KR20180100136A - 이중특이적 항체 플랫폼 - Google Patents
이중특이적 항체 플랫폼 Download PDFInfo
- Publication number
- KR20180100136A KR20180100136A KR1020187020661A KR20187020661A KR20180100136A KR 20180100136 A KR20180100136 A KR 20180100136A KR 1020187020661 A KR1020187020661 A KR 1020187020661A KR 20187020661 A KR20187020661 A KR 20187020661A KR 20180100136 A KR20180100136 A KR 20180100136A
- Authority
- KR
- South Korea
- Prior art keywords
- domain
- polypeptide
- amino acid
- acid sequence
- seq
- Prior art date
Links
Images

















Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
- C07K16/468—Immunoglobulins having two or more different antigen binding sites, e.g. multifunctional antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/04—Immunostimulants
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/76—Albumins
- C07K14/765—Serum albumin, e.g. HSA
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/524—CH2 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/526—CH3 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/66—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising a swap of domains, e.g. CH3-CH2, VH-CL or VL-CH1
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/31—Fusion polypeptide fusions, other than Fc, for prolonged plasma life, e.g. albumin
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Biochemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Engineering & Computer Science (AREA)
- Epidemiology (AREA)
- Mycology (AREA)
- Microbiology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Oncology (AREA)
- Zoology (AREA)
- Toxicology (AREA)
- Gastroenterology & Hepatology (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
이중특이적 항체에서 중쇄 및 경쇄 짝짓기오류 문제에 대한 해결책이 본 명세서에서 제공된다. 상기 해결책의 하나의 일부는 상기 이중특이적 항체의 2 중쇄의 헤테로이량체화를 구동하기 위해 라이신 재위치결정에 의해 그들의 CH3 도메인에서 조작되는 Fc 영역을 포함한다. 상기 해결책의 제2 일부는 이중특이적 항체에서 경쇄의 짝짓기오류를 예방하기 위해 이중특이적 항체의 2 Fab 아암 중 하나의 변형을 포함한다. 특이적으로, 이중특이적 항체의 Fab 아암 중 하나의 CH1 및 CL 도메인은 IgE CH2 도메인 또는 IgM CH2 도메인으로 치환된다.
Description
관련 출원에 대한 교차 참조
본원은 하기의 우선권의 이점을 주장한다: 미국 가출원 번호 62/269,664 (2015년 12월 18일 출원, 이들의 내용은 그들의 전체가 본 명세서에서 참고로 편입됨).
대부분, 2 종래의 단일특이적 항체의 조합으로 달성될 수 없는 신규한 작용 기전 달성의 잠재력으로 인해 생물제제 약물로서 이중특이적 항체의 사용에서 관심이 증가하고 있다. 이중특이적 항체의 효율적인 생성 방법은 따라서 구해지고 있다. 생물제제 약물로서 이중특이적 항체를 생산하기 위한 초기 시도는 단일특이적 항체의 콘주게이션 및 mAb-발현 세포의 화학적 융합을 관여하였지만, 풍부한 부산물로부터 정제의 필요성 및 낮은 효율은 이들 전략의 약점이다. 단백질 공학 및 분자 생물학에서 진전된 방법은 다양한 신규한 이중특이적 항체 포맷의 생성을 가능하게 하고 있다. 그러나, 이들 조작된 이중특이적 항체 포맷의 변경된 생화학적/생체물리학적 특성, 혈청 반감기, 또는 안정성은 이롭지 않을 수 있다. 따라서, 이들 문제의 일부를 극복할 수 있는 이중특이적 항체의 생성용 효율적인 플랫폼은 유용할 것이다.
본원은 상이한 에피토프에 결합하는 임의의 2 항체를 이중특이적 항체로 전환시킬 수 있는 항체 플랫폼 기술에 관한 것이다. 이러한 플랫폼 기술은, 부분적으로, 이중특이적 항체의 2 중쇄의 헤테로이량체화를 구동시키기 위한 라이신 재위치결정에 의해 그들의 CH3 도메인에서 조작되는 Fc 영역을 포함한다. 게다가, 이러한 기술은 이중특이적 항체에서 경쇄의 짝짓기오류을 예방하기 위해 이중특이적 항체의 2 Fab 아암 중 하나의 변형을 포함한다. 특이적으로, 이중특이적 항체의 Fab 아암 중 하나의 CH1 및 CL 도메인은 IgE CH2 도메인 또는 IgM CH2 도메인으로 치환된다. 일부 경우에서, 이중특이적 항체의 Fab 아암 중 하나의 CH1 및 CL 도메인은 IgE CH2 도메인 (또는 IgM CH2 도메인)의 한 단편으로 치환되고, 여기서 상기 단편은 여전히 IgE CH2 도메인 (또는 IgM CH2 도메인)을 이량체화할 수 있다.
하나의 측면에서, 본 개시내용은 제1 중쇄 가변 도메인 (제1 VH) 및 제1 경쇄 가변 도메인 (제1 VL)을 포함하는 항체 또는 이의 항원-결합 단편을 제공하고, 여기서 상기 제1 VH 및 상기 제1 VL은 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성한다. 제1 VH는 어느 한쪽으로 직접적으로 연결되거나 인간 면역글로불린 E (IgE)의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결된다. 제1 VL은 어느 한쪽으로 직접적으로 연결되거나 인간 IgE의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결된다. 제1 폴리펩타이드 및 제2 폴리펩타이드는 짝짓기하여 이량체를 형성한다.
이러한 측면의 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 직접적으로 Fc 도메인에 연결된다. 특정 경우에서, Fc 도메인은 IgG1 항체의 CH2 및 CH3 도메인을 포함한다. 특정 경우에서, Fc 도메인은 IgG4 항체의 CH2 및 CH3 도메인을 포함한다. 특정 경우에서, Fc 도메인은 IgG4 항체의 CH2 및 IgG1 항체의 CH3 도메인을 포함한다. 이들 구현예 모두의 일부에서, Fc 도메인은 하기를 포함한다: IgG4 항체의 힌지 영역 (예를 들면, IgG4P - 즉,S228P 돌연변이를 가진 IgG4 힌지 영역). 일부 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:1에서 제시된 아미노산 서열을 포함한다. 일부 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:1에서 제시된 아미노산 서열의 아미노산 9-107에 적어도 90% 동일한 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:1에서 제시된 아미노산 서열의 아미노산 9-107을 포함한다. 일부 구현예에서, 제1 폴리펩타이드는 서열 식별 번호:5에서 제시된 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함한다. 특정한 구현예에서, 제1 폴리펩타이드는 서열 식별 번호:5에서 제시된 아미노산 서열을 포함한다. 일부 구현예에서, 제2 폴리펩타이드는 서열 식별 번호:6에서 제시된 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함한다. 특정한 구현예에서, 제2 폴리펩타이드는 서열 식별 번호:6에서 제시된 아미노산 서열에 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 12 이하 아미노산 잔기에서 서열 식별 번호:1의 아미노산 9-107에서 제시된 아미노산 서열과 상이하다. 일부 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 쇄내 디설파이드 결합을 형성하지 않는 서열 식별 번호:1의 2 시스테인 잔기 중 적어도 하나에서 시스테인 이외 아미노산을 함유한다. 특정 구현예에서, 제1 폴리펩타이드 및 제2 폴리펩타이드는 각각 IgE CH2 도메인 또는 이의 단편에서 N-연결된 당화 부위의 돌연변이를 함유하여서 N-연결된 당화 부위는 당화되지 않는다 (예를 들면, 아스파라긴 및/또는 트레오닌 잔기는 또 다른 아미노산으로 치환된다). 특정 구현예에서, 제1 폴리펩타이드 또는 제2 폴리펩타이드는 IgE CH2 도메인 또는 이의 단편에서 N-연결된 당화 부위의 돌연변이를 함유하여서 N-연결된 당화 부위는 당화되지 않는다. 특정 구현예에서, 항체 또는 이의 항원-결합 단편은 제2 중쇄 가변 도메인 (제2 VH) 및 제2 경쇄 가변 도메인 (제2 VL)을 포함하고, 여기서 상기 제2 VH 및 상기 제2 VL은 짝짓기하여 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성한다. 특정 구현예에서, 제2 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결되고 제2 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결된다. 특정 구현예에서, 본 개시내용은 상기 기재된 항체 또는 항원-결합 단편을 인코딩하는 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 제공한다. 일부 구현예에서, 상기 기재된 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 포함하는 발현 벡터는 제공된다. 다른 구현예에서, 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 포함하는 숙주 세포 또는 발현 벡터는 제공된다. 더욱 다른 구현예에서, 상기 기재된 항체 또는 항원-결합 단편의 발현을 초래하는 조건하에 상기 기재된 숙주 세포의 배양 및 세포 배양액으로부터 항체 또는 항원-결합 단편의 단리를 포함하는 상기 기재된 항체 또는 항원-결합 단편의 제조 방법은 제공된다. 특정 구현예에서, 단리된 항체 또는 항원-결합 단편은 필요로 하는 인간 대상체에 투여용 멸균 조성물로서 제형화된다.
제2 측면에서, 본 개시내용은 제1 VH 및 제1 VL을 포함하는 항체 또는 이의 항원-결합 단편을 제공하고, 여기서 상기 제1 VH 및 상기 제1 VL은 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성한다. 제1 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 M (IgM)의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결된다. 제1 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결된다. 제1 폴리펩타이드 및 제2 폴리펩타이드는 짝짓기하여 이량체를 형성한다.
이러한 측면의 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 직접적으로 Fc 도메인에 연결된다. 특정 경우에서, Fc 도메인은 IgG1 항체의 CH2 및 CH3 도메인을 포함한다. 특정 경우에서, Fc 도메인은 IgG4 항체의 CH2 및 CH3 도메인을 포함한다. 특정 경우에서, Fc 도메인은 IgG4 항체의 CH2 및 IgG1 항체의 CH3 도메인을 포함한다. 이들 구현예 모두의 일부에서, Fc 도메인은 하기를 포함한다: IgG4 항체의 힌지 영역 (예를 들면, IgG4P - 즉,S228P 돌연변이를 가진 IgG4 힌지 영역). 일부 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:2에서 제시된 아미노산 서열을 포함한다. 일부 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:2에서 제시된 아미노산 서열의 아미노산 7-112에 적어도 90% 동일한 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:2에서 제시된 아미노산 서열의 아미노산 7-112를 포함한다. 일부 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 12 이하 아미노산 잔기에서 서열 식별 번호:2의 아미노산 7-112에서 제시된 아미노산 서열과 상이하다. 일부 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 쇄내 디설파이드 결합을 형성하지 않는 서열 식별 번호:2의 시스테인 잔기에서 시스테인 이외 아미노산을 함유한다. 특정 구현예에서, 제1 폴리펩타이드 및 제2 폴리펩타이드는 각각 IgM CH2 도메인 또는 이의 단편에서 N-연결된 당화 부위의 돌연변이를 함유하여서 N-연결된 당화 부위는 당화되지 않는다 (예를 들면, 아스파라긴 및/또는 세린 잔기는 또 다른 아미노산으로 치환된다). 특정 구현예에서, 제1 폴리펩타이드 또는 제2 폴리펩타이드는 IgM CH2 도메인 또는 이의 단편에서 N-연결된 당화 부위의 돌연변이를 함유하여서 N-연결된 당화 부위는 당화되지 않는다. 특정 구현예에서, 항체 또는 이의 항원-결합 단편은 제2 중쇄 가변 도메인 (제2 VH) 및 제2 경쇄 가변 도메인 (제2 VL)을 포함하고, 여기서 상기 제2 VH 및 상기 제2 VL은 짝짓기하여 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성한다. 특정 구현예에서, 제2 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결되고 제2 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결된다. 특정 구현예에서, 본 개시내용은 상기 기재된 항체 또는 항원-결합 단편을 인코딩하는 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 제공한다. 일부 구현예에서, 상기 기재된 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 포함하는 발현 벡터는 제공된다. 다른 구현예에서, 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 포함하는 숙주 세포 또는 발현 벡터는 제공된다. 더욱 다른 구현예에서, 상기 기재된 항체 또는 항원-결합 단편의 발현을 초래하는 조건하에 상기 기재된 숙주 세포의 배양 및 세포 배양액으로부터 항체 또는 항원-결합 단편의 단리를 포함하는 상기 기재된 항체 또는 항원-결합 단편의 제조 방법은 제공된다. 특정 구현예에서, 단리된 항체 또는 항원-결합 단편은 필요로 하는 인간 대상체에 투여용 멸균 조성물로서 제형화된다.
또 다른 측면에서, 본 개시내용은 제1 VH 및 제1 VL을 포함하는 제1 단편 항원-결합 (제1 Fab)를 포함하는 이중특이적 항체를 제공하고, 여기서 상기 제1 VH 및 상기 제1 VL은 짝짓기하여 제1 가변 영역을 형성한다. 제1 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 E (IgE)의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결된다. 제1 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결된다. 이중특이적 항체는 제2 VH 및 제2 VL을 포함하는 제2 Fab를 추가로 포함하고, 여기서 상기 제2 VH 및 상기 제2 VL은 짝짓기하여 제2 가변 영역을 형성하고, 여기서 상기 제2 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결되고 제2 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결된다. 제1 Fab 및 제2 Fab는 상이한 항원에 또는 동일한 항원의 상이한 에피토프에 특이적으로 결합하고 제1 Fab는 제2 Fab에 연결된다.
이러한 측면의 일부 구현예에서, 제1 Fab는 제2 Fab에 링커에 의해 연결된다. 특정 구현예에서, 제1 Fab는 제2 Fab에 이종 폴리펩타이드에 의해 연결된다. 일부 구현예에서, 이종 폴리펩타이드는 인간 혈청 알부민이다. 일부 구현예에서, 이종 폴리펩타이드는 하기이다: XTEN (예를 들면, AE144, AE288). 일부 구현예에서, 제1 Fab는 제2 Fab에 폴리에틸렌 글리콜 (PEG)에 의해 연결된다. 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 각각 서열 식별 번호:1에서 제시된 아미노산 서열을 포함한다. 일부 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:1에서 제시된 아미노산 서열의 아미노산 9-107에 적어도 90% 동일한 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:1에서 제시된 아미노산 서열의 아미노산 9-107을 포함한다. 일부 구현예에서, 제1 폴리펩타이드는 서열 식별 번호:5에서 제시된 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 제1 폴리펩타이드는 서열 식별 번호:5에서 제시된 아미노산 서열을 포함한다. 특정 구현예에서, 제2 폴리펩타이드는 서열 식별 번호:6에서 제시된 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 제2 폴리펩타이드는 서열 식별 번호:6에서 제시된 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 12 이하 아미노산 잔기에서 서열 식별 번호:1의 아미노산 9-107에서 제시된 아미노산 서열과 상이하다. 다른 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 쇄간 디설파이드 결합을 형성할 수 있는 서열 식별 번호:1의 2 시스테인 잔기 중 적어도 하나에서 시스테인 이외 아미노산을 함유한다. 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 IgE CH2 도메인 또는 이의 단편에서 N-연결된 당화 부위의 돌연변이를 함유하여서 N-연결된 당화 부위는 당화되지 않는다. 예를 들어, IgE CH2 도메인 N-연결된 당화 부위의 아스파라긴 및/또는 트레오닌은 이러한 모티프의 당화를 예방하기 위해 또 다른 아미노산으로 치환될 수 있다. 특정 구현예에서, 본 개시내용은 상기 기재된 이중특이적 항체를 인코딩하는 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 제공한다. 일부 구현예에서, 상기 기재된 이중특이적 항체를 포함하는 발현 벡터는 제공된다. 다른 구현예에서, 이중특이적 항체를 포함하는 숙주 세포 또는 발현 벡터는 제공된다. 더욱 다른 구현예에서, 이중특이적 항체의 발현을 초래하는 조건하에 상기 기재된 숙주 세포의 배양 및 세포 배양액으로부터 이중특이적 항체의 단리를 포함하는 이중특이적 항체의 제조 방법은 제공된다. 특정 구현예에서, 단리된 이중특이적 항체는 필요로 하는 인간 대상체에 투여용 멸균 조성물로서 제형화된다.
또 다른 측면에서, 본 개시내용은 제1 VH 및 제1 VL을 포함하는 제1 단편 항원-결합 (제1 Fab)를 포함하는 이중특이적 항체를 제공하고, 여기서 상기 제1 VH 및 상기 제1 VL은 짝짓기하여 제1 가변 영역을 형성한다. 제1 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 M (IgM)의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결된다. 제1 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결된다. 이중특이적 항체는 제2 VH 및 제2 VL을 포함하는 제2 Fab를 추가로 포함한다. 제2 VH 및 제2 VL은 짝짓기하여 제2 가변 영역을 형성하고, 여기서 상기 제2 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결되고 제2 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결된다. 제1 Fab 및 제2 Fab는 상이한 항원에 또는 동일한 항원의 상이한 에피토프에 특이적으로 결합한다. 제1 Fab는 제2 Fab에 연결된다.
이러한 측면의 일부 구현예에서, 제1 Fab는 제2 Fab에 링커에 의해 연결된다. 특정 구현예에서, 제1 Fab는 제2 Fab에 이종 폴리펩타이드에 의해 연결된다. 일부 구현예에서, 이종 폴리펩타이드는 인간 혈청 알부민이다. 일부 구현예에서, 이종 폴리펩타이드는 하기이다: XTEN (예를 들면, AE144, AE288). 일부 구현예에서, 제1 Fab는 제2 Fab에 폴리에틸렌 글리콜 (PEG)에 의해 연결된다. 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 각각 서열 식별 번호:2에서 제시된 아미노산 서열을 포함한다. 일부 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:2에서 제시된 아미노산 서열의 아미노산 7-112에 적어도 90% 동일한 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:2에서 제시된 아미노산 서열의 아미노산 7-112를 포함한다. 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 12 이하 아미노산 잔기에서 서열 식별 번호:2의 아미노산 7-112에서 제시된 아미노산 서열과 상이하다. 다른 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 쇄간 디설파이드 결합을 형성할 수 있는 서열 식별 번호:2의 시스테인 잔기에서 시스테인 이외 아미노산을 함유한다. 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 IgM CH2 도메인 또는 이의 단편에서 N-연결된 당화 부위의 돌연변이를 함유하여서 N-연결된 당화 부위는 당화되지 않는다. 예를 들어, IgM CH2 도메인 N-연결된 당화 부위의 아스파라긴 및/또는 세린은 이러한 모티프의 당화를 예방하기 위해 또 다른 아미노산으로 치환될 수 있다. 특정 구현예에서, 본 개시내용은 상기 기재된 이중특이적 항체를 인코딩하는 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 제공한다. 일부 구현예에서, 상기 기재된 이중특이적 항체를 포함하는 발현 벡터는 제공된다. 다른 구현예에서, 이중특이적 항체를 포함하는 숙주 세포 또는 발현 벡터는 제공된다. 더욱 다른 구현예에서, 이중특이적 항체의 발현을 초래하는 조건하에 상기 기재된 숙주 세포의 배양 및 세포 배양액으로부터 이중특이적 항체의 단리를 포함하는 이중특이적 항체의 제조 방법은 제공된다. 특정 구현예에서, 단리된 이중특이적 항체는 필요로 하는 인간 대상체에 투여용 멸균 조성물로서 제형화된다.
또 다른 측면에서, 본 개시내용은 제1 항원의 제1 에피토프에 특이적으로 결합하는 전체 IgG 항체, 상기 전체 IgG 항체는 제1 CH3 도메인 및 제2 CH3 도메인을 포함함; 그리고 제1 Fab 및 제2 Fab를 포함하는 4가 이중특이적 항체를 제공한다. 제1 Fab는 제1 중쇄 가변 도메인 (제1 VH) 및 제1 경쇄 가변 도메인 (제1 VL)을 포함하고, 여기서 상기 제1 VH 및 상기 제1 VL은 짝짓기하여 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제1 가변 영역을 형성한다. 제2 Fab는 제2 중쇄 가변 도메인 (제2 VH) 및 제2 경쇄 가변 도메인 (제2 VL)을 포함하고, 여기서 상기 제2 VH 및 상기 제2 VL은 짝짓기하여 제1 Fab와 동일한 에피토프에 특이적으로 결합하는 제2 가변 영역을 형성한다. 제1 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 E (IgE)의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결된다. 제1 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결된다. 제2 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제3 폴리펩타이드에 링커를 통해 연결된다. 제2 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제4 폴리펩타이드에 링커를 통해 연결된다. 제1 Fab는 전체 IgG 항체의 제1 CH3 도메인의 C-말단에 연결되고 제2 Fab는 전체 IgG 항체의 제2 CH3 도메인의 C-말단에 연결된다.
이러한 측면의 일부 구현예에서, 제1 Fab는 제1 링커를 통해 전체 항체의 제1 CH3 도메인의 C-말단에 연결되고 제2 Fab는 제2 링커를 통해 전체 항체의 제2 CH3 도메인의 C-말단에 연결된다. 특정 구현예에서, 제1 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제1 VH의 N-말단을 연결시킨다. 특정 구현예에서, 제1 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제1 VL의 N-말단을 연결시킨다. 특정 구현예에서, 제1 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제1 폴리펩타이드의 N-말단을 연결시킨다. 특정 구현예에서, 제1 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제2 폴리펩타이드의 N-말단을 연결시킨다. 특정 구현예에서, 제2 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제2 VH의 N-말단을 연결시킨다. 특정 구현예에서, 제2 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제2 VL의 N-말단을 연결시킨다. 특정 구현예에서, 제2 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제3 폴리펩타이드의 N-말단을 연결시킨다. 특정 구현예에서, 제2 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제4 폴리펩타이드의 N-말단을 연결시킨다. 특정 구현예에서, 제1 및 제2 링커는 펩타이드 링커이다. 일부 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드, 및/또는 제4 폴리펩타이드는 서열 식별 번호:1에서 제시된 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드, 및/또는 제4 폴리펩타이드는 서열 식별 번호:1에서 제시된 아미노산 서열의 아미노산 9-107에 적어도 90% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드, 및/또는 제4 폴리펩타이드는 서열 식별 번호:1에서 제시된 아미노산 서열의 아미노산 9-107을 포함한다. 일부 구현예에서, 제1 폴리펩타이드 및 제3 폴리펩타이드는 각각 서열 식별 번호:5에서 제시된 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드 및 제3 폴리펩타이드는 각각 서열 식별 번호:5에서 제시된 아미노산 서열을 포함한다. 특정 구현예에서, 제2 폴리펩타이드 및 제4 폴리펩타이드는 각각 서열 식별 번호:6에서 제시된 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 제2 폴리펩타이드 및 제4 폴리펩타이드는 각각 서열 식별 번호:6에서 제시된 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드 및/또는 제4 폴리펩타이드는 적어도 12 아미노산 잔기에서 서열 식별 번호:1의 아미노산 9-107에서 제시된 아미노산 서열과 상이하다. 특정 구현예에서, 본 개시내용은 상기 기재된 이중특이적 항체를 인코딩하는 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 제공한다. 일부 구현예에서, 상기 기재된 이중특이적 항체를 포함하는 발현 벡터는 제공된다. 다른 구현예에서, 이중특이적 항체를 포함하는 숙주 세포 또는 발현 벡터는 제공된다. 더욱 다른 구현예에서, 이중특이적 항체의 발현을 초래하는 조건하에 상기 기재된 숙주 세포의 배양 및 세포 배양액으로부터 이중특이적 항체의 단리를 포함하는 이중특이적 항체의 제조 방법은 제공된다. 특정 구현예에서, 단리된 이중특이적 항체는 필요로 하는 인간 대상체에 투여용 멸균 조성물로서 제형화된다.
또 다른 측면에서, 본 개시내용은 제1 항원의 제1 에피토프에 특이적으로 결합하는 전체 IgG 항체, 상기 전체 IgG 항체는 제1 CH3 도메인 및 제2 CH3 도메인을 포함함; 그리고 제1 Fab 및 제2 Fab를 포함하는 4가 이중특이적 항체를 제공한다. 제1 Fab는 제1 중쇄 가변 도메인 (제1 VH) 및 제1 경쇄 가변 도메인 (제1 VL)을 포함하고, 여기서 상기 제1 VH 및 상기 제1 VL은 짝짓기하여 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제1 가변 영역을 형성한다. 제2 Fab는 제2 중쇄 가변 도메인 (제2 VH) 및 제2 경쇄 가변 도메인 (제2 VL)을 포함하고, 여기서 상기 제2 VH 및 상기 제2 VL은 짝짓기하여 제1 Fab와 동일한 에피토프에 특이적으로 결합하는 제2 가변 영역을 형성한다. 제1 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 M (IgM)의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결된다. 제1 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결된다. 제2 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제3 폴리펩타이드에 링커를 통해 연결된다. 제2 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제4 폴리펩타이드에 링커를 통해 연결된다. 제1 Fab는 전체 IgG 항체의 제1 CH3 도메인의 C-말단에 연결되고 제2 Fab는 전체 IgG 항체의 제2 CH3 도메인의 C-말단에 연결된다.
이러한 측면의 일부 구현예에서, 제1 Fab는 제1 링커를 통해 전체 항체의 제1 CH3 도메인의 C-말단에 연결되고 제2 Fab는 제2 링커를 통해 전체 항체의 제2 CH3 도메인의 C-말단에 연결된다. 특정 구현예에서, 제1 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제1 VH의 N-말단을 연결시킨다. 특정 구현예에서, 제1 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제1 VL의 N-말단을 연결시킨다. 특정 구현예에서, 제1 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제1 폴리펩타이드의 N-말단을 연결시킨다. 특정 구현예에서, 제1 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제2 폴리펩타이드의 N-말단을 연결시킨다. 특정 구현예에서, 제2 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제2 VH의 N-말단을 연결시킨다. 특정 구현예에서, 제2 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제2 VL의 N-말단을 연결시킨다. 특정 구현예에서, 제2 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제3 폴리펩타이드의 N-말단을 연결시킨다. 특정 구현예에서, 제2 링커는 전체 항체의 제1 CH3 도메인의 C-말단 및 제4 폴리펩타이드의 N-말단을 연결시킨다. 특정 구현예에서, 제1 및 제2 링커는 펩타이드 링커이다. 일부 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드, 및/또는 제4 폴리펩타이드는 서열 식별 번호:2에서 제시된 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드, 및/또는 제4 폴리펩타이드는 서열 식별 번호:2에서 제시된 아미노산 서열의 아미노산 7-112에 적어도 90% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드, 및/또는 제4 폴리펩타이드는 서열 식별 번호:2에서 제시된 아미노산 서열의 아미노산 7-112를 포함한다. 특정 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드 및/또는 제4 폴리펩타이드는 적어도 12 아미노산 잔기에서 서열 식별 번호:2의 아미노산 7-112에서 제시된 아미노산 서열과 상이하다. 특정 구현예에서, 본 개시내용은 상기 기재된 이중특이적 항체를 인코딩하는 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 제공한다. 일부 구현예에서, 상기 기재된 이중특이적 항체를 포함하는 발현 벡터는 제공된다. 다른 구현예에서, 이중특이적 항체를 포함하는 숙주 세포 또는 발현 벡터는 제공된다. 더욱 다른 구현예에서, 이중특이적 항체의 발현을 초래하는 조건하에 상기 기재된 숙주 세포의 배양 및 세포 배양액으로부터 이중특이적 항체의 단리를 포함하는 이중특이적 항체의 제조 방법은 제공된다. 특정 구현예에서, 단리된 이중특이적 항체는 필요로 하는 인간 대상체에 투여용 멸균 조성물로서 제형화된다.
또 다른 측면에서, 본 개시내용은 제1 Fab 및 제2 Fab를 포함하는 4가 이중특이적 항체에 관한 것이고, 여기서 상기 제1 Fab는 제1 중쇄 가변 도메인 (제1 VH) 및 제1 경쇄 가변 도메인 (제1 VL)을 포함하고, 여기서 상기 제1 VH 및 상기 제1 VL은 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성하고, 그리고
여기서 상기 제2 Fab는 제2 중쇄 가변 도메인 (제2 VH) 및 제2 경쇄 가변 도메인 (제2 VL)을 포함하고, 여기서 상기 제2 VH 및 상기 제2 VL은 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제2 가변 영역을 형성한다. 4가 이중특이적 항체는 또한 제1 IgG CH2 도메인 및 제1 IgG CH3 도메인을 포함하는 제1 중쇄, 제2 IgG CH2 도메인 및 제2 IgG CH3 도메인을 포함하는 제2 중쇄, 제1 경쇄, 및 제2 경쇄를 포함하는 전체 항체를 포함하고, 여기서 상기 항체는 제3 VH 및 제3 VL 및 제4 VH 및 제4 VL을 포함하고, 여기서 상기 제3 VH 및 상기 제3 VL은 짝짓기하여 제2 항원의 에피토프에 특이적으로 결합하는 제3 가변 영역을 형성하고, 여기서 상기 제4 VH 및 상기 제4 VL은 짝짓기하여 제2 항원의 동일한 에피토프에 특이적으로 결합하는 제4 가변 영역을 형성한다. 제3 VH은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 E (IgE)의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결된다. 제3 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결된다. 제4 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제3 폴리펩타이드에 링커를 통해 연결된다. 제4 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제4 폴리펩타이드에 링커를 통해 연결된다. 제1 폴리펩타이드는 제1 IgG CH2 도메인의 N-말단에 연결되고 제3 폴리펩타이드는 제2 IgG CH2 도메인의 N-말단에 연결된다. 제1 Fab는 제1 IgG CH3 도메인의 C-말단에 연결되고 제2 Fab는 제2 IgG CH3 도메인의 C-말단에 연결된다.
이러한 측면의 일부 구현예에서, 제1 Fab는 제1 링커를 통해 전체 항체의 제1 CH3 도메인의 C-말단에 연결되고 제2 Fab는 제2 링커를 통해 전체 항체의 제2 CH3 도메인의 C-말단에 연결된다. 특정 구현예에서, 제1 및 제2 링커는 펩타이드 링커이다. 일부 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드, 및/또는 제4 폴리펩타이드는 서열 식별 번호:1에서 제시된 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드, 및/또는 제4 폴리펩타이드는 서열 식별 번호:1에서 제시된 아미노산 서열의 아미노산 9-107에 적어도 90% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드, 및/또는 제4 폴리펩타이드는 서열 식별 번호:1에서 제시된 아미노산 서열의 아미노산 9-107을 포함한다. 일부 구현예에서, 제1 폴리펩타이드 및 제3 폴리펩타이드는 각각 서열 식별 번호:5에서 제시된 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드 및 제3 폴리펩타이드는 각각 서열 식별 번호:5에서 제시된 아미노산 서열을 포함한다. 특정 구현예에서, 제2 폴리펩타이드 및 제4 폴리펩타이드는 각각 서열 식별 번호:6에서 제시된 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 제2 폴리펩타이드 및 제4 폴리펩타이드는 각각 서열 식별 번호:6에서 제시된 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드 및/또는 제4 폴리펩타이드는 적어도 12 아미노산 잔기에서 서열 식별 번호:1의 아미노산 9-107에서 제시된 아미노산 서열과 상이하다. 특정 구현예에서, 본 개시내용은 상기 기재된 이중특이적 항체를 인코딩하는 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 제공한다. 일부 구현예에서, 상기 기재된 이중특이적 항체를 포함하는 발현 벡터는 제공된다. 다른 구현예에서, 이중특이적 항체를 포함하는 숙주 세포 또는 발현 벡터는 제공된다. 더욱 다른 구현예에서, 이중특이적 항체의 발현을 초래하는 조건하에 상기 기재된 숙주 세포의 배양 및 세포 배양액으로부터 이중특이적 항체의 단리를 포함하는 이중특이적 항체의 제조 방법은 제공된다. 특정 구현예에서, 단리된 이중특이적 항체는 필요로 하는 인간 대상체에 투여용 멸균 조성물로서 제형화된다.
또 다른 측면에서, 본 개시내용은 제1 Fab 및 제2 Fab를 포함하는 4가 이중특이적 항체에 관한 것이고, 여기서 상기 제1 Fab는 제1 중쇄 가변 도메인 (제1 VH) 및 제1 경쇄 가변 도메인 (제1 VL)을 포함하고, 여기서 상기 제1 VH 및 상기 제1 VL은 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성하고, 그리고
여기서 상기 제2 Fab는 제2 중쇄 가변 도메인 (제2 VH) 및 제2 경쇄 가변 도메인 (제2 VL)을 포함하고, 여기서 상기 제2 VH 및 상기 제2 VL은 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제2 가변 영역을 형성한다. 4가 이중특이적 항체는 또한 제1 IgG CH2 도메인 및 제1 IgG CH3 도메인을 포함하는 제1 중쇄, 제2 IgG CH2 도메인 및 제2 IgG CH3 도메인을 포함하는 제2 중쇄, 제1 경쇄, 및 제2 경쇄를 포함하는 전체 항체를 포함하고, 여기서 상기 항체는 제3 VH 및 제3 VL 및 제4 VH 및 제4 VL을 포함하고, 여기서 상기 제3 VH 및 상기 제3 VL은 짝짓기하여 제2 항원의 에피토프에 특이적으로 결합하는 제3 가변 영역을 형성하고, 여기서 상기 제4 VH 및 상기 제4 VL은 짝짓기하여 제2 항원의 동일한 에피토프에 특이적으로 결합하는 제4 가변 영역을 형성한다. 제3 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 M (IgM)의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결된다. 제3 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결된다. 제4 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제3 폴리펩타이드에 링커를 통해 연결된다. 제4 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제4 폴리펩타이드에 링커를 통해 연결된다. 제1 폴리펩타이드는 제1 IgG CH2 도메인의 N-말단에 연결되고 제3 폴리펩타이드는 제2 IgG CH2 도메인의 N-말단에 연결된다. 제1 Fab는 제1 IgG CH3 도메인의 C-말단에 연결되고 제2 Fab는 제2 IgG CH3 도메인의 C-말단에 연결된다.
이러한 측면의 일부 구현예에서, 제1 Fab는 제1 링커를 통해 전체 항체의 제1 CH3 도메인의 C-말단에 연결되고 제2 Fab는 제2 링커를 통해 전체 항체의 제2 CH3 도메인의 C-말단에 연결된다. 특정 구현예에서, 제1 및 제2 링커는 펩타이드 링커이다. 일부 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드, 및/또는 제4 폴리펩타이드는 서열 식별 번호:2에서 제시된 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드, 및/또는 제4 폴리펩타이드는 서열 식별 번호:2에서 제시된 아미노산 서열의 아미노산 7-112에 적어도 90% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드, 및/또는 제4 폴리펩타이드는 서열 식별 번호:2에서 제시된 아미노산 서열의 아미노산 7-112를 포함한다. 특정 구현예에서, 제1 폴리펩타이드, 제2 폴리펩타이드, 제3 폴리펩타이드 및/또는 제4 폴리펩타이드는 적어도 12 아미노산 잔기에서 서열 식별 번호:2의 아미노산 7-112에서 제시된 아미노산 서열과 상이하다. 특정 구현예에서, 본 개시내용은 상기 기재된 이중특이적 항체를 인코딩하는 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 제공한다. 일부 구현예에서, 상기 기재된 이중특이적 항체를 포함하는 발현 벡터는 제공된다. 다른 구현예에서, 이중특이적 항체를 포함하는 숙주 세포 또는 발현 벡터는 제공된다. 더욱 다른 구현예에서, 이중특이적 항체의 발현을 초래하는 조건하에 상기 기재된 숙주 세포의 배양 및 세포 배양액으로부터 이중특이적 항체의 단리를 포함하는 이중특이적 항체의 제조 방법은 제공된다. 특정 구현예에서, 단리된 이중특이적 항체는 필요로 하는 인간 대상체에 투여용 멸균 조성물로서 제형화된다.
더욱 또 다른 측면에서, 본 개시내용은 하기를 포함하는 헤테로이량체화 모듈을 제공한다: 서열 식별 번호:11에서 제시된 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제1 IgG1 CH3 도메인, 여기서 위치 364 및 370에서 아미노산은 라이신이고 위치 409에서 아미노산은 세린임; 및 서열 식별 번호:11에서 제시된 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제2 IgG1 CH3 도메인, 여기서 위치 370에서 아미노산은 세린이고 위치 405 및 409에서 아미노산은 라이신임.아미노산 위치는 EU 넘버링 시스템에 기반된다. 제1 IgG1 CH3 도메인 및 제2 IgG1 CH3은 짝짓기하여 헤테로이량체를 형성한다.
이러한 측면의 특정 구현예에서, 헤테로이량체화 모듈은 제1 IgG1 CH2 도메인 및 제2 IgG1 CH2 도메인을 포함하고, 여기서 상기 제1 IgG1 CH2 도메인은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 제1 IgG1 CH3 도메인의 N-말단에 링커를 통해 연결되고 제2 IgG1 CH2 도메인은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 제2 IgG1 CH3 도메인의 N-말단에 링커를 통해 연결된다.
일부 구현예에서, 헤테로이량체화 모듈은 제1 Fab 포함 2 폴리펩타이드 쇄를 포함하고, 여기서 Fab의 2 폴리펩타이드 쇄 중 하나의 C-말단은 제1 힌지 영역의 N-말단에 연결되고, 여기서 제1 힌지 영역은 제1 IgG1 CH2 도메인의 N-말단에 연결된다.
다른 구현예에서, 헤테로이량체화 모듈은 제2 IgG1 CH2 도메인의 N-말단에 연결되는 제2 힌지 영역의 N-말단에 제1 IgG1 CH3 도메인의 C-말단을 연결시키는 링커를 포함한다. 특정 구현예에서, 헤테로이량체화 모듈은 제2 IgG1 CH2 도메인의 N-말단에 제2 힌지 영역을 통해 연결된 제2 Fab를 포함한다.
특정 구현예에서, 헤테로이량체화 모듈은 VH 도메인, CH1 도메인, VL 도메인, 및 CL 도메인을 포함한다. VH 도메인의 C-말단은 CH1 도메인의 N-말단에 연결되고, CH1 도메인의 C-말단은 제1 힌지 영역의 N-말단에 연결되고, 제1 힌지 영역의 C-말단은 제1 IgG1 CH3 도메인에 직접적으로 연결되는 제1 IgG1 CH2 도메인의 N-말단에 연결된다. VL 도메인의 C-말단은 CL 도메인의 N-말단에 연결되고, CL 도메인의 C-말단은 제2 힌지 영역의 N-말단에 연결되고, 제2 힌지 영역의 C-말단은 제2 IgG1 CH3 도메인에 직접적으로 연결되는 제2 IgG1 CH2 도메인의 N-말단에 연결된다. VH 도메인 및 VL 도메인은 짝짓기하여 항원에 특이적으로 결합하는 가변 영역을 형성한다.
특정 구현예에서, 헤테로이량체화 모듈은 제1 VH 및 제1 VL 및 제2 VH 및 제2 VL을 포함한다. 제1 VH 및 제1 VL은 짝짓기하여 제1 항원에 특이적으로 결합하는 제1 가변 영역을 형성한다. 제2 VH 및 제2 VL은 짝짓기하여 제1 항원의 상이한 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성한다. 일부 경우에서, 제1 VL의 아미노산 서열은 제2 VL의 아미노산 서열과 동일하다.
특정 구현예에서, 헤테로이량체화 모듈은 제1 IgG4 CH2 도메인 및 제2 IgG4 CH2 도메인을 포함하고, 여기서 제1 IgG4 CH2 도메인은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 제1 IgG1 CH3 도메인의 N-말단에 링커를 통해 연결되고 제2 IgG4 CH2 도메인은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 제2 IgG1 CH3 도메인의 N-말단에 링커를 통해 연결된다. 일부 경우에서, 헤테로이량체화 모듈은 제1 Fab 포함 2 폴리펩타이드 쇄를 포함하고, 여기서 Fab의 2 폴리펩타이드 쇄 중 하나의 C-말단은 제1 IgG4 힌지 영역의 N-말단에 연결되고, 여기서 제1 IgG4 힌지 영역은 제1 IgG4 CH2 도메인의 N-말단에 연결된다. 일부 경우에서, 제1 IgG4 힌지 영역은 S228P 돌연변이를 포함한다 (EU 넘버링). 일부 경우에서, 헤테로이량체화 모듈은 제2 IgG4 CH2 도메인의 N-말단에 연결되는 제2 IgG4 힌지 영역의 N-말단에 제1 IgG1 CH3 도메인의 C-말단을 연결시키는 링커를 포함한다. 특정 경우에서, 제2 IgG4 힌지 영역은 S228P 돌연변이를 포함한다 (EU 넘버링). 일부 경우에서, 헤테로이량체화 모듈은 제2 IgG4 CH2 도메인의 N-말단에 제2 IgG4 힌지 영역을 통해 연결된 제2 Fab를 포함한다. 특정 경우에서, 제2 IgG4 힌지 영역은 S228P 돌연변이를 포함한다 (EU 넘버링).
일부 구현예에서, 헤테로이량체화 모듈은 VH 도메인, CH1 도메인, VL 도메인, 및 CL 도메인을 포함한다. VH 도메인의 C-말단은 CH1 도메인의 N-말단에 연결되고, CH1 도메인의 C-말단은 제1 IgG4 힌지 영역의 N-말단에 연결되고, 제1 IgG4 힌지 영역의 C-말단은 제1 IgG1 CH3 도메인에 직접적으로 연결되는 제1 IgG4 CH2 도메인의 N-말단에 연결된다. VL 도메인의 C-말단은 CL 도메인의 N-말단에 연결되고, CL 도메인의 C-말단은 제2 IgG4 힌지 영역의 N-말단에 연결되고, 제2 IgG4 힌지 영역의 C-말단은 제2 IgG1 CH3 도메인에 직접적으로 연결되는 제2 IgG4 CH2 도메인의 N-말단에 연결된다. VH 도메인 및 VL 도메인은 짝짓기하여 항원에 특이적으로 결합하는 가변 영역을 형성한다. 일부 경우에서, 제1 IgG4 힌지 영역 및 제2 IgG4 힌지 영역은 각각 S228P 돌연변이를 포함한다 (EU 넘버링).
일부 구현예에서, 헤테로이량체화 모듈은 제1 VH 및 제1 VL 및 제2 VH 및 제2 VL을 포함한다. 제1 VH 및 제1 VL은 짝짓기하여 제1 항원에 특이적으로 결합하는 제1 가변 영역을 형성한다. 제2 VH 및 제2 VL은 짝짓기하여 제1 항원의 상이한 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성한다. 일부 경우에서, 제1 VL의 아미노산 서열은 제2 VL의 아미노산 서열과 동일하다.
특정 구현예에서, 본 개시내용은 상기-기재된 헤테로이량체화 모듈을 인코딩하는 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 특성화한다. 일부 경우에서, 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 포함하는 발현 벡터 또는 발현 벡터들은 특성화된다. 다른 경우에서, 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들 또는 발현 벡터 또는 벡터들을 포함하는 숙주 세포는 제공된다. 일부 경우에서, 헤테로이량체화 모듈의 생산 방법은 포괄된다. 상기 방법은 헤테로이량체화 모듈의 발현을 초래하는 조건하에 숙주 세포의 배양 및 이의 단리를 포함한다.
또 다른 측면에서, 본 개시내용은 하기를 포함하는 헤테로이량체화 모듈에 관한 것이다: 서열 식별 번호:11에서 제시된 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제1 IgG1 CH3 도메인, 여기서 위치 364 및 370에서 아미노산은 라이신이고 위치 409에서 아미노산은 류신임; 및 서열 식별 번호:11에서 제시된 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제2 IgG1 CH3 도메인, 여기서 위치 370에서 아미노산은 세린이고, 위치 397에서 아미노산은은 이소류신이고, 위치 405 및 409에서 아미노산은 라이신임.아미노산 위치는 EU 넘버링 시스템에 기반된다. 제1 IgG1 CH3 도메인 및 제2 IgG1 CH3은 짝짓기하여 헤테로이량체를 형성한다.
이러한 측면의 특정 구현예에서, 헤테로이량체화 모듈은 제1 IgG1 CH2 도메인 및 제2 IgG1 CH2 도메인을 포함하고, 여기서 상기 제1 IgG1 CH2 도메인은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 제1 IgG1 CH3 도메인의 N-말단에 링커를 통해 연결되고 제2 IgG1 CH2 도메인은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 제2 IgG1 CH3 도메인의 N-말단에 링커를 통해 연결된다.
일부 구현예에서, 헤테로이량체화 모듈은 제1 Fab 포함 2 폴리펩타이드 쇄를 포함하고, 여기서 Fab의 2 폴리펩타이드 쇄 중 하나의 C-말단은 제1 힌지 영역의 N-말단에 연결되고, 여기서 제1 힌지 영역은 제1 IgG1 CH2 도메인의 N-말단에 연결된다.
다른 구현예에서, 헤테로이량체화 모듈은 제2 IgG1 CH2 도메인의 N-말단에 연결되는 제2 힌지 영역의 N-말단에 제1 IgG1 CH3 도메인의 C-말단을 연결시키는 링커를 포함한다. 특정 구현예에서, 헤테로이량체화 모듈은 제2 IgG1 CH2 도메인의 N-말단에 제2 힌지 영역을 통해 연결된 제2 Fab를 포함한다.
특정 구현예에서, 헤테로이량체화 모듈은 VH 도메인, CH1 도메인, VL 도메인, 및 CL 도메인을 포함한다. VH 도메인의 C-말단은 CH1 도메인의 N-말단에 연결되고, CH1 도메인의 C-말단은 제1 힌지 영역의 N-말단에 연결되고, 제1 힌지 영역의 C-말단은 제1 IgG1 CH3 도메인에 직접적으로 연결되는 제1 IgG1 CH2 도메인의 N-말단에 연결된다. VL 도메인의 C-말단은 CL 도메인의 N-말단에 연결되고, CL 도메인의 C-말단은 제2 힌지 영역의 N-말단에 연결되고, 제2 힌지 영역의 C-말단은 제2 IgG1 CH3 도메인에 직접적으로 연결되는 제2 IgG1 CH2 도메인의 N-말단에 연결된다. VH 도메인 및 VL 도메인은 짝짓기하여 항원에 특이적으로 결합하는 가변 영역을 형성한다.
특정 구현예에서, 헤테로이량체화 모듈은 제1 VH 및 제1 VL 및 제2 VH 및 제2 VL을 포함한다. 제1 VH 및 제1 VL은 짝짓기하여 제1 항원에 특이적으로 결합하는 제1 가변 영역을 형성한다. 제2 VH 및 제2 VL은 짝짓기하여 제1 항원의 상이한 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성한다. 일부 경우에서, 제1 VL의 아미노산 서열은 제2 VL의 아미노산 서열과 동일하다.
특정 구현예에서, 헤테로이량체화 모듈은 제1 IgG4 CH2 도메인 및 제2 IgG4 CH2 도메인을 포함하고, 여기서 제1 IgG4 CH2 도메인은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 제1 IgG1 CH3 도메인의 N-말단에 링커를 통해 연결되고 제2 IgG4 CH2 도메인은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 제2 IgG1 CH3 도메인의 N-말단에 링커를 통해 연결된다. 일부 경우에서, 헤테로이량체화 모듈은 제1 Fab 포함 2 폴리펩타이드 쇄를 포함하고, 여기서 Fab의 2 폴리펩타이드 쇄 중 하나의 C-말단은 제1 IgG4 힌지 영역의 N-말단에 연결되고, 여기서 제1 IgG4 힌지 영역은 제1 IgG4 CH2 도메인의 N-말단에 연결된다. 일부 경우에서, 제1 IgG4 힌지 영역은 S228P 돌연변이를 포함한다 (EU 넘버링). 일부 경우에서, 헤테로이량체화 모듈은 제2 IgG4 CH2 도메인의 N-말단에 연결되는 제2 IgG4 힌지 영역의 N-말단에 제1 IgG1 CH3 도메인의 C-말단을 연결시키는 링커를 포함한다. 특정 경우에서, 제2 IgG4 힌지 영역은 S228P 돌연변이를 포함한다 (EU 넘버링). 일부 경우에서, 헤테로이량체화 모듈은 제2 IgG4 CH2 도메인의 N-말단에 제2 IgG4 힌지 영역을 통해 연결된 제2 Fab를 포함한다. 특정 경우에서, 제2 IgG4 힌지 영역은 S228P 돌연변이를 포함한다 (EU 넘버링).
일부 구현예에서, 헤테로이량체화 모듈은 VH 도메인, CH1 도메인, VL 도메인, 및 CL 도메인을 포함한다. VH 도메인의 C-말단은 CH1 도메인의 N-말단에 연결되고, CH1 도메인의 C-말단은 제1 IgG4 힌지 영역의 N-말단에 연결되고, 제1 IgG4 힌지 영역의 C-말단은 제1 IgG1 CH3 도메인에 직접적으로 연결되는 제1 IgG4 CH2 도메인의 N-말단에 연결된다. VL 도메인의 C-말단은 CL 도메인의 N-말단에 연결되고, CL 도메인의 C-말단은 제2 IgG4 힌지 영역의 N-말단에 연결되고, 제2 IgG4 힌지 영역의 C-말단은 제2 IgG1 CH3 도메인에 직접적으로 연결되는 제2 IgG4 CH2 도메인의 N-말단에 연결된다. VH 도메인 및 VL 도메인은 짝짓기하여 항원에 특이적으로 결합하는 가변 영역을 형성한다. 일부 경우에서, 제1 IgG4 힌지 영역 및 제2 IgG4 힌지 영역은 각각 S228P 돌연변이를 포함한다 (EU 넘버링).
일부 구현예에서, 헤테로이량체화 모듈은 제1 VH 및 제1 VL 및 제2 VH 및 제2 VL을 포함한다. 제1 VH 및 제1 VL은 짝짓기하여 제1 항원에 특이적으로 결합하는 제1 가변 영역을 형성한다. 제2 VH 및 제2 VL은 짝짓기하여 제1 항원의 상이한 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성한다. 일부 경우에서, 제1 VL의 아미노산 서열은 제2 VL의 아미노산 서열과 동일하다.
특정 구현예에서, 본 개시내용은 상기-기재된 헤테로이량체화 모듈을 인코딩하는 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 특성화한다. 일부 경우에서, 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 포함하는 발현 벡터 또는 발현 벡터들은 특성화된다. 다른 경우에서, 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들 또는 발현 벡터 또는 벡터들을 포함하는 숙주 세포는 제공된다. 일부 경우에서, 헤테로이량체화 모듈의 생산 방법은 포괄된다. 상기 방법은 헤테로이량체화 모듈의 발현을 초래하는 조건하에 숙주 세포의 배양 및 이의 단리를 포함한다.
또 다른 측면에서, 본 개시내용은 제1 VH 및 제1 VL을 포함하는 이중특이적 항체를 제공하고, 여기서 상기 제1 VH 및 상기 제1 VL은 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성한다. 제1 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 E (IgE)의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결된다. 제1 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결된다. 제1 폴리펩타이드 및 제2 폴리펩타이드는 짝짓기하여 이량체를 형성한다. 이중특이적 항체는 또한 제2 VH 및 제2 VL을 포함하고, 여기서 상기 제2 VH 및 상기 제2 VL은 짝짓기하여 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성한다. 제2 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결된다. 제2 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결된다. CH1 도메인 및 CL 도메인은 짝짓기하여 이량체를 형성한다. 이중특이적 항체는 또한 서열 식별 번호:11에서 제시된 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제1 IgG1 CH3 도메인을 포함하는 헤테로이량체화 모듈을 포함하고, 여기서 위치 364 및 370에서 아미노산은 라이신이고 위치 409에서 아미노산은 세린이다. 헤테로이량체화 모듈은 또한 서열 식별 번호:11에서 제시된 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제2 IgG1 CH3 도메인을 포함하고, 여기서 위치 370에서 아미노산은 세린이고 위치 405 및 409에서 아미노산은 라이신이다. 아미노산 위치 모두는 EU 넘버링 시스템에 기반된다. (IgE CH2 도메인이 제1 IgG1 CH3 도메인 또는 제2 IgG1 CH3 도메인을 포함하는 폴리펩타이드의 일부일 수 있음을 언급하는 것이 중요하다. )
또 다른 측면에서, 본 개시내용은 제1 VH 및 제1 VL을 포함하는 이중특이적 항체를 제공하고, 여기서 상기 제1 VH 및 상기 제1 VL은 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성한다. 제1 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 E (IgE)의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결된다. 제1 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 CH2 도메인의 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결된다. 제1 폴리펩타이드 및 제2 폴리펩타이드는 짝짓기하여 이량체를 형성한다. 이중특이적 항체는 또한 제2 VH 및 제2 VL을 포함하고, 여기서 상기 제2 VH 및 상기 제2 VL은 짝짓기하여 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성한다. 제2 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결된다. 제2 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결된다. CH1 도메인 및 CL 도메인은 짝짓기하여 이량체를 형성한다. 이중특이적 항체는 또한 서열 식별 번호:11에서 제시된 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제1 IgG1 CH3 도메인을 포함하는 헤테로이량체화 모듈을 포함하고, 여기서 위치 364 및 370에서 아미노산은 라이신이고 위치 409에서 아미노산은 류신이다. 헤테로이량체화 모듈은 또한 서열 식별 번호:11에서 제시된 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제2 IgG1 CH3 도메인을 포함하고, 여기서 위치 370에서 아미노산은 세린이고, 위치 397에서 아미노산은 이소류신이고, 위치 405 및 409에서 아미노산은 라이신이다. 아미노산 위치 모두는 EU 넘버링 시스템에 기반된다. (IgE CH2 도메인이 제1 IgG1 CH3 도메인 또는 제2 IgG1 CH3 도메인을 포함하는 폴리펩타이드의 일부일 수 있음을 언급하는 것이 중요하다. )
상기 2 측면의 일부 구현예에서, 이중특이적 항체는 2 IgG1 CH2 도메인을 포함한다. 상기 2 측면의 일부 구현예에서, 이중특이적 항체는 2 IgG4 CH2 도메인을 포함한다. 일부 구현예에서, 단일 폴리펩타이드 쇄는 제1 VH, 제1 폴리펩타이드, 및 제1 IgG1 CH3 도메인을 포함한다. 일부 구현예에서, 단일 폴리펩타이드 쇄는 제1 VH, 제1 폴리펩타이드, 및 제2 IgG1 CH3 도메인을 포함한다. 다른 구현예에서, 단일 폴리펩타이드 쇄는 제1 VL, 제2 폴리펩타이드, 및 제1 IgG1 CH3 도메인을 포함한다. 더욱 다른 구현예에서, 단일 폴리펩타이드 쇄는 제1 VL, 제2 폴리펩타이드, 및 제2 IgG1 CH3 도메인을 포함한다. 일부 구현예에서, 제2 단일 폴리펩타이드 쇄는 제2 VH, CH1 도메인, 및 제2 IgG1 CH3 도메인을 포함한다. 일부 구현예에서, 제2 단일 폴리펩타이드 쇄는 제2 VH, CH1 도메인, 및 제1 IgG1 CH3 도메인을 포함한다. 일부 구현예에서, 제2 단일 폴리펩타이드 쇄는 제2 VL, CL 도메인, 및 제2 IgG1 CH3 도메인을 포함한다. 일부 구현예에서, 제2 단일 폴리펩타이드 쇄는 제2 VL, CL 도메인, 및 제1 IgG1 CH3 도메인을 포함한다. 일부 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:1에서 제시된 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:1에서 제시된 아미노산 서열의 아미노산 9-107에 적어도 90% 동일한 아미노산 서열을 포함한다. 다른 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:1에서 제시된 아미노산 서열의 아미노산 9-107을 포함한다. 다른 구현예에서, 제1 폴리펩타이드는 서열 식별 번호:5에서 제시된 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함한다. 다른 구현예에서, 제1 폴리펩타이드는 서열 식별 번호:5에서 제시된 아미노산 서열을 포함한다. 특정 구현예에서, 제2 폴리펩타이드는 서열 식별 번호:6에서 제시된 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 제2 폴리펩타이드는 서열 식별 번호:6에서 제시된 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 적어도 12 아미노산 잔기에서 서열 식별 번호:1에서 제시된 아미노산 서열과 상이하다. 일부 구현예에서, 제1 폴리펩타이드 및 제2 폴리펩타이드는 각각 쇄내 디설파이드 결합을 형성하지 않는 서열 식별 번호:1의 2 시스테인 잔기 중 적어도 하나에서 시스테인 이외 아미노산을 함유한다. 특정 구현예에서, 제1 폴리펩타이드 및 제2 폴리펩타이드는 N-연결된 당화 부위에서 돌연변이 또는 돌연변이들을 가져서 제1 폴리펩타이드 및 제2 폴리펩타이드는 N-연결된 당화 부위에서 당화되지 않는다. 다른 구현예에서, 제1 폴리펩타이드 또는 제2 폴리펩타이드는 N-연결된 당화 부위에서 돌연변이 또는 돌연변이들을 가져서 제1 폴리펩타이드 및 제2 폴리펩타이드는 N-연결된 당화 부위에서 당화되지 않는다. 이들 돌연변이는 다른 아미노산(들)에 대한 N-연결된 당화 부위의 트레오닌 또는 세린 혹은 아스파라긴의 것일 수 있다.
또 다른 측면에서, 본 개시내용은 제1 VH 및 제1 VL을 포함하는 이중특이적 항체를 제공하고, 여기서 상기 제1 VH 및 상기 제1 VL은 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성한다. 제1 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 M (IgM)의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결된다. 제1 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결된다. 제1 폴리펩타이드 및 제2 폴리펩타이드는 짝짓기하여 이량체를 형성한다. 이중특이적 항체는 또한 제2 VH 및 제2 VL을 포함하고, 여기서 상기 제2 VH 및 제2 VL은 짝짓기하여 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성한다. 제2 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결된다. 제2 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결되고, 여기서 상기 CH1 도메인 및 상기 CL 도메인은 짝짓기하여 이량체를 형성한다. 이중특이적 항체는 또한 하기를 포함하는 헤테로이량체화 모듈을 포함한다: 서열 식별 번호:11에서 제시된 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제1 IgG1 CH3 도메인, 여기서 위치 364 및 370에서 아미노산은 라이신이고 위치 409에서 아미노산은 세린임; 및 서열 식별 번호:11에서 제시된 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제2 IgG1 CH3 도메인, 여기서 위치 370에서 아미노산은 세린이고 위치 405 및 409에서 아미노산은 라이신임.상기 아미노산 위치는 EU 넘버링 시스템에 기반된다.
또 다른 측면에서, 본 개시내용은 제1 VH 및 제1 VL을 포함하는 이중특이적 항체에 관한 것이고, 여기서 상기 제1 VH 및 상기 제1 VL은 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성한다. 제1 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 M (IgM)의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결된다. 제1 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 CH2 도메인의 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결된다. 제1 폴리펩타이드 및 제2 폴리펩타이드는 짝짓기하여 이량체를 형성한다. 이중특이적 항체는 또한 제2 VH 및 제2 VL을 포함하고, 여기서 상기 제2 VH 및 제2 VL은 짝짓기하여 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성한다. 제2 VH는 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결된다. 제2 VL은 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결되고, 여기서 상기 CH1 도메인 및 상기 CL 도메인은 짝짓기하여 이량체를 형성한다. 이중특이적 항체는 또한 하기를 포함하는 헤테로이량체화 모듈을 포함한다: 서열 식별 번호:11에서 제시된 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제1 IgG1 CH3 도메인, 여기서 위치 364 및 370에서 아미노산은 라이신이고 위치 409에서 아미노산은 류신임; 및 서열 식별 번호:11에서 제시된 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제2 IgG1 CH3 도메인, 여기서 위치 370에서 아미노산은 세린이고, 위치 397에서 아미노산은 이소류신이고, 위치 405 및 409에서 아미노산은 라이신임.상기 아미노산 위치는 EU 넘버링 시스템에 기반된다.
상기 2 측면의 일부 구현예에서, 이중특이적 항체는 2 IgG1 CH2 도메인을 포함한다. 상기 2 측면의 일부 구현예에서, 이중특이적 항체는 2 IgG4 CH2 도메인을 포함한다. 일부 구현예에서, 단일 폴리펩타이드 쇄는 제1 VH 및 제1 IgG1 CH3 도메인을 포함한다. 일부 구현예에서, 단일 폴리펩타이드 쇄는 제1 VH 및 제2 IgG1 CH3 도메인을 포함한다. 다른 구현예에서, 단일 폴리펩타이드 쇄는 제1 VL 및 제1 IgG1 CH3 도메인을 포함한다. 더욱 다른 구현예에서, 단일 폴리펩타이드 쇄는 제1 VL 및 제2 IgG1 CH3 도메인을 포함한다. 일부 구현예에서, 단일 폴리펩타이드 쇄는 제2 VH 및 제2 IgG1 CH3 도메인을 포함한다. 일부 구현예에서, 단일 폴리펩타이드 쇄는 제2 VH 및 제1 IgG1 CH3 도메인을 포함한다. 일부 구현예에서, 단일 폴리펩타이드 쇄는 제2 VH 및 제2 IgG1 CH3 도메인을 포함한다. 일부 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:2에서 제시된 아미노산 서열을 포함한다. 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:2에서 제시된 아미노산 서열의 아미노산 7-112에 적어도 90% 동일한 아미노산 서열을 포함한다. 다른 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 서열 식별 번호:2에서 제시된 아미노산 서열의 아미노산 7-112를 포함한다. 특정 구현예에서, 제1 폴리펩타이드 및/또는 제2 폴리펩타이드는 적어도 12 아미노산 잔기에서 서열 식별 번호:2에서 제시된 아미노산 서열과 상이하다. 일부 구현예에서, 제1 폴리펩타이드 및 제2 폴리펩타이드는 각각 쇄내 디설파이드 결합을 형성하지 않는 서열 식별 번호:2의 시스테인 잔기에서 시스테인 이외 아미노산을 함유한다. 특정 구현예에서, 제1 폴리펩타이드 및 제2 폴리펩타이드는 N-연결된 당화 부위에서 돌연변이 또는 돌연변이들을 가져서 제1 폴리펩타이드 및 제2 폴리펩타이드는 N-연결된 당화 부위에서 당화되지 않는다. 다른 구현예에서, 제1 폴리펩타이드 또는 제2 폴리펩타이드는 N-연결된 당화 부위에서 돌연변이 또는 돌연변이들을 가져서 제1 폴리펩타이드 및 제2 폴리펩타이드는 N-연결된 당화 부위에서 당화되지 않는다. 이들 돌연변이는 다른 아미노산(들)에 대한 N-연결된 당화 부위의 트레오닌 또는 세린 혹은 아스파라긴의 것일 수 있다. 특정 구현예에서, 본 개시내용은 상기 기재된 이중특이적 항체를 인코딩하는 폴리뉴클레오타이드 또는 폴리뉴클레오타이드들을 제공한다. 일부 구현예에서, 상기 기재된 이중특이적 항체를 포함하는 발현 벡터는 제공된다. 다른 구현예에서, 이중특이적 항체를 포함하는 숙주 세포 또는 발현 벡터는 제공된다. 더욱 다른 구현예에서, 이중특이적 항체의 발현을 초래하는 조건하에 상기 기재된 숙주 세포의 배양 및 세포 배양액으로부터 이중특이적 항체의 단리를 포함하는 이중특이적 항체의 제조 방법은 제공된다. 특정 구현예에서, 단리된 이중특이적 항체는 필요로 하는 인간 대상체에 투여용 멸균 조성물로서 제형화된다.
달리 정의되지 않는 한, 본 명세서에서 사용된 모든 기술 및 과학 용어들은 본 발명이 속하는 당해 분야의 숙련가에 의해 통상적으로 이해되는 바와 동일한 의미를 갖는다. 본 명세서에서 기재된 것과 유사한 또는 동등한 방법 및 물질이 본 발명의 실시 또는 시험에서 사용될 수 있어도, 예시적인 방법 및 물질은 아래에 기재되어 있다. 모든 공보, 특허 출원, 특허, 및 본 명세서에서 언급된 다른 참고문헌은 그들의 전체가 참고로 편입된다. 상충의 경우에, 정의를 포함하여, 본원은 제어할 것이다. 물질, 방법, 및 예는 설명적일뿐이고 제한되는 의도는 아니다.
본 발명의 다른 특성 및 이점은 다음과 같은 상세한 설명으로부터, 그리고 청구범위로부터 분명할 것이다.
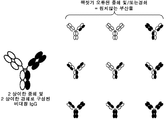
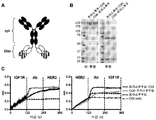
도 1은 비대칭 항체에서 짝짓기오류로부터 원치않는 부산물의 도식적 표현이다. 상기 도는 2 항체가 공-발현되는 경우 몇 개의 원치않는 부산물이 경쇄 및/또는 중쇄의 짝짓기오류에 의해 형성할 수 있다는 것을 보여준다. 원하는 비대칭 항체는 소수의 분획을 나타낼 수 있고, 그 원하는 항체의 정제는 어려움을 나타낼 수 있다.
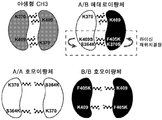
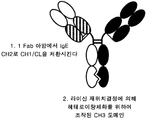
도 2는 라이신 재위치결정에 의한 CH3 헤테로이량체화의 도식적 표현이다. 라이신 370 및 라이신 409는 인간 IgG1의 야생형 CH3 도메인의 정상 헤드-투-테일 호모이량체에서 적층된다. 단량체 A내 돌연변이 S364K/K409S 및 단량체 B내 K370S/F405K는 라이신에서 적층된 것의 배향을 반전시켜, A/B 헤테로이량체의 형성을 가능하게 하지만 호모이량체에서 충돌을 초래한다 (최하부). 따라서, 라이신 재위치결정은 중쇄 헤테로이량체화에 효과적인 전략을 제공한다. 상기 지칭된 아미노산 위치는 EU 넘버링에 기반된다.
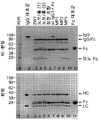
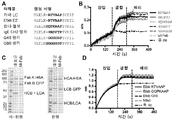
도 3A는 IgG/Fc 헤테로이량체의 SDS-PAGE 분석의 도시이다. 단백질 A-정제된 헤테로이량체의 분취액은 SDS 페이지에 의해 분석되었다. IgG1과 Fc 사이 헤테로이량체는 우세한 종이다. 2 분획의 노브-인투-홀은 장입되었다. 절반-설계 MP1은 다량의 헤테로이량체를 보여주지만, Fc 이량체의 형성을 예방하는 돌연변이가 부족하고 따라서 Fc 단량체를 함유하지 않는다.
도 3B는 LC-MS로부터 추정된 성분의 상대량 및 몰비를 보여주는 막대 그래프이다.
도 3C는 DSC에 의해 결정된 정제된 헤테로이량체의 용융 온도의 도시이다.
도 4A는 헤테로이량체화 돌연변이체의 발현 및 절반-항체 형성을 보여준다. CHO 세포는, 동일한 Fab (M60-A02 항 EGFR)을 함유하는, mp4a 및 mp4b 중쇄의 다양한 비로 형질감염되었다. 발현된 단백질에서 절반-항체 형성은 SDS PAGE에 의해 분석되었다
도 4B는 절반-항체 형성을 정량화하는데 사용된 일련의 질량 스펙트럼을 보여준다. 샘플의 MS 스펙트럼은 헤테로이량체의 최대 양을 보여주었고 최소 호모이량체는 형질감염 비 1:1로 있다.
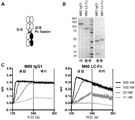
도 5A는, E-fab의 창출인, 경쇄 짝짓기 문제에 대한 적용 해결책 중 하나의 도식적 표현이다. E-fab에서, CH1 및 CL 도메인은, 천연 이량체를 형성하는, IgE CH2 (Cε2) 도메인에 의해 치환된다.
도 5B는 Ig-폴드의 전반적인 유사성을 보여주는 인간 Cε2 도메인 (백색) 및 인간 IgG1 CH1/카파 불변 도메인 (흑색)의 구조의 중첩이다. Cε2 도메인은 상이한 각에서 그리고 계면의 상부에서 더 큰 거리로, 하위 계면에서 더욱 밀착 팩킹으로 짝짓기한다. (구형체로서 표시되는) β-가닥 A의 시작에서 Pro는 CH1/CL 및 Cε2 도메인에서 매우 유사한 위치 및 배향이다.
도 5C는 Cε2 도메인 및 E-Fab 중쇄 및 경쇄를 가진 인간 IgG1 CH1 및 카파 상수의 서열 정렬이다. 서열은 상기 나타낸 IMGT 넘버링으로 정렬되고, Ig-폴드의 7 β-가닥은 화살표로 표시되고, β-가닥 A의 시작에서 보존된 Pro는 볼드체이고 밑줄쳐진다. E-Fabs 및 쇄간 디설파이드 시스테인에서 agly 돌연변이 (N38Q)는 볼드체이고 밑줄쳐진다.
도 5D는 인간, 침팬지, 마우스, 랫트, 및 토끼로부터 IgE CH2 도메인의 서열 정렬이다. 동일한 잔기는 점으로 보여진다.
도 6A는 경쇄 짝짓기를 시험하는 전략의 도식적 표현이다. Fab A (HCA)의 중쇄는 HSA에 융합되고, 한편 Fab B (LCB)의 경쇄는 GFP로 N-말단에서 태깅되었다. 쇄의 올바른 짝짓기는 Fabs의 분자량에 의해 체크될 수 있다.
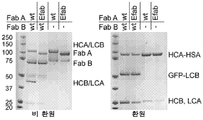
도 6B는 SDS-page에 의한 Fab-짝짓기의 분석이다. 표시된 HSA-태깅된 항- EGFR M60-A02 Fabs 또는 E-Fabs는 GFP-태깅된 Fab 항-IGF-1R C06으로 공-발현되었다 (참조 또한, 표 3). 중쇄 및 경쇄의 올바른 짝짓기는 비-환원 조건하에 114 및 74 kDa에서 밴드를 생산하고, 한편 47 또는 140 kDa에서 밴드는 짝짓기오류를 표시한다.
도 6C는 SDS-page에 의한 Fab-짝짓기의 분석이다. 항-IGF-1R Fab C06은 E-fab로서 빌딩되었고 또 다른 항-IGF-1R Fab (G11)로 경쇄 짝짓기는 도 6B에서처럼 시험되었다.
도 6D는 Octet에 의해 시험된 바와 같이 항-IGF-1R E-Fab의 빌딩을 도시하는 그래프이다. Fabs는 개별적으로 발현되었고, 단백질 A 스핀 칼럼에서 정제되었고, His-tips상에 장입된 가용성 IGF1-R에 Octet 결합 (300 nM, 100 nM, 및 30 nM)에서 사용되었다.
도 7은 E-Fab 및 라이신 재위치결정을 가진 비대칭 IgG의 도식적 표현이다. 하나의 Fab 아암의 불변 도메인은 E-Fab로 대체되고, 한편 다른 Fab 아암은 경쇄 짝짓기 문제를 해결하기 위해 야생형 IgG CH1/CL 도메인을 함유한다. 라이신 재위치결정 돌연변이는 2 중쇄의 CH3 도메인에서 포함되어 헤테로이량체화를 시행한다.
도 8A는 SDS-PAGE에 의한 상청액 및 CHO-S 세포에서 발현된 EGFR/IGF-1R 이중특이적 항체의 분석이다. E-바디 E0 및 E2는 E-Fab로서 항-EGFR을 함유하고, 한편 IgG1-헤테로이량체 대조군은 경쇄 용액을 함유하지 않는다.
도 8B는 E-바디에서 경쇄 짝짓기오류는 없지만 대조군에서 짝짓기오류된 LC를 가진 항체의 상당한 양을 보여주는 도 8A로부터 비대칭 IgGs의 질량 분광분석법 분석의 표현이다. 중쇄 호모이량체는 어느 한쪽 샘플에서 검출불가능하였다.
도 8C는 His-태깅된 EGFR에 이중특이적 항체의 결합을 도시하는 그래프이다. CHO-S 세포로부터 희석되지 않은 상청액은 his-태깅된 리간드 (5 μg/mL)의 장입후 Octet 결합에서 사용되었다.
도 8D는 His-태깅된 IGF-1R에 이중특이적 항체의 결합을 도시하는 그래프이다. CHO-S 세포로부터 희석되지 않은 상청액은 his-태깅된 리간드 (5 μg/mL)의 장입후 Octet 결합에서 사용되었다.
도 9A는 트라스투주맙/세툭시맙 이중특이적 항체에 의한 2 항원의 동시 결합을 도시하는 그래프이다. His-태깅된 가용성 HER2 (5 μg/ml)는 다음 단계에서 이중특이적 항체 (200 nM)의 포착을 허용하는 Octet 팁상에 장입되었다. EGFR (15 μg/ml)의 후속적인 결합은 이중특이성에 의한 양쪽 리간드의 동시 결합을 입증한다.
도 9B는 도 9A에서 보여진 실험의 반전의 결과를 도시하는 그래프이다. EGFR은 먼저 장입되었고, 이어서 이중특이적 항체 및 HER2이 결합되었다.
도 10A는 다양한 엘보 링커 서열을 가진 Efab 작제물을 보여준다. 항-HER2 항체 트라스투주맙은 Efab로서 조작되었다. 경쇄에서 포함된 다양한 엘보 링커 서열은 표에서 열거된다. 상기 서열은 가변 도메인의 마지막 5 아미노산 뿐만 아니라 엘보 서열 (볼드체)에 더하여 IgE CH2 도메인의 최초 5 아미노산을 포함한다.
도 10B는 Octet 결합 연구의 그래프이다. 상기 Efabs는 (도 9에서처럼) CHO 세포에서 세툭시맙을 가진 비대칭 IgG로서 표현되었고, 정제되었고 항-His 팁상에 장입된 His-태깅된 HER2 (5 μg/ml)로 Octet 결합 연구 (100 nM)에서 사용되었다.
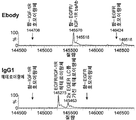
도 10C는 SDS-page에 의한 Fab-짝짓기의 분석이다. IgM CH2 도메인이 IgE CH2 도메인과 똑같이 양호하게 경쇄 짝짓기를 해결할 수 있는지를 평가하기 위해, 2 Fabs (항-EGFR M60 및 항-IGF-1R C06)은 공-발현되었다:HSA에 융합된 하나의 Fab 및 GFP에 융합된 또 다른 Fab로.Fab의 카파 및 CH1 불변 도메인은 IgM CH2 도메인으로 대체되었다 (수득한 분자는 M-Fab로 명명되었다). SDS-PAGE에 의한 쇄 짝짓기의 분석은 M-Fab가 대조군에서 두드러지게 관측된 M60과 C06 사이 경쇄 짝짓기오류를 해결하였다는 것을 보여주었다.
도 10D는 Octet 결합 연구의 그래프이다. Efabs 및 M-Fab는 (Fc 없이) Fabs로서 CHO-S에서 발현되었고, 상청액은 Octet에 의해 HER2에 결합 시험용으로 사용되었다.
도 11A는 CHO 세포에서 발현된 및 단백질 A에 의해 정제된 mp3 헤테로이량체 돌연변이를 함유하는 IgG1 agly (T299A) 불변 영역을 가진 정상 Fab로서 항-EGFR M60-A02 Efab 및 항-IGF1R M13.C06을 포함하는 이중특이적 항체의 겔의 사진을 보여준다.
도 11B는 이중특이성이 동시 결합에 시험된 Octet 연구의 결과를 보여준다. 상위 패널에서, His-태깅된 가용성 IGF1R (5 μg/ml)은 Octet 팁에 결합되었고, 이어서 이중특이적 항체 또는 각각의 mAbs이 결합되었다. 제3 단계에서 제2 항원 (EGFR)은 표시된 바와 같이 항체-항원 복합체에 결합되었다. 제3 단계에서 무 EGFR 대조군에 비교된 양성 신호는 동시 결합을 입증한다. 하위 패널에서, His-태깅된 가용성 EGFR (5 μg/ml)는 Octet 팁에 결합되었고, 이어서 이중특이적 항체 또는 각각의 mAbs가 결합되었다. 제3 단계에서 제2 항원 (IGF1R)은 표시된 바와 같이 항체-항원 복합체에 결합되었다. 제3 단계에서 무 IGF1R 대조군에 비교된 양성 신호는 동시 결합을 입증한다.
도 12A는 mp4 헤테로이량체를 함유하는 IgG4P/IgG1 불변 영역 및 Efab를 가진 이중특이적 항체의 개략도이다. 항체는 또한 불변 도메인 (IgG4P/IgG1 agly)에서 N297Q 치환을 포함한다.
도 12B는, 항상 먼저 명명된 항체가 Efab인, 양쪽 배향에서 항-IGF1R 항체 C06 및 항-HER2 항체 페르투주맙으로 생성되었던 (A)에서 나타낸 바와 같이 이중특이적 항체의 겔의 사진이다. CHO 세포로부터 단백질-A-정제된 물질의 분취액은 SDS-PAGE에 의해 분석되었다.
도 12C는 가용성 IGF1R 및 HER2 단백질을 이용하여 Octet에 의해 시험된 경우 결합의 결과를 보여준다. 상위 패널에서, His-태깅된 가용성 IGF1R (5 μg/ml)은 Octet 팁에 결합되었고, 이어서 이중특이적 항체 또는 각각의 mAbs이 결합되었다. 제3 단계에서 제2 항원 (HER2)는 표시된 바와 같이 항체-항원 복합체에 결합되었다. 제3 단계에서 무 HER2 대조군에 비교된 양성 신호는 동시 결합을 입증한다. 하위 패널에서, His-태깅된 가용성 HER2 (5 μg/ml)는 Octet 팁에 결합되었고, 이어서 이중특이적 항체 또는 각각의 mAbs가 결합되었다. 제3 단계에서 제2 항원 (IGF1R)은 표시된 바와 같이 항체-항원 복합체에 결합되었다. 제3 단계에서 무 IGF1R 대조군에 비교된 양성 신호는 동시 결합을 입증한다.
도 13A는 중쇄의 C-말단에 융합된 Efab를 가진 IgG (“Mab-Fab”)의 개략도이다.
도 13B는 트라스투주맙 및 항-IGF-1R 항체 C06의 Mab-Fabs의 겔의 사진이다. 트라스투주맙 및 항-IGF-1R 항체 C06의 Mab-Fabs는 CHO 세포에서 일시적으로 발현되었고 단백질 A에 의해 정제되었다. SDS-PAGE는 단백질이 ~240 kDa Mab-Fabs 형성을 정확하게 조립하였다는 것을 보여준다.
도 13C는 Octet에 의해 시험된 경우 결합의 결과를 보여준다. His-태깅된 가용성 IGF1R 또는 HER2 (5 μg/ml)는 다음 단계에서 이중특이적 항체 (200 nM)의 포착을 허용하는 Octet 팁상에 장입되었다. 제2 리간드 (15 μg/ml)의 후속적인 결합은 이중특이적 항체에 의한 양쪽 리간드의 동시 결합을 입증한다.
도 14A는 LC-Fc 융합 및 Fc 헤테로이량체 돌연변이를 함유하는 1가 항체의 개략도이다.
도 14B는 CHO 세포로부터 생산된 LC-Fc 1가 항체 및 상응하는 2가 IgG1 (항-EGFR M60-A02)를 가진 겔의 사진이다. 단백질-A 정제된 물질의 SDS-PAGE는 1가 LC-Fc 항체의 깨끗한 어셈블리를 보여준다.
도 14C는 다양한 농도로 Octet 결합 연구에서 1가 LC-Fc 및 2가 IgG를 도시하는 그래프이다. 1가 LC-Fc는 열렬한 결합이 부족하고 항원-항체 복합체의 해리는 보여진다.
도 15A는 HAS (좌) 펩타이드 링커 (우)를 통해 규칙적 Fab에 연결된 Efab를 가진 이중특이적 항체의 개략도를 제공한다.
도 15B는 CHO 세포에서 발현되었고, 단백질 A-정제되었고, SDS-PAGE에 의해 분석되었던 도 15A에서 나타낸 바와 같이 이중특이성의 2 예의 겔의 사진이다. 항-EGFR 및 항 IGF1R 항체 M60-A02 및 M13.C06은, Efab 또는 규칙적 Fab으로서, 각각 양쪽 배향에서 사용되었다.
도 15C는 Octet 결합 연구에서 사용된 정제된 이중특이성의 그래프이다. 이들 이중특이성에 의한 양쪽 항원의 동시 결합은 이중특이성이 먼저 EGFR에 결합되었고 이어서 IGF-1R 결합된 경우만 관측되었다.
도 15D는 Octet 결합 연구에서 사용된 정제된 이중특이성의 그래프이다. 이들 이중특이성에 의해 양쪽 항원의 동시 결합은 이중특이성이 먼저 IGF-1R에 결합되었고 이어서 EGFR이 결합된 경우 관측되지 않았다.
도 2는 라이신 재위치결정에 의한 CH3 헤테로이량체화의 도식적 표현이다. 라이신 370 및 라이신 409는 인간 IgG1의 야생형 CH3 도메인의 정상 헤드-투-테일 호모이량체에서 적층된다. 단량체 A내 돌연변이 S364K/K409S 및 단량체 B내 K370S/F405K는 라이신에서 적층된 것의 배향을 반전시켜, A/B 헤테로이량체의 형성을 가능하게 하지만 호모이량체에서 충돌을 초래한다 (최하부). 따라서, 라이신 재위치결정은 중쇄 헤테로이량체화에 효과적인 전략을 제공한다. 상기 지칭된 아미노산 위치는 EU 넘버링에 기반된다.
도 3A는 IgG/Fc 헤테로이량체의 SDS-PAGE 분석의 도시이다. 단백질 A-정제된 헤테로이량체의 분취액은 SDS 페이지에 의해 분석되었다. IgG1과 Fc 사이 헤테로이량체는 우세한 종이다. 2 분획의 노브-인투-홀은 장입되었다. 절반-설계 MP1은 다량의 헤테로이량체를 보여주지만, Fc 이량체의 형성을 예방하는 돌연변이가 부족하고 따라서 Fc 단량체를 함유하지 않는다.
도 3B는 LC-MS로부터 추정된 성분의 상대량 및 몰비를 보여주는 막대 그래프이다.
도 3C는 DSC에 의해 결정된 정제된 헤테로이량체의 용융 온도의 도시이다.
도 4A는 헤테로이량체화 돌연변이체의 발현 및 절반-항체 형성을 보여준다. CHO 세포는, 동일한 Fab (M60-A02 항 EGFR)을 함유하는, mp4a 및 mp4b 중쇄의 다양한 비로 형질감염되었다. 발현된 단백질에서 절반-항체 형성은 SDS PAGE에 의해 분석되었다
도 4B는 절반-항체 형성을 정량화하는데 사용된 일련의 질량 스펙트럼을 보여준다. 샘플의 MS 스펙트럼은 헤테로이량체의 최대 양을 보여주었고 최소 호모이량체는 형질감염 비 1:1로 있다.
도 5A는, E-fab의 창출인, 경쇄 짝짓기 문제에 대한 적용 해결책 중 하나의 도식적 표현이다. E-fab에서, CH1 및 CL 도메인은, 천연 이량체를 형성하는, IgE CH2 (Cε2) 도메인에 의해 치환된다.
도 5B는 Ig-폴드의 전반적인 유사성을 보여주는 인간 Cε2 도메인 (백색) 및 인간 IgG1 CH1/카파 불변 도메인 (흑색)의 구조의 중첩이다. Cε2 도메인은 상이한 각에서 그리고 계면의 상부에서 더 큰 거리로, 하위 계면에서 더욱 밀착 팩킹으로 짝짓기한다. (구형체로서 표시되는) β-가닥 A의 시작에서 Pro는 CH1/CL 및 Cε2 도메인에서 매우 유사한 위치 및 배향이다.
도 5C는 Cε2 도메인 및 E-Fab 중쇄 및 경쇄를 가진 인간 IgG1 CH1 및 카파 상수의 서열 정렬이다. 서열은 상기 나타낸 IMGT 넘버링으로 정렬되고, Ig-폴드의 7 β-가닥은 화살표로 표시되고, β-가닥 A의 시작에서 보존된 Pro는 볼드체이고 밑줄쳐진다. E-Fabs 및 쇄간 디설파이드 시스테인에서 agly 돌연변이 (N38Q)는 볼드체이고 밑줄쳐진다.
도 5D는 인간, 침팬지, 마우스, 랫트, 및 토끼로부터 IgE CH2 도메인의 서열 정렬이다. 동일한 잔기는 점으로 보여진다.
도 6A는 경쇄 짝짓기를 시험하는 전략의 도식적 표현이다. Fab A (HCA)의 중쇄는 HSA에 융합되고, 한편 Fab B (LCB)의 경쇄는 GFP로 N-말단에서 태깅되었다. 쇄의 올바른 짝짓기는 Fabs의 분자량에 의해 체크될 수 있다.
도 6B는 SDS-page에 의한 Fab-짝짓기의 분석이다. 표시된 HSA-태깅된 항- EGFR M60-A02 Fabs 또는 E-Fabs는 GFP-태깅된 Fab 항-IGF-1R C06으로 공-발현되었다 (참조 또한, 표 3). 중쇄 및 경쇄의 올바른 짝짓기는 비-환원 조건하에 114 및 74 kDa에서 밴드를 생산하고, 한편 47 또는 140 kDa에서 밴드는 짝짓기오류를 표시한다.
도 6C는 SDS-page에 의한 Fab-짝짓기의 분석이다. 항-IGF-1R Fab C06은 E-fab로서 빌딩되었고 또 다른 항-IGF-1R Fab (G11)로 경쇄 짝짓기는 도 6B에서처럼 시험되었다.
도 6D는 Octet에 의해 시험된 바와 같이 항-IGF-1R E-Fab의 빌딩을 도시하는 그래프이다. Fabs는 개별적으로 발현되었고, 단백질 A 스핀 칼럼에서 정제되었고, His-tips상에 장입된 가용성 IGF1-R에 Octet 결합 (300 nM, 100 nM, 및 30 nM)에서 사용되었다.
도 7은 E-Fab 및 라이신 재위치결정을 가진 비대칭 IgG의 도식적 표현이다. 하나의 Fab 아암의 불변 도메인은 E-Fab로 대체되고, 한편 다른 Fab 아암은 경쇄 짝짓기 문제를 해결하기 위해 야생형 IgG CH1/CL 도메인을 함유한다. 라이신 재위치결정 돌연변이는 2 중쇄의 CH3 도메인에서 포함되어 헤테로이량체화를 시행한다.
도 8A는 SDS-PAGE에 의한 상청액 및 CHO-S 세포에서 발현된 EGFR/IGF-1R 이중특이적 항체의 분석이다. E-바디 E0 및 E2는 E-Fab로서 항-EGFR을 함유하고, 한편 IgG1-헤테로이량체 대조군은 경쇄 용액을 함유하지 않는다.
도 8B는 E-바디에서 경쇄 짝짓기오류는 없지만 대조군에서 짝짓기오류된 LC를 가진 항체의 상당한 양을 보여주는 도 8A로부터 비대칭 IgGs의 질량 분광분석법 분석의 표현이다. 중쇄 호모이량체는 어느 한쪽 샘플에서 검출불가능하였다.
도 8C는 His-태깅된 EGFR에 이중특이적 항체의 결합을 도시하는 그래프이다. CHO-S 세포로부터 희석되지 않은 상청액은 his-태깅된 리간드 (5 μg/mL)의 장입후 Octet 결합에서 사용되었다.
도 8D는 His-태깅된 IGF-1R에 이중특이적 항체의 결합을 도시하는 그래프이다. CHO-S 세포로부터 희석되지 않은 상청액은 his-태깅된 리간드 (5 μg/mL)의 장입후 Octet 결합에서 사용되었다.
도 9A는 트라스투주맙/세툭시맙 이중특이적 항체에 의한 2 항원의 동시 결합을 도시하는 그래프이다. His-태깅된 가용성 HER2 (5 μg/ml)는 다음 단계에서 이중특이적 항체 (200 nM)의 포착을 허용하는 Octet 팁상에 장입되었다. EGFR (15 μg/ml)의 후속적인 결합은 이중특이성에 의한 양쪽 리간드의 동시 결합을 입증한다.
도 9B는 도 9A에서 보여진 실험의 반전의 결과를 도시하는 그래프이다. EGFR은 먼저 장입되었고, 이어서 이중특이적 항체 및 HER2이 결합되었다.
도 10A는 다양한 엘보 링커 서열을 가진 Efab 작제물을 보여준다. 항-HER2 항체 트라스투주맙은 Efab로서 조작되었다. 경쇄에서 포함된 다양한 엘보 링커 서열은 표에서 열거된다. 상기 서열은 가변 도메인의 마지막 5 아미노산 뿐만 아니라 엘보 서열 (볼드체)에 더하여 IgE CH2 도메인의 최초 5 아미노산을 포함한다.
도 10B는 Octet 결합 연구의 그래프이다. 상기 Efabs는 (도 9에서처럼) CHO 세포에서 세툭시맙을 가진 비대칭 IgG로서 표현되었고, 정제되었고 항-His 팁상에 장입된 His-태깅된 HER2 (5 μg/ml)로 Octet 결합 연구 (100 nM)에서 사용되었다.
도 10C는 SDS-page에 의한 Fab-짝짓기의 분석이다. IgM CH2 도메인이 IgE CH2 도메인과 똑같이 양호하게 경쇄 짝짓기를 해결할 수 있는지를 평가하기 위해, 2 Fabs (항-EGFR M60 및 항-IGF-1R C06)은 공-발현되었다:HSA에 융합된 하나의 Fab 및 GFP에 융합된 또 다른 Fab로.Fab의 카파 및 CH1 불변 도메인은 IgM CH2 도메인으로 대체되었다 (수득한 분자는 M-Fab로 명명되었다). SDS-PAGE에 의한 쇄 짝짓기의 분석은 M-Fab가 대조군에서 두드러지게 관측된 M60과 C06 사이 경쇄 짝짓기오류를 해결하였다는 것을 보여주었다.
도 10D는 Octet 결합 연구의 그래프이다. Efabs 및 M-Fab는 (Fc 없이) Fabs로서 CHO-S에서 발현되었고, 상청액은 Octet에 의해 HER2에 결합 시험용으로 사용되었다.
도 11A는 CHO 세포에서 발현된 및 단백질 A에 의해 정제된 mp3 헤테로이량체 돌연변이를 함유하는 IgG1 agly (T299A) 불변 영역을 가진 정상 Fab로서 항-EGFR M60-A02 Efab 및 항-IGF1R M13.C06을 포함하는 이중특이적 항체의 겔의 사진을 보여준다.
도 11B는 이중특이성이 동시 결합에 시험된 Octet 연구의 결과를 보여준다. 상위 패널에서, His-태깅된 가용성 IGF1R (5 μg/ml)은 Octet 팁에 결합되었고, 이어서 이중특이적 항체 또는 각각의 mAbs이 결합되었다. 제3 단계에서 제2 항원 (EGFR)은 표시된 바와 같이 항체-항원 복합체에 결합되었다. 제3 단계에서 무 EGFR 대조군에 비교된 양성 신호는 동시 결합을 입증한다. 하위 패널에서, His-태깅된 가용성 EGFR (5 μg/ml)는 Octet 팁에 결합되었고, 이어서 이중특이적 항체 또는 각각의 mAbs가 결합되었다. 제3 단계에서 제2 항원 (IGF1R)은 표시된 바와 같이 항체-항원 복합체에 결합되었다. 제3 단계에서 무 IGF1R 대조군에 비교된 양성 신호는 동시 결합을 입증한다.
도 12A는 mp4 헤테로이량체를 함유하는 IgG4P/IgG1 불변 영역 및 Efab를 가진 이중특이적 항체의 개략도이다. 항체는 또한 불변 도메인 (IgG4P/IgG1 agly)에서 N297Q 치환을 포함한다.
도 12B는, 항상 먼저 명명된 항체가 Efab인, 양쪽 배향에서 항-IGF1R 항체 C06 및 항-HER2 항체 페르투주맙으로 생성되었던 (A)에서 나타낸 바와 같이 이중특이적 항체의 겔의 사진이다. CHO 세포로부터 단백질-A-정제된 물질의 분취액은 SDS-PAGE에 의해 분석되었다.
도 12C는 가용성 IGF1R 및 HER2 단백질을 이용하여 Octet에 의해 시험된 경우 결합의 결과를 보여준다. 상위 패널에서, His-태깅된 가용성 IGF1R (5 μg/ml)은 Octet 팁에 결합되었고, 이어서 이중특이적 항체 또는 각각의 mAbs이 결합되었다. 제3 단계에서 제2 항원 (HER2)는 표시된 바와 같이 항체-항원 복합체에 결합되었다. 제3 단계에서 무 HER2 대조군에 비교된 양성 신호는 동시 결합을 입증한다. 하위 패널에서, His-태깅된 가용성 HER2 (5 μg/ml)는 Octet 팁에 결합되었고, 이어서 이중특이적 항체 또는 각각의 mAbs가 결합되었다. 제3 단계에서 제2 항원 (IGF1R)은 표시된 바와 같이 항체-항원 복합체에 결합되었다. 제3 단계에서 무 IGF1R 대조군에 비교된 양성 신호는 동시 결합을 입증한다.
도 13A는 중쇄의 C-말단에 융합된 Efab를 가진 IgG (“Mab-Fab”)의 개략도이다.
도 13B는 트라스투주맙 및 항-IGF-1R 항체 C06의 Mab-Fabs의 겔의 사진이다. 트라스투주맙 및 항-IGF-1R 항체 C06의 Mab-Fabs는 CHO 세포에서 일시적으로 발현되었고 단백질 A에 의해 정제되었다. SDS-PAGE는 단백질이 ~240 kDa Mab-Fabs 형성을 정확하게 조립하였다는 것을 보여준다.
도 13C는 Octet에 의해 시험된 경우 결합의 결과를 보여준다. His-태깅된 가용성 IGF1R 또는 HER2 (5 μg/ml)는 다음 단계에서 이중특이적 항체 (200 nM)의 포착을 허용하는 Octet 팁상에 장입되었다. 제2 리간드 (15 μg/ml)의 후속적인 결합은 이중특이적 항체에 의한 양쪽 리간드의 동시 결합을 입증한다.
도 14A는 LC-Fc 융합 및 Fc 헤테로이량체 돌연변이를 함유하는 1가 항체의 개략도이다.
도 14B는 CHO 세포로부터 생산된 LC-Fc 1가 항체 및 상응하는 2가 IgG1 (항-EGFR M60-A02)를 가진 겔의 사진이다. 단백질-A 정제된 물질의 SDS-PAGE는 1가 LC-Fc 항체의 깨끗한 어셈블리를 보여준다.
도 14C는 다양한 농도로 Octet 결합 연구에서 1가 LC-Fc 및 2가 IgG를 도시하는 그래프이다. 1가 LC-Fc는 열렬한 결합이 부족하고 항원-항체 복합체의 해리는 보여진다.
도 15A는 HAS (좌) 펩타이드 링커 (우)를 통해 규칙적 Fab에 연결된 Efab를 가진 이중특이적 항체의 개략도를 제공한다.
도 15B는 CHO 세포에서 발현되었고, 단백질 A-정제되었고, SDS-PAGE에 의해 분석되었던 도 15A에서 나타낸 바와 같이 이중특이성의 2 예의 겔의 사진이다. 항-EGFR 및 항 IGF1R 항체 M60-A02 및 M13.C06은, Efab 또는 규칙적 Fab으로서, 각각 양쪽 배향에서 사용되었다.
도 15C는 Octet 결합 연구에서 사용된 정제된 이중특이성의 그래프이다. 이들 이중특이성에 의한 양쪽 항원의 동시 결합은 이중특이성이 먼저 EGFR에 결합되었고 이어서 IGF-1R 결합된 경우만 관측되었다.
도 15D는 Octet 결합 연구에서 사용된 정제된 이중특이성의 그래프이다. 이들 이중특이성에 의해 양쪽 항원의 동시 결합은 이중특이성이 먼저 IGF-1R에 결합되었고 이어서 EGFR이 결합된 경우 관측되지 않았다.
이중특이적 항체는 신규한 치료 작용 기전 달성의 잠재력을 보유하는 생물제제 약물의 신흥 부류이다. 그러나, 이중특이적 항체의 발현 및 적절하게 형성과 관련된 몇 개의 과제가 있다. 특이적으로, 2 문제는 4 상이한 쇄로 구성된 비대칭 IgG의 형성에서 이중특이적 항체를 효율적으로 발현시키기 위해 해결되어야 한다: 소위 중쇄 짝짓기오류 문제 및 경쇄 짝짓기오류 문제.2 상이한 중쇄 및 2 상이한 경쇄가 있는 경우, 이들은 몇 개의 상이한 순열에서 짝짓기오류를 할 수 있다 (참고, 도 1). 따라서, 적절하게 짝짓기된 이중특이적 항체를 형성하기 위해, 2 중쇄는 헤테로이량체를 형성해야 하고, 각각의 중쇄는 그것의 동족 경쇄와 짝짓기 해야 한다. 본 개시내용은 비대칭 IgG의 형태로 이중특이적 항체 속으로 상이한 에피토프를 각각 결합시키는 임의의 2 항체를 전환시킬 수 있는 이중특이적 항체 플랫폼을 제공한다. 플랫폼은 중쇄 헤테로이량체화 전략 일명 라이신 재위치결정, 및 항체의 가변 도메인의 공학기술을 요구하지 않는 경쇄 짝짓기오류 문제에 대한 해결책에 기반된다. 하나의 구현예에서, 플랫폼은, 이중특이적 항체의 2 중쇄의 헤테로이량체화를 구동하기 위한 라이신 재위치결정에 의해 CH3 도메인에서 조작되는, Fc 영역을 함유한다. 또 다른 구현예에서, Fab 아암 중 하나의 CH1 및 CL 도메인은 IgE CH2 도메인 (또는 IgM CH2 도메인), 또는 IgE CH2 도메인 (또는 IgM CH2 도메인)과 여전히 짝짓기할 수 있는 이의 단편으로 치환된다. Fabs의 이러한 공학기술은 이중특이적 항체에서 경쇄의 짝짓기오류를 감소 또는 예방할 수 있다. 본 개시내용은, 공-발현에 의해 2 항체로부터 비대칭 IgG를 효율적으로 생성할 수 있는, 이중특이적 항체 플랫폼의 설계, 조작, 및 시험을 기재한다.
경쇄 짝짓기오류 문제에 대한 해결책
도 1에서 설명된 바와 같이 이중특이적 항체에서 경쇄 (LC): 중쇄 (HC) 쌍의 올바른 어셈블리를 달성하기 위해, 본 명세서에서 개시된 해결책은 경쇄 및 중쇄의 아미노산 서열을 변형시켜서 이들 쇄의 불변 도메인 (즉, CL 및 CH1 도메인)이 Ig-폴드 도메인 (또는 경쇄 및 중쇄의 Ig-폴드 도메인 사이 안정적인 디설파이드-연결된 이량체를 여전히 형성할 수 있는 이의 단편)으로 대체되는 것이다.
하나의 경우에서 CH1 및 CL 도메인을 대체하는 Ig-폴드 도메인은 또 다른 CH2E와 안정적인 디설파이드-연결된 이량체를 형성할 수 있는 IgE의 CH2 도메인 (“CH2E”), 또는 이의 단편이다. 예시적인 CH2E 도메인의 아미노산 서열은 하기 제공된다:
1 VCSRDFTPPT VKILQSSCDG GGHFPPTIQL L C LVSGYTPG TINITWLEDG
51 QVMDVDLSTA STTQEGELAS TQSELTLSQK HWLSDRTYT C QVTYQGHTFE
101 DSTKKCA (서열 식별 번호:1)
상기 나타낸 서열에서, 쇄간 디설파이드 결합 형성에 관여될 수 있는 2 시스테인은 볼드체이고; 도메인내 디설파이드 결합을 형성할 수 있는 2 시스테인은 볼드체이고 이탤릭체이고; N-연결된 당화 부위는 밑줄쳐진다.
또 다른 경우에서, 중쇄 및 경쇄의 CH1 및 CL 도메인을 대체하는 Ig-폴드 도메인은 안정적인 디설파이드-연결된 이량체를 형성할 수 있는 IgM의 CH2 도메인 (“CH2M”), 또는 이의 단편이다. 예시적인 CH2M 도메인의 아미노산 서열은 하기 제공된다:
1 VIAELPPKVS VFVPPRDGFF GNPRKSKLIC QATGFSPRQI QVSWLREGKQ
51 VGSGVTTDQV QAEAKESGPT TYKVTSTLTI KESDWLGQSM FTCRVDHRGL
101 TFQQNASSMC VP (서열 식별 번호:2)
상기 나타낸 서열에서, 쇄간 디설파이드 결합 형성에 관여될 수 있는 시스테인은 볼드체이고; 도메인내 디설파이드 결합을 형성할 수 있는 2 시스테인은 이탤릭체이고; N-연결된 당화 부위는 밑줄쳐진다.
본 개시내용은 경쇄 짝짓기 문제에 대한 해결책을 사용하는 항체의 몇 개의 예를 제공한다. 하나의 구현예에서, 항체는 하기 식을 갖는 아미노산 서열을 특성화한다:
VH1 작제물:VH1-L-X-CH2E (또는 CH2M); 및
VL1 작제물:VL1-L-X-CH2E (또는 CH2M),
여기서 “VH1” 및 “VL1”은 짝짓기하여 제1 에피토프용 제1 항원-결합 부위를 형성하는 중쇄 가변 도메인 및 경쇄 가변 도메인이고; 여기서 “L”은 (하기 추가로 기재된) 선택적인 링커이고; 여기서 “X”는 (하기 추가로 기재된) 선택적인 엘보 영역이고; 여기서 “CH2E”는 서열 식별 번호:1 (예를 들면, 서열 식별 번호:1의 아미노산 9-107)로 안정적인 디설파이드-연결된 이량체를 형성할 수 있는 서열 식별 번호:1 또는 이의 단편을 지칭하고, 여기서 “CH2M”은 서열 식별 번호:2 (예를 들면, 서열 식별 번호:2의 아미노산 7-112)로 안정적인 디설파이드-연결된 이량체를 형성할 수 있는 서열 식별 번호:2 또는 이의 단편을 지칭한다. 특정 구현예에서, 한쪽 또는 양쪽 “L” 및 “X”는 VH1 및 VL1 작제물에서 부재이다.
또 다른 구현예에서, 항체는 하기 식을 갖는 아미노산 서열을 특성화한다: VH1 작제물:VH1-X-L-CH2E (또는 CH2M), 및
VL1 작제물:VL1-X-L-CH2E (또는 CH2M).
추가 구현예에서, 항체는 하기 식을 갖는 아미노산 서열을 특성화한다:
VH1 작제물:VH1-L-X-L-CH2E (또는 CH2M), 및
VL1 작제물:VL1-L-X-L-CH2E (또는 CH2M).
CH2E가 상기 기재된 VH1 작제물에서 사용되는 경우, CH2E가 상응하는 VL1 작제물에서 또한 사용되는 것이 이해되어야 한다. 유사하게, CH2M이 상기 기재된 VH1 작제물에서 사용되는 경우, CH2M은 상응하는 VL1 작제물에서 또한 사용된다. 상기 기재된 짝짓기된 VH1 및 VL1 작제물에서 CH2E 및 CH2M 도메인은 아미노산 서열에서 동일할 수 있지만; 이들은 동일할 필요는 없다. 이들은, 예를 들면, 12 이하, 11 이하, 10 이하, 9 이하, 8 이하, 7, 이하, 6 이하, 5 이하, 4 이하, 3 이하, 2 이하, 또는 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 또는 12 아미노산에서 상이할 수 있다. 특정 구현예에서, 상기 기재된 VH1 및 VL1 작제물의 CH2E 도메인은 서열 식별 번호:1과 비교된 12 이하, 11 이하, 10 이하, 9 이하, 8 이하, 7, 이하, 6 이하, 5 이하, 4 이하, 3 이하, 2 이하, 또는 1 아미노산 위치(들)에서 상이하다. 특정 구현예에서, 상기 기재된 VH1 및 VL1 작제물의 CH2M 도메인은 서열 식별 번호:2와 비교된 12 이하, 11 이하, 10 이하, 9 이하, 8 이하, 7, 이하, 6 이하, 5 이하, 4 이하, 3 이하, 2 이하, 또는 1 아미노산 위치(들)에서 상이하다. 이들 차이는 아미노산 치환, 결실, 및/또는 삽입의 결과일 수 있다. 예를 들어, 하기에서 N-당화 부위: 서열 식별 번호:1 또는 2 는 변형될 수 있다 (예를 들면, 서열 식별 번호:1의 NIT 서열에서, N 잔기는 Q로 변화될 수 있거나 T 잔기는 A 또는 C로 변화될 수 있고; 서열 식별 번호:2의 NAS 서열에서, N 잔기는 Q로 변화될 수 있거나 S 잔기는 A 또는 C로 변화될 수 있다). 대안적으로, 또는 게다가, 도메인내 디설파이드 결합을 형성하는 하나 이상의 시스테인은 VH1 및 VL1 작제물 중 하나의 CH2E (또는 CH2M) 도메인에서만 돌연변이될 수 있다. 특정 경우에서, VH1 및 VL1 작제물의 CH2E 도메인 (또는 CH2M 도메인) 모두에서 쇄간 디설파이드 결합 형성에 관여된 시스테인 또는 시스테인들은 (예를 들면, 보존적 아미노산으로) 치환된다. 또한, CH2E 도메인 (또는 CH2M 도메인)의 호모이량체화를 예방하기 위한 돌연변이 (예를 들면, 서열 식별 번호:1의 위치 17에서 세린의 예를 들면, 이소류신 또는 트레오닌으로의 대체; 및 서열 식별 번호:1의 위치 103에서 트레오닌의 예를 들면, 글리신 또는 세린으로의 대체)는 실시될 수 있다. 인간, 침팬지, 마우스, 랫트, 및 토끼로부터 IgE CH2 도메인의 정렬 (도 5D)는 모든 종 사이 보존되지 않는 아미노산 잔기를 확인하고 생물활성 제거 없이 치환될 수 있을 것 같다.
일부 경우에서 CH2E 도메인에 대한 아미노산 치환은 보존적일 수 있다. 보존적 치환은 유사한 특징을 가진 또 다른 것에 대하여 하나의 아미노산의 치환이다. 보존적 치환은 다음과 같은 그룹 내에서 치환을 포함한다: 발린, 알라닌 및 글리신; 류신, 발린, 및 이소류신; 아스파르트산 및 글루탐산; 아스파라긴 및 글루타민; 세린, 시스테인, 및 트레오닌; 라이신 및 아르기닌; 및 페닐알라닌 및 티로신.무극성 소수성 아미노산은 알라닌, 류신, 이소류신, 발린, 프롤린, 페닐알라닌, 트립토판 및 메티오닌을 포함한다. 극성 중성 아미노산은 글리신, 세린, 트레오닌, 시스테인, 티로신, 아스파라긴 및 글루타민을 포함한다. 양으로 하전된 (염기성) 아미노산은 아르기닌, 라이신 및 히스티딘을 포함한다. 음으로 하전된 (산성) 아미노산은 아스파르트산 및 글루탐산을 포함한다. 동일한 그룹의 또 다른 구성원에 의한 상기-언급된 극성, 염기성 또는 산성 그룹 중 하나의 구성원의 임의의 치환은 보존적 치환으로 간주될 수 있다.
일부 경우에서 CH2E 도메인에 대한 아미노산 치환은 비-보존적일 수 있다. 비-보존적 치환은 하기인 것을 포함한다: (i) 하기를 갖는 잔기: 양전기 측쇄 (예를 들면, Arg, His 또는 Lys)가 하기로, 또는 하기에 의해 치환되거나: 음전기 잔기 (예를 들면, Glu 또는 Asp), (ii) 친수성 잔기 (예를 들면, Ser 또는 Thr)은 하기로, 또는 하기에 의해 치환되거나: 소수성 잔기 (예를 들면, Ala, Leu, Ile, Phe 또는 Val), (iii) 시스테인 또는 프롤린은 임의의 다른 잔기로, 또는 상기에 의해 치환되거나, (iv) 하기를 갖는 잔기: 큰 부피의 소수성 또는 방향족 측쇄 (예를 들면, Val, Ile, Phe 또는 Trp) 는 하기로, 또는 하기에 의해 치환된다: 하기를 갖는 것: 더 작은 측쇄 (예를 들면, Ala, Ser) 또는 무 측쇄 (예를 들면, Gly).
특정 구현예에서, 상기 기재된 VH1 및 VL1 작제물의 CH2E 도메인은 서열 식별 번호:1에서 제시된 아미노산 서열에 적어도 75%, 적어도 80%, 적어도 85%, 적어도 86%, 적어도 87%, 적어도 88%, 적어도 88%, 적어도 89%, 적어도 90%, 적어도 91%, 적어도 92%, 적어도 93%, 적어도 94%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 또는 적어도 99% 동일하고 VH1 및 VL1 작제물의 CH2E 도메인은 여전히 함께 짝짓기할 수 있다. 특정 구현예에서, 상기 기재된 VH1 및 VL1 작제물의 CH2E 도메인은 서열 식별 번호:3에서 제시된 아미노산 서열에 적어도 75%, 적어도 80%, 적어도 85%, 적어도 86%, 적어도 87%, 적어도 88%, 적어도 88%, 적어도 89%, 적어도 90%, 적어도 91%, 적어도 92%, 적어도 93%, 적어도 94%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 또는 적어도 99% 동일하고 VH1 및 VL1 작제물의 CH2E 도메인은 여전히 함께 짝짓기할 수 있다.
특정 구현예에서, CH2M 도메인이 상기 기재된 VH1 및 VL1 작제물에서 이용되면, CH2M 도메인은 서열 식별 번호:2에서 제시된 아미노산 서열에 적어도 75%, 적어도 80%, 적어도 85%, 적어도 86%, 적어도 87%, 적어도 88%, 적어도 88%, 적어도 89%, 적어도 90%, 적어도 91%, 적어도 92%, 적어도 93%, 적어도 94%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 또는 적어도 99% 동일하고 VH1 및 VL1 작제물의 CH2M 도메인은 여전히 함께 짝짓기할 수 있다.
아미노산 서열 사이 동일성 퍼센트는 BLAST 2.0 프로그램을 이용하여 결정될 수 있다. 서열 비교는 미갭핑된 정렬을 이용하여 그리고 디폴트 파라미터 (Blossom 62 매트릭스, 갭 실재 비용 11, 잔기당 갭 비용 1, 및 람다 비 0.85)를 이용하여 수행될 수 있다. BLAST 프로그램에서 사용된 수학적 알고리즘은 하기에서 기재된다: Altschul 등, Nucleic Acids Research, 25:3389-3402 (1997).
특정 구현예에서, 상기 기재된 VH1 및 VL1 작제물 모두에서 사용되는 CH2E 도메인은 서열 식별 번호:1에 100% 동일하다. 일부 구현예에서, 상기 기재된 VH1 및 VL1 작제물에서 사용되는 CH2E 도메인은 서열 식별 번호:1의 단편, 예를 들면, 서열 식별 번호:1의 N 및/또는 C-말단에서 누락 아미노산이고, 이것은 서열 식별 번호:1에 의해 인코딩된 폴리펩타이드와 안정적인 디설파이드-연결된 이량체를 형성할 수 있다. 예를 들어, 서열 식별 번호:1의 단편은 서열 식별 번호:1의 N- 및/또는 C-말단에서 20, 19, 18, 17, 16, 15, 14, 13, 12, 10, 9, 8, 7, 6, 5, 4, 3, 2, 또는 1 아미노산(들) 누락일 수 있다. 특정 구현예에서, 상기 기재된 VH1 및 VL1 작제물에서 사용되는 CH2E 도메인은 서열 식별 번호:1의 아미노산 2-107, 3-107, 4-107, 5-107, 6-107, 7-107, 8-107, 9-107, 10-107, 11-107, 12-107, 13-107, 14-107, 15-107, 16-107, 17-107, 18-107, 19-107, 또는 20-107을 포함하거나 상기로 구성된다. 다른 구현예에서, 상기 기재된 VH1 및 VL1 작제물에서 사용되는 CH2E 도메인은 서열 식별 번호:1의 아미노산 2-106, 3-106, 4-106, 5-106, 6-106, 7-106, 8-106, 9-106, 10-106, 11-106, 12-106, 13-106, 14-106, 15-106, 16-106, 17-106, 18-106, 19-106, 또는 20-106을 포함하거나 상기로 구성된다. 더욱 다른 구현예에서, 상기 기재된 VH1 및 VL1 작제물에서 사용되는 CH2E 도메인은 서열 식별 번호:1의 아미노산 2-105, 3-105, 4-105, 5-105, 6-105, 7-105, 8-105, 9-105, 10-105, 11-105, 12-105, 13-105, 14-105, 15-105, 16-105, 17-105, 18-105, 19-105, 또는 20-105를 포함하거나 상기로 구성된다. 특정 구현예에서, 상기 기재된 VH1 및 VL1 작제물에서 사용되는 CH2E 도메인은 서열 식별 번호:1의 아미노산 9-107, 9-106, 9-105, 9-104, 9-103, 9-102, 9-101, 9-100, 9-99, 9-98, 또는 9-97을 포함하거나 상기로 구성된다. 이들 구현예 모두에서, 상기 기재된 VH1 및 VL1 작제물에서 사용된 한쪽 또는 양쪽 CH2E 도메인내 서열 식별 번호:1에서 제시된 아미노 서열에 비교된 1 내지 12 (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 또는 12) 치환이 있을 수 있다. 예를 들어, N-연결된 당화 부위는 돌연변이될 수 있거나 (예를 들면, NIT 부위의 아스파라긴은 글루타민에 의해 치환될 수 있거나 NIT 부위의 트레오닌은 알라닌 또는 시스테인에 의해 치환될 수 있다); 쇄간 디설파이드 결합 형성에 관여된 시스테인의 한쪽 또는 양쪽은 또 다른 아미노산 (예를 들면, 보존적 아미노산)으로 치환될 수 있거나; 돌연변이는 (CH2E 도메인이 중쇄 및 경쇄의 일부인 경우) 중쇄:중쇄 또는 경쇄:경쇄 이량체의 형성을 예방하는 CH2E 속으로 도입될 수 있다.
특정 구현예에서, 상기 기재된 VH1 및 VL1 작제물에서 사용되는 CH2M 도메인은 서열 식별 번호:2에 100% 동일하다. 일부 구현예에서, 상기 기재된 VH1 및 VL1 작제물에서 사용되는 CH2M 도메인은 서열 식별 번호:2의 단편, 예를 들면, 서열 식별 번호:2의 N 및/또는 C-말단에서 누락 아미노산이고, 이것은 서열 식별 번호:2에 의해 인코딩된 폴리펩타이드로 안정적인 디설파이드-연결된 이량체를 형성할 수 있다. 예를 들어, 서열 식별 번호:2의 단편은 서열 식별 번호:2의 N- 및/또는 C-말단에서 20, 19, 18, 17, 16, 15, 14, 13, 12, 10, 9, 8, 7, 6, 5, 4, 3, 2, 또는 1 아미노산(들) 누락일 수 있다. 특정 구현예에서, 상기 기재된 VH1 및 VL1 작제물에서 사용되는 CH2M 도메인은 서열 식별 번호:2의 아미노산 2-112, 3-112, 4-112, 5-112, 6-112, 7-112, 8-112, 9-112, 10-112, 11-112, 12-112, 13-112, 14-112, 15-112, 16-112, 17-112, 18-112, 19-112, 또는 20-112를 포함하거나 상기로 구성된다. 다른 구현예에서, 상기 기재된 VH1 및 VL1 작제물에서 사용되는 CH2M 도메인은 서열 식별 번호:2의 아미노산 2-111, 3-106, 4-111, 5-111, 6-111, 7-111, 8-111, 9-111, 10-111, 11-111, 12-111, 13-111, 14-111, 15-111, 16-111, 17-111, 18-111, 19-111, 또는 20-111을 포함하거나 상기로 구성된다. 더욱 다른 구현예에서, 상기 기재된 VH1 및 VL1 작제물에서 사용되는 CH2M 도메인은 서열 식별 번호:2의 아미노산 2-110, 3-110, 4-110, 5-110, 6-110, 7-110, 8-110, 9-110, 10-110, 11-110, 12-110, 13-110, 14-110, 15-110, 16-110, 17-110, 18-110, 19-110, 또는 20-110을 포함하거나 상기로 구성된다. 특정 구현예에서, 상기 기재된 VH1 및 VL1 작제물에서 사용되는 CH2M 도메인은 서열 식별 번호:1의 아미노산 7-112, 7-111, 7-110, 7-109, 7-108, 7-107, 7-105, 7-104, 7-103, 7-102, 7-101, 7-100, 또는 7-99를 포함하거나 상기로 구성된다. 이들 구현예 모두에서, 상기 기재된 VH1 및 VL1 작제물에서 사용된 한쪽 또는 양쪽 CH2M 도메인내 서열 식별 번호:2에서 제시된 아미노 서열에 비교된 1 내지 12 (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 또는 12) 치환이 있을 수 있다. 예를 들어, N-연결된 당화 부위는 돌연변이될 수 있거나 (예를 들면, NAS 부위의 아스파라긴은 글루타민에 의해 치환될 수 있거나 NAS 부위의 세린은 알라닌 또는 시스테인에 의해 치환될 수 있다); 쇄간 디설파이드 결합 형성에서 관여된 시스테인의 한쪽 또는 양쪽은 또 다른 아미노산 (예를 들면, 보존적 아미노산)으로 치환될 수 있거나; 돌연변이는 (CH2M 도메인이 중쇄 및 경쇄의 일부인 경우) 중쇄:중쇄 또는 경쇄:경쇄 이량체의 형성을 예방하는 CH2M 속으로 도입될 수 있다.
하나의 구현예에서, 상기 기재된 VH1 작제물에서 사용된 CH2 도메인은 인간 면역글로불린 E의 CH2 도메인이고, 여기에서 N-당화 부위는 글루타민으로 돌연변이되고, 최초 8 아미노산은 인간 IgG1 CH1 도메인의 최초 5 아미노산으로 대체된다. 상기 CH2E 도메인의 아미노산 서열은 하기 제공된다:
1 ASTKGPTVKI LQSSCDGGGH FPPTIQLLCL VSGYTPGTI Q ITWLEDGQVM
51 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDST
101 KKCA (서열 식별 번호:3)
하나의 구현예에서, 상기 기재된 VL1 작제물에서 사용된 CH2 도메인은 인간 면역글로불린 E의 CH2 도메인이고, 여기에서 N-당화 부위는 글루타민으로 돌연변이되고, 최초 8 아미노산은 인간 카파 도메인의 최초 5 아미노산으로 대체된다. 상기 CH2E 도메인의 아미노산 서열은 하기 제공된다:
1 RTVAAPTVKI LQSSCDGGGH FPPTIQLLCL VSGYTPGTI Q ITWLEDGQVM
51 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDST
101 KKCA (서열 식별 번호:4)
또 다른 구현예에서, 상기 기재된 VH1 작제물에서 사용될, 그리고 상기 기재된 VL1 작제물로 헤테로이량체를 형성하기 위해 조작되는 인간 면역글로불린 E의 예시적인 CH2 도메인의 아미노산 서열은 서열 식별 번호:1의 위치 17에서 세린의 이소류신으로의 대체에 의해 실시된다. 상기 CH2E 도메인의 아미노산 서열은 하기 제공된다 (상기 서열에서 N-연결된 당화 부위가 또한 돌연변이되고 서열 식별 번호:1의 최초 8 아미노산이 IgG1 CH1의 최초 5 아미노산으로 대체되는 것을 언급한다):
1 ASTKGPTVKI LQS I CDGGGH FPPTIQLLCL VSGYTPGTI Q ITWLEDGQVM
51 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDST
101 KKCA (서열 식별 번호:5)
상기 기재된 VL1 작제물의 VL 도메인으로 연결될, 그리고 상기 기재된 VH1 작제물로 헤테로이량체를 형성하기 위해 조작되는 인간 면역글로불린 E의 예시적인 CH2 도메인의 아미노산 서열은 서열 식별 번호:1의 위치 103에서 트레오닌의 글리신으로의 대체에 의해 실시된다. 상기 CH2E 도메인의 아미노산 서열은 하기 제공된다 (상기 서열에서 N-연결된 당화 부위가 또한 돌연변이되고 서열 식별 번호:1의 최초 8 아미노산이 카파 쇄의 최초 5 아미노산으로 대체되는 것을 언급한다):
1 RTVAAPTVKI LQSSCDGGGH FPPTIQLLCL VSGYTPGTIQ ITWLEDGQVM
51 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDS G
101 KKCA (서열 식별 번호:6)
특정 구현예에서, 상기 기재된 VH1 및 VL1 작제물에서 사용되는 CH2E 도메인은 하기의 C-말단 절단물을 포함한다: 서열 식별 번호:5 및/또는 6.특정 경우에서, 서열 식별 번호:5 및/또는 서열 식별 번호:6의 C-말단 대부분 9, 8, 7, 6, 5, 4, 3, 2, 또는 1 아미노산은 결실된다. 특정한 구현예에서, 상기 기재된 VH1 작제물에서 사용되는 CH2E 도메인은 서열 식별 번호:5의 아미노산 1-103, 1-102, 1-101, 1-100, 1-99, 1-98, 1-97, 1-96, 또는 1-95를 포함하거나 상기로 구성된다. 또 다른 특이적인 구현예에서, 상기 기재된 VL1 작제물에서 사용되는 CH2E 도메인은 서열 식별 번호:6의 아미노산 1-103, 1-102, 1-101, 1-100, 1-99, 1-98, 1-97, 1-96, 또는 1-95를 포함하거나 상기로 구성된다. 더욱 다른 구현예에서, 상기 기재된 VH1 작제물에서 사용되는 CH2E 도메인은 서열 식별 번호:5의 아미노산 6-103, 7-103, 8-103, 9-103, 또는 10-103을 포함하거나 상기로 구성된다. 더욱 다른 구현예에서, 상기 기재된 VL1 작제물에서 사용되는 CH2E 도메인은 서열 식별 번호:6의 아미노산 6-103, 7-103, 8-103, 9-103, 또는 10-103을 포함하거나 상기로 구성된다. 특정 구현예에서, 서열 식별 번호:5 및/또는 서열 식별 번호:6, 또는 상기 기재된 이의 단편은 서열 식별 번호:1에 대해 5 이하, 4 이하, 3 이하, 2 이하 또는 1 추가 돌연변이를 추가로 함유할 수 있다.
특정 구현예에서, 상기 기재된 항체는 중쇄 가변 도메인 “VH2” 및 경쇄 가변 도메인 “VL2”를 추가로 포함하고, 여기서 상기 VH2는 CH1 도메인에 연결되고 VL2 도메인은 CL 도메인에 연결되고, 여기서 VH2 및 VL2는 짝짓기하여 제2 에피토프용 제2 항원-결합 부위를 형성한다. 일부 구현예에서, 상기 기재된 항체는 2 Fc 도메인을 추가로 포함한다. Fc 도메인은 항체의 힌지 영역, CH2 도메인 및 CH3 도메인을 포함한다. 특정 경우에서, 힌지, CH2, 및 CH3 도메인은 IgG1 출신이다. 특정 경우에서, 힌지 및 CH3 도메인은 IgG4 출신이고 CH2 도메인은 IgG1 출신이다. 특정한 구현예에서, 힌지 영역이 IgG4 출신인 경우, S228P (EU 넘버링) 돌연변이를 포함한다. 항체의 2 Fc 도메인 중 하나는 항체의 2 Fabs 중 하나의 CH2E 도메인 (또는 CH2M 도메인) 중 하나에 직접적으로 연결될 수 있거나, 링커를 통해 연결될 수 있다. Fc 영역은 VH1 작제물 또는 VL1 작제물에 연결될 수 있다. Fc 영역은 돌연변이(들) 없이 동일한 Fc 영역에 대해 이중특이적 항체의 중쇄 사이 헤테로이량체화를 증가시키는 임의의 돌연변이(들)을 포함할 수 있다. 예를 들어, Fc 영역은 본원의 실시예 1의 표 2에서 기재된 노브-인투-홀 돌연변이, 전기조향 돌연변이, 또는 다른 돌연변이를 포함할 수 있다. 특정한 구현예에서, 이중특이적 항체의 Fc 영역은 본 명세서에서 기재된 라이신 재위치결정 돌연변이를 포함한다.
특정 구현예에서, 상기 기재된 항체는 중쇄 가변 도메인 “VH2” 및 경쇄 가변 도메인 “VL2”를 추가로 포함하고, 여기서 VH2는 CH1 도메인에 연결되고 VL2 도메인은 CL 도메인에 연결되고, 여기서 VH2 및 VL2는 짝짓기하여 제2 에피토프용 제2 항원-결합 부위를 형성하지만, 항체는 Fc 도메인(들)이 부족하다. 상기 기재된 작제물의 VH1 또는 VL1 도메인에 연결된 CH2E 도메인 (또는 CH2M 도메인)은 VH2 및 VL2 도메인을 포함하는 항체에 연결될 수 있다. 예를 들어, VH1 작제물의 CH2E 도메인 (또는 CH2M 도메인)의 C-말단은 VH2에 연결되는 CH1 도메인의 C-말단에 연결될 수 있거나, VH1 작제물의 CH2E 도메인 (또는 CH2M 도메인)의 C-말단은 VH2 도메인의 N-말단에 연결될 수 있다. 다른 예시적인 배치형태는 VH2에 연결되는 CH1 도메인의 C-말단에 연결될 수 있는 VL1 작제물의 CH2E 도메인 (또는 CH2M 도메인)의 C-말단, 또는 VH2 도메인의 N-말단에 연결될 수 있는 VL1 작제물의 CH2E 도메인 (또는 CH2M 도메인)의 C-말단에 대한 것이다. 다른 예시적인 배치형태는 VL2에 연결되는 CL 도메인의 C-말단에 연결된 VH1 작제물의 CH2E 도메인 (또는 CH2M 도메인)의 C-말단, 또는 VL2 도메인의 N-말단에 연결된 VH1 작제물의 CH2E 도메인 (또는 CH2M 도메인)의 C-말단을 포함한다. 추가로 예시적인 배치형태는 VL2에 연결되는 CL 도메인의 C-말단에 연결될 VL1 작제물의 CH2E 도메인 (또는 CH2M 도메인)의 C-말단, 또는 VL2 도메인의 N-말단에 연결될 VL1 작제물의 CH2E 도메인 (또는 CH2M 도메인)의 C-말단에 대한 것이다. 일부 경우에서, VH1 또는 VL1 작제물의 CH2E 도메인 (또는 CH2M 도메인)과 제2 Fab 사이 링커는 펩타이드 링커이다. 다른 경우에서, VH1 또는 VL1 작제물의 CH2E 도메인 (또는 CH2M 도메인)과 제2 Fab 사이 링커는 인간 혈청 알부민 (HSA)이다. 일부 경우에서, VH1 또는 VL1 작제물의 CH2E 도메인 (또는 CH2M 도메인)과 제2 Fab 사이 링커는 폴리에틸렌 글리콜이다. 더욱 다른 경우에서, VH1 또는 VL1 작제물의 CH2E 도메인과 제2 Fab 사이 링커는 하기이다: XTEN 분자 (예를 들면, AE-144, AE-288).
특정 경우에서, VH1 및 VL1 작제물은 4가 이중특이적 항체의 일부이다. 이들 4가 항체는 (i) 항원의 하나의 에피토프를 결합시키는 가변 도메인인, 전체 항체, 및 (ii) 동일한 항원 또는 상이한 항원의 또 다른 에피토프를 각각 결합시키는 2 Fabs를 포함한다. 일부 구현예에서, 전체 항체는 IgG1이다. 다른 구현예에서, 전체 항체는 IgG4(G1) - 즉, IgG1의 CH3 도메인이 아닌 IgG4의 힌지 및 CH2 영역을 포함하는 항체이다. 특정 구현예에서, 전체 항체는 IgG4(G1)P - 즉, 힌지 영역이 S228P (EU 넘버링) 돌연변이를 갖는 것을 제외하고 항체가 IgG4(G1)인 것이다. 2 Fabs는 전체 항체의 CH3 도메인의 C-말단에 연결된다. 2 Fabs는 어느 한쪽으로 하기를 통해 전체 항체의 CH3 도메인에 연결될 수 있다: 하기 중 하나의 N-말단: 2 가변 도메인 (즉,VH 또는 VL) (각각의 Fab의) 또는 각각의 2 Fabs의 불변 도메인 중 하나의 C-말단.Fab 불변 도메인이 CH2E 또는 CH2M 도메인에 의해 대체되지 않으면, 연결은 어느 한쪽으로 CH1 도메인의 C-말단 또는 CL 도메인의 C-말단에 대한 것일 수 있다. Fab 불변 도메인이 CH2E 도메인 (또는 CH2M 도메인)으로 대체되면, 연결은 CH2E 도메인 (또는 CH2M 도메인))의 C-말단에 대한 것일 수 있다. 4가 이중특이적 항체는 어느 한쪽으로 전체 항체의 2 아암에서 또는 2 Fabs에서 상기 상세히 설명된 CH2E 도메인 (또는 CH2M 도메인)을 포함할 수 있다. 상기 사례에서, 용어 “전체 항체”가 하기 보다는 상이하게 사용되는 것을 주목한다: 그것의 통상적인 의미 (즉, 하기를 포함하는 항체: 4 쇄:VL1-CL, VH1-CH1-힌지-CH2-CH3, VL2-CL, 및 VH2-CH1-힌지-CH2-CH3) 또한 하기 4 쇄를 포함하는 항체를 포함하기 위해:VL1-CH2E (또는 CH2M), VH1-CH2E(또는 CH2M)-힌지-CH2-CH3, VL2-CH2E(또는 CH2M), 및 VH2-CH2E(또는 CH2M)-힌지-CH2-CH3.
상기 기재된 작제물에서 사용될 수 있는 링커에서 특정한 제한은 없다. 일부 구현예에서, 링커는 펩타이드 링커이다. 하기를 포함하는 어느 임의의 단일-쇄 펩타이드: 약 1 내지 25 잔기 (예를 들면, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 아미노산) 는 링커로서 사용될 수 있다. 특정 경우에서, 링커는 글리신 및/또는 세린 잔기만을 함유한다. 상기 펩타이드 링커의 예는 하기를 포함한다: Gly, Ser; Gly Ser; Gly Gly Ser; Ser Gly Gly; Gly Gly Gly Ser (서열 식별 번호:10); Ser Gly Gly Gly (서열 식별 번호:55); Gly Gly Gly Gly Ser (서열 식별 번호:56); Ser Gly Gly Gly Gly (서열 식별 번호:57); Gly Gly Gly Gly Gly Ser (서열 식별 번호:58); Ser Gly Gly Gly Gly Gly (서열 식별 번호:59); Gly Gly Gly Gly Gly Gly Ser (서열 식별 번호:60); Ser Gly Gly Gly Gly Gly Gly (서열 식별 번호:61); (Gly Gly Gly Gly Ser)n (서열 식별 번호:56)n, 여기서 n은 하나 이상의 정수임; 및 (Ser Gly Gly Gly Gly)n (서열 식별 번호:57)n, 여기서 n은 하나 이상의 정수임.다른 구현예에서, 링커 펩타이드는 변형되어서 (전통적 Gly/Ser 링커 펩타이드 반복부의 접합에서 발생하는) 아미노산 서열 GSG가 존재하지 않는다. 예를 들어, 펩타이드 링커는 하기로 구성된 군으로부터 선택된 아미노산 서열을 포함한다: (GGGXX)nGGGGS (서열 식별 번호:62) 및 GGGGS(XGGGS)n (서열 식별 번호:63), 여기에서 X는 서열 속으로 삽입될 수 있고 서열 GSG를 포함하는 폴리펩타이드를 초래하지 않는 임의의 아미노산이고, n은 0 내지 4임.하나의 구현예에서, 링커 펩타이드의 서열은 (GGGX1X2)nGGGGS이고 X1는 P이고 X2는 S이고 n은 0 내지 4이다 (서열 식별 번호:64). 또 다른 구현예에서, 링커 펩타이드의 서열은 (GGGX1X2)nGGGGS이고 X1은 G이고 X2는 Q이고 n은 0 내지 4이다 (서열 식별 번호:65). 또 다른 구현예에서, 링커 펩타이드의 서열은 (GGGX1X2)nGGGGS이고 X1은 G이고 X2는 A이고 n은 0 내지 4이다 (서열 식별 번호:66). 더욱 또 다른 구현예에서, 링커 펩타이드의 서열은 GGGGS(XGGGS)n이고, X는 P이고 n은 0 내지 4이다 (서열 식별 번호:67). 하나의 구현예에서, 본 발명의 링커 펩타이드는 아미노산 서열 (GGGGA)2GGGGS (서열 식별 번호:68)을 포함하거나 상기로 구성된다. 또 다른 구현예에서, 링커 펩타이드는 아미노산 서열 (GGGGQ)2GGGGS (서열 식별 번호:69)를 포함하거나 상기로 구성된다. 더욱 또 다른 구현예에서, 링커 펩타이드는 아미노산 서열 (GGGPS)2GGGGS (서열 식별 번호:70)을 포함하거나 상기로 구성된다. 추가 구현예에서, 링커 펩타이드는 아미노산 서열 GGGGS(PGGGS)2 (서열 식별 번호:71)을 포함하거나 상기로 구성된다.
특정 구현예에서, 링커는 합성 화합물 링커 (화학적 가교결합제)이다. 시장에서 이용가능한 가교결합제의 예는 하기를 포함한다: N-하이드록시석신이미드 (NHS), 디석신이미딜우베레이트 (DSS), 비스(설포석신이미딜)우베레이트 (BS3), 디티오비스(석신이미딜프로피오네이트) (DSP), 디티오비스(설포석신이미딜프로피오네이트) (DTSSP), 에틸렌글리콜 비스(석신이미딜석시네이트) (EGS), 에틸렌글리콜 비스(설포석신이미딜석시네이트) (설포-EGS), 디석신이미딜 타르트레이트 (DST), 디설포석신이미딜 타르트레이트 (설포-DST), 비스[2-(석신이미도옥시카보닐옥시)에틸]설폰 (BSOCOES), 및 비스[2-(설포석신이미도옥시카보닐옥시)에틸]설폰 (설포-BSOCOES).
VH1 작제물용 엘보 영역은, 예를 들면, IgG CH1 도메인의 단편 (예를 들면, IgG CH1 도메인으로부터 1 내지 10, 1 내지 9, 1 내지 8, 1 내지 7, 1 내지 6, 1 내지 5개의, 1 내지 4, 1 내지 3, 또는 1 내지 2 연속적인 아미노산)일 수 있다. 하나의 구현예에서 엘보 도메인은 IgG1 출신이고 IgG1 CH1 도메인의 N 또는 C-말단으로부터 1 내지 10, 1 내지 9, 1 내지 8, 1 내지 7, 1 내지 6, 1 내지 5, 1 내지 4, 1 내지 3, 또는 1 내지 2 연속적인 아미노산을 포함하거나 상기로 구성된다. IgG1 CH1 도메인의 아미노산 서열은 하기 제공된다:
ASTKGPSVFP LAPSSKSTSG GTAALGCLVK DYFPEPVTVS WNSGALTSGV HTFPAVLQSS GLYSLSSVVT VPSSSLGTQT YICNVNHKPS NTKVDKKV (서열 식별 번호:72)
상기 기재된 VH1 작제물용 엘보 영역의 비-제한 예는 ASTKG (서열 식별 번호:7)이다. 하나의 구현예에서 VH1 작제물은 다음과 같은 아미노산 서열을 포함한다:
1 ASTKGPTVKI LQSSCDGGGH FPPTIQLLCL VSGYTPGTIN ITWLEDGQVM
51 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDST
101 KKCA (서열 식별 번호:45)
여기서 CH2E의 최초 8 아미노산 (VCSRDFTP (서열 식별 번호:8)은 인간 IgG1 CH2 도메인의 최초 5 아미노산 (엘보 영역 ASTKG (서열 식별 번호:7))로 대체된다. 또 다른 구현예에서, 상기 기재된 VH1 작제물용 엘보 영역은 SRDFT (서열 식별 번호:77)이다. 특정 구현예에서, VH1 작제물은 링커를 갖지만 엘보 영역은 없다. 그와 같은 사례에서, 링커는, 예를 들면, 하기일 수 있다: 서열 식별 번호:56 또는 서열 식별 번호:58.
VL1 작제물용 엘보 영역은, 예를 들면, 카파 또는 람다 CL 도메인의 단편 (예를 들면, 카파 또는 람다 도메인으로부터 1 내지 10, 1 내지 9, 1 내지 8, 1 내지 7, 1 내지 6, 1 내지 5, 1 내지 4, 1 내지 3, 1 내지 2 연속적인 아미노산)일 수 있다. 하나의 구현예에서 엘보 도메인은 카파 도메인 출신이고 카파 도메인의 N 또는 C-말단으로부터 1 내지 10, 1 내지 9, 1 내지 8, 1 내지 7, 1 내지 6, 1 내지 5, 1 내지 4, 1 내지 3, 또는 1 내지 2 연속적인 아미노산을 포함하거나 상기로 구성된다. 인간 카파 CL 도메인의 아미노산 서열은 하기 제공된다:
RTVAAPSVFI FPPSDEQLKS GTASVVCLLN NFYPREAKVQ WKVDNALQSG NSQESVTEQD SKDSTYSLSS TLTLSKADYE KHKVYACEVT HQGLSSPVTK SFNRGEC (서열 식별 번호:73)
인간 람다 CL 도메인의 아미노산 서열은 하기 제공된다 (엘보 영역은, 볼드체/밑줄로서 보여진, 최초 6 아미노산이다):
GQPKAA PSVT LFPPSSEELQ ANKATLVCLI SDFYPGAVTV AWKADSSPVK
AGVETTTPSK QSNNKYAASS YLSLTPEQWK S시간YSCQVT HEGSTVEKTV
APTECS(서열 식별 번호:74)
상기 기재된 VL1 작제물용 엘보 영역의 비-제한 예는 RTVAA (서열 식별 번호:9)이다. 하나의 구현예에서 VL1 작제물은 다음과 같은 아미노산 서열을 포함한다:
1 RTVAAPTVKI LQSSCDGGGH FPPTIQLLCL VSGYTPGTIN ITWLEDGQVM
51 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDST
101 KKCA (서열 식별 번호:46)
여기서 CH2E의 최초 8 아미노산 (VCSRDFTP (서열 식별 번호:8))은 인간 카파 도메인의 최초 5 아미노산 (엘보 영역 RTVAA (서열 식별 번호:9))로 대체된다. 또 다른 구현예에서, 상기 기재된 VL1 작제물용 엘보 영역은 GQPKAA (서열 식별 번호:78)이다. 특정 구현예에서, VL1 작제물은 링커를 갖지만 엘보 영역은 없다. 그와 같은 사례에서, 링커는, 예를 들면, 하기일 수 있다: 서열 식별 번호:56 또는 서열 식별 번호:58.
중쇄 짝짓기오류 문제에 대한 해결책
본원은 또한 중쇄 헤테로이량체화에 대하여 효과적인 전략으로서 라이신 재위치결정을 개시한다. CH3 도메인의 구조적 분석, 모델링, 및 잠재적인 계면 돌연변이의 분석에 기반하여, 라이신 재위치결정의 전략은 비대칭 상보적 CH3 계면을 조작하기 위해 고안되었다 (참고, 도 2). 특이적으로, CH3 단량체 A에서 Lys409 (EU 넘버링)의 Ser로의 그리고 Ser364 (EU 넘버링)의 Lys로의 치환은 β-가닥 E부터 인접한 역평행 β-가닥 B까지 라이신을 재위치결정시킨다. 반대로, CH3 단량체 B에서 Lys370 (EU 넘버링)의 Ser로의 그리고 Phe405 (EU 넘버링)의 Lys로의 치환은 β-가닥 B부터 β-가닥 E까지 라이신을 재위치결정시킨다. 다른 구현예에서, 라이신 재위치결정은 표 2의 MP4의 돌연변이를 포함한다. 재위치결정된 라이신은 헤테로이량체에서 적층되지만, 호모이량체에서 입체 및 전하 충돌을 시행하여, 그들의 형성을 예방하고, 따라서 CH3 도메인의 헤테로이량체화를 구동시킨다. 따라서, 하기의 CH3 도메인 속으로 이들 전하를 편입시킴으로써: 항체 (예를 들면, IgG1 항체의 CH3) 이들 돌연변이 없이 항체에 대해 항체의 중쇄의 헤테로이량체화를 증가시킬 수 있다. 이러한 전략은 공개된 Fc 헤테로이량체화 돌연변이에 우월한 또는 비교할만한 효율을 가진 중쇄 헤테로이량체화에 대하여 고도로 효과적인 전략인 것으로 밝혀졌다.
야생형 인간 IgG1 CH3 도메인의 아미노산 서열은 하기 제공된다:
1
GQPREPQVYT LPPSRDELTK NQVSLTCLVK GFYPSDIAVE WESNGQPENN
51 YKTTPPVLDS DGSFFLYSKL TVDKSRWQQG NVFSCSVMHE ALHNHYTQKS
101 LSLSPGK (서열 식별 번호:11)
야생형 인간 IgG4 CH3 도메인의 아미노산 서열은 하기 제공된다:
1
GQPREPQVYT LPPSQEEMTK NQVSLTCLVK GFYPSDIAVE WESNGQPENN
51 YKTTPPVLDS DGSFFLYSRL TVDKSRWQEG NVFSCSVMHE ALHNHYTQKS
101 LSLSLGK (서열 식별 번호:12)
하나의 구현예에서 항체의 Fc 영역의 2 CH3 도메인 중 하나는 아래에 제시된 아미노산 서열을 포함한다:
1 GQPREPQVYT LPPSRDELTK NQVKLTCLVK GFYPSDIAVE WESNGQPENN YKTTPPVLDS 61 DGSFFLYSLL TVDKSRWQQG NVFSCSVMHE ALHNHYTQKS LSLSPG (서열 식별 번호:13)
상기 구현예에서, 항체의 Fc 영역의 2 CH3 도메인의 두번째는 아래에 제시된 아미노산 서열을 포함한다:
1
GQPREPQVYT LPPSRDELTK NQVSLTCLVS GFYPSDIAVE WESNGQPENN YKTTPPILDS
61
DGSFKLYSKL TVDKSRWQQG NVFSCSVMHE ALHNHYTQKS LSLSPG (서열 식별 번호:14)
일부 구현예에서, 상기-언급된 2 CH3 도메인은 한쪽 또는 양쪽 CH3 도메인에서 5 이하, 4 이하, 3 이하, 2 이하, 또는 1 아미노산 치환을 포함할 수 있다. 예를 들어, CH3 도메인은 항체의 하나 이상의 효과기 기능을 변경시키기 위해 돌연변이될 수 있다. 하나 이상의 효과기 기능을 변경시키기 위해 CH3 도메인에서 변형될 수 있는 (EU 넘버링에 따른) 위치의 비-제한 예는 위치 342, 344, 356, 358, 359, 360, 361, 362, 373, 375, 376, 378, 380, 382, 383, 384, 386, 388, 389, 398, 414, 416, 419, 428, 430, 433, 434, 435, 437, 438, 및 439를 포함한다. 또한 하기에서 가능한 치환 부위의 예 및 돌연변이의 예를 참고한다: 미국특허 번호:US 8,586,713 B2 칼럼 10, 라인 32-64.하나 이상의 효과기 기능을 변경시키기 위해 CH3 도메인에서 실시될 수 있는 (EU 넘버링에 따라 열거된) 치환의 다른 비-제한 예는 하기를 포함한다: E345R, H433A, N434A, H435A, Y436D, Q438D, K439E, S440K, 및/또는 K439E/S440K (참고, Diebolder CA 등, Science, 343(6176):1260-1263 (2014)). CH3 도메인에 실시될 수 있는 다른 치환은 단백질 A에 결합을 작용시키는 것을 포함한다. 그와 같은 치환의 비-제한 예는 하기를 포함한다: H435R, H435R, 및/또는 Y436F (미국 특허 번호:US 8,586,713 B2) (모두 EU 넘버링). 치환은 또한 인공 디설파이드 결합을 도입시키기 위해 실시될 수 있다. 그와 같은 치환의 비-제한 예는 하기를 포함한다: P445G, G446E, 및 K447C; P343C 및 A431C; 및 S375C 및 P396C (WO2011/003811 A1) (모두 EU 넘버링). CH3 도메인은 표면 잔기에 변화를 만들기 위해 돌연변이될 수 있다. 이것은, 예를 들면, 항체의 등전점 (pI) 변경용일 수 있다. 그와 같은 치환의 비-제한 예는 하기를 포함한다: E345K, Q347E/K/R, R355E, R355Q, K392E, K392N, Q419E (US 2014/0294835 A1) (모두 EU 넘버링). 일부 경우에서, CH3 도메인의 C-말단은 절단 및/또는 변형될 수 있다. 예를 들어, CH3 도메인의 C-말단에 펩타이드 DEDE 또는 다른 아미노산을 부가시킬 수 있고/있거나 K447 (EU 넘버링)을 결실시킬 수 있다. 특정 경우에서, CH3 도메인은 도메인의 당화를 작용시키기 위해 돌연변이될 수 있다. 그와 같은 돌연변이의 비-제한 예는 하기이다: Y407E (EU 넘버링) (Rose 등, MAbs, 5(2):219-28 (2013)).
상기 기재된 CH3 도메인은 Fc 도메인의 일부일 수 있다. 항체의 중쇄의 Fc 도메인은 힌지 영역, CH2 도메인 및 CH3 도메인을 포함한다. CH3 도메인은 상기 논의된 라이신 재위치결정 돌연변이에 더하여 돌연변이를 포함할 수 있다.
Fc 도메인에서 힌지 영역은 임의의 항체 부류의 힌지 영역일 수 있다. IgG1, IgG2, 및 IgG4 항체의 힌지 영역은 위치 216에서 아미노산부터 위치 230에서 아미노산까지 일반적으로 연장한다 (EU 넘버링에 따른 위치 넘버링). 특정 구현예에서, 힌지 영역은 IgG1 항체로부터 힌지이다. 다른 구현예에서, 힌지 영역은 IgG4 항체로부터 힌지이다. 힌지 영역이 IgG4 부류 출신인 경우 S228P (EU 넘버링) 돌연변이를 함유할 수 있다. 하기는 한쪽 전체 또는 부분적으로 이용될 수 있는 예시적인 힌지 영역이다 (예를 들면, N- 및/또는 C-말단 절단이 있을 수 있다).
인간 IgG1 힌지:EPKSCDKTHTCPPCP (서열 식별 번호:15)
인간 IgG4 힌지:ESKYGPPCPSCP (서열 식별 번호:16)
돌연변이체 인간 IgG4 (S228P) 힌지:ESKYGPPCPPCP (서열 식별 번호:17)
특정 경우에서, 1, 2, 3, 4, 또는 5 아미노산은 상기 힌지 서열의 N- 및/또는 C-말단에서 결실될 수 있다. 특정 경우에서, 힌지 서열 또는 이의 N- 및/또는 C-말단 절단부에서 4 이하, 3 이하, 2 이하, 1, 2, 3, 또는 4 아미노산 치환, 결실, 및/또는 삽입이 있을 수 있다.
CH2 도메인은 항체의 임의의 부류 출신일 수 있다. 특정 구현예에서, CH2 도메인은 IgG1 항체 출신이다. 다른 구현예에서, CH2 도메인은 IgG4 항체 출신이다. CH2 도메인은 하나 또는 돌연변이를 함유할 수 있다. 예를 들어, CH2 도메인은 N-연결된 당화 부위의 돌연변이를 가질 수 있어서 그 부위는 당화되지 않는다. 특정 구현예에서, CH2 도메인의 N-연결된 당화 부위에서 아스파라긴은 하기로 돌연변이된다: 글루타민 (예를 들면, Asn297Gln). 다른 구현예에서, CH2 도메인의 N-연결된 당화 부위에서 트레오닌은 하기로 돌연변이된다: 알라닌 또는 시스테인 (예를 들면, Thr299Ala 또는 Thr299Cys). 다른 예에서, CH2 도메인은 하기를 변화시키기 위해 돌연변이될 수 있다: 효과기 기능, 예를 들면, Leu234Ala/Leu235Ala, Pro329Gly, 및/또는 Pro331Ser.CH2 도메인은 또한 FcRn에 결합을 변화시키기 위해 돌연변이될 수 있다.
특정 구현예에서, 불변 도메인은 IgG4P/IgG1 하이브리드이다. 특정 경우에서, 불변 도메인은 IgG4P/IgG1 (agly) 하이브리드이다. 이들 하이브리드는 IgG4의 힌지 영역 및 CH2 도메인 그리고 IgG1의 CH3 도메인을 포함한다. IgG4의 힌지 영역은 S228P 돌연변이를 갖는다. agly 작제물에서, 추가로, N297Q, T299A, 또는 T299C 돌연변이의 것을 포함한다.
하나의 구현예에서, 2 Fc 영역 중 하나는 아래에 제시된 아미노산 서열을 포함한다 (이탤릭체된 힌지 영역; 밑줄친 N-연결된 당화 부위; 규칙적 폰트로 CH2 영역; 볼드체된 CH3 도메인).
DKTHTCPPCP APELLGGPSV FLFPPKPKDT LMISRTPEVT CVVVDVSHED
PEVKFNWYVD GVEVHNAKTK PREEQYNSTY RVVSVLTVLH QDWLNGKEYK
CKVSNKALPA PIEKTISKAK GQPREPQVYT LPPSRDELTK NQV K LTCLVK
GFYPSDIAVE WESNGQPENN YKTTPPVLDS DGSFFLYS
L
L TVDKSRWQQG
NVFSCSVMHE ALHNHYTQKS LSLSPG (서열 식별 번호:18)
이러한 구현예에서, 2 Fc 영역의 두번째는 아래에 제시된 아미노산 서열을 포함한다 (이탤릭체된 힌지 영역; 밑줄친 N-연결된 당화 부위; 규칙적 폰트로 CH2 영역; 볼드체된 CH3 도메인):
DKTHTCPPCP APELLGGPSV FLFPPKPKDT LMISRTPEVT CVVVDVSHED
PEVKFNWYVD GVEVHNAKTK PREEQYNSTY RVVSVLTVLH QDWLNGKEYK
CKVSNKALPA PIEKTISKAK GQPREPQVYT LPPSRDELTK NQVSLTCLV S
GFYPSDIAVE WESNGQPENN YKTTPP
I
LDS DGSF
K
LYS
K
L TVDKSRWQQG
NVFSCSVMHE ALHNHYTQKS LSLSPG (서열 식별 번호:19)
또 다른 구현예에서, 2 Fc 영역 중 하나는 아래에 제시된 아미노산 서열을 포함한다 (이탤릭체된 힌지 영역; 밑줄친 돌연변이된 N-연결된 당화 부위; 규칙적 폰트로 CH2 영역; 볼드체된 CH3 도메인):
DKTHTCPPCP APELLGGPSV FLFPPKPKDT LMISRTPEVT CVVVDVSHED
PEVKFNWYVD GVEVHNAKTK PREEQYQSTY RVVSVLTVLH QDWLNGKEYK
CKVSNKALPA PIEKTISKAK GQPREPQVYT LPPSRDELTK NQV K LTCLVK
GFYPSDIAVE WESNGQPENN YKTTPPVLDS DGSFFLYS
L
L TVDKSRWQQG
NVFSCSVMHE ALHNHYTQKS LSLSPG (서열 식별 번호:20)
이러한 구현예에서, 2 Fc 영역의 두번째는 아래에 제시된 아미노산 서열을 포함한다 (이탤릭체된 힌지 영역; 밑줄친 CH2 도메인의 돌연변이된 N-연결된 당화 부위를 가진 규칙적 폰트로 CH2 영역; 볼드체된 CH3 도메인):
DKTHTCPPCP APELLGGPSV FLFPPKPKDT LMISRTPEVT CVVVDVSHED
PEVKFNWYVD GVEVHNAKTK PREEQYQSTY RVVSVLTVLH QDWLNGKEYK
CKVSNKALPA PIEKTISKAK GQPREPQVYT LPPSRDELTK NQVSLTCLV S
GFYPSDIAVE WESNGQPENN YKTTPP
I
LDS DGSF
K
LYS
K
L TVDKSRWQQG
NVFSCSVMHE ALHNHYTQKS LSLSPG (서열 식별 번호:21)
이들 Fc 영역은 Fc 도메인이 헤테로이량체화할 수 있는 한 9 이하, 8 이하, 7 이하, 6 이하, 5 이하, 4 이하, 3 이하, 2 이하, 1, 2, 3, 4, 5, 6, 7 8, 또는 9 아미노산 치환, 삽입, 및/또는 결실을 포함할 수 있다. 아미노산 치환은 보존적 또는 비-보존적 아미노산 치환일 수 있다.
상기 기재된 임의의 CH3 도메인 및 Fc 도메인은 CH2E 도메인 (또는 CH2M 도메인)으로 대체된 그들의 CL 도메인을 갖는 상기 기재된 경쇄와 짝짓기하는 중쇄의 일부일 수 있다. 특이적으로, 중쇄는 VH 도메인에 직접적으로 연결되거나, 개입 서열을 통해, 연결되는 제2 CH2 도메인을 포함할 수 있고, 여기서 제2 CH2 도메인은 CH2E 도메인, 또는 CH2E 도메인과 이량체화할 수 있는 이의 단편이다. 특정 경우에서, 중쇄는 VH 도메인에 직접적으로 연결되거나, 개입 서열을 통해, 연결되는 제2 CH2 도메인을 포함할 수 있고, 여기서 제2 CH2 도메인은 CH2M 도메인, 또는 CH2M 도메인과 이량체화할 수 있는 이의 단편이다. 상기 기재된 임의의 CH3 도메인 및 Fc 도메인은 또한 CH1 및 CL 도메인을 갖는 상기 기재된 경쇄와 짝짓기하는 중쇄의 일부일 수 있다. 특정 경우에서, 상기 기재된 임의의 CH3 도메인 및 Fc 도메인은 CH2E 도메인 (또는 CH2M 도메인)으로 대체된 그들의 CL 도메인을 갖는 상기 기재된 경쇄와 짝짓기하는 제1 중쇄의 일부이고 상기 기재된 임의의 CH3 도메인 및 Fc 도메인은 CH1 및 CL 도메인을 포함하는 상기 기재된 경쇄와 짝짓기하는 제2 중쇄의 일부이다.
하나의 구현예에서, 중쇄는 다음과 같은 아미노산 서열을 포함한다:
ASTKGPTVKI LQS I CDGGGH FPPTIQLLCL VSGYTPGTIQ ITWLEDGQVM DVDLSTASTT
QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDST KKCASDKTHT CPPCPAPELL
GGPSVFLFPP KPKDTLMISR TPEVTCVVVD VSHEDPEVKF NWYVDGVEVH NAKTKPREEQ
YQSTYRVVSV LTVLHQDWLN GKEYKCKVSN KALPAPIEKT ISKAKGQPRE PQVYTLPPSR
DELTKNQV
K
L TCLVKGFYPS DIAVEWESNG QPENNYKTTP PVLDSDGSFF LYS
L
LTVDKS
RWQQGNVFSC SVMHEALHNH YTQKSLSLSP G (서열 식별 번호:22)
하나의 구현예에서, 이러한 중쇄는 다음과 같은 아미노산 서열을 포함하는 경쇄와 헤테로이량체화한다:
RTVAAPTVKI LQSSCDGGGH FPPTIQLLCL VSGYTPGTIQ ITWLEDGQVM DVDLSTASTTQEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDSG KKCA (서열 식별 번호:6)
이들 중쇄 및 경쇄 서열은 중쇄 및 경쇄가 헤테로이량체화할 수 있도록 9 이하, 8 이하, 7 이하, 6 이하, 5 이하, 4 이하, 3 이하, 2 이하, 1, 2, 3, 4, 5, 6, 7 8, 또는 9 아미노산 치환, 삽입, 및/또는 결실을 각각 포함할 수 있다. 아미노산 치환은 보존적 또는 비-보존적 아미노산 치환일 수 있다.
일부 구현예에서, 헤테로이량체화하는 상기 기재된 CH3 도메인 및 Fc 도메인은 1가 항체의 일부일 수 있다. 1가 항체는 항체의 2 Fc 영역 중 하나에 직접적으로 또는 개입 링커 서열을 통해 연결되는 Fab를 포함하고; 다른 Fc 영역은 이에 부착된 Fab 영역을 갖지 않는다.
다른 구현예에서, 헤테로이량체화하는 상기 기재된 CH3 도메인 및 Fc 도메인은 단일 쇄 Fc (scFc)의 일부일 수 있다. 특정 경우에서, Fab의 CH1 또는 CL 도메인은 제1 Fc 영역에 직접적으로 또는 개입 링커를 통해 연결되고 Fc 영역은 제2 Fc 영역에 연결된다 (예를 들면, 제1 Fc 영역의 CH3 도메인의 C-말단은 제2 Fc 영역의 N-말단 힌지 영역에 연결된다).
특정 구현예에서, 헤테로이량체화하는 상기 기재된 Fc 도메인은 Fab에 직접적으로 연결되거나, 링커를 통해 연결된다. 즉, Fab의 일부를 함유하는 VH/CH1은 제1 Fc의 N-말단 힌지 영역에 그것의 C-말단을 통해 연결되고 Fab의 일부를 함유하는 VL/CL은 제2 Fc 영역의 N-말단 힌지 영역에 그것의 C-말단을 통해 연결된다.
더욱 다른 구현예에서, 헤테로이량체화하는 상기 기재된 CH3 도메인 및 Fc 도메인은 제1 중쇄 및 제2 중쇄를 포함하는 항체의 일부이고, 여기서 상기 제1 및 제2 중쇄는 공통 경쇄와 짝짓기한다.
핵산
본 개시내용은 본 명세서에서 기재된 헤테로이량체성 이중특이적 및 1가 항체의 중쇄 및 경쇄를 인코딩하는 핵산을 또한 포함한다. VH, VL, 힌지, CH1, CH2, CH3, 및 CH4 영역을 포함하는 면역글로불린 영역을 인코딩하는 많은 핵산 서열은 당해 기술에 공지되어 있다. 참고, 예를 들면, Kabat 등 (SEQUENCES OF IMMUNOLOGICAL INTEREST, Public Health Service N.I.H., Bethesda, Md., 1991). 본 명세서에서 제공된 안내를 이용하여, 당해 분야의 숙련가는 본 명세서에서 기재된 헤테로이량체성 이중특이적 항체를 인코딩하는 핵산 서열을 창출하기 위해 당해 분야에서 공지된 그와 같은 핵산 서열 및/또는 다른 핵산 서열을 조합시킬 수 있다.
게다가, 본 명세서에서 기재된 헤테로이량체성 이중특이적 항체를 인코딩하는 핵산 서열은 본 명세서에서 제공된 아미노산 서열 및 당해 분야에서 지식에 기반하여 당해 분야의 숙련가에 의해 결정될 수 있다. 특정한 아미노산 서열을 인코딩하는 클로닝된 DNA 분절의 더욱 전통적 생산 방법 이외에, 회사들은 현재 주문에 따라 임의의 원하는 서열의 화학적으로 합성된, 유전자-크기의 DNAs를 일상적으로 생산하고, 따라서 그와 같은 DNAs의 생산 공정을 능률화시킨다.
이중특이적 항체의 제조 방법
본 명세서에서 기재된 이중특이적 및 1가 항체는 당해 분야에서 잘 알려진 방법을 이용하여 제조될 수 있다. 예를 들어, 이중특이적 항체의 4 폴리펩타이드 쇄를 인코딩하는 핵산은 다양한 공지된 방법, 예를 들면, 전환, 형질감염, 전기천공, 핵산-코팅된 미세투사물로 폭격, 등으로 숙주 세포 속에 도입될 수 있다. 일부 경우에서, 이중특이적 항체를 인코딩하는 핵산은 숙주 세포 속에 도입되기 전 숙주 세포에서 발현에 적절한 벡터 속에 삽입될 수 있다. 전형적으로, 그와 같은 벡터는 RNA 및 단백질 수준에서 삽입된 핵산의 발현을 가능하게 하는 서열 요소를 함유할 수 있다. 그와 같은 벡터는 당해 분야에서 잘 알려지고, 다수는 상업적으로 입수가능하다. 핵산을 함유하는 숙주 세포는 세포가 핵산을 발현시키게 하기 위한 조건하에 배양될 수 있다. 수득한 헤테로이량체성 이중특이적 항체는 세포 덩이 또는 배양 배지로부터 수집될 수 있다. 대안적으로, 헤테로이량체성 이중특이적 항체는 생체내, 예를 들어 식물 잎에서 생산될 수 있다 (참고, 예를 들면, Scheller 등, Nature Biotechnol., 19:573-577 (2001) 및 본 명세서에서 인용된 참조문헌), 새 알류 (참고, 예를 들면, Zhu 등(2005), Nature Biotechnol., 23:1159-1169 (2005) 및 본 명세서에서 인용된 참조문헌), 또는 포유동물 밀크 (참고, 예를 들면, Laible 등, Reprod.Fertil.Dev.25(1):315 (2012)). 단리된 항체는 인간 대상체에 투여용 멸균 조성물로서 제형화될 수 있다.
많은 다른 것들 중에서, 예를 들면, 박테리아 세포 예컨대 에스케리치아 콜라이 또는 바실러스 스테아로테모필루스, 진균 세포 예컨대 사카로마이세스 세레비지애 또는 피치아 패스토리스, 곤충 세포 예컨대 스포도프테라 프루지페르다 세포를 포함하는 레피돕테란 곤충 세포, 또는 포유동물 세포 예컨대 차이니즈 햄스터 난소 (CHO) 세포, 어린 햄스터 신장 (BHK) 세포, 원숭이 신장 세포, HeLa 세포, 인간 간세포 암종 세포, 또는 293 세포를 포함하는, 숙주 세포의 몇 개의 종류는 사용될 수 있다.
하기는 본 발명의 실시의 예이다. 이들은 어떤 식으로든 본 발명의 범위 제한으로서 해석되지 않아야 한다.
실시예
다음과 같은 실시예는 청구된 발명을 더 양호하게 설명하기 위해 제공되고 본 발명의 범위 제한으로서 해석되지 않아야 한다. 구체적 물질이 언급되지 않는 정도로, 단지 실례의 목적이고 본 발명을 제한하기 위해 의도되지 않는다. 당해 분야의 숙련가는 본 발명 수용력의 연습 없이 그리고 본 발명의 범위로부터 이탈 없이 동등한 수단 또는 반응물을 개발할 수 있다.
실시예 1:중쇄 헤테로이량체화 조작
CH3 도메인은 IgG의 2 중쇄 사이 접촉의 주요 지점 중 하나이다. 2 CH3 도메인은 계면에서 접촉 잔기의 밀착 팩킹으로 헤드-투-테일 배향에서 서로 결합한다. 중쇄 헤테로이량체화는 2 CH3 도메인 사이 접촉의 코어에서 소수성 표면의 조작에 의해 또는 접촉 표면의 주변에서 충전된 잔기의 변경에 의해 달성될 수 있다. 소수성 접촉 잔기의 밀착 팩킹을 유지시키기 위해, CH3 계면의 주변은 비대칭 조작을 위하여 선택되었다. CH3 도메인의 돌연변이용 추가 설계 기준은 하기를 포함하였다: (i) 헤테로이량체화의 효율적인 드라이버; (ii) 소수의 돌연변이; 및 (iii) 총 전하-중성 변화.돌연변이의 설계 및 CH3 도메인의 구조적 분석은 인간 IgG1 Fc의 결정 구조 (PDB 코드 3AVE)를 이용하여 실시되었다. 비교 분석은 구조의 선택을 시사하는 인간 Fc 도메인의 다중 공개된 구조 사이 높은 동일성이 CH3 조작용 핵심일 수 없다는 것을 보여주었다. 잠재적인 계면 돌연변이의 분석 및 모델링에 기반하여, 라이신 재위치결정의 전략은 비대칭 상보적 CH3 계면을 조작하기 위해 고안되었다 (도 2). 단량체 A에서 Lys409 (EU 넘버링)의 Ser로의 그리고 Ser364 (EU 넘버링)의 Lys로의 치환은 β-가닥 E부터 인접한 역평행 β-가닥 B까지 라이신을 재위치결정시킨다. 반대로, 단량체 B에서 Lys370 (EU 넘버링)의 Ser로의 그리고 Phe405 (EU 넘버링)의 Lys로의 치환은 β-가닥 B부터 β-가닥 E까지 라이신을 재위치결정시킨다. 재위치결정된 라이신은 헤테로이량체에서 적층되지만, 호모이량체에서 입체 및 전하 충돌을 시행하여, 그들의 형성을 예방할 수 있고, 따라서 헤테로이량체화를 구동시킬 수 있다.
라이신 재위치결정에 의해 헤테로이량체화의 유효성을 실험적으로 시험하기 위해, 시험 항체는 모노-mAbs로서 작제되었고, 여기에서 한쪽은 전체 인간 IgG1 중쇄이고 다른쪽은 Fab 없는 자유 Fc이다. 수득한 헤테로이량체는 분자량에서 유의차로 인해 호모이량체와 쉽게 식별될 수 있고, 헤테로이량체화는 SDS-PAGE상의 분리에 의해 평가될 수 있다. 항-EGFR 항체 M60-A02는 이들 시험 작제물에서 사용되었다. CH3 도메인에서 돌연변이는 표 1에서 열거된 프라이머를 이용하는 PCR-기반 돌연변이유발에 의해 생성되었다.
표 1. 중첩 PCR에 의해 인간 IgG1에서 CH3 돌연변이 S364K/K409S 및 K370S/F405K 생성용 프라이머.

증폭은 Q5 Hot Start High-Fidelity DNA Polymerase (NEB #M0493L)을 이용하여 수행되었고, PCR 생성물은 작제물을 구축하기 위해 HiFi Gibson 어셈블리 키트 (SGI #GA1100-50)과 함께 사용되었다.
재위치결정된 라이신의 개별 효과 속으로 일부 통찰력을 얻기 위해, 개별 돌연변이를 가진 작제물은 또한 구축되었다. 이들 절반-설계는 MP1 및 MP2, 각각으로 명명되었다 (표 2).
표 2. Fc 헤테로이량체화 시험용 작제물.

완전한 설계는 재위치결정된 양쪽 라이신을 갖고 (pMP237은 돌연변이 S364K/K409S를 갖고, pMP238은 K370S/F405K를 갖는다) 헤테로이량체화 구동에서 가장 효과적이어야 한다. 상기 설계는 MP3으로 명명되었다. MP3의 CH3 도메인의 펩타이드 서열은 하기 보여진다:
CH3 도메인 MP3 단량체 A의 아미노산 서열 (돌연변이는 볼드체이고 밑줄쳐진다)
1 GQPREPQVYT LPPSRDELTK NQV K LTCLVK GFYPSDIAVE WESNGQPENN YKTTPPVLDS 61 DGSFFLYS S L TVDKSRWQQG NVFSCSVMHE ALHNHYTQKS LSLSPG (서열 식별 번호:39)
CH3 도메인 MP3 단량체 B의 아미노산 서열 (돌연변이는 볼드체이고 밑줄쳐진다)
1 GQPREPQVYT LPPSRDELTK NQVSLTCLV S GFYPSDIAVE WESNGQPENN YKTTPPVLDS 61 DGSF K LYSKL TVDKSRWQQG NVFSCSVMHE ALHNHYTQKS LSLSPG (서열 식별 번호:40)
추가로, 몇 개의 공개된 CH3 헤테로이량체화 돌연변이는 비교를 위하여 생성되었다 (Atwell 등, J. Mol. Biol., 270:26-35, 1997; Gunasekaran 등, J.Biol.Chem., 285:19637-19646, 2010; Von Kreudenstein 등, mAbs 5:646-654, 2013). 더욱이, 작제물 pMP221 및 pMP222는 야생형 IgG1 대조군을 나타내기 위해 구축되었다. 헤테로이량체화의 상기 초기 시험을 위하여 생성되었던 모든 작제물은 표 2에서 요약되고, 모든 플라스미드는 DNA 서열분석에 의해 확인되었다.
항체는 일시적 형질감염에 의해 CHO 세포에서 발현되었다. 다음 날 280C로 온도 이동 및 2:1 비로 Fectopro 및 DNA를 가진 6 X 106 세포/ml로 형질감염된 CHO 세포를 이용하여 9 일 발현후 100과 200 mg/L 사이 역가를 생산하는, 모든 항체는 양호하게 발현하였다. 상청액은 단백질 A 칼럼상에서 정제되었고 분취액은 SDS-PAGE에 의해 분석되었다 (도 3A). IgG1 중쇄 및 자유 Fc의 헤테로이량체는 모든 샘플에서 우세하게 발견되었다. 게다가, 야생형 IgG1 및 Fc의 공-형질감염은 또한 양쪽 호모이량체에 상응하는 강한 밴드를 생산하였다. 이들 밴드는 공개된 돌연변이체 및 모든 라이신 재위치결정 돌연변이체에서 상당히 더욱 약했다. 따라서, 라이신 재위치결정 및 공개된 돌연변이는 중쇄 헤테로이량체의 형성을 구동하고 호모이량체화를 감소시킨다. 단백질 A-정제된 물질은 질량 분광분석법에 의해 추가로 분석되었고 주요 구성요소의 상대량은 추정되었다. 샘플에서 헤테로이량체의 양은 35% 내지 80% 범위이었고, 공개된 설계보다 라이신 재위치결정 돌연변이체 MP1, MP2 및 MP3에서 약간 더 높았다 (도 3B). 그러나, 개별 쇄의 다양한 발현 수준은 직접적인 비교를 어렵게 하는 이들 결과에 영향을 미친다. 중요하게는, 설계 MP2 및 MP3 뿐만 아니라 ZW1 및 노브-인투-홀 돌연변이 모두는 모노머성 Fc를 함유하였다. 모노머성 Fc의 존재는 Fc 이량체가 CH3에서 돌연변이에 의해 탈안정화되고, 따라서 덜 형성될 것 같다는 것을 입증한다. 대체로, 이들 결과는 라이신 재위치결정이, 몇 개의 공개된 돌연변이만큼 효율적으로 호모이량체화를 예방하는, 효율적인 중쇄 헤테로이량체화 전략이라는 것을 보여준다.
상기 초기 시험 후, 추가의 구조적 모델링은 계면 잔기의 팩킹을 개선할 수 있는 돌연변이를 확인하기 위해 실시되었다. 그와 같은 돌연변이는 헤테로이량체화의 효율 또는 이량체의 안정성을 잠재적으로 증가시킬 수 있고, 따라서 유익할 것이다. 최초 라이신 재위치결정 설계 MP3을 개선할 수 있는 2 변화는 확인되었다. 상기 신규한 설계는 MP4로 명명되었고 아미노산 변화는 표 2에서 보여진다. MP4 돌연변이를 가진 IgG1/Fc 헤테로이량체는 상기 기재된 바와 같이 CHO 세포에서 발현되었고 단백질 A에 의해 상청액으로부터 정제되었다. 질량 분광분석법 분석은 MP4가 MP3만큼 효율적으로 IgG1 중쇄와 자유 Fc 사이 헤테로이량체를 생산하였다는 것을 실증하였다 (도 3B).
모든 헤테로이량체성 단백질은 Fc 이량체 및 단량체를 제거하기 위해 KappaSelect 칼럼상에서 추가로 정제되었고, 탠덤 Superdex S200상에서 폴리싱 단계가 뒤따랐다. 상기 3-단계 정제는 용융 온도를 결정하기 위해 시차 주사 열량측정 (DSC)에 사용되었던 상대적으로 순수한 헤테로이량체를 수득하였다. 야생형 IgG1 대조군은 CH3 도메인의 기대된 Tm ~83ºC를 보여주었다 (도 3C). ZW1 설계는, 야생형 IgG1 (Von Kreudenstein 등, mAbs 5:646-654, 2013)의 열적 안정성을 되찾기 위해 반복적인 공정에서 광범위하게 조작된 바와 같이, 유사한 CH3 용융 온도를 갖는다 (도 3C). 노브-인투-홀 및 정전기 조향 비교측정기 분자는 DSC 프로파일에서 단 하나의 피크를 보여주었고, CH3 도메인의 Tm이 ~70 ℃로 감소되고 도메인은, DSC에서 단일 피크를 생산하는, CH2 및 Fab 도메인으로 용융중인 것을 시사한다 (도 3C). MP3 분자는, CH3의 Tm이 유사하게 떨어지는 것을 나타내는, DSC 프로파일내 ~70 ℃에서 단 하나의 피크를 또한 보여주었다 (도 3C). 단백질 MP4 및 MP4a3b (MP4 단량체 A 및 MP3 단량체 B)는 CH2/Fab 피크의 우측에서 숄더를 보여주었고 (도 3C), 돌연변이 K409L이 최초 돌연변이 K409S보다 약간 증가된 안정성을 부여하고, 추가 조작에 의해 Tm을 개선하는 것이 가능할 수 있다는 것을 시사한다. 그럼에도 불구하고, 설계 MP4는 야생형 IgG1 CH3 도메인에 비교하여 감소된 Tm을 갖는다.
MP4의 CH3 도메인의 펩타이드 서열은 하기 보여진다:
CH3 도메인 MP4 단량체 A의 서열 (돌연변이는 볼드체이고 밑줄쳐진다)
1 GQPREPQVYT LPPSRDELTK NQV K LTCLVK GFYPSDIAVE WESNGQPENN YKTTPPVLDS 61 DGSFFLYS L L TVDKSRWQQG NVFSCSVMHE ALHNHYTQKS LSLSPG (서열 식별 번호:41)
CH3 도메인 MP4 단량체 B의 서열 (돌연변이는 볼드체이고 밑줄쳐진다)
1 GQPREPQVYT LPPSRDELTK NQVSLTCLV S GFYPSDIAVE WESNGQPENN YKTTPP I LDS 61 DGSF K LYSKL TVDKSRWQQG NVFSCSVMHE ALHNHYTQKS LSLSPG (서열 식별 번호:42)
MP4를 인코딩하는 플라스미드 (pMP254 및 pMP259)의 DNA 서열은 하기 제공된다:
MP4A 돌연변이 (S634K, K409L)를 가진 pMP254, 항-EGFR M60-A02 IgG1 중쇄의 DNA 서열:
1 agcttgacat tgattattga ctagttatta atagtaatca attacggggt cattagttca
61 tagcccatat atggagttcc gcgttacata acttacggta aatggcccgc ctggctgacc
121 gcccaacgac ccccgcccat tgacgtcaat aatgacgtat gttcccatag taacgccaat
181 agggactttc cattgacgtc aatgggtgga gtatttacgg taaactgccc acttggcagt
241 acatcaagtg tatcatatgc caagtacgcc ccctattgac gtcaatgacg gtaaatggcc
301 cgcctggcat tatgcccagt acatgacctt atgggacttt cctacttggc agtacatcta
361 cgtattagtc atcgctatta ccatggtgat gcggttttgg cagtacatca atgggcgtgg
421 atagcggttt gactcacggg gatttccaag tctccacccc attgacgtca atgggagttt
481 gttttggcac caaaatcaac gggactttcc aaaatgtcgt aacaactccg ccccattgac
541 gcaaatgggc ggtaggcgtg tacggtggga ggtctatata agcagagctc gtttagtgaa
601 ccgtcagatc gcctggagac gccatccacg ctgttttgac ctccatagaa gacaccggga
661 ccgatccagc ctccgcggcc gggaacggtg cattggaacg cggattcccc gtgccaagag
721 tgacgtaagt accgcctata gagtctatag gcccaccccc ttggcttctt atgcatgcta
781 tactgttttt ggcttggggt ctatacaccc ccgcttcctc atgttatagg tgatggtata
841 gcttagccta taggtgtggg ttattgacca ttattgacca ctcccctatt ggtgacgata
901 ctttccatta ctaatccata acatggctct ttgccacaac tctctttatt ggctatatgc
961 caatacactg tccttcagag actgacacgg actctgtatt tttacaggat ggggtctcat
1021 ttattattta caaattcaca tatacaacac caccgtcccc agtgcccgca gtttttatta
1081 aacataacgt gggatctcca cgcgaatctc gggtacgtgt tccggaacgg tggagggcag
1141 tgtagtctga gcagtactcg ttgctgccgc gcgcgccacc agacataata gctgacagac
1201 taacagactg ttcctttcca tgggtctttt ctgcagtcac cgtccttgac acgggatccg
1261 cggccgccac cATGGGTTGG AGCCTCATCT TGCTCTTCCT TGTCGCTGTT GCTACGCGTG
1321 TCCTGTCCGA GGTGCAGCTG TTGGAGTCTG GGGGAGGCTT GGTCCAGCCT GGGGGGTCCC
1381 TGAGACTCTC CTGTGCAGCC TCTGGATTCA CCTTCAGTGA CTATATTATG CACTGGGTCC
1441 GCCAGGCTCC AGGGAAGGGG CTGGAGTGGG TCTCAGTTAT TAGTAGTTCT GGTGGCGACA
1501 CATCCTACGC AGACTCCGTG AAGGGCCGAT TCACCATCTC CAGAGACAAT TCCAAGAACA
1561 CGCTGTATCT GCAAATGAAC AGCCTGAGAG CCGAGGACAC GGCCGTGTAT TACTGTGCGA
1621 AAGTCCTCGC GGGTTACTTC GACTGGTTAC CCTTTGACTA CTGGGGCCAG GGAACCCTGG
1681 TCACCGTCTC GAGCGCCTCC ACCAAGGGCC CATCGGTCTT CCCCCTGGCA CCCTCCTCCA
1741 AGAGCACCTC TGGGGGCACA GCGGCCCTGG GCTGCCTGGT CAAGGACTAC TTCCCCGAAC
1801 CGGTGACGGT GTCGTGGAAC TCAGGCGCCC TGACCAGCGG CGTGCACACC TTCCCGGCTG
1861 TCCTACAGTC CTCAGGACTC TACTCCCTCA GCAGCGTGGT GACCGTGCCC TCCAGCAGCT
1921 TGGGCACCCA GACCTACATC TGCAACGTGA ATCACAAGCC CAGCAACACC AAGGTGGACA
1981 AGAAAGTTGA GCCCAAATCT TGTGACAAGA CTCACACATG CCCACCGTGC CCAGCACCTG
2041 AACTCCTGGG GGGACCGTCA GTCTTCCTCT TCCCCCCAAA ACCCAAGGAC ACCCTCATGA
2101 TCTCCCGGAC CCCTGAGGTC ACATGCGTGG TGGTGGACGT GAGCCACGAA GACCCTGAGG
2161 TCAAGTTCAA CTGGTACGTG GACGGCGTGG AGGTGCATAA TGCCAAGACA AAGCCGCGGG
2221 AGGAGCAGTA CAACAGCACG TACCGTGTGG TCAGCGTCCT CACCGTCCTG CACCAGGACT
2281 GGCTGAATGG CAAGGAGTAC AAGTGCAAGG TCTCCAACAA AGCCCTCCCA GCCCCCATCG
2341 AGAAAACCAT CTCCAAAGCC AAAGGGCAGC CCCGAGAACC ACAGGTGTAC ACCCTGCCCC
2401 CATCCCGGGA TGAGCTGACC AAGAACCAGG TCAAACTGAC CTGCCTGGTC AAAGGCTTCT
2461 ATCCCAGCGA CATCGCCGTG GAGTGGGAGA GCAATGGGCA GCCGGAGAAC AACTACAAGA
2521 CCACGCCTCC CGTGTTGGAC TCCGACGGCT CCTTCTTCCT CTACAGCCTC CTCACCGTGG
2581 ACAAGAGCAG GTGGCAGCAG GGGAACGTCT TCTCATGCTC CGTGATGCAT GAGGCTCTGC
2641 ACAACCACTA CACGCAGAAG AGCCTCTCCC TGTCTCCGGG TTAGtaatta attaatgcat
2701 ctagggcggc caattccgcc cctctccctc ccccccccct aacgttactg gccgaagccg
2761 cttggaataa ggccggtgtg cgtttgtcta tatgtgattt tccaccatat tgccgtcttt
2821 tggcaatgtg agggcccgga aacctggccc tgtcttcttg acgagcattc ctaggggtct
2881 ttcccctctc gccaaaggaa tgcaaggtct gttgaatgtc gtgaaggaag cagttcctct
2941 ggaagcttct tgaagacaaa caacgtctgt agcgaccctt tgcaggcagc ggaacccccc
3001 acctggcgac aggtgcctct gcggccaaaa gccacgtgta taagatacac ctgcaaaggc
3061 ggcacaaccc cagtgccacg ttgtgagttg gatagttgtg gaaagagtca aatggctctc
3121 ctcaagcgta ttcaacaagg ggctgaagga tgcccagaag gtaccccatt gtatgggatc
3181 tgatctgggg cctcggtgca catgctttac atgtgtttag tcgaggttaa aaaaacgtct
3241 aggccccccg aaccacgggg acgtggtttt cctttgaaaa acacgatgat aagcttgcca
3301 caagctagca tggttcgacc attgaactgc atcgtcgccg tgtcccaaaa tatggggatt
3361 ggcaagaacg gagacctacc ctggcctccg ctcaggaacg agttcaagta cttccaaaga
3421 atgaccacaa cctcttcagt ggaaggtaaa cagaatctgg tgattatggg taggaaaacc
3481 tggttctcca ttcctgagaa gaatcgacct ttaaaggaca gaattaatat agttctcagt
3541 agagaactca aagaaccacc acgaggagct cattttcttg ccaaaagttt ggatgatgcc
3601 ttaagactta ttgaacaacc ggaattggca agtaaagtag acatggtttg gatagtcgga
3661 ggcagttctg tttaccagga agccatgaat caaccaggcc acctcagact ctttgtgaca
3721 aggatcatgc aggaatttga aagtgacacg tttttcccag aaattgattt ggggaaatat
3781 aaacttctcc cagaataccc aggcgtcctc tctgaggtcc aggaggaaaa aggcatcaag
3841 tataagtttg aagtctacga gaagaaagac taatcgagaa ttgtctagac tgcccgggtg
3901 gcatccctgt gacccctccc cagtgcctct cctggtcgtg gaaggtgcta ctccagtgcc
3961 caccagcctt gtcctaataa aattaagttg catcattttg tttgactagg tgtccttgta
4021 taatattatg gggtggaggc gggtggtatg gagcaagggg caggttggga agacaacctg
4081 tagggccttc agggtctatt gggaaccagg ctggagtgca gtggcacgat cttggctcgc
4141 tgcaatctcc gcctcctggg ttcaagcgat tctcctgcct cagtctcccg aatagttggg
4201 attccaggca tgcacgacca ggctcagcta atttttgtat ttttggtaga gacggggttt
4261 caccatattg gccagtctgg tctccatctc ctgacctcag gtaatccgcc cgcctcggcc
4321 tcccaaattg ctgggattac aggtatgagc cactgggccc ttccctgtcc tgtgatttta
4381 aaataattat accagcagaa ggacgtccag acacagcatg ggctacctgg ccatgcccag
4441 ccagttggac atttgagttg tttgcttggc actgtcctct catcaattca ctggccgtcg
4501 ttttacaacg tcgtgactgg gaaaaccctg gcgttaccca acttaatcgc cttgcagcac
4561 atcccccttt cgccagctgg cgtaatagcg aagaggcccg caccgatcgc ccttcccaac
4621 agttgcgcag cctgaatggc gaatggcgcc tgatgcggta ttttctcctt acgcatctgt
4681 gcggtatttc acaccgcata tggtgcactc tcagtacaat ctgctctgat gccgcatagt
4741 taagccagcc ccgacacccg ccaacacccg ctgacgcgcc ctgacgggct tgtctgctcc
4801 cggcatccgc ttacagacaa gctgtgaccg tctccgggag ctgcatgtgt cagaggtttt
4861 caccgtcatc accgaaacgc gcgagacgaa agggcctcgt gatacgccta tttttatagg
4921 ttaatgtcat gataataatg gtttcttaga cgtcaggtgg cacttttcgg ggaaatgtgc
4981 gcggaacccc tatttgttta tttttctaaa tacattcaaa tatgtatccg ctcatgagac
5041 aataaccctg ataaatgctt caataatatt gaaaaaggaa gagtatgagt attcaacatt
5101 tccgtgtcgc ccttattccc ttttttgcgg cattttgcct tcctgttttt gctcacccag
5161 aaacgctggt gaaagtaaaa gatgctgaag atcagttggg tgcacgagtg ggttacatcg
5221 aactggatct caacagcggt aagatccttg agagttttcg ccccgaagaa cgttttccaa
5281 tgatgagcac ttttaaagtt ctgctatgtg gcgcggtatt atcccgtatt gacgccgggc
5341 aagagcaact cggtcgccgc atacactatt ctcagaatga cttggttgag tactcaccag
5401 tcacagaaaa gcatcttacg gatggcatga cagtaagaga attatgcagt gctgccataa
5461 ccatgagtga taacactgcg gccaacttac ttctgacaac gatcggagga ccgaaggagc
5521 taaccgcttt tttgcacaac atgggggatc atgtaactcg ccttgatcgt tgggaaccgg
5581 agctgaatga agccatacca aacgacgagc gtgacaccac gatgcctgta gcaatggcaa
5641 caacgttgcg caaactatta actggcgaac tacttactct agcttcccgg caacaattaa
5701 tagactggat ggaggcggat aaagttgcag gaccacttct gcgctcggcc cttccggctg
5761 gctggtttat tgctgataaa tctggagccg gtgagcgtgg gtctcgcggt atcattgcag
5821 cactggggcc agatggtaag ccctcccgta tcgtagttat ctacacgacg gggagtcagg
5881 caactatgga tgaacgaaat agacagatcg ctgagatagg tgcctcactg attaagcatt
5941 ggtaactgtc agaccaagtt tactcatata tactttagat tgatttaaaa cttcattttt
6001 aatttaaaag gatctaggtg aagatccttt ttgataatct catgaccaaa atcccttaac
6061 gtgagttttc gttccactga gcgtcagacc ccgtagaaaa gatcaaagga tcttcttgag
6121 atcctttttt tctgcgcgta atctgctgct tgcaaacaaa aaaaccaccg ctaccagcgg
6181 tggtttgttt gccggatcaa gagctaccaa ctctttttcc gaaggtaact ggcttcagca
6241 gagcgcagat accaaatact gttcttctag tgtagccgta gttaggccac cacttcaaga
6301 actctgtagc accgcctaca tacctcgctc tgctaatcct gttaccagtg gctgctgcca
6361 gtggcgataa gtcgtgtctt accgggttgg actcaagacg atagttaccg gataaggcgc
6421 agcggtcggg ctgaacgggg ggttcgtgca cacagcccag cttggagcga acgacctaca
6481 ccgaactgag atacctacag cgtgagctat gagaaagcgc cacgcttccc gaagggagaa
6541 aggcggacag gtatccggta agcggcaggg tcggaacagg agagcgcacg agggagcttc
6601 cagggggaaa cgcctggtat ctttatagtc ctgtcgggtt tcgccacctc tgacttgagc
6661 gtcgattttt gtgatgctcg tcaggggggc ggagcctatg gaaaaacgcc agcaacgcgg
6721 cctttttacg gttcctggcc ttttgctggc cttttgctca catgttcttt cctgcgttat
6781 cccctgattc tgtggataac cgtattaccg cctttgagtg agctgatacc gctcgccgca
6841 gccgaacgac cgagcgcagc gagtcagtga gcgaggaagc ggaagagcgc ccaatacgca
6901 aaccgcctct ccccgcgcgt tggccgattc attaatgcag ctggcacgac aggtttcccg
6961 actggaaagc gggcagtgag cgcaacgcaa ttaatgtgag ttagctcact cattaggcac
7021 cccaggcttt acactttatg cttccggctc gtatgttgtg tggaattgtg agcggataac
7081 aatttcacac aggaaacagc tatgaccatg attacgcca (서열 식별 번호:43)
MP4B 돌연변이 (K370S, V397I, F405K)를 가진 pMP259, IgG1 Fc의 DNA 서열:
1 agcttgacat tgattattga ctagttatta atagtaatca attacggggt cattagttca
61 tagcccatat atggagttcc gcgttacata acttacggta aatggcccgc ctggctgacc
121 gcccaacgac ccccgcccat tgacgtcaat aatgacgtat gttcccatag taacgccaat
181 agggactttc cattgacgtc aatgggtgga gtatttacgg taaactgccc acttggcagt
241 acatcaagtg tatcatatgc caagtacgcc ccctattgac gtcaatgacg gtaaatggcc
301 cgcctggcat tatgcccagt acatgacctt atgggacttt cctacttggc agtacatcta
361 cgtattagtc atcgctatta ccatggtgat gcggttttgg cagtacatca atgggcgtgg
421 atagcggttt gactcacggg gatttccaag tctccacccc attgacgtca atgggagttt
481 gttttggcac caaaatcaac gggactttcc aaaatgtcgt aacaactccg ccccattgac
541 gcaaatgggc ggtaggcgtg tacggtggga ggtctatata agcagagctc gtttagtgaa
601 ccgtcagatc gcctggagac gccatccacg ctgttttgac ctccatagaa gacaccggga
661 ccgatccagc ctccgcggcc gggaacggtg cattggaacg cggattcccc gtgccaagag
721 tgacgtaagt accgcctata gagtctatag gcccaccccc ttggcttctt atgcatgcta
781 tactgttttt ggcttggggt ctatacaccc ccgcttcctc atgttatagg tgatggtata
841 gcttagccta taggtgtggg ttattgacca ttattgacca ctcccctatt ggtgacgata
901 ctttccatta ctaatccata acatggctct ttgccacaac tctctttatt ggctatatgc
961 caatacactg tccttcagag actgacacgg actctgtatt tttacaggat ggggtctcat
1021 ttattattta caaattcaca tatacaacac caccgtcccc agtgcccgca gtttttatta
1081 aacataacgt gggatctcca cgcgaatctc gggtacgtgt tccggaacgg tggagggcag
1141 tgtagtctga gcagtactcg ttgctgccgc gcgcgccacc agacataata gctgacagac
1201 taacagactg ttcctttcca tgggtctttt ctgcagtcac cgtccttgac acgggatccg
1261 cggccgccAT GGAGACAGAC ACACTCCTGC TATGGGTACT GCTGCTCTGG GTTCCAGGTT
1321 CCAccggTGA CAAGACTCAC ACATGCCCAC CGTGCCCAGC ACCTGAACTC CTGGGGGGAC
1381 CGTCAGTCTT CCTCTTCCCC CCAAAACCCA AGGACACCCT CATGATCTCC CGGACCCCTG
1441 AGGTCACATG CGTGGTGGTG GACGTGAGCC ACGAAGACCC TGAGGTCAAG TTCAACTGGT
1501 ACGTGGACGG CGTGGAGGTG CATAATGCCA AGACAAAGCC GCGGGAGGAG CAGTACAACA
1561 GCACGTACCG TGTGGTCAGC GTCCTCACCG TCCTGCACCA GGACTGGCTG AATGGCAAGG
1621 AGTACAAGTG CAAGGTCTCC AACAAAGCCC TCCCAGCCCC CATCGAGAAA ACCATCTCCA
1681 AAGCCAAAGG GCAGCCCCGA GAACCACAGG TGTACACCCT GCCCCCATCC CGGGATGAGC
1741 TGACCAAGAA CCAGGTCAGC CTGACCTGCC TGGTCAGCGG CTTCTATCCC AGCGACATCG
1801 CCGTGGAGTG GGAGAGCAAT GGGCAGCCGG AGAACAACTA CAAGACCACG CCTCCCATCT
1861 TGGACTCCGA CGGCTCCTTC AAACTCTACA GCAAGCTCAC CGTGGACAAG AGCAGGTGGC
1921 AGCAGGGGAA CGTCTTCTCA TGCTCCGTGA TGCATGAGGC TCTGCACAAC CACTACACGC
1981 AGAAGAGCCT CTCCCTGTCT CCGGGTTAGt aattaattaa tgcatctagg gcggccaatt
2041 ccgcccctct ccctcccccc cccctaacgt tactggccga agccgcttgg aataaggccg
2101 gtgtgcgttt gtctatatgt tattttccac catattgccg tcttttggca atgtgagggc
2161 ccggaaacct ggccctgtct tcttgacgag cattcctagg ggtctttccc ctctcgccaa
2221 aggaatgcaa ggtctgttga atgtcgtgaa ggaagcagtt cctctggaag cttcttgaag
2281 acaaacaacg tctgtagcga ccctttgcag gcagcggaac cccccacctg gcgacaggtg
2341 cctctgcggc caaaagccac gtgtataaga tacacctgca aaggcggcac aaccccagtg
2401 ccacgttgtg agttggatag ttgtggaaag agtcaaatgg ctctcctcaa gcgtattcaa
2461 caaggggctg aaggatgccc agaaggtacc ccattgtatg ggatctgatc tggggcctcg
2521 gtgcacatgc tttacatgtg tttagtcgag gttaaaaaaa cgtctaggcc ccccgaacca
2581 cggggacgtg gttttccttt gaaaaacacg atgataatat ggccacaacc atggttaccg
2641 agtacaagcc cacggtgcgc ctcgccaccc gcgacgacgt ccccagggcc gtacgcaccc
2701 tcgccgccgc gttcgccgac taccccgcca cgcgccacac cgtcgatccg gaccgccaca
2761 tcgagcgggt caccgagctg caagaactct tcctcacgcg cgtcgggctc gacatcggca
2821 aggtgtgggt cgcggacgac ggcgccgcgg tggcggtctg gaccacgccg gagagcgtcg
2881 aagcgggggc ggtgttcgcc gagatcggcc cgcgcatggc cgagttgagc ggttcccggc
2941 tggccgcgca gcaacagatg gaaggcctcc tggcgccgca ccggcccaag gagcccgcgt
3001 ggttcctggc caccgtcggc gtctcgcccg accaccaggg caagggtctg ggcagcgccg
3061 tcgtgctccc cggagtggag gcggccgagc gcgccggggt gcccgccttc ctggagacct
3121 ccgcgccccg caacctcccc ttctacgagc ggctcggctt caccgtcacc gccgacgtcg
3181 aggtgcccga aggaccgcgc acctggtgca tgacccgcaa gcccggtgcc tgagtcgatg
3241 ataatcgatt agactgcccg ggtggcatcc ctgtgacccc tccccagtgc ctctcctggt
3301 cgtggaaggt gctactccag tgcccaccag ccttgtccta ataaaattaa gttgcatcat
3361 tttgtttgac taggtgtcct tgtataatat tatggggtgg aggcgggtgg tatggagcaa
3421 ggggcaggtt gggaagacaa cctgtagggc cttcagggtc tattgggaac caggctggag
3481 tgcagtggca cgatcttggc tcgctgcaat ctccgcctcc tgggttcaag cgattctcct
3541 gcctcagtct cccgaatagt tgggattcca ggcatgcacg accaggctca gctaattttt
3601 gtatttttgg tagagacggg gtttcaccat attggccagt ctggtatcca tctcctgacc
3661 tcaggtaatc cgcccgcctc ggcctcccaa attgctggga ttacaggtat gagccactgg
3721 gcccttccct gtcctgtgat tttaaaataa ttataccagc agaaggacgt ccagacacag
3781 catgggctac ctggccatgc ccagccagtt ggacatttga gttgtttgct tggcactgtc
3841 ctctcatcaa ttcgagctca ctggccgtcg ttttacaacg tcgtgactgg gaaaaccctg
3901 gcgttaccca acttaatcgc cttgcagcac atcccccttt cgccagctgg cgtaatagcg
3961 aagaggcccg caccgatcgc ccttcccaac agttgcgcag cctgaatggc gaatggcgcc
4021 tgatgcggta ttttctcctt acgcatctgt gcggtatttc acaccgcata tggtgcactc
4081 tcagtacaat ctgctctgat gccgcatagt taagccagcc ccgacacccg ccaacacccg
4141 ctgacgcgcc ctgacgggct tgtctgctcc cggcatccgc ttacagacaa gctgtgaccg
4201 tctccgggag ctgcatgtgt cagaggtttt caccgtcatc accgaaacgc gcgagacgaa
4261 agggcctcgt gatacgccta tttttatagg ttaatgtcat gataataatg gtttcttaga
4321 cgtcaggtgg cacttttcgg ggaaatgtgc gcggaacccc tatttgttta tttttctaaa
4381 tacattcaaa tatgtatccg ctcatgagac aataaccctg ataaatgctt caataatatt
4441 gaaaaaggaa gagtatgagt attcaacatt tccgtgtcgc ccttattccc ttttttgcgg
4501 cattttgcct tcctgttttt gctcacccag aaacgctggt gaaagtaaaa gatgctgaag
4561 atcagttggg tgcacgagtg ggttacatcg aactggatct caacagcggt aagatccttg
4621 agagttttcg ccccgaagaa cgttttccaa tgatgagcac ttttaaagtt ctgctatgtg
4681 gcgcggtatt atcccgtatt gacgccgggc aagagcaact cggtcgccgc atacactatt
4741 ctcagaatga cttggttgag tactcaccag tcacagaaaa gcatcttacg gatggcatga
4801 cagtaagaga attatgcagt gctgccataa ccatgagtga taacactgcg gccaacttac
4861 ttctgacaac gatcggagga ccgaaggagc taaccgcttt tttgcacaac atgggggatc
4921 atgtaactcg ccttgatcgt tgggaaccgg agctgaatga agccatacca aacgacgagc
4981 gtgacaccac gatgcctgta gcaatggcaa caacgttgcg caaactatta actggcgaac
5041 tacttactct agcttcccgg caacaattaa tagactggat ggaggcggat aaagttgcag
5101 gaccacttct gcgctcggcc cttccggctg gctggtttat tgctgataaa tctggagccg
5161 gtgagcgtgg ttcccgcggt atcattgcag cactggggcc agatggtaag ccctcccgta
5221 tcgtagttat ctacacgacg gggagtcagg caactatgga tgaacgaaat agacagatcg
5281 ctgagatagg tgcctcactg attaagcatt ggtaactgtc agaccaagtt tactcatata
5341 tactttagat tgatttaaaa cttcattttt aatttaaaag gatctaggtg aagatccttt
5401 ttgataatct catgaccaaa atcccttaac gtgagttttc gttccactga gcgtcagacc
5461 ccgtagaaaa gatcaaagga tcttcttgag atcctttttt tctgcgcgta atctgctgct
5521 tgcaaacaaa aaaaccaccg ctaccagcgg tggtttgttt gccggatcaa gagctaccaa
5581 ctctttttcc gaaggtaact ggcttcagca gagcgcagat accaaatact gttcttctag
5641 tgtagccgta gttaggccac cacttcaaga actctgtagc accgcctaca tacctcgctc
5701 tgctaatcct gttaccagtg gctgctgcca gtggcgataa gtcgtgtctt accgggttgg
5761 actcaagacg atagttaccg gataaggcgc agcggtcggg ctgaacgggg ggttcgtgca
5821 cacagcccag cttggagcga acgacctaca ccgaactgag atacctacag cgtgagctat
5881 gagaaagcgc cacgcttccc gaagggagaa aggcggacag gtatccggta agcggcaggg
5941 tcggaacagg agagcgcacg agggagcttc cagggggaaa cgcctggtat ctttatagtc
6001 ctgtcgggtt tcgccacctc tgacttgagc gtcgattttt gtgatgctcg tcaggggggc
6061 ggagcctatg gaaaaacgcc agcaacgcgg cctttttacg gttcctggcc ttttgctggc
6121 cttttgctca catgttcttt cctgcgttat cccctgattc tgtggataac cgtattaccg
6181 cctttgagtg agctgatacc gctcgccgca gccgaacgac cgagcgcagc gagtcagtga
6241 gcgaggaagc ggaagggcgc ccaatacgca aaccgcctct ccccgcgcgt tggccgattc
6301 attaatgcag ctggcacgac aggtttcccg actggaaagc gggcagtgag cgcaacgcaa
6361 ttaatgtgag ttagctcact cattaggcac cccaggcttt acactttatg cttccggctc
6421 gtatgttgtg tggaattgtg agcggataac aatttcacac aggaaacagc tatgaccatg
6481 attacgcca (서열 식별 번호:44)
실시예 2: 중쇄 헤테로이량체화 돌연변이체의 시험
라이신 재위치결정 설계를 추가로 특성규명하기 위해, 돌연변이는 전체 IgG1 중쇄 속으로 편입되었다. 이들 작제물은 잠재적인 영향을 제한하기 위해 그리고 경쇄 짝짓기 문제를 피하기 위해 양쪽 중쇄에서 동일한 Fab (항-EGFR M60-A02)를 함유하였다. M60-A02의 2 중쇄 및 경쇄의 동등량은 CHO 일시적 균에서 발현되었고 상청액은 SDS-PAGE에 의해 분석되었다. 모든 상청액은 1 중쇄 및 1 경쇄로 구성된 절반-항체의 상당한 양을 함유하였지만, 설계 MP4는 LC-MS 피크의 정량화에 의해 보여진 바와 같이 MP3보다 절반-항체의 더 적은 양을 생산하였다 (데이터 도시되지 않음). 질량 분광분석법 분석은 또한 절반-항체가 이들 샘플에서 중쇄 B에 의해서만 형성되었다는 것을 드러냈다 (데이터 도시되지 않음). 이것은 절반-항체 형성이, 2 중쇄 사이 비 최적화에 의해 절반-항체의 수준을 감소시키기 위해 가능성을 개방하는, 중쇄 B의 과-발현의 결과일 수 있다는 것을 시사한다. 따라서, 동일한 Fabs를 가진 설계 MP4의 중쇄 (플라스미드 pMP254 및 pMP399)는 1:5 내지 5:1의 다양한 비로 CHO-S 세포 속으로 형질감염되었다. 중쇄 (14 μg)의 총량 및 경쇄의 양은 이들 형질감염에서 일정하게 유지되었다. 쇄 A의 과-발현은 절반-항체의 형성을 감소시켰고 상청액에서 전체 IgG의 양을 증가시켜서, 절반-항체 형성이 쇄 사이 차별적인 발현에 의해 영향받는다는 것을 확인하였다 (도 4A). 이들 실험내 양쪽 중쇄가 동일한 Fab (항-EGFR M60)을 함유하였기 때문에, 2 중쇄의 차별적인 발현은 CH3 돌연변이때문일 수 있다. 그러나, 질량 분광분석법 분석은 또한 어느 한쪽 쇄의 과-발현이 각각의 호모이량체의 증가된 형성으로 이어진다는 것을 실증하였다 (도 4B). 따라서, 2 중쇄 사이 똑 같은 비는 원치않는 부산물을 최소화하기 위한 양호한 타협이다.
실시예 3: 경쇄 짝짓기 문제에 대한 해결책의 개발
하기의 올바른 어셈블리를 구동시키기 위해: 경쇄:중쇄 (LC:HC) 쌍 (도 1에서 설명된 바와 같이 이중특이적 항체에서), 쇄 사이 계면은 조작될 수 있어서 입체 충돌 또는 밀어내는 전하는 부정확한 어셈블리를 방지시킨다. 항체의 경쇄는 가변 도메인 및 불변 도메인에서 중쇄와 접촉하고, 양쪽 접촉 (VL:VH 및 CL:CH1)은 인식 및 참여에 기여한다. 결과적으로, 불변 도메인에서 포인트 돌연변이는 올바른 짝짓기에 대해 각각의 경쇄를 조향하기에 충분하지 않을 수 있고, 가변 도메인의 조작은 필요해질 수 있다. 따라서, 경쇄 짝짓기 해결을 위한 대안적인 전략은 추구되었다.
항체의 가변 도메인은 불변 영역의 부재하에 또는 이들이 이종 단백질에 융합되는 경우 그들의 결합 특성을 유지시킬 수 있다. 우리는 Ig-폴드 도메인이 경쇄의 짝짓기오류를 예방하기 위한 전략으로서 CH1/CL 대신에 사용될 수 있다는 것을 가정하였고 CH1:CL 도메인으로 치환시키기 위한 후보 Ig-폴드 도메인으로서 IgE의 CH2 도메인 (C2)를 선택하였다 (도 5A). IgE의 CH2 도메인 (C2)는 2 쇄간 디설파이드에 의해 연결되는 호모이량체를 형성한다. 상기 도메인은, IgE에서 존재하지 않는, 힌지 영역 대신에 IgE 중쇄 사이 이량체화 계면으로서 작용한다. 또한, IgG의 CH2 도메인과 달리 Cε2 도메인은 효과기 기능에서 관여되지 않고 FcRiα와 접촉하지 않는다 (Holdom 등, Nature Struct.& Mol. Biol., 18:571-576, 2011).
Cε2 도메인의 구조는 다른 Ig-폴드 도메인 예컨대 CL 및 CH1 도메인과 유사하지만, 이량체의 유닛 사이 양쪽 계면 및 각은 구별된다 (도 5B). 이량체에서 2 Cε2 도메인은 다른 Ig-폴드 이량체보다 덜 광범위한 상호작용을 갖고, 상호작용은 일반 무극성 잔기보다는 극성에 의해 지배된다. 따라서, C2 및 CH1:CL은 전반적으로 상당히 상이하여서 Ig-폴드 도메인의 교차-짝짓기는 개연성이 낮다. 그러나, (도 5C에서 볼드체 및 밑줄로 강조된) Ig-폴드의 제1 β-가닥의 시작을 마킹하는 2 프롤린은 C2 및 CH1/카파 불변 도메인의 구조에서 유사한 위치이다. 따라서, Cε2 도메인상에 항체의 가변 도메인을 융합시키는 것이, 그리고 VH:VL 쌍의 기하학 및 따라서 그것의 결합 특성을 유지하는 것이 가능해 보인다. Cε2 도메인에 융합된 항체의 가변 도메인으로 구성된 상기 하이브리드 Fab 작제물은 "E-Fab"로 명명된다 (도 5C). 인간 면역글로불린 E (IgE)의 CH2 도메인의 아미노산 서열은 하기 제공된다 (N-연결된 당화 부위는 밑줄쳐진다):
1 VCSRDFTPPT VKILQSSCDG GGHFPPTIQL LCLVSGYTPG TINITWLEDG
51 QVMDVDLSTA STTQEGELAS TQSELTLSQK HWLSDRTYTC QVTYQGHTFE
101 DSTKKCA (서열 식별 번호:1)
Cε2 도메인에 VH 도메인을 융합시키기 위해, IgG1 CH1 불변 영역의 커넥터 서열 (ASTKG (서열 식별 번호:7))은 Pro2로 시작하는 Cε2 도메인의 제1 β-가닥에 연결되었다 (C-도메인의 IMGT 특유의 넘버링, 도 5C). 최초 8 아미노산 (VCSRDFTP (서열 식별 번호:8))이 인간 IgG1 CH1 도메인의 최초 5 아미노산 (엘보 영역 ASTKG (서열 식별 번호:7)은 밑줄쳐진다)으로 대체되는 인간 면역글로불린 E (IgE)의 CH2 도메인의 아미노산 서열은 하기 제공된다:
1 ASTKGPTVKI LQSSCDGGGH FPPTIQLLCL VSGYTPGTIN ITWLEDGQVM
51 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDST
101 KKCA (서열 식별 번호:45)
동일한 전략은 카파 불변 영역 (RTVAA (서열 식별 번호:9))로부터 커넥터를 가진 Cε2 도메인에 VL 융합에 사용되었다. 최초 8 아미노산 (VCSRDFTP (서열 식별 번호:8))이 인간 카파 도메인 (엘보 영역 RTVAA (서열 식별 번호:9)는 밑줄쳐진다)의 최초 5 아미노산으로 대체되는, 인간 면역글로불린 E의 CH2 도메인의 아미노산 서열은 하기 제공된다:
1 RTVAAPTVKI LQSSCDGGGH FPPTIQLLCL VSGYTPGTIN ITWLEDGQVM
51 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDST
101 KKCA (서열 식별 번호:46)
인간 Cε2 도메인은, E-Fab에서 상기 부위의 당화를 예방하기 위해 Gln으로 돌연변이된, Asn38 (IMGT 넘버링)에서 하나의 N-연결된 당화 부위를 갖는다. 이러한 초기 설계에서, 가변 도메인은, 중쇄와 경쇄 사이 동일한 그리고 agly 돌연변이를 제외하고 변경되는, Cε2 도메인 상에 그라프팅되었다. 이러한 최초 설계는 E-Fab E0으로 명명되었다. E-Fab의 중쇄의 E0 설계의 아미노산 서열은 하기 제공된다 (N-당화 부위는 글루타민으로 돌연변이된다):
1 ASTKGPTVKI LQSSCDGGGH FPPTIQLLCL VSGYTPGTIQ ITWLEDGQVM
51 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDST
101 KKCA (서열 식별 번호:3)
E-Fab의 경쇄의 E0 설계의 아미노산 서열은 하기 제공된다 (N-당화 부위는 글루타민으로 돌연변이된다):
1 RTVAAPTVKI LQSSCDGGGH FPPTIQLLCL VSGYTPGTIQ ITWLEDGQVM
51 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDST
101 KKCA (서열 식별 번호:4)
그러나, Cε2 도메인이 정상적으로 호모이량체화하기 때문에, 추가의 돌연변이는 HC:HC 또는 LC:LC 이량체의 형성을 예방하기 위해 도메인 속으로 도입되었고, 이들 설계는 E-Fab E1 내지 E3으로 명명되었다 (표 3; IMGT 넘버링 시스템에 따른 위치).
표 3. E-Fab 시험용 작제물.

E-Fab의 중쇄의 E1 설계의 아미노산 서열은 하기 제공된다:
1 ASTKGPTVKI WQSSCDGGGH FPPTIQLLCL VSGYTPGTIQ ITWLEDGQVM
51 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDST
101 KKCA (서열 식별 번호:47)
E-Fab의 경쇄의 E1 설계의 아미노산 서열은 하기 제공된다:
1 RTVAAPTVKI LQSSCDGGGH FPPTIQLGCL VSGYTPGTIQ ITWLEDGQVM
51 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDST
101 KKCA (서열 식별 번호:48)
E-Fab의 중쇄 및 경쇄의 E2 설계의 아미노산 서열은 본 실시예의 마지막에 제공된다.
E-Fab의 중쇄의 E3 설계의 아미노산 서열은 하기 제공된다:
1 ASTKGPTVKI LQSTCDGGGH FPPTIQLLCL VSGYTPGTIQ ITWLEDGQVM
51 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDST
101 KKCA (서열 식별 번호:49)
E-Fab의 경쇄의 E3 설계의 아미노산 서열은 하기 제공된다:
1 RTVAAPTVKI LQSSCDGGGH FPPTIQLLCL VSGYTPGTIQ ITWLEDGQVM
51 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDSS
101 KKCA (서열 식별 번호:50)
경쇄 짝짓기 제어에서 E-Fab 설계를 평가하기 위해, 시험 작제물은 2 Fabs M60-A02 항-EGFR 및 M13.C06 항-IGF1R을 이용하여 구축되었다. 양쪽 중쇄는 하위그룹 HV3에 속하고, 따라서 단백질 A를 이용하여 정제될 수 있다. 시험 분자는 SDS page상의 이동에 의한 올바른 대 부정확한 짝짓기의 단순 분화를 가능하게 하기 위해 GFP (30 kDa, Fab B 항 IGF-1R의 LC) 또는 HSA (66 kDa, Fab A 또는 E-Fab의 HC, 항-EGFR)로 태깅되었다 (도 6A). E-Fab 작제물은 gBlocks으로부터 구축되었다. 추가의 돌연변이는 PCR-기반 돌연변이유발에 의해 Cε2 도메인 속으로 도입되었고, 생성물은 제한 효소-기반 방법에 의해 pV90/pV100에서 유래된 CHO 발현 벡터 속으로 클로닝되었다 (표 3). Fabs는 40 ml 척도에서 CHO-S 세포내 일시적 형질감염으로 공-발현되었다. 세포는 형질감염후 24 시간 발현을 위하여 280C로 이동되었고, 상청액은 8 일후 수확되었고 원심분리 및 여과 (0.22 μm)에 의해 청소되었다.
SDS-PAGE에 의한 발현된 단백질의 분석은 Cε2 도메인에 융합된 규칙적 항체의 가변 도메인으로 구성된 E-Fab가 경쇄 짝짓기 제어에서 고도로 효율적이었다는 것을 보여주었다. 2 Fabs M60-A02 및 M13-C036이 야생형 IgG1/카파 Fab로서 공-발현된 경우, M13-C06 중쇄와 M60-A02 경쇄의 짝짓기오류는 쉽게 검출되었다 (도 6B). 그러나, M60-A02가 E-Fab로서 제조된 경우, 짝짓기오류는 보이지 않았다. 그에 반해서, CH1/CL 도메인에서 포인트 돌연변이는 본 실험에서 경쇄 짝짓기오류를 폐지하는데 실패하였다 (데이터 도시되지 않음). 유사하게, 항-IGF-1R M13-C06이 E-Fab로서 작제된 경우, 짝짓기오류는 또 다른 Fab (항 IGF-1R G11)로 공-발현된 경우 검출되지 않았다 (도 6C). 중요하게는 Fabs가 개별적으로 발현되고 항원에 결합이 Octet에 의해 시험된 경우, E-fabs 및 야생형 Fabs는, 항-His 팁상에 장입된, His-태깅된 IGF-1R에 유사하게 결합되었다 (도 6D).
따라서, 상기 데이터에 기반하여 E-Fab는 이중특이적 항체에서 경쇄 짝짓기 문제를 해결하기 위한 탁월한 전략이고, 엄격히 시행함에 따라 Fab의 올바른 쇄 짝짓기 및 결합 특성은 유지된다. 흥미롭게도, Cε2 도메인은 E-Fab의 쇄 사이 호모이량체의 형성을 강하게 유도하지 않았다. 그럼에도 불구하고, 중쇄와 경쇄 사이 헤테로이량체를 형성하기 위해 조작되는, 설계 E2 및 E3은 이월되었고 전체 이중특이성의 문맥에서 시험되었다. 중쇄 사이 일부 이량체화를 유도하는 것처럼 보였던 (도 6B), 설계 E1만이 추가로 시험되지 않았다. E-Fab 설계 E2의 불변 도메인의 펩타이드 서열은 하기 보여진다:
E-Fab 경쇄 불변 영역의 아미노산 서열, agly N38Q (설계 E2, T121G, pMP463)
1 RTVAAPTVKI LQSSCDGGGH FPPTIQLLCL VSGYTPGTIQ ITWLEDGQVM
61 DVDLSTASTT QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDSG KKCA (서열 식별 번호:6)
E-Fab 중쇄 불변 영역의 아미노산 서열, agly N38Q (설계 E2, S10I, pMP392)
1 ASTKGPTVKI LQSICDGGGH FPPTIQLLCL VSGYTPGTIQ ITWLEDGQVM DVDLSTASTT
61 QEGELASTQS ELTLSQKHWL SDRTYTCQVT YQGHTFEDST KKCA (서열 식별 번호:5)
실시예 4: 이중특이적 비대칭 IgG의 구축 및 시험
E-Fab 및 라이신 재위치결정 작제물은 조합되어 전체 IgG-유사 이중특이적 항체를 생성하였다. 그와 같은 이중특이적 항체는 4 상이한 쇄로 구성되고, 양쪽 경쇄 짝짓기 및 중쇄 헤레로이량체화 해결책을 함유한다 (도 7). 항-EGFR 항체 M60-A02, 및 항-IGF1R M13.C06 또는 G11을 재차 이용하여, 2 상이한 IgG1 중쇄는 헤테로이량체화 돌연변이 MP3으로 구축되었다.
성숙한 M60-A02 Ebody 중쇄의 아미노산 서열 (EFab E2, mp3a 헤테로이량체화, pMP401) )(밑줄친 CH2 도메인; 볼드체 CH3 도메인)
EVQLLESGGG LVQPGGSLRL SCAASGFTFS DYIMHWVRQA PGKGLEWVSV ISSSGGDTSY ADSVKGRFTI SRDNSKNTLY LQMNSLRAED TAVYYCAKVL AGYFDWLPFD YWGQGTLVTV SSASTKGPTV KILQSICDGG GHFPPTIQLL CLVSGYTPGT IQITWLEDGQ VMDVDLSTAS TTQEGELAST QSELTLSQKH WLSDRTYTCQ VTYQGHTFED STKKCASDKT HTCPPCPAPE LLGGPSVFLF PPKPKDTLMI SRTPEVTCVV VDVSHEDPEV KFNWYVDGVE VHNAKTKPRE EQYNSTYRVV SVLTVLHQDW LNGKEYKCKV SNKALPAPIE KTISKAKGQP REPQVYTLPP SRDELTKNQV KLTCLVKGFY PSDIAVEWES NGQPENNYKT TPPVLDSDGS FFLYSSLTVD KSRWQQGNVF SCSVMHEALH NHYTQKSLSL SPG (서열 식별 번호:51)
성숙한 M60-A02 Ebody 경쇄의 아미노산 서열 (EFab E2, pMP463)(밑줄친 CH2 도메인)
DIQMTQSPAT LSLSPGETAT LSCRASQSVS YYLAWYQQKP GQAPRLLIYD TFNRATGIPA RFSGSGSGTD FTLTISRLEP EDFAVYYCQQ YGSSPPWLTF GGGTKVEIKR TVAAPTVKIL QSSCDGGGHF PPTIQLLCLV SGYTPGTIQI TWLEDGQVMD VDLSTASTTQ EGELASTQSE LTLSQKHWLS DRTYTCQVTY QGHTFEDSGK KCA (서열 식별 번호:52)
성숙한 M13.C06 IgG1 중쇄의 아미노산 서열 (mp3b 헤테로이량체화, pMP404) (볼드체 CH3 도메인)
EVQLLESGGG LVQPGGSLRL SCAASGFTFS IYRMQWVRQA PGKGLEWVSG ISPSGGTTWY ADSVKGRFTI SRDNSKNTLY LQMNSLRAED TAVYYCARWS GGSGYAFDIW GQGTMVTVSS ASTKGPSVFP LAPSSKSTSG GTAALGCLVK DYFPEPVTVS WNSGALTSGV HTFPAVLQSS GLYSLSSVVT VPSSSLGTQT YICNVNHKPS NTKVDKKVEP KSCDKTHTCP PCPAPELLGG PSVFLFPPKP KDTLMISRTP EVTCVVVDVS HEDPEVKFNW YVDGVEVHNA KTKPREEQYN STYRVVSVLT VLHQDWLNGK EYKCKVSNKA LPAPIEKTIS KAKGQPREPQ VYTLPPSRDE LTKNQVSLTC LVSGFYPSDI AVEWESNGQP ENNYKTTPPV LDSDGSFKLY SKLTVDKSRW QQGNVFSCSV MHEALHNHYT QKSLSLSPG (서열 식별 번호:53)
성숙한 M13.C06 카파 경쇄 (pMP407)의 아미노산 서열
DIQMTQSPLS LSASVGDRVT ITCQASRDIR NYLNWYQQKP GKAPKLLIYD ASSLQTGVPS RFGGSGSGTD FSFTIGSLQP EDEATYYCQQ FDSLPHTFGQ GTKLEIKRTV AAPSVFIFPP SDEQLKSGTA SVVCLLNNFY PREAKVQWKV DNALQSGNSQ ESVTEQDSKD STYSLSSTLT LSKADYEKHK VYACEVTHQG LSSPVTKSFN RGEC (서열 식별 번호:54)
상이한 경쇄의 짝짓기를 제어하기 위해, 항-EGFR Fab는 Efab로서 작제되었다 (도 7). 대조군 항체는 라이신 재위치결정 돌연변이로 구축되어 경쇄 짝짓기 해결책이 부족한 IgG1 중쇄 헤테로이량체를 생성하였다.
항체는 일시적 형질감염에 의해 CHO-S 세포에서 재차 발현되었고 상청액은 수확되었고 배양의 8 일후 청소되었다. SDS-PAGE에 의한 분리는 전체 IgG의 크기에서 이동하는 밴드 그리고 절반-항체에 상응하는 추가의 밴드를 보여주었다 (도 8A). 질량 분광분석법 분석은 절반-항체가 이들 실험에서 중쇄 B에 의해 재차 형성되었다는 것을 실증하였다. 중요하게는, 경쇄 짝짓기오류는 LC-MS에 의해 E-Fabs에서 검출되지 않았다. IgG1 헤테로이량체는 중쇄의 그들의 경쇄와의 일부 올바른 짝짓기를 보여주었지만, 2 항-EGFR 경쇄를 가진 중쇄 헤테로이량체의 강한 피크는 또한 검출가능하였다 (도 8B). 이들 결과는 E-Fab가 경쇄 짝짓기 문제를 해결한다는 것을 재차 확인한다.
중요하게는, 중쇄 사이 호모이량체는 질량 분광분석법 프로파일에서 검출불가능하였어서, 라이신 재위치결정에 의한 중쇄 헤테로이량체화가 E-Fab와 조합된 경우 고도로 효율적이라는 것을 실증하였다 (도 8B). 그러나, 질량 분광분석법은 또한 IgG1 대조군이 아닌 Efab 이중특이성에서 나타났던 O-글리칸의 작은 수준을 드러냈다.
다음으로, 미정제 상청액은 가용성 His-태깅된 EGFR (도 8C) 및 IGF-1R (도 8D)로 Octet 결합 실험에서 사용되었다. IgG1 대조군 뿐만 아니라 이중특이적 Ebody는 양쪽 EGFR 및 IGF-1R에 결합하였지만, 결합은 Ebody와 대조군 사이 어느 정도 상이한 것처럼 보였다. 그러나, 이들 결과의 해석은 상이한 발현, 절반 항체의 양 그리고 이들 미정제 샘플내 경쇄 짝짓기오류로 인해 복잡하다.
대체로, 결합 데이터와 함께 질량 분광분석법에 의한 분석은 Ebody가 비대칭 IgG로 정확하게 조립하였다는 것을 입증한다. 이것은 CHO 세포에서 4 상이한 쇄 (2HC 및 2 LC)의 공-발현에 의해 간단히 달성된다. E-fab는 경쇄 짝짓기를 완전히 해결하였고, 라이신 재위치결정은 이들 실험에서 중쇄 헤테로이량체화를 엄격히 시행하였다.
실시예 5: 이중특이적 플랫폼의 추가 시험
Efab 및 Fc 헤테로이량체화를 이용하여 이중특이적 플랫폼을 추가로 시험하기 위해, 또 다른 IgG-유사 이중특이적 항체는, 다양한 암의 치료를 위하여 승인되고 있는, 2 치료 항체, 트라스투주맙 및 세툭시맙으로부터 생성되었다. 이중특이성을 생성하기 위해, 항-HER 항체 트라스투주맙은 경쇄 짝짓기-해결책 Efab를 이용하여 클로닝되었고, 그 다음 mp4 중쇄 헤테로이량체화 돌연변이 (S364K/K409L 및 K370S/V397I/F405K)를 이용하여 항-EGFR 항체 세툭시맙과 조합되었다. 항체의 2 중쇄 및 2 경쇄를 인코딩하는 4 플라스미드 (pMP521, pMP526, pMP528, 및 pMP530)은 그 다음 일시적 형질감염에 의해 CHO-S 세포에서 공-발현되었고, 수득한 이중특이적 항체는 단백질 A에 의해 정제되었다. 상기 항체는 그 다음 2 항원, HER2 및 EGFR의 가용성 버전으로 Octet 결합 연구에서 사용되었다 (참조, 도 9A 및 9B). 도 9A 및 9B에서 나타낸 바와 같이, 이중특이적 항체는 그의 항원 양쪽에 동시 결합할 수 있다.
pMP530 트라스투주맙 Efab IgG1 mp4a
1 EVQLVESGGG LVQPGGSLRL SCAASGFNIK DTYIHWVRQA PGKGLEWVAR
51 IYPTNGYTRY ADSVKGRFTI SADTSKNTAY LQMNSLRAED TAVYYCSRWG
101 GDGFYAMDYW GQGTLVTVSS ASTKGPTVKI LQSICDGGGH FPPTIQLLCL
151 VSGYTPGTIQ ITWLEDGQVM DVDLSTASTT QEGELASTQS ELTLSQKHWL
201 SDRTYTCQVT YQGHTFEDST KKCASDKTHT CPPCPAPELL GGPSVFLFPP
251 KPKDTLMISR TPEVTCVVVD VSHEDPEVKF NWYVDGVEVH NAKTKPREEQ
301 YNSTYRVVSV LTVLHQDWLN GKEYKCKVSN KALPAPIEKT ISKAKGQPRE
351 PQVYTLPPSR DELTKNQVKL TCLVKGFYPS DIAVEWESNG QPENNYKTTP
401 PVLDSDGSFF LYSLLTVDKS RWQQGNVFSC SVMHEALHNH YTQKSLSLSP
451 G (서열 식별 번호:79)
pMP528 트라스투주맙 Efab 경쇄
1 DIQMTQSPSS LSASVGDRVT ITCRASQDVN TAVAWYQQKP GKAPKLLIYS
1 DIQMTQSPSS LSASVGDRVT ITCRASQDVN TAVAWYQQKP GKAPKLLIYS
101 GTKVEIKRTV AAPTVKILQS SCDGGGHFPP TIQLLCLVSG YTPGTIQITW
151 LEDGQVMDVD LSTASTTQEG ELASTQSELT LSQKHWLSDR TYTCQVTYQG
201 HTFEDSGKKC A (서열 식별 번호:80)
pMP521 세툭시맙 IgG1 mp4b
1 DILLTQSPVI LSVSPGERVS FSCRASQSIG TNIHWYQQRT NGSPRLLIKY
51 ASESISGIPS RFSGSGSGTD FTLSINSVES EDIADYYCQQ NNNWPTTFGA
101 GTKLELKRTV AAPSVFIFPP SDEQLKSGTA SVVCLLNNFY PREAKVQWKV
151 DNALQSGNSQ ESVTEQDSKD STYSLSSTLT LSKADYEKHK VYACEVTHQG
201 LSSPVTKSFN RGEC (서열 식별 번호:81)
pMP526 세툭시맙 카파
1 QVQLKQSGPG LVQPSQSLSI TCTVSGFSLT NYGVHWVRQS PGKGLEWLGV
51 IWSGGNTDYN TPFTSRLSIN KDNSKSQVFF KMNSLQSNDT AIYYCARALT
101 YYDYEFAYWG QGTLVTVSAA STKGPSVFPL APSSKSTSGG TAALGCLVKD
151 YFPEPVTVSW NSGALTSGVH TFPAVLQSSG LYSLSSVVTV PSSSLGTQTY
201 ICNVNHKPSN TKVDKKVEPK SCDKTHTCPP CPAPELLGGP SVFLFPPKPK
251 DTLMISRTPE VTCVVVDVSH EDPEVKFNWY VDGVEVHNAK TKPREEQYNS
301 TYRVVSVLTV LHQDWLNGKE YKCKVSNKAL PAPIEKTISK AKGQPREPQV
351 YTLPPSRDEL TKNQVSLTCL VSGFYPSDIA VEWESNGQPE NNYKTTPPIL
401 DSDGSFKLYS KLTVDKSRWQ QGNVFSCSVM HEALHNHYTQ KSLSLSPG
(서열 식별 번호:82)
실시예 6: 경쇄 짝짓기 해결책의 추가 시험
Efabs의 작제를 추가로 최적화하기 위해, IgE의 CH2 도메인과 가변 도메인 사이 링커는 추가로 조사되었다. 이전의 실시예에서 인간 카파 및 CH1 도메인으로부터 엘보 영역은 가변 도메인과 IgE CH2 사이 링커로서 사용되었다. 그러나, 다른 링커 서열은 기하학을 잠재적으로 변경시킬 수 있거나 상이한 정도의 가요성을 제공할 수 있고, 따라서 Efab에 의해 항원의 결합 또는 쇄의 올바른 어셈블리에 영향을 준다. 잉것을 시험하기 위해, 항-HER2 항체 트라스투주맙은 Efab로서 조작되었고 경쇄 내에서 다양한 엘보 서열을 포함하였다. 사용된 링커는 람다 경쇄 출신이었거나 인간 IgE CH2 도메인, 또는 상이한 길이의 가요성 Gly-Ser 링커 출신이었다 (도 10). Efabs는 일시적 형질감염에 의해 CHO 세포에서 (도 9에서처럼) 세툭시맙을 가진 비대칭 IgG로서 표현되었다. 물질은 단백질 A에 의해 정제되었고 Octet 결합 연구에서 시험되었다. 흥미롭게도, 다양한 엘보 링커 서열은 HER2에 결합하는 트라스투주맙의 능력에서 효과가 거의 없었고, 모든 작제물은 야생형 트라스투주맙 Fab에 비교하여 유사한 결합을 보여주었다.
항체의 IgM 부류는, 디설파이드 브릿지에 의해 2 중쇄를 짝짓기하기 위해 힌지 영역 대신에 작용하는, IgE와 유사하게 CH2 도메인을 함유한다. 따라서, IgM CH2 도메인 이용이 IgE CH2 도메인으로서 똑같이 양호하게 경쇄 짝짓기를 해결할 수 있는지가 시험되었다. 이것을 시험하기 위해, 2 Fabs (M60 및 C06)은 도 6A에서 나타낸 바와 같이 재차 공-발현되었고, one Fab는 HSA에 융합되었고 또 다른 Fab는 GFP에 융합되었다. 이 경우에, 그러나, 하나의 Fab의 카파 및 CH1 불변 도메인은 IgM CH2 도메인으로 대체되었고, 수득한 분자는 M-Fab로 명명되었다 (도 10C). SDS-PAGE에 의한 쇄 짝짓기의 분석은 대조군에서 두드러지게 관측된 M60과 C06 사이 경쇄 짝짓기오류를 M-Fab가 해결하였다는 것을 보여주었다 (도 10C). 따라서, M-Fab는 경쇄 짝짓기 문제 해결에서 Efab만큼 효율적으로 기능하는 것처럼 보인다.
다음으로, 항원을 결합시키는 M-Fab의 능력은 경쇄에서 다양한 엘보 영역을 가진 Efabs에 비교되었다. 이들 Efab 및 the M-Fab는 항-HER2 항체 트라스투주맙의 가변 도메인을 이용하여 재차 작제되었다. M-Fab 작제물의 중쇄 및 경쇄의 성숙한 펩타이드 서열은 하기 보여진다.
6x His 태그를 가진 트라스투주맙 M-fab 중쇄 (pMP623)의 아미노산 서열 (볼드체된 엘보 영역; 밑줄친 IgM CH2 도메인; 이탤릭체된 6xHis)
EVQLVESGGG LVQPGGSLRL SCAASGFNIK DTYIHWVRQA PGKGLEWVAR IYPTNGYTRY ADSVKGRFTI SADTSKNTAY LQMNSLRAED TAVYYCSRWG GDGFYAMDYW GQGTLVTVSS ASTKGP KVSV FVPPRDGFFG NPRKSKLICQ ATGFSPRQIQ VSWLREGKQV GSGVTTDQVQ AEAKESGPTT YKVTSTLTIK ESDWLGQSMF TCRVDHRGLT FQQQASSMC H HHHHH (서열 식별 번호:75)
트라스투주맙 M-fab 경쇄 (pMP596)의 아미노산 서열 (볼드체된 엘보 영역; 밑줄친 IgM CH2 도메인
DIQMTQSPSS LSASVGDRVT ITCRASQDVN TAVAWYQQKP GKAPKLLIYS ASFLYSGVPS RFSGSRSGTD FTLTISSLQP EDFATYYCQQ HYTTPPTFGQ GTKVEIKRTV AAP KVSVFVP PRDGFFGNPR KSKLICQATG FSPRQIQVSW LREGKQVGSG VTTDQVQAEA KESGPTTYKV TSTLTIKESD WLGQSMFTCR VDHRGLTFQQ QASSMC (서열 식별 번호:76)
Efabs 및 M-Fab는 (Fc 없이) Fabs로서 CHO-S에서 발현되었고, 상청액은 Octet에 의해 HER2에 결합 시험에 사용되었다. 상기 결합 검정에서 Mfab 및 다양한 Efab 작제물은 매우 유사한 결합을 보여주었다 (도 10D).
전체적으로 이들 결과는 Fab (M-fab)의 불변 도메인으로서 IgM CH2 도메인 이용이 경쇄 짝짓기 문제를 해결하고 Fab의 결합 특징을 유지한다는 것을 보여준다. 따라서, M-Fab는 또 다른 유용한 경쇄 짝짓기 해결책이다.
실시예 7: 중쇄 및 경쇄 짝짓기 기술의 추가의 적용
다음으로, 중쇄 및 경쇄 짝짓기 해결책은 이들 기술이 얼마나 다용도 및 기능성인지 탐구하기 위해 다양한 다른 이중특이적 및 단일특이적 포맷의 문맥에서 추가로 시험되었다.
첫째, Fc 헤테로이량체화 돌연변이는 다른 Fc 영역의 CH3 도메인 속으로 도입되었고 그와 같은 이중특이적 항체의 기능성은 결합 연구에서 시험되었다. 이를 위해, mp3 헤테로이량체 돌연변이 (S364K/K409S 및 K370S/F405K)는 IgG1 agly T299A 스캐폴드 속으로 클로닝되었고, 이것은 Asn297에서 N-연결된 당화가 부족하고 따라서 당화된 IgG1에 비교하여 감소된 효과기 기능을 갖는다. 항-EGFR 항체 M60-A02의 Efab 및 항-IGF-1R 항체 M13.C06의 규칙적 Fab를 가진 비대칭 IgG의 형태로 이러한 Fc 영역을 가진 이중특이적 항체는 CHO 세포에서 일시적 발현에 의해 생산되었다 (도 11A). 수득한 이중특이적 항체는 샌드위치-포맷 Octet 결합 검정에서 양쪽 리간드에 강력한 동시 결합을 보여주었고(도 11B), 이중특이적 항체가 4 공-발현된 쇄 (플라스미드 pMP463, pMP402, pMP405, pMP407)로부터 효율적으로 형성하였다는 것을 입증한다. 따라서, 라이신 재위치결정에 의한 Fc 헤테로이량체화 전략은 Fc 당화에 독립적으로 기능하는 것처럼 보인다.
pMP402 M60 Efab IgG1 agly T299A mp3a S364K/K409S
1 EVQLLESGGG LVQPGGSLRL SCAASGFTFS DYIMHWVRQA PGKGLEWVSV
51 ISSSGGDTSY ADSVKGRFTI SRDNSKNTLY LQMNSLRAED TAVYYCAKVL
101 AGYFDWLPFD YWGQGTLVTV SSASTKGPTV KILQSICDGG GHFPPTIQLL
151 CLVSGYTPGT IQITWLEDGQ VMDVDLSTAS TTQEGELAST QSELTLSQKH
201 WLSDRTYTCQ VTYQGHTFED STKKCASDKT HTCPPCPAPE LLGGPSVFLF
251 PPKPKDTLMI SRTPEVTCVV VDVSHEDPEV KFNWYVDGVE VHNAKTKPRE
301 EQYNSAYRVV SVLTVLHQDW LNGKEYKCKV SNKALPAPIE KTISKAKGQP
351 REPQVYTLPP SRDELTKNQV KLTCLVKGFY PSDIAVEWES NGQPENNYKT
401 TPPVLDSDGS FFLYSSLTVD KSRWQQGNVF SCSVMHEALH NHYTQKSLSL
451 SPG (서열 식별 번호:83)
pMP405 C06 IgG1 agly T299A mp3b K370S/F405K
1 EVQLLESGGG LVQPGGSLRL SCAASGFTFS IYRMQWVRQA PGKGLEWVSG
51 ISPSGGTTWY ADSVKGRFTI SRDNSKNTLY LQMNSLRAED TAVYYCARWS
101 GGSGYAFDIW GQGTMVTVSS ASTKGPSVFP LAPSSKSTSG GTAALGCLVK
151 DYFPEPVTVS WNSGALTSGV HTFPAVLQSS GLYSLSSVVT VPSSSLGTQT
201 YICNVNHKPS NTKVDKKVEP KSCDKTHTCP PCPAPELLGG PSVFLFPPKP
251 KDTLMISRTP EVTCVVVDVS HEDPEVKFNW YVDGVEVHNA KTKPREEQYN
301 SAYRVVSVLT VLHQDWLNGK EYKCKVSNKA LPAPIEKTIS KAKGQPREPQ
351 VYTLPPSRDE LTKNQVSLTC LVSGFYPSDI AVEWESNGQP ENNYKTTPPV
401 LDSDGSFKLY SKLTVDKSRW QQGNVFSCSV MHEALHNHYT QKSLSLSPG
(서열 식별 번호:84)
둘째, 또 다른 Fc 포맷에서 중쇄 헤테로이량체화를 시험하기 위해, mp4 헤테로이량체 돌연변이 (S364K/K409L 및 K370S/V397I/F405K)는, IgG1 CH3 도메인의 안정성과 비당화된 IgG4 CH2 도메인의 최소 효과기 기능을 짝짓기하는, IgG4P/IgG1 agly (N297Q) 하이브리드 불변 도메인 속으로 클로닝되었다 (도 12). 상기 Fc는 또한 힌지-안정화 돌연변이 S228P를 함유한다. 그러므로, 상기 하이브리드 IgG4P/IgG1 불변 도메인 그리고 항-HER2 항체 페르투주맙 및 항-IGF-1R 항체 C06의 가변 도메인을 가진 이중특이적 항체는 생성되었다. 가변 도메인은 양쪽 배향으로, Efab로서 쇄 A상에 또는 규칙적 Fab로서 쇄 B상에, 각각에 사용되었다. 항체는 CHO 세포에서 재차 생산되었고, 단백질 A-정제된 물질은 Octet 결합 연구에서 사용되었다 (도 12). 흥미롭게도, 정제된 이중특이적 항체는, 가용성 항원상의 태그의 상이한 위치 때문일 수 있는, 역순으로 시험된 경우가 아닌, IGF1R이 먼저 이어서 항체 및 HER2가 장입된 경우에만 양쪽 항원에 동시 결합을 보여주었다 (도 12C).
셋째, 이중특이적 기술은 Mab-Fab의 문맥에서 고려되었다. 이중특이적 항체를 작제하는 상이한 방식은, 중쇄의 C-말단에 융합된 Fab를 가진 IgG를 함유하는, Mab-Fab이다 (도 13A). 상기 포맷은, Fc 헤테로이량체 기술을 불필요하게 만드는, 2 동일한 중쇄를 가진 대칭 분자를 닮는다. 그러나, 그것의 특유의 경쇄를 각각 함유하는, 2 상이한 Fabs의 존재는 경쇄 짝짓기 해결책을 요구한다. Efab가 올바른 경쇄 어셈블리를 촉진시키기 위한 상기 문맥에서 기능할지를 시험하기 위해, Mab-Fab는 그것의 C-말단에 융합된 항-IGF-1R 항체 C06의 Efab를 가진 IgG1로서 항-HER2 항체 트라스투주맙으로 작제되었다 (도 13). 추가로, C-말단에 융합된 트라스투주맙의 Efab를 가진 IgG1로서 C06의 역 작제물은 또한 생성되었다. 양쪽 사례에서 Efab는 IgG 중쇄의 C-말단에 단일 G4S(서열 식별 번호:56)-링커로 그것의 중쇄의 N-말단에 연결되었다. Mab-Fabs는 3 플라스미드 (1 중쇄 및 2 경쇄, pMP759/pMP519/pMP511 또는 pMP760/pMP528/pMP407)의 공-발현에 의해 CHO 일시적 균에서 재차 생산되었고, 단백질 A에 의해 정제되었다. SDS-PAGE에 의한 정제된 물질의 분석은 Mab-Fab의 3 쇄가 250 kDa 단백질 속으로 정확하게 조립하였다는 것을 보여주었다 (도 13B). 더욱이, 이중특이적 항체는 샌드위치 Octet 결합 검정에서 어느 정도의 동시 결합을 보여주었다 (도 13C). 그러나, 상기 동시 결합은, C06 또는 트라스투주맙이 Efab이었는지와 무관하게, Efab가 먼저 결합된 경우 단지 관측되었고, 상기 포맷에서 입체 장애의 일부 형태가 양쪽 항원의 동시 결합에 영향을 줄 수 있다는 것을 시사하였다.
pMP759 트라스투주맙 IgG1-C06 EFab
1 EVQLVESGGG LVQPGGSLRL SCAASGFNIK DTYIHWVRQA PGKGLEWVAR
51 IYPTNGYTRY ADSVKGRFTI SADTSKNTAY LQMNSLRAED TAVYYCSRWG
101 GDGFYAMDYW GQGTLVTVSS ASTKGPSVFP LAPSSKSTSG GTAALGCLVK
151 DYFPEPVTVS WNSGALTSGV HTFPAVLQSS GLYSLSSVVT VPSSSLGTQT
201 YICNVNHKPS NTKVDKKVEP KSCDKTHTCP PCPAPELLGG PSVFLFPPKP
251 KDTLMISRTP EVTCVVVDVS HEDPEVKFNW YVDGVEVHNA KTKPREEQYN
301 STYRVVSVLT VLHQDWLNGK EYKCKVSNKA LPAPIEKTIS KAKGQPREPQ
351 VYTLPPSRDE LTKNQVSLTC LVKGFYPSDI AVEWESNGQP ENNYKTTPPV
401 LDSDGSFFLY SKLTVDKSRW QQGNVFSCSV MHEALHNHYT QKSLSLSPGS
451 GGGGSEVQLL ESGGGLVQPG GSLRLSCAAS GFTFSIYRMQ WVRQAPGKGL
501 EWVSGISPSG GTTWYADSVK GRFTISRDNS KNTLYLQMNS LRAEDTAVYY
551 CARWSGGSGY AFDIWGQGTM VTVSSASTKG PTVKILQSIC DGGGHFPPTI
601 QLLCLVSGYT PGTIQITWLE DGQVMDVDLS TASTTQEGEL ASTQSELTLS
651 QKHWLSDRTY TCQVTYQGHT FEDSTKKCA (서열 식별 번호:85)
pMP511 C06 Efab 경쇄
1 DIQMTQSPLS LSASVGDRVT ITCQASRDIR NYLNWYQQKP GKAPKLLIYD
51 ASSLQTGVPS RFGGSGSGTD FSFTIGSLQP EDEATYYCQQ FDSLPHTFGQ
101 GTKLEIKRTV AAPTVKILQS SCDGGGHFPP TIQLLCLVSG YTPGTIQITW
151 LEDGQVMDVD LSTASTTQEG ELASTQSELT LSQKHWLSDR TYTCQVTYQG
201 HTFEDSGKKC A (서열 식별 번호:86)
pMP519 트라스투주맙 카파 경쇄
1 DIQMTQSPSS LSASVGDRVT ITCRASQDVN TAVAWYQQKP GKAPKLLIYS
1 DIQMTQSPSS LSASVGDRVT ITCRASQDVN TAVAWYQQKP GKAPKLLIYS
101 GTKVEIKRTV AAPSVFIFPP SDEQLKSGTA SVVCLLNNFY PREAKVQWKV
151 DNALQSGNSQ ESVTEQDSKD STYSLSSTLT LSKADYEKHK VYACEVTHQG
201 LSSPVTKSFN RGEC (서열 식별 번호:87)
pMP760 C06-IgG1-트라스투주맙 Efab
1 EVQLLESGGG LVQPGGSLRL SCAASGFTFS IYRMQWVRQA PGKGLEWVSG
51 ISPSGGTTWY ADSVKGRFTI SRDNSKNTLY LQMNSLRAED TAVYYCARWS
101 GGSGYAFDIW GQGTMVTVSS ASTKGPSVFP LAPSSKSTSG GTAALGCLVK
151 DYFPEPVTVS WNSGALTSGV HTFPAVLQSS GLYSLSSVVT VPSSSLGTQT
201 YICNVNHKPS NTKVDKKVEP KSCDKTHTCP PCPAPELLGG PSVFLFPPKP
251 KDTLMISRTP EVTCVVVDVS HEDPEVKFNW YVDGVEVHNA KTKPREEQYN
301 STYRVVSVLT VLHQDWLNGK EYKCKVSNKA LPAPIEKTIS KAKGQPREPQ
351 VYTLPPSRDE LTKNQVSLTC LVKGFYPSDI AVEWESNGQP ENNYKTTPPV
401 LDSDGSFFLY SKLTVDKSRW QQGNVFSCSV MHEALHNHYT QKSLSLSPGS
451 GGGGSEVQLV ESGGGLVQPG GSLRLSCAAS GFNIKDTYIH WVRQAPGKGL
501 EWVARIYPTN GYTRYADSVK GRFTISADTS KNTAYLQMNS LRAEDTAVYY
551 CSRWGGDGFY AMDYWGQGTL VTVSSASTKG PTVKILQSIC DGGGHFPPTI
601 QLLCLVSGYT PGTIQITWLE DGQVMDVDLS TASTTQEGEL ASTQSELTLS
651 QKHWLSDRTY TCQVTYQGHT FEDSTKKCA (서열 식별 번호:88)
넷째, 이중특이성 생성에서 다양한 적용에 더하여, Fc-헤테로이량체화 기술은 또한 단일특이적 1가 항체를 생성하는데 이용될 수 있다. 도 3에서 나타낸 바와 같이 절반 항체와 자유 Fc 사이 헤테로이량체는 단일특이적 1가의 하나의 그러한 예이다. 또 다른 예는, 그 다음 매칭 중쇄로 공-발현되는, Fc에 LC의 직접적인 융합이다 (도 14A). Fc 헤테로이량체화 전략은 경쇄 또는 중쇄의 호모이량체의 형성을 예방하기 위해 상기 포멧에서 요구된다. mp4 Fc 헤테로이량체가 또한 이러한 유형의 1가 단일특이적 항체를 작제하기에 적합할지를 시험하기 위해, LC-Fc 융합 작제물은 항-EGFR 항체 M60-A02의 가변 도메인으로 생성되었다. CHO 세포에서 상응하는 Fc 헤테로이량체 돌연변이 (플라스미드 pMP254)를 함유하는 M60-A02의 중쇄와 함께 상기 플라스미드 (pMP533)의 발현은 단일 단백질 종을 생산하였다 (도 14B). 상기 단백질이 Octet 결합에서 분석된 경우 1가 결합의 특징을 보여주었다 (도 14C). 대체로, 상기 데이터는 라이신 재위치결정에 의한 Fc 헤테로이량체화가 1가 단일특이적 항체 생성의 다용도 및 효율적인 방식인 것처럼 보인다는 것을 보여준다.
마지막으로, Efab 경쇄 짝짓기 해결책의 이용은, IgG의 Fc 부분이 부족한, 이중특이적 항체에서 또한 시험되었다. 상기 이중특이성은 예를 들어 펩타이드 링커로 2 Fabs의 직접적인 융합에 의해 생성될 수 있다 (도 15A, 우측 다이어그램). 대안적으로, 2 Fabs를 연결하는 펩타이드는 이종 단백질 예컨대 인간 혈청 알부민 (HSA)일 수 있다 (도 15A, 좌측 다이어그램). 어느 경우에나, 2 Fabs의 경쇄 및 중쇄의 짝짓기는 이중특이성이 기능하도록 정확해질 필요가 있다. 따라서, Efab 경쇄 짝짓기 해결책은 이중특이적 분자 속으로 2 Fabs의 그와 같은 융합을 가능하게 할 수 있다. 이것을 시험하기 위해, M60-A02 및 M13.C06 항체는 재차 사용되었고, 이중특이성은 양쪽 배향에서 2 Fabs로 재차 생성되었다. 이들 이중특이성이 CHO 세포에서 발현된 경우 이들은 항체 쇄가 정확하게 조립하였다는 것을 재차 시사하는 단일 단백질을 생산하였다 (도 15B). 항체가 Octet 결합 연구에서 시험된 경우, 동시 결합은 하나의 특정한 배향에서만 재차 관측되었다 (도 15C). 그럼에도 불구하고, 본 데이터는 Efab 경쇄 짝짓기 해결책이 정상 IgG의 Fc가 부족한 다양한 포맷에서 2 Fabs로부터 이중특이성을 효율적으로 생성하는데 이용될 수 있다는 것을 보여준다.
다른 구현예
본 발명이 이의 상세한 설명과 함께 기재되는 동안, 전술한 설명은, 첨부된 청구항들의 범위에 의해 정의되는, 본 발명의 범위를 설명하고 제한하지 않는 의도이다. 다른 측면, 이점, 및 변형은 다음과 같은 청구항의 범위 내이다.
SEQUENCE LISTING
<110> BIOGEN MA INC.
<120> BISPECIFIC ANTIBODY PLATFORM
<130> 13751-0240WO1
<140> PCT/US2016/066865
<141> 2016-12-15
<150> 62/269,664
<151> 2015-12-18
<160> 106
<170> PatentIn version 3.5
<210> 1
<211> 107
<212> PRT
<213> Homo sapiens
<400> 1
Val Cys Ser Arg Asp Phe Thr Pro Pro Thr Val Lys Ile Leu Gln Ser
1 5 10 15
Ser Cys Asp Gly Gly Gly His Phe Pro Pro Thr Ile Gln Leu Leu Cys
20 25 30
Leu Val Ser Gly Tyr Thr Pro Gly Thr Ile Asn Ile Thr Trp Leu Glu
35 40 45
Asp Gly Gln Val Met Asp Val Asp Leu Ser Thr Ala Ser Thr Thr Gln
50 55 60
Glu Gly Glu Leu Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys
65 70 75 80
His Trp Leu Ser Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly
85 90 95
His Thr Phe Glu Asp Ser Thr Lys Lys Cys Ala
100 105
<210> 2
<211> 112
<212> PRT
<213> Homo sapiens
<400> 2
Val Ile Ala Glu Leu Pro Pro Lys Val Ser Val Phe Val Pro Pro Arg
1 5 10 15
Asp Gly Phe Phe Gly Asn Pro Arg Lys Ser Lys Leu Ile Cys Gln Ala
20 25 30
Thr Gly Phe Ser Pro Arg Gln Ile Gln Val Ser Trp Leu Arg Glu Gly
35 40 45
Lys Gln Val Gly Ser Gly Val Thr Thr Asp Gln Val Gln Ala Glu Ala
50 55 60
Lys Glu Ser Gly Pro Thr Thr Tyr Lys Val Thr Ser Thr Leu Thr Ile
65 70 75 80
Lys Glu Ser Asp Trp Leu Gly Gln Ser Met Phe Thr Cys Arg Val Asp
85 90 95
His Arg Gly Leu Thr Phe Gln Gln Asn Ala Ser Ser Met Cys Val Pro
100 105 110
<210> 3
<211> 104
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 3
Ala Ser Thr Lys Gly Pro Thr Val Lys Ile Leu Gln Ser Ser Cys Asp
1 5 10 15
Gly Gly Gly His Phe Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser
20 25 30
Gly Tyr Thr Pro Gly Thr Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln
35 40 45
Val Met Asp Val Asp Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu
50 55 60
Leu Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu
65 70 75 80
Ser Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe
85 90 95
Glu Asp Ser Thr Lys Lys Cys Ala
100
<210> 4
<211> 104
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 4
Arg Thr Val Ala Ala Pro Thr Val Lys Ile Leu Gln Ser Ser Cys Asp
1 5 10 15
Gly Gly Gly His Phe Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser
20 25 30
Gly Tyr Thr Pro Gly Thr Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln
35 40 45
Val Met Asp Val Asp Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu
50 55 60
Leu Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu
65 70 75 80
Ser Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe
85 90 95
Glu Asp Ser Thr Lys Lys Cys Ala
100
<210> 5
<211> 104
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 5
Ala Ser Thr Lys Gly Pro Thr Val Lys Ile Leu Gln Ser Ile Cys Asp
1 5 10 15
Gly Gly Gly His Phe Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser
20 25 30
Gly Tyr Thr Pro Gly Thr Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln
35 40 45
Val Met Asp Val Asp Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu
50 55 60
Leu Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu
65 70 75 80
Ser Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe
85 90 95
Glu Asp Ser Thr Lys Lys Cys Ala
100
<210> 6
<211> 104
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 6
Arg Thr Val Ala Ala Pro Thr Val Lys Ile Leu Gln Ser Ser Cys Asp
1 5 10 15
Gly Gly Gly His Phe Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser
20 25 30
Gly Tyr Thr Pro Gly Thr Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln
35 40 45
Val Met Asp Val Asp Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu
50 55 60
Leu Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu
65 70 75 80
Ser Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe
85 90 95
Glu Asp Ser Gly Lys Lys Cys Ala
100
<210> 7
<211> 5
<212> PRT
<213> Homo sapiens
<400> 7
Ala Ser Thr Lys Gly
1 5
<210> 8
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 8
Val Cys Ser Arg Asp Phe Thr Pro
1 5
<210> 9
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 9
Arg Thr Val Ala Ala
1 5
<210> 10
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 10
Gly Gly Gly Ser
1
<210> 11
<211> 107
<212> PRT
<213> Homo sapiens
<400> 11
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
1 5 10 15
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
20 25 30
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
35 40 45
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
50 55 60
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
65 70 75 80
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
85 90 95
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
100 105
<210> 12
<211> 107
<212> PRT
<213> Homo sapiens
<400> 12
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu
1 5 10 15
Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
20 25 30
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
35 40 45
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
50 55 60
Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly
65 70 75 80
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
85 90 95
Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
100 105
<210> 13
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 13
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
1 5 10 15
Glu Leu Thr Lys Asn Gln Val Lys Leu Thr Cys Leu Val Lys Gly Phe
20 25 30
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
35 40 45
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
50 55 60
Phe Leu Tyr Ser Leu Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
65 70 75 80
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
85 90 95
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
100 105
<210> 14
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 14
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
1 5 10 15
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Ser Gly Phe
20 25 30
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
35 40 45
Asn Asn Tyr Lys Thr Thr Pro Pro Ile Leu Asp Ser Asp Gly Ser Phe
50 55 60
Lys Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
65 70 75 80
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
85 90 95
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
100 105
<210> 15
<211> 15
<212> PRT
<213> Homo sapiens
<400> 15
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro
1 5 10 15
<210> 16
<211> 12
<212> PRT
<213> Homo sapiens
<400> 16
Glu Ser Lys Tyr Gly Pro Pro Cys Pro Ser Cys Pro
1 5 10
<210> 17
<211> 12
<212> PRT
<213> Homo sapiens
<400> 17
Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro
1 5 10
<210> 18
<211> 226
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 18
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Lys
130 135 140
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Leu Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly
225
<210> 19
<211> 226
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 19
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Thr Cys Leu Val Ser Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Ile Leu Asp Ser Asp Gly Ser Phe Lys Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly
225
<210> 20
<211> 226
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 20
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Gln Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Lys
130 135 140
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Leu Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly
225
<210> 21
<211> 226
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 21
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Gln Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Thr Cys Leu Val Ser Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Ile Leu Asp Ser Asp Gly Ser Phe Lys Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly
225
<210> 22
<211> 331
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 22
Ala Ser Thr Lys Gly Pro Thr Val Lys Ile Leu Gln Ser Ile Cys Asp
1 5 10 15
Gly Gly Gly His Phe Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser
20 25 30
Gly Tyr Thr Pro Gly Thr Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln
35 40 45
Val Met Asp Val Asp Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu
50 55 60
Leu Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu
65 70 75 80
Ser Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe
85 90 95
Glu Asp Ser Thr Lys Lys Cys Ala Ser Asp Lys Thr His Thr Cys Pro
100 105 110
Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
115 120 125
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
130 135 140
Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe
145 150 155 160
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
165 170 175
Arg Glu Glu Gln Tyr Gln Ser Thr Tyr Arg Val Val Ser Val Leu Thr
180 185 190
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
195 200 205
Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala
210 215 220
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
225 230 235 240
Asp Glu Leu Thr Lys Asn Gln Val Lys Leu Thr Cys Leu Val Lys Gly
245 250 255
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
260 265 270
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
275 280 285
Phe Phe Leu Tyr Ser Leu Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
290 295 300
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
305 310 315 320
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
325 330
<210> 23
<211> 17
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 23
tgggctgcct ggtcaag 17
<210> 24
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 24
gtcagtttga cctggttctt g 21
<210> 25
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 25
caagaaccag gtcaaactga c 21
<210> 26
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 26
gaattggccg ccctagatg 19
<210> 27
<211> 17
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 27
tgggctgcct ggtcaag 17
<210> 28
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 28
ggtgaggctg ctgtagagga 20
<210> 29
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 29
tcctctacag cagcctcacc 20
<210> 30
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 30
gaattggccg ccctagatg 19
<210> 31
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 31
gctctgggtt ccaggttc 18
<210> 32
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 32
gatagaagcc gctgaccagg 20
<210> 33
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 33
cctggtcagc ggcttctatc 20
<210> 34
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 34
gaattggccg ccctagatg 19
<210> 35
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 35
gctctgggtt ccaggttc 18
<210> 36
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 36
tgtagagttt gaaggagccg t 21
<210> 37
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 37
acggctcctt caaactctac a 21
<210> 38
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 38
gaattggccg ccctagatg 19
<210> 39
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 39
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
1 5 10 15
Glu Leu Thr Lys Asn Gln Val Lys Leu Thr Cys Leu Val Lys Gly Phe
20 25 30
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
35 40 45
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
50 55 60
Phe Leu Tyr Ser Ser Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
65 70 75 80
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
85 90 95
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
100 105
<210> 40
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 40
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
1 5 10 15
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Ser Gly Phe
20 25 30
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
35 40 45
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
50 55 60
Lys Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
65 70 75 80
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
85 90 95
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
100 105
<210> 41
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 41
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
1 5 10 15
Glu Leu Thr Lys Asn Gln Val Lys Leu Thr Cys Leu Val Lys Gly Phe
20 25 30
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
35 40 45
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
50 55 60
Phe Leu Tyr Ser Leu Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
65 70 75 80
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
85 90 95
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
100 105
<210> 42
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 42
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
1 5 10 15
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Ser Gly Phe
20 25 30
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
35 40 45
Asn Asn Tyr Lys Thr Thr Pro Pro Ile Leu Asp Ser Asp Gly Ser Phe
50 55 60
Lys Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
65 70 75 80
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
85 90 95
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
100 105
<210> 43
<211> 7119
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 43
agcttgacat tgattattga ctagttatta atagtaatca attacggggt cattagttca 60
tagcccatat atggagttcc gcgttacata acttacggta aatggcccgc ctggctgacc 120
gcccaacgac ccccgcccat tgacgtcaat aatgacgtat gttcccatag taacgccaat 180
agggactttc cattgacgtc aatgggtgga gtatttacgg taaactgccc acttggcagt 240
acatcaagtg tatcatatgc caagtacgcc ccctattgac gtcaatgacg gtaaatggcc 300
cgcctggcat tatgcccagt acatgacctt atgggacttt cctacttggc agtacatcta 360
cgtattagtc atcgctatta ccatggtgat gcggttttgg cagtacatca atgggcgtgg 420
atagcggttt gactcacggg gatttccaag tctccacccc attgacgtca atgggagttt 480
gttttggcac caaaatcaac gggactttcc aaaatgtcgt aacaactccg ccccattgac 540
gcaaatgggc ggtaggcgtg tacggtggga ggtctatata agcagagctc gtttagtgaa 600
ccgtcagatc gcctggagac gccatccacg ctgttttgac ctccatagaa gacaccggga 660
ccgatccagc ctccgcggcc gggaacggtg cattggaacg cggattcccc gtgccaagag 720
tgacgtaagt accgcctata gagtctatag gcccaccccc ttggcttctt atgcatgcta 780
tactgttttt ggcttggggt ctatacaccc ccgcttcctc atgttatagg tgatggtata 840
gcttagccta taggtgtggg ttattgacca ttattgacca ctcccctatt ggtgacgata 900
ctttccatta ctaatccata acatggctct ttgccacaac tctctttatt ggctatatgc 960
caatacactg tccttcagag actgacacgg actctgtatt tttacaggat ggggtctcat 1020
ttattattta caaattcaca tatacaacac caccgtcccc agtgcccgca gtttttatta 1080
aacataacgt gggatctcca cgcgaatctc gggtacgtgt tccggaacgg tggagggcag 1140
tgtagtctga gcagtactcg ttgctgccgc gcgcgccacc agacataata gctgacagac 1200
taacagactg ttcctttcca tgggtctttt ctgcagtcac cgtccttgac acgggatccg 1260
cggccgccac catgggttgg agcctcatct tgctcttcct tgtcgctgtt gctacgcgtg 1320
tcctgtccga ggtgcagctg ttggagtctg ggggaggctt ggtccagcct ggggggtccc 1380
tgagactctc ctgtgcagcc tctggattca ccttcagtga ctatattatg cactgggtcc 1440
gccaggctcc agggaagggg ctggagtggg tctcagttat tagtagttct ggtggcgaca 1500
catcctacgc agactccgtg aagggccgat tcaccatctc cagagacaat tccaagaaca 1560
cgctgtatct gcaaatgaac agcctgagag ccgaggacac ggccgtgtat tactgtgcga 1620
aagtcctcgc gggttacttc gactggttac cctttgacta ctggggccag ggaaccctgg 1680
tcaccgtctc gagcgcctcc accaagggcc catcggtctt ccccctggca ccctcctcca 1740
agagcacctc tgggggcaca gcggccctgg gctgcctggt caaggactac ttccccgaac 1800
cggtgacggt gtcgtggaac tcaggcgccc tgaccagcgg cgtgcacacc ttcccggctg 1860
tcctacagtc ctcaggactc tactccctca gcagcgtggt gaccgtgccc tccagcagct 1920
tgggcaccca gacctacatc tgcaacgtga atcacaagcc cagcaacacc aaggtggaca 1980
agaaagttga gcccaaatct tgtgacaaga ctcacacatg cccaccgtgc ccagcacctg 2040
aactcctggg gggaccgtca gtcttcctct tccccccaaa acccaaggac accctcatga 2100
tctcccggac ccctgaggtc acatgcgtgg tggtggacgt gagccacgaa gaccctgagg 2160
tcaagttcaa ctggtacgtg gacggcgtgg aggtgcataa tgccaagaca aagccgcggg 2220
aggagcagta caacagcacg taccgtgtgg tcagcgtcct caccgtcctg caccaggact 2280
ggctgaatgg caaggagtac aagtgcaagg tctccaacaa agccctccca gcccccatcg 2340
agaaaaccat ctccaaagcc aaagggcagc cccgagaacc acaggtgtac accctgcccc 2400
catcccggga tgagctgacc aagaaccagg tcaaactgac ctgcctggtc aaaggcttct 2460
atcccagcga catcgccgtg gagtgggaga gcaatgggca gccggagaac aactacaaga 2520
ccacgcctcc cgtgttggac tccgacggct ccttcttcct ctacagcctc ctcaccgtgg 2580
acaagagcag gtggcagcag gggaacgtct tctcatgctc cgtgatgcat gaggctctgc 2640
acaaccacta cacgcagaag agcctctccc tgtctccggg ttagtaatta attaatgcat 2700
ctagggcggc caattccgcc cctctccctc ccccccccct aacgttactg gccgaagccg 2760
cttggaataa ggccggtgtg cgtttgtcta tatgtgattt tccaccatat tgccgtcttt 2820
tggcaatgtg agggcccgga aacctggccc tgtcttcttg acgagcattc ctaggggtct 2880
ttcccctctc gccaaaggaa tgcaaggtct gttgaatgtc gtgaaggaag cagttcctct 2940
ggaagcttct tgaagacaaa caacgtctgt agcgaccctt tgcaggcagc ggaacccccc 3000
acctggcgac aggtgcctct gcggccaaaa gccacgtgta taagatacac ctgcaaaggc 3060
ggcacaaccc cagtgccacg ttgtgagttg gatagttgtg gaaagagtca aatggctctc 3120
ctcaagcgta ttcaacaagg ggctgaagga tgcccagaag gtaccccatt gtatgggatc 3180
tgatctgggg cctcggtgca catgctttac atgtgtttag tcgaggttaa aaaaacgtct 3240
aggccccccg aaccacgggg acgtggtttt cctttgaaaa acacgatgat aagcttgcca 3300
caagctagca tggttcgacc attgaactgc atcgtcgccg tgtcccaaaa tatggggatt 3360
ggcaagaacg gagacctacc ctggcctccg ctcaggaacg agttcaagta cttccaaaga 3420
atgaccacaa cctcttcagt ggaaggtaaa cagaatctgg tgattatggg taggaaaacc 3480
tggttctcca ttcctgagaa gaatcgacct ttaaaggaca gaattaatat agttctcagt 3540
agagaactca aagaaccacc acgaggagct cattttcttg ccaaaagttt ggatgatgcc 3600
ttaagactta ttgaacaacc ggaattggca agtaaagtag acatggtttg gatagtcgga 3660
ggcagttctg tttaccagga agccatgaat caaccaggcc acctcagact ctttgtgaca 3720
aggatcatgc aggaatttga aagtgacacg tttttcccag aaattgattt ggggaaatat 3780
aaacttctcc cagaataccc aggcgtcctc tctgaggtcc aggaggaaaa aggcatcaag 3840
tataagtttg aagtctacga gaagaaagac taatcgagaa ttgtctagac tgcccgggtg 3900
gcatccctgt gacccctccc cagtgcctct cctggtcgtg gaaggtgcta ctccagtgcc 3960
caccagcctt gtcctaataa aattaagttg catcattttg tttgactagg tgtccttgta 4020
taatattatg gggtggaggc gggtggtatg gagcaagggg caggttggga agacaacctg 4080
tagggccttc agggtctatt gggaaccagg ctggagtgca gtggcacgat cttggctcgc 4140
tgcaatctcc gcctcctggg ttcaagcgat tctcctgcct cagtctcccg aatagttggg 4200
attccaggca tgcacgacca ggctcagcta atttttgtat ttttggtaga gacggggttt 4260
caccatattg gccagtctgg tctccatctc ctgacctcag gtaatccgcc cgcctcggcc 4320
tcccaaattg ctgggattac aggtatgagc cactgggccc ttccctgtcc tgtgatttta 4380
aaataattat accagcagaa ggacgtccag acacagcatg ggctacctgg ccatgcccag 4440
ccagttggac atttgagttg tttgcttggc actgtcctct catcaattca ctggccgtcg 4500
ttttacaacg tcgtgactgg gaaaaccctg gcgttaccca acttaatcgc cttgcagcac 4560
atcccccttt cgccagctgg cgtaatagcg aagaggcccg caccgatcgc ccttcccaac 4620
agttgcgcag cctgaatggc gaatggcgcc tgatgcggta ttttctcctt acgcatctgt 4680
gcggtatttc acaccgcata tggtgcactc tcagtacaat ctgctctgat gccgcatagt 4740
taagccagcc ccgacacccg ccaacacccg ctgacgcgcc ctgacgggct tgtctgctcc 4800
cggcatccgc ttacagacaa gctgtgaccg tctccgggag ctgcatgtgt cagaggtttt 4860
caccgtcatc accgaaacgc gcgagacgaa agggcctcgt gatacgccta tttttatagg 4920
ttaatgtcat gataataatg gtttcttaga cgtcaggtgg cacttttcgg ggaaatgtgc 4980
gcggaacccc tatttgttta tttttctaaa tacattcaaa tatgtatccg ctcatgagac 5040
aataaccctg ataaatgctt caataatatt gaaaaaggaa gagtatgagt attcaacatt 5100
tccgtgtcgc ccttattccc ttttttgcgg cattttgcct tcctgttttt gctcacccag 5160
aaacgctggt gaaagtaaaa gatgctgaag atcagttggg tgcacgagtg ggttacatcg 5220
aactggatct caacagcggt aagatccttg agagttttcg ccccgaagaa cgttttccaa 5280
tgatgagcac ttttaaagtt ctgctatgtg gcgcggtatt atcccgtatt gacgccgggc 5340
aagagcaact cggtcgccgc atacactatt ctcagaatga cttggttgag tactcaccag 5400
tcacagaaaa gcatcttacg gatggcatga cagtaagaga attatgcagt gctgccataa 5460
ccatgagtga taacactgcg gccaacttac ttctgacaac gatcggagga ccgaaggagc 5520
taaccgcttt tttgcacaac atgggggatc atgtaactcg ccttgatcgt tgggaaccgg 5580
agctgaatga agccatacca aacgacgagc gtgacaccac gatgcctgta gcaatggcaa 5640
caacgttgcg caaactatta actggcgaac tacttactct agcttcccgg caacaattaa 5700
tagactggat ggaggcggat aaagttgcag gaccacttct gcgctcggcc cttccggctg 5760
gctggtttat tgctgataaa tctggagccg gtgagcgtgg gtctcgcggt atcattgcag 5820
cactggggcc agatggtaag ccctcccgta tcgtagttat ctacacgacg gggagtcagg 5880
caactatgga tgaacgaaat agacagatcg ctgagatagg tgcctcactg attaagcatt 5940
ggtaactgtc agaccaagtt tactcatata tactttagat tgatttaaaa cttcattttt 6000
aatttaaaag gatctaggtg aagatccttt ttgataatct catgaccaaa atcccttaac 6060
gtgagttttc gttccactga gcgtcagacc ccgtagaaaa gatcaaagga tcttcttgag 6120
atcctttttt tctgcgcgta atctgctgct tgcaaacaaa aaaaccaccg ctaccagcgg 6180
tggtttgttt gccggatcaa gagctaccaa ctctttttcc gaaggtaact ggcttcagca 6240
gagcgcagat accaaatact gttcttctag tgtagccgta gttaggccac cacttcaaga 6300
actctgtagc accgcctaca tacctcgctc tgctaatcct gttaccagtg gctgctgcca 6360
gtggcgataa gtcgtgtctt accgggttgg actcaagacg atagttaccg gataaggcgc 6420
agcggtcggg ctgaacgggg ggttcgtgca cacagcccag cttggagcga acgacctaca 6480
ccgaactgag atacctacag cgtgagctat gagaaagcgc cacgcttccc gaagggagaa 6540
aggcggacag gtatccggta agcggcaggg tcggaacagg agagcgcacg agggagcttc 6600
cagggggaaa cgcctggtat ctttatagtc ctgtcgggtt tcgccacctc tgacttgagc 6660
gtcgattttt gtgatgctcg tcaggggggc ggagcctatg gaaaaacgcc agcaacgcgg 6720
cctttttacg gttcctggcc ttttgctggc cttttgctca catgttcttt cctgcgttat 6780
cccctgattc tgtggataac cgtattaccg cctttgagtg agctgatacc gctcgccgca 6840
gccgaacgac cgagcgcagc gagtcagtga gcgaggaagc ggaagagcgc ccaatacgca 6900
aaccgcctct ccccgcgcgt tggccgattc attaatgcag ctggcacgac aggtttcccg 6960
actggaaagc gggcagtgag cgcaacgcaa ttaatgtgag ttagctcact cattaggcac 7020
cccaggcttt acactttatg cttccggctc gtatgttgtg tggaattgtg agcggataac 7080
aatttcacac aggaaacagc tatgaccatg attacgcca 7119
<210> 44
<211> 6489
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 44
agcttgacat tgattattga ctagttatta atagtaatca attacggggt cattagttca 60
tagcccatat atggagttcc gcgttacata acttacggta aatggcccgc ctggctgacc 120
gcccaacgac ccccgcccat tgacgtcaat aatgacgtat gttcccatag taacgccaat 180
agggactttc cattgacgtc aatgggtgga gtatttacgg taaactgccc acttggcagt 240
acatcaagtg tatcatatgc caagtacgcc ccctattgac gtcaatgacg gtaaatggcc 300
cgcctggcat tatgcccagt acatgacctt atgggacttt cctacttggc agtacatcta 360
cgtattagtc atcgctatta ccatggtgat gcggttttgg cagtacatca atgggcgtgg 420
atagcggttt gactcacggg gatttccaag tctccacccc attgacgtca atgggagttt 480
gttttggcac caaaatcaac gggactttcc aaaatgtcgt aacaactccg ccccattgac 540
gcaaatgggc ggtaggcgtg tacggtggga ggtctatata agcagagctc gtttagtgaa 600
ccgtcagatc gcctggagac gccatccacg ctgttttgac ctccatagaa gacaccggga 660
ccgatccagc ctccgcggcc gggaacggtg cattggaacg cggattcccc gtgccaagag 720
tgacgtaagt accgcctata gagtctatag gcccaccccc ttggcttctt atgcatgcta 780
tactgttttt ggcttggggt ctatacaccc ccgcttcctc atgttatagg tgatggtata 840
gcttagccta taggtgtggg ttattgacca ttattgacca ctcccctatt ggtgacgata 900
ctttccatta ctaatccata acatggctct ttgccacaac tctctttatt ggctatatgc 960
caatacactg tccttcagag actgacacgg actctgtatt tttacaggat ggggtctcat 1020
ttattattta caaattcaca tatacaacac caccgtcccc agtgcccgca gtttttatta 1080
aacataacgt gggatctcca cgcgaatctc gggtacgtgt tccggaacgg tggagggcag 1140
tgtagtctga gcagtactcg ttgctgccgc gcgcgccacc agacataata gctgacagac 1200
taacagactg ttcctttcca tgggtctttt ctgcagtcac cgtccttgac acgggatccg 1260
cggccgccat ggagacagac acactcctgc tatgggtact gctgctctgg gttccaggtt 1320
ccaccggtga caagactcac acatgcccac cgtgcccagc acctgaactc ctggggggac 1380
cgtcagtctt cctcttcccc ccaaaaccca aggacaccct catgatctcc cggacccctg 1440
aggtcacatg cgtggtggtg gacgtgagcc acgaagaccc tgaggtcaag ttcaactggt 1500
acgtggacgg cgtggaggtg cataatgcca agacaaagcc gcgggaggag cagtacaaca 1560
gcacgtaccg tgtggtcagc gtcctcaccg tcctgcacca ggactggctg aatggcaagg 1620
agtacaagtg caaggtctcc aacaaagccc tcccagcccc catcgagaaa accatctcca 1680
aagccaaagg gcagccccga gaaccacagg tgtacaccct gcccccatcc cgggatgagc 1740
tgaccaagaa ccaggtcagc ctgacctgcc tggtcagcgg cttctatccc agcgacatcg 1800
ccgtggagtg ggagagcaat gggcagccgg agaacaacta caagaccacg cctcccatct 1860
tggactccga cggctccttc aaactctaca gcaagctcac cgtggacaag agcaggtggc 1920
agcaggggaa cgtcttctca tgctccgtga tgcatgaggc tctgcacaac cactacacgc 1980
agaagagcct ctccctgtct ccgggttagt aattaattaa tgcatctagg gcggccaatt 2040
ccgcccctct ccctcccccc cccctaacgt tactggccga agccgcttgg aataaggccg 2100
gtgtgcgttt gtctatatgt tattttccac catattgccg tcttttggca atgtgagggc 2160
ccggaaacct ggccctgtct tcttgacgag cattcctagg ggtctttccc ctctcgccaa 2220
aggaatgcaa ggtctgttga atgtcgtgaa ggaagcagtt cctctggaag cttcttgaag 2280
acaaacaacg tctgtagcga ccctttgcag gcagcggaac cccccacctg gcgacaggtg 2340
cctctgcggc caaaagccac gtgtataaga tacacctgca aaggcggcac aaccccagtg 2400
ccacgttgtg agttggatag ttgtggaaag agtcaaatgg ctctcctcaa gcgtattcaa 2460
caaggggctg aaggatgccc agaaggtacc ccattgtatg ggatctgatc tggggcctcg 2520
gtgcacatgc tttacatgtg tttagtcgag gttaaaaaaa cgtctaggcc ccccgaacca 2580
cggggacgtg gttttccttt gaaaaacacg atgataatat ggccacaacc atggttaccg 2640
agtacaagcc cacggtgcgc ctcgccaccc gcgacgacgt ccccagggcc gtacgcaccc 2700
tcgccgccgc gttcgccgac taccccgcca cgcgccacac cgtcgatccg gaccgccaca 2760
tcgagcgggt caccgagctg caagaactct tcctcacgcg cgtcgggctc gacatcggca 2820
aggtgtgggt cgcggacgac ggcgccgcgg tggcggtctg gaccacgccg gagagcgtcg 2880
aagcgggggc ggtgttcgcc gagatcggcc cgcgcatggc cgagttgagc ggttcccggc 2940
tggccgcgca gcaacagatg gaaggcctcc tggcgccgca ccggcccaag gagcccgcgt 3000
ggttcctggc caccgtcggc gtctcgcccg accaccaggg caagggtctg ggcagcgccg 3060
tcgtgctccc cggagtggag gcggccgagc gcgccggggt gcccgccttc ctggagacct 3120
ccgcgccccg caacctcccc ttctacgagc ggctcggctt caccgtcacc gccgacgtcg 3180
aggtgcccga aggaccgcgc acctggtgca tgacccgcaa gcccggtgcc tgagtcgatg 3240
ataatcgatt agactgcccg ggtggcatcc ctgtgacccc tccccagtgc ctctcctggt 3300
cgtggaaggt gctactccag tgcccaccag ccttgtccta ataaaattaa gttgcatcat 3360
tttgtttgac taggtgtcct tgtataatat tatggggtgg aggcgggtgg tatggagcaa 3420
ggggcaggtt gggaagacaa cctgtagggc cttcagggtc tattgggaac caggctggag 3480
tgcagtggca cgatcttggc tcgctgcaat ctccgcctcc tgggttcaag cgattctcct 3540
gcctcagtct cccgaatagt tgggattcca ggcatgcacg accaggctca gctaattttt 3600
gtatttttgg tagagacggg gtttcaccat attggccagt ctggtatcca tctcctgacc 3660
tcaggtaatc cgcccgcctc ggcctcccaa attgctggga ttacaggtat gagccactgg 3720
gcccttccct gtcctgtgat tttaaaataa ttataccagc agaaggacgt ccagacacag 3780
catgggctac ctggccatgc ccagccagtt ggacatttga gttgtttgct tggcactgtc 3840
ctctcatcaa ttcgagctca ctggccgtcg ttttacaacg tcgtgactgg gaaaaccctg 3900
gcgttaccca acttaatcgc cttgcagcac atcccccttt cgccagctgg cgtaatagcg 3960
aagaggcccg caccgatcgc ccttcccaac agttgcgcag cctgaatggc gaatggcgcc 4020
tgatgcggta ttttctcctt acgcatctgt gcggtatttc acaccgcata tggtgcactc 4080
tcagtacaat ctgctctgat gccgcatagt taagccagcc ccgacacccg ccaacacccg 4140
ctgacgcgcc ctgacgggct tgtctgctcc cggcatccgc ttacagacaa gctgtgaccg 4200
tctccgggag ctgcatgtgt cagaggtttt caccgtcatc accgaaacgc gcgagacgaa 4260
agggcctcgt gatacgccta tttttatagg ttaatgtcat gataataatg gtttcttaga 4320
cgtcaggtgg cacttttcgg ggaaatgtgc gcggaacccc tatttgttta tttttctaaa 4380
tacattcaaa tatgtatccg ctcatgagac aataaccctg ataaatgctt caataatatt 4440
gaaaaaggaa gagtatgagt attcaacatt tccgtgtcgc ccttattccc ttttttgcgg 4500
cattttgcct tcctgttttt gctcacccag aaacgctggt gaaagtaaaa gatgctgaag 4560
atcagttggg tgcacgagtg ggttacatcg aactggatct caacagcggt aagatccttg 4620
agagttttcg ccccgaagaa cgttttccaa tgatgagcac ttttaaagtt ctgctatgtg 4680
gcgcggtatt atcccgtatt gacgccgggc aagagcaact cggtcgccgc atacactatt 4740
ctcagaatga cttggttgag tactcaccag tcacagaaaa gcatcttacg gatggcatga 4800
cagtaagaga attatgcagt gctgccataa ccatgagtga taacactgcg gccaacttac 4860
ttctgacaac gatcggagga ccgaaggagc taaccgcttt tttgcacaac atgggggatc 4920
atgtaactcg ccttgatcgt tgggaaccgg agctgaatga agccatacca aacgacgagc 4980
gtgacaccac gatgcctgta gcaatggcaa caacgttgcg caaactatta actggcgaac 5040
tacttactct agcttcccgg caacaattaa tagactggat ggaggcggat aaagttgcag 5100
gaccacttct gcgctcggcc cttccggctg gctggtttat tgctgataaa tctggagccg 5160
gtgagcgtgg ttcccgcggt atcattgcag cactggggcc agatggtaag ccctcccgta 5220
tcgtagttat ctacacgacg gggagtcagg caactatgga tgaacgaaat agacagatcg 5280
ctgagatagg tgcctcactg attaagcatt ggtaactgtc agaccaagtt tactcatata 5340
tactttagat tgatttaaaa cttcattttt aatttaaaag gatctaggtg aagatccttt 5400
ttgataatct catgaccaaa atcccttaac gtgagttttc gttccactga gcgtcagacc 5460
ccgtagaaaa gatcaaagga tcttcttgag atcctttttt tctgcgcgta atctgctgct 5520
tgcaaacaaa aaaaccaccg ctaccagcgg tggtttgttt gccggatcaa gagctaccaa 5580
ctctttttcc gaaggtaact ggcttcagca gagcgcagat accaaatact gttcttctag 5640
tgtagccgta gttaggccac cacttcaaga actctgtagc accgcctaca tacctcgctc 5700
tgctaatcct gttaccagtg gctgctgcca gtggcgataa gtcgtgtctt accgggttgg 5760
actcaagacg atagttaccg gataaggcgc agcggtcggg ctgaacgggg ggttcgtgca 5820
cacagcccag cttggagcga acgacctaca ccgaactgag atacctacag cgtgagctat 5880
gagaaagcgc cacgcttccc gaagggagaa aggcggacag gtatccggta agcggcaggg 5940
tcggaacagg agagcgcacg agggagcttc cagggggaaa cgcctggtat ctttatagtc 6000
ctgtcgggtt tcgccacctc tgacttgagc gtcgattttt gtgatgctcg tcaggggggc 6060
ggagcctatg gaaaaacgcc agcaacgcgg cctttttacg gttcctggcc ttttgctggc 6120
cttttgctca catgttcttt cctgcgttat cccctgattc tgtggataac cgtattaccg 6180
cctttgagtg agctgatacc gctcgccgca gccgaacgac cgagcgcagc gagtcagtga 6240
gcgaggaagc ggaagggcgc ccaatacgca aaccgcctct ccccgcgcgt tggccgattc 6300
attaatgcag ctggcacgac aggtttcccg actggaaagc gggcagtgag cgcaacgcaa 6360
ttaatgtgag ttagctcact cattaggcac cccaggcttt acactttatg cttccggctc 6420
gtatgttgtg tggaattgtg agcggataac aatttcacac aggaaacagc tatgaccatg 6480
attacgcca 6489
<210> 45
<211> 104
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 45
Ala Ser Thr Lys Gly Pro Thr Val Lys Ile Leu Gln Ser Ser Cys Asp
1 5 10 15
Gly Gly Gly His Phe Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser
20 25 30
Gly Tyr Thr Pro Gly Thr Ile Asn Ile Thr Trp Leu Glu Asp Gly Gln
35 40 45
Val Met Asp Val Asp Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu
50 55 60
Leu Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu
65 70 75 80
Ser Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe
85 90 95
Glu Asp Ser Thr Lys Lys Cys Ala
100
<210> 46
<211> 104
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 46
Arg Thr Val Ala Ala Pro Thr Val Lys Ile Leu Gln Ser Ser Cys Asp
1 5 10 15
Gly Gly Gly His Phe Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser
20 25 30
Gly Tyr Thr Pro Gly Thr Ile Asn Ile Thr Trp Leu Glu Asp Gly Gln
35 40 45
Val Met Asp Val Asp Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu
50 55 60
Leu Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu
65 70 75 80
Ser Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe
85 90 95
Glu Asp Ser Thr Lys Lys Cys Ala
100
<210> 47
<211> 104
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 47
Ala Ser Thr Lys Gly Pro Thr Val Lys Ile Trp Gln Ser Ser Cys Asp
1 5 10 15
Gly Gly Gly His Phe Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser
20 25 30
Gly Tyr Thr Pro Gly Thr Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln
35 40 45
Val Met Asp Val Asp Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu
50 55 60
Leu Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu
65 70 75 80
Ser Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe
85 90 95
Glu Asp Ser Thr Lys Lys Cys Ala
100
<210> 48
<211> 104
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 48
Arg Thr Val Ala Ala Pro Thr Val Lys Ile Leu Gln Ser Ser Cys Asp
1 5 10 15
Gly Gly Gly His Phe Pro Pro Thr Ile Gln Leu Gly Cys Leu Val Ser
20 25 30
Gly Tyr Thr Pro Gly Thr Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln
35 40 45
Val Met Asp Val Asp Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu
50 55 60
Leu Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu
65 70 75 80
Ser Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe
85 90 95
Glu Asp Ser Thr Lys Lys Cys Ala
100
<210> 49
<211> 104
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 49
Ala Ser Thr Lys Gly Pro Thr Val Lys Ile Leu Gln Ser Thr Cys Asp
1 5 10 15
Gly Gly Gly His Phe Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser
20 25 30
Gly Tyr Thr Pro Gly Thr Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln
35 40 45
Val Met Asp Val Asp Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu
50 55 60
Leu Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu
65 70 75 80
Ser Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe
85 90 95
Glu Asp Ser Thr Lys Lys Cys Ala
100
<210> 50
<211> 104
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 50
Arg Thr Val Ala Ala Pro Thr Val Lys Ile Leu Gln Ser Ser Cys Asp
1 5 10 15
Gly Gly Gly His Phe Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser
20 25 30
Gly Tyr Thr Pro Gly Thr Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln
35 40 45
Val Met Asp Val Asp Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu
50 55 60
Leu Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu
65 70 75 80
Ser Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe
85 90 95
Glu Asp Ser Ser Lys Lys Cys Ala
100
<210> 51
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 51
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Ile Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Ser Ser Ser Gly Gly Asp Thr Ser Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Val Leu Ala Gly Tyr Phe Asp Trp Leu Pro Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Thr Val Lys Ile Leu Gln Ser Ile Cys Asp Gly Gly Gly His Phe Pro
130 135 140
Pro Thr Ile Gln Leu Leu Cys Leu Val Ser Gly Tyr Thr Pro Gly Thr
145 150 155 160
Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln Val Met Asp Val Asp Leu
165 170 175
Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu Leu Ala Ser Thr Gln Ser
180 185 190
Glu Leu Thr Leu Ser Gln Lys His Trp Leu Ser Asp Arg Thr Tyr Thr
195 200 205
Cys Gln Val Thr Tyr Gln Gly His Thr Phe Glu Asp Ser Thr Lys Lys
210 215 220
Cys Ala Ser Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
225 230 235 240
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
245 250 255
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
260 265 270
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
275 280 285
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
290 295 300
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
305 310 315 320
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
325 330 335
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
340 345 350
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn
355 360 365
Gln Val Lys Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
370 375 380
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
385 390 395 400
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Ser
405 410 415
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
420 425 430
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
435 440 445
Ser Leu Ser Pro Gly
450
<210> 52
<211> 213
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 52
Asp Ile Gln Met Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Thr Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Tyr Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Asp Thr Phe Asn Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Gly Ser Ser Pro Pro
85 90 95
Trp Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val
100 105 110
Ala Ala Pro Thr Val Lys Ile Leu Gln Ser Ser Cys Asp Gly Gly Gly
115 120 125
His Phe Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser Gly Tyr Thr
130 135 140
Pro Gly Thr Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln Val Met Asp
145 150 155 160
Val Asp Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu Leu Ala Ser
165 170 175
Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu Ser Asp Arg
180 185 190
Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe Glu Asp Ser
195 200 205
Gly Lys Lys Cys Ala
210
<210> 53
<211> 449
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 53
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ile Tyr
20 25 30
Arg Met Gln Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Pro Ser Gly Gly Thr Thr Trp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Ser Gly Gly Ser Gly Tyr Ala Phe Asp Ile Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Ser Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Lys Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly
<210> 54
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 54
Asp Ile Gln Met Thr Gln Ser Pro Leu Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Arg Asp Ile Arg Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Ser Leu Gln Thr Gly Val Pro Ser Arg Phe Gly Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Ser Phe Thr Ile Gly Ser Leu Gln Pro
65 70 75 80
Glu Asp Glu Ala Thr Tyr Tyr Cys Gln Gln Phe Asp Ser Leu Pro His
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 55
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 55
Ser Gly Gly Gly
1
<210> 56
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 56
Gly Gly Gly Gly Ser
1 5
<210> 57
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 57
Ser Gly Gly Gly Gly
1 5
<210> 58
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 58
Gly Gly Gly Gly Gly Ser
1 5
<210> 59
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 59
Ser Gly Gly Gly Gly Gly
1 5
<210> 60
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 60
Gly Gly Gly Gly Gly Gly Ser
1 5
<210> 61
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 61
Ser Gly Gly Gly Gly Gly Gly
1 5
<210> 62
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<220>
<221> MISC_FEATURE
<222> (1)..(20)
<223> /note="This region may encompass 0-4 'Gly Gly Gly Xaa Xaa'
repeating units"
<220>
<221> MOD_RES
<222> (4)..(5)
<223> Any amino acid
<220>
<221> MOD_RES
<222> (9)..(10)
<223> Any amino acid
<220>
<221> MOD_RES
<222> (14)..(15)
<223> Any amino acid
<220>
<221> MOD_RES
<222> (19)..(20)
<223> Any amino acid
<220>
<221> source
<223> /note="See specification as filed for detailed description of
substitutions and preferred embodiments"
<400> 62
Gly Gly Gly Xaa Xaa Gly Gly Gly Xaa Xaa Gly Gly Gly Xaa Xaa Gly
1 5 10 15
Gly Gly Xaa Xaa Gly Gly Gly Gly Ser
20 25
<210> 63
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<220>
<221> MISC_FEATURE
<222> (6)..(25)
<223> /note="This region may encompass 0-4 'Xaa Gly Gly Gly Ser'
repeating units"
<220>
<221> MOD_RES
<222> (6)..(6)
<223> Any amino acid
<220>
<221> MOD_RES
<222> (11)..(11)
<223> Any amino acid
<220>
<221> MOD_RES
<222> (16)..(16)
<223> Any amino acid
<220>
<221> MOD_RES
<222> (21)..(21)
<223> Any amino acid
<220>
<221> source
<223> /note="See specification as filed for detailed description of
substitutions and preferred embodiments"
<400> 63
Gly Gly Gly Gly Ser Xaa Gly Gly Gly Ser Xaa Gly Gly Gly Ser Xaa
1 5 10 15
Gly Gly Gly Ser Xaa Gly Gly Gly Ser
20 25
<210> 64
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<220>
<221> MISC_FEATURE
<222> (1)..(20)
<223> /note="This region may encompass 0-4 'Gly Gly Gly Pro Ser'
repeating units"
<400> 64
Gly Gly Gly Pro Ser Gly Gly Gly Pro Ser Gly Gly Gly Pro Ser Gly
1 5 10 15
Gly Gly Pro Ser Gly Gly Gly Gly Ser
20 25
<210> 65
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<220>
<221> MISC_FEATURE
<222> (1)..(20)
<223> /note="This region may encompass 0-4 'Gly Gly Gly Gly Gln'
repeating units"
<400> 65
Gly Gly Gly Gly Gln Gly Gly Gly Gly Gln Gly Gly Gly Gly Gln Gly
1 5 10 15
Gly Gly Gly Gln Gly Gly Gly Gly Ser
20 25
<210> 66
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<220>
<221> MISC_FEATURE
<222> (1)..(20)
<223> /note="This region may encompass 0-4 'Gly Gly Gly Gly Ala'
repeating units"
<400> 66
Gly Gly Gly Gly Ala Gly Gly Gly Gly Ala Gly Gly Gly Gly Ala Gly
1 5 10 15
Gly Gly Gly Ala Gly Gly Gly Gly Ser
20 25
<210> 67
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<220>
<221> MISC_FEATURE
<222> (6)..(25)
<223> /note="This region may encompass 0-4 'Pro Gly Gly Gly Ser'
repeating units"
<400> 67
Gly Gly Gly Gly Ser Pro Gly Gly Gly Ser Pro Gly Gly Gly Ser Pro
1 5 10 15
Gly Gly Gly Ser Pro Gly Gly Gly Ser
20 25
<210> 68
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 68
Gly Gly Gly Gly Ala Gly Gly Gly Gly Ala Gly Gly Gly Gly Ser
1 5 10 15
<210> 69
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 69
Gly Gly Gly Gly Gln Gly Gly Gly Gly Gln Gly Gly Gly Gly Ser
1 5 10 15
<210> 70
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 70
Gly Gly Gly Pro Ser Gly Gly Gly Pro Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 71
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 71
Gly Gly Gly Gly Ser Pro Gly Gly Gly Ser Pro Gly Gly Gly Ser
1 5 10 15
<210> 72
<211> 98
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 72
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val
<210> 73
<211> 107
<212> PRT
<213> Homo sapiens
<400> 73
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 74
<211> 106
<212> PRT
<213> Homo sapiens
<400> 74
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
20 25 30
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
35 40 45
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
100 105
<210> 75
<211> 235
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 75
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr Ala Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Lys Val
115 120 125
Ser Val Phe Val Pro Pro Arg Asp Gly Phe Phe Gly Asn Pro Arg Lys
130 135 140
Ser Lys Leu Ile Cys Gln Ala Thr Gly Phe Ser Pro Arg Gln Ile Gln
145 150 155 160
Val Ser Trp Leu Arg Glu Gly Lys Gln Val Gly Ser Gly Val Thr Thr
165 170 175
Asp Gln Val Gln Ala Glu Ala Lys Glu Ser Gly Pro Thr Thr Tyr Lys
180 185 190
Val Thr Ser Thr Leu Thr Ile Lys Glu Ser Asp Trp Leu Gly Gln Ser
195 200 205
Met Phe Thr Cys Arg Val Asp His Arg Gly Leu Thr Phe Gln Gln Gln
210 215 220
Ala Ser Ser Met Cys His His His His His His
225 230 235
<210> 76
<211> 216
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 76
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Asn Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Phe Leu Tyr Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Pro
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Lys Val Ser Val Phe Val Pro Pro Arg Asp Gly Phe Phe Gly Asn
115 120 125
Pro Arg Lys Ser Lys Leu Ile Cys Gln Ala Thr Gly Phe Ser Pro Arg
130 135 140
Gln Ile Gln Val Ser Trp Leu Arg Glu Gly Lys Gln Val Gly Ser Gly
145 150 155 160
Val Thr Thr Asp Gln Val Gln Ala Glu Ala Lys Glu Ser Gly Pro Thr
165 170 175
Thr Tyr Lys Val Thr Ser Thr Leu Thr Ile Lys Glu Ser Asp Trp Leu
180 185 190
Gly Gln Ser Met Phe Thr Cys Arg Val Asp His Arg Gly Leu Thr Phe
195 200 205
Gln Gln Gln Ala Ser Ser Met Cys
210 215
<210> 77
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 77
Ser Arg Asp Phe Thr
1 5
<210> 78
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 78
Gly Gln Pro Lys Ala Ala
1 5
<210> 79
<211> 451
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 79
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr Ala Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Thr Val
115 120 125
Lys Ile Leu Gln Ser Ile Cys Asp Gly Gly Gly His Phe Pro Pro Thr
130 135 140
Ile Gln Leu Leu Cys Leu Val Ser Gly Tyr Thr Pro Gly Thr Ile Gln
145 150 155 160
Ile Thr Trp Leu Glu Asp Gly Gln Val Met Asp Val Asp Leu Ser Thr
165 170 175
Ala Ser Thr Thr Gln Glu Gly Glu Leu Ala Ser Thr Gln Ser Glu Leu
180 185 190
Thr Leu Ser Gln Lys His Trp Leu Ser Asp Arg Thr Tyr Thr Cys Gln
195 200 205
Val Thr Tyr Gln Gly His Thr Phe Glu Asp Ser Thr Lys Lys Cys Ala
210 215 220
Ser Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu
225 230 235 240
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
245 250 255
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
260 265 270
His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu
275 280 285
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
290 295 300
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
305 310 315 320
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro
325 330 335
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
340 345 350
Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val
355 360 365
Lys Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
370 375 380
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
385 390 395 400
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Leu Leu Thr
405 410 415
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
420 425 430
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
435 440 445
Ser Pro Gly
450
<210> 80
<211> 211
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 80
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Asn Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Phe Leu Tyr Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Pro
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Thr Val Lys Ile Leu Gln Ser Ser Cys Asp Gly Gly Gly His Phe
115 120 125
Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser Gly Tyr Thr Pro Gly
130 135 140
Thr Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln Val Met Asp Val Asp
145 150 155 160
Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu Leu Ala Ser Thr Gln
165 170 175
Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu Ser Asp Arg Thr Tyr
180 185 190
Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe Glu Asp Ser Gly Lys
195 200 205
Lys Cys Ala
210
<210> 81
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 81
Asp Ile Leu Leu Thr Gln Ser Pro Val Ile Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Val Ser Phe Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr Asn
20 25 30
Ile His Trp Tyr Gln Gln Arg Thr Asn Gly Ser Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Glu Ser Ile Ser Gly Ile Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Ser Ile Asn Ser Val Glu Ser
65 70 75 80
Glu Asp Ile Ala Asp Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 82
<211> 448
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 82
Gln Val Gln Leu Lys Gln Ser Gly Pro Gly Leu Val Gln Pro Ser Gln
1 5 10 15
Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro Phe Thr
50 55 60
Ser Arg Leu Ser Ile Asn Lys Asp Asn Ser Lys Ser Gln Val Phe Phe
65 70 75 80
Lys Met Asn Ser Leu Gln Ser Asn Asp Thr Ala Ile Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ala Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Ser Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Ile Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Lys Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 83
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 83
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Ile Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Ser Ser Ser Gly Gly Asp Thr Ser Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Val Leu Ala Gly Tyr Phe Asp Trp Leu Pro Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Thr Val Lys Ile Leu Gln Ser Ile Cys Asp Gly Gly Gly His Phe Pro
130 135 140
Pro Thr Ile Gln Leu Leu Cys Leu Val Ser Gly Tyr Thr Pro Gly Thr
145 150 155 160
Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln Val Met Asp Val Asp Leu
165 170 175
Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu Leu Ala Ser Thr Gln Ser
180 185 190
Glu Leu Thr Leu Ser Gln Lys His Trp Leu Ser Asp Arg Thr Tyr Thr
195 200 205
Cys Gln Val Thr Tyr Gln Gly His Thr Phe Glu Asp Ser Thr Lys Lys
210 215 220
Cys Ala Ser Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
225 230 235 240
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
245 250 255
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
260 265 270
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
275 280 285
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
290 295 300
Ser Ala Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
305 310 315 320
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
325 330 335
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
340 345 350
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn
355 360 365
Gln Val Lys Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
370 375 380
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
385 390 395 400
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Ser
405 410 415
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
420 425 430
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
435 440 445
Ser Leu Ser Pro Gly
450
<210> 84
<211> 449
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 84
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ile Tyr
20 25 30
Arg Met Gln Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Pro Ser Gly Gly Thr Thr Trp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Ser Gly Gly Ser Gly Tyr Ala Phe Asp Ile Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Ala Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Ser Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Lys Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly
<210> 85
<211> 679
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 85
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr Ala Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Leu Glu Ser Gly Gly
450 455 460
Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser
465 470 475 480
Gly Phe Thr Phe Ser Ile Tyr Arg Met Gln Trp Val Arg Gln Ala Pro
485 490 495
Gly Lys Gly Leu Glu Trp Val Ser Gly Ile Ser Pro Ser Gly Gly Thr
500 505 510
Thr Trp Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
515 520 525
Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu
530 535 540
Asp Thr Ala Val Tyr Tyr Cys Ala Arg Trp Ser Gly Gly Ser Gly Tyr
545 550 555 560
Ala Phe Asp Ile Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser Ala
565 570 575
Ser Thr Lys Gly Pro Thr Val Lys Ile Leu Gln Ser Ile Cys Asp Gly
580 585 590
Gly Gly His Phe Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser Gly
595 600 605
Tyr Thr Pro Gly Thr Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln Val
610 615 620
Met Asp Val Asp Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu Leu
625 630 635 640
Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu Ser
645 650 655
Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe Glu
660 665 670
Asp Ser Thr Lys Lys Cys Ala
675
<210> 86
<211> 211
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 86
Asp Ile Gln Met Thr Gln Ser Pro Leu Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Arg Asp Ile Arg Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Ser Leu Gln Thr Gly Val Pro Ser Arg Phe Gly Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Ser Phe Thr Ile Gly Ser Leu Gln Pro
65 70 75 80
Glu Asp Glu Ala Thr Tyr Tyr Cys Gln Gln Phe Asp Ser Leu Pro His
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Thr Val Lys Ile Leu Gln Ser Ser Cys Asp Gly Gly Gly His Phe
115 120 125
Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser Gly Tyr Thr Pro Gly
130 135 140
Thr Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln Val Met Asp Val Asp
145 150 155 160
Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu Leu Ala Ser Thr Gln
165 170 175
Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu Ser Asp Arg Thr Tyr
180 185 190
Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe Glu Asp Ser Gly Lys
195 200 205
Lys Cys Ala
210
<210> 87
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 87
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Asn Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Phe Leu Tyr Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Pro
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 88
<211> 679
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 88
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ile Tyr
20 25 30
Arg Met Gln Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Pro Ser Gly Gly Thr Thr Trp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Ser Gly Gly Ser Gly Tyr Ala Phe Asp Ile Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly
450 455 460
Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser
465 470 475 480
Gly Phe Asn Ile Lys Asp Thr Tyr Ile His Trp Val Arg Gln Ala Pro
485 490 495
Gly Lys Gly Leu Glu Trp Val Ala Arg Ile Tyr Pro Thr Asn Gly Tyr
500 505 510
Thr Arg Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Ala Asp
515 520 525
Thr Ser Lys Asn Thr Ala Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu
530 535 540
Asp Thr Ala Val Tyr Tyr Cys Ser Arg Trp Gly Gly Asp Gly Phe Tyr
545 550 555 560
Ala Met Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala
565 570 575
Ser Thr Lys Gly Pro Thr Val Lys Ile Leu Gln Ser Ile Cys Asp Gly
580 585 590
Gly Gly His Phe Pro Pro Thr Ile Gln Leu Leu Cys Leu Val Ser Gly
595 600 605
Tyr Thr Pro Gly Thr Ile Gln Ile Thr Trp Leu Glu Asp Gly Gln Val
610 615 620
Met Asp Val Asp Leu Ser Thr Ala Ser Thr Thr Gln Glu Gly Glu Leu
625 630 635 640
Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His Trp Leu Ser
645 650 655
Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly His Thr Phe Glu
660 665 670
Asp Ser Thr Lys Lys Cys Ala
675
<210> 89
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 89
Asp Glu Asp Glu
1
<210> 90
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
6xHis tag"
<400> 90
His His His His His His
1 5
<210> 91
<211> 113
<212> PRT
<213> Homo sapiens
<400> 91
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro
<210> 92
<211> 106
<212> PRT
<213> Pan sp.
<400> 92
Val Cys Ser Arg Asp Phe Thr Pro Thr Val Lys Val Leu Gln Ser Ser
1 5 10 15
Cys Asp Gly Gly Gly His Phe Pro Pro Thr Ile Gln Leu Leu Cys Leu
20 25 30
Val Ser Gly Tyr Thr Pro Gly Thr Ile Asn Ile Thr Trp Leu Glu Asp
35 40 45
Gly Gln Val Met Asp Val Asp Leu Ser Thr Ala Ser Ala Thr Gln Glu
50 55 60
Gly Glu Leu Ala Ser Thr Gln Ser Glu Leu Thr Leu Ser Gln Lys His
65 70 75 80
Trp Leu Ser Asp Arg Thr Tyr Thr Cys Gln Val Thr Tyr Gln Gly Gly
85 90 95
Thr Phe Glu Asp Ser Thr Lys Lys Cys Ala
100 105
<210> 93
<211> 102
<212> PRT
<213> Mus sp.
<400> 93
Asn Ile Thr Glu Pro Thr Leu Glu Leu Leu His Ser Ser Cys Asp Pro
1 5 10 15
Asn Ala Phe His Ser Thr Ile Gln Leu Tyr Cys Phe Ile Tyr Gly His
20 25 30
Ile Leu Asn Asp Val Ser Val Ser Trp Leu Met Asp Asp Arg Glu Ile
35 40 45
Thr Asp Thr Leu Ala Gln Thr Val Leu Ile Lys Glu Glu Gly Lys Leu
50 55 60
Ala Ser Thr Cys Ser Lys Leu Asn Ile Thr Glu Gln Gln Trp Met Ser
65 70 75 80
Glu Ser Thr Phe Thr Cys Lys Val Thr Ser Gln Gly Val Asp Tyr Leu
85 90 95
Ala His Thr Arg Arg Cys
100
<210> 94
<211> 103
<212> PRT
<213> Rattus sp.
<400> 94
Asn Ile Thr Lys Pro Thr Val Asp Leu Leu His Ser Ser Cys Asp Pro
1 5 10 15
Asn Ala Phe His Ser Thr Ile Gln Leu Tyr Cys Phe Val Tyr Gly His
20 25 30
Ile Gln Asn Asp Val Ser Ile His Trp Leu Met Asp Asp Arg Lys Ile
35 40 45
Tyr Glu Thr His Ala Gln Asn Val Leu Ile Lys Glu Glu Gly Lys Leu
50 55 60
Ala Ser Thr Tyr Ser Arg Leu Asn Ile Thr Gln Gln Gln Trp Met Ser
65 70 75 80
Glu Ser Thr Phe Thr Cys Lys Val Thr Ser Gln Gly Glu Asn Tyr Trp
85 90 95
Ala His Thr Arg Arg Cys Ser
100
<210> 95
<211> 107
<212> PRT
<213> Oryctolagus sp.
<400> 95
Ala Cys Ser Val Ser Phe Thr Pro Pro Ala Val Arg Leu Phe His Ser
1 5 10 15
Ser Cys Asp Pro Arg Glu Asn Asp Thr Tyr Thr Val Gln Leu Leu Cys
20 25 30
Leu Ile Ser Gly Tyr Thr Pro Gly Asp Ile Glu Val Thr Trp Leu Val
35 40 45
Asp Gly Gln Lys Asp Pro Asn Met Phe Ser Ile Thr Ala Gln Pro Arg
50 55 60
Gln Glu Gly Lys Leu Ala Ser Thr His Ser Glu Leu Asn Ile Thr Gln
65 70 75 80
Gly Glu Trp Ala Ser Lys Arg Thr Tyr Thr Cys Arg Val Ala Tyr Gln
85 90 95
Gly Glu Leu Phe Glu Ala His Ala Arg Glu Cys
100 105
<210> 96
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 96
Lys Leu Glu Leu Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe
1 5 10 15
<210> 97
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 97
Lys Leu Glu Leu Lys Arg Thr Val Ala Ala Pro Thr Val Lys Ile Leu
1 5 10 15
<210> 98
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 98
Lys Leu Glu Leu Lys Gly Gln Pro Lys Ala Ala Pro Thr Val Lys Ile
1 5 10 15
Leu
<210> 99
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 99
Lys Leu Glu Leu Lys Ser Arg Asp Phe Thr Pro Thr Val Lys Ile Leu
1 5 10 15
<210> 100
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 100
Lys Leu Glu Leu Lys Gly Gly Gly Gly Ser Pro Thr Val Lys Ile Leu
1 5 10 15
<210> 101
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 101
Lys Leu Glu Leu Lys Gly Gly Gly Gly Ser Gly Pro Thr Val Lys Ile
1 5 10 15
Leu
<210> 102
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 102
Arg Thr Val Ala Ala Pro
1 5
<210> 103
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 103
Ser Arg Asp Phe Thr Pro
1 5
<210> 104
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 104
Gly Gln Pro Lys Ala Ala Pro
1 5
<210> 105
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 105
Gly Gly Gly Gly Ser Pro
1 5
<210> 106
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 106
Gly Gly Gly Gly Ser Gly Pro
1 5
Claims (168)
- 제1 중쇄 가변 도메인 (제1 VH) 및 제1 경쇄 가변 도메인 (제1 VL)을 포함하는 항체 또는 이의 항원-결합 단편에 있어서, 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성하고, 상기 제1 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 E (IgE)의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 짝짓기하여 이량체를 형성하는, 항체 또는 이의 항원-결합 단편.
- 청구항 1에 있어서, 상기 제1 폴리펩타이드가 Fc 도메인에 직접적으로 연결되는, 항체.
- 청구항 1에 있어서, 상기 제2 폴리펩타이드가 Fc 도메인에 직접적으로 연결되는, 항체.
- 청구항 1 내지 3 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:1에서 제시된 상기 아미노산 서열을 포함하는, 항체 또는 이의 항원-결합 단편.
- 청구항 1 내지 3 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:1에서 제시된 상기 아미노산 서열의 아미노산 9-107에 적어도 90% 동일한 아미노산 서열을 포함하는, 항체 또는 이의 항원-결합 단편.
- 청구항 1 내지 3 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:1에서 제시된 상기 아미노산 서열의 아미노산 9-107을 포함하는, 항체 또는 이의 항원-결합 단편.
- 청구항 1 내지 6 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드가 서열 식별 번호:5에서 제시된 상기 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함하는, 항체 또는 이의 항원-결합 단편.
- 청구항 1 내지 6 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드가 서열 식별 번호:5에서 제시된 상기 아미노산 서열을 포함하는, 항체 또는 이의 항원-결합 단편.
- 청구항 1 내지 8 중 어느 한 항에 있어서, 상기 제2 폴리펩타이드가 서열 식별 번호:6에서 제시된 상기 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함하는, 항체 또는 이의 항원-결합 단편.
- 청구항 1 내지 8 중 어느 한 항에 있어서, 상기 제2 폴리펩타이드가 서열 식별 번호:6에서 제시된 상기 아미노산 서열을 포함하는, 항체 또는 이의 항원-결합 단편.
- 청구항 1 내지 3 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 12 이하 아미노산 잔기에서 서열 식별 번호:1의 아미노산 9-107에서 제시된 상기 아미노산 서열과 상이한, 항체 또는 이의 항원-결합 단편.
- 청구항 1 내지 3 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 쇄내 디설파이드 결합을 형성하지 않는 서열 식별 번호:1의 상기 2 시스테인 잔기 중 적어도 하나에서 시스테인 이외 아미노산을 함유하는, 항체 또는 이의 항원-결합 단편.
- 청구항 1 내지 3, 5, 11, 또는 12 중 어느 한 항에 있어서, 하기인, 항체 또는 이의 항원-결합 단편:
(i) 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 각각 서열 식별 번호:1내 상기 N-당화 모티프에서 아스파라긴 및/또는 트레오닌 또는 세린 이외 아미노산을 함유하여서 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 N-당화되지 않음; 또는
(ii) 상기 제1 폴리펩타이드 또는 상기 제2 폴리펩타이드가 서열 식별 번호:1내 상기 N-당화 모티프에서 아스파라긴 및/또는 트레오닌 또는 세린 이외 아미노산을 함유하여서 상기 제1 폴리펩타이드 또는 상기 제2 폴리펩타이드가 N-당화되지 않음. - 청구항 1 내지 13 중 어느 한 항에 있어서, 상기 항체 또는 이의 항원-결합 단편이 제2 중쇄 가변 도메인 (제2 VH) 및 제2 경쇄 가변 도메인 (제2 VL)을 포함하고, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 상기 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성하는, 항체 또는 이의 항원-결합 단편.
- 청구항 14에 있어서, 상기 제2 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결되고 상기 제2 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결되는, 항체 또는 이의 항원-결합 단편.
- 제1 중쇄 가변 도메인 (제1 VH) 및 제1 경쇄 가변 도메인 (제1 VL)을 포함하는 항체 또는 이의 항원-결합 단편에 있어서, 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성하고, 상기 제1 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 M (IgM) (서열 식별 번호:2)의 상기 CH2 도메인의 상기 아미노산 서열의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM (서열 식별 번호:2)의 상기 CH2 도메인의 상기 아미노산 서열의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 짝짓기하여 이량체를 형성하는, 항체 또는 이의 항원-결합 단편.
- 청구항 16에 있어서, 상기 제1 폴리펩타이드가 Fc 도메인에 직접적으로 연결되는, 항체.
- 청구항 16에 있어서, 상기 제2 폴리펩타이드가 Fc 도메인에 직접적으로 연결되는, 항체.
- 청구항 16 내지 18 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:2에서 제시된 상기 아미노산 서열을 포함하는, 항체 또는 이의 항원-결합 단편.
- 청구항 16 내지 18 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:2에서 제시된 상기 아미노산 서열의 아미노산 7-112에 적어도 90% 동일한 아미노산 서열을 포함하는, 항체 또는 이의 항원-결합 단편.
- 청구항 16 내지 18 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:2에서 제시된 상기 아미노산 서열의 아미노산 7-112를 포함하는, 항체 또는 이의 항원-결합 단편.
- 청구항 16 내지 18 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 적어도 12 아미노산 잔기에서 서열 식별 번호:2의 아미노산 7-112에서 제시된 상기 아미노산 서열과 상이한, 항체 또는 이의 항원-결합 단편.
- 청구항 16 내지 18, 20, 또는 22 중 어느 한 항에 있어서, 하기인, 항체 또는 이의 항원-결합 단편:
(i) 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 각각 서열 식별 번호:2내 상기 N-당화 모티프에서 아스파라긴 및/또는 트레오닌 또는 세린 이외 아미노산을 함유하여서 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 N-당화되지 않음; 또는
(ii) 상기 제1 폴리펩타이드 또는 상기 제2 폴리펩타이드가 서열 식별 번호:2내 상기 N-당화 모티프에서 아스파라긴 및/또는 트레오닌 또는 세린 이외 아미노산을 함유하여서 상기 제1 폴리펩타이드 또는 상기 제2 폴리펩타이드가 N-당화되지 않음. - 청구항 16 내지 23 중 어느 한 항에 있어서, 상기 항체 또는 이의 항원-결합 단편이 제2 중쇄 가변 도메인 (제2 VH) 및 제2 경쇄 가변 도메인 (제2 VL)을 포함하고, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 상기 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성하는, 항체 또는 이의 항원-결합 단편.
- 청구항 24에 있어서, 상기 제2 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결되고 상기 제2 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결되는, 항체 또는 이의 항원-결합 단편.
- 하기를 포함하는, 이중특이적 항체:
(i) 제1 중쇄 가변 도메인 (제1 VH) 및 제1 경쇄 가변 도메인 (제1 VL)을 포함하는 제1 단편 항원-결합 (제1 Fab), 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 제1 가변 영역을 형성하고, 상기 제1 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 E (IgE)의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결됨; 및
(ii) 제2 VH 및 제2 VL을 포함하는 제2 Fab, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 제2 가변 영역을 형성하고, 상기 제2 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결되고 상기 제2 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결됨,
상기 제1 Fab 및 상기 제2 Fab가 상이한 항원에 또는 상기 동일한 항원의 상이한 에피토프에 특이적으로 결합하고,
상기 제1 Fab가 상기 제2 Fab에 연결되는, 이중특이적 항체. - 청구항 26에 있어서, 상기 제1 Fab가 링커에 의해 상기 제2 Fab에 연결되는, 이중특이적 항체.
- 청구항 26에 있어서, 상기 제1 Fab가 이종 폴리펩타이드에 의해 상기 제2 Fab에 연결되는, 이중특이적 항체.
- 청구항 28에 있어서, 상기 이종 폴리펩타이드가 인간 혈청 알부민인, 이중특이적 항체.
- 청구항 28에 있어서, 상기 이종 폴리펩타이드가 XTEN인, 이중특이적 항체.
- 청구항 26에 있어서, 상기 제1 Fab가 폴리에틸렌 글리콜 (PEG)에 의해 상기 제2 Fab에 연결되는, 이중특이적 항체.
- 청구항 26 내지 31 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 각각 서열 식별 번호:1에서 제시된 상기 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 26 내지 31 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:1에서 제시된 상기 아미노산 서열의 아미노산 9-107에 적어도 90% 동일한 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 26 내지 31 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:1에서 제시된 상기 아미노산 서열의 아미노산 9-107을 포함하는, 이중특이적 항체.
- 청구항 26 내지 34 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드가 서열 식별 번호:5에서 제시된 상기 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 26 내지 34 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드가 서열 식별 번호:5에서 제시된 상기 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 26 내지 36 중 어느 한 항에 있어서, 상기 제2 폴리펩타이드가 서열 식별 번호:6에서 제시된 상기 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 26 내지 36 중 어느 한 항에 있어서, 상기 제2 폴리펩타이드가 서열 식별 번호:6에서 제시된 상기 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 26 내지 31 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 12 아미노산 잔기 이하에서 서열 식별 번호:1의 아미노산 9-107에서 제시된 상기 아미노산 서열과 상이한, 이중특이적 항체.
- 청구항 26 내지 31 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 쇄간 디설파이드 결합을 형성할 수 있는 서열 식별 번호:1의 상기 2 시스테인 잔기 중 적어도 하나에서 시스테인 이외 아미노산을 함유하는, 이중특이적 항체.
- 청구항 26 내지 31, 33, 39, 또는 40 중 어느 한 항에 있어서, 하기인, 이중특이적 항체:
(i) 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 각각 서열 식별 번호:1 내 상기 N-당화 모티프에서 아스파라긴 및/또는 트레오닌 또는 세린 이외 아미노산을 함유하여서 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 N-당화되지 않음; 또는
(ii) 상기 제1 폴리펩타이드 또는 상기 제2 폴리펩타이드가 서열 식별 번호:1 내 상기 N-당화 모티프에서 아스파라긴 및/또는 트레오닌 또는 세린 이외 아미노산을 함유하여서 상기 제1 폴리펩타이드 또는 상기 제2 폴리펩타이드가 N-당화되지 않음. - 하기를 포함하는, 이중특이적 항체:
(i) 제1 중쇄 가변 도메인 (제1 VH) 및 제1 경쇄 가변 도메인 (제1 VL)을 포함하는 제1 단편 항원-결합 (제1 Fab), 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 제1 가변 영역을 형성하고, 상기 제1 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 M (IgM)의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결됨; 및
(ii) 제2 VH 및 제2 VL을 포함하는 제2 Fab, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 제2 가변 영역을 형성하고, 상기 제2 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결되고 상기 제2 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결됨,
상기 제1 Fab 및 상기 제2 Fab가 상이한 항원에 또는 상기 동일한 항원의 상이한 에피토프에 특이적으로 결합하고,
상기 제1 Fab가 상기 제2 Fab에 연결되는, 이중특이적 항체. - 청구항 42에 있어서, 상기 제1 Fab가 링커에 의해 상기 제2 Fab에 연결되는, 이중특이적 항체.
- 청구항 43에 있어서, 상기 링커가 펩타이드 링커인, 이중특이적 항체.
- 청구항 42에 있어서, 상기 제1 Fab가 이종 폴리펩타이드에 의해 상기 제2 Fab에 연결되는, 이중특이적 항체.
- 청구항 45에 있어서, 상기 이종 폴리펩타이드가 인간 혈청 알부민인, 이중특이적 항체.
- 청구항 45에 있어서, 상기 이종 폴리펩타이드가 XTEN인, 이중특이적 항체.
- 청구항 42에 있어서, 상기 제1 Fab가 폴리에틸렌 글리콜 (PEG)에 의해 상기 제2 Fab에 연결되는, 이중특이적 항체.
- 청구항 42 내지 48 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 각각 서열 식별 번호:2에서 제시된 상기 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 42 내지 48 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:2에서 제시된 상기 아미노산 서열의 아미노산 7-112에 적어도 90% 동일한 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 42 내지 48 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:2에서 제시된 상기 아미노산 서열의 아미노산 7-112를 포함하는, 이중특이적 항체.
- 청구항 42 내지 48 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 적어도 12 아미노산 잔기에서 서열 식별 번호:2에서 제시된 상기 아미노산 서열과 상이한, 이중특이적 항체.
- 청구항 42 내지 48 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 쇄간 디설파이드 결합을 형성할 수 있는 서열 식별 번호:2의 상기 시스테인 잔기에서 시스테인 이외 아미노산을 함유하는, 이중특이적 항체.
- 청구항 42 내지 48, 50, 52, 또는 53 중 어느 한 항에 있어서, 하기인, 이중특이적 항체:
(i) 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 각각 서열 식별 번호:2 내 상기 N-당화 모티프에서 아스파라긴 및/또는 트레오닌 또는 세린 이외 아미노산을 함유하여서 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 N-당화되지 않음; 또는
(ii) 상기 제1 폴리펩타이드 또는 상기 제2 폴리펩타이드가 서열 식별 번호:2 내 상기 N-당화 모티프에서 아스파라긴 및/또는 트레오닌 또는 세린 이외 아미노산을 함유하여서 상기 제1 폴리펩타이드 또는 상기 제2 폴리펩타이드가 N-당화되지 않음. - 하기를 포함하는, 4가 이중특이적 항체로서:
(i) 제1 항원의 제1 에피토프에 특이적으로 결합하는 전체 IgG 항체, 상기 전체 IgG 항체는 제1 CH3 도메인 및 제2 CH3 도메인을 포함함; 및
(ii) 제1 Fab 및 제2 Fab,
상기 제1 Fab가 제1 중쇄 가변 도메인 (제1 VH) 및 제1 경쇄 가변 도메인 (제1 VL)을 포함하고, 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 상기 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제1 가변 영역을 형성하고,
상기 제2 Fab가 제2 중쇄 가변 도메인 (제2 VH) 및 제2 경쇄 가변 도메인 (제2 VL)을 포함하고, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 상기 제1 Fab와 동일한 에피토프에 특이적으로 결합하는 제2 가변 영역을 형성하고;
상기 제1 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 E (IgE)의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결되고, 상기 제2 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제3 폴리펩타이드에 링커를 통해 연결되고, 상기 제2 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제4 폴리펩타이드에 링커를 통해 연결되고;
상기 제1 Fab가 상기 전체 IgG 항체의 상기 제1 CH3 도메인의 상기 C-말단에 연결되고 상기 제2 Fab가 상기 전체 IgG 항체의 상기 제2 CH3 도메인의 상기 C-말단에 연결되는, 4가 항체. - 청구항 55에 있어서, 상기 제1 Fab가 제1 링커를 통해 상기 전체 항체의 상기 제1 CH3 도메인의 상기 C-말단에 연결되고 상기 제2 Fab가 제2 링커를 통해 상기 전체 항체의 상기 제2 CH3 도메인의 상기 C-말단에 연결되는, 4가 항체.
- 청구항 56에 있어서, 상기 제1 및 제2 링커가 펩타이드 링커인, 4가 항체.
- 청구항 55 내지 57 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드, 및/또는 상기 제4 폴리펩타이드가 서열 식별 번호:1에서 제시된 상기 아미노산 서열을 포함하는, 4가 항체.
- 청구항 55 내지 57 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드, 및/또는 상기 제4 폴리펩타이드가 서열 식별 번호:1에서 제시된 상기 아미노산 서열의 아미노산 9-107에 적어도 90% 동일한 아미노산 서열을 포함하는, 4가 항체.
- 청구항 55 내지 57 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드, 및/또는 상기 제4 폴리펩타이드가 서열 식별 번호:1에서 제시된 상기 아미노산 서열의 아미노산 9-107을 포함하는, 4가 항체.
- 청구항 55 내지 60 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및 상기 제3 폴리펩타이드가 각각 서열 식별 번호:5에서 제시된 상기 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함하는, 4가 항체.
- 청구항 55 내지 60 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및 상기 제3 폴리펩타이드가 각각 서열 식별 번호:5에서 제시된 상기 아미노산 서열을 포함하는, 4가 항체.
- 청구항 55 내지 62 중 어느 한 항에 있어서, 상기 제2 폴리펩타이드 및 상기 제4 폴리펩타이드가 각각 서열 식별 번호:6에서 제시된 상기 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함하는, 4가 항체.
- 청구항 55 내지 62 중 어느 한 항에 있어서, 상기 제2 폴리펩타이드 및 상기 제4 폴리펩타이드가 각각 서열 식별 번호:6에서 제시된 상기 아미노산 서열을 포함하는, 4가 항체.
- 청구항 55 내지 57 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드 및/또는 상기 제4 폴리펩타이드가 적어도 12 아미노산 잔기에서 서열 식별 번호:1의 아미노산 9-107에서 제시된 상기 아미노산 서열과 상이한, 4가 항체.
- 하기를 포함하는, 4가 이중특이적 항체로서:
(i) 제1 항원의 제1 에피토프에 특이적으로 결합하는 전체 IgG 항체, 상기 전체 IgG 항체는 제1 CH3 도메인 및 제2 CH3 도메인을 포함함; 및
(ii) 제1 Fab 및 제2 Fab,
상기 제1 Fab가 제1 중쇄 가변 도메인 (제1 VH) 및 제1 경쇄 가변 도메인 (제1 VL)을 포함하고, 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 상기 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제1 가변 영역을 형성하고,
상기 제2 Fab가 제2 중쇄 가변 도메인 (제2 VH) 및 제2 경쇄 가변 도메인 (제2 VL)을 포함하고, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 상기 제1 Fab와 동일한 에피토프에 특이적으로 결합하는 제2 가변 영역을 형성하고;
상기 제1 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 M (IgM)의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결되고, 상기 제2 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제3 폴리펩타이드에 링커를 통해 연결되고, 상기 제2 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제4 폴리펩타이드에 링커를 통해 연결되고;
상기 제1 Fab가 상기 전체 IgG 항체의 상기 제1 CH3 도메인의 상기 C-말단에 연결되고 상기 제2 Fab가 상기 전체 IgG 항체의 상기 제2 CH3 도메인의 상기 C-말단에 연결되는, 4가 항체. - 청구항 66에 있어서, 상기 제1 Fab가 제1 링커를 통해 상기 전체 항체의 상기 제1 CH3 도메인의 상기 C-말단에 연결되고 상기 제2 Fab가 제2 링커를 통해 상기 전체 항체의 상기 제2 CH3 도메인의 상기 C-말단에 연결되는, 4가 항체.
- 청구항 65 내지 67 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드, 및/또는 상기 제4 폴리펩타이드가 각각 서열 식별 번호:2에서 제시된 상기 아미노산 서열을 포함하는, 4가 항체.
- 청구항 66 또는 67에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드, 및/또는 상기 제4 폴리펩타이드가 서열 식별 번호:2에서 제시된 상기 아미노산 서열의 아미노산 7-112에 적어도 90% 동일한 아미노산 서열을 포함하는, 4가 항체.
- 청구항 66 또는 67에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드, 및/또는 상기 제4 폴리펩타이드가 서열 식별 번호:2에서 제시된 상기 아미노산 서열의 아미노산 7-112를 포함하는, 4가 항체.
- 청구항 66 또는 67에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드 및/또는 상기 제4 폴리펩타이드가 적어도 12 아미노산 잔기에서 서열 식별 번호:2의 아미노산 7-112에서 제시된 상기 아미노산 서열과 상이한, 4가 항체.
- 하기를 포함하는, 4가 이중특이적 항체로서:
(i) 제1 Fab 및 제2 Fab,
상기 제1 Fab가 제1 중쇄 가변 도메인 (제1 VH) 및 제1 경쇄 가변 도메인 (제1 VL)을 포함하고, 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성하고,
상기 제2 Fab는 제2 중쇄 가변 도메인 (제2 VH) 및 제2 경쇄 가변 도메인 (제2 VL)을 포함하고, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 상기 제1 항원의 상기 제1 에피토프에 특이적으로 결합하는 제2 가변 영역을 형성함; 및
(ii) 제1 IgG CH2 도메인 및 제1 IgG CH3 도메인을 포함하는 제1 중쇄, 제2 IgG CH2 도메인 및 제2 IgG CH3 도메인을 포함하는 제2 중쇄, 제1 경쇄, 및 제2 경쇄를 포함하는 전체 항체, 상기 항체가 제3 VH 및 제3 VL 및 제4 VH 및 제4 VL을 포함하고, 상기 제3 VH 및 상기 제3 VL이 짝짓기하여 제2 항원의 에피토프에 특이적으로 결합하는 제3 가변 영역을 형성하고, 상기 제4 VH 및 상기 제4 VL이 짝짓기하여 상기 제2 항원의 동일한 에피토프에 특이적으로 결합하는 제4 가변 영역을 형성함,
상기 제3 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 E (IgE)의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결되고, 상기 제3 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결되고, 상기 제4 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제3 폴리펩타이드에 링커를 통해 연결되고, 상기 제4 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제4 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 폴리펩타이드가 상기 제1 IgG CH2 도메인의 상기 N-말단에 연결되고 상기 제3 폴리펩타이드가 상기 제2 IgG CH2 도메인의 상기 N-말단에 연결되고;
상기 제1 Fab가 상기 제1 IgG CH3 도메인의 상기 C-말단에 연결되고 상기 제2 Fab가 상기 제2 IgG CH3 도메인의 상기 C-말단에 연결되는, 4가 이중특이적 항체. - 청구항 72에 있어서, 상기 제1 Fab가 제1 링커를 통해 상기 제1 IgG CH3 도메인의 상기 C-말단에 연결되고 상기 제2 Fab가 제2 링커를 통해 상기 제2 IgG CH3 도메인의 상기 C-말단에 연결되는, 4가 항체.
- 청구항 73에 있어서, 상기 제1 및 제2 링커가 펩타이드 링커인, 4가 항체.
- 청구항 72 내지 74 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드, 및/또는 상기 제4 폴리펩타이드가 서열 식별 번호:1에서 제시된 상기 아미노산 서열을 포함하는, 4가 항체.
- 청구항 72 내지 74 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드, 및/또는 상기 제4 폴리펩타이드가 서열 식별 번호:1에서 제시된 상기 아미노산 서열의 아미노산 9-107에 적어도 90% 동일한 아미노산 서열을 포함하는, 4가 항체.
- 청구항 72 내지 74 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드, 및/또는 상기 제4 폴리펩타이드가 서열 식별 번호:1에서 제시된 상기 아미노산 서열의 아미노산 9-107을 포함하는, 4가 항체.
- 청구항 72 내지 77 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제3 폴리펩타이드가 서열 식별 번호:5에서 제시된 상기 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함하는, 4가 항체.
- 청구항 72 내지 77 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제3 폴리펩타이드가 서열 식별 번호:5에서 제시된 상기 아미노산 서열을 포함하는, 4가 항체.
- 청구항 72 내지 79 중 어느 한 항에 있어서, 상기 제2 폴리펩타이드 및/또는 상기 제4 폴리펩타이드가 서열 식별 번호:6에서 제시된 상기 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함하는, 4가 항체.
- 청구항 72 내지 79 중 어느 한 항에 있어서, 상기 제2 폴리펩타이드 및/또는 상기 제4 폴리펩타이드가 서열 식별 번호:6에서 제시된 상기 아미노산 서열을 포함하는, 4가 항체.
- 청구항 72 내지 74 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드 및/또는 상기 제4 폴리펩타이드가 적어도 12 아미노산 잔기에서 서열 식별 번호:1에서 제시된 상기 아미노산 서열과 상이한, 4가 항체.
- 하기를 포함하는, 4가 이중특이적 항체로서:
(i) 제1 Fab 및 제2 Fab,
상기 제1 Fab가 제1 중쇄 가변 도메인 (제1 VH) 및 제1 경쇄 가변 도메인 (제1 VL)을 포함하고, 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성하고,
상기 제2 Fab는 제2 중쇄 가변 도메인 (제2 VH) 및 제2 경쇄 가변 도메인 (제2 VL)을 포함하고, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 상기 제1 항원의 상기 제1 에피토프에 특이적으로 결합하는 제2 가변 영역을 형성함; 및
(ii) 제1 IgG CH2 도메인 및 제1 IgG CH3 도메인을 포함하는 제1 중쇄, 제2 IgG CH2 도메인 및 제2 IgG CH3 도메인을 포함하는 제2 중쇄, 제1 경쇄, 및 제2 경쇄를 포함하는 전체 항체, 상기 항체가 제3 VH 및 제3 VL 및 제4 VH 및 제4 VL을 포함하고, 상기 제3 VH 및 상기 제3 VL이 짝짓기하여 제2 항원의 에피토프에 특이적으로 결합하는 제3 가변 영역을 형성하고, 상기 제4 VH 및 상기 제4 VL이 짝짓기하여 상기 제2 항원의 동일한 에피토프에 특이적으로 결합하는 제4 가변 영역을 형성함,
상기 제3 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 M (IgM)의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결되고, 상기 제3 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결되고, 상기 제4 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제3 폴리펩타이드에 링커를 통해 연결되고, 상기 제4 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제4 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 폴리펩타이드가 상기 제1 IgG CH2 도메인의 상기 N-말단에 연결되고 상기 제3 폴리펩타이드가 상기 제2 IgG CH2 도메인의 상기 N-말단에 연결되고;
상기 제1 Fab가 상기 제1 IgG CH3 도메인의 상기 C-말단에 연결되고 상기 제2 Fab가 상기 제2 IgG CH3 도메인의 상기 C-말단에 연결되는, 4가 이중특이적 항체. - 청구항 83에 있어서, 상기 제1 Fab가 제1 링커를 통해 상기 제1 IgG CH3 도메인의 상기 C-말단에 연결되고 상기 제2 Fab가 제2 링커를 통해 상기 제2 IgG CH3 도메인의 상기 C-말단에 연결되는, 4가 항체.
- 청구항 84에 있어서, 상기 제1 및 제2 링커가 펩타이드 링커인, 4가 항체.
- 청구항 83 내지 85 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드, 및/또는 상기 제4 폴리펩타이드가 서열 식별 번호:2에서 제시된 상기 아미노산 서열을 포함하는, 4가 항체.
- 청구항 83 내지 85 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드, 및/또는 상기 제4 폴리펩타이드가 서열 식별 번호:2에서 제시된 상기 아미노산 서열의 아미노산 7-112에 적어도 90% 동일한 아미노산 서열을 포함하는, 4가 항체.
- 청구항 83 내지 85 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드, 및/또는 상기 제4 폴리펩타이드가 서열 식별 번호:2에서 제시된 상기 아미노산 서열의 아미노산 7-112를 포함하는, 4가 항체.
- 청구항 83 내지 85 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드, 상기 제2 폴리펩타이드, 상기 제3 폴리펩타이드 및/또는 상기 제4 폴리펩타이드가 적어도 12 아미노산 잔기에서 서열 식별 번호:2에서 제시된 상기 아미노산 서열과 상이한, 4가 항체.
- 하기를 포함하는, 헤테로이량체화 모듈:
(i) 서열 식별 번호:11에서 제시된 상기 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제1 IgG1 CH3 도메인, 여기서 위치 364 및 370에서 상기 아미노산은 라이신이고 위치 409에서 상기 아미노산은 세린임; 및
(ii) 서열 식별 번호:11에서 제시된 상기 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제2 IgG1 CH3 도메인, 여기서 위치 370에서 상기 아미노산은 세린이고 위치 405 및 409에서 상기 아미노산은 라이신임,
여기서 (i) 및 (ii)에서 상기 아미노산 위치는 상기 EU 넘버링 시스템에 기반되고,
상기 제1 IgG1 CH3 도메인 및 상기 제2 IgG1 CH3이 짝짓기하여 헤테로이량체를 형성함. - 청구항 90에 있어서, 제1 IgG1 CH2 도메인 및 제2 IgG1 CH2 도메인을 추가로 포함하는, 헤테로이량체화 모듈로서, 상기 제1 IgG1 CH2 도메인이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 상기 제1 IgG1 CH3 도메인의 상기 N-말단에 링커를 통해 연결되고 상기 제2 IgG1 CH2 도메인이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 상기 제2 IgG1 CH3 도메인의 상기 N-말단에 링커를 통해 연결되는, 헤테로이량체화 모듈.
- 청구항 91에 있어서, 제1 Fab 포함 2 폴리펩타이드 쇄를 추가로 포함하는, 헤테로이량체화 모듈로서, 상기 Fab의 상기 2 폴리펩타이드 쇄 중 하나의 상기 C-말단이 제1 힌지 영역의 상기 N-말단에 연결되고, 상기 제1 힌지 영역이 상기 제1 IgG1 CH2 도메인의 상기 N-말단에 연결되는, 헤테로이량체화 모듈.
- 청구항 92에 있어서, 상기 제2 IgG1 CH2 도메인의 상기 N-말단에 연결되는 제2 힌지 영역의 상기 N-말단에 상기 제1 IgG1 CH3 도메인의 상기 C-말단을 연결시키는 링커를 추가로 포함하는, 헤테로이량체화 모듈.
- 청구항 92에 있어서, 상기 제2 IgG1 CH2 도메인의 상기 N-말단에 제2 힌지 영역을 통해 연결된 제2 Fab를 추가로 포함하는, 헤테로이량체화 모듈.
- 청구항 91에 있어서, VH 도메인, CH1 도메인, VL 도메인, 및 CL 도메인을 추가로 포함하는, 헤테로이량체화 모듈로서, (i) 상기 VH 도메인의 상기 C-말단이 상기 CH1 도메인의 상기 N-말단에 연결되고, 상기 CH1 도메인의 상기 C-말단이 제1 힌지 영역의 상기 N-말단에 연결되고, 상기 제1 힌지 영역의 상기 C-말단이 상기 제1 IgG1 CH3 도메인에 직접적으로 연결되는 상기 제1 IgG1 CH2 도메인의 상기 N-말단에 연결되고, (ii) 상기 VL 도메인의 상기 C-말단이 상기 CL 도메인의 상기 N-말단에 연결되고, 상기 CL 도메인의 상기 C-말단이 제2 힌지 영역의 상기 N-말단에 연결되고, 상기 제2 힌지 영역의 상기 C-말단이 상기 제2 IgG1 CH3 도메인에 직접적으로 연결되는 상기 제2 IgG1 CH2 도메인의 상기 N-말단에 연결되고, (iii) 상기 VH 도메인 및 상기 VL 도메인이 짝짓기하여 항원에 특이적으로 결합하는 가변 영역을 형성하는, 헤테로이량체화 모듈.
- 청구항 91에 있어서, 제1 VH 및 제1 VL 및 제2 VH 및 제2 VL을 추가로 포함하는, 헤테로이량체화 모듈로서, 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 제1 항원에 특이적으로 결합하는 제1 가변 영역을 형성하고, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 상기 제1 항원의 상이한 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성하는, 헤테로이량체화 모듈.
- 청구항 96에 있어서, 상기 제1 VL의 상기 아미노산 서열이 상기 제2 VL의 상기 아미노산 서열과 동일한, 헤테로이량체화 모듈.
- 청구항 90에 있어서, 제1 IgG4 CH2 도메인 및 제2 IgG4 CH2 도메인을 추가로 포함하는, 헤테로이량체화 모듈로서, 상기 제1 IgG4 CH2 도메인이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 상기 제1 IgG1 CH3 도메인의 상기 N-말단에 링커를 통해 연결되고 상기 제2 IgG4 CH2 도메인이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 상기 제2 IgG1 CH3 도메인의 상기 N-말단에 링커를 통해 연결되는, 헤테로이량체화 모듈.
- 청구항 98에 있어서, 제1 Fab 포함 2 폴리펩타이드 쇄를 추가로 포함하는, 헤테로이량체화 모듈로서, 상기 Fab의 상기 2 폴리펩타이드 쇄 중 하나의 상기 C-말단이 제1 IgG4 힌지 영역의 상기 N-말단에 연결되고, 상기 제1 IgG4 힌지 영역이 상기 제1 IgG4 CH2 도메인의 상기 N-말단에 연결되는, 헤테로이량체화 모듈.
- 청구항 99에 있어서, 상기 제1 IgG4 힌지 영역이 상기 S228P 돌연변이 (EU 넘버링)을 포함하는, 헤테로이량체화 모듈.
- 청구항 98에 있어서, 상기 제2 IgG4 CH2 도메인의 상기 N-말단에 연결되는 제2 IgG4 힌지 영역의 상기 N-말단에 상기 제1 IgG1 CH3 도메인의 상기 C-말단을 연결시키는 링커를 추가로 포함하는, 헤테로이량체화 모듈.
- 청구항 101에 있어서, 상기 제2 IgG4 힌지 영역이 상기 S228P 돌연변이 (EU 넘버링)을 포함하는, 헤테로이량체화 모듈.
- 청구항 99에 있어서, 상기 제2 IgG4 CH2 도메인의 상기 N-말단에 제2 IgG4 힌지 영역을 통해 연결된 제2 Fab를 추가로 포함하는, 헤테로이량체화 모듈.
- 청구항 103에 있어서, 상기 제2 IgG4 힌지 영역이 상기 S228P 돌연변이 (EU 넘버링)을 포함하는, 헤테로이량체화 모듈.
- 청구항 98에 있어서, VH 도메인, CH1 도메인, VL 도메인, 및 CL 도메인을 추가로 포함하는, 헤테로이량체화 모듈로서, (i) 상기 VH 도메인의 상기 C-말단이 상기 CH1 도메인의 상기 N-말단에 연결되고, 상기 CH1 도메인의 상기 C-말단이 제1 IgG4 힌지 영역의 상기 N-말단에 연결되고, 상기 제1 IgG4 힌지 영역의 상기 C-말단이 상기 제1 IgG1 CH3 도메인에 직접적으로 연결되는 상기 제1 IgG4 CH2 도메인의 상기 N-말단에 연결되고, (ii) 상기 VL 도메인의 상기 C-말단이 상기 CL 도메인의 상기 N-말단에 연결되고, 상기 CL 도메인의 상기 C-말단이 제2 IgG4 힌지 영역의 상기 N-말단에 연결되고, 상기 제2 IgG4 힌지 영역의 상기 C-말단이 상기 제2 IgG1 CH3 도메인에 직접적으로 연결되는 상기 제2 IgG4 CH2 도메인의 상기 N-말단에 연결되고, (iii) 상기 VH 도메인 및 상기 VL 도메인이 짝짓기하여 항원에 특이적으로 결합하는 가변 영역을 형성하는, 헤테로이량체화 모듈.
- 청구항 105에 있어서, 상기 제1 IgG4 힌지 영역 및 상기 제2 IgG4 힌지 영역이 각각 상기 S228P 돌연변이 (EU 넘버링)을 포함하는, 헤테로이량체화 모듈.
- 청구항 98에 있어서, 제1 VH 및 제1 VL 및 제2 VH 및 제2 VL을 추가로 포함하는, 헤테로이량체화 모듈로서, 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 제1 항원에 특이적으로 결합하는 제1 가변 영역을 형성하고, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 상기 제1 항원의 상이한 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성하는, 헤테로이량체화 모듈.
- 청구항 107에 있어서, 상기 제1 VL의 상기 아미노산 서열이 상기 제2 VL의 상기 아미노산 서열과 동일한, 헤테로이량체화 모듈.
- 하기를 포함하는, 헤테로이량체화 모듈:
(i) 서열 식별 번호:11에서 제시된 상기 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제1 IgG1 CH3 도메인, 여기서 위치 364 및 370에서 상기 아미노산은 라이신이고 위치 409에서 상기 아미노산은 류신임; 및
(ii) 서열 식별 번호:11에서 제시된 상기 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제2 IgG1 CH3 도메인, 여기서 위치 370에서 상기 아미노산은 세린이고, 위치 397에서 상기 아미노산은 이소류신이고, 위치 405 및 409에서 상기 아미노산은 라이신임,
여기서 (i) 및 (ii)에서 상기 아미노산 위치는 상기 EU 넘버링 시스템에 기반되고,
상기 제1 IgG1 CH3 도메인 및 상기 제2 IgG1 CH3이 짝짓기하여 헤테로이량체를 형성함. - 청구항 109에 있어서, 제1 IgG1 CH2 도메인 및 제2 IgG1 CH2 도메인을 추가로 포함하는, 헤테로이량체화 모듈로서, 상기 제1 IgG1 CH2 도메인이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 상기 제1 IgG1 CH3 도메인의 상기 N-말단에 링커를 통해 연결되고 상기 제2 IgG1 CH2 도메인이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 상기 제2 IgG1 CH3 도메인의 상기 N-말단에 링커를 통해 연결되는, 헤테로이량체화 모듈.
- 청구항 110에 있어서, 제1 IgG1 CH2 도메인 및 제2 IgG1 CH2 도메인을 추가로 포함하는, 헤테로이량체화 모듈로서, 상기 제1 IgG1 CH2 도메인이 상기 제1 IgG1 CH3 도메인의 상기 N-말단에 직접적으로 연결되고 상기 제2 IgG1 CH2 도메인이 상기 제2 IgG1 CH3 도메인의 상기 N-말단에 직접적으로 연결되는, 헤테로이량체화 모듈.
- 청구항 110에 있어서, 제1 Fab 포함 2 폴리펩타이드 쇄를 추가로 포함하는, 헤테로이량체화 모듈로서, 상기 Fab의 상기 2 폴리펩타이드 쇄 중 하나의 상기 C-말단이 제1 힌지 영역의 상기 N-말단에 연결되고, 상기 제1 힌지 영역이 상기 제1 IgG1 CH2 도메인의 상기 N-말단에 연결되는, 헤테로이량체화 모듈.
- 청구항 112에 있어서, 상기 제2 IgG1 CH2 도메인의 상기 N-말단에 연결되는 제2 힌지 영역의 상기 N-말단에 상기 제1 IgG1 CH3 도메인의 상기 C-말단을 연결시키는 링커를 추가로 포함하는, 헤테로이량체화 모듈.
- 청구항 112에 있어서, 상기 제2 IgG1 CH2 도메인의 상기 N-말단에 제2 힌지 영역을 통해 연결된 제2 Fab를 추가로 포함하는, 헤테로이량체화 모듈.
- 청구항 110에 있어서, VH 도메인, CH1 도메인, VL 도메인, 및 CL 도메인을 추가로 포함하는, 헤테로이량체화 모듈로서, (i) 상기 VH 도메인의 상기 C-말단이 상기 CH1 도메인의 상기 N-말단에 연결되고, 상기 CH1 도메인의 상기 C-말단이 제1 힌지 영역의 상기 N-말단에 연결되고, 상기 제1 힌지 영역의 상기 C-말단이 상기 제1 IgG1 CH3 도메인에 직접적으로 연결되는 상기 제1 IgG1 CH2 도메인의 상기 N-말단에 연결되고, (ii) 상기 VL 도메인의 상기 C-말단이 상기 CL 도메인의 상기 N-말단에 연결되고, 상기 CL 도메인의 상기 C-말단이 제2 힌지 영역의 상기 N-말단에 연결되고, 상기 제2 힌지 영역의 상기 C-말단이 상기 제2 IgG1 CH3 도메인에 직접적으로 연결되는 상기 제2 IgG1 CH2 도메인의 상기 N-말단에 연결되고, (iii) 상기 VH 도메인 및 상기 VL 도메인이 짝짓기하여 항원에 특이적으로 결합하는 가변 영역을 형성하는, 헤테로이량체화 모듈.
- 청구항 110에 있어서, 제1 VH 및 제1 VL 및 제2 VH 및 제2 VL을 추가로 포함하는, 헤테로이량체화 모듈로서, 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 제1 항원에 특이적으로 결합하는 제1 가변 영역을 형성하고, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 상기 제1 항원의 상이한 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성하는, 헤테로이량체화 모듈.
- 청구항 116에 있어서, 상기 제1 VL의 상기 아미노산 서열이 상기 제2 VL의 상기 아미노산 서열과 동일한, 헤테로이량체화 모듈.
- 청구항 109에 있어서, 제1 IgG4 CH2 도메인 및 제2 IgG4 CH2 도메인을 추가로 포함하는, 헤테로이량체화 모듈로서, 상기 제1 IgG4 CH2 도메인이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 상기 제1 IgG1 CH3 도메인의 상기 N-말단에 링커를 통해 연결되고 상기 제2 IgG4 CH2 도메인이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 상기 제2 IgG1 CH3 도메인의 상기 N-말단에 링커를 통해 연결되는, 헤테로이량체화 모듈.
- 청구항 118에 있어서, 제1 Fab 포함 2 폴리펩타이드 쇄를 추가로 포함하는, 헤테로이량체화 모듈로서, 상기 Fab의 상기 2 폴리펩타이드 쇄 중 하나의 상기 C-말단이 제1 IgG4 힌지 영역의 상기 N-말단에 연결되고, 상기 제1 IgG4 힌지 영역이 상기 제1 IgG4 CH2 도메인의 상기 N-말단에 연결되는, 헤테로이량체화 모듈.
- 청구항 119에 있어서, 상기 제1 IgG4 힌지 영역이 상기 S228P 돌연변이 (EU 넘버링)을 포함하는, 헤테로이량체화 모듈.
- 청구항 118에 있어서, 상기 제2 IgG4 CH2 도메인의 상기 N-말단에 연결되는 제2 IgG4 힌지 영역의 상기 N-말단에 상기 제1 IgG1 CH3 도메인의 상기 C-말단을 연결시키는 링커를 추가로 포함하는, 헤테로이량체화 모듈.
- 청구항 121에 있어서, 상기 제2 IgG4 힌지 영역이 상기 S228P 돌연변이 (EU 넘버링)을 포함하는, 헤테로이량체화 모듈.
- 청구항 119에 있어서, 상기 제2 IgG4 CH2 도메인의 상기 N-말단에 제2 IgG4 힌지 영역을 통해 연결된 제2 Fab를 추가로 포함하는, 헤테로이량체화 모듈.
- 청구항 123에 있어서, 상기 제2 IgG4 힌지 영역이 상기 S228P 돌연변이 (EU 넘버링)을 포함하는, 헤테로이량체화 모듈.
- 청구항 118에 있어서, VH 도메인, CH1 도메인, VL 도메인, 및 CL 도메인을 추가로 포함하는, 헤테로이량체화 모듈로서, (i) 상기 VH 도메인의 상기 C-말단이 상기 CH1 도메인의 상기 N-말단에 연결되고, 상기 CH1 도메인의 상기 C-말단이 제1 IgG4 힌지 영역의 상기 N-말단에 연결되고, 상기 제1 IgG4 힌지 영역의 상기 C-말단이 상기 제1 IgG1 CH3 도메인에 직접적으로 연결되는 상기 제1 IgG4 CH2 도메인의 상기 N-말단에 연결되고, (ii) 상기 VL 도메인의 상기 C-말단이 상기 CL 도메인의 상기 N-말단에 연결되고, 상기 CL 도메인의 상기 C-말단이 제2 IgG4 힌지 영역의 상기 N-말단에 연결되고, 상기 제2 IgG4 힌지 영역의 상기 C-말단이 상기 제2 IgG1 CH3 도메인에 직접적으로 연결되는 상기 제2 IgG4 CH2 도메인의 상기 N-말단에 연결되고, (iii) 상기 VH 도메인 및 상기 VL 도메인이 짝짓기하여 항원에 특이적으로 결합하는 가변 영역을 형성하는, 헤테로이량체화 모듈.
- 청구항 125에 있어서, 상기 제1 IgG4 힌지 영역 및 상기 제2 IgG4 힌지 영역이 각각 상기 S228P 돌연변이 (EU 넘버링)을 포함하는, 헤테로이량체화 모듈.
- 청구항 118에 있어서, 제1 VH 및 제1 VL 및 제2 VH 및 제2 VL을 추가로 포함하는, 헤테로이량체화 모듈로서, 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 제1 항원에 특이적으로 결합하는 제1 가변 영역을 형성하고, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 상기 제1 항원의 상이한 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성하는, 헤테로이량체화 모듈.
- 청구항 127에 있어서, 상기 제1 VL의 상기 아미노산 서열이 상기 제2 VL의 상기 아미노산 서열과 동일한, 헤테로이량체화 모듈.
- 하기를 포함하는, 이중특이적 항체:
(i) 제1 VH 및 제1 VL, 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성하고, 상기 제1 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 E (IgE)의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 짝짓기하여 이량체를 형성함;
(ii) 제2 VH 및 제2 VL, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 상기 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성하고, 상기 제2 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결되고, 상기 제2 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결되고, 상기 CH1 도메인 및 상기 CL 도메인이 짝짓기하여 이량체를 형성함; 및
(iii) 하기를 포함하는 헤테로이량체화 모듈:
(a) 서열 식별 번호:11에서 제시된 상기 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제1 IgG1 CH3 도메인, 여기서 위치 364 및 370에서 상기 아미노산은 라이신이고 위치 409에서 상기 아미노산은 세린임; 및
(b) 서열 식별 번호:11에서 제시된 상기 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제2 IgG1 CH3 도메인, 여기서 위치 370에서 상기 아미노산은 세린이고 위치 405 및 409에서 상기 아미노산은 라이신임,
여기서 (a) 및 (b)에서 상기 아미노산 위치는 상기 EU 넘버링 시스템에 기반됨. - 하기를 포함하는, 이중특이적 항체:
(i) 제1 VH 및 제1 VL, 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성하고, 상기 제1 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 E (IgE)의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgE의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:1)의 아미노산 9-107에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 짝짓기하여 이량체를 형성함;
(ii) 제2 VH 및 제2 VL, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 상기 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성하고, 상기 제2 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결되고, 상기 제2 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결되고, 상기 CH1 도메인 및 상기 CL 도메인이 짝짓기하여 이량체를 형성함; 및
(iii) 하기를 포함하는 헤테로이량체화 모듈:
(a) 서열 식별 번호:11에서 제시된 상기 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제1 IgG1 CH3 도메인, 여기서 위치 364 및 370에서 상기 아미노산은 라이신이고 위치 409에서 상기 아미노산은 류신임; 및
(b) 서열 식별 번호:11에서 제시된 상기 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제2 IgG1 CH3 도메인, 여기서 위치 370에서 상기 아미노산은 세린이고, 위치 397에서 상기 아미노산은 이소류신이고, 위치 405 및 409에서 상기 아미노산은 라이신임,
여기서 (a) 및 (b)에서 상기 아미노산 위치는 상기 EU 넘버링 시스템에 기반됨. - 청구항 129 또는 130에 있어서, 2 IgG1 CH2 도메인을 추가로 포함하는, 이중특이적 항체.
- 청구항 129 또는 130에 있어서, 2 IgG4 CH2 도메인을 추가로 포함하는, 이중특이적 항체.
- 청구항 129 내지 132 중 어느 한 항에 있어서, 단일 폴리펩타이드 쇄가 상기 제1 VH, 상기 제1 폴리펩타이드, 및 상기 제1 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 129 내지 132 중 어느 한 항에 있어서, 단일 폴리펩타이드 쇄가 상기 제1 VH, 상기 제1 폴리펩타이드, 및 상기 제2 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 129 내지 132 중 어느 한 항에 있어서, 단일 폴리펩타이드 쇄가 상기 제1 VL, 상기 제2 폴리펩타이드, 및 상기 제1 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 129 내지 132 중 어느 한 항에 있어서, 단일 폴리펩타이드 쇄가 상기 제1 VL, 상기 제2 폴리펩타이드, 및 상기 제2 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 133에 있어서, 제2 단일 폴리펩타이드 쇄가 상기 제2 VH, 상기 CH1 도메인, 및 상기 제2 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 134에 있어서, 제2 단일 폴리펩타이드 쇄가 상기 제2 VH, 상기 CH1 도메인, 및 상기 제1 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 135에 있어서, 제2 단일 폴리펩타이드 쇄가 상기 제2 VL, 상기 CL 도메인, 및 상기 제2 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 136에 있어서, 제2 단일 폴리펩타이드 쇄가 상기 제2 VL, 상기 CL 도메인, 및 상기 제1 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 129 내지 140 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:1에서 제시된 상기 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 129 내지 140 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:1에서 제시된 상기 아미노산 서열의 아미노산 9-107에 적어도 90% 동일한 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 129 내지 140 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:1에서 제시된 상기 아미노산 서열의 아미노산 9-107을 포함하는, 이중특이적 항체.
- 청구항 129 내지 140 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드가 서열 식별 번호:5에서 제시된 상기 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 129 내지 140 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드가 서열 식별 번호:5에서 제시된 상기 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 129 내지 145 중 어느 한 항에 있어서, 상기 제2 폴리펩타이드가 서열 식별 번호:6에서 제시된 상기 아미노산 서열에 적어도 80% 동일한 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 129 내지 145 중 어느 한 항에 있어서, 상기 제2 폴리펩타이드가 서열 식별 번호:6에서 제시된 상기 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 129 내지 140 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 적어도 12 아미노산 잔기에서 서열 식별 번호:1에서 제시된 상기 아미노산 서열과 상이한, 이중특이적 항체.
- 청구항 129 내지 140 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 각각 쇄내 디설파이드 결합을 형성하지 않는 서열 식별 번호:1의 상기 2 시스테인 잔기 중 적어도 하나에서 시스테인 이외 아미노산을 함유하는, 이중특이적 항체.
- 청구항 129 내지 140 또는 142 중 어느 한 항에 있어서, 하기인, 이중특이적 항체:
(i) 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 각각 서열 식별 번호:1내 상기 N-당화 모티프에서 아스파라긴 및/또는 트레오닌 또는 세린 이외 아미노산을 함유하여서 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 N-당화되지 않음; 또는
(ii) 상기 제1 폴리펩타이드 또는 상기 제2 폴리펩타이드가 서열 식별 번호:1내 상기 N-당화 모티프에서 아스파라긴 및/또는 트레오닌 또는 세린 이외 아미노산을 함유하여서 상기 제1 폴리펩타이드 또는 상기 제2 폴리펩타이드가 N-당화되지 않음. - 하기를 포함하는, 이중특이적 항체:
(i) 제1 VH 및 제1 VL, 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성하고, 상기 제1 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 M (IgM)의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 짝짓기하여 이량체를 형성함;
(ii) 제2 VH 및 제2 VL, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 상기 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성하고, 상기 제2 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결되고, 상기 제2 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결되고, 상기 CH1 도메인 및 상기 CL 도메인이 짝짓기하여 이량체를 형성함; 및
(iii) 하기를 포함하는 헤테로이량체화 모듈:
(a) 서열 식별 번호:11에서 제시된 상기 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제1 IgG1 CH3 도메인, 여기서 위치 364 및 370에서 상기 아미노산은 라이신이고 위치 409에서 상기 아미노산은 세린임; 및
(b) 서열 식별 번호:11에서 제시된 상기 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제2 IgG1 CH3 도메인, 여기서 위치 370에서 상기 아미노산은 세린이고 위치 405 및 409에서 상기 아미노산은 라이신임,
여기서 (a) 및 (b)에서 상기 아미노산 위치는 상기 EU 넘버링 시스템에 기반됨. - 하기를 포함하는, 이중특이적 항체:
(i) 제1 VH 및 제1 VL, 상기 제1 VH 및 상기 제1 VL이 짝짓기하여 제1 항원의 제1 에피토프에 특이적으로 결합하는 제1 가변 영역을 형성하고, 상기 제1 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 면역글로불린 M (IgM)의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제1 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) 인간 IgM의 상기 CH2 도메인의 상기 아미노산 서열 (서열 식별 번호:2)의 아미노산 7-112에 적어도 80% 동일한 아미노산 서열을 포함하는 제2 폴리펩타이드에 링커를 통해 연결되고, 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 짝짓기하여 이량체를 형성함;
(ii) 제2 VH 및 제2 VL, 상기 제2 VH 및 상기 제2 VL이 짝짓기하여 상기 제1 항원의 제2 에피토프에 또는 제2 항원에 특이적으로 결합하는 제2 가변 영역을 형성하고, 상기 제2 VH가 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CH1 도메인에 링커를 통해 연결되고, 상기 제2 VL이 어느 한쪽으로 (i) 직접적으로 연결되거나 (ii) CL 도메인에 링커를 통해 연결되고, 상기 CH1 도메인 및 상기 CL 도메인이 짝짓기하여 이량체를 형성함; 및
(iii) 하기를 포함하는 헤테로이량체화 모듈:
(a) 서열 식별 번호:11에서 제시된 상기 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제1 IgG1 CH3 도메인, 여기서 위치 364 및 370에서 상기 아미노산은 라이신이고 위치 409에서 상기 아미노산은 류신임; 및
(b) 서열 식별 번호:11에서 제시된 상기 서열에 적어도 80% 동일한 아미노산 서열을 갖는 제2 IgG1 CH3 도메인, 여기서 위치 370에서 상기 아미노산은 세린이고, 위치 397에서 상기 아미노산은 이소류신이고, 위치 405 및 409에서 상기 아미노산은 라이신임,
여기서 (a) 및 (b)에서 상기 아미노산 위치는 상기 EU 넘버링 시스템에 기반됨. - 청구항 151 또는 152에 있어서, 2 IgG1 CH2 도메인을 추가로 포함하는, 이중특이적 항체.
- 청구항 151 또는 152에 있어서, 2 IgG4 CH2 도메인을 추가로 포함하는, 이중특이적 항체.
- 청구항 151 내지 154 중 어느 한 항에 있어서, 단일 폴리펩타이드 쇄가 상기 제1 VH, 상기 제1 폴리펩타이드, 및 상기 제1 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 151 내지 154 중 어느 한 항에 있어서, 단일 폴리펩타이드 쇄가 상기 제1 VH, 상기 제1 폴리펩타이드, 및 상기 제2 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 151 내지 154 중 어느 한 항에 있어서, 단일 폴리펩타이드 쇄가 상기 제1 VL, 상기 제2 폴리펩타이드, 및 상기 제1 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 151 내지 154 중 어느 한 항에 있어서, 단일 폴리펩타이드 쇄가 상기 제1 VL, 상기 제2 폴리펩타이드, 및 상기 제2 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 155에 있어서, 제2 단일 폴리펩타이드 쇄가 상기 제2 VH, 상기 CH1 도메인, 및 상기 제2 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 156에 있어서, 제2 단일 폴리펩타이드 쇄가 상기 제2 VH, 상기 CH1 도메인, 및 상기 제1 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 157에 있어서, 제2 단일 폴리펩타이드 쇄가 상기 제2 VL, 상기 CL 도메인, 및 상기 제2 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 158에 있어서, 제2 단일 폴리펩타이드 쇄가 상기 제2 VL, 상기 CL 도메인, 및 상기 제1 IgG1 CH3 도메인을 포함하는, 이중특이적 항체.
- 청구항 151 내지 162 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:2에서 제시된 상기 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 151 내지 162 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:2에서 제시된 상기 아미노산 서열의 아미노산 7-112에 적어도 90% 동일한 아미노산 서열을 포함하는, 이중특이적 항체.
- 청구항 151 내지 162 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 서열 식별 번호:2에서 제시된 상기 아미노산 서열의 아미노산 7-112를 포함하는, 이중특이적 항체.
- 청구항 151 내지 162 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및/또는 상기 제2 폴리펩타이드가 적어도 12 아미노산 잔기에서 서열 식별 번호:2에서 제시된 상기 아미노산 서열과 상이한, 이중특이적 항체.
- 청구항 151 내지 162 중 어느 한 항에 있어서, 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 각각 쇄내 디설파이드 결합을 형성하지 않는 서열 식별 번호:2의 상기 시스테인 잔기에서 시스테인 이외 아미노산을 함유하는, 이중특이적 항체.
- 청구항 151 내지 162 또는 166 중 어느 한 항에 있어서, 하기인, 이중특이적 항체:
(i) 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 각각 서열 식별 번호:2내 상기 N-당화 모티프에서 아스파라긴 및/또는 트레오닌 또는 세린 이외 아미노산을 함유하여서 상기 제1 폴리펩타이드 및 상기 제2 폴리펩타이드가 N-당화되지 않음; 또는
(ii) 상기 제1 폴리펩타이드 또는 상기 제2 폴리펩타이드가 서열 식별 번호:2내 상기 N-당화 모티프에서 아스파라긴 및/또는 트레오닌 또는 세린 이외 아미노산을 함유하여서 상기 제1 폴리펩타이드 또는 상기 제2 폴리펩타이드가 N-당화되지 않음.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201562269664P | 2015-12-18 | 2015-12-18 | |
| US62/269,664 | 2015-12-18 | ||
| PCT/US2016/066865 WO2017106462A1 (en) | 2015-12-18 | 2016-12-15 | Bispecific antibody platform |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20180100136A true KR20180100136A (ko) | 2018-09-07 |
Family
ID=57681809
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020187020661A KR20180100136A (ko) | 2015-12-18 | 2016-12-15 | 이중특이적 항체 플랫폼 |
Country Status (9)
| Country | Link |
|---|---|
| US (1) | US11447575B2 (ko) |
| EP (1) | EP3389710A1 (ko) |
| JP (2) | JP7138046B2 (ko) |
| KR (1) | KR20180100136A (ko) |
| CN (1) | CN108601830B (ko) |
| AU (1) | AU2016370821A1 (ko) |
| CA (1) | CA3008840A1 (ko) |
| MA (1) | MA44054A (ko) |
| WO (1) | WO2017106462A1 (ko) |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| MX2019002307A (es) * | 2016-08-26 | 2019-07-04 | Sanofi Sa | Anticuerpos multiespecificos que facilitan el emparejamiento selectivo de cadenas ligeras. |
| CN111356477A (zh) | 2017-08-01 | 2020-06-30 | Ab工作室有限公司 | 双特异性抗体及其用途 |
| CN110028588A (zh) * | 2018-01-11 | 2019-07-19 | 上海细胞治疗研究院 | 抗原-Fc融合蛋白及其检测阳性CAR-T细胞的应用 |
| CN113508135A (zh) | 2018-10-29 | 2021-10-15 | 比奥根Ma公司 | 增强血脑屏障转运的人源化和稳定化的fc5变体 |
| JP2022514262A (ja) | 2018-12-17 | 2022-02-10 | レビトープ リミテッド | 双子型免疫細胞エンゲージャー |
| WO2020192648A1 (en) * | 2019-03-25 | 2020-10-01 | Dingfu Biotarget Co., Ltd. | Proteinaceous heterodimer and use thereof |
| KR20220050166A (ko) * | 2019-08-23 | 2022-04-22 | 아이쥐엠 바이오사이언스 인코포레이티드 | Igm 글리코변이체 |
| CN114746440A (zh) * | 2020-01-09 | 2022-07-12 | 江苏恒瑞医药股份有限公司 | 新型多肽复合物 |
| CN113563473A (zh) * | 2020-04-29 | 2021-10-29 | 三生国健药业(上海)股份有限公司 | 四价双特异性抗体、其制备方法和用途 |
| AU2022273737A1 (en) * | 2021-05-14 | 2023-11-16 | Jiangsu Hengrui Pharmaceuticals Co., Ltd. | Antigen-binding molecule |
| WO2023010060A2 (en) | 2021-07-27 | 2023-02-02 | Novab, Inc. | Engineered vlrb antibodies with immune effector functions |
| WO2024073482A1 (en) * | 2022-09-28 | 2024-04-04 | Dren Bio, Inc. | Multispecific antibodies and methods of use thereof |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20090162359A1 (en) | 2007-12-21 | 2009-06-25 | Christian Klein | Bivalent, bispecific antibodies |
| EP2681240B1 (en) * | 2011-02-28 | 2017-08-16 | F. Hoffmann-La Roche AG | Monovalent antigen binding proteins |
| US9738707B2 (en) * | 2011-07-15 | 2017-08-22 | Biogen Ma Inc. | Heterodimeric Fc regions, binding molecules comprising same, and methods relating thereto |
| WO2013156054A1 (en) * | 2012-04-16 | 2013-10-24 | Universität Stuttgart | The igm and ige heavy chain domain 2 as covalently linked homodimerization modules for the generation of fusion proteins with dual specificity |
| CA2869529A1 (en) | 2012-05-24 | 2013-11-28 | Raffaella CASTOLDI | Multispecific antibodies |
| EP3057990B1 (en) * | 2013-10-18 | 2019-09-04 | Regeneron Pharmaceuticals, Inc. | Compositions comprising a combination of a vegf antagonist and an anti-ctla-4 antibody |
| WO2017011342A1 (en) | 2015-07-10 | 2017-01-19 | Abbvie Inc. | Igm-or-ige-modified binding proteins and uses thereof |
| MX2019002307A (es) * | 2016-08-26 | 2019-07-04 | Sanofi Sa | Anticuerpos multiespecificos que facilitan el emparejamiento selectivo de cadenas ligeras. |
| JP2022514262A (ja) * | 2018-12-17 | 2022-02-10 | レビトープ リミテッド | 双子型免疫細胞エンゲージャー |
-
2016
- 2016-12-15 WO PCT/US2016/066865 patent/WO2017106462A1/en active Application Filing
- 2016-12-15 CA CA3008840A patent/CA3008840A1/en active Pending
- 2016-12-15 JP JP2018531487A patent/JP7138046B2/ja active Active
- 2016-12-15 MA MA044054A patent/MA44054A/fr unknown
- 2016-12-15 KR KR1020187020661A patent/KR20180100136A/ko unknown
- 2016-12-15 CN CN201680081272.6A patent/CN108601830B/zh active Active
- 2016-12-15 US US16/061,903 patent/US11447575B2/en active Active
- 2016-12-15 EP EP16820131.7A patent/EP3389710A1/en active Pending
- 2016-12-15 AU AU2016370821A patent/AU2016370821A1/en active Pending
-
2021
- 2021-06-01 JP JP2021092180A patent/JP2021121642A/ja active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| WO2017106462A1 (en) | 2017-06-22 |
| CN108601830B (zh) | 2023-02-03 |
| US11447575B2 (en) | 2022-09-20 |
| JP2019502694A (ja) | 2019-01-31 |
| AU2016370821A1 (en) | 2018-07-12 |
| JP2021121642A (ja) | 2021-08-26 |
| EP3389710A1 (en) | 2018-10-24 |
| CA3008840A1 (en) | 2017-06-22 |
| US20190048098A1 (en) | 2019-02-14 |
| JP7138046B2 (ja) | 2022-09-15 |
| CN108601830A (zh) | 2018-09-28 |
| MA44054A (fr) | 2018-10-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11447575B2 (en) | Bispecific antibody platform | |
| JP7405444B2 (ja) | 修飾t細胞に対する条件的活性型キメラ抗原受容体 | |
| BR112020000769A2 (pt) | anticorpo de dupla especificidade, moléculas polipeptídicas, ácido nucleico, célula hospedeira, composição farmacêutica e método de tratamento de uma doença ou condição | |
| JP2021137013A5 (ko) | ||
| KR102609667B1 (ko) | 비통합성 바이러스 전달 시스템 및 이와 관련된 방법 | |
| KR101204229B1 (ko) | 최적화된 TACI-Fc 융합 단백질 | |
| JP2022081654A (ja) | 低粘度の抗原結合タンパク質およびそれらの作製方法 | |
| AU2016326449A1 (en) | CD3 binding polypeptides | |
| KR20100113112A (ko) | 개선된 포유동물 발현 벡터 및 이의 용도 | |
| CN101291692A (zh) | 抗addl单克隆抗体及其应用 | |
| KR102449406B1 (ko) | 백시니아 바이러스/진핵 세포에서 폴리뉴클레오티드 라이브러리를 생산하기 위한 개선된 방법 | |
| KR20140114833A (ko) | 신생아 Fc 수용체에 대해 향상된 결합을 지니는 변이체 Fc-폴리펩타이드 | |
| JP7008406B2 (ja) | ポリペプチドを発現する宿主細胞を選択するための発現構築物および方法 | |
| AU2013211001B2 (en) | Tools and methods for expression of membrane proteins | |
| JP2013509188A (ja) | Sorf構築物および複数の遺伝子発現 | |
| WO2017180555A1 (en) | Humanized anti-rage antibody | |
| CN115836087A (zh) | 抗cd26蛋白及其用途 | |
| KR20160035084A (ko) | 진핵세포의 폴리펩티드 발현 방법 및 발현 구조체 | |
| RU2787060C1 (ru) | НУКЛЕОТИДНАЯ ПОСЛЕДОВАТЕЛЬНОСТЬ, КОДИРУЮЩАЯ СЛИТЫЙ БЕЛОК, СОСТОЯЩИЙ ИЗ РАСТВОРИМОГО ВНЕКЛЕТОЧНОГО ФРАГМЕНТА ЧЕЛОВЕЧЕСКОГО Dll4 И КОНСТАНТНОЙ ЧАСТИ ТЯЖЕЛОЙ ЦЕПИ ЧЕЛОВЕЧЕСКОГО IgG4 | |
| US20220281957A1 (en) | Modified human variable domains | |
| KR101718764B1 (ko) | 항체 발현용 바이시스트로닉 발현벡터 및 이를 이용한 항체의 생산 방법 | |
| KR20240052854A (ko) | Mhc 단백질 기반 이종 이량체를 포함하는 이중 특이적 항체 | |
| CN117177998A (zh) | 用于靶向调节性t细胞以增强免疫监视的材料和方法 | |
| EA042409B1 (ru) | Полипептиды, связывающие cd3 |