WO2019074110A1 - 一本鎖核酸分子およびその製造方法 - Google Patents
一本鎖核酸分子およびその製造方法 Download PDFInfo
- Publication number
- WO2019074110A1 WO2019074110A1 PCT/JP2018/038174 JP2018038174W WO2019074110A1 WO 2019074110 A1 WO2019074110 A1 WO 2019074110A1 JP 2018038174 W JP2018038174 W JP 2018038174W WO 2019074110 A1 WO2019074110 A1 WO 2019074110A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- region
- nucleic acid
- acid molecule
- stranded nucleic
- residue
- Prior art date
Links
- 0 CC(C(C12)C1C1CC(C)C*C1)C2C1CC(C2)C2C1 Chemical compound CC(C(C12)C1C1CC(C)C*C1)C2C1CC(C2)C2C1 0.000 description 3
- BONNYNBXMCRXBJ-UHFFFAOYSA-N O=C(CBr)NCCOCCOCCOCCOCCC(ON(C(CC1)=O)C1=O)=O Chemical compound O=C(CBr)NCCOCCOCCOCCOCCC(ON(C(CC1)=O)C1=O)=O BONNYNBXMCRXBJ-UHFFFAOYSA-N 0.000 description 1
Images




Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07H—SUGARS; DERIVATIVES THEREOF; NUCLEOSIDES; NUCLEOTIDES; NUCLEIC ACIDS
- C07H21/00—Compounds containing two or more mononucleotide units having separate phosphate or polyphosphate groups linked by saccharide radicals of nucleoside groups, e.g. nucleic acids
- C07H21/02—Compounds containing two or more mononucleotide units having separate phosphate or polyphosphate groups linked by saccharide radicals of nucleoside groups, e.g. nucleic acids with ribosyl as saccharide radical
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07H—SUGARS; DERIVATIVES THEREOF; NUCLEOSIDES; NUCLEOTIDES; NUCLEIC ACIDS
- C07H21/00—Compounds containing two or more mononucleotide units having separate phosphate or polyphosphate groups linked by saccharide radicals of nucleoside groups, e.g. nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/111—General methods applicable to biologically active non-coding nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/11—Antisense
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/14—Type of nucleic acid interfering N.A.
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/50—Physical structure
- C12N2310/53—Physical structure partially self-complementary or closed
- C12N2310/531—Stem-loop; Hairpin
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2330/00—Production
- C12N2330/30—Production chemically synthesised
Definitions
- the present invention relates to single stranded nucleic acid molecules and methods for their production.
- single-stranded nucleic acid molecules for example, those described in Patent Documents 1 and 2 are known.
- nucleic acid represented by formula (II) with the compound represented by formula (IV) and then represented by formula (III)
- the method of reacting with nucleic acid can significantly avoid the contamination of short oligomers such as N-1, 2, 3 etc. which are often a problem in the synthesis of long chain oligomers, and the purification of the reaction product is easy.
- the present invention has been completed.
- R 2 is a region containing an oligonucleotide or a polynucleotide, the 5 ′ terminal nucleotide residue of which is linked to —O—;
- X 1 and X 2 each independently represent NH, S or O;
- L 1 and L 2 are each independently a C 1-30 alkylene chain, or- (CH 2 ) l- (O- (CH 2 ) m- ) n- (wherein l is an integer of 1 to 3)
- M represents an integer of 1 to 3 and n represents an integer of 1 to 10);
- -C ( O) -AA-NR 3 -represents an amino acid residue;
- R 3 represents a hydrogen atom or a C 1-6 alkyl group
- nucleic acid (II) is represented by the following general formula (IV):
- Z 1 represents a succinimidyl oxy group, a benzotriazolyloxy group, a pentafluorophenoxy group or a halogen atom
- Z 2 represents a halogen atom
- Other symbols are as defined above.
- a step of obtaining a nucleic acid represented by (hereinafter also referred to as a nucleic acid (V)); and (step 2) a nucleic acid represented by the general formula (V):
- nucleic acid (III) Reacting with the nucleic acid represented by (hereinafter also referred to as nucleic acid (III)) to obtain a single-stranded nucleic acid molecule represented by the above general formula (I);
- a method of manufacture including [2] The production method of the above-mentioned [1], wherein the amino acid residue is a proline residue, a glycine residue, or a lysine residue whose side chain amino group may be protected. [3] The production method according to the above-mentioned [1], wherein X 2 is S. [4] The production method of the above-mentioned [1], wherein X 1 is NH.
- R 2 is a region containing an oligonucleotide or a polynucleotide, the 5 ′ terminal nucleotide residue of which is linked to —O—;
- L 1 and L 2 are each independently a C 1-30 alkylene chain, or- (CH 2 ) l- (O- (CH 2 ) m- ) n- (wherein l is an integer of 1 to 3)
- M represents an integer of 1 to 3 and n represents an integer of 1 to 10);
- -C ( O) -AA-NR 3 -represents an amino acid residue;
- R 3 represents a hydrogen atom or a C 1-6 alkyl group, or together with AA forms a nitrogen-containing heterocycle.
- a single-stranded nucleic acid molecule represented by (hereinafter also referred to as a single-stranded nucleic acid molecule (Ia)).
- the compound of the above-mentioned [20] wherein the amino acid residue is a proline residue, a glycine residue, or a lysine residue whose side chain amino group may be protected.
- Z 2 is a chlorine atom or a bromine atom.
- a novel method for producing a single-stranded nucleic acid molecule which enables synthesis of a high difficulty long-chain oligomer by exploiting the technique of short-chain oligomer, and a novel single strand produced by the method It can provide stranded nucleic acid molecules.
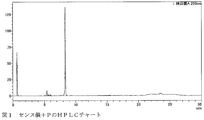
- FIG. 1 is an HPLC chart of sense strand + P synthesized in Example 2.
- FIG. 2 is an HPLC chart of the antisense strand (SH form) synthesized in Example 2.
- FIG. 3 is an HPLC chart of the single-stranded nucleic acid molecule PS-0001-C3 synthesized in Example 2.
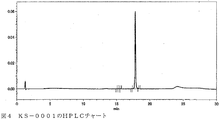
- FIG. 4 is an HPLC chart of the single-stranded nucleic acid molecule KS-0001 synthesized in Example 4.
- FIG. 5 is an HPLC chart of single-stranded nucleic acid molecule AS-0001 synthesized in the reference example.
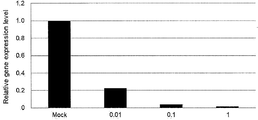
- FIG. 6 is a graph showing the relative value of the expression level of the TGF- ⁇ 1 gene in Test Example 1.
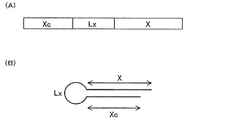
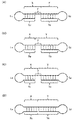
- FIG. 7 is a schematic view showing an example of a single-stranded nucleic acid molecule of the present invention.
- FIG. 8 is a schematic view showing another example of the single-stranded nucleic acid molecule of the present invention.
- FIG. 9 is a schematic view showing another example of the single-stranded nucleic acid molecule of the present invention.
- Nucleotide residue refers to OH in the phosphate group at the 5 'position of the nucleotide (where the phosphate is attached to the hydroxyl group at the 5' position of the sugar moiety of the nucleoside) and H in the hydroxyl group at the 3 'position
- a “3′-terminal nucleotide residue” in R 1 is a divalent group, and its 3 ′ position is a group in formula (I)
- R 1 is a region (X) containing oligonucleotides or polynucleotides each having deoxyribonucleotides (DNA) and / or ribonucleotides (RNA) as constituent units in the first single-stranded nucleic acid molecule of the present invention described later and R 1 It may be one of the regions (Xc) and R 2 may be the other.
- R 1 is a region (X) containing oligonucleotides or polynucleotides each having deoxyribonucleotide (DNA) and / or ribonucleotide (RNA) in the second single-stranded nucleic acid molecule of the present invention described later (X And region (Y) and region (Xc) and region (Yc), and R 2 may be the other. Further, as described later, the area (Yc) and the area (Y) may be, for example, directly linked or may be indirectly linked.
- Each of X 1 and X 2 independently represents NH, S or O.
- X 1 is preferably NH.
- X 2 is preferably S.
- L 1 and L 2 are each independently a C 1-30 alkylene chain, or- (CH 2 ) l- (O- (CH 2 ) m- ) n- (wherein l is an integer of 1 to 3) And m represents an integer of 1 to 3, and n represents an integer of 1 to 10.).
- C 1-30 alkylene chain represented by L 1 or L 2 , —CH 2 —, — (CH 2 ) 2 —, — (CH 2 ) 3 —, — (CH 2 ) 4 —, —CH 2 (CH 3) -, - C (CH 3) 2 -, - CH (C 2 H 5) -, - CH (C 3 H 7) -, - (CH (CH 3)) 2 -, - CH 2 - CH (CH 3) -, - CH (CH 3) -CH 2 -, - (CH 2) 4 -, - (CH 2) 5 -, - (CH 2) 6 -, - (CH 2) 7 -, -(CH 2 ) 8 -,-(CH 2 ) 9 -,-(CH 2 ) 10 -,-(CH 2 ) 11 -,-(CH 2 ) 12- and the like.
- the “C 1-30 alkylene chain” is preferably a C 2-11 alkylene chain, more preferably a C 3-6 alkylene chain, and particularly preferably a C 4-6 alkylene chain in L 1 .
- L 2 is a C 3 alkylene chain.
- l is preferably an integer of 1 to 2 and m is preferably 1 It is an integer of -2.
- n is preferably an integer of 1 to 5, and more preferably an integer of 1 to 2.
- a further preferred example is —CH 2 CH 2 (OCH 2 CH 2 ) n — (wherein n is an integer of 1 to 5).
- a particularly preferred embodiment is —CH 2 CH 2 (OCH 2 CH 2 ) n — (wherein n is an integer of 1 to 2).
- L 1 and L 2 are preferably each independently a C 2-11 alkylene chain or —CH 2 CH 2 (OCH 2 CH 2 ) n — (wherein n is an integer of 1 to 5). It is. More preferably, L 1 and L 2 are each independently a C 3-6 alkylene chain or -CH 2 CH 2 (OCH 2 CH 2 ) n- (wherein n is an integer of 1 to 2). ). Particularly preferably, L 1 is a C 4-6 alkylene chain and L 2 is a C 3 alkylene chain.
- -C ( O) -AA-NR 3 -represents an amino acid residue, and R 3 represents a hydrogen atom or C A 1-6 alkyl group is shown or, together with AA, forms a nitrogen-containing heterocycle.
- Examples of the “C 1-6 alkyl group” represented by R 3 include methyl, ethyl, propyl, isopropyl, butyl, isobutyl, sec-butyl, tert-butyl, pentyl, isopentyl, neopentyl, 1-ethylpropyl and hexyl , Isohexyl, 1,1-dimethylbutyl, 2,2-dimethylbutyl, 3,3-dimethylbutyl, 2-ethylbutyl.
- Examples of the “nitrogen-containing heterocycle” formed together with R 3 and AA include pyrroline, pyrrolidine, imidazoline, imidazolidine, oxazoline, oxazolidine, pyrazoline, pyrazolidine, thiazoline, thiazolidine, piperidine, piperazine, tetrahydropyridine, And 3- to 8-membered monocyclic nitrogen-containing non-aromatic heterocycles such as dihydropyridine, tetrahydropyrimidine, tetrahydropyridazine, morpholine, thiomorpholine, azepanine, diazepam, azepine and the like. Among these, pyrrolidine is preferred.
- R 3 is preferably a hydrogen atom or taken together with AA to form pyrrolidine.
- the said "amino acid residue” means bivalent group except OH of the carboxy group of an amino acid, and one hydrogen atom of an amino group. When a carboxy group or an amino group is present in the side chain of an amino acid, the “amino acid residue” also includes divalent groups obtained by removing OH and hydrogen atoms from these groups.
- the “amino acid residue” is not particularly limited, and all known residues derived from amino acids are exemplified, and residues derived from ⁇ -amino acids, residues derived from ⁇ -amino acids, residues derived from ⁇ -amino acids And the like.
- R 3 may combine with AA to form a nitrogen-containing heterocycle, and such “amino acid residue” includes cyclic amino acid residues such as proline residues.
- the side chain functional group eg, amino group, carboxy group, hydroxy group, sulfanyl group (SH), amido group (CONH 2 ), etc.
- the side chain functional group is known and appropriate. May be protected by any protective group. Examples of protecting groups for amino groups include tert-butoxycarbonyl (Boc), benzyloxycarbonyl (Z), 9-fluorenylmethyloxycarbonyl (Fmoc) and the like, and protecting groups for carboxy include A methyl group, an ethyl group, a benzyl group etc.
- the side chain functional group of the amino acid residue may be modified with a sugar, a lipid, a peptide or the like.
- Preferred specific examples of the "amino acid residue” include proline residue, glycine residue, lysine residue, phenylalanine residue, beta alanine residue and the like.
- the side chain amino group may be protected with a tert-butoxycarbonyl group, or may be modified with a sugar, a lipid, a peptide or the like.
- amino acid residue is a proline residue, a glycine residue, or a lysine residue whose side chain amino group may be protected (eg, the side chain amino group is protected with a tert-butoxycarbonyl group) Is a good lysine residue), and a proline residue, or a lysine residue whose side chain amino group may be protected (eg, a lysine residue whose side chain amino group may be protected with a tert-butoxycarbonyl group) Group is more preferred.
- Z 1 represents a succinimidyl oxy group, a benzotriazolyloxy group, a pentafluorophenoxy group or a halogen atom.
- the “halogen atom” represented by Z 1 includes a fluorine atom, a chlorine atom, a bromine atom and an iodine atom, and among them, a chlorine atom or a bromine atom is preferable.
- Z 1 is preferably a succinimidyl oxy group.
- Z 2 represents a halogen atom.
- the “halogen atom” represented by Z 2 include a fluorine atom, a chlorine atom, a bromine atom and an iodine atom, and among them, a chlorine atom or a bromine atom is preferable.
- Z 3 represents a halogen atom.
- the “halogen atom” represented by Z 3 include a fluorine atom, a chlorine atom, a bromine atom and an iodine atom, and among them, a chlorine atom or a bromine atom is preferable.
- Single stranded nucleic acid molecule (I) can be produced, for example, by the following production method 1.
- Step 1 Nucleic acid (II) is reacted with compound (IV) to produce nucleic acid (V).
- the reaction is usually carried out under basic conditions (preferably pH 8 to 9) (for example, in a phosphate buffer or carbonate buffer, or in the presence of a base such as diisopropylethylamine or triethylamine).
- the reaction is usually carried out in a solvent at 0 ° C. to room temperature.
- the solvent examples include amide solvents such as N, N-dimethylformamide and N, N-dimethylacetamide; ether solvents such as tetrahydrofuran (THF) and dioxane; polar solvents such as dimethyl sulfoxide and acetonitrile; water and the like; Among them, a mixed solvent of dimethylformamide and water or water is preferable.
- amide solvents such as N, N-dimethylformamide and N, N-dimethylacetamide
- ether solvents such as tetrahydrofuran (THF) and dioxane
- polar solvents such as dimethyl sulfoxide and acetonitrile
- water and the like Among them, a mixed solvent of dimethylformamide and water or water is preferable.
- the low molecular weight compound is removed by a simple gel filtration column or the like to obtain a nucleic acid (V).
- Step 2 Nucleic acid (V) is reacted with nucleic acid (III) to produce single stranded nucleic acid molecule (I).
- the reaction is usually carried out under basic conditions (preferably pH 8 to 9) (for example, in phosphate buffer or carbonate buffer).
- the reaction is usually carried out in a solvent at room temperature.
- purification is performed by HPLC or the like to obtain a single-stranded nucleic acid molecule (I).
- Compound (IV) used in Production method 1 can be produced, for example, by the following production method 2.
- Z 3 represents a halogen atom, and the other symbols are as defined above].
- Step 3 Compound (VI) which is an amino acid is reacted with compound (VII) to produce compound (VIII).
- Z 3 is a chlorine atom
- the reaction is usually carried out in a solvent at room temperature to heating.
- the solvent include ether solvents such as tetrahydrofuran (THF) and dioxane; and polar solvents such as acetonitrile and dimethylformamide. Among them, tetrahydrofuran is preferable.
- Z 3 is a bromine atom
- the reaction is usually carried out in a solvent, in the presence of a base, under cooling to room temperature.
- the solvent examples include ether solvents such as water, tetrahydrofuran (THF) and dioxane; polar solvents such as acetonitrile and dimethylformamide; and the like. Among them, a mixed solvent of water and tetrahydrofuran is preferable.
- the base examples include sodium hydroxide and the like.
- Z 1 is a succinimidyl oxy group
- compound (VIII) is reacted with N-hydroxysuccinimide in the presence of a condensing agent such as 1-ethyl-3- (3-dimethylaminopropyl) carbodiimide hydrochloride. It is done by.
- the reaction is usually carried out in a solvent at room temperature.
- the solvent include halogen solvents such as dichloromethane and chloroform, and ether solvents such as tetrahydrofuran (THF) and dioxane. Among them, dichloromethane is preferable.
- the nucleic acid (II) used in production method 1 is N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-(N-N-N-N
- DMTr represents 4,4′-dimethoxytrityl group, and the other symbols are as defined above].
- Nucleic acid (III) to be used in production method 1 is obtained by removing the protecting group at the 5 'terminal hydroxyl group in the final step of solid phase synthesis, introducing the corresponding reagent by the phosphoroamidite method, and treating it appropriately. It can be synthesized.
- nucleic acid (III) is
- the nucleic acid represented by the following is removed by the phosphoroamidite method after removing the protecting group at the 5 'terminal hydroxyl group.
- DMTr is as defined above.
- the compound can be synthesized by treating it with dithiothreitol after extraction from the solid phase and deprotection according to a conventional method.
- single-stranded nucleic acid molecules (hereinafter also referred to as single-stranded nucleic acid molecules (Ia)) are novel.
- Preferred examples of the single stranded nucleic acid molecule (Ia) include single stranded nucleic acid molecules represented by the following formula.
- n1 and n2 each independently represent an integer of 1 to 10
- n3 and n4 each independently represent an integer of 1 to 5, and the other symbols are as defined above].
- n1 is preferably an integer of 3 to 5 and n2 is preferably 2 and n3 is preferably an integer of 1 to 2 and n4 is preferably an integer of 1 to 2.
- More preferable examples of the single stranded nucleic acid molecule (Ia) include single stranded nucleic acid molecules represented by the following formula.
- reaction can also be carried out according to the above-mentioned production method, using compounds (IV'b) to (IV'g) instead of compound (IV).
- compounds (IV'b) to (IV'g) instead of compound (IV).
- the structures of compounds (IV'b) to (IV'g) and specific examples thereof are shown below.
- R represents a hydrogen atom, an optionally substituted C 6-10 aryl group, a protected amino group, a protected sulfanyl group (SH);
- W represents a C 1-6 alkyl group which may be substituted, a C 1-6 alkoxy group;
- p represents an integer of 0 to 6;
- q represents an integer of 0 to 6;
- r represents an integer of 0 to 6;
- Trt represents a trityl group;
- Other symbols are as defined above.
- C 6-10 aryl group examples include phenyl, 1-naphthyl and 2-naphthyl.
- substituent of the “ optionally substituted C 6-10 aryl group” include an optionally substituted C 1-6 alkyl group.
- C 1-6 alkyl group for example, methyl, ethyl, propyl, isopropyl, butyl, isobutyl, sec-butyl, tert-butyl, pentyl, isopentyl, neopentyl, 1-ethylpropyl, hexyl, isohexyl, 1, Examples include 1-dimethylbutyl, 2,2-dimethylbutyl, 3,3-dimethylbutyl and 2-ethylbutyl.
- the “optionally substituted C 1-6 alkyl group” is, for example, a C 1-6 alkyl group; a substituted amino group selected from a protected amino group and a protected sulfanyl group (SH) C 1-6 alkyl group.
- a protected amino group for example, an amino group protected by a protecting group such as tert-butoxycarbonyl group and benzyloxycarbonyl group can be mentioned.
- Examples of the "protected sulfanyl group” include a sulfanyl group protected by a protecting group such as trityl (triphenylmethyl) group.
- the " optionally substituted C 1-6 alkyl group” include a C 1-6 alkyl group having an amino group protected by a tert-butoxycarbonyl group (eg, methyl), trityl And C 1-6 alkyl groups (eg, methyl) having a sulfanyl group protected by a phenylmethyl group).
- Examples of the "C 1-6 alkoxy group” include methoxy, ethoxy, propoxy, isopropoxy, butoxy, isobutoxy, sec-butoxy, tert-butoxy, pentyloxy and hexyloxy.
- nucleic acids (I'b) to (I'g) can be produced by using the above compounds (IV'b) to (IV'g).
- the structures of the nucleic acids (I'b) to (I'g) and specific examples thereof are shown below.
- nucleic acids are mentioned as a specific example of a nucleic acid (I'b).
- nucleic acid (I'c) examples include the following nucleic acids.
- nucleic acids are mentioned as a specific example of a nucleic acid (I'd).
- nucleic acid (I'e) examples include the following nucleic acids.
- nucleic acids are mentioned as a specific example of a nucleic acid (I'f).
- nucleic acids are mentioned as a specific example of a nucleic acid (I'g).
- nucleic acids are mentioned as a specific example of a nucleic acid (I'h).
- the single-stranded nucleic acid molecule (I) of the present invention produced by the above-mentioned production method is, as described above, a single-stranded nucleic acid molecule comprising an expression suppression sequence for suppressing the expression of a target gene.
- Region (X), linker region (Lx) and region (Xc) (wherein R 1 in formula (I) is one of region (X) and region (Xc) Single-stranded nucleic acid molecule) or one of the regions (X) and (Xc) (a second single-stranded nucleic acid molecule described later), and whether R 2 is the other (a first one described later)
- the linker region (Lx) is linked between the region (X) and the region (Xc), or a chained acetic acid molecule) or the other (a second single-stranded nucleic acid molecule described later)
- At least one of the region (X) and the region (Xc) contains the expression suppression sequence;
- Linker region (Lx) characterized in that a structure shown in the following formula (IL).
- “suppressing the expression of a target gene” means, for example, inhibiting the expression of the target gene.
- the mechanism of the suppression is not particularly limited, and may be, for example, down regulation or silencing.
- the suppression of the expression of the target gene may be, for example, a reduction in the amount of production of a transcript from the target gene, a reduction in the activity of the transcript, a reduction in the amount of production of a translation product from the target gene, or It can be confirmed by the decrease of Examples of the protein include a mature protein or a precursor protein before being subjected to processing or post-translational modification.
- the single-stranded nucleic acid molecule of the present invention can be used, for example, to suppress the expression of a target gene in vivo or in vitro, and thus “a single-stranded nucleic acid molecule for suppressing the expression of a target gene” or “an agent for suppressing the expression of a target gene It is also called.
- a single-stranded nucleic acid molecule for suppressing the expression of a target gene or “an agent for suppressing the expression of a target gene It is also called.
- the single-stranded nucleic acid molecule of the present invention can suppress the expression of the target gene by, for example, RNA interference, "single-stranded nucleic acid molecule for RNA interference", “RNA interference inducing molecule", “RNA interference agent” Or “RNA interference inducer”.
- the single-stranded nucleic acid molecule of the present invention can suppress side effects such as induction of interferon in a living body, for example, and is excellent in nuclease resistance
- the single-stranded nucleic acid molecule of the present invention is not linked at its 5 'end and 3' end, and may be referred to as a linear single-stranded nucleic acid molecule.
- the expression suppression sequence suppresses the expression of the target gene, for example, when the single-stranded nucleic acid molecule of the present invention is introduced into cells in vivo or in vitro.
- Sequence showing the activity to be The expression suppression sequence is not particularly limited, and can be appropriately set according to the type of target gene of interest.
- a sequence involved in RNA interference by siRNA can be appropriately applied.
- dsRNA long double-stranded RNA
- siRNA small interfering RNA
- One of the single-stranded RNAs binds to a target mRNA to degrade the mRNA, thereby suppressing the translation of the mRNA.
- Various types of single-stranded RNA sequences in the siRNA that bind to the target mRNA have been reported, for example, depending on the type of target gene.
- the sequence of single-stranded RNA of the siRNA can be used as the expression suppression sequence.
- a sequence to be clarified in the future can be used as the expression suppression sequence.
- the expression suppression sequence preferably has, for example, 90% or more complementarity to a predetermined region of the target gene, more preferably 95%, still more preferably 98%, in particular Preferably it is 100%.
- complementarity for example, off-target can be sufficiently reduced.
- the target gene is TGF- ⁇ 1
- a sequence of 19 bases in length shown in SEQ ID NO: 1 can be used as the expression suppression sequence. 5'-UAUGCUGUGUGUACUCUCC-3 '(SEQ ID NO: 1)
- the linker region is represented by, for example, the following formula (IL).
- the region (Xc) is complementary to the region (X). Therefore, in the single-stranded nucleic acid molecule of the present invention, the region (Xc) is folded toward the region (X), and the region (Xc) and the region (X) are double-stranded by self-annealing. Can be formed.
- the single stranded nucleic acid molecule of the invention is thus capable of forming a duplex within the molecule, eg, two separate single stranded RNAs, such as siRNA used for conventional RNA interference. What forms double-stranded RNA by annealing is a distinctly different structure.
- the single-stranded nucleic acid molecule of the present invention for example, only the region (Xc) may be folded to form a duplex with the region (X), and further, a new duplex may be formed in another region. You may form.
- the former single-stranded nucleic acid molecule ie, a molecule in which duplex formation is one place
- a molecule in which two are two is referred to as a "second single-stranded nucleic acid molecule”.
- the first single-stranded nucleic acid molecule and the second single-stranded nucleic acid molecule are exemplified, but the present invention is not limited thereto.
- the first single-stranded nucleic acid molecule is, for example, a molecule comprising the region (X), the region (Xc) and the linker region (Lx).
- the first single-stranded nucleic acid molecule may have, for example, the region (Xc), the linker region (Lx) and the region (X) in the above order from the 5 'side to the 3' side
- the region (Xc), the linker region (Lx) and the region (X) may be provided in the above order from the 3 'to the 5' side.
- the region (Xc) is complementary to the region (X).
- the region (Xc) may have a sequence complementary to the entire region of the region (X) or a partial region thereof, and preferably, the entire region of the region (X) or the region thereof It comprises a sequence complementary to a partial region, or consists of the complementary sequence.
- the region (Xc) may be, for example, completely complementary, or one or several bases are non-complementary to the entire region complementary to the region (X) or the partial region complementary to the region (X). Although it is preferred that they are completely complementary.
- the one or more bases are, for example, 1 to 3 bases, preferably 1 or 2 bases.
- the expression suppression sequence is contained in at least one of the region (Xc) and the region (X) as described above.
- the first single-stranded nucleic acid molecule may have, for example, one or two or more of the expression suppression sequences.
- one single-stranded nucleic acid molecule may have, for example, two or more of the same expression suppression sequence for the same target gene, or may have two or more different expression suppression sequences for the same target It is good, and may have two or more different expression suppression sequences for different target genes.
- the location of each expression suppression sequence is not particularly limited, and either of the region (X) and the region (Xc) It may be an area or a different area.
- the first single-stranded nucleic acid molecule has two or more of the expression suppression sequences for different target genes, for example, the first single-stranded nucleic acid molecule suppresses the expression of two or more different target genes It is possible.
- FIG. 7A is a schematic view showing an outline of the order of the respective regions for the single stranded nucleic acid molecule as an example
- FIG. 7B is a schematic diagram showing the single stranded nucleic acid molecule in the molecule. It is a schematic diagram which shows the state which forms the double chain
- FIG. 7 (B) the single-stranded nucleic acid molecule forms a double strand between the region (Xc) and the region (X) to form a short hairpin structure.
- FIG. 7 shows, to the last, the connection order of the above-mentioned regions and the positional relationship of each region forming a double chain, and, for example, the length of each region, the shape of the linker region (Lx), etc. It is not restricted.
- the number of bases in the region (Xc) and the region (X) is not particularly limited. Although the length of each area is illustrated below, the present invention is not limited to this.
- the “number of bases” means, for example, “length” and can also be referred to as “base length”.
- the numerical range of the number of bases is, for example, the disclosure of all positive integers belonging to the range, and as a specific example, the description of “1 to 4 bases” means “1, 2, 3, It means the entire disclosure of “4 bases” (the same applies hereinafter).
- the region (Xc) may, for example, be completely complementary to the entire region of the region (X).
- the region (Xc) means, for example, a base sequence complementary to the entire region from the 5 'end to the 3' end of the region (X), ie, the region (Xc) It means that the region (X) has the same base length, and all the bases in the region (Xc) are complementary to all the bases in the region (X).
- the region (Xc) may be, for example, completely complementary to a partial region of the region (X).
- the region (Xc) means, for example, a base sequence complementary to a partial region of the region (X), that is, the region (Xc) is larger than the region (X), It consists of a base sequence having a base length of one or more bases short, and all bases in the region (Xc) are complementary to all bases in the partial region of the region (X).
- the partial region of the region (X) is, for example, a region consisting of a base sequence which continues from the base at the end on the region (Xc) side (the first base) in the region (X).
- the relationship between the number of bases (X) in the region (X) and the number of bases (Xc) in the region (Xc) is, for example, the following (3) or (5) In the case of the former, specifically, for example, the condition of the following (11) is satisfied.
- X-Xc 1 to 10, preferably 1, 2 or 3, More preferably, 1 or 2 (11)
- X Xc (5)
- the region may be, for example, a region consisting of only the expression suppression sequence, or a region including the expression suppression sequence.
- the number of bases of the expression suppression sequence is, for example, 19 to 30 bases, preferably 19, 20 or 21 bases.
- the region including the expression suppression sequence may further have an additional sequence, for example, 5 'and / or 3' of the expression suppression sequence.
- the number of bases of the addition sequence is, for example, 1 to 31 bases, preferably 1 to 21 bases, and more preferably 1 to 11 bases.
- the number of bases in the region (X) is not particularly limited.
- the lower limit is, for example, 19 bases.
- the upper limit thereof is, for example, 50 bases, preferably 30 bases, more preferably 25 bases.
- a specific example of the number of bases in the region (X) is, for example, 19 to 50 bases, preferably 19 to 30 bases, more preferably 19 to 25 bases.
- the number of bases in the region (Xc) is not particularly limited.
- the lower limit is, for example, 19 bases, preferably 20 bases, and more preferably 21 bases.
- the upper limit thereof is, for example, 50 bases, more preferably 40 bases, further preferably 30 bases.
- the length of the linker region (Lx) is not particularly limited.
- the linker region (Lx) preferably has, for example, a length such that the region (X) and the region (Xc) can form a duplex.
- the total length of the first single-stranded nucleic acid molecule is not particularly limited.
- the lower limit of the total number of bases is, for example, 38 bases, preferably 42 bases, more preferably 50 bases, further It is preferably 51 bases, particularly preferably 52 bases, and the upper limit thereof is, for example, 300 bases, preferably 200 bases, more preferably 150 bases, still more preferably 100 bases, in particular Preferably it is 80 bases.
- the lower limit of the total number of bases excluding the linker region (Lx) is, for example, 38 bases, preferably 42 bases, more preferably 50 bases, More preferably, it is 51 bases, particularly preferably 52 bases, and the upper limit is, for example, 300 bases, preferably 200 bases, more preferably 150 bases, still more preferably 100 bases, in particular Preferably it is 80 bases.
- the second single-stranded nucleic acid molecule is, for example, a region (X), a linker region (Lx) and a region (Xc), Y) and a molecule having a region (Yc) complementary to the region (Y).
- the region (X) and the region (Y) are linked to form an internal region (Z).
- the description of the first single-stranded nucleic acid molecule can be incorporated into the second single-stranded nucleic acid molecule unless otherwise indicated.
- the second single-stranded nucleic acid molecule has, for example, the region (Xc), the linker region (Lx), the region (X), the region (Y), and the region (Y) from the 5 'side to the 3' side. You may have Yc) in the said order.
- the region (Xc) is also referred to as the 5 'region (Xc)
- the region (X) in the internal region (Z) is also referred to as the internal 5' region (X).
- the region (Y) in Z) is also referred to as an internal 3 'region (Y)
- the region (Yc) is also referred to as a 3' side region (Yc).
- the second single-stranded nucleic acid molecule may be, for example, the region (Xc), the linker region (Lx), the region (X), the region (Y), and the region from the 3 'side to the 5' side.
- the regions (Yc) may be included in the above order.
- the region (Xc) is also referred to as a 3'-side region (Xc)
- the region (X) in the inner region (Z) is also referred to as an inner 3'-region (X).
- the region (Y) in Z) is also referred to as an internal 5 'region (Y), and the region (Yc) is also referred to as a 5' region (Yc).
- the region (X) and the region (Y) are connected.
- the region (X) and the region (Y) are, for example, directly linked, with no intervening sequence therebetween.
- the internal area (Z) is defined as "constituted by the area (X) and the area (Y)" to indicate the arrangement relationship between the area (Xc) and the area (Yc). Restricting that in the inner region (Z), the region (X) and the region (Y) are separate independent regions in the use of the single stranded nucleic acid molecule is not. That is, for example, when the internal region (Z) has the expression suppression sequence, the expression suppression sequence is arranged in the internal region (Z) over the region (X) and the region (Y). It is also good.
- the region (Xc) is complementary to the region (X).
- the region (Xc) may have a sequence complementary to the entire region of the region (X) or a partial region thereof, and preferably, the entire region of the region (X) or the region thereof It comprises a sequence complementary to a partial region, or consists of the complementary sequence.
- the region (Xc) may be, for example, completely complementary, or one or several bases are non-complementary to the entire region complementary to the region (X) or the partial region complementary to the region (X). Although it is preferred that they are completely complementary.
- the one or more bases are, for example, 1 to 3 bases, preferably 1 or 2 bases.
- the region (Yc) is complementary to the region (Y).
- the region (Yc) may have a sequence complementary to the entire region or a partial region of the region (Y), and preferably, the entire region of the region (Y) or a partial region thereof Or comprises a sequence complementary to the above.
- the region (Yc) may be, for example, completely complementary, or one or several bases are non-complementary to the entire region complementary to the region (Y) or the partial region complementary to the region (Y). Although it is preferred that they are completely complementary.
- the one or more bases are, for example, 1 to 3 bases, preferably 1 or 2 bases.
- the expression suppression sequence is, for example, at least one of the internal region (Z) and the region (Xc) formed from the region (X) and the region (Y). May be further included in the area (Yc).
- the expression suppression sequence may be provided in any of the region (X) and the region (Y), and the region (X) You may have the said expression suppression sequence over the said area
- the second single-stranded nucleic acid molecule may have, for example, one or two or more of the expression suppression sequences.
- each expression suppression sequence is not particularly limited, and in the internal region (Z) and the region (Xc) Either one may be used, or one of the inner area (Z) and the area (Xc) and another different area may be used.
- the region (Yc) and the region (Y) may be directly linked or may be indirectly linked.
- direct linkage includes, for example, linkage by phosphodiester bond and the like.
- a linker region (Ly) is provided between the region (Yc) and the region (Y), and the region (Yc) and the region (Y) are interposed via the linker region (Ly).
- lifted is mention
- the constituent unit of the linker region (Ly) is not particularly limited, and may be, for example, a linker consisting of nucleotide residues or the above-mentioned formula It may be a linker having a structure represented by (IL). In the latter case, all the descriptions of the formula (IL) in the linker region (Lx) can be incorporated.
- the linker region (Ly) may include, for example, at least one selected from the group consisting of an amino acid residue, a polyamine residue, and a polycarboxylic acid residue.
- the linker region may or may not contain residues other than amino acid residues, polyamine residues and polycarboxylic acid residues.
- the linker region may contain either a polycarboxylic acid residue, a terephthalic acid residue or an amino acid residue.
- polyamine refers to any compound containing a plurality (two or more) of amino groups.
- the “amino group” is not limited to —NH 2 group, and includes imino group (—NH—).
- the polyamine is not particularly limited, and examples thereof include 1,4-diaminobenzene, 1,3-diaminobenzene, 1,2-diaminobenzene and the like.
- polycarboxylic acid refers to any compound containing a plurality (two or more) of carboxy groups. In the present invention, the polycarboxylic acid is not particularly limited.
- amino acid refers to any organic compound having one or more amino group and one or more carboxy group in the molecule.
- the “amino group” is not limited to —NH 2 group, and includes imino group (—NH—).
- imino group —NH—
- proline, hydroxyproline and the like do not contain an —NH 2 group in the molecule and an imino group (—NH—) but are included in the definition of “amino acid” in the present invention.
- the "amino acid” may be a natural amino acid or an artificial amino acid.
- the amino acid residue may be one in which a plurality of amino acid residues are linked.
- an amino acid residue in which a plurality of amino acid residues are linked means, for example, a residue containing a peptide structure. More specifically, for example, structures such as glycylglycine (Gly-Gly) can be mentioned.
- the amino acid residue may be a glycine residue, a terephthalic acid amide residue, a proline residue or a lysine residue.
- the amino acid residue may also be a modified amino acid residue or a derivative of an amino acid.
- the linker region (Ly) comprises WO 2012/017919 pamphlet, WO 2013/103146 pamphlet, WO 2012/005368 pamphlet, WO 2013/077446 pamphlet, It may be a linker region described in WO2013 / 133393 pamphlet, WO2016 / 108264 pamphlet, WO2016 / 104775 pamphlet and the like, and the present invention can incorporate these documents.
- n and m are not particularly limited.
- m is an integer in the range of 0 to 30, and n is an integer in the range of 0 to 30 It is.
- the structures are shown in the following chemical formulas (I-1a), (I-1b), (I-4a), (I-6a) and (I-7a).
- n, m and q are not particularly limited.
- m is an integer in the range of 0 to 30, for example, n is 0 to 30
- q is an integer of 0 to 10.
- terminal nucleotide residue in any one of the regions (Yc) and the terminal nucleotide residue in any one of the regions (Y) are, for example, bound to the linker region (Ly) by a phosphodiester bond, respectively There is.
- FIG. 8A is a schematic view showing an outline of the order of the respective regions from the 5 'side to the 3' side of the single stranded nucleic acid molecule as an example
- FIG. 8B is a schematic view It is a schematic diagram which shows the state which the single stranded nucleic acid molecule has formed the duplex within the said molecule.
- the single-stranded nucleic acid molecule is separated between the region (Xc) and the region (X), between the region (Y) and the region (Yc).
- FIG. 8 shows only the connection order of each region and the positional relationship of each region forming a double strand, and for example, the length of each region, the shape of the linker region, and the like are not limited thereto. Moreover, although FIG. 8 showed the said area
- the number of bases in the region (Xc), the region (X), the region (Y) and the region (Yc) is not particularly limited.
- the length of each region is exemplified below, but the present invention is not limited thereto.
- the region (Xc) may, for example, be complementary to the entire region of the region (X) as described above.
- the region (Xc) has, for example, the same base length as the region (X) and has a base sequence complementary to the entire region of the region (X).
- the region (Xc) is more preferably the same base length as the region (X), and all the bases of the region (Xc) are complementary to all the bases of the region (X) That is, for example, completely complementary.
- the region (Xc) may be complementary to, for example, a partial region of the region (X).
- the region (Xc) has, for example, the same base length as the partial region of the region (X), that is, consists of a base sequence having a base length one base or more shorter than the region (X).
- the region (Xc) is more preferably the same base length as the partial region of the region (X), and all the bases of the region (Xc) are the same as the partial region of the region (X).
- the partial region of the region (X) is, for example, a region consisting of a base sequence which continues from the base at the end on the region (Xc) side (the first base) in the region (X).
- the region (Yc) may be, for example, complementary to the entire region of the region (Y) as described above.
- the region (Yc) has, for example, the same base length as the region (Y) and has a base sequence complementary to the entire region of the region (Y).
- the region (Yc) is more preferably the same base length as the region (Y), and all the bases in the region (Yc) are complementary to all the bases in the region (Y). That is, for example, completely complementary.
- the region (Yc) may be complementary to, for example, a partial region of the region (Y).
- the region (Yc) has, for example, the same base length as the partial region of the region (Y), that is, consists of a base sequence having a base length one base or more shorter than the region (Y).
- the region (Yc) is more preferably the same base length as the partial region of the region (Y), and all the bases of the region (Yc) are the same as the partial region of the region (Y).
- the partial region of the region (Y) is, for example, a region consisting of a base sequence which continues from the base at the end on the region (Yc) side (the first base) in the region (Y).
- the number of bases (Z) in the internal region (Z) and the number of bases (X) in the region (X) and the number of bases (Y) in the region (Y) The relationship between the number of bases (Z) in the internal region (Z) and the number of bases (X) in the region (X) and the number of bases (Xc) in the region (Xc) is, for example, ) And the condition of (2).
- Z X + Y (1)
- the number of bases (X) in the region (X), the number of bases (Xc) in the region (Xc), the number of bases (Y) in the region (Y), and the region (Yc) The relationship of the number of bases (Yc) of) satisfies, for example, any one of the following (a) to (d).
- B) The conditions of the following formulas (5) and (6) are satisfied.
- X Xc (5) Y> Yc (6) (C)
- the conditions of the following formulas (7) and (8) are satisfied.
- X> Xc (7) Y> Yc (8) (D)
- the conditions of the following formulas (9) and (10) are satisfied.
- X Xc (9)
- Y Yc (10)
- the difference in the number of bases (Yc) of (Yc) preferably satisfies, for example, the following condition.
- (B) The conditions of the following formulas (13) and (14) are satisfied.
- X-Xc 0 ...
- Y-Yc 1 to 10, preferably 1, 2, 3 or 4, More preferably 1, 2 or 3 ...
- C The conditions of the following formulas (15) and (16) are satisfied.
- X-Xc 1 to 10, preferably 1, 2 or 3, More preferably, 1 or 2 (15)
- Y-Yc 1 to 10, preferably 1, 2 or 3, More preferably 1 or 2 (16)
- D The conditions of the following formulas (17) and (18) are satisfied.
- X-Xc 0 ... (17)
- Y-Yc 0 ... (18)
- FIG. 9 shows a single-stranded nucleic acid molecule comprising the linker region (Lx) and the linker region (Ly), wherein (A) is a single-stranded nucleic acid molecule of (a), (B) is b) single-stranded nucleic acid molecule, (C) is the single-stranded nucleic acid molecule of (c), and (D) is an example of the single-stranded nucleic acid molecule of (d).
- dotted lines indicate the state in which duplexes are formed by self-annealing.
- FIG. 9 is a schematic view showing the relationship between the region (X) and the region (Xc) and the relationship between the region (Y) and the region (Yc) to the last, for example, the length of each region
- the shape, the presence or absence of the linker region (Ly), and the like are not limited thereto.
- it can be said to be a structure having a base which is not aligned with either the region (Xc) or the region (Yc) in the internal region (Z), and a structure having a base which does not form a duplex.
- the base not to be aligned also referred to as a base which does not form a double strand
- free base region is indicated by "F”.
- the number of bases in the region (F) is not particularly limited.
- the number of bases (F) of the region (F) is, for example, the number of bases of “X-Xc” in the case of the single-stranded nucleic acid molecule of the above (a), and the number of bases of the single-stranded nucleic acid molecule of the above (b) In the case of the single-stranded nucleic acid molecule of (c), it is the total number of the number of bases of "X-Xc" and the number of bases of "Y-Yc".
- the single-stranded nucleic acid molecule of (d) is, for example, a structure in which the entire region of the inner region (Z) is aligned with the region (Xc) and the region (Yc). It can be said that the entire region of) forms a double chain.
- the 5 'end of the region (Xc) and the 3' end of the region (Yc) are not linked.
- the total number of bases of the free base (F) in the region (Xc), the region (Yc), and the inner region (Z) is the number of bases in the inner region (Z).
- the lengths of the region (Xc) and the region (Yc) can be appropriately determined according to, for example, the length of the internal region (Z), the number of free bases, and the position thereof.
- the number of bases in the internal region (Z) is, for example, 19 or more.
- the lower limit of the number of bases is, for example, 19 bases, preferably 20 bases, and more preferably 21 bases.
- the upper limit of the number of bases is, for example, 50 bases, preferably 40 bases, and more preferably 30 bases.
- Specific examples of the number of bases in the internal region (Z) include, for example, 19 bases, 20 bases, 21 bases, 22 bases, 23 bases, 24 bases, 25 bases, 26 bases, 27 bases, 28 bases, 28 bases, or , 30 bases.
- this condition is preferable.
- the internal region (Z) may be, for example, a region constituted of only the expression suppression sequence or a region containing the expression suppression sequence.
- the number of bases of the expression suppression sequence is, for example, 19 to 30 bases, preferably 19, 20 or 21 bases.
- the internal region (Z) contains the expression suppression sequence it may further have an additional sequence on the 5 'side and / or 3' side of the expression suppression sequence.
- the number of bases of the addition sequence is, for example, 1 to 31 bases, preferably 1 to 21 bases, more preferably 1 to 11 bases, and still more preferably 1 to 7 bases.
- the number of bases in the region (Xc) is, for example, 1 to 29 bases, preferably 1 to 11 bases, preferably 1 to 7 bases, more preferably 1 to 4 bases, still more preferably 1 base, 2 bases, 3 bases.
- the internal region (Z) or the region (Yc) contains the expression suppression sequence, for example, such a number of bases is preferable.
- the number of bases in the internal region (Z) is 19 to 30 bases (for example, 19 bases)
- the number of bases in the region (Xc) is, for example, 1 to 11 bases, preferably 1 It is a ⁇ 7 base, more preferably 1 to 4 bases, and still more preferably 1 base, 2 bases, 3 bases.
- the region (Xc) may be, for example, a region consisting of only the expression suppression sequence or a region containing the expression suppression sequence.
- the length of the expression suppression sequence is, for example, as described above.
- the region (Xc) may further have an additional sequence on the 5 'side and / or 3' side of the expression suppression sequence.
- the number of bases of the addition sequence is, for example, 1 to 11 bases, preferably 1 to 7 bases.
- the number of bases in the region (Yc) is, for example, 1 to 29 bases, preferably 1 to 11 bases, preferably 1 to 7 bases, more preferably 1 to 4 bases, still more preferably 1 base, 2 bases, 3 bases.
- the internal region (Z) or the region (Xc) contains the expression suppression sequence, for example, such a number of bases is preferable.
- the number of bases in the internal region (Z) is 19 to 30 bases (for example, 19 bases)
- the number of bases in the region (Yc) is, for example, 1 to 11 bases, preferably 1 It is a ⁇ 7 base, more preferably 1 base, 2 bases, 3 bases or 4 bases, still more preferably 1 base, 2 bases, 3 bases.
- the region (Yc) may be, for example, a region consisting of only the expression suppression sequence or a region containing the expression suppression sequence.
- the length of the expression suppression sequence is, for example, as described above.
- the region (Yc) may further have an additional sequence on the 5 'side and / or 3' side of the expression suppression sequence.
- the number of bases of the addition sequence is, for example, 1 to 11 bases, preferably 1 to 7 bases.
- the number of bases in the internal region (Z), the region (Xc) and the region (Yc) can be represented, for example, by “Z ⁇ Xc + Yc” in the formula (2).
- the number of bases of “Xc + Yc” is, for example, the same as the internal region (Z) or smaller than the internal region (Z).
- “Z ⁇ (Xc + Yc)” is, for example, 1 to 10, preferably 1 to 4, more preferably 1, 2 or 3.
- the “Z ⁇ (Xc + Yc)” corresponds to, for example, the number of bases (F) of the free region (F) in the inner region (Z).
- the lengths of the linker region (Lx) and the linker region (Ly) are not particularly limited.
- the linker region (Lx) is as described above.
- the lower limit of the number of bases of the linker region (Ly) is, for example, 1 base, preferably 2 bases, more preferably 3 bases
- the upper limit is, for example, 100 bases, preferably 80 bases, more preferably 50 bases.
- Specific examples of the number of bases in each of the linker regions include 1 to 50 bases, 1 to 30 bases, 1 to 20 bases, 1 to 10 bases, 1 to 7 bases, and 1 to 4 bases. It is not limited to this.
- the linker region (Ly) may be, for example, the same as or different from the linker region (Lx).
- the total length of the second single stranded nucleic acid molecule is not particularly limited.
- the lower limit of the total number of bases is, for example, 38 bases, preferably 42 bases, more preferably 50 bases, and further It is preferably 51 bases, particularly preferably 52 bases, and the upper limit thereof is, for example, 300 bases, preferably 200 bases, more preferably 150 bases, still more preferably 100 bases, in particular Preferably it is 80 bases.
- the lower limit of the total number of bases excluding the linker region (Lx) and the linker region (Ly) is, for example, 38 bases, preferably 42 bases, and more preferably Is 50 bases, more preferably 51 bases, particularly preferably 52 bases, and the upper limit is, for example, 300 bases, preferably 200 bases, more preferably 150 bases, more preferably It is 100 bases, particularly preferably 80 bases.
- the linker region (Lx) may have a structure represented by formula (IL), and the other constituent units are not particularly limited.
- the constituent unit include nucleotide residues and the like.
- the nucleotide residue include ribonucleotide residues and deoxyribonucleotide residues.
- the nucleotide residues include unmodified unmodified nucleotide residues and modified modified nucleotide residues.
- the single-stranded nucleic acid molecule of the present invention can improve nuclease resistance and stability, for example, by including the modified nucleotide residue.
- the single-stranded nucleic acid molecule of the present invention may further contain, for example, non-nucleotide residues in addition to the above-mentioned nucleotide residues.
- the constituent units of the region (Xc), the region (X), the region (Y) and the region (Yc) are each preferably the nucleotide residue.
- Each of the regions is composed of, for example, the following residues (1) to (3). (1) unmodified nucleotide residue (2) modified nucleotide residue (3) unmodified nucleotide residue and modified nucleotide residue
- the linker region (Lx) is composed of only the non-nucleotide residue.
- the constituent unit of the linker region (Ly) is not particularly limited, and examples thereof include the nucleotide residues and the non-nucleotide residues as described above.
- the linker region may be composed, for example, of only the nucleotide residue, only the non-nucleotide residue, or may be composed of the nucleotide residue and the non-nucleotide residue.
- the linker region (Ly) is composed of, for example, the following residues (1) to (7).
- the single-stranded nucleic acid molecule of the present invention is, for example, a molecule comprising only the nucleotide residue except the linker region (Lx), a molecule comprising the non-nucleotide residue in addition to the nucleotide residue, etc.
- the nucleotide residue may be, for example, only the unmodified nucleotide residue, or only the modified nucleotide residue, or the unmodified nucleotide residue. And both of the modified nucleotide residues.
- the number of modified nucleotide residues is not particularly limited, and is, for example, "one or several", specifically Specifically, it is, for example, 1 to 5, preferably 1 to 4, more preferably 1 to 3, and most preferably 1 or 2.
- the single-stranded nucleic acid molecule of the present invention contains the non-nucleotide residue, the number of non-nucleotide residues is not particularly limited, and is, for example, "one or several", specifically, for example, , 1 or 2 pieces.
- the nucleotide residue is preferably, for example, a ribonucleotide residue.
- the single-stranded nucleic acid molecule of the present invention is, for example, referred to as "single-stranded RNA molecule".
- the ssRNA molecule include, except for the linker region (Lx), a molecule composed only of the ribonucleotide residue, a molecule containing the non-nucleotide residue in addition to the ribonucleotide residue, and the like.
- the ribonucleotide residue may be, for example, only the unmodified ribonucleotide residue, or only the modified ribonucleotide residue, or the unmodified ribonucleotide residue and Both of the modified ribonucleotide residues may be included.
- the number of the modified ribonucleotide residue is not particularly limited, and, for example, “one or several”. Specifically, it is, for example, 1 to 5, preferably 1 to 4, more preferably 1 to 3, and most preferably 1 or 2.
- the modified ribonucleotide residue relative to the non-modified ribonucleotide residue include the deoxyribonucleotide residue and the like in which a ribose residue is substituted with a deoxyribose residue.
- the number of deoxyribonucleotide residues is not particularly limited, and is, for example, “one or several”. Specifically, for example, it is 1 to 5, preferably 1 to 4, more preferably 1 to 3, and most preferably 1 or 2.
- the single-stranded nucleic acid molecule of the present invention contains, for example, a labeling substance, and may be labeled with the labeling substance.
- the labeling substance is not particularly limited, and examples thereof include fluorescent substances, dyes, isotopes and the like.
- the labeling substance include fluorophores such as pyrene, TAMRA, fluorescein, Cy3 dye and Cy5 dye, and examples of the dye include Alexa dyes such as Alexa 488.
- the isotope include stable isotopes and radioactive isotopes, and preferably stable isotopes.
- the stable isotope is, for example, low in risk of exposure and unnecessary in a dedicated facility, so that it can be handled easily and cost can be reduced.
- the said stable isotope does not have the physical-property change of the labeled compound, for example, and is excellent also in the property as a tracer.
- the stable isotope is not particularly limited, and examples thereof include 2 H, 13 C, 15 N, 17 O, 18 O, 33 S, 34 S and 36 S.
- the labeling substance in the single-stranded nucleic acid molecule of the present invention, as described above, for example, it is preferable to introduce the labeling substance into the non-nucleotide structure, and introduce the labeling substance into the non-nucleotide residue of the linker region (Lx). It is preferable to do.
- the introduction of the labeling substance to the non-nucleotide residue can be performed, for example, conveniently and inexpensively.
- the single-stranded nucleic acid molecule of the present invention can suppress the expression of the target gene. Therefore, the single-stranded nucleic acid molecule of the present invention can be used, for example, as a therapeutic agent for a disease caused by a gene. If the single-stranded nucleic acid molecule contains a sequence that suppresses the expression of a gene that causes the disease as the expression suppression sequence, the disease can be treated, for example, by suppressing the expression of the target gene.
- “treatment” includes, for example, the meaning of prevention of the above-mentioned disease, improvement of the disease, improvement of prognosis, and may be any.
- the method of using the single-stranded nucleic acid molecule of the present invention is not particularly limited.
- the single-stranded nucleic acid molecule may be administered to a subject having the target gene.
- Examples of the administration subject include cells, tissues, organs and the like.
- Examples of the administration target include non-human animals such as humans and non-human mammals except humans.
- the administration may, for example, be in vivo or in vitro.
- the cells are not particularly limited. For example, various cultured cells such as HeLa cells, 293 cells, NIH 3T3 cells, and COS cells, stem cells such as ES cells and hematopoietic stem cells, and cells isolated from living bodies such as primary cultured cells can give.
- the target gene to be subjected to expression suppression is not particularly limited, and a desired gene can be set, and the expression suppression sequence may be appropriately designed according to the gene.
- the base sequence of the single-stranded nucleic acid molecule may be, for example, the base sequence of SEQ ID NO: 1 when the target gene is TGF- ⁇ 1, and for the prorenin receptor, for example, the base sequence of SEQ ID NO: 2, In the case of mir-29b, for example, the base sequence of SEQ ID NO: 3 can be exemplified.
- the base sequence may be, for example, one or several deletions, substitutions and / or additions.
- the single-stranded nucleic acid molecule of the present invention can suppress the expression of a target gene as described above, and is thus useful as, for example, pharmaceuticals, diagnostic agents and agrochemicals, and as research tools for agrochemicals, medicine, life sciences, etc. is there.
- nucleotide residues constituting the single-stranded nucleic acid molecule of the present invention are as described above, and examples thereof include ribonucleotide residues and deoxyribonucleotide residues.
- the ribonucleotide residue has, for example, a ribose residue as a sugar, and has adenine (A), guanine (G), cytosine (C) and uracil (U) as bases
- the deoxyribose residue is For example, it has a deoxyribose residue as a sugar, and has adenine (A), guanine (G), cytosine (C) and thymine (T) as bases.
- nucleotide residues examples include unmodified nucleotide residues and modified nucleotide residues.
- the unmodified nucleotide residue is, for example, the same as or substantially the same as the naturally occurring one, preferably, the same or substantially the same as the one naturally occurring in the human body. .
- the modified nucleotide residue is, for example, a nucleotide residue obtained by modifying the unmodified nucleotide residue.
- any component of the unmodified nucleotide residue may be modified.
- “modification” is, for example, substitution, addition and / or deletion of the component, substitution of atoms and / or functional groups in the component, addition and / or deletion, and “modification”. be able to.
- the modified nucleotide residue include naturally occurring nucleotide residues, artificially modified nucleotide residues and the like.
- the naturally-occurring modified nucleotide residues can be referred to, for example, Limbach et al.
- modified nucleotide residue may be, for example, a residue of an alternative to the nucleotide.
- the modification of the nucleotide residue may be, for example, modification of a ribose-phosphate backbone (hereinafter, a ribophosphate backbone).
- ribose residues can be modified in the ribophosphate backbone.
- the ribose residue can be modified at, for example, the 2 'carbon, and specifically, for example, a hydroxyl group bonded to the 2' carbon can be substituted with hydrogen or fluoro.
- the ribose residue can be substituted with deoxyribose by substituting the hydroxyl group at the 2'-position carbon with hydrogen.
- the ribose residue may be substituted, for example, to a stereoisomer, for example, may be substituted to an arabinose residue.
- the ribophosphate backbone may be substituted, for example, to a non-ribophosphate backbone having non-ribose residues and / or non-phosphate.
- examples of the non-ribophosphate backbone include uncharged members of the above-described ribophosphate backbone.
- Alternatives to the nucleotides substituted in the non-ribophosphate backbone include, for example, morpholino, cyclobutyl, pyrrolidine and the like. Other than the above, for example, artificial nucleic acid monomer residues and the like can be mentioned.
- PNA peptide nucleic acid
- LNA Locked Nucleic Acid
- ENA 2'-O, 4'-C-Ethylene bridged Nucleic Acids
- a phosphate group can be modified in the ribophosphate backbone.
- the phosphate group closest to the sugar residue is called the alpha phosphate group.
- the alpha phosphate group is negatively charged, and its charge is uniformly distributed over the two oxygen atoms not bound to the sugar residue.
- two oxygen atoms which are not bonded to the sugar residue in the phosphodiester bond between nucleotide residues are hereinafter also referred to as “non-linking oxygen”.
- linking oxygen the two oxygen atoms linked to the sugar residue are hereinafter referred to as "linking oxygen”. It is preferable that, for example, the ⁇ -phosphate group be modified to be uncharged or to have an asymmetric charge distribution at the non-bonding atom.
- the phosphate group may, for example, replace the non-bonding oxygen.
- the oxygen is, for example, S (sulfur), Se (selenium), B (boron), C (carbon), H (hydrogen), N (nitrogen) and OR (R is, for example, an alkyl group or an aryl group) It can be substituted by any atom, preferably substituted by S.
- the non-binding oxygen is preferably, for example, both substituted, and more preferably both substituted with S.
- modified phosphate group examples include phosphorothioate, phosphorodithioate, phosphoroselenate, boranophosphate, boranophosphate ester, phosphonate hydrogen, phosphoroamidate, alkyl or aryl phosphonate, and phosphotriester.
- Preferred among these are phosphorodithioates in which the two non-linking oxygens are both substituted with S.
- the phosphate group may, for example, replace the attached oxygen.
- the oxygen can be substituted by, for example, any atom of S (sulfur), C (carbon) and N (nitrogen).
- Examples of the modified phosphate group include cross-linked phosphoroamidates substituted with N, cross-linked phosphorothioates substituted with S, and cross-linked methylene phosphonates substituted with C.
- the substitution of the binding oxygen is preferably performed, for example, at least one of the 5 'terminal nucleotide residue and the 3' terminal nucleotide residue of the single-stranded nucleic acid molecule of the present invention, and in the case of 5 ' Preferably, on the 3 'side, substitution by N is preferred.
- the phosphate group may be substituted, for example, to the non-phosphorus-containing linker.
- the linker is, for example, siloxane, carbonate, carboxymethyl, carbamate, amide, thioether, ethylene oxide linker, sulfonate, sulfonamide, thioform acetal, form acetal, oxime, methylene imino, methylene methyl imino, methylene hydrazo, methylene dimethyl Hydrazo, methylene oxymethyl imino and the like are preferable, and preferably, methylene carbonyl amino group and methylene methyl imino group are included.
- the single-stranded nucleic acid molecule of the present invention may be modified, for example, at least one of the 3 'and 5' terminal nucleotide residues.
- the modification may be, for example, either one or both of the 3 'end and the 5' end.
- the modification is, for example, as described above, and preferably performed on the terminal phosphate group.
- the phosphate group may be, for example, entirely modified or one or more atoms in the phosphate group may be modified. In the former case, for example, the entire phosphate group may be substituted or deleted.
- the modification of the terminal nucleotide residue includes, for example, addition of other molecules.
- the other molecules include labeling substances as described above, functional molecules such as protecting groups, and the like.
- the protective group include S (sulfur), Si (silicon), B (boron), and an ester-containing group.
- the functional molecule such as the labeling substance can be used, for example, for detection of a single-stranded nucleic acid molecule of the present invention.
- the other molecule may be attached to, for example, the phosphate group of the nucleotide residue, or may be attached to the phosphate group or the sugar residue via a spacer.
- the terminal atom of the spacer can be added or substituted, for example, to the attached oxygen of the phosphate group or O, N, S or C of a sugar residue.
- the binding site of the sugar residue is preferably, for example, C at the 3'position or C at the 5'position, or an atom binding thereto.
- the spacer can also be added or substituted, for example, at the terminal atom of a nucleotide substitute such as the PNA.
- the spacer is not particularly limited, and, for example,-(CH 2 ) n -,-(CH 2 ) n N-,-(CH 2 ) n O-,-(CH 2 ) n S-, O (CH 2) CH 2 O) n CH 2 CH 2 OH, abasic sugars, amides, carboxy, amines, oxyamines, oxyimines, thioethers, disulfides, thioureas, sulfonamides, and morpholinos, etc., as well as biotin reagents and fluorescein reagents etc. Good.
- the molecules to be added to the terminal may be, for example, dyes, intercalating agents (eg, acridine), crosslinkers (eg, psoralens, mitomycin C), porphyrins (TPPC4, texaphyrin, saffirins), polycyclic, etc.
- intercalating agents eg, acridine
- crosslinkers eg, psoralens, mitomycin C
- porphyrins TPPC4, texaphyrin, saffirins
- polycyclic etc.
- Aromatic hydrocarbon eg phenazine, dihydrophenazine
- artificial endonuclease eg EDTA
- lipophilic carrier eg cholesterol, cholic acid, adamantane acetic acid, 1-pyrenebutyric acid, dihydrotestosterone, 1,3-bis- O (hexadecyl) glycerol, geranyl oxyhexyl group, hexadecyl glycerol, borneol, menthol, 1,3-propanediol, heptadecyl group, palmitic acid, myristic acid, O3- (oleoyl) lithocholic acid, O3- (oleoyl) Cor Acid, dimethoxytrityl, or phenoxazine) and peptide conjugates (eg, antennapedia peptide, Tat peptide), alkylating agents, phosphoric acid, amino, mercapto, PEG
- the single-stranded nucleic acid molecule of the present invention may be modified at its 5 'end with, for example, a phosphate group or a phosphate group analog.
- the said phosphorylation is 5 'monophosphate ((HO) 2 (O) PO-5'), 5 'diphosphate ((HO) 2 (O) POP (HO) (O) -O-5, for example.
- the base is not particularly limited.
- the base may be, for example, a natural base or a non-natural base.
- the base may be, for example, naturally derived or synthetic.
- As the base for example, a general base, a modified analog thereof or the like can be used.
- Examples of the base include purine bases such as adenine and guanine, and pyrimidine bases such as cytosine, uracil and thymine.
- Other examples of the base include inosine, thymine, xanthine, hypoxanthine, purine, nubularine, isoguanisine, tubercidine, 7-deazaadenine and the like.
- the bases are, for example, alkyl derivatives such as 2-aminoadenine, 6-methylated purine and the like; alkyl derivatives such as 2-propylated purine; 5-halouracil and 5-halocytosine; 5-propynyluracil and 5-propynylcytosine; -Azouracil, 6-azocytosine and 6-azothymine; 5-uracil (pseudouracil), 4-thiouracil, 5-halouracil, 5- (2-aminopropyl) uracil, 5-aminoallyluracil; 8-haloation, amination, Thiolated, thioalkylated, hydroxylated and other 8-substituted purines; 5-trifluoromethylated and other 5-substituted pyrimidines; 7-methyl guanine; 5-substituted pyrimidines; 6-aza pyrimidines; N-2, N -6 and O-6 substituted purines (2-a
- the modified nucleotide residue may further include, for example, a residue that deletes a base, that is, an abasic ribophosphate backbone.
- the modified nucleotide residue may be prepared, for example, from US Provisional Application No. 60 / 465,665 (filing date: April 25, 2003), and International Application No. PCT / US04 / 07070 (filing date: 2004 3) The residue described on May 8) can be used, and the present invention can incorporate these documents.
- Non-nucleotide Residue The non-nucleotide residue is not particularly limited.
- the single-stranded nucleic acid molecule of the present invention may have, for example, a non-nucleotide structure including an amino acid residue or a peptide residue as the non-nucleotide residue.
- the amino acids constituting the amino acid residue or the peptide residue include basic amino acids and acidic amino acids.
- Examples of the basic amino acid include lysine, arginine, histidine and the like.
- Examples of the acidic amino acids include aspartic acid and glutamic acid.
- the composition for suppressing expression of the present invention is a composition for suppressing the expression of a target gene, and is characterized by containing the single-stranded nucleic acid molecule of the present invention.
- the composition of the present invention is characterized by containing the single-stranded nucleic acid molecule of the present invention, and the other constitution is not limited in any way.
- the composition for suppression of expression of the present invention can also be referred to, for example, as a reagent for suppression of expression.
- the present invention it is possible to suppress the expression of the target gene, for example, by administering it to a subject in which the target gene is present.
- the pharmaceutical composition of the present invention is characterized by containing the single-stranded nucleic acid molecule of the present invention.
- the composition of the present invention is characterized by containing the single-stranded nucleic acid molecule of the present invention, and the other constitution is not limited at all.
- the pharmaceutical composition of the present invention can also be referred to, for example, as a pharmaceutical.
- the pharmaceutical composition of the present invention can also be referred to, for example, as a pharmaceutical.
- treatment includes, for example, the meaning of prevention of the disease, improvement of the disease, improvement of the prognosis, and may be any.
- the disease to be treated is not particularly limited, and examples thereof include diseases caused by gene expression.
- a gene causing the disease may be set as the target gene, and the expression suppression sequence may be appropriately set according to the target gene.
- a disease that is expected to have a therapeutic effect by suppressing TGF- ⁇ 1 It can be used for the treatment of pathological conditions such as inflammatory diseases, specifically acute lung injury and the like.
- composition for suppressing expression and the pharmaceutical composition (hereinafter referred to as the composition) of the present invention
- the method of using the composition for suppressing expression and the pharmaceutical composition (hereinafter referred to as the composition) of the present invention is not particularly limited, and for example, the single stranded nucleic acid molecule is administered to a subject having the target gene. Just do it.
- Examples of the administration subject include cells, tissues, organs and the like.
- Examples of the administration target include non-human animals such as humans and non-human mammals except humans.
- the administration may, for example, be in vivo or in vitro.
- the cells are not particularly limited. For example, various cultured cells such as HeLa cells, 293 cells, NIH 3T3 cells, and COS cells, stem cells such as ES cells and hematopoietic stem cells, and cells isolated from living bodies such as primary cultured cells can give.
- the administration method is not particularly limited, and can be appropriately determined, for example, according to the administration subject.
- the administration target is a cultured cell
- a method using a transfection reagent, an electroporation method and the like can be mentioned.
- the administration is in vivo, for example, it may be administered orally or parenterally. Examples of the parenteral administration include injection, subcutaneous administration, topical administration and the like.
- composition of the present invention may, for example, contain only the single-stranded nucleic acid molecule of the present invention, or may further contain other additives.
- the additive is not particularly limited, and, for example, a pharmaceutically acceptable additive is preferable.
- the type of the additive is not particularly limited, and can be appropriately selected according to, for example, the type of administration target.
- the single stranded nucleic acid molecule may, for example, form a complex with the additive.
- the additive can also be referred to, for example, as a complexing agent.
- the complex can, for example, efficiently deliver the single-stranded nucleic acid molecule.
- the bond between the single-stranded nucleic acid molecule and the complexing agent is not particularly limited, and examples thereof include non-covalent bonds and the like. Examples of the complex include an inclusion complex and the like.
- the complexing agent is not particularly limited, and examples thereof include a polymer, cyclodextrin, adamantine and the like.
- examples of the cyclodextrin include linear cyclodextrin copolymers, linear oxidized cyclodextrin copolymers, and the like.
- additives include carriers, binding substances to target cells, condensing agents, fusion agents and the like.
- the carrier is, for example, preferably a polymer, more preferably a biopolymer.
- the carrier is preferably biodegradable, for example.
- the carrier is, for example, a protein such as human serum albumin (HSA), low density lipoprotein (LDL), globulin or the like; eg, dextran, pullulan, chitin, chitosan, inulin, cyclodextrin, carbohydrate such as hyaluronic acid; Can be mentioned.
- synthetic polymers such as synthetic polyamino acids can also be used.
- the polyamino acid is, for example, polylysine (PLL), poly L-aspartic acid, poly L-glutamic acid, styrene-maleic anhydride copolymer, poly (L-lactide-co-glycolide) copolymer, divinyl ether-maleic anhydride Copolymer, N- (2-hydroxypropyl) methacrylamide copolymer (HMPA), polyethylene glycol (PEG), polyvinyl alcohol (PVA), polyurethane, poly (2-ethyl acrylic acid), N-isopropyl acrylamide polymer, or poly phosphazine (poly phosphazine) Etc.).
- PLL polylysine
- poly L-aspartic acid poly L-glutamic acid
- styrene-maleic anhydride copolymer poly (L-lactide-co-glycolide) copolymer
- the binding substance is, for example, thyroid stimulating hormone, melanocyte stimulating hormone, lectin, glycoprotein, surfactant protein A, mucin carbohydrate, polyvalent lactose, polyvalent galactose, N-acetylgalactosamine, N-acetylglucosamine, polyvalent mannose , Polyvalent fucose, glycosylated polyamino acid, polyvalent galactose, transferrin, bisphosphonate, polyglutamic acid, polyaspartic acid, lipid, cholesterol, steroid, bile acid, folate, vitamin B12, biotin, neproxin (Neproxin), RGD peptide, RGD peptide mimetics and the like can be mentioned.
- thyroid stimulating hormone melanocyte stimulating hormone, lectin, glycoprotein, surfactant protein A, mucin carbohydrate, polyvalent lactose, polyvalent galactose, N-acetylgalactosamine, N-acetylglucos
- PEI polyethyleneimine
- PEI may be, for example, either linear or branched, and may be synthetic or natural.
- the PEI may be, for example, alkyl-substituted or lipid-substituted.
- fusion agent for example, polyhistidine, polyimidazole, polypyridine, polypropylene imine, melittin, polyacetal substance (eg, cationic polyacetal etc.) and the like can be used.
- the fusion agent may have, for example, an alpha helical structure.
- the fusion agent may be, for example, a membrane disintegrant such as melittin.
- composition of the present invention for example, US Pat. No. 6,509,323, US Patent Publication No. 2003/0008818, PCT / US04 / 07070 etc. can be incorporated for the formation of the complex and the like.
- amphiphilic molecules examples include amphiphilic molecules and the like.
- the amphiphilic molecule is, for example, a molecule having a hydrophobic region and a hydrophilic region.
- the molecule is preferably, for example, a polymer.
- the polymer is, for example, a polymer having a secondary structure, and preferably a polymer having a repetitive secondary structure.
- a polypeptide is preferable, more preferably an ⁇ -helical polypeptide and the like.
- the amphiphilic polymer may be, for example, a polymer having two or more amphiphilic subunits.
- the subunit include subunits having a cyclic structure having at least one hydrophilic group and one hydrophobic group.
- the subunit may have, for example, a steroid such as cholic acid, an aromatic structure, and the like.
- the polymer may, for example, have both cyclic structural subunits, such as aromatic subunits, and amino acids.
- the method for suppressing expression of the present invention is a method for suppressing the expression of a target gene, and is characterized by using the single-stranded nucleic acid molecule of the present invention.
- the expression suppression method of the present invention is characterized by using the single-stranded nucleic acid molecule of the present invention, and the other steps and conditions are not limited at all.
- the mechanism of expression suppression of the gene is not particularly limited, and examples thereof include expression suppression by RNA interference.
- the expression suppression method of the present invention is, for example, a method of inducing RNA interference which suppresses the expression of the target gene, and using the single-stranded nucleic acid molecule of the present invention, the expression induction method It can be said that.
- the expression suppression method of the present invention includes, for example, a step of administering the single-stranded nucleic acid molecule to a subject in which the target gene is present.
- the single-stranded nucleic acid molecule is brought into contact with the administration subject.
- the administration subject include cells, tissues, organs and the like.
- the administration target include non-human animals such as humans and non-human mammals except humans.
- the administration may, for example, be in vivo or in vitro.
- the single stranded nucleic acid molecule may be administered alone, or the composition of the present invention containing the single stranded nucleic acid molecule may be administered.
- the administration method is not particularly limited, and can be appropriately selected according to, for example, the type of administration target.
- the therapeutic method of the disease of the present invention includes the step of administering the single-stranded nucleic acid molecule of the present invention to a patient, and the single-stranded nucleic acid molecule is the above-mentioned expression suppression sequence. It is characterized by having a sequence that suppresses the expression of a gene that causes disease.
- the treatment method of the present invention is characterized by using the single-stranded nucleic acid molecule of the present invention, and the other steps and conditions are not limited at all.
- the treatment method of the present invention can employ, for example, the expression suppression method of the present invention.
- the use of the present invention is the use of the single-stranded nucleic acid molecule of the present invention for suppressing the expression of the target gene. Also, the use of the present invention is the use of the single stranded nucleic acid molecule of the present invention for induction of RNA interference.
- the nucleic acid molecule of the present invention is a nucleic acid molecule for use in treating a disease, wherein the nucleic acid molecule is the single-stranded nucleic acid molecule of the present invention, and the single-stranded nucleic acid molecule is the expression suppression sequence
- the present invention is characterized by having a sequence that suppresses the expression of a gene that causes the disease.
- Example 1 Synthesis of N-2-chloroacetyl-L-proline-succin imidyl ester (3) N-2-chloroacetyl-L-proline-succin imidyl ester (3) was synthesized according to the following scheme.
- Example 2 Synthesis of Novel Single-Stranded Nucleic Acid Molecule (PS-0001-C3) (1) Nucleic Acid Synthesis
- the nucleic acids shown below were synthesized by a nucleic acid synthesizer (trade name: ABI Expedite (registered trademark) 8909 Nucleic Acid Synthesis System, Applied Biosystems) based on the phosphoroamidite method. Solid phase synthesis was performed using TBDMS amidite as the RNA amidite. In the synthesis of the sense strand, Phthalamido Amino C6 lcaa CPG (ChemGenes) (the structure is shown below) was used at the 3 'end.
- PS-0001-C3 which is a single-stranded nucleic acid molecule of the present invention, is shown below.
- PS-0001-C3 was selected from the group consisting of N-2-chloroacetyl-L-proline-succinimido obtained in Example 1 by the method described later, at the 3 'end of the sense strand and the 5' end of the antisense strand. It is a single-stranded nucleic acid molecule obtained by binding through ester (3).
- the reaction solution was purified by illustra MicroSpin G-25 Columns (GE Healthcare) using distilled water for injection (Otsuka Pharmaceutical) as an elution solution to obtain sense strand + P. Mass spectrometry: 7689.00 (calculated: 7689.29).
- the HPLC analysis results are shown in FIG.
- the analysis conditions are: X Bridge OST C 18 (4.6 ⁇ 50 mm), mobile phase A: 50 mM TEAA (pH 7), 5% CH 3 CN, mobile phase B: 50 mM TEAA (pH 7), 50% CH 3 CN, gradient B: 0-30% / 20 min, flow rate: 1 mL / min, column temperature: 60 ° C., detection: UV 260 nm.
- antisense strand (SH form) 40 ⁇ L of 1 mmol / L antisense strand, 20 ⁇ L of 1 mol / L phosphate buffer (pH 8.0), 20 ⁇ L of 10 mg / mL aqueous solution of dithiothreitol, and 20 ⁇ L of distilled water for injection Mix and stir at 25 ° C. for 45 minutes. Further, 5 ⁇ L of 10 mg / mL aqueous dithiothreitol aqueous solution was added, and stirred for 1.5 hours.
- the reaction solution was purified by illustra MicroSpin G-25 Columns (GE Healthcare) using distilled water for injection (Otsuka Pharmaceutical) as an elution solution to obtain an antisense strand (SH form). Mass spectrometry: 8084.30 (calculated: 8084.85).
- the HPLC analysis results are shown in FIG. The analysis conditions are: X Bridge OST C 18 (4.6 ⁇ 50 mm), mobile phase A: 50 mM TEAA (pH 7), 5% CH 3 CN, mobile phase B: 50 mM TEAA (pH 7), 50% CH 3 CN, gradient B: 0-30% / 20 min, flow rate: 1 mL / min, column temperature: 60 ° C., detection: UV 260 nm.
- HPLC column: X Bridge Oligonucleotide BEH C18, 2.5 ⁇ m, 10 ⁇ 50 mm; flow rate: 4 mL / min; detection: UV 260 nm; column temperature: 40 ° C .; mobile phase A: 50 mmol / L TEAA (pH 7.0), 5% CH 3 CN; mobile phase B: 50mmol / L TEAA (pH7.0 ), and purified by 50% CH 3 CN), a peak was fractionated of the object. The precipitated fraction was subjected to ethanol precipitation to obtain PS-0001-C3. Mass spectrometry: 15737.80 (calculated: 15737.67). The HPLC analysis results after purification are shown in FIG.
- Example 3 Synthesis of N ⁇ 2-bromoacetyl-N ⁇ -tert-butoxycarbonyl-L-lysine-succinimidyl ester (6) According to the following scheme, N ⁇ 2-bromoacetyl-N ⁇ -tert-butoxy The carbonyl-L-lysine-succinimidyl ester (6) was synthesized.
- Example 4 Synthesis of Novel Single-Stranded Nucleic Acid Molecule (KS-0001) The following sense and antisense strands prepared in Example 2 were used.
- KS-0001 which is a single-stranded nucleic acid molecule of the present invention, is shown below.
- KS-0001 the 5 'end of the end and the antisense strand 3' of the sense strand, N alpha-2-bromoacetyl -N epsilon-tert-butoxycarbonyl -L- lysine by the method described below - succinimidyl ester (6)
- a single-stranded nucleic acid molecule obtained by binding through (6).
- AS-0001 is a single-stranded nucleic acid molecule obtained by combining the 3 'end of the sense strand with the 5' end of the antisense strand via 2-bromoacetic acid succinimidyl ester by the method described later .
- Test Example 1 Method for measuring gene expression suppression activity
- A549 cells DS Pharma Biomedical
- DMEM Invitrogen
- the culture conditions were 37 ° C., 5% CO 2 .
- cells were cultured in a medium, and the cell suspension was aliquoted into 24-well plates in 400 ⁇ L aliquots at 4 ⁇ 10 4 cells / well.
- the transfection reagent Lipofectamine RNAiMAX Transfection Reagent (Invitrogen)
- the nucleic acid molecule was transfected to cells in the well according to the attached protocol. Specifically, transfection was performed by setting the composition per well as follows.
- (B) is Opti-MEM (Invitrogen) and (C) is a nucleic acid molecule solution, and 98.5 ⁇ L of both were added in total. In the wells, the final concentration of the nucleic acid molecule was 0.01, 0.1, 1 nmol / L.
- RNA was recovered using NucleoSpin RNA Plus (Takara Bio) according to the attached protocol.
- cDNA was synthesized from RNA using reverse transcriptase (Transcriptor First Strand cDNA Synthesis Kit, Roche) according to the attached protocol. Then, as shown below, PCR was performed using the synthesized cDNA as a template to measure the expression level of the TGF- ⁇ 1 gene and the expression level of the internal standard ⁇ -actin gene. The expression level of the TGF- ⁇ 1 gene was corrected by the expression level of the ⁇ -actin gene.
- the PCR used LightCycler 480 SYBR Green I Master (Roche) as a reagent, and Light Cycler 480 Instrument II (Roche) as an instrument.
- the following primer sets were used for amplification of the TGF- ⁇ 1 gene and ⁇ -actin gene, respectively.
- the gene expression level was measured also in cells treated in the same manner except that in the transfection, no nucleic acid molecule was added and a total of 100 ⁇ L of (A) transfection reagent and 1.5 ⁇ L of (B) were added. (Mock).
- the expression level of the corrected TGF- ⁇ 1 gene the relative expression level in cells into which each nucleic acid molecule was introduced was determined, with the expression level in control (mock) cells as 1.
- a novel method for producing a single-stranded nucleic acid molecule which enables synthesis of a high difficulty long-chain oligomer by exploiting the technique of short-chain oligomer, and a novel single strand produced by the method It can provide stranded nucleic acid molecules.
Abstract
本発明は、新規な一本鎖核酸分子およびその製造方法を提供する。 本発明は、一般式(I): [式中の各記号は明細書に記載の通りである。] で表される一本鎖核酸分子の製造方法に関する。
Description
本発明は、一本鎖核酸分子およびその製造方法に関する。
一本鎖核酸分子としては、例えば特許文献1および2に記載のものが知られている。
一般的な長鎖オリゴマーの合成では、技術的および生産的課題として、反応収量の低下、副生成物の除去の困難さ、アミダイトモノマーの使用の制限、コスト高などが挙げられており、これらの課題を解決することができる新たな簡易で汎用性を伴う、実用的な製造方法の開発が望まれている。
本発明者らは、上記課題を解決すべく鋭意検討した結果、式(II)で表される核酸と式(IV)で表される化合物とを反応させた後、式(III)で表される核酸と反応させる方法が、長鎖オリゴマーの合成でしばしば問題となるN-1、2、3等の短いオリゴマーのコンタミネーションを顕著に回避でき、そして反応生成物の精製が容易であることを見出し、本発明を完成するに至った。
すなわち、本発明は、以下の通りである。
[1] 下記一般式(I):
[1] 下記一般式(I):
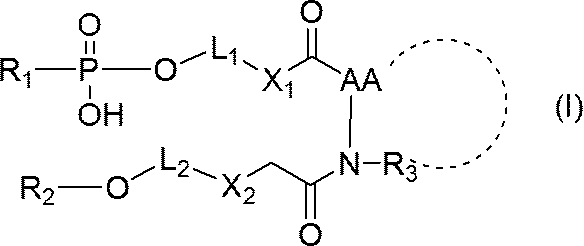
[式中、
R1は、オリゴヌクレオチド又はポリヌクレオチドを含む領域であって、その3’末端ヌクレオチド残基が-P(=O)(OH)-O-と結合し;
R2は、オリゴヌクレオチド又はポリヌクレオチドを含む領域であって、その5’末端ヌクレオチド残基が-O-と結合し;
X1およびX2は、それぞれ独立して、NH、SまたはOを示し;
L1およびL2は、それぞれ独立して、C1-30アルキレン鎖、または-(CH2)l-(O-(CH2)m-)n-(式中、lは1~3の整数を示し、mは1~3の整数を示し、nは1~10の整数を示す。)を示し;
-C(=O)-AA-NR3-は、アミノ酸残基を示し;
R3は、水素原子またはC1-6アルキル基を示すか、あるいは、AAと一緒になって窒素含有複素環を形成する。]
で表される一本鎖核酸分子(以下、一本鎖核酸分子(I)ともいう)の製造方法であって、
(工程1)下記一般式(II):
R1は、オリゴヌクレオチド又はポリヌクレオチドを含む領域であって、その3’末端ヌクレオチド残基が-P(=O)(OH)-O-と結合し;
R2は、オリゴヌクレオチド又はポリヌクレオチドを含む領域であって、その5’末端ヌクレオチド残基が-O-と結合し;
X1およびX2は、それぞれ独立して、NH、SまたはOを示し;
L1およびL2は、それぞれ独立して、C1-30アルキレン鎖、または-(CH2)l-(O-(CH2)m-)n-(式中、lは1~3の整数を示し、mは1~3の整数を示し、nは1~10の整数を示す。)を示し;
-C(=O)-AA-NR3-は、アミノ酸残基を示し;
R3は、水素原子またはC1-6アルキル基を示すか、あるいは、AAと一緒になって窒素含有複素環を形成する。]
で表される一本鎖核酸分子(以下、一本鎖核酸分子(I)ともいう)の製造方法であって、
(工程1)下記一般式(II):

[式中の各記号は前記と同義である。]
で表される核酸(以下、核酸(II)ともいう)を、下記一般式(IV):
で表される核酸(以下、核酸(II)ともいう)を、下記一般式(IV):
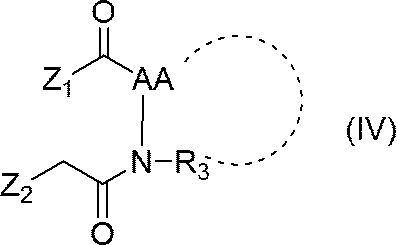
[式中、
Z1は、スクシンイミジルオキシ基、ベンゾトリアゾリルオキシ基、ペンタフルオロフェノキシ基またはハロゲン原子を示し;
Z2は、ハロゲン原子を示し;
その他の記号は前記と同義である。]
で表される化合物(以下、化合物(IV)ともいう)と反応させて、下記一般式(V):
Z1は、スクシンイミジルオキシ基、ベンゾトリアゾリルオキシ基、ペンタフルオロフェノキシ基またはハロゲン原子を示し;
Z2は、ハロゲン原子を示し;
その他の記号は前記と同義である。]
で表される化合物(以下、化合物(IV)ともいう)と反応させて、下記一般式(V):

[式中の各記号は前記と同義である。]
で表される核酸(以下、核酸(V)ともいう)を得る工程;および
(工程2)一般式(V)で表される核酸を、下記一般式(III):
で表される核酸(以下、核酸(V)ともいう)を得る工程;および
(工程2)一般式(V)で表される核酸を、下記一般式(III):
[式中の各記号は前記と同義である。]
で表される核酸(以下、核酸(III)ともいう)と反応させて、上記一般式(I)で表される一本鎖核酸分子を得る工程;
を包含する、製造方法。
[2] アミノ酸残基が、プロリン残基、グリシン残基、または側鎖アミノ基が保護されていてもよいリジン残基である、上記[1]に記載の製造方法。
[3] X2がSである、上記[1]に記載の製造方法。
[4] X1がNHである、上記[1]に記載の製造方法。
[5] L1が、C2-11アルキレン鎖である、請求項1に記載の製造方法。
[6] L1が、-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数を示す。)である、上記[1]に記載の製造方法。
[7] L2が、C2-11アルキレン鎖である、上記[1]に記載の製造方法。
[8] L2が、-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数を示す。)である、上記[1]に記載の製造方法。
[9] Z1が、スクシンイミジルオキシ基である、上記[1]に記載の製造方法。
[10] 一本鎖核酸分子が、標的遺伝子の発現を抑制する配列を含む、上記[1]~[9]のいずれかに記載の製造方法。
[11] 下記一般式(Ia):
で表される核酸(以下、核酸(III)ともいう)と反応させて、上記一般式(I)で表される一本鎖核酸分子を得る工程;
を包含する、製造方法。
[2] アミノ酸残基が、プロリン残基、グリシン残基、または側鎖アミノ基が保護されていてもよいリジン残基である、上記[1]に記載の製造方法。
[3] X2がSである、上記[1]に記載の製造方法。
[4] X1がNHである、上記[1]に記載の製造方法。
[5] L1が、C2-11アルキレン鎖である、請求項1に記載の製造方法。
[6] L1が、-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数を示す。)である、上記[1]に記載の製造方法。
[7] L2が、C2-11アルキレン鎖である、上記[1]に記載の製造方法。
[8] L2が、-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数を示す。)である、上記[1]に記載の製造方法。
[9] Z1が、スクシンイミジルオキシ基である、上記[1]に記載の製造方法。
[10] 一本鎖核酸分子が、標的遺伝子の発現を抑制する配列を含む、上記[1]~[9]のいずれかに記載の製造方法。
[11] 下記一般式(Ia):
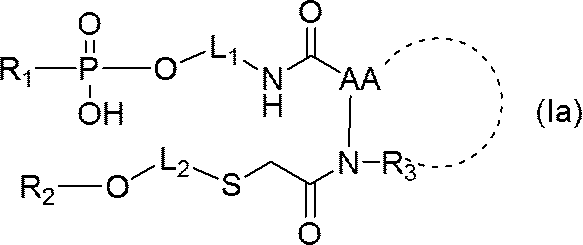
[式中、
R1は、オリゴヌクレオチド又はポリヌクレオチドを含む領域であって、その3’末端ヌクレオチド残基が-P(=O)(OH)-O-と結合し;
R2は、オリゴヌクレオチド又はポリヌクレオチドを含む領域であって、その5’末端ヌクレオチド残基が-O-と結合し;
L1およびL2は、それぞれ独立して、C1-30アルキレン鎖、または-(CH2)l-(O-(CH2)m-)n-(式中、lは1~3の整数を示し、mは1~3の整数を示し、nは1~10の整数を示す。)を示し;
-C(=O)-AA-NR3-は、アミノ酸残基を示し;
R3は、水素原子またはC1-6アルキル基を示すか、あるいは、AAと一緒になって窒素含有複素環を形成する。]
で表される一本鎖核酸分子(以下、一本鎖核酸分子(Ia)ともいう)。
[12] アミノ酸残基が、プロリン残基、グリシン残基、または側鎖アミノ基が保護されていてもよいリジン残基である、上記[11]に記載の一本鎖核酸分子。
[13] L1が、C2-11アルキレン鎖である、上記[11]に記載の一本鎖核酸分子。
[14] L1が、-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数を示す。)である、上記[11]に記載の一本鎖核酸分子。
[15] L2が、C2-11アルキレン鎖である、上記[11]に記載の一本鎖核酸分子。
[16] L2が、-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数を示す。)である、上記[11]に記載の一本鎖核酸分子。
[17] 標的遺伝子の発現を抑制する配列を含む、上記[11]~[16]のいずれかに記載の一本鎖核酸分子。
[18] 上記[11]~[17]のいずれかに記載の一本鎖核酸分子を含む、医薬組成物。
[19] 上記[17]に記載の一本鎖核酸分子を含む、標的遺伝子の発現抑制剤。
[20] 下記一般式(IVa):
R1は、オリゴヌクレオチド又はポリヌクレオチドを含む領域であって、その3’末端ヌクレオチド残基が-P(=O)(OH)-O-と結合し;
R2は、オリゴヌクレオチド又はポリヌクレオチドを含む領域であって、その5’末端ヌクレオチド残基が-O-と結合し;
L1およびL2は、それぞれ独立して、C1-30アルキレン鎖、または-(CH2)l-(O-(CH2)m-)n-(式中、lは1~3の整数を示し、mは1~3の整数を示し、nは1~10の整数を示す。)を示し;
-C(=O)-AA-NR3-は、アミノ酸残基を示し;
R3は、水素原子またはC1-6アルキル基を示すか、あるいは、AAと一緒になって窒素含有複素環を形成する。]
で表される一本鎖核酸分子(以下、一本鎖核酸分子(Ia)ともいう)。
[12] アミノ酸残基が、プロリン残基、グリシン残基、または側鎖アミノ基が保護されていてもよいリジン残基である、上記[11]に記載の一本鎖核酸分子。
[13] L1が、C2-11アルキレン鎖である、上記[11]に記載の一本鎖核酸分子。
[14] L1が、-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数を示す。)である、上記[11]に記載の一本鎖核酸分子。
[15] L2が、C2-11アルキレン鎖である、上記[11]に記載の一本鎖核酸分子。
[16] L2が、-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数を示す。)である、上記[11]に記載の一本鎖核酸分子。
[17] 標的遺伝子の発現を抑制する配列を含む、上記[11]~[16]のいずれかに記載の一本鎖核酸分子。
[18] 上記[11]~[17]のいずれかに記載の一本鎖核酸分子を含む、医薬組成物。
[19] 上記[17]に記載の一本鎖核酸分子を含む、標的遺伝子の発現抑制剤。
[20] 下記一般式(IVa):

[式中、
Z2は、ハロゲン原子を示し;
-C(=O)-AA-NR3-は、アミノ酸残基を示し;
R3は、水素原子またはC1-6アルキル基を示すか、あるいは、AAと一緒になって窒素含有複素環を形成する。]
で表される化合物(以下、化合物(IVa)ともいう)。
[21] アミノ酸残基が、プロリン残基、グリシン残基、または側鎖アミノ基が保護されていてもよいリジン残基である、上記[20]に記載の化合物。
[22] Z2が、塩素原子または臭素原子である、上記[20]に記載の化合物。
Z2は、ハロゲン原子を示し;
-C(=O)-AA-NR3-は、アミノ酸残基を示し;
R3は、水素原子またはC1-6アルキル基を示すか、あるいは、AAと一緒になって窒素含有複素環を形成する。]
で表される化合物(以下、化合物(IVa)ともいう)。
[21] アミノ酸残基が、プロリン残基、グリシン残基、または側鎖アミノ基が保護されていてもよいリジン残基である、上記[20]に記載の化合物。
[22] Z2が、塩素原子または臭素原子である、上記[20]に記載の化合物。
本発明によれば、高難易度の長鎖オリゴマーの合成が短鎖オリゴマーの技術を駆使して可能となる新規な一本鎖核酸分子の製造方法、および該方法によって製造される新規な一本鎖核酸分子を提供できる。
以下に、本発明を詳細に説明する。まず、式中の各記号の定義について詳述する。
R1は、オリゴヌクレオチド又はポリヌクレオチドを含む領域であって、その3’末端ヌクレオチド残基が-P(=O)(OH)-O-と結合し、R2は、オリゴヌクレオチド又はポリヌクレオチドを含む領域であって、その5’末端ヌクレオチド残基が-O-と結合している。
「ヌクレオチド残基」とは、ヌクレオチド(ヌクレオシドの糖部分の5’位の水酸基にリン酸が結合)の5’位のリン酸基中のOHと、3’位の水酸基中のHを除いた2価の基をいい、R1中の「3’末端ヌクレオチド残基」では、その3’位が、式(I)中の
「ヌクレオチド残基」とは、ヌクレオチド(ヌクレオシドの糖部分の5’位の水酸基にリン酸が結合)の5’位のリン酸基中のOHと、3’位の水酸基中のHを除いた2価の基をいい、R1中の「3’末端ヌクレオチド残基」では、その3’位が、式(I)中の
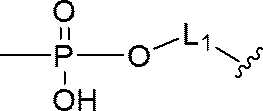
と結合し、R2中の「5’末端ヌクレオチド残基」では、その5’位が、式(I)中の
R1は、後述する本発明の第1の一本鎖核酸分子中のデオキシリボヌクレオチド(DNA)および/またはリボヌクレオチド(RNA)を構成単位とするオリゴヌクレオチド又はポリヌクレオチドをそれぞれ含む領域(X)及び領域(Xc)の一方であってもよく、かつR2は他方であってもよい。あるいは、R1は、後述する本発明の第2の一本鎖核酸分子中のデオキシリボヌクレオチド(DNA)および/またはリボヌクレオチド(RNA)を構成単位とするオリゴヌクレオチド又はポリヌクレオチドをそれぞれ含む領域(X)および領域(Y)ならびに領域(Xc)および領域(Yc)の一方であってもよく、かつR2は他方であってもよい。また、前記領域(Yc)と前記領域(Y)とは、後述するように、例えば、直接連結してもよいし、間接的に連結してもよい。
X1およびX2は、それぞれ独立して、NH、SまたはOを示す。
X1は、好ましくは、NHである。
X2は、好ましくは、Sである。
X1は、好ましくは、NHである。
X2は、好ましくは、Sである。
L1およびL2は、それぞれ独立して、C1-30アルキレン鎖、または-(CH2)l-(O-(CH2)m-)n-(式中、lは1~3の整数を示し、mは1~3の整数を示し、nは1~10の整数を示す。)を示す。
L1またはL2で示される「C1-30アルキレン鎖」としては、-CH2-、-(CH2)2-、-(CH2)3-、-(CH2)4-、-CH(CH3)-、-C(CH3)2-、-CH(C2H5)-、-CH(C3H7)-、-(CH(CH3))2-、-CH2-CH(CH3)-、-CH(CH3)-CH2-、-(CH2)4-、-(CH2)5-、-(CH2)6-、-(CH2)7-、-(CH2)8-、-(CH2)9-、-(CH2)10-、-(CH2)11-、-(CH2)12-等が挙げられる。当該「C1-30アルキレン鎖」は、好ましくはC2-11アルキレン鎖であり、より好ましくはC3-6アルキレン鎖であり、特に好ましくは、L1においてはC4-6アルキレン鎖であり、L2においてはC3アルキレン鎖である。
L1またはL2で示される「C1-30アルキレン鎖」としては、-CH2-、-(CH2)2-、-(CH2)3-、-(CH2)4-、-CH(CH3)-、-C(CH3)2-、-CH(C2H5)-、-CH(C3H7)-、-(CH(CH3))2-、-CH2-CH(CH3)-、-CH(CH3)-CH2-、-(CH2)4-、-(CH2)5-、-(CH2)6-、-(CH2)7-、-(CH2)8-、-(CH2)9-、-(CH2)10-、-(CH2)11-、-(CH2)12-等が挙げられる。当該「C1-30アルキレン鎖」は、好ましくはC2-11アルキレン鎖であり、より好ましくはC3-6アルキレン鎖であり、特に好ましくは、L1においてはC4-6アルキレン鎖であり、L2においてはC3アルキレン鎖である。
L1またはL2で示される「-(CH2)l-(O-(CH2)m-)n-」において、lは、好ましくは1~2の整数であり、mは、好ましくは1~2の整数である。nは、好ましくは1~5の整数であり、より好ましくは1~2の整数である。
L1またはL2で示される「-(CH2)l-(O-(CH2)m-)n-」の具体例は、-CH2(OCH2)n-、-CH2CH2(OCH2CH2)n-および-CH2CH2CH2(OCH2CH2CH2)n-(式中、nは1~5の整数である。)であり、
好適な具体例は、-CH2(OCH2)n-および-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数である。)であり、
さらに好適な具体例は、-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数である。)であり、
特に好適な具体例は、-CH2CH2(OCH2CH2)n-(式中、nは1~2の整数である。)である。
L1またはL2で示される「-(CH2)l-(O-(CH2)m-)n-」の具体例は、-CH2(OCH2)n-、-CH2CH2(OCH2CH2)n-および-CH2CH2CH2(OCH2CH2CH2)n-(式中、nは1~5の整数である。)であり、
好適な具体例は、-CH2(OCH2)n-および-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数である。)であり、
さらに好適な具体例は、-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数である。)であり、
特に好適な具体例は、-CH2CH2(OCH2CH2)n-(式中、nは1~2の整数である。)である。
L1およびL2は、好ましくは、それぞれ独立して、C2-11アルキレン鎖または-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数である。)である。
L1およびL2は、より好ましくは、それぞれ独立して、C3-6アルキレン鎖または-CH2CH2(OCH2CH2)n-(式中、nは1~2の整数である。)である。
特に好ましくは、L1は、C4-6アルキレン鎖であり、かつL2は、C3アルキレン鎖である。
L1およびL2は、より好ましくは、それぞれ独立して、C3-6アルキレン鎖または-CH2CH2(OCH2CH2)n-(式中、nは1~2の整数である。)である。
特に好ましくは、L1は、C4-6アルキレン鎖であり、かつL2は、C3アルキレン鎖である。
式(I)、(Ia)、(IV)、(IVa)および(V)において、-C(=O)-AA-NR3-は、アミノ酸残基を示し、R3は、水素原子またはC1-6アルキル基を示すか、あるいは、AAと一緒になって窒素含有複素環を形成する。
R3で示される「C1-6アルキル基」としては、例えば、メチル、エチル、プロピル、イソプロピル、ブチル、イソブチル、sec-ブチル、tert-ブチル、ペンチル、イソペンチル、ネオペンチル、1-エチルプロピル、ヘキシル、イソヘキシル、1,1-ジメチルブチル、2,2-ジメチルブチル、3,3-ジメチルブチル、2-エチルブチルが挙げられる。
R3とAAと一緒になって形成する「窒素含有複素環」としては、例えば、ピロリン、ピロリジン、イミダゾリン、イミダゾリジン、オキサゾリン、オキサゾリジン、ピラゾリン、ピラゾリジン、チアゾリン、チアゾリジン、ピペリジン、ピペラジン、テトラヒドロピリジン、ジヒドロピリジン、テトラヒドロピリミジン、テトラヒドロピリダジン、モルホリン、チオモルホリン、アゼパニン、ジアゼパン、アゼピンなどの3ないし8員単環式窒素含有非芳香族複素環が挙げられる。中でも、ピロリジンが好ましい。
R3は、好ましくは、水素原子であるか、あるいはAAと一緒になってピロリジンを形成する。
当該「アミノ酸残基」とは、アミノ酸のカルボキシ基のOHとアミノ基の1個の水素原子を除いた2価の基を意味する。アミノ酸の側鎖にカルボキシ基やアミノ基が存在する場合、これらの基からのOHや水素原子を除いた2価の基も「アミノ酸残基」に含まれる。
当該「アミノ酸残基」は、特に限定されず、公知の全てのアミノ酸由来の残基がいずれも例示され、α-アミノ酸由来の残基、β-アミノ酸由来の残基、γ-アミノ酸由来の残基等が挙げられる。
R3は、AAと一緒になって窒素含有複素環を形成してもよく、このような「アミノ酸残基」としては、プロリン残基等の環状アミノ酸残基が挙げられる。
また、アミノ酸残基が側鎖官能基(例、アミノ基、カルボキシ基、ヒドロキシ基、スルファニル基(SH)、アミド基(CONH2)等)を有する場合は、当該側鎖官能基は公知の適切な保護基で保護されていてもよい。アミノ基の保護基としては、tert-ブトキシカルボニル(Boc)基、ベンジルオキシカルボニル(Z)基、9-フルオレニルメチルオキシカルボニル(Fmoc)基等が挙げられ、カルボキシ基の保護基としては、メチル基、エチル基、ベンジル基等が挙げられる。ヒドロキシ基やスルファニル基(SH)の保護基としては、トリチル(トリフェニルメチル)基等が挙げられる。
さらに、アミノ酸残基は、側鎖官能基が糖、脂質、ペプチド等で修飾されていてもよい。
当該「アミノ酸残基」の好適な具体例としては、プロリン残基、グリシン残基、リジン残基、フェニルアラニン残基、ベータアラニン残基等が挙げられる。ここで、リジン残基は側鎖アミノ基が、tert-ブトキシカルボニル基で保護されていてもよいし、又は、糖、脂質、ペプチド等で修飾されていてもよい。
好ましい「アミノ酸残基」としては、プロリン残基、グリシン残基、または側鎖アミノ基が保護されていてもよいリジン残基(例えば、側鎖アミノ基がtert-ブトキシカルボニル基で保護されていてもよいリジン残基)であり、プロリン残基、または側鎖アミノ基が保護されていてもよいリジン残基(例えば、側鎖アミノ基がtert-ブトキシカルボニル基で保護されていてもよいリジン残基)がより好ましい。
R3で示される「C1-6アルキル基」としては、例えば、メチル、エチル、プロピル、イソプロピル、ブチル、イソブチル、sec-ブチル、tert-ブチル、ペンチル、イソペンチル、ネオペンチル、1-エチルプロピル、ヘキシル、イソヘキシル、1,1-ジメチルブチル、2,2-ジメチルブチル、3,3-ジメチルブチル、2-エチルブチルが挙げられる。
R3とAAと一緒になって形成する「窒素含有複素環」としては、例えば、ピロリン、ピロリジン、イミダゾリン、イミダゾリジン、オキサゾリン、オキサゾリジン、ピラゾリン、ピラゾリジン、チアゾリン、チアゾリジン、ピペリジン、ピペラジン、テトラヒドロピリジン、ジヒドロピリジン、テトラヒドロピリミジン、テトラヒドロピリダジン、モルホリン、チオモルホリン、アゼパニン、ジアゼパン、アゼピンなどの3ないし8員単環式窒素含有非芳香族複素環が挙げられる。中でも、ピロリジンが好ましい。
R3は、好ましくは、水素原子であるか、あるいはAAと一緒になってピロリジンを形成する。
当該「アミノ酸残基」とは、アミノ酸のカルボキシ基のOHとアミノ基の1個の水素原子を除いた2価の基を意味する。アミノ酸の側鎖にカルボキシ基やアミノ基が存在する場合、これらの基からのOHや水素原子を除いた2価の基も「アミノ酸残基」に含まれる。
当該「アミノ酸残基」は、特に限定されず、公知の全てのアミノ酸由来の残基がいずれも例示され、α-アミノ酸由来の残基、β-アミノ酸由来の残基、γ-アミノ酸由来の残基等が挙げられる。
R3は、AAと一緒になって窒素含有複素環を形成してもよく、このような「アミノ酸残基」としては、プロリン残基等の環状アミノ酸残基が挙げられる。
また、アミノ酸残基が側鎖官能基(例、アミノ基、カルボキシ基、ヒドロキシ基、スルファニル基(SH)、アミド基(CONH2)等)を有する場合は、当該側鎖官能基は公知の適切な保護基で保護されていてもよい。アミノ基の保護基としては、tert-ブトキシカルボニル(Boc)基、ベンジルオキシカルボニル(Z)基、9-フルオレニルメチルオキシカルボニル(Fmoc)基等が挙げられ、カルボキシ基の保護基としては、メチル基、エチル基、ベンジル基等が挙げられる。ヒドロキシ基やスルファニル基(SH)の保護基としては、トリチル(トリフェニルメチル)基等が挙げられる。
さらに、アミノ酸残基は、側鎖官能基が糖、脂質、ペプチド等で修飾されていてもよい。
当該「アミノ酸残基」の好適な具体例としては、プロリン残基、グリシン残基、リジン残基、フェニルアラニン残基、ベータアラニン残基等が挙げられる。ここで、リジン残基は側鎖アミノ基が、tert-ブトキシカルボニル基で保護されていてもよいし、又は、糖、脂質、ペプチド等で修飾されていてもよい。
好ましい「アミノ酸残基」としては、プロリン残基、グリシン残基、または側鎖アミノ基が保護されていてもよいリジン残基(例えば、側鎖アミノ基がtert-ブトキシカルボニル基で保護されていてもよいリジン残基)であり、プロリン残基、または側鎖アミノ基が保護されていてもよいリジン残基(例えば、側鎖アミノ基がtert-ブトキシカルボニル基で保護されていてもよいリジン残基)がより好ましい。
Z1は、スクシンイミジルオキシ基、ベンゾトリアゾリルオキシ基、ペンタフルオロフェノキシ基またはハロゲン原子を示す。
Z1で示される「ハロゲン原子」としては、フッ素原子、塩素原子、臭素原子、ヨウ素原子が挙げられ、中でも、塩素原子または臭素原子が好ましい。
Z1は、好ましくはスクシンイミジルオキシ基である。
Z1で示される「ハロゲン原子」としては、フッ素原子、塩素原子、臭素原子、ヨウ素原子が挙げられ、中でも、塩素原子または臭素原子が好ましい。
Z1は、好ましくはスクシンイミジルオキシ基である。
Z2は、ハロゲン原子を示す。
Z2で示される「ハロゲン原子」としては、フッ素原子、塩素原子、臭素原子、ヨウ素原子が挙げられ、中でも、塩素原子または臭素原子が好ましい。
Z2で示される「ハロゲン原子」としては、フッ素原子、塩素原子、臭素原子、ヨウ素原子が挙げられ、中でも、塩素原子または臭素原子が好ましい。
Z3は、ハロゲン原子を示す。
Z3で示される「ハロゲン原子」としては、フッ素原子、塩素原子、臭素原子、ヨウ素原子が挙げられ、中でも、塩素原子または臭素原子が好ましい。
Z3で示される「ハロゲン原子」としては、フッ素原子、塩素原子、臭素原子、ヨウ素原子が挙げられ、中でも、塩素原子または臭素原子が好ましい。
一本鎖核酸分子(I)の製造法について以下に説明する。一本鎖核酸分子(I)は、例えば、以下の製造法1により製造することができる。
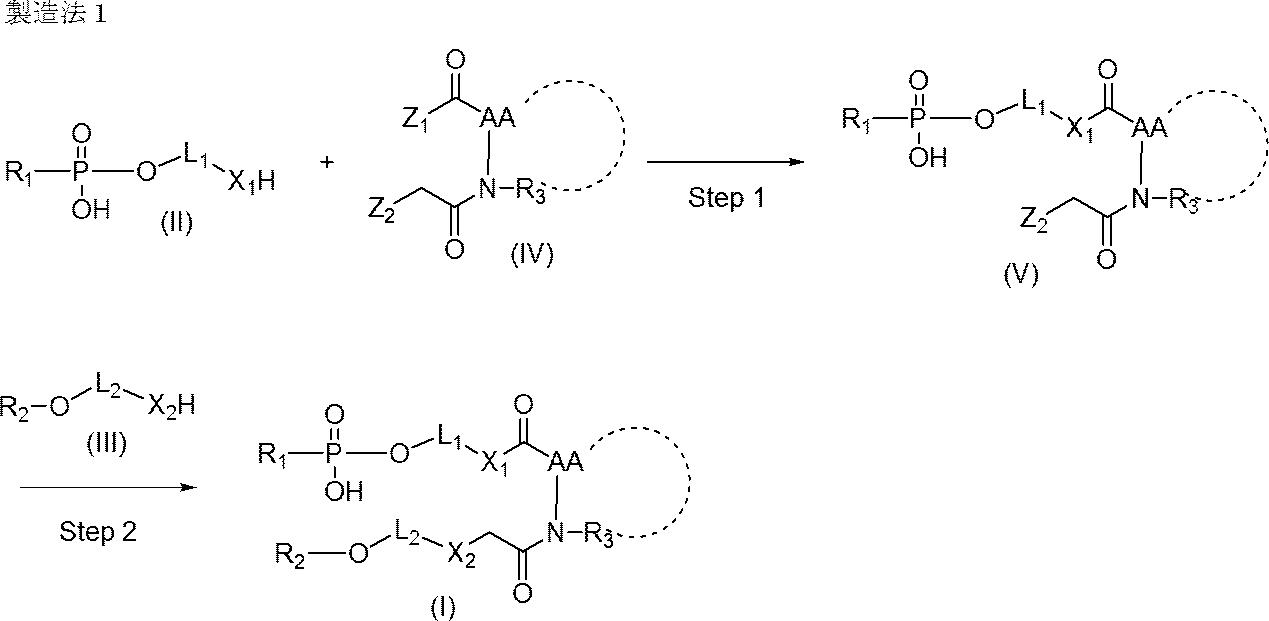
[式中の各記号は前記と同義である。]
(工程1)
核酸(II)を化合物(IV)と反応させて、核酸(V)を製造する。
反応は、通常、塩基性条件下(好ましくはpH8~9)(例えば、リン酸緩衝液または炭酸緩衝液中、あるいは、ジイソプロピルエチルアミン、トリエチルアミン等の塩基存在下)で行われる。
また反応は、通常、溶媒中、0℃~室温で行われる。溶媒としては、N,N-ジメチルホルムアミド、N,N-ジメチルアセトアミド等のアミド系溶媒;テトラヒドロフラン(THF)、ジオキサン等のエーテル系溶媒、ジメチルスルホキシド、アセトニトリル等の極性溶媒;水等が挙げられ、中でも、ジメチルホルムアミドと水の混合溶媒又は水が好ましい。
反応終了後、簡易ゲルろ過カラム等で低分子化合物を除き、核酸(V)を得る。
核酸(II)を化合物(IV)と反応させて、核酸(V)を製造する。
反応は、通常、塩基性条件下(好ましくはpH8~9)(例えば、リン酸緩衝液または炭酸緩衝液中、あるいは、ジイソプロピルエチルアミン、トリエチルアミン等の塩基存在下)で行われる。
また反応は、通常、溶媒中、0℃~室温で行われる。溶媒としては、N,N-ジメチルホルムアミド、N,N-ジメチルアセトアミド等のアミド系溶媒;テトラヒドロフラン(THF)、ジオキサン等のエーテル系溶媒、ジメチルスルホキシド、アセトニトリル等の極性溶媒;水等が挙げられ、中でも、ジメチルホルムアミドと水の混合溶媒又は水が好ましい。
反応終了後、簡易ゲルろ過カラム等で低分子化合物を除き、核酸(V)を得る。
(工程2)
核酸(V)を核酸(III)と反応させて、一本鎖核酸分子(I)を製造する。
反応は、通常、塩基性条件下(好ましくはpH8~9)(例えば、リン酸緩衝液または炭酸緩衝液中)で行われる。
また反応は、通常、溶媒中、室温で行われる。
反応終了後、HPLC等により精製して、一本鎖核酸分子(I)を得る。
核酸(V)を核酸(III)と反応させて、一本鎖核酸分子(I)を製造する。
反応は、通常、塩基性条件下(好ましくはpH8~9)(例えば、リン酸緩衝液または炭酸緩衝液中)で行われる。
また反応は、通常、溶媒中、室温で行われる。
反応終了後、HPLC等により精製して、一本鎖核酸分子(I)を得る。
-C(=O)-AA-NR3-が、側鎖官能基が保護されたアミノ酸残基である一本鎖核酸分子(I)は、-C(=O)-AA-NR3-が、側鎖官能基が保護されたアミノ酸残基である化合物(IV)を用いて、工程1および工程2を行うことにより得ることができる。
-C(=O)-AA-NR3-が、側鎖官能基が保護されたアミノ酸残基である一本鎖核酸分子(I)は、自体公知の方法に従って脱保護を行い、-C(=O)-AA-NR3-が、側鎖官能基が保護されていないアミノ酸残基である一本鎖核酸分子(I)に導くことができる。例えば、-C(=O)-AA-NR3-が、側鎖アミノ基がtert-ブトキシカルボニル基で保護されたリジン残基である一本鎖核酸分子(I)は、塩化水素、トリフルオロ酢酸等の酸処理により、-C(=O)-AA-NR3-が、側鎖アミノ基が保護されていないリジン残基である一本鎖核酸分子(I)に導くことができる。
-C(=O)-AA-NR3-が、側鎖官能基が保護されたアミノ酸残基である一本鎖核酸分子(I)は、自体公知の方法に従って脱保護を行い、-C(=O)-AA-NR3-が、側鎖官能基が保護されていないアミノ酸残基である一本鎖核酸分子(I)に導くことができる。例えば、-C(=O)-AA-NR3-が、側鎖アミノ基がtert-ブトキシカルボニル基で保護されたリジン残基である一本鎖核酸分子(I)は、塩化水素、トリフルオロ酢酸等の酸処理により、-C(=O)-AA-NR3-が、側鎖アミノ基が保護されていないリジン残基である一本鎖核酸分子(I)に導くことができる。
-C(=O)-AA-NR3-が、側鎖官能基が修飾されたアミノ酸残基である一本鎖核酸分子(I)は、-C(=O)-AA-NR3-が、側鎖官能基が修飾されたアミノ酸残基である化合物(IV)を用いて、工程1および工程2を行うことにより得ることができる。
あるいは、-C(=O)-AA-NR3-が、側鎖官能基が保護されていないアミノ酸残基である一本鎖核酸分子(I)の当該側鎖官能基に、糖、脂質、ペプチド等を、アミド化反応、エステル化反応、エーテル化反応等により導入することにより、-C(=O)-AA-NR3-が、側鎖官能基が修飾されたアミノ酸残基である一本鎖核酸分子(I)に導くことができる。
あるいは、-C(=O)-AA-NR3-が、側鎖官能基が保護されていないアミノ酸残基である一本鎖核酸分子(I)の当該側鎖官能基に、糖、脂質、ペプチド等を、アミド化反応、エステル化反応、エーテル化反応等により導入することにより、-C(=O)-AA-NR3-が、側鎖官能基が修飾されたアミノ酸残基である一本鎖核酸分子(I)に導くことができる。
製造法1で使用する化合物(IV)は、例えば、以下の製造法2により製造することができる。
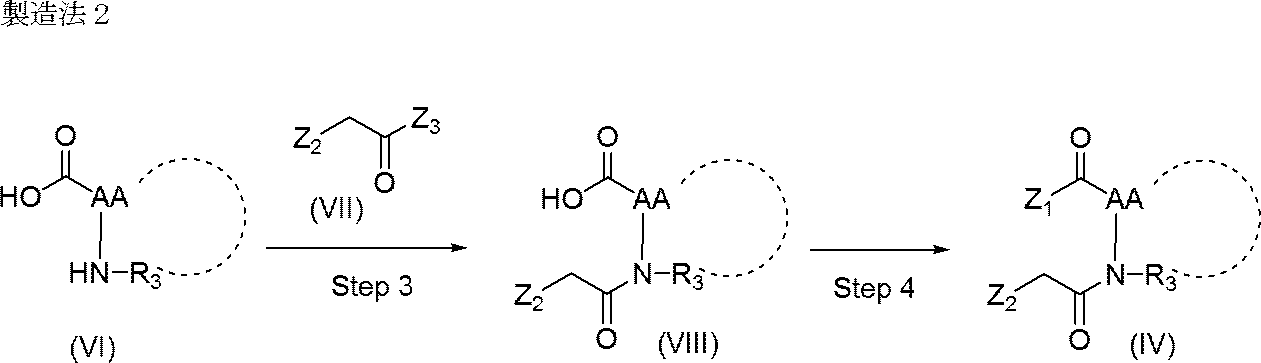
[式中、Z3は、ハロゲン原子を示し、その他の記号は前記と同義である。]
(工程3)
アミノ酸である化合物(VI)を化合物(VII)と反応させて、化合物(VIII)を製造する。
Z3が塩素原子の場合、反応は、通常、溶媒中、室温~加熱下で行われる。溶媒としては、テトラヒドロフラン(THF)、ジオキサン等のエーテル系溶媒;アセトニトリル、ジメチルホルムアミド等の極性溶媒等が挙げられ、中でも、テトラヒドロフランが好ましい。
Z3が臭素原子の場合、反応は、通常、溶媒中、塩基存在下、冷却下~室温で行われる。溶媒としては、水、テトラヒドロフラン(THF)、ジオキサン等のエーテル系溶媒;アセトニトリル、ジメチルホルムアミド等の極性溶媒等が挙げられ、中でも、水とテトラヒドロフランの混合溶媒が好ましい。塩基としては、水酸化ナトリウム等が挙げられる。
反応終了後、公知の後処理を行い、化合物(VIII)を得る。
アミノ酸である化合物(VI)を化合物(VII)と反応させて、化合物(VIII)を製造する。
Z3が塩素原子の場合、反応は、通常、溶媒中、室温~加熱下で行われる。溶媒としては、テトラヒドロフラン(THF)、ジオキサン等のエーテル系溶媒;アセトニトリル、ジメチルホルムアミド等の極性溶媒等が挙げられ、中でも、テトラヒドロフランが好ましい。
Z3が臭素原子の場合、反応は、通常、溶媒中、塩基存在下、冷却下~室温で行われる。溶媒としては、水、テトラヒドロフラン(THF)、ジオキサン等のエーテル系溶媒;アセトニトリル、ジメチルホルムアミド等の極性溶媒等が挙げられ、中でも、水とテトラヒドロフランの混合溶媒が好ましい。塩基としては、水酸化ナトリウム等が挙げられる。
反応終了後、公知の後処理を行い、化合物(VIII)を得る。
(工程4)
化合物(VIII)のカルボキシル基を-C(=O)Z1に変換して、化合物(IV)を製造する。
Z1がスクシンイミジルオキシ基の場合、1-エチル-3-(3-ジメチルアミノプロピル)カルボジイミド塩酸塩等の縮合剤の存在下、化合物(VIII)をN-ヒドロキシこはく酸イミドと反応させることにより行われる。
反応は、通常、溶媒中、室温で行われる。溶媒としては、ジクロロメタン、クロロホルム等のハロゲン系溶媒、テトラヒドロフラン(THF)、ジオキサン等のエーテル系溶媒等が挙げられ、中でも、ジクロロメタンが好ましい。
あるいは、塩基存在下、化合物(VIII)をジ(N-スクシンイミジルカーボネート)と反応させることにより行われる。
塩基としては、N,N-ジメチルアミノピリジン等が挙げられる。
反応は、通常、溶媒中、室温で行われる。溶媒としては、アセトニトリル、ジメチルホルムアミド等の極性溶媒等が挙げられ、中でも、アセトニトリルが好ましい。
Z1がベンゾトリアゾリルオキシ基の場合、化合物(VIII)を1-ヒドロキシベンゾトリアゾールと反応させることにより行われる。この反応は、Z1がスクシンイミジルオキシ基の場合と同様の方法で行われる。
Z1がペンタフルオロフェノキシ基の場合、化合物(VIII)をペンタフルオロフェノールと反応させることにより行われる。この反応は、Z1がスクシンイミジルオキシ基の場合と同様の方法で行われる。
Z1が塩素原子の場合、化合物(VIII)を塩化チオニル等の塩素化剤と反応させることにより行われる。
化合物(VIII)のカルボキシル基を-C(=O)Z1に変換して、化合物(IV)を製造する。
Z1がスクシンイミジルオキシ基の場合、1-エチル-3-(3-ジメチルアミノプロピル)カルボジイミド塩酸塩等の縮合剤の存在下、化合物(VIII)をN-ヒドロキシこはく酸イミドと反応させることにより行われる。
反応は、通常、溶媒中、室温で行われる。溶媒としては、ジクロロメタン、クロロホルム等のハロゲン系溶媒、テトラヒドロフラン(THF)、ジオキサン等のエーテル系溶媒等が挙げられ、中でも、ジクロロメタンが好ましい。
あるいは、塩基存在下、化合物(VIII)をジ(N-スクシンイミジルカーボネート)と反応させることにより行われる。
塩基としては、N,N-ジメチルアミノピリジン等が挙げられる。
反応は、通常、溶媒中、室温で行われる。溶媒としては、アセトニトリル、ジメチルホルムアミド等の極性溶媒等が挙げられ、中でも、アセトニトリルが好ましい。
Z1がベンゾトリアゾリルオキシ基の場合、化合物(VIII)を1-ヒドロキシベンゾトリアゾールと反応させることにより行われる。この反応は、Z1がスクシンイミジルオキシ基の場合と同様の方法で行われる。
Z1がペンタフルオロフェノキシ基の場合、化合物(VIII)をペンタフルオロフェノールと反応させることにより行われる。この反応は、Z1がスクシンイミジルオキシ基の場合と同様の方法で行われる。
Z1が塩素原子の場合、化合物(VIII)を塩化チオニル等の塩素化剤と反応させることにより行われる。
化合物(IV)のうち、Z1がスクシンイミジルオキシ基である下記一般式(IVa):
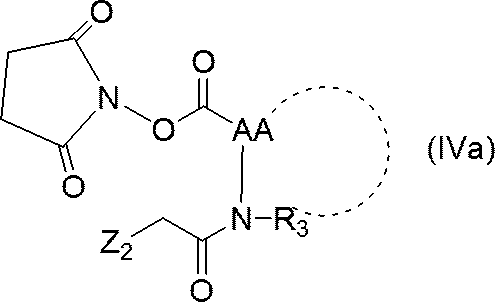
[式中の各記号は前記と同義である。]
で表される化合物は特に好適に使用される。
で表される化合物は特に好適に使用される。
製造法1で使用する核酸(II)は、
[式中、DMTrは4,4’-ジメトキシトリチル基を示し、その他の記号は前記と同義である。]
を含む担体から、DMTr基を除去後、ホスホロアミダイト法による固相合成を開始することにより合成できる。
を含む担体から、DMTr基を除去後、ホスホロアミダイト法による固相合成を開始することにより合成できる。
製造法1で使用する核酸(III)は、固相合成の最終工程で、5’末端水酸基の保護基を除去後、対応する試剤をホスホロアミダイト法により導入し、適切な処理をすることにより合成できる。例えば、核酸(III)が、
で表される核酸は、5’末端水酸基の保護基を除去後、ホスホロアミダイト法により
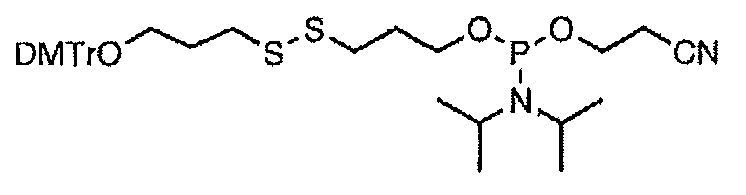
[式中、DMTrは前記と同義である。]
を導入し、定法に従い固相からの切り出しと脱保護を行った後、ジチオトレイトールで処理することにより、合成することができる。
を導入し、定法に従い固相からの切り出しと脱保護を行った後、ジチオトレイトールで処理することにより、合成することができる。
このようにして製造される一本鎖核酸分子(I)のうち、下記一般式(Ia):

[式中の各記号は前記と同義である。]
で表される一本鎖核酸分子(以下、一本鎖核酸分子(Ia)ともいう)は新規である。
で表される一本鎖核酸分子(以下、一本鎖核酸分子(Ia)ともいう)は新規である。
一本鎖核酸分子(Ia)の好適な例としては、以下の式で表される一本鎖核酸分子が挙げられる。

[式中、n1およびn2は、それぞれ独立して1~10の整数を示し、n3およびn4は、それぞれ独立して1~5の整数を示し、その他の記号は前記と同義である。]
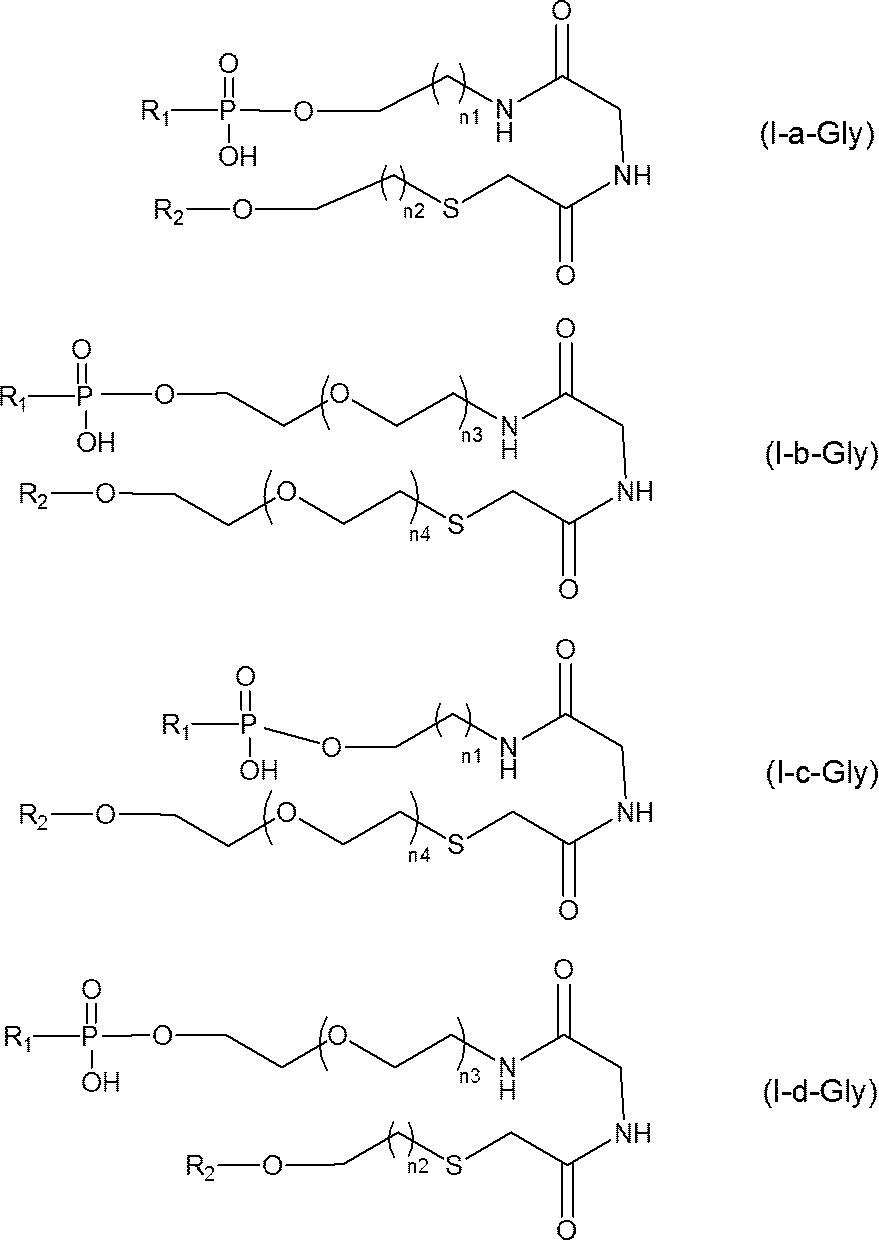
[式中の各記号は前記と同義である。]

[式中の各記号は前記と同義である。]
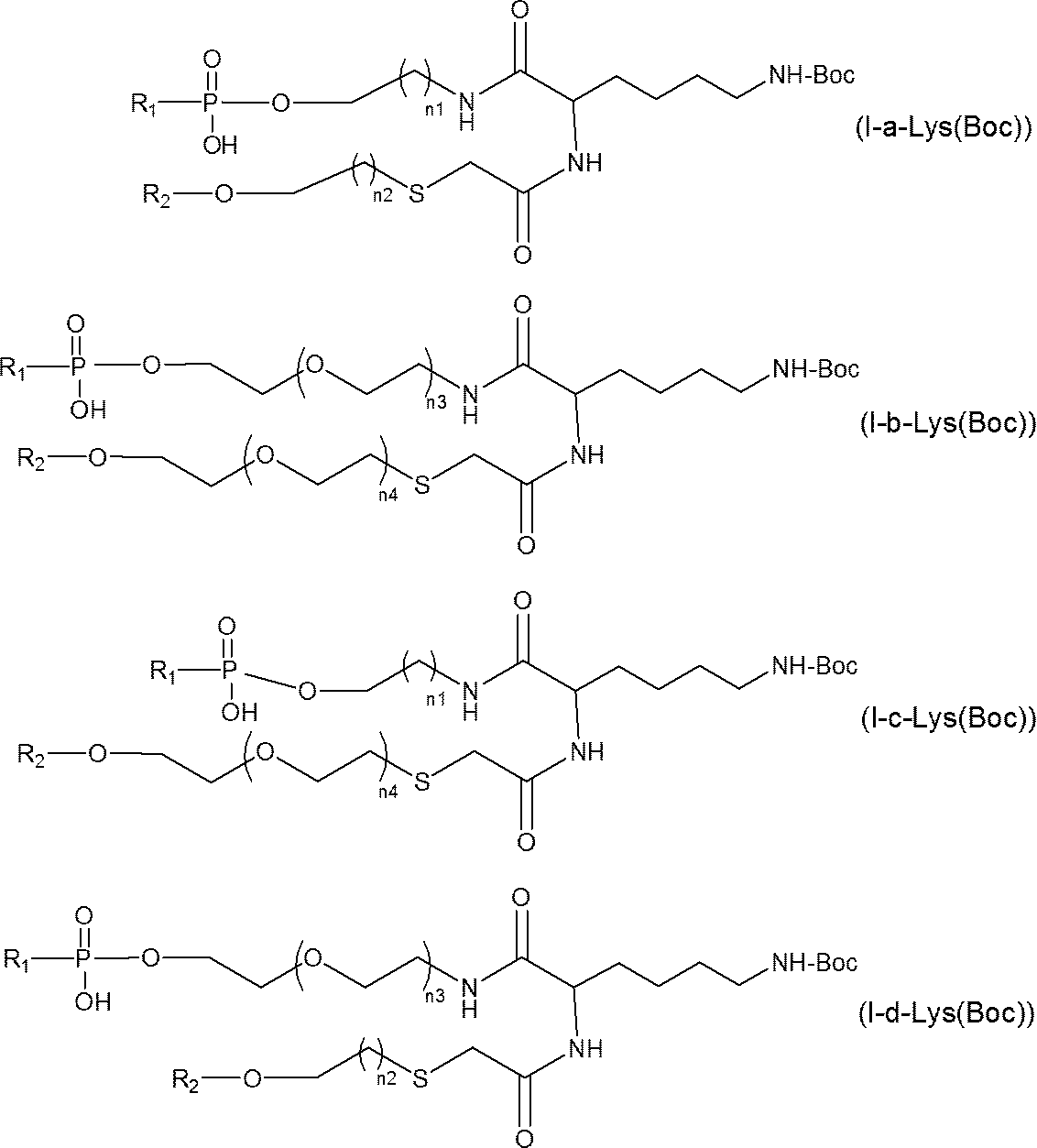
[式中、Bocはtert-ブトキシカルボニル基を示し、その他の記号は前記と同義である。]
上記式において、
n1は、好ましくは3~5の整数であり、
n2は、好ましくは2であり、
n3は、好ましくは1~2の整数であり、
n4は、好ましくは1~2の整数である。
上記式において、
n1は、好ましくは3~5の整数であり、
n2は、好ましくは2であり、
n3は、好ましくは1~2の整数であり、
n4は、好ましくは1~2の整数である。
一本鎖核酸分子(Ia)のより好適な例としては、以下の式で表される一本鎖核酸分子が挙げられる。
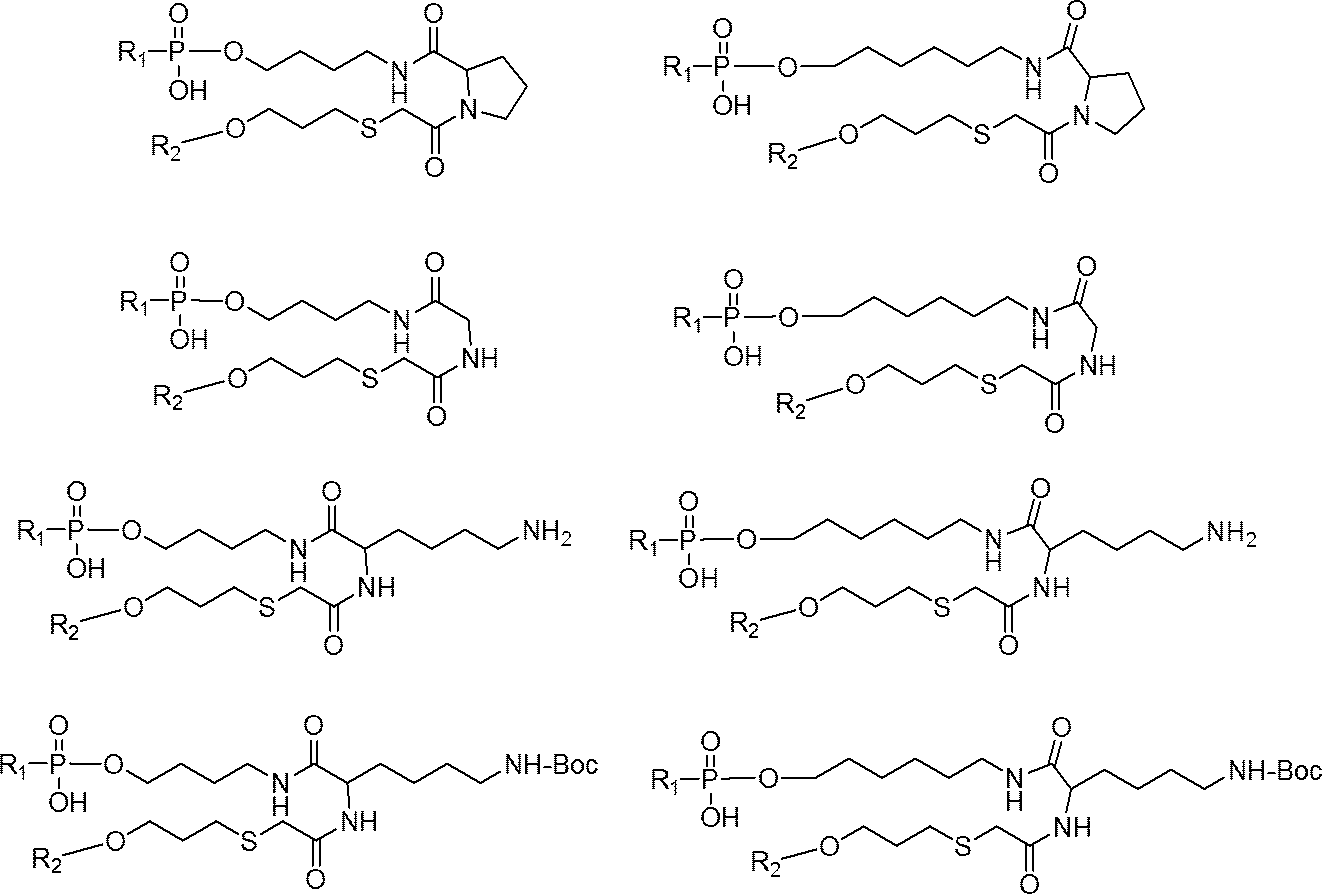
[式中、Bocはtert-ブトキシカルボニル基を示し、その他の記号は前記と同義である。]
一本鎖核酸分子(Ia)のさらに好適な例としては、以下のものが挙げられる。
一本鎖核酸分子(Ia)のさらに好適な例としては、以下のものが挙げられる。
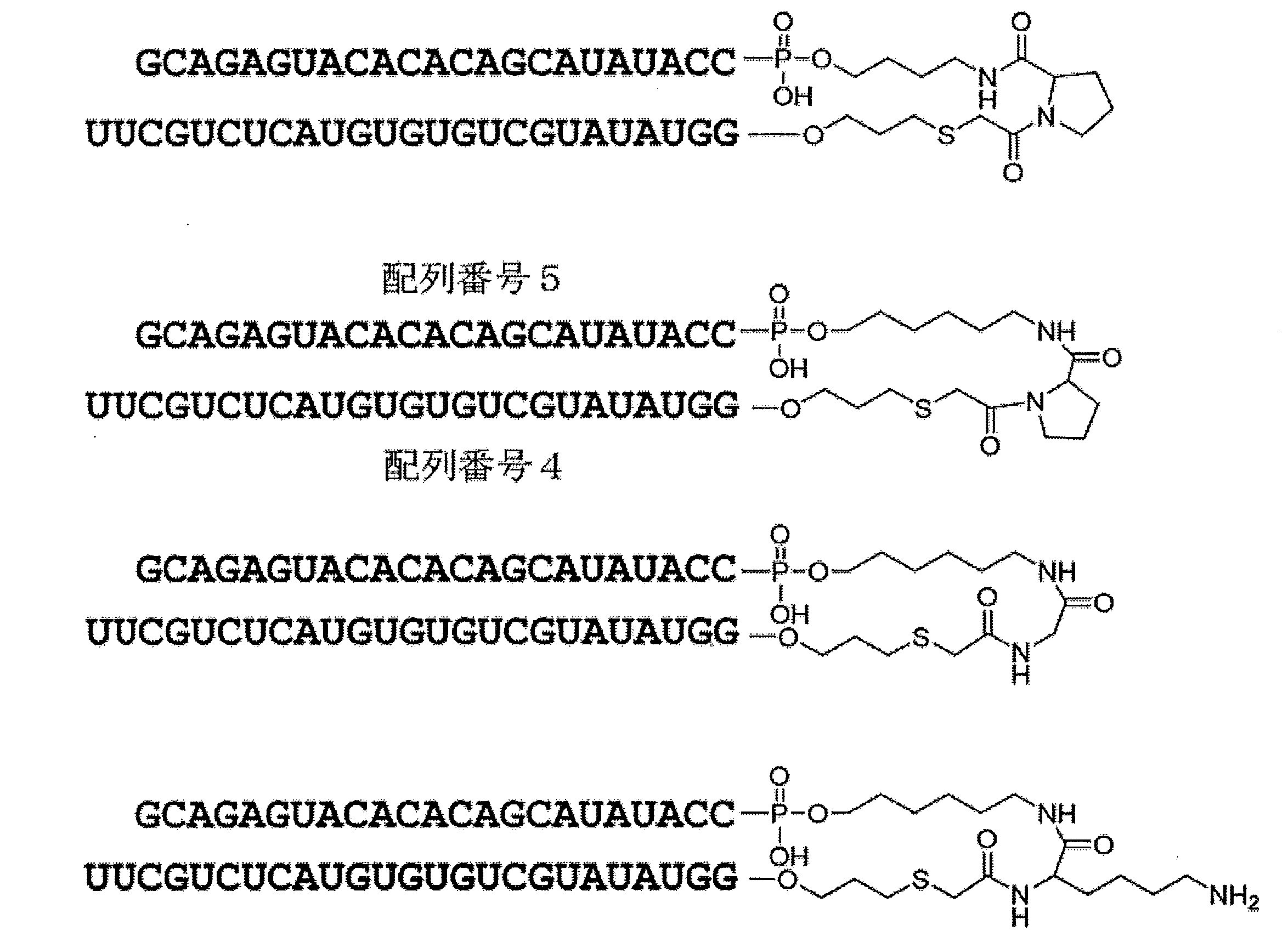

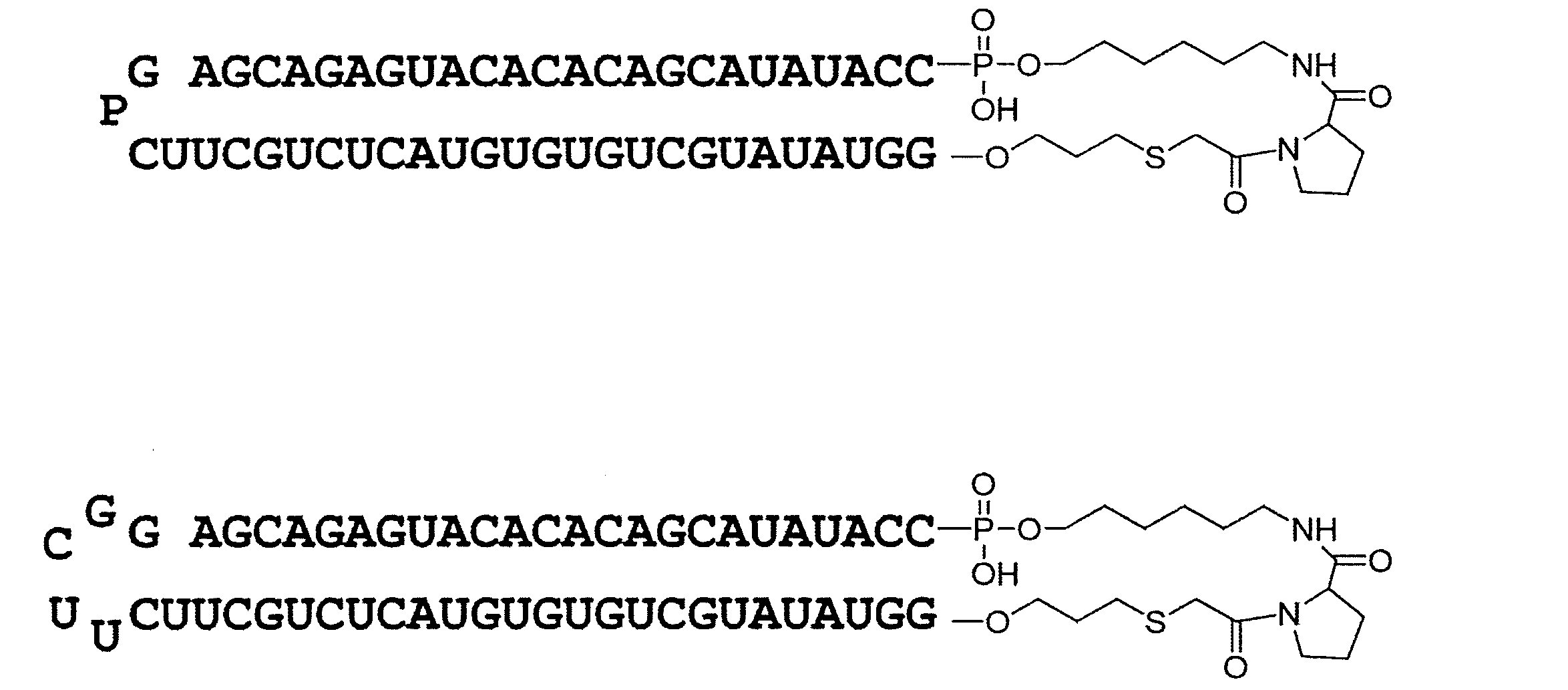
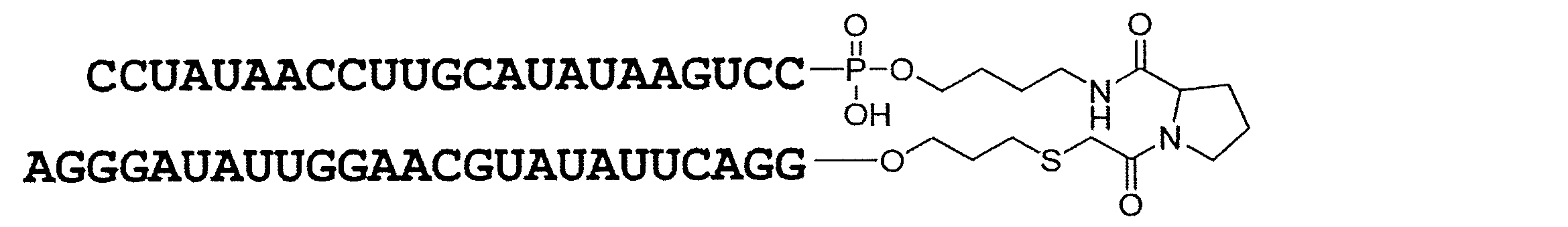
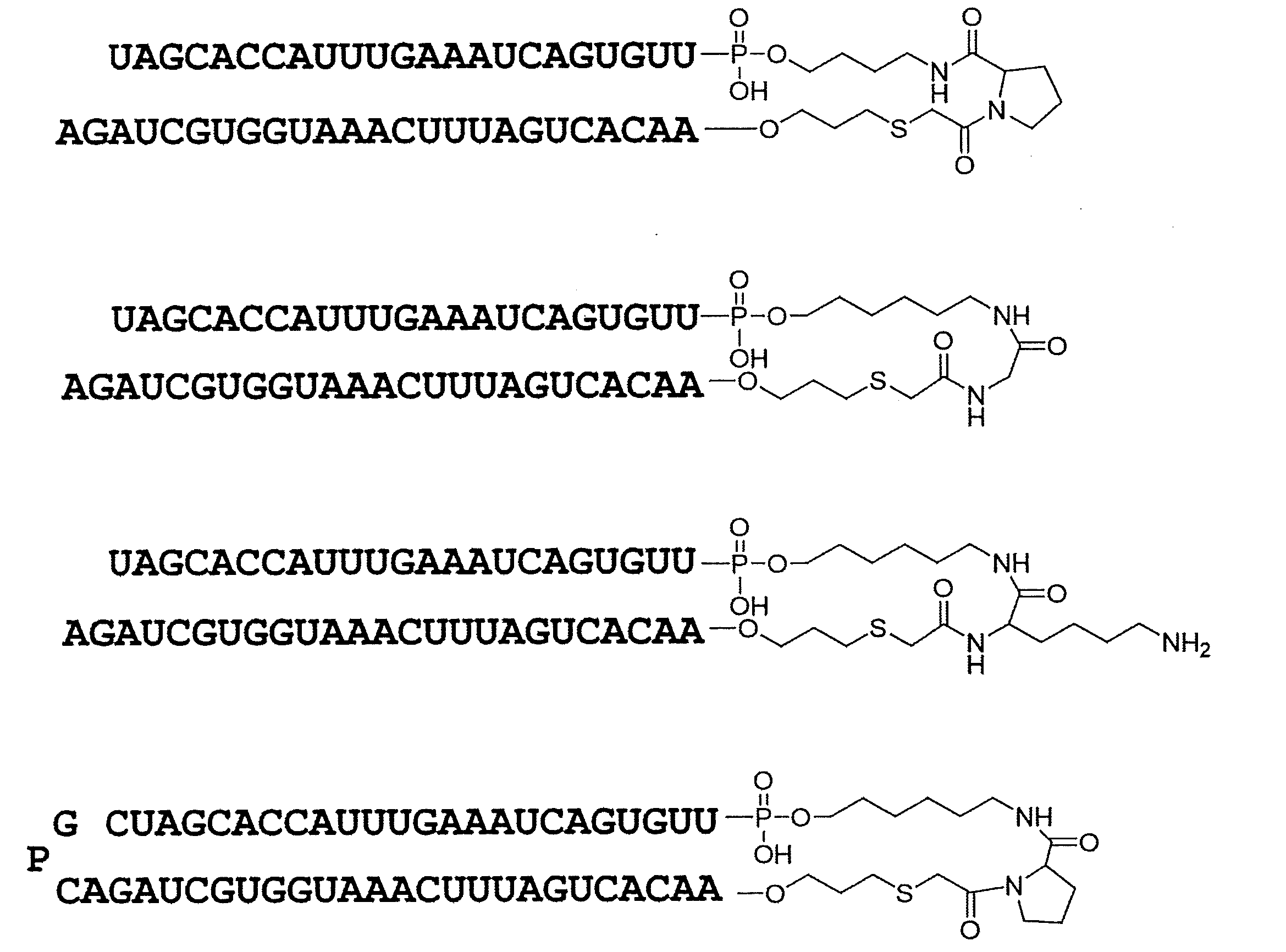
化合物(IV)の代わりに、化合物(IV’b)~(IV’g)を用い、上記製造法に従って反応を行うこともできる。以下に、化合物(IV’b)~(IV’g)の構造とその具体例を示す。

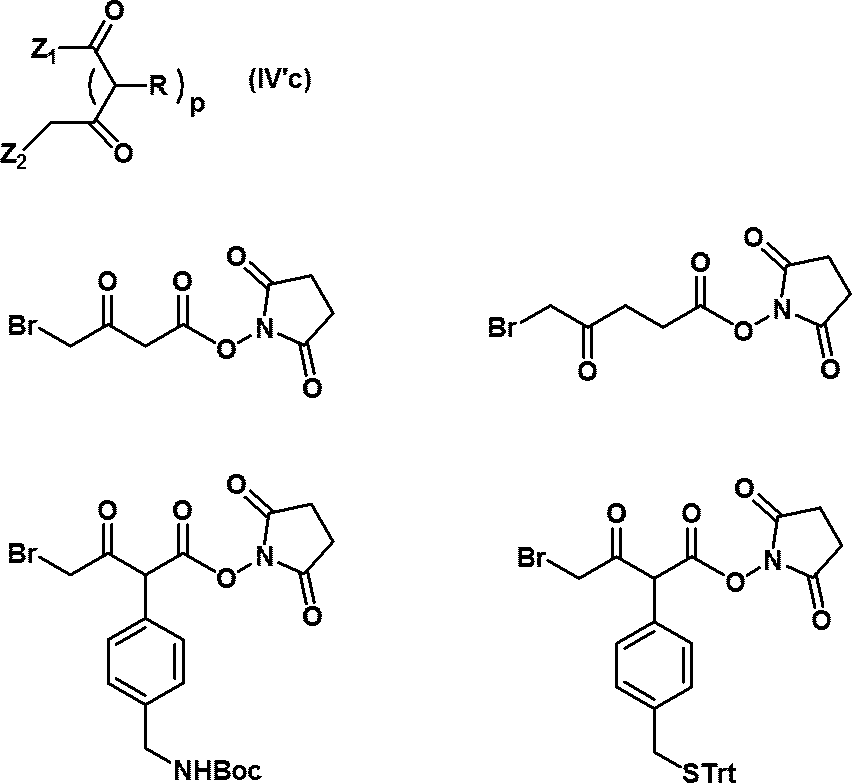
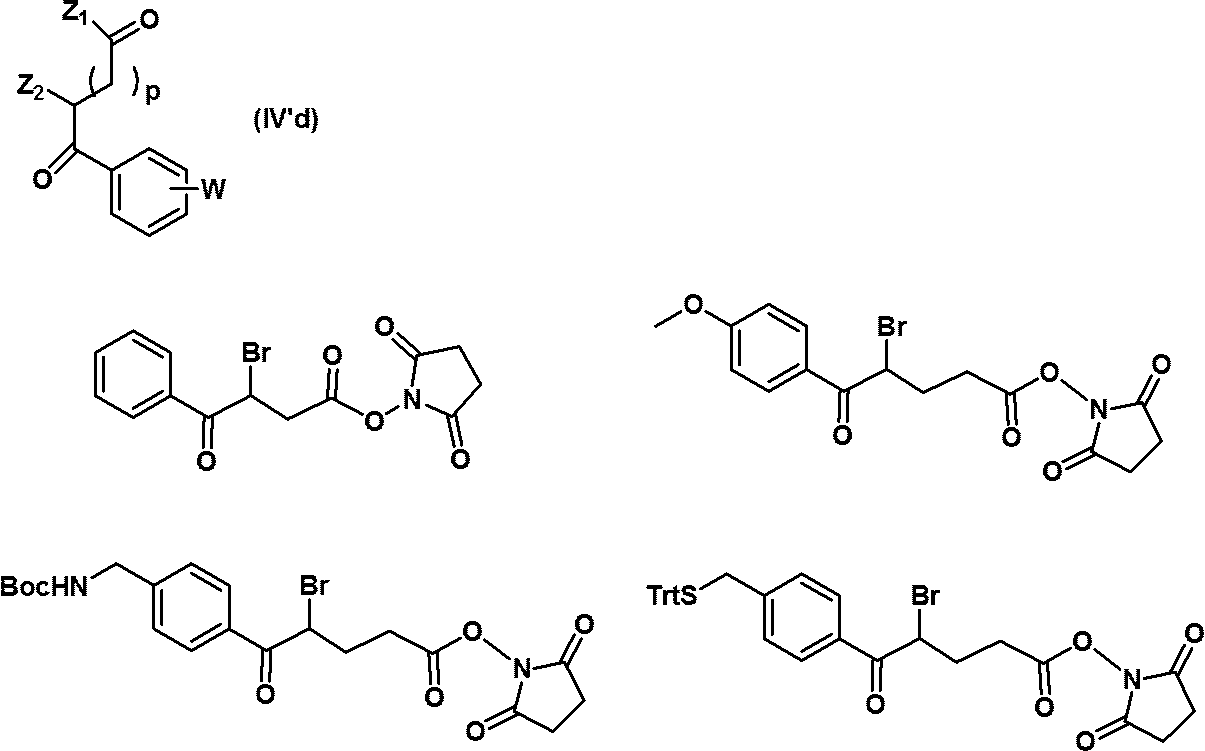
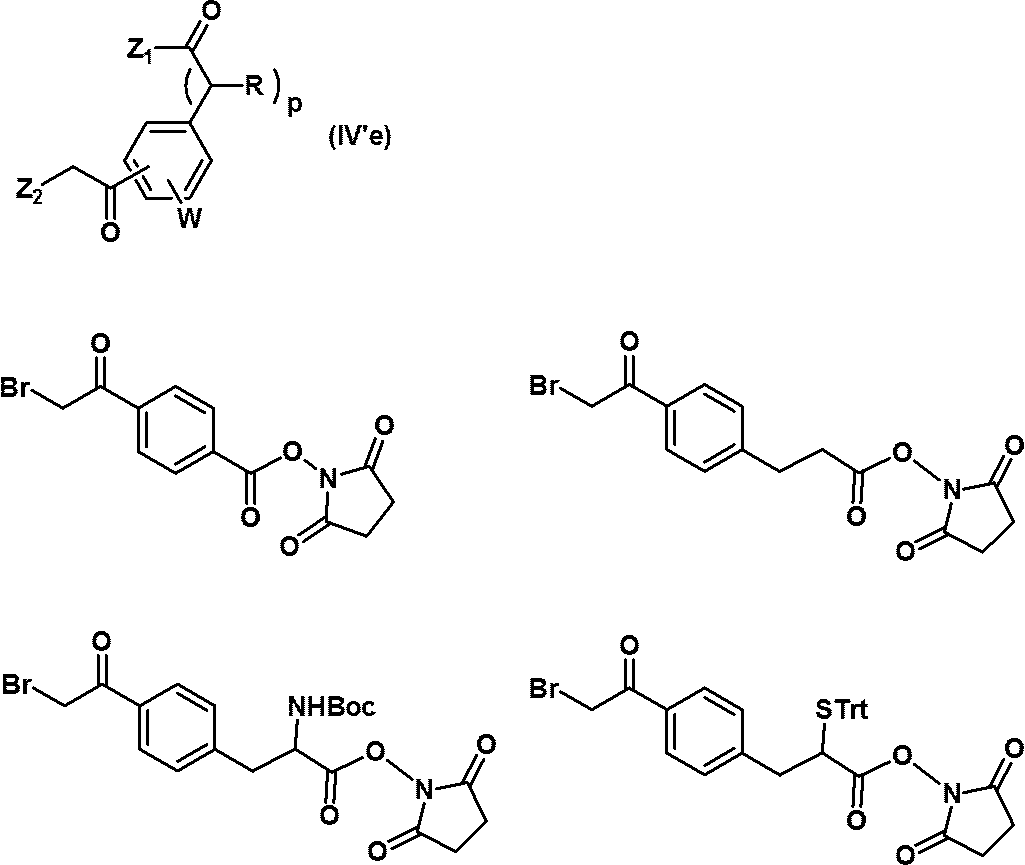


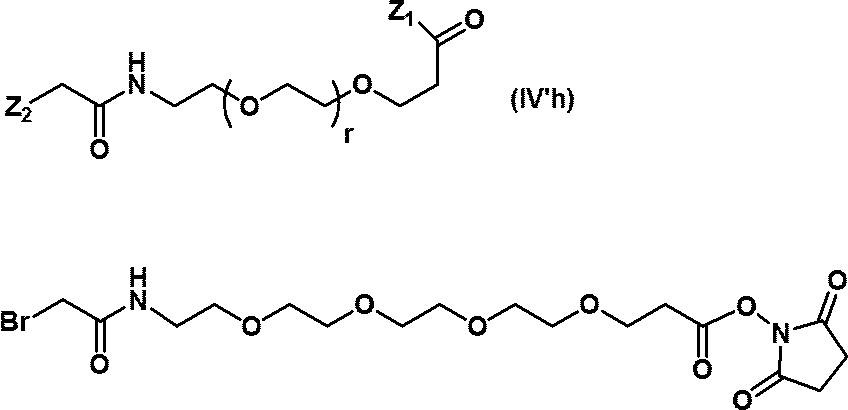
各式中において、
Rは、水素原子、置換されていてもよいC6-10アリール基、保護されたアミノ基、保護されたスルファニル基(SH)を示し;
Wは、置換されていてもよいC1-6アルキル基、C1-6アルコキシ基を示し;
pは、0~6の整数を示し;
qは、0~6の整数を示し;
rは、0~6の整数を示し;
Trtはトリチル基を示し;
その他の記号は前記と同義である。
Rは、水素原子、置換されていてもよいC6-10アリール基、保護されたアミノ基、保護されたスルファニル基(SH)を示し;
Wは、置換されていてもよいC1-6アルキル基、C1-6アルコキシ基を示し;
pは、0~6の整数を示し;
qは、0~6の整数を示し;
rは、0~6の整数を示し;
Trtはトリチル基を示し;
その他の記号は前記と同義である。
「C6-10アリール基」としては、例えば、フェニル、1-ナフチル、2-ナフチルが挙げられる。
「置換されていてもよいC6-10アリール基」における置換基としては、置換されていてもよいC1-6アルキル基が挙げられる。
「C1-6アルキル基」としては、例えば、メチル、エチル、プロピル、イソプロピル、ブチル、イソブチル、sec-ブチル、tert-ブチル、ペンチル、イソペンチル、ネオペンチル、1-エチルプロピル、ヘキシル、イソヘキシル、1,1-ジメチルブチル、2,2-ジメチルブチル、3,3-ジメチルブチル、2-エチルブチルが挙げられる。
「置換されていてもよいC1-6アルキル基」としては、例えば、C1-6アルキル基;保護されたアミノ基、保護されたスルファニル基(SH)から選択される置換基で置換されたC1-6アルキル基;が挙げられる。
「保護されたアミノ基」としては、例えば、tert-ブトキシカルボニル基、ベンジルオキシカルボニル基等の保護基で保護されたアミノ基が挙げられる。
「保護されたスルファニル基」としては、例えば、トリチル(トリフェニルメチル)基等の保護基で保護されたスルファニル基が挙げられる。
「置換されていてもよいC1-6アルキル基」の好適な具体例としては、tert-ブトキシカルボニル基で保護されたアミノ基を有するC1-6アルキル基(例、メチル)、トリチル(トリフェニルメチル)基で保護されたスルファニル基を有するC1-6アルキル基(例、メチル)等が挙げられる。
「C1-6アルコキシ基」としては、例えば、メトキシ、エトキシ、プロポキシ、イソプロポキシ、ブトキシ、イソブトキシ、sec-ブトキシ、tert-ブトキシ、ペンチルオキシ、ヘキシルオキシが挙げられる。
「置換されていてもよいC6-10アリール基」における置換基としては、置換されていてもよいC1-6アルキル基が挙げられる。
「C1-6アルキル基」としては、例えば、メチル、エチル、プロピル、イソプロピル、ブチル、イソブチル、sec-ブチル、tert-ブチル、ペンチル、イソペンチル、ネオペンチル、1-エチルプロピル、ヘキシル、イソヘキシル、1,1-ジメチルブチル、2,2-ジメチルブチル、3,3-ジメチルブチル、2-エチルブチルが挙げられる。
「置換されていてもよいC1-6アルキル基」としては、例えば、C1-6アルキル基;保護されたアミノ基、保護されたスルファニル基(SH)から選択される置換基で置換されたC1-6アルキル基;が挙げられる。
「保護されたアミノ基」としては、例えば、tert-ブトキシカルボニル基、ベンジルオキシカルボニル基等の保護基で保護されたアミノ基が挙げられる。
「保護されたスルファニル基」としては、例えば、トリチル(トリフェニルメチル)基等の保護基で保護されたスルファニル基が挙げられる。
「置換されていてもよいC1-6アルキル基」の好適な具体例としては、tert-ブトキシカルボニル基で保護されたアミノ基を有するC1-6アルキル基(例、メチル)、トリチル(トリフェニルメチル)基で保護されたスルファニル基を有するC1-6アルキル基(例、メチル)等が挙げられる。
「C1-6アルコキシ基」としては、例えば、メトキシ、エトキシ、プロポキシ、イソプロポキシ、ブトキシ、イソブトキシ、sec-ブトキシ、tert-ブトキシ、ペンチルオキシ、ヘキシルオキシが挙げられる。
上記化合物(IV’b)~(IV’g)を用いることにより、以下の核酸(I’b)~(I’g)を製造することができる。以下に、核酸(I’b)~(I’g)の構造とその具体例を示す。
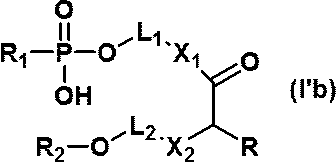
核酸(I’b)の具体例としては、以下の核酸が挙げられる。
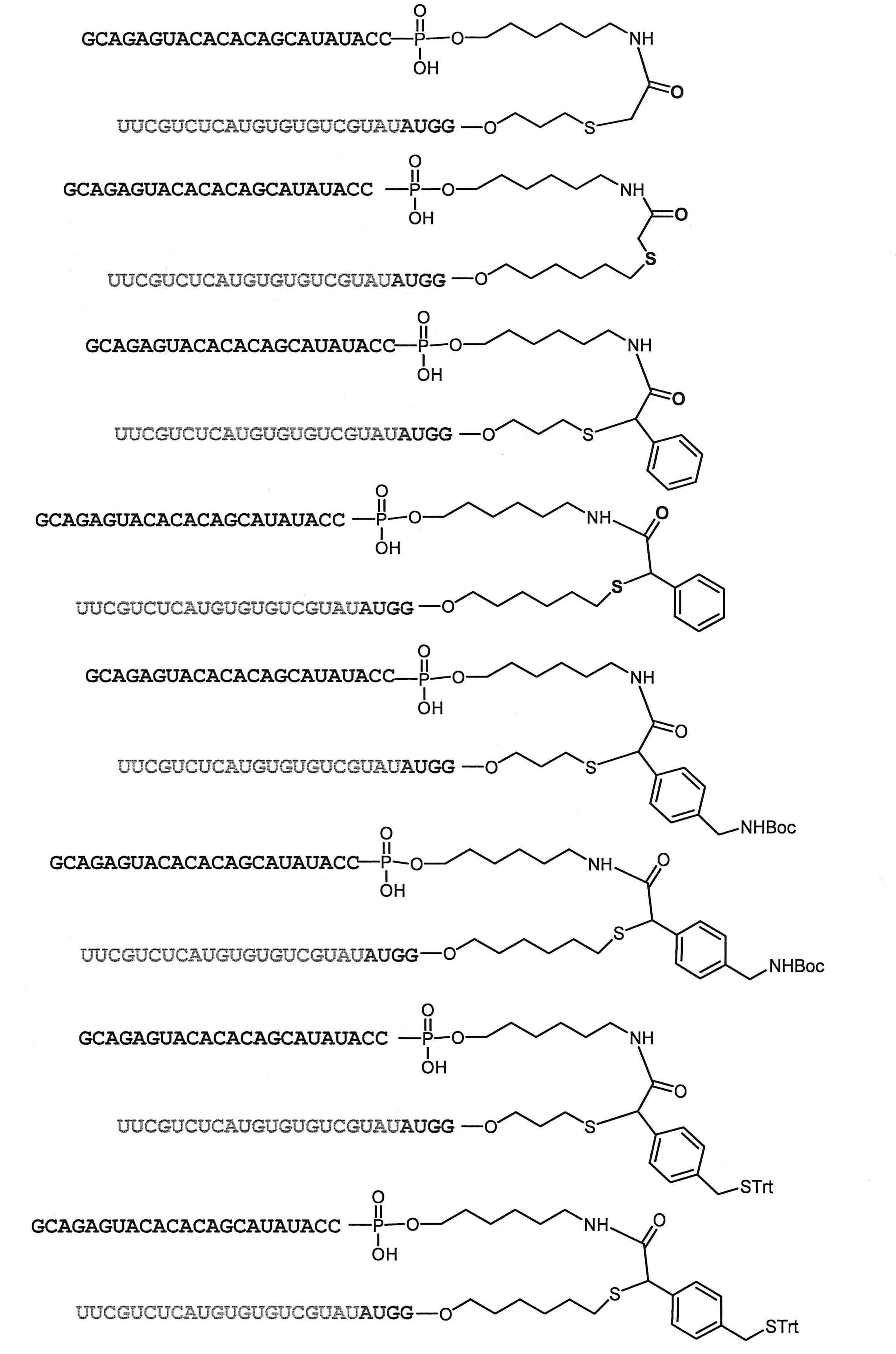

核酸(I’c)の具体例としては、以下の核酸が挙げられる。

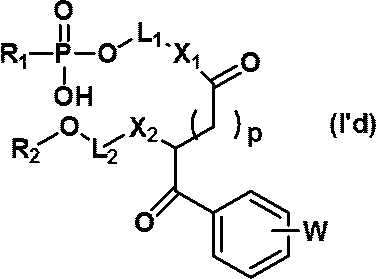
核酸(I’d)の具体例としては、以下の核酸が挙げられる。
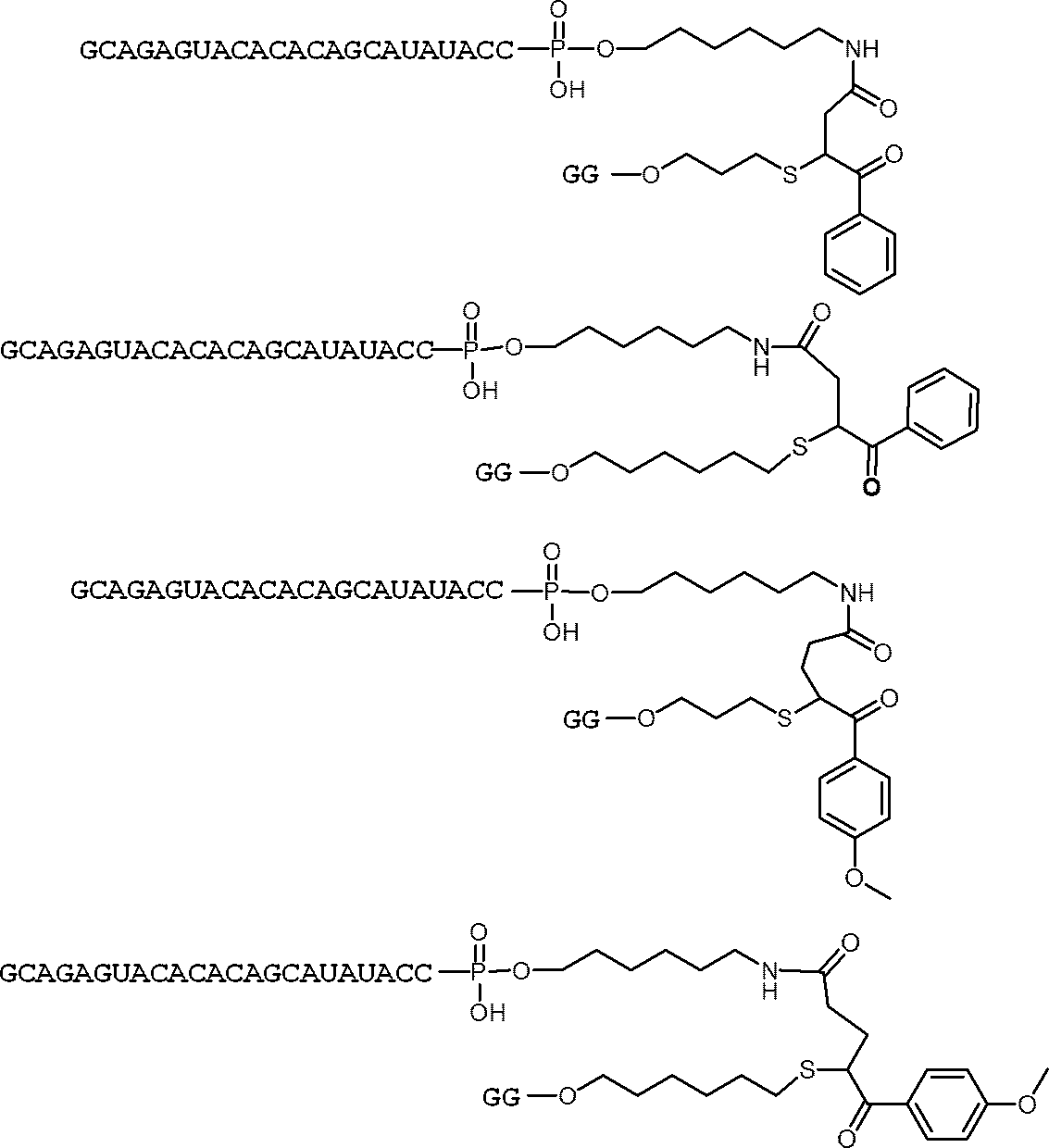
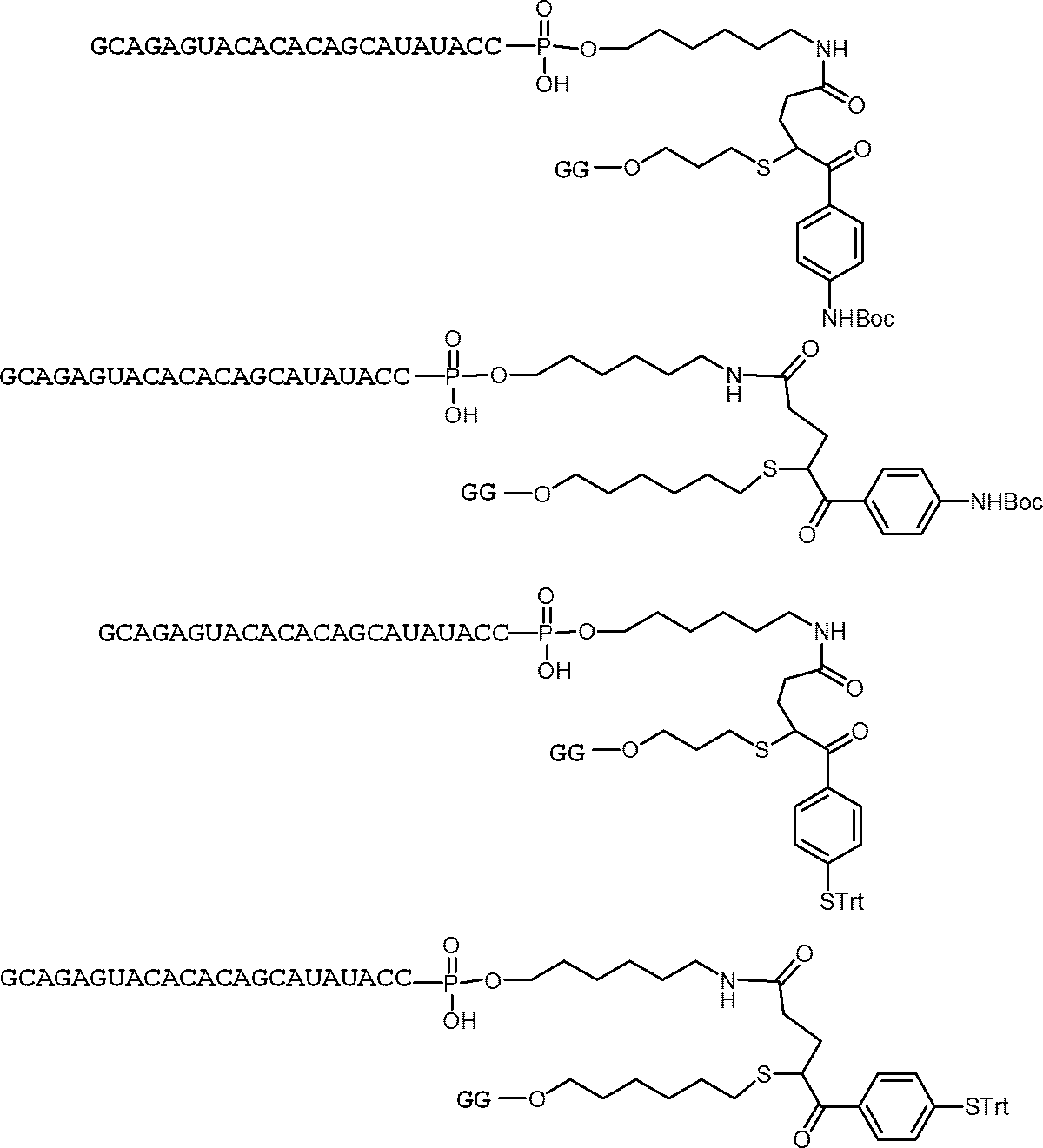

核酸(I’e)の具体例としては、以下の核酸が挙げられる。
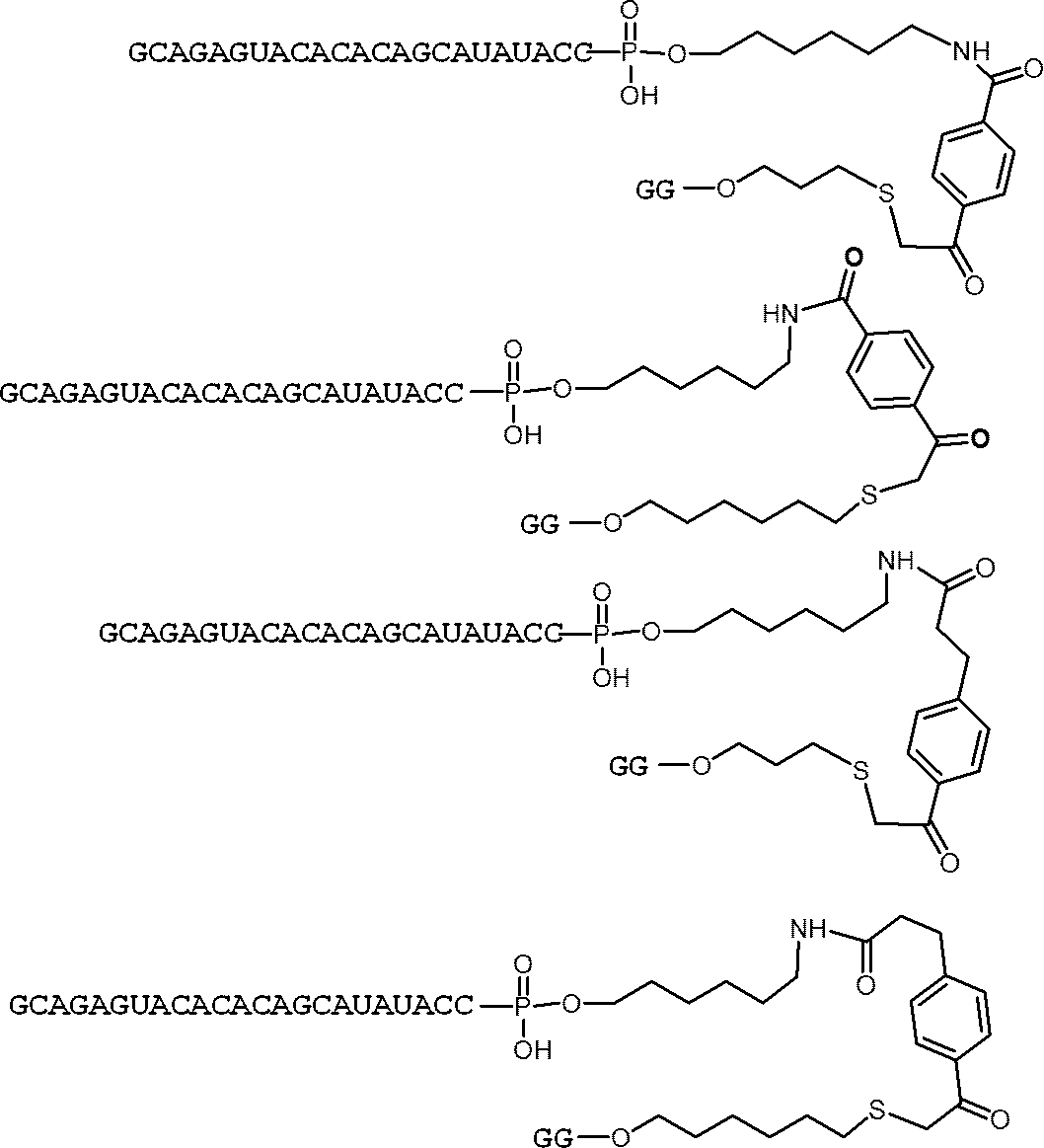

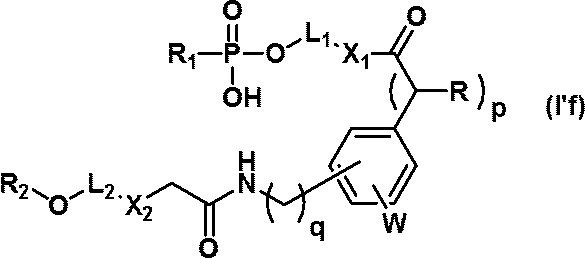
核酸(I’f)の具体例としては、以下の核酸が挙げられる。

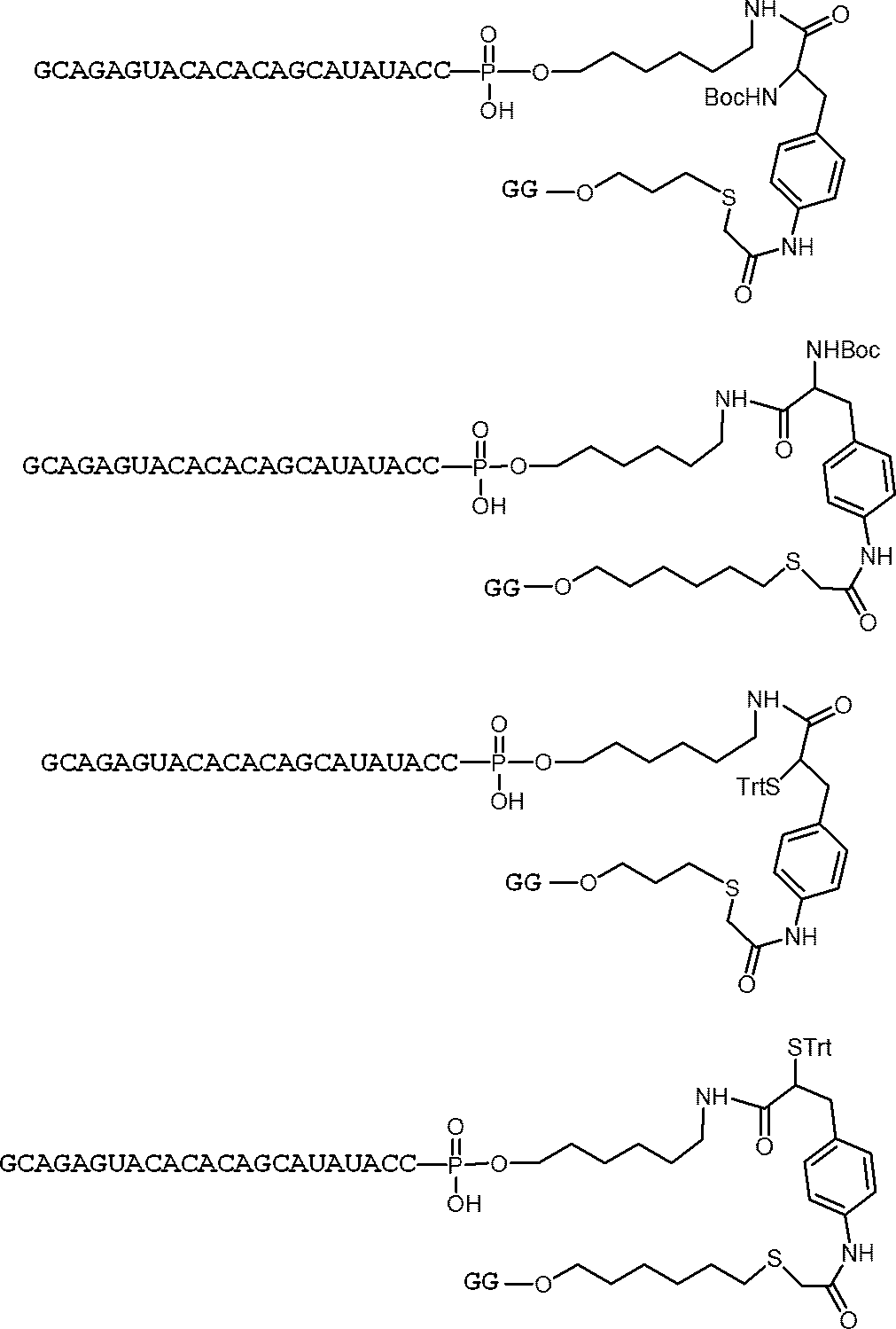

核酸(I’g)の具体例としては、以下の核酸が挙げられる。

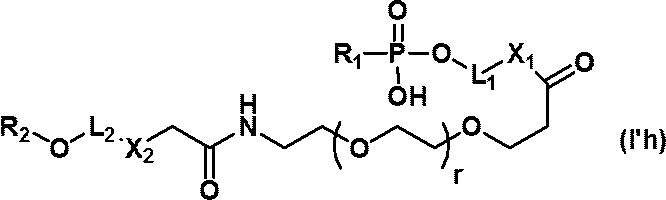
核酸(I’h)の具体例としては、以下の核酸が挙げられる。
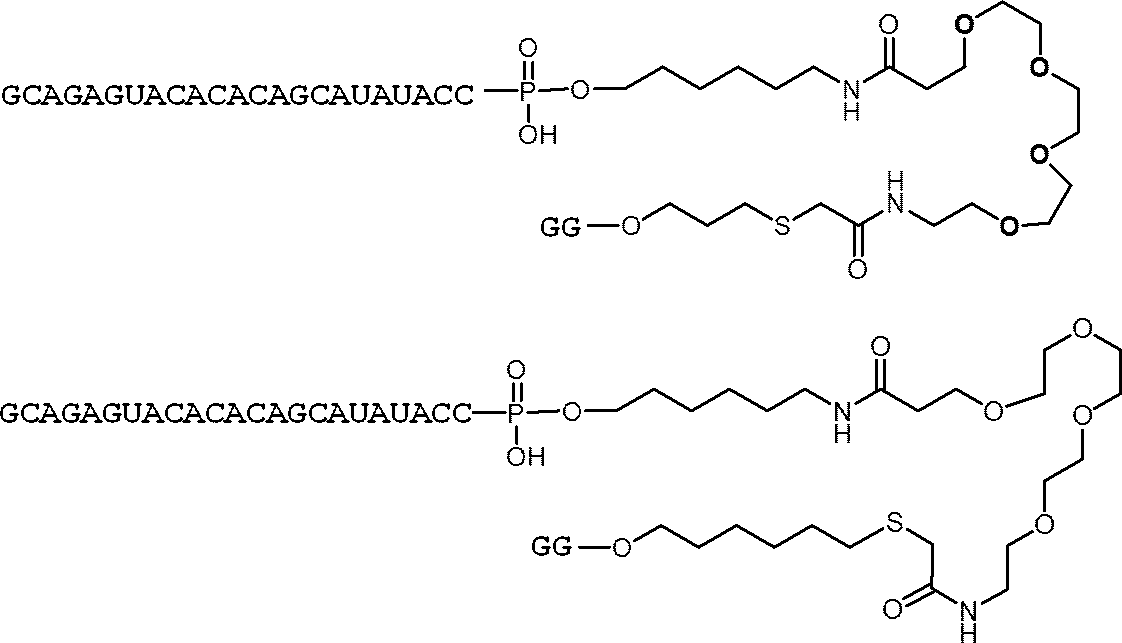
1.一本鎖核酸分子
上述した製造方法で製造される本発明の一本鎖核酸分子(I)は、前述のように、標的遺伝子の発現を抑制する発現抑制配列を含む一本鎖核酸分子であって、領域(X)、リンカー領域(Lx)および領域(Xc)を含み(式(I)中のR1が、領域(X)および領域(Xc)の一方であるか(後述する第1の一本鎖核酸分子)、あるいは領域(X)および領域(Xc)の一方を含み(後述する第2の一本鎖核酸分子)、かつR2が他方であるか(後述する第1の一本鎖酢酸分子)、あるいは他方を含む(後述する第2の一本鎖核酸分子)。)、前記領域(X)と前記領域(Xc)との間に、前記リンカー領域(Lx)が連結され、前記領域(X)および前記領域(Xc)の少なくとも一方が、前記発現抑制配列を含み、前記リンカー領域(Lx)が、下記式(IL)中に示す構造を有することを特徴とする。
上述した製造方法で製造される本発明の一本鎖核酸分子(I)は、前述のように、標的遺伝子の発現を抑制する発現抑制配列を含む一本鎖核酸分子であって、領域(X)、リンカー領域(Lx)および領域(Xc)を含み(式(I)中のR1が、領域(X)および領域(Xc)の一方であるか(後述する第1の一本鎖核酸分子)、あるいは領域(X)および領域(Xc)の一方を含み(後述する第2の一本鎖核酸分子)、かつR2が他方であるか(後述する第1の一本鎖酢酸分子)、あるいは他方を含む(後述する第2の一本鎖核酸分子)。)、前記領域(X)と前記領域(Xc)との間に、前記リンカー領域(Lx)が連結され、前記領域(X)および前記領域(Xc)の少なくとも一方が、前記発現抑制配列を含み、前記リンカー領域(Lx)が、下記式(IL)中に示す構造を有することを特徴とする。
本発明において、「標的遺伝子の発現抑制」は、例えば、前記標的遺伝子の発現を阻害することを意味する。前記抑制のメカニズムは、特に制限されず、例えば、ダウンレギュレーションまたはサイレンシングでもよい。前記標的遺伝子の発現抑制は、例えば、前記標的遺伝子からの転写産物の生成量の減少、前記転写産物の活性の減少、前記標的遺伝子からの翻訳産物の生成量の減少、または前記翻訳産物の活性の減少等によって確認できる。前記タンパク質は、例えば、成熟タンパク質、または、プロセシングもしくは翻訳後修飾を受ける前の前駆体タンパク質等があげられる。
本発明の一本鎖核酸分子は、例えば、in vivoまたはin vitroにおいて、標的遺伝子の発現抑制に使用できることから、「標的遺伝子の発現抑制用一本鎖核酸分子」または「標的遺伝子の発現抑制剤」ともいう。また、本発明の一本鎖核酸分子は、例えば、RNA干渉により、前記標的遺伝子の発現を抑制できることから、「RNA干渉用一本鎖核酸分子」、「RNA干渉誘導分子」、「RNA干渉剤」または「RNA干渉誘導剤」ともいう。また、本発明の一本鎖核酸分子は、例えば、生体内におけるインターフェロン誘導等の副作用を抑制でき、ヌクレアーゼ耐性にも優れる。
本発明の一本鎖核酸分子は、その5’末端と3’末端とが未連結であり、線状一本鎖核酸分子ということもできる。
本発明の一本鎖核酸分子において、前記発現抑制配列は、例えば、本発明の一本鎖核酸分子が、in vivoまたはin vitroで細胞内に導入された場合に、前記標的遺伝子の発現を抑制する活性を示す配列である。前記発現抑制配列は、特に制限されず、目的の標的遺伝子の種類に応じて、適宜設定できる。前記発現抑制配列は、例えば、siRNAによるRNA干渉に関与する配列を適宜適用できる。RNA干渉は、一般に、長い二本鎖RNA(dsRNA)が、細胞内において、Dicerにより、3’末端が突出した19~21塩基対程度の二本鎖RNA(siRNA:small interfering RNA)に切断され、その一方の一本鎖RNAが標的mRNAに結合して、前記mRNAを分解することにより、前記mRNAの翻訳を抑制する現象である。前記標的mRNAに結合する前記siRNAにおける一本鎖RNAの配列は、例えば、標的遺伝子の種類に応じて様々な種類が報告されている。本発明は、例えば、前記siRNAの一本鎖RNAの配列を、前記発現抑制配列として使用できる。本発明においては、例えば、出願時において公知となっている前記siRNAの一本鎖RNA配列の他、将来的に明らかとなる配列に関しても、前記発現抑制配列として利用できる。
前記発現抑制配列は、例えば、前記標的遺伝子の所定領域に対して、90%以上の相補性を有していることが好ましく、より好ましくは95%であり、さらに好ましくは98%であり、特に好ましくは100%である。このような相補性を満たすことにより、例えば、オフターゲットを十分に軽減できる。
具体例として、標的遺伝子がTGF-β1の場合、前記発現抑制配列は、例えば、配列番号1に示す19塩基長の配列が使用できる。
5’-UAUGCUGUGUGUACUCUGC-3’(配列番号1)
5’-UAUGCUGUGUGUACUCUGC-3’(配列番号1)
本発明の一本鎖核酸分子において、前記リンカー領域は、例えば、下記式(IL)で表される。

[式中の各記号は前記式(I)と同義である。]
前記領域(Xc)の3’末端ヌクレオチド残基とリンカー領域(Lx)中の-P(=O)(OH)-O-とが結合し、前記領域(X)の5’末端ヌクレオチド残基とリンカー領域(Lx)中の-O-とが結合してもよく、あるいは前記領域(X)の3’末端ヌクレオチド残基とリンカー領域(Lx)中の-P(=O)(OH)-O-とが結合し、前記領域(Xc)の5’末端ヌクレオチド残基とリンカー領域(Lx)中の-O-とが結合してもよい。
本発明の一本鎖核酸分子において、前記領域(Xc)は、前記領域(X)と相補的である。このため、本発明の一本鎖核酸分子において、前記領域(Xc)が前記領域(X)に向かって折り返し、前記領域(Xc)と前記領域(X)とが、自己アニーリングによって、二重鎖を形成可能である。本発明の一本鎖核酸分子は、このように、分子内で二重鎖を形成可能であり、例えば、従来のRNA干渉に使用するsiRNAのように、分離した2本の一本鎖RNAがアニーリングによって二本鎖RNAを形成するものとは、明らかに異なる構造である。
本発明の一本鎖核酸分子は、例えば、前記領域(Xc)のみが折り返して前記領域(X)と二重鎖を形成してもよいし、さらに、他の領域において新たな二重鎖を形成してもよい。以下、前者の一本鎖核酸分子、すなわち、二重鎖形成が1カ所である分子を「第1の一本鎖核酸分子」といい、後者の一本鎖核酸分子、すなわち、二重鎖形成が2カ所である分子を「第2の一本鎖核酸分子」という。以下に、前記第1の一本鎖核酸分子および前記第2の一本鎖核酸分子について、例示するが、本発明は、これには制限されない。
(1)第1の一本鎖核酸分子
前記第1の一本鎖核酸分子は、例えば、前記領域(X)、前記領域(Xc)および前記リンカー領域(Lx)からなる分子である。
前記第1の一本鎖核酸分子は、例えば、前記領域(X)、前記領域(Xc)および前記リンカー領域(Lx)からなる分子である。
前記第1の一本鎖核酸分子は、例えば、5’側から3’側にかけて、前記領域(Xc)、前記リンカー領域(Lx)および前記領域(X)を、前記順序で有してもよいし、3’側から5’側にかけて、前記領域(Xc)、前記リンカー領域(Lx)および前記領域(X)を、前記順序で有してもよい。
前記第1の一本鎖核酸分子において、前記領域(Xc)は、前記領域(X)に相補的である。ここで、前記領域(Xc)は、前記領域(X)の全領域またはその部分領域に対して相補的な配列を有していればよく、好ましくは、前記領域(X)の全領域またはその部分領域に相補的な配列を含む、または、前記相補的な配列からなる。前記領域(Xc)は、前記領域(X)の相補的な前記全領域または相補的な前記部分領域に対して、例えば、完全に相補的でもよいし、1もしくは数塩基が非相補的であってもよいが、完全に相補的であることが好ましい。前記1塩基若しくは数塩基は、例えば、1~3塩基、好ましくは1塩基または2塩基である。
前記第1の一本鎖核酸分子において、前記発現抑制配列は、前述のように、前記領域(Xc)および前記領域(X)の少なくとも一方に含まれる。前記第1の一本鎖核酸分子は、前記発現抑制配列を、例えば、1つ有してもよいし、2つ以上有してもよい。
後者の場合、前記1の一本鎖核酸分子は、例えば、同じ標的遺伝子に対する同じ発現抑制配列を2つ以上有してもよいし、同じ標的に対する異なる発現抑制配列を2つ以上有してもよいし、異なる標的遺伝子に対する異なる発現抑制配列を2つ以上有してもよい。前記第1の一本鎖核酸分子が、2つ以上の前記発現抑制配列を有する場合、各発現抑制配列の配置箇所は、特に制限されず、前記領域(X)および前記領域(Xc)のいずれか一領域でもよいし、異なる領域であってもよい。前記第1の一本鎖核酸分子が、異なる標的遺伝子に対する前記発現抑制配列を2つ以上有する場合、例えば、前記第1の一本鎖核酸分子によって、2種類以上の異なる標的遺伝子の発現を抑制可能である。
前記第1の一本鎖核酸分子の一例を、図7の模式図に示す。図7(A)は、一例として、前記一本鎖核酸分子について、各領域の順序の概略を示す模式図であり、図7(B)は、前記一本鎖核酸分子が、前記分子内において二重鎖を形成している状態を示す模式図である。図7(B)に示すように、前記一本鎖核酸分子は、前記領域(Xc)と前記領域(X)との間で、二重鎖が形成され、ショートヘアピン構造をとる。図7は、あくまでも、前記領域の連結順序および二重鎖を形成する各領域の位置関係を示すものであり、例えば、各領域の長さ、前記リンカー領域(Lx)の形状等は、これに制限されない。
前記第1の一本鎖核酸分子において、前記領域(Xc)および前記領域(X)の塩基数は、特に制限されない。以下に各領域の長さを例示するが、本発明は、これには制限されない。本発明において、「塩基数」は、例えば、「長さ」を意味し、「塩基長」ということもできる。本発明において、塩基数の数値範囲は、例えば、その範囲に属する正の整数を全て開示するものであり、具体例として、「1~4塩基」との記載は、「1、2、3、4塩基」の全ての開示を意味する(以下、同様)。
前記領域(Xc)は、例えば、前記領域(X)の全領域に完全に相補的でもよい。この場合、前記領域(Xc)は、例えば、前記領域(X)の5’末端から3’末端の全領域に相補的な塩基配列からなることを意味し、すなわち、前記領域(Xc)と前記領域(X)とが、同じ塩基長であり、且つ、前記領域(Xc)の全ての塩基が、前記領域(X)の全ての塩基と相補的であることを意味する。
また、前記領域(Xc)は、例えば、前記領域(X)の部分領域に完全に相補的でもよい。この場合、前記領域(Xc)は、例えば、前記領域(X)の部分領域に相補的な塩基配列からなることを意味し、すなわち、前記領域(Xc)は、前記領域(X)よりも、1塩基以上短い塩基長の塩基配列からなり、前記領域(Xc)の全ての塩基が、前記領域(X)の前記部分領域の全ての塩基と相補的であることを意味する。前記領域(X)の前記部分領域は、例えば、前記領域(X)における、前記領域(Xc)側の末端の塩基(1番目の塩基)から連続する塩基配列からなる領域であることが好ましい。
前記第1の一本鎖核酸分子において、前記領域(X)の塩基数(X)と前記領域(Xc)の塩基数(Xc)との関係は、例えば、下記(3)または(5)の条件を満たし、前者の場合、具体的には、例えば、下記(11)の条件を満たす。
X>Xc ・・・(3)
X-Xc=1~10、好ましくは1、2または3、
より好ましくは1または2 ・・・(11)
X=Xc ・・・(5)
X>Xc ・・・(3)
X-Xc=1~10、好ましくは1、2または3、
より好ましくは1または2 ・・・(11)
X=Xc ・・・(5)
前記領域(X)および/または前記領域(Xc)が前記発現抑制配列を含む場合、前記領域は、例えば、前記発現抑制配列のみから構成される領域でもよいし、前記発現抑制配列を含む領域でもよい。前記発現抑制配列の塩基数は、例えば、19~30塩基であり、好ましくは、19、20または21塩基である。前記発現抑制配列を含む領域は、例えば、前記発現抑制配列の5’側および/または3’側に、さらに付加配列を有してもよい。前記付加配列の塩基数は、例えば、1~31塩基であり、好ましくは、1~21塩基であり、より好ましくは、1~11塩基である。
前記領域(X)の塩基数は、特に制限されない。前記領域(X)が、前記発現抑制配列を含む場合、その下限は、例えば、19塩基である。その上限は、例えば、50塩基であり、好ましくは30塩基であり、より好ましくは25塩基である。前記領域(X)の塩基数の具体例は、例えば、19塩基~50塩基であり、好ましくは、19塩基~30塩基、より好ましくは19塩基~25塩基である。
前記領域(Xc)の塩基数は、特に制限されない。その下限は、例えば、19塩基であり、好ましくは20塩基であり、より好ましくは21塩基である。その上限は、例えば、50塩基であり、より好ましくは40塩基であり、さらに好ましくは30塩基である。
前記一本鎖核酸分子において、前記リンカー領域(Lx)の長さは、特に制限されない。前記リンカー領域(Lx)は、例えば、前記領域(X)と前記領域(Xc)とが二重鎖を形成可能な長さであることが好ましい。
前記第1の一本鎖核酸分子の全長は、特に制限されない。前記第1の一本鎖核酸分子において、前記塩基数の合計(全長の塩基数)は、下限が、例えば、38塩基であり、好ましくは42塩基であり、より好ましくは50塩基であり、さらに好ましくは51塩基であり、特に好ましくは52塩基であり、その上限は、例えば、300塩基であり、好ましくは200塩基であり、より好ましくは150塩基であり、さらに好ましくは100塩基であり、特に好ましくは80塩基である。前記第1の一本鎖核酸分子において、前記リンカー領域(Lx)を除く塩基数の合計は、下限が、例えば、38塩基であり、好ましくは42塩基であり、より好ましくは50塩基であり、さらに好ましくは51塩基であり、特に好ましくは52塩基であり、上限が、例えば、300塩基であり、好ましくは200塩基であり、より好ましくは150塩基であり、さらに好ましくは100塩基であり、特に好ましくは80塩基である。
(2)第2の一本鎖核酸分子
前記第2の一本鎖核酸分子は、例えば、前記領域(X)、前記リンカー領域(Lx)および前記領域(Xc)の他に、さらに、領域(Y)および前記領域(Y)に相補的な領域(Yc)を有する分子である。前記第2の一本鎖核酸分子において、前記領域(X)と前記領域(Y)とが連結して、内部領域(Z)を形成している。なお、特に示さない限り、前記第2の一本鎖核酸分子は、前記第1の一本鎖核酸分子の記載を援用できる。
前記第2の一本鎖核酸分子は、例えば、前記領域(X)、前記リンカー領域(Lx)および前記領域(Xc)の他に、さらに、領域(Y)および前記領域(Y)に相補的な領域(Yc)を有する分子である。前記第2の一本鎖核酸分子において、前記領域(X)と前記領域(Y)とが連結して、内部領域(Z)を形成している。なお、特に示さない限り、前記第2の一本鎖核酸分子は、前記第1の一本鎖核酸分子の記載を援用できる。
前記第2の一本鎖核酸分子は、例えば、5’側から3’側にかけて、前記領域(Xc)、前記リンカー領域(Lx)、前記領域(X)、前記領域(Y)および前記領域(Yc)を、前記順序で有してもよい。この場合、前記領域(Xc)を、5’側領域(Xc)ともいい、前記内部領域(Z)中の前記領域(X)を、内部5’側領域(X)ともいい、前記内部領域(Z)中の前記領域(Y)を、内部3’領域(Y)ともいい、前記領域(Yc)を、3’側領域(Yc)ともいう。また、前記第2の一本鎖核酸分子は、例えば、3’側から5’側にかけて、前記領域(Xc)、前記リンカー領域(Lx)、前記領域(X)、前記領域(Y)および前記領域(Yc)を、前記順序で有してもよい。この場合、前記領域(Xc)を、3’側領域(Xc)ともいい、前記内部領域(Z)中の前記領域(X)を、内部3’側領域(X)ともいい、前記内部領域(Z)中の前記領域(Y)を、内部5’領域(Y)ともいい、前記領域(Yc)を、5’側領域(Yc)ともいう。
前記内部領域(Z)は、前述のように、例えば、前記領域(X)と前記領域(Y)とが連結されている。前記領域(X)と前記領域(Y)は、例えば、直接的に連結され、その間に介在配列を有していない。前記内部領域(Z)は、前記領域(Xc)および前記領域(Yc)との配列関係を示すために、「前記領域(X)と前記領域(Y)が連結して構成される」と定義するものであって、前記内部領域(Z)において、前記領域(X)と前記領域(Y)とが、前記一本鎖核酸分子の使用において、別個の独立した領域であることを限定するものではない。すなわち、例えば、前記内部領域(Z)が、前記発現抑制配列を有する場合、前記内部領域(Z)において、前記領域(X)と前記領域(Y)とにわたって、前記発現抑制配列が配置されてもよい。
前記第2の一本鎖核酸分子において、前記領域(Xc)は、前記領域(X)に相補的である。ここで、前記領域(Xc)は、前記領域(X)の全領域またはその部分領域に対して相補的な配列を有していればよく、好ましくは、前記領域(X)の全領域またはその部分領域に相補的な配列を含む、または、前記相補的な配列からなる。前記領域(Xc)は、前記領域(X)の相補的な前記全領域または相補的な前記部分領域に対して、例えば、完全に相補的でもよいし、1もしくは数塩基が非相補的であってもよいが、完全に相補的であることが好ましい。前記1塩基若しくは数塩基は、例えば、1~3塩基、好ましくは1塩基または2塩基である。
前記第2の一本鎖核酸分子において、前記領域(Yc)は、前記領域(Y)に相補的である。ここで、前記領域(Yc)は、前記領域(Y)の全領域またはその部分領域に相補的な配列を有していればよく、好ましくは、前記領域(Y)の全領域またはその部分領域に対して相補的な配列を含む、または、前記相補的な配列からなる。前記領域(Yc)は、前記領域(Y)の相補的な前記全領域または相補的な前記部分領域に対して、例えば、完全に相補的でもよいし、1もしくは数塩基が非相補的であってもよいが、完全に相補的であることが好ましい。前記1塩基若しくは数塩基は、例えば、1~3塩基、好ましくは1塩基または2塩基である。
前記第2の一本鎖核酸分子において、前記発現抑制配列は、例えば、前記領域(X)と前記領域(Y)とから形成される前記内部領域(Z)および前記領域(Xc)の少なくとも一つに含まれ、さらに、前記領域(Yc)に含まれてもよい。前記内部領域(Z)が前記発現抑制配列を有する場合、例えば、前記領域(X)および前記領域(Y)のいずれに前記発現抑制配列を有してもよく、また、前記領域(X)と前記領域(Y)とにわたって、前記発現抑制配列を有してもよい。前記第2の一本鎖核酸分子は、前記発現抑制配列を、例えば、1つ有してもよいし、2つ以上有してもよい。
前記第2の一本鎖核酸分子が、2つ以上の前記発現抑制配列を有する場合、各発現抑制配列の配置箇所は、特に制限されず、前記内部領域(Z)および前記領域(Xc)のいずれか一方でもよいし、前記内部領域(Z)および前記領域(Xc)のいずれか一方と、さらに他の異なる領域であってもよい。
前記第2の一本鎖核酸分子において、前記領域(Yc)と前記領域(Y)とは、例えば、直接連結してもよいし、間接的に連結してもよい。前者の場合、直接的な連結は、例えば、ホスホジエステル結合による連結等があげられる。後者の場合、例えば、前記領域(Yc)と前記領域(Y)との間に、リンカー領域(Ly)を有し、前記リンカー領域(Ly)を介して、前記領域(Yc)と前記領域(Y)とが連結している形態等があげられる。
前記第2の一本鎖核酸分子が前記リンカー領域(Ly)を有する場合、前記リンカー領域(Ly)の構成単位は特に制限されず、例えば、ヌクレオチド残基からなるリンカーでもよいし、前述した式(IL)で表される構造を有するリンカーでもよい。後者の場合、前記リンカー領域(Lx)における前記式(IL)の説明を全て援用できる。
また、前記リンカー領域(Ly)は、例えば、アミノ酸残基、ポリアミン残基、およびポリカルボン酸残基からなる群から選択される少なくとも一つを含んでいてもよい。前記リンカー領域は、アミノ酸残基、ポリアミン残基、およびポリカルボン酸残基以外の残基を含んでいてもよいし、含んでいなくてもよい。例えば、前記リンカー領域は、ポリカルボン酸残基、テレフタル酸残基またはアミノ酸残基のいずれかを含むものであってよい。
本発明において、「ポリアミン」は、アミノ基を複数(2つ、または3つ以上)含む任意の化合物をいう。前記「アミノ基」は、-NH2基に限定されず、イミノ基(-NH-)も含む。本発明において、前記ポリアミンは、特に限定されないが、例えば、1,4-ジアミノベンゼン、1,3-ジアミノベンゼン、1,2-ジアミノベンゼン等が挙げられる。また、本発明において、「ポリカルボン酸」は、カルボキシ基を複数(2つ、または3つ以上)含む任意の化合物をいう。本発明において、前記ポリカルボン酸は、特に限定されないが、例えば、1,4-ジカルボキシベンゼン(テレフタル酸)、1,3-ジカルボキシベンゼン(イソフタル酸)、1,2-ジカルボキシベンゼン(フタル酸)等が挙げられる。また、本発明において、「アミノ酸」は、分子中にアミノ基およびカルボキシ基をそれぞれ1つ以上含む任意の有機化合物をいう。前記「アミノ基」は、-NH2基に限定されず、イミノ基(-NH-)も含む。例えば、プロリン、ヒドロキシプロリン等は、分子中に-NH2基を含まず、イミノ基(-NH-)を含むが、本発明における「アミノ酸」の定義に含まれる。本発明において、前記「アミノ酸」は、天然アミノ酸でもよいし、人工アミノ酸でもよい。
前記一本鎖核酸分子において、前記アミノ酸残基は、複数のアミノ酸残基が連結したものであってもよい。なお、本発明において、複数のアミノ酸残基が連結したアミノ酸残基とは、例えば、ペプチド構造を含む残基をいう。より具体的には、例えば、グリシルグリシン(Gly-Gly)などの構造があげられる。
前記一本鎖核酸分子において、前記アミノ酸残基は、グリシン残基、テレフタル酸アミド残基、プロリン残基またはリシン残基であってもよい。また、前記アミノ酸残基は、修飾アミノ酸残基またはアミノ酸の誘導体であってもよい。
好ましい一実施態様において、前記リンカー領域(Ly)は、国際公開第2012/017919号パンフレット、国際公開第2013/103146号パンフレット、国際公開第2012/005368号パンフレット、国際公開第2013/077446号パンフレット、国際公開第2013/133393号パンフレット、国際公開第2016/108264号パンフレット、国際公開第2016/104775号パンフレット等に記載されるリンカー領域であり得、本発明はこれらの文献を援用し得る。
より具体的には、例えば、国際公開第2016/104775号パンフレット中に記載の以下の構造を含むものがあげられる。


前記化学式(I-1)~(I-7)において、nおよびmは、特に制限されず、例えば、mは、0~30の範囲の整数であり、nは、0~30の範囲の整数である。具体例として、前記化学式(I-1)においてn=11およびm=12、または、n=5およびm=4と、前記化学式(I-4)においてn=5およびm=4と、前記化学式(I-6)において、n=4およびm=4と、前記化学式(1-7)においてn=5およびm=4とがあげられる。その構造を、下記化学式(I-1a)、(I-1b)、(I-4a)、(I-6a)および(I-7a)に示す。
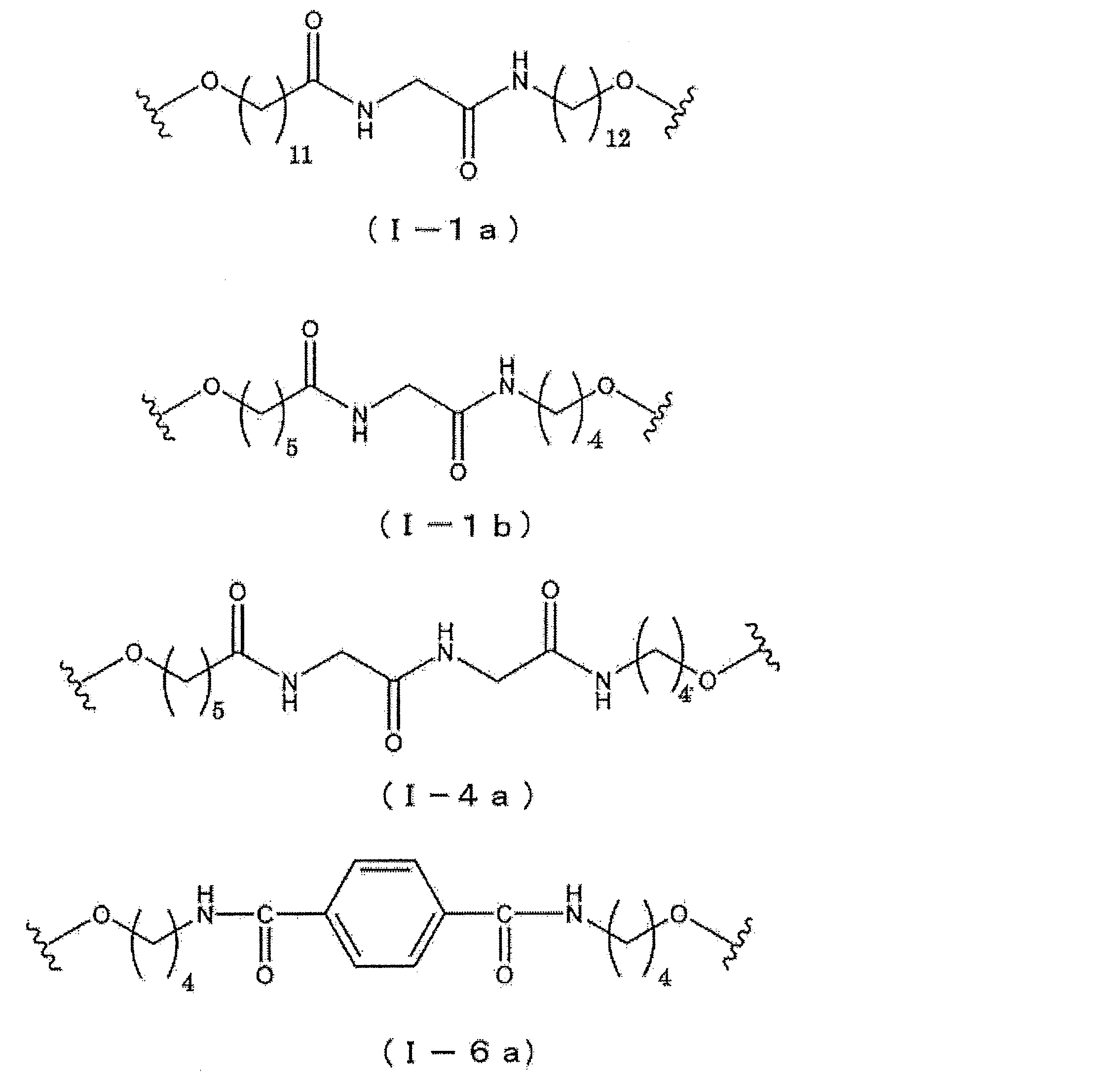


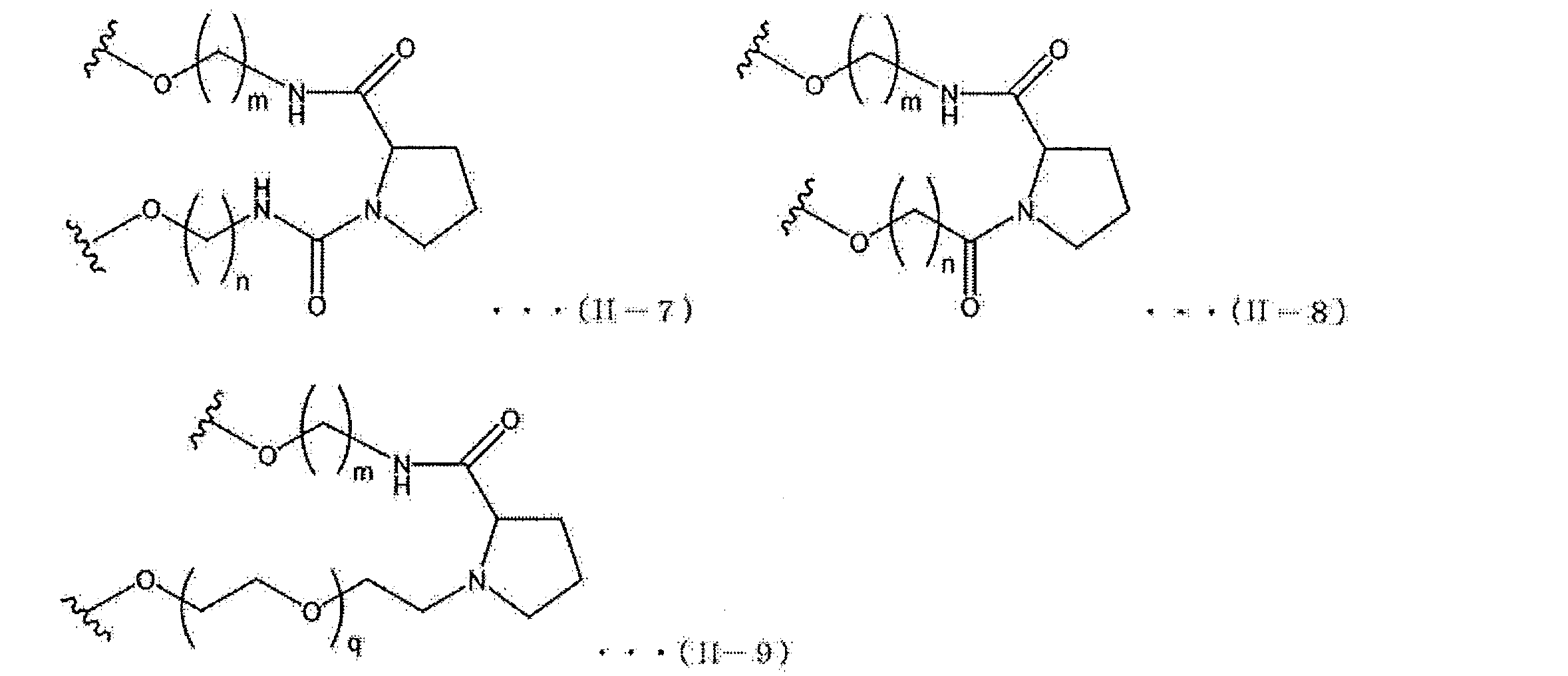
前記式(II-1)~(II-9)において、n、mおよびqは、特に制限されず、例えば、例えば、mは、0~30の範囲の整数であり、nは、0~30の範囲の整数であり、qは、0~10の整数である。具体例として、前記式(II-1)において、n=8、前記(II-2)において、n=3、前記式(II-3)において、n=4または8、前記(II-4)において、n=7または8、前記式(II-5)において、n=3およびm=4、前記(II-6)において、n=8およびm=4、前記式(II-7)において、n=8およびm=4、前記(II-8)において、n=5およびm=4、前記式(II-9)において、q=1およびm=4があげられる。前記式(II-4)の一例(n=8)を、下記式(II-4a)に、前記式(II-8)の一例(n=5、m=4)を、下記式(II-8a)に示す。

前記領域(Yc)のいずれか一方の末端ヌクレオチド残基、および前記領域(Y)のいずれか一方の末端ヌクレオチド残基は、例えば、それぞれ、前記リンカー領域(Ly)とホスホジエステル結合により結合している。
前記第2の一本鎖核酸分子について、前記リンカー領域(Ly)を有する一本鎖核酸分子の一例を、図8の模式図に示す。図8(A)は、一例として、前記一本鎖核酸分子について、5’側から3’側に向かって、各領域の順序の概略を示す模式図であり、図8(B)は、前記一本鎖核酸分子が、前記分子内において二重鎖を形成している状態を示す模式図である。図8(B)に示すように、前記一本鎖核酸分子は、前記領域(Xc)と前記領域(X)との間、前記領域(Y)と前記領域(Yc)との間で、二重鎖が形成された両端折り返し構造をとる。図8は、あくまでも、各領域の連結順番および二重鎖を形成する各領域の位置関係を示すものであり、例えば、各領域の長さ、リンカー領域の形状等は、これに制限されない。また、図8は、前記領域(Xc)を5’側に示したが、これには制限されず、前記領域(Xc)が、3’側に位置してもよい。
前記第2の一本鎖核酸分子において、前記領域(Xc)、前記領域(X)、前記領域(Y)および前記領域(Yc)の塩基数は、特に制限されない。各領域の長さを以下に例示するが、本発明は、これには制限されない。
前記領域(Xc)は、前述のように、例えば、前記領域(X)の全領域に相補的でもよい。この場合、前記領域(Xc)は、例えば、前記領域(X)と同じ塩基長であり、前記領域(X)の全領域に相補的な塩基配列からなることが好ましい。前記領域(Xc)は、より好ましくは、前記領域(X)と同じ塩基長であり、且つ、前記領域(Xc)の全ての塩基が、前記領域(X)の全ての塩基と相補的である、つまり、例えば、完全に相補的である。なお、これには制限されず、例えば、前述のように、1もしくは数塩基が非相補的であってもよい。
また、前記領域(Xc)は、前述のように、例えば、前記領域(X)の部分領域に相補的でもよい。この場合、前記領域(Xc)は、例えば、前記領域(X)の部分領域と同じ塩基長であり、すなわち、前記領域(X)よりも、1塩基以上短い塩基長の塩基配列からなることが好ましい。前記領域(Xc)は、より好ましくは、前記領域(X)の前記部分領域と同じ塩基長であり、且つ、前記領域(Xc)の全ての塩基が、前記領域(X)の前記部分領域の全ての塩基と相補的である、つまり、例えば、完全に相補的である。前記領域(X)の前記部分領域は、例えば、前記領域(X)における、前記領域(Xc)側の末端の塩基(1番目の塩基)から連続する塩基配列からなる領域であることが好ましい。
前記領域(Yc)は、前述のように、例えば、前記領域(Y)の全領域に相補的でもよい。この場合、前記領域(Yc)は、例えば、前記領域(Y)と同じ塩基長であり、前記領域(Y)の全領域に相補的な塩基配列からなることが好ましい。前記領域(Yc)は、より好ましくは、前記領域(Y)と同じ塩基長であり、且つ、前記領域(Yc)の全ての塩基が、前記領域(Y)の全ての塩基と相補的である、つまり、例えば、完全に相補である。なお、これには制限されず、例えば、前述のように、1もしくは数塩基が非相補的であってもよい。
また、前記領域(Yc)は、前述のように、例えば、前記領域(Y)の部分領域に相補的でもよい。この場合、前記領域(Yc)は、例えば、前記領域(Y)の部分領域と同じ塩基長であり、すなわち、前記領域(Y)よりも、1塩基以上短い塩基長の塩基配列からなることが好ましい。前記領域(Yc)は、より好ましくは、前記領域(Y)の前記部分領域と同じ塩基長であり、且つ、前記領域(Yc)の全ての塩基が、前記領域(Y)の前記部分領域の全ての塩基と相補的である、つまり、例えば、完全に相補である。前記領域(Y)の前記部分領域は、例えば、前記領域(Y)における、前記領域(Yc)側の末端の塩基(1番目の塩基)から連続する塩基配列からなる領域であることが好ましい。
前記第2の一本鎖核酸分子において、前記内部領域(Z)の塩基数(Z)と、前記領域(X)の塩基数(X)および前記領域(Y)の塩基数(Y)との関係、前記内部領域(Z)の塩基数(Z)と、前記領域(X)の塩基数(X)および前記領域(Xc)の塩基数(Xc)との関係は、例えば、下記式(1)および(2)の条件を満たす。
Z=X+Y ・・・(1)
Z≧Xc+Yc ・・・(2)
Z=X+Y ・・・(1)
Z≧Xc+Yc ・・・(2)
前記第2の一本鎖核酸分子において、前記領域(X)の塩基数(X)と前記領域(Y)の塩基数(Y)の関係は、特に制限されず、例えば、下記式のいずれの条件を満たす。
X=Y ・・・(19)
X<Y ・・・(20)
X>Y ・・・(21)
X=Y ・・・(19)
X<Y ・・・(20)
X>Y ・・・(21)
第2の一本鎖核酸分子において、前記領域(X)の塩基数(X)、前記領域(Xc)の塩基数(Xc)、前記領域(Y)の塩基数(Y)および前記領域(Yc)の塩基数(Yc)の関係は、例えば、下記(a)~(d)のいずれかの条件を満たす。
(a)下記式(3)および(4)の条件を満たす。
X>Xc ・・・(3)
Y=Yc ・・・(4)
(b)下記式(5)および(6)の条件を満たす。
X=Xc ・・・(5)
Y>Yc ・・・(6)
(c)下記式(7)および(8)の条件を満たす。
X>Xc ・・・(7)
Y>Yc ・・・(8)
(d)下記式(9)および(10)の条件を満たす。
X=Xc ・・・(9)
Y=Yc ・・・(10)
(a)下記式(3)および(4)の条件を満たす。
X>Xc ・・・(3)
Y=Yc ・・・(4)
(b)下記式(5)および(6)の条件を満たす。
X=Xc ・・・(5)
Y>Yc ・・・(6)
(c)下記式(7)および(8)の条件を満たす。
X>Xc ・・・(7)
Y>Yc ・・・(8)
(d)下記式(9)および(10)の条件を満たす。
X=Xc ・・・(9)
Y=Yc ・・・(10)
前記(a)~(d)において、前記領域(X)の塩基数(X)と前記領域(Xc)の塩基数(Xc)の差、前記領域(Y)の塩基数(Y)と前記領域(Yc)の塩基数(Yc)の差は、例えば、下記条件を満たすことが好ましい。
(a)下記式(11)および(12)の条件を満たす。
X-Xc=1~10、好ましくは1、2、3または4、
より好ましくは1、2または3 ・・・(11)
Y-Yc=0 ・・・(12)
(b)下記式(13)および(14)の条件を満たす。
X-Xc=0 ・・・(13)
Y-Yc=1~10、好ましくは1、2、3または4、
より好ましくは1、2または3 ・・・(14)
(c)下記式(15)および(16)の条件を満たす。
X-Xc=1~10、好ましくは、1、2または3、
より好ましくは1または2 ・・・(15)
Y-Yc=1~10、好ましくは、1、2または3、
より好ましくは1または2 ・・・(16)
(d)下記式(17)および(18)の条件を満たす。
X-Xc=0 ・・・(17)
Y-Yc=0 ・・・(18)
(a)下記式(11)および(12)の条件を満たす。
X-Xc=1~10、好ましくは1、2、3または4、
より好ましくは1、2または3 ・・・(11)
Y-Yc=0 ・・・(12)
(b)下記式(13)および(14)の条件を満たす。
X-Xc=0 ・・・(13)
Y-Yc=1~10、好ましくは1、2、3または4、
より好ましくは1、2または3 ・・・(14)
(c)下記式(15)および(16)の条件を満たす。
X-Xc=1~10、好ましくは、1、2または3、
より好ましくは1または2 ・・・(15)
Y-Yc=1~10、好ましくは、1、2または3、
より好ましくは1または2 ・・・(16)
(d)下記式(17)および(18)の条件を満たす。
X-Xc=0 ・・・(17)
Y-Yc=0 ・・・(18)
前記(a)~(d)の第2の一本鎖核酸分子について、それぞれの構造の一例を、図9の模式図に示す。図9は、前記リンカー領域(Lx)および前記リンカー領域(Ly)を含む一本鎖核酸分子であり、(A)は、前記(a)の一本鎖核酸分子、(B)は、前記(b)の一本鎖核酸分子、(C)は、前記(c)の一本鎖核酸分子、(D)は、前記(d)の一本鎖核酸分子の例である。図9において、点線は、自己アニーリングにより二重鎖を形成している状態を示す。図9の一本鎖核酸分子は、前記領域(X)の塩基数(X)と前記領域(Y)の塩基数(Y)を、前記式(20)の「X<Y」と表わしたが、これには制限されず、前述のように、前記式(19)の「X=Y」でも、前記式(21)の「X>Y」でもよい。また、図9は、あくまでも前記領域(X)と前記領域(Xc)との関係、前記領域(Y)と前記領域(Yc)との関係を示す模式図であり、例えば、各領域の長さ、形状、リンカー領域(Ly)の有無等は、これには制限されない。
前記(a)~(c)の一本鎖核酸分子は、例えば、前記領域(Xc)と前記領域(X)、および、前記領域(Yc)と前記領域(Y)が、それぞれ二重鎖を形成することによって、前記内部領域(Z)において、前記領域(Xc)および前記領域(Yc)のいずれともアライメントしない塩基を有する構造であり、二重鎖を形成しない塩基を有する構造ともいえる。前記内部領域(Z)において、前記アライメントしない塩基(二重鎖を形成しない塩基ともいう)を、以下、「フリー塩基」という。図9において、前記フリー塩基の領域を、「F」で示す。前記領域(F)の塩基数は、特に制限されない。前記領域(F)の塩基数(F)は、例えば、前記(a)の一本鎖核酸分子の場合、「X-Xc」の塩基数であり、前記(b)の一本鎖核酸分子の場合、「Y-Yc」の塩基数であり、前記(c)の一本鎖核酸分子の場合、「X-Xc」の塩基数と「Y-Yc」の塩基数との合計数である。
他方、前記(d)の一本鎖核酸分子は、例えば、前記内部領域(Z)の全領域が、前記領域(Xc)および前記領域(Yc)とアライメントする構造であり、前記内部領域(Z)の全領域が二重鎖を形成する構造ともいえる。なお、前記(d)の一本鎖核酸分子において、前記領域(Xc)の5’末端と前記領域(Yc)の3’末端は、未連結である。
前記領域(Xc)、前記領域(Yc)、および前記内部領域(Z)における前記フリー塩基(F)の塩基数の合計は、前記内部領域(Z)の塩基数となる。このため、前記領域(Xc)および前記領域(Yc)の長さは、例えば、前記内部領域(Z)の長さ、前記フリー塩基の数およびその位置に応じて、適宜決定できる。
前記内部領域(Z)の塩基数は、例えば、19塩基以上である。前記塩基数の下限は、例えば、19塩基であり、好ましくは20塩基であり、より好ましくは21塩基である。前記塩基数の上限は、例えば、50塩基であり、好ましくは40塩基であり、より好ましくは30塩基である。前記内部領域(Z)の塩基数の具体例は、例えば、19塩基、20塩基、21塩基、22塩基、23塩基、24塩基、25塩基、26塩基、27塩基、28塩基、29塩基、または、30塩基である。前記内部領域(Z)が、前記発現抑制配列を有する場合、例えば、この条件が好ましい。
前記内部領域(Z)が前記発現抑制配列を含む場合、前記内部領域(Z)は、例えば、前記発現抑制配列のみから構成される領域でもよいし、前記発現抑制配列を含む領域でもよい。前記発現抑制配列の塩基数は、例えば、19~30塩基であり、好ましくは、19、20または21塩基である。前記内部領域(Z)が前記発現抑制配列を含む場合、前記発現抑制配列の5’側および/または3’側に、さらに付加配列を有してもよい。前記付加配列の塩基数は、例えば、1~31塩基であり、好ましくは、1~21塩基であり、より好ましくは、1~11塩基であり、さらに好ましくは、1~7塩基である。
前記領域(Xc)の塩基数は、例えば、1~29塩基であり、好ましくは1~11塩基であり、好ましくは1~7塩基であり、より好ましくは1~4塩基であり、さらに好ましくは1塩基、2塩基、3塩基である。前記内部領域(Z)または前記領域(Yc)が前記発現抑制配列を含む場合、例えば、このような塩基数が好ましい。具体例として、前記内部領域(Z)の塩基数が、19~30塩基(例えば、19塩基)の場合、前記領域(Xc)の塩基数は、例えば、1~11塩基であり、好ましくは1~7塩基であり、より好ましくは1~4塩基であり、さらに好ましくは1塩基、2塩基、3塩基である。
前記領域(Xc)が前記発現抑制配列を含む場合、前記領域(Xc)は、例えば、前記発現抑制配列のみから構成される領域でもよいし、前記発現抑制配列を含む領域でもよい。前記発現抑制配列の長さは、例えば、前述の通りである。前記領域(Xc)が前記発現抑制配列を含む場合、前記発現抑制配列の5’側および/または3’側に、さらに付加配列を有してもよい。前記付加配列の塩基数は、例えば、1~11塩基であり、好ましくは、1~7塩基である。
前記領域(Yc)の塩基数は、例えば、1~29塩基であり、好ましくは1~11塩基であり、好ましくは1~7塩基であり、より好ましくは1~4塩基であり、さらに好ましくは1塩基、2塩基、3塩基である。前記内部領域(Z)または前記領域(Xc)が前記発現抑制配列を含む場合、例えば、このような塩基数が好ましい。具体例として、前記内部領域(Z)の塩基数が、19~30塩基(例えば、19塩基)の場合、前記領域(Yc)の塩基数は、例えば、1~11塩基であり、好ましくは1~7塩基であり、より好ましくは1塩基、2塩基、3塩基または4塩基であり、さらに好ましくは1塩基、2塩基、3塩基である。
前記領域(Yc)が前記発現抑制配列を含む場合、前記領域(Yc)は、例えば、前記発現抑制配列のみから構成される領域でもよいし、前記発現抑制配列を含む領域でもよい。前記発現抑制配列の長さは、例えば、前述の通りである。前記領域(Yc)が前記発現抑制配列を含む場合、前記発現抑制配列の5’側および/または3’側に、さらに付加配列を有してもよい。前記付加配列の塩基数は、例えば、1~11塩基であり、好ましくは、1~7塩基である。
前述のように、前記内部領域(Z)、前記領域(Xc)および前記領域(Yc)の塩基数は、例えば、前記式(2)の「Z≧Xc+Yc」で表わすことができる。具体例として、「Xc+Yc」の塩基数は、例えば、前記内部領域(Z)と同じ、または、前記内部領域(Z)より小さい。後者の場合、「Z-(Xc+Yc)」は、例えば、1~10、好ましくは1~4、より好ましくは1、2または3である。前記「Z-(Xc+Yc)」は、例えば、前記内部領域(Z)におけるフリーの領域(F)の塩基数(F)に相当する。
前記第2の一本鎖核酸分子において、前記リンカー領域(Lx)および前記リンカー領域(Ly)の長さは、特に制限されない。前記リンカー領域(Lx)は、前述の通りである。前記リンカー領域(Ly)の構成単位が塩基を含む場合、前記リンカー領域(Ly)の塩基数は、その下限が、例えば、1塩基であり、好ましくは2塩基であり、より好ましくは3塩基であり、その上限が、例えば、100塩基であり、好ましくは80塩基であり、より好ましくは50塩基である。前記各リンカー領域の塩基数は、具体例として、例えば、1~50塩基、1~30塩基、1~20塩基、1~10塩基、1~7塩基、1~4塩基等が例示できるが、これには制限されない。
前記リンカー領域(Ly)は、例えば、前記リンカー領域(Lx)と同じでもよいし、異なってもよい。
前記第2の一本鎖核酸分子の全長は、特に制限されない。前記第2の一本鎖核酸分子において、前記塩基数の合計(全長の塩基数)は、下限が、例えば、38塩基であり、好ましくは42塩基であり、より好ましくは50塩基であり、さらに好ましくは51塩基であり、特に好ましくは52塩基であり、その上限は、例えば、300塩基であり、好ましくは200塩基であり、より好ましくは150塩基であり、さらに好ましくは100塩基であり、特に好ましくは80塩基である。前記第2の一本鎖核酸分子において、前記リンカー領域(Lx)およびリンカー領域(Ly)を除く塩基数の合計は、下限が、例えば、38塩基であり、好ましくは42塩基であり、より好ましくは50塩基であり、さらに好ましくは51塩基であり、特に好ましくは52塩基であり、上限が、例えば、300塩基であり、好ましくは200塩基であり、より好ましくは150塩基であり、さらに好ましくは100塩基であり、特に好ましくは80塩基である。
本発明の一本鎖核酸分子は、前述のように、前記リンカー領域(Lx)が、式(IL)で表される構造を有していればよく、その他の構成単位は、特に制限されない。前記構成単位は、例えば、ヌクレオチド残基等があげられる。前記ヌクレオチド残基は、例えば、リボヌクレオチド残基およびデオキシリボヌクレオチド残基等があげられる。前記ヌクレオチド残基は、例えば、修飾されていない非修飾ヌクレオチド残基および修飾された修飾ヌクレオチド残基等があげられる。本発明の一本鎖核酸分子は、例えば、前記修飾ヌクレオチド残基を含むことによって、ヌクレアーゼ耐性を向上し、安定性を向上可能である。また、本発明の一本鎖核酸分子は、例えば、前記ヌクレオチド残基の他に、さらに、非ヌクレオチド残基を含んでもよい。
前記領域(Xc)、前記領域(X)、前記領域(Y)および前記領域(Yc)の構成単位は、それぞれ、前記ヌクレオチド残基が好ましい。前記各領域は、例えば、下記(1)~(3)の残基で構成される。
(1)非修飾ヌクレオチド残基
(2)修飾ヌクレオチド残基
(3)非修飾ヌクレオチド残基および修飾ヌクレオチド残基
(1)非修飾ヌクレオチド残基
(2)修飾ヌクレオチド残基
(3)非修飾ヌクレオチド残基および修飾ヌクレオチド残基
前記リンカー領域(Lx)は、前記非ヌクレオチド残基のみから構成される。
前記リンカー領域(Ly)の構成単位は、特に制限されず、例えば、前述のように、前記ヌクレオチド残基および前記非ヌクレオチド残基等があげられる。前記リンカー領域は、例えば、前記ヌクレオチド残基のみから構成されてもよいし、前記非ヌクレオチド残基のみから構成されてもよいし、前記ヌクレオチド残基と前記非ヌクレオチド残基から構成されてもよい。前記リンカー領域(Ly)は、例えば、下記(1)~(7)の残基で構成される。
(1)非修飾ヌクレオチド残基
(2)修飾ヌクレオチド残基
(3)非修飾ヌクレオチド残基および修飾ヌクレオチド残基
(4)非ヌクレオチド残基
(5)非ヌクレオチド残基および非修飾ヌクレオチド残基
(6)非ヌクレオチド残基および修飾ヌクレオチド残基
(7)非ヌクレオチド残基、非修飾ヌクレオチド残基および修飾ヌクレオチド残基
(1)非修飾ヌクレオチド残基
(2)修飾ヌクレオチド残基
(3)非修飾ヌクレオチド残基および修飾ヌクレオチド残基
(4)非ヌクレオチド残基
(5)非ヌクレオチド残基および非修飾ヌクレオチド残基
(6)非ヌクレオチド残基および修飾ヌクレオチド残基
(7)非ヌクレオチド残基、非修飾ヌクレオチド残基および修飾ヌクレオチド残基
本発明の一本鎖核酸分子は、例えば、前記リンカー領域(Lx)を除き、前記ヌクレオチド残基のみから構成される分子、前記ヌクレオチド残基の他に前記非ヌクレオチド残基を含む分子等があげられる。本発明の一本鎖核酸分子において、前記ヌクレオチド残基は、前述のように、例えば、前記非修飾ヌクレオチド残基のみでもよいし、前記修飾ヌクレオチド残基のみでもよいし、前記非修飾ヌクレオチド残基および前記修飾ヌクレオチド残基の両方であってもよい。前記一本鎖核酸分子が、前記非修飾ヌクレオチド残基と前記修飾ヌクレオチド残基を含む場合、前記修飾ヌクレオチド残基の個数は、特に制限されず、例えば、「1もしくは数個」であり、具体的には、例えば、1~5個、好ましくは1~4個、より好ましくは1~3個、最も好ましくは1または2個である。本発明の一本鎖核酸分子が、前記非ヌクレオチド残基を含む場合、前記非ヌクレオチド残基の個数は、特に制限されず、例えば、「1もしくは数個」であり、具体的には、例えば、1または2個である。
本発明の一本鎖核酸分子において、前記ヌクレオチド残基は、例えば、リボヌクレオチド残基が好ましい。この場合、本発明の一本鎖核酸分子は、例えば、「一本鎖RNA分子」という。前記ssRNA分子は、例えば、前記リンカー領域(Lx)を除き、前記リボヌクレオチド残基のみから構成される分子、前記リボヌクレオチド残基の他に前記非ヌクレオチド残基を含む分子等があげられる。前記ssRNA分子において、前記リボヌクレオチド残基は、前述のように、例えば、前記非修飾リボヌクレオチド残基のみでもよいし、前記修飾リボヌクレオチド残基のみでもよいし、前記非修飾リボヌクレオチド残基および前記修飾リボヌクレオチド残基の両方を含んでもよい。
前記ssRNA分子が、例えば、前記非修飾リボヌクレオチド残基の他に前記修飾リボヌクレオチド残基を含む場合、前記修飾リボヌクレオチド残基の個数は、特に制限されず、例えば、「1もしくは数個」であり、具体的には、例えば、1~5個、好ましくは1~4個、より好ましくは1~3個、最も好ましくは1または2個である。前記非修飾リボヌクレオチド残基に対する前記修飾リボヌクレオチド残基は、例えば、リボース残基がデオキシリボース残基に置換された前記デオキシリボヌクレオチド残基等があげられる。前記ssRNA分子が、例えば、前記非修飾リボヌクレオチド残基の他に前記デオキシリボヌクレオチド残基を含む場合、前記デオキシリボヌクレオチド残基の個数は、特に制限されず、例えば、「1もしくは数個」であり、具体的には、例えば、1~5個、好ましくは1~4個、より好ましくは1~3個、最も好ましくは1または2個である。
本発明の一本鎖核酸分子は、例えば、標識物質を含み、前記標識物質で標識化されてもよい。前記標識物質は、特に制限されず、例えば、蛍光物質、色素、同位体等があげられる。前記標識物質は、例えば、ピレン、TAMRA、フルオレセイン、Cy3色素、Cy5色素等の蛍光団があげられ、前記色素は、例えば、Alexa488等のAlexa色素等があげられる。前記同位体は、例えば、安定同位体および放射性同位体があげられ、好ましくは安定同位体である。前記安定同位体は、例えば、被ばくの危険性が少なく、専用の施設も不要であることから取り扱い性に優れ、また、コストも低減できる。また、前記安定同位体は、例えば、標識した化合物の物性変化がなく、トレーサーとしての性質にも優れる。前記安定同位体は、特に制限されず、例えば、2H、13C、15N、17O、18O、33S、34Sおよび36S等があげられる。
本発明の一本鎖核酸分子は、前述のように、例えば、前記非ヌクレオチド構造に前記標識物質を導入することが好ましく、前記リンカー領域(Lx)の前記非ヌクレオチド残基に前記標識物質を導入することが好ましい。前記非ヌクレオチド残基への標識物質の導入は、例えば、簡便かつ安価に行うことができる。
本発明の一本鎖核酸分子は、前述のように、前記標的遺伝子の発現を抑制ができる。このため、本発明の一本鎖核酸分子は、例えば、遺伝子が原因となる疾患の治療剤として使用できる。前記発現抑制配列として、前記疾患の原因となる遺伝子の発現を抑制する配列を含む前記一本鎖核酸分子であれば、例えば、前記標的遺伝子の発現抑制により、前記疾患を治療できる。本発明において、「治療」は、例えば、前記疾患の予防、疾患の改善、予後の改善の意味を含み、いずれでもよい。
本発明の一本鎖核酸分子の使用方法は、特に制限されず、例えば、前記標的遺伝子を有する投与対象に、前記一本鎖核酸分子を投与すればよい。
前記投与対象は、例えば、細胞、組織または器官等があげられる。前記投与対象は、例えば、ヒト、ヒトを除く非ヒト哺乳類等の非ヒト動物等があげられる。前記投与は、例えば、in vivoでもin vitroでもよい。前記細胞は、特に制限されず、例えば、HeLa細胞、293細胞、NIH3T3細胞、COS細胞等の各種培養細胞、ES細胞、造血幹細胞等の幹細胞、初代培養細胞等の生体から単離した細胞等があげられる。
本発明において、発現抑制の対象となる前記標的遺伝子は、特に制限されず、所望の遺伝子を設定でき、前記遺伝子に応じて、前記発現抑制配列を適宜設計すればよい。
本発明の一本鎖核酸分子の具体例を以下に示すが、本発明はこれには何ら制限されない。前記一本鎖核酸分子の塩基配列は、標的遺伝子がTGF-β1の場合、例えば、配列番号1の塩基配列が例示でき、プロレニン受容体の場合、例えば、配列番号2の塩基配列が例示でき、mir―29bの場合、例えば、配列番号3の塩基配列が例示できる。また、前記塩基配列において、例えば、1もしくは数個の欠失、置換および/または付加された塩基配列でもよい。
プロレニン受容体 5'- UUAUAUGCAAGGUUAUAGGGA -3'(配列番号2)
miR-29b 5'-UAGCACCAUUUGAAAUCAGUGUU-3'(配列番号3)
miR-29b 5'-UAGCACCAUUUGAAAUCAGUGUU-3'(配列番号3)
本発明の一本鎖核酸分子の使用に関しては、後述する本発明の組成物、発現抑制方法および治療方法等の記載を援用できる。
本発明の一本鎖核酸分子は、前述のように標的遺伝子の発現を抑制可能であることから、例えば、医薬品、診断薬および農薬、ならびに、農薬、医学、生命科学等の研究ツールとして有用である。
2.ヌクレオチド残基
本発明の一本鎖核酸分子を構成するヌクレオチド残基は、前述の通りであり、例えば、リボヌクレオチド残基およびデオキシリボヌクレオチド残基等があげられる。前記リボヌクレオチド残基は、例えば、糖としてリボース残基を有し、塩基として、アデニン(A)、グアニン(G)、シトシン(C)およびウラシル(U)を有し、前記デオキシリボース残基は、例えば、糖としてデオキシリボース残基を有し、塩基として、アデニン(A)、グアニン(G)、シトシン(C)およびチミン(T)を有する。
本発明の一本鎖核酸分子を構成するヌクレオチド残基は、前述の通りであり、例えば、リボヌクレオチド残基およびデオキシリボヌクレオチド残基等があげられる。前記リボヌクレオチド残基は、例えば、糖としてリボース残基を有し、塩基として、アデニン(A)、グアニン(G)、シトシン(C)およびウラシル(U)を有し、前記デオキシリボース残基は、例えば、糖としてデオキシリボース残基を有し、塩基として、アデニン(A)、グアニン(G)、シトシン(C)およびチミン(T)を有する。
前記ヌクレオチド残基は、未修飾ヌクレオチド残基および修飾ヌクレオチド残基等があげられる。前記未修飾ヌクレオチド残基は、前記各構成要素が、例えば、天然に存在するものと同一または実質的に同一であり、好ましくは、人体において天然に存在するものと同一または実質的に同一である。
前記修飾ヌクレオチド残基は、例えば、前記未修飾ヌクレオチド残基を修飾したヌクレオチド残基である。前記修飾ヌクレオチドは、例えば、前記未修飾ヌクレオチド残基の構成要素のいずれが修飾されてもよい。本発明において、「修飾」は、例えば、前記構成要素の置換、付加および/または欠失、前記構成要素における原子および/または官能基の置換、付加および/または欠失であり、「改変」ということができる。前記修飾ヌクレオチド残基は、例えば、天然に存在するヌクレオチド残基、人工的に修飾したヌクレオチド残基等があげられる。前記天然由来の修飾ヌクレオチド残基は、例えば、リンバックら(Limbach et al.、1994、Summary:the modified nucleosides of RNA、Nucleic Acids Res.22:2183~2196)を参照できる。また、前記修飾ヌクレオチド残基は、例えば、前記ヌクレオチドの代替物の残基であってもよい。
前記ヌクレオチド残基の修飾は、例えば、リボース-リン酸骨格(以下、リボリン酸骨格)の修飾等があげられる。
前記リボリン酸骨格において、例えば、リボース残基を修飾できる。前記リボース残基は、例えば、2’位炭素を修飾でき、具体的には、例えば、2’位炭素に結合する水酸基を、水素またはフルオロ等に置換できる。前記2’位炭素の水酸基を水素に置換することで、リボース残基をデオキシリボースに置換できる。前記リボース残基は、例えば、立体異性体に置換でき、例えば、アラビノース残基に置換してもよい。
前記リボリン酸骨格は、例えば、非リボース残基および/または非リン酸を有する非リボリン酸骨格に置換してもよい。前記非リボリン酸骨格は、例えば、前記リボリン酸骨格の非荷電体等があげられる。前記非リボリン酸骨格に置換された、前記ヌクレオチドの代替物は、例えば、モルホリノ、シクロブチル、ピロリジン等があげられる。前記代替物は、この他に、例えば、人工核酸モノマー残基等があげられる。具体例として、例えば、PNA(ペプチド核酸)、LNA(Locked Nucleic Acid)、ENA(2’-O,4’-C-Ethylenebridged Nucleic Acids)等があげられ、好ましくはPNAである。
前記リボリン酸骨格において、例えば、リン酸基を修飾できる。前記リボリン酸骨格において、糖残基に最も近いリン酸基は、αリン酸基と呼ばれる。前記αリン酸基は、負に荷電し、その電荷は、糖残基に非結合の2つの酸素原子にわたって、均一に分布している。前記αリン酸基における4つの酸素原子のうち、ヌクレオチド残基間のホスホジエステル結合において、糖残基と非結合である2つの酸素原子は、以下、「非結合(non-linking)酸素」ともいう。他方、前記ヌクレオチド残基間のホスホジエステル結合において、糖残基と結合している2つの酸素原子は、以下、「結合(linking)酸素」という。前記αリン酸基は、例えば、非荷電となる修飾、または、前記非結合原子における電荷分布が非対称型となる修飾を行うことが好ましい。
前記リン酸基は、例えば、前記非結合酸素を置換してもよい。前記酸素は、例えば、S(硫黄)、Se(セレン)、B(ホウ素)、C(炭素)、H(水素)、N(窒素)およびOR(Rは、例えば、アルキル基またはアリール基)のいずれかの原子で置換でき、好ましくは、Sで置換される。前記非結合酸素は、例えば、両方が置換されていることが好ましく、より好ましくは、両方がSで置換される。前記修飾リン酸基は、例えば、ホスホロチオエート、ホスホロジチオエート、ホスホロセレネート、ボラノホスフェート、ボラノホスフェートエステル、ホスホネート水素、ホスホロアミデート、アルキルまたはアリールホスホネート、およびホスホトリエステル等があげられ、中でも、前記2つの非結合酸素が両方ともSで置換されているホスホロジチオエートが好ましい。
前記リン酸基は、例えば、前記結合酸素を置換してもよい。前記酸素は、例えば、S(硫黄)、C(炭素)およびN(窒素)のいずれかの原子で置換できる。前記修飾リン酸基は、例えば、Nで置換した架橋ホスホロアミデート、Sで置換した架橋ホスホロチオエート、およびCで置換した架橋メチレンホスホネート等があげられる。前記結合酸素の置換は、例えば、本発明の一本鎖核酸分子の5’末端ヌクレオチド残基および3’末端ヌクレオチド残基の少なくとも一方において行うことが好ましく、5’側の場合、Cによる置換が好ましく、3’側の場合、Nによる置換が好ましい。
前記リン酸基は、例えば、前記リン非含有のリンカーに置換してもよい。前記リンカーは、例えば、シロキサン、カーボネート、カルボキシメチル、カルバメート、アミド、チオエーテル、エチレンオキサイドリンカー、スルホネート、スルホンアミド、チオホルムアセタール、ホルムアセタール、オキシム、メチレンイミノ、メチレンメチルイミノ、メチレンヒドラゾ、メチレンジメチルヒドラゾ、およびメチレンオキシメチルイミノ等を含み、好ましくは、メチレンカルボニルアミノ基およびメチレンメチルイミノ基を含む。
本発明の一本鎖核酸分子は、例えば、3’末端および5’末端の少なくとも一方のヌクレオチド残基が修飾されてもよい。前記修飾は、例えば、3’末端および5’末端のいずれか一方でもよいし、両方でもよい。前記修飾は、例えば、前述の通りであり、好ましくは、末端のリン酸基に行うことが好ましい。前記リン酸基は、例えば、全体を修飾してもよいし、前記リン酸基における1つ以上の原子を修飾してもよい。前者の場合、例えば、リン酸基全体の置換でもよいし、欠失でもよい。
前記末端のヌクレオチド残基の修飾は、例えば、他の分子の付加等があげられる。前記他の分子は、例えば、前述のような標識物質、保護基等の機能性分子等があげられる。前記保護基は、例えば、S(硫黄)、Si(ケイ素)、B(ホウ素)、エステル含有基等があげられる。前記標識物質等の機能性分子は、例えば、本発明の一本鎖核酸分子の検出等に利用できる。
前記他の分子は、例えば、前記ヌクレオチド残基のリン酸基に付加してもよいし、スペーサーを介して、前記リン酸基または前記糖残基に付加してもよい。前記スペーサーの末端原子は、例えば、前記リン酸基の前記結合酸素、または、糖残基のO、N、SもしくはCに、付加または置換できる。前記糖残基の結合部位は、例えば、3’位のCもしくは5’位のC、またはこれらに結合する原子が好ましい。前記スペーサーは、例えば、前記PNA等のヌクレオチド代替物の末端原子に、付加または置換することもできる。
前記スペーサーは、特に制限されず、例えば、-(CH2)n-、-(CH2)nN-、-(CH2)nO-、-(CH2)nS-、O(CH2CH2O)nCH2CH2OH、無塩基糖、アミド、カルボキシ、アミン、オキシアミン、オキシイミン、チオエーテル、ジスルフィド、チオ尿素、スルホンアミド、およびモルホリノ等、ならびに、ビオチン試薬およびフルオレセイン試薬等を含んでもよい。前記式において、nは、正の整数であり、n=3または6が好ましい。
前記末端に付加する分子は、これらの他に、例えば、色素、インターカレート剤(例えば、アクリジン)、架橋剤(例えば、ソラレン、マイトマイシンC)、ポルフィリン(TPPC4、テキサフィリン、サッフィリン)、多環式芳香族炭化水素(例えば、フェナジン、ジヒドロフェナジン)、人工エンドヌクレアーゼ(例えば、EDTA)、親油性担体(例えば、コレステロール、コール酸、アダマンタン酢酸、1-ピレン酪酸、ジヒドロテストステロン、1,3-ビス-O(ヘキサデシル)グリセロール、ゲラニルオキシヘキシル基、ヘキサデシルグリセロール、ボルネオール、メントール、1,3-プロパンジオール、ヘプタデシル基、パルミチン酸、ミリスチン酸、O3-(オレオイル)リトコール酸、O3-(オレオイル)コール酸、ジメトキシトリチル、またはフェノキサジン)およびペプチド複合体(例えば、アンテナペディアペプチド、Tatペプチド)、アルキル化剤、リン酸、アミノ、メルカプト、PEG(例えば、PEG-40K)、MPEG、[MPEG]2、ポリアミノ、アルキル、置換アルキル、放射線標識マーカー、酵素、ハプテン(例えば、ビオチン)、輸送/吸収促進剤(例えば、アスピリン、ビタミンE、葉酸)、合成リボヌクレアーゼ(例えば、イミダゾール、ビスイミダゾール、ヒスタミン、イミダゾールクラスター、アクリジン-イミダゾール複合体、テトラアザマクロ環のEu3+複合体)等があげられる。
本発明の一本鎖核酸分子は、前記5’末端が、例えば、リン酸基またはリン酸基アナログで修飾されてもよい。前記リン酸化は、例えば、5’一リン酸((HO)2(O)P-O-5’)、5’二リン酸((HO)2(O)P-O-P(HO)(O)-O-5’)、5’三リン酸((HO)2(O)P-O-(HO)(O)P-O-P(HO)(O)-O-5’)、5’-グアノシンキャップ(7-メチル化または非メチル化、7m-G-O-5’-(HO)(O)P-O-(HO)(O)PO-P(HO)(O)-O-5’)、5’-アデノシンキャップ(Appp)、任意の修飾または非修飾ヌクレオチドキャップ構造(N-O-5’-(HO)(O)P-O-(HO)(O)P-O-P(HO)(O)-O-5’)、5’一チオリン酸(ホスホロチオエート:(HO)2(S)P-O-5’)、5’一ジチオリン酸(ホスホロジチオエート:(HO)(HS)(S)P-O-5’)、5’-ホスホロチオール酸((HO)2(O)P-S-5’)、硫黄置換の一リン酸、二リン酸および三リン酸(例えば、5’-α-チオ三リン酸、5’-γ-チオ三リン酸等)、5’-ホスホルアミデート((HO)2(O)P-NH-5’、(HO)(NH2)(O)PO-5’)、5’-アルキルホスホン酸(例えば、RP(OH)(O)-O-5’、(OH)2(O)P-5’-CH2、Rはアルキル(例えば、メチル、エチル、イソプロピル、プロピル等))、5’-アルキルエーテルホスホン酸(例えば、RP(OH)(O)-O-5’、Rはアルキルエーテル(例えば、メトキシメチル、エトキシメチル等))等があげられる。
前記ヌクレオチド残基において、前記塩基は、特に制限されない。前記塩基は、例えば、天然の塩基でもよいし、非天然の塩基でもよい。前記塩基は、例えば、天然由来でもよいし、合成品でもよい。前記塩基は、例えば、一般的な塩基、その修飾アナログ等が使用できる。
前記塩基は、例えば、アデニンおよびグアニン等のプリン塩基、シトシン、ウラシルおよびチミン等のピリミジン塩基等があげられる。前記塩基は、この他に、イノシン、チミン、キサンチン、ヒポキサンチン、プリン、ヌバラリン(nubularine)、イソグアニシン(isoguanisine)、ツベルシジン(tubercidine)、7-デアザアデニン等があげられる。前記塩基は、例えば、2-アミノアデニン、6-メチル化プリン等のアルキル誘導;2-プロピル化プリン等のアルキル誘導体;5-ハロウラシルおよび5-ハロシトシン;5-プロピニルウラシルおよび5-プロピニルシトシン;6-アゾウラシル、6-アゾシトシンおよび6-アゾチミン;5-ウラシル(プソイドウラシル)、4-チオウラシル、5-ハロウラシル、5-(2-アミノプロピル)ウラシル、5-アミノアリルウラシル;8-ハロ化、アミノ化、チオール化、チオアルキル化、ヒドロキシル化および他の8-置換プリン;5-トリフルオロメチル化および他の5-置換ピリミジン;7-メチルグアニン;5-置換ピリミジン;6-アザピリミジン;N-2、N-6、およびO-6置換プリン(2-アミノプロピルアデニンを含む);5-プロピニルウラシルおよび5-プロピニルシトシン;ジヒドロウラシル;3-デアザ-5-アザシトシン;2-アミノプリン;5-アルキルウラシル;7-アルキルグアニン;5-アルキルシトシン;7-デアザアデニン;N6,N6-ジメチルアデニン;2,6-ジアミノプリン;5-アミノ-アリル-ウラシル;N3-メチルウラシル;置換1,2,4-トリアゾール;2-ピリジノン;5-ニトロインドール;3-ニトロピロール;5-メトキシウラシル;ウラシル-5-オキシ酢酸;5-メトキシカルボニルメチルウラシル;5-メチル-2-チオウラシル;5-メトキシカルボニルメチル-2-チオウラシル;5-メチルアミノメチル-2-チオウラシル;3-(3-アミノ-3-カルボキシプロピル)ウラシル;3-メチルシトシン;5-メチルシトシン;N4-アセチルシトシン;2-チオシトシン;N6-メチルアデニン;N6-イソペンチルアデニン;2-メチルチオ-N6-イソペンテニルアデニン;N-メチルグアニン;O-アルキル化塩基等があげられる。また、プリンおよびピリミジンは、例えば、米国特許第3,687,808号、「Concise Encyclopedia Of Polymer Science And Engineering」、858~859頁、クロシュビッツジェーアイ(Kroschwitz J.I.)編、John Wiley & Sons、1990、およびイングリッシュら(Englischら)、Angewandte Chemie、International Edition、1991、30巻、p.613に開示されるものが含まれる。
前記修飾ヌクレオチド残基は、これらの他に、例えば、塩基を欠失する残基、すなわち、無塩基のリボリン酸骨格を含んでもよい。また、前記修飾ヌクレオチド残基は、例えば、米国仮出願第60/465,665号(出願日:2003年4月25日)、および国際出願第PCT/US04/07070号(出願日:2004年3月8日)に記載される残基が使用でき、本発明は、これらの文献を援用できる。
3.非ヌクレオチド残基
前記非ヌクレオチド残基は、特に制限されない。本発明の一本鎖核酸分子は、例えば、前記非ヌクレオチド残基として、アミノ酸残基またはペプチド残基を含む非ヌクレオチド構造を有してもよい。前記アミノ酸残基またはペプチド残基を構成するアミノ酸としては、例えば、塩基性アミノ酸、酸性アミノ酸等があげられる。前記塩基性アミノ酸としては、例えば、リシン、アルギニン、ヒスチジン等があげられる。前記酸性アミノ酸としては、例えば、アスパラギン酸、グルタミン酸等があげられる。
前記非ヌクレオチド残基は、特に制限されない。本発明の一本鎖核酸分子は、例えば、前記非ヌクレオチド残基として、アミノ酸残基またはペプチド残基を含む非ヌクレオチド構造を有してもよい。前記アミノ酸残基またはペプチド残基を構成するアミノ酸としては、例えば、塩基性アミノ酸、酸性アミノ酸等があげられる。前記塩基性アミノ酸としては、例えば、リシン、アルギニン、ヒスチジン等があげられる。前記酸性アミノ酸としては、例えば、アスパラギン酸、グルタミン酸等があげられる。
4.組成物
本発明の発現抑制用組成物は、前述のように、標的遺伝子の発現を抑制するための組成物であり、前記本発明の一本鎖核酸分子を含むことを特徴とする。本発明の組成物は、前記本発明の一本鎖核酸分子を含むことが特徴であり、その他の構成は、何ら制限されない。本発明の発現抑制用組成物は、例えば、発現抑制用試薬ということもできる。
本発明の発現抑制用組成物は、前述のように、標的遺伝子の発現を抑制するための組成物であり、前記本発明の一本鎖核酸分子を含むことを特徴とする。本発明の組成物は、前記本発明の一本鎖核酸分子を含むことが特徴であり、その他の構成は、何ら制限されない。本発明の発現抑制用組成物は、例えば、発現抑制用試薬ということもできる。
本発明によれば、例えば、前記標的遺伝子が存在する対象に投与することで、前記標的遺伝子の発現抑制を行うことができる。
また、本発明の薬学的組成物は、前述のように、前記本発明の一本鎖核酸分子を含むことを特徴とする。本発明の組成物は、前記本発明の一本鎖核酸分子を含むことが特徴であり、その他の構成は何ら制限されない。本発明の薬学的組成物は、例えば、医薬品ということもできる。本発明の薬学的組成物は、例えば、医薬品ということもできる。
本発明によれば、例えば、遺伝子が原因となる疾患の患者に投与することで、前記遺伝子の発現を抑制し、前記疾患を治療することができる。本発明において、「治療」は、前述のように、例えば、前記疾患の予防、疾患の改善、予後の改善の意味を含み、いずれでもよい。
本発明において、治療の対象となる疾患は、特に制限されず、例えば、遺伝子の発現が原因となる疾患等があげられる。前記疾患の種類に応じて、その疾患の原因となる遺伝子を前記標的遺伝子に設定し、さらに、前記標的遺伝子に応じて、前記発現抑制配列を適宜設定すればよい。
具体例として、前記標的遺伝子を前記TGF-β1遺伝子に設定し、前記遺伝子に対する発現抑制配列を前記一本鎖核酸分子に配置すれば、TGF-β1を抑制することにより治療効果が期待される疾患や病態、例えば、炎症性疾患、具体的には、急性肺傷害等の治療に使用できる。
本発明の発現抑制用組成物および薬学的組成物(以下、組成物という)の使用方法は、特に制限されず、例えば、前記標的遺伝子を有する投与対象に、前記一本鎖核酸分子を投与すればよい。
前記投与対象は、例えば、細胞、組織または器官等があげられる。前記投与対象は、例えば、ヒト、ヒトを除く非ヒト哺乳類等の非ヒト動物等があげられる。前記投与は、例えば、in vivoでもin vitroでもよい。前記細胞は、特に制限されず、例えば、HeLa細胞、293細胞、NIH3T3細胞、COS細胞等の各種培養細胞、ES細胞、造血幹細胞等の幹細胞、初代培養細胞等の生体から単離した細胞等があげられる。
前記投与方法は、特に制限されず、例えば、投与対象に応じて適宜決定できる。前記投与対象が培養細胞の場合、例えば、トランスフェクション試薬を使用する方法、エレクトロポレーション法等があげられる。前記投与がin vivoの場合、例えば、経口投与でもよいし、非経口投与でもよい。前記非経口投与は、例えば、注射、皮下投与、局所投与等があげられる。
本発明の組成物は、例えば、本発明の一本鎖核酸分子のみを含んでもよいし、さらにその他の添加物を含んでもよい。前記添加物は、特に制限されず、例えば、薬学的に許容された添加物が好ましい。前記添加物の種類は、特に制限されず、例えば、投与対象の種類に応じて適宜選択できる。
本発明の組成物において、前記一本鎖核酸分子は、例えば、前記添加物と複合体を形成してもよい。前記添加物は、例えば、複合化剤ということもできる。前記複合体により、例えば、前記一本鎖核酸分子を効率よくデリバリーできる。前記一本鎖核酸分子と前記複合化剤との結合は、特に制限されず、例えば、非共有結合等があげられる。前記複合体は、例えば、包接複合体等があげられる。
前記複合化剤は、特に制限されず、ポリマー、シクロデキストリン、アダマンチン等があげられる。前記シクロデキストリンは、例えば、線状シクロデキストリンコポリマー、線状酸化シクロデキストリンコポリマー等があげられる。
前記添加剤は、この他に、例えば、担体、標的細胞への結合物質、縮合剤、融合剤等があげられる。
前記担体は、例えば、高分子が好ましく、より好ましくは、生体高分子である。前記担体は、例えば、生分解性が好ましい。前記担体は、例えば、ヒト血清アルブミン(HSA)、低密度リポタンパク質(LDL)、グロブリン等のタンパク質;例えば、デキストラン、プルラン、キチン、キトサン、イヌリン、シクロデキストリン、ヒアルロン酸等の糖質;脂質等があげられる。前記担体は、例えば、合成ポリアミノ酸等の合成ポリマーも使用できる。前記ポリアミノ酸は、例えば、ポリリシン(PLL)、ポリL-アスパラギン酸、ポリL-グルタミン酸、スチレン-マレイン酸無水物コポリマー、ポリ(L-ラクチド-コ-グリコリド)コポリマー、ジビニルエーテル-マレイン酸無水物コポリマー、N-(2-ヒドロキシプロピル)メタクリルアミドコポリマー(HMPA)、ポリエチレングリコール(PEG)、ポリビニルアルコール(PVA)、ポリウレタン、ポリ(2-エチルアクリル酸)、N-イソプロピルアクリルアミドポリマー、又はポリホスファジン(polyphosphazine)等があげられる。
前記結合物質は、例えば、甲状腺刺激ホルモン、メラニン細胞刺激ホルモン、レクチン、糖タンパク質、サーファクタントプロテインA、ムチン糖質、多価ラクトース、多価ガラクトース、N-アセチルガラクトサミン、N-アセチルグルコサミン、多価マンノース、多価フコース、グリコシル化ポリアミノ酸、多価ガラクトース、トランスフェリン、ビスホスホネート、ポリグルタミン酸、ポリアスパラギン酸、脂質、コレステロール、ステロイド、胆汁酸、葉酸塩、ビタミンB12、ビオチン、ネプロキシン(Neproxin)、RGDペプチド、RGDペプチド擬似体等があげられる。
前記融合剤および縮合剤は、例えば、ポリエチレンイミン(PEI)等のポリアミノ鎖等があげられる。PEIは、例えば、直鎖状および分岐状のいずれでもよく、また、合成物および天然物のいずれでもよい。前記PEIは、例えば、アルキル置換されてもよいし、脂質置換されてもよい。また、前記融合剤は、この他に、例えば、ポリヒスチジン、ポリイミダゾール、ポリピリジン、ポリプロピレンイミン、メリチン、ポリアセタール物質(例えば、カチオン性ポリアセタール等)等が使用できる。前記融合剤は、例えば、αらせん構造を有してもよい。前記融合剤は、例えば、メリチン等の膜崩壊剤でもよい。
本発明の組成物は、例えば、前記複合体の形成等について、米国特許第6,509,323号、米国特許公報第2003/0008818号、PCT/US04/07070号等を援用できる。
前記添加剤は、この他に、例えば、両親媒性分子等があげられる。前記両親媒性分子は、例えば、疎水性領域および親水性領域を有する分子である。前記分子は、例えば、ポリマーが好ましい。前記ポリマーは、例えば、二次構造を有するポリマーであり、反復性の二次構造を有するポリマーが好ましい。具体例としては、例えば、ポリペプチドが好ましく、より好ましくは、αらせん状ポリペプチド等である。
前記両親媒性ポリマーは、例えば、2つ以上の両親媒性サブユニットを有するポリマーでもよい。前記サブユニットは、例えば、少なくとも1つの親水性基および1つの疎水性基を有する環状構造を有するサブユニット等があげられる。前記サブユニットは、例えば、コール酸等のステロイド、芳香族構造等を有してもよい。前記ポリマーは、例えば、芳香族サブユニット等の環状構造サブユニットとアミノ酸の両方を有してもよい。
5.発現抑制方法
本発明の発現抑制方法は、前述のように、標的遺伝子の発現を抑制する方法であって、前記本発明の一本鎖核酸分子を使用することを特徴とする。本発明の発現抑制方法は、前記本発明の一本鎖核酸分子を使用することが特徴であって、その他の工程および条件は、何ら制限されない。
本発明の発現抑制方法は、前述のように、標的遺伝子の発現を抑制する方法であって、前記本発明の一本鎖核酸分子を使用することを特徴とする。本発明の発現抑制方法は、前記本発明の一本鎖核酸分子を使用することが特徴であって、その他の工程および条件は、何ら制限されない。
本発明の発現抑制方法において、前記遺伝子の発現抑制のメカニズムは、特に制限されず、例えば、RNA干渉による発現抑制等があげられる。ここで、本発明の発現抑制方法は、例えば、前記標的遺伝子の発現を抑制するRNA干渉を誘導する方法であり、前記本発明の一本鎖核酸分子を使用することを特徴とする発現誘導方法ともいえる。
本発明の発現抑制方法は、例えば、前記標的遺伝子が存在する対象に、前記一本鎖核酸分子を投与する工程を含む。前記投与工程により、例えば、前記投与対象に前記一本鎖核酸分子を接触させる。前記投与対象は、例えば、細胞、組織または器官等があげられる。前記投与対象は、例えば、ヒト、ヒトを除く非ヒト哺乳類等の非ヒト動物等があげられる。前記投与は、例えば、in vivoでもin vitroでもよい。
本発明の発現抑制方法は、例えば、前記一本鎖核酸分子を単独で投与してもよいし、前記一本鎖核酸分子を含む前記本発明の組成物を投与してもよい。前記投与方法は、特に制限されず、例えば、投与対象の種類の種類に応じて適宜選択できる。
6.治療方法
本発明の疾患の治療方法は、前述のように、前記本発明の一本鎖核酸分子を、患者に投与する工程を含み、前記一本鎖核酸分子が、前記発現抑制配列として、前記疾患の原因となる遺伝子の発現を抑制する配列を有することを特徴とする。本発明の治療方法は、前記本発明の一本鎖核酸分子を使用することが特徴であって、その他の工程および条件は、何ら制限されない。本発明の治療方法は、例えば、前記本発明の発現抑制方法を援用できる。
本発明の疾患の治療方法は、前述のように、前記本発明の一本鎖核酸分子を、患者に投与する工程を含み、前記一本鎖核酸分子が、前記発現抑制配列として、前記疾患の原因となる遺伝子の発現を抑制する配列を有することを特徴とする。本発明の治療方法は、前記本発明の一本鎖核酸分子を使用することが特徴であって、その他の工程および条件は、何ら制限されない。本発明の治療方法は、例えば、前記本発明の発現抑制方法を援用できる。
7.一本鎖核酸分子の使用
本発明の使用は、前記標的遺伝子の発現抑制のための、前記本発明の一本鎖核酸分子の使用である。また、本発明の使用は、RNA干渉の誘導のための、前記本発明の一本鎖核酸分子の使用である。
本発明の使用は、前記標的遺伝子の発現抑制のための、前記本発明の一本鎖核酸分子の使用である。また、本発明の使用は、RNA干渉の誘導のための、前記本発明の一本鎖核酸分子の使用である。
本発明の核酸分子は、疾患の治療に使用するための核酸分子であって、前記核酸分子は、前記本発明の一本鎖核酸分子であり、前記一本鎖核酸分子が、前記発現抑制配列として、前記疾患の原因となる遺伝子の発現を抑制する配列を有することを特徴とする。
本発明は、更に以下の実施例、試験例および製剤例によって詳しく説明されるが、これらは本発明を限定するものではなく、また本発明の範囲を逸脱しない範囲で変化させてもよい。
実施例1:N-2-クロロアセチル-L-プロリン-サクシンイミジルエステル(3)の合成
下記スキームに従い、N-2-クロロアセチル-L-プロリン-サクシンイミジルエステル(3)を合成した。
下記スキームに従い、N-2-クロロアセチル-L-プロリン-サクシンイミジルエステル(3)を合成した。
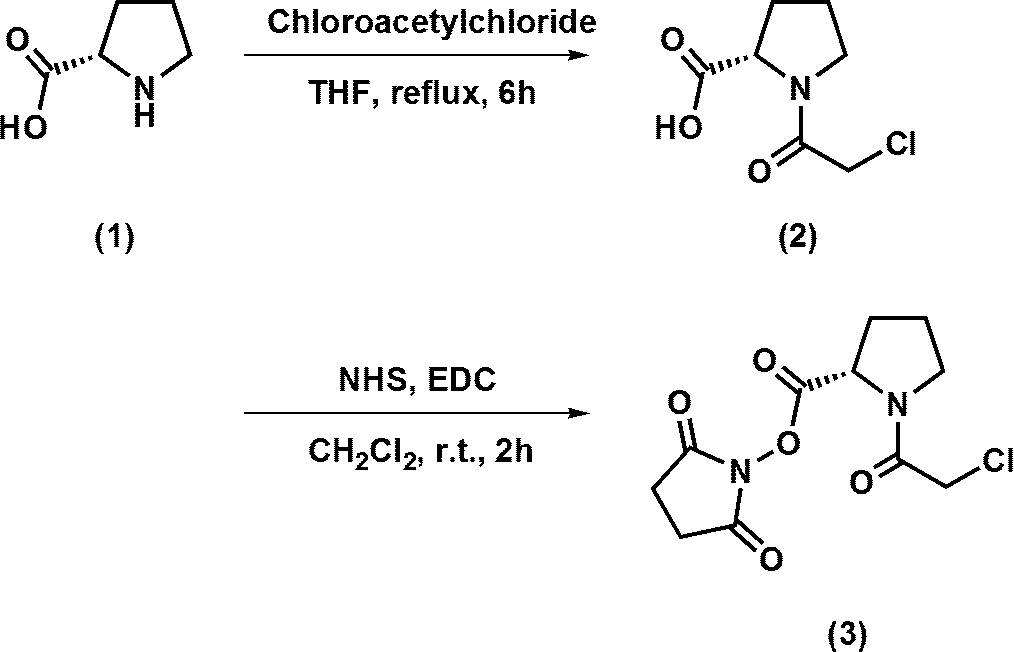
〔1〕N-2-クロロアセチル-L-プロリン(2)の合成
L-プロリン(1)(1.0 g, 8.7 mmol)と脱水THF(10 mL)を加えた懸濁液に、クロロアセチルクロリド(1.05 mL, 13.2 mmol)と脱水THF(1.5 mL)の溶液をアルゴン雰囲気下で滴下しながら撹拌した。この反応混合物を6時間加熱還流し、室温に戻してから脱イオン水(2 mL)を加え10分間撹拌し、飽和食塩水と酢酸エチルにて分液操作を行い、有機層を分けた。残った水層がpH2より低いことを確認し、酢酸エチルにて2回抽出した。有機層を合わせて硫酸マグネシウムで乾燥した後、溶媒を減圧留去した。得られた残渣をジイソプロピルエーテルでトリチュレーションし、白色粉末の化合物(2)(0.97 g, 収率58.4%)を得た。以下に、化合物(2)の機器分析値を示す。
化合物(2):
1H-NMR (500 MHz, CDCl3) δ: 8.35 (1H, br.s), 4.56-4.63 (1H, m), 4.00-4.14 (2H, m), 3.57-3.73 (2H, m), 1.93-2.35 (4H, m).
融点:110-111℃
ESI-MS:214.03[M+Na]+
L-プロリン(1)(1.0 g, 8.7 mmol)と脱水THF(10 mL)を加えた懸濁液に、クロロアセチルクロリド(1.05 mL, 13.2 mmol)と脱水THF(1.5 mL)の溶液をアルゴン雰囲気下で滴下しながら撹拌した。この反応混合物を6時間加熱還流し、室温に戻してから脱イオン水(2 mL)を加え10分間撹拌し、飽和食塩水と酢酸エチルにて分液操作を行い、有機層を分けた。残った水層がpH2より低いことを確認し、酢酸エチルにて2回抽出した。有機層を合わせて硫酸マグネシウムで乾燥した後、溶媒を減圧留去した。得られた残渣をジイソプロピルエーテルでトリチュレーションし、白色粉末の化合物(2)(0.97 g, 収率58.4%)を得た。以下に、化合物(2)の機器分析値を示す。
化合物(2):
1H-NMR (500 MHz, CDCl3) δ: 8.35 (1H, br.s), 4.56-4.63 (1H, m), 4.00-4.14 (2H, m), 3.57-3.73 (2H, m), 1.93-2.35 (4H, m).
融点:110-111℃
ESI-MS:214.03[M+Na]+
〔2〕N-2-クロロアセチル-L-プロリン-サクシンイミジルエステル(3)の合成
N-2-クロロアセチル-L-プロリン(2)(0.1 g, 0.5 mmol)をジクロロメタン(3 mL)に溶解し、1-エチル-3-(3-ジメチルアミノプロピル)カルボジイミド塩酸塩(0.12 g, 0.6 mmol)とN-ヒドロキシこはく酸イミド(0.07 g, 0.6 mmol)を加えて室温で2時間撹拌した。反応終了後、ジクロロメタンを加えて水で2回、飽和食塩水で2回洗浄した。有機層を無水硫酸ナトリウムにて乾燥後、減圧濃縮し白色発泡体の化合物(3)(0.11 g, 収率73%)を得た。以下に、化合物(3)の機器分析値を示す。
化合物(3):
1H-NMR (500 MHz, CDCl3) δ: 4.83-4.96 (1H, m), 4.04-4.11 (2H, m), 3.61-3.78 (2H, m), 2.83-2.87 (4H, m), 2.02-2.50 (4H, m).
ESI-MS:311.05[M+Na]+
N-2-クロロアセチル-L-プロリン(2)(0.1 g, 0.5 mmol)をジクロロメタン(3 mL)に溶解し、1-エチル-3-(3-ジメチルアミノプロピル)カルボジイミド塩酸塩(0.12 g, 0.6 mmol)とN-ヒドロキシこはく酸イミド(0.07 g, 0.6 mmol)を加えて室温で2時間撹拌した。反応終了後、ジクロロメタンを加えて水で2回、飽和食塩水で2回洗浄した。有機層を無水硫酸ナトリウムにて乾燥後、減圧濃縮し白色発泡体の化合物(3)(0.11 g, 収率73%)を得た。以下に、化合物(3)の機器分析値を示す。
化合物(3):
1H-NMR (500 MHz, CDCl3) δ: 4.83-4.96 (1H, m), 4.04-4.11 (2H, m), 3.61-3.78 (2H, m), 2.83-2.87 (4H, m), 2.02-2.50 (4H, m).
ESI-MS:311.05[M+Na]+
実施例2:新規一本鎖核酸分子の合成(PS-0001-C3)
(1)核酸合成
以下に示す核酸を、ホスホロアミダイト法に基づき、核酸合成機(商品名ABI Expedite(商標登録)8909 Nucleic Acid Synthesis System、アプライドバイオシステムス)により合成した。RNAアミダイトとして、TBDMSアミダイトを用いた固相合成を行った。センス鎖の合成では、3’末端にPhthalamido Amino C6 lcaa CPG(ChemGenes)(以下に構造を示す)を用いた。アンチセンス鎖の合成では、5’末端に5’-Thiol C-3 Disulfide Modifier CED phosphoramidite(ChemGenes)(以下に構造を示す)を用いた。固相からの切り出しと脱保護は、定法に従った。合成した核酸は、HPLCにより精製した。下記アンチセンス鎖核酸中の下線部は、ヒトTGF-β1遺伝子の発現抑制配列である。
(1)核酸合成
以下に示す核酸を、ホスホロアミダイト法に基づき、核酸合成機(商品名ABI Expedite(商標登録)8909 Nucleic Acid Synthesis System、アプライドバイオシステムス)により合成した。RNAアミダイトとして、TBDMSアミダイトを用いた固相合成を行った。センス鎖の合成では、3’末端にPhthalamido Amino C6 lcaa CPG(ChemGenes)(以下に構造を示す)を用いた。アンチセンス鎖の合成では、5’末端に5’-Thiol C-3 Disulfide Modifier CED phosphoramidite(ChemGenes)(以下に構造を示す)を用いた。固相からの切り出しと脱保護は、定法に従った。合成した核酸は、HPLCにより精製した。下記アンチセンス鎖核酸中の下線部は、ヒトTGF-β1遺伝子の発現抑制配列である。


(2)新規一本鎖核酸分子の合成
以下に本発明の一本鎖核酸分子であるPS-0001-C3の構造を示す。
PS-0001-C3は、前記センス鎖の3’末端とアンチセンス鎖の5’末端を、後述する方法にて、実施例1で得られたN-2-クロロアセチル-L-プロリン-サクシンイミジルエステル(3)を介して結合させることにより得られる一本鎖核酸分子である。
以下に本発明の一本鎖核酸分子であるPS-0001-C3の構造を示す。
PS-0001-C3は、前記センス鎖の3’末端とアンチセンス鎖の5’末端を、後述する方法にて、実施例1で得られたN-2-クロロアセチル-L-プロリン-サクシンイミジルエステル(3)を介して結合させることにより得られる一本鎖核酸分子である。

センス鎖+Pの合成
1mmol/Lのセンス鎖 40μL、1mol/Lのリン酸緩衝液(pH 8.5) 20μL、2.0mg/100μLのN-2-クロロアセチル-L-プロリン-サクシンイミジルエステル(3)/DMF 10μL(693nmol)、注射用蒸留水 30μLを混合し、25℃にて50分間撹拌した。さらに、2.0mg/100μLのN-2-クロロアセチル-L-プロリン-サクシンイミジルエステル(3)/DMF 5μLを追加し、70分間静置した。この反応液について、注射用蒸留水(大塚製薬)を溶出液としたillustra MicroSpin G-25 Columns(GE Healthcare)にて精製し、センス鎖+Pを得た。質量分析:7689.00(計算値:7689.29)。HPLC分析結果を図1に示す。分析条件は、XBridge OST C18(4.6×50mm)、移動相A:50mM TEAA(pH7)、5%CH3CN、移動相B:50mM TEAA(pH7)、50%CH3CN、グラジエントB:0-30%/20min、流速:1mL/min、カラム温度:60℃、検出:UV260nmである。
1mmol/Lのセンス鎖 40μL、1mol/Lのリン酸緩衝液(pH 8.5) 20μL、2.0mg/100μLのN-2-クロロアセチル-L-プロリン-サクシンイミジルエステル(3)/DMF 10μL(693nmol)、注射用蒸留水 30μLを混合し、25℃にて50分間撹拌した。さらに、2.0mg/100μLのN-2-クロロアセチル-L-プロリン-サクシンイミジルエステル(3)/DMF 5μLを追加し、70分間静置した。この反応液について、注射用蒸留水(大塚製薬)を溶出液としたillustra MicroSpin G-25 Columns(GE Healthcare)にて精製し、センス鎖+Pを得た。質量分析:7689.00(計算値:7689.29)。HPLC分析結果を図1に示す。分析条件は、XBridge OST C18(4.6×50mm)、移動相A:50mM TEAA(pH7)、5%CH3CN、移動相B:50mM TEAA(pH7)、50%CH3CN、グラジエントB:0-30%/20min、流速:1mL/min、カラム温度:60℃、検出:UV260nmである。

アンチセンス鎖(SH体)の合成
1mmol/Lのアンチセンス鎖 40μL、1mol/Lのリン酸緩衝液(pH 8.0) 20μL、10mg/mLのジチオトレイトール水溶液 20μL、注射用蒸留水 20μLを混合し、25℃にて45分間撹拌した。さらに、10mg/mLのジチオトレイトール水溶液 5μLを追加し、1.5時間撹拌した。この反応液について、注射用蒸留水(大塚製薬)を溶出液としたillustra MicroSpin G-25 Columns(GE Healthcare)にて精製し、アンチセンス鎖(SH体)を得た。質量分析:8084.30(計算値:8084.85)。HPLC分析結果を図2に示す。分析条件は、XBridge OST C18(4.6×50mm)、移動相A:50mM TEAA(pH7)、5%CH3CN、移動相B:50mM TEAA(pH7)、50%CH3CN、グラジエントB:0-30%/20min、流速:1mL/min、カラム温度:60℃、検出:UV260nmである。
1mmol/Lのアンチセンス鎖 40μL、1mol/Lのリン酸緩衝液(pH 8.0) 20μL、10mg/mLのジチオトレイトール水溶液 20μL、注射用蒸留水 20μLを混合し、25℃にて45分間撹拌した。さらに、10mg/mLのジチオトレイトール水溶液 5μLを追加し、1.5時間撹拌した。この反応液について、注射用蒸留水(大塚製薬)を溶出液としたillustra MicroSpin G-25 Columns(GE Healthcare)にて精製し、アンチセンス鎖(SH体)を得た。質量分析:8084.30(計算値:8084.85)。HPLC分析結果を図2に示す。分析条件は、XBridge OST C18(4.6×50mm)、移動相A:50mM TEAA(pH7)、5%CH3CN、移動相B:50mM TEAA(pH7)、50%CH3CN、グラジエントB:0-30%/20min、流速:1mL/min、カラム温度:60℃、検出:UV260nmである。
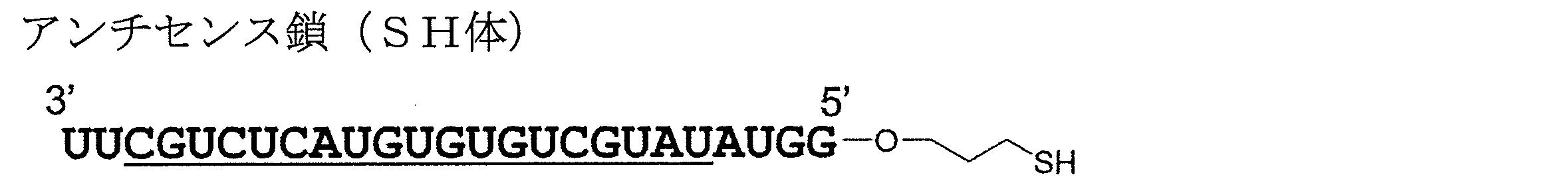
PS-0001-C3の合成
センス鎖+P 170μL、アンチセンス鎖(SH体) 170μL、1mol/Lのリン酸緩衝液(pH 8.5) 100μL、注射用蒸留水 60μLを混合し、25℃にて2時間撹拌した。反応液をHPLC(カラム:XBridge Oligonucleotide BEH C18、2.5μm、10×50mm;流速:4mL/min;検出:UV260nm;カラム温度:40℃;移動相A:50mmol/L TEAA(pH7.0)、5%CH3CN;移動相B:50mmol/L TEAA(pH7.0)、50%CH3CN)にて精製し、目的物のピークを分取した。分取したフラクションのエタノール沈殿を行い、PS-0001-C3を得た。質量分析:15737.80(計算値:15737.67)。精製後のHPLC分析結果を図3に示す。分析条件は、DNAPac PA-100(4×250mm)、移動相A:25mM Tris-HCl(pH8)、10%CH3CN、8M Urea、移動相B:25mM Tris-HCl(pH8)、10%CH3CN、8M Urea、700mM NaClO4、グラジエントB:10-40%/20min、流速:1mL/min、カラム温度:80℃、検出:UV260nmである。
センス鎖+P 170μL、アンチセンス鎖(SH体) 170μL、1mol/Lのリン酸緩衝液(pH 8.5) 100μL、注射用蒸留水 60μLを混合し、25℃にて2時間撹拌した。反応液をHPLC(カラム:XBridge Oligonucleotide BEH C18、2.5μm、10×50mm;流速:4mL/min;検出:UV260nm;カラム温度:40℃;移動相A:50mmol/L TEAA(pH7.0)、5%CH3CN;移動相B:50mmol/L TEAA(pH7.0)、50%CH3CN)にて精製し、目的物のピークを分取した。分取したフラクションのエタノール沈殿を行い、PS-0001-C3を得た。質量分析:15737.80(計算値:15737.67)。精製後のHPLC分析結果を図3に示す。分析条件は、DNAPac PA-100(4×250mm)、移動相A:25mM Tris-HCl(pH8)、10%CH3CN、8M Urea、移動相B:25mM Tris-HCl(pH8)、10%CH3CN、8M Urea、700mM NaClO4、グラジエントB:10-40%/20min、流速:1mL/min、カラム温度:80℃、検出:UV260nmである。
実施例3:N α -2-ブロモアセチル―N ε -tert-ブトキシカルボニル-L-リジン-サクシンイミジルエステル(6)の合成
下記スキームに従い、Nα-2-ブロモアセチル―Nε-tert-ブトキシカルボニル-L-リジン-サクシンイミジルエステル(6)を合成した。
下記スキームに従い、Nα-2-ブロモアセチル―Nε-tert-ブトキシカルボニル-L-リジン-サクシンイミジルエステル(6)を合成した。

〔1〕Nα-2-ブロモアセチル―Nε-tert-ブトキシカルボニル-L-リジン(5)の合成
Nε-tert-ブトキシカルボニル-L-リジン(4)(1.00 g, 4.06 mmol) に水(4 mL)、THF (4 mL) および4N NaOH水溶液(880 μL, 3.52 mmol) を室温で加えて溶解した。この溶液を0 ℃に冷却し、4mol/L 水酸化ナトリウム水溶液(1.2 mL, 4.8 mmol) およびブロモアセチルブロミド (400 μL, 4.62 mmol) を添加した。反応後の溶液に3mol/L臭化水素酸(2 mL) を添加し、メチルtert-ブチルエーテル10mLで3回抽出した。合わせた有機層を炭酸水素ナトリウム水溶液で洗浄し、洗浄後の有機層を減圧濃縮し、化合物(5)(307 mg, 収率21%)を無色油状物として得た。以下に、化合物(5)の機器分析値を示す。
化合物(5):
1H-NMR (400 MHz, DMSO-d6) δ: 8.54 (1H, br.s), 6.76 (1H, br.s), 4.10-4.15 (1H, m), 3.85-3.91 (2H, m), 2.84-2.89 (2H, m), 1.51-1.71 (2H, m),1.19-1.39 (4H, m), 1.35 (9H, s).
ESI-MS:389.10[M+Na]+
Nε-tert-ブトキシカルボニル-L-リジン(4)(1.00 g, 4.06 mmol) に水(4 mL)、THF (4 mL) および4N NaOH水溶液(880 μL, 3.52 mmol) を室温で加えて溶解した。この溶液を0 ℃に冷却し、4mol/L 水酸化ナトリウム水溶液(1.2 mL, 4.8 mmol) およびブロモアセチルブロミド (400 μL, 4.62 mmol) を添加した。反応後の溶液に3mol/L臭化水素酸(2 mL) を添加し、メチルtert-ブチルエーテル10mLで3回抽出した。合わせた有機層を炭酸水素ナトリウム水溶液で洗浄し、洗浄後の有機層を減圧濃縮し、化合物(5)(307 mg, 収率21%)を無色油状物として得た。以下に、化合物(5)の機器分析値を示す。
化合物(5):
1H-NMR (400 MHz, DMSO-d6) δ: 8.54 (1H, br.s), 6.76 (1H, br.s), 4.10-4.15 (1H, m), 3.85-3.91 (2H, m), 2.84-2.89 (2H, m), 1.51-1.71 (2H, m),1.19-1.39 (4H, m), 1.35 (9H, s).
ESI-MS:389.10[M+Na]+
〔2〕Nα-2-ブロモアセチル―Nε-tert-ブトキシカルボニル-L-リジン-サクシンイミジルエステル(6)の合成
Nα-2-ブロモアセチル―Nε-tert-ブトキシカルボニル-L-リジン(5)(439.4 mg, 1.20mmol) およびジ(N-スクシンイミジルカーボネート)(322.0mg, 1.26 mmol) のアセトニトリル(4.4 mL) 懸濁液に、室温でN,N-ジメチルアミノピリジン(29.6 mg, 0.24 mmol) を加えた。20分間攪拌した後、反応液を減圧濃縮し、残渣をクロロホルム(11 mL) で希釈した。水(8.8mL) で 4 回洗浄した後、有機層を無水硫酸マグネシウムにて乾燥し、減圧濃縮して化合物(6)(507.1mg, 収率91%)を無色泡状の固体として得た。以下に、化合物(6)の機器分析値を示す。
化合物(6):
1H-NMR (400 MHz, DMSO-d6) δ: 8.98 (1H, br.s), 6.79 (1H, br.s), 4.59-4.64 (1H, m), 3.89-3.95 (2H, m), 2.89-2.91 (2H, m), 2.81-2.83 (4H, m), 1.73-1.90 (2H, m), 1.34-1.40 (4H, m), 1.37 (9H, s).
ESI-MS:486.08[M+Na]+
Nα-2-ブロモアセチル―Nε-tert-ブトキシカルボニル-L-リジン(5)(439.4 mg, 1.20mmol) およびジ(N-スクシンイミジルカーボネート)(322.0mg, 1.26 mmol) のアセトニトリル(4.4 mL) 懸濁液に、室温でN,N-ジメチルアミノピリジン(29.6 mg, 0.24 mmol) を加えた。20分間攪拌した後、反応液を減圧濃縮し、残渣をクロロホルム(11 mL) で希釈した。水(8.8mL) で 4 回洗浄した後、有機層を無水硫酸マグネシウムにて乾燥し、減圧濃縮して化合物(6)(507.1mg, 収率91%)を無色泡状の固体として得た。以下に、化合物(6)の機器分析値を示す。
化合物(6):
1H-NMR (400 MHz, DMSO-d6) δ: 8.98 (1H, br.s), 6.79 (1H, br.s), 4.59-4.64 (1H, m), 3.89-3.95 (2H, m), 2.89-2.91 (2H, m), 2.81-2.83 (4H, m), 1.73-1.90 (2H, m), 1.34-1.40 (4H, m), 1.37 (9H, s).
ESI-MS:486.08[M+Na]+
実施例4:新規一本鎖核酸分子の合成(KS-0001)
実施例2で調製された以下のセンス鎖およびアンチセンス鎖を用いた。
実施例2で調製された以下のセンス鎖およびアンチセンス鎖を用いた。

以下に本発明の一本鎖核酸分子であるKS-0001の構造を示す。
KS-0001は、前記センス鎖の3’末端とアンチセンス鎖の5’末端を、後述する方法にてNα-2-ブロモアセチル―Nε-tert-ブトキシカルボニル-L-リジン-サクシンイミジルエステル(6)を介して結合させることにより得られる一本鎖核酸分子である。
KS-0001は、前記センス鎖の3’末端とアンチセンス鎖の5’末端を、後述する方法にてNα-2-ブロモアセチル―Nε-tert-ブトキシカルボニル-L-リジン-サクシンイミジルエステル(6)を介して結合させることにより得られる一本鎖核酸分子である。

KS-0001の合成
844μmol/Lのセンス鎖 48μL、注射用蒸留水 438μL、ジイソプロピルエチルアミン 14μLの混合溶液を、17.2mg/200μLの、実施例3で得られたNα-2-ブロモアセチル―Nε-tert-ブトキシカルボニル-L-リジン-サクシンイミジルエステル(6)/DMF 200μLに5回に分けて添加し、25℃にて20分間撹拌した。
1mmol/Lのアンチセンス鎖 20μL、1mol/Lのリン酸緩衝液(pH 8.0) 20μL、10mg/mLのジチオトレイトール水溶液 20μL、注射用蒸留水 40μLを混合し、25℃にて2時間撹拌した。この反応液を前出の反応液に添加し、25℃にて20分間撹拌した。反応液をエタノール沈殿後、HPLC(カラム:Develosil C8-UG-5、5μm、10×50mm;流速:4.7mL/min;検出:UV260nm;カラム温度:50℃;移動相A:50mmol/L TEAA(pH7.0)、5%CH3CN;移動相B:50mmol/L TEAA(pH7.0)、50%CH3CN)にて精製し、目的物のピークを分取した。分取したフラクションを減圧濃縮し、KS-0001を得た。質量分析:15869.50(計算値:15868.85)。精製後のHPLC分析結果を図4に示す。分析条件は、DNAPac PA-100(4×250mm)、移動相A:25mM Tris-HCl(pH8)、10%CH3CN、8M Urea、移動相B:25mM Tris-HCl(pH8)、10%CH3CN、8M Urea、700mM NaClO4、グラジエントB:10-40%/20min、流速:1mL/min、カラム温度:80℃、検出:UV260nmである。
844μmol/Lのセンス鎖 48μL、注射用蒸留水 438μL、ジイソプロピルエチルアミン 14μLの混合溶液を、17.2mg/200μLの、実施例3で得られたNα-2-ブロモアセチル―Nε-tert-ブトキシカルボニル-L-リジン-サクシンイミジルエステル(6)/DMF 200μLに5回に分けて添加し、25℃にて20分間撹拌した。
1mmol/Lのアンチセンス鎖 20μL、1mol/Lのリン酸緩衝液(pH 8.0) 20μL、10mg/mLのジチオトレイトール水溶液 20μL、注射用蒸留水 40μLを混合し、25℃にて2時間撹拌した。この反応液を前出の反応液に添加し、25℃にて20分間撹拌した。反応液をエタノール沈殿後、HPLC(カラム:Develosil C8-UG-5、5μm、10×50mm;流速:4.7mL/min;検出:UV260nm;カラム温度:50℃;移動相A:50mmol/L TEAA(pH7.0)、5%CH3CN;移動相B:50mmol/L TEAA(pH7.0)、50%CH3CN)にて精製し、目的物のピークを分取した。分取したフラクションを減圧濃縮し、KS-0001を得た。質量分析:15869.50(計算値:15868.85)。精製後のHPLC分析結果を図4に示す。分析条件は、DNAPac PA-100(4×250mm)、移動相A:25mM Tris-HCl(pH8)、10%CH3CN、8M Urea、移動相B:25mM Tris-HCl(pH8)、10%CH3CN、8M Urea、700mM NaClO4、グラジエントB:10-40%/20min、流速:1mL/min、カラム温度:80℃、検出:UV260nmである。
参考例:新規一本鎖核酸分子の合成(AS-0001)
実施例2で調製された以下のセンス鎖およびアンチセンス鎖を用いた。
実施例2で調製された以下のセンス鎖およびアンチセンス鎖を用いた。
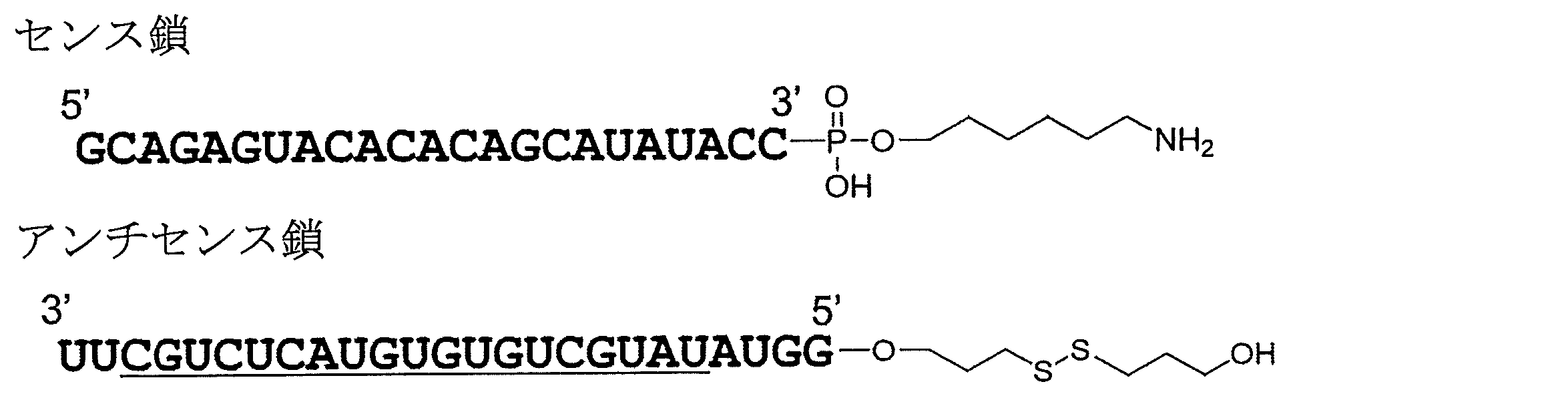
以下に本発明の一本鎖核酸分子であるAS-0001の構造を示す。
AS-0001は、前記センス鎖の3’末端とアンチセンス鎖の5’末端を、後述する方法にて2-ブロモ酢酸サクシンイミジルエステルを介して結合させることにより得られる一本鎖核酸分子である。
AS-0001は、前記センス鎖の3’末端とアンチセンス鎖の5’末端を、後述する方法にて2-ブロモ酢酸サクシンイミジルエステルを介して結合させることにより得られる一本鎖核酸分子である。
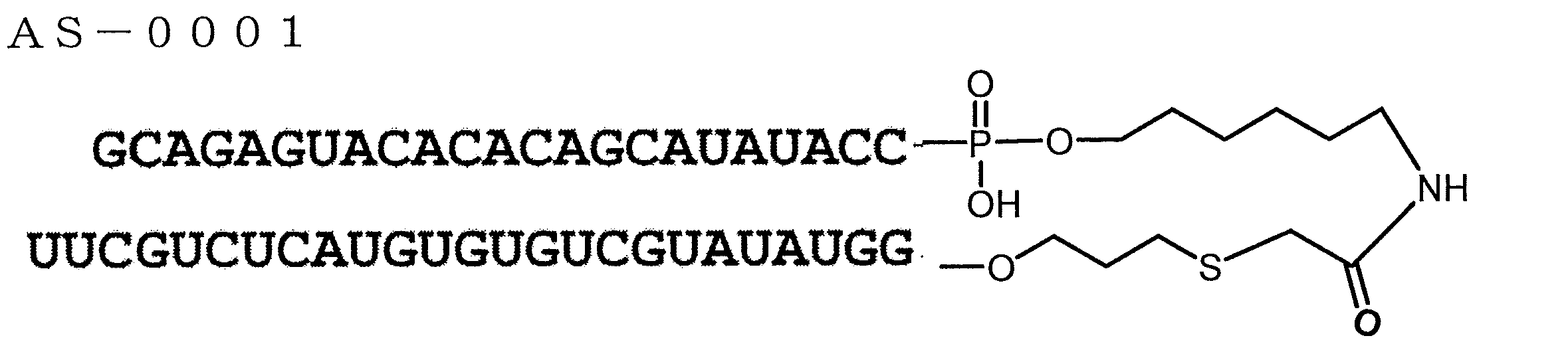
AS-0001の合成
844μmol/Lのセンス鎖 48μL、注射用蒸留水 438μL、ジイソプロピルエチルアミン 14μLの混合溶液を、7.5μmol/Lの2-ブロモ酢酸サクシンイミジルエステル/DMF 200μLに5回に分けて添加し、25℃にて20分間撹拌した。反応液をエタノール沈殿後、HPLC(カラム:Develosil C8-UG-5、5μm、10×50mm;流速:4.7mL/min;検出:UV260nm;カラム温度:50℃;移動相A:50mmol/L TEAA(pH7.0)、5%CH3CN;移動相B:50mmol/L TEAA(pH7.0)、50%CH3CN)にて精製し、目的物のピークを分取した。分取したフラクションを減圧濃縮し、センス鎖+ブロモアセチル体を得た。質量分析:7636.90(計算値:7636.62)。
1mmol/Lのアンチセンス鎖 4μL、1mol/Lのリン酸緩衝液(pH 8.0) 4μL、10mg/mLのジチオトレイトール水溶液 4μL、注射用蒸留水 8μLを混合し、25℃にて30分間撹拌した。この反応液17.5μLとセンス鎖+ブロモアセチル体 750μL(3.45nmol)、1mol/Lのリン酸緩衝液(pH 8.5) 85μLを混合し、25℃にて30分間撹拌した。反応液をエタノール沈殿後、注射用蒸留水(大塚製薬)を溶出液としたillustra MicroSpin G-25 Columns(GE Healthcare)にて精製し、AS-0001を得た。質量分析:15641.40(計算値:15640.56)。精製後のHPLC分析結果を図5に示す。分析条件は、DNAPac PA-100(4×250mm)、移動相A:25mM Tris-HCl(pH8)、10%CH3CN、8M Urea、移動相B:25mM Tris-HCl(pH8)、10%CH3CN、8M Urea、700mM NaClO4、グラジエントB:10-40%/20min、流速:1mL/min、カラム温度:80℃、検出:UV260nmである。
844μmol/Lのセンス鎖 48μL、注射用蒸留水 438μL、ジイソプロピルエチルアミン 14μLの混合溶液を、7.5μmol/Lの2-ブロモ酢酸サクシンイミジルエステル/DMF 200μLに5回に分けて添加し、25℃にて20分間撹拌した。反応液をエタノール沈殿後、HPLC(カラム:Develosil C8-UG-5、5μm、10×50mm;流速:4.7mL/min;検出:UV260nm;カラム温度:50℃;移動相A:50mmol/L TEAA(pH7.0)、5%CH3CN;移動相B:50mmol/L TEAA(pH7.0)、50%CH3CN)にて精製し、目的物のピークを分取した。分取したフラクションを減圧濃縮し、センス鎖+ブロモアセチル体を得た。質量分析:7636.90(計算値:7636.62)。
1mmol/Lのアンチセンス鎖 4μL、1mol/Lのリン酸緩衝液(pH 8.0) 4μL、10mg/mLのジチオトレイトール水溶液 4μL、注射用蒸留水 8μLを混合し、25℃にて30分間撹拌した。この反応液17.5μLとセンス鎖+ブロモアセチル体 750μL(3.45nmol)、1mol/Lのリン酸緩衝液(pH 8.5) 85μLを混合し、25℃にて30分間撹拌した。反応液をエタノール沈殿後、注射用蒸留水(大塚製薬)を溶出液としたillustra MicroSpin G-25 Columns(GE Healthcare)にて精製し、AS-0001を得た。質量分析:15641.40(計算値:15640.56)。精製後のHPLC分析結果を図5に示す。分析条件は、DNAPac PA-100(4×250mm)、移動相A:25mM Tris-HCl(pH8)、10%CH3CN、8M Urea、移動相B:25mM Tris-HCl(pH8)、10%CH3CN、8M Urea、700mM NaClO4、グラジエントB:10-40%/20min、流速:1mL/min、カラム温度:80℃、検出:UV260nmである。
試験例1(遺伝子発現抑制活性測定法)
細胞は、A549細胞(DSファーマバイオメディカル)を使用した。培地は、10%FBSを含むDMEM(Invitrogen)を使用した。培養条件は、37℃、5%CO2下とした。
まず、細胞を培地中で培養し、その細胞懸濁液を24穴プレートに400μLずつ、4×104細胞/ウェルとなるように分注した。さらに、トランスフェクション試薬Lipofectamine RNAiMAX Transfection Reagent(Invitrogen)を用い、添付のプロトコールに従って、核酸分子をウェル中の細胞にトランスフェクションした。具体的には、ウェルあたりの組成を以下のように設定しトランスフェクションを行った。下記組成において、(B)は、Opti-MEM(Invitrogen)、(C)は、核酸分子溶液であり、両者をあわせて98.5μL添加した。なお、ウェルにおいて、核酸分子の終濃度は0.01、0.1、1 nmol/Lとした。
細胞は、A549細胞(DSファーマバイオメディカル)を使用した。培地は、10%FBSを含むDMEM(Invitrogen)を使用した。培養条件は、37℃、5%CO2下とした。
まず、細胞を培地中で培養し、その細胞懸濁液を24穴プレートに400μLずつ、4×104細胞/ウェルとなるように分注した。さらに、トランスフェクション試薬Lipofectamine RNAiMAX Transfection Reagent(Invitrogen)を用い、添付のプロトコールに従って、核酸分子をウェル中の細胞にトランスフェクションした。具体的には、ウェルあたりの組成を以下のように設定しトランスフェクションを行った。下記組成において、(B)は、Opti-MEM(Invitrogen)、(C)は、核酸分子溶液であり、両者をあわせて98.5μL添加した。なお、ウェルにおいて、核酸分子の終濃度は0.01、0.1、1 nmol/Lとした。

トランスフェクション後24時間培養した後、NucleoSpin RNA Plus(タカラバイオ)を用い、添付のプロトコールに従って、RNAを回収した。次に、逆転写酵素(Transcriptor First Strand cDNA Synthesis Kit、Roche)を用い、添付のプロトコールに従って、RNAからcDNAを合成した。そして、以下に示すように、合成したcDNAを鋳型としてPCRを行い、TGF-β1遺伝子の発現量および内部標準であるβ-アクチン遺伝子の発現量を測定した。TGF-β1遺伝子の発現量は、β-アクチン遺伝子の発現量により補正した。
PCRは、試薬としてLightCycler480 SYBR Green I Master(Roche)、機器としてLight Cycler480 Instrument II(Roche)を用いた。TGF-β1遺伝子およびβ-アクチン遺伝子の増幅には、それぞれ、以下のプライマーセットを使用した。
TGF-β1遺伝子用PCRプライマーセット
5’-ttgtgcggcagtggttgagccg-3’ (配列番号6)
5’-gaagcaggaaaggccggttcatgc-3’ (配列番号7)
β-アクチン遺伝子用プライマーセット
5’-gccacggctgcttccagctcctc-3’ (配列番号8)
5’-aggtctttgcggatgtccacgtcac-3’ (配列番号9)
TGF-β1遺伝子用PCRプライマーセット
5’-ttgtgcggcagtggttgagccg-3’ (配列番号6)
5’-gaagcaggaaaggccggttcatgc-3’ (配列番号7)
β-アクチン遺伝子用プライマーセット
5’-gccacggctgcttccagctcctc-3’ (配列番号8)
5’-aggtctttgcggatgtccacgtcac-3’ (配列番号9)
コントロールとして、トランスフェクションにおいて、核酸分子を未添加とし、(A)トランスフェクション試薬 1.5μLと(B)とを合計100μL添加した以外は、同様にして処理した細胞についても、遺伝子発現量を測定した(mock)。
補正後のTGF-β1遺伝子の発現量について、コントロール(mock)の細胞における発現量を1として、各核酸分子を導入した細胞での発現量の相対値を求めた。
これらの結果を図6に示す。図6に示すように、実施例の核酸分子は強い遺伝子発現抑制活性を示すことがわかった。
補正後のTGF-β1遺伝子の発現量について、コントロール(mock)の細胞における発現量を1として、各核酸分子を導入した細胞での発現量の相対値を求めた。
これらの結果を図6に示す。図6に示すように、実施例の核酸分子は強い遺伝子発現抑制活性を示すことがわかった。
本発明によれば、高難易度の長鎖オリゴマーの合成が短鎖オリゴマーの技術を駆使して可能となる新規な一本鎖核酸分子の製造方法、および該方法によって製造される新規な一本鎖核酸分子を提供できる。
本出願は、日本で2017年10月13日に出願された特願2017-199945号を基礎としており、その内容は本明細書にすべて包含される。
Claims (22)
- 下記一般式(I):
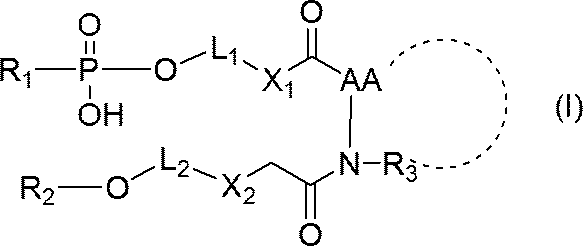
R1は、オリゴヌクレオチド又はポリヌクレオチドを含む領域であって、その3’末端ヌクレオチド残基が-P(=O)(OH)-O-と結合し;
R2は、オリゴヌクレオチド又はポリヌクレオチドを含む領域であって、その5’末端ヌクレオチド残基が-O-と結合し;
X1およびX2は、それぞれ独立して、NH、SまたはOを示し;
L1およびL2は、それぞれ独立して、C1-30アルキレン鎖、または-(CH2)l-(O-(CH2)m-)n-(式中、lは1~3の整数を示し、mは1~3の整数を示し、nは1~10の整数を示す。)を示し;
-C(=O)-AA-NR3-は、アミノ酸残基を示し;
R3は、水素原子またはC1-6アルキル基を示すか、あるいは、AAと一緒になって窒素含有複素環を形成する。]
で表される一本鎖核酸分子の製造方法であって、
(工程1)下記一般式(II):
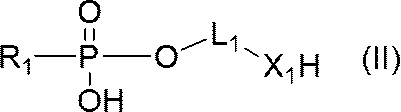
で表される核酸を、下記一般式(IV):
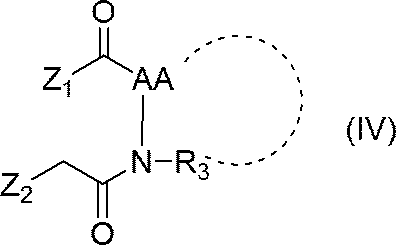
Z1は、スクシンイミジルオキシ基、ベンゾトリアゾリルオキシ基、ペンタフルオロフェノキシ基またはハロゲン原子を示し;
Z2は、ハロゲン原子を示し;
その他の記号は前記と同義である。]
で表される化合物と反応させて、下記一般式(V):
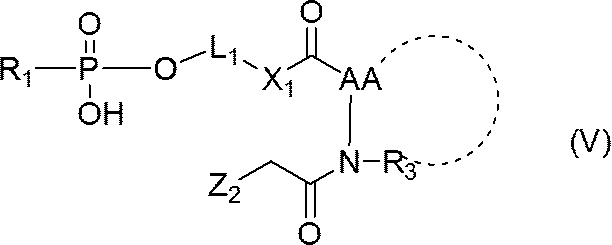
で表される核酸を得る工程;および
(工程2)一般式(V)で表される核酸を、下記一般式(III):

で表される核酸と反応させて、上記一般式(I)で表される一本鎖核酸分子を得る工程;
を包含する、製造方法。 - アミノ酸残基が、プロリン残基、グリシン残基、または側鎖アミノ基が保護されていてもよいリジン残基である、請求項1に記載の製造方法。
- X2がSである、請求項1に記載の製造方法。
- X1がNHである、請求項1に記載の製造方法。
- L1が、C2-11アルキレン鎖である、請求項1に記載の製造方法。
- L1が、-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数を示す。)である、請求項1に記載の製造方法。
- L2が、C2-11アルキレン鎖である、請求項1に記載の製造方法。
- L2が、-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数を示す。)である、請求項1に記載の製造方法。
- Z1が、スクシンイミジルオキシ基である、請求項1に記載の製造方法。
- 一本鎖核酸分子が、標的遺伝子の発現を抑制する配列を含む、請求項1~9のいずれかに記載の製造方法。
- 下記一般式(Ia):

R1は、オリゴヌクレオチド又はポリヌクレオチドを含む領域であって、その3’末端ヌクレオチド残基が-P(=O)(OH)-O-と結合し;
R2は、オリゴヌクレオチド又はポリヌクレオチドを含む領域であって、その5’末端ヌクレオチド残基が-O-と結合し;
L1およびL2は、それぞれ独立して、C1-30アルキレン鎖、または-(CH2)l-(O-(CH2)m-)n-(式中、lは1~3の整数を示し、mは1~3の整数を示し、nは1~10の整数を示す。)を示し;
-C(=O)-AA-NR3-は、アミノ酸残基を示し;
R3は、水素原子またはC1-6アルキル基を示すか、あるいは、AAと一緒になって窒素含有複素環を形成する。]
で表される一本鎖核酸分子。 - アミノ酸残基が、プロリン残基、グリシン残基、または側鎖アミノ基が保護されていてもよいリジン残基である、請求項11に記載の一本鎖核酸分子。
- L1が、C2-11アルキレン鎖である、請求項11に記載の一本鎖核酸分子。
- L1が、-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数を示す。)である、請求項11に記載の一本鎖核酸分子。
- L2が、C2-11アルキレン鎖である、請求項11に記載の一本鎖核酸分子。
- L2が、-CH2CH2(OCH2CH2)n-(式中、nは1~5の整数を示す。)である、請求項11に記載の一本鎖核酸分子。
- 標的遺伝子の発現を抑制する配列を含む、請求項11~16のいずれかに記載の一本鎖核酸分子。
- 請求項11~17のいずれかに記載の一本鎖核酸分子を含む、医薬組成物。
- 請求項17に記載の一本鎖核酸分子を含む、標的遺伝子の発現抑制剤。
- 下記一般式(IVa):

Z2は、ハロゲン原子を示し;
-C(=O)-AA-NR3-は、アミノ酸残基を示し;
R3は、水素原子またはC1-6アルキル基を示すか、あるいは、AAと一緒になって窒素含有複素環を形成する。]
で表される化合物。 - アミノ酸残基が、プロリン残基、グリシン残基、または側鎖アミノ基が保護されていてもよいリジン残基である、請求項20に記載の化合物。
- Z2が、塩素原子または臭素原子である、請求項20に記載の化合物。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP18865423.0A EP3696269A4 (en) | 2017-10-13 | 2018-10-12 | SINGLE STRAND NUCLEIC ACID MOLECULE AND ITS PRODUCTION PROCESS |
| JP2019548260A JPWO2019074110A1 (ja) | 2017-10-13 | 2018-10-12 | 一本鎖核酸分子およびその製造方法 |
| US16/755,824 US20210188895A1 (en) | 2017-10-13 | 2018-10-12 | Single-stranded nucleic acid molecule, and production method therefor |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017199945 | 2017-10-13 | ||
| JP2017-199945 | 2017-10-13 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2019074110A1 true WO2019074110A1 (ja) | 2019-04-18 |
Family
ID=66100770
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2018/038174 WO2019074110A1 (ja) | 2017-10-13 | 2018-10-12 | 一本鎖核酸分子およびその製造方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20210188895A1 (ja) |
| EP (1) | EP3696269A4 (ja) |
| JP (1) | JPWO2019074110A1 (ja) |
| WO (1) | WO2019074110A1 (ja) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021070494A1 (ja) | 2019-10-11 | 2021-04-15 | 住友化学株式会社 | 核酸オリゴマーの製造方法 |
| WO2021153770A1 (en) | 2020-01-29 | 2021-08-05 | Sumitomo Chemical Company, Limited | Process of preparing nucleic acid oligomer |
| WO2021153047A1 (ja) | 2020-01-29 | 2021-08-05 | 住友化学株式会社 | 核酸オリゴマーの製造方法 |
| WO2021193954A1 (ja) | 2020-03-27 | 2021-09-30 | 住友化学株式会社 | 核酸オリゴマーの製造方法 |
| WO2022009959A1 (ja) | 2020-07-09 | 2022-01-13 | 住友化学株式会社 | 核酸オリゴマーの製造方法 |
| WO2022064908A1 (ja) | 2020-09-24 | 2022-03-31 | 住友化学株式会社 | 核酸オリゴマーの製造方法 |
Citations (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3687808A (en) | 1969-08-14 | 1972-08-29 | Univ Leland Stanford Junior | Synthetic polynucleotides |
| JP2002504096A (ja) * | 1997-04-24 | 2002-02-05 | ヘンリー エム.ジャクソン ファウンデーション フォー ザ アドバンスメント オブ ミリタリー メディシン | タンパク質−多糖ワクチンの調製のための未修飾タンパク質とハロアシルまたはジハロアシル誘導体化された多糖との結合 |
| US20030008818A1 (en) | 2000-12-19 | 2003-01-09 | California Institute Of Technology And Insert Therapeutics, Inc | Compositions containing inclusion complexes |
| US6509323B1 (en) | 1998-07-01 | 2003-01-21 | California Institute Of Technology | Linear cyclodextrin copolymers |
| US20050130244A1 (en) * | 2003-12-15 | 2005-06-16 | Zheng Yi F. | Assay for entactogens |
| WO2005103697A2 (en) * | 2004-04-05 | 2005-11-03 | Dade Behring Inc. | Immunoassays for buprenorphine and norbuprenorphine |
| WO2012005368A1 (ja) | 2010-07-08 | 2012-01-12 | 株式会社ボナック | 遺伝子発現制御のための一本鎖核酸分子 |
| WO2012017919A1 (ja) | 2010-08-03 | 2012-02-09 | 株式会社ボナック | 含窒素脂環式骨格を有する一本鎖核酸分子 |
| WO2013077446A1 (ja) | 2011-11-26 | 2013-05-30 | 株式会社ボナック | 遺伝子発現制御のための一本鎖核酸分子 |
| WO2013103146A1 (ja) | 2012-01-07 | 2013-07-11 | 株式会社ボナック | アミノ酸骨格を有する一本鎖核酸分子 |
| WO2013133393A1 (ja) | 2012-03-07 | 2013-09-12 | 学校法人東京医科大学 | Vegf遺伝子の発現抑制用一本鎖核酸分子 |
| WO2016061562A2 (en) * | 2014-10-17 | 2016-04-21 | Kodiak Sciences Inc. | Butyrylcholinesterase zwitterionic polymer conjugates |
| WO2016100113A2 (en) * | 2014-12-17 | 2016-06-23 | Siemens Healthcare Diagnostics Inc. | Conjugates for assays for oxycodone and oxymorphone |
| WO2016104775A1 (ja) | 2014-12-27 | 2016-06-30 | 株式会社ボナック | 遺伝子発現制御のための天然型miRNAおよびその用途 |
| WO2016108264A1 (ja) | 2014-12-29 | 2016-07-07 | 株式会社ボナック | 核酸分子を安定に含有する組成物 |
| JP2017199945A (ja) | 2016-04-25 | 2017-11-02 | 株式会社ナカヨ | 強制ログアウト機能を有する通信装置 |
| WO2018185131A2 (en) * | 2017-04-05 | 2018-10-11 | Novo Nordisk A/S | Oligomer extended insulin-fc conjugates |
-
2018
- 2018-10-12 WO PCT/JP2018/038174 patent/WO2019074110A1/ja unknown
- 2018-10-12 US US16/755,824 patent/US20210188895A1/en not_active Abandoned
- 2018-10-12 JP JP2019548260A patent/JPWO2019074110A1/ja not_active Abandoned
- 2018-10-12 EP EP18865423.0A patent/EP3696269A4/en not_active Withdrawn
Patent Citations (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3687808A (en) | 1969-08-14 | 1972-08-29 | Univ Leland Stanford Junior | Synthetic polynucleotides |
| JP2002504096A (ja) * | 1997-04-24 | 2002-02-05 | ヘンリー エム.ジャクソン ファウンデーション フォー ザ アドバンスメント オブ ミリタリー メディシン | タンパク質−多糖ワクチンの調製のための未修飾タンパク質とハロアシルまたはジハロアシル誘導体化された多糖との結合 |
| US6509323B1 (en) | 1998-07-01 | 2003-01-21 | California Institute Of Technology | Linear cyclodextrin copolymers |
| US20030008818A1 (en) | 2000-12-19 | 2003-01-09 | California Institute Of Technology And Insert Therapeutics, Inc | Compositions containing inclusion complexes |
| US20050130244A1 (en) * | 2003-12-15 | 2005-06-16 | Zheng Yi F. | Assay for entactogens |
| WO2005103697A2 (en) * | 2004-04-05 | 2005-11-03 | Dade Behring Inc. | Immunoassays for buprenorphine and norbuprenorphine |
| WO2012005368A1 (ja) | 2010-07-08 | 2012-01-12 | 株式会社ボナック | 遺伝子発現制御のための一本鎖核酸分子 |
| WO2012017919A1 (ja) | 2010-08-03 | 2012-02-09 | 株式会社ボナック | 含窒素脂環式骨格を有する一本鎖核酸分子 |
| WO2013077446A1 (ja) | 2011-11-26 | 2013-05-30 | 株式会社ボナック | 遺伝子発現制御のための一本鎖核酸分子 |
| WO2013103146A1 (ja) | 2012-01-07 | 2013-07-11 | 株式会社ボナック | アミノ酸骨格を有する一本鎖核酸分子 |
| WO2013133393A1 (ja) | 2012-03-07 | 2013-09-12 | 学校法人東京医科大学 | Vegf遺伝子の発現抑制用一本鎖核酸分子 |
| WO2016061562A2 (en) * | 2014-10-17 | 2016-04-21 | Kodiak Sciences Inc. | Butyrylcholinesterase zwitterionic polymer conjugates |
| WO2016100113A2 (en) * | 2014-12-17 | 2016-06-23 | Siemens Healthcare Diagnostics Inc. | Conjugates for assays for oxycodone and oxymorphone |
| WO2016104775A1 (ja) | 2014-12-27 | 2016-06-30 | 株式会社ボナック | 遺伝子発現制御のための天然型miRNAおよびその用途 |
| WO2016108264A1 (ja) | 2014-12-29 | 2016-07-07 | 株式会社ボナック | 核酸分子を安定に含有する組成物 |
| JP2017199945A (ja) | 2016-04-25 | 2017-11-02 | 株式会社ナカヨ | 強制ログアウト機能を有する通信装置 |
| WO2018185131A2 (en) * | 2017-04-05 | 2018-10-11 | Novo Nordisk A/S | Oligomer extended insulin-fc conjugates |
Non-Patent Citations (6)
| Title |
|---|
| "Concise Encyclopedia of Polymer Science and Engineering", 1990, JOHN WILEY SONS |
| ENGLISCH ET AL., ANGEWANDTE CHEMIE, INTERNATIONAL EDITION, vol. 30, 1991, pages 613 |
| LIMBACH ET AL.: "Summary: the modified nucleosides of RNA", NUCLEIC ACIDS RES., vol. 22, 1994, pages 2183 - 2196, XP001152667 |
| See also references of EP3696269A4 |
| SUCHY, MOJMIR ET AL.: "Analogs of Eu3+ DOTAM-Gly- Phe-OH and Tm3+ DOTAM-Gly-Lys-OH: Synthesis and magnetic properties of potential PARACEST MRI contrast agents", BIOORG. MED. CHEM., vol. 16, 2008, pages 6156 - 6166, XP022700345, DOI: doi:10.1016/j.bmc.2008.04.038 * |
| ZAITSU, KIYOSHI ET AL.: "New Heterobifunctional Cross-Linking Reagents for Protein Conjugation, N-(Bromoacetamido-n-alkanoyloxy)succinimides", CHEM. PHARM. BULL., vol. 35, 1987, pages 1991 - 1997, XP002027736 * |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021070494A1 (ja) | 2019-10-11 | 2021-04-15 | 住友化学株式会社 | 核酸オリゴマーの製造方法 |
| WO2021153770A1 (en) | 2020-01-29 | 2021-08-05 | Sumitomo Chemical Company, Limited | Process of preparing nucleic acid oligomer |
| WO2021153047A1 (ja) | 2020-01-29 | 2021-08-05 | 住友化学株式会社 | 核酸オリゴマーの製造方法 |
| WO2021193954A1 (ja) | 2020-03-27 | 2021-09-30 | 住友化学株式会社 | 核酸オリゴマーの製造方法 |
| WO2022009959A1 (ja) | 2020-07-09 | 2022-01-13 | 住友化学株式会社 | 核酸オリゴマーの製造方法 |
| WO2022064908A1 (ja) | 2020-09-24 | 2022-03-31 | 住友化学株式会社 | 核酸オリゴマーの製造方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2019074110A1 (ja) | 2020-12-24 |
| EP3696269A1 (en) | 2020-08-19 |
| EP3696269A4 (en) | 2021-09-01 |
| US20210188895A1 (en) | 2021-06-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2938193T3 (es) | Acidos nucleicos para inhibir la expresión de LPA en una célula | |
| WO2019074110A1 (ja) | 一本鎖核酸分子およびその製造方法 | |
| ES2805026T3 (es) | Acido nucleico unido a un glucoconjugado trivalente | |
| ES2550487T3 (es) | Molécula de ácido nucleico monocatenario para controlar la expresión génica | |
| KR20210018267A (ko) | 간외 전달 | |
| ES2932295T3 (es) | Acidos nucleicos para inhibir la expresión de LPA en una célula | |
| AU2018247925A1 (en) | Products and compositions | |
| EP3604533A1 (en) | Site-specific delivery of nucleic acids by combining targeting ligands with endosomolytic components | |
| ES2926369T3 (es) | Molécula de ácido nucleico monocatenario que tiene función de suministro y capacidad de control de la expresión génica | |
| WO2011163121A1 (en) | Multifunctional copolymers for nucleic acid delivery | |
| KR20220110749A (ko) | 간외 전달 | |
| WO2018185239A1 (en) | Products and compositions | |
| WO2019092280A1 (en) | Nucleic acids for inhibiting expression of a target gene comprising phosphorodithioate linkages | |
| EP3550021A1 (en) | Products and compositions for inhibiting expression of a target gene | |
| EP3385272A1 (en) | Further novel oligonucleotide-ligand conjugates | |
| JP2017046596A (ja) | TGF−β1遺伝子発現制御のための一本鎖核酸分子 | |
| RU2812806C2 (ru) | Нуклеиновые кислоты для ингибирования экспрессии гена-мишени, содержащие фосфодитиоатные связи | |
| AU2017206154A1 (en) | Site-specific delivery of nucleic acids by combining targeting ligands with endosomolytic components | |
| JP6726105B2 (ja) | TGF−β1発現抑制のための一本鎖核酸分子 | |
| EA045986B1 (ru) | Нуклеиновые кислоты для ингибирования экспрессии lpa в клетке | |
| WO2019074071A1 (ja) | 核酸分子発現の調節 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 18865423 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2019548260 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2018865423 Country of ref document: EP Effective date: 20200513 |