JP4480997B2 - Simd整数乗算上位丸めシフト - Google Patents
Simd整数乗算上位丸めシフト Download PDFInfo
- Publication number
- JP4480997B2 JP4480997B2 JP2003425711A JP2003425711A JP4480997B2 JP 4480997 B2 JP4480997 B2 JP 4480997B2 JP 2003425711 A JP2003425711 A JP 2003425711A JP 2003425711 A JP2003425711 A JP 2003425711A JP 4480997 B2 JP4480997 B2 JP 4480997B2
- Authority
- JP
- Japan
- Prior art keywords
- packed
- data
- bits
- bit
- data elements
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/52—Multiplying; Dividing
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
- G06F9/30014—Arithmetic instructions with variable precision
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/52—Multiplying; Dividing
- G06F7/523—Multiplying only
- G06F7/533—Reduction of the number of iteration steps or stages, e.g. using the Booth algorithm, log-sum, odd-even
- G06F7/5334—Reduction of the number of iteration steps or stages, e.g. using the Booth algorithm, log-sum, odd-even by using multiple bit scanning, i.e. by decoding groups of successive multiplier bits in order to select an appropriate precalculated multiple of the multiplicand as a partial product
- G06F7/5336—Reduction of the number of iteration steps or stages, e.g. using the Booth algorithm, log-sum, odd-even by using multiple bit scanning, i.e. by decoding groups of successive multiplier bits in order to select an appropriate precalculated multiple of the multiplicand as a partial product overlapped, i.e. with successive bitgroups sharing one or more bits being recoded into signed digit representation, e.g. using the Modified Booth Algorithm
- G06F7/5338—Reduction of the number of iteration steps or stages, e.g. using the Booth algorithm, log-sum, odd-even by using multiple bit scanning, i.e. by decoding groups of successive multiplier bits in order to select an appropriate precalculated multiple of the multiplicand as a partial product overlapped, i.e. with successive bitgroups sharing one or more bits being recoded into signed digit representation, e.g. using the Modified Booth Algorithm each bitgroup having two new bits, e.g. 2nd order MBA
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2207/00—Indexing scheme relating to methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F2207/38—Indexing scheme relating to groups G06F7/38 - G06F7/575
- G06F2207/3804—Details
- G06F2207/3808—Details concerning the type of numbers or the way they are handled
- G06F2207/3812—Devices capable of handling different types of numbers
- G06F2207/382—Reconfigurable for different fixed word lengths
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2207/00—Indexing scheme relating to methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F2207/38—Indexing scheme relating to groups G06F7/38 - G06F7/575
- G06F2207/3804—Details
- G06F2207/3808—Details concerning the type of numbers or the way they are handled
- G06F2207/3828—Multigauge devices, i.e. capable of handling packed numbers without unpacking them
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F5/00—Methods or arrangements for data conversion without changing the order or content of the data handled
- G06F5/01—Methods or arrangements for data conversion without changing the order or content of the data handled for shifting, e.g. justifying, scaling, normalising
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/499—Denomination or exception handling, e.g. rounding or overflow
- G06F7/49942—Significance control
- G06F7/49947—Rounding
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Mathematical Physics (AREA)
- Computing Systems (AREA)
- Executing Machine-Instructions (AREA)
- Complex Calculations (AREA)
Description

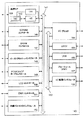
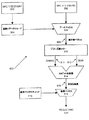
102、166、200 プロセッサ
104、167 キャッシュ
106、208、210 レジスタファイル
108 実行ユニット
109 Packed命令セット
110 プロセッサバス
112 グラフィックス/ビデオカード
114 AGPインターコネクト
116 メモリコントローラハブ(MCH)
118 メモリインタフェース
120 メモリ
122 専用ハブインタフェースバス
124 データ記憶装置
126 無線送信機
128 フラッシュBIOS
130 I/Oコントローラハブ(ICH)
134 ネットワークコントローラ
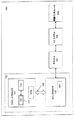
141 バス
142、162 実行ユニット
143 Packed命令セット
144、165 デコーダ
145、164 レジスタファイル
146 SDRAMコントロール
147 SRAMコントロール
148 バーストフラッシュメモリインタフェース
149 PCMCIA/CFカードコントロール
150 LCDコントロール
151 DMAコントロール
152 代替バスマスタインタフェース
153 I/Oバス
154 I/Oブリッジ
155 UART
156 USB
157 ブルートゥースUART
158 I/O拡張インタフェース
159、170 処理コア
161 SIMDコプロセッサ
163 命令セット
168 I/Oシステム
169 無線インタフェース
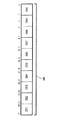
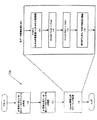
201 フロントエンド
202 高速スケジューラ
203 アウト・オブ・オーダーエンジン
204 低速/通常浮動小数点スケジューラ
206 シンプル浮動小数点スケジューラ
211 実行ブロック
212、214 アドレス生成ユニット(AGU)
216、218 高速ALU
220 低速ALU
222 浮動小数点ALU
224 浮動小数点移動ユニット
226 命令プリフェッチャ
228 命令デコーダ
230 トレースキャッシュ
232 マイクロコードROM
234 uopキュー
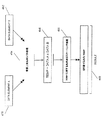
430 乗算上位丸めシフト計算論理
Claims (4)
- 乗算上位丸めシフト処理を実行するためのコンピュータにより実現される方法であって、
当該方法は、L個のデータ要素の第1セットを有する第1レジスタにおける第1オペランドと、L個のデータ要素の第2セットを有する第2レジスタにおける第2オペランドとを特定する単一命令に応答して、
マイクロプロセッサが、
各ペアが、前記L個のデータ要素の第1セットからの第1データ要素と、前記L個のデータ要素の第2セットの対応するデータ要素位置からの第2データ要素とを有するL個のデータ要素ペアを掛け合わせ、L個の積のセットを生成するステップと、
前記L個の積のそれぞれを右に14ビットシフトし、L個のシフトされた値を18ビット長となるように生成するステップと、
前記L個のシフトされた値のそれぞれの最下位ビット位置に“1”を付加することによって、前記L個のシフトされた値のそれぞれを丸め処理し、L個の丸められた値を生成するステップと、
前記L個の丸められた値のそれぞれを右に1ビットだけスケーリングし、L個のスケーリングされた値のセットを生成するステップと、
L個の切り捨てられた値を取得するため、前記L個のスケーリングされた値から最下位の16ビットを選択することによって、前記L個のスケーリングされた値のそれぞれを切り捨て処理し、L個の切り捨てられた値を生成するステップと、
前記単一命令の最終結果として、前記L個の切り捨てられた値を前記単一命令により示される宛先レジスタに格納するステップと、
を実行することによって前記単一命令を実行することからなり、
各切り捨て処理された値は、それのデータ要素のペアに対応するデータ要素位置に格納されることを特徴とする方法。 - 単一命令を受け付け、該単一命令に応答して、マイクロプロセッサのハードウェア実行ユニットに2つのオペランドに対してPacked乗算上位丸めシフト処理を実行させるステップと、
前記マイクロプロセッサのハードウェア実行ユニットにおいて前記単一命令を実行し、切り捨て処理された結果のセットを生成するステップと、
Packedデータ要素として宛先レジスタに前記切り捨て処理された結果のセットを格納するステップと、
から構成される方法であって、
前記Packed乗算上位丸めシフト処理は、
Packedデータ要素の第1セットの各データ要素と、Packedデータ要素の第2セットの対応するデータ要素とを乗算し、積のセットを生成し、
前記積のセットのそれぞれを右に14ビットシフトし、その後に丸め処理して、18ビット長となるように結果のセットを生成し、
前記結果のそれぞれから複数のビットを選択し、切り捨て処理された結果のセットを生成することから構成され、
前記単一命令は、
前記Packed乗算上位丸めシフト処理に関する情報を提供するため、前記Packed乗算上位丸めシフト処理に対する前記切り捨てられた結果のセットが、前記結果のセットの上位ビット又は下位ビットから構成されるか示すオペコードを指定する第1フィールドと、
前記Packedデータ要素の第1セットを有する第1オペランドに対して、第1ソースアドレスを指定する第2フィールドと、
前記Packedデータ要素の第2セットを有する第2オペランドに対して、第2ソースアドレスを指定する第3フィールドと、
から構成されるフォーマットを有することを特徴とする方法。 - 単一命令に応答してPacked乗算丸めシフト処理を実行するマイクロプロセッサのハードウェア実行ユニットから構成される装置であって、
前記ハードウェア実行ユニットは、前記単一命令に応答して、
Packedデータ要素の第1セットの各データ要素と、Packedデータ要素の第2セットの対応するデータ要素とを乗算し、積のセットを生成し、
シフトされた値のそれぞれの最下位ビット位置に“1”を付加することによって、前記積のセットのそれぞれを丸め処理し、結果のセットを生成し、
前記結果のセットのそれぞれを右に14ビットシフトし、18ビット長となるように結果の中間セットを生成し、
前記結果の中間セットのそれぞれから複数のビットを選択し、切り捨てられた結果のセットを生成し、
最終結果として前記切り捨てられた結果のセットを格納し、
前記単一命令は、
前記Packed乗算丸めシフト処理に関する情報を提供するため、前記Packed乗算上位丸めシフト処理に対する前記切り捨てられた結果のセットが、前記結果のセットの上位ビット又は下位ビットから構成されるか示すオペコードを指定する第1フィールドと、
前記Packedデータ要素の第1セットを有する第1オペランドに対して、第1ソースアドレスを指定する第2フィールドと、
前記Packedデータ要素の第2セットを有する第2オペランドに対して、第2ソースアドレスを指定する第3フィールドと、
から構成されるフォーマットを有することを特徴とする装置。 - 第1命令を格納するメモリと、
前記メモリから前記第1命令をフェッチするプロセッサと、
から構成されるシステムであって、
前記プロセッサは、前記第1命令の実行に応答して、
Packedデータ要素の第1セットの各データ要素と、Packedデータ要素の第2セットの対応するデータ要素とを乗算し、積のセットを生成し、
シフトされた値のそれぞれの最下位ビット位置に“1”を付加することによって、前記積のセットのそれぞれを丸め処理し、一時的結果のセットを生成し、
前記一時的結果のセットのそれぞれをスケーリングし、スケーリングされた一時的結果のセットを生成し、
前記スケーリングされた一時的結果のそれぞれから複数のビットを選択し、切り捨て処理された結果のセットを生成し、
最終結果として前記切り捨て処理された結果のセットを格納し、
前記第1命令は、
前記Packed乗算丸めシフト処理に関する情報であって、符号付き整数のPacked乗算丸めシフト処理を示す情報を提供するオペコードであって、前記切り捨てられた結果のセットのそれぞれの上位ビットを選択するためのオペコードを指定する第1フィールドと、
前記Packedデータ要素の第1セットを有する第1オペランドに対して、第1ソースアドレスを指定する第2フィールドと、
前記Packedデータ要素の第2セットを有する第2オペランドに対して、第2ソースアドレスを指定する第3フィールドと、
から構成されるフォーマットを有することを特徴とするシステム。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US10/610,833 US7689641B2 (en) | 2003-06-30 | 2003-06-30 | SIMD integer multiply high with round and shift |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2005025718A JP2005025718A (ja) | 2005-01-27 |
| JP2005025718A5 JP2005025718A5 (ja) | 2007-02-01 |
| JP4480997B2 true JP4480997B2 (ja) | 2010-06-16 |
Family
ID=33541207
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003425711A Expired - Fee Related JP4480997B2 (ja) | 2003-06-30 | 2003-12-22 | Simd整数乗算上位丸めシフト |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US7689641B2 (ja) |
| JP (1) | JP4480997B2 (ja) |
| KR (1) | KR100597930B1 (ja) |
| CN (1) | CN100541422C (ja) |
| NL (1) | NL1025106C2 (ja) |
| RU (1) | RU2263947C2 (ja) |
| TW (1) | TWI245219B (ja) |
Families Citing this family (120)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6986023B2 (en) * | 2002-08-09 | 2006-01-10 | Intel Corporation | Conditional execution of coprocessor instruction based on main processor arithmetic flags |
| JP4288461B2 (ja) * | 2002-12-17 | 2009-07-01 | 日本電気株式会社 | 対称型画像フィルタ処理装置、プログラム、及びその方法 |
| US7467176B2 (en) * | 2004-02-20 | 2008-12-16 | Altera Corporation | Saturation and rounding in multiply-accumulate blocks |
| US7987222B1 (en) * | 2004-04-22 | 2011-07-26 | Altera Corporation | Method and apparatus for implementing a multiplier utilizing digital signal processor block memory extension |
| US20060155955A1 (en) * | 2005-01-10 | 2006-07-13 | Gschwind Michael K | SIMD-RISC processor module |
| US8234326B2 (en) * | 2005-05-05 | 2012-07-31 | Mips Technologies, Inc. | Processor core and multiplier that support both vector and single value multiplication |
| US8229991B2 (en) * | 2005-05-05 | 2012-07-24 | Mips Technologies, Inc. | Processor core and multiplier that support a multiply and difference operation by inverting sign bits in booth recoding |
| US8620980B1 (en) | 2005-09-27 | 2013-12-31 | Altera Corporation | Programmable device with specialized multiplier blocks |
| US7725516B2 (en) * | 2005-10-05 | 2010-05-25 | Qualcomm Incorporated | Fast DCT algorithm for DSP with VLIW architecture |
| US8082287B2 (en) | 2006-01-20 | 2011-12-20 | Qualcomm Incorporated | Pre-saturating fixed-point multiplier |
| US8954943B2 (en) * | 2006-01-26 | 2015-02-10 | International Business Machines Corporation | Analyze and reduce number of data reordering operations in SIMD code |
| US8266198B2 (en) | 2006-02-09 | 2012-09-11 | Altera Corporation | Specialized processing block for programmable logic device |
| US8301681B1 (en) | 2006-02-09 | 2012-10-30 | Altera Corporation | Specialized processing block for programmable logic device |
| US8041759B1 (en) | 2006-02-09 | 2011-10-18 | Altera Corporation | Specialized processing block for programmable logic device |
| US8266199B2 (en) | 2006-02-09 | 2012-09-11 | Altera Corporation | Specialized processing block for programmable logic device |
| US8127117B2 (en) * | 2006-05-10 | 2012-02-28 | Qualcomm Incorporated | Method and system to combine corresponding half word units from multiple register units within a microprocessor |
| US7949701B2 (en) * | 2006-08-02 | 2011-05-24 | Qualcomm Incorporated | Method and system to perform shifting and rounding operations within a microprocessor |
| US8386550B1 (en) | 2006-09-20 | 2013-02-26 | Altera Corporation | Method for configuring a finite impulse response filter in a programmable logic device |
| US20080071851A1 (en) * | 2006-09-20 | 2008-03-20 | Ronen Zohar | Instruction and logic for performing a dot-product operation |
| US9069547B2 (en) | 2006-09-22 | 2015-06-30 | Intel Corporation | Instruction and logic for processing text strings |
| US9495724B2 (en) * | 2006-10-31 | 2016-11-15 | International Business Machines Corporation | Single precision vector permute immediate with “word” vector write mask |
| US20080100628A1 (en) * | 2006-10-31 | 2008-05-01 | International Business Machines Corporation | Single Precision Vector Permute Immediate with "Word" Vector Write Mask |
| US8332452B2 (en) * | 2006-10-31 | 2012-12-11 | International Business Machines Corporation | Single precision vector dot product with “word” vector write mask |
| US8386553B1 (en) | 2006-12-05 | 2013-02-26 | Altera Corporation | Large multiplier for programmable logic device |
| US7930336B2 (en) | 2006-12-05 | 2011-04-19 | Altera Corporation | Large multiplier for programmable logic device |
| US8650231B1 (en) | 2007-01-22 | 2014-02-11 | Altera Corporation | Configuring floating point operations in a programmable device |
| US8645450B1 (en) | 2007-03-02 | 2014-02-04 | Altera Corporation | Multiplier-accumulator circuitry and methods |
| US8819095B2 (en) * | 2007-08-28 | 2014-08-26 | Qualcomm Incorporated | Fast computation of products by dyadic fractions with sign-symmetric rounding errors |
| KR101098758B1 (ko) * | 2007-09-20 | 2011-12-26 | 서울대학교산학협력단 | Fp-ra를 구성하는 pe 구조 및 그 fp-ra제어하는 fp-ra 제어 회로 |
| US8667250B2 (en) * | 2007-12-26 | 2014-03-04 | Intel Corporation | Methods, apparatus, and instructions for converting vector data |
| US20090172348A1 (en) * | 2007-12-26 | 2009-07-02 | Robert Cavin | Methods, apparatus, and instructions for processing vector data |
| US8959137B1 (en) | 2008-02-20 | 2015-02-17 | Altera Corporation | Implementing large multipliers in a programmable integrated circuit device |
| US8437433B2 (en) * | 2008-03-28 | 2013-05-07 | Qualcomm Incorporated | Zeroing-out LLRs using demod-bitmap to improve performance of modem decoder |
| US8103858B2 (en) * | 2008-06-30 | 2012-01-24 | Intel Corporation | Efficient parallel floating point exception handling in a processor |
| US8755515B1 (en) | 2008-09-29 | 2014-06-17 | Wai Wu | Parallel signal processing system and method |
| US8307023B1 (en) | 2008-10-10 | 2012-11-06 | Altera Corporation | DSP block for implementing large multiplier on a programmable integrated circuit device |
| US8706790B1 (en) | 2009-03-03 | 2014-04-22 | Altera Corporation | Implementing mixed-precision floating-point operations in a programmable integrated circuit device |
| US8468192B1 (en) | 2009-03-03 | 2013-06-18 | Altera Corporation | Implementing multipliers in a programmable integrated circuit device |
| US8645449B1 (en) | 2009-03-03 | 2014-02-04 | Altera Corporation | Combined floating point adder and subtractor |
| US8386755B2 (en) * | 2009-07-28 | 2013-02-26 | Via Technologies, Inc. | Non-atomic scheduling of micro-operations to perform round instruction |
| US8650236B1 (en) | 2009-08-04 | 2014-02-11 | Altera Corporation | High-rate interpolation or decimation filter in integrated circuit device |
| US8396914B1 (en) | 2009-09-11 | 2013-03-12 | Altera Corporation | Matrix decomposition in an integrated circuit device |
| US8412756B1 (en) | 2009-09-11 | 2013-04-02 | Altera Corporation | Multi-operand floating point operations in a programmable integrated circuit device |
| US10163187B2 (en) | 2009-10-30 | 2018-12-25 | Intel Corproation | Graphics rendering using a hierarchical acceleration structure |
| JP5456167B2 (ja) | 2009-11-30 | 2014-03-26 | マルティン・ラウブッフ | マイクロプロセッサおよびマイクロプロセッサ上での精度が改善された積の和計算のための方法 |
| US8539016B1 (en) | 2010-02-09 | 2013-09-17 | Altera Corporation | QR decomposition in an integrated circuit device |
| US8601044B2 (en) | 2010-03-02 | 2013-12-03 | Altera Corporation | Discrete Fourier Transform in an integrated circuit device |
| US8484265B1 (en) | 2010-03-04 | 2013-07-09 | Altera Corporation | Angular range reduction in an integrated circuit device |
| US8510354B1 (en) | 2010-03-12 | 2013-08-13 | Altera Corporation | Calculation of trigonometric functions in an integrated circuit device |
| US8539014B2 (en) | 2010-03-25 | 2013-09-17 | Altera Corporation | Solving linear matrices in an integrated circuit device |
| US8589463B2 (en) | 2010-06-25 | 2013-11-19 | Altera Corporation | Calculation of trigonometric functions in an integrated circuit device |
| US8862650B2 (en) | 2010-06-25 | 2014-10-14 | Altera Corporation | Calculation of trigonometric functions in an integrated circuit device |
| US8577951B1 (en) | 2010-08-19 | 2013-11-05 | Altera Corporation | Matrix operations in an integrated circuit device |
| US8914430B2 (en) * | 2010-09-24 | 2014-12-16 | Intel Corporation | Multiply add functional unit capable of executing scale, round, GETEXP, round, GETMANT, reduce, range and class instructions |
| US8645451B2 (en) | 2011-03-10 | 2014-02-04 | Altera Corporation | Double-clocked specialized processing block in an integrated circuit device |
| JP5691752B2 (ja) * | 2011-04-01 | 2015-04-01 | セイコーエプソン株式会社 | データの書き換え方法、データ書き換え装置及び書き換えプログラム |
| US9600278B1 (en) | 2011-05-09 | 2017-03-21 | Altera Corporation | Programmable device using fixed and configurable logic to implement recursive trees |
| US8812576B1 (en) | 2011-09-12 | 2014-08-19 | Altera Corporation | QR decomposition in an integrated circuit device |
| US8949298B1 (en) | 2011-09-16 | 2015-02-03 | Altera Corporation | Computing floating-point polynomials in an integrated circuit device |
| US9053045B1 (en) | 2011-09-16 | 2015-06-09 | Altera Corporation | Computing floating-point polynomials in an integrated circuit device |
| US8762443B1 (en) | 2011-11-15 | 2014-06-24 | Altera Corporation | Matrix operations in an integrated circuit device |
| US20130159680A1 (en) * | 2011-12-19 | 2013-06-20 | Wei-Yu Chen | Systems, methods, and computer program products for parallelizing large number arithmetic |
| WO2013095578A1 (en) * | 2011-12-22 | 2013-06-27 | Intel Corporation | Systems, apparatuses, and methods for mapping a source operand to a different range |
| WO2013095592A1 (en) * | 2011-12-22 | 2013-06-27 | Intel Corporation | Apparatus and method for vector compute and accumulate |
| US9870338B2 (en) * | 2011-12-23 | 2018-01-16 | Intel Corporation | Systems, apparatuses, and methods for performing vector packed compression and repeat |
| CN106775592B (zh) * | 2011-12-23 | 2019-03-12 | 英特尔公司 | 处理器、用于计算系统的方法、机器可读介质和计算机系统 |
| US8543634B1 (en) | 2012-03-30 | 2013-09-24 | Altera Corporation | Specialized processing block for programmable integrated circuit device |
| US9098332B1 (en) | 2012-06-01 | 2015-08-04 | Altera Corporation | Specialized processing block with fixed- and floating-point structures |
| US8996600B1 (en) | 2012-08-03 | 2015-03-31 | Altera Corporation | Specialized processing block for implementing floating-point multiplier with subnormal operation support |
| US9128698B2 (en) * | 2012-09-28 | 2015-09-08 | Intel Corporation | Systems, apparatuses, and methods for performing rotate and XOR in response to a single instruction |
| US9207909B1 (en) | 2012-11-26 | 2015-12-08 | Altera Corporation | Polynomial calculations optimized for programmable integrated circuit device structures |
| US9189200B1 (en) | 2013-03-14 | 2015-11-17 | Altera Corporation | Multiple-precision processing block in a programmable integrated circuit device |
| US9207941B2 (en) * | 2013-03-15 | 2015-12-08 | Intel Corporation | Systems, apparatuses, and methods for reducing the number of short integer multiplications |
| US9348795B1 (en) | 2013-07-03 | 2016-05-24 | Altera Corporation | Programmable device using fixed and configurable logic to implement floating-point rounding |
| CN106126189B (zh) | 2014-07-02 | 2019-02-15 | 上海兆芯集成电路有限公司 | 微处理器中的方法 |
| US9910670B2 (en) * | 2014-07-09 | 2018-03-06 | Intel Corporation | Instruction set for eliminating misaligned memory accesses during processing of an array having misaligned data rows |
| US9684488B2 (en) | 2015-03-26 | 2017-06-20 | Altera Corporation | Combined adder and pre-adder for high-radix multiplier circuit |
| US11061672B2 (en) | 2015-10-02 | 2021-07-13 | Via Alliance Semiconductor Co., Ltd. | Chained split execution of fused compound arithmetic operations |
| US10228911B2 (en) | 2015-10-08 | 2019-03-12 | Via Alliance Semiconductor Co., Ltd. | Apparatus employing user-specified binary point fixed point arithmetic |
| US11029949B2 (en) | 2015-10-08 | 2021-06-08 | Shanghai Zhaoxin Semiconductor Co., Ltd. | Neural network unit |
| US10725934B2 (en) | 2015-10-08 | 2020-07-28 | Shanghai Zhaoxin Semiconductor Co., Ltd. | Processor with selective data storage (of accelerator) operable as either victim cache data storage or accelerator memory and having victim cache tags in lower level cache wherein evicted cache line is stored in said data storage when said data storage is in a first mode and said cache line is stored in system memory rather then said data store when said data storage is in a second mode |
| US11226840B2 (en) | 2015-10-08 | 2022-01-18 | Shanghai Zhaoxin Semiconductor Co., Ltd. | Neural network unit that interrupts processing core upon condition |
| US10776690B2 (en) | 2015-10-08 | 2020-09-15 | Via Alliance Semiconductor Co., Ltd. | Neural network unit with plurality of selectable output functions |
| US11221872B2 (en) | 2015-10-08 | 2022-01-11 | Shanghai Zhaoxin Semiconductor Co., Ltd. | Neural network unit that interrupts processing core upon condition |
| US10664751B2 (en) | 2016-12-01 | 2020-05-26 | Via Alliance Semiconductor Co., Ltd. | Processor with memory array operable as either cache memory or neural network unit memory |
| US10380481B2 (en) | 2015-10-08 | 2019-08-13 | Via Alliance Semiconductor Co., Ltd. | Neural network unit that performs concurrent LSTM cell calculations |
| US10552370B2 (en) | 2015-10-08 | 2020-02-04 | Via Alliance Semiconductor Co., Ltd. | Neural network unit with output buffer feedback for performing recurrent neural network computations |
| US11216720B2 (en) | 2015-10-08 | 2022-01-04 | Shanghai Zhaoxin Semiconductor Co., Ltd. | Neural network unit that manages power consumption based on memory accesses per period |
| CN106650923B (zh) * | 2015-10-08 | 2019-04-09 | 上海兆芯集成电路有限公司 | 具有神经存储器与神经处理单元与定序器的神经网络单元 |
| GB2543303B (en) * | 2015-10-14 | 2017-12-27 | Advanced Risc Mach Ltd | Vector data transfer instruction |
| US10671347B2 (en) * | 2016-01-28 | 2020-06-02 | International Business Machines Corporation | Stochastic rounding floating-point multiply instruction using entropy from a register |
| US10489152B2 (en) | 2016-01-28 | 2019-11-26 | International Business Machines Corporation | Stochastic rounding floating-point add instruction using entropy from a register |
| GB2548908B (en) * | 2016-04-01 | 2019-01-30 | Advanced Risc Mach Ltd | Complex multiply instruction |
| US10241757B2 (en) * | 2016-09-30 | 2019-03-26 | International Business Machines Corporation | Decimal shift and divide instruction |
| US10127015B2 (en) | 2016-09-30 | 2018-11-13 | International Business Machines Corporation | Decimal multiply and shift instruction |
| US10078512B2 (en) | 2016-10-03 | 2018-09-18 | Via Alliance Semiconductor Co., Ltd. | Processing denormal numbers in FMA hardware |
| US10423876B2 (en) | 2016-12-01 | 2019-09-24 | Via Alliance Semiconductor Co., Ltd. | Processor with memory array operable as either victim cache or neural network unit memory |
| US10438115B2 (en) | 2016-12-01 | 2019-10-08 | Via Alliance Semiconductor Co., Ltd. | Neural network unit with memory layout to perform efficient 3-dimensional convolutions |
| US10430706B2 (en) | 2016-12-01 | 2019-10-01 | Via Alliance Semiconductor Co., Ltd. | Processor with memory array operable as either last level cache slice or neural network unit memory |
| US10515302B2 (en) | 2016-12-08 | 2019-12-24 | Via Alliance Semiconductor Co., Ltd. | Neural network unit with mixed data and weight size computation capability |
| US10586148B2 (en) | 2016-12-31 | 2020-03-10 | Via Alliance Semiconductor Co., Ltd. | Neural network unit with re-shapeable memory |
| US10565494B2 (en) | 2016-12-31 | 2020-02-18 | Via Alliance Semiconductor Co., Ltd. | Neural network unit with segmentable array width rotator |
| US10565492B2 (en) | 2016-12-31 | 2020-02-18 | Via Alliance Semiconductor Co., Ltd. | Neural network unit with segmentable array width rotator |
| US10140574B2 (en) | 2016-12-31 | 2018-11-27 | Via Alliance Semiconductor Co., Ltd | Neural network unit with segmentable array width rotator and re-shapeable weight memory to match segment width to provide common weights to multiple rotator segments |
| US10162633B2 (en) * | 2017-04-24 | 2018-12-25 | Arm Limited | Shift instruction |
| US10942706B2 (en) | 2017-05-05 | 2021-03-09 | Intel Corporation | Implementation of floating-point trigonometric functions in an integrated circuit device |
| US20200073635A1 (en) * | 2017-06-29 | 2020-03-05 | Intel Corporation | Systems, apparatuses, and methods for vector-packed fractional multiplication of signed words with rounding, saturation, and high-result selection |
| US11347964B2 (en) * | 2017-08-07 | 2022-05-31 | Renesas Electronics Corporation | Hardware circuit |
| US11803377B2 (en) * | 2017-09-08 | 2023-10-31 | Oracle International Corporation | Efficient direct convolution using SIMD instructions |
| US10719296B2 (en) * | 2018-01-17 | 2020-07-21 | Macronix International Co., Ltd. | Sum-of-products accelerator array |
| US11048661B2 (en) * | 2018-04-16 | 2021-06-29 | Simple Machines Inc. | Systems and methods for stream-dataflow acceleration wherein a delay is implemented so as to equalize arrival times of data packets at a destination functional unit |
| US10846056B2 (en) * | 2018-08-20 | 2020-11-24 | Arm Limited | Configurable SIMD multiplication circuit |
| RU2689819C1 (ru) * | 2018-08-21 | 2019-05-29 | Акционерное общество Научно-производственный центр "Электронные вычислительно-информационные системы" (АО НПЦ "ЭЛВИС") | Векторный мультиформатный умножитель |
| RU185346U1 (ru) * | 2018-08-21 | 2018-11-30 | Акционерное общество Научно-производственный центр "Электронные вычислительно-информационные системы" (АО НПЦ "ЭЛВИС") | Векторный мультиформатный умножитель |
| GB2589066B (en) * | 2019-10-24 | 2023-06-28 | Advanced Risc Mach Ltd | Encoding data arrays |
| CN111596888A (zh) * | 2020-03-02 | 2020-08-28 | 成都优博创通信技术股份有限公司 | 一种在低位宽mcu上实现32位无符号数整型乘法运算的方法 |
| US11789701B2 (en) | 2020-08-05 | 2023-10-17 | Arm Limited | Controlling carry-save adders in multiplication |
| US20230004387A1 (en) * | 2021-06-26 | 2023-01-05 | Intel Corporation | Apparatus and method for vector packed multiply of signed and unsigned words |
| US20250036363A1 (en) * | 2023-07-26 | 2025-01-30 | Arm Limited | Flooring divide using multiply with right shift |
| CN117130722B (zh) * | 2023-08-04 | 2024-06-11 | 北京中电华大电子设计有限责任公司 | WebAssembly指令集的优化方法及装置 |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3910664A (en) * | 1973-01-04 | 1975-10-07 | Amp Inc | Multi-contact electrical connector for a ceramic substrate or the like |
| JPS6297033A (ja) * | 1985-10-24 | 1987-05-06 | Hitachi Ltd | 乗算装置 |
| US4769780A (en) * | 1986-02-10 | 1988-09-06 | International Business Machines Corporation | High speed multiplier |
| US4841468A (en) * | 1987-03-20 | 1989-06-20 | Bipolar Integrated Technology, Inc. | High-speed digital multiplier architecture |
| US4982352A (en) * | 1988-06-17 | 1991-01-01 | Bipolar Integrated Technology, Inc. | Methods and apparatus for determining the absolute value of the difference between binary operands |
| RU2021633C1 (ru) * | 1991-07-10 | 1994-10-15 | Научно-исследовательский институт электронных вычислительных машин | Устройство для умножения чисел |
| EP0795155B1 (en) * | 1994-12-01 | 2003-03-19 | Intel Corporation | A microprocessor having a multiply operation |
| MX9801571A (es) * | 1995-08-31 | 1998-05-31 | Intel Corp | Aparato para realizar operaciones de multiplica-suma en datos empacados. |
| GB2317465B (en) * | 1996-09-23 | 2000-11-15 | Advanced Risc Mach Ltd | Data processing apparatus registers. |
| US6014684A (en) * | 1997-03-24 | 2000-01-11 | Intel Corporation | Method and apparatus for performing N bit by 2*N-1 bit signed multiplication |
| US6167419A (en) * | 1997-04-01 | 2000-12-26 | Matsushita Electric Industrial Co., Ltd. | Multiplication method and multiplication circuit |
| US6839728B2 (en) | 1998-10-09 | 2005-01-04 | Pts Corporation | Efficient complex multiplication and fast fourier transform (FFT) implementation on the manarray architecture |
| US6457036B1 (en) * | 1999-08-24 | 2002-09-24 | Avaya Technology Corp. | System for accurately performing an integer multiply-divide operation |
-
2003
- 2003-06-30 US US10/610,833 patent/US7689641B2/en not_active Expired - Fee Related
- 2003-10-13 TW TW092128279A patent/TWI245219B/zh not_active IP Right Cessation
- 2003-12-22 NL NL1025106A patent/NL1025106C2/nl not_active IP Right Cessation
- 2003-12-22 JP JP2003425711A patent/JP4480997B2/ja not_active Expired - Fee Related
- 2003-12-25 RU RU2003137661/09A patent/RU2263947C2/ru not_active IP Right Cessation
- 2003-12-29 CN CNB2003101215939A patent/CN100541422C/zh not_active Expired - Fee Related
- 2003-12-30 KR KR1020030100215A patent/KR100597930B1/ko not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| US7689641B2 (en) | 2010-03-30 |
| CN1577257A (zh) | 2005-02-09 |
| RU2003137661A (ru) | 2005-06-10 |
| JP2005025718A (ja) | 2005-01-27 |
| CN100541422C (zh) | 2009-09-16 |
| NL1025106A1 (nl) | 2005-01-03 |
| KR100597930B1 (ko) | 2006-07-13 |
| NL1025106C2 (nl) | 2007-10-19 |
| KR20050005730A (ko) | 2005-01-14 |
| TWI245219B (en) | 2005-12-11 |
| TW200500940A (en) | 2005-01-01 |
| RU2263947C2 (ru) | 2005-11-10 |
| US20040267857A1 (en) | 2004-12-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4480997B2 (ja) | Simd整数乗算上位丸めシフト | |
| JP7052171B2 (ja) | プロセッサ、システム及び方法 | |
| JP4697639B2 (ja) | ドット積演算を行うための命令および論理 | |
| JP4869552B2 (ja) | 符号乗算処理を実行する方法及び装置 | |
| US10474466B2 (en) | SIMD sign operation | |
| CN104603766B (zh) | 经加速的通道间的向量归约指令 | |
| CN104598204A (zh) | 用于在单个指令中执行移位和异或运算的方法和装置 | |
| WO2013089791A1 (en) | Instruction and logic to provide vector linear interpolation functionality |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20061213 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20061213 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20081023 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20081028 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090128 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20090728 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20091130 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20091208 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20100216 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20100317 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130326 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4480997 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130326 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140326 Year of fee payment: 4 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |