도면. 도 5I는 HSC2 세포 상의 Gv4.2H, Gv4.2K, Gv4.2L, Gv4.2O, Gv4.2P, Gv4.2Q, Gv4.2R 및 Gv4.2S의 결합을 도시하고; 도 5J는 HSC2 세포 상의 1361-D, 1361-H, 1361-1 및 1361-L의 결합을 도시하며; 도 5K는 HSC2 세포 상의 1565-A, 1565-F, 1565-G, 1565-S, 1565-T, 1565-V 및 1565- Y의 결합을 도시한다. 도 5L은 cyno 1차 신장 상피세포 상의 Gv4.2H, Gv4.2K, Gv4.2L, Gv4.2O, Gv4.2P, Gv4.2Q, Gv4.2R 및 Gv4.2S의 결합을 도시하고; 도 5M은 cyno 1차 신장 상피세포 상의 1361-D, 1361-H, 1361-1 및 1361-L의 결합을 도시하며; 도 5N은 cyno 1차 신장 상피세포 1565-A, 1565-F, 1565-G, 1565-S, 1565-T, 1565-V 및 1565-Y의 결합을 도시한 도면.
도 6A 및 도 6B는 HSC2 세포 및 cyno 1차 신장 상피세포 상에 다양한 표시를 한 무손상 및 uPA-활성화된 huEpCAM23Gv4.2 활성화 가능한 항체의 결합 곡선을 도시한 도면. 특히, 도 6A는 HSC2 세포 상에서 무손상 및 uPA-활성화된 huEpCAM23과 기질 3014 및 마스크 Ep01-2, Ep02, Ep03, Ep04, Ep05, Ep07 및 Ep11과의 결합을 도시하고, 도 6B는 cyno 1차 신장 상피세포 상에서 무손상 및 uPA-활성화된 huEpCAM23과 기질 3014 및 마스크 Ep02, Ep03, Ep04, Ep05 및 Ep07과의 결합을 도시한 도면.
도 7A 및 도 7B는 HSC2 세포 상에서 huEpCAM23의 다양한 uPA-처리된 활성화 가능한 항체 약물의 결합 곡선을 도시한 도면. 특히, 도 7A는 HSC2 세포 상에서 uPA-처리된 huEpCAM23Gv4.2-sSPDB-DM4와 기질 3014 및 마스크 Ep01-2, Ep02, Ep03, Ep04, Ep05, Ep07 및 Ep11과의 결합을 도시하고, 그리고 7B는 HSC2 세포 상에서 uPA-활성화된 huEpCAM23Gv4.2-lys-DGN549와 기질 3014 및 마스크 Ep01-2, Ep02, Ep03, Ep04, Ep05, Ep07 및 Ep11과의 결합을 도시한 도면.
도 8A 내지 도 8D는 HSC2 세포 상에서 다양한 활성화 가능한 항체-약물 접합체와 기질 2014 또는 3014의 결합 곡선을 도시한 도면. 특히, 도 8A는 HSC2 세포 상의 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-2014-sSPDB-DM4의 결합을 도시하고, 도 8B는 HSC2 세포 상의 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-3014-sSPDB-DM4 결합을 도시하며, 도 8C는 HSC2 세포 상의 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-EpO5- 3014-lys-DGN549의 결합을 도시하고, 도 8D는 HSC2 세포 상의 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-3014-GMBS-DM21L 및 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-2014-GMBS-DM21L의 결합을 도시한 도면.
도 9는 신호 펩타이드의 절단 후 인간 EpCAM의 세포외 도메인(서열번호 1) 및 마우스 EpCAM(서열번호 210)의 정렬을 도시한 도면.
도 10a 및 도 10b는 인간 EpCAM(서열번호 1), 마우스 EpCAM(서열번호 210), 및 다양한 키메라화된 EpCAM 변이체(서열번호 211 내지 214)의 세포외 영역의 정렬을 도시한 도면. 도 10a는 아미노산 잔기 1 내지 160의 정렬을 도시하고, 도 10b는 아미노산 잔기 161 내지 243의 정렬을 도시한 도면.
도 11은 인간 EpCAM 및 마우스 EpCAM의 세포외 도메인에 대한 huEpCAM23Gv4.2의 결합 곡선을 도시한 도면.
도 12A 내지 도 12K는 다양한 세포주에서 huEpCAM23Gv4.2의 항체-약물 접합체(antibody-drug conjugate: ADC)의 용량-반응 곡선을 도시한 도면. 특히, 도 12A 내지 도 12E는 H1568 세포(도 12A)에서, H292 세포(도 12B)에서, H2110 세포(도 12C)에서, LoVo 세포(도 12D)에서, 그리고 Detroit562 세포(도 12E)에서의 huEpCAM23Gv4.2-sSPDB-DM4의 용량-반응 곡선을 도시한 도면. 도 12F는 H2110 세포에서의 huEpCAM23Gv4.2-lys-DGN549 및 huEpCAM23Gv4.2-C442-DGN549의 용량-반응 곡선을 도시한 도면. 도 12G 내지 도 12K는 Calu3 세포(도 12G), Detroit562 세포(도 12H), EBC-1 세포(도 121), H2110 세포(도 12J), 및 H441 세포(도 12K)에서 huEpCAM23Gv4.2-GMBS-DM21L의 용량-반응 곡선을 도시한 도면.
도 13A 내지 도 13D는 다양한 세포주에서 huEpCAM23Gv4.2-sSPDB-DM4의 무손상 및 uPA-활성화된 활성화 가능한 항체-약물 접합체(AADC)의 용량-반응 곡선을 도시한 도면. 특히, 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-EpO5- 2014-sSPDB-DM4 및 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-3014-sSPDB-DM4의 용량-반응 곡선은 Calu3 세포(도 13A), OV90 세포(도13B), EBC-1 세포(도 13C), 및 H2110 세포(도 13D)에 나타낸다.
도 14A 내지 도 14D는 다양한 세포주에서 huEpCAM23Gv4.2-GMBS-DM21L의 무손상 및 uPA-활성화된 AADC의 용량-반응 곡선을 도시한 도면. 특히, 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-2014-GMBS-DM21L 및 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-3014-GMBS-DM21L의 용량-반응 곡선은 Calu3 세포(도 14A), Detroit562 세포(도14B), EBC-1 세포(도 14C), 및 H2110 세포(도 14D)에 나타낸다.
도 15A 내지 도 15D는 다양한 세포주에서 huEpCAM23-lys-DGN549의 무손상 및 uPA-활성화된 AADC의 용량-반응 곡선을 도시한 도면. 특히, 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-3014-lys-DGN549의 용량-반응 곡선은 H2110 세포(도 15A), EBC-1 세포(도 15B), Calu3 세포(도 15C), 및 OV90 세포(도 15D)에 나타낸다.
도 16은 H2110 비소세포 폐암 이종이식 모델에서의 huEpCAM23Gv4.2-lys-DGN549의 항-종양 활성을 도시한 도면.
도 17A 내지 도 17F는 H2110 비소세포 폐암 이종이식 모델에서 huEpCAM23Gv4.2의 다양한 AADC의 항-종양 활성을 도시한 도면. 특히, 도 17A는 마스크 Ep02, EpOl, Ep11 및 Ep04를 갖는 huEpCAM23-lys-DGN549의 항-종양 활성을 도시하며, 도 17B는 마스크 Ep03, Ep05, Ep07 및 Ep04를 갖는 huEpCAM23-lys-DGN549의 항-종양 활성을 도시하고, 도 17C는 비-절단성 접합체에 비교되는 huEpCAM23-Ep05-3014-lys-DGN549 및 huEpCAM23-Ep07-3014-lys-DGN549의 항-종양 활성을 도시한 도면. 도 17D는 비-절단성 접합체 및 ADC huEpCAM23Gv4.2-sSPDB-DM4와 비교되는 huEpCAM23Gv4.2-Ep01-02-2014-sSPDB-DM4의 항-종양 활성을 나타내고, 도 17E는 비-절단성 접합체와 비교되는 huEpCAM23Gv4.2-Ep05-2014-sSPDB-DM4 및 huEpCAM23Gv4.2-Ep05-3014-sSPDB-DM4의 항-종양 활성을 나타내고, 도 17F는 비-절단성 접합체와 비교되는 huEpCAM23Gv4.2-Ep05-2014-lys-DGN549 및 huEpCAM23Gv4.2-Ep05-3014-lys-DGN549의 항-종양 활성을 도시한 도면.
도 18은 Calu3 비소세포 폐암 이종이식 모델에서 huEpCAM23Gv4.2- sSPDB-DM4의 다양한 AADC의 항-종양 활성을 도시한 도면.
도 19는 H292 비소세포 폐암 이종이식 모델에서 huEpCAM23Gv4.2- sSPDB-DM4의 다양한 AADC의 항-종양 활성을 도시한 도면.
도 20은 Detroit 562 HNSCC 이종이식을 보유하는 C.B-17 SCID 마우스에서 Ep05-3014-DM4, Ep05-2014-DM4, Ep05-3014-DM21, 및 Ep05-2014-DM21의 항-종양 활성을 도시한 도면.
도 21은 NCI-H441 NSCLC 이종이식을 보유하는 C.B-17 SCID 마우스에서 Ep05-3014-DM21 및 Ep05-2014-DM21의 항-종양 활성을 도시한 도면.
도 22는 OV-90 EOC 이종이식을 보유하는 C.B-17 SCID 마우스에서 Ep05-2014-DM21의 항-종양 활성을 도시한 도면.
도 23는 Calu-3 NSCLC 이종이식을 보유하는 C.B-17 SCID 마우스에서 Ep05-2014-DM21의 항-종양 활성을 도시한 도면.
도 24는 사이노몰거스 원숭이에서의 EpCAM-표적화 ADC (huEpCAM23Gv4.2-sSPDB-DM4 (Anti-EpCAM-DM4)) 및 EpCAM-표적화 AADCs (huEpCAM23Gv4.2-Ep05-2014-sSPDB-DM4 (M05-2014-DM4)) 및 huEpCAM23Gv4.2-Ep05-3014-sSPDB- DM4 (M05-3014-DM4))의 내약성을 도시한 도면.
도 25A 내지 도 25E는 EpCAM-표적화 ADC(huEpCAM23Gv4.2-sSPDB-DM4) 또는 EpCAM-표적화 AADC (huEpCAM23Gv4.2-Ep05-2014-sSPDB-DM4)를 투여한 사이노몰거스 원숭이의 혈청 화학을 도시한 도면. 특히, 도 25A는 A/G 비를 나타내고, 도 25B는 요소 질소 농도를 나타내며, 도 25C는 크레아티닌 농도를 나타내고, 도 25D는 리파제 농도를 나타내며, 도 25E는 아밀라제 농도를 나타낸다.
도 26은 8㎎/㎏의 EpCAM-표적화 ADC(huEpCAM23Gv4.2-sSPDB-DM4 (Anti-EpCAM-DM4 ADC)) 또는 8㎎/㎏의 EpCAM-표적화 AADC(huEpCAM23Gv4.2-Ep05-2014-sSPDB-DM4 (M05-2014-DM4 AADC)), 또는 huEpCAM23Gv4.2-Ep05-3014-sSPDB-DM4(M05-3014- DM4 AADC))를 받는 사이노몰거스 원숭이의 약물동태학적 프로파일을 도시한 도면.
도 27은 사이노몰거스 원숭이에서 huEpCAM23Gv4.2-Ep05-2014-DM21L (Ep05-2014-DM21L) 및 huEpCAM23Gv4.2-Ep05-3014-DM21L (Ep05-3014-DM21L)의 내약성을 도시한 도면.
도 28A 내지 도 28E는 12
mg/kg의 huEpCAM23Gv4.2-Ep05-2014-DM21L (Ep05-2014-DM21L) 및 huEpCAM 23Gv4.2-Ep05-3014-DM21L(Ep05-3014-DM21L)을 투여한 사이노몰거스 원숭이의 혈청 화학을 도시한 도면. 특히, 도 28A는 A/G 비를 나타내고, 도 28B는 요소 질소 농도를 나타내며, 도 28C는 크레아티닌 농도를 나타내고, 도 28D는 리파제 농도를 나타내며, 도 28E는 아밀라제 농도를 나타낸다.
도 29는 12㎎/㎏의 huEpCAM23Gv4.2-Ep05-2014-DM21L(Ep05-2014-DM21)을 투여한 사이노몰거스 원숭이의 약물동태학적 프로파일을 도시한 도면.
도 30은 적응증-특이적 조직 마이크로어레이에서 EpCAM 발현의 확장된 분석을 도시한 도면.
도 2A 및 도 2B는 본래의 muEpCAM-23 경쇄 및 중쇄 서열의 가변 영역과 이들의 가장 가까운 인간 생식계열 매치 간의 서열 정렬을 도시한 도면. 정렬 결과에 기반하여, EpCAM-23 항체의 VL 및 VH 도메인에 대한 억셉터(수용자) 프레임워크로서 선택된 인간 생식계열 서열은 각각 IGKV2D- 29*02(도 2A) 및 IGHV1-3*01(도 2B)였다.
도 3A 내지 도 3F는 mEpCAM23의 다양한 인간화 항체의 결합 곡선을 도시한 도면. 특히, 도 3A는 HSC2 세포에 대한 mEpCAM23의 결합을 나타내고, 도 3B는 cyno 1차 신장 상피세포에 대한 mEpCAM23의 결합을 나타내며, 도 3C는 HSC2 세포에 대한 다양한 인간화 EpCAM23 항체의 결합을 나타내고, 도 3D는 cyno 1차 신장 상피세포에 대한 다양한 인간화 EpCAM23 항체의 결합을 나타낸다. 도 3E는 HSC2 세포에 대한 부위-특이적 변형 항체 huEpCAM23Gv4.2-C442의 결합을 도시하고, 도 3F는 cyno 1차 신장 상피세포에 대한 동일 항체의 결합을 도시한 도면.
도 4A 및 도 4B는 본래의 뮤린 EpCAM-23 항체, 접합 형태 Gv2.2, 및 접합 형태 Gv4.2의 가변 영역의 서열 정렬을 도시한 도면. 특히, 도 4A는 항체 경쇄의 가변 영역 정렬을 도시하며, 도 4B는 항체 중쇄의 가변 영역 정렬을 도시한 도면.
도 5A 내지 도 5N은 HSC2 세포 및 cyno 1차 신장 상피세포 상의 huEpCAM23Gv4.2의 다양한 친화도 변이체에 대한 결합 곡선을 도시한 도면. 특히, 도 5A는 huEpCAM-mFc에 대한 Gv4a.2, Gv4b.2 및 Gv4c.2의 결합을 도시하고; 도 5B는 cynoEpCAM-mFc에 대한 Gv4a.2, Gv4b.2 및 Gv4c.2의 결합을 도시하며; 도 5C는 huEpCAM-mFc에 대한 Gv4.2a, Gv4.2b, Gv4.2c 및 Gv4.2d의 결합을 도시하고; 도 5D는 cynoEpCAM-mFc에 대한 Gv4.2a, Gv4.2b, Gv4.2c 및 Gv4.2d의 결합을 도시하며; 도 5E는 HSC2 세포에 대한 Gv4a.2a, Gv4b.2a 및 Gv4c.2a의 결합을 도시하고; 도 5F는 cyno 1차 신장 상피세포에 대한 Gv4a.2a, Gv4b.2a 및 Gv4c.2a의 결합을 도시하며; 도 5G는 HSC2 세포에 대한 Gv4a.2b, Gv4a.2d, Gv4b.2b, Gv4b.2d, Gv4c.2b 및 Gv4c.2d의 결합을 도시하고; 그리고 도 5H는 cyno 1차 신장 상피세포에 대한 Gv4a.2b, Gv4a.2d, Gv4b.2b, Gv4b.2d, Gv4c.2b 및 Gv4c.2d의 결합을 도시한 도면. 도 5I는 HSC2 세포 상의 Gv4.2H, Gv4.2K, Gv4.2L, Gv4.2O, Gv4.2P, Gv4.2Q, Gv4.2R 및 Gv4.2S의 결합을 도시하고; 도 5J는 HSC2 세포 상의 1361-D, 1361-H, 1361-1 및 1361-L의 결합을 도시하며; 도 5K는 HSC2 세포 상의 1565-A, 1565-F, 1565-G, 1565-S, 1565-T, 1565-V 및 1565- Y의 결합을 도시한다. 도 5L은 cyno 1차 신장 상피세포 상의 Gv4.2H, Gv4.2K, Gv4.2L, Gv4.2O, Gv4.2P, Gv4.2Q, Gv4.2R 및 Gv4.2S의 결합을 도시하고; 도 5M은 cyno 1차 신장 상피세포 상의 1361-D, 1361-H, 1361-1 및 1361-L의 결합을 도시하며; 도 5N은 cyno 1차 신장 상피세포 1565-A, 1565-F, 1565-G, 1565-S, 1565-T, 1565-V 및 1565-Y의 결합을 도시한 도면.
도 6A 및 도 6B는 HSC2 세포 및 cyno 1차 신장 상피세포 상에 다양한 표시를 한 무손상 및 uPA-활성화된 huEpCAM23Gv4.2 활성화 가능한 항체의 결합 곡선을 도시한 도면. 특히, 도 6A는 HSC2 세포 상에서 무손상 및 uPA-활성화된 huEpCAM23과 기질 3014 및 마스크 Ep01-2, Ep02, Ep03, Ep04, Ep05, Ep07 및 Ep11과의 결합을 도시하고, 도 6B는 cyno 1차 신장 상피세포 상에서 무손상 및 uPA-활성화된 huEpCAM23과 기질 3014 및 마스크 Ep02, Ep03, Ep04, Ep05 및 Ep07과의 결합을 도시한 도면.
도 7A 및 도 7B는 HSC2 세포 상에서 huEpCAM23의 다양한 uPA-처리된 활성화 가능한 항체 약물의 결합 곡선을 도시한 도면. 특히, 도 7A는 HSC2 세포 상에서 uPA-처리된 huEpCAM23Gv4.2-sSPDB-DM4와 기질 3014 및 마스크 Ep01-2, Ep02, Ep03, Ep04, Ep05, Ep07 및 Ep11과의 결합을 도시하고, 그리고 7B는 HSC2 세포 상에서 uPA-활성화된 huEpCAM23Gv4.2-lys-DGN549와 기질 3014 및 마스크 Ep01-2, Ep02, Ep03, Ep04, Ep05, Ep07 및 Ep11과의 결합을 도시한 도면.
도 8A 내지 도 8D는 HSC2 세포 상에서 다양한 활성화 가능한 항체-약물 접합체와 기질 2014 또는 3014의 결합 곡선을 도시한 도면. 특히, 도 8A는 HSC2 세포 상의 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-2014-sSPDB-DM4의 결합을 도시하고, 도 8B는 HSC2 세포 상의 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-3014-sSPDB-DM4 결합을 도시하며, 도 8C는 HSC2 세포 상의 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-EpO5- 3014-lys-DGN549의 결합을 도시하고, 도 8D는 HSC2 세포 상의 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-3014-GMBS-DM21L 및 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-2014-GMBS-DM21L의 결합을 도시한 도면.
도 9는 신호 펩타이드의 절단 후 인간 EpCAM의 세포외 도메인(서열번호 1) 및 마우스 EpCAM(서열번호 210)의 정렬을 도시한 도면.
도 10a 및 도 10b는 인간 EpCAM(서열번호 1), 마우스 EpCAM(서열번호 210), 및 다양한 키메라화된 EpCAM 변이체(서열번호 211 내지 214)의 세포외 영역의 정렬을 도시한 도면. 도 10a는 아미노산 잔기 1 내지 160의 정렬을 도시하고, 도 10b는 아미노산 잔기 161 내지 243의 정렬을 도시한 도면.
도 11은 인간 EpCAM 및 마우스 EpCAM의 세포외 도메인에 대한 huEpCAM23Gv4.2의 결합 곡선을 도시한 도면.
도 12A 내지 도 12K는 다양한 세포주에서 huEpCAM23Gv4.2의 항체-약물 접합체(antibody-drug conjugate: ADC)의 용량-반응 곡선을 도시한 도면. 특히, 도 12A 내지 도 12E는 H1568 세포(도 12A)에서, H292 세포(도 12B)에서, H2110 세포(도 12C)에서, LoVo 세포(도 12D)에서, 그리고 Detroit562 세포(도 12E)에서의 huEpCAM23Gv4.2-sSPDB-DM4의 용량-반응 곡선을 도시한 도면. 도 12F는 H2110 세포에서의 huEpCAM23Gv4.2-lys-DGN549 및 huEpCAM23Gv4.2-C442-DGN549의 용량-반응 곡선을 도시한 도면. 도 12G 내지 도 12K는 Calu3 세포(도 12G), Detroit562 세포(도 12H), EBC-1 세포(도 121), H2110 세포(도 12J), 및 H441 세포(도 12K)에서 huEpCAM23Gv4.2-GMBS-DM21L의 용량-반응 곡선을 도시한 도면.
도 13A 내지 도 13D는 다양한 세포주에서 huEpCAM23Gv4.2-sSPDB-DM4의 무손상 및 uPA-활성화된 활성화 가능한 항체-약물 접합체(AADC)의 용량-반응 곡선을 도시한 도면. 특히, 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-EpO5- 2014-sSPDB-DM4 및 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-3014-sSPDB-DM4의 용량-반응 곡선은 Calu3 세포(도 13A), OV90 세포(도13B), EBC-1 세포(도 13C), 및 H2110 세포(도 13D)에 나타낸다.
도 14A 내지 도 14D는 다양한 세포주에서 huEpCAM23Gv4.2-GMBS-DM21L의 무손상 및 uPA-활성화된 AADC의 용량-반응 곡선을 도시한 도면. 특히, 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-2014-GMBS-DM21L 및 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-3014-GMBS-DM21L의 용량-반응 곡선은 Calu3 세포(도 14A), Detroit562 세포(도14B), EBC-1 세포(도 14C), 및 H2110 세포(도 14D)에 나타낸다.
도 15A 내지 도 15D는 다양한 세포주에서 huEpCAM23-lys-DGN549의 무손상 및 uPA-활성화된 AADC의 용량-반응 곡선을 도시한 도면. 특히, 무손상 및 uPA-활성화된 huEpCAM23Gv4.2-Ep05-3014-lys-DGN549의 용량-반응 곡선은 H2110 세포(도 15A), EBC-1 세포(도 15B), Calu3 세포(도 15C), 및 OV90 세포(도 15D)에 나타낸다.
도 16은 H2110 비소세포 폐암 이종이식 모델에서의 huEpCAM23Gv4.2-lys-DGN549의 항-종양 활성을 도시한 도면.
도 17A 내지 도 17F는 H2110 비소세포 폐암 이종이식 모델에서 huEpCAM23Gv4.2의 다양한 AADC의 항-종양 활성을 도시한 도면. 특히, 도 17A는 마스크 Ep02, EpOl, Ep11 및 Ep04를 갖는 huEpCAM23-lys-DGN549의 항-종양 활성을 도시하며, 도 17B는 마스크 Ep03, Ep05, Ep07 및 Ep04를 갖는 huEpCAM23-lys-DGN549의 항-종양 활성을 도시하고, 도 17C는 비-절단성 접합체에 비교되는 huEpCAM23-Ep05-3014-lys-DGN549 및 huEpCAM23-Ep07-3014-lys-DGN549의 항-종양 활성을 도시한 도면. 도 17D는 비-절단성 접합체 및 ADC huEpCAM23Gv4.2-sSPDB-DM4와 비교되는 huEpCAM23Gv4.2-Ep01-02-2014-sSPDB-DM4의 항-종양 활성을 나타내고, 도 17E는 비-절단성 접합체와 비교되는 huEpCAM23Gv4.2-Ep05-2014-sSPDB-DM4 및 huEpCAM23Gv4.2-Ep05-3014-sSPDB-DM4의 항-종양 활성을 나타내고, 도 17F는 비-절단성 접합체와 비교되는 huEpCAM23Gv4.2-Ep05-2014-lys-DGN549 및 huEpCAM23Gv4.2-Ep05-3014-lys-DGN549의 항-종양 활성을 도시한 도면.
도 18은 Calu3 비소세포 폐암 이종이식 모델에서 huEpCAM23Gv4.2- sSPDB-DM4의 다양한 AADC의 항-종양 활성을 도시한 도면.
도 19는 H292 비소세포 폐암 이종이식 모델에서 huEpCAM23Gv4.2- sSPDB-DM4의 다양한 AADC의 항-종양 활성을 도시한 도면.
도 20은 Detroit 562 HNSCC 이종이식을 보유하는 C.B-17 SCID 마우스에서 Ep05-3014-DM4, Ep05-2014-DM4, Ep05-3014-DM21, 및 Ep05-2014-DM21의 항-종양 활성을 도시한 도면.
도 21은 NCI-H441 NSCLC 이종이식을 보유하는 C.B-17 SCID 마우스에서 Ep05-3014-DM21 및 Ep05-2014-DM21의 항-종양 활성을 도시한 도면.
도 22는 OV-90 EOC 이종이식을 보유하는 C.B-17 SCID 마우스에서 Ep05-2014-DM21의 항-종양 활성을 도시한 도면.
도 23는 Calu-3 NSCLC 이종이식을 보유하는 C.B-17 SCID 마우스에서 Ep05-2014-DM21의 항-종양 활성을 도시한 도면.
도 24는 사이노몰거스 원숭이에서의 EpCAM-표적화 ADC (huEpCAM23Gv4.2-sSPDB-DM4 (Anti-EpCAM-DM4)) 및 EpCAM-표적화 AADCs (huEpCAM23Gv4.2-Ep05-2014-sSPDB-DM4 (M05-2014-DM4)) 및 huEpCAM23Gv4.2-Ep05-3014-sSPDB- DM4 (M05-3014-DM4))의 내약성을 도시한 도면.
도 25A 내지 도 25E는 EpCAM-표적화 ADC(huEpCAM23Gv4.2-sSPDB-DM4) 또는 EpCAM-표적화 AADC (huEpCAM23Gv4.2-Ep05-2014-sSPDB-DM4)를 투여한 사이노몰거스 원숭이의 혈청 화학을 도시한 도면. 특히, 도 25A는 A/G 비를 나타내고, 도 25B는 요소 질소 농도를 나타내며, 도 25C는 크레아티닌 농도를 나타내고, 도 25D는 리파제 농도를 나타내며, 도 25E는 아밀라제 농도를 나타낸다.
도 26은 8㎎/㎏의 EpCAM-표적화 ADC(huEpCAM23Gv4.2-sSPDB-DM4 (Anti-EpCAM-DM4 ADC)) 또는 8㎎/㎏의 EpCAM-표적화 AADC(huEpCAM23Gv4.2-Ep05-2014-sSPDB-DM4 (M05-2014-DM4 AADC)), 또는 huEpCAM23Gv4.2-Ep05-3014-sSPDB-DM4(M05-3014- DM4 AADC))를 받는 사이노몰거스 원숭이의 약물동태학적 프로파일을 도시한 도면.
도 27은 사이노몰거스 원숭이에서 huEpCAM23Gv4.2-Ep05-2014-DM21L (Ep05-2014-DM21L) 및 huEpCAM23Gv4.2-Ep05-3014-DM21L (Ep05-3014-DM21L)의 내약성을 도시한 도면.
도 28A 내지 도 28E는 12
mg/kg의 huEpCAM23Gv4.2-Ep05-2014-DM21L (Ep05-2014-DM21L) 및 huEpCAM 23Gv4.2-Ep05-3014-DM21L(Ep05-3014-DM21L)을 투여한 사이노몰거스 원숭이의 혈청 화학을 도시한 도면. 특히, 도 28A는 A/G 비를 나타내고, 도 28B는 요소 질소 농도를 나타내며, 도 28C는 크레아티닌 농도를 나타내고, 도 28D는 리파제 농도를 나타내며, 도 28E는 아밀라제 농도를 나타낸다.
도 29는 12㎎/㎏의 huEpCAM23Gv4.2-Ep05-2014-DM21L(Ep05-2014-DM21)을 투여한 사이노몰거스 원숭이의 약물동태학적 프로파일을 도시한 도면.
도 30은 적응증-특이적 조직 마이크로어레이에서 EpCAM 발현의 확장된 분석을 도시한 도면.
본 개시내용은 항체, 항체 단편 및 활성화 가능한 항체를 포함하는 활성화 가능한 항체(EpCAM 항체 또는 EpCAM-결합 항체 단편의 활성화 가능한 형태), 및 면역접합체를 포함하는, 인간 EpCAM에 특이적으로 결합하는 항체 및 항원-결합 항체 단편을 제공한다. EpCAM은 상피에서의 세포-세포 부착과 연관되고 세포 신호전달, 분화, 증식 및 이동과 관련되는 것으로 알려져 있다. EpCAM의 과발현은 질환 및 장애, 예컨대 암의 발병에 관련되었다. 예를 들어, EpCAM은 다양한 암 유형, 예컨대, 유방 암, 폐 암, 간암, 위암, 두경부암, 전립선 암, 췌장암, 난소암, 결장암, 및 신장암, 및 상피 유래의 대부분의 암(및 전이)에서 고도로 발현된다. EpCAM은 또한 종양 개시/암 줄기 세포에서 고도로 발현된다. 제공된 EpCAM 항체, EpCAM-결합 항체 단편, EpCAM 활성화 가능한 항체, 및 면역접합체는 이러한 질환 및 암 치료를 포함하는 용도를 가진다.
정의
이해를 더 용이하게 하기 위해, 다수의 용어 및 어구를 이하에 정의한다.
본 명세서에 사용되는 바와 같은 용어 "상피세포 부착 분자" 또는 "EpCAM"은 달리 표시되지 않는 한, 임의의 천연 인간 EpCAM을 지칭한다. 상기 용어는 또한 EpCAM의 천연 유래 변이체, 예를 들어, 스플라이스 변이체, 대립유전자 변이체 및 동형단백질을 포함한다. EpCAM 폴리펩타이드는 다양한 공급원으로부터, 예컨대 인간 또는 사이노몰거스 조직 또는 기타 생물학적 샘플로부터 단리될 수 있거나, 공지된 재조합 또는 합성 방법에 의해 제조될 수 있다. EpCAM은 CD326, 17-1A 항원, HEA125, MK-1, EGP-2, EGP314, EGP40, GA733-2, KSA, TACSTD1, TROP1, KS1/4, M4S1, DIAR5, MIC18, HNPCC8 및 ESA로도 알려져 있다. EpCAM 서열의 예는 NCBI 참조 번호 NP_002345.2(아미노산 잔기 24 내지 314는 성숙 EpCAM에 대응하고, 아미노산 24 내지 265는 성숙 EpCAM의 세포외 영역에 대응함(서열번호 1))를 포함하지만, 이들로 제한되지 않는다. 성숙 EpCAM의 세포외 영역은 추가로 3개의 도메인으로 나누어질 수 있다: D1(서열번호 1의 아미노산 1 내지 36(서열번호 2)), D2(서열번호 1의 아미노산 43 내지 112(서열번호 3)) 및 D3(서열번호 1의 아미노산 113 내지 243(서열번호 4)).
용어 "항체" 및 "항원-결합 항체 단편" 등은 면역글로불린 분자의 적어도 일부, 예컨대, 이하로 제한되는 것은 아니지만, 중쇄 또는 경쇄 또는 이의 항원 결합 부분의 적어도 하나의 상보성 결정 영역(CDR)을 포함하는 임의의 단백질 또는 펩타이드를 포함한다. 이러한 항체는 선택적으로 적어도 하나의 EpCAM 활성에 추가로 영향을 미치고, 예컨대, 이하로 제한되는 것은 아니지만, 이러한 항체는 시험관내, 인시추, 생체내 및/또는 생체외에서 적어도 하나의 EpCAM 활성 또는 결합을 조절하고/하거나, 감소시키고/시키거나, 증가시키고/시키거나, 길항하고/하거나, 작용하고/하거나, 부분적으로 작용화하고/하거나, 부분적으로 길항하고/하거나, 경감하고/하거나 완화하고/하거나, 차단하고/하거나 저해하고/하거나, 없애고/없애거나 방해한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 리간드 결합, 수용체 신호전달, 막 결합, 세포 이동, 세포 증식, 수용체 결합 활성, RNA, DNA 또는 단백질 생성 및/또는 합성으로부터 선택된 적어도 하나의 EpCAM-매개 활성 또는 작용에 영향을 미친다.
항체는 2개의 동일한 경쇄(LC) 및 2개의 동일한 중쇄(HC)로 구성된 이형사량체 당단백질이다. 전형적으로, 각 경쇄는 하나의 공유 이황화결합에 의해 중쇄에 연결되는 한편, 이황화 결합의 수는 상이한 면역글로불린 아이소타입 중쇄 간에 다르다. 각 중쇄 및 경쇄는 또한 이격된 사슬내 이황화 브리지를 가진다. 각각의 중쇄는 하나의 단부에서 가변 영역(VH)을 갖고, 다음에 다수의 불변 도메인이 이어진다. 각 경쇄는 하나의 단부(VL)에서 가변 영역을 갖고, 이의 다른 단부에서 불변 도메인을 갖고; 경쇄의 불변 도메인은 중쇄의 제1 불변 도메인과 함께 정렬되고, 경쇄 가변 영역은 중쇄의 가변 영역과 함께 정렬된다. 임의의 척추동물종의 항체 경쇄는 이들의 불변 도메인의 아미노산 서열에 기반하여 2개의 분명하게 별개인 유형, 즉, 카파 및 람타 중 하나로 부여될 수 있다. 면역글로불린은 중쇄 불변 도메인 아미노산 서열에 따라서 5가지 주요 부류, 즉, IgA, IgD, IgE, IgG 및 IgM으로 부여될 수 있다. IgA 및 IgG는 추가로 아이소타입 IgAl, IgA2, IgG1, IgG2, IgG3 및 IgG4로서 다시 분류된다.
용어 "항체"는 또한 단일쇄 항체 및 항원(예를 들어, EpCAM)-결합 항체 단편을 포함하는 항체 또는 특정된 단편 또는 이의 일부의 구조 및/또는 작용을 모방하는 항체 모방체를 포함하거나 항체의 일부를 포함하는, 단편, 특정된 부분 및 이들의 변이체를 포함한다. 기능성 단편은 포유류 항원에 결합하는 항원-결합 단편, 예컨대 EpCAM을 단독으로, 또는 다른 항원과 조합하여 포함한다. 예를 들어, Fab(예를 들어, 파파인 분해에 의함), Fab'(예를 들어, 펩신 분해 및 부분적 환원에 의함) 및 F(ab')2(예를 들어, 펩신 분해에 의함), facb(예를 들어, 플라스민 분해에 의함), pFc'(예를 들어, 펩신 또는 플라스민 분해에 의함), Fd(예를 들어, 펩신 분해, 부분적 감소 및 재응집에 의함), Fv 또는 scFv(예를 들어, 분자 생물학 기법에 의함) 단편을 포함하지만, 이들로 제한되지 않는 항원 또는 이의 부분에 결합할 수 있는 항체 단편은 본 개시내용에 의해 포함된다(예를 들어, 문헌[Colligan, I㎜unology] 참조).
이러한 단편은 당업계에 공지되어 있고/있거나 본 명세서에 개시된 바와 같은 효소 절단, 합성 또는 재조합 기법에 의해 생성될 수 있다. 항체는 또한 하나 이상의 정지 코돈이 천연 정지 부위 상류에 도입된 항체 유전자를 이용하여 다양한 절단 형태에서 생성될 수 있다. 예를 들어, F(ab')2 중쇄 부분을 암호화하는 조합 유전자는 CH1 도메인 및/또는 중쇄의 힌지 영역을 암호화하는 DNA 서열을 포함하도록 설계될 수 있다. 항체의 다양한 부분은 통상적인 기법에 의해 함께 화학적으로 결합될 수 있거나, 또는 유전자 조작 기법을 이용하여 인접한 단백질로서 제조될 수 있다.
용어 "항체 단편"은 무손상 항체의 일부, 일반적으로 무손상 항체의 항원 결합 또는 가변 영역을 지칭한다. 항체 단편의 예는 특히, Fab, Fab', F(ab')2, 단일쇄(scFv) 및 Fv 단편, 다이어바디; 선형 항체; 단일쇄 항체 분자; 단일 Fab 아암 "1 아암" 항체 및 항체 단편으로부터 형성된 다중특이성 항체를 포함하지만, 이들로 제한되지 않는다.
항체 단편은 본 명세서에 제공된 EpCAM 항체에 혼입될 수 있는 면역글로불린 분자의 적어도 일부, 예컨대, 이하로 제한되는 것은 아니지만, 중쇄 또는 경쇄 또는 이의 리간드 결합 부분의 적어도 하나의 상보성 결정 영역(CDR), 중쇄 또는 경쇄 가변 영역, 중쇄 또는 경쇄 불변 영역, 프레임워크 영역 또는 이의 임의의 부분, 또는 항원 또는 항원 수용체 또는 결합 단백질의 적어도 하나의 부분을 포함하는 분자를 포함하는 임의의 단백질 또는 펩타이드를 포함한다.
용어 "가변"은 항체 가변 영역의 특정 부분이 항체 중에서 서열에 대해 광범위하게 다르고, 이의 특정 항원에 대한 각각의 특정 항체의 결합 및 특이성에서 사용된다는 사실을 지칭한다. 그러나, 가변성은 항체 가변 영역 전체적으로 균일하게 분포되지 않는다. 가변성은 경쇄 및 중쇄 가변 영역 둘 다에서 상보성-결정 영역(CDR) 또는 초가변 영역으로 불리는 3개의 세그먼트에 집중된다. 가변 영역의 보다 고도로 보존된 부분은 프레임워크(FR)로 불린다. 천연 중쇄 및 경쇄의 가변 영역은 각각 베타-시트 구조를 연결하고, 일부 경우에 부분을 형성하는 루프를 형성하는 3개의 CDR에 의해 연결되는 베타-시트 입체배치(configuration)를 대체로 채택하는 4개의 FR 영역을 포함한다. 각 쇄에서 CDR은 FR 영역에 의해 근위에서 함께, 다른 쇄로부터의 CDR과 함께 보유되어, 항체의 항원-결합 부위 형성에 기여한다. 불변 도메인은 항원에 항체를 결합함에 있어서 직접 관련되지 않지만, 다양한 효과기 기능, 예컨대 항체-의존적 세포 독성에서 항체의 참여를 나타낸다. CDR을 결정하기 위한 적어도 2가지의 기법이 있다: (1) 교배종 서열 가변성에 기반한 접근(즉, 문헌[Kabat et al., Sequences of Proteins of I㎜unological Interest, (5th ed., 1991, National Institutes of Health, Bethesda Md.)]); 및 (2) 항원-항체 복합체의 결정학적 연구에 기반한 접근(Al-lazikani et al., J. Molec. Biol. 273:927-948 (1997)). 또한, 이들 두 접근의 조합은 때때로 CDR을 결정하기 위해 당업계에서 사용된다.
카바트 넘버링 시스템은 일반적으로 가변 영역(경쇄의 대략 잔기 1 내지 107 및 중쇄의 잔기 1 내지 113)에서의 잔기를 언급할 때 사용된다(예를 들어, 문헌[Kabat et al., Sequences of I㎜unological Interest. 5th Ed. Public Health Service, National Institutes of Health, Bethesda, Md. (1991)]).
카바트에서와 같은 아미노산 위치 넘버링은 문헌[Kabat et al., Sequences of Proteins of I㎜unological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, Md. (1991)]에서의 항체 편집본의 중쇄 가변 영역 또는 경쇄 가변 영역에 대해 사용되는 넘버링 시스템을 지칭한다. 이 넘버링 시스템을 이용하여, 실제 선형 아미노산 서열은 가변 영역의 FR 또는 CDR의 단축 또는 이들에 대한 삽입에 대응하는 보다 소수의 또는 추가적인 아미노산을 포함할 수 있다. 예를 들어, 중쇄 가변 영역은 H2의 잔기 52 다음에 단일 아미노산 삽입(카바트에 따른 잔기 52a) 및 중쇄 FR 잔기 82 후에 삽입된 잔기(예를 들어, 카바트에 따른 잔기 82a, 82b 및 82c)를 포함할 수 있다. 잔기의 카바트 넘버링은 "표준" 카바트 넘버링 서열에 의한 항체 서열의 상동성 영역에서의 정렬에 의해 주어진 항체에 대해 결정될 수 있다. 코티아는 대신에 구조적 루프 위치를 지칭한다(Chothia et al., J. Mol. Biol. 196:901-917 (1987)). 카바트 넘버링 협약을 이용하여 넘버링할 때 코티아 CDR-H1 루프의 말단은 루프 길이에 따라 H32 내지 H34로 달라진다(이는 카바트 넘버링 체계가 H35A 및 H35B에서 삽입을 위치시키기 때문이며; 35A도 35B도 존재하지 않는다면, 루프는 32에서 종결되고; 35A만이 존재한다면, 루프는 33에서 종결되고; 35A와 35B가 둘 다 존재한다면, 루프는 34에서 종결된다). AbM 초가변 영역은 카바트 CDR과 코티아 구조적 루프 사이의 중간물을 나타내며, Oxford Molecular의 AbM 항체 모델링 소프트웨어에 의해 사용된다.
용어 "EpCAM 항체", "EpCAM 항체", "EpCAM에 특이적으로 결합하는 항체", "EpCAM-결합 항체 단편", "EpCAM에 특이적으로 결합하는 항체 단편"은 항체는 EpCAM을 표적화함에 있어서 진단제 및/또는 치료제로서 유용하도록 충분한 친화도를 갖는 EpCAM에 결합할 수 있는 항체를 지칭한다. 관련없는, 비-EpCAM 단백질에 대한 EpCAM 항체의 결합 정도는, 예를 들어, 방사면역측정법(RIA)에 의해 측정할 때, EpCAM에 대한 항체 결합의 항체 결합의 약 10% 미만이다.

용어 "에피토프"는 항체에 특이적으로 결합할 수 있는 단백질 결정소를 지칭한다. 에피토프는 보통 분자, 예컨대 아미노산 또는 당 측쇄의 화학적으로 활성인 표면 그룹으로 이루어지고, 보통 특정 3차원 구조 특징뿐만 아니라 특정 하전 특징을 가진다. 항원이 폴리펩타이드일 때, 에피토프는 인접한 아미노산과 단백질의 3차 폴딩에 의해 병치되는 비인접 아미노산 둘 다로부터 형성될 수 있다. 인접한 아미노산으로부터 형성된 에피토프는 전형적으로 단백질 변성 시 유지되는 반면, 3차 폴딩에 의해 형성되는 에피토프는 전형적으로 단백질 변성 시 상실된다. 에피토프는 전형적으로 독특한 공간적 입체구조에서 적어도 3개, 더 보통으로는, 적어도 5 또는 8 내지 10개의 아미노산을 포함한다.
"차단" 항체는, 예컨대 EpCAM에 결합하는 항원의 생물학적 활성을 저해하거나 감소시키는 것이다. 바람직한 차단 항체는 항원의 생물학적 활성을 실질적으로 또는 완전히 저해한다. 바람직하게는, 생물학적 활성은 10%, 20%, 30%, 50%, 70%, 80%, 90%, 95% 또는 심지어 100%만큼 감소된다. 일 실시형태에서, 차단 항체는 타이로신 키나제 활성과 관련된 EpCAM을 10%, 20%, 30%, 50%, 70%, 80%, 90%, 95%, 또는 심지어 100%만큼 감소시킨다.
"단리된" 항체는 이의 천연 환경으로부터 분리되고/되거나 회수된 것이다.
이의 천연 환경의 오염 성분은 항체에 대한 진단 또는 치료 용도를 방해하는 물질이며, 효소, 호르몬 및 기타 단백질성 또는 비단백질성 용질을 포함할 수 있다. 바람직한 양상에서, 항체는 (1) 예를 들어, 로리법(Lowry method)에 의해 결정할 때 항체의 95중량% 초과, 가장 바람직하게는 99중량% 초과로, (2) 스피닝 컵 서열분석기(spinning cup sequenator)의 사용에 의해 N-말단 또는 내부 아미노산 서열의 적어도 15개 잔기를 얻는 데 충분한 정도로, 또는 (3) 쿠마씨 블루(Coomassie blue) 또는 바람직하게는 은 염색을 이용하여 환원 또는 비환원 조건 하에 SDS-PAGE(도데실황산나트륨 겔 전기영동)에 의해 동질성에 대해 정제될 것이다. 단리된 항체는 항체의 천연 환경의 적어도 하나의 성분이 존재하지 않을 것이기 때문에 재조합 세포 내에서 인시추로 EpCAM 항체를 포함한다. 그러나, 보통, 단리된 항체는 적어도 하나의 정제 단계에 의해 제조될 것이다.
"인간 항체"는 인간에 의해 생성된 항체 또는 당업계에 공지된 임의의 기법을 이용하여 제조된 인간에 의해 생성된 항체에 대응하는 아미노산 서열을 갖는 항체를 지칭한다. 인간 항체의 이런 정의는 무손상 또는 전장 항체, 활성화 가능한 항체, 항원(예를 들어, 인간 또는 사이노몰거스 EpCAM)-결합 항체 단편, 및/또는 적어도 하나의 인간 중쇄 및/또는 경쇄 폴리펩타이드를 포함하는 항체, 예를 들어, 뮤린 경쇄 및 인간 중쇄 폴리펩타이드를 포함하는 항체를 포함한다.
본 명세서에 사용되는 바와 같은 용어 "키메라 항체"는 면역글로불린 분자의 서열이 둘 이상의 종으로부터 유래된 항체를 지칭한다. 전형적으로, 경쇄와 중쇄 둘 다의 가변 영역은 목적하는 특이성, 친화도 및 능력을 갖는 포유류의 하나의 종(예를 들어, 마우스, 랫트, 토끼 등)으로부터 유래된 항체의 가변 영역에 대응하는 한편, 불변 영역은 해당 종에서의 면역 반응을 유발하는 것을 피하기 위해 다른 종(보통 인간)으로부터 유래된 서열에 상동성이다.
본 명세서에서 사용되는 바와 같은 용어 "인간화 항체"는 최소 비인간(예를 들어, 뮤린) 서열을 포함하는 특정 면역글로불린 쇄, 키메라 면역글로불린, 또는 항원-결합 항체 단편인 비인간(예를 들어, 뮤린) 항체 형태를 지칭한다. 전형적으로, 인간화 항체는 상보성 결정 영역(CDR)으로부터의 잔기가 목적하는 특이성, 친화도 및 능력을 갖는 비인간 종(예를 들어, 마우스, 랫트, 토끼, 햄스터)의 CDR로부터의 잔기로 대체되는 인간 면역글로불린이다(Jones et al., Nature 321:522-525 (1986); Riechmann et al., Nature 332:323-327 (1988); Verhoeyen et al., Science 239:1534-1536 (1988)). 일부 예에서, 인간 면역글로불린의 Fv 프레임워크 영역(FR) 잔기는 목적하는 특이성, 친화도 및 능력을 갖는 비인간 종으로부터의 항체에서 대응하는 잔기로 대체된다. 인간화 항체는 항체 특이성, 친화도 및/또는 능력을 개선하고 최적화하기 위해 Fv 프레임워크 영역에서 그리고/또는 대체된 비인간 잔기 내에서 추가적인 잔기의 치환에 의해 추가로 변형될 수 있다. 일반적으로, 항체는 비인간 면역글로불린에 대응하는 CDR 영역 모두 또는 실질적으로 모두를 포함하는 적어도 1개, 전형적으로 2 또는 3개의 가변 영역의 실질적으로 모두를 포함할 것이지만, FR 영역의 모두 또는 실질적으로 모두는 인간 면역글로불린 공통 서열이다. 항체는 또한 면역글로불린 불변 영역 또는 도메인(Fc)의 적어도 일부, 전형적으로 인간 면역글로불린의 적어도 일부를 포함할 수 있다. 인간화 항체를 생성하기 위해 사용되는 방법의 예는 미국 특허 제5,225,539호에 기재되어 있다.
항체 "효과기 작용"은 항체의 Fc 영역(천연 서열 Fc 영역 또는 아미노산 서열 변이체 Fc 영역)에 기여하는 해당 생물학적 활성을 지칭하며, 항체 아이소타입에 따라 다르다. 항체 효과기 작용의 예는 하기를 포함한다: C1q 결합 및 보체 의존적 세포독성(CDC); Fc 수용체 결합; 항체 의존적 세포-매개 세포독성(ADCC); 및 항체-의존적 세포-매개 식세포작용(ADCP).
"인간 효과기 세포"는 하나 이상의 FcR를 발현시키고, 효과기 작용을 수행하는 백혈구이다. 특정 양상에서, 세포는 적어도 FcyRIII을 발현시키며, ADCC 또는 ADCP 효과기 작용(들)을 수행한다. ADCC 또는 ADCP를 매개하는 인간 백혈구의 예는 말초 혈액 단핵 세포(PBMC), 자연 살해(NK) 세포, 단핵구, 세포독성 T 세포 및 호중구를 포함한다. 효과기 세포는 천연 공급원으로부터, 예를 들어, 혈액으로부터 단리될 수 있다.
본 명세서에서 사용되는 바와 같은 용어 "Fc 영역"은 제1 불변 영역 면역글로불린 도메인을 제외한 항체의 불변 영역을 포함하는 폴리펩타이드를 포함한다. 따라서 Fc는 IgA, IgD 및 IgG의 마지막 2개의 불변 영역 면역글로불린 도메인, 및 IgE 및 IgM의 마지막 3개의 불변 영역 면역글로불린 도메인, 및 이들 도메인에 대해 N-말단의 가요성 힌지를 지칭한다. IgA 및 IgM에 대해, Fc는 J 쇄를 포함할 수 있다. IgG에 대해, Fc는 면역글로불린 도메인 Cγ2 및 Cγ3(Cγ2 및 Cγ3) 및 Cγ1(Cγ1)과 Cγ2(Cγ2) 사이의 힌지를 포함한다. Fc 영역의 경계는 다를 수 있지만, 인간 IgG 중쇄 Fc 영역은 보통 이의 카복실-말단에 잔기 C226 또는 P230을 포함하도록 정의되되, 넘버링은 카바트 등(1991, NIH Publication 91-3242, National Technical Information Service, Springfield, Va.)에서와 같은 EU 색인에 따른다. "카바트에 제시된 바와 같은 EU 색인"은 문헌[Kabat et al., 상기 참조]에 기재한 바와 같은 인간 IgG1 EU 항체의 잔기 넘버링을 지칭한다. Fc는 단리에서 이런 영역, 또는 항체, 항체 단편 또는 Fc 융합 단백질과 관련하여 이런 영역을 지칭할 수 있다. Fc 변이체 단백질은 항체, Fc 융합, 또는 Fc 영역을 포함하는 임의의 단백질 또는 단백질 도메인일 수 있단. Fc의 비천연 유래 변이체인 변이체 Fc 영역을 포함하는 단백질이 특히 바람직하다. 다형성은 카바트 270, 272, 312, 315, 356 및 358을 포함하지만, 이들로 제한되지 않는 다수의 Fc 위치에서 관찰되었고, 따라서 제시된 서열과 선형 기술의 서열 간에 약간의 차이가 존재할 수 있으며, 본 교시에 기반하여 당업자에 의해 이해될 것이다.
본 명세서에 사용된 바와 같은 용어 "접합체", "면역접합체", "ADC" 또는 "AADC"는 세포 결합제(즉, EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체)에 연결되고 하기 일반식에 의해 정해지는 화합물 또는 이의 유도체를 지칭한다: C-L-A, 식 중, C= 화합물, L= 링커, 및 A= EpCAM-결합제(EpBA)(예를 들어, 본 명세서에 개시된 바와 같은 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체). 일부 실시형태에서, 일반식: D-L-A이 또한 동일한 방식으로 사용될 수 있으며, D=약물, L=링커이고, A=세포 결합제(예를 들어, EpCAM 항체, EpCAM-결합 항체 단편 또는 EpCAM 활성화 가능한 항체)는 항체 단편 또는 EpCAM 활성화 가능한 항체)이다.
"링커"는 안정한 공유 방식으로 화합물, 보통 약물, 예컨대, 메이탄시노이드 또는 인돌리노벤조다이아제핀 화합물을 세포-결합제, 예컨대 항 EpCAM 항체 또는 EpCAM-결합 항체 단편을 연결할 수 있는 임의의 화학적 모이어티이다. 링커는 화합물 또는 항체가 활성으로 남아있는 조건 하에 산-유도 절단, 광-유도 절단, 펩티다제-유도 절단, 에스터라제-유도 절단, 및 이황화 결합 절단에 민감하거나 또는 실질적으로 저항성일 수 있다. 적합한 링커는 당업계에 잘 공지되어 있고, 예를 들어, 이황화기, 티오에터기, 산 불안정기, 광불안정기, 펩티다제 불안정기 및 에스터라제 불안정기를 포함한다. 링커는 또한 본 명세서에 개시되고 당업계에 공지된 바와 같은 펩타이드 링커 및 하전된 링커, 및 이들의 친수성 형태를 포함한다.
본 명세서에 사용되는 바와 같은 "비정상 세포 증식"은, 달리 표시되지 않는 한, 정상 조절 메커니즘(예를 들어, 접촉 저해의 상실)과 독립적인 세포 성장을 지칭한다. 이는, 예를 들어, 하기의 비정상적 성장을 포함한다: (1) 돌연변이된 타이로신 키나제 또는 수용체 타이로신 키나제의 과발현을 발현시킴으로써 증식되는 종양 세포(종양들); (2) 비정상적 타이로신 키나제 활성화가 일어나는 기타 증식성 질환의 양성 및 악성종양 세포; (3) 수용체 타이로신 키나제에 의해 증식되는 임의의 종양; (4) 비정상적 세린/트레오닌 키나제 활성화에 의해 증식되는 임의의 종양; (5) 비정상적 세린/트레오닌 키나제 활성화가 일어나는 기타 증식성 질환의 양성 및 악성 세포, 및 (6) 기타 증식성 질환의 양성 및 악성 세포.
용어 "암" 및 "암성"은 전형적으로 비조절 세포 성장을 특징으로 하는 포유류에서의 생리적 병태를 지칭하거나 기재한다. "종양"은 하나 이상의 암성 세포를 포함한다. 암의 예는 암종, 아세포종, 육종, 골수종, 백혈병 또는 림프종 악성종양을 포함하지만, 이들로 제한되지 않는다. 본 명세서에 정의된 바와 같은 용어 "암" 또는 "암성"은 치료되지 않는 다면, 암성 병태로 진행될 수 있는 "전암성" 병태를 포함한다. 특정 실시형태에서, 암은 상피암이다. 상피암의 예는 유방 암, 폐 암, 간암, 위암, 두경부암, 전립선 암, 췌장암, 난소암, 결장암, 및 신장암을 포함한다. 제공된 EpCAM 항체, EpCAM-결합 항체 단편, EpCAM 활성화 가능한 항체 또는 면역접합체로 진단되거나 치료될 수 있는 추가적인 암은 식도암, 기관암, 뇌암, 암종, 담관세포 암, 자궁내막암, 자궁경부암, 위암, 방광암, 자궁암, 고환암, 직장암, 피부암(흑색종), 소장암, 담낭암, 담관암, 침샘암을 포함한다. 일부 실시형태에서, 암은 난소암, 자궁암, 위암, 췌장암 또는 결장직장암이다.
용어 "암세포", "종양 세포" 및 문법적 동등물은 종양 세포 집단, 및 종양형성 줄기 세포(암 줄기 세포)의 벌크를 포함하는 비종양형성 세포를 둘 다 포함하는 종양 또는 전암성 병변으로부터 유래된 총 세포 집단을 지칭한다.
본 명세서에 사용되는 용어 "세포독성제"는 하나 이상의 세포 작용을 저해 또는 방지하고/하거나 세포사를 야기하는 물질을 지칭한다.
본 명세서에서 사용되는 "치료"는 치료 중인 개체 또는 세포의 천연 과정을 변경시키기 위한 시도에서의 임상적 개입을 지칭하며, 예방 동안 또는 임상 병리 과정 동안 수행될 수 있다. 바람직한 치료 효과는 질환 발생 또는 재발 방지, 증상의 완화, 질환의 임의의 임의의 직접적 또는 간접적인 병리학적 결과의 감소, 전이 방지, 질환 진행률 감소, 질환 상태의 개선 또는 경감, 및 관해 또는 개선된 예후를 포함한다. 일부 실시형태에서, 본 명세서에 제공된 방법 및 조성물은 질환 또는 장애의 발생을 지연시키는 시도에서 유용하다.
"치료하는" 또는 "치료" 또는 "치료하기 위한" 또는 "완화하는" 또는 "완화하기 위한"과 같은 용어는 1) 진단된 병리학적 병태 또는 장애를 치유하고/하거나, 늦추고/늦추거나, 증상을 줄이는 치료적 척도 및 2) 표적화된 병리학적 병태 또는 장애의 발생을 방지하고/하거나 늦추는 예방적 또는 방지적 척도를 둘 다 지칭한다. 따라서, 치료가 필요한 대상은 이미 장애를 갖는 대상; 장애를 갖는 경향이 있는 대상; 및 장애가 예방되어야 할 대상을 포함한다. 특정 실시형태에서, 대상체는 환자가 다음 중 하나 이상을 나타낸다면 본 명세서에 제공된 방법에 따라 암에 대해 성공적으로 "치료된다": 암세포 수의 감소 또는 완전한 부재; 종양 크기 감소; 말초 기관 내로의 암세포 침윤의 저해 또는 부재, 예를 들어, 연조직 및 뼈에 대한 암의 확산; 종양 전이의 저해 또는 부재; 종양 성장의 저해 또는 부재; 특정 암과 연관된 하나 이상의 증상의 경감; 감소된 이환율 및 사망률; 삶의 질 개선; 종양의 종양원성, 종양형성 빈도, 또는 종양형성 능력의 감소; 종양에서 암 줄기 세포의 수 또는 빈도의 감소; 종양형성 세포의 비-종양형성 상태로의 분화; 또는 효과의 일부 조합.
본 명세서에 개시된 바와 같은 항체의 "유효량"은 구체적으로 언급된 목적을 수행하는 데 충분한 양이다. "치료적 유효량"은 목적하는 치료 결과를 달성하기 위해 필요한 투약랑 및 일정 기간 동안의 유효량을 지칭한다. 치료제(예를 들어, 접합체 또는 면역접합체)의 "치료적 유효량"은 개체의 질환 상태, 연령, 성별 및 체중 및 항체가 개체에서 목적하는 반응을 유발하는 능력과 같은 인자에 따라 다를 수 있다. 치료적 유효량은 또한 치료적으로 유리한 효과가 치료제의 임의의 독성 또는 해로운 효과보다 우세한 것이다.
"치료제"는 생물학적 제제, 예컨대 항체, 펩타이드, 단백질, 효소, 화학치료제 또는 접합체 또는 면역접합체를 모두 포함한다.
용어 "대상체", "개체", "동물", "환자" 및 "포유류"는 진단, 예후 또는 치료가 요망되는 임의의 대상체, 특히 포유류 대상체를 지칭한다. 포유류 대상체는 특정 치료의 수용자인 인간, 비인간 영장류, 가축 동물, 농장 동물, 설치류 등을 포함하지만, 이들로 제한되지 않는다.
본 명세서에서 상호 호환적으로 사용되는 용어 "폴리뉴클레오타이드" 또는 "핵산"은 임의의 길이의 뉴클레오타이드의 중합체를 지칭하고, DNA 및 RNA를 포함한다. 뉴클레오타이드는 DNA 또는 RNA 중합효소에 의해 중합체에 혼입될 수 있는 데옥시리보뉴클레오타이드, 리보뉴클레오타이드, 변형된 뉴클레오타이드 또는 염기 및/또는 이들의 유사체 또는 임의의 기질일 수 있다. 폴리뉴클레오타이드는 변형된 뉴클레오타이드, 예컨대, 메틸화된 뉴클레오타이드 및 이들의 유사체를 포함할 수 있다. 존재한다면, 뉴클레오타이드 구조에 대한 변형은 중합체의 조립 전에 또는 후에 부여될 수 있다. 뉴클레오타이드 서열은 비-뉴클레오타이드 성분이 끼어있을 수 있다. 폴리뉴클레오타이드는 중합 후에, 예컨대, 표지 성분과의 접합에 의해 추가로 변형될 수 있다. 다른 유형의 변형은, 예를 들어, "캡", 천연 유래 뉴클레오타이드 중 하나 이상의 유사체로의 치환, 뉴클레오타이드간 변형, 예를 들어, 비하전 결합을 갖는 것(예를 들어, 메틸 포스포네이트, 포스포트라이에스터, 포스포아미데이트, 카바메이트 등) 및 하전된 결합을 갖는 것(예를 들어, 포스포로티오에티느, 포스포로다이티오에이트 등), 현수 모이어티를 포함하는 것, 예컨대, 단백질(예를 들어, 뉴클레아제, 독소, 항체, 신호 펩타이드, ply-L-라이신 등), 삽입제를 갖는 것(예를 들어, 아크리딘, 소랄렌 등), 킬레이트제를 함유하는 것(예를 들어, 금속, 방사성 금속, 붕소, 산화적 금속 등), 알킬화제를 함유하는 것, 변형된 결합을 갖는 것(예를 들어, 알파 아노머 핵산 등)뿐만 아니라 폴리뉴클레오타이드(들)의 비변형 형태를 포함한다. 추가로, 보통 당에 존재하는 임의의 하이드록실기는, 예를 들어, 포스포네이트기, 포스페이트기에 의해 대체될 수 있고, 표준 보호기에 의해 보호되거나, 추가적인 뉴클레오타이드에 대한 추가적인 결합을 제조하도록 활성화되거나, 고체 지지체에 접합될 수 있다. 5' 및 3' 말단의 OH는 인산화될 수 있거나, 1 내지 20개의 탄소 원자의 아민 또는 유기 캡핑기로 치환될 수 있다. 기타 하이드록실은 또한 표준 보호기로 유도체화될 수 있다. 폴리뉴클레오타이드는, 예를 들어, 2'-O-메틸-, 2'-O-알릴, 2'-플루오로- 또는 2' 아지도-리보스, 탄소고리 당 유사체, 알파-아노머 당, 에피머 당, 예컨대 아라비노스, 자일로스 또는 릭소스, 피라노스 당, 푸라노스 당, 세도헵툴로스, 아크릴산 유사체 및 비염기성 뉴클레오사이드 유사체, 예컨대 메틸 리보사이드를 포함하는, 당업계에 일반적으로 공지되어 있는 리보스 또는 데옥시리보스 당의 유사체 형태를 함유할 수 있다. 하나 이상의 포스포다이에스터 결합은 대안의 연결기에 의해 대체될 수 있다. 이들 대안의 연결기는 인산염이 P(O)S("티오에이트"), P(S)S("다이티오에이트"), "(O)NR2("아미데이트"), P(O)R, P(O)OR', CO 또는 CH2("폼아세탈")에 의해 대체되며, 각각의 R 또는 R'는 독립적으로 H, 또는 선택적으로 에터(--O--) 결합, 아릴, 알켄일, 사이클로알킬, 사이클로알켄일 또는 아랄딜을 포함하는 치환된 또는 비치환된 알킬(1-20C)인 실시형태를 포함하지만, 이들로 제한되지 않는다. 폴리뉴클레오타이드에서 모든 결합이 동일할 필요는 없다. 앞서 언급한 설명은 RNA 및 DNA를 포함하는 본 명세서에 지칭되는 모든 폴리뉴클레오타이드에 적용된다.
용어 "벡터"는 숙주 세포에서 관심 대상의 하나 이상의 유전자(들) 또는 서열(들)을 전달하고, 선택적으로 발현시킬 수 있는 작제물을 의미한다. 벡터의 예는 바이러스 벡터, 네이키드 DNA 또는 RNA 발현 벡터, 플라스미드, 코스미드 또는 파지 벡터, 양이온성 축합제와 결합된 DNA 또는 RNA 발현 벡터, 리포좀에서 캡슐화된 DNA 또는 RNA 발현 벡터, 및 특정 진행 세포, 예컨대 생산자 세포를 포함하지만, 이들로 제한되지 않는다.
용어 "폴리펩타이드", "펩타이드" 및 "단백질"은 임의의 길이의 아미노산의 중합체를 지칭하기 위해 본 명세서에서 상호 호환적으로 사용된다. 중합체는 선형 또는 분지형일 수 있고, 이는 변형된 아미노산을 포함할 수 있으며, 비아미노산이 끼어있을 수 있단. 용어는 또한 자연적으로 또는 개입; 예를 들어, 이황화 결합 형성, 글리코실화, 지질화, 아세틸화, 인산화, 또는 임의의 다른 조작 또는 변형, 예컨대 표지 성분과의 접합에 의해 변형된 아미노산 중합체를 포함한다. 또한, 예를 들어, 아미노산(예를 들어, 비천연 아미노산 등을 포함)의 하나 이상의 유사체를 포함하는 폴리펩타이드뿐만 아니라 당업계에 공지된 다른 변형이 정의에 포함된다.
당업계에 공지된 바와 같은 용어 "동일한" 또는 "동일성" 백분율은 이들의 서열을 비교함으로써 결정된 바와 같은 두 폴리뉴클레오타이드 또는 두 폴리펩타이드 사이의 관계의 척도이다. 서열에 대한 동일성 또는 유사성은 필요하다면, 최대 서열 동일성 백분율을 달성하기 위해, 서열을 정렬하고 갭을 도입한 후에, EpCAM 항체 잔기와 동일(즉, 동일한 잔기) 또는 유사한(즉, 공통 측쇄 특성에 기반하여 동일한 기로부터의 아미노산 잔기, 이하 참조) 후보 서열에서의 아미노산 잔기 백분율로서 본 명세서에서 정의된다. 가변 영역 외부의 항체 서열에 N-말단, C-말단 또는 내부의 확장, 결실 또는 삽입 중 어느 것도 서열 동일성 또는 유사성에 영향을 미치는 것으로 해석되어서는 안 될 것이다. 일반적으로, 비교될 두 서열은 서열 간의 최대 상관관계를 제공하도록 정렬된다. 두 서열의 정렬은 시험되고, 두 서열 사이의 정확한 아미노산 또는 뉴클레오타이드 대응도를 제공하는 위치 수가 결정되며, 정렬의 총 길이로 나누고, 100을 곱하여서 동일성% 수치를 제공한다. 이런 동일성% 수치는 동일 또는 매우 유사한 길이의 서열에 특히 적합하고, 고도로 상동성일 수 있는 비교될 서열의 전체 길이에 대해, 또는 동일하지 않은 길이의 서열에 더 적합하거나 더 낮은 수주의 상동성을 갖는 보다 짧게 정해진 길이에 대해 결정될 수 있다. 마찬가지로 유사성 백분율은 동일하고 유사한 잔기 둘 다의 존재에 기반하여 유사한 방식으로 결정될 수 있다.
동일성 백분율은 서열 비교 소프트웨어 또는 알고리즘을 이용하거나 시각적 검사에 의해 측정될 수 있다. 아미노산 또는 뉴클레오타이드 서열의 정렬을 얻기 위해 사용될 수 있는 다양한 알고리즘 및 소프트웨어는 당업계에 공지되어 있다. 서열 정렬 알고리즘의 한 가지 이러한 비제한적 예는 문헌[Karlin et al., Proc. Natl. Acad. Sci. 87:2264-2268 (1990)]에 기재되고, 문헌[Karlin et al., Proc. Natl. Acad. Sci. 90:5873-5877 (1993)]에서 변형되며, NBLAST 및 XBLAST 프로그램에 포함되는 알고리즘이다(Altschul etal., Nucleic Acids Res., 25:3389-3402 (1991)). 특정 실시형태에서, 갭화된 BLAST는 문헌[Altschul et al., Nucleic Acids Res. 25:3389-3402 (1997)]에 기재된 바와 같이 사용될 수 있다. BLAST-2, WU-BLAST-2(Altschul et al., Meth. Enzym. 266:460-480 (1996)), ALIGN, ALIGN-2(Genentech, 캘리포니아주 사우스 샌프란시스코) 또는 Megalign(DNASTAR®은 서열을 정렬하는 데 사용될 수 있는 추가적인 공개적으로 입수 가능한 소프트웨어 프로그램이다. 특정 실시형태에서, 두 뉴클레오타이드 서열 간의 동일성 백분율은 GCG 소프트웨어(예를 들어, NWSgapdna.CMP 매트릭스 및 40, 50, 60, 70 또는 90의 갭 가중치 및 1, 2, 3, 4, 5 또는 6의 길이 가중치를 이용)에서 GAP 프로그램을 이용하여 결정된다. 특정 대안의 실시형태에서, 니들만 및 분슈(Needleman and Wunsch) 알고리즘을 포함하는 GCG 소프트웨어 패키지의 GAP 프로그램(J. Mol. Biol. (48):444-453 (1970))은 두 아미노산 서열 간의 동일성 백분율(예를 들어, Blossum 62 매트릭스 또는 PAM250 매트릭스, 및 of 16, 14, 12, 10, 8, 6 또는 4의 갭 가중치, 및 1, 2, 3, 4, 5의 길이 가중치를 이용)을 결정하는 데 사용될 수 있다. 대안적으로, 특정 실시형태에서, 뉴클레오타이드 또는 아미노산 서열 간의 동일성 백분율은 Myers 및 Miller의 알고리즘을 이용하여 결정된다(CABIOS 4:11-17 (1989)). 예를 들어, 동일성 백분율은 ALIGN 알고리즘(버전 2.0)을 이용하여 그리고 잔기 표, 12의 갭 길이 페널티 및 4의 갭 페널티를 갖는 PAM120을 이용하여 결정될 수 있다. 특정 정렬 소프트웨어에 의한 최대 정렬을 위한 적절한 파라미터는 당업자에 의해 결정될 수 있다. 특정 실시형태에서, 정렬 소프트웨어의 디폴트 파라미터가 사용된다. 특정 실시형태에서, 제2 서열 아미노산에 대한 제1 아미노산 서열의 동일성 백분율 "X"는 100×(Y/Z)로서 계산되며, 여기서, Y는 제1 및 제2 서열의 정렬(시각적 검사 또는 특정 서열 정렬 프로그램에 의해 정렬된 바와 같음)에서 동일한 매치로서 스코어링되는 아미노산 잔기의 수이고, Z는 제2 서열에서 잔기의 총 수이다. 제1 서열의 길이가 제2 서열보다 길다면, 제2 서열에 대한 제1 서열의 동일성 백분율은 제1 서열에 대한 제2 서열의 동일성 백분율보다 더 길 것이다.
비제한적 예로서, 임의의 특정 폴리뉴클레오타이드가 기준 서열에 대해 특정 서열 동일성 백분율을 갖는지의(예를 들어, 적어도 80% 동일, 적어도 85% 동일, 적어도 90% 동일하고, 일부 실시형태에서, 적어도 95%, 96%, 97%, 98% 또는 99% 동일한지의) 여부는, 특정 실시형태에서, Bestfit 프로그램(Wisconsin Sequence Analysis Package, Version 8 for Unix, Genetics Computer Group, 위스콘신주 53711 메디슨 사이언스 드라이브 575에 소재한 University Research Park)을 이용하여 결정될 수 있다. Bestfit은 두 서열 간의 최고의 상동성 세그먼트를 찾기 위해 문헌[Smith and Waterman, Advances in Applied Mathematics 2: 482-489 (1981)]의 국소 상동성 알고리즘을 사용한다. 특정 서열이, 예를 들어 본 명세서에 제공된 바와 같은 기줄 서열에 대해 95% 동일한지의 여부를 결정하기 위해 Bestfit 또는 임의의 다른 서열 정렬을 이용할 때, 동일성 백분율이 기준 뉴클레오타이드 서열의 전장에 대해 계산되며 기준 서열의 총 뉴클레오타이드 수의 최대 5%의 상동성 갭이 허용되도록 파라미터가 설정된다.
"보존적 아미노산 치환"은 아미노산 잔기가 유사한 측쇄를 갖는 다른 아미노산 잔기로 대체되는 것이다. 예를 들어, 염기성 측쇄(예를 들어, 라이신, 알기닌, 히스티딘), 산성 측쇄(예를 들어, 아스파트산, 글루탐산), 비하전 극성 측쇄(예를 들어, 글리신, 아스파라긴, 글루타민, 세린, 트레오닌, 타이로신, 시스테인), 비극성 측쇄(예를 들어, 알라닌, 발린, 류신, 아이소류신, 프롤린, 페닐알라닌, 메티오닌, 트립토판), 베타-분지형 측쇄(예를 들어, 트레오닌, 발린, 아이소류신) 및 방향족 측쇄(예를 들어, 타이로신, 페닐알라닌, 트립토판, 히스티딘)를 포함하는, 유사한 측쇄를 갖는 아미노산 잔기의 패밀리가 당업계에 정의되어 있다. 예를 들어, 타이로신의 페닐알라닌으로의 치환은 보존적 치환이다. 일부 실시형태에서, 본 명세서에 제공된 폴리펩타이드 및 항체의 서열에서 보존적 치환은, 폴리펩타이드 또는 항체가 결합하는 항원(들)에 대한 아미노산 서열을 포함하는 폴리펩타이드 또는 항체의 결합을 제거하지 않는다. 항원 결합을 제거하지 않는 뉴클레오타이드 및 보존적 아미노산 치환을 확인하는 방법은 당업계에 잘 공지되어 있다(예를 들어, Bru㎜ell et al., Biochem. 32:1180-1187 (1993); Kobayashi et al., Protein Eng. 12(10):879-884 (1999); 및 Burks et al., Proc. Natl. Acad. Sci. USA 94:412-417 (1997)).
본 명세서에 사용되는 바와 같은 "알킬"은 1 내지 20개 탄소 원자의 포화된 선형 또는 분지쇄 1가 탄화수소 라디칼을 지칭한다. 알킬의 예는 메틸, 에틸, 1-프로필, 2-프로필, 1-뷰틸, 2-메틸-1-프로필, -CH2CH(CH3)2), 2 뷰틸, 2-메틸-2-프로필, 1-펜틸, 2-펜틸 3-펜틸, 2-메틸-2-뷰틸, 3-메틸-2-뷰틸, 3 메틸-1-뷰틸, 2-메틸-1-뷰틸, 1-헥실), 2-헥실, 3-헥실, 2-메틸-2-펜틸, 3-메틸-2 펜틸, 4-메틸-2-펜틸, 3-메틸-3-펜틸, 2-메틸-3-펜틸, 2,3-다이메틸-2-뷰틸, 3,3 다이메틸-2-뷰틸, 1-헵틸, 1-옥틸 등을 포함하지만, 이들로 제한되지 않는다. 바람직하게는, 알킬은 1 내지 10개의 탄소 원자를 가진다. 더 바람직하게는, 알킬은 1 내지 4개의 탄소 원자를 가진다.
기에서 탄소의 수는 본 명세서에서 접두사 "Cx-xx"에 의해 구체화될 수 있다, 식 중, x 및 xx는 정수이다. 예를 들어, "C1-4알킬"은 1 내지 4개의 탄소 원자를 갖는 알킬기이다.
용어 "화합물" 또는 "세포독성 화합물" 또는 "세포독성제"는 상호 호환적으로 사용된다. 이들은 구조식 또는 화학식 또는 이들의 임의의 유도체가 본 명세서에 개시된 화합물 또는 참고로 포함된 구조식 또는 화학식 또는 이들의 임의의 유도체를 포함하는 것으로 의도된다. 상기 용어는 또한 본 명세서에 개시된 모든 화학식의 화합물의 입체이성질체, 기하이성질체, 호변이성질체, 용매화물, 대사물질 및 염(예를 들어, 약제학적으로 허용 가능한 염)을 포함한다. 상기 용어는 또한 임의의 앞서 언급한 것의 임의의 용매화물, 수화물 및 다형체를 포함한다. 본 명세서에서 제공되는 특정 실시형태에서, "입체이성질체", "기하이성질체", "호변이성질체", "용매화물," "대사물질," "염", "접합체", "접합체 염", "용매화물", "수화물" 또는 "다형체"의 구체적 열거는 다른 개시된 실시형태에서 이들 형태의 의도된 누락으로서 해석되지 않을 것이며, 용어 "화합물"은 이들 다른 형태의 열거 없이 사용된다.
용어 "이민 반응성 시약"은 이민기와 반응할 수 있는 시약을 지칭한다. 이민 반응성 시약의 예는, 아황산염(H2SO3, H2SO2 또는 양이온과 함께 형성된 HSO3-, SO32- 또는 HSO2-의 염), 메타중아황산염(H2S2O5 또는 양이온과 함께 형성된 S2O52-의 염), 모노, 다이, 트라이 및 테트라-티오인산염(PO3SH3, PO2S2H3, POS3H3, PS4H3 또는 양이온과 함께 형성된 PO3S3-, PO2S23-, POS33- 또는 PS43-의 염), 티오인산염 에스터((RiO)2PS(ORi), RiSH, RiSOH, RiSO2H, RiSO3H), 다양한 아민(하이드록실 아민(예를 들어, NH2OH), 하이드라진(예를 들어, NH2NH2), NH2O-Ri, Ri'NH-Ri, NH2-Ri), NH2-CO-NH2, NH2-C(=S)-NH2, 티오황산염 (H2S2O3 또는 양이온과 함께 형성된 S2O32-의 염), 다이티오나이트(H2S2O4 또는 양이온과 함께 형성된 S2O42-의 염), 포스포로다이티오에이트(P(=S)(ORk)(SH)(OH) 또는 양이온과 함께 형성된 이들의 염), 하이드록삼산(RkC(=O)NHOH 또는 양이온과 함께 형성된 염), 하이드라자이드(RkCONHNH2), 폼알데하이드 설폭실레이트(HOCH2SO2H 또는 양이온과 함께 형성된 HOCH2SO2-의 염, 예컨대 HOCH2SO2-Na+), 당화된 뉴클레오타이드(예컨대, GDP-만노스), 플루다라빈 또는 이들의 혼합물을 포함하지만, 이들로 제한되지 않되, Ri 및 Ri'는 각각 독립적으로 1 내지 10개의 탄소 원자를 갖는 선형 또는 분지형 알킬이고, N(Rj)2, -CO2H, SO3H 및 PO3H로부터 선택된 적어도 하나의 치환체로 치환되며; Ri 및 Ri'는 추가로 본 명세서에 개시된 알킬에 대한 치환체로 선택적으로 치환될 수 있고; Rj는 1 내지 6개의 탄소 원자를 갖는 선형 또는 분지형 알킬이며; Rk는 1 내지 10개의 탄소 원자를 갖는 선형, 분지형 또는 환식 알킬, 알켄일 또는 알킨일, 아릴, 헤테로사이클릴 또는 헤테로아릴이다(바람직하게는, Rk는 1 내지 4개의 탄소 원자를 갖는 선형 또는 분지형 알킬이고; 더 바람직하게는, Rk는 메틸, 에틸 또는 프로필이다). 바람직하게는, 양이온은 1가 양이온, 예컨대 Na+ 또는 K+이다. 바람직하게는, 이민 반응성 시약은 아황산염, 하이드록실 아민, 유레아 및 하이드라진으로부터 선택된다. 더 바람직하게는, 이민 반응성 시약은 NaHSO3 또는 KHSO3이다.
용어 "양이온"은 양전하를 갖는 이온을 지칭한다. 양이온은 1가(예를 들어, Na+, K+, NH4+ 등), 2가(예를 들어, Ca2+, Mg2+ 등) 또는 다가(예를 들어, A13+ 등)일 수 있다. 바람직하게는, 양이온은 1가이다.
본 명세서에서 사용되는 바와 같은 어구 "약제학적으로 허용 가능한 염"은 본 명세서에 제공된 화합물의 약제학적으로 허용 가능한 유기 또는 무기염을 지칭한다. 예시적인 염은 황산염, 시트르산염, 아세트산염, 옥살산염, 염화물, 브로민화물, 아이오딘화물, 질산염, 중황산염, 인산염, 산 인산염, 아이소니코틴산염, 락트산염, 살리실산염, 산 시트르산염, 타르타르산염, 올레산염, 탄산염, 판토텐산염, 중주석산염, 아스코브산염, 석신산염, 말레산염, 겐티스산염, 퓨마르산염, 글루콘산염, 글루쿠론산염, 당산염, 폼산염, 벤조산염, 글루탐산염, 메탄설폰산염 "메실레이트", 에탄설폰산염, 벤젠설폰산염, p-톨루엔설폰산염, 파모산염(즉, 1,1'-메틸렌-비스-(2-하이드록시-3-나프토에이트)) 염, 알칼리 금속(예를 들어, 나트륨 및 칼륨)염, 알칼리 토금속(예를 들어, 마그네슘) 염 및 암모늄 염을 포함하지만, 이들로 제한되지 않는다. 약제학적으로 허용 가능한 염은 다른 분자, 예컨대, 아세트산염 이온, 석신산 이온 또는 기타 반대 이온의 포함을 수반할 수 있다. 반대 이온은 모 화합물 상의 전하를 안정화시키는 임의의 유기 또는 무기 모이어티일 수 있다. 더 나아가, 약제학적으로 허용 가능한 염은 이의 구조에서 하나 초과의 하전된 원자를 가질 수 있다. 다중 하전 원자가 약제학적으로 허용 가능한 염의 부분인 예는 다중 반대 이온을 가질 수 있다. 그러므로, 약제학적으로 허용 가능한 염은 하나 이상의 하전된 원자 및/또는 하나 이상의 반대 이온을 가질 수 있다.
본 명세서에 제공된 화합물이 염기라면, 목적하는 약제학적으로 허용 가능한 염은 당업계에서 이용 가능한 임의의 적합한 방법, 예를 들어, 무기산, 예컨대 염산, 브로민화수소산, 황산, 질산, 메탄설폰산, 인산 등에 의한, 또는 유기산, 예컨대 아세트산, 말레산, 석신산, 만델산, 퓨마르산, 말론산, 피루브산, 옥살산, 글리콜산, 살리실산, 피라노시딜산, 예컨대 글루쿠론산 또는 갈락투론산, 알판 하이드록시산, 예컨대 시트르산 또는 타르타르산, 아미노산, 예컨대, 아스파트산 또는 글루탐산, 방향족산, 예컨대 벤조산 또는 신남산, 설폰산, 예컨댄 p-톨루엔설폰산 또는 에탄설폰산 등에 의한 유리 염기의 처리에 의해 제조될 수 있다.
본 명세서에 제공된 화합물이 산이라면, 목적하는 약제학적으로 허용 가능한 염은 임의의 적합한 방법, 예를 들어, 무기 또는 유기 염기, 예컨대 아민(1차, 2차 또는 3차), 알칼리 금속 수산화물 또는 알칼리 토금속 수산화물 등에 의한 유리산의 처리에 의해 제조될 수 있다. 적합한 염의 예시적 예는 아미노산, 예컨대 글리신 및 알기닌, 암모니아, 1차, 2차 및 3차 아민, 및 환식 아민, 예컨대, 피페리딘, 몰폴린 및 피페라진으로부터 유도된 유기염, 및 나트륨, 칼슘, 칼륨, 마그네슘, 망간, 철, 구리, 아연, 알루미늄 및 리튬으로부터 유도된 무기염을 포함하지만, 이들로 제한되지 않는다.
본 명세서에 사용된 바와 같은 용어 "용매화물"은 비공유 분자간 힘에 의해 결합되는 화학량론적 또는 비-화학량론적 양의 용매, 예컨대, 물, 아이소프로판올, 아세톤, 에탄올, 메탄올, DMSO, 에틸 아세트산염, 아세트산, 및 에탄올아민 다이클로로메탄, 2 프로판올 등을 추가로 포함하는 화합물을 의미한다. 화합물의 용매화물 또는 수화물은 이민 모이어티의 용매화 또는 수화를 초래하는 화합물에 대한 적어도 1몰 당량의 하이드록실 용매, 예컨대, 메탄올, 에탄올, 1-프로판올, 2-프로판올 또는 물의 첨가에 의해 용이하게 제조된다.
"대사물질" 또는 "분해대사물질"은 명시된 화합물, 이의 유도체 또는 이의 접합체, 또는 이의 염의 신체에서의 대사 또는 이화작용을 통해 생성되는 생성물이다. 화합물, 이의 유도체, 또는 이의 접합체의 대사물질은 당업계에 공지되어 있는 일상적인 기법을 이용하여 확인될 수 있고, 이들의 활성은 본 명세서에 개시된 것과 같은 시험을 이용하여 결정된다. 이러한 생성물은, 예를 들어, 투여되는 화합물의 산화, 하이드록실화, 환원, 가수분해, 아마이드화, 탈아마이드화, 에스터화, 탈에스터화, 효소적 절단 등을 초래할 수 있다. 따라서, 본 개시내용은 개시된 EpCAM 화합물, 이의 유도체 또는 이의 접합체를 이의 대사 산물을 수득하기에 충분한 시간 기간 동안 포유류와 접촉시키는 단계를 포함하는 과정에 의해 생성된 화합물, 이의 유도체 또는 이의 접합체를 포함하는, 본 명세서에 개시된 EpCAM 조성물의 화합물, 이의 유도체, 또는 이의 접합체의 대사물질을 포함한다.
어구 "약제학적으로 허용 가능한"은 물질 또는 조성물이 제형을 포함하는 다른 성분과 화학적으로 그리고/또는 독성학적으로 양립 가능하여야 하고, 포유류는 이에 의해 치료 중이라는 것을 나타낸다.
용어 "보호기" 또는 "보호 모이어티"는 특정 작용기를 차단 또는 보호하는 한편 화합물, 이의 유도체 또는 이의 접합체 상의 다른 작용기와 반응할 수 있는 통상적으로 사용되는 치환체를 지칭한다. 예를 들어, "아민-보호기" 또는 "아미노-보호 모이어티"는 화합물에서 아미노 작용기를 차단하거나 보호하는 아미노기에 부착되는 치환체이다. 이러한 기는 당업계에 잘 공지되어 있으며(예를 들어, 문헌[P. Wuts and T. Greene, 2007, Protective Groups in Organic Synthesis, Chapter 7, J. Wiley & Sons, NJ] 참조), 1,6-β-제거("자기 희생"으로도 지칭됨), 유레아, 아마이드, 펩타이드, 알킬 및 아릴 유도체에 의해 절단되는 메틸 및 에틸 카바메이트, FMOC, 치환된 에틸 카바메이트, 카바메이트와 같은 카바메이트에 의해 예시된다. 적합한 아미노-보호기는 아세틸, 트라이플루오로아세틸, t-뷰톡시카보닐(BOC), 벤질옥시카보닐(CBZ) 및 9-플루오렌일메틸렌옥시카보닐(Fmoc)을 포함한다. 보호기 및 이들의 용도의 일반적 설명을 위해, 문헌[P. G.M. Wuts & T. W. Greene, Protective Groups in Organic Synthesis, John Wiley & Sons, New York, 2007]을 참조한다.
용어 "아미노산"은 천연 유래 아미노산 또는 비천연 유래 아미노산을 지칭한다. 일 실시형태에서, 아미노산은 NH2-C(Raa'Raa)-C(=O)OH로 표시되되, Raa 및 Raa'는 각각 독립적으로 H, 선택적으로 치환된 1 내지 10개의 탄소 원자를 갖는 선형, 분지형 또는 환식 알킬, 알켄일 또는 알킨일, 아릴, 헤테로아릴 또는 헤테로사이클릴이거나, Raa 및 N-말단의 질소 원자는 함께 (예를 들어, 프롤린에서와 같이) 복소환식 고리를 형성할 수 있다. 용어 "아미노산 잔기"는 하나의 수소 원자가 아미노산의 아민 및/또는 카복시 말단으로부터 제거된 대응하는 잔기, 예컨대, -NH-C(Raa'Raa)-C(=O)O-를 지칭한다.
용어 "펩타이드"는 펩타이드(아마이드) 결합에 의해 연결된 아미노산 단량체의 단쇄를 지칭한다. 일부 실시형태에서, 펩타이드는 2 내지 20개의 아미노산 잔기를 포함한다. 다른 실시형태에서, 펩타이드는 2 내지 10개의 아미노산 잔기를 포함한다. 또 다른 실시형태에서, 펩타이드는 2 내지 5개의 아미노산 잔기를 포함한다. 본 명세서에 사용된 바와 같이, 펩타이드가 아미노산의 특정 서열로 표시되는 본 명세서에 개시된 세포독성제 또는 링커의 일부일 때, 펩타이드는 양 방향 모두에서 세포독성제 또는 링커의 나머지에 연결될 수 있다. 예를 들어, 다이펩타이드 X1-X2는 X1-X2 및 X2-X1을 포함한단. 유사하게, 트라이펩타이드 X1-X2-X3는 X1-X2-X3 및 X3-X2-X1을 포함하고, 테트라펩타이드 X1-X2-X3-X4는 X1-X2-X3-X4 및 X4-X2-X3-X1을 포함한다. X1, X2, X3 및 X4는 아미노산 잔기를 나타낸다.
용어 "반응성 에스터기"는 아민기와 용이하게 반응하여 아마이드 결합을 형성할 수 있는 에스터기를 지칭한다. 예시적인 반응성 에스터기는 N-하이드록시석신이미드 에스터, N-하이드록시프탈이미드 에스터, N-하이드록시 설포석신이미드 에스터, 파라-나이트로페닐 에스터, 다이나이트로페닐 에스터, 펜타플루오로페닐 에스터 및 이들의 유도체를 포함하지만, 이들로 제한되지 않되, 유도체는 아마이드 결합 형성을 용이하게 한다. 특정 실시형태에서, 반응성 에스터기는 N-하이드록시석신이미드 에스터 또는 N 하이드록시 설포석신이미드 에스터이다.
용어 "아민 반응성기"는 아민기와 반응하여 공유 결합을 형성할 수 있는 기를 지칭한다. 예시적인 아민 반응기는 반응성 에스터기, 아실 할로겐화물, 설폰일 할로겐화물, 이미도에스터, 또는 반응성 티오에스터기를 포함하지만, 이들로 제한되지 않는다. 특정 실시형태에서, 아민 반응기는 반응성 에스터기이다. 일 실시형태에서, 아민 반응기는 N-하이드록시석신이미드 에스터 또는 N-하이드록시 설포-석신이미드 에스터이다.
용어 "티올 반응성기"는 티올(-SH) 기와 반응하여 공유 결합을 형성할 수 있는 기를 지칭한다. 예시적인 티올-반응기는 말레이미드, 할로아세틸, 알로아세트아마이드, 비닐 설폰, 비닐 설폰아마이드 또는 비닐알 피리딘을 포함하지만, 이들로 제한되지 않는다. 일 실시형태에서, 티올-반응기는 말레이미드이다.
본 개시내용 및 청구범위에서 사용되는 바와 같은 단수 형태는 문맥에서 달리 분명하게 표시되지 않는 한 복수의 형태를 포함한다.
본 명세서에서 사용되는 용어 "및/또는"은 다른 것과 함께 또는 다른 것 없이 둘 이상의 명시된 특징 또는 성분 각각의 구체적 개시내용으로서 취해져야 한다. 따라서, 어구에서 사용되는 용어 "및/또는", 예컨대 본 명세서의 "A 및/또는 B"는 "A 및 B," "A 또는 B", "A"(단독), 및 "B"(단독)을 포함하는 것으로 의도된다. 마찬가지로, 어구에서 사용되는 용어 "및/또는", 예컨대, "A, B 및/또는 C"는 다음의 양상 각각을 포함하는 것으로 의도된다: A, B 및 C; A, B 또는 C; A 또는 C; A 또는 B; B 또는 C; A 및 C; A 및 B; B 및 C; A(단독); B(단독); 및 C(단독).
실시형태 어디에서나, "포함하는"이라는 용어와 함께 본 명세서에 개시되어 있으며, "이루어진" 및/또는 "본질적으로 이루어진"에 관해 기재된 달리 유사한 실시형태가 또한 제공된다.
EpCAM 항체 및 EpCAM-결합 항체 단편
인간 EpCAM에 특이적으로 결합하는 단백질이 제공된다. 일부 실시형태에서, 단백질은 본 명세서에서 "EpCAM-결합제" 또는 "EpBA"로서 지칭된다.
추가적인 실시형태에서, EpCAM-결합제는 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체이다. 일부 실시형태에서, EpBA는 전장 EpCAM 항체(즉, EpCAM에 특이적으로 결합하는 전장 항체)이다. 일부 실시형태에서, EpCAM 항체는 단클론성 항체이다. 일부 실시형태에서, EpCAM 항체는 재조합 항체, 인간 항체, 인간화 항체, 키메라 항체, 다중 특이성 항체(예를 들어, 이중특이성 항체), 또는 이의 EpCAM-결합 항체 단편이다. 일부 실시형태에서, EpCAM 항체는 인간 EpCAM에 특이적으로 결합한다. 추가 실시형태에서, EpCAM 항체는 인간 EpCAM 및 cyno EpCAM에 특이적으로 결합한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 마우스, 기타 설치류, 키메라, 인간화 또는 완전 인간 단클론성 항체이다.
일부 실시형태에서, EpCAM 항체는 EpCAM-결합 항체 단편이다. 추가적인 실시형태에서, EpCAM-결합 항체 단편은 Fab, Fab', F(ab')2, Fv 단편, 다이어바디, 또는 단일쇄 항체 분자이다. 추가 양상에서, EpCAM 항체는 EpCAM-결합 항체이고, 단편은 Fd, 단일쇄 Fv(scFv), 이황화 연결된 Fv, V-NAR 도메인, IgNar, 인트라바디, IgGΔCH2, 미니바디, F(ab')3, scAb, dAb, 테트라바디, 트라이어바디, 다이어바디, 단일-도메인 중쇄 항체, 단일-도메인 경쇄 항체, DVD-Ig, Fcab, mAb2, (scFv)2, scFv-Fc 또는 비스-scFv이다.
본 명세서에 제공된 EpCAM 항체 및 EpCAM-결합 항체 단편은 선택적으로 매우 다양한 친화도(KD)로 EpCAM(예를 들어, 인간 EpCAM 및/또는 뮤린 EpCAM)에 결합한다. 바람직한 실시형태에서, 항체는 고친화도로 인간 EpCAM에 결합한다. 예를 들어, 인간 또는 인간 조작된 또는 인간화 또는 재표면화된 mAb는 표준 작업 절차를 이용하는 유세포측정 염기 분석, 효소-결합 면역흡착 분석(ELISA), 표면 플라즈몬 공명(SPR) 또는 KinExA®방법에 의해 결정할 때, 약 10-7M 이하의 KD, 예컨대, 이하로 제한되는 것은 아니지만, 0.1 내지 9.9(또는 이 사이의 임의의 범위 또는 값)×10-7, 10-8, 10-9, 10-10, 10-11 또는 10-12, 또는 이의 임의의 범위 또는 값으로 인간 항원에 결합할 수 있다. 일부 실시형태에서, EpCAM 항체는 약 10-9 M 이하, 더 구체적으로는 약 10-9 내지 10-10 M의 Kd로 결합한다.
EpCAM에 대한 항체 또는 항체 단편의 친화도 또는 결합활성(avidity)은 표준 작업 절차를 이용하는 당업계에 공지된 임의의 적합한 방법, 예를 들어, 유세포분석, 효소-결합 면역흡착 분석(ELISA), 또는 방사면역측정법(RIA), 또는 동력학(예를 들어, BIACORE™분석)을 이용하여 실험적으로 결정될 수 있다. 직접 결합 분석뿐만 아니라 경쟁 결합 분석 형식(예를 들어, 문헌[Berzofsky, et al., "Antibody-Antigen Interactions," In Fundamental I㎜unology, Paul, W. E., Ed., Raven Press: New York, N.Y. (1984); Kuby, Janis I㎜unology, W. H. Freeman and Company: New York, N.Y. (1992)]); 및 본 명세서에 개시된 방법이 일상적으로 사용될 수 있다. 특정 항체-EpCAM 상호작용의 측정된 친화도는 상이한 조건(예를 들어, 염 농도, pH, 온도) 하에 측정된다면 다를 수 있다. 따라서, 친화도 및 기타 EpCAM-결합 파라미터(예를 들어, KD 또는 Kd, Kon, Koff)의 측정은 바람직하게는 항체 및 EpCAM의 표준화된 용액, 및 당업계에 공지된 바와 같은 표준화된 완충제, 예컨대 본 명세서에 개시된 완충제로 이루어진다.
일 실시형태에서, 결합 분석은 표면 상에서 EpCAM 항원을 발현시키는 세포에 대해 유세포 분석을 이용하여 수행된다. 예를 들어, 이러한 EpCAM-양성 세포는 100μL FACS 완충제(2% 정상 염소 혈청을 보충한 RPMI-1640 배지) 중 샘플당 1 ×105개의 세포를 이용하여 다양한 농도의 EpCAM 항체와 함께 인큐베이션시켰다. 이어서, 세포를 펠릿화하고, 세척하고 나서, 1시간 동안 FACS 완충제 중 100㎕의 FITC-접합 염소 항마우스 IgG-항체(예컨대, Jackson I㎜unoResearch로부터 얻을 수 있음)와 함께 인큐베이션시켰다. 세포를 다시 펠릿화하고 나서, FACS 완충제로 세척하고, 1% 폼알데하이드를 함유하는 200㎕의 PBS 중에서 재현탁시킨다. 예를 들어, HTS 멀티웰 샘플러를 갖는 FACSCalibur™유세포분석기를 이용하여 샘플을 획득하고, CellQuest®Pro(모두 미국 샌디에이고에 소재한 BD Biosciences제)를 이용하여 분석한다. 각 샘플에 대해, FL1에 대한 평균 형광 강도(MFI)를 내보내고, 반대수(semi-log) 플롯에서 항체 농도에 대해 플롯팅하여 결합 곡선을 생성하였다. S자형 용량-반응 곡선을 결합 곡선에 적합화시키고, 디폴트 파라미터를 이용하는 GraphPad Prism v4(캘리포니아주 샌디에이고에 소재한 GraphPad 소프트웨어)와 같은 프로그램을 이용하여 EC50 값을 계산하였다. 각 항체에 대한 겉보기 해리 상수 "Kd" 또는 "KD"에 대한 척도로서 EC50 값을 사용할 수 있다.
특정 실시형태에서, EpCAM 항체는 EpCAM 및/또는 EpCAM 항원성 단편에 대한 이들의 결합 친화도를 변경시키도록 변형된다. 결합 특성은 다양한 시험관내 분석에 의해 그리고, 예를 들어, 효소-결합 면역흡착 분석(ELISA), 방사면역측정법(RIA)), 또는 동력학(예를 들어, BIACORE™분석)을 포함하는 당업계에 공지된 표준 작업 절차를 이용하여 결정될 수 있다.
일 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 10-5M 미만, 또는 10-6M 미만, 또는 10-7M 미만, 또는 10-8M 미만, 또는 10-9M 미만, 또는 10-10M 미만, 또는 10-11M 미만, 또는 10-12M 미만, 또는 10-13M 미만의 해리 상수 또는 KD 또는 Kd(koff/kon)로 인간 또는 사이노몰거스 EpCAM 및/또는 EpCAM 항원성 단편에 특이적으로 결합한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 1.0×10-9M 이하, 2.0×10-9M 이하, 3.0×10-9M 이하, 4.0×10-9M 이하, 5.0×10-9M 이하, 6.0×10-9M 이하, 7.0×10-9M 이하, 8.0×10-9M 이하, 또는 9.0×10-9M 이하의 KD로 인간 또는 사이노몰거스 EpCAM 및/또는 EpCAM 항원성 단편에 특이적으로 결합한다. 특정 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 3.0×10-9M 이하의 KD로 인간과 사이노몰거스 EpCAM 및/또는 EpCAM 항원성 단편 둘 다에 결합한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 약 0.4×10-9의 KD로 인간 EpCAM에 결합한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 약 0.8×10-9의 KD로 인간 EpCAM에 결합한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 약 0.8×10-9의 KD로 사이노몰거스 EpCAM에 결합한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 약 2.2×10-9의 KD로 사이노몰거스 EpCAM에 결합한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 약 2.8×10-9의 KD로 사이노몰거스 EpCAM에 결합한다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 인간 EpCAM의 세포외 영역(서열번호 1) 내의 에피토프에 특이적으로 결합한다. 인간 EpCAM의 세포외 영역은 추가로 3개의 별개의 도메인: D1(서열번호 2), D2(서열번호 3) 및 D3(서열번호 4)으로 나누어질 수 있다. 특정 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 인간 EpCAM의 제1 세포외 도메인(D1) 내의 에피토프에 특이적으로 결합한다.
일 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 X1YX3X4H를 포함하는 VH-CDR1(여기서, X1은 N 및 S로부터 선택되며, X3은 Y, N, F, S, H, D, L, I 및 W로부터 선택되고, X4는 I 및 M으로부터 선택됨)(서열번호 5); WX2X3PGX6VYIQYX12X13KFX17G를 포함하는 VH-CDR2(여기서, X2는 I 및 F로부터 선택되며, X3은 Y 및 N으로부터 선택되고, X6은 N 및 D로부터 선택되며, X12는 N 및 S로부터 선택되고, X13은 E 및 Q로부터 선택되며, X17은 K 및 Q로부터 선택됨(서열번호 7)); 및 X1GX3X4FAY를 포함하는 VH-CDR3(여기서, X1은 D 및 E로부터 선택되고, X3은 P, A, S, Y, F, G, T 및 V로부터 선택되며, X4는 Y 및 W로부터 선택됨)(서열번호 8)을 포함한다.
추가적인 실시형태에서, 본 개시내용은 RSSX4SLLHSX10GX12TYLX16을 포함하는 경쇄 CDR1(VL-CDR1)(여기서, X4는 R 및 K로부터 선택되고, X10은 N 및 D로부터 선택되며, X12는 F 및 I로부터 선택되고, X16은 Y 및 S로부터 선택됨)(서열번호 10); QTSNLAS를 포함하는 경쇄 VL-CDR2(서열번호 40); 및 X1QX3LELPX8T를 포함하는 VL-CDR3(여기서, X1은 A, L 및 Q로부터 선택되고, X3은 S, G, Y 및 N으로부터 선택되며, X8은 N 및 W로부터 선택됨)(서열번호 11)을 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 서열번호 13의 서열을 포함하는 중쇄 CDR1(VH-CDR1); 서열번호 14의 서열을 포함하는 중쇄 CDR2(VH-CDR2); 서열번호 15의 서열을 포함하는 중쇄 CDR3(VH-CDR3); 서열번호 42의 서열을 포함하는 경쇄 CDR1(VL-CDR1); 서열번호 40의 서열을 포함하는 경쇄 CDR2(VL-CDR2); 및 서열번호 41의 서열을 포함하는 경쇄 CDR3(VL-CDR3)을 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다.
일부 실시형태에서, VH-CDR1은 서열 NYX3IH을 포함하되, X3은 Y, N, F, S, H, D, L, I 및 W로부터 선택된다(서열번호 6). 일부 실시형태에서, VH-CDR3은 서열 DGPX4FAY를 포함하되, X4는 Y 및 W로부터 선택된다(서열번호 9). 일부 실시형태에서, VL-CDR3은 서열 AQX3LELPNT를 포함하되, X3은 S, G, Y 및 N으로부터 선택된다(서열번호 12). 일부 실시형태에서, 본 개시내용은 서열번호 13의 서열을 포함하는 중쇄 CDR1(VH-CDR1); 서열번호 14의 서열을 포함하는 중쇄 CDR2 (VH-CDR2); 서열번호 15의 서열을 포함하는 중쇄 CDR3(VH-CDR3); 서열번호 42의 서열을 포함하는 경쇄 CDR1(VL-CDR1); 서열번호 40의 서열을 포함하는 경쇄 CDR2(VL-CDR2); 및 서열번호 41의 서열을 포함하는 경쇄 CDR3(VL-CDR3)을 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 상보성 결정 영역(CDR)의 세트: 중쇄 가변 영역(VH)-CDR1, VH-CDR2, VH-CDR3, 경쇄 가변 영역(VL) CDR1, VL-CDR2 및 VL-CDR3을 포함하되, 중쇄 CDR은 표 2에 개시되어 있다.



일부 실시형태에서, 본 개시내용은 표 2의 단일행의 중쇄 CDR을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 서열번호 13 및 16 내지 25로부터 선택된 VH-CDR1; 서열번호 14 및 26 내지 29로부터 선택된 VH-CDR2; 및 서열번호 15 및 30 내지 38로부터 선택된 VH-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 서열번호 13의 VH-CDR1; 서열번호 14의 VH-CDR2; 및 서열번호 15의 VH-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 서열번호 13의 VH-CDR1; 서열번호 26의 VH-CDR2; 및 서열번호 15의 VH-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다.
일 실시형태에서, 본 개시내용은 NYYIH를 포함하는 VH-CDR1(서열번호 13), 또는 1, 2, 3 또는 4개의 보존적 아미노산 치환을 포함하는 이의 변이체; WIYPGNVYIQYNEKFKG를 포함하는 VH-CDR2(서열번호 14), 또는 1, 2, 3 또는 4개의 아미노산 보존적 치환을 포함하는 이의 변이체; 및 DGPWFAY를 포함하는 중쇄 CDR3(서열번호 15), 또는 1, 2, 3 또는 4개의 보존적 아미노산 치환을 포함하는 이의 변이체를 포함하는, EpCAM 항체, EpCAM-결합 항체 단편 또는 EpCAM 활성화 가능한 항체를 제공한다.
일부 실시형태에서, 본 개시내용은 서열번호 22의 VH-CDR1; 서열번호 14의 VH-CDR2; 및 서열번호 15의 VH-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 서열번호 13의 VH-CDR1; 서열번호 14의 VH-CDR2; 및 서열번호 33의 VH-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 서열번호 23의 VH-CDR1; 서열번호 14의 VH-CDR2; 및 서열번호 15의 VH-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 서열번호 25의 VH-CDR1; 서열번호 14의 VH-CDR2; 및 서열번호 15의 VH-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다.
일 실시형태에서, 본 개시내용은 NYHIH를 포함하는 VH-CDR1(서열번호 22), 또는 1, 2, 3 또는 4개의 보존적 아미노산 치환을 포함하는 이의 변이체; WIYPGNVYIQYNEKFKG를 포함하는 VH-CDR2(서열번호 14), 또는 1, 2, 3 또는 4개의 보존적 아미노산 치환을 포함하는 이의 변이체; 및 DGPWFAY를 포함하는 중쇄 CDR3(서열번호 15), 또는 1, 2, 3 또는 4개의 보존적 아미노산 치환을 포함하는 이의 변이체를 포함하는, EpCAM 항체, EpCAM-결합항체 단편 또는 EpCAM 활성화 가능한 항체를 제공한다. 일 실시형태에서, 본 개시내용은 NYYIH를 포함하는 VH-CDR1(서열번호 13), 또는 1, 2, 3 또는 4개의 보존적 아미노산 치환을 포함하는 이의 변이체; WIYPGNVYIQYNEKFKG를 포함하는 VH-CDR2(서열번호 14), 또는 1, 2, 3 또는 4개의 보존적 아미노산 치환을 포함하는 이의 변이체; 및 DGYWFAY를 포함하는 중쇄 CDR3(서열번호 33), 또는 1, 2, 3 또는 4개의 보존적 아미노산 치환을 포함하는 이의 변이체를 포함하는, EpCAM 항체, EpCAM-결합항체 단편 또는 EpCAM 활성화 가능한 항체를 제공한다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 상보성 결정 영역(CDR)의 세트: 중쇄 가변 영역(VH)-CDR1, VH-CDR2, VH-CDR3, 경쇄 가변 영역 (VL) CDR1, VL-CDR2 및 VL-CDR3을 포함하되, 경쇄 CDR은 표 3에 개시되어 있다.

일부 실시형태에서, 본 개시내용은 표 3의 단일행의 경쇄 CDR을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 서열번호 39 및 42 내지 45으로부터 선택된 VL-CDR1; 서열번호 40의 VL-CDR2; 및 서열번호 41, 및 46 내지 51로부터 선택된 VL-CDR3을 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 서열번호 42의 VL-CDR1; 서열번호 40의 VL-CDR2; 및 서열번호 41의 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 서열번호 39의 VL-CDR1; 서열번호 40의 VL-CDR2; 및 서열번호 41의 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다.
일 실시형태에서, 본 개시내용은 RSSRSLLHSDGFTYLY를 포함하는 VL-CDR1(서열번호 42), 또는 1, 2, 3 또는 4개의 보존적 아미노산 치환을 포함하는 이의 변이체; QTSNLAS를 포함하는 VL-CDR2(서열번호 40), 또는 1, 2, 3 또는 4개의 보존적 아미노산 치환을 포함하는 이의 변이체; 및 AQNLELPNT를 포함하는 VL-CDR3(서열번호 41), 또는 1, 2, 3 또는 4개의 보존적 아미노산 치환을 포함하는 이의 변이체를 포함하는, EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 제공한다. 일 실시형태에서, 본 개시내용은 RSSKSLLHSDGFTYLY를 포함하는 VL-CDR1(서열번호 39), 또는 1, 2, 3 또는 4개의 보존적 아미노산 치환을 포함하는 이의 변이체; QTSNLAS를 포함하는 VL-CDR2(서열번호 40), 또는 1, 2, 3 또는 4개의 보존적 아미노산 치환을 포함하는 이의 변이체; 및 AQNLELPNT를 포함하는 VL-CDR3(서열번호 41), 또는 1, 2, 3 또는 4개의 보존적 아미노산 치환을 포함하는 이의 변이체를 포함하는, EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 제공한다.
일부 실시형태에서, 본 개시내용은 서열번호 13 및 16 내지 25로부터 선택된 VH-CDR1; 서열번호 14 및 26 내지 29로부터 선택된 VH-CDR2; 서열번호 15, 및 30 내지 38로부터 선택된 VH-CDR3; 서열번호 39 및 42 내지 45로부터 선택된 VL-CDR1; 서열번호 40의 VL-CDR2; 및 서열번호 41 및 46 내지 51로부터 선택된 VL-CDR3을 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 각각 서열번호 13 내지 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 각각 서열번호 13 내지 15, 39 내지 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 각각 서열번호 13, 26, 15 및 39 내지 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 각각 서열번호 13, 26, 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다.
일부 실시형태에서, 본 개시내용은 각각 서열번호 22, 14, 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 각각 서열번호 13, 14, 33, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 각각 서열번호 23, 14, 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다. 일부 실시형태에서, 본 개시내용은 각각 서열번호 25, 14, 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 표 4에 개시된 중쇄 가변 영역(VH) 서열을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 표 4에 개시된 VH 서열에 대해 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 VH 서열을 포함한다.




일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 53 내지 84로부터 선택된 기준 VH 서열로부터 총 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개, 15개 미만 또는 0개의 아미노산 치환, 결실 및/또는 삽입을 갖는 VH 서열을 포함한다. 일부 실시형태에서, 삽입, 치환, 결실 및/또는 삽입은 기준 서열의 프레임워크 영역(들)에 있다. 일부 실시형태에서, 치환은 보존적이다. 다른 실시형태에서, 치환은 비-보존적이다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 53 내지 84로부터 선택된 서열을 갖는 VH를 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 53 내지 56로부터 선택된 서열을 갖는 VH를 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 54의 서열을 갖는 VH를 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 53 내지 56으로부터 선택된 서열에 대해 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 VH 서열을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 54의 서열에 대해 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 및 99% 동일한 VH 서열을 포함한다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 75 내지 77, 및 84로부터 선택된 서열을 갖는 VH를 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 75의 서열을 갖는 VH를 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 77의 서열을 갖는 VH를 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 75 내지 77 및 84로부터 선택된 서열에 대해 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 VH 서열을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 75의 서열에 대해 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 및 99% 동일한 VH 서열을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 77의 서열에 대해 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 및 99% 동일한 VH 서열을 포함한다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 표 5에 개시된 경쇄 가변 영역(VL) 서열을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 표 5에 개시된 VL 서열에 대해 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 VL 서열을 포함한다.


일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 86 내지 99로부터 선택된 기준 VH 서열로부터 총 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개, 15개 미만 또는 0개의 아미노산 치환, 결실 및/또는 삽입을 갖는 VL 서열을 포함한다. 일부 실시형태에서, 삽입, 치환, 결실 및/또는 삽입은 기준 서열의 프레임워크 영역(들)에 있다. 일부 실시형태에서, 치환은 보존적이다. 다른 실시형태에서, 치환은 비-보존적이다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 86 내지 99로부터 선택된 서열을 갖는 VL을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 86 내지 89로부터 선택된 서열을 갖는 VL을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 89의 서열을 갖는 VL을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 87의 서열을 갖는 VL을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 86 내지 89으로부터 선택된 서열에 대해 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 VH 서열을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 89의 서열에 대해 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 및 99% 동일한 VL 서열을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 87의 서열에 대해 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 및 99% 동일한 VL 서열을 포함한다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 53 내지 84로부터 선택된 서열을 포함하는 VH 및 서열번호 86 내지 89로부터 선택된 서열을 포함하는 VL을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 54의 서열을 포함하는 VH 및 서열번호 89의 서열을 포함하는 VL을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 54의 서열을 포함하는 VH 및 서열번호 87의 서열을 포함하는 VL을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 55의 서열을 포함하는 VH 및 서열번호 87의 서열을 포함하는 VL을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 56의 서열을 포함하는 VH 및 서열번호 88의 서열을 포함하는 VL을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 55의 서열을 포함하는 VH 및 서열번호 89의 서열을 포함하는 VL을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 56의 서열을 포함하는 VH 및 서열번호 89의 서열을 포함하는 VL을 포함한다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 75의 서열을 포함하는 VH 및 서열번호 89의 서열을 포함하는 VL을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 77의 서열을 포함하는 VH 및 서열번호 89의 서열을 포함하는 VL을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 76의 서열을 포함하는 VH 및 서열번호 89의 서열을 포함하는 VL을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 84의 서열을 포함하는 VH 및 서열번호 89의 서열을 포함하는 VL을 포함한다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 인간 EpCAM에 대한 결합에 대해 각각 표 4 및 표 5에 개시된 VH 및 VL 서열을 포함하는 항체와 경쟁한다.
일 실시형태에서, 본 개시내용은 인간 EpCAM에 대한 결합에 대해 하기로부터 선택된 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하는 항체와 경쟁하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 제공한다:
(a) 서열번호 54의 중쇄 가변 영역(VH) 및 서열번호 89의 경쇄 가변 영역 (VL);
(b)
서열번호 54의 VH
및
서열번호
87의
VL;
(c)
서열번호 75의 VH
및
서열번호
89의
VL; 및
(d)
서열번호 77의 VH
및
서열번호
89의
VL.
EpCAM 항체 또는 EpCAM-결합 항체 단편은 인간 EpCAM에 대한 기준 분자의 결함을 어느 정도까지 차단하는 정도로 인간 EpCAM에 결합한다면 EpCAM에 대한 결합에 대해 기준 분자와 "경쟁하는" 것으로 언급된다. 단백질이 EpCAM에 대한 결합에 대해 경쟁하고, 그에 따라 EpCAM에 대한 다른 결합을 방해하거나, 차단하거나, "교차-차단"하는 능력은, 예를 들어, 경쟁 ELISA 분석, 표면 플라즈몬 공명(SPR; BIACORE®, Biosensor, 뉴욕주 피스카타웨이)을 포함하는 당업계에 공지된 임의의 표준 경쟁적 결합 분석에 의해 또는 문헌[Scatchard et al. (Ann. N.Y. Acad. Sci. 51:660-672 (1949))]에 의해 기재된 방법에 따라 결정될 수 있다. 항체는 인간 EpCAM에 대한 기준 EpCAM 항체의 결합을, 예를 들어, 적어도 90%, 적어도 80%, 적어도 70%, 적어도 60% 또는 적어도 50%만큼 경쟁적으로 저해하는 것으로 언급될 수 있다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 중쇄 불변 영역 또는 이의 단편을 추가로 포함한다. 일부 양상에서, 항체 또는 항체 단편은, (a) 인간 IgA 불변 영역, 또는 이의 단편; (b) 인간 IgD 불변 영역, 또는 이의 단편; (c) 인간 IgE 불변 도메인, 또는 이의 단편; (d) 인간 IgG1 불변 영역, 또는 이의 단편; (e) 인간 IgG2 불변 영역, 또는 이의 단편; (f) 인간 IgG3 불변 영역, 또는 이의 단편; (g) 인간 IgG4 불변 영역, 또는 이의 단편; 및 (h) 인간 IgM 불변 영역, 또는 이의 단편으로 이루어진 군으로부터 선택된 중쇄 면역글로불린 불변 영역을 포함한다. 특정 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 중쇄 불변 영역 또는 이의 단편, 예를 들어, 인간 IgG 불변 영역 또는 이의 단편을 포함한다. 추가 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 변경된 효과기 작용 및/또는 반감기를 갖거나, 이들을 갖도록 돌연변이된 중쇄 면역글로불린 불변 도메인을 포함한다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 표 6에 개시된 중쇄 서열을 포함한다.









일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 102 내지 134로부터 선택된 중쇄(HC) 서열을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 102 내지 106로부터 선택된 중쇄(HC) 서열을 포함한다. 구체적 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 103의 HC 서열을 포함한다. 대안의 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 125 내지 127 및 134로부터 선택된 HC 서열을 포함한다. 구체적 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 125의 HC 서열을 포함한다. 구체적 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 127의 HC 서열을 포함한다.
추가적인 양상에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 경쇄 면역글로불린 불변 영역을 포함한다. 추가 양상에서, 항체는 인간 Ig 카파 불변 영역 또는 인간 Ig 람다 불변 영역을 포함한다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 표 7에 개시된 경쇄 서열을 포함한다.



일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 137 내지 150으로부터 선택된 경쇄(LC) 서열을 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 137 내지 140으로부터 선택된 경쇄(LC) 서열을 포함한다. 구체적 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 140의 LC 서열을 포함한다. 다른 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 138의 LC 서열을 포함한다.
추가적인 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 102 내지 134로부터 선택된 서열을 갖는 HC 및 서열번호 137 내지 150으로부터 선택된 서열을 갖는 LC를 포함한다. 추가적인 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 103의 서열을 갖는 HC 및 서열번호 140의 서열을 갖는 LC를 포함한다. 추가적인 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 103의 서열을 갖는 HC 및 서열번호 138의 서열을 갖는 LC를 포함한다. 추가적인 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 105의 서열을 갖는 HC 및 서열번호 138의 서열을 갖는 LC를 포함한다. 추가적인 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 106의 서열을 갖는 HC 및 서열번호 139의 서열을 갖는 LC를 포함한다. 추가적인 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 105의 서열을 갖는 HC 및 서열번호 140의 서열을 갖는 LC를 포함한다. 추가적인 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 106의 서열을 갖는 HC 및 서열번호 140의 서열을 갖는 LC를 포함한다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 125의 서열을 갖는 HC 및 서열번호 140의 서열을 갖는 LC를 포함한다. 추가적인 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 127의 서열을 갖는 HC 및 서열번호 140의 서열을 갖는 LC를 포함한다. 추가적인 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 126의 서열을 갖는 HC 및 서열번호 140의 서열을 갖는 LC를 포함한다. 추가적인 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 서열번호 134의 서열을 갖는 HC 및 서열번호 140의 서열을 갖는 LC를 포함한다.
일부 실시형태에서, EpCAM 항체는 변경된(예를 들어, 돌연변이 또는 조작된) Fc 영역을 포함한다. 예를 들어, 일부 양상에서, Fc 영역은 항체의 효과기 작용을 감소시키거나 향상시키거나, 혈청 반감기 또는 항체의 기타 작용성 특성을 변경시키도록 변경되었다. 효과기 작용의 감소 또는 제거는 특정 경우에, 예를 들어, 작용 메커니즘이 차단 또는 길항작용을 수반하지만, 표적 항원을 보유하는 세포를 사멸시키지 않는 항체의 경우에 바람직하다. 증가된 효과기 작용은 일반적으로 FcγR이 저수준에서 발현되는 바람직하지 않은 세포, 예컨대 종양 및 외래 세포, 예를 들어, 저수준의 FcγRIIB를 갖는 종양-특이적 B 세포(예를 들어, 비호지킨 림프종, CLL, 및 버킷 림프종)에 관한 것일 때 바람직하다. 이러한 부여된 또는 변경된 효과기 작용 활성을 갖는 본 발명의 면역접합체는 효과기 작용 활성의 향상된 효능이 바람직한 질환, 장애 또는 감염의 치료 및/또는 예방에 유용하다. 일부 양상에서, Fc 영역은 IgM, IgA, IgG, IgE, 또는 기타 아이소타입으로부터 선택된 아이소타입이다.
EpCAM 항체 및 EpCAM-결합 항체 단편의 Fc 영역이 하나 이상의 Fc 수용체(예를 들어, FcγR(들))에 결합하는 능력을 가질 수도 있지만, 특정 실시형태에서, 항체 또는 항체 단편은 (야생형 Fc 영역에 의하 나타나는 결합에 비해) FcγRIA(CD64), FcγRIIA(CD32A), FcγRIIB(CD32B), FcγRIIIA(CD16a) 또는 FcγRIIIB(CD16b)에 대해 변경된 결합을 갖는 변이체 Fc 영역을 포함하고, 예를 들어, 활성화 수용체에 대해 향상된 결합을 가질 것이고/이거나, 저해 수용체(들)에 결합하는 실질적으로 감소된 능력을 갖거나 능력이 없을 것이다. 따라서, EpCAM 항체 또는 EpCAM-결합 항체 단편의 Fc 영역은 완전한 Fc 영역의 CH2 도메인의 일부 또는 모두 및/또는 CH3 도메인의 일부 또는 모두를 포함할 수 있거나, 또는 (완전한 Fc 영역의 CH2 또는 CH3 도메인에 대해 하나 이상의 삽입 및/또는 하나 이상의 결실을 포함할 수 있는) 변이체 CH2 및/또는 변이체 CH3 서열을 포함할 수 있다. 이러한 Fc 영역은 비-Fc 폴리펩타이드 부분을 포함할 수 있거나, 비천연 완전 Fc 영역 부분을 포함할 수 있거나, CH2 및/또는 CH3 도메인(예를 들어, 2개의 CH2 도메인 또는 2개의 CH3 도메인, 또는 N-말단에서 C-말단까지의 방향으로, CH2 도메인에 연결된 CH3 도메인 등)의 비-천연 유래 배향을 포함할 수 있다.
활성화 수용체(예를 들어, FcγRIIA(CD 16A))에 대한 결합을 증가시키고 저해 수용체(예를 들어, FcγRIIB(CD32B))에 대한 결합을 감소시키는 변형을 포함하는, 효과기 작용을 변경하는 것으로 확인된 Fc 영역 변형은 당업계에 공지되어 있다(예를 들어, 문헌[Stavenhagen, et al., Cancer Res. 57(18):8882-8890 (2007)] 참조). 표 8은 활성화 수용체에 대한 결합을 증가시키고/시키거나 저해 수용체에 대한 결합을 감소시키는 예시적인 변형의 예시적인 단일, 이중, 삼중, 사중 및 오중 치환(넘버링은 카바트에서와 같이 EU 색인의 넘버링이며, 치환은 서열번호 304의 아미노산 서열에 대한 것임)을 열거한다.

CD32B에 대해 감소된 결합 및/또는 CD16A에 대해 증가된 결합을 갖는 인간 IgG1 Fc의 예시적인 변이체는 F243L, R292P, Y300L, V3O5I 또는 P396L 치환을 포함하되, 넘버링은 카바트에서와 같은 EU 색인의 넘버링이다. 이들 아미노산 치환은 인간 IgG1 Fc 영역에 임의의 조합으로 존재할 수 있다. 일 실시형태에서, 변이체 인간 IgG1 Fc 영역은 F243L, R292P 및 Y300L 치환을 포함한다. 다른 실시형태에서, 변이체 인간 IgG1 Fc 영역은 F243L, R292P, Y300L, V3O5I 및 P396L 치환을 포함한다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 효과기 작용을 감소시키는 변형을 포함하는 면역글로불린 중쇄 불변 영역을 포함한다(예를 들어, 각각 본 명세서에 전문에 참조에 의해 원용된 문헌[Idusogie et al., J. I㎜unol. 166:2571-2575 (2001); Sazinsky et al., PNAS USA 105:20167-20172 (2008); Davis etal.,J. Rheumatol. 34:2204-2210 (2007); Bolt et al., Eur. J. I㎜unol. 23:403-411 (1993); Alegre et al., Transplantation 57:1537-1543 (1994); Xu etal., Celll㎜unol. 200:16-26 (2000); Cole etal., Transplantation 68:563-571 (1999); Hutchins et al., PNAS USA 92:11980-11984 (1995); Reddy et al., J. I㎜unol. 164:1925-1933 (2000)]; WO97/11971, 및 WO07/106585; 미국 특허 공개 제2007/0148167A1호; 문헌[McEarchern et al., Blood 109:1185-1192 (2007); Strohl, Curr. Op. Biotechnol. 20:685-691 (2009); 및 Kumagai et al., J. Clin. Pharmacol. 47:1489-1497 (2007)] 참조).
일부 실시형태에서, 야생형 IgG Fc 영역에 의해 나타나는 결합에 비해 FcγRIA(CD64), FcγRIIA(CD32A)(알로타입(allotype) R131 및 H131), FcγRIIB(CD32B), FcγRIIIA(CD16a)(알로타입 V158 및 F158) 및 FcγRIIIB(CD16b)(알로타입 FcγIIIb-NA1 및 FcγIIIb-NA2)로 이루어진 군으로부터 선택된 효과기 수용체에 대해 감소된(또는 실질적으로 없는) 결합을 나타내는 EpCAM 항체 또는 EpCAM-결합 항체 단편의 Fc 영역이 바람직하다(서열번호 304). 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편 Fc 영역 변이체 효과기 수용체 결합 친화도는 대응하는 면역글로불린의 야생형 Fc 영역을 포함하는 대응하는 항체 또는 항체 결합 단편의 결합 친화도에 비해 1/10 이하, 1/50 이하 또는 1/100 이하로 감소되었다.
구체적 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 감소된 효과기 작용(예를 들어, 감소된 ADCC)을 나타내는 IgG Fc 영역을 포함하고, 233, 234, 235, 236, 237, 238, 239, 265, 266, 267, 269, 270, 271, 295, 296, 297, 298, 300, 324, 325, 327, 328, 329, 331 및 332로 이루어진 군으로부터 선택된 하나 이상의 아미노산 위치에서 변형을 포함하되, 아미노산 위치 넘버링은 카바트에 제시된 바와 같은 EU 색인에 따른다. 일 실시형태에서, EpCAM 항체의 CH2-CH3 도메인은 치환: L234A, L235A, D265A, N297Q, N297A 및 N297G 중 임의의 1, 2, 3 또는 4개를 포함하되, 넘버링은 카바트에서와 같은 EU 색인의 넘버링이다. 다른 실시형태에서, CH2-CH3 도메인은 N297Q 치환, N297A 치환 또는 L234A 및 L235A 치환을 포함하는데, 이들 돌연변이가 FcR 결합을 제거하기 때문이다. 대안적으로, EpCAM 항체 또는 EpCAM-결합 항체 단편은 (야생형 IgG1 Fc 영역(서열번호 304)에 의해 나타나는 결합 및 효과기 작용에 비해) FcγRIIIA(CD16a)에 대해 감소된(또는 실질적으로 없는) 결합 및/또는 감소된 효과기 작용을 본질적으로 나타내는 천연 유래 Fc 영역의 CH2- CH3 도메인을 포함한다. 구체적 실시형태에서, EpCAM 항체의 Fc 불변 영역은 IgG2 Fc 영역(서열번호 305) 또는 IgG4 Fc 영역(서열번호 306)을 포함한다. N297A, N297G, N297Q, L234A, L235A 및 D265A 치환이 효과기 작용을 제거하기 때문에, 효과기 작용이 요망되는 환경에서, 이들 치환은 바람직하게는 사용되지 않을 것이다.
감소 또는 제거된 효과기 작용을 갖는 Fc 영역-함유 EpCAM 항체 또는 EpCAM-결합 항체 단편의 CH2 및 CH3 도메인의 바람직한 IgG1 서열은 치환 L234A/L235A(밑줄로 나타냄)(서열번호 307)을 포함한다:

감소 또는 제거된 효과기 작용을 갖는 Fc 영역-함유 EpCAM 항체 또는 EpCAM-결합 항체 단편의 CH2 및 CH3 도메인의 바람직한 IgG1 서열은 치환 N297A(밑줄로 나타냄)(서열번호 308)을 포함한다:

감소 또는 제거된 효과기 작용을 갖는 Fc 영역-함유 EpCAM 항체 또는 EpCAM-결합 항체 단편의 CH2 및 CH3 도메인의 바람직한 IgG1 서열은 치환 N297Q(밑줄로 나타냄)(서열번호 309)를 포함한다:

일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편 EpCAM 항체 또는 EpCAM-결합 항체 단편은 하기에 대응하는 하나 이상의 변형을 포함한다: IgG1-C220S, C226S, C229S, P238S; IgG1-C226S, C229S; IgG1-C226S, C229S, E233P, L234V, L235A; IgG1-L234A, L235A; IgG1-L234F, L235E, P331S; IgG1- L234F, L235E, P331S; IgG1-H268Q, A330S, P331S; IgG1-G236R, L328R; IgG1-L235G, G236R, IgG1-N297A; IgG1-N325A, L328R; IgG1-N325L, L328R; IgG1-K326W, E333S; IgG2-V234A, G237A; IgG2-E333S; IgG2 H268Q, V309L, A330S, A331S; IgG4-S228P, L236E; IgG4-F234A, L235A; IgG4-F234A, G237A, E318A; IgG4-L235A, G237A, E318A; IgG4-L236E; IgG2-EU 서열 118-260; 및 IgG4-EU 서열 261-447; 여기서 위치 넘버링은 카바트에서와 같이 EU 색인에 따른다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 감소된 CDC 활성을 갖는 중쇄 면역글로불린 불변 도메인을 포함한다. 특정 양상에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 CDC 활성을 감소시키는 돌연변이를 포함하는 IgG1 중쇄 불변 영역(예를 들어, WO 1997/11971 및 WO 2007/106585; 미국 특허 공개 제2007/0148167A1호; 문헌[McEarchern et al., Blood 109:1185-1192 (2007); Hayden-Ledbetter et al., Clin. Cancer 15:2739-2746 (2009); Lazar et al., PNAS USA 103:4005-4010 (2006); Bruckheimer et al., Neoplasia 11:509-517 (2009); Strohl, Curr. Op. Biotechnol. 20:685-691 (2009); 및 Sazinsky et al., PNAS USA 105:20167-20172 (2008)]; 이들 각각은 본 명세서에 전문이 참조에 의해 원용됨). CDC를 감소시키는 중쇄 불변 도메인 서열 변형의 예는 하기에 대응하는 하나 이상의 변형을 포함한다: IgG1-C226S, C229S, E233P, L234V, L235A; IgG1-C226S, P230S; IgG1-L234F, L235E, P331S; IgG1-S239D, A330L, I332E; IgG2 EU 서열 118-260; IgG4-EU 서열 261-447; 및 IgG2-H268Q, V309L, A330S, A331S, EU 색인에 따름.
일부 실시형태에서, 제공된 EpCAM 항체 또는 EpCAM-결합 항체 단편은 하나 이상의 반감기 연장 아미노산 변형(예를 들어, 치환)을 포함하는 중쇄 면역글로불린 불변 도메인을 포함한다. Fc 영역-함유 분자의 반감기를 증가시킬 수 있는 수많은 돌연변이는 당업계에 공지되어 있으며, 본 명세서에 제공된 EpCAM 항체 및 EpCAM-결합 항체 단편 성분으로서 포함된다. 예를 들어, 미국 특허 제6,277,375호; 제7,083,784호; 제7,217,797호 및 제8,088,376호; 미국 특허 공개 제2002/0147311호; 및 제2007/0148164호; 및 국제 특허 출원 공개 WO 1998/23289; WO 2009/058492; 및 WO 2010/033279를 참조하며, 이들 각각의 내용은 본 명세서에 전무이 참조에 의해 원용된다.
Fc 영역을 포함하는 단백질의 혈청 반감기는 FcRn에 대한 Fc 영역의 결합 친화도를 증가시킴으로써 증가될 수 있다. 본 명세서에 사용된 바와 같은 용어 "반감기"는 분자의 투여 후 분자의 평균 생존 시간의 척도인 분자의 약물동태학적 특성을 의미한다. 반감기는, 예를 들어, 혈청에서, 즉, 순환 반감기, 또는 기타 조직에서 측정한 바와 같은, 대상체(예를 들어, 인간 환자 또는 기타 포유류)의 신체 또는 이의 특정 구획으로부터의 분자의 공지된 양의 오십%(50%)를 제거하는 데 필요한 시간으로서 표현될 수 있다. 일반적으로, 반감기의 증가는 투여된 분자에 대한 순환에서의 평균 체류 시간(mean residence time: MRT)의 증가를 초래한다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 하기로 이루어진 군으로부터 선택된 하나 이상의 위치에서 반감기 연장 아미노산 치환을 포함한다: 238, 250, 252, 254, 256, 257, 256, 265, 272, 286, 288, 303, 305, 307, 308, 309, 311, 312, 317, 340, 356, 360, 362, 376, 378, 380, 382, 413, 424,428, 433, 434, 435 및 436, 여기서 아미노산 위치 넘버링은 EU 색인에 따른다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 251 내지 257, 285 내지 290, 308 내지 314, 385 내지 389, 및 428 내지 436번 위치에서 아미노산 잔기의 하나 이상의 아미노산 치환을 포함하되, 아미노산 위치 넘버링은 EU 색인에 따른다. 일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 252번 카바트 위치에서 아미노산의 Tyr, Phe, Trp 또는 Thr로의 치환; 254번 카바트 위치에서 아미노산의 Thr으로의 치환; 256번 카바트 위치에서 아미노산의 Ser, Arg, Gin, Glu, Asp 또는 Thr으로의 치환; 257번 카바트 위치에서 아미노산의 Leu으로의 치환; 309번 카바트 위치에서 아미노산의 Pro으로의 치환; 311번 카바트 위치에서 아미노산의 Ser으로의 치환; 428번 카바트 위치에서 아미노산의 Thr, Leu, Phe, 또는 Ser으로의 치환; 433번 카바트 위치에서 아미노산의 Arg, Ser, Iso, Pro 또는 Gln으로의 치환; 또는 434번 카바트 위치에서 아미노산의 Trp, Met, Ser, His, Phe 또는 Tyr으로의 치환 중 하나 이상을 포함한다. 더 구체적으로는, EpCAM 항체 또는 EpCAM-결합 항체 단편 도메인은 252번 카바트 위치에서의 아미노산의 Tyr으로의 치환, 254번 카바트 위치에서의 아미노산의 Thr으로의 치환, 및 256번 카바트 위치에서의 아미노산의 Glu으로의 치환을 포함하는 야생형 인간 IgG 불변 도메인에 대한 아미노산 치환을 포함할 수 있다.
일부 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 하기로부터 선택된 적어도 하나의 치환을 포함한다: T250Q, M252Y, S254T, T256E, K288D, T307Q, V308P, A378V, M428L, N434A, N434S, N434H, N434Y, H435K 및 Y436I, 여기서 넘버링은 카바트에서와 같이 EU 색인의 넘버링이다. 추가 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은, (a) M252Y, S254T 및 T256E; (b) M252Y 및 S254T; (c) M252Y 및 T256E; (d) T250Q 및 M428L; (e) T307Q 및 N434A; (f) A378V 및 N434A; (g) N434A 및 Y436I; (h) V308P 및 N434A; 및 (i) K288D 및 H435K로부터 선택된 치환을 포함한다.
바람직한 실시형태에서, EpCAM 항체 또는 EpCAM-결합 항체 단편은 치환: M252Y, S254T 및 T256E 중 임의의 1, 2 또는 3개를 포함하는 변이체 IgG Fc 영역을 포함한다. 본 개시내용은: (a) 효과기 작용 및/또는 FcγR을 변경시키는 하나 이상의 돌연변이; 및 (b) 혈청 반감기를 연장시키는 하나 이상의 돌연변이를 포함하는 변이체 Fc 영역을 갖는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 추가로 제공한다.
EpCAM 활성화 가능한 항체
추가적인 실시형태에서, 본 개시내용은 EpCAM 활성화 가능한 항체(예를 들어, 활성화 가능한 EpCAM 항체 및 활성화 가능한 EpCAM-결합 항체 단편)를 제공한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 EpCAM 항체 또는 EpCAM-결합 항체 단편이 EpCAM에 결합하는 능력을 MM의 결합이 감소시키도록 마스킹 모이어티(MM)에 결합된 EpCAM(예를 들어, 인간 EpCAM)에 특이적으로 결합하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함한다. 일부 실시형태에서, MM은 프로테아제, 예를 들어, 질환 조직에서 활성인 프로테아제 및/또는 대상체에서의 치료 부위에서 EpCAM과 공동 국소화되는 프로테아제에 대한 기질을 포함하는 서열을 통해 결합된다. EpCAM 활성화 가능한 항체는 바람직하게는 순환 시 안정하고, 요법 및/또는 진단의 의도된 부위에서 활성화되지만, 정상, 예를 들어, 건강한 조직 또는 치료 및/또는 진단을 위해 표적화되지 않은 다른 조직에서는 그렇지 않고, 활성화될 때, 대응하는, 비변형 항체와 적어도 비슷한 EpCAM에 대한 결합을 나타낸다. EpCAM 활성화 가능한 항체를 포함하는 면역접합체는 또한 EpCAM 활성화 가능한 항체를 암호화하는 핵산 또는 핵산의 세트, 및 벡터 및 핵산을 포함하는 숙주 세포와 같이 제공된다. 활성화 가능한 항체, 면역접합체, 핵산, 벡터 및 숙주 세포를 포함하는 약제학적 조성물이 또한 제공된다.
일부 실시형태에서, EpCAM 활성화 가능한 항체 또는 항체 단편은 추가로 하기를 포함한다:
(a) 항체 또는 항체 단편에 결합된 절단 가능 모이어티로서, 프로테아제에 대한 기질로서 작용하는 폴리펩타이드인, 절단 가능 모이어티; 및
(b) 항체 또는 항체 단편에 결합된 마스킹 모이어티로서, 활성화 가능한 항체가 비절단 상태일 때 EpCAM에 대한 항체 또는 항체 단편의 결합을 저해하는, 마스킹 모이어티,
비절단 상태의 활성화 가능한 항체는 N-말단으로부터 C-말단까지 다음과 같은 구조적 배열을 가진다: (마스킹 모이어티)-(절단 가능 모이어티)-(항체 또는 항체 단편) 또는 (항체 또는 항체 단편)-(절단 가능 모이어티)-(마스킹 모이어티).
하기를 포함하는 EpCAM 활성화 가능한 항체:
(a) 하기 군으로부터 선택된 구성원의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편:
(i) 각각 서열번호 13 내지 15, 42, 40 및 41;
(ii) 각각 서열번호 13 내지 15, 및 39 내지 41;
(iii) 각각 서열번호 13, 26, 15 및 39 내지 41; 및
(iv) 각각 서열번호 13, 24, 15, 42, 40 및 41;
(b) EpCAM 항체 또는 EpCAM-결합 항체 단편에 결합된 마스킹 모이어티로서, 활성화 가능한 항체가 비절단 상태일 때 EpCAM에 대한 항체 또는 항체 단편의 결합을 저해하는, 마스킹 모이어티; 및
(c) EpCAM 항체 또는 EpCAM-결합 항체 단편에 결합된 절단 가능 모이어티로서, 프로테아제에 대한 기질로서 작용하는 폴리펩타이드인, 절단 가능 모이어티;
비절단 상태의 활성화 가능한 항체는 N-말단으로부터 C-말단까지 다음과 같은 구조적 배열을 가진다: (마스킹 모이어티)-(절단 가능 모이어티)-(항체 또는 항체 단편) 또는 (항체 또는 항체 단편)-(절단 가능 모이어티)-(마스킹 모이어티);
활성화된 상태의 EpCAM 활성화 가능한 항체는 인간 EpCAM에 결합하며, (i) 인간 EpCAM에 특이적으로 결합하는 EpCAM 항체 또는 EpCAM-결합 항체 단편(Ab)(예를 들어, 본 명세서에 개시된 바와 같음); (ii) EpCAM 활성화 가능한 항체가 비절단 상태일 때 EpCAM에 대한 EpCAM 활성화 가능한 항체 결합을 저해하는 마스킹 모이어티(MM); 및 (c) EpCAM 항체 또는 EpCAM-결합 항체 단편에 결합된 절단 가능 모이어티(CM)를 포함하되, CM은 프로테아제에 대한 기질로서 작용하는 폴리펩타이드이다. 일부 실시형태에서, 비절단 상태의 EpCAM 활성화 가능한 항체는 N-말단으로부터 C-말단까지 다음과 같은 구조적 배열을 가진다: MM-CM-Ab 또는 Ab-CM-MM. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 MM과 CM 사이에 연결 펩타이드를 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 CM과 Ab 사이에 연결 펩타이드를 포함한다.
일부 실시형태에서, 비절단 상태의 EpCAM 활성화 가능한 항체는 1nM 이하, 5nM 이하, 10nM 이하, 15nM 이하, 20nM 이하, 25nM 이하, 50nM 이하, 100nM 이하, 150nM 이하, 250nM 이하, 500nM 이하, 750nM 이하, 1000nM 이하, 및 122. /이하 또는 2000nM 이하의 해리 상수로 포유류 EpCAM에 특이적으로 결합한다.
일부 실시형태에서, 비절단 상태의 EpCAM 활성화 가능한 항체는 1nM 이상, 5nM 이상, 10nM 이상, 15nM 이상, 20nM 이상, 25nM 이상, 50nM 이상, 100nM 이상, 150nM 이상, 250nM 이상, 500nM 이상, 750nM 이상, 1000nM 이상, 및 122. /이상 내지 2000nM 이상의 해리 상수로 포유류 EpCAM(예를 들어, 인간 EpCAM 또는 사이노몰거스 EpCAM)에 특이적으로 결합한다.
일부 실시형태에서, 비절단 상태의 EpCAM 활성화 가능한 항체는 1nM 내지 2000nM, 1nM 내지 1000nM, 1nM 내지 750nM, 1nM 내지 500nM, 1nM 내지 250nM, 1nM 내지 150nM, 1nM 내지 100nM, 1nM 내지 50nM, 1nM 내지 25nM, 1nM 내지 15nM, 1nM 내지 10nM, 1nM 내지 5nM, 5nM 내지 2000nM, 5nM 내지 1000nM, 5nM 내지 750nM, 5nM 내지 500nM, 5nM 내지 250nM, 5nM 내지 150nM, 5nM 내지 100nM, 5nM 내지 50nM, 5nM 내지 25nM, 5nM 내지 15nM, 5nM 내지 10nM, 10nM 내지 2000nM, 10nM 내지 1000nM, 10nM 내지 750nM, 10nM 내지 500nM, 10nM 내지 250nM, 10nM 내지 150nM, 10nM 내지 100nM, 10nM 내지 50nM, 10nM 내지 25nM, 10nM 내지 15nM, 15nM 내지 2000nM, 15nM 내지 1000nM, 15nM 내지 750nM, 15nM 내지 500nM, 15nM 내지 250nM, 15nM 내지 150nM, 15nM 내지 100nM, 15nM 내지 50nM, 15nM 내지 25nM, 25nM 내지 2000nM, 25nM 내지 1000nM, 25nM 내지 750nM, 25nM 내지 500nM, 25nM 내지 250nM, 25nM 내지 150nM, 25nM 내지 100nM, 25nM 내지 50nM, 50nM 내지 2000nM, 50nM 내지 1000nM, 50nM 내지 750nM, 50nM 내지 500nM, 50nM 내지 250nM, 50nM 내지 150nM, 50nM 내지 100nM, 100nM 내지 2000nM, 100nM 내지 1000nM, 100nM 내지 750nM, 100nM 내지 500nM, 100nM 내지 250nM, 100nM 내지 150nM, 150nM 내지 2000nM, 150nM 내지 1000nM, 150nM 내지 750nM, 150nM 내지 500nM, 150nM 내지 250nM, 250nM 내지 2000nM, 250nM 내지 1000nM, 250nM 내지 750nM, 250nM 내지 500nM, 500nM 내지 2000nM, 500nM 내지 1000nM, 500nM 내지 750nM, 500nM 내지 500nM, 500nM 내지 250nM, 500nM 내지 150nM, 500nM 내지 100nM, 500nM 내지 50nM, 750nM 내지 2000nM, 750nM 내지 1000nM, 또는 1000nM 내지 2000nM 범위의 해리 상수로 포유류 EpCAM(예를 들어, 인간 EpCAM 또는 사이노몰거스 EpCAM)에 특이적으로 결합한다.
일부 실시형태에서, 활성화된 상태의 EpCAM 활성화 가능한 항체는 0.01nM, 0.05nM, 0.1nM, 0.5nM, 1nM, 5nM 또는 10nM 이하인 해리 상수로 포유류 EpCAM(예를 들어, 인간 EpCAM 또는 사이노몰거스 EpCAM)에 특이적으로 결합한다. 일부 실시형태에서, 활성화된 상태의 EpCAM 활성화 가능한 항체는 0.01nM, 0.05nM, 0.1nM, 0.5nM, 1nM, 5nM 또는 10nM 이상의 해리 상수로 포유류 EpCAM에 특이적으로 결합한다.
일부 실시형태에서, 활성화된 상태의 EpCAM 활성화 가능한 항체는 0.01nM 내지 100nM, 0.01nM 내지 10nM, 0.01nM 내지 5nM, 0.01nM 내지 1nM, 0.01 내지 0.5nM, 0.01 nm 내지 0.1nM, 0.01 nm 내지 0.05nM, 0.05nM 내지 100nM, 0.05nM 내지 10nM, 0.05nM 내지 5nM, 0.05nM 내지 1nM, 0.05 내지 0.5nM, 0.05 nm 내지 0.1nM, 0.1nM 내지 100nM, 0.1nM 내지 10nM, 0.1nM 내지 5nM, 0.1nM 내지 1nM, 0.1 내지 0.5nM, 0.5nM 내지 100nM, 0.5nM 내지 10nM, 0.5nM 내지 5nM, 0.5nM 내지 1nM, 1nM 내지 100nM, 1nM 내지 10nM, 1nM 내지 5nM, 5nM 내지 100nM, 5nM 내지 10nM, 또는 10nM 내지 100 Nm 범위의 해리 상수로 포유류 EpCAM(예를 들어, 인간 EpCAM 또는 사이노몰거스 EpCAM)에 특이적으로 결합한다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 1nM 미만의 해리 상수로 인간 EpCAM에 특이적으로 결합한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 1nM 미만의 해리 상수로 사이노몰거스 EpCAM에 특이적으로 결합한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 1nM 미만의 해리 상수로 인간 EpCAM 및 사이노몰거스 EpCAM에 특이적으로 결합한다.
일부 실시형태에서, EpCAM 활성화 가능한 항체의 혈청 반감기는 대응하는 항체의 반감기보다 길고; 예를 들어, EpCAM 활성화 가능한 항체의 pK는 대응하는 항체의 pK보다 길다. 일부 실시형태에서, EpCAM 활성화 가능한 항체의 혈청 반감기는 대응하는 항체의 혈청 반감기와 유사하다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 표 2의 1행에 제시된 서열을 갖는 VH-CDR1, VH-CDR2 및 VH-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 표 3의 1행에 제시된 서열을 갖는 VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함한다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 13 및 16 내지 25로부터 선택된 VH-CDR1; 서열번호 14, 및 26 내지 29로부터 선택된 VH-CDR2; 서열번호 15 및 30 내지 38로부터 선택된 VH-CDR3; 서열번호39, 및 42 내지 45로부터 선택된 VL-CDR1; 서열번호 40의 VL-CDR2; 및 서열번호41 및 46 내지 51로부터 선택된 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함한다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는: (i) 각각 서열번호 13 내지 15, 42, 40 및 41; (ii) 각각 서열번호 13 내지 15 및 39 내지 41; (iii) 각각 서열번호 13, 26, 15 및 39 내지 41; 및 (iv) 각각 서열번호 13, 26, 15, 42, 40 및 41로 이루어진 군으로부터 선택된 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 각각 서열번호 13 내지 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함한다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는: (i) 각각 서열번호 22, 14, 15, 42, 40 및 41; (ii) 각각 서열번호 13, 14, 33, 42, 40 및 41; (iii) 각각 서열번호 23, 14, 15, 42, 40 및 41, 및; (iv) 각각 서열번호 25, 14, 15, 42, 40 및 41로 이루어진 군으로부터 선택된 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 각각 서열번호 22, 14, 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 각각 서열번호 13, 14, 33, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함한다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 표 4에 개시된 VH를 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 표 5에 개시된 VL을 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 54의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 75의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함하는 EpCAM 항체 또는 모이어티(또는 "기질")는 항체 단편을 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 77의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함한다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 54, 75 및 77로부터 선택된 서열에 대해 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 VH 서열을 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 89를 포함하는 서열에 대해 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 VL 서열을 포함한다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 표 6에 개시된 HC를 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 표 7에 개시된 LC를 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 103의 서열을 갖는 HC 및 서열번호 140의 서열을 갖는 LC를 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 125의 서열을 갖는 HC 및 서열번호 140의 서열을 갖는 LC를 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 127의 서열을 갖는 HC 및 서열번호 140의 서열을 갖는 경쇄를 포함한다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 인간 EpCAM의 세포외 영역(서열번호 1) 내의 에피토프에 특이적으로 결합하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함한다. 특정 실시형태에서, EpCAM 활성화 가능한 항체는 인간 EpCAM의 제1 세포외 도메인(D1)(서열번호 2) 내의 에피토프에 특이적으로 결합하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함한다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 X1YX3X4H를 포함하는 VH-CDR1(여기서, X1은 N 및 S로부터 선택되며, X3은 Y, N, F, S, D, L, I 및 W로부터 선택되고, X4는 I 및 M으로부터 선택됨)(서열번호 5); WX2X3PGX6VYIQYX12X13KFX17G를 포함하는 VH-CDR2(여기서, X2는 I 및 F로부터 선택되며, X3은 Y 및 N으로부터 선택되고, X6은 N 및 D로부터 선택되며, X12는 N 및 S로부터 선택되고, X13은 E 및 Q로부터 선택되며, X17은 K 및 Q로부터 선택됨)(서열번호 7); 및 X1GX3X4FAY를 포함하는 VH-CDR3(여기서, X1은 D 및 E로부터 선택되고, X3은 P, A, S, Y, F, G, T 및 V로부터 선택되며, X4는 Y 및 W로부터 선택됨)(서열번호 8)을 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 RSSX4SLLHSX10G X12TYLX16을 포함하는 VL-CDR1(여기서, X4는 R 및 K로부터 선택되고, X10은 N 및 D로부터 선택되며, X12는 F 및 I로부터 선택되고, X16은 Y 및 S로부터 선택됨)(서열번호 10); QTSNLAS를 포함하는 경쇄 VL-CDR2(서열번호 40); 및 X1QX3LELPX8T를 포함하는 VL-CDR3(여기서, X1은 A, L 및 Q로부터 선택되고, X3은 S, G, Y 및 N으로부터 선택되고, X8은 N 및 W로부터 선택됨)(서열번호 11)을 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 13의 서열을 포함하는 VH-CDR1; 서열번호 14의 서열을 포함하는 VH-CDR2; 서열번호 15의 서열을 포함하는 VH-CDR3; 서열번호 42의 서열을 포함하는 VL-CDR1; 서열번호 40의 서열을 포함하는 VL-CDR2; 및 서열번호 41의 서열을 포함하는 VL-CDR3을 포함한다.
일부 실시형태에서, EpCAM 활성화 가능한 항체의 VH-CDR1은 서열 NYX3IH을 포함하되, X3은 Y, N, F, S, H, D, L, I 및 W로부터 선택된다(서열번호 6). 일부 실시형태에서, EpCAM 활성화 가능한 항체의 VH-CDR3은 서열 DGPX4FAY를 포함하되, X4는 Y 및 W로부터 선택된다(서열번호 9). 일부 실시형태에서, EpCAM 활성화 가능한 항체의 VL-CDR3은 서열 AQX3LELPNT를 포함하되, X3은 S, G, Y 및 N으로부터 선택된다(서열번호 12). 일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 13의 서열을 포함하는 VH-CDR1; 서열번호 14의 서열을 포함하는 VH-CDR2; 서열번호 15의 서열을 포함하는 VH-CDR3; 서열번호 42의 서열을 포함하는 VL-CDR1; 서열번호 40의 서열을 포함하는 VL-CDR2; 및 서열번호 41의 서열을 포함하는 VL-CDR3을 포함한다.
개시된 EpCAM 활성화 가능한 항체의 적합한 성분은 또한 인간 EpCAM 및/또는 사이노몰거스 EpCAM에 대한 결합에 대해 서열번호 54의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함하는 EpCAM 항체와 교차 경쟁하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함한다. 추가적인 적합한 EpCAM 활성화 가능한 항체는 인간 EpCAM 및/또는 사이노몰거스 EpCAM에 대한 결합에 대해 서열번호 75의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함하는 EpCAM 항체와 교차 경쟁한다. 추가적인 적합한 EpCAM 활성화 가능한 항체는 인간 EpCAM 및/또는 사이노몰거스 EpCAM에 대한 결합에 대해 서열번호 77의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함하는 EpCAM 항체와 교차 경쟁한다.
본 명세서에 제공된 EpCAM 활성화 가능한 항체는 마스킹 모이어티(MM)를 포함한다. 일부 실시형태에서, 마스킹 모이어티(또는 "마스크")는, EpCAM 항체가 EpCAM에 특이적으로 결합하는 능력을 마스킹 모이어티가 감소시키도록 EpCAM 항체에 결합 또는 달리 부착되고 EpCAM 활성화 가능한 항체 작제물 내에 위치되는 아미노산 서열이다. 적합한 마스킹 모이어티는 임의의 다양한 공지된 기법을 이용하여 확인된다. 예를 들어, 펩타이드 마스킹 모이어티는 WO 2009/025846에 기재된 방법을 이용하여 확인되며, 이의 내용은 본 명세서에 전문이 참조에 의해 원용된다.
일부 실시형태에서, 활성화 가능한 항체의 MM는 EpCAM에 대한 Ab의 해리상수보다 큰 Ab에 대한 결합에 대한 해리상수를 가진다. 일부 실시형태에서, MM은 EpCAM의 Ab의 해리상수를 초과하지 않는 Ab에 대한 결합에 대한 해리상수를 가진다.
일부 실시형태에서, MM은 EpCAM의 Ab의 해리상수 미만인 Ab에 대한 결합에 대한 해리상수를 가진다.
일부 실시형태에서, Ab로 향하는 MM의 해리상수(Kd)는 표적에 대한 Ab의 해리상수보다 2, 3, 4, 5, 10, 25, 50, 100, 250, 500, 1,000, 2,500, 5,000, 10,000, 50,000, 100,000, 500,000, 1,000,000, 5,000,000, 10,000,000, 50,000,000배 이상, 또는 1 내지 5, 5 내지 10, 10 내지 100, 10 내지 1,000, 10 내지 10,000, 10 내지 100,000, 10 내지 1,000,000, 10 내지 10,000,000, 100 내지 1,000, 100 내지 10,000, 100 내지 100,000, 100 내지 1,000,000, 100 내지 10,000,000, 1,000 내지 10,000, 1,000 내지 100,000, 1,000 내지 1,000,000, 1000 내지 10,000,000, 10,000 내지 100,000, 10,000 내지 1,000,000, 10,000 내지 10,000,000, 100,000 내지 1,000,000, 또는 100,000 내지 10,000,000배 이상의 수 이하이다.
일부 실시형태에서, EpCAM 활성화 가능한 항체가 절단된 상태일 때, MM은 EpCAM에 대한 결합에 대해 Ab를 방해 또는 경쟁하지 않는다. 일부 실시형태에서, MM은 길이가 약 2 내지 40개의 아미노산인 폴리펩타이드이다. 일부 실시형태에서, MM은 길이가 최대 약 40개의 아미노산인 폴리펩타이드이다.
일부 실시형태에서, MM 폴리펩타이드 서열은 EpCAM의 서열과 상이하다. 일부 실시형태에서, MM 폴리펩타이드 서열은 Ab의 임의의 천연 결합 상태와 50% 이하로 동일하다. 일부 실시형태에서, MM 폴리펩타이드 서열은 EpCAM의 폴리펩타이드 서열과 상이하며, Ab의 임의의 천연 결합 상대에 대해 40%, 30%, 25%, 20%, 15% 또는 10% 이하로 동일하다.
일부 실시형태에서, EpCAM으로 향하는 MM에 결합될 때 Ab의 해리상수(IQ)가 EpCAM으로 향하는 MM에 결합되지 않을 때 Ab의 IQ보다 적어도 2, 5, 10, 20, 40, 100, 1,000, 10,000 초과가 되도록 Ab에 대한 MM의 결합은 Ab가 EpCAM에 결합하는 능력을 감소시킨다.
일부 실시형태에서, 표적 변위 분석, 예를 들어, 본 명세서에 전문이 참조에 의해 원용된 WO 2010/081173에 기재된 분석을 이용하여 시험관내에서 분석될 때 CM이 절단될 때에 비해 CM이 비절단인 때에, EpCAM의 존재 하에서 MM은 Ab가 EpCAM에 결합하는 능력을 적어도 90%만큼 감소시킨다.
Ab이 MM에 의해 변형되고 인간 EpCAM의 존재 하에 있을 때, MM에 의해 변형되지 않는 Ab의 특이적 결합 또는 인간 EpCAM에 대한 모 Ab의 특이적 결합에 비해 인간 EpCAM에 대한 Ab의 특이적 결합은 감소되거나 저해된다.
인간 EpCAM으로 향하는 MM에 대해 변형된 Ab의 IQ는 MM으로 변형되지 않은 Ab 또는 인간 EpCAM으로 향하는 모 Ab의 IC보다 적어도 5, 10, 25, 50, 100, 250, 500, 1,000, 2,500, 5,000, 10,000, 50,000, 100,000, 500,000, 1,000,000, 5,000,000, 10,000,000, 50,000,000 이상, 또는 5 내지 10, 10 내지 100, 10 내지 1,000, 10 내지 10,000, 10 내지 100,000, 10 내지 1,000,000, 10 내지 10,000,000, 100 내지 1,000, 100 내지 10,000, 100 내지 100,000, 100 내지 1,000,000, 100 내지 10,000,000, 1,000 내지 10,000, 1,000 내지 100,000, 1,000 내지 1,000,000, 1000 내지 10,000,000, 10,000 내지 100,000, 10,000 내지 1,000,000, 10,000 내지 10,000,000, 100,000 내지 1,000,000, 또는 100,000 내지 10,000,000배 이상이다. 대조적으로, 인간 EpCAM으로 향하는 MM에 의해 변형된 Ab의 결합 친화도는 MM으로 변형되지 않은 Ab 또는 인간 EpCAM으로 향하는 모 Ab의 결합 친화도보다 적어도 2, 3, 4, 5, 10, 25, 50, 100, 250, 500, 1,000, 2,500, 5,000, 10,000, 50,000, 100,000, 500,000, 1,000,000, 5,000,000, 10,000,000, 50,000,000 이상, 또는 5 내지 10, 10 내지 100, 10 내지 1,000, 10 내지 10,000, 10 내지 100,000, 10 내지 1,000,000, 10 내지 10,000,000, 100 내지 1,000, 100 내지 10,000, 100 내지 100,000, 100 내지 1,000,000, 100 내지 10,000,000, 1,000 내지 10,000, 1,000 내지 100,000, 1,000 내지 1,000,000, 1000 내지 10,000,000, 10,000 내지 100,000, 10,000 내지 1,000,000, 10,000 내지 10,000,000, 100,000 내지 1,000,000, 또는 100,000 내지 10,000,000배 더 낮다.
일부 실시형태에서, Ab로 향하는 MM의 해리상수(Kd)는 인간 EpCAM으로 향하는 Ab의 Kd와 거의 동일하다. 일부 실시형태에서, Ab로 향하는 MM의 해리상수(Kd)는 인간 EpCAM으로 향하는 Ab의 해리상수 이하이다. 일부 실시형태에서, Ab로 향하는 MM의 해리상수(Kd)는 인간 EpCAM으로 향하는 Ab의 해리상수 미만이다. 일부 실시형태에서, Ab로 향하는 MM의 해리상수(Kd)는 인간 EpCAM으로 향하는 Ab의 해리상수 초과이다.
일부 실시형태에서, MM은 Ab에 대한 결합에 대한 Kd가 인간 EpCAM에 대한 Ab의 결합에 대한 Kd 이하이다.
일부 실시형태에서, MM은 인간 EpCAM에 대한 Ab의 결합에 대한 Kd 이상인 를 가진다. 일부 실시형태에서, MM은 Ab에 대한 결합에 대한 Kd가 인간 EpCAM에 대한 Ab의 결합에 대한 Kd와 거의 동일하다. 일부 실시형태에서, MM은 Ab에 대한 결합에 대한 Kd가 인간 EpCAM에 대한 Ab의 결합에 대한 Kd 미만이다. 일부 실시형태에서, MM은 Ab에 대한 결합에 대한 Kd가 인간 EpCAM에 대한 Ab의 결합에 대한 Kd 초과이다. 일부 실시형태에서, MM은 Ab에 대한 결합에 대한 Kd가 인간 EpCAM에 대한 Ab의 결합에 대한 Kd보다 2, 3, 4, 5, 10, 25, 50, 100, 250, 500 또는 1,000배 초과의 수 이하이다. 일부 실시형태에서, MM은 Ab에 대한 결합에 대한 Kd가 인간 EpCAM에 대한 Ab의 결합에 대한 Kd보다 1 내지 5, 2 내지 5, 2 내지 10, 5 내지 10, 5 내지 20, 5 내지 50, 5 내지 100, 10 내지 100, 10 내지 1,000, 20 내지 100, 20 내지 1000, 또는 100 내지 1,000 초과이다.
일부 실시형태에서, MM은 Ab에 대한 결합에 대한 친화도가 인간 EpCAM에 대한 Ab의 결합에 대한 친화도 미만이다. 일부 실시형태에서, MM은 Ab에 대한 결합에 대한 친화도가 인간 EpCAM에 대한 Ab의 결합에 대한 친화도 이하이다. 일부 실시형태에서, MM은 Ab에 대한 결합에 대한 친화도가 인간 EpCAM에 대한 Ab의 결합에 대한 친화도와 거의 동일하다. 일부 실시형태에서, MM은 Ab에 대한 결합에 대한 친화도가 인간 EpCAM에 대한 Ab의 결합에 대한 친화도 이상이다. 일부 실시형태에서, MM은 Ab에 대한 결합에 대한 친화도가 인간 EpCAM에 대한 Ab의 결합에 대한 친화도 초과이다.
일부 실시형태에서, MM은 Ab에 대한 결합에 대한 친화도가 인간 EpCAM에 대한 Ab의 결합에 대한 친화도보다 2, 3, 4, 5, 10, 25, 50, 100, 250, 500 또는 1,000배 미만이다. I 일부 실시형태에서, MM는 Ab에 대한 결합에 대한 친화도가 인간 EpCAM에 대한 Ab의 결합 친화도보다 1 내지 5, 2 내지 5, 2 내지 10, 5 내지 10, 5 내지 20, 5 내지 50, 5 내지 100, 10 내지 100, 10 내지 1,000, 20 내지 100, 20 내지 1000, 또는 100 내지 1,000배 미만이다. 일부 실시형태에서, MM은 Ab에 대한 결합에 대한 친화도가 인간 EpCAM에 대한 Ab의 결합에 대한 친화도보다 2 내지 20배 미만이다. 일부 실시형태에서, Ab에 공유결합되지 않고 EpCAM 활성화 가능한 항체에 대해 등물 농도인 MM은 인간 EpCAM에 대한 Ab 결합을 저해하지 않는다.
Ab이 MM에 의해 변형되고 인간 EpCAM의 존재 하에 있을 때, MM에 의해 변형되지 않는 Ab의 특이적 결합 또는 인간 EpCAM에 대한 모 Ab의 특이적 결합에 비해 인간 EpCAM에 대한 Ab의 특이적 결합은 감소되거나 저해된다. MM에 의해 변형되지 않는 Ab의 결합 또는 인간 EpCAM에 대한 모 Ab의 결합과 비교할 때, MM에 의해 변형될 때에 Ab가 인간 EpCAM에 결합하는 능력은 생체내 또는 시험관내 분석에서 측정할 때 생체내 또는 시험관내 분석에서 측정될 때 적어도 2, 4, 6, 8, 12, 28, 24, 30, 36, 48, 60, 72, 84 또는 96시간, 또는 5, 10, 15, 30, 45, 60, 90, 120, 150 또는 180일, 또는 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 또는 12개월 이상 동안 적어도 50%, 60%, 70%, 80%, 90%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 및 심지어 100%만큼 감소될 수 있다.
MM은 인간 EpCAM에 대한 Ab의 결합을 저해한다. MM은 Ab의 항원 결합 도메인에 결합하고, 인간 EpCAM에 대한 Ab의 결합을 저해한다. MM은 인간 EpCAM에 대한 Ab의 결합을 입체적으로 저해할 수 있다. MM은 Ab이 이의 표적에 결합하는 것을 다른자리 입체성에 의해 저해할 수 있다. 이들 실시형태에서, 생체내 또는 시험관내 분석에서 측정할 때 적어도 2, 4, 6, 8, 12, 28, 24, 30, 36, 48, 60, 72, 84 또는 96시간, 또는 5, 10, 15, 30, 45, 60, 90, 120, 150 또는 180일, 또는 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 또는 12개월 이상 동안 MM에 의해 변형되지 않은 Ab, 모 Ab, 또는 MM에 결합되지 않은 Ab의 인간 EpCAM에 대한 결합에 비해, Ab가 변형되거나 MM에 결합될 때, 그리고 표적의 존재 하에, 인간 EpCAM에 대한 Ab의 결합이 없거나, 실질적으로 없거나, 인간 EpCAM에 대한 Ab 결합의 0.001%, 0.01%, 0.1%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 15%, 20%, 25%, 30%, 35%, 40% 또는 50% 이하이다.
Ab가 MM에 결합되거나 MM에 의해 변형될 때, MM은 인간 EpCAM에 대한 Ab의 특이적 결합을 '마스킹'하거나 감소시키거나 또는 달리 저해한다. Ab가 MM에 결합되거나 MM에 의해 변형될 때, 이러한 결합 또는 변형은 Ab가 이의 표적에 특이적으로 결합하는 능력을 감소시키거나 저해하는 구조적 변화를 달성할 수 있다.
MM에 결합되거나 MM에 의해 변형된 Ab는 다음으로 나타낼 수 있다
식(아미노(N) 말단 영역으로부터 카복실(C) 말단 영역의 순서로):

여기서, MM은 마스킹 모이어티이고, Ab는 EpCAM 항체, EpCAM-결합 항원 단편이고, L은 링커이다. 다수의 실시형태에서, 가요성을 제공하기 위해 하나 이상의 링커, 예를 들어, 가요성 링커를 조성물에 삽입하는 것이 바람직할 수 있다.
특정 실시형태에서, MM은 Ab의 천연 결합 상대가 아니다. 일부 실시형태에서, MM은 Ab의 임의의 천연 결합 상대에 대해 상동성을 포함하지 않거나 실질적으로 포함하지 않는다. 일부 실시형태에서, MM은 Ab의 임의의 천연 결합 상대와 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75% 또는 80% 이하로 유사하다. 일부 실시형태에서, MM은 Ab의 임의의 천연 결합 상대와 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75% 또는 80% 이하로 동일하다. 일부 실시형태에서, MM은 Ab의 임의의 천연 결합 상태와 25% 이하로 동일하다. 일부 실시형태에서, MM은 Ab의 임의의 천연 결합 상태와 50% 이하로 동일하다. 일부 실시형태에서, MM은 Ab의 임의의 천연 결합 상태와 20% 이하로 동일하다. 일부 실시형태에서, MM은 Ab의 임의의 천연 결합 상태와 10% 이하로 동일하다.
일부 실시형태에서, MM은 표 9에 개시된 서열을 포함한다. 일부 실시형태에서, MM은 서열번호 151 내지 157로부터 선택된 서열을 포함한다. 일부 실시형태에서, MM은 서열번호 158 내지 161로부터 선택된 서열을 포함한다. 일부 실시형태에서, MM은 서열번호 162 내지 167로부터 선택된 서열을 포함한다. 일부 실시형태에서, MM은 서열번호 155의 서열을 포함한다.

본 명세서에 제공된 EpCAM 활성화 가능한 항체는 절단 가능 모이어티를 포함한다. 일부 실시형태에서, 절단 가능 모이어티(또는 "기질")는 프로테아제, 보통 세포외 프로테아제에 대한 기질인 아미노산 서열을 포함한다. 적합한 기질은 임의의 다양한 공지된 기법을 이용하여 확인된다. 예를 들어, 펩타이드 기질은 미국 특허 제7,666,817호 및 제8,563,269호; 및 WO 2014/026136에 기재된 방법을 이용하여 확인되며, 이들 각각의 내용은 본 명세서에 전문이 참조에 의해 원용된다. (또한 문헌[Boulware et al., Biotechnol Bioeng. 106(3):339-346 (2010)] 참조).
일부 실시형태에서, EpCAM 활성화 가능한 항체는 MM에 의해 변형되고 또한 하나 이상의 절단 가능 모이어티(CM)를 포함하는 Ab를 포함한다. 이러한 EpCAM 활성화 가능한 항체는 인간 EpCAM에 대해 활성화 가능하고/전환 가능한 결합을 나타낸다. EpCAM 활성화 가능한 항체는 일반적으로 마스킹 모이어티(MM) 및 변형 가능한 또는 절단 가능 모이어티(CM)에 의해 변형되거나 이에 결합된 항체 또는 항원-결합 항체 단편(Ab)을 포함한다. 일부 실시형태에서, CM은 적어도 하나의 프로테아제에 대한 기질로서 작용하는 아미노산 서열을 포함한다.
절단된(또는 상대적으로 활성인) 상대에서 그리고 인간 EpCAM의 존재 하에, EpCAM 활성화 가능한 항체가 인간 EpCAM에 결합하지만, EpCAM 활성화 가능한 항체가 인간 EpCAM의 존재 하에 비절단(또는 상대적으로 비활성인) 상태일 때, 인간 EpCAM에 대한 EpCAM 활성화 가능한 항체의 특이적 결합이 감소 또는 저해되도록, EpCAM 활성화 가능한 항체의 요소가 배열된다. EpCAM 활성화 가능한 항체가 MM에 의해 인간 EpCAM에 특이적으로 결합하는 능력을 저해 또는 마스킹하는 것으로 인해 인간 EpCAM에 대한 EpCAM 활성화 가능한 항체의 특이적 결합은 감소될 수 있다.
인간 EpCAM으로 향하는 MM 및 CM에 의해 변형된 EpCAM 활성화 가능한 항체의 IQ는 MM 및 CM으로 변형되지 않은 EpCAM 활성화 가능한 항체 또는 인간 EpCAM으로 향하는 모 Ab의 Kj보다 적어도 5, 10, 25, 50, 100, 250, 500, 1,000, 2,500, 5,000, 10,000, 50,000, 100,000, 500,000, 1,000,000, 5,000,000, 10,000,000, 50,000,000 이상, 또는 5 내지 10, 10 내지 100, 10 내지 1,000, 10 내지 10,000, 10 내지 100,000, 10 내지 1,000,000, 10 내지 10,000,000, 100 내지 1,000, 100 내지 10,000, 100 내지 100,000, 100 내지 1,000,000, 100 내지 10,000,000, 1,000 내지 10,000, 1,000 내지 100,000, 1,000 내지 1,000,000, 1000 내지 10,000,000, 10,000 내지 100,000, 10,000 내지 1,000,000, 10,000 내지 10,000,000, 100,000 내지 1,000,000, 또는 100,000 내지 10,000,000배 초과이다. 대조적으로, 인간 EpCAM으로 향하는 MM 및 CM에 의해 변형된 Ab의 결합 친화도는 MM 및 CM에 의해 변형되지 않은 EpCAM 활성화 가능한 항체 또는 인간 EpCAM으로 향하는 모 Ab의 결합 친화도보다 적어도 5, 10, 25, 50, 100, 250, 500, 1,000, 2,500, 5,000, 10,000, 50,000, 100,000, 500,000, 1,000,000, 5,000,000, 10,000,000, 50,000,000 이상, 또는 5 내지 10, 10 내지 100, 10 내지 1,000, 10 내지 10,000, 10 내지 100,000, 10 내지 1,000,000, 10 내지 10,000,000, 100 내지 1,000, 100 내지 10,000, 100 내지 100,000, 100 내지 1,000,000, 100 내지 10,000,000, 1,000 내지 10,000, 1,000 내지 100,000, 1,000 내지 1,000,000, 1000 내지 10,000,000, 10,000 내지 100,000, 10,000 내지 1,000,000, 10,000 내지 10,000,000, 100,000 내지 1,000,000, 또는 100,000 내지 10,000,000배 더 낮다.
EpCAM 활성화 가능한 항체가 MM 및 CM에 의해 변형되고 인간 EpCAM의 존재 하에 있지만 변형제(예를 들어 적어도 1종의 프로테아제)의 존재 하에는 있지 않을 때, 인간 EpCAM에 대한 EpCAM 활성화 가능한 항체의 특이적 결합은, MM 및 CM으로 변형되지 않은 EpCAM 활성화 가능한 항체 또는 인간 EpCAM에 대한 모 Ab의 특이적 결합에 비해, 감소되거나 저해된다. 모 Ab의 결합 또는 MM 및 CM으로 변형되지 않은 EpCAM 활성화 가능한 항체의 인간 EpCAM에 대한 결합과 비교할 때, MM 및 CM에 의해 변형될 때에 EpCAM 활성화 가능한 항체가 인간 EpCAM에 결합하는 능력은 생체내 또는 시험관내 분석에서 측정할 때 적어도 2, 4, 6, 8, 12, 28, 24, 30, 36, 48, 60, 72, 84 또는 96시간 또는 5, 10, 15, 30, 45, 60, 90, 120, 150 또는 180일, 또는 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 또는 12개월 이상 동안 적어도 50%, 60%, 70%, 80%, 90%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 및 심지어 100%만큼 감소될 수 있다.
본 명세서에 사용된 바와 같은 용어 절단된 상태는 적어도 1종의 프로테아제에 의한 CM의 변형 후 EpCAM 활성화 가능한 항체의 상태를 지칭한다. 본 명세서에서 사용되는 바와 같은 용어 비절단 또는 무손상 상태는 프로테아제에 의한 CM 절단의 부재 하에 EpCAM 활성화 가능한 항체의 상태를 지칭한다. 상기 논의한 바와 같은 용어 "활성화 가능한 항체" 또는 "활성화 가능한 항체"는 본 명세서에서 이의 비절단(천연 또는 무손상) 상태뿐만 아니라 이의 절단 상태 둘 다의 EpCAM 활성화 가능한 항체를 지칭하기 위해 사용된다. 일부 실시형태에서, 절단된 EpCAM 활성화 가능한 항체가 프로테아제에 의한 CM의 절단으로 인해 MM을 결여하여, 적어도 MM의 방출을 초래할 수 있다는 것은 당업자에게 분명할 것이다(예를 들어, MM이 공유 결합, 예를 들어, 시스테인 잔기 사이의 이황화 결합에 의해 EpCAM 활성화 가능한 항체에 결합하지 않는 경우).
활성화 가능한 또는 전환 가능한은 EpCAM 활성화 가능한 항체가 EpCAM 활성화 가능한 항체가가 저해되고, 마스킹된, 무손상 또는 비절단 상태(즉, 제1 입체구조)일 때 표적에 대해 제1 결합 수준을 나타내고, 비저해, 비마스킹 및/또는 절단 상태(즉, 제2 입체구조)의 인간 EpCAM에 대해 제2 결합 수준을 나타낸다는 것을 의미하며, 제2 표적 결합 수준은 제1 결합 수준보다 크다. 일반적으로, EpCAM 활성화 가능한 항체의 Ab에 대한 인간 EpCAM의 접근은 이러한 절단제의 부재 하에서보다 CM을 절단할 수 있는 절단제, 즉, 프로테아제의 존재 하에 더 크다. 따라서, EpCAM 활성화 가능한 항체가 비절단 상태일 때, Ab는 결합 인간 EpCAM으로부터 저해되고, 인간 EpCAM-결합(즉, Ab가 인간 EpCAM에 결합할 수 없는 제1 입체구조)으로부터, Ab가 저해되지 않거나 표적 결합에 대해 마스킹되지 않는 절단된 상태로 마스킹될 수 있다.
Ab가 주어진 표적에 대해 결합 모이어티를 나타내고, CM이 프로테아제에 대한 기질을 나타내도록 EpCAM 활성화 가능한 항체의 CM 및 Ab는 선택된다. 일부 실시형태에서, 프로테아제는 대상체에서의 치료 부위 또는 진단 부위에서 인간 EpCAM과 함께 공동 국소화된다. 본 명세서에 사용된 바와 같이, 공동 국소화는 동일한 부위 또는 상대적으로 근처에 있는 것을 지칭한다. 일부 실시형태에서, 프로테아제는 CM을 절단하여, 절단 부위 근처에 위치된 표적에 결합하는 활성화된 항체를 수득한다. 본 명세서에 개시된 EpCAM 활성화 가능한 항체는 특정 용도를 발견하며, 여기서, 예를 들어, C메서 부위를 절단할 수 있는 프로테아제, 즉, 프로테아제는 비처리 부위의 조직에서(예를 들어, 건강한 조직에서)보다 치료 부위 또는 진단 부위의 조직을포함하는 표적에서 상대적으로 더 고수준으로 존재한다. 일부 실시형태에서, 본 개시내용은 CM은 또한 하나 이상의 다른 프로테아제에 의해 절단된다. 일부 실시형태에서, 이는 인간 EpCAM과 함께 공동 국소화되고 생체내 CM의 절단을 초래하는 하나 이상의 다른 프로테아제이다.
일부 실시형태에서, EpCAM 활성화 가능한 항체가 인간 EpCAM에 대한 결합으로부터 마스킹 또는 달리 저해되지 않는다면, EpCAM 활성화 가능한 항체는 비처리 부위에서 EpCAM 활성화 가능한 항체의 결합으로부터 달리 초래될 수 있는 감소된 독성 및/또는 유해한 부작용을 제공한다.
일반적으로, EpCAM 활성화 가능한 항체는 관심 대상의 Ab를 선택하고, EpCAM 활성화 가능한 항체의 나머지를 작제함으로써 설계될 수 있고, 따라서, 입체구조적으로 제한될 때, MM은 EpCAM 활성화 가능한 항체의 마스킹 또는 인간 EpCAM에 대한 EpCAM 활성화 가능한 항체 결합의 감소를 제공한다. 구조적 설계 기준은 이런 기능적 특징을 제공하는 것으로 이 기능적 특징을 제공하는 것으로 고려될 수 있다.
비저해 입체구조에 비해 저해된 입체구조에서 표적 결합을 위한 목적하는 역학 범위의 전환 가능한 표현형을 나타내는 EpCAM 활성화 가능한 항체가 제공된다. 역학적 범위는 일반적으로 (a) 조건의 제1 세트 하에 파라미터의 최대 검출 수준 대 (b) 조건의 제2 세트 하에 해당 파라미터의 최소 검출 값의 비를 지칭한다. 예를 들어, EpCAM 활성화 가능한 항체와 관련하여, 역학 범위는 (a) EpCAM 활성화 가능한 항체의 CM을 절단할 수 있는 적어도 하나의 프로테아제의 존재 하에, EpCAM 활성화 가능한 항체에 대한 표적 단백질 결합의 최대 검출 수준 (b) 프로테아제의 부재 하에 EpCAM 활성화 가능한 항체에 대한 표적 단백질 결합의 최소 검출 수준의 비를 지칭한다. EpCAM 활성화 가능한 항체의 역학 범위는 EpCAM 활성화 가능한 항체, 절단제(예를 들어, 효소) 처리의 해리 상수 대 EpCAM 활성화 가능한 항체 절단제 처리의 해리 상수의 비로서 계산될 수 있다. EpCAM 활성화 가능한 항체의 역학 범위가 클수록, EpCAM 활성화 가능한 항체의 전환 가능한 표현형은 더 양호하다.
EpCAM 활성화 가능한 항체에 의한 표적 단백질 결합이 절단제의 부재 하에서보다 EpCAM 활성화 가능한 항체의 CM을 절단할 수 있는 절단제(예를 들어, 효소)의 존재 하에 더 큰 정도로 일어나도록(예를 들어, 우세하게 일어나도록), 상대적으로 더 높은 역학 범위 값(예를 들어, 1 초과)을 갖는 EpCAM 활성화 가능한 항체는 더 바람직한 전환 표현형을 나타낸다.
EpCAM 활성화 가능한 항체는 다양한 구조적 입체배치로 제공될 수 있다. EpCAM 활성화 가능한 항체에 대한 예시적인 식을 이하에 제공한다. Ab, MM 및 CM의 N- 내지 C-말단의 순서는 EpCAM 활성화 가능한 항체 내에서 반전될 수 있다는 것이 구체적으로 상정된다. 또한, 예를 들어, CM이 MM 내에 포함되도록, CM 및 MM은 아미노산 서열에서 중복된다는 것이 구체적으로 상정된다.
예를 들어, EpCAM 활성화 가능한 항체는 아미노(N) 말단 영역으로부터 카복실(C) 말단 영역까지의 순서로 다음의 식에 의해 표시될 수 있다:

식 중, MM은 마스킹 모이어티이고, CM은 절단 가능 모이어티이며, Ab는 EpCAM 항체 또는 EpCAM-결합 항체 단편이다. MM 및 CM은 상기 식의 별개의 성분으로서 표시되지만, 본 명세서에 개시된 모든 예시적인 실시형태에서, (식을 포함하여), 예를 들어, CM이 MM 내에 완전히 또는 부분적으로 포함되도록, MM 및 CM의 아미노산 서열이 중복될 수 있다는 것이 상정된다는 것을 주목하여야 한다. 또한, 상기 식은 EpCAM 활성화 가능한 항체 요소에 대해 N-말단 또는 C-말단에 위치될 수 있는 추가적인 아미노산 서열을 제공한다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 프로테아제에 의해 절단될 수 있는 CM을 포함한다. 일부 실시형태에서, CM을 절단하는 프로테아제는 질환 조직에서 활성이며, 예를 들어, 상향 조절 또는 다르게 하향조절되고, EpCAM 활성화 가능한 항체가 프로테아제에 노출될 때 프로테아제는 EpCAM 활성화 가능한 항체에서 CM을 절단한다.
일부 실시형태에서, 프로테아제는 조직에서 EpCAM과 공동국소화되고, EpCAM 활성화 가능한 항체가 프로테아제에 노출될 때, 프로테아제는 EpCAM 활성화 가능한 항체에서 CM을 절단한다.
일부 실시형태에서, EpCAM 활성화 가능한 항체가 비절단 상태일 때, EpCAM에 대한 EpCAM 활성화 가능한 항체의 결합은 EpCAM에 대한 비변형 Ab의 해리상수보다 적어도 2, 5, 10, 20, 40, 50, 100 또는 200 초과인 해리상수로 일어나도록 감소되는 반면, 절단된 상태에서(즉, EpCAM 활성화 가능한 항체가 절단된 상태일 때), Ab가 EpCAM에 결합하도록, CM이 EpCAM 활성화 가능한 항체에 위치된다.
일부 실시형태에서, CM은 길이가 최대 15개의 아미노산인 폴리펩타이드이다.
일부 실시형태에서, CM은 적어도 하나의 매트릭스 메탈로프로테아제(MMP)에 대한 기질인 제1 절단 가능 모이어티(CM1) 및 적어도 하나의 세린 프로테아제(SP)에 대한 기질인 제2 절단 가능 모이어티(CM2)를 포함하는 폴리펩타이드이다. 일부 실시형태에서, CM 1-CM2 기질의 CM1 기질 서열 및 CM2 기질 서열 각각은 독립적으로 길이가 최대 15개의 아미노산인 폴리펩타이드이다.
일부 실시형태에서, CM은 암에서 상향조절되거나 다르게 비조절되거나, 그렇게 되는 것으로 여겨지는 적어도 하나의 프로테아제에 대한 기질이다. 일부 실시형태에서, CM은 염증에서 상향조절되거나 상향조절되는 것으로 여겨지는 적어도 하나의 프로테아제에 대한 기질이다. 일부 실시형태에서, CM은 자가면역에서 상향조절되거나 다르게 상향조절되거나, 그렇게 되는 것으로 여겨지는 적어도 1종의 프로테아제에 대한 기질이다.
일부 실시형태에서, CM은 매트릭스 메탈로프로테아제(MMP), 트롬빈, 호중구 엘라스타제, 시스테인 프로테아제, 레구메인, 및 세린 프로테아제, 예컨대 매트립타제(MT-SP1), 및 유로키나제(uPA)로부터 선택된 적어도 1종의 프로테아제에 대한 기질이다. 이론으로 구속되지 않고, 이들 프로테아제는 암, 염증 및/또는 자가면역 중 적어도 하나에서 상향조절되거나 또는 달리 비조절된다.
예시적인 기질은 다음의 효소 또는 프로테아제 중 하나 이상에 의해 절단 가능한 기질을 포함하지만, 이들로 제한되지 않는다: ADAMS/ADAMTS, (예를 들어, ADAM8, ADAM9, ADAM10, ADAM12, ADAM 15, ADAM17/TACE, ADAMDEC1, ADAMTS 1, ADAMTS4, ADAMTS5); 아스파테이트 프로테아제(예를 들어, BACE, 레닌(Renin)); 아스파트산 카텝신(예를 들어, 카텝신 D 및 카텝신 E); 카스파제(예를 들어, 카스파제 1-10, 및 카스파제 14); 시스테인 카텝신(예를 들어, 카텝신 B, 카텝신 C, 카텝신 K, 카텝신 L, 카텝신 S, 카텝신 V/L2 및 카텝신 X/Z/P); 시스테인 프로테이나제(예를 들어, 크루지파인(Cruzipain), 레구메인(Legumain) 및 오투베인(Otubain)-2); KLK(예를 들어, KLK4-8, KLK10, KLK11, KLK 13, 및 KLK14); 메탈로프로테이나제(예를 들어, 메프린(Meprin), 네프릴라이신(Neprilysin), PSMA, 및 BMP1); MMP(예를 들어, MMP1-3, MMP 7-17, MMP 19, MMP 20, MMP 23, MMP 24, MMP 26 및 MMP 27); 세린 프로테아제(예를 들어, 활성화된 단백질 C, 카텝신 A, 카텝신 C, 키마제 및 응고인자 프로테아제, 예컨대 FVIIa, FIXa, FXa, FXIa 및 FXIIa), 엘라스타제(예를 들어, 인간 호중성 엘라스타제); 그랜자임 B; 구아니디노벤조아타제; HtrA1; 락토페린; 마랍신; NS3/4A; PACE4; 플라스민; PSA, tPA; 트롬빈; 트립타제; uPA; II형 막관통 세린 프로테아제(TTSP)(예를 들어, DESC1, DPP-4, FAP, 헵신, 매트립타제-2, MT-SP1/매트립타제 및 TMPRSS2-4).
일부 실시형태에서, CM은 특정 프로테아제, 예를 들어, EpCAM 활성화 가능한 항체의 표적과 공동 국소화되는 것으로 알려진 프로테아제와 함께 사용하기 위해 선택된다.
일부 실시형태에서, CM은 적어도 하나의 MMP에 대한 기질이다. MMP의 예는 MMP1-3, MMP 7-17, MMP19, MMP20, MMP23, MMP24, MMP26 및 MMP27을 포함한다. 일부 실시형태에서, CM은 MMP 9, MMP 14, MMP1, MMP3, MMP 13, MMP 17, MMP11 및 MMP 19로부터 선택된 프로테아제에 대한 기질이다. 일부 실시형태에서, CM은 MMP9에 대한 기질이다. 일부 실시형태에서, CM은 MMP14에 대한 기질이다.
제공된 활성화 가능한 항체에 일상적으로 혼입되는 적합한 CM은 당업계에 공지되어 있다. 예를 들어, WO 2016/179285, 예를 들어, 페이지 40 내지 47를 참조하며, 이의 내용은 본 명세서에 전문이 참조에 의해 원용된다.
일부 실시형태에서, CM은 호중구 엘라스타제에 대한 기질이다. 일부 실시형태에서, CM은 세린 프로테아제에 대한 기질이다. 일부 실시형태에서, CM은 레구메인에 대한 기질이다. 일부 실시형태에서, CM은 매트립타제에 대한 기질이다. 일부 실시형태에서, CM은 시스테인 프로테아제에 대한 기질이다. 일부 실시형태에서, CM은 시스테인 프로테아제, 예컨대, 카텝신에 대한 기질이다. 다른 실시형태에서, CM은 uPA에 대한 기질이다.
특정 실시형태에서, CM은 uPA에 대한 기질이다. 일부 실시형태에서, CM은 표 10에 개시된 서열을 포함한다.

일부 실시형태에서, CM은 서열 AVGLLAPPGGLSGRSDNI(서열번호 168)를 포함한다.
일부 실시형태에서, CM은 서열 ISSGLLSGRSDNI(서열번호 169)를 포함한다.
일부 실시형태에서, CM은 적어도 2종의 프로테아제에 대한 기질이다. 일부 실시형태에서, 각 프로테아제는 ADAMS/ADAMTS, (예를 들어, ADAM8, ADAM9, ADAM 10, ADAM 12, ADAM 15, ADAM 17/TACE, ADAMDEC1, ADAMTS1, ADAMTS4, ADAMTS5); 아스파테이트 프로테아제(예를 들어, BACE, 레닌(Renin)); 아스파트산 카텝신(예를 들어, 카텝신 D 및 카텝신 E); 카스파제(예를 들어, 카스파제 1-10, 및 카스파제 14); 시스테인 카텝신(예를 들어, 카텝신 B, 카텝신 C, 카텝신 K, 카텝신 L, 카텝신 S, 카텝신 V/L2 및 카텝신 X/Z/P); 시스테인 프로테이나제(예를 들어, 크루지파인(Cruzipain), 레구메인(Legumain) 및 오투베인(Otubain)-2); KLK(예를 들어, KLK4-8, KLK10, KLK11, KLK 13, 및 KLK14); 메탈로프로테이나제(예를 들어, 메프린(Meprin), 네프릴라이신(Neprilysin), PSMA, 및 BMP1); MMP(예를 들어, MMP1-3, MMP 7-17, MMP 19, MMP 20, MMP 23, MMP 24, MMP 26 및 MMP 27); 세린 프로테아제(예를 들어, 활성화된 단백질 C, 카텝신 A, 카텝신 C, 키마제 및 응고인자 프로테아제, 예컨대 FVIIa, FIXa, FXa, FXIa 및 FXIIa), 엘라스타제(예를 들어, 인간 호중성 엘라스타제); 그랜자임 B; 구아니디노벤조아타제; HtrA1; 락토페린; 마랍신; NS3/4A; PACE4; 플라스민; PSA, tPA; 트롬빈; 트립타제; uPA; II형 막관통 세린 프로테아제(TTSP)(예를 들어, DESC1, DPP-4, FAP, 헵신, 매트립타제-2, MT-SP1/매트립타제 및 TMPRSS2-4로부터 선택된다. 일부 실시형태에서, CM은 적어도 2종의 프로테아제에 대한 기질이되, 프로테아제 중 하나는 MMP, 트롬빈, 호중구 엘라스타제, 시스테인 프로테아제, uPA, 레구메인 및 매트립타제로부터 선택되고, 다른 프로테아제는 상기 열거한 것으로부터 선택된다. 일부 실시형태에서, CM은 MMP, 트롬빈, 호중구 엘라스타제, 시스테인 프로테아제, uPA, 레구메인 및 매트립타제의 군으로부터 선택된 적어도 2종의 프로테아제에 대한 기질이다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 적어도 제1 CM 및 제2 CM을 포함한다. 일부 실시형태에서, 제1 CM 및 제2 CM은 각각 15개 이하의 아미노산 길이의 폴리펩타이드이다. 일부 실시형태에서, 비절단 상태에서 EpCAM 활성화 가능한 항체에서 제1 CM 및 제2 CM은 N-말단으로부터 C-말단까지 다음과 같은 구조적 배열을 가진다: MM-CM1-CM2-Ab 또는 Ab-CM2- CM1-MM. 일부 실시형태에서, 제1 CM 및 제2 CM 중 적어도 하나는 MMP, 트롬빈, 호중구 엘라스타제, 시스테인 프로테아제, uPA, 레구메인 및 매트립타제로부터 선택된 프로테아제에 대한 기질로서 작용하는 폴리펩타이드이다. 일부 실시형태에서, 제1 CM은 표적 조직에서 MMP, 트롬빈, 호중구 엘라스타제, 시스테인 프로테아제, uPA, 레구메인, 및 매트립타제로부터 선택된 제1 절단제에 의해 절단되고, 제2 CM은 표적 조직에서 제2 절단제에 의해 절단된다. 일부 실시형태에서, 기타 프로테아제는 앞 단락에 제시된 목록으로부터 선택된다. 일부 실시형태에서, 제1 절단제 및 제2 절단제는 MMP, 트롬빈, 호중구 엘라스타제, 시스테인 프로테아제, uPA, 레구메인 및 매트립타제로부터 선택된 동일한 프로테아제이고, 제1 CM 및 제2 CM은 효소에 대한 상이한 기질이다. 일부 실시형태에서, 제1 절단제 및 제2 절단제는 앞 단락의 목록으로부터 선택된 동일한 프로테아제이다. 일부 실시형태에서, 제1 절단제 및 제2 절단제는 상이한 프로테아제이다. 일부 실시형태에서, 제1 절단제 및 제2 절단제는 표적 조직에서 공동 국소화된다. 일부 실시형태에서, 제1 CM 및 제2 CM은 표적 조직에서 적어도 1종의 절단제에 의해 절단된다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 또한 신호 펩타이드를 포함한다. 일부 실시형태에서, 신호 펩타이드는 스페이서를 통해 EpCAM 활성화 가능한 항체에 접합된다. 일부 실시형태에서, 스페이서는 신호 펩타이드의 부재 하에 EpCAM 활성화 가능한 항체에 접합된다. 일부 실시형태에서, 스페이서는 EpCAM 활성화 가능한 항체의 MM에 직접 결합된다. 일부 실시형태에서, 스페이서는 스페이서-MM-CM-Ab의 N-말단으로부터 C-말단까지의 구조적 배열에서 EpCAM 활성화 가능한 항체의 MM에 직접 결합된다.
적합한 스페이서 및 스페이서 기술은 당업계에 공지되어 있고, 제공된 활성화 가능한 항체의 일부 실시형태에서 스페이서를 혼입하는 데 일상적으로 사용될 수 있다. 예를 들어, WO 2016/179285(예를 들어, 페이지 52 내지 53에서)를 참조하며, 이의 내용은 본 명세서에 전문이 참조에 의해 원용된다.
다수의 실시형태에서, MM-CM 접합, CM-Ab 접합 중 하나 이상 또는 둘 다에서 가요성을 제공하기 위해 하나 이상의 링커, 예를 들어, 가요성 링커를 EpCAM 활성화 가능한 항체, 작제물에 삽입하는 것이 바람직할 수 있다. 예를 들어, Ab, MM 및/또는 CM은 목적하는 가요성을 제공하기 위해 충분한 수의 잔기(예를 들어, Gly, Ser, Asp, Asn, 특히 Gly 및 Ser, 특히 Gly)을 포함하지 않을 수도 있다. 이렇게 해서, 이러한 EpCAM 활성화 가능한 항체, 작제물의 전환 가능한 표현형은 가요성 링커를 제공하기 위해 하나 이상의 아미노산을 도입하는 것이 유리할 수 있다. 또한, 이하에 기재하는 바와 같이, EpCAM 활성화 가능한 항체가 입체구조적으로 제한된 작제물로서 제공되는 경우에, 가요성 링커는 비절단 EpCAM 활성화 가능한 항체에서 환식 구조의 형성 및 유지를 용이하게 하기 위해 작동 가능하게 삽입될 수 있다.
예를 들어, 특정 실시형태에서, EpCAM 활성화 가능한 항체는 하기 식 중 하나를 포함한다(이하의 식은 N- 내지 C-말단 방향 또는 C- 내지 N-말단 방향 중 하나로 아미노산 서열을 나타냄):

식 중, MM, CM 및 Ab는 상기 정의한 바와 같고; L1 및 L2는 각각 독립적으로 그리고 선택적으로 존재하거나 또는 존재하지 않고, 적어도 1 가요성 아미노산(예를 들어, Gly)을 포함하는 동일 또는 상이한 가요성 링커이다. 또한, 상기 식은 EpCAM 활성화 가능한 항체 요소에 대해 N-말단 또는 C-말단에 위치될 수 있는 추가적인 아미노산 서열을 제공한다. 예는 표적화 모이어티(예를 들어, 표적 조직에 존재하는 세포의 수용체에 대한 리간드) 및 혈청 반감기 연장 모이어티(예를 들어, 면역글로불린(예를 들어, IgG) 또는 혈청 알부민(예를 들어, 인간 혈청 알부민(HSA)과 같은 혈청 단백질에 결합하는 폴리펩타이드)을 포함하지만, 이들로 제한되지 않는다.
일부 실시형태에서, 프로테아제가 CM을 절단한 후에 활성화 또는 절단 상태에서, 활성화된 항체가 LP2 및/또는 CM 서열의 적어도 일부를 포함하는 경쇄 서열을 포함하도록 EpCAM 활성화 가능한 항체는 프로테아제에 노출되거나 프로테아제에 의해 절단된다.
CM은 약 0.001, 0.005, 0.01, 0.005, 0.1, 0.5, 1, 2.5, 5, 7.5, 10, 15, 20, 25, 50, 75, 100, 125, 150, 200, 250, 500, 750, 1000, 1250 또는 1500×104 M-1S-1 또는 적어도×104 M-1S-1의 속도로 적어도 1종의 프로테아제에 의해 특이적으로 절단된다. 일부 실시형태에서, CM은 약 100,000 M-1S-1의 속도로 특이적으로 절단된다. 일부 실시형태에서, CM은 약 1×102 내지 약 1×106 M-1S-1(즉, 약 1×102 내지 약 1×106 M-1S-1)의 속도로 특이적으로 절단된다.
효소에 의한 특이적 절단에 대해, 효소와 CM 간의 접촉이 만들어진다. MM 및 CM에 결합된 Ab(예를 들어, EpCAM 항체 또는 EpCAM-결합 항체 단편)을 포함하는 EpCAM 활성화 가능한 항체가 EpCAM 및 충분한 효소 활성의 존재 하에 있을 때, CM이 절단될 수 있다. 충분한 효소 활성은 효소가 CM과의 접촉을 만들고 절단을 달성하는 능력을 지칭할 수 있다. 효소가 CM 근처에 있을 수 있지만, 기타 세포 인자 또는 효소의 단백질 변형 때문에 절단할 수 없다는 것은 용이하게 생각될 수 있다.
본 명세서에 개시된 조성물인 EpCAM 활성화 가능한 항체에서 사용하기에 적합한 링커는 일반적으로 변형된 Ab(예를 들어, EpCAM 항체 또는 EpCAM-결합 항체 단편) 또는 EpCAM 활성화 가능한 항체의 가요성을 제공하여, 인간 EpCAM에 대한 EpCAM 활성화 가능한 항체의 결합 저해를 용이하게 하는 것이다. 이러한 링커는 일반적으로 가요성 링커로서 지칭된다. 적합한 링커는 용이하게 선택될 수 있고, 임의의 적합한 상이한 길이, 예컨대, 1개의 아미노산(예를 들어, Gly) 내지 20개의 아미노산, 2개의 아미노산 내지 15개의 아미노산, 3개의 아미노산 내지 12개의 아미노산, 예를 들어, 4개의 아미노산 내지 10개의 아미노산, 5개의 아미노산 내지 9개의 아미노산, 6개의 아미노산 내지 8개의 아미노산, 또는 7개의 아미노산 내지 8개의 아미노산을 가질 수 있으며, 길이가 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 또는 20개의 아미노산일 수 있다.
본 명세서에 제공된 활성화 가능한 항체, 항체 및 항체 단편에 대한 예시적인 가요성 링커는, 글리신 중합체(G)n, 글리신-세린 중합체를 포함하고, 예를 들어, (GS)n을 포함한다. 적합한 링커 및 링커 기술은 당업계에 공지되어 있고, 제공된 활성화 가능한 항체의 일부 실시형태에서 스페이서를 혼입하는 데 일상적으로 사용될 수 있다. 예를 들어, WO 2016/179285(예를 들어, 페이지 26, 113 내지 116에서)를 참조하며, 이의 내용은 본 명세서에 전문이 참조에 의해 원용된다. 당업자는 링커가 가요성 링커뿐만 아니라 목적하는 EpCAM 활성화 가능한 항체 구조를 제공하기 위해 덜 가요성인 구조를 부여하는 하나 이상의 부분을 포함할 수 있도록 EpCAM 활성화 가능한 항체의 설계가 모두 또는 부분적으로 가요성인 링커를 포함할 수 있다는 것을 인식할 것이다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 제1 연결 펩타이드(LP1) 및 제2 연결 펩타이드(LP2)를 포함하고, 비절단 상태의 EpCAM 활성화 가능한 항체는 N-말단으로부터 C-말단까지 다음과 같은 구조적 배열을 가진다: MM-LP1-CM-LP2-Ab 또는 Ab-LP2-CM-LP1-MM. 일부 실시형태에서, 두 연결 펩타이드가 서로 동일할 필요는 없다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 제1 연결 펩타이드(LP1) 및 제2 연결 펩타이드(LP2)를 포함하고, 비절단 상태의 EpCAM 활성화 가능한 항체는 N-말단으로부터 C-말단까지 다음과 같은 구조적 배열을 가진다: MM-LP1-CM-LP2-Ab 또는 Ab-LP2-CM-LP1-MM. 일부 실시형태에서, 두 연결 펩타이드가 서로 동일할 필요는 없다.
일부 실시형태에서, EpCAM 활성화 가능한 항체의 LP1 또는 LP2 중 적어도 하나는 가요성 링커를 포함한다. 적합한 링커 및 링커 기술은 당업계에 공지되어 있고, 제공된 활성화 가능한 항체의 일부 실시형태에서 스페이서를 혼입하는 데 일상적으로 사용될 수 있다. 예를 들어, WO 2016/179285(예를 들어, 페이지 26, 113 내지 116에서)를 참조하며, 이의 내용은 본 명세서에 전문이 참조에 의해 원용된다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 표 11에 개시된 서열을 갖는 경쇄를 포함한다. 일부 실시형태에서, 활성화 가능한 항체는 서열번호 174의 서열을 갖는 경쇄를 포함한다. 일부 실시형태에서, 활성화 가능한 항체는 서열번호 179의 서열을 갖는 경쇄를 포함한다.





일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 170 내지 180으로부터 선택된 서열을 갖는 경쇄 및 서열번호 103, 125 및 127로부터 선택된 서열을 갖는 중쇄를 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 170 내지 180으로부터 선택된 서열을 갖는 경쇄 및 서열번호 103의 서열을 갖는 중쇄를 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 174의 서열을 갖는 경쇄 및 서열번호 103의 서열을 갖는 중쇄를 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 179의 서열을 갖는 경쇄 및 서열번호 103의 서열을 갖는 중쇄를 포함한다.
일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 181 내지 188로부터 선택된 서열을 갖는 경쇄 및 서열번호 127의 서열을 갖는 중쇄를 포함한다. 일부 실시형태에서, EpCAM 활성화 가능한 항체는 서열번호 189 내지 200으로부터 선택된 서열을 갖는 경쇄 및 서열번호 125의 서열을 갖는 중쇄를 포함한다.
특정 실시형태에서, huEpCAM23 항체는 버지니아주 20110 매너서스 불바드 유니버시티(University Boulevard) 10801에 위치된 미국 미생물 보존 센터(American Type Culture Collection: ATCC)에 부다페스트 조약의 조항 하에 2018년 10월 4일자로 기탁되고, ATCC 수탁번호가 PTA-125343 및 PTA-125344 또는 PTA-125345인, 플라스미드에 의해 암호화된다. EpCAM 항체, EpCAM-결합 항체 단편 및 EpCAM 활성화 가능한 항체, 면역접합체의 예는 본 명세서에 제공된다.
폴리뉴클레오타이드, 벡터, 숙주 세포 및 재조합 방법
본 개시내용은 본 명세서에 개시된 EpCAM 항체, EpCAM-결합 항체 단편 및 EpCAM 활성화 가능한 항체를 암호화하는 뉴클레오타이드 서열을 포함하는 폴리뉴클레오타이드를 추가로 제공한다.
당업계에 공지된 방법을 이용하여 폴리뉴클레오타이드가 얻어질 수 있고, 폴리뉴클레오타이드의 뉴클레오타이드 서열이 결정된다. 예를 들어, 항체의 뉴클레오타이드 서열이 공지되어 있다면, 항체를 암호화하는 폴리뉴클레오타이드는 화학적으로 합성된 올리고뉴클레오타이드로부터(예를 들어, 문헌[Kutmeier et al., BioTechniques 17:242 (1994)]에 기재되어 있는 바와 같이) 조립될 수 있고, 이는 간략하게, 항체를 암호화하는 서열 부분을 포함하는 중복 올리고뉴클레오타이드의 합성, 해당 올리고뉴클레오타이드의 어닐링 및 결찰, 및 이어서, PCR에 의한 결찰 올리고뉴클레오타이드의 증폭을 수반한다.
일부 실시형태에서, 본 개시내용의 폴리뉴클레오타이드는 표 12에 제시된 서열을 포함한다.




일부 실시형태에서, 본 개시내용의 EpBA는 서열번호 201의 중쇄 핵산 서열 및 서열번호 202의 경쇄 핵산 서열을 포함한다. 일부 실시형태에서, 본 개시내용의 EpBA는 서열번호 203의 중쇄 핵산 서열 및 서열번호 204의 경쇄 핵산 서열을 포함한다. 일부 실시형태에서, 본 개시내용의 EpBA는 서열번호 205의 중쇄 핵산 서열 및 서열번호 204의 경쇄 핵산 서열을 포함한다. 일부 실시형태에서, 본 개시내용의 EpBA는 서열번호 206의 중쇄 핵산 서열 및 서열번호 204의 경쇄 핵산 서열을 포함한다. 일부 실시형태에서, 본 개시내용의 EpBA는 서열번호 207의 중쇄 핵산 서열 및 서열번호 204의 경쇄 핵산 서열을 포함한다.
일부 실시형태에서, 본 개시내용의 EpBA는 서열번호 203의 중쇄 핵산 서열 및 서열번호 208의 경쇄 핵산 서열을 포함한다. 일부 실시형태에서, 본 개시내용의 EpBA는 서열번호 203의 중쇄 핵산 서열 및 서열번호 209의 경쇄 핵산 서열을 포함한다.
일부 실시형태에서, 본 개시내용의 EpBA는 (i) PTA-125343으로서 미국 미생물 보존센터(ATCC®)에 기탁된 플라스미드에 의해 암호화된 중쇄 가변 영역의 아미노산 서열과 동일한 아미노산 서열을 포함하는 중쇄 가변 영역 및 (ii) PTA-125342로서 ATCC®에 기탁된 플라스미드에 의해 암호화된 경쇄 가변 영역의 아미노산 서열과 동일한 아미노산 서열을 포함하는 경쇄 가변 영역을 포함한다. EpBA를 포함하는 EpCAM 항체 및 EpCAM-결합 항체 단편을 제조하고 이용하는 방법이 또한 본 개시내용에 의해 포함된다.
일부 실시형태에서, 본 개시내용은 (i) PTA-125343으로서 ATCC®에 기탁된 플라스미드에 의해 암호화된 중쇄의 아미노산 서열과 동일한 아미노산 서열을 포함하는 중쇄 및 (ii) PTA-125342로서 ATCC®에 기탁된 플라스미드에 의해 암호화된 경쇄 가변 영역의 아미노산 서열과 동일한 아미노산 서열을 포함하는 경쇄를 포함하는 EpCAM 항체를 제공한다. EpCAM 항체를 제조하고 이용하는 방법이 또한 본 개시내용에 의해 포함된다.
일부 실시형태에서, 본 개시내용은 (i) PTA-125343으로서 ATCC®에 기탁된 플라스미드에 의해 암호화된 중쇄 가변 영역의 아미노산 서열과 동일한 아미노산 서열을 포함하는 중쇄 가변 영역 및 (ii) PTA-125344로서 ATCC®에 기탁된 플라스미드에 의해 암호화된 경쇄 가변 영역의 아미노산 서열과 동일한 아미노산 서열을 포함하는 경쇄 가변 영역을 포함하는 EpCAM 활성화 가능한 항체 또는 EpCAM-결합 활성화 가능한 항체 단편을 제공한다. EpCAM 활성화 가능한 항체 또는 EpCAM-결합 활성화 가능한 항체 단편의 제조 및 이용 방법이 또한 본 개시내용에 의해 포함된다.
다른 실시형태에서, 본 개시내용은 (i) PTA-125343으로서 ATCC®에 기탁된 플라스미드에 의해 암호화된 중쇄 가변 영역의 아미노사 ㄴ서열과 동일한 아미노산 서열을 포함하는 중쇄 가변 영역 및 (ii) PTA-125345로서 ATCC®에 기탁된 플라스미드에 의해 암호화된 경쇄 가변 영역의 아미노산 서열과 동일한 아미노산 서열을 포함하는 경쇄 가변 영역을 포함하는 EpCAM 활성화 가능한 항체 또는 EpCAM-결합 활성화 가능한 항체 단편을 제공한다. EpCAM 활성화 가능한 항체 또는 EpCAM-결합 활성화 가능한 항체 단편의 제조 및 이용 방법이 또한 본 개시내용에 의해 포함된다.
항체 암호화 서열 및 적절한 전사 및 번역 제어 신호를 포함하는 재조합 벡터의 작제 방법은 당업계에 잘 공지되어 있다. 일단 항체가 재조합적으로 발현되면, 면역글로불린 분자의 정제를 위한 당업계에 공지된 임의의 방법에 의해, 예를 들어, 크로마토그래피(예를 들어, 이온 교환, 친화도에 의해, 특히 단백질 A 다음에 특정 항원에 대한 친화도, 및 크기조정 칼럼 크로마토그래피에 의해), 원심분리, 차별적 용해도에 의해, 또는 단백질 정제를 위한 임의의 다른 표준 기법에 의해 정제될 수 있다. 이와 관련하여, 미국 특허 제7,538,195호는 본 개시내용에 관해 언급하며, 이의 내용은 본 명세서에 전문이 참조에 의해 원용된다.
본 개시내용은 또한 항체 및/또는 EpCAM 활성화 가능한 항체의 발현을 야기하는 조건 하에 세포를 배양시킴으로써 본 명세서에 개시된 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체의 생성 방법을 제공하되, 세포는 항체, 항체 단편 또는 활성화 가능한 항체를 암호화하는 핵산 분자를 포함한다.
본 개시내용은 또한 (a) EpCAM 활성화 가능한 항체의 발현을 야기하는 조건 하에 EpCAM 활성화 가능한 항체를 암호화하는 핵산 작제물을 포함하는 세포를 배양시키는 단계로서, EpCAM 활성화 가능한 항체는 마스킹 모이어티(MM), 절단 가능 모이어티(CM), 및 Ab(예를 들어, EpCAM 항체 또는 EpCAM-결합 항체 단편)을 포함하되, (i) CM은 프로테아제에 대한 기질로서 작용하는 폴리펩타이드이고; 그리고 (ii) EpCAM 활성화 가능한 항체가 비절단 상태일 때, MM이 EpCAM에 대한 Ab의 특이적 결합을 방해하고, 절단 상태일 때, MM이 EpCAM에 대한 Ab의 특이적 결합을 방해 또는 경쟁하지 않도록, CM이 EpCAM 활성화 가능한 항체에 위치되는, 상기 배양시키는 단계; 및 (b) EpCAM 활성화 가능한 항체를 회수하는 단계에 의해, 활성화된 상태로 EpCAM에 결합하는 EpCAM 활성화 가능한 항체의 제조 방법을 제공한다. 적합한 Ab, MM 및/또는 CM은 본 명세서에 개시된 임의의 Ab, MM 및/또는 CM을 포함한다.
면역접합체
일 실시형태에서, 본 개시내용은 세포독성제에 접합 또는 공유 결합된 (예를 들어, 본 명세서에 개시된 바와 같은) EpCAM 항체 또는 EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 포함하는 면역접합체를 제공한다. 세포독성제는, 예를 들어, 슈도모나스(Pseudomonas) 외독소, 디프테리아(Diptheria) 독소, 보툴리늄(botulinum) 독소 A 내지 F, 리신 아브린(ricin abrin), 사포린 및 이들 제제의 세포독성 단편과 같은 세포에 해로운 임의의 제제를 포함한다. 세포독성제는 또한 장애를 예방적으로 또는 치료적으로 치료하기 위해 치료 효과를 갖는 임의의 제제를 포함한다. 이러한 치료제는 화학적 치료제, 단백질 또는 폴리펩타이드 치료제일 수 있고, 목적하는 생물학적 활성을 갖고/갖거나 주어진 생물학적 반응을 변형시키는 치료제를 포함한다. 치료제의 예는 알킬화제, 혈관신생 저해제, 항유사분열제, 호르몬 요법제 및 세포 증식 장애의 치료에 유용한 항체를 포함하지만, 이들로 제한되지 않는다. 특정 실시형태에서, 치료제는 메이탄시노이드 화합물, 예컨대 미국 특허 제5,208,020호 및 제7,276,497호에 기재된 것이고, 이들 각각의 내용은 이들의 전문이 본 명세서에 참조에 의해 원용된다. 특정 실시형태에서, 치료제는 벤조다이아제핀 화합물, 예컨대 피롤로벤조다이아제핀(PBD)(예컨대 WO 2010/043880, WO 2011/130616, WO 2009/016516, WO 2013/177481 및 WO 2012/112708에 기재된 것) 및 인돌리노벤조다이아제핀(IGN) 화합물(예컨대 WO 2010/091150, 및 WO 2012/128868 및 미국 특허 제20170014522호에 기재된 것)이며, 이들 각각의 내용은 본 명세서에 전문이 참조에 의해 원용된다.
본 명세서에 사용되는 바와 같은 "피롤로벤조다이아제핀"(PBD) 화합물은 피롤로벤조다이아제핀 코어 구조를 갖는 화합물이다. 피롤로벤조다이아제핀은 치환 또는 비치환될 수 있다. "피롤로벤조다이아제핀" 화합물은 또한 링커에 의해 연결되는 2개의 피롤로벤조다이아제핀 코어를 갖는 화합물을 포함할 수 있다. 인돌리노벤조다이아제핀 코어의 부분으로서 이민 작용기(-C=N-)는 환원될 수 있다.
특정 실시형태에서, 피롤로벤조다이아제핀 화합물은 선택적으로 치환될 수 있는  으로 표시되는 코어 구조를 포함한다.
으로 표시되는 코어 구조를 포함한다.
특정 실시형태에서, 피롤로벤조다이아제핀 화합물은 선택적으로 치환될 수 있는 4e3  으로 표시되는 코어 구조를 포함한다.
으로 표시되는 코어 구조를 포함한다.
본 명세서에 사용되는 바와 같은 "인돌리노벤조다이아제핀"(IGN)은 인돌리노벤조다이아제핀 코어 구조를 갖는 화합물이다. 인돌리노벤조다이아제핀은 치환 또는 비치환될 수 있다. "인돌리노벤조다이아제핀"(IGN) 화합물은 또한 링커에 의해 연결된 2개의 인돌리노벤조다이아제핀 코어를 갖는 화합물을 포함한다.
인돌리노벤조다이아제핀 코어의 부분으로서 이민 작용기(-C=N-)는 환원될 수 있다.
특정 실시형태에서, 인돌리노벤조다이아제핀 화합물은 선택적으로 치환될 수 있는  으로 표시되는 코어 구조를 포함한다.
으로 표시되는 코어 구조를 포함한다.
일부 실시형태에서, 인돌리노벤조다이아제핀 화합물은 추가로 치환될 수 있는  으로 표시되는 코어 구조를 포함한다.
으로 표시되는 코어 구조를 포함한다.
세포독성제는 EpCAM-결합제(예를 들어, 본 명세서에 개시된 EpCAM 항체 또는 EpCAM-결합 항체 단편 또는 EpCAM 활성화 가능한 항체)에 직접적으로 또는 "면역접합체", "접합체", "ADC" 또는 "AADC"를 생성하기 위해 당업계에 공지된 기법을 이용하여 링커를 통해 간접적으로 결합 또는 접합될 수 있다.
링커 분자
당업계에 공지된 임의의 적합한 링커는 개시된 면역접합체를 제조하는 데 사용될 수 있다. 특정 실시형태에서, 링커는 2작용성 링커이다. 본 명세서에 사용된 바와 같이, 용어 "2작용성 링커"는 2개의 반응기를 갖는 변형제를 지칭하며; 이들 중 하나는 세포 결합제와 반응할 수 있는 한편, 다른 하나는 두 모이어티를 함께 연결하는 세포독성 화합물과 반응한다. 이러한 2작용성 교차링커는 당업계에 잘 공지되어 있다(예를 들어, 문헌[Isalm and Dent in Bioconjugation chapter 5, p218- 363, Groves Dictionaries Inc. New York, 1999] 참조). 예를 들어, 티오에터 결합을 통해 결합을 가능하게 하는 2작용성 가교제는 말레이미도기를 도입하기 위해 N-석신이미딜-4-(N-말레이미도메틸)-사이클로헥산-1-카복실레이트(SMCC), 또는 아이오도아세틸기를 도입하기 위해 N-석신이미딜- 4-(아이오도아세틸)-아미노벤조에이트(SICBA)를 포함한다. 세포 결합제 상에 말레이미도기 또는 할로아세틸기를 도입하는 기타 2작용성 가교제는 당업계에 잘 공지되어 있으며(예를 들어, 미국 특허 제2008/0050310호 및 미국 특허 제20050169933호 참조, 미국 일리노이주 61105 록랜드 피.오. 박스 117에 소재한 Pierce Biotechnology Inc.로부터 입수 가능), 비스-말레이미도폴리에틸렌글리콜(BMPEO), BM(PEO)2, BM(PEO)3, N-(β-말레이미도-프로필옥시)석신이미드 에스터(BMPS), γ-말레이미도뷰티르산 N-석신이미딜 에스터(GMBS), 6-말레이미도카프론산 N-하이드록시석신이미드 에스터(EMCS), 5-말레이미도발레르산 NHS, HBVS, SMCC(LC- SMCC)의 "장쇄" 유사체인 N-석신이미딜-4-(N-말레이미도메틸)-사이클로-헥산-1-카복시-(6-아미도카프로에이트), m-말레이미도벤조일-N-하이드록시석신이미드 에스터(MBS), 4-(4-N-말레이미도- 페닐)-뷰티르산 하이드라자이드 또는 HCl 염(MPBH), N-석신이미딜 3-(브로모아세트아미도)프로피오네이트(SBAP), N-석신이미딜 아이오도아세트산염(SIA), κ-말레이미도운데칸산 N- 석신이미딜 에스터(KMUA), N-석신이미딜 4-(p-말레이미도페닐)-뷰티레이트(SMPB), 석신이미딜-6-(β-말레이미도프로피온아미도)헥사노에이트(SMPH), 석신이미딜-(4- 비닐설폰일)벤조에이트(SVSB), 다이티오비스-말레이미도에탄(DTME), 1,4-비스- 말레이미도부탄(BMB), 1,4 비스말레이미딜-2,3-다이하이드록시부탄(BMDB), 비스- 말레이미도헥산(BMH), 비스-말레이미도에탄(BMOE), 설포석신이미딜 4-(N-말레이미도- 메틸)사이클로헥산-1-카복실레이트(설포-SMCC), 설포석신이미딜(4-아이오도-아세틸)아미노벤조에이트(설포-SICBA), m-말레이미도벤조일-N-하이드록시설포석신이미드 에스터(설포-MBS), N-(γ-말레이미도뷰트릴-옥시)설포석신이미드 에스터(설포-GMBS), N-(ε-말레이미도카프로일옥시)설포석시미도 에스터(설포-EMCS), N-(κ-말레이미도운데크-아노일-옥시)설포석신이미드 에스터(설포-KMUS), 및 설포석신이미딜 4-(p-말레이미도페닐) 뷰티레이트(설포-SMPB)를 포함하지만, 이들로 제한되지 않는다.
헤테로2작용성 가교제는 2개의 상이한 반응기를 갖는 2작용성 가교제이다. 아민반응성 N-하이드록시석신이미드기(NHS 기) 및 카보닐-반응성 하이드라진기를 둘 다 포함하는 헤테로2작용성 가교제는 또한 세포 결합제(예를 들어, EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체)와 함께 본 명세서에 개시된 세포독성 화합물을 연결하는 데 사용될 수 있다. 이러한 상업적으로 입수 가능한 헤테로2작용성 가교제의 예는 석신이미딜 6-하이드라지노니코틴아마이드 아세톤 하이드라존(SANH), 석신이미딜 4-하이드라지도테레프탈레이트 하이드로클로라이드(SHTH) 및 석신이미딜 하이드라지늄 니코틴에이트 하이드로클로라이드(SHNH)를 포함한다. 산-불안정 결합을 보유하는 접합체는 또한 본 개시내용의 하이드라진-보유 벤조다이아제핀 유도체를 이용하여 제조될 수 있다. 사용될 수 있는 2작용성 가교제의 예는 석신이미딜-p-폼일 벤조에이트(SFB) 및 석신이미딜-p-폼일페녹시아세트산염(SFPA)을 포함한다.
이황화결합을 통해 세포독성 화합물과의 세포 결합제 결합을 가능하게 하는 2작용성 가교제는 당업계에 공지되어 있으며, 다이티오피리딜기를 도입하기 위해 N-석신이미딜-3-(2-피리딜다이티오)프로피오네이트(SPDP), N-석신이미딜-4-(2-피리딜다이티오)펜타노에이트(SPP), N-석신이미딜-4-(2-피리딜다이티오)부타노에이트(SPDB), N-석신이미딜-4-(2-피리딜다이티오)2-설포 부타노에이트(설포-SPDB)를 포함한다. 이황화기를 도입하기 위해 사용될 수 있는 다른 2작용성 가교제는 당업계에 공지되어 있으며, 미국 특허 제6,913,748호, 제6,716,821호 및 미국 특허 공개 제20090274713호 및 제20100129314호에 개시되어 있고, 이들 각각의 내용은 본 명세서에 전문이 참조에 의해 원용된다. 대안적으로, 티올기를 도입하는 가교제, 예컨대 2-이미노티올란, 호모시스테인 티올락톤 또는 S-아세틸석신산 무수물이 또한 사용될 수 있다.
특정 실시형태에서, 2작용성 링커는 이하에 기재하는 식 (a1L) 내지 (a10L) 중 임의의 하나로 표시된다.
세포독성제
A. 메이탄시노이드
특정 실시형태에서, 세포독성제는 메이탄시노이드 화합물, 예컨대 미국 특허 제5,208,020호 및 제7,276,497호에 기재된 것이고, 이들 각각의 내용은 이들의 전문이 본 명세서에 참조에 의해 원용된다. 특정 실시형태에서, 메이탄시노이드 화합물은 다음의 식으로 표시된다:

여기서, 변수는 상기 제1 실시형태 및 본 명세서에 기재된 임의의 더 많은 실시형태 중 제13 내지 제15의 구체적 실시형태 중 어느 하나에 상기 기재한 바와 같다.
더 구체적인 실시형태에서, 메이탄시노이드 화합물은 DM4이다:

다른 실시형태에서, 메이탄시노이드 화합물은 DM1이다:

B. 벤조다이아제핀
특정 실시형태에서, 세포독성제는 벤조다이아제핀 화합물, 예컨대 피롤로벤조다이아제핀(PBD)(예컨대 WO 2010/043880, WO 2011/130616, WO 2009/016516, WO 2013/177481 및 WO 2012/112708에 기재된 것) 및 인돌리노벤조다이아제핀(IGN) 화합물(예컨대 WO 2010/091150, 및 WO 2012/128868 및 미국 특허 제20170014522호에 기재된 것)이다. 이들 특허, 특허 간행물 및 특허출원의 전체 교시는 본 명세서에 참조에 의해 원용된다.
본 명세서에 사용된 바와 같이, "벤조다이아제핀" 화합물은 벤조다이아제핀 코어 구조를 갖는 화합물이다. 벤조다이아제핀 코어는 치환 또는 비치환되고/되거나 하나 이상의 고리 구조와 축합될 수 있다. 이는 또한 링커에 의해 연결되는 2개의 벤조다이아제핀 코어를 갖는 화합물을 포함한다. 벤조다이아제핀 코어의 부분으로서 이민 작용기(-C=N-)는 환원될 수 있다.
본 명세서에 사용된 바와 같은 "피롤로벤조다이아제핀"(PBD) 화합물은 피롤로벤조다이아제핀 코어 구조를 갖는 화합물이다. 피롤로벤조다이아제핀은 치환 또는 비치환될 수 있다. 이는 또한 링커에 의해 연결되는 2개의 피롤로벤조다이아제핀 코어를 갖는 화합물을 포함한다. 인돌리노벤조다이아제핀 코어의 부분으로서 이민 작용기(-C=N-)는 환원될 수 있다.
특정 실시형태에서, 세포독성제는 다음의 식으로 표시되는 인돌리노벤조다이아제핀 화합물이다:


또는 이의 약제학적으로 허용 가능한 염, 식 중: Lc'는 다음의 식으로 표시된다:
-NR5-P-C(=O)-(CRaRb)m-C(=O)E (B1); 또는
-NR5-P-C(=O)-(CRaRb)m-S-Zs (B2)
C(=O)E는 반응성 에스터기, 예컨대 N-하이드록시석신이미드 에스터, N-하이드록시 설포석신이미드 에스터, 나이트로페닐(예를 들어, 2 또는 4-나이트로페닐) 에스터, 다이나이트로페닐(예를 들어, 2,4- 다이나이트로페닐) 에스터, 설포-테트라플루오로페닐(예를 들어, 4-설포-2,3,5,6-테트라플루오로페닐) 에스터, 또는 펜타플루오로페닐 에스터, 바람직하게는 N-하이드록시석신이미드 에스터이고;

식 중:
q는 1 내지 5의 정수이며; 그리고
U는 -H 또는 SO3H 또는 이의 약제학적으로 허용 가능한 염이고; 그리고
여기서, 남아있는 변수는 상기 기재한 제1 실시형태 또는 본 명세서에 기재된 임의의 더 많은 실시형태 중 제1 내지 제12 및 제17의 구체적 실시형태 중 어느 하나에 기재한 바와 같다.
특정 실시형태에서, 세포독성제는 다음의 식으로 표시되는 인돌리노벤조다이아제핀 화합물이다:


또는 이의 약제학적으로 허용 가능한 염, 식 중:
- 화학식 (C1a'), (C1a'1), (C1b') 및 (C1b'1)에 대한 Lcc는 다음의 식으로 표시된다:

여기서, 변수는 상기 기재한 제2 실시형태 또는 본 명세서에 기재된 임의의 더 많은 실시형태 중 제1 내지 제9 및 제23의 구체적 실시형태 중 어느 하나에 상기 기재한 바와 같고; 그리고
화학식 (C2a"), (C2a"1), (C2b") 및 (C2b"1)에 대한 Lcc'는 다음의 식으로 표시된다:

여기서, 변수는 상기 기재한 제2 실시형태 또는 본 명세서에 기재된 임의의 더 많은 실시형태 중 제10 내지 제16 및 제23의 구체적 실시형태 중 어느 하나에 상기 기재한 바와 같다.
특정 실시형태에서, 세포독성제는 다음 중 어느 하나의 인돌리노벤조다이아제핀 화합물 또는 이의 약제학적으로 허용 가능한 염이다:




상기 나타낸 화합물 D1, sD1, D2, sD2, DGN462, sDGN462, D3 및 sD3은, 예를 들어, 미국 특허 제9,381,256호, 제8,765,740호, 제8,426,402호 및 제9,353,127호, 및 미국 특허 공개 제2016/0082114호에 기재된 바와 같은 당업계에 공지된 절차에 따라 제조될 수 있고, 이들 각각의 내용은 본 명세서에 전문이 참조에 의해 원용된다.
특정 실시형태에서, 상기 나타낸 화합물(예를 들어, sD1, sD2, sD4, sDGN462, sD3, sD4, sD5, sD5', sD6 또는 sD7)의 약제학적으로 허용 가능한 염은 나트륨 또는 칼륨염이다. 특정 실시형태에서, 약제학적으로 허용 가능한 염은 나트륨염이다.
구체적 실시형태에서, 세포독성제는 다음의 식으로 표시된다:

또는 이의 약제학적으로 허용 가능한 염. 구체적 실시형태에서, 약제학적으로 허용 가능한 염은 나트륨 또는 칼륨염이다.
다른 구체적 실시형태에서, 세포독성제는 다음의 식으로 표시된다:

예시적인 면역접합체
제1 실시형태에서, 면역접합체는 EpBA 상에 위치된 하나 이상의 라이신 잔기의 ε-아미노기를 통해 본 명세서에 개시된 세포독성제에 공유 결합되는 EpCAM-결합제(EpBA, 예를 들어, 본 명세서에 개시된 EpCAM 항체 또는 EpCAM-결합 항체 단편 또는 EpCAM 활성화 가능한 항체)를 포함한다.
제1 실시형태의 제1 구체적 실시형태에서, 면역접합체는 다음의 식으로 표시된다:

식 중:
라이신 잔기를 통해 CyL1에 공유 결합된 EpBA(예를 들어, 본 명세서에 개시된 EpCAM 항체 또는 EpCAM-결합 항체 단편 또는 EpCAM 활성화 가능한 항체);
WL은 1 내지 20의 정수이고; 그리고
CyL1은 다음의 식으로 표시되는 세포독성제이며:

또는 이의 약제학적으로 허용 가능한 염, 식 중:
N과 C 사이의 이중선 은 단일 결합 또는 이중 결합을 나타내며, 단, 이것이 이중 결합일 때, X는 존재하지 않으며, Y는 -H 또는 (C1-C4)알킬이고; 이것이 단일 결합일 때, X는 -H 또는 아민 보호 모이어티이며, Y는 -OH 또는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이고;
은 단일 결합 또는 이중 결합을 나타내며, 단, 이것이 이중 결합일 때, X는 존재하지 않으며, Y는 -H 또는 (C1-C4)알킬이고; 이것이 단일 결합일 때, X는 -H 또는 아민 보호 모이어티이며, Y는 -OH 또는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이고;
W'는 -NRe'이고,
Re'는 -(CH2-CH2-O)n-Rk이며;
n은 2 내지 6의 정수이고;
Rk는 -H 또는 -Me이며;
Rx3은 (C1-C6)알킬이고;
L'은 다음의 식으로 표시되며:

R5는 -H 또는 (C1-C3)알킬이고;
P는 아미노산 잔기 또는 2 내지 20개의 아미노산 잔기를 포함하는 펩타이드이며;
Ra 및 Rb는, 각각의 경우에 대해, 각각 독립적으로 -H, (C1-C3)알킬, 또는 하전된 치환체 또는 이온화 가능한 기 Q이고;
m은 1 내지 6의 정수이고; 그리고
Zs1은 하기 식 중 어느 하나로부터 선택되고:

식 중, q는 1 내지 5의 정수이다.
제2 구체적 실시형태에서, 화학식 (L1)의 접합체에 대해, CyL1은 화학식 (L1a) 또는 (L1a1)로 표시되며; 남아있는 변수는 제1 구체적 실시형태에서 상기 기재한 바와 같다.
제3 구체적 실시형태에서, 화학식 (L1)의 접합체에 대해, CyL1은 화학식 (L1b) 또는 (L1b1)로 표시되며; 남아있는 변수는 제1 구체적 실시형태에서 상기 기재한 바와 같다. 더 구체적으로는, Rx3은 (C2-C4)알킬이다.
제4 구체적 실시형태에서, 화학식 (L1)의 접합체에 대해, CyL1은 화학식 (L1a)로 표시되며; Ra와 Rb는 둘 다 H이고; R5는 H 또는 Me이며, 남아있는 변수는 제1 구체적 실시형태에서 상기 기재한 바와 같다.
제5 구체적 실시형태에서, P는 2 내지 5개의 아미노산 잔기를 포함하는 펩타이드이며; 남아있는 변수는 제1, 제2 또는 제4 구체적 실시형태에서 상기 기재한 바와 같다. 더 구체적인 실시형태에서, P는 하기로부터 선택된다: Gly-Gly-Gly, Ala-Val, Val-Ala, Val-Cit, Val-Lys, Phe-Lys, Lys-Lys, Ala-Lys, Phe-Cit, Leu-Cit, Ile-Cit, Trp, Cit, Phe-Ala, Phe-N9-토실-Arg, Phe-N9-나이트로-Arg, Phe-Phe-Lys, D-Phe-Phe-Lys, Gly-Phe-Lys, Leu-Ala-Leu, Ile-Ala- Leu, Val-Ala-Val, Ala-Leu-Ala-Leu(서열번호 215), β-Ala-Leu-Ala-Leu(서열번호 216), Gly-Phe-Leu-Gly(서열번호 217), Val-Arg, Arg-Val, Arg-Arg, Val-D-Cit, Val-D-Lys, Val-D-Arg, D-Val-Cit, D-Val-Lys, D-Val-Arg, D-Val-D-Cit, D-Val-D-Lys, D-Val-D-Arg, D-Arg-D-Arg, Ala-Ala, Ala-D-Ala, D-Ala-Ala, D-Ala-D-Ala, Ala-Met, Met-Ala, Gln-Val, Asn-Ala, Gln-Phe 및 Gln-Ala. 더 구체적으로는, P는 Gly-Gly-Gly, Ala-Val, Ala-Ala, Ala-D-Ala, D-Ala-Ala 또는 D-Ala-D-Ala이다.
제6 구체적 실시형태에서, Q는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이고; 남아있는 변수는 제1, 제2, 제4 또는 제5 구체적 실시형태, 또는 거기에 기재된 임의의 다른 실시형태에서 상기 기재된 바와 같다.
제7 구체적 실시형태에서, 제1 실시형태의 면역접합체는 다음의 식으로 표시된다:










또는 이의 약제학적으로 허용 가능한 염, 식 중, WL은 1 내지 10의 정수이고; N과 C 사이의 이중선  은 단일 결합 또는 이중 결합을 나타내며, 단, 이것이 이중 결합일 때, X는 존재하지 않고, Y는 -H이며; 이것이 단일 결합일 때, X는 -H이며, Y는 -OH 또는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이다. 더 구체적인 실시형태에서, N과 C 사이의 이중선
은 단일 결합 또는 이중 결합을 나타내며, 단, 이것이 이중 결합일 때, X는 존재하지 않고, Y는 -H이며; 이것이 단일 결합일 때, X는 -H이며, Y는 -OH 또는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이다. 더 구체적인 실시형태에서, N과 C 사이의 이중선  은 이중 결합을 표시하고, X는 존재하지 않으며, Y는 -H이다. 다른 더 구체적인 실시형태에서, N과 C 사이의 이중선
은 이중 결합을 표시하고, X는 존재하지 않으며, Y는 -H이다. 다른 더 구체적인 실시형태에서, N과 C 사이의 이중선  은 단일 결합을 나타내고, X는 -H이며, Y는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이다.
은 단일 결합을 나타내고, X는 -H이며, Y는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이다.
일부 실시형태에서, 제1 내지 제7 구체적 실시형태의 EpBA는 본 명세서에 개시된 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 포함한다. 일부 실시형태에서, 제1 내지 제7 구체적 실시형태의 EpBA는 X1YX3X4H를 포함하는 VH-CDR1(여기서, X1은 N 및 S로부터 선택되며, X3은 Y, N, F, S, H, D, L, I 및 W로부터 선택되고, X4는 I 및 M으로부터 선택됨)(서열번호 5); WX2X3PGX6VYIQYX12X13KFX17G를 포함하는 VH-CDR2(여기서, X2는 I 및 F로부터 선택되며, X3은 Y 및 N으로부터 선택되고, X6은 N 및 D로부터 선택되며, X12는 N 및 S로부터 선택되고, X13은 E 및 Q로부터 선택되며, X17은 K 및 Q로부터 선택됨(서열번호 7); 및 X1GX3X4FAY를 포함하는 VH-CDR3(여기서, X1은 D 및 E로부터 선택되고, X3은 P, A, S, Y, F, G, T 및 V로부터 선택되며, X4는 Y 및 W로부터 선택됨)(서열번호 8)을 포함한다. 일부 실시형태에서, 제1 내지 제7 구체적 실시형태의 EpBA는 RSSX4SLLHSX10G X12TYLX16을 포함하는 VL-CDR1(여기서, X4는 R 및 K로부터 선택되고, X10은 N 및 D로부터 선택되며, X12는 F 및 I로부터 선택되고, X16은 Y 및 S로부터 선택됨)(서열번호 10); QTSNLAS를 포함하는 경쇄 VL-CDR2(서열번호 40); 및 X1QX3LELPX8T를 포함하는 VL-CDR3(여기서, X1은 A, L 및 Q로부터 선택되고, X3은 S, G, Y 및 N으로부터 선택되고, X8은 N 및 W로부터 선택됨)(서열번호 11)을 포함한다.
일부 실시형태에서, EpBA의 VH-CDR1은 서열 NYX3IH을 포함하되, X3은 Y, N, F, S, H, D, L, I 및 W로부터 선택된다(서열번호 6). 일부 실시형태에서, EpBA의 VH-CDR3은 서열 DGPX4FAY를 포함하되, X4는 Y 및 W로부터 선택된다(서열번호 9). 일부 실시형태에서, EpBA의 VL-CDR3은 서열 AQX3LELPNT를 포함하되, X3은 S, G, Y 및 N으로부터 선택된다(서열번호 12).
일부 실시형태에서, 제1 내지 제7 구체적 실시형태의 EpBA는 각각 서열번호 13 내지 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 포함한다. 일부 실시형태에서, 제1 내지 제7 구체적 실시형태의 EpBA는 서열번호 54의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함하는 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 포함한다. 일부 실시형태에서, 제1 내지 제7 구체적 실시형태의 EpBA는 서열번호 103의 서열을 갖는 HC 및 서열번호 140의 서열을 갖는 LC를 포함하는 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 포함한다.
일부 실시형태에서, 제1 내지 제7 구체적 실시형태의 EpBA는 서열번호 155의 MM을 포함하는 EpCAM 활성화 가능한 항체를 포함한다. 일부 실시형태에서, 제1 내지 제7 구체적 실시형태의 EpBA는 서열번호 168의 CM을 포함하는 EpCAM 활성화 가능한 항체를 포함한다. 대안의 실시형태에서, 제1 내지 제7 구체적 실시형태의 EpBA는 서열번호 169의 CM을 포함하는 EpCAM 활성화 가능한 항체를 포함한다. 일 실시형태에서, 제1 내지 제7 구체적 실시형태의 EpBA는 서열번호 103의 서열을 갖는 중쇄 및 서열번호 174의 서열을 갖는 경쇄를 포함하는 EpCAM 활성화 가능한 항체를 포함한다. 일 실시형태에서, 제1 내지 제7 구체적 실시형태의 EpBA는 서열번호 103의 서열을 갖는 중쇄 및 서열번호 179의 서열을 갖는 경쇄를 포함하는 EpCAM 활성화 가능한 항체를 포함한다.
제8 구체적 실시형태에서, 제1 실시형태의 면역접합체는 다음의 식으로 표시된다:

식 중:
EpBA는 Lys 잔기를 통해 CyL2에 공유 결합된 본 명세서에 개시된 EpCAM-결합제(예를 들어, EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체)이며;
WL은 1 내지 20의 정수이고; 그리고
CyL2는 다음의 식으로 표시된다:

제9 구체적 실시형태에서, 제1 실시형태의 면역접합체는 다음의 식으로 표시된다:

식 중:
EpBA는 Lys 잔기를 통해 CyL2에 공유 결합된 본 명세서에 개시된 EpCAM-결합제(예를 들어, EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체)이며;
WL은 1 내지 20의 정수이고; 그리고
CyL2는 다음의 식으로 표시되며:

m'는 1 또는 2이고;
R1 및 R2는, 각각 독립적으로 H 또는 (C1-C3)알킬이며; Zs1은 하기 식 중 어느 하나로부터 선택되고:
Zs1은 하기 식 중 어느 하나로부터 선택된다:

식 중, q는 1 내지 5의 정수이다.
제10 구체적 실시형태에서, 화학식 (L2)의 면역접합체에 대해, m'는 1이고, R1 및 R2는 둘 다 H이며; 남아있는 변수는 제13 구체적 실시형태에서 상기 기재한 바와 같다.
제11 구체적 실시형태에서, 화학식 (L2)의 면역접합체에 대해, m'는 2이고, R1 및 R2는 둘 다 Me이며; 남아있는 변수는 제13 구체적 실시형태에서 상기 기재한 바와 같다.
제12 구체적 실시형태에서, 제1 실시형태의 면역접합체는 다음의 식으로 표시된다:

또는 이의 약제학적으로 허용 가능한 염, 식 중 WL은 1 내지 10의 정수이다.
제12 구체적 실시형태에서, 제1 실시형태의 면역접합체에 대해, Y는 -SO3H, -SO3Na 또는 -SO3K이며; 남아있는 변수는 제1 내지 제16 구체적 실시형태 또는 그에 기재된 임의의 구체적 실시형태 중 어느 하나에 상기 기재된 바와 같다. 일 실시형태에서, Y는 -SO3Na이다.
일부 실시형태에서, 제8 내지 제12 구체적 실시형태의 EpBA는 본 명세서에 개시된 EpCAM 항체, EpCAM-결합 항체 단편 또는 EpCAM 활성화 가능한 항체를 포함한다. 일부 실시형태에서, 제8 내지 제12 구체적 실시형태의 EpBA는 X1YX3X4H를 포함하는 VH-CDR1(여기서, X1은 N 및 S로부터 선택되며, X3은 Y, N, F, S, H, D, L, I 및 W로부터 선택되고, X4는 I 및 M으로부터 선택됨)(서열번호 5); WX2X3PGX6VYIQYX12X13KFX17G를 포함하는 VH-CDR2(여기서, X2는 I 및 F로부터 선택되며, X3은 Y 및 N으로부터 선택되고, X6은 N 및 D로부터 선택되며, X12는 N 및 S로부터 선택되고, X13은 E 및 Q로부터 선택되며, X17은 K 및 Q로부터 선택됨(서열번호 7); 및 X1GX3X4FAY를 포함하는 VH-CDR3(여기서, X1은 D 및 E로부터 선택되고, X3은 P, A, S, Y, F, G, T 및 V로부터 선택되며, X4는 Y 및 W로부터 선택됨)(서열번호 8)을 포함한다. 일부 실시형태에서, 제8 내지 제12 구체적 실시형태의 EpBA는 RSSX4SLLHSX10GX12TYLX16을 포함하는 경쇄 CDR1(VL-CDR1)(여기서, X4는 R 및 K로부터 선택되고, X10은 N 및 D로부터 선택되며, X12는 F 및 I로부터 선택되고, X16은 Y 및 S로부터 선택됨)(서열번호 10); QTSNLAS를 포함하는 경쇄 VL-CDR2(서열번호 40); 및 X1QX3LELPX8T를 포함하는 VL-CDR3(여기서, X1은 A, L 및 Q로부터 선택되고, X3은 S, G, Y 및 N으로부터 선택되고, X8은 N 및 W로부터 선택됨)(서열번호 11)을 포함한다.
일부 실시형태에서, EpBA의 VH-CDR1은 서열 NYX3IH을 포함하되, X3은 Y, N, F, S, H, D, L, I 및 W로부터 선택된다(서열번호 6). 일부 실시형태에서, EpBA의 VH-CDR3은 서열 DGPX4FAY를 포함하되, X4는 Y 및 W로부터 선택된다(서열번호 9). 일부 실시형태에서, EpBA의 VL-CDR3은 서열 AQX3LELPNT를 포함하되, X3은 S, G, Y 및 N으로부터 선택된다(서열번호 12).
일부 실시형태에서, 제8 내지 제12 구체적 실시형태의 EpBA는 각각 서열번호 13 내지 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 포함한다. 일부 실시형태에서, 제8 내지 제12 구체적 실시형태의 EpBA는 서열번호 54의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함하는 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 포함한다. 일부 실시형태에서, 제8 내지 제12 구체적 실시형태의 EpBA는 서열번호 103의 서열을 갖는 HC 및 서열번호 140의 서열을 갖는 LC를 포함하는 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 포함한다.
일부 실시형태에서, 제8 내지 제12 구체적 실시형태의 EpBA는 서열번호 155의 MM을 포함하는 EpCAM 활성화 가능한 항체를 포함한다. 일부 실시형태에서, 제8 내지 제12 구체적 실시형태의 EpBA는 서열번호 168의 CM을 포함하는 EpCAM 활성화 가능한 항체를 포함한다. 대안의 실시형태에서, 제8 내지 제12 구체적 실시형태의 EpBA는 서열번호 169의 CM을 포함하는 EpCAM 활성화 가능한 항체를 포함한다. 일 실시형태에서, 제8 내지 제12 구체적 실시형태의 EpBA는 서열번호 103의 서열을 갖는 중쇄 및 서열번호 174의 서열을 갖는 경쇄를 포함하는 EpCAM 활성화 가능한 항체를 포함한다. 일 실시형태에서, 제8 내지 제12 구체적 실시형태의 EpBA는 서열번호 103의 서열을 갖는 중쇄 및 서열번호 179의 서열을 갖는 경쇄를 포함하는 EpCAM 활성화 가능한 항체를 포함한다.
특정 실시형태에서, 제1 실시형태, 또는 제1, 제2, 제3, 제4, 제5, 제6, 제7, 제8, 제9, 제10, 제11 또는 제12 구체적 실시형태의 면역접합체를 포함하는 조성물(예를 들어, 약제학적 조성물)에 대해, 조성물 중의 약물-항체비(DAR)로도 알려진 항체 분자당 세포독성제의 평균 수(즉, wL의 평균값)는 1.0 내지 8.0의 범위이다. 일부 실시형태에서, DAR은 1.0 내지 5.0, 1.0 내지 4.0, 1.0 내지 3.4, 1.0 내지 3.0, 1.5 내지 2.5, 2.0 내지 2.5, 또는 1.8 내지 2.2 범위이다. 일부 실시형태에서, DAR은 4.0 미만, 3.8 미만, 3.6 미만, 3.5 미만, 3.0 또는 2.5 미만이다.
제2 실시형태에서, 면역접합체는 EpBA 상에 위치된 하나 이상의 시스테인 잔기의 티올기(-SH)를 통해 본 명세서에 개시된 세포독성제에 공유 결합된 EpBA를 포함한다.
제1 구체적 실시형태에서, 제2 실시형태의 면역접합체는 다음의 식으로 표시된다:

식 중:
EpBA는 시스테인 잔기를 통해 Cyc1에 공유 결합된 본 명세서에 개시된 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체이고;
Wc는 1 또는 2이고
Cyc1은 다음의 식으로 표시된다:

또는 이의 약제학적으로 허용 가능한 염, 식 중:
N과 C 사이의 이중선  은 단일 결합 또는 이중 결합을 나타내며, 단,
은 단일 결합 또는 이중 결합을 나타내며, 단,
이것이 이중 결합일 때, X는 존재하지 않으며, Y는 -H 또는 (C1-C4)알킬이고; 이것이 단일 결합일 때, X는 -H 또는 아민 보호 모이어티이며, Y는 -OH 또는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이고;
R5는 -H 또는 (C1-C3)알킬이고;
P는 아미노산 잔기 또는 2 내지 20개의 아미노산 잔기를 포함하는 펩타이드이며;
Ra 및 Rb는, 각각의 경우에 대해, 독립적으로 -H, (C1-C3)알킬, 또는 하전된 치환체 또는 이온화 가능한 기 Q이고;
m은 1 내지 6의 정수이고;
W'는 -NRe'이고,
Re'는 -(CH2-CH2-O)n-Rk이며;
n은 2 내지 6의 정수이고;
Rk는 -H 또는 -Me이며;
Rx3은 (C1-C6)알킬이고; 그리고
LC는 다음의 식으로 표시되고:

식 중, s1은 EpBA에 공유 결합된 부위이고, s2는 CyC1 상의 -C(=O)- 기에 공유 결합된 부위이며;
R19 및 R20은 각각의 경우에 대해, 독립적으로 -H 또는 (C1-C3)알킬이고;
m"는 1 내지 10의 정수이고; 그리고
Rh는 -H 또는 (C1-C3)알킬이다.
제2 구체적 실시형태에서, 화학식 (C1)의 면역접합체에 대해, CyC1은 화학식 (C1a) 또는 (C1a1)로 표시되고; 남아있는 변수는 제2 실시형태의 제1 구체적 실시형태에서 상기 기재한 바와 같다.
제3 구체적 실시형태에서, 화학식 (C1)의 면역접합체에 대해, CyC1은 화학식 (C1b) 또는 (C1b1)로 표시되고; 남아있는 변수는 제2 실시형태의 제1 구체적 실시형태에서 상기 기재한 바와 같다.
제4 구체적 실시형태에서, 화학식 (C1)의 면역접합체에 대해, CyC1은 화학식 (C1a) 또는 (C1a1)로 표시되고; Ra 및 Rb는 둘 다 H이며; R5는 H 또는 Me이며; 남아있는 변수는 제2 실시형태의 제1 또는 제2 구체적 실시형태에서 상기 기재한 바와 같다.
제5 구체적 실시형태에서, 화학식 (C1)의 면역접합체에 대해, P는 2 내지 5개의 아미노산 잔기를 포함하는 펩타이드이며; 남아있는 변수는 제2 실시형태의 제1, 제2 또는 제4 구체적 실시형태에서 상기 기재한 바와 같다. 더 구체적인 실시형태에서, P는 Gly-Gly-Gly, Ala-Val, Val-Ala, Val-Cit, Val-Lys, Phe-Lys, Lys-Lys, Ala-Lys, Phe-Cit, Leu-Cit, Ile-Cit, Trp, Cit, Phe-Ala, Phe-N9-토실-Arg, Phe-N9- 나이트로-Arg, Phe-Phe-Lys, D-Phe-Phe-Lys, Gly-Phe-Lys, Leu-Ala-Leu, Ile-Ala-Leu, Val-Ala-Val, Ala-Leu-Ala-Leu(서열번호 215), β-Ala-Leu-Ala-Leu(서열번호 216), Gly-Phe- Leu-Gly(서열번호 217), Val-Arg, Arg-Val, Arg-Arg, Val-D-Cit, Val-D-Lys, Val-D-Arg, D-Val-Cit, D-Val-Lys, D-Val-Arg, D-Val-D-Cit, D-Val-D-Lys, D-Val-D-Arg, D-Arg-D-Arg, Ala-Ala, Ala-D-Ala, D-Ala-Ala, D-Ala-D-Ala, Ala-Met, Met-Ala, Gln-Val, Asn-Ala, Gln-Phe 및 Gln-Ala로부터 선택된다. 다른 더 구체적인 실시형태에서, P는 Gly-Gly-Gly, Ala-Val, Ala-Ala, Ala-D-Ala, D-Ala-Ala, 또는 D-Ala-D-Ala이다.
제6 구체적 실시형태에서, 화학식 (C1)의 면역접합체에 대해, Q는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이고; 남아있는 변수는 제2 실시형태 또는 거기에 기재된 임의의 더 구체적인 실시형태의 제1, 제2, 제4 또는 제5 구체적 실시형태에서 상기 기재한 바와 같다.
제7 구체적 실시형태에서, 화학식 (C1)의 면역접합체에 대해, R19 및 R20은 둘 다 H이고; m"는 1 내지 6의 정수이고; 남아있는 변수는 제2 실시형태 또는 거기에 기재된 임의의 더 구체적인 실시형태의 제1, 제2, 제3, 제4, 제5 또는 제6 구체적 실시형태에서 상기 기재한 바와 같다.
제8 구체적 실시형태에서, 화학식 (C1)의 면역접합체에 대해, -L-LC-는 다음의 식으로 표시된다:

남아있는 변수는 제2 실시형태 또는 거기에 기재된 임의의 더 구체적인 실시형태의 제1, 제2, 제3, 제4, 제5, 제6 또는 제7 구체적 실시형태에서 상기 기재한 바와 같다.
제9 구체적 실시형태에서, 제2 실시형태의 면역접합체는 다음의 식으로 표시된다:


또는 이의 약제학적으로 허용 가능한 염, 식 중, N과 C 사이의 이중선  은 단일 결합 또는 이중 결합을 나타내며, 단, 이것이 이중 결합일 때, X는 존재하지 않고, Y는 -H이며; 이것이 단일 결합일 때, X는 -H이며, Y는 -OH 또는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이다. 더 구체적인 실시형태에서, N과 C 사이의 이중선
은 단일 결합 또는 이중 결합을 나타내며, 단, 이것이 이중 결합일 때, X는 존재하지 않고, Y는 -H이며; 이것이 단일 결합일 때, X는 -H이며, Y는 -OH 또는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이다. 더 구체적인 실시형태에서, N과 C 사이의 이중선  은 이중 결합을 표시하고, X는 존재하지 않으며, Y는 -H이다. 다른 더 구체적인 실시형태에서, N과 C 사이의 이중선
은 이중 결합을 표시하고, X는 존재하지 않으며, Y는 -H이다. 다른 더 구체적인 실시형태에서, N과 C 사이의 이중선  은 단일 결합을 나타내고, X는 -H이며, Y는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이다.
은 단일 결합을 나타내고, X는 -H이며, Y는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이다.
제3 구체적 실시형태에서, 본 발명의 면역접합체는 다음의 식으로 표시된다:

또는 이의 약제학적으로 허용 가능한 염, 식 중:

m1, m3, n1, r1 s1 및 t1은 각각 독립적으로 1 내지 6의 정수이고; m2, n2, r2, s2 및 t2는 각각 독립적으로 1 내지 7의 정수이며;
t3은 1 내지 12의 정수이고;
D1은 다음의 식으로 표시되며:

q는 1 내지 20의 정수이고. 더 구체적인 실시형태에서, D1은 다음의 식으로 표시된다:

제3 실시형태의 제1 구체적 실시형태에서, 본 발명의 면역접합체는 다음의 식으로 표시된다:

식 중:
m1 및 m3은 각각 독립적으로 2 내지 4의 정수이고;
m2는 2 내지 5의 정수이며;
r1은 2 내지 6의 정수이고;
r2는 2 내지 5의 정수이고; 그리고
남아있는 변수는 제3 실시형태에 기재된 바와 같다.
제2 구체적 실시형태에서, 제3 구체적 실시형태 및 제1 구체적 실시형태에 기재된 면역접합체에 대해, A는 Ala-Ala-Ala, Ala-D-Ala-Ala, Ala-Ala, D-Ala- Ala, Val-Ala, D-Val-Ala, D-Ala-Pro, 또는 D-Ala-tBu-Gly이다. 더 구체적인 실시형태에서, 제3 실시형태 및 제1 실시형태에 기재된 면역접합체에 대해, A는 L-Ala-D-Ala-L-Ala이다.
제3 구체적 실시형태에서, 본 발명의 면역접합체는 다음의 식으로 표시된다:









또는 이의 약제학적으로 허용 가능한 염, 식 중:
A는 Ala-Ala-Ala, Ala-D-Ala-Ala, Ala-Ala, D-Ala-Ala, Val-Ala, D-Val-Ala, D-Ala-Pro, 또는 D-Ala-tBu-Gly이고, 그리고
D1은 다음의 식으로 표시되며:

남아있는 변수는 제3 실시형태 및 이의 제1 및 제2 구체적 실시형태에 기재된 바와 같다. 더 구체적인 실시형태에서, A는 L-Ala-D-Ala-L-Ala이다. 더 구체적인 실시형태에서, D1은 다음의 식으로 표시된다:

제4 구체적 실시형태에서, 본 발명의 면역접합체는 다음의 식으로 표시된다:


D1은 다음의 식으로 표시된다:

제5 구체적 실시형태에서, 본 발명의 면역접합체는 다음의 식으로 표시된다:

식 중:
CBA는 EpBA이고;
q는 1 또는 2이며;
D1은 다음의 식으로 표시된다:

제6 구체적 실시형태에서, 본 발명의 면역접합체는 다음의 식으로 표시된다:

식 중:
CBA는 EpBA이며;
q는 1 내지 10의 정수이고;
D1은 다음의 식으로 표시된다:

다른 구체적 실시형태에서, 본 개시내용은 γ-말레이미도뷰티르산 N-석신이미딜 에스터(GMBS) 또는 N-(γ-말레이미도뷰틸옥시)설포석신이미드 에스터(설포-GMBS 또는 sGMBS) 링커를 통해 하기 식으로 표시되는 메이탄시노이드 화합물 DM21L(LDL-DM으로도 지칭됨)에 결합된 EpBA(예를 들어, EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체)를 포함하는 EpBA 면역접합체를 제공한다:

GMBS 및 설포-GMBS(또는 sGMBS) 링커는 당업계에 공지되어 있고, 다음의 구조식으로 제시될 수 있다:

일 실시형태에서, 면역접합체는 다음의 식으로 표시된다:

식 중:
EpBA는 Lys 아민기를 통해 메이탄시노이드 화합물에 결합된 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체이되, q는 1 내지 10의 정수이다.
일부 실시형태에서, EpBA-DM21L 접합체의 EpBA는 본 명세서에 개시된 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 포함한다. 일부 실시형태에서, EpBA-DM21L 접합체의 EpBA는 X1YX3X4H를 포함하는 VH-CDR1(여기서, X1은 N 및 S로부터 선택되며, X3은 Y, N, F, S, H, D, L, I 및 W로부터 선택되고, X4는 I 및 M으로부터 선택됨)(서열번호 5); WX2X3PGX6VYIQYX12X13KFX17G를 포함하는 VH-CDR2(여기서, X2는 I 및 F로부터 선택되며, X3은 Y 및 N으로부터 선택되고, X6은 N 및 D로부터 선택되며, X12는 N 및 S로부터 선택되고, X13은 E 및 Q로부터 선택되며, X17은 K 및 Q로부터 선택됨(서열번호 7); 및 X1GX3X4FAY를 포함하는 VH-CDR3(여기서, X1은 D 및 E로부터 선택되고, X3은 P, A, S, Y, F, G, T 및 V로부터 선택되며, X4는 Y 및 W로부터 선택됨)(서열번호 8)을 포함한다.
일부 실시형태에서, EpBA-DM21L 접합체의 EpBA는 RSSX4SLLHSX10GX12TYLX16을 포함하는 경쇄 CDR1(VL-CDR1)(여기서, X4는 R 및 K로부터 선택되고, X10은 N 및 D로부터 선택되며, X12는 F 및 I로부터 선택되고, X16은 Y 및 S로부터 선택됨)(서열번호 10); QTSNLAS를 포함하는 경쇄 VL-CDR2(서열번호 40); 및 X1QX3LELPX8T를 포함하는 VL-CDR3(여기서, X1은 A, L 및 Q로부터 선택되고, X3은 S, G, Y 및 N으로부터 선택되고, X8은 N 및 W로부터 선택됨)(서열번호 11)을 포함한다.
일부 실시형태에서, EpBA의 VH-CDR1은 서열 NYX3IH을 포함하되, X3은 Y, N, F, S, H, D, L, I 및 W로부터 선택된다(서열번호 6). 일부 실시형태에서, EpBA의 VH-CDR3은 서열 DGPX4FAY를 포함하되, X4는 Y 및 W로부터 선택된다(서열번호 9). 일부 실시형태에서, EpBA의 VL-CDR3은 서열 AQX3LELPNT를 포함하되, X3은 S, G, Y 및 N으로부터 선택된다(서열번호 12).
일부 실시형태에서, EpBA-DM21L 접합체의 EpBA는 각각 서열번호 13 내지 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 포함한다. 일부 실시형태에서, EpBA-DM21L 접합체의 EpBA는 서열번호 54의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함하는 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 포함한다. 일부 실시형태에서, EpBA-DM21L 접합체의 EpBA는 서열번호 103의 서열을 갖는 HC 및 서열번호 140의 서열을 갖는 LC를 포함하는 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 포함한다.
일부 실시형태에서, EpBA-DM21L 접합체의 EpBA는 서열번호 155의 MM을 포함하는 EpCAM 활성화 가능한 항체를 포함한다. 일부 실시형태에서, EpBA-DM21L 접합체의 EpBA는 서열번호 168의 CM을 포함하는 EpCAM 활성화 가능한 항체를 포함한다. 대안의 실시형태에서, EpBA-DM21L 접합체의 EpBA는 서열번호 169의 CM을 포함하는 EpCAM 활성화 가능한 항체를 포함한다. 일 실시형태에서, EpBA-DM21L 접합체의 EpBA는 서열번호 103의 서열을 갖는 중쇄 및 서열번호 174의 서열을 갖는 경쇄를 포함하는 EpCAM 활성화 가능한 항체를 포함한다. 일 실시형태에서, EpBA-DM21L 접합체의 EpBA는 서열번호 103의 서열을 갖는 중쇄 및 서열번호 179의 서열을 갖는 경쇄를 포함하는 EpCAM 활성화 가능한 항체를 포함한다.
특정 실시형태에서, EpBA-LDL-DM 면역접합체를 포함하는 조성물(예를 들어, 약제학적 조성물)에 대해, 약물-항체비(DAR)로 알려진 항체 분자당 세포독성제의 평균 수(즉, 평균 값 q)인 DAR은 3.0 내지 4.0, 3.2 내지 3.8, 또는 3.4 내지 3.7의 범위이다. 일부 실시형태에서, DAR은 3.2, 3.3, 3.4, 3.5, 3.5, 3.7 또는 3.8이다.
면역접합체의 제조 방법
상기 제1 실시형태 또는 그에 기재된 임의의 구체적 실시형태에 기재된 바와 같이 EpBA 상에 위치된 하나 이상의 라이신 잔기의 s-아미노기를 통해 세포독성제에 공유 결합된 EpCAM-결합제(EpBA, 예를 들어, EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체)를 포함하는 면역접합체는 당업계에 공지된 임의의 방법에 따라 제조될 수 있고, 예를 들어, WO 2012/128868 및 WO 2012/112687을 참조하며, 이들 각각의 전체 내용은 본 명세서에 전문이 참조에 의해 원용된다.
특정 실시형태에서, 제1 실시형태의 면역접합체는 EpBA(예를 들어, 본 명세서에 개시된 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체)를 아민 반응기를 갖는 세포독성제와 반응시키는 단계를 포함하는 제1 방법에 의해 제조된다.
일 실시형태에서, 상기 기재한 제1 방법에 대해, 반응은 이민 반응성 시약, 예컨대, NaHSO3의 존재 하에 수행된다.
일 실시형태에서, 상기 기재한 제1 방법에 대해, 아민 반응기를 갖는 세포독성제는 다음의 식으로 표시된다:

또는 이의 약제학적으로 허용 가능한 염, 식 중, 변수에 대한 정의는 화학식 (L1a'), (L1a'1), (L1b') 및 (L1b'1)에 대해 상기 기재되어 있다.
특정 실시형태에서, 제1 실시형태의 면역접합체는 다음의 단계들을 포함하는 제2 방법에 의해 제조된다:
(a) 세포독성제를 아민 반응기 및 티올 반응기를 갖는 링커 화합물과 반응시켜 이에 결합된 아민 반응기를 갖는 세포독성제-링커 화합물을 형성하는 단계; 및
(b) EpBA를 세포독성제-링커 화합물과 반응시키는 단계.
일 실시형태에서, 단계 (a)의 반응은 이민 반응성 시약(예를 들어, NaHSO3)의 존재 하에 수행된다. 일 실시형태에서, 세포독성제-링커 화합물은 정제 없이 EpBA와 반응된다. 대안적으로, 세포독성제-링커 화합물은 EpBA와 반응하기 전에 우선 정제된다.
특정 실시형태에서, 제1 실시형태의 면역접합체는 다음의 단계들을 포함하는 제3 방법에 의해 제조된다:
(a) EpBA를 아민 반응기 및 티올 반응기를 갖는 링커 화합물과 반응시켜 이에 결합된 티올 반응기를 갖는 변형된 EpBA를 형성하는 단계; 및
(b) 변형된 EpBA를 세포독성제와 반응시키는 단계.
일 실시형태에서, 단계 (b)의 반응은 이민 반응성 시약(예를 들어, NaHSO3)의 존재 하에 수행된다.
특정 실시형태에서, 제1 실시형태는 EpBA, 세포독성 화합물 및 아민 반응기 및 티올 반응기를 갖는 링커 화합물을 반응시키는 단계를 포함하는 제4 방법에 의해 제조된다.
일 실시형태에서, 반응은 이민 반응제(예를 들어, NaHSO3)의 존재 하에 수행된다.
특정 실시형태에서, 상기 기재한 제2, 제3 또는 제4 방법에 대해, 아민 반응기 및 티올 반응기를 갖는 링커 화합물은 다음의 식으로 표시된다:

식 중, X는 할로겐; JD -SH, -SSRd, 또는 -SC(=O)Rg이고; Rd는 페닐, 나이트로페닐, 다이나이트로페닐, 카복시나이트로페닐, 피리딜 또는 나이트로피리딜이며; Rg는 알킬이고; 남아있는 변수는 화학식 (a1) 내지 (a10)에 대해 상기 기재한 바와 같고; 세포독성제는 다음의 식으로 표시된다:

또는 이의 약제학적으로 허용 가능한 염, 식 중, 변수에 대한 정의는 화학식 (L1a'), (L1a'1), (L1b'), (L1b'1), (L2a'), (L2a'1), (L2b') 및 (L2b'1)에 대해 상기 기재되어 있다.
특정 실시형태에서, 상기 기재한 제2, 제3 또는 제4 방법에 대해, 아민 반응기 및 티올 반응기를 갖는 링커 화합물은 화학식 (a1L) 내지 (a10L) 중 어느 하나로 표시되고, 세포독성제는 다음의 식으로 표시된다:

여기서, 변수는 상기 기재된 제1 실시형태 및 본 명세서에 기재된 임의의 더 많은 실시형태 중 제13 내지 제15의 구체적 실시형태 중 어느 하나에 상기 기재한 바와 같다.
구체적 실시형태에서, 상기 기재한 제2, 제3 또는 제4 방법에 대해, 링커는 설포-SPDB이고, 세포독성제는 DM4이며, 면역접합체는 다음의 식으로 표시된다:

이의 약제학적으로 허용 가능한 염, 식 중 WL은 1 내지 10의 정수이다.
상기 제2 실시형태에 기재된 바와 같은 EpCAM-결합제 상에 위치된 하나 이상의 시스테인의 티올기(-SH)를 통해 세포독성제에 공유 결합된 EpCAM-결합제를 포함하는 면역접합체(예를 들어, 본 명세서에 기재된 제1 내지 제23 구체적 실시형태 중 어느 하나, 또는 그 이상의 구체적 실시형태의 면역접합체)는 하나 이상의 유리 시스테인을 갖는 EpBA를 본 명세서에 개시된 티올-반응기를 갖는 세포독성제와 반응시킴으로써 제조될 수 있다.
일 실시형태에서, 티올-반응기를 갖는 세포독성제는 다음의 식으로 표시된다:


또는 이의 약제학적으로 허용 가능한 염, 식 중, -Lcc는 다음의 식으로 표시된다:

여기서, 변수는 상기 기재한 제2 실시형태 또는 본 명세서에 기재된 임의의 더 많은 실시형태 중 제1 내지 제9 및 제23의 구체적 실시형태 중 어느 하나에 상기 기재한 바와 같다.
다른 실시형태에서, 티올-반응기를 갖는 세포독성제는 다음의 식으로 표시된다:

또는 이의 약제학적으로 허용 가능한 염, 식 중, -Lcc'는 다음의 식으로 표시된다:

여기서, 변수는 상기 기재한 제2 실시형태 또는 본 명세서에 기재된 임의의 더 많은 실시형태 중 제10 내지 제16 및 제23의 구체적 실시형태 중 어느 하나에 상기 기재한 바와 같다. 또 다른 실시형태에서, 티올-반응기를 갖는 세포독성제는 다음의 식으로 표시된다:

또는 이의 약제학적으로 허용 가능한 염, 식 중, LCc'는 상기 기재되어 있고, 남아있는 변수는 상기 기재한 제2 실시형태 또는 본 명세서에 기재된 임의의 더 많은 실시형태 중 제17 내지 제23의 구체적 실시형태 중 어느 하나에 상기 기재한 바와 같다.
특정 실시형태에서, 유기 용매는 세포독성제를 가용화하기 위해 EpBA와 세포독성제의 반응에서 사용된다. 예시적인 유기 용매는 다이메틸아세트아마이드(DMA), 프로필렌 글리콜 등을 포함하지만, 이들로 제한되지 않는다. 일 실시형태에서, EpBA와 세포독성제의 반응은 DMA 및 프로필렌 글리콜의 존재 하에 수행된다.
구체적 실시형태에서, 세포독성제는 다음의 식으로 표시된다:

또는 이의 약제학적으로 허용 가능한 염은 EpBA(예를 들어, 본 명세서에 개시된 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체)와 반응되어 다음의 식으로 표시되는 면역접합체를 형성한다:

또는 이의 약제학적으로 허용 가능한 염, 식 중:
식 중, N과 C 사이의 이중선  은 단일 결합 또는 이중 결합을 나타내며, 단, 이것이 이중 결합일 때, X는 존재하지 않고, Y는 -H이며; 이것이 단일 결합일 때, X는 -H이며, Y는 -SO3H 또는 이의 약제학적으로 허용 가능한 염; 그리고 WC는 1 또는 2이다. 더 구체적인 실시형태에서, N과 C 사이의 이중선
은 단일 결합 또는 이중 결합을 나타내며, 단, 이것이 이중 결합일 때, X는 존재하지 않고, Y는 -H이며; 이것이 단일 결합일 때, X는 -H이며, Y는 -SO3H 또는 이의 약제학적으로 허용 가능한 염; 그리고 WC는 1 또는 2이다. 더 구체적인 실시형태에서, N과 C 사이의 이중선  은 이중 결합을 표시하고, X는 존재하지 않으며, Y는 -H이다. 다른 더 구체적인 실시형태에서, N과 C 사이의 이중선
은 이중 결합을 표시하고, X는 존재하지 않으며, Y는 -H이다. 다른 더 구체적인 실시형태에서, N과 C 사이의 이중선  은 단일 결합을 나타내고, X는 -H이며, Y는 -SO3H 또는 이의 약제학적으로 허용 가능한 염인, 면역접합체; 훨씬 더 구체적으로는, 약제학적으로 허용 가능한 염은 나트륨 또는 칼륨염이다.
은 단일 결합을 나타내고, X는 -H이며, Y는 -SO3H 또는 이의 약제학적으로 허용 가능한 염인, 면역접합체; 훨씬 더 구체적으로는, 약제학적으로 허용 가능한 염은 나트륨 또는 칼륨염이다.
특정 실시형태에서, Y가 -SO3H 또는 이의 약제학적으로 허용 가능한 염일 때, 면역접합체는 (a) pH 1.9 내지 5.0의 수용액에서 상기 기재한 티올-반응기를 갖는 이민-함유 세포독성제에서 이민-모이어티(즉, 화학식 (C1a'), (C1a'1), (C1b'), (C1b'1), (C2a"), (C2a"1), (C2b") 또는 (C2b"1), N과 C 사이의 이중선 은 이중 결합을 표시하고, X는 존재하지 않으며, Y는 -H임)를 이산화황, 중아황산염 또는 메타중아황산염과 반응하여, 다음의 식:
은 이중 결합을 표시하고, X는 존재하지 않으며, Y는 -H임)를 이산화황, 중아황산염 또는 메타중아황산염과 반응하여, 다음의 식:

또는 이의 약제학적으로 허용 가능한 염으로 표시되는 변형된 이민 모이어티를 포함하는 변형된 세포독성제를 형성하는 단계; 및 (b) 변형된 세포독성제를 본 명세서에 개시된 EpCAM-결합제(예를 들어, 본 명세서에 개시된 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체)를 반응시켜 면역접합체를 형성하는 단계에 의해 제조된다.
제1 양상에서, 상기 기재한 방법에 대해, 단계 (a)의 반응은 1.9 내지 5.0의 pH에서 수행된다. 더 구체적으로는, pH는 2.5 내지 4.9, 1.9 내지 4.8, 2.0 내지 4.8, 2.5 내지 4.5, 2.9 내지 4.5, 2.9 내지 4.0, 2.9 내지 3.7, 3.1 내지 3.5, 또는 3.2 내지 3.4이다. 다른 구체적 실시형태에서, 단계 (a)의 반응은 1.9, 2.0, 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9, 3.0, 3.1, 3.2, 3.3, 3.4, 3.5, 3.6, 3.7, 3.8, 3.9, 4.0, 4.1, 4.2, 4.3, 4.5, 4.6, 4.7, 4.8, 4.9 또는 5.0의 pH에서 수행된다. 또 다른 구체적 실시형태에서, 단계 (a)의 반응은 3.3의 pH에서 수행된다. 본 명세서에 사용된 바와 같이, 특정 pH 값은 특정 값 ± 0.05를 의미한다.
일부 실시형태에서, 단계 (a)의 반응은 완충제 용액의 존재 하에 수행된다. 당업계에 공지된 임의의 적합한 완충제 용액은 제공된 방법에서 사용될 수 있다. 적합한 완충제 용액은, 예를 들어, 시트르산염 완충제, 아세트산염 완충제, 석신산염 완충제, 인산염 완충제, 글리신-함유 완충제(예를 들어, 글리신-HCl 완충제), 프탈산염 완충제(예를 들어, 프탈산수소나트륨 또는 칼륨을 포함하는 완충제 용액) 및 이들의 조합물을 포함하지만, 이들로 제한되지 않는다. 일부 실시형태에서, 완충제 용액은 석신산염 완충제이다. 일부 실시형태에서, 완충제 용액은 인산염 완충제이다. 일부 실시형태에서, 완충제는 시트르산염-인산염 완충제이다. 일부 실시형태에서, 완충제는 시트르산 및 Na2HPO4를 포함하는 시트르산염-인산염 완충제이다. 다른 실시형태에서, 완충제는 시트르산 및 K2HPO4를 포함하는 시트르산염인산염 완충제이다. 일부 실시형태에서, 상기 기재한 완충제 용액의 농도는 10 내지 250mM, 10 내지 200mM, 10 내지 150mM, 10 내지 100mM, 25 내지 100mM, 25 내지 75mM, 10 내지 50mM, 또는 20 내지 50mM 범위일 수 있다.
제2 양상에서, 반응 단계 (a)는 완충제 용액(예를 들어, 제1 양상에 기재된 완충제)이 존재하지 않을 때 수행된다. 일부 실시형태에서, 본 방법은 (a) 상기 기재한 티올-반응기를 갖는 이민-함유 세포독성제에서 이민-모이어티(즉, 화학식 (C1a'), (C1a'1), (C1b'), (C1b'1), (C2a"), (C2a"1), (C2b") 또는 (C2b"1), N과 C 사이의 이중선 은 이중 결합을 표시하고, X는 존재하지 않으며, Y는 -H임)를 이산화황, 중아황산염 또는 메타중아황산염과 반응하여, 다음의 식:
은 이중 결합을 표시하고, X는 존재하지 않으며, Y는 -H임)를 이산화황, 중아황산염 또는 메타중아황산염과 반응하여, 다음의 식:

또는 이의 약제학적으로 허용 가능한 염으로 표시되는 변형된 이민 모이어티를 포함하는 변형된 세포독성제를 형성하는 단계로서, 수용액은 완충제를 포함하지 않는, 단계; 및 (b) 변형된 세포독성제를 본 명세서에 개시된 EpCAM-결합제(예를 들어, 본 명세서에 개시된 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체)를 반응시켜 면역접합체를 형성하는 단계를 포함한다. 일부 실시형태에서, 단계 (a)의 반응은 유기 용매와 물의 혼합물에서 수행된다. 더 구체적으로는, 단계 (a)의 반응은 다이메틸아세트아마이드 (DMA)와 물의 혼합물에서 수행된다. 일부 실시형태에서, DMA와 물의 혼합물은 DMA의 60용적% 미만을 포함한다. 훨씬 더 구체적으로는, DMA와 물의 용적비는 1:1이다.
제3 양상에서, 상기 기재한 또는 제1 또는 제2 양상의 방법에 대해, 0.5 내지 5.0 당량의 중아황산염 또는 0.25 또는 2.5 당량의 메타중아황산염은 단계 (a)의 반응에서 1당량의 이민-함유 세포독성제마다 사용된다. 일부 실시형태에서, 0.5 내지 4.5, 0.5 내지 4.0, 0.5 내지 3.5, 0.5 내지 4.0, 0.5 내지 3.5, 0.5 내지 3.0, 0.5 내지 2.5, 0.8 내지 2.0, 0.9 내지 1.8, 1.0 내지 1.7, 1.1 내지 1.6, 또는 1.2 내지 1.5 당량의 중아황산염 또는 0.25 내지 2.25, 0.25 내지 2.0, 0.25 내지 1.75, 0.25 내지 2.0, 0.25 내지 1.75, 0.25 내지 1.5, 0.25 내지 1.25, 0.4 내지 1.0, 0.45 내지 0.9, 0.5 내지 0.85, 0.55 내지 0.8, 또는 0.6 내지 0.75 당량의 메타중아황산염이 1 당량의 이민-함유 세포독성제마다 사용된다. 다른 실시형태에서, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2, 1.3 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0, 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9, 3.0, 3.1, 3.2, 3.3, 3.4, 3.5, 4.0, 4.5 또는 5.0 당량의 중아황산염 또는 0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6, 0.65 0.7, 0.75, 0.8, 0.85, 0.9, 0.95, 1.0, 1.05, 1.1, 1.15, 1.2, 1.25, 1.3, 1.35, 1.4, 1.45, 1.5, 1.55, 1.6, 1.65, 1.7, 1.75, 2.0, 2.25 또는 2.5 당량의 메타중아황산염이 1 당량의 이민-함유 세포독성제마다 사용된다. 또 다른 실시형태에서, 1.4 당량의 중아황산염 또는 0.7 당량의 메타중아황산염이 1 당량의 이민-함유 세포독성제마다 사용된다. 다른 실시형태에서, 1.2 당량의 중아황산염 또는 0.6 당량의 메타중아황산염이 1 당량의 이민-함유 세포독성제마다 사용된다. 본 명세서에 사용된 바와 같이, 특정 당량은 특정 값 ± 0.05를 의미한다.
제4 양상에서, 상기 기재한 방법에 대해, 단계 (a)의 반응은 pH 2.9 내지 3.7에서 수행되며, 1.0 내지 1.8 당량의 중아황산염 또는 0.5 내지 0.9 당량의 메타중아황산염은 1 당량의 이민-함유 세포독성제와 반응된다. 일부 실시형태에서, 단계 (a)의 반응은 3.1 내지 3.5의 pH에서 수행되고, 1.1 내지 1.6 당량의 중아황산염 또는 0.55 내지 0.8 당량의 메타중아황산염은 1 당량의 이민-함유 세포독성제와 반응된다. 다른 실시형태에서, 단계 (a)의 반응은 3.2 내지 3.4의 pH에서 수행되고, 1.3 내지 1.5 당량의 중아황산염 또는 0.65 내지 0.75 당량의 메타중아황산염은 1 당량의 이민-함유 세포독성제와 반응된다. 다른 실시형태에서, 단계 (a)의 반응은 pH 3.3에서 수행되고, 1.4 당량의 중아황산염 또는 0.7 당량의 메타중아황산염은 1 당량의 이민-함유 세포독성제와 반응된다. 또 다른 실시형태에서, 단계 (a)의 반응은 3.3의 pH에서 수행되고, 1.4 당량의 중아황산나트륨은 1 당량의 이민-함유 세포독성제와 반응된다.
제5 양상에서, 상기 또는 제1, 제2, 제3 또는 제4 양상에 기재된 방법에 대해, 단계 (a)의 반응은 유기 용매와 물의 혼합물에서 수행된다. 임의의 적합한 유기 용매가 사용될 수 있다. 예시적인 유기 용매는 알코올(예를 들어, 메탄올, 에탄올, 프로판올 등), 다이메틸폼아마이드(DMF), 다이메틸설폭사이드(DMSO), 아세토나이트릴, 아세톤, 염화메틸렌 등을 포함하지만, 이들로 제한되지 않는다. 일부 실시형태에서, 유기 용매는 물과 혼화성이다. 다른 실시형태에서, 유기 용매는 물과 혼화성이 아니며, 즉, 단계 (a)의 반응은 2상 용액에서 수행된다. 일부 실시형태에서, 유기 용매는 다이메틸아세트아마이드(DMA)이다. 유기 용매(예를 들어, DMA)는 물과 유기 용매의 총 용적의 1용적% 내지 99용적%, 1 내지 95용적%, 10 내지 80용적%, 20 내지 70용적%, 30 내지 70용적%, 1 내지 60용적%, 5 내지 60용적%, 10 내지 60용적%, 20 내지 60용적%, 30 내지 60용적%, 40 내지 60용적%, 45 내지 55용적%, 10 내지 50용적%, 또는 20 내지 40용적%의 양으로 존재할 수 있다. 일부 실시형태에서, 단계 (a)의 반응은 DMA와 물의 혼합물에서 수행되되, DMA와 물의 용적비는 1:1이다.
제6 양상에서, 상기 또는 제1, 제2, 제3, 제4 또는 제5 양상에 기재된 방법에 대해, 단계 (a)의 반응은 임의의 적합한 온도에서 수행될 수 있다. 일부 실시형태에서, 반응은 0℃ 내지 50℃, 10℃ 내지 50℃, 10℃ 내지 40℃, 또는 10℃ 내지 30℃의 온도에서 수행된다. 다른 실시형태에서, 반응은 15℃ 내지 30℃, 20℃ 내지 30℃, 15℃ 내지 25℃, 16℃ 내지 24℃, 17℃ 내지 23℃, 18℃ 내지 22℃ 또는 19℃ 내지 21℃의 온도에서 수행된다. 또 다른 실시형태에서, 반응은 15℃, 16℃, 17℃, 18℃, 19℃, 20℃, 21℃, 22℃, 23℃, 24℃ 또는 25℃에서 수행된다. 일부 실시형태에서, 반응은 0℃ 내지 15℃, 0℃ 내지 10℃, 1℃ 내지 10℃, 5℃ 내지 15℃, 또는 5℃ 내지 10℃의 온도에서 수행된다.
제7 양상에서, 상기 또는 제1, 제2, 제3, 제4, 제5 또는 제6 양상에 기재된 방법에 대해, 단계 (a)의 반응은 1분 내지 48시간, 5분 내지 36시간, 10분 내지 24시간, 30분 내지 24시간, 30분 내지 20시간, 1시간 내지 20시간, 1시간 내지 15시간, 1시간 내지 10시간, 2시간 내지 10시간, 3시간 내지 9시간, 3시간 내지 8시간, 4시간 내지 6시간, 또는 1시간 내지 4시간 동안 수행된다. 일부 실시형태에서, 반응은 4 내지 6시간 동안 진행된다. 다른 실시형태에서, 반응은 10분, 15분, 20분, 30분, 1시간, 2시간, 3시간, 4시간, 5시간, 6시간, 7시간, 8시간, 9시간, 10시간, 11시간, 12시간, 13시간, 14시간, 15시간 등 동안 진행된다. 다른 실시형태에서, 반응은 4시간 동안 진행된다. 또 다른 실시형태에서, 반응은 2시간 동안 진행된다.
제8 양상에서, 본 명세서에 또는 제1, 제2, 제3, 제4, 제5, 제6 또는 제7 양상에 개시된 방법에 대해, 단계 (b)의 반응은 pH 4 내지 9에서 수행된다. 일부 실시형태에서, 단계 (b)의 반응은 4.5 내지 8.5, 5 내지 8.5, 5 내지 8, 5 내지 7.5, 5 내지 7, 5 내지 6.5, 또는 5.5 내지 6.5의 pH에서 수행된다. 다른 실시형태에서, 단계 (b)의 반응은 pH 5.0, 5.1, 5.2, 5.3, 5.4, 5.5, 5.6, 5.7, 5.8, 5.9, 6.0, 6.1, 6.2, 6.3, 6.4, 6.5, 6.6, 6.7, 6.8, 6.9, 7.0, 7.1, 7.2, 7.3, 7.4, 7.5, 7.6, 7.7, 7.8, 7.9 또는 8.0에서 수행된다.
일부 실시형태에서, 상기 또는 제1, 제2, 제3, 제4, 제5, 제6, 제7 또는 제8 양상에 기재된 방법에 대해, 단계 (b)의 반응은 물과 유기 용매의 혼합물을 포함하는 수용액에서 수행된다. 상기 기재한 임의의 적합한 유기 용매가 사용될 수 있다. 더 구체적으로는, 유기 용매는 DMA이다. 일부 실시형태에서, 수용액은 50용적% 미만, 40용적% 미만, 30용적% 미만, 25용적% 미만, 20용적% 미만, 15용적% 미만, 10용적% 미만, 5용적% 미만, 3용적% 미만, 2용적%, 1용적% 미만의 유기 용매(예를 들어, DMA)를 포함한다.
일부 실시형태에서, 상기 또는 제1, 제2, 제3, 제4, 제5, 제6, 제7 또는 제8 양상에 기재된 방법에 대해, 중아황산염은 중아황산나트륨 또는 칼륨이고, 메타중아황산염은 메타중아황산나트륨 또는 칼륨이다. 구체적 실시형태에서, 중아황산염은 중아황산나트륨이고, 메타중아황산염은 메타중아황산나트륨이다.
일부 실시형태에서, 상기 또는 제1, 제2, 제3, 제4, 제5, 제6, 제7 또는 제8 양상에 기재된 방법에 대해, 변형된 세포독성제는 단계 (b)의 세포 결합제와 반응하기 전에 정제되지 않는다. 대안적으로, 변형된 세포독성제는 단계 (b)의 세포 결합제와 반응하기 전에 정제된다. 본 명세서에 개시된 임의의 적합한 방법은 변형된 세포독성제를 정제하는 데 사용될 수 있다.
일부 실시형태에서, 상기 기재한 방법에 대해, 단계 (a)의 반응은 말레이미드기의 실질적인 설폰화를 초래하지 않는다. 일부 실시형태에서, 50%, 40%, 30%, 20%, 10%, 9%, 8%, 7%, 6%, 5%, 4%, 3%, 2% 또는 1% 미만의 말레이미드기는 설폰산염이다. 말레이미드 설폰화의 백분율은 말레이미드-설폰산염 세포독성제(말레이미드 단독에 대해 설폰화를 갖는 세포독성제) 및 다이-설폰산염 세포독성제(말레이미드와 이민 모이어티 둘 다에 대해 설폰화를 갖는 세포독성제)의 총량을 중아황산염 또는 메타중아황산염과의 반응 전에 이민-함유 세포독성제의 시작하는 양으로 나눈 것이다.
일부 실시형태에서, 상기 기재한 임의의 방법에 의해 제조된 면역접합체는 정제 단계로 처리된다. 이와 관련하여, 면역접합체는 접선유동여과(TFF), 비흡착 크로마토그래피, 흡착 크로마토그래피, 흡착 여과, 선택적 침전 또는 임의의 다른 적합한 정제 방법뿐만 아니라 이들의 조합물을 이용하여 혼합물의 다른 성분으로부터 정제될 수 있다.
일부 실시형태에서, 면역접합체는 단일 정제 단계(예를 들어, TFF)를 이용하여 정제된다. 바람직하게는, 접합체는 단일 정제 단계(예를 들어, TFF)를 이용하여 정제되고 적절한 제형으로 교환된다. 다른 실시형태에서, 면역접합체는 2회의 순차적 정제 단계를 이용하여 정제된다. 예를 들어, 면역접합체는 선택적 침전, 흡착 여과, 흡착 크로마토그래피 또는 비-흡착 크로마토그래피, 다음에 TFF에 의한 정제에 의해 처음 정제된다. 당업자는 면역접합체의 정제가 세포독성제에 화학적으로 결합된 세포 결합제를 포함하는 안정한 접합체의 단리를 가능하게 한다는 것을 인식할 것이다.
펠리컨형 시스템(Pellicon type system)(Millipore, 매사추세츠주 빌러리카에 소재), 사토콘 카세트 시스템(Sartocon Cassette system)(Sartorius AG, 뉴욕주 에지우드에 소재) 및 센트라세트형 시스템(Centrasette type system)(Pall Corp., 뉴욕주 이스트 힐에 소재)을 포함하는 임의의 적합한 TFF 시스템이 이용될 수 있다.
임의의 적합한 흡착 크로마토그래피 수지가 정제를 위해 이용될 수 있다. 바람직한 흡착 크로마토그래피 수지는 수산화인회석 크로마토그래피, 소수성 전하 유도 크로마토그래피(HCIC), 소수성 상호작용 크로마토그래피(HIC), 이온 교환 크로마토그래피, 혼합 방식 이온 교환 크로마토그래피, 고정 금속 친화도 크로마토그래피(IMAC), 염료 리간드 크로마토그래피, 친화도 크로마토그래피, 역상 크로마토그래피 및 이들의 조합물을 포함한다. 적합한 수산화인회석 수지의 예는 세라믹 수산화인회석(CHT I형 및 II형, Bio-Rad Laboratories, 캘리포니아주 허큘레스에 소재), HA Ultrogel 수산화인회석(Pall Corp., 뉴욕주 이스트힐에 소재), 및 세라믹 플루오린화인회석(CFT I형 및 II형, Bio-Rad Laboratories, 캘리포니아주 허큘레스에 소재)를 포함한다. 적합한 HCIC 수지의 예는 MEP Hypercel 수지(Pall Corp., 뉴욕주 이스트힐에 소재)이다. 적합한 HIC 수지의 예는 뷰틸-세파로스, 헥실-세파로스, 페닐-세파로스, 및 옥틸 세파로스 수지(모두 GE Healthcare제, 뉴욕주 피스카타웨이에 소재)뿐만 아니라 Macro-분취 메틸 및 Macro-분취 t 뷰틸 수지(Biorad Laboratories, 캘리포니아주 허큘레스에 소재)를 포함한다. 적합한 이온 교환 수지의 예는 SP-세파로스, CM-세파로스, 및 Q-세파로스 수지(모두 GE Healthcare제, 뉴욕주 피스카타웨이), 및 Unosphere S 수지(Bio-Rad Laboratories, 캘리포니아주 허큘레스에 소재)를 포함한다. 적합한 혼합 방식 이온 교환기의 예는 Bakerbond CBAx 수지(JT Baker, 뉴저지주 필립스버그에 소재)를 포함한다. 적합한 IMAC 수지의 예는 킬레이팅 세파로스 수지(GE Healthcare, 뉴욕주 피스카타웨이) 및 Profinity IMAC 수지(Bio-Rad Laboratories, 캘리포니아주 허큘레스에 소재)를 포함한다. 적합한 염료 리간드 수지의 예는 Blue 세파로스 수지(GE Healthcare, 뉴욕주 피스카타웨이) 및 Affi-gel Blue 수지(Bio-Rad Laboratories, 캘리포니아주 허큘레스에 소재)를 포함한다. 적합한 친화도 수지의 예는 단백질 A 세파로스 수지(예를 들어, MabSelect, GE Healthcare, 뉴욕주 피스카타웨이)를 포함하며, 여기서, 세포 결합제는 항체, 및 렉틴 친화도 수지, 예를 들어, 렌틸 렉틴(Lentil Lectin) 세파로스 수지(GE Healthcare, 뉴욕주 피스카타웨이)이며, 여기서 세포 결합제는 적절한 렉틴 결합 부위를 보유한다. 대안적으로, 세포 결합제에 특이적인 항체가 사용될 수 있다. 이러한 항체는, 예를 들어, 세파로스 4 Fast Flow 수지(GE Healthcare, 뉴욕주 피스카타웨이)에 고정될 수 있다. 적합한 역상 수지의 예는 C4, C8 및 C18 수지(Grace Vydac, 캘리포니아주 헤스페리아에 소재)를 포함한다.
임의의 적합한 비흡착 크로마토그래피 수지가 정제에 이용될 수 있다.
적합한 비흡착 크로마토그래피 수지의 예는 SEPHADEX™ G-25, G-50, G-100, SEPHACRYL™ 수지(예를 들어, S-200 및 S-300), SUPERDEX™ 수지(예를 들어, SUPERDEX™ 75 및 SUPERDEX™ 200), BIO-GEL® 수지(예를 들어, P-6, P-10, P-30, P-60 및 P-100), 및 당업자에게 공지된 기타를 포함하지만, 이들로 제한되지 않는다.
본 명세서의 제3 실시형태에 기재된 메이탄시노이드 화합물에 공유 결합된 EpBA를 포함하는 면역접합체는 당업계에 공지된 임의의 적합한 방법에 따라 제조될 수 있다.
특정 실시형태에서, 면역접합체는 EpBA를 화학식 (II)의 메이탄시노이드 화합물과 반응시키는 단계를 포함하는 제1 방법에 의해 제조될 수 있다:
특정 실시형태에서, 면역접합체는 다음의 단계들을 포함하는 제2 방법에 의해 제조될 수 있다:
(a) 화학식 (III) 또는 (IV)의 메이탄시노이드 화합물을 본 명세서에 기재된 링커 화합물과 반응시켜 EpBA에 공유 결합될 수 있는 아민반응기 또는 티올-반응기가 결합된 세포독성제-메이탄시노이드 화합물을 형성하는 단계로서, 화학식 (III) 및 (IV)는 하기 식으로 표시되는 단계:

(b) EpBA를 메이탄시노이드-링커 화합물과 반응시켜 면역접합체를 형성하는 단계.
특정 실시형태에서, 면역접합체는 다음의 단계들을 포함하는 제3 방법에 의해 제조될 수 있다:
(a) EpBA를 본 명세서에 기재된 링커 화합물과 반응시켜, 화학식 (III) 또는 (IV)의 메이탄시노이드 화합물에 공유결합될 수 있는 아민-반응기 또는 티올-반응기가 결합된 변형된 항- EpBA를 형성하는 단계(예를 들어, 화학식 (II)의 화합물); 및
(b) 변형된 EpBA를 화학식 (III) 또는 (IV)의 메이탄시노이드 화합물과 반응시켜 면역접합체를 형성하는 단계.
특정 실시형태에서, 면역접합체는 EpBA, 링커 화합물 및 화학식 (III) 또는 (IV)의 메이탄시노이드 화합물을 반응시켜 면역접합체를 형성하는 단계를 포함하는 제3 방법에 의해 제조될 수 있다. 일 실시형태에서, 화학식 (III) 또는 (IV)의 EpBA 및 메이탄시노이드 화합물은 처음 혼합된 후에, 링커 화합물이 첨가된다.
특정 실시형태에서, 상기 기재한 제2, 제3 또는 제4 방법에 대해, 링커 화합물은 화학식 (a1L) 내지 (a10L) 중 어느 하나로 표시된다:

X는 할로겐; JD-SH, 또는 -SSRd이고; Rd는 페닐, 나이트로페닐, 다이나이트로페닐, 카복시나이트로페닐, 피리딜 또는 나이트로피리딜이며; Rg는 알킬이고; U는 -H 또는 SO3H 또는 이의 약제학적으로 허용 가능한 염이다.
일 실시형태에서, 링커 화합물은 화학식 (a9L)로 표시되는 GMBS 또는 설포-GMBS이되, U는 -H 또는 SO3H 또는 이의 약제학적으로 허용 가능한 염이다.
구체적 실시형태에서, 본 발명의 면역접합체는 다음의 식으로 표시된다:


D1은 다음의 식으로 표시된다:

더 구체적인 실시형태에서, 화학식 (I-1)의 면역접합체는 화학식 (D-1)의 메이탄시노이드 화합물을 링커 화합물 GMBS 또는 설포-GMBS와 반응시켜 메이탄시노이드-링커 화합물을 형성하고, EpBA를 메이탄시노이드-링커 화합물과 반응시킴으로써 제조된다. 훨씬 더 구체적인 실시형태에서, 메이탄시노이드 링커 화합물은 EpBA와 반응되기 전에 정제되지 않는다.
다른 구체적 실시형태에서, 면역접합체는 다음의 식으로 표시된다:

다른 구체적 실시형태에서, 면역접합체는 다음의 식으로 표시된다:


다른 구체적 실시형태에서, 면역접합체는 다음의 식으로 표시된다:


다른 구체적 실시형태에서, 면역접합체는 다음의 식으로 표시된다:


다른 구체적 실시형태에서, 면역접합체는 다음의 식으로 표시된다:


일부 실시형태에서, 상기 기재한 임의의 방법에 의해 제조된 면역접합체는 정제 단계로 처리된다. 이와 관련하여, 면역접합체는 접선유동여과(TFF), 비흡착 크로마토그래피, 흡착 크로마토그래피, 흡착 여과, 선택적 침전 또는 임의의 다른 적합한 정제 방법뿐만 아니라 이들의 조합물을 이용하여 혼합물의 다른 성분으로부터 정제될 수 있다.
일부 실시형태에서, 면역접합체는 단일 정제 단계(예를 들어, TFF)를 이용하여 정제된다. 바람직하게는, 접합체는 단일 정제 단계(예를 들어, TFF)를 이용하여 정제되고 적절한 제형으로 교환된다. 본 발명의 다른 실시형태에서, 면역접합체는 2회의 순차적 정제 단계를 이용하여 정제된다. 예를 들어, 면역접합체는 선택적 침전, 흡착 여과, 흡착 크로마토그래피 또는 비-흡착 크로마토그래피, 다음에 TFF에 의한 정제에 의해 처음 정제된다. 당업자는 면역접합체의 정제가 세포독성제에 화학적으로 결합된 세포 결합제를 포함하는 안정한 접합체의 단리를 가능하게 한다는 것을 인식할 것이다.
펠리컨형 시스템(Pellicon type system)(Millipore, 매사추세츠주 빌러리카에 소재), 사토콘 카세트 시스템(Sartocon Cassette system)(Sartorius AG, 뉴욕주 에지우드에 소재) 및 센트라세트형 시스템(Centrasette type system)(Pall Corp., 뉴욕주 이스트 힐에 소재)을 포함하는 임의의 적합한 TFF 시스템이 이용될 수 있다.
임의의 적합한 흡착 크로마토그래피 수지가 정제를 위해 이용될 수 있다.
바람직한 흡착 크로마토그래피 수지는 수산화인회석 크로마토그래피, 소수성 전하 유도 크로마토그래피(HCIC), 소수성 상호작용 크로마토그래피(HIC), 이온 교환 크로마토그래피, 혼합 방식 이온 교환 크로마토그래피, 고정 금속 친화도 크로마토그래피(IMAC), 염료 리간드 크로마토그래피, 친화도 크로마토그래피, 역상 크로마토그래피 및 이들의 조합물을 포함한다.
적합한 수산화인회석 수지의 예는 세라믹 수산화인회석(CHT I형 및 II형, Bio-Rad Laboratories, 캘리포니아주 허큘레스에 소재), HA Ultrogel 수산화인회석(Pall Corp., 뉴욕주 이스트힐에 소재), 및 세라믹 플루오린화인회석(CFT I형 및 II형, Bio-Rad Laboratories, 캘리포니아주 허큘레스에 소재)를 포함한다. 적합한 HCIC 수지의 예는 MEP Hypercel 수지(Pall Corp., 뉴욕주 이스트힐에 소재)이다. 적합한 HIC 수지의 예는 뷰틸-세파로스, 헥실-세파로스, 페닐-세파로스, 및 옥틸 세파로스 수지(모두 GE Healthcare제, 뉴욕주 피스카타웨이에 소재)뿐만 아니라 Macro-분취 메틸 및 Macro-분취 t 뷰틸 수지(Biorad Laboratories, 캘리포니아주 허큘레스에 소재)를 포함한다. 적합한 이온 교환 수지의 예는 SP-세파로스, CM-세파로스, 및 Q-세파로스 수지(모두 GE Healthcare제, 뉴욕주 피스카타웨이), 및 Unosphere S 수지(Bio-Rad Laboratories, 캘리포니아주 허큘레스에 소재)를 포함한다. 적합한 혼합 방식 이온 교환기의 예는 Bakerbond ABx 수지(JT Baker, 뉴저지주 필립스버그에 소재)를 포함한다. 적합한 IMAC 수지의 예는 킬레이팅 세파로스 수지(GE Healthcare, 뉴욕주 피스카타웨이) 및 Profinity IMAC 수지(Bio-Rad Laboratories, 캘리포니아주 허큘레스에 소재)를 포함한다. 적합한 염료 리간드 수지의 예는 Blue 세파로스 수지(GE Healthcare, 뉴욕주 피스카타웨이) 및 Affi-gel Blue 수지(Bio-Rad Laboratories, 캘리포니아주 허큘레스에 소재)를 포함한다. 적합한 친화도 수지의 예는 단백질 A 세파로스 수지(예를 들어, MabSelect, GE Healthcare, 뉴욕주 피스카타웨이)를 포함하며, 여기서, 세포 결합제는 항체, 및 렉틴 친화도 수지, 예를 들어, 렌틸 렉틴(Lentil Lectin) 세파로스 수지(GE Healthcare, 뉴욕주 피스카타웨이)이며, 여기서 세포 결합제는 적절한 렉틴 결합 부위를 보유한다. 대안적으로, 세포 결합제에 특이적인 항체가 사용될 수 있다. 이러한 항체는, 예를 들어, 세파로스 4 Fast Flow 수지(GE Healthcare, 뉴욕주 피스카타웨이)에 고정될 수 있다. 적합한 역상 수지의 예는 C4, C8 및 C18 수지(Grace Vydac, 캘리포니아주 헤스페리아에 소재)를 포함한다.
임의의 적합한 비흡착 크로마토그래피 수지가 정제에 이용될 수 있다.
적합한 비흡착 크로마토그래피 수지의 예는 SEPHADEX™ G-25, G-50, G-100, SEPHACRYL™ 수지(예를 들어, S-200 및 S-300), SUPERDEX™ 수지(예를 들어, SUPERDEX™ 75 및 SUPERDEX™ 200), BIO-GEL®수지(예를 들어, P-6, P-10, P-30, P-60 및 P-100), 및 당업자에게 공지된 기타를 포함하지만, 이들로 제한되지 않는다.
진단 및 연구 적용
본 명세서에 논의된 항체의 치료적 용도에 추가로, 본 명세서에 제공된 항체 단편 및 활성화 가능한 항체는 다수의 공지된 진단 및 연구 적용에서 사용될 수 있다. 제공된 EpCAM 항체 및/또는 EpCAM-결합 항체 단편은, 예를 들어, 시험관내 및 생체내 진단 방법 둘 다에 포함되는 EpCAM의 정제, 검출 및 표적화에서 사용될 수 있다. 예를 들어, 항체 및/또는 단편은 생물학적 샘플에서 세포에 의해 발현되는 EpCAM(예를 들어, 인간 EpCAM 또는 사이노몰거스 EpCAM)의 수준을 정성적 및 정량적으로 측정하기 위한 면역분석에서 사용될 수 있다. 예를 들어, 문헌[Harlow et al., Antibodies: A Laboratory Manual (Cold Spring Harbor Laboratory Press, 2nd ed. 1988)], 이들의 전문은 본 명세서에 참조에 의해 원용된다.
제공된 EpCAM 항체 및/또는 EpCAM-결합 항체 단편은, 예를 들어, 경쟁적 결합 분석, 직접 및 간접 샌드위치 분석 및 면역침전 분석에서 사용될 수 있다(Zola, Monoclonal Antibodies: A Manual of Techniques, pp.147-158 (CRC Press, Inc., 1987)).
EpCAM 항체, EpCAM-결합 항체 단편 및/또는 EpCAM 활성화 가능한 항체를 검출 가능하게 표지하는 것은 효소 면역분석(EIA), 또는 효소-결합 면역흡착 분석(ELISA)에서 사용하기 위한 효소에 대한 결합에 의해 수행될 수 있다. 연결된 효소는, 예를 들어, 분광광도법적, 형광측정에 의해 또는 시각적 수단에 의해 검출될 수 있는 화학적 모이어티를 생성하기 위해 노출된 기질과 반응한다. 예를 들어, 개시된 EpCAM 항체, EpCAM-결합 항체 단편 및 EpCAM 활성화 가능한 항체를 검출 가능하게 표지하기 위해 사용될 수 있는 효소는 말산 탈수소효소, 스타필로코커스 뉴클레아제, 델타-5-스테로이드 아이소머라제, 효모 알코올 탈수소효소, 알파-글리세로인산염 탈수소효소, 트라이오스 인산염 아이소머라제, 겨자무과산화효소, 알칼리성 포스파타제, 아스파라기나제, 글루코스 옥시다제, 베타갈락토시다제, 리보뉴클레아제, 유레아제, 카탈라제, 글루코스-6-인산염 탈수소효소, 글루코아밀라제 및 아세틸콜린에스터라제를 포함하지만, 이들로 제한되지 않는다.
EpCAM 항체, EpCAM-결합 항체 단편 및 EpCAM 활성화 가능한 항체를 방사성 표지함으로써, 방사면역측정법(RIA)의 사용을 통해 EpCAM을 검출할 수 있다(예를 들어, 문헌[Work, et al., Laboratory Techniques and Biochemistry in Molecular Biology, North Holland Publishing Company, N.Y. (1978)] 참조). 방사성 동위원소는 감마 계수기 또는 섬광 계수기의 사용과 같은 수단에 의해 또는 자기방사법에 의해 검출될 수 있다. 본 개시내용의 목적에 특히 유용한 동위원소는 3H, 125I, 131I, 35S, 14C, 및 바람직하게는, 125I이다.
또한 형광 화합물로 EpCAM 항체, EpCAM-결합 항체 단편 및 EpCAM 활성화 가능한 항체를 표지할 수 있다. 형광 표지된 항체, 항체 단편 또는 활성화 가능한 항체가 적절한 파장의 광에 노출될 때, 이어서, 이의 존재는 형광으로 인해 검출될 수 있다. 가장 통상적으로 사용되는 형광 표지 화합물 중에 플루오레세인 아이소티오사이아네이트, 로다민, 피코에리트린, 피코사이아닌, 알로피코사이아닌, o-프탈알데하이드 및 플루오레스카민이 있다.
EpCAM 항체, EpCAM-결합 항체 단편 및 EpCAM 활성화 가능한 항체는 또한 형광-방출 금속, 예컨대, 125Eu, 또는 란탄족 계열의 다른 것을 이용하여 검출 가능하게 표지될 수 있다. 이들 금속은 다이에틸렌트라이아민펜타아세트산(DTPA) 또는 에틸렌다이아민-테트라아세트산(EDTA)과 같은 금속 킬레이트기를 이용하여 EpCAM 항체, EpCAM-결합 항체 단편 및 EpCAM 활성화 가능한 항체에 부착될 수 있다.
추가적인 실시형태에서, EpCAM 항체, EpCAM-결합 항체 단편 및 EpCAM 활성화 가능한 항체는 화학발광 화합물에 결합함으로써 검출 가능하게 표지된다. 이어서, 화학발광 표지된 항체 또는 항체 단편의 존재는 화학적 반응의 과정 동안 일어나는 발광의 존재를 검출함으로써 결정된다. 특히 유용한 화학발광 표지 화합물의 예는 루미놀, 아이소루미놀, 써로마틱 아크리디늄(theromatic acridinium) 에스터, 이미다졸, 아크리듐염 및 옥살산염 에스터이다. 마찬가지로, 생발광 화합물은 EpCAM 항체, EpCAM-결합 항체 단편, EpCAM 활성화 가능한 항체 또는 이의 유도체를 표지하는 데 사용될 수 있다. 생발광은 촉매적 단백질이 화학발광 반응 효율을 증가시키는 생물학적 시스템에서 발견되는 화학발광 유형이다. 생발광 단백질의 존재는 발광의 존재를 검출함으로써 결정된다. 표지 목적을 위한 중요한 생발광 화합물은 루시페린, 루시퍼라제 및 에쿠오린이다.
EpCAM 항체 EpCAM-결합 항체 단편 및 EpCAM 활성화 가능한 항체는 생체내 영상화에 유용하되, 방사성-불투명화제 또는 방사성동위원소와 같은 검출 가능한 모이어티로 표지된 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체는 대상체에게, 바람직하게는 혈류에 투여되고, 숙주에서 표지된 항체 또는 항체 단편의 존재 및 위치는 분석된다. 이런 영상화 기법은 악성종양의 병기화 및 치료에 유용하다. EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체는 핵 자기 공명, 방사선학 또는 당업계에 공지된 기타 검출 수단에 의해 숙주에서 검출 가능한 임의의 모이어티로 표지될 수 있다.
개시된 방법에 따라 사용되는 표지는 직접적으로 또는 간접적으로 검출 가능한 신호를 생성할 수 있는 임의의 검출 가능한 모이어티일 수 있다. 예를 들어, 표지는 바이오틴 표지, 효소 표지(예를 들어, 루시퍼라제, 알칼리성 포스파타제, 베타갈락토시다제 및 겨자무과산화효소), 방사성 표지(예를 들어, 3H, 14C, 32P, 35S 및 125I), 형광단, 예컨대 형광 또는 화학발광 화합물(예를 들어, 플루오레세인 아이소티오사이아네이트, 로다민), 영상화제(예를 들어, Tc-m99 및 인듐(111In)) 및 금속 이온(예를 들어, 갈륨 및 유로퓸)일 수 있다.
문헌[Hunter et al., Nature 144:945 (1962); David et al., Biochemistry 13:1014 (1974); Pain et al., J. I㎜unol. Meth. 40:219 (1981); Nygren, Histochem. and Cytochem. 30:407 (1982)]에 의해 기재된 예시적인 방법을 포함하는, 표지를 위해 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체에 접합하기 위한 당업계에 공지된 임의의 방법이 사용될 수 있다.
치료적 적용
또한 EpCAM(예를 들어, 인간 EpCAM 또는 사이노몰거스 EpCAM)을 발현시키는 세포의 성장을 저해하기 위한 방법이 포함된다. 본 명세서에 제공된 바와 같은 개시된 EpCAM 항체, EpCAM-결합 항체 단편, EpCAM 활성화 가능한 항체 및/또는 이의 접합체는 세포(예를 들어, 인간 세포 또는 사이노몰거스 세포) 표면 상에 존재하는 EpCAM에 결합하고 세포 사멸을 매개하는 능력을 가진다. 특정 실시형태에서, 면역접합체는 세포독성 페이로드(payload), 예를 들어, 인돌리노벤조다이아제핀 DNA-알킬화제를 포함하며, 세포독성 페이로드, 예를 들어, 벤조다이아제핀, 예를 들어, 인돌리노벤조다이아제핀 DNA-알킬화제의 활성을 통해 내재화되고 세포 사멸을 매개한다. 이러한 세포 사멸 활성은 면역접합체 유도성 활성-의존적 세포-매개 세포독성(ADCC) 및/또는 보체 의존적 세포독성(CDC)에 의해 증가될 수 있다.
본 명세서에서 사용되는 용어 "저해하다" 및 "저해하는"은 세포사를 포함하는 세포 성장에 대해 임의의 저해 효소를 포함한다. 저해 효과는 일시적 효과, 지속 효과 및 영구적 효과를 포함한다.
본 명세서에 제공된 치료적 적용분야는 질환을 갖는 대상체를 치료하는 방법을 포함한다. 제공된 방법으로 치료되는 질환은 발현(예를 들어, EpCAM 과발현)을 특징으로 하는 것이다. 이러한 질환은, 예를 들어, 유방 암, 폐 암, 위암, 전립선 암, 난소암, 결장직장암, 결장암, 식도암, 기관암, 위암, 방광암, 자궁암, 직장암, 또는 소장의 암, 췌장암, 또는 기타 상피 암, 또는 이들과 관련된 전이를 포함한다. 당업자는 본 개시내용의 방법은 또한 아직 기재되지는 않았지만 EpCAM의 발현을 특징으로 하는 다른 질환을 치료하기 위해 사용될 수 있다는 것이 이해될 것이다.
또 다른 실시형태에서, 개시된 EpCAM 항체, EpCAM-결합 항체 단편, EpCAM 활성화 가능한 항체, 및/또는 이들의 접합체는 EpCAM을 발현시키는 암 치료에서 유용하다. 일부 실시형태에서, 암은 상피 또는 편평세포암이다. 일부 실시형태에서, 암은 유방 암, 폐 암, 위암, 전립선 암, 난소암, 결장직장암, 결장암, 식도암, 기관암, 위암, 방광암, 자궁암, 직장암, 췌장암, 또는 소장암이다.
본 명세서에 제공된 치료적 적용은 또한 시험관내 및 생체외에서 실행될 수 있다.
본 개시내용은 또한 개시된 EpCAM 항체, EpCAM-결합 항체 단편, EpCAM 활성화 가능한 항체, 및/또는 이들의 접합체의 치료적 적용을 제공하되, 항체, 항체 단편, 활성화 가능한 항체, 또는 접합체는 대상체에게 약제학적으로 허용 가능한 투약 형태로 투여된다. 이들은 볼루스로서 정맥내로 또는 일정 기간에 걸쳐 계속적 주입에 의해, 근육내, 피하, 비경구, 관절내, 활액내, 척추강내, 경구, 국소 또는 흡입 경로에 의해 투여될 수 있다. 이들은 또한 국소뿐만 아니라 전신 치료 효과를 발휘하도록 종양내, 종양주위, 병변내, 또는 병변주위 경로에 의해 투여될 수 있다.
또한 EpCAM 및/또는 EpCAM-매개 신호전달의 적어도 하나의 생물학적 활성에 결합하고, 중화시키거나 또는 달리 저해하는 EpCAM, 특히 EpCAM 활성화 가능한 항체에 결합하는 EpCAM 활성화 가능한 항체를 이용하여 대상체에서 EpCAM의 비정상 발현 및/또는 활성과 관련된 증상의 개시 또는 진행을 치료, 예방 및/또는 지연하거나, 완화시키는 방법이 제공된다.
일부 실시형태에서, 본 개시내용은 EpCAM을 발현시키거나 비정상적으로 발현시키는 세포의 적어도 하나의 생물학적 활성에 결합하건, 표적화하거나, 중화시키거나, 사멸시키거나 또는 달리 저해하는 EpCAM, 특히 EpCAM 활성화 가능한 항체에 결합하는 EpCAM 활성화 가능한 항체를 이용하여 대상체에서 EpCAM을 발현시키거나 또는 EpCAM을 비정상적으로 발현시키는 세포의 존재, 성장, 증식, 전이 및/또는 활성과 관련된 증상의 개시 또는 진행을 치료, 예방 및/또는 지연시키거나, 완화시키는 방법이 제공된다. 본 개시내용은 또한 EpCAM을 발현시키는 세포의 적어도 하나의 생물학적 활성에 결합하건, 표적화하거나, 중화시키거나, 사멸시키거나 또는 달리 저해하는 EpCAM, 특히 EpCAM 활성화 가능한 항체에 결합하는 EpCAM 활성화 가능한 항체를 이용하여 대상체에서 EpCAM을 발현시키는 세포의 존재, 성장, 증식, 전이 및/또는 활성과 관련된 증상의 개시 또는 진행을 치료, 예방 및/또는 지연시키거나, 완화시키는 방법이 제공된다.
본 개시내용은 또한 EpCAM을 비정상적으로 발현시키는 세포의 적어도 하나의 생물학적 활성에 결합하건, 표적화하거나, 중화시키거나, 사멸시키거나 또는 달리 저해하는 EpCAM, 특히 EpCAM 활성화 가능한 항체에 결합하는 EpCAM 활성화 가능한 항체를 이용하여 대상체에서 EpCAM을 비정상적으로 발현시키는 세포의 존재, 성장, 증식, 전이 및/또는 활성과 관련된 증상의 개시 또는 진행을 치료, 예방 및/또는 지연시키거나, 완화시키는 방법이 제공된다.
본 개시내용은 치료적 유효량의 본 명세서에 개시된 EpCAM 항체, 접합된 EpCAM 항체, EpCAM 활성화 가능한 항체 및/또는 접합된 EpCAM 활성화 가능한 항체를 치료가 필요한 대상체에게 투여함으로써 대상체에서 EpCAM 매개 질환을 예방하거나, 이의 진행을 지연시키거나, 증상을 치료, 완화하거나, 또는 달리 개선시키는 방법을 제공한다.
본 개시내용은 치료적 유효량의 본 명세서에 개시된 EpCAM 항체, 접합된 EpCAM 항체, EpCAM 활성화 가능한 항체 및/또는 접합된 EpCAM 활성화 가능한 항체를 치료가 필요한 대상체에게 투여함으로써 대상체에서 암(예를 들어, 상피암 및 이들의 전이)을 예방하거나, 이의 진행을 지연시키거나, 증상을 치료, 완화하거나, 또는 달리 개선시키는 방법을 제공한다. EpCAM은 상피 유래의 대부분의 암(및 전이)를 포함하는 다양한 암에서 발현되는 것으로 알려져 있다.
일부 실시형태에서, 암은 상피 또는 편평세포암이다.
일부 실시형태에서, 암은 유방 암, 폐 암, 위암, 전립선 암, 난소암, 결장직장암, 결장암, 식도암, 기관암, 위암, 방광암, 자궁암, 직장암, 췌장암, 또는 소장암이다.
일부 실시형태에서, 암은 유방 암, 폐 암, 위암, 결장직장암, 결장암, 직장암, 소장암, 난소암, 위암, 또는 식도암이다.
일부 실시형태에서, 암은 난소암, 자궁암, 위암, 췌장암 또는 결장직장암이다.
일부 실시형태에서, 암은 난소암이다.
일부 실시형태에서, 암은 자궁암이다.
일부 실시형태에서, 암은 위암이다.
일부 실시형태에서, 암은 췌장암이다.
일부 실시형태에서, 암은 결장직장암이다.
일부 실시형태에서, 암은 유방암이다. 특정 실시형태에서, 암은 삼중 음성 유방암이다.
일부 실시형태에서, 암은 폐암이다. 일부 실시형태에서, 폐암은 비소세포 폐암이다. 일부 실시형태에서, 비소세포 폐암은 비편평 비소세포 폐암이다.
이들 방법 및 용도의 임의의 실시형태에서 사용되는 EpCAM 항체, 접합된 EpCAM 항체, EpCAM 활성화 가능한 항체 및/또는 접합된 EpCAM 활성화 가능한 항체는 임의의 질환 병기에서 투여될 수 있다. 예를 들어, 이러한 EpCAM 항체, 접합된 EpCAM 항체, EpCAM 활성화 가능한 항체, 및/또는 접합된 EpCAM 활성화 가능한 항체는 초기로부터 전이까지의 임의의 병기를 앓고 있는 환자에게 투여될 수 있다. 용어 대상체 및 환자는 본 명세서에서 상호 호환적으로 사용된다.
일부 실시형태에서, 대상체는 포유류, 예컨대 인간, 비-인간 영장류, 반려 동물(예를 들어, 고양이, 개, 말), 농장 동물, 작업 동물 또는 동물원 동물이다. 일부 실시형태에서, 대상체는 인간이다. 일부 실시형태에서, 대상체는 반려 동물이다. 일부 실시형태에서, 대상체는 수의사의 관리 하에 있는 동물이다.
EpCAM 항체, 접합된 EpCAM 항체, EpCAM 활성화 가능한 항체 및/또는 접합된 EpCAM 활성화 가능한 항체, 및 이의 치료적 제형은 비정상적 EpCAM 발현 및/또는 활성과 관련된 질환 또는 장애, 예컨대 암을 앓고 있거나, 이에 걸리기 쉬운 대상체에게 투여된다. 비정상적 EpCAM 발현 및/또는 활성과 관련된 질환 또는 장애를 앓고 있거나, 이에 걸리기 쉬운 대상체는 당업계에 공지된 임의의 다양한 방법을 이용하여 확인된다. 예를 들어, 암 또는 기타 신생물 병태를 앓고 있는 대상체는 건강 상태를 평가하기 위해 임의의 다양한 임상 및/또는 실험 검정, 예컨대, 신체 검사 및 혈액, 소변 및/또는 대변 분석을 이용하여 확인된다. 예를 들어, 염증 및/또는 염증 장애를 앓고 있는 대상체는 건강 상태를 평가하기 위해 임의의 다양한 임상 및/또는 실험 검정, 예컨대 신체 검사 및/또는 체액 분석, 예를 들어, 혈액, 소변 및/또는 대변 분석을 이용하여 확인된다.
비정상적 EpCAM 발현 및/또는 활성과 관련된 질환 또는 장애(예를 들어, 암, 예컨대 암종)을 앓고 있는 환자에 대한 EpCAM 항체, 접합된 EpCAM 항체, EpCAM 활성화 가능한 항체, 및/또는 접합된 EpCAM 활성화 가능한 항체의 투여는, 임의의 다양한 실험 또는 임상 목적이 달성된다면 성공적인 것으로 간주된다. 예를 들어, 비정상적 EpCAM 발현 및/또는 활성과 관련된 질환 또는 장애(예를 들어, 암, 예컨대 암종)을 앓고 있는 환자에 대한 EpCAM 항체, 접합된 EpCAM 항체, EpCAM 활성화 가능한 항체, 및/또는 접합된 EpCAM 활성화 가능한 항체의 투여는, 질환 또는 장애와 관련된 증상 중 하나 이상이 완화되거나, 감소되거나, 저해되거나 또는 추가로 진행되지 않는다면, 즉, 상태를 악화시키지 않는다면, 성공적인 것으로 간주된다. 비정상적 EpCAM 발현 및/또는 활성과 관련된 질환 또는 장애(예를 들어, 암, 예컨대 암종)을 앓고 있는 환자에 대한 EpCAM 항체, 접합된 항-EpCAM 항체, EpCAM 활성화 가능한 항체, 및/또는 접합된 EpCAM 활성화 가능한 항체의 투여는, 질환 또는 장애가 관해로 들어가거나 또는 추가로 진행되지 않는다면, 즉, 상태를 악화시키지 않는다면, 성공적인 것으로 간주된다.
일부 실시형태에서, EpCAM 항체, 접합된 EpCAM 항체, EpCAM 활성화 가능한 항체, 및/또는 접합된 EpCAM 활성화 가능한 항체, 및 이의 치료적 제형은 질환 또는 장애를 앓고 있거나 걸리기 쉬운 대상체, 예컨대, 암 또는 기타 신생물 병태를 앓고 있는 대상체에게 투여되되, 대상체의 질환 세포는 발현 EpCAM이다. 일부 실시형태에서, 질환 세포는 비정상적 EpCAM 발현 및/또는 활성과 관련된다. 일부 실시형태에서, 질환 세포는 정상적 EpCAM 발현 및/또는 활성과 관련된다. 대상체의 질환 세포가 EpCAM을 발현시키는 질환 또는 장애를 앓고 있거나 걸리기 쉬운 대상체는 임의의 다양한 당업계에 공지된 방법을 이용하여 확인된다. 예를 들어, 암 또는 기타 신생물 병태를 앓고 있는 대상체는 건강 상태를 평가하기 위해 임의의 다양한 임상 및/또는 실험 검정, 예컨대, 신체 검사 및 혈액, 소변 및/또는 대변 분석을 이용하여 확인된다. 예를 들어, 염증 및/또는 염증 장애를 앓고 있는 대상체는 건강 상태를 평가하기 위해 임의의 다양한 임상 및/또는 실험 검정, 예컨대 신체 검사 및/또는 체액 분석, 예를 들어, 혈액, 소변 및/또는 대변 분석을 이용하여 확인된다.
일부 실시형태에서, EpCAM 항체, 접합된 EpCAM 항체, EpCAM 활성화 가능한 항체, 및/또는 접합된 EpCAM 활성화 가능한 항체, 및 이의 치료적 제형은 EpCAM을 발현시키는 세포 또는 이러한 세포의 존재, 성장, 증식, 전이 및/또는 활성과 관련된 질환 또는 장애를 앓고 있거나 걸리기 쉬운 대상체, 예컨대, 암 또는 기타 신생물 병태를 앓고 있는 대상체에게 투여된다. 일부 실시형태에서, 세포는 비정상적 EpCAM 발현 및/또는 활성과 관련된다. 일부 실시형태에서, 세포는 정상적 EpCAM 발현 및/또는 활성과 관련된다. EpCAM을 발현시키는 세포와 관련된 질환 또는 장애를 앓고 있거나 걸리기 쉬운 대상체는 임의의 다양한 당업계에 공지된 방법을 이용하여 확인된다. 예를 들어, 암 또는 기타 신생물 병태를 앓고 있는 대상체는 건강 상태를 평가하기 위해 임의의 다양한 임상 및/또는 실험 검정, 예컨대, 신체 검사 및 혈액, 소변 및/또는 대변 분석을 이용하여 확인된다. 예를 들어, 염증 및/또는 염증 장애를 앓고 있는 대상체는 건강 상태를 평가하기 위해 임의의 다양한 임상 및/또는 실험 검정, 예컨대 신체 검사 및/또는 체액 분석, 예를 들어, 혈액, 소변 및/또는 대변 분석을 이용하여 확인된다.
EpCAM을 발현시키는 세포와 관련된 질환 또는 장애(예를 들어, 암, 예컨대 암종)을 앓고 있는 환자에 대한 EpCAM 항체, 접합된 EpCAM 항체, EpCAM 활성화 가능한 항체, 및/또는 접합된 EpCAM 활성화 가능한 항체의 투여는, 임의의 다양한 실험 또는 임상 목적이 달성된다면 성공적인 것으로 간주된다. 예를 들어, EpCAM을 발현시키는 세포와 관련된 질환 또는 장애(예를 들어, 암, 예컨대 암종)을 앓고 있는 환자에 대한 EpCAM 항체, 접합된 EpCAM 항체, EpCAM 활성화 가능한 항체, 및/또는 접합된 EpCAM 활성화 가능한 항체의 투여는, 질환 또는 장애와 관련된 증상 중 하나 이상이 완화되거나, 감소되거나, 저해되거나 또는 추가로 진행되지 않는다면, 즉, 상태를 악화시키지 않는다면, 성공적인 것으로 간주된다. EpCAM을 발현시키는 세포와 관련된 질환 또는 장애(예를 들어, 암, 예컨대 암종)을 앓고 있는 환자에 대한 EpCAM 항체, 접합된 EpCAM 항체, EpCAM 활성화 가능한 항체, 및/또는 접합된 EpCAM 활성화 가능한 항체의 투여는, 질환 또는 장애가 관해로 들어가거나 또는 추가로 진행되지 않는다면, 즉, 상태를 악화시키지 않는다면, 성공적인 것으로 간주된다.
본 개시내용은 비정상적 EpCAM 발현 및/또는 활성과 관련된 질환 또는 장애의 증상을 치료, 예방하고/하거나 진행을 지연시키고/시키거나, 개선시키고/시키거나 증상을 완화시키는 방법에서 유용한 인간 EpCAM, EpCAM 활성화 가능한 항체, 및 접합된 EpCAM 항체, 항체 단편, 또는 활성화 가능한 항체에 특이적으로 결합하는 항체 및 항체 단편이 제공된다. 예를 들어, EpCAM 활성화 가능한 항체는 암 또는 기타 신생물 병태를 치료, 예방하고/하거나, 진행을 지연시키고/시키거나, 개선시키고/시키거나 증상을 완화시키는 방법에서 사용된다.
본 개시내용은 EpCAM을 발현시키는 세포와 관련된 질환 또는 장애의 증상을 치료, 예방하고/하거나 진행을 지연시키고/시키거나, 개선시키고/시키거나 증상을 완화시키는 방법에서 유용한 인간 EpCAM, EpCAM 활성화 가능한 항체, 및 접합된 EpCAM 항체, 항체 단편, 또는 활성화 가능한 항체에 특이적으로 결합하는 항체 및 항체 단편이 제공된다. 일부 실시형태에서, 세포는 비정상적 EpCAM 발현 및/또는 활성과 관련된다. 일부 실시형태에서, 세포는 정상적 EpCAM 발현 및/또는 활성과 관련된다. 예를 들어, EpCAM 활성화 가능한 항체는 암 또는 기타 신생물 병태를 치료, 예방하고/하거나, 진행을 지연시키고/시키거나, 개선시키고/시키거나 증상을 완화시키는 방법에서 사용될 수 있다.
본 개시내용은 질환 세포가 EpCAM을 발현시키는 질환 또는 장애를 치료, 예방하고/하거나, 진행을 지연시키고/시키거나 개선시키고/시키거나 증상을 완화시키는 방법에서 유용한 인간 EpCAM, EpCAM 활성화 가능한 항체, 접합된 EpCAM 항체 및 항체 단편, 및/또는 접합된 EpCAM 활성화 가능한 항체에 특이적으로 결합하는 항체 및 항체 단편을 제공한다. 일부 실시형태에서, 질환 세포는 비정상적 EpCAM 발현 및/또는 활성과 관련된다. 일부 실시형태에서, 질환 세포는 정상적 EpCAM 발현 및/또는 활성과 관련된다. 예를 들어, EpCAM 활성화 가능한 항체는 암 또는 기타 신생물 병태를 치료, 예방하고/하거나, 진행을 지연시키고/시키거나, 개선시키고/시키거나 증상을 완화시키는 방법에서 사용된다.
약제학적 조성물
제공된 조성물은 단위 투약 형태의 제조에서 사용될 수 있는 약제학적 조성물(예를 들어, 비순수 또는 비멸균 조성물) 및 약제학적 조성물(즉, 대상체 또는 환자에 대한 투여에 적합한 조성물)의 제조에서 유용한 벌크 약물 조성물을 포함한다. 이러한 조성물은 제공된 면역접합체 및 약제학적으로 허용 가능한 담체의 예방적 또는 치료적 유효량을 포함한다.
바람직하게는, 제공된 조성물은 예방적 또는 치료적 유효량의 개시된 면역접합체 및 약제학적으로 허용 가능한 담체를 포함한다.
구체적 실시형태에서, 용어 "약제학적으로 허용 가능한"은 동물 및 더 구체적으로는 인간에서 사용하기 위한 연방정부의 규제 기관에 의해 승인되거나 미국 약전 또는 기타 일반적으로 인식되는 약전에 열거된 것을 의미한다. 용어 "담체"는 치료제와 함께 투여되는 희석제, 보조제(예를 들어, 프로인트 보조제(완전 및 불완전)), 부형제 또는 비히클을 지칭한다. 일반적으로, 본 명세서에 제공된 조성물의 성분은 별개로 공급되거나 또는 단위 투약 형태로 함께, 예를 들어, 활성제의 양을 표시하는 밀폐 밀봉 용기, 예컨대 앰플 또는 사쉐에 건조 동결건조 분말 또는 무수 농축물로서 공급된다. 조성물이 주입에 의해 투여될 경우에, 멸균 약제 등급수 또는 식염수를 함유하는 주입 보틀로 제공될 수 있다. 조성물이 주사에 의해 투여되는 경우에, 투여 전에 성분이 혼합될 수 있는 멸균 주사용수 또는 식염수의 앰플이 제공될 수 있다.
본 개시내용은 또한 본 명세서에 제공된 면역접합체 단독으로 또는 이러한 약제학적으로 허용 가능한 담체와 함께 채워진 하나 이상의 용기를 포함하는 약제학적 팩 또는 키트를 제공한다. 본 개시내용은 또한 본 명세서에 제공된 약제학적 조성물의 성분 중 하나 이상으로 채워진 하나 이상의 용기를 포함하는 약제학적 팩 또는 키트를 제공한다. 선택적으로 이러한 용기(들)와 제조를 규제하는 정부 기관에 의해 처방되는 형태, 약제 또는 생물학적 제품의 사용 또는 판매의 안내문이 결합될 수 있고, 이 안내문은 제조기관에 의한 승인, 인간 투여용도 또는 판매를 반영한다.
본 개시내용은 상기 방법에서 사용될 수 있는 키트를 제공한다. 키트는 본 명세서에 개시된 임의의 면역접합체를 포함할 수 있다.
투여 방법
개시된 조성물은 치료적 유효량의 본 명세서에 제공된 면역접합체를 대상체에게 투여함으로써 질환, 장애와 관련된 하나 이상의 증상의 치료, 예방 및 개선을 제공할 수 있다. 바람직한 양상에서, 이러한 조성물은 실질적으로 정제된다(즉, 이의 효과를 제한하거나 바람직하지 않은 부작용을 생성하는 물질이 실질적으로 없다). 구체적 실시형태에서, 대상체는 동물, 바람직하게는 포유류, 예컨대 비영장류(예를 들어, 소, 말, 고양이, 개, 설치류 등) 또는 영장류(예를 들어, 원숭이, 예컨대, 사이노몰거스 원숭이, 인간 등)이다. 바람직한 실시형태에서, 대상체는 인간이다.
본 명세서에 제공된 면역접합체를 투여하는 방법은 비경구 투여(예를 들어, 진피내, 근육내, 복강내, 정맥내 및 피하), 경막외 및 점막(예를 들어, 비강내 및 경구 경로)를 포함하지만, 이들로 제한되지 않는다. 구체적 실시형태에서, 본 명세서에 제공된 면역접합체는 근육내로, 정맥내로 또는 피하로 투여된다. 조성물은 임의의 편리한 경로에 의해, 예를 들어, 주입 또는 볼루스 주사에 의해 투여될 수 있고, 기타 생물학적 활성제와 함께 투여될 수 있다. 투여는 전신 또는 국소일 수 있다.
본 개시내용은 또한 개시된 면역접합체의 제제가 분자의 양을 표시하는 밀폐 밀봉된 용기, 예컨대 앰플 또는 사쉐에 패키징된다는 것을 제공한다. 일 실시형태에서, 이러한 분자는 밀폐 밀봉된 용기에서 건조 멸균 동결건조된 분말 또는 무수 농축물로서 공급되고, 대상체에 대한 투여를 위한 적절한 농도로, 예를 들어, 물 또는 식염수에 의해 재구성될 수 있다. 바람직하게는, 면역접합체는 밀폐 밀봉된 용기에서 건조 멸균 동결건조 분말로서 공급된다.
본 명세서에 제공된 면역접합체의 동결건조 제제는 이들의 본래의 용기에서 2℃ 내지 8 ℃에서 저장되어야 하고, 분자는 재구성된 후에 12시간 이내에, 바람직하게는 6시간 이내에, 5시간 이내에, 3시간 이내에, 또는 1시간 이내에 투여되어야 한다. 대안의 실시형태에서, 이러한 분자는 분자, 융합 단백질 또는 접합 분자의 양 및 농도를 표시하는 밀폐 밀봉된 용기에서 액체 형태로 공급된다. 바람직하게는, 이러한 면역접합체는 액체 형태로 제공될 때에 밀폐 밀봉된 용기로 공급된다.
본 명세서에 사용된 바와 같은 약제학적 조성물의 "치료적 유효량"은 임상 결과, 예컨대 암 증상(예를 들어, 암 세포의 증식, 종양 존재, 종양 전이 등)의 감소, 이에 의한 질환을 앓고 있는 대상의 삶의 질 증가, 질환을 치료하는 데 필요한 다른 의약의 용량 감소, 예컨대 표적화 및/또는 내재화를 통한 다른 의학 효과 향상, 질환 진행의 지연 및/또는 개체 생존 연장을 포함하지만, 이들로 제한되지 않는 유리한 또는 목적하는 결과를 달성하는 데 충분한 양이다.
치료적 유효량은 1회 이상의 투여로 투여될 수 있다. 본 개시내용의 목적을 위해, 치료적 유효량의 약물, 화합물 또는 약제학적 조성물은 직접적으로 또는 간접적으로 바이러스 존재의(또는 효과의) 증식을 감소시키고 바이러스 질환 발생을 감소시키고/시키거나 지연시키는 데 충분한 양이다.
실시예
실시예 1: 인간 및 사이노몰거스 EpCAM(CD326) 항원에 대한 마우스 단클론성 항체의 생성
인간 및 사이노몰거스(cyno) EpCAM에 대한 단클론성 항체를 생성하기 위해, 3가지 상이한 면역화 프로토콜을 사용하였다. 제1 면역화 프로토콜에서, 야생형 BALB/c 암컷 마우스에 BALB/c 유래 전-B 세포인 cyno-EpCAM 발현 300-19 세포주를 3회 피하로 주사하고, 이어서, 인간-EpCAM 발현 300-19 세포주를 2회 주사하였다. 제2 면역화 프로토콜에서, 야생형 BALB/c 암컷 마우스에 NSCLC 세포주 H1568을 피하로 4회 주사하고, 이어서, cyno 1차 신장 상피세포를 4회 주사하였다. 제3 면역화 프로토콜, Fc감마R2b ko/ko BALB/c 암컷 마우스(모델 # 579, Taconic)에 인간-EpCAM 발현 300-19 세포로 3회 피하로 주사하고, 이어서, cyno-EpCAM 발현 300-19 세포로 2회 주사하였다. 모두 3개의 프로토콜에서, 세포를 PBS에서 제조하고, 마우스에 5×106개의 세포/마우스/주사의 용량으로 주사 간에 2주 간격으로 주사하였다. 면역 반응을 부스팅하기 위해, 항 GITR Ab(클론 DTA-1)을 제1 면역화 후 1주에 주사하였다. 하이브리도마(Hybridoma) 생성을 위해 희생시키기 3일 전에, 면역화된 마우스는 인간-EpCAM 발현 300-19 세포의 다른 용량의 복강내 주사를 받았다. 마우스 비장을 표준 동물 프로토콜에 따라 수집하고, 2개의 멸균, 냉동시킨 현미경 슬라이드 사이에 두어서 RPMI-1640 배지에서 단일 세포 현탁액을 얻었다. 적혈구를 ACK 용해 완충제로 용해시킨 후에, 이어서, 비장 세포를 뮤린 골수종 P363Ag8.653 세포(P3 세포)와 1 P3 세포: 3 비장 세포의 비로 혼합하였다. 비장 세포와 P3 세포의 혼합물을 세척하고, 실온에서 3분 동안 융합 배지(0.3M 만니톨/D-솔비톨, 0.1mM CaCl2, 0.5mM MgCl2 및 1㎎/㎖ BSA)에서 프로나제로 처리하였다. 소태아 혈청(FBS)의 첨가에 의해 반응을 중단시키고, 이어서, 세포를 세척하고 나서, 2㎖의 차가운 융합 배지에서 재현탁시키고, BTX ECM 2001 전기융합기를 이용하여 융합시켰다. 융합 세포를 하이포잔틴-아미노프테린-티미딘(HAT)을 함유하는 RPMI-1640 선택 배지에 부드럽게 첨가하고, 20분 동안 37℃에서 인큐베이션시키고, 이어서, 200㎕/웰로 10개의 편평 바닥 96-웰 플레이트에 파종하였다. 이어서, 하이브리도마 클론이 항체 선별에 대해 용이하게 될 때까지 플레이트를 5% CO2 인큐베이터 내 37℃에서 인큐베이션시켰다. 문헌[J. Langone and H. Vunakis (Eds., Methods in Enzymology, Vol. 121, I㎜unochemical Techniques, Part I, Academic Press, Florida); 및 E. Harlow and D. Lane (Antibodies: A Laboratory Manual, 1988, Cold Spring Harbor Laboratory Press, New York, NY)]에 기재된 것을 포함하는 면역화 및 하이브리도마 생성의 다른 기법이 또한 사용될 수 있다.
하이브리도마 선별 및 서브클로닝
인간 EpCAM 발현 300-19 세포 및 야생형 300-19 세포를 이용하는 유세포측정 결합 분석을 이용하여 하이브리도마 선별을 수행하였다. 간략하게, CELLTRACE™근적외선 DDAO-SE를 이용하여 야생형 300-19 세포를 처음 표지하고, 1:1 비로 비처리 세포와 혼합하고 나서, 얼음 상에서 2시간 동안 하이브리도마 상청액과 함께 인큐베이션시켰다. 이어서, 세포를 세척하고, PE-표지된 항 마우스 IgG와 함께 인큐베이션시키고 나서, 세척하고, 포말린으로 고정시키고 나서, FACS 어레이를 이용하여 분석하였다. 인간-EpCAM 항원에 대해 특이적 반응성을 갖는 하이브리도마를 확장시키고, 3개의 독립적 세포주: 인간-EpCAM 발현 300-19 세포, cyno-EpCAM 발현 300-19 세포및 야생형 300-19 세포를 이용하여 유세포측정 결합 분석에 의해 상청액을 재선별하였다. 인간 및 cyno EpCAM 항원에 대해 양성 결합이지만, 야생형 300-19 세포에 대해 음성인 하이브리도마를 한계희석법에 의해 추가로 서브클로닝하였다. 인간 및 cyno EpCAM 항원에 대해 특이적 결합을 나타낸 각 하이브리도마로부터의 하나의 서브클론을 후속 분석을 위해 선택하였다.
이 연구 과정에 걸쳐 총 20개의 융합을 수행하였다. 인간 및 사이노몰거스 EpCAM 항원에 특이적인 63개의 하이브리도마를 생성하고, 29개의 하이브리도마를 서브클로닝하였다. 안정한 서브클론을 배양하고 나서, 상업적 마우스 IgG 아이소타이핑 시약을 이용하여 단클론성 항체의 아이소타입을 확인하였다.
뮤린 항체 정제
2가지의 크로마토그래피 단계: 단백질 A 친화도 및 세라믹 수산화인회석(CHT)으로 본질적으로 이루어진 체계를 이용하여 하이브리도마 서브클론으로부터의 여과 상청액을 정제하였다. 간략하게, 1:10 용적의 1 M Tris/HCl 완충제(pH 8.0)의 첨가에 의해 여과시킨 상청액을 중화시켰다. 1 PBS(pH 7.3±0.1)로 사전 평형상태로 만든 단백질 A 칼럼(HiTrap 단백질 A HP, 1㎖) 상에 중화 상청액을 장입하였다. 칼럼을 1X PBS(pH 7.3±0.1)로 세척하여 비특이적 숙주 세포 단백질을 환원시켰다. 이어서, 50mM 염화나트륨(pH 3.2)을 함유하는 25mM 아세트산을 이용하여 결합된 항체를 용리시키고, 1M Tris-염기를 이용하여 pH 7.0±0.2까지 즉시 중화시켰다. 중화시킨 풀을 CHT 결합 완충제(15mM 인산나트륨, pH 7.0±0.1)에 1:10으로 희석시키고, CHT 결합 완충제로 사전 평형화시킨 II형 CHT 칼럼(40㎛ 입자 크기) 상에 장입하였다. 이어서, 결합된 단백질을 선형 구배 (10개 칼럼 용적에서 15mM 내지 160mM 인산나트륨)를 이용하여 용리시키고, 관심 대상의 분획(크기 배제 크로마토그래피(SEC)에 의해 높은 단량체 백분율)을 풀링하고, 1X PBS(pH 7.3±0.1)에 대해 투석하고 나서, 멸균여과시켰다. 280㎚의 흡광도 및 1.44㎖㎎-1㎝-1의 흡광계수를 측정함으로써 최종 항체 농도를 결정하였다.
인 라인(in-line) UV, 전도도 및 pH 프로브를 구비한 AKTA 정제 시스템 상에서 모든 정제 실험을 수행하였다. 칼럼 수명을 연장시키기 위해 또한 인라인 가드 칼럼(6.0×40 ㎜)을 갖는 TSKgel G3000SWXL 칼럼(7.8×300 ㎜) 상에 40 μg의 샘플을 주사함으로써 Agilent HPVL 1100 시스템을 이용하여 SEC 분석을 수행하였다. 이동상은 50㎜ 인산나트륨 완충제 및 400㎜ 과염소산나트륨을 함유하였고, 유속은 1.0㎖/분의 등용매 용리였다.
실시예 2: 뮤린 EpCAM 항체의 결합 친화도
정제된 항체 mEpCAM23(실시예 1에 기재한 제3 면역화 프로토콜을 이용하여 얻음)를 이용하여 유세포측정 결합 분석에 의해 결합 친화도를 분석하고, HSC2 세포(도 1A) 또는 cyno 1차 신장 상피세포(도 1B)를 이용하여 수행하였다. 결합 분석에서, 샘플당 2×104개의 세포를 2시간 동안 얼음 상에서 200㎕ FACS 완충제(2% 정상 염소 혈청으로 보충한 RPMI1640 배지) 중 다양한 농도의 mEpCAM23과 함께 인큐베이션시켰다. 이어서, 세포를 펠릿화하고, 2회 세척하고 나서, ALexa Flour Plus 488와 접합된 30분 동안 100㎕의 염소 항-마우스 IgG-항체와 함께 인큐베이션시켰다. 세포를 다시 펠릿화하고 나서, FACS 완충제로 세척하고, 1% 폼알데하이드를 함유하는 200㎕의 PBS 중에서 재현탁시켰다. HTS 멀티웰 샘플러를 갖는 FACSCalibur™ 유세포분석기를 이용하여 샘플을 획득하고, CellQuest™를 이용하여 분석하였다. 각 샘플에 대해, FL1에 대한 기하평균 형광 강도(MFI)를 계산하고, 반대수(semi-log) 플롯에서 항체 농도에 대해 플롯팅하였다. 각 곡선의 비선형 회귀, 및 각 항체의 겉보기 해리상수(Kd)에 대응하는 EC50 값에 의해 용량-반응 곡선을 생성하였고, 그래프패드 프리즘 v4를 이용하여 계산하였다.
도 1A 및 도 1B에 나타낸 바와 같이, mEpCAM23 항체의 겉보기 Kd는 3.8×1010 내지 7.9×1010의 범위였다. mEpCAM23의 서열을 확인하고, 키메라화, 인간화 및 추가 평가를 위해 mEpCAM23 클론을 선택하였다.
실시예 3: EpCAM 항체의 VL 및 VH의 클로닝 및 서열분석
V
L
및 V
H
영역의 클로닝
제조업자의 프로토콜에 따라 Quick-RNA® 미니-프렙 키트를 이용하여 EpCAM 하이브리도마의 5×106개의 세포로부터 총 세포의 RNA를 제조하였다. 제조업자의 지침에 따라 SuperScript III® cDNA 합성 키트를 이용하여 총 RNA로부터 cDNA를 후속적으로 합성하였다.
하이브리도마 세포로부터 유래된 항체 가변 영역 cDNA를 증폭시키기 위한 PCR 절차는 문헌[Wang et al. (J. I㎜unol. Methods 233:167-177(2000)) 및 Co et al. (J. I㎜unol. 148:1149-54 (1992))]에 기재된 방법에 기반하였다. 간략하게, VL 및 VH 서열을 5'-단부 상의 축퇴 프라이머 및 3'-단부 상의 뮤린 카파 또는 IgG1 불변 영역 특이적 프라이머 각각에 의해 증폭시켰다. 생어(Sanger) 서열분석을 위해 정제된 앰플리콘을 Genewiz에 보냈다.
VL 및 VH cDNA 서열을 클로닝하기 위해 사용한 축퇴 프라이머는 5'-말단을 변경시킬 수 있기 때문에, 완전한 cDNA 서열을 확인하기 위해 추가적인 서열분석 노력이 필요하였다. 항체 서열이 유래된 뮤린 생식계열 서열을 확인하기 위해 NCBI IgBlast 부위의 탐색 질의(search query)에 예비 서열을 입력하였다. 이어서, 새로운 PCR 반응이 완전한 가변 영역 cDNA 서열을 수득하고, PCR 프라이머에 의해 비변경되도록, 뮤린 항체의 생식계열 연결된 리더 서열에 대한 어닐링을 위해 PCR 프라이머를 설계하였다.
서열 확인을 위한 질량 결정
EpCAM 항체 각각에 대해 얻은 가변 영역 cDNA 서열을 생식계열 불변 영역 서열과 합하여 전장 항체 cDNA 서열을 얻었다. 이들 서열분석 결과를 확인하기 위해, 전장 중쇄 및 경쇄 cDNA 서열의 분자 가중치를 정제된 뮤린 EpCAM 항체의 LC/MS 분석에 의해 얻은 분자 가중치와 비교하였다.
키메라 항체 발현 및 정제
뮤린 EpCAM 항체에 대한 가변 영역 아미노산 서열을 코돈-최적화하고, 합성하고 나서, GenScript(뉴저지주에 소재)에 의해 인간 IgG1 불변 영역을 갖는 프레임에 클로닝하여 EpCAM 항체의 키메라 형태를 구성하였다. 간략하게, 경쇄 가변 영역을 내부 pAbKZeo 플라스미드의 EcoRI 및 BsiWI 부위에 클로닝시키고, 중쇄 가변 영역을 내부 pAbG1Neo 플라스미드의 HindIII 및 Apal 부위에 클로닝시켰다. 이들 발현 작제물을 진탕 플라스크에서 형질감염 시약으로서 PEI를 이용하여 현탁액 적합화시킨 HEK-293T 세포에서 일시적으로 생성하였다. HEK-293T 세포를 Freestyle 293(Invitrogen)에서 성장시키고, PEI-DNA 복합체의 첨가 후에 배양 용적을 희석시키지 않고 둔 것을 제외하고, PEI 일시적 형질감염을 앞서 기재한 바와 같이 수행하였다(문헌[Durocher et al., Nucleic Acids Res. 30(2):E9 (2002)] 참조). 형질감염을 1주 동안 인큐베이션시키고, 채취하고 나서, 여과시킨 상청액을 실시예 1에 기재한 것과 같은 절차를 이용하여 단백질 A 및 CHT 크로마토그래피의 조합을 이용하여 정제하였다.
실시예 4: 항체 인간화
문헌[Jones etal., Nature 321: 604-608 (1986), Verhoeyen et al., Science 239:1534-1536 (1988)], 미국 특허 제5,225,539호 및 제5,585,089호에 본질적으로 기재한 바와 같이 상보성 결정 영역(CDR) 접합 절차를 이용하여 항체 인간화를 수행하였다. CDR 접합은 일반적으로 마우스 항체의 Fv 프레임워크 영역(FR)을 인간 항체 Fv 프레임워크 영역으로 대체하는 한편, 모 항체의 특정 항원-결합 특성에 중요한 마우스 CDR 잔기를 보존하는 것으로 이루어진다. Kabat CDR 정의 후 뮤린 EpCAM-23 항체의 예시적인 CDR은 이하의 표 13에 나타낸다.

전형적으로 모 뮤린 항체에 대해 가장 높은 서열 상동성을 공유하는 인간 항체 유전자로부터 유래된 것인 적절한 인간 수용자(acceptor) 프레임워크를 선택함으로써 CDR-접합 과정을 시작한다. 문헌[Ehrenmann et al., Nucleic Acids Res. 38: D301-307 (2010)]에 기재된 바와 같은 International ImMunoGeneTics information system®(http://imgt.cines.fr/))의 상호작용 도구인 DomainGapAlign을 이용하여 이들 수용자 프레임워크를 일반적으로 확인하였다. 뮤린 서열과 가장 큰 서열 동일성을 공유하는 VL 및 VH 인간 생식계열 서열의 선택 후에, 뮤린 CDR을 인간 생식계열 서열에 접합시킴으로써 항체의 인간화 형식을 생성하였다. CDR 접합 후에 감소 또는 제거된 항원-결합 친화도는 뮤린 CDR과 인간 프레임워크 간의 부적합성(incompatibility)의 결과로서 종종 관찰되지만, 문헌[Foote and Winter, J. Mol. Biol. 224:487-499 (1992)]; 그러나, 버니어(vernier) 구역 잔기로서 지칭되는 CDR 바로 밑의 잔기 플랫폼은 항체의 특이성 및 친화도를 지시하는 CDR 루프의 입체구조를 보존하게 할 수 있다. 따라서, 뮤린 잔기로의 이들 버니어 주역 잔기의 역돌연변이는 종종 결합 친화도를 회복하는 데 필요하다.
도 2A 및 도 2B는 본래의 muEpCAM-23 경쇄 및 중쇄 서열의 가변 영역과 이들의 가장 가까운 인간 생식계열 매치 간의 서열 정렬을 나타낸다. 정렬 결과에 기반하여, EpCAM-23 항체의 VL 및 VH 도메인에 대한 억셉터(acceptor) 프레임워크로서 선택된 인간 생식계열 서열은 각각 IGKV2D- 29*02(도 2A) 및 IGHV1-3*01(도 2B)였다.
muEpCAM-23의 초기 CDR 접합은 접합 VL의 카바트 24 내지 34번 위치 (CDR-L1), 50 내지 56번 위치(CDR-L2), 및 89-97번 위치(CDR-L2) 및 VH의 카바트 31 내지 35번 위치(CDR-H1), 50 내지 65번 위치(CDR-H2), 및 95 내지 102번 위치(CDR-H3)의 대응하는 인간 생식계열 IGKV2D-29*01 및 IGHV1-3*01 프레임워크에 접합에 의해 생성되었다. 초기 CDR 접합 형태는 VL에서의 12개의 프레임워크 잔기 치환 및 VH에서의 27개의 프레임워크 잔기 변화를 포함하였다. 추가적으로, 버니어 구역 잔기의 하나 이상의 역돌연변이를 포함하는 변이체를 또한 생성하고, 후속적으로 EpCAM-결합에 대해 평가하였다. 시험한 버니어 구역 잔기 역돌연변이는 VL에서 3개의 잔기(FW-L1에서 4번 위치, 및 FW-L2에서 36, 64번 위치) 및 VH에서 6개의 잔기(FW-H2에서 47, 48번 위치, 및 FW-H3에서 67, 69, 71 및 73번 위치)를 포함하였다. 더 나아가, CDR에 속하는 접합 라이신 잔기의 잠재적 영향을 최소화하기 위해, 일부 형태의 CDR 영역에서 라이신 잔기를 알기닌으로 대체하였다. 추가적으로, 일부 접합 형태에서, 인간화 정도를 증가시키기 위해 특정 CDRH2 잔기를 IGHV1-3*01 생식계열 잔기로 바꾸었다. 표 14 및 표 15는 각각 다양한 인간화된 VL과 VH 형태 간의 모든 잔기 변화를 열거한다. 인간화 DNA 작제물을 합성하고, 발현시키고, 후속적 인간 EpCAM 및 cyno EpCAM-결합 분석을 위해 실시예 2에 기재한 절차를 이용하여 재조합 항체를 본질적으로 정제하였다.



키메라화/인간화된 EpCAM 항체의 결합 친화도
유세포측정 결합 분석을 수행하고, 2차 Alexa Flour Plus 488 접합 염소-항-인간 항체(Invitrogen)를 이용하여 실시예 2에 기재한 바와 같이 분석하였다.
HSC2 세포(도 3A) 및 cyno 1차 신장 상피세포(도 3B)에 대한 결합 친화도에 대해 키메라 항체 chEpCAM23을 분석하였다.
EpCAM23의 몇몇 인간화 형태는 인간 HSC2 세포에 대한 결합을 보유하였다(도 3C). 그러나, 형태 Gv2.2(VL Gv2 및 VH Gv2) 및 형태 Gv4.2(VL Gv4 및 VH Gv2)만이 또한 cyno 1차 신장 상피세포에 대한 결합을 보유하였다(도 3D). 또한, 시스테인 특이적 접합 부위인 huEpCAM23Gv4.2-C442를 갖는 Gv4.2의 다른 형태를 생성하고, 평가하였다. 도 3E 및 도 3F에 나타낸 바와 같이, 이 항체는 huEpCAM23Gv4.2의 Kd와 유사한 Kd로 HSC2 및 cyno 1차 신장 상피세포에 결합한다. 도 4A 및 도 4B는 본래의 뮤린 EpCAM-23 항체, 접합 형태 Gv2.2, 및 접합 형태 Gv4.2의 가변 영역의 서열 정렬을 도시한 도면. 일반적으로 라이신 또는 시스테인 잔기를 이용하여 페이로드를 항체에 접합하고, 접합된 형태 Gv4.2는 단일 아미노산(23번 위치에서 알기닌에 대해 라이신)만에 의해 접합된 형태 Gv4.2는 형태 Gv2.2와 다르게 되었다. 따라서, 접합의 용이함을 위해, 추가 평가를 위해 Gv4.2를 선택하였다.
실시예 5: huEpCAM-23Gv4.2 항체의 친화도 조절
지속 가능한 종양 보유를 위해, 단클론성 항체는 고친화도로 항원에 결합하여야 한다. 그러나, 항원과 종양 항원 간의 상호작용이 너무 높다면, 단클론성 항체의 효율적인 종양 침투를 손상시켜, 감소된 생체내 효능을 초래할 수 있다는 가설을 세웠다. 최적의 친화도는 항원 발현 및 이질성; 종양 크기; 수용체 내재화 및 재순환 속도; 혈관구조; 방관자 사멸 활성; 및 약물 대 항체비(DAR)와 같은 다수의 변수의 함수일 가능성이 있다(Vasalou et al., PLoS ONE 10(3):e0118977(2015) doi:10.1371/joumal.pone. 0118977). 따라서, 모든 이들 변수의 상호작용을 더 양호하게 이해하기 위해, 인간화 항체 Gv4.2의 친화도 변이체를 생성하였다. 마우스/인간 천연 레퍼토리에서 거의 발생하지 않는(5% 미만의 빈도) 용매 노출된 CDR 잔기 또는 VH/VL 프레임워크 잔기를 돌연변이시킴으로써 변이체를 생성하였다. 상업적 소프트웨어 MOE(Chemical computing group)의 항체-모델링 특징을 이용하여 Gv4.2 항체의 상동성 모델을 생성함으로써 용매 노출된 위치를 확인하였다. 표 16은 탐색한 모든 위치를 열거하며, 표 17은 인간 HSC2 세포 및 cyno 1차 신장 상피세포에 대한 다양한 변이체의 결합 KD를 나타낸다. 모든 변이체를 발현시키고, 정제하고, 실시예 2 및 4에 기재한 절차를 본질적으로 이용하여 FACS에 대해 특성규명하였다.





실시예 6: 인간화 항-EpCAM23Gv4.2 항체의 친화도 변이체의 결합 친화도
인간화 항-EpCAM23Gv4.2 친화도 변이체의 초기 세트를 mFc-태그된 huEpCAM 또는 cynoEpCAM 단백질을 이용하여 효소-결합 면역흡착 분석(ELISA)에서 시험하였다. 간략하게, 각각의 mFc-태그된 EpCAM 단백질을 pH 9.6의 50mM 중탄산나트륨 완충제에서 0.5㎍/㎖까지 희석시키고, 100㎕를 각각의 웰에 첨가하였다. 4℃에서 16시간 동안 인큐베이션시킨 후에, 플레이트를 0.1% Tween-20(TBST)와 함께 Tris-완충제 식염수로 세척하고, 이어서, 200㎕의 차단 완충제(1% BSA와 함께 TBS)로 차단하였다. 다음에, 100㎕의 1차 항체, 즉, 차단 완충제에서 연속 희석시킨 친화도 변이체를 ELISA 웰에 2회 첨가하였고, 실온에서 1시간 동안 인큐베이션시켰다. 이어서, 플레이트를 TBST로 3회 세척한 후에, 100㎕의 항-인간 IgG (H+L)-HRP를 각 웰에 첨가하였다. 플레이트를 다시 1시간 동안 실온에서 인큐베이션시킨 후에, TBST로 3회 세척하였다. 최종적으로, 100㎕의 TMB 일 성분 HRP 마이크로웰 기질을 각 웰에 첨가하고, 5분 동안 인큐베이션시켰다. 100㎕ 중단 용액을 첨가함으로써 반응을 중단시키고, 다중웰 플레이트 판독기 내 450㎚에서 흡광도를 판독하였다. OD450을 반대수 플롯에서 항체 농도에 대해 플롯팅하였다. 각 곡선의 비선형 회귀, 및 EC50 값에 의해 용량-반응 곡선을 생성하였고, 그래프패드 프리즘 v6을 이용하여 계산하였다.
ELISA 분석으로부터의 결과는 (경쇄에서 돌연변이를 포함하는 변이체에 대해)도 5A 및 도 5B에 그리고 (중쇄에서 돌연변이를 포함하는 변이체에 대해)도 5C a및 도 5D에 나타낸다. 도 5A 내지 도 5D에 나타낸 7가지 변이체는 상이한 결합 프로파일을 나타내었고, 특히 경쇄 변이체 Gv4c.2 및 중쇄 변이체 Gv4.2c에 의해 별개의 결합이 나타내었다. 변이체 Gv4c.2는 이의 모 항체보다 약 3배 더 약한 친화도로, 3개의 경쇄 돌연변이 변이체 중 cynoEpCAM- mFc 단백질에 대해 가장 약한 결합을 나타내었다(도 5B). 그러나, 변이체 Gv4c.2는 모 항체와 유사한 huEpCAM-mFc에 대한 KD를 나타내었다(도 5A). 4개의 중쇄 돌연변이 변이체 중에, 변이체 Gv4.2c는 cynoEpCAM-mFc에 대해 유의하게 감소된 결합을 나타내었지만(도 5D), 모 항체와 비교할 때 huEpCAM-mFc에 대해 유사한 결합을 나타내었다(도 5C). 이들 중쇄 및 경쇄 변이체의 상이한 조합을 이용하여, 상기 언급한 단일 돌연변이 변이체에 추가로 이중 돌연변이 변이체를 생성하였다.
HSC2 세포 및 cyno 1차 신장 상피세포에 대한 추가적인 인간화 항-EpCAM23Gv4.2 친화도 변이체의 결합 친화도를 모 항체의 친화도와 비교하였다. 유세포측정 결합 분석을 수행하고, 실시예 2 및 4에 기재한 바와 같이 분석하고, 총 60개의 변이체를 평가하였다. 도 5E 내지 도 5H는 이중 돌연변이체에 대한 결합 곡선을 나타내고, 도 5I 내지 도 5K는 huEpCAM23Gv4.2 중쇄에서 단일 돌연변이를 포함하는 특정 친화도 변이체의 결합 곡선을 나타낸다. 도 5E 내지 도 5K에 나타낸 바와 같이, 다양한 결합 프로파일을 이용하여 변이체를 생성하였다. 특히, 이중 돌연변이 변이체 Gv4a.2a, Gv4b.2a 및 Gv4c.2a는 매우 높은 형광 강도를 나타내었고, 세포 유형 둘 다: HSC2(도 5E) 및 cyno 1차 신장 상피세포(도 5F)를 포화시키지 못하였다. 추가적으로, 변이체 Gv4a.2b 및 Gv4b.2b는 cyno 1차 신장 상피세포 상의 모 항체에 비해 친화도의 약 4배 감소를 나타내었지만(도 5H), HSC2 세포 상에서 유사한 결합을 나타내었다(도 5G). 이중 돌연변이 변이체 Gv4b.2d, Gv4c.2b 및 Gv4c.2d는 cyno 1차 신장 상피세포 상에서 매우 불량한 결합을 갖지만, 모 항체에 비해 HSC2 세포 상에서 유사한 결합을 가졌다. 도 5I 내지 도 5K에 나타낸 바와 같이, 단일 돌연변이 친화도 변이체의 겉보기 해리상수(Kd)는 0.8nM 내지 약 6nM의 범위였고, 이는 HSC2 세포 상의 모 항체 huEpCAM23Gv4.2(Kd 0.4 nM)에 비해 2 내지 15배 증가를 나타낸다. cyno 1차 신장 상피세포를 이용하여 이들 단일 돌연변이 변이체를 또한 시험하였고, 데이터를 도 5L 내지 도 5N에 나타낸다.
특히, huEpCAM23Gv4.2Q는 HSC2 세포 및 cyno 1차 신장 세포 둘 다에 대해 높은 형광 강도를 나타낸 반면, huEpCAM23Gv4.2R만이 HSC2 세포 상에서 높은 형광 강도를 나타내었다(도 5I 및 도 5L). huEpCAM23Gv4.2H 및 huEpCAM23Gv4.2L은 유사한 Kd 값을 나타내었지만, cyno 1차 신장 상피세포 상에서 매우 불량한 결합과 관련되었다. 도 5I 및 도 5L에 나타낸 다른 클론을 세포 유형 둘 다에 대해 포화시켰고, 다양한 Kd 값과 관련되었다.
도 5J 및 도 5M은 CDR1의 동일 위치에서 특정 아미노산 치환(즉, 33번 위치에서 다른 아미노산을 본래의 Y 잔기로의 치환)을 포함하는 친화도 변이체에 대한 결합 특징을 나타낸다. 도 5J 및 도 5M에 나타낸 모든 변이체는 모 항체의 Kd 값에 비해 HSC2 세포 상에서 감소된 Kd 값을 가지며, cyno 1차 신장 상피세포 상에서 (huEpCAM23Gv4.2-1361-1을 제외하고) 매우 불량한 결합을 나타내었다. 도 5K 및 도 5N은 CDR3의 동일 위치에서 특정 아미노산 치환(즉, 97번 위치에서 다른 아미노산을 본래의 P 잔기로의 치환)을 포함하는 친화도 변이체에 대한 결합 특징을 나타낸다. huEpCAM23Gv4.2-1565- Y 변이체는 모 항체의 Kd에 비해 감소된 Kd로 HSC2 세포와 cyno 1차 상피세포를 둘 다 포화시킨 반면, 변이체의 나머지는 HSC2 세포상에서만 포화되었고, cyno 1차 신장 상피세포 상에서는 포화되지 않았다.
총괄적으로, 이들 데이터는 친화도 변이체가 다양한 기하평균 형광 결합 강도로 그리고 다양한 Kd로 생성되었다는 것을 나타낸다. 이들 결과에 기반하여, 추가 평가를 위해 두 친화도 변이체, 즉, huEpCAM23Gv4.2-1361-H 및 huEpCAM23Gv4.2-1565-Y를 선택하였다. 특히, 모 항체 및 이들의 상이한 돌연변이 부위에 비해 HSC2 세포 상에서의 다소 더 낮은 결합 친화도(즉, HSC2 세포 상의 모 항체에 비해 약 3배 감소된 Kd)로 인해 이들 변이체를 선택하였다.
실시예 7: 마스크 발견
활성화 가능한 항-EpCAM 항체("활성화 가능한 항체")에서 사용하기 위한 마스킹 모이어티(MM 또는 "마스크")를 확인하고 특성규명하기 위해 본 명세서에 제공된 연구를 설계하였다.
2010년 7월 15일자로 공개된 국제특허출원 공개 번호 WO 2010/081173에 기재된 것과 유사한 방법을 이용하여, 인간 및 사이노몰거스 EpCAM과 교차 반응하는 인간화 항-인간 EpCAM 단클론성 항체(EpCAM23Gv4.2)를 사용하여 무작위 X15 펩타이드 라이브러리(여기서 X는 임의의 아미노산임)를 선별하였다. 선별은 1회 라운드의 MACS 및 3회 라운드의 FACS 분류로 이루어졌다. 항-EpCAM 항체와 함께 단백질-A Dynabeads(Invitrogen)를 이용하여 초기 MACS 분류를 행하였다. MACS에 대해, 항-EpCAM 항체를 DyLight-488(ThermoFisher)와 접합시키고, EpCAM 결합 활성을 확인하고 나서, 항-EpCAM-488을 모든 FACS 라운드에 대한 형광 프로브로서 사용하였다. 개개 펩타이드 클론을 각 FACS 라운드로부터의 서열 분석에 의해 확인하였다.
2010년 7월 15일자로 공개된 국제특허출원 공개 번호 WO 2010/081173에 기재된 것과 유사한 방법을 이용하여, 인간화 항-인간 EpCAM 단클론성 항체(EpCAM23(1361-H) 및 EpCAM23(1565-Y))의 두 중쇄 변이체를 생성하고, 이를 사용하여 무작위 X15 펩타이드 라이브러리(여기서 X는 임의의 아미노산임)를 선별하였다. EpCAM23(1565-Y) 중쇄 변이체를 이용하여 마스크 EP101 내지 EP104를 확인하였다. EpCAM23(1361-H) 중쇄 변이체를 이용하여 마스크 EP105 내지 EP110을 확인하였다. Ep107 마스킹 모이어티에서 라이신 잔기의 돌연변이를 또한 생성하였다.
선택된 항-EpCAM 마스킹 모이어티의 서열을 표 18에 열거한다.


이들 마스킹 펩타이드를 사용하여 본 개시내용의 항-EpCAM 활성화 가능한 항체를 생성하였다. 특정 이들 항-EpCAM 활성화 가능한 항체에 대한 아미노산 서열을 이하의 표 19에 나타낸다. 일부 실시형태에서, 본 개시내용의 이들 항-EpCAM 활성화 가능한 항체는 ISSGLLSGRSDNH(서열번호 242), AVGLLAPPGGLSGRSDNH(서열번호 243), ISSGLLSGRSDIH(서열번호 244), ISSGLLSGRSDQH(서열번호 245), ISSGLLSGRSDNP(서열번호 246), ISSGLLSGRSANP(서열번호 247), ISSGLLSGRSANI(서열번호 248), ISSGLLSGRSDNI(서열번호 169), AVGLLAPPGGLSGRSDIH(서열번호 249), AVGLLAPPGGLSGRSDQH(서열번호 250), AVGLLAPPGGLSGRSDNP(서열번호 251), AVGLLAPPGGLSGRSANP(서열번호 252), AVGLLAPPGGLSGRSANI(서열번호 253), 또는 AVGLLAPPGGLSGRSDNI(서열번호 168)를 포함한다. 일부 실시형태에서, 본 개시내용의 특정 항-EpCAM 활성화 가능한 항체는 절단될 것으로 예상되지 않는 비-절단 가능 모이어티 "NSUB"를 포함한다.
이하에 나타내는 본 개시내용의 활성화 가능한 항체의 특정 경쇄 서열은 QGQSGQG(서열번호 254)의 N-말단 스페이서 서열을 포함하지만, 당업자는 본 개시내용의 활성화 가능한 항-EpCAM 항체가 임의의 적합한 스페이서 서열, 예를 들어, QGQSGQ(서열번호 255), QGQSG(서열번호 256), QGQS(서열번호 257), QGQ, QG, GQSGQG(서열번호 258), QSGQG(서열번호 259), SGQG(서열번호 260), GQG, G 또는 Q로 이루어진 군으로부터 선택된 스페이서 서열을 포함할 수 있다는 것을 인식한다.
일부 실시형태에서, 본 개시내용의 활성화 가능한 항-EpCAM 항체의 경쇄는 N-말단에 결합된 스페이서 서열을 가질 수 없다.





다음의 중쇄 및 경쇄를 갖는 예시적인 항-EpCAM 활성화 가능한 항체를 이하의 표 20에 나타낸다.




본 개시내용의 항-인간 EpCAM 항체의 결합을 입증하기 위해 고체상 결합 분석을 사용하였다. 간략하게, 재조합 인간 EpCAM-mFC 단백질(I㎜unogen)을 ELISA 플레이트(1㎍/㎖의 50㎕) 상에 코팅하고, 이어서, 연속 희석시킨 항-EpCAM 항체(62.5nM에서 시작) 또는 활성화 가능한 항-EpCAM 항체(1 μM에서 시작)와 함께 인큐베이션시키고, 여기서, 활성화 가능한 항체를 이들의 비절단 형태로 분석하였다. Ultra TMB-ELISA 시약(Thermo Fisher Scientific)과 함께 겨자무과산화효소(Sigma)에 접합된 항-인간 IgG(항-Fab)를 이용하여 결합 항체의 양을 검출하고, OD를 450nM에서 측정하였다. KD를 각 항체 및 활성화 가능한 항체에 대해 측정하였고, 비마스킹된 항체에 비해 각 활성화 가능한 항체에 대한 ELISA 마스킹 효율(ME)을 계산하고, 예시적인 결과를 표 21 및 표 22에 나타낸다. 총괄적으로, 이들 데이터는 본 개시내용의 항-인간 EpCAM 활성화 가능한 항체가 본 개시내용의 모 항-EpCAM 항체에 비해 재조합 EpCAM 단백질에 대해 이동된 결합 친화도를 입증한다는 것을 나타낸다.


표 21 및 도 22에 도시한 바와 같이, 이들 예시적인 결과는 항 인간 EpCAM 활성화 가능한 항체가 비마스킹된 항-EpCAM 항체에 비해 다양한 마스킹 효율을 나타내었다는 것을 입증하였다.
실시예 8: 항-EpCAM23Gv4.2 활성화 가능한 항체, 항체-약물 접합체 및 활성화 가능한 항체-약물 접합체의 결합 친화도
huEpCAM23Gv4.2 및 7개의 상이한 마스크 중 하나를 포함하는 활성화 가능한 항체 및 활성화 가능한 항체-약물 접합체("AADC")의 결합 친화도를 유세포측정에 의해 평가하였다. 특히, 항체 huEpCAM23Gv4.2, 효소 민감성 기질 3014, 및 Ep1-2, Ep-2, Ep03, Ep04, Ep05, Ep07 및 Ep11로부터 선택된 마스크를 이용하여 활성화 가능한 항체 및 활성화 가능한 항체 약물 접합체를 생성하였다. 음성 대조군으로서 사용하기 위해 비-절단성 펩타이드 모이어티("NSUB" 또는 "비-기질")에 의해 항체에 연결된 마스크를 포함하는 활성화 가능한 항체를 또한 생성하였다. NSUB는 프로테아제에 대한 기질이 아니며, 마스크는 NSUB를 포함하는 활성화 가능한 항체로부터 제거할 수 없다. 따라서, NSUB를 포함하는 활성화 가능한 항체는 uPA로 처리 후조차 비활성으로 남아있는 것으로 예상되었다.
시험관내 EpCAM 활성화 가능한 항체/AADC 활성화
시험관내 기질화된 EpCAM 활성화 가능한 항체를 활성화시키기 위해, 목적하는 양의 활성화 가능한 항체를 1㎎/㎖에서 PBS 중에서 제조하고, uPA를 (단백질 농도를 기준으로) 1μM의 최종 농도로 용액에 첨가하였다. 이어서, 용액을 밤새 습윤화된 5% CO2 인큐베이터에서 37℃에서 인큐베이션시켰다.
EpCAM 활성화 가능한 항체 결합 친화도
HSC2 세포에 대한 EpCAM 활성화 가능한 항체의 결합 친화도를 모 항체 huEpCAM23Gv4.2의 결합 친화도와 그리고 활성화 형태와 비활성화된 형태 간에 비교하였다. 활성화 가능한 항체를 상기 기재한 바와 같이 활성화하였다. 유세포측정 결합 분석을 수행하고, 2차 Alexa Flour plus 488 접합 염소-항-인간 항체를 이용하여 실시예 2에 기재한 바와 같이 분석하였다. 도 6A에 나타낸 바와 같이, 활성화 없이 활성화 가능한 항체는 겉보기 Kd > 1×10-7M로 세포에 대해 매우 불량한 결합을 갖는 반면, 활성화된 활성화 가능한 항체는 모 항체의 결합 친화도와 유사한 수준으로 결합 친화도를 보유하였다. cyno 1차 신장 세포를 이용하여 활성화 가능한 항체 중 5개에 대해 추가 시험을 수행하였고, 유사한 결과가 관찰되었다(도 6B 참조). 비활성화된 활성화 가능한 항체에 대한 활성화된 활성화 가능한 항체의 겉보기 Kd 값은 HSC2와 cyno 1차 신장 상피세포 둘 다에서 10배 초과만큼 상이하였다.
항-huEpCAM23Gv4.2 항체와 그리고 항-huEpCAM23Gv4.2-Ep05-3014 활성화 가능한 항체와 접합된 sSPDB-DM4 및 DGN549의 결합 친화도
huEpCAM23Gv4.2의 sSPDB-DM4 및 DGN549 ADC 접합체 및 3014/NSUB 및 다양한 마스크에 의해 기질화된 huEpCAM23Gv4.2의 활성화된 AADC의 결합 친화도를 HSC2 세포를 이용하여 분석하였다. 활성화 가능한 항체를 상기 기재한 바와 같이 활성화하였다. 유세포측정 결합 분석을 수행하고, 2차 Alexa Flour plus 488 접합 염소-항-인간 항체를 이용하여 실시예 2에 기재한 바와 같이 분석하였다. 특히, 3014로 기질화된 활성화된 DGN549 AADC의 결합 친화도를 DGN549 ADC의 결합 친화도와 비교하였고, 3014로 기질화된 활성화된 sSPDB-DM4 AADC를 sSPDB-DM4 ADC 및 이들의 NSUB 형태 상대와 비교하였다. sSPDB-DM4 접합체에 대한 결합 곡선을 도 7A에 제공하고, DGN549 접합체에 대한 결합 곡선을 도 7B에 제공한다. 도 7A 및 도 7B에 나타낸 바와 같이, 활성화된 AADC는 대응하는 ADC와 유사한 HSC2 세포에 대한 결합을 가졌다. 대조적으로, NSUB AADC는 세포에 대해 불량한 결합을 나타내었다. 이들 데이터는 세포에 대한 활성화 가능한 항체의 결합 능력이 3014 기질을 통해(NSUB 기질을 통해서는 아님) 활성화 가능한 항체로부터의 마스크를 제거하는 uPA에 의한 처리에 의해 회복될 수 있다는 것을 입증한다.
실시예 9: huEpCAM23Gv4.2-Ep05-3014 및 huEpCAM23Gv4.2-Ep05-2014와 접합된 sSPDB-DM4, DM21 및 DGN549의 결합 친화도
Ep05 마스크와 함께 huEpCAM23Gv4.2를 포함하는 추가적인 활성화 가능한 항체를 다른 기질인 2014로 생성하였다. 추가 평가를 위해 sSPDB-DM4, DM21L 및 DGN549를 huEpCAM23Gv4.2-Ep05-3014에 접합시킴으로써 그리고 sSPDB-DM4 및 DM21L을 huEpCAM23Gv4.2-Ep05-2014에 접합시킴으로써 AADC를 생성하였다. HSC2 세포에 대한 접합체의 결합 친화도를 활성화 형태와 비-활성화 형태 둘 다에서 분석하였고, AADC의 친화도를 대응하는 활성화 가능한 항체와 야생형 항체 둘 다와 비교하였다. 유세포측정 결합 분석을 수행하고, 2차 PE-접합 염소-항-인간 항체를 이용하여 실시예 2에 기재한 바와 같이 분석하였다. 활성화 가능한 항체 및 AADC를 실시예 8에 기재한 바와 같이 활성화하였다. huEpCAM23Gv4.2-Ep05-2014-sSPDB-DM4, huEpCAM23Gv4.2-Ep05-3014-sSPDB-DM4 및 huEpCAM23Gv4.2-Ep05-3014-DGN549의 결합 친화도를 각각 도 8A, 도 8B 및 도 8C에 나타낸다. huEpCAM23Gv4.2-Ep05-3014-DM21L 및 huEpCAM23Gv4.2- Ep05-2014-DM21L의 결합 친화도를 도 8D에 나타낸다. 활성화된 활성화 가능한 항체 및 AADC는 야생형 항체와 유사한 HSC2 세포에 대한 결합 친화도를 갖는 한편, 비활성화 형태는 세포에 잘 결합하지 않았다. 이들 결과는 실시예 4 내지 6 및 8에 기재한 결과와 일치된다.
실시예 10: 에피토프 맵핑
인간 CD326 항원, EpCAM(상피세포 부착 분자)는 265-아미노산 세포외 도메인, 23-아미노산 막관통 도메인 및 26개 아미노산의 세포질 꼬리를 포함하는 314개의 아미노산으로 구성된다. 세포외 도메인을 3개의 도메인으로 추가로 나눌 수 있다(D1, D2 및 D3). 세포외 도메인은 성숙 단백질의 24번 위치에서(즉, 신호 펩타이드 절단 전에) 글루타민으로부터 59번 위치에서의 시스테인까지의 영역을 포함하는 제1 도메인(서열번호 2 참조), 및 66번 위치에서의 시스테인으로부터 135번 위치에서의 시스테인까지의 영역을 포함하는 제2 도메인(서열번호 3 참조)을 포함하는 2개의 시스테인 풍부 상피 성장 인자 유사(EGF-유사) 반복부를 포함한다. 이어서, 처음 2개의 도메인과 한 줄로, 아미노산 잔기 136 내지 243을 포함하는 무 시스테인 제3 도메인(D3)이 있다(서열번호 4 참조).

인간화 EpCAM 항체 Gv4.2에 대한 에피토프를 인간 및 마우스 EpCAM의 세포외 도메인의 조합을 이용하는 키메라 단백질을 조작함으로써 맵핑하였다. 인간 및 마우스 EpCAM은 82% 초과의 아미노산 서열 동일성 및 85% 유사성을 공유하기 때문에(도 9 참조), 키메라 단백질의 위상은 무손상으로 남아있어야 한다.
EpCAM 키메라 변이체 클로닝 및 발현
인간 EpCAM의 세포외 영역(잔기 1 내지 265)을 코돈 최적화하고, 합성하고 나서, Genscript에서 HindIII 및 BamHI 제한 부위를 이용하여 마우스 IgG2a Fc 영역을 포함하는 벡터(pGSmuFc2ANL)에 프레임내로 클로닝하였다. 유사하게, 인간/마우스 EpCAM 세포외 도메인의 다양한 키메라 변이체를 포함하는 다른 발현 벡터를 인간 EpCAM 도메인 D1(24-59), 도메인 D2(66-135), 도메인 D3(136-265) 또는 이들의 조합물에 대응하는 잔기를 대응하는 마우스 잔기로 대체함으로써 합성하였다. 도 10a 및 도 10b는 다양한 키메라화된 변이체의 세포외 영역의 정렬을 나타낸다. 이들 발현 작제물을 진탕 플라스크에서 형질감염 시약으로서 PEI를 이용하여 현탁액 적합화시킨 HEK-293T 세포에서 일시적으로 생성하였다. 형질감염을 1주 동안 인큐베이션시키고, 채취하고 나서, 여과시킨 상청액을 실시예 1에 기재한 것과 같은 절차를 본질적으로 이용하여 단백질 A 및 CHT 크로마토그래피의 조합을 이용하여 정제하였다.
다양한 EpCAM 작제물에 대한 항체 결합
상기 기재한 EpCAM 단백질에 대한 결합에 대해 인간화 EpCAM 항체 huEpCAM23Gv4.2를 효소-결합 면역흡착 분석(ELISA) 형식으로 시험하였다. 간략하게, 실시예 1에 본질적으로 기재한 바와 같은 단백질 A 및 CHT 크로마토그래피의 조합을 이용하여 각각의 mFc-태그된 EpCAM 단백질을 정제하였다. 각각의 mFc-태그된 EpCAM 단백질을 pH 9.6의 50mM 중탄산나트륨 완충제에서 0.5㎍/㎖까지 희석시키고, 100㎕를 각각의 웰에 첨가하였다. 4℃에서 16시간 동안 인큐베이션시킨 후에, 플레이트를 0.1% Tween-20(TBST)와 함께 Tris-완충제 식염수로 세척하고, 이어서, 200㎕의 차단 완충제(1% BSA와 함께 TBS)로 차단하였다. 다음에, 100㎕의 1차 항체인, 차단 완충제에서 연속 희석시킨 huEpCAM23Gv4.2를 ELISA 웰에 2회 첨가하였고, 실온에서 1시간 동안 인큐베이션시켰다. 이어서, 플레이트를 TBST로 3회 세척한 후에, 100㎕의 항-인간 IgG (H+L)-HRP를 각 웰에 첨가하였다. 플레이트를 다시 1시간 동안 실온에서 인큐베이션시킨 후에, TBST로 3회 세척하였다. 최종적으로, 100㎕의 TMB 일 성분 HRP 마이크로웰 기질을 각 웰에 첨가하고, 5분 동안 인큐베이션시켰다. 100㎕ 중단 용액을 첨가함으로써 반응을 중단시키고, 다중웰 플레이트 판독기 내 450㎚에서 흡광도를 판독하였다. OD450을 반대수 플롯에서 항체 농도에 대해 플롯팅하였다. 각 곡선의 비선형 회귀, 및 EC50 값에 의해 용량-반응 곡선을 생성하였고, 그래프패드 프리즘 v6을 이용하여 계산하였다.
키메라 EpCAM 단백질에 대한 huEpCAM23Gv4.2 항체의 결합을 야생형 EpCAM에 비교하여 평가하였다. 도 11은 huEpCAM23Gv4.2 항체가 야생형 EpCAM과 유사한 친화도로 EpCAM-D2(66-135) 및 EpCAM-D3(136-265) 둘 다에 결합한다는 것을 입증한다. 대조적으로, huEpCAM23Gv4.2 항체는 EpCAM-D1 및 D1/D2 작제물에 결합하지 않으며, 키메라 단백질 EpCAM-D1(24-59) 작제물에 대한 결합은 거의 제거된다. 이들 결과는 huEpCAM23Gv4.2 항체의 에피토프가 본래 EpCAM의 D1(24-59) 도메인 내에 위치된다는 것을 나타낸다.
실시예 11: EpCAM 항체 약물 접합체 및 활성화 가능한 항체 약물 접합체의 제조
huEpCAM23Gv4.2-설포-SPDB-DM4 접합체의 제조
280, 343 및 412㎚에서의 UV/Vis 흡광도 값 및 흡광계수를 각각 이용하여 베르의 법칙(Beer's law)에 따라 huEpCAM23Gv4.2, 설포-SPDB 및 DM4의 몰농도를 계산하였다. 50mM 인산칼륨 완충제 pH 7.5에서 링커를 50mM DTT와 반응시키고 343㎚에서 티오피리딘 방출을 측정함으로써 링커 농도를 결정하였다. pH 7.5의 50mM 인산칼륨 완충제에서 DM4를 10mM DTNB [5,5-다이티오비스-(2-나이트로벤조산)]를 반응하고 412㎚에서의 흡광도를 측정함으로써 약물 농도를 결정한다.
항체 접합 전에, 30% 수성[50mM EPPS pH 8.0 (4-(2-하이드록실에틸)-피페라진프로판설폰산)] 및 70% 유기[(N-N-다이메틸아세트아마이드, DMA, SAFC)] 중 20℃에서 90분 동안 5.0mM 설포-SPDB를 6.3mM DM4와 반응시킴으로써 설포-SPDB-DM4 인시추 혼합물을 제조하였다. 접합 반응 동안, 8 내지 10㎎/㎖의 항체 용액을 15 내지 20시간 동안 25℃에서 50mM EPPS pH 8.0에서 항체에 대해 5 내지 6배 몰 과량의 설포-SPDB-DM4를 8% DMA(v/v)와 반응시켰다. NAP 탈염 칼럼을 이용하여 반응물을 10mM 히스티딘, 250mM 글리신, 1% 수크로스 및 0.01% Tween-20, pH 5.0 제형 완충제로 정제하고, 0.22㎛ PVDF 막을 이용하여 주사기 필터를 통해 여과시켰다.
항체에 접합된 DM4의 몰비(DAR) 및 비접합 메이탄시노이드 종의 백분율을 이하에 기재하는 바와 같이 결정하였다. 정제된 접합체는 UV-Vis에 의해 3.7㏖ DM4/㏖ 항체, SEC에 의해 95% 단량체, 및 HPLC Hisep 칼럼 분석에 의해 1% 미만의 유리 약물을 갖는 것을 발견하였다.
252 및 280㎚에서의 UV/Vis 흡광도를 측정하고, 각 성분의 기여를 설명하는 이항식을 이용하여 [Ab] 및 [DM4]를 계산함으로써 DAR을 결정하였다. HISEP 칼럼(25㎝×4.6 ㎜, 5㎛)을 통해 분석한 샘플에서 관찰된 얻어진 피크 면적으로부터 최종 huEpCAM23Gv4.2-설포-SPDB-DM4 접합체에 존재하는 비결합 메이탄시노이드의 양을 계산하였다. 다음의 식을 이용하여 접합체 샘플에 존재하는 유리 메이탄시노이드 백분율(FM%)을 계산하였다: 메이탄시노이드% = (DM4로 인한 역상 PA 252) /(DM4로 인한 역상 PA 252 + DM4로 인한 PA 252를 통한 유동)×100%.
huEpCAM23Gv4.2 Ep05-3014-설포-SPDB-DM4 AADC 접합체의 제조
항체 접합 전에, 30% 수성[50mM EPPS pH 8.0 (4-(2-하이드록실에틸)-피페라진프로판설폰산)] 및 70% 유기[(N-N-다이메틸아세트아마이드, DMA, SAFC)] 중 20℃에서 90분 동안 5.0mM 설포-SPDB를 6.3mM DM4와 반응시킴으로써 설포-SPDB-DM4 인시추 혼합물을 제조하였다. 접합 반응 동안, 8 내지 10㎎/㎖의 항체 용액을 4 내지 5시간 동안 25℃에서 50mM EPPS pH 8.0에서 항체에 대해 5 내지 6배 몰 과량의 설포-SPDB-DM4를 8% DMA(v/v)와 반응시켰다. NAP 탈염 칼럼을 이용하여 반응물을 10mM 히스티딘, 250mM 글리신, 1% 수크로스 및 0.01% Tween-20, pH 5.0 제형 완충제로 정제하고, 0.22㎛ PVDF 막을 이용하여 주사기 필터를 통해 여과시켰다. 정제된 접합체는 UV-Vis에 의해 3.6㏖ DM4/㏖ 활성화 가능한 항체, SEC에 의해 98% 단량체, 및 HPLC Hisep 칼럼 분석에 의해 1% 미만의 유리 약물을 갖는 것을 발견하였다.
huEpCAM23Gv4.2 Ep05-2014-설포-SPDB-DM4 AADC 접합체의 제조
항체 접합 전에, 30% 수성[50mM EPPS pH 8.0 (4-(2-하이드록실에틸)-피페라진프로판설폰산)] 및 70% 유기[(N-N-다이메틸아세트아마이드, DMA, SAFC)] 중 20℃에서 90분 동안 5.0mM 설포-SPDB를 6.3mM DM4와 반응시킴으로써 설포-SPDB-DM4 인시추 혼합물을 제조하였다. 접합 반응 동안, 8 내지 10㎎/㎖의 항체 용액을 4 내지 5시간 동안 25℃에서 50mM EPPS pH 8.0에서 항체에 대해 5 내지 6배 몰 과량의 설포-SPDB-DM4를 8% DMA(v/v)와 반응시켰다. NAP 탈염 칼럼을 이용하여 반응물을 10mM 히스티딘, 250mM 글리신, 1% 수크로스 및 0.01% Tween-20, pH 5.0 제형 완충제로 정제하고, 0.22㎛ PVDF 막을 이용하여 주사기 필터를 통해 여과시켰다. 정제된 접합체는 UV-Vis에 의해 3.6㏖ DM4/㏖ 활성화 가능한 항체, SEC에 의해 98% 단량체, 및 HPLC Hisep 칼럼 분석에 의해 1% 미만의 유리 약물을 갖는 것을 발견하였다.
huEpCAM23Gv4.2 Ep05-NSUB-설포-SPDB-DM4 AADC 접합체의 제조
항체 접합 전에, 30% 수성[50mM EPPS pH 8.0 (4-(2-하이드록실에틸)-피페라진프로판설폰산)] 및 70% 유기[(N-N-다이메틸아세트아마이드, DMA, SAFC)] 중 20℃에서 90분 동안 5.0mM 설포-SPDB를 6.3mM DM4와 반응시킴으로써 설포-SPDB-DM4 인시추 혼합물을 제조하였다. 접합 반응 동안, 8 내지 10㎎/㎖의 항체 용액을 4 내지 5시간 동안 25℃에서 50mM EPPS pH 8.0에서 항체에 대해 5 내지 6배 몰 과량의 설포-SPDB-DM4를 8% DMA(v/v)와 반응시켰다. NAP 탈염 칼럼을 이용하여 반응물을 10mM 히스티딘, 250mM 글리신, 1% 수크로스 및 0.01% Tween-20, pH 5.0 제형 완충제로 정제하고, 0.22㎛ PVDF 막을 이용하여 주사기 필터를 통해 여과시켰다. 정제된 접합체는 UV-Vis에 의해 3.8㏖ DM4/㏖ 활성화 가능한 항체, SEC에 의해 99% 단량체, 및 HPLC Hisep 칼럼 분석에 의해 1% 미만의 유리 약물을 갖는 것을 발견하였다.
huEpCAM23Gv4.2-GMBS-DM21L 접합체의 제조
280, 343 및 412㎚에서의 UV/Vis 흡광도 값 및 흡광계수를 각각 이용하여 베르의 법칙(Beer's law)에 따라 huEpCAM23Gv4.2, 설포-GMBS 및 DM21의 몰농도를 계산하였다. 50mM 인산칼륨 완충제 pH 7.5에서 링커를 50mM DTT와 반응시키고 343㎚에서 티오피리딘 방출을 측정함으로써 링커 농도를 결정하였다. pH 7.5의 50mM 인산칼륨 완충제에서 DM21을 10mM DTNB [5,5-다이티오비스-(2-나이트로벤조산)]를 반응하고 412㎚에서의 흡광도를 측정함으로써 약물 농도를 결정한다.
접합 전에, 60/40 (v/v) DMA 및 석신산염 완충제 pH 5.0에서 각각 3mM 설포-GMBS를 3.9mM DM21와 반응시킴으로써 설포-GMBS-DM21 인시추 혼합물을 제조하였다. 60mM 4-(2-하이드록시에틸)-1-피페라진프로판설폰산(EPPS) pH 8.5 중 5㎎/㎖ 항체 이상으로 과량의 설포-GMBS-DM21의 6-7 링커와 15% DMA(v/v)와의 접합을 수행하였다. 25℃에서 4 내지 5시간 인큐베이션 후에, 탈염 칼럼을 이용하여 반응물을 10mM 히스티딘, 250mM 글리신, 1% 수크로스, 및 0.01% Tween-20, pH 5.0에 정제하고, 0.22㎛ PVDF 막 필터를 통해 여과시켰다.
항체에 접합된 DM21의 몰비(DAR) 및 비접합 메이탄시노이드 종의 백분율을 이하에 기재하는 바와 같이 결정하였다. 정제된 접합체는 UV-Vis에 의해 3.7㏖ DM21/㏖ 항체, SEC에 의해 95% 단량체, 및 HPLC Hisep 칼럼 분석에 의해 1% 미만의 유리 약물을 갖는 것을 발견하였다.
252 및 280㎚에서의 UV/Vis 흡광도를 측정하고, 각 성분의 기여를 설명하는 이항식을 이용하여 [Ab] 및 [DM21]를 계산함으로써 항체에 접합된 DM21(DAR)의 몰비를 결정하였다. HISEP 칼럼(25㎝×4.6 ㎜, 5㎛)을 통해 분석한 샘플에서 관찰된 얻어진 피크 면적으로부터 최종 huEpCAM23Gv4.2-GMBS-DM21 접합체에 존재하는 비결합 메이탄시노이드의 양을 계산하였다. 다음의 식을 이용하여 접합체 샘플에 존재하는 유리 메이탄시노이드 백분율(FM%)을 계산하였다: 메이탄시노이드% = (DM21로 인한 역상 PA 252)/(DM21로 인한 역상 PA 252 + DM21로 인한 PA 252를 통한 유동)×100%.
huEpCAM23Gv4.2 Ep05-3014-GMBS-DM21L 접합체의 제조
접합 전에, 60/40(v/v) DMA 및 석신산염 완충제 pH 5.0에서 각각 3mM 설포-GMBS를 3.9mM DM21와 반응시킴으로써 설포-GMBS-DM21 인시추 혼합물을 제조하였다. 60mM 4-(2-하이드록시에틸)-1- 피페라진프로판설폰산(EPPS) pH 8.5 중 5㎎/㎖로 활성화 가능한 항체 이상으로 과량의 설포-GMBS-DM21의 6-7 링커와 15% DMA(v/v)와의 접합을 수행하였다. 25℃에서 4 내지 5시간 인큐베이션 후에, 탈염 칼럼을 이용하여 반응물을 10mM 히스티딘, 250mM 글리신, 1% 수크로스, 및 0.01% Tween-20, pH 5.0에 정제하고, 0.22㎛ PVDF 막 필터를 통해 여과시켰다. 정제된 접합체는 UV-Vis에 의해 3.6㏖ DM21/㏖ 활성화 가능한 항체, SEC에 의해 99% 단량체, 및 HPLC Hisep 칼럼 분석에 의해 1% 미만의 유리 약물을 갖는 것을 발견하였다.
huEpCAM23Gv4.2 Ep05-2014-GMBS-DM21L 접합체의 제조
접합 전에, 60/40(v/v) DMA 및 석신산염 완충제 pH 5.0에서 각각 3mM 설포-GMBS를 3.9mM DM21와 반응시킴으로써 설포-GMBS-DM21 인시추 혼합물을 제조하였다. 60mM 4-(2-하이드록시에틸)-1- 피페라진프로판설폰산(EPPS) pH 8.5 중 5㎎/㎖로 활성화 가능한 항체 이상으로 과량의 설포-GMBS-DM21의 6-7 링커와 15% DMA(v/v)와의 접합을 수행하였다. 25℃에서 4 내지 5시간 인큐베이션 후에, 탈염 칼럼을 이용하여 반응물을 10mM 히스티딘, 250mM 글리신, 1% 수크로스, 및 0.01% Tween-20, pH 5.0에 정제하고, 0.22㎛ PVDF 막 필터를 통해 여과시켰다. 정제된 접합체는 UV-Vis에 의해 3.6㏖ DM21/㏖ 활성화 가능한 항체, SEC에 의해 99% 단량체, 및 HPLC Hisep 칼럼 분석에 의해 1% 미만의 유리 약물을 갖는 것을 발견하였다.
huEpCAM23Gv4.2-DGN549 접합체의 제조(라이신 결합)
280 및 330㎚에서의 UV/Vis 흡광도 값 및 이들의 흡광계수를 각각 이용하여 베르의 법칙(Beer's law)에 따라 huEpCAM23Gv4.2, SO3-DGN549-NHS의 몰농도를 계산하였다. DMA에서 DGN549-NHS 약물 저장액을 제조하고, 330㎚ 흡광도를 측정하기 위해 에탄올에 희석시켰다. 90% DMA 및 10% 50mM 석신산염 pH 5.0에서 DGN549-NHS 이상으로 5 내지 10몰 과량의 NaHSO3을 첨가함으로써 실온에서 3 내지 4시간 동안 DGN549-NHS 설폰화 반응을 수행하였다.
50mM EPPS pH 8.0, 15% DMA(v/v) 중 2㎎/㎖의 항체 이상으로 4 내지 5 몰 과량의 설폰산염화된 DGN549-NHS 시약(D2)을 반응시킴으로써 huEpCAM23Gv4.2-DGN549 접합체를 생성하였다. 25℃에서 3 내지 5시간 동안 반응을 수행하였다. 10mM 히스티딘, 250mM 글리신, 1% 수크로스 및 0.01% Tween-20, 50μM 중아황산나트륨, pH 5.0를 함유하는 완충제에서 평형상태로 만든 세파덱스 G-25 칼럼을 통해 반응 혼합물을 정제하고, 0.22㎛ PVDF 필터에 대해 여과시켰다. 항체당 DGN549의 몰비(DAR) 및 총 유리 DGN549 종의 백분율을 이하에 기재한 바와 같이 결정하였다. 비접합 DGN549로서 1% 미만으로 제시되는 항체당 2.7 DGN549 분자와의 huEpCAM23Gv4.2-DGN549 접합체를 얻었다.
DGN 접합체에 대해, 280 및 330㎚에서의 UV/Vis 흡광도를 측정하고, 베르의 법칙에 따라 [Ab] 및 [DGN549]를 계산함으로써 DAR을 결정하였다. 비접합 DGN549의 양을 결정하기 위해, 이중칼럼 시스템(TOSOH SEC QC-PAK GFC 300 및 Agilent Zorbax C18 칼럼)을 통해 접합체를 통과시켜 유리 DGN549에 대한 총 AUC를 계산하였다. 유리 DGN549를 총 DGN549에 대한 비접합 DGN549의 비로서 보고하였다.
huEpCAM23Gv4.2-Ep05-3014-DGN549 접합체의 제조(라이신 결합)
50mM EPPS pH 8.0, 15% DMA(v/v) 중 2㎎/㎖의 활성화 가능한 항체 이상으로 4 내지 5 몰 과량의 설폰산염화된 DGN549-NHS 시약(D2)을 반응시킴으로써 huEpCAM23Gv4.2-DGN549 접합체를 생성하였다. 25℃에서 3 내지 5시간 동안 반응을 수행하였다. 10mM 히스티딘, 250mM 글리신, 1% 수크로스 및 0.01% Tween-20, 50μM 중아황산나트륨, pH 5.0를 함유하는 완충제에서 평형상태로 만든 세파덱스 G-25 칼럼을 통해 반응 혼합물을 정제하고, 0.22㎛ PVDF 필터에 대해 여과시켰다. 비접합 DGN549로서 1% 미만으로 제시되는 활성화 가능한 항체당 2.6 DGN549 분자와의 접합체를 얻었다.
huEpCAM23Gv4.2-Ep05-2014-DGN549 접합체의 제조(라이신 결합)
50mM EPPS pH 8.0, 15% DMA(v/v) 중 2㎎/㎖의 활성화 가능한 항체 이상으로 4 내지 5 몰 과량의 설폰산염화된 DGN549-NHS 시약(D2)을 반응시킴으로써 huEpCAM23Gv4.2-DGN549 접합체를 생성하였다. 25℃에서 3 내지 5시간 동안 반응을 수행하였다. 10mM 히스티딘, 250mM 글리신, 1% 수크로스 및 0.01% Tween-20, 50μM 중아황산나트륨, pH 5.0를 함유하는 완충제에서 평형상태로 만든 세파덱스 G-25 칼럼을 통해 반응 혼합물을 정제하고, 0.22㎛ PVDF 필터에 대해 여과시켰다. 비접합 DGN549로서 1% 미만으로 제시되는 활성화 가능한 항체당 2.8 DGN549 분자와의 접합체를 얻었다.
huEpCAM23Gv4.2-Ep05-NSUB-DGN549 접합체의 제조(라이신 결합)
50mM EPPS pH 8.0, 15% DMA(v/v) 중 2㎎/㎖의 활성화 가능한 항체 이상으로 4 내지 5 몰 과량의 설폰산염화된 DGN549-NHS 시약(D2)을 반응시킴으로써 huEpCAM23Gv4.2-DGN549 접합체를 생성하였다. 25℃에서 3 내지 5시간 동안 반응을 수행하였다. 10mM 히스티딘, 250mM 글리신, 1% 수크로스 및 0.01% Tween-20, 50μM 중아황산나트륨, pH 5.0를 함유하는 완충제에서 평형상태로 만든 세파덱스 G-25 칼럼을 통해 반응 혼합물을 정제하고, 0.22㎛ PVDF 필터에 대해 여과시켰다. 비접합 DGN549로서 1% 미만으로 제시되는 활성화 가능한 항체당 2.9 DGN549 분자와의 접합체를 얻었다.
huEpCAM23Gv4.2-C442-DGN549 접합체의 제조
표준 절차를 이용하여 환원 상태의 2개의 짝지어지지 않은 시스테인 잔기를 보유하는 huEpCAM23Gv4.2-C442 항체를 제조하였다. 2% v/v DMA 및 38% v/v 프로필렌 글리콜과 함께 5mM EDTA, pH 6.0 및 10 몰 당량의 Mal-DGN549(또는 D5, DMA 중 8.2mM 저장 용액으로서)를 함유하는PBS 중 1㎎/㎖의 최종 항체 농도에서 이 중간체를 이용하여 접합 반응을 수행하였다. 25℃에서 수욕 내 15 내지 20시간 동안 접합 반응을 수행하였다. 접합체를 세파덱스 G-25 칼럼을 통해 10mM 히스티딘, 250mM 글리신, 1% 수크로스, 0.01% Tween-20 및 50μM 중아황산나트륨, pH 5.0 완충제에 정제하였고, 0.22㎛ PVDF 주사기 필터를 통해 여과시켰다. 비접합 DGN549로서 1% 미만으로 제시되는 항체당 2.0 DGN549 분자와의 접합체를 얻었다.
실시예 12: EpCAM 항체 및 EpCAM 활성화 가능한 항체 접합체의 시험관내 세포독성
EpCAM-표적화 항체-약물 접합체(ADC) 및 활성화 가능한 항체-약물 접합체(AADC)가 종양 세포를 사멸시키는 능력을 시험관내 세포독성 분석을 이용하여 측정하였다. 특이적 사멸을 평가하기 위해, 차단 항체를 이용하여 그리고 차단 항체 없이 항-EpCAM ADC 효능을 측정하였다. 간략하게, 표적 세포를 ATCC에 의해 권장되는 100㎕의 완전 세포 배양 배지에서 웰당 2000개의 세포로 플레이팅하였다. 50㎕/웰의 배지 단독(비차단 조건) 또는 네이키드 EpCAM 항체(차단에 대해)를 500 nM로 용액에 첨가하였다. 접합체를 완전 세포 배양 배지에서 연속 희석하고, 50㎕의 각 희석물을 웰당 첨가하였다. 접합체의 최종 농도는 전형적으로 1.5×10-13M 내지 5×10-8M의 범위였다. 이어서, 세포를 5 내지 6일 동안 습윤화된 5% CO2 인큐베이터에서 37℃에서 인큐베이션시키고, 남아있는 세포의 생존도를 비색 WST-8 분석에 의해 결정하였다. WST-8은 생세포에서 탈수소효소에 의해 조직 배양 배지에서 가용성인 오렌지색 포마잔 생성물로 환원시키고, 생성된 포마잔의 양은 생세포 수에 바로 비례된다. WST-8을 10%의 최종 용적까지 첨가하고, 플레이트를 습윤화된 5% CO2 인큐베이터에서 추가 2 내지 4시간 동안 37℃에서 인큐베이션시켰다. 플레이트를 다중웰 플레이트 판독기에서 450㎚에서의 흡광도(A450)를 측정함으로써 분석하고, 배지 및 WST-8 단독을 갖는 웰의 배경 A450 흡광도를 모든 값으로부터 차감하였다. 각각의 처리 샘플값을 비처리 세포를 갖는 웰의 평균값으로 나누어서 생존도 백분율을 계산하였다. 생존도 백분율 = 100*(A450 처리 샘플 - A450 배경)/(A450비처리 샘플 - A450 배경). 생존도 백분율 값을 각 처리에 대한 반대수 플롯의 항체 농도에 대해 플롯팅하고, 각 곡선의 비선형 회귀, 및 EC50 값에 의해 용량-반응 곡선을 생성하였고, 그래프패드 프리즘 6을 이용하여 계산하였다.
NSCLC, CRC 및 HNC에서의 EpCAM ADC 시험관내 세포독성 활성
EpCAM-발현 NSCLC 세포주 H1568, H292 및 H2110, CRC 세포주 LoVo, 및 HNC 세포주 Detroit562에서의 EpCAM 항체 차단을 이용하여 그리고 이것 없이 huEpCAM23Gv4.2-sSBDP-DM4 접합체의 시험관내 세포독성을 평가하였다. 세포독성 분석으로부터의 결과를 도 12A 내지 도 12E에 나타낸다. 특히, huEpCAM23Gv4.2-sSBDP-DM4는 시험한 모든 5종의 세포주에서 특이적인 세포 사멸을 가졌다. 차단 없이 huEpCAM23Gv4.2-sSPDB-DM4 접합체에 대한 EC50 값은 H1568 세포에서 0.06nM, H292 세포에서 0.07nM, H2110 세포에서 0.09nM, Lovo 세포에서 0.02nM 및 Detroit562 세포에서 0.03 nM이었다. 대조적으로, 동일한 접합체의 EpCAM 항체 차단은 H1568 세포에서 3.9nM, H292 세포 2.2nM, H2110 세포에서 2.8nM, Lovo 세포에서 20nM 및 Detroit562 세포에서 1.4nM의 EC50값으로 세포 사멸을 초래하였다.
추가로, DGN549를 Lys 및 부위 특이적 C442 부위에서 각각 huEpCAM23Gv4.2에 접합시켰다. 접합체를 평가하고, H2110 세포를 이용하여 비-표적화 아이소타입 대조군 IgG1 접합체인 chKTI-DGN549와 비교하였다. 도 12F에 나타낸 바와 같이, 접합체인 huEpCAM23Gv4.2-lys-DGN549와 -C442-DGN549는 둘 다 유사한 EC50을 가졌고, chKTI-DGN549보다 100배 초과로 강력하였다.
추가적인 실험에서, DM21을 huEpCAM23Gv4.2에 접합시켰다. 4종의 NSCLC 세포주 및 1종의 두경부 세포주에서의 huEpCAM23Gv4.2 차단에 의해 그리고 차단 없이 huEpCAM23Gv4.2-DM21L 접합체의 효능을 분석하였다. 도 12G 내지 도 12K에 나타낸 결과는 huEpCAM23Gv4.2-DM21L 접합체가 시험한 5종의 세포주 모두에서 강력하고, 모 항체의 첨가에 의해 세포독성이 차단될 수 있다는 것을 나타낸다.
NSCLC 및 난소암세포 계통에서의 시험관내 세포독성 활성 EpCAM AADC
huEpCAM23Gv4.2-sSPDB-DM4, DM21 및 DGN549 접합체를 이용하여 관찰된 시험관내 세포독성 활성을 확장시키기 위해, 동일한 페이로드를 이용하여 EpCAM AADC를 제조하였다. 특히, sSPDB-DM4 및 DM21L을 활성화 가능한 항체 huEpCAM-Ep05-3014 및 huEpCAM-Ep05-2014에 접합시켰고, DGN549를 huEpCAM23Gv4.2-3014에 접합시켰다. DM4, DM21 및 DGN549 접합체의 활성을 NSCLC 세포주 Calu3, EBC-1 및 H2110에서 분석하였다. 또한, DM21L AADC를 Detroit562 세포에서 시험하고, DM4 및 DGN549 AADC를 OV90 세포에서 각각 시험하였다. 활성화 및 비활성화된 형태에서 AADC의 효능을 평가하고, 이들의 상대 EpCAM-표적화된 ADC와 또는 비-표적화 아이소타입 대조군 IgG1 접합체인 chKTI ADC와 비교하였다. 시험관내 AADC 활성화를 실시예 8에 기재한 바와 같이 수행하였다. 전형적인 세포독성 분석으로부터의 결과를 도 13 내지 도 15에 나타낸다. 특히, DM4 접합체의 시험관내 활성을 도 13A 내지 도 13D에 나타내고, DM21L 접합체의 시험관내 활성을 도 14A 내지 도 14D에 나타내며, DGN549 접합체의 시험관내 활성을 도 15A 내지 도 15D에 나타낸다. 예상한 바와 같이, 활성화된 AADC는 EpCAM-특이적 ADC와 유사한 활성을 갖고, 비-활성화된 AADC는 세포에 대해 훨씬 덜 강력하다. EC50 값은 sSPDB-DM4 ADC에 대해 0.06 내지 0.46nM 및 활성화된 sSPDB-DM4 AADC에 대해 0.08nM 내지 1.4nM의 범위였다(표 23 참조). 활성화된 DM21 AADC에 대한 EC50은 0.3 내지 2nM의 범위였다(표 24 참조). 추가적으로, huEpCAM-DGN549 ADC 및 활성화된 huEpCAM-Ep05-3014-DGN549 AADC는 매우 강력하였고, EC50 값은 ADC에 대해 0.006 내지 0.02nM 범위이고, AADC에 대해 0.017 내지 0.06 nM이었다(표 25). 이들 결과는 ADC와 AADC 접합체 둘 다에 대해 양호한 특이성 창이 관찰되었는데, 세포독성이 표적 세포에 대한 항-EpCAM 항체 결합의 결과라는 것을 시사한다는 것을 나타낸다.



추가적인 마스크를 포함하는 huEpCAM23Gv4.2-DGN549 AADC의 시험관내 효능을 또한 평가하고, 개개 마스크 효율과 비교하였다. 표 26에 나타낸 바와 같이, huEpCAM23Gv4.2 AADC의 시험환내 활성의 창은 마스크 효율과 상당히 상관관계가 있다.

실시예 13: NCI-H2110 인간 NSCLC 이종이식편을 보유하는 CB17 SCID 마우스에서의 EpCAM ADC 및 AADC의 활성
3014 또는 2014 기질 중 하나와 함께 마스킹된 항체를 포함한 다양한 용량의 EpCAMG23v4.2-DGN549 및 huEpCAMG23v4.2-s-SPDB-DM4 항체-약물 접합체(ADC)뿐만 아니라 이들의 유래된 활성화 가능한 항체-약물-접합체(AADC)의 항종양 활성을 일련의 생체내 연구에서 평가하였다. NCI-H2110 종양, 인간 NSCLC 피하 이종이식 모델을 보유하는 6 내지 8주령 암컷 CB17 SCID 마우스(CB17/lcr-PrdxSCID)에서 연구를 수행하였다. 동물을 Charles River Laboratories로부터 얻었고, 연구에 배정하기 전에 5일의 관찰 기간 동안 질환 또는 질병의 징후는 나타내지 않았다.
NCI-H2110 세포를 98% 초과의 세포 생존도와 일치되게 조직 배양물로부터 채취하고, 트립판 블루 절단에 의해 결정하였다. 각각의 마우스에 27게이지 바늘을 이용하여 우측 옆구리 상에 피하 주사에 의해 무혈청 배지 및 매트리겔(Matrigel)(SFM:Mat)의 0.1㎖의 1:1 용액에서 107개의 NCI- H2110 세포를 접종하였다. 종양 용적(TV)에 기반하여 물품(시험 제제 및 비히클 대조군)의 투여 전에 마우스를 처리군으로 무작위화하였다. 개개 체중(BW)에 기반하여 다음날 물품을 동물에 투여하였다. 물품을 27-게이지 바늘으로 적합화시킨 1.0㎖ 주사기를 이용하여 단일 i.v. 볼루스로서 투여하였다.
종양 용적(TV) 및 체중(BW) 측정을 주당 2회 StudyDirector 소프트웨어에서 기록하였다. 다음과 같은 원통 용적에 대한 식에 따라 캘리퍼 측정으로부터 종양 용적(㎣)을 추정하였다: TV(㎣) = (L×W×H)/2, 여기서 L, W 및 H는 각각의 직교 종양 길이, 폭 및 높이 측정(㎜)이다. 처리 동물에서의 체중 변화(BWC)에 따라 마우스에 대한 체중(g)을 사용하였고, 다음과 같이 계산한 전처리, 초기 체중(BWi)와 비교되는 주어진 측정 시간에서의 체중(BWt) 백분율로서 표현한다: BWC% = [(BWt / BWi) - 1]×100.
치료 효능을 평가하기 위해 사용한 1차 종말점은 종양 성장 저해 및 종양 퇴행이었다. 종양 성장 저해(TGI)는 대조군 위약군(C)의 중위 TV가 1000㎣에 가까운 크기에 도달될 때의 처리군(T)의 중위 TV 비이며, 다음의 식을 이용하여 무작위 시 초기 TV의 백분율로서 표현한다: TGI = T/C×100. NCI 표준에 따라, 42% 미만의 TGI는 최소 수준의 항-종양 활성(활성에 대해 A로 표시)이며, 10% 미만의 TGI는 높은 항-종양 활성 수준(고도 활성에 대해 HA로 표시)으로 간주하는 한편, 42% 초과의 TGI에 의한 처리는 비활성(IA)으로 간주한다. 마우스는 처리 시의 TV에 비해 50% 이상만큼 TV가 감소될 때 부분적 퇴행(PR)을 갖는 것으로 정의되고, 감지할 수 있는 종양이 검출되지 않을 때 완전한 종양 퇴행(CR)으로 정의되며, 연구 종료 시(EoS) 종양이 없다면 무종양 생존자(TFS)로서 정의한다.
LCK(log 세포 사멸) 활성 및 증가된 수명(ILS)에 의해 측정할 때, 화합물 효능을 정하는 2차 종말점은 종양 성장 지연이다. 다음 식에 따라 LCK 활성을 계산한다: LCK = (T-C)/(Td×3.32), 여기서 시간을 지나 대조군(비히클) 그룹의 중위 TV에 대해 결정할 때, T는 그룹의 중위 생존(일수)이고, TFS를 제외하며, C는 대조군의 중위 생존(일수)이고, Td는 종양 배가 시간(일수)이다. NCI 표준에 따르면, 2.8 초과의 LCK는 고도로 활성(++++)인 화합물을 정의하며, [0.7; 2.8]의 LCK는 활성인 한편(3 수준이 정의됨), 0.7 미만의 LCK는 비활성을 정의한다(-). 증가된 수명(ILS)은 다음의 식에 따라, 대조군(C)과 비교되는 처리군(T)(모든 동물을 포함)의 중위 생존 백분율로서 표현한다
ILS = (T-C)/C×100. NCI 표준에 따라, 25% 초과의 ILS는 최소 수준의 활성을 나타내는 한편, 50% 초과의 ILS는 고수준의 활성의 나타낸다.
종양이 1000㎣를 초과하거나; 동물이 대략의 독성 지표인 이들의 초기 체중의 20% 초과를 상실하거나(BWC% < -20%); 종양이 괴사되거나; 또는 연구 동안의 임의의 시점에 마우스가 빈사 상태라면, 마우스를 안락사시켰다.
huEpCAMG23v4.2-DGN549의 생체내 효능
마우스에 접종하고 나서, 접종 후 6일(dpi)에 6마리 마우스의 그룹으로 무작위화시켰다.
각 그룹에 대한 평균 종양 용적(TV)은 118 내지 122.1㎣였다. 접종 후 116일에 연구를 종료하였다(EOS = 116dpi).
처리군은 위약 대조군 투여 비히클(200㎕/㎳) 및 3개의 huEpCAMG23v4.2-DGN549 ADC 그룹을 포함하였고, 각각 0.5, 1.5 및 3㎍/㎏으로 투여하고, 모든 용량은 약물 농도를 기준으로 하였다.
본 연구에서, TGI를 27 dpi에서 결정하고, 대조군 위약그룹의 중위 TV는 1070.4㎣에 도달되었다.
연구 결과를 도 16에 나타낸다. 표시된 용량에서 모든 처리는 잘 용인되며, 체중 감소는 관찰되지 않았다. ADC huEpCAM23Gv4.2-DGN549는 3㎍/㎏에서 고도로 활성(HA)이었고, TGI 값은 1.8%, 6/6 PR, 3/6 CR 및 1/6 TSF였다. 더 나아가, 이 그룹은 또한 LCK = 1.77을 나타내고, 처리를 활성(++) 및 179% ILS(고도 활성)으로서 정량화하고, 이는 양호한 종양 성장 지연을 입증한다. ADC 투여 후 초기 시점에 3㎍/㎏ 요법의 종양 퇴행이 시작되었고, 처리 후 7일만큼 빨리 다수의 부분적 퇴행을 초래하였다. 특히, 1.5㎍/㎏ 용량은 활성이고, TGI 값은 31.6%이며, 1/6 PR 및 ILS는 46%였다(활성). 대조적으로, huEpCAM23Gv4.2-DGN549의 0.5㎍/㎏ 용량은 비활성이었다. 따라서, 이들 데이터는 huEpCAM23Gv4.2-DGN549에 의한 처리가 이 종양 모델에서 종양 퇴행의 높은 발생을 유도하며, 1.5㎍/㎏만큼 낮은 용량에서 강한 항-종양 활성을 초래한다는 것을 나타낸다.
3014 절단 가능 모이어티와 함께 Ep02, Ep01-02, Ep11 및 Ep04 마스킹 모이어티를 보유하는 마스킹된-EpCAM-DGN549의 효능
마우스에 접종하고 나서, 접종 후 6일(dpi)에 6마리 마우스의 그룹으로 무작위화시켰다.
각 그룹에 대한 평균 종양 용적(TV)은 105.8 내지 115.4㎣였다. 접종 후 120일에 연구를 종료하였다(EOS = 120dpi).
처리군은 약물 농도에 기반하여 3 및 5㎍/㎏으로 투여한 위약 대조군 투여 비히클(200㎕/㎳) 및 4개의 마스킹된-huEpCAMG23v4.2-DGN549 AADC 그룹(즉, 3014 기질에 연결된 마스크 Ep02, Ep01-02, Ep11 및 Ep04를 보유하는 AADC)을 포함하였다. 5㎍/㎏의 huEpCAM23Gv4.2-DGN549 ADC로 처리한 양성 대조군을 또한 본 연구에 포함시켰다.
본 연구에서, TGI를 25 dpi에서 결정하고, 대조군 위약(비히클) 그룹의 중위 TV는 1072.4㎣에 도달되었다.
연구 결과를 도 17A에 나타낸다. 표시된 용량에서 모든 처리는 잘 용인되며, 본 연구에서 체중 감소는 관찰되지 않았다.
ADC huEpCAM23Gv4.2-DGN549는 5㎍/㎏에서 고도로 활성(HA)이었고, 연구 종료일에 0.3%의 TGI 값, 6/6 PR, 6/6 CR, 6/6 무종양 동물, 및 380% ILS를 초래한 120 dpi였다.
Ep01-02-3014-DGN549는 5㎍/㎏에서 최소 활성, 34.5%의 TGI 및 48%의 ILS를 나타내었다. Ep11-3014-DGN549는 5㎍/㎏ 용량에서 활성이었고, 10.1% TGI, 1/6 PR, 0.89 LCK(+), 및 78% ILS였지만, 보다 저용량에서는 비활성이었다. Ep02-3014-DGN549 AADC는 3㎍/㎏에서 활성이며(38.6% TGI, 1/6 PR) 5 ug/kg에서 고도로 활성(9.9% TGI, 2/6 PR, 66% ILS)이었다. Ep04-3014-DGN549 AADC는 3㎍/㎏에서 활서잉고(19.7% TGI, 60% ILS), 5㎍/㎏에서 고도로 활성이며(4.2% TGI), 다수의 퇴행을 유도하고(6/6 PR, 1/6 CR), 그룹의 수명을 유의하게 증가시켰다(LCK = 1.48, 144% ILS). 따라서, 이들 데이터는 EpO4-DGN549 AADC에 의한 처리가 이 종양 모델에서 5㎍/㎏의 용량에서 고도로 효율적인 반면, Ep02- 및 Ep01-02- 및 Ep11- 3014-DGN549 AADC에 의한 처리는 더 적은 항-종양 활성을 나타낸다는 것을 나타낸다.
3014 절단 가능 모이어티를 갖는 Ep03, Ep05, Ep07 및 Ep04 마스크를 보유하는 마스킹된-EpCAM-DGN549의 효능
마우스에 접종하고 나서, 접종 후 6일(dpi)에 6마리 마우스의 그룹으로 무작위화시켰다. 각 그룹에 대한 평균 종양 용적(TV)은 98.5 내지 104.8㎣였다. 접종 후 118일에 연구를 종료하였다(EOS = 118dpi).
처리군은 약물 농도에 기반하여 3 및 5㎍/㎏으로 투여한 위약 대조군 투여 비히클(200㎕/㎳) 및 4개의 마스킹된-huEpCAMG23v4.2-DGN549 AADC 그룹(즉, 3014 기질에 연결된 마스크 Ep03, Ep05, Ep07 및 Ep04를 보유하는 AADC)을 포함하였다. huEpCAM23Gv4.2-DGN549 ADC으로 5㎍/㎏에서 처리한 양성 대조군과 같이, 비절단성 Ep04 마스크인 EpO4-NSUB-DGN549를 보유하는 AADC를 투여한 음성 대조군을 또한 포함시켰다.
본 연구에서, TGI를 25 dpi에서 결정하고, 대조군 위약(비히클) 그룹의 중위 TV는 1293.4㎣에 도달되었다.
연구 결과를 도 17B에 나타낸다. 표시된 용량에서 모든 처리는 잘 용인되며, 본 연구에서 체중 감소는 관찰되지 않았다.
양성 대조군으로서 사용한 huEpCAM23Gv4.2-DGN549 ADC는 종양 성장 저해에 기반하여 5㎍/㎏에서 고도로 활성(HA)이었고(TGI = 0.0%), 다수의 퇴행(연구 종료 시 6/6 PR, 6/6 CR 및 6/6 무종양 동, 118dpi) 및 전반적 종양 성장 지연(372% ILS)이 있었고, 이는 앞의 결과와 일치된다.
예상한 바와 같이, 비-절단성 EpO4-NSUB-DGN549는 활성이었고(TGI = 43.6%, LCK = 0.5), 퇴행을 유도하지 않았으며, 특이적 항원-관련 항-종양 반응보다는 페이로드에 기인할 가능성이 있는 종양 성장의 약간의 저해가 있었다. 앞의 결과와 일치되게, 5㎍/㎏로 투여한 Ep04-3014-DGN549 AADC는 종양 성장 저해(TGI = 3.2%) 및 종양 성장 지연(LCK = 2.37, +++, 및 210% ILS)으로 정의되는 바와 같은 활성을 입증하였고, 다수의 퇴행을 유도하였다(5/6 PR, 3/6 CR 및 2/6 TFS).
Ep03- 및 Ep07-3014-DGN549 AADC는 각각 3μg/kg에서 활성이며, 종양 성장 저해율은 21.7% 및 35.9%였고, LCK 값은 0.79 (+) 및 44% ILS이지만, 이 용량에서 퇴행을 유도하지 않았다. 5㎍/㎏에서, Ep03-과 Ep07-3014-DGN549 AADC는 둘 다 고도로 활성이며(TGI는 각각 7.6% 및 6.4%, LCK = 1.69 (++), 94% ILS), 소수의 퇴행을 유도하였다(각각 2/6 및 3/6 PR).
Ep05-3014-DGN549 AADC는 3㎍/㎏(17.5% TGI, 1/6 PR, LCK = 1.4 (++) 및 78% ILS)에서 활성이었고, Ep04-3014-DGN549 AADC와 유사하게 5 ug/kg에서 고도로 활성이었다. 구체적으로는, 5 ug/kg으로 투여한 Ep05-3014-DGN549 AADC는 종양 성장 저해 내지 3.7%, LCK = 2.4 (+++), 134% ILS, 및 다수의 퇴행(6/6 PR, 2/6 CR)을 입증하였다. 따라서, 이들 데이터는 Ep04- 및 Ep05-3014- EpCAM AADC에 의한 처리가 이 모델의 5㎍/㎏에서 고활성을 초래한다는 것을 나타낸다. Ep04-와 Ep05-3014-DGN549는 둘 다 이 용량에서 다수의 종양 퇴행을 유도하였고, 3㎍/㎏의 보다 저용량에서 활성으로 남아있었다.
Ep05-2014-DM4 및 Ep05-2014-DGN549의 효능
마우스에 접종하고 나서, 접종 후 7일(dpi)에 6마리의 마우스 그룹으로 무작위화하였다. 각 그룹에 대한 평균 종양 용적(TV)은 96.7 내지 102.3㎣였다. 접종 후 58일에 연구를 종료하였다(EOS = 58dpi).
연구의 파트 1에서, 처리군은 약물 농도에 기반하여 5㎍/㎏을 투여한 위약 대조군 투여 비히클(200㎕/㎳) 및 2개의 마스킹된-huEpCAMG23v4.2-DGN549 AADC 그룹(즉, 3014 기질을 보유하는 절단 가능한 마스크를 갖는 AADC, 및 비절단성-NSUB(기질 없음) 형태의 비절단성 AADC)를 포함하였다. 본 연구의 파트 2에서, 처리군은 위약 대조군 투여 비히클(200㎕/㎳), 15, 30 및 45㎍/㎏(약물 농도에 기반)로 투여한 huEpCAMG23v4.2-s-SPDB-DM4 ADC 그룹, 2개의 Ep01-02-2014-s-SPDB AADC 그룹(45 및 30㎍/㎏을 투여), 및 비절단성 변이체 Ep01-02-NSUB- S-SPDB-DM4 그룹을 포함하였다.
본 연구에서, TGI를 23 dpi에서 결정하고, 대조군 위약(비히클) 그룹의 중위 TV는 1156.9㎣에 도달되었다.
연구 결과를 도 17C 및 도 17D에 나타낸다. 표시된 용량에서 모든 처리는 잘 용인되며, 본 연구에서 체중 감소는 관찰되지 않았다.
A.
Ep05 및 Ep07 마스크를 보유하는 마스킹된-EpCAM-3014-DGN549 AADC의 효능.
본 연구의 파트 A의 결과를 도 17C에 나타낸다. 5㎍/㎏으로 투여한 Ep05-3014-DGN549 및 Ep07-3014-DGN549 AADC는 종양 성장 저해(2.9 및 3.9%)에 기반하여 고도로 활성(HA)이었고, 다수의 부분적 퇴행(각각 6/6 및 5/6)이 있었지만, 연구 종료 시(58dpi) CR 및 TFS는 없었다.
Ep05-3014-DGN549 AADC로 처리한 군에 대한 중위 생존은 58일 초과였고, Ep07-3014-DGN549 AADC로 처리한 군에 대한 중위 생존은 56일이었는데, 이는 각각 2.56 및 2.41의 LCK 값(+++ 활성), 및 152% 및 143% 초과의 대응하는 ILS를 초래하였다. 예상한 바와 같이, 비절단성 Ep05-NSUB-DGN549 및 Ep07-NSUB-DGN549 AADC는 비활성이었다(TGI > 70%, LCK = 0.29, 및 ILS = 17%).
B.
huEpCAMG23v4.2-s-SPDB-DM4, 및 Ep01-02-2014-s-SPDB-DM4의 효능.
본 연구의 파트 B의 결과를 도 17D에 나타낸다. 약물에 기반하여 45, 30 및 15㎍/㎏으로 투여한 huEpCAMG23Gv4.2-s-SPDB-DM4 ADC(모 EpCAM-DM4)로 메이탄시노이드 페이로드의 효율을 시험하였다. 모 EpCAM-DM4 ADC는 30 μg/k만큼 낮은 용량에서 고도로 활성이고(TGI <1%, ILS > 152%), 다수의 퇴행을 유도하였다(45 및 30㎍/㎏ 용량에 대해 6/6 PR, 6/6 및 5/6 CR 및 TFS). 15㎍/㎏의 용량에서, 모 EpCAM-DM4 ADC는 활성으로 남아있었고(TGI = 20.3%, LCK = 1.02), 다수의 PR(6/6)은 모두 CR 및 TFS(1/6)로 진행되지 않았지만, 그룹의 수명은 대조군(비히클) 그룹에 비해 70%만큼 증가되었다. 메이탄시노이드 페이로드의 효능을 또한 Ep01-02 마스크 및 2014 기질: Ep01-02-2014-DM4를 이용하여 AADC 형식에서 시험하였다. 45㎍/㎏의 용량은 종양 성장 저해당 최소 활성을 나타내었지만(35.6%), 임의의 퇴행은 유도하지 않았고, 그룹의 수명을 단지 약간 증가시켰다. 총괄적으로, 이들 데이터는 Ep01-02 마스크 및 2014 기질을 이용하여 AADC 형식의 DM4 페이로드의 활성을 제한하여 EpCAM-DGN549 AADC의 항-종양 활성이 종양-특이적이며(비절단성 마스크와 함께 Ab를 포함하는 AADC는 비활성이기 때문), 절단성 DM4 페이로드는 ADC 형식에서 매우 활성이라는 것을 나타낸다.
Ep05-2014-DM4 및 Ep05-2014-DGN549의 효능
마우스에 접종하고 나서, 접종 후 8일(dpi)에 6마리의 마우스 그룹으로 무작위화하였다. 각 그룹에 대한 평균 종양 용적(TV)은 90.8 내지 99.1㎣였다. 접종 후 62일에 연구를 종료하였다(EOS = 62dpi).
처리군은 위약 대조군 투여 비히클(200㎕/㎳) 및 3014 기질을 갖는 2개의 Ep05 AADC(Ab에 기반하여 1.5㎎/㎏(약물에 기반하여 대략 25㎍/㎏)을 투여한 Ep05-3014-DM4 AADC 및 약물에 기반하여 5㎍/㎏로 투여한 Ep05-3014-DGN549 AADC)를 포함하였다. 두 그룹은 음성 대조군으로서 대응하는 비 절단성-NSUB AADC와 유사하게 투여 받았다. 3개의 추가적인 그룹에 1.5, 2.5 및 5㎎/㎏(Ab에 기반)으로 Ep05-2014-DM4 AADC를 투여하였고, 두 추가적인 그룹에 3 및 5㎍/㎏(약물에 기반)으로 Ep05-2014-DGN549 AADC를 투여하였다. 모든 동물은 무작위화 5일 후에 투여 받았다(13dpi).
본 연구에서, TGI를 30 dpi에서 결정하고, 대조군 위약(비히클) 그룹의 중위 TV는 1241.8㎣에 도달되었다.
연구 결과를 도 17E 및 도 17F에 나타낸다. 표시된 용량에서 모든 처리는 잘 용인되며, 본 연구에서 체중 감소는 관찰되지 않았다.
예상한 바와 같이, Ep05-NSUB AADC는 모두 사용한 페이로드와 독립적으로 비활성이었다. Ep05-2014-DM4 AADC는 5㎎/㎏에서 고도로 활성이었고(TGI = 0%), 6/6 마우스에서 CR을 유도하였으며, 모두 EoS에서 TFS로서 정의한다. 2.5㎎/㎏으로 투여한 Ep05-2014-DM4 AADC는 또한 TGI에 기반하여 고도로 활성이었지만(7.2%), 3 PR 및 1 CR, 1 TSF만을 유도하였다. Ep05-3014-DM4 AADC의 용량과 동일하게 1.5㎎/㎏으로 투여한 Ep05-2014-DM4 AADC는 비활성이었다(도 17E). Ep05-3014-DGN549 AADC는 5㎍/㎏에서 고도로 활성(HA)이었지만(TGI = 5.5%), 2 PR만을 유도하였다. 2014-차감 AADC, Ep05-2014-DGN549는 사용한 용량 둘 다에서 비활성이었고, 종양 성장의 퇴행을 유도하지 않았다(도 17F). 따라서, 이들 데이터는 Ep05 AADC의 항-종양 활성이 종양-특이적인데, 비절단성 마스크와 함께 Ab를 포함하는 AADC가 페이로드와 독립적으로 비활성이기 때문이라는 것을 나타낸다. 추가적으로, 3014 기질과 함께 사용할 때, Ep05-DGN549 AADC는 5㎍/㎏에서 고도로 활성이었지만, 2014 기질이 사용되었다면 활성을 상실하였다. 대조적으로, 절단 가능한 -S-SPDB-DM4 페이로드를 보유하는 Ep05-2014-DM4 AADC는 고도로 활성이며, 용량 의존적 방식으로 다수의 종양 퇴행을 유도한다.
실시예 14: Calu-3 NSCLC 이종이식을 보유하는 C.B-17 SCID 마우스에서 Ep05- 3014-DM4 및 2014-DM4의 효능
6 내지 8주령의 암컷 마우스에 0.2㎖의 SFM:Matrigel에서 5×106개의 Calu-3 세포/마우스로 우측 옆구리 영역에 피하로 접종하였다. 마우스를 접종 후 10일(dpi)에 6마리의 마우스 그룹으로 무작위화하였다. 각 그룹에 대한 평균 종양 용적(TV)은 97.6 내지 106.4㎣였다. 접종 후 119일에 연구를 종료하였다(EOS = 119dpi).
처리군은 위약 대조군 투여 비히클(200㎕/㎳), 양성 대조군으로서 모 huEpCAMG23v4.2-s-SPDB-DM4 ADC 그룹, 음성 대조군으로서 비절단성 Ep05-NSUB-DM4 AADC, Ep05-3014-DM4 AADC 그룹 및 Ep05-2014-DM4 AADC 그룹을 포함하였고, 모든 AADC 화합물은 (활성화 가능한 항체 농도에 기반하여) 5 및 2.5㎎/㎏에서 시험하였다.
본 연구에서, TGI를 73 dpi에서 결정하고, 대조군 위약(비히클) 그룹의 중위 TV는 1138㎣에 도달되었다.
연구 결과를 도 18에 나타낸다. 표시된 용량에서 모든 처리는 잘 용인되며, 본 연구에서 체중 감소는 관찰되지 않았다.
예상한 바와 같이, Ep05-NSUB-DM4 AADC는 비활성이었지만, 모 EpCAM-DM4 ADC는 5㎎/㎏의 용량에서 활성이고, 5㎎/㎏에서 TGI = 15.6%이고, 2.5㎎/㎏에서 21%였다. 또한, EpCAM-DM4 ADC는 종양 성장을 지연시켰지만, 임의의 퇴행을 유도하지 않았다. 유사하게, E05-3014-DM4 및 Ep05-2014- DM4 AADC에 의해 퇴행이 관찰되지 않았다. Ep05-3014-DM4 AADC는 5와 2.5㎎/㎏ 둘 다에서 활성인 반면(각각 15.6% 및 21%의 TGI 값), Ep05-2014-DM4 AADC는 비활성이었다(TGI > 40%). 따라서, 이들 데이터는 EpCAM-DM4 ADC 또는 Ep05-DM4 AADC에 의한 처리가 Calu-3 종양 모델에서 일부 종양 성장 지연을 초래하지만, 최소량의 전반적인 항-종양 활성을 나타낸다는 것을 나타낸다.
실시예 15: NCI-H292 NSCLC 이종이식을 보유하는 C.B-17 SCID 마우스에서 Ep05- 3014-DM4 및 2014-DM4의 효능
6 내지 8주령의 암컷 마우스에 0.1㎖의 SFM에서 2.5×106개의 NCI-H292 세포/마우스로 우측 옆구리 영역에 피하로 접종하였다. 마우스를 접종 후 13일(dpi)에 6마리의 마우스 그룹으로 무작위화하였다. 각 그룹에 대한 평균 종양 용적(TV)은 88.7 내지 94.1㎣였다. 연구를 64 dpi에 종결하였다.
처리군은 위약 대조군 투여 비히클(200㎕/㎳), 양성 대조군으로서 모 huEpCAMG23v4.2-s-SPDB-DM4 ADC 그룹, 2.5㎎/㎏으로 투여한 음성 대조군으로서 비절단성 Ep05-NSUB-DM4 AADC 그룹, 및 Ep05-3014-DM4 AADC 및 Ep05-2014-DM4 AADC의 두 그룹 각각(둘 다 활성화 가능한 항체 농도에 기반하여 5 및 2.5㎎/㎏으로 투여함)을 포함하였다.
본 연구에서, TGI를 28 dpi에서 결정하고, 대조군 위약(비히클) 그룹의 중위 TV는 939.8㎣에 도달되었다.
연구 결과를 도 19에 나타낸다. 모든 처리는 표시된 용량에서 잘 용인되지만, 몇몇 동물은 체중감소로 인해 희생되어야 하며, 이는 처리보다는 이종이식 모델의 특징으로 인한 것이었다.
예상한 바와 같이, Ep05-NSUB-DM4 AADC는 비활성이었지만, 모 EpCAM- DM4 ADC는 2.5㎎/㎏에서 활성이고, 22.7%의 TGI였다. EpCAM-DM4 ADC는 종양 성장(ILS= 100%(28.5일))을 지연시켰지만, 임의의 퇴행을 유도하지 않았다. 2.5㎎/㎏으로 투약한 E05-3014-DM4 그룹에서 짧은, 비-유지 PR을 제외하고, 이 모델에서 퇴행이 관찰되지 않았다. 그러나, Ep05-3014-DM4와 Ep05-2014-DM4 AADC는 둘 다 2.5㎎/㎏만큼 낮은 용량에서 고도로 활성이었고(각각 10% 및 11.45%의 TGI), 2배 초과로 대응하는 그룹 수명을 증가시켰다(100%). 따라서, 이들 데이터는 NCI-H292 종양이 EpCAM-DM4 ADC뿐만 아니라 유도된 Ep05-DM4 AADC에 대해 민감하다는 것을 나타낸다. 유의한 종양 퇴행이 관찰되지 않았지만, 처리군에서의 유의한 종양 성장 지연 및 증가된 수명이 있었다. 또한, 3014-차감 AADC와 2014-차감 AADC 둘 다에 대한 반응은 유사하였다.
실시예 16: Detroit 562 HNSCC 이종이식을 보유하는 C.B-17 SCID 마우스에서의 Ep05- 3014-DM4, Ep05-2014-DM4, Ep05-3014-DM21 및 Ep05-2014-DM21의 효능
6 내지 8주령의 암컷 마우스에 0.2㎖의 SFM:Matrigel의 1:1 용액에서 107개의 Detroit 562 세포/마우스로 우측 옆구리 영역에 피하로 접종하였다. 마우스를 접종 후 4일(dpi)에 8마리의 마우스 그룹으로 무작위화하였다. 각 그룹에 대한 평균 종양 용적(TV)은 99.2 내지 106㎣였다. 연구를 90 dpi에 종결하였다.
처리군은 위약 대조군 투여 비히클(200㎕/㎳), 2.5㎎/㎏으로 투여한 Ep05-3014-DM4 AADC 그룹, 2.5㎎/㎏으로 투여한 Ep05-2014-DM4 AADC 그룹, 2.5㎎/㎏으로 투여한 Ep05-3014-DM21L AADC 그룹, 5㎎/㎏으로 투여한 Ep05-3014-DM21L AADC 그룹, 2.5㎎/㎏으로 투여한 Ep05-2014-DM21L AADC 그룹, 및 5㎎/㎏으로 투여한 Ep05-2014-DM21L AADC 그룹을 포함하였다. 모든 AADC는 활성화 가능한 항체 농도에 기반하여 투여하였다. 추가적으로, 양성 대조군 ADC 그룹에 항체 농도에 기반하여 2.5㎎/㎏로 huEpCAM23Gv4.2-DM21L을 투여하였다.
본 연구에서, TGI를 28 dpi에서 결정하고, 대조군 위약(비히클) 그룹의 중위 TV는 1004.2㎣에 도달되었다.
연구 결과를 도 20에 나타낸다. 표시된 용량에서 모든 처리는 잘 용인되었다.
본 연구에서 사용한 모든 AADC(Ep05-3014-DM4, Ep05-2014-DM4, Ep05-3014-DM21L, 및 Ep05-2014-DM21L)뿐만 아니라 huEpCAM23Gv4.2-DM21L ADC는 모든 시험 용량에서 고도로 활성이었고(0.7%의 TGI를 갖는 2.5㎎/㎏에서의 Ep05-3014-DM21L을 제외한 모든 그룹에 대해 0%의 TGI), 3배 초과로 대응하는 그룹의 수명을 증가시켰다(200%). 모든 그룹은 87.5%의 부분적 퇴행을 유도한 2.5㎎/㎏에서의 Ep05-2014-DM21L 그룹을 제외하고 100%의 부분적 퇴행을 유도하였다. 이들 부분적 퇴행은 대부분 연구 종결시까지 유지되는 완전한 퇴행으로 진행되어(즉, 75% 초과의 PR이 CR로 진행됨) 다수의 무 종양 생존자를 초래하였다. 각각의 그룹과 관련된 TGI, PR, CR 및 TFS에 관한 추가적인 상세한 설명을 도 20에 제공한다.
따라서, 이들 데이터는 Detroit 562 종양이 Ep05- DM4 AADC에 대해 고도로 민감하여, 처리군에서의 유의한 종양 퇴행, 종양 성장 지연, 및 증가된 수명을 초래한다는 것을 나타낸다.
실시예 17: NCI-H441 NSCLC 이종이식을 보유하는 C.B-17 SCID 마우스에서의 Ep05-3014-DM21 및 Ep05-2014-DM21의 효능
6 내지 8주령의 암컷 마우스에 0.2㎖의 SFM에서 107개의 NCI-H441 세포/마우스로 우측 옆구리 영역에 피하로 접종하였다. 마우스를 접종 후 8일(dpi)에 8마리의 마우스 그룹으로 무작위화하였다. 각 그룹에 대한 평균 종양 용적(TV)은 95.1 내지 101.4㎣였다. 연구를 92 dpi에 종결하였다.
처리군은 위약 대조군 투여 비히클(200㎕/㎳), (항체 농도에 기반하여) 2.5㎎/㎏으로 투약한 모 huEpCAM23Gv4.2-DM21L ADC 그룹, 2.5㎎/㎏으로 투여한 Ep05-3014-DM21L AADC 그룹, 5㎎/㎏으로 투여한 Ep05-3014-DM21L AADC 그룹, 2.5㎎/㎏으로 투여한 Ep05-2014-DM21L AADC 그룹, 및 5㎎/㎏으로 투여한 Ep05-2014-DM21L AADC 그룹을 포함하였다. 모든 AADC는 활성화 가능한 항체 농도에 기반하여 투여하였다.
본 연구에서, TGI를 37 dpi에서 결정하고, 대조군 위약(비히클) 그룹의 중위 TV는 1109.7㎣에 도달되었다.
연구 결과를 도 21에 나타낸다. 표시된 용량에서 모든 처리는 잘 용인되었다.
모든 처리는 활성 내지 고도로 활성이었고, 149% 초과만큼 그룹의 수명을 증가시켰고, 각 그룹에서 100% PR을 유도하였다. 다수의 CR이 도달되었고, 연구종료까지 지속적으로 유지되어, 다수의 TFS를 초래하였다. huEpCAM23Gv4.2-DM21 ADC는 2.5㎎/㎏에서 고도로 활성이었고, 7.7%의 TGI, 8/8 PR 및 7/8 CR이었다. 유사하게, Ep05-2014-DM21 AADC는 2.5와 5㎎/㎏ 용량 둘 다에서 고도로 활성이었고, 각각 6.2% 및 4.2%의 TGI, 및 각각 6/8 및 5/8 CR이었다. Ep05-3014-DM21 AADC는 5㎎/㎏ 용량에서 활성이었고, 10.1% 및 5/8 CR의 TGI였다. 2.5㎎/㎏ 용량에서, Ep05-3014-DM21 AADC는 고도로 활성이었고, 6.3%의 TGI 및 6/8 CR이었다.
따라서, 이들 데이터는 NCI-H441 종양이 EpO5-DM21L AADC에 대해 민감하여, 처리군에서의 유의한 종양 퇴행, 종양 성장 지연, 및 증가된 수명을 초래한다는 것을 나타낸다.
실시예 18: OV-90 EOC 이종이식을 보유하는 C.B-17 SCID 마우스에서 Ep05-2014-DM21의 효능
6 내지 8주령의 암컷 마우스에 0.1㎖의 SFM:Matrigel에서 107개의 OV-90 세포/마우스로 우측 옆구리 영역에 피하로 접종하였다. 마우스를 접종 후 7일(dpi)에 각각 6마리의 마우스 그룹으로 무작위화하였다. 각 그룹에 대한 평균 종양 용적(TV)은 92.2 내지 98.5㎣였다. 연구를 71 dpi에 종결하였다.
처리군은 위약 대조군 투여 비히클(200㎕/㎳), (항체 농도에 기반하여) 1.25㎎/㎏으로 투약한 모 huEpCAM23Gv4.2-DM21 ADC 그룹, (활성화 가능한 항체 농도에 기반하여) 1.25㎎/㎏으로 투여한 Ep05-2014-DM21L AADC 그룹, (활성화 가능한 항체 농도에 기반하여) 2.5㎎/㎏으로 투여한 Ep05-2014-DM21L AADC 그룹, (항체 농도에 기반하여) 1.25㎎/㎏으로 투여한 chKTI-DM21L 비표적화 음성 대조군 ADC 그룹, 및 (항체 농도에 기반하여) 2.5㎎/㎏으로 투여한 chKTI-DM21L 비표적화 음성 대조군 ADC 그룹을 포함하였다.
본 연구에서, TGI를 34 dpi에서 결정하고, 대조군 위약(비히클) 그룹의 중위 TV는 1436.7㎣에 도달되었다.
연구 결과를 도 22에 나타낸다. 표시된 용량에서 모든 처리는 잘 용인되었다.
본 연구에서 사용한 모든 EpCAM 표적화 처리(1.25㎎/㎏의 huEpCAM23Gv4.2-DM21 ADC 그룹 및 2.5와 1.25㎎/㎏ 둘 다의 Ep05-2014-DM21L AADC 그룹)는 고도로 활성이었고, 비처리 동물에 비해 5% 미만의 TGI, 그룹의 수명에서 109% 초과의 증가, 및 각 그룹에서 100% PR이었다. 이들 그룹에서 모든 PR은 완전한 퇴행(CR)으로 진행되었고, 연구 종료까지 유지하여, TFS를 초래하였다. 비표적화된 chKTI-DM21 ADC는 2.5 및 1.25㎎/㎏에서 OV-90 종양에 대해 활성이 아니었고, 74.5% 초과의 TGI이며, 종양 퇴행이 없었다.
따라서, 이들 데이터는 OV-90 종양이 Ep05-2014- DM21L AADC에 대해 민감하여, 처리군에서의 유의한 종양 퇴행, 및 증가된 수명을 초래한다는 것을 나타낸다.
실시예 19: Calu-3 NSCLC 이종이식을 보유하는 C.B-17 SCID 마우스에서 Ep05-2014-DM21의 효능
6 내지 8주령의 암컷 마우스에 0.2㎖의 SFM:Matrigel에서 5×106개의 Calu-3 세포/마우스로 우측 옆구리 영역에 피하로 접종하였다. 마우스를 접종 후 6일(dpi)에 각각 6마리의 마우스 그룹으로 무작위화하였다. 각 그룹에 대한 평균 종양 용적(TV)은 110.3 내지 116.5㎣였다.
처리군은 위약 대조군 투여 비히클(200㎕/㎳), (항체 농도에 기반하여) 2.5㎎/㎏으로 투약한 모 huEpCAM23Gv4.2-DM21L ADC 그룹, (활성화 가능한 항체 농도에 기반하여) 2.5㎎/㎏으로 투여한 Ep05-2014-DM21L AADC 그룹, (활성화 가능한 항체 농도에 기반하여) 5㎎/㎏으로 투여한 Ep05-2014-DM21L AADC 그룹, (항체 농도에 기반하여) 2.5㎎/㎏으로 투여한 chKTI-DM21L 비표적화 음성 대조군 ADC 그룹, 및 (항체 농도에 기반하여) 5㎎/㎏으로 투여한 chKTI-DM21L 비표적화 음성 대조군 ADC 그룹을 포함하였다.
본 연구에서, TGI를 62 dpi에서 결정하고, 대조군 위약(비히클) 그룹의 중위 TV는 963.8㎣에 도달되었다.
연구 결과를 도 23에 나타낸다. 표시된 용량에서 모든 처리는 잘 용인되었다.
huEpCAM23Gv4.2-DM21 ADC는 2.5㎎/㎏에서 고도로 활성이었고, 마지막 측정(75dpi)에서 7.8%의 TGI, 6/6 PR, 5/6 CR, 및 1/6 마우스 무종양이었다. Ep05-2014-DM21L AADC는 5㎎/㎏에서 고도로 활성이었고, 마지막 측정(75dpi)에서 4.4% TGI, CR로 진행되는 5/6 PR, 및 2/6 마우스 무종양이었다. Ep05-2014-DM21L AADC는 2.5㎎/㎏에서 활성이었고, 30.4% TGI 및 3/6 PR이었다. 비표적화된 chKTI- DM21L ADC 대조군은 5 및 2.5㎎/㎏의 Calu-3 종양에 대해 비활성이었고, 5㎎/㎏의 용량에서 90% 초과의 TGI 및 종양 퇴행 없음이었다.
따라서, 이들 데이터는 Calu-3 종양이 Ep05-2014- DM21L AADC에 대해 민감하여, 유의한 종양 퇴행 및 종양 성장 지연을 초래한다는 것을 나타낸다.
실시예 20: 사이노몰거스 원숭이에서 EpCAM-표적화 AADC 약물동태학 및 내약성의 분석
DM4 접합체의 약물동태학 및 내약성
EpCAM-표적화 ADC 및 AADC와 관련된 내약성 및 약물동태학을 추가로 평가하기 위해, 수컷 사이노몰거스 원숭이에게 표 27에 나타낸 연구 설계에 따라 huEpCAM23 Gv4.2-s-SPDB-DM4, huEpCAM23Gv4.2-Ep05-2014-s-SPDB-DM4, 또는 huEpCAM23Gv4.2-Ep05-3014-s-SPDB-DM4를 투여하였다.

ADC 또는 AADC의 단일 IV 주입 후에, 사이노몰거스 원숭이를 28일 동안 관찰하였고, 약물동태학적 분석을 위해 샘플을 수집하였다. 특히, 체중 변화, 임상 관찰 및 임상 병리 평가(예를 들어, 리파제 및 아밀라제)를 위해 원숭이를 모니터링하였다.
도 24에 나타낸 바와 같이, EpCAM-표적화 AADC는 사이노몰거스 원숭이에서 8㎎/㎏에서 잘 용인되었다. 특히, 8㎎/㎏의 huEpCAM23Gv4.2-Ep05-2014-s-SPDB-DM4 또는 huEpCAM23Gv4.2-Ep05-3014-s-SPDB-DM4를 투여 받고 있는 원숭이에서의 임상 관찰은 주사 부위에서의 붉어진 피부로 제한되며, 배설은 정상으로 간주하였다. 12㎎/㎏의 huEpCAM23Gv4.2- Ep05-2014-s-SPDB-DM4를 투여 받는 원숭이에 대해 유사한 결과를 얻었다. 대조적으로, 8㎎/㎏의 ADC를 투여 받고 있는 원숭이는 빈사상태로 간주하였고, 비정상적 보행, 감소된 활동, 감소된 식욕, 만졌을 때 차가움, 경증의 피부 소견(불그스름함 또는 박리), 무른 변 및 탈수로 이루어진 임상 관찰을 의심하였다.
EpCAM-표적화 DM4 AADC를 투여 받고 있는 사이노몰거스 원숭이는 또한 EpCAM-표적화 DM4 ADC를 투여 받고 있는 원숭이에 비해 개선된 혈청 화학을 나타내었다. 특히, ADC 그룹에서만 알부민, TP, A/G 비(도 25A), 요소 질소(도 25B), 및 크레아티닌(도 25C)의 변화가 관찰되었고, 리파제(도 25D) 및 아밀라제(도 25E) 혈청 농도는 ADC 그룹에만 유사하게 관련되었다.
도 26 및 표 28에 나타낸 바와 같이, AADC의 투여는 또한 개선된 접합체 노출과 관련되었다. 총괄적으로, 이들 데이터는 DM4 AADC의 효과적인 마스킹은 약물동태학적 및 독성 프로파일에 대한 EpCAM의 정상 조직 발현 영향을 감소시킨다는 것을 제시한다.

DM21 접합체의 약물동태학 및 내약성
별개의 연구에서, 수컷 사이노몰거스 원숭이에 표 29에 나타낸 연구 설계에 따라 huEpCAM23Gv4.2- Ep05-2014-DM21L 또는 huEpCAM23Gv4.2-Ep05-3014-DM21L을 투여하였다.

ADC 또는 AADC의 단일 IV 주입 후에, 사이노몰거스 원숭이를 28일 동안 관찰하였고, 약물동태학적 분석을 위해 샘플을 수집하였다. 특히, 체중 변화, 임상 관찰 및 임상 병리 평가(예를 들어, 리파제 및 아밀라제)를 위해 원숭이를 모니터링하였다.
도 27에 나타낸 바와 같이, huEpCAM23Gv4.2-Ep05-2014-DM21L은 사이노몰거스 원숭이에서 12㎎/㎏에서 잘 용인되었다. 특히, 임상 관찰은 붉어진/어두워진 피부, 묽은 변 및 퀭한 눈(탈수)으로 제한하였다. 대조적으로, 12㎎/㎏의 huEpCAM23Gv4.2-Ep05-3014-DM21L을 투여 받고 있는 원숭이는 이전 연구에서 huEpCAM23Gv4.2-s-SPDB-DM4를 투여 받고 있는 원숭이와 유사한 임상 관찰을 나타내었다.
12㎎/㎏의 huEpCAM23Gv4.2-Ep05-2014-DM21L을 투여 받고 있는 사이노몰거스 원숭이는 또한 이전 연구에서 12㎎/㎏의 huEpCAMGv4.2- Ep05-2014-s-SPDB-DM4를 투여 받고 있는 원숭이와 유사한 혈청 화학을 나타내었다. 특히, A/G 비(도 28A), 요소 질소(도 28B), 및 크레아티닌(도 28C), 리파제(도 28D), 및 아밀라제(도 28E) 혈청 농도의 변화는 이들 두 그룹에 대해 유사한 한편, huEpCAM23Gv4.2-Ep05-3014-DM21L 그룹에 대한 혈청 화학 파라미터는 이전 연구에서 DM4 ADC 그룹에 대해 얻은 것에 대한 경향을 나타내었다.
도 29 및 표 30에 나타낸 바와 같이, huEpCAM23Gv4.2-Ep05-2014- DM21L의 투여는 또한 모든 다른 시험 접합체(DM4와 DM21L 접합체를 둘 다 포함)에 비해 개선된 접합체 노출과 관련되었다. 총괄적으로, 이들 데이터는 DM21 AADC의 효과적인 마스킹은 약물동태학적 및 독성 프로파일에 대한 EpCAM의 정상 조직 발현 영향을 감소시킨다는 것을 제시한다.

실시예 21: EpCAM 발현의 분석
EpCAM 종양 발현
상이한 적응증에 걸쳐 EpCAM 발현을 평가하기 위해, 예비 연구 용도용으로 ImmunoGen에서 개발한 EpCAM 면역조직화학(IHC) 분석을 이용하여 10가지 상이한 종양 유형을 나타내는 조직 마이크로어레이(TMA)를 처음 평가하였다.
분석한 모든 종양은 FFPE(포말린 고정 및 파라핀 포매) 샘플이었다. 특히, 10가지 상이한 적응증을 나타내는 2개의 다중-암종 TMA뿐만 아니라 삼중 음성 유방암(TNBC), 난소암 및 방광암을 나타내는 적응증-특이적 TMA를 분석하였다. 폐암 및 난소암에 대한 전체 종양 조직 FFPE 블록과 같이 결장직장암(CRC) TMA를 또한 분석하였다.
Ventana Discovery Ultra 자동염색기를 이용하여 EpCAM에 대한 면역조직화학 염색을 수행하였다. EpCAM에 대한 1차 항체는 상업적으로 입수 가능한 토끼 단클론성 항체였다. 모든 샘플을 평가하고, 스코어링 알고리즘에서 훈련받은 면허가 있는 병리학자에 의해 점수화하였다. 스코어링을 위해 적어도 100개의 생 종양 세포의 존재가 필요하였다. 0 내지 3의 반정량적 정수 등급으로 염색 강도를 스코어링하였고, 0은 염색 없음을 나타내고, 1은 약한 염색을 나타내며, 2는 보통을 나타내고, 3은 강한 염색을 나타내었다. 각 강도 수준에서 양성으로 염색되는 세포의 백분율을 기록하였다. 스코어링은 세포막 단독에 대한 EpCAM의 국소화에 기반하였다. 염색 강도 성분을 양성 세포의 백분율과 합한 H-스코어로 염색 결과를 분석하였다. 값은 0 내지 300 사이였고, 다음과 같이 정의한다:

이하의 표 31은 다중-암중 TMA로부터의 모두 10가지의 적응증에 대해 막 염색에 기반하여 EpCAM의 출현율을 요약한다.

다중 암종 TMA로부터의 결과에 따라서, 확장된 출현율 분석을 위해 5가지 적응증-특이적 TMA를 선택하였다: 42가지 사례를 갖는 결장직장암(CRC) TMA(40가지 평가 가능), 37 코어를 갖는 난소암 TMA, 81개의 코어를 갖는 삼중-음성 유방암(TNBC) TMA, 60개의 암종 코어를 갖는 방광암 TMA 및 선암종에 대해 80개의 코어 및 편평세포암종에 대해 80개의 코어를 갖는 비소세포 폐암(NSCLC) TMA(각각에 대해 79가지를 평가 가능). 도 30은 각 종양 적응증 내에서 H-스코어의 붕괴에 따른 EpCAM 발현을 기재한다.
추가적으로, NSCLC-선암종(n = 86), NSCLC-편평세포암종(n =19) 및 난소 암종(n = 29)의 전체 종양 조직 절편을 EpCAM 발현에 대해 IHC에 의해 분석하였다. 이들 샘플 모두를 막 염색에 대해 스코어링하고, 결과를 표 32에 요약한다.

이들 예비 연구 결과는 EpCAM이 다양한 고형암에서 발현되고, 다수의 상이한 EpCAM-발현 고형 종양에서의 항-EpCAM9 약물 접합체의 사용을 뒷받침한다는 것을 나타낸다.
정상 인간 조직에서의 EpCAM 발현
EpCAM의 정상 인간 조직 발현을 동일한 항-EpCAM 토끼 단클론성 항체 및 Ventana Discovery Ultra 자동염색기를 이용하여 상기 기재한 것과 유사한 방식으로 IHC에 의해 평가하였다.
분석한 모든 조직은 3명의 별개의 개체로부터의 35개의 상이한 기관/해부학적 부위를 나타내는 다중-조직 마이크로어레이 TMA을 이용하는 FFPE(포말린 고정 및 파라핀 포매) 샘플이었다. 모든 샘플을 평가하고, 스코어링 알고리즘에서 훈련받은 면허가 있는 병리학자에 의해 점수화하였다. 스코어링을 위해 적어도 100개의 생 종양 세포의 존재가 필요하였다. 종양 샘플에 대해, 0 내지 3의 반정량적 정수 등급으로 염색 강도를 스코어링하였고, 0은 염색 없음을 나타내고, 1은 약한 염색을 나타내며, 2는 보통을 나타내고, 3은 강한 염색을 나타내었다. 그러나, 종양과 달리, 염색을 부정확하게 반영하는 H-스코어를 생성하는 상이한 조직에서 정상적으로 발견된 다양한 구조로 인해 H-스코어를 계산하지 못하였다. 각 기관에서 관찰된 임의의 염색 패턴의 병리학자의 설명을 기록하였고, 결과를 표 33에 요약하였다.
다수의 정상 인간 조직, 특허 소장, 결장 및 직장에서 유의한, 강한 염색이 관찰되었다. 따라서, 대안의 표적화 접근, 예컨대 활성화 가능한 항체-기반 기술은 잠재적인 독성 위험을 극복하기 위한 매력적인 선택을 나타낸다.

*
*
*

*
*
*
발명의 내용 및 요약 부분이 아닌 발명을 실시하기 위한 구체겆인 내용 부문은 청구범위를 설명하기 위해 사용한 것으로 의도된다는 것이 인식되어야 한다. 발명의 내용 및 요약 부문은 본 발명자(들)에 의해 상정된 바와 같은 하나 이상이지만, 모두는 아닌 본 개시내용의 예시적인 실시형태를 제시하며, 따라서, 본 개시내용 및 첨부하는 청구범위를 임의의 방법으로 제한하는 것으로 의도되지 않는다.
본 개시내용은 명시된 작용 및 이의 관계의 실행을 설명하는 예시적인 표지 및 기타 기능적 빌딩 블록의 도움으로 상기 기재되었다. 이들 기능적 빌딩 블록의 경계는 설명의 편리함을 위해 본 명세서에서 임의의 정의하였다. 명시된 기능 및 이의 관계가 적절하게 수행된다면 대안의 경계가 정의될 수 있다.
구체적 실시형태의 앞서 언급한 설명은, 다른 사람이 당업계의 기술 내인 지식을 적용함으로써, 본 개시내용의 일반적 개념을 벗어나지 않고 과도한 실험 없이 다양한 적용에 대해 이러한 구체적 실시형태를 용이하게 변형 및/또는 적합화할 수 있는 포함된 조성물 및 방법의 일반적 특성을 완전히 나타낼 것이다. 따라서, 이러한 적용 및 변형은 본 명세서에 제시된 교시 및 가이드에 기반하여 개시된 실시형태의 균등물의 의미 및 범위 이내인 것으로 의도된다. 본 명세서의 용어 또는 어법이 교시 및 가이드에 비추어 당업자에 의해 해석되도록, 본 명세서의 어법 또는 용어는 설명의 목적을 위한 것이며, 제한하지는 않는다.
본 개시내용의 범위 및 범주는 임의의 상기 기재한 예시적인 실시형태에 의해 제한되어서는 안 되지만, 다음의 청구범위 및 이들의 균등물에 따라서만 정해져야 한다.
SEQUENCE LISTING
<110> ImmunoGen, Inc.,
CytomX Therapeutics, Inc.
<120> EpCAM antibodies, activatable antibodies, and immunoconjugates,
and uses thereof
<130> WO/2020/086665
<140> PCT/US2019/057569
<141> 2019-10-23
<150> US 62/846,297
<151> 2019-05-10
<150> US 62/824,539
<151> 2019-03-27
<150> US 62/751,530
<151> 2018-10-26
<160> 214
<170> PatentIn version 3.5
<210> 1
<211> 242
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 1
Gln Glu Glu Cys Val Cys Glu Asn Tyr Lys Leu Ala Val Asn Cys Phe
1 5 10 15
Val Asn Asn Asn Arg Gln Cys Gln Cys Thr Ser Val Gly Ala Gln Asn
20 25 30
Thr Val Ile Cys Ser Lys Leu Ala Ala Lys Cys Leu Val Met Lys Ala
35 40 45
Glu Met Asn Gly Ser Lys Leu Gly Arg Arg Ala Lys Pro Glu Gly Ala
50 55 60
Leu Gln Asn Asn Asp Gly Leu Tyr Asp Pro Asp Cys Asp Glu Ser Gly
65 70 75 80
Leu Phe Lys Ala Lys Gln Cys Asn Gly Thr Ser Met Cys Trp Cys Val
85 90 95
Asn Thr Ala Gly Val Arg Arg Thr Asp Lys Asp Thr Glu Ile Thr Cys
100 105 110
Ser Glu Arg Val Arg Thr Tyr Trp Ile Ile Ile Glu Leu Lys His Lys
115 120 125
Ala Arg Glu Lys Pro Tyr Asp Ser Lys Ser Leu Arg Thr Ala Leu Gln
130 135 140
Lys Glu Ile Thr Thr Arg Tyr Gln Leu Asp Pro Lys Phe Ile Thr Ser
145 150 155 160
Ile Leu Tyr Glu Asn Asn Val Ile Thr Ile Asp Leu Val Gln Asn Ser
165 170 175
Ser Gln Lys Thr Gln Asn Asp Val Asp Ile Ala Asp Val Ala Tyr Tyr
180 185 190
Phe Glu Lys Asp Val Lys Gly Glu Ser Leu Phe His Ser Lys Lys Met
195 200 205
Asp Leu Thr Val Asn Gly Glu Gln Leu Asp Leu Asp Pro Gly Gln Thr
210 215 220
Leu Ile Tyr Tyr Val Asp Glu Lys Ala Pro Glu Phe Ser Met Gln Gly
225 230 235 240
Leu Lys
<210> 2
<211> 36
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 2
Gln Glu Glu Cys Val Cys Glu Asn Tyr Lys Leu Ala Val Asn Cys Phe
1 5 10 15
Val Asn Asn Asn Arg Gln Cys Gln Cys Thr Ser Val Gly Ala Gln Asn
20 25 30
Thr Val Ile Cys
35
<210> 3
<211> 70
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 3
Cys Leu Val Met Lys Ala Glu Met Asn Gly Ser Lys Leu Gly Arg Arg
1 5 10 15
Ala Lys Pro Glu Gly Ala Leu Gln Asn Asn Asp Gly Leu Tyr Asp Pro
20 25 30
Asp Cys Asp Glu Ser Gly Leu Phe Lys Ala Lys Gln Cys Asn Gly Thr
35 40 45
Ser Met Cys Trp Cys Val Asn Thr Ala Gly Val Arg Arg Thr Asp Lys
50 55 60
Asp Thr Glu Ile Thr Cys
65 70
<210> 4
<211> 130
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 4
Ser Glu Arg Val Arg Thr Tyr Trp Ile Ile Ile Glu Leu Lys His Lys
1 5 10 15
Ala Arg Glu Lys Pro Tyr Asp Ser Lys Ser Leu Arg Thr Ala Leu Gln
20 25 30
Lys Glu Ile Thr Thr Arg Tyr Gln Leu Asp Pro Lys Phe Ile Thr Ser
35 40 45
Ile Leu Tyr Glu Asn Asn Val Ile Thr Ile Asp Leu Val Gln Asn Ser
50 55 60
Ser Gln Lys Thr Gln Asn Asp Val Asp Ile Ala Asp Val Ala Tyr Tyr
65 70 75 80
Phe Glu Lys Asp Val Lys Gly Glu Ser Leu Phe His Ser Lys Lys Met
85 90 95
Asp Leu Thr Val Asn Gly Glu Gln Leu Asp Leu Asp Pro Gly Gln Thr
100 105 110
Leu Ile Tyr Tyr Val Asp Glu Lys Ala Pro Glu Phe Ser Met Gln Gly
115 120 125
Leu Lys
130
<210> 5
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<220>
<221> MISC_FEATURE
<222> (1)..(1)
<223> Xaa is any amino acid
<220>
<221> MISC_FEATURE
<222> (3)..(3)
<223> Xaa is Y,N,F,S,H,D,L,I,W
<220>
<221> MISC_FEATURE
<222> (4)..(4)
<223> Xaa is I or M
<400> 5
Xaa Tyr Xaa Xaa His
1 5
<210> 6
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<220>
<221> MISC_FEATURE
<222> (3)..(3)
<223> Xaa is Y,N,F,S,H,D,L,I,W
<220>
<221> MISC_FEATURE
<222> (3)..(3)
<223> Xaa is Y,N,F,S,H,D,L,I, or W
<400> 6
Asn Tyr Xaa Ile His
1 5
<210> 7
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<220>
<221> MISC_FEATURE
<222> (2)..(2)
<223> Xaa is I, S, or V
<220>
<221> MISC_FEATURE
<222> (3)..(3)
<223> Xaa is Y or N
<220>
<221> MISC_FEATURE
<222> (6)..(6)
<223> Xaa is N or D
<220>
<221> MISC_FEATURE
<222> (12)..(12)
<223> Xaa is N or S
<220>
<221> MISC_FEATURE
<222> (13)..(13)
<223> Xaa is E or Q
<220>
<221> MISC_FEATURE
<222> (17)..(17)
<223> Xaa is K or Q
<400> 7
Trp Xaa Xaa Pro Gly Xaa Val Tyr Ile Gln Tyr Xaa Xaa Lys Phe Lys
1 5 10 15
Xaa
<210> 8
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<220>
<221> MISC_FEATURE
<222> (1)..(1)
<223> Xaa is D or E
<220>
<221> MISC_FEATURE
<222> (3)..(3)
<223> Xaa is P,A,S,Y,F,G,T,V, or A
<220>
<221> MISC_FEATURE
<222> (4)..(4)
<223> Xaa is Y or w
<220>
<221> MISC_FEATURE
<222> (4)..(4)
<223> Xaa is Y or W
<400> 8
Xaa Gly Xaa Xaa Phe Ala Tyr
1 5
<210> 9
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<220>
<221> MISC_FEATURE
<222> (4)..(4)
<223> Xaa is Y or W
<400> 9
Asp Gly Pro Xaa Phe Ala Tyr
1 5
<210> 10
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<220>
<221> MISC_FEATURE
<222> (10)..(10)
<223> Xaa is N or D
<220>
<221> MISC_FEATURE
<222> (12)..(12)
<223> Xaa is F or I
<220>
<221> MISC_FEATURE
<222> (16)..(16)
<223> Xaa is Y or S
<400> 10
Arg Ser Ser Arg Ser Leu Leu His Ser Xaa Gly Xaa Thr Tyr Leu Xaa
1 5 10 15
<210> 11
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<220>
<221> MISC_FEATURE
<222> (1)..(1)
<223> Xaa is A,K, or Q
<220>
<221> MISC_FEATURE
<222> (1)..(1)
<223> Xaa is A,L, or Q
<220>
<221> MISC_FEATURE
<222> (3)..(3)
<223> Xaa is S,G,Y,or N
<220>
<221> MISC_FEATURE
<222> (8)..(8)
<223> Xaa is N or W
<400> 11
Xaa Gln Xaa Leu Glu Leu Pro Xaa Thr
1 5
<210> 12
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<220>
<221> MISC_FEATURE
<222> (3)..(3)
<223> Xaa is S, G, Y, or N
<400> 12
Ala Gln Xaa Leu Glu Leu Pro Asn Thr
1 5
<210> 13
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 13
Asn Tyr Tyr Ile His
1 5
<210> 14
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 14
Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 15
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 15
Asp Gly Pro Trp Phe Ala Tyr
1 5
<210> 16
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 16
Ser Tyr Tyr Ile His
1 5
<210> 17
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 17
Asn Tyr Asn Ile His
1 5
<210> 18
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 18
Asn Tyr Phe Ile His
1 5
<210> 19
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 19
Asn Tyr Ser Ile His
1 5
<210> 20
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 20
Asn Tyr Trp Ile His
1 5
<210> 21
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 21
Asn Tyr Tyr Met His
1 5
<210> 22
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 22
Asn Tyr His Ile His
1 5
<210> 23
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 23
Asn Tyr Asp Ile His
1 5
<210> 24
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 24
Asn Tyr Ile Ile His
1 5
<210> 25
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 25
Asn Tyr Leu Ile His
1 5
<210> 26
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 26
Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Ser Gln Lys Phe Gln
1 5 10 15
Gly
<210> 27
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 27
Trp Ile Tyr Pro Gly Asp Val Tyr Ile Gln Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 28
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 28
Trp Phe Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 29
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 29
Trp Ile Asn Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 30
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 30
Glu Gly Pro Trp Phe Ala Tyr
1 5
<210> 31
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 31
Asp Gly Pro Tyr Phe Ala Tyr
1 5
<210> 32
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 32
Asp Gly Ala Trp Phe Ala Tyr
1 5
<210> 33
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 33
Asp Gly Tyr Trp Phe Ala Tyr
1 5
<210> 34
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 34
Asp Gly Ser Trp Phe Ala Tyr
1 5
<210> 35
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 35
Asp Gly Phe Trp Phe Ala Tyr
1 5
<210> 36
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 36
Asp Gly Gly Trp Phe Ala Tyr
1 5
<210> 37
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 37
Asp Gly Thr Trp Phe Ala Tyr
1 5
<210> 38
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 38
Asp Gly Val Trp Phe Ala Tyr
1 5
<210> 39
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 39
Arg Ser Ser Lys Ser Leu Leu His Ser Asp Gly Phe Thr Tyr Leu Tyr
1 5 10 15
<210> 40
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 40
Gln Thr Ser Asn Leu Ala Ser
1 5
<210> 41
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 41
Ala Gln Asn Leu Glu Leu Pro Asn Thr
1 5
<210> 42
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 42
Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly Phe Thr Tyr Leu Tyr
1 5 10 15
<210> 43
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 43
Arg Ser Ser Arg Ser Leu Leu His Ser Asn Gly Phe Thr Tyr Leu Tyr
1 5 10 15
<210> 44
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 44
Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly Ile Thr Tyr Leu Tyr
1 5 10 15
<210> 45
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 45
Ala Gln Asn Leu Glu Leu Pro Trp Thr
1 5
<210> 46
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 46
Gln Gln Asn Leu Glu Leu Pro Asn Thr
1 5
<210> 47
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 47
Leu Gln Asn Leu Glu Leu Pro Asn Thr
1 5
<210> 48
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 48
Ala Gln Tyr Leu Glu Leu Pro Asn Thr
1 5
<210> 49
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 49
Ala Gln Gly Leu Glu Leu Pro Asn Thr
1 5
<210> 50
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 50
Ala Gln Ser Leu Glu Leu Pro Asn Thr
1 5
<210> 51
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 51
Glu Val Lys Leu Glu Glu Ser Gly Pro Ala Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Arg Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Asp Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Phe
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 52
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 52
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Trp Met
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Ser Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Arg Asp Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 53
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 53
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 54
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 54
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Trp Met
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Ile Thr Arg Asp Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 55
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 55
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Ser Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 56
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 56
Gln Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 57
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 57
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 58
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 58
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Asn Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 59
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 59
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asp Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 60
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 60
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Phe Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 61
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 61
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Ser Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 62
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 62
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Trp Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 63
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 63
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Phe Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 64
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 64
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Trp Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 65
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 65
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Asn Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 66
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 66
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 67
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 67
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Tyr Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 68
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 68
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Ala Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 69
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 69
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 70
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 70
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Val Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 71
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 71
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Ile Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 72
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 72
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Arg Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 73
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 73
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 74
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 74
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
His Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 75
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 75
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Asp Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 76
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 76
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Tyr Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 77
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 77
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Ser Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 78
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 78
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Phe Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 79
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 79
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Gly Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 80
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 80
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Thr Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 81
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 81
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Val Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 82
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 82
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Ile Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 83
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 83
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Leu Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 84
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 84
Asp Ile Val Leu Thr Gln Thr Pro Phe Ser Asn Pro Val Thr Leu Gly
1 5 10 15
Thr Ser Ala Ser Ile Ser Cys Arg Ser Ser Lys Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro His Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Arg Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 85
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 85
Asp Ile Val Met Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 86
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 86
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Lys Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 87
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 87
Asp Ile Val Met Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Lys Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 88
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 88
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 89
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 89
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asn Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 90
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 90
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Ile Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 91
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 91
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 92
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 92
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Ser Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 93
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 93
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 94
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 94
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Gln Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 95
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 95
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Leu Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 96
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 96
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Tyr
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 97
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 97
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Gly
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 98
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 98
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Ser
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 99
<211> 452
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 99
Glu Val Lys Leu Glu Glu Ser Gly Pro Ala Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Arg Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Asp Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Phe
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Lys Thr Thr Pro Pro Ser Val Tyr Pro Leu Ala
115 120 125
Pro Gly Cys Gly Asp Thr Thr Gly Ser Ser Val Thr Leu Gly Cys Leu
130 135 140
Val Lys Gly Tyr Phe Pro Glu Ser Val Thr Val Thr Trp Asn Ser Gly
145 150 155 160
Ser Leu Ser Ser Ser Val His Thr Phe Pro Ala Leu Leu Gln Ser Gly
165 170 175
Leu Tyr Thr Met Ser Ser Ser Val Thr Val Pro Ser Ser Thr Trp Pro
180 185 190
Ser Gln Thr Val Thr Cys Ser Val Ala His Pro Ala Ser Ser Thr Thr
195 200 205
Val Asp Lys Lys Leu Glu Pro Ser Gly Pro Ile Ser Thr Ile Asn Pro
210 215 220
Cys Pro Pro Cys Lys Glu Cys His Lys Cys Pro Ala Pro Asn Leu Glu
225 230 235 240
Gly Gly Pro Ser Val Phe Ile Phe Pro Pro Asn Ile Lys Asp Val Leu
245 250 255
Met Ile Ser Leu Thr Pro Lys Val Thr Cys Val Val Val Asp Val Ser
260 265 270
Glu Asp Asp Pro Asp Val Arg Ile Ser Trp Phe Val Asn Asn Val Glu
275 280 285
Val His Thr Ala Gln Thr Gln Thr His Arg Glu Asp Tyr Asn Ser Thr
290 295 300
Ile Arg Val Val Ser Ala Leu Pro Ile Gln His Gln Asp Trp Met Ser
305 310 315 320
Gly Lys Glu Phe Lys Cys Lys Val Asn Asn Lys Asp Leu Pro Ser Pro
325 330 335
Ile Glu Arg Thr Ile Ser Lys Ile Lys Gly Leu Val Arg Ala Pro Gln
340 345 350
Val Tyr Ile Leu Pro Pro Pro Ala Glu Gln Leu Ser Arg Lys Asp Val
355 360 365
Ser Leu Thr Cys Leu Val Val Gly Phe Asn Pro Gly Asp Ile Ser Val
370 375 380
Glu Trp Thr Ser Asn Gly His Thr Glu Glu Asn Tyr Lys Asp Thr Ala
385 390 395 400
Pro Val Leu Asp Ser Asp Gly Ser Tyr Phe Ile Tyr Ser Lys Leu Asp
405 410 415
Ile Lys Thr Ser Lys Trp Glu Lys Thr Asp Ser Phe Ser Cys Asn Val
420 425 430
Arg His Glu Gly Leu Lys Asn Tyr Tyr Leu Lys Lys Thr Ile Ser Arg
435 440 445
Ser Pro Gly Lys
450
<210> 100
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 100
Glu Val Lys Leu Glu Glu Ser Gly Pro Ala Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Arg Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Asp Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Phe
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 101
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 101
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Trp Met
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Ser Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Arg Asp Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 102
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 102
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 103
<211> 450
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 103
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Cys Leu Ser Pro Gly Ser Leu Ser
435 440 445
Pro Gly
450
<210> 104
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 104
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Trp Met
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Ile Thr Arg Asp Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 105
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 105
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Ser Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 106
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 106
Gln Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 107
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 107
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 108
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 108
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Asn Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 109
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 109
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asp Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 110
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 110
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Phe Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 111
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 111
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Ser Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 112
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 112
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Trp Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 113
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 113
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Phe Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 114
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 114
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Trp Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 115
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 115
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Asn Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 116
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 116
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 117
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 117
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Tyr Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 118
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 118
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Ala Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 119
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 119
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 120
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 120
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Val Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 121
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 121
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Ile Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 122
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 122
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Arg Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 123
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 123
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 124
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 124
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
His Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 125
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 125
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Asp Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 126
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 126
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Tyr Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 127
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 127
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Ser Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 128
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 128
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Phe Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 129
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 129
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Gly Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 130
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 130
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Thr Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 131
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 131
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Val Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 132
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 132
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Ile Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 133
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 133
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Leu Ile His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Tyr Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Tyr Ile Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Leu Thr Ala Asp Lys Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Pro Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 134
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 134
Asp Ile Val Leu Thr Gln Thr Pro Phe Ser Asn Pro Val Thr Leu Gly
1 5 10 15
Thr Ser Ala Ser Ile Ser Cys Arg Ser Ser Lys Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro His Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Arg Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Ala Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu
115 120 125
Gln Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe
130 135 140
Tyr Pro Lys Asp Ile Asn Val Lys Trp Lys Ile Asp Gly Ser Glu Arg
145 150 155 160
Gln Asn Gly Val Leu Asn Ser Trp Thr Asp Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Met Ser Ser Thr Leu Thr Leu Thr Lys Asp Glu Tyr Glu
180 185 190
Arg His Asn Ser Tyr Thr Cys Glu Ala Thr His Lys Thr Ser Thr Ser
195 200 205
Pro Ile Val Lys Ser Phe Asn Arg Asn Glu Cys
210 215
<210> 135
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 135
Asp Ile Val Leu Thr Gln Thr Pro Phe Ser Asn Pro Val Thr Leu Gly
1 5 10 15
Thr Ser Ala Ser Ile Ser Cys Arg Ser Ser Lys Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro His Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Arg Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 136
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 136
Asp Ile Val Met Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 137
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 137
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Lys Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 138
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 138
Asp Ile Val Met Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Lys Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 139
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 139
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 140
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 140
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asn Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 141
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 141
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Ile Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 142
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 142
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 143
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 143
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Ser Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 144
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 144
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 145
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 145
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Gln Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 146
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 146
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Leu Gln Asn
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 147
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 147
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Tyr
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 148
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 148
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Gly
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 149
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 149
Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Ser
85 90 95
Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 150
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 150
Pro Leu Met Thr Cys Ser Asp Tyr Tyr Thr Cys Leu Asn Asn Leu
1 5 10 15
<210> 151
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 151
Leu Ser Cys Thr His Ser Arg Tyr Asp Met His Cys Pro His Met
1 5 10 15
<210> 152
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 152
His Tyr Cys His Ser Arg Thr Asp Thr Ile Thr His Cys Asn Ala
1 5 10 15
<210> 153
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 153
Trp Cys Pro Arg Leu Phe Asp Arg Pro Ser Met Gly Cys Pro Thr
1 5 10 15
<210> 154
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 154
Trp Trp Pro Pro Cys Gln Gly Gly Ala Trp Cys Glu Gln Arg Ile
1 5 10 15
<210> 155
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 155
His Ser Gly Cys Pro Arg Leu Phe Asp Arg Cys Ser Ala Pro Ala
1 5 10 15
<210> 156
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 156
Phe Ile Cys Pro Thr Leu Tyr Asp Arg Pro His Cys Met His Thr
1 5 10 15
<210> 157
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 157
Ser Trp Cys His Ser Ala Thr Asp Thr Ile Leu Pro Cys Ser Asn
1 5 10 15
<210> 158
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 158
Ser Pro Ala Cys Ser Asp Arg Tyr Tyr Gln Thr Cys Val Leu Asn
1 5 10 15
<210> 159
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 159
Met Ser Cys Val Val Asp Arg Phe Asp Arg Gln Cys Pro His Leu
1 5 10 15
<210> 160
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 160
Thr Thr Arg Cys Glu His Tyr Trp Phe Thr Cys Pro Leu Ser Pro
1 5 10 15
<210> 161
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 161
Asp Cys Thr Gly Tyr Ser Pro Ser Val Leu Pro Ala Cys Arg Val
1 5 10 15
<210> 162
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 162
Phe Cys Ser Gly Tyr Ser Pro Ser Val Leu Pro Ser Cys Leu Met
1 5 10 15
<210> 163
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 163
Ser Lys Pro Cys Ser Tyr Met His Pro Tyr Cys Phe Tyr Asn Ser
1 5 10 15
<210> 164
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 164
Leu Thr Arg Cys Thr Ile Ala His Pro Tyr Cys Tyr Tyr Asn Tyr
1 5 10 15
<210> 165
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 165
Pro Asn Thr Cys Met Ser Glu Arg Arg Ile Cys Ser Leu Thr Tyr
1 5 10 15
<210> 166
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 166
Pro Arg Pro His Cys Ala Ile Leu Arg Gln Cys Leu Ala Ala Thr
1 5 10 15
<210> 167
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 167
Ala Val Gly Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp
1 5 10 15
Asn Ile
<210> 168
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 168
Ser Ile Ser Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile
1 5 10
<210> 169
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 169
Gln Gly Gln Ser Gly Gln Gly Pro Leu Met Thr Cys Ser Asp Tyr Tyr
1 5 10 15
Thr Cys Leu Asn Asn Leu Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 170
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 170
Gln Gly Gln Ser Gly Gln Gly Leu Ser Cys Thr His Ser Arg Tyr Asp
1 5 10 15
Met His Cys Pro His Met Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 171
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 171
Gln Gly Gln Ser Gly Gln Gly His Tyr Cys His Ser Arg Thr Asp Thr
1 5 10 15
Ile Thr His Cys Asn Ala Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 172
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 172
Gln Gly Gln Ser Gly Gln Gly Trp Cys Pro Arg Leu Phe Asp Arg Pro
1 5 10 15
Ser Met Gly Cys Pro Thr Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 173
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 173
Gln Gly Gln Ser Gly Gln Gly Trp Trp Pro Pro Cys Gln Gly Gly Ala
1 5 10 15
Trp Cys Glu Gln Arg Ile Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 174
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 174
Gln Gly Gln Ser Gly Gln Gly His Ser Gly Cys Pro Arg Leu Phe Asp
1 5 10 15
Arg Cys Ser Ala Pro Ala Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 175
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 175
Gln Gly Gln Ser Gly Gln Gly Phe Ile Cys Pro Thr Leu Tyr Asp Arg
1 5 10 15
Pro His Cys Met His Thr Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 176
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 176
Gln Gly Gln Ser Gly Gln Gly Pro Leu Met Thr Cys Ser Asp Tyr Tyr
1 5 10 15
Thr Cys Leu Asn Asn Leu Gly Gly Gly Ser Ser Gly Gly Ser Ile Ser
20 25 30
Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile Gly Gly Ser Asp Ile
35 40 45
Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro
50 55 60
Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly
65 70 75 80
Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser Pro Gln
85 90 95
Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro Asp Arg
100 105 110
Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg
115 120 125
Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn Leu Glu
130 135 140
Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr
145 150 155 160
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
165 170 175
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
180 185 190
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
195 200 205
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
210 215 220
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
225 230 235 240
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
245 250 255
Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 177
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 177
Gln Gly Gln Ser Gly Gln Gly Trp Cys Pro Arg Leu Phe Asp Arg Pro
1 5 10 15
Ser Met Gly Cys Pro Thr Gly Gly Gly Ser Ser Gly Gly Ser Ile Ser
20 25 30
Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile Gly Gly Ser Asp Ile
35 40 45
Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro
50 55 60
Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly
65 70 75 80
Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser Pro Gln
85 90 95
Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro Asp Arg
100 105 110
Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg
115 120 125
Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn Leu Glu
130 135 140
Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr
145 150 155 160
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
165 170 175
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
180 185 190
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
195 200 205
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
210 215 220
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
225 230 235 240
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
245 250 255
Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 178
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 178
Gln Gly Gln Ser Gly Gln Gly Trp Trp Pro Pro Cys Gln Gly Gly Ala
1 5 10 15
Trp Cys Glu Gln Arg Ile Gly Gly Gly Ser Ser Gly Gly Ser Ile Ser
20 25 30
Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile Gly Gly Ser Asp Ile
35 40 45
Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro
50 55 60
Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly
65 70 75 80
Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser Pro Gln
85 90 95
Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro Asp Arg
100 105 110
Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg
115 120 125
Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn Leu Glu
130 135 140
Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr
145 150 155 160
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
165 170 175
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
180 185 190
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
195 200 205
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
210 215 220
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
225 230 235 240
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
245 250 255
Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 179
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 179
Gln Gly Gln Ser Gly Gln Gly His Ser Gly Cys Pro Arg Leu Phe Asp
1 5 10 15
Arg Cys Ser Ala Pro Ala Gly Gly Gly Ser Ser Gly Gly Ser Ile Ser
20 25 30
Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile Gly Gly Ser Asp Ile
35 40 45
Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro
50 55 60
Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly
65 70 75 80
Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser Pro Gln
85 90 95
Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro Asp Arg
100 105 110
Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg
115 120 125
Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn Leu Glu
130 135 140
Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr
145 150 155 160
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
165 170 175
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
180 185 190
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
195 200 205
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
210 215 220
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
225 230 235 240
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
245 250 255
Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 180
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 180
Gln Gly Gln Ser Gly Gln Gly Ser Trp Cys His Ser Ala Thr Asp Thr
1 5 10 15
Ile Leu Pro Cys Ser Asn Gly Gly Gly Ser Ser Gly Gly Ser Ile Ser
20 25 30
Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile Gly Gly Ser Asp Ile
35 40 45
Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro
50 55 60
Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly
65 70 75 80
Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser Pro Gln
85 90 95
Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro Asp Arg
100 105 110
Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg
115 120 125
Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn Leu Glu
130 135 140
Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr
145 150 155 160
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
165 170 175
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
180 185 190
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
195 200 205
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
210 215 220
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
225 230 235 240
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
245 250 255
Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 181
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 181
Gln Gly Gln Ser Gly Gln Gly Ser Pro Ala Cys Ser Asp Arg Tyr Tyr
1 5 10 15
Gln Thr Cys Val Leu Asn Gly Gly Gly Ser Ser Gly Gly Ser Ile Ser
20 25 30
Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile Gly Gly Ser Asp Ile
35 40 45
Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro
50 55 60
Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly
65 70 75 80
Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser Pro Gln
85 90 95
Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro Asp Arg
100 105 110
Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg
115 120 125
Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn Leu Glu
130 135 140
Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr
145 150 155 160
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
165 170 175
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
180 185 190
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
195 200 205
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
210 215 220
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
225 230 235 240
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
245 250 255
Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 182
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 182
Gln Gly Gln Ser Gly Gln Gly Met Ser Cys Val Val Asp Arg Phe Asp
1 5 10 15
Arg Gln Cys Pro His Leu Gly Gly Gly Ser Ser Gly Gly Ser Ile Ser
20 25 30
Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile Gly Gly Ser Asp Ile
35 40 45
Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro
50 55 60
Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly
65 70 75 80
Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser Pro Gln
85 90 95
Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro Asp Arg
100 105 110
Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg
115 120 125
Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn Leu Glu
130 135 140
Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr
145 150 155 160
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
165 170 175
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
180 185 190
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
195 200 205
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
210 215 220
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
225 230 235 240
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
245 250 255
Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 183
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 183
Gln Gly Gln Ser Gly Gln Gly Thr Thr Arg Cys Glu His Tyr Trp Phe
1 5 10 15
Thr Cys Pro Leu Ser Pro Gly Gly Gly Ser Ser Gly Gly Ser Ile Ser
20 25 30
Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile Gly Gly Ser Asp Ile
35 40 45
Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro
50 55 60
Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly
65 70 75 80
Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser Pro Gln
85 90 95
Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro Asp Arg
100 105 110
Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg
115 120 125
Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn Leu Glu
130 135 140
Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr
145 150 155 160
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
165 170 175
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
180 185 190
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
195 200 205
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
210 215 220
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
225 230 235 240
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
245 250 255
Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 184
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 184
Gln Gly Gln Ser Gly Gln Gly Ser Trp Cys His Ser Ala Thr Asp Thr
1 5 10 15
Ile Leu Pro Cys Ser Asn Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 185
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 185
Gln Gly Gln Ser Gly Gln Gly Ser Pro Ala Cys Ser Asp Arg Tyr Tyr
1 5 10 15
Gln Thr Cys Val Leu Asn Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 186
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 186
Gln Gly Gln Ser Gly Gln Gly Met Ser Cys Val Val Asp Arg Phe Asp
1 5 10 15
Arg Gln Cys Pro His Leu Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 187
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 187
Gln Gly Gln Ser Gly Gln Gly Thr Thr Arg Cys Glu His Tyr Trp Phe
1 5 10 15
Thr Cys Pro Leu Ser Pro Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 188
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 188
Gln Gly Gln Ser Gly Gln Gly Asp Cys Thr Gly Tyr Ser Pro Ser Val
1 5 10 15
Leu Pro Ala Cys Arg Val Gly Gly Gly Ser Ser Gly Gly Ser Ile Ser
20 25 30
Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile Gly Gly Ser Asp Ile
35 40 45
Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro
50 55 60
Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly
65 70 75 80
Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser Pro Gln
85 90 95
Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro Asp Arg
100 105 110
Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg
115 120 125
Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn Leu Glu
130 135 140
Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr
145 150 155 160
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
165 170 175
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
180 185 190
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
195 200 205
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
210 215 220
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
225 230 235 240
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
245 250 255
Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 189
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 189
Gln Gly Gln Ser Gly Gln Gly Phe Cys Ser Gly Tyr Ser Pro Ser Val
1 5 10 15
Leu Pro Ser Cys Leu Met Gly Gly Gly Ser Ser Gly Gly Ser Ile Ser
20 25 30
Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile Gly Gly Ser Asp Ile
35 40 45
Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro
50 55 60
Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly
65 70 75 80
Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser Pro Gln
85 90 95
Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro Asp Arg
100 105 110
Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg
115 120 125
Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn Leu Glu
130 135 140
Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr
145 150 155 160
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
165 170 175
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
180 185 190
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
195 200 205
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
210 215 220
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
225 230 235 240
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
245 250 255
Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 190
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 190
Gln Gly Gln Ser Gly Gln Gly Ser Lys Pro Cys Ser Tyr Met His Pro
1 5 10 15
Tyr Cys Phe Tyr Asn Ser Gly Gly Gly Ser Ser Gly Gly Ser Ile Ser
20 25 30
Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile Gly Gly Ser Asp Ile
35 40 45
Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro
50 55 60
Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly
65 70 75 80
Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser Pro Gln
85 90 95
Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro Asp Arg
100 105 110
Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg
115 120 125
Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn Leu Glu
130 135 140
Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr
145 150 155 160
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
165 170 175
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
180 185 190
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
195 200 205
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
210 215 220
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
225 230 235 240
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
245 250 255
Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 191
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 191
Gln Gly Gln Ser Gly Gln Gly Leu Thr Arg Cys Thr Ile Ala His Pro
1 5 10 15
Tyr Cys Tyr Tyr Asn Tyr Gly Gly Gly Ser Ser Gly Gly Ser Ile Ser
20 25 30
Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile Gly Gly Ser Asp Ile
35 40 45
Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro
50 55 60
Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly
65 70 75 80
Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser Pro Gln
85 90 95
Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro Asp Arg
100 105 110
Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg
115 120 125
Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn Leu Glu
130 135 140
Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr
145 150 155 160
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
165 170 175
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
180 185 190
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
195 200 205
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
210 215 220
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
225 230 235 240
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
245 250 255
Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 192
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 192
Gln Gly Gln Ser Gly Gln Gly Pro Asn Thr Cys Met Ser Glu Arg Arg
1 5 10 15
Ile Cys Ser Leu Thr Tyr Gly Gly Gly Ser Ser Gly Gly Ser Ile Ser
20 25 30
Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile Gly Gly Ser Asp Ile
35 40 45
Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro
50 55 60
Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly
65 70 75 80
Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser Pro Gln
85 90 95
Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro Asp Arg
100 105 110
Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg
115 120 125
Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn Leu Glu
130 135 140
Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr
145 150 155 160
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
165 170 175
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
180 185 190
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
195 200 205
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
210 215 220
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
225 230 235 240
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
245 250 255
Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 193
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 193
Gln Gly Gln Ser Gly Gln Gly Pro Arg Pro His Cys Ala Ile Leu Arg
1 5 10 15
Gln Cys Leu Ala Ala Thr Gly Gly Gly Ser Ser Gly Gly Ser Ile Ser
20 25 30
Ser Gly Leu Leu Ser Gly Arg Ser Asp Asn Ile Gly Gly Ser Asp Ile
35 40 45
Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro
50 55 60
Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu His Ser Asp Gly
65 70 75 80
Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly Gln Ser Pro Gln
85 90 95
Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly Val Pro Asp Arg
100 105 110
Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg
115 120 125
Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn Leu Glu
130 135 140
Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr
145 150 155 160
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
165 170 175
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
180 185 190
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
195 200 205
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
210 215 220
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
225 230 235 240
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
245 250 255
Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 194
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 194
Gln Gly Gln Ser Gly Gln Gly Asp Cys Thr Gly Tyr Ser Pro Ser Val
1 5 10 15
Leu Pro Ala Cys Arg Val Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 195
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 195
Gln Gly Gln Ser Gly Gln Gly Phe Cys Ser Gly Tyr Ser Pro Ser Val
1 5 10 15
Leu Pro Ser Cys Leu Met Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 196
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 196
Gln Gly Gln Ser Gly Gln Gly Ser Lys Pro Cys Ser Tyr Met His Pro
1 5 10 15
Tyr Cys Phe Tyr Asn Ser Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 197
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 197
Gln Gly Gln Ser Gly Gln Gly Leu Thr Arg Cys Thr Ile Ala His Pro
1 5 10 15
Tyr Cys Tyr Tyr Asn Tyr Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 198
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 198
Gln Gly Gln Ser Gly Gln Gly Pro Asn Thr Cys Met Ser Glu Arg Arg
1 5 10 15
Ile Cys Ser Leu Thr Tyr Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 199
<211> 269
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 199
Gln Gly Gln Ser Gly Gln Gly Pro Arg Pro His Cys Ala Ile Leu Arg
1 5 10 15
Gln Cys Leu Ala Ala Thr Gly Gly Gly Ser Ser Gly Gly Ala Val Gly
20 25 30
Leu Leu Ala Pro Pro Gly Gly Leu Ser Gly Arg Ser Asp Asn Ile Gly
35 40 45
Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr
50 55 60
Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Leu
65 70 75 80
His Ser Asp Gly Phe Thr Tyr Leu Tyr Trp Phe Leu Gln Lys Pro Gly
85 90 95
Gln Ser Pro Gln Leu Leu Ile Tyr Gln Thr Ser Asn Leu Ala Ser Gly
100 105 110
Val Pro Asp Arg Phe Ser Ser Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala
130 135 140
Gln Asn Leu Glu Leu Pro Asn Thr Phe Gly Gln Gly Thr Lys Leu Glu
145 150 155 160
Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
165 170 175
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
180 185 190
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
195 200 205
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
210 215 220
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
225 230 235 240
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
245 250 255
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
260 265
<210> 200
<211> 1335
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Oligonucleotide
<400> 200
gaggtgaagc tggaggagag cggccccgcc ctggtgaagc ctggagcttc cgtgaggatc 60
agctgtaagg cctctggcta cacctttaca aactactata tccattgggt gaagcagcgg 120
ccaggacagg gcctggacta catcggctgg atctatcccg gcaacgtgta catccagtat 180
aatgagaagt tcaagggcaa ggccaccctg acagctgata agtccagctc taccgctttt 240
atgcagctgt ccagcctgac aagcgaggac tctgccgtgt acttctgcgc tagggatggc 300
ccttggtttg cctattgggg ccagggcacc ctggtgacag tgtcttccgc ttccaccaag 360
ggcccatcag ttttcccctt ggctccaagt tctaaatcca caagcggtgg aacagctgca 420
ctgggatgcc tcgttaaaga ttatttccct gagcctgtga cagtgagctg gaatagcgga 480
gcattgactt caggtgtgca cacttttccc gctgtgttgc agtcctccgg tctgtactca 540
ctgtccagtg tcgtaaccgt cccttctagc agcttgggaa cccagaccta catctgtaac 600
gtcaaccata aaccatccaa cacaaaggtg gataagaagg ttgaaccaaa gagctgtgat 660
aagacacata catgccctcc ttgtcctgca ccagagctcc tcggaggtcc atctgtgttc 720
ctgtttcccc ccaaacccaa ggacactctt atgatctctc gtactccaga ggtcacctgt 780
gttgttgtcg acgtgagcca tgaagatccc gaggttaaat tcaactggta cgtggatgga 840
gtcgaggttc acaatgccaa gaccaagccc agggaggagc aatataattc tacatatcgg 900
gtagtgagcg ttctgaccgt gctccaccaa gattggctca atggaaaaga gtacaagtgc 960
aaggtgtcca acaaggctct tcccgctccc attgagaaaa ctatctccaa agccaagggg 1020
cagccacggg aaccccaggt gtatacattg cccccatcta gagacgagct gaccaagaac 1080
caggtgagtc tcacttgtct ggtcaagggg ttttaccctt ctgacattgc tgtagagtgg 1140
gagtctaacg gacagccaga aaacaactac aagacaactc ccccagtgct ggacagcgac 1200
gggagcttct tcctctactc caagttgact gtagacaagt ctagatggca gcaaggaaac 1260
gttttctcct gctcagtaat gcatgaggct ctgcacaatc actataccca gaaatcactg 1320
tcccttagcc caggg 1335
<210> 201
<211> 657
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Oligonucleotide
<400> 201
gatattgtgc tgacccagac tccattctcc aatcccgtca ctcttggaac atcagcttcc 60
atctcctgca ggtctagtaa gagtctccta catagtgatg gcttcactta tttgtattgg 120
tttctgcaga agccaggcca gtctcctcat ctcctgattt atcagacgtc caaccttgcc 180
tcaggagtcc cagacaggtt cagtagcagt gggtcaggaa ctgatttcac actgagaatc 240
agcagagtgg aggctgaaga tgtgggtgtt tattactgtg ctcaaaatct agaacttccc 300
aacacgttcg gaggggggac caagctggaa atcaaacgta cggtggctgc accatctgtc 360
ttcatcttcc cgccatctga tgagcagttg aaatctggaa ctgcctctgt tgtgtgcctg 420
ctgaataact tctatcccag agaggccaaa gtacagtgga aggtggataa cgccctccaa 480
tcgggtaact cccaggagag tgtcacagag caggacagca aggacagcac ctacagcctc 540
agcagcaccc tgacgctgag caaagcagac tacgagaaac acaaagtcta cgcctgcgaa 600
gtcacccatc agggcctgag ctcgcccgtc acaaagagct tcaacagggg agagtgt 657
<210> 202
<211> 1335
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Oligonucleotide
<400> 202
caggtgcagc tggtgcagag cggagctgag gtgaagaagc caggagcttc cgtgaaggtg 60
agctgtaagg cctctggcta caccttcaca aactactata tccattgggt gaggcaggct 120
ccaggacagc ggctggagta catcggatgg atctatcctg gcaacgtgta catccagtat 180
aatgagaagt ttaagggcag ggccaccctg acagctgaca agagcgcctc taccgcttac 240
atggagctgt ccagcctgag atctgaggac acagccgtgt actattgcgc tcgcgatggc 300
ccttggtttg cctattgggg ccagggcacc ctggtgacag tgtcttccgc ttccaccaag 360
ggcccatcag ttttcccctt ggctccaagt tctaaatcca caagcggtgg aacagctgca 420
ctgggatgcc tcgttaaaga ttatttccct gagcctgtga cagtgagctg gaatagcgga 480
gcattgactt caggtgtgca cacttttccc gctgtgttgc agtcctccgg tctgtactca 540
ctgtccagtg tcgtaaccgt cccttctagc agcttgggaa cccagaccta catctgtaac 600
gtcaaccata aaccatccaa cacaaaggtg gataagaagg ttgaaccaaa gagctgtgat 660
aagacacata catgccctcc ttgtcctgca ccagagctcc tcggaggtcc atctgtgttc 720
ctgtttcccc ccaaacccaa ggacactctt atgatctctc gtactccaga ggtcacctgt 780
gttgttgtcg acgtgagcca tgaagatccc gaggttaaat tcaactggta cgtggatgga 840
gtcgaggttc acaatgccaa gaccaagccc agggaggagc aatataattc tacatatcgg 900
gtagtgagcg ttctgaccgt gctccaccaa gattggctca atggaaaaga gtacaagtgc 960
aaggtgtcca acaaggctct tcccgctccc attgagaaaa ctatctccaa agccaagggg 1020
cagccacggg aaccccaggt gtatacattg cccccatcta gagacgagct gaccaagaac 1080
caggtgagtc tcacttgtct ggtcaagggg ttttaccctt ctgacattgc tgtagagtgg 1140
gagtctaacg gacagccaga aaacaactac aagacaactc ccccagtgct ggacagcgac 1200
gggagcttct tcctctactc caagttgact gtagacaagt ctagatggca gcaaggaaac 1260
gttttctcct gctcagtaat gcatgaggct ctgcacaatc actataccca gaaatcactg 1320
tcccttagcc caggg 1335
<210> 203
<211> 657
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Oligonucleotide
<400> 203
gacatcgtgc tgacccagac accactgtct ctgtccgtga ccccaggaca gcctgctagc 60
atctcttgta ggtccagcag gtccctgctg catagcgatg gcttcaccta cctgtattgg 120
tttctgcaga agccaggcca gtctccccag ctgctgatct accagacatc taacctggct 180
tccggcgtgc ctgacaggtt ctcttccagc ggcagcggca ccgacttcac cctgaagatc 240
tctcgggtgg aggctgagga cgtgggcgtg tactattgcg ctcagaacct ggagctgcca 300
aatacctttg gccagggcac aaagctggag atcaagcgta cggtggctgc accatctgtc 360
ttcatcttcc cgccatctga tgagcagttg aaatctggaa ctgcctctgt tgtgtgcctg 420
ctgaataact tctatcccag agaggccaaa gtacagtgga aggtggataa cgccctccaa 480
tcgggtaact cccaggagag tgtcacagag caggacagca aggacagcac ctacagcctc 540
agcagcaccc tgacgctgag caaagcagac tacgagaaac acaaagtcta cgcctgcgaa 600
gtcacccatc agggcctgag ctcgcccgtc acaaagagct tcaacagggg agagtgt 657
<210> 204
<211> 1338
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Oligonucleotide
<400> 204
caggtgcagc tggtgcagag cggagctgag gtgaagaagc caggagcttc cgtgaaggtg 60
agctgtaagg cctctggcta caccttcaca aactaccaca tccattgggt gaggcaggct 120
ccaggacagc ggctggagta catcggatgg atctatcctg gcaacgtgta catccagtat 180
aatgagaagt ttaagggcag ggccaccctg acagctgaca agagcgcctc taccgcttac 240
atggagctgt ccagcctgag atctgaggac acagccgtgt actattgcgc tcgcgatggc 300
ccttggtttg cctattgggg ccagggcacc ctggtgacag tgtcttccgc ttccaccaag 360
ggcccatcag ttttcccctt ggctccaagt tctaaatcca caagcggtgg aacagctgca 420
ctgggatgcc tcgttaaaga ttatttccct gagcctgtga cagtgagctg gaatagcgga 480
gcattgactt caggtgtgca cacttttccc gctgtgttgc agtcctccgg tctgtactca 540
ctgtccagtg tcgtaaccgt cccttctagc agcttgggaa cccagaccta catctgtaac 600
gtcaaccata aaccatccaa cacaaaggtg gataagaagg ttgaaccaaa gagctgtgat 660
aagacacata catgccctcc ttgtcctgca ccagagctcc tcggaggtcc atctgtgttc 720
ctgtttcccc ccaaacccaa ggacactctt atgatctctc gtactccaga ggtcacctgt 780
gttgttgtcg acgtgagcca tgaagatccc gaggttaaat tcaactggta cgtggatgga 840
gtcgaggttc acaatgccaa gaccaagccc agggaggagc aatataattc tacatatcgg 900
gtagtgagcg ttctgaccgt gctccaccaa gattggctca atggaaaaga gtacaagtgc 960
aaggtgtcca acaaggctct tcccgctccc attgagaaaa ctatctccaa agccaagggg 1020
cagccacggg aaccccaggt gtatacattg cccccatcta gagacgagct gaccaagaac 1080
caggtgagtc tcacttgtct ggtcaagggg ttttaccctt ctgacattgc tgtagagtgg 1140
gagtctaacg gacagccaga aaacaactac aagacaactc ccccagtgct ggacagcgac 1200
gggagcttct tcctctactc caagttgact gtagacaagt ctagatggca gcaaggaaac 1260
gttttctcct gctcagtaat gcatgaggct ctgcacaatc actataccca gaaatcactg 1320
tcccttagcc cagggtga 1338
<210> 205
<211> 1338
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Oligonucleotide
<400> 205
caggtgcagc tggtgcagag cggagctgag gtgaagaagc caggagcttc cgtgaaggtg 60
agctgtaagg cctctggcta caccttcaca aactacgaca tccattgggt gaggcaggct 120
ccaggacagc ggctggagta catcggatgg atctatcctg gcaacgtgta catccagtat 180
aatgagaagt ttaagggcag ggccaccctg acagctgaca agagcgcctc taccgcttac 240
atggagctgt ccagcctgag atctgaggac acagccgtgt actattgcgc tcgcgatggc 300
ccttggtttg cctattgggg ccagggcacc ctggtgacag tgtcttccgc ttccaccaag 360
ggcccatcag ttttcccctt ggctccaagt tctaaatcca caagcggtgg aacagctgca 420
ctgggatgcc tcgttaaaga ttatttccct gagcctgtga cagtgagctg gaatagcgga 480
gcattgactt caggtgtgca cacttttccc gctgtgttgc agtcctccgg tctgtactca 540
ctgtccagtg tcgtaaccgt cccttctagc agcttgggaa cccagaccta catctgtaac 600
gtcaaccata aaccatccaa cacaaaggtg gataagaagg ttgaaccaaa gagctgtgat 660
aagacacata catgccctcc ttgtcctgca ccagagctcc tcggaggtcc atctgtgttc 720
ctgtttcccc ccaaacccaa ggacactctt atgatctctc gtactccaga ggtcacctgt 780
gttgttgtcg acgtgagcca tgaagatccc gaggttaaat tcaactggta cgtggatgga 840
gtcgaggttc acaatgccaa gaccaagccc agggaggagc aatataattc tacatatcgg 900
gtagtgagcg ttctgaccgt gctccaccaa gattggctca atggaaaaga gtacaagtgc 960
aaggtgtcca acaaggctct tcccgctccc attgagaaaa ctatctccaa agccaagggg 1020
cagccacggg aaccccaggt gtatacattg cccccatcta gagacgagct gaccaagaac 1080
caggtgagtc tcacttgtct ggtcaagggg ttttaccctt ctgacattgc tgtagagtgg 1140
gagtctaacg gacagccaga aaacaactac aagacaactc ccccagtgct ggacagcgac 1200
gggagcttct tcctctactc caagttgact gtagacaagt ctagatggca gcaaggaaac 1260
gttttctcct gctcagtaat gcatgaggct ctgcacaatc actataccca gaaatcactg 1320
tcccttagcc cagggtga 1338
<210> 206
<211> 1338
<212> DNA
<213> Artifical Sequence
<400> 206
caggtgcagc tggtgcagag cggagctgag gtgaagaagc caggagcttc cgtgaaggtg 60
agctgtaagg cctctggcta caccttcaca aactacgaca tccattgggt gaggcaggct 120
ccaggacagc ggctggagta catcggatgg atctatcctg gcaacgtgta catccagtat 180
aatgagaagt ttaagggcag ggccaccctg acagctgaca agagcgcctc taccgcttac 240
atggagctgt ccagcctgag atctgaggac acagccgtgt actattgcgc tcgcgatggc 300
ccttggtttg cctattgggg ccagggcacc ctggtgacag tgtcttccgc ttccaccaag 360
ggcccatcag ttttcccctt ggctccaagt tctaaatcca caagcggtgg aacagctgca 420
ctgggatgcc tcgttaaaga ttatttccct gagcctgtga cagtgagctg gaatagcgga 480
gcattgactt caggtgtgca cacttttccc gctgtgttgc agtcctccgg tctgtactca 540
ctgtccagtg tcgtaaccgt cccttctagc agcttgggaa cccagaccta catctgtaac 600
gtcaaccata aaccatccaa cacaaaggtg gataagaagg ttgaaccaaa gagctgtgat 660
aagacacata catgccctcc ttgtcctgca ccagagctcc tcggaggtcc atctgtgttc 720
ctgtttcccc ccaaacccaa ggacactctt atgatctctc gtactccaga ggtcacctgt 780
gttgttgtcg acgtgagcca tgaagatccc gaggttaaat tcaactggta cgtggatgga 840
gtcgaggttc acaatgccaa gaccaagccc agggaggagc aatataattc tacatatcgg 900
gtagtgagcg ttctgaccgt gctccaccaa gattggctca atggaaaaga gtacaagtgc 960
aaggtgtcca acaaggctct tcccgctccc attgagaaaa ctatctccaa agccaagggg 1020
cagccacggg aaccccaggt gtatacattg cccccatcta gagacgagct gaccaagaac 1080
caggtgagtc tcacttgtct ggtcaagggg ttttaccctt ctgacattgc tgtagagtgg 1140
gagtctaacg gacagccaga aaacaactac aagacaactc ccccagtgct ggacagcgac 1200
gggagcttct tcctctactc caagttgact gtagacaagt ctagatggca gcaaggaaac 1260
gttttctcct gctcagtaat gcatgaggct ctgcacaatc actataccca gaaatcactg 1320
tcccttagcc cagggtga 1338
<210> 207
<211> 1338
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Oligonucleotide
<400> 207
caggtgcagc tggtgcagag cggagctgag gtgaagaagc caggagcttc cgtgaaggtg 60
agctgtaagg cctctggcta caccttcaca aactactata tccattgggt gaggcaggct 120
ccaggacagc ggctggagta catcggatgg atctatcctg gcaacgtgta catccagtat 180
aatgagaagt ttaagggcag ggccaccctg acagctgaca agagcgcctc taccgcttac 240
atggagctgt ccagcctgag atctgaggac acagccgtgt actattgcgc tcgcgatggc 300
tactggtttg cctattgggg ccagggcacc ctggtgacag tgtcttccgc ttccaccaag 360
ggcccatcag ttttcccctt ggctccaagt tctaaatcca caagcggtgg aacagctgca 420
ctgggatgcc tcgttaaaga ttatttccct gagcctgtga cagtgagctg gaatagcgga 480
gcattgactt caggtgtgca cacttttccc gctgtgttgc agtcctccgg tctgtactca 540
ctgtccagtg tcgtaaccgt cccttctagc agcttgggaa cccagaccta catctgtaac 600
gtcaaccata aaccatccaa cacaaaggtg gataagaagg ttgaaccaaa gagctgtgat 660
aagacacata catgccctcc ttgtcctgca ccagagctcc tcggaggtcc atctgtgttc 720
ctgtttcccc ccaaacccaa ggacactctt atgatctctc gtactccaga ggtcacctgt 780
gttgttgtcg acgtgagcca tgaagatccc gaggttaaat tcaactggta cgtggatgga 840
gtcgaggttc acaatgccaa gaccaagccc agggaggagc aatataattc tacatatcgg 900
gtagtgagcg ttctgaccgt gctccaccaa gattggctca atggaaaaga gtacaagtgc 960
aaggtgtcca acaaggctct tcccgctccc attgagaaaa ctatctccaa agccaagggg 1020
cagccacggg aaccccaggt gtatacattg cccccatcta gagacgagct gaccaagaac 1080
caggtgagtc tcacttgtct ggtcaagggg ttttaccctt ctgacattgc tgtagagtgg 1140
gagtctaacg gacagccaga aaacaactac aagacaactc ccccagtgct ggacagcgac 1200
gggagcttct tcctctactc caagttgact gtagacaagt ctagatggca gcaaggaaac 1260
gttttctcct gctcagtaat gcatgaggct ctgcacaatc actataccca gaaatcactg 1320
tcccttagcc cagggtga 1338
<210> 208
<211> 807
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Oligonucleotide
<400> 208
cagggacagt ctggacaggg atggtggcca ccttgccagg gaggagcttg gtgtgagcag 60
aggatcggag gaggctccag cggaggagct gtgggcctgc tggctccacc aggaggactg 120
tctggcagat ccgacaacat cggcggctcc gatatcgtgc tgacccagac acccctgagc 180
ctgtctgtga cccctggcca gccagcctcc atcagctgca ggtcttcccg gtccctgctg 240
catagcgacg gcttcaccta cctgtattgg tttctgcaga agcccggcca gagccctcag 300
ctgctgatct accagacatc taatctggct tccggcgtgc cagacagatt cagctcttcc 360
ggcagcggca ccgacttcac cctgaagatc tctcgcgtgg aggccgagga tgtgggcgtg 420
tactattgtg ctcagaacct ggagctgccc aatacctttg gccagggcac aaagctggag 480
atcaagcgta cggtggctgc accatctgtc ttcatcttcc cgccatctga tgagcagttg 540
aaatctggaa ctgcctctgt tgtgtgcctg ctgaataact tctatcccag agaggccaaa 600
gtacagtgga aggtggataa cgccctccaa tcgggtaact cccaggagag tgtcacagag 660
caggacagca aggacagcac ctacagcctc agcagcaccc tgacgctgag caaagcagac 720
tacgagaaac acaaagtcta cgcctgcgaa gtcacccatc agggcctgag ctcgcccgtc 780
acaaagagct tcaacagggg agagtgt 807
<210> 209
<211> 795
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Oligonucleotide
<400> 209
cagggacaga gcggacaggg atggtggcca ccttgccagg gaggagcttg gtgtgagcag 60
aggatcggag gaggctccag cggaggctct atctcttccg gcctgctgag cggcagatct 120
gacaacatcg gcggctccga tatcgtgctg acccagacac cactgtccct gagcgtgacc 180
ccaggacagc cagcctctat ctcctgcagg agctctcggt ctctgctgca ttccgacggc 240
ttcacctacc tgtattggtt tctgcagaag cctggccagt ctccacagct gctgatctac 300
cagacaagca atctggcttc tggcgtgccc gacagattct ccagctctgg ctccggcacc 360
gacttcaccc tgaagatcag ccgcgtggag gctgaggatg tgggcgtgta ctattgtgct 420
cagaacctgg agctgcctaa tacctttggc cagggcacaa agctggagat caagcgtacg 480
gtggctgcac catctgtctt catcttcccg ccatctgatg agcagttgaa atctggaact 540
gcctctgttg tgtgcctgct gaataacttc tatcccagag aggccaaagt acagtggaag 600
gtggataacg ccctccaatc gggtaactcc caggagagtg tcacagagca ggacagcaag 660
gacagcacct acagcctcag cagcaccctg acgctgagca aagcagacta cgagaaacac 720
aaagtctacg cctgcgaagt cacccatcag ggcctgagct cgcccgtcac aaagagcttc 780
aacaggggag agtgt 795
<210> 210
<211> 283
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 210
Gln Arg Asp Cys Val Cys Asp Asn Tyr Lys Leu Ala Thr Ser Cys Ser
1 5 10 15
Leu Asn Glu Tyr Gly Glu Cys Gln Cys Thr Ser Tyr Gly Thr Gln Asn
20 25 30
Thr Val Ile Cys Ser Lys Leu Ala Ser Lys Cys Leu Ala Met Lys Ala
35 40 45
Glu Met Thr His Ser Lys Ser Gly Arg Arg Ile Lys Pro Glu Gly Ala
50 55 60
Ile Gln Asn Asn Asp Gly Leu Tyr Asp Pro Asp Cys Asp Glu Gln Gly
65 70 75 80
Ser Lys Cys Leu Ala Met Lys Ala Glu Met Thr His Ser Lys Ser Gly
85 90 95
Arg Arg Ile Lys Pro Glu Gly Ala Ile Gln Asn Asn Asp Gly Leu Tyr
100 105 110
Asp Pro Asp Cys Asp Glu Gln Gly Leu Phe Lys Ala Lys Gln Cys Asn
115 120 125
Gly Thr Ala Thr Cys Trp Cys Val Asn Thr Ala Gly Val Arg Arg Thr
130 135 140
Asp Lys Asp Thr Glu Ile Thr Cys Ser Glu Arg Val Arg Thr Tyr Trp
145 150 155 160
Ile Ile Ile Glu Leu Lys His Lys Glu Arg Glu Ser Pro Tyr Asp His
165 170 175
Gln Ser Leu Gln Thr Ala Leu Gln Glu Ala Phe Thr Ser Arg Tyr Lys
180 185 190
Leu Asn Gln Lys Phe Ile Lys Asn Ile Met Tyr Glu Asn Asn Val Ile
195 200 205
Thr Ile Asp Leu Met Gln Asn Ser Ser Gln Lys Thr Gln Asp Asp Val
210 215 220
Asp Ile Ala Asp Val Ala Tyr Tyr Phe Glu Lys Asp Val Lys Gly Glu
225 230 235 240
Ser Leu Phe His Ser Ser Lys Ser Met Asp Leu Arg Val Asn Gly Glu
245 250 255
Pro Leu Asp Leu Asp Pro Gly Gln Thr Leu Ile Tyr Tyr Val Asp Glu
260 265 270
Lys Ala Pro Glu Phe Ser Met Gln Gly Leu Thr
275 280
<210> 211
<211> 282
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 211
Gln Arg Asp Cys Val Cys Asp Asn Tyr Lys Leu Ala Thr Ser Cys Ser
1 5 10 15
Leu Asn Glu Tyr Gly Glu Cys Gln Cys Thr Ser Tyr Gly Thr Gln Asn
20 25 30
Thr Val Ile Cys Ser Lys Leu Ala Ala Lys Cys Leu Val Met Lys Ala
35 40 45
Glu Met Asn Gly Ser Lys Leu Gly Arg Arg Ala Lys Pro Glu Gly Ala
50 55 60
Leu Gln Asn Asn Asp Gly Leu Tyr Asp Pro Asp Cys Asp Glu Ser Gly
65 70 75 80
Ala Lys Cys Leu Val Met Lys Ala Glu Met Asn Gly Ser Lys Leu Gly
85 90 95
Arg Arg Ala Lys Pro Glu Gly Ala Leu Gln Asn Asn Asp Gly Leu Tyr
100 105 110
Asp Pro Asp Cys Asp Glu Ser Gly Leu Phe Lys Ala Lys Gln Cys Asn
115 120 125
Gly Thr Ser Met Cys Trp Cys Val Asn Thr Ala Gly Val Arg Arg Thr
130 135 140
Asp Lys Asp Thr Glu Ile Thr Cys Ser Glu Arg Val Arg Thr Tyr Trp
145 150 155 160
Ile Ile Ile Glu Leu Lys His Lys Ala Arg Glu Lys Pro Tyr Asp Ser
165 170 175
Lys Ser Leu Arg Thr Ala Leu Gln Lys Glu Ile Thr Thr Arg Tyr Gln
180 185 190
Leu Asp Pro Lys Phe Ile Thr Ser Ile Leu Tyr Glu Asn Asn Val Ile
195 200 205
Thr Ile Asp Leu Val Gln Asn Ser Ser Gln Lys Thr Gln Asn Asp Val
210 215 220
Asp Ile Ala Asp Val Ala Tyr Tyr Phe Glu Lys Asp Val Lys Gly Glu
225 230 235 240
Ser Leu Phe His Ser Lys Lys Met Asp Leu Thr Val Asn Gly Glu Gln
245 250 255
Leu Asp Leu Asp Pro Gly Gln Thr Leu Ile Tyr Tyr Val Asp Glu Lys
260 265 270
Ala Pro Glu Phe Ser Met Gln Gly Leu Lys
275 280
<210> 212
<211> 282
<212> PRT
<213> Synthetic Polypeptide
<400> 212
Gln Glu Glu Cys Val Cys Glu Asn Tyr Lys Leu Ala Val Asn Cys Phe
1 5 10 15
Val Asn Asn Asn Arg Gln Cys Gln Cys Thr Ser Val Gly Ala Gln Asn
20 25 30
Thr Val Ile Cys Ser Lys Leu Ala Ala Lys Cys Leu Ala Met Lys Ala
35 40 45
Glu Met Thr His Ser Lys Ser Gly Arg Arg Ile Lys Pro Glu Gly Ala
50 55 60
Ile Gln Asn Asn Asp Gly Leu Tyr Asp Pro Asp Cys Asp Glu Gln Gly
65 70 75 80
Ala Lys Cys Leu Ala Met Lys Ala Glu Met Thr His Ser Lys Ser Gly
85 90 95
Arg Arg Ile Lys Pro Glu Gly Ala Ile Gln Asn Asn Asp Gly Leu Tyr
100 105 110
Asp Pro Asp Cys Asp Glu Gln Gly Leu Phe Lys Ala Lys Gln Cys Asn
115 120 125
Gly Thr Ala Thr Cys Trp Cys Val Asn Thr Ala Gly Val Arg Arg Thr
130 135 140
Asp Lys Asp Thr Glu Ile Thr Cys Ser Glu Arg Val Arg Thr Tyr Trp
145 150 155 160
Ile Ile Ile Glu Leu Lys His Lys Ala Arg Glu Lys Pro Tyr Asp Ser
165 170 175
Lys Ser Leu Arg Thr Ala Leu Gln Lys Glu Ile Thr Thr Arg Tyr Gln
180 185 190
Leu Asp Pro Lys Phe Ile Thr Ser Ile Leu Tyr Glu Asn Asn Val Ile
195 200 205
Thr Ile Asp Leu Val Gln Asn Ser Ser Gln Lys Thr Gln Asn Asp Val
210 215 220
Asp Ile Ala Asp Val Ala Tyr Tyr Phe Glu Lys Asp Val Lys Gly Glu
225 230 235 240
Ser Leu Phe His Ser Lys Lys Met Asp Leu Thr Val Asn Gly Glu Gln
245 250 255
Leu Asp Leu Asp Pro Gly Gln Thr Leu Ile Tyr Tyr Val Asp Glu Lys
260 265 270
Ala Pro Glu Phe Ser Met Gln Gly Leu Lys
275 280
<210> 213
<211> 282
<212> PRT
<213> Synthetic Polypeptide
<400> 213
Gln Arg Asp Cys Val Cys Asp Asn Tyr Lys Leu Ala Thr Ser Cys Ser
1 5 10 15
Leu Asn Glu Tyr Gly Glu Cys Gln Cys Thr Ser Tyr Gly Thr Gln Asn
20 25 30
Thr Val Ile Cys Ser Lys Leu Ala Ser Lys Cys Leu Ala Met Lys Ala
35 40 45
Glu Met Thr His Ser Lys Ser Gly Arg Arg Ile Lys Pro Glu Gly Ala
50 55 60
Ile Gln Asn Asn Asp Gly Leu Tyr Asp Pro Asp Cys Asp Glu Gln Gly
65 70 75 80
Ser Lys Cys Leu Ala Met Lys Ala Glu Met Thr His Ser Lys Ser Gly
85 90 95
Arg Arg Ile Lys Pro Glu Gly Ala Ile Gln Asn Asn Asp Gly Leu Tyr
100 105 110
Asp Pro Asp Cys Asp Glu Gln Gly Leu Phe Lys Ala Lys Gln Cys Asn
115 120 125
Gly Thr Ala Thr Cys Trp Cys Val Asn Thr Ala Gly Val Arg Arg Thr
130 135 140
Asp Lys Asp Thr Glu Ile Thr Cys Ser Glu Arg Val Arg Thr Tyr Trp
145 150 155 160
Ile Ile Ile Glu Leu Lys His Lys Ala Arg Glu Lys Pro Tyr Asp Ser
165 170 175
Lys Ser Leu Arg Thr Ala Leu Gln Lys Glu Ile Thr Thr Arg Tyr Gln
180 185 190
Leu Asp Pro Lys Phe Ile Thr Ser Ile Leu Tyr Glu Asn Asn Val Ile
195 200 205
Thr Ile Asp Leu Val Gln Asn Ser Ser Gln Lys Thr Gln Asn Asp Val
210 215 220
Asp Ile Ala Asp Val Ala Tyr Tyr Phe Glu Lys Asp Val Lys Gly Glu
225 230 235 240
Ser Leu Phe His Ser Lys Lys Met Asp Leu Thr Val Asn Gly Glu Gln
245 250 255
Leu Asp Leu Asp Pro Gly Gln Thr Leu Ile Tyr Tyr Val Asp Glu Lys
260 265 270
Ala Pro Glu Phe Ser Met Gln Gly Leu Lys
275 280
<210> 214
<211> 283
<212> PRT
<213> Synthetic Polypeptide
<400> 214
Gln Glu Glu Cys Val Cys Glu Asn Tyr Lys Leu Ala Val Asn Cys Phe
1 5 10 15
Val Asn Asn Asn Arg Gln Cys Gln Cys Thr Ser Val Gly Ala Gln Asn
20 25 30
Thr Val Ile Cys Ser Lys Leu Ala Ala Lys Cys Leu Val Met Lys Ala
35 40 45
Glu Met Asn Gly Ser Lys Leu Gly Arg Arg Ala Lys Pro Glu Gly Ala
50 55 60
Leu Gln Asn Asn Asp Gly Leu Tyr Asp Pro Asp Cys Asp Glu Ser Gly
65 70 75 80
Ala Lys Cys Leu Val Met Lys Ala Glu Met Asn Gly Ser Lys Leu Gly
85 90 95
Arg Arg Ala Lys Pro Glu Gly Ala Leu Gln Asn Asn Asp Gly Leu Tyr
100 105 110
Asp Pro Asp Cys Asp Glu Ser Gly Leu Phe Lys Ala Lys Gln Cys Asn
115 120 125
Gly Thr Ser Met Cys Trp Cys Val Asn Thr Ala Gly Val Arg Arg Thr
130 135 140
Asp Lys Asp Thr Glu Ile Thr Cys Ser Glu Arg Val Arg Thr Tyr Trp
145 150 155 160
Ile Ile Ile Glu Leu Lys His Lys Glu Arg Glu Ser Pro Tyr Asp His
165 170 175
Gln Ser Leu Gln Thr Ala Leu Gln Glu Ala Phe Thr Ser Arg Tyr Lys
180 185 190
Leu Asn Gln Lys Phe Ile Lys Asn Ile Met Tyr Glu Asn Asn Val Ile
195 200 205
Thr Ile Asp Leu Met Gln Asn Ser Ser Gln Lys Thr Gln Asp Asp Val
210 215 220
Asp Ile Ala Asp Val Ala Tyr Tyr Phe Glu Lys Asp Val Lys Gly Glu
225 230 235 240
Ser Leu Phe His Ser Ser Lys Ser Met Asp Leu Arg Val Asn Gly Glu
245 250 255
Pro Leu Asp Leu Asp Pro Gly Gln Thr Leu Ile Tyr Tyr Val Asp Glu
260 265 270
Lys Ala Pro Glu Phe Ser Met Gln Gly Leu Thr
275 280
Claims (108)
- EpCAM 항체 또는 EpCAM-결합 항체 단편으로서, 상기 항체 또는 항체 단편은,
(a) 서열 X1YX3X4H(X1은 N 및 S로부터 선택되며, X3은 Y, N, F, S, H, D, L, I 및 W로부터 선택되고, X4는 I 및 M으로부터 선택됨)(서열번호 5)를 포함하는 중쇄 CDR1(VH-CDR1);
(b) 서열 WX2X3PGX6VYIQYX12X13KFX17G(X2는 I 및 F로부터 선택되며, X3은 Y 및 N으로부터 선택되고, X6은 N 및 D로부터 선택되며, X12는 N 및 S로부터 선택되고, X13은 E 및 Q로부터 선택되며, X17은 K 및 Q로부터 선택됨)(서열번호 7)를 포함하는 중쇄 CDR2(VH-CDR2);
(c) 서열 X1GX3X4FAY(X1은 D 및 E로부터 선택되고, X3은 P, A, S, Y, F, G, T 및 V로부터 선택되며, X4는 Y 및 W로부터 선택됨)(서열번호 8)를 포함하는 중쇄 CDR3(VH-CDR3);
(d) 서열 RSSX4SLLHSX10GX12TY LX16(X4는 R 및 K로부터 선택되고, X10은 N 및 D로부터 선택되며, X12는 F 및 I로부터 선택되고, X16은 Y 및 S로부터 선택됨)(서열번호 10)을 포함하는 경쇄 CDR1(VL-CDR1);
(e) 서열 QTSNLAS(서열번호 40)를 포함하는 경쇄 CDR2(VL-CDR2); 및
(f) 서열 X1QX3LELPX8T(X1은 A, L 및 Q로부터 선택되고, X3은 S, G, Y 및 N으로부터 선택되며, X8은 N 및 W로부터 선택됨)(서열번호 11)를 포함하는 경쇄 CDR3(VL-CDR3)
을 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편. - 제1항에 있어서, 상기 항체 또는 항체 단편은,
(a) 서열 NYX3IH(X3은 Y, N, F, S, H, D, L, I 및 W로부터 선택됨)(서열번호 6)를 포함하는 중쇄 CDR1(VH-CDR1);
(b) 서열 WX2X3PGX6VYIQYX12X13KFX17G(X2는 I 및 F로부터 선택되며, X3은 Y 및 N으로부터 선택되고, X6은 N 및 D로부터 선택되며, X3은 N 및 S로부터 선택되고, X13은 E 및 Q로부터 선택되며, X17은 K 및 Q로부터 선택됨)(서열번호 7)를 포함하는 중쇄 CDR2(VH-CDR2);
(c) 서열 DGPX4FAY(X4는 Y 및 W로부터 선택됨)(서열번호 9)를 포함하는 중쇄 CDR3(VH-CDR3);
(d) 서열 RSSX4SLLHSX10GX12TYLX16(X4는 R 및 K로부터 선택되고, X10은 N 및 D로부터 선택되며, X12는 F 및 I로부터 선택되고, X16은 Y 및 S로부터 선택됨)(서열번호 10)을 포함하는 경쇄 CDR1(VL-CDR1);
(e) 서열 QTSNLAS(서열번호 40)를 포함하는 경쇄 CDR2(VL-CDR2); 및
(f) 서열 AQX3LELPNT(X3은 S, G, Y 및 N으로부터 선택됨)(서열번호 12)를 포함하는 경쇄 CDR3(VL-CDR3)
을 포함하는, 항체 또는 항체 단편. - 제1항 또는 제2항에 있어서, 상기 항체 또는 항체 단편은,
(a) 각각 서열번호 13 내지 15, 42, 40 및 41;
(b) 각각 서열번호 13 내지 15, 및 39 내지 41;
(c) 각각 서열번호 13, 26, 15 및 39 내지 41; 및
(d) 각각 서열번호 13, 24, 15, 42, 40 및 41
로부터 선택된 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편. - 제1항 내지 제3항 중 어느 하나에 있어서, 상기 항체 또는 항체 단편은 인간 EpCAM과 사이노몰거스(cynomolgus) EpCAM 둘 다에 대해 3.0nM 이하의 KD로 결합하는, EpCAM 항체 또는 EpCAM-결합 항체 단편.
- 제4항에 있어서, 상기 항체 또는 항체 단편은 서열번호 2의 아미노산 서열을 갖는 인간 EpCAM의 세포외 도메인 내의 에피토프에 특이적으로 결합하는, EpCAM 항체 또는 EpCAM-결합 항체 단편.
- 제5항에 있어서, 상기 항체 또는 항체 단편은,
(a) 서열 NYYIH(서열번호 13)를 포함하는 VH-CDR1;
(b) 서열 WIYPGNVYIQYNEKFKG(서열번호 14)를 포함하는 VH-CDR2;
(c) 서열 DGPWFAY(서열번호 15)를 포함하는 VH-CDR3;
(d) 서열 RSSRSLLHSDGFTYLY(서열번호 42)를 포함하는 VL-CDR1;
(e) 서열 QTSNLAS(서열번호 40)를 포함하는 VL-CDR2: 및
(f) 및 서열 AQNLELPNT(서열번호 41)를 포함하는 VL-CDR3
을 포함하는, 항체 또는 항체 단편. - 제4항에 있어서, 상기 항체 또는 항체 단편은,
(a) 서열 NYYIH(서열번호 13)를 포함하는 VH-CDR1;
(b) 서열 WIYPGNVYIQYNEKFKG(서열번호 14)를 포함하는 VH-CDR2;
(c) 서열 DGPWFAY(서열번호 15)를 포함하는 VH-CDR3;
(d) 서열 RSSKSLLHSDGFTYLY(서열번호 39)를 포함하는 VL-CDR1;
(e) 서열 QTSNLAS(서열번호 40)를 포함하는 VL-CDR2; 및
(f) 서열 AQNLELPNT(서열번호 41)를 포함하는 VL-CDR3
을 포함하는, 항체 또는 항체 단편. - 제3항에 있어서, 상기 항체 또는 항체 단편은,
(a) 서열번호 54의 서열을 갖는 VH, 및 서열번호 89의 서열을 갖는 VL:
(b) 서열번호 54의 서열을 갖는 VH, 및 서열번호 87의 서열을 갖는 VL;
(c) 서열번호 55의 서열을 갖는 VH, 및 서열번호 87의 서열을 갖는 VL;
(d) 서열번호 56의 서열을 갖는 VH, 및 서열번호 88의 서열을 갖는 VL;
(e) 서열번호 55의 서열을 갖는 VH, 및 서열번호 89의 서열을 갖는 VL; 및
(f) 서열번호 56의 서열을 갖는 VH, 및 서열번호 89의 서열을 갖는 VL
로부터 선택된 VH 및 VL을 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편. - 제8항에 있어서, 상기 항체 또는 항체 단편은 서열번호 54의 VH 및 서열번호 89의 VL을 포함하는, 항체 또는 항체 단편.
- 제8항에 있어서, 상기 항체 또는 항체 단편은 서열번호 54의 VH 및 서열번호 87의 VL을 포함하는, 항체 또는 항체 단편.
- 제8항에 있어서, 상기 항체 또는 항체 단편은
(a) 서열번호 103의 서열을 갖는 HC, 및 서열번호 140의 서열을 갖는 LC
(b) 서열번호 103의 서열을 갖는 HC, 및 서열번호 138의 서열을 갖는 LC;
(c) 서열번호 105의 서열을 갖는 HC, 및 서열번호 139의 서열을 갖는 LC;
(d) 서열번호 106의 서열을 갖는 HC, 및 서열번호 139의 서열을 갖는 LC;
(e) 서열번호 105의 서열을 갖는 HC, 및 서열번호 140의 서열을 갖는 LC; 및
(f) 서열번호 106의 서열을 갖는 HC, 및 서열번호 140의 서열을 갖는 LC
로부터 선택된 중쇄 및 경쇄를 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편. - 제11항에 있어서, 상기 항체 또는 항체 단편은 서열번호 103의 HC 및 서열번호 140의 LC를 포함하는, 항체 또는 항체 단편.
- 제11항에 있어서, 상기 항체 또는 항체 단편은 서열번호 103의 HC 및 서열번호 138의 LC를 포함하는, 항체 또는 항체 단편.
- 제1항 또는 제2항에 있어서, 상기 항체 또는 항체 단편은,
(a) 각각 서열번호 22, 14, 15, 42, 40 및 41;
(b) 각각 서열번호 13, 14, 33, 42, 40 및 41, ;
(c) 각각 서열번호 23, 14, 15, 42, 40 및 41; 및
(d) 각각 서열번호 25, 14, 15, 42, 40 및 41
로 이루어진 군으로부터 선택된 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편. - 제14항에 있어서, 상기 항체 또는 항체 단편은,
(a) 서열 NYHIH(서열번호 22)를 포함하는 VH-CDR1;
(b) 서열 WIYPGNVYIQYNEKFKG(서열번호 14)를 포함하는 VH-CDR2;
(c) 서열 DGPWFAY(서열번호 15)를 포함하는 VH-CDR3;
(d) 서열 RSSRSLLHSDGFTYLY(서열번호 42)를 포함하는 VL-CDR1;
(e) 서열 QTSNLAS(서열번호 40)를 포함하는 VL-CDR2: 및
(f) 서열 AQNLELPNT(서열번호 41)를 포함하는 VL-CDR3
을 포함하는, 항체 또는 항체 단편. - 제14항에 있어서, 상기 항체 또는 항체 단편은,
(a) 서열 NYYIH(서열번호 13)를 포함하는 VH-CDR1;
(b) 서열 WIYPGNVYIQYNEKFKG(서열번호 14)를 포함하는 VH-CDR2;
(c) 서열 DGYWFAY(서열번호 33)를 포함하는 VH-CDR3;
(d) 서열 RSSRSLLHSDGFTYLY(서열번호 42)를 포함하는 VL-CDR1;
(e) 서열 QTSNLAS(서열번호 40)를 포함하는 VL-CDR2: 및
(f) 서열 AQNLELPNT(서열번호 41)를 포함하는 VL-CDR3
을 포함하는, 항체 또는 항체 단편. - 제14항에 있어서, 상기 항체 또는 항체 단편은,
(a) 서열번호 75의 서열을 갖는 VH, 및 서열번호 89의 서열을 갖는 VL;
(b) 서열번호 77의 서열을 갖는 VH, 및 서열번호 89의 서열을 갖는 VL;
(c) 서열번호 76의 서열을 갖는 VH, 및 서열번호 89의 서열을 갖는 VL; 및
(d) 서열번호 84의 서열을 갖는 VH, 및 서열번호 89의 서열을 갖는 VL
로부터 선택된 VH 및 VL을 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편. - 제17항에 있어서, 상기 항체 또는 항체 단편은 서열번호 75의 VH 및 서열번호 89의 VL을 포함하는, 항체 또는 항체 단편.
- 제17항에 있어서, 상기 항체 또는 항체 단편은 서열번호 77의 VH 및 서열번호 89의 VL을 포함하는, 항체 또는 항체 단편.
- 제17항에 있어서, 상기 항체 또는 항체 단편은
(a) 서열번호 125의 서열을 갖는 HC, 및 서열번호 140의 서열을 갖는 LC;
(b) 서열번호 127의 서열을 갖는 HC, 및 서열번호 140의 서열을 갖는 LC;
(c) 서열번호 126의 서열을 갖는 HC, 및 서열번호 140의 서열을 갖는 LC; 및
(d) 서열번호 134의 서열을 갖는 HC, 및 서열번호 140의 서열을 갖는 LC
로부터 선택된 중쇄 및 경쇄를 포함하는, EpCAM 항체 또는 EpCAM-결합 항체 단편. - 제20항에 있어서, 상기 항체 또는 항체 단편은 서열번호 125의 HC 및 서열번호 140의 LC를 포함하는, 항체 또는 항체 단편;
- 제20항에 있어서, 상기 항체 또는 항체 단편은 서열번호 127의 HC 및 서열번호 140의 LC를 포함하는, 항체 또는 항체 단편;
- 제1항 내지 제22항 중 어느 한 항에 있어서, 상기 항체 또는 항체 단편은 뮤린, 비-인간 포유류, 키메라, 인간화 또는 인간 항체인, 항체 또는 항체 단편.
- 제1항 내지 제23항 중 어느 한 항에 있어서, 상기 항체는 전장 항체인, 항체 또는 항체 단편.
- 제24항에 있어서, 상기 항체는 인간 IgG1인, 전장 항체.
- 제1항 내지 제23항 중 어느 한 항에 있어서, 항체 단편은 Fab, Fab', F(ab')2, Fd, 단일쇄 Fv 또는 scFv, 이황화 연결된 Fv, V-NAR 도메인, IgNar, 인트라바디, IgGΔCH2, 미니바디, F(ab')3, 테트라바디, 트라이어바디(triabody), 다이어바디(diabody), 단일-도메인 항체, DVD-Ig, Fcab, mAb2, (scFv)2 또는 scFv-Fc인, 항체 또는 항체 단편.
- 제1항 내지 제26항 중 어느 한 항에 있어서, 상기 활성화 가능한 항체는,
(a) 상기 항체 또는 항체 단편에 결합된 절단 가능 모이어티로서, 프로테아제에 대한 기질로서 작용하는 폴리펩타이드인, 상기 절단 가능 모이어티; 및
(b) 상기 항체 또는 항체 단편에 결합된 마스킹 모이어티로서, 상기 활성화 가능한 항체가 비절단 상태일 때 EpCAM에 대한 항체 또는 항체 단편의 결합을 저해하는, 마스킹 모이어티
를 더 포함하되,
상기 비절단 상태의 상기 활성화 가능한 항체는 N-말단으로부터 C-말단까지 다음과 같은 구조적 배열: (마스킹 모이어티)-(절단 가능 모이어티)-(항체 또는 항체 단편) 또는 (항체 또는 항체 단편)-(절단 가능 모이어티)-(마스킹 모이어티)
를 갖는, 항체 또는 항체 단편을 포함하는 활성화 가능한 항체. - EpCAM 활성화 가능한 항체로서,
(a) 하기 (i) 내지 (iv)의 군으로부터 선택된 구성원의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편:
(i) 각각 서열번호 13 내지 15, 42, 40 및 41;
(ii) 각각 서열번호 13 내지 15, 및 39 내지 41;
(iii) 각각 서열번호 13, 26, 15 및 39 내지 41; 및
(iv) 각각 서열번호 13, 24, 15, 42, 40 및 41;
(b) 상기 EpCAM 항체 또는 EpCAM-결합 항체 단편에 결합된 마스킹 모이어티로서, 상기 활성화 가능한 항체가 비절단 상태일 때 상기 EpCAM에 대한 항체 또는 항체 단편의 결합을 저해하는, 상기 마스킹 모이어티; 및
(c) 상기 EpCAM 항체 또는 EpCAM-결합 항체 단편에 결합된 절단 가능 모이어티로서, 프로테아제에 대한 기질로서 작용하는 폴리펩타이드인, 절단 가능 모이어티
를 포함하되,
상기 비절단 상태의 활성화 가능한 항체는 N-말단으로부터 C-말단까지 다음과 같은 구조적 배열: (마스킹 모이어티)-(절단 가능 모이어티)-(항체 또는 항체 단편) 또는 (항체 또는 항체 단편)-(절단 가능 모이어티)-(마스킹 모이어티)
을 갖는, EpCAM 활성화 가능한 항체. - 제28항에 있어서, 상기 활성화 가능한 항체는 각각 서열번호 13 내지 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체.
- 제29항에 있어서, 상기 활성화 가능한 항체는 서열번호 54의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체.
- 제30항에 있어서, 상기 활성화 가능한 항체는 서열번호 103의 서열을 갖는 중쇄 및 서열번호 140의 서열을 갖는 LC를 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체.
- 제29항 내지 제31항 중 어느 한 항에 있어서, 상기 활성화 가능한 항체는 서열번호 151 내지 157로부터 선택된 아미노산 서열을 갖는 마스킹 모이어티를 포함하는, EpCAM 활성화 가능한 항체.
- 제32항에 있어서, 상기 활성화 가능한 항체는 서열번호 155의 아미노산 서열을 갖는 마스킹 모이어티를 포함하는, EpCAM 활성화 가능한 항체.
- 제29항 내지 제33항 중 어느 한 항에 있어서, 상기 활성화 가능한 항체는 서열번호 168 또는 169의 아미노산 서열을 포함하는 절단 가능한 모이어티를 포함하는, EpCAM 활성화 가능한 항체.
- EpCAM 활성화 가능한 항체로서,
(a) 하기 (i) 내지 (iv)로 이루어진 군으로부터 선택된 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편:
(i) 각각 서열번호 22, 14, 15, 42, 40 및 41;
(ii)각각 서열번호 13, 14, 33, 42, 40 및 41;
(iii) 각각 서열번호 23, 14, 15, 42, 40 및 41; 및
(iv) 각각 서열번호 25, 14, 15, 42, 40 및 41,
(b) 상기 EpCAM 항체 또는 EpCAM-결합 항체 단편에 결합된 마스킹 모이어티로서, 상기 활성화 가능한 항체가 비절단 상태일 때 EpCAM에 대한 항체 또는 항체 단편의 결합을 저해하는, 마스킹 모이어티; 및
(c) EpCAM 항체 또는 EpCAM-결합 항체 단편에 결합된 절단 가능 모이어티로서, 프로테아제에 대한 기질로서 작용하는 폴리펩타이드인, 절단 가능 모이어티
를 포함하되,
상기 비절단 상태의 활성화 가능한 항체는 N-말단으로부터 C-말단까지 다음과 같은 구조적 배열: (마스킹 모이어티)-(절단 가능 모이어티)-(항체 또는 항체 단편) 또는 (항체 또는 항체 단편)-(절단 가능 모이어티)-(마스킹 모이어티)
을 갖는, EpCAM 활성화 가능한 항체. - 제35항에 있어서, 상기 활성화 가능한 항체는 각각 서열번호 22, 14, 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체.
- 제36항에 있어서, 상기 활성화 가능한 항체는 서열번호 75의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체.
- 제37항에 있어서, 상기 활성화 가능한 항체는 서열번호 125의 서열을 갖는 중쇄 및 서열번호 140의 서열을 갖는 경쇄를 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체.
- 제36항 내지 제38항 중 어느 한 항에 있어서, 상기 활성화 가능한 항체는 서열번호 151 내지 157 및 162 내지 167로부터 선택된 아미노산 서열을 갖는 마스킹 모이어티를 포함하는, EpCAM 활성화 가능한 항체.
- 제39항에 있어서, 상기 활성화 가능한 항체는 서열번호 162 내지 167로부터 선택된 아미노산 서열을 갖는 마스킹 모이어티를 포함하는, EpCAM 활성화 가능한 항체.
- 제36항 내지 제40항 중 어느 한 항에 있어서, 상기 활성화 가능한 항체는 서열번호 168 또는 169의 아미노산 서열을 포함하는 절단 가능한 모이어티를 포함하는, EpCAM 활성화 가능한 항체.
- 제35항에 있어서, 상기 활성화 가능한 항체는 각각 서열번호 13, 14, 33, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체.
- 제42항에 있어서, 상기 활성화 가능한 항체는 서열번호 77의 서열을 갖는 VH 및 서열번호 89의 서열을 갖는 VL을 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체.
- 제43항에 있어서, 상기 활성화 가능한 항체는 서열번호 127의 서열을 갖는 중쇄 및 서열번호 140의 서열을 갖는 경쇄를 포함하는 EpCAM 항체 또는 EpCAM-결합 항체 단편을 포함하는, EpCAM 활성화 가능한 항체.
- 제42항 내지 제44항 중 어느 한 항에 있어서, 상기 활성화 가능한 항체는 서열번호 151 내지 161로부터 선택된 아미노산 서열을 갖는 마스킹 모이어티를 포함하는, EpCAM 활성화 가능한 항체.
- 제45항에 있어서, 상기 활성화 가능한 항체는 서열번호 158 내지 161로부터 선택된 아미노산 서열을 갖는 마스킹 모이어티를 포함하는, EpCAM 활성화 가능한 항체.
- 제42항 내지 제46항 중 어느 한 항에 있어서, 상기 활성화 가능한 항체는 서열번호 168 또는 169의 아미노산 서열을 포함하는 절단 가능한 모이어티를 포함하는, EpCAM 활성화 가능한 항체.
- 제1항 내지 제26항 중 어느 한 항의 항체 또는 EpCAM-결합 항체 단편 또는 제27항 내지 제47항 중 어느 한 항의 활성화 가능한 항체를 생성하는 세포;
- EpCAM 항체 또는 EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 생성하는 방법으로서,
(a) 제48항의 세포를 배양시키는 단계; 및,
(b) 세포 또는 세포 배양물로부터 EpCAM 항체, EpCAM-결합 항체 단편, 또는 EpCAM 활성화 가능한 항체를 단리시키는 단계
를 포함하는, 방법. - 제49항에 있어서, 상기 세포는 진핵 세포인, 방법.
- 제50항에 있어서, 상기 세포는 CHO 세포인, 방법;
- 제1항 내지 제26항 중 어느 한 항의 항체 또는 항체 단편 또는 제27항 내지 제47항 중 어느 한 항의 EpCAM 활성화 가능한 항체를 포함하는 진단 시약.
- 제52항에 있어서, 상기 항체, 항체 단편, 또는 활성화 가능한 항체는 표지된, 진단 시약.
- 제53항에 있어서, 상기 표지는 방사성표지, 형광단, 발색단, 영상화제 및 금속 이온으로부터 선택된, 진단 시약.
- 제1항 내지 제26항 중 어느 한 항의 항체 또는 항체 단편 또는 제27항 내지 제47항 중 어느 한 항의 활성화 가능한 항체를 암호화하는 폴리뉴클레오타이드 또는 폴리뉴클레오타이드의 세트.
- 제55항의 폴리뉴클레오타이드를 포함하는 벡터 또는 벡터의 세트.
- 제55항의 폴리뉴클레오타이드 또는 폴리뉴클레오타이드의 세트 또는 제56항의 벡터를 포함하는, 숙주 세포.
- 다음의 식으로 표시되는 면역접합체 또는 이의 약제학적으로 허용 가능한 염:

식 중:
EpBA는 라이신 잔기를 통해 CyL1에 공유적으로 연결된, 제1항 내지 제47항 중 어느 한 항에 따른 EpCAM 항체, EpCAM 항체 단편, 또는 EpCAM 활성화 가능한 항체이고;
WL은 1 내지 20의 정수이고; 그리고
CyL1은 다음의 식으로 표시되되:

식 중:
N과 C 사이의 이중선은 단일 결합 또는 이중 결합을 나타내며, 단, 이것이 이중 결합일 때, X는 존재하지 않고, Y는 -H 또는 (C1-C4)알킬이며; 이것이 단일 결합일 때, X는 -H 또는 아민 보호 모이어티이며, Y는 -OH 또는 -SO3H이고 또는 이의 약제학적으로 허용 가능한 염이고;
W'는 -NRe'이고,
Re'는 -(CH2-CH2-O)n-Rk이며;
n은 2 내지 6의 정수이고;
Rk는 -H 또는 -Me이며;
Rx3은 (C1-C6)알킬이고;
L'은 다음의 식으로 표시되며:

R5는 -H 또는 (C1-C3)알킬이고;
P는 아미노산 잔기 또는 2 내지 20개의 아미노산 잔기를 포함하는 펩타이드이며;
Ra 및 Rb는, 각각의 경우에 대해, 각각 독립적으로 -H, (C1-C3)알킬, 또는 하전된 치환체 또는 이온화 가능한 기 Q이고;
m은 1 내지 6의 정수이고; 그리고
Zs1은 하기 식 중 어느 하나로부터 선택되고:

q는 1 내지 5의 정수이다. - 제58항에 있어서, Ra와 Rb는 둘 다 H이고; R5는 H 또는 Me인, 면역접합체.
- 제58항 또는 제59항에 있어서, P는 2 내지 5개의 아미노산 잔기를 포함하는 펩타이드인, 면역접합체.
- 제58항 내지 제60항 중 어느 한 항에 있어서, P는 Gly-Gly-Gly, Ala-Val, Va-Ala, Val-Cit, Val-Lys, Phe-Lys, Lys-Lys, Ala-Lys, Phe-Cit, Leu-Cit, He-Cit, Trp, Cit, Phe-Ala, Phe-N9-토실-Arg, Phe-N9-나이트로-Arg, Phe-Phe-Lys, D-Phe-Phe-Lys, Gly- Phe-Lys, Leu-Ala-Leu, Ile-Ala-Leu, Val-Ala-Val, Ala-Leu-Ala-Leu(서열번호 215), β-Ala-Leu-Ala-Leu(서열번호 216), Gly-Phe-Leu-Gly(서열번호 217), Val-Arg, Arg-Val, Arg-Arg, Val-D-Cit, Val-D-Lys, Val-D-Arg, D-Val-Cit, D-Val-Lys, D-Val-Arg, D-Val-D-Cit, D-Val-D-Lys, D-Val-D-Arg, D-Arg-D-Arg, Ala-Ala, Ala-D-Ala, D-Ala-Ala, D-Ala-D-Ala, Ala-Met, Met-Ala, Gln-Val, Asn-Ala, Gln-Phe 및 Gln-Ala으로부터 선택된, 면역접합체.
- 제61항에 있어서, P는 Gly-Gly-Gly, Ala-Val, Ala-Ala, Ala-D-Ala, D-Ala-Ala, 또는 D-Ala-D-Ala인, 면역접합체.
- 제58항 내지 제62항 중 어느 한 항에 있어서, Q는 -SO3H 또는 이의 약제학적으로 허용 가능한 염인, 면역접합체.
- 제58항에 있어서, 상기 면역접합체는 하기 식으로 표시되는, 면역접합체 또는 이의 약제학적으로 허용 가능한 염:






식 중,
WL은 1 내지 10의 정수이고; N과 C 사이의 이중선은 단일 결합 또는 이중 결합을 나타내며, 단, 이것이 이중 결합일 때, X는 존재하지 않고, Y는 -H이며; 이것이 단일 결합일 때, X는 -H이며, Y는 -OH 또는 -SO3H 또는 이의 약제학적으로 허용 가능한 염이다.
- 제58항 내지 제64항 중 어느 한 항에 있어서, N과 C 사이의 이중선은 이중 결합을 나타내고, X는 존재하지 않으며, Y는 -H인, 면역접합체.

- 제58항 내지 제64항 중 어느 한 항에 있어서, N과 C 사이의 이중선은 단일 결합을 나타내고, X는 -H이며, Y는 -SO3H 또는 이의 약제학적으로 허용 가능한 염인, 면역접합체.

- 제66항에 있어서, Y는 -SO3H, -SO3Na 또는 -SO3K인, 면역접합체.
- 제66항에 있어서, Y는 -SO3Na인, 면역접합체.
- 다음의 식으로 표시되는 면역접합체:

식 중:
EpBA는 라이신 잔기를 통해 CyL2에 공유적으로 연결된, 제1항 내지 제47항 중 어느 한 항에 따른 EpCAM 항체, EpCAM 항체 단편, 또는 EpCAM 활성화 가능한 항체;
WL은 1 내지 20의 정수이고;
CyL2는 다음의 식으로 표시되며:

m'는 1 또는 2이고;
R1 및 R2는, 각각 독립적으로 H 또는 (C1-C3)알킬이며;
Zs1은 하기 식 중 어느 하나로부터 선택되고:

식 중, q는 1 내지 5의 정수이다. - 제69항에 있어서, m'는 1이고, R1와 R2는 둘 다 H인, 면역접합체.
- 제69항에 있어서, m'는 2이고, R1와 R2는 둘 다 Me인, 면역접합체.
- 제69항에 있어서, 상기 면역접합체는 하기 식으로 표시되는, 면역접합체 또는 이의 약제학적으로 허용 가능한 염:


식 중 WL은 1 내지 10의 정수이다. - 제69항에 있어서, 상기 면역접합체는 하기 식으로 표시되는, 면역접합체 또는 이의 약제학적으로 허용 가능한 염:
.
- 다음의 식으로 표시되는 면역접합체 또는 이의 약제학적으로 허용 가능한 염:

식 중:
WL은 1 내지 10의 정수이고
EpBA는 각각 서열번호 13 내지 15, 42, 40 및 41의 서열을 갖는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는 EpCAM 항체, EpCAM 항체 단편, 또는 EpCAM 활성화 가능한 항체이다. - 제74항에 있어서, 상기 단리된 항체 또는 EpCAM-결합 항체 단편은 각각 서열번호 54 및 서열번호 89의 서열을 갖는 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하는, 면역접합체.
- 제74항에 있어서, 상기 단리된 항체는 각각 서열번호 103 및 서열번호 140의 서열을 갖는 중쇄 및 경쇄를 포함하는, 면역접합체.
- 제74항 내지 제76항 중 어느 한 항에 있어서, 상기 면역접합체는 서열번호 151 내지 157로부터 선택된 아미노산 서열을 갖는 마스킹 모이어티를 포함하는 활성화 가능한 항체를 포함하는, 면역접합체.
- 제77항에 있어서, 상기 마스킹 모이어티는 서열번호 155의 아미노산 서열을 갖는, 면역접합체.
- 제77항 또는 제78항에 있어서, 상기 면역접합체는 서열번호 168 또는 서열번호 169의 절단 가능한 모이어티를 더 포함하는 활성화 가능한 항체를 포함하는, 면역접합체.
- γ-말레이미도뷰티르산 N-석신이미딜 에스터(GMBS) 또는 N-(γ-말레이미도뷰틸옥시)설포석신이미드 에스터(설포-GMBS 또는 sGMBS) 링커를 통해, 다음의 구조식으로 표시되는 메이탄시노이드 화합물 DM21L(LDL-DM으로도 지칭됨)에 결합된 EpBA를 포함하는 면역접합체:

식 중, EpBA는 제1항 내지 제47항 중 어느 한 항에 따른 EpCAM 항체, EpCAM 항체 단편, 또는 EpCAM 활성화 가능한 항체이다. - 제80항에 있어서, GMBS 및 설포-GMBS(또는 sGMBS) 링커는 하기 식으로 표시되는, 면역접합체:
.
- 제80항 또는 제81항에 있어서, 하기 식으로 표시되는, 면역접합체:

식 중:
EpBA는 Lys 아민기를 통해 메이탄시노이드 화합물에 연결되되, q는 1 내지 10의 정수이다. - 제80항 내지 제82항 중 어느 한 항에 있어서, 상기 EpBA는 각각 서열번호 13 내지 15, 42, 40 및 41의 서열을 포함하는 VH-CDR1, VH-CDR2, VH-CDR3, VL-CDR1, VL-CDR2 및 VL-CDR3을 포함하는, 면역접합체.
- 제83항에 있어서, 상기 EpBA는 각각 서열번호 54 및 서열번호 89의 서열을 갖는 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하는, 면역접합체.
- 제84항에 있어서, 상기 EpBA는 각각 서열번호 103 및 서열번호 140의 서열을 갖는 중쇄 및 경쇄를 포함하는, 면역접합체.
- 제83항 내지 제85항 중 어느 한 항에 있어서, 상기 면역접합체는 서열번호 151 내지 157로부터 선택된 아미노산 서열을 갖는 마스킹 모이어티를 포함하는 활성화 가능한 항체를 포함하는, 면역접합체.
- 제86항에 있어서, 상기 마스킹 모이어티는 서열번호 155의 아미노산 서열을 갖는, 면역접합체.
- 제86항 또는 제87항에 있어서, 상기 면역접합체는 서열번호 168 또는 서열번호 169의 절단 가능한 모이어티를 더 포함하는 활성화 가능한 항체를 포함하는, 면역접합체.
- 제58항 내지 제88항 중 어느 한 항에 있어서, 약제학적으로 허용 가능한 염은 나트륨 또는 칼륨염인, 면역접합체.
- 제1항 내지 제47항 중 어느 한 항의 항체, 항원-결합 단편, 또는 활성화 가능한 항체 및 약제학적으로 허용 가능한 담체를 포함하는, 약제학적 조성물.
- 제58항 내지 제88항 중 어느 한 항의 면역접합체 및 약제학적으로 허용 가능한 담체를 포함하는, 약제학적 조성물.
- 암세포의 사멸 방법으로서,
암세포를 유효량의 제1항 내지 제47항 중 어느 한 항의 항체, 항원-결합 단편, 또는 활성화 가능한 항체, 제58항 내지 제88항 중 어느 한 항의 면역접합체, 또는 제90항 또는 제91항의 약제학적 조성물과 접촉시키는 단계를 포함하는, 암세포의 사멸 방법. - 제92항에 있어서, 상기 암세포는 상피 암세포, 유방 암세포, 폐 암세포, 위암세포, 결장직장암, 전립선 암세포, 난소암세포, 결장암세포, 직장암세포 또는 암 줄기 세포인, 암세포의 사멸 방법.
- 제92항에 있어서, 상기 암세포는 난소암세포, 자궁암세포, 위암세포, 췌장암세포, 또는 결장직장암세포인, 암세포의 사멸 방법.
- EpCAM을 발현시키는 암의 치료 방법으로서,
치료적 유효량의 제1항 내지 제47항 중 어느 한 항의 항체 또는 항원-결합 단편, 제58항 내지 제88항 중 어느 한 항의 면역접합체, 또는 제90항 또는 제91항의 약제학적 조성물을 암 치료가 필요한 대상체에게 투여하는 단계를 포함하는, 암의 치료 방법. - 제95항에 있어서, 상기 암은 상피암인, 암의 치료 방법.
- 제95항에 있어서, 상기 암은 유방 암, 폐 암, 위암, 결장직장암, 전립선 암, 난소암, 결장암, 식도암, 기관암, 위암 방광암, 자궁암, 직장암, 소장암, 또는 이들의 전이인, 암의 치료 방법.
- 제95항에 있어서, 상기 암은 난소암, 자궁암, 위암, 췌장암, 결장직장암, 또는 이들의 전이인, 암의 치료 방법.
- 제97항에 있어서, 상기 암은 폐암인, 암의 치료 방법.
- 제99항에 있어서, 상기 폐암은 비소세포 폐암인, 암의 치료 방법.
- 제100항에 있어서, 상기 비소세포 폐암은 비-편평 비소세포 폐암인, 암의 치료 방법.
- 제95항에 있어서, 상기 암은 난소암인, 암의 치료 방법.
- 제95항에 있어서, 상기 암은 삼중 음성 유방암인, 암의 치료 방법.
- 제95항에 있어서, 상기 암은 결장직장암인, 암의 치료 방법.
- 제95항에 있어서, 상기 암은 식도암인, 암의 치료 방법.
- 제95항에 있어서, 상기 암은 위암인, 암의 치료 방법.
- 제95항에 있어서, 암은 자궁암인, 암의 치료 방법.
- 제95항에 있어서, 암은 췌장암인, 암의 치료 방법.
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862751530P | 2018-10-26 | 2018-10-26 | |
| US62/751,530 | 2018-10-26 | ||
| US201962824539P | 2019-03-27 | 2019-03-27 | |
| US62/824,539 | 2019-03-27 | ||
| US201962846297P | 2019-05-10 | 2019-05-10 | |
| US62/846,297 | 2019-05-10 | ||
| PCT/US2019/057569 WO2020086665A1 (en) | 2018-10-26 | 2019-10-23 | Epcam antibodies, activatable antibodies, and immunoconjugates, and uses thereof |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210095874A true KR20210095874A (ko) | 2021-08-03 |
Family
ID=70331831
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217015710A KR20210095874A (ko) | 2018-10-26 | 2019-10-23 | Epcam 항체, 활성화 가능한 항체 및 면역접합체, 그리고 이들의 용도 |
Country Status (13)
| Country | Link |
|---|---|
| US (1) | US20210403594A1 (ko) |
| EP (1) | EP3873512A4 (ko) |
| JP (1) | JP2022506072A (ko) |
| KR (1) | KR20210095874A (ko) |
| CN (1) | CN113194985A (ko) |
| AU (1) | AU2019364400A1 (ko) |
| BR (1) | BR112021007918A2 (ko) |
| CA (1) | CA3117548A1 (ko) |
| IL (1) | IL282496A (ko) |
| MX (1) | MX2021004808A (ko) |
| SG (1) | SG11202103949SA (ko) |
| TW (1) | TW202029980A (ko) |
| WO (1) | WO2020086665A1 (ko) |
Families Citing this family (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP4359438A1 (en) * | 2021-06-21 | 2024-05-01 | Bristol-Myers Squibb Company | Use of sucrose, mannitol and glycine to reduce reconstitution time of high concentration lyophilized biologics drug products |
| WO2023183888A1 (en) | 2022-03-23 | 2023-09-28 | Cytomx Therapeutics, Inc. | Activatable antigen-binding protein constructs and uses of the same |
| WO2023183923A1 (en) | 2022-03-25 | 2023-09-28 | Cytomx Therapeutics, Inc. | Activatable dual-anchored masked molecules and methods of use thereof |
| WO2023192606A2 (en) | 2022-04-01 | 2023-10-05 | Cytomx Therapeutics, Inc. | Cd3-binding proteins and methods of use thereof |
| WO2023192973A1 (en) | 2022-04-01 | 2023-10-05 | Cytomx Therapeutics, Inc. | Activatable multispecific molecules and methods of use thereof |
| WO2024015830A1 (en) | 2022-07-12 | 2024-01-18 | Cytomx Therapeutics, Inc. | Epcam immunoconjugates and uses thereof |
| WO2024030843A1 (en) | 2022-08-01 | 2024-02-08 | Cytomx Therapeutics, Inc. | Protease-cleavable moieties and methods of use thereof |
| WO2024030858A1 (en) | 2022-08-01 | 2024-02-08 | Cytomx Therapeutics, Inc. | Protease-cleavable substrates and methods of use thereof |
| WO2024030845A1 (en) | 2022-08-01 | 2024-02-08 | Cytomx Therapeutics, Inc. | Protease-cleavable moieties and methods of use thereof |
| WO2024030847A1 (en) | 2022-08-01 | 2024-02-08 | Cytomx Therapeutics, Inc. | Protease-cleavable moieties and methods of use thereof |
| WO2024030850A1 (en) | 2022-08-01 | 2024-02-08 | Cytomx Therapeutics, Inc. | Protease-cleavable substrates and methods of use thereof |
Family Cites Families (48)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5225539A (en) | 1986-03-27 | 1993-07-06 | Medical Research Council | Recombinant altered antibodies and methods of making altered antibodies |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| US5208020A (en) | 1989-10-25 | 1993-05-04 | Immunogen Inc. | Cytotoxic agents comprising maytansinoids and their therapeutic use |
| AU7378096A (en) | 1995-09-28 | 1997-04-17 | Alexion Pharmaceuticals, Inc. | Porcine cell interaction proteins |
| WO1998023289A1 (en) | 1996-11-27 | 1998-06-04 | The General Hospital Corporation | MODULATION OF IgG BINDING TO FcRn |
| US6277375B1 (en) | 1997-03-03 | 2001-08-21 | Board Of Regents, The University Of Texas System | Immunoglobulin-like domains with increased half-lives |
| ES2269366T3 (es) | 2000-02-11 | 2007-04-01 | Merck Patent Gmbh | Mejoramiento de la vida media en circulacion de proteinas de fusion basadas en anticuerpos. |
| EP2341060B1 (en) | 2000-12-12 | 2019-02-20 | MedImmune, LLC | Molecules with extended half-lives, compositions and uses thereof |
| US6716821B2 (en) | 2001-12-21 | 2004-04-06 | Immunogen Inc. | Cytotoxic agents bearing a reactive polyethylene glycol moiety, cytotoxic conjugates comprising polyethylene glycol linking groups, and methods of making and using the same |
| US7538195B2 (en) | 2002-06-14 | 2009-05-26 | Immunogen Inc. | Anti-IGF-I receptor antibody |
| JP2005532051A (ja) * | 2002-07-01 | 2005-10-27 | バイオジェン, インコーポレイテッド | ヒト化抗リンホトキシンβレセプター抗体 |
| EP1542723B1 (en) | 2002-08-16 | 2011-02-23 | ImmunoGen, Inc. | Cross-linkers with high reactivity and solubility and their use in the preparation of conjugates for targeted delivery of small molecule drugs |
| US7217797B2 (en) | 2002-10-15 | 2007-05-15 | Pdl Biopharma, Inc. | Alteration of FcRn binding affinities or serum half-lives of antibodies by mutagenesis |
| US8088387B2 (en) | 2003-10-10 | 2012-01-03 | Immunogen Inc. | Method of targeting specific cell populations using cell-binding agent maytansinoid conjugates linked via a non-cleavable linker, said conjugates, and methods of making said conjugates |
| US7276497B2 (en) | 2003-05-20 | 2007-10-02 | Immunogen Inc. | Cytotoxic agents comprising new maytansinoids |
| CA2545603A1 (en) | 2003-11-12 | 2005-05-26 | Biogen Idec Ma Inc. | Neonatal fc receptor (fcrn)-binding polypeptide variants, dimeric fc binding proteins and methods related thereto |
| US8367805B2 (en) | 2004-11-12 | 2013-02-05 | Xencor, Inc. | Fc variants with altered binding to FcRn |
| US8802820B2 (en) | 2004-11-12 | 2014-08-12 | Xencor, Inc. | Fc variants with altered binding to FcRn |
| US7700099B2 (en) | 2005-02-14 | 2010-04-20 | Merck & Co., Inc. | Non-immunostimulatory antibody and compositions containing the same |
| EP1919931A4 (en) | 2005-08-31 | 2010-01-20 | Univ California | CELLULAR LIBRARIES OF PEPTIDE SEQUENCES (CLIPS) AND METHODS OF USE THEREOF |
| EP4316465A3 (en) | 2006-03-15 | 2024-04-24 | Alexion Pharmaceuticals, Inc. | Treatment of paroxysmal nocturnal hemoglobinuria patients by an inhibitor of complement |
| CN101448853A (zh) * | 2006-03-17 | 2009-06-03 | 比奥根艾迪克Ma公司 | 稳定的多肽组合物 |
| AR060978A1 (es) | 2006-05-30 | 2008-07-23 | Genentech Inc | Anticuerpos e inmunoconjugados y sus usos |
| SI2019104T1 (sl) | 2007-07-19 | 2013-12-31 | Sanofi | Citotoksična sredstva, ki obsegajo nove tomaimicinske derivate, in njihova terapevtska uporaba |
| US20090304719A1 (en) | 2007-08-22 | 2009-12-10 | Patrick Daugherty | Activatable binding polypeptides and methods of identification and use thereof |
| SG189817A1 (en) | 2008-04-30 | 2013-05-31 | Immunogen Inc | Potent conjugates and hydrophilic linkers |
| US8236319B2 (en) | 2008-04-30 | 2012-08-07 | Immunogen, Inc. | Cross-linkers and their uses |
| WO2010033279A2 (en) | 2008-06-04 | 2010-03-25 | Macrogenics, Inc. | Antibodies with altered binding to fcrn and methods of using same |
| GB0819095D0 (en) | 2008-10-17 | 2008-11-26 | Spirogen Ltd | Pyrrolobenzodiazepines |
| RU2636046C2 (ru) | 2009-01-12 | 2017-11-17 | Сайтомкс Терапьютикс, Инк | Композиции модифицированных антител, способы их получения и применения |
| EP3360879A1 (en) | 2009-02-05 | 2018-08-15 | ImmunoGen, Inc. | Benzodiazepine derivatives as cytotoxic agents |
| KR20110140124A (ko) * | 2009-04-08 | 2011-12-30 | 하인즈 파울스티히 | 암치료용 아미톡신-활성 표적 결합 부위 |
| GB0909904D0 (en) * | 2009-06-09 | 2009-07-22 | Affitech As | Product |
| AU2011239525B2 (en) | 2010-04-15 | 2015-04-09 | Medimmune Limited | Pyrrolobenzodiazepines used to treat proliferative diseases |
| MX346635B (es) | 2011-02-15 | 2017-03-27 | Immunogen Inc | Derivados citotoxicos de la benzodiazepina. |
| WO2013177481A1 (en) | 2012-05-25 | 2013-11-28 | Immunogen, Inc. | Benzodiazepines and conjugates thereof |
| EP2882844B1 (en) | 2012-08-10 | 2018-10-03 | Cytomx Therapeutics Inc. | Protease-resistant systems for polypeptide display and methods of making and using thereof |
| US9790274B2 (en) * | 2013-03-14 | 2017-10-17 | The Board Of Regents Of The University Of Texas System | Monoclonal antibodies targeting EpCAM for detection of prostate cancer lymph node metastases |
| PE20170263A1 (es) * | 2014-08-04 | 2017-03-30 | Hoffmann La Roche | Moleculas biespecificas de union a antigeno activadoras de celulas t |
| JP2017527562A (ja) | 2014-09-03 | 2017-09-21 | イミュノジェン・インコーポレーテッド | 細胞毒性ベンゾジアゼピン誘導体 |
| ES2815353T3 (es) | 2014-09-03 | 2021-03-29 | Immunogen Inc | Derivados de benzodiazepina citotóxicos |
| CN108513547A (zh) * | 2015-03-12 | 2018-09-07 | 维文蒂亚生物公司 | 用于epcam阳性膀胱癌的治疗方法 |
| CN114773476A (zh) * | 2015-04-13 | 2022-07-22 | 辉瑞公司 | 治疗性抗体和它们的用途 |
| CA2984948A1 (en) | 2015-05-04 | 2016-11-10 | Cytomx Therapeutics, Inc. | Anti-cd166 antibodies, activatable anti-cd166 antibodies, and methods of use thereof |
| EA039366B1 (ru) * | 2015-06-24 | 2022-01-19 | Джей Си Ар ФАРМАСЬЮТИКАЛЗ КО., ЛТД. | Антитело к рецептору трансферрина человека, проникающее через гематоэнцефалический барьер |
| LT3313845T (lt) | 2015-06-29 | 2020-12-10 | Immunogen, Inc. | Cisteino inžinerijos antikūnų konjugatai |
| US11098131B2 (en) * | 2015-07-31 | 2021-08-24 | Sutro Biopharma, Inc. | Anti-EpCAM antibodies, compositions comprising anti-EpCAM antibodies and methods of making and using anti-EpCAM antibodies |
| ES2841799T3 (es) * | 2015-08-06 | 2021-07-09 | Agency Science Tech & Res | Anticuerpos frente a IL2R-Beta/cadena gamma común |
-
2019
- 2019-10-22 TW TW108138004A patent/TW202029980A/zh unknown
- 2019-10-23 WO PCT/US2019/057569 patent/WO2020086665A1/en unknown
- 2019-10-23 MX MX2021004808A patent/MX2021004808A/es unknown
- 2019-10-23 CN CN201980084482.4A patent/CN113194985A/zh active Pending
- 2019-10-23 EP EP19876033.2A patent/EP3873512A4/en active Pending
- 2019-10-23 KR KR1020217015710A patent/KR20210095874A/ko active Search and Examination
- 2019-10-23 BR BR112021007918-1A patent/BR112021007918A2/pt unknown
- 2019-10-23 AU AU2019364400A patent/AU2019364400A1/en active Pending
- 2019-10-23 JP JP2021523230A patent/JP2022506072A/ja active Pending
- 2019-10-23 US US17/288,469 patent/US20210403594A1/en active Pending
- 2019-10-23 SG SG11202103949SA patent/SG11202103949SA/en unknown
- 2019-10-23 CA CA3117548A patent/CA3117548A1/en active Pending
-
2021
- 2021-04-20 IL IL282496A patent/IL282496A/en unknown
Also Published As
| Publication number | Publication date |
|---|---|
| EP3873512A4 (en) | 2022-11-23 |
| MX2021004808A (es) | 2021-06-23 |
| WO2020086665A1 (en) | 2020-04-30 |
| TW202029980A (zh) | 2020-08-16 |
| JP2022506072A (ja) | 2022-01-17 |
| CN113194985A (zh) | 2021-07-30 |
| BR112021007918A2 (pt) | 2021-08-03 |
| EP3873512A1 (en) | 2021-09-08 |
| AU2019364400A1 (en) | 2021-05-13 |
| CA3117548A1 (en) | 2020-04-30 |
| SG11202103949SA (en) | 2021-05-28 |
| IL282496A (en) | 2021-06-30 |
| US20210403594A1 (en) | 2021-12-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20210095874A (ko) | Epcam 항체, 활성화 가능한 항체 및 면역접합체, 그리고 이들의 용도 | |
| JP6869218B2 (ja) | Liv−1に対するヒト化抗体および癌治療のためのその使用 | |
| AU2013203459B2 (en) | DLL3 modulators and methods of use | |
| ES2912266T3 (es) | Inmunoconjugados dirigidos a ADAM9 y procedimientos de uso de los mismos | |
| CA2952758A1 (en) | Antibodies binding axl | |
| KR20220004687A (ko) | 이중파라토프 fr-알파 항체 및 면역접합체 | |
| CA3104511A1 (en) | Immunoconjugates targeting adam9 and methods of use thereof | |
| US20180230218A1 (en) | Met antibodies and immunoconjugates and uses thereof | |
| TW202306995A (zh) | 治療具有可溶性FR-α之患者之癌症 | |
| US11827709B2 (en) | Anti-AVB6 antibodies and antibody-drug conjugates | |
| WO2024015830A1 (en) | Epcam immunoconjugates and uses thereof | |
| RU2791445C2 (ru) | Новые анти-cd19-антитела |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination |