ES2877539T3 - Acidos nucleicos que codifican secuencias repetitivas de aminoácidos ricos en residuos de prolina y alanina que tienen bajas secuencias de nucleótidos repetitivas - Google Patents
Acidos nucleicos que codifican secuencias repetitivas de aminoácidos ricos en residuos de prolina y alanina que tienen bajas secuencias de nucleótidos repetitivas Download PDFInfo
- Publication number
- ES2877539T3 ES2877539T3 ES16828736T ES16828736T ES2877539T3 ES 2877539 T3 ES2877539 T3 ES 2877539T3 ES 16828736 T ES16828736 T ES 16828736T ES 16828736 T ES16828736 T ES 16828736T ES 2877539 T3 ES2877539 T3 ES 2877539T3
- Authority
- ES
- Spain
- Prior art keywords
- seq
- nucleic acid
- nucleotide sequence
- acid molecule
- proline
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 150000007523 nucleic acids Chemical class 0.000 title claims abstract description 387
- 102000039446 nucleic acids Human genes 0.000 title claims abstract description 378
- 108020004707 nucleic acids Proteins 0.000 title claims abstract description 378
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 title claims abstract description 208
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 title claims abstract description 207
- 125000003275 alpha amino acid group Chemical group 0.000 title claims description 122
- 108091028043 Nucleic acid sequence Proteins 0.000 title description 106
- 230000003252 repetitive effect Effects 0.000 title description 61
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 title description 29
- 125000003729 nucleotide group Chemical group 0.000 claims abstract description 539
- 239000002773 nucleotide Substances 0.000 claims abstract description 533
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 332
- 102000004196 processed proteins & peptides Human genes 0.000 claims abstract description 286
- 229920001184 polypeptide Polymers 0.000 claims abstract description 280
- 235000004279 alanine Nutrition 0.000 claims abstract description 210
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 claims abstract description 209
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 claims abstract description 114
- 125000000539 amino acid group Chemical group 0.000 claims abstract description 38
- 108090000623 proteins and genes Proteins 0.000 claims description 185
- 102000004169 proteins and genes Human genes 0.000 claims description 147
- 235000018102 proteins Nutrition 0.000 claims description 146
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 claims description 115
- 238000000034 method Methods 0.000 claims description 102
- 239000013598 vector Substances 0.000 claims description 89
- 235000001014 amino acid Nutrition 0.000 claims description 64
- 229940079593 drug Drugs 0.000 claims description 46
- 239000003814 drug Substances 0.000 claims description 46
- 230000002068 genetic effect Effects 0.000 claims description 27
- 150000003384 small molecules Chemical class 0.000 claims description 16
- 125000001500 prolyl group Chemical group [H]N1C([H])(C(=O)[*])C([H])([H])C([H])([H])C1([H])[H] 0.000 claims description 15
- 150000001720 carbohydrates Chemical class 0.000 claims description 14
- 230000000295 complement effect Effects 0.000 claims description 14
- 238000012258 culturing Methods 0.000 claims description 14
- 230000001976 improved effect Effects 0.000 claims description 7
- 210000004027 cell Anatomy 0.000 description 87
- 229940024606 amino acid Drugs 0.000 description 66
- 150000001413 amino acids Chemical class 0.000 description 50
- -1 and optionally Chemical compound 0.000 description 44
- 239000013612 plasmid Substances 0.000 description 35
- 108091008146 restriction endonucleases Proteins 0.000 description 35
- 238000011144 upstream manufacturing Methods 0.000 description 29
- 230000014509 gene expression Effects 0.000 description 27
- 238000010367 cloning Methods 0.000 description 26
- 239000013604 expression vector Substances 0.000 description 25
- 108020001507 fusion proteins Proteins 0.000 description 25
- 102000037865 fusion proteins Human genes 0.000 description 25
- 239000003112 inhibitor Substances 0.000 description 22
- 108020004414 DNA Proteins 0.000 description 21
- 241000588724 Escherichia coli Species 0.000 description 20
- 238000004458 analytical method Methods 0.000 description 20
- 239000012634 fragment Substances 0.000 description 20
- 239000005557 antagonist Substances 0.000 description 18
- 108020004705 Codon Proteins 0.000 description 15
- 230000027455 binding Effects 0.000 description 15
- 230000000875 corresponding effect Effects 0.000 description 15
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 15
- 235000014633 carbohydrates Nutrition 0.000 description 13
- 238000001727 in vivo Methods 0.000 description 13
- 238000003780 insertion Methods 0.000 description 13
- 230000037431 insertion Effects 0.000 description 13
- 230000004962 physiological condition Effects 0.000 description 13
- 238000009396 hybridization Methods 0.000 description 12
- 108091026890 Coding region Proteins 0.000 description 11
- 206010028980 Neoplasm Diseases 0.000 description 11
- 230000001580 bacterial effect Effects 0.000 description 11
- 108091081062 Repeated sequence (DNA) Proteins 0.000 description 10
- 239000000427 antigen Substances 0.000 description 10
- 230000008901 benefit Effects 0.000 description 10
- 201000010099 disease Diseases 0.000 description 10
- 102000004190 Enzymes Human genes 0.000 description 9
- 108090000790 Enzymes Proteins 0.000 description 9
- 101001063991 Homo sapiens Leptin Proteins 0.000 description 9
- 239000002253 acid Substances 0.000 description 9
- 230000004071 biological effect Effects 0.000 description 9
- 238000003776 cleavage reaction Methods 0.000 description 9
- 229940088598 enzyme Drugs 0.000 description 9
- 102000049953 human LEP Human genes 0.000 description 9
- 238000004519 manufacturing process Methods 0.000 description 9
- 230000007017 scission Effects 0.000 description 9
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 9
- 102000051628 Interleukin-1 receptor antagonist Human genes 0.000 description 8
- 108091007433 antigens Proteins 0.000 description 8
- 102000036639 antigens Human genes 0.000 description 8
- 230000000670 limiting effect Effects 0.000 description 8
- 239000000203 mixture Substances 0.000 description 8
- 230000001105 regulatory effect Effects 0.000 description 8
- 102000014914 Carrier Proteins Human genes 0.000 description 7
- 108091033380 Coding strand Proteins 0.000 description 7
- 102000053602 DNA Human genes 0.000 description 7
- 108010069091 Dystrophin Proteins 0.000 description 7
- 108010076504 Protein Sorting Signals Proteins 0.000 description 7
- 108091008324 binding proteins Proteins 0.000 description 7
- 239000000872 buffer Substances 0.000 description 7
- 239000000470 constituent Substances 0.000 description 7
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 7
- 101001076407 Homo sapiens Interleukin-1 receptor antagonist protein Proteins 0.000 description 6
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 6
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 6
- 229940119178 Interleukin 1 receptor antagonist Drugs 0.000 description 6
- 125000000174 L-prolyl group Chemical group [H]N1C([H])([H])C([H])([H])C([H])([H])[C@@]1([H])C(*)=O 0.000 description 6
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 6
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 description 6
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 6
- 241000700605 Viruses Species 0.000 description 6
- 230000021615 conjugation Effects 0.000 description 6
- 239000000499 gel Substances 0.000 description 6
- 238000000338 in vitro Methods 0.000 description 6
- 229940044601 receptor agonist Drugs 0.000 description 6
- 239000000018 receptor agonist Substances 0.000 description 6
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 6
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 6
- 125000006850 spacer group Chemical group 0.000 description 6
- 230000010473 stable expression Effects 0.000 description 6
- 230000008685 targeting Effects 0.000 description 6
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 5
- 241000894006 Bacteria Species 0.000 description 5
- 241000701076 Macacine alphaherpesvirus 1 Species 0.000 description 5
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 5
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 5
- 230000000692 anti-sense effect Effects 0.000 description 5
- 239000007864 aqueous solution Substances 0.000 description 5
- 238000004422 calculation algorithm Methods 0.000 description 5
- 238000012512 characterization method Methods 0.000 description 5
- 238000001962 electrophoresis Methods 0.000 description 5
- 230000001965 increasing effect Effects 0.000 description 5
- 239000003407 interleukin 1 receptor blocking agent Substances 0.000 description 5
- 239000003446 ligand Substances 0.000 description 5
- 210000004962 mammalian cell Anatomy 0.000 description 5
- 239000002609 medium Substances 0.000 description 5
- 102000040430 polynucleotide Human genes 0.000 description 5
- 108091033319 polynucleotide Proteins 0.000 description 5
- 239000002157 polynucleotide Substances 0.000 description 5
- 229920001282 polysaccharide Polymers 0.000 description 5
- 239000005017 polysaccharide Substances 0.000 description 5
- 229940044551 receptor antagonist Drugs 0.000 description 5
- 239000002464 receptor antagonist Substances 0.000 description 5
- 230000002829 reductive effect Effects 0.000 description 5
- 230000002441 reversible effect Effects 0.000 description 5
- 229940126586 small molecule drug Drugs 0.000 description 5
- 239000000243 solution Substances 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- 230000001225 therapeutic effect Effects 0.000 description 5
- 238000013518 transcription Methods 0.000 description 5
- 230000035897 transcription Effects 0.000 description 5
- XJOTXKZIRSHZQV-RXHOOSIZSA-N (3S)-3-amino-4-[[(2S,3R)-1-[[(2S)-1-[[(2S)-1-[(2S)-2-[[(2S,3S)-1-[[(1R,6R,12R,17R,20S,23S,26R,31R,34R,39R,42S,45S,48S,51S,59S)-51-(4-aminobutyl)-31-[[(2S)-6-amino-1-[[(1S,2R)-1-carboxy-2-hydroxypropyl]amino]-1-oxohexan-2-yl]carbamoyl]-20-benzyl-23-[(2S)-butan-2-yl]-45-(3-carbamimidamidopropyl)-48-(hydroxymethyl)-42-(1H-imidazol-4-ylmethyl)-59-(2-methylsulfanylethyl)-7,10,19,22,25,33,40,43,46,49,52,54,57,60,63,64-hexadecaoxo-3,4,14,15,28,29,36,37-octathia-8,11,18,21,24,32,41,44,47,50,53,55,58,61,62,65-hexadecazatetracyclo[32.19.8.26,17.212,39]pentahexacontan-26-yl]amino]-3-methyl-1-oxopentan-2-yl]carbamoyl]pyrrolidin-1-yl]-1-oxo-3-phenylpropan-2-yl]amino]-3-(1H-imidazol-4-yl)-1-oxopropan-2-yl]amino]-3-hydroxy-1-oxobutan-2-yl]amino]-4-oxobutanoic acid Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H]1CCCN1C(=O)[C@H](Cc1ccccc1)NC(=O)[C@H](Cc1cnc[nH]1)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)[C@@H](C)O)C(=O)N[C@H]1CSSC[C@H](NC(=O)[C@@H]2CSSC[C@@H]3NC(=O)[C@@H]4CSSC[C@H](NC(=O)[C@H](Cc5ccccc5)NC(=O)[C@@H](NC1=O)[C@@H](C)CC)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](Cc1cnc[nH]1)NC3=O)C(=O)NCC(=O)N[C@@H](CCSC)C(=O)N2)C(=O)NCC(=O)N4)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XJOTXKZIRSHZQV-RXHOOSIZSA-N 0.000 description 4
- LMDZBCPBFSXMTL-UHFFFAOYSA-N 1-ethyl-3-(3-dimethylaminopropyl)carbodiimide Chemical compound CCN=C=NCCCN(C)C LMDZBCPBFSXMTL-UHFFFAOYSA-N 0.000 description 4
- 241000699802 Cricetulus griseus Species 0.000 description 4
- 241000701022 Cytomegalovirus Species 0.000 description 4
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 4
- 241000196324 Embryophyta Species 0.000 description 4
- 241000287828 Gallus gallus Species 0.000 description 4
- 108010041872 Islet Amyloid Polypeptide Proteins 0.000 description 4
- 102000036770 Islet Amyloid Polypeptide Human genes 0.000 description 4
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 4
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 4
- 241000124008 Mammalia Species 0.000 description 4
- 108010079246 OMPA outer membrane proteins Proteins 0.000 description 4
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 4
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 4
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 4
- 150000001371 alpha-amino acids Chemical class 0.000 description 4
- 235000008206 alpha-amino acids Nutrition 0.000 description 4
- 230000003321 amplification Effects 0.000 description 4
- 210000004369 blood Anatomy 0.000 description 4
- 239000008280 blood Substances 0.000 description 4
- 201000011510 cancer Diseases 0.000 description 4
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 4
- 238000012217 deletion Methods 0.000 description 4
- 230000037430 deletion Effects 0.000 description 4
- 238000003745 diagnosis Methods 0.000 description 4
- 230000029087 digestion Effects 0.000 description 4
- 208000035475 disorder Diseases 0.000 description 4
- 238000002330 electrospray ionisation mass spectrometry Methods 0.000 description 4
- 239000003623 enhancer Substances 0.000 description 4
- 238000001415 gene therapy Methods 0.000 description 4
- 150000004676 glycans Chemical class 0.000 description 4
- 102000018511 hepcidin Human genes 0.000 description 4
- 108060003558 hepcidin Proteins 0.000 description 4
- 229940066919 hepcidin Drugs 0.000 description 4
- 230000001939 inductive effect Effects 0.000 description 4
- 239000011159 matrix material Substances 0.000 description 4
- 229930182817 methionine Natural products 0.000 description 4
- 238000003199 nucleic acid amplification method Methods 0.000 description 4
- 239000000816 peptidomimetic Substances 0.000 description 4
- 239000008194 pharmaceutical composition Substances 0.000 description 4
- 238000013492 plasmid preparation Methods 0.000 description 4
- 229920000642 polymer Polymers 0.000 description 4
- 239000000047 product Substances 0.000 description 4
- 230000010076 replication Effects 0.000 description 4
- 239000002904 solvent Substances 0.000 description 4
- 230000009466 transformation Effects 0.000 description 4
- 108030001720 Bontoxilysin Proteins 0.000 description 3
- 102100031168 CCN family member 2 Human genes 0.000 description 3
- 241000193155 Clostridium botulinum Species 0.000 description 3
- 108010039419 Connective Tissue Growth Factor Proteins 0.000 description 3
- 102400000739 Corticotropin Human genes 0.000 description 3
- 101800000414 Corticotropin Proteins 0.000 description 3
- 238000001712 DNA sequencing Methods 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- 206010014596 Encephalitis Japanese B Diseases 0.000 description 3
- 101150096822 Fuca1 gene Proteins 0.000 description 3
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 3
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 3
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 3
- 241000238631 Hexapoda Species 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- PMMYEEVYMWASQN-DMTCNVIQSA-N Hydroxyproline Chemical compound O[C@H]1CN[C@H](C(O)=O)C1 PMMYEEVYMWASQN-DMTCNVIQSA-N 0.000 description 3
- PWWVAXIEGOYWEE-UHFFFAOYSA-N Isophenergan Chemical compound C1=CC=C2N(CC(C)N(C)C)C3=CC=CC=C3SC2=C1 PWWVAXIEGOYWEE-UHFFFAOYSA-N 0.000 description 3
- 201000005807 Japanese encephalitis Diseases 0.000 description 3
- 241000710842 Japanese encephalitis virus Species 0.000 description 3
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 3
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 3
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 3
- 108090001090 Lectins Proteins 0.000 description 3
- 102000004856 Lectins Human genes 0.000 description 3
- 102000016267 Leptin Human genes 0.000 description 3
- 108010092277 Leptin Proteins 0.000 description 3
- NQTADLQHYWFPDB-UHFFFAOYSA-N N-Hydroxysuccinimide Chemical compound ON1C(=O)CCC1=O NQTADLQHYWFPDB-UHFFFAOYSA-N 0.000 description 3
- 108010006232 Neuraminidase Proteins 0.000 description 3
- 102000005348 Neuraminidase Human genes 0.000 description 3
- 101800004937 Protein C Proteins 0.000 description 3
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 3
- 102400000827 Saposin-D Human genes 0.000 description 3
- 101800001700 Saposin-D Proteins 0.000 description 3
- 108020004459 Small interfering RNA Proteins 0.000 description 3
- 241000191967 Staphylococcus aureus Species 0.000 description 3
- 108010055044 Tetanus Toxin Proteins 0.000 description 3
- 108090000373 Tissue Plasminogen Activator Proteins 0.000 description 3
- 102000003978 Tissue Plasminogen Activator Human genes 0.000 description 3
- QTBSBXVTEAMEQO-UHFFFAOYSA-N acetic acid Substances CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 3
- 150000007513 acids Chemical class 0.000 description 3
- 230000003213 activating effect Effects 0.000 description 3
- 238000000246 agarose gel electrophoresis Methods 0.000 description 3
- 108010050122 alpha 1-Antitrypsin Proteins 0.000 description 3
- 102000015395 alpha 1-Antitrypsin Human genes 0.000 description 3
- 239000000935 antidepressant agent Substances 0.000 description 3
- 239000002246 antineoplastic agent Substances 0.000 description 3
- 229960000074 biopharmaceutical Drugs 0.000 description 3
- 231100001103 botulinum neurotoxin Toxicity 0.000 description 3
- 238000005277 cation exchange chromatography Methods 0.000 description 3
- 230000032823 cell division Effects 0.000 description 3
- 210000003169 central nervous system Anatomy 0.000 description 3
- 239000003795 chemical substances by application Substances 0.000 description 3
- 230000001268 conjugating effect Effects 0.000 description 3
- IDLFZVILOHSSID-OVLDLUHVSA-N corticotropin Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)NC(=O)[C@@H](N)CO)C1=CC=C(O)C=C1 IDLFZVILOHSSID-OVLDLUHVSA-N 0.000 description 3
- 229960000258 corticotropin Drugs 0.000 description 3
- 239000002537 cosmetic Substances 0.000 description 3
- 238000001514 detection method Methods 0.000 description 3
- PMMYEEVYMWASQN-UHFFFAOYSA-N dl-hydroxyproline Natural products OC1C[NH2+]C(C([O-])=O)C1 PMMYEEVYMWASQN-UHFFFAOYSA-N 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 210000003527 eukaryotic cell Anatomy 0.000 description 3
- 210000002950 fibroblast Anatomy 0.000 description 3
- 235000013305 food Nutrition 0.000 description 3
- 230000004927 fusion Effects 0.000 description 3
- MASNOZXLGMXCHN-ZLPAWPGGSA-N glucagon Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O)C(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C1=CC=CC=C1 MASNOZXLGMXCHN-ZLPAWPGGSA-N 0.000 description 3
- 239000003102 growth factor Substances 0.000 description 3
- 229960002591 hydroxyproline Drugs 0.000 description 3
- 206010022000 influenza Diseases 0.000 description 3
- 230000000977 initiatory effect Effects 0.000 description 3
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 3
- 238000002955 isolation Methods 0.000 description 3
- 239000002523 lectin Substances 0.000 description 3
- 229940039781 leptin Drugs 0.000 description 3
- NRYBAZVQPHGZNS-ZSOCWYAHSA-N leptin Chemical compound O=C([C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC(C)C)CCSC)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CS)C(O)=O NRYBAZVQPHGZNS-ZSOCWYAHSA-N 0.000 description 3
- 230000007774 longterm Effects 0.000 description 3
- 239000003550 marker Substances 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 239000000546 pharmaceutical excipient Substances 0.000 description 3
- 230000000144 pharmacologic effect Effects 0.000 description 3
- 238000002360 preparation method Methods 0.000 description 3
- 229940002612 prodrug Drugs 0.000 description 3
- 239000000651 prodrug Substances 0.000 description 3
- 125000006239 protecting group Chemical group 0.000 description 3
- 229960000856 protein c Drugs 0.000 description 3
- 102000005962 receptors Human genes 0.000 description 3
- 108020003175 receptors Proteins 0.000 description 3
- 238000012163 sequencing technique Methods 0.000 description 3
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 3
- 238000010186 staining Methods 0.000 description 3
- 210000000130 stem cell Anatomy 0.000 description 3
- 150000003431 steroids Chemical class 0.000 description 3
- 238000006467 substitution reaction Methods 0.000 description 3
- 238000001890 transfection Methods 0.000 description 3
- 230000014616 translation Effects 0.000 description 3
- 238000011282 treatment Methods 0.000 description 3
- 241001529453 unidentified herpesvirus Species 0.000 description 3
- 229960005486 vaccine Drugs 0.000 description 3
- 230000000007 visual effect Effects 0.000 description 3
- QWPXBEHQFHACTK-KZVYIGENSA-N (10e,12e)-86-chloro-12,14,4-trihydroxy-85,14-dimethoxy-33,2,7,10-tetramethyl-15,16-dihydro-14h-7-aza-1(6,4)-oxazina-3(2,3)-oxirana-8(1,3)-benzenacyclotetradecaphane-10,12-dien-6-one Chemical compound CN1C(=O)CC(O)C2(C)OC2C(C)C(OC(=O)N2)CC2(O)C(OC)\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 QWPXBEHQFHACTK-KZVYIGENSA-N 0.000 description 2
- MFRNYXJJRJQHNW-DEMKXPNLSA-N (2s)-2-[[(2r,3r)-3-methoxy-3-[(2s)-1-[(3r,4s,5s)-3-methoxy-5-methyl-4-[methyl-[(2s)-3-methyl-2-[[(2s)-3-methyl-2-(methylamino)butanoyl]amino]butanoyl]amino]heptanoyl]pyrrolidin-2-yl]-2-methylpropanoyl]amino]-3-phenylpropanoic acid Chemical compound CN[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFRNYXJJRJQHNW-DEMKXPNLSA-N 0.000 description 2
- LAQPKDLYOBZWBT-NYLDSJSYSA-N (2s,4s,5r,6r)-5-acetamido-2-{[(2s,3r,4s,5s,6r)-2-{[(2r,3r,4r,5r)-5-acetamido-1,2-dihydroxy-6-oxo-4-{[(2s,3s,4r,5s,6s)-3,4,5-trihydroxy-6-methyloxan-2-yl]oxy}hexan-3-yl]oxy}-3,5-dihydroxy-6-(hydroxymethyl)oxan-4-yl]oxy}-4-hydroxy-6-[(1r,2r)-1,2,3-trihydrox Chemical compound O[C@H]1[C@H](O)[C@H](O)[C@H](C)O[C@H]1O[C@H]([C@@H](NC(C)=O)C=O)[C@@H]([C@H](O)CO)O[C@H]1[C@H](O)[C@@H](O[C@]2(O[C@H]([C@H](NC(C)=O)[C@@H](O)C2)[C@H](O)[C@H](O)CO)C(O)=O)[C@@H](O)[C@@H](CO)O1 LAQPKDLYOBZWBT-NYLDSJSYSA-N 0.000 description 2
- HMLGSIZOMSVISS-ONJSNURVSA-N (7r)-7-[[(2z)-2-(2-amino-1,3-thiazol-4-yl)-2-(2,2-dimethylpropanoyloxymethoxyimino)acetyl]amino]-3-ethenyl-8-oxo-5-thia-1-azabicyclo[4.2.0]oct-2-ene-2-carboxylic acid Chemical compound N([C@@H]1C(N2C(=C(C=C)CSC21)C(O)=O)=O)C(=O)\C(=N/OCOC(=O)C(C)(C)C)C1=CSC(N)=N1 HMLGSIZOMSVISS-ONJSNURVSA-N 0.000 description 2
- VHYRLCJMMJQUBY-UHFFFAOYSA-N 1-[4-[4-(2,5-dioxopyrrol-1-yl)phenyl]butanoyloxy]-2,5-dioxopyrrolidine-3-sulfonic acid Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)CCCC1=CC=C(N2C(C=CC2=O)=O)C=C1 VHYRLCJMMJQUBY-UHFFFAOYSA-N 0.000 description 2
- VOXZDWNPVJITMN-ZBRFXRBCSA-N 17β-estradiol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 VOXZDWNPVJITMN-ZBRFXRBCSA-N 0.000 description 2
- NFLLKCVHYJRNRH-UHFFFAOYSA-N 8-chloro-1,3-dimethyl-7H-purine-2,6-dione 2-(diphenylmethyl)oxy-N,N-dimethylethanamine Chemical compound O=C1N(C)C(=O)N(C)C2=C1NC(Cl)=N2.C=1C=CC=CC=1C(OCCN(C)C)C1=CC=CC=C1 NFLLKCVHYJRNRH-UHFFFAOYSA-N 0.000 description 2
- 239000000275 Adrenocorticotropic Hormone Substances 0.000 description 2
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 2
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 2
- 102400000345 Angiotensin-2 Human genes 0.000 description 2
- 101800000733 Angiotensin-2 Proteins 0.000 description 2
- 102000004411 Antithrombin III Human genes 0.000 description 2
- 108090000935 Antithrombin III Proteins 0.000 description 2
- 208000035913 Atypical hemolytic uremic syndrome Diseases 0.000 description 2
- 108010081589 Becaplermin Proteins 0.000 description 2
- 206010004446 Benign prostatic hyperplasia Diseases 0.000 description 2
- 101100354809 Caenorhabditis elegans pxl-1 gene Proteins 0.000 description 2
- KLWPJMFMVPTNCC-UHFFFAOYSA-N Camptothecin Natural products CCC1(O)C(=O)OCC2=C1C=C3C4Nc5ccccc5C=C4CN3C2=O KLWPJMFMVPTNCC-UHFFFAOYSA-N 0.000 description 2
- 108090000565 Capsid Proteins Proteins 0.000 description 2
- 108010003320 Carboxyhemoglobin Proteins 0.000 description 2
- 108010022366 Carcinoembryonic Antigen Proteins 0.000 description 2
- 102100025475 Carcinoembryonic antigen-related cell adhesion molecule 5 Human genes 0.000 description 2
- 208000024172 Cardiovascular disease Diseases 0.000 description 2
- 102100025064 Cellular tumor antigen p53 Human genes 0.000 description 2
- 102100023321 Ceruloplasmin Human genes 0.000 description 2
- 102000009016 Cholera Toxin Human genes 0.000 description 2
- 108010049048 Cholera Toxin Proteins 0.000 description 2
- 102100023804 Coagulation factor VII Human genes 0.000 description 2
- 206010009944 Colon cancer Diseases 0.000 description 2
- 208000035473 Communicable disease Diseases 0.000 description 2
- 229940124073 Complement inhibitor Drugs 0.000 description 2
- 241000186216 Corynebacterium Species 0.000 description 2
- 102000004127 Cytokines Human genes 0.000 description 2
- 108090000695 Cytokines Proteins 0.000 description 2
- 102000012410 DNA Ligases Human genes 0.000 description 2
- 108010061982 DNA Ligases Proteins 0.000 description 2
- 108091008102 DNA aptamers Proteins 0.000 description 2
- 241000702421 Dependoparvovirus Species 0.000 description 2
- 101100125027 Dictyostelium discoideum mhsp70 gene Proteins 0.000 description 2
- 108010053187 Diphtheria Toxin Proteins 0.000 description 2
- 102000016607 Diphtheria Toxin Human genes 0.000 description 2
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 2
- 108010015960 EBI-005 Proteins 0.000 description 2
- 238000002965 ELISA Methods 0.000 description 2
- 208000017701 Endocrine disease Diseases 0.000 description 2
- 241000991587 Enterovirus C Species 0.000 description 2
- WKRLQDKEXYKHJB-UHFFFAOYSA-N Equilin Natural products OC1=CC=C2C3CCC(C)(C(CC4)=O)C4C3=CCC2=C1 WKRLQDKEXYKHJB-UHFFFAOYSA-N 0.000 description 2
- 108010054218 Factor VIII Proteins 0.000 description 2
- 102000001690 Factor VIII Human genes 0.000 description 2
- 102000051325 Glucagon Human genes 0.000 description 2
- 108060003199 Glucagon Proteins 0.000 description 2
- 102000003886 Glycoproteins Human genes 0.000 description 2
- 108090000288 Glycoproteins Proteins 0.000 description 2
- 102000004269 Granulocyte Colony-Stimulating Factor Human genes 0.000 description 2
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 description 2
- 239000000095 Growth Hormone-Releasing Hormone Substances 0.000 description 2
- 206010056438 Growth hormone deficiency Diseases 0.000 description 2
- 208000035895 Guillain-Barré syndrome Diseases 0.000 description 2
- 101150031823 HSP70 gene Proteins 0.000 description 2
- 102000002812 Heat-Shock Proteins Human genes 0.000 description 2
- 108010004889 Heat-Shock Proteins Proteins 0.000 description 2
- 101000899361 Homo sapiens Bone morphogenetic protein 7 Proteins 0.000 description 2
- 101000721661 Homo sapiens Cellular tumor antigen p53 Proteins 0.000 description 2
- 101001055531 Homo sapiens Matrix extracellular phosphoglycoprotein Proteins 0.000 description 2
- 101000595923 Homo sapiens Placenta growth factor Proteins 0.000 description 2
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 2
- 102000002265 Human Growth Hormone Human genes 0.000 description 2
- 102000001974 Hyaluronidases Human genes 0.000 description 2
- CZGUSIXMZVURDU-JZXHSEFVSA-N Ile(5)-angiotensin II Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C=CC=CC=1)C([O-])=O)NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=[NH2+])NC(=O)[C@@H]([NH3+])CC([O-])=O)C(C)C)C1=CC=C(O)C=C1 CZGUSIXMZVURDU-JZXHSEFVSA-N 0.000 description 2
- 108010047761 Interferon-alpha Proteins 0.000 description 2
- 102000006992 Interferon-alpha Human genes 0.000 description 2
- 229940118432 Interleukin receptor antagonist Drugs 0.000 description 2
- 108700021006 Interleukin-1 receptor antagonist Proteins 0.000 description 2
- 108010002350 Interleukin-2 Proteins 0.000 description 2
- 102000000588 Interleukin-2 Human genes 0.000 description 2
- 102000004388 Interleukin-4 Human genes 0.000 description 2
- 108090000978 Interleukin-4 Proteins 0.000 description 2
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 2
- 241000235058 Komagataella pastoris Species 0.000 description 2
- XNSAINXGIQZQOO-UHFFFAOYSA-N L-pyroglutamyl-L-histidyl-L-proline amide Natural products NC(=O)C1CCCN1C(=O)C(NC(=O)C1NC(=O)CC1)CC1=CN=CN1 XNSAINXGIQZQOO-UHFFFAOYSA-N 0.000 description 2
- 102000019298 Lipocalin Human genes 0.000 description 2
- 108050006654 Lipocalin Proteins 0.000 description 2
- 102100028198 Macrophage colony-stimulating factor 1 receptor Human genes 0.000 description 2
- 102100026142 Matrix extracellular phosphoglycoprotein Human genes 0.000 description 2
- 102000001796 Melanocortin 4 receptors Human genes 0.000 description 2
- 229940122938 MicroRNA inhibitor Drugs 0.000 description 2
- 108700011259 MicroRNAs Proteins 0.000 description 2
- 206010049567 Miller Fisher syndrome Diseases 0.000 description 2
- 208000023178 Musculoskeletal disease Diseases 0.000 description 2
- VIUAUNHCRHHYNE-JTQLQIEISA-N N-[(2S)-2,3-dihydroxypropyl]-3-(2-fluoro-4-iodoanilino)-4-pyridinecarboxamide Chemical compound OC[C@@H](O)CNC(=O)C1=CC=NC=C1NC1=CC=C(I)C=C1F VIUAUNHCRHHYNE-JTQLQIEISA-N 0.000 description 2
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 2
- 229930012538 Paclitaxel Natural products 0.000 description 2
- 108010067372 Pancreatic elastase Proteins 0.000 description 2
- 102000016387 Pancreatic elastase Human genes 0.000 description 2
- 241000711504 Paramyxoviridae Species 0.000 description 2
- 102000003982 Parathyroid hormone Human genes 0.000 description 2
- 108090000445 Parathyroid hormone Proteins 0.000 description 2
- 208000018737 Parkinson disease Diseases 0.000 description 2
- 208000000733 Paroxysmal Hemoglobinuria Diseases 0.000 description 2
- 229930182555 Penicillin Natural products 0.000 description 2
- 102000035195 Peptidases Human genes 0.000 description 2
- 108091005804 Peptidases Proteins 0.000 description 2
- 102000007079 Peptide Fragments Human genes 0.000 description 2
- 108010033276 Peptide Fragments Proteins 0.000 description 2
- 102100036050 Phosphatidylinositol N-acetylglucosaminyltransferase subunit A Human genes 0.000 description 2
- 241000195888 Physcomitrella Species 0.000 description 2
- 241000195887 Physcomitrella patens Species 0.000 description 2
- 102100035194 Placenta growth factor Human genes 0.000 description 2
- 102000013566 Plasminogen Human genes 0.000 description 2
- 108010051456 Plasminogen Proteins 0.000 description 2
- 229920002873 Polyethylenimine Polymers 0.000 description 2
- 108010071690 Prealbumin Proteins 0.000 description 2
- 208000004403 Prostatic Hyperplasia Diseases 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- 102000008022 Proto-Oncogene Proteins c-met Human genes 0.000 description 2
- 108010089836 Proto-Oncogene Proteins c-met Proteins 0.000 description 2
- 108091008103 RNA aptamers Proteins 0.000 description 2
- 102000003743 Relaxin Human genes 0.000 description 2
- 108090000103 Relaxin Proteins 0.000 description 2
- 241000714474 Rous sarcoma virus Species 0.000 description 2
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 2
- 102100022831 Somatoliberin Human genes 0.000 description 2
- 101710142969 Somatoliberin Proteins 0.000 description 2
- 101100288418 Staphylococcus xylosus lacP gene Proteins 0.000 description 2
- MUMGGOZAMZWBJJ-DYKIIFRCSA-N Testostosterone Chemical compound O=C1CC[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 MUMGGOZAMZWBJJ-DYKIIFRCSA-N 0.000 description 2
- 102000007501 Thymosin Human genes 0.000 description 2
- 108010046075 Thymosin Proteins 0.000 description 2
- 239000000627 Thyrotropin-Releasing Hormone Substances 0.000 description 2
- 102400000336 Thyrotropin-releasing hormone Human genes 0.000 description 2
- 101800004623 Thyrotropin-releasing hormone Proteins 0.000 description 2
- 241000710771 Tick-borne encephalitis virus Species 0.000 description 2
- 239000007983 Tris buffer Substances 0.000 description 2
- 108010021436 Type 4 Melanocortin Receptor Proteins 0.000 description 2
- 208000025609 Urogenital disease Diseases 0.000 description 2
- GXBMIBRIOWHPDT-UHFFFAOYSA-N Vasopressin Natural products N1C(=O)C(CC=2C=C(O)C=CC=2)NC(=O)C(N)CSSCC(C(=O)N2C(CCC2)C(=O)NC(CCCN=C(N)N)C(=O)NCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(CCC(N)=O)NC(=O)C1CC1=CC=CC=C1 GXBMIBRIOWHPDT-UHFFFAOYSA-N 0.000 description 2
- 108010004977 Vasopressins Proteins 0.000 description 2
- 102000002852 Vasopressins Human genes 0.000 description 2
- 208000003152 Yellow Fever Diseases 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- 239000000556 agonist Substances 0.000 description 2
- 229940024142 alpha 1-antitrypsin Drugs 0.000 description 2
- 125000003277 amino group Chemical group 0.000 description 2
- 229960000723 ampicillin Drugs 0.000 description 2
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 2
- 229960004238 anakinra Drugs 0.000 description 2
- 239000004037 angiogenesis inhibitor Substances 0.000 description 2
- 229940121369 angiogenesis inhibitor Drugs 0.000 description 2
- 229950006323 angiotensin ii Drugs 0.000 description 2
- 238000005571 anion exchange chromatography Methods 0.000 description 2
- 230000036436 anti-hiv Effects 0.000 description 2
- 230000002924 anti-infective effect Effects 0.000 description 2
- 229940124599 anti-inflammatory drug Drugs 0.000 description 2
- 239000000043 antiallergic agent Substances 0.000 description 2
- 239000002220 antihypertensive agent Substances 0.000 description 2
- 229940127088 antihypertensive drug Drugs 0.000 description 2
- 239000000164 antipsychotic agent Substances 0.000 description 2
- 229960005348 antithrombin iii Drugs 0.000 description 2
- RMTMMKNSPRRFHW-SVAVBUBPSA-N apatorsen Chemical compound N1([C@@H]2O[C@H](COP(O)(=S)OC3C([C@@H](O[C@@H]3COP(O)(=S)OC3C([C@@H](O[C@@H]3COP(O)(=S)OC3C([C@@H](O[C@@H]3COP(O)(=S)OC3[C@H](O[C@H](C3)N3C4=C(C(NC(N)=N4)=O)N=C3)COP(O)(=S)OC3[C@H](O[C@H](C3)N3C4=C(C(NC(N)=N4)=O)N=C3)COP(O)(=S)OC3[C@H](O[C@H](C3)N3C(N=C(N)C(C)=C3)=O)COP(O)(=S)OC3[C@H](O[C@H](C3)N3C(NC(=O)C(C)=C3)=O)COP(O)(=S)OC3[C@H](O[C@H](C3)N3C(N=C(N)C(C)=C3)=O)COP(O)(=S)OC3[C@H](O[C@H](C3)N3C4=C(C(NC(N)=N4)=O)N=C3)COP(O)(=S)OC3[C@H](O[C@H](C3)N3C(N=C(N)C(C)=C3)=O)COP(O)(=S)OC3[C@H](O[C@H](C3)N3C4=C(C(NC(N)=N4)=O)N=C3)COP(O)(=S)OC3[C@H](O[C@H](C3)N3C4=C(C(NC(N)=N4)=O)N=C3)COP(O)(=S)OC3[C@H](O[C@H](C3)N3C(N=C(N)C(C)=C3)=O)COP(S)(=O)OC3[C@H](O[C@H](C3)N3C4=C(C(NC(N)=N4)=O)N=C3)COP(O)(=S)OC3[C@H](O[C@H](C3)N3C(N=C(N)C(C)=C3)=O)COP(O)(=S)OC3C([C@@H](O[C@@H]3COP(O)(=S)OC3C([C@@H](O[C@@H]3COP(O)(=S)OC3C([C@@H](O[C@@H]3COP(O)(=S)OC3C([C@@H](O[C@@H]3CO)N3C4=C(C(NC(N)=N4)=O)N=C3)OCCOC)N3C4=C(C(NC(N)=N4)=O)N=C3)OCCOC)N3C4=C(C(NC(N)=N4)=O)N=C3)OCCOC)N3C4=NC=NC(N)=C4N=C3)OCCOC)N3C(NC(=O)C(C)=C3)=O)OCCOC)N3C(N=C(N)C(C)=C3)=O)OCCOC)N3C4=C(C(NC=N4)=N)N=C3)OCCOC)C(O)C2OCCOC)C=C(C)C(=O)NC1=O RMTMMKNSPRRFHW-SVAVBUBPSA-N 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- KBZOIRJILGZLEJ-LGYYRGKSSA-N argipressin Chemical compound C([C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CSSC[C@@H](C(N[C@@H](CC=2C=CC(O)=CC=2)C(=O)N1)=O)N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(N)=O)C1=CC=CC=C1 KBZOIRJILGZLEJ-LGYYRGKSSA-N 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 108010006025 bovine growth hormone Proteins 0.000 description 2
- 210000004899 c-terminal region Anatomy 0.000 description 2
- 239000001506 calcium phosphate Substances 0.000 description 2
- 229910000389 calcium phosphate Inorganic materials 0.000 description 2
- 235000011010 calcium phosphates Nutrition 0.000 description 2
- 229940127093 camptothecin Drugs 0.000 description 2
- VSJKWCGYPAHWDS-FQEVSTJZSA-N camptothecin Chemical compound C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-FQEVSTJZSA-N 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 238000004113 cell culture Methods 0.000 description 2
- 210000001175 cerebrospinal fluid Anatomy 0.000 description 2
- JUFFVKRROAPVBI-PVOYSMBESA-N chembl1210015 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)N[C@H]1[C@@H]([C@@H](O)[C@H](O[C@H]2[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO[C@]3(O[C@@H](C[C@H](O)[C@H](O)CO)[C@H](NC(C)=O)[C@@H](O)C3)C(O)=O)O2)O)[C@@H](CO)O1)NC(C)=O)C(=O)NCC(=O)NCC(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 JUFFVKRROAPVBI-PVOYSMBESA-N 0.000 description 2
- 238000012412 chemical coupling Methods 0.000 description 2
- 229960005091 chloramphenicol Drugs 0.000 description 2
- WIIZWVCIJKGZOK-RKDXNWHRSA-N chloramphenicol Chemical compound ClC(Cl)C(=O)N[C@H](CO)[C@H](O)C1=CC=C([N+]([O-])=O)C=C1 WIIZWVCIJKGZOK-RKDXNWHRSA-N 0.000 description 2
- NJMYODHXAKYRHW-DVZOWYKESA-N cis-flupenthixol Chemical compound C1CN(CCO)CCN1CC\C=C\1C2=CC(C(F)(F)F)=CC=C2SC2=CC=CC=C2/1 NJMYODHXAKYRHW-DVZOWYKESA-N 0.000 description 2
- 239000013599 cloning vector Substances 0.000 description 2
- 229960002271 cobimetinib Drugs 0.000 description 2
- BSMCAPRUBJMWDF-KRWDZBQOSA-N cobimetinib Chemical compound C1C(O)([C@H]2NCCCC2)CN1C(=O)C1=CC=C(F)C(F)=C1NC1=CC=C(I)C=C1F BSMCAPRUBJMWDF-KRWDZBQOSA-N 0.000 description 2
- 239000004074 complement inhibitor Substances 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- NKLPQNGYXWVELD-UHFFFAOYSA-M coomassie brilliant blue Chemical compound [Na+].C1=CC(OCC)=CC=C1NC1=CC=C(C(=C2C=CC(C=C2)=[N+](CC)CC=2C=C(C=CC=2)S([O-])(=O)=O)C=2C=CC(=CC=2)N(CC)CC=2C=C(C=CC=2)S([O-])(=O)=O)C=C1 NKLPQNGYXWVELD-UHFFFAOYSA-M 0.000 description 2
- RMRCNWBMXRMIRW-BYFNXCQMSA-M cyanocobalamin Chemical compound N#C[Co+]N([C@]1([H])[C@H](CC(N)=O)[C@]\2(CCC(=O)NC[C@H](C)OP(O)(=O)OC3[C@H]([C@H](O[C@@H]3CO)N3C4=CC(C)=C(C)C=C4N=C3)O)C)C/2=C(C)\C([C@H](C/2(C)C)CCC(N)=O)=N\C\2=C\C([C@H]([C@@]/2(CC(N)=O)C)CCC(N)=O)=N\C\2=C(C)/C2=N[C@]1(C)[C@@](C)(CC(N)=O)[C@@H]2CCC(N)=O RMRCNWBMXRMIRW-BYFNXCQMSA-M 0.000 description 2
- 231100000433 cytotoxic Toxicity 0.000 description 2
- 230000001472 cytotoxic effect Effects 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 230000030609 dephosphorylation Effects 0.000 description 2
- 238000006209 dephosphorylation reaction Methods 0.000 description 2
- 235000014113 dietary fatty acids Nutrition 0.000 description 2
- ZWIBGKZDAWNIFC-UHFFFAOYSA-N disuccinimidyl suberate Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCCC(=O)ON1C(=O)CCC1=O ZWIBGKZDAWNIFC-UHFFFAOYSA-N 0.000 description 2
- VSJKWCGYPAHWDS-UHFFFAOYSA-N dl-camptothecin Natural products C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)C5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-UHFFFAOYSA-N 0.000 description 2
- 101150052825 dnaK gene Proteins 0.000 description 2
- 229960003668 docetaxel Drugs 0.000 description 2
- 229960004679 doxorubicin Drugs 0.000 description 2
- 238000004520 electroporation Methods 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- HESCAJZNRMSMJG-HGYUPSKWSA-N epothilone A Natural products O=C1[C@H](C)[C@H](O)[C@H](C)CCC[C@H]2O[C@H]2C[C@@H](/C(=C\c2nc(C)sc2)/C)OC(=O)C[C@H](O)C1(C)C HESCAJZNRMSMJG-HGYUPSKWSA-N 0.000 description 2
- HESCAJZNRMSMJG-KKQRBIROSA-N epothilone A Chemical class C/C([C@@H]1C[C@@H]2O[C@@H]2CCC[C@@H]([C@@H]([C@@H](C)C(=O)C(C)(C)[C@@H](O)CC(=O)O1)O)C)=C\C1=CSC(C)=N1 HESCAJZNRMSMJG-KKQRBIROSA-N 0.000 description 2
- WKRLQDKEXYKHJB-HFTRVMKXSA-N equilin Chemical compound OC1=CC=C2[C@H]3CC[C@](C)(C(CC4)=O)[C@@H]4C3=CCC2=C1 WKRLQDKEXYKHJB-HFTRVMKXSA-N 0.000 description 2
- 150000002148 esters Chemical class 0.000 description 2
- 229930195729 fatty acid Natural products 0.000 description 2
- 239000000194 fatty acid Substances 0.000 description 2
- 150000004665 fatty acids Chemical class 0.000 description 2
- NGGMYCMLYOUNGM-CSDLUJIJSA-N fumagillin Chemical compound C([C@H]([C@H]([C@@H]1[C@]2(C)[C@H](O2)CC=C(C)C)OC)OC(=O)\C=C\C=C\C=C\C=C\C(O)=O)C[C@@]21CO2 NGGMYCMLYOUNGM-CSDLUJIJSA-N 0.000 description 2
- 125000000524 functional group Chemical group 0.000 description 2
- BRZYSWJRSDMWLG-CAXSIQPQSA-N geneticin Chemical compound O1C[C@@](O)(C)[C@H](NC)[C@@H](O)[C@H]1O[C@@H]1[C@@H](O)[C@H](O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](C(C)O)O2)N)[C@@H](N)C[C@H]1N BRZYSWJRSDMWLG-CAXSIQPQSA-N 0.000 description 2
- 229960004666 glucagon Drugs 0.000 description 2
- TWSALRJGPBVBQU-PKQQPRCHSA-N glucagon-like peptide 2 Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O)[C@@H](C)CC)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CO)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)CC)C1=CC=CC=C1 TWSALRJGPBVBQU-PKQQPRCHSA-N 0.000 description 2
- XLXSAKCOAKORKW-AQJXLSMYSA-N gonadorelin Chemical compound C([C@@H](C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)NCC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 XLXSAKCOAKORKW-AQJXLSMYSA-N 0.000 description 2
- 239000001963 growth medium Substances 0.000 description 2
- LNEPOXFFQSENCJ-UHFFFAOYSA-N haloperidol Chemical compound C1CC(O)(C=2C=CC(Cl)=CC=2)CCN1CCCC(=O)C1=CC=C(F)C=C1 LNEPOXFFQSENCJ-UHFFFAOYSA-N 0.000 description 2
- 208000005252 hepatitis A Diseases 0.000 description 2
- 238000004128 high performance liquid chromatography Methods 0.000 description 2
- 229940088597 hormone Drugs 0.000 description 2
- 239000005556 hormone Substances 0.000 description 2
- 102000046107 human BMP7 Human genes 0.000 description 2
- 230000007062 hydrolysis Effects 0.000 description 2
- 238000006460 hydrolysis reaction Methods 0.000 description 2
- 230000008676 import Effects 0.000 description 2
- USSYUMHVHQSYNA-SLDJZXPVSA-N indolicidin Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(N)=O)CC1=CNC2=CC=CC=C12 USSYUMHVHQSYNA-SLDJZXPVSA-N 0.000 description 2
- 208000027866 inflammatory disease Diseases 0.000 description 2
- 230000002401 inhibitory effect Effects 0.000 description 2
- 229940028885 interleukin-4 Drugs 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 208000002551 irritable bowel syndrome Diseases 0.000 description 2
- CSSYQJWUGATIHM-IKGCZBKSSA-N l-phenylalanyl-l-lysyl-l-cysteinyl-l-arginyl-l-arginyl-l-tryptophyl-l-glutaminyl-l-tryptophyl-l-arginyl-l-methionyl-l-lysyl-l-lysyl-l-leucylglycyl-l-alanyl-l-prolyl-l-seryl-l-isoleucyl-l-threonyl-l-cysteinyl-l-valyl-l-arginyl-l-arginyl-l-alanyl-l-phenylal Chemical compound C([C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 CSSYQJWUGATIHM-IKGCZBKSSA-N 0.000 description 2
- 101150066555 lacZ gene Proteins 0.000 description 2
- 239000002502 liposome Substances 0.000 description 2
- 210000004072 lung Anatomy 0.000 description 2
- GUKVIRCHWVCSIZ-ROKJYLDNSA-N lusupultide Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O)C(C)C)[C@@H](C)CC)C(C)C)C(C)C)C(C)C)[C@@H](C)CC)C(C)C)C(C)C)C(C)C)C(C)C)C(C)C)C(C)C)[C@@H](C)CC)NC(=O)[C@@H](NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](NC(=O)CN)[C@@H](C)CC)C(C)C)C1=CN=CN1 GUKVIRCHWVCSIZ-ROKJYLDNSA-N 0.000 description 2
- 229950003037 lusupultide Drugs 0.000 description 2
- 210000002751 lymph Anatomy 0.000 description 2
- 201000001441 melanoma Diseases 0.000 description 2
- 102000006240 membrane receptors Human genes 0.000 description 2
- 208000030159 metabolic disease Diseases 0.000 description 2
- 108091070501 miRNA Proteins 0.000 description 2
- 239000002679 microRNA Substances 0.000 description 2
- 108010059074 monomethylauristatin F Proteins 0.000 description 2
- 230000035772 mutation Effects 0.000 description 2
- FDLYAMZZIXQODN-UHFFFAOYSA-N olaparib Chemical compound FC1=CC=C(CC=2C3=CC=CC=C3C(=O)NN=2)C=C1C(=O)N(CC1)CCN1C(=O)C1CC1 FDLYAMZZIXQODN-UHFFFAOYSA-N 0.000 description 2
- 229960001592 paclitaxel Drugs 0.000 description 2
- 108010085108 pamiteplase Proteins 0.000 description 2
- 229950003603 pamiteplase Drugs 0.000 description 2
- 239000000199 parathyroid hormone Substances 0.000 description 2
- 229960001319 parathyroid hormone Drugs 0.000 description 2
- 201000003045 paroxysmal nocturnal hemoglobinuria Diseases 0.000 description 2
- 229940049954 penicillin Drugs 0.000 description 2
- 239000002953 phosphate buffered saline Substances 0.000 description 2
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 2
- 239000013600 plasmid vector Substances 0.000 description 2
- 229960003910 promethazine Drugs 0.000 description 2
- 235000019419 proteases Nutrition 0.000 description 2
- XNSAINXGIQZQOO-SRVKXCTJSA-N protirelin Chemical compound NC(=O)[C@@H]1CCCN1C(=O)[C@@H](NC(=O)[C@H]1NC(=O)CC1)CC1=CN=CN1 XNSAINXGIQZQOO-SRVKXCTJSA-N 0.000 description 2
- 239000003488 releasing hormone Substances 0.000 description 2
- 208000023504 respiratory system disease Diseases 0.000 description 2
- 230000000717 retained effect Effects 0.000 description 2
- 206010039073 rheumatoid arthritis Diseases 0.000 description 2
- 230000028327 secretion Effects 0.000 description 2
- 238000004904 shortening Methods 0.000 description 2
- 230000037432 silent mutation Effects 0.000 description 2
- NHXLMOGPVYXJNR-ATOGVRKGSA-N somatostatin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CO)C(=O)N[C@@H](CSSC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(=O)N1)[C@@H](C)O)NC(=O)CNC(=O)[C@H](C)N)C(O)=O)=O)[C@H](O)C)C1=CC=CC=C1 NHXLMOGPVYXJNR-ATOGVRKGSA-N 0.000 description 2
- 230000004936 stimulating effect Effects 0.000 description 2
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 2
- 201000000596 systemic lupus erythematosus Diseases 0.000 description 2
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 2
- OGBMKVWORPGQRR-UMXFMPSGSA-N teriparatide Chemical compound C([C@H](NC(=O)[C@H](CCSC)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)[C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CNC=N1 OGBMKVWORPGQRR-UMXFMPSGSA-N 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 229930101283 tetracycline Natural products 0.000 description 2
- 125000003396 thiol group Chemical group [H]S* 0.000 description 2
- LCJVIYPJPCBWKS-NXPQJCNCSA-N thymosin Chemical compound SC[C@@H](N)C(=O)N[C@H](CO)C(=O)N[C@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@H](C(C)C)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](C(C)C)C(=O)N[C@H](CO)C(=O)N[C@H](CO)C(=O)N[C@H](CCC(O)=O)C(=O)N[C@H]([C@@H](C)CC)C(=O)N[C@H]([C@H](C)O)C(=O)N[C@H](C(C)C)C(=O)N[C@H](CCCCN)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N[C@H](CCC(O)=O)C(=O)N[C@H](CCCCN)C(=O)N[C@H](CCCCN)C(=O)N[C@H](CCC(O)=O)C(=O)N[C@H](C(C)C)C(=O)N[C@H](C(C)C)C(=O)N[C@H](CCC(O)=O)C(=O)N[C@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@H](CCC(O)=O)C(O)=O LCJVIYPJPCBWKS-NXPQJCNCSA-N 0.000 description 2
- 229940034199 thyrotropin-releasing hormone Drugs 0.000 description 2
- 210000001519 tissue Anatomy 0.000 description 2
- 238000004448 titration Methods 0.000 description 2
- 231100000419 toxicity Toxicity 0.000 description 2
- 230000001988 toxicity Effects 0.000 description 2
- FGMPLJWBKKVCDB-UHFFFAOYSA-N trans-L-hydroxy-proline Natural products ON1CCCC1C(O)=O FGMPLJWBKKVCDB-UHFFFAOYSA-N 0.000 description 2
- 230000002103 transcriptional effect Effects 0.000 description 2
- 238000013519 translation Methods 0.000 description 2
- 230000005945 translocation Effects 0.000 description 2
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 2
- 210000004881 tumor cell Anatomy 0.000 description 2
- 238000002255 vaccination Methods 0.000 description 2
- 229960003726 vasopressin Drugs 0.000 description 2
- 229960004449 vismodegib Drugs 0.000 description 2
- BPQMGSKTAYIVFO-UHFFFAOYSA-N vismodegib Chemical compound ClC1=CC(S(=O)(=O)C)=CC=C1C(=O)NC1=CC=C(Cl)C(C=2N=CC=CC=2)=C1 BPQMGSKTAYIVFO-UHFFFAOYSA-N 0.000 description 2
- 108010047303 von Willebrand Factor Proteins 0.000 description 2
- WFPIAZLQTJBIFN-DVZOWYKESA-N zuclopenthixol Chemical compound C1CN(CCO)CCN1CC\C=C\1C2=CC(Cl)=CC=C2SC2=CC=CC=C2/1 WFPIAZLQTJBIFN-DVZOWYKESA-N 0.000 description 2
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 2
- WWYNJERNGUHSAO-XUDSTZEESA-N (+)-Norgestrel Chemical compound O=C1CC[C@@H]2[C@H]3CC[C@](CC)([C@](CC4)(O)C#C)[C@@H]4[C@@H]3CCC2=C1 WWYNJERNGUHSAO-XUDSTZEESA-N 0.000 description 1
- DNXHEGUUPJUMQT-UHFFFAOYSA-N (+)-estrone Natural products OC1=CC=C2C3CCC(C)(C(CC4)=O)C4C3CCC2=C1 DNXHEGUUPJUMQT-UHFFFAOYSA-N 0.000 description 1
- FCCNKYGSMOSYPV-DEDISHTHSA-N (-)-Epothilone E Natural products O=C1[C@H](C)[C@H](O)[C@@H](C)CCC[C@H]2O[C@H]2C[C@@H](/C(=C\c2nc(CO)sc2)/C)OC(=O)C[C@H](O)C1(C)C FCCNKYGSMOSYPV-DEDISHTHSA-N 0.000 description 1
- UKIMCRYGLFQEOE-RLHMMOOASA-N (-)-Epothilone F Natural products O=C1[C@H](C)[C@H](O)[C@@H](C)CCC[C@@]2(C)O[C@H]2C[C@@H](/C(=C\c2nc(CO)sc2)/C)OC(=O)C[C@H](O)C1(C)C UKIMCRYGLFQEOE-RLHMMOOASA-N 0.000 description 1
- AYIRNRDRBQJXIF-NXEZZACHSA-N (-)-Florfenicol Chemical compound CS(=O)(=O)C1=CC=C([C@@H](O)[C@@H](CF)NC(=O)C(Cl)Cl)C=C1 AYIRNRDRBQJXIF-NXEZZACHSA-N 0.000 description 1
- NGGMYCMLYOUNGM-UHFFFAOYSA-N (-)-fumagillin Natural products O1C(CC=C(C)C)C1(C)C1C(OC)C(OC(=O)C=CC=CC=CC=CC(O)=O)CCC21CO2 NGGMYCMLYOUNGM-UHFFFAOYSA-N 0.000 description 1
- PROQIPRRNZUXQM-UHFFFAOYSA-N (16alpha,17betaOH)-Estra-1,3,5(10)-triene-3,16,17-triol Natural products OC1=CC=C2C3CCC(C)(C(C(O)C4)O)C4C3CCC2=C1 PROQIPRRNZUXQM-UHFFFAOYSA-N 0.000 description 1
- HZSBSRAVNBUZRA-RQDPQJJXSA-J (1r,2r)-cyclohexane-1,2-diamine;tetrachloroplatinum(2+) Chemical compound Cl[Pt+2](Cl)(Cl)Cl.N[C@@H]1CCCC[C@H]1N HZSBSRAVNBUZRA-RQDPQJJXSA-J 0.000 description 1
- JKHVDAUOODACDU-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(2,5-dioxopyrrol-1-yl)propanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCN1C(=O)C=CC1=O JKHVDAUOODACDU-UHFFFAOYSA-N 0.000 description 1
- WCWUXEGQKLTGDX-LLVKDONJSA-N (2R)-1-[[4-[(4-fluoro-2-methyl-1H-indol-5-yl)oxy]-5-methyl-6-pyrrolo[2,1-f][1,2,4]triazinyl]oxy]-2-propanol Chemical compound C1=C2NC(C)=CC2=C(F)C(OC2=NC=NN3C=C(C(=C32)C)OC[C@H](O)C)=C1 WCWUXEGQKLTGDX-LLVKDONJSA-N 0.000 description 1
- SBKVPJHMSUXZTA-MEJXFZFPSA-N (2S)-2-[[(2S)-2-[[(2S)-1-[(2S)-5-amino-2-[[2-[[(2S)-1-[(2S)-6-amino-2-[[(2S)-2-[[(2S)-5-amino-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-amino-3-(1H-indol-3-yl)propanoyl]amino]-3-(1H-imidazol-4-yl)propanoyl]amino]-3-(1H-indol-3-yl)propanoyl]amino]-4-methylpentanoyl]amino]-5-oxopentanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]pyrrolidine-2-carbonyl]amino]acetyl]amino]-5-oxopentanoyl]pyrrolidine-2-carbonyl]amino]-4-methylsulfanylbutanoyl]amino]-3-(4-hydroxyphenyl)propanoic acid Chemical compound C([C@@H](C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CNC=N1 SBKVPJHMSUXZTA-MEJXFZFPSA-N 0.000 description 1
- KIUKXJAPPMFGSW-DNGZLQJQSA-N (2S,3S,4S,5R,6R)-6-[(2S,3R,4R,5S,6R)-3-Acetamido-2-[(2S,3S,4R,5R,6R)-6-[(2R,3R,4R,5S,6R)-3-acetamido-2,5-dihydroxy-6-(hydroxymethyl)oxan-4-yl]oxy-2-carboxy-4,5-dihydroxyoxan-3-yl]oxy-5-hydroxy-6-(hydroxymethyl)oxan-4-yl]oxy-3,4,5-trihydroxyoxane-2-carboxylic acid Chemical compound CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O[C@H]1[C@H](O)[C@@H](O)[C@H](O[C@H]2[C@@H]([C@@H](O[C@H]3[C@@H]([C@@H](O)[C@H](O)[C@H](O3)C(O)=O)O)[C@H](O)[C@@H](CO)O2)NC(C)=O)[C@@H](C(O)=O)O1 KIUKXJAPPMFGSW-DNGZLQJQSA-N 0.000 description 1
- NOENHWMKHNSHGX-IZOOSHNJSA-N (2s)-1-[(2s)-2-[[(2s)-2-[[(2r)-2-[[(2r)-2-[[(2s)-2-[[(2r)-2-[[(2s)-2-[[(2r)-2-acetamido-3-naphthalen-2-ylpropanoyl]amino]-3-(4-chlorophenyl)propanoyl]amino]-3-pyridin-3-ylpropanoyl]amino]-3-hydroxypropanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-6-(ca Chemical compound C([C@H](C(=O)N[C@H](CCCCNC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCNC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@H](C)C(N)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](CC=1C=NC=CC=1)NC(=O)[C@H](CC=1C=CC(Cl)=CC=1)NC(=O)[C@@H](CC=1C=C2C=CC=CC2=CC=1)NC(C)=O)C1=CC=C(O)C=C1 NOENHWMKHNSHGX-IZOOSHNJSA-N 0.000 description 1
- ZDRRIRUAESZNIH-BZGUUIOASA-N (2s)-1-[(4r,7s,10s,13s,16s,19r)-19-amino-7-(2-amino-2-oxoethyl)-13-[(2s)-butan-2-yl]-10-[(1r)-1-hydroxyethyl]-16-[(4-hydroxyphenyl)methyl]-6,9,12,15,18-pentaoxo-1,2-dithia-5,8,11,14,17-pentazacycloicosane-4-carbonyl]-n-[(2s)-1-[(2-amino-2-oxoethyl)amino]- Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@H](C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CSSC[C@H](N)C(=O)N1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(N)=O)[C@@H](C)O)=O)[C@@H](C)CC)C1=CC=C(O)C=C1 ZDRRIRUAESZNIH-BZGUUIOASA-N 0.000 description 1
- NMDDZEVVQDPECF-LURJTMIESA-N (2s)-2,7-diaminoheptanoic acid Chemical compound NCCCCC[C@H](N)C(O)=O NMDDZEVVQDPECF-LURJTMIESA-N 0.000 description 1
- LGNCNVVZCUVPOT-FUVGGWJZSA-N (2s)-2-[[(2r,3r)-3-[(2s)-1-[(3r,4s,5s)-4-[[(2s)-2-[[(2s)-2-(dimethylamino)-3-methylbutanoyl]amino]-3-methylbutanoyl]-methylamino]-3-methoxy-5-methylheptanoyl]pyrrolidin-2-yl]-3-methoxy-2-methylpropanoyl]amino]-3-phenylpropanoic acid Chemical compound CC(C)[C@H](N(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 LGNCNVVZCUVPOT-FUVGGWJZSA-N 0.000 description 1
- XQIXDDUJIUUELO-JZOOTMHBSA-N (2s)-2-[[(2s,3s)-2-[[2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s,3s)-2-[[(2s,3s)-2-amino-3-methylpentanoyl]amino]-3-methylpentanoyl]amino]-3-hydroxypropanoyl]amino]propanoyl]amino]-3-methylbutanoyl]amino]-3-methylbutanoyl]amino]acetyl]amino]-3-methylpenta Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O XQIXDDUJIUUELO-JZOOTMHBSA-N 0.000 description 1
- YLOCGHYTXIINAI-XKUOMLDTSA-N (2s)-2-amino-3-(4-hydroxyphenyl)propanoic acid;(2s)-2-aminopentanedioic acid;(2s)-2-aminopropanoic acid;(2s)-2,6-diaminohexanoic acid Chemical compound C[C@H](N)C(O)=O.NCCCC[C@H](N)C(O)=O.OC(=O)[C@@H](N)CCC(O)=O.OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 YLOCGHYTXIINAI-XKUOMLDTSA-N 0.000 description 1
- PNFORBBPPMQASU-JTQLQIEISA-N (2s)-2-amino-6-[[4-(2-methoxyethoxy)-4-oxobutanoyl]amino]hexanoic acid Chemical compound COCCOC(=O)CCC(=O)NCCCC[C@H](N)C(O)=O PNFORBBPPMQASU-JTQLQIEISA-N 0.000 description 1
- DLKUYSQUHXBYPB-NSSHGSRYSA-N (2s,4r)-4-[[2-[(1r,3r)-1-acetyloxy-4-methyl-3-[3-methylbutanoyloxymethyl-[(2s,3s)-3-methyl-2-[[(2r)-1-methylpiperidine-2-carbonyl]amino]pentanoyl]amino]pentyl]-1,3-thiazole-4-carbonyl]amino]-2-methyl-5-(4-methylphenyl)pentanoic acid Chemical class N([C@@H]([C@@H](C)CC)C(=O)N(COC(=O)CC(C)C)[C@H](C[C@@H](OC(C)=O)C=1SC=C(N=1)C(=O)N[C@H](C[C@H](C)C(O)=O)CC=1C=CC(C)=CC=1)C(C)C)C(=O)[C@H]1CCCCN1C DLKUYSQUHXBYPB-NSSHGSRYSA-N 0.000 description 1
- YQINXCSNGCDFCQ-CMOCDZPBSA-N (3s,4s,12s,13s)-3,4,12,13-tetrahydronaphtho[1,2-b]phenanthrene-3,4,12,13-tetrol Chemical compound C1([C@H](O)[C@H]2O)=CC=CC=C1C1=C2C=C2C(C=C[C@@H]([C@H]3O)O)=C3C=CC2=C1 YQINXCSNGCDFCQ-CMOCDZPBSA-N 0.000 description 1
- WSEVKKHALHSUMB-RYVRVIGHSA-N (4S)-4-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2R)-5-amino-2-[[(2S)-6-amino-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-amino-3-carboxypropanoyl]amino]-4-methylpentanoyl]amino]-3-hydroxypropanoyl]amino]hexanoyl]amino]-5-oxopentanoyl]amino]-4-methylsulfanylbutanoyl]amino]-4-carboxybutanoyl]amino]-4-carboxybutanoyl]amino]-5-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S,3S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-4-amino-1-[[2-[[2-[(2S)-2-[[(2S)-1-[[(2S)-1-[[2-[[(2S)-1-[(2S)-2-[(2S)-2-[(2S)-2-[[(2S)-1-amino-3-hydroxy-1-oxopropan-2-yl]carbamoyl]pyrrolidine-1-carbonyl]pyrrolidine-1-carbonyl]pyrrolidin-1-yl]-1-oxopropan-2-yl]amino]-2-oxoethyl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]carbamoyl]pyrrolidin-1-yl]-2-oxoethyl]amino]-2-oxoethyl]amino]-1,4-dioxobutan-2-yl]amino]-1-oxohexan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-3-(1H-indol-3-yl)-1-oxopropan-2-yl]amino]-4-carboxy-1-oxobutan-2-yl]amino]-3-methyl-1-oxopentan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-1-oxopropan-2-yl]amino]-5-oxopentanoic acid Chemical compound CC[C@H](C)[C@H](NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](CCC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O)C(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(=O)NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(N)=O WSEVKKHALHSUMB-RYVRVIGHSA-N 0.000 description 1
- SNAJPQVDGYDQSW-DYCFWDQMSA-N (4r,7s,10r,13s,16r)-7-(4-aminobutyl)-n-[(2s,3r)-1-amino-3-hydroxy-1-oxobutan-2-yl]-16-[[(2r)-2-amino-3-phenylpropanoyl]amino]-13-[(4-hydroxyphenyl)methyl]-10-(1h-indol-3-ylmethyl)-6,9,12,15-tetraoxo-1,2-dithia-5,8,11,14-tetrazacycloheptadecane-4-carboxami Chemical compound C([C@@H](N)C(=O)N[C@H]1CSSC[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](CC=2C3=CC=CC=C3NC=2)NC(=O)[C@H](CC=2C=CC(O)=CC=2)NC1=O)C(=O)N[C@@H]([C@H](O)C)C(N)=O)C1=CC=CC=C1 SNAJPQVDGYDQSW-DYCFWDQMSA-N 0.000 description 1
- DEQANNDTNATYII-OULOTJBUSA-N (4r,7s,10s,13r,16s,19r)-10-(4-aminobutyl)-19-[[(2r)-2-amino-3-phenylpropanoyl]amino]-16-benzyl-n-[(2r,3r)-1,3-dihydroxybutan-2-yl]-7-[(1r)-1-hydroxyethyl]-13-(1h-indol-3-ylmethyl)-6,9,12,15,18-pentaoxo-1,2-dithia-5,8,11,14,17-pentazacycloicosane-4-carboxa Chemical compound C([C@@H](N)C(=O)N[C@H]1CSSC[C@H](NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](CC=2C3=CC=CC=C3NC=2)NC(=O)[C@H](CC=2C=CC=CC=2)NC1=O)C(=O)N[C@H](CO)[C@H](O)C)C1=CC=CC=C1 DEQANNDTNATYII-OULOTJBUSA-N 0.000 description 1
- PUDHBTGHUJUUFI-SCTWWAJVSA-N (4r,7s,10s,13r,16s,19r)-10-(4-aminobutyl)-n-[(2s,3r)-1-amino-3-hydroxy-1-oxobutan-2-yl]-19-[[(2r)-2-amino-3-naphthalen-2-ylpropanoyl]amino]-16-[(4-hydroxyphenyl)methyl]-13-(1h-indol-3-ylmethyl)-6,9,12,15,18-pentaoxo-7-propan-2-yl-1,2-dithia-5,8,11,14,17-p Chemical compound C([C@H]1C(=O)N[C@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(N[C@@H](CSSC[C@@H](C(=O)N1)NC(=O)[C@H](N)CC=1C=C2C=CC=CC2=CC=1)C(=O)N[C@@H]([C@@H](C)O)C(N)=O)=O)C(C)C)C1=CC=C(O)C=C1 PUDHBTGHUJUUFI-SCTWWAJVSA-N 0.000 description 1
- GMVPRGQOIOIIMI-UHFFFAOYSA-N (8R,11R,12R,13E,15S)-11,15-Dihydroxy-9-oxo-13-prostenoic acid Natural products CCCCCC(O)C=CC1C(O)CC(=O)C1CCCCCCC(O)=O GMVPRGQOIOIIMI-UHFFFAOYSA-N 0.000 description 1
- BGRJTUBHPOOWDU-NSHDSACASA-N (S)-(-)-sulpiride Chemical compound CCN1CCC[C@H]1CNC(=O)C1=CC(S(N)(=O)=O)=CC=C1OC BGRJTUBHPOOWDU-NSHDSACASA-N 0.000 description 1
- WSPOMRSOLSGNFJ-AUWJEWJLSA-N (Z)-chlorprothixene Chemical compound C1=C(Cl)C=C2C(=C/CCN(C)C)\C3=CC=CC=C3SC2=C1 WSPOMRSOLSGNFJ-AUWJEWJLSA-N 0.000 description 1
- BWDQBBCUWLSASG-MDZDMXLPSA-N (e)-n-hydroxy-3-[4-[[2-hydroxyethyl-[2-(1h-indol-3-yl)ethyl]amino]methyl]phenyl]prop-2-enamide Chemical compound C=1NC2=CC=CC=C2C=1CCN(CCO)CC1=CC=C(\C=C\C(=O)NO)C=C1 BWDQBBCUWLSASG-MDZDMXLPSA-N 0.000 description 1
- IJUQCWMZCMFFJP-GQSLRNSLSA-N 1-[(2R,4S,5R)-4-[[(2R,3S,5R)-3-[[(2R,3S,5R)-3-[[(2R,3S,5R)-5-(4-amino-5-methyl-2-oxopyrimidin-1-yl)-3-[[(2R,3S,5R)-5-(4-amino-5-methyl-2-oxopyrimidin-1-yl)-3-[[(2R,3S,5R)-3-[[(2R,3S,5R)-3-[[(2R,3S,5R)-5-(4-amino-5-methyl-2-oxopyrimidin-1-yl)-3-[[(2R,3R,4R,5R)-3-[[(2R,3R,4R,5R)-3-[[(2R,3R,4R,5R)-3-[[(2R,3R,4R,5R)-5-(6-aminopurin-9-yl)-3-[hydroxy-[[(2R,3R,4R,5R)-3-hydroxy-4-(2-methoxyethoxy)-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy]phosphinothioyl]oxy-4-(2-methoxyethoxy)oxolan-2-yl]methoxy-hydroxyphosphinothioyl]oxy-4-(2-methoxyethoxy)-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphinothioyl]oxy-4-(2-methoxyethoxy)-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphinothioyl]oxy-4-(2-methoxyethoxy)-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphinothioyl]oxyoxolan-2-yl]methoxy-hydroxyphosphinothioyl]oxy-5-(2-amino-6-oxo-1H-purin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphinothioyl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphinothioyl]oxyoxolan-2-yl]methoxy-hydroxyphosphinothioyl]oxyoxolan-2-yl]methoxy-hydroxyphosphinothioyl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphinothioyl]oxy-5-(2-amino-6-oxo-1H-purin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphinothioyl]oxy-5-[[[(2R,3S,5R)-2-[[[(2R,3S,5R)-5-(4-amino-5-methyl-2-oxopyrimidin-1-yl)-2-[[[(2R,3R,4R,5R)-2-[[[(2R,3R,4R,5R)-2-[[[(2R,3R,4R,5R)-5-(4-amino-5-methyl-2-oxopyrimidin-1-yl)-2-[[[(2R,3R,4R,5R)-5-(2-amino-6-oxo-1H-purin-9-yl)-2-[[[(2R,3R,4R,5R)-5-(6-aminopurin-9-yl)-2-(hydroxymethyl)-4-(2-methoxyethoxy)oxolan-3-yl]oxy-hydroxyphosphinothioyl]oxymethyl]-4-(2-methoxyethoxy)oxolan-3-yl]oxy-sulfanylphosphoryl]oxymethyl]-4-(2-methoxyethoxy)oxolan-3-yl]oxy-hydroxyphosphinothioyl]oxymethyl]-4-(2-methoxyethoxy)-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-3-yl]oxy-hydroxyphosphinothioyl]oxymethyl]-4-(2-methoxyethoxy)-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-3-yl]oxy-hydroxyphosphinothioyl]oxymethyl]oxolan-3-yl]oxy-hydroxyphosphinothioyl]oxymethyl]-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-3-yl]oxy-hydroxyphosphinothioyl]oxymethyl]oxolan-2-yl]-5-methylpyrimidine-2,4-dione Chemical compound COCCO[C@@H]1[C@H](O)[C@@H](COP(O)(=S)O[C@@H]2[C@@H](COP(O)(=S)O[C@@H]3[C@@H](COP(O)(=S)O[C@@H]4[C@@H](COP(O)(=S)O[C@@H]5[C@@H](COP(O)(=S)O[C@H]6C[C@@H](O[C@@H]6COP(O)(=S)O[C@H]6C[C@@H](O[C@@H]6COP(O)(=S)O[C@H]6C[C@@H](O[C@@H]6COP(O)(=S)O[C@H]6C[C@@H](O[C@@H]6COP(O)(=S)O[C@H]6C[C@@H](O[C@@H]6COP(O)(=S)O[C@H]6C[C@@H](O[C@@H]6COP(O)(=S)O[C@H]6C[C@@H](O[C@@H]6COP(O)(=S)O[C@H]6C[C@@H](O[C@@H]6COP(O)(=S)O[C@H]6C[C@@H](O[C@@H]6COP(O)(=S)O[C@H]6C[C@@H](O[C@@H]6COP(O)(=S)O[C@@H]6[C@@H](COP(O)(=S)O[C@@H]7[C@@H](COP(O)(=S)O[C@@H]8[C@@H](COP(S)(=O)O[C@@H]9[C@@H](COP(O)(=S)O[C@@H]%10[C@@H](CO)O[C@H]([C@@H]%10OCCOC)n%10cnc%11c(N)ncnc%10%11)O[C@H]([C@@H]9OCCOC)n9cnc%10c9nc(N)[nH]c%10=O)O[C@H]([C@@H]8OCCOC)n8cc(C)c(N)nc8=O)O[C@H]([C@@H]7OCCOC)n7cc(C)c(=O)[nH]c7=O)O[C@H]([C@@H]6OCCOC)n6cc(C)c(=O)[nH]c6=O)n6cc(C)c(N)nc6=O)n6cc(C)c(=O)[nH]c6=O)n6cc(C)c(=O)[nH]c6=O)n6cnc7c6nc(N)[nH]c7=O)n6cc(C)c(=O)[nH]c6=O)n6cc(C)c(N)nc6=O)n6cc(C)c(N)nc6=O)n6cnc7c(N)ncnc67)n6cnc7c6nc(N)[nH]c7=O)n6cc(C)c(N)nc6=O)O[C@H]([C@@H]5OCCOC)n5cc(C)c(=O)[nH]c5=O)O[C@H]([C@@H]4OCCOC)n4cc(C)c(=O)[nH]c4=O)O[C@H]([C@@H]3OCCOC)n3cc(C)c(=O)[nH]c3=O)O[C@H]([C@@H]2OCCOC)n2cnc3c(N)ncnc23)O[C@H]1n1cc(C)c(=O)[nH]c1=O IJUQCWMZCMFFJP-GQSLRNSLSA-N 0.000 description 1
- SPMVMDHWKHCIDT-UHFFFAOYSA-N 1-[2-chloro-4-[(6,7-dimethoxy-4-quinolinyl)oxy]phenyl]-3-(5-methyl-3-isoxazolyl)urea Chemical compound C=12C=C(OC)C(OC)=CC2=NC=CC=1OC(C=C1Cl)=CC=C1NC(=O)NC=1C=C(C)ON=1 SPMVMDHWKHCIDT-UHFFFAOYSA-N 0.000 description 1
- KKVYYGGCHJGEFJ-UHFFFAOYSA-N 1-n-(4-chlorophenyl)-6-methyl-5-n-[3-(7h-purin-6-yl)pyridin-2-yl]isoquinoline-1,5-diamine Chemical compound N=1C=CC2=C(NC=3C(=CC=CN=3)C=3C=4N=CNC=4N=CN=3)C(C)=CC=C2C=1NC1=CC=C(Cl)C=C1 KKVYYGGCHJGEFJ-UHFFFAOYSA-N 0.000 description 1
- FUFLCEKSBBHCMO-UHFFFAOYSA-N 11-dehydrocorticosterone Natural products O=C1CCC2(C)C3C(=O)CC(C)(C(CC4)C(=O)CO)C4C3CCC2=C1 FUFLCEKSBBHCMO-UHFFFAOYSA-N 0.000 description 1
- FPIPGXGPPPQFEQ-UHFFFAOYSA-N 13-cis retinol Natural products OCC=C(C)C=CC=C(C)C=CC1=C(C)CCCC1(C)C FPIPGXGPPPQFEQ-UHFFFAOYSA-N 0.000 description 1
- CTLOSZHDGZLOQE-UHFFFAOYSA-N 14-methoxy-9-[(4-methylpiperazin-1-yl)methyl]-9,19-diazapentacyclo[10.7.0.02,6.07,11.013,18]nonadeca-1(12),2(6),7(11),13(18),14,16-hexaene-8,10-dione Chemical compound O=C1C2=C3C=4C(OC)=CC=CC=4NC3=C3CCCC3=C2C(=O)N1CN1CCN(C)CC1 CTLOSZHDGZLOQE-UHFFFAOYSA-N 0.000 description 1
- ABEXEQSGABRUHS-UHFFFAOYSA-N 16-methylheptadecyl 16-methylheptadecanoate Chemical compound CC(C)CCCCCCCCCCCCCCCOC(=O)CCCCCCCCCCCCCCC(C)C ABEXEQSGABRUHS-UHFFFAOYSA-N 0.000 description 1
- GCKMFJBGXUYNAG-UHFFFAOYSA-N 17alpha-methyltestosterone Natural products C1CC2=CC(=O)CCC2(C)C2C1C1CCC(C)(O)C1(C)CC2 GCKMFJBGXUYNAG-UHFFFAOYSA-N 0.000 description 1
- NVUUMOOKVFONOM-GPBSYSOESA-N 19-Norprogesterone Chemical compound C1CC2=CC(=O)CC[C@@H]2[C@@H]2[C@@H]1[C@@H]1CC[C@H](C(=O)C)[C@@]1(C)CC2 NVUUMOOKVFONOM-GPBSYSOESA-N 0.000 description 1
- RWEVIPRMPFNTLO-UHFFFAOYSA-N 2-(2-fluoro-4-iodoanilino)-N-(2-hydroxyethoxy)-1,5-dimethyl-6-oxo-3-pyridinecarboxamide Chemical compound CN1C(=O)C(C)=CC(C(=O)NOCCO)=C1NC1=CC=C(I)C=C1F RWEVIPRMPFNTLO-UHFFFAOYSA-N 0.000 description 1
- BOHCOUQZNDPURZ-ICNZIKDASA-N 2-[(1R,4S,8R,10S,13S,16S,27R,34S)-34-[(2S)-butan-2-yl]-13-[(2R,3R)-3,4-dihydroxybutan-2-yl]-8-hydroxy-2,5,11,14,27,30,33,36,39-nonaoxo-27lambda4-thia-3,6,12,15,25,29,32,35,38-nonazapentacyclo[14.12.11.06,10.018,26.019,24]nonatriaconta-18(26),19,21,23-tetraen-4-yl]acetamide Chemical compound CC[C@H](C)[C@@H]1NC(=O)CNC(=O)[C@@H]2Cc3c([nH]c4ccccc34)[S@](=O)C[C@H](NC(=O)CNC1=O)C(=O)N[C@@H](CC(N)=O)C(=O)N1C[C@H](O)C[C@H]1C(=O)N[C@@H]([C@@H](C)[C@@H](O)CO)C(=O)N2 BOHCOUQZNDPURZ-ICNZIKDASA-N 0.000 description 1
- ACTOXUHEUCPTEW-BWHGAVFKSA-N 2-[(4r,5s,6s,7r,9r,10r,11e,13e,16r)-6-[(2s,3r,4r,5s,6r)-5-[(2s,4r,5s,6s)-4,5-dihydroxy-4,6-dimethyloxan-2-yl]oxy-4-(dimethylamino)-3-hydroxy-6-methyloxan-2-yl]oxy-10-[(2s,5s,6r)-5-(dimethylamino)-6-methyloxan-2-yl]oxy-4-hydroxy-5-methoxy-9,16-dimethyl-2-o Chemical compound O([C@H]1/C=C/C=C/C[C@@H](C)OC(=O)C[C@@H](O)[C@@H]([C@H]([C@@H](CC=O)C[C@H]1C)O[C@H]1[C@@H]([C@H]([C@H](O[C@@H]2O[C@@H](C)[C@H](O)[C@](C)(O)C2)[C@@H](C)O1)N(C)C)O)OC)[C@@H]1CC[C@H](N(C)C)[C@@H](C)O1 ACTOXUHEUCPTEW-BWHGAVFKSA-N 0.000 description 1
- AHIVQGOUBLVTCB-AWEZNQCLSA-N 2-[2-fluoro-4-[(2s)-pyrrolidin-2-yl]phenyl]-1h-benzimidazole-4-carboxamide Chemical compound N=1C=2C(C(=O)N)=CC=CC=2NC=1C(C(=C1)F)=CC=C1[C@@H]1CCCN1 AHIVQGOUBLVTCB-AWEZNQCLSA-N 0.000 description 1
- KISWVXRQTGLFGD-UHFFFAOYSA-N 2-[[2-[[6-amino-2-[[2-[[2-[[5-amino-2-[[2-[[1-[2-[[6-amino-2-[(2,5-diamino-5-oxopentanoyl)amino]hexanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]pyrrolidine-2-carbonyl]amino]-3-hydroxypropanoyl]amino]-5-oxopentanoyl]amino]-5-(diaminomethylideneamino)p Chemical group C1CCN(C(=O)C(CCCN=C(N)N)NC(=O)C(CCCCN)NC(=O)C(N)CCC(N)=O)C1C(=O)NC(CO)C(=O)NC(CCC(N)=O)C(=O)NC(CCCN=C(N)N)C(=O)NC(CO)C(=O)NC(CCCCN)C(=O)NC(C(=O)NC(CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 KISWVXRQTGLFGD-UHFFFAOYSA-N 0.000 description 1
- ASJSAQIRZKANQN-CRCLSJGQSA-N 2-deoxy-D-ribose Chemical compound OC[C@@H](O)[C@@H](O)CC=O ASJSAQIRZKANQN-CRCLSJGQSA-N 0.000 description 1
- NDMPLJNOPCLANR-UHFFFAOYSA-N 3,4-dihydroxy-15-(4-hydroxy-18-methoxycarbonyl-5,18-seco-ibogamin-18-yl)-16-methoxy-1-methyl-6,7-didehydro-aspidospermidine-3-carboxylic acid methyl ester Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 NDMPLJNOPCLANR-UHFFFAOYSA-N 0.000 description 1
- IAYGCINLNONXHY-LBPRGKRZSA-N 3-(carbamoylamino)-5-(3-fluorophenyl)-N-[(3S)-3-piperidinyl]-2-thiophenecarboxamide Chemical compound NC(=O)NC=1C=C(C=2C=C(F)C=CC=2)SC=1C(=O)N[C@H]1CCCNC1 IAYGCINLNONXHY-LBPRGKRZSA-N 0.000 description 1
- JXPWLIYXIWGWSA-CLBRJLNISA-N 3-[(3s,6s,9s,12s,15s,18s,21s,24s)-6,15-bis(3-amino-3-oxopropyl)-12-[3-(diaminomethylideneamino)propyl]-3-(hydroxymethyl)-18-(1h-imidazol-5-ylmethyl)-2,5,8,11,14,17,20,23-octaoxo-9-propan-2-yl-1,4,7,10,13,16,19,22-octazabicyclo[22.3.0]heptacosan-21-yl]prop Chemical compound C([C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@H](C(N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N2CCC[C@H]2C(=O)N[C@@H](CCC(O)=O)C(=O)N1)=O)C(C)C)C1=CN=CN1 JXPWLIYXIWGWSA-CLBRJLNISA-N 0.000 description 1
- MAUCONCHVWBMHK-UHFFFAOYSA-N 3-[(dimethylamino)methyl]-N-[2-[4-[(hydroxyamino)-oxomethyl]phenoxy]ethyl]-2-benzofurancarboxamide Chemical compound O1C2=CC=CC=C2C(CN(C)C)=C1C(=O)NCCOC1=CC=C(C(=O)NO)C=C1 MAUCONCHVWBMHK-UHFFFAOYSA-N 0.000 description 1
- FEBOTPHFXYHVPL-UHFFFAOYSA-N 3-[1-[4-(4-fluorophenyl)-4-oxobutyl]-4-piperidinyl]-1H-benzimidazol-2-one Chemical compound C1=CC(F)=CC=C1C(=O)CCCN1CCC(N2C(NC3=CC=CC=C32)=O)CC1 FEBOTPHFXYHVPL-UHFFFAOYSA-N 0.000 description 1
- GSCPDZHWVNUUFI-UHFFFAOYSA-N 3-aminobenzamide Chemical compound NC(=O)C1=CC=CC(N)=C1 GSCPDZHWVNUUFI-UHFFFAOYSA-N 0.000 description 1
- VOUAQYXWVJDEQY-QENPJCQMSA-N 33017-11-7 Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)NCC(=O)NCC(=O)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](C)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N1[C@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)CCC1 VOUAQYXWVJDEQY-QENPJCQMSA-N 0.000 description 1
- DPEUWKZJZIPZKE-OFANTOPUSA-N 330936-69-1 Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O)[C@@H](C)O)NC(=O)CNC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](C)NC(=O)[C@@H](N)CCSC)C1=CC=CC=C1 DPEUWKZJZIPZKE-OFANTOPUSA-N 0.000 description 1
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 description 1
- JHSXDAWGLCZYSM-UHFFFAOYSA-N 4-(4-chloro-2-methylphenoxy)-N-hydroxybutanamide Chemical compound CC1=CC(Cl)=CC=C1OCCCC(=O)NO JHSXDAWGLCZYSM-UHFFFAOYSA-N 0.000 description 1
- HHFBDROWDBDFBR-UHFFFAOYSA-N 4-[[9-chloro-7-(2,6-difluorophenyl)-5H-pyrimido[5,4-d][2]benzazepin-2-yl]amino]benzoic acid Chemical compound C1=CC(C(=O)O)=CC=C1NC1=NC=C(CN=C(C=2C3=CC=C(Cl)C=2)C=2C(=CC=CC=2F)F)C3=N1 HHFBDROWDBDFBR-UHFFFAOYSA-N 0.000 description 1
- 108010068327 4-hydroxyphenylpyruvate dioxygenase Proteins 0.000 description 1
- MDOJTZQKHMAPBK-UHFFFAOYSA-N 4-iodo-3-nitrobenzamide Chemical compound NC(=O)C1=CC=C(I)C([N+]([O-])=O)=C1 MDOJTZQKHMAPBK-UHFFFAOYSA-N 0.000 description 1
- UAHFGYDRQSXQEB-PWPYQVNISA-N 4-nle-α-msh Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(N)=O)NC(=O)[C@H](CO)NC(C)=O)C1=CC=C(O)C=C1 UAHFGYDRQSXQEB-PWPYQVNISA-N 0.000 description 1
- 101710169336 5'-deoxyadenosine deaminase Proteins 0.000 description 1
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 1
- PLIVFNIUGLLCEK-UHFFFAOYSA-N 7-[4-(3-ethynylanilino)-7-methoxyquinazolin-6-yl]oxy-n-hydroxyheptanamide Chemical compound C=12C=C(OCCCCCCC(=O)NO)C(OC)=CC2=NC=NC=1NC1=CC=CC(C#C)=C1 PLIVFNIUGLLCEK-UHFFFAOYSA-N 0.000 description 1
- ZCYVEMRRCGMTRW-UHFFFAOYSA-N 7553-56-2 Chemical compound [I] ZCYVEMRRCGMTRW-UHFFFAOYSA-N 0.000 description 1
- QOYHHIBFXOOADH-UHFFFAOYSA-N 8-[4,4-bis(4-fluorophenyl)butyl]-1-phenyl-1,3,8-triazaspiro[4.5]decan-4-one Chemical compound C1=CC(F)=CC=C1C(C=1C=CC(F)=CC=1)CCCN1CCC2(C(NCN2C=2C=CC=CC=2)=O)CC1 QOYHHIBFXOOADH-UHFFFAOYSA-N 0.000 description 1
- ZGXJTSGNIOSYLO-UHFFFAOYSA-N 88755TAZ87 Chemical compound NCC(=O)CCC(O)=O ZGXJTSGNIOSYLO-UHFFFAOYSA-N 0.000 description 1
- 208000030507 AIDS Diseases 0.000 description 1
- 239000012827 ATM inhibitor Substances 0.000 description 1
- GBJVVSCPOBPEIT-UHFFFAOYSA-N AZT-1152 Chemical compound N=1C=NC2=CC(OCCCN(CC)CCOP(O)(O)=O)=CC=C2C=1NC(=NN1)C=C1CC(=O)NC1=CC=CC(F)=C1 GBJVVSCPOBPEIT-UHFFFAOYSA-N 0.000 description 1
- 108010022752 Acetylcholinesterase Proteins 0.000 description 1
- 102100033639 Acetylcholinesterase Human genes 0.000 description 1
- 206010000599 Acromegaly Diseases 0.000 description 1
- 108010059616 Activins Proteins 0.000 description 1
- 102000005606 Activins Human genes 0.000 description 1
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 1
- 241001164825 Adeno-associated virus - 8 Species 0.000 description 1
- 102100036664 Adenosine deaminase Human genes 0.000 description 1
- 208000000230 African Trypanosomiasis Diseases 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- WPWUFUBLGADILS-WDSKDSINSA-N Ala-Pro Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(O)=O WPWUFUBLGADILS-WDSKDSINSA-N 0.000 description 1
- 102100036826 Aldehyde oxidase Human genes 0.000 description 1
- 102100025683 Alkaline phosphatase, tissue-nonspecific isozyme Human genes 0.000 description 1
- 102100034561 Alpha-N-acetylglucosaminidase Human genes 0.000 description 1
- 208000024827 Alzheimer disease Diseases 0.000 description 1
- 108010027164 Amanitins Proteins 0.000 description 1
- 108010039224 Amidophosphoribosyltransferase Proteins 0.000 description 1
- 102100032187 Androgen receptor Human genes 0.000 description 1
- 102100025668 Angiopoietin-related protein 3 Human genes 0.000 description 1
- 101710085848 Angiopoietin-related protein 3 Proteins 0.000 description 1
- 102100035765 Angiotensin-converting enzyme 2 Human genes 0.000 description 1
- 108090000975 Angiotensin-converting enzyme 2 Proteins 0.000 description 1
- 206010002556 Ankylosing Spondylitis Diseases 0.000 description 1
- 108010049777 Ankyrins Proteins 0.000 description 1
- 102000008102 Ankyrins Human genes 0.000 description 1
- 235000002198 Annona diversifolia Nutrition 0.000 description 1
- 102000044503 Antimicrobial Peptides Human genes 0.000 description 1
- 108700042778 Antimicrobial Peptides Proteins 0.000 description 1
- 102100022977 Antithrombin-III Human genes 0.000 description 1
- 102100037435 Antiviral innate immune response receptor RIG-I Human genes 0.000 description 1
- 101710127675 Antiviral innate immune response receptor RIG-I Proteins 0.000 description 1
- 102100040202 Apolipoprotein B-100 Human genes 0.000 description 1
- 108010008150 Apolipoprotein B-100 Proteins 0.000 description 1
- 102000030169 Apolipoprotein C-III Human genes 0.000 description 1
- 108010056301 Apolipoprotein C-III Proteins 0.000 description 1
- 102000010565 Apoptosis Regulatory Proteins Human genes 0.000 description 1
- 108010063104 Apoptosis Regulatory Proteins Proteins 0.000 description 1
- IYMAXBFPHPZYIK-BQBZGAKWSA-N Arg-Gly-Asp Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O IYMAXBFPHPZYIK-BQBZGAKWSA-N 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 108010082340 Arginine deiminase Proteins 0.000 description 1
- 102100022146 Arylsulfatase A Human genes 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 201000001320 Atherosclerosis Diseases 0.000 description 1
- 241001203868 Autographa californica Species 0.000 description 1
- MLDQJTXFUGDVEO-UHFFFAOYSA-N BAY-43-9006 Chemical compound C1=NC(C(=O)NC)=CC(OC=2C=CC(NC(=O)NC=3C=C(C(Cl)=CC=3)C(F)(F)F)=CC=2)=C1 MLDQJTXFUGDVEO-UHFFFAOYSA-N 0.000 description 1
- 208000004429 Bacillary Dysentery Diseases 0.000 description 1
- 241000193830 Bacillus <bacterium> Species 0.000 description 1
- 241000194107 Bacillus megaterium Species 0.000 description 1
- 244000063299 Bacillus subtilis Species 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- 101000588395 Bacillus subtilis (strain 168) Beta-hexosaminidase Proteins 0.000 description 1
- 208000023328 Basedow disease Diseases 0.000 description 1
- 102100023995 Beta-nerve growth factor Human genes 0.000 description 1
- 102100035687 Bile salt-activated lipase Human genes 0.000 description 1
- 206010005003 Bladder cancer Diseases 0.000 description 1
- 102000015081 Blood Coagulation Factors Human genes 0.000 description 1
- 108010039209 Blood Coagulation Factors Proteins 0.000 description 1
- 108010049931 Bone Morphogenetic Protein 2 Proteins 0.000 description 1
- 108010049974 Bone Morphogenetic Protein 6 Proteins 0.000 description 1
- 102000001893 Bone Morphogenetic Protein Receptors Human genes 0.000 description 1
- 108010040422 Bone Morphogenetic Protein Receptors Proteins 0.000 description 1
- 102100022525 Bone morphogenetic protein 6 Human genes 0.000 description 1
- 241000589969 Borreliella burgdorferi Species 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 1
- 241000701822 Bovine papillomavirus Species 0.000 description 1
- 101800000407 Brain natriuretic peptide 32 Proteins 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- 108010073975 Brinolase Proteins 0.000 description 1
- RKLNONIVDFXQRX-UHFFFAOYSA-N Bromperidol Chemical compound C1CC(O)(C=2C=CC(Br)=CC=2)CCN1CCCC(=O)C1=CC=C(F)C=C1 RKLNONIVDFXQRX-UHFFFAOYSA-N 0.000 description 1
- 108010037003 Buserelin Proteins 0.000 description 1
- 102100021935 C-C motif chemokine 26 Human genes 0.000 description 1
- 108010075254 C-Peptide Proteins 0.000 description 1
- 108010074051 C-Reactive Protein Proteins 0.000 description 1
- 102000012421 C-Type Natriuretic Peptide Human genes 0.000 description 1
- 102100032752 C-reactive protein Human genes 0.000 description 1
- 101800000060 C-type natriuretic peptide Proteins 0.000 description 1
- OBMZMSLWNNWEJA-XNCRXQDQSA-N C1=CC=2C(C[C@@H]3NC(=O)[C@@H](NC(=O)[C@H](NC(=O)N(CC#CCN(CCCC[C@H](NC(=O)[C@@H](CC4=CC=CC=C4)NC3=O)C(=O)N)CC=C)NC(=O)[C@@H](N)C)CC3=CNC4=C3C=CC=C4)C)=CNC=2C=C1 Chemical compound C1=CC=2C(C[C@@H]3NC(=O)[C@@H](NC(=O)[C@H](NC(=O)N(CC#CCN(CCCC[C@H](NC(=O)[C@@H](CC4=CC=CC=C4)NC3=O)C(=O)N)CC=C)NC(=O)[C@@H](N)C)CC3=CNC4=C3C=CC=C4)C)=CNC=2C=C1 OBMZMSLWNNWEJA-XNCRXQDQSA-N 0.000 description 1
- 229940110394 C5a inhibitor Drugs 0.000 description 1
- 108010079458 CBLB502 Proteins 0.000 description 1
- 108010040471 CC Chemokines Proteins 0.000 description 1
- 102000001902 CC Chemokines Human genes 0.000 description 1
- LQRNAUZEMLGYOX-LZVIIAQDSA-N CC(=O)N[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1OCCCCC(=O)NCCCNC(=O)CCOCC(COCCC(=O)NCCCNC(=O)CCCCO[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1NC(C)=O)(COCCC(=O)NCCCNC(=O)CCCCO[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1NC(C)=O)NC(=O)CCCCCCCCCCC(=O)N1C[C@H](O)C[C@H]1COP(O)(O)=O Chemical compound CC(=O)N[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1OCCCCC(=O)NCCCNC(=O)CCOCC(COCCC(=O)NCCCNC(=O)CCCCO[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1NC(C)=O)(COCCC(=O)NCCCNC(=O)CCCCO[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1NC(C)=O)NC(=O)CCCCCCCCCCC(=O)N1C[C@H](O)C[C@H]1COP(O)(O)=O LQRNAUZEMLGYOX-LZVIIAQDSA-N 0.000 description 1
- 229940117974 CD19 antagonist Drugs 0.000 description 1
- 229940123494 CD20 antagonist Drugs 0.000 description 1
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 1
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 description 1
- 108010029697 CD40 Ligand Proteins 0.000 description 1
- 229940122551 CD40 antagonist Drugs 0.000 description 1
- 102100032937 CD40 ligand Human genes 0.000 description 1
- 108010071134 CRM197 (non-toxic variant of diphtheria toxin) Proteins 0.000 description 1
- 229940045513 CTLA4 antagonist Drugs 0.000 description 1
- 102000055006 Calcitonin Human genes 0.000 description 1
- 108060001064 Calcitonin Proteins 0.000 description 1
- 229940086563 Calcitonin gene-related peptide inhibitor Drugs 0.000 description 1
- 229940127291 Calcium channel antagonist Drugs 0.000 description 1
- 101710132601 Capsid protein Proteins 0.000 description 1
- 101710197658 Capsid protein VP1 Proteins 0.000 description 1
- 206010007556 Cardiac failure acute Diseases 0.000 description 1
- 102100032616 Caspase-2 Human genes 0.000 description 1
- 108090000552 Caspase-2 Proteins 0.000 description 1
- 208000009132 Catalepsy Diseases 0.000 description 1
- 108010001857 Cell Surface Receptors Proteins 0.000 description 1
- 229930186147 Cephalosporin Natural products 0.000 description 1
- 108010036867 Cerebroside-Sulfatase Proteins 0.000 description 1
- 241000195597 Chlamydomonas reinhardtii Species 0.000 description 1
- 206010008631 Cholera Diseases 0.000 description 1
- 241000251730 Chondrichthyes Species 0.000 description 1
- 229920002567 Chondroitin Polymers 0.000 description 1
- 108010062540 Chorionic Gonadotropin Proteins 0.000 description 1
- 102000011022 Chorionic Gonadotropin Human genes 0.000 description 1
- 208000006545 Chronic Obstructive Pulmonary Disease Diseases 0.000 description 1
- 108010038061 Chymotrypsinogen Proteins 0.000 description 1
- 241000223782 Ciliophora Species 0.000 description 1
- 241000710777 Classical swine fever virus Species 0.000 description 1
- 102000003780 Clusterin Human genes 0.000 description 1
- 108090000197 Clusterin Proteins 0.000 description 1
- 102100022641 Coagulation factor IX Human genes 0.000 description 1
- 102100029117 Coagulation factor X Human genes 0.000 description 1
- 206010009900 Colitis ulcerative Diseases 0.000 description 1
- 102000029816 Collagenase Human genes 0.000 description 1
- 108060005980 Collagenase Proteins 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- 108010028780 Complement C3 Proteins 0.000 description 1
- 102000016918 Complement C3 Human genes 0.000 description 1
- 102100024339 Complement component C6 Human genes 0.000 description 1
- 101710203188 Complement component C6 Proteins 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 229940093817 Convertase inhibitor Drugs 0.000 description 1
- 108010022152 Corticotropin-Releasing Hormone Proteins 0.000 description 1
- 239000000055 Corticotropin-Releasing Hormone Substances 0.000 description 1
- 102000012289 Corticotropin-Releasing Hormone Human genes 0.000 description 1
- MFYSYFVPBJMHGN-ZPOLXVRWSA-N Cortisone Chemical compound O=C1CC[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 MFYSYFVPBJMHGN-ZPOLXVRWSA-N 0.000 description 1
- MFYSYFVPBJMHGN-UHFFFAOYSA-N Cortisone Natural products O=C1CCC2(C)C3C(=O)CC(C)(C(CC4)(O)C(=O)CO)C4C3CCC2=C1 MFYSYFVPBJMHGN-UHFFFAOYSA-N 0.000 description 1
- 241000186226 Corynebacterium glutamicum Species 0.000 description 1
- 108010091893 Cosyntropin Proteins 0.000 description 1
- 241000699798 Cricetulus Species 0.000 description 1
- 208000011231 Crohn disease Diseases 0.000 description 1
- 239000004971 Cross linker Substances 0.000 description 1
- 229930188224 Cryptophycin Natural products 0.000 description 1
- 241000195493 Cryptophyta Species 0.000 description 1
- 208000008953 Cryptosporidiosis Diseases 0.000 description 1
- 206010011502 Cryptosporidiosis infection Diseases 0.000 description 1
- 102000001189 Cyclic Peptides Human genes 0.000 description 1
- 108010069514 Cyclic Peptides Proteins 0.000 description 1
- QASFUMOKHFSJGL-LAFRSMQTSA-N Cyclopamine Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H](CC2=C3C)[C@@H]1[C@@H]2CC[C@@]13O[C@@H]2C[C@H](C)CN[C@H]2[C@H]1C QASFUMOKHFSJGL-LAFRSMQTSA-N 0.000 description 1
- 201000003883 Cystic fibrosis Diseases 0.000 description 1
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 1
- 102000016896 DCC Receptor Human genes 0.000 description 1
- 108010014066 DCC Receptor Proteins 0.000 description 1
- 101150074155 DHFR gene Proteins 0.000 description 1
- 102100026139 DNA damage-inducible transcript 4 protein Human genes 0.000 description 1
- 241000238557 Decapoda Species 0.000 description 1
- 108010002069 Defensins Proteins 0.000 description 1
- 102000000541 Defensins Human genes 0.000 description 1
- 208000001490 Dengue Diseases 0.000 description 1
- 206010012310 Dengue fever Diseases 0.000 description 1
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 1
- 102000007260 Deoxyribonuclease I Human genes 0.000 description 1
- 108010002156 Depsipeptides Proteins 0.000 description 1
- 201000004624 Dermatitis Diseases 0.000 description 1
- 108700022150 Designed Ankyrin Repeat Proteins Proteins 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 102000002148 Diacylglycerol O-acyltransferase Human genes 0.000 description 1
- 108010001348 Diacylglycerol O-acyltransferase Proteins 0.000 description 1
- LVHOURKCKUYIGK-RGUJTQARSA-N Dimethisterone Chemical compound C1([C@@H](C)C2)=CC(=O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@](C#CC)(O)[C@@]2(C)CC1 LVHOURKCKUYIGK-RGUJTQARSA-N 0.000 description 1
- 101100339887 Drosophila melanogaster Hsp27 gene Proteins 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- 101150029707 ERBB2 gene Proteins 0.000 description 1
- 241001115402 Ebolavirus Species 0.000 description 1
- 102000002322 Egg Proteins Human genes 0.000 description 1
- 108010000912 Egg Proteins Proteins 0.000 description 1
- 108010051021 Eledoisin Proteins 0.000 description 1
- 206010014733 Endometrial cancer Diseases 0.000 description 1
- 206010014759 Endometrial neoplasm Diseases 0.000 description 1
- 102100031780 Endonuclease Human genes 0.000 description 1
- 108010042407 Endonucleases Proteins 0.000 description 1
- 102400001047 Endostatin Human genes 0.000 description 1
- 108010079505 Endostatins Proteins 0.000 description 1
- 101710204837 Envelope small membrane protein Proteins 0.000 description 1
- 102400001368 Epidermal growth factor Human genes 0.000 description 1
- 101800003838 Epidermal growth factor Proteins 0.000 description 1
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 1
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 description 1
- QXRSDHAAWVKZLJ-OXZHEXMSSA-N Epothilone B Natural products O=C1[C@H](C)[C@H](O)[C@@H](C)CCC[C@@]2(C)O[C@H]2C[C@@H](/C(=C\c2nc(C)sc2)/C)OC(=O)C[C@H](O)C1(C)C QXRSDHAAWVKZLJ-OXZHEXMSSA-N 0.000 description 1
- BEFZAMRWPCMWFJ-JRBBLYSQSA-N Epothilone C Natural products O=C1[C@H](C)[C@@H](O)[C@@H](C)CCC/C=C\C[C@@H](/C(=C\c2nc(C)sc2)/C)OC(=O)C[C@H](O)C1(C)C BEFZAMRWPCMWFJ-JRBBLYSQSA-N 0.000 description 1
- XOZIUKBZLSUILX-SDMHVBBESA-N Epothilone D Natural products O=C1[C@H](C)[C@@H](O)[C@@H](C)CCC/C(/C)=C/C[C@@H](/C(=C\c2nc(C)sc2)/C)OC(=O)C[C@H](O)C1(C)C XOZIUKBZLSUILX-SDMHVBBESA-N 0.000 description 1
- UKIMCRYGLFQEOE-UHFFFAOYSA-N Epothilone F Natural products O1C(=O)CC(O)C(C)(C)C(=O)C(C)C(O)C(C)CCCC2(C)OC2CC1C(C)=CC1=CSC(CO)=N1 UKIMCRYGLFQEOE-UHFFFAOYSA-N 0.000 description 1
- 102000003951 Erythropoietin Human genes 0.000 description 1
- 108090000394 Erythropoietin Proteins 0.000 description 1
- 241000588722 Escherichia Species 0.000 description 1
- 241001524679 Escherichia virus M13 Species 0.000 description 1
- 229940122601 Esterase inhibitor Drugs 0.000 description 1
- DNXHEGUUPJUMQT-CBZIJGRNSA-N Estrone Chemical compound OC1=CC=C2[C@H]3CC[C@](C)(C(CC4)=O)[C@@H]4[C@@H]3CCC2=C1 DNXHEGUUPJUMQT-CBZIJGRNSA-N 0.000 description 1
- 108010011459 Exenatide Proteins 0.000 description 1
- 108010037362 Extracellular Matrix Proteins Proteins 0.000 description 1
- 102000010834 Extracellular Matrix Proteins Human genes 0.000 description 1
- 102100020903 Ezrin Human genes 0.000 description 1
- 108091008794 FGF receptors Proteins 0.000 description 1
- 208000024720 Fabry Disease Diseases 0.000 description 1
- 108010076282 Factor IX Proteins 0.000 description 1
- 108010023321 Factor VII Proteins 0.000 description 1
- 108010014173 Factor X Proteins 0.000 description 1
- 108010071289 Factor XIII Proteins 0.000 description 1
- 101710196208 Fibrinolytic enzyme Proteins 0.000 description 1
- 102000003971 Fibroblast Growth Factor 1 Human genes 0.000 description 1
- 108090000386 Fibroblast Growth Factor 1 Proteins 0.000 description 1
- 102000044168 Fibroblast Growth Factor Receptor Human genes 0.000 description 1
- 102100024785 Fibroblast growth factor 2 Human genes 0.000 description 1
- 108090000379 Fibroblast growth factor 2 Proteins 0.000 description 1
- 102000003973 Fibroblast growth factor 21 Human genes 0.000 description 1
- 108090000376 Fibroblast growth factor 21 Proteins 0.000 description 1
- 102000003972 Fibroblast growth factor 7 Human genes 0.000 description 1
- 108090000385 Fibroblast growth factor 7 Proteins 0.000 description 1
- 229940122991 Fibroblast growth factor receptor 2 antagonist Drugs 0.000 description 1
- 102100027844 Fibroblast growth factor receptor 4 Human genes 0.000 description 1
- 101710182387 Fibroblast growth factor receptor 4 Proteins 0.000 description 1
- 208000001640 Fibromyalgia Diseases 0.000 description 1
- 102100037362 Fibronectin Human genes 0.000 description 1
- 108010067306 Fibronectins Proteins 0.000 description 1
- PLDUPXSUYLZYBN-UHFFFAOYSA-N Fluphenazine Chemical compound C1CN(CCO)CCN1CCCN1C2=CC(C(F)(F)F)=CC=C2SC2=CC=CC=C21 PLDUPXSUYLZYBN-UHFFFAOYSA-N 0.000 description 1
- 101150094690 GAL1 gene Proteins 0.000 description 1
- 229940125993 GP2 peptide Drugs 0.000 description 1
- 101150099798 GSK1 gene Proteins 0.000 description 1
- 102400001370 Galanin Human genes 0.000 description 1
- 101800002068 Galanin Proteins 0.000 description 1
- 102100028501 Galanin peptides Human genes 0.000 description 1
- 102100031416 Gastric triacylglycerol lipase Human genes 0.000 description 1
- 208000015872 Gaucher disease Diseases 0.000 description 1
- 102000013382 Gelatinases Human genes 0.000 description 1
- 108010026132 Gelatinases Proteins 0.000 description 1
- JRZJKWGQFNTSRN-UHFFFAOYSA-N Geldanamycin Natural products C1C(C)CC(OC)C(O)C(C)C=C(C)C(OC(N)=O)C(OC)CCC=C(C)C(=O)NC2=CC(=O)C(OC)=C1C2=O JRZJKWGQFNTSRN-UHFFFAOYSA-N 0.000 description 1
- 108700004714 Gelonium multiflorum GEL Proteins 0.000 description 1
- 108010072051 Glatiramer Acetate Proteins 0.000 description 1
- 229940123232 Glucagon receptor agonist Drugs 0.000 description 1
- DTHNMHAUYICORS-KTKZVXAJSA-N Glucagon-like peptide 1 Chemical class C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1N=CNC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 DTHNMHAUYICORS-KTKZVXAJSA-N 0.000 description 1
- 102400000326 Glucagon-like peptide 2 Human genes 0.000 description 1
- 101800000221 Glucagon-like peptide 2 Proteins 0.000 description 1
- 102000008214 Glutamate decarboxylase Human genes 0.000 description 1
- 108091022930 Glutamate decarboxylase Proteins 0.000 description 1
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Natural products NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 102100040870 Glycine amidinotransferase, mitochondrial Human genes 0.000 description 1
- 102000002254 Glycogen Synthase Kinase 3 Human genes 0.000 description 1
- 108010014905 Glycogen Synthase Kinase 3 Proteins 0.000 description 1
- 102100032530 Glypican-3 Human genes 0.000 description 1
- 102400000932 Gonadoliberin-1 Human genes 0.000 description 1
- 239000000579 Gonadotropin-Releasing Hormone Substances 0.000 description 1
- 108010069236 Goserelin Proteins 0.000 description 1
- BLCLNMBMMGCOAS-URPVMXJPSA-N Goserelin Chemical compound C([C@@H](C(=O)N[C@H](COC(C)(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(=O)NNC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 BLCLNMBMMGCOAS-URPVMXJPSA-N 0.000 description 1
- 208000015023 Graves' disease Diseases 0.000 description 1
- 108010051696 Growth Hormone Proteins 0.000 description 1
- 102000018997 Growth Hormone Human genes 0.000 description 1
- 101150096895 HSPB1 gene Proteins 0.000 description 1
- 241000193159 Hathewaya histolytica Species 0.000 description 1
- 101710154606 Hemagglutinin Proteins 0.000 description 1
- 241000700721 Hepatitis B virus Species 0.000 description 1
- 208000005176 Hepatitis C Diseases 0.000 description 1
- 241000724675 Hepatitis E virus Species 0.000 description 1
- 102000003745 Hepatocyte Growth Factor Human genes 0.000 description 1
- 108090000100 Hepatocyte Growth Factor Proteins 0.000 description 1
- 108010007267 Hirudins Proteins 0.000 description 1
- 102000007625 Hirudins Human genes 0.000 description 1
- 101710109444 Homeobox protein 2 Proteins 0.000 description 1
- 101000928314 Homo sapiens Aldehyde oxidase Proteins 0.000 description 1
- 101000574445 Homo sapiens Alkaline phosphatase, tissue-nonspecific isozyme Proteins 0.000 description 1
- 101000757319 Homo sapiens Antithrombin-III Proteins 0.000 description 1
- 101000793686 Homo sapiens Azurocidin Proteins 0.000 description 1
- 101000897493 Homo sapiens C-C motif chemokine 26 Proteins 0.000 description 1
- 101000911390 Homo sapiens Coagulation factor VIII Proteins 0.000 description 1
- 101000912753 Homo sapiens DNA damage-inducible transcript 4 protein Proteins 0.000 description 1
- 101000846416 Homo sapiens Fibroblast growth factor 1 Proteins 0.000 description 1
- 101001060261 Homo sapiens Fibroblast growth factor 7 Proteins 0.000 description 1
- 101100121078 Homo sapiens GAL gene Proteins 0.000 description 1
- 101000893303 Homo sapiens Glycine amidinotransferase, mitochondrial Proteins 0.000 description 1
- 101001014668 Homo sapiens Glypican-3 Proteins 0.000 description 1
- 101500026183 Homo sapiens Gonadoliberin-1 Proteins 0.000 description 1
- 101000988651 Homo sapiens Humanin-like 1 Proteins 0.000 description 1
- 101001041117 Homo sapiens Hyaluronidase PH-20 Proteins 0.000 description 1
- 101000976075 Homo sapiens Insulin Proteins 0.000 description 1
- 101000599951 Homo sapiens Insulin-like growth factor I Proteins 0.000 description 1
- 101001002657 Homo sapiens Interleukin-2 Proteins 0.000 description 1
- 101001018026 Homo sapiens Lysosomal alpha-glucosidase Proteins 0.000 description 1
- 101000916644 Homo sapiens Macrophage colony-stimulating factor 1 receptor Proteins 0.000 description 1
- 101001028702 Homo sapiens Mitochondrial-derived peptide MOTS-c Proteins 0.000 description 1
- 101001066305 Homo sapiens N-acetylgalactosamine-6-sulfatase Proteins 0.000 description 1
- 101001128608 Homo sapiens NADH dehydrogenase [ubiquinone] 1 beta subcomplex subunit 4 Proteins 0.000 description 1
- 101001135770 Homo sapiens Parathyroid hormone Proteins 0.000 description 1
- 101001001487 Homo sapiens Phosphatidylinositol-glycan biosynthesis class F protein Proteins 0.000 description 1
- 101001135995 Homo sapiens Probable peptidyl-tRNA hydrolase Proteins 0.000 description 1
- 101001098868 Homo sapiens Proprotein convertase subtilisin/kexin type 9 Proteins 0.000 description 1
- 101000691455 Homo sapiens Serine/threonine-protein kinase N3 Proteins 0.000 description 1
- 101001092910 Homo sapiens Serum amyloid P-component Proteins 0.000 description 1
- 101000617130 Homo sapiens Stromal cell-derived factor 1 Proteins 0.000 description 1
- 101000617738 Homo sapiens Survival motor neuron protein Proteins 0.000 description 1
- 101000763314 Homo sapiens Thrombomodulin Proteins 0.000 description 1
- 101000831567 Homo sapiens Toll-like receptor 2 Proteins 0.000 description 1
- 101000831496 Homo sapiens Toll-like receptor 3 Proteins 0.000 description 1
- 101000669447 Homo sapiens Toll-like receptor 4 Proteins 0.000 description 1
- 101000848014 Homo sapiens Trypsin-2 Proteins 0.000 description 1
- 101001052849 Homo sapiens Tyrosine-protein kinase Fer Proteins 0.000 description 1
- 101000939387 Homo sapiens Urocortin-3 Proteins 0.000 description 1
- 101150043003 Htt gene Proteins 0.000 description 1
- 108010000521 Human Growth Hormone Proteins 0.000 description 1
- 239000000854 Human Growth Hormone Substances 0.000 description 1
- 102000003839 Human Proteins Human genes 0.000 description 1
- 108090000144 Human Proteins Proteins 0.000 description 1
- 108091006905 Human Serum Albumin Proteins 0.000 description 1
- 101000807236 Human cytomegalovirus (strain AD169) Membrane glycoprotein US3 Proteins 0.000 description 1
- 101900082162 Human immunodeficiency virus type 1 group M subtype B Surface protein gp120 Proteins 0.000 description 1
- 108700005307 Human papillomavirus HPV L1 Proteins 0.000 description 1
- 241000702617 Human parvovirus B19 Species 0.000 description 1
- 208000023105 Huntington disease Diseases 0.000 description 1
- 208000015178 Hurler syndrome Diseases 0.000 description 1
- 108010003272 Hyaluronate lyase Proteins 0.000 description 1
- 108050009363 Hyaluronidases Proteins 0.000 description 1
- 208000008852 Hyperoxaluria Diseases 0.000 description 1
- 201000002980 Hyperparathyroidism Diseases 0.000 description 1
- 206010020850 Hyperthyroidism Diseases 0.000 description 1
- 208000013016 Hypoglycemia Diseases 0.000 description 1
- 229940124672 IMA901 Drugs 0.000 description 1
- 229940124673 IMA910 Drugs 0.000 description 1
- 108010016032 IMA950 Proteins 0.000 description 1
- 108010035620 INGAP peptide Proteins 0.000 description 1
- XDXDZDZNSLXDNA-UHFFFAOYSA-N Idarubicin Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XDXDZDZNSLXDNA-UHFFFAOYSA-N 0.000 description 1
- XDXDZDZNSLXDNA-TZNDIEGXSA-N Idarubicin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XDXDZDZNSLXDNA-TZNDIEGXSA-N 0.000 description 1
- 102100029199 Iduronate 2-sulfatase Human genes 0.000 description 1
- 101710096421 Iduronate 2-sulfatase Proteins 0.000 description 1
- PVHLMTREZMEJCG-GDTLVBQBSA-N Ile(5)-angiotensin II (1-7) Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N1[C@@H](CCC1)C([O-])=O)NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=[NH2+])NC(=O)[C@@H]([NH3+])CC([O-])=O)C(C)C)C1=CC=C(O)C=C1 PVHLMTREZMEJCG-GDTLVBQBSA-N 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 1
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 1
- 241000764773 Inna Species 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- 101710186643 Insulin-2 Proteins 0.000 description 1
- 102100037852 Insulin-like growth factor I Human genes 0.000 description 1
- 108010041012 Integrin alpha4 Proteins 0.000 description 1
- 108010064593 Intercellular Adhesion Molecule-1 Proteins 0.000 description 1
- 102100037877 Intercellular adhesion molecule 1 Human genes 0.000 description 1
- 108010054698 Interferon Alfa-n3 Proteins 0.000 description 1
- 229940105188 Interferon alpha antagonist Drugs 0.000 description 1
- 102000003996 Interferon-beta Human genes 0.000 description 1
- 108090000467 Interferon-beta Proteins 0.000 description 1
- 108010074328 Interferon-gamma Proteins 0.000 description 1
- 102000008070 Interferon-gamma Human genes 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 229940106002 Interleukin 17 receptor antagonist Drugs 0.000 description 1
- 229940123716 Interleukin 6 receptor antagonist Drugs 0.000 description 1
- 102000003815 Interleukin-11 Human genes 0.000 description 1
- 108090000177 Interleukin-11 Proteins 0.000 description 1
- 108010065805 Interleukin-12 Proteins 0.000 description 1
- 102000013462 Interleukin-12 Human genes 0.000 description 1
- 108090000171 Interleukin-18 Proteins 0.000 description 1
- 102100030703 Interleukin-22 Human genes 0.000 description 1
- 102100022723 Interleukin-22 receptor subunit alpha-1 Human genes 0.000 description 1
- 102100020941 Interleukin-4 Human genes 0.000 description 1
- 102100021592 Interleukin-7 Human genes 0.000 description 1
- 108010002586 Interleukin-7 Proteins 0.000 description 1
- 102100024319 Intestinal-type alkaline phosphatase Human genes 0.000 description 1
- 101710184243 Intestinal-type alkaline phosphatase Proteins 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 108090000862 Ion Channels Proteins 0.000 description 1
- 102000004310 Ion Channels Human genes 0.000 description 1
- 229940123915 Ion channel antagonist Drugs 0.000 description 1
- 102400001216 Irisin Human genes 0.000 description 1
- 101800001026 Irisin Proteins 0.000 description 1
- 241000764238 Isis Species 0.000 description 1
- 102000001399 Kallikrein Human genes 0.000 description 1
- 108060005987 Kallikrein Proteins 0.000 description 1
- 101710172072 Kexin Proteins 0.000 description 1
- 208000008839 Kidney Neoplasms Diseases 0.000 description 1
- 102000010638 Kinesin Human genes 0.000 description 1
- 108010063296 Kinesin Proteins 0.000 description 1
- 235000014663 Kluyveromyces fragilis Nutrition 0.000 description 1
- 241001138401 Kluyveromyces lactis Species 0.000 description 1
- AHLPHDHHMVZTML-BYPYZUCNSA-N L-Ornithine Chemical compound NCCC[C@H](N)C(O)=O AHLPHDHHMVZTML-BYPYZUCNSA-N 0.000 description 1
- 125000003412 L-alanyl group Chemical group [H]N([H])[C@@](C([H])([H])[H])(C(=O)[*])[H] 0.000 description 1
- 150000008575 L-amino acids Chemical class 0.000 description 1
- RHGKLRLOHDJJDR-BYPYZUCNSA-N L-citrulline Chemical compound NC(=O)NCCC[C@H]([NH3+])C([O-])=O RHGKLRLOHDJJDR-BYPYZUCNSA-N 0.000 description 1
- 229930182816 L-glutamine Natural products 0.000 description 1
- ZFOMKMMPBOQKMC-KXUCPTDWSA-N L-pyrrolysine Chemical compound C[C@@H]1CC=N[C@H]1C(=O)NCCCC[C@H]([NH3+])C([O-])=O ZFOMKMMPBOQKMC-KXUCPTDWSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- 239000005411 L01XE02 - Gefitinib Substances 0.000 description 1
- 239000005551 L01XE03 - Erlotinib Substances 0.000 description 1
- 239000002147 L01XE04 - Sunitinib Substances 0.000 description 1
- 239000005511 L01XE05 - Sorafenib Substances 0.000 description 1
- 239000002136 L01XE07 - Lapatinib Substances 0.000 description 1
- 239000002176 L01XE26 - Cabozantinib Substances 0.000 description 1
- BPFYOAJNDMUVBL-UHFFFAOYSA-N LSM-5799 Chemical compound C1CN(C)CCN1C1=C(F)C=C2C(=O)C(C(O)=O)=CN3N(C)COC1=C32 BPFYOAJNDMUVBL-UHFFFAOYSA-N 0.000 description 1
- 241000186660 Lactobacillus Species 0.000 description 1
- 108010063045 Lactoferrin Proteins 0.000 description 1
- 102000010445 Lactoferrin Human genes 0.000 description 1
- 241000282838 Lama Species 0.000 description 1
- 201000010743 Lambert-Eaton myasthenic syndrome Diseases 0.000 description 1
- ORFLZNAGUTZRLQ-ZMBVWFSWSA-N Larazotide Chemical compound NCC(=O)NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O ORFLZNAGUTZRLQ-ZMBVWFSWSA-N 0.000 description 1
- 208000004554 Leishmaniasis Diseases 0.000 description 1
- 108010000817 Leuprolide Proteins 0.000 description 1
- 108090001060 Lipase Proteins 0.000 description 1
- 102000004882 Lipase Human genes 0.000 description 1
- 102000004895 Lipoproteins Human genes 0.000 description 1
- 108090001030 Lipoproteins Proteins 0.000 description 1
- 108010019598 Liraglutide Proteins 0.000 description 1
- YSDQQAXHVYUZIW-QCIJIYAXSA-N Liraglutide Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCNC(=O)CC[C@H](NC(=O)CCCCCCCCCCCCCCC)C(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=C(O)C=C1 YSDQQAXHVYUZIW-QCIJIYAXSA-N 0.000 description 1
- XVVOERDUTLJJHN-UHFFFAOYSA-N Lixisenatide Chemical compound C=1NC2=CC=CC=C2C=1CC(C(=O)NC(CC(C)C)C(=O)NC(CCCCN)C(=O)NC(CC(N)=O)C(=O)NCC(=O)NCC(=O)N1C(CCC1)C(=O)NC(CO)C(=O)NC(CO)C(=O)NCC(=O)NC(C)C(=O)N1C(CCC1)C(=O)N1C(CCC1)C(=O)NC(CO)C(=O)NC(CCCCN)C(=O)NC(CCCCN)C(=O)NC(CCCCN)C(=O)NC(CCCCN)C(=O)NC(CCCCN)C(=O)NC(CCCCN)C(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)CC)NC(=O)C(NC(=O)C(CC(C)C)NC(=O)C(CCCNC(N)=N)NC(=O)C(NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(CCC(O)=O)NC(=O)C(CCC(O)=O)NC(=O)C(CCSC)NC(=O)C(CCC(N)=O)NC(=O)C(CCCCN)NC(=O)C(CO)NC(=O)C(CC(C)C)NC(=O)C(CC(O)=O)NC(=O)C(CO)NC(=O)C(NC(=O)C(CC=1C=CC=CC=1)NC(=O)C(NC(=O)CNC(=O)C(CCC(O)=O)NC(=O)CNC(=O)C(N)CC=1NC=NC=1)C(C)O)C(C)O)C(C)C)CC1=CC=CC=C1 XVVOERDUTLJJHN-UHFFFAOYSA-N 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 208000019693 Lung disease Diseases 0.000 description 1
- 102000009151 Luteinizing Hormone Human genes 0.000 description 1
- 108010073521 Luteinizing Hormone Proteins 0.000 description 1
- 108090000856 Lyases Proteins 0.000 description 1
- 102000004317 Lyases Human genes 0.000 description 1
- 102100030983 Lymphocyte expansion molecule Human genes 0.000 description 1
- 101710144914 Lymphocyte expansion molecule Proteins 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 102000043136 MAP kinase family Human genes 0.000 description 1
- 108091054455 MAP kinase family Proteins 0.000 description 1
- QQDIFLSJMFDTCQ-UHFFFAOYSA-N MC1568 Chemical compound CN1C(C=CC(=O)NO)=CC=C1C=CC(=O)C1=CC=CC(F)=C1 QQDIFLSJMFDTCQ-UHFFFAOYSA-N 0.000 description 1
- 102000043131 MHC class II family Human genes 0.000 description 1
- 108091054438 MHC class II family Proteins 0.000 description 1
- 108010058398 Macrophage Colony-Stimulating Factor Receptor Proteins 0.000 description 1
- PEEHTFAAVSWFBL-UHFFFAOYSA-N Maleimide Chemical compound O=C1NC(=O)C=C1 PEEHTFAAVSWFBL-UHFFFAOYSA-N 0.000 description 1
- DINOPBPYOCMGGD-VEDJBHDQSA-N Man(a1-2)Man(a1-2)Man(a1-3)[Man(a1-2)Man(a1-3)[Man(a1-2)Man(a1-6)]Man(a1-6)]Man(b1-4)GlcNAc(b1-4)GlcNAc Chemical compound O[C@@H]1[C@@H](NC(=O)C)C(O)O[C@H](CO)[C@H]1O[C@H]1[C@H](NC(C)=O)[C@@H](O)[C@H](O[C@H]2[C@H]([C@@H](O[C@@H]3[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O3)O[C@@H]3[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O3)O[C@@H]3[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O3)O)[C@H](O)[C@@H](CO[C@@H]3[C@H]([C@@H](O[C@@H]4[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O4)O[C@@H]4[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O4)O)[C@H](O)[C@@H](CO[C@@H]4[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O4)O[C@@H]4[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O4)O)O3)O)O2)O)[C@@H](CO)O1 DINOPBPYOCMGGD-VEDJBHDQSA-N 0.000 description 1
- 108010054377 Mannosidases Proteins 0.000 description 1
- 102000001696 Mannosidases Human genes 0.000 description 1
- 101710140452 Mating factor alpha-1 Proteins 0.000 description 1
- 108010000684 Matrix Metalloproteinases Proteins 0.000 description 1
- 102000002274 Matrix Metalloproteinases Human genes 0.000 description 1
- 229930126263 Maytansine Natural products 0.000 description 1
- QWPXBEHQFHACTK-UHFFFAOYSA-N Maytansinol Natural products CN1C(=O)CC(O)C2(C)OC2C(C)C(OC(=O)N2)CC2(O)C(OC)C=CC=C(C)CC2=CC(OC)=C(Cl)C1=C2 QWPXBEHQFHACTK-UHFFFAOYSA-N 0.000 description 1
- 201000005505 Measles Diseases 0.000 description 1
- 241000712079 Measles morbillivirus Species 0.000 description 1
- 108010036176 Melitten Proteins 0.000 description 1
- 201000009906 Meningitis Diseases 0.000 description 1
- 101000610097 Mesocricetus auratus Pancreatic beta cell growth factor Proteins 0.000 description 1
- 241001465754 Metazoa Species 0.000 description 1
- 102100022465 Methanethiol oxidase Human genes 0.000 description 1
- 101710134383 Methanethiol oxidase Proteins 0.000 description 1
- 101710181812 Methionine aminopeptidase Proteins 0.000 description 1
- GCKMFJBGXUYNAG-HLXURNFRSA-N Methyltestosterone Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@](C)(O)[C@@]1(C)CC2 GCKMFJBGXUYNAG-HLXURNFRSA-N 0.000 description 1
- 108091092539 MiR-208 Proteins 0.000 description 1
- 108091081013 MiR-33 Proteins 0.000 description 1
- UEQUQVLFIPOEMF-UHFFFAOYSA-N Mianserin Chemical compound C1C2=CC=CC=C2N2CCN(C)CC2C2=CC=CC=C21 UEQUQVLFIPOEMF-UHFFFAOYSA-N 0.000 description 1
- 108010021062 Micafungin Proteins 0.000 description 1
- 108091028684 Mir-145 Proteins 0.000 description 1
- 108091028049 Mir-221 microRNA Proteins 0.000 description 1
- 102100037173 Mitochondrial-derived peptide MOTS-c Human genes 0.000 description 1
- 102000005431 Molecular Chaperones Human genes 0.000 description 1
- 108010006519 Molecular Chaperones Proteins 0.000 description 1
- 101710182606 Mono-ADP-ribosyltransferase C3 Proteins 0.000 description 1
- 108010008707 Mucin-1 Proteins 0.000 description 1
- 102100034256 Mucin-1 Human genes 0.000 description 1
- 208000002678 Mucopolysaccharidoses Diseases 0.000 description 1
- 206010056886 Mucopolysaccharidosis I Diseases 0.000 description 1
- 206010028095 Mucopolysaccharidosis IV Diseases 0.000 description 1
- 208000025915 Mucopolysaccharidosis type 6 Diseases 0.000 description 1
- 101100381978 Mus musculus Braf gene Proteins 0.000 description 1
- 101100260876 Mus musculus Tmprss6 gene Proteins 0.000 description 1
- 206010028424 Myasthenic syndrome Diseases 0.000 description 1
- 241000186359 Mycobacterium Species 0.000 description 1
- PTJGLFIIZFVFJV-UHFFFAOYSA-N N'-hydroxy-N-(3-pyridinyl)octanediamide Chemical compound ONC(=O)CCCCCCC(=O)NC1=CC=CN=C1 PTJGLFIIZFVFJV-UHFFFAOYSA-N 0.000 description 1
- HRNLUBSXIHFDHP-UHFFFAOYSA-N N-(2-aminophenyl)-4-[[[4-(3-pyridinyl)-2-pyrimidinyl]amino]methyl]benzamide Chemical compound NC1=CC=CC=C1NC(=O)C(C=C1)=CC=C1CNC1=NC=CC(C=2C=NC=CC=2)=N1 HRNLUBSXIHFDHP-UHFFFAOYSA-N 0.000 description 1
- OUSFTKFNBAZUKL-UHFFFAOYSA-N N-(5-{[(5-tert-butyl-1,3-oxazol-2-yl)methyl]sulfanyl}-1,3-thiazol-2-yl)piperidine-4-carboxamide Chemical compound O1C(C(C)(C)C)=CN=C1CSC(S1)=CN=C1NC(=O)C1CCNCC1 OUSFTKFNBAZUKL-UHFFFAOYSA-N 0.000 description 1
- 102100031688 N-acetylgalactosamine-6-sulfatase Human genes 0.000 description 1
- 101710099863 N-acetylgalactosamine-6-sulfatase Proteins 0.000 description 1
- 230000004988 N-glycosylation Effects 0.000 description 1
- PAWIYAYFNXQGAP-UHFFFAOYSA-N N-hydroxy-2-[4-[[(1-methyl-3-indolyl)methylamino]methyl]-1-piperidinyl]-5-pyrimidinecarboxamide Chemical compound C12=CC=CC=C2N(C)C=C1CNCC(CC1)CCN1C1=NC=C(C(=O)NO)C=N1 PAWIYAYFNXQGAP-UHFFFAOYSA-N 0.000 description 1
- 108010006140 N-sulfoglucosamine sulfohydrolase Proteins 0.000 description 1
- 102100027661 N-sulphoglucosamine sulphohydrolase Human genes 0.000 description 1
- 102100032205 NADH dehydrogenase [ubiquinone] 1 beta subcomplex subunit 4 Human genes 0.000 description 1
- RHGKLRLOHDJJDR-UHFFFAOYSA-N Ndelta-carbamoyl-DL-ornithine Natural products OC(=O)C(N)CCCNC(N)=O RHGKLRLOHDJJDR-UHFFFAOYSA-N 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 108010025020 Nerve Growth Factor Proteins 0.000 description 1
- 102400000058 Neuregulin-1 Human genes 0.000 description 1
- 108090000556 Neuregulin-1 Proteins 0.000 description 1
- 208000000693 Neurogenic Urinary Bladder Diseases 0.000 description 1
- 206010029279 Neurogenic bladder Diseases 0.000 description 1
- 208000002537 Neuronal Ceroid-Lipofuscinoses Diseases 0.000 description 1
- 101710138657 Neurotoxin Proteins 0.000 description 1
- ZBBHBTPTTSWHBA-UHFFFAOYSA-N Nicardipine Chemical compound COC(=O)C1=C(C)NC(C)=C(C(=O)OCCN(C)CC=2C=CC=CC=2)C1C1=CC=CC([N+]([O-])=O)=C1 ZBBHBTPTTSWHBA-UHFFFAOYSA-N 0.000 description 1
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 1
- 206010029748 Noonan syndrome Diseases 0.000 description 1
- IMONTRJLAWHYGT-ZCPXKWAGSA-N Norethindrone Acetate Chemical compound C1CC2=CC(=O)CC[C@@H]2[C@@H]2[C@@H]1[C@@H]1CC[C@](C#C)(OC(=O)C)[C@@]1(C)CC2 IMONTRJLAWHYGT-ZCPXKWAGSA-N 0.000 description 1
- 101900322896 Norwalk virus Capsid protein VP1 Proteins 0.000 description 1
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 1
- 108090001074 Nucleocapsid Proteins Proteins 0.000 description 1
- 102100021010 Nucleolin Human genes 0.000 description 1
- 101710141454 Nucleoprotein Proteins 0.000 description 1
- MEMKXPGBFFKUER-NDDSAYQWSA-N O=C1N[C@@H](CSCCCN)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(=O)NCC(=O)NCC(=O)N[C@@H](CSCNC(=O)C)C(=O)NCC(=O)N[C@@H](CSCNC(C)=O)C(=O)NCC(=O)NCC(=O)N[C@@H](CS)C(N)=O)CSCC(=O)N[C@@H]1CC1=CC=C(O)C=C1 Chemical compound O=C1N[C@@H](CSCCCN)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(=O)NCC(=O)NCC(=O)N[C@@H](CSCNC(=O)C)C(=O)NCC(=O)N[C@@H](CSCNC(C)=O)C(=O)NCC(=O)NCC(=O)N[C@@H](CS)C(N)=O)CSCC(=O)N[C@@H]1CC1=CC=C(O)C=C1 MEMKXPGBFFKUER-NDDSAYQWSA-N 0.000 description 1
- 208000008589 Obesity Diseases 0.000 description 1
- 108010016076 Octreotide Proteins 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 108010084331 Omiganan Proteins 0.000 description 1
- 241000243985 Onchocerca volvulus Species 0.000 description 1
- 108700020796 Oncogene Proteins 0.000 description 1
- AHLPHDHHMVZTML-UHFFFAOYSA-N Orn-delta-NH2 Natural products NCCCC(N)C(O)=O AHLPHDHHMVZTML-UHFFFAOYSA-N 0.000 description 1
- UTJLXEIPEHZYQJ-UHFFFAOYSA-N Ornithine Natural products OC(=O)C(C)CCCN UTJLXEIPEHZYQJ-UHFFFAOYSA-N 0.000 description 1
- 241000238890 Ornithodoros moubata Species 0.000 description 1
- 108700006640 OspA Proteins 0.000 description 1
- 208000001132 Osteoporosis Diseases 0.000 description 1
- 102000008108 Osteoprotegerin Human genes 0.000 description 1
- 108010035042 Osteoprotegerin Proteins 0.000 description 1
- 101710093908 Outer capsid protein VP4 Proteins 0.000 description 1
- 101710135467 Outer capsid protein sigma-1 Proteins 0.000 description 1
- 239000004100 Oxytetracycline Substances 0.000 description 1
- 239000012661 PARP inhibitor Substances 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 229940124060 PD-1 antagonist Drugs 0.000 description 1
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 1
- 208000013612 Parathyroid disease Diseases 0.000 description 1
- 208000004362 Penile Induration Diseases 0.000 description 1
- 101710176384 Peptide 1 Proteins 0.000 description 1
- 102000002508 Peptide Elongation Factors Human genes 0.000 description 1
- 108010068204 Peptide Elongation Factors Proteins 0.000 description 1
- 208000020758 Peyronie disease Diseases 0.000 description 1
- 241000286209 Phasianidae Species 0.000 description 1
- 108700023158 Phenylalanine ammonia-lyases Proteins 0.000 description 1
- 201000011252 Phenylketonuria Diseases 0.000 description 1
- 102000004160 Phosphoric Monoester Hydrolases Human genes 0.000 description 1
- 108090000608 Phosphoric Monoester Hydrolases Proteins 0.000 description 1
- 229940127354 Platelet-derived Growth Factor Receptor Inhibitors Drugs 0.000 description 1
- 206010035664 Pneumonia Diseases 0.000 description 1
- 229940121906 Poly ADP ribose polymerase inhibitor Drugs 0.000 description 1
- 101710159752 Poly(3-hydroxyalkanoate) polymerase subunit PhaE Proteins 0.000 description 1
- 108010076039 Polyproteins Proteins 0.000 description 1
- 101100382437 Porcine circovirus 2 Cap gene Proteins 0.000 description 1
- 101000984477 Porcine circovirus 2 Capsid protein Proteins 0.000 description 1
- 201000010769 Prader-Willi syndrome Diseases 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- 101710130262 Probable Vpr-like protein Proteins 0.000 description 1
- 101710186352 Probable membrane antigen 3 Proteins 0.000 description 1
- 101710181078 Probable membrane antigen 75 Proteins 0.000 description 1
- 102100031169 Prohibitin 1 Human genes 0.000 description 1
- 101710098085 Prohibitin-1 Proteins 0.000 description 1
- 108010076181 Proinsulin Proteins 0.000 description 1
- 108010044159 Proprotein Convertases Proteins 0.000 description 1
- 102000006437 Proprotein Convertases Human genes 0.000 description 1
- 102100038955 Proprotein convertase subtilisin/kexin type 9 Human genes 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 108010072866 Prostate-Specific Antigen Proteins 0.000 description 1
- 102100038358 Prostate-specific antigen Human genes 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 101710176177 Protein A56 Proteins 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 108050003896 Protein yellow Proteins 0.000 description 1
- 241000589516 Pseudomonas Species 0.000 description 1
- 101900161471 Pseudomonas aeruginosa Exotoxin A Proteins 0.000 description 1
- 201000001263 Psoriatic Arthritis Diseases 0.000 description 1
- 208000036824 Psoriatic arthropathy Diseases 0.000 description 1
- 206010037660 Pyrexia Diseases 0.000 description 1
- 101100372762 Rattus norvegicus Flt1 gene Proteins 0.000 description 1
- 101710100968 Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 1
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 1
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 1
- 208000015634 Rectal Neoplasms Diseases 0.000 description 1
- 206010038389 Renal cancer Diseases 0.000 description 1
- 101710088839 Replication initiation protein Proteins 0.000 description 1
- 241000725643 Respiratory syncytial virus Species 0.000 description 1
- 108010083644 Ribonucleases Proteins 0.000 description 1
- 102000006382 Ribonucleases Human genes 0.000 description 1
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 1
- 239000006146 Roswell Park Memorial Institute medium Substances 0.000 description 1
- 241000702670 Rotavirus Species 0.000 description 1
- 108700031314 Rotavirus VP6 Proteins 0.000 description 1
- 108700012261 Rotavirus VP7 Proteins 0.000 description 1
- 206010067470 Rotavirus infection Diseases 0.000 description 1
- 241000710799 Rubella virus Species 0.000 description 1
- 241000315672 SARS coronavirus Species 0.000 description 1
- 102000000395 SH3 domains Human genes 0.000 description 1
- 108050008861 SH3 domains Proteins 0.000 description 1
- 101150012871 SHOX gene Proteins 0.000 description 1
- 108010017324 STAT3 Transcription Factor Proteins 0.000 description 1
- 101001117144 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) [Pyruvate dehydrogenase (acetyl-transferring)] kinase 1, mitochondrial Proteins 0.000 description 1
- 244000253911 Saccharomyces fragilis Species 0.000 description 1
- 235000018368 Saccharomyces fragilis Nutrition 0.000 description 1
- 241000607142 Salmonella Species 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- 241000235347 Schizosaccharomyces pombe Species 0.000 description 1
- 108010082455 Sebelipase alfa Proteins 0.000 description 1
- 108010086019 Secretin Proteins 0.000 description 1
- 102100037505 Secretin Human genes 0.000 description 1
- 241000710961 Semliki Forest virus Species 0.000 description 1
- 206010040047 Sepsis Diseases 0.000 description 1
- 102100026219 Serine/threonine-protein kinase N3 Human genes 0.000 description 1
- 102100036202 Serum amyloid P-component Human genes 0.000 description 1
- 241000607762 Shigella flexneri Species 0.000 description 1
- 206010040550 Shigella infections Diseases 0.000 description 1
- 102100024040 Signal transducer and activator of transcription 3 Human genes 0.000 description 1
- 208000021386 Sjogren Syndrome Diseases 0.000 description 1
- 102000005157 Somatostatin Human genes 0.000 description 1
- 108010056088 Somatostatin Proteins 0.000 description 1
- 102000011971 Sphingomyelin Phosphodiesterase Human genes 0.000 description 1
- 108010061312 Sphingomyelin Phosphodiesterase Proteins 0.000 description 1
- 239000004187 Spiramycin Substances 0.000 description 1
- 241000256248 Spodoptera Species 0.000 description 1
- 241000256251 Spodoptera frugiperda Species 0.000 description 1
- 101000857870 Squalus acanthias Gonadoliberin Proteins 0.000 description 1
- 101710145796 Staphylokinase Proteins 0.000 description 1
- 108091081024 Start codon Proteins 0.000 description 1
- 108010034396 Streptogramins Proteins 0.000 description 1
- 108010023197 Streptokinase Proteins 0.000 description 1
- 241000187747 Streptomyces Species 0.000 description 1
- 102100021669 Stromal cell-derived factor 1 Human genes 0.000 description 1
- 108090000787 Subtilisin Proteins 0.000 description 1
- 102100021947 Survival motor neuron protein Human genes 0.000 description 1
- 241001453296 Synechococcus elongatus Species 0.000 description 1
- 108091008874 T cell receptors Proteins 0.000 description 1
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 1
- 210000001744 T-lymphocyte Anatomy 0.000 description 1
- 108700002718 TACI receptor-IgG Fc fragment fusion Proteins 0.000 description 1
- 108091000182 THR-184 Proteins 0.000 description 1
- 229940123237 Taxane Drugs 0.000 description 1
- 101710178472 Tegument protein Proteins 0.000 description 1
- 102100038126 Tenascin Human genes 0.000 description 1
- 108010008125 Tenascin Proteins 0.000 description 1
- 108010039185 Tenecteplase Proteins 0.000 description 1
- 108010049264 Teriparatide Proteins 0.000 description 1
- 108010010056 Terlipressin Proteins 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- 241000223892 Tetrahymena Species 0.000 description 1
- 241000248384 Tetrahymena thermophila Species 0.000 description 1
- 101000712605 Theromyzon tessulatum Theromin Proteins 0.000 description 1
- KLBQZWRITKRQQV-UHFFFAOYSA-N Thioridazine Chemical compound C12=CC(SC)=CC=C2SC2=CC=CC=C2N1CCC1CCCCN1C KLBQZWRITKRQQV-UHFFFAOYSA-N 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 229940122388 Thrombin inhibitor Drugs 0.000 description 1
- 108010000499 Thromboplastin Proteins 0.000 description 1
- 102000002262 Thromboplastin Human genes 0.000 description 1
- 102000036693 Thrombopoietin Human genes 0.000 description 1
- 108010041111 Thrombopoietin Proteins 0.000 description 1
- 108010046722 Thrombospondin 1 Proteins 0.000 description 1
- 102100036034 Thrombospondin-1 Human genes 0.000 description 1
- 108010078233 Thymalfasin Proteins 0.000 description 1
- 102400000800 Thymosin alpha-1 Human genes 0.000 description 1
- 208000024770 Thyroid neoplasm Diseases 0.000 description 1
- AUYYCJSJGJYCDS-LBPRGKRZSA-N Thyrolar Chemical class IC1=CC(C[C@H](N)C(O)=O)=CC(I)=C1OC1=CC=C(O)C(I)=C1 AUYYCJSJGJYCDS-LBPRGKRZSA-N 0.000 description 1
- 108010055141 Tifacogin Proteins 0.000 description 1
- 102100024333 Toll-like receptor 2 Human genes 0.000 description 1
- 102100024324 Toll-like receptor 3 Human genes 0.000 description 1
- 102100039360 Toll-like receptor 4 Human genes 0.000 description 1
- 206010044013 Tonsillitis streptococcal Diseases 0.000 description 1
- 108091023040 Transcription factor Proteins 0.000 description 1
- 102000040945 Transcription factor Human genes 0.000 description 1
- 108700029229 Transcriptional Regulatory Elements Proteins 0.000 description 1
- 108700002109 Transmembrane Activator and CAML Interactor Proteins 0.000 description 1
- 102000050862 Transmembrane Activator and CAML Interactor Human genes 0.000 description 1
- 102100032452 Transmembrane protease serine 6 Human genes 0.000 description 1
- 101710081839 Transmembrane protease serine 6 Proteins 0.000 description 1
- 102100029290 Transthyretin Human genes 0.000 description 1
- 241000255985 Trichoplusia Species 0.000 description 1
- 241000255993 Trichoplusia ni Species 0.000 description 1
- RTKIYFITIVXBLE-UHFFFAOYSA-N Trichostatin A Natural products ONC(=O)C=CC(C)=CC(C)C(=O)C1=CC=C(N(C)C)C=C1 RTKIYFITIVXBLE-UHFFFAOYSA-N 0.000 description 1
- 108010039203 Tripeptidyl-Peptidase 1 Proteins 0.000 description 1
- 102100034197 Tripeptidyl-peptidase 1 Human genes 0.000 description 1
- 108010050144 Triptorelin Pamoate Proteins 0.000 description 1
- 108010028230 Trp-Ser- His-Pro-Gln-Phe-Glu-Lys Proteins 0.000 description 1
- 241000223105 Trypanosoma brucei Species 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 208000026928 Turner syndrome Diseases 0.000 description 1
- 206010067584 Type 1 diabetes mellitus Diseases 0.000 description 1
- 208000037386 Typhoid Diseases 0.000 description 1
- 102100024537 Tyrosine-protein kinase Fer Human genes 0.000 description 1
- 108010001957 Ularitide Proteins 0.000 description 1
- 201000006704 Ulcerative Colitis Diseases 0.000 description 1
- 108010092464 Urate Oxidase Proteins 0.000 description 1
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 1
- 102100029794 Urocortin-3 Human genes 0.000 description 1
- 102400001279 Urodilatin Human genes 0.000 description 1
- 108010047196 Urofollitropin Proteins 0.000 description 1
- 108090000435 Urokinase-type plasminogen activator Proteins 0.000 description 1
- 102000003990 Urokinase-type plasminogen activator Human genes 0.000 description 1
- 108090000203 Uteroglobin Proteins 0.000 description 1
- 102000003848 Uteroglobin Human genes 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- 241000238584 Vargula Species 0.000 description 1
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 description 1
- 108010003205 Vasoactive Intestinal Peptide Proteins 0.000 description 1
- 102400000015 Vasoactive intestinal peptide Human genes 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 1
- 229940122803 Vinca alkaloid Drugs 0.000 description 1
- FPIPGXGPPPQFEQ-BOOMUCAASA-N Vitamin A Natural products OC/C=C(/C)\C=C\C=C(\C)/C=C/C1=C(C)CCCC1(C)C FPIPGXGPPPQFEQ-BOOMUCAASA-N 0.000 description 1
- 206010047853 Waxy flexibility Diseases 0.000 description 1
- 230000004156 Wnt signaling pathway Effects 0.000 description 1
- KLGQSVMIPOVQAX-UHFFFAOYSA-N XAV939 Chemical compound N=1C=2CCSCC=2C(O)=NC=1C1=CC=C(C(F)(F)F)C=C1 KLGQSVMIPOVQAX-UHFFFAOYSA-N 0.000 description 1
- 241000710772 Yellow fever virus Species 0.000 description 1
- PTFCDOFLOPIGGS-UHFFFAOYSA-N Zinc dication Chemical compound [Zn+2] PTFCDOFLOPIGGS-UHFFFAOYSA-N 0.000 description 1
- IEDXPSOJFSVCKU-HOKPPMCLSA-N [4-[[(2S)-5-(carbamoylamino)-2-[[(2S)-2-[6-(2,5-dioxopyrrolidin-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl N-[(2S)-1-[[(2S)-1-[[(3R,4S,5S)-1-[(2S)-2-[(1R,2R)-3-[[(1S,2R)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]-N-methylcarbamate Chemical compound CC[C@H](C)[C@@H]([C@@H](CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)c1ccccc1)OC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCc1ccc(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN2C(=O)CCC2=O)C(C)C)cc1)C(C)C IEDXPSOJFSVCKU-HOKPPMCLSA-N 0.000 description 1
- 229960000446 abciximab Drugs 0.000 description 1
- 229950008805 abexinostat Drugs 0.000 description 1
- RUDNHCHNENLLKM-UHFFFAOYSA-N ac1mj1v6 Chemical compound O=C1NC(CC(O)=O)C(=O)N2CC(O)CC2C(=O)NC(C(C)C(O)CO)C(=O)NC(C2)C(=O)NCC(=O)NC(C(C)CC)C(=O)NCC(=O)NC1CSC1=C2C2=CC=C(O)C=C2N1 RUDNHCHNENLLKM-UHFFFAOYSA-N 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 239000008351 acetate buffer Substances 0.000 description 1
- 125000002777 acetyl group Chemical group [H]C([H])([H])C(*)=O 0.000 description 1
- 108010052004 acetyl-2-naphthylalanyl-3-chlorophenylalanyl-1-oxohexadecyl-seryl-4-aminophenylalanyl(hydroorotyl)-4-aminophenylalanyl(carbamoyl)-leucyl-ILys-prolyl-alaninamide Proteins 0.000 description 1
- 229940022698 acetylcholinesterase Drugs 0.000 description 1
- 239000000488 activin Substances 0.000 description 1
- 230000010933 acylation Effects 0.000 description 1
- 238000005917 acylation reaction Methods 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 1
- 210000001789 adipocyte Anatomy 0.000 description 1
- 201000005188 adrenal gland cancer Diseases 0.000 description 1
- 208000024447 adrenal gland neoplasm Diseases 0.000 description 1
- 238000005273 aeration Methods 0.000 description 1
- 229960005075 afamelanotide Drugs 0.000 description 1
- 108700026906 afamelanotide Proteins 0.000 description 1
- ULXXDDBFHOBEHA-CWDCEQMOSA-N afatinib Chemical compound N1=CN=C2C=C(O[C@@H]3COCC3)C(NC(=O)/C=C/CN(C)C)=CC2=C1NC1=CC=C(F)C(Cl)=C1 ULXXDDBFHOBEHA-CWDCEQMOSA-N 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 108010087924 alanylproline Proteins 0.000 description 1
- 108700004695 alarelin Proteins 0.000 description 1
- 108010049769 albutrepenonacog alfa Proteins 0.000 description 1
- 229960001354 albutrepenonacog alfa Drugs 0.000 description 1
- 229940060516 alferon n Drugs 0.000 description 1
- 229960004593 alglucosidase alfa Drugs 0.000 description 1
- ZMJWRJKGPUDEOX-LMXUULCNSA-A alicaforsen Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](COP([O-])(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C=C2)=O)COP([O-])(=S)O[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP([O-])(=S)O[C@@H]2[C@H](O[C@H](C2)N2C3=NC=NC(N)=C3N=C2)COP([O-])(=S)O[C@@H]2[C@H](O[C@H](C2)N2C3=NC=NC(N)=C3N=C2)COP([O-])(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C=C2)=O)COP([O-])(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C=C2)=O)COP([O-])(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C=C2)=O)COP([O-])(=S)O[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)CO)[C@@H](OP([O-])(=S)OC[C@@H]2[C@H](C[C@@H](O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OP([O-])(=S)OC[C@@H]2[C@H](C[C@@H](O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OP([S-])(=O)OC[C@@H]2[C@H](C[C@@H](O2)N2C(N=C(N)C=C2)=O)OP([O-])(=S)OC[C@@H]2[C@H](C[C@@H](O2)N2C3=NC=NC(N)=C3N=C2)OP([O-])(=S)OC[C@@H]2[C@H](C[C@@H](O2)N2C(NC(=O)C(C)=C2)=O)OP([O-])(=S)OC[C@@H]2[C@H](C[C@@H](O2)N2C(N=C(N)C=C2)=O)OP([O-])(=S)OC[C@@H]2[C@H](C[C@@H](O2)N2C(N=C(N)C=C2)=O)OP([O-])(=S)OC[C@@H]2[C@H](C[C@@H](O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OP([O-])(=S)OC[C@@H]2[C@H](C[C@@H](O2)N2C(NC(=O)C(C)=C2)=O)OP([O-])(=S)OC[C@@H]2[C@H](C[C@@H](O2)N2C(N=C(N)C=C2)=O)OP([O-])(=S)OC[C@@H]2[C@H](C[C@@H](O2)N2C3=NC=NC(N)=C3N=C2)O)C1 ZMJWRJKGPUDEOX-LMXUULCNSA-A 0.000 description 1
- 229950011466 alicaforsen Drugs 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- FPIPGXGPPPQFEQ-OVSJKPMPSA-N all-trans-retinol Chemical compound OC\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C FPIPGXGPPPQFEQ-OVSJKPMPSA-N 0.000 description 1
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 1
- 102000005840 alpha-Galactosidase Human genes 0.000 description 1
- 108010030291 alpha-Galactosidase Proteins 0.000 description 1
- 102000016679 alpha-Glucosidases Human genes 0.000 description 1
- 108010028144 alpha-Glucosidases Proteins 0.000 description 1
- 108010009380 alpha-N-acetyl-D-glucosaminidase Proteins 0.000 description 1
- FPQFYIAXQDXNOR-QDKLYSGJSA-N alpha-Zearalenol Chemical compound O=C1O[C@@H](C)CCC[C@H](O)CCC\C=C\C2=CC(O)=CC(O)=C21 FPQFYIAXQDXNOR-QDKLYSGJSA-N 0.000 description 1
- 229960000711 alprostadil Drugs 0.000 description 1
- 229960003318 alteplase Drugs 0.000 description 1
- 108010004258 amaninamide Proteins 0.000 description 1
- BOHCOUQZNDPURZ-UHFFFAOYSA-N amaninamide Natural products O=C1NC(CC(N)=O)C(=O)N2CC(O)CC2C(=O)NC(C(C)C(O)CO)C(=O)NC(C2)C(=O)NCC(=O)NC(C(C)CC)C(=O)NCC(=O)NC1CS(=O)C1=C2C2=CC=CC=C2N1 BOHCOUQZNDPURZ-UHFFFAOYSA-N 0.000 description 1
- 108010070826 amediplase Proteins 0.000 description 1
- 229950011356 amediplase Drugs 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 229940126575 aminoglycoside Drugs 0.000 description 1
- 229940043215 aminolevulinate Drugs 0.000 description 1
- 238000012870 ammonium sulfate precipitation Methods 0.000 description 1
- 229960003022 amoxicillin Drugs 0.000 description 1
- LSQZJLSUYDQPKJ-NJBDSQKTSA-N amoxicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=C(O)C=C1 LSQZJLSUYDQPKJ-NJBDSQKTSA-N 0.000 description 1
- 229960002616 ancestim Drugs 0.000 description 1
- 108700024685 ancestim Proteins 0.000 description 1
- 108010080146 androgen receptors Proteins 0.000 description 1
- 230000001548 androgenic effect Effects 0.000 description 1
- 108010021281 angiotensin I (1-7) Proteins 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 108010070670 antarelix Proteins 0.000 description 1
- 229940045799 anthracyclines and related substance Drugs 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 230000001093 anti-cancer Effects 0.000 description 1
- 230000001028 anti-proliverative effect Effects 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 239000002111 antiemetic agent Substances 0.000 description 1
- 239000000739 antihistaminic agent Substances 0.000 description 1
- 229940125715 antihistaminic agent Drugs 0.000 description 1
- 229940041181 antineoplastic drug Drugs 0.000 description 1
- 229940045985 antineoplastic platinum compound Drugs 0.000 description 1
- 239000004019 antithrombin Substances 0.000 description 1
- 229950002986 apatorsen Drugs 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 108010072041 arginyl-glycyl-aspartic acid Proteins 0.000 description 1
- 206010003246 arthritis Diseases 0.000 description 1
- 210000003567 ascitic fluid Anatomy 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 238000003556 assay Methods 0.000 description 1
- 208000006673 asthma Diseases 0.000 description 1
- 108010063987 astressin Proteins 0.000 description 1
- HPYIIXJJVYSMCV-MGDXKYBTSA-N astressin Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCC)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]1C(N[C@@H](C)C(=O)N[C@@H](CC=2N=CNC=2)C(=O)N[C@@H](CCCCNC(=O)CC1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(N)=O)=O)C(C)C)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CNC=N1 HPYIIXJJVYSMCV-MGDXKYBTSA-N 0.000 description 1
- 229950009925 atacicept Drugs 0.000 description 1
- 239000012298 atmosphere Substances 0.000 description 1
- 108700007535 atosiban Proteins 0.000 description 1
- VWXRQYYUEIYXCZ-OBIMUBPZSA-N atosiban Chemical compound C1=CC(OCC)=CC=C1C[C@@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(=O)N2[C@@H](CCC2)C(=O)N[C@@H](CCCN)C(=O)NCC(N)=O)CSSCCC(=O)N1 VWXRQYYUEIYXCZ-OBIMUBPZSA-N 0.000 description 1
- 229960002403 atosiban Drugs 0.000 description 1
- 230000001746 atrial effect Effects 0.000 description 1
- 108010044540 auristatin Proteins 0.000 description 1
- 229960003005 axitinib Drugs 0.000 description 1
- RITAVMQDGBJQJZ-FMIVXFBMSA-N axitinib Chemical compound CNC(=O)C1=CC=CC=C1SC1=CC=C(C(\C=C\C=2N=CC=CC=2)=NN2)C2=C1 RITAVMQDGBJQJZ-FMIVXFBMSA-N 0.000 description 1
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 239000003899 bactericide agent Substances 0.000 description 1
- SGUXGJPBTNFBAD-UHFFFAOYSA-L barium iodide Chemical compound [I-].[I-].[Ba+2] SGUXGJPBTNFBAD-UHFFFAOYSA-L 0.000 description 1
- 229940075444 barium iodide Drugs 0.000 description 1
- 229910001638 barium iodide Inorganic materials 0.000 description 1
- 238000002869 basic local alignment search tool Methods 0.000 description 1
- 229950003269 bectumomab Drugs 0.000 description 1
- 229960003094 belinostat Drugs 0.000 description 1
- NCNRHFGMJRPRSK-MDZDMXLPSA-N belinostat Chemical compound ONC(=O)\C=C\C1=CC=CC(S(=O)(=O)NC=2C=CC=CC=2)=C1 NCNRHFGMJRPRSK-MDZDMXLPSA-N 0.000 description 1
- 229940088007 benadryl Drugs 0.000 description 1
- 229960002507 benperidol Drugs 0.000 description 1
- 229950008872 beroctocog alfa Drugs 0.000 description 1
- CXQCLLQQYTUUKJ-ALWAHNIESA-N beta-D-GalpNAc-(1->4)-[alpha-Neup5Ac-(2->8)-alpha-Neup5Ac-(2->3)]-beta-D-Galp-(1->4)-beta-D-Glcp-(1<->1')-Cer(d18:1/18:0) Chemical compound O[C@@H]1[C@@H](O)[C@H](OC[C@H](NC(=O)CCCCCCCCCCCCCCCCC)[C@H](O)\C=C\CCCCCCCCCCCCC)O[C@H](CO)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@]2(O[C@H]([C@H](NC(C)=O)[C@@H](O)C2)[C@H](O)[C@@H](CO)O[C@]2(O[C@H]([C@H](NC(C)=O)[C@@H](O)C2)[C@H](O)[C@H](O)CO)C(O)=O)C(O)=O)[C@@H](O[C@H]2[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O2)NC(C)=O)[C@@H](CO)O1 CXQCLLQQYTUUKJ-ALWAHNIESA-N 0.000 description 1
- 102000005936 beta-Galactosidase Human genes 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- SQVRNKJHWKZAKO-UHFFFAOYSA-N beta-N-Acetyl-D-neuraminic acid Natural products CC(=O)NC1C(O)CC(O)(C(O)=O)OC1C(O)C(O)CO SQVRNKJHWKZAKO-UHFFFAOYSA-N 0.000 description 1
- 229960000397 bevacizumab Drugs 0.000 description 1
- 125000002619 bicyclic group Chemical group 0.000 description 1
- 108010087173 bile salt-stimulated lipase Proteins 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 230000031018 biological processes and functions Effects 0.000 description 1
- 108010055460 bivalirudin Proteins 0.000 description 1
- OIRCOABEOLEUMC-GEJPAHFPSA-N bivalirudin Chemical compound C([C@@H](C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)CNC(=O)CNC(=O)CNC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 OIRCOABEOLEUMC-GEJPAHFPSA-N 0.000 description 1
- 229960001500 bivalirudin Drugs 0.000 description 1
- 229930189065 blasticidin Natural products 0.000 description 1
- 239000003114 blood coagulation factor Substances 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 230000036760 body temperature Effects 0.000 description 1
- 229940098773 bovine serum albumin Drugs 0.000 description 1
- UYRCOTSOPWOSJK-JXTBTVDRSA-N bradykinin antagonist Chemical compound C1C2=CC=CC=C2CC1[C@@H](NC(=O)C(CO)NC(=O)C(NC(=O)CNC(=O)[C@H]1N(C[C@H](O)C1)C(=O)C1N(CCC1)C(=O)C(CCCNC(N)=N)NC(=O)[C@@H](CCCNC(N)=N)NC(=N)CCCCCCC(=N)N[C@H](CCCNC(N)=N)C(=O)NC(CCCNC(N)=N)C(=O)N1C(CCC1)C(=O)N1[C@@H](C[C@@H](O)C1)C(=O)NCC(=O)NC(C1CC2=CC=CC=C2C1)C(=O)NC(CO)C(=O)N[C@H](C1CC2=CC=CC=C2C1)C(=O)N1C2CCCCC2CC1C(=O)NC(CCCNC(N)=N)C(O)=O)C1CC2=CC=CC=C2C1)C(=O)N1C2CCCCC2CC1C(=O)NC(CCCNC(=N)N)C(O)=O UYRCOTSOPWOSJK-JXTBTVDRSA-N 0.000 description 1
- 239000003152 bradykinin antagonist Substances 0.000 description 1
- 238000009395 breeding Methods 0.000 description 1
- 230000001488 breeding effect Effects 0.000 description 1
- 108010072543 bremelanotide Proteins 0.000 description 1
- FFHBJDQSGDNCIV-MFVUMRCOSA-N bremelanotide Chemical compound C([C@@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@@H](CCCCNC(=O)C[C@@H](C(N[C@@H](CC=2NC=NC=2)C(=O)N1)=O)NC(=O)[C@@H](NC(C)=O)CCCC)C(O)=O)C1=CC=CC=C1 FFHBJDQSGDNCIV-MFVUMRCOSA-N 0.000 description 1
- 229950000740 bremelanotide Drugs 0.000 description 1
- 229960002473 brinase Drugs 0.000 description 1
- 229960004037 bromperidol Drugs 0.000 description 1
- 210000000424 bronchial epithelial cell Anatomy 0.000 description 1
- 229950009621 bucelipase alfa Drugs 0.000 description 1
- RMRJXGBAOAMLHD-IHFGGWKQSA-N buprenorphine Chemical compound C([C@]12[C@H]3OC=4C(O)=CC=C(C2=4)C[C@@H]2[C@]11CC[C@]3([C@H](C1)[C@](C)(O)C(C)(C)C)OC)CN2CC1CC1 RMRJXGBAOAMLHD-IHFGGWKQSA-N 0.000 description 1
- 229960001736 buprenorphine Drugs 0.000 description 1
- 229950002931 burlulipase Drugs 0.000 description 1
- 229960002719 buserelin Drugs 0.000 description 1
- CUWODFFVMXJOKD-UVLQAERKSA-N buserelin Chemical compound CCNC(=O)[C@@H]1CCCN1C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](COC(C)(C)C)NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1NC(=O)CC1)CC1=CC=C(O)C=C1 CUWODFFVMXJOKD-UVLQAERKSA-N 0.000 description 1
- 229960001292 cabozantinib Drugs 0.000 description 1
- ONIQOQHATWINJY-UHFFFAOYSA-N cabozantinib Chemical compound C=12C=C(OC)C(OC)=CC2=NC=CC=1OC(C=C1)=CC=C1NC(=O)C1(C(=O)NC=2C=CC(F)=CC=2)CC1 ONIQOQHATWINJY-UHFFFAOYSA-N 0.000 description 1
- 229960004015 calcitonin Drugs 0.000 description 1
- BBBFJLBPOGFECG-VJVYQDLKSA-N calcitonin Chemical compound N([C@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(N)=O)C(C)C)C(=O)[C@@H]1CSSC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1 BBBFJLBPOGFECG-VJVYQDLKSA-N 0.000 description 1
- 239000000480 calcium channel blocker Substances 0.000 description 1
- 244000309466 calf Species 0.000 description 1
- 229930195731 calicheamicin Natural products 0.000 description 1
- 238000007707 calorimetry Methods 0.000 description 1
- 229940041011 carbapenems Drugs 0.000 description 1
- NSTRIRCPWQHTIA-DTRKZRJBSA-N carbetocin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CSCCCC(=O)N1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(N)=O)=O)[C@@H](C)CC)C1=CC=C(OC)C=C1 NSTRIRCPWQHTIA-DTRKZRJBSA-N 0.000 description 1
- 229960001118 carbetocin Drugs 0.000 description 1
- 108700021293 carbetocin Proteins 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 125000004432 carbon atom Chemical group C* 0.000 description 1
- 229960004562 carboplatin Drugs 0.000 description 1
- 150000007942 carboxylates Chemical group 0.000 description 1
- 210000004413 cardiac myocyte Anatomy 0.000 description 1
- 108010021331 carfilzomib Proteins 0.000 description 1
- 229960002438 carfilzomib Drugs 0.000 description 1
- BLMPQMFVWMYDKT-NZTKNTHTSA-N carfilzomib Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(C)C)C(=O)[C@]1(C)OC1)NC(=O)CN1CCOCC1)CC1=CC=CC=C1 BLMPQMFVWMYDKT-NZTKNTHTSA-N 0.000 description 1
- 229960001684 catridecacog Drugs 0.000 description 1
- 229960002100 cefepime Drugs 0.000 description 1
- HVFLCNVBZFFHBT-ZKDACBOMSA-N cefepime Chemical compound S([C@@H]1[C@@H](C(N1C=1C([O-])=O)=O)NC(=O)\C(=N/OC)C=2N=C(N)SC=2)CC=1C[N+]1(C)CCCC1 HVFLCNVBZFFHBT-ZKDACBOMSA-N 0.000 description 1
- 229960000484 ceftazidime Drugs 0.000 description 1
- ORFOPKXBNMVMKC-DWVKKRMSSA-N ceftazidime Chemical compound S([C@@H]1[C@@H](C(N1C=1C([O-])=O)=O)NC(=O)\C(=N/OC(C)(C)C(O)=O)C=2N=C(N)SC=2)CC=1C[N+]1=CC=CC=C1 ORFOPKXBNMVMKC-DWVKKRMSSA-N 0.000 description 1
- 229960005229 ceftiofur Drugs 0.000 description 1
- ZBHXIWJRIFEVQY-IHMPYVIRSA-N ceftiofur Chemical compound S([C@@H]1[C@@H](C(N1C=1C(O)=O)=O)NC(=O)\C(=N/OC)C=2N=C(N)SC=2)CC=1CSC(=O)C1=CC=CO1 ZBHXIWJRIFEVQY-IHMPYVIRSA-N 0.000 description 1
- 230000021164 cell adhesion Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 208000015114 central nervous system disease Diseases 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 229940124587 cephalosporin Drugs 0.000 description 1
- 150000001780 cephalosporins Chemical class 0.000 description 1
- 208000026106 cerebrovascular disease Diseases 0.000 description 1
- 229960003230 cetrorelix Drugs 0.000 description 1
- 108700008462 cetrorelix Proteins 0.000 description 1
- SBNPWPIBESPSIF-MHWMIDJBSA-N cetrorelix Chemical compound C([C@@H](C(=O)N[C@H](CCCNC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)N[C@H](C)C(N)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](CC=1C=NC=CC=1)NC(=O)[C@@H](CC=1C=CC(Cl)=CC=1)NC(=O)[C@@H](CC=1C=C2C=CC=CC2=CC=1)NC(C)=O)C1=CC=C(O)C=C1 SBNPWPIBESPSIF-MHWMIDJBSA-N 0.000 description 1
- DDPFHDCZUJFNAT-PZPWKVFESA-N chembl2104402 Chemical compound N([C@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](C)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(N)=O)C(C)C)C(=O)[C@@H]1CCCCCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1 DDPFHDCZUJFNAT-PZPWKVFESA-N 0.000 description 1
- TZRFSLHOCZEXCC-HIVFKXHNSA-N chembl2219536 Chemical compound N1([C@H]2C[C@@H]([C@H](O2)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C(NC(=O)C(C)=C2)=O)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C(C)=C2)=O)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C(NC(=O)C(C)=C2)=O)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C3=NC=NC(N)=C3N=C2)COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2CO)N2C3=C(C(NC(N)=N3)=O)N=C2)OCCOC)N2C(N=C(N)C(C)=C2)=O)OCCOC)N2C(N=C(N)C(C)=C2)=O)OCCOC)N2C(NC(=O)C(C)=C2)=O)OCCOC)N2C(N=C(N)C(C)=C2)=O)OCCOC)SP(O)(=O)OC[C@H]2O[C@H](C[C@@H]2SP(O)(=O)OC[C@H]2O[C@H](C[C@@H]2SP(O)(=O)OC[C@H]2O[C@H](C[C@@H]2SP(O)(=O)OC[C@@H]2[C@H]([C@H]([C@@H](O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OCCOC)SP(O)(=O)OC[C@H]2[C@@H]([C@@H]([C@H](O2)N2C(N=C(N)C(C)=C2)=O)OCCOC)SP(O)(=O)OC[C@H]2[C@@H]([C@@H]([C@H](O2)N2C3=NC=NC(N)=C3N=C2)OCCOC)SP(O)(=O)OC[C@H]2[C@@H]([C@@H]([C@H](O2)N2C(N=C(N)C(C)=C2)=O)OCCOC)SP(O)(=O)OC[C@H]2[C@H](O)[C@@H]([C@H](O2)N2C(N=C(N)C(C)=C2)=O)OCCOC)N2C(N=C(N)C(C)=C2)=O)N2C(NC(=O)C(C)=C2)=O)N2C(NC(=O)C(C)=C2)=O)C=C(C)C(N)=NC1=O TZRFSLHOCZEXCC-HIVFKXHNSA-N 0.000 description 1
- HWGQMRYQVZSGDQ-HZPDHXFCSA-N chembl3137320 Chemical compound CN1N=CN=C1[C@H]([C@H](N1)C=2C=CC(F)=CC=2)C2=NNC(=O)C3=C2C1=CC(F)=C3 HWGQMRYQVZSGDQ-HZPDHXFCSA-N 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 229960003996 chlormadinone Drugs 0.000 description 1
- VUHJZBBCZGVNDZ-TTYLFXKOSA-N chlormadinone Chemical compound C1=C(Cl)C2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(=O)C)(O)[C@@]1(C)CC2 VUHJZBBCZGVNDZ-TTYLFXKOSA-N 0.000 description 1
- ZPEIMTDSQAKGNT-UHFFFAOYSA-N chlorpromazine Chemical compound C1=C(Cl)C=C2N(CCCN(C)C)C3=CC=CC=C3SC2=C1 ZPEIMTDSQAKGNT-UHFFFAOYSA-N 0.000 description 1
- 229960001076 chlorpromazine Drugs 0.000 description 1
- 229960001552 chlorprothixene Drugs 0.000 description 1
- 102000049842 cholesterol binding protein Human genes 0.000 description 1
- 108010011793 cholesterol binding protein Proteins 0.000 description 1
- 239000000064 cholinergic agonist Substances 0.000 description 1
- 229960004681 choriogonadotropin alfa Drugs 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- AHMIRVCNZZUANP-LPBAWZRYSA-N chrysalin Chemical compound CC(O)=O.CC(O)=O.C([C@@H](C(=O)N[C@@H](C(C)C)C(N)=O)NC(=O)[C@H]1N(CCC1)C(=O)CNC(=O)CNC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CS)NC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](C)N)C1=CC=CC=C1.C([C@@H](C(=O)N[C@@H](C(C)C)C(N)=O)NC(=O)[C@H]1N(CCC1)C(=O)CNC(=O)CNC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CS)NC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](C)N)C1=CC=CC=C1.C([C@@H](C(=O)N[C@@H](C(C)C)C(N)=O)NC(=O)[C@H]1N(CCC1)C(=O)CNC(=O)CNC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CS)NC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](C)N)C1=CC=CC=C1 AHMIRVCNZZUANP-LPBAWZRYSA-N 0.000 description 1
- 210000004081 cilia Anatomy 0.000 description 1
- 229960004316 cisplatin Drugs 0.000 description 1
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 1
- 239000007979 citrate buffer Substances 0.000 description 1
- 229960002173 citrulline Drugs 0.000 description 1
- 235000013477 citrulline Nutrition 0.000 description 1
- 229960001184 clopenthixol Drugs 0.000 description 1
- 229960004170 clozapine Drugs 0.000 description 1
- QZUDBNBUXVUHMW-UHFFFAOYSA-N clozapine Chemical compound C1CN(C)CCN1C1=NC2=CC(Cl)=CC=C2NC2=CC=CC=C12 QZUDBNBUXVUHMW-UHFFFAOYSA-N 0.000 description 1
- 229940105774 coagulation factor ix Drugs 0.000 description 1
- 229940105778 coagulation factor viii Drugs 0.000 description 1
- 229940105756 coagulation factor x Drugs 0.000 description 1
- 229940105784 coagulation factor xiii Drugs 0.000 description 1
- AGVAZMGAQJOSFJ-WZHZPDAFSA-M cobalt(2+);[(2r,3s,4r,5s)-5-(5,6-dimethylbenzimidazol-1-yl)-4-hydroxy-2-(hydroxymethyl)oxolan-3-yl] [(2r)-1-[3-[(1r,2r,3r,4z,7s,9z,12s,13s,14z,17s,18s,19r)-2,13,18-tris(2-amino-2-oxoethyl)-7,12,17-tris(3-amino-3-oxopropyl)-3,5,8,8,13,15,18,19-octamethyl-2 Chemical compound [Co+2].N#[C-].[N-]([C@@H]1[C@H](CC(N)=O)[C@@]2(C)CCC(=O)NC[C@@H](C)OP(O)(=O)O[C@H]3[C@H]([C@H](O[C@@H]3CO)N3C4=CC(C)=C(C)C=C4N=C3)O)\C2=C(C)/C([C@H](C\2(C)C)CCC(N)=O)=N/C/2=C\C([C@H]([C@@]/2(CC(N)=O)C)CCC(N)=O)=N\C\2=C(C)/C2=N[C@]1(C)[C@@](C)(CC(N)=O)[C@@H]2CCC(N)=O AGVAZMGAQJOSFJ-WZHZPDAFSA-M 0.000 description 1
- FDJOLVPMNUYSCM-WZHZPDAFSA-L cobalt(3+);[(2r,3s,4r,5s)-5-(5,6-dimethylbenzimidazol-1-yl)-4-hydroxy-2-(hydroxymethyl)oxolan-3-yl] [(2r)-1-[3-[(1r,2r,3r,4z,7s,9z,12s,13s,14z,17s,18s,19r)-2,13,18-tris(2-amino-2-oxoethyl)-7,12,17-tris(3-amino-3-oxopropyl)-3,5,8,8,13,15,18,19-octamethyl-2 Chemical compound [Co+3].N#[C-].N([C@@H]([C@]1(C)[N-]\C([C@H]([C@@]1(CC(N)=O)C)CCC(N)=O)=C(\C)/C1=N/C([C@H]([C@@]1(CC(N)=O)C)CCC(N)=O)=C\C1=N\C([C@H](C1(C)C)CCC(N)=O)=C/1C)[C@@H]2CC(N)=O)=C\1[C@]2(C)CCC(=O)NC[C@@H](C)OP([O-])(=O)O[C@H]1[C@@H](O)[C@@H](N2C3=CC(C)=C(C)C=C3N=C2)O[C@@H]1CO FDJOLVPMNUYSCM-WZHZPDAFSA-L 0.000 description 1
- 206010009887 colitis Diseases 0.000 description 1
- 229960002424 collagenase Drugs 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 208000029742 colonic neoplasm Diseases 0.000 description 1
- 229940126681 complement 5a receptor antagonist Drugs 0.000 description 1
- 108010073240 complement C5a-inhibitors Proteins 0.000 description 1
- 102000006834 complement receptors Human genes 0.000 description 1
- 108010047295 complement receptors Proteins 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 108700005721 conestat alfa Proteins 0.000 description 1
- 229960005020 conestat alfa Drugs 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000013270 controlled release Methods 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- GBONBLHJMVUBSJ-FAUHKOHMSA-N corticorelin Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(N)=O)[C@@H](C)CC)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](C)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H]1N(CCC1)C(=O)[C@H]1N(CCC1)C(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CO)[C@@H](C)CC)[C@@H](C)O)C(C)C)C1=CNC=N1 GBONBLHJMVUBSJ-FAUHKOHMSA-N 0.000 description 1
- 229960004544 cortisone Drugs 0.000 description 1
- ZOEFCCMDUURGSE-SQKVDDBVSA-N cosyntropin Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(O)=O)NC(=O)[C@@H](N)CO)C1=CC=C(O)C=C1 ZOEFCCMDUURGSE-SQKVDDBVSA-N 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 238000004132 cross linking Methods 0.000 description 1
- RCFZILUHCNXXFY-DEDWCYLFSA-N custirsen Chemical compound N1([C@@H]2O[C@H](COP(O)(=S)O[C@H]3[C@H]([C@@H](O[C@@H]3COP(S)(=O)O[C@H]3[C@H]([C@@H](O[C@@H]3COP(O)(=S)O[C@H]3[C@H]([C@@H](O[C@@H]3COP(O)(=S)O[C@@H]3[C@H](O[C@H](C3)N3C4=NC=NC(N)=C4N=C3)COP(O)(=S)O[C@@H]3[C@H](O[C@H](C3)N3C(N=C(N)C=C3)=O)COP(O)(=S)O[C@@H]3[C@H](O[C@H](C3)N3C(NC(=O)C(C)=C3)=O)COP(O)(=S)O[C@@H]3[C@H](O[C@H](C3)N3C(NC(=O)C(C)=C3)=O)COP(O)(=S)O[C@@H]3[C@H](O[C@H](C3)N3C(N=C(N)C=C3)=O)COP(O)(=S)O[C@@H]3[C@H](O[C@H](C3)N3C(NC(=O)C(C)=C3)=O)COP(O)(=S)O[C@@H]3[C@H](O[C@H](C3)N3C4=C(C(NC(N)=N4)=O)N=C3)COP(O)(=S)O[C@@H]3[C@H](O[C@H](C3)N3C4=NC=NC(N)=C4N=C3)COP(O)(=S)O[C@@H]3[C@H](O[C@H](C3)N3C4=C(C(NC(N)=N4)=O)N=C3)COP(O)(=S)O[C@@H]3[C@H](O[C@H](C3)N3C4=NC=NC(N)=C4N=C3)COP(O)(=S)O[C@@H]3[C@H](O[C@H](C3)N3C(N=C(N)C=C3)=O)COP(O)(=S)O[C@@H]3[C@H](O[C@H](C3)N3C4=C(C(NC(N)=N4)=O)N=C3)COP(O)(=S)O[C@@H]3[C@H](O[C@H](C3)N3C4=NC=NC(N)=C4N=C3)COP(O)(=S)O[C@H]3[C@H]([C@@H](O[C@@H]3COP(O)(=S)O[C@H]3[C@H]([C@@H](O[C@@H]3COP(O)(=S)O[C@H]3[C@H]([C@@H](O[C@@H]3COP(O)(=S)O[C@H]3[C@H]([C@@H](O[C@@H]3CO)N3C(N=C(N)C(C)=C3)=O)OCCOC)N3C4=NC=NC(N)=C4N=C3)OCCOC)N3C4=C(C(NC(N)=N4)=O)N=C3)OCCOC)N3C(N=C(N)C(C)=C3)=O)OCCOC)N3C(NC(=O)C(C)=C3)=O)OCCOC)N3C(N=C(N)C(C)=C3)=O)OCCOC)N3C4=NC=NC(N)=C4N=C3)OCCOC)[C@@H](O)[C@H]2OCCOC)C=C(C)C(=O)NC1=O RCFZILUHCNXXFY-DEDWCYLFSA-N 0.000 description 1
- 229950001605 custirsen Drugs 0.000 description 1
- 238000005520 cutting process Methods 0.000 description 1
- 229960002104 cyanocobalamin Drugs 0.000 description 1
- 235000000639 cyanocobalamin Nutrition 0.000 description 1
- 239000011666 cyanocobalamin Substances 0.000 description 1
- 108060002021 cyanovirin N Proteins 0.000 description 1
- 239000002875 cyclin dependent kinase inhibitor Substances 0.000 description 1
- 229940043378 cyclin-dependent kinase inhibitor Drugs 0.000 description 1
- QASFUMOKHFSJGL-UHFFFAOYSA-N cyclopamine Natural products C1C=C2CC(O)CCC2(C)C(CC2=C3C)C1C2CCC13OC2CC(C)CNC2C1C QASFUMOKHFSJGL-UHFFFAOYSA-N 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 239000000824 cytostatic agent Substances 0.000 description 1
- 230000001085 cytostatic effect Effects 0.000 description 1
- 229940127089 cytotoxic agent Drugs 0.000 description 1
- 108010022561 danegaptide Proteins 0.000 description 1
- BIZKIHUJGMSVFD-MNOVXSKESA-N danegaptide Chemical compound C1[C@@H](C(O)=O)N(C(=O)CN)C[C@@H]1NC(=O)C1=CC=CC=C1 BIZKIHUJGMSVFD-MNOVXSKESA-N 0.000 description 1
- 229950002922 danegaptide Drugs 0.000 description 1
- 229960000975 daunorubicin Drugs 0.000 description 1
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 1
- 229960002272 degarelix Drugs 0.000 description 1
- MEUCPCLKGZSHTA-XYAYPHGZSA-N degarelix Chemical compound C([C@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCNC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@H](C)C(N)=O)NC(=O)[C@H](CC=1C=CC(NC(=O)[C@H]2NC(=O)NC(=O)C2)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](CC=1C=NC=CC=1)NC(=O)[C@@H](CC=1C=CC(Cl)=CC=1)NC(=O)[C@@H](CC=1C=C2C=CC=CC2=CC=1)NC(C)=O)C1=CC=C(NC(N)=O)C=C1 MEUCPCLKGZSHTA-XYAYPHGZSA-N 0.000 description 1
- 229960001853 demegestone Drugs 0.000 description 1
- JWAHBTQSSMYISL-MHTWAQMVSA-N demegestone Chemical compound C1CC2=CC(=O)CCC2=C2[C@@H]1[C@@H]1CC[C@@](C(=O)C)(C)[C@@]1(C)CC2 JWAHBTQSSMYISL-MHTWAQMVSA-N 0.000 description 1
- 210000004443 dendritic cell Anatomy 0.000 description 1
- 208000025729 dengue disease Diseases 0.000 description 1
- 108010017271 denileukin diftitox Proteins 0.000 description 1
- BEFZAMRWPCMWFJ-UHFFFAOYSA-N desoxyepothilone A Natural products O1C(=O)CC(O)C(C)(C)C(=O)C(C)C(O)C(C)CCCC=CCC1C(C)=CC1=CSC(C)=N1 BEFZAMRWPCMWFJ-UHFFFAOYSA-N 0.000 description 1
- XOZIUKBZLSUILX-UHFFFAOYSA-N desoxyepothilone B Natural products O1C(=O)CC(O)C(C)(C)C(=O)C(C)C(O)C(C)CCCC(C)=CCC1C(C)=CC1=CSC(C)=N1 XOZIUKBZLSUILX-UHFFFAOYSA-N 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000002059 diagnostic imaging Methods 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- GDLBFKVLRPITMI-UHFFFAOYSA-N diazoxide Chemical compound ClC1=CC=C2NC(C)=NS(=O)(=O)C2=C1 GDLBFKVLRPITMI-UHFFFAOYSA-N 0.000 description 1
- 229960004042 diazoxide Drugs 0.000 description 1
- 229960001843 dibotermin alfa Drugs 0.000 description 1
- QKSGNWJOQMSBEP-UHFFFAOYSA-N diethyl-[[6-[[4-(hydroxycarbamoyl)phenyl]carbamoyloxymethyl]naphthalen-2-yl]methyl]azanium;chloride Chemical compound [Cl-].C1=CC2=CC(C[NH+](CC)CC)=CC=C2C=C1COC(=O)NC1=CC=C(C(=O)NO)C=C1 QKSGNWJOQMSBEP-UHFFFAOYSA-N 0.000 description 1
- RGLYKWWBQGJZGM-ISLYRVAYSA-N diethylstilbestrol Chemical compound C=1C=C(O)C=CC=1C(/CC)=C(\CC)C1=CC=C(O)C=C1 RGLYKWWBQGJZGM-ISLYRVAYSA-N 0.000 description 1
- 229960000452 diethylstilbestrol Drugs 0.000 description 1
- 238000003748 differential diagnosis Methods 0.000 description 1
- 229960004993 dimenhydrinate Drugs 0.000 description 1
- 229950006690 dimethisterone Drugs 0.000 description 1
- ZZVUWRFHKOJYTH-UHFFFAOYSA-N diphenhydramine Chemical compound C=1C=CC=CC=1C(OCCN(C)C)C1=CC=CC=C1 ZZVUWRFHKOJYTH-UHFFFAOYSA-N 0.000 description 1
- 229960000520 diphenhydramine Drugs 0.000 description 1
- PCHPORCSPXIHLZ-UHFFFAOYSA-N diphenhydramine hydrochloride Chemical compound [Cl-].C=1C=CC=CC=1C(OCC[NH+](C)C)C1=CC=CC=C1 PCHPORCSPXIHLZ-UHFFFAOYSA-N 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- BNIILDVGGAEEIG-UHFFFAOYSA-L disodium hydrogen phosphate Chemical compound [Na+].[Na+].OP([O-])([O-])=O BNIILDVGGAEEIG-UHFFFAOYSA-L 0.000 description 1
- 229910000397 disodium phosphate Inorganic materials 0.000 description 1
- 235000019800 disodium phosphate Nutrition 0.000 description 1
- 239000006185 dispersion Substances 0.000 description 1
- 208000007784 diverticulitis Diseases 0.000 description 1
- AMRJKAQTDDKMCE-UHFFFAOYSA-N dolastatin Chemical compound CC(C)C(N(C)C)C(=O)NC(C(C)C)C(=O)N(C)C(C(C)C)C(OC)CC(=O)N1CCCC1C(OC)C(C)C(=O)NC(C=1SC=CN=1)CC1=CC=CC=C1 AMRJKAQTDDKMCE-UHFFFAOYSA-N 0.000 description 1
- 229930188854 dolastatin Natural products 0.000 description 1
- 108010067396 dornase alfa Proteins 0.000 description 1
- 229960000533 dornase alfa Drugs 0.000 description 1
- 230000002222 downregulating effect Effects 0.000 description 1
- 229940099182 dramamine Drugs 0.000 description 1
- 229940075060 driminate Drugs 0.000 description 1
- 229960005501 duocarmycin Drugs 0.000 description 1
- 229930184221 duocarmycin Natural products 0.000 description 1
- 229960004913 dydrogesterone Drugs 0.000 description 1
- JGMOKGBVKVMRFX-HQZYFCCVSA-N dydrogesterone Chemical compound C1=CC2=CC(=O)CC[C@@]2(C)[C@H]2[C@@H]1[C@@H]1CC[C@H](C(=O)C)[C@@]1(C)CC2 JGMOKGBVKVMRFX-HQZYFCCVSA-N 0.000 description 1
- 108010011867 ecallantide Proteins 0.000 description 1
- 229960001174 ecallantide Drugs 0.000 description 1
- 230000002500 effect on skin Effects 0.000 description 1
- 239000012636 effector Substances 0.000 description 1
- QBEPNUQJQWDYKU-BMGKTWPMSA-N egrifta Chemical compound C([C@H](NC(=O)C/C=C/CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(N)=O)C1=CC=C(O)C=C1 QBEPNUQJQWDYKU-BMGKTWPMSA-N 0.000 description 1
- 108700032313 elcatonin Proteins 0.000 description 1
- 229960000756 elcatonin Drugs 0.000 description 1
- 238000000119 electrospray ionisation mass spectrum Methods 0.000 description 1
- AYLPVIWBPZMVSH-FCKMLYJASA-N eledoisin Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H]1NC(=O)CC1)C1=CC=CC=C1 AYLPVIWBPZMVSH-FCKMLYJASA-N 0.000 description 1
- 229950011049 eledoisin Drugs 0.000 description 1
- 229960002294 elosulfase alfa Drugs 0.000 description 1
- 210000002308 embryonic cell Anatomy 0.000 description 1
- 210000001671 embryonic stem cell Anatomy 0.000 description 1
- 210000003890 endocrine cell Anatomy 0.000 description 1
- 239000000147 enterotoxin Substances 0.000 description 1
- INVTYAOGFAGBOE-UHFFFAOYSA-N entinostat Chemical compound NC1=CC=CC=C1NC(=O)C(C=C1)=CC=C1CNC(=O)OCC1=CC=CN=C1 INVTYAOGFAGBOE-UHFFFAOYSA-N 0.000 description 1
- 229950005837 entinostat Drugs 0.000 description 1
- 229950009493 entolimod Drugs 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 230000007247 enzymatic mechanism Effects 0.000 description 1
- 229950010264 epafipase Drugs 0.000 description 1
- 229940116977 epidermal growth factor Drugs 0.000 description 1
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 1
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 1
- 229960001904 epirubicin Drugs 0.000 description 1
- 210000002919 epithelial cell Anatomy 0.000 description 1
- 229930013356 epothilone Natural products 0.000 description 1
- QXRSDHAAWVKZLJ-PVYNADRNSA-N epothilone B Chemical compound C/C([C@@H]1C[C@@H]2O[C@]2(C)CCC[C@@H]([C@@H]([C@@H](C)C(=O)C(C)(C)[C@@H](O)CC(=O)O1)O)C)=C\C1=CSC(C)=N1 QXRSDHAAWVKZLJ-PVYNADRNSA-N 0.000 description 1
- BEFZAMRWPCMWFJ-QJKGZULSSA-N epothilone C Chemical compound O1C(=O)C[C@H](O)C(C)(C)C(=O)[C@H](C)[C@@H](O)[C@@H](C)CCC\C=C/C[C@H]1C(\C)=C\C1=CSC(C)=N1 BEFZAMRWPCMWFJ-QJKGZULSSA-N 0.000 description 1
- XOZIUKBZLSUILX-GIQCAXHBSA-N epothilone D Chemical compound O1C(=O)C[C@H](O)C(C)(C)C(=O)[C@H](C)[C@@H](O)[C@@H](C)CCC\C(C)=C/C[C@H]1C(\C)=C\C1=CSC(C)=N1 XOZIUKBZLSUILX-GIQCAXHBSA-N 0.000 description 1
- FCCNKYGSMOSYPV-UHFFFAOYSA-N epothilone E Natural products O1C(=O)CC(O)C(C)(C)C(=O)C(C)C(O)C(C)CCCC2OC2CC1C(C)=CC1=CSC(CO)=N1 FCCNKYGSMOSYPV-UHFFFAOYSA-N 0.000 description 1
- FCCNKYGSMOSYPV-OKOHHBBGSA-N epothilone e Chemical compound C/C([C@@H]1C[C@@H]2O[C@@H]2CCC[C@@H]([C@@H]([C@@H](C)C(=O)C(C)(C)[C@@H](O)CC(=O)O1)O)C)=C\C1=CSC(CO)=N1 FCCNKYGSMOSYPV-OKOHHBBGSA-N 0.000 description 1
- UKIMCRYGLFQEOE-RGJAOAFDSA-N epothilone f Chemical compound C/C([C@@H]1C[C@@H]2O[C@]2(C)CCC[C@@H]([C@@H]([C@@H](C)C(=O)C(C)(C)[C@@H](O)CC(=O)O1)O)C)=C\C1=CSC(CO)=N1 UKIMCRYGLFQEOE-RGJAOAFDSA-N 0.000 description 1
- 229960001433 erlotinib Drugs 0.000 description 1
- AAKJLRGGTJKAMG-UHFFFAOYSA-N erlotinib Chemical compound C=12C=C(OCCOC)C(OCCOC)=CC2=NC=NC=1NC1=CC=CC(C#C)=C1 AAKJLRGGTJKAMG-UHFFFAOYSA-N 0.000 description 1
- 239000002329 esterase inhibitor Substances 0.000 description 1
- 229960005309 estradiol Drugs 0.000 description 1
- PROQIPRRNZUXQM-ZXXIGWHRSA-N estriol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H]([C@H](O)C4)O)[C@@H]4[C@@H]3CCC2=C1 PROQIPRRNZUXQM-ZXXIGWHRSA-N 0.000 description 1
- 229960001348 estriol Drugs 0.000 description 1
- 229940011871 estrogen Drugs 0.000 description 1
- 239000000262 estrogen Substances 0.000 description 1
- 229960003399 estrone Drugs 0.000 description 1
- 229950005470 eteplirsen Drugs 0.000 description 1
- CHNXZKVNWQUJIB-CEGNMAFCSA-N ethisterone Chemical compound O=C1CC[C@]2(C)[C@H]3CC[C@](C)([C@](CC4)(O)C#C)[C@@H]4[C@@H]3CCC2=C1 CHNXZKVNWQUJIB-CEGNMAFCSA-N 0.000 description 1
- 229960000445 ethisterone Drugs 0.000 description 1
- CAYJBRBGZBCZKO-BHGBQCOSSA-N ethyl (e,4s)-4-[[(2r,5s)-2-[(4-fluorophenyl)methyl]-6-methyl-5-[(5-methyl-1,2-oxazole-3-carbonyl)amino]-4-oxoheptanoyl]amino]-5-[(3s)-2-oxopyrrolidin-3-yl]pent-2-enoate Chemical compound C([C@@H](/C=C/C(=O)OCC)NC(=O)[C@@H](CC(=O)[C@@H](NC(=O)C1=NOC(C)=C1)C(C)C)CC=1C=CC(F)=CC=1)[C@@H]1CCNC1=O CAYJBRBGZBCZKO-BHGBQCOSSA-N 0.000 description 1
- ONKUMRGIYFNPJW-KIEAKMPYSA-N ethynodiol diacetate Chemical compound C1C[C@]2(C)[C@@](C#C)(OC(C)=O)CC[C@H]2[C@@H]2CCC3=C[C@@H](OC(=O)C)CC[C@@H]3[C@H]21 ONKUMRGIYFNPJW-KIEAKMPYSA-N 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 229960001519 exenatide Drugs 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 210000002744 extracellular matrix Anatomy 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 108010055671 ezrin Proteins 0.000 description 1
- 229940012413 factor vii Drugs 0.000 description 1
- 229940012414 factor viia Drugs 0.000 description 1
- 229960000301 factor viii Drugs 0.000 description 1
- 108700020627 fertirelin Proteins 0.000 description 1
- DGCPIBPDYFLAAX-YTAGXALCSA-N fertirelin Chemical compound CCNC(=O)[C@@H]1CCCN1C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1NC(=O)CC1)CC1=CC=C(O)C=C1 DGCPIBPDYFLAAX-YTAGXALCSA-N 0.000 description 1
- 229950001491 fertirelin Drugs 0.000 description 1
- 102000003977 fibroblast growth factor 18 Human genes 0.000 description 1
- 108090000370 fibroblast growth factor 18 Proteins 0.000 description 1
- 229940029303 fibroblast growth factor-1 Drugs 0.000 description 1
- 229950000133 filanesib Drugs 0.000 description 1
- LLXISKGBWFTGEI-FQEVSTJZSA-N filanesib Chemical compound C1([C@]2(CCCN)SC(=NN2C(=O)N(C)OC)C=2C(=CC=C(F)C=2)F)=CC=CC=C1 LLXISKGBWFTGEI-FQEVSTJZSA-N 0.000 description 1
- 229960003760 florfenicol Drugs 0.000 description 1
- 239000012530 fluid Substances 0.000 description 1
- MGCCHNLNRBULBU-WZTVWXICSA-N flunixin meglumine Chemical compound CNC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO.C1=CC=C(C(F)(F)F)C(C)=C1NC1=NC=CC=C1C(O)=O MGCCHNLNRBULBU-WZTVWXICSA-N 0.000 description 1
- 229960000469 flunixin meglumine Drugs 0.000 description 1
- 229940124307 fluoroquinolone Drugs 0.000 description 1
- YLRFCQOZQXIBAB-RBZZARIASA-N fluoxymesterone Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1CC[C@](C)(O)[C@@]1(C)C[C@@H]2O YLRFCQOZQXIBAB-RBZZARIASA-N 0.000 description 1
- 229960001751 fluoxymesterone Drugs 0.000 description 1
- 229960002419 flupentixol Drugs 0.000 description 1
- 229960002690 fluphenazine Drugs 0.000 description 1
- 229960003532 fluspirilene Drugs 0.000 description 1
- 108010006578 follitropin alfa Proteins 0.000 description 1
- 229960005210 follitropin alfa Drugs 0.000 description 1
- 108010081934 follitropin beta Proteins 0.000 description 1
- 229960002907 follitropin beta Drugs 0.000 description 1
- 229960000936 fumagillin Drugs 0.000 description 1
- UIWYJDYFSGRHKR-UHFFFAOYSA-N gadolinium atom Chemical compound [Gd] UIWYJDYFSGRHKR-UHFFFAOYSA-N 0.000 description 1
- FJEKYHHLGZLYAT-FKUIBCNASA-N galp Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(N)=O)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(O)=O)[C@@H](C)CC)[C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H]1N(CCC1)C(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)CNC(=O)CNC(=O)[C@H](CCCNC(N)=N)NC(=O)CNC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H](C)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](C)N)[C@@H](C)O)C(C)C)C1=CNC=N1 FJEKYHHLGZLYAT-FKUIBCNASA-N 0.000 description 1
- BTCSSZJGUNDROE-UHFFFAOYSA-N gamma-aminobutyric acid Chemical compound NCCCC(O)=O BTCSSZJGUNDROE-UHFFFAOYSA-N 0.000 description 1
- GIVLTTJNORAZON-HDBOBKCLSA-N ganglioside GM2 (18:0) Chemical compound O[C@@H]1[C@@H](O)[C@H](OC[C@H](NC(=O)CCCCCCCCCCCCCCCCC)[C@H](O)\C=C\CCCCCCCCCCCCC)O[C@H](CO)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@]2(O[C@H]([C@H](NC(C)=O)[C@@H](O)C2)[C@H](O)[C@H](O)CO)C(O)=O)[C@@H](O[C@H]2[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O2)NC(C)=O)[C@@H](CO)O1 GIVLTTJNORAZON-HDBOBKCLSA-N 0.000 description 1
- 150000002270 gangliosides Chemical class 0.000 description 1
- 229960003794 ganirelix Drugs 0.000 description 1
- 108700032141 ganirelix Proteins 0.000 description 1
- GJNXBNATEDXMAK-PFLSVRRQSA-N ganirelix Chemical compound C([C@@H](C(=O)N[C@H](CCCCN=C(NCC)NCC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN=C(NCC)NCC)C(=O)N1[C@@H](CCC1)C(=O)N[C@H](C)C(N)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](CC=1C=NC=CC=1)NC(=O)[C@@H](CC=1C=CC(Cl)=CC=1)NC(=O)[C@@H](CC=1C=C2C=CC=CC2=CC=1)NC(C)=O)C1=CC=C(O)C=C1 GJNXBNATEDXMAK-PFLSVRRQSA-N 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- 108010091264 gastric triacylglycerol lipase Proteins 0.000 description 1
- 229960002584 gefitinib Drugs 0.000 description 1
- XGALLCVXEZPNRQ-UHFFFAOYSA-N gefitinib Chemical compound C=12C=C(OCCCN3CCOCC3)C(OC)=CC2=NC=NC=1NC1=CC=C(F)C(Cl)=C1 XGALLCVXEZPNRQ-UHFFFAOYSA-N 0.000 description 1
- QTQAWLPCGQOSGP-GBTDJJJQSA-N geldanamycin Chemical compound N1C(=O)\C(C)=C/C=C\[C@@H](OC)[C@H](OC(N)=O)\C(C)=C/[C@@H](C)[C@@H](O)[C@H](OC)C[C@@H](C)CC2=C(OC)C(=O)C=C1C2=O QTQAWLPCGQOSGP-GBTDJJJQSA-N 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 238000012215 gene cloning Methods 0.000 description 1
- 238000001476 gene delivery Methods 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 210000004602 germ cell Anatomy 0.000 description 1
- 210000002980 germ line cell Anatomy 0.000 description 1
- 208000004104 gestational diabetes Diseases 0.000 description 1
- 229940042385 glatiramer Drugs 0.000 description 1
- 108060003196 globin Proteins 0.000 description 1
- 102000018146 globin Human genes 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 125000000404 glutamine group Chemical group N[C@@H](CCC(N)=O)C(=O)* 0.000 description 1
- 150000002339 glycosphingolipids Chemical class 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 229960001442 gonadorelin Drugs 0.000 description 1
- 239000002474 gonadorelin antagonist Substances 0.000 description 1
- 229940035638 gonadotropin-releasing hormone Drugs 0.000 description 1
- 229960002913 goserelin Drugs 0.000 description 1
- MFWNKCLOYSRHCJ-BTTYYORXSA-N granisetron Chemical compound C1=CC=C2C(C(=O)N[C@H]3C[C@H]4CCC[C@@H](C3)N4C)=NN(C)C2=C1 MFWNKCLOYSRHCJ-BTTYYORXSA-N 0.000 description 1
- 229960003727 granisetron Drugs 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 239000000122 growth hormone Substances 0.000 description 1
- 230000010005 growth-factor like effect Effects 0.000 description 1
- 229960003878 haloperidol Drugs 0.000 description 1
- 239000003481 heat shock protein 90 inhibitor Substances 0.000 description 1
- 239000000185 hemagglutinin Substances 0.000 description 1
- 108010013846 hematide Proteins 0.000 description 1
- 208000006750 hematuria Diseases 0.000 description 1
- 208000002672 hepatitis B Diseases 0.000 description 1
- 210000003494 hepatocyte Anatomy 0.000 description 1
- 229940022353 herceptin Drugs 0.000 description 1
- 229940006607 hirudin Drugs 0.000 description 1
- WQPDUTSPKFMPDP-OUMQNGNKSA-N hirudin Chemical compound C([C@@H](C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC(OS(O)(=O)=O)=CC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCCCN)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@H]1NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]2CSSC[C@@H](C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(=O)N[C@H](C(NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N2)=O)CSSC1)C(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]1NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=2C=CC(O)=CC=2)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)C(C)C)[C@@H](C)O)CSSC1)C(C)C)[C@@H](C)O)[C@@H](C)O)C1=CC=CC=C1 WQPDUTSPKFMPDP-OUMQNGNKSA-N 0.000 description 1
- 239000003276 histone deacetylase inhibitor Substances 0.000 description 1
- HHXHVIJIIXKSOE-QILQGKCVSA-N histrelin Chemical compound CCNC(=O)[C@@H]1CCCN1C(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)CC(N=C1)=CN1CC1=CC=CC=C1 HHXHVIJIIXKSOE-QILQGKCVSA-N 0.000 description 1
- 108700020746 histrelin Proteins 0.000 description 1
- 229960002193 histrelin Drugs 0.000 description 1
- 239000002835 hiv fusion inhibitor Substances 0.000 description 1
- 230000006801 homologous recombination Effects 0.000 description 1
- 238000002744 homologous recombination Methods 0.000 description 1
- 208000029080 human African trypanosomiasis Diseases 0.000 description 1
- 102000053391 human F Human genes 0.000 description 1
- 108700031895 human F Proteins 0.000 description 1
- 102000057593 human F8 Human genes 0.000 description 1
- 102000057239 human FGF7 Human genes 0.000 description 1
- 102000045921 human GAA Human genes 0.000 description 1
- 102000049489 human GALNS Human genes 0.000 description 1
- 102000055277 human IL2 Human genes 0.000 description 1
- 102000043864 human PRSS2 Human genes 0.000 description 1
- 102000058004 human PTH Human genes 0.000 description 1
- 108700038605 human Smooth muscle Proteins 0.000 description 1
- 102000043827 human Smooth muscle Human genes 0.000 description 1
- 102000051206 human THBD Human genes 0.000 description 1
- 229940084986 human chorionic gonadotropin Drugs 0.000 description 1
- 229960000900 human factor viii Drugs 0.000 description 1
- 102000011854 humanin Human genes 0.000 description 1
- 229950003450 hyalosidase Drugs 0.000 description 1
- 229920002674 hyaluronan Polymers 0.000 description 1
- 229960003160 hyaluronic acid Drugs 0.000 description 1
- 229960002773 hyaluronidase Drugs 0.000 description 1
- 238000004191 hydrophobic interaction chromatography Methods 0.000 description 1
- 230000033444 hydroxylation Effects 0.000 description 1
- 238000005805 hydroxylation reaction Methods 0.000 description 1
- ZQDWXGKKHFNSQK-UHFFFAOYSA-N hydroxyzine Chemical compound C1CN(CCOCCO)CCN1C(C=1C=CC(Cl)=CC=1)C1=CC=CC=C1 ZQDWXGKKHFNSQK-UHFFFAOYSA-N 0.000 description 1
- 229960003220 hydroxyzine hydrochloride Drugs 0.000 description 1
- 201000001421 hyperglycemia Diseases 0.000 description 1
- 230000002218 hypoglycaemic effect Effects 0.000 description 1
- QURWXBZNHXJZBE-SKXRKSCCSA-N icatibant Chemical compound NC(N)=NCCC[C@@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(=O)NCC(=O)N[C@@H](CC=2SC=CC=2)C(=O)N[C@@H](CO)C(=O)N2[C@H](CC3=CC=CC=C3C2)C(=O)N2[C@@H](C[C@@H]3CCCC[C@@H]32)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)C[C@@H](O)C1 QURWXBZNHXJZBE-SKXRKSCCSA-N 0.000 description 1
- 229960001062 icatibant Drugs 0.000 description 1
- 108700023918 icatibant Proteins 0.000 description 1
- 229960000908 idarubicin Drugs 0.000 description 1
- 238000005417 image-selected in vivo spectroscopy Methods 0.000 description 1
- XZZXIYZZBJDEEP-UHFFFAOYSA-N imipramine hydrochloride Chemical compound [Cl-].C1CC2=CC=CC=C2N(CCC[NH+](C)C)C2=CC=CC=C21 XZZXIYZZBJDEEP-UHFFFAOYSA-N 0.000 description 1
- 229960002102 imipramine hydrochloride Drugs 0.000 description 1
- 230000028993 immune response Effects 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 238000001114 immunoprecipitation Methods 0.000 description 1
- 239000002596 immunotoxin Substances 0.000 description 1
- 231100000608 immunotoxin Toxicity 0.000 description 1
- 230000002637 immunotoxin Effects 0.000 description 1
- 229940051026 immunotoxin Drugs 0.000 description 1
- 238000000530 impalefection Methods 0.000 description 1
- 239000012535 impurity Substances 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 208000000509 infertility Diseases 0.000 description 1
- 230000036512 infertility Effects 0.000 description 1
- 231100000535 infertility Toxicity 0.000 description 1
- 229950002133 iniparib Drugs 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- PBGKTOXHQIOBKM-FHFVDXKLSA-N insulin (human) Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@H]1CSSC[C@H]2C(=O)N[C@H](C(=O)N[C@@H](CO)C(=O)N[C@H](C(=O)N[C@H](C(N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=3C=CC(O)=CC=3)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=3C=CC(O)=CC=3)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=3C=CC(O)=CC=3)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=3NC=NC=3)NC(=O)[C@H](CO)NC(=O)CNC1=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O)=O)CSSC[C@@H](C(N2)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](NC(=O)CN)[C@@H](C)CC)[C@@H](C)CC)[C@@H](C)O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C=CC=CC=1)C(C)C)C1=CN=CN1 PBGKTOXHQIOBKM-FHFVDXKLSA-N 0.000 description 1
- 239000004026 insulin derivative Substances 0.000 description 1
- 230000002608 insulinlike Effects 0.000 description 1
- 238000012739 integrated shape imaging system Methods 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 229940125798 integrin inhibitor Drugs 0.000 description 1
- 108010044426 integrins Proteins 0.000 description 1
- 102000006495 integrins Human genes 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 229940079322 interferon Drugs 0.000 description 1
- 229950000038 interferon alfa Drugs 0.000 description 1
- 229940109242 interferon alfa-n3 Drugs 0.000 description 1
- 229960003130 interferon gamma Drugs 0.000 description 1
- 108700027921 interferon tau Proteins 0.000 description 1
- 229960001388 interferon-beta Drugs 0.000 description 1
- 229940074383 interleukin-11 Drugs 0.000 description 1
- 229940117681 interleukin-12 Drugs 0.000 description 1
- 108010074109 interleukin-22 Proteins 0.000 description 1
- 108010027445 interleukin-22 receptor Proteins 0.000 description 1
- 229940100994 interleukin-7 Drugs 0.000 description 1
- 230000000968 intestinal effect Effects 0.000 description 1
- 108010090785 inulinase Proteins 0.000 description 1
- VBUWHHLIZKOSMS-RIWXPGAOSA-N invicorp Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC=1NC=NC=1)C(C)C)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=C(O)C=C1 VBUWHHLIZKOSMS-RIWXPGAOSA-N 0.000 description 1
- 239000011630 iodine Substances 0.000 description 1
- 229910052740 iodine Inorganic materials 0.000 description 1
- 229960005386 ipilimumab Drugs 0.000 description 1
- 229950010897 iproplatin Drugs 0.000 description 1
- LNQCUTNLHUQZLR-OZJWLQQPSA-N iridin Chemical compound OC1=C(OC)C(OC)=CC(C=2C(C3=C(O)C(OC)=C(O[C@H]4[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O4)O)C=C3OC=2)=O)=C1 LNQCUTNLHUQZLR-OZJWLQQPSA-N 0.000 description 1
- VBGWSQKGUZHFPS-VGMMZINCSA-N kalbitor Chemical compound C([C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@H](C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]2C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=3C=CC=CC=3)C(=O)N[C@H](C(=O)N[C@@H](CC=3C=CC(O)=CC=3)C(=O)NCC(=O)NCC(=O)N[C@H]3CSSC[C@H](NC(=O)[C@@H]4CCCN4C(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC=4C=CC=CC=4)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC=4C=CC=CC=4)NC(=O)[C@H](CO)NC(=O)[C@H](CC=4NC=NC=4)NC(=O)[C@H](CCSC)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O)CSSC[C@H](NC(=O)[C@H](CCSC)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC=4C=CC=CC=4)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC3=O)CSSC2)C(=O)N[C@@H]([C@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=2NC=NC=2)C(=O)N2CCC[C@H]2C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N1)[C@@H](C)CC)[C@H](C)O)=O)[C@@H](C)CC)C1=CC=CC=C1 VBGWSQKGUZHFPS-VGMMZINCSA-N 0.000 description 1
- 229960003709 kallidinogenase Drugs 0.000 description 1
- 229960000318 kanamycin Drugs 0.000 description 1
- 229930027917 kanamycin Natural products 0.000 description 1
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 1
- 229930182823 kanamycin A Natural products 0.000 description 1
- OZWKMVRBQXNZKK-UHFFFAOYSA-N ketorolac Chemical compound OC(=O)C1CCN2C1=CC=C2C(=O)C1=CC=CC=C1 OZWKMVRBQXNZKK-UHFFFAOYSA-N 0.000 description 1
- 229960004752 ketorolac Drugs 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 201000010982 kidney cancer Diseases 0.000 description 1
- 229940031154 kluyveromyces marxianus Drugs 0.000 description 1
- 229940039696 lactobacillus Drugs 0.000 description 1
- 229940078795 lactoferrin Drugs 0.000 description 1
- 235000021242 lactoferrin Nutrition 0.000 description 1
- 108010051044 lanoteplase Proteins 0.000 description 1
- 229950010645 lanoteplase Drugs 0.000 description 1
- 108010021336 lanreotide Proteins 0.000 description 1
- 229960002437 lanreotide Drugs 0.000 description 1
- 229960004891 lapatinib Drugs 0.000 description 1
- BCFGMOOMADDAQU-UHFFFAOYSA-N lapatinib Chemical compound O1C(CNCCS(=O)(=O)C)=CC=C1C1=CC=C(N=CN=C2NC=3C=C(Cl)C(OCC=4C=C(F)C=CC=4)=CC=3)C2=C1 BCFGMOOMADDAQU-UHFFFAOYSA-N 0.000 description 1
- 229950000060 larazotide Drugs 0.000 description 1
- 108010080415 lecirelin Proteins 0.000 description 1
- 108091023663 let-7 stem-loop Proteins 0.000 description 1
- 108091063478 let-7-1 stem-loop Proteins 0.000 description 1
- 108091049777 let-7-2 stem-loop Proteins 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- 210000000265 leukocyte Anatomy 0.000 description 1
- GFIJNRVAKGFPGQ-LIJARHBVSA-N leuprolide Chemical compound CCNC(=O)[C@@H]1CCCN1C(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)CC1=CC=C(O)C=C1 GFIJNRVAKGFPGQ-LIJARHBVSA-N 0.000 description 1
- 229960004338 leuprorelin Drugs 0.000 description 1
- 229960004400 levonorgestrel Drugs 0.000 description 1
- 108010024409 linaclotide Proteins 0.000 description 1
- KXGCNMMJRFDFNR-WDRJZQOASA-N linaclotide Chemical compound C([C@H](NC(=O)[C@@H]1CSSC[C@H]2C(=O)N[C@H]3CSSC[C@H](N)C(=O)N[C@H](C(N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=4C=CC(O)=CC=4)C(=O)N2)=O)CSSC[C@H](NC(=O)[C@H](C)NC(=O)[C@@H]2CCCN2C(=O)[C@H](CC(N)=O)NC3=O)C(=O)N[C@H](C(NCC(=O)N1)=O)[C@H](O)C)C(O)=O)C1=CC=C(O)C=C1 KXGCNMMJRFDFNR-WDRJZQOASA-N 0.000 description 1
- 229960000812 linaclotide Drugs 0.000 description 1
- TYZROVQLWOKYKF-ZDUSSCGKSA-N linezolid Chemical compound O=C1O[C@@H](CNC(=O)C)CN1C(C=C1F)=CC=C1N1CCOCC1 TYZROVQLWOKYKF-ZDUSSCGKSA-N 0.000 description 1
- 229960003907 linezolid Drugs 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 229960002701 liraglutide Drugs 0.000 description 1
- 108010004367 lixisenatide Proteins 0.000 description 1
- 229960001093 lixisenatide Drugs 0.000 description 1
- 238000011068 loading method Methods 0.000 description 1
- 238000002865 local sequence alignment Methods 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 229940040129 luteinizing hormone Drugs 0.000 description 1
- 229960002332 lutropin alfa Drugs 0.000 description 1
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 201000004792 malaria Diseases 0.000 description 1
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 1
- 229960002531 marbofloxacin Drugs 0.000 description 1
- WKPWGQKGSOKKOO-RSFHAFMBSA-N maytansine Chemical compound CO[C@@H]([C@@]1(O)C[C@](OC(=O)N1)([C@H]([C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(C)=O)CC(=O)N1C)C)[H])\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 WKPWGQKGSOKKOO-RSFHAFMBSA-N 0.000 description 1
- 108010004051 measles virus hemagglutinin protein G Proteins 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 238000013160 medical therapy Methods 0.000 description 1
- 229960004616 medroxyprogesterone Drugs 0.000 description 1
- FRQMUZJSZHZSGN-HBNHAYAOSA-N medroxyprogesterone Chemical compound C([C@@]12C)CC(=O)C=C1[C@@H](C)C[C@@H]1[C@@H]2CC[C@]2(C)[C@@](O)(C(C)=O)CC[C@H]21 FRQMUZJSZHZSGN-HBNHAYAOSA-N 0.000 description 1
- VDXZNPDIRNWWCW-JFTDCZMZSA-N melittin Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(N)=O)CC1=CNC2=CC=CC=C12 VDXZNPDIRNWWCW-JFTDCZMZSA-N 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 108020004084 membrane receptors Proteins 0.000 description 1
- ANZJBCHSOXCCRQ-FKUXLPTCSA-N mertansine Chemical compound CO[C@@H]([C@@]1(O)C[C@H](OC(=O)N1)[C@@H](C)[C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(=O)CCS)CC(=O)N1C)\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 ANZJBCHSOXCCRQ-FKUXLPTCSA-N 0.000 description 1
- IMSSROKUHAOUJS-MJCUULBUSA-N mestranol Chemical compound C1C[C@]2(C)[C@@](C#C)(O)CC[C@H]2[C@@H]2CCC3=CC(OC)=CC=C3[C@H]21 IMSSROKUHAOUJS-MJCUULBUSA-N 0.000 description 1
- 229960001390 mestranol Drugs 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- VRQVVMDWGGWHTJ-CQSZACIVSA-N methotrimeprazine Chemical compound C1=CC=C2N(C[C@H](C)CN(C)C)C3=CC(OC)=CC=C3SC2=C1 VRQVVMDWGGWHTJ-CQSZACIVSA-N 0.000 description 1
- 229940042053 methotrimeprazine Drugs 0.000 description 1
- 229960001566 methyltestosterone Drugs 0.000 description 1
- 108091064399 miR-10b stem-loop Proteins 0.000 description 1
- 108091057645 miR-15 stem-loop Proteins 0.000 description 1
- 108091062762 miR-21 stem-loop Proteins 0.000 description 1
- 108091041631 miR-21-1 stem-loop Proteins 0.000 description 1
- 108091044442 miR-21-2 stem-loop Proteins 0.000 description 1
- 108091061917 miR-221 stem-loop Proteins 0.000 description 1
- 108091063489 miR-221-1 stem-loop Proteins 0.000 description 1
- 108091055391 miR-221-2 stem-loop Proteins 0.000 description 1
- 108091031076 miR-221-3 stem-loop Proteins 0.000 description 1
- 108091007431 miR-29 Proteins 0.000 description 1
- 108091074487 miR-34 stem-loop Proteins 0.000 description 1
- 108091092493 miR-34-1 stem-loop Proteins 0.000 description 1
- 108091059780 miR-34-2 stem-loop Proteins 0.000 description 1
- 108091056170 miR-499 stem-loop Proteins 0.000 description 1
- 108091050885 miR-499-1 stem-loop Proteins 0.000 description 1
- 108091038523 miR-499-2 stem-loop Proteins 0.000 description 1
- 108091059456 miR-92-1 stem-loop Proteins 0.000 description 1
- 108091084336 miR-92-2 stem-loop Proteins 0.000 description 1
- 229960003955 mianserin Drugs 0.000 description 1
- 229960002159 micafungin Drugs 0.000 description 1
- PIEUQSKUWLMALL-YABMTYFHSA-N micafungin Chemical compound C1=CC(OCCCCC)=CC=C1C1=CC(C=2C=CC(=CC=2)C(=O)N[C@@H]2C(N[C@H](C(=O)N3C[C@H](O)C[C@H]3C(=O)N[C@H](C(=O)N[C@H](C(=O)N3C[C@H](C)[C@H](O)[C@H]3C(=O)N[C@H](O)[C@H](O)C2)[C@H](O)CC(N)=O)[C@H](O)[C@@H](O)C=2C=C(OS(O)(=O)=O)C(O)=CC=2)[C@@H](C)O)=O)=NO1 PIEUQSKUWLMALL-YABMTYFHSA-N 0.000 description 1
- 108010068982 microplasmin Proteins 0.000 description 1
- 238000001768 microscale thermophoresis Methods 0.000 description 1
- 108091060283 mipomersen Proteins 0.000 description 1
- 229960004778 mipomersen Drugs 0.000 description 1
- 108010022050 mistletoe lectin I Proteins 0.000 description 1
- 210000003470 mitochondria Anatomy 0.000 description 1
- 229950007812 mocetinostat Drugs 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- SLZIZIJTGAYEKK-CIJSCKBQSA-N molport-023-220-247 Chemical compound C([C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(N)=O)NC(=O)[C@H]1N(CCC1)C(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)CN)[C@@H](C)O)C1=CNC=N1 SLZIZIJTGAYEKK-CIJSCKBQSA-N 0.000 description 1
- 108010093470 monomethyl auristatin E Proteins 0.000 description 1
- 229950003483 moroctocog alfa Drugs 0.000 description 1
- 229950003968 motesanib Drugs 0.000 description 1
- RAHBGWKEPAQNFF-UHFFFAOYSA-N motesanib Chemical compound C=1C=C2C(C)(C)CNC2=CC=1NC(=O)C1=CC=CN=C1NCC1=CC=NC=C1 RAHBGWKEPAQNFF-UHFFFAOYSA-N 0.000 description 1
- 206010028093 mucopolysaccharidosis Diseases 0.000 description 1
- 201000002273 mucopolysaccharidosis II Diseases 0.000 description 1
- 208000005340 mucopolysaccharidosis III Diseases 0.000 description 1
- 208000000690 mucopolysaccharidosis VI Diseases 0.000 description 1
- 208000022018 mucopolysaccharidosis type 2 Diseases 0.000 description 1
- 208000011045 mucopolysaccharidosis type 3 Diseases 0.000 description 1
- 208000010978 mucopolysaccharidosis type 4 Diseases 0.000 description 1
- 201000006417 multiple sclerosis Diseases 0.000 description 1
- 210000000663 muscle cell Anatomy 0.000 description 1
- 210000001665 muscle stem cell Anatomy 0.000 description 1
- 201000006938 muscular dystrophy Diseases 0.000 description 1
- 230000000869 mutational effect Effects 0.000 description 1
- 208000031225 myocardial ischemia Diseases 0.000 description 1
- QCQYVCMYGCHVMR-AAZUGDAUSA-N n-[(2r,3r,4s,5r)-4,5,6-trihydroxy-1-oxo-3-[(2r,3r,4s,5r,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyhexan-2-yl]acetamide Chemical compound CC(=O)N[C@@H](C=O)[C@H]([C@@H](O)[C@H](O)CO)O[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O QCQYVCMYGCHVMR-AAZUGDAUSA-N 0.000 description 1
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 1
- JVCWPUFNLFSKFS-UHFFFAOYSA-N n-[4-[(5-tert-butyl-1,2-oxazol-3-yl)carbamoylamino]phenyl]-5-(1-ethyl-2,2,6,6-tetramethylpiperidin-4-yl)oxypyridine-2-carboxamide Chemical compound C1C(C)(C)N(CC)C(C)(C)CC1OC1=CC=C(C(=O)NC=2C=CC(NC(=O)NC3=NOC(=C3)C(C)(C)C)=CC=2)N=C1 JVCWPUFNLFSKFS-UHFFFAOYSA-N 0.000 description 1
- UZHSEJADLWPNLE-GRGSLBFTSA-N naloxone Chemical compound O=C([C@@H]1O2)CC[C@@]3(O)[C@H]4CC5=CC=C(O)C2=C5[C@@]13CCN4CC=C UZHSEJADLWPNLE-GRGSLBFTSA-N 0.000 description 1
- 229960004127 naloxone Drugs 0.000 description 1
- 229950003830 nasaruplase beta Drugs 0.000 description 1
- 239000000692 natriuretic peptide Substances 0.000 description 1
- 210000000822 natural killer cell Anatomy 0.000 description 1
- 229940086322 navelbine Drugs 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- 201000008383 nephritis Diseases 0.000 description 1
- 229940053128 nerve growth factor Drugs 0.000 description 1
- 210000002569 neuron Anatomy 0.000 description 1
- 201000008051 neuronal ceroid lipofuscinosis Diseases 0.000 description 1
- 239000002581 neurotoxin Substances 0.000 description 1
- 231100000618 neurotoxin Toxicity 0.000 description 1
- 210000000440 neutrophil Anatomy 0.000 description 1
- 229960001783 nicardipine Drugs 0.000 description 1
- PCHKPVIQAHNQLW-CQSZACIVSA-N niraparib Chemical compound N1=C2C(C(=O)N)=CC=CC2=CN1C(C=C1)=CC=C1[C@@H]1CCCNC1 PCHKPVIQAHNQLW-CQSZACIVSA-N 0.000 description 1
- IAIWVQXQOWNYOU-FPYGCLRLSA-N nitrofural Chemical compound NC(=O)N\N=C\C1=CC=C([N+]([O-])=O)O1 IAIWVQXQOWNYOU-FPYGCLRLSA-N 0.000 description 1
- 229960001907 nitrofurazone Drugs 0.000 description 1
- 229950003943 nonacog gamma Drugs 0.000 description 1
- 229940053934 norethindrone Drugs 0.000 description 1
- 229960001652 norethindrone acetate Drugs 0.000 description 1
- VIKNJXKGJWUCNN-XGXHKTLJSA-N norethisterone Chemical compound O=C1CC[C@@H]2[C@H]3CC[C@](C)([C@](CC4)(O)C#C)[C@@H]4[C@@H]3CCC2=C1 VIKNJXKGJWUCNN-XGXHKTLJSA-N 0.000 description 1
- 239000002853 nucleic acid probe Substances 0.000 description 1
- 108010044762 nucleolin Proteins 0.000 description 1
- 235000016709 nutrition Nutrition 0.000 description 1
- 230000035764 nutrition Effects 0.000 description 1
- 235000020824 obesity Nutrition 0.000 description 1
- 229960001905 ocriplasmin Drugs 0.000 description 1
- XXUPLYBCNPLTIW-UHFFFAOYSA-N octadec-7-ynoic acid Chemical compound CCCCCCCCCCC#CCCCCCC(O)=O XXUPLYBCNPLTIW-UHFFFAOYSA-N 0.000 description 1
- 229960002700 octreotide Drugs 0.000 description 1
- 229960000572 olaparib Drugs 0.000 description 1
- 229960000470 omalizumab Drugs 0.000 description 1
- MVPAMLBUDIFYGK-BHDRXCTLSA-N omiganan Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H]3CCCN3C(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H]3CCCN3C(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)[C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(N)=O)=CNC2=C1 MVPAMLBUDIFYGK-BHDRXCTLSA-N 0.000 description 1
- 229950008583 omiganan Drugs 0.000 description 1
- 208000002042 onchocerciasis Diseases 0.000 description 1
- 230000000771 oncological effect Effects 0.000 description 1
- 229950001933 opebacan Drugs 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 229960001607 oritavancin Drugs 0.000 description 1
- VHFGEBVPHAGQPI-MYYQHNLBSA-N oritavancin Chemical compound O([C@@H]1C2=CC=C(C(=C2)Cl)OC=2C=C3C=C(C=2O[C@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)O[C@@H]2O[C@@H](C)[C@H](O)[C@@](C)(NCC=4C=CC(=CC=4)C=4C=CC(Cl)=CC=4)C2)OC2=CC=C(C=C2Cl)[C@@H](O)[C@H](C(N[C@@H](CC(N)=O)C(=O)N[C@H]3C(=O)N[C@H]2C(=O)N[C@@H]1C(N[C@H](C1=CC(O)=CC(O)=C1C=1C(O)=CC=C2C=1)C(O)=O)=O)=O)NC(=O)[C@@H](CC(C)C)NC)[C@H]1C[C@](C)(N)[C@@H](O)[C@H](C)O1 VHFGEBVPHAGQPI-MYYQHNLBSA-N 0.000 description 1
- 108010006945 oritavancin Proteins 0.000 description 1
- 229950008017 ormaplatin Drugs 0.000 description 1
- 229960003104 ornithine Drugs 0.000 description 1
- 201000008482 osteoarthritis Diseases 0.000 description 1
- 230000002611 ovarian Effects 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 210000004681 ovum Anatomy 0.000 description 1
- 229960001756 oxaliplatin Drugs 0.000 description 1
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 description 1
- 229960000625 oxytetracycline Drugs 0.000 description 1
- IWVCMVBTMGNXQD-PXOLEDIWSA-N oxytetracycline Chemical compound C1=CC=C2[C@](O)(C)[C@H]3[C@H](O)[C@H]4[C@H](N(C)C)C(O)=C(C(N)=O)C(=O)[C@@]4(O)C(O)=C3C(=O)C2=C1O IWVCMVBTMGNXQD-PXOLEDIWSA-N 0.000 description 1
- 235000019366 oxytetracycline Nutrition 0.000 description 1
- LSQZJLSUYDQPKJ-UHFFFAOYSA-N p-Hydroxyampicillin Natural products O=C1N2C(C(O)=O)C(C)(C)SC2C1NC(=O)C(N)C1=CC=C(O)C=C1 LSQZJLSUYDQPKJ-UHFFFAOYSA-N 0.000 description 1
- 102000002574 p38 Mitogen-Activated Protein Kinases Human genes 0.000 description 1
- 108010068338 p38 Mitogen-Activated Protein Kinases Proteins 0.000 description 1
- 229960002131 palonosetron Drugs 0.000 description 1
- CPZBLNMUGSZIPR-NVXWUHKLSA-N palonosetron Chemical compound C1N(CC2)CCC2[C@@H]1N1C(=O)C(C=CC=C2CCC3)=C2[C@H]3C1 CPZBLNMUGSZIPR-NVXWUHKLSA-N 0.000 description 1
- 201000002528 pancreatic cancer Diseases 0.000 description 1
- 208000008443 pancreatic carcinoma Diseases 0.000 description 1
- 229960005184 panobinostat Drugs 0.000 description 1
- FPOHNWQLNRZRFC-ZHACJKMWSA-N panobinostat Chemical compound CC=1NC2=CC=CC=C2C=1CCNCC1=CC=C(\C=C\C(=O)NO)C=C1 FPOHNWQLNRZRFC-ZHACJKMWSA-N 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 108700017947 pasireotide Proteins 0.000 description 1
- 229960005415 pasireotide Drugs 0.000 description 1
- VMZMNAABQBOLAK-DBILLSOUSA-N pasireotide Chemical compound C([C@H]1C(=O)N2C[C@@H](C[C@H]2C(=O)N[C@H](C(=O)N[C@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@H](C(N[C@@H](CC=2C=CC(OCC=3C=CC=CC=3)=CC=2)C(=O)N1)=O)CCCCN)C=1C=CC=CC=1)OC(=O)NCCN)C1=CC=CC=C1 VMZMNAABQBOLAK-DBILLSOUSA-N 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 230000007918 pathogenicity Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 229950003183 pegadricase Drugs 0.000 description 1
- 235000019371 penicillin G benzathine Nutrition 0.000 description 1
- 229940056360 penicillin g Drugs 0.000 description 1
- 229940023041 peptide vaccine Drugs 0.000 description 1
- 210000001322 periplasm Anatomy 0.000 description 1
- 230000035699 permeability Effects 0.000 description 1
- 108010062940 pexiganan Proteins 0.000 description 1
- KGZGFSNZWHMDGZ-KAYYGGFYSA-N pexiganan Chemical compound C([C@H](NC(=O)[C@H](CCCCN)NC(=O)CNC(=O)[C@@H](NC(=O)CN)[C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=CC=C1 KGZGFSNZWHMDGZ-KAYYGGFYSA-N 0.000 description 1
- 229950001731 pexiganan Drugs 0.000 description 1
- 230000004526 pharmaceutical effect Effects 0.000 description 1
- 230000003285 pharmacodynamic effect Effects 0.000 description 1
- 229940107333 phenergan Drugs 0.000 description 1
- 108010055837 phosphocarrier protein HPr Proteins 0.000 description 1
- 150000004713 phosphodiesters Chemical class 0.000 description 1
- 230000001766 physiological effect Effects 0.000 description 1
- 229960002292 piperacillin Drugs 0.000 description 1
- WCMIIGXFCMNQDS-IDYPWDAWSA-M piperacillin sodium Chemical compound [Na+].O=C1C(=O)N(CC)CCN1C(=O)N[C@H](C=1C=CC=CC=1)C(=O)N[C@@H]1C(=O)N2[C@@H](C([O-])=O)C(C)(C)S[C@@H]21 WCMIIGXFCMNQDS-IDYPWDAWSA-M 0.000 description 1
- 229950008185 pitrakinra Drugs 0.000 description 1
- 108010010907 pitrakinra Proteins 0.000 description 1
- 230000003169 placental effect Effects 0.000 description 1
- 150000003058 platinum compounds Chemical class 0.000 description 1
- 229920002401 polyacrylamide Polymers 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 238000003752 polymerase chain reaction Methods 0.000 description 1
- 239000003910 polypeptide antibiotic agent Substances 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 229960003611 pramlintide Drugs 0.000 description 1
- 108010029667 pramlintide Proteins 0.000 description 1
- NRKVKVQDUCJPIZ-MKAGXXMWSA-N pramlintide acetate Chemical compound C([C@@H](C(=O)NCC(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CCCCN)[C@@H](C)O)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 NRKVKVQDUCJPIZ-MKAGXXMWSA-N 0.000 description 1
- GCYXWQUSHADNBF-AAEALURTSA-N preproglucagon 78-108 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1N=CNC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 GCYXWQUSHADNBF-AAEALURTSA-N 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- MFDFERRIHVXMIY-UHFFFAOYSA-N procaine Chemical compound CCN(CC)CCOC(=O)C1=CC=C(N)C=C1 MFDFERRIHVXMIY-UHFFFAOYSA-N 0.000 description 1
- 229960004919 procaine Drugs 0.000 description 1
- 239000000583 progesterone congener Substances 0.000 description 1
- 102000016670 prohibitin Human genes 0.000 description 1
- 108010028138 prohibitin Proteins 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 229960001584 promegestone Drugs 0.000 description 1
- QFFCYTLOTYIJMR-XMGTWHOFSA-N promegestone Chemical compound C1CC2=CC(=O)CCC2=C2[C@@H]1[C@@H]1CC[C@@](C(=O)CC)(C)[C@@]1(C)CC2 QFFCYTLOTYIJMR-XMGTWHOFSA-N 0.000 description 1
- 230000000069 prophylactic effect Effects 0.000 description 1
- GMVPRGQOIOIIMI-DWKJAMRDSA-N prostaglandin E1 Chemical compound CCCCC[C@H](O)\C=C\[C@H]1[C@H](O)CC(=O)[C@@H]1CCCCCCC(O)=O GMVPRGQOIOIIMI-DWKJAMRDSA-N 0.000 description 1
- 230000012846 protein folding Effects 0.000 description 1
- 239000003197 protein kinase B inhibitor Substances 0.000 description 1
- 239000012474 protein marker Substances 0.000 description 1
- 238000009163 protein therapy Methods 0.000 description 1
- 229940023143 protein vaccine Drugs 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- YUOCYTRGANSSRY-UHFFFAOYSA-N pyrrolo[2,3-i][1,2]benzodiazepine Chemical class C1=CN=NC2=C3C=CN=C3C=CC2=C1 YUOCYTRGANSSRY-UHFFFAOYSA-N 0.000 description 1
- 229950010654 quisinostat Drugs 0.000 description 1
- UGGITRSRFHZMKU-WEIZIPMPSA-N radavirsen Chemical compound N1([C@H]2CN(C[C@H](O2)COP(=O)(N(C)C)N2CCN(CC2)C(=O)OCCOCCOCCO)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CN(C2)P(=O)(OC[C@H]2O[C@H](CNC2)N2C(NC(=O)C(C)=C2)=O)N(C)C)N2C(NC(=O)C(C)=C2)=O)N(C)C)N2C(NC(=O)C(C)=C2)=O)N2CCNCC2)N2C(N=C(N)C=C2)=O)N(C)C)N2C(NC(=O)C(C)=C2)=O)N(C)C)N2C3=NC=NC(N)=C3N=C2)N(C)C)N2C(N=C(N)C=C2)=O)N(C)C)N2C(NC(=O)C(C)=C2)=O)N2CCNCC2)N2C(N=C(N)C=C2)=O)N(C)C)N2C3=NC=NC(N)=C3N=C2)N(C)C)N2C3=C(C(NC(N)=N3)=O)N=C2)N(C)C)N2C3=NC=NC(N)=C3N=C2)N(C)C)N2C3=NC=NC(N)=C3N=C2)N(C)C)N2C3=C(C(NC(N)=N3)=O)N=C2)N(C)C)N2C3=NC=NC(N)=C3N=C2)N(C)C)N2C(NC(=O)C(C)=C2)=O)N2CCNCC2)N2C(NC(=O)C(C)=C2)=O)N(C)C)N2C3=C(C(NC(N)=N3)=O)N=C2)N(C)C)N2C3=C(C(NC(N)=N3)=O)N=C2)N(C)C)C=CC(N)=NC1=O UGGITRSRFHZMKU-WEIZIPMPSA-N 0.000 description 1
- 108010061338 ranpirnase Proteins 0.000 description 1
- 102000016914 ras Proteins Human genes 0.000 description 1
- 108010014186 ras Proteins Proteins 0.000 description 1
- 229960000424 rasburicase Drugs 0.000 description 1
- 108010084837 rasburicase Proteins 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 108010013773 recombinant FVIIa Proteins 0.000 description 1
- 108010033652 recombinant factor VIII N8 Proteins 0.000 description 1
- 108010025139 recombinant factor VIII SQ Proteins 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 206010038038 rectal cancer Diseases 0.000 description 1
- 201000001275 rectum cancer Diseases 0.000 description 1
- DTLOVISJEFBXLX-REAFJZEQSA-N relexan 2 Chemical compound C([C@H]1C(=O)N[C@H](C(=O)NCC(=O)N[C@H]2CSSC[C@@H](C(=O)N[C@H](C(N1)=O)CSSC[C@@H](C(NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(=O)N[C@@H](C)C(=O)N[C@H](C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@H]([C@@H](C)O)NC2=O)C(O)=O)C(=O)NCC(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CO)C(O)=O)[C@@H](C)CC)[C@@H](C)CC)C(C)C)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(O)=O)C(C)C)[C@@H](C)CC)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]1NC(=O)CC1)C(C)C)C1=CN=CN1 DTLOVISJEFBXLX-REAFJZEQSA-N 0.000 description 1
- 210000002345 respiratory system Anatomy 0.000 description 1
- 108010051412 reteplase Proteins 0.000 description 1
- 229960002917 reteplase Drugs 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 229950002666 reveglucosidase alfa Drugs 0.000 description 1
- 238000004007 reversed phase HPLC Methods 0.000 description 1
- 108700010851 rhabdoviridae proteins Proteins 0.000 description 1
- 229960004641 rituximab Drugs 0.000 description 1
- HMABYWSNWIZPAG-UHFFFAOYSA-N rucaparib Chemical compound C1=CC(CNC)=CC=C1C(N1)=C2CCNC(=O)C3=C2C1=CC(F)=C3 HMABYWSNWIZPAG-UHFFFAOYSA-N 0.000 description 1
- 229950004707 rucaparib Drugs 0.000 description 1
- 229950007656 rupintrivir Drugs 0.000 description 1
- 108010018091 rusalatide acetate Proteins 0.000 description 1
- 210000003079 salivary gland Anatomy 0.000 description 1
- 239000000523 sample Substances 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 201000004409 schistosomiasis Diseases 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 210000001732 sebaceous gland Anatomy 0.000 description 1
- 229960004542 sebelipase alfa Drugs 0.000 description 1
- 229960002101 secretin Drugs 0.000 description 1
- OWMZNFCDEHGFEP-NFBCVYDUSA-N secretin human Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(N)=O)[C@@H](C)O)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)C1=CC=CC=C1 OWMZNFCDEHGFEP-NFBCVYDUSA-N 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 210000002955 secretory cell Anatomy 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- CYOHGALHFOKKQC-UHFFFAOYSA-N selumetinib Chemical compound OCCONC(=O)C=1C=C2N(C)C=NC2=C(F)C=1NC1=CC=C(Br)C=C1Cl CYOHGALHFOKKQC-UHFFFAOYSA-N 0.000 description 1
- 229950009184 senrebotase Drugs 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 229960002792 serelaxin Drugs 0.000 description 1
- 239000003001 serine protease inhibitor Substances 0.000 description 1
- WGWPRVFKDLAUQJ-MITYVQBRSA-N sermorelin Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(N)=O)C1=CC=C(O)C=C1 WGWPRVFKDLAUQJ-MITYVQBRSA-N 0.000 description 1
- 229960002758 sermorelin Drugs 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- 108010045789 sfericase Proteins 0.000 description 1
- 229950010531 sfericase Drugs 0.000 description 1
- 201000005113 shigellosis Diseases 0.000 description 1
- SQVRNKJHWKZAKO-OQPLDHBCSA-N sialic acid Chemical compound CC(=O)N[C@@H]1[C@@H](O)C[C@@](O)(C(O)=O)OC1[C@H](O)[C@H](O)CO SQVRNKJHWKZAKO-OQPLDHBCSA-N 0.000 description 1
- 125000005630 sialyl group Chemical group 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 229960003095 simoctocog alfa Drugs 0.000 description 1
- 201000002612 sleeping sickness Diseases 0.000 description 1
- 210000001057 smooth muscle myoblast Anatomy 0.000 description 1
- 210000000329 smooth muscle myocyte Anatomy 0.000 description 1
- 230000008410 smoothened signaling pathway Effects 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 229960000553 somatostatin Drugs 0.000 description 1
- 229960003787 sorafenib Drugs 0.000 description 1
- 238000004611 spectroscopical analysis Methods 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- DUYSYHSSBDVJSM-KRWOKUGFSA-N sphingosine 1-phosphate Chemical compound CCCCCCCCCCCCC\C=C\[C@@H](O)[C@@H](N)COP(O)(O)=O DUYSYHSSBDVJSM-KRWOKUGFSA-N 0.000 description 1
- 229960001294 spiramycin Drugs 0.000 description 1
- 235000019372 spiramycin Nutrition 0.000 description 1
- 229930191512 spiramycin Natural products 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 238000003153 stable transfection Methods 0.000 description 1
- 229940041030 streptogramins Drugs 0.000 description 1
- 229960005202 streptokinase Drugs 0.000 description 1
- 229960005322 streptomycin Drugs 0.000 description 1
- FCENQCVTLJEGOT-KIHVXQRMSA-N stresscopin Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C=CC=CC=1)[C@@H](C)O)C(C)C)[C@@H](C)O)[C@@H](C)CC)[C@@H](C)CC)C1=CN=CN1 FCENQCVTLJEGOT-KIHVXQRMSA-N 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- IHBMMJGTJFPEQY-UHFFFAOYSA-N sulfanylidene(sulfanylidenestibanylsulfanyl)stibane Chemical compound S=[Sb]S[Sb]=S IHBMMJGTJFPEQY-UHFFFAOYSA-N 0.000 description 1
- 229960004940 sulpiride Drugs 0.000 description 1
- 229960001796 sunitinib Drugs 0.000 description 1
- WINHZLLDWRZWRT-ATVHPVEESA-N sunitinib Chemical compound CCN(CC)CCNC(=O)C1=C(C)NC(\C=C/2C3=CC(F)=CC=C3NC\2=O)=C1C WINHZLLDWRZWRT-ATVHPVEESA-N 0.000 description 1
- 230000002483 superagonistic effect Effects 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 1
- 229940080796 surfaxin Drugs 0.000 description 1
- 229960002557 susoctocog alfa Drugs 0.000 description 1
- 238000004114 suspension culture Methods 0.000 description 1
- 210000000106 sweat gland Anatomy 0.000 description 1
- 208000024891 symptom Diseases 0.000 description 1
- 208000011580 syndromic disease Diseases 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 230000009897 systematic effect Effects 0.000 description 1
- AYUNIORJHRXIBJ-TXHRRWQRSA-N tanespimycin Chemical class N1C(=O)\C(C)=C\C=C/[C@H](OC)[C@@H](OC(N)=O)\C(C)=C\[C@H](C)[C@@H](O)[C@@H](OC)C[C@H](C)CC2=C(NCC=C)C(=O)C=C1C2=O AYUNIORJHRXIBJ-TXHRRWQRSA-N 0.000 description 1
- 108010073046 teduglutide Proteins 0.000 description 1
- CILIXQOJUNDIDU-ASQIGDHWSA-N teduglutide Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O)[C@@H](C)CC)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CO)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)CC)C1=CC=CC=C1 CILIXQOJUNDIDU-ASQIGDHWSA-N 0.000 description 1
- 229960002444 teduglutide Drugs 0.000 description 1
- 229960000216 tenecteplase Drugs 0.000 description 1
- 229960005460 teriparatide Drugs 0.000 description 1
- BENFXAYNYRLAIU-QSVFAHTRSA-N terlipressin Chemical compound NCCCC[C@@H](C(=O)NCC(N)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC=2C=CC=CC=2)NC(=O)[C@H](CC=2C=CC(O)=CC=2)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)CN)CSSC1 BENFXAYNYRLAIU-QSVFAHTRSA-N 0.000 description 1
- 229960003813 terlipressin Drugs 0.000 description 1
- IWVCMVBTMGNXQD-UHFFFAOYSA-N terramycin dehydrate Natural products C1=CC=C2C(O)(C)C3C(O)C4C(N(C)C)C(O)=C(C(N)=O)C(=O)C4(O)C(O)=C3C(=O)C2=C1O IWVCMVBTMGNXQD-UHFFFAOYSA-N 0.000 description 1
- 229960001874 tesamorelin Drugs 0.000 description 1
- 108700002800 tesamorelin Proteins 0.000 description 1
- 229960003604 testosterone Drugs 0.000 description 1
- 229940118376 tetanus toxin Drugs 0.000 description 1
- 229960001423 tetracosactide Drugs 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- OFVLGDICTFRJMM-WESIUVDSSA-N tetracycline Chemical compound C1=CC=C2[C@](O)(C)[C@H]3C[C@H]4[C@H](N(C)C)C(O)=C(C(N)=O)C(=O)[C@@]4(O)C(O)=C3C(=O)C2=C1O OFVLGDICTFRJMM-WESIUVDSSA-N 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- 229950011372 teverelix Drugs 0.000 description 1
- 238000002560 therapeutic procedure Methods 0.000 description 1
- 229960002784 thioridazine Drugs 0.000 description 1
- 239000003868 thrombin inhibitor Substances 0.000 description 1
- 229950010888 thrombomodulin alfa Drugs 0.000 description 1
- 230000035921 thrombopoiesis Effects 0.000 description 1
- NZVYCXVTEHPMHE-ZSUJOUNUSA-N thymalfasin Chemical compound CC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O NZVYCXVTEHPMHE-ZSUJOUNUSA-N 0.000 description 1
- 229960004231 thymalfasin Drugs 0.000 description 1
- 201000002510 thyroid cancer Diseases 0.000 description 1
- 210000001685 thyroid gland Anatomy 0.000 description 1
- 239000005495 thyroid hormone Substances 0.000 description 1
- 229940036555 thyroid hormone Drugs 0.000 description 1
- 229950005830 tifacogin Drugs 0.000 description 1
- 229960000187 tissue plasminogen activator Drugs 0.000 description 1
- 229960000940 tivozanib Drugs 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- MEHHPFQKXOUFFV-OWSLCNJRSA-N trenbolone Chemical compound C1CC(=O)C=C2CC[C@@H]([C@H]3[C@@](C)([C@H](CC3)O)C=C3)C3=C21 MEHHPFQKXOUFFV-OWSLCNJRSA-N 0.000 description 1
- 229960000312 trenbolone Drugs 0.000 description 1
- RTKIYFITIVXBLE-QEQCGCAPSA-N trichostatin A Chemical compound ONC(=O)/C=C/C(/C)=C/[C@@H](C)C(=O)C1=CC=C(N(C)C)C=C1 RTKIYFITIVXBLE-QEQCGCAPSA-N 0.000 description 1
- ZEWQUBUPAILYHI-UHFFFAOYSA-N trifluoperazine Chemical compound C1CN(C)CCN1CCCN1C2=CC(C(F)(F)F)=CC=C2SC2=CC=CC=C21 ZEWQUBUPAILYHI-UHFFFAOYSA-N 0.000 description 1
- 229960002324 trifluoperazine Drugs 0.000 description 1
- XSCGXQMFQXDFCW-UHFFFAOYSA-N triflupromazine Chemical compound C1=C(C(F)(F)F)C=C2N(CCCN(C)C)C3=CC=CC=C3SC2=C1 XSCGXQMFQXDFCW-UHFFFAOYSA-N 0.000 description 1
- 229960003904 triflupromazine Drugs 0.000 description 1
- 229960004824 triptorelin Drugs 0.000 description 1
- VXKHXGOKWPXYNA-PGBVPBMZSA-N triptorelin Chemical compound C([C@@H](C(=O)N[C@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)NCC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 VXKHXGOKWPXYNA-PGBVPBMZSA-N 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- 229960001005 tuberculin Drugs 0.000 description 1
- 201000008827 tuberculosis Diseases 0.000 description 1
- 229960004568 turoctocog alfa Drugs 0.000 description 1
- 208000001072 type 2 diabetes mellitus Diseases 0.000 description 1
- 201000008297 typhoid fever Diseases 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- IUCCYQIEZNQWRS-DWWHXVEHSA-N ularitide Chemical compound C([C@H]1C(=O)NCC(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@H](C(NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CSSC[C@@H](C(=O)N1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](C)NC(=O)[C@@H](N)[C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)=O)[C@@H](C)CC)C1=CC=CC=C1 IUCCYQIEZNQWRS-DWWHXVEHSA-N 0.000 description 1
- 241000712461 unidentified influenza virus Species 0.000 description 1
- 241000701366 unidentified nuclear polyhedrosis viruses Species 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 201000005112 urinary bladder cancer Diseases 0.000 description 1
- VBEQCZHXXJYVRD-GACYYNSASA-N uroanthelone Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(C)C)[C@@H](C)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C1=CC=C(O)C=C1 VBEQCZHXXJYVRD-GACYYNSASA-N 0.000 description 1
- 229960004371 urofollitropin Drugs 0.000 description 1
- 229960005356 urokinase Drugs 0.000 description 1
- 229950000578 vatalanib Drugs 0.000 description 1
- YCOYDOIWSSHVCK-UHFFFAOYSA-N vatalanib Chemical compound C1=CC(Cl)=CC=C1NC(C1=CC=CC=C11)=NN=C1CC1=CC=NC=C1 YCOYDOIWSSHVCK-UHFFFAOYSA-N 0.000 description 1
- 229950011257 veliparib Drugs 0.000 description 1
- JNAHVYVRKWKWKQ-CYBMUJFWSA-N veliparib Chemical compound N=1C2=CC=CC(C(N)=O)=C2NC=1[C@@]1(C)CCCN1 JNAHVYVRKWKWKQ-CYBMUJFWSA-N 0.000 description 1
- 229950006040 velmanase alfa Drugs 0.000 description 1
- 229960003862 vemurafenib Drugs 0.000 description 1
- GPXBXXGIAQBQNI-UHFFFAOYSA-N vemurafenib Chemical compound CCCS(=O)(=O)NC1=CC=C(F)C(C(=O)C=2C3=CC(=CN=C3NC=2)C=2C=CC(Cl)=CC=2)=C1F GPXBXXGIAQBQNI-UHFFFAOYSA-N 0.000 description 1
- 229950006864 verpasep caltespen Drugs 0.000 description 1
- 229960003048 vinblastine Drugs 0.000 description 1
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 1
- 229960004355 vindesine Drugs 0.000 description 1
- UGGWPQSBPIFKDZ-KOTLKJBCSA-N vindesine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(N)=O)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1N=C1[C]2C=CC=C1 UGGWPQSBPIFKDZ-KOTLKJBCSA-N 0.000 description 1
- CILBMBUYJCWATM-PYGJLNRPSA-N vinorelbine ditartrate Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O.OC(=O)[C@H](O)[C@@H](O)C(O)=O.C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC CILBMBUYJCWATM-PYGJLNRPSA-N 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 238000011179 visual inspection Methods 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 235000019155 vitamin A Nutrition 0.000 description 1
- 239000011719 vitamin A Substances 0.000 description 1
- 229940045997 vitamin a Drugs 0.000 description 1
- QCZXQEYEVLCQHL-HGJJDEFOSA-N viw95i76gy Chemical compound O=C1N[C@@H](CC(O)=O)C(=O)N2C[C@H](O)C[C@H]2C(=O)N[C@@H]([C@@H](C)[C@@H](O)CO)C(=O)N[C@@H](C2)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H]1C[S@@](=O)C1=C2C2=CC=CC=C2N1 QCZXQEYEVLCQHL-HGJJDEFOSA-N 0.000 description 1
- 229950010266 volanesorsen Drugs 0.000 description 1
- 102100036537 von Willebrand factor Human genes 0.000 description 1
- 229950009132 vonapanitase Drugs 0.000 description 1
- 229950010395 vorhyaluronidase alfa Drugs 0.000 description 1
- WAEXFXRVDQXREF-UHFFFAOYSA-N vorinostat Chemical compound ONC(=O)CCCCCCC(=O)NC1=CC=CC=C1 WAEXFXRVDQXREF-UHFFFAOYSA-N 0.000 description 1
- 229960000237 vorinostat Drugs 0.000 description 1
- 239000002699 waste material Substances 0.000 description 1
- 238000004804 winding Methods 0.000 description 1
- JFCFGYGEYRIEBE-YVLHJLIDSA-N wob38vs2ni Chemical compound CO[C@@H]([C@@]1(O)C[C@H](OC(=O)N1)[C@@H](C)[C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(=O)CCC(C)(C)S)CC(=O)N1C)\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 JFCFGYGEYRIEBE-YVLHJLIDSA-N 0.000 description 1
- 229940051021 yellow-fever virus Drugs 0.000 description 1
- 229960002300 zeranol Drugs 0.000 description 1
- BPKIMPVREBSLAJ-QTBYCLKRSA-N ziconotide Chemical compound C([C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]2C(=O)N[C@@H]3C(=O)N[C@H](C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CSSC2)C(N)=O)=O)CSSC[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)CNC(=O)[C@H](CCCCN)NC(=O)CNC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CSSC3)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(N1)=O)CCSC)[C@@H](C)O)C1=CC=C(O)C=C1 BPKIMPVREBSLAJ-QTBYCLKRSA-N 0.000 description 1
- 229960002811 ziconotide Drugs 0.000 description 1
- 229960004141 zuclopenthixol Drugs 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/62—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being a protein, peptide or polyamino acid
- A61K47/64—Drug-peptide, drug-protein or drug-polyamino acid conjugates, i.e. the modifying agent being a peptide, protein or polyamino acid which is covalently bonded or complexed to a therapeutically active agent
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/001—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof by chemical synthesis
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/575—Hormones
- C07K14/5759—Products of obesity genes, e.g. leptin, obese (OB), tub, fat
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/715—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons
- C07K14/7155—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons for interleukins [IL]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/64—General methods for preparing the vector, for introducing it into the cell or for selecting the vector-containing host
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/67—General methods for enhancing the expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/67—General methods for enhancing the expression
- C12N15/68—Stabilisation of the vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/70—Vectors or expression systems specially adapted for E. coli
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/31—Fusion polypeptide fusions, other than Fc, for prolonged plasma life, e.g. albumin
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/22—Vectors comprising a coding region that has been codon optimised for expression in a respective host
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2537/00—Reactions characterised by the reaction format or use of a specific feature
- C12Q2537/10—Reactions characterised by the reaction format or use of a specific feature the purpose or use of
- C12Q2537/165—Mathematical modelling, e.g. logarithm, ratio
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Genetics & Genomics (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Zoology (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Wood Science & Technology (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- Medicinal Chemistry (AREA)
- Gastroenterology & Hepatology (AREA)
- Immunology (AREA)
- Cell Biology (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Toxicology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Epidemiology (AREA)
- Analytical Chemistry (AREA)
- Endocrinology (AREA)
- Obesity (AREA)
- Child & Adolescent Psychology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Peptides Or Proteins (AREA)
Abstract
Una molécula de ácido nucleico, en la que dicha molécula de ácido nucleico comprende una secuencia de nucleótidos que codifica un polipéptido que consta de al menos 100 residuos de aminoácidos de prolina, alanina y, opcionalmente, serina, donde dicho polipéptido forma un enrollado aleatorio, donde la secuencia de nucleótidos de dicho ácido nucleico tiene una longitud de al menos 300 nucleótidos, en el que dicha secuencia de nucleótidos tiene una puntuación de repetición de nucleótidos (NRS) inferior a 1000, donde dicha puntuación de repetición de nucleótidos (NRS) se determina de acuerdo con la fórmula: **(Ver fórmula)** donde Ntot es la longitud de dicha secuencia de nucleótidos, n es la longitud de una repetición dentro de dicha secuencia de nucleótidos, y fi(n) es la frecuencia de dicha repetición de longitud n, donde si hay más de una repetición de longitud n, k(n) es el número de dichas secuencias diferentes de dicha repetición de longitud n, de otro modo k(n) es 1 para dicha repetición de longitud n.
Description
DESCRIPCIÓN
Ácidos nucleicos que codifican secuencias repetitivas de aminoácidos ricos en residuos de prolina y alanina que tienen bajas secuencias de nucleótidos repetitivas
[0001] La presente invención se refiere a una molécula de ácido nucleico que comprende una secuencia de nucleótidos de baja repetición que codifica una secuencia de repetición de aminoácidos rica en prolina / alanina. El polipéptido codificado comprende una secuencia de aminoácidos repetitiva que forma un enrollamiento aleatorio. La molécula de ácido nucleico que comprende dichas secuencias de nucleótidos de baja repetición puede comprender además una secuencia de nucleótidos que codifica una proteína biológica o farmacológicamente activa. Además, la presente invención proporciona medios y métodos de selección para identificar dicha molécula de ácido nucleico que comprende dicha secuencia de nucleótidos de baja repetición. La presente invención también se refiere a un método para preparar dicha(s) molécula(s) de ácido nucleico. También se proporcionan en este documento métodos para preparar el polipéptido codificado o conjugado(s) de fármaco con el polipéptido codificado usando las moléculas de ácido nucleico proporcionadas en este documento. El conjugado de fármaco puede comprender una proteína activa biológica o farmacológicamente o un fármaco de molécula pequeña. También se proporcionan en el presente documento vectores y huéspedes no humanos que comprenden dichas moléculas de ácido nucleico.
[0002] Los polipéptidos que forman enrollados aleatorios se conocen en la técnica anterior. Por ejemplo, WO 2008/155134 describe proteínas que comprenden una secuencia de aminoácidos de al menos aproximadamente 100 residuos de aminoácidos y que consisten en residuos de prolina, alanina y serina (PAS). La secuencia de aminoácidos que forma la conformación de enrollado aleatorio puede comprender una pluralidad de repeticiones de aminoácidos. Estas repeticiones pueden constar de al menos 3 a 30 o más residuos de aminoácidos. WO 2011/144756 describe polipéptidos que comprenden secuencias repetitivas de aminoácidos que consisten únicamente en residuos de prolina y alanina (PA). Estos polipéptidos también forman enrollados aleatorios y constan de al menos 50 residuos de prolina y alanina. Wo 2015/132004 describe una neurotoxina clostridial recombinante que comprende un dominio de enrollado aleatorio que consiste en PAS. US 2006/0252120 A1 describe glicoproteínas ricas en hidroxiprolina, que contienen segmentos codificados como glicomódulos ricos en prolina con el motivo de secuencia de aminoácidos [(AP)5]n. También los polipéptidos de origen natural abarcan secuencias ricas en prolina y alanina, como el gen de la proteína muy grande de tegumento de1 Herpesvirus macacino 1 publicado con el número de acceso del banco de genes (AAP41454.1). Los métodos para la optimización de codones se describen en WO 2007/142954.
[0003] Los polipéptidos repetitivos de la técnica anterior, como las secuencias PAS o PA, están codificados típicamente por los correspondientes ácidos nucleicos repetitivos. Por consiguiente, los ácidos nucleicos de la técnica anterior reflejan la estructura repetitiva de las secuencias de aminoácidos que también codifican en su secuencia de nucleótidos. Por tanto, los ácidos nucleicos de la técnica anterior son muy repetitivos en su nivel de secuencia. La repetitividad de los ácidos nucleicos de la técnica anterior puede conducir a advertencias tales como inestabilidad genética parcial, en particular cuando se codifican secuencias largas de PAS o PA, por ejemplo de 300 residuos o más.
[0004] El problema técnico subyacente a la presente invención es por lo tanto la provisión de medios y métodos para la preparación conveniente y fiable de polipéptidos que contienen repeticiones de aminoácidos, en particular polipéptidos que contienen repeticiones de aminoácidos que consisten en prolina, alanina y, opcionalmente, serina.
[0005] El problema técnico se resuelve mediante la provisión de las realizaciones que se proporcionan a continuación y que se caracterizan en las reivindicaciones adjuntas.
[0006] La presente invención se refiere a una molécula de ácido nucleico, en la que dicha molécula de ácido nucleico comprende una secuencia de nucleótidos que codifica un polipéptido que consiste en al menos 100 residuos de aminoácidos de prolina, alanina y, opcionalmente, serina,
donde dicho polipéptido forma una enrollado aleatorio, donde la secuencia de nucleótidos de dicho ácido nucleico tiene una longitud de al menos 300 nucleótidos,
donde dicha secuencia de nucleótidos tiene una puntuación de repetición de nucleótidos (NRS) inferior a 1000, en la que dicha puntuación de repetición de nucleótidos (NRS) se determina de acuerdo con la fórmula:

donde
Ntot es la longitud de dicha secuencia de nucleótidos,
n es la longitud de una repetición dentro de dicha secuencia de nucleótidos, y
Fi(n) es la frecuencia de dicha repetición de longitud n,
donde si hay más de una repetición de longitud n, k(n) es el número de dichas secuencias diferentes de dicha repetición de longitud n, de otro modo k(n) es 1 para dicha repetición de longitud n.
[0007] La presente invención se refiere a moléculas de ácido nucleico con secuencias de nucleótidos de baja repetición que codifican polipéptidos que consisten en prolina, alanina y, opcionalmente, serina. Dichos polipéptidos también se denominan en el presente documento polipéptidos ricos en PA o ricos en prolina / alanina. Las moléculas de ácido nucleico de la invención proporcionadas en este documento tienen pocas o ninguna repetición de nucleótidos de una cierta longitud máxima, tal como una longitud máxima de aproximadamente 14, 15, 16 o 17 nucleótidos por secuencia de repetición de nucleótidos. Además, la secuencia de nucleótidos codificante rica en PA tiene una longitud total de al menos 300 nucleótidos y las repeticiones de nucleótidos individuales dentro de esta secuencia codificante tienen una longitud máxima individual de 14, 15, 16, 17, aproximadamente 20, aproximadamente 25, aproximadamente 30, aproximadamente 35, aproximadamente 40, aproximadamente 45, aproximadamente 50 o aproximadamente 55 nucleótidos.
[0008] La puntuación de repetición de nucleótidos (NRS) se determina de acuerdo con la fórmula:

[0009] En esta fórmula, Ntot es la longitud de dicha secuencia de nucleótidos, n es la longitud de una repetición dentro de dicha secuencia de nucleótidos, yfi(n) es la frecuencia de dicha repetición de longitud n, y donde, si hay más de una repetición de longitud n, k(n) es el número de dichas secuencias diferentes de dicha repetición de longitud n, de lo contrario k(n) es 1 para dicha repetición de longitud n. Más abajo se incluye una definición.
[0010] En un cierto aspecto, la molécula de ácido nucleico de la invención codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, en el que una secuencia de nucleótidos se extiende repetidamente dentro de la secuencia de nucleótidos de dicha molécula de ácido nucleico (es decir, una "repetición") que tiene como máximo una longitud de 14, 15, 16, 17, aproximadamente 20, aproximadamente 25, aproximadamente 30, aproximadamente 35, aproximadamente 40, aproximadamente 45, aproximadamente 50 o aproximadamente 55 nucleótidos. En otras palabras, la molécula de ácido nucleico comprende una secuencia de nucleótidos que codifica un polipéptido rico en PA, donde dicha secuencia de nucleótidos codificante comprende repeticiones de nucleótidos que tienen una longitud máxima de 14, 15, 16, 17, aproximadamente 20, aproximadamente 25, aproximadamente 30, aproximadamente. 35, aproximadamente 40, aproximadamente 45, aproximadamente 50 o aproximadamente 55 nucleótidos. Las moléculas / secuencias de ácido nucleico de la invención también pueden comprender secuencias codificantes adicionales, como, entre otras, proteínas biológica o farmacológicamente activas.
[0011] En los ejemplos adjuntos se demuestra que las moléculas de ácido nucleico de baja repetición de la invención son ventajosas en comparación con las moléculas de ácido nucleico altamente repetitivas de la técnica anterior. En particular, la estabilidad genética de las moléculas de ácido nucleico de baja repetición proporcionadas en el presente documento se mejora como se documenta en el presente documento y se muestra en los ejemplos adjuntos. Para evaluar la estabilidad genética de moléculas repetitivas de ácido nucleico de la técnica anterior que codifican polipéptidos ricos en PA, se construyó un vector que comprende una molécula repetitiva de ácido nucleico de la técnica anterior que codifica una secuencia repetitiva rica en prolina / alanina (PAS # la(600); SEQ ID NO: 12; Ejemplo 6, Fig.2B) que se compone de múltiples unidades de secuencia de nucleótidos de 60meros como se describe en WO 2008/155134. El vector se denomina en el presente documento "pASK75-PAS #1a(600)-IL1Ra" (SEQ ID NO: 51). El anfitrión (E. coli) se transformó con el vector y se cultivó durante varios días, por ejemplo, 7 días. El día 7, después de un crecimiento continuo durante aproximadamente 70 generaciones, las células se sembraron en placas de agar LB / Amp, se recogieron los clones y se realizaron preparaciones de plásmidos. Los plásmidos se analizaron utilizando enzimas de restricción y la posterior electroforesis en gel de agarosa (Fig. 5). Cuatro de los cinco clones analizados de pASK75-PAS #1a (600)-IL1Ra mostraron fragmentos acortados de ácido nucleico que codifican las secuencias ricas en prolina / alanina (Fig. 5 carriles 1-5).
[0012] Por consiguiente, las moléculas repetitivas de ácido nucleico de la técnica anterior que codifican secuencias repetitivas ricas en prolina / alanina son genéticamente inestables. En otras palabras, las moléculas de ácido nucleico de la técnica anterior tienen una baja estabilidad in vivo. Sin estar limitado por la teoría, la inestabilidad genética podría ser el resultado de una recombinación homóloga. Debido a la inestabilidad genética y al acortamiento del casete del gen, la secuencia de aminoácidos rica en prolina / alanina resultante también se verá alterada. Por tanto, la secuencia de aminoácidos rica en prolina / alanina codificada por los plásmidos inestables durante el cultivo a largo plazo será diferente de la codificada por el plásmido original. Por lo tanto, existe un riesgo considerable de que los polipéptidos obtenidos durante el cultivo a largo plazo utilizando moléculas repetitivas de ácido nucleico de la técnica anterior no sean los polipéptidos deseados.
[0013] Además, existe el riesgo de que la composición polipeptídica resultante pueda comprender una variedad de polipéptidos diferentes (por ejemplo, polipéptidos ricos en prolina / alanina de varios tamaños, longitudes y / o secuencias) que es contraria a la conformidad deseada de los productos biológicos, particularmente para uso biofarmacéutico. Por tanto, la inestabilidad genética de moléculas repetitivas de ácido nucleico de la técnica anterior que codifican polipéptidos ricos en prolina / alanina puede conducir a una disminución de la calidad del producto biológico final, haciendo que su producción sea inconveniente y poco fiable, especialmente en aspectos regulatorios para la aplicación terapéutica.
[0014] En la presente invención, el problema de la inestabilidad genética se resuelve diseñando moléculas de ácido nucleico con bajas repeticiones internas de nucleótidos. Sin embargo, dado el bajo número de codones de tripletes de nucleótidos disponibles para codificar secuencias de aminoácidos ricas en prolina / alanina, esta no fue una tarea trivial.
[0015] Como se muestra en los ejemplos no limitantes adjuntos, las moléculas de ácido nucleico de la invención evitan las desventajas mencionadas anteriormente; ver p. ej. Ejemplos 5 y 6 y Fig. 4 y Fig. 5 carriles 6-10. No obstante, al igual que las moléculas de ácido nucleico de la técnica anterior, las moléculas de ácido nucleico de la invención codifican polipéptidos ricos en prolina / alanina que contienen una pluralidad de repeticiones ricas en prolina / alanina. Sin embargo, en fuerte contraste con las moléculas de ácido nucleico de la técnica anterior, las moléculas de ácido nucleico de la presente invención tienen una secuencia de nucleótidos repetitiva baja (es decir, contienen pocas y / o solo cortas repeticiones de nucleótidos).
[0016] El Ejemplo ilustrativo 5 muestra la preparación de un vector ejemplar de la invención que comprende una secuencia de nucleótidos poco repetitiva que codifica un polipéptido rico en prolina / alanina. La secuencia de nucleótidos de baja repetición denominada "PAS# f/1c/1b(600)" como se usa en el vector de ejemplo se muestra en SEQ ID NO: 38. El plásmido resultante se denominó "pASK75-PAS#1f/1c/1b(600 )-IL1Ra” (SEQ ID NO: 50) y se muestra en la Fig. 4.
[0017] El plásmido de la invención, "pASK75-PAS#1f/1c/1b(600)-IL1Ra" se sometió al mismo cultivo descrito anteriormente en relación con el vector "pASK75-PAS#1a(600)-IL1Ra", este último vector que comprende una molécula repetitiva de ácido nucleico de la técnica anterior que codifica una secuencia repetitiva rica en prolina / alanina (PAS # la(600); SEQ ID NO: 12), que se compone de múltiples unidades de secuencia de nucleótidos de 60meros como se describe en WO 2008/155134 (Figura 1A). A diferencia de "pASK75-PAS#1a(600)-IL1Ra", el plásmido de la invención, "pASK75-PAS #1f/1c/1b(600)-IL1Ra", mostró una alta estabilidad genética: todos los clones analizados de "pASK75-PAS #1f/1c/1b(600)" solo mostró las bandas esperadas a 3093 pb y 2377 pb (Fig. 5 carriles 6-10), lo que indica una alta estabilidad genética del casete de genes repetitivo bajo PAS #1f/1c/1b( 600) que comprende 1800 pares de bases y que codifica la secuencia PAS #1 rica en prolina / alanina. Debido a esta alta estabilidad genética, se evitan las desventajas de las moléculas de ácido nucleico de la técnica anterior. Esto demuestra claramente que las moléculas de ácido nucleico de la invención que comprenden una secuencia de nucleótidos poco repetitiva son útiles para la biosíntesis conveniente y fiable de polipéptidos ricos en prolina / alanina y / o proteínas de fusión correspondientes.
[0018] El Ejemplo ilustrativo 4 demuestra una ventaja adicional de las moléculas de ácido nucleico proporcionadas de acuerdo con la presente invención. Aquí, la molécula de ácido nucleico ejemplar que comprende una secuencia de nucleótidos de baja repetición de la invención (denominada casete PAS #1f/1c/1b(600); s Eq ID NO: 38; ver, por ejemplo, el Ejemplo 1) se sometió a secuenciación automatizada de ADN. Como resultado, se obtuvo un electroferograma claramente definido y libre de error que comprendía más de 900 pares de bases (Fig. 3), que no mostraba signos de unión de cebador inespecífica. Por tanto, a diferencia de las secuencias de nucleótidos repetitivas, que solo pueden secuenciarse de forma fiable con cebadores que se hibridan cadena arriba o cadena abajo del correspondiente casete de gen clonado, los fragmentos de ADN largos y repetitivos que codifican secuencias ricas en prolina / alanina se pueden secuenciar completamente de forma sencilla. En este caso, también se pueden aplicar cebadores de unión interna, generando así múltiples lecturas de secuencia superpuestas si se desea; en particular, el uso de tales cebadores de hibridación interna no da como resultado patrones de secuenciación únicos en el caso de secuencias de nucleótidos repetitivas. Por consiguiente, las moléculas de ácido nucleico de la invención que comprenden la secuencia de nucleótidos de baja repetición evitan estos problemas de secuenciación.
[0019] En resumen, la presente invención tiene, Entre otros, las siguientes ventajas sobre las moléculas de ácido nucleico de la técnica anterior que comprenden secuencias altamente repetitivas. Las ventajosas secuencias de nucleótidos de baja repetición de la presente invención pueden secuenciarse completamente sin más preámbulos en contraste con las moléculas de ácido nucleico de la técnica anterior. Una ventaja adicional de las moléculas de ácido nucleico de la presente invención es que tienen propiedades de amplificación mejoradas, p. ej. mediante la reacción en cadena de la polimerasa PCR, debido a la baja repetitividad. Además, las moléculas de ácido nucleico de la invención mejoran el procedimiento de clonación en comparación con las secuencias de nucleótidos que comprenden secuencias repetidas / repetitivas. Una ventaja particular de las moléculas de ácido nucleico proporcionadas en este documento es que tienen una estabilidad genética mejorada en comparación con las moléculas de ácido nucleico altamente repetitivas de la técnica anterior. Esto permite una producción fiable de polipéptidos ricos en prolina / alanina y / o proteínas de fusión de los mismos.
[0020] El rasgo característico de las moléculas de ácido nucleico de la presente invención es que las secuencias de nucleótidos que codifican un polipéptido que consiste en prolina, alanina y, opcionalmente, serina son "secuencias de nucleótidos de baja repetición", lo que confiere los efectos técnicos ventajosos descritos anteriormente. En los Ejemplos adjuntos, se demuestran métodos que pueden emplearse para analizar si una molécula de ácido nucleico comprende una secuencia de nucleótidos de baja repetición según la invención. En particular, los Ejemplos adjuntos proporcionan una puntuación denominada en el presente documento "Puntuación de repetición de nucleótidos (NRs)". Esta puntuación de repetición de nucleótidos (NRS) se determina en este documento de acuerdo con la fórmula que se discutió anteriormente:

donde Ntot es la longitud de dicha secuencia de nucleótidos, n es la longitud de una repetición dentro de dicha secuencia de nucleótidos, yfi(n) es la frecuencia de dicha repetición de longitud n, y donde, si hay más de una repetición de longitud n, k(n) es el número de dichas secuencias diferentes de dicha repetición de longitud n, de lo contrario k(n) es 1 para dicha repetición de longitud n. Esta puntuación se describe en detalle a continuación y se ilustra en los ejemplos adjuntos.
[0021] La NRS permite al experto en la materia seleccionar secuencias de nucleótidos de baja repetición para su uso en la presente invención. En otras palabras, la NRS proporciona una herramienta para determinar el grado de repetitividad de una secuencia de nucleótidos. Para identificar automáticamente las repeticiones y calcular la NRS, se puede emplear el algoritmo denominado NRS-Calculator proporcionado en este documento.
[0022] Como se demuestra en los ejemplos ilustrativos adjuntos, por ejemplo, el Ejemplo 13, varios ácidos nucleicos de la técnica anterior que codifican secuencias ricas en prolina / alanina se compararon con ácidos nucleicos de baja repetición que codifican secuencias ricas en prolina / alanina de acuerdo con esta invención utilizando la calculadora n Rs descrita en Ejemplo 14. Por ejemplo, se determinó la NRS de las siguientes secuencias de la técnica anterior: PAS#la(200) divulgada en WO 2008/155134, PA #1a(200) divulgado en WO2011144756, [(AP)5]20APA divulgada en US 20060252120, [AAPAPAPAP]10AS publicado con el número de acceso de GenBank DQ399411a, la proteína de tegumento grande del virus del herpes macacino 1 publicada con el número de acceso de GenBank NP_851896. Además, se determinaron histogramas que muestran las frecuencias de las repeticiones de nucleótidos representadas frente a la longitud respectiva para estas secuencias de nucleótidos de la técnica anterior y para las secuencias de nucleótidos de baja repetición de la presente invención, como PAS#1b(200) (SEQ ID NO: 19). o PA#1e/1d/1c/1b(800) (SEQ ID nO: 44) (Fig. 9). Los histogramas de las secuencias de nucleótidos de la técnica anterior revelaron una naturaleza altamente repetitiva. En contraste, los histogramas de las secuencias de nucleótidos de baja repetición de la invención, por ejemplo, PAS#1b(200) y PA#1e/1d/1c/1b(800), demuestran solo unas pocas repeticiones con una longitud máxima de 14 nucleótidos; ver p. ej. Figura 9F-I.
[0023] La diferencia en la repetitividad entre las secuencias de nucleótidos de la técnica anterior y las secuencias de nucleótidos de la invención resulta incluso más evidente cuando se comparan sus puntuaciones de repetición de nucleótidos. Las secuencias de la técnica anterior analizadas en este documento revelan una NRS superior a 80000 (Tabla 2). Por el contrario, las secuencias de nucleótidos de la invención ejemplares demuestran puntuaciones de repetición de nucleótidos bajas, por ejemplo, por debajo de 34; ver Tabla 1. En consecuencia, se demuestra claramente en el presente documento que la calidad de repetición de las secuencias de nucleótidos que codifican las secuencias ricas en prolina / alanina de la invención es mucho mayor en comparación con las secuencias de la técnica anterior, con menos repeticiones de secuencias de nucleótidos y más cortas. Por consiguiente, las moléculas de ácido nucleico de la presente invención tienen pocas secuencias repetitivas.
[0024] Como se indicó anteriormente, el experto en la materia conoce varias alternativas para analizar el grado de repetitividad de una molécula de ácido nucleico. En los ejemplos adjuntos se muestra que la repetitividad de las moléculas de ácido nucleico de la invención y de las de la técnica anterior también se analizó mediante análisis de gráficos de puntos; ver p. ej. Ejemplo 3. El análisis de la gráfica de puntos se realizó para los ácidos nucleicos que codifican la secuencia repetitiva rica en prolina / alanina PA#3a (SEQ ID NO: 15; Fig. 2A) descrita en Wo 2011/144756, PAS# 1 (SEQ ID NO: 11; Fig. 2B) divulgado en WO 2008/155134, un [(AP)a]n multímero (SEQ ID NO: 16) descrito en US2006/0252120 y una región repetitiva rica en prolina / alanina del gen de la proteína del tegumento muy grande de Herpesvirus macacino 1, publicado con el número de acceso de GenBank AAP41454.1 (SEQ ID NO: 18; Fig. 2C). En los ejemplos adjuntos, se empleó la herramienta "dottup" del paquete de software Geneious versión 8.1 (Biomatters, Auckland, Nueva Zelanda). El algoritmo alinea la secuencia respectiva consigo mismo y aplica una ventana de repetición de, por ejemplo, 14 o 15 nucleótidos. Los gráficos de puntos de las secuencias de nucleótidos de la técnica anterior se compararon con los gráficos de puntos de las secuencias de nucleótidos de baja repetición de la invención, por ejemplo, las unidades PA#3b(200) (SEQ ID NO: 36), PA#1b (SEQ ID NO: 28) o las secuencias de nucleótidos de baja repetición ensambladas PAS#1f/1c/1b (600) (SeQ ID NO: 38) y
PAS#1d/1f/1c/1b(800) (SEQ ID NO: 39). Mientras que todas las secuencias de la técnica anterior analizadas revelaron una naturaleza altamente repetitiva en el nivel de la secuencia de nucleótidos, como se ilustra mediante líneas diagonales paralelas negras (Fig.2A-C), los gráficos de puntos de las secuencias de nucleótidos ejemplares de acuerdo con la invención muestran pocas repeticiones dispersas o ninguna de una longitud máxima de 14 nucleótidos (líneas negras) dentro de la secuencia de nucleótidos completa de 600 nucleótidos (Fig. 2A, C), 1800 nucleótidos o 2400 nucleótidos, respectivamente (Fig. 2B). Por consiguiente, se demuestra en el presente documento que las secuencias de nucleótidos proporcionadas en el presente documento son secuencias de nucleótidos de baja repetición que comprenden ninguna o solo unas pocas repeticiones cortas.
[0025] En resumen, los ejemplos adjuntos demuestran claramente que las moléculas de ácido nucleico de la invención tienen secuencias de nucleótidos repetitivas bajas mientras que codifican una secuencia de repetición de aminoácidos rica en prolina / alanina. Se demuestra además en el presente documento que la "baja repetitividad" o la "baja repetitividad" de las moléculas de ácido nucleico proporcionadas en este documento se pueden evaluar fácilmente mediante estrategias alternativas, por ejemplo, la puntuación de repetición de nucleótidos proporcionada en este documento o métodos conocidos por los expertos, como el gráfico de puntos análisis. Alternativamente, una persona experta puede identificar las repeticiones de secuencias de nucleótidos y, por lo tanto, el grado de repetitividad de la secuencia de nucleótidos, ya sea manualmente o con la ayuda de programas de software genéricos como Visual Gene Developer (Jung (2011) BMC Bioinformatics 12: 340), o la herramienta Repfind (Betley (2002) Curr Biol 12: 1756-1761). Por tanto, las moléculas de ácido nucleico de la invención que tienen propiedades ventajosas inesperadas se pueden distinguir fácilmente de las moléculas de ácido nucleico de la técnica anterior que carecen de estas características.
[0026] Como se describió anteriormente, la secuencia de nucleótidos de baja repetición de la invención puede tener una NRS inferior a 1000 o puede tener repeticiones con una longitud máxima de aproximadamente 17, aproximadamente 20, aproximadamente 25, aproximadamente 30, aproximadamente 35, aproximadamente 40, aproximadamente 45, alrededor de 50 o alrededor de 55 nucleótidos. La secuencia de nucleótidos de baja repetición de la invención tiene una longitud de al menos 300 nucleótidos, más preferiblemente de al menos 350 nucleótidos, incluso más preferiblemente de al menos 600 nucleótidos, incluso más preferiblemente de al menos 900, incluso más preferiblemente de al menos 1200, incluso más preferiblemente de al menos 1500 nucleótidos, o más preferiblemente de al menos 1800 nucleótidos. En otras palabras, la molécula de ácido nucleico de la invención comprende o consiste en una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, donde la secuencia de nucleótidos de dicho ácido nucleico tiene una longitud de al menos 300 nucleótidos, más preferiblemente de al menos 350 nucleótidos, incluso más preferiblemente de al menos 400 o 500 nucleótidos, incluso más preferiblemente de al menos 600 nucleótidos, incluso más preferiblemente de al menos 700 u 800 nucleótidos, incluso más preferiblemente de al menos 900 nucleótidos, incluso más preferiblemente de al menos 1000 o 1100, incluso más preferiblemente de al menos 1200 nucleótidos (por ejemplo, 1203 nucleótidos), incluso más preferiblemente de al menos 1300 o 1400 nucleótidos, incluso más preferiblemente de al menos 1500 nucleótidos, incluso más preferiblemente de al menos 1600 o 1700 nucleótidos, o lo más preferiblemente de al menos 1800 nucleótidos.
[0027] La molécula de ácido nucleico de la invención puede comprender o consistir en una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, en donde la secuencia de nucleótidos de dicho ácido nucleico tiene una longitud máxima de 5000 nucleótidos, preferiblemente como máximo 4800 nucleótidos, 3600 nucleótidos o 2400 nucleótidos. La molécula de ácido nucleico de la invención puede comprender o consistir en una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, en donde la secuencia de nucleótidos de dicho ácido nucleico tiene una longitud máxima de 5000 nucleótidos, 4900 nucleótidos, 4800 nucleótidos, 4700 nucleótidos, 4600 nucleótidos, 4500 nucleótidos, 4400 nucleótidos, 4300 nucleótidos, 4200 nucleótidos, 4100 nucleótidos, 4000 nucleótidos, 3900 nucleótidos, 3800 nucleótidos, 3700 nucleótidos, 3600 nucleótidos, 3500 nucleótidos, 3400 nucleótidos, 3300 nucleótidos, 3200 nucleótidos, 3100 nucleótidos nucleótidos, 3000 nucleótidos, 2900 nucleótidos, 2800 nucleótidos, 2700 nucleótidos, 2600 nucleótidos, 2500 nucleótidos, 2400 nucleótidos, 2300 nucleótidos, 2200 nucleótidos, 2100 nucleótidos, 2000 nucleótidos o, como máximo, 1900 nucleótidos.
[0028] En un aspecto particularmente preferido, la molécula de ácido nucleico de la invención puede comprender o consistir en una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, en donde la secuencia de nucleótidos de dicho ácido nucleico tiene una longitud de 1200 a 3600 nucleótidos.
[0029] Además, la secuencia de nucleótidos repetitiva baja tiene una puntuación de repetición de nucleótidos (NRS) inferior a 1000, más preferiblemente inferior a 500, incluso más preferiblemente inferior a 100. Se prefieren particularmente las secuencias de nucleótidos repetitivas bajas que tienen una puntuación de repetición de nucleótidos (NRS) de menor que 50, más preferiblemente menor que 48, más preferiblemente menor que 45, más preferiblemente menor que 43, más preferiblemente menor que 40, más preferiblemente menor que 38, o más preferiblemente menor que 35. En otras palabras, la molécula de ácido nucleico de la invención comprende una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, en el que dicha secuencia de nucleótidos tiene una puntuación de repetición de nucleótidos (NRS) menor de 50.000, preferiblemente menor de 40.000, más preferiblemente menor de 30.000, más preferiblemente menor de 20.000,
más preferiblemente menos de 10.000, más preferiblemente menos de 1000, más preferiblemente menos de 500, incluso más preferiblemente menos de 400, 300, 200 y incluso más preferiblemente menor de 100. Se prefieren particularmente las moléculas de ácido nucleico que comprenden una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, en donde dicha secuencia de nucleótidos tiene una puntuación de repetición de nucleótidos (NRS) menor de 90, 80, 70 , 60, más preferiblemente menor que 50, más preferiblemente menor que 48, más preferiblemente un puntaje NRS de 45 o menor que 45, más preferiblemente menor que 43, más preferiblemente menor que 40, más preferiblemente un puntaje n Rs de 39, 38, 37 , o 36 o menos de 39, 38, 37 o 36, o lo más preferiblemente una puntuación de NRS de 35 o menos de 35. Incluso más particularmente preferidas son las moléculas de ácido nucleico que comprenden una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, en la que dicha secuencia de nucleótidos tiene una puntuación de repetición de nucleótidos (NRS) de 34, 32, 31,30, 29, 28, 27, 26, 25, 24, 23, 22, 21,20, 19, 18, 17 , 16, 15, 14, 13, 12, 11, 10, 9 u 8 o un NRS inferior a 34, 32, 31, 30, 29, 28, 27, 26, 25, 24, 23, 22, 21,20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9 u 8.
[0030] Como se discutió anteriormente, la "Puntuación de repetición de nucleótidos" o "NRS" se puede determinar de acuerdo con la siguiente fórmula:
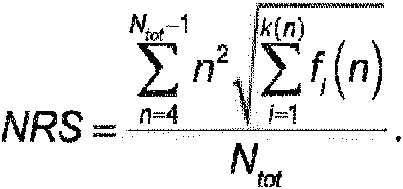
[0031] En consecuencia, el NRS se define como la suma, sobre todas las longitudes de repetición posibles (desde n = 4 hasta Ntot - 1), de cada longitud de repetición al cuadrado (n) multiplicada por la raíz cuadrada de su frecuencia total, dividida por la longitud total de la secuencia de nucleótidos analizada (Ntot). En otras palabras, el NRS es la suma de la longitud al cuadrado de las repeticiones dentro de dicha secuencia de nucleótidos multiplicada por la raíz cuadrada de la suma de la frecuencia de dicha repetición de longitud n (fi(n)), donde, si hay más de una repetición de longitud n, k(n) es el número de dichas secuencias diferentes de dicha repetición de longitud n, de lo contrario k(n) es 1 para dicha repetición de longitud n; y en el que dicha suma se divide por la longitud total de dicha secuencia de nucleótidos.
[0032] Como se usa en este documento, "Ntot" es la longitud total de dicha secuencia de nucleótidos que codifica el polipéptido que consiste en prolina, alanina y, opcionalmente, serina. La longitud Ntot es también el número de nucleótidos de dicha secuencia de nucleótidos. Por lo tanto, Ntot es la longitud total de la secuencia de nucleótidos analizada.
[0033] Como se usa en este documento, "n" es la longitud de una repetición dentro de dicha secuencia de nucleótidos que codifica el polipéptido que consiste en prolina, alanina y, opcionalmente, serina. La longitud n es también el número de nucleótidos de dicha repetición. Por tanto, n es la longitud de una repetición dentro de la secuencia de nucleótidos analizada. Por definición, la repetición más larga posible puede tener una longitud un nucleótido más corta que la longitud total de la secuencia de nucleótidos analizada (Ntot), es decir, n = Ntot - 1. Por otro lado, la longitud más corta de una repetición considerada para el análisis NRS es n = 4, que corresponde al tramo más corto de nucleótidos que es más largo que un solo codón triplete para un aminoácido. Dado que tales codones aparecen varias veces simplemente como consecuencia de la secuencia de aminoácidos codificada, no deben considerarse como repeticiones de la secuencia de nucleótidos con respecto al problema técnico a resolver.
[0034] El término "repetir" como se usa en este documento significa que la secuencia de nucleótidos comprende una secuencia contigua idéntica de nucleótidos de una longitud n (es decir, la repetición) más de una vez. En otras palabras, la secuencia de nucleótidos comprende una parte / tramo / secuencia contigua de una cierta longitud de nucleótidos en al menos dos o múltiples copias. En otras palabras, el término repetición se refiere a secuencias de nucleótidos de longitud n que están presentes en la secuencia de nucleótidos más de una vez. En la presente descripción se contempla que puede haber solo un tipo de repetición de una longitud n o puede haber más de una repetición diferente de la misma longitud n dentro de la longitud total de la secuencia de nucleótidos analizada. Por tanto, una secuencia de nucleótidos puede, por ejemplo, tener una repetición de una longitud n, cuyas apariciones tienen todas las mismas secuencias; se entiende que dicha repetición ocurre al menos dos veces pero también puede ocurrir múltiples veces dentro de la longitud total de la secuencia de nucleótidos analizada. Alternativamente, hay repeticiones de la misma longitud n que tienen diferentes secuencias, es decir, las repeticiones comparten la misma longitud (n) pero no son idénticas en el nivel de secuencia. En este caso, cada secuencia de repetición diferente constituye otro tipo de repetición.
[0035] Como se usa en este documento, "fi(n) "es la frecuencia de una repetición de longitud n. En otras palabras, fi(n) es el número de ocurrencias de la repetición de longitud n. Si solo hay un tipo de repetición de longitud n, k(n) es 1. Alternativamente, si hay más de una repetición diferente de longitud n, k(n) es el número de secuencias diferentes de dichas repeticiones de longitud n. En otras palabras, si hay más de una repetición de longitud n con secuencias diferentes, k(n) es el número de dichas secuencias diferentes de dichas repeticiones de longitud n. Por tanto, si hay
dos o más repeticiones de longitud n de tipo diferente, k (n) es el número de dichas secuencias diferentes de dichas repeticiones de longitud n. De lo contrario, si las repeticiones de una longitud n tienen todas la misma (es decir, idéntica) secuencia, k(n) es 1 para dicha repetición de longitud n.
[0036] Por ejemplo, la frecuencia de una repetición de una longitud de 14 nucleótidos (n = 14) puede ser cinco dentro de una secuencia de nucleótidos (de longitud Ntot). Esto puede significar que las cinco repeticiones con una longitud de 14 nucleótidos tienen todas una secuencia idéntica (perteneciente al mismo tipo), es decir, la secuencia de la repetición ocurre cinco veces dentro de la secuencia de nucleótidos. En este caso, k(n) es 1 y f¡(n) = 5. En otro escenario, las cinco repeticiones de 14 nucleótidos de longitud pueden tener secuencias diferentes. En este escenario, se prevé que dos de las cinco repeticiones comparten una secuencia idéntica (que constituyen un tipo) y tres de las cinco repeticiones comparten otra secuencia idéntica (que constituyen un segundo tipo), por lo que la secuencia de las dos primeras repeticiones comparten una secuencia y la secuencia de las últimas tres repeticiones que comparten otra secuencia son diferentes entre sí. Por lo tanto, en este escenario, el número de dichas secuencias diferentes de longitud n es 2, es decir, k(n) es 2, y f-i(n) = 2 y f2(n) = 3. El índice "i" en el término f se puede entender que representa el tipo de repetición dentro de un conjunto de repeticiones diferentes que tienen la longitud del nombre n.
[0037] La fórmula para determinar el NRS comprende la suma de la longitud al cuadrado de las repeticiones (n2), donde n es el índice de suma, 4 es el límite inferior de la suma y Ntot -1 es el límite superior de la suma. Por tanto, la longitud de la repetición que se considera mínima es 4. Una repetición de una longitud de 4 nucleótidos incluye todas las secuencias de más de un triplete de codones de aminoácidos. El índice, n, se incrementa en 1 para cada término sucesivo, deteniéndose cuando n = Ntot-1.
[0038] Además, la fórmula para determinar la NRS comprende la raíz cuadrada de la suma de las frecuencias de dichas repeticiones de longitud n (fi(n)), donde i es el índice de la suma, fi(n) es una variable indexada que representa cada término sucesivo de la serie, 1 es el límite inferior de la suma y k(n) es el límite superior de la suma. El índice, i, se incrementa en 1 para cada término sucesivo, deteniéndose cuando i = k(n). Por lo tanto, si solo hay un tipo de repetición de longitud n, es decir, todas las repeticiones de longitud n tienen una secuencia idéntica, k(n) es 1 para dicha repetición de longitud n y, en lugar de una suma, solo se analiza la frecuencia fi(n) de esta repetición de longitud n dentro de la longitud total de la secuencia de nucleótidos (Ntot).
[0039] Por ejemplo, el siguiente código NRS-Calculator puede usarse de acuerdo con la invención para determinar un NRS:
import math
import sys
class NRSCalculator:
def_init_(self):
self.repeats = dict()
self.sums = dict()
self.seq = None
self.range min = None
self.range_max = None
def_match_at(self, row, colman):
return self.seq[row] == self.seq[column]
def get. repeats atfself, row, column) :
length = 1
search_row = row
search_column = colman
whfle True:
if not 0 <= search row < len(self.seq):
break
if not 0 <— search column < search row:
break
if length > self.rangemax:
break
if not self. match at(search row, search column):
break
if length >= self.rangemin:
repeats =
self.repeats.setdefault(self.seq[row:row length], set ())
repeats.add(row)
repeats.add(column)
search row = 1
search column = 1
length = 1
def_get_repeats(self):
self.repeats = dict()
for row in xrange(len(self.seq)):
for column in xrange{row): self._get_repeats_at(row, column) def_get_sums(self):
self.sums— dict()
for (seq, repeats) in self.repeats.iteritems():
length = len(seq)
self.sums[length] = self.sums.get(length, 0) len(repeats)
def set _range(self, range_min, range_max):
self.range_min = range_min
self.range max =range max
def set sequence(self, seq):
self.seq = seq
def work(self):
if not self.seq and not self.range min and not self.range_max:
raise RuntimeError('Can not work without initialization' )
self._get_repeats()
self._get_sums()
def print repeats(self):
print('Sequence (Length bp) : NumRepeats (Positions)')
for seq, repeats in sorted (self.repeats.iteritems(), key=lambda t: len(t[0])):
list =[seq, len(seq), len(repeats)] list.extend(map(lambda valué: valué 1, sorted(repeats) ))
print (r%s Ntot = %u : %u (%s)' % (seq, len(seq) len(repeats), ', '.join(map(lambda valué: str(valué 1), sorted(repeats)))) )
def print_sums (self) :
print ('Length\tFrequency' )
for Ítem in self.sums.iteritems{):
print('%u\t%u' % Ítem)
def print_score(self):
sum = 0
for length, count in self.sums.iteritems{):
sum = (length ** 2) * math.sqrt(count) print('NRS = %.0f' % (sum / len(self.seq))) def handle sequence(finder, ñame, sequence): finder.set_range(4 , len(sequence)) finder.set_sequence(sequence)
finder.work()
print('%s: Ntot = %ur % (ñame, len(sequence)))
#finder.print_repeats()
finder.print_sums()
finder.print score ()
if len (sys.argv) != 2:
prínt('Usage: %s FILENAME' % sys.argv[0])
sys .exit. (1)
finder = NRSCalculator()
with open(sys.argv[1], 'r') as infile:
ñame = 'Unnamed'
seq = ''
for line in infile:
line = line.stripO
if line.startswith('>'):
if len(seq) > 0:
handle_sequence(finder, ñame, seq)
ñame = line
seq = ' '
continué
seq = line.upper()
handle_sequence(finder, ñame, seq)
[0040] Además, la invención también se refiere a una secuencia de nucleótidos que comprende repeticiones de nucleótidos, en donde dichas repeticiones tienen una longitud máxima nmax, donde nmax se determina de acuerdo con la fórmula

y donde Nto es la longitud total de dicha secuencia de nucleótidos. El término "longitud máxima" o "longitud máxima" o "nmax" como se usa en este documento define el número de nucleótidos de la parte / tramo / secuencia de nucleótidos contigua más larga que está presente en al menos dos copias dentro de dicha secuencia de nucleótidos o molécula de ácido nucleico. En otras palabras, el término" longitud máxima" o "máxima longitud" o "nmax" como se usa en este documento significa que la secuencia de nucleótidos de la molécula de ácido nucleico de acuerdo con esta invención no tiene repeticiones que sean más largas que esta longitud.
[0041] En los ejemplos adjuntos se demuestra que las moléculas de ácido nucleico ejemplares de la invención comprenden solo unas pocas repeticiones, p. ej. de una longitud de 14 nucleótidos; ver p. ej. Ejemplo 2 adjunto. Como se explicó anteriormente, el análisis repetido se puede realizar con cualquier herramienta adecuada, como el análisis NRS proporcionado en este documento, manualmente o con la ayuda de programas de software genéricos como el análisis de diagrama de puntos, por ejemplo, utilizando Visual Gene Developer (Jung (2011) loc. Cit) o la herramienta Repfind (Betley (2002) loc. Cit). Un diagrama de puntos es una representación visual de las similitudes entre dos secuencias.
[0042] En los ejemplos adjuntos, las secuencias de nucleótidos proporcionadas en el presente documento se alinearon entre sí. Cada eje de una matriz rectangular representa una de las dos secuencias de nucleótidos (idénticas en general) que se van a comparar. Todas las posiciones de la primera secuencia de entrada se comparan con todas las posiciones de la segunda secuencia de entrada y se puntúan, utilizando una matriz de sustitución especificada. Esto produce una matriz de puntuaciones a partir de la cual se identifican las regiones locales de similitud / identidad (correspondientes a las diagonales en el diagrama de puntos). Una ventana / umbral de repetición de longitud especificada por el usuario se mueve a lo largo de todas las diagonales posibles. Cada posición en la ventana / umbral de repetición corresponde a una puntuación por pares de la matriz de puntuación. La puntuación de toda la ventana es la suma de las puntuaciones de las posiciones individuales dentro de ella. Si la puntuación de la ventana está por encima del umbral definido por el usuario, se traza una línea en el diagrama de puntos correspondiente a la ventana (consulte, por ejemplo, http://emboss.sourceforge. net/apps/cvs/emboss/apps/dotmatcher.html).
[0043] El análisis del diagrama de puntos se emplea en los ejemplos adjuntos, p. ej. Ejemplo 3, para analizar la repetitividad de las secuencias de nucleótidos de las moléculas de ácido nucleico. Se demuestra allí que las moléculas de ácido nucleico de la invención, por ejemplo, SEQ ID NO: 36 (denominada PA#3b(200) en este documento) o SEQ ID NO: 28 (denominada PA#lb en este documento), tienen solo unas pocas repeticiones de 14 nucleótidos dispersas dentro de la longitud total de 600 nucleótidos en caso de que se aplique una ventana / umbral
de repetición de 14. Un aumento de la ventana / umbral de repetición de 14 en un nucleótido, es decir, una ventana / umbral de repetición de 15 nucleótidos, no revela más repeticiones dentro de la secuencia de nucleótidos completa analizada (ver Figura 2 y Ejemplo 3). Esto significa que la longitud máxima de la repetición dentro de toda la secuencia de ácido nucleico investigada tiene una longitud de 14 nucleótidos (que también incluye repeticiones más cortas). Generalmente, se puede suponer que cuanto más cortas sean dichas repeticiones de nucleótidos, menos desempeñarán un papel perjudicial para la estabilidad genética.
[0044] Sin embargo, las moléculas de ácido nucleico que codifican secuencias ricas en prolina / alanina descritas en la técnica anterior muestran secuencias más largas y / o más repetidas si se aplica una ventana / umbral de repetición de, por ejemplo, 14 o 15 nucleótidos como se usa en los Ejemplos adjuntos (ver Ejemplo 3). Por ejemplo, la secuencia rica en prolina / alanina descrita en WO 2011/144756 (SEQ ID NO: 15; denominada PA#3a(200) en este documento) posee múltiples repeticiones de nucleótidos de longitud 60, que son consecutivas e incluso superpuestas y, por tanto, dan lugar a un gran número de líneas paralelas largas. Otras moléculas de ácido nucleico descritas en la técnica anterior tales como PAS#1a(600) como se muestra en SEQ ID NO: 12 y como se describe en WO 2008/155134, un multímero [AP)5]n como se muestra en SEQ ID NO: 16 y como se describe en US2006/0252120, o la proteína tegumento grande de Herpesvirus macacino 1 como se muestra en SEQ ID NO: 18 y como se describe en la entrada AAP41454.1 de GenBank también documenta la naturaleza altamente repetitiva de estas secuencias de nucleótidos.
[0045] Esto está en marcado contraste con las moléculas de ácido nucleico de la presente invención, que demuestran una baja repetitividad en el nivel de la secuencia de nucleótidos. Cuando, por ejemplo, se compara el número de repeticiones de la secuencia de la técnica anterior PA#3a(200) (SEQ ID NO: 15), usando una ventana / umbral de repetición de 14 nucleótidos, con el número de repeticiones de un nucleótido repetitivo bajo secuencia de la invención, PA#3b(200) (SEQ ID NO: 36), se puede observar que la secuencia de la invención tiene 29 repeticiones (por 600 residuos de nucleótidos) en comparación con muchas más de 100 repeticiones (por 600 residuos de nucleótidos) de la secuencia de la técnica anterior. Si se aplica una ventana de 15 nucleótidos, la molécula de ácido nucleico analizada ejemplar o la secuencia de nucleótidos de la invención no comprende ninguna repetición. Por el contrario, las moléculas de ácido nucleico de la técnica anterior revelan numerosas repeticiones con una longitud de 15 nucleótidos y más. Como se demuestra en los ejemplos adjuntos, una ventana / umbral de repetición de 14 a 20, p. 14, 15, 16, 17, 18, 19 o 20 nucleótidos, en particular, es adecuado para confirmar que una molécula de ácido nucleico de la invención tiene una secuencia de nucleótidos poco repetitiva. Se aprecia que la longitud de la ventana / umbral de repetición se correlaciona inversamente con el número de repeticiones que se identificarán en una secuencia de nucleótidos específica. Por ejemplo, si la ventana / umbral de repetición es "1", el número de repeticiones puede ser igual al número de todos los residuos de nucleótidos (A, T, G y / o C) en una secuencia de nucleótidos (siempre que cada tipo de nucleótido que se encuentre en la secuencia analizada está presente en al menos dos copias). Si aumenta la longitud de la ventana / umbral de repetición, el número de repeticiones en la secuencia de nucleótidos analizada disminuirá de una manera específica de secuencia. En consecuencia, también las secuencias de nucleótidos de "baja repetición" de la invención pueden contener repeticiones; sin embargo, en comparación con las secuencias de la técnica anterior, estas son más cortas y menos si se aplican los mismos parámetros para el análisis.
[0046] Por lo tanto, las moléculas de ácido nucleico proporcionadas en este documento comprenden repeticiones de una longitud máxima de 14, 15, 16, 17, aproximadamente 18, aproximadamente 19, aproximadamente 20, aproximadamente 21, aproximadamente 25, aproximadamente 30, aproximadamente 35, aproximadamente 40, aproximadamente 45, aproximadamente 50 o aproximadamente 55 nucleótidos. Además, la molécula de ácido nucleico proporcionada en este documento comprende repeticiones de una longitud máxima de aproximadamente 17 nucleótidos hasta una longitud máxima de aproximadamente 55 nucleótidos. En el contexto de la longitud máxima de la repetición, el término "aproximadamente" significa que la longitud máxima de la repetición es /- 4 nucleótidos de la longitud de repetición indicada. En otras palabras, en este contexto, "aproximadamente" se refiere a un rango, en el que la longitud de la repetición puede ser 4 nucleótidos más larga o más corta que la longitud de repetición indicada. Por ejemplo, una longitud máxima de repetición de aproximadamente 55 nucleótidos se refiere a una secuencia de nucleótidos que comprende repeticiones de una longitud máxima de 51 a 59 nucleótidos. Además, una longitud máxima de repetición de aproximadamente 17 nucleótidos se refiere a una secuencia de nucleótidos que comprende repeticiones de una longitud máxima de 13 a 21 nucleótidos.
[0047] Además, la invención se refiere a una molécula de ácido nucleico que comprende repeticiones de una longitud máxima de 59 nucleótidos, preferiblemente 54 nucleótidos, más preferiblemente 50 nucleótidos, más preferiblemente 48 nucleótidos, más preferiblemente 40 nucleótidos, más preferiblemente 36 nucleótidos, más preferiblemente 35 nucleótidos, más preferiblemente 30 nucleótidos, más preferiblemente 25 nucleótidos, más preferiblemente 24 nucleótidos, más preferiblemente 21 nucleótidos, más preferiblemente 20 nucleótidos, más preferiblemente 19 nucleótidos, más preferiblemente 18 nucleótidos, más preferiblemente 16 nucleótidos, más preferiblemente 15 nucleótidos, más preferiblemente 14 nucleótidos, o lo más preferiblemente 17 nucleótidos.
[0048] Como se usa en este documento, una molécula de ácido nucleico que comprende repeticiones de una longitud máxima de, por ejemplo, 17 nucleótidos se relaciona con una molécula de ácido nucleico que comprende secuencias repetidas con longitudes de 1, 2, 3, 4, 5, 6, 7, 8, 9 , 10, 11, 12, 13, 14, 15, 16 o 17 nucleótidos. Asimismo, la molécula de ácido nucleico que comprende repeticiones de una longitud máxima de 14 nucleótidos se refiere a
una molécula de ácido nucleico que comprende repeticiones de hasta 14 nucleótidos, es decir, "< 14 nucleótidos" o "1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 o 14 nucleótidos". En otras palabras, la molécula de ácido nucleico que comprende repeticiones de una longitud máxima de 14 nucleótidos no comprende repeticiones de más de 14 nucleótidos, es decir, "> 14 nucleótidos".
[0049] La invención además se refiere a una molécula de ácido nucleico de baja repetición, en la que baja repetición significa que un tramo de secuencia de nucleótidos que ocurre repetidamente dentro de una secuencia de nucleótidos más larga que codifica una secuencia de aminoácidos repetitiva corresponde como máximo al 0,05%, preferiblemente al 0,1%, más preferiblemente al 0,5%, más preferiblemente 1%, más preferiblemente 2%, más preferiblemente 3%, más preferiblemente 4%, más preferiblemente 5%, más preferiblemente 6%, más preferiblemente 7%, más preferiblemente 8%, más preferiblemente 9%, más preferiblemente 10%, más preferiblemente 15%, más preferiblemente 20%, más preferiblemente 25%, más preferiblemente 30%, más preferiblemente 40% o más preferiblemente 50% de la longitud de la secuencia de nucleótidos que codifica el tramo de secuencia de aminoácidos repetida. En otras palabras, el ácido nucleico de la presente invención comprende repeticiones, en donde dichas repeticiones tienen una longitud máxima correspondiente al 0.05%, preferiblemente al 0.1%, más preferiblemente al 0.5%, más preferiblemente al 1%, más preferiblemente al 2%, más preferiblemente al 3%, más preferiblemente 4%, más preferiblemente 5%, más preferiblemente 6%, más preferiblemente 7%, más preferiblemente 8%, más preferiblemente 9%, más preferiblemente 10%, más preferiblemente 15%, más preferiblemente 20%, más preferiblemente 25%, más preferiblemente 30%, más preferiblemente 40% o lo más preferiblemente 50% de la longitud de dicha secuencia de nucleótidos que codifica la secuencia de aminoácidos repetida en el polipéptido que consiste en prolina, alanina y, opcionalmente, serina.
[0050] Es evidente que la presente invención no solo proporciona secuencias de nucleótidos novedosas e inventivas que codifican secuencias ricas en PA y que tienen una longitud de al menos 300 nucleótidos (correspondientes a 100 residuos de aminoácidos), sino que la presente invención también proporciona medios y métodos de selección para moléculas de ácido nucleico recombinantes y / o sintéticas que conducen a secuencias genéticamente estables y / o que permiten una clonación, secuenciación y / o amplificación convenientes. Este método de selección se basa en la NRS proporcionada en este documento y / o la longitud máxima de repetición descrita en este documento. En consecuencia, la presente invención se refiere a un método para seleccionar una molécula de ácido nucleico genéticamente estable, en el que dicha molécula de ácido nucleico comprende una secuencia de nucleótidos que codifica un polipéptido que consta de al menos 100 residuos de aminoácidos de prolina, alanina y, opcionalmente, serina, donde dich0 polipéptido forma una enrollado aleatorio, en la que dicha secuencia de nucleótidos tiene una longitud de al menos 300 nucleótidos, el método comprende un paso de seleccionar una molécula de ácido nucleico que comprende una secuencia de nucleótidos que tiene una puntuación de repetición de nucleótidos (NRS) inferior a 1000, donde dicha puntuación de repetición de nucleótidos (NRS) se determina de acuerdo con la fórmula proporcionada anteriormente en este documento. Además, el método para seleccionar una molécula de ácido nucleico genéticamente estable, en el que dicha molécula de ácido nucleico comprende una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, puede comprender una etapa de seleccionar dicha secuencia de nucleótidos que comprende repeticiones que tienen una longitud máxima de nmax. Además, el método para seleccionar una molécula de ácido nucleico genéticamente estable, en el que dicha molécula de ácido nucleico comprende una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, puede comprender una etapa de seleccionar dicha secuencia de nucleótidos que comprende repeticiones de una longitud máxima de aproximadamente 17 nucleótidos hasta una longitud máxima de aproximadamente 55 nucleótidos. Las realizaciones y los parámetros de la fórmula NRS y las secuencias de nucleótidos de baja repetición proporcionadas en el presente documento anteriormente en el contexto de los ácidos nucleicos de la invención que codifican secuencias ricas en PA se aplican, mutatis mutandis, a los métodos de selección proporcionados e ilustrados en este documento para moléculas de ácido nucleico genéticamente estables codificando secuencias ricas en PA así como para las realizaciones adicionales.
[0051] En este documento, se encontró y demostró sorprendentemente que las moléculas de ácido nucleico de la invención tienen una estabilidad in vivo mejorada. Como se muestra en los ejemplos ilustrativos adjuntos, por ejemplo, el Ejemplo 6, las moléculas de ácido nucleico proporcionadas en este documento son más estables que las moléculas de ácido nucleico que comprenden secuencias de nucleótidos más repetitivas. El ejemplo 6 compara moléculas de ácido nucleico que codifican polipéptidos que consisten en prolina, alanina y serina que difieren en la repetitividad de las secuencias de nucleótidos. Las moléculas de ácido nucleico de la invención que comprenden secuencias de nucleótidos de baja repetición proporcionadas en este documento (véase también la Fig. 2B), por ejemplo, como se indica en SEQ ID NO: 50, tienen una mayor estabilidad genética en comparación con las secuencias de nucleótidos altamente repetitivas como las que se dan en la técnica anterior, por ejemplo, SEQ ID NO: 51. Por tanto, el término "estabilidad in vivo" como se usa en este documento se refiere particularmente a "estabilidad genética". El término "estabilidad genética" como se usa en este documento significa que el ácido nucleico se mantiene estable en la célula huésped y que la secuencia no está modificada genéticamente, por ejemplo, por mutación, inserción o deleción. Como se usa en el presente documento, las mutaciones se refieren a cambios en la secuencia de nucleótidos, por ejemplo, sustituciones, deleciones, inserciones o extensiones. Se muestra en los ejemplos adjuntos que las moléculas de ácido nucleico que comprenden secuencias de nucleótidos altamente repetitivas son propensas a deleciones o acortamientos; ver, por ejemplo, el Ejemplo 6. Las moléculas de ácido nucleico que comprenden secuencias de nucleótidos altamente repetitivas / casetes de genes repetitivos
tienen, por tanto, una estabilidad genética inferior, que puede surgir de eventos de recombinación durante la división celular, por ejemplo. Los parámetros NRS o nmax definidos en el presente documento proporcionan medios objetivos para distinguir secuencias de nucleótidos altamente repetitivas, como las de la técnica anterior, que tienen números altos para NRS y / o nmax, a partir de secuencias de nucleótidos de baja repetición de la invención, que tienen números bajos para NRS y / o nmax.
[0052] Las moléculas de ácido nucleico proporcionadas en este documento codifican polipéptidos que comprenden secuencias repetitivas de aminoácidos. En particular, la secuencia de aminoácidos repetitiva codificada también puede ser parte / fragmento de una proteína de fusión. Por ejemplo, la molécula de ácido nucleico descrita en este documento puede codificar un polipéptido que consiste en repeticiones ricas en prolina / alanina, p. repeticiones que consisten en prolina, alanina y, opcionalmente, serina. El polipéptido rico en prolina / alanina puede formar un enrollado aleatorio. En ciertos aspectos, la molécula de ácido nucleico descrita en el presente documento codifica un polipéptido que consiste en prolina, alanina y serina, en el que dicho polipéptido forma un enrollado aleatorio. En ciertos aspectos, la molécula de ácido nucleico descrita en el presente documento codifica un polipéptido que consiste en prolina y alanina, en el que dicho polipéptido forma un enrollado aleatorio.
[0053] En particular, la secuencia de nucleótidos codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina. Este polipéptido codificado forma un enrollado aleatorio. La secuencia de nucleótidos está comprendida en la molécula de ácido nucleico proporcionada en este documento. Por tanto, en ciertos aspectos, la molécula de ácido nucleico descrita en el presente documento codifica un polipéptido que comprende una secuencia de aminoácidos repetitiva y que consta de prolina, alanina y, opcionalmente, serina, en el que dicho polipéptido forma un enrollado aleatorio. En ciertos aspectos, la molécula de ácido nucleico descrita en el presente documento codifica un polipéptido que comprende una secuencia de aminoácidos repetitiva y que consta de prolina, alanina y serina, en el que dicho polipéptido forma un enrollado aleatorio. En ciertos aspectos, la molécula de ácido nucleico descrita en el presente documento codifica un polipéptido que comprende una secuencia de aminoácidos repetitiva y que consta de prolina y alanina, en el que dicho polipéptido forma un enrollado aleatorio.
[0054] Como se usa en este documento, el término "enrollado aleatorio" se refiere a cualquier conformación de una molécula polimérica, incluidos los polímeros de aminoácidos, en particular los polipéptidos hechos de L-aminoácidos, en los que los elementos monoméricos individuales que forman dicha estructura polimérica están esencialmente orientados al azar hacia el elemento o elementos monoméricos adyacentes mientras aún están unidos químicamente. En particular, el polipéptido o polímero de aminoácidos codificado que adopta / tiene / forma una "conformación de enrollado aleatorio" carece sustancialmente de una estructura secundaria y terciaria definida. La naturaleza de los enrollados aleatorios de polipéptidos codificados y sus métodos de identificación experimental son conocidos por el experto en la técnica y se han descrito en la literatura científica (Cantor (1980) Biophysical Chemistry, 2a ed., W. H. Freeman and Company, Nueva York; Creighton (1993) Proteins - Structures and Molecular Properties, 2a ed., W. H. Freeman and Company, Nueva York; Smith (1996) Fold. Des. 1: R95-R106) y literatura de patentes, por ejemplo, WO2011/144756 y WO2008/155134.
[0055] Los polipéptidos de enrollado aleatorios codificados de la presente invención adoptan / forman una conformación de enrollado aleatorio, por ejemplo, en solución acuosa y / o en condiciones fisiológicas. El término "condiciones fisiológicas" es conocido en la técnica y se refiere a aquellas condiciones en las que las proteínas adoptan habitualmente su conformación plegada nativa. Más específicamente, el término "condiciones fisiológicas" se refiere a los parámetros biofísicos ambientales ya que son típicamente válidos para formas superiores de vida y, particularmente, para mamíferos, más preferiblemente seres humanos. El término "condiciones fisiológicas" puede referirse a los parámetros bioquímicos y biofísicos que se encuentran normalmente en el cuerpo, en particular en fluidos corporales, de mamíferos y en particular en humanos. Dichas "condiciones fisiológicas" pueden estar relacionadas con los parámetros correspondientes que se encuentran en el cuerpo sano, así como con los parámetros que se encuentran en condiciones de enfermedad o en pacientes humanos. Por ejemplo, un mamífero enfermo o un paciente humano puede tener una temperatura corporal más alta, aunque "fisiológica" (es decir, una condición de temperatura) cuando dicho mamífero o dicho ser humano padece fiebre. Con respecto a las "condiciones fisiológicas" en las que las proteínas adoptan su conformación / estado nativo, los parámetros más importantes son la temperatura (37 ° C para el cuerpo humano sano), el pH (7,35-7,45 para la sangre humana), la osmolaridad (280-300 mmol/kg H2O) y, si es necesario, contenido proteico general (66-85 g / l de suero).
[0056] Sin embargo, el experto en la técnica es consciente de que en condiciones fisiológicas estos parámetros pueden variar, p. ej. la temperatura, el pH, la osmolaridad y el contenido de proteínas pueden ser diferentes en determinados líquidos corporales o tisulares, como sangre, líquido cerebroespinal, líquido peritoneal y linfa (Klinke (2005) Physiologie, 4a edición., Georg Thieme Verlag, Stuttgart). Por ejemplo, en el líquido cerebroespinal la osmolaridad puede rondar los 290 mmol /kg H2O y la concentración de proteína puede estar entre 0,15 g /l y 0,45 g/l, mientras que en la linfa el pH puede estar alrededor de 7,4 y el contenido de proteína puede estar entre 3 g /l y 5 g/l. Cuando se determina si una secuencia de polipéptido / aminoácido codificado forma / adopta una conformación de enrollado aleatorio en condiciones experimentales, los parámetros biofísicos tales como temperatura, pH, osmolaridad y contenido de proteína pueden ser diferentes de las condiciones fisiológicas que normalmente se encuentran in vivo. Las temperaturas entre 1 °C y 42 °C o preferiblemente 4 °C a 25 °C pueden considerarse útiles para probar y / o verificar las propiedades biofísicas y la actividad biológica de una proteína en condiciones fisiológicas in vitro.
[0057] Se considera que varios tampones, que pueden incluir disolventes y / o excipientes para composiciones farmacéuticas, representan "soluciones fisiológicas" / "condiciones fisiológicas" in vitro, en particular, en entornos experimentales, por ejemplo en el contexto de las mediciones de CD u otros métodos que permiten al experto en la técnica determinar las propiedades estructurales de una secuencia de proteína / aminoácido. Ejemplos de tales tampones son, por ejemplo, solución salina tamponada con fosfato (PBS, por ejemplo: NaCl 115 mM, 4 mM KH2SO4, 16 mM Na2HPO4 pH 7,4), tampones Tris, tampones de acetato, tampones de citrato o tampones similares. Generalmente, el pH de un tampón que representa las "condiciones fisiológicas de la solución" debe estar en un rango de 6,5 a 8,5, preferiblemente en un rango de 7,0 a 8,0, más preferiblemente en un rango de 7,2 a 7,7, y la osmolaridad debe estar en un rango de 10 a 1000 mmol /kg H2O, más preferiblemente en un rango de 50 a 500 mmol /kg H2O y lo más preferiblemente en un rango de 200 a 350 mmol /kg H2O. Opcionalmente, el contenido de proteína de una solución fisiológica puede estar en un rango de 0 a 100 g /l, despreciando la proteína investigada que adopta la propia conformación de enrollado aleatorio; además, pueden estar presentes proteínas estabilizadoras típicas, por ejemplo albúmina de suero humano o bovino.
[0058] Los polipéptidos codificados por las moléculas de ácido nucleico de la invención no solo forman una conformación de enrollado aleatorio en condiciones fisiológicas sino, más generalmente, en solución acuosa; por ejemplo, c.f. WO2011/144756. El término "solución acuosa" es bien conocido en la técnica. Una "solución acuosa" puede ser una solución con contenido en agua (H2O) de al menos aproximadamente 20%, de al menos aproximadamente 30%, de al menos aproximadamente 40%, de al menos aproximadamente 50%, de al menos aproximadamente 60%, de al menos aproximadamente 70%, de al menos aproximadamente 80 % o de al menos aproximadamente 90% de H2O (peso / peso). Por consiguiente, los polipéptidos codificados proporcionados en la presente invención pueden formar una conformación de enrollado aleatorio en solución acuosa, que posiblemente contenga otros disolventes miscibles, o en dispersiones acuosas con un intervalo más amplio de temperaturas, valores de pH, osmolaridades o contenido de proteínas. Esto es particularmente relevante para aplicaciones del polipéptido en enrollado aleatorio fuera de la terapia médica o diagnósticos in vivo, por ejemplo, en cosmética, nutrición o tecnología alimentaria.
[0059] También se prevé en el contexto de esta invención que la conformación de enrollado aleatorio del polipéptido codificado se mantenga en composiciones farmacéuticas como productos farmacéuticos / biológicos líquidos o composiciones farmacéuticas liofilizadas. Esto es particularmente importante en el contexto de las proteínas biológicamente activas codificadas o los conjugados de fármacos proporcionados en este documento que comprenden, inter alia, el polipéptido enrollado aleatorio. Preferiblemente, las "condiciones fisiológicas" deben usarse en los correspondientes sistemas tampón, disolventes y / o excipientes. Sin embargo, por ejemplo, en composiciones liofilizadas o secas (como, por ejemplo, composiciones farmacéuticas / productos biológicos), se prevé que la conformación en enrollado aleatorio del polipéptido en enrollado aleatorio codificado que aquí se proporciona pueda no estar presente transitoriamente y / o no pueda detectarse. Sin embargo, dicho polipéptido de enrollado aleatorio codificado adoptará / formará su enrollado aleatorio de nuevo después de la reconstitución en tampones / soluciones / excipientes / disolventes correspondientes o después de la administración al cuerpo de un paciente o de un animal.
[0060] En ciertos aspectos de la presente invención, las moléculas de ácido nucleico descritas en este documento codifican polipéptidos que (principal o exclusivamente) consisten en prolina, alanina y, opcionalmente, serina, en los que no más de 9 residuos de aminoácidos consecutivos son idénticos. Dichos polipéptidos codificados forman un enrollado aleatorio. En un cierto aspecto, las secuencias de aminoácidos / polipéptidos codificados que adoptan una conformación de enrollado aleatorio pueden comprender una pluralidad de repeticiones de aminoácidos, en donde dichas "repeticiones de aminoácidos" consisten principal o exclusivamente en residuos de aminoácidos de prolina, alanina y, opcionalmente, serina, en donde no más de 9 residuos de aminoácidos consecutivos son idénticos. En un cierto aspecto, las secuencias de aminoácidos / polipéptidos codificados que adoptan una conformación helicoidal aleatorio (el polipéptido helicoidal aleatorio como se define aquí) pueden comprender una pluralidad de repeticiones de aminoácidos, donde dichas "repeticiones de aminoácidos" consisten principal o exclusivamente en prolina, alanina y residuos de aminoácidos de serina, en los que no más de 9 residuos de aminoácidos consecutivos son idénticos. En cierto aspecto, las secuencias de aminoácidos / polipéptidos codificados que adoptan una conformación de enrollado aleatorio pueden comprender una pluralidad de repeticiones de aminoácidos, en las que dichas "repeticiones de aminoácidos" consisten principal o exclusivamente en residuos de aminoácidos de prolina y alanina, en los que no más de 9 residuos consecutivos de aminoácidos son idénticos.
[0061] En aspectos preferidos, la molécula de ácido nucleico descrita en este documento codifica un polipéptido que comprende una secuencia de aminoácidos repetitiva con una pluralidad de repeticiones de aminoácidos, en el que no más de 8 residuos de aminoácidos consecutivos son idénticos y en el que dicho polipéptido forma una enrollado aleatorio. Preferiblemente, la molécula de ácido nucleico descrita en este documento codifica un polipéptido que comprende una secuencia de aminoácidos repetitiva con una pluralidad de repeticiones de aminoácidos, en el que no más de 7 residuos de aminoácidos consecutivos son idénticos y en el que dicho polipéptido forma un enrollado aleatorio. Más preferiblemente, la molécula de ácido nucleico descrita en este documento codifica un polipéptido que comprende una secuencia de aminoácidos repetitiva con una pluralidad de repeticiones de aminoácidos, en el que no más de 6 residuos de aminoácidos consecutivos son idénticos y en el que dicho polipéptido forma un enrollado aleatorio. Particularmente preferible, la molécula de ácido nucleico descrita en este documento codifica un polipéptido que comprende una secuencia de aminoácidos repetitiva con una pluralidad de repeticiones de
aminoácidos, en el que no más de 5 residuos de aminoácidos consecutivos son idénticos y en el que dicho polipéptido forma un enrollado aleatorio. Más particularmente preferible, la molécula de ácido nucleico descrita en este documento codifica un polipéptido que comprende una secuencia de aminoácidos repetitiva con una pluralidad de repeticiones de aminoácidos, en el que no más de 4 residuos de aminoácidos consecutivos son idénticos y en el que dicho polipéptido forma un enrollado aleatorio. Lo más preferiblemente, la molécula de ácido nucleico descrita en este documento codifica un polipéptido que comprende una secuencia de aminoácidos repetitiva con una pluralidad de repeticiones de aminoácidos, en el que no más de 3 residuos de aminoácidos consecutivos son idénticos y en el que dicho polipéptido forma un enrollado aleatorio.
[0062] A continuación se proporciona un ejemplo no limitante de una repetición de aminoácidos que consiste exclusivamente en residuos de prolina, alanina y serina; ver, p. ej. SEQ ID NO: 6. A continuación se proporciona un ejemplo no limitante de una repetición de aminoácidos codificada que consiste exclusivamente en residuos de prolina y alanina; ver, p. ej. SEQ ID NO: 8. El polipéptido codificado puede comprender múltiples copias de la misma secuencia o secuencias diferentes.
[0063] La molécula de ácido nucleico descrita en este documento codifica un polipéptido que consiste principal o exclusivamente en los tres residuos de aminoácidos prolina (Pro, P), alanina (Ala, A) y, opcionalmente, serina (Ser, S). El término "opcionalmente" como se usa en este documento significa que el polipéptido codificado de la presente invención consiste principal o exclusivamente en prolina, alanina y serina o consiste principal o exclusivamente en prolina y alanina. El polipéptido codificado que consiste principal o exclusivamente en los tres residuos de aminoácidos prolina, alanina y serina se denomina en el presente documento polipéptido "PAS". El polipéptido codificado que consiste principal o exclusivamente en los dos residuos de aminoácidos prolina y alanina se denomina en el presente documento polipéptido "PA". Un ejemplo no limitante de un polipéptido codificado que consiste en prolina y alanina se da en SEQ ID NO: 8. Un ejemplo no limitante de un polipéptido codificado que consiste en prolina, alanina y serina se da en SEQ ID NO: 6. El término "principalmente" como se usa en este documento significa que preferiblemente al menos aproximadamente el 90% o al menos aproximadamente el 95% de los aminoácidos codificados son prolina, alanina y, opcionalmente, serina, por lo que la prolina, alanina y serina en suma constituyen la mayoría pero pueden no ser los únicos residuos de aminoácidos; por lo tanto, las secuencias de aminoácidos codificadas no son necesariamente 100% de prolina, alanina y, opcionalmente, serina. Por tanto, los polipéptidos / secuencias de aminoácidos codificados también pueden comprender otros aminoácidos además de prolina, alanina y, opcionalmente, serina como constituyentes minoritarios siempre que la secuencia de aminoácidos forme / adopte / tenga la conformación de enrollado aleatorio. Una conformación de enrollado aleatorio de este tipo se puede determinar fácilmente mediante los medios y métodos descritos en el presente documento. Por consiguiente, la presente invención se refiere en una realización a una molécula de ácido nucleico que codifica un polipéptido enrollado aleatorio en el que la secuencia de aminoácidos consiste principalmente en prolina, alanina y, opcionalmente, serina.
[0064] En caso de que el polipéptido codificado consista en prolina y alanina, dichos residuos de prolina constituyen más de aproximadamente el 10% y menos de aproximadamente el 75% de dicha secuencia de aminoácidos codificada. Por consiguiente, el polipéptido enrollado aleatorio codificado consiste principalmente en prolina y alanina, donde los residuos de prolina constituyen más del 10% y menos del 75% de la secuencia de aminoácidos. Los residuos de alanina comprenden al menos del 25% al 90% restante de dicha secuencia de aminoácidos.
[0065] Preferiblemente, la secuencia de aminoácidos codificada comprende más de aproximadamente 10%, preferiblemente más de aproximadamente 12%, más preferiblemente más de aproximadamente 14%, 18%, 20%, más preferiblemente más de aproximadamente 22%, 23%, 24% o 25%, más preferiblemente más de aproximadamente 27%, 29% o 30%, más preferiblemente más de aproximadamente 32%, 33% o 34% y lo más preferiblemente más de aproximadamente 35% de residuos de prolina. La secuencia de aminoácidos comprende preferiblemente menos de aproximadamente 75%, más preferiblemente menos de 70%, más preferiblemente menos de 65%, más preferiblemente menos de 60%, más preferiblemente menos de 55%, más preferiblemente menos de 50% de residuos de prolina, donde se prefieren los valores más bajos. Incluso más preferiblemente, la secuencia de aminoácidos comprende menos de aproximadamente 48%, 46%, 44%, 42% de residuos de prolina. Son más preferidas las secuencias de aminoácidos que comprenden menos de aproximadamente 41%, 40%, 39% 38%, 37% o 36% de residuos de prolina, por lo que se prefieren valores más bajos. Son más preferidas las secuencias de aminoácidos que comprenden menos de aproximadamente 34%, 32% o 30%. Son más preferidas las secuencias de aminoácidos que comprenden menos de aproximadamente 28%, 26% o 25%. Lo más preferiblemente, las secuencias de aminoácidos comprenden menos de aproximadamente un 35% de residuos de prolina.
[0066] Viceversa, la secuencia de aminoácidos comprende preferiblemente menos de aproximadamente 90%, más preferiblemente menos de 88%, 86%, 84%, 82% u 80% de residuos de alanina, en donde se prefieren los valores más bajos. Más preferiblemente, la secuencia de aminoácidos comprende menos de aproximadamente 79%, 78%, 77%, 76% de residuos de alanina, por lo que se prefieren valores más bajos. Más preferiblemente, la secuencia de aminoácidos comprende menos de aproximadamente 74%, 72% o 70% de residuos de alanina, por lo que se prefieren valores más bajos. Más preferiblemente, la secuencia de aminoácidos comprende menos de aproximadamente 69%, 67% o 65% de residuos de alanina, por lo que se prefieren valores más bajos. Lo más preferiblemente, la secuencia de aminoácidos comprende menos de aproximadamente 75% de residuos de alanina. También se prefiere en este documento una secuencia de aminoácidos que comprende más de aproximadamente el
25%, preferiblemente más de aproximadamente el 30%, más preferiblemente más de aproximadamente el 35%, más preferiblemente más de aproximadamente el 40%, más preferiblemente más de aproximadamente el 45%, más preferiblemente más de aproximadamente el 50%, más preferiblemente más de aproximadamente 52%, 54%, 56%, 58% o 59% de residuos de alanina, en donde se prefieren los valores más altos. Incluso más preferiblemente, la secuencia de aminoácidos comprende más de aproximadamente 60%, 61%, 62%, 63% o 64% de residuos de alanina. Más preferiblemente, la secuencia de aminoácidos comprende más de aproximadamente 66%, 67%, 69% o 70% de residuos de alanina. Más preferiblemente, la secuencia de aminoácidos comprende más de aproximadamente 72%, 74% o 75% de residuos de alanina. Lo más preferiblemente, la secuencia de aminoácidos comprende más de aproximadamente un 65% de residuos de alanina.
[0067] Por consiguiente, el polipéptido enrollado aleatorio puede comprender una secuencia de aminoácidos que consta de aproximadamente 25% o 30% de residuos de prolina y aproximadamente 75% o 70%, respectivamente, de residuos de alanina. Alternativamente, el polipéptido enrollado aleatorio puede comprender una secuencia de aminoácidos que consta de aproximadamente 35% de residuos de prolina y aproximadamente 65% de residuos de alanina. El término "aproximadamente X%" como se usa aquí anteriormente no se limita al número conciso del porcentaje, sino que también comprende valores de 10% a 20% adicionales o 10% a 20% menos de residuos. Por ejemplo, el término 10% también puede referirse al 11% o 12% y al 9% u 8%, respectivamente.
[0068] En caso de que el polipéptido codificado consista en prolina, alanina y serina, dichos residuos de prolina constituyen más de aproximadamente el 4% y menos de aproximadamente el 40% de dicha secuencia de aminoácidos codificada. Los residuos de alanina y serina constituyen la cantidad restante de dicha secuencia de aminoácidos.
[0069] Preferiblemente, la secuencia de aminoácidos codificada comprende más de aproximadamente 4%, preferiblemente más de aproximadamente 6%, más preferiblemente más de aproximadamente 10%, más preferiblemente más de aproximadamente 15%, más preferiblemente más de aproximadamente 20%, más preferiblemente más de aproximadamente 22%, 23% o 24%, más preferiblemente más de aproximadamente 26%, 29% o 30%, más preferiblemente más de aproximadamente 31%, 32%, 33%, 34% o 35% y lo más preferiblemente más de aproximadamente 25 % de residuos de prolina. La secuencia de aminoácidos codificada comprende preferiblemente menos de aproximadamente 40%, más preferiblemente menos de 38%, 35%, 30%, 26% de residuos de prolina, en donde se prefieren los valores más bajos.
[0070] La secuencia de aminoácidos codificada comprende preferiblemente menos de aproximadamente 95%, más preferiblemente menos de 90%, 86%, 84%, 82% u 80% de residuos de alanina, en donde se prefieren los valores más bajos. Más preferiblemente, la secuencia de aminoácidos codificada comprende menos de aproximadamente 79%, 78%, 77%, 76% de residuos de alanina, por lo que se prefieren valores más bajos. Más preferiblemente, la secuencia de aminoácidos codificada comprende menos de aproximadamente 75%, 73%, 71% o 70% de residuos de alanina, por lo que se prefieren valores más bajos. Más preferiblemente, la secuencia de aminoácidos codificada comprende menos de aproximadamente 69%, 67%, 66% o 65% de residuos de alanina, por lo que se prefieren valores más bajos. Más preferiblemente, la secuencia de aminoácidos codificada comprende menos de aproximadamente 64%, 63%, 62% o 60% de residuos de alanina, por lo que se prefieren valores más bajos. Más preferiblemente, la secuencia de aminoácidos codificada comprende menos de aproximadamente 59%, 57%, 56% o 55% de residuos de alanina, por lo que se prefieren valores más bajos. Más preferiblemente, la secuencia de aminoácidos codificada comprende menos de aproximadamente 54%, 53% o 51% de residuos de alanina, por lo que se prefieren valores más bajos. Lo más preferiblemente, la secuencia de aminoácidos codificada comprende menos de aproximadamente 50% de residuos de alanina.
[0071] También se prefiere aquí una secuencia de aminoácidos codificada que comprende más de aproximadamente 10%, preferiblemente más de aproximadamente 15%, 17%, 19% o 20%, más preferiblemente más de aproximadamente 22%, 24% o 25%, más preferiblemente más de aproximadamente 27%, 29% o 30%, más preferiblemente más de aproximadamente 32%, 34% o 35%, más preferiblemente más de aproximadamente 37%, 39% o 40%, más preferiblemente más de aproximadamente 42% , 44% o 45%, más preferiblemente más de aproximadamente 46%, 47% o 49% de residuos de alanina, en donde se prefieren los valores más altos. Lo más preferiblemente, la secuencia de aminoácidos codificada comprende más de aproximadamente 50 residuos de alanina. Como se mencionó anteriormente, los residuos de serina comprenden la cantidad restante de dicha secuencia de aminoácidos.
[0072] Por consiguiente, el polipéptido enrollado aleatorio codificado puede comprender una secuencia de aminoácidos que consta de aproximadamente 35% de residuos de prolina, aproximadamente 50% de alanina y 15% de residuos de serina. Las secuencias de nucleótidos ejemplares y los polipéptidos codificados de las mismas se pueden encontrar en la Tabla 1. El término "aproximadamente X%" como se usa en este documento anteriormente no se limita al número conciso del porcentaje, sino que también comprende valores de 10% a 20% adicionales o 10 % a 20% menos residuos. Por ejemplo, el término 10% también puede relacionarse con 11% o 12% o con 9% y 8%, respectivamente.
[0073] Sin embargo, como se mencionó anteriormente y se detalla adicionalmente a continuación, dicho polipéptido helicoidal aleatorio codificado y, en particular, la secuencia de aminoácidos también pueden comprender
aminoácidos adicionales que difieren de prolina, alanina y, opcionalmente, serina como constituyentes minoritarios. Como ya se ha discutido en el presente documento anteriormente, dicho constituyente o constituyentes minoritarios, es decir, aminoácidos diferentes de prolina, alanina u, opcionalmente, serina, pueden comprender menos de aproximadamente 10% o menos de aproximadamente 5% del polipéptido enrollado aleatorio codificado de esta invención.
[0074] El experto en la materia es consciente de que la secuencia de aminoácidos / polipéptido codificados también puede formar una conformación de enrollado aleatorio cuando otros residuos distintos de prolina, alanina y, opcionalmente, serina están comprendidos como constituyente menor en dicha secuencia de aminoácidos / polipéptido (fragmento de polipéptido). El término "constituyente minoritario" como se usa en este documento significa que un máximo del 5% o un máximo del 10% de residuos de aminoácidos son diferentes de prolina, alanina o serina en los polipéptidos en enrollado aleatorios codificados de esta invención. Esto significa que como máximo 10 de 100 aminoácidos pueden ser diferentes de prolina, alanina y, opcionalmente, serina, preferiblemente como máximo 8%, es decir, como máximo 8 de 100 aminoácidos pueden ser diferentes de prolina, alanina y, opcionalmente, serina, más preferiblemente como máximo 6%, es decir, como máximo 6 de 100 aminoácidos pueden ser diferentes de prolina, alanina y, opcionalmente, serina, incluso más preferiblemente como máximo 5%, es decir, como máximo 5 de 100 aminoácidos pueden ser diferentes de prolina, alanina y, opcionalmente, serina, particularmente preferiblemente como máximo 4%, es decir, como máximo 4 de 100 aminoácidos pueden ser diferentes de prolina, alanina y, opcionalmente, serina, más particularmente preferiblemente como máximo 3%, es decir, como máximo 3 de 100 aminoácidos pueden ser diferentes de prolina, alanina y, opcionalmente, serina, incluso más particularmente preferible como máximo 2%, es decir, como máximo 2 de 100 aminoácidos pueden ser diferentes de prolina, alanina y, opcionalmente, serina y lo más preferiblemente como máximo 1%, es decir, como máximo 1 de 100 de los aminoácidos que están comprendidos en el polipéptido en enrollado aleatorio pueden ser diferentes de prolina, alanina y, opcionalmente, serina. Dichos aminoácidos diferentes de prolina, alanina y, opcionalmente, serina pueden seleccionarse del grupo formado por Arg, Asn, Asp, Cys, Gln, Glu, Gly, His, Ile, Leu, Lys, Met, Phe, Thr, Trp , Tyr y Val, incluidos los aminoácidos modificados postraduccionalmente o los aminoácidos no naturales (ver, p. ej., Budisa (2004) Angew Chem Int Ed Engl 43: 6426-6463; Young (2010) J Biol Chem 285: 11039-11044; Liu (2010) Annu Rev Biochem 79: 413-444; Wagner (1983) AngewChem Int Ed Engl 22: 816 828; Walsh (2010) Drug Discov Today 15: 773-780. En ciertos casos, las secuencias ricas en PA también pueden comprender Ser como un componente menor. Por ejemplo, en caso de que el polipéptido en enrollado aleatorio codificado consista en prolina y alanina, la serina también se puede considerar como constituyente menor.
[0075] Generalmente, se prefiere en este documento que estos aminoácidos "menores" (distintos de prolina, alanina y, opcionalmente, serina) no estén presentes en el polipéptido en enrollado aleatorio codificado como se describe en este documento o en el polipéptido en enrollado aleatorio codificado como parte / fragmento de una proteína de fusión. De acuerdo con la invención, la secuencia de aminoácidos / polipéptido en enrollado aleatorio codificada puede, en particular, consistir exclusivamente en residuos de prolina, alanina y, opcionalmente, serina (es decir, no hay otros residuos de aminoácidos presentes en el polipéptido en enrollado aleatorio codificado o en el secuencia de aminoácidos).
[0076] En el contexto de la presente invención, la molécula de ácido nucleico que codifica el polipéptido que consiste en prolina, alanina y, opcionalmente, serina o la secuencia de nucleótidos que codifica el polipéptido que consiste en prolina, alanina y, opcionalmente, serina puede consistir en al menos 300 nucleótidos. Sin embargo, es evidente para un experto en la técnica que la longitud de la secuencia de nucleótidos proporcionada en este documento no está limitada siempre que el polipéptido codificado forme un enrollado aleatorio. Los ejemplos adjuntos documentan que las moléculas de ácido nucleico proporcionadas en este documento que comprenden secuencias de nucleótidos de baja repetición pueden sintetizarse de forma sorprendente independientemente de sus longitudes. En el presente documento se demuestra que, por ejemplo, se pueden sintetizar secuencias de nucleótidos que tienen una longitud de aproximadamente 600 nucleótidos. Estas secuencias de nucleótidos se pueden emplear para ensamblar secuencias de nucleótidos incluso más largas. En otras palabras, estas secuencias de nucleótidos se pueden emplear como unidades / módulos / bloques de construcción para combinar / ensamblar secuencias de nucleótidos más largas incluidas en la molécula de ácido nucleico de la invención. En una realización, una única unidad de secuencia de nucleótidos / módulo / bloque de construcción también corresponde a una molécula de ácido nucleico de la invención.
[0077] Según esta invención, las unidades / módulos / bloques de construcción de secuencia de nucleótidos idénticos o no idénticos pueden combinarse entre sí siempre que la secuencia de nucleótidos ensamblada codifique un polipéptido que consiste en prolina, alanina y, opcionalmente, serina. Además, según esta invención, las unidades / módulos / bloques de construcción de secuencia de nucleótidos idénticos o no idénticos pueden combinarse entre sí siempre que la secuencia de nucleótidos ensamblada que codifica un polipéptido con secuencia de aminoácidos repetitiva forme un enrollado aleatorio. Como se mencionó anteriormente, es particularmente ventajoso ensamblar las moléculas de ácido nucleico proporcionadas en este documento que comprenden secuencias de nucleótidos de baja repetición empleando estas unidades / módulos / bloques de construcción. Se documenta a continuación en el presente documento que se pueden ensamblar secuencias de nucleótidos largas con al menos una longitud de 2400 nucleótidos. Las secuencias de nucleótidos de la invención se pueden combinar entre sí o con secuencias de nucleótidos no idénticas adicionales. Por tanto, la molécula de ácido nucleico proporcionada en el presente documento puede ensamblarse a partir de secuencias de nucleótidos idénticas o no
idénticas, en las que dichas secuencias de nucleótidos son secuencias de nucleótidos de baja repetición. En ciertos aspectos, la molécula de ácido nucleico proporcionada en este documento comprende al menos una secuencia de nucleótidos seleccionada del grupo que consiste en SEQ ID NO: 19, SEQ ID nO: 20, SEQ ID NO: 21, SEQ ID NO:
22, SEQ ID NO: 23, SEQ ID NO: 24, SEQ ID NO: 25, SEQ ID NO: 26, SEQ ID NO: 27, SEQ ID NO: 28, SEQ ID NO:
29, SEQ ID NO: 30, SEQ ID NO: 31, SEQ ID NO: 32, SEQ ID NO: 33, SEQ ID NO: 34, SEQ ID NO: 35, SEQ ID NO:
36, SEQ ID NO: 37, SEQ ID NO: 87, SEQ ID NO: 88, SEQ ID NO: 89, SEQ ID NO: 90, SEQ ID NO: 91, SEQ ID NO:
92, SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID NO: 95, SEQ ID NO: 96, SEQ ID NO: 97, SEQ ID N.°: 98, SEQ ID N.°:
99, SEQ ID N.°: 100, SEQ ID N.°: 101, SEQ ID N.°: 102, SEQ ID N.°: 103, SEQ ID N.°: 104, SEQ ID N.°: 105, SEQ ID
NO: 106, SEQ ID NO: 107, SEQ ID NO: 108, SEQ ID NO: 109, SEQ ID NO: 110, SEQ ID NO: 111, SEQ ID NO: 112,
SEQ ID NO: 113, SEQ ID NO: 114, SEQ ID NO: 115, SEQ ID NO: 116, SEQ ID NO: 117, SEQ ID NO: 118, SEQ ID
NO: 119, SEQ ID NO: 120, SEQ ID NO: 121, SEQ ID NO: 122, SEQ ID N.°: 123, SEQ ID NO: 124, SEQ ID NO: 125,
SEQ ID NO: 126, SEQ ID NO: 127, SEQ ID NO: 128, SEQ ID NO: 129, SEQ ID NO: 130, SEQ ID NO: 131, SEQ ID
NO: 132, SEQ ID NO: 133, SEQ ID NO: 134, SEQ ID NO: 135, SEQ ID NO: 136, SEQ ID NO: 137, SEQ ID NO: 138,
SEQ ID NO: 139, SEQ ID NO: 140, SEQ ID NO: 141, SEQ ID NO: 142, SEQ ID NO: 143, SEQ ID NO: 144, SEQ ID
NO: 145, SEQ ID NO: 146, SEQ ID NO: 147, SEQ ID NO: 148, SEQ ID NO: 149, SEQ ID NO: 150, SEQ ID NO: 151,
SEQ ID NO: 152, SEQ ID NO: 192, SEQ ID NO: 193, SEQ ID NO: 194 y SEQ ID NO: 195. Como estas secuencias de nucleótidos ejemplares pueden emplearse para ensamblar secuencias de nucleótidos más largas, estas secuencias de nucleótidos pueden denominarse unidades o módulos o bloques de construcción. Por lo tanto, se entiende en el presente documento que las moléculas de ácido nucleico de la invención pueden comprender una pluralidad de estos módulos de nucleótidos o secuencias de nucleótidos que se ensamblan en una secuencia de nucleótidos más larga, en la que dicha secuencia de nucleótidos más larga en sí misma es una secuencia de nucleótidos de baja repetición como se describe previamente aquí. El experto en la técnica entenderá que la molécula de ácido nucleico de la invención también puede comprender fragmentos de los módulos de secuencia de nucleótidos dados. En otras palabras, la molécula de ácido nucleico proporcionada en este documento comprende o es al menos una secuencia de nucleótidos, o un fragmento de la misma, seleccionada del grupo que consiste en
SEQ ID NO: 19, SEQ ID NO: 20, SEQ ID NO: 21, SEQ ID NO : 22, 23, SEQ ID NO: 24, SEQ ID NO: 25, SEQ ID NO: 26, SEQ ID NO: 27, SEQ ID NO: 28, SEQ ID NO: 29, 30 , SEQ ID NO: 31, SEQ ID NO: 32, SEQ ID NO: 33, SEQ ID NO: 34, SEQ ID NO: 35, SEQ ID NO: 36, 37, SEQ ID NO: 87, SEQ ID NO: 88, SEQ ID NO: 89, SEQ ID NO: 90, SEQ ID NO: 91, SEQ ID NO: 92, 93, SEQ ID NO: 94, SEQ ID NO: 95, SEQ ID NO : 96, SEQ ID NO: 97, SEQ ID NO: 98, SEQ ID NO: 99, SEQ I NO: 101, SEQ ID NO:
NO: 101, SEQ ID NO:
102, SEQ ID NO: 103, SEQ ID NO: 104 , SEQ ID NO: 105, SEQ ID NO: 106, SEQ ID NO: 107, SEQ ID NO: 108,
SEQ ID NO: 109, SEQ ID NO: 110, SEQ ID NO: 111, SEQ ID NO: 112, SEQ ID. NO: 113, SEQ ID NO: 114, SEQ ID
NO: 115, SEQ ID NO: 116, SEQ ID NO: 117, SEQ ID NO: 118, SEQ ID NO: 119, SEQ ID NO: 120, SEQ ID NO : 121,
S EQ ID NO: 122, SEQ ID NO: 123, SEQ ID NO: 124, SEQ ID NO: 125, SEQ ID NO: 126, SEQ ID NO: 127, SEQ ID
NO: 128, SEQ ID NO: 129, SEQ ID SEQ ID N.°: 130, SEQ ID N.°: 131, SEQ ID N.°: 132, SEQ ID N.°: 133, SEQ ID
N.°: 134, SEQ ID N.°: 135, SEQ ID N.°: 136, SEQ ID N.°: 137, SEQ ID N.°: 138, SEQ ID N.°: 139, SEQ ID N.°: 140,
SEQ ID N.°: 141, SEQ ID N.°: 142, SEQ ID N.°: 143, SEQ ID N.°: 144, SEQ ID N.°: 145, SEQ ID N.°: 146, SEQ ID
NO: 147, SEQ ID NO: 148, SEQ ID NO: 149, SEQ ID NO: 150, SEQ ID NO: 151, SEQ ID NO: 152, SEQ ID NO: 192,
SEQ ID NO: 193, SEQ ID NO: 194 y SEQ ID NO: 195.
[0078] Se entiende en este documento que las secuencias de nucleótidos de baja repetición o las unidades o módulos o bloques de construcción proporcionados en este documento pueden permutarse o combinarse entre sí en cualquier combinación siempre que la secuencia de nucleótidos ensamblada comprenda una secuencia de nucleótidos de baja repetición según la presente invención. A continuación se presentan ejemplos de secuencias de nucleótidos ensambladas, por ejemplo, SEQ ID NO: 38 o se describe en este documento como PAS # 1f/1c/1b(600),
SEQ ID NO: 39 o se describe en este documento como PAS #1d/1f/1c/1b( 800), SEQ ID NO: 40 o aquí representada como PAS #1h/1e/1i(600), SEQ ID NO: 41 o aquí representada como PAS #1j/1h/1e/1i(800), SEQ ID NO: 42 aquí representado como Pa #1d/1c/1b(600), SEQ ID NO: 43 o aquí representado como PA # 1i/1h/1g/1f(800), SEQ ID nO: 44 o aquí representado como PA #1e/1d/1c/1b(800), SEQ ID NO: 45 o aquí representado como PA #1i/1h/1g/1f/1e/1d/1c/1b (1600), SEQ ID NO: 153, SEQ ID NO: 154, SEQ ID NO: 155, SEQ ID NO: 156, SEQ ID NO:
: 169, SEQ 176, Q ID N.°: 1  189, SEQ N.°: 190 y / o SEQ. ID NO: 191.
189, SEQ N.°: 190 y / o SEQ. ID NO: 191.
[0079] Por lo tanto, en aspectos preferidos de la invención la molécula de ácido nucleico proporcionada en este documento tiene, comprende o es dicha secuencia de nucleótidos ensamblada.
[0080] Como se documenta en los ejemplos adjuntos (ver Ejemplo 1), una secuencia de nucleótidos larga de acuerdo con la invención puede ensamblarse de manera escalonada. La secuencia de nucleótidos ensamblada mantiene la baja repetitividad. Se demuestra en los ejemplos adjuntos cómo se ensambla una secuencia de nucleótidos ejemplar como se da en SEQ ID NO: 39 o aquí representada como PAS #1d/1f/1c/1b(800) que comprende 2400 nucleótidos y codifica 800 aminoácidos.
[0081] En el presente documento se entiende que estas secuencias de nucleótidos ensambladas son secuencias de
nucleótidos de baja repetición. Por ejemplo, los ejemplos adjuntos documentan que la secuencia de nucleótidos ejemplar como se indica en SEQ ID NO: 39 o representada en este documento como secuencia PAS # 1d/1f/1c/1b(800) no muestra repeticiones en el caso de una ventana de repetición de 15, o sólo una única repetición de 14 nucleótidos, dentro de la secuencia de nucleótidos completa de 2400 nucleótidos; vea la Figura 2B. A modo de comparación, la secuencia de nucleótidos larga como se describe en la técnica anterior comprende secuencias de nucleótidos repetitivas como se demuestra a modo de ejemplo en el caso de PAS #1a(600) dado en este documento como SEQ ID NO: 12. Por consiguiente, las moléculas de ácido nucleico largas de acuerdo con la presente invención tienen pocas secuencias de nucleótidos repetitivos y, por lo tanto, superan los desafíos técnicos asociados con los tramos de nucleótidos repetidos como se mencionó anteriormente.
[0082] Moléculas de ácido nucleico y moléculas de ácido nucleico relacionadas (como variantes, fragmentos, moléculas de ácido nucleico que tienen una identidad de al menos 66%, por ejemplo, al menos 66,6% con las secuencias de nucleótidos específicas que codifican un polipéptido que consiste en prolina y alanina; o variantes similares, fragmentos, moléculas de ácido nucleico que tienen una identidad de al menos el 56%, por ejemplo, al menos el 56,6% de las secuencias de nucleótidos específicas que codifican un polipéptido que consiste en prolina, alanina y serina como se proporciona y define en este documento, y similares) comprenden o son secuencias de nucleótidos de baja repetición codificando el polipéptido, que forma la conformación en enrollado aleatorio aumentando la estabilidad in vivo / in vitro.
[0083] Las moléculas de ácido nucleico y las moléculas de ácido nucleico relacionadas tienen, comprenden o son secuencias de nucleótidos de baja repetición que codifican polipéptidos que forman una conformación en enrrollado aleatorio y aumentan la estabilidad in vivo / vitro de una proteína o fármaco biológicamente o farmacológicamente activo. Dichas moléculas de ácido nucleico relacionadas comprenden o son variantes y fragmentos de dichas moléculas de ácido nucleico. Dichas moléculas de ácido nucleico relacionadas tienen una identidad de al menos el 66%, p. al menos 66,6%, a una secuencia de nucleótidos específica que codifica un polipéptido que consiste en prolina y alanina o que tiene una identidad de al menos 56%, p. al menos 56,6%, a una secuencia de nucleótidos específica que codifica un polipéptido que consiste en prolina, alanina y serina como se proporciona y se define en el presente documento, y similares.
[0084] En ciertos aspectos, la molécula de ácido nucleico que comprende una secuencia de nucleótidos ortóloga / homóloga / idéntica / similar (y por lo tanto relacionada) que codifica un polipéptido que consiste en prolina y alanina es al menos 66%, p. al menos 66,6% homóloga / idéntica a la secuencia de nucleótidos como, entre otros, se muestra en las SEQ ID NO: 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 42, 43, 44, 45, 87, 88, 89, 90, 91, 92, 93, 94, 95,
96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119,
120, 121, 122, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172,
173, 192 y 193. Más preferiblemente, la molécula de ácido nucleico que comprende la secuencia de nucleótidos ortóloga / homóloga / idéntica / similar (y por lo tanto relacionada) que codifica un polipéptido que consiste en prolina y alanina es al menos 68%, 70%, 75%, 80%, 85%, 90%, 92%, 93%, 94%, 95%, 96%, 97% o 98% homólogo / idéntico a la secuencia de nucleótidos como, entre alia, mostrado en 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 42, 43, 44,45, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111,
112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164,
165, 166, 167, 168, 169, 170, 171, 172, 173, 192 y 193, en donde se prefieren los valores más altos. Lo más preferiblemente, la molécula de ácido nucleico que comprende la secuencia de nucleótidos ortóloga / homóloga / idéntica / similar (y por lo tanto relacionada) que codifica un polipéptido que consiste en prolina y alanina es al menos 99% homóloga / idéntica / similar a la secuencia de nucleótidos como, entre otras cosas, se muestra en 28,
29, 30, 31, 32, 33, 34, 35, 36, 37, 42, 43, 44, 45, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102,
103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 153, 154, 155,
156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 192 y 193.
[0085] En aspectos adicionales, la molécula de ácido nucleico que comprende una secuencia de nucleótidos ortóloga / homóloga / idéntica / similar (y por lo tanto relacionada) que codifica un polipéptido que consiste en prolina, alanina y serina es al menos 56%, por ejemplo, al menos 56,6% homóloga / idéntica / similar a la secuencia de nucleótidos como, entre otros, se muestra en las SEQ ID NO: 19, 20, 21, 22, 23, 24, 25, 26, 27, 38, 39, 40, 41,
123, 124, 125, 126, 127 , 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145,
146, 147, 148, 149, 150, 151, 152 , 174, 175, 176, 177, 178, 179, 180, 181, 182, 184, 185,186, 187, 188, 189, 190,
191, 194 y 195. Más preferiblemente, la molécula de ácido nucleico que comprende la secuencia de nucleótidos ortóloga / homóloga / idéntica / similar (y por lo tanto relacionada) que codifica un polipéptido que consiste en prolina, alanina y serina es al menos 58%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97% o 98% homóloga / idéntica a la secuencia de nucleótidos como, entre otras cosas, se muestra en 19, 20,
21, 22, 23, 24, 25, 26, 27, 3839, 40, 41, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137,
138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 174, 175, 176, 177, 178, 179, 180, 181,
182, 184, 185,186, 187, 188, 189, 190, 191, 194 y 195. Lo más preferiblemente, la molécula de ácido nucleico que comprende la secuencia de nucleótidos ortóloga / homóloga / idéntica / similar (y por lo tanto relacionada) que codifica un polipéptido que consiste en prolina, alanina y serina son al menos un 99% homólogas / idénticas / similares a la secuencia de nucleótidos como, entre otras cosas, se muestra en las SEQ ID NO: 19, 20, 21,22, 23,
24, 25, 26, 27, 38, 39,40, 41, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145 , 146, 147, 148, 149, 150, 151, 152, 174, 175, 176, 177, 178, 179, 180, 181, 182, 184,
185,186, 187, 188, 189, 190, 191, 194 y 195 .Las secuencias de nucleótidos relacionadas definidas anteriormente también pueden incluirse en isotermas largas o cortas, variantes empalmadas (spliced) o constructos de fusión.
[0086] En ciertos aspectos, la molécula de ácido nucleico proporcionada en este documento puede hibridar en condiciones rigurosas con la cadena complementaria de la secuencia de nucleótidos como, entre otros, se muestra en las SEQ ID NO: 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39,40, 41, 42, 43, 44,45, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 184, 185,186, 187, 188, 189, 190, 191, 192, 193, 194 y 195. El término "hibridación" o "hibrida" como se usa en este documento puede referirse a hibridaciones en condiciones rigurosas o no rigurosas. Si no se especifica más, las condiciones son preferiblemente rigurosas. Dichas condiciones de hibridación se pueden establecer de acuerdo con protocolos convencionales descritos, por ejemplo, en Sambrook (2001) Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory Press, 3ra ed., Nueva York; Ausubel (1989) Current Protocols in Molecular Biology, Green Publishing Associates y Wiley Interscience, Nueva York, o Higgins (1985) Nucleic Acids hybridization, a practical approach IRL Press Oxford, Washington DC. El establecimiento de las condiciones adecuadas está dentro del conocimiento del experto y puede determinarse de acuerdo con los protocolos descritos en la técnica. Por lo tanto, la detección de secuencias que hibridan solo específicamente requerirá normalmente condiciones rigurosas de hibridación y lavado como, por ejemplo, tampón de citrato de sodio (SSC) salino 0,1 x, SDS al 0,1% p / v a 65 °C o 2 x SSC, 60 °C, SDS al 0,1% p / v. Las condiciones de hibridación poco rigurosas para la detección de secuencias homólogas o no exactamente complementarias pueden establecerse, por ejemplo, en 6 x SSC, SDS al 1% p / v a 65 °C. Como es bien sabido, la longitud de la sonda de ácido nucleico y la composición del ácido nucleico a determinar constituyen parámetros adicionales de las condiciones de hibridación.
[0087] De acuerdo con la presente invención, el término "homología" o "porcentaje de homología" o "idéntico" o "porciento de identidad" o "porcentaje de identidad" o "identidad de secuencia" en el contexto de dos o más secuencias de nucleótidos se refiere a dos o más secuencias o subsecuencias que son iguales, o que tienen un porcentaje específico de nucleótidos que son iguales (preferiblemente al menos 66%, por ejemplo, al menos 66,6% de identidad en el caso de la molécula de ácido nucleico que codifica el polipéptido que consiste en prolina y alanina, más preferiblemente al menos 68%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97% o 98% de identidad, lo más preferiblemente en al menos 99% de identidad; o preferiblemente al menos 56%, por ejemplo, al menos 56,6% de identidad en el caso de la molécula de ácido nucleico que codifica prolina, alanina y serina, más preferiblemente al menos 58%, 60%, 65%, 70%, 75 %, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97% o 98% de identidad, más preferiblemente al menos 99% de identidad) cuando se compara y alinea para un máximo correspondencia sobre una ventana de comparación (preferiblemente en toda la longitud), o en una región designada medida usando un algoritmo de comparación de secuencias como se conoce en la técnica, o por alineación manual e inspección visual.
[0088] Las secuencias que tienen, por ejemplo, 70% a 90% o más de identidad de secuencia pueden considerarse sustancialmente idénticas o similares. Esta definición también se aplica al complemento de una secuencia de ácido nucleico de prueba. Preferiblemente, la identidad descrita existe sobre una región que tiene al menos aproximadamente 15 a 25 nucleótidos de longitud, más preferiblemente, sobre una región que tiene al menos aproximadamente 50 a 100 nucleótidos de longitud, más preferiblemente sobre una región que es al menos aproximadamente 125 a 200 nucleótidos de longitud, más preferiblemente sobre una región que tiene al menos aproximadamente 225 a 300 nucleótidos de longitud, incluso más preferiblemente sobre una región que tiene al menos aproximadamente 325 a 600 nucleótidos de longitud, incluso más preferiblemente sobre una región que está en al menos de aproximadamente 625 a 800 nucleótidos de longitud, y más preferiblemente, en una región que tiene al menos aproximadamente de 825 a 1200 nucleótidos de longitud. Los expertos en la técnica sabrán cómo determinar el porcentaje de identidad entre secuencias utilizando, por ejemplo, algoritmos como los basados en el programa informático ClUSTALW (Thompson (1994) Nucl. Acids Res. 2: 4673-4680), CLUSTAL Omega (Sievers (2014) Curr. Protoc. Bioinformátics 48: 3.13.1-3.13.16) o FASTDB (Brutlag (1990) Comp App Biosci 6: 237-245). También están disponibles para los expertos en esta técnica el BLAST, que significa Herramienta de búsqueda de alineación local básica, y los algoritmos BLAST 2.0 (Altschul, (1997) Nucl. Acids Res. 25: 3389-3402; Altschul (1990) J. Mol. Biol. 215: 403-410). El programa BLASTN para secuencias de ácido nucleico utiliza por defecto una longitud de palabra (W) de 11, una expectativa (E) de 10, M = 5, N = 4 y una comparación de ambas cadenas. La matriz de puntuación BLOSUM62 (Henikoff (1992) Proc. Natl. Acad. Sci. Ee .UU. 89: 10915-10919) usa alineaciones (B) de 50, expectativa (E) de 10, M = 5, N = 4 y una comparación de ambas cadenas.
[0089] Para determinar si un residuo de nucleótidos en una secuencia de nucleótidos dada corresponde a una determinada posición en la secuencia de nucleótidos de, por ejemplo, SEQ ID NO: 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41,42, 43, 44,45, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 184, 185,186, 187, 188, 189, 190, 191, 192, 193, 194 y 195, respectivamente, el experto en la materia puede utilizar medios y métodos bien conocidos en la
técnica, por ejemplo, alineaciones, ya sea manualmente o mediante el uso de programas informáticos como los mencionados en el presente documento. Por ejemplo, BLAST 2.0 se puede utilizar para buscar alineamientos de secuencias locales. BLAST o BLAST 2.0, como se discutió anteriormente, produce alineamientos de secuencias de nucleótidos para determinar la similitud de secuencia. Debido a la naturaleza local de las alineaciones, BLAST o BLAST 2.0 son especialmente útiles para determinar coincidencias exactas o para identificar secuencias similares o idénticas.
[0090] Como se muestra en los ejemplos adjuntos, se proporcionan en este documento medios y métodos para clonar rápida y fácilmente las secuencias de nucleótidos largas y poco repetitivas o las moléculas de ácido nucleico largas y poco repetitivas que comprenden dichas secuencias de nucleótidos; véanse, por ejemplo, los Ejemplos 1, 2, 5, 7 y 10. Como se demuestra en los ejemplos adjuntos, en este documento se proporcionan vectores ejemplares que son particularmente adecuados para ensamblar secuencias de nucleótidos de la invención en construcciones más largas. Como se mencionó anteriormente, las moléculas de ácido nucleico o las secuencias de nucleótidos proporcionadas en este documento se pueden ensamblar de manera escalonada para construir moléculas de ácido nucleico largas o secuencias de nucleótidos largas. Se prevé en este documento que el tamaño de la molécula de ácido nucleico ensamblada o secuencia de nucleótidos no está limitado o está limitado por circunstancias prácticas, como el tamaño del plásmido o la eficacia de transformación / transfección, en el mejor de los casos.
[0091] Un ensamblaje ejemplar de una molécula de ácido nucleico que comprende una secuencia de nucleótidos repetitiva baja o una molécula de ácido nucleico que codifica una secuencia de aminoácidos repetitiva de prolina, alanina y serina de una longitud de aproximadamente 2400 nucleótidos (que codifica un polipéptido con una longitud de 800 residuos de aminoácidos) se demuestra en el Ejemplo 2 adjunto. Se muestra en el mismo que primero la unidad de secuencia de nucleótidos (bloque de construcción) PAS # lb (200) como se indica en SEQ ID NO: 19, luego la unidad de secuencia de nucleótidos PAS # lc (200) como indicada en SEQ ID NO: 20, y posteriormente la unidad de secuencia de nucleótidos PAS # 1f (200) como se indica en SEQ ID NO: 23, y finalmente la unidad de secuencia de nucleótidos PAS # ld (200) como se indica en SEQ ID NO: 21 es clonado y ensamblado en el ejemplo de vector pXL2. Esta molécula de ácido nucleico ensamblada ejemplar o secuencia de nucleótidos ensamblada se representa en el presente documento como PAS #1d/1f/1c/1b (800) y se proporciona en la SEQ ID NO: 39. Además, se demuestra en este documento que estas moléculas de ácido nucleico de la invención ensambladas tienen o comprenden secuencias de nucleótidos de baja repetición. En particular, se muestra en el Ejemplo 2 que esta secuencia de nucleótidos ensamblada ejemplar como se da en la SEQ ID NO: 39 posee solo secuencias repetidas de una longitud máxima de 14 nucleótidos.
[0092] La invención también se refiere a un método para proporcionar las moléculas de ácido nucleico de la invención; ver, por ejemplo, la Figura IE, que ilustra un procedimiento ejemplar para ensamblar secuencias de nucleótidos más largas. Además, la invención se refiere a un vector que es particularmente adecuado para ensamblar las moléculas de ácido nucleico de baja repetición que codifican los polipéptidos ricos en PA.
[0093] De acuerdo con lo anterior, la molécula de ácido nucleico proporcionada en este documento puede codificar un polipéptido que consiste en prolina y alanina.
[0094] Por consiguiente, la molécula de ácido nucleico proporcionada en este documento se puede seleccionar del grupo que consiste en:
(a) la molécula de ácido nucleico que comprende al menos una secuencia de nucleótidos seleccionada del grupo que consiste en SEQ ID NO: 28, SEQ ID NO: 29, SEQ ID NO: 30, SEQ ID NO: 31, SEQ ID NO: 32, SEQ ID NO: 33, SEQ ID NO: 34, SEQ ID NO: 35, SEQ ID NO: 36, SEQ ID NO: 37, SEQ ID NO: 87, SEQ ID NO: 88, SEQ ID NO: 89, SEQ ID NO : 90, SEQ ID NO: 91, SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID NO: 95, SEQ ID NO: 96, SEQ ID NO: 97, SEQ ID NO: 98 , SEQ ID NO: 99, SEQ ID NO: 100, SEQ ID NO: 101, SEQ ID NO: 102, SEQ ID NO: 103, SEQ ID NO: 104, SEQ ID NO: 105, SEQ ID NO: 106, SEQ ID. NO: 107, SEQ ID NO: 108, SEQ ID NO: 109, SEQ ID NO: 110, SEQ ID NO: 111, SEQ ID NO: 112, SEQ ID NO: 113, SEQ ID NO: 114, SEQ ID NO: 115, SEQ ID N.°: 116, SEQ ID N.°: 117, SEQ ID N.°: 118, SEQ ID N.°: 119, SEQ ID N.°: 120, SEQ ID N.°: 121, SEQ ID N.°: 122, SEQ ID N.°: 192 y SEQ ID NO: 193;
(b) la molécula de ácido nucleico que comprende la secuencia de nucleótidos que consiste de SEQ ID NO: 42, SEQ ID NO: 43, SEQ ID NO: 44, SEQ ID NO: 45, SEQ ID NO: 153, SEQ ID NO: 154, SEQ ID. NO: 155, SEQ ID NO: 156, SEQ ID NO: 157, SEQ ID NO: 158, SEQ ID NO: 159, SEQ ID NO: 160, SEQ ID NO: 161, SEQ ID NO: 162, SEQ ID NO : 163, SEQ ID N.°: 164, SEQ ID N.°: 165, SEQ ID N.°: 166, SEQ ID N.°: 167, SEQ ID N.°: 168, SEQ ID N.°: 169, SEQ ID N.°: 170, SEQ ID N.°: 171 , SEQ ID NO: 172 y / o SEQ ID NO: 173;
(c) la molécula de ácido nucleico que hibrida en condiciones rigurosas con la hebra complementaria de la secuencia de nucleótidos como se define en (a) o (b);
(d) la molécula de ácido nucleico que comprende la secuencia de nucleótidos que tiene al menos un 66,7% de identidad con la secuencia de nucleótidos como se define en cualquiera de (a), (b) y (c); y
(e) la molécula de ácido nucleico que degenera como resultado del código genético de la secuencia de nucleótidos como se define en (a) o (b).
[0095] De acuerdo con lo anterior, la molécula de ácido nucleico proporcionada en este documento puede codificar un polipéptido que consiste en prolina, alanina y serina.
[0096] Por consiguiente, la molécula de ácido nucleico proporcionada en este documento se puede seleccionar del grupo que consiste en:
(a) la molécula de ácido nucleico que comprende al menos una secuencia de nucleótidos seleccionada del grupo que consiste en SEQ ID NO: 19, SEQ ID NO: 20, SEQ ID NO: 21, SEQ ID NO: 22, SEQ ID NO: 23, SEQ ID. NO: 24, SEQ ID NO: 25, SEQ ID NO: 26, SEQ ID NO: 27, SEQ ID NO: 123, SEQ ID NO: 124, SEQ ID NO: 125, SEQ ID NO: 126, SEQ ID NO : 127, SEQ ID N.°: 128, SEQ ID N.°: 129, SEQ ID N.°: 130, SEQ ID N.°: 131, SEQ ID N.°: 132, SEQ ID N.°: 133, SEQ ID N.°: 134, SEQ ID N.°: 135 , SEQ ID NO: 136, SEQ ID NO: 137, SEQ ID NO: 138, SEQ ID NO: 139, SEQ ID NO: 140, SEQ ID NO: 141, SEQ ID NO: 142, SEQ ID NO: 143, SEQ ID. NO: 144, SEQ ID NO: 145, SEQ ID NO: 146, SEQ ID NO: 147, SEQ ID NO: 148, SEQ ID NO: 149, SEQ ID NO: 150, SEQ ID NO: 151, SEQ ID NO: 152; SEQ ID NO: 194 y SEQ ID NO: 195;
(b) la molécula de ácido nucleico que comprende la secuencia de nucleótidos seleccionada del grupo que consiste en SEQ ID NO: 38, SEQ ID NO: 39, SEQ ID NO: 40, SEQ ID NO: 41, SEQ ID NO: 174, SEQ ID NO : 175, SEQ ID N.°: 176, SEQ ID N.°: 177, SEQ ID N.°: 178, SEQ ID N.°: 179, SEQ ID N.°: 180, SEQ ID N.°: 181, SEQ ID N.°: 182, SEQ ID N.°: 184 , SEQ ID NO: 185, SEQ ID NO: 186, SEQ ID NO: 187, SEQ ID NO: 188, SEQ ID NO: 189, SEQ ID NO: 190 y SEQ ID NO: 191;
(c) la molécula de ácido nucleico que hibrida en condiciones rigurosas con la hebra complementaria de la secuencia de nucleótidos como se define en (a) o (b);
(d) la molécula de ácido nucleico que comprende la secuencia de nucleótidos que tiene al menos un 56% de identidad con la secuencia de nucleótidos como se define en cualquiera de (a), (b) y (c);
(e) la molécula de ácido nucleico que degenera como resultado del código genético de la secuencia de nucleótidos como se define en (a) o (b).
[0097] En ciertos aspectos, la invención se refiere a un método para preparar una molécula de ácido nucleico que comprende la secuencia de nucleótidos de baja repetición de la invención, donde el método comprende:
(a) proporcionar un vector que comprende una secuencia de reconocimiento cadena arriba que es reconocida por una enzima de restricción de endonucleasa y una secuencia de reconocimiento cadena abajo que es reconocida por una enzima de restricción endonucleasa,
en el que opcionalmente dicha enzima de restricción de endonucleasa que reconoce dicha secuencia de reconocimiento cadena abajo es diferente de la enzima de restricción de endonucleasa que reconoce la secuencia de reconocimiento cadena arriba,
en el que dicha secuencia de reconocimiento cadena arriba y dicha secuencia de reconocimiento cadena abajo están en una orientación complementaria inversa,
donde dicha secuencia de reconocimiento cadena arriba comprende dos secuencias de reconocimiento para dos enzimas de restricción diferentes,
en el que dicha secuencia de reconocimiento cadena abajo está comprendida en la secuencia de reconocimiento cadena arriba, y / o
en el que dicha secuencia de reconocimiento cadena arriba y / o dicha secuencia de reconocimiento cadena abajo son sitios de reconocimiento para enzimas de restricción que escinden fuera de la secuencia de reconocimiento;
(b) escindir dicho vector de (a) con la(s) enzima(s) de restricción que reconocen dicha secuencia de reconocimiento cadena arriba y / o dicha secuencia de reconocimiento cadena abajo;
(c) opcionalmente, desfosforilar dicho vector de (b) para evitar la hibridación de los extremos pegajosos complementarios;
(d) proporcionar una molécula de ácido nucleico que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, en el que los extremos de la secuencia de nucleótidos se hibridan con los extremos escindidos del vector de (b) o (c); y
(e) insertar dicha molécula de ácido nucleico de (d) en dicho vector escindido en presencia de una ADN ligasa.
[0098] En ciertos aspectos de la invención, el método proporcionado en este documento puede usarse para preparar moléculas de ácido nucleico más largas, en donde la molécula de ácido nucleico comprende una secuencia de nucleótidos de baja repetición ensamblada, en donde el método para preparar la molécula de ácido nucleico como se describe anteriormente comprende adicionalmente:
(f) escindir dicho vector de (e) con una enzima de restricción que reconoce dicha secuencia de reconocimiento cadena arriba o cadena abajo;
(g) opcionalmente, desfosforilar dicho vector de (f) para evitar la hibridación de los extremos pegajosos complementarios;
(h) proporcionar una molécula de ácido nucleico que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, en el que los extremos de la secuencia de nucleótidos se hibridan con los extremos escindidos del vector de (f) o (g);
(i) insertar dicha secuencia de nucleótidos de (h) en dicho vector escindido en presencia de una ADN ligasa, (j) repetir los pasos (f) a (i) hasta que se alcance la longitud deseada de la secuencia de nucleótidos.
[0099] El experto en la técnica comprende que las etapas de este método pueden repetirse iterativamente hasta que se obtenga la longitud deseada de la secuencia de nucleótidos ensamblada o la molécula de ácido nucleico ensamblada que codifica el polipéptido rico en PA.
[0100] Con el fin de proporcionar medios y métodos para clonar ventajosamente las moléculas de ácido nucleico proporcionadas en este documento, un vector de clonación adecuado comprende una secuencia de reconocimiento cadena arriba que es reconocida por una enzima de restricción endonucleasa y una secuencia de reconocimiento cadena abajo que es reconocida por una enzima de restricción endonucleasa, en donde opcionalmente dicha enzima de restricción endonucleasa que reconoce dicha secuencia de reconocimiento cadena abajo es diferente de dicha enzima de restricción endonucleasa que reconoce dicha secuencia de reconocimiento cadena arriba, en donde dicha secuencia de reconocimiento cadena arriba y dicha secuencia de reconocimiento cadena abajo están en una orientación complementaria inversa. Además, dicha secuencia de reconocimiento cadena arriba puede comprender dos secuencias de reconocimiento para dos enzimas de restricción diferentes. Además, dicha secuencia de reconocimiento cadena abajo puede estar comprendida en la secuencia de reconocimiento cadena arriba. Por tanto, dicha secuencia de reconocimiento cadena abajo puede estar comprendida en una de las secuencias de reconocimiento cadena arriba. Los ejemplos ilustrativos adjuntos muestran los vectores y moléculas de ácidos nucleicos ejemplares, así como los métodos para proporcionarlos, en particular, las Figuras 1,4, 6 y 8.
[0101] Está documentado en los ejemplos adjuntos que es particularmente beneficioso que la secuencia de reconocimiento cadena abajo esté comprendida en la secuencia de reconocimiento cadena arriba. Mediante el uso de tal estrategia, el sitio de reconocimiento cadena arriba puede emplearse para ensamblar secuencias de nucleótidos adicionales en el vector proporcionado en este documento. Por supuesto, las posiciones de los sitios de restricción cadena arriba y cadena abajo en dicho vector son intercambiables. En la Figura ID se muestra una región de clonación ejemplar con una secuencia de nucleótidos inventiva insertada. En este caso, la enzima de restricción que reconoce la secuencia de reconocimiento cadena abajo también reconoce y escinde la secuencia de reconocimiento cadena arriba. Por lo tanto, la secuencia de nucleótidos de la invención o la molécula de ácido nucleico que codifica el polipéptido que consiste en prolina, alanina y, opcionalmente, serina se puede escindir del vector proporcionado en el presente documento empleando la enzima de restricción que reconoce la secuencia de reconocimiento cadena abajo y cadena arriba, permitiendo así su uso para la ligación con otros ácidos nucleicos o vectores, p. ej. para permitir la expresión génica o para crear una región codificante para una proteína de fusión. A continuación, se ilustra un ejemplo de esta estrategia de clonación para lograr el ensamblaje de una secuencia de nucleótidos repetitiva baja larga; ver p. ej. Figura IE.
[0102] En ciertos aspectos, el primer saliente puede comprender un triplete de nucleótidos / codón que codifica alanina, en particular GCC, pero también GCT, GCA o GCG. En un aspecto preferido, la molécula de ácido nucleico de la invención comprende dos salientes 5' complementarios, es decir, un saliente 5' está en la hebra codificante y el otro saliente 5' está en la hebra no codificante. En una realización particularmente preferida, el saliente 5' de la hebra codificante es GCC, y el saliente 5' de la hebra no codificante es GGC.
[0103] En ciertos aspectos adicionales, el primer saliente también puede comprender tripletes / codones de nucleótidos que codifican prolina o serina, por ejemplo, CCT, CCC, CcA, CCG, TcT, TCC, TCA, TCG, AGT o AGC. Sin embargo, la persona experta en la técnica sabe que el método para preparar la molécula de ácido nucleico proporcionado en este documento no se limita a salientes sino que la molécula de ácido nucleico o la secuencia de nucleótidos pueden, por ejemplo, también ligarse mediante extremos romos. Como se usa en el presente documento, el término "saliente" se refiere a una porción final de una hebra de ácido nucleico como parte de la molécula de ADN de doble hebra sin complemento unido, también conocido como extremo pegajoso. Como se usa en el presente documento, el término "extremo romo" se refiere a una porción terminal de una hebra de ADN sin
saliente. Se prevé que la longitud del saliente no esté limitada; sin embargo, un saliente que comprende de 1 a 10 nucleótidos parece ser particularmente adecuado. En los ejemplos adjuntos, se empleó un saliente de 3 nucleótidos que codifica el aminoácido alanina. Este tipo de saliente triplete ofrece la ventaja de que es directamente compatible con el marco de lectura para la traducción de aminoácidos de la molécula de ácido nucleico de acuerdo con esta invención.
[0104] En particular, el saliente introduce un triplete adicional en la secuencia de nucleótidos o la molécula de ácido nucleico que codifica el polipéptido que consiste en prolina, alanina y, opcionalmente, serina. Por consiguiente, la estrategia de clonación de la invención introduce un aminoácido adicional, por ejemplo, alanina. Este aminoácido adicional o el triplete / codón correspondiente se puede considerar como parte del polipéptido que consiste en prolina, alanina y, opcionalmente, serina o el ácido nucleico codificante, respectivamente. En consecuencia, como sabe el experto en la técnica, cuando se emplea la estrategia de clonación descrita anteriormente para una secuencia de nucleótidos que comprende, por ejemplo, 300 nucleótidos, la molécula de ácido nucleico escindida comprende 303 nucleótidos si también se cuentan ambos salientes 5' de tres nucleótidos. Se prevé en este documento que, dependiendo de la longitud de los salientes empleados en el presente documento, se pueden introducir incluso más tripletes / codones o, en consecuencia, más residuos de aminoácidos mediante este procedimiento de clonación.
[0105] Además, cuando se clona en un vector, o como parte de un fragmento de ADN sintético más largo (por ejemplo, una hebra), la molécula de ácido nucleico o la secuencia de nucleótidos proporcionada en este documento comprende dicha secuencia de reconocimiento cadena arriba y / o dicha secuencia de reconocimiento cadena abajo, en la que dicha secuencia cadena arriba y / o dicha secuencia de reconocimiento cadena abajo son sitios de reconocimiento para enzimas de restricción que se escinden fuera de la secuencia de reconocimiento. Las enzimas de restricción empleadas en este documento, p. los de la clase de tipo IIS preferiblemente se escinden fuera de su secuencia de reconocimiento hacia un lado, lo que da como resultado una molécula de ácido nucleico escindida o una secuencia de nucleótidos que no comprende el sitio o sitios de reconocimiento, dependiendo de la orientación adecuada de la secuencia de reconocimiento asimétrica.
[0106] Además, en el vector proporcionado en el presente documento, la escisión con tales enzimas de restricción mantiene las secuencias de reconocimiento para las enzimas de restricción. El sitio de clonación del vector ejemplar pXL2 se muestra en la Figura 1C. Una molécula de ácido nucleico o una secuencia de nucleótidos escindida de este vector carece de los sitios de reconocimiento de las enzimas de restricción utilizadas para su clonación o escisión, lo cual es particularmente ventajoso para el ensamblaje de moléculas de ácido nucleico más largas o secuencias de nucleótidos más largas, por ejemplo, de acuerdo con el procedimiento descrito en el presente documento, para la clonación en un vector de expresión o para crear una región codificante para una proteína de fusión.
[0107] En una realización adicional, se proporciona el vector ejemplar pXL1 (SEQ ID NO: 55) y se muestra en la Figura 1B. En este caso, la molécula de ácido nucleico o secuencia de nucleótidos clonada / insertada de acuerdo con esta invención está flanqueada por dos sitios de restricción SapI. Por lo tanto, la molécula de ácido nucleico que codifica el polipéptido que consiste en prolina, alanina y, opcionalmente, serina se puede escindir simplemente de este vector mediante digestión / escisión con una única enzima de restricción, es decir, SapI (o también EarI), lo cual es particularmente ventajoso para la clonación posterior en un vector de expresión y / o para crear una región codificante para una proteína de fusión.
[0108] Como se muestra en los ejemplos adjuntos, las moléculas de ácido nucleico o las secuencias de nucleótidos proporcionadas en este documento se ensamblan en el vector pXL2 (SEQ ID NO: 48) de una manera iterativa; ver, por ejemplo, el Ejemplo 2. Por lo tanto, uno o ambos de los sitios de reconocimiento en el vector se pueden emplear para insertar una secuencia de nucleótidos adicional en el vector (en un lado de un inserto presente) o, alternativamente, para escindir la secuencia de nucleótidos total (ensamblada) o molécula de ácido nucleico del vector.
[0109] Como ventaja adicional, en el método para producir la molécula de ácido nucleico de la invención proporcionado en este documento, la ausencia de los sitios de reconocimiento para las enzimas de restricción dentro de la molécula de ácido nucleico de acuerdo con esta invención (i) evita que una secuencia de nucleótidos ensamblada más larga proporcionada en este documento sea escindida internamente, por ejemplo, entre las unidades / módulos de las secuencias de nucleótidos ensambladas y (ii) conduce a una transición no g>sesgada entre las secuencias de aminoácidos codificadas en unidades / módulos vecinos de las secuencias de nucleótidos ensambladas o entre las secuencias de aminoácidos codificadas en el nucleótido secuencia de la invención y la secuencia de nucleótidos para una proteína biológicamente activa. Esta estrategia puede denominarse ensamblaje o clonación "sin rastro" o "sin enlaces".
[0110] En los ejemplos adjuntos se demuestra que pueden emplearse enzimas de restricción del tipo IIS; ver Ejemplos 1 y 2. Las enzimas de restricción de esta clase tienen sitios de reconocimiento separados de sus sitios de escisión y algunos de ellos, por ejemplo Sapl y EarI, escinden fuera de su secuencia de reconocimiento en un lado. A continuación se muestra en el presente documento que dicha secuencia de reconocimiento cadena arriba en pXL2 es reconocida por Sapl y EarI y dicha secuencia de reconocimiento cadena abajo es reconocida por EarI. Por tanto, dicha secuencia de reconocimiento cadena arriba tiene la secuencia de nucleótidos 5-GCTCTTC-3 'y dicha
secuencia de reconocimiento cadena abajo tiene la secuencia de nucleótidos 5'-CTCTTC-3'. El experto en la técnica sabe que las enzimas de restricción no están particularmente limitadas en este documento siempre que cumplan el propósito o las limitaciones definidas en este documento.
[0111] Como se usa en este documento, el término "enzima de restricción de endonucleasa" se refiere a una enzima endonucleasa que corta / escinde / hidroliza oligo / polinucleótidos en el enlace fosfodiéster que conecta ciertos nucleótidos dentro de una molécula de ácido nucleico o secuencia de nucleótidos, por ejemplo, ADN, en o cerca de un reconocimiento específico de una secuencia que comprende un tramo de nucleótidos. Por tanto, las enzimas de restricción catalizan la hidrólisis de enlaces fosfodiéster dentro de una secuencia de nucleótidos o molécula de ácido nucleico. Las enzimas de restricción se clasifican comúnmente en tres tipos que difieren en su estructura y si cortan / escinden su sustrato en su secuencia de reconocimiento o en un sitio separado. Para cortar / escindir el ADN de doble hebra, las enzimas de restricción suelen escindir dos enlaces fosfodiéster, uno en cada esqueleto de azúcarfosfato (es decir, cada hebra) de la doble hélice del ADN.
[0112] Como se usa en este documento, el término "secuencia de reconocimiento" se refiere a una secuencia específica de nucleótidos, por ejemplo, de 4 a 8 pares de bases específicos de longitud, que son reconocidos por una enzima de restricción.
[0113] Como se usa en este documento, el término "escisión" significa que la molécula de ácido nucleico y / o el vector se cortan / digieren / hidrolizan con una enzima de restricción. Como se mencionó anteriormente, la enzima de restricción escinde un enlace fosfodiéster dentro de una cadena de polinucleótidos.
[0114] Como se usa en este documento, el término "insertar" se refiere a la unión de la molécula de ácido nucleico en el vector a través de la acción de una enzima. De ese modo, los extremos de los polinucleótidos se unen mediante la formación de enlaces fosfodiéster entre el grupo 3'-hidroxilo en el extremo de un polinucleótido con el grupo 5'-fosforilo de otro. La molécula de ácido nucleico que codifica el polipéptido que consiste en prolina, alanina y, opcionalmente, serina o la secuencia de nucleótidos tiene extremos que pueden hibridar con los extremos escindidos del vector. En aspectos preferidos de la invención, tales extremos son proyecciones que pueden hibridar con las respectivas protuberancias del vector escindido.
[0115] Para la inserción de la molécula de ácido nucleico en el vector, es preferible desfosforilar el vector para evitar un alto fondo de ADN del vector recircularizado sin inserto. Una enzima ejemplar para la desfosforilación puede ser la fosfatasa alcalina intestinal de ternera (CIP o CIAP) o la fosfatasa alcalina de camarón, que eliminan el grupo fosfato del extremo 5 'de los polinucleótidos digeridos.
[0116] Como se usa en el presente documento, los términos "cadena arriba" y "cadena abajo" se refieren ambos a una posición relativa en una molécula de ácido nucleico o secuencia de nucleótidos. Cada hebra de la molécula de ácido nucleico o la secuencia de nucleótidos tiene un extremo 5' y un extremo 3', llamados así por los átomos de carbono del azúcar desoxirribosa (o ribosa). En general, cadena arriba y cadena abajo se relacionan con la dirección 5 'a 3' de la cadena codificante en la que tiene lugar la transcripción del ARN. Cuando se considera el ADN de doble hebra, cadena arriba está hacia el extremo 5' de la cadena codificante del gen o marco de lectura en cuestión y cadena abajo está hacia el extremo 3'. Debido a la naturaleza antiparalela del ADN de doble hebra, esto significa que el extremo 3 'de la hebra no codificante está cadena arriba del gen y su extremo 5' está cadena abajo.
[0117] Como se usa en el presente documento, el término "molécula de ácido nucleico" o "secuencia de nucleótidos" pretende incluir moléculas de ácido nucleico tales como moléculas de ADN y moléculas de ARN. Se entiende en el presente documento que el término "secuencia de nucleótidos" es igual al término "secuencia de ácido nucleico" y que estos términos se pueden usar indistintamente en el presente documento. Dicha molécula de ácido nucleico o dicha secuencia de nucleótidos puede ser monocatenaria o bicatenaria, pero preferiblemente es ADN bicatenario. El experto en la técnica sabe que el ADN de doble hebra comprende realmente dos moléculas de ácido nucleico diferentes, con secuencias de nucleótidos en gran parte complementarias (despreciando los extremos pegajosos si están presentes), que están asociadas / hibridadas no covalentemente para formar una doble hebra.
[0118] En un aspecto de la invención, la secuencia de nucleótidos o la molécula de ácido nucleico que codifica el polipéptido que consiste en prolina, alanina y, opcionalmente, serina está unida operativamente en el mismo marco de lectura a un ácido nucleico que codifica una proteína biológica o farmacológicamente activa. En aspectos preferidos de la invención, la secuencia de nucleótidos o la molécula de ácido nucleico que codifica el polipéptido que consiste en prolina, alanina y, opcionalmente, serina está unida operativamente en el mismo marco de lectura a un ácido nucleico que codifica una proteína biológica o farmacológicamente activa. Por tanto, la molécula de ácido nucleico codifica un conjugado de fármaco heterólogo que comprende el polipéptido que consiste en prolina, alanina y, opcionalmente, serina y la proteína biológica o farmacológicamente activa. Como se usa en este documento, heterólogo significa que la molécula de ácido nucleico que codifica el polipéptido que consiste en prolina, alanina y, opcionalmente, serina y la proteína biológica o farmacológicamente activa no se encuentra en la naturaleza.
[0119] Como se usa en el presente documento, el término "unido operativamente" se refiere a una yuxtaposición, en la que los componentes en cuestión están en una relación que les permite funcionar de la manera prevista.
[0120] La secuencia de nucleótidos que codifica el polipéptido que consiste en prolina, alanina y, opcionalmente,
serina se puede conjugar sin problemas con la secuencia de nucleótidos que codifica la proteína biológica o farmacológicamente activa, es decir, no hay enlazadores entre estas dos secuencias. Alternativamente, una estructura de enlazador (linker) o de espaciador está comprendida entre el polipéptido enrollado aleatorio y la proteína biológica o farmacológicamente activa. Por tanto, en ciertos aspectos de la invención, se inserta una secuencia de nucleótidos que codifica un enlazador de aminoácidos entre la secuencia de nucleótidos que codifica el polipéptido rico en prolina / alanina y la secuencia de nucleótidos que codifica la proteína biológica o farmacológicamente activa. Un enlazador ejemplar puede ser un sitio de escisión sensible a proteasa, un enlazador de serina / glicina, una etiqueta de afinidad tal como His6-tag o la Strep-tag II, un péptido señal, péptido de retención, un péptido de direccionamiento como un péptido de translocación de membrana o dominios efectores adicionales, por ejemplo, fragmentos de anticuerpos para el direccionamiento de tumores asociados con una toxina antitumoral o una enzima para la activación de profármacos, etc. El polipéptido que comprende un enlazador / espaciador puede tener un sitio de escisión por proteasa plasmática que permita la liberación controlada de dicha proteína biológicamente activa. Pueden identificarse enlazadores / espaciadores de diferentes tipos o longitudes sin una carga excesiva para obtener una actividad biológica óptima de proteínas específicas.
[0121] Los enlazadores / espaciadores pueden provocar una respuesta inmune en el sujeto que recibe la proteína de fusión que lleva una estructura enlazadora o espaciadora. Por lo tanto, en aspectos preferidos de la invención, la secuencia de nucleótidos que codifica el polipéptido rico en prolina / alanina se conjuga sin enlace con la secuencia de nucleótidos que codifica la proteína biológica o farmacológicamente activa. Como se usa en este documento, "sin enlace" significa que la secuencia de nucleótidos que codifica el polipéptido en enrollado aleatorio se conjuga directamente con la secuencia de nucleótidos que codifica la proteína biológica o farmacológicamente activa. Por tanto, no se introducen nucleótidos adicionales que codifiquen residuos de aminoácidos distintos de prolina, alanina u, opcionalmente, serina. Como se demuestra en los ejemplos adjuntos, se logró una clonación sin enlace mediante el uso de salientes que codifican el residuo de aminoácido alanina; ver p. ej. Ejemplo 7. Por tanto, la presente invención se refiere además a un método para preparar la molécula de ácido nucleico, en el que dicha molécula de ácido nucleico comprende una secuencia de nucleótidos que codifica prolina, alanina y, opcionalmente, serina y una secuencia de nucleótidos que codifica la proteína biológica o farmacológicamente activa o péptido, y en el que dicha secuencia de nucleótidos se conjuga sin enlace con dicha secuencia de nucleótidos que codifica la proteína biológica o farmacológicamente activa. También se demuestra en los ejemplos adjuntos y en el presente documento anterior que la clonación sin enlace puede usarse para ensamblar secuencias de nucleótidos más largas que codifican polipéptidos ricos en PA. Por tanto, si se aplica el método de clonación sin enlace, la secuencia de nucleótidos resultante que codifica el polipéptido que consiste en prolina, alanina y, opcionalmente, serina es una secuencia de nucleótidos de baja repetición como se describe en el presente documento.
[0122] Como se usa en este documento, el término "actividad biológica" describe el efecto biológico de una sustancia sobre la materia viva, por ejemplo, un organismo. Por consiguiente, el término "proteína biológicamente activa" o "péptido biológicamente activo" como se usa en este documento se refiere a proteínas o péptidos que son capaces de inducir un efecto biológico en células / organismos vivos que están expuestos a dicha proteína o polipéptido o péptido. En el contexto de la invención, la secuencia de nucleótidos o la molécula de ácido nucleico que codifica el polipéptido que consiste en prolina, alanina y, opcionalmente, serina está unida operativamente en el mismo marco de lectura a un ácido nucleico heterólogo que codifica una proteína biológicamente activa.
[0123] Se entiende aquí que la proteína o péptido biológicamente activo codificado es una "secuencia de aminoácidos que tiene y / o que media una actividad biológica" o es una "secuencia de aminoácidos con actividad biológica" y / o es una secuencia de aminoácidos que tiene y / o que media una actividad farmacológica. También comprendida en los términos "proteína biológicamente activa", "secuencia de aminoácidos que tiene y / o media actividad biológica" o "secuencia de aminoácidos con actividad biológica" y / o "secuencia de aminoácidos que tiene y / o que media una actividad farmacológica" están todas proteínas o péptidos de interés (y fragmentos funcionales de los mismos, tales como fragmentos de anticuerpos, fragmentos que comprenden dominios extracelulares o intracelulares de un receptor de membrana, formas truncadas de un factor de crecimiento o citocina y similares) para los cuales la prolongación de la vida media, ya sea in vivo o in vitro, es beneficioso. El experto en la técnica sabe que la conformación en enrollado aleatorio del polipéptido que consiste en prolina, alanina y, opcionalmente, serina media una mayor estabilidad in vivo y / o in vitro de la proteína o proteínas biológicamente / farmacológicamente activas ("funcionales") o péptido(s), en particular, una vida media plasmática aumentada.
[0124] En una realización de esta invención, la secuencia de aminoácidos codificada que tiene y / o media actividad biológica de acuerdo con la presente invención puede deducirse de cualquier "proteína de interés", es decir, cualquier proteína de interés farmacéutico o biológico o cualquier proteína que sea útil como proteína terapéuticamente eficaz. Por consiguiente, dicha proteína o péptido biológicamente activo puede ser una proteína o péptido farmacológicamente activo o terapéuticamente eficaz. Las proteínas o péptidos farmacológicamente activos o terapéuticamente eficaces son cualquier proteína o péptido que tenga un efecto farmacológico, farmacéutico y / o fisiológico deseado. El efecto puede ser (i) profiláctico en términos de prevención y / o mejora total o parcial de una enfermedad / afección / trastorno médico o síntoma de la misma; y / o puede ser (ii) terapéutico en términos de inhibir parcial o completamente la enfermedad / condición médica / trastorno, es decir, detener su desarrollo, o aliviar la enfermedad / condición médica / trastorno, es decir, causar la regresión de la enfermedad / condición médica / trastorno. Más preferiblemente, dicha proteína biológicamente activa es una proteína terapéuticamente eficaz, p. ej. para su uso como vacuna. Por tanto, dicha proteína biológicamente activa también se puede utilizar en vacunación.
[0125] Además, dicha proteína biológicamente activa puede ser una proteína relevante para el diagnóstico. Como se usa en el presente documento, una "proteína relevante para el diagnóstico" se refiere a una proteína o polipéptido que se emplea en el diagnóstico. En el contexto de la presente invención, el diagnóstico se refiere al reconocimiento y detección (temprana) de una enfermedad, p. ej. cáncer y tumor, o una condición clínica en un sujeto. También puede comprender el diagnóstico diferencial. Además, la evaluación de la gravedad de una enfermedad o afección clínica puede, en determinadas realizaciones, estar englobada por el término "diagnóstico". En particular, los polipéptidos y / o conjugados de fármacos codificados por las moléculas de ácido nucleico de la presente invención pueden usarse para diagnósticos in vitro o in vivo. Por ejemplo, los polipéptidos codificados y / o conjugados de fármacos pueden usarse en métodos para la formación de imágenes médicas. Los polipéptidos codificados ricos en PA y / o conjugados de fármacos son adecuados en particular para estos métodos, ya que tienen una captación mejorada en las células tumorales. Además, los polipéptidos ricos en PA codificados y / o conjugados de fármacos muestran un mayor contraste entre las células tumorales y la sangre o las células / tejidos sanos.
[0126] La proteína biológicamente activa codificada se selecciona del grupo que consiste en una proteína de unión, un fragmento de anticuerpo, una citocina, un factor de crecimiento, una hormona, una enzima, una vacuna proteica, una vacuna peptídica o un péptido o un peptidomimético. Como se usa en este documento, un "péptido" preferiblemente comprende / consiste en hasta 50 residuos de aminoácidos, mientras que una "proteína" preferiblemente comprende / consiste en 50 o más residuos de aminoácidos.
[0127] Como se usa en este documento, el término "proteína de unión" se refiere a una molécula que es capaz de interactuar específicamente con (un) socio(s) de unión potencial de modo que sea capaz de discriminar entre dicho socio(s) de unión potencial y una pluralidad de moléculas. diferente de dicho(s) socio(s) de unión potencial hasta tal punto que, de un grupo de dicha pluralidad de moléculas diferentes como socio(s) de unión potencial, solo dicho(s) socio(s) de unión potencial está(n) unido(s), o está(n) significativamente ligado. Los métodos para medir la actividad de unión entre una proteína de unión y un socio de unión potencial se conocen en la técnica y se pueden realizar de forma rutinaria, por ejemplo, mediante el uso de un ensayo inmunoabsorbente ligado a enzimas (ELISA), calorimetría de titulación isotérmica (ITC), diálisis de equilibrio, ensayos de extracción, termoforesis a microescala, titulación de fluorescencia o espectroscopía de resonancia de plasmón de superficie (SPR) usando, por ejemplo, un instrumento Biacore.
[0128] Ejemplos de proteínas de unión / moléculas de unión que son útiles en el contexto de la presente invención incluyen, pero no se limitan a anticuerpos, fragmentos de anticuerpos tales como fragmentos Fab, fragmentos Fab', fragmentos F(ab')2 , fragmentos variables monocatenarios (scFv), anticuerpos de dominio (único), en particular los derivados de camélidos, llamas o tiburones, regiones variables aisladas de anticuerpos (regiones VL y / o VH), en particular los de humanos o primates, CDR , dominios de inmunoglobulina, peptidomiméticos derivados de CDR, lectinas, dominios de fibronectina, dominios de tenascina, dominios de proteína A, dominios SH3, dominios de repetición de anquirina y lipocalinas o varios tipos de proteínas de unión derivadas de estructura como se describe, por ejemplo, en Skerra (2000) J. Mol. Recognit. 13: 167-187, Gebauer (2009) Curr. Opin. Chem. Biol. 13: 245 255 o Binz (2005) Nat. Biotechnol. 23: 1257-1268.
[0129] Otros ejemplos de proteínas codificadas biológicamente, farmacológicamente activas o proteínas terapéuticamente eficaces de interés que son útiles en el contexto de la presente invención incluyen, pero no se limitan a, antagonista del receptor de interleucina, antagonista del receptor de interleucina-1 como EBI-005 o anakinra, leptina, acetilcolinesterasa, proteína C activada (drotrecogina), antagonista del receptor de activina IIB, adenosina desaminasa, agalsidasa alfa, agonista del receptor tipo toll 5 como entolimod, alfa-1 antitripsina, inhibidor de proteinasa alfa-1, alfa-galactosidasa, péptido alfa-natriurético auricular humano, alfa-N-acetilglucosaminidasa, alteplasa, amediplasa, amilina, análogo de amilina, ANF-Rho, angiotensina (1-7), angiotensina II, enzima convertidora de angiotensina 2, molécula de adhesión de células antiepiteliales fragmento de anticuerpo monocatenario, antitrombina alfa, antitrombina III, enzima inductora de apoptosis mi-APO, arginina deiminasa, asparaginasas como calaspargasa, pegaspargasa, crisantaspasa, factor VIII de dominio B eliminado como beroctocog alfa u octofactor, bectumomab (Lymphoscan), lipasas estimuladas por sales biliares como bucelipasa alfa, proteína de unión dirigida contra el virus respiratorio sincitial como pavlizumab, proteínas morfogenéticas óseas como BMP-2 (dibotermin alfa) o BMP-6, bouganin, carboxihemoglobina bovina, hormona del crecimiento bovino, inhibidor de la Cl-esterasa, proteína exoenzima C3, carboxihemoglobina, antagonista CD19, antagonista CD20 como rituxan, antagonista del receptor CD3, antagonista CD40, antagonista CD40L como dapirolizumab o Antova, cerebroside sulfatasa, cetrina como VGX-210, condroitin liasa, factor de coagulación IX como nonacog gamma, conacog beta, albutrepenonacog alfa, factor de coagulación VIIa como eptacog alfa, marzeptacog alfa, vatreptacog alfa, oreptacog alfa, factor de coagulación VIII como susoctocog alfa, damoctocog alfa, turoctocog alfa, rurioctocog alfa, efmoroctocog alfa, efraloctocog alfa, simoctocog alfa, factor de coagulación X, factor de coagulación XIII como catridecacog, colagenasa o f clostridium histolyticum, inhibidor del complemento del factor C3, antagonista del complemento del receptor 5a, factor de liberación de corticotropina, antagonistas del receptor CSF1 como FPA008, antagonista CSF1R, antagonista CTLA-4 como ipilimumab, cianovirina-N, desoxirribonucleasa I como dornasa alfa, antagonista del receptor EGFR, elastasas como elastasa pancreática humana tipo I como vonapanitasa, endostatina, enkastim, factor de crecimiento epidérmico, eritropoyetina alfa, eritropoyetina zeta, antagonistas del receptor FcyIIB, fibrinogenasa, enzima fibrinolítica como brinasa, factor de crecimiento de fibroblastos 1 (factor de crecimiento de fibroblastos ácido humano), factor de crecimiento de fibroblastos 18 factor de crecimiento de fibroblastos 2 (factor de crecimiento de fibroblastos básico humano), factor de crecimiento de fibroblastos 21,
antagonistas del receptor 2 del factor de crecimiento de fibroblastos como FPA144, ligando de tirosina quinasa 3 similar a Fms, hormonas estimulantes del folículo como folitropina alfa o folitropina beta, fragmento de bactericida / proteína 21 que aumenta la permeabilidad (opebacán / rBPI 21), gelonina, agonista del receptor glucagón, antagonista de la glucoproteína IIb / IIIa como abciximab, enzimas que degradan los glucosaminoglicanos como la condoliasa, gp120 / gp160, factor estimulante de colonias de granulocitos (G-CSF), factor estimulante de colonias de granulocitos y macrófagos (GM-CSF), proteína de choque térmico hsp 65 de Mycobacterium BCG fusionado con factor de transcripción E7 (verpasep caltespen), factor de crecimiento de hepatocitos, antagonista del receptor del factor de crecimiento de hepatocitos (HGFR), antagonista de hepcidina, antagonista del receptor Her2 / neu como herceptin, heterodimérico 15: IL-15Ra (hetIL-15), hirudina, antagonista de hsp70, esfingomielinasa ácida humana, gonadotropina coriónica humana como coriogonadotropina alfa, a-glucosidasas ácidas de enzimas humanas como reveglucosidasa alfa o alglucosidasa alfa, hormona del crecimiento humano, factor de crecimiento de queratinocitos humanos (KGF), metaloproteinasa de matriz humana, fragmento de proteína básica de mielina, proteína osteogénica 1 humana, proteína osteogénica humana-1, hormona paratiroidea humana, trombomodulina alfa humana, hialuronidasa como rHuPH20, hialuronidasas como hialuronidasa humana PH-20 (vorhialuronidasa alfa), hialosidasa o bovhialuronidasa, enzimas hidrolíticas lisosomales específicas de glucocerebrósido como glucocerebrosidasa, velaglucerasa alfa o taliglucerasa alfa, iduronato-2-sulfatasa, antagonistas de IGe como omalizumab, ilroquois homeobox proteina 2 (IRX-2), insulina, análogo de insulina, antagonista de integrina a4p1, interferón tau, interferón alfa, antagonista de interferón alfa, superagonista de interferón alfa, interferón alfa-n3 (inyección de Alferon N), interferón beta, interferón gamma, interferón lambda , proteínas de fusión de interleucina 2 como DAB (389) IL-2, interleucina-11 como oprelevkin, interleucina-12, antagonista del receptor de interleucina-17, proteína de unión a interleucina-18, interleucina-2, interleucina-22, interleucina-4 como pitrakinra, muteína de interleucina-4, antagonista del receptor de interleucina-6, interleucina-7, antagonista de la subunidad alfa del receptor de interleucina-22 (IL-22ra), irisina, proteína asociada a la neogénesis de los islotes, calidinogenasa, lactoferrina, fragmento de lactoferrina, lanoteplasa, enzimas lipasa como burlulipasa, rizolipasa, epafipasa o sebelipasa alfa, hormona luteinizante, lutropina alfa, molécula de expansión de linfocitos, lisostafina, enzima lipasa gástrica de mamíferos (merispace), manosidasas como velmanasa alfa, agonista del receptor de melanocortina-4, péptido de 23 aminoácidos derivado de MEPE, factor metionil de células madre humanas (ancestim), microplasmina, N-acetilgalactosamina-6-sulfatasa como elosulfase alfa, N-acetilglucosaminidasa, nasaruplasa beta, factor de crecimiento nervioso, neurregulina-1, neurotoxina (p. ej., una neurotoxina clostridial, como una neurotoxina de Clostridium botulinum (como neurotoxina de Clostridium botulinum serotipo A, B, C, D, E, F o G, particularmente neurotoxina de Clostridium botulinum serotipo A), lipocalina asociada a gelatinasa de neutrófilos, ocriplasmina, inhibidor del complemento de Ornithodoros moubata (OmCI / Coversin), osteoprotegerina, P128 (StaphTAME), pamiteplasa, parathormona (PTH), antagonista de PD-1, antagonista de PDGF, proteína pentraxina-2, fago lisina como HY133, fenilalanina amoniaco liasa como valiasa, fosfatasas como fosfatasa alcalina inespecífica de tejido o asfotasa alfa, plasminógeno, variante de plasminógeno como V10153, factor de crecimiento derivado de plaquetas BB, hormona de crecimiento porcina, péptido 1 que se dirige a la prohibitina, proinsulina, proteína A, proteína C como drotrecognina, ligandos del receptor del factor de crecimiento de fibroblastos de unión a proteínas como FP-1039, inhibidor de la vía del factor tisular recombinante (tifacogina), relaxina, análogo de relaxina como serelaxina, reteplasa, rhPDGF-BB, ribonucleasa como onconasa o anfinasa, senrebotasa, inhibidores de serina proteasa como conestat alfa, sfericasa, sialidasa, receptor de complemento soluble tipo 1, receptor de DCC (eliminado en cáncer colorrectal) soluble, receptor TACI soluble (atacicept), receptor soluble del factor de necrosis tumoral I (sTNF-RI), receptor soluble del factor de necrosis tumoral II (sTNF-RIl), receptor soluble de VEGF Flt-1, receptor FcyIIB humano, estafiloquinasa, estreptoquinasa, sulfamidasa, ligando del receptor de células T, tenecteplasa, proteína estimulante de la trombopoyesis (AMG-531), trombopoyetina, trombospondina-1, hormona tiroidea, análogo de la hormona liberadora de tirotropina (TRH) como la taltirelina, activador del plasminógeno tisular, activador del plasminógeno de tipo tisular como la pamiteplasa, tripeptidil peptidasa I, factor de necrosis tumoral (TNFalfa), antagonista del factor de necrosis tumoral a, uricasa como rasburicasa o pegadricasa, urodilatina, urofolitropina, uroquinasa, uteroglobina, antagonista de VEGF como ranbizumab o bevacizumab, antagonista de VEGF / PDGF como un antagonista múltiple de VEGF / PDGF DARPin o una proteína de fusión, viscumina, factores de von Willebrand como vonicog alfa. Antagonista del receptor de interleucina, especialmente antagonistas del receptor de interleucina-1, como EBI-005 o anakinra, y leptina, especialmente leptina humana, o una leptina humana mutante (huLeptin (W100Q), se prefieren aquí una leptina humana mutante con una sustitución de triptófano por glutamina en la posición 100 en la cadena polipeptídica madura. La secuencia de aminoácidos de la leptina humana se describe, p. Ej. en el código de acceso de UniProtKB P41159. La huLeptina mutante (W100Q) es descrita por Ricci (2006) Enfoque mutacional para mejorar la estabilidad física de las terapias de proteínas susceptibles a la agregación, en Murphy (ed.) Misbehaving proteins: protein (mis)folding, aggregation, and stability, Springer, primera edición, Nueva York.
[0130] Los péptidos y peptidomiméticos ejemplares incluyen, pero no se limitan a, hormona adrenocorticotrópica (ACTH), afamelanotida, alarelina, inhibidor de la integrina alfa 4, inhibidor de la fusión anti-VIH (como enfurvitida, V2o, SC34EK, SC35EK, IQN17 o IZN17), angiotensina II tipo 2 ( AT2) agonista del receptor (como LT2), péptido p53 antiidiotípico, amilina, análogo de amilina, astressina, atosiban, fragmento de péptido bacteriano con actividad anticancerosa y anti-VIH (como ATP-01), péptido bicíclico (como TG-758), bivalirudina, antagonista de bradicinina (como icatibant), bremelanotida, péptido natriurético de tipo B, calcitonina, carbetocina, carfilzomib, crisalina, cilengitida, péptido natriurético de tipo C, colostrinina, factor de liberación de corticotropina (como Xerecept, coisntropina), péptido de localización de tumor CNGRCG, péptido ú>-conotox¡na (como ziconotida), péptido C,
danegaptido, defensina, ecallantida, elcatonina, eledoisina, exendina-4, análogo de exendina-4 (como exendina 9 39), péptido ezrina 1, fragmentos de la fosfoglicoproteína de la matriz extracelular humana (como AC-100), galanina, polipéptido inhibidor gástrico (GIP), análogo de GIP, glatiramer, glucagón, análogo de glucagón, péptido similar al glucagón 1 (GLP-1), análogo de GLP-1 (como lixisenatida, liraglutida o semiglutida), péptido 2 similar al glucagón (GLP-2), análogo de GLP-2 (como teduglutida), gonadorelina, agonista de la hormona liberadora de gonadotropina (como goserelina, buserelina, triptorelina, leuprolida, protirelina, lecirelina, fertirelina o desiorelina), antagonista hormonal liberadora de gonadotropina (como abarelix, cetrorelix, degarelix, ganirelix o teverelix), grehlin, análogo de grehlin (como AZP-531), hormona liberadora de la hormona del crecimiento, análogo de la hormona liberadora de la hormona del crecimiento (como sermorelina o tesamorelina), hematida, péptido mimético de hepcidina, histrelina, indolicidina, análogo de indolicidina (como omiganan), péptido regulador a la baja de IgE (como SC-01), péptido INGAP (exulina), factor de crecimiento similar a la insulina 1, factor de crecimiento similar a la insulina 2, antagonista del canal iónico Kv1.3 (como cgtxA, cgtxE o cgtxF), lanreotida, péptido ligando de lectina (como sv6B, sv6D, svC2, svH1C, svHID o svL4), lantipéptido, larazotida, linaclotida, lusupultida, agonista del receptor de melanocortina-4 (como AZD2820), péptido de 23 aminoácidos derivado de MEPE, péptido derivado de mitocondrias (como MOTS-c, humanina, SHLP-6 o SHLP-2), mutante de la proteína de unión al factor de crecimiento similar a la insulina-2 (como I-HBD1), moduladores del canal de iones Nav (como GTx1-15 o VSTx3), octreótido, péptido inhibidor de la proproteína convertasa subtilisina / kexina tipo 9 (PCSK9), fragmento peptídico de azurina, Phylomer, péptido antagonista del péptido invariante asociado al MHC Clase II (CLIP) (como VG1177), péptido derivado de una proteína de choque térmico (como enkastim), pexiganan, plovamer, pramlintida, péptido de dirección prohibitina 1, péptido proislet, péptido tirosina tirosina (PYY 3-36), péptido o peptidomimético RGD, ramoplanina, secretina, sinapultida, somatostatina, análogo de somatostatina (como pasireotida o CAP-232), específicamente péptido antimicrobiano dirigido (STAMP) (como C16G2), agonista del receptor de la proteína morfogenética ósea (como THR-184 o THR-575), stresscopin, surfaxin, Tc99m apcitide, teriparatide (PTH 1-34), tetracosactide, timosina alfa 1, péptido inhibidor de TLR2, péptido inhibidor de TLR3, péptido inhibidor de TLR4, timosina B4, timosina B15, péptido intestinal vasoactivo, vasopresina, análogos de vasopresina (desompresina, felipresina o terlipresina).
[0131] Las proteínas biológicamente activas ejemplares de interés que son útiles en el contexto de la vacunación incluyen, entre otras, el péptido AE37, el péptido liberador de bombesina-gastrina, el antígeno carcinoembrionario (CEA), la proteína de la cápside con marco de lectura abierto 2 (ORF2), la proteína del virus de la hepatitis E, toxina B del cólera, factor de agrupamiento A de Staphylococcus aureus, toxina de la difteria, mutante de la toxina de la difteria (como CRM 197), enterotoxina termolábil de E. coli, exotoxina A de pseudomonas aeruginosa, proteína F del virus del sarampión, glicoproteína E de la encefalitis japonesa (JE), péptido derivado de GPC3, poliproteína de la hepatitis A, péptido GP2 derivado de HER2, herregulina, péptido Her2neu, antígeno de superficie del virus de la hepatitis B (HbSAg), isoforma de la proteína descarboxilasa del ácido glutámico humano 65 kDa (rhGAD65), antígenos de hemaglutinina de la influenza (HA), neuraminidasa de influenza (NA), proteína L1 del virus del papiloma humano, péptido híbrido li-Key / HER2 / neu, lipoproteína en la superficie externa de borrelia burgdorferi (OspA), proteína de la cápside externa principal de rota virus, péptido mucina-1 (MUC-1), proteína de la cápside del virus Norwalk (rNVP), VLP del parvovirus B19, péptido derivado del factor estimulante de colonias de granulocitosmacrófagos, proteína de la cápside del circovirus 2 porcino (PCV2 ORF2), proteína C del virus de la encefalitis transmitida por garrapatas, proteína E del virus de la encefalitis transmitida por garrapatas, proteína E del virus de la fiebre amarilla, proteína E-1 del virus de la rubéola, proteína G de rhabdoviridae, proteína H del virus del sarampión, proteína H de paramyxoviridae, proteína NS de la fiebre amarilla, proteína N de paramyxoviridae, antígeno prostático específico E2, proteína del virus de la peste porcina, proteína VP6 del rotavirus, proteína VP7 del rotavirus, proteína de espicula del virus del SARS (D3252), proteína VP1 del poliovirus, proteína VP4 de virus de la poliomielitis, oncoproteína Ras, péptidos derivados de esperma (como YLP12, P10G, A9D, mFA-12-19, SP56 o mFA-1117-136), toxina tetánica, tuberculina, péptidos asociados a tumores (TUMAP) (como IMA901, IMA910 o IMA950) y similares.
[0132] En un aspecto, la presente invención se refiere a una molécula de ácido nucleico como se describe en este documento, por ejemplo, una molécula de ácido nucleico que comprende una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y serina, donde la secuencia de nucleótidos de dicho ácido nucleico tiene una longitud de al menos 300 nucleótidos; o
la presente invención se refiere en un aspecto a una molécula de ácido nucleico descrita en este documento que está operativamente unida en el mismo marco de lectura a un ácido nucleico que codifica una proteína biológicamente activa, por ejemplo, una molécula de ácido nucleico que comprende una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y serina, donde la secuencia de nucleótidos de dicho ácido nucleico tiene una longitud de al menos 300 nucleótidos, donde la molécula de ácido nucleico está operativamente unida en el mismo marco de lectura a un ácido nucleico que codifica una proteína biológicamente activa;
donde dicha secuencia de nucleótidos no es
ATGGGCAGCAGCCATCATCATCACCATCATGGTAGCCTGGTTCCGCGTAGCTCTTCTGCA AGTCCGGCAGCACCGGCACCGGCTTCACCAGCTGCACCAGCACCTAGCGCACCGGCAGCA TCTCCAGCAGCCCCTGCACCGGCAAGCCCTGCAGCTCCAGCACCGTCAGCACCAGCAGCA AGCCCAGCTGCTCCTGCTCCAGCGAGCCCAGCAGCGCCAGCTCCTAGTGCCCCTGCTGCC TCTCCTGCTGCTCCGGCACCAGCAAGTCCTGCTGCGCCTGCACCGAGTGCTCCGGCTGCT AGTCCTGCCGCACCAGCTCCGGCTAGTCCAGCTGCTCCAGCCCCTTCAGCTCCGGCAGCT TCCCCTGCAGCGCCTGCCCCTGCCAGTCCAGCGGCTCCTGCACCTAGTGCGCCTGCAGCT TCACCGGCTGCCCCTGCGCCAGCTTCTCCTGCGGCTCCAGCTCCATCTGCCCCAGCCGCA TCCCCAGCGGCACCAGCTCCAGCTTCTCCGGCAGCGCCAGCACCTTCTGCGCCTGCCGCA TCTCCTGCAGCACCAGCGCCTGCGAGTCCTGCAGCTCCTGCTCCTTCAGCCCCTGCGGCA AGTCCAGCAGCACCAGCCCCAGCAAGCCCAGCCGCACCAGCACCATCTGCCCCTGCAGCA CCATTTGTGAACAAGCAGTTTAACTATAAGGACCCGGTGAACGGTGTGGATATCGCGTAT ATCAAAATCCCGAATGCGGGCCAGATGCAACCAGTCAAGGCGTTCAAGATTCATAACAAG ATTTGGGTTATTCCGGAACGTGATACCTTCACCAATCCGGAAGAAGGCGACTTAAACCCG CCGCCAGAAGCCAAACAAGTGCCGGTGAGCTACTATGATAGCACGTATCTTAGCACCGAT AATGAAAAAGACAATTACCTGAAGGGCGTGACCAAGTTGTTCGAGCGCATCTACAGTACC GACTTAGGCCGCATGTTGTTGACGAGCATCGTTCGCGGTATCCCGTTCTGGGGCGGCTCG ACCATTGATACCGAGTTGAAAGTCATTGACACGAACTGTATCAATGTTATCCAACCGGAC
GGCAGTTATCGCAGCGAGGAGTTAAATTTGGTCATCATCGGTCCAAGCGCAGATATTATT CAGTTCGAATGCAAGAGCTTCGGCCATGAGGTCTTGAATTTGACGCGCAACGGTTACGGC AGCACCCAATACATCCGCTTTAGCCCGGATTTCACCTTTGGCTTCGAGGAGAGCTTGGAG GTGGACACCAACCCGCTGTTAGGTGCCGGCAAATTCGCAACCGACCCGGCAGTGACGTTG GCGCACGAATTGATTCATGCGGGTCACCGCTTATACGGTATCGCGATCAATCCGAATCGC GTCTTTAAAGTCAATACCAACGCGTACTACGAAATGAGCGGCTTAGAGGTTAGCTTTGAA GAATTACGCACCTTCGGTGGCCACGACGCCAAGTTCATCGACAGCCTGCAGGAAAATGAG TTCCGCTTGTACTATTACAATAAATTCAAGGACATCGCGAGCACCTTAAATAAAGCAAAG AGCATTGTGGGCACCACCGCAAGCTTGCAGTACATGAAGAACGTATTTAAGGAAAAATAT TTGTTGTCGGAGGATACCAGCGGGAAATTCAGCGTCGATAAGCTGAAATTCGACAAATTG TATAAAATGCTGACCGAGATTTACACCGAGGATAACTTCGTCAAGTTTTTTAAGGTGTTA AATCGTAAGACCTATTTAAACTTTGATAAAGCGGTGTTTAAAATTAATATCGTGCCGAAG GTGAATTACACCATCTACGATGGTTTCAATTTACGCAACACGAATCTGGCGGCGAATTTT AAT GGCCAAAACAC C GAAATT AACAAC AT GAAC T T TAC GAAGT T AAAGAAT T T C AC GGGC TTATTCGAATTCTACAAGT-TATTATGCGTGCGCGGCATCATTACCAGCAAGGCAGGTGCG GGCAAGTCCTTGGTTCCGCGTGGCAGCGCCGGCGCCGGCGCGCTCAATGATCTGTGTATT AAAGTCAATAACTGGGACCTGTTCTTCAGCCCGAGCGAGGATAACTTTACCAACGACTTA AACAAAGGCGAGGAGATCACGAGCGATACGAACATCGAGGCGGCGGAGGAAAATATTAGC CTGGACCTCATTCAGCAGTACTATCTGACGTTCAATTTTGACAATGAGCCGGAGAACATC AGCATTGAAAATCTCAGCAGCGACATCATCGGTCAGTTGGAACTGATGCCGAACATTGAA CGCTTTCCGAACGGCAAAAAATATGAACTGGACAAGTATACCATGTTCCATTACTTACGC GCACAGGAATTTGAGCACGGCAAGAGCCGCATTGCGCTGACCAATAGCGTTAACGAGGCC TTGTTAAATCCGAGCCGTGTCTACACGTTCTTCAGCAGCGATTATGTCAAAAAAGTGAAC AAGGCGACCGAAGCCGCGATGTTTTTGGGCTGGGTCGAGCAATTGGTTTACGATTTTACC GACGAAACCAGCGAGGTGAGCACGACCGACAAAATTGCAGATATCACCATCATCATTCCG TACATCGGTCCGGCGCTCAATATCGGCAATATGTTATACAAGGACGACTTTGTGGGCGCG CTGATCTTTAGCGGCGCGGTTATCTTATTAGAATTCATCCCGGAGATCGCAATCCCGGTC TTGGGCACCTTTGCGTTGGTGAGCTATATCGCGAATAAAGTGCTCACGGTCCAAACCATC GATAACGCGCTCAGCAAGCGTAATGAGAAATGGGACGAGGTTTATAAGTATATCGTGACC AACTGGTTAGCAAAAGTCAATACGCAGATCGATCTCATCCGCAAAAAAATGAAAGAAGCC TTGGAAAATCAAGCGGAGGCAACCAAAGCCATCATTAATTACCAGTATAACCAATATACC GAAGAAGAAAAAAACAATATCAACTTCAATATCGATGATTTGAGCAGCAAACTGAACGAG AGCATTAACAAAGCGATGATTAACATCAACAAGTTCTTGAATCAATGCAGCGTGAGCTAT CTCATGAACAGCATGATCCCGTATGGCGTCAAACGCTTGGAAGATTTTGACGCCAGCCTG AAAGATGCGCTCCTCAAGTATATTTATGACAACCGCGGCACCCTCATTGGCCAGGTGGAC CGCTTGAAGGATAAAGTGAACAATACGCTCAGCACGGATATCCCGTTCCAGCTGAGCAAG TACGTCGACAACCAGCGCTTACTGAGCACCTTTACCGAGTATATCAAGAACATCATTAAT ACCAGCATCCTCAACTTGCGCTATGAGAGCAATCACCTGATCGACCTCAGCCGCTACGCC AGCAAGATCAACATCGGCAGCAAGGTCAATTTCGACCCGATCGATAAGAATCAGATCCAA TTGTTTAACCTGGAAAGCAGCAAGATCGAGGTTATCTTGAAGAACGCGATTGTGTACAAC AGCATGTACGAGAACTTTAGCACGAGCTTCTGGATTCGTATCCCGAAGTATTTCAATAGC ATTAGCCTGAATAACGAATATACCATTATCAACTGCATGGAAAATAATAGCGGCTGGAAG GTGAGCTTAAATTACGGCGAGATCATTTGGACCTTACAGGATACCCAAGAAATCAAACAG CGCGTCGTCTTTAAGTATAGCCAGATGATCAACATCAGCGATTACATCAACCGCTGGATC TTCGTGACCATCACCAATAATCGCTTGAATAATAGCAAGATTTACATCAATGGTCGCTTG ATTGATCAAAAACCGATCAGCAATCTCGGTAATATCCATGCCAGCAATAACATCATGTTT AAGTTAGACGGTTGCCGCGATACCCACCGCTATATCTGGATCAAGTATTTTAACTTATTT GATAAGGAACTCAACGAAAAGGAAATTAAAGACTTATATGACAATCAGAGCAATAGCGGC ATCCTGAAGGATTTCTGGGGCGACTACCTGCAGTACGATAAGCCGTACTATATGTTGAAC TTGTATGACCCGAACAAATATGTCGATGTGAACAATGTGGGTATTCGTGGCTATATGTAC
TTAAAGGGCCCGCGTGGTAGCGTGATGACCACGAATATTTACTTAAACAGCAGCTTATAC CGCGGCACGAAGTTTATTATCAAGAAGTATGCCAGCGGCAACAAGGACAATATCGTCCGC AACAACGACCGTGTGTATATTAACGTGGTGGTGAAGAATAAAGAGTACCGCTTGGCCACG AATGCGAGCCAGGCGGGCGTGGAAAAAATCTTGAGCGCGTTGGAGATCCCGGACGTCGGC.
AACCTCAGCCAGGTTGTGGTGATGAAGTCTAAAAACGACCAGGGCATCACGAACAAGTGC AAAAT G AAT T T GC AAG ATAAC AAC GGC AACGAC AT C G GCT T T AT T GG T T T T C AC CAGT TC AATAACATCGCCAAACTCGTGGCCAGCAATTGGTATAACCGCCAAATTGAACGCAGCAGC CGCACGCTCGGCTGTAGCTGGGAGTTCATCCCGGTGGACGATGGCTGGGGCGAGCGCCCG CTCGGAGATCTGGTGCCACGCGGTTCCGCGAATTCGAGCTCCGTCGACAAGCTTTGGAGC CACCCGCAGTTCGAAAAATAA _
(SEQ ID No. 196)
[0133] En un aspecto, la presente invención se refiere a una molécula de ácido nucleico como se describe en este documento, por ejemplo, una molécula de ácido nucleico que comprende una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y serina, donde la secuencia de nucleótidos de dicho ácido nucleico tiene una longitud de al menos 300 nucleótidos; o
la presente invención se refiere en un aspecto a una molécula de ácido nucleico descrita en este documento que está operativamente unida en el mismo marco de lectura a un ácido nucleico que codifica una proteína biológicamente activa, por ejemplo, una molécula de ácido nucleico que comprende una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y serina, donde la secuencia de nucleótidos de dicho ácido nucleico tiene una longitud de al menos 300 nucleótidos, donde la molécula de ácido nucleico está operativamente unida en el mismo marco de lectura a un ácido nucleico que codifica una proteína biológicamente activa;
donde dicha secuencia de nucleótidos no es
ATGGGTAGCAGCCATCATCATCACCATCATGGTAGCCTGGTTCCGCGTAGCTCTTCTGCA AGTCCGGCAGCACCGGCACCGGCTTCACCAGCTGCACCAGCACCTAGCGCACCGGCAGCA TCTCCAGCAGCCCCTGCACCGGCAAGCCCTGCAGCTCCAGCACCGTCAGCACCAGCAGCA AGCCCAGCTGCTCCTGCTCCAGCGAGCCCAGCAGCGCCAGCTCCTAGTGCCCCTGCTGCC TCTCCTGCTGCTCCGGCACCAGCAAGTCCTGCTGCGCCTGCACCGAGTGCTCCGGCTGCT AGTCCTGCCGCACCAGCTCCGGCTAGTCCAGCTGCTCCAGCCCCTTCAGCCCCTGCAGCA CCATTTGTGAACAAGCAGTTTAACTATAAGGACCCGGTGAACGGTGTGGATATCGCGTAT ATCAAAATCCCGAATGCGGGCCAGATGCAACCAGTCAAGGCGTTCAAGATTCATAACAAG ATTTGGGTTATTCCGGAACGTGATACCTTCACCAATCCGGAAGAAGGCGATTTAAATCCG CCGCCAGAAGCCAAACAAGTGCCGGTGAGCTACTATGATAGCACGTATCTTAGCACCGAT AATGAAAAAGACAATTACCTGAAGGGCGTGACCAAGTTGTTCGAGCGCATCTACAGTACC GACTTAGGCCGCATGTTGTTGACGAGCATCGTTCGCGGTATCCCGTTCTGGGGCGGCTCG ACCATTGATACCGAGTTGAAAGTCATTGACACGAACTGTATCAATGTTATCCAACCGGAC GGCAGTTATCGCAGCGAGGAGTTAAATTTGGTCATCATCGGTCCAAGCGCAGATATTATT CAGTTCGAATGCAAGAGCTTCGGCCATGAGGTCTTGAATTTGACGCGCAACGGTTACGGC AGCACCCAATACATCCGCTTTAGCCCGGATTTCACCTTTGGCTTCGAGGAGAGCTTGGAG GTGGACACCAACCCGCTGTTAGGTGCCGGCAAATTCGCAACCGACCCGGCAGTGACGTTG GCGCACGAATTGATTCATGCGGGTCACCGCTTATACGGTATCGCGATCAATCCGAATCGC GTCTTTAAAGTCAATACCAACGCGTACTACGAAATGAGCGGCTTAGAGGTTAGCTTTGAA GAATTACGCACCTTCGGTGGCCACGACGCCAAGTTCATCGACAGCCTGCAGGAAAATGAG TTCCGCTTGTACTATTACAATAAATTCAAGGACATCGCGAGCACCTTAAATAAAGCAAAG AGCATTGTGGGCACCACCGCAAGCTTGCAGTACATGAAGAACGTATTTAAGGAAAAATAT TTGTTGTCGGAGGATACCAGCGGGAAATTCAGCGTCGATAAGCTGAAATTCGACAAATTG TATAAAATGCTGACCGAGATTTACACCGAGGATAACTTCGTCAAGTTTTTTAAGGTGTTA AATCGTAAGACCTATTTAAACTTTGATAAAGCGGTGTTTAAAATTAATATCGTGCCGAAG GTGAATTACACCATCTACGATGGTTTCAATTTACGCAACACGAATCTGGCGGCGAATTTT AATGGCCAAAACACCGAAATTAACAACATGAACTTTACGAAGTTAAAGAATTTCACGGGC TTATTCGAATTCTACAAGTTATTATGCGTGCGCGGCATCATTACCAGCAAGGCAGGTGCG GGCAAGTCCTTGGTTCCGCGTGGCAGCGCCGGCGCCGGCGCGCTCAATGATCTGTGTATT AAAGTCAATAACTGGGACCTGTTCTTCAGCCCGAGCGAGGATAACTTTACCAACGACTTA AACAAAGGCGAGGAGATCACGAGCGATACGAACATCGAGGCGGCGGAGGAAAATATTAGC CTGGACCTCATTCAGCAGTACTATCTGACGTTCAATTTTGACAATGAGCCGGAGAACATC AGCATTGAAAATCTCAGCAGCGACATCATCGGTCAGTTGGAACTGATGCCGAACATTGAA CGCTTTCCGAACGGCAAAAAATATGAACTGGACAAGTATACCATGTTCCATTACTTACGC GCACAGGAATTTGAGCACGGCAAGAGCCGCATTGCGCTGACCAATAGCGTTAACGAGGCC TTGTTAAATCCGAGCCGTGTCTACACGTTCTTCAGCAGCGATTATGTCAAAAAAGTGAAC AAGGCGACCGAAGCCGCGATGTTTTTGGGCTGGGTCGAGCAATTGGTTTACGATTTTACC
GACGAAACCAGCGAGGTGAGCACGACCGACAAAATTGCAGATATCACCATCATCATTCCG TACATCGGTCCGGCGCTCAATATCGGCAATATGTTATACAAGGACGACTTTGTGGGCGCG CTGATCTTTAGCGGCGCGGTTATCTTATTAGAATTCATCCCGGAGATCGCAATCCCGGTC TTGGGCACCTTTGCGTTGGTGAGCTATATCGCGAATAAAGTGCTCACGGTCCAAACCATC GATAACGCGCTCAGCAAGCGTAATGAGAAATGGGACGAGGTTTATAAGTATATCGTGACC AAC T GG T T AGC AAAAG T C A AT AC G C AGAT C GAT C T C AT C C G C AA A A A A A T G AAAGAAG C C TTGGAAAATCAAGCGGAGGCAACCAAAGCCATCATTAATTACCAGTATAACCAATATACC GAAGAAGAAAAAAACAATATCAACTTCAATATCGATGATTTGAGCAGCAAACTGAACGAG AGC ATT AAC AAAGC GAT GAT T AAC AT C AAC AAG T TCT T G A A T C A A T GC AGC GT GAGC T A T CTCATGAACAGCATGATCCCGTATGGCGTCAAACGCTTGGAAGATTTTGACGCCAGCCTG AAAGATGCGCTCCTCAAGTATATTTATGACAACCGCGGCACCCTCATTGGCCAGGTGGAC CGCTTGAAGGATAAAGTGAACAATACGCTCAGCACGGATATCCCGTTCCAGCTGAGCAAG TACGTCGACAACCAGCGCTTACTGAGCACCTTTACCGAGTATATCAAGAACATCATTAAT ACCAGCATCCTCAACTTGCGCTATGAGAGCAATCACCTGATCGACCTCAGCCGCTACGCC AGCAAGATCAACATCGGCAGCAAGGTCAATTTCGACCCGATCGATAAGAATCAGATCCAA TTGTTTAACCTGGAAAGCAGCAAGATCGAGGTTATCTTGAAGAACGCGATTGTGTACAAC AGC ATG T ACGAGAACT T TAGCAC GAGCTTCTGGATTCGTATC CCGAAGTATTTCAATAGC ATTAGCCTGAATAACGAATATACCATTATCAACTGCATGGAAAATAATAGCGGCTGGAAG GTGAGCTTAAATTACGGCGAGATCATTTGGACCTTACAGGATACCCAAGAAATCAAACAG CGCGTCGTCTTTAAGTATAGCCAGATGATCAACATCAGCGATTACATCAACCGCTGGATC TTCGTGACCATCACCAATAATCGCTTGAATAATAGCAAGATTTACATCAATGGTCGCTTG ATTGATCAAAAACCGATCAGCAATCTCGGTAATATCCATGCCAGCAATAACATCATGTTT AAGTTAGACGGTTGCCGCGATACCCACCGCTATATCTGGATCAAGTATTTTAACTTATTT GATAAGGAACTCAACGAAAAGGAAATTAAAGACTTATATGACAATCAGAGCAATAGCGGC ATCCTGAAGGATTTCTGGGGCGACTACCTGCAGTACGATAAGCCGTACTATATGTTGAAC TTGTATGACCCGAACAAATATGTCGATGTGAACAATGTGGGTATTCGTGGCTATATGTAC TTAAAGGGCCCGCGTGGTAGCGTGATGACCACGAATATTTACTTAAACAGCAGCTTATAC CGCGGCACGAAGTTTATTATCAAGAAGTATGCCAGCGGCAACAAGGACAATATCGTCCGC AACAACGACCGTGTGTATATTAACGTGGTGGTGAAGAATAAAGAGTACCGCTTGGCCACG AATGCGAGCCAGGCGGGCGTGGAAAAAATCTTGAGCGCGTTGGAGATCCCGGACGTCGGC AAC C T C AGC C AGGT T G T GGT GAT G AAG T C T AAAAAC G AC C AG G G C A T C AC G AAC AAGT G C AAAATGAATTTGCAAGATAACAACGGCAACGACATCGGCTTTATTGGTTTTCACCAGTTC AATAACATCGCCAAACTCGTGGCCAGCAATTGGTATAACCGCCAAATTGAACGCAGCAGC CGCACGCTCGGCTGTAGCTGGGAGTTCATCCCGGTGGACGATGGCTGGGGCGAGCGCCCG CTCGGAGATCTGGTGCCACGCGGTTCCGCGAATTCGAGCTCCGTCGACAAGCTTTGGAGC CAC C CGCAGT T CGAAAAATAA
(SEQ ID No. 197)
[0134] La presente invención se refiere a una molécula de ácido nucleico, en la que dicha molécula de ácido nucleico consiste en una secuencia de nucleótidos que codifica un polipéptido que consiste en al menos 100 residuos de aminoácidos de prolina, alanina y, opcionalmente, serina,
donde dicho polipéptido forma un enrollado aleatorio, donde la secuencia de nucleótidos de dicho ácido nucleico tiene una longitud de al menos 300 nucleótidos,
en el que dicha secuencia de nucleótidos tiene una puntuación de repetición de nucleótidos (NRS) inferior a 1000,
donde dicha puntuación de repetición de nucleótidos (NRS) se determina de acuerdo con la fórmula:
donde
Ntot es la longitud de dicha secuencia de nucleótidos,
n es la longitud de una repetición dentro de dicha secuencia de nucleótidos, y
Fi(n) es la frecuencia de dicha repetición de longitud n,
donde si hay más de una repetición de longitud n, k(n) es el número de dichas secuencias diferentes de dicha repetición de longitud n, en caso contrario k(n) es 1 para dicha repetición de longitud n.
[0135] Además, la presente invención también se refiere a un vector que comprende la molécula de ácido nucleico o la secuencia de nucleótidos de la invención. El vector también se puede emplear para proporcionar una molécula de ácido nucleico que comprende (i) una secuencia de nucleótidos que codifica un polipéptido que consiste en alanina, prolina y, opcionalmente, serina y (ii) una secuencia de nucleótidos que codifica una proteína biológicamente activa; ver, por ejemplo, la Fig.4 y el Ejemplo 7.
[0136] Dicho vector puede emplearse como vector de expresión para expresar proteínas de fusión que comprenden los polipéptidos en enrollado aleatorios codificados y las proteínas biológicamente activas. Por consiguiente, la proteína de fusión codificada abarca (i) un polipéptido en enrollado aleatorio, que está codificado por la secuencia de nucleótidos de baja repetición, acoplado a (ii) una proteína biológicamente activa. Preferiblemente, el polipéptido enrollado aleatorio consiste en alanina, prolina y, opcionalmente, serina. Se proporciona un vector ejemplar en SEQ ID NO: 56. En los ejemplos adjuntos, se demuestra un método ejemplar para proporcionar tal vector o molécula de ácido nucleico; ver p. ej. Fig.6 y Ejemplo 7.
[0137] En este método inventivo, el vector proporcionado en el presente documento comprende la secuencia de nucleótidos que codifica la proteína biológicamente activa y, en un segundo paso, la secuencia de nucleótidos que codifica el polipéptido rico en PA se introduce en el vector. Para introducir la secuencia de nucleótidos que codifica la secuencia rica en prolina / alanina en el vector que comprende la secuencia de nucleótidos que codifica la proteína biológicamente activa, se pueden emplear salientes que comprenden al menos un triplete de nucleótidos / codón que codifica, p. alanina, prolina y / u opcionalmente serina; véase más arriba. Por consiguiente, tal triplete o codón puede codificar un aminoácido que se considera parte de la secuencia rica en prolina / alanina, en particular alanina.
[0138] En consecuencia, el método y el vector proporcionados en este documento evitan la introducción de enlazadores de aminoácidos adicionales que pueden introducirse utilizando sitios de restricción convencionales. Por lo tanto, los medios y métodos proporcionados en este documento permiten una clonación perfecta de la molécula de ácido nucleico de la invención que comprende (i) la secuencia de nucleótidos que codifica el polipéptido que consiste en alanina, prolina y, opcionalmente, serina y (ii) la secuencia de nucleótidos que codifica la proteína biológicamente activa.
[0139] Los expertos en biología molecular conocen muchos vectores adecuados. La elección de un vector adecuado depende de la función deseada, incluidos plásmidos, cósmidos, virus, bacteriófagos y otros vectores usados convencionalmente en ingeniería genética.
[0140] Preferiblemente, el vector es un plásmido, más preferiblemente un plásmido basado en el vector de expresión genérico E. coli pASK37, pASK75 o pXL2.
[0141] Pueden usarse métodos que son bien conocidos por los expertos en la técnica para construir varios plásmidos; véanse, por ejemplo, las técnicas descritas en Sambrook (2001) loc cit. y Ausubel (1989) loc. cit. Los vectores plásmidos típicos incluyen, por ejemplo, pQE-12, la serie pUC de plásmidos, pBluescript (Stratagene), la serie pET de vectores de expresión (Novagen) o pCRTOPO (Invitrogen), lambda gt11, pJOE, la serie pBBR1-MCS, pJB861, pBSMuL, pBC2, pUCPKS, pTACT1. Los vectores típicos compatibles con la expresión en células de mamíferos incluyen el sistema de vector E-027 pCAG Kosak-Cherry (L45a), pREP (Invitrogen), pCEP4 (Invitrogen), pMClneo (Stratagene), pXT1 (Stratagene), pSG5 (Stratagene), EBO-pSV2neo , pBPV-1, pdBPVMMTneo, pRSVgpt, pRSVneo, pSV2-dhfr, pIZD35, vector de expresión de cDNA de Okayama-Berg pcDV1 (Pharmacia), pRc / CMV, pcDNA1, pcDNA3 (Invitrogen), pcDNA3.1, pCOGEMHRLE (GIBGEMBHRLE) (Promega), pLXIN, pSIR (Clontech), pIRES-EGFP (Clontech), pEAK-10 (Edge Biosystems) pTriEx-Hygro (Novagen) y pCINeo (Promega). Los ejemplos no limitantes de vectores plásmidos adecuados para Pichia pastoris comprenden, p. Ej. los plásmidos pAO815, pPIC9K y pPIC3.5K (todos Invitrogen).
[0142] Generalmente, los vectores pueden contener uno o más orígenes de replicación (ori) y sistemas de herencia para la clonación o expresión, uno o más marcadores para la selección en el huésped, por ejemplo, resistencia a antibióticos y uno o más casetes de expresión. Los ejemplos de orígenes de replicación adecuados incluyen, por ejemplo, el ColEl de longitud completa, sus versiones truncadas tales como las presentes en los plásmidos pUC, el virus SV40 y los orígenes de replicación del fago M13. Los ejemplos no limitantes de marcadores seleccionables incluyen ampicilina, cloranfenicol, tetraciclina, kanamicina, dhfr, gpt, neomicina, higromicina, blasticidina o
geneticina.
[0143] Además, dicho vector comprende una secuencia reguladora que está operativamente unida a dicha secuencia de nucleótidos o la molécula de ácido nucleico definida en el presente documento.
[0144] La secuencia o secuencias codificantes, por ejemplo, dicha secuencia de nucleótidos que codifica el polipéptido rico en PA, comprendida en el vector, puede unirse a un elemento o elementos reguladores de la transcripción y / u otras secuencias codificantes de aminoácidos usando métodos establecidos. Tales secuencias reguladoras son bien conocidas por los expertos en la técnica e incluyen, sin ser limitantes, secuencias reguladoras que aseguran el inicio de la transcripción, sitios internos de entrada al ribosoma (IRES) y, opcionalmente, elementos reguladores que aseguran la terminación de la transcripción y la estabilización de la transcripción. Los ejemplos no limitantes de tales secuencias reguladoras que aseguran el inicio de la transcripción comprenden promotores, un codón de iniciación de la traducción, potenciadores, aislantes y / o elementos reguladores que aseguran la terminación de la transcripción. Otros ejemplos incluyen secuencias de Kozak y secuencias intermedias flanqueadas por sitios donantes y aceptores para el corte y empalme de ARN, secuencias de ácidos nucleicos que codifican señales de secreción o, dependiendo del sistema de expresión utilizado, secuencias de señales capaces de dirigir la proteína expresada a un compartimento celular o al medio de cultivo.
[0145] Ejemplos de promotores adecuados incluyen, sin ser limitativos, el promotor de citomegalovirus (CMV), el promotor de SV40, el promotor de RSV (virus del sarcoma de Rous), el promotor lacZ, el promotor de p-actina de pollo, el promotor de CAG (una combinación de promotor de p-actina de pollo y citomegalovirus potenciador temprano inmediato), el promotor del factor de elongación humano 1a, el promotor AOX1, el promotor GAL1, el promotor CaM-quinasa, el promotor lac, trp o tac, el promotor lacUV5, el promotor T7 o T5, el promotor poliédrico del virus Autographa californica de la polihedrosis nuclear múltiple (AcMNPV) o un intrón de globina en células de mamíferos y otros animales. Un ejemplo de potenciador es, por ejemplo, el potenciador SV40. Los ejemplos adicionales no limitantes de elementos / secuencias reguladores que garantizan la terminación de la transcripción incluyen el sitio poli-A de SV40, el sitio poli-A tk o las señales de poliadenilación poliédrica de AcMNPV.
[0146] Además, dependiendo del sistema de expresión, pueden añadirse a la secuencia codificante de la molécula de ácido nucleico proporcionada en este documento secuencias líder capaces de dirigir el polipéptido a un compartimento celular o de secretarlo al medio. La(s) secuencia(s) líder(es) se ensambla(n) en marco con secuencias de traducción, iniciación y terminación y, preferiblemente, una secuencia líder es capaz de dirigir la secreción de la proteína traducida, o una porción de la misma, al espacio periplásmico o al medio extracelular. Las secuencias líder adecuadas son, por ejemplo, las secuencias señal de BAP (fosfatasa alcalina bacteriana), CTB (subunidad B de la toxina del cólera), DsbA, ENX, OmpA, PhoA, stII, OmpT, PelB, Tat (translocación de arginina gemela) en E. coli, y las secuencias señal de la hormona del crecimiento bovino, quimotripsinógeno humano, factor VIII humano, ig-kappa humana, insulina humana, interleucina-2 humana, luciferasa de Metrida o Vargula, tripsinógeno-2 humano, inulinasa de Kluyveromyces marxianus, factor de apareamiento alfa-1 de Saccharomyces cerevisiae, melitina, azurocidina humana y similares en células eucariotas. Los vectores también pueden contener una secuencia adicional de ácido nucleico expresable que codifique una o más chaperonas para facilitar el plegamiento correcto de proteínas.
[0147] Preferiblemente, el vector de la presente invención es un vector de expresión. Un vector de expresión de acuerdo con esta invención es capaz de dirigir la replicación y la expresión de la molécula de ácido nucleico de la invención, por ejemplo, la molécula de ácido nucleico que comprende la secuencia de nucleótidos que codifica el polipéptido rico en prolina / alanina y la secuencia de nucleótidos que codifica biológicamente proteína activa. En los ejemplos adjuntos, se construyó un vector de expresión que comprende (i) una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y serina y (ii) una proteína biológicamente activa, tal como IL-1Ra; véase el Ejemplo 6. En el Ejemplo 10 se muestra un vector de expresión ejemplar que comprende la molécula de ácido nucleico que codifica un polipéptido que consiste en prolina y alanina.
[0148] Los huéspedes de expresión bacteriana adecuados comprenden, por ejemplo, cepas derivadas de Escherichia coli JM83, W3110, KS272, TG1, BL21 (como BL21 (DE3), BL21 (DE3) PlysS, BL21 (DE3) RIL, BL21 (DE3) PRARE), Origami (K-12), Origami B o Rosetta. Para la modificación de vectores, amplificación por PCR y técnicas de ligación, véanse los métodos descritos en Sambrook (2001) loc. cit.
[0149] Además, los sistemas baculovirales también pueden usarse como vector para expresar las moléculas de ácido nucleico de la invención en sistemas de expresión eucariotas. En estos aspectos, el vector pFBDM se puede utilizar como vector de expresión. La inserción en el ADN baculoviral MultiBac está mediada por la secuencia de transposición de Tn7 tras la transformación de DH10 MultiBac E. coli células (Berger (2013) J. Vis. Exp.
77:50159, Fitzgerald (2006) Nat. Méthods. 2006 3: 1021-1032.). La amplificación y expresión del virus se puede realizar en células Sf21 (Spodoptera frugiperda) o High Five (Trichoplusia ni).
[0150] Las moléculas de ácido nucleico y / o los vectores de la invención como se describen anteriormente en el presente documento pueden diseñarse para su introducción en las células mediante, por ejemplo, métodos no químicos (electroporación, sonoporación, transfección óptica, electrotransferencia de genes, administración hidrodinámica o transformación natural al entrar en contacto con las células con la molécula de ácido nucleico de la
invención), métodos químicos (fosfato cálcico, DMSO, PEG, liposomas, DEAE-dextrano, polietilenimina, nucleofección, etc.), métodos basados en partículas (pistola de genes, magnetofección, impalefección), fagos o métodos basados en vectores fagémidos y métodos virales. Por ejemplo, los vectores de expresión derivados de virus tales como retrovirus, virus vaccinia, virus adeno asociado, virus del herpes, virus del bosque de Semliki o virus del papiloma bovino, pueden usarse para el suministro de moléculas de ácido nucleico a una población de células diana.
[0151] Preferiblemente, las moléculas de ácido nucleico y / o vectores de la invención se diseñan para la transformación de E. coli electrocompetentes por electroporación o para la transfección estable de células CHO por transfección de fosfato cálcico, polietilenimina o lipofectamina (Pham (2006) Mol. Biotechnol. 34: 225-237; Geisse (2012) Methods Mol. Biol. 899: 203-219; Hacker (2013) Protein Expr. Purif. 92: 67-76).
[0152] La presente invención también se refiere a una célula huésped o un huésped no humano transformado con un vector o la molécula de ácido nucleico de esta invención. Se apreciará que el término "célula huésped o un huésped no humano transformado con el vector de la invención", de acuerdo con la presente invención, se refiere a una célula huésped o un huésped no humano que comprende el vector o el núcleo molécula de ácido de la invención. Las células huésped para la expresión de polipéptidos son bien conocidas en la técnica y comprenden células procariotas así como células eucariotas. Por tanto, el hospedador puede seleccionarse del grupo que consiste en una bacteria, una célula de mamífero, una célula de algas, un cilio, una levadura y una célula vegetal.
[0153] Las bacterias típicas incluyen Escherichia, Corynebacterium (glutamicum), Pseudomonas (fluorescens), Lactobacillus, Streptomyces, Salmonella Bacillus (como Bacillus megaterium o Bacillus subtilis), o Corynebacterium (como Corynebacterium glutamicum). La bacteria hospedante más preferida en la presente es E. coli. Un ejemplo de ciliado que se utilizará en la presente es Tetrahymena p.ej. Tetrahymena thermophila.
[0154] Las células de mamífero típicas incluyen, células Hela, HEK293, HEK293T, H9, Per.C6 y Jurkat, células NIH3T3, NS0 y C127 de ratón, c Os 1, COS 7 y CV1, células QC1-3 de codorniz, células L de ratón, células de sarcoma de ratón, células de melanoma de Bowes y células de ovario de hámster chino (CHO). Las células huésped de mamífero más preferidas de acuerdo con la presente invención son las células CHO. Un ejemplo de hospedador que se utilizará en la presente es Cricetulus, p.ej. Cricetulus griseus (Hámster chino). Además, se prefieren las células de riñón embrionario humano (HEK).
[0155] Otras células huésped eucariotas adecuadas son, p. ej. levaduras como Pichia pastoris, Kluyveromyces lactis, Saccharomyces cerevisiae y Schizosaccharomyces pombe o células de pollo, como p. ej. Células DT40. Las células de insectos adecuadas para la expresión son p. ej. células de Drosophila S2, Drosophila Kc, Spodoptera Sf9 y Sf21 o Trichoplusia Hi5. Las células de algas preferibles son Chlamydomonas reinhardtii o células de Synechococcus elongatus y similares. Una planta ejemplar es Physcomitrella, por ejemplo Physcomitrella patens. Una célula vegetal ejemplar es una célula vegetal de Physcomitrella, p. ej. una célula vegetal de Physcomitrella patens.
[0156] También dentro del alcance de la presente invención están las células o líneas celulares primarias de mamíferos. Las células primarias son células que se obtienen directamente de un organismo. Las células primarias adecuadas son, por ejemplo, fibroblastos embrionarios de ratón (MEF), hepatocitos primarios de ratón, cardiomiocitos y células neuronales, así como células madre de músculo de ratón (células satélite), fibroblastos dérmicos y pulmonares humanos, células epiteliales humanas (nasales, traqueales, renales), células epiteliales placentarias, intestinales, bronquiales), células secretoras humanas (de glándulas salivales, sebáceas y sudoríparas), células endocrinas humanas (células tiroideas), células adiposas humanas, células del músculo liso humano, células del músculo esquelético humano, leucocitos humanos como células B, células T, células NK o células dendríticas y líneas celulares estables inmortalizadas derivadas de las mismas (por ejemplo, hTERT o células inmortalizadas con oncogén). Se conocen en la técnica medios de cultivo y condiciones apropiados para las células huésped descritas anteriormente.
[0157] Las células huésped pueden, por ejemplo, emplearse para producir grandes cantidades de la molécula de ácido nucleico proporcionada aquí, el polipéptido codificado proporcionado aquí, y / o dicho conjugado de fármaco proporcionado aquí. Por tanto, las células huésped pueden emplearse para producir grandes cantidades de la molécula de ácido nucleico proporcionada en este documento, el polipéptido codificado por la molécula de ácido nucleico que comprende la secuencia de nucleótidos que codifica el polipéptido rico en PA y / o el polipéptido codificado por la molécula de ácido nucleico que comprende la secuencia de nucleótidos que codifica el polipéptido rico en PA y la proteína biológicamente activa.
[0158] Por consiguiente, la presente invención también se refiere a un método para preparar la molécula de ácido nucleico o el vector proporcionado en este documento, comprendiendo el método cultivar la célula huésped o huésped de la invención en condiciones adecuadas y aislar opcionalmente la molécula de ácido nucleico y / o vector producidos.
[0159] Además, la presente invención se refiere a un método para preparar un polipéptido codificado por la molécula de ácido nucleico o la secuencia de nucleótidos proporcionada en este documento, comprendiendo el método
cultivar la célula huésped o huésped de la invención en condiciones adecuadas y aislar opcionalmente el polipéptido producido.
[0160] Además, la presente invención se refiere a un método para preparar un fármaco conjugado, comprendiendo el método cultivar la célula huésped de la invención en condiciones adecuadas y, opcionalmente, aislar dicho fármaco conjugado producido. Preferiblemente, la presente invención se refiere a un método para preparar un conjugado de fármaco, en el que dicho conjugado de fármaco está codificado por la molécula de ácido nucleico, en el que dicha molécula de ácido nucleico comprende una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina y una proteína biológicamente activa.
[0161] Por tanto, la presente invención se refiere en un aspecto a un método para preparar un conjugado de fármaco, en el que dicho conjugado de fármaco comprende el polipéptido codificado por la molécula de ácido nucleico como se define en el presente documento y además comprende (i) una proteína biológicamente activa y / o (ii) una molécula pequeña y / o (iii) un carbohidrato, en el que el método comprende además cultivar la célula huésped o huésped como se proporciona en el presente documento y, opcionalmente, aislar el polipéptido producido y / o conjugado de fármaco. Por ejemplo, si el fármaco conjugado es una proteína de fusión que comprende el polipéptido codificado por la molécula de ácido nucleico como se define en este documento y comprende además una proteína biológicamente activa, el método puede comprender además cultivar la célula huésped o huésped como se proporciona en este documento (es decir, un huésped o célula huésped que comprende un ácido nucleico que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, como se proporciona en este documento y el ácido nucleico que codifica una proteína biológicamente activa como se define aquí, particularmente una proteína terapéuticamente activa), y opcionalmente aislar la proteína de fusión producida (conjugado de drogas). Por supuesto, si el fármaco conjugado es una proteína, el método también puede comprender cultivar la célula huésped o huésped como se proporciona en este documento (es decir, una célula huésped o huésped que comprende un ácido nucleico que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, como se proporciona en el presente documento) y / o cultivar el huésped o la célula huésped que comprende un ácido nucleico que codifica una proteína biológicamente activa como se define en este documento, particularmente una proteína terapéuticamente activa, y opcionalmente aislar el polipéptido producido que consiste en prolina, alanina y, opcionalmente, serina y / o aislar la proteína biológicamente activa producida y, además, conjugar opcionalmente el polipéptido y la proteína biológicamente activa (por ejemplo, mediante acoplamiento químico) para producir el fármaco conjugado.
Por ejemplo, si el fármaco conjugado es un conjugado de un polipéptido codificado por la molécula de ácido nucleico como se define en este documento (es decir, un ácido nucleico que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, como se proporciona en este documento) y de una molécula pequeña y / o de un carbohidrato, el método puede comprender además cultivar la célula huésped o huésped como se proporciona en este documento (es decir, una célula huésped o huésped que comprende un ácido nucleico que codifica un polipéptido que consiste en prolina, alanina y, opcionalmente, serina, como se proporciona en este documento) y, opcionalmente, aislar el polipéptido producido, y además conjugar opcionalmente el polipéptido con la molécula pequeña y / o carbohidrato (por ejemplo, mediante acoplamiento químico). "Cultivar la célula huésped o huésped" incluye en este contexto la expresión del polipéptido como se define en el presente documento y / o de la proteína biológicamente activa en la célula huésped o huésped.
[0162] Se demuestra en los ejemplos adjuntos que dicha molécula de ácido nucleico que comprende (i) una secuencia de nucleótidos que codifica un polipéptido que consiste en prolina, alanina y serina y (ii) una proteína biológicamente activa, como IL-IRa, puede expresarse bacterianamente y, posteriormente, purificarse; véanse el Ejemplo 8 y la Figura 7. Además, se muestra en la presente memoria que un polipéptido que consiste en prolina y alanina codificada por la molécula de ácido nucleico proporcionada en la presente puede expresarse y purificarse; ver p. ej. Ejemplo 11 y Figura 8. Mediante la conjugación del polipéptido codificado que consiste en prolina, alanina y, opcionalmente, serina a un fármaco de molécula pequeña, un carbohidrato y / o una proteína biológicamente activa, puede aumentar la vida media plasmática y / o la solubilidad la molécula / fármaco de molécula pequeña y / o proteína biológicamente activa, puede reducirse la toxicidad inespecífica y la exposición prolongada del fármaco activo a las células o estructuras diana en el cuerpo y puede resultar en una farmacodinámica mejorada.
[0163] El vector presente en el huésped de la invención es un vector de expresión o el vector media la integración estable de la molécula de ácido nucleico de la presente invención en el genoma de la célula huésped de tal manera que se asegura la expresión de la proteína. Los medios y métodos para seleccionar una célula huésped en la que se ha introducido con éxito la molécula de ácido nucleico de la presente invención de modo que se asegure la expresión de la proteína son bien conocidos en la técnica y se han descrito (Browne (2007) Trends Biotechnol. 25: 425-432; Matasci (2008) Drug Discov. Today: Technol. 5: e37-e42; Sierpe (2004) Nat. Biotechnol. 22: 1393-1398).
[0164] Las condiciones adecuadas para cultivar células huésped procariotas o eucariotas son bien conocidas por los expertos en la técnica. Por ejemplo, bacterias como p. ej. E. coli se puede cultivar bajo aireación en medio Luria Bertani (LB), típicamente a una temperatura de 4 a aproximadamente 37 °C. Para aumentar el rendimiento y la solubilidad del producto de expresión, el medio puede tamponarse o complementarse con aditivos adecuados que se sabe que potencian o facilitan ambos. En aquellos casos en los que un promotor inducible controla la molécula de ácido nucleico de la invención en el vector presente en la célula huésped, la expresión del polipéptido puede
inducirse mediante la adición de un agente inductor apropiado, tal como, por ejemplo, isopropil-p-D-tiogalactopiranósido (IPTG) o anhidrotetraciclina (aTc) como se emplea en los ejemplos adjuntos. Se han descrito en la técnica protocolos y estrategias de expresión adecuados, p. ej. en Sambrook (2001) loc. cit., (Gebauer (2012) Meth. Enzymol. 503: 157-188) y se puede adaptar a las necesidades de las células huésped específicas y a los requisitos de la proteína que se va a expresar, si es necesario.
[0165] Dependiendo del tipo de célula y sus requisitos específicos, el cultivo de células de mamífero se puede realizar, por ejemplo, en RPMI, Williams 'E o medio DMEM que contenga FCS al 10% (v / v), L-glutamina 2 mM y 100 U / ml. penicilina /estreptomicina. Las células se pueden mantener, por ejemplo, a 37 °C, o a 41 °C para las células de pollo DT40, en un 5% de CO2, atmósfera saturada de agua. Un medio adecuado para el cultivo de células de insectos es, por ejemplo, medio TNM FCS al 10%, SF900 o HyClone SFX-Insect. Las células de insectos generalmente se cultivan a 27 °C como cultivos de adhesión o suspensión. Los expertos en la técnica conocen bien los protocolos de expresión adecuados para células eucariotas o de vertebrados y pueden recuperarse, por ejemplo, de Sambrook (2001) (loc. Cit).
[0166] Preferiblemente, el método para preparar la molécula de ácido nucleico, el vector, el polipéptido y / o el fármaco conjugado de la invención se lleva a cabo usando células bacterianas, tales como, por ejemplo, células E. coli o células de mamífero, tales como, por ejemplo, células CHO. Más preferiblemente, el método se lleva a cabo usando células E. coli o células CHO y lo más preferiblemente, el método se lleva a cabo usando células E. coli.
[0167] Los métodos para el aislamiento de los polipéptidos codificados producidos comprenden, sin limitación, etapas de purificación como la cromatografía de afinidad (preferiblemente usando una etiqueta de fusión como la Esfreptococoetiqueta II o la His6-tag), filtración en gel (cromatografía de exclusión por tamaño), cromatografía de intercambio aniónico, cromatografía de intercambio catiónico, cromatografía de interacción hidrófoba, cromatografía líquida de alta presión (HPLC), HPLC de fase inversa, precipitación con sulfato de amonio o inmunoprecipitación. Estos métodos son bien conocidos en la técnica y se han descrito en general, por ejemplo, en Sambrook (2001) loc. cit. y también se describen en los ejemplos adjuntos, ver p. Ejemplos 8 y 11. Dichos métodos proporcionan polipéptidos sustancialmente puros. Dichos polipéptidos puros tienen una homogeneidad de, preferiblemente, al menos aproximadamente 90 a 95% (a nivel de proteína), más preferiblemente, al menos aproximadamente 98 a 99%. Lo más preferiblemente, estos polipéptidos puros son adecuados para uso / aplicaciones farmacéuticas. Además, aquí se contempla la aplicación en la industria alimentaria o cosmética. Dependiendo de la célula / organismo huésped empleado en el procedimiento de producción, los polipéptidos codificados de la presente invención pueden estar glicosilados o no glicosilados. Preferiblemente, el polipéptido que consiste en prolina, alanina y, opcionalmente, serina codificada por la molécula de ácido nucleico de la invención no está glicosilado. Lo más preferiblemente, el polipéptido que consiste en prolina, alanina y, opcionalmente, serina codificada por la molécula de ácido nucleico de la invención no se modifica postraduccionalmente en sus cadenas laterales como, por ejemplo, por hidroxilación de prolina.
[0168] El polipéptido enrollado aleatorio codificado consiste predominantemente en alanina, prolina y, opcionalmente, residuos de serina, mientras que serina, treonina o asparagina, que se requieren para la O- o N-glicosilación, está preferiblemente ausente. Por tanto, la producción del propio polipéptido o de una proteína biológicamente activa que comprende el polipéptido en enrollado aleatorio codificado puede dar como resultado un producto monodisperso, preferiblemente desprovisto de modificaciones postraduccionales dentro de la secuencia Pro / Ala / Ser o Pro / Ala. Esta es una ventaja para la producción de proteínas recombinantes en células eucariotas, como las células ováricas de hámster chino (CHO), las células HEK o la levadura, que a menudo se eligen para la biosíntesis de proteínas complejas.
[0169] La invención también se refiere a un método para preparar un conjugado de fármaco, en el que dicho conjugado de fármaco comprende el polipéptido codificado por la molécula de ácido nucleico de la invención proporcionada en este documento y además comprende (i) una proteína biológicamente activa y / o (ii) una molécula pequeña y / o (iii) un carbohidrato. Tales conjugados de carbohidratos pueden ser particularmente útiles como vacunas.
[0170] Como se describió anteriormente, se puede preparar un conjugado de fármaco que comprende el polipéptido rico en PA y la proteína biológicamente activa expresando la molécula de ácido nucleico que comprende la secuencia de nucleótidos que codifica el polipéptido rico en PA y la secuencia de ácido nucleico que codifica la proteína biológicamente activa. El conjugado de fármaco expresado puede aislarse. Alternativamente, el fármaco conjugado puede prepararse cultivando / criando el hospedador que comprende la secuencia de nucleótidos o la molécula de ácido nucleico que codifica dicho polipéptido que consiste en prolina, alanina y, opcionalmente, serina. Por tanto, la molécula de ácido nucleico se expresa en el huésped. Opcionalmente, se aísla dicho polipéptido producido. El polipéptido producido que consta de prolina, alanina y, opcionalmente, serina se puede conjugar con la proteína biológicamente activa, por ejemplo, mediante un enlace peptídico o un enlace no peptídico.
[0171] Se demuestra en los ejemplos ilustrativos que el polipéptido rico en PA codificado por la molécula de ácido nucleico proporcionada en este documento puede expresarse en bacterias y puede purificarse a partir de ellas; ver p. ej. Ejemplo 11 y Figura 8. En particular, se mostró sorprendentemente que la metionina de partida (metionina N-terminal) del polipéptido preparado se escinde y, por tanto, falta en el polipéptido producido; ver p. ej. Ejemplo 12 y
Figura 8D. La metionina inicial que falta en el polipéptido preparado permite la conjugación perfecta del grupo amino primario del siguiente aminoácido (después de la metionina inicial) en el extremo N-terminal a una proteína biológicamente activa, una molécula pequeña y / o un carbohidrato. Por tanto, las moléculas de ácido nucleico de la invención y los polipéptidos preparados de las mismas son particularmente ventajosas para la conjugación con, por ejemplo, las proteínas biológicamente activas.
[0172] En particular, la proteína biológicamente activa se puede conjugar de manera sitio-específica, por ejemplo, en presencia de un agente activador como N-(3-dimetilaminopropil) -N'-etilcarbodiimida (EDC) o como un éster de N-hidroxisuccinimida (NHS). (Hermanson (1996) Bioconjugate Techniques, 1ra edición, Academic Press, San Diego, CA) al extremo N-terminal del polipéptido en enrollado aleatorio producido. Alternativamente, la proteína biológicamente activa se puede conjugar de manera sitio-específica al extremo C-terminal del polipéptido enrollado aleatorio producido que consiste en prolina, alanina y, opcionalmente, serina, p. ej., en presencia de un agente activante como EDC o después de la activación como un éster de NHS.
[0173] Además, el polipéptido producido que consiste en prolina, alanina y, opcionalmente, serina se puede conjugar con la molécula pequeña y / o con el carbohidrato mediante un enlace no peptídico. Los enlaces no peptídicos que son útiles para la reticulación de proteínas se conocen en la técnica y pueden incluir enlaces disulfuro, por ejemplo, entre dos cadenas laterales Cys y / o grupos tiol, enlaces tioéter y enlaces amida entre grupos carboxilo y grupos amino. Los enlaces covalentes no peptídicos también pueden proporcionarse mediante reticuladores químicos, tales como suberato de disuccinimidilo (DSS), éster de N-p-maleimidopropil-oxisuccinimida (BMPS) o 4-[p-maleimidofenil] butirato de sulfosuccinimidilo (Sulfo-SMPB), grupos quelantes / complejantes de metales, así como interacciones proteína-proteína o proteína-péptido no covalentes.
[0174] Además, un fármaco de molécula pequeña puede conjugarse de forma sitio-específica con el polipéptido que forma el enrollado aleatorio. Opcionalmente, el extremo N-terminal del polipéptido se puede modificar con un grupo protector adecuado, por ejemplo, un grupo acetilo o un grupo piroglutamilo, y después de la activación del grupo carboxilato C-terminal, p.ej. utilizando los reactivos comunes EDC y NHS (Hermanson (1996) loc. cit ), se puede lograr el acoplamiento específico del sitio del fármaco al extremo C-terminal del polipéptido enrollado aleatorio. De esta manera, se pueden obtener fácilmente conjugados de fármacos uniformes.
[0175] Como alternativa a una conjugación específica de sitio único, el polipéptido en enrollado aleatorio que consiste en prolina, alanina y, opcionalmente, serina puede estar equipado con cadenas laterales adicionales, en el extremo N- o C-terminal o internamente, adecuadas para modificación química, como residuos lisina con sus grupos £-amino, residuos de cisteína con sus grupos tiol, o incluso aminoácidos no naturales, que permiten la conjugación de una, dos o múltiples moléculas pequeñas utilizando, por ejemplo, NHS o grupos activos maleimida.
[0176] Aparte de la conjugación estable, un profármaco puede unirse transitoriamente al polipéptido en enrollado aleatorio. El enlace puede diseñarse para ser cortado in vivo, de manera predecible, ya sea a través de un mecanismo enzimático o por hidrólisis lenta iniciada a pH fisiológico de manera similar a como, por ejemplo, el agente antitumoral poco soluble camptotecina se conjugó con un polímero de PEG, logrando así una mayor biodistribución, menor toxicidad, mayor eficacia y acumulación de tumores (Conover (1998) Cancer Chemother. Pharmacol. 42: 407-414). Ejemplos de profármacos adicionales son agentes quimioterapéuticos como docetaxel (Liu (2008) J. Pharm. Sci. 97: 3274-3290), doxorrubicina (Veronese (2005) Bioconjugate Chem. 16: 775-784) o paclitaxel (Greenwald (2001) J. Control Release 74: 159-171).
[0177] También se prevé en el presente documento que la molécula pequeña se pueda acoplar a una proteína de fusión, por ejemplo, el polipéptido que forma el enrollado aleatorio que consiste en prolina, alanina y, opcionalmente, serina fusionada genéticamente a un dominio de direccionamiento, p. un fragmento de anticuerpo, lo que da como resultado la administración específica del fármaco de molécula pequeña. La inmunotoxina generada en el último caso por conjugación con una molécula pequeña citotóxica es particularmente útil si el dominio de direccionamiento se dirige contra un receptor de la superficie celular que sufre internalización, por ejemplo.
[0178] Como se usa en este documento, el término "fármaco" se refiere a una molécula pequeña, una proteína biológicamente activa, un péptido o un carbohidrato. Como se usa en este documento, el término "molécula pequeña" puede referirse a un compuesto (orgánico) de bajo peso molecular (<900 Daltons). Las moléculas pequeñas pueden ayudar a regular un proceso biológico y suelen tener un tamaño del orden de nanómetros. En el presente documento se prevé que la molécula pequeña se utilice en un método de terapia, diagnóstico o se utilice en la industria alimentaria o cosmética. Por ejemplo, el fármaco conjugado con el polipéptido producido que está codificado por la secuencia de nucleótidos o la molécula de ácido nucleico proporcionada en este documento puede comprender (a) moléculas pequeñas que se seleccionan del grupo que consiste en inhibidores de la angiogénesis, antialérgicos fármacos, fármacos antieméticos, fármacos antidepresivos, fármacos antihipertensivos, fármacos antiinflamatorios, fármacos antiinfecciosos, fármacos antipsicóticos, fármacos antiproliferativos (citotóxicos y citostáticos), antagonistas del calcio y otros fármacos de órganos circulatorios, agonistas colinérgicos, fármacos que actúan sobre el sistema nervioso central, fármacos que actúan sobre el sistema respiratorio, esteroides, ácidos nucleicos antisentido, ARN de pequeña interferencia (ARNip), inhibidores de microARN (miR), miméticos de microARN, aptámeros de ADN y aptámeros de ARN.
[0179] Ejemplos de inhibidores de la angiogénesis incluyen, entre otros, inhibidores de MetAP2 (como fumagilina, derivados de fumagilina, ácido 2-{3-[3,5-bis [4-nitrobenciliden] -4-oxopiperidin-1-il] -3-oxopropilsulfanil} etanosulfónico), Inhibidores de VGFR (como axitinib, brivanib, cabozantinib, tivozanib y motesanib), inhibidores del factor de crecimiento placentario (PIGF), inhibidores del receptor del factor de crecimiento derivado de plaquetas (como AC 710, sorafenib, sunitinib y vatalanib) y similares.
[0180] Los fármacos antialérgicos ejemplares incluyen, pero no se limitan a, antihistamínicos (como difenhidramina (benadryl), dimenhidrinato (dramamina, driminato), hidrocloruro de hidroxicina (restall, vistacot), prometazina (phenergan)) y similares.
[0181] Los fármacos antidepresivos ejemplares incluyen, pero no se limitan a, granisetrón, palonosetrón y similares.
[0182] Los fármacos antidepresivos ejemplares incluyen, pero no se limitan a, cis-flupentixol, hidrocloruro de imipramina, mianserina y similares.
[0183] Los fármacos antihipertensivos ejemplares incluyen, pero no se limitan a, alprostadil, diazóxido, nicardipina y similares.
[0184] Los fármacos antiinflamatorios ejemplares incluyen, pero no se limitan a, cortisona, ácido hialurónico, ketorolaco y similares.
[0185] Fármacos antiinfecciosos ejemplares incluyen, pero no se limitan a, aminoglucósidos, amadovir, amoxicilina, ampicilina, bencilpenicilina, carbapenéms, cefalosporina, ceftiofur, cloranfenicol, cefepima, ceftazidima, ceftobiprol, clindamicina, draxxina, dalbavancina, daptomicina, dihydrostreptomicina, eritromicina, florfenicol, fluoroquinolonas, flunixina meglumina, linezolid, marbofloxacina, micafungina, nitrofurazona, oritavancina, oxitetraciclina, penicilina, piperacilina, procaína, rupintrivir, espiramicina, estreptograminas, sulfadimetoxina, sulfametazina, tedizolida, telanvacina, ticarcillina, tilmicosina, tigecyclina, tildipirosina, tilosina, vancomicina y similares.
[0186] Los fármacos antipsicóticos ejemplares incluyen, pero no se limitan a, amisulprid, ariprazol, benperidol, bromperidol, clorpromazina, clorprotixeno, clopentixol, clozapina, flupentixol, flufenazina, fluspirilen, haloperidol, levomepromazina, melperona, operonazipazina , prometazina, protipendilo, quetiapina, risperido, sulpirida, tioridazina, trifluoperazina, triflupromazina, zuclopentixol y similares.
[0187] Ejemplos de fármacos antitumorales incluyen, entre otros, antraciclinas (como doxorrubicina, epirrubicina, idarrubicina y daunorrubicina), agentes alquilantes (como caliqueamicinas, dactinomicinas, mitromicinas y pirrolobenzodiazepinas), inhibidores de AKT (como AT7867, amanitinas, P-amanitinas, y-amanitinas, c-amanitinas, amanulina, ácido amanúlico, amaninamida, amanina y proamanulina, SN-38 y camptotecina), inhibidores de ATM, auristatinas (como auristatina EB (AEB), auristatinas EFP (AEFP), monometil auristatina E (MMAE), monometil auristatina F (MMAF), auristatina F y dolastatina), criptoficinas, inhibidores de quinasas dependientes de ciclina (como BMS-387032, PD0332991, GSK429286, AZD7762; AZD 1152, MLN8054; BI 2536, B16727, GSK461364, ON-01910, SB 743921, SB 715992, MK-0731, AZD8477, AZ3146 y ARRY-520), duocarmicinas, inhibidores de DNA-PK, epotilonas (como epotilona A, B, C, D, E o F, y derivados), inhibidores de GSK-3, inhibidores de HDAC (como belinostat, CUDC-101, droxino stat, ITF2357, JNJ-26481585, LAQ824 y panobinostat MC1568, mocetinostat, entinostat, PCI-24781, piroxamida, tricostatina A y vorinostat), inhibidores de hsp70, inhibidores de hsp90 (como derivados de 17AAG, B11B021, -AUY-922, KW-2478 y geldanamicina), inhibidores de la vía de señalización de MAPK (como MEK, Racs, JNK, B-Raf), maitansinoides, análogos de maitansinoides (como maitansinol, análogos de maitansinol, maitansina, DM-1 y DM- 4), inhibidores p38 MAPK (como GDC-0973, GSK1 120212, MSC1936369B, AS703026, R05126766 y R04987655, PD0325901, AZD6244, AZD 8330, GDC-0973, CDC-0879, PLX-4032, SB590885, L SBY2228820, BIRB 202190, AEE788, BIBW2992, afatinib, lapatinib, erlotinib y gefitinib), inhibidores de PARP (como iniparib, olaparib, veliparib, AG014699, CEP 9722, MK 4827, KU-0059436, LT-673, 3 aminobenzamida, A-966492 y A-966492 AZD2461), inhibidores de PDK-1, compuestos de platino (como cisplatino, carboplatino, oxaliplatino, iproplatino, ormaplatino o tetraplatino), taxanos (como paclitaxel o docetaxel), tubulisinas (como tubulisina A, tubulisina B y derivados de tubulisina), alcaloides de la vinca (como vinblastina, vindesina y navelbina), inhibidores de la vía de señalización Wnt / Hedgehog como (vismodegib, GDC-0449, ciclopamina y XAV-939), y similares.
[0188] Los fármacos ejemplares que actúan sobre el sistema nervioso central incluyen, pero no se limitan a, buprenorfina, criostatina, naltroxrexona, naloxona y similares.
[0189] Vitaminas ejemplares incluyen, pero no se limitan a, vitamina B-12 (cianocobalamina), vitamina A y similares.
[0190] Los esteroides ejemplares incluyen, pero no se limitan a, esteroides androgénicos (como fluoximesterona, metiltestosterona, testosterona, trembolona), estrógenos (como beta-estradiol, dietilestilbestrol, estrona, estriol, equilina, estropipato equilina, mestranol), compuestos progestacionales (como 19-norprogesterona, alfaprostol, clormadinona, demegestona, didrogesterona, dimetisterona, etisterona, diacetato de etinodiol, noretindrona, acetato de noretindrona, medroxiprogesterona, melengestrolprogesterona, norgestrel, promegestona, zeranol) y similares.
[0191] Ejemplos de ácidos nucleicos antisentido incluyen, entre otros, ácidos nucleicos antisentido dirigidos al receptor de andrógenos (como ISIS-AR, AZD5312), proteína 3 similar a angiopoyetina (como ISIS-ANGPTL3), apolipoproteína B100 (como mipomersen), apolipoproteína CIII (como ISIS-APOCIII, volanesorsen), el factor de crecimiento del tejido conectivo (CTGF) (como EXC 001, PF-06473871), clusterina (como custirsen, OGX-011), proteína C reactiva (como ISIS-CRP), diacilglicerol aciltransferasa (como ISIS -DGAT2), factor VII (como ISIS-FVII), receptor 4 del factor de crecimiento de fibroblastos (como ISIS-FGFR4), hepcidina (como XEN701), Hsp27 (como apatorsen, OGX-427), el gen HTT (como ISIS-HTT), ICAM-1 (como alicaforsen), prekallikren (como ISIS-PKK), SMN2 (como ISIS-SMN), STAT3 (como ISIS-STAT3-2.5, AZD9150), el gen transtiretina (como ISIS-TTR) y similares.
[0192] Ejemplos de ARN de interferencia pequeños (ARNip) incluyen, entre otros, ARNip que se dirigen al mutante de alfa-1-antitripsina Z-AAT (como ALN-Aa T), aminolevulinato sintasa 1 (ALAS-1) (como ALN-AS1, ALN-AS2) , antitrombina III (como ALN-AT3), el componente del complemento C5 (como ALN-CC5), el componente del complemento C6 (como ALN-CC6), el factor de crecimiento del tejido conectivo (como RXI-109), el exón 8 del gen de la distrofina (como SRP-4008), exón 44 del gen de la distrofina (como SRP-4044), exón 45 del gen de la distrofina (como SRP-4045), exón 50 del gen de la distrofina (como SRP-4050), el virus del ébola ( como AVI-7537), exón 51 del gen de la distrofina (como eteplirsen, AVI-4658), exón 52 del gen de la distrofina (como SRP-4052), exón 53 del gen de la distrofina (como SRP-4053), el virus de la influenza (como AVI-7100), la proteína del huso de kinesina (KSP), enfermedades pulmonares (como Atu111), el virus de Marburg (como AVI-7288), cócteles de ARN interferente pequeño (ARNip) de múltiples objetivos (como STP503, STP523, sTp601, STP702, STP705, STP801, STP805, STP900, sTp902, STP911, STP916, siPOOLs), la nucleocápside N del genoma del virus (como ALN-RSV01), PCSK9 (como ALN-PCS01, ALN-PCSsc), la proteína proapoptótica caspasa 2 (como QPI-1007), la proteína proapoptótica p53 (como QPI-1002), RTP801 (como PF-655), SERPINC1 (como ALN-AT4), la proteasa transmembrana serina 6 (Tmprss6) (como ALN-TMP), transtiretina (como ALN-TTRsc, ALN-TTR02), p Cs K10 (como ALN-PCS02), PKN3 (como Atu027), el factor de crecimiento endotelial vascular (VEGF) (como ALN-VSP) y similares.
[0193] Ejemplos de inhibidores de microARN incluyen, entre otros, inhibidores de miR-10b, miR-15, miR-21, miR-29, miR-33, miR-92, miR-145, miR195, miR-208, miR-221, miR -451, miR-499 y similares.
[0194] Los miméticos de microARN ejemplares incluyen, pero no se limitan a, un análogo de miR-34 (como MRX34), miR-Rx06, miR-Rx07, miR-Rx16, un análogo de let7 (como miR-Rxlet-7) y similares. Los aptámeros de ADN ejemplares incluyen, pero no se limitan a, inhibidor de nucleolina (como As 1411), inhibidor de pGDF (como E10030), inhibidor de trombina (como NU172), inhibidor de vWF (como ARC1779) y similares.
[0195] Los aptámeros de ARN ejemplares incluyen, pero no se limitan a, inhibidor de C5a (como NOX-D21 o ARC1905), inhibidor de péptido relacionado con el gen de la calcitonina (como NOX-L41), inhibidor del ligando 2 de quimiocinas CC (como NOX-E36), inhibidor de CXCL12 (como NOX -A12), inhibidor de glucagón (como NOX-G16), antagonista de hepcidina (como NOX-H94), agonista del receptor de reconocimiento de patógenos (como un agonista de RIG-I), inhibidor de esfingosina-1-fosfato (como NOX-S93), antagonista de VEGf (como NX1838) y similares.
[0196] Los carbohidratos ejemplares que son potencialmente útiles para la preparación de vacunas incluyen, entre otros, epítopos de carbohidratos unidos específicamente por lectinas, antígeno-O O121 de E. coli, derivados del antígeno-O O121 de E. coli, Man9 de gp120 del VIH-I, O-polisacáridos 2a Shigella flexneri, polisacárido capsular de polisacárido de Staphylococcus aureus 5, polisacárido capsular de polisacárido de Staphylococcus aureus 8, antígenos de carbohidratos asociados a tumores (TACA) (como antígenos Tn (p. ej. NeuAca (2,6) -GalNAca-O-Ser / Thr), antígeno de Thomsen-Friedenreich (Galp1-3GalNAca1), LewisY (p. ej., Fuca (1,2) -Galp (1,4) - [Fuca (1,3) ] -GalNAc), sialil LewisX y sialil LewisA, LewisX (antígeno embrionario específico de estadio-1 / SSEA-1), antígeno Globo H (p. Ej., Fuca (1,2) -Galp (1,3) -GalNAcp (1,3 ) -Gala (1,4) -Galp (1,4) -Glc), antígeno T (p. ej., Galp (1,3) -GalNAca-O-Ser / Thr), antígeno embrionario específico de etapa de glucoesfingolípidos-3 (SSEA- 3), ácido siálico que contiene glucoesfingolípidos, gangliósido GD 2, GD3, gangliósido GM2, gangliósido fucosil GM y gangliósido Neu5GcGM3) y similares.
[0197] El conjugado de fármaco que comprende el polipéptido codificado por la molécula de ácido nucleico de la invención proporcionada en este documento que comprende una proteína biológicamente activa y / o una molécula pequeña y / o un carbohidrato puede usarse para el tratamiento de enfermedades inflamatorias, enfermedades infecciosas, enfermedades respiratorias, trastornos endocrinos, enfermedades del sistema nervioso central, enfermedades musculoesqueléticas, enfermedades cardiovasculares, enfermedades oncológicas, enfermedades urogenitales y enfermedades metabólicas.
[0198] Las enfermedades inflamatorias ejemplares incluyen, pero no se limitan a, espondilitis anquilosante, artritis, aterosclerosis, síndrome urémico hemolítico atípico (SHUa), fibromialgia, síndrome de Guillain Barre (GBS), síndrome del intestino irritable (IBS), enfermedad de Crohn, colitis, dermatitis, diverticulitis, osteoartritis, artritis psoriásica, síndrome miasténico de Lambert-Eaton, lupus eritematoso sistémico (LES), nefritis, enfermedad de Parkinson, esclerosis múltiple, hemoglobinuria paroxística nocturna (HPN), artritis reumatoide (AR), síndrome de Sjogren, colitis ulcerosa y similares.
[0199] Las enfermedades infecciosas ejemplares incluyen, pero no se limitan a, tripanosomiasis africana, borreliosis, cólera, criptosporidiosis, dengue, hepatitis A, hepatitis B, hepatitis C, VIH / SIDA, influenza, encefalitis japonesa, leishmaniasis, malaria, sarampión, meningitis, oncocercosis, neumonía, infección por rotavirus, esquistosomiasis, sepsis, shigelosis, amigdalitis estreptocócica, tuberculosis, tifoidea, fiebre amarilla y similares.
[0200] Las enfermedades respiratorias ejemplares incluyen, pero no se limitan a, asma, enfermedad pulmonar obstructiva crónica (EPOC), fibrosis quística y similares.
[0201] Los trastornos endocrinos ejemplares incluyen, pero no se limitan a, acromegalia, diabetes tipo I, diabetes tipo II, diabetes gestacional, enfermedad de Graves, deficiencia de la hormona del crecimiento, hiperglucemia, hiperparatiroidismo, hipertiroidismo, hipoglucemia, infertilidad, obesidad, enfermedades paratiroideas, síndrome de Morquio A, mucopolisacaridosis y similares.
[0202] Enfermedades ejemplares del sistema nervioso central incluyen, pero no se limitan a, enfermedad de Alzheimer, catalepsia, enfermedad de Huntington, enfermedad de Parkinson y similares.
[0203] Las enfermedades musculoesqueléticas ejemplares incluyen, pero no se limitan a, osteoporosis, distrofia muscular y similares.
[0204] Las enfermedades cardiovasculares ejemplares incluyen, pero no se limitan a, insuficiencia cardíaca aguda, enfermedad cerebrovascular (accidente cerebrovascular), enfermedad cardíaca isquémica y similares.
[0205] Enfermedades oncológicas ejemplares incluyen pero no se limitan a cáncer suprarrenal, cáncer de vejiga, cáncer de mama, cáncer de colon y recto, cáncer de endometrio, cáncer de riñón, leucemia linfoblástica aguda (ALL) y otros tipos de leucemia, cáncer de pulmón, melanoma, linfoma no Hodgkin, cáncer de páncreas, cáncer de próstata, cáncer de tiroides y similares.
[0206] Las enfermedades urogenitales ejemplares incluyen, pero no se limitan a, hiperplasia prostática benigna (BPH), hematuria, vejiga neurogénica, enfermedad de Peyronie y similares.
[0207] Enfermedades metabólicas ejemplares incluyen, pero no se limitan a, enfermedad de Gaucher, enfermedad de Fabry, deficiencia de la hormona del crecimiento, síndrome de Hurler, síndrome de Hunter, hiperoxaluria, lipofuscinosis ceroide neuronal, síndrome de Maroteaux-Lamy, síndrome de Morquio, síndrome de Noonan, haploinsuficiencia del gen SHOX, síndrome de Turner, Prader -Síndrome de Willi, fenilcetonuria, síndrome de Sanfilippo, y similares.
[0208] Como se describió anteriormente, la molécula de ácido nucleico proporcionada en este documento también se puede emplear sola o como parte de un vector con fines de terapia génica. Terapia génica, que se basa en la introducción de genes terapéuticos en las células mediante técnicas ex vivo o in vivo, es una de las aplicaciones más importantes de la transferencia genética. Vectores, métodos o sistemas de administración de genes adecuados para las terapias génicas in vivo se describen en la bibliografía y son conocidas por el experto en la técnica; ver, por ejemplo, Giordano (1996) Nat. Med. 2: 534-539; Schaper (1996) Circ. Res. 79: 911-919; Anderson (1992) Ciencia 256: 808-813; Verma (1997) Naturaleza 389: 239-249; Isner (1996) Lancet 348: 370-374; Muhlhauser (1995) Circ. Res. 77: 1077-1086; Onodera (1998) Blood 91: 30-36; Verma (1998) Gene Ther. 5: 692-699; Nabel (1997) Ann. N.Y. Acad. Sci. 811: 289-292; Verzeletti (1998) Hum. Gene Ther. 9: 2243-2251; Wang (1996) Nat. Med. 2: 714-716; WO 94/29469; WO 97/00957, US 5,580,859; US 5,589,466; o Schaper (1996) Curr. Opin. Biotechnol. 7: 635-640. Las moléculas de ácido nucleico y los vectores proporcionados en este documento pueden diseñarse para la introducción directa o para la introducción a través de liposomas o vectores virales (por ejemplo, adenovirales, retrovirales) en la célula. Por ejemplo, el vector puede ser un vector de virus adenoasociado (AAV), en particular, un vector AAV8. Los vectores a Av son atractivos para la terapia génica. El sistema AAV tiene varias ventajas que incluyen la expresión génica a largo plazo, la incapacidad de replicarse de forma autónoma sin un virus auxiliar, la transducción de células en división y no en división y la falta de patogenicidad de las infecciones de tipo salvaje. Preferiblemente, dicha célula en la que se introduce la molécula de ácido nucleico o el vector es una célula de línea germinal, una célula embrionaria o un óvulo o derivada de la misma, lo más preferiblemente dicha célula es una célula madre. Un ejemplo de una célula madre embrionaria puede ser, entre otras cosas, una célula madre como se describe en Nagy (1993) Proc. Natl. Acad. Sci. USA 90: 8424-8428.
[0209] Los términos "polipéptido", "péptido" y "proteína" se utilizan aquí indistintamente y se refieren a un polímero de dos o más aminoácidos unidos mediante enlaces amida o peptídico que se forman entre un grupo amino de un aminoácido y un grupo carboxilo de otro aminoácido. Preferiblemente, se forma un enlace peptídico entre el grupo aamino de un aminoácido y el grupo a-carboxilo de otro aminoácido. Los aminoácidos comprendidos en el péptido o proteína, que también se denominan residuos de aminoácidos, pueden seleccionarse entre los 20 a-aminoácidos proteinogénicos estándar (es decir, Ala, Arg, Asn, Asp, Cys, Glu, Gln, Gly , His, Ile, Leu, Lys, Met, Phe, Pro, Ser, Thr, Trp, Tyr y Val) pero también de a-aminoácidos no proteinogénicos y / o no estándar (tales como, por ejemplo, ornitina, citrulina, homolisina, pirrolisina o 4-hidroxiprolina) así como p-aminoácidos (por ejemplo, p-alanina), yaminoácidos y 5-aminoácidos. Preferiblemente, los residuos de aminoácidos comprendidos en el péptido o proteína se seleccionan de a-aminoácidos, más preferiblemente de los 20 a-aminoácidos proteinogénicos estándar (que pueden estar presentes como el isómero L o el isómero D, y preferiblemente todos, excepto Gly, están presentes
como isómero L).
[0210] El polipéptido o proteína codificados puede estar sin modificar o puede modificarse, por ejemplo, en su extremo N-terminal, en su extremo C-terminal y / o en la cadena lateral de cualquiera de sus residuos de aminoácidos (particularmente en el grupo funcional de la cadena lateral de uno o más residuos Lys, His, Ser, Thr, Tyr, Cys, Asp, Glu y / o Arg). Tales modificaciones pueden incluir, por ejemplo, la unión de cualquiera de los grupos protectores descritos para los grupos funcionales correspondientes en: Wuts (2006) Greene's protective groups in organic syhtesis, John Wiley & Sons, 4a edición, Hoboken, N.J.. Tales modificaciones también pueden incluir glicosilación y / o acilación con uno o más ácidos grasos (por ejemplo, uno o más ácidos alcanoicos o alquenoicos C8-30; formando un péptido o proteína acilado de ácido graso). El polipéptido codificado preferiblemente no está hidroxilado, en particular no comprende hidroxiprolina.
[0211] Los residuos de aminoácidos codificados comprendidos en el péptido o proteína pueden, por ejemplo, estar presentes como una cadena molecular lineal (formando un péptido o proteína lineal) o pueden formar uno o más anillos (correspondientes a un péptido o proteína cíclicos), por ejemplo, circularizados a través de un enlace peptídico o isopeptídico o un puente disulfuro. El péptido o la proteína también pueden formar oligómeros que constan de dos o más moléculas idénticas o diferentes. Como se usa en el presente documento, el término "dominio" se refiere a cualquier región / parte de una secuencia de aminoácidos que es capaz de adoptar de forma autónoma una estructura y / o función específicas. Por consiguiente, en el contexto de la presente invención, un "dominio" puede representar un dominio funcional o un dominio estructural, que puede, por ejemplo, formar parte de un polipéptido más grande.
[0212] Como se usa en el presente documento, los términos "que comprende" y "que incluye" o variantes gramaticales de los mismos deben tomarse como una especificación de las características, números enteros, pasos o componentes indicados, pero no excluyen la adición de una o más características, números enteros, pasos o componentes adicionales o grupos de los mismos. Estos términos abarcan los términos "que consiste en" y "que consiste esencialmente en".
[0213] Por tanto, los términos "que comprende" / "que incluye" / "que tiene" significan que cualquier componente adicional (o igualmente características, números enteros, etapas y similares) puede / podría estar presente. Por tanto, siempre que los términos "que comprende" / "que incluye" / "que tiene" se utilizan en este documento, pueden sustituirse por "que consiste esencialmente en" o, preferiblemente, por "que consiste en".
[0214] El término "que consta de" significa que no está presente ningún componente adicional (o igualmente características, números enteros, etapas y similares).
[0215] El término "que consiste esencialmente en" o variantes gramaticales del mismo cuando se usa en este documento debe tomarse como que especifica las características, números enteros, pasos o componentes indicados, pero no excluye la adición de una o más características, números enteros, pasos, componentes o grupos adicionales de los mismos pero solo si las características adicionales, números enteros, etapas, componentes o grupos de los mismos no alteran materialmente las características básicas y novedosas de la composición, dispositivo o método reivindicado.
[0216] Por tanto, el término "que consiste esencialmente en" significa que pueden estar presentes componentes adicionales específicos (o igualmente características, números enteros, etapas y similares), es decir, aquellos que no afectan materialmente a las características esenciales de la composición, dispositivo o método. En otras palabras, el término "que consiste esencialmente en" (que puede usarse indistintamente en este documento con el término "que comprende sustancialmente"), permite la presencia de otros componentes en la composición, dispositivo o método además de los componentes obligatorios (o características similares, números enteros, pasos y similares), siempre que las características esenciales del dispositivo o método no se vean afectadas materialmente por la presencia de otros componentes.
[0217] El término "método" se refiere a maneras, medios, técnicas y procedimientos para realizar una tarea determinada, incluidos, entre otros, aquellos modos, medios, técnicas y procedimientos que se conocen o se desarrollan fácilmente a partir de maneras, medios, técnicas y procedimientos conocidos, por practicantes de las técnicas química, biológica y biofísica.
[0218] Como se usa aquí y si no se indica de otra manera, el término "aproximadamente" se refiere preferiblemente a ± 10% del valor numérico indicado, más preferiblemente a ± 5% del valor numérico indicado, y en particular al valor numérico exacto indicado.
[0219] La presente invención se describe adicionalmente con referencia a las siguientes figuras y ejemplos no limitativos. A menos que se indique lo contrario, se utilizaron métodos establecidos de tecnología de genes recombinantes como se describe, por ejemplo, en Sambrook (2001) loc. cit.
[0220] La presente invención se describe adicionalmente con referencia a las siguientes figuras y ejemplos no limitativos. Las figuras muestran:
Figura 1: Ensamblaje de ácidos nucleicos de baja repetición que codifican secuencias ricas en prolina / alanina utilizando el plásmido pXL2.
(A) Mapa de plásmido de pXL2 (SEQ ID NO: 48). Un sitio de reconocimiento Sapl (5-GCTCTTC-3 ') y un sitio de reconocimiento Earl (5-CTCTTC-3 ') se insertan en el gen marcador seleccionable lacZ, que está bajo el control transcripcional del promotor lac (lacP/O). El sitio de restricción Sapl permite la inserción consecutiva de una o más unidades (bloques de construcción) de moléculas de ácido nucleico de baja repetición que codifican secuencias ricas en prolina / alanina. Cortar con Earl, una enzima de restricción cuya secuencia de reconocimiento se superpone con / es un subconjunto de la secuencia de reconocimiento Sapl permite la escisión y / o aislamiento de la molécula de ácido nucleico de baja repetición ensamblada (casete de genes) que codifica una secuencia rica en prolina / alanina. El esqueleto del plásmido es idéntico al del vector de clonación genérico pUC19 (Yanisch-Perron (1985) Gene 33: 103-119), a excepción de la eliminación adicional de sitios de restricción Sapl y Earl mediante mutación silenciosa. (B) Mapa de plásmido de pXL1 (SEQ ID NO: 55). Dos sitios de reconocimiento Sapl (5'-GCTCTTC-3 ') en orientación opuesta se insertan en el gen marcador seleccionable lacZ, que está bajo el control transcripcional del promotor/operador lac (lacP/°). El sitio de restricción Sapl permite la inserción / clonación así como la propagación / amplificación y la posterior escisión y / o aislamiento de una molécula de ácido nucleico de baja repetición (casete génico) que codifica una secuencia rica en prolina / alanina. El esqueleto del plásmido es idéntico al de pUC19, excepto por la deleción de un sitio de restricción adicional Sapl mediante mutación silenciosa. Tenga en cuenta que el casete de genes insertado tiene orientación inversa en comparación con pXL2. (C) Tramo de secuencia de nucleótidos de y alrededor del sitio de clonación de pXL2 útil para la clonación y ensamblaje de moléculas de ácido nucleico de baja repetición. La secuencia de nucleótidos contiene un sitio de restricción Sapl y un sitio de restricción Earl en orientación inversa. Como la secuencia de reconocimiento Earl también es parte de la secuencia de reconocimiento Sapl, Earl corta en ambos sitios de reconocimiento. Independientemente de la enzima de restricción utilizada, Sapl o Earl; digerir conduce a extremos GCC / CGG que sobresalen (que codifican Ala), que son compatibles con los salientes GCC / CGG de moléculas de ácido nucleico repetitivas bajas que codifican secuencias ricas en prolina / alanina y, por lo tanto, permiten una ligación eficaz. Las secuencias de reconocimiento están subrayadas. (D) Secuencia de nucleótidos y secuencia de aminoácidos codificada del sitio de clonación de pXL2 después de la inserción de una unidad de ácido nucleico / bloque de construcción de baja repetición, PAS # lb (200) (SEQ ID NO: 19). Los sitios de restricción Sapl y Earl que flanquean la unidad de ácido nucleico / bloque de construcción de baja repetición clonada están marcados (las secuencias de reconocimiento están subrayadas). (E) Ensamblaje de unidades de secuencia de ácido nucleico de baja repetición para obtener secuencias de nucleótidos clonadas más largas (moléculas de ácido nucleico) que codifican secuencias repetidas de aminoácidos ricas en prolina / alanina. En el primer paso, pXL2 se digiere con SapI, desfosforilado y ligado con la primera unidad de secuencia, PAS # 1b (200). En el segundo paso, el plásmido resultante se abre / lineariza cadena arriba de la unidad de secuencia clonada por restricción singular por Sapl, seguido de desfosforilación y ligación con la segunda unidad de secuencia de nucleótidos, PAS # 1c (200). El plásmido resultante pXL2-PAS # 1c / 1b (400) contiene un casete de gen / ADN insertado que comprende un total de 1200 pares de bases de longitud. En general, la secuencia de nucleótidos de baja repetición clonada resultante que codifica una secuencia de repetición de aminoácidos rica en prolina / alanina contiene sólo repeticiones de nucleótidos con una longitud máxima de 14 nucleótidos (SEQ ID NO: 52). Todo el casete génico ensamblado / molécula de ácido nucleico se puede escindir fácilmente mediante digestión con EarI y posteriormente utilizado para subclonar en vectores de expresión, por ejemplo, en el mismo marco de lectura con una secuencia de nucleótidos que codifica una proteína biológicamente activa, y similares. En particular, repitiendo el segundo paso, los casetes de genes con una longitud que aumenta sucesivamente pueden ensamblarse y clonarse en pXL2 de una manera sistemática. Si se usan diferentes unidades de secuencia de nucleótidos adecuadas, la molécula de ácido nucleico larga y repetitiva resultante que codifica una secuencia de repetición de aminoácidos rica en prolina / alanina contiene sólo pocas repeticiones de nucleótidos o cortas.
Figura 2: Análisis repetido de secuencias ricas en prolina / alanina.
(A) Los gráficos de puntos de la secuencia PA # 3a (200) rica en prolina / alanina de la técnica anterior (SEQ ID NO: 15) se comparan con los gráficos de puntos de una secuencia de nucleótidos de baja repetición según esta invención, PA # 3b (200) (SEQ ID NO: 36), ambos generados utilizando la herramienta de diagrama de puntos "dottup" incluida en el paquete de software Geneious V8.1 (Biomatters, Auckland, Nueva Zelanda), aplicando una ventana de repetición de 14 o 15. Comparando la secuencia del nucleótido analizado a sí mismo en los ejes x e y, respectivamente, de un gráfico bidimensional la herramienta "dottup" identifica todas las regiones donde ocurre una secuencia idéntica de longitud especificada (ventana de repetición) y dibuja una línea diagonal, indicando así las posiciones de una secuencia repetida en el eje x e y (si está representado por una línea diagonal diferente de la línea diagonal central, esta última indica identidad propia). Las repeticiones sucesivas extienden una línea diagonal. La secuencia de nucleótidos de PA # 3a (200) analizada aquí revela una naturaleza altamente repetitiva como lo ilustran las muchas y / o largas líneas diagonales. En este caso, la secuencia de nucleótidos muestra numerosas repeticiones de 60 pares de bases cada una. Al aplicar una ventana de repetición de 14, aparece incluso una repetición más corta de 14 pb dentro de la repetición de 60 pb. Por el contrario, la secuencia de nucleótidos PA # 3b (200) muestra solo unas pocas repeticiones de 14 pb dispersas dentro de la secuencia de nucleótidos analizada completa de 600 pb, mientras que no se detecta ninguna repetición cuando se aplica una ventana de repetición ligeramente mayor de 15 para el análisis. (B) Gráficos de puntos del ácido nucleico PAS # 1a (600) (SEQ ID NO: 12)
divulgado en WO2008155134 que codifican una secuencia rica en prolina / alanina, se comparan con gráficos de puntos de las secuencias de nucleótidos de baja repetición ensambladas que codifican secuencias repetidas de aminoácidos ricas en prolina / alanina de acuerdo con esta invención, PAS # 1d / 1f / 1c / 1b (800) (SEQ ID NO: 39) y PAS # 1f / 1c / 1b (600) (SEQ ID NO: 38), usando ventanas de repetición de 14 y 15 pares de bases. Mientras que la secuencia de nucleótidos PAS # 1a (600) revela una composición de repeticiones de 60 pares de bases, las secuencias de nucleótidos PAS # 1d / 1f / 1c / 1b (800) y PAS # 1f / 1c / 1b (600) no muestran o, en el caso de la ventana de repetición de 14 nucleótidos, sólo una única repetición de 14 nucleótidos (línea diagonal) dentro de todas las secuencias de nucleótidos analizadas de 2400 o 1800 pb, respectivamente. (C) Análisis de diagrama de puntos de una secuencia de ADN sintético que codifica un multímero [(AP)5]n (SEQ ID NO: 16) descrito en US2006/0252120 y de una secuencia de ADN natural que codifica una región repetitiva rica en prolina / alanina de la proteína del tegumento muy grande de Herpesvirus macacino 1 (GenBank AAP41454.1) (SEQ ID NO: 18) en comparación con la secuencia de nucleótidos de baja repetición según esta invención, PA # 3a (200) (SEQ ID NO: 15), aplicando ventanas de repetición de 14 y 15 nucleótidos. Gráficos de puntos de las secuencias de ADN que codifican el multímero [(AP)5]n y la región rica en prolina / alanina de la proteína tegumento muy grande de Herpesvirus macacino 1 ilustran la naturaleza altamente repetitiva de estas secuencias de nucleótidos. Por el contrario, el gráfico de puntos de la secuencia de nucleótidos Pa # 1b (200) muestra solo unas pocas repeticiones de 14 nucleótidos dispersas (ventana de repetición de 14 nucleótidos) o ninguna repetición (ventana de repetición de 15 nucleótidos) dentro de la secuencia de nucleótidos analizada completa de 600 pb.
Figura 3: Electroferograma de la secuenciación de ADN de una molécula de ácido nucleico de baja repetición que codifica secuencias de aminoácidos ricas en prolina / alanina.
Electroferograma de secuenciación de ADN de pXL2-PAS # 1f / 1c / 1b (600) (SEQ ID NO: 38) que tiene una secuencia de nucleótidos repetitiva baja que codifica una secuencia rica en prolina / alanina según esta invención. El ADN plasmídico bicatenario se secuenció usando el cebador XLP-1 (SEQ ID NO: 3), que hibrida específicamente dentro de la región codificante de la unidad de secuencia de nucleótidos PAS # 1b (200) (SEQ ID NO: 19). En este electroferograma se pueden leer más de 900 bases y corresponden a la secuencia de nucleótidos conocida de pXL2-PAS # 1f / 1c / 1b (600). En particular, el electroferograma no muestra signos de hibridación de cebadores múltiples o inespecíficos.
Figura 4: pASK75-PAS # 1f / 1c / 1b (600) -IL1Ra, un vector de expresión genéticamente estable para la producción bacteriana de la proteína de fusión PAS # 1 (600) -IL1Ra que tiene relevancia terapéutica.
(A) Mapa de plásmido de pASK75-IL1Ra (SEQ ID NO: 49) y (B) de su derivado pASK75-PAS # 1f / 1c / 1b (600) -IL1Ra (SEQ ID NO: 50) después de la inserción de un casete de genes PAS # 1f / 1c / 1b (600). El gen estructural para la (pre) proteína PAS # 1 (600) -IL1Ra biológicamente / farmacológicamente activa que comprende la secuencia de nucleótidos de baja repetición que codifica un polipéptido PAS # 1 con 601 residuos de aminoácidos y el gen estructural para IL-1Ra humana, así como regiones codificantes para la secuencia señal bacteriana OmpA y una His6-tag se clona bajo control transcripcional del promotor / operador tet (tetp/o). El esqueleto del plásmido fuera del casete de expresión flanqueado por sitios de restricción Xbaly HindIII es idéntico al del vector de expresión genérico pASK75 (Skerra (1994) Gene 151: 131-135). Se indica el sitio de restricción singular Sapl que se retuvo después de la inserción de la molécula de ácido nucleico de baja repetición que codifica una secuencia de repetición de aminoácidos rica en prolina / alanina de acuerdo con esta invención.
Figura 5: Análisis de la estabilidad genética de la molécula de ácido nucleico de baja repetición que codifica una secuencia repetida de aminoácidos rica en prolina / alanina, PAS # 1f / 1c / 1b (600), en comparación con la secuencia de nucleótidos de la técnica anterior PAS # 1a (600)
Electroforesis en gel de agarosa después análisis de restricción XbaIlHindIII de 10 preparaciones de plásmido Clones de JM83 de E. coli transformados con pASK75-PAS # 1a (600) -IL1Ra (carriles 1-5) (SEQ ID NO: 51) o pASK75-PAS # 1f / 1c /1 b (600) -IL1Ra (carriles 1-10) (SEQ ID NO: 50) cultivados durante 7 días, lo que corresponde a aproximadamente 70 generaciones de división celular bacteriana. 4 de 5 clones analizados de pASK75-PAS # 1a (600) -IL1Ra revelaron fragmentos de ADN acortados que comprenden el inserto de ácido nucleico que codifica la secuencia de repetición de aminoácidos rica en prolina / alanina (Figura 5A), lo que indica claramente una inestabilidad genética. En contraste, los 5 clones de pASK75-PAS # 1f / 1c / 1b (600) -IL1Ra mostraron solo las bandas esperadas correspondientes a 3093 pb y 2377 pb, respectivamente, lo que indica un inserto de ácido nucleico intacto que codifica secuencias de repetición de aminoácidos ricas en prolina / alanina y alta estabilidad genética del plásmido. Por tanto, las secuencias de nucleótidos de baja repetición que codifican secuencias repetidas de aminoácidos ricas en prolina / alanina de acuerdo con esta invención ofrecen una clara ventaja sobre las secuencias de nucleótidos repetitivas de la técnica anterior.
Figura 6: Clonación perfecta de una secuencia de nucleótidos de baja repetición que codifica secuencias repetidas de aminoácidos ricas en prolina / alanina en un plásmido de expresión que codifica la proteína biológicamente activa IL-1Ra.
(A) Ilustración esquemática de una región codificante para una proteína de fusión que comprende el gen de secuencia señal OmpA seguido de un codón de alanina GCC, una primera secuencia de reconocimiento Sapl
GCTCTTC en la hebra no codificante, un espaciador de dinucleótidos GC y un segundo reconocimiento Sapl en orientación inversa, con su secuencia de reconocimiento GCTCTTC en la hebra codificante, finalmente seguida por un codón de alanina GCC y la secuencia codificante para IL-1Ra madura (UniProt ID P18510). La secuencia completa que se muestra se clonó a través de sitios de restricción XbaI/HindIII en el vector de expresión genérico pASK75. (B) Ilustración esquemática del casete de ADN descrito en (A) después de escisiónSapl y escisión del inserto corto de 24 pb flanqueado por los dos sitios de restricción SapI. Es de destacar que debido a los dos salientes en 5 ', solo los 18 nucleótidos del medio forman una doble hebra de ADN y, por lo tanto, comprenden pares de bases en el verdadero sentido. (C) Inserción sin enlaces de manera unidireccional del fragmento de ADN que comprende la secuencia de nucleótidos de baja repetitividad PA # 1b (200), p. ej., escindido de pXL2-PA # lb (200) (SEQ ID NO: 54), a través de extremos pegajosos compatibles GCC / CGG generados por digestión con restricción Earl (cf. Figura 1). El casete de expresión resultante que comprende la secuencia de nucleótidos de baja repetición que codifica una secuencia de repetición de aminoácidos rica en prolina / alanina de acuerdo con esta invención se muestra como SEQ ID NO: 47 más adelante en el presente documento.
Figura 7: Caracterización de la proteína de fusión PAS # 1 (600) -ILIRa producida en E. coli utilizando el vector de expresión genéticamente estable pASK75-PAS # 1f / 1c / 1b (600) -IL1Ra
(A) Análisis de la proteína de fusión PAS # 1 (600) -IL1Ra purificada mediante IMAC, AEX, CEX y SEQ mediante SDS-PAGE al 10%. El gel muestra muestras de 2 pg de pAS # 1 (600) -IL1Ra reducidas con 2-mercaptoetanol (carril 1) y no reducidas (carril 2). Los tamaños de las proteínas marcadoras de proteínas (M) se indican a la izquierda. La proteína de fusión PAS # 1 (600) -IL1Ra aparece como una única banda homogénea con un tamaño molecular aparente superior a 116 kDa. Debido a la escasa unión a SDS, las proteínas de fusión de PAS generalmente muestran tamaños significativamente mayores (Schlapschy (2013) Protein Eng Des Sel. 26: 489-501) que, por ejemplo, la masa calculada de 68 kDa para PAS # 1 (600) -IL1Ra. (B) Caracterización de la proteína de fusión PAS # 1 (600) mediante espectrometría de masas por ionización por electropulverización (ESI-MS). Un espectro de ESI-MS desconvolucionado de la proteína de fusión PAS # 1 (600) -IL1Ra purificada revela una masa medida de 67994,8 Da, que corresponde casi perfectamente a la masa calculada de 67994,9 Da.
Figura 8: Caracterización de un polipéptido PA # 1 (600 /) puro producido en E. coli utilizando el vector de expresión genéticamente estable pASK37-MP-PA # ld / lc / lb (600)
(A) Mapa de plásmido de pASK37-MP-PA # 1d / 1c / 1b (600) (SEQ ID NO: 53). La secuencia de nucleótidos de baja repetición que codifica el polipéptido PA # 1 (600) se clonó bajo el control transcripcional del promotor / operador lacUV5 (lacUV5p/o) precedido por codones para un residuo de inicio Met y un residuo Pro. El esqueleto del plásmido fuera del casete de expresión flanqueado por los sitios de restricción Xbaly HindIII es idéntico al del vector de expresión genérico pASK37 (Skerra (1991) Protein Eng. 4: 971-979). (B) Análisis del polipéptido PA # 1 (600) recombinante mediante SDS-PAGE al 10%, seguido de tinción con yoduro de bario. Las muestras cargadas son células lisadas después de 3 h de expresión (carril 1), proteína precipitada con 20% p / v (NH4)2SO4 (carril 2), el sobrenadante del (NH4)2SO4 precipitado disuelto en Tris / HCl 20 mM después de centrifugación durante 20 min a 17.000 rpm y un tratamiento posterior con AcOH al 1% v / v (carril 3) y el flujo a través de la cromatografía de intercambio catiónico substractiva del polipéptido tratamiento PA # 1 (600) (carril 4). El polipéptido PA # 1 (600) se une pobremente a SDS; por tanto, el polipéptido PA # 1 (600) aparece como una banda teñida con yodo rojo / amarillo dentro del gel de apilamiento, lo que indica una composición homogénea. (C) El gel que se muestra en (B) después de decolorar con agua y teñir con azul brillante de Coomassie. El polipéptido Pa # 1 (600) se une pobremente al SDS y no se tiñe con el colorante Coomassie; por lo tanto, solo las impurezas (proteínas de la célula huésped) son visibles en el gel teñido con Coomassie. (D) Caracterización del polipéptido PA # 1 (600) puro mediante espectrometría de masas de ionización por electropulverización (ESI-MS). El espectro deconvolucionado revela una masa medida de 48301,78 Da, que coincide casi perfectamente con la masa calculada para el polipéptido PA # 1 (600) recombinante, que lleva un residuo Pro adicional en el extremo N-terminal como se explicó anteriormente y un residuo Ala adicional en el C -terminus debido al sitio de restricción SapI que se empleó para la clonación de genes (48301,4 Da). Tenga en cuenta que este polipéptido recombinante ya no lleva el residuo Met de inicio, muy probablemente como resultado de la acción intracelular de la metionina aminopeptidasa (Giglione (2015) Biochimie 114: 134-46).
Figura 9: Análisis repetido automatizado de secuencias de nucleótidos que codifican secuencias de aminoácidos ricas en prolina / alanina.
Se analizaron repeticiones de secuencias de nucleótidos naturales y sintéticas que codifican secuencias de aminoácidos ricas en prolina / alanina de la técnica anterior como se describe en el Ejemplo 13 utilizando el script de Python NRS-Calculator (ver Ejemplo 14) y se compararon aquí con las secuencias de nucleótidos de baja repetición. PAS # 1b (200) y PA # 1e / 1d / 1c / 1b (800) de acuerdo con esta invención. La frecuencia (número de apariciones) de todas las repeticiones de una determinada longitud dentro de la secuencia de nucleótidos analizada se representó frente a la longitud de la repetición. (A) Histograma de la secuencia de nucleótidos de la técnica anterior PAS # la (200) (SEQ ID NO: 11). (B) Histograma de la secuencia de nucleótidos PA # 1a (200) (SEQ ID NO: 14) (C) Histograma de la secuencia de nucleótidos que codifica el glicomódulo [(AlaPro)5]20APA (SEQ ID NO: 16) . (D) Histograma de la secuencia de nucleótidos que codifica el glicomódulo [a ApAPa PAp ]1üAS (SEQ ID NO: 17) . (MI) Histograma de la secuencia de nucleótidos que codifica un tramo rico en prolina / alanina dentro de la
proteína de tegumento grande del herpesvirus 1 de macacina (SEQ ID NO: 18). (F) Histograma de la secuencia de nucleótidos de baja repetición PAS # 1b (200) (SEQ ID NO: 19). (G) Vista en primer plano de los datos de PAS # 1b (200) ilustrados en (F). (H) Histograma de la secuencia de nucleótidos de baja repetición PA # 1e / 1d / 1c / 1b (800) según esta invención (SEQ ID NO: 44). (I) Vista cercana de los datos de pA # 1e / 1d / 1c / 1b (800) ilustrados en (H). La longitud total de la secuencia de nucleótidos analizada (Ntot) y su puntuación de repetición de nucleótidos (NRS), que es una medida para evaluar la calidad de las moléculas de ácido nucleico que codifican secuencias de aminoácidos ricas en prolina / alanina con respecto a la frecuencia y longitud de las repeticiones, se resumen para las diferentes secuencias de nucleótidos en las Tablas. 1 y 2.
Figura 10: pASK75-PA # 1d / 1c / 1b (600) -ILIRa, un vector de expresión genéticamente estable para la producción bacteriana de la proteína de fusión PA # 1 (600) -IL1Ra que tiene relevancia terapéutica.
Mapa de plásmido de pASK75-PA # 1d / 1c / 1b (600) -IL1Ra (SEQ ID NO: 77). El gen estructural para la (pre) proteína Pa # 1 (600) -IL1Ra biológicamente / farmacológicamente activa que comprende la secuencia de nucleótidos de baja repetición que codifica un polipéptido PA # 1 con 601 residuos de aminoácidos y el gen estructural para IL-1Ra humana, así como regiones codificantes para la secuencia señal bacteriana OmpA y una etiqueta His6 se clona bajo el control transcripcional del promotor / operador tet (tetp/o). El esqueleto del plásmido fuera del casete de expresión flanqueado por los sitios de restricción XbaI y HindIII es idéntico al del vector de expresión genérico pASK75 (Skerra (1994) Gene 151: 131-135). Se indica el sitio de restricción singular SapI que se retuvo después de la inserción de la molécula de ácido nucleico de baja repetición que codifica una secuencia de repetición de aminoácidos rica en prolina / alanina de acuerdo con esta invención.
Figura 11: Análisis de la estabilidad genética de la molécula de ácido nucleico de baja repetición PA # 1d / 1c / 1b (600), que codifica una secuencia de repetición de aminoácidos rica en prolina / alanina, en comparación con la secuencia de nucleótidos de la técnica anterior PA # 1a (600)
Electroforesis en gel de agarosa después de análisis de restricción XbaI/HindIII de 10 preparaciones de plásmido de clones de JM83 E. coli transformados con pASK75-PA # 1d / 1c / 1b (600) -IL1Ra (Fig. 10) (SEQ ID NO: 77) o 10 preparaciones de plásmido de pASK75-PA # 1a (600) -IL1Ra (SEQ ID NO: 78) cultivadas durante 7 días, lo que corresponde a aproximadamente 70 generaciones de división celular bacteriana. Carriles: M, estándar de tamaño molecular (GeneRuler 1 kb DNA Ladder: 500, 750, 1000, 1500, 2000, 2500, 3000, 3500, 4000, 5000, 6000, 8000 y 10000 bp); 1 a 10: muestras de plásmido de clones individuales después de la digestión de restricción. Al menos 4 de 10 clones analizados de pASK75-PA # 1a (600) -IL1Ra revelaron fragmentos de ADN acortados que comprenden el inserto de ácido nucleico que codifica la secuencia de repetición de aminoácidos rica en prolina / alanina (Fig. 11 A), lo que indica claramente una inestabilidad genética. En contraste, los 10 clones de pASK75-PA # 1d / 1c / 1b (600) -IL1Ra (Fig. 11 B) mostró solo las bandas esperadas correspondientes a 3093 pb y 2377 pb, respectivamente, lo que indica un inserto de ácido nucleico intacto que codifica las secuencias repetidas de aminoácidos ricas en prolina / alanina y una alta estabilidad genética del plásmido. Por tanto, las secuencias de nucleótidos de baja repetición que codifican secuencias repetidas de aminoácidos ricas en prolina / alanina de acuerdo con esta invención ofrecen una clara ventaja sobre las secuencias de nucleótidos repetitivas de la técnica anterior.
Figura 12: Construcción de vectores de expresión genéticamente estables para la producción bacteriana de leptina humana fusionada con secuencias de aminoácidos ricas en prolina / alanina
(A) Mapa de plásmido de pASK37-MP-huLeptin (SEQ ID NO: 81) que contiene un casete de clonación sin enlaces flanqueado por sitios de restricción SapI para permitir la clonación directa y sin enlaces de una secuencia de nucleótidos repetitiva baja que codifica secuencias repetidas de aminoácidos ricas en prolina / alanina en marco con el gen estructural de la leptina humana. (B) Mapa de plásmido de pASK37-MP-huLeptin-PA # 1d / 1c / 1b (600) (SEQ ID NO: 82), un derivado de pASK37-MP-huLeptin con la inserción de un casete de genes PA # 1d / 1c / 1b (600) (SEQ ID NO: 42). (C) Mapa de plásmidos de pASK37-MP-huLeptin-PAS # 1f / 1c / 1b (600) (SEQ ID NO: 83), un derivado de pASK37-MP-huLeptin con la inserción de un casete de genes PAS # 1f / 1c / 1b (600) (SEQ ID NO: 38). Los genes estructurales de la proteína humana biológicamente / farmacológicamente activa Leptina, la Leptina humana fusionada con la secuencia de nucleótidos de baja repetición que codifica el PA # 1 (600) y la Leptina humana fusionada con la secuencia de nucleótidos de baja repetición que codifica el polipéptido PAS # 1 (600) fueron clonados bajo control transcripcional del promotor / operador lacUV5 (lacUV5p/o), todos precedidos por codones para un residuo de inicio Met y un residuo Pro. El esqueleto del plásmido fuera del casete de expresión flanqueado por sitios de restricción XbaI y HindIII es idéntico al del vector de expresión genérico pASK37 (Skerra (1991) Protein Eng. 4: 971-979).
Figura 13: Caracterización de una variante de leptina humana fusionada con un polipéptido PA # 1 (600) y producida en E. coli utilizando el vector de expresión genéticamente estable pASK37-MP-PA # 1d / 1c / 1b (600) -huLeptin (W100Q)
(A) Análisis SDS-PAGE de la proteína de fusión PA # 1 (600) -huLeptin (W100Q) usando un gel de poliacrilamida al 10% seguido de tinción con azul brillante de Coomassie R-250. El gel muestra un marcador de peso molecular (MW) de proteína (carril M; Thermo Fisher Scientific, Waltham, MA), extracto de células E. coli completas después de 19 h de expresión en condiciones reductoras de la muestra (carril 1), proteína precipitada con (NH4)2SO41 M reducida
(línea 2) y no reducida (línea 5), la proteína después de la cromatografía de intercambio aniónico reducida (línea 3) y no reducida (línea 6), y la proteína después de la cromatografía de exclusión por tamaño reducida (línea 4) y no reducida (línea 7 ). PA # 1 (600) -huLeptin (W100Q) aparece como una sola banda, lo que indica una composición homogénea. (B) Caracterización de la proteína de fusión PA # 1 (600) -huLeptin (W100Q) mediante espectrometría de masas de lonización por electropulverización (ESI-MS). El espectro deconvolucionado revela una masa medida de 64249,5 Da, que coincide con la masa calculada para la proteína de fusión recombinante (64249,8 Da), lo que indica la escisión satisfactoria del residuo Met inicial por la metionina aminopeptidasa bacteriana.
[0221] La presente invención se describe adicionalmente mediante los siguientes ejemplos ilustrativos no limitantes que proporcionan una mejor comprensión de la presente invención y de sus muchas ventajas.
Ejemplo 1: Síntesis de unidades de secuencia de nucleótidos de baja repetición que codifican secuencias de repetición de aminoácidos ricas en prolina / alanina
[0222] Se optimizó un conjunto de diferentes secuencias de nucleótidos, incluido el ajuste manual, cada una de las cuales codificaba una secuencia repetida de aminoácidos rica en prolina / alanina de 200 residuos, con respecto a la baja repetibilidad en el nivel de nucleótidos, bajo contenido de GC, baja estructura secundaria de ARN, uso de codón preferido para expresarse en E. coli y evitación de motivos antivirales así como elementos que actúan CIS. Con este fin, se aplicaron algoritmos establecidos como la aproximación de optimización de codón de condición específica (Lanza (2014) BMC Syst Biol 8:33) o el algoritmo GeneOptimizer (Raab (2010) Syst Synth Biol 4: 215 225). Las secuencias iniciales obtenidas de las mismas se ajustaron manualmente de la siguiente manera.
[0223] Se identificaron repeticiones más largas que un umbral determinado (por ejemplo, 14 nucleótidos) utilizando la versión 1.2 del software Visual Gene Developer, que está disponible gratuitamente en http://visualgenedeveloper.net. Posteriormente, se sustituyeron por etapas los codones dentro de las repeticiones identificadas. En particular, los codones ricos en GC dentro de las repeticiones identificadas fueron reemplazados por codones ricos en AT prevalentes en genes altamente expresados en un organismo huésped de elección (p. Ej., E. coli, P. pastoris o CHO). Después de cada sustitución, se analizó de nuevo la secuencia de nucleótidos completa en busca de repeticiones. En caso de que la sustitución condujera a una nueva repetición más larga que el umbral dado, se rechazaron los intercambios de nucleótidos y se sustituyó por un codón diferente dentro de la repetición previamente identificada. Si este enfoque fallaba, se sustituían en paralelo dos codones dentro de la repetición larga identificada. De esta manera, todas las repeticiones identificadas por encima de un umbral dado se eliminaron iterativamente mientras se mantenía la secuencia codificada de aminoácidos rica en prolina / alanina.
[0224] En un segundo paso, el índice de adaptación de codones (CAI), el contenido de GC y las estructuras de ARNm estable de la secuencia de nucleótidos optimizada se analizaron utilizando el software Visual Gene Developer y se compararon con la secuencia de inicio. Se realizaron ajustes manuales adicionales, nuevamente por sustitución de codones / mutación silenciosa, hasta que la secuencia de nucleótidos optimizada alcanzó un contenido de CAI, GC o una estructura de ARNm igual o mejor que la secuencia de inicio. Se volvió a realizar el análisis de repetición del paso 1 y, si fue necesario, se intercambiaron otros codones para cumplir los objetivos, que eran umbral de repetición, CAI, contenido de GC y estructuras de ARNm (estructuras secundarias).
[0225] En un tercer paso, se combinaron diferentes secuencias de nucleótidos optimizadas individualmente, cada una de las cuales codificaba la misma secuencia repetida de aminoácidos rica en prolina / alanina de 200 residuos, es decir, se unieron entre sí, y la secuencia de nucleótidos más larga resultante se optimizó de la misma manera que en los pasos 1 y 2. Finalmente, la secuencia de ácido larga resultante se dividió en casetes de ADN más cortos, por ejemplo, de 600 nucleótidos de longitud. Por ejemplo, la secuencia de 2400 nucleótidos PAS # 1d / 1f / 1c / 1b (SEQ ID NO: 39) se dividió en cuatro casetes más cortos (SEQ ID NO: 19, 20, 21, 23). De forma similar, la secuencia de 2400 nucleótidos PA # 1e / 1d / 1c / 1b (SEQ ID NO: 44) se dividió en cuatro casetes más cortos (SEQ ID NO: 28, 29, 30, 31), cada uno de los cuales comprendía 600 nucleótidos.
[0226] Flanqueado por dos sitios de reconocimiento SapI (5-GCTCTTC-3 ') en orientación complementaria inversa, resultando en salientes de nucleótidos 5'-GCC / 5'-GGC después de la digestión con enzimas de restricción, estas unidades de secuencia de nucleótidos optimizadas fueron sintetizadas individualmente por diferentes proveedores comerciales. Es de destacar que debido a la presencia de los dos salientes de nucleótidos GCC / GGC, solo los 597 nucleótidos del medio forman una doble hebra de ADN después de la escisión y, por lo tanto, comprenden pares de bases (pb). Además, la secuencia optimizada de 600 nucleótidos se extiende por un codón Ala adicional debido a la presencia del segundo sitio de restricción SapI, lo que conduce a un casete de ADN clonado de 603 nucleótidos totales que codifican una secuencia de aminoácidos rica en prolina / alanina. La presencia flanqueando de los dos sitios de restricción Sapl permiten la escisión y subclonación precisas, por ejemplo, en pXL2, de todo el casete de ADN de la invención.
[0227] Conjuntos adicionales de unidades de secuencia de nucleótidos que codifican secuencias repetidas de aminoácidos ricas en prolina / alanina, codones optimizados para la expresión en Escherichia coli, Pichia pastoris, células de riñón embrionario humano (HEK), Pseudomonas fluorescens, Corynebacterium glutamicum,
Bacillus subtilis, Tetrahymena thermophila, Saccharomyces cerevisiae, Kluyveromyces lactis, Physcomitrella patens o Cricetulus griseus, fueron diseñados y sintetizados de la misma manera. Las tablas de preferencias de codones para estos organismos están disponibles para su descarga en http://www.kazusa.or.jp/codon. Las moléculas de ácido nucleico sintetizadas de acuerdo con la invención y sus características de secuencia de nucleótidos se resumen en la Tabla 1.
Ejemplo 2: Ensamblaje de unidades de secuencia de nucleótidos de baja repetición en secuencias de nucleótidos más largas que codifican secuencias de repetición de aminoácidos ricas en prolina / alanina
[0228] Los plásmidos obtenidos de proveedores comerciales, cada uno con un fragmento de ADN sintetizado clonado, se digirieron con SapI y el fragmento de ADN de 600 nucleótidos resultante se purificó mediante electroforesis en gel de agarosa de acuerdo con procedimientos estándar (Sambrook (2001) loc. Cit.) Las unidades de secuencia de nucleótidos individuales se ensamblaron en secuencias de nucleótidos más largas utilizando el plásmido pXL2 (SEQ ID NO: 48), un derivado de pUC19 (Yanisch-Perron (1985). Gene. 33, 103-119) que se muestra en la Figura 1A. pXL2 contiene un solo sitio de restricción SapI y digerir con esta enzima de restricción de tipo IIS genera una codificación de saliente 5'-GCC / 5'-GGC para alanina, que es compatible con los extremos pegajosos de los fragmentos de ADN purificados sintetizados (Figura 1C). Después de la inserción / ligación de una unidad de secuencia de nucleótidos, el plásmido se puede abrir en un extremo, aquí cadena arriba, de la unidad de secuencia clonada por otra digestión de restricción Sapl (Figura 1D). Este diseño de vector permite la inserción escalonada de unidades de secuencia de nucleótidos de baja repetición idénticas o diferentes, produciendo casetes de genes clonados más largos que codifican secuencias de repetición de aminoácidos ricas en prolina / alanina (Figura 1E).
[0229] Como ejemplo, primero la unidad de secuencia de nucleótidos PAS # 1b (200) (SEQ ID NO: 19), luego la unidad de secuencia PAS # lc (200) (SEQ ID NO: 20), y posteriormente la unidad de secuencia PAS # 1f ( 200) (SEQ ID NO: 23) se insertaron en pXL2 a través del sitio de restricción SapI de la manera descrita, dando como resultado el plásmido pXL2-PAS # 1f / 1c / 1b (600) (SEQ ID NO: 38). En un paso posterior, la unidad de secuencia PAS # 1d (200) (SEQ ID NO: 19) se insertó adicionalmente de la misma manera usando el sitio de restricción SapI. El plásmido resultante contenía el casete de ADN de 2400 pb ensamblado PAS # 1d / 1f / 1c / 1b (800) que en total reveló que la secuencia de nucleótidos se repite con una longitud máxima de 14 nucleótidos (SEQ ID NO: 39). Como la secuencia de reconocimiento de EarI (5-CTCTTC-3 ') cadena abajo del casete de ADN de baja repetición clonado en pXL2 también es parte de la secuencia de reconocimiento de SapI, todo el casete de ADN ensamblado se puede escindir fácilmente mediante digestión de restricción con EarI, cortando así dos veces, lo que permite el uso posterior para una subclonación adicional.
[0230] De la misma manera, la secuencia de nucleótidos de baja repetición PA # 1e / 1d / 1c / 1b (800) (SEQ ID NO: 44) se ensambló a partir de las unidades de secuencia de nucleótidos PA # 1b (200) (SEQ ID NO: 28), Pa # lc (200) (SEQ ID NO: 29), PA # 1d (200) (SEQ ID NO: 30) y PA # 1e (200) (SEQ ID NO: 31) en el orden indicado. Las secuencias de nucleótidos ensambladas descritas así como otras moléculas de ácido nucleico de baja repetición ejemplares que codifican secuencias repetidas de aminoácidos ricas en prolina / alanina de acuerdo con esta invención, también con el uso de codones optimizado para organismos hospedadores diferentes de E. coli, se resumen en la Tabla 1. La estrategia de clonación descrita ofrece un ensamblaje simple y escalonado de casetes de genes complejos que comprenden moléculas de ácido nucleico largas y repetitivas que codifican secuencias repetidas de aminoácidos ricas en prolina / alanina, que no pueden obtenerse directamente mediante métodos comunes de síntesis de genes.
Ejemplo 3: Análisis de repetibilidad de secuencias de nucleótidos que codifican secuencias repetidas de aminoácidos ricas en prolina / alanina
[0231] Se realizó un análisis de gráfico de puntos para diferentes secuencias de nucleótidos que codifican las secuencias repetidas de aminoácidos ricas en prolina / alanina PA # 3 (SEQ ID NO: 15) (Figura 2A) como se describe en WO 2011144756, PAS # 1 (SEQ ID NO: 11) (Figura 2B) como se describe en WO2008155134, al multímero [(AP)s]n (SEQ ID NO: 16) como se describe en WO2004094590, y una región repetitiva de secuencia de aminoácidos rica en prolina / alanina del gen de la proteína del tegumento muy grande de Herpesvirus macacino 1, publicado con el número de acceso de GenBank AAP41454.1 (SEQ ID NO: 18) (Figura 2C). El análisis se realizó alineando cada secuencia de nucleótidos consigo misma usando la herramienta de diagrama de puntos "dottup" del paquete de software Geneious versión 8.1 (Biomatters, Auckland, Nueva Zelanda) y aplicando una ventana de repetición de 14 o 15 nucleótidos. El algoritmo de este software se basa en la herramienta EMBOSS 6.5.7 disponible gratuitamente "dottup" (Sanger Institute, Cambridge, Reino Unido). Los gráficos de diagrama de puntos bidimensionales resultantes obtenidos para las secuencias de nucleótidos de la técnica anterior se compararon con los diagramas de puntos de las unidades de secuencia de nucleótidos de baja repetición PA # 3b (200) (SEQ ID NO: 36), PA # 1b (200) (SEQ ID NO : 28) y las secuencias de nucleótidos ensambladas PAS # 1f / 1c / 1b (600) (SEQ ID n O: 38) y pAs # 1d / 1f / 1c / 1b (800) (SEQ ID NO: 39) que codifican secuencias más largas repetidas de
aminoácidos ricas en prolina / alanina. Mientras que todas las secuencias de nucleótidos de la técnica anterior analizadas revelaron una naturaleza altamente repetitiva en el nivel de la secuencia de nucleótidos, como se ilustra con líneas diagonales negras (Fig. 2 A B C), los gráficos de puntos de las secuencias de nucleótidos optimizadas que codifican secuencias de repetición de aminoácidos ricas en prolina / alanina de acuerdo con esta invención mostraron solo unas pocas repeticiones de 14 nucleótidos (líneas negras) dispersas o cortas dentro de la secuencia de nucleótidos analizada completa de 600 nucleótidos del PA # Casetes 3b (200) y PA # 1b (200) (Fig. 2 A, C), el casete PAS # 1f / 1c / 1b (600) de 1800 nucleótidos (Figura 2B) o el casete PAS # 1d / 1f / 1c / 1b (800) de 2400 nucleótidos (Fig. 2 B).
Ejemplo 4: secuenciación de ADN de moléculas de ácido nucleico de baja repetición que codifican secuencias largas de repetición de aminoácidos ricas en prolina / alanina
[0232] El casete de ADN PAS # 1f / 1c / 1b (600) de baja repetición (SEQ ID NO: 38) clonado en el plásmido pXL2 y descrito en el Ejemplo 2 fue secuenciado por un proveedor de servicios de secuenciación de ADN (Eurofins Genomics, Ebersberg, Alemania) usando Secuenciación del ciclo Sanger en un instrumento ABI 3730XL (Thermo Fisher Scientific, Waltham, MA). Con este fin, 8 pl (150 ng / pl) de ADN plasmídico pXL2-PAS # 1f / 1c / 1b (600), aislado de células transformadas XL1-blue de E. coli usando el kit QIAprep Spin Miniprep (Qiagen, Hilden, Alemania) se mezcló con 5 pl de H2O doblemente destilada y 2 pl del cebador XLP-1 (10 pM) (Se Q ID NO: 3), que se hibrida dentro de la región codificante de la unidad de secuencia de nucleótidos PAS # 1b (200) y se envía al proveedor de servicios de secuenciación de ADN. Como resultado, se obtuvo un electroferograma sin errores que comprende más de 900 nucleótidos asignables (Fig. 3), que no mostró signos de unión de cebadores múltiples o inespecíficos. Por lo tanto, en contraste con las secuencias de nucleótidos repetitivas largas, que solo pueden secuenciarse parcialmente usando cebadores que hibridan con secuencias de nucleótidos del vector cadena arriba o cadena abajo del ADN clonado, las moléculas de ácido nucleico largas y de baja repetitividad de acuerdo con esta invención que codifican las secuencias repetidas de aminoácidos ricos en prolina / alanina se pueden secuenciar fácilmente también usando cebadores que hibridan internamente de forma específica, dentro de la secuencia de nucleótidos clonada. Esto permite múltiples lecturas de secuencias superpuestas usando diferentes cebadores adecuados, permitiendo así una cobertura de secuencia completa incluso de moléculas de ácido nucleico muy largas de acuerdo con la invención.
Ejemplo 5: Construcción de pASK75-PAS # 1f / 1c / 1b (600), un vector de expresión genéticamente estable para la producción bacteriana de la proteína de fusión terapéutica PAS # 1 (600) -IL1Ra
[0233] Para la construcción de un plásmido de expresión que codifica el antagonista del receptor de interleucina-1 (IL-1Ra) como fusión con una secuencia repetida de aminoácidos PAS # 1 de 600 residuos (SEQ ID NO: 38), el vector pASK75-IL1Ra (Fig. 4 A) (SEQ ID NO: 49) se cortó con SapI, desfosforiló con fosfatasa alcalina de camarón (Thermo Fisher Scientific, Waltham, MA) y ligado con un fragmento de ADN correspondiente al casete de secuencia de nucleótidos de baja repetición que codifica el polipéptido PAS # 1 de 600 residuos, que fue escindido del plásmido pXL2-PAS # 1f / 1c / 1b (600) por restricción digestiva con Earí. Después de la transformación de XL1-Azul E. coli (Bullock (1987) Biotechniques 5: 376-378), se preparó ADN plasmídico y se confirmó la presencia del fragmento de ADN insertado mediante análisis de restricción y secuenciación del ADN. El plásmido resultante se denominó pASK75-PAS # 1f / 1c / 1b (600) -IL1Ra (SEQ ID NO: 50) y se muestra en Fig. 4 B.
Ejemplo 6: Prueba de estabilidad genética a largo plazo de un plásmido que alberga una molécula de ácido nucleico de baja repetición que codifica una secuencia de repetición de aminoácidos rica en prolina / alanina [0234] La estabilidad genética del plásmido pASK75-PAS # 1f / 1c / 1b (600) -IL1Ra (SEQ ID NO: 50) se comparó con la estabilidad genética de pASK75-PAS # 1a (600) -IL1Ra (SEQ ID No : 51), un derivado en el que el casete de ADN PAS # 1f / 1c / 1b (600) fue sustituido por el ácido nucleico repetitivo PAS # 1a (600) (SEQ ID NO: 12). Para tal fin, E. coli KS272 (Strauch (1988) Proc. Natl. Acad. Sci. EE. UU. 85: 1576-1580) se transformó con el plásmido respectivo mediante el método del cloruro de calcio (Sambrook (2001) loc. cit.) y se cultivó durante 7 días a 37 ° C, 170 rpm, en 50 ml de medio Luria Bertani (LB) suplementado con 100 mg / ml ampicilina en un matraz de agitación de 100 ml sin inducción de la expresión génica. Durante este período, las células bacterianas se transfirieron dos veces al día (por la mañana y por la noche) a un medio fresco usando una dilución de 1: 1000. El día 7, después de un crecimiento continuo durante aproximadamente 70 generaciones, el cultivo finalmente se hizo crecer hasta la fase estacionaria y las células se sembraron en placas sobre agar LB / Amp. Luego, se seleccionaron clones individuales, se usaron para la inoculación de cultivos de 50 mL en medio LB y, después del crecimiento hasta la fase estacionaria durante la noche, se preparó el ADN plasmídico de cinco clones para cada uno de los dos plásmidos utilizando el kit Qiagen Miniprep (Qiagen, Hilden, Alemania) y analizado por una digestión de restricción XbaI/HindIII (Fig. 5).
[0235] Solo 1 de 5 clones analizados de pASK75-PAS # 1a (600) -IL1Ra mostró las bandas esperadas
correspondientes a 3093 pb y 2377 pb (Fig. 5, carril 1). Dos clones (Fig. 5, carriles 3 y 5) revelaron una banda a 573 pb, el tamaño aproximado de las secuencias de genes combinadas que codifican OmpA e IL1Ra, lo que indica una pérdida más o menos completa del casete de secuencia repetitiva PAS # la (600), posiblemente por recombinación. Otros dos clones mostraron fragmentos de ADN significativamente más cortos (Fig. 5, carriles 2 y 4), lo que también indica eventos de deleción dentro del casete repetitivo de secuencia PAS # 1a (600) y, por lo tanto, inestabilidad genética. En contraste, los cinco clones analizados de pASK75-PAS # 1f / 1c / 1b (600) -IL1Ra revelaron las bandas esperadas a 3093 pb y 2377 pb (Fig. 5, carriles 6-10), que indica un casete génico intacto que codifica secuencias repetidas de aminoácidos ricas en prolina / alanina y, por tanto, una alta estabilidad genética del plásmido de las moléculas de ácido nucleico de baja repetición según esta invención.
Ejemplo 7: Clonación directa y sin enlaces de una secuencia de nucleótidos de baja repetición que codifica secuencias repetidas de aminoácidos ricas en prolina / alanina en un plásmido de expresión que codifica la proteína biológicamente activa IL-1Ra.
[0236] Con el objetivo de una aplicación farmacéutica, se desean proteínas de fusión que comprendan únicamente la proteína biológicamente activa y una secuencia repetida de aminoácidos rica en prolina / alanina. La ausencia de enlazadores de aminoácidos adicionales, por ejemplo, introducidos con el fin de proporcionar o utilizar sitios de restricción para la clonación, puede prevenir respuestas inmunes potenciales durante el uso clínico y / o evitar interacciones no deseadas a nivel de proteína. Por lo tanto, se desarrolló una estrategia de clonación sin enlaces (Fig. 6) para la inserción dirigida de secuencias de nucleótidos de baja repetición, aquí ejemplificado para el fragmento de ADN que comprende PA # 1b (200) (SEQ ID NO: 28), en un derivado del plásmido de expresión genérico pASK75 (Skerra (1994) loc. cit.) que codifica la proteína biológicamente activa IL1-Ra (Molto (2010) Joint Bone Spine. 77: 102-107).
[0237] Al principio, se obtuvo un fragmento de ADN sintético que codifica la secuencia de aminoácidos madura de IL1-Ra (UniProt ID P18510) de un proveedor de síntesis de genes (Thermo Fisher Scientific, Regensburg, Alemania). Este fragmento de gen (SEQ ID NO: 46) comprendía un sitio de restricción XbaI, seguido de un sitio de unión ribosomal, la secuencia de nucleótidos que codifica el péptido señal OmpA, seguida de un codón de alanina GCC, una primera secuencia de reconocimiento SapI GCTCTTC en la hebra no codificante, un espaciador de dinucleótidos GC y una segunda secuencia de restricción SapI en orientación complementaria inversa, con su secuencia de reconocimiento GCTCTTC en la hebra codificante, seguida de un codón de alanina GCC directamente ligado a la secuencia codificante de IL1Ra madura (UniProt ID P18510), que finalmente fue seguida por un sitio de restricción HindIII.
[0238] Este fragmento de gen se clonó en pASk75 a través de los sitios de restricción flanqueantes Xbal y HindIII según procedimientos estándar (Sambrook (2001) loc. Cit.). El plásmido resultante (cf. Figura 6A) fue digerido con SapI, que condujo a la liberación de un inserto de ADN pequeño (24 pb) que contiene tanto los sitios de reconocimiento SapI como un esqueleto de vector escindido con extremos pegajosos 5'-GCC / 5'-GGC compatibles en la posición directamente en frente del extremo N-terminal maduro codificado de IL-1Ra, que es ideal para la inserción de la molécula de ácidos nucleicos de baja repetición que codifica la secuencia de repetición de aminoácidos rica en prolina / alanina (Figura 6B). Después del aislamiento del fragmento de vector utilizando el kit de extracción en gel QIAquick (Qiagen, Hilden, Alemania) y la desfosforilación con la fosfatasa alcalina termosensible FastAP (Thermo Fisher Scientific, Waltham, MA), ambos según las instrucciones del fabricante, se ligó con el casete de genes PA # 1b (200) escindido de pXL2-PA # 1b (200) (SEQ ID NO: 54) a través de una digestión de restricción Earl (Figura 6C). El plásmido resultante (SEQ ID NO: 56) permite la expresión bacteriana de una proteína de fusión (SEQ ID NO: 10) que consiste únicamente en una secuencia repetida de aminoácidos rica en prolina / alanina fusionada con la proteína biológicamente activa IL-1Ra (después del procesamiento in vivo del péptido señal OmpA tras la secreción periplásmica en E. coli).
Ejemplo 8: Producción y purificación bacteriana de una proteína de fusión entre la secuencia PAS # 1 (600) e IL-1Ra codificada en el plásmido genéticamente estable pASK75-PAS # 1f / 1c / 1b (600) -IL1Ra
[0239] La proteína de fusión PAS # 1 (600) -IL1-Ra (masa calculada: 68 kDa) se produjo a 25 ° C en E. coli KS272 que alberga el plásmido de expresión genéticamente estable pASK75-PAS # 1f / 1c / 1b (600) -IL1Ra del Ejemplo 6 y el plásmido auxiliar de plegado pTUM4 (Schlapschy (2006) Protein Eng. Des. Sel. 20: 273-284) utilizando un fermentador de mesa de 8 L con un medio mineral de glucosa sintético suplementado con 100 mg / L de ampicilina y 30 mg / L de cloranfenicol de acuerdo con un procedimiento publicado (Schiweck (1995) Proteins 23: 561-565). La expresión génica recombinante se indujo mediante la adición de 500 pg / L de anhidrotetraciclina (Skerra (1994) loc. Cit.) tan pronto como el cultivo alcanzó la DO.550 = 28. Después de un período de inducción de 2.5 h, las células se recolectaron por centrifugación y se resuspendieron durante 10 min en tampón de fraccionamiento periplásmico enfriado con hielo (sacarosa 500 mM, EDTA 1 mM, Tris / HCl 100 mM pH 8.0; 2 ml por L y OD550). Después de añadir EDTA 15 mM y 250 pg / ml de lisozima, la suspensión celular se incubó durante 20 min en hielo, se centrifugó varias veces y se recuperó el sobrenadante aclarado que contenía la proteína recombinante.
[0240] El extracto periplásmico se dializó cuatro veces a 4 °C frente a 5 L de fosfato de sodio 40 mM pH 7,5, NaCI 500 mM, respectivamente y se purificó mediante el His.6-tag con una columna HisTrap HP de 80 ml (GE Healthcare, Freiburg, Alemania). La proteína se eluyó con un gradiente de concentración de imidazol / HCl pH 7,5 de 0 a 200 mM en fosfato de sodio 40 mM pH 7,5, NaCl 0,5 M. La proteína purificada se recogió y se dializó dos veces frente a 5 l de Tris / HCl 20 mM pH 8,0, EDTA 1 mM a 4°C durante al menos 6 h, respectivamente. La solución de proteína dializada se sometió a cromatografía de intercambio aniónico utilizando una columna XK de 60 ml (GE Healthcare, Freiburg, Alemania) empaquetada con resina Source15Q, conectada a un sistema purificador Ákta (GE Healthcare, Freiburg, Alemania), utilizando Tris / HCl 20 mM pH 8,0, EDTA 1 mM como tampón de funcionamiento. La proteína se eluyó usando un gradiente de concentración de NaCl de 0 a 200 mM en tampón de ejecución.
[0241] Las fracciones eluidas se dializaron dos veces contra MES / HCl 10 mM pH 6,0, EDTA 1 mM a 4 °C durante al menos 6 h, respectivamente, y posteriormente se sometieron a una cromatografía de intercambio catiónico utilizando una columna XK empaquetada con 36 ml de resina Sourcel5S (GE Healthcare , Friburgo, Alemania). La cromatografía de intercambio catiónico se realizó en un sistema purificador Akta usando MES / HCl 10 mM pH 6,0, EDTA 1 mM como tampón de ejecución y un gradiente de concentración de NaCl de 0 a 500 mM en tampón de ejecución sobre 4 volúmenes de columna para eluir la proteína. Las fracciones de proteína eluidas que contenían PAS # 1 (600) -IL1-Ra se combinaron de nuevo, se dializaron contra 5 L de solución salina tamponada con fosfato (PBS: NaCl 115 mM, KH2PO44 mM y Na2HPO416 mM pH 7,4) a 4 °C durante la noche, concentrado a 5 mg / ml usando un dispositivo de filtro centrífugo Amicon Ultra (30000 MWCO; 15 ml; Millipore, Billerica, MA) y purificado adicionalmente mediante cromatografía de exclusión por tamaño usando una columna HiLoad 26/60 Superdex 200 prepgrade (GE Healthcare, Freiburg, Alemania) equilibrada con PBS.
[0242] Se obtuvo una preparación proteica homogénea sin signos de agregación con un rendimiento final de 70 mg de un fermentador de 8 L. La concentración de proteína se determinó midiendo la absorción a 280 nm usando un coeficiente de extinción calculado (Gill (1989) Anal. Biochem. 182: 319-326) de 15720 M-1 cm-1. SDS-PAGE se realizó utilizando un sistema tampón Tris de alta molaridad (Fling (1986) Anal. Biochem. 155: 83-88) (Fig. 7A).
Ejemplo 9: análisis ESI-MS de la proteína de fusión PAS # 1 (600) -ILIRa
[0243] PAS # 1 (600) -IL1Ra producido y purificado como se describe en el Ejemplo 8 se dializó dos veces contra un volumen de 1000 veces de acetato de amonio 10 mM pH 6,8 y se analizó mediante espectrometría de masas ESI en un instrumento Q-Tof Ultima (Waters, Eschbronn, Alemania) utilizando el modo de iones positivos. El espectro deconvolucionado de la proteína de fusión PA # 1 (600) -IL1Ra reveló una masa de 67994,8 Da, que esencialmente coincide con la masa calculada de 67994,8 Da (Figura 7B). Esto demuestra claramente que toda la proteína de fusión PA # 1 (600) -IL1Ra se puede producir de manera eficiente en E. coli utilizando el plásmido de expresión genéticamente estable pASK75-PAS # 1f / 1c / 1b (600) -IL1Ra.
Ejemplo 10: Construcción de pASK37-MP-PA # 1d / 1c / 1b (600), un plásmido genéticamente estable para la producción de un polipéptido repetido de aminoácidos rico en prolina / alanina en E. coli
[0244] Para la construcción de un plásmido de expresión estable que codifique el polipéptido PA # 1 (600) puro, 100 pmol de los cebadores NdeI-MP-SapI-HindIIIfW (SEQ ID NO: 4) y NdeI-MP-SapI-HindIIIrev (SEQ ID NO : 5) se fosforilaron, se mezclaron, se calentaron hasta 80 ° C durante 10 min y se enfriaron lentamente hasta temperatura ambiente durante la noche para permitir la hibridación. El fragmento de ADN bicatenario resultante exhibió extremos pegajosos compatibles con salientes Ndel y HindlIl. El plásmido pASK37 (Skerra (1991) loc. Cit) se cortó con Ndel y HindlII y el fragmento de la cadena principal se ligó con los cebadores hibridados.
[0245] El plásmido resultante se digirió con SapI, que condujo a la liberación de un pequeño inserto (24 pb) que contiene dos sitios de reconocimiento SapI y un esqueleto de vector escindido con extremos pegajosos 5'-GCC / 5'-GGC compatibles. Estos extremos pegajosos son ideales para la inserción de la secuencia de nucleótidos repetitiva baja que codifica la secuencia de repetición de aminoácidos rica en prolina / alanina en la posición directamente cadena abajo del codón de metionina de inicio N-terminal (ATG) seguido por el codón de prolina CCA, que se encontró que permite una iniciación traslacional eficiente. Después del aislamiento del fragmento de vector utilizando el kit de extracción en gel QIAquick y la desfosforilación con la fosfatasa alcalina termosensible FastAP de acuerdo con las instrucciones del fabricante, se ligó con el casete de genes de baja repetición PA # 1d / 1c / 1b (600) (SEQ ID NO: 42) extirpado de pXL2-PA # 1d / 1c / 1b (600) a través de digestión de restricción Earl. El plásmido resultante (SEQ ID NO: 53) permite la expresión de un polipéptido que comprende únicamente una secuencia de repetición de aminoácidos rica en prolina / alanina (Figura 8A).
Ejemplo 11: Expresión bacteriana y purificación de un polipéptido PA # 1 (600) codificado en el plásmido genéticamente estable pASK37-MP-PA # 1d / 1c / 1b (600)
[0246] El polipéptido PA # 1 (600), con un residuo Pro adicional en el extremo N-terminal y un residuo Ala adicional en el extremo terminal C (masa calculada: 48302 Da), se produjo en el citoplasma de E. coli KS272 que alberga el plásmido de expresión pASK37-PA # 1d / 1c / 1b (600) descrito en el Ejemplo 10. 4 ml de medio LB en un tubo estéril de polipropileno de 13 ml (Sarstedt, Nümbrecht, Alemania), sustituido con glucosa al 1% p / v y 100 mg / L de ampicilina, se inocularon con una colonia de E. coli KS272 transformada con pASK37-PA # 1d / 1c / 1b (600) y se hizo crecer durante la noche a 37°C, 170 rpm. La producción de proteína bacteriana se realizó a 30 °C en un matraz de agitación de 5 L con 2 L de medio Terrific Broth (TB) (Sambrook (2001) loc. Cit.) Suplementado con 2.5 g / L de D-glucosa y 100 mg / L de ampicilina.
[0247] Los cultivos E. coli se inocularon con 2 ml de cultivo durante la noche, las células se cultivaron durante la noche y la expresión génica recombinante se indujo a DO.550 = 5 mediante la adición de isopropil-p-D-tiogalactopiranósido (IPTG) hasta una concentración final de 0,5 mM. Las bacterias se recogieron 3 h después de la inducción, se resuspendieron en 20 ml de fosfato de sodio 40 mM pH 7,2, EDTA 1 mM y se lisaron usando una celda de presión French (Thermo Scientific, Waltham, MA). Después de la centrifugación (17.000 rpm, 1 h, 4 ° C) del lisado, no se observaron cuerpos de inclusión. El sobrenadante que contiene el polipéptido soluble PA # 1 (600) se sometió a una precipitación con sulfato de amonio mediante la adición gradual de (NH4)2SO4 sólido hasta una concentración final del 20% p / v con agitación continua a temperatura ambiente. El sobrenadante se centrifugó a 17.000 rpm a temperatura ambiente durante 20 min. El sedimento que contenía el polipéptido PA # 1 (600) precipitado se disolvió en Tris / HCl 20 mM pH 8,0 y la solución se centrifugó (13.000 rpm, 10 min, temperatura ambiente) para eliminar los contaminantes insolubles.
[0248] Se añadió ácido acético puro (Sigma-Aldrich, Steinheim, Alemania) hasta una concentración final del 1% v / v y se sedimentaron las impurezas mediante centrifugación a 13.000 rpm durante 10 min. El sobrenadante que contenía el polipéptido PA # 1 (600) casi puro se dializó frente a un volumen de 100 veces de ácido acético al 1% v / v durante la noche a 4 °C. Para eliminar las impurezas residuales, la proteína dializada se sometió a una cromatografía de intercambio catiónico sustractivo utilizando una columna Source15S de 1 ml (GE Healthcare, Freiburg, Alemania) conectada a un sistema purificador Akta utilizando ácido acético al 1% v / v como tampón de elución.
[0249] Las muestras de cada paso de purificación se analizaron mediante SDS-PAGE usando un sistema de tampón Tris de alta molaridad (Fling (1986) loc. Cit.). Después de SDS-PAGE, el gel se tiñó primero con yoduro de bario como se describe para el análisis de PEG (Kurfurst (1992) Anal. Biochem. 200: 244-248). Brevemente, el gel de poliacrilamida se enjuagó con agua y luego se incubó en una solución en agua de Bal22,5% p / v (yoduro de bario dihidrato; Sigma-Aldrich, Steinheim, Alemania) durante 5 min. Después de enjuagar con agua, el gel se transfirió a una solución de Lugol (10% p / v p.a. grado KI (AppliChem, Darmstadt, Alemania) 5% p.a. grado I2 (Riedel de Haen AG, Seelze, Alemania) en agua) durante 5 min. Después de decolorarse en ácido acético al 10% v / v, las bandas de polipéptido naranja PA # 1 (600) se hicieron visibles (Figura 8B). Posteriormente, el gel se destiñó con agua y se sometió a una segunda tinción con azul brillante de Coomassie R250 (Applichem), disuelto en ácido acético al 10% (Honeywell Specialty Chemicals, Seelze, Alemania), 65% H2O e isopropanol al 25% (CLN, Niederhummel, Alemania). Después de decolorarse en ácido acético al 10% v / v, las bandas de proteína azul (para las proteínas de la célula huésped) se hicieron visibles (Fig. 8C).
Ejemplo 12: análisis ESI-MS de un polipéptido PA # 1 (600) puro
[0250] 200|jl del polipéptido PA # 1 (600) aislado del Ejemplo 11 a una concentración de 5 mg / ml se aplicó a una columna Resource RPC de 1 ml (GE Healthcare, Freiburg, Alemania) conectada a un sistema purificador Ákta usando 2% v / v acetonitrilo, ácido fórmico al 1% v / v como tampón de funcionamiento. La proteína se eluyó usando un gradiente de acetonitrilo desde acetonitrilo al 2% v / v, ácido fórmico al 1% v / v hasta acetonitrilo al 80% v / v, ácido fórmico al 0,1% v / v en 20 volúmenes de columna. La proteína eluida se analizó directamente mediante espectrometría de masas ESI en un instrumento Q-Tof Ultima utilizando el modo de iones positivos. El espectro deconvolucionado del polipéptido PA # 1 (600) reveló una masa de 48301.78 Da, que esencialmente coincide con la masa calculada del polipéptido PA # 1 (600), con un residuo Pro adicional en el extremo N-terminal y un Ala adicional residuo en el extremo C-terminal pero desprovisto de la metionina inicial (48301,4 Da) (Fig. 8D). Esto demuestra claramente que un polipéptido PA # 1 (600) puro (sin una etiqueta de afinidad), codificado por una secuencia de nucleótidos genéticamente estable, se puede producir en E. coli en su forma intacta.
Ejemplo 13: Análisis repetido de secuencias de nucleótidos que codifican secuencias de aminoácidos ricas en prolina / alanina
[0251] Como medida para evaluar la calidad de las moléculas de ácido nucleico que codifican secuencias ricas en prolina / alanina con respecto a la frecuencia (ocurrencia) de las repeticiones de secuencias de nucleótidos, hemos diseñado la puntuación de repetición de nucleótidos (NRS), que se calcula de acuerdo con la siguiente fórmula:

[0252] En esta fórmula, Ntot es la longitud total de la secuencia de nucleótidos analizada, n es la longitud de una secuencia repetida dentro de la secuencia de nucleótidos analizada y la frecuencia fi(n) es el número de apariciones de esta secuencia repetida. En caso de que haya varias repeticiones de secuencia diferentes con la misma longitud n, estas repeticiones de secuencia diferentes se distinguen por el índice i y el número de repeticiones de secuencia diferentes con la misma longitud n es k(n). Si solo hay un tipo de repetición de secuencia con longitud n, k (n) es igual a 1. El NRS se define como la suma de la longitud de repetición al cuadrado multiplicada por la raíz de la frecuencia total respectiva, dividida por la longitud total de la secuencia de nucleótidos analizada. La longitud mínima de repetición considerada para el cálculo de NRS comprende 4 nucleótidos, que incluye todas las secuencias de nucleótidos más largas que un triplete de codones, y varía hasta Ntot-1, que es la longitud de la secuencia de nucleótidos repetida más larga que puede ocurrir más de una vez en la secuencia de nucleótidos analizada.
[0253] En este contexto, el término repetición significa que una secuencia de nucleótidos aparece al menos dos veces dentro de la secuencia de nucleótidos analizada. Al contar las frecuencias, hemos considerado ambos tramos de nucleótidos con secuencia idéntica que ocurren al menos dos veces, así como secuencias diferentes de la misma longitud que también ocurren al menos dos veces. Por ejemplo, si la frecuencia total de una repetición de 14meros es cinco, esto puede significar que el mismo tramo de nucleótidos de 14meros ocurre 5 veces, o una secuencia de nucleótidos de 14meros ocurre dos veces y una secuencia de 14 nucleótidos diferente ocurre tres veces en la secuencia de nucleótidos analizada.
[0254] Además, cada repetición más corta contenida dentro de una repetición de secuencia de nucleótidos más larga se cuenta por separado. Por ejemplo, si la secuencia de nucleótidos analizada contiene dos tramos de nucleótidos de GCACC (es decir, repeticiones), las repeticiones de GCAC y CACC también se cuentan individualmente, independientemente de si ocurren dentro de dicho tramo de nucleótidos de GCACC o, posiblemente, además en otro lugar dentro de la secuencia de nucleótidos analizada. Es de destacar que solo se consideran las repeticiones en la cadena codificante de la molécula de ácido nucleico.
[0255] Una persona experta en la técnica puede identificar repeticiones de secuencias de nucleótidos manualmente o con la ayuda de programas de software genéricos tales como Visual Gene Developer (Jung (2011) loc. Cit.), Disponible para su descarga en http: //www.visualgenedeveloper.net, o la herramienta Repfind (Betley (2002) loc. cit), disponible en http://zlab.bu.edu/repfind. Sin embargo, no todos los algoritmos detectan cada tipo de repetición, por ejemplo, el resultado del Visual Gene Developer no incluye repeticiones superpuestas. Por lo tanto, los resultados de las herramientas de software deben verificarse y, si es necesario, corregirse manualmente. Alternativamente, el algoritmo denominado NRS-Calculator descrito en el Ejemplo 14 puede usarse para identificar sin ambigüedades las repeticiones de secuencias de nucleótidos y para calcular el NRS automáticamente.
[0256] Se conocen en la técnica ácidos nucleicos naturales así como ciertos sintéticos que codifican secuencias de aminoácidos ricas en prolina / alanina. Sin embargo, todas esas secuencias son altamente repetitivas a nivel genético, como se hace claramente evidente a partir del análisis NRS que se describe a continuación y, por lo tanto, su uso para aplicaciones biotecnológicas y / o biofarmacéuticas es limitado.
[0257] Varias secuencias de nucleótidos de la técnica anterior que codifican secuencias de aminoácidos ricas en prolina / alanina se compararon con moléculas de ácido nucleico de baja repetición que codifican secuencias repetidas de aminoácidos ricas en prolina / alanina de acuerdo con esta invención utilizando la calculadora NRS descrita en el Ejemplo 14: la secuencia de nucleótidos PAS # 1a (200) (SEQ ID NO: 11) divulgada en WO 2008/155134 (Figura 9A), la secuencia de nucleótidos PA # la (200) (SEQ ID NO: 14) descrita en WO2011144756 (Figura 9B), la secuencia de nucleótidos que codifica un Glicomódulo [(AP)5]20APA (SEQ ID NO: 16) divulgado en US 20060252120 (Figura 9C), la secuencia de nucleótidos de una construcción genética sintética que codifica el glicomódulo [AAPAPAPAP]™AS (SEQ ID NO: 17) publicado con el número de acceso de GenBank DQ399411.1 (Figura 9D), la secuencia de 225 nucleótidos que codifica una secuencia rica en prolina / alanina dentro de la proteína de tegumento grande del virus del herpes macacino 1 (SEQ ID NO: 18) publicada con el número de acceso de GenBank NP_851896 (Figura 9E), la secuencia de nucleótidos de baja repetición PAS # lb (200) (SEQ ID NO: 19) de acuerdo con esta invención (Figura 9F,G) y la secuencia de nucleótidos de baja repetición PA # 1e / 1d / 1c / 1b (800) (SEQ ID NO: 44) de acuerdo con esta invención (Figura 9H,I).
[0258] Las frecuencias de repetición calculadas se trazaron frente a la longitud de repetición respectiva utilizando el software Kaleidagraph V3.6 (Synergy Software, Reading, PA) (Fig. 9). Todos los histogramas de las secuencias de nucleótidos de la técnica anterior revelan una naturaleza altamente repetitiva, como se ilustra por un gran número de barras altas con una amplia distribución de longitudes de repetición, hasta repeticiones muy largas. En particular, en estos casos, la frecuencia de repetición disminuye solo lentamente al aumentar la longitud de repetición (Figura 9A-E). Por el contrario, los histogramas de las secuencias de nucleótidos de baja repetición PAS # 1b (200) y PA # 1e / 1d / 1c / 1b (800) según esta invención muestran solo unas pocas repeticiones con una longitud máxima de 14
nucleótidos, cuyas frecuencias disminuyen rápidamente a cero al pasar de repeticiones más cortas a más largas (Figura 9F, G, H, I).
[0259] La diferencia en la repetitividad entre las secuencias de nucleótidos de la técnica anterior y las secuencias de nucleótidos de baja repetición de la invención resulta incluso más evidente cuando se comparan sus puntuaciones de repetición de nucleótidos. Mientras que todas las secuencias de la técnica anterior revelan un NRS por encima de 80000 (Tabla 2), la secuencia de 600 nucleótidos PAS # 1b (200) y la secuencia de 2400 nucleótidos PA # 1e / 1d / 1c / 1b (800) muestran valores de NRS de solo 13 y 14, respectivamente (Tabla 1). Esto demuestra claramente que la calidad de repetición de las secuencias de nucleótidos de baja repetición que codifican secuencias de repetición de aminoácidos ricas en prolina / alanina de acuerdo con esta invención es mucho mayor en comparación con las secuencias de la técnica anterior, con menos repeticiones de secuencias de nucleótidos y más cortas.
Tabla 1: Características de las moléculas de ácido nucleico según esta invención.














Secuencia de nucleótidos SEQ Optimización de Repetición de aminoácidos Nm ax Nto t NRS de baja repetición núm. ID: codones para: codificados

A: unidades de secuencia de nucleótidos (bloques de construcción)
169 PAS # 1ao (200) 194 E. coli ASPAAP APASP 211
APAPSAPA



170 PAS # 1ap (200) 195 E. coli ASPAAP APASP 105
APAPSAPA


B: secuencias ensambladas de nucleótidos de baja repetición





Tabla 2: Características de las secuencias de nucleótidos de la técnica anterior

Ejemplo 14: NRS-Calculator, un algoritmo para identificar sin ambigüedades las repeticiones de secuencias de nucleótidos y calcular la puntuación de repetición de nucleótidos
[0260] Los programas de software generalmente disponibles como Visual Gene Developer (Jung (2011) loc. Cit) o la herramienta Repfind (Betley (2002) loc. Cit) no siempre funcionan de manera confiable y pueden requerir correcciones manuales para calcular todas las repeticiones de secuencia dentro de una secuencia de nucleótidos analizada correctamente. Además, las repeticiones deben contarse manualmente y el NRS debe calcularse por separado de acuerdo con la fórmula descrita en el Ejemplo 13. Para proporcionar un algoritmo que arroje resultados inequívocos y para facilitar el cálculo del NRS, se describe aquí un simple script de Python denominado NRS-Calculator. Este script, ejecutado en el entorno de ejecución Python 2.7.10 (http://www.python.org), se basa en una comparación de secuencia de matriz de puntos e identifica todas las repeticiones hacia delante dentro de una secuencia de nucleótidos potencialmente larga, incluidas las repeticiones superpuestas, sin considerar huecos. La comparación de secuencias de matriz de puntos es un método bien conocido por una persona experta en la técnica y se describe en libros de texto de bioinformática comunes tales como, por ejemplo, Mount (2004) Bioinformatics: Sequence and Genome Analysis, Cold Spring Harbor Laboratory Press, segunda edición, Nueva York.
[0261] NRS-Calculator cuenta las frecuencias para cada longitud de repetición y calcula automáticamente el NRS de acuerdo con la fórmula descrita en el Ejemplo 13. Para ejecutar el script NRS-Calculator, el entorno de ejecución Python versión 2.7.10 se descargó de https: //www.python. org / downloads e instalado en un portátil ThinkPad L530 (Lenovo, Stuttgart, Alemania) con un sistema operativo Windows 7. La secuencia de comandos NRS-Calculator que
se muestra a continuación se guardó como un archivo de texto sin formato designado NRScalculator.py y utilizando Microsoft Windows Editor Versión 6.1. La secuencia de nucleótidos a analizar se guardó como archivo FASTA llamado sequence.fas dentro de la misma carpeta. Posteriormente, se abrió el shell de la línea de comandos y se seleccionó el directorio que contiene tanto el archivo NRScalculator.py como el archivo sequence.fas. Para iniciar el cálculo, se ejecutó la siguiente línea de comando:
c: \ user \ admin \ NRSfolder> c: \ Python27 \ python.exe NRScalculator.py sequence.fas
[0262] Este comando dio como resultado una salida de pantalla de dos filas: la fila de la izquierda que indica la longitud de repetición (Longitud) y la fila de la derecha (segunda) que indica la frecuencia de repetición respectiva (Frecuencia). Además, Nto y NRS (número redondeado como entero) se indicaron al principio y al final de la salida, respectivamente.
Secuencia de comandos de NRS-Calculator:

def print_repeats(self):
print ('Sequence (Length bp) : NumRepeats (Positions)')
for seq, repeats in aorted(self.repeats.iteritems(), key=lambda t : len (t[0])):
list = [seq, len(seq), len(repeats)] list.extend(map(lambda valué: valué 1, sorted(repeats)))
print('%s Ntot = %u : %u (%s)' % (seq, len(seq), len (repeats), ', join(map(lambda valué: str(valué 1), sorted(repeats)))))
def print sums(self):
print('LengthXtFrequency')
for Ítem in self.sums.iteritems():
print('%u\t%u' % Ítem)
def print score(self):
sum = 0
for length, count in self.sums.iteritems():
sum = (length ** 2) * math.sqrt(count) print('NRS = %.0f' t (sum / len(self.seq)))
def handle sequence(finder, ñame, sequence):
finder.set range(4 , len(sequence)) finder.set_sequence(sequence)
finder .work.()
print('%3: Ntot = %u' % (ñame, len(sequence))) #finder.print repeats()
finder.print sums ()
finder.print_score()
if len(sys.argv) !— 2:
print('üsage: %s FILENAME' % sys.argv[0])
sys.exit(1)
finder = NRSCalculator()
with open(sys.argv[1], 'r') as infile:
ñame = 'Unnamed'
seq =
' '
for line in infile:
line = line.strip()
if line.startswith('>'):
if len(seq) > 0:
handle_sequence(finder, ñame, seq) ñame = line
seq =
' '
continué
seq = line.upper()
handle_sequence(finder, ñame, seq)
Salida ejemplar de NRS-Calculator:
[0264] > PAS # 1b (200): Ntot = 600
Largo Frecuencia
4 587
5 547
6 478
7 388
8 281
9 158
10 90
11 45
12 6
13 4
14 2
NRS = 13
Ejemplo 15: Construcción de pASK75-PA # 1d / 1c / 1b (600) -ILIRa, un vector de expresión genéticamente estable para la producción bacteriana de una proteína de fusión PA # 1 (600) -IL1Ra terapéutica
[0265] Para la construcción de un plásmido de expresión que codifica el antagonista del receptor de interleucina-1 (IL-1Ra) como fusión con una secuencia repetida de aminoácidos PA # 1 de 600 residuos, el vector pASK75-IL1Ra (Figura 4 A) (SEQ ID NO: 49) se cortó con SapI, desfosforiló con fosfatasa alcalina de camarón (Thermo Fisher Scientific, Waltham, MA) y ligó con un fragmento de ADN correspondiente al casete de secuencia de nucleótidos de baja repetición que codifica el polipéptido PA # 1 de 600 residuos, que fue escindido del plásmido pXL1-PA # 1d / 1c / 1b (600) (SEQ ID NO: 79) por digestión de restricción con SapI. Después de la transformación de E. coli XL1-Blue (Bullock (1987) loc. Cit.), se preparó ADN plasmídico y se confirmó la presencia del fragmento de ADN insertado mediante análisis de restricción y secuenciación de ADN. El plásmido resultante se denominó pASK75-PA # 1d / 1c / 1b (600) -IL1Ra (SEQ ID NO: 77) y se muestra en Fig. 10.
Ejemplo 16: Prueba de estabilidad genética a largo plazo del plásmido pASK75-PA # 1b / 1c / 1b (600) -IL1Ra que alberga la molécula de ácido nucleico de baja repetición PA # 1d / 1c / 1b (600) que codifica una secuencia de repetición de aminoácidos rica en prolina / alanina.
[0266] La estabilidad genética del plásmido pASK75-PA # 1d / 1c / 1b (600) -IL1Ra (SEQ ID NO: 77) se comparó con la estabilidad genética de pASK75-PA # 1a (600) -IL1Ra (SEQ ID NO: 78), un derivado en el que el casete de ADN PA # 1d / 1c / 1b (600) fue reemplazado por el ácido nucleico repetitivo Pa # 1a (600) (SEQ ID NO: 80). Para tal fin, E. coli JM83 (Yanisch-Perron C. (1985) loc. Cit.) se transformó con el plásmido respectivo usando el método del cloruro de calcio (Sambrook (2001) loc. Cit.) y se cultivó durante 7 días a 37 °C, 170 rpm, en 50 ml de medio Luria Bertani (LB) suplementado con 100 mg / L de ampicilina en un matraz de agitación de 100 ml sin inducción de la expresión génica. Durante este período, las células bacterianas se transfirieron dos veces al día (por la mañana y por la noche) a un medio fresco usando una dilución de 1:1000. El día 7, después de un crecimiento continuo durante aproximadamente 70 generaciones, el cultivo finalmente se hizo crecer hasta la fase estacionaria y las células se sembraron en placas sobre agar LB / Amp. Después, se seleccionaron diez colonias individuales para cada uno de los dos plásmidos, cada una utilizada para la inoculación de un cultivo de 50 ml en medio LB / Amp y, después del crecimiento hasta la fase estacionaria durante la noche, se preparó el ADN plasmídico utilizando el Kit Qiagen Miniprep (Qiagen, Hilden, Alemania) y analizado a través de digestión de restricción XbaI/HindIII (Fig. 11).
[0267] Solo 6 de los 10 clones analizados de pASK75-PA # 1a (600) -IL1Ra mostraron las bandas esperadas correspondientes a 3093 pb y 2377 pb (Fig. 11 A, carriles 1,3, 4, 5, 7 y 8). Cuatro clones mostraron fragmentos de ADN significativamente más cortos. (Fig. 11 A, carriles 2, 6, 9 y 10), indicando deleciones dentro del casete repetitivo de secuencia PA # la (600) y, por tanto, inestabilidad genética. En contraste, los diez clones analizados de
pASK75-PA # 1d / 1c / 1b (600) -ILIRa revelaron las bandas esperadas a 3093 pb y 2377 pb (Fig. 11 B, carriles 1 10), indicando un casete génico intacto que codifica secuencias repetidas de aminoácidos ricos en prolina / alanina y, por tanto, alta estabilidad genética del plásmido de la molécula de ácido nucleico de baja repetición según esta invención.
Ejemplo 17: Construcción de vectores de expresión genéticamente estables para la producción bacteriana de leptina humana fusionada con secuencias repetidas de aminoácidos ricas en prolina / alanina.
[0268] Para la construcción de un plásmido de expresión que codifica leptina humana (huLeptin) fusionada en el extremo N-terminal con una secuencia repetida de aminoácidos PA # 1 de 600 residuos (SEQ ID NO: 82), el vector pASK37-MP-huLeptin (Figura 12 A) (SEQ ID NO: 81) se cortó con SapI, lo que condujo a la escisión de un inserto de ADN pequeño (24 pb) que contenía tanto sitios de reconocimiento SapI como un esqueleto de vector escindido con extremos pegajosos 5'-GCC / 5'-GGC compatibles en la posición directamente cadena arriba del extremo N-terminal maduro codificado de leptina humana. Estos extremos pegajosos son ideales para la inserción de la secuencia de nucleótidos de baja repetitividad que codifica la secuencia de repetición de aminoácidos rica en prolina / alanina en la posición directamente cadena abajo del codón de metionina de inicio N-terminal (ATG) seguido por el codón de prolina CCA, que fue encontrado para permitir una iniciación traslacional eficiente. Después del aislamiento del fragmento de vector utilizando el kit de extracción en gel QIAquick (Qiagen, Hilden, Alemania) y la desfosforilación con la fosfatasa alcalina termosensible FastAP (Thermo Fisher Scientific, Waltham, MA), ambos según las instrucciones de los fabricantes, el plásmido se ligó con un fragmento de ADN correspondiente al casete de secuencia de nucleótidos de baja repetición que codifica el polipéptido PA # 1 de 600 residuos, que se escindió del plásmido pXL1-PA # 1d / 1c / 1b (600) (SEQ ID NO: 79) mediante digestión de restricción con SapI. Después de la transformación de E. coli XL1-Blue (Bullock (1987) loc. Cit ), se preparó ADN plasmídico y se confirmó la presencia del fragmento de ADN insertado mediante análisis de restricción y secuenciación de ADN. El plásmido resultante se denominó pASK37-MP-PA # 1d / 1c / 1b (600) -huLeptin (SeQ ID NO: 82) y se representa en Fig. 12 B. De la misma manera, pASK37-MP-PAS # 1f / 1c / 1b (600) -huLeptin (SEQ ID NO: 83), un plásmido de expresión que codifica la leptina humana (huLeptin) N-terminalmente fusionado con una secuencia de repetición PAS # 1 de 600 residuos de aminoácidos que se muestra en Fig. 12 C, se construyó mediante la inserción de la secuencia de nucleótidos de baja repetición Pa S # 1f / 1c / 1b (SEQ ID No: 38) escindida de pXL1-PAS # 1f / 1c / 1b (SEQ ID No: 84) en el plásmido pASK37-MP-huLeptin (Figura 12 A) (SEQ ID NO: 81). Se puede aplicar una estrategia de clonación similar para construir versiones de leptina con secuencias de repetición de aminoácidos ricas en prolina / alanina fusionadas en el extremo C-terminal.
Ejemplo 18: Producción, purificación y caracterización bacteriana de una proteína de fusión entre una secuencia repetida de aminoácidos rica en prolina / alanina y un mutante de leptina humana codificada en el plásmido pASK37-PA # 1d / 1c / 1b (600) hu-Leptina genéticamente estable (W100Q)
[0269] PA # 1 (600) -huLeptin (W100Q) una proteína de fusión entre un mutante de leptina humana con una sustitución de triptófano a glutamina en la posición 100 de la secuencia de aminoácidos maduros (código de acceso UniProtKB P41159) y la secuencia de repetición de aminoácidos ricos en prolina / alanina PA # 1 (600) (SEQ ID NO: 85) (masa calculada: 64,25 kDa) se produjo a 30 °C en el citoplasma de Origami B (Novagene / Merck Millipore, Billerica, MA), una cepa de E. coli que tiene un citoplasma oxidante debido a mutaciones trxB, gor y ahpC (Bessette (1999) Proc. Natl. Acad. Sci. Estados Unidos 96: 13703-13708). Para ello, se inocularon 4 ml de medio LB en un tubo estéril de polipropileno de 13 ml (Sarstedt, Nümbrecht, Alemania), suplementado con D-glucosa al 1% p / v y 100 mg / L de ampicilina, con una colonia de E. coli Origami B transformada con el plásmido de expresión genéticamente estable pASK37-MP-PA # 1d /1 c /1 b (600) -huLep (W100Q) (SEQ ID NO: 86). Las células bacterianas se cultivaron durante la noche a 30 °C en un agitador a 170 rpm.
[0270] La producción de proteína bacteriana se realizó a 30 °C en un matraz deflector de 5 L con 2 L de medio Terrific Broth (TB) (Sambrook (2001) loc. Cit.) suplementado con 2.5 g / L de D-glucosa y 100 mg / L de ampicilina, que se inoculó con 2 ml del cultivo de E. coli de la noche a la mañana. Las células bacterianas se cultivaron a 30 °C y la expresión génica recombinante se indujo a OD550 = 0,85 mediante la adición de isopropil-p-D-tiogalactopiranósido (IPTG) hasta una concentración final de 0,5 mM. Las bacterias se recolectaron 19 h después de la inducción, se resuspendieron en 3 ml de PBS / E (PBS suplementado con EDTA 10 mM) por 1 g de peso húmedo de células bacterianas y se lisaron usando un homogeneizador de células Panda (GEA, Parma, Italia). Después de la centrifugación (20.000 rpm, 30 min, 4 °C) del lisado, no se observaron cuerpos de inclusión. Se añadió 2,2'-ditiodipiridina 1 mM al sobrenadante para estimular la formación de puentes disulfuro en la leptina recombinante. El sobrenadante que contenía la proteína de fusión de leptina soluble se dializó durante la noche a 4 °C frente a un volumen de 100 veces de PBS. Posteriormente, la proteína de fusión se precipitó a temperatura ambiente mediante la adición gota a gota de (NH4)2SO44 M (disuelto en agua) bajo agitación continua hasta que una concentración final de 1 M (NH4)2SO4fue alcanzada. Después de centrifugar durante 20 min a 17.000 rpm a temperatura ambiente, el sedimento que contenía la proteína de fusión PA # 1 (600) -hu-leptina (W100 / Q) precipitada se disolvió en PBS y la solución se centrifugó (13.000 rpm, 10 min, ambiente temperatura) para eliminar los contaminantes insolubles.
Claims (23)
1. Una molécula de ácido nucleico, en la que dicha molécula de ácido nucleico comprende una secuencia de nucleótidos que codifica un polipéptido que consta de al menos 100 residuos de aminoácidos de prolina, alanina y, opcionalmente, serina,
donde dicho polipéptido forma un enrollado aleatorio, donde la secuencia de nucleótidos de dicho ácido nucleico tiene una longitud de al menos 300 nucleótidos,
en el que dicha secuencia de nucleótidos tiene una puntuación de repetición de nucleótidos (NRS) inferior a 1000, donde dicha puntuación de repetición de nucleótidos (NRS) se determina de acuerdo con la fórmula:
donde
Ntot es la longitud de dicha secuencia de nucleótidos,
n es la longitud de una repetición dentro de dicha secuencia de nucleótidos, y
fi(n) es la frecuencia de dicha repetición de longitud n,
donde si hay más de una repetición de longitud n, k(n) es el número de dichas secuencias diferentes de dicha repetición de longitud n, de otro modo k(n) es 1 para dicha repetición de longitud n.
2. Molécula de ácido nucleico según la reivindicación 1, en la que dicho polipéptido codificado consiste en prolina y alanina.
3. Molécula de ácido nucleico según la reivindicación 2, en la que dichos residuos de prolina constituyen más de aproximadamente el 10% y menos de aproximadamente el 75% de dicho polipéptido codificado.
4. Molécula de ácido nucleico según la reivindicación 1, en la que dicho polipéptido codificado consiste en prolina, alanina y serina.
5. Molécula de ácido nucleico según la reivindicación 4, en la que dichos residuos de prolina constituyen más del 4% y menos del 40% de dicho polipéptido codificado.
6. Molécula de ácido nucleico según cualquiera de las reivindicaciones 1 a 5, en la que dicha puntuación de repetición de nucleótidos (NRS) es inferior a 100, inferior a 50 o inferior a 35.
7. Molécula de ácido nucleico según cualquiera de las reivindicaciones 1 a 6, en la que la secuencia de nucleótidos de dicho ácido nucleico tiene una longitud de al menos 900 nucleótidos.
8. Molécula de ácido nucleico según cualquiera de las reivindicaciones 1 a 7, en la que dicha molécula de ácido nucleico tiene una estabilidad genética mejorada.
9. Molécula de ácido nucleico según cualquiera de las reivindicaciones 1 a 8, en la que dicha secuencia de nucleótidos comprende dichas repeticiones, en la que dichas repeticiones tienen una longitud máxima nmax, donde nmax se determina según la fórmula:
n
N
max sí17 h— 60 — 0
y donde Ntot es la longitud de dicha secuencia de nucleótidos.
10. Molécula de ácido nucleico según cualquiera de las reivindicaciones 1 a 9, en la que dichas repeticiones tienen una longitud máxima de aproximadamente 14, 15, 16 o 17 nucleótidos a aproximadamente 55 nucleótidos.
11. La molécula de ácido nucleico según cualquiera de las reivindicaciones 1 a 10, en la que dicho polipéptido codificado comprende una secuencia de aminoácidos repetitiva con una pluralidad de repeticiones de aminoácidos, en la que no más de 9 residuos de aminoácidos consecutivos son idénticos y en la que dicho polipéptido forma un
enrollado aleatorio.
12. La molécula de ácido nucleico según una cualquiera de las reivindicaciones 1 a 3 y 6 a 11, en la que dicha molécula de ácido nucleico se selecciona del grupo que consiste en:
(a) la molécula de ácido nucleico que comprende al menos una secuencia de nucleótidos seleccionada del grupo que consiste en SEQ ID NO: 28, SEQ ID NO: 29, SEQ ID NO: 30, SEQ ID NO: 31, 32, SEQ ID NO: 33, SEQ ID NO: 34, SEQ ID NO: 35, SEQ ID NO: 36, SEQ ID NO: 37, SEQ ID NO: 87, 88, SEQ ID NO: 89, SEQ ID NO : 90, SEQ ID NO: 91, SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 94, 95, SEQ ID NO: 96, SEQ ID NO: 97, SEQ ID NO: 98 , SEQ ID NO: 99, SEQ ID NO: 100, SEQ ID NO: 101 SEQ ID NO: 103, SEQ ID NO: 104, SEQ ID NO: 105, SEQ ID NO: 106, SEQ ID. NO: 107, SEQ ID NO: 109, SEQ ID NO: 110, SEQ ID NO: 111, SEQ ID NO: 112, SEQ ID NO: 113, SEQ ID NO: 115, SEQ ID N.°: 116, SEQ ID N.°: 117, SEQ ID N.°: 118, SEQ ID N.°: 119, SEQ ID N.°: 120, SE ID N.°: 122,
ID N.°: 122,
SEQ ID N.°: 192 y SEQ ID NO: 193;
(b) la molécula de ácido nucleico que comprende la secuencia de nucleótidos que consiste en SEQ ID NO: 42, SEQ ID NO: 43, SEQ ID NO: 44, SEQ ID NO: 45, SEQ ID NO: 153, SEQ ID NO: 154, SEQ ID. NO: 155, SEQ ID NO: 156, SEQ ID NO: 157, SEQ ID NO: 158, SEQ ID NO: 159, SEQ ID NO: 160, SEQ ID NO: 161, SEQ ID NO: 162, SEQ ID NO : 163, SEQ ID N.°: 164, SEQ ID N.°: 165, SEQ ID N.°: 166, SEQ ID N.°: 167, SEQ ID N.°: 168, SEQ ID N.°: 169, SEQ ID N.°: 170, SEQ ID N.°: 171 , SEQ ID NO: 172 y / o SEQ ID NO: 173;
(c) la molécula de ácido nucleico que hibrida en condiciones rigurosas con la hebra complementaria de la secuencia de nucleótidos como se define en (a) o (b);
(d) la molécula de ácido nucleico que comprende la secuencia de nucleótidos que tiene al menos un 66,7% de identidad con la secuencia de nucleótidos como se define en cualquiera de (a), (b) y (c); y
(e) la molécula de ácido nucleico degenerada como resultado del código genético de la secuencia de nucleótidos como se define en (a) o (b).
13. Molécula de ácido nucleico según cualquiera de las reivindicaciones 1 y 4 a 11, en la que dicha molécula de ácido nucleico se selecciona del grupo que consiste en:
(a) la molécula de ácido nucleico que comprende al menos una secuencia de nucleótidos seleccionada del grupo que consiste en SEQ ID NO: 19, SEQ ID NO: 20, SEQ ID NO: 21, SEQ ID NO: 22, SEQ ID NO: 23, SEQ ID. NO: 24, SEQ ID NO: 25, SEQ ID NO: 26, SEQ ID NO: 27, SEQ ID NO: 123, SEQ ID NO: 124, SEQ ID NO: 125, SEQ ID NO: 126, SEQ ID NO : 127, SEQ ID N.°: 128, SEQ ID N.°: 129, SEQ ID N.°: 130, SEQ ID N.°: 131, SEQ ID N.°: 132, SEQ ID N.°: 133, SEQ ID N.°: 134, SEQ ID N.°: 135 , SEQ ID NO: 136, SEQ ID NO: 137, SEQ ID NO: 138, SEQ ID NO: 139, SEQ ID NO: 140, SEQ ID NO: 141, SEQ ID NO: 142, SEQ ID NO: 143, SEQ ID. NO: 144, SEQ ID NO: 145, SEQ ID NO: 146, SEQ ID NO: 147, SEQ ID NO: 148, SEQ ID NO: 149, SEQ ID NO: 150, SEQ ID NO: 151, SEQ ID NO: 152, SEQ ID NO: 194 y SEQ ID NO: 195;
(b) la molécula de ácido nucleico que comprende la secuencia de nucleótidos seleccionada del grupo que consiste en SEQ ID NO: 38, SEQ ID NO: 39, SEQ ID NO: 40, SEQ ID NO: 41, SEQ ID NO: 174, SEQ ID NO : 175, SEQ ID N.°: 176, SEQ ID N.°: 177, SEQ ID N.°: 178, SEQ ID N.°: 179, SEQ ID N.°: 180, SEQ ID N.°: 181, SEQ ID N.°: 182, SEQ ID N.°: 184 , SEQ ID NO: 185, SEQ ID NO: 186, SEQ ID NO: 187, SEQ ID NO: 188, SEQ ID NO: 189, SEQ ID NO: 190 y SEQ ID NO: 191;
(c) la molécula de ácido nucleico que hibrida en condiciones rigurosas con la hebra complementaria de la secuencia de nucleótidos como se define en (a) o (b);
(d) la molécula de ácido nucleico que comprende la secuencia de nucleótidos que tiene al menos un 56% de identidad con la secuencia de nucleótidos como se define en cualquiera de (a), (b) y (c);
(e) la molécula de ácido nucleico degenerada como resultado del código genético de la secuencia de nucleótidos como se define en (a) o (b).
14. Molécula de ácido nucleico según cualquiera de las reivindicaciones 1 a 13, unida operativamente en el mismo marco de lectura a un ácido nucleico que codifica una proteína biológicamente activa.
15. Molécula de ácido nucleico según la reivindicación 14, en la que dicha proteína biológicamente activa es una proteína terapéuticamente eficaz.
16. Un vector que comprende la molécula de ácido nucleico de cualquiera de las reivindicaciones 1 a 15.
17. Una célula huésped que comprende la molécula de ácido nucleico según cualquiera de las reivindicaciones 1 a 15, una célula huésped que comprende el vector según la reivindicación 16.
18. Un método para preparar la molécula de ácido nucleico según una cualquiera de las reivindicaciones 1 a 15, en
el que el método comprende cultivar la célula huésped de la reivindicación 17 y, opcionalmente, aislar la molécula de ácido nucleico producida.
19. Un método para preparar el vector de la reivindicación 16, en el que el método comprende cultivar la célula huésped de la reivindicación 17 y, opcionalmente, aislar el vector producido.
20. Un método para preparar un polipéptido codificado por la molécula de ácido nucleico según una cualquiera de las reivindicaciones 1 a 15, en el que el método comprende cultivar / criar la célula huésped de la reivindicación 17 y aislar opcionalmente el polipéptido producido.
21. Un método para preparar un fármaco conjugado, en el que dicho fármaco conjugado comprende el polipéptido codificado por la molécula de ácido nucleico de cualquiera de las reivindicaciones 1 a 13 y además comprende (i) una proteína biológicamente activa y / o (ii) una molécula pequeña y / o (iii) un carbohidrato, en el que el método comprende además cultivar la célula huésped de la reivindicación 17 y aislar opcionalmente el polipéptido producido y / o conjugado de fármaco.
22. El método para preparar el fármaco conjugado de la reivindicación 21, en el que dicha proteína biológicamente activa es una proteína terapéuticamente eficaz.
23. Un método para seleccionar una molécula de ácido nucleico genéticamente estable, donde dicha molécula de ácido nucleico comprende una secuencia de nucleótidos que codifica un polipéptido que consta de al menos 100 residuos de aminoácidos de prolina, alanina y, opcionalmente, serina, donde dicho polipéptido forma una enrollado aleatorio, donde dicha secuencia de nucleótidos tiene una longitud de al menos 300 nucleótidos,
el método comprende un paso de seleccionar una molécula de ácido nucleico que comprende una secuencia de nucleótidos que tiene una puntuación de repetición de nucleótidos (NRS) inferior a 1000, en la que dicha puntuación de repetición de nucleótidos (NRS) se determina de acuerdo con la fórmula:

donde
Ntot es la longitud de dicha secuencia de nucleótidos,
n es la longitud de una repetición dentro de dicha secuencia de nucleótidos, y
fi(n) es la frecuencia de dicha repetición de longitud n,
donde si hay más de una repetición de longitud n, k(n) es el número de dichas secuencias diferentes de dicha repetición de longitud n, de otro modo k(n) es 1 para dicha repetición de longitud n.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP15202093 | 2015-12-22 | ||
| PCT/EP2016/082407 WO2017109087A1 (en) | 2015-12-22 | 2016-12-22 | Nucleic acids encoding repetitive amino acid sequences rich in proline and alanine residues that have low repetitive nucleotide sequences |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2877539T3 true ES2877539T3 (es) | 2021-11-17 |
Family
ID=55129435
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES16828736T Active ES2877539T3 (es) | 2015-12-22 | 2016-12-22 | Acidos nucleicos que codifican secuencias repetitivas de aminoácidos ricos en residuos de prolina y alanina que tienen bajas secuencias de nucleótidos repetitivas |
Country Status (19)
| Country | Link |
|---|---|
| US (1) | US11401305B2 (es) |
| EP (2) | EP3394266B1 (es) |
| JP (1) | JP7065772B2 (es) |
| KR (1) | KR102654180B1 (es) |
| CN (1) | CN109153996B (es) |
| AU (1) | AU2016378646B2 (es) |
| BR (1) | BR112018012784A2 (es) |
| CA (1) | CA3005115A1 (es) |
| DK (1) | DK3394266T3 (es) |
| EA (1) | EA201891127A1 (es) |
| ES (1) | ES2877539T3 (es) |
| HU (1) | HUE055267T2 (es) |
| IL (1) | IL259352B (es) |
| LT (1) | LT3394266T (es) |
| MX (1) | MX2018007680A (es) |
| PL (1) | PL3394266T3 (es) |
| SG (1) | SG11201803958WA (es) |
| SI (1) | SI3394266T1 (es) |
| WO (1) | WO2017109087A1 (es) |
Families Citing this family (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10704021B2 (en) | 2012-03-15 | 2020-07-07 | Flodesign Sonics, Inc. | Acoustic perfusion devices |
| EP3092049A1 (en) | 2014-01-08 | 2016-11-16 | Flodesign Sonics Inc. | Acoustophoresis device with dual acoustophoretic chamber |
| US11708572B2 (en) | 2015-04-29 | 2023-07-25 | Flodesign Sonics, Inc. | Acoustic cell separation techniques and processes |
| US11377651B2 (en) | 2016-10-19 | 2022-07-05 | Flodesign Sonics, Inc. | Cell therapy processes utilizing acoustophoresis |
| US11214789B2 (en) | 2016-05-03 | 2022-01-04 | Flodesign Sonics, Inc. | Concentration and washing of particles with acoustics |
| US10174302B1 (en) | 2017-06-21 | 2019-01-08 | Xl-Protein Gmbh | Modified L-asparaginase |
| CN111406071B (zh) * | 2017-11-16 | 2024-01-16 | 成都硕德药业有限公司 | Pas化的vegfr/pdgfr融合蛋白及其在治疗中的用途 |
| US11548931B2 (en) | 2017-11-16 | 2023-01-10 | Xl-Protein Gmbh | PASylated VEGFR/PDGFR fusion proteins and their use in therapy |
| EP3725092A4 (en) | 2017-12-14 | 2021-09-22 | FloDesign Sonics, Inc. | DRIVE AND CONTROL UNIT FOR ACOUSTIC CONVERTER |
| WO2019165345A1 (en) * | 2018-02-23 | 2019-08-29 | Innovate Biopharmaceuticals, Inc. | Compositions and methods for treating or preventing intestinal paracellular permeability |
| KR102209198B1 (ko) * | 2019-04-02 | 2021-02-02 | 주식회사 바이오앱 | 식물에서의 발현이 최적화된 재조합 이리신 유전자 및 이를 이용한 재조합 이리신 단백질의 생산 방법 |
| CN110038120B (zh) * | 2019-04-02 | 2022-12-23 | 河南师范大学 | 豹蛙抗瘤酶融合蛋白作为治疗肿瘤药物的应用 |
| US20200327961A1 (en) * | 2019-04-15 | 2020-10-15 | Bruker Daltonik Gmbh | Methods for determining isomeric amino acid residues of proteins and peptides |
| WO2020227341A1 (en) * | 2019-05-06 | 2020-11-12 | 9 Meters Biopharma, Inc. | Compositions and methods for treating sjogren's syndrome |
| WO2021078988A1 (en) | 2019-10-25 | 2021-04-29 | Jazz Pharmaceuticals Ireland Ltd. | Recombinant l-asparaginase |
| AU2021405029A1 (en) | 2020-12-22 | 2023-07-20 | Technische Universität München | Antibodies specific for structurally disordered sequences |
| CN113340864B (zh) * | 2021-06-07 | 2023-04-07 | 郑州轻工业大学 | 基于mef效应二次放大ins信号的适体传感器及其制备方法和应用 |
| CN114470170B (zh) * | 2022-02-22 | 2023-09-19 | 广州新济药业科技有限公司 | 一种司美格鲁肽可溶性微针组合物及其制备方法 |
| WO2024042236A1 (en) | 2022-08-26 | 2024-02-29 | Ethris Gmbh | Stable lipid or lipidoid nanoparticle suspensions |
| GB202218084D0 (en) | 2022-12-01 | 2023-01-18 | Volution Immuno Pharmaceuticals Sa | Fusion proteins |
| WO2024124142A2 (en) * | 2022-12-08 | 2024-06-13 | Insmed Incorporated | Uricase conjugates and methods of use thereof |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5703055A (en) | 1989-03-21 | 1997-12-30 | Wisconsin Alumni Research Foundation | Generation of antibodies through lipid mediated DNA delivery |
| JP3626187B2 (ja) | 1993-06-07 | 2005-03-02 | バイカル インコーポレイテッド | 遺伝子治療に適するプラスミド |
| CA2225460A1 (en) | 1995-06-23 | 1997-01-09 | Winston Campbell Patterson | Transcriptional regulation of genes encoding vascular endothelial growth factor receptors |
| US7378506B2 (en) | 1997-07-21 | 2008-05-27 | Ohio University | Synthetic genes for plant gums and other hydroxyproline-rich glycoproteins |
| US20060252120A1 (en) | 2003-05-09 | 2006-11-09 | Kieliszewski Marcia J | Synthetic genes for plant gums and other hydroxyproline-rich glycoproteins |
| US20070292918A1 (en) | 2006-05-30 | 2007-12-20 | Stelman Steven J | Codon optimization method |
| ES2362386T3 (es) | 2007-06-21 | 2011-07-04 | Technische Universität München | Proteínas activas biológicas que tienen estabilidad aumentada in vivo y/o in vitro. |
| NZ602522A (en) * | 2010-05-21 | 2014-06-27 | Xl Protein Gmbh | Biosynthetic proline/alanine random coil polypeptides and their uses |
| ES2704237T3 (es) | 2014-03-05 | 2019-03-15 | Merz Pharma Gmbh & Co Kgaa | Nuevas neurotoxinas clostridiales recombinantes con un aumento de la duración del efecto |
| EP3418383A1 (en) | 2017-06-21 | 2018-12-26 | XL-protein GmbH | Modified l-asparaginase |
| AU2018287145B2 (en) | 2017-06-21 | 2024-04-18 | Jazz Pharmaceuticals Ireland Limited | Modified L-asparaginase |
| US10174302B1 (en) | 2017-06-21 | 2019-01-08 | Xl-Protein Gmbh | Modified L-asparaginase |
| US20200282071A1 (en) | 2017-06-21 | 2020-09-10 | Xl-Protein Gmbh | Conjugates of protein drugs and p/a peptides |
| US11548931B2 (en) | 2017-11-16 | 2023-01-10 | Xl-Protein Gmbh | PASylated VEGFR/PDGFR fusion proteins and their use in therapy |
-
2016
- 2016-12-22 LT LTEP16828736.5T patent/LT3394266T/lt unknown
- 2016-12-22 WO PCT/EP2016/082407 patent/WO2017109087A1/en active Application Filing
- 2016-12-22 HU HUE16828736A patent/HUE055267T2/hu unknown
- 2016-12-22 EP EP16828736.5A patent/EP3394266B1/en active Active
- 2016-12-22 DK DK16828736.5T patent/DK3394266T3/da active
- 2016-12-22 CN CN201680072372.2A patent/CN109153996B/zh active Active
- 2016-12-22 SG SG11201803958WA patent/SG11201803958WA/en unknown
- 2016-12-22 EA EA201891127A patent/EA201891127A1/ru unknown
- 2016-12-22 AU AU2016378646A patent/AU2016378646B2/en active Active
- 2016-12-22 PL PL16828736T patent/PL3394266T3/pl unknown
- 2016-12-22 CA CA3005115A patent/CA3005115A1/en active Pending
- 2016-12-22 BR BR112018012784A patent/BR112018012784A2/pt active Search and Examination
- 2016-12-22 EP EP21166789.4A patent/EP3919623A1/en not_active Withdrawn
- 2016-12-22 KR KR1020187020867A patent/KR102654180B1/ko active IP Right Grant
- 2016-12-22 SI SI201631254T patent/SI3394266T1/sl unknown
- 2016-12-22 ES ES16828736T patent/ES2877539T3/es active Active
- 2016-12-22 US US16/064,951 patent/US11401305B2/en active Active
- 2016-12-22 JP JP2018532638A patent/JP7065772B2/ja active Active
- 2016-12-22 MX MX2018007680A patent/MX2018007680A/es unknown
-
2018
- 2018-05-14 IL IL259352A patent/IL259352B/en unknown
Also Published As
| Publication number | Publication date |
|---|---|
| EP3919623A1 (en) | 2021-12-08 |
| CN109153996A (zh) | 2019-01-04 |
| JP7065772B2 (ja) | 2022-05-12 |
| NZ742902A (en) | 2023-12-22 |
| IL259352A (en) | 2018-07-31 |
| SG11201803958WA (en) | 2018-07-30 |
| JP2019508020A (ja) | 2019-03-28 |
| US20190010192A1 (en) | 2019-01-10 |
| EP3394266B1 (en) | 2021-04-14 |
| MX2018007680A (es) | 2018-11-14 |
| US11401305B2 (en) | 2022-08-02 |
| PL3394266T3 (pl) | 2021-12-13 |
| KR20180088484A (ko) | 2018-08-03 |
| SI3394266T1 (sl) | 2021-08-31 |
| IL259352B (en) | 2022-02-01 |
| CA3005115A1 (en) | 2017-06-29 |
| AU2016378646A1 (en) | 2018-06-14 |
| BR112018012784A2 (pt) | 2019-02-05 |
| AU2016378646B2 (en) | 2023-03-09 |
| CN109153996B (zh) | 2022-03-25 |
| EA201891127A1 (ru) | 2019-01-31 |
| DK3394266T3 (da) | 2021-06-07 |
| HUE055267T2 (hu) | 2021-11-29 |
| LT3394266T (lt) | 2021-08-25 |
| WO2017109087A1 (en) | 2017-06-29 |
| KR102654180B1 (ko) | 2024-04-04 |
| EP3394266A1 (en) | 2018-10-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2877539T3 (es) | Acidos nucleicos que codifican secuencias repetitivas de aminoácidos ricos en residuos de prolina y alanina que tienen bajas secuencias de nucleótidos repetitivas | |
| ES2691642T3 (es) | Polipéptidos de enrollamiento al azar de prolina/alanina biosintéticos y sus usos | |
| JP2021192606A (ja) | ヒト疾患に関連する生物製剤およびタンパク質の産生のための修飾ポリヌクレオチド | |
| US20120258104A1 (en) | Delivery System and Conjugates For Compound Delivery Via Naturally Occurring Intracellular Transport Routes | |
| AU2024202093A1 (en) | Peptides and nanoparticles for intracellular delivery of mrna | |
| US20200376139A1 (en) | Multi-armed polyrotaxane platform for protected nucleic acid delivery | |
| CN116115629A (zh) | 核酸产品及其施用方法 | |
| WO2019126240A1 (en) | Tumor homing and cell penetrating peptide-immuno-oncology agent complexes and methods of use thereof | |
| CN114375190A (zh) | 用于皮肤和伤口的组合物及其使用方法 | |
| Hong et al. | Aerosol gene delivery using viral vectors and cationic carriers for in vivo lung cancer therapy | |
| US20220249706A1 (en) | Viral vector therapy | |
| BR112021008832A2 (pt) | Proteínas de núcleo de mininucleossoma e uso em distribuição de ácido nucleico | |
| CN113677360A (zh) | 使用糖聚唾液酸化治疗性蛋白的方法 | |
| US20060286657A1 (en) | Novel bioconjugation reactions for acylating polyethylene glycol reagents | |
| EA041113B1 (ru) | Нуклеиновые кислоты, кодирующие повторяющиеся аминокислотные последовательности с высоким содержанием пролиновых и аланиновых остатков, имеющие нуклеотидные последовательности с низкой повторяемостью | |
| US20210324010A1 (en) | Fusion products and bioconjugates containing mixed charge peptides | |
| EP4331609A1 (en) | Methods and compositions for enhanced polyplex delivery | |
| Meng et al. | Clinical application of polysialylated therapeutic proteins | |
| US10870690B2 (en) | Protein therapeutant and method for treating cancer | |
| WO2024046622A1 (en) | Compositions of polyplexes and saponins | |
| White | Novel Bioconjugate Strategies to Improve Nonviral Gene Deliver to Liver: Systematic Optimization of Multi-Component Delivery Vehicles | |
| WO2024263729A1 (en) | Lipid nanoparticles comprising coding rna molecules for use in gene editing and as vaccines and therapeutic agents | |
| Price | Matrix metalloproteinase responsive silk-elastinlike protein polymers for cancer gene therapy |