JP4607105B2 - データをシャッフルするための方法及び装置 - Google Patents
データをシャッフルするための方法及び装置 Download PDFInfo
- Publication number
- JP4607105B2 JP4607105B2 JP2006515370A JP2006515370A JP4607105B2 JP 4607105 B2 JP4607105 B2 JP 4607105B2 JP 2006515370 A JP2006515370 A JP 2006515370A JP 2006515370 A JP2006515370 A JP 2006515370A JP 4607105 B2 JP4607105 B2 JP 4607105B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- shuffle
- operand
- mask
- packed
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims abstract description 124
- 238000012545 processing Methods 0.000 claims description 150
- 238000003860 storage Methods 0.000 claims description 25
- 230000006870 function Effects 0.000 claims description 15
- 230000004044 response Effects 0.000 claims description 7
- 230000008569 process Effects 0.000 description 78
- 238000004422 calculation algorithm Methods 0.000 description 39
- 238000007667 floating Methods 0.000 description 27
- 238000010586 diagram Methods 0.000 description 11
- 238000005516 engineering process Methods 0.000 description 11
- 238000013500 data storage Methods 0.000 description 10
- 238000010845 search algorithm Methods 0.000 description 10
- 238000004891 communication Methods 0.000 description 7
- 238000001914 filtration Methods 0.000 description 6
- 238000004519 manufacturing process Methods 0.000 description 5
- 101100285899 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) SSE2 gene Proteins 0.000 description 4
- 230000001419 dependent effect Effects 0.000 description 4
- 238000013461 design Methods 0.000 description 4
- 230000006872 improvement Effects 0.000 description 4
- 230000003287 optical effect Effects 0.000 description 4
- 239000000872 buffer Substances 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 3
- 229910052760 oxygen Inorganic materials 0.000 description 3
- 238000013459 approach Methods 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 239000003086 colorant Substances 0.000 description 2
- 230000006835 compression Effects 0.000 description 2
- 238000007906 compression Methods 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 230000003068 static effect Effects 0.000 description 2
- 229910052799 carbon Inorganic materials 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 239000002131 composite material Substances 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 238000013479 data entry Methods 0.000 description 1
- 230000006837 decompression Effects 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000006073 displacement reaction Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 230000005291 magnetic effect Effects 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 230000001343 mnemonic effect Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 238000000059 patterning Methods 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 229910052698 phosphorus Inorganic materials 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 238000013139 quantization Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 238000004088 simulation Methods 0.000 description 1
- 230000001360 synchronised effect Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
Images

































Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30032—Movement instructions, e.g. MOVE, SHIFT, ROTATE, SHUFFLE
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/76—Arrangements for rearranging, permuting or selecting data according to predetermined rules, independently of the content of the data
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
- G06F9/30014—Arithmetic instructions with variable precision
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30018—Bit or string instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
- G06F9/30105—Register structure
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
- G06F9/30105—Register structure
- G06F9/30109—Register structure having multiple operands in a single register
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
- G06F9/3012—Organisation of register space, e.g. banked or distributed register file
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
- G06F9/3012—Organisation of register space, e.g. banked or distributed register file
- G06F9/3013—Organisation of register space, e.g. banked or distributed register file according to data content, e.g. floating-point registers, address registers
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30145—Instruction analysis, e.g. decoding, instruction word fields
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline, look ahead
- G06F9/3802—Instruction prefetching
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline, look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline, look ahead using a plurality of independent parallel functional units
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline, look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline, look ahead using a plurality of independent parallel functional units
- G06F9/3887—Concurrent instruction execution, e.g. pipeline, look ahead using a plurality of independent parallel functional units controlled by a single instruction for multiple data lanes [SIMD]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30025—Format conversion instructions, e.g. Floating-Point to Integer, decimal conversion
Description
[発明の技術分野]
本発明は、一般にマイクロプロセッサ及びコンピュータシステムの技術分野に関する。より詳細には、本発明は、データをシャッフルするための方法及び装置に関する。
[発明の背景]
コンピュータシステムが、私たちの社会においてますます普及してきている。コンピュータの処理能力は、広範な分野における労働者の効率性と生産性を向上させてきた。コンピュータを購入及び主有する費用が下落し続けるに従い、ますます多くの消費者がより新しく高速のマシーンを利用することが可能となってきている。さらに、多数の人々がその自由性によりノートブックコンピュータを使用することを享有している。モバイルコンピュータは、ユーザがオフィスを離れたり、旅行に出かけたりするとき、容易にデータを移送し、作業することを可能にする。このシナリオは、マーケティングスタッフ、企業役員及び学生に大変なじみのあるものであろう。
[詳細な説明]
データをシャッフルするための方法及び装置が開示される。SIMD命令を用いてパラレルなテーブル検索のための方法及び装置がまた開示される。複数のレジスタ間においてデータを再構成するための方法及び装置がまた開示される。ここで説明される実施例は、マイクロプロセッサに関して説明されるが、それに限定されるものではない。以下の実施例はプロセッサに関して説明されるが、他の実施例は、他のタイプの集積回路やロジック装置に適用可能である。本発明の同様の技術及び教示が、より大きなパイプラインスループット及びパフォーマンス向上を可能にする他のタイプの回路または半導体装置に容易に適用することができる。本発明の教示は、データ操作を実行する任意のプロセッサまたはマシーンに適用可能である。しかしながら、本発明は256ビット、128ビット、64ビット、32ビットあるいは16ビットデータ処理を実行するプロセッサまたはマシーンに限定されるものではなく、データのシャッフリングが必要とされる任意のプロセッサ及びマシーンに適用可能である。

Claims (27)
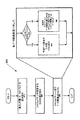
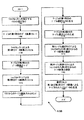
- 制御ロジックが、L個のデータ要素を有する第1オペランドと、各シャッフルマスクが一意的な結果のデータ要素位置に関連付けされるL個のシャッフルマスクの形式によるL個の制御要素を有する第2オペランドとを受け取り、結果の各データ要素位置について選択信号とゼロクリア信号とを提供するステップと、
前記制御ロジックに接続されるL個のマルチプレクサの各マルチプレクサであって、一意的な結果のデータ要素位置に関連付けされる各マルチプレクサを介して、それの関連付けされたゼロクリア信号がアクティブである場合にはゼロを出力し、それの関連付けされたゼロクリア信号が非アクティブである場合には、それの関連付けされた選択信号に基づきL個のデータ要素から選択されたデータを出力するステップと、
を有するデータシャッフル方法であって、
前記シャッフルマスクのそれぞれは、ゼロクリアビットである第1部分と、前記L個のデータ要素の1つの位置を示す位置選択フィールドである第2部分と、予約フィールドである第3部分との3つの部分に分割されるデータシャッフル方法。 - 請求項1記載の方法であって、
前記L個の制御要素のそれぞれは、前記第2オペランドに配置されることを特徴とする方法。 - 請求項2記載の方法であって、
前記L個のデータ要素のそれぞれは、前記第1オペランドに配置されることを特徴とする方法。 - 請求項3記載の方法であって、
前記結果のデータ要素位置のそれぞれは、それの関連付けされたマルチプレクサからの出力を保持することを特徴とする方法。 - 請求項4記載の方法であって、
前記制御要素のそれぞれは、前記ゼロクリアビットと前記位置選択フィールドとから構成され、
前記ゼロクリアビットは、該制御要素に係るデータ要素位置がゼロの値により充填されるべきか示し、
前記位置選択フィールドは、データをシャッフルする第1オペランドデータ要素を示す、
ことを特徴とする方法。 - 請求項5記載の方法であって、
前記制御要素のそれぞれはさらに、前記予約フィールドから構成されることを特徴とする方法。 - 請求項2記載の方法であって、さらに、
前記第2オペランドの制御要素に応答して、前記第1オペランドからシャッフルされたデータを有する結果のデータブロックを出力するステップを有することを特徴とする方法。 - 請求項1記載の方法であって、
前記データ要素のそれぞれは、1バイトのデータから構成されることを特徴とする方法。 - 請求項8記載の方法であって、
前記制御要素のそれぞれは、1バイト長であることを特徴とする方法。 - 請求項9記載の方法であって、
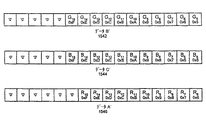
Lは8であり、前記第1オペランド、前記第2オペランド及び前記結果は、それぞれ64ビット長packedデータから構成されることを特徴とする方法。 - 請求項9記載の方法であって、
Lは16であり、前記第1オペランド、前記第2オペランド及び前記結果は、それぞれ128ビット長packedデータから構成されることを特徴とする方法。 - 前記第1オペランドの受け取り、前記第2オペランドの受け取り及び前記データを関連付けされた結果のデータ要素に配置することは、3ビットにより前記第1オペランドを格納する第1レジスタを指定し、3ビットにより前記第2オペランドを格納する第2レジスタを指定する1つのpackedシャッフル命令を受け取ることに応答して実行され、前記第1オペランドと前記第2オペランドとは同じサイズを有し、前記L個のデータ要素とL個の制御要素とのキャッシュは同じサイズを有しており、
前記L個の制御要素のそれぞれは、3つの部分に分割され、第1部分は各シャッフルマスクの最上位ビットを占有するゼロクリアビットであり、第2部分は少なくともlog2Lのビット長であって、前記L個のデータ要素の1つの位置を示す位置選択フィールドである、請求項1記載の方法。 - 複数のソースデータ要素を格納する第1記憶位置と、
各制御要素が結果のデータ要素位置に対応し、ゼロクリアビットと選択フィールドとを有するL個のシャッフルマスクの形式による複数の制御要素を格納する第2記憶位置と、
前記第2記憶位置に接続され、前記制御要素の値に応答して、複数の選択信号と複数のゼロクリア信号とを生成する制御ロジックと、
前記第1記憶位置に接続され、前記複数の選択信号を受信する複数の第1マルチプレクサであって、各マルチプレクサが特定の結果のデータ要素位置に対応する選択信号に応答して、前記特定の結果のデータ要素位置のデータ要素をシャッフルする複数の第1マルチプレクサと、
前記複数の第1マルチプレクサに接続され、前記複数のゼロクリア信号を受信する複数の第2マルチプレクサであって、各マルチプレクサが特定の結果のデータ要素位置に関連付けされ、それのゼロクリア信号がアクティブである場合にはゼロを出力し、または、前記特定の結果のデータ要素位置に対してシャッフルされたデータ要素を出力する複数の第2マルチプレクサと、
から構成されることを特徴とするデータシャッフル装置。 - 請求項13記載の装置であって、
前記複数のソースデータ要素は、第1packedデータオペランドであることを特徴とする装置。 - 請求項14記載の装置であって、
前記複数の制御要素は、第2packedデータオペランドであることを特徴とする装置。 - 請求項14記載の装置であって、
前記第1及び第2記憶位置は、SIMD(Single Instruction Multiple Data)レジスタであることを特徴とする装置。 - 請求項15記載の装置であって、
前記第1packedオペランドは64ビット長であり、前記ソースデータ要素のそれぞれは1バイト長であり、
前記第2packedオペランドは64ビット長であり、前記制御要素のそれぞれは1バイト長である、
ことを特徴とする装置。 - 請求項15記載の装置であって、
前記第1packedオペランドは128ビット長であり、前記ソースデータ要素のそれぞれは1バイト長であり、
前記第2packedオペランドは128ビット長であり、前記制御要素のそれぞれは1バイト長である、
ことを特徴とする装置。 - 各シャッフルマスクが一意的な結果のデータ要素位置に関連付けされるL個のシャッフルマスクを受け付け、各結果のデータ要素位置に対して、選択信号とゼロ設定信号とを提供する制御ロジックと、
前記制御ロジックに接続され、各マルチプレクサもまた一意的な結果のデータ要素位置に関連付けされ、それの関連付けされたゼロクリア信号がアクティブである場合にはゼロを、それの関連付けされたゼロクリア信号が非アクティブである場合には、それの関連付けされた選択信号に基づきL個のデータ要素から選択されたデータを出力するL個のマルチプレクサと、
から構成され、
前記L個のシャッフルマスクのそれぞれは、ゼロクリアビットである第1部分と、データ要素の位置を示す位置選択フィールドである第2部分と、予約フィールドである第3部分との3つの部分に分割されることを特徴とするデータシャッフル装置。 - 請求項19記載の装置であって、さらに、
各データ要素位置がそれの関連付けされたマルチプレクサからの出力を保持するL個の一意的なデータ要素位置を有するレジスタを有することを特徴とする装置。 - 請求項20記載の装置であって、
Lは16であることを特徴とする装置。 - データ及び命令を格納するメモリと、
前記メモリから、プロセッサにデータシャッフル処理を実行させる命令を受信するバスと、
前記メモリに前記バスを介して接続され、前記データシャッフル処理を実行可能なプロセッサと、
から構成されるシステムであって、
前記プロセッサは、
L個のデータ要素を有する第1オペランドと、各シャッフルマスクが一意的な結果のデータ要素位置に関連付けされるL個のシャッフルマスクの形式によるL個の制御要素を有する第2オペランドとを受け取り、結果の各データ要素位置について選択信号とゼロクリア信号とを提供する制御ロジックと、
各マルチプレクサが一意的な結果のデータ要素位置に関連付けされ、それの関連付けされたゼロクリア信号がアクティブである場合にはゼロを出力し、それの関連付けされたゼロクリア信号が非アクティブである場合には、それの関連付けされた選択信号に基づきL個のデータ要素から選択されたデータを出力する、前記制御ロジックに接続されたL個のマルチプレクサと、
から構成され、
前記L個のシャッフルマスクのそれぞれは、ゼロクリアビットである第1部分と、前記L個のデータ要素の1つの位置を示す位置選択フィールドである第2部分と、予約フィールドである第3部分との3つの部分に分割されることを特徴とするシステム。 - 請求項22記載のシステムであって、
各シャッフル制御要素は、前記ゼロクリアビットと前記位置選択フィールドとから構成され、
前記ゼロクリアビットは、該シャッフル制御要素に係るデータ要素位置がゼロの値により充填されるべきか示し、
前記位置選択フィールドは、データをシャッフルする第1オペランドデータ要素を示す、
ことを特徴とするシステム。 - 請求項23記載のシステムであって、
前記L個のデータ要素のそれぞれは、ソース選択フィールドから構成されることを特徴とするシステム。 - 請求項22記載のシステムであって、
前記命令は、ゼロクリア機能を有するpackedバイトシャッフルであることを特徴とするシステム。 - 請求項22記載のシステムであって、
前記L個のデータ要素のそれぞれは1バイト長であり、
各シャッフルコマンド要素は1バイト長であり、
Lは8である、
ことを特徴とするシステム。 - 請求項22記載のシステムであって、
前記第1オペランドは64ビット長であり、
前記第2オペランドは64ビット長である、
ことを特徴とするシステム。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US10/611,344 US20040054877A1 (en) | 2001-10-29 | 2003-06-30 | Method and apparatus for shuffling data |
| PCT/US2004/020601 WO2005006183A2 (en) | 2003-06-30 | 2004-06-24 | Method and apparatus for shuffling data |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2010180413A Division JP5490645B2 (ja) | 2003-06-30 | 2010-08-11 | データをシャッフルするための方法及び装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2007526536A JP2007526536A (ja) | 2007-09-13 |
| JP4607105B2 true JP4607105B2 (ja) | 2011-01-05 |
Family
ID=34062338
Family Applications (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006515370A Active JP4607105B2 (ja) | 2003-06-30 | 2004-06-24 | データをシャッフルするための方法及び装置 |
| JP2010180413A Active JP5490645B2 (ja) | 2003-06-30 | 2010-08-11 | データをシャッフルするための方法及び装置 |
| JP2011045001A Active JP5535965B2 (ja) | 2003-06-30 | 2011-03-02 | データをシャッフルするための方法及び装置 |
| JP2013115254A Active JP5567181B2 (ja) | 2003-06-30 | 2013-05-31 | データをシャッフルするための方法及び装置 |
Family Applications After (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2010180413A Active JP5490645B2 (ja) | 2003-06-30 | 2010-08-11 | データをシャッフルするための方法及び装置 |
| JP2011045001A Active JP5535965B2 (ja) | 2003-06-30 | 2011-03-02 | データをシャッフルするための方法及び装置 |
| JP2013115254A Active JP5567181B2 (ja) | 2003-06-30 | 2013-05-31 | データをシャッフルするための方法及び装置 |
Country Status (11)
| Country | Link |
|---|---|
| US (8) | US20040054877A1 (ja) |
| EP (1) | EP1639452B1 (ja) |
| JP (4) | JP4607105B2 (ja) |
| KR (1) | KR100831472B1 (ja) |
| CN (2) | CN101620525B (ja) |
| AT (1) | ATE442624T1 (ja) |
| DE (1) | DE602004023081D1 (ja) |
| HK (1) | HK1083657A1 (ja) |
| RU (1) | RU2316808C2 (ja) |
| TW (1) | TWI270007B (ja) |
| WO (1) | WO2005006183A2 (ja) |
Families Citing this family (115)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20040054877A1 (en) | 2001-10-29 | 2004-03-18 | Macy William W. | Method and apparatus for shuffling data |
| US7739319B2 (en) * | 2001-10-29 | 2010-06-15 | Intel Corporation | Method and apparatus for parallel table lookup using SIMD instructions |
| US7925891B2 (en) * | 2003-04-18 | 2011-04-12 | Via Technologies, Inc. | Apparatus and method for employing cryptographic functions to generate a message digest |
| US7647557B2 (en) * | 2005-06-29 | 2010-01-12 | Intel Corporation | Techniques for shuffling video information |
| US20070073925A1 (en) * | 2005-09-28 | 2007-03-29 | Arc International (Uk) Limited | Systems and methods for synchronizing multiple processing engines of a microprocessor |
| US20070106883A1 (en) * | 2005-11-07 | 2007-05-10 | Choquette Jack H | Efficient Streaming of Un-Aligned Load/Store Instructions that Save Unused Non-Aligned Data in a Scratch Register for the Next Instruction |
| US20070226469A1 (en) * | 2006-03-06 | 2007-09-27 | James Wilson | Permutable address processor and method |
| US8290095B2 (en) | 2006-03-23 | 2012-10-16 | Qualcomm Incorporated | Viterbi pack instruction |
| US20080071851A1 (en) * | 2006-09-20 | 2008-03-20 | Ronen Zohar | Instruction and logic for performing a dot-product operation |
| US20080077772A1 (en) * | 2006-09-22 | 2008-03-27 | Ronen Zohar | Method and apparatus for performing select operations |
| US9069547B2 (en) * | 2006-09-22 | 2015-06-30 | Intel Corporation | Instruction and logic for processing text strings |
| US7536532B2 (en) | 2006-09-27 | 2009-05-19 | International Business Machines Corporation | Merge operations of data arrays based on SIMD instructions |
| JP4686435B2 (ja) * | 2006-10-27 | 2011-05-25 | 株式会社東芝 | 演算装置 |
| US8700884B2 (en) * | 2007-10-12 | 2014-04-15 | Freescale Semiconductor, Inc. | Single-instruction multiple-data vector permutation instruction and method for performing table lookups for in-range index values and determining constant values for out-of-range index values |
| US7962718B2 (en) * | 2007-10-12 | 2011-06-14 | Freescale Semiconductor, Inc. | Methods for performing extended table lookups using SIMD vector permutation instructions that support out-of-range index values |
| US8515052B2 (en) | 2007-12-17 | 2013-08-20 | Wai Wu | Parallel signal processing system and method |
| US8078836B2 (en) | 2007-12-30 | 2011-12-13 | Intel Corporation | Vector shuffle instructions operating on multiple lanes each having a plurality of data elements using a common set of per-lane control bits |
| GB2456775B (en) * | 2008-01-22 | 2012-10-31 | Advanced Risc Mach Ltd | Apparatus and method for performing permutation operations on data |
| US9513905B2 (en) | 2008-03-28 | 2016-12-06 | Intel Corporation | Vector instructions to enable efficient synchronization and parallel reduction operations |
| WO2009144681A1 (en) * | 2008-05-30 | 2009-12-03 | Nxp B.V. | Vector shuffle with write enable |
| US8195921B2 (en) * | 2008-07-09 | 2012-06-05 | Oracle America, Inc. | Method and apparatus for decoding multithreaded instructions of a microprocessor |
| JP5375114B2 (ja) * | 2009-01-16 | 2013-12-25 | 富士通株式会社 | プロセッサ |
| JP5438551B2 (ja) * | 2009-04-23 | 2014-03-12 | 新日鉄住金ソリューションズ株式会社 | 情報処理装置、情報処理方法及びプログラム |
| US9507670B2 (en) * | 2010-06-14 | 2016-11-29 | Veeam Software Ag | Selective processing of file system objects for image level backups |
| CN103460181B (zh) * | 2011-03-30 | 2017-10-24 | 飞思卡尔半导体公司 | 集成电路器件和执行其位操纵的方法 |
| US20120254588A1 (en) * | 2011-04-01 | 2012-10-04 | Jesus Corbal San Adrian | Systems, apparatuses, and methods for blending two source operands into a single destination using a writemask |
| US20120278591A1 (en) * | 2011-04-27 | 2012-11-01 | Advanced Micro Devices, Inc. | Crossbar switch module having data movement instruction processor module and methods for implementing the same |
| KR101918464B1 (ko) | 2011-09-14 | 2018-11-15 | 삼성전자 주식회사 | 스위즐드 버추얼 레지스터 기반의 프로세서 및 스위즐 패턴 제공 장치 |
| JP5988222B2 (ja) * | 2011-10-18 | 2016-09-07 | パナソニックIpマネジメント株式会社 | シャッフルパターン生成回路、プロセッサ、シャッフルパターン生成方法、命令 |
| WO2013089750A1 (en) * | 2011-12-15 | 2013-06-20 | Intel Corporation | Methods to optimize a program loop via vector instructions using a shuffle table and a blend table |
| WO2013095554A1 (en) | 2011-12-22 | 2013-06-27 | Intel Corporation | Processors, methods, systems, and instructions to generate sequences of consecutive integers in numerical order |
| US9513918B2 (en) * | 2011-12-22 | 2016-12-06 | Intel Corporation | Apparatus and method for performing permute operations |
| CN108681465B (zh) | 2011-12-22 | 2022-08-02 | 英特尔公司 | 用于产生整数序列的处理器、处理器核及系统 |
| US10223111B2 (en) | 2011-12-22 | 2019-03-05 | Intel Corporation | Processors, methods, systems, and instructions to generate sequences of integers in which integers in consecutive positions differ by a constant integer stride and where a smallest integer is offset from zero by an integer offset |
| CN104011644B (zh) | 2011-12-22 | 2017-12-08 | 英特尔公司 | 用于产生按照数值顺序的相差恒定跨度的整数的序列的处理器、方法、系统和指令 |
| CN104025040B (zh) * | 2011-12-23 | 2017-11-21 | 英特尔公司 | 用于混洗浮点或整数值的装置和方法 |
| US9495162B2 (en) * | 2011-12-23 | 2016-11-15 | Intel Corporation | Apparatus and method for performing a permute operation |
| WO2013095657A1 (en) * | 2011-12-23 | 2013-06-27 | Intel Corporation | Instruction and logic to provide vector blend and permute functionality |
| JP5935319B2 (ja) * | 2011-12-26 | 2016-06-15 | 富士通株式会社 | 回路エミュレーション装置、回路エミュレーション方法及び回路エミュレーションプログラム |
| US8683296B2 (en) | 2011-12-30 | 2014-03-25 | Streamscale, Inc. | Accelerated erasure coding system and method |
| US8914706B2 (en) | 2011-12-30 | 2014-12-16 | Streamscale, Inc. | Using parity data for concurrent data authentication, correction, compression, and encryption |
| US9329863B2 (en) | 2012-03-13 | 2016-05-03 | International Business Machines Corporation | Load register on condition with zero or immediate instruction |
| JP5730812B2 (ja) * | 2012-05-02 | 2015-06-10 | 日本電信電話株式会社 | 演算装置、その方法およびプログラム |
| US9268683B1 (en) * | 2012-05-14 | 2016-02-23 | Kandou Labs, S.A. | Storage method and apparatus for random access memory using codeword storage |
| US9953436B2 (en) | 2012-06-26 | 2018-04-24 | BTS Software Solutions, LLC | Low delay low complexity lossless compression system |
| US9542839B2 (en) | 2012-06-26 | 2017-01-10 | BTS Software Solutions, LLC | Low delay low complexity lossless compression system |
| US9218182B2 (en) * | 2012-06-29 | 2015-12-22 | Intel Corporation | Systems, apparatuses, and methods for performing a shuffle and operation (shuffle-op) |
| US9342479B2 (en) * | 2012-08-23 | 2016-05-17 | Qualcomm Incorporated | Systems and methods of data extraction in a vector processor |
| US9804840B2 (en) | 2013-01-23 | 2017-10-31 | International Business Machines Corporation | Vector Galois Field Multiply Sum and Accumulate instruction |
| US9471308B2 (en) | 2013-01-23 | 2016-10-18 | International Business Machines Corporation | Vector floating point test data class immediate instruction |
| US9778932B2 (en) * | 2013-01-23 | 2017-10-03 | International Business Machines Corporation | Vector generate mask instruction |
| US9513906B2 (en) | 2013-01-23 | 2016-12-06 | International Business Machines Corporation | Vector checksum instruction |
| US9715385B2 (en) | 2013-01-23 | 2017-07-25 | International Business Machines Corporation | Vector exception code |
| US9823924B2 (en) | 2013-01-23 | 2017-11-21 | International Business Machines Corporation | Vector element rotate and insert under mask instruction |
| US9207942B2 (en) * | 2013-03-15 | 2015-12-08 | Intel Corporation | Systems, apparatuses,and methods for zeroing of bits in a data element |
| US9405539B2 (en) * | 2013-07-31 | 2016-08-02 | Intel Corporation | Providing vector sub-byte decompression functionality |
| US10001993B2 (en) | 2013-08-08 | 2018-06-19 | Linear Algebra Technologies Limited | Variable-length instruction buffer management |
| US11768689B2 (en) | 2013-08-08 | 2023-09-26 | Movidius Limited | Apparatus, systems, and methods for low power computational imaging |
| CN103501348A (zh) * | 2013-10-16 | 2014-01-08 | 华仪风能有限公司 | 一种风力发电机组主控系统与监控系统的通讯方法及系统 |
| US9582419B2 (en) * | 2013-10-25 | 2017-02-28 | Arm Limited | Data processing device and method for interleaved storage of data elements |
| KR102122406B1 (ko) | 2013-11-06 | 2020-06-12 | 삼성전자주식회사 | 셔플 명령어 처리 장치 및 방법 |
| US9880845B2 (en) * | 2013-11-15 | 2018-01-30 | Qualcomm Incorporated | Vector processing engines (VPEs) employing format conversion circuitry in data flow paths between vector data memory and execution units to provide in-flight format-converting of input vector data to execution units for vector processing operations, and related vector processor systems and methods |
| EP3087473A1 (en) * | 2013-12-23 | 2016-11-02 | Intel Corporation | Instruction and logic for identifying instructions for retirement in a multi-strand out-of-order processor |
| US9552209B2 (en) * | 2013-12-27 | 2017-01-24 | Intel Corporation | Functional unit for instruction execution pipeline capable of shifting different chunks of a packed data operand by different amounts |
| US9256534B2 (en) | 2014-01-06 | 2016-02-09 | International Business Machines Corporation | Data shuffling in a non-uniform memory access device |
| US9274835B2 (en) | 2014-01-06 | 2016-03-01 | International Business Machines Corporation | Data shuffling in a non-uniform memory access device |
| KR101826707B1 (ko) * | 2014-03-27 | 2018-02-07 | 인텔 코포레이션 | 마스킹된 결과 요소들로의 전파를 이용하여 연속 소스 요소들을 마스킹되지 않은 결과 요소들에 저장하기 위한 프로세서, 방법, 시스템 및 명령어 |
| EP3123300A1 (en) * | 2014-03-28 | 2017-02-01 | Intel Corporation | Processors, methods, systems, and instructions to store source elements to corresponding unmasked result elements with propagation to masked result elements |
| US10169803B2 (en) | 2014-06-26 | 2019-01-01 | Amazon Technologies, Inc. | Color based social networking recommendations |
| US9996579B2 (en) * | 2014-06-26 | 2018-06-12 | Amazon Technologies, Inc. | Fast color searching |
| US9424039B2 (en) * | 2014-07-09 | 2016-08-23 | Intel Corporation | Instruction for implementing vector loops of iterations having an iteration dependent condition |
| CN106796504B (zh) * | 2014-07-30 | 2019-08-13 | 线性代数技术有限公司 | 用于管理可变长度指令的方法和设备 |
| US9619214B2 (en) | 2014-08-13 | 2017-04-11 | International Business Machines Corporation | Compiler optimizations for vector instructions |
| US9785649B1 (en) | 2014-09-02 | 2017-10-10 | Amazon Technologies, Inc. | Hue-based color naming for an image |
| JP2017199045A (ja) * | 2014-09-02 | 2017-11-02 | パナソニックIpマネジメント株式会社 | プロセッサ及びデータ並び替え方法 |
| US10133570B2 (en) * | 2014-09-19 | 2018-11-20 | Intel Corporation | Processors, methods, systems, and instructions to select and consolidate active data elements in a register under mask into a least significant portion of result, and to indicate a number of data elements consolidated |
| EP3001307B1 (en) * | 2014-09-25 | 2019-11-13 | Intel Corporation | Bit shuffle processors, methods, systems, and instructions |
| US10169014B2 (en) | 2014-12-19 | 2019-01-01 | International Business Machines Corporation | Compiler method for generating instructions for vector operations in a multi-endian instruction set |
| US10296489B2 (en) * | 2014-12-27 | 2019-05-21 | Intel Corporation | Method and apparatus for performing a vector bit shuffle |
| US10296334B2 (en) * | 2014-12-27 | 2019-05-21 | Intel Corporation | Method and apparatus for performing a vector bit gather |
| KR20160139823A (ko) | 2015-05-28 | 2016-12-07 | 손규호 | 두 키 값과 바이트 중첩을 이용한 다중 자료형 데이터 패킹 또는 패킹 복원 방법 |
| US10001995B2 (en) * | 2015-06-02 | 2018-06-19 | Intel Corporation | Packed data alignment plus compute instructions, processors, methods, and systems |
| CN105022609A (zh) * | 2015-08-05 | 2015-11-04 | 浪潮(北京)电子信息产业有限公司 | 一种数据混洗方法和数据混洗单元 |
| US9880821B2 (en) | 2015-08-17 | 2018-01-30 | International Business Machines Corporation | Compiler optimizations for vector operations that are reformatting-resistant |
| US10503502B2 (en) | 2015-09-25 | 2019-12-10 | Intel Corporation | Data element rearrangement, processors, methods, systems, and instructions |
| US10620957B2 (en) * | 2015-10-22 | 2020-04-14 | Texas Instruments Incorporated | Method for forming constant extensions in the same execute packet in a VLIW processor |
| US20170177350A1 (en) * | 2015-12-18 | 2017-06-22 | Intel Corporation | Instructions and Logic for Set-Multiple-Vector-Elements Operations |
| US20170177351A1 (en) * | 2015-12-18 | 2017-06-22 | Intel Corporation | Instructions and Logic for Even and Odd Vector Get Operations |
| US10338920B2 (en) * | 2015-12-18 | 2019-07-02 | Intel Corporation | Instructions and logic for get-multiple-vector-elements operations |
| US20170177354A1 (en) | 2015-12-18 | 2017-06-22 | Intel Corporation | Instructions and Logic for Vector-Based Bit Manipulation |
| US9946541B2 (en) * | 2015-12-18 | 2018-04-17 | Intel Corporation | Systems, apparatuses, and method for strided access |
| US10467006B2 (en) * | 2015-12-20 | 2019-11-05 | Intel Corporation | Permutating vector data scattered in a temporary destination into elements of a destination register based on a permutation factor |
| US10565207B2 (en) * | 2016-04-12 | 2020-02-18 | Hsilin Huang | Method, system and program product for mask-based compression of a sparse matrix |
| US10331830B1 (en) * | 2016-06-13 | 2019-06-25 | Apple Inc. | Heterogeneous logic gate simulation using SIMD instructions |
| US10592468B2 (en) * | 2016-07-13 | 2020-03-17 | Qualcomm Incorporated | Shuffler circuit for lane shuffle in SIMD architecture |
| US10169040B2 (en) * | 2016-11-16 | 2019-01-01 | Ceva D.S.P. Ltd. | System and method for sample rate conversion |
| CN106775587B (zh) * | 2016-11-30 | 2020-04-14 | 上海兆芯集成电路有限公司 | 计算机指令的执行方法以及使用此方法的装置 |
| EP3336692B1 (en) | 2016-12-13 | 2020-04-29 | Arm Ltd | Replicate partition instruction |
| EP3336691B1 (en) * | 2016-12-13 | 2022-04-06 | ARM Limited | Replicate elements instruction |
| US9959247B1 (en) | 2017-02-17 | 2018-05-01 | Google Llc | Permuting in a matrix-vector processor |
| US10140239B1 (en) | 2017-05-23 | 2018-11-27 | Texas Instruments Incorporated | Superimposing butterfly network controls for pattern combinations |
| US11194630B2 (en) | 2017-05-30 | 2021-12-07 | Microsoft Technology Licensing, Llc | Grouped shuffling of partition vertices |
| US10970081B2 (en) * | 2017-06-29 | 2021-04-06 | Advanced Micro Devices, Inc. | Stream processor with decoupled crossbar for cross lane operations |
| CN109324981B (zh) * | 2017-07-31 | 2023-08-15 | 伊姆西Ip控股有限责任公司 | 高速缓存管理系统和方法 |
| US10460416B1 (en) * | 2017-10-17 | 2019-10-29 | Xilinx, Inc. | Inline image preprocessing for convolution operations using a matrix multiplier on an integrated circuit |
| US10891274B2 (en) | 2017-12-21 | 2021-01-12 | International Business Machines Corporation | Data shuffling with hierarchical tuple spaces |
| US10956125B2 (en) | 2017-12-21 | 2021-03-23 | International Business Machines Corporation | Data shuffling with hierarchical tuple spaces |
| US11789734B2 (en) * | 2018-08-30 | 2023-10-17 | Advanced Micro Devices, Inc. | Padded vectorization with compile time known masks |
| US10620958B1 (en) | 2018-12-03 | 2020-04-14 | Advanced Micro Devices, Inc. | Crossbar between clients and a cache |
| CN109783054B (zh) * | 2018-12-20 | 2021-03-09 | 中国科学院计算技术研究所 | 一种rsfq fft处理器的蝶形运算处理方法及系统 |
| US11200239B2 (en) | 2020-04-24 | 2021-12-14 | International Business Machines Corporation | Processing multiple data sets to generate a merged location-based data set |
| KR102381644B1 (ko) * | 2020-11-27 | 2022-04-01 | 한국전자기술연구원 | 고속 이차원 FFT 신호처리를 위한 데이터 정렬 방법 및 이를 적용한 SoC |
| US20220197974A1 (en) * | 2020-12-22 | 2022-06-23 | Intel Corporation | Processors, methods, systems, and instructions to select and store data elements from two source two-dimensional arrays indicated by permute control elements in a result two-dimensional array |
| CN114297138B (zh) * | 2021-12-10 | 2023-12-26 | 龙芯中科技术股份有限公司 | 向量混洗方法、处理器及电子设备 |
| CN115061731B (zh) * | 2022-06-23 | 2023-05-23 | 摩尔线程智能科技(北京)有限责任公司 | 混洗电路和方法、以及芯片和集成电路装置 |
Family Cites Families (84)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3711692A (en) | 1971-03-15 | 1973-01-16 | Goodyear Aerospace Corp | Determination of number of ones in a data field by addition |
| US3723715A (en) | 1971-08-25 | 1973-03-27 | Ibm | Fast modulo threshold operator binary adder for multi-number additions |
| US4139899A (en) | 1976-10-18 | 1979-02-13 | Burroughs Corporation | Shift network having a mask generator and a rotator |
| US4161784A (en) | 1978-01-05 | 1979-07-17 | Honeywell Information Systems, Inc. | Microprogrammable floating point arithmetic unit capable of performing arithmetic operations on long and short operands |
| US4418383A (en) | 1980-06-30 | 1983-11-29 | International Business Machines Corporation | Data flow component for processor and microprocessor systems |
| US4393468A (en) | 1981-03-26 | 1983-07-12 | Advanced Micro Devices, Inc. | Bit slice microprogrammable processor for signal processing applications |
| JPS57209570A (en) | 1981-06-19 | 1982-12-22 | Fujitsu Ltd | Vector processing device |
| US4498177A (en) | 1982-08-30 | 1985-02-05 | Sperry Corporation | M Out of N code checker circuit |
| US4569016A (en) | 1983-06-30 | 1986-02-04 | International Business Machines Corporation | Mechanism for implementing one machine cycle executable mask and rotate instructions in a primitive instruction set computing system |
| US4707800A (en) | 1985-03-04 | 1987-11-17 | Raytheon Company | Adder/substractor for variable length numbers |
| JPS6297060A (ja) | 1985-10-23 | 1987-05-06 | Mitsubishi Electric Corp | デイジタルシグナルプロセツサ |
| US4989168A (en) | 1987-11-30 | 1991-01-29 | Fujitsu Limited | Multiplying unit in a computer system, capable of population counting |
| US5019968A (en) | 1988-03-29 | 1991-05-28 | Yulan Wang | Three-dimensional vector processor |
| EP0363176B1 (en) | 1988-10-07 | 1996-02-14 | International Business Machines Corporation | Word organised data processors |
| US4903228A (en) | 1988-11-09 | 1990-02-20 | International Business Machines Corporation | Single cycle merge/logic unit |
| KR920007505B1 (ko) | 1989-02-02 | 1992-09-04 | 정호선 | 신경회로망을 이용한 곱셈기 |
| US5081698A (en) | 1989-02-14 | 1992-01-14 | Intel Corporation | Method and apparatus for graphics display data manipulation |
| US5497497A (en) | 1989-11-03 | 1996-03-05 | Compaq Computer Corp. | Method and apparatus for resetting multiple processors using a common ROM |
| US5168571A (en) | 1990-01-24 | 1992-12-01 | International Business Machines Corporation | System for aligning bytes of variable multi-bytes length operand based on alu byte length and a number of unprocessed byte data |
| FR2666472B1 (fr) | 1990-08-31 | 1992-10-16 | Alcatel Nv | Systeme de memorisation temporaire d'information comprenant une memoire tampon enregistrant des donnees en blocs de donnees de longueur fixe ou variable. |
| US5268995A (en) | 1990-11-21 | 1993-12-07 | Motorola, Inc. | Method for executing graphics Z-compare and pixel merge instructions in a data processor |
| US5680161A (en) | 1991-04-03 | 1997-10-21 | Radius Inc. | Method and apparatus for high speed graphics data compression |
| US5187679A (en) | 1991-06-05 | 1993-02-16 | International Business Machines Corporation | Generalized 7/3 counters |
| US5321810A (en) | 1991-08-21 | 1994-06-14 | Digital Equipment Corporation | Address method for computer graphics system |
| US5423010A (en) | 1992-01-24 | 1995-06-06 | C-Cube Microsystems | Structure and method for packing and unpacking a stream of N-bit data to and from a stream of N-bit data words |
| JP2642039B2 (ja) | 1992-05-22 | 1997-08-20 | インターナショナル・ビジネス・マシーンズ・コーポレイション | アレイ・プロセッサ |
| US5426783A (en) | 1992-11-02 | 1995-06-20 | Amdahl Corporation | System for processing eight bytes or less by the move, pack and unpack instruction of the ESA/390 instruction set |
| US5408670A (en) | 1992-12-18 | 1995-04-18 | Xerox Corporation | Performing arithmetic in parallel on composite operands with packed multi-bit components |
| US5465374A (en) | 1993-01-12 | 1995-11-07 | International Business Machines Corporation | Processor for processing data string by byte-by-byte |
| US5568415A (en) | 1993-02-19 | 1996-10-22 | Digital Equipment Corporation | Content addressable memory having a pair of memory cells storing don't care states for address translation |
| US5524256A (en) | 1993-05-07 | 1996-06-04 | Apple Computer, Inc. | Method and system for reordering bytes in a data stream |
| JPH0721034A (ja) | 1993-06-28 | 1995-01-24 | Fujitsu Ltd | 文字列複写処理方法 |
| US5625374A (en) * | 1993-09-07 | 1997-04-29 | Apple Computer, Inc. | Method for parallel interpolation of images |
| US5390135A (en) | 1993-11-29 | 1995-02-14 | Hewlett-Packard | Parallel shift and add circuit and method |
| US5487159A (en) | 1993-12-23 | 1996-01-23 | Unisys Corporation | System for processing shift, mask, and merge operations in one instruction |
| US5399135A (en) | 1993-12-29 | 1995-03-21 | Azzouni; Paul | Forearm workout bar |
| US5781457A (en) | 1994-03-08 | 1998-07-14 | Exponential Technology, Inc. | Merge/mask, rotate/shift, and boolean operations from two instruction sets executed in a vectored mux on a dual-ALU |
| US5594437A (en) | 1994-08-01 | 1997-01-14 | Motorola, Inc. | Circuit and method of unpacking a serial bitstream |
| US5579253A (en) | 1994-09-02 | 1996-11-26 | Lee; Ruby B. | Computer multiply instruction with a subresult selection option |
| US6275834B1 (en) | 1994-12-01 | 2001-08-14 | Intel Corporation | Apparatus for performing packed shift operations |
| US5819101A (en) | 1994-12-02 | 1998-10-06 | Intel Corporation | Method for packing a plurality of packed data elements in response to a pack instruction |
| US5636352A (en) | 1994-12-16 | 1997-06-03 | International Business Machines Corporation | Method and apparatus for utilizing condensed instructions |
| TW388982B (en) | 1995-03-31 | 2000-05-01 | Samsung Electronics Co Ltd | Memory controller which executes read and write commands out of order |
| GB9509989D0 (en) | 1995-05-17 | 1995-07-12 | Sgs Thomson Microelectronics | Manipulation of data |
| US6381690B1 (en) | 1995-08-01 | 2002-04-30 | Hewlett-Packard Company | Processor for performing subword permutations and combinations |
| CN1264085C (zh) | 1995-08-31 | 2006-07-12 | 英特尔公司 | 一种用于执行多媒体应用的操作的装置、系统和方法 |
| US7085795B2 (en) * | 2001-10-29 | 2006-08-01 | Intel Corporation | Apparatus and method for efficient filtering and convolution of content data |
| US5819117A (en) | 1995-10-10 | 1998-10-06 | Microunity Systems Engineering, Inc. | Method and system for facilitating byte ordering interfacing of a computer system |
| US5838984A (en) | 1996-08-19 | 1998-11-17 | Samsung Electronics Co., Ltd. | Single-instruction-multiple-data processing using multiple banks of vector registers |
| US5909572A (en) | 1996-12-02 | 1999-06-01 | Compaq Computer Corp. | System and method for conditionally moving an operand from a source register to a destination register |
| US6061521A (en) * | 1996-12-02 | 2000-05-09 | Compaq Computer Corp. | Computer having multimedia operations executable as two distinct sets of operations within a single instruction cycle |
| DE19654846A1 (de) | 1996-12-27 | 1998-07-09 | Pact Inf Tech Gmbh | Verfahren zum selbständigen dynamischen Umladen von Datenflußprozessoren (DFPs) sowie Bausteinen mit zwei- oder mehrdimensionalen programmierbaren Zellstrukturen (FPGAs, DPGAs, o. dgl.) |
| US5933650A (en) | 1997-10-09 | 1999-08-03 | Mips Technologies, Inc. | Alignment and ordering of vector elements for single instruction multiple data processing |
| US6223277B1 (en) | 1997-11-21 | 2001-04-24 | Texas Instruments Incorporated | Data processing circuit with packed data structure capability |
| US6211892B1 (en) | 1998-03-31 | 2001-04-03 | Intel Corporation | System and method for performing an intra-add operation |
| US6307553B1 (en) | 1998-03-31 | 2001-10-23 | Mohammad Abdallah | System and method for performing a MOVHPS-MOVLPS instruction |
| US6041404A (en) | 1998-03-31 | 2000-03-21 | Intel Corporation | Dual function system and method for shuffling packed data elements |
| US6122725A (en) * | 1998-03-31 | 2000-09-19 | Intel Corporation | Executing partial-width packed data instructions |
| US6192467B1 (en) | 1998-03-31 | 2001-02-20 | Intel Corporation | Executing partial-width packed data instructions |
| US6115812A (en) | 1998-04-01 | 2000-09-05 | Intel Corporation | Method and apparatus for efficient vertical SIMD computations |
| US6288723B1 (en) | 1998-04-01 | 2001-09-11 | Intel Corporation | Method and apparatus for converting data format to a graphics card |
| US5996057A (en) * | 1998-04-17 | 1999-11-30 | Apple | Data processing system and method of permutation with replication within a vector register file |
| US6098087A (en) | 1998-04-23 | 2000-08-01 | Infineon Technologies North America Corp. | Method and apparatus for performing shift operations on packed data |
| US6263426B1 (en) | 1998-04-30 | 2001-07-17 | Intel Corporation | Conversion from packed floating point data to packed 8-bit integer data in different architectural registers |
| JP3869947B2 (ja) * | 1998-08-04 | 2007-01-17 | 株式会社日立製作所 | 並列処理プロセッサ、および、並列処理方法 |
| US20020002666A1 (en) * | 1998-10-12 | 2002-01-03 | Carole Dulong | Conditional operand selection using mask operations |
| US6405300B1 (en) * | 1999-03-22 | 2002-06-11 | Sun Microsystems, Inc. | Combining results of selectively executed remaining sub-instructions with that of emulated sub-instruction causing exception in VLIW processor |
| US6484255B1 (en) | 1999-09-20 | 2002-11-19 | Intel Corporation | Selective writing of data elements from packed data based upon a mask using predication |
| US6446198B1 (en) | 1999-09-30 | 2002-09-03 | Apple Computer, Inc. | Vectorized table lookup |
| US6546480B1 (en) | 1999-10-01 | 2003-04-08 | Hitachi, Ltd. | Instructions for arithmetic operations on vectored data |
| US20050188182A1 (en) * | 1999-12-30 | 2005-08-25 | Texas Instruments Incorporated | Microprocessor having a set of byte intermingling instructions |
| US6745319B1 (en) | 2000-02-18 | 2004-06-01 | Texas Instruments Incorporated | Microprocessor with instructions for shuffling and dealing data |
| US6816961B2 (en) * | 2000-03-08 | 2004-11-09 | Sun Microsystems, Inc. | Processing architecture having field swapping capability |
| WO2001069938A1 (en) | 2000-03-15 | 2001-09-20 | Digital Accelerator Corporation | Coding of digital video with high motion content |
| US7155601B2 (en) | 2001-02-14 | 2006-12-26 | Intel Corporation | Multi-element operand sub-portion shuffle instruction execution |
| KR100446235B1 (ko) | 2001-05-07 | 2004-08-30 | 엘지전자 주식회사 | 다중 후보를 이용한 움직임 벡터 병합 탐색 방법 |
| US7162607B2 (en) * | 2001-08-31 | 2007-01-09 | Intel Corporation | Apparatus and method for a data storage device with a plurality of randomly located data |
| US7685212B2 (en) | 2001-10-29 | 2010-03-23 | Intel Corporation | Fast full search motion estimation with SIMD merge instruction |
| US20040054877A1 (en) | 2001-10-29 | 2004-03-18 | Macy William W. | Method and apparatus for shuffling data |
| US7272622B2 (en) | 2001-10-29 | 2007-09-18 | Intel Corporation | Method and apparatus for parallel shift right merge of data |
| US7631025B2 (en) * | 2001-10-29 | 2009-12-08 | Intel Corporation | Method and apparatus for rearranging data between multiple registers |
| US7739319B2 (en) | 2001-10-29 | 2010-06-15 | Intel Corporation | Method and apparatus for parallel table lookup using SIMD instructions |
| US7343389B2 (en) * | 2002-05-02 | 2008-03-11 | Intel Corporation | Apparatus and method for SIMD modular multiplication |
| US6914938B2 (en) | 2002-06-18 | 2005-07-05 | Motorola, Inc. | Interlaced video motion estimation |
-
2003
- 2003-06-30 US US10/611,344 patent/US20040054877A1/en not_active Abandoned
-
2004
- 2004-06-24 AT AT04756204T patent/ATE442624T1/de not_active IP Right Cessation
- 2004-06-24 RU RU2006102503A patent/RU2316808C2/ru active
- 2004-06-24 CN CN200910130582.4A patent/CN101620525B/zh active Active
- 2004-06-24 DE DE602004023081T patent/DE602004023081D1/de active Active
- 2004-06-24 CN CNB2004800184438A patent/CN100492278C/zh active Active
- 2004-06-24 JP JP2006515370A patent/JP4607105B2/ja active Active
- 2004-06-24 EP EP04756204A patent/EP1639452B1/en active Active
- 2004-06-24 WO PCT/US2004/020601 patent/WO2005006183A2/en active Application Filing
- 2004-06-24 KR KR20057025313A patent/KR100831472B1/ko active IP Right Grant
- 2004-06-28 TW TW93118830A patent/TWI270007B/zh not_active IP Right Cessation
-
2006
- 2006-05-18 HK HK06105784.3A patent/HK1083657A1/xx not_active IP Right Cessation
-
2009
- 2009-03-31 US US12/387,958 patent/US8214626B2/en not_active Expired - Lifetime
-
2010
- 2010-08-11 JP JP2010180413A patent/JP5490645B2/ja active Active
- 2010-10-08 US US12/901,336 patent/US8225075B2/en not_active Expired - Lifetime
-
2011
- 2011-03-02 JP JP2011045001A patent/JP5535965B2/ja active Active
-
2012
- 2012-07-02 US US13/540,576 patent/US9477472B2/en not_active Expired - Lifetime
- 2012-09-10 US US13/608,953 patent/US8688959B2/en not_active Expired - Lifetime
-
2013
- 2013-05-31 JP JP2013115254A patent/JP5567181B2/ja active Active
-
2014
- 2014-12-30 US US14/586,558 patent/US9229718B2/en not_active Expired - Fee Related
- 2014-12-30 US US14/586,581 patent/US9229719B2/en not_active Expired - Fee Related
-
2016
- 2016-10-21 US US15/299,914 patent/US10152323B2/en not_active Expired - Fee Related
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4607105B2 (ja) | データをシャッフルするための方法及び装置 | |
| US7739319B2 (en) | Method and apparatus for parallel table lookup using SIMD instructions | |
| JP7052171B2 (ja) | プロセッサ、システム及び方法 | |
| US7631025B2 (en) | Method and apparatus for rearranging data between multiple registers | |
| JP4480997B2 (ja) | Simd整数乗算上位丸めシフト | |
| JP4697639B2 (ja) | ドット積演算を行うための命令および論理 | |
| US7725521B2 (en) | Method and apparatus for computing matrix transformations | |
| JP6508850B2 (ja) | プロセッサ、方法、システム、装置、コンピュータプログラムおよびコンピュータ可読記録媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20080902 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20080930 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090105 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20090331 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090629 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20090730 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20091104 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100204 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100511 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100811 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20100907 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20101006 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4607105 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20131015 Year of fee payment: 3 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |