CN103459415B - 设计的与血清白蛋白结合的重复蛋白 - Google Patents
设计的与血清白蛋白结合的重复蛋白 Download PDFInfo
- Publication number
- CN103459415B CN103459415B CN201180066086.2A CN201180066086A CN103459415B CN 103459415 B CN103459415 B CN 103459415B CN 201180066086 A CN201180066086 A CN 201180066086A CN 103459415 B CN103459415 B CN 103459415B
- Authority
- CN
- China
- Prior art keywords
- ala
- leu
- gly
- asp
- amino acid
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 102000007562 Serum Albumin Human genes 0.000 title claims abstract description 60
- 108010071390 Serum Albumin Proteins 0.000 title claims abstract description 60
- 108090000623 proteins and genes Proteins 0.000 title abstract description 99
- 102000004169 proteins and genes Human genes 0.000 title abstract description 92
- 230000027455 binding Effects 0.000 claims abstract description 148
- 102000014914 Carrier Proteins Human genes 0.000 claims abstract description 129
- 108091008324 binding proteins Proteins 0.000 claims abstract description 129
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 12
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 12
- 150000007523 nucleic acids Chemical class 0.000 claims abstract description 12
- 239000008194 pharmaceutical composition Substances 0.000 claims abstract description 12
- 150000001413 amino acids Chemical class 0.000 claims description 149
- 102000008102 Ankyrins Human genes 0.000 claims description 110
- 108010049777 Ankyrins Proteins 0.000 claims description 110
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 62
- 150000001875 compounds Chemical class 0.000 claims description 26
- 241000124008 Mammalia Species 0.000 claims description 14
- 102000008100 Human Serum Albumin Human genes 0.000 claims description 13
- 108091006905 Human Serum Albumin Proteins 0.000 claims description 13
- 238000010494 dissociation reaction Methods 0.000 claims description 13
- 230000005593 dissociations Effects 0.000 claims description 13
- 241000282412 Homo Species 0.000 claims description 4
- 239000003937 drug carrier Substances 0.000 claims description 4
- 239000003085 diluting agent Substances 0.000 claims description 3
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 claims description 2
- 108090000765 processed proteins & peptides Proteins 0.000 abstract description 70
- 102000004196 processed proteins & peptides Human genes 0.000 abstract description 66
- 229920001184 polypeptide Polymers 0.000 abstract description 65
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 abstract description 7
- 238000011282 treatment Methods 0.000 abstract description 7
- 201000010099 disease Diseases 0.000 abstract description 6
- 108700022150 Designed Ankyrin Repeat Proteins Proteins 0.000 description 166
- 235000001014 amino acid Nutrition 0.000 description 152
- 125000000539 amino acid group Chemical group 0.000 description 127
- 235000018102 proteins Nutrition 0.000 description 80
- 210000004899 c-terminal region Anatomy 0.000 description 76
- LXKNSJLSGPNHSK-KKUMJFAQSA-N Leu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N LXKNSJLSGPNHSK-KKUMJFAQSA-N 0.000 description 53
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 47
- PLOKOIJSGCISHE-BYULHYEWSA-N Asp-Val-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O PLOKOIJSGCISHE-BYULHYEWSA-N 0.000 description 44
- YWCJXQKATPNPOE-UKJIMTQDSA-N Ile-Val-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N YWCJXQKATPNPOE-UKJIMTQDSA-N 0.000 description 40
- DEGCBBCMYWNJNA-RHYQMDGZSA-N Thr-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O DEGCBBCMYWNJNA-RHYQMDGZSA-N 0.000 description 38
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 38
- 239000002953 phosphate buffered saline Substances 0.000 description 38
- VYUXYMRNGALHEA-DLOVCJGASA-N His-Leu-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O VYUXYMRNGALHEA-DLOVCJGASA-N 0.000 description 37
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 36
- RLFSBAPJTYKSLG-WHFBIAKZSA-N Gly-Ala-Asp Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O RLFSBAPJTYKSLG-WHFBIAKZSA-N 0.000 description 36
- FSPVILZGHUJOHS-QWRGUYRKSA-N Gly-His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CNC=N1 FSPVILZGHUJOHS-QWRGUYRKSA-N 0.000 description 36
- VIPDPMHGICREIS-GVXVVHGQSA-N Glu-Val-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VIPDPMHGICREIS-GVXVVHGQSA-N 0.000 description 35
- FXGRXIATVXUAHO-WEDXCCLWSA-N Gly-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN FXGRXIATVXUAHO-WEDXCCLWSA-N 0.000 description 34
- KWKQGHSSNHPGOW-BQBZGAKWSA-N Arg-Ala-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)NCC(O)=O KWKQGHSSNHPGOW-BQBZGAKWSA-N 0.000 description 33
- RUFHOVYUYSNDNY-ACZMJKKPSA-N Glu-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O RUFHOVYUYSNDNY-ACZMJKKPSA-N 0.000 description 33
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 33
- FQZPTCNSNPWHLJ-AVGNSLFASA-N Leu-Gln-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O FQZPTCNSNPWHLJ-AVGNSLFASA-N 0.000 description 33
- 108010041407 alanylaspartic acid Proteins 0.000 description 33
- CSFVADKICPDRRF-KKUMJFAQSA-N Leu-His-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CN=CN1 CSFVADKICPDRRF-KKUMJFAQSA-N 0.000 description 32
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 32
- 238000000034 method Methods 0.000 description 32
- 108010090894 prolylleucine Proteins 0.000 description 32
- OHUKZZYSJBKFRR-WHFBIAKZSA-N Gly-Ser-Asp Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O OHUKZZYSJBKFRR-WHFBIAKZSA-N 0.000 description 31
- ZVFVBBGVOILKPO-WHFBIAKZSA-N Ala-Gly-Ala Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O ZVFVBBGVOILKPO-WHFBIAKZSA-N 0.000 description 30
- PDQBXRSOSCTGKY-ACZMJKKPSA-N Asn-Ala-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N PDQBXRSOSCTGKY-ACZMJKKPSA-N 0.000 description 30
- REPBGZHJKYWFMJ-KKUMJFAQSA-N Leu-Lys-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N REPBGZHJKYWFMJ-KKUMJFAQSA-N 0.000 description 22
- AAQGRPOPTAUUBM-ZLUOBGJFSA-N Ala-Ala-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O AAQGRPOPTAUUBM-ZLUOBGJFSA-N 0.000 description 21
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 21
- 229920000642 polymer Polymers 0.000 description 21
- BDFHWFUAQLIMJO-KXNHARMFSA-N Lys-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N)O BDFHWFUAQLIMJO-KXNHARMFSA-N 0.000 description 20
- 108010054155 lysyllysine Proteins 0.000 description 20
- 238000001542 size-exclusion chromatography Methods 0.000 description 20
- OQDLKDUVMTUPPG-AVGNSLFASA-N His-Leu-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O OQDLKDUVMTUPPG-AVGNSLFASA-N 0.000 description 19
- FPTXMUIBLMGTQH-ONGXEEELSA-N Phe-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 FPTXMUIBLMGTQH-ONGXEEELSA-N 0.000 description 19
- OMMDTNGURYRDAC-NRPADANISA-N Ala-Glu-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OMMDTNGURYRDAC-NRPADANISA-N 0.000 description 18
- SDZRIBWEVVRDQI-CIUDSAMLSA-N Ala-Lys-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O SDZRIBWEVVRDQI-CIUDSAMLSA-N 0.000 description 18
- IESFZVCAVACGPH-PEFMBERDSA-N Glu-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O IESFZVCAVACGPH-PEFMBERDSA-N 0.000 description 18
- RNMNYMDTESKEAJ-KKUMJFAQSA-N His-Leu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 RNMNYMDTESKEAJ-KKUMJFAQSA-N 0.000 description 18
- ILGCZYGFYQLSDZ-KKUMJFAQSA-N Phe-Ser-His Chemical compound N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CO)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O ILGCZYGFYQLSDZ-KKUMJFAQSA-N 0.000 description 18
- APKRGYLBSCWJJP-FXQIFTODSA-N Pro-Ala-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O APKRGYLBSCWJJP-FXQIFTODSA-N 0.000 description 18
- 108010036413 histidylglycine Proteins 0.000 description 18
- DVWVZSJAYIJZFI-FXQIFTODSA-N Ala-Arg-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O DVWVZSJAYIJZFI-FXQIFTODSA-N 0.000 description 17
- PYXXJFRXIYAESU-PCBIJLKTSA-N Asp-Ile-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PYXXJFRXIYAESU-PCBIJLKTSA-N 0.000 description 17
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 17
- BTBUEVAGZCKULD-XPUUQOCRSA-N Ala-Gly-His Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CN=CN1 BTBUEVAGZCKULD-XPUUQOCRSA-N 0.000 description 16
- 108010047495 alanylglycine Proteins 0.000 description 16
- 229910052739 hydrogen Inorganic materials 0.000 description 16
- 238000004925 denaturation Methods 0.000 description 15
- 230000036425 denaturation Effects 0.000 description 15
- NKVZTQVGUNLLQW-JBDRJPRFSA-N Ile-Ala-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)O)N NKVZTQVGUNLLQW-JBDRJPRFSA-N 0.000 description 14
- DXVMJJNAOVECBA-WHFBIAKZSA-N Asn-Gly-Asn Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O DXVMJJNAOVECBA-WHFBIAKZSA-N 0.000 description 13
- 238000002965 ELISA Methods 0.000 description 13
- JVSBYEDSSRZQGV-GUBZILKMSA-N Glu-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O JVSBYEDSSRZQGV-GUBZILKMSA-N 0.000 description 13
- NTBFKPBULZGXQL-KKUMJFAQSA-N Lys-Asp-Tyr Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NTBFKPBULZGXQL-KKUMJFAQSA-N 0.000 description 13
- 241000282567 Macaca fascicularis Species 0.000 description 13
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 13
- 230000003993 interaction Effects 0.000 description 13
- 108020001580 protein domains Proteins 0.000 description 13
- GGNHBHYDMUDXQB-KBIXCLLPSA-N Ala-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)N GGNHBHYDMUDXQB-KBIXCLLPSA-N 0.000 description 12
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 12
- AGGIYSLVUKVOPT-HTFCKZLJSA-N Ile-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N AGGIYSLVUKVOPT-HTFCKZLJSA-N 0.000 description 12
- 241000699670 Mus sp. Species 0.000 description 12
- 210000004027 cell Anatomy 0.000 description 12
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 12
- BFMIRJBURUXDRG-DLOVCJGASA-N Ala-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 BFMIRJBURUXDRG-DLOVCJGASA-N 0.000 description 11
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 11
- MYGQXVYRZMKRDB-SRVKXCTJSA-N Leu-Asp-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN MYGQXVYRZMKRDB-SRVKXCTJSA-N 0.000 description 10
- ZRHDPZAAWLXXIR-SRVKXCTJSA-N Leu-Lys-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O ZRHDPZAAWLXXIR-SRVKXCTJSA-N 0.000 description 10
- AOIZTZRWMSPPAY-KAOXEZKKSA-N Tyr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)O AOIZTZRWMSPPAY-KAOXEZKKSA-N 0.000 description 10
- 238000004458 analytical method Methods 0.000 description 10
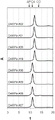
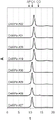
- 238000002983 circular dichroism Methods 0.000 description 10
- 239000003814 drug Substances 0.000 description 10
- 108010025306 histidylleucine Proteins 0.000 description 10
- 238000005259 measurement Methods 0.000 description 10
- 241000588724 Escherichia coli Species 0.000 description 9
- 241000699666 Mus <mouse, genus> Species 0.000 description 9
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 9
- 108010047926 leucyl-lysyl-tyrosine Proteins 0.000 description 9
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 9
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 8
- YWLDTBBUHZJQHW-KKUMJFAQSA-N Asp-Lys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N YWLDTBBUHZJQHW-KKUMJFAQSA-N 0.000 description 8
- 241000282414 Homo sapiens Species 0.000 description 8
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 8
- 101000677856 Stenotrophomonas maltophilia (strain K279a) Actin-binding protein Smlt3054 Proteins 0.000 description 8
- 238000003556 assay Methods 0.000 description 8
- 238000002347 injection Methods 0.000 description 8
- 239000007924 injection Substances 0.000 description 8
- 210000002966 serum Anatomy 0.000 description 8
- HHGYNJRJIINWAK-FXQIFTODSA-N Ala-Ala-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N HHGYNJRJIINWAK-FXQIFTODSA-N 0.000 description 7
- KUDREHRZRIVKHS-UWJYBYFXSA-N Ala-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KUDREHRZRIVKHS-UWJYBYFXSA-N 0.000 description 7
- RMAWDDRDTRSZIR-ZLUOBGJFSA-N Ala-Ser-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RMAWDDRDTRSZIR-ZLUOBGJFSA-N 0.000 description 7
- CTQIOCMSIJATNX-WHFBIAKZSA-N Asn-Gly-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O CTQIOCMSIJATNX-WHFBIAKZSA-N 0.000 description 7
- GPSHCSTUYOQPAI-JHEQGTHGSA-N Glu-Thr-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O GPSHCSTUYOQPAI-JHEQGTHGSA-N 0.000 description 7
- 108060003951 Immunoglobulin Proteins 0.000 description 7
- 239000012505 Superdex™ Substances 0.000 description 7
- CNLKDWSAORJEMW-KWQFWETISA-N Tyr-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O CNLKDWSAORJEMW-KWQFWETISA-N 0.000 description 7
- 230000000975 bioactive effect Effects 0.000 description 7
- 239000000872 buffer Substances 0.000 description 7
- 229940079593 drug Drugs 0.000 description 7
- 102000018358 immunoglobulin Human genes 0.000 description 7
- 238000002702 ribosome display Methods 0.000 description 7
- 239000000523 sample Substances 0.000 description 7
- 238000012216 screening Methods 0.000 description 7
- WCFCYFDBMNFSPA-ACZMJKKPSA-N Asp-Asp-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(O)=O WCFCYFDBMNFSPA-ACZMJKKPSA-N 0.000 description 6
- 108091035707 Consensus sequence Proteins 0.000 description 6
- KZEUVLLVULIPNX-GUBZILKMSA-N Gln-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N KZEUVLLVULIPNX-GUBZILKMSA-N 0.000 description 6
- 239000007987 MES buffer Substances 0.000 description 6
- HBGFEEQFVBWYJQ-KBPBESRZSA-N Phe-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HBGFEEQFVBWYJQ-KBPBESRZSA-N 0.000 description 6
- 239000002202 Polyethylene glycol Substances 0.000 description 6
- FYPGHGXAOZTOBO-IHRRRGAJSA-N Pro-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@@H]2CCCN2 FYPGHGXAOZTOBO-IHRRRGAJSA-N 0.000 description 6
- GUIYPEKUEMQBIK-JSGCOSHPSA-N Val-Tyr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)NCC(O)=O GUIYPEKUEMQBIK-JSGCOSHPSA-N 0.000 description 6
- 108010092854 aspartyllysine Proteins 0.000 description 6
- 230000001580 bacterial effect Effects 0.000 description 6
- 239000011230 binding agent Substances 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- 239000012634 fragment Substances 0.000 description 6
- 108010087823 glycyltyrosine Proteins 0.000 description 6
- 230000002209 hydrophobic effect Effects 0.000 description 6
- 238000011534 incubation Methods 0.000 description 6
- 229920001223 polyethylene glycol Polymers 0.000 description 6
- 239000000243 solution Substances 0.000 description 6
- ODWSTKXGQGYHSH-FXQIFTODSA-N Ala-Arg-Ala Chemical compound C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O ODWSTKXGQGYHSH-FXQIFTODSA-N 0.000 description 5
- 108010039627 Aprotinin Proteins 0.000 description 5
- KRQSPVKUISQQFS-FJXKBIBVSA-N Arg-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCN=C(N)N KRQSPVKUISQQFS-FJXKBIBVSA-N 0.000 description 5
- DPNWSMBUYCLEDG-CIUDSAMLSA-N Asp-Lys-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O DPNWSMBUYCLEDG-CIUDSAMLSA-N 0.000 description 5
- 241000282693 Cercopithecidae Species 0.000 description 5
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 5
- DZQMXBALGUHGJT-GUBZILKMSA-N Leu-Glu-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O DZQMXBALGUHGJT-GUBZILKMSA-N 0.000 description 5
- OVIVOCSURJYCTM-GUBZILKMSA-N Lys-Asp-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(O)=O OVIVOCSURJYCTM-GUBZILKMSA-N 0.000 description 5
- AAORVPFVUIHEAB-YUMQZZPRSA-N Lys-Asp-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O AAORVPFVUIHEAB-YUMQZZPRSA-N 0.000 description 5
- HVAUKHLDSDDROB-KKUMJFAQSA-N Lys-Lys-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O HVAUKHLDSDDROB-KKUMJFAQSA-N 0.000 description 5
- 241000283973 Oryctolagus cuniculus Species 0.000 description 5
- LVVBAKCGXXUHFO-ZLUOBGJFSA-N Ser-Ala-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O LVVBAKCGXXUHFO-ZLUOBGJFSA-N 0.000 description 5
- QPZMOUMNTGTEFR-ZKWXMUAHSA-N Val-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N QPZMOUMNTGTEFR-ZKWXMUAHSA-N 0.000 description 5
- UEHRGZCNLSWGHK-DLOVCJGASA-N Val-Glu-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UEHRGZCNLSWGHK-DLOVCJGASA-N 0.000 description 5
- 238000002835 absorbance Methods 0.000 description 5
- 229960004405 aprotinin Drugs 0.000 description 5
- 108010047857 aspartylglycine Proteins 0.000 description 5
- 239000008280 blood Substances 0.000 description 5
- 238000001727 in vivo Methods 0.000 description 5
- ZPNFWUPYTFPOJU-LPYSRVMUSA-N iniprol Chemical compound C([C@H]1C(=O)NCC(=O)NCC(=O)N[C@H]2CSSC[C@H]3C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@H](C(N[C@H](C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=4C=CC(O)=CC=4)C(=O)N[C@@H](CC=4C=CC=CC=4)C(=O)N[C@@H](CC=4C=CC(O)=CC=4)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC=4C=CC=CC=4)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC2=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](CC=2C=CC=CC=2)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H]2N(CCC2)C(=O)[C@@H](N)CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N2[C@@H](CCC2)C(=O)N2[C@@H](CCC2)C(=O)N[C@@H](CC=2C=CC(O)=CC=2)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N2[C@@H](CCC2)C(=O)N3)C(=O)NCC(=O)NCC(=O)N[C@@H](C)C(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@H](C(=O)N1)C(C)C)[C@@H](C)O)[C@@H](C)CC)=O)[C@@H](C)CC)C1=CC=C(O)C=C1 ZPNFWUPYTFPOJU-LPYSRVMUSA-N 0.000 description 5
- 239000011780 sodium chloride Substances 0.000 description 5
- 230000007704 transition Effects 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical group N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- XWTNPSHCJMZAHQ-QMMMGPOBSA-N 2-[[2-[[2-[[(2s)-2-amino-4-methylpentanoyl]amino]acetyl]amino]acetyl]amino]acetic acid Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)NCC(=O)NCC(O)=O XWTNPSHCJMZAHQ-QMMMGPOBSA-N 0.000 description 4
- AJBVYEYZVYPFCF-CIUDSAMLSA-N Ala-Lys-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O AJBVYEYZVYPFCF-CIUDSAMLSA-N 0.000 description 4
- AYFVRYXNDHBECD-YUMQZZPRSA-N Asp-Leu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AYFVRYXNDHBECD-YUMQZZPRSA-N 0.000 description 4
- 102000003846 Carbonic anhydrases Human genes 0.000 description 4
- 108090000209 Carbonic anhydrases Proteins 0.000 description 4
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 4
- YADRBUZBKHHDAO-XPUUQOCRSA-N His-Gly-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](C)C(O)=O YADRBUZBKHHDAO-XPUUQOCRSA-N 0.000 description 4
- 101000920778 Homo sapiens DNA excision repair protein ERCC-8 Proteins 0.000 description 4
- HPBCTWSUJOGJSH-MNXVOIDGSA-N Leu-Glu-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HPBCTWSUJOGJSH-MNXVOIDGSA-N 0.000 description 4
- NJNRBRKHOWSGMN-SRVKXCTJSA-N Lys-Leu-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O NJNRBRKHOWSGMN-SRVKXCTJSA-N 0.000 description 4
- 241000009328 Perro Species 0.000 description 4
- 229920001213 Polysorbate 20 Polymers 0.000 description 4
- 241000700159 Rattus Species 0.000 description 4
- 108020004511 Recombinant DNA Proteins 0.000 description 4
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 4
- 108010005233 alanylglutamic acid Proteins 0.000 description 4
- 238000005571 anion exchange chromatography Methods 0.000 description 4
- 210000004369 blood Anatomy 0.000 description 4
- 238000000978 circular dichroism spectroscopy Methods 0.000 description 4
- 235000018417 cysteine Nutrition 0.000 description 4
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 4
- 238000010828 elution Methods 0.000 description 4
- 239000013613 expression plasmid Substances 0.000 description 4
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 4
- 108010018006 histidylserine Proteins 0.000 description 4
- 102000048696 human ERCC8 Human genes 0.000 description 4
- 108010073093 leucyl-glycyl-glycyl-glycine Proteins 0.000 description 4
- 108010003700 lysyl aspartic acid Proteins 0.000 description 4
- 239000000203 mixture Substances 0.000 description 4
- 230000001575 pathological effect Effects 0.000 description 4
- 239000012146 running buffer Substances 0.000 description 4
- 150000003384 small molecules Chemical class 0.000 description 4
- 238000010561 standard procedure Methods 0.000 description 4
- 239000000126 substance Substances 0.000 description 4
- 238000006467 substitution reaction Methods 0.000 description 4
- 238000003786 synthesis reaction Methods 0.000 description 4
- 230000008685 targeting Effects 0.000 description 4
- HKZAAJSTFUZYTO-LURJTMIESA-N (2s)-2-[[2-[[2-[[2-[(2-aminoacetyl)amino]acetyl]amino]acetyl]amino]acetyl]amino]-3-hydroxypropanoic acid Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O HKZAAJSTFUZYTO-LURJTMIESA-N 0.000 description 3
- SSSROGPPPVTHLX-FXQIFTODSA-N Ala-Arg-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSROGPPPVTHLX-FXQIFTODSA-N 0.000 description 3
- SVBXIUDNTRTKHE-CIUDSAMLSA-N Ala-Arg-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O SVBXIUDNTRTKHE-CIUDSAMLSA-N 0.000 description 3
- CSAHOYQKNHGDHX-ACZMJKKPSA-N Ala-Gln-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CSAHOYQKNHGDHX-ACZMJKKPSA-N 0.000 description 3
- NKJBKNVQHBZUIX-ACZMJKKPSA-N Ala-Gln-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKJBKNVQHBZUIX-ACZMJKKPSA-N 0.000 description 3
- 102000009027 Albumins Human genes 0.000 description 3
- 108010088751 Albumins Proteins 0.000 description 3
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 3
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 3
- SLKLLQWZQHXYSV-CIUDSAMLSA-N Asn-Ala-Lys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O SLKLLQWZQHXYSV-CIUDSAMLSA-N 0.000 description 3
- HCAUEJAQCXVQQM-ACZMJKKPSA-N Asn-Glu-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HCAUEJAQCXVQQM-ACZMJKKPSA-N 0.000 description 3
- GWTLRDMPMJCNMH-WHFBIAKZSA-N Asp-Asn-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GWTLRDMPMJCNMH-WHFBIAKZSA-N 0.000 description 3
- KLYPOCBLKMPBIQ-GHCJXIJMSA-N Asp-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N KLYPOCBLKMPBIQ-GHCJXIJMSA-N 0.000 description 3
- OAMLVOVXNKILLQ-BQBZGAKWSA-N Asp-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](N)CC(O)=O OAMLVOVXNKILLQ-BQBZGAKWSA-N 0.000 description 3
- 241000894006 Bacteria Species 0.000 description 3
- 102000004506 Blood Proteins Human genes 0.000 description 3
- 108010017384 Blood Proteins Proteins 0.000 description 3
- 108010026206 Conalbumin Proteins 0.000 description 3
- FYYSIASRLDJUNP-WHFBIAKZSA-N Glu-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(O)=O FYYSIASRLDJUNP-WHFBIAKZSA-N 0.000 description 3
- MLILEEIVMRUYBX-NHCYSSNCSA-N Glu-Val-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O MLILEEIVMRUYBX-NHCYSSNCSA-N 0.000 description 3
- GBYYQVBXFVDJPJ-WLTAIBSBSA-N Gly-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)CN)O GBYYQVBXFVDJPJ-WLTAIBSBSA-N 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- 108010093488 His-His-His-His-His-His Proteins 0.000 description 3
- YGDWPQCLFJNMOL-MNXVOIDGSA-N Ile-Leu-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YGDWPQCLFJNMOL-MNXVOIDGSA-N 0.000 description 3
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 3
- CQQGCWPXDHTTNF-GUBZILKMSA-N Leu-Ala-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O CQQGCWPXDHTTNF-GUBZILKMSA-N 0.000 description 3
- DSWOTZCVCBEPOU-IUCAKERBSA-N Met-Arg-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCNC(N)=N DSWOTZCVCBEPOU-IUCAKERBSA-N 0.000 description 3
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 3
- 108091081062 Repeated sequence (DNA) Proteins 0.000 description 3
- IOVBCLGAJJXOHK-SRVKXCTJSA-N Ser-His-His Chemical compound C([C@H](NC(=O)[C@H](CO)N)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 IOVBCLGAJJXOHK-SRVKXCTJSA-N 0.000 description 3
- KEGBFULVYKYJRD-LFSVMHDDSA-N Thr-Ala-Phe Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KEGBFULVYKYJRD-LFSVMHDDSA-N 0.000 description 3
- KKHRWGYHBZORMQ-NHCYSSNCSA-N Val-Arg-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N KKHRWGYHBZORMQ-NHCYSSNCSA-N 0.000 description 3
- PFNZJEPSCBAVGX-CYDGBPFRSA-N Val-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](C(C)C)N PFNZJEPSCBAVGX-CYDGBPFRSA-N 0.000 description 3
- 108010044940 alanylglutamine Proteins 0.000 description 3
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 3
- 229960000723 ampicillin Drugs 0.000 description 3
- 108010013835 arginine glutamate Proteins 0.000 description 3
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 3
- 238000012512 characterization method Methods 0.000 description 3
- 239000003153 chemical reaction reagent Substances 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 238000001514 detection method Methods 0.000 description 3
- 239000012636 effector Substances 0.000 description 3
- 238000000605 extraction Methods 0.000 description 3
- 230000004927 fusion Effects 0.000 description 3
- 239000003102 growth factor Substances 0.000 description 3
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 3
- 238000012417 linear regression Methods 0.000 description 3
- 108010025153 lysyl-alanyl-alanine Proteins 0.000 description 3
- 230000035772 mutation Effects 0.000 description 3
- 239000000546 pharmaceutical excipient Substances 0.000 description 3
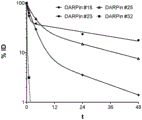
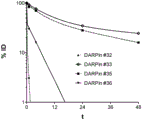
- 230000036470 plasma concentration Effects 0.000 description 3
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 3
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 3
- 238000003753 real-time PCR Methods 0.000 description 3
- 230000003252 repetitive effect Effects 0.000 description 3
- 238000002864 sequence alignment Methods 0.000 description 3
- 241000894007 species Species 0.000 description 3
- DJQYYYCQOZMCRC-UHFFFAOYSA-N 2-aminopropane-1,3-dithiol Chemical group SCC(N)CS DJQYYYCQOZMCRC-UHFFFAOYSA-N 0.000 description 2
- JNLDTVRGXMSYJC-UVBJJODRSA-N Ala-Pro-Trp Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O JNLDTVRGXMSYJC-UVBJJODRSA-N 0.000 description 2
- QGZKDVFQNNGYKY-UHFFFAOYSA-N Ammonia Chemical compound N QGZKDVFQNNGYKY-UHFFFAOYSA-N 0.000 description 2
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 description 2
- 102000016904 Armadillo Domain Proteins Human genes 0.000 description 2
- 108010014223 Armadillo Domain Proteins Proteins 0.000 description 2
- GWNMUVANAWDZTI-YUMQZZPRSA-N Asn-Gly-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N GWNMUVANAWDZTI-YUMQZZPRSA-N 0.000 description 2
- KTTCQQNRRLCIBC-GHCJXIJMSA-N Asp-Ile-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O KTTCQQNRRLCIBC-GHCJXIJMSA-N 0.000 description 2
- JNNVNVRBYUJYGS-CIUDSAMLSA-N Asp-Leu-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O JNNVNVRBYUJYGS-CIUDSAMLSA-N 0.000 description 2
- CTWCFPWFIGRAEP-CIUDSAMLSA-N Asp-Lys-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O CTWCFPWFIGRAEP-CIUDSAMLSA-N 0.000 description 2
- YZQCXOFQZKCETR-UWVGGRQHSA-N Asp-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 YZQCXOFQZKCETR-UWVGGRQHSA-N 0.000 description 2
- 108020004414 DNA Proteins 0.000 description 2
- 241000289632 Dasypodidae Species 0.000 description 2
- 102000004190 Enzymes Human genes 0.000 description 2
- 108090000790 Enzymes Proteins 0.000 description 2
- 102000005664 GA-Binding Protein Transcription Factor Human genes 0.000 description 2
- 108010045298 GA-Binding Protein Transcription Factor Proteins 0.000 description 2
- ULXXDWZMMSQBDC-ACZMJKKPSA-N Gln-Asp-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N ULXXDWZMMSQBDC-ACZMJKKPSA-N 0.000 description 2
- FKXCBKCOSVIGCT-AVGNSLFASA-N Gln-Lys-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O FKXCBKCOSVIGCT-AVGNSLFASA-N 0.000 description 2
- CAVMESABQIKFKT-IUCAKERBSA-N Glu-Gly-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)O)N CAVMESABQIKFKT-IUCAKERBSA-N 0.000 description 2
- QXDXIXFSFHUYAX-MNXVOIDGSA-N Glu-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O QXDXIXFSFHUYAX-MNXVOIDGSA-N 0.000 description 2
- JIUYRPFQJJRSJB-QWRGUYRKSA-N His-His-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)NCC(O)=O)C1=CN=CN1 JIUYRPFQJJRSJB-QWRGUYRKSA-N 0.000 description 2
- MMFKFJORZBJVNF-UWVGGRQHSA-N His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](N)CC1=CN=CN1 MMFKFJORZBJVNF-UWVGGRQHSA-N 0.000 description 2
- PYNPBMCLAKTHJL-SRVKXCTJSA-N His-Pro-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O PYNPBMCLAKTHJL-SRVKXCTJSA-N 0.000 description 2
- UPJODPVSKKWGDQ-KLHWPWHYSA-N His-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N)O UPJODPVSKKWGDQ-KLHWPWHYSA-N 0.000 description 2
- 229920001612 Hydroxyethyl starch Polymers 0.000 description 2
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 2
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 2
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 2
- ONPJGOIVICHWBW-BZSNNMDCSA-N Leu-Lys-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 ONPJGOIVICHWBW-BZSNNMDCSA-N 0.000 description 2
- CPONGMJGVIAWEH-DCAQKATOSA-N Leu-Met-Ala Chemical compound CSCC[C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](C)C(O)=O CPONGMJGVIAWEH-DCAQKATOSA-N 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- 102000019298 Lipocalin Human genes 0.000 description 2
- 108050006654 Lipocalin Proteins 0.000 description 2
- MSSJJDVQTFTLIF-KBPBESRZSA-N Lys-Phe-Gly Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](Cc1ccccc1)C(=O)NCC(O)=O MSSJJDVQTFTLIF-KBPBESRZSA-N 0.000 description 2
- PLOUVAYOMTYJRG-JXUBOQSCSA-N Lys-Thr-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O PLOUVAYOMTYJRG-JXUBOQSCSA-N 0.000 description 2
- 238000005481 NMR spectroscopy Methods 0.000 description 2
- 206010028980 Neoplasm Diseases 0.000 description 2
- 229910019142 PO4 Inorganic materials 0.000 description 2
- IUVYJBMTHARMIP-PCBIJLKTSA-N Phe-Asp-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O IUVYJBMTHARMIP-PCBIJLKTSA-N 0.000 description 2
- XEXSSIBQYNKFBX-KBPBESRZSA-N Phe-Gly-His Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1N=CNC=1)C(O)=O)C1=CC=CC=C1 XEXSSIBQYNKFBX-KBPBESRZSA-N 0.000 description 2
- 241000255969 Pieris brassicae Species 0.000 description 2
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 2
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 2
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 2
- 238000012300 Sequence Analysis Methods 0.000 description 2
- BGOWRLSWJCVYAQ-CIUDSAMLSA-N Ser-Asp-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BGOWRLSWJCVYAQ-CIUDSAMLSA-N 0.000 description 2
- BKZYBLLIBOBOOW-GHCJXIJMSA-N Ser-Ile-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O BKZYBLLIBOBOOW-GHCJXIJMSA-N 0.000 description 2
- 241000191967 Staphylococcus aureus Species 0.000 description 2
- YSXYEJWDHBCTDJ-DVJZZOLTSA-N Thr-Gly-Trp Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N)O YSXYEJWDHBCTDJ-DVJZZOLTSA-N 0.000 description 2
- WTMPKZWHRCMMMT-KZVJFYERSA-N Thr-Pro-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WTMPKZWHRCMMMT-KZVJFYERSA-N 0.000 description 2
- OLFOOYQTTQSSRK-UNQGMJICSA-N Thr-Pro-Phe Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 OLFOOYQTTQSSRK-UNQGMJICSA-N 0.000 description 2
- 230000002776 aggregation Effects 0.000 description 2
- 238000004220 aggregation Methods 0.000 description 2
- 108010011559 alanylphenylalanine Proteins 0.000 description 2
- 229960002685 biotin Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 239000011616 biotin Substances 0.000 description 2
- 230000036772 blood pressure Effects 0.000 description 2
- 201000011510 cancer Diseases 0.000 description 2
- 239000000969 carrier Substances 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 238000012411 cloning technique Methods 0.000 description 2
- 230000002860 competitive effect Effects 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 2
- 239000000975 dye Substances 0.000 description 2
- 230000005284 excitation Effects 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 239000008103 glucose Substances 0.000 description 2
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Chemical compound NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 2
- 108010050848 glycylleucine Proteins 0.000 description 2
- 229940050526 hydroxyethylstarch Drugs 0.000 description 2
- 230000002163 immunogen Effects 0.000 description 2
- 229940072221 immunoglobulins Drugs 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 2
- 238000000111 isothermal titration calorimetry Methods 0.000 description 2
- 108010034529 leucyl-lysine Proteins 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 239000013642 negative control Substances 0.000 description 2
- 108010087904 neutravidin Proteins 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 2
- 239000010452 phosphate Substances 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 239000012460 protein solution Substances 0.000 description 2
- -1 protein therapeutics Chemical class 0.000 description 2
- 230000004850 protein–protein interaction Effects 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 230000005258 radioactive decay Effects 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 239000003381 stabilizer Substances 0.000 description 2
- 239000000758 substrate Substances 0.000 description 2
- 239000013076 target substance Substances 0.000 description 2
- 230000001225 therapeutic effect Effects 0.000 description 2
- 108010038745 tryptophylglycine Proteins 0.000 description 2
- 210000003462 vein Anatomy 0.000 description 2
- 238000005406 washing Methods 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- 238000002424 x-ray crystallography Methods 0.000 description 2
- XDIYNQZUNSSENW-UUBOPVPUSA-N (2R,3S,4R,5R)-2,3,4,5,6-pentahydroxyhexanal Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C=O.OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C=O XDIYNQZUNSSENW-UUBOPVPUSA-N 0.000 description 1
- OTLLEIBWKHEHGU-UHFFFAOYSA-N 2-[5-[[5-(6-aminopurin-9-yl)-3,4-dihydroxyoxolan-2-yl]methoxy]-3,4-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-3,5-dihydroxy-4-phosphonooxyhexanedioic acid Chemical compound C1=NC=2C(N)=NC=NC=2N1C(C(C1O)O)OC1COC1C(CO)OC(OC(C(O)C(OP(O)(O)=O)C(O)C(O)=O)C(O)=O)C(O)C1O OTLLEIBWKHEHGU-UHFFFAOYSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- KQLXBKWUVBMXEM-UHFFFAOYSA-N 2-amino-3,7-dihydropurin-6-one;7h-purin-6-amine Chemical compound NC1=NC=NC2=C1NC=N2.O=C1NC(N)=NC2=C1NC=N2 KQLXBKWUVBMXEM-UHFFFAOYSA-N 0.000 description 1
- UAIUNKRWKOVEES-UHFFFAOYSA-N 3,3',5,5'-tetramethylbenzidine Chemical compound CC1=C(N)C(C)=CC(C=2C=C(C)C(N)=C(C)C=2)=C1 UAIUNKRWKOVEES-UHFFFAOYSA-N 0.000 description 1
- DKJPOZOEBONHFS-ZLUOBGJFSA-N Ala-Ala-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O DKJPOZOEBONHFS-ZLUOBGJFSA-N 0.000 description 1
- GFBLJMHGHAXGNY-ZLUOBGJFSA-N Ala-Asn-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O GFBLJMHGHAXGNY-ZLUOBGJFSA-N 0.000 description 1
- PXKLCFFSVLKOJM-ACZMJKKPSA-N Ala-Asn-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PXKLCFFSVLKOJM-ACZMJKKPSA-N 0.000 description 1
- GSCLWXDNIMNIJE-ZLUOBGJFSA-N Ala-Asp-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GSCLWXDNIMNIJE-ZLUOBGJFSA-N 0.000 description 1
- ZIWWTZWAKYBUOB-CIUDSAMLSA-N Ala-Asp-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O ZIWWTZWAKYBUOB-CIUDSAMLSA-N 0.000 description 1
- BLIMFWGRQKRCGT-YUMQZZPRSA-N Ala-Gly-Lys Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN BLIMFWGRQKRCGT-YUMQZZPRSA-N 0.000 description 1
- CNQAFFMNJIQYGX-DRZSPHRISA-N Ala-Phe-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 CNQAFFMNJIQYGX-DRZSPHRISA-N 0.000 description 1
- 108010011170 Ala-Trp-Arg-His-Pro-Gln-Phe-Gly-Gly Proteins 0.000 description 1
- BVLPIIBTWIYOML-ZKWXMUAHSA-N Ala-Val-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BVLPIIBTWIYOML-ZKWXMUAHSA-N 0.000 description 1
- 239000004382 Amylase Substances 0.000 description 1
- 102000013142 Amylases Human genes 0.000 description 1
- 108010065511 Amylases Proteins 0.000 description 1
- XYOVHPDDWCEUDY-CIUDSAMLSA-N Asn-Ala-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O XYOVHPDDWCEUDY-CIUDSAMLSA-N 0.000 description 1
- GFFRWIJAFFMQGM-NUMRIWBASA-N Asn-Glu-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GFFRWIJAFFMQGM-NUMRIWBASA-N 0.000 description 1
- JQSWHKKUZMTOIH-QWRGUYRKSA-N Asn-Gly-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N JQSWHKKUZMTOIH-QWRGUYRKSA-N 0.000 description 1
- WUQXMTITJLFXAU-JIOCBJNQSA-N Asn-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N)O WUQXMTITJLFXAU-JIOCBJNQSA-N 0.000 description 1
- HPNDBHLITCHRSO-WHFBIAKZSA-N Asp-Ala-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)NCC(O)=O HPNDBHLITCHRSO-WHFBIAKZSA-N 0.000 description 1
- UQBGYPFHWFZMCD-ZLUOBGJFSA-N Asp-Asn-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O UQBGYPFHWFZMCD-ZLUOBGJFSA-N 0.000 description 1
- JHFNSBBHKSZXKB-VKHMYHEASA-N Asp-Gly Chemical compound OC(=O)C[C@H](N)C(=O)NCC(O)=O JHFNSBBHKSZXKB-VKHMYHEASA-N 0.000 description 1
- ZSVJVIOVABDTTL-YUMQZZPRSA-N Asp-Gly-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)O)N ZSVJVIOVABDTTL-YUMQZZPRSA-N 0.000 description 1
- PGUYEUCYVNZGGV-QWRGUYRKSA-N Asp-Gly-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PGUYEUCYVNZGGV-QWRGUYRKSA-N 0.000 description 1
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 1
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 1
- SQIARYGNVQWOSB-BZSNNMDCSA-N Asp-Tyr-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQIARYGNVQWOSB-BZSNNMDCSA-N 0.000 description 1
- WAEDSQFVZJUHLI-BYULHYEWSA-N Asp-Val-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O WAEDSQFVZJUHLI-BYULHYEWSA-N 0.000 description 1
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 1
- 102000008203 CTLA-4 Antigen Human genes 0.000 description 1
- 229940045513 CTLA4 antagonist Drugs 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 108010078791 Carrier Proteins Proteins 0.000 description 1
- 108010076119 Caseins Proteins 0.000 description 1
- 108050001186 Chaperonin Cpn60 Proteins 0.000 description 1
- 102000052603 Chaperonins Human genes 0.000 description 1
- 102000004127 Cytokines Human genes 0.000 description 1
- 108090000695 Cytokines Proteins 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 239000012624 DNA alkylating agent Substances 0.000 description 1
- 229940126161 DNA alkylating agent Drugs 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- LVGKNOAMLMIIKO-UHFFFAOYSA-N Elaidinsaeure-aethylester Natural products CCCCCCCCC=CCCCCCCCC(=O)OCC LVGKNOAMLMIIKO-UHFFFAOYSA-N 0.000 description 1
- 241000588722 Escherichia Species 0.000 description 1
- 102000002090 Fibronectin type III Human genes 0.000 description 1
- 108050009401 Fibronectin type III Proteins 0.000 description 1
- 108010067306 Fibronectins Proteins 0.000 description 1
- 102000016359 Fibronectins Human genes 0.000 description 1
- 102000003688 G-Protein-Coupled Receptors Human genes 0.000 description 1
- 108090000045 G-Protein-Coupled Receptors Proteins 0.000 description 1
- 101710198884 GATA-type zinc finger protein 1 Proteins 0.000 description 1
- CRRFJBGUGNNOCS-PEFMBERDSA-N Gln-Asp-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CRRFJBGUGNNOCS-PEFMBERDSA-N 0.000 description 1
- 102000006395 Globulins Human genes 0.000 description 1
- 108010044091 Globulins Proteins 0.000 description 1
- MWMJCGBSIORNCD-AVGNSLFASA-N Glu-Leu-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O MWMJCGBSIORNCD-AVGNSLFASA-N 0.000 description 1
- DTHNMHAUYICORS-KTKZVXAJSA-N Glucagon-like peptide 1 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1N=CNC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 DTHNMHAUYICORS-KTKZVXAJSA-N 0.000 description 1
- 102400000322 Glucagon-like peptide 1 Human genes 0.000 description 1
- NZAFOTBEULLEQB-WDSKDSINSA-N Gly-Asn-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)CN NZAFOTBEULLEQB-WDSKDSINSA-N 0.000 description 1
- JMQFHZWESBGPFC-WDSKDSINSA-N Gly-Gln-Asp Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JMQFHZWESBGPFC-WDSKDSINSA-N 0.000 description 1
- ORXZVPZCPMKHNR-IUCAKERBSA-N Gly-His-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CNC=N1 ORXZVPZCPMKHNR-IUCAKERBSA-N 0.000 description 1
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 1
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 239000012981 Hank's balanced salt solution Substances 0.000 description 1
- SDTPKSOWFXBACN-GUBZILKMSA-N His-Glu-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O SDTPKSOWFXBACN-GUBZILKMSA-N 0.000 description 1
- AIPUZFXMXAHZKY-QWRGUYRKSA-N His-Leu-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AIPUZFXMXAHZKY-QWRGUYRKSA-N 0.000 description 1
- KAXZXLSXFWSNNZ-XVYDVKMFSA-N His-Ser-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KAXZXLSXFWSNNZ-XVYDVKMFSA-N 0.000 description 1
- 101001027128 Homo sapiens Fibronectin Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 102000002265 Human Growth Hormone Human genes 0.000 description 1
- 108010000521 Human Growth Hormone Proteins 0.000 description 1
- 239000000854 Human Growth Hormone Substances 0.000 description 1
- JRHFQUPIZOYKQP-KBIXCLLPSA-N Ile-Ala-Glu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O JRHFQUPIZOYKQP-KBIXCLLPSA-N 0.000 description 1
- FVEWRQXNISSYFO-ZPFDUUQYSA-N Ile-Arg-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N FVEWRQXNISSYFO-ZPFDUUQYSA-N 0.000 description 1
- NBJAAWYRLGCJOF-UGYAYLCHSA-N Ile-Asp-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N NBJAAWYRLGCJOF-UGYAYLCHSA-N 0.000 description 1
- WKSHBPRUIRGWRZ-KCTSRDHCSA-N Ile-Trp-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)NCC(=O)O)N WKSHBPRUIRGWRZ-KCTSRDHCSA-N 0.000 description 1
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 1
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 1
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 1
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102000015696 Interleukins Human genes 0.000 description 1
- 108010063738 Interleukins Proteins 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- QPRQGENIBFLVEB-BJDJZHNGSA-N Leu-Ala-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O QPRQGENIBFLVEB-BJDJZHNGSA-N 0.000 description 1
- ZURHXHNAEJJRNU-CIUDSAMLSA-N Leu-Asp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZURHXHNAEJJRNU-CIUDSAMLSA-N 0.000 description 1
- UCDHVOALNXENLC-KBPBESRZSA-N Leu-Gly-Tyr Chemical compound CC(C)C[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=C(O)C=C1 UCDHVOALNXENLC-KBPBESRZSA-N 0.000 description 1
- 108010006444 Leucine-Rich Repeat Proteins Proteins 0.000 description 1
- QYOXSYXPHUHOJR-GUBZILKMSA-N Lys-Asn-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QYOXSYXPHUHOJR-GUBZILKMSA-N 0.000 description 1
- LMVOVCYVZBBWQB-SRVKXCTJSA-N Lys-Asp-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN LMVOVCYVZBBWQB-SRVKXCTJSA-N 0.000 description 1
- QIJVAFLRMVBHMU-KKUMJFAQSA-N Lys-Asp-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QIJVAFLRMVBHMU-KKUMJFAQSA-N 0.000 description 1
- WAIHHELKYSFIQN-XUXIUFHCSA-N Lys-Ile-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O WAIHHELKYSFIQN-XUXIUFHCSA-N 0.000 description 1
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 1
- PEEHTFAAVSWFBL-UHFFFAOYSA-N Maleimide Chemical compound O=C1NC(=O)C=C1 PEEHTFAAVSWFBL-UHFFFAOYSA-N 0.000 description 1
- 241001465754 Metazoa Species 0.000 description 1
- 108091028043 Nucleic acid sequence Proteins 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 102000000470 PDZ domains Human genes 0.000 description 1
- 108050008994 PDZ domains Proteins 0.000 description 1
- 229920000954 Polyglycolide Polymers 0.000 description 1
- 241000589517 Pseudomonas aeruginosa Species 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- WSTIOCFMWXNOCX-YUMQZZPRSA-N Ser-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N WSTIOCFMWXNOCX-YUMQZZPRSA-N 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- 241000282898 Sus scrofa Species 0.000 description 1
- 108091008874 T cell receptors Proteins 0.000 description 1
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 1
- JQAWYCUUFIMTHE-WLTAIBSBSA-N Thr-Gly-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JQAWYCUUFIMTHE-WLTAIBSBSA-N 0.000 description 1
- FNOQJVHFVLVMOS-AAEUAGOBSA-N Trp-Gly-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N FNOQJVHFVLVMOS-AAEUAGOBSA-N 0.000 description 1
- OZUJUVFWMHTWCZ-HOCLYGCPSA-N Trp-Gly-His Chemical compound N[C@@H](Cc1c[nH]c2ccccc12)C(=O)NCC(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O OZUJUVFWMHTWCZ-HOCLYGCPSA-N 0.000 description 1
- NVZVJIUDICCMHZ-BZSNNMDCSA-N Tyr-Phe-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O NVZVJIUDICCMHZ-BZSNNMDCSA-N 0.000 description 1
- XLDYBRXERHITNH-QSFUFRPTSA-N Val-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)C(C)C XLDYBRXERHITNH-QSFUFRPTSA-N 0.000 description 1
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- 230000021736 acetylation Effects 0.000 description 1
- 238000006640 acetylation reaction Methods 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 238000007792 addition Methods 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 230000000996 additive effect Effects 0.000 description 1
- 230000009824 affinity maturation Effects 0.000 description 1
- 230000004931 aggregating effect Effects 0.000 description 1
- 230000001270 agonistic effect Effects 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 229910021529 ammonia Inorganic materials 0.000 description 1
- 235000019418 amylase Nutrition 0.000 description 1
- 239000004037 angiogenesis inhibitor Substances 0.000 description 1
- 230000003042 antagnostic effect Effects 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 1
- 239000002246 antineoplastic agent Substances 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 239000003809 bile pigment Substances 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 230000006287 biotinylation Effects 0.000 description 1
- 238000007413 biotinylation Methods 0.000 description 1
- 230000002051 biphasic effect Effects 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 239000008366 buffered solution Substances 0.000 description 1
- 238000011088 calibration curve Methods 0.000 description 1
- 125000001314 canonical amino-acid group Chemical group 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 239000005018 casein Substances 0.000 description 1
- 108010079058 casein hydrolysate Proteins 0.000 description 1
- BECPQYXYKAMYBN-UHFFFAOYSA-N casein, tech. Chemical compound NCCCCC(C(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(CC(C)C)N=C(O)C(CCC(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(C(C)O)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(COP(O)(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(N)CC1=CC=CC=C1 BECPQYXYKAMYBN-UHFFFAOYSA-N 0.000 description 1
- 235000021240 caseins Nutrition 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 230000009137 competitive binding Effects 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 229920001577 copolymer Polymers 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 235000014113 dietary fatty acids Nutrition 0.000 description 1
- 239000012470 diluted sample Substances 0.000 description 1
- 238000006471 dimerization reaction Methods 0.000 description 1
- VIYFPAMJCJLZKD-UHFFFAOYSA-L disodium;(4-nitrophenyl) phosphate Chemical compound [Na+].[Na+].[O-][N+](=O)C1=CC=C(OP([O-])([O-])=O)C=C1 VIYFPAMJCJLZKD-UHFFFAOYSA-L 0.000 description 1
- 238000002296 dynamic light scattering Methods 0.000 description 1
- 239000000839 emulsion Substances 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- LVGKNOAMLMIIKO-QXMHVHEDSA-N ethyl oleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC LVGKNOAMLMIIKO-QXMHVHEDSA-N 0.000 description 1
- 229940093471 ethyl oleate Drugs 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 231100000776 exotoxin Toxicity 0.000 description 1
- 239000002095 exotoxin Substances 0.000 description 1
- 239000013604 expression vector Substances 0.000 description 1
- 229930195729 fatty acid Natural products 0.000 description 1
- 239000000194 fatty acid Substances 0.000 description 1
- 150000004665 fatty acids Chemical class 0.000 description 1
- 210000003191 femoral vein Anatomy 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 102000034238 globular proteins Human genes 0.000 description 1
- 108091005896 globular proteins Proteins 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 1
- 108010045126 glycyl-tyrosyl-glycine Proteins 0.000 description 1
- 108010015792 glycyllysine Proteins 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 238000003505 heat denaturation Methods 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 229940047122 interleukins Drugs 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000012804 iterative process Methods 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 210000004901 leucine-rich repeat Anatomy 0.000 description 1
- 239000006166 lysate Substances 0.000 description 1
- 108010009298 lysylglutamic acid Proteins 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 239000002609 medium Substances 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 239000002207 metabolite Substances 0.000 description 1
- 230000011987 methylation Effects 0.000 description 1
- 238000007069 methylation reaction Methods 0.000 description 1
- 230000009149 molecular binding Effects 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 238000002703 mutagenesis Methods 0.000 description 1
- 231100000350 mutagenesis Toxicity 0.000 description 1
- 230000003472 neutralizing effect Effects 0.000 description 1
- 239000000346 nonvolatile oil Substances 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000003204 osmotic effect Effects 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 238000011197 physicochemical method Methods 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 108091009565 pigment binding proteins Proteins 0.000 description 1
- 239000013612 plasmid Substances 0.000 description 1
- 229920000233 poly(alkylene oxides) Polymers 0.000 description 1
- 229920000747 poly(lactic acid) Polymers 0.000 description 1
- 229920001451 polypropylene glycol Polymers 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 239000002244 precipitate Substances 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 150000003141 primary amines Chemical class 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 238000003157 protein complementation Methods 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 238000004445 quantitative analysis Methods 0.000 description 1
- 239000000700 radioactive tracer Substances 0.000 description 1
- 238000007670 refining Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 239000011347 resin Substances 0.000 description 1
- 229920005989 resin Polymers 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 238000010839 reverse transcription Methods 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 238000003118 sandwich ELISA Methods 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 239000007858 starting material Substances 0.000 description 1
- 238000011146 sterile filtration Methods 0.000 description 1
- 239000011550 stock solution Substances 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 230000002195 synergetic effect Effects 0.000 description 1
- 229950001790 tendamistat Drugs 0.000 description 1
- 108010037401 tendamistate Proteins 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 125000003396 thiol group Chemical group [H]S* 0.000 description 1
- 108010061238 threonyl-glycine Proteins 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 231100000167 toxic agent Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 239000003440 toxic substance Substances 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 108700012359 toxins Proteins 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 239000013598 vector Substances 0.000 description 1
Images



Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/62—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being a protein, peptide or polyamino acid
- A61K47/64—Drug-peptide, drug-protein or drug-polyamino acid conjugates, i.e. the modifying agent being a peptide, protein or polyamino acid which is covalently bonded or complexed to a therapeutically active agent
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K19/00—Hybrid peptides, i.e. peptides covalently bound to nucleic acids, or non-covalently bound protein-protein complexes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B01—PHYSICAL OR CHEMICAL PROCESSES OR APPARATUS IN GENERAL
- B01D—SEPARATION
- B01D15/00—Separating processes involving the treatment of liquids with solid sorbents; Apparatus therefor
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/001—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof by chemical synthesis
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4702—Regulators; Modulating activity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2318/00—Antibody mimetics or scaffolds
- C07K2318/20—Antigen-binding scaffold molecules wherein the scaffold is not an immunoglobulin variable region or antibody mimetics
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/20—Fusion polypeptide containing a tag with affinity for a non-protein ligand
- C07K2319/21—Fusion polypeptide containing a tag with affinity for a non-protein ligand containing a His-tag
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/20—Fusion polypeptide containing a tag with affinity for a non-protein ligand
- C07K2319/22—Fusion polypeptide containing a tag with affinity for a non-protein ligand containing a Strep-tag
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/31—Fusion polypeptide fusions, other than Fc, for prolonged plasma life, e.g. albumin
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/55—Fusion polypeptide containing a fusion with a toxin, e.g. diphteria toxin
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/60—Fusion polypeptide containing spectroscopic/fluorescent detection, e.g. green fluorescent protein [GFP]
Landscapes
- Chemical & Material Sciences (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Medicinal Chemistry (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Engineering & Computer Science (AREA)
- Gastroenterology & Hepatology (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Toxicology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- General Chemical & Material Sciences (AREA)
- Epidemiology (AREA)
- Immunology (AREA)
- Biotechnology (AREA)
- Wood Science & Technology (AREA)
- General Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Physics & Mathematics (AREA)
- Plant Pathology (AREA)
- Microbiology (AREA)
- Analytical Chemistry (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Medicinal Preparation (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
Abstract
描述了新设计的对血清白蛋白具有结合特异性的重复蛋白、以及编码这类血清白蛋白结合蛋白的核酸、包含这类蛋白的药物组合物、这类蛋白用于改变治疗相关多肽的药代动力学的用途、和这类蛋白用于治疗疾病的用途。与不结合血清白蛋白的蛋白相比,本发明的重复蛋白在血浆中具有大幅增加的半衰期。
Description
技术领域
本发明涉及设计的对血清白蛋白具有结合特异性的重复蛋白、以及编码这类血清白蛋白结合蛋白的核酸、包含这类蛋白的药物组合物、这类蛋白用于改变生物活性化合物的药代动力学的用途、和这类蛋白在疾病治疗中的用途。
背景技术
制药工业热烈渴求通过调节或增加生物活性化合物(诸如蛋白治疗剂)的体内药代动力学(PK)性质来增加它们的有效性。就通过肾清除从循环中快速地消除的生物活性化合物而言,尤其如此。肾脏通常会从循环中滤出具有低于60 kDa的表观分子量的分子。改善如此小的生物活性化合物的药代动力学性质的一个策略是,简单地增加它们的表观分子大小(即增加它们的流体动力学半径),例如通过添加非蛋白性聚合物部分诸如聚乙二醇聚合物或糖残基,或添加蛋白性聚合物部分诸如球状蛋白或未结构化的多肽,诸如在WO 2007/103515和WO 2008/155134中描述的那些。
其它策略利用血清蛋白(诸如免疫球蛋白和血清白蛋白)的长循环半衰期。具有67kDa分子量的血清白蛋白是血浆中的最丰富的蛋白,以约50 mg/ml (0.6 mM)存在,且在人类中具有19天的血清半衰期。血清白蛋白帮助维持血浆pH,有助于胶体血压(colloidalblood pressure),对许多代谢物和脂肪酸起载体的作用,并充当血浆的主要药物运输蛋白。已经描述了白蛋白中的几个主要的小分子结合位点。
已经证实,与血清白蛋白的非共价结合可以延长短寿命的小分子或多肽的半衰期(WO 1991/001743)。与血清白蛋白特异性地结合并由此可以延长与其偶联的其它分子的体内半衰期的多肽包括:细菌白蛋白结合域的变体(例如WO 2005/097202和WO 2009/016043),小肽(例如Dennis, M.S., 等人, J. Biol. Chem. 277(3), 35035-43, 2002和WO 2001/045746)和免疫球蛋白片段(例如WO 2008/043822、WO 2004/003019、WO 2008/043821、WO 2006/040153、WO 2006/122787和WO 2004/041865)。WO 2008/043822涉及除了免疫球蛋白片段以外的其它结合蛋白,诸如基于蛋白A结构域、淀粉酶抑肽(tendamistat)、纤连蛋白、脂质运载蛋白、CTLA-4、T-细胞受体、设计的锚蛋白重复序列和PDZ结构域的分子,可能制备它们来特异性地结合血清白蛋白。尽管如此,WO 2008/043822既没有公开设计的对血清白蛋白(SA)具有结合特异性的锚蛋白重复结构域的选择,也没有公开与SA特异性地结合的重复结构域的具体重复序列基序。此外,据称,通过多肽与血清白蛋白的遗传融合,可以延长所述多肽的体内半衰期(例如WO 1991/001743)。药物的体内半衰期的这种改变可能积极地改变它们的药代动力学(PK)和/或药物动力学(PD) 性质。在新的和有效的治疗剂和疾病治疗方法的开发中,这是一个关键问题。因此,本领域需要改变生物活性化合物的PK和/或PD的新途径。
除了抗体以外,新颖的结合蛋白或结合域也可以用于特异性地结合靶分子(例如Binz, H.K., Amstutz, P.和Plückthun, A., Nat. Biotechnol. 23, 1257-1268,2005)。一类这样的新颖的结合蛋白或结合域是基于设计的重复蛋白或设计的重复结构域(WO 2002/020565; Binz, H.K., Amstutz, P., Kohl, A., Stumpp, M.T., Briand, C.,Forrer, P., Grütter, M.G., 和Plückthun, A., Nat. Biotechnol. 22, 575-582,2004; Stumpp, M.T., Binz, H.K和Amstutz, P., Drug Discov. Today 13, 695-701,2008)。WO 2002/020565描述了如何构建重复蛋白的大文库和它们的一般用途。尽管如此,WO 2002/020565既没有公开对SA具有结合特异性的重复结构域的选择,也没有公开与SA特异性地结合的重复结构域的具体重复序列基序。此外,WO 2002/020565没有提示,对SA具有结合特异性的重复结构域可以用于调节其它分子的PK或PD。这些设计的重复结构域利用重复蛋白的模块性质,并具有N-端和C-端加帽模块,以通过屏蔽所述结构域的疏水核心来防止设计的重复结构域发生聚集(Forrer, P., Stumpp, M.T., Binz, H.K.和Plückthun,A., FEBS letters 539, 2-6, 2003)。这些加帽模块是基于天然的鸟嘌呤-腺嘌呤-结合蛋白(GA-结合蛋白)的加帽重复序列。经显示,通过改进从GA-结合蛋白衍生出的C-端加帽重复序列,可以进一步增加这些设计的锚蛋白重复结构域的热稳定性和热力学稳定性(Interlandi, G., Wetzel, S.K, Settanni, G., Plückthun, A.和Caflisch, A., J.Mol. Biol. 375, 837-854, 2008; Kramer, M.A, Wetzel, S.K., Plückthun, A.,Mittl, P.R.E,和Grütter, M.G., J. Mol. Biol. 404, 381-391, 2010)。所述作者将共8个突变引入了该加帽模块,并通过添加3个独特氨基酸来延长了它的C-端螺旋。尽管如此,这些修饰在C-端加帽模块中的引入,导致设计的携带该突变的C-端加帽模块的重复结构域的不希望的二聚化趋势。因而,需要制备锚蛋白重复结构域的进一步优化的C-端加帽模块或C-端加帽重复序列。
利用目前可得到的方案靶向SA来调节PK和/或PD,并非总是有效的。甚至日趋明显的是,通过结合(hijacking)SA来调节分子的PK和/或PD是复杂的,且仍然没有被充分理解。
总之,需要改进的对SA具有特异性的结合蛋白,其能够改善用于治疗癌症和其它病理学状况的治疗相关分子或多肽的PK和/或PD。
本发明要解决的技术问题是,鉴定新颖的结合蛋白(诸如对SA具有结合特异性的重复结构域),其能够改变用于癌症和其它病理学状况的改善治疗的治疗相关分子的PK和/或PD。通过提供在权利要求书中表征的实施方案,实现了该技术问题的解决方案。
发明概述
本发明涉及包含至少一个锚蛋白重复结构域的结合蛋白,其中所述锚蛋白重复结构域对哺乳动物血清白蛋白具有结合特异性,且其中所述锚蛋白重复结构域包含锚蛋白重复模块,所述锚蛋白重复模块具有选自下述的氨基酸序列:SEQ ID NO:49、50、51和52,和这样的序列,其中在SEQ ID NO:49、50、51和52中的最多9个氨基酸被任意氨基酸替换。
在另一个实施方案中,本发明涉及包含至少一个锚蛋白重复结构域的结合蛋白,其中所述重复结构域对哺乳动物血清白蛋白具有结合特异性,且其中所述锚蛋白重复结构域包含与选自下述的一个锚蛋白重复结构域具有至少70%氨基酸序列同一性的氨基酸序列:SEQ ID NO: 17-31和43-48,其中所述锚蛋白重复结构域的在1位处的G和/或在2位处的S任选地缺失。
具体地,本发明涉及如上文定义的结合蛋白,其中所述锚蛋白重复结构域与选自下述的锚蛋白重复结构域竞争结合哺乳动物血清白蛋白:SEQ ID NO: 17-31和43-48。
此外,本发明涉及这样的包含生物活性化合物的结合蛋白,尤其是包含的生物活性化合物在哺乳动物中的终末血浆半衰期与所述未修饰的生物活性化合物的终末血浆半衰期相比高至少2倍的结合蛋白。
本发明另外涉及编码本发明的结合蛋白的核酸分子,以及包含一种或更多种上述结合蛋白或核酸分子的药物组合物。
本发明另外涉及使用本发明的结合蛋白治疗病理学状况的方法。
附图说明
图1.通过SEC对选择的DARPin的稳定性分析。
用Superdex 200柱5/150 (图1a或图1b)或用superdex200 10/300GL (图1c)分析的对xSA具有特异性的DARPin在下述情况下的尺寸排阻色谱法(SEC)运行的洗脱曲线:温育前(图1a),在PBS中在40℃以30 mg/ml (约2 mM)温育28天以后(图1b),或在-80℃贮存1个月以后(图1c)。如在实施例1中所述,表达和纯化所有样品。为了SEC分析,将样品稀释至500µM的浓度。用箭头指示了分子质量标准品抑酶肽(AP) 6.5 kDa、碳酸酐酶(CA) 29 kDa和伴清蛋白(CO) 75 kDa。
,哺乳动物血清白蛋白,A,在280 nm的吸光度;t,按分钟计的保留时间;
DARPin #19 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:19);
DARPin #20 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:20);
DARPin #21 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:21);
DARPin #22 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:22);
DARPin #27 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:27);
DARPin #28 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:28);
DARPin #29 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:29);
DARPin #30 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:30)。
DARPin #43 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:43)。
DARPin #44 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:44)。
DARPin #45 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:45)。
DARPin #46 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:46)。
DARPin #47 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:47)。
DARPin #48 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:48)。
图2. 选择的DARPin的热稳定性。
对xSA具有特异性的DARPin在pH 7.4的PBS中(图2a)和在pH 5.8的MES缓冲液(250mM (2-N-吗啉代)-乙磺酸pH 5.5)、150 mM NaCl以1:4 (v/v)与pH 7.4的PBS混合,并将pH调至5.8)中(图2b) 的热变性迹线(通过存在于缓冲液中的染料SYPRO Orange的荧光强度增加来跟踪)。
,相对荧光单位(RFU),在515-535 nm激发,在560-580 nm检测;T,按℃计的温度;DARPin的定义参见上文。
图3.选择的DARPin在小鼠中的血浆清除率。
在小鼠中评估了对MSA (小鼠血清白蛋白)具有特异性的DARPin和对照DARPin的血浆清除率。
(图3a) 与对MSA没有结合特异性的DARPin #32 (参见下文)相比,包含仅一个对MSA具有结合特异性的重复结构域的DARPin。
(图3b) 与对MSA没有结合特异性的DARPin #32相比,包含2个蛋白结构域(其中之一是对MSA具有结合特异性的重复结构域) 的DARPin。
经由His-标签(His-Tag),用99mTc-羰基化合物标记DARPin,并静脉内地注射给小鼠。在注射后的不同时间点测量被注射的小鼠的血液的放射性,并显示为针对99mTc的放射性衰变校正过的注射剂量的比率(%ID)。拟合曲线显示了在不同时间点处测量的放射性的非线性回归的结果——两阶段衰变(Graphpad Prism)。每个数据点代表每组2只小鼠的平均值。
,针对99mTc的放射性衰变校正过的注射剂量百分比;t,按小时计的时间;
DARPin #18 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:18);
DARPin #23 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:23);
DARPin #25 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:25);
DARPin #32 (对xSA没有结合特异性的阴性对照DARPin,具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:32);
DARPin #33 (包含2个重复结构域的DARPin,其中一个重复结构域对xSA具有结合特异性,具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:33);
DARPin #35 (包含2个重复结构域的DARPin,其中一个重复结构域对xSA具有结合特异性,具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:35);
DARPin #36 (包含2个重复结构域的DARPin,其中一个重复结构域对xSA具有结合特异性,具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:36)。
图4.选择的DARPin在食蟹猴(cynomolgus monkeys)中的血浆清除率。
在食蟹猴中评估了对CSA (食蟹猴血清白蛋白)具有特异性的DARPin和对照DARPin的血浆清除率。
(图4a) 将DARPin #26与对CSA没有结合特异性的DARPin #32进行了对比。
(图4b) 将DARPin #24、34和17与对CSA没有结合特异性的DARPin #32进行了对比。在t = 0小时,以0.5 mg/ml (DARPin #26、DARPin #24、DARPin #17和DARPin #32)或1mg/ml (DARPin #34)的浓度,将下述DARPin静脉内地注射给食蟹猴:在注射后的不同时间点,通过ELISA测量猴血浆中的DARPin浓度。曲线显示了在不同时间点测得的浓度的非线性回归的结果——两阶段衰变(Graphpad Prism)。从第二阶段,可以确定DARPin的终末血浆半衰期。每个单独数据点代表同一血清样品的2次独立ELISA测量的平均值。
,按nM计的DARPin浓度;t,按小时计的时间;
DARPin #17 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:17);
DARPin #24 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:24);
DARPin #26 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:26);
DARPin #32 (对xSA没有结合特异性的阴性对照DARPin,具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:32);
DARPin #34 (包含2个重复结构域的DARPin,其中一个重复结构域对xSA具有结合特异性,具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:34)。
具体实施方式
根据本发明的结合域对哺乳动物血清白蛋白(xSA)是特异性的。优选地,根据本发明的结合域对小鼠、大鼠、狗、兔、猴或人起源的血清白蛋白是特异性的。更优选地,根据本发明的结合域对人起源的血清白蛋白(HSA)是特异性的。
术语“蛋白”指多肽,其中多肽的至少部分具有或者能够在其多肽链内和/或之间通过形成二级、三级或四级结构获得限定的三维排列。如果蛋白包含两条或更多条多肽,则每条多肽链可非共价连接或者例如通过两条多肽之间的二硫键共价连接。各自具有或者能够通过形成二级或三级结构获得限定的三维排列的蛋白部分,称为“蛋白结构域”。此类蛋白结构域为本领域技术人员熟知。
在重组蛋白、重组蛋白结构域、重组结合蛋白等中使用的术语“重组”意指,所述多肽通过使用相关领域技术人员熟知的重组DNA技术制备。例如,可将编码多肽的重组DNA分子(如通过基因合成制备)克隆入细菌表达质粒(例如pQE30,Qiagen)、酵母表达质粒或哺乳动物表达质粒内。当例如将这样构建的重组细菌表达质粒插入适当的细菌(例如大肠杆菌(Escherichia coli))时,该细菌可产生由这种重组DNA编码的多肽。相应产生的多肽称为重组多肽。
在本发明范围内,术语“多肽”是指由经肽键连接的多个(即两个或更多个)氨基酸的一条或多条链组成的分子。优选地,多肽由超过八个经肽键连接的氨基酸组成。
术语“多肽标签”指连接于多肽/蛋白的氨基酸序列,其中所述氨基酸序列可用于纯化、检测或靶向所述多肽/蛋白,或者其中所述氨基酸序列改善多肽/蛋白的物理化学行为,或者其中所述氨基酸序列具备效应子功能。结合蛋白的个别多肽标签、部分和/或结构域相互之间可直接或经多肽接头连接。这些多肽标签在本领域众所周知,本领域技术人员完全可获得。多肽标签的实例是允许检测所述多肽/蛋白的小的多肽序列,例如His (例如SEQ ID NO:15的His-标签)、myc、FLAG或者Strep-标签或部分诸如酶(例如酶如碱性磷酸酶),或者可用于靶向(诸如免疫球蛋白或其片段)和/或作为效应分子的部分。
术语“多肽接头”指氨基酸序列,它能够连接例如两个蛋白结构域,多肽标签和蛋白结构域,蛋白结构域和非多肽部分诸如聚乙二醇,或两个序列标签。相关领域技术人员已知此类另外的结构域、标签、非多肽部分和接头。在专利申请WO 2002/020565的说明书中提供实例的列表。此类接头的具体实例是各种长度的甘氨酸-丝氨酸-接头和脯氨酸-苏氨酸-接头;优选所述接头具有2至24个氨基酸的长度;更优选所述接头具有2至16个氨基酸的长度。在SEQ ID NO:16中提供了甘氨酸-丝氨酸-接头的一个实例。
术语“聚合物部分”指蛋白性聚合物部分或者非蛋白性聚合物部分。“蛋白性聚合物部分”优选是这样的多肽,其在室温(RT)以约0.1 mM浓度在磷酸盐缓冲盐水(PBS) 中贮存1月时,不形成稳定的三级结构,同时不形成超过10% ,优选不超过5%;还优选不超过2%;甚至更优选不超过1%;最优选没有可检测到的量的通过尺寸排阻色谱法(SEC)确定的寡聚体或聚集体。当使用球蛋白作为SEC的分子量标准时,此类蛋白性聚合物部分以高于其有效分子量的表观分子量在SEC中运行。优选通过SEC确定的所述蛋白性聚合物部分的表观分子量为用其氨基酸序列计算的其有效分子量的1.5x、2x或2.5x。还优选通过SEC确定的所述非蛋白性聚合物部分的表观分子量为用其分子组成计算的其有效分子量的2x、4x或8x。优选所述蛋白性聚合物部分超过50%、70%或甚至90%氨基酸以约0.1 mM浓度在PBS中在RT下不形成稳定的二级结构,通过圆二色性(CD)测量确定。最优选所述蛋白性聚合物显示无规卷曲构象的典型近UV CD-谱。本领域技术人员熟知此类CD分析。还优选的是,由超过50、优选超过100、200、300、400、500、600、700或最优选超过800个氨基酸组成的蛋白性聚合物部分。蛋白性聚合物部分的实例是XTEN®(Amunix的注册商标; WO 2007/103515)多肽,或者包含脯氨酸、丙氨酸和丝氨酸残基的多肽,如在WO 2008/155134中所述。通过用标准DNA克隆技术制备基因融合多肽,可将此类蛋白性聚合物部分共价连接于例如本发明的结合域,接着进行标准表达和纯化。
本发明的聚合物部分在分子量上可宽泛地变化(即约1 kDa至约150 kDa)。优选所述聚合物部分具有至少2、更优选至少5、10、20、30、50、70或最优选至少100 kDa的分子量。优选所述聚合物部分通过多肽接头与结合域连接。
非蛋白性聚合物部分的实例是羟乙基淀粉(HES)、聚乙二醇(PEG)、聚丙二醇或聚氧化烯。术语“聚乙二醇化”意指PEG部分共价连接于例如本发明的多肽。
在具体实施方案中,PEG部分或任何其它非蛋白性聚合物可以例如经马来酰亚胺接头与半胱氨酸巯基偶联,半胱氨酸经肽接头与本文所述结合域的N-或C-端偶联。
术语“结合蛋白”指包含一个或多个结合域、一个或多个生物活性化合物和一个或多个聚合物部分的蛋白,如下文进一步解释。优选所述结合蛋白包含至多四个结合域。更优选所述结合蛋白包含至多两个结合域。最优选所述结合蛋白只包含一个结合域。而且,任何此类结合蛋白可包含非结合域的另外的蛋白结构域、多聚化部分、多肽标签、多肽接头和/或单个Cys残基。多聚化部分的实例是免疫球蛋白重链恒定区(其配对以提供功能性免疫球蛋白Fc域),和亮氨酸拉链或者包含在两条此类多肽之间形成分子间二硫键的游离巯基的多肽。单个Cys残基可用于使其它部分与多肽缀合,例如通过使用本领域技术人员熟知的马来酰亚胺化学。优选地,所述结合蛋白是重组结合蛋白。也优选地,结合蛋白的结合域具有不同的靶标特异性。
术语“结合域”意指表现与蛋白支架相同的“折叠”(三维排列)且具有如下文限定的预定性质的蛋白结构域。此类结合域可通过合理的,或者最通常是组合的蛋白工程技术的本领域已知的技术获得(Binz等, 2005, 在上述引文中)。例如,具有预定性质的结合域可通过包含以下步骤的方法获得:(a)提供表现与如下文进一步限定的蛋白支架相同的折叠的不同蛋白结构域集合;和(b)筛选所述不同的集合和/或从所述不同集合选择以获得至少一种具有所述预定性质的蛋白结构域。不同的蛋白结构域集合可根据所用筛选和/或选择系统通过几种方法提供,并可包括使用本领域技术人员熟知的方法,诸如噬菌体展示或核糖体展示。优选地,所述结合域是重组结合域。
术语“蛋白支架”意指具有其中高度耐受氨基酸插入、取代或缺失的暴露表面区域的蛋白。可用于产生本发明结合域的蛋白支架实例是抗体或其片段诸如单链Fv或Fab片段,来自金黄色葡萄球菌(Staphylococcus aureus)的蛋白A,来自大菜粉蝶(Pieris brassicae)的后胆色素结合蛋白或其它脂质运载蛋白,锚蛋白重复蛋白或其它重复蛋白,和人纤连蛋白。本领域技术人员已知蛋白支架(Binz等, 2005, 在上述引文中; Binz等,2004, 在上述引文中)。
术语“预定性质”指诸如结合靶标、阻断靶标、激活靶标介导的反应、酶活性和相关其它性质等性质。根据期望的性质类型,普通技术人员将能够鉴定用于进行筛选和/或选择具有期望性质的结合域的格式和必需步骤。优选所述预定性质是结合靶标。
下文关于重复蛋白的定义基于专利申请WO 2002/020565。专利申请WO 2002/020565进一步含有重复蛋白特征、技术和应用的一般描述。
术语“重复蛋白”指包含一个或多个重复结构域的蛋白。优选每个所述重复蛋白包含至多四个重复结构域。更优选每个所述重复蛋白包含至多两个重复结构域。最优选每个重复蛋白只包含一个重复结构域。而且,所述重复蛋白可包含另外的非重复蛋白结构域、多肽标签和/或多肽接头。
术语“重复结构域”指包含两个或更多个连续重复单元(模块)作为结构单元的蛋白结构域,其中所述结构单元具有相同的折叠,并紧密堆叠以产生例如具有接合疏水核心的超螺旋结构。优选地,重复结构域另外包含N-端和/或C-端加帽单元(或模块)。甚至更优选地,所述N-端和/或C-端加帽单元(或模块)是加帽重复序列。
术语“设计的重复蛋白”和“设计的重复结构域”分别指通过专利申请WO 2002/020565中解释的发明程序获得的重复蛋白或重复结构域。设计的重复蛋白和设计的重复结构域是合成的,并非出于天然。它们分别是通过对应设计的核酸的表达所得的人造蛋白或结构域。优选表达是在真核或原核细胞诸如细菌细胞中进行,或者通过使用无细胞体外表达系统进行。因此,设计的锚蛋白重复蛋白(即DARPin) 与包含至少一个锚蛋白重复结构域的本发明的结合蛋白对应。
术语“结构单元”指局部有序的多肽部分,其通过沿多肽链相互靠近的两个或更多个二级结构区段之间的三维相互作用形成。此类结构单元表现结构基序。术语“结构基序”指存在于至少一个结构单元中的二级结构元件的三维排列。本领域技术人员熟知结构基序。单独的结构单元不能获得限定的三维排列;但是,它们的连续排列,例如作为重复结构域的重复模块,导致相邻单元的相互稳定,产生超螺旋结构。
术语“重复单元”指包含一种或多种天然存在的重复蛋白的重复序列基序的氨基酸序列,其中所述“重复单元”以多个拷贝出现,且其表现确定蛋白折叠的所有所述基序共同的限定的折叠拓扑学。这样的重复单元对应于:Forrer等人(2003, 在上述引文中)所述的重复蛋白的“重复结构单元(重复序列)”,或Binz等人(2004, 在上述引文中)所述的重复蛋白的“连续同源结构单元(重复序列)”。此类重复单元包含框架残基和相互作用残基。此类重复单元的实例是犰狳重复单元、富亮氨酸重复单元、锚蛋白重复单元、三十四肽重复单元、HEAT重复单元和富亮氨酸变体重复单元。含有两个或更多个此类重复单元的天然存在的蛋白称为“天然存在的重复蛋白”。重复蛋白的各重复单元的氨基酸序列相互之间比较时可具有显著数量的突变、取代、添加和/或缺失,但仍然基本保留重复单元的一般模式或基序。
术语“锚蛋白重复单元”是指这样的重复单元,它是例如Forrer等人(2003, 在上述引文中)所述的锚蛋白重复序列。锚蛋白重复序列是本领域技术人员熟知的。
术语“框架残基”是指重复单元的氨基酸残基,或重复模块的相应氨基酸残基,其参予折叠拓扑学,即其参予所述重复单元(或模块)的折叠或其参予与相邻单元(或模块)的相互作用。这类参予可以是与重复单元(或模块)中的其它残基的相互作用,或对α-螺旋或β-折叠中存在的多肽主链构象或形成线型多肽或环的氨基酸段的影响。
术语“靶标相互作用残基”是指重复单元的氨基酸残基,或重复模块的相应氨基酸残基,其参予与靶物质的相互作用。这类参予可以是与靶物质的直接相互作用,或对其它直接相互作用残基的影响,例如通过稳定重复单元(或模块)的多肽构象以允许或增强直接相互作用残基与所述靶标的相互作用。这类框架和靶标相互作用残基可以通过以下方法鉴定:对通过物理化学方法(诸如X-射线晶体学、NMR和/或CD光谱法)获得的结构数据进行分析,或与结构生物学和/或生物信息学领域的技术人员公知的已知的和相关的结构信息进行比较。
优选地,用于推断重复序列基序的重复单元是同源重复单元,其中所述重复单元包括相同的结构基序,并且其中所述重复单元的超过70%的框架残基是彼此同源的。优选地,所述重复单元的超过80%的框架残基是同源的。最优选地,所述重复单元的超过90%的框架残基是同源的。用于确定多肽之间同源性百分比的计算机程序(诸如Fasta、Blast或Gap)是本领域技术人员已知的。进一步优选地,用于推断重复序列基序的重复单元是从靶标上选择的重复结构域获得(如实施例1所述)并具有相同靶标特异性的同源重复单元。
术语“重复序列基序”是指从一个或多个重复单元或重复模块推断得出的氨基酸序列。优选地,所述重复单元或重复模块来自于对相同靶标具有结合特异性的重复结构域。这类重复序列基序包括框架残基位置和靶标相互作用残基位置。所述框架残基位置对应于重复单元(或模块)的框架残基的位置。同样,所述靶标相互作用残基位置对应于重复单元(或模块)的靶标相互作用残基的位置。重复序列基序包括固定位置和随机化位置。术语“固定位置”是指这样的重复序列基序中的氨基酸位置,其中所述位置被设置为特定氨基酸。最常见的是,这类固定位置对应于框架残基的位置和/或对某靶标特异性的靶标相互作用残基的位置。术语“随机化位置”表示这样的重复序列基序中的氨基酸位置,其中在所述氨基酸位置允许两个或更多个氨基酸,例如,其中允许任意的常见的二十种天然存在的氨基酸,或其中允许二十种天然存在氨基酸的大部分,诸如除了半胱氨酸以外的氨基酸,或除了甘氨酸、半胱氨酸和脯氨酸以外的氨基酸。最常见的是,这类随机化位置对应靶标相互作用残基的位置。但是,框架残基的一些位置也可以是随机化的。
术语“折叠拓扑学”指所述重复单元或重复模块的三级结构。折叠拓扑学取决于形成α-螺旋或β-折叠的至少部分的氨基酸段,或者形成线型多肽或环,或者α-螺旋、β-折叠和/或线型多肽/环的任何组合的氨基酸段。
术语“连续”指这样的排列,其中重复单元或重复模块串联排列。在设计的重复蛋白中,有至少2个,通常为约2至6个,特别是至少约6个,经常是20个或更多个重复单元(或模块)。在大多数情况下,重复结构域的重复单元(或模块) 将表现高度的序列同一性(在对应位置的相同氨基酸残基)或序列相似性(氨基酸残基不同,但具有相似的物理化学性质),以及一些氨基酸残基可能是非常保守的关键残基。但是,在重复结构域的不同重复单元(或模块)之间因氨基酸插入和/或缺失和/或取代所致的高度序列变异性将是可能的,只要维持重复单元(或模块)的共同折叠拓扑学。
本领域技术人员熟知通过物理化学方式诸如X-射线晶体学、NMR或CD光谱学直接确定重复蛋白的折叠拓扑学的方法。在生物信息学领域充分建立了且本领域技术人员熟知鉴定和确定重复单元或重复序列基序或者鉴定包含此类重复单元或基序的相关蛋白家族的方法,诸如同源性检索(BLAST等)。精化初始重复序列基序的步骤可包含迭代过程。
术语“重复模块”指设计的重复结构域的重复氨基酸序列,它们最初来自天然存在重复蛋白的重复单元。包含在重复结构域中的各重复模块来自天然存在重复蛋白家族或亚家族(如犰狳重复蛋白或锚蛋白重复蛋白的家族)的一种或多种重复单元。
“重复模块”可包含具有存在于对应重复模块的所有拷贝中的氨基酸残基的位置(“固定位置”)和具有不同或“随机化”氨基酸残基的位置(“随机化位置”)。
根据本发明的结合蛋白包含至少一个锚蛋白重复结构域,其中所述重复结构域对哺乳动物血清白蛋白(xSA)具有结合特异性。
术语“对靶标具有结合特异性”、“特异性地结合靶标”或“靶标特异性”等是指,结合蛋白或结合域在PBS中与靶标结合的解离常数低于与诸如大肠杆菌麦芽糖结合蛋白(MBP)等无关蛋白结合的解离常数。优选地,在PBS中对靶标的解离常数比对MBP的相应解离常数低至少10倍、更优选102倍、甚至更优选103倍或最优选104倍。
本发明的结合蛋白不是抗体或其片段,诸如Fab或scFv片段。本领域技术人员熟知抗体及其片段。
并且,本发明的结合域不包含免疫球蛋白折叠(如存在于抗体中)和/或III型纤连蛋白结构域。免疫球蛋白折叠是常见的全β蛋白折叠,由排列在两个β折叠中的约7条反向平行β-链的2层夹心组成。本领域技术人员熟知免疫球蛋白折叠。例如,此类包含免疫球蛋白折叠的结合域描述于WO 2007/080392或WO 2008/097497。
具体地,本发明涉及包含至少一个锚蛋白重复结构域的结合蛋白,其中所述锚蛋白重复结构域对哺乳动物血清白蛋白具有结合特异性,且其中所述锚蛋白重复结构域包含锚蛋白重复模块,所述锚蛋白重复模块具有选自下述的氨基酸序列:SEQ ID NO:49、50、51和52,和这样的序列,其中在SEQ ID NO:49、50、51和52中的最多9个氨基酸被任意氨基酸替换。
优选地,在SEQ ID NO:49、50、51和52中的最多8个氨基酸被其它氨基酸替换,在SEQ ID NO:49、50、51和52中更优选最多7个氨基酸、更优选最多6个氨基酸、更优选最多5个氨基酸、甚至更优选最多4个氨基酸、更优选最多3个氨基酸、更优选最多2个氨基酸、更优选最多1个氨基酸,和最优选零个氨基酸被替换。
优选地,当SEQ ID NO:49、50、51和52中的氨基酸被替换时,这些氨基酸选自:A、D、E、F、H、I、K、L、M、N、Q、R、S、T、V、W和Y;更优选地选自:A、D、E、H、I、K、L、Q、R、S、T、V和Y。也优选地,氨基酸被同源氨基酸替换;即氨基酸被含有具有类似生物物理性质的侧链的氨基酸替换。例如,带负电荷的氨基酸D可以被带负电荷的氨基酸E替换,或者疏水氨基酸诸如L可以被A、I或V替换。同源氨基酸对氨基酸的替换是本领域技术人员熟知的。
优选的结合蛋白包含至少一个锚蛋白重复结构域,其中所述重复结构域在PBS中与xSA结合的解离常数(Kd) 低于10-4M。优选地,所述重复结构域在PBS中与xSA结合的Kd低于10-4M,更优选地低于10-5M、10-6M、10-7M,或最优选地低于10-8M。
用于确定蛋白-蛋白相互作用的解离常数的方法,诸如基于表面等离子体共振(SPR)的技术(例如SPR平衡分析)或等温滴定量热法(ITC),是本领域技术人员熟知的。如果在不同条件(例如,盐浓度、pH)下测量,测得的特定蛋白-蛋白相互作用的Kd值可以变化。因而,优选地用标准化的蛋白溶液和标准化的缓冲液(诸如PBS),进行Kd值的测量。
在实施例中显示了包含锚蛋白重复结构域的结合蛋白,所述锚蛋白重复结构域在PBS中以低于10-4M的Kd与xSA结合。
本发明的结合蛋白的锚蛋白重复结构域会结合xSA。优选的是,包含与人血清白蛋白(HSA)结合的锚蛋白重复结构域的结合蛋白。
进一步优选的是,包含70-300个氨基酸、尤其是100-200个氨基酸的结合域。
进一步优选的是,不含游离Cys残基的结合蛋白或结合域。“游离Cys残基”不参与二硫键的形成。甚至更优选的是,不含任何Cys残基的结合蛋白或结合域。
本发明的结合域是锚蛋白重复结构域或设计的锚蛋白重复结构域(Binz等人,2004, 在上述引文中),优选地如在WO 2002/020565中所述。设计的锚蛋白重复结构域的实例显示在实施例中。
在另一个实施方案中,本发明涉及包含至少一个锚蛋白重复结构域的结合蛋白,其中所述重复结构域对哺乳动物血清白蛋白具有结合特异性,且其中所述锚蛋白重复结构域包含与选自下述的一个锚蛋白重复结构域具有至少70%氨基酸序列同一性的氨基酸序列:SEQ ID NO: 17-31和43-48,其中所述锚蛋白重复结构域的在1位处的G和/或在2位处的S任选地缺失。
优选地,在本发明的结合蛋白中的这种锚蛋白重复结构域包含与选自下述的一个锚蛋白重复结构域具有至少70% 氨基酸序列同一性的氨基酸序列:SEQ ID NO: 21、27和46;优选地27和46。如上所定义的,所述锚蛋白重复结构域在PBS中与xSA结合的解离常数(Kd)低于10-4M。优选地,所述重复结构域在PBS中与xSA结合的Kd低于10-4M,更优选地低于10-5M、10-6M、10-7M,或最优选地低于10-8M。
优选地,在本发明的结合蛋白中的这种锚蛋白重复结构域包含与在选自下述的锚蛋白重复结构域中的“随机化重复单元”或“随机化位置”具有至少70%氨基酸序列同一性的氨基酸序列:SEQ ID NO: 17-31和43-48。
优选地,作为70% 氨基酸序列同一性的替代,在本发明的结合蛋白中的这种锚蛋白重复结构域具有至少75%、更优选至少80%、更优选至少85%、更优选至少90%或最优选至少95% 的氨基酸序列同一性的氨基酸序列。
在一个具体实施方案中,对哺乳动物血清白蛋白具有结合特异性的结合蛋白(通过替换SEQ ID NO:49、50、51和52的锚蛋白重复模块中的最多9个氨基酸来定义,或者通过与选自SEQ ID NO: 17-31和43-48的一个锚蛋白重复结构域具有至少70% 氨基酸序列同一性来定义)在哺乳动物中的终末血浆半衰期比不与哺乳动物血清白蛋白结合的对应结合蛋白(例如SEQ ID NO:32的锚蛋白重复结构域)高至少5倍。在这样的优选的结合蛋白中,在人类中的最小终末血浆半衰期是至少1天,更优选至少3天,甚至更优选至少5天。
在另一个实施方案中,本发明涉及这样的结合蛋白,其中所述锚蛋白重复结构域包含具有下述锚蛋白重复序列基序的重复模块:X1DX2X3X4X5TPLHLAAX6X7GHLX8IVEVLLKX9GADVNA (SEQ ID NO:53)
其中X1、X2、X3、X4、X5、X6、X7、X8和X9、彼此独立地代表选自下述的氨基酸残基:A、D、E、F、H、I、K、L、M、N、Q、R、S、T、V、W和Y;
优选地,其中
X1代表选自下述的氨基酸残基:A、D、M、F、S、I、T、N、Y和K;更优选K和A;
X2代表选自下述的氨基酸残基:E、K、D、F、M、N、I和Y;更优选I、E和Y;
X3代表选自下述的氨基酸残基:W、R、N、T、H、K、A和F;更优选W、R和F;
X4代表选自下述的氨基酸残基:G和S;
X5代表选自下述的氨基酸残基:N、T和H;
X6代表选自下述的氨基酸残基:N、V和R;
X7代表选自下述的氨基酸残基:E、Y、N、D、H、S、A、Q、T和G;更优选E、Y和N;
X8代表选自下述的氨基酸残基:E和K;
X9代表选自下述的氨基酸残基:S、A、Y、H和N;更优选Y和H;且
其中任选地最多5个在SEQ ID NO:53中用X表示的位置以外的氨基酸被任意氨基酸替换。
具体地,本发明涉及这样的结合蛋白,其中所述锚蛋白重复结构域包含具有下述锚蛋白重复序列基序的重复模块:X1DX2X3GX4TPLHLAAX5X6GHLEIVEVLLKX7GADVNA (SEQ IDNO:10)
其中
X1代表选自下述的氨基酸残基:A、D、M、F、S、I、T、N、Y和K;优选K和A;
X2代表选自下述的氨基酸残基:E、K、D、F、M、N、I和Y;优选I、E和Y;
X3代表选自下述的氨基酸残基:W、R、N、T、H、K、A和F;优选W、R和F;
X4代表选自下述的氨基酸残基:N、T和H;
X5代表选自下述的氨基酸残基:N、V和R;
X6代表选自下述的氨基酸残基:E、Y、N、D、H、S、A、Q、T和G;优选E、Y和N;
X7代表选自下述的氨基酸残基:S、A、Y、H和N;优选Y和H;且
其中任选地最多5个在SEQ ID NO:10中用X表示的位置以外的氨基酸被任意氨基酸替换。
在另一个实施方案中,本发明涉及这样的结合蛋白,其中所述锚蛋白重复结构域包含具有下述锚蛋白重复序列基序的重复模块:
X1DYFX2HTPLHLAARX3X4HLX5IVEVLLKX6GADVNA (SEQ ID NO:11)
其中
X1代表选自下述的氨基酸残基:D、K和A;优选地K和A;
X2代表选自下述的氨基酸残基:D、G和S;优选地G和S;
X3代表选自下述的氨基酸残基:E、N、D、H、S、A、Q、T和G;优选地Q、D和N;更优选Q和N;
X4代表选自下述的氨基酸残基:G和D;
X5代表选自下述的氨基酸残基:E、K和G;优选地E和K;
X6代表选自下述的氨基酸残基:H、Y、A和N;优选地H、A和Y;更优选A和Y;且
其中任选地最多5个在SEQ ID NO:11中用X表示的位置以外的氨基酸被任意氨基酸替换。
在另一个实施方案中,本发明涉及这样的结合蛋白,其中所述锚蛋白重复结构域包含具有下述锚蛋白重复序列基序的重复模块:
X1DFX2G X3TPLHLAAX4X5GHLEIVEVLLKX6GADVNA (SEQ ID NO:54)
其中
X1代表选自下述的氨基酸残基:F、S、L和K;优选S和K;
X2代表选自下述的氨基酸残基:V和A;
X3代表选自下述的氨基酸残基:R和K;
X4代表选自下述的氨基酸残基:S和N;
X5代表选自下述的氨基酸残基:N、D、Q、S、A、T和E;优选地D和Q;
X6代表选自下述的氨基酸残基:A、H、Y、S和N;优选A和H;且
其中任选地最多5个在SEQ ID NO:54中用X表示的位置以外的氨基酸被任意氨基酸替换。
具体地,本发明涉及这样的结合蛋白,其中所述锚蛋白重复结构域包含具有下述锚蛋白重复序列基序的重复模块:
X1DFX2G X3TPLHLAAX4DGHLEIVEVLLKX5GADVNA (SEQ ID NO:12)
其中
X1代表选自下述的氨基酸残基:F、S、L和K;优选地S和K;
X2代表选自下述的氨基酸残基:V和A;
X3代表选自下述的氨基酸残基:R和K;
X4代表选自下述的氨基酸残基:S和N;
X5代表选自下述的氨基酸残基:A、H、Y、S和N;优选地A和H;且
其中任选地最多5个在SEQ ID NO:12中用X表示的位置以外的氨基酸被任意氨基酸替换。
优选的是这样的结合蛋白,其中所述锚蛋白重复结构域包含具有SEQ ID NO:12的锚蛋白重复序列基序的重复模块,该重复模块前面是具有SEQ ID NO:11的锚蛋白重复序列基序的重复模块。
在另一个实施方案中,本发明涉及这样的结合蛋白,其中所述锚蛋白重复结构域包含具有下述锚蛋白重复序列基序的重复模块:
X1DX2X3GTTPLHLAAVYGHLEX4VEVLLKX5GADVNA (SEQ ID NO:13)
其中
X1代表选自下述的氨基酸残基:K、A、D、M、F、S、I、T、N和Y;优选地K和A;
X2代表选自下述的氨基酸残基:E、K、D、F、M、N和Y;优选地E、D和Y;
X3代表选自下述的氨基酸残基:R、N、T、H、K、A和F;优选地R和F;
X4代表选自下述的氨基酸残基:I和M;
X5代表选自下述的氨基酸残基:H、Y、K、A和N;优选地K和A;且
其中任选地最多5个在SEQ ID NO:13中用X表示的位置以外的氨基酸被任意氨基酸替换。
在另一个实施方案中,本发明涉及这样的结合蛋白,其中所述锚蛋白重复结构域包含具有下述锚蛋白重复序列基序的重复模块:
X1NETGYTPLHLADSSGHX2EIVEVLLKX3X4X5DX6NA (SEQ ID NO:14)
其中
X1代表选自下述的氨基酸残基:Q和K;
X2代表选自下述的氨基酸残基:L和P;
X3代表选自下述的氨基酸残基:H、N、Y和A;优选地H和A;
X4代表选自下述的氨基酸残基:G和S;
X5代表选自下述的氨基酸残基:A、V、T和S;优选地S和A;
X6代表选自下述的氨基酸残基:V和F;和其中任选地最多5个在SEQ ID NO:14中用X表示的位置以外的氨基酸被任意氨基酸替换。
优选的是这样的结合蛋白,其中所述锚蛋白重复结构域包含具有SEQ ID NO:14的锚蛋白重复序列基序的重复模块,该重复模块前面是具有SEQ ID NO:13的锚蛋白重复序列基序的重复模块。
术语“加帽模块”指与重复结构域的N-端或C-端重复模块融合的多肽,其中所述加帽模块与所述重复模块形成紧密的三级相互作用(即三级结构相互作用),从而提供帽,其将所述重复模块的疏水核心在不与连续重复模块接触的侧部与溶剂隔开。所述N-端和/或C-端加帽模块可以是,或者可来自,存在于天然存在的重复蛋白中邻近重复单元的加帽单元或其它结构单元。术语“加帽单元”指天然存在的折叠多肽,其中所述多肽限定在N-端或C-端与重复单元融合的特定结构单元,其中所述多肽与所述重复单元形成紧密的三级结构相互作用,从而提供帽,其将所述重复单元的疏水核心在一侧与溶剂隔开。优选地,加帽模块或加帽单元是加帽重复序列。术语“加帽重复序列”表示这样的加帽模块或加帽单元:其具有与所述邻近重复单元(或模块)类似或相同的折叠、和/或与所述邻近重复单元(或模块)的序列相似性。加帽模块和加帽重复序列参见:WO 2002/020565,和Interlandi等人,2008 (在上述引文中)。例如,WO 2002/020565描述了具有下述氨基酸序列的N-端加帽模块(即加帽重复序列):
GSDLGKKLLEAARAGQDDEVRILMANGADVNA (SEQ ID NO:1),和
具有下述氨基酸序列的C-端加帽模块(即加帽重复序列)
QDKFGKTAFDISIDNGNEDLAEILQKLN (SEQ ID NO:2)。
等人, 2008 (在上述引文中) 描述了具有下述氨基酸序列的C-端加帽模块:QDKFGKTPFDLAIREGHEDIAEVLQKAA (SEQ ID NO:3)和QDKFGKTPFDLAIDNGNEDIAEVLQKAA (SEQID NO:4)。
例如,SEQ ID NO:17的N-端加帽模块由1-32位的氨基酸编码,SEQ ID NO:17的C-端加帽模块由99-126位的氨基酸编码。
一种优选的N-端加帽模块包含下述序列基序
X1LX2KKLLEAARAGQDDEVRILX3AX4GADVNA (SEQ ID NO:5)
其中X1代表氨基酸残基G、A或D;
其中X2代表氨基酸残基G或D;
其中X3代表氨基酸残基L、V、I、A或M;优选地,L或M;且
其中X4代表氨基酸残基A、H、Y、K、R或N;优选地,A或N。
进一步优选的是,任意这样的包含N-端加帽重复序列的N-端加帽模块,其中所述加帽重复序列中的一个或多个氨基酸残基被特定氨基酸残基替换,所述特定氨基酸残基在比对相应加帽单元或重复单元时存在于对应位置处。
一种优选的C-端加帽模块包含下述序列基序
X1DKX2GKTX3X4D X5X6X7DX8GX9EDX10AEX11LQKAA (SEQ ID NO:6)
其中X1代表氨基酸残基Q或K;
其中X2代表氨基酸残基A、S或F;优选地,S或F;
其中X3代表氨基酸残基A或P;
其中X4代表氨基酸残基A或F;
其中X5代表氨基酸残基I或L;
其中X6代表氨基酸残基S或A;
其中X7代表氨基酸残基I或A;
其中X8代表氨基酸残基A、E或N;优选地,A或N;
其中X9代表氨基酸残基N或H;
其中X10代表氨基酸残基L或I;
其中X11代表氨基酸残基I或V;且
其中如果X4代表F、且X7代表I、且X8代表N或E,那么X2不代表F。
另一种优选的C-端加帽模块包含下述序列基序
X1DKX2GKTX3ADX4X5X6DX7GX8EDX9AEX10LQKAA (SEQ ID NO:7)
其中X1代表氨基酸残基Q或K;
其中X2代表氨基酸残基A、S或F;优选地,S或F;
其中X3代表氨基酸残基A或P;
其中X4代表氨基酸残基I或L;
其中X5代表氨基酸残基S或A;
其中X6代表氨基酸残基I或A;
其中X7代表氨基酸残基A、E或N;优选地,A或N;
其中X8代表氨基酸残基N或H;
其中X9代表氨基酸残基L或I;且
其中X10代表氨基酸残基I或V。
另一种优选的C-端加帽模块包含下述序列基序
X1DKX2GKTX3ADX4X5ADX6GX7EDX8AEX9LQKAA (SEQ ID NO:8)
其中X1代表氨基酸残基Q或K;
其中X2代表氨基酸残基A、S或F;优选地,S或F;
其中X3代表氨基酸残基A或P;
其中X4代表氨基酸残基I或L;
其中X5代表氨基酸残基S或A;
其中X6代表氨基酸残基A、E或N;优选地,A或N;
其中X7代表氨基酸残基N或H;
其中X8代表氨基酸残基L或I;且
其中X9代表氨基酸残基I或V。
优选地,这样的包含SEQ ID NO:6、7或8的序列基序的C-端加帽模块在与所述序列基序的3位相对应的位置处具有氨基酸残基A、I或K;优选,I或K。
也优选地,这样的包含SEQ ID NO:6、7或8的序列基序的C-端加帽模块在与所述序列基序的14位相对应的位置处具有氨基酸残基R或D。
一种优选的C-端加帽模块是具有下述氨基酸序列的C-端加帽模块:QDKSGKTPADLAADAGHEDIAEVLQKAA (SEQ ID NO:9)。
进一步优选的是,具有SEQ ID NO:9的氨基酸序列的C-端加帽模块,其中
在1位的氨基酸残基是Q或K;
在4位的氨基酸残基是S或F;
在9位的氨基酸残基是A或F;
在13位的氨基酸残基是A或I;
在15位的氨基酸残基是A、E或N;且
其中所述C-端加帽模块不具有SEQ ID NO:2、3或4的氨基酸序列。
进一步优选的是这样的C-端加帽模块,其具有在与SEQ ID NO:9或2比对时具有至少70%、优选至少75%、80%、85%、90%或最优选至少95% 氨基酸序列同一性的氨基酸序列。优选地,所述C-端加帽模块在比对时在与SEQ ID:9的4位相对应的位置处的氨基酸残基是S,所述C-端加帽模块在比对时在与SEQ ID:9的9位相对应的位置处的氨基酸残基是A,所述C-端加帽模块在比对时在与SEQ ID:9的13位相对应的位置处的氨基酸残基是A,和/或所述C-端加帽模块在比对时在与SEQ ID:9的15位相对应的位置处的氨基酸残基是A。进一步优选地,所述C-端加帽模块在比对时在与SEQ ID:9的9位相对应的位置处的氨基酸残基是A,和/或所述C-端加帽模块在比对时在与SEQ ID:9的13位相对应的位置处的氨基酸残基是A。也优选地,所述C-端加帽模块包含28个氨基酸。
进一步优选的是这样的C-端加帽模块,其具有SEQ ID NO:2或9的氨基酸序列,其中
所述C-端加帽模块的一个或多个氨基酸残基被特定氨基酸替换,所述特定氨基酸在比对对应的C-端加帽重复序列或加帽单元时存在于对应位置处,且其中
在4位的氨基酸残基是S;
在9位的氨基酸残基是A;
在13位的氨基酸残基是A;和/或者
在15位的氨基酸残基是A。
优选地,所述C-端加帽模块的最多30%的氨基酸残基被替换,更优选最多20%和甚至更优选最多10% 的氨基酸残基被替换。也优选地,这样的C-端加帽模块是天然存在的C-端加帽重复序列。
还优选的是这样的C-端加帽模块,其包含基于SEQ ID NO:9的任意上述C-端加帽模块的1-25位或1-26位的氨基酸。
进一步优选的是这样的C-端加帽模块,其具有不包含氨基酸N和随后的G的氨基酸序列。
还优选的是这样的C-端加帽模块,其与基于SEQ ID NO:9的任意上述C-端加帽模块或与SEQ ID NO:9本身具有至少70%、优选至少75%、80%、85%、90%、或最优选至少95% 氨基酸序列同一性。
进一步优选的是这样的C-端加帽模块,其与SEQ ID NO:2或9具有至少70%、优选至少75%、80%、85%、90%或最优选至少95% 氨基酸序列同一性,且其中所述C-端加帽模块具有在9位处的氨基酸A;优选地,所述C-端加帽模块具有在9和13位处的氨基酸A;更优选地,所述C-端加帽模块具有在9、13和15位处的氨基酸A;最优选地,所述C-端加帽模块具有在9、13和15位处的氨基酸A和在4位处的氨基酸S。
进一步优选的是这样的C-端加帽模块,其不具有在14位处的氨基酸R,和/或不具有在15位处的氨基酸E。
还优选的是这样的C-端加帽模块,其不具有与SEQ ID NO:2、3或4相同的氨基酸序列。
进一步优选的是这样的C-端加帽模块,其具有基于SEQ ID NO:9的氨基酸序列,其中所述C-端加帽模块具有在26、27和28位处的选自下述的氨基酸:A、L、R、M、K和N;更优选A、L、R和K;且最优选K、A和L。
通过组合本领域技术人员已知的技术(诸如氨基酸序列比对、诱变和基因合成),可以用本发明的加帽模块替换重复结构域的加帽模块。例如,可以如下用SEQ ID NO:9的C-端加帽重复序列替换SEQ ID NO:17的C-端加帽重复序列:(i) 通过与SEQ ID NO:9进行序列比对,确定SEQ ID NO:17的C-端加帽重复序列(即序列位置99-126),(ii) 用SEQ ID NO:9的序列替换确定的SEQ ID NO:17的C-端加帽重复序列的序列,(iii) 制备编码重复结构域的基因,所述重复结构域编码替换的C-端加帽模块,(iv) 在大肠杆菌的细胞质中表达修饰的重复结构域,和(v) 通过标准方式纯化修饰的重复结构域。
此外,可以如下遗传地构建本发明的重复结构域:借助于基因合成,装配N-端加帽模块(即SEQ ID NO:1的N-端加帽重复序列),继之以一个或多个重复模块(即包含SEQ IDNO:17的33-98位氨基酸残基的重复模块)和C-端加帽模块(即SEQ ID NO:9的C-端加帽重复序列)。然后可以如上所述在大肠杆菌中表达遗传地装配的重复结构域基因。
还优选的是这样的结合蛋白,其中所述锚蛋白重复结构域或设计的锚蛋白重复结构域包含具有SEQ ID NO:6、7或8的序列基序的C-端加帽模块,其中所述加帽模块具有在3位处的氨基酸I,且其中所述重复模块的前面是具有SEQ ID NO:12的锚蛋白重复序列基序的重复模块。
进一步优选的是,具有不含氨基酸C、M或N的氨基酸序列的结合蛋白、重复结构域、N-端加帽模块或C-端加帽模块。
进一步优选的是,具有不含氨基酸N和随后的G的氨基酸序列的结合蛋白、重复结构域、N-端加帽模块或C-端加帽模块。
进一步优选的是,任意这样的包含C-端加帽重复序列的C-端加帽模块,其中所述加帽重复序列中的一个或多个氨基酸残基被特定氨基酸残基替换,所述特定氨基酸残基在比对相应加帽单元或重复单元时存在于对应位置处。
进一步优选的是,包含任意这样的N-端或C-端加帽模块的结合蛋白。
这样的C-端加帽模块的氨基酸序列的实例是,在SEQ ID NO:19、21、27、28、38、40和42中的99-126位的氨基酸序列。实施例6证实,通过用本发明的加帽模块替换它们的C-端加帽模块,可以增加重复结构域的热稳定性。
术语“靶标”指个别分子诸如核酸分子、多肽或蛋白、碳水化合物,或者任何其它天然存在的分子,包括此类个别分子的任何部分,或者两个或更多个此类分子的复合物。靶标可以是整个细胞或组织样品,或者可以是任何非天然的分子或部分。优选靶标是天然存在或非天然的多肽或者含有化学修饰的多肽,例如通过天然或非天然的磷酸化、乙酰化或甲基化修饰。在本发明的特定应用中,靶标是xSA。
术语“xSA”表示哺乳动物血清白蛋白,诸如得自小鼠、大鼠、兔、狗、猪、猴或人的血清白蛋白。术语“MSA”表示小鼠血清白蛋白(UniProtKB/Swiss-Prot基本登录号P07724),术语“CSA”表示食蟹猴(即成束猴(macaca fascicularis)) 血清白蛋白(UniProtKB/Swiss-Prot基本登录号A2V9Z4),术语“HSA”表示人血清白蛋白(UniProtKB/Swiss-Prot基本登录号P02768)。
术语“共有序列”指氨基酸序列,其中所述共有序列通过多个重复单元的结构和/或序列比对获得。使用两个或更多个经结构和/或序列比对的重复单元并且在比对时允许空位,可以确定各位置最常见的氨基酸残基。共有序列是包含在各位置最常出现的氨基酸的序列。在其中两种或更多种氨基酸超过平均数地出现在单个位置的情况下,共有序列可包括那些氨基酸的子集。所述两个或更多个重复单元可取自包含在单种重复蛋白中或者来自两种或更多种不同的重复蛋白的重复单元。
本领域技术人员熟知共有序列及其确定方法。
“共有氨基酸残基”是见于共有序列的特定位置的氨基酸。如果两种或更多种,如三、四或五种氨基酸残基以相似概率见于所述两个或更多个重复单元中,共有氨基酸可以是最常见的氨基酸之一或者所述两种或更多种氨基酸残基的组合。
进一步优选非天然存在的加帽模块、重复模块、结合蛋白或结合域。
术语“非天然存在的”意指合成的或不来自天然,更具体来讲,术语意指用人手制造。术语“非天然存在的结合蛋白”或“非天然存在的结合域”意指所述结合蛋白或所述结合域是合成的(即通过化学合成用氨基酸制备)或重组的且不来自天然。“非天然存在的结合蛋白”或“非天然存在的结合域”分别是通过对应设计的核酸表达获得的人造蛋白或结构域。优选表达在真核或细菌细胞中进行,或者通过使用无细胞体外表达系统进行。而且,术语意指所述结合蛋白或所述结合域的序列不作为非人造序列条目存在于序列数据库,例如GenBank、EMBL-Bank或Swiss-Prot中。本领域技术人员熟知这些数据库及其它相似的序列数据库。
本发明涉及包含结合域的结合蛋白,其中所述结合域是锚蛋白重复结构域且特异性地结合xSA,其中所述结合蛋白和/或结合域在PBS中热解折叠以后具有高于40℃的中点变性温度(Tm),并在最高10 g/L的浓度在PBS中在37℃温育1天时形成小于5% (w/w) 的不溶性聚集体。
术语“PBS”意指含有137 mM NaCl、10 mM磷酸盐和2.7 mM KCl且具有pH 7.4的磷酸盐缓冲水溶液。
优选地,所述结合蛋白和/或结合域在pH 7.4的PBS中或在pH 5.8的MES缓冲液中热解折叠以后具有高于45℃,更优选高于50℃,更优选高于55℃,和最优选高于60℃的中点变性温度(Tm)。本发明的结合蛋白或结合域在生理条件下具有确定的二级和三级结构。这样的多肽的热解折叠会导致它的三级和二级结构的丧失,这可以通过例如圆二色性(CD)测量来跟踪。结合蛋白或结合域在热解折叠以后的中点变性温度与这样的温度相对应:通过将温度从10℃缓慢地升高至约100℃使所述蛋白或结构域热变性以后,在生理缓冲液中的协同转变的中点处的温度。在热解折叠以后的中点变性温度的确定,是本领域技术人员熟知的。结合蛋白或结合域在热解折叠以后的该中点变性温度会指示所述多肽的热稳定性。
还优选的是这样的结合蛋白和/或结合域,其在最高20 g/L、优选地最高40 g/L、更优选最高60 g/L、甚至更优选最高80 g/L和最优选最高100 g/L的浓度,当在PBS中在37℃温育超过5天、优选地超过10天、更优选地超过20天、更优选地超过40天和最优选地超过100天时,形成小于5% (w/w)的不溶性聚集体。通过肉眼可见沉淀的出现、凝胶过滤或动态光散射(其在不溶性聚集体形成后强烈增加),可以检测不溶性聚集体的形成。通过在10’000 x g离心10分钟,可以从蛋白样品中除去不溶性聚集体。优选地,结合蛋白和/或结合域在PBS中在37℃的所述温育条件下形成小于2%、更优选地小于1%、0.5%、0.2%、0.1%或最优选地小于0.05% (w/w)的不溶性聚集体。可以如下确定不溶性聚集体的百分比:使不溶性聚集体与可溶性蛋白分离,随后通过标准定量方法确定在可溶性级分和不溶性级分中的蛋白量。
还优选的是,在含有100 mM二硫苏糖醇(DTT)的PBS中在37℃温育1或10小时后不丧失其自然三维结构的结合蛋白和/或结合域。
在一个特定实施方案中,本发明涉及包含结合域的结合蛋白,所述结合域是锚蛋白重复结构域,其特异性地结合xSA,并具有如上文限定的所示或优选的中点变性温度和非聚集性质,其中所述结合蛋白在哺乳动物中的终末血浆半衰期比不结合血清蛋白(诸如xSA)的结合域高至少5倍。
优选地,所述结合域在哺乳动物中的终末血浆半衰期比不结合血清蛋白(诸如xSA)的结合域高至少10倍、更优选至少20倍、40倍、100倍、300倍或最优选至少103倍。
也优选地,所述结合域不结合xSA,这表现为与xSA结合的Kd高于10-4M、更优选高于10-3M或最优选高于10-2M。不结合xSA的结合域的一个实例是SEQ ID NO:32的重复结构域。
进一步优选地,所述结合域是重复结构域,且与SEQ ID NO:32的重复结构域相比,或者与DARPin #32、DARPin #41或DARPin #42相比,其在哺乳动物中的终末血浆半衰期高(即长)至少5倍、更优选至少10倍、20倍、40倍、100倍、300倍或最优选至少103倍。
一种优选的结合蛋白包含对HSA具有结合特异性的结合域,其在人类中具有超过1天、更优选超过3天、5天、7天、10天、15天或最优选超过20天的终末血浆半衰期。
通过本领域技术人员熟知的测定(Toutain, P.L., 和Bousquet-Mélou, A., J.Vet. Pharmacol. Ther. 27(5), 427-439, 2004),可以确定结合域的终末血浆半衰期。在实施例中给出了确定终末血浆半衰期的实例。
术语药物(诸如本发明的结合蛋白或结合域)的“终末血浆半衰期”表示,施用给哺乳动物的药物在达到假平衡以后,达到血浆浓度的半数所需的时间。该半衰期没有被定义为消除施用给哺乳动物的药物的半数剂量所需的时间。
在一个具体实施方案中,本发明涉及包含结合域的结合蛋白,所述结合域是锚蛋白重复结构域,特异性地结合xSA,且所述结合蛋白包含生物活性化合物。
术语“生物活性化合物”表示,当施用给具有疾病的哺乳动物时,会改变所述疾病的化合物。生物活性化合物可以具有拮抗或激动性质,且可以是蛋白性生物活性化合物或非蛋白性生物活性化合物。
通过用标准DNA克隆技术制备基因融合多肽,可将这样的蛋白性生物活性化合物共价连接至例如本发明的结合域,接着进行标准表达和纯化。例如,DARPin #36包含对人生长因子(即生物活性化合物)具有结合特异性的重复结构域和随后的对HSA具有结合特异性的重复结构域。
通过化学方法,例如,经由马来酰亚胺接头与半胱氨酸巯基偶联,其中半胱氨酸经由肽接头与本文所述的结合域的N-或C-端偶联,可以将这样的非蛋白性生物活性化合物共价连接至例如本发明的结合域。
蛋白性生物活性化合物的实例是,具有独特靶标特异性的结合域(例如通过结合生长因子来中和它)、细胞因子(例如白介素)、生长因子(例如人生长激素)、抗体及其片段、激素(例如GLP-1)和任何可能的蛋白性药物。
非蛋白性生物活性化合物的实例是,毒素(例如得自免疫原(ImmunoGen)的DM1)、靶向GPCR的小分子、抗生素和任何可能的非蛋白性药物。
在一个具体实施方案中,本发明涉及包含锚蛋白重复结构域的结合蛋白,所述锚蛋白重复结构域特异性地结合xSA,且所述结合蛋白另外包含生物活性化合物,其中所述结合蛋白在哺乳动物中的终末半衰期比所述未修饰的生物活性化合物的终末半衰期高至少2倍,其中所述更高的终末半衰期由所述重复结构域赋予给所述结合蛋白。
优选地,所述结合蛋白在哺乳动物中的终末血浆半衰期比所述未修饰的生物活性化合物高至少5倍、更优选至少10倍、20倍、40倍、100倍、300倍或最优选至少103倍。
另一个优选的实施方案是这样的重组结合蛋白,其包含特异性地结合xSA的结合域,且其中所述结合域是锚蛋白重复结构域或设计的锚蛋白重复结构域。这类锚蛋白重复结构域可以包含1个、2个、3个或更多个内部重复模块,所述重复模块将参与结合xSA。优选地,这类锚蛋白重复结构域包含N-端加帽模块、2-4个内部重复模块和C-端加帽模块。优选地,所述结合域是锚蛋白重复结构域或设计的锚蛋白重复结构域。也优选地,所述加帽模块是加帽重复序列。
具体地,本发明涉及如上文定义的结合蛋白,其中所述锚蛋白重复结构域与选自下述的锚蛋白重复结构域竞争结合哺乳动物血清白蛋白:SEQ ID NO: 17-31和43-48;优选SEQ ID NO: 17-31;更优选SEQ ID NO:19、21、27和28,尤其是SEQ ID NO:19和27。
最优选的是这样的结合蛋白,其中所述锚蛋白重复结构域选自:SEQ ID NO: 17-31和43-48,其中所述锚蛋白重复结构域的在1位处的G和/或在2位处的S任选地缺失。
也优选地,所述重复结构域与选自DARPin #17-31和43-48的结合蛋白竞争结合xSA。优选地,所述重复结构域与选自DARPin #19、21、27、28、45、46、47和48的结合蛋白竞争结合xSA。更优选地,所述重复结构域与结合蛋白DARPin #19、45、46、48或27竞争结合xSA;甚至更优选地,所述重复结构域与结合蛋白DARPin #46或27竞争结合xSA。
术语“竞争结合”意指本发明的两种不同结合域不能同时与相同靶标结合,但两者各自能够与相同靶标结合。因此,这样的两种结合域竞争结合所述靶标。优选地,所述两种竞争性结合域会结合在所述靶标上的重叠或相同结合表位。本领域技术人员熟知确定两种结合域是否竞争结合靶标的方法,诸如竞争性酶联免疫吸附测定(ELISA)或竞争性SPR测量(如通过使用BioRad的Proteon仪器)。
另一个优选的实施方案是这样的结合蛋白,其包含选自下述的对xSA具有结合特异性的重复结构域:SEQ ID NO:17-31的重复结构域。优选地,所述重复结构域是SEQ IDNO:19、21、27或28的重复结构域。更优选地,所述重复结构域是SEQ ID NO:19的重复结构域。还更优选地,所述重复结构域是SEQ ID NO:21的重复结构域。还更优选地,所述重复结构域是SEQ ID NO:27的重复结构域。还更优选地,所述重复结构域是SEQ ID NO:28的重复结构域。
进一步优选的是这样的结合蛋白,其中所述对xSA具有结合特异性的重复结构域包含与所述重复结构域集合的重复结构域具有至少70% 氨基酸序列同一性的氨基酸序列。优选地,所述氨基酸序列同一性是至少75%、更优选至少80%、更优选至少85%、更优选至少90%和最优选至少95%。
进一步优选的是这样的结合蛋白,其中所述对xSA具有结合特异性的重复结构域包含这样的重复模块,其与所述重复结构域集合的重复结构域的重复模块具有至少70%氨基酸序列同一性。优选地,所述氨基酸序列同一性是至少75%、更优选至少80%、更优选至少85%、更优选至少90%和最优选至少95%。
进一步优选的是这样的结合蛋白,其中所述结合蛋白包含2个或更多个所述对xSA具有结合特异性的重复结构域。优选地,所述结合蛋白包含2个或3个所述重复结构域。所述2个或更多个重复结构域具有相同的或不同的氨基酸序列。
在根据本发明的包含重复结构域的结合蛋白的另一个优选的实施方案中,所述重复结构域的重复模块的一个或多个氨基酸残基被比对重复单元时在对应位置上发现的氨基酸残基替换。优选地,最多30%的氨基酸残基被替换,更优选地,最多20%,和甚至更优选地,最多10%的氨基酸残基被替换。最优选地,这类重复单元是天然存在的重复单元。
在根据本发明的包含重复结构域的结合蛋白的另一个优选的实施方案中,所述重复结构域的N-端加帽模块的一个或多个氨基酸残基被比对N-端加帽单元时在对应位置上发现的氨基酸残基替换。优选地,最多30%的氨基酸残基被替换,更优选地,最多20%,和甚至更优选地,最多10%的氨基酸残基被替换。最优选地,这类N-端加帽单元是天然存在的N-端加帽单元。
在根据本发明的包含重复结构域的结合蛋白的另一个优选的实施方案中,所述重复结构域的C-端加帽模块的一个或多个氨基酸残基被比对C-端加帽单元时在对应位置上发现的氨基酸残基替换。优选地,最多30%的氨基酸残基被替换,更优选地,最多20%,和甚至更优选地,最多10%的氨基酸残基被替换。最优选地,这类C-端加帽单元是天然存在的C-端加帽单元。
在另一个具体实施方案中,最多30%的氨基酸残基,更优选地,最多20%,和甚至更优选地,最多10%的氨基酸残基被不是在重复单元、N-端加帽单元或C-端加帽单元的对应位置发现的氨基酸替换。
在其它实施方案中,本文描述的任一种xSA结合蛋白或结构域可以与一个或多个额外部分共价结合,所述额外部分包括例如结合不同靶标以产生双特异性结合剂的部分、生物活性化合物、标记部分(例如荧光标记诸如荧光素,或放射性示踪剂)、促进蛋白纯化的部分(例如小肽标签,诸如His-或strep-标签)、提供改善的治疗效果的效应物功能的部分(例如提供抗体依赖性细胞介导的细胞毒性的抗体Fc部分,毒性蛋白部分诸如铜绿假单胞 菌(Pseudomonas aeruginosa)外毒素A (ETA)或小分子毒性剂诸如美登木素生物碱或DNA烷化剂)或提供改善的药代动力学的部分。可以根据感知的治疗需要评估改善的药代动力学。经常希望增加生物利用度和/或增加给药之间的时间,其可能通过增加给药后血清中的蛋白维持可用的时间实现。在一些情况下,希望改善蛋白血清浓度随时间的连续性(例如,减少在施用后不久的浓度和下次施用前不久的浓度之间的蛋白血清浓度差异)。
在另一个实施方案中,本发明涉及编码特定结合蛋白、特定N-端加帽模块或特定C-端加帽模块的核酸分子。此外,还涉及包含所述核酸分子的载体。
此外,涉及药物组合物,其包含一种或更多种上述结合蛋白(尤其是包含重复结构域的结合蛋白)、或编码特定结合蛋白的核酸分子、以及任选的药学上可接受的载体和/或稀释剂。药学上可接受的载体和/或稀释剂是本领域技术人员已知的,将在下文更详细的解释。更进一步,涉及包括一种或更多种上述结合蛋白(尤其是包含重复结构域的结合蛋白)的诊断组合物。
药物组合物包含如上所述的结合蛋白和药学上可接受的载体、赋形剂或稳定剂例如如在Remington's Pharmaceutical Sciences第16版, Osol, A. 编[1980]中所述。技术人员已知的合适载体、赋形剂或稳定剂是盐水、林格溶液、葡萄糖(dextrose)溶液、汉克氏(Hank's)溶液、非挥发油、油酸乙酯、5%葡萄糖盐水、提高等渗性和化学稳定性的物质、缓冲剂和防腐剂。其它合适载体包括本身不引起产生对接受组合物的个体有害的抗体的任何载体,诸如蛋白、多糖、聚乳酸、聚乙醇酸、聚合氨基酸和氨基酸共聚物。药物组合物还可以是组合制剂,其包含另外的活性剂,诸如抗癌剂或抗血管生成剂。
将用于体内给药的制剂必须消毒或无菌。这通过过滤用无菌过滤膜容易完成。
药物组合物可通过技术人员知识范围内的任何合适方法给药。优选的给药途径是胃肠外。在胃肠外给药中,将本发明的药物配制成与如上文限定的与药学上可接受的赋形剂组合的单位剂量可注射形式,诸如溶液剂、混悬剂或乳剂。给药的剂量和方式将取决于将治疗的个体和具体疾病。一般而言,施用药物组合物,使得以1 μg/kg至20 mg/kg、更优选10μg/kg至5 mg/kg、最优选0.1至2 mg/kg的剂量施用本发明的结合蛋白。优选其以推注剂量(bolus dose)给药。也可使用连续输注,包括经渗透性微型泵连续皮下递送。如果这样的话,可将药物组合物以5至20 μg/kg/分钟、更优选7至15 μg/kg/分钟的剂量输注。
此外,考虑将任一种上述药物组合物用于病症的治疗。
本发明另外提供了治疗方法。所述方法包括:给有此需要的患者施用治疗有效量的本发明的结合蛋白。
此外,考虑到治疗哺乳动物(包括人类)的病理学状况的方法,所述方法包括:给有此需要的患者施用有效量的上述药物组合物。
根据本发明的结合蛋白可通过几种方法获得和/或进一步进化,诸如在噬菌体(WO1990/002809、WO 2007/006665)或细菌细胞(WO 1993/010214)表面上展示、核糖体展示(WO1998/048008)、质粒展示(WO 1993/008278)、或者通过使用共价的RNA-重复蛋白杂合构建体(WO 2000/032823),或者例如通过蛋白互补测定(WO 1998/341120)进行的细胞内表达和选择/筛选。本领域技术人员已知此类方法。
用于选择/筛选根据本发明的结合蛋白的锚蛋白重复蛋白文库,可根据本领域技术人员已知的方案获得(WO 2002/020565, Binz, H.K., 等人, J. Mol. Biol., 332,489-503, 2003,和Binz等人, 2004, 在上述引文中)。在实施例1给出了此类文库用于选择xSA特异性的DARPin的用途。类似地,如上文提出的锚蛋白重复序列基序可用于建立可用于选择或筛选xSA特异性的DARPin的锚蛋白重复蛋白文库。此外,使用标准重组DNA技术(例如WO 2002/020565, Binz等人, 2003, 在上述引文中和Binz等人, 2004, 在上述引文中),可以从本发明的重复模块和适当的加帽模块或加帽重复序列模块地(modularly)装配本发明的重复结构域(Forrer, P., 等人, FEBS letters 539, 2-6, 2003) 。
本发明不限于在实施例描述的特定实施方案。按照下文描述的概要可使用和处理其它来源。
实施例
下文公开的所有起始原料和试剂已为本领域技术人员所知,且可商购得到或者可用众所周知的技术制备。
材料
化学品购自Fluka (瑞士)。寡核苷酸来自Microsynth (瑞士)。除非另外说明,DNA聚合酶、限制酶和缓冲液来自New England Biolabs (美国)或Fermentas (立陶宛)。克隆和蛋白制备株是大肠杆菌XL1-blue (Stratagene, 美国)或BL21 (Novagen, 美国)。购买得自不同物种的纯化的血清白蛋白和血清(例如从Sigma-Aldrich, 瑞士或InnovativeResearch, 美国)。使用标准的生物素化试剂和方法(Pierce, 美国),将生物素部分与纯化的血清白蛋白的伯胺偶联,以化学方式获得不同物种的生物素化的血清白蛋白。
分子生物学
除非另外说明,根据所述方案(Sambrook J., Fritsch E.F. 和Maniatis T.,Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory 1989,New York),执行方法。
设计的锚蛋白重复蛋白文库
描述了N2C和N3C设计的锚蛋白重复蛋白文库(WO 2002/020565; Binz等人.2003, 在上述引文中; Binz等人. 2004, 在上述引文中)。在N2C和N3C中的数字描述了存在于N-端和C-端加帽模块之间的随机化重复模块的数目。用于定义重复单元和模块内的位置的命名法是基于:Binz等人. 2004, 在上述引文中,修改是,将锚蛋白重复模块和锚蛋白重复单元的边缘移动一个氨基酸位置。例如,Binz等人. 2004 (在上述引文中) 的锚蛋白重复模块的1位对应于本公开内容的锚蛋白重复模块的2位,因此,Binz等人. 2004(在上述引文中)的锚蛋白重复模块的33位对应于本公开内容的下一锚蛋白重复模块的1位。
所有DNA序列都通过测序确认,所有所述蛋白的计算分子量都通过质谱确认。
实施例1: 包含对xSA具有结合特异性的重复结构域的结合蛋白的选择
使用核糖体展示(Hanes, J.和Plückthun, A., PNAS 94, 4937-42, 1997),从由Binz等人. 2004 (在上述引文中)描述的N2C或N3C DARPin文库选择出许多对xSA具有结合特异性的设计的锚蛋白重复蛋白(DARPin)。通过粗提取ELISA,评估了所选克隆对特异性的(xSA;即MSA、HSA或CSA)和非特异性的(MBP,大肠杆菌麦芽糖结合蛋白)靶标的结合,提示成功选择xSA结合蛋白。SEQ ID NO:17-31的重复结构域构成所选结合蛋白的氨基酸序列,所述结合蛋白包含对xSA具有结合特异性的重复结构域。所选结合剂(binder)的序列分析揭示了某些所选结合剂家族固有的特异性锚蛋白重复序列基序。在SEQ ID NO:11-14中提供了存在于对xSA具有结合特异性的重复结构域中的这类锚蛋白重复序列基序。
通过核糖体展示选择血清白蛋白特异性的锚蛋白重复蛋白
用HSA、CSA或MSA作为靶蛋白,使用如描述的设计的锚蛋白重复蛋白文库(WO2002/020565, Binz等人, 2003, 在上述引文中和Binz等人, 2004, 在上述引文中)和建立的方案(Zahnd, C., Amstutz, P. 和Plückthun, A., Nat. Methods 4, 69-79,2007),通过核糖体展示(Hanes和Plückthun, 在上述引文中) 进行了血清白蛋白特异性的锚蛋白重复蛋白的选择。使用建立的方案(Binz等人. 2004, 在上述引文中),用N2C和N3CDARPin文库两者对HSA、CSA或MSA(包括用Neutravidin或抗生蛋白链菌素固定的HSA或MSA的生物素化变体)进行核糖体展示选择循环。每个选择循环后的反转录(RT)-PCR循环数恒定地从40减至30,因应富含结合剂的收率作出调节。对HSA、CSA或MSA的4个选择循环得到了微摩尔至纳摩尔-亲和力DARPin库,如通过对单一克隆的ELISA和SPR测量所揭示的。通过本领域技术人员熟知的方法(例如通过易错PCR使DARPin克隆多样化,并如上所述选择和筛选改进的结合剂),使用亲和力成熟,进一步提高某些DARPin的亲和力。
如通过粗提取ELISA所示,经选择的克隆特异性地结合血清白蛋白
利用标准方案,用DARPin表达细胞的粗制大肠杆菌提取物,通过酶联免疫吸附测定(ELISA)鉴定各种所选特异性地结合xSA的DARPin。通过核糖体展示,将所选克隆克隆入pQE30 (Qiagen)表达载体内,转化入大肠杆菌XL1-Blue (Stratagene)内,然后在装有1 ml生长培养基(2YT,含有1% 葡萄糖和100µg/ml氨苄西林)的96深孔板(每个克隆在单个孔内)中,在37℃培养过夜。在新的96深孔板中,用100µl过夜培养物接种1 ml含有50µg/ml氨苄西林的新鲜2YT。在37℃温育2小时后,用IPTG (1 mM终浓度)诱导表达,并继续3小时。将细胞收集,再悬浮于100µl B-PERII (Pierce)中,在室温振荡温育15分钟。然后加入900µl PBS-TC (补充了0.25% 酪蛋白水解物、0.1% 吐温20®、pH 7.4的PBS),离心除去细胞碎片。将100µl各裂解的克隆施加于NeutrAvidin包被的MaxiSorp板的孔内,所述孔装有通过其生物素部分固定的xSA或不相关MBP,并在室温温育1小时。用PBS-T (补充了0.1% 吐温20®、pH7.4的PBS)充分洗涤后,用标准ELISA程序使板显影,所述程序使用单克隆抗-RGS(His)4抗体(34650, Qiagen)作为第一抗体,并使用与碱性磷酸酶缀合的多克隆山羊抗小鼠抗体(A3562, Sigma)作为第二试剂。然后用4-硝基苯基磷酸二钠(4NPP, Fluka)作为碱性磷酸酶的底物,检测结合。在405 nm测量颜色显影。通过此类粗制细胞提取物ELISA对几百个克隆的筛选,揭示了超过一百种对xSA具有特异性的不同DARPin。选择这些结合蛋白用于进一步分析。在SEQ ID NO:17-31、37-40和43-48中提供了特异性地结合xSA的所选重复结构域的氨基酸序列实例。
从对xSA具有结合特异性的所选重复结构域推断重复序列基序(motives)
通过本领域技术人员已知的序列分析工具(WO 2002/020565; Forrer等人,2003, 在上述引文中; Forrer, P., Binz, H.K., Stumpp, M.T.和Plückthun, A.,ChemBioChem, 5(2), 183-189, 2004),进一步分析对xSA具有结合特异性的所选重复结构域的氨基酸序列。但是,与其中使用天然存在的重复基序来推断重复序列基序的WO 2002/020565相反,这里从对xSA具有结合特异性的所选重复结构域的重复单元推断重复序列基序。从而确定了包含共同重复序列基序的所选重复结构域家族。在SEQ ID NO:11-14中提供了对xSA具有结合特异性的重复结构域中存在的这类重复序列基序。
DARPin的高水平和可溶性表达
为了进一步分析,将如上所述在粗制细胞提取ELISA中显示出特异性xSA结合的所选克隆在大肠杆菌BL21或XL1-Blue细胞中表达,并用标准方案利用其His-标签纯化。用25ml静止过夜的培养物(LB,1% 葡萄糖,100 mg/l的氨苄西林;37℃) 接种1 l培养物(相同培养基)。在600 nm吸光度为0.7时,用0.5 mM IPTG诱导培养物,并在37℃温育4小时。将培养物离心,使所得沉淀再悬浮于40 ml TBS500 (50 mM Tris–HCl, 500 mM NaCl, pH 8)中,并超声处理。将裂解物再次离心,将甘油(10% (v/v)终浓度)和咪唑(20 mM终浓度)加入所得上清液中。根据生产商的说明书(QIAgen, 德国),用Ni-次氮基三乙酸柱(2.5 ml柱体积)纯化蛋白。可替换地,根据本领域技术人员已知的标准树脂和方案,通过阴离子交换色谱法和随后的尺寸排阻色谱法,纯化不含6xHis-标签的DARPin或所选重复结构域。从1升大肠杆菌培养物中可纯化至多200 mg对血清白蛋白具有结合特异性的高度可溶性DARPin,根据SDS-15% PAGE估计的纯度> 95%。这样纯化的DARPin用于进一步表征。
实施例2: 对xSA具有结合特异性的DARPin的稳定性分析和尺寸排阻色谱法
如上所述使用它们的His-标签将对xSA具有结合特异性的DARPin #19-22和DARPin #27-30纯化至接近同质,并以30 mg/ml (约2 mM) 在PBS中在40℃储存28天(稳定性研究)。在第0天(图1a)和第28天(图1b),取出样品,稀释至500µM,并通过尺寸排阻色谱法(SEC)进行分析,以评估它们的表观分子量和随时间的稳定性(即它们的聚集、多聚化或降解趋势)。
在另一个实验(图1c)中,如上所述使用它们的His-标签将对xSA具有结合特异性的DARPin #19和43-48纯化至接近同质,并以约100 mg/ml在PBS中在-80℃储存28天,稀释至500µM,并通过尺寸排阻色谱法(SEC)进行分析,用于表征(即它们的聚集、多聚化或降解趋势)。值得注意的是,与第一个分析系列相比,使用更大的柱(参见下文)。
尺寸排阻色谱法(SEC)
使用HPLC系统(Agilent 1200系列),使用Superdex 200 5/150柱(图1a和图1b)或Superdex 200 10/300GL柱(图1c) (GE Healthcare),在20℃进行分析型SEC。Superdex200 5/150柱具有3.0 ml的床体积和1.08 ml的外水体积(使用蓝葡聚糖经实验确定)。Superdex 200 10/300GL柱具有24 ml的床体积和约8 ml的外水体积。根据本领域技术人员已知的标准规程,进行测量。在0.2 ml/min的流速和15巴的最大压力(Superdex 200 5/150),或者在0.6 ml/min的流速和18巴的最大压力(Superdex 200 10/300GL),在PBS中运行。将蛋白样品在PBS中稀释至约20-500µM,过滤(0.22µm),并将20-100µl稀释的样品注射到柱上进行分离。通过读出在280 nm的吸光度,记录蛋白样品的洗脱曲线。使用分子量为6.5 kDa的抑酶肽(AP)、分子量为29 kDa的碳酸酐酶(CA)和分子量为75 kDa的伴清蛋白(CO) 作为标准蛋白来得到校正曲线,从该校正曲线可以确定样品蛋白的表观分子量。
结果显示在图1中。DARPin #19-22和27-30在稳定性研究的第0天和第28天显示出不能辨别的SEC色谱图(即不能辨别的洗脱曲线)。结论是,所有DARPin在测定条件下作为单体洗脱,且DARPin #19-23和27-30在PBS中在40℃稳定至少1个月(即它们的洗脱曲线没有揭示任何聚集、多聚化或降解趋势)。
实施例3: 对xSA具有结合特异性的DARPin的热稳定性
用基于荧光的热稳定性测定(Niesen, F.H., Nature Protocols 2(9): 2212-2221, 2007),分析了对xSA具有特异性的DARPin的热稳定性。由此,通过对蛋白的疏水部分(其随着蛋白解折叠而暴露)具有亲和力的染料(例如SYPRO Orange; Invitrogen, 目录号S6650) 的荧光的增加,测量蛋白(即这样的DARPin)解折叠时的温度。在由此得到的荧光转变中点(从较低荧光强度至较高荧光强度)处的温度则对应于分析的蛋白的中点变性温度(Tm)。
基于荧光的热稳定性测定
使用实时PCR仪器(即与CFX96光学系统(BioRad)相组合的C1000热循环仪(BioRad)),使用SYPRO Orange作为荧光染料,测量了DARPin的热变性。在含有1x SYPROOrange (从5’000x SYPRO Orange储备溶液稀释, Invitrogen)的pH 7.4的PBS或pH 5.8的MES缓冲液中,制备了80µM浓度的DARPin,并将50µl这样的蛋白溶液或仅缓冲液加入白色96-孔PCR板(Bio-Rad)中。用Microseal 'B' Adhesive Seals (Bio-Rad)密封所述板,并在实时PCR仪器中以0.5℃的增量从20℃加热至95℃,包括在每个温度增量以后的25秒保温步骤,在DARPin的热变性之后,测量样品在每个温度增量处的相对荧光单位。使用实时PCR仪器的通道2(即在515-535 nm激发和在560-580 nm检测),测量板孔中的相对荧光单位,并减去用仅缓冲液得到的对应值。从由此得到的热变性转变中点,可以确定分析的DARPin的Tm值。
在图2和图3中显示了DARPin在pH7.4的PBS或pH 5.8的MES-缓冲液中的热变性结果,所述热变性通过SYPRO Orange的荧光强度增加来跟踪。测得的热变性转变证实,分析的所有对xSA具有结合特异性的DARPin都具有远高于40℃的Tm值(在pH 7.4和pH 5.8两者)。
实施例4:通过表面等离子体共振分析表征对xSA具有结合特异性的DARPin
经由它们的His-标签,在流动池中将对xSA具有结合特异性的DARPin固定至包被的α-RGS-His抗体(Qiagen, 目录号34650)上,并分析人、食蟹猴(cyno)、小鼠、大鼠、兔和狗血清白蛋白与固定的DARPin的相互作用。
表面等离子体共振(SPR) 分析
使用ProteOn仪器(BioRad)测量SPR,并根据本领域技术人员已知的标准规程进行测量。运行缓冲液为pH 7.4的PBS,其含有0.01% 吐温20®。将抗-RGS-His抗体共价地固定至GLC芯片(BioRad)上,达到约2000共振单位(RU)的水平。然后通过在300 s中注射150µl 1µM DARPin溶液(流速= 30µl/min),进行DARPin在抗体包被的芯片上的固定化。然后如下测量与不同物种的血清白蛋白的相互作用:在60秒中注射100µl体积的运行缓冲液(含有0.01% 吐温的PBS),其含有浓度为400 nM、200 nM、100 nM、50 nM的不同血清白蛋白(结合速率测量),随后让运行缓冲液流动10-30分钟(流速= 100µl/min) (解离速率测量)。从注射血清白蛋白以后得到的RU迹线减去未包被的参考池和参考注射(即仅注射运行缓冲液)的信号(即共振单位(RU)值)(双重参考)。从得自结合速率和解离速率测量的SRP迹线,可以确定对应的DARPin血清白蛋白相互作用的结合速率和解离速率。
结果总结在表1和表2中。使用本领域技术人员已知的标准规程,从估测的结合速率和解离速率计算出解离常数(Kd),并发现是在约3nM至约300 nM范围内。尽管分析的所有DARPin都结合人和食蟹猴血清白蛋白,兔、小鼠、大鼠和狗血清白蛋白仅被这些DARPin的子集结合。

实施例5: 对xSA具有结合特异性的DARPin的终末血浆半衰期
根据本领域技术人员已知的标准规程(Toutain, 等人, 在上述引文中),确定DARPin在小鼠和食蟹猴(成束猴, 也缩写为“cyno”) 中的终末血浆半衰期。将一定量的DARPin静脉内地注射进哺乳动物中,并通过跟踪DARPin的血浆浓度,跟踪DARPin随时间而变化的从血浆清除。DARPin浓度最初下降,直到达到假平衡(α-期),随后是DARPin血浆浓度的指数式进一步下降(β-期)。然后可以从该β-期计算出DARPin终末血浆半衰期。
DARPin在小鼠中的血浆清除的确定
为了评估对xSA具有结合特异性的DARPin的血浆清除,将试验蛋白进行放射性标记,并注射进首次用于实验的Balb/c小鼠的尾静脉中。注射下述的DARPin:DARPin#19、DARPin#21、DARPin #23、DARPin #25、DARPin #18、、DARPin #32、DARPin #35、DARPin #36、DARPin #33、DARPin #34、DARPin #37、DARPin #38、DARPin #43、DARPin#44、DARPin#45、DARPin#46、DARPin#47和DARPin#48。如以前所述(Waibel, R., 等人, NatureBiotechnol. 17(9), 897-901, 1999),用99mTc-羰基复合物对DARPin进行放射性标记。将DARPin (40µg)与99mTc-羰基(0.8-1.6 m Ci)一起温育1 h,然后在PBS (pH 7.4)中稀释至400µl。给每只小鼠静脉内注射100µl由此得到的标记的DARPin溶液(相当于10µg蛋白和0.2-0.4 m Ci)。在初次注射以后1 h、4 h、24 h和48 h,采集小鼠的血液样品,并测量样品的放射性。在特定时间点测得的放射性水平,是在该时间点时在血浆中仍然存在的DARPin的量的直接量度。%注射剂量是,在特定时间点测得的小鼠全血(就18 g小鼠而言,1.6 ml)的总放射性相对于针对99mTc的放射性衰变校正过的注射样品的总放射性的百分比。
与对xSA没有结合特异性的DARPin #32相比,对MSA具有结合特异性的DARPin在小鼠中具有大幅增加的终末血浆半衰期(图4)。DARPin#19、DARPin#21、DARPin#23、DARPin#33、DARPin #37、DARPin #43、DARPin#44、DARPin#45、DARPin#46、DARPin#47和DARPin#48在小鼠中具有约2–2.5天的终末血浆半衰期。
DARPin在食蟹猴中的血浆清除的确定
将在PBS中稀释的DARPin作为快速推注注射进食蟹猴的头静脉中。注射下述DARPin:DARPin #26 (0,5 mg/kg)、DARPin #24 (0.5 mg/kg)、DARPin #17 (0.5 mg/kg)、DARPin #34 (1 mg/kg)和DARPin #32 (0.5 mg/kg)。在注射后的不同时间点,从采自动物股静脉的血液制备血浆。然后使用本领域技术人员已知的标准方案和具有已知DARPin浓度的适当DARPin标准曲线,通过夹心ELISA确定血浆样品中的DARPin浓度。
在用抗-DARPin的特异性兔单克隆抗体包被的MaxiSorp ELISA平板上,在PBS-C(含有0.25% 酪蛋白的PBS, pH 7.4)中对食蟹猴的血浆样品进行系列稀释。在用PBS-T (补充了0.1% 吐温20®的PBS,pH 7.4) 充分洗涤以后,用被辣根过氧化物酶HRP标记的单克隆抗-RGS(His)4抗体(Qiagen)使平板显影。然后使用100µl BM-Blue POD底物(RocheDiagnostics),检测结合。通过加入50µl 1 M H2SO4,停止反应,并测量在450 nm的吸光度(和减去在620 nm的吸光度)。通过对在猴血清中稀释的DARPin的标准曲线进行单指数回归(GraphPad Prism),计算血浆样品中的DARPin的浓度。通过对注射最多240 h测得的浓度值进行非线性回归(两阶段衰变),计算DARPin的血浆终末半衰期。第二(β)阶段的半衰期对应于终末血浆半衰期。
与对xSA没有结合特异性的DARPin #32相比,对xSA具有结合特异性的DARPin在食蟹猴中具有增加的终末血浆半衰期(图4、表3)。DARPin#19、DARPin#21、DARPin #43、DARPin#44、DARPin#45、DARPin#46、DARPin#47和DARPin#48在食蟹猴中具有约10-15天的终末血浆半衰期。

实施例6:具有改进的C-端加帽模块的DARPin的较高热稳定性
如在实施例3中所述,用基于荧光的热稳定性测定来分析DARPin的热稳定性。可替换地,通过CD光谱测定法分析DARPin的热稳定性;即通过本领域技术人员熟知的技术跟踪它在222 nm的圆二色性(CD) 信号,从而测量它的热变性。在Jasco J-715仪器(Jasco, 日本)中在222 nm记录样品的CD信号,同时使用1℃/min的温度增量,将浓度为0.02 mM的蛋白(在pH 7.4的PBS中)缓慢地从20℃加热至95℃。这是跟踪DARPin的变性的有效方式,因为DARPin主要由α螺旋组成,所述α螺旋在解折叠后在222 nm处表现出它们的CD信号的强烈变化。观察到的DARPin的这样测量的CD信号迹线的转变中点对应于它的Tm值。
使用基于荧光的热稳定性测定,将DARPin #37 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:37)的热稳定性与DARPin #38 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:38)的热稳定性进行了对比。除了它们的重复结构域的C-端加帽模块以外,这2种DARPin具有相同的氨基酸序列。DARPin #38的重复结构域包含如本文所述的改进的C-加帽模块,但是DARPin #37不包含。测得的DARPin #37和DARPin#38在pH 7.4的PBS中的Tm值分别为约63℃和约73℃。测得的DARPin #37和DARPin #38在pH5.8的MES缓冲液中的Tm值分别为约54.5℃和约66℃。
使用基于荧光的热稳定性测定,将DARPin #39 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:39) 的热稳定性与DARPin #40 (具有融合在它的N-端处的His-标签(SEQ ID NO:15)的SEQ ID NO:40)的热稳定性进行了对比。除了它们的重复结构域的C-端加帽模块以外,这2种DARPin具有相同的氨基酸序列。DARPin #40的重复结构域包含如本文所述的改进的C-加帽模块,但是DARPin #39不包含。测得的DARPin #39和DARPin #40在pH 5.8的MES缓冲液中的Tm值分别为约51℃和约55℃。
使用CD光谱法,将DARPin #41 (SEQ ID NO:41)的热稳定性与DARPin #42 (SEQID NO:42)的热稳定性进行了对比。除了它们的重复结构域的C-端加帽模块以外,这2种DARPin具有相同的氨基酸序列。DARPin #42的重复结构域包含如本文所述的改进的C-加帽模块,但是DARPin #41不包含。测得的DARPin #41和DARPin #42在pH 7.4的PBS中的Tm值分别为约59.5℃和约73℃。
序列表
<110> Molecular Partners AG
Steiner, Daniel
Binz, Hans Kaspar
Gulotti-Georgieva, Maya
Merz, Frieder W.
Phillips, Douglas
Sonderegger, Ivo
<120> 设计的与血清白蛋白结合的重复蛋白
<130> P393A
<150> EP10192711.9
<151> 2010-11-26
<160> 54
<170> PatentIn 3.5版
<210> 1
<211> 32
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 1
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
<210> 2
<211> 28
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 2
Gln Asp Lys Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile Asp Asn Gly
1 5 10 15
Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Asn
20 25
<210> 3
<211> 28
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 3
Gln Asp Lys Phe Gly Lys Thr Pro Phe Asp Leu Ala Ile Arg Glu Gly
1 5 10 15
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
20 25
<210> 4
<211> 28
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 4
Gln Asp Lys Phe Gly Lys Thr Pro Phe Asp Leu Ala Ile Asp Asn Gly
1 5 10 15
Asn Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
20 25
<210> 5
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<220>
<221> misc_feature
<222> (1)..(1)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (22)..(22)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (24)..(24)
<223> Xaa可以是任意天然存在的氨基酸
<400> 5
Xaa Leu Xaa Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln Asp Asp
1 5 10 15
Glu Val Arg Ile Leu Xaa Ala Xaa Gly Ala Asp Val Asn Ala
20 25 30
<210> 6
<211> 28
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<220>
<221> misc_feature
<222> (1)..(1)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (8)..(9)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (11)..(13)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (15)..(15)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (17)..(17)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (20)..(20)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (23)..(23)
<223> Xaa可以是任意天然存在的氨基酸
<400> 6
Xaa Asp Lys Xaa Gly Lys Thr Xaa Xaa Asp Xaa Xaa Xaa Asp Xaa Gly
1 5 10 15
Xaa Glu Asp Xaa Ala Glu Xaa Leu Gln Lys Ala Ala
20 25
<210> 7
<211> 28
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<220>
<221> misc_feature
<222> (1)..(1)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (8)..(8)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (11)..(13)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (15)..(15)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (17)..(17)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (20)..(20)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (23)..(23)
<223> Xaa可以是任意天然存在的氨基酸
<400> 7
Xaa Asp Lys Xaa Gly Lys Thr Xaa Ala Asp Xaa Xaa Xaa Asp Xaa Gly
1 5 10 15
Xaa Glu Asp Xaa Ala Glu Xaa Leu Gln Lys Ala Ala
20 25
<210> 8
<211> 28
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<220>
<221> misc_feature
<222> (1)..(1)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (8)..(8)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (11)..(12)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (15)..(15)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (17)..(17)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (20)..(20)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (23)..(23)
<223> Xaa可以是任意天然存在的氨基酸
<400> 8
Xaa Asp Lys Xaa Gly Lys Thr Xaa Ala Asp Xaa Xaa Ala Asp Xaa Gly
1 5 10 15
Xaa Glu Asp Xaa Ala Glu Xaa Leu Gln Lys Ala Ala
20 25
<210> 9
<211> 28
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 9
Gln Asp Lys Ser Gly Lys Thr Pro Ala Asp Leu Ala Ala Asp Ala Gly
1 5 10 15
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
20 25
<210> 10
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<220>
<221> misc_feature
<222> (1)..(1)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (3)..(4)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (6)..(6)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (14)..(15)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (27)..(27)
<223> Xaa可以是任意天然存在的氨基酸
<400> 10
Xaa Asp Xaa Xaa Gly Xaa Thr Pro Leu His Leu Ala Ala Xaa Xaa Gly
1 5 10 15
His Leu Glu Ile Val Glu Val Leu Leu Lys Xaa Gly Ala Asp Val Asn
20 25 30
Ala
<210> 11
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<220>
<221> misc_feature
<222> (1)..(1)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (15)..(16)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (19)..(19)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (27)..(27)
<223> Xaa可以是任意天然存在的氨基酸
<400> 11
Xaa Asp Tyr Phe Xaa His Thr Pro Leu His Leu Ala Ala Arg Xaa Xaa
1 5 10 15
His Leu Xaa Ile Val Glu Val Leu Leu Lys Xaa Gly Ala Asp Val Asn
20 25 30
Ala
<210> 12
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<220>
<221> misc_feature
<222> (1)..(1)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (6)..(6)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (14)..(14)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (27)..(27)
<223> Xaa可以是任意天然存在的氨基酸
<400> 12
Xaa Asp Phe Xaa Gly Xaa Thr Pro Leu His Leu Ala Ala Xaa Asp Gly
1 5 10 15
His Leu Glu Ile Val Glu Val Leu Leu Lys Xaa Gly Ala Asp Val Asn
20 25 30
Ala
<210> 13
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<220>
<221> misc_feature
<222> (1)..(1)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (3)..(4)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (20)..(20)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (27)..(27)
<223> Xaa可以是任意天然存在的氨基酸
<400> 13
Xaa Asp Xaa Xaa Gly Thr Thr Pro Leu His Leu Ala Ala Val Tyr Gly
1 5 10 15
His Leu Glu Xaa Val Glu Val Leu Leu Lys Xaa Gly Ala Asp Val Asn
20 25 30
Ala
<210> 14
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<220>
<221> misc_feature
<222> (1)..(1)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (18)..(18)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (27)..(29)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (31)..(31)
<223> Xaa可以是任意天然存在的氨基酸
<400> 14
Xaa Asn Glu Thr Gly Tyr Thr Pro Leu His Leu Ala Asp Ser Ser Gly
1 5 10 15
His Xaa Glu Ile Val Glu Val Leu Leu Lys Xaa Xaa Xaa Asp Xaa Asn
20 25 30
Ala
<210> 15
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 15
Met Arg Gly Ser His His His His His His
1 5 10
<210> 16
<211> 20
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 16
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser
20
<210> 17
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 17
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Ala Asp Tyr Phe Gly His Thr Pro Leu His Leu Ala Ala Arg Asp Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Tyr Gly Ala Asp Val Asn
50 55 60
Ala Ser Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Lys Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile Asp
100 105 110
Asn Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Asn
115 120 125
<210> 18
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 18
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Ala Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asp Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Tyr Gly Ala Asp Val Asn
50 55 60
Ala Ser Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile Asp
100 105 110
Asn Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Asn
115 120 125
<210> 19
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 19
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 20
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 20
Gly Ser Asp Leu Asp Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 21
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 21
Gly Ser Asp Leu Asp Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 22
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 22
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 23
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 23
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Leu Ala Ala Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 24
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 24
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Ser Gly Ala Asp Val Asn Ala
20 25 30
Ala Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asp Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Tyr Gly Ala Asp Val Asp
50 55 60
Ala Ser Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Asp Ala Asp Val
85 90 95
Asn Ala Gln Asp Lys Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile Asp
100 105 110
Asn Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Asn
115 120 125
<210> 25
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 25
Gly Ser Asp Leu Gly Lys Glu Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Ala Asp Tyr Phe Gly His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Tyr Gly Ala Asp Val Asn
50 55 60
Ala Ser Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Ala Phe Glu Ile Ser Ile Asp
100 105 110
Asn Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Asn
115 120 125
<210> 26
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 26
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Phe Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Ala Asp Glu Arg Gly Thr Thr Pro Leu His Leu Ala Ala Val Tyr Gly
35 40 45
His Leu Glu Ile Val Glu Val Leu Leu Lys Asn Gly Ala Asp Val Asn
50 55 60
Ala Gln Asn Glu Thr Gly Tyr Thr Pro Leu His Leu Ala Asp Ser Ser
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Ser Ala Asp Val
85 90 95
Asn Ala Gln Asp Lys Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile Asp
100 105 110
Asn Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Asn
115 120 125
<210> 27
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 27
Gly Ser Asp Leu Asp Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Glu Arg Gly Thr Thr Pro Leu His Leu Ala Ala Val Tyr Gly
35 40 45
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asn Glu Thr Gly Tyr Thr Pro Leu His Leu Ala Asp Ser Ser
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Lys Ser Gly Lys Thr Pro Ala Asp Leu Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 28
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 28
Gly Ser Asp Leu Asp Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Glu Arg Gly Thr Thr Pro Leu His Leu Ala Ala Val Tyr Gly
35 40 45
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asn Glu Thr Gly Tyr Thr Pro Leu His Leu Ala Asp Ser Ser
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Ser Ala Asp Val
85 90 95
Asn Ala Gln Asp Lys Ser Gly Lys Thr Pro Ala Asp Leu Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 29
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 29
Gly Ser Asp Leu Asp Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Glu Arg Gly Thr Thr Pro Leu His Leu Ala Ala Val Tyr Gly
35 40 45
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asn Glu Thr Gly Tyr Thr Pro Leu His Leu Ala Asp Ser Ser
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Lys Ser Gly Lys Thr Pro Ala Asp Leu Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 30
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 30
Gly Ser Asp Leu Asp Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Glu Arg Gly Thr Thr Pro Leu His Leu Ala Ala Val Tyr Gly
35 40 45
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asn Glu Thr Gly Tyr Thr Pro Leu His Leu Ala Asp Ser Ser
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Ser Ala Asp Val
85 90 95
Asn Ala Gln Asp Lys Ser Gly Lys Thr Pro Ala Asp Leu Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 31
<211> 157
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 31
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Val Asp Ile Trp Gly Asn Thr Pro Leu His Leu Ala Ala Asn Glu Gly
35 40 45
His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val Asn
50 55 60
Ala Leu Asp His Trp Gly Asp Thr Pro Leu His Leu Ala Ala Met Trp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Leu Asp Asn Asn Gly Phe Thr Pro Leu His Leu Gly Tyr Gly
100 105 110
His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val Asn
115 120 125
Ala Gln Asp Lys Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile Asp Asn
130 135 140
Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Asn
145 150 155
<210> 32
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 32
Gly Ser Asp Leu Asp Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Arg Asp Ser Thr Gly Trp Thr Pro Leu His Leu Ala Ala Pro Trp Gly
35 40 45
His Pro Glu Ile Val Glu Val Leu Leu Lys Asn Gly Ala Asp Val Asn
50 55 60
Ala Ala Asp Phe Gln Gly Trp Thr Pro Leu His Leu Ala Ala Ala Val
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Tyr Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Lys Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile Asp
100 105 110
Asn Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Asn
115 120 125
<210> 33
<211> 271
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 33
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Leu Ala Ala Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Arg Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly
145 150 155 160
Gln Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn
165 170 175
Ala Lys Asp Lys Asp Gly Tyr Thr Pro Leu His Leu Ala Ala Arg Glu
180 185 190
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val
195 200 205
Asn Ala Lys Asp Lys Asp Gly Tyr Thr Pro Leu His Leu Ala Ala Arg
210 215 220
Glu Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp
225 230 235 240
Val Asn Ala Gln Asp Lys Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile
245 250 255
Asp Asn Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Asn
260 265 270
<210> 34
<211> 271
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 34
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Ala Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Tyr Gly Ala Asp Val Asn
50 55 60
Ala Ser Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile Asp
100 105 110
Asn Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Arg Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly
145 150 155 160
Gln Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn
165 170 175
Ala Lys Asp Lys Asp Gly Tyr Thr Pro Leu His Leu Ala Ala Arg Glu
180 185 190
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val
195 200 205
Asn Ala Lys Asp Lys Asp Gly Tyr Thr Pro Leu His Leu Ala Ala Arg
210 215 220
Glu Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp
225 230 235 240
Val Asn Ala Gln Asp Lys Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile
245 250 255
Asp Asn Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Asn
260 265 270
<210> 35
<211> 271
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 35
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Lys Asp Gly Tyr Thr Pro Leu His Leu Ala Ala Arg Glu Gly
35 40 45
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asp Lys Asp Gly Tyr Thr Pro Leu His Leu Ala Ala Arg Glu
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Lys Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile Asp
100 105 110
Asn Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Arg Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly
145 150 155 160
Gln Asp Asp Glu Val Arg Ile Leu Leu Ala Ala Gly Ala Asp Val Asn
165 170 175
Ala Lys Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn
180 185 190
Gly His Leu Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val
195 200 205
Asn Ala Lys Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn
210 215 220
Asp Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp
225 230 235 240
Val Asn Ala Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala
245 250 255
Asp Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
260 265 270
<210> 36
<211> 302
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 36
Gly Ser Asp Leu Asp Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Arg Asp Ser Thr Gly Trp Thr Pro Leu His Leu Ala Ala Pro Trp Gly
35 40 45
His Pro Glu Ile Val Glu Val Leu Leu Lys Asn Gly Ala Asp Val Asn
50 55 60
Ala Ala Asp Phe Gln Gly Trp Thr Pro Leu His Leu Ala Ala Ala Val
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Tyr Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Lys Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile Asp
100 105 110
Asn Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Arg Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly
145 150 155 160
Gln Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn
165 170 175
Ala Val Asp Ile Trp Gly Asn Thr Pro Leu His Leu Ala Ala Asn Glu
180 185 190
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
195 200 205
Asn Ala Leu Asp His Trp Gly Asp Thr Pro Leu His Leu Ala Ala Met
210 215 220
Trp Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp
225 230 235 240
Val Asn Ala Leu Asp Asn Asn Gly Phe Thr Pro Leu His Leu Gly Tyr
245 250 255
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
260 265 270
Asn Ala Gln Asp Lys Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile Asp
275 280 285
Asn Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Asn
290 295 300
<210> 37
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 37
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Ala Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Tyr Gly Ala Asp Val Asn
50 55 60
Ala Ser Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile Asp
100 105 110
Asn Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Asn
115 120 125
<210> 38
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 38
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Met Ala Asn Gly Ala Asp Val Asn Ala
20 25 30
Ala Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Tyr Gly Ala Asp Val Asn
50 55 60
Ala Ser Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp
100 105 110
Asn Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 39
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 39
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Leu Ala Ala Gly Ala Asp Val Asn Ala
20 25 30
Ala Asp Glu Arg Gly Thr Thr Pro Leu His Leu Ala Ala Val Tyr Gly
35 40 45
His Leu Glu Ile Val Glu Val Leu Leu Lys Asn Gly Ala Asp Val Asn
50 55 60
Ala Gln Asn Glu Thr Gly Tyr Thr Pro Leu His Leu Ala Asp Ser Ser
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Ser Ala Asp Val
85 90 95
Asn Ala Gln Asp Lys Phe Gly Lys Thr Ala Phe Asp Ile Ser Ile Asp
100 105 110
Asn Gly Asn Glu Asp Leu Ala Glu Ile Leu Gln Lys Leu Asn
115 120 125
<210> 40
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 40
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Leu Ala Ala Gly Ala Asp Val Asn Ala
20 25 30
Ala Asp Glu Arg Gly Thr Thr Pro Leu His Leu Ala Ala Val Tyr Gly
35 40 45
His Leu Glu Ile Val Glu Val Leu Leu Lys Asn Gly Ala Asp Val Asn
50 55 60
Ala Gln Asn Glu Thr Gly Tyr Thr Pro Leu His Leu Ala Asp Ser Ser
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Ser Ala Asp Val
85 90 95
Asn Ala Gln Asp Lys Ser Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp
100 105 110
Asn Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 41
<211> 103
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 41
Met Arg Gly Ser His His His His His His Gly Ser Asp Leu Gly Lys
1 5 10 15
Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln Asp Asp Glu Val Arg Ile
20 25 30
Leu Met Ala Asn Gly Ala Asp Val Asn Ala Lys Asp Lys Asp Gly Tyr
35 40 45
Thr Pro Leu His Leu Ala Ala Arg Glu Gly His Leu Glu Ile Val Glu
50 55 60
Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Gln Asp Lys Phe Gly
65 70 75 80
Lys Thr Ala Phe Asp Ile Ser Ile Asp Asn Gly Asn Glu Asp Leu Ala
85 90 95
Glu Ile Leu Gln Lys Leu Asn
100
<210> 42
<211> 103
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 42
Met Arg Gly Ser His His His His His His Gly Ser Asp Leu Gly Lys
1 5 10 15
Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln Asp Asp Glu Val Arg Ile
20 25 30
Leu Met Ala Asn Gly Ala Asp Val Asn Ala Lys Asp Lys Asp Gly Tyr
35 40 45
Thr Pro Leu His Leu Ala Ala Arg Glu Gly His Leu Glu Ile Val Glu
50 55 60
Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Gln Asp Lys Ser Gly
65 70 75 80
Lys Thr Pro Ala Asp Leu Ala Ala Asp Asn Gly His Glu Asp Ile Ala
85 90 95
Glu Val Leu Gln Lys Ala Ala
100
<210> 43
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 43
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 44
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 44
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys His Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 45
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 45
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 46
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 46
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 47
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 47
Gly Ser Asp Leu Asp Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Ile Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 48
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 48
Gly Ser Asp Leu Asp Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln
1 5 10 15
Asp Asp Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
20 25 30
Lys Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
35 40 45
His Leu Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
50 55 60
Ala Lys Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp
65 70 75 80
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val
85 90 95
Asn Ala Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp
100 105 110
Ala Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120 125
<210> 49
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 49
Lys Asp Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly
1 5 10 15
His Leu Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
20 25 30
Ala
<210> 50
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 50
Lys Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Asp Gly
1 5 10 15
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
20 25 30
Ala
<210> 51
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 51
Lys Asp Glu Arg Gly Thr Thr Pro Leu His Leu Ala Ala Val Tyr Gly
1 5 10 15
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
20 25 30
Ala
<210> 52
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<400> 52
Lys Asn Glu Thr Gly Tyr Thr Pro Leu His Leu Ala Asp Ser Ser Gly
1 5 10 15
His Leu Glu Ile Val Glu Val Leu Leu Lys His Ser Ala Asp Val Asn
20 25 30
Ala
<210> 53
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<220>
<221> misc_feature
<222> (1)..(1)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (3)..(6)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (14)..(15)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (19)..(19)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (27)..(27)
<223> Xaa可以是任意天然存在的氨基酸
<400> 53
Xaa Asp Xaa Xaa Xaa Xaa Thr Pro Leu His Leu Ala Ala Xaa Xaa Gly
1 5 10 15
His Leu Xaa Ile Val Glu Val Leu Leu Lys Xaa Gly Ala Asp Val Asn
20 25 30
Ala
<210> 54
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 合成的构建体
<220>
<221> misc_feature
<222> (1)..(1)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (6)..(6)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (14)..(15)
<223> Xaa可以是任意天然存在的氨基酸
<220>
<221> misc_feature
<222> (27)..(27)
<223> Xaa可以是任意天然存在的氨基酸
<400> 54
Xaa Asp Phe Xaa Gly Xaa Thr Pro Leu His Leu Ala Ala Xaa Xaa Gly
1 5 10 15
His Leu Glu Ile Val Glu Val Leu Leu Lys Xaa Gly Ala Asp Val Asn
20 25 30
Ala
Claims (13)
1.一种包含至少一个锚蛋白重复结构域的结合蛋白,其中所述锚蛋白重复结构域对哺乳动物血清白蛋白具有结合特异性,且其中所述锚蛋白重复结构域包含锚蛋白重复模块,所述锚蛋白重复模块由选自下述的氨基酸序列组成:SEQ ID NO:49、50、51和52。
2.一种包含至少一个锚蛋白重复结构域的结合蛋白,其中所述重复结构域对哺乳动物血清白蛋白具有结合特异性,且其中所述锚蛋白重复结构域选自SEQ ID NO: 17-31和43-48。
3.权利要求1或2所述的结合蛋白,其中所述锚蛋白重复结构域在哺乳动物中的终末血浆半衰期比SEQ ID NO:32的锚蛋白重复结构域高至少5倍。
4.权利要求1或2所述的结合蛋白,其中所述锚蛋白重复结构域在人类中具有至少1天的终末血浆半衰期。
5.权利要求1或2所述的结合蛋白,所述结合蛋白另外包含生物活性化合物,且其中所述结合蛋白在哺乳动物中的终末血浆半衰期比所述生物活性化合物单独的终末血浆半衰期高至少2倍,其中所述高至少2倍的终末血浆半衰期由所述锚蛋白重复结构域赋予所述结合蛋白。
6.权利要求1或2所述的结合蛋白,其中所述锚蛋白重复结构域与选自SEQ ID NO: 17-31和43-48的锚蛋白重复结构域竞争结合哺乳动物血清白蛋白。
7.权利要求1的结合蛋白,其中所述锚蛋白重复模块由SEQ ID NO:50的氨基酸序列组成。
8.权利要求1的结合蛋白,其中所述锚蛋白重复模块由SEQ ID NO:49的氨基酸序列组成。
9.权利要求8的结合蛋白,其中所述锚蛋白重复结构域还包含锚蛋白重复模块,所述锚蛋白重复模块由选自SEQ ID NO:50的氨基酸序列组成,和这样的序列,其中SEQ ID NO:50中最多2个氨基酸被另外的氨基酸替换。
10.权利要求2的结合蛋白,其中所述锚蛋白重复结构域是SEQ ID NO: 46的锚蛋白重复结构域。
11.权利要求1、2和7-10中任一项的结合蛋白,其中所述锚蛋白重复结构域在PBS中与人血清白蛋白的解离常数低于10-7M。
12.一种核酸,其编码权利要求1-11中的任一项所述的结合蛋白。
13.一种药物组合物,其包含权利要求1-11中的任一项所述的结合蛋白或权利要求12所述的核酸,和任选的药学上可接受的载体和/或稀释剂。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110301133.2A CN113278077A (zh) | 2010-11-26 | 2011-11-25 | 设计的与血清白蛋白结合的重复蛋白 |
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP10192711.9 | 2010-11-26 | ||
| EP10192711 | 2010-11-26 | ||
| PCT/EP2011/071083 WO2012069654A1 (en) | 2010-11-26 | 2011-11-25 | Designed repeat proteins binding to serum albumin |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110301133.2A Division CN113278077A (zh) | 2010-11-26 | 2011-11-25 | 设计的与血清白蛋白结合的重复蛋白 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN103459415A CN103459415A (zh) | 2013-12-18 |
| CN103459415B true CN103459415B (zh) | 2021-04-09 |
Family
ID=43858162
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110301133.2A Pending CN113278077A (zh) | 2010-11-26 | 2011-11-25 | 设计的与血清白蛋白结合的重复蛋白 |
| CN201180066086.2A Active CN103459415B (zh) | 2010-11-26 | 2011-11-25 | 设计的与血清白蛋白结合的重复蛋白 |
| CN201180066084.3A Active CN103403024B (zh) | 2010-11-26 | 2011-11-25 | 设计的锚蛋白重复蛋白的改进的n‑端加帽模块 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110301133.2A Pending CN113278077A (zh) | 2010-11-26 | 2011-11-25 | 设计的与血清白蛋白结合的重复蛋白 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201180066084.3A Active CN103403024B (zh) | 2010-11-26 | 2011-11-25 | 设计的锚蛋白重复蛋白的改进的n‑端加帽模块 |
Country Status (13)
| Country | Link |
|---|---|
| US (5) | US9221892B2 (zh) |
| EP (3) | EP2643349B1 (zh) |
| JP (3) | JP6173216B2 (zh) |
| KR (3) | KR20140032356A (zh) |
| CN (3) | CN113278077A (zh) |
| AU (2) | AU2011333665B2 (zh) |
| BR (3) | BR112013013043A2 (zh) |
| CA (2) | CA2818990C (zh) |
| DK (1) | DK2643349T3 (zh) |
| ES (2) | ES2758352T3 (zh) |
| PL (1) | PL2643349T3 (zh) |
| RU (2) | RU2625882C2 (zh) |
| WO (2) | WO2012069655A2 (zh) |
Families Citing this family (78)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| TWI510246B (zh) | 2010-04-30 | 2015-12-01 | Molecular Partners Ag | 抑制vegf-a受體交互作用的經修飾結合性蛋白質 |
| CA2818990C (en) | 2010-11-26 | 2021-06-15 | Molecular Partners Ag | Designed repeat proteins binding to serum albumin |
| PL2846836T3 (pl) | 2012-05-07 | 2020-01-31 | Allergan, Inc. | Sposób leczenia amd u pacjentów opornych na terapię anty- vegf |
| US9163070B2 (en) * | 2012-06-28 | 2015-10-20 | Molecular Partners Ag | Designed ankyrin repeat proteins binding to platelet-derived growth factor |
| CA2883264A1 (en) * | 2012-10-15 | 2014-04-24 | Universitat Zurich Prorektorat Mnw | Bispecific her2 ligands for cancer therapy |
| EP2738180A1 (en) | 2012-11-30 | 2014-06-04 | Molecular Partners AG | Binding proteins comprising at least two binding domains against HER2. |
| CN110845618A (zh) | 2013-02-26 | 2020-02-28 | 罗切格利卡特公司 | 双特异性t细胞活化抗原结合分子 |
| JP6486908B2 (ja) | 2013-05-31 | 2019-03-20 | モレキュラー パートナーズ アクチェンゲゼルシャフト | 肝細胞増殖因子に結合する設計アンキリン反復タンパク質 |
| KR20150097304A (ko) | 2014-02-18 | 2015-08-26 | 삼성전자주식회사 | 항 EGFR DARPin을 포함하는 EGFR/HER2 이중 특이 항체 |
| JP2017526053A (ja) | 2014-07-07 | 2017-09-07 | イェダ リサーチ アンド ディベロップメント カンパニー リミテッドYeda Research And Development Co.Ltd. | コンピュータ計算によるタンパク質設計方法 |
| JP6552636B2 (ja) | 2015-04-02 | 2019-07-31 | モレキュラー パートナーズ アクチェンゲゼルシャフト | 血清アルブミンに対する結合特異性を有する設計アンキリンリピートドメイン |
| JP6976335B2 (ja) | 2016-09-22 | 2021-12-08 | モレキュラー パートナーズ アクチェンゲゼルシャフト | 組み換え結合タンパク質及びその使用 |
| IL266343B2 (en) * | 2016-11-01 | 2024-01-01 | Arrowhead Pharmaceuticals Inc | Alpha-v beta-6 integrin ligands and uses thereof |
| US11127483B2 (en) | 2017-03-07 | 2021-09-21 | Igc Bio, Inc. | Computational pipeline for antibody modeling and design |
| EP3623382A1 (en) | 2018-09-14 | 2020-03-18 | Universität Zürich | Ligands to gm-csf or gm-csf-receptor for use in leukemia in a patient having undergone allo-hct |
| US11655293B2 (en) | 2018-02-22 | 2023-05-23 | Universitat Zurich | Ligands to GM-CSF or GM-CSF-receptor for use in leukemia in a patient having undergone allo-HCT |
| EP3768833A1 (en) | 2018-03-22 | 2021-01-27 | Charité - Universitätsmedizin Berlin | Crispr associated protein reactive t cell immunity |
| US20210253723A1 (en) | 2018-06-15 | 2021-08-19 | Universität Bern | LIGANDS TO LIGHT OR ITS RECEPTOR LTßR FOR USE IN HAEMATOLOGIC MALIGNANCIES |
| EP3864054A1 (en) | 2018-10-08 | 2021-08-18 | Universität Zürich | Her2-binding tetrameric polypeptides |
| WO2020104627A1 (en) | 2018-11-21 | 2020-05-28 | Universität Zürich | Photochemically induced conjugation of radiometals to small molecules, peptides and nanoparticles in a simultaneous one-pot reaction |
| EP3677911A3 (en) | 2019-01-03 | 2020-07-29 | Universität Basel | Use of non-agonist ligands for suppression of metastasis |
| US20220088144A1 (en) | 2019-01-11 | 2022-03-24 | Universitätsspital Basel | Sglt-2 inhibitors or il-1r antagonists for reduction of hypoglycaemia after bariatric surgery |
| WO2020207771A1 (en) | 2019-04-10 | 2020-10-15 | Universität Zürich | A method for determining the likelihood of a patient being responsive to cancer immunotherapy |
| MX2021014649A (es) * | 2019-06-04 | 2022-01-06 | Molecular Partners Ag | Dominio de repetición de anquirina diseñado con estabilidad mejorada. |
| SG11202112921VA (en) | 2019-06-04 | 2021-12-30 | Molecular Partners Ag | Multispecific proteins |
| EP3980045A1 (en) * | 2019-06-04 | 2022-04-13 | Molecular Partners AG | Recombinant fap binding proteins and their use |
| US20220332845A1 (en) | 2019-09-05 | 2022-10-20 | Genome Biologics Ug | Inhibition of mthfd1l for use in hypertrophic heart disease and heart failure |
| WO2021116470A2 (en) | 2019-12-11 | 2021-06-17 | Molecular Partners Ag | Recombinant peptide-mhc complex binding proteins and their generation and use |
| EP4073091A1 (en) | 2019-12-11 | 2022-10-19 | Molecular Partners AG | Designed ankyrin repeat domains with altered surface residues |
| WO2021122813A1 (en) | 2019-12-16 | 2021-06-24 | Universität Basel | Angiogenesis promoting agents for prevention of metastatic cancer |
| WO2021176008A1 (en) | 2020-03-04 | 2021-09-10 | Cornell University | Agents targeting baf155 or brg1 for use in treatment of advanced prostate cancer |
| WO2021204781A1 (en) | 2020-04-06 | 2021-10-14 | Universität Zürich | Artc1 ligands for cancer treatment |
| JP2023525518A (ja) | 2020-05-06 | 2023-06-16 | モレキュラー パートナーズ アクチェンゲゼルシャフト | 新規アンキリンリピート結合タンパク質とその用途 |
| AU2021271129A1 (en) | 2020-05-14 | 2022-12-15 | Molecular Partners Ag | Multispecific proteins |
| WO2021229076A1 (en) * | 2020-05-14 | 2021-11-18 | Molecular Partners Ag | Recombinant cd40 binding proteins and their use |
| US12146000B2 (en) | 2020-05-19 | 2024-11-19 | Boehringer Ingelheim International Gmbh | Bispecific and tetravalent CD137 and FAP molecules for the treatment of cancer |
| WO2021239844A1 (en) | 2020-05-27 | 2021-12-02 | Universitätsspital Basel | Sglt-2 inhibitors or il-1r antagonists for reduction of hypoglycaemia in prediabetes |
| WO2021239999A1 (en) | 2020-05-28 | 2021-12-02 | Universität Zürich | Il-12 pd-l1 ligand fusion protein |
| US11981710B2 (en) * | 2020-08-18 | 2024-05-14 | Athebio Ag | N-terminal capping modules of ankyrin repeat domains |
| EP3957649A1 (en) | 2020-08-18 | 2022-02-23 | Athebio AG | Improved n-terminal capping modules of ankyrin repeat domains |
| KR20230048151A (ko) | 2020-08-18 | 2023-04-10 | 유니버시타트 취리히 | Cd25 편향된 항-il-2 항체 |
| CN114106194B (zh) * | 2020-08-31 | 2024-01-16 | 中国科学院天津工业生物技术研究所 | 一种用于治疗糖尿病和/或肥胖症的融合蛋白 |
| WO2022098743A1 (en) | 2020-11-03 | 2022-05-12 | Indi Molecular, Inc. | Compositions, imaging, and therapeutic methods targeting folate receptor 1 (folr1) |
| WO2022098745A1 (en) | 2020-11-03 | 2022-05-12 | Indi Molecular, Inc. | Compositions, delivery systems, and methods useful in tumor therapy |
| CA3202358A1 (en) | 2020-12-16 | 2022-06-23 | Andreas BOSSHART | Novel slow-release prodrugs |
| AU2021403658A1 (en) | 2020-12-16 | 2023-06-29 | Molecular Partners Ag | Recombinant cd3 binding proteins and their use |
| EP4291901B1 (en) | 2021-02-11 | 2025-05-07 | Universität Zürich | Use of markers found on lymph node metastatic samples for the prognosis of breast cancer |
| EP4043481A1 (en) | 2021-02-15 | 2022-08-17 | Affilogic | Compounds and methods for extending half life of biomolecules |
| WO2022190010A1 (en) | 2021-03-09 | 2022-09-15 | Molecular Partners Ag | Novel darpin based cd33 engagers |
| WO2022190008A1 (en) | 2021-03-09 | 2022-09-15 | Molecular Partners Ag | Protease cleavable prodrugs |
| JP2024509241A (ja) | 2021-03-09 | 2024-02-29 | モレキュラー パートナーズ アクチェンゲゼルシャフト | 新規のDARPinに基づくCD123エンゲージャ |
| BR112023018293A2 (pt) | 2021-03-09 | 2023-10-31 | Molecular Partners Ag | Acopladores de célula t multiespecíficos à base de darpin |
| EP4323388B1 (en) | 2021-04-16 | 2025-01-29 | Athebio AG | N-terminal capping modules of ankyrin repeat domains |
| US20240366718A1 (en) | 2021-08-05 | 2024-11-07 | Immunos Therapeutics Ag | Pharmaceutical compositions comprising hla fusion proteins |
| AU2022322029A1 (en) | 2021-08-05 | 2024-02-15 | Immunos Therapeutics Ag | Combination medicaments comprising hla fusion proteins |
| WO2023021006A1 (en) | 2021-08-16 | 2023-02-23 | Universität Zürich | Il-1 targeting agents for treatment of pitiyriasis rubra pilaris |
| WO2023021050A1 (en) | 2021-08-17 | 2023-02-23 | Athebio Ag | Variants of ankyrin repeat domains |
| EP4137508A1 (en) | 2021-08-17 | 2023-02-22 | Athebio AG | Variants of ankyrin repeat domains |
| WO2023036849A1 (en) | 2021-09-07 | 2023-03-16 | ETH Zürich | Identifying and predicting future coronavirus variants |
| EP4163380A1 (en) | 2021-10-08 | 2023-04-12 | ETH Zurich | Device and method for manipulation of extracellular vesicles |
| IL313411A (en) | 2021-12-14 | 2024-08-01 | Molecular Partners Ag | Designed repeat domains with dual binding specificity and their use |
| WO2023110942A1 (en) | 2021-12-14 | 2023-06-22 | Charité-Universitätsmedizin Berlin | Prevention of impaired fracture healing |
| EP4260907A1 (en) | 2022-04-11 | 2023-10-18 | Universität Zürich | Agents for treatment of endometriosis and other benign gynecological neoplasms |
| WO2024002914A1 (en) | 2022-06-27 | 2024-01-04 | Charité-Universitätsmedizin Berlin | Prediction of, and composition to improve, tendon healing |
| WO2024028278A1 (en) | 2022-08-01 | 2024-02-08 | Molecular Partners Ag | Charge modified designed repeat domains and their use |
| WO2024037743A1 (en) | 2022-08-16 | 2024-02-22 | Athebio Ag | Variants of ankyrin repeat domains |
| WO2023194628A2 (en) | 2022-08-16 | 2023-10-12 | Athebio Ag | Variants of ankyrin repeat domains |
| WO2024038307A1 (en) | 2022-08-19 | 2024-02-22 | Novartis Ag | Dosing regimens for sars-cov-2 binding molecules |
| WO2024064200A2 (en) * | 2022-09-20 | 2024-03-28 | The Texas A&M University System | Darpin-containing compositions and methods thereof |
| WO2024133013A1 (en) | 2022-12-19 | 2024-06-27 | Max-Planck-Gesellschaft zur Förderung der Wissenschaften e. V. | Means and methods to target endogenous condensates |
| WO2024165671A1 (en) | 2023-02-08 | 2024-08-15 | Immunos Therapeutics Ag | FUSION PROTEINS OF ß2 MICROGLOBULIN, HLA HEAVY CHAIN POLYPEPTIDES, AND INHIBITOR OF CD47-SIRPA |
| WO2024170756A1 (en) | 2023-02-17 | 2024-08-22 | Ablynx N.V. | Polypeptides binding to the neonatal fc receptor |
| WO2024179981A1 (en) | 2023-02-27 | 2024-09-06 | Molecular Partners Ag | Darpins for use in reducing renal accumulation of drugs |
| WO2024251695A1 (en) | 2023-06-06 | 2024-12-12 | Molecular Partners Ag | Recombinant cd47 binding proteins and their use |
| WO2024251742A1 (en) | 2023-06-06 | 2024-12-12 | Molecular Partners Ag | Recombinant cd2 binding proteins and their use |
| WO2024251628A1 (en) | 2023-06-06 | 2024-12-12 | Molecular Partners Ag | Recombinant cd16a binding proteins and their use |
| WO2025008519A1 (en) | 2023-07-05 | 2025-01-09 | Universität Bern | Il-1ra blockers for treatment and prevention of sepsis |
| WO2025021293A1 (en) | 2023-07-25 | 2025-01-30 | Universität Zürich | Disruption of rbr1 expression in plant cells |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010060748A1 (en) * | 2008-11-03 | 2010-06-03 | Molecular Partners Ag | Binding proteins inhibiting the vegf-a receptor interaction |
Family Cites Families (37)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA1340288C (en) | 1988-09-02 | 1998-12-29 | Robert Charles Ladner | Generation and selection of novel binding proteins |
| SE509359C2 (sv) | 1989-08-01 | 1999-01-18 | Cemu Bioteknik Ab | Användning av stabiliserade protein- eller peptidkonjugat för framställning av ett läkemedel |
| US5270170A (en) | 1991-10-16 | 1993-12-14 | Affymax Technologies N.V. | Peptide library and screening method |
| US5348867A (en) | 1991-11-15 | 1994-09-20 | George Georgiou | Expression of proteins on bacterial surface |
| CA2196496A1 (en) | 1997-01-31 | 1998-07-31 | Stephen William Watson Michnick | Protein fragment complementation assay for the detection of protein-protein interactions |
| JP4086325B2 (ja) | 1997-04-23 | 2008-05-14 | プリュックテュン,アンドレアス | 標的分子と相互作用する(ポリ)ペプチドをコードする核酸分子の同定方法 |
| IL143238A0 (en) | 1998-12-02 | 2002-04-21 | Phylos Inc | Dna-protein fusions and uses thereof |
| US20060228364A1 (en) | 1999-12-24 | 2006-10-12 | Genentech, Inc. | Serum albumin binding peptides for tumor targeting |
| CA2390691C (en) | 1999-12-24 | 2016-05-10 | Genentech, Inc. | Methods and compositions for prolonging elimination half-times of bioactive compounds |
| ATE448301T1 (de) * | 2000-09-08 | 2009-11-15 | Univ Zuerich | Sammlung von proteinen mit sich wiederholenden sequenzen (repeat proteins), die repetitive sequenzmodule enthalten |
| RU2299208C2 (ru) * | 2001-05-08 | 2007-05-20 | Шеринг Акциенгезельшафт | Антраниламидпиридинамиды избирательного действия в качестве ингибиторов vegfr-2 и vegfr-3 |
| EP1517921B1 (en) | 2002-06-28 | 2006-06-07 | Domantis Limited | Dual specific ligands with increased serum half-life |
| US7696320B2 (en) | 2004-08-24 | 2010-04-13 | Domantis Limited | Ligands that have binding specificity for VEGF and/or EGFR and methods of use therefor |
| US9321832B2 (en) | 2002-06-28 | 2016-04-26 | Domantis Limited | Ligand |
| US20070178082A1 (en) | 2002-11-08 | 2007-08-02 | Ablynx N.V. | Stabilized single domain antibodies |
| EP1900753B1 (en) | 2002-11-08 | 2017-08-09 | Ablynx N.V. | Method of administering therapeutic polypeptides, and polypeptides therefor |
| US7772188B2 (en) * | 2003-01-28 | 2010-08-10 | Ironwood Pharmaceuticals, Inc. | Methods and compositions for the treatment of gastrointestinal disorders |
| EP2380594B1 (en) | 2004-04-06 | 2019-12-04 | Affibody AB | Use of a serum albumin binding peptide to reduce the immunogenicity of a protein |
| WO2006040153A2 (en) | 2004-10-13 | 2006-04-20 | Ablynx N.V. | Single domain camelide anti -amyloid beta antibodies and polypeptides comprising the same for the treatment and diagnosis of degenarative neural diseases such as alzheimer's disease |
| EP2949668B1 (en) | 2005-05-18 | 2019-08-14 | Ablynx N.V. | Improved nanobodies tm against tumor necrosis factor-alpha |
| JP5042218B2 (ja) | 2005-07-08 | 2012-10-03 | ユニバーシティ・オブ・チューリッヒ | 融合ポリペプチドの翻訳と同時のトランスロケーションを使用するファージディスプレイ |
| EP2863222A1 (en) | 2006-03-06 | 2015-04-22 | Amunix Operating Inc. | Unstructured recombinant polymers and uses thereof |
| JP2010502208A (ja) | 2006-09-08 | 2010-01-28 | アブリンクス エン.ヴェー. | 半減期の長い血清アルブミン結合タンパク質 |
| WO2008043821A1 (en) | 2006-10-11 | 2008-04-17 | Ablynx N. V. | Amino acid sequences that bind to serum proteins in a manner that is essentially independent of the ph, compounds comprising the same, and use thereof |
| US20100034194A1 (en) * | 2006-10-11 | 2010-02-11 | Siemens Communications Inc. | Eliminating unreachable subscribers in voice-over-ip networks |
| EP2111228B1 (en) | 2007-02-02 | 2011-07-20 | Bristol-Myers Squibb Company | 10Fn3 domain for use in treating diseases associated with inappropriate angiogenesis |
| PT2173890E (pt) | 2007-06-21 | 2011-05-06 | Tech Universit T M Nchen | Prote?nas biologicamente activas com estabilidade in vivo e/ou in vitro aumentada |
| US8937153B2 (en) | 2007-07-31 | 2015-01-20 | Affibody Ab | Compositions, methods and uses |
| EP2198022B1 (en) | 2007-09-24 | 2024-03-06 | University Of Zurich | Designed armadillo repeat proteins |
| US20110262964A1 (en) * | 2008-03-19 | 2011-10-27 | Hugues Bedouelle | Reagentless fluorescent biosensors comprising a designed ankyrin repeat protein module, rational design methods to create reagentless fluorescent biosensors and methods of their use |
| TWI510246B (zh) * | 2010-04-30 | 2015-12-01 | Molecular Partners Ag | 抑制vegf-a受體交互作用的經修飾結合性蛋白質 |
| EP2636236A4 (en) * | 2010-11-03 | 2016-06-29 | Ericsson Telefon Ab L M | RADIO BASE STATION AND METHOD THEREFOR |
| CA2818990C (en) * | 2010-11-26 | 2021-06-15 | Molecular Partners Ag | Designed repeat proteins binding to serum albumin |
| WO2012149439A2 (en) | 2011-04-29 | 2012-11-01 | Janssen Biotech, Inc. | Il4/il13 binding repeat proteins and uses |
| US9163070B2 (en) * | 2012-06-28 | 2015-10-20 | Molecular Partners Ag | Designed ankyrin repeat proteins binding to platelet-derived growth factor |
| EP2738180A1 (en) * | 2012-11-30 | 2014-06-04 | Molecular Partners AG | Binding proteins comprising at least two binding domains against HER2. |
| JP6552636B2 (ja) * | 2015-04-02 | 2019-07-31 | モレキュラー パートナーズ アクチェンゲゼルシャフト | 血清アルブミンに対する結合特異性を有する設計アンキリンリピートドメイン |
-
2011
- 2011-11-25 CA CA2818990A patent/CA2818990C/en active Active
- 2011-11-25 BR BR112013013043A patent/BR112013013043A2/pt not_active Application Discontinuation
- 2011-11-25 CN CN202110301133.2A patent/CN113278077A/zh active Pending
- 2011-11-25 KR KR1020137014339A patent/KR20140032356A/ko not_active Ceased
- 2011-11-25 KR KR1020177010815A patent/KR101838037B1/ko active Active
- 2011-11-25 CN CN201180066086.2A patent/CN103459415B/zh active Active
- 2011-11-25 WO PCT/EP2011/071084 patent/WO2012069655A2/en active Application Filing
- 2011-11-25 PL PL11788815T patent/PL2643349T3/pl unknown
- 2011-11-25 RU RU2013128896A patent/RU2625882C2/ru active
- 2011-11-25 JP JP2013540387A patent/JP6173216B2/ja active Active
- 2011-11-25 AU AU2011333665A patent/AU2011333665B2/en active Active
- 2011-11-25 JP JP2013540386A patent/JP6105479B2/ja active Active
- 2011-11-25 RU RU2013128895A patent/RU2636552C2/ru active
- 2011-11-25 KR KR1020137014067A patent/KR101782790B1/ko active Active
- 2011-11-25 US US13/989,181 patent/US9221892B2/en active Active
- 2011-11-25 AU AU2011333666A patent/AU2011333666B2/en active Active
- 2011-11-25 EP EP11788815.6A patent/EP2643349B1/en active Active
- 2011-11-25 US US13/989,174 patent/US9284361B2/en active Active
- 2011-11-25 WO PCT/EP2011/071083 patent/WO2012069654A1/en active Application Filing
- 2011-11-25 ES ES11788815T patent/ES2758352T3/es active Active
- 2011-11-25 BR BR112013012786-4A patent/BR112013012786B1/pt active IP Right Grant
- 2011-11-25 EP EP11788152.4A patent/EP2643348B1/en active Active
- 2011-11-25 ES ES19160342T patent/ES2981441T3/es active Active
- 2011-11-25 CA CA2818969A patent/CA2818969C/en active Active
- 2011-11-25 DK DK11788815T patent/DK2643349T3/da active
- 2011-11-25 EP EP19160342.2A patent/EP3514169B1/en active Active
- 2011-11-25 CN CN201180066084.3A patent/CN103403024B/zh active Active
- 2011-11-25 BR BR122020011428-2A patent/BR122020011428B1/pt active IP Right Grant
-
2015
- 2015-11-20 US US14/947,148 patent/US9717802B2/en active Active
-
2016
- 2016-02-02 US US15/013,092 patent/US9775912B2/en active Active
- 2016-10-28 JP JP2016211658A patent/JP2017048216A/ja active Pending
-
2017
- 2017-06-23 US US15/631,028 patent/US10322190B2/en active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010060748A1 (en) * | 2008-11-03 | 2010-06-03 | Molecular Partners Ag | Binding proteins inhibiting the vegf-a receptor interaction |
Non-Patent Citations (1)
| Title |
|---|
| 锚蛋白重复序列介导的蛋白质2蛋白质相互作用;杜海宁;《生物化学与生物物理进展》;20020131;第29卷(第1期);6-9 * |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN103459415B (zh) | 设计的与血清白蛋白结合的重复蛋白 | |
| EP2867360B1 (en) | Designed ankyrin repeat proteins binding to platelet-derived growth factor | |
| WO2014165093A2 (en) | Fibronectin based scaffold domains linked to serum albumin or a moiety binding thereto | |
| WO2024074762A1 (en) | Ultrastable antibody fragments with a novel disuldide bridge |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| REG | Reference to a national code |
Ref country code: HK Ref legal event code: DE Ref document number: 1189386 Country of ref document: HK |
|
| GR01 | Patent grant | ||
| GR01 | Patent grant |