KR20220145894A - 신규 항체 - Google Patents
신규 항체 Download PDFInfo
- Publication number
- KR20220145894A KR20220145894A KR1020227033455A KR20227033455A KR20220145894A KR 20220145894 A KR20220145894 A KR 20220145894A KR 1020227033455 A KR1020227033455 A KR 1020227033455A KR 20227033455 A KR20227033455 A KR 20227033455A KR 20220145894 A KR20220145894 A KR 20220145894A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- antibody
- fragment
- sequence
- optionally
- Prior art date
Links
- 239000012634 fragment Substances 0.000 claims abstract description 423
- 108091008874 T cell receptors Proteins 0.000 claims abstract description 232
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 claims abstract description 211
- 238000000034 method Methods 0.000 claims abstract description 72
- 238000011282 treatment Methods 0.000 claims abstract description 14
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 233
- 210000004027 cell Anatomy 0.000 claims description 200
- 108091007433 antigens Proteins 0.000 claims description 189
- 102000036639 antigens Human genes 0.000 claims description 189
- 101100112922 Candida albicans CDR3 gene Proteins 0.000 claims description 188
- 239000000427 antigen Substances 0.000 claims description 187
- 230000027455 binding Effects 0.000 claims description 169
- 238000009739 binding Methods 0.000 claims description 169
- 241000282414 Homo sapiens Species 0.000 claims description 133
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 129
- 102000040430 polynucleotide Human genes 0.000 claims description 57
- 108091033319 polynucleotide Proteins 0.000 claims description 57
- 239000002157 polynucleotide Substances 0.000 claims description 57
- 125000000539 amino acid group Chemical group 0.000 claims description 53
- 239000013604 expression vector Substances 0.000 claims description 46
- 239000008194 pharmaceutical composition Substances 0.000 claims description 24
- 206010028980 Neoplasm Diseases 0.000 claims description 22
- 239000000203 mixture Substances 0.000 claims description 20
- 230000009258 tissue cross reactivity Effects 0.000 claims description 20
- 201000011510 cancer Diseases 0.000 claims description 17
- 239000003814 drug Substances 0.000 claims description 14
- 230000001404 mediated effect Effects 0.000 claims description 13
- 230000003213 activating effect Effects 0.000 claims description 12
- 230000002147 killing effect Effects 0.000 claims description 11
- 208000035473 Communicable disease Diseases 0.000 claims description 8
- 208000015181 infectious disease Diseases 0.000 claims description 8
- 208000027866 inflammatory disease Diseases 0.000 claims description 8
- 239000013543 active substance Substances 0.000 claims description 6
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 4
- 239000003085 diluting agent Substances 0.000 claims description 4
- 230000005754 cellular signaling Effects 0.000 claims description 2
- 235000001014 amino acid Nutrition 0.000 description 81
- 229940024606 amino acid Drugs 0.000 description 73
- 108090000623 proteins and genes Proteins 0.000 description 68
- 108090000765 processed proteins & peptides Proteins 0.000 description 65
- 102000004196 processed proteins & peptides Human genes 0.000 description 59
- 235000018102 proteins Nutrition 0.000 description 58
- 102000004169 proteins and genes Human genes 0.000 description 56
- 229920001184 polypeptide Polymers 0.000 description 55
- 150000001413 amino acids Chemical class 0.000 description 53
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Chemical compound NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 47
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 37
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 37
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 33
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 33
- 108010008355 arginyl-glutamine Proteins 0.000 description 33
- 108010089804 glycyl-threonine Proteins 0.000 description 33
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 32
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 32
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 32
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 32
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 31
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 31
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 30
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 30
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 29
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 28
- 108010068265 aspartyltyrosine Proteins 0.000 description 28
- 241000880493 Leptailurus serval Species 0.000 description 26
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 26
- 239000013598 vector Substances 0.000 description 26
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 25
- 238000006467 substitution reaction Methods 0.000 description 25
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 24
- 101100315624 Caenorhabditis elegans tyr-1 gene Proteins 0.000 description 23
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 22
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 22
- 108010026333 seryl-proline Proteins 0.000 description 22
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 21
- 210000001519 tissue Anatomy 0.000 description 21
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 20
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 20
- 229940027941 immunoglobulin g Drugs 0.000 description 20
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 19
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 19
- 238000002703 mutagenesis Methods 0.000 description 19
- 231100000350 mutagenesis Toxicity 0.000 description 19
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 18
- 238000003556 assay Methods 0.000 description 18
- 238000010186 staining Methods 0.000 description 18
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 17
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 17
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 17
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 17
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 17
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 17
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 17
- 230000003828 downregulation Effects 0.000 description 17
- 238000000684 flow cytometry Methods 0.000 description 17
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 17
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 16
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 16
- 108060003951 Immunoglobulin Proteins 0.000 description 16
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 16
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 16
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 16
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 16
- 102000018358 immunoglobulin Human genes 0.000 description 16
- VKKYFICVTYKFIO-CIUDSAMLSA-N Arg-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N VKKYFICVTYKFIO-CIUDSAMLSA-N 0.000 description 15
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 15
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 15
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 15
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 15
- WUFHZIRMAZZWRS-OSUNSFLBSA-N Val-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C(C)C)N WUFHZIRMAZZWRS-OSUNSFLBSA-N 0.000 description 15
- 108010081404 acein-2 Proteins 0.000 description 15
- 230000006870 function Effects 0.000 description 15
- 230000001965 increasing effect Effects 0.000 description 15
- 238000012360 testing method Methods 0.000 description 15
- JBDLMLZNDRLDIX-HJGDQZAQSA-N Asn-Thr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O JBDLMLZNDRLDIX-HJGDQZAQSA-N 0.000 description 14
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 14
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 14
- XHVONGZZVUUORG-WEDXCCLWSA-N Gly-Thr-Lys Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN XHVONGZZVUUORG-WEDXCCLWSA-N 0.000 description 14
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 14
- 239000002609 medium Substances 0.000 description 14
- 239000013642 negative control Substances 0.000 description 14
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 14
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 13
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 13
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 13
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 13
- HSBZWINKRYZCSQ-KKUMJFAQSA-N Tyr-Lys-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O HSBZWINKRYZCSQ-KKUMJFAQSA-N 0.000 description 13
- KXEVYGKATAMXJJ-ACZMJKKPSA-N Ala-Glu-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KXEVYGKATAMXJJ-ACZMJKKPSA-N 0.000 description 12
- UGXYFDQFLVCDFC-CIUDSAMLSA-N Asn-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O UGXYFDQFLVCDFC-CIUDSAMLSA-N 0.000 description 12
- IKFZXRLDMYWNBU-YUMQZZPRSA-N Gln-Gly-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N IKFZXRLDMYWNBU-YUMQZZPRSA-N 0.000 description 12
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 12
- GBYYQVBXFVDJPJ-WLTAIBSBSA-N Gly-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)CN)O GBYYQVBXFVDJPJ-WLTAIBSBSA-N 0.000 description 12
- SJDQOYTYNGZZJX-SRVKXCTJSA-N Met-Glu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SJDQOYTYNGZZJX-SRVKXCTJSA-N 0.000 description 12
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 12
- 238000012217 deletion Methods 0.000 description 12
- 230000037430 deletion Effects 0.000 description 12
- 239000000975 dye Substances 0.000 description 12
- 238000002955 isolation Methods 0.000 description 12
- 230000004048 modification Effects 0.000 description 12
- 238000012986 modification Methods 0.000 description 12
- 108010051242 phenylalanylserine Proteins 0.000 description 12
- RMAWDDRDTRSZIR-ZLUOBGJFSA-N Ala-Ser-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RMAWDDRDTRSZIR-ZLUOBGJFSA-N 0.000 description 11
- 238000002965 ELISA Methods 0.000 description 11
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 11
- LJBVRCDPWOJOEK-PPCPHDFISA-N Leu-Thr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LJBVRCDPWOJOEK-PPCPHDFISA-N 0.000 description 11
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 11
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 11
- 238000007792 addition Methods 0.000 description 11
- 230000002998 immunogenetic effect Effects 0.000 description 11
- 238000001727 in vivo Methods 0.000 description 11
- 238000004519 manufacturing process Methods 0.000 description 11
- 238000013507 mapping Methods 0.000 description 11
- 241000894007 species Species 0.000 description 11
- 108010076441 Ala-His-His Proteins 0.000 description 10
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 10
- 102100025137 Early activation antigen CD69 Human genes 0.000 description 10
- WZZSKAJIHTUUSG-ACZMJKKPSA-N Glu-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O WZZSKAJIHTUUSG-ACZMJKKPSA-N 0.000 description 10
- 101000934374 Homo sapiens Early activation antigen CD69 Proteins 0.000 description 10
- 108010002350 Interleukin-2 Proteins 0.000 description 10
- GNRMAQSIROFNMI-IXOXFDKPSA-N Phe-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GNRMAQSIROFNMI-IXOXFDKPSA-N 0.000 description 10
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 10
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 10
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 10
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 10
- DIPIPFHFLPTCLK-LOKLDPHHSA-N Thr-Gln-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O DIPIPFHFLPTCLK-LOKLDPHHSA-N 0.000 description 10
- LIXBDERDAGNVAV-XKBZYTNZSA-N Thr-Gln-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O LIXBDERDAGNVAV-XKBZYTNZSA-N 0.000 description 10
- PKZIWSHDJYIPRH-JBACZVJFSA-N Trp-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKZIWSHDJYIPRH-JBACZVJFSA-N 0.000 description 10
- CKTMJBPRVQWPHU-JSGCOSHPSA-N Val-Phe-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)O)N CKTMJBPRVQWPHU-JSGCOSHPSA-N 0.000 description 10
- JQTYTBPCSOAZHI-FXQIFTODSA-N Val-Ser-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N JQTYTBPCSOAZHI-FXQIFTODSA-N 0.000 description 10
- 201000010099 disease Diseases 0.000 description 10
- 230000004927 fusion Effects 0.000 description 10
- 210000004602 germ cell Anatomy 0.000 description 10
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 10
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 10
- 239000002953 phosphate buffered saline Substances 0.000 description 10
- AWAXZRDKUHOPBO-GUBZILKMSA-N Ala-Gln-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O AWAXZRDKUHOPBO-GUBZILKMSA-N 0.000 description 9
- ATABBWFGOHKROJ-GUBZILKMSA-N Arg-Pro-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O ATABBWFGOHKROJ-GUBZILKMSA-N 0.000 description 9
- DATSKXOXPUAOLK-KKUMJFAQSA-N Asn-Tyr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O DATSKXOXPUAOLK-KKUMJFAQSA-N 0.000 description 9
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 9
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 9
- 108090000172 Interleukin-15 Proteins 0.000 description 9
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 9
- QLQHWWCSCLZUMA-KKUMJFAQSA-N Leu-Asp-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QLQHWWCSCLZUMA-KKUMJFAQSA-N 0.000 description 9
- 238000004458 analytical method Methods 0.000 description 9
- 108010093581 aspartyl-proline Proteins 0.000 description 9
- 239000011230 binding agent Substances 0.000 description 9
- 230000000975 bioactive effect Effects 0.000 description 9
- 108010028295 histidylhistidine Proteins 0.000 description 9
- 238000011534 incubation Methods 0.000 description 9
- 150000007523 nucleic acids Chemical class 0.000 description 9
- 238000002823 phage display Methods 0.000 description 9
- 239000013612 plasmid Substances 0.000 description 9
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 9
- 230000000638 stimulation Effects 0.000 description 9
- 108010044292 tryptophyltyrosine Proteins 0.000 description 9
- JBGSZRYCXBPWGX-BQBZGAKWSA-N Ala-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N JBGSZRYCXBPWGX-BQBZGAKWSA-N 0.000 description 8
- BTRULDJUUVGRNE-DCAQKATOSA-N Ala-Pro-Lys Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O BTRULDJUUVGRNE-DCAQKATOSA-N 0.000 description 8
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 8
- OGTCOKZFOJIZFG-CIUDSAMLSA-N Asp-His-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(O)=O OGTCOKZFOJIZFG-CIUDSAMLSA-N 0.000 description 8
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 8
- 108020004414 DNA Proteins 0.000 description 8
- 238000012286 ELISA Assay Methods 0.000 description 8
- CRRFJBGUGNNOCS-PEFMBERDSA-N Gln-Asp-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CRRFJBGUGNNOCS-PEFMBERDSA-N 0.000 description 8
- MADFVRSKEIEZHZ-DCAQKATOSA-N Gln-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N MADFVRSKEIEZHZ-DCAQKATOSA-N 0.000 description 8
- GNPVTZJUUBPZKW-WDSKDSINSA-N Gly-Gln-Ser Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GNPVTZJUUBPZKW-WDSKDSINSA-N 0.000 description 8
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 8
- NXRNRBOKDBIVKQ-CXTHYWKRSA-N Ile-Tyr-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N NXRNRBOKDBIVKQ-CXTHYWKRSA-N 0.000 description 8
- 108010065920 Insulin Lispro Proteins 0.000 description 8
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 8
- 108010079364 N-glycylalanine Proteins 0.000 description 8
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 8
- ICHZYBVODUVUKN-SRVKXCTJSA-N Ser-Asn-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ICHZYBVODUVUKN-SRVKXCTJSA-N 0.000 description 8
- MPPHJZYXDVDGOF-BWBBJGPYSA-N Ser-Cys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CO MPPHJZYXDVDGOF-BWBBJGPYSA-N 0.000 description 8
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 8
- KRPKYGOFYUNIGM-XVSYOHENSA-N Thr-Asp-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O KRPKYGOFYUNIGM-XVSYOHENSA-N 0.000 description 8
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 8
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 8
- RVMNUBQWPVOUKH-HEIBUPTGSA-N Thr-Ser-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMNUBQWPVOUKH-HEIBUPTGSA-N 0.000 description 8
- 230000004913 activation Effects 0.000 description 8
- 230000000890 antigenic effect Effects 0.000 description 8
- 238000010367 cloning Methods 0.000 description 8
- 238000013461 design Methods 0.000 description 8
- 238000011161 development Methods 0.000 description 8
- 230000018109 developmental process Effects 0.000 description 8
- 238000002474 experimental method Methods 0.000 description 8
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 8
- 108010015792 glycyllysine Proteins 0.000 description 8
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 8
- 239000003446 ligand Substances 0.000 description 8
- 108010017391 lysylvaline Proteins 0.000 description 8
- 102000039446 nucleic acids Human genes 0.000 description 8
- 108020004707 nucleic acids Proteins 0.000 description 8
- ATAKEVCGTRZKLI-UWJYBYFXSA-N Ala-His-His Chemical compound C([C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 ATAKEVCGTRZKLI-UWJYBYFXSA-N 0.000 description 7
- ISJWBVIYRBAXEB-CIUDSAMLSA-N Arg-Ser-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISJWBVIYRBAXEB-CIUDSAMLSA-N 0.000 description 7
- QLSRIZIDQXDQHK-RCWTZXSCSA-N Arg-Val-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QLSRIZIDQXDQHK-RCWTZXSCSA-N 0.000 description 7
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 7
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 7
- 206010009944 Colon cancer Diseases 0.000 description 7
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 7
- BPHKULHWEIUDOB-FXQIFTODSA-N Cys-Gln-Gln Chemical compound SC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O BPHKULHWEIUDOB-FXQIFTODSA-N 0.000 description 7
- YZCKVEUIGOORGS-OUBTZVSYSA-N Deuterium Chemical group [2H] YZCKVEUIGOORGS-OUBTZVSYSA-N 0.000 description 7
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 7
- GHAXJVNBAKGWEJ-AVGNSLFASA-N Gln-Ser-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GHAXJVNBAKGWEJ-AVGNSLFASA-N 0.000 description 7
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 7
- KSOBNUBCYHGUKH-UWVGGRQHSA-N Gly-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN KSOBNUBCYHGUKH-UWVGGRQHSA-N 0.000 description 7
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 7
- 241000282412 Homo Species 0.000 description 7
- 101001023379 Homo sapiens Lysosome-associated membrane glycoprotein 1 Proteins 0.000 description 7
- WNQKUUQIVDDAFA-ZPFDUUQYSA-N Ile-Gln-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCSC)C(=O)O)N WNQKUUQIVDDAFA-ZPFDUUQYSA-N 0.000 description 7
- FBGXMKUWQFPHFB-JBDRJPRFSA-N Ile-Ser-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N FBGXMKUWQFPHFB-JBDRJPRFSA-N 0.000 description 7
- ZLFNNVATRMCAKN-ZKWXMUAHSA-N Ile-Ser-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZLFNNVATRMCAKN-ZKWXMUAHSA-N 0.000 description 7
- RKQAYOWLSFLJEE-SVSWQMSJSA-N Ile-Thr-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)O)N RKQAYOWLSFLJEE-SVSWQMSJSA-N 0.000 description 7
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 7
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 7
- OIQSIMFSVLLWBX-VOAKCMCISA-N Lys-Leu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OIQSIMFSVLLWBX-VOAKCMCISA-N 0.000 description 7
- 102100035133 Lysosome-associated membrane glycoprotein 1 Human genes 0.000 description 7
- 108010066427 N-valyltryptophan Proteins 0.000 description 7
- GOMUXSCOIWIJFP-GUBZILKMSA-N Pro-Ser-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GOMUXSCOIWIJFP-GUBZILKMSA-N 0.000 description 7
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 7
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 7
- JCLAFVNDBJMLBC-JBDRJPRFSA-N Ser-Ser-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JCLAFVNDBJMLBC-JBDRJPRFSA-N 0.000 description 7
- JURQXQBJKUHGJS-UHFFFAOYSA-N Ser-Ser-Ser-Ser Chemical compound OCC(N)C(=O)NC(CO)C(=O)NC(CO)C(=O)NC(CO)C(O)=O JURQXQBJKUHGJS-UHFFFAOYSA-N 0.000 description 7
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 7
- JVTHIXKSVYEWNI-JRQIVUDYSA-N Thr-Asn-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JVTHIXKSVYEWNI-JRQIVUDYSA-N 0.000 description 7
- DJEVQCWNMQOABE-RCOVLWMOSA-N Val-Gly-Asp Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)O)C(=O)O)N DJEVQCWNMQOABE-RCOVLWMOSA-N 0.000 description 7
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 7
- 108010087924 alanylproline Proteins 0.000 description 7
- 108010060035 arginylproline Proteins 0.000 description 7
- 108010047857 aspartylglycine Proteins 0.000 description 7
- 108010092854 aspartyllysine Proteins 0.000 description 7
- 210000004369 blood Anatomy 0.000 description 7
- 239000008280 blood Substances 0.000 description 7
- 230000008859 change Effects 0.000 description 7
- 229910052805 deuterium Inorganic materials 0.000 description 7
- 238000010494 dissociation reaction Methods 0.000 description 7
- 230000005593 dissociations Effects 0.000 description 7
- 230000000694 effects Effects 0.000 description 7
- 238000005516 engineering process Methods 0.000 description 7
- 229940088598 enzyme Drugs 0.000 description 7
- 108010078144 glutaminyl-glycine Proteins 0.000 description 7
- 108010037850 glycylvaline Proteins 0.000 description 7
- 210000005024 intraepithelial lymphocyte Anatomy 0.000 description 7
- 108010003700 lysyl aspartic acid Proteins 0.000 description 7
- 239000002773 nucleotide Substances 0.000 description 7
- 125000003729 nucleotide group Chemical group 0.000 description 7
- 230000035755 proliferation Effects 0.000 description 7
- 239000000243 solution Substances 0.000 description 7
- 108010061238 threonyl-glycine Proteins 0.000 description 7
- 108010003137 tyrosyltyrosine Proteins 0.000 description 7
- YYAVDNKUWLAFCV-ACZMJKKPSA-N Ala-Ser-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O YYAVDNKUWLAFCV-ACZMJKKPSA-N 0.000 description 6
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 6
- ASQKVGRCKOFKIU-KZVJFYERSA-N Arg-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ASQKVGRCKOFKIU-KZVJFYERSA-N 0.000 description 6
- LGCVSPFCFXWUEY-IHPCNDPISA-N Asn-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N LGCVSPFCFXWUEY-IHPCNDPISA-N 0.000 description 6
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 6
- BJDHEININLSZOT-KKUMJFAQSA-N Asp-Tyr-Lys Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(O)=O BJDHEININLSZOT-KKUMJFAQSA-N 0.000 description 6
- 101100028791 Caenorhabditis elegans pbs-5 gene Proteins 0.000 description 6
- 102000004190 Enzymes Human genes 0.000 description 6
- 108090000790 Enzymes Proteins 0.000 description 6
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 6
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 6
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 6
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 6
- IXHKPDJKKCUKHS-GARJFASQSA-N Lys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IXHKPDJKKCUKHS-GARJFASQSA-N 0.000 description 6
- DIBZLYZXTSVGLN-CIUDSAMLSA-N Lys-Ser-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O DIBZLYZXTSVGLN-CIUDSAMLSA-N 0.000 description 6
- BPCLGWHVPVTTFM-QWRGUYRKSA-N Phe-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O BPCLGWHVPVTTFM-QWRGUYRKSA-N 0.000 description 6
- YXHYJEPDKSYPSQ-AVGNSLFASA-N Pro-Leu-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 YXHYJEPDKSYPSQ-AVGNSLFASA-N 0.000 description 6
- QKWYXRPICJEQAJ-KJEVXHAQSA-N Pro-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@@H]2CCCN2)O QKWYXRPICJEQAJ-KJEVXHAQSA-N 0.000 description 6
- 108010076504 Protein Sorting Signals Proteins 0.000 description 6
- WTWGOQRNRFHFQD-JBDRJPRFSA-N Ser-Ala-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WTWGOQRNRFHFQD-JBDRJPRFSA-N 0.000 description 6
- AMRRYKHCILPAKD-FXQIFTODSA-N Ser-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CO)N AMRRYKHCILPAKD-FXQIFTODSA-N 0.000 description 6
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 6
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 6
- HQJOVVWAPQPYDS-ZFWWWQNUSA-N Trp-Gly-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQJOVVWAPQPYDS-ZFWWWQNUSA-N 0.000 description 6
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 6
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 6
- NUQZCPSZHGIYTA-HKUYNNGSSA-N Tyr-Trp-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N NUQZCPSZHGIYTA-HKUYNNGSSA-N 0.000 description 6
- AGDDLOQMXUQPDY-BZSNNMDCSA-N Tyr-Tyr-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O AGDDLOQMXUQPDY-BZSNNMDCSA-N 0.000 description 6
- 230000004075 alteration Effects 0.000 description 6
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 6
- 238000001574 biopsy Methods 0.000 description 6
- 210000004899 c-terminal region Anatomy 0.000 description 6
- 239000003795 chemical substances by application Substances 0.000 description 6
- 108010054812 diprotin A Proteins 0.000 description 6
- 208000035475 disorder Diseases 0.000 description 6
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 6
- 230000003993 interaction Effects 0.000 description 6
- 230000000968 intestinal effect Effects 0.000 description 6
- 108010038320 lysylphenylalanine Proteins 0.000 description 6
- 230000035772 mutation Effects 0.000 description 6
- 108010025826 prolyl-leucyl-arginine Proteins 0.000 description 6
- 230000001225 therapeutic effect Effects 0.000 description 6
- 210000003171 tumor-infiltrating lymphocyte Anatomy 0.000 description 6
- 230000003827 upregulation Effects 0.000 description 6
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 5
- ADPACBMPYWJJCE-FXQIFTODSA-N Arg-Ser-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O ADPACBMPYWJJCE-FXQIFTODSA-N 0.000 description 5
- OOXUBGLNDRGOKT-FXQIFTODSA-N Asn-Ser-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OOXUBGLNDRGOKT-FXQIFTODSA-N 0.000 description 5
- HTSSXFASOUSJQG-IHPCNDPISA-N Asp-Tyr-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HTSSXFASOUSJQG-IHPCNDPISA-N 0.000 description 5
- LOJYQMFIIJVETK-WDSKDSINSA-N Gln-Gln Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(O)=O LOJYQMFIIJVETK-WDSKDSINSA-N 0.000 description 5
- RBWKVOSARCFSQQ-FXQIFTODSA-N Gln-Gln-Ser Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O RBWKVOSARCFSQQ-FXQIFTODSA-N 0.000 description 5
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 5
- SBHVGKBYOQKAEA-SDDRHHMPSA-N Gln-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SBHVGKBYOQKAEA-SDDRHHMPSA-N 0.000 description 5
- SXFPZRRVWSUYII-KBIXCLLPSA-N Gln-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N SXFPZRRVWSUYII-KBIXCLLPSA-N 0.000 description 5
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 5
- OTQSTOXRUBVWAP-NRPADANISA-N Gln-Ser-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O OTQSTOXRUBVWAP-NRPADANISA-N 0.000 description 5
- NPSWCZIRBAYNSB-JHEQGTHGSA-N Gly-Gln-Thr Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NPSWCZIRBAYNSB-JHEQGTHGSA-N 0.000 description 5
- TWTPDFFBLQEBOE-IUCAKERBSA-N Gly-Leu-Gln Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O TWTPDFFBLQEBOE-IUCAKERBSA-N 0.000 description 5
- VBOBNHSVQKKTOT-YUMQZZPRSA-N Gly-Lys-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O VBOBNHSVQKKTOT-YUMQZZPRSA-N 0.000 description 5
- VNNRLUNBJSWZPF-ZKWXMUAHSA-N Gly-Ser-Ile Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNNRLUNBJSWZPF-ZKWXMUAHSA-N 0.000 description 5
- POJJAZJHBGXEGM-YUMQZZPRSA-N Gly-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)CN POJJAZJHBGXEGM-YUMQZZPRSA-N 0.000 description 5
- FFALDIDGPLUDKV-ZDLURKLDSA-N Gly-Thr-Ser Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O FFALDIDGPLUDKV-ZDLURKLDSA-N 0.000 description 5
- DNAZKGFYFRGZIH-QWRGUYRKSA-N Gly-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 DNAZKGFYFRGZIH-QWRGUYRKSA-N 0.000 description 5
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 5
- ZJSMFRTVYSLKQU-DJFWLOJKSA-N His-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC1=CN=CN1)N ZJSMFRTVYSLKQU-DJFWLOJKSA-N 0.000 description 5
- NZGTYCMLUGYMCV-XUXIUFHCSA-N Ile-Lys-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N NZGTYCMLUGYMCV-XUXIUFHCSA-N 0.000 description 5
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 5
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 5
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 5
- IBQMEXQYZMVIFU-SRVKXCTJSA-N Lys-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCCN)N IBQMEXQYZMVIFU-SRVKXCTJSA-N 0.000 description 5
- 239000004472 Lysine Substances 0.000 description 5
- FVKRQMQQFGBXHV-QXEWZRGKSA-N Met-Asp-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O FVKRQMQQFGBXHV-QXEWZRGKSA-N 0.000 description 5
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 5
- 241001465754 Metazoa Species 0.000 description 5
- NAXPHWZXEXNDIW-JTQLQIEISA-N Phe-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 NAXPHWZXEXNDIW-JTQLQIEISA-N 0.000 description 5
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 5
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 5
- WLJPJRGQRNCIQS-ZLUOBGJFSA-N Ser-Ser-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O WLJPJRGQRNCIQS-ZLUOBGJFSA-N 0.000 description 5
- PPCZVWHJWJFTFN-ZLUOBGJFSA-N Ser-Ser-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPCZVWHJWJFTFN-ZLUOBGJFSA-N 0.000 description 5
- VVKVHAOOUGNDPJ-SRVKXCTJSA-N Ser-Tyr-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VVKVHAOOUGNDPJ-SRVKXCTJSA-N 0.000 description 5
- -1 TRGV4 Proteins 0.000 description 5
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 5
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 5
- LMKKMCGTDANZTR-BZSNNMDCSA-N Tyr-Phe-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 LMKKMCGTDANZTR-BZSNNMDCSA-N 0.000 description 5
- LUMQYLVYUIRHHU-YJRXYDGGSA-N Tyr-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUMQYLVYUIRHHU-YJRXYDGGSA-N 0.000 description 5
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 5
- USXYVSTVPHELAF-RCWTZXSCSA-N Val-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](C(C)C)N)O USXYVSTVPHELAF-RCWTZXSCSA-N 0.000 description 5
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 5
- 235000004279 alanine Nutrition 0.000 description 5
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 5
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 5
- 108010038633 aspartylglutamate Proteins 0.000 description 5
- 230000000903 blocking effect Effects 0.000 description 5
- 238000006243 chemical reaction Methods 0.000 description 5
- 239000002299 complementary DNA Substances 0.000 description 5
- 238000001514 detection method Methods 0.000 description 5
- 239000007850 fluorescent dye Substances 0.000 description 5
- 210000001035 gastrointestinal tract Anatomy 0.000 description 5
- 108010010147 glycylglutamine Proteins 0.000 description 5
- 239000000833 heterodimer Substances 0.000 description 5
- 230000001939 inductive effect Effects 0.000 description 5
- 230000002401 inhibitory effect Effects 0.000 description 5
- 238000002360 preparation method Methods 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- 208000024891 symptom Diseases 0.000 description 5
- 230000008685 targeting Effects 0.000 description 5
- 108010033670 threonyl-aspartyl-tyrosine Proteins 0.000 description 5
- VNYMOTCMNHJGTG-JBDRJPRFSA-N Ala-Ile-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O VNYMOTCMNHJGTG-JBDRJPRFSA-N 0.000 description 4
- QDGMZAOSMNGBLP-MRFFXTKBSA-N Ala-Trp-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N QDGMZAOSMNGBLP-MRFFXTKBSA-N 0.000 description 4
- ULBHWNVWSCJLCO-NHCYSSNCSA-N Arg-Val-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N ULBHWNVWSCJLCO-NHCYSSNCSA-N 0.000 description 4
- SLKLLQWZQHXYSV-CIUDSAMLSA-N Asn-Ala-Lys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O SLKLLQWZQHXYSV-CIUDSAMLSA-N 0.000 description 4
- NCXTYSVDWLAQGZ-ZKWXMUAHSA-N Asn-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O NCXTYSVDWLAQGZ-ZKWXMUAHSA-N 0.000 description 4
- 102100025430 Butyrophilin-like protein 3 Human genes 0.000 description 4
- XZWYTXMRWQJBGX-VXBMVYAYSA-N FLAG peptide Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)CC1=CC=C(O)C=C1 XZWYTXMRWQJBGX-VXBMVYAYSA-N 0.000 description 4
- SHERTACNJPYHAR-ACZMJKKPSA-N Gln-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O SHERTACNJPYHAR-ACZMJKKPSA-N 0.000 description 4
- NKCZYEDZTKOFBG-GUBZILKMSA-N Gln-Gln-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NKCZYEDZTKOFBG-GUBZILKMSA-N 0.000 description 4
- QGZSAHIZRQHCEQ-QWRGUYRKSA-N Gly-Asp-Tyr Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QGZSAHIZRQHCEQ-QWRGUYRKSA-N 0.000 description 4
- OJNZVYSGVYLQIN-BQBZGAKWSA-N Gly-Met-Asp Chemical compound [H]NCC(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O OJNZVYSGVYLQIN-BQBZGAKWSA-N 0.000 description 4
- LSQHWKPPOFDHHZ-YUMQZZPRSA-N His-Asp-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N LSQHWKPPOFDHHZ-YUMQZZPRSA-N 0.000 description 4
- 101000934741 Homo sapiens Butyrophilin-like protein 3 Proteins 0.000 description 4
- UAELWXJFLZBKQS-WHOFXGATSA-N Ile-Phe-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](Cc1ccccc1)C(=O)NCC(O)=O UAELWXJFLZBKQS-WHOFXGATSA-N 0.000 description 4
- RMJWFINHACYKJI-SIUGBPQLSA-N Ile-Tyr-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N RMJWFINHACYKJI-SIUGBPQLSA-N 0.000 description 4
- ZSESFIFAYQEKRD-CYDGBPFRSA-N Ile-Val-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(=O)O)N ZSESFIFAYQEKRD-CYDGBPFRSA-N 0.000 description 4
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 4
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 4
- 239000007760 Iscove's Modified Dulbecco's Medium Substances 0.000 description 4
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 4
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 4
- HPBCTWSUJOGJSH-MNXVOIDGSA-N Leu-Glu-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HPBCTWSUJOGJSH-MNXVOIDGSA-N 0.000 description 4
- JDBQSGMJBMPNFT-AVGNSLFASA-N Leu-Pro-Val Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O JDBQSGMJBMPNFT-AVGNSLFASA-N 0.000 description 4
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 4
- ORVFEGYUJITPGI-IHRRRGAJSA-N Lys-Leu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCCN ORVFEGYUJITPGI-IHRRRGAJSA-N 0.000 description 4
- UOENBSHXYCHSAU-YUMQZZPRSA-N Met-Gln-Gly Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O UOENBSHXYCHSAU-YUMQZZPRSA-N 0.000 description 4
- 241000699666 Mus <mouse, genus> Species 0.000 description 4
- 241000699670 Mus sp. Species 0.000 description 4
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 4
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 4
- QPVFUAUFEBPIPT-CDMKHQONSA-N Phe-Gly-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O QPVFUAUFEBPIPT-CDMKHQONSA-N 0.000 description 4
- 229920001213 Polysorbate 20 Polymers 0.000 description 4
- BGWKULMLUIUPKY-BQBZGAKWSA-N Pro-Ser-Gly Chemical compound OC(=O)CNC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 BGWKULMLUIUPKY-BQBZGAKWSA-N 0.000 description 4
- KHRLUIPIMIQFGT-AVGNSLFASA-N Pro-Val-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KHRLUIPIMIQFGT-AVGNSLFASA-N 0.000 description 4
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 4
- SWSRFJZZMNLMLY-ZKWXMUAHSA-N Ser-Asp-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O SWSRFJZZMNLMLY-ZKWXMUAHSA-N 0.000 description 4
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 4
- ILZAUMFXKSIUEF-SRVKXCTJSA-N Ser-Ser-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ILZAUMFXKSIUEF-SRVKXCTJSA-N 0.000 description 4
- WUXCHQZLUHBSDJ-LKXGYXEUSA-N Ser-Thr-Asp Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC(O)=O)C(O)=O WUXCHQZLUHBSDJ-LKXGYXEUSA-N 0.000 description 4
- JZRYFUGREMECBH-XPUUQOCRSA-N Ser-Val-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O JZRYFUGREMECBH-XPUUQOCRSA-N 0.000 description 4
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 4
- GLQFKOVWXPPFTP-VEVYYDQMSA-N Thr-Arg-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O GLQFKOVWXPPFTP-VEVYYDQMSA-N 0.000 description 4
- UTCFSBBXPWKLTG-XKBZYTNZSA-N Thr-Cys-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O UTCFSBBXPWKLTG-XKBZYTNZSA-N 0.000 description 4
- KBBRNEDOYWMIJP-KYNKHSRBSA-N Thr-Gly-Thr Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KBBRNEDOYWMIJP-KYNKHSRBSA-N 0.000 description 4
- NSTPFWRAIDTNGH-BZSNNMDCSA-N Tyr-Asn-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O NSTPFWRAIDTNGH-BZSNNMDCSA-N 0.000 description 4
- NZFCWALTLNFHHC-JYJNAYRXSA-N Tyr-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NZFCWALTLNFHHC-JYJNAYRXSA-N 0.000 description 4
- MVFQLSPDMMFCMW-KKUMJFAQSA-N Tyr-Leu-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O MVFQLSPDMMFCMW-KKUMJFAQSA-N 0.000 description 4
- XYNFFTNEQDWZNY-ULQDDVLXSA-N Tyr-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N XYNFFTNEQDWZNY-ULQDDVLXSA-N 0.000 description 4
- VCAWFLIWYNMHQP-UKJIMTQDSA-N Val-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N VCAWFLIWYNMHQP-UKJIMTQDSA-N 0.000 description 4
- PIFJAFRUVWZRKR-QMMMGPOBSA-N Val-Gly-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O PIFJAFRUVWZRKR-QMMMGPOBSA-N 0.000 description 4
- KSFXWENSJABBFI-ZKWXMUAHSA-N Val-Ser-Asn Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O KSFXWENSJABBFI-ZKWXMUAHSA-N 0.000 description 4
- 238000012258 culturing Methods 0.000 description 4
- 238000002825 functional assay Methods 0.000 description 4
- 108010049041 glutamylalanine Proteins 0.000 description 4
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 4
- 108010010096 glycyl-glycyl-tyrosine Proteins 0.000 description 4
- 108010050848 glycylleucine Proteins 0.000 description 4
- 210000004408 hybridoma Anatomy 0.000 description 4
- 229940127121 immunoconjugate Drugs 0.000 description 4
- 230000000670 limiting effect Effects 0.000 description 4
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 4
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 4
- 239000000047 product Substances 0.000 description 4
- 108010070643 prolylglutamic acid Proteins 0.000 description 4
- 108010029020 prolylglycine Proteins 0.000 description 4
- 230000002285 radioactive effect Effects 0.000 description 4
- 239000000523 sample Substances 0.000 description 4
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 4
- 230000004083 survival effect Effects 0.000 description 4
- 238000002560 therapeutic procedure Methods 0.000 description 4
- 108010060175 trypsinogen activation peptide Proteins 0.000 description 4
- 108010038745 tryptophylglycine Proteins 0.000 description 4
- 239000004474 valine Substances 0.000 description 4
- 108010073969 valyllysine Proteins 0.000 description 4
- JNTMAZFVYNDPLB-PEDHHIEDSA-N (2S,3S)-2-[[[(2S)-1-[(2S,3S)-2-amino-3-methyl-1-oxopentyl]-2-pyrrolidinyl]-oxomethyl]amino]-3-methylpentanoic acid Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JNTMAZFVYNDPLB-PEDHHIEDSA-N 0.000 description 3
- IGXNPQWXIRIGBF-KEOOTSPTSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-amino-3-(1h-imidazol-5-yl)propanoyl]amino]-3-(1h-imidazol-5-yl)propanoyl]amino]-3-(1h-imidazol-5-yl)propanoyl]amino]-3-(1h-imidazol-5-yl)propanoyl]amino]-3-(1h-imidazol-5-yl)propanoic acid Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 IGXNPQWXIRIGBF-KEOOTSPTSA-N 0.000 description 3
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 3
- XQJAFSDFQZPYCU-UWJYBYFXSA-N Ala-Asn-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N XQJAFSDFQZPYCU-UWJYBYFXSA-N 0.000 description 3
- SDZRIBWEVVRDQI-CIUDSAMLSA-N Ala-Lys-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O SDZRIBWEVVRDQI-CIUDSAMLSA-N 0.000 description 3
- MAEQBGQTDWDSJQ-LSJOCFKGSA-N Ala-Met-His Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N MAEQBGQTDWDSJQ-LSJOCFKGSA-N 0.000 description 3
- AWNAEZICPNGAJK-FXQIFTODSA-N Ala-Met-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(O)=O AWNAEZICPNGAJK-FXQIFTODSA-N 0.000 description 3
- IPWKGIFRRBGCJO-IMJSIDKUSA-N Ala-Ser Chemical compound C[C@H]([NH3+])C(=O)N[C@@H](CO)C([O-])=O IPWKGIFRRBGCJO-IMJSIDKUSA-N 0.000 description 3
- DCVYRWFAMZFSDA-ZLUOBGJFSA-N Ala-Ser-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DCVYRWFAMZFSDA-ZLUOBGJFSA-N 0.000 description 3
- KLALXKYLOMZDQT-ZLUOBGJFSA-N Ala-Ser-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(N)=O KLALXKYLOMZDQT-ZLUOBGJFSA-N 0.000 description 3
- REWSWYIDQIELBE-FXQIFTODSA-N Ala-Val-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O REWSWYIDQIELBE-FXQIFTODSA-N 0.000 description 3
- OTOXOKCIIQLMFH-KZVJFYERSA-N Arg-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N OTOXOKCIIQLMFH-KZVJFYERSA-N 0.000 description 3
- XEPSCVXTCUUHDT-AVGNSLFASA-N Arg-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CCCN=C(N)N XEPSCVXTCUUHDT-AVGNSLFASA-N 0.000 description 3
- HGKHPCFTRQDHCU-IUCAKERBSA-N Arg-Pro-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HGKHPCFTRQDHCU-IUCAKERBSA-N 0.000 description 3
- FRBAHXABMQXSJQ-FXQIFTODSA-N Arg-Ser-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FRBAHXABMQXSJQ-FXQIFTODSA-N 0.000 description 3
- DXVMJJNAOVECBA-WHFBIAKZSA-N Asn-Gly-Asn Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O DXVMJJNAOVECBA-WHFBIAKZSA-N 0.000 description 3
- GMUOCGCDOYYWPD-FXQIFTODSA-N Asn-Pro-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O GMUOCGCDOYYWPD-FXQIFTODSA-N 0.000 description 3
- VAWNQIGQPUOPQW-ACZMJKKPSA-N Asp-Glu-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VAWNQIGQPUOPQW-ACZMJKKPSA-N 0.000 description 3
- WBDWQKRLTVCDSY-WHFBIAKZSA-N Asp-Gly-Asp Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O WBDWQKRLTVCDSY-WHFBIAKZSA-N 0.000 description 3
- KYQNAIMCTRZLNP-QSFUFRPTSA-N Asp-Ile-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O KYQNAIMCTRZLNP-QSFUFRPTSA-N 0.000 description 3
- JSHWXQIZOCVWIA-ZKWXMUAHSA-N Asp-Ser-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JSHWXQIZOCVWIA-ZKWXMUAHSA-N 0.000 description 3
- AWPWHMVCSISSQK-QWRGUYRKSA-N Asp-Tyr-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O AWPWHMVCSISSQK-QWRGUYRKSA-N 0.000 description 3
- ALMIMUZAWTUNIO-BZSNNMDCSA-N Asp-Tyr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ALMIMUZAWTUNIO-BZSNNMDCSA-N 0.000 description 3
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 3
- 108020004705 Codon Proteins 0.000 description 3
- HHABWQIFXZPZCK-ACZMJKKPSA-N Cys-Gln-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N HHABWQIFXZPZCK-ACZMJKKPSA-N 0.000 description 3
- 102000004127 Cytokines Human genes 0.000 description 3
- 108090000695 Cytokines Proteins 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- XOKGKOQWADCLFQ-GARJFASQSA-N Gln-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XOKGKOQWADCLFQ-GARJFASQSA-N 0.000 description 3
- LVRKAFPPFJRIOF-GARJFASQSA-N Gln-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N LVRKAFPPFJRIOF-GARJFASQSA-N 0.000 description 3
- ROHVCXBMIAAASL-HJGDQZAQSA-N Gln-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(=O)N)N)O ROHVCXBMIAAASL-HJGDQZAQSA-N 0.000 description 3
- QIZJOTQTCAGKPU-KWQFWETISA-N Gly-Ala-Tyr Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CC1=CC=C(O)C=C1 QIZJOTQTCAGKPU-KWQFWETISA-N 0.000 description 3
- OCQUNKSFDYDXBG-QXEWZRGKSA-N Gly-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N OCQUNKSFDYDXBG-QXEWZRGKSA-N 0.000 description 3
- IWAXHBCACVWNHT-BQBZGAKWSA-N Gly-Asp-Arg Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IWAXHBCACVWNHT-BQBZGAKWSA-N 0.000 description 3
- RPLLQZBOVIVGMX-QWRGUYRKSA-N Gly-Asp-Phe Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O RPLLQZBOVIVGMX-QWRGUYRKSA-N 0.000 description 3
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 3
- XMPXVJIDADUOQB-RCOVLWMOSA-N Gly-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C([O-])=O)NC(=O)CNC(=O)C[NH3+] XMPXVJIDADUOQB-RCOVLWMOSA-N 0.000 description 3
- UPADCCSMVOQAGF-LBPRGKRZSA-N Gly-Gly-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)CNC(=O)CN)C(O)=O)=CNC2=C1 UPADCCSMVOQAGF-LBPRGKRZSA-N 0.000 description 3
- BHPQOIPBLYJNAW-NGZCFLSTSA-N Gly-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN BHPQOIPBLYJNAW-NGZCFLSTSA-N 0.000 description 3
- HAXARWKYFIIHKD-ZKWXMUAHSA-N Gly-Ile-Ser Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HAXARWKYFIIHKD-ZKWXMUAHSA-N 0.000 description 3
- FXGRXIATVXUAHO-WEDXCCLWSA-N Gly-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN FXGRXIATVXUAHO-WEDXCCLWSA-N 0.000 description 3
- QAMMIGULQSIRCD-IRXDYDNUSA-N Gly-Phe-Tyr Chemical compound C([C@H](NC(=O)C[NH3+])C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C([O-])=O)C1=CC=CC=C1 QAMMIGULQSIRCD-IRXDYDNUSA-N 0.000 description 3
- IALQAMYQJBZNSK-WHFBIAKZSA-N Gly-Ser-Asn Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O IALQAMYQJBZNSK-WHFBIAKZSA-N 0.000 description 3
- WCORRBXVISTKQL-WHFBIAKZSA-N Gly-Ser-Ser Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WCORRBXVISTKQL-WHFBIAKZSA-N 0.000 description 3
- BXDLTKLPPKBVEL-FJXKBIBVSA-N Gly-Thr-Met Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(O)=O BXDLTKLPPKBVEL-FJXKBIBVSA-N 0.000 description 3
- WTUSRDZLLWGYAT-KCTSRDHCSA-N Gly-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)CN WTUSRDZLLWGYAT-KCTSRDHCSA-N 0.000 description 3
- YJDALMUYJIENAG-QWRGUYRKSA-N Gly-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN)O YJDALMUYJIENAG-QWRGUYRKSA-N 0.000 description 3
- LYZYGGWCBLBDMC-QWHCGFSZSA-N Gly-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)CN)C(=O)O LYZYGGWCBLBDMC-QWHCGFSZSA-N 0.000 description 3
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- AKAPKBNIVNPIPO-KKUMJFAQSA-N His-His-Lys Chemical compound C([C@@H](C(=O)N[C@@H](CCCCN)C(O)=O)NC(=O)[C@@H](N)CC=1NC=NC=1)C1=CN=CN1 AKAPKBNIVNPIPO-KKUMJFAQSA-N 0.000 description 3
- JGFWUKYIQAEYAH-DCAQKATOSA-N His-Ser-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JGFWUKYIQAEYAH-DCAQKATOSA-N 0.000 description 3
- FOCSWPCHUDVNLP-PMVMPFDFSA-N His-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC4=CN=CN4)N FOCSWPCHUDVNLP-PMVMPFDFSA-N 0.000 description 3
- HDOYNXLPTRQLAD-JBDRJPRFSA-N Ile-Ala-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)O)N HDOYNXLPTRQLAD-JBDRJPRFSA-N 0.000 description 3
- RSDHVTMRXSABSV-GHCJXIJMSA-N Ile-Asn-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N RSDHVTMRXSABSV-GHCJXIJMSA-N 0.000 description 3
- UKTUOMWSJPXODT-GUDRVLHUSA-N Ile-Asn-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N UKTUOMWSJPXODT-GUDRVLHUSA-N 0.000 description 3
- UWLHDGMRWXHFFY-HPCHECBXSA-N Ile-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1CCC[C@@H]1C(=O)O)N UWLHDGMRWXHFFY-HPCHECBXSA-N 0.000 description 3
- HJDZMPFEXINXLO-QPHKQPEJSA-N Ile-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N HJDZMPFEXINXLO-QPHKQPEJSA-N 0.000 description 3
- DTPGSUQHUMELQB-GVARAGBVSA-N Ile-Tyr-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=C(O)C=C1 DTPGSUQHUMELQB-GVARAGBVSA-N 0.000 description 3
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 3
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 3
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 3
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 3
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 3
- HBJZFCIVFIBNSV-DCAQKATOSA-N Leu-Arg-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(N)=O)C(O)=O HBJZFCIVFIBNSV-DCAQKATOSA-N 0.000 description 3
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 3
- YSKSXVKQLLBVEX-SZMVWBNQSA-N Leu-Gln-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 YSKSXVKQLLBVEX-SZMVWBNQSA-N 0.000 description 3
- KGCLIYGPQXUNLO-IUCAKERBSA-N Leu-Gly-Glu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O KGCLIYGPQXUNLO-IUCAKERBSA-N 0.000 description 3
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 3
- MUXNCRWTWBMNHX-SRVKXCTJSA-N Lys-Leu-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O MUXNCRWTWBMNHX-SRVKXCTJSA-N 0.000 description 3
- GHQFLTYXGUETFD-UFYCRDLUSA-N Met-Tyr-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N GHQFLTYXGUETFD-UFYCRDLUSA-N 0.000 description 3
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 3
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 3
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 3
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 3
- 108091028043 Nucleic acid sequence Proteins 0.000 description 3
- 108091034117 Oligonucleotide Proteins 0.000 description 3
- BKWJQWJPZMUWEG-LFSVMHDDSA-N Phe-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 BKWJQWJPZMUWEG-LFSVMHDDSA-N 0.000 description 3
- ACJULKNZOCRWEI-ULQDDVLXSA-N Phe-Met-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O ACJULKNZOCRWEI-ULQDDVLXSA-N 0.000 description 3
- ILGCZYGFYQLSDZ-KKUMJFAQSA-N Phe-Ser-His Chemical compound N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CO)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O ILGCZYGFYQLSDZ-KKUMJFAQSA-N 0.000 description 3
- LTAWNJXSRUCFAN-UNQGMJICSA-N Phe-Thr-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O LTAWNJXSRUCFAN-UNQGMJICSA-N 0.000 description 3
- RAGOJJCBGXARPO-XVSYOHENSA-N Phe-Thr-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RAGOJJCBGXARPO-XVSYOHENSA-N 0.000 description 3
- MGDFPGCFVJFITQ-CIUDSAMLSA-N Pro-Glu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MGDFPGCFVJFITQ-CIUDSAMLSA-N 0.000 description 3
- FKYKZHOKDOPHSA-DCAQKATOSA-N Pro-Leu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FKYKZHOKDOPHSA-DCAQKATOSA-N 0.000 description 3
- RCYUBVHMVUHEBM-RCWTZXSCSA-N Pro-Pro-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O RCYUBVHMVUHEBM-RCWTZXSCSA-N 0.000 description 3
- DMNANGOFEUVBRV-GJZGRUSLSA-N Pro-Trp-Gly Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(=O)O)C(=O)[C@@H]1CCCN1 DMNANGOFEUVBRV-GJZGRUSLSA-N 0.000 description 3
- LVVBAKCGXXUHFO-ZLUOBGJFSA-N Ser-Ala-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O LVVBAKCGXXUHFO-ZLUOBGJFSA-N 0.000 description 3
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 3
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 3
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 3
- BKZYBLLIBOBOOW-GHCJXIJMSA-N Ser-Ile-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O BKZYBLLIBOBOOW-GHCJXIJMSA-N 0.000 description 3
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 3
- RHAPJNVNWDBFQI-BQBZGAKWSA-N Ser-Pro-Gly Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O RHAPJNVNWDBFQI-BQBZGAKWSA-N 0.000 description 3
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 3
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 3
- PMTWIUBUQRGCSB-FXQIFTODSA-N Ser-Val-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O PMTWIUBUQRGCSB-FXQIFTODSA-N 0.000 description 3
- MFQMZDPAZRZAPV-NAKRPEOUSA-N Ser-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CO)N MFQMZDPAZRZAPV-NAKRPEOUSA-N 0.000 description 3
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 3
- 101150006914 TRP1 gene Proteins 0.000 description 3
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 3
- UKBSDLHIKIXJKH-HJGDQZAQSA-N Thr-Arg-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O UKBSDLHIKIXJKH-HJGDQZAQSA-N 0.000 description 3
- GUHLYMZJVXUIPO-RCWTZXSCSA-N Thr-Met-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O GUHLYMZJVXUIPO-RCWTZXSCSA-N 0.000 description 3
- DEGCBBCMYWNJNA-RHYQMDGZSA-N Thr-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O DEGCBBCMYWNJNA-RHYQMDGZSA-N 0.000 description 3
- WPSKTVVMQCXPRO-BWBBJGPYSA-N Thr-Ser-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WPSKTVVMQCXPRO-BWBBJGPYSA-N 0.000 description 3
- HUPLKEHTTQBXSC-YJRXYDGGSA-N Thr-Ser-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUPLKEHTTQBXSC-YJRXYDGGSA-N 0.000 description 3
- LVTKHGUGBGNBPL-UHFFFAOYSA-N Trp-P-1 Chemical compound N1C2=CC=CC=C2C2=C1C(C)=C(N)N=C2C LVTKHGUGBGNBPL-UHFFFAOYSA-N 0.000 description 3
- UMSZZGTXGKHTFJ-SRVKXCTJSA-N Tyr-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 UMSZZGTXGKHTFJ-SRVKXCTJSA-N 0.000 description 3
- LDKDSFQSEUOCOO-RPTUDFQQSA-N Tyr-Thr-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LDKDSFQSEUOCOO-RPTUDFQQSA-N 0.000 description 3
- MWUYSCVVPVITMW-IGNZVWTISA-N Tyr-Tyr-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 MWUYSCVVPVITMW-IGNZVWTISA-N 0.000 description 3
- UEOOXDLMQZBPFR-ZKWXMUAHSA-N Val-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N UEOOXDLMQZBPFR-ZKWXMUAHSA-N 0.000 description 3
- XXROXFHCMVXETG-UWVGGRQHSA-N Val-Gly-Val Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXROXFHCMVXETG-UWVGGRQHSA-N 0.000 description 3
- ZXYPHBKIZLAQTL-QXEWZRGKSA-N Val-Pro-Asp Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N ZXYPHBKIZLAQTL-QXEWZRGKSA-N 0.000 description 3
- 241000700605 Viruses Species 0.000 description 3
- 108010044940 alanylglutamine Proteins 0.000 description 3
- 150000001412 amines Chemical class 0.000 description 3
- 238000013459 approach Methods 0.000 description 3
- 235000003704 aspartic acid Nutrition 0.000 description 3
- 210000003719 b-lymphocyte Anatomy 0.000 description 3
- 230000001580 bacterial effect Effects 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 3
- 230000033228 biological regulation Effects 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 230000030833 cell death Effects 0.000 description 3
- 230000001413 cellular effect Effects 0.000 description 3
- 238000012512 characterization method Methods 0.000 description 3
- 231100000599 cytotoxic agent Toxicity 0.000 description 3
- 239000002619 cytotoxin Substances 0.000 description 3
- 238000010790 dilution Methods 0.000 description 3
- 239000012895 dilution Substances 0.000 description 3
- 239000003937 drug carrier Substances 0.000 description 3
- 230000002255 enzymatic effect Effects 0.000 description 3
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical group O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 3
- 210000004475 gamma-delta t lymphocyte Anatomy 0.000 description 3
- 235000013922 glutamic acid Nutrition 0.000 description 3
- 239000004220 glutamic acid Substances 0.000 description 3
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 3
- 108010085059 glutamyl-arginyl-proline Proteins 0.000 description 3
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 3
- 108010084389 glycyltryptophan Proteins 0.000 description 3
- 108010087823 glycyltyrosine Proteins 0.000 description 3
- 230000012010 growth Effects 0.000 description 3
- 230000003394 haemopoietic effect Effects 0.000 description 3
- 108010018006 histidylserine Proteins 0.000 description 3
- 229910052739 hydrogen Inorganic materials 0.000 description 3
- 239000001257 hydrogen Substances 0.000 description 3
- 230000002209 hydrophobic effect Effects 0.000 description 3
- 230000028993 immune response Effects 0.000 description 3
- 230000036039 immunity Effects 0.000 description 3
- 230000005764 inhibitory process Effects 0.000 description 3
- 238000003780 insertion Methods 0.000 description 3
- 230000037431 insertion Effects 0.000 description 3
- 108010034529 leucyl-lysine Proteins 0.000 description 3
- 108010000761 leucylarginine Proteins 0.000 description 3
- 239000002502 liposome Substances 0.000 description 3
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 3
- 210000004962 mammalian cell Anatomy 0.000 description 3
- 239000011159 matrix material Substances 0.000 description 3
- 229930182817 methionine Natural products 0.000 description 3
- 239000013641 positive control Substances 0.000 description 3
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 3
- 108010077112 prolyl-proline Proteins 0.000 description 3
- 108010079317 prolyl-tyrosine Proteins 0.000 description 3
- 238000000159 protein binding assay Methods 0.000 description 3
- 238000003127 radioimmunoassay Methods 0.000 description 3
- 238000003259 recombinant expression Methods 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 230000010076 replication Effects 0.000 description 3
- 239000012146 running buffer Substances 0.000 description 3
- 238000009738 saturating Methods 0.000 description 3
- 230000028327 secretion Effects 0.000 description 3
- 238000002741 site-directed mutagenesis Methods 0.000 description 3
- 238000001542 size-exclusion chromatography Methods 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 239000000725 suspension Substances 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 239000003053 toxin Substances 0.000 description 3
- 238000013519 translation Methods 0.000 description 3
- 230000007306 turnover Effects 0.000 description 3
- 108010035534 tyrosyl-leucyl-alanine Proteins 0.000 description 3
- 108010009962 valyltyrosine Proteins 0.000 description 3
- 239000013603 viral vector Substances 0.000 description 3
- 238000005406 washing Methods 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 2
- SSSROGPPPVTHLX-FXQIFTODSA-N Ala-Arg-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSROGPPPVTHLX-FXQIFTODSA-N 0.000 description 2
- STACJSVFHSEZJV-GHCJXIJMSA-N Ala-Asn-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O STACJSVFHSEZJV-GHCJXIJMSA-N 0.000 description 2
- BTYTYHBSJKQBQA-GCJQMDKQSA-N Ala-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N)O BTYTYHBSJKQBQA-GCJQMDKQSA-N 0.000 description 2
- KUDREHRZRIVKHS-UWJYBYFXSA-N Ala-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KUDREHRZRIVKHS-UWJYBYFXSA-N 0.000 description 2
- NWVVKQZOVSTDBQ-CIUDSAMLSA-N Ala-Glu-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NWVVKQZOVSTDBQ-CIUDSAMLSA-N 0.000 description 2
- NBTGEURICRTMGL-WHFBIAKZSA-N Ala-Gly-Ser Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O NBTGEURICRTMGL-WHFBIAKZSA-N 0.000 description 2
- OKEWAFFWMHBGPT-XPUUQOCRSA-N Ala-His-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CN=CN1 OKEWAFFWMHBGPT-XPUUQOCRSA-N 0.000 description 2
- RGQCNKIDEQJEBT-CQDKDKBSSA-N Ala-Leu-Tyr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 RGQCNKIDEQJEBT-CQDKDKBSSA-N 0.000 description 2
- QUIGLPSHIFPEOV-CIUDSAMLSA-N Ala-Lys-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O QUIGLPSHIFPEOV-CIUDSAMLSA-N 0.000 description 2
- SUHLZMHFRALVSY-YUMQZZPRSA-N Ala-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O SUHLZMHFRALVSY-YUMQZZPRSA-N 0.000 description 2
- NINQYGGNRIBFSC-CIUDSAMLSA-N Ala-Lys-Ser Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CO)C(O)=O NINQYGGNRIBFSC-CIUDSAMLSA-N 0.000 description 2
- RAAWHFXHAACDFT-FXQIFTODSA-N Ala-Met-Asn Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CC(N)=O)C(O)=O RAAWHFXHAACDFT-FXQIFTODSA-N 0.000 description 2
- DYXOFPBJBAHWFY-JBDRJPRFSA-N Ala-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N DYXOFPBJBAHWFY-JBDRJPRFSA-N 0.000 description 2
- JJHBEVZAZXZREW-LFSVMHDDSA-N Ala-Thr-Phe Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](Cc1ccccc1)C(O)=O JJHBEVZAZXZREW-LFSVMHDDSA-N 0.000 description 2
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 2
- APKFDSVGJQXUKY-KKGHZKTASA-N Amphotericin-B Natural products O[C@H]1[C@@H](N)[C@H](O)[C@@H](C)O[C@H]1O[C@H]1C=CC=CC=CC=CC=CC=CC=C[C@H](C)[C@@H](O)[C@@H](C)[C@H](C)OC(=O)C[C@H](O)C[C@H](O)CC[C@@H](O)[C@H](O)C[C@H](O)C[C@](O)(C[C@H](O)[C@H]2C(O)=O)O[C@H]2C1 APKFDSVGJQXUKY-KKGHZKTASA-N 0.000 description 2
- NONSEUUPKITYQT-BQBZGAKWSA-N Arg-Asn-Gly Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)NCC(=O)O)N)CN=C(N)N NONSEUUPKITYQT-BQBZGAKWSA-N 0.000 description 2
- PQWTZSNVWSOFFK-FXQIFTODSA-N Arg-Asp-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)CN=C(N)N PQWTZSNVWSOFFK-FXQIFTODSA-N 0.000 description 2
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 description 2
- WVNFNPGXYADPPO-BQBZGAKWSA-N Arg-Gly-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O WVNFNPGXYADPPO-BQBZGAKWSA-N 0.000 description 2
- QEHMMRSQJMOYNO-DCAQKATOSA-N Arg-His-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N QEHMMRSQJMOYNO-DCAQKATOSA-N 0.000 description 2
- UAOSDDXCTBIPCA-QXEWZRGKSA-N Arg-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UAOSDDXCTBIPCA-QXEWZRGKSA-N 0.000 description 2
- VENMDXUVHSKEIN-GUBZILKMSA-N Arg-Ser-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VENMDXUVHSKEIN-GUBZILKMSA-N 0.000 description 2
- ICRHGPYYXMWHIE-LPEHRKFASA-N Arg-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ICRHGPYYXMWHIE-LPEHRKFASA-N 0.000 description 2
- HUZGPXBILPMCHM-IHRRRGAJSA-N Asn-Arg-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HUZGPXBILPMCHM-IHRRRGAJSA-N 0.000 description 2
- ACRYGQFHAQHDSF-ZLUOBGJFSA-N Asn-Asn-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ACRYGQFHAQHDSF-ZLUOBGJFSA-N 0.000 description 2
- VYLVOMUVLMGCRF-ZLUOBGJFSA-N Asn-Asp-Ser Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O VYLVOMUVLMGCRF-ZLUOBGJFSA-N 0.000 description 2
- UYXXMIZGHYKYAT-NHCYSSNCSA-N Asn-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC(=O)N)N UYXXMIZGHYKYAT-NHCYSSNCSA-N 0.000 description 2
- HDHZCEDPLTVHFZ-GUBZILKMSA-N Asn-Leu-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O HDHZCEDPLTVHFZ-GUBZILKMSA-N 0.000 description 2
- XTMZYFMTYJNABC-ZLUOBGJFSA-N Asn-Ser-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N XTMZYFMTYJNABC-ZLUOBGJFSA-N 0.000 description 2
- DPSUVAPLRQDWAO-YDHLFZDLSA-N Asn-Tyr-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC(=O)N)N DPSUVAPLRQDWAO-YDHLFZDLSA-N 0.000 description 2
- NJIKKGUVGUBICV-ZLUOBGJFSA-N Asp-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O NJIKKGUVGUBICV-ZLUOBGJFSA-N 0.000 description 2
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 2
- CELPEWWLSXMVPH-CIUDSAMLSA-N Asp-Asp-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O CELPEWWLSXMVPH-CIUDSAMLSA-N 0.000 description 2
- ZSJFGGSPCCHMNE-LAEOZQHASA-N Asp-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N ZSJFGGSPCCHMNE-LAEOZQHASA-N 0.000 description 2
- JUWZKMBALYLZCK-WHFBIAKZSA-N Asp-Gly-Asn Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O JUWZKMBALYLZCK-WHFBIAKZSA-N 0.000 description 2
- HAFCJCDJGIOYPW-WDSKDSINSA-N Asp-Gly-Gln Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O HAFCJCDJGIOYPW-WDSKDSINSA-N 0.000 description 2
- RQYMKRMRZWJGHC-BQBZGAKWSA-N Asp-Gly-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)O)N RQYMKRMRZWJGHC-BQBZGAKWSA-N 0.000 description 2
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 2
- TZOZNVLBTAFJRW-UGYAYLCHSA-N Asp-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)O)N TZOZNVLBTAFJRW-UGYAYLCHSA-N 0.000 description 2
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 2
- YFSLJHLQOALGSY-ZPFDUUQYSA-N Asp-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N YFSLJHLQOALGSY-ZPFDUUQYSA-N 0.000 description 2
- KOWYNSKRPUWSFG-IHPCNDPISA-N Asp-Phe-Trp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)NC(=O)[C@H](CC(=O)O)N KOWYNSKRPUWSFG-IHPCNDPISA-N 0.000 description 2
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 2
- FAUPLTGRUBTXNU-FXQIFTODSA-N Asp-Pro-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O FAUPLTGRUBTXNU-FXQIFTODSA-N 0.000 description 2
- SXLCDCZHNCLFGZ-BPUTZDHNSA-N Asp-Pro-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O SXLCDCZHNCLFGZ-BPUTZDHNSA-N 0.000 description 2
- XYPJXLLXNSAWHZ-SRVKXCTJSA-N Asp-Ser-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XYPJXLLXNSAWHZ-SRVKXCTJSA-N 0.000 description 2
- GYNUXDMCDILYIQ-QRTARXTBSA-N Asp-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N GYNUXDMCDILYIQ-QRTARXTBSA-N 0.000 description 2
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- 241000282472 Canis lupus familiaris Species 0.000 description 2
- 241000283707 Capra Species 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- 108090000317 Chymotrypsin Proteins 0.000 description 2
- 239000004971 Cross linker Substances 0.000 description 2
- YWEHYKGJWHPGPY-XGEHTFHBSA-N Cys-Thr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CS)N)O YWEHYKGJWHPGPY-XGEHTFHBSA-N 0.000 description 2
- 101710112752 Cytotoxin Proteins 0.000 description 2
- 229920002307 Dextran Polymers 0.000 description 2
- 241000588724 Escherichia coli Species 0.000 description 2
- 108010087819 Fc receptors Proteins 0.000 description 2
- 102000009109 Fc receptors Human genes 0.000 description 2
- OVQXQLWWJSNYFV-XEGUGMAKSA-N Gln-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCC(N)=O)C)C(O)=O)=CNC2=C1 OVQXQLWWJSNYFV-XEGUGMAKSA-N 0.000 description 2
- GNMQDOGFWYWPNM-LAEOZQHASA-N Gln-Gly-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)CNC(=O)[C@@H](N)CCC(N)=O)C(O)=O GNMQDOGFWYWPNM-LAEOZQHASA-N 0.000 description 2
- MSHXWFKYXJTLEZ-CIUDSAMLSA-N Gln-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MSHXWFKYXJTLEZ-CIUDSAMLSA-N 0.000 description 2
- NMYFPKCIGUJMIK-GUBZILKMSA-N Gln-Met-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N NMYFPKCIGUJMIK-GUBZILKMSA-N 0.000 description 2
- NPMFDZGLKBNFOO-SRVKXCTJSA-N Gln-Pro-His Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CN=CN1 NPMFDZGLKBNFOO-SRVKXCTJSA-N 0.000 description 2
- KUBFPYIMAGXGBT-ACZMJKKPSA-N Gln-Ser-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KUBFPYIMAGXGBT-ACZMJKKPSA-N 0.000 description 2
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 2
- LTUVYLVIZHJCOQ-KKUMJFAQSA-N Glu-Arg-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LTUVYLVIZHJCOQ-KKUMJFAQSA-N 0.000 description 2
- PAQUJCSYVIBPLC-AVGNSLFASA-N Glu-Asp-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PAQUJCSYVIBPLC-AVGNSLFASA-N 0.000 description 2
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 2
- GPSHCSTUYOQPAI-JHEQGTHGSA-N Glu-Thr-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O GPSHCSTUYOQPAI-JHEQGTHGSA-N 0.000 description 2
- ZSIDREAPEPAPKL-XIRDDKMYSA-N Glu-Trp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N ZSIDREAPEPAPKL-XIRDDKMYSA-N 0.000 description 2
- VXEFAWJTFAUDJK-AVGNSLFASA-N Glu-Tyr-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O VXEFAWJTFAUDJK-AVGNSLFASA-N 0.000 description 2
- JRDYDYXZKFNNRQ-XPUUQOCRSA-N Gly-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN JRDYDYXZKFNNRQ-XPUUQOCRSA-N 0.000 description 2
- KRRMJKMGWWXWDW-STQMWFEESA-N Gly-Arg-Phe Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KRRMJKMGWWXWDW-STQMWFEESA-N 0.000 description 2
- FMNHBTKMRFVGRO-FOHZUACHSA-N Gly-Asn-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)CN FMNHBTKMRFVGRO-FOHZUACHSA-N 0.000 description 2
- LLXVQPKEQQCISF-YUMQZZPRSA-N Gly-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN LLXVQPKEQQCISF-YUMQZZPRSA-N 0.000 description 2
- CQZDZKRHFWJXDF-WDSKDSINSA-N Gly-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CN CQZDZKRHFWJXDF-WDSKDSINSA-N 0.000 description 2
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 2
- AAHSHTLISQUZJL-QSFUFRPTSA-N Gly-Ile-Ile Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AAHSHTLISQUZJL-QSFUFRPTSA-N 0.000 description 2
- CCBIBMKQNXHNIN-ZETCQYMHSA-N Gly-Leu-Gly Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CCBIBMKQNXHNIN-ZETCQYMHSA-N 0.000 description 2
- LRQXRHGQEVWGPV-NHCYSSNCSA-N Gly-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN LRQXRHGQEVWGPV-NHCYSSNCSA-N 0.000 description 2
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 2
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 2
- JQFILXICXLDTRR-FBCQKBJTSA-N Gly-Thr-Gly Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)NCC(O)=O JQFILXICXLDTRR-FBCQKBJTSA-N 0.000 description 2
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 2
- SFOXOSKVTLDEDM-HOTGVXAUSA-N Gly-Trp-Leu Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)CN)=CNC2=C1 SFOXOSKVTLDEDM-HOTGVXAUSA-N 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- STOOMQFEJUVAKR-KKUMJFAQSA-N His-His-His Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CC=1N=CNC=1)C(O)=O)C1=CNC=N1 STOOMQFEJUVAKR-KKUMJFAQSA-N 0.000 description 2
- UXSATKFPUVZVDK-KKUMJFAQSA-N His-Lys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CN=CN1)N UXSATKFPUVZVDK-KKUMJFAQSA-N 0.000 description 2
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 2
- AQCUAZTZSPQJFF-ZKWXMUAHSA-N Ile-Ala-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O AQCUAZTZSPQJFF-ZKWXMUAHSA-N 0.000 description 2
- DCQMJRSOGCYKTR-GHCJXIJMSA-N Ile-Asp-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O DCQMJRSOGCYKTR-GHCJXIJMSA-N 0.000 description 2
- AQTWDZDISVGCAC-CFMVVWHZSA-N Ile-Asp-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N AQTWDZDISVGCAC-CFMVVWHZSA-N 0.000 description 2
- NZOCIWKZUVUNDW-ZKWXMUAHSA-N Ile-Gly-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O NZOCIWKZUVUNDW-ZKWXMUAHSA-N 0.000 description 2
- UWBDLNOCIDGPQE-GUBZILKMSA-N Ile-Lys Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(O)=O)CCCCN UWBDLNOCIDGPQE-GUBZILKMSA-N 0.000 description 2
- YKZAMJXNJUWFIK-JBDRJPRFSA-N Ile-Ser-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)O)N YKZAMJXNJUWFIK-JBDRJPRFSA-N 0.000 description 2
- JODPUDMBQBIWCK-GHCJXIJMSA-N Ile-Ser-Asn Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O JODPUDMBQBIWCK-GHCJXIJMSA-N 0.000 description 2
- WRDTXMBPHMBGIB-STECZYCISA-N Ile-Tyr-Val Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=C(O)C=C1 WRDTXMBPHMBGIB-STECZYCISA-N 0.000 description 2
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 2
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 2
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 2
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 2
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 2
- 102000014150 Interferons Human genes 0.000 description 2
- 108010050904 Interferons Proteins 0.000 description 2
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 2
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 2
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 2
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- USTCFDAQCLDPBD-XIRDDKMYSA-N Leu-Asn-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N USTCFDAQCLDPBD-XIRDDKMYSA-N 0.000 description 2
- VQPPIMUZCZCOIL-GUBZILKMSA-N Leu-Gln-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O VQPPIMUZCZCOIL-GUBZILKMSA-N 0.000 description 2
- CQGSYZCULZMEDE-SRVKXCTJSA-N Leu-Gln-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CQGSYZCULZMEDE-SRVKXCTJSA-N 0.000 description 2
- CIVKXGPFXDIQBV-WDCWCFNPSA-N Leu-Gln-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CIVKXGPFXDIQBV-WDCWCFNPSA-N 0.000 description 2
- OYQUOLRTJHWVSQ-SRVKXCTJSA-N Leu-His-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O OYQUOLRTJHWVSQ-SRVKXCTJSA-N 0.000 description 2
- FAELBUXXFQLUAX-AJNGGQMLSA-N Leu-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C FAELBUXXFQLUAX-AJNGGQMLSA-N 0.000 description 2
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 2
- SUYRAPCRSCCPAK-VFAJRCTISA-N Leu-Trp-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SUYRAPCRSCCPAK-VFAJRCTISA-N 0.000 description 2
- ABHIXYDMILIUKV-CIUDSAMLSA-N Lys-Asn-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ABHIXYDMILIUKV-CIUDSAMLSA-N 0.000 description 2
- GGNOBVSOZPHLCE-GUBZILKMSA-N Lys-Gln-Asp Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O GGNOBVSOZPHLCE-GUBZILKMSA-N 0.000 description 2
- GQFDWEDHOQRNLC-QWRGUYRKSA-N Lys-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN GQFDWEDHOQRNLC-QWRGUYRKSA-N 0.000 description 2
- FHIAJWBDZVHLAH-YUMQZZPRSA-N Lys-Gly-Ser Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FHIAJWBDZVHLAH-YUMQZZPRSA-N 0.000 description 2
- JOSAKOKSPXROGQ-BJDJZHNGSA-N Lys-Ser-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JOSAKOKSPXROGQ-BJDJZHNGSA-N 0.000 description 2
- MIFFFXHMAHFACR-KATARQTJSA-N Lys-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN MIFFFXHMAHFACR-KATARQTJSA-N 0.000 description 2
- QVTDVTONTRSQMF-WDCWCFNPSA-N Lys-Thr-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CCCCN QVTDVTONTRSQMF-WDCWCFNPSA-N 0.000 description 2
- VHTOGMKQXXJOHG-RHYQMDGZSA-N Lys-Thr-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O VHTOGMKQXXJOHG-RHYQMDGZSA-N 0.000 description 2
- QLFAPXUXEBAWEK-NHCYSSNCSA-N Lys-Val-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QLFAPXUXEBAWEK-NHCYSSNCSA-N 0.000 description 2
- GILLQRYAWOMHED-DCAQKATOSA-N Lys-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN GILLQRYAWOMHED-DCAQKATOSA-N 0.000 description 2
- RIPJMCFGQHGHNP-RHYQMDGZSA-N Lys-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCCCN)N)O RIPJMCFGQHGHNP-RHYQMDGZSA-N 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- XDGFFEZAZHRZFR-RHYQMDGZSA-N Met-Leu-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XDGFFEZAZHRZFR-RHYQMDGZSA-N 0.000 description 2
- OVTOTTGZBWXLFU-QXEWZRGKSA-N Met-Val-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O OVTOTTGZBWXLFU-QXEWZRGKSA-N 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- 108010067372 Pancreatic elastase Proteins 0.000 description 2
- 102000016387 Pancreatic elastase Human genes 0.000 description 2
- 229930182555 Penicillin Natural products 0.000 description 2
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 2
- ZENDEDYRYVHBEG-SRVKXCTJSA-N Phe-Asp-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 ZENDEDYRYVHBEG-SRVKXCTJSA-N 0.000 description 2
- IUVYJBMTHARMIP-PCBIJLKTSA-N Phe-Asp-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O IUVYJBMTHARMIP-PCBIJLKTSA-N 0.000 description 2
- RIYZXJVARWJLKS-KKUMJFAQSA-N Phe-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 RIYZXJVARWJLKS-KKUMJFAQSA-N 0.000 description 2
- CUMXHKAOHNWRFQ-BZSNNMDCSA-N Phe-Asp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 CUMXHKAOHNWRFQ-BZSNNMDCSA-N 0.000 description 2
- YYKZDTVQHTUKDW-RYUDHWBXSA-N Phe-Gly-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N YYKZDTVQHTUKDW-RYUDHWBXSA-N 0.000 description 2
- BSKMOCNNLNDIMU-CDMKHQONSA-N Phe-Thr-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O BSKMOCNNLNDIMU-CDMKHQONSA-N 0.000 description 2
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 2
- IEIFEYBAYFSRBQ-IHRRRGAJSA-N Phe-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N IEIFEYBAYFSRBQ-IHRRRGAJSA-N 0.000 description 2
- 206010035226 Plasma cell myeloma Diseases 0.000 description 2
- XQLBWXHVZVBNJM-FXQIFTODSA-N Pro-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 XQLBWXHVZVBNJM-FXQIFTODSA-N 0.000 description 2
- OOLOTUZJUBOMAX-GUBZILKMSA-N Pro-Ala-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O OOLOTUZJUBOMAX-GUBZILKMSA-N 0.000 description 2
- JARJPEMLQAWNBR-GUBZILKMSA-N Pro-Asp-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JARJPEMLQAWNBR-GUBZILKMSA-N 0.000 description 2
- ZCXQTRXYZOSGJR-FXQIFTODSA-N Pro-Asp-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZCXQTRXYZOSGJR-FXQIFTODSA-N 0.000 description 2
- XZONQWUEBAFQPO-HJGDQZAQSA-N Pro-Gln-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XZONQWUEBAFQPO-HJGDQZAQSA-N 0.000 description 2
- WSRWHZRUOCACLJ-UWVGGRQHSA-N Pro-Gly-His Chemical compound C([C@@H](C(=O)O)NC(=O)CNC(=O)[C@H]1NCCC1)C1=CN=CN1 WSRWHZRUOCACLJ-UWVGGRQHSA-N 0.000 description 2
- RMODQFBNDDENCP-IHRRRGAJSA-N Pro-Lys-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O RMODQFBNDDENCP-IHRRRGAJSA-N 0.000 description 2
- CZCCVJUUWBMISW-FXQIFTODSA-N Pro-Ser-Cys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O CZCCVJUUWBMISW-FXQIFTODSA-N 0.000 description 2
- VBZXFFYOBDLLFE-HSHDSVGOSA-N Pro-Trp-Thr Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H]([C@H](O)C)C(O)=O)C(=O)[C@@H]1CCCN1 VBZXFFYOBDLLFE-HSHDSVGOSA-N 0.000 description 2
- XDKKMRPRRCOELJ-GUBZILKMSA-N Pro-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 XDKKMRPRRCOELJ-GUBZILKMSA-N 0.000 description 2
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 2
- 241000700159 Rattus Species 0.000 description 2
- 239000006146 Roswell Park Memorial Institute medium Substances 0.000 description 2
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 2
- HQTKVSCNCDLXSX-BQBZGAKWSA-N Ser-Arg-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O HQTKVSCNCDLXSX-BQBZGAKWSA-N 0.000 description 2
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 2
- HBOABDXGTMMDSE-GUBZILKMSA-N Ser-Arg-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O HBOABDXGTMMDSE-GUBZILKMSA-N 0.000 description 2
- FIDMVVBUOCMMJG-CIUDSAMLSA-N Ser-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO FIDMVVBUOCMMJG-CIUDSAMLSA-N 0.000 description 2
- KAAPNMOKUUPKOE-SRVKXCTJSA-N Ser-Asn-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KAAPNMOKUUPKOE-SRVKXCTJSA-N 0.000 description 2
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 2
- SMIDBHKWSYUBRZ-ACZMJKKPSA-N Ser-Glu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O SMIDBHKWSYUBRZ-ACZMJKKPSA-N 0.000 description 2
- IOVHBRCQOGWAQH-ZKWXMUAHSA-N Ser-Gly-Ile Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOVHBRCQOGWAQH-ZKWXMUAHSA-N 0.000 description 2
- CICQXRWZNVXFCU-SRVKXCTJSA-N Ser-His-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O CICQXRWZNVXFCU-SRVKXCTJSA-N 0.000 description 2
- UIPXCLNLUUAMJU-JBDRJPRFSA-N Ser-Ile-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UIPXCLNLUUAMJU-JBDRJPRFSA-N 0.000 description 2
- HDBOEVPDIDDEPC-CIUDSAMLSA-N Ser-Lys-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O HDBOEVPDIDDEPC-CIUDSAMLSA-N 0.000 description 2
- UGTZYIPOBYXWRW-SRVKXCTJSA-N Ser-Phe-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O UGTZYIPOBYXWRW-SRVKXCTJSA-N 0.000 description 2
- NVNPWELENFJOHH-CIUDSAMLSA-N Ser-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CO)N NVNPWELENFJOHH-CIUDSAMLSA-N 0.000 description 2
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 2
- ZSDXEKUKQAKZFE-XAVMHZPKSA-N Ser-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N)O ZSDXEKUKQAKZFE-XAVMHZPKSA-N 0.000 description 2
- BDMWLJLPPUCLNV-XGEHTFHBSA-N Ser-Thr-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O BDMWLJLPPUCLNV-XGEHTFHBSA-N 0.000 description 2
- GSCVDSBEYVGMJQ-SRVKXCTJSA-N Ser-Tyr-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N)O GSCVDSBEYVGMJQ-SRVKXCTJSA-N 0.000 description 2
- YEDSOSIKVUMIJE-DCAQKATOSA-N Ser-Val-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O YEDSOSIKVUMIJE-DCAQKATOSA-N 0.000 description 2
- 108700005078 Synthetic Genes Proteins 0.000 description 2
- 230000006044 T cell activation Effects 0.000 description 2
- 108090001109 Thermolysin Proteins 0.000 description 2
- XSLXHSYIVPGEER-KZVJFYERSA-N Thr-Ala-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O XSLXHSYIVPGEER-KZVJFYERSA-N 0.000 description 2
- NRUPKQSXTJNQGD-XGEHTFHBSA-N Thr-Cys-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NRUPKQSXTJNQGD-XGEHTFHBSA-N 0.000 description 2
- WLDUCKSCDRIVLJ-NUMRIWBASA-N Thr-Gln-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O WLDUCKSCDRIVLJ-NUMRIWBASA-N 0.000 description 2
- LGNBRHZANHMZHK-NUMRIWBASA-N Thr-Glu-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O LGNBRHZANHMZHK-NUMRIWBASA-N 0.000 description 2
- SLUWOCTZVGMURC-BFHQHQDPSA-N Thr-Gly-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O SLUWOCTZVGMURC-BFHQHQDPSA-N 0.000 description 2
- JKGGPMOUIAAJAA-YEPSODPASA-N Thr-Gly-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O JKGGPMOUIAAJAA-YEPSODPASA-N 0.000 description 2
- YUPVPKZBKCLFLT-QTKMDUPCSA-N Thr-His-Val Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](C(C)C)C(=O)O)N)O YUPVPKZBKCLFLT-QTKMDUPCSA-N 0.000 description 2
- FLPZMPOZGYPBEN-PPCPHDFISA-N Thr-Leu-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FLPZMPOZGYPBEN-PPCPHDFISA-N 0.000 description 2
- ISLDRLHVPXABBC-IEGACIPQSA-N Thr-Leu-Trp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O ISLDRLHVPXABBC-IEGACIPQSA-N 0.000 description 2
- IJVNLNRVDUTWDD-MEYUZBJRSA-N Thr-Leu-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IJVNLNRVDUTWDD-MEYUZBJRSA-N 0.000 description 2
- IQPWNQRRAJHOKV-KATARQTJSA-N Thr-Ser-Lys Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN IQPWNQRRAJHOKV-KATARQTJSA-N 0.000 description 2
- WKGAAMOJPMBBMC-IXOXFDKPSA-N Thr-Ser-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WKGAAMOJPMBBMC-IXOXFDKPSA-N 0.000 description 2
- JAWUQFCGNVEDRN-MEYUZBJRSA-N Thr-Tyr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O JAWUQFCGNVEDRN-MEYUZBJRSA-N 0.000 description 2
- ILUOMMDDGREELW-OSUNSFLBSA-N Thr-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O ILUOMMDDGREELW-OSUNSFLBSA-N 0.000 description 2
- BKVICMPZWRNWOC-RHYQMDGZSA-N Thr-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O BKVICMPZWRNWOC-RHYQMDGZSA-N 0.000 description 2
- PWONLXBUSVIZPH-RHYQMDGZSA-N Thr-Val-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O PWONLXBUSVIZPH-RHYQMDGZSA-N 0.000 description 2
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 2
- AVYVKJMBNLPWRX-WFBYXXMGSA-N Trp-Ala-Ser Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 AVYVKJMBNLPWRX-WFBYXXMGSA-N 0.000 description 2
- SAKLWFSRZTZQAJ-GQGQLFGLSA-N Trp-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N SAKLWFSRZTZQAJ-GQGQLFGLSA-N 0.000 description 2
- HJWLQSFTGDQSRX-BPUTZDHNSA-N Trp-Met-Ser Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(O)=O HJWLQSFTGDQSRX-BPUTZDHNSA-N 0.000 description 2
- GQEXFCQNAJHJTI-IHPCNDPISA-N Trp-Phe-Asp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N GQEXFCQNAJHJTI-IHPCNDPISA-N 0.000 description 2
- ZHDQRPWESGUDST-JBACZVJFSA-N Trp-Phe-Gln Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O)C1=CC=CC=C1 ZHDQRPWESGUDST-JBACZVJFSA-N 0.000 description 2
- AOLQJUGGZLTUBD-WIRXVTQYSA-N Trp-Trp-Phe Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O AOLQJUGGZLTUBD-WIRXVTQYSA-N 0.000 description 2
- UUZYQOUJTORBQO-ZVZYQTTQSA-N Trp-Val-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 UUZYQOUJTORBQO-ZVZYQTTQSA-N 0.000 description 2
- 108090000631 Trypsin Proteins 0.000 description 2
- 102000004142 Trypsin Human genes 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- GFHYISDTIWZUSU-QWRGUYRKSA-N Tyr-Asn-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GFHYISDTIWZUSU-QWRGUYRKSA-N 0.000 description 2
- XMNDQSYABVWZRK-BZSNNMDCSA-N Tyr-Asn-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XMNDQSYABVWZRK-BZSNNMDCSA-N 0.000 description 2
- GAYLGYUVTDMLKC-UWJYBYFXSA-N Tyr-Asp-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GAYLGYUVTDMLKC-UWJYBYFXSA-N 0.000 description 2
- TZXFLDNBYYGLKA-BZSNNMDCSA-N Tyr-Asp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 TZXFLDNBYYGLKA-BZSNNMDCSA-N 0.000 description 2
- AKLNEFNQWLHIGY-QWRGUYRKSA-N Tyr-Gly-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)O)C(=O)O)N)O AKLNEFNQWLHIGY-QWRGUYRKSA-N 0.000 description 2
- DZKFGCNKEVMXFA-JUKXBJQTSA-N Tyr-Ile-His Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)Cc1ccc(O)cc1)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O DZKFGCNKEVMXFA-JUKXBJQTSA-N 0.000 description 2
- OGPKMBOPMDTEDM-IHRRRGAJSA-N Tyr-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N OGPKMBOPMDTEDM-IHRRRGAJSA-N 0.000 description 2
- ZPFLBLFITJCBTP-QWRGUYRKSA-N Tyr-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O ZPFLBLFITJCBTP-QWRGUYRKSA-N 0.000 description 2
- RMRFSFXLFWWAJZ-HJOGWXRNSA-N Tyr-Tyr-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 RMRFSFXLFWWAJZ-HJOGWXRNSA-N 0.000 description 2
- RVGVIWNHABGIFH-IHRRRGAJSA-N Tyr-Val-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O RVGVIWNHABGIFH-IHRRRGAJSA-N 0.000 description 2
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 2
- PWRITNSESKQTPW-NRPADANISA-N Val-Gln-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N PWRITNSESKQTPW-NRPADANISA-N 0.000 description 2
- OXVPMZVGCAPFIG-BQFCYCMXSA-N Val-Gln-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N OXVPMZVGCAPFIG-BQFCYCMXSA-N 0.000 description 2
- BZWUSZGQOILYEU-STECZYCISA-N Val-Ile-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BZWUSZGQOILYEU-STECZYCISA-N 0.000 description 2
- LJSZPMSUYKKKCP-UBHSHLNASA-N Val-Phe-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 LJSZPMSUYKKKCP-UBHSHLNASA-N 0.000 description 2
- DEGUERSKQBRZMZ-FXQIFTODSA-N Val-Ser-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DEGUERSKQBRZMZ-FXQIFTODSA-N 0.000 description 2
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 2
- PDDJTOSAVNRJRH-UNQGMJICSA-N Val-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](C(C)C)N)O PDDJTOSAVNRJRH-UNQGMJICSA-N 0.000 description 2
- QHSSPPHOHJSTML-HOCLYGCPSA-N Val-Trp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)NCC(=O)O)N QHSSPPHOHJSTML-HOCLYGCPSA-N 0.000 description 2
- YKZVPMUGEJXEOR-JYJNAYRXSA-N Val-Val-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N YKZVPMUGEJXEOR-JYJNAYRXSA-N 0.000 description 2
- 230000002378 acidificating effect Effects 0.000 description 2
- 230000002776 aggregation Effects 0.000 description 2
- 238000004220 aggregation Methods 0.000 description 2
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 2
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 2
- 108010041407 alanylaspartic acid Proteins 0.000 description 2
- 108010005233 alanylglutamic acid Proteins 0.000 description 2
- 108010047495 alanylglycine Proteins 0.000 description 2
- APKFDSVGJQXUKY-INPOYWNPSA-N amphotericin B Chemical compound O[C@H]1[C@@H](N)[C@H](O)[C@@H](C)O[C@H]1O[C@H]1/C=C/C=C/C=C/C=C/C=C/C=C/C=C/[C@H](C)[C@@H](O)[C@@H](C)[C@H](C)OC(=O)C[C@H](O)C[C@H](O)CC[C@@H](O)[C@H](O)C[C@H](O)C[C@](O)(C[C@H](O)[C@H]2C(O)=O)O[C@H]2C1 APKFDSVGJQXUKY-INPOYWNPSA-N 0.000 description 2
- 229960003942 amphotericin b Drugs 0.000 description 2
- 239000005557 antagonist Substances 0.000 description 2
- 108010080488 arginyl-arginyl-leucine Proteins 0.000 description 2
- 210000001106 artificial yeast chromosome Anatomy 0.000 description 2
- 235000009582 asparagine Nutrition 0.000 description 2
- 229960001230 asparagine Drugs 0.000 description 2
- 230000003416 augmentation Effects 0.000 description 2
- 108091006004 biotinylated proteins Proteins 0.000 description 2
- 229910052799 carbon Inorganic materials 0.000 description 2
- 239000006143 cell culture medium Substances 0.000 description 2
- 229960002376 chymotrypsin Drugs 0.000 description 2
- 238000003776 cleavage reaction Methods 0.000 description 2
- 230000000052 comparative effect Effects 0.000 description 2
- 238000012875 competitive assay Methods 0.000 description 2
- 239000012228 culture supernatant Substances 0.000 description 2
- 235000018417 cysteine Nutrition 0.000 description 2
- 230000002950 deficient Effects 0.000 description 2
- 239000006185 dispersion Substances 0.000 description 2
- 231100000673 dose–response relationship Toxicity 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 239000012636 effector Substances 0.000 description 2
- 230000006862 enzymatic digestion Effects 0.000 description 2
- 229930195712 glutamate Natural products 0.000 description 2
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 2
- 108010072405 glycyl-aspartyl-glycine Proteins 0.000 description 2
- 239000001963 growth medium Substances 0.000 description 2
- 238000004896 high resolution mass spectrometry Methods 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 125000004435 hydrogen atom Chemical group [H]* 0.000 description 2
- 210000000987 immune system Anatomy 0.000 description 2
- 238000003018 immunoassay Methods 0.000 description 2
- 230000005847 immunogenicity Effects 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- 229940079322 interferon Drugs 0.000 description 2
- 210000000936 intestine Anatomy 0.000 description 2
- 238000001990 intravenous administration Methods 0.000 description 2
- 238000011835 investigation Methods 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 239000007951 isotonicity adjuster Substances 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 108010012058 leucyltyrosine Proteins 0.000 description 2
- 210000004698 lymphocyte Anatomy 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 238000004949 mass spectrometry Methods 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 2
- 201000000050 myeloid neoplasm Diseases 0.000 description 2
- 229940049954 penicillin Drugs 0.000 description 2
- 210000005259 peripheral blood Anatomy 0.000 description 2
- 239000011886 peripheral blood Substances 0.000 description 2
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 2
- 239000000843 powder Substances 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 2
- 108010031719 prolyl-serine Proteins 0.000 description 2
- 230000001737 promoting effect Effects 0.000 description 2
- 230000017854 proteolysis Effects 0.000 description 2
- 230000009257 reactivity Effects 0.000 description 2
- 102000005962 receptors Human genes 0.000 description 2
- 108020003175 receptors Proteins 0.000 description 2
- 230000006798 recombination Effects 0.000 description 2
- 238000005215 recombination Methods 0.000 description 2
- 238000011084 recovery Methods 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- 229920006395 saturated elastomer Polymers 0.000 description 2
- 230000007017 scission Effects 0.000 description 2
- 238000002864 sequence alignment Methods 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 238000003998 size exclusion chromatography high performance liquid chromatography Methods 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 2
- DAEPDZWVDSPTHF-UHFFFAOYSA-M sodium pyruvate Chemical compound [Na+].CC(=O)C([O-])=O DAEPDZWVDSPTHF-UHFFFAOYSA-M 0.000 description 2
- 239000007790 solid phase Substances 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 238000010561 standard procedure Methods 0.000 description 2
- 230000004936 stimulating effect Effects 0.000 description 2
- 229960005322 streptomycin Drugs 0.000 description 2
- 229940124597 therapeutic agent Drugs 0.000 description 2
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 2
- 238000004448 titration Methods 0.000 description 2
- 231100000765 toxin Toxicity 0.000 description 2
- 108700012359 toxins Proteins 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- 230000002103 transcriptional effect Effects 0.000 description 2
- 238000001890 transfection Methods 0.000 description 2
- 239000012588 trypsin Substances 0.000 description 2
- 108010084932 tryptophyl-proline Proteins 0.000 description 2
- 210000004881 tumor cell Anatomy 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 108010005834 tyrosyl-alanyl-glycine Proteins 0.000 description 2
- 241001430294 unidentified retrovirus Species 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- OOIBFPKQHULHSQ-UHFFFAOYSA-N (3-hydroxy-1-adamantyl) 2-methylprop-2-enoate Chemical compound C1C(C2)CC3CC2(O)CC1(OC(=O)C(=C)C)C3 OOIBFPKQHULHSQ-UHFFFAOYSA-N 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- ODHCTXKNWHHXJC-VKHMYHEASA-N 5-oxo-L-proline Chemical compound OC(=O)[C@@H]1CCC(=O)N1 ODHCTXKNWHHXJC-VKHMYHEASA-N 0.000 description 1
- SVBXIUDNTRTKHE-CIUDSAMLSA-N Ala-Arg-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O SVBXIUDNTRTKHE-CIUDSAMLSA-N 0.000 description 1
- KVWLTGNCJYDJET-LSJOCFKGSA-N Ala-Arg-His Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KVWLTGNCJYDJET-LSJOCFKGSA-N 0.000 description 1
- TTXMOJWKNRJWQJ-FXQIFTODSA-N Ala-Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N TTXMOJWKNRJWQJ-FXQIFTODSA-N 0.000 description 1
- PAIHPOGPJVUFJY-WDSKDSINSA-N Ala-Glu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O PAIHPOGPJVUFJY-WDSKDSINSA-N 0.000 description 1
- GGNHBHYDMUDXQB-KBIXCLLPSA-N Ala-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)N GGNHBHYDMUDXQB-KBIXCLLPSA-N 0.000 description 1
- QHASENCZLDHBGX-ONGXEEELSA-N Ala-Gly-Phe Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QHASENCZLDHBGX-ONGXEEELSA-N 0.000 description 1
- PIXQDIGKDNNOOV-GUBZILKMSA-N Ala-Lys-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O PIXQDIGKDNNOOV-GUBZILKMSA-N 0.000 description 1
- VHEVVUZDDUCAKU-FXQIFTODSA-N Ala-Met-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O VHEVVUZDDUCAKU-FXQIFTODSA-N 0.000 description 1
- CJQAEJMHBAOQHA-DLOVCJGASA-N Ala-Phe-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CJQAEJMHBAOQHA-DLOVCJGASA-N 0.000 description 1
- BFMIRJBURUXDRG-DLOVCJGASA-N Ala-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 BFMIRJBURUXDRG-DLOVCJGASA-N 0.000 description 1
- FQNILRVJOJBFFC-FXQIFTODSA-N Ala-Pro-Asp Chemical compound C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N FQNILRVJOJBFFC-FXQIFTODSA-N 0.000 description 1
- HOVPGJUNRLMIOZ-CIUDSAMLSA-N Ala-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N HOVPGJUNRLMIOZ-CIUDSAMLSA-N 0.000 description 1
- NZGRHTKZFSVPAN-BIIVOSGPSA-N Ala-Ser-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N NZGRHTKZFSVPAN-BIIVOSGPSA-N 0.000 description 1
- LFFOJBOTZUWINF-ZANVPECISA-N Ala-Trp-Gly Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O)=CNC2=C1 LFFOJBOTZUWINF-ZANVPECISA-N 0.000 description 1
- OMSKGWFGWCQFBD-KZVJFYERSA-N Ala-Val-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OMSKGWFGWCQFBD-KZVJFYERSA-N 0.000 description 1
- ZDILXFDENZVOTL-BPNCWPANSA-N Ala-Val-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDILXFDENZVOTL-BPNCWPANSA-N 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 108700028369 Alleles Proteins 0.000 description 1
- DBKNLHKEVPZVQC-LPEHRKFASA-N Arg-Ala-Pro Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O DBKNLHKEVPZVQC-LPEHRKFASA-N 0.000 description 1
- KMSHNDWHPWXPEC-BQBZGAKWSA-N Arg-Asp-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KMSHNDWHPWXPEC-BQBZGAKWSA-N 0.000 description 1
- SQKPKIJVWHAWNF-DCAQKATOSA-N Arg-Asp-Lys Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(O)=O SQKPKIJVWHAWNF-DCAQKATOSA-N 0.000 description 1
- ASQYTJJWAMDISW-BPUTZDHNSA-N Arg-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N ASQYTJJWAMDISW-BPUTZDHNSA-N 0.000 description 1
- YHQGEARSFILVHL-HJGDQZAQSA-N Arg-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N)O YHQGEARSFILVHL-HJGDQZAQSA-N 0.000 description 1
- CYXCAHZVPFREJD-LURJTMIESA-N Arg-Gly-Gly Chemical compound NC(=N)NCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O CYXCAHZVPFREJD-LURJTMIESA-N 0.000 description 1
- OQCWXQJLCDPRHV-UWVGGRQHSA-N Arg-Gly-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O OQCWXQJLCDPRHV-UWVGGRQHSA-N 0.000 description 1
- ZZZWQALDSQQBEW-STQMWFEESA-N Arg-Gly-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZZZWQALDSQQBEW-STQMWFEESA-N 0.000 description 1
- HJDNZFIYILEIKR-OSUNSFLBSA-N Arg-Ile-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HJDNZFIYILEIKR-OSUNSFLBSA-N 0.000 description 1
- OTZMRMHZCMZOJZ-SRVKXCTJSA-N Arg-Leu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O OTZMRMHZCMZOJZ-SRVKXCTJSA-N 0.000 description 1
- YTMKMRSYXHBGER-IHRRRGAJSA-N Arg-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N YTMKMRSYXHBGER-IHRRRGAJSA-N 0.000 description 1
- KMFPQTITXUKJOV-DCAQKATOSA-N Arg-Ser-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O KMFPQTITXUKJOV-DCAQKATOSA-N 0.000 description 1
- JOTRDIXZHNQYGP-DCAQKATOSA-N Arg-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N JOTRDIXZHNQYGP-DCAQKATOSA-N 0.000 description 1
- JPAWCMXVNZPJLO-IHRRRGAJSA-N Arg-Ser-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JPAWCMXVNZPJLO-IHRRRGAJSA-N 0.000 description 1
- OQPAZKMGCWPERI-GUBZILKMSA-N Arg-Ser-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O OQPAZKMGCWPERI-GUBZILKMSA-N 0.000 description 1
- AUZAXCPWMDBWEE-HJGDQZAQSA-N Arg-Thr-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O AUZAXCPWMDBWEE-HJGDQZAQSA-N 0.000 description 1
- DDBMKOCQWNFDBH-RHYQMDGZSA-N Arg-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O DDBMKOCQWNFDBH-RHYQMDGZSA-N 0.000 description 1
- OGZBJJLRKQZRHL-KJEVXHAQSA-N Arg-Thr-Tyr Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 OGZBJJLRKQZRHL-KJEVXHAQSA-N 0.000 description 1
- VJIQPOJMISSUPO-BVSLBCMMSA-N Arg-Trp-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VJIQPOJMISSUPO-BVSLBCMMSA-N 0.000 description 1
- NVPHRWNWTKYIST-BPNCWPANSA-N Arg-Tyr-Ala Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=C(O)C=C1 NVPHRWNWTKYIST-BPNCWPANSA-N 0.000 description 1
- CNBIWSCSSCAINS-UFYCRDLUSA-N Arg-Tyr-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CNBIWSCSSCAINS-UFYCRDLUSA-N 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- APHUDFFMXFYRKP-CIUDSAMLSA-N Asn-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N APHUDFFMXFYRKP-CIUDSAMLSA-N 0.000 description 1
- BVLIJXXSXBUGEC-SRVKXCTJSA-N Asn-Asn-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BVLIJXXSXBUGEC-SRVKXCTJSA-N 0.000 description 1
- PAXHINASXXXILC-SRVKXCTJSA-N Asn-Asp-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N)O PAXHINASXXXILC-SRVKXCTJSA-N 0.000 description 1
- XWFPGQVLOVGSLU-CIUDSAMLSA-N Asn-Gln-Arg Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N XWFPGQVLOVGSLU-CIUDSAMLSA-N 0.000 description 1
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 1
- IKLAUGBIDCDFOY-SRVKXCTJSA-N Asn-His-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O IKLAUGBIDCDFOY-SRVKXCTJSA-N 0.000 description 1
- NLRJGXZWTKXRHP-DCAQKATOSA-N Asn-Leu-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NLRJGXZWTKXRHP-DCAQKATOSA-N 0.000 description 1
- KHCNTVRVAYCPQE-CIUDSAMLSA-N Asn-Lys-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O KHCNTVRVAYCPQE-CIUDSAMLSA-N 0.000 description 1
- RBOBTTLFPRSXKZ-BZSNNMDCSA-N Asn-Phe-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RBOBTTLFPRSXKZ-BZSNNMDCSA-N 0.000 description 1
- PLTGTJAZQRGMPP-FXQIFTODSA-N Asn-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(N)=O PLTGTJAZQRGMPP-FXQIFTODSA-N 0.000 description 1
- QXOPPIDJKPEKCW-GUBZILKMSA-N Asn-Pro-Arg Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)N)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O QXOPPIDJKPEKCW-GUBZILKMSA-N 0.000 description 1
- JTXVXGXTRXMOFJ-FXQIFTODSA-N Asn-Pro-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O JTXVXGXTRXMOFJ-FXQIFTODSA-N 0.000 description 1
- YRTOMUMWSTUQAX-FXQIFTODSA-N Asn-Pro-Asp Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O YRTOMUMWSTUQAX-FXQIFTODSA-N 0.000 description 1
- HPBNLFLSSQDFQW-WHFBIAKZSA-N Asn-Ser-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O HPBNLFLSSQDFQW-WHFBIAKZSA-N 0.000 description 1
- BEHQTVDBCLSCBY-CFMVVWHZSA-N Asn-Tyr-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BEHQTVDBCLSCBY-CFMVVWHZSA-N 0.000 description 1
- LRCIOEVFVGXZKB-BZSNNMDCSA-N Asn-Tyr-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LRCIOEVFVGXZKB-BZSNNMDCSA-N 0.000 description 1
- PBVLJOIPOGUQQP-CIUDSAMLSA-N Asp-Ala-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O PBVLJOIPOGUQQP-CIUDSAMLSA-N 0.000 description 1
- OERMIMJQPQUIPK-FXQIFTODSA-N Asp-Arg-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O OERMIMJQPQUIPK-FXQIFTODSA-N 0.000 description 1
- HMQDRBKQMLRCCG-GMOBBJLQSA-N Asp-Arg-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HMQDRBKQMLRCCG-GMOBBJLQSA-N 0.000 description 1
- KNMRXHIAVXHCLW-ZLUOBGJFSA-N Asp-Asn-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)C(=O)O KNMRXHIAVXHCLW-ZLUOBGJFSA-N 0.000 description 1
- RSMIHCFQDCVVBR-CIUDSAMLSA-N Asp-Gln-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCNC(N)=N RSMIHCFQDCVVBR-CIUDSAMLSA-N 0.000 description 1
- DTNUIAJCPRMNBT-WHFBIAKZSA-N Asp-Gly-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O DTNUIAJCPRMNBT-WHFBIAKZSA-N 0.000 description 1
- PGUYEUCYVNZGGV-QWRGUYRKSA-N Asp-Gly-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PGUYEUCYVNZGGV-QWRGUYRKSA-N 0.000 description 1
- PAYPSKIBMDHZPI-CIUDSAMLSA-N Asp-Leu-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O PAYPSKIBMDHZPI-CIUDSAMLSA-N 0.000 description 1
- YWLDTBBUHZJQHW-KKUMJFAQSA-N Asp-Lys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N YWLDTBBUHZJQHW-KKUMJFAQSA-N 0.000 description 1
- NONWUQAWAANERO-BZSNNMDCSA-N Asp-Phe-Tyr Chemical compound C([C@H](NC(=O)[C@H](CC(O)=O)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 NONWUQAWAANERO-BZSNNMDCSA-N 0.000 description 1
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 1
- BRRPVTUFESPTCP-ACZMJKKPSA-N Asp-Ser-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O BRRPVTUFESPTCP-ACZMJKKPSA-N 0.000 description 1
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 1
- YIDFBWRHIYOYAA-LKXGYXEUSA-N Asp-Ser-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YIDFBWRHIYOYAA-LKXGYXEUSA-N 0.000 description 1
- CXEFNHOVIIDHFU-IHPCNDPISA-N Asp-Trp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CC(=O)O)N CXEFNHOVIIDHFU-IHPCNDPISA-N 0.000 description 1
- BOXNGMVEVOGXOJ-UBHSHLNASA-N Asp-Trp-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N BOXNGMVEVOGXOJ-UBHSHLNASA-N 0.000 description 1
- GHAHOJDCBRXAKC-IHPCNDPISA-N Asp-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC(=O)O)N GHAHOJDCBRXAKC-IHPCNDPISA-N 0.000 description 1
- NJLLRXWFPQQPHV-SRVKXCTJSA-N Asp-Tyr-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O NJLLRXWFPQQPHV-SRVKXCTJSA-N 0.000 description 1
- XWKPSMRPIKKDDU-RCOVLWMOSA-N Asp-Val-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O XWKPSMRPIKKDDU-RCOVLWMOSA-N 0.000 description 1
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 1
- 229940045513 CTLA4 antagonist Drugs 0.000 description 1
- 101100512078 Caenorhabditis elegans lys-1 gene Proteins 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 201000009030 Carcinoma Diseases 0.000 description 1
- 241000700198 Cavia Species 0.000 description 1
- 102000000844 Cell Surface Receptors Human genes 0.000 description 1
- 108010001857 Cell Surface Receptors Proteins 0.000 description 1
- 108091026890 Coding region Proteins 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- GEEXORWTBTUOHC-FXQIFTODSA-N Cys-Arg-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N)CN=C(N)N GEEXORWTBTUOHC-FXQIFTODSA-N 0.000 description 1
- XABFFGOGKOORCG-CIUDSAMLSA-N Cys-Asp-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O XABFFGOGKOORCG-CIUDSAMLSA-N 0.000 description 1
- BVFQOPGFOQVZTE-ACZMJKKPSA-N Cys-Gln-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O BVFQOPGFOQVZTE-ACZMJKKPSA-N 0.000 description 1
- SFRQEQGPRTVDPO-NRPADANISA-N Cys-Gln-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O SFRQEQGPRTVDPO-NRPADANISA-N 0.000 description 1
- XLLSMEFANRROJE-GUBZILKMSA-N Cys-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CS)N XLLSMEFANRROJE-GUBZILKMSA-N 0.000 description 1
- NXQCSPVUPLUTJH-WHFBIAKZSA-N Cys-Ser-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O NXQCSPVUPLUTJH-WHFBIAKZSA-N 0.000 description 1
- ZLFRUAFDAIFNHN-LKXGYXEUSA-N Cys-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CS)N)O ZLFRUAFDAIFNHN-LKXGYXEUSA-N 0.000 description 1
- ALNKNYKSZPSLBD-ZDLURKLDSA-N Cys-Thr-Gly Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O ALNKNYKSZPSLBD-ZDLURKLDSA-N 0.000 description 1
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- 241000702421 Dependoparvovirus Species 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- 241000283073 Equus caballus Species 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 241000724791 Filamentous phage Species 0.000 description 1
- 229930182566 Gentamicin Natural products 0.000 description 1
- CEAZRRDELHUEMR-URQXQFDESA-N Gentamicin Chemical compound O1[C@H](C(C)NC)CC[C@@H](N)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](NC)[C@@](C)(O)CO2)O)[C@H](N)C[C@@H]1N CEAZRRDELHUEMR-URQXQFDESA-N 0.000 description 1
- RZSLYUUFFVHFRQ-FXQIFTODSA-N Gln-Ala-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O RZSLYUUFFVHFRQ-FXQIFTODSA-N 0.000 description 1
- PRBLYKYHAJEABA-SRVKXCTJSA-N Gln-Arg-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O PRBLYKYHAJEABA-SRVKXCTJSA-N 0.000 description 1
- KCJJFESQRXGTGC-BQBZGAKWSA-N Gln-Glu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O KCJJFESQRXGTGC-BQBZGAKWSA-N 0.000 description 1
- CLPQUWHBWXFJOX-BQBZGAKWSA-N Gln-Gly-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O CLPQUWHBWXFJOX-BQBZGAKWSA-N 0.000 description 1
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 1
- XFAUJGNLHIGXET-AVGNSLFASA-N Gln-Leu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XFAUJGNLHIGXET-AVGNSLFASA-N 0.000 description 1
- MLSKFHLRFVGNLL-WDCWCFNPSA-N Gln-Leu-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MLSKFHLRFVGNLL-WDCWCFNPSA-N 0.000 description 1
- IHSGESFHTMFHRB-GUBZILKMSA-N Gln-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(N)=O IHSGESFHTMFHRB-GUBZILKMSA-N 0.000 description 1
- ILKYYKRAULNYMS-JYJNAYRXSA-N Gln-Lys-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ILKYYKRAULNYMS-JYJNAYRXSA-N 0.000 description 1
- UESYBOXFJWJVSB-AVGNSLFASA-N Gln-Phe-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O UESYBOXFJWJVSB-AVGNSLFASA-N 0.000 description 1
- ZVQZXPADLZIQFF-FHWLQOOXSA-N Gln-Phe-Tyr Chemical compound C([C@H](NC(=O)[C@H](CCC(N)=O)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 ZVQZXPADLZIQFF-FHWLQOOXSA-N 0.000 description 1
- FNAJNWPDTIXYJN-CIUDSAMLSA-N Gln-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O FNAJNWPDTIXYJN-CIUDSAMLSA-N 0.000 description 1
- XQDGOJPVMSWZSO-SRVKXCTJSA-N Gln-Pro-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N XQDGOJPVMSWZSO-SRVKXCTJSA-N 0.000 description 1
- RWQCWSGOOOEGPB-FXQIFTODSA-N Gln-Ser-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O RWQCWSGOOOEGPB-FXQIFTODSA-N 0.000 description 1
- VLOLPWWCNKWRNB-LOKLDPHHSA-N Gln-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O VLOLPWWCNKWRNB-LOKLDPHHSA-N 0.000 description 1
- VXAIXLOYBPMZPT-JBACZVJFSA-N Gln-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N VXAIXLOYBPMZPT-JBACZVJFSA-N 0.000 description 1
- FTMLQFPULNGION-ZVZYQTTQSA-N Gln-Val-Trp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O FTMLQFPULNGION-ZVZYQTTQSA-N 0.000 description 1
- NLKVNZUFDPWPNL-YUMQZZPRSA-N Glu-Arg-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O NLKVNZUFDPWPNL-YUMQZZPRSA-N 0.000 description 1
- VPKBCVUDBNINAH-GARJFASQSA-N Glu-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)O)N)C(=O)O VPKBCVUDBNINAH-GARJFASQSA-N 0.000 description 1
- YKLNMGJYMNPBCP-ACZMJKKPSA-N Glu-Asn-Asp Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YKLNMGJYMNPBCP-ACZMJKKPSA-N 0.000 description 1
- NTBDVNJIWCKURJ-ACZMJKKPSA-N Glu-Asp-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O NTBDVNJIWCKURJ-ACZMJKKPSA-N 0.000 description 1
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 1
- DSPQRJXOIXHOHK-WDSKDSINSA-N Glu-Asp-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O DSPQRJXOIXHOHK-WDSKDSINSA-N 0.000 description 1
- JVSBYEDSSRZQGV-GUBZILKMSA-N Glu-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O JVSBYEDSSRZQGV-GUBZILKMSA-N 0.000 description 1
- CYHBMLHCQXXCCT-AVGNSLFASA-N Glu-Asp-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CYHBMLHCQXXCCT-AVGNSLFASA-N 0.000 description 1
- WATXSTJXNBOHKD-LAEOZQHASA-N Glu-Asp-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O WATXSTJXNBOHKD-LAEOZQHASA-N 0.000 description 1
- MTAOBYXRYJZRGQ-WDSKDSINSA-N Glu-Gly-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MTAOBYXRYJZRGQ-WDSKDSINSA-N 0.000 description 1
- GXMXPCXXKVWOSM-KQXIARHKSA-N Glu-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N GXMXPCXXKVWOSM-KQXIARHKSA-N 0.000 description 1
- ZHNHJYYFCGUZNQ-KBIXCLLPSA-N Glu-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O ZHNHJYYFCGUZNQ-KBIXCLLPSA-N 0.000 description 1
- ZSWGJYOZWBHROQ-RWRJDSDZSA-N Glu-Ile-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZSWGJYOZWBHROQ-RWRJDSDZSA-N 0.000 description 1
- AQNYKMCFCCZEEL-JYJNAYRXSA-N Glu-Lys-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AQNYKMCFCCZEEL-JYJNAYRXSA-N 0.000 description 1
- QJVZSVUYZFYLFQ-CIUDSAMLSA-N Glu-Pro-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O QJVZSVUYZFYLFQ-CIUDSAMLSA-N 0.000 description 1
- SYAYROHMAIHWFB-KBIXCLLPSA-N Glu-Ser-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SYAYROHMAIHWFB-KBIXCLLPSA-N 0.000 description 1
- HMJULNMJWOZNFI-XHNCKOQMSA-N Glu-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N)C(=O)O HMJULNMJWOZNFI-XHNCKOQMSA-N 0.000 description 1
- JWNZHMSRZXXGTM-XKBZYTNZSA-N Glu-Ser-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JWNZHMSRZXXGTM-XKBZYTNZSA-N 0.000 description 1
- KIEICAOUSNYOLM-NRPADANISA-N Glu-Val-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O KIEICAOUSNYOLM-NRPADANISA-N 0.000 description 1
- ZALGPUWUVHOGAE-GVXVVHGQSA-N Glu-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZALGPUWUVHOGAE-GVXVVHGQSA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- QXPRJQPCFXMCIY-NKWVEPMBSA-N Gly-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN QXPRJQPCFXMCIY-NKWVEPMBSA-N 0.000 description 1
- DUYYPIRFTLOAJQ-YUMQZZPRSA-N Gly-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)CN DUYYPIRFTLOAJQ-YUMQZZPRSA-N 0.000 description 1
- XCLCVBYNGXEVDU-WHFBIAKZSA-N Gly-Asn-Ser Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O XCLCVBYNGXEVDU-WHFBIAKZSA-N 0.000 description 1
- LURCIJSJAKFCRO-QWRGUYRKSA-N Gly-Asn-Tyr Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LURCIJSJAKFCRO-QWRGUYRKSA-N 0.000 description 1
- MHHUEAIBJZWDBH-YUMQZZPRSA-N Gly-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN MHHUEAIBJZWDBH-YUMQZZPRSA-N 0.000 description 1
- JSNNHGHYGYMVCK-XVKPBYJWSA-N Gly-Glu-Val Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O JSNNHGHYGYMVCK-XVKPBYJWSA-N 0.000 description 1
- UFPXDFOYHVEIPI-BYPYZUCNSA-N Gly-Gly-Asp Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O UFPXDFOYHVEIPI-BYPYZUCNSA-N 0.000 description 1
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 1
- SIYTVHWNKGIGMD-HOTGVXAUSA-N Gly-His-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC3=CN=CN3)NC(=O)CN SIYTVHWNKGIGMD-HOTGVXAUSA-N 0.000 description 1
- NSTUFLGQJCOCDL-UWVGGRQHSA-N Gly-Leu-Arg Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NSTUFLGQJCOCDL-UWVGGRQHSA-N 0.000 description 1
- LLZXNUUIBOALNY-QWRGUYRKSA-N Gly-Leu-Lys Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN LLZXNUUIBOALNY-QWRGUYRKSA-N 0.000 description 1
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 1
- RVGMVLVBDRQVKB-UWVGGRQHSA-N Gly-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN RVGMVLVBDRQVKB-UWVGGRQHSA-N 0.000 description 1
- FJWSJWACLMTDMI-WPRPVWTQSA-N Gly-Met-Val Chemical compound [H]NCC(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O FJWSJWACLMTDMI-WPRPVWTQSA-N 0.000 description 1
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 1
- ABPRMMYHROQBLY-NKWVEPMBSA-N Gly-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)CN)C(=O)O ABPRMMYHROQBLY-NKWVEPMBSA-N 0.000 description 1
- FOKISINOENBSDM-WLTAIBSBSA-N Gly-Thr-Tyr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O FOKISINOENBSDM-WLTAIBSBSA-N 0.000 description 1
- UMRIXLHPZZIOML-OALUTQOASA-N Gly-Trp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)CN UMRIXLHPZZIOML-OALUTQOASA-N 0.000 description 1
- WSLHFAFASQFMSK-SFTDATJTSA-N Gly-Trp-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)CN)C(O)=O)=CNC2=C1 WSLHFAFASQFMSK-SFTDATJTSA-N 0.000 description 1
- IZVICCORZOSGPT-JSGCOSHPSA-N Gly-Val-Tyr Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IZVICCORZOSGPT-JSGCOSHPSA-N 0.000 description 1
- 208000009329 Graft vs Host Disease Diseases 0.000 description 1
- 239000007995 HEPES buffer Substances 0.000 description 1
- 229920000209 Hexadimethrine bromide Polymers 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- DZMVESFTHXSSPZ-XVYDVKMFSA-N His-Ala-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DZMVESFTHXSSPZ-XVYDVKMFSA-N 0.000 description 1
- YADRBUZBKHHDAO-XPUUQOCRSA-N His-Gly-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](C)C(O)=O YADRBUZBKHHDAO-XPUUQOCRSA-N 0.000 description 1
- QAMFAYSMNZBNCA-UWVGGRQHSA-N His-Gly-Met Chemical compound CSCC[C@H](NC(=O)CNC(=O)[C@@H](N)Cc1cnc[nH]1)C(O)=O QAMFAYSMNZBNCA-UWVGGRQHSA-N 0.000 description 1
- 108010093488 His-His-His-His-His-His Proteins 0.000 description 1
- VFBZWZXKCVBTJR-SRVKXCTJSA-N His-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N VFBZWZXKCVBTJR-SRVKXCTJSA-N 0.000 description 1
- AYUOWUNWZGTNKB-ULQDDVLXSA-N His-Phe-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AYUOWUNWZGTNKB-ULQDDVLXSA-N 0.000 description 1
- ZVKDCQVQTGYBQT-LSJOCFKGSA-N His-Pro-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O ZVKDCQVQTGYBQT-LSJOCFKGSA-N 0.000 description 1
- QCBYAHHNOHBXIH-UWVGGRQHSA-N His-Pro-Gly Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)NCC(O)=O)C1=CN=CN1 QCBYAHHNOHBXIH-UWVGGRQHSA-N 0.000 description 1
- CWSZWFILCNSNEX-CIUDSAMLSA-N His-Ser-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CWSZWFILCNSNEX-CIUDSAMLSA-N 0.000 description 1
- GGXUJBKENKVYNV-ULQDDVLXSA-N His-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N GGXUJBKENKVYNV-ULQDDVLXSA-N 0.000 description 1
- DRKZDEFADVYTLU-AVGNSLFASA-N His-Val-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O DRKZDEFADVYTLU-AVGNSLFASA-N 0.000 description 1
- 101000935040 Homo sapiens Integrin beta-2 Proteins 0.000 description 1
- 101000939741 Homo sapiens Probable non-functional T cell receptor gamma variable 10 Proteins 0.000 description 1
- 101000939740 Homo sapiens Probable non-functional T cell receptor gamma variable 11 Proteins 0.000 description 1
- 101000649128 Homo sapiens T cell receptor delta variable 1 Proteins 0.000 description 1
- 101000679305 Homo sapiens T cell receptor gamma variable 3 Proteins 0.000 description 1
- 101000680679 Homo sapiens T cell receptor gamma variable 5 Proteins 0.000 description 1
- 101000680681 Homo sapiens T cell receptor gamma variable 9 Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 206010020400 Hostility Diseases 0.000 description 1
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 1
- ASCFJMSGKUIRDU-ZPFDUUQYSA-N Ile-Arg-Gln Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O ASCFJMSGKUIRDU-ZPFDUUQYSA-N 0.000 description 1
- NPROWIBAWYMPAZ-GUDRVLHUSA-N Ile-Asp-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N NPROWIBAWYMPAZ-GUDRVLHUSA-N 0.000 description 1
- LBRCLQMZAHRTLV-ZKWXMUAHSA-N Ile-Gly-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LBRCLQMZAHRTLV-ZKWXMUAHSA-N 0.000 description 1
- UAQSZXGJGLHMNV-XEGUGMAKSA-N Ile-Gly-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N UAQSZXGJGLHMNV-XEGUGMAKSA-N 0.000 description 1
- GTSAALPQZASLPW-KJYZGMDISA-N Ile-His-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N GTSAALPQZASLPW-KJYZGMDISA-N 0.000 description 1
- BBQABUDWDUKJMB-LZXPERKUSA-N Ile-Ile-Ile Chemical compound CC[C@H](C)[C@H]([NH3+])C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C([O-])=O BBQABUDWDUKJMB-LZXPERKUSA-N 0.000 description 1
- PNTWNAXGBOZMBO-MNXVOIDGSA-N Ile-Lys-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PNTWNAXGBOZMBO-MNXVOIDGSA-N 0.000 description 1
- RQJUKVXWAKJDBW-SVSWQMSJSA-N Ile-Ser-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N RQJUKVXWAKJDBW-SVSWQMSJSA-N 0.000 description 1
- QGXQHJQPAPMACW-PPCPHDFISA-N Ile-Thr-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)O)N QGXQHJQPAPMACW-PPCPHDFISA-N 0.000 description 1
- WCNWGAUZWWSYDG-SVSWQMSJSA-N Ile-Thr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)O)N WCNWGAUZWWSYDG-SVSWQMSJSA-N 0.000 description 1
- MITYXXNZSZLHGG-OBAATPRFSA-N Ile-Trp-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N MITYXXNZSZLHGG-OBAATPRFSA-N 0.000 description 1
- HQLSBZFLOUHQJK-STECZYCISA-N Ile-Tyr-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HQLSBZFLOUHQJK-STECZYCISA-N 0.000 description 1
- OMDWJWGZGMCQND-CFMVVWHZSA-N Ile-Tyr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N OMDWJWGZGMCQND-CFMVVWHZSA-N 0.000 description 1
- GNXGAVNTVNOCLL-SIUGBPQLSA-N Ile-Tyr-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N GNXGAVNTVNOCLL-SIUGBPQLSA-N 0.000 description 1
- PRTZQMBYUZFSFA-XEGUGMAKSA-N Ile-Tyr-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)NCC(=O)O)N PRTZQMBYUZFSFA-XEGUGMAKSA-N 0.000 description 1
- GVEODXUBBFDBPW-MGHWNKPDSA-N Ile-Tyr-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 GVEODXUBBFDBPW-MGHWNKPDSA-N 0.000 description 1
- ZUWSVOYKBCHLRR-MGHWNKPDSA-N Ile-Tyr-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCCN)C(=O)O)N ZUWSVOYKBCHLRR-MGHWNKPDSA-N 0.000 description 1
- NSPNUMNLZNOPAQ-SJWGOKEGSA-N Ile-Tyr-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N NSPNUMNLZNOPAQ-SJWGOKEGSA-N 0.000 description 1
- ZGKVPOSSTGHJAF-HJPIBITLSA-N Ile-Tyr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CO)C(=O)O)N ZGKVPOSSTGHJAF-HJPIBITLSA-N 0.000 description 1
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 1
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 1
- 102000013463 Immunoglobulin Light Chains Human genes 0.000 description 1
- 108010065825 Immunoglobulin Light Chains Proteins 0.000 description 1
- 102000012745 Immunoglobulin Subunits Human genes 0.000 description 1
- 108010079585 Immunoglobulin Subunits Proteins 0.000 description 1
- 206010061218 Inflammation Diseases 0.000 description 1
- 102100022297 Integrin alpha-X Human genes 0.000 description 1
- 102100025390 Integrin beta-2 Human genes 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- KWTVLKBOQATPHJ-SRVKXCTJSA-N Leu-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N KWTVLKBOQATPHJ-SRVKXCTJSA-N 0.000 description 1
- XBBKIIGCUMBKCO-JXUBOQSCSA-N Leu-Ala-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XBBKIIGCUMBKCO-JXUBOQSCSA-N 0.000 description 1
- DUBAVOVZNZKEQQ-AVGNSLFASA-N Leu-Arg-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CCCN=C(N)N DUBAVOVZNZKEQQ-AVGNSLFASA-N 0.000 description 1
- DLCOFDAHNMMQPP-SRVKXCTJSA-N Leu-Asp-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O DLCOFDAHNMMQPP-SRVKXCTJSA-N 0.000 description 1
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 1
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 1
- LOLUPZNNADDTAA-AVGNSLFASA-N Leu-Gln-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LOLUPZNNADDTAA-AVGNSLFASA-N 0.000 description 1
- HFBCHNRFRYLZNV-GUBZILKMSA-N Leu-Glu-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HFBCHNRFRYLZNV-GUBZILKMSA-N 0.000 description 1
- NEEOBPIXKWSBRF-IUCAKERBSA-N Leu-Glu-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O NEEOBPIXKWSBRF-IUCAKERBSA-N 0.000 description 1
- HVJVUYQWFYMGJS-GVXVVHGQSA-N Leu-Glu-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVJVUYQWFYMGJS-GVXVVHGQSA-N 0.000 description 1
- LAPSXOAUPNOINL-YUMQZZPRSA-N Leu-Gly-Asp Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O LAPSXOAUPNOINL-YUMQZZPRSA-N 0.000 description 1
- VBZOAGIPCULURB-QWRGUYRKSA-N Leu-Gly-His Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N VBZOAGIPCULURB-QWRGUYRKSA-N 0.000 description 1
- VGPCJSXPPOQPBK-YUMQZZPRSA-N Leu-Gly-Ser Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O VGPCJSXPPOQPBK-YUMQZZPRSA-N 0.000 description 1
- UCDHVOALNXENLC-KBPBESRZSA-N Leu-Gly-Tyr Chemical compound CC(C)C[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=C(O)C=C1 UCDHVOALNXENLC-KBPBESRZSA-N 0.000 description 1
- HGFGEMSVBMCFKK-MNXVOIDGSA-N Leu-Ile-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O HGFGEMSVBMCFKK-MNXVOIDGSA-N 0.000 description 1
- HRTRLSRYZZKPCO-BJDJZHNGSA-N Leu-Ile-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HRTRLSRYZZKPCO-BJDJZHNGSA-N 0.000 description 1
- UBZGNBKMIJHOHL-BZSNNMDCSA-N Leu-Leu-Phe Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 UBZGNBKMIJHOHL-BZSNNMDCSA-N 0.000 description 1
- UCNNZELZXFXXJQ-BZSNNMDCSA-N Leu-Leu-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCNNZELZXFXXJQ-BZSNNMDCSA-N 0.000 description 1
- FKQPWMZLIIATBA-AJNGGQMLSA-N Leu-Lys-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FKQPWMZLIIATBA-AJNGGQMLSA-N 0.000 description 1
- AUNMOHYWTAPQLA-XUXIUFHCSA-N Leu-Met-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AUNMOHYWTAPQLA-XUXIUFHCSA-N 0.000 description 1
- KQFZKDITNUEVFJ-JYJNAYRXSA-N Leu-Phe-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CC=CC=C1 KQFZKDITNUEVFJ-JYJNAYRXSA-N 0.000 description 1
- INCJJHQRZGQLFC-KBPBESRZSA-N Leu-Phe-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O INCJJHQRZGQLFC-KBPBESRZSA-N 0.000 description 1
- MVVSHHJKJRZVNY-ACRUOGEOSA-N Leu-Phe-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MVVSHHJKJRZVNY-ACRUOGEOSA-N 0.000 description 1
- SVBJIZVVYJYGLA-DCAQKATOSA-N Leu-Ser-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O SVBJIZVVYJYGLA-DCAQKATOSA-N 0.000 description 1
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 1
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 1
- ONHCDMBHPQIPAI-YTQUADARSA-N Leu-Trp-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N3CCC[C@@H]3C(=O)O)N ONHCDMBHPQIPAI-YTQUADARSA-N 0.000 description 1
- ISSAURVGLGAPDK-KKUMJFAQSA-N Leu-Tyr-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O ISSAURVGLGAPDK-KKUMJFAQSA-N 0.000 description 1
- TUIOUEWKFFVNLH-DCAQKATOSA-N Leu-Val-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O TUIOUEWKFFVNLH-DCAQKATOSA-N 0.000 description 1
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 1
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- SWWCDAGDQHTKIE-RHYQMDGZSA-N Lys-Arg-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SWWCDAGDQHTKIE-RHYQMDGZSA-N 0.000 description 1
- LZWNAOIMTLNMDW-NHCYSSNCSA-N Lys-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N LZWNAOIMTLNMDW-NHCYSSNCSA-N 0.000 description 1
- DRCILAJNUJKAHC-SRVKXCTJSA-N Lys-Glu-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DRCILAJNUJKAHC-SRVKXCTJSA-N 0.000 description 1
- GRADYHMSAUIKPS-DCAQKATOSA-N Lys-Glu-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRADYHMSAUIKPS-DCAQKATOSA-N 0.000 description 1
- PRSBSVAVOQOAMI-BJDJZHNGSA-N Lys-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN PRSBSVAVOQOAMI-BJDJZHNGSA-N 0.000 description 1
- VMTYLUGCXIEDMV-QWRGUYRKSA-N Lys-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCCN VMTYLUGCXIEDMV-QWRGUYRKSA-N 0.000 description 1
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 1
- YSPZCHGIWAQVKQ-AVGNSLFASA-N Lys-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN YSPZCHGIWAQVKQ-AVGNSLFASA-N 0.000 description 1
- WQDKIVRHTQYJSN-DCAQKATOSA-N Lys-Ser-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N WQDKIVRHTQYJSN-DCAQKATOSA-N 0.000 description 1
- UGCIQUYEJIEHKX-GVXVVHGQSA-N Lys-Val-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O UGCIQUYEJIEHKX-GVXVVHGQSA-N 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- PJWDQHNOJIBMRY-JYJNAYRXSA-N Met-Arg-Tyr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PJWDQHNOJIBMRY-JYJNAYRXSA-N 0.000 description 1
- 102000016943 Muramidase Human genes 0.000 description 1
- 108010014251 Muramidase Proteins 0.000 description 1
- 108010062010 N-Acetylmuramoyl-L-alanine Amidase Proteins 0.000 description 1
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 1
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 1
- 238000005481 NMR spectroscopy Methods 0.000 description 1
- 101100068676 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gln-1 gene Proteins 0.000 description 1
- 101710153660 Nuclear receptor corepressor 2 Proteins 0.000 description 1
- 239000004677 Nylon Substances 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- CDNPIRSCAFMMBE-SRVKXCTJSA-N Phe-Asn-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CDNPIRSCAFMMBE-SRVKXCTJSA-N 0.000 description 1
- FSPGBMWPNMRWDB-AVGNSLFASA-N Phe-Cys-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N FSPGBMWPNMRWDB-AVGNSLFASA-N 0.000 description 1
- NPLGQVKZFGJWAI-QWHCGFSZSA-N Phe-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O NPLGQVKZFGJWAI-QWHCGFSZSA-N 0.000 description 1
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 1
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 1
- ZLAKUZDMKVKFAI-JYJNAYRXSA-N Phe-Pro-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O ZLAKUZDMKVKFAI-JYJNAYRXSA-N 0.000 description 1
- IAOZOFPONWDXNT-IXOXFDKPSA-N Phe-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IAOZOFPONWDXNT-IXOXFDKPSA-N 0.000 description 1
- MSSXKZBDKZAHCX-UNQGMJICSA-N Phe-Thr-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O MSSXKZBDKZAHCX-UNQGMJICSA-N 0.000 description 1
- UMIHVJQSXFWWMW-JBACZVJFSA-N Phe-Trp-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N UMIHVJQSXFWWMW-JBACZVJFSA-N 0.000 description 1
- GCFNFKNPCMBHNT-IRXDYDNUSA-N Phe-Tyr-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)NCC(=O)O)N GCFNFKNPCMBHNT-IRXDYDNUSA-N 0.000 description 1
- IFMDQWDAJUMMJC-DCAQKATOSA-N Pro-Ala-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O IFMDQWDAJUMMJC-DCAQKATOSA-N 0.000 description 1
- LNLNHXIQPGKRJQ-SRVKXCTJSA-N Pro-Arg-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 LNLNHXIQPGKRJQ-SRVKXCTJSA-N 0.000 description 1
- ZSKJPKFTPQCPIH-RCWTZXSCSA-N Pro-Arg-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZSKJPKFTPQCPIH-RCWTZXSCSA-N 0.000 description 1
- ORPZXBQTEHINPB-SRVKXCTJSA-N Pro-Arg-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H]1CCCN1)C(O)=O ORPZXBQTEHINPB-SRVKXCTJSA-N 0.000 description 1
- KIGGUSRFHJCIEJ-DCAQKATOSA-N Pro-Asp-His Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O KIGGUSRFHJCIEJ-DCAQKATOSA-N 0.000 description 1
- SFECXGVELZFBFJ-VEVYYDQMSA-N Pro-Asp-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SFECXGVELZFBFJ-VEVYYDQMSA-N 0.000 description 1
- HJSCRFZVGXAGNG-SRVKXCTJSA-N Pro-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H]1CCCN1 HJSCRFZVGXAGNG-SRVKXCTJSA-N 0.000 description 1
- DMKWYMWNEKIPFC-IUCAKERBSA-N Pro-Gly-Arg Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O DMKWYMWNEKIPFC-IUCAKERBSA-N 0.000 description 1
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 1
- VYWNORHENYEQDW-YUMQZZPRSA-N Pro-Gly-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 VYWNORHENYEQDW-YUMQZZPRSA-N 0.000 description 1
- DXTOOBDIIAJZBJ-BQBZGAKWSA-N Pro-Gly-Ser Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CO)C(O)=O DXTOOBDIIAJZBJ-BQBZGAKWSA-N 0.000 description 1
- AFXCXDQNRXTSBD-FJXKBIBVSA-N Pro-Gly-Thr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O AFXCXDQNRXTSBD-FJXKBIBVSA-N 0.000 description 1
- FXGIMYRVJJEIIM-UWVGGRQHSA-N Pro-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FXGIMYRVJJEIIM-UWVGGRQHSA-N 0.000 description 1
- PCWLNNZTBJTZRN-AVGNSLFASA-N Pro-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 PCWLNNZTBJTZRN-AVGNSLFASA-N 0.000 description 1
- FNGOXVQBBCMFKV-CIUDSAMLSA-N Pro-Ser-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O FNGOXVQBBCMFKV-CIUDSAMLSA-N 0.000 description 1
- KWMZPPWYBVZIER-XGEHTFHBSA-N Pro-Ser-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWMZPPWYBVZIER-XGEHTFHBSA-N 0.000 description 1
- GZNYIXWOIUFLGO-ZJDVBMNYSA-N Pro-Thr-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZNYIXWOIUFLGO-ZJDVBMNYSA-N 0.000 description 1
- 102100029686 Probable non-functional T cell receptor gamma variable 11 Human genes 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- LCTONWCANYUPML-UHFFFAOYSA-M Pyruvate Chemical compound CC(=O)C([O-])=O LCTONWCANYUPML-UHFFFAOYSA-M 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 1
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 1
- 102100037486 Reverse transcriptase/ribonuclease H Human genes 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- BTKUIVBNGBFTTP-WHFBIAKZSA-N Ser-Ala-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)NCC(O)=O BTKUIVBNGBFTTP-WHFBIAKZSA-N 0.000 description 1
- JPIDMRXXNMIVKY-VZFHVOOUSA-N Ser-Ala-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPIDMRXXNMIVKY-VZFHVOOUSA-N 0.000 description 1
- PZZJMBYSYAKYPK-UWJYBYFXSA-N Ser-Ala-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O PZZJMBYSYAKYPK-UWJYBYFXSA-N 0.000 description 1
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 1
- OOKCGAYXSNJBGQ-ZLUOBGJFSA-N Ser-Asn-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OOKCGAYXSNJBGQ-ZLUOBGJFSA-N 0.000 description 1
- VGNYHOBZJKWRGI-CIUDSAMLSA-N Ser-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO VGNYHOBZJKWRGI-CIUDSAMLSA-N 0.000 description 1
- RDFQNDHEHVSONI-ZLUOBGJFSA-N Ser-Asn-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RDFQNDHEHVSONI-ZLUOBGJFSA-N 0.000 description 1
- KNZQGAUEYZJUSQ-ZLUOBGJFSA-N Ser-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N KNZQGAUEYZJUSQ-ZLUOBGJFSA-N 0.000 description 1
- MMAPOBOTRUVNKJ-ZLUOBGJFSA-N Ser-Asp-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CO)N)C(=O)O MMAPOBOTRUVNKJ-ZLUOBGJFSA-N 0.000 description 1
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 1
- CXBFHZLODKPIJY-AAEUAGOBSA-N Ser-Gly-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N CXBFHZLODKPIJY-AAEUAGOBSA-N 0.000 description 1
- JEHPKECJCALLRW-CUJWVEQBSA-N Ser-His-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEHPKECJCALLRW-CUJWVEQBSA-N 0.000 description 1
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 1
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 1
- NUEHQDHDLDXCRU-GUBZILKMSA-N Ser-Pro-Arg Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NUEHQDHDLDXCRU-GUBZILKMSA-N 0.000 description 1
- PJIQEIFXZPCWOJ-FXQIFTODSA-N Ser-Pro-Asp Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O PJIQEIFXZPCWOJ-FXQIFTODSA-N 0.000 description 1
- WNDUPCKKKGSKIQ-CIUDSAMLSA-N Ser-Pro-Gln Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O WNDUPCKKKGSKIQ-CIUDSAMLSA-N 0.000 description 1
- FKYWFUYPVKLJLP-DCAQKATOSA-N Ser-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FKYWFUYPVKLJLP-DCAQKATOSA-N 0.000 description 1
- DINQYZRMXGWWTG-GUBZILKMSA-N Ser-Pro-Pro Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DINQYZRMXGWWTG-GUBZILKMSA-N 0.000 description 1
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 1
- KQNDIKOYWZTZIX-FXQIFTODSA-N Ser-Ser-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQNDIKOYWZTZIX-FXQIFTODSA-N 0.000 description 1
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 1
- RXUOAOOZIWABBW-XGEHTFHBSA-N Ser-Thr-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RXUOAOOZIWABBW-XGEHTFHBSA-N 0.000 description 1
- PURRNJBBXDDWLX-ZDLURKLDSA-N Ser-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CO)N)O PURRNJBBXDDWLX-ZDLURKLDSA-N 0.000 description 1
- ZKOKTQPHFMRSJP-YJRXYDGGSA-N Ser-Thr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKOKTQPHFMRSJP-YJRXYDGGSA-N 0.000 description 1
- PQEQXWRVHQAAKS-SRVKXCTJSA-N Ser-Tyr-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CO)N)CC1=CC=C(O)C=C1 PQEQXWRVHQAAKS-SRVKXCTJSA-N 0.000 description 1
- FHXGMDRKJHKLKW-QWRGUYRKSA-N Ser-Tyr-Gly Chemical compound OC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 FHXGMDRKJHKLKW-QWRGUYRKSA-N 0.000 description 1
- PLQWGQUNUPMNOD-KKUMJFAQSA-N Ser-Tyr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O PLQWGQUNUPMNOD-KKUMJFAQSA-N 0.000 description 1
- OQSQCUWQOIHECT-YJRXYDGGSA-N Ser-Tyr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OQSQCUWQOIHECT-YJRXYDGGSA-N 0.000 description 1
- HAYADTTXNZFUDM-IHRRRGAJSA-N Ser-Tyr-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O HAYADTTXNZFUDM-IHRRRGAJSA-N 0.000 description 1
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 108091081024 Start codon Proteins 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- 241000282898 Sus scrofa Species 0.000 description 1
- 102100029452 T cell receptor alpha chain constant Human genes 0.000 description 1
- 102100027949 T cell receptor delta variable 1 Human genes 0.000 description 1
- 102100022591 T cell receptor gamma variable 3 Human genes 0.000 description 1
- 102100022391 T cell receptor gamma variable 5 Human genes 0.000 description 1
- 102100022393 T cell receptor gamma variable 9 Human genes 0.000 description 1
- 210000000662 T-lymphocyte subset Anatomy 0.000 description 1
- GFDUZZACIWNMPE-KZVJFYERSA-N Thr-Ala-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O GFDUZZACIWNMPE-KZVJFYERSA-N 0.000 description 1
- CAJFZCICSVBOJK-SHGPDSBTSA-N Thr-Ala-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAJFZCICSVBOJK-SHGPDSBTSA-N 0.000 description 1
- NAXBBCLCEOTAIG-RHYQMDGZSA-N Thr-Arg-Lys Chemical compound NC(N)=NCCC[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CCCCN)C(O)=O NAXBBCLCEOTAIG-RHYQMDGZSA-N 0.000 description 1
- UNURFMVMXLENAZ-KJEVXHAQSA-N Thr-Arg-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O UNURFMVMXLENAZ-KJEVXHAQSA-N 0.000 description 1
- IRKWVRSEQFTGGV-VEVYYDQMSA-N Thr-Asn-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IRKWVRSEQFTGGV-VEVYYDQMSA-N 0.000 description 1
- DCLBXIWHLVEPMQ-JRQIVUDYSA-N Thr-Asp-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 DCLBXIWHLVEPMQ-JRQIVUDYSA-N 0.000 description 1
- MMTOHPRBJKEZHT-BWBBJGPYSA-N Thr-Cys-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O MMTOHPRBJKEZHT-BWBBJGPYSA-N 0.000 description 1
- GARULAKWZGFIKC-RWRJDSDZSA-N Thr-Gln-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O GARULAKWZGFIKC-RWRJDSDZSA-N 0.000 description 1
- YUOCMLNTUZAGNF-KLHWPWHYSA-N Thr-His-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N2CCC[C@@H]2C(=O)O)N)O YUOCMLNTUZAGNF-KLHWPWHYSA-N 0.000 description 1
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 1
- RFKVQLIXNVEOMB-WEDXCCLWSA-N Thr-Leu-Gly Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)O)N)O RFKVQLIXNVEOMB-WEDXCCLWSA-N 0.000 description 1
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 1
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 1
- WYLAVUAWOUVUCA-XVSYOHENSA-N Thr-Phe-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O WYLAVUAWOUVUCA-XVSYOHENSA-N 0.000 description 1
- MUAFDCVOHYAFNG-RCWTZXSCSA-N Thr-Pro-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MUAFDCVOHYAFNG-RCWTZXSCSA-N 0.000 description 1
- LKJCABTUFGTPPY-HJGDQZAQSA-N Thr-Pro-Gln Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O LKJCABTUFGTPPY-HJGDQZAQSA-N 0.000 description 1
- XKWABWFMQXMUMT-HJGDQZAQSA-N Thr-Pro-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XKWABWFMQXMUMT-HJGDQZAQSA-N 0.000 description 1
- MXDOAJQRJBMGMO-FJXKBIBVSA-N Thr-Pro-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O MXDOAJQRJBMGMO-FJXKBIBVSA-N 0.000 description 1
- MROIJTGJGIDEEJ-RCWTZXSCSA-N Thr-Pro-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 MROIJTGJGIDEEJ-RCWTZXSCSA-N 0.000 description 1
- YGCDFAJJCRVQKU-RCWTZXSCSA-N Thr-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O YGCDFAJJCRVQKU-RCWTZXSCSA-N 0.000 description 1
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 1
- YRJOLUDFVAUXLI-GSSVUCPTSA-N Thr-Thr-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(O)=O YRJOLUDFVAUXLI-GSSVUCPTSA-N 0.000 description 1
- KHTIUAKJRUIEMA-HOUAVDHOSA-N Thr-Trp-Asp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC(O)=O)C(O)=O)=CNC2=C1 KHTIUAKJRUIEMA-HOUAVDHOSA-N 0.000 description 1
- LXXCHJKHJYRMIY-FQPOAREZSA-N Thr-Tyr-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O LXXCHJKHJYRMIY-FQPOAREZSA-N 0.000 description 1
- XVHAUVJXBFGUPC-RPTUDFQQSA-N Thr-Tyr-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XVHAUVJXBFGUPC-RPTUDFQQSA-N 0.000 description 1
- LVRFMARKDGGZMX-IZPVPAKOSA-N Thr-Tyr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CC1=CC=C(O)C=C1 LVRFMARKDGGZMX-IZPVPAKOSA-N 0.000 description 1
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 1
- BPGDJSUFQKWUBK-KJEVXHAQSA-N Thr-Val-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BPGDJSUFQKWUBK-KJEVXHAQSA-N 0.000 description 1
- VYVBSMCZNHOZGD-RCWTZXSCSA-N Thr-Val-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O VYVBSMCZNHOZGD-RCWTZXSCSA-N 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 101710120037 Toxin CcdB Proteins 0.000 description 1
- PNKDNKGMEHJTJQ-BPUTZDHNSA-N Trp-Arg-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N PNKDNKGMEHJTJQ-BPUTZDHNSA-N 0.000 description 1
- HYLNRGXEQACDKG-NYVOZVTQSA-N Trp-Asn-Trp Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HYLNRGXEQACDKG-NYVOZVTQSA-N 0.000 description 1
- KIMOCKLJBXHFIN-YLVFBTJISA-N Trp-Ile-Gly Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O)=CNC2=C1 KIMOCKLJBXHFIN-YLVFBTJISA-N 0.000 description 1
- UJRIVCPPPMYCNA-HOCLYGCPSA-N Trp-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N UJRIVCPPPMYCNA-HOCLYGCPSA-N 0.000 description 1
- GBEAUNVBIMLWIB-IHPCNDPISA-N Trp-Ser-Phe Chemical compound C([C@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(O)=O)C1=CC=CC=C1 GBEAUNVBIMLWIB-IHPCNDPISA-N 0.000 description 1
- JTMZSIRTZKLBOA-NWLDYVSISA-N Trp-Thr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O JTMZSIRTZKLBOA-NWLDYVSISA-N 0.000 description 1
- YXSSXUIBUJGHJY-SFJXLCSZSA-N Trp-Thr-Phe Chemical compound C([C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)[C@H](O)C)C(O)=O)C1=CC=CC=C1 YXSSXUIBUJGHJY-SFJXLCSZSA-N 0.000 description 1
- YCEHCFIOIYNQTR-NYVOZVTQSA-N Trp-Trp-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)N[C@@H](CO)C(=O)O)N YCEHCFIOIYNQTR-NYVOZVTQSA-N 0.000 description 1
- RPTAWXPQXXCUGL-OYDLWJJNSA-N Trp-Trp-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](Cc1c[nH]c2ccccc12)NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(O)=O RPTAWXPQXXCUGL-OYDLWJJNSA-N 0.000 description 1
- UIDJDMVRDUANDL-BVSLBCMMSA-N Trp-Tyr-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UIDJDMVRDUANDL-BVSLBCMMSA-N 0.000 description 1
- SGQSAIFDESQBRA-IHPCNDPISA-N Trp-Tyr-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SGQSAIFDESQBRA-IHPCNDPISA-N 0.000 description 1
- SJWLQICJOBMOGG-PMVMPFDFSA-N Trp-Tyr-His Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)N[C@@H](CC4=CN=CN4)C(=O)O)N SJWLQICJOBMOGG-PMVMPFDFSA-N 0.000 description 1
- DVLHKUWLNKDINO-PMVMPFDFSA-N Trp-Tyr-Leu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O DVLHKUWLNKDINO-PMVMPFDFSA-N 0.000 description 1
- JONPRIHUYSPIMA-UWJYBYFXSA-N Tyr-Ala-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JONPRIHUYSPIMA-UWJYBYFXSA-N 0.000 description 1
- LGEYOIQBBIPHQN-UWJYBYFXSA-N Tyr-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 LGEYOIQBBIPHQN-UWJYBYFXSA-N 0.000 description 1
- KSVMDJJCYKIXTK-IGNZVWTISA-N Tyr-Ala-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 KSVMDJJCYKIXTK-IGNZVWTISA-N 0.000 description 1
- MICSYKFECRFCTJ-IHRRRGAJSA-N Tyr-Arg-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O MICSYKFECRFCTJ-IHRRRGAJSA-N 0.000 description 1
- IIJWXEUNETVJPV-IHRRRGAJSA-N Tyr-Arg-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)O)N)O IIJWXEUNETVJPV-IHRRRGAJSA-N 0.000 description 1
- AYHSJESDFKREAR-KKUMJFAQSA-N Tyr-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AYHSJESDFKREAR-KKUMJFAQSA-N 0.000 description 1
- BEIGSKUPTIFYRZ-SRVKXCTJSA-N Tyr-Asp-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O BEIGSKUPTIFYRZ-SRVKXCTJSA-N 0.000 description 1
- JWHOIHCOHMZSAR-QWRGUYRKSA-N Tyr-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JWHOIHCOHMZSAR-QWRGUYRKSA-N 0.000 description 1
- MNMYOSZWCKYEDI-JRQIVUDYSA-N Tyr-Asp-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MNMYOSZWCKYEDI-JRQIVUDYSA-N 0.000 description 1
- SMLCYZYQFRTLCO-UWJYBYFXSA-N Tyr-Cys-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O SMLCYZYQFRTLCO-UWJYBYFXSA-N 0.000 description 1
- QOIKZODVIPOPDD-AVGNSLFASA-N Tyr-Cys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QOIKZODVIPOPDD-AVGNSLFASA-N 0.000 description 1
- ZAGPDPNPWYPEIR-SRVKXCTJSA-N Tyr-Cys-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O ZAGPDPNPWYPEIR-SRVKXCTJSA-N 0.000 description 1
- HKYTWJOWZTWBQB-AVGNSLFASA-N Tyr-Glu-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 HKYTWJOWZTWBQB-AVGNSLFASA-N 0.000 description 1
- UNUZEBFXGWVAOP-DZKIICNBSA-N Tyr-Glu-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UNUZEBFXGWVAOP-DZKIICNBSA-N 0.000 description 1
- OLWFDNLLBWQWCP-STQMWFEESA-N Tyr-Gly-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O OLWFDNLLBWQWCP-STQMWFEESA-N 0.000 description 1
- AZGZDDNKFFUDEH-QWRGUYRKSA-N Tyr-Gly-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AZGZDDNKFFUDEH-QWRGUYRKSA-N 0.000 description 1
- BSCBBPKDVOZICB-KKUMJFAQSA-N Tyr-Leu-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BSCBBPKDVOZICB-KKUMJFAQSA-N 0.000 description 1
- YKCXQOBTISTQJD-BZSNNMDCSA-N Tyr-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N YKCXQOBTISTQJD-BZSNNMDCSA-N 0.000 description 1
- ZOBLBMGJKVJVEV-BZSNNMDCSA-N Tyr-Lys-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N)O ZOBLBMGJKVJVEV-BZSNNMDCSA-N 0.000 description 1
- YSGAPESOXHFTQY-IHRRRGAJSA-N Tyr-Met-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N YSGAPESOXHFTQY-IHRRRGAJSA-N 0.000 description 1
- XJPXTYLVMUZGNW-IHRRRGAJSA-N Tyr-Pro-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O XJPXTYLVMUZGNW-IHRRRGAJSA-N 0.000 description 1
- SZEIFUXUTBBQFQ-STQMWFEESA-N Tyr-Pro-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O SZEIFUXUTBBQFQ-STQMWFEESA-N 0.000 description 1
- GQVZBMROTPEPIF-SRVKXCTJSA-N Tyr-Ser-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GQVZBMROTPEPIF-SRVKXCTJSA-N 0.000 description 1
- QPOUERMDWKKZEG-HJPIBITLSA-N Tyr-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 QPOUERMDWKKZEG-HJPIBITLSA-N 0.000 description 1
- MDXLPNRXCFOBTL-BZSNNMDCSA-N Tyr-Ser-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MDXLPNRXCFOBTL-BZSNNMDCSA-N 0.000 description 1
- ZYVAAYAOTVJBSS-GMVOTWDCSA-N Tyr-Trp-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O ZYVAAYAOTVJBSS-GMVOTWDCSA-N 0.000 description 1
- OJCISMMNNUNNJA-BZSNNMDCSA-N Tyr-Tyr-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 OJCISMMNNUNNJA-BZSNNMDCSA-N 0.000 description 1
- TYGHOWWWMTWVKM-HJOGWXRNSA-N Tyr-Tyr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 TYGHOWWWMTWVKM-HJOGWXRNSA-N 0.000 description 1
- SQUMHUZLJDUROQ-YDHLFZDLSA-N Tyr-Val-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O SQUMHUZLJDUROQ-YDHLFZDLSA-N 0.000 description 1
- DJIJBQYBDKGDIS-JYJNAYRXSA-N Tyr-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)Cc1ccc(O)cc1)C(C)C)C(O)=O DJIJBQYBDKGDIS-JYJNAYRXSA-N 0.000 description 1
- LTFLDDDGWOVIHY-NAKRPEOUSA-N Val-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N LTFLDDDGWOVIHY-NAKRPEOUSA-N 0.000 description 1
- XLDYBRXERHITNH-QSFUFRPTSA-N Val-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)C(C)C XLDYBRXERHITNH-QSFUFRPTSA-N 0.000 description 1
- HHSILIQTHXABKM-YDHLFZDLSA-N Val-Asp-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](Cc1ccccc1)C(O)=O HHSILIQTHXABKM-YDHLFZDLSA-N 0.000 description 1
- DDNIHOWRDOXXPF-NGZCFLSTSA-N Val-Asp-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N DDNIHOWRDOXXPF-NGZCFLSTSA-N 0.000 description 1
- ROLGIBMFNMZANA-GVXVVHGQSA-N Val-Glu-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N ROLGIBMFNMZANA-GVXVVHGQSA-N 0.000 description 1
- LAYSXAOGWHKNED-XPUUQOCRSA-N Val-Gly-Ser Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LAYSXAOGWHKNED-XPUUQOCRSA-N 0.000 description 1
- MJXNDRCLGDSBBE-FHWLQOOXSA-N Val-His-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N MJXNDRCLGDSBBE-FHWLQOOXSA-N 0.000 description 1
- MYLNLEIZWHVENT-VKOGCVSHSA-N Val-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](C(C)C)N MYLNLEIZWHVENT-VKOGCVSHSA-N 0.000 description 1
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 1
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 1
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 1
- JAKHAONCJJZVHT-DCAQKATOSA-N Val-Lys-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N JAKHAONCJJZVHT-DCAQKATOSA-N 0.000 description 1
- YLRAFVVWZRSZQC-DZKIICNBSA-N Val-Phe-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N YLRAFVVWZRSZQC-DZKIICNBSA-N 0.000 description 1
- VSCIANXXVZOYOC-AVGNSLFASA-N Val-Pro-His Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N VSCIANXXVZOYOC-AVGNSLFASA-N 0.000 description 1
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 1
- PGQUDQYHWICSAB-NAKRPEOUSA-N Val-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N PGQUDQYHWICSAB-NAKRPEOUSA-N 0.000 description 1
- QTPQHINADBYBNA-DCAQKATOSA-N Val-Ser-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN QTPQHINADBYBNA-DCAQKATOSA-N 0.000 description 1
- GBIUHAYJGWVNLN-AEJSXWLSSA-N Val-Ser-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N GBIUHAYJGWVNLN-AEJSXWLSSA-N 0.000 description 1
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 1
- SDHZOOIGIUEPDY-JYJNAYRXSA-N Val-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 SDHZOOIGIUEPDY-JYJNAYRXSA-N 0.000 description 1
- PQSNETRGCRUOGP-KKHAAJSZSA-N Val-Thr-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O PQSNETRGCRUOGP-KKHAAJSZSA-N 0.000 description 1
- DLRZGNXCXUGIDG-KKHAAJSZSA-N Val-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O DLRZGNXCXUGIDG-KKHAAJSZSA-N 0.000 description 1
- QPJSIBAOZBVELU-BPNCWPANSA-N Val-Tyr-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N QPJSIBAOZBVELU-BPNCWPANSA-N 0.000 description 1
- GUIYPEKUEMQBIK-JSGCOSHPSA-N Val-Tyr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)NCC(O)=O GUIYPEKUEMQBIK-JSGCOSHPSA-N 0.000 description 1
- JVGDAEKKZKKZFO-RCWTZXSCSA-N Val-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N)O JVGDAEKKZKKZFO-RCWTZXSCSA-N 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 239000003070 absorption delaying agent Substances 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 230000001154 acute effect Effects 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 238000003314 affinity selection Methods 0.000 description 1
- 238000012867 alanine scanning Methods 0.000 description 1
- 108010070944 alanylhistidine Proteins 0.000 description 1
- 108010011559 alanylphenylalanine Proteins 0.000 description 1
- 230000000735 allogeneic effect Effects 0.000 description 1
- 230000008485 antagonism Effects 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 230000003097 anti-respiratory effect Effects 0.000 description 1
- 239000000611 antibody drug conjugate Substances 0.000 description 1
- 238000011091 antibody purification Methods 0.000 description 1
- 230000005875 antibody response Effects 0.000 description 1
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 1
- 229940049595 antibody-drug conjugate Drugs 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 239000003429 antifungal agent Substances 0.000 description 1
- 230000009831 antigen interaction Effects 0.000 description 1
- 239000002246 antineoplastic agent Substances 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 108010001271 arginyl-glutamyl-arginine Proteins 0.000 description 1
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 1
- 108010010430 asparagine-proline-alanine Proteins 0.000 description 1
- 229940009098 aspartate Drugs 0.000 description 1
- 238000007845 assembly PCR Methods 0.000 description 1
- 230000001363 autoimmune Effects 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 102000005936 beta-Galactosidase Human genes 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 238000012219 cassette mutagenesis Methods 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 239000006285 cell suspension Substances 0.000 description 1
- 230000003833 cell viability Effects 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 230000001684 chronic effect Effects 0.000 description 1
- 238000013377 clone selection method Methods 0.000 description 1
- 238000003501 co-culture Methods 0.000 description 1
- 238000000576 coating method Methods 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 230000000112 colonic effect Effects 0.000 description 1
- 230000009137 competitive binding Effects 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 230000004154 complement system Effects 0.000 description 1
- 238000003271 compound fluorescence assay Methods 0.000 description 1
- 239000000562 conjugate Substances 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 238000006880 cross-coupling reaction Methods 0.000 description 1
- 230000005574 cross-species transmission Effects 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 150000001945 cysteines Chemical class 0.000 description 1
- 210000005220 cytoplasmic tail Anatomy 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 229940127089 cytotoxic agent Drugs 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 238000010908 decantation Methods 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- 238000002050 diffraction method Methods 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 239000002612 dispersion medium Substances 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 238000005538 encapsulation Methods 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 239000003797 essential amino acid Substances 0.000 description 1
- 235000020776 essential amino acid Nutrition 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 239000012737 fresh medium Substances 0.000 description 1
- 230000002538 fungal effect Effects 0.000 description 1
- 108020001507 fusion proteins Proteins 0.000 description 1
- 102000037865 fusion proteins Human genes 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 229960002518 gentamicin Drugs 0.000 description 1
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 1
- 108010075431 glycyl-alanyl-phenylalanine Proteins 0.000 description 1
- YMAWOPBAYDPSLA-UHFFFAOYSA-N glycylglycine Chemical compound [NH3+]CC(=O)NCC([O-])=O YMAWOPBAYDPSLA-UHFFFAOYSA-N 0.000 description 1
- 108010077515 glycylproline Proteins 0.000 description 1
- 208000024908 graft versus host disease Diseases 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 1
- 231100000844 hepatocellular carcinoma Toxicity 0.000 description 1
- 238000005734 heterodimerization reaction Methods 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 108010036413 histidylglycine Proteins 0.000 description 1
- 108010025306 histidylleucine Proteins 0.000 description 1
- 108010085325 histidylproline Proteins 0.000 description 1
- 239000000710 homodimer Substances 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 238000003364 immunohistochemistry Methods 0.000 description 1
- 238000009169 immunotherapy Methods 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 238000000338 in vitro Methods 0.000 description 1
- 230000004054 inflammatory process Effects 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 239000011147 inorganic material Substances 0.000 description 1
- 102000006495 integrins Human genes 0.000 description 1
- 108010044426 integrins Proteins 0.000 description 1
- 230000004068 intracellular signaling Effects 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000010255 intramuscular injection Methods 0.000 description 1
- 239000007927 intramuscular injection Substances 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 210000003292 kidney cell Anatomy 0.000 description 1
- 229910052747 lanthanoid Inorganic materials 0.000 description 1
- 150000002602 lanthanoids Chemical class 0.000 description 1
- 239000008297 liquid dosage form Substances 0.000 description 1
- 239000006193 liquid solution Substances 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 229960000274 lysozyme Drugs 0.000 description 1
- 239000004325 lysozyme Substances 0.000 description 1
- 235000010335 lysozyme Nutrition 0.000 description 1
- 230000003211 malignant effect Effects 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 238000000816 matrix-assisted laser desorption--ionisation Methods 0.000 description 1
- 229960000282 metronidazole Drugs 0.000 description 1
- VAOCPAMSLUNLGC-UHFFFAOYSA-N metronidazole Chemical compound CC1=NC=C([N+]([O-])=O)N1CCO VAOCPAMSLUNLGC-UHFFFAOYSA-N 0.000 description 1
- 239000004530 micro-emulsion Substances 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 230000033607 mismatch repair Effects 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 210000004897 n-terminal region Anatomy 0.000 description 1
- 239000013631 noncovalent dimer Substances 0.000 description 1
- 230000009871 nonspecific binding Effects 0.000 description 1
- 210000004940 nucleus Anatomy 0.000 description 1
- 229920001778 nylon Polymers 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 239000011368 organic material Substances 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 239000013610 patient sample Substances 0.000 description 1
- 230000007030 peptide scission Effects 0.000 description 1
- 210000005105 peripheral blood lymphocyte Anatomy 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- 239000012071 phase Substances 0.000 description 1
- 108010024607 phenylalanylalanine Proteins 0.000 description 1
- 239000006187 pill Substances 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000002062 proliferating effect Effects 0.000 description 1
- 108010004914 prolylarginine Proteins 0.000 description 1
- 108010015796 prolylisoleucine Proteins 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 230000001902 propagating effect Effects 0.000 description 1
- 238000011321 prophylaxis Methods 0.000 description 1
- 230000009993 protective function Effects 0.000 description 1
- 238000002818 protein evolution Methods 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 229940043131 pyroglutamate Drugs 0.000 description 1
- 229940076788 pyruvate Drugs 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 238000010791 quenching Methods 0.000 description 1
- 238000002708 random mutagenesis Methods 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 230000007115 recruitment Effects 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 230000003252 repetitive effect Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical group [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 238000002702 ribosome display Methods 0.000 description 1
- 102220080600 rs797046116 Human genes 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- HOZOZZFCZRXYEK-HNHWXVNLSA-M scopolamine butylbromide Chemical compound [Br-].C1([C@@H](CO)C(=O)OC2C[C@@H]3[N+]([C@H](C2)[C@@H]2[C@H]3O2)(C)CCCC)=CC=CC=C1 HOZOZZFCZRXYEK-HNHWXVNLSA-M 0.000 description 1
- 239000008299 semisolid dosage form Substances 0.000 description 1
- 238000012882 sequential analysis Methods 0.000 description 1
- 108010048818 seryl-histidine Proteins 0.000 description 1
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- 230000009131 signaling function Effects 0.000 description 1
- 238000007860 single-cell PCR Methods 0.000 description 1
- 235000020183 skimmed milk Nutrition 0.000 description 1
- 210000003491 skin Anatomy 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 229940054269 sodium pyruvate Drugs 0.000 description 1
- 239000007909 solid dosage form Substances 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 230000000392 somatic effect Effects 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 238000004611 spectroscopical analysis Methods 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 210000004003 subcutaneous fat Anatomy 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 150000005846 sugar alcohols Polymers 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- 239000000829 suppository Substances 0.000 description 1
- 239000003826 tablet Substances 0.000 description 1
- 238000004885 tandem mass spectrometry Methods 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 108010020532 tyrosyl-proline Proteins 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 229940035893 uracil Drugs 0.000 description 1
- 230000035899 viability Effects 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 238000002424 x-ray crystallography Methods 0.000 description 1
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 1
Images





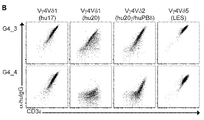






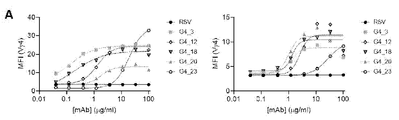






Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/14—Blood; Artificial blood
- A61K35/17—Lymphocytes; B-cells; T-cells; Natural killer cells; Interferon-activated or cytokine-activated lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/74—Inducing cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/20—Cytokines; Chemokines
- C12N2501/23—Interleukins [IL]
Landscapes
- Health & Medical Sciences (AREA)
- Immunology (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Medicinal Chemistry (AREA)
- Genetics & Genomics (AREA)
- Biomedical Technology (AREA)
- Biochemistry (AREA)
- Zoology (AREA)
- Biotechnology (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Biophysics (AREA)
- Cell Biology (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Hematology (AREA)
- Microbiology (AREA)
- General Engineering & Computer Science (AREA)
- Communicable Diseases (AREA)
- Oncology (AREA)
- Developmental Biology & Embryology (AREA)
- Virology (AREA)
- Epidemiology (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Organic Low-Molecular-Weight Compounds And Preparation Thereof (AREA)
Abstract
γδ T 세포 수용체(TCR)의 감마 가변 4(Vγ4) 사슬에 특이적으로 결합하고 γδ TCR의 감마 가변 2(Vγ2) 사슬에는 결합하지 않는 단리된 항체 또는 이의 단편이 본원에서 제공된다. 상기 항체의 치료 방법 및 기타 용도가 또한 상기 항체를 생산하는 방법과 함께 제공된다.
Description
본 발명은 감마 델타 T 세포의 T 세포 수용체에 대한 항체 및 이의 단편에 관한 것이다.
암에 대한 T 세포 면역치료법에서의 관심 증가는 특히 PD-1, CTLA-4 및 기타 수용체에 의해 발휘되는 억제 경로에 의해 임상적으로 매개된 길항작용에 의해 억제될 때, 암 세포를 인식하고 숙주 보호 기능 잠재력을 매개하는 CD8+ 및 CD4+ 알파 베타(αβ) T 세포 하위세트의 명백한 능력에 초점을 맞추었다. 그러나 αβ T 세포는 이식편 대 숙주 질환을 유발할 수 있는 MHC로 제한되어 있다.
감마 델타 T 세포(γδ T 세포)는 이의 표면 상에 고유한, γδ T 세포 수용체(TCR)를 발현하는 T 세포 하위세트를 나타낸다. 이 TCR은 하나의 감마(γ)와 하나의 델타(δ) 사슬로 구성되며, 각각은 사슬 재배열을 거치지만 αβ T 세포에 비해 제한된 수의 V 유전자를 가지고 있다. Vγ를 암호화하는 주요 TRVG 유전자 절편은 TRGV2, TRGV3, TRGV4, TRGV5, TRGV8, TRGV9 및 비기능적 유전자 TRGV10, TRGV11, TRGVA 및 TRGVB이다. 가장 빈번한 TRDV 유전자 절편은 Vδ1, Vδ2 및 Vδ3에 더하여 Vδ 및 Vα 지정을 모두 갖는 몇몇 V 절편을 암호화한다(Adams et al., 296:30-40 (2015) Cell Immunol.). 특정 γ 및 δ 유형이 하나 이상의 조직 유형에서 배타적이지는 않지만 더 우세하게 세포 상에서 발견되므로, 인간 γδ T 세포는 TCR 사슬에 기반하여 광범위하게 분류될 수 있다. 예를 들어, 대부분의 혈액 잔류 γδ T 세포는 Vδ2 TCR, 일반적으로 Vγ9Vδ2를 발현하는 반면, 이것은 예를 들어 종종 장에서 Vγ4와 쌍을 이루는, 감마 사슬과 쌍을 이루는 Vδ1 TCR을 더 자주 사용하는 피부와 같은 조직 잔류 γδ T 세포에서는 덜 일반적이다.
그러나 현재까지 Vγ4 TCR 및 Vγ2 TCR과 같은 다른 TRGV 패밀리 구성원 간의 높은 상동성으로 인해, Vγ4 TCR만을 표적화할 수 있는 방식은 가능하지 않았다. 따라서 Vγ4 TCR에 특이적으로 결합하거나 이를 조절하는 특이적 항체를 포함하여, Vγ4에 특이적 항체에 대한 충족되지 않은 요구가 존재한다.
본 발명의 제1 측면에 따르면, γδ T 세포 수용체(TCR)의 감마 가변 4(Vγ4) 사슬에 특이적으로 결합하고 γδ TCR의 감마 가변 2(Vγ2) 사슬에는 결합하지 않는 단리된 항체 또는 이의 단편이 제공된다. 이는 동일한 종의 Vγ4 사슬 및 Vγ2에 관한 것임이 이해되어야 한다. 바람직하게는, 본원에 기재된 모든 측면 및 구현예에 따르면, 종은 호모 사피엔스(인간)이고 따라서 본 발명은 γδ T 세포 수용체(TCR)의 인간 감마 가변 4(Vγ4) 사슬에 특이적으로 결합하고 γδ TCR의 인간 감마 가변 2(Vγ2) 사슬에는 결합하지 않는 단리된 항체 또는 이의 단편을 제공한다. 예를 들어, 인간 Vγ4 사슬은 서열 번호 1의 아미노산 1-99에 따른 서열을 가질 수 있고/있거나 인간 Vγ2 사슬은 서열 번호 335에 따른 서열을 가질 수 있다. 다른 종에서, 단리된 항체 또는 이의 단편은 γδ T 세포 수용체(TCR)의 인간 감마 가변 4(Vγ4) 사슬의 종 특이적 오르토로그에 특이적으로 결합하고, γδ TCR의 인간 감마 가변 2(Vγ2) 사슬의 종 특이적 오르토로그에는 결합하지 않는다. 따라서, 본 발명은 서열 번호 1의 아미노산 1-99에 상응하는 서열을 갖는 γδ T 세포 수용체(TCR)의 인간 감마 가변 4(Vγ4) 사슬 또는 이의 비-인간 오르토로그에 특이적으로 결합하며 서열 번호 335에 상응하는 서열을 갖는 γδ TCR의 인간 감마 가변 2(Vγ2) 사슬 또는 이의 비인간 오르토로그에는 결합하지 않는 단리된 항체 또는 이의 단편을 제공한다. 이러한 맥락에서 오르토로그는 참조 서열에 대해 가장 높은 서열 유사성을 갖는 감마 사슬 서열, 또는 바람직하게는 동일한 기능(예를 들어, 생체내 오르토로그 인지체 리간드와의 상호작용)을 보유하는 것을 의미할 수 있다. 예를 들어, 마우스에서 Heilig & Tonegave 명명법에 따라 Vγ7로 지정된 단백질은 인간 Vγ4와 기능적으로 가장 밀접하게 관련되어 있다(Barros et al. (2016) Cell, 167:203-218.e17).
이는 이 분야에서 유의한 발전이다. 예를 들어, 인간에서 Vγ4 사슬과 Vγ2 사슬은 매우 상동성(서열 동일성 91%)이며 9개의 아미노산만 상이하다. 이들 9개 변경 중 3개는 CDR1 및 CDR2에 걸쳐 매핑되는 반면, 이러한 9개 변경 중 4개는 프레임워크 영역 3(FR3)의 하위영역-서열 번호 1의 아미노산 67-82에 매핑된다. Vγ4 사슬 및 Vγ2 사슬간 매우 높은 서열 유사성으로 인해, 이전에는 γδ TCR의 인간 Vγ4 사슬과 Vγ2 사슬을 특이적으로 구별할 수 있는 항체 또는 이의 단편을 개발하는 것이 불가능할 것이라고 생각되었다. 놀랍게도 그리고 당분야의 지배적인 견해와는 반대로, 본 발명자들은 본원에 더 상세히 기재된 방법을 사용하여 이러한 항체를 개발할 수 있었다. 따라서, 본 발명은 Vγ4-함유 γδ TCR을 특이적으로 조절할 수 있는 항체 및 이의 단편을 제공한다.
본 발명의 항체 또는 이의 단편은 서열 번호 1의 아미노산 영역 67-82 내의 하나 이상의 아미노산 잔기를 포함하는 γδ TCR의 인간 Vγ4 사슬의 에피토프에 결합할 수 있다.
본 발명의 추가 측면에 따르면, 다음 중 하나 이상을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편이 제공된다:
서열 번호 2-47 중 어느 하나, 바람직하게는 서열 번호 10 및/또는 33과 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3;
서열 번호 48-70 및 서열 A1-A23(도 1) 중 어느 하나, 바람직하게는 서열 번호 56 및/또는 A9와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR2; 및/또는
서열 번호 71-116 중 어느 하나, 바람직하게는 서열 번호 79 및/또는 102와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR1.
일부 측면에서, 단리된 항-Vγ4 항체 또는 이의 단편은 다음 중 하나 이상을 포함할 수 있다:
서열 번호 2-24 중 어느 하나, 바람직하게는 서열 번호 10과 적어도 80% 서열 동일성을 갖는 서열을 포함하는 중쇄 CDR3(HCDR3);
서열 번호 48-70 중 어느 하나, 바람직하게는 서열 번호 56과 적어도 80% 서열 동일성을 갖는 서열을 포함하는 중쇄 CDR2(HCDR2); 및/또는
서열 번호 71-93 중 어느 하나, 바람직하게는 서열 번호 79와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 중쇄 CDR1(HCDR1).
대안적으로 또는 부가적으로, 단리된 항-Vγ4 항체 또는 이의 단편은 다음 중 하나 이상을 포함할 수 있다:
서열 번호 25-47 중 어느 하나, 바람직하게는 서열 번호 33과 적어도 80% 서열 동일성을 갖는 서열을 포함하는 경쇄 CDR3(LCDR3);
서열 A1-A23(도 1) 중 어느 하나, 바람직하게는 서열 A9와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 경쇄 CDR2(LCDR2); 및/또는
서열 번호 94-116 중 어느 하나, 바람직하게는 서열 번호 102와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 경쇄 CDR1(LCDR1).
본 발명의 추가 측면에 따르면, 서열 번호 117-162 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편이 제공된다. 일부 측면에서, 단리된 항-Vγ4 항체 또는 이의 단편은 서열 번호 117-139 중 어느 하나, 바람직하게는 서열 번호 125와 적어도 80% 서열 동일성을 갖는 중쇄 가변(VH) 아미노산 서열을 포함할 수 있다. 대안적으로 또는 부가적으로, 단리된 항-Vγ4 항체 또는 이의 단편은 서열 번호 140-162, 바람직하게는 서열 번호 148과 적어도 80% 서열 동일성을 갖는 경쇄 가변(VL) 아미노산 서열을 포함할 수 있다.
본 발명은 다음 중 하나 이상을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편을 추가로 제공한다:
(a) 서열 번호 79를 갖는 HCDR1, 서열 번호 56을 갖는 HCDR2 및 서열 번호 10을 갖는 HCDR3을 포함하며, 임의로 서열 번호 125를 포함하는 VH; 및
서열 번호 102를 갖는 LCDR1, 서열 A9(도 1)를 갖는 LCDR2 및 서열 번호 33을 갖는 LCDR3을 포함하며, 임의로 서열 번호 148을 포함하는 VL;
(b) 서열 번호 86을 갖는 HCDR1, 서열 번호 63을 갖는 HCDR2 및 서열 번호 17을 갖는 HCDR3을 포함하며, 임의로 서열 번호 132를 포함하는 VH; 및
서열 번호 109를 갖는 LCDR1, 서열 A16(도 1)을 갖는 LCDR2 및 서열 번호 40을 갖는 LCDR3을 포함하며, 임의로 서열 번호 155를 포함하는 VL;
(c) 서열 번호 73을 갖는 HCDR1, 서열 번호 50을 갖는 HCDR2 및 서열 번호 4를 갖는 HCDR3을 포함하며, 임의로 서열 번호 119를 포함하는 VH; 및
서열 번호 96을 갖는 LCDR1, 서열 A3(도 1)을 갖는 LCDR2 및 서열 번호 27을 갖는 LCDR3을 포함하며, 임의로 서열 번호 142를 포함하는 VL;
(d) 서열 번호 83을 갖는 HCDR1, 서열 번호 60을 갖는 HCDR2 및 서열 번호 14를 갖는 HCDR3을 포함하며, 임의로 서열 번호 129를 포함하는 VH; 및
서열 번호 106을 갖는 LCDR1, 서열 A13(도 1)을 갖는 LCDR2 및 서열 번호 37을 갖는 LCDR3을 포함하며, 임의로 서열 번호 152를 포함하는 VL;
(e) 서열 번호 84를 갖는 HCDR1, 서열 번호 61을 갖는 HCDR2 및 서열 번호 15를 갖는 HCDR3을 포함하며, 임의로 서열 번호 130을 포함하는 VH; 및
서열 번호 107을 갖는 LCDR1, 서열 A14(도 1)를 갖는 LCDR2 및 서열 번호 38을 갖는 LCDR3을 포함하며, 임의로 서열 번호 153을 포함하는 VL;
(f) 서열 번호 88을 갖는 HCDR1, 서열 번호 65를 갖는 HCDR2 및 서열 번호 19를 갖는 HCDR3을 포함하며, 임의로 서열 번호 134를 포함하는 VH; 및
서열 번호 111을 갖는 LCDR1, 서열 A18(도 1)을 갖는 LCDR2 및 서열 번호 42를 갖는 LCDR3을 포함하며, 임의로 서열 번호 157을 포함하는 VL;
(g) 서열 번호 92를 갖는 HCDR1, 서열 번호 69를 갖는 HCDR2 및 서열 번호 23을 갖는 HCDR3을 포함하며, 임의로 서열 번호 138을 포함하는 VH; 및
서열 번호 115를 갖는 LCDR1, 서열 A22(도 1)를 갖는 LCDR2 및 서열 번호 46을 갖는 LCDR3을 포함하며, 임의로 서열 번호 161을 포함하는 VL;
(h) 서열 번호 71을 갖는 HCDR1, 서열 번호 48을 갖는 HCDR2 및 서열 번호 2를 갖는 HCDR3을 포함하며, 임의로 서열 번호 117을 포함하는 VH; 및
서열 번호 94를 갖는 LCDR1, 서열 A1(도 1)을 갖는 LCDR2 및 서열 번호 25를 갖는 LCDR3을 포함하며, 임의로 서열 번호 140을 포함하는 VL;
(i) 서열 번호 72를 갖는 HCDR1, 서열 번호 49를 갖는 HCDR2 및 서열 번호 3을 갖는 HCDR3을 포함하며, 임의로 서열 번호 118을 포함하는 VH; 및
서열 번호 95를 갖는 LCDR1, 서열 A2(도 1)를 갖는 LCDR2 및 서열 번호 26을 갖는 LCDR3을 포함하며, 임의로 서열 번호 141을 포함하는 VL;
(j) 서열 번호 74를 갖는 HCDR1, 서열 번호 51을 갖는 HCDR2 및 서열 번호 5를 갖는 HCDR3을 포함하며, 임의로 서열 번호 120을 포함하는 VH; 및
서열 번호 97을 갖는 LCDR1, 서열 A4(도 1)를 갖는 LCDR2 및 서열 번호 28을 갖는 LCDR3을 포함하며, 임의로 서열 번호 143을 포함하는 VL;
(k) 서열 번호 75를 갖는 HCDR1, 서열 번호 52를 갖는 HCDR2 및 서열 번호 6을 갖는 HCDR3을 포함하며, 임의로 서열 번호 121을 포함하는 VH; 및
서열 번호 98을 갖는 LCDR1, 서열 A5(도 1)를 갖는 LCDR2 및 서열 번호 29를 갖는 LCDR3을 포함하며, 임의로 서열 번호 144를 포함하는 VL;
(l) 서열 번호 76을 갖는 HCDR1, 서열 번호 53을 갖는 HCDR2 및 서열 번호 7을 갖는 HCDR3을 포함하며, 임의로 서열 번호 122를 포함하는 VH; 및
서열 번호 99를 갖는 LCDR1, 서열 A6(도 1)을 갖는 LCDR2 및 서열 번호 30을 갖는 LCDR3을 포함하며, 임의로 서열 번호 145를 포함하는 VL;
(m) 서열 번호 77을 갖는 HCDR1, 서열 번호 54를 갖는 HCDR2 및 서열 번호 8을 갖는 HCDR3을 포함하며, 임의로 서열 번호 123을 포함하는 VH; 및
서열 번호 100을 갖는 LCDR1, 서열 A7(도 1)을 갖는 LCDR2 및 서열 번호 31을 갖는 LCDR3을 포함하며, 임의로 서열 번호 146을 포함하는 VL;
(n) 서열 번호 78을 갖는 HCDR1, 서열 번호 55를 갖는 HCDR2 및 서열 번호 9를 갖는 HCDR3을 포함하며, 임의로 서열 번호 124를 포함하는 VH; 및
서열 번호 101을 갖는 LCDR1, 서열 A8(도 1)을 갖는 LCDR2 및 서열 번호 32를 갖는 LCDR3을 포함하며, 임의로 서열 번호 147을 포함하는 VL;
(o) 서열 번호 80을 갖는 HCDR1, 서열 번호 57을 갖는 HCDR2 및 서열 번호 11을 갖는 HCDR3을 포함하며, 임의로 서열 번호 126을 포함하는 VH; 및
서열 번호 103을 갖는 LCDR1, 서열 A10(도 1)을 갖는 LCDR2 및 서열 번호 34를 갖는 LCDR3을 포함하며, 임의로 서열 번호 149를 포함하는 VL;
(p) 서열 번호 81을 갖는 HCDR1, 서열 번호 58을 갖는 HCDR2 및 서열 번호 12를 갖는 HCDR3을 포함하며, 임의로 서열 번호 127을 포함하는 VH; 및
서열 번호 104를 갖는 LCDR1, 서열 A11(도 1)을 갖는 LCDR2 및 서열 번호 35를 갖는 LCDR3을 포함하며, 임의로 서열 번호 150을 포함하는 VL;
(q) 서열 번호 82를 갖는 HCDR1, 서열 번호 59를 갖는 HCDR2 및 서열 번호 13을 갖는 HCDR3을 포함하며, 임의로 서열 번호 128을 포함하는 VH; 및
서열 번호 105를 갖는 LCDR1, 서열 A12(도 1)를 갖는 LCDR2 및 서열 번호 36을 갖는 LCDR3을 포함하며, 임의로 서열 번호 151을 포함하는 VL;
(r) 서열 번호 85를 갖는 HCDR1, 서열 번호 62를 갖는 HCDR2 및 서열 번호 16을 갖는 HCDR3을 포함하며, 임의로 서열 번호 131을 포함하는 VH; 및
서열 번호 108을 갖는 LCDR1, 서열 A15(도 1)를 갖는 LCDR2 및 서열 번호 39를 갖는 LCDR3을 포함하며, 임의로 서열 번호 154를 포함하는 VL;
(s) 서열 번호 87을 갖는 HCDR1, 서열 번호 64를 갖는 HCDR2 및 서열 번호 18을 갖는 HCDR3을 포함하며, 임의로 서열 번호 133을 포함하는 VH; 및
서열 번호 110을 갖는 LCDR1, 서열 A17(도 1)을 갖는 LCDR2 및 서열 번호 41을 갖는 LCDR3을 포함하며, 임의로 서열 번호 156을 포함하는 VL;
(t) 서열 번호 89를 갖는 HCDR1, 서열 번호 66을 갖는 HCDR2 및 서열 번호 20을 갖는 HCDR3을 포함하며, 임의로 서열 번호 135를 포함하는 VH; 및
서열 번호 112를 갖는 LCDR1, 서열 A19(도 1)를 갖는 LCDR2 및 서열 번호 43을 갖는 LCDR3을 포함하며, 임의로 서열 번호 158을 포함하는 VL;
(u) 서열 번호 90을 갖는 HCDR1, 서열 번호 67을 갖는 HCDR2 및 서열 번호 21을 갖는 HCDR3을 포함하며, 임의로 서열 번호 136을 포함하는 VH; 및
서열 번호 113을 갖는 LCDR1, 서열 A20(도 1)을 갖는 LCDR2 및 서열 번호 44를 갖는 LCDR3을 포함하며, 임의로 서열 번호 159를 포함하는 VL;
(v) 서열 번호 91을 갖는 HCDR1, 서열 번호 68을 갖는 HCDR2 및 서열 번호 22를 갖는 HCDR3을 포함하며, 임의로 서열 번호 137을 포함하는 VH; 및
서열 번호 114를 갖는 LCDR1, 서열 A21(도 1)을 갖는 LCDR2 및 서열 번호 45를 갖는 LCDR3을 포함하며, 임의로 서열 번호 160을 포함하는 VL; 및/또는
(w) 서열 번호 93을 갖는 HCDR1, 서열 번호 70을 갖는 HCDR2 및 서열 번호 24를 갖는 HCDR3을 포함하며, 임의로 서열 번호 139를 포함하는 VH; 및
서열 번호 116을 갖는 LCDR1, 서열 A23(도 1)을 갖는 LCDR2 및 서열 번호 47을 갖는 LCDR3을 포함하며, 임의로 서열 번호 162를 포함하는 VL.
본 발명의 추가 측면에 따르면, 서열 번호 163-185 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편이 제공된다.
본 발명의 추가 측면에 따르면, 서열 번호 233-255 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항-Vγ4 항체가 제공된다. 본 발명의 관련 측면에서, 서열 번호 284-306 중 어느 하나와 적어도 80% 서열 동일성을 갖는 중쇄 아미노산 서열 및/또는 서열 번호 307-329 중 어느 하나와 적어도 80% 서열 동일성을 갖는 경쇄 아미노산 서열을 포함하거나 이로 구성되는, 단리된 항-Vγ4 항체가 제공된다.
본 발명은 추가로 γδ T 세포 수용체(TCR)의 Vγ4 사슬에 특이적으로 결합하고 본원에 정의된 바와 같은 본 발명의 항체 또는 이의 단편과 γδ T 세포 수용체(TCR)의 Vγ4 사슬에 대한 결합을 경쟁하는 항-Vγ4 항체 또는 이의 단편을 제공한다.
본 발명의 추가 측면에 따르면, 본원에 정의된 바와 같은 항-Vγ4 항체 또는 이의 단편을 암호화하는 폴리뉴클레오티드 서열이 제공된다. 예를 들어, 서열 번호 187-232 중 어느 하나와 적어도 70% 서열 동일성을 갖는 서열을 포함하는 항-Vγ4 항체 또는 이의 단편을 암호화하는 폴리뉴클레오티드 서열이 제공된다. 바람직하게는, 항-Vγ4 항체 또는 이의 단편을 암호화하는 폴리뉴클레오티드 서열은 서열 번호 187-232 중 어느 하나의 서열을 포함한다.
본 발명의 추가 측면에 따르면, 본원에 정의된 바와 같은 본 발명의 폴리뉴클레오티드 서열을 포함하는 발현 벡터가 제공된다. 예를 들어, 서열 번호 187-209 중 어느 하나의 VH-암호화 폴리뉴클레오티드 서열 및/또는 서열 번호 210-232 중 어느 하나의 VL-암호화 폴리뉴클레오티드 서열을 포함하는 발현 벡터가 제공된다.
본 발명의 추가 측면에 따르면, 본원에 정의된 바와 같은 본 발명의 폴리뉴클레오티드 서열 또는 발현 벡터를 포함하는 세포가 제공된다. 세포 배양 배지에서 본 발명의 세포를 배양하는 단계를 포함하는, 본 발명의 임의의 항체 또는 이의 단편을 생산하는 방법이 또한 제공된다. 이러한 맥락에서 상기 세포는 본원에 추가로 정의된 바와 같이 "숙주 세포"로 지칭될 수 있음이 이해될 것이다.
본 발명의 추가 측면에 따르면, 본원에 정의된 바와 같은 본 발명의 항체 또는 이의 단편을 포함하는 조성물이 제공된다. 본원에 정의된 바와 같은 본 발명의 항체 또는 이의 단편을 약학적으로 허용 가능한 희석제 또는 담체와 함께 포함하는 약학 조성물이 또한 제공된다.
본 발명의 추가 측면에서, 임의로 사용 설명서 및/또는 추가 치료 활성제를 포함하는, 본 발명의 항-Vγ4 항체 또는 이의 단편 또는 본 발명의 약학 조성물을 포함하는 키트가 제공된다.
본 발명의 추가 측면에 따르면, 약제로서 사용하기 위한, 본원에 정의된 바와 같은 본 발명의 단리된 항-Vγ4 항체 또는 이의 단편 또는 본 발명의 약학 조성물이 제공된다. 유사하게, 치료 유효량의 본원에 정의된 바와 같은 본 발명의 단리된 항-Vγ4 항체 또는 단편 또는 본 발명의 약학 조성물을 대상체에 투여하는 단계를 포함하는, 치료를 필요로 하는 대상체에서 질환 또는 장애(예를 들어, 암, 감염성 질환 또는 염증성 질환)를 치료하는 방법이 제공된다.
전술한 바와 같이, 본 발명의 개발 전에는 통상적으로 Vγ4 사슬, 특히 인간 Vγ4에 특이적으로 결합할 수 있는 항체 또는 이의 단편을 개발하는 것이 불가능할 것이라고 여겨졌다. 이것은 γδ TCR의 인간 Vγ4 사슬 및 Vγ2 사슬 간 고도의 서열 유사성(91%) 때문이었다. 이러한 상당한 난제를 극복하기 위해, 본 발명자들은 특정 항원 및 방법론을 개발하였다. 따라서, 본 발명의 추가 측면에 따르면, 항-Vγ4 항체 또는 이의 단편을 생성하는 데 사용하기 위한 서열 번호 256과 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항원이 제공된다. 항원 제조 과정의 또 다른 중요한 측면은 단백질로의 발현에 적합한 항원을 설계하는 것이었다. γδ TCR은 사슬간 및 사슬내 디설피드 결합이 있는 이종이량체가 관여되는 복합 단백질이다. 류신 지퍼(LZ) 형식 및 Fc 형식을 사용하여 파지 디스플레이 선택에 사용할 가용성 TCR 항원을 생성했다. 따라서, 본 발명은 또한 항-Vγ4 항체 또는 이의 단편을 생성하는 데 사용하기 위한 서열 번호 257 또는 258과 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항원을 제공한다.
또한, 감마 델타(γδ) T 세포는 CDR3 폴리클론성을 갖는 폴리클론날 세포이다. 생성된 항체가 CDR3 서열에 대해 선택되는 상황을 피하기 위해(CDR3 서열은 TCR 클론과 TCR 클론마다 다를 것이기 때문에), 항원 설계는 상이한 형식으로 일관된 CDR3을 유지하는 것이 관여되었다. 이 설계는 생식계열에서 암호화되므로 모든 클론에서 동일한 감마-4 가변 도메인 내 서열을 인식하는 항체를 생성하여 γδ T 세포의 더 넓은 하위세트를 인식하는 항체를 제공하는 것을 목표로 했다. 또한, 매우 유사한 감마-2 특이적 영역에도 결합하고 정확히 동일한 초가변 CDR3 서열을 포함하는 결합제의 선택해제와 조합된 다중 형식으로 이 감마-4 특이적 영역에 결합하는 항체를 선택하는 이러한 반복적 접근을 통해, 항체는 뛰어난 선택성을 가지고 확인되었다. 특히, 그리고 놀랍게도, 본원에 기재된 바와 같은 일부 경우에, 인간 감마 4 항원 상의 CDR3의 N-말단 영역에는 결합하지만 고도로 관련된 인간 감마 2 항원의 CDR3의 동등 영역 N-말단에는 결합하지 않는 항체가 확인되었다. 이것은 이 두 감마 사슬 사이의 아주 작은 서열 차이가 흩어져 있다는 사실과 조합된 이 영역에서 감마-4와 감마-2 사이의 고도의 상동성을 고려할 때 놀라운 것이었다: 9개의 변경 중 3개는 감마 가면 사슬 CDR1 및 CDR2에 걸쳐 매핑되는 반면, 9개의 변경 중 4개는 감마 가변 사슬 CDR3의 N-말단인 '초가변 영역 4'로 알려진 프레임워크 영역 3(FR3)의 하위영역에 매핑된다.
따라서, 본 발명의 추가 측면에 따르면, 다음 단계를 포함하는, 항-Vγ4 항체 또는 이의 단편을 생성하는 방법이 제공된다:
(i) TCR 감마 가변 4(TRGV4) 아미노산 서열을 포함하는 항원 시리즈를 설계하는 단계로서, TRGV4의 CDR3 서열은 시리즈의 모든 항원에 있어서 동일한 단계;
(ii) 단계 (i)에서 설계된 제1 항원을 항체 라이브러리에 노출시키는 단계;
(iii) 항원에 결합하는 항체 또는 이의 단편을 단리하는 단계;
(iv) 단리된 항체 또는 이의 단편을 단계 (i)에서 설계된 제2 항원에 노출시키는 단계; 및
(v) 제1 항원 및 제2 항원 모두에 결합하는 항체 또는 이의 단편을 단리하는 단계.
방법은 다음을 추가로 포함할 수 있다:
제1 항원 및/또는 제2 항원에 결합하는 단리된 항체 또는 이의 단편을 TRGV4가 아닌 TCR 감마 가변 아미노산 서열(예를 들어, TCR 감마 가변 2(TRGV2) 또는 TCR 감마 가변 8(TRGV8) 아미노산 서열)을 포함하는 항원에 노출시키는 단계; 및
제1 항원 및/또는 제2 항원에는 결합하지만 TRGV4가 아닌 TCR 감마 가변 아미노산 서열을 포함하는 항원에는 결합하지 않는 항체 또는 이의 단편을 단리하는 단계.
TRGV4, TRGV2 및 TRGV8 아미노산 서열은 바람직하게는 각각 인간 TRGV4, TRGV2 및 TRGV8에 상응한다. 인간 TRGV4는 서열 번호 1의 아미노산 1-99에 상응한다. 인간 TRGV2 및 TRGV8은 각각 서열 번호 335 및 336에 상응하는 아미노산 서열에 상응한다.
본 발명의 추가 측면에 따르면, 본원에 정의된 바와 같은 방법에 의해 수득된 항체가 제공된다.
도 1: 본 발명의 예시적인 항-Vγ4 항체의 상보성 결정 영역(CDR) 서열. 본 발명의 예시적인 항-Vγ4 항체에 대한 CDR 서열을 나타낸다. 해당 서열 번호를 각 서열의 오른쪽에 나타낸다.
도 2: DELFIA Elisa 검정을 통한 이종이량체 TCR 항원에 대한 항체 특이성. (a) QC 평가(분석용 SEC-HPLC)를 통과하고 또한 인간 Vγ4 사슬에 대한 특이성을 나타낸 모든 항체에 대한 결과가 표시된다. 이들 항체(X-축)를 각각 4개의 상이한 재조합 이종이량체 인간 TCR(DV1-GV4; DV2-GV4; DV1-GV2; DV1-GV8)로의 결합에 대해 시험하였다. 대조군은 이소형 대조군 항-닭 리소자임 D1.3 항체(사내, 맨 왼쪽)와 항-Vδ1 항체 REA173(Miltenyi) 및 TS8.2(Fisher)-맨 오른쪽을 포함한다. (b) (a)에 나타낸 데이터의 정량 및 인간 Vγ2 사슬 대비 인간 Vγ4 사슬에 대한 각각의 예시적인 클론의 결합에서의 증가 변화 배율을 추가로 나타낸다.
도 3: 재조합 항원 또는 재조합 세포 표면 수용체로 제시된 Vγ4Vδ1 TCR에 대한 항체 결합의 비교. (a) Delfia ELISA를 통해 DV1-GV4 항원(Y-축) 또는 JRT3-hu17 세포(X-축)에 결합하는 항체의 정규화되고 로그 변환된 X/Y 그래프. 수직 회색 점선은 이 연구에서 JRT3-hu17 결합에 대해 음성(왼쪽) 및 양성(오른쪽)으로 간주되는 mAbs에 대한 컷오프를 표시한다. X-축 gMFI 신호는 각 구축물 간 TCR 발현의 변화를 설명하기 위해 CD3에 대해 정규화되었다. (b) 음수/양수 컷오프를 추가로 예시하는 흐름 데이터 그래프. 항체 G4_26(중앙 왼쪽 패널)은 음성 그룹 중에서 가장 높은 정규화된 gMFI 값을 나타내고 음성 이소형 대조군(D1.3; 맨 왼쪽 패널)과 유사한 그래프를 나타낸다. G4_15(중앙 패널)는 양성 그룹 중에서 가장 낮은 정규화된 gMFI 값을 가지며 D1.3 이소형 대조군과 비교할 때 약하지만 명확한 염색 향상을 나타낸다. 중간(G4_16; 중앙 오른쪽) 및 강한(G4_18; 맨 오른쪽) 신호의 예도 참조용으로 제공된다.
도 4: 상이한 CDR3 서열을 포함하고/하거나 상이한 델타 사슬과 쌍을 이루는 재조합적으로 발현된 γ4 TCR 패널에 대한 항체 결합. (a) Jurkat 세포 상에서 발현된 재조합 TCR에 대해 생성된 항체 결합 신호의 히스토그램 표시. 순차적 분석은 하기와 같았다: Vγ4Vδ1-hu17에 대한 항체 결합 신호(검정색 막대); Vγ4Vδ1-hu20에 대한 항체 결합 신호(가로선 막대); Vγ4Vδ2 hu20γ-PBδ에 대한 항체 결합 신호(대각선 막대); Vγ4Vδ5-LES에 대한 항체 결합 신호(흰색 막대). JRT3 세포에서 상이한 TCR 구축물 간 TCR 발현의 변화를 설명하기 위해 모든 결합 신호를 CD3에 대해 정규화하였다. (b) 모든 Vγ4 TCR에 대해 양성으로 나타난 예시적인 항체(G4_3) 대 Vγ4 TCR 중 일부에 대해서만 양성으로 나타난 다른 선도 항체(G4_4) 간 차이를 추가로 예시하기 위한 이 연구에서의 2개의 선도 항체에 대한 예시적인 흐름 데이터.
도 5: JRT3 세포 상에서 발현된 키메라 hu17 TCR에 대한 항체 결합 및 에피토프 매핑. (a) 표시된 키메라 hu17 구축물의 생식계열-암호화 가변 감마 영역의 정렬이 제시된다. 공간 제한으로 인해, 성숙 Vγ2/3/4 서열의 처음 10개 아미노산(서열 번호 256의 아미노산 1-10[SSNLEGRTKS])은 생략되지만 모든 구축물에서 동일함을 주지한다. 참조 hu17 서열(야생형 Vγ4 TCR)과 상이한 아미노산이 표시된다. (b) 표시된 키메라 TCR 구축물에 대한 각 항체의 반응성의 요약 표. 결과는 JRT3 세포 상에서 발현된 개별 TCR에 대한 각각의 표시된 항체의 상대 결합 특이성을 강조한다. (c) 이 연구에서 관찰된 차별적 결합 신호를 예시하기 위한 에피토프 매핑의 예시적인 흐름 데이터.
도 6: Vγ4 TCR(hu17) 발현 세포 상의 예시적인 항체 결합 및 부여된 기능. (a) JRT3-hu17 세포에 결합된 모든 예시적인 항체를 나타내는 JRT3-hu17에 대한 항체의 적정된 결합. hu17의 발현이 항체 결합에 필수적임을 실증하는 음성 대조군으로 사용된 형질도입되지 않은 JRT3 세포(TCR 없음). (b) 적정된 항체에 의해 부여된 TCR 하향조절 대 양성 대조군 항체: 항-CD3ε(UCHT-1, Biolegend) 또는 항-범-TCRγδ(B1, Biolegend)에 의해 부여된 하향조절. (c) 적정된 항체에 의한 부여된 CD69 상향조절 대 비교 항체: 항-CD3ε(UCHT-1, Biolegend) 또는 항-범-TCRγδ(B1, Biolegend)에 의해 관찰된 상향조절.
도 7: 1차 Vγ4 양성 세포의 예시적인 항체 표적화 및 조절. (a) 본 발명의 모든 예시적인 항체가 용량 의존적 방식으로 1차 피부 유래 Vγ4+ T 세포에 결합할 수 있음을 나타내는, 2명의 개별 공여자의 피부로부터 증식된 1차 Vγ4+ T 세포에 대한 항-Vγ4 항체의 저정된 결합. 예시적인 항체의 Vγ4에 대한 특이성을 실증하는 음성 대조군으로서 이소형 대조군이 사용되었다. (b) 본 발명의 실질적으로 모든 예시적인 항체가 1차 혈액 유래 Vγ4+ T 세포에 결합할 수 있음을 나타내는, 말초 혈액 단핵 세포(PBMC)로부터 유래된 Vγ4+ T 세포에 대한 항-Vγ4 항체의 결합. RSV 이소형 대조군이 음성 대조군으로 사용되었다. (c) 이 세포 집단에 대한 3개의 예시적인 항체 모두의 결합을 나타내는, 결장직장암(CRC) 환자로부터의 장 유래 상피내 림프구(IEL)에 대한 항-Vγ4 항체 G4_3, G4_12 및 G4_18의 결합. 세포는 단일, 살아있는, γδ+, IgG1+(Vγ4)+로 관문화되었다. (d) 예시적인 항체 G4_18이 Vγ4+ 세포를 확인하기 위해 사용될 수 있음을 나타내는, 항-Vγ4 항체로의 자극 전 장 소화물에서 Vγ4+ γδ T 세포의 표현형 분석. 살아있는, 단일 세포의 1.4%는 Vδ1+였다. 이들 중 44.2%가 Vγ4와 쌍을 이루었고, 이들은 조직 잔류 마커(CD69+ CD103+)를 디스플레이했다. (e) 대표적인 FACS 그래프가 동반되는, 예시적인 항체, 각각 G4_12 및 G4_18에 의해 부여된 TCR 하향조절 대 이소형 음성 대조군에 의해 부여된 하향조절.
도 8: 1차 인간 Vγ4 T 세포수를 증가시키기 위한 Vγ4-특이적 항체의 용도. (a) IL-2 또는 IL-2 + IL-15의 존재 하에, 이소형 대조군 대비 플레이트-결합 항-Vγ4 클론 G4_12와 PBMC의 14일 배양 후 Vγ4 T 세포(클론 G4_18로의 염색에 의해 결정됨)의 증가를 예시하기 위한 예시적인 흐름 데이터. (b) IL-2 또는 IL-2 + IL-15의 존재 하에, 이소형 대조군 대비 플레이트-결합 항-Vγ4 클론 G4_12와 2명의 공여자로부터의 PBMC의 7일(상부열) 및 14일(하부열) 배양 후 Vγ4 T 세포(클론 G4_18로의 염색에 의해 결정됨)의 증가 요약.
도 2: DELFIA Elisa 검정을 통한 이종이량체 TCR 항원에 대한 항체 특이성. (a) QC 평가(분석용 SEC-HPLC)를 통과하고 또한 인간 Vγ4 사슬에 대한 특이성을 나타낸 모든 항체에 대한 결과가 표시된다. 이들 항체(X-축)를 각각 4개의 상이한 재조합 이종이량체 인간 TCR(DV1-GV4; DV2-GV4; DV1-GV2; DV1-GV8)로의 결합에 대해 시험하였다. 대조군은 이소형 대조군 항-닭 리소자임 D1.3 항체(사내, 맨 왼쪽)와 항-Vδ1 항체 REA173(Miltenyi) 및 TS8.2(Fisher)-맨 오른쪽을 포함한다. (b) (a)에 나타낸 데이터의 정량 및 인간 Vγ2 사슬 대비 인간 Vγ4 사슬에 대한 각각의 예시적인 클론의 결합에서의 증가 변화 배율을 추가로 나타낸다.
도 3: 재조합 항원 또는 재조합 세포 표면 수용체로 제시된 Vγ4Vδ1 TCR에 대한 항체 결합의 비교. (a) Delfia ELISA를 통해 DV1-GV4 항원(Y-축) 또는 JRT3-hu17 세포(X-축)에 결합하는 항체의 정규화되고 로그 변환된 X/Y 그래프. 수직 회색 점선은 이 연구에서 JRT3-hu17 결합에 대해 음성(왼쪽) 및 양성(오른쪽)으로 간주되는 mAbs에 대한 컷오프를 표시한다. X-축 gMFI 신호는 각 구축물 간 TCR 발현의 변화를 설명하기 위해 CD3에 대해 정규화되었다. (b) 음수/양수 컷오프를 추가로 예시하는 흐름 데이터 그래프. 항체 G4_26(중앙 왼쪽 패널)은 음성 그룹 중에서 가장 높은 정규화된 gMFI 값을 나타내고 음성 이소형 대조군(D1.3; 맨 왼쪽 패널)과 유사한 그래프를 나타낸다. G4_15(중앙 패널)는 양성 그룹 중에서 가장 낮은 정규화된 gMFI 값을 가지며 D1.3 이소형 대조군과 비교할 때 약하지만 명확한 염색 향상을 나타낸다. 중간(G4_16; 중앙 오른쪽) 및 강한(G4_18; 맨 오른쪽) 신호의 예도 참조용으로 제공된다.
도 4: 상이한 CDR3 서열을 포함하고/하거나 상이한 델타 사슬과 쌍을 이루는 재조합적으로 발현된 γ4 TCR 패널에 대한 항체 결합. (a) Jurkat 세포 상에서 발현된 재조합 TCR에 대해 생성된 항체 결합 신호의 히스토그램 표시. 순차적 분석은 하기와 같았다: Vγ4Vδ1-hu17에 대한 항체 결합 신호(검정색 막대); Vγ4Vδ1-hu20에 대한 항체 결합 신호(가로선 막대); Vγ4Vδ2 hu20γ-PBδ에 대한 항체 결합 신호(대각선 막대); Vγ4Vδ5-LES에 대한 항체 결합 신호(흰색 막대). JRT3 세포에서 상이한 TCR 구축물 간 TCR 발현의 변화를 설명하기 위해 모든 결합 신호를 CD3에 대해 정규화하였다. (b) 모든 Vγ4 TCR에 대해 양성으로 나타난 예시적인 항체(G4_3) 대 Vγ4 TCR 중 일부에 대해서만 양성으로 나타난 다른 선도 항체(G4_4) 간 차이를 추가로 예시하기 위한 이 연구에서의 2개의 선도 항체에 대한 예시적인 흐름 데이터.
도 5: JRT3 세포 상에서 발현된 키메라 hu17 TCR에 대한 항체 결합 및 에피토프 매핑. (a) 표시된 키메라 hu17 구축물의 생식계열-암호화 가변 감마 영역의 정렬이 제시된다. 공간 제한으로 인해, 성숙 Vγ2/3/4 서열의 처음 10개 아미노산(서열 번호 256의 아미노산 1-10[SSNLEGRTKS])은 생략되지만 모든 구축물에서 동일함을 주지한다. 참조 hu17 서열(야생형 Vγ4 TCR)과 상이한 아미노산이 표시된다. (b) 표시된 키메라 TCR 구축물에 대한 각 항체의 반응성의 요약 표. 결과는 JRT3 세포 상에서 발현된 개별 TCR에 대한 각각의 표시된 항체의 상대 결합 특이성을 강조한다. (c) 이 연구에서 관찰된 차별적 결합 신호를 예시하기 위한 에피토프 매핑의 예시적인 흐름 데이터.
도 6: Vγ4 TCR(hu17) 발현 세포 상의 예시적인 항체 결합 및 부여된 기능. (a) JRT3-hu17 세포에 결합된 모든 예시적인 항체를 나타내는 JRT3-hu17에 대한 항체의 적정된 결합. hu17의 발현이 항체 결합에 필수적임을 실증하는 음성 대조군으로 사용된 형질도입되지 않은 JRT3 세포(TCR 없음). (b) 적정된 항체에 의해 부여된 TCR 하향조절 대 양성 대조군 항체: 항-CD3ε(UCHT-1, Biolegend) 또는 항-범-TCRγδ(B1, Biolegend)에 의해 부여된 하향조절. (c) 적정된 항체에 의한 부여된 CD69 상향조절 대 비교 항체: 항-CD3ε(UCHT-1, Biolegend) 또는 항-범-TCRγδ(B1, Biolegend)에 의해 관찰된 상향조절.
도 7: 1차 Vγ4 양성 세포의 예시적인 항체 표적화 및 조절. (a) 본 발명의 모든 예시적인 항체가 용량 의존적 방식으로 1차 피부 유래 Vγ4+ T 세포에 결합할 수 있음을 나타내는, 2명의 개별 공여자의 피부로부터 증식된 1차 Vγ4+ T 세포에 대한 항-Vγ4 항체의 저정된 결합. 예시적인 항체의 Vγ4에 대한 특이성을 실증하는 음성 대조군으로서 이소형 대조군이 사용되었다. (b) 본 발명의 실질적으로 모든 예시적인 항체가 1차 혈액 유래 Vγ4+ T 세포에 결합할 수 있음을 나타내는, 말초 혈액 단핵 세포(PBMC)로부터 유래된 Vγ4+ T 세포에 대한 항-Vγ4 항체의 결합. RSV 이소형 대조군이 음성 대조군으로 사용되었다. (c) 이 세포 집단에 대한 3개의 예시적인 항체 모두의 결합을 나타내는, 결장직장암(CRC) 환자로부터의 장 유래 상피내 림프구(IEL)에 대한 항-Vγ4 항체 G4_3, G4_12 및 G4_18의 결합. 세포는 단일, 살아있는, γδ+, IgG1+(Vγ4)+로 관문화되었다. (d) 예시적인 항체 G4_18이 Vγ4+ 세포를 확인하기 위해 사용될 수 있음을 나타내는, 항-Vγ4 항체로의 자극 전 장 소화물에서 Vγ4+ γδ T 세포의 표현형 분석. 살아있는, 단일 세포의 1.4%는 Vδ1+였다. 이들 중 44.2%가 Vγ4와 쌍을 이루었고, 이들은 조직 잔류 마커(CD69+ CD103+)를 디스플레이했다. (e) 대표적인 FACS 그래프가 동반되는, 예시적인 항체, 각각 G4_12 및 G4_18에 의해 부여된 TCR 하향조절 대 이소형 음성 대조군에 의해 부여된 하향조절.
도 8: 1차 인간 Vγ4 T 세포수를 증가시키기 위한 Vγ4-특이적 항체의 용도. (a) IL-2 또는 IL-2 + IL-15의 존재 하에, 이소형 대조군 대비 플레이트-결합 항-Vγ4 클론 G4_12와 PBMC의 14일 배양 후 Vγ4 T 세포(클론 G4_18로의 염색에 의해 결정됨)의 증가를 예시하기 위한 예시적인 흐름 데이터. (b) IL-2 또는 IL-2 + IL-15의 존재 하에, 이소형 대조군 대비 플레이트-결합 항-Vγ4 클론 G4_12와 2명의 공여자로부터의 PBMC의 7일(상부열) 및 14일(하부열) 배양 후 Vγ4 T 세포(클론 G4_18로의 염색에 의해 결정됨)의 증가 요약.
정의
달리 정의되지 않는 한, 본원에 사용된 모든 기술 및 과학 용어는 본 발명이 속하는 기술 분야의 당업자에 의해 일반적으로 이해되는 의미를 갖는다. 본원에 사용된 바와 같이, 하기 용어는 아래에 부여된 의미를 갖는다.
감마 델타(γδ) T 세포는 이의 표면 상에 고유한, 정의하는 T 세포 수용체(TCR)를 발현하는 T 세포의 작은 하위세트를 나타낸다. 이 TCR은 하나의 감마(γ) 및 하나의 델타(δ) 사슬로 구성된다. 각 사슬은 가변(V) 영역, 불변(C) 영역, 막횡단 영역 및 세포질 꼬리를 포함한다. V 영역은 항원 결합 부위를 포함한다. 인간 γδ T 세포에는 두 가지 주요 하위유형이 있다: 하나는 말초 혈액에서 우세하고 다른 하나는 비조혈 조직에서 우세하다. 두 개의 하위유형은 세포 상에 존재하는 δ 및/또는 γ의 유형에 의해 정의될 수 있다. 예를 들어, 대부분의 혈액 잔류 γδ T 세포는 Vδ2 TCR, 예를 들어 Vγ9Vδ2를 발현하는 반면, 이는 예를 들어 피부에서 Vδ1을, 그리고 장에서 Vγ4를 더 자주 사용하는, 조직 잔류 γδ T 세포에서는 덜 일반적이다. "Vγ4 T 세포"에 대한 언급은 Vγ4 사슬을 갖는 γδ T 세포, 즉 Vγ4+ 세포를 지칭한다.
"감마 가변 4"에 대한 언급은 Vγ4 또는 Vg4로도 지칭될 수 있다. 감마 가변 4 폴리펩티드, 또는 이 영역을 포함하는 TCR 사슬을 암호화하는 뉴클레오티드, 또는 이 영역을 포함하는 TCR 단백질 복합체는 "TRGV4"로 지칭될 수 있다. γδ TCR의 Vγ4 사슬과 상호작용하는 항체 또는 이의 단편은 모두 Vγ4에 결합하는 효과적인 항체 또는 이의 단편이고 "항-TCR 감마 가변 4 항체 또는 이의 단편" 또는 "항-Vγ4 항체 또는 이의 단편"으로 지칭될 수 있다. 인간 Vγ4 폴리펩티드에 대한 언급은 서열 번호 1의 아미노산 1-99에 상응하는 아미노산 서열을 갖는 폴리펩티드를 의미할 수 있다. 이 99개의 아미노산 서열은 또한 서열 번호 334에 상응한다. 따라서, 서열 번호 1의 아미노산 1-99에 대한 본원의 언급은 본 발명의 모든 측면 및 구현예에 따라 서열 번호 334에 대한 언급과 상호교환적으로 사용될 수 있다. 예를 들어, 서열 번호 1의 아미노산 영역 67-82에 대한 본원의 언급은 서열 번호 334의 아미노산 영역 67-82와 동등하며 본원에서 상호교환적으로 사용될 수 있다.
"델타 가변 1"에 대한 언급은 Vδ1 또는 Vd1로도 지칭될 수 있다. 델타 가변 1 폴리펩티드, 또는 이 영역을 포함하는 TCR 사슬을 암호화하는 뉴클레오티드, 또는 이 영역을 포함하는 TCR 단백질 복합체는 "TRDV1"으로 지칭될 수 있다. γδ TCR의 Vδ1 사슬과 상호작용하는 항체 또는 이의 단편은 모두 Vδ1에 결합하는 효과적인 항체 또는 이의 단편이고 "항-TCR 델타 가변 1 항체 또는 이의 단편" 또는 "항-Vδ1 항체 또는 이의 단편"으로 지칭될 수 있다. 인간 Vδ1 폴리펩티드에 대한 언급은 서열 번호 337에 상응하는 아미노산 서열을 갖는 폴리펩티드를 의미할 수 있다.
"감마 가변 2"에 대한 언급은 Vγ2 또는 Vg2로도 지칭될 수 있다. 감마 가변 2 폴리펩티드, 또는 이 영역을 포함하는 TCR 사슬을 암호화하는 뉴클레오티드, 또는 이 영역을 포함하는 TCR 단백질 복합체는 "TRGV2"로 지칭될 수 있다. γδ TCR의 Vγ2 사슬과 상호작용하는 항체 또는 이의 단편은 모두 Vγ2에 결합하는 효과적인 항체 또는 이의 단편이며 "항-TCR 감마 가변 2 항체 또는 이의 단편" 또는 "항-Vγ2 항체 또는 이의 단편"으로 지칭될 수 있다. 인간 Vγ2 폴리펩티드에 대한 언급은 서열 번호 335에 상응하는 아미노산 서열을 갖는 폴리펩티드를 의미할 수 있다.
"감마 가변 8"에 대한 언급은 Vγ8 또는 Vg8로도 지칭될 수 있다. 감마 가변 8 폴리펩티드, 또는 이 영역을 포함하는 TCR 사슬을 암호화하는 뉴클레오티드, 또는 이 영역을 포함하는 TCR 단백질 복합체는 "TRGV8"로 지칭될 수 있다. γδ TCR의 Vγ8 사슬과 상호작용하는 항체 또는 이의 단편은 모두 Vγ8에 결합하는 효과적인 항체 또는 이의 단편이고 "항-TCR 감마 가변 8 항체 또는 이의 단편" 또는 "항-Vγ8 항체 또는 이의 단편"으로 지칭될 수 있다. 인간 Vγ8 폴리펩티드에 대한 언급은 서열 번호 336에 상응하는 아미노산 서열을 갖는 폴리펩티드를 의미할 수 있다.
용어 "항체"는 적어도 하나의 항원 결합 부위(ABS)를 포함하는 적어도 하나의 항체 가변 도메인을 포함하는 임의의 항체 단백질 구축물을 포함한다. 항체는 IgA, IgG, IgE, IgD, IgM 유형의 면역글로불린(뿐만 아니라 이의 하위유형)을 포함하지만 이에 제한되지 않는다. 2개의 동일한 중(H)쇄 및 2개의 동일한 경(L)쇄 폴리펩티드로부터 조립된 면역글로불린 G(IgG) 항체의 전체 구조는 잘 확립되어 있고 포유류에서 고도로 보존되어 있다(Padlan (1994) Mol. Immunol. 31:169-217).
통상적인 항체 또는 면역글로불린(Ig)은 4개의 폴리펩티드 사슬: 즉 2개의 중쇄(H) 및 2개의 경쇄(L)를 포함하는 단백질이다. 각 사슬은 불변 영역 및 가변 영역으로 나뉜다. 중쇄(H) 가변 도메인은 본원에서 VH로 약칭되고, 경쇄(L) 가변 도메인은 본원에서 VL로 약칭된다. 이들 도메인, 이와 관련된 도메인 및 이로부터 유래된 도메인은 본원에서 면역글로불린 사슬 가변 도메인으로 지칭될 수 있다. VH 및 VL 도메인(VH 및 VL 영역으로도 지칭됨)은 "프레임워크 영역"("FR")으로도 불리는 더 보존된 영역이 산재되어 있는, "상보성 결정 영역"("CDR")으로 불리는 영역으로 더 세분화될 수 있다. 프레임워크 및 상보성 결정 영역은 정확하게 정의되었다(Kabat et al. Sequences of Proteins of Immunological Interest, Fifth Edition U.S. Department of Health and Human Services, (1991) NIH Publication Number 91-3242). CDR 서열에 대한 대안적인 넘버링 관례, 예를 들어 Chothia et al. (1989) Nature 342: 877-883에 제시된 것들이 또한 존재한다. 통상적인 항체에서, 각각의 VH 및 VL은 아미노 말단부터 카복시 말단까지 하기 순서: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4의 순서로 배열된 3개의 CDR 및 4개의 FR로 이루어진다. 2개의 면역글로불린 중쇄 및 2개의 면역글로불린 경쇄의 통상적인 항체 사량체는 면역글로불린 중쇄 및 경쇄가 예를 들어 디설피드 결합에 의해 상호 연결되고 중쇄가 유사하게 연결되어 형성된다. 중쇄 불변 영역은 3개 도메인, CH1, CH2 및 CH3을 포함한다. 경쇄 불변 영역은 하나의 도메인 CL로 이루어진다. 중쇄의 가변 도메인 및 경쇄의 가변 도메인은 항원과 상호작용하는 결합 도메인이다. 항체의 불변 영역은 전형적으로 면역계의 다양한 세포(예를 들어, 효과기 세포) 및 전통적 보체 시스템의 제1 성분(C1q)을 포함하는 숙주 조직 또는 인자에 대한 항체의 결합을 매개한다.
본원에 사용된 바와 같은 항체의 단편("항체 단편", "면역글로불린 단편", "항원-결합 단편" 또는 "항원-결합 폴리펩티드"로도 지칭될 수 있음)은 표적, γδ T 세포 수용체의 감마 가변 4(Vγ4) 사슬에 특이적으로 결합하는 항체(또는 상기 부분을 포함하는 구축물)의 일부(예를 들어, 하나 이상의 면역글로불린 사슬이 전장이 아니지만 표적에 특이적으로 결합하는 분자)를 지칭한다. 용어 항체 단편에 포괄되는 결합 단편의 예는 다음을 포함한다:
(i) Fab 단편(VL, VH, CL 및 CH1 도메인으로 구성되는 1가 단편);
(ii) F(ab')2 단편(힌지 영역에서 디설피드 가교에 의해 연결된 2개의 Fab 단편으로 구성되는 2가 단편);
(iii) Fd 단편(VH 및 CH1 도메인으로 구성됨);
(iv) Fv 단편(항체의 단일 아암의 VL 및 VH 도메인으로 구성됨);
(v) 단일쇄 가변 단편, scFv(재조합 방법을 사용하여, VL 및 VH 영역이 쌍을 이루어 1가 분자를 형성하는 단일 단백질 사슬로 만들 수 있도록 하는 합성 링커에 의해 연결된 VL 및 VH 도메인으로 구성됨);
(vi) VH(VH 도메인으로 구성되는 면역글로불린 사슬 가변 도메인);
(vii) VL(VL 도메인으로 구성되는 면역글로불린 사슬 가변 도메인);
(viii) 도메인 항체(VH 또는 VL 도메인으로 구성되는, dAb);
(ix) 미니바디(CH3 도메인을 통해 연결된 한 쌍의 scFv 단편으로 구성됨); 및
(x) 디아바디(작은 펩티드 링커에 의해 또 다른 항체의 VL 도메인에 연결된 한 항체의 VH 도메인으로 구성되는 scFv 단편의 비공유 이량체로 구성됨).
"인간 항체"는 인간 생식계열 면역글로불린 서열로부터 유래된 가변 및 불변 영역을 갖는 항체를 지칭한다. 상기 인간 항체가 투여된 인간 대상체는 상기 항체 내에 포함된 1차 아미노산에 대해 교차-종 항체 반응(예를 들어, HAMA 반응 - 인간-항-마우스 항체로 불림)을 생성하지 않는다. 상기 인간 항체는 예를 들어, CDR, 특히 CDR3에, 인간 생식계열 면역글로불린 서열에 의해 암호화되지 않은 아미노산 잔기(예를 들어, 무작위 또는 부위-특이적 돌연변이유발에 의해 또는 체세포 돌연변이에 의해 도입된 돌연변이)를 포함할 수 있다. 그러나, 이 용어는 마우스와 같은 다른 포유류 종의 생식계열로부터 유래된 CDR 서열이 인간 프레임워크 서열 상으로 이식된 항체를 포함하는 것으로 의도되지 않는다. 숙주 세포 내로 형질감염된 재조합 발현 벡터를 사용하여 발현된 항체, 재조합, 조합 인간 항체 라이브러리로부터 단리된 항체, 인간 면역글로불린 유전자에 대한 트랜스제닉 동물(예를 들어, 마우스)로부터 단리된 항체와 같이, 재조합 수단에 의해 제조, 발현, 생성 또는 단리된 인간 항체 또는 다른 DNA 서열로의 인간 면역글로불린 유전자 서열의 스플라이싱이 관여되는 임의의 다른 수단에 의해 제조, 발현, 생성 또는 단리된 항체는 "재조합 인간 항체"로도 지칭될 수 있다.
비-인간 면역글로불린 가변 도메인의 프레임워크 영역에서 적어도 하나의 아미노산 잔기를 인간 가변 도메인으로부터의 상응하는 잔기로 치환하는 것은 "인간화"로 지칭된다. 가변 도메인의 인간화는 인간에서 면역원성을 감소시킬 수 있다.
"특이성"은 특정 항체 또는 이의 단편이 결합할 수 있는 상이한 유형의 항원 또는 항원 결정기의 수를 지칭한다. 항체의 특이성은 특정 항원을 고유한 분자 실체로 인식하고 이를 또 다른 항원과 구별하는 항체의 능력이다. 항원 또는 에피토프에 "특이적으로 결합하는" 항체는 당분야에서 잘 이해되는 용어이다. 분자가 대안적 표적보다 특정 표적 항원 또는 에피토프와 더 자주, 더 빠르게, 더 긴 지속기간으로 및/또는 더 큰 친화도로 반응하는 경우, 이는 "특이적 결합"을 나타낸다고 한다. 항체가 다른 물질에 결합하는 것보다 더 큰 친화도, 결합력, 더 쉽게 및/또는 더 긴 지속기간으로 결합하는 경우, 이는 표적 항원 또는 에피토프에 "특이적으로 결합한다". 항체(또는 이의 단편)는 결합이 관련 없는 결합제와 비교하여 통계적으로 유의한 경우 표적에 특이적으로 결합하는 것으로 간주될 수 있다.
항원과 항원 결합 폴리펩티드(KD)의 해리에 대한 평형 상수로 표시되는 "친화도"는 항원 결정기 및 항체(또는 이의 단편) 상 항원 결합 부위 간 결합 강도의 척도이다: KD 값이 작을수록 항원 결정기 및 항원 결합 폴리펩티드 간 결합 강도가 강하다. 대안적으로, 친화도는 1/KD인 친화도 상수(KA)로 표현될 수도 있다. 친화도는 특정 관심 항원에 따라, 알려진 방법으로 결정될 수 있다. 예를 들어 KD는 표면 플라즈몬 공명에 의해 결정될 수 있다.
10-6 미만의 임의의 KD 값은 결합을 나타내는 것으로 간주된다. 항원 또는 항원 결정기에 대한 항체 또는 이의 단편의 특이적 결합은 예를 들어 스캐차드 분석 및/또는 방사성면역검정(RIA), 효소 면역검정(EIA) 및 샌드위치 경쟁 검정과 같은 경쟁적 결합 검정, 평형 투석, 평형 결합, 겔 여과, ELISA, 표면 플라즈몬 공명, 또는 분광법(예를 들어, 형광 검정 사용) 및 당분야에 알려진 이의 상이한 변화를 포함하는 임의의 적합한 알려진 방식으로 결정될 수 있다.
"결합력"은 항체 또는 이의 단편 및 관련 항원 간 결합 강도의 척도이다. 결합력은 항원 결정기 및 항체 상의 그 항원 결합 부위 간 친화도 및 항체 상에 존재하는 적절한 결합 부위의 수 모두와 관련이 있다.
"인간 조직 Vγ4+ 세포", 및 "조혈 및 혈액 Vγ4+ 세포" 및 "종양 침윤 림프구(TIL) Vγ4+ 세포"는 각각 인간 조직 또는 조혈 혈액계 또는 인간 종양에 포함되거나 이로부터 유래된 Vγ4+ 세포로 정의된다. 모든 상기 세포 유형은 이의 (i) 위치 또는 이들이 유래된 곳 및 (ii) Vγ4+ TCR의 발현에 의해 확인될 수 있다.
적합하게는, 본 발명의 항체 또는 이의 단편(즉, 폴리펩티드)은 단리된다. "단리된" 폴리펩티드는 그 원래 환경으로부터 제거된 것이다. 용어 "단리된"은 상이한 항원 특이성을 갖는 다른 항체가 실질적으로 없는 항체를 지칭하기 위해 사용될 수 있다(예를 들어, Vγ4에 특이적으로 결합하는 단리된 항체 또는 이의 단편은 Vγ4 이외의 항원에 특이적으로 결합하는 항체가 실질적으로 없음). 용어 "단리된"은 또한 단리된 항체가 약학 조성물의 활성 성분으로 제형화될 때 치료적으로 투여하기 충분히 순수하거나, 적어도 70-80%(w/w) 순수하거나, 보다 바람직하게는 적어도 80-90%(w/w) 순수하거나, 훨씬 더 바람직하게는 90-95% 순수하고; 가장 바람직하게는 적어도 95%, 96%, 97%, 98%, 99% 또는 100%(w/w) 순수한 조제물을 지칭하기 위해 사용될 수 있다.
적합하게는, 본 발명에서 사용되는 폴리뉴클레오티드가 단리된다. "단리된" 폴리뉴클레오티드는 그 원래 환경으로부터 제거된 것이다. 예를 들어, 자연 발생 폴리뉴클레오티드는 자연계에 공존하는 물질의 일부 또는 전체로부터 분리되는 경우 단리된다. 예를 들어 폴리뉴클레오티드가 그 자연 환경의 일부가 아닌 벡터 내로 클로닝되거나 cDNA 내에 포함되는 경우, 이는 단리된 것으로 간주된다.
항체 또는 이의 단편은 자연 발생 대립유전자 변이체 뿐만 아니라 돌연변이체 또는 임의의 다른 비-자연 발생 변이체를 또한 포함하는 "기능적 활성 변이체"일 수 있다. 당분야에 알려진 바와 같이, 대립유전자 변이체는 본질적으로 폴리펩티드의 생물학적 기능을 변경하지 않는 하나 이상의 아미노산의 치환, 결실 또는 부가를 갖는 것을 특징으로 하는 (폴리)펩티드의 대안적 형태이다. 비제한적인 예로서, 상기 기능적 활성 변이체는 CDR을 포함하는 프레임워크가 변형될 때, CDR 자체가 변형될 때, 상기 CDR이 대안적 프레임워크에 이식될 때, 또는 N- 또는 C-말단 연장부가 포함될 때 여전히 기능할 수 있다. 또한, CDR-함유 결합 도메인은 또 다른 항체와 공유되는 것과 같은 상이한 파트너 사슬과 쌍을 이룰 수 있다. 소위 '공통' 경쇄 또는 '공통' 중쇄와의 공유 시, 상기 결합 도메인은 여전히 기능할 수 있다. 추가로, 상기 결합 도메인은 다량체화될 때 기능할 수 있다. 추가로, '항체 또는 이의 단편'은 또한 VH 또는 VL 또는 불변 도메인이 상이한 정규 서열(예를 들어, IMGT.org에 나열됨)과 멀리 또는 가까이 변형되고 여전히 기능하는 기능적 변이체를 포함할 수 있다.
2개의 밀접하게 관련된 폴리펩티드 서열을 비교하기 위해, 제1 폴리펩티드 서열 및 제2 폴리펩티드 서열 간 "서열 동일성%"는 폴리펩티드 서열에 대한 표준 설정(BLASTP)을 사용하여 NCBI BLAST v2.0을 사용해서 계산될 수 있다. 2개의 밀접하게 관련된 폴리뉴클레오티드 서열을 비교하기 위해, 제1 뉴클레오티드 서열 및 제2 뉴클레오티드 서열 간 "서열 동일성%"는 뉴클레오티드 서열에 대한 표준 설정(BLASTN)을 사용하여 NCBI BLAST v2.0을 사용해서 계산될 수 있다.
폴리펩티드 또는 폴리뉴클레오티드 서열은 이의 전체 길이에 걸쳐 100% 서열 동일성을 공유하는 경우, 다른 폴리펩티드 또는 폴리뉴클레오티드 서열과 같거나 "동일한" 것으로 언급된다. 서열의 잔기는 왼쪽에서 오른쪽으로, 즉 폴리펩티드의 경우 N-말단에서 C-말단으로; 폴리뉴클레오티드의 경우 5'에서 3' 말단으로 번호가 매겨진다.
일부 구현예에서, 서열의 임의의 특정된 서열 동일성%는 항체의 모든 6개 CDR의 서열 없이 계산된다. 예를 들어, 항-Vγ4 항체 또는 이의 항원-결합 단편은 특정된 가변 중쇄 영역 서열과 적어도 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%를 갖는 가변 중쇄 영역 서열 및/또는 특정된 가변 경쇄 영역 서열과 적어도 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일성을 갖는 가변 경쇄 영역 서열을 포함할 수 있고, 임의의 아미노산 변이는 가변 중쇄 및 경쇄 영역 서열의 프레임워크 영역에서만 발생한다. 이러한 구현예에서, 특정 서열 동일성을 갖는 항-Vγ4 항체 또는 이의 단편은 상응하는 항-Vγ4 항체 또는 이의 단편의 전체 중쇄 및 경쇄 CDR1, CDR2 및 CDR3 서열을 보유한다.
서열 간 "차이"는 제1 서열과 비교하여 제2 서열의 위치에서의 단일 아미노산 잔기의 삽입, 결실 또는 치환을 지칭한다. 2개의 폴리펩티드 서열은 1개, 2개 이상의 아미노산 차이를 포함할 수 있다. 다르게는 제1 서열과 동일한(100% 서열 동일성) 제2 서열에서의 삽입, 결실 또는 치환은 서열 동일성(%)을 감소시킨다. 예를 들어, 동일한 서열이 9개 아미노산 잔기 길이인 경우, 제2 서열에서의 하나의 치환은 88.9% 서열 동일성을 초래한다. 제1 및 제2 폴리펩티드 서열이 9개 아미노산 잔기 길이이고 6개의 동일한 잔기를 공유하는 경우, 제1 및 제2 폴리펩티드 서열은 66% 초과의 동일성을 공유한다(제1 및 제2 폴리펩티드 서열은 66.7% 동일성을 공유함).
대안적으로, 제1 참조 폴리펩티드 서열을 제2 비교 폴리펩티드 서열과 비교하기 위해, 제2 서열을 생산하기 위해 제1 서열에 수행된 부가, 치환 및/또는 결실의 수가 확인될 수 있다. "부가"는 하나의 아미노산 잔기의 제1 폴리펩티드의 서열 내로의 추가이다(제1 폴리펩티드의 어느 한 말단에서의 추가 포함). "치환"은 제1 폴리펩티드의 서열에서 하나의 아미노산 잔기의 하나의 상이한 아미노산 잔기로의 치환이다. 상기 치환은 보존적이거나 비보존적일 수 있다. "결실"은 제1 폴리펩티드의 서열로부터 하나의 아미노산 잔기의 결실이다(제1 폴리펩티드의 어느 한쪽 말단에서의 결실 포함).
세 글자 및 한 글자 코드를 사용하여, 자연 발생 아미노산은 하기와 같이: 글리신(G 또는 Gly), 알라닌(A 또는 Ala), 발린(V 또는 Val), 류신(L 또는 Leu), 이소류신(I 또는 Ile), 프롤린(P 또는 Pro), 페닐알라닌(F 또는 Phe), 티로신(Y 또는 Tyr), 트립토판(W 또는 Trp), 라이신(K 또는 Lys), 아르기닌(R 또는 Arg), 히스티딘(H 또는 His), 아스파르트산(D 또는 Asp), 글루탐산(E 또는 Glu), 아스파라긴(N 또는 Asn), 글루타민(Q 또는 Gln), 시스테인(C 또는 Cys), 메티오닌(M 또는 Met), 세린(S 또는 Ser) 및 트레오닌(T 또는 Thr)으로 지칭될 수 있다. 잔기가 아스파르트산 또는 아스파라긴일 수 있는 경우, 기호 Asx 또는 B가 사용될 수 있다. 잔기가 글루탐산 또는 글루타민일 수 있는 경우, 기호 Glx 또는 Z가 사용될 수 있다. 맥락에서 달리 특정되지 않는 한, 아스파르트산에 대한 언급은 아스파르테이트를 포함하고, 글루탐산은 글루타메이트를 포함한다.
"보존적" 아미노산 치환은 아미노산 잔기가 유사한 화학 구조의 또 다른 아미노산 잔기로 대체되고 폴리펩티드의 기능, 활성 또는 기타 생물학적 특성에 거의 영향을 미치지 않을 것으로 예상되는 아미노산 치환이다. 이러한 보존적 치환은 적합하게는 하기 그룹 내의 하나의 아미노산이 동일한 그룹 내로부터의 또 다른 아미노산 잔기에 의해 치환되는 치환이다:

적합하게는, 소수성 아미노산 잔기는 비극성 아미노산이다. 더 적합하게는, 소수성 아미노산 잔기는 V, I, L, M, F, W 또는 C로부터 선택된다. 일부 구현예에서, 소수성 아미노산 잔기는 글리신, 알라닌, 발린, 메티오닌, 류신, 이소류신, 페닐알라닌, 티로신 또는 트립토판으로부터 선택된다.
본원에 사용된 바와 같이, 폴리펩티드 서열의 넘버링 그리고 CDR 및 FR의 정의는 Kabat 시스템에 따라 정의된 바와 같다(Kabat et al., 1991, 그 전문이 본원에 참조로 포함됨). 제1 및 제2 폴리펩티드 서열 간 "상응하는" 아미노산 잔기는 제2 서열의 아미노산 잔기와 Kabat 시스템에 따른 동일한 위치를 공유하는 제1 서열의 아미노산 잔기인 반면, 제2 서열의 아미노산 잔기는 제1 서열로부터와 정체가 상이할 수 있다. 적합하게 상응하는 잔기는 프레임워크 및 CDR이 Kabat 정의에 따라 동일한 길이인 경우 동일한 수(및 문자)를 공유한다. 정렬은 수동으로 또는 예를 들어 표준 설정을 사용하여 NCBI BLAST v2.0(BLASTP 또는 BLASTN)과 같은 서열 정렬을 위한 알려진 컴퓨터 알고리즘을 사용해서 달성될 수 있다.
본원에서 "에피토프"에 대한 언급은 항체 또는 이의 단편에 의해 특이적으로 결합되는 표적의 부분을 지칭한다. 에피토프는 또한 "항원 결정기"로 지칭될 수 있다. 항체는 이들이 둘 다 동일하거나 입체적으로 중첩되는 에피토프를 인식할 때, 또 다른 항체와 "본질적으로 동일한 에피토프"에 결합한다. 두 항체가 동일하거나 중첩되는 에피토프에 결합하는지 여부를 결정하기 위해 일반적으로 사용되는 방법은 경쟁 검정이며, 이는 표지된 항원 또는 표지된 항체를 사용하는 여러 상이한 형식(에를 들어, 방사성 또는 효소 표지를 사용하는 웰 플레이트, 또는 항원-발현 세포 상의 유세포 분석)으로 구성될 수 있다. 항체는 둘 다 동일한 에피토프를 인식할 때(즉, 항원 및 항체 간 모든 접촉점이 동일함) 또 다른 항체와 "동일한 에피토프"에 결합한다. 예를 들어, 항체는 항체/항원 가교-커플링 MS, HDX, X선 결정학, 저온-EM 또는 돌연변이유발과 같은 특성화 방법의 보조로 항원의 특정된 영역에 걸쳐 모든 접촉점이 동일한 것으로 확인될 때 또 다른 항체와 동일한 에피토프에 결합할 수 있다.
또한, 이러한 특성화 방법의 도움으로, 동일한 접촉점의 전부는 아니지만 일부를 인식함으로써 본질적으로 동일한 에피토프에 결합하는 항체를 특성화하는 것도 가능하다. 구체적으로, 이러한 항체는 특정 항원 영역에서 충분한 수의 동일한 접촉점을 공유하여 광범위하게 동등한 기술적 효과 및/또는 동등한 항원 상호작용 선택성을 전달할 수 있다. 추가로, 항체가 본질적으로 동일한 에피토프를 인식하고 광범위하게 동등한 기술적 효과 및/또는 상호작용 선택성을 부여하는 일부 경우에, 가장 N-말단 항원 접촉점에서 가장 C-말단 항원 접촉점까지를 포함하는 전체 항원 접촉에 의해 에피토프 결합 발자국(footprint)을 정의하는 것도 유용할 수 있다.
단백질 표적 상에서 발견되는 에피토프는 "선형 에피토프" 또는 "입체형태 에피토프"로 정의될 수 있다. 선형 에피토프는 단백질 항원에서 연속적인 아미노산 서열에 의해 형성된다. 입체형태 에피토프는 단백질 서열에서는 불연속적이지만 단백질이 그 3차원 구조로 접힐 때 함께 모이는 아미노산으로 형성된다.
본원에 사용된 용어 "벡터"는 이것이 연결된 또 다른 핵산을 수송할 수 있는 핵산 분자를 지칭하는 것으로 의도된다. 벡터의 한 유형은 추가 DNA 절편이 결찰될 수 있는 원형 이중 가닥 DNA 루프를 지칭하는 "플라스미드"이다. 또 다른 유형의 벡터는 바이러스 벡터이며, 추가 DNA 절편이 바이러스 게놈 내로 결찰될 수 있다. 특정 벡터는 이들이 도입된 숙주 세포에서 자율 복제할 수 있다(예를 들어, 박테리아 복제 기점을 갖는 박테리아 벡터 및 에피솜 포유류 및 효모 벡터). 다른 벡터(예를 들어, 비-에피솜 포유류 벡터)는 숙주 세포 내로의 도입 시 숙주 세포의 게놈 내로 통합될 수 있고, 이에 의해 숙주 게놈과 함께 복제된다. 또한, 특정 벡터는 이들이 작동 가능하게 연결된 유전자의 발현을 지시할 수 있다. 이러한 벡터는 본원에서 "재조합 발현 벡터"(또는 간단히 "발현 벡터")로 지칭된다. 일반적으로 재조합 DNA 기법에서 유용한 발현 벡터는 종종 플라스미드 형태이다. 본 명세서에서, "플라스미드" 및 "벡터"는 플라스미드가 가장 일반적으로 사용되는 벡터 형태이므로 상호교환적으로 사용될 수 있다. 그러나, 본 발명은 동등한 기능을 하는 바이러스 벡터(예를 들어, 복제 결함 레트로바이러스, 아데노바이러스 및 아데노-관련 바이러스)와 같은 다른 형태의 발현 벡터, 및 또한 박테리오파지 및 파지미드 시스템을 포함하는 것으로 의도된다. 본원에 사용된 용어 "재조합 숙주 세포"(또는 간단히 "숙주 세포")는 재조합 발현 벡터가 도입된 세포를 지칭하는 것으로 의도된다. 이러한 용어는 특정 대상 세포뿐만 아니라, 예를 들어, 이러한 세포의 자손이 세포주 또는 세포 은행을 만드는 데 사용되고 임의로 보관, 제공, 판매, 전달되는 경우, 또는 본원에 기재된 바와 같은 항체 또는 이의 단편을 제조하기 위해 사용되는 경우, 상기 세포의 자손을 지칭하는 것으로 의도된다.
"대상체", "환자" 또는 "개체"에 대한 언급은 치료받을 대상체, 특히 포유류 대상체를 지칭한다. 포유류 대상체는 인간, 비인간 영장류, 농장 동물(예컨대 소), 스포츠 동물, 또는 개, 고양이, 기니피그, 토끼, 래트 또는 마우스와 같은 애완 동물을 포함한다. 일부 구현예에서, 대상체는 인간이다. 대안적 구현예에서, 대상체는 마우스와 같은 비인간 포유류이다.
용어 "충분한 양"은 원하는 효과를 생산하기에 충분한 양을 의미한다. 용어 "치료 유효량"은 질환 또는 장애의 증상을 완화하는 데 효과적인 양이다. 예방이 치료법으로 간주될 수 있으므로, 치료 유효량은 "예방 유효량"일 수 있다.
질환 또는 장애의 징후 또는 증상의 중증도, 대상체가 경험하는 이러한 징후 또는 증상의 빈도, 또는 둘 모두가 감소되는 경우, 질환 또는 장애는 "완화"된다.
본원에 사용된 바와 같은 "질환 또는 장애의 치료"는 대상체가 경험하는 질환 또는 장애의 적어도 하나의 징후 또는 증상의 빈도 및/또는 중증도를 감소시키는 것을 의미한다.
본원에 사용된 바와 같은 "암"은 세포의 비정상적인 성장 또는 분열을 지칭한다. 일반적으로 암세포의 성장 및/또는 수명은 정상 세포 및 그 주변 조직의 성장 및/또는 수명을 초과하며 이와 조율되지 않는다. 암은 양성, 전악성 또는 악성일 수 있다. 암은 다양한 세포 및 조직에서 발생한다.
"염증"은 염증이 있는 세포, 세포 유형, 조직 또는 기관을 초래하는 면역계의 만성 또는 급성 유발을 의미한다.
본원에 사용된 용어 "약"은 특정된 값보다 최대 10% 더 크고 최대 10% 더 작은, 적합하게는 특정된 값보다 최대 5% 더 크고 최대 5% 더 작은, 특히 특정된 값을 포함한다. 용어 "사이"는 특정된 경계 값을 포함한다.
γδ T 세포의 생체내 조절 방법
본 발명의 한 측면에 따르면, 환자에 본원에 정의된 바와 같은 항-Vγ4 항체 또는 이의 단편을 투여하는 단계를 포함하는, 감마 가변 4 사슬(Vγ4) T 세포의 생체내 조절 방법이 제공된다.
Vγ4 T 세포의 생체내 조절은 다음을 포함할 수 있다:
- 예를 들어, Vγ4 T 세포 수의 선택적 증가 또는 Vγ4 T 세포의 생존 촉진에 의한, Vγ4 T 세포의 증식;
- 예를 들어, Vγ4 T 세포의 역가 증가, 즉 표적 세포 사멸의 증가에 의한, Vγ4 T 세포의 자극;
- Vγ4 T 세포의 탈과립.
Vγ4 T 세포의 이러한 조절은, 예를 들어 Vγ4 T 세포 활성화 또는 Vγ4 T 세포 억제를 포함할 수 있다. 한 구현예에서, Vγ4 T 세포는 본원에 정의된 바와 같은 항-Vγ4 항체 또는 이의 단편을 투여함으로써 활성화된다. 대안적 구현예에서, Vγ4 T 세포는 본원에 정의된 바와 같은 항-Vγ4 항체 또는 이의 단편을 투여함으로써 억제된다. 대안적 구현예에서, Vγ4 T 세포는 본원에 정의된 바와 같은 항-Vγ4 항체 또는 이의 단편의 투여 후 억제되지 않는다.
한 구현예에서, 환자에 항-TCR 감마 4 가변 항체 또는 이의 단편을 투여하는 단계를 포함하는, Vγ4 T 세포를 조절하는 방법이 제공된다. 한 구현예에서, Vγ4 T 세포의 생체내 조절 방법에서 사용하기 위한 항-TCR 감마 4 가변 항체 또는 이의 단편이 제공된다. 한 구현예에서, Vγ4 T 세포의 생체내 조절용 약제의 제조에서 항-TCR 감마 4 가변 항체 또는 이의 단편의 용도가 제공된다.
한 구현예에서, 생체내 조절은 Vγ4 T 세포의 활성화, 특히 Vγ4 T 세포의 생체내 증식을 포함한다. 따라서, 본 발명의 측면에 따르면, 환자에 본원에 정의된 바와 같은 항-Vγ4 항체 또는 이의 단편을 투여하는 단계를 포함하는, Vγ4 T 세포의 생체내 증식 방법이 제공된다. Vγ4 T 세포의 이러한 증식은 Vγ4 T 세포수의 선택적 증가를 통해 및/또는 Vγ4 T 세포의 생존 촉진을 통해 달성될 수 있다.
본원에 사용된 언급 "증식된"은 항체 또는 이의 단편의 투여 전보다 많은 수의 세포를 갖는 환자를 지칭한다.
항체 또는 이의 단편
본 발명의 제1 측면에 따르면, γδ T 세포 수용체(TCR)의 가변 감마 4(Vγ4) 사슬에 특이적으로 결합하는, 단리된 항체 또는 이의 단편이 제공된다. 특히, 항체 또는 이의 단편은 γδ TCR의 가변 감마 2(Vγ 2) 사슬에 결합(또는 이와 교차 반응)하지 않는다. 이것은 동일한 종으로부터의 Vγ4 사슬 및 Vγ2에 관한 것임이 이해되어야 한다. 바람직하게는, 종은 호모 사피엔스(인간)이고, 따라서 본 발명은 γδ T 세포 수용체(TCR)의 인간 감마 가변 4(Vγ4) 사슬에 특이적으로 결합하고 γδ TCR의 인간 감마 가변 2(Vγ2) 사슬에는 결합하지 않는 단리된 항체 또는 이의 단편을 제공한다. 예를 들어, 인간 Vγ4 사슬은 서열 번호 1의 아미노산 1-99에 따른 서열을 가질 수 있고/있거나 인간 Vγ2 사슬은 서열 번호 335에 따른 서열을 가질 수 있다. 다른 종에서, 단리된 항체 또는 이의 단편은 γδ T 세포 수용체(TCR)의 인간 감마 가변 4(Vγ4) 사슬의 종 특이적 오르토로그에 특이적으로 결합하고, γδ TCR의 인간 감마 가변 2(Vγ2) 사슬의 종 특이적 오르토로그에는 결합하지 않는다. 따라서, 본 발명은 서열 번호 1의 아미노산 1-99에 상응하는 서열을 갖는 γδ T 세포 수용체(TCR)의 인간 감마 가변 4(Vγ4) 사슬 또는 이의 비인간 오르토로그에 특이적으로 결합하고 서열 번호 335에 상응하는 서열을 갖는 γδ TCR의 인간 감마 가변 2(Vγ2) 사슬 또는 이의 비인간 오르토로그에는 결합하지 않는, 단리된 항체 또는 이의 단편을 제공한다. 이러한 맥락에서 오르토로그는 참조 서열에 대해 가장 높은 서열 유사성을 갖는 감마 사슬 서열, 또는 바람직하게는 동일한 기능(예를 들어, 생체내 오르토로그 인지체 리간드와의 상호작용)을 보유하는 것을 의미할 수 있다. 예를 들어, 마우스에서 Heilig & Tonegave 명명법에 따라 Vγ7로 지정된 단백질이 기능적으로 인간 Vγ4와 가장 밀접하게 관련되어 있다(Barros et al. (2016) Cell, 167:203-218.e17).
이러한 발전은 통찰력 깊은 것이다. 예를 들어 인간에서, Vγ4 및 Vγ2 사슬은 91% 서열 동일성을 공유한다(9개의 아미노산만 다름). 따라서 이것은 (인간) Vγ4에 결합하고 (인간) Vγ2에는 결합하지 않는 항체를 수득하는 것을 어렵게 만들었고, 본 발명 전에는 이러한 항체를 생산하는 것이 가능할 것으로 당분야에서 예상되지 않았다.
γδ TCR의 Vγ4 사슬에 특이적으로 결합하는 본 발명의 항체 또는 이의 단편을 언급할 때, 이는 일반적으로 Vγ4 사슬에 대한 항체 또는 이의 단편의 결합이 음성 대조군 항체 및/또는 음성 대조군 항원에 비해 통계적으로 유의하게 증가됨을 의미한다(예를 들어, ELISA 검정, 임의로 DELFIA ELISA 검정 또는 SPR에서 결합을 통해 측정됨). 음성 대조군 항체 및/또는 음성 대조군 항원과 관련하여 검출된 수준은 사용된 검정에 대한 배경 수준으로 간주될 수 있으며, 이는 당업자가 잘 이해할 검정 시스템에서의 "노이즈"를 나타낸다. 특정 구현예에서, 배경 수준에 비해 미리 결정된 역치를 초과하는 신호 수준은 결합의 검출을 나타내는 것으로 간주될 수 있다(예를 들어, 약 1배, 2배, 3배, 4배, 5배 이상 배경 수준 초과). 예를 들어, DELFIA ELISA 검정에서 배경 수준보다 5배 이상 높은 신호 수준은 항원에 대한 항체의 결합을 표시하는 것으로 간주될 수 있다. 당업자는 사용 중인 검정 시스템에 기반하여 적합한 역치를 잘 결정할 수 있다. 역으로, γδ TCR의 Vγ2 사슬에 결합하지 않는(또는 이와 교차 반응하지 않는) 본 발명의 항체 또는 이의 단편을 언급할 때, 이것은 일반적으로 Vγ2 사슬에 대한 항체 또는 이의 단편의 결합이 음성 대조군 항체 및/또는 음성 대조군 항원에 비해 통계적으로 유의하게 증가됨을 의미한다(예를 들어, ELISA 검정, 임의로 DELFIA ELISA 검정 또는 SPR에서의 결합을 통해 측정됨). 이것은 예를 들어 도 2a에서 실증되고 실시예 4에서 논의된다. 본원에 개시된 본 발명의 모든 측면 및 구현예에 따르면, 이 특징은 또한 항체 또는 이의 단편 및 Vγ4 사슬 대 항체 또는 이의 단편 및 Vγ2 사슬의 검출된 결합 수준(예를 들어, ELISA 검정, 임의로 DELFIA ELISA 검정, 또는 SPR에서의 결합을 통해 측정됨)의 차이 변화 배율로도 표현될 수 있다. 예를 들어, 항체 또는 이의 단편은 Vγ2 사슬에 대한 결합과 비교하여 적어도 약 50배, 60배, 70배, 80배, 90배, 100배, 150배, 200배, 300배, 400배, 500배, 600배, 700배, 800배, 900배, 1000배, 2000배, 3000배, 4000배, 5000배, 6000배, 7000배, 8000배, 9000배, 10000배, 15000배, 25000배, 50000배, 75000배, 95000배 이상의 Vγ4 사슬에 대한 결합 증가를 나타낼 수 있다. 이것은 예를 들어 도 2b에서 실증되고 실시예 4에서 논의된다. 그러나 이러한 증가 배율은 대조군을 초과하는 모든 Vγ2 신호가 배경 노이즈가 아니라고 가정하고 이를 계산한 만큼 보수적인 것으로 간주된다. 그러나, 그리고 이전에 논의된 바와 같이, 당업자는 대신에 검정 노이즈로서 DELFIA ELISA 검정에서와 같은 배경을 초과하는(예를 들어, 배경 수준을 약 1배, 2배, 3배, 4배, 5배 이상 초과하는) 낮은 신호를 제외할 수 있다. 따라서 이러한 역치 아래의 신호를 비특이적 배경 결합으로 간주할 수 있다.
한 구현예에서, 항체 또는 이의 단편은 scFv, Fab, Fab', F(ab')2, Fv, 가변 도메인(예를 들어, VH 또는 VL), 디아바디, 미니바디 또는 모노클로날 항체이다. 특정 구현예에서, 항체 또는 이의 단편은 scFv이다. 또 다른 특정 구현예에서, 항체는 모노클로날 항체이다.
본 발명의 항체는 임의의 클래스, 예를 들어 IgG, IgA, IgM, IgE, IgD 또는 이의 이소형일 수 있고, 카파 또는 람다 경쇄를 포함할 수 있다. 한 구현예에서, 항체는 IgG 항체, 예를 들어, 이소형 IgG1, IgG2, IgG3 또는 IgG4 중 적어도 하나이다. 한 구현예에서, 항체는 IgG1이다. 추가 구현예에서, 항체는 효과기 기능을 감소시키거나, 반감기를 연장하거나, ADCC를 변경하거나, 힌지 안정성을 개선하기 위해 Fc를 돌연변이시키는 것과 같이 원하는 특성을 부여하기 위해 변형된 IgG 형식과 같은 형식일 수 있다. 이러한 변형은 당분야에 잘 알려져 있고 예시적인 구현예가 본원에 기재되어 있다. 예를 들어, 본 발명의 항체 또는 이의 단편은 서열 번호 332 또는 333에 따른 아미노산 서열을 포함하는 IgG1 불변 도메인을 포함할 수 있다.
한 구현예에서, 항체 또는 이의 단편은 인간이다. 따라서, 항체 또는 이의 단편은 인간 면역글로불린(Ig) 서열로부터 유래될 수 있다. 항체(또는 이의 단편)의 CDR, 프레임워크 및/또는 불변 영역은 인간 Ig 서열, 특히 인간 IgG 서열로부터 유래될 수 있다. CDR, 프레임워크 및/또는 불변 영역은 인간 Ig 서열, 특히 인간 IgG 서열에 대해 실질적으로 동일할 수 있다. 인간 항체를 사용하는 이점은 인간에서 면역원성이 낮거나 없다는 것이다.
항체 또는 이의 단편은 또한 키메라, 예를 들어 마우스-인간 항체 키메라일 수 있다.
대안적으로, 항체 또는 이의 단편은 마우스와 같은 비인간 종으로부터 유래된다. 이러한 비-인간 항체는 인간에서 자연적으로 생산된 항체 변이체와의 유사성을 증가시키도록 변형될 수 있으며, 따라서 항체 또는 이의 단편은 부분적으로 또는 완전히 인간화될 수 있다. 따라서, 한 구현예에서, 항체 또는 이의 단편은 인간화된다.
에피토프에 표적화된 항체
γδ TCR의 Vγ4 사슬의 에피토프에 결합하는 항체(또는 이의 단편)가 본원에서 제공된다. Vγ4 사슬 상 에피토프의 결합은 임의로 활성화 또는 억제와 같은 γδ TCR 활성에 영향을 미칠 수 있다. 항체(또는 이의 단편)는 또 다른 항체 또는 분자의 결합 또는 상호작용을 방지함으로써 차단 효과를 가질 수 있다. 본 발명의 항체는 γδ TCR의 Vγ4 사슬에 특이적이며, 본원에 정의된 바와 같이, γδ TCR의 Vγ2 사슬 또는 γδ TCR의 Vγ8 사슬과 같은 다른 항원의 에피토프에는 결합하지 않는다.
한 구현예에서, 에피토프는 γδ T 세포의 활성화 에피토프일 수 있다. "활성화" 에피토프는 예를 들어, TCR 하향조절, 세포의 탈과립, 세포독성, 증대, 동원, 증가된 생존 또는 고갈에 대한 저항성, 세포내 신호전달, 사이토카인 또는 성장 인자 분비, 표현형 변화, 또는 유전자 발현의 변화와 같은 TCR 관련 기능의 조절을 포함할 수 있다. 예를 들어, 활성화 에피토프의 결합은 γδ T 세포 집단, 바람직하게는 Vγ4+ T 세포 집단의 증식(즉, 증대)을 자극할 수 있다. 따라서, 이들 항체는 γδ T 세포 활성화를 조절하고, 이에 따라 면역 반응을 조절하기 위해 사용될 수 있다. 따라서, 한 구현예에서, 활성화 에피토프의 결합은 γδ TCR을 하향조절한다. 추가적 또는 대안적 구현예에서, 활성화 에피토프의 결합은 γδ T 세포의 탈과립을 활성화한다. 추가의 추가적 또는 대안적 구현예에서, 활성화 에피토프의 결합은 표적 세포(예를 들어, 암세포)를 사멸하도록 γδ T 세포를 활성화한다.
한 구현예에서, 본 발명은 Vγ4를 차단하고 TCR 결합을(예를 들어, 입체 장애를 통해) 방지하는 단리된 항체 또는 이의 단편을 제공한다. Vγ4를 차단함으로써, 항체는 TCR 활성화 및/또는 신호전달을 방지할 수 있다. 따라서 에피토프는 γδ T 세포의 억제 에피토프일 수 있다. "억제" 에피토프는 예를 들어 TCR 기능을 차단하여 TCR 활성화를 억제하는 것을 포함할 수 있다.
에피토프는 바람직하게는 γδ TCR의 Vγ4 사슬의 적어도 하나의 세포외, 가용성, 친수성, 외부 또는 세포질 부분으로 이루어진다.
특정 구현예에서, 에피토프는 γδ TCR의 Vγ4 사슬, 특히 Vγ4 사슬의 CDR3의 비-생식계열 암호화 영역에서 발견되는 에피토프를 포함하지 않는다. 바람직한 구현예에서, 에피토프는 γδ TCR의 Vγ4 사슬의 프레임워크 영역 내에 있으며, 이는 프레임워크 영역 3의 초가변 4 영역일 수 있다. 이러한 결합은 Vγ4 사슬(특히 CDR3) 간에 매우 가변적인 TCR의 서열에 대한 제한없이 일반적으로 Vγ4 사슬의 고유한 인식을 허용한다는 것이 이해될 것이다. 이와 같이, 임의의 Vγ4 사슬-포함 γδ TCR은 γδ TCR의 특이성과 무관하게, 본원에 정의된 바와 같은 항체 또는 이의 단편을 사용하여 인식될 수 있음이 이해될 것이다.
γδ 수용체가 다양한 조절 리간드에 독립적으로 그리고 공간적으로 구별되는 도메인을 통해 결합할 수 있는 것이 가능하다. 이러한 다중 모드 리간드 결합과 일치하게, Melandri et al. (2018) Nat. Immunol. 19: 1352-1365에 의한 최근 연구는 내인성 BTNL3 리간드에 대한 인간 TCR 결합이 γ4 사슬 상에서 CDR3의 N-말단에 위치한 별개의 도메인을 통한다는 것을 나타내었다. 저자들은 BTNL3 결합이 TCR의 이 특정 생식계열 영역을 통해 매개되기 때문에, 더 C-말단의, 체세포적으로 재조합된 CDR3 루프가 다른 리간드에 독립적으로 결합할 수 있는 상태로 유지된다는 것을 강조한다. 또한, 프레임워크 영역 3(FR3)의 이 하위영역('초가변 영역 4'(HV4)으로도 지칭될 수 있음)은 4개의 아미노산이 인간 γ2 사슬에서와 상이하다. 그러나 특정 항-Vγ4 항체가 Melandri 등의 문헌에서 개시되지도 않았고 이러한 항체가 어떻게 유도될 수 있는지 제안되지도 않았다. 실제로, 인간 Vγ4 및 Vγ2 사슬(91% 서열 동일성) 간 공유되는 상당한 서열 상동성으로 인해 이것이 가능하지 않을 것이라는 것이 지배적인 견해였다.
HV4 영역 내에서 결합하는 항체는 γ4 사슬의 CDR3 영역이 여전히 결합하도록 할 수 있으며, γ2에 비해 γ4에 특이적인 결합제를 제공하는 추가 이점이 있다. 또한, HV4가 생식계열-암호화되기 때문에, 이 영역을 표적화하는 일부 항체는 모든 Vγ4 사슬을 인식할 수 있는 반면 Vγ4를 인식하는 다른 항체는 특정 Vγ4 사슬에 특이적일 수 있다.
본 발명은 이제 Vγ4 사슬의 HV4 영역에 특이적으로 결합할 수 있는 항체 및 이의 단편을 제공한다. 따라서, 한 구현예에서, 항체 또는 이의 단편은 Vγ4 사슬의 HV4 영역의 에피토프에 결합한다. HV4 영역은 서열 번호 1의 아미노산 67 내지 82를 포함한다. 따라서, 한 구현예에서, 에피토프는 서열 번호 1의 아미노산 영역 67-82 내의 하나 이상의 아미노산 잔기, 예를 들어 CDR1, CDR2 및/또는 CDR3 서열의 일부가 아닌 Vγ4 사슬의 일부를 포함한다. 그렇게 함으로써, 항체 또는 이의 단편은 Vγ4+ TCR 및 BTNL3/8 간 상호작용을 조절할 수 있다. 한 구현예에서, 에피토프는 서열 번호 1의 아미노산 영역 96-106(CDR3) 내의 아미노산 잔기를 포함하지 않는다. 한 구현예에서, 에피토프는 서열 번호 1의 아미노산 영역 50-57(CDR2) 내의 아미노산 잔기를 포함하지 않는다. 한 구현예에서, 에피토프는 서열 번호 1의 아미노산 영역 27-32(CDR1) 내의 아미노산 잔기를 포함하지 않는다.
특정 구현예에서, 항체 또는 이의 단편은 서열 번호 1의 아미노산 67 내지 82 중 하나 이상에 결합 시, Vγ4+ TCR을 활성화할 수 있다.
잘 특성화된 αβ T 세포와 유사한 방식으로, γδ T 세포는 체세포적으로 재배열된 가변(V), 다양성(D)(β 및 δ만), 연결(J) 및 불변(C) 유전자의 고유한 세트를 이용하지만, γδ T 세포는 αβ T 세포보다 적은 V, D 및 J 절편을 포함한다. 한 구현예에서, 항체(또는 이의 단편)에 의해 결합된 에피토프는 Vγ4 사슬의 J 영역에서 발견되는 에피토프를 포함하지 않는다. 따라서 항체 또는 단편은 Vγ4 사슬의 V 영역에만 결합할 수 있다. 따라서, 한 구현예에서, 에피토프는 γδ TCR의 V 영역의 에피토프로 구성된다(예를 들어, 서열 번호 1의 아미노산 잔기 1-99).
에피토프에 대한 참조는 서열 번호 1로 표시된, Luoma et al. (2013) Immunity 39: 1032-1042 및 RCSB 단백질 데이터 뱅크 엔트리: 4MNH에 기재된 Vγ4 서열과 관련하여 수행된다:
SSNLEGRTKSVIRQTGSSAEITCDLAEGSTGYIHWYLHQEGKAPQRLLYYDSYTSSVVLESGISPGKYDTYGSTRKNLRMILRNLIENDSGVYYCATWDEKYYKKLFGSGTTLVVTEDLKNVFPPEVAVFEPSEAEISHTQKATLVCLATGFYPDHVELSWWVNGKEVHSGVCTDPQPLKEQPALNDSRYALSSRLRVSATFWQNPRNHFRCQVQFYGLSENDEWTQDRAKPVTQIVSAEAWGRADSRGGLEVLFQ(서열 번호 1)
서열 번호 1은 V 영역(가변 도메인으로도 지칭됨) 및 J 영역을 포함하는 가용성 TCR을 나타낸다. V 영역은 아미노산 잔기 1-99를 포함하고, J 영역은 아미노산 잔기 102-116을 포함하고, TCRβ로부터의 불변 영역은 아미노산 잔기 117-256을 포함한다. V 영역 내에서, CDR1은 서열 번호 1의 아미노산 잔기 27 내지 32로 정의되고, CDR2는 서열 번호 1의 아미노산 잔기 50 내지 57로 정의되고, CDR3은 서열 번호 1의 아미노산 잔기 96 내지 106으로 정의된다.
본 발명자들은 서열 번호 1의 아미노산 K76(즉, 위치 76의 라이신) 및 M80(즉, 위치 80의 메티오닌)이 (인간) Vγ4 사슬의 HV4 영역에 대한 결합에 특히 중요할 수 있음을 확인하였다(실시예 6). 따라서, 에피토프는 서열 번호 1의 K76 및/또는 M80을 포함하거나 이로 구성될 수 있다.
본 발명자들은 서열 번호 1의 아미노산 영역 71-79 내의 아미노산이 (인간) Vγ4 사슬의 HV4 영역에 대한 결합에 특히 중요할 수 있음을 추가로 확인하였다. 따라서, 추가 구현예에서, 에피토프는 서열 번호 1의 아미노산 영역 71-79 내의 하나 이상의 아미노산 잔기를 포함한다.
한 구현예에서, 에피토프는 기재된 영역 내의 하나 이상, 예컨대 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 10개 이상의 아미노산 잔기를 포함한다.
한 구현예에서, 에피토프는 서열 번호 1의 아미노산 영역 67-82 내의 하나 이상(예를 들어, 5개 이상, 예컨대 10개 이상)의 아미노산 잔기를 포함한다. 추가 구현예에서 에피토프는 서열 번호 1의 아미노산 영역 71-79 내의 하나 이상(예를 들어, 3개 이상, 예컨대 5개 이상)의 아미노산 잔기를 포함한다.
상기 항체(또는 이의 단편)가 정의된 범위 내의 모든 아미노산에 결합할 필요가 없다는 것이 추가로 이해될 것이다. 이러한 에피토프는 선형 에피토프로 지칭될 수 있다. 예를 들어, 서열 번호 1의 아미노산 영역 67-82 내의 아미노산 잔기를 포함하는 에피토프에 결합하는 항체는 상기 범위 내의 하나 이상의 아미노산 잔기, 예를 들어 범위의 각 말단에 있는 아미노산 잔기(즉, 아미노산 67 및 82), 임의로 범위 내의 아미노산(즉, 아미노산 71, 73, 75, 76 및 79)을 포함하는 잔기와만 결합할 수 있다.
예를 들어, 본 발명자들은 서열 번호 1의 아미노산 잔기 71, 73, 75, 76 및 79가 항-Vγ4 항체 또는 이의 단편이 결합하는 에피토프를 형성할 수 있음을 발견하였다(실시예 8). 따라서, 한 구현예에서, 에피토프는 서열 번호 1의 아미노산 잔기 71, 73, 75, 76 및 79 중 적어도 하나를 포함한다. 추가 구현예에서, 에피토프는 서열 번호 1의 아미노산 잔기 71, 73, 75, 76 및 79로부터 선택된 1, 2, 3, 4 또는 5개(특히 4 또는 5개) 아미노산을 포함한다.
추가 구현예에서, 에피토프는 서열 번호 1의 아미노산 영역 67-82 내의 하나 이상의 아미노산 잔기로 구성된다. 추가 구현예에서, 에피토프는 서열 번호 1의 아미노산 영역 71-79 내의 하나 이상의 아미노산 잔기로 구성된다.
추가 구현예에서, 에피토프는 서열 번호 1의 아미노산 잔기 71-79를 포함하거나, 적합하게는 서열 번호 1의 아미노산 잔기 71-79로 구성된다. 또 다른 추가 구현예에서, 에피토프는 서열 번호 1의 아미노산 잔기 71, 73, 75, 76 및 79를 포함하거나, 적합하게는 서열 번호 1의 아미노산 잔기 71, 73, 75, 76 및 79로 구성된다.
항체에 의해 결합되는 에피토프를 확립하기 위한 다양한 기법이 당분야에 알려져 있다. 예시적인 기법은 예를 들어 일상적인 교차 차단 검정, 알라닌 스캐닝 돌연변이 분석, 펩티드 블롯 분석, 펩티드 절단 분석 결정학 연구 및 NMR 분석을 포함한다. 또한 에피토프 절제, 에피토프 추출 및 항원의 화학적 변형과 같은 방법이 사용될 수 있다. 항체가 상호작용하는 폴리펩티드 내의 아미노산을 확인하기 위해 사용될 수 있는 또 다른 방법은 질량 분광법에 의해 검출되는 수소/중수소 교환이다(실시예 8에 기재됨). 일반적으로, 수소/중수소 교환 방법에는 관심 단백질의 중수소 표지 후 중수소-표지 단백질에 대한 항체의 결합이 관여된다. 다음으로, 단백질/항체 복합체는 물로 옮겨지고 항체 복합체에 의해 보호되는 아미노산 내의 교환 가능한 양성자는 계면의 일부가 아닌 아미노산 내의 교환 가능한 양성자보다 느린 속도로 중수소에서 수소로의 역교환을 거친다. 결과적으로 단백질/항체 계면의 일부를 형성하는 아미노산은 중수소를 보유할 수 있으므로 계면에 포함되지 않은 아미노산에 비해 상대적으로 더 높은 질량을 나타낼 수 있다. 항체의 해리 후, 표적 단백질은 프로테아제 절단 및 질량 분광법 분석을 거쳐 항체가 상호작용하는 특정 아미노산에 상응하는 중수소-표지 잔기를 드러낸다.
추가로, 또는 대안으로서, 항원 키메라화 및 돌연변이유발 연구를 사용하여 항체가 상호작용하는 폴리펩티드 내의 아미노산을 확인할 수 있다(실시예 6에 기재됨). 일반적으로, 이 방법에는 일련의 하나 이상의 키메라 항원의 생성이 관여되며, 제2 참조 항원의 각각의 아미노산으로 제1 참조 항원의 하나 이상의 아미노산을 대체하기 위해 제1 참조 항원의 아미노산 서열은 제2 참조 항원의 아미노산 서열에 기반하여 체계적으로 변경될 수 있다. 본 맥락에서 "각각의 아미노산"은 이의 서열 정렬 시 제1 참조 항원 및 제2 참조 항원의 서열 내에서 동등한 위치에 있는 아미노산을 의미한다. 이어서, 제1 참조 항원, 제2 참조 항원 및/또는 일련의 하나 이상의 키메라 항원 각각에 대한 시험 항체의 결합이 측정된다. 이후 각 항원에 대한 결합의 손실/증가는 제1 참조 서열 및/또는 제2 참조 서열과 관련하여 수행된 특정 아미노산 변화에 기인할 수 있다. 항체가 제1 참조 항원 및/또는 제2 참조 항원에 결합할 수 있는지 여부는 이미 알려져 있을 수 있다. 예를 들어, 실시예 6에 기재된 바와 같이, 제1 참조 항원은 인간 Vγ4 사슬일 수 있고 제2 참조 항원은 인간 Vγ2 사슬일 수 있으며, 일련의 키메라 항원은 Vγ4 사슬 서열의 하나 이상의 아미노산을 Vγ2 사슬 서열의 각각의 하나 이상의 아미노산으로 대체하여 제조된다.
항체 서열
본 발명의 단리된 항-Vγ4 항체 또는 이의 단편은 이의 CDR 서열을 참조하여 기재될 수 있다.
본 발명의 추가 측면에 따르면, 다음 중 하나 이상을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편이 제공된다:
서열 번호 2-47 중 어느 하나, 바람직하게는 서열 번호 10 및/또는 33과 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3;
서열 번호 48-70 및 서열 A1-A23(도 1) 중 어느 하나, 바람직하게는 서열 번호 56 및/또는 A9와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR2; 및/또는
서열 번호 71-116 중 어느 하나, 바람직하게는 서열 번호 79 및/또는 102와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR1.
본 발명의 한 측면에 따르면, 서열 번호 2-47 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편이 제공된다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 48-70 및 서열 A1-A23(도 1) 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR2를 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 71-116 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR1을 포함한다.
일부 측면에서, 단리된 항-Vγ4 항체 또는 이의 단편은 다음 중 하나 이상을 포함할 수 있다:
서열 번호 2-24 중 어느 하나, 바람직하게는 서열 번호 10과 적어도 80% 서열 동일성을 갖는 서열을 포함하는 중쇄 CDR3(HCDR3);
서열 번호 48-70 중 어느 하나, 바람직하게는 서열 번호 56과 적어도 80% 서열 동일성을 갖는 서열을 포함하는 중쇄 CDR2(HCDR2); 및/또는
서열 번호 71-93 중 어느 하나, 바람직하게는 서열 번호 79와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 중쇄 CDR1(HCDR1).
대안적으로 또는 부가적으로, 단리된 항-Vγ4 항체 또는 이의 단편은 다음 중 하나 이상을 포함할 수 있다:
서열 번호 25-47 중 어느 하나, 바람직하게는 서열 번호 33과 적어도 80% 서열 동일성을 갖는 서열을 포함하는 경쇄 CDR3(LCDR3);
서열 A1-A23(도 1) 중 어느 하나, 바람직하게는 서열 A9와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 경쇄 CDR2(LCDR2); 및/또는
서열 번호 94-116 중 어느 하나, 바람직하게는 서열 번호 102와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 경쇄 CDR1(LCDR1).
한 구현예에서, 항체 또는 이의 단편은 서열 번호 2-47 중 어느 하나와 적어도 85%, 90%, 95%, 97%, 98% 또는 99% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 48-70 및 서열 A1-A23(도 1) 중 어느 하나와 적어도 85%, 90%, 95%, 97%, 98% 또는 99% 서열 동일성을 갖는 서열을 포함하는 CDR2를 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 71-116 중 어느 하나와 적어도 85%, 90%, 95%, 97%, 98% 또는 99% 서열 동일성을 갖는 서열을 포함하는 CDR1을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 2-47 중 어느 하나와 적어도 85%, 90%, 95%, 97%, 98% 또는 99% 서열 동일성을 갖는 서열로 구성되는 CDR3을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 48-70 및 서열 A1-A23(도 1)과 적어도 85%, 90%, 95%, 97%, 98% 또는 99% 서열 동일성을 갖는 서열로 구성되는 CDR2를 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 71-116 중 어느 하나와 적어도 85%, 90%, 95%, 97%, 98% 또는 99% 서열 동일성을 갖는 서열로 구성되는 CDR1을 포함한다.
본 발명의 추가 측면에 따르면, 서열 번호 2-24 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VH 영역 및/또는 서열 번호 25-47 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VL 영역을 포함하는 항체 또는 이의 단편이 제공된다. 본 발명의 추가 측면에 따르면, 서열 번호 2-24 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열로 구성되는 CDR3을 포함하는 VH 영역 및/또는 서열 번호 25-47 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열로 구성되는 CDR3을 포함하는 VL 영역을 포함하는 항체 또는 이의 단편이 제공된다.
본 발명의 추가 측면에 따르면, 서열 번호 2-24 중 어느 하나와 적어도 90% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VH 영역 및/또는 서열 번호 25-47 중 어느 하나와 적어도 90% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VL 영역을 포함하는 항체 또는 이의 단편이 제공된다. 본 발명의 추가 측면에 따르면, 서열 번호 2-24 중 어느 하나와 적어도 90% 서열 동일성을 갖는 서열로 구성되는 CDR3을 포함하는 VH 영역 및/또는 서열 번호 25-47 중 어느 하나와 적어도 90% 서열 동일성을 갖는 서열로 구성되는 CDR3을 포함하는 VL 영역을 포함하는 항체 또는 이의 단편이 제공된다.
본 발명의 추가 측면에 따르면, 서열 번호 2-24 중 어느 하나와 적어도 95% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VH 영역 및/또는 서열 번호 25-47 중 어느 하나와 적어도 95% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VL 영역을 포함하는 항체 또는 이의 단편이 제공된다. 본 발명의 추가 측면에 따르면, 서열 번호 2-24 중 어느 하나와 적어도 95% 서열 동일성을 갖는 서열로 구성되는 CDR3을 포함하는 VH 영역 및/또는 서열 번호 25-47 중 어느 하나와 적어도 95% 서열 동일성을 갖는 서열로 구성되는 CDR3을 포함하는 VL 영역을 포함하는 항체 또는 이의 단편이 제공된다.
본 발명의 추가 측면에 따르면, 서열 번호 2-24 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VH 영역 및/또는 서열 번호 25-47 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VL 영역을 포함하는 항체 또는 이의 단편이 제공된다. 본 발명의 추가 측면에 따르면, 서열 번호 2-24 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열로 구성되는 CDR3을 포함하는 VH 영역 및 서열 번호 25-47 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열로 구성되는 CDR3을 포함하는 VL 영역을 포함하는 항체 또는 이의 단편이 제공된다.
본원에서 "적어도 80%" 또는 "80% 이상"을 언급하는 구현예는 80% 이상의 모든 값, 예컨대 85%, 90%, 95%, 97%, 98%, 99% 또는 100% 서열 동일성을 포함함이 이해될 것이다. 한 구현예에서, 본 발명의 항체 또는 단편은 특정된 서열과 적어도 85%, 예컨대 적어도 90%, 적어도 95%, 적어도 97%, 적어도 98% 또는 적어도 99% 서열 동일성을 포함한다.
서열 동일성 백분율 대신에, 구현예는 또한 하나 이상의 아미노산 변화, 예를 들어 하나 이상의 부가, 치환 및/또는 결실로 정의될 수 있다. 한 구현예에서, 서열은 최대 5개의 아미노산 변화, 예컨대 최대 3개의 아미노산 변화, 특히 최대 2개의 아미노산 변화를 포함할 수 있다. 예를 들어, 서열은 최대 5개의 아미노산 치환, 예를 들어 최대 3개의 아미노산 치환, 특히 최대 1 또는 2개의 아미노산 치환을 포함할 수 있다. 예를 들어, 본 발명의 항체 또는 이의 단편의 CDR3은 서열 번호 2-47 중 어느 하나와 비교하여 2개 이하, 보다 적합하게는 1개 이하의 치환(들)을 갖는 서열을 포함하거나 보다 적합하게는 이로 구성될 수 있다.
적합하게는 서열 번호 2-116 및 서열 A1-A23의 상응하는 잔기와 상이한 CDR1, CDR2 또는 CDR3의 임의의 잔기는 상응하는 잔기에 대한 보존적 치환이다. 예를 들어, 서열 번호 2-47의 상응하는 잔기와 상이한 CDR3의 임의의 잔기는 상응하는 잔기에 대한 보존적 치환이다.
한 구현예에서, 항체 또는 이의 단편은 다음을 포함한다:
(i) 서열 번호 2-24 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VH 영역;
(ii) 서열 번호 48-70 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR2를 포함하는 VH 영역;
(iii) 서열 번호 71-93 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR1을 포함하는 VH 영역;
(iv) 서열 번호 25-47 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VL 영역;
(v) 서열 A1-A23(도 1) 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR2를 포함하는 VL 영역; 및/또는
(vi) 서열 번호 94-116 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR1을 포함하는 VL 영역.
한 구현예에서, 항체 또는 이의 단편은 다음을 갖는 중쇄를 포함한다:
(i) 서열 번호 2-24 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VH 영역;
(ii) 서열 번호 48-70 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR2를 포함하는 VH 영역; 및
(iii) 서열 번호 71-93 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR1을 포함하는 VH 영역.
한 구현예에서, 항체 또는 이의 단편은 다음을 갖는 경쇄를 포함한다:
(i) 서열 번호 25-47 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VL 영역;
(ii) 서열 A1-A23(도 1) 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR2를 포함하는 VL 영역; 및
(iii) 서열 번호 94-116 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR1을 포함하는 VL 영역.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 10, 4, 14, 15, 17, 19 또는 23과 같은 서열 번호 2-24 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VH 영역을 포함한다(또는 이로 구성됨). 한 구현예에서, 항체 또는 이의 단편은 서열 번호 56, 50, 60, 61, 63, 65 또는 69와 같은 서열 번호 48-70 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR2를 포함하는 VH 영역을 포함한다(또는 이로 구성됨). 한 구현예에서, 항체 또는 이의 단편은 서열 번호 79, 73, 83, 84, 86, 88 또는 92와 같은 서열 번호 71-93 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR1을 포함하는 VH 영역을 포함한다(또는 이로 구성됨).
한 구현예에서, VH 영역은 서열 번호 10의 서열을 포함하는 CDR3, 서열 번호 56의 서열을 포함하는 CDR2, 및 서열 번호 79의 서열을 포함하는 CDR1을 포함한다. 한 구현예에서, CDR3은 서열 번호 10의 서열로 구성되고, CDR2는 서열 번호 56의 서열로 구성되며, CDR1은 서열 번호 79의 서열로 구성된다.
한 구현예에서, VH 영역은 서열 번호 4의 서열을 포함하는 CDR3, 서열 번호 50의 서열을 포함하는 CDR2, 및 서열 번호 73의 서열을 포함하는 CDR1을 포함한다. 한 구현예에서, CDR3은 서열 번호 4의 서열로 구성되고, CDR2는 서열 번호 50의 서열로 구성되며, CDR1은 서열 번호 73의 서열로 구성된다.
한 구현예에서, VH 영역은 서열 번호 14의 서열을 포함하는 CDR3, 서열 번호 60의 서열을 포함하는 CDR2, 및 서열 번호 83의 서열을 포함하는 CDR1을 포함한다. 한 구현예에서, CDR3은 서열 번호 14의 서열로 구성되고, CDR2는 서열 번호 60의 서열로 구성되며, CDR1은 서열 번호 83의 서열로 구성된다.
한 구현예에서, VH 영역은 서열 번호 15의 서열을 포함하는 CDR3, 서열 번호 61의 서열을 포함하는 CDR2, 및 서열 번호 84의 서열을 포함하는 CDR1을 포함한다. 한 구현예에서, CDR3은 서열 번호 15의 서열로 구성되고, CDR2는 서열 번호 61의 서열로 구성되며, CDR1은 서열 번호 84의 서열로 구성된다.
한 구현예에서, VH 영역은 서열 번호 17의 서열을 포함하는 CDR3, 서열 번호 63의 서열을 포함하는 CDR2, 및 서열 번호 86의 서열을 포함하는 CDR1을 포함한다. 한 구현예에서, CDR3은 서열 번호 17의 서열로 구성되고, CDR2는 서열 번호 63의 서열로 구성되며, CDR1은 서열 번호 86의 서열로 구성된다.
한 구현예에서, VH 영역은 서열 번호 19의 서열을 포함하는 CDR3, 서열 번호 65의 서열을 포함하는 CDR2, 및 서열 번호 88의 서열을 포함하는 CDR1을 포함한다. 한 구현예에서, CDR3은 서열 번호 19의 서열로 구성되고, CDR2는 서열 번호 65의 서열로 구성되며, CDR1은 서열 번호 88의 서열로 구성된다.
한 구현예에서, VH 영역은 서열 번호 23의 서열을 포함하는 CDR3, 서열 번호 69의 서열을 포함하는 CDR2, 및 서열 번호 92의 서열을 포함하는 CDR1을 포함한다. 한 구현예에서, CDR3은 서열 번호 23의 서열로 구성되고, CDR2는 서열 번호 69의 서열로 구성되며, CDR1은 서열 번호 92의 서열로 구성된다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 33, 27, 37, 38, 40, 42 또는 46과 같은 서열 번호 25-47 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VL 영역을 포함한다(또는 이로 구성됨). 한 구현예에서, 항체 또는 이의 단편은 서열 A9, A3, A13, A14, A16, A18 또는 A22와 같은 서열 A1-A23(도 1) 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR2를 포함하는 VL 영역을 포함한다(또는 이로 구성됨). 한 구현예에서, 항체 또는 이의 단편은 서열 번호 102, 96, 106, 107, 109, 111 또는 115와 같은 서열 번호 94-116 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR1을 포함하는 VL 영역을 포함한다(또는 이로 구성됨).
한 구현예에서, VL 영역은 서열 번호 33의 서열을 포함하는 CDR3, 서열 A9의 서열을 포함하는 CDR2, 및 서열 번호 102의 서열을 포함하는 CDR1을 포함한다. 한 구현예에서, CDR3은 서열 번호 33의 서열로 구성되고, CDR2는 서열 A9의 서열로 구성되고, CDR1은 서열 번호 102의 서열로 구성된다.
한 구현예에서, VL 영역은 서열 번호 27의 서열을 포함하는 CDR3, 서열 A3의 서열을 포함하는 CDR2, 및 서열 번호 96의 서열을 포함하는 CDR1을 포함한다. 한 구현예에서, CDR3은 서열 번호 27의 서열로 구성되고, CDR2는 서열 A3의 서열로 구성되고 CDR1은 서열 번호 96의 서열로 구성된다.
한 구현예에서, VL 영역은 서열 번호 37의 서열을 포함하는 CDR3, 서열 A13의 서열을 포함하는 CDR2, 및 서열 번호 106의 서열을 포함하는 CDR1을 포함한다. 한 구현예에서, CDR3은 서열 번호 37의 서열로 구성되고, CDR2는 서열 A13의 서열로 구성되고, CDR1은 서열 번호 106의 서열로 구성된다.
한 구현예에서, VL 영역은 서열 번호 38의 서열을 포함하는 CDR3, 서열 A14의 서열을 포함하는 CDR2, 및 서열 번호 107의 서열을 포함하는 CDR1을 포함한다. 한 구현예에서, CDR3은 서열 번호 38의 서열로 구성되고, CDR2는 서열 A14의 서열로 구성되고, CDR1은 서열 번호 107의 서열로 구성된다.
한 구현예에서, VL 영역은 서열 번호 40의 서열을 포함하는 CDR3, 서열 A16의 서열을 포함하는 CDR2, 및 서열 번호 109의 서열을 포함하는 CDR1을 포함한다. 한 구현예에서, CDR3은 서열 번호 40의 서열로 구성되고, CDR2는 서열 A16의 서열로 구성되고, CDR1은 서열 번호 109의 서열로 구성된다.
한 구현예에서, VL 영역은 서열 번호 42의 서열을 포함하는 CDR3, 서열 A18의 서열을 포함하는 CDR2, 및 서열 번호 111의 서열을 포함하는 CDR1을 포함한다. 한 구현예에서, CDR3은 서열 번호 42의 서열로 구성되고, CDR2는 서열 A18의 서열로 구성되고, CDR1은 서열 번호 111의 서열로 구성된다.
한 구현예에서, VL 영역은 서열 번호 46의 서열을 포함하는 CDR3, 서열 A22의 서열을 포함하는 CDR2, 및 서열 번호 115의 서열을 포함하는 CDR1을 포함한다. 한 구현예에서, CDR3은 서열 번호 46의 서열로 구성되고, CDR2는 서열 A22의 서열로 구성되고, CDR1은 서열 번호 115의 서열로 구성된다.
한 구현예에서, 항체 또는 이의 단편은 도 1에 기재된 바와 같은 하나 이상의 CDR 서열을 포함한다. 추가 구현예에서, 항체 또는 이의 단편은 도 1에 기재된 바와 같은 클론 1140_P01_G08[G4_12] 또는 클론 1139_P01_A04[G4_03]의 하나 이상의(예컨대 모든) CDR 서열을 포함한다.
따라서, 본 발명은 다음 중 하나 이상을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편을 제공한다:
(a) 서열 번호 79를 갖는 HCDR1, 서열 번호 56을 갖는 HCDR2 및 서열 번호 10을 갖는 HCDR3을 포함하고, 임의로 서열 번호 125를 포함하거나 이로 구성되는 VH; 및
서열 번호 102를 갖는 LCDR1, 서열 A9(도 1)를 갖는 LCDR2 및 서열 번호 33을 갖는 LCDR3을 포함하고, 임의로 서열 번호 148을 포함하거나 이로 구성되는 VL;
(b) 서열 번호 86을 갖는 HCDR1, 서열 번호 63을 갖는 HCDR2 및 서열 번호 17을 갖는 HCDR3을 포함하고, 임의로 서열 번호 132를 포함하거나 이로 구성되는 VH; 및
서열 번호 109를 갖는 LCDR1, 서열 A16(도 1)을 갖는 LCDR2 및 서열 번호 40을 갖는 LCDR3을 포함하고, 임의로 서열 번호 155를 포함하거나 이로 구성되는 VL;
(c) 서열 번호 73을 갖는 HCDR1, 서열 번호 50을 갖는 HCDR2 및 서열 번호 4를 갖는 HCDR3을 포함하고, 임의로 서열 번호 119를 포함하거나 이로 구성되는 VH; 및
서열 번호 96을 갖는 LCDR1, 서열 A3(도 1)을 갖는 LCDR2 및 서열 번호 27을 갖는 LCDR3을 포함하고 임의로 서열 번호 142를 포함하거나 이로 구성되는 VL;
(d) 서열 번호 83을 갖는 HCDR1, 서열 번호 60을 갖는 HCDR2 및 서열 번호 14를 갖는 HCDR3을 포함하고, 임의로 서열 번호 129를 포함하거나 이로 구성되는 VH; 및
서열 번호 106을 갖는 LCDR1, 서열 A13(도 1)을 갖는 LCDR2 및 서열 번호 37을 갖는 LCDR3을 포함하고, 임의로 서열 번호 152를 포함하거나 이로 구성되는 VL;
(e) 서열 번호 84를 갖는 HCDR1, 서열 번호 61을 갖는 HCDR2 및 서열 번호 15를 갖는 HCDR3을 포함하고, 임의로 서열 번호 130을 포함하거나 이로 구성되는 VH; 및
서열 번호 107을 갖는 LCDR1, 서열 A14(도 1)를 갖는 LCDR2 및 서열 번호 38을 갖는 LCDR3을 포함하고, 임의로 서열 번호 153을 포함하거나 이로 구성되는 VL;
(f) 서열 번호 88을 갖는 HCDR1, 서열 번호 65를 갖는 HCDR2 및 서열 번호 19를 갖는 HCDR3을 포함하고, 임의로 서열 번호 134를 포함하거나 이로 구성되는 VH; 및
서열 번호 111을 갖는 LCDR1, 서열 A18(도 1)을 갖는 LCDR2 및 서열 번호 42를 갖는 LCDR3을 포함하고, 임의로 서열 번호 157을 포함하거나 이로 구성되는 VL;
(g) 서열 번호 92를 갖는 HCDR1, 서열 번호 69를 갖는 HCDR2 및 서열 번호 23을 갖는 HCDR3을 포함하고, 임의로 서열 번호 138을 포함하거나 이로 구성되는 VH; 및
서열 번호 115를 갖는 LCDR1, 서열 A22(도 1)를 갖는 LCDR2 및 서열 번호 46을 갖는 LCDR3을 포함하고, 임의로 서열 번호 161을 포함하거나 이로 구성되는 VL;
(h) 서열 번호 71을 갖는 HCDR1, 서열 번호 48을 갖는 HCDR2 및 서열 번호 2를 갖는 HCDR3을 포함하고, 임의로 서열 번호 117을 포함하거나 이로 구성되는 VH; 및
서열 번호 94를 갖는 LCDR1, 서열 A1(도 1)을 갖는 LCDR2 및 서열 번호 25를 갖는 LCDR3을 포함하고, 임의로 서열 번호 140을 포함하거나 이로 구성되는 VL;
(i) 서열 번호 72를 갖는 HCDR1, 서열 번호 49를 갖는 HCDR2 및 서열 번호 3을 갖는 HCDR3을 포함하고, 임의로 서열 번호 118을 포함하거나 이로 구성되는 VH; 및
서열 번호 95를 갖는 LCDR1, 서열 A2(도 1)를 갖는 LCDR2 및 서열 번호 26을 갖는 LCDR3을 포함하고, 임의로 서열 번호 141을 포함하거나 이로 구성되는 VL;
(j) 서열 번호 74를 갖는 HCDR1, 서열 번호 51을 갖는 HCDR2 및 서열 번호 5를 갖는 HCDR3을 포함하고, 임의로 서열 번호 120을 포함하거나 이로 구성되는 VH; 및
서열 번호 97을 갖는 LCDR1, 서열 A4(도 1)를 갖는 LCDR2 및 서열 번호 28을 갖는 LCDR3을 포함하고, 임의로 서열 번호 143을 포함하거나 이로 구성되는 VL;
(k) 서열 번호 75를 갖는 HCDR1, 서열 번호 52를 갖는 HCDR2 및 서열 번호 6을 갖는 HCDR3을 포함하고, 임의로 서열 번호 121을 포함하거나 이로 구성되는 VH; 및
서열 번호 98을 갖는 LCDR1, 서열 A5(도 1)를 갖는 LCDR2 및 서열 번호 29를 갖는 LCDR3을 포함하고, 임의로 서열 번호 144를 포함하거나 이로 구성되는 VL;
(l) 서열 번호 76을 갖는 HCDR1, 서열 번호 53을 갖는 HCDR2 및 서열 번호 7을 갖는 HCDR3을 포함하고, 임의로 서열 번호 122를 포함하거나 이로 구성되는 VH; 및
서열 번호 99를 갖는 LCDR1, 서열 A6(도 1)을 갖는 LCDR2 및 서열 번호 30을 갖는 LCDR3을 포함하고, 임의로 서열 번호 145를 포함하거나 이로 구성되는 VL;
(m) 서열 번호 77을 갖는 HCDR1, 서열 번호 54를 갖는 HCDR2 및 서열 번호 8을 갖는 HCDR3을 포함하고, 임의로 서열 번호 123을 포함하거나 이로 구성되는 VH; 및
서열 번호 100을 갖는 LCDR1, 서열 A7(도 1)을 갖는 LCDR2 및 서열 번호 31을 갖는 LCDR3을 포함하고, 임의로 서열 번호 146을 포함하거나 이로 구성되는 VL;
(n) 서열 번호 78을 갖는 HCDR1, 서열 번호 55를 갖는 HCDR2 및 서열 번호 9를 갖는 HCDR3을 포함하고, 임의로 서열 번호 124를 포함하거나 이로 구성되는 VH; 및
서열 번호 101을 갖는 LCDR1, 서열 A8(도 1)을 갖는 LCDR2 및 서열 번호 32를 갖는 LCDR3을 포함하고, 임의로 서열 번호 147을 포함하거나 이로 구성되는 VL;
(o) 서열 번호 80을 갖는 HCDR1, 서열 번호 57을 갖는 HCDR2 및 서열 번호 11을 갖는 HCDR3을 포함하고, 임의로 서열 번호 126을 포함하거나 이로 구성되는 VH; 및
서열 번호 103을 갖는 LCDR1, 서열 A10(도 1)을 갖는 LCDR2 및 서열 번호 34를 갖는 LCDR3을 포함하고, 임의로 서열 번호 149를 포함하거나 이로 구성되는 VL;
(p) 서열 번호 81을 갖는 HCDR1, 서열 번호 58을 갖는 HCDR2 및 서열 번호 12를 갖는 HCDR3을 포함하고, 임의로 서열 번호 127을 포함하거나 이로 구성되는 VH; 및
서열 번호 104를 갖는 LCDR1, 서열 A11(도 1)을 갖는 LCDR2 및 서열 번호 35를 갖는 LCDR3을 포함하고, 임의로 서열 번호 150을 포함하거나 이로 구성되는 VL;
(q) 서열 번호 82를 갖는 HCDR1, 서열 번호 59를 갖는 HCDR2 및 서열 번호 13을 갖는 HCDR3을 포함하고, 임의로 서열 번호 128을 포함하거나 이로 구성되는 VH; 및
서열 번호 105를 갖는 LCDR1, 서열 A12(도 1)를 갖는 LCDR2 및 서열 번호 36을 갖는 LCDR3을 포함하고, 임의로 서열 번호 151을 포함하거나 이로 구성되는 VL;
(r) 서열 번호 85를 갖는 HCDR1, 서열 번호 62를 갖는 HCDR2 및 서열 번호 16을 갖는 HCDR3을 포함하고, 임의로 서열 번호 131을 포함하거나 이로 구성되는 VH; 및
서열 번호 108을 갖는 LCDR1, 서열 A15(도 1)를 갖는 LCDR2 및 서열 번호 39를 갖는 LCDR3을 포함하고, 임의로 서열 번호 154를 포함하거나 이로 구성되는 VL;
(s) 서열 번호 87을 갖는 HCDR1, 서열 번호 64를 갖는 HCDR2 및 서열 번호 18을 갖는 HCDR3을 포함하고, 임의로 서열 번호 133을 포함하거나 이로 구성되는 VH; 및
서열 번호 110을 갖는 LCDR1, 서열 A17(도 1)을 갖는 LCDR2 및 서열 번호 41을 갖는 LCDR3을 포함하고, 임의로 서열 번호 156을 포함하거나 이로 구성되는 VL;
(t) 서열 번호 89를 갖는 HCDR1, 서열 번호 66을 갖는 HCDR2 및 서열 번호 20을 갖는 HCDR3을 포함하고, 임의로 서열 번호 135를 포함하거나 이로 구성되는 VH; 및
서열 번호 112를 갖는 LCDR1, 서열 A19(도 1)를 갖는 LCDR2 및 서열 번호 43을 갖는 LCDR3을 포함하고, 임의로 서열 번호 158을 포함하거나 이로 구성되는 VL;
(u) 서열 번호 90을 갖는 HCDR1, 서열 번호 67을 갖는 HCDR2 및 서열 번호 21을 갖는 HCDR3을 포함하고, 임의로 서열 번호 136을 포함하거나 이로 구성되는 VH; 및
서열 번호 113을 갖는 LCDR1, 서열 A20(도 1)을 갖는 LCDR2 및 서열 번호 44를 갖는 LCDR3을 포함하고, 임의로 서열 번호 159를 포함하거나 이로 구성되는 VL;
(v) 서열 번호 91을 갖는 HCDR1, 서열 번호 68을 갖는 HCDR2 및 서열 번호 22를 갖는 HCDR3을 포함하고, 임의로 서열 번호 137을 포함하거나 이로 구성되는 VH; 및
서열 번호 114를 갖는 LCDR1, 서열 A21(도 1)을 갖는 LCDR2 및 서열 번호 45를 갖는 LCDR3을 포함하고, 임의로 서열 번호 160을 포함하거나 이로 구성되는 VL; 및/또는
(w) 서열 번호 93을 갖는 HCDR1, 서열 번호 70을 갖는 HCDR2 및 서열 번호 24를 갖는 HCDR3을 포함하고, 임의로 서열 번호 139를 포함하거나 이로 구성되는 VH; 및
서열 번호 116을 갖는 LCDR1, 서열 A23(도 1)을 갖는 LCDR2 및 서열 번호 47을 갖는 LCDR3을 포함하고, 임의로 서열 번호 162를 포함하거나 이로 구성되는 VL.
적합하게는 상기 언급된 VH 및 VL 영역은 각각 4개의 프레임워크 영역(FR1-FR4)을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 117-162 중 어느 하나의 프레임워크 영역과 적어도 80% 서열 동일성을 갖는 서열을 포함하는 프레임워크 영역(예를 들어, FR1, FR2, FR3 및/또는 FR4)을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 117-162 중 어느 하나의 프레임워크 영역과 적어도 90%, 예컨대 적어도 95%, 97% 또는 99% 서열 동일성을 갖는 서열을 포함하는 프레임워크 영역(예를 들어, FR1, FR2, FR3 및/또는 FR4)을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 117-162 중 어느 하나의 서열을 포함하는 프레임워크 영역(예를 들어, FR1, FR2, FR3 및/또는 FR4)을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 117-162 중 어느 하나의 서열로 구성되는 프레임워크 영역(예를 들어, FR1, FR2, FR3 및/또는 FR4)을 포함한다.
본원에 기재된 항체는 이의 전체 경쇄 및/또는 중쇄 가변 서열에 의해 정의될 수 있다. 따라서, 본 발명의 추가 측면에 따르면, 서열 번호 117-162 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편이 제공된다. 본 발명의 추가 측면에 따르면, 서열 번호 117-162 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열로 구성되는 단리된 항-Vγ4 항체 또는 이의 단편이 제공된다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 117-139 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 VH 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 117-139 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열로 구성되는 VH 영역을 포함한다. 추가 구현예에서, VH 영역은 서열 번호 125, 119, 129, 130, 132, 134 또는 138 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함한다. 추가 구현예에서, VH 영역은 서열 번호 125, 119, 129, 130, 132, 134 또는 138 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열로 구성된다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 140-162 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 VL 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 140-162 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열로 구성되는 VL 영역을 포함한다. 추가 구현예에서, VL 영역은 서열 번호 148, 142, 152, 153, 155, 157 또는 161 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함한다. 추가 구현예에서, VL 영역은 서열 번호 148, 142, 152, 153, 155, 157 또는 161 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열로 구성된다.
추가 구현예에서, 항체 또는 이의 단편은 서열 번호 117-139 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 VH 영역 및 서열 번호 140-162 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 VL 영역을 포함한다. 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 117-139 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열로 구성되는 VH 영역 및 서열 번호 140-162 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열로 구성되는 VL 영역을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 125의 아미노산 서열을 포함하는 VH 영역을 포함한다(1140_P01_G08)[G4_12]. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 125의 아미노산 서열로 구성되는 VH 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 148의 아미노산 서열을 포함하는 VL 영역을 포함한다(1140_P01_G08)[G4_12]. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 148의 아미노산 서열로 구성되는 VL 영역을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 125의 아미노산 서열을 포함하는 VH 영역 및 서열 번호 148의 아미노산 서열을 포함하는 VL 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 125의 아미노산 서열로 구성되는 VH 영역 및 서열 번호 148의 아미노산 서열로 구성되는 VL 영역을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 119의 아미노산 서열을 포함하는 VH 영역을 포함한다(1139_P01_A04)[G4_3]. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 119의 아미노산 서열로 구성되는 VH 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 142의 아미노산 서열을 포함하는 VL 영역을 포함한다(1139_P01_A04)[G4_3]. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 142의 아미노산 서열로 구성되는 VL 영역을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 119의 아미노산 서열을 포함하는 VH 영역 및 서열 번호 142의 아미노산 서열을 포함하는 VL 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 119의 아미노산 서열로 구성되는 VH 영역 및 서열 번호 142의 아미노산 서열로 구성되는 VL 영역을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 129의 아미노산 서열을 포함하는 VH 영역을 포함한다(1248_P02_D10)[G4_16]. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 129의 아미노산 서열로 구성되는 VH 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 152의 아미노산 서열을 포함하는 VL 영역을 포함한다(1248_P02_D10)[G4_16]. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 152의 아미노산 서열로 구성되는 VL 영역을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 129의 아미노산 서열을 포함하는 VH 영역 및 서열 번호 152의 아미노산 서열을 포함하는 VL 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 129의 아미노산 서열로 구성되는 VH 영역 및 서열 번호 152의 아미노산 서열로 구성되는 VL 영역을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 130의 아미노산 서열을 포함하는 VH 영역을 포함한다(1254_P01_H04)[G4_18]. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 130의 아미노산 서열로 구성되는 VH 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 153의 아미노산 서열을 포함하는 VL 영역을 포함한다(1254_P01_H04)[G4_18]. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 153의 아미노산 서열로 구성되는 VL 영역을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 130의 아미노산 서열을 포함하는 VH 영역 및 서열 번호 153의 아미노산 서열을 포함하는 VL 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 130의 아미노산 서열로 구성되는 VH 영역 및 서열 번호 153의 아미노산 서열로 구성되는 VL 영역을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 132의 아미노산 서열을 포함하는 VH 영역을 포함한다(1254_P02_G02)[G4_20]. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 132의 아미노산 서열로 구성되는 VH 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 155의 아미노산 서열을 포함하는 VL 영역을 포함한다(1254_P02_G02)[G4_20]. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 155의 아미노산 서열로 구성되는 VL 영역을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 132의 아미노산 서열을 포함하는 VH 영역 및 서열 번호 155의 아미노산 서열을 포함하는 VL 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 132의 아미노산 서열로 구성되는 VH 영역 및 서열 번호 155의 아미노산 서열로 구성되는 VL 영역을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 134의 아미노산 서열을 포함하는 VH 영역을 포함한다(1253_P03_H05)[G4_23]. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 134의 아미노산 서열로 구성되는 VH 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 157의 아미노산 서열을 포함하는 VL 영역을 포함한다(1253_P03_H05)[G4_23]. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 157의 아미노산 서열로 구성되는 VL 영역을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 134의 아미노산 서열을 포함하는 VH 영역 및 서열 번호 157의 아미노산 서열을 포함하는 VL 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 134의 아미노산 서열로 구성되는 VH 영역 및 서열 번호 157의 아미노산 서열로 구성되는 VL 영역을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 138의 아미노산 서열을 포함하는 VH 영역을 포함한다(1248_P02_C10)[G4_27]. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 138의 아미노산 서열로 구성되는 VH 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 161의 아미노산 서열을 포함하는 VL 영역을 포함한다(1248_P02_C10)[G4_27]. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 161의 아미노산 서열로 구성되는 VL 영역을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 138의 아미노산 서열을 포함하는 VH 영역 및 서열 번호 161의 아미노산 서열을 포함하는 VL 영역을 포함한다. 한 구현예에서, 항체 또는 이의 단편은 서열 번호 138의 아미노산 서열로 구성되는 VH 영역 및 서열 번호 161의 아미노산 서열로 구성되는 VL 영역을 포함한다.
VH 및 VL 영역 둘 다를 포함하는 단편의 경우, 이들은 공유적으로(예를 들어, 디설피드 결합 또는 링커를 통해) 또는 비공유적으로 연합될 수 있다. 본원에 기재된 항체 단편은 scFv, 즉, 링커에 의해 연결된 VH 영역 및 VL 영역을 포함하는 단편을 포함할 수 있다. 한 구현예에서, VH 및 VL 영역은 (예를 들어 합성) 폴리펩티드 링커에 의해 연결된다. 폴리펩티드 링커는 (Gly4Ser)n 링커를 포함할 수 있으며, n은 1 내지 8, 예를 들어 2, 3, 4, 5 또는 7이다. 폴리펩티드 링커는 [(Gly4Ser)n(Gly3AlaSer)m]p 링커를 포함할 수 있으며, n = 1 내지 8, 예를 들어 2, 3, 4, 5 또는 7이고, m = 0 내지 8, 예를 들어 0, 1, 2 또는 3이고, p = 1 내지 8, 예를 들어 1, 2 또는 3이다. 추가 구현예에서, 링커는 서열 번호 186을 포함한다. 추가 구현예에서, 링커는 서열 번호 186으로 구성된다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 163-185 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함한다. 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 163-185 중 어느 하나의 아미노산 서열을 포함한다. 또 다른 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 171, 165, 175, 176, 178, 180 또는 184의 아미노산 서열을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 163-185 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열로 구성된다. 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 163-185 중 어느 하나의 아미노산 서열로 구성된다. 또 다른 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 171, 165, 175, 176, 178, 180 또는 184의 아미노산 서열로 구성된다.
본원에 기재된 바와 같이, 항체는 임의의 형식일 수 있다. 바람직한 구현예에서, 항체는 IgG1 형식이다. 따라서, 한 구현예에서, 항체 또는 이의 단편은 서열 번호 233-255 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함한다. 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 233-255 중 어느 하나의 아미노산 서열을 포함한다. 또 다른 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 235, 241, 245, 246 또는 254의 아미노산 서열을 포함한다.
한 구현예에서, 항체 또는 이의 단편은 서열 번호 233-255 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열로 구성된다. 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 233-255 중 어느 하나의 아미노산 서열로 구성된다. 또 다른 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 235, 241, 245, 246 또는 254의 아미노산 서열로 구성된다.
대안적으로, 서열 번호 284-306 중 어느 하나와 적어도 80% 서열 동일성을 갖는 중쇄 아미노산 서열 및/또는 서열 번호 307-329 중 어느 하나와 적어도 80% 서열 동일성을 갖는 경쇄 아미노산 서열을 포함하거나 이로 구성되는 항체 또는 이의 단편이 제공된다. 따라서, 서열 번호 284-306 중 어느 하나에 따른 중쇄 아미노산 서열 및/또는 서열 번호 307-329 중 어느 하나에 따른 경쇄 아미노산 서열을 포함하거나 이로 구성되는 항체 또는 이의 단편이 제공된다. 특정 구현예에서, 항체 또는 이의 단편은 서열 번호 292에 따른 중쇄 아미노산 서열 및 서열 번호 315에 따른 경쇄 아미노산 서열을 포함하거나 이로 구성된다(클론 G4_12). 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 286에 따른 중쇄 아미노산 서열 및 서열 번호 309에 따른 경쇄 아미노산 서열을 포함하거나 이로 구성된다(클론 G4_3). 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 296에 따른 중쇄 아미노산 서열 및 서열 번호 319에 따른 경쇄 아미노산 서열을 포함하거나 이로 구성된다(클론 G4_16). 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 297에 따른 중쇄 아미노산 서열 및 서열 번호 320에 따른 경쇄 아미노산 서열을 포함하거나 이로 구성된다(클론 G4_18). 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 299에 따른 중쇄 아미노산 서열 및 서열 번호 322에 따른 경쇄 아미노산 서열을 포함하거나 이로 구성된다(클론 G4_20). 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 301에 따른 중쇄 아미노산 서열 및 서열 번호 324에 따른 경쇄 아미노산 서열을 포함하거나 이로 구성된다(클론 G4_23). 추가 구현예에서, 항체 또는 이의 단편은 서열 번호 305에 따른 중쇄 아미노산 서열 및 서열 번호 328에 따른 경쇄 아미노산 서열을 포함하거나 이로 구성된다(클론 G4_27). 다른 구현예에서, 항체 또는 이의 단편은 다음을 포함하거나 이로 구성된다:
(a) 서열 번호 284에 따른 중쇄 아미노산 서열 및 서열 번호 307에 따른 경쇄 아미노산 서열(클론 G4_1);
(b) 서열 번호 285에 따른 중쇄 아미노산 서열 및 서열 번호 308에 따른 경쇄 아미노산 서열(클론 G4_2);
(c) 서열 번호 287에 따른 중쇄 아미노산 서열 및 서열 번호 310에 따른 경쇄 아미노산 서열(클론 G4_4);
(d) 서열 번호 288에 따른 중쇄 아미노산 서열 및 서열 번호 311에 따른 경쇄 아미노산 서열(클론 G4_5);
(e) 서열 번호 289에 따른 중쇄 아미노산 서열 및 서열 번호 312에 따른 경쇄 아미노산 서열(클론 G4_6);
(f) 서열 번호 290에 따른 중쇄 아미노산 서열 및 서열 번호 313에 따른 경쇄 아미노산 서열(클론 G4_7);
(g) 서열 번호 291에 따른 중쇄 아미노산 서열 및 서열 번호 314에 따른 경쇄 아미노산 서열(클론 G4_10);
(h) 서열 번호 293에 따른 중쇄 아미노산 서열 및 서열 번호 316에 따른 경쇄 아미노산 서열(클론 G4_13);
(i) 서열 번호 294에 따른 중쇄 아미노산 서열 및 서열 번호 317에 따른 경쇄 아미노산 서열(클론 G4_14);
(j) 서열 번호 295에 따른 중쇄 아미노산 서열 및 서열 번호 318에 따른 경쇄 아미노산 서열(클론 G4_15);
(k) 서열 번호 298에 따른 중쇄 아미노산 서열 및 서열 번호 321에 따른 경쇄 아미노산 서열(클론 G4_19);
(l) 서열 번호 300에 따른 중쇄 아미노산 서열 및 서열 번호 323에 따른 경쇄 아미노산 서열(클론 G4_22);
(m) 서열 번호 302에 따른 중쇄 아미노산 서열 및 서열 번호 325에 따른 경쇄 아미노산 서열(클론 G4_24);
(n) 서열 번호 303에 따른 중쇄 아미노산 서열 및 서열 번호 326에 따른 경쇄 아미노산 서열(클론 G4_25);
(o) 서열 번호 304에 따른 중쇄 아미노산 서열 및 서열 번호 327에 따른 경쇄 아미노산 서열(클론 G4_26); 또는
(p) 서열 번호 306에 따른 중쇄 아미노산 서열 및 서열 번호 329에 따른 경쇄 아미노산 서열(클론 G4_28).
경쟁 항체
한 구현예에서, γδ TCR의 Vγ4 사슬에 특이적으로 결합하고 γδ TCR의 Vγ2 사슬에는 결합하지 않는 항체 또는 이의 단편은 본원에 정의되거나 예시된 항체 또는 이의 단편과 동일하거나 본질적으로 동일한 에피토프에 결합하거나 이와 경쟁한다. 당분야에 알려진 일상적인 방법을 사용하여 항체가 참조 항-Vγ4 항체와 동일한 에피토프에 결합하는지 또는 이와 결합에 대해 경쟁하는지 여부를 쉽게 결정할 수 있다. 예를 들어, 시험 항체가 본 발명의 참조 항-Vγ4 항체와 동일한 에피토프에 결합하는지 결정하기 위해, 참조 항체는 포화 조건 하에 Vγ4 단백질 또는 펩티드에 결합하도록 허용된다. 다음으로, Vγ4 사슬에 결합하는 시험 항체의 능력이 평가된다. 시험 항체가 참조 항-Vγ4 항체와의 포화 결합 후 Vγ4에 결합할 수 있는 경우, 시험 항체는 참조 항-Vγ4 항체와 상이한 에피토프에 결합한다고 결론지을 수 있다. 반면에, 시험 항체가 참조 항-Vγ4 항체와의 포화 결합 후 Vγ4 사슬에 결합할 수 없는 경우, 시험 항체는 본 발명의 참조 항-Vγ4 항체에 의해 결합된 에피토프와 동일한 에피토프에 결합할 수 있다.
본 발명은 또한 본원에 정의된 바와 같은 항체 또는 이의 단편, 또는 본원에 기재된 임의의 예시적인 항체의 CDR 서열을 갖는 항체와 Vγ4로의 결합에 대해 경쟁하는 항-Vγ4 항체 또는 이의 단편을 포함한다. 예를 들어, 어느 단백질, 항체 및 기타 길항제가 본 발명의 항체와 Vγ4 사슬로의 결합에 대해 경쟁하고/하거나 에피토프를 공유하는지를 결정하기 위해 본 발명의 항체를 사용하여 경쟁 검정이 수행될 수 있다. 이러한 검정은 당업자에게 쉽게 알려져 있으며; 이들은 단백질, 예를 들어, Vγ4의 제한된 결합 부위 수에 대한 길항제 또는 리간드 간 경쟁을 평가한다. 항체(또는 이의 단편)는 경쟁 전후에 고정되거나 불용화되며 Vγ4 사슬에 결합된 샘플은 예를 들어 경사분리(항체가 사전 불용화된 경우) 또는 원심분리(항체가 경쟁 반응 후에 침전된 경우)에 의해, 미결합 샘플로부터 분리된다. 또한, 경쟁적 결합은 기능이 단백질에 대한 항체의 결합 또는 결합의 부재에 의해 변경되는지 여부, 예를 들어 항체 분자가 예를 들어 표지의 효소 활성을 억제하거나 강화하는지 여부에 의해 결정될 수 있다. ELISA 및 기타 기능적 검정이 당분야에 알려지고 본원에 기재된 바와 같이 사용될 수 있다.
2개의 항체는 각각이 표적 항원에 대한 다른 항체의 결합을 경쟁적으로 억제(차단)하는 경우, 동일하거나 중첩되는 에피토프에 결합한다. 즉, 1-, 5-, 10-, 20- 또는 100-배 이상 과량의 하나의 항체는 다른 항체의 결합을 경쟁적 결합 검정에서 측정된 바와 같이 적어도 50%, 그러나 바람직하게는 75%, 90% 또는 심지어 99%만큼 억제한다. 대안적으로, 한 항체의 결합을 감소시키거나 제거하는 표적 항원에서의 본질적으로 모든 아미노산 돌연변이가 또한 다른 항체의 결합을 감소시키거나 제거하는 경우, 2개의 항체는 동일한 에피토프를 갖는다.
이어서 관찰된 시험 항체의 결합 부재가 참조 항체와 실제로 동일한 에피토프에 대한 결합 때문인지 또는 입체 차단(또는 또 다른 현상)이 관찰된 결합 부재에 관여되는지를 확인하기 위해 추가적인 일상적 실험(예를 들어, 펩티드 돌연변이 및 결합 분석)이 수행될 수 있다. 이러한 종류의 실험은 ELISA, RIA, 표면 플라즈몬 공명, 유세포 분석 또는 당분야에서 이용 가능한 임의의 다른 정량적 또는 정성적 항체 결합 검정을 사용하여 수행될 수 있다.
항체 서열 변형
항체 및 이의 단편은 알려진 방법을 사용하여 변형될 수 있다. 본원에 기재된 항체 분자에 대한 서열 변형은 당업자에 의해 용이하게 포함될 수 있다. 하기 예는 비제한적이다.
항체 발견 및 파지 라이브러리로부터의 서열 회수 동안, 원하는 항체 가변 도메인은 서브-클로닝에 의해 전장 IgG로 재형식화될 수 있다. 이 과정을 가속화하기 위해 가변 도메인은 종종 제한 효소를 사용하여 전달된다. 이러한 제한 부위는 추가/대안적 아미노산을 도입하고 정규 서열에서 멀어질 수 있다(이러한 정규 서열은 예를 들어 국제 ImMunoGeneTics[IMGT] 정보 시스템에서 찾을 수 있음, http://www.imgt.org 참조). 이들은 카파 또는 람다 경쇄 서열 변형으로 도입될 수 있다.
카파 경쇄 변형
카파 경쇄 가변 서열은 전장 IgG로 재형식화하는 동안 제한 부위(예를 들어, Nhe1-Not1)를 사용하여 클로닝될 수 있다. 보다 구체적으로, 카파 경쇄 N-말단에서 클로닝을 지원하기 위해 추가 Ala-Ser 서열이 도입되었다. 바람직하게는, 이후 이 추가 AS 서열은 정규 N-말단 서열을 생성하기 위해 추가 개발 동안 제거된다. 따라서, 한 구현예에서, 본원에 기재된 카파 경쇄 포함 항체는 이의 N-말단에 AS 서열을 포함하지 않으며, 즉 서열 번호 140-147 및 156-158은 초기 AS 서열을 포함하지 않는다. 이 구현예가 또한 이 서열을 포함하는 본원에 포함된 다른 서열에 적용된다는 것이 이해될 것이다.
클로닝을 지원하기 위해 추가 아미노산 변경이 수행될 수 있다. 예를 들어, 본원에 기재된 항체의 경우, 카파 경쇄 가변 도메인/불변 도메인 경계에서 전장 서열을 제조할 때 클로닝을 지원하기 위해 발린에서 알라닌으로의 변경이 도입되었다. 그 결과 카파 불변 도메인 변형을 생성했다. 특히 이것은 RTAAAPS(NotI 제한 부위로부터)로 시작하는 불변 도메인을 생성한다. 바람직하게는, 이 서열은 RTVAAPS로 시작하는 정규 카파 경쇄 불변 영역을 생성하기 위해 추가 개발 동안 변형될 수 있다. 이러한 변형은 항체의 기능적 특성을 변경하지 않는다. 따라서, 한 구현예에서 본원에 기재된 카파 경쇄 포함 항체는 서열 RTV로 시작하는 불변 도메인을 포함한다. 따라서, 한 구현예에서, 서열 번호 233-240, 249-251, 307-314 및 323-325의 서열 RTAAAPS는 서열 RTVAAPS로 대체된다. 바람직한 카파 경쇄 불변 도메인 동종이형을 포함하는 바람직한 구현예에서, 카파 경쇄 불변 도메인은 서열 번호 330에 따른 아미노산 서열을 가지며 본원에 개시된 임의의 경쇄 가변 도메인과 조합될 수 있다.
람다 경쇄 변형
위의 카파 예와 유사하게, 람다 경쇄 가변 도메인은 전장 IgG로 재형식화하는 동안 제한 부위(예를 들어, Nhe1-Not1)를 도입함으로써 클로닝될 수도 있다. 보다 구체적으로, 람다 경쇄 N-말단에서, 클로닝을 지원하기 위해 추가 Ala-Ser 서열이 도입될 수 있다. 바람직하게는, 이후 이 추가 AS 서열은 정규 N-말단 서열을 생성하기 위해 추가 개발 동안 제거된다. 따라서, 한 구현예에서, 본원에 기재된 람다 경쇄 포함 항체는 이의 N-말단에 AS 서열을 포함하지 않으며, 즉 서열 번호 148-155 및 159-162는 초기 AS 서열을 포함하지 않는다. 이 구현예가 또한 이 서열을 포함하는 본원에 포함된 다른 서열에 적용된다는 것이 이해될 것이다.
또 다른 예로서, 람다 경쇄 가변 도메인/불변 도메인 경계에서 본원에 기재된 항체의 경우, 전장 서열을 제조할 때 클로닝을 지원하기 위해 라이신에서 알라닌으로의 서열 변경이 도입되었다. 이는 람다 불변 도메인 변형을 초래했다. 특히 이는 GQPAAAPS(NotI 제한 부위로부터)로 시작하는 불변 도메인을 초래한다. 바람직하게는, 이 서열은 GQPKAAPS를 시작하는 정규 람다 경쇄 불변 영역을 생성하기 위해 추가 개발 동안 변형될 수 있다. 이러한 변형은 항체의 기능적 특성을 변경하지 않는다. 따라서, 한 구현예에서, 본원에 기재된 람다 경쇄 포함 항체는 서열 GQPK로 시작하는 불변 도메인을 포함한다. 따라서, 한 구현예에서, 서열 번호 241-248, 252-255, 315-322 및 326-329의 서열 GQPAAAPS는 서열 GQPKAAPS로 대체된다. 바람직한 람다 경쇄 불변 도메인 동종이형을 포함하는 바람직한 구현예에서, 람다 경쇄 불변 도메인은 서열 번호 331에 따른 아미노산 서열을 갖고 본원에 개시된 임의의 경쇄 가변 도메인과 조합될 수 있다.
람다 및 카파 경쇄 변형
서열 번호 140-162로서 본원에 개시된 람다 및/또는 카파 경쇄 가변 도메인으로부터 N-말단 AS 잔기의 제거에 관한 상기 개시의 관점에서, 본 발명의 단리된 항-Vγ4 항체 또는 이의 단편은 N-말단 AS 잔기가 없는 서열 번호 140-162에 상응하는 서열 번호 번호 261-283 중 어느 하나에 따른 경쇄 가변(VL) 아미노산 서열을 포함할 수 있다. 따라서, 서열 번호 140-162 중 하나 이상에 따른 VL 아미노산 서열에 대한 본 명세서에서의 임의의 언급은 각각 서열 번호 번호 261-283에 따른 VL 아미노산 서열로 치환될 수 있으며, 이러한 모든 구현예가 본원에 개시된다. 예시로서, 서열 번호 148에 따른 경쇄 가변 도메인(클론 G4_12로부터 유래됨)에 대한 본원의 언급은 서열 번호 269에 대한 언급으로 치환될 수 있다.
중쇄 변형
전형적으로 인간 가변 중쇄 서열은 염기성 글루타민(Q) 또는 산성 글루타메이트(E)로 시작한다. 그러나 이후 이러한 서열은 모두 산성 아미노산 잔기인 피로글루타메이트(pE)로 전환되는 것으로 알려져 있다. Q에서 pE로의 전환은 항체에 대한 전하 변경을 초래하는 반면, E에서 pE로의 전환은 항체의 전하를 변경하지 않는다. 따라서 경시적인 가변 전하 변경을 피하기 위해, 한 가지 옵션은 처음에 Q에서 E로 시작 중쇄 서열을 변형하는 것이다. 따라서, 한 구현예에서, 중쇄의 N-말단에 Q 잔기를 갖는 본원에 기재된 항체의 중쇄는 N-말단에 Q에서 E로의 변형을 포함할 수 있다. 특히, 서열 번호 118, 120, 124, 126, 132, 133, 135, 137, 138 및/또는 139 중 임의의 것의 초기 잔기가 Q에서 E로 변형될 수 있다. 이러한 구현예가 이 서열을 포함하는 본원에 포함된 다른 서열(즉, 이들 서열을 예를 들어 전장 항체 또는 이의 단편 내로 통합하는 임의의 구현예)에 적용된다는 것이 또한 이해될 것이다. 일부 구현예에서, 중쇄의 N-말단에서 E 잔기를 Q 잔기로 치환하는 것이 유리할 수 있다. 따라서, 일부 구현예에서, 서열 번호 117, 119, 121-123, 125, 127-131, 134 및/또는 136 중 어느 하나의 N-말단에서 E 잔기는 Q 잔기로 치환될 수 있다.
또한, IgG1 불변 도메인의 C-말단은 PGK로 끝난다. 그러나 이후 말단 염기성 라이신(K)은 발현 동안 종종 절단된다(예를 들어, CHO 세포에서). 이것은 다시 C-말단 라이신 잔기의 다양한 손실을 통해 항체에 대한 전하 변경을 초래한다. 따라서 한 가지 옵션은 처음에 라이신을 제거하여 PG로 끝나는 균일하고 일관된 중쇄 C-말단 서열을 생성하는 것이다. 따라서, 한 구현예에서, 본원에 기재된 항체의 중쇄는 그 C-말단으로부터 말단 K가 제거된다. 특히, 본 발명의 항체는 말단 라이신 잔기가 제거된 서열 번호 233-255 또는 284-306 중 어느 하나를 포함할 수 있다.
임의의 동종이형 변형
항체 발견 동안, 특정 인간 동종이형이 사용될 수 있다. 임의로, 항체는 개발 동안 다른 인간 동종이형으로 전환될 수 있다. 비제한적인 예로서, 카파 사슬에 대해 3개의 Km 대립유전자(동종이형 넘버링 사용)를 정의하는 Km1, Km1,2 및 Km3으로 지정된 3개의 인간 동종이형이 있다: Km1은 발린153(IMGT V45.1) 및 류신 191(IMGT L101)과 상관관계가 있으며; Km1,2는 알라닌 153(IMGT A45.1) 및 류신 191(IMGT L101)과 상관관계가 있고; Km3은 알라닌 153(IMGT A45.1) 및 발린 191(IMGT V101)과 상관관계가 있다. 임의로, 이에 따라 표준 클로닝 접근에 의해 한 동종이형에서 또 다른 동종이형으로 서열을 변형할 수 있다. 예를 들어 L191V(IMGT L101V) 변경은 Km1,2 동종이형을 Km3 동종이형으로 전환할 것이다. 이러한 동종이형에 대한 추가 언급은 본원에 참조로 포함되는 Jefferis and Lefranc (2009) MAbs 1(4):332-8을 참조한다.
따라서 한 구현예에서 본원에 기재된 항체는 동일한 유전자의 또 다른 인간 동종이형으로부터 유래된 아미노산 치환을 포함한다. 추가 구현예에서, 항체는 c-도메인을 km1,2에서 km3 동종이형으로 전환하기 위해 카파 사슬에 대한 L191V(IMGT L101V) 치환을 포함한다.
바람직한 카파 경쇄 불변 도메인 동종이형을 포함하는 바람직한 구현예에서, 카파 경쇄 불변 도메인은 서열 번호 330에 따른 아미노산 서열을 가지며 본원에 개시된 임의의 경쇄 가변 도메인과 조합될 수 있다. 바람직한 람다 경쇄 불변 도메인 동종이형을 포함하는 대안적인 바람직한 구현예에서, 람다 경쇄 불변 도메인은 서열 번호 331에 따른 아미노산 서열을 갖고 본원에 개시된 임의의 경쇄 가변 도메인과 조합될 수 있다.
항체 결합
본 발명의 항체 또는 이의 단편은 3.0 x 10-7 M(즉, 300 nM) 미만 또는 1.5 x 10-7 M(즉, 150 nM) 미만의 표면 플라스몬 공명에 의해 측정된 결합 친화도(KD)로 γδ TCR의 Vγ4 사슬에 결합할 수 있다. 추가 구현예에서, KD는 1.3 x 10-7 M(즉, 130 nM) 이하, 예컨대 1.0 x 10-7 M(즉, 100 nM) 이하이다. 또 다른 구현예에서, KD는 6.0 x 10-8 M(즉, 60 nM) 미만, 예컨대 5.0 x 10-8 M(즉, 50 nM) 미만, 4.0 x 10-8 M(즉, 40 nM) 미만, 3.0 x 10-8 M(즉, 30 nM) 미만 또는 2.0 x 10-8 M(즉, 20 nM) 미만이다. 추가 구현예에서, KD는 1.0 x 10-8 M(즉, 10 nM) 이하, 예컨대 5.0 x 10-9 M(즉, 5 nM) 이하, 4.0 x 10-9 M(즉, 4 nM) 이하, 3.0 x 10-9 M(즉, 3 nM) 이하, 2.0 x 10-9 M(즉, 2 nM) 이하, 또는 1.0 x 10-9 M(즉, 1 nM) 이하일 수 있다. 예를 들어, 한 측면에 따르면, 1.5 x 10-7 M(즉, 150 nM) 미만의 표면 플라즈몬 공명에 의해 측정된 결합 친화도(KD)로 γδ TCR의 Vγ4 사슬에 결합하는 (예를 들어, 인간) 항-Vγ4 항체가 제공된다.
본 발명의 한 측면에서, 4.0 x 10-8 M(즉, 40 nM) 미만, 3.0 x 10-8 M(즉, 30 nM) 미만 또는 2.0 x 10-8 M(즉, 20 nM) 미만의 표면 플라즈몬 공명에 의해 측정된 결합 친화도(KD)로 γδ TCR의 Vγ4 사슬에 결합하는 항체 또는 이의 단편이 제공된다.
한 구현예에서, 항체 또는 이의 단편의 결합 친화도는 항체 또는 이의 단편을 센서(예를 들어, 아민 고용량 칩 또는 동등물)의 표면 상에 직접적으로 또는 간접적으로(예를 들어, 항-인간 IgG Fc로의 포획에 의해) 코팅함으로써 확립되며, 항체 또는 이의 단편(즉, γδ TCR의 Vγ4 사슬)에 의해 결합된 표적은 결합을 검출하기 위해 칩 위로 흘려진다. 대안적인 구현예에서, 항원은 센서의 표면 상에 직접적으로 또는 간접적으로 코팅될 수 있고, 이후 그 위에 시험 항체 또는 이의 단편이 흘려진다. 당업자는 적합한 시험 조건을 잘 결정할 수 있다. 예를 들어, 적합하게는 MASS-2 기기(Sierra SPR-32로도 지칭될 수 있음)가 25℃에서 PBS + 0.02% Tween 20 실행 완충액 중 30 μl/분으로 사용될 수 있다. 다른 적합한 구현예에서, Reichert 4SPR 기기가 실온(예를 들어, 25℃)에서 PBS + 0.05% Tween 20 중 25 μl/분의 유속으로 사용될 수 있다.
항체 기능적 특성화
항체 기능을 정의하기 위해 사용될 수 있는 검정이 본원에 기재되어 있다. 예를 들어, 본원에 기재된 항체 또는 이의 단편은 γδ TCR 연루에 의해, 예를 들어 항체 결합 시 γδ TCR의 하향조절 및/또는 항체 결합 시 CD69 표면 발현의 상향조절을 측정함으로써 평가될 수 있다. 항체 또는 이의 단편(임의로 세포 표면 상에 제시됨)의 적용 후 γδ TCR 또는 CD69의 표면 발현은 예를 들어 유세포 분석에 의해 측정될 수 있다.
본원에 기재된 항체 또는 이의 단편은 또한 γδ T 세포 탈과립을 측정함으로써 평가될 수 있다. 예를 들어, 세포 탈과립에 대한 마커인 CD107a의 발현이 항체 또는 이의 단편(임의로 세포 표면 상에 제시됨)의 γδ T 세포로의 적용 후, 예를 들어 유세포 분석에 의해 측정될 수 있다. 본원에 기재된 항체 또는 이의 단편은 또한 γδ T 세포-매개 사멸 활성을 측정함으로써 평가될 수 있다(γδ T 세포의 사멸 활성, 즉 항체가 표적 세포를 직접적으로 또는 간접적으로 죽이기 위해 γδ T 세포를 유도하는 항체의 능력에 영향을 미치는지 시험하기 위해). 예를 들어, 표적 세포는 항체 또는 이의 단편(임의로 세포 표면 상에 제시됨)의 존재 하에 γδ T 세포와 인큐베이션될 수 있다. 인큐베이션 후, 배양은 살아있는 표적 세포와 죽은 표적 세포를 구별하기 위해 세포 생활성 염료로 염색될 수 있다. 그런 다음 죽은 세포의 비율이, 예를 들어 유세포 분석에 의해 측정될 수 있다.
본원에 기재된 바와 같이, 검정에 사용된 항체 또는 이의 단편은 표면, 예를 들어 Fc 수용체를 포함하는 세포와 같은 세포의 표면 상에 제시될 수 있다. 예를 들어, 항체 또는 이의 단편은 TIB 202™ 세포(American Type Culture Collection(ATCC)에서 이용 가능)와 같은 THP-1 세포의 표면 상에 제시될 수 있다. 대안적으로, 항체 또는 이의 단편은 검정에서 직접 사용될 수 있다.
이러한 기능적 검정에서, 산출물은 "EC50" 또는 "50%에서의 유효 농도"로도 지칭되는 최대 농도의 절반을 계산하여 측정될 수 있다. 용어 "IC50"은 억제 농도를 지칭한다. EC50 및 IC50 둘 모두는 유세포 분석 방법과 같은 당분야에 알려진 방법을 사용하여 측정될 수 있다. 의혹을 피하기 위해, 본 출원에서 EC50의 값은 IgG1 형식화된 항체를 사용하여 제공된다. 이러한 값은 하기와 같이 동등한 값에 대한 항체 형식의 분자량에 기반하여 쉽게 전환될 수 있다.
(μg/ml) / (MW(kDa)) = μM
밀리리터는 본원에서 "ml" 또는 "mL"로 표시될 수 있고 상호교환적으로 사용될 수 있다.
항체(또는 단편) 결합 시 γδ TCR의 하향조절에 대한 EC50은 0.5 μg/ml 미만, 예컨대 0.4 μg/ml, 0.3 μg/ml, 0.2 μg/ml, 0.15 μg/ml, 0.1 μg/ml 또는 0.05 μg/ml 미만일 수 있다. 특히, 상기 EC50 값은 항체가 IgG1 형식으로 측정될 때의 값이다. 예를 들어, EC50 γδ TCR 하향조절 값은 유세포 분석을 사용하여 측정될 수 있다.
항체(또는 단편) 결합 시 γδ T 세포 탈과립에 대한 EC50은 0.05 μg/ml 미만, 예컨대 0.04 μg/ml, 0.03 μg/ml, 0.02 μg/ml, 0.015 μg/ml, 0.01 μg/ml 또는 0.008 μg/ml 미만일 수 있다. 특히, 상기 EC50 값은 항체가 IgG1 형식으로 측정될 때의 값이다. 예를 들어, γδ T 세포 탈과립 EC50 값은 유세포 분석을 사용하여 CD107a 발현(즉, 세포 탈과립 마커)을 검출함으로써 측정될 수 있다. 한 구현예에서, CD107a 발현은 항-인간 CD107a BV421(클론 H4A3)(BD Biosciences)과 같은 항-CD107a 항체를 사용하여 측정된다.
항체(또는 단편) 결합 시 γδ T 세포-매개 사멸에 대한 EC50은 0.5 μg/ml 미만, 예컨대 0.4 μg/ml, 0.3 μg/ml, 0.2 μg/ml, 0.15 μg/ml 미만, 0.1 μg/ml 또는 0.07 μg/ml 미만일 수 있다. 특히, 상기 EC50 값은 항체가 IgG1 형식으로 측정될 때의 값이다. 예를 들어, EC50 γδ T 세포-매개 사멸 값은 항체, γδ T 세포 및 표적 세포의 인큐베이션 후 유세포 분석을 사용하여 죽은 세포의 비율을 검출함으로써(즉, 세포 생활성 염료를 사용하여) 측정될 수 있다. 한 구현예에서, 표적 세포의 사멸은 세포 생활성 염료인 Viability Dye eFluor™ 520(ThermoFisher)을 사용하여 측정된다.
이들 측면에서 기재된 검정에서, 항체 또는 이의 단편은 THP-1 세포, 예를 들어 TIB-202™(ATCC)와 같은 세포의 표면 상에 제시될 수 있다. THP-1 세포는 임의로 CellTracker™ Orange CMTMR(ThermoFisher)과 같은 염료로 표지된다.
면역접합체
본 발명의 항체 또는 이의 단편은 세포독소 또는 화학치료제와 같은 치료적 모이어티에 접합될 수 있다. 이러한 접합체는 면역접합체로 지칭될 수 있다. 본원에 사용된 용어 "면역접합체"는 세포독소, 방사성 제제, 사이토카인, 인터페론, 표적 또는 리포터 모이어티, 효소, 독소, 펩티드 또는 단백질 또는 치료제와 같은 또 다른 모이어티에 화학적으로 또는 생물학적으로 연결된 항체 또는 이의 단편을 지칭한다. 항체 또는 이의 단편은 그 표적에 결합할 수 있는 한, 분자를 따라 임의의 위치에서 세포독소, 방사성 제제, 사이토카인, 인터페론, 표적 또는 리포터 모이어티, 효소, 독소, 펩티드 또는 치료제에 연결될 수 있다. 면역접합체의 예는 항체-약물 접합체 및 항체-독소 융합 단백질을 포함한다. 한 구현예에서, 제제는 Vγ4에 대한 제2의 상이한 항체일 수 있다. 특정 구현예에서, 항체는 종양 세포 또는 바이러스 감염된 세포에 특이적인 제제에 접합될 수 있다. 항-Vγ4 항체에 접합될 수 있는 치료적 모이어티의 유형은 치료받을 병태 및 달성되기 원하는 치료 효과를 고려할 것이다.
다중특이적 항체
본 발명의 항체는 단일-특이적일 수 있거나 추가 표적에 결합할 수 있으므로 이중-특이적 또는 다중-특이적일 수 있다. 다중-특이적 항체는 하나의 표적 폴리펩티드의 상이한 에피토프에 대해 특이적일 수 있거나 하나 초과의 표적 폴리펩티드에 대해 특이적일 수 있다. 따라서, 한 구현예에서, 항체 또는 이의 단편은 Vγ4에 대한 제1 결합 특이성 및 제2 표적 에피토프에 대한 제2 결합 특이성을 포함한다.
제2 결합 특이성은 Vγ4와 동일한 세포 상의 또는 동일한 조직 유형 또는 상이한 조직 유형의 상이한 세포 상의 항원을 표적화할 수 있다. 특정 구현예에서, 표적 에피토프는 상이한 T-세포, B-세포, 종양 세포, 자가면역 조직 세포 또는 바이러스 감염된 세포를 포함하는 상이한 세포 상에 있을 수 있다. 대안적으로, 표적 에피토프는 동일한 세포 상에 있을 수 있다.
폴리뉴클레오티드 및 발현 벡터
본 발명의 한 측면에서, 본 발명의 항-Vγ4 항체 또는 단편을 암호화하는 폴리뉴클레오티드가 제공된다. 한 구현예에서, 폴리뉴클레오티드는 서열 번호 187-232와 적어도 70%, 예컨대 적어도 80%, 예컨대 적어도 90%, 예컨대 적어도 95%, 예컨대 적어도 99% 서열 동일성을 갖는 서열을 포함하거나 이로 구성된다. 한 구현예에서, 발현 벡터는 서열 번호 187-209의 VH 영역을 포함한다. 또 다른 구현예에서, 발현 벡터는 서열 번호 210-232의 VL 영역을 포함한다. 추가 구현예에서 폴리뉴클레오티드는 서열 번호 187-232를 포함하거나 이로 구성된다. 추가 측면에서, 상기 폴리뉴클레오티드를 포함하는 cDNA가 제공된다.
한 구현예에서, 폴리뉴클레오티드는 서열 번호 195, 189, 199, 200, 202, 204, 208, 218, 212, 222, 223, 225, 227 또는 231과 적어도 70%, 예컨대 적어도 80%, 예컨대 적어도 90%, 예컨대 적어도 95%, 예컨대 적어도 99% 서열 동일성을 갖는 서열을 포함하거나 이로 구성된다. 한 구현예에서, 발현 벡터는 서열 번호 195, 189, 199, 200, 202, 204, 또는 208의 VH 영역을 포함한다. 또 다른 구현예에서, 발현 벡터는 서열 번호 218, 212, 222, 223, 225, 227 또는 231의 VL 영역을 포함한다. 추가 구현예에서 폴리뉴클레오티드는 서열 번호 195, 189, 199, 200, 202, 204, 208, 218, 212, 222, 223, 225, 227 또는 231, 특히 서열 번호 195 및/또는 218; 또는 서열 번호 189 및/또는 212를 포함하거나 이로 구성된다. 추가 측면에서, 상기 폴리뉴클레오티드를 포함하는 cDNA가 제공된다.
본 발명의 한 측면에서, 암호화된 면역글로불린 사슬 가변 도메인의 CDR1, CDR2 및/또는 CDR3을 암호화하는 서열 번호 187-232의 부분 중 어느 하나와 적어도 70%, 예컨대 적어도 80%, 예컨대 적어도 90%, 예컨대 적어도 95%, 예컨대 적어도 99% 서열 동일성을 갖는 서열을 포함하거나 이로 구성되는 폴리뉴클레오티드가 제공된다. 한 구현예에서, 폴리뉴클레오티드는 암호화된 면역글로불린 사슬 가변 도메인의 CDR1, CDR2 및/또는 CDR3을 암호화하는 서열 번호 195, 189, 199, 200, 202, 204, 208, 218, 212, 222, 223, 225, 227 또는 231의 부분 중 어느 하나와 적어도 70%, 예컨대 적어도 80%, 예컨대 적어도 90%, 예컨대 적어도 95%, 예컨대 적어도 99% 서열 동일성을 갖는 서열을 포함하거나 이로 구성된다.
본 발명의 한 측면에서, 암호화된 면역글로불린 사슬 가변 도메인의 FR1, FR2, FR3 및/또는 FR4를 암호화하는 서열 번호 187-232의 부분 중 어느 하나와 적어도 70%, 예컨대 적어도 80%, 예컨대 적어도 90%, 예컨대 적어도 95%, 예컨대 적어도 99% 서열 동일성 갖는 서열을 포함하거나 이로 구성되는 폴리뉴클레오티드가 제공된다. 한 구현예에서, 폴리뉴클레오티드는 암호화된 면역글로불린 사슬 가변 도메인의 FR1, FR2, FR3 및/또는 FR4를 암호화하는 서열 번호 195, 189, 199, 200, 202, 204, 208, 218, 212, 222, 223, 225, 227 또는 231의 부분 중 어느 하나와 적어도 70%, 예컨대 적어도 80%, 예컨대 적어도 90%, 예컨대 적어도 95%, 예컨대 적어도 99% 서열 동일성을 갖는 서열을 포함하거나 이로 구성된다.
항체 또는 이의 단편을 발현하기 위해, 본원에 기재된 바와 같이 부분 또는 전장 경쇄 및 중쇄를 암호화하는 폴리뉴클레오티드는 유전자가 전사 및 번역 제어 서열(이는 당분야에서 잘 이해되는 '발현 카세트'로 명명될 수 있음)에 작동 가능하게 연결되도록 발현 벡터 내로 삽입된다. 따라서, 본 발명의 한 측면에서 본원에 정의된 바와 같은 본 발명의 폴리뉴클레오티드 서열을 포함하는 발현 벡터가 제공된다. 한 구현예에서, 발현 벡터는 서열 번호 195, 189, 199, 200, 202, 204 또는 208 중 어느 하나와 같은 서열 번호 187-209 중 어느 하나의 VH 서열을 포함한다. 또 다른 구현예에서, 발현 벡터는 서열 번호 218, 212, 222, 223, 225, 227 또는 231 중 어느 하나와 같은 서열 번호 210-232 중 어느 하나의 VL 영역을 포함한다. 이러한 발현 벡터 또는 카세트는 쌍으로 사용되어, 본원에 개시된 본 발명의 항체를 제공하는 다양한 아미노산 서열의 쌍 형성에 따라 중쇄 및 경쇄 가변 서열을 적합하게 쌍으로 형성할 수 있다. 일부 구현예에서, 발현 벡터는 서열 번호 187-209 중 어느 하나(가변 중쇄 영역을 암호화함)와 적어도 70%, 예컨대 적어도 80%, 예컨대 적어도 90%, 예컨대 적어도 95%, 예컨대 적어도 99% 서열 동일성 또는 100% 서열 동일성을 갖는 서열을 포함하고 추가로 서열 번호 210-232 중 어느 하나(가변 경쇄 영역을 암호화함)와 적어도 70%, 예컨대 적어도 80%, 예컨대 적어도 90%, 예컨대 적어도 95%, 예컨대 적어도 99% 서열 동일성 또는 100% 동일성을 갖는 서열을 포함한다. 다시, 서열은 본 발명의 항체를 암호화하기 위해 본원에 기재된 바와 같이 특이적 쌍으로 제공될 수 있다.
본 발명은 또한 임의로 하나 이상의 아미노산 치환을 포함하는 본원에 개시된 임의의 변이체 항체 서열을 포함하는 본원에 개시된 모든 항체 서열을 암호화하는 폴리뉴클레오티드 서열 그리고 발현 벡터 및 플라스미드를 제공한다.
본 발명의 폴리뉴클레오티드 및 발현 벡터는 또한 암호화된 아미노산 서열을 참조하여 기재될 수 있다. 따라서, 한 구현예에서, 폴리뉴클레오티드는 서열 번호 1 내지 186, 233-260 중 어느 하나의 아미노산 서열을 암호화하는 서열을 포함하거나 이로 구성된다.
돌연변이는 폴리펩티드의 아미노산 서열로서는 침묵하지만 특정 숙주에서 번역을 위한 바람직한 코돈을 제공하는 폴리펩티드를 암호화하는 DNA 또는 cDNA로 만들어질 수 있다. 예를 들어, 대장균 및 S. 세레비시애(S. cerevisiae)뿐만 아니라 포유류, 특히 인간에서 핵산의 번역을 위해 바람직한 코돈이 알려져 있다.
폴리펩티드의 돌연변이는 예를 들어 폴리펩티드를 암호화하는 핵산에 대한 치환, 부가 또는 결실에 의해 달성될 수 있다. 폴리펩티드를 암호화하는 핵산에 대한 치환, 부가 또는 결실은 예를 들어 오류가 발생하기 쉬운 PCR, 셔플링, 올리고뉴클레오티드-지정 돌연변이유발, 어셈블리 PCR, PCR 돌연변이유발, 생체내 돌연변이유발, 카세트 돌연변이유발, 반복적 앙상블 돌연변이유발, 지수적 앙상블 돌연변이유발, 부위 특이적 돌연변이유발, 유전자 재조립, 인공 유전자 합성, 유전자 부위 포화 돌연변이유발(GSSM), 합성 결찰 재조립(SLR) 또는 이들 방법의 조합을 포함하는 많은 방법에 의해 도입될 수 있다. 핵산에 대한 변형, 부가 또는 결실은 또한 재조합, 반복적 서열 재조합, 포스포티오에이트-변형 DNA 돌연변이유발, 우라실-함유 주형 돌연변이유발, 갭 포함(gapped) 이중체 돌연변이유발, 점 미스매치 복구 돌연변이유발, 복구-결핍 숙주 균주 돌연변이유발, 화학적 돌연변이유발, 방사성 돌연변이유발, 결실 돌연변이유발, 제한-선택 돌연변이유발, 제한-정제 돌연변이유발, 앙상블 돌연변이유발, 키메라 핵산 다량체 생성, 또는 이의 조합을 포함하는 방법에 의해 도입될 수 있다.
특히 인공 유전자 합성이 사용될 수 있다. 본 발명의 폴리펩티드를 암호화하는 유전자는 예를 들어 고상 DNA 합성에 의해 합성적으로 생산될 수 있다. 전체 유전자는 전구체 주형 DNA가 필요 없이 새로 합성될 수 있다. 원하는 올리고뉴클레오티드를 수득하기 위해, 빌딩 블록은 산물의 서열에 필요한 순서대로 성장하는 올리고뉴클레오티드 사슬에 순차적으로 커플링된다. 사슬 조립의 완료 시, 산물은 고상으로부터 용액으로 방출되고, 탈보호되고, 수집된다. 산물은 고성능 액체 크로마토그래피(HPLC)에 의해 단리되어 원하는 올리고뉴클레오티드를 고순도로 수득할 수 있다.
발현 벡터는 예를 들어 플라스미드, 레트로바이러스, 코스미드, 효모 인공 염색체(YAC) 및 엡스타인-바 바이러스(EBV) 유래 에피솜을 포함한다. 폴리뉴클레오티드는 벡터 내의 전사 및 번역 제어 서열이 폴리뉴클레오티드의 전사 및 번역을 조절하는 의도된 기능을 제공하도록 벡터 내에 결찰된다. 발현 및/또는 제어 서열은 프로모터, 인핸서, 전사 종결자, 코딩 서열에 대해 5' 시작 코돈(즉, ATG), 인트론에 대한 스플라이싱 신호 및 정지 코돈을 포함할 수 있다. 발현 벡터 및 발현 제어 서열은 사용되는 발현 숙주 세포와 상용성이도록 선택된다. 따라서, 본 발명은 합성 링커(서열 번호 186을 암호화함)에 의해 연결된 VH 영역 및 VL 영역을 포함하는, 서열 번호 163-185 중 어느 하나에 따른 본 발명의 단일쇄 가변 단편을 암호화하는 뉴클레오티드 서열을 추가로 제공한다. 본 발명의 폴리뉴클레오티드 또는 발현 벡터는 VH 영역, VL 영역 또는 둘 모두(임의로 링커를 포함함)를 포함할 수 있음이 이해될 것이다. 따라서, VH 및 VL 영역을 암호화하는 폴리뉴클레오티드는 별도의 벡터 내에 삽입될 수 있으며, 대안적으로 두 영역을 모두 암호화하는 서열이 동일한 발현 벡터 내에 삽입된다. 폴리뉴클레오티드(들)는 표준 방법(예를 들어, 폴리뉴클레오티드 및 벡터 상의 상보적 제한 부위의 결찰, 또는 제한 부위가 존재하지 않는 경우 평활 말단 결찰)에 의해 발현 벡터 내에 삽입된다.
편리한 벡터는 본원에 기재된 바와 같이 임의의 VH 또는 VL 서열이 쉽게 삽입되고 발현될 수 있도록 조작된 적절한 제한 부위와 함께, 기능적으로 완전한 인간 CH 또는 CL 면역글로불린 서열을 암호화하는 벡터이다. 발현 벡터는 또한 숙주 세포로부터 항체(또는 이의 단편)의 분비를 촉진하는 신호 펩티드를 암호화할 수 있다. 폴리뉴클레오티드는 신호 펩티드가 항체의 아미노 말단과 같은-프레임으로 연결되도록 벡터 내로 클로닝될 수 있다. 신호 펩티드는 면역글로불린 신호 펩티드 또는 이종성 신호 펩티드(즉, 비-면역글로불린 단백질로부터의 신호 펩티드)일 수 있다.
본 발명의 한 측면에서, 본원에 정의된 바와 같은 폴리뉴클레오티드 또는 발현 벡터를 포함하는 세포(예를 들어, 숙주 세포)가 제공된다. 세포가 항체 또는 이의 단편의 경쇄를 암호화하는 제1 벡터, 및 항체 또는 이의 단편의 중쇄를 암호화하는 제2 벡터를 포함할 수 있음이 이해될 것이다. 대안적으로, 중쇄 및 경쇄는 모두 세포 내로 도입된 동일한 발현 벡터 상에서 암호화될 수 있다.
한 구현예에서, 폴리뉴클레오티드 또는 발현 벡터는 항체 또는 이의 단편에 융합된 막 앵커 또는 막횡단 도메인을 암호화하고, 항체 또는 이의 단편은 세포의 세포외 표면 상에 제시된다.
형질전환은 폴리뉴클레오티드를 숙주 세포 내로 도입하기 위한 임의의 알려진 방법에 의해 수행될 수 있다. 포유류 세포 내에 이종성 폴리뉴클레오티드를 도입하는 방법은 당분야에 잘 알려져 있으며, 덱스트란-매개 형질감염, 인산칼슘 침전, 폴리브렌-매개 형질감염, 원형질체 융합, 전기천공, 형질도입, 리포솜 내 폴리뉴클레오티드(들)의 캡슐화, 생물학적 주입 및 DNA의 핵 내로의 직접적 미세주입을 포함한다. 또한, 핵산 분자는 바이러스 벡터에 의해 포유류 세포 내로 도입될 수 있다.
발현을 위한 숙주로서 이용 가능한 포유류 세포주는 당분야에 잘 알려져 있고, 미국 유형 배양 컬렉션(ATCC)으로부터 이용 가능한 많은 불멸화 세포주를 포함한다. 이들은 특히 중국 햄스터 난소(CHO) 세포, NSO, SP2 세포, HeLa 세포, 아기 햄스터 신장(BHK) 세포, 원숭이 신장 세포(COS), 인간 간세포 암종 세포(예를 들어, Hep G2), A549 세포, 3T3 세포 및 다수의 다른 세포주를 포함한다. 포유류 숙주 세포는 인간, 마우스, 래트, 개, 원숭이, 돼지, 염소, 소, 말 및 햄스터 세포를 포함한다. 특히 선호되는 세포주는 높은 발현 수준을 갖는 세포주의 결정을 통해 선택된다. 사용될 수 있는 다른 세포주는 Sf9 세포와 같은 곤충 세포주, 양서류 세포, 박테리아 세포, 식물 세포 및 진균 세포이다. scFv 및 Fv 단편과 같은 항체의 항원 결합 단편은 당분야에 알려진 방법을 사용하여 대장균에서 단리 및 발현될 수 있다.
항체는 숙주 세포에서 항체의 발현, 보다 바람직하게는 숙주 세포가 성장하는 배양 배지 내로의 항체 분비를 허용하기 충분한 시기 동안 숙주 세포를 배양함으로써 생산된다. 항체는 표준 단백질 정제 방법을 사용하여 배양 배지로부터 회수될 수 있다.
본 발명의 항체(또는 단편)는 예를 들어 Green and Sambrook, Molecular Cloning: A Laboratory Manual (2012) 4th Edition Cold Spring Harbor Laboratory Press에 개시된 기법을 사용하여 수득되고 조작될 수 있다.
모노클로날 항체는 하이브리도마 기술을 사용하여, 특정 항체-생산 B 세포를 조직 배양에서 성장하는 능력 및 항체 사슬 합성의 부재로 인해 선택된 골수종(B 세포암) 세포와 융합함으로써 생산될 수 있다.
결정된 항원에 대한 모노클로날 항체는 예를 들어 다음 단계에 의해 수득될 수 있다:
a) 하이브리도마를 형성하기 위해, 결정된 항원, 불멸 세포, 바람직하게는 골수종 세포로 이전에 면역화된 동물의 말초 혈액으로부터 수득된 림프구를 불멸화하는 단계,
b) 형성된 불멸화된 세포(하이브리도마)를 배양하고 원하는 특이성을 갖는 항체를 생산하는 세포를 회수하는 단계.
대안적으로, 하이브리도마 세포를 사용할 필요가 없다. 본원에 기재된 바와 같은 표적 항원에 결합할 수 있는 항체는 예를 들어, 파지 디스플레이, 효모 디스플레이, 리보솜 디스플레이 또는 당분야에 알려진 포유류 디스플레이 기술을 사용하여, 일상적인 실행을 통해 적합한 항체 라이브러리로부터 단리될 수 있다. 따라서, 모노클로날 항체는 예를 들어 다음 단계를 포함하는 공정에 의해 수득될 수 있다:
a) 벡터, 특히 파지, 보다 특히 사상 박테리오파지 내로, 림프구, 특히 동물의 말초 혈액 림프구(결정된 항원으로 적합하게 이전에 면역화됨)로부터 수득된 DNA 또는 cDNA 서열을 클로닝하는 단계,
b) 항체의 생산을 허용하는 조건에서 상기 벡터로 원핵 세포를 형질전환하는 단계,
c) 항체로 항원-친화도 선택을 거쳐, 항체를 선택하는 단계,
d) 원하는 특이성을 갖는 항체를 회수하는 단계.
임의로, 본원에 기재된 바와 같고 γδ T 세포의 Vγ4 사슬에 결합하는 항체 또는 이의 단편을 암호화하는 단리된 폴리뉴클레오티드는 또한 질환의 징후 또는 증상을 완화하기 위한 약제로 사용되기 충분한 양을 만들기 위해 용이하게 제조될 수 있다. 이러한 방식으로 약제로 사용될 때, 전형적으로 관심 폴리뉴클레오티드는 먼저 대상체 또는 환자에서 상기 항체 또는 이의 단편을 발현하도록 설계된 발현 벡터 또는 발현 카세트에 작동 가능하게 연결된다. 이러한 발현 카세트 및 폴리뉴클레오티드의 전달 방법 또는 때때로 '핵 기반' 약제로 명명되는 것은 당분야에 잘 알려져 있다. 최근 리뷰는 Hollevoet and Declerck (2017) J. Transl. Med. 15(1): 131을 참조한다.
또한, 본 발명의 숙주 세포를 세포 내부에서 플라스미드 또는 벡터의 암호화 핵산 서열을 발현하는 조건 하에 세포 배양 배지 중에 배양하는 단계를 포함하는, 항-Vγ4 항체 또는 이의 단편 또는 변이체의 생산 방법이 제공된다. 방법은 세포 배양 상청액으로부터 항-Vγ4 항체 또는 이의 단편 또는 변이체를 수득하는 단계를 추가로 포함할 수 있다. 수득된 항원 결합 분자는 그 후 약학 조성물로 제형화될 수 있다. 추가로, 항-Vγ4 항체 또는 이의 단편 또는 변이체를 발현하는 세포를 본 발명의 플라스미드 또는 벡터로 형질감염시키는 단계를 포함하는, 상기 세포를 생산하는 방법이 제공된다. 이어서, 상기 세포는 항-Vγ4 항체 또는 이의 단편 또는 변이체의 생산을 위해 배양될 수 있다.
약학 조성물
본 발명의 추가 측면에 따르면, 본원에 정의된 바와 같은 항체 또는 이의 단편을 포함하는 조성물이 제공된다. 이러한 구현예에서, 조성물은 임의로 다른 부형제와 조합하여 항체를 포함할 수 있다. 또한 하나 이상의 추가 활성제(예를 들어, 본원에 언급된 질환을 치료하기 적합한 활성제)를 포함하는 조성물이 포함된다.
본 발명의 추가 측면에 따르면, 약학적으로 허용 가능한 희석제 또는 담체와 함께, 본원에 정의된 바와 같은 항체 또는 이의 단편을 포함하는 약학 조성물이 제공된다. 본 발명의 항체는 대상체로의 투여에 적합한 약학 조성물 내에 포함될 수 있다. 전형적으로, 약학 조성물은 본 발명의 항체 및 약학적으로 허용 가능한 담체를 포함한다. 본원에 사용된 바와 같은 "약학적으로 허용 가능한 담체"는 생리학적으로 상용성인 임의의 모든 용매, 분산 매질, 코팅제, 항균제 및 항진균제, 등장성 제제 및 흡수 지연제 등을 포함한다. 약학적으로 허용 가능한 담체의 예는 물, 식염수, 염, 인산염 완충 식염수, 덱스트로스, 글리세롤, 에탄올 등 중 하나 이상 뿐만 아니라 이의 조합을 포함한다. 많은 경우에, 등장성 제제, 예를 들어 당, 만니톨, 소르비톨과 같은 다가 알코올 또는 염화나트륨을 조성물에 포함시키는 것이 바람직할 것이다. 수화제와 같은 약학적으로 허용 가능한 물질 또는 항체 또는 이의 단편의 저장 수명 또는 효과를 향상시키는 수화제 또는 유화제, 보존제 또는 완충제와 같은 소량의 보조 물질이 포함될 수 있다.
본 발명의 조성물은 다양한 형태일 수 있다. 이는 예를 들어 액체, 반고체 및 고체 투여형, 예컨대 액체 용액(예를 들어, 주사 가능한 및 주입 가능한 용액), 분산액 또는 현탁액, 정제, 환제, 분말, 리포솜 및 좌제를 포함한다. 바람직한 형태는 의도된 투여 방식 및 치료 적용에 의존한다. 전형적인 바람직한 조성물은 주사 가능한 또는 주입 가능한 용액 형태이다.
바람직한 투여 방식은 비경구(예를 들어, 정맥내, 피하, 복강내, 근육내)이다. 바람직한 구현예에서, 항체는 정맥내 주입 또는 주사에 의해 투여된다. 또 다른 바람직한 구현예에서, 항체는 근육내 또는 피하 주사에 의해 투여된다.
치료 조성물은 전형적으로 제조 및 보관 조건 하에서 멸균이고 안정해야 한다. 조성물은 용액, 마이크로에멀젼, 분산액, 리포솜, 또는 높은 약물 농도에 적합한 다른 정렬된 구조로 제형화될 수 있다.
본원에 기재된 바와 같은 질환의 치료에 일반적으로 사용되는 다른 확립된 치료법에 대한 보조로서 또는 이와 함께, 이러한 질환의 치료를 위한 치료 방법에서 본 발명의 약학 조성물을 사용하는 것은 본 발명의 범위 내이다.
본 발명의 추가 측면에서, 항체, 조성물 또는 약학 조성물은 적어도 하나의 활성제와 순차적으로, 동시에 또는 별도로 투여된다.
치료 방법
본 발명의 추가 측면에 따르면, 약제로서 사용하기 위한 본원에 정의된 바와 같은 단리된 항-Vγ4 항체 또는 이의 단편이 제공된다.
한 구현예에서, 항체 또는 이의 단편은 치료법에 사용하기 위한 것이다. 특히, 항체 또는 이의 단편은 암, 감염성 질환 또는 염증성 질환의 치료에 사용하기 위한 것일 수 있다. 추가 구현예에서, 항체 또는 이의 단편은 암 치료에 사용하기 위한 것이다.
본 발명의 추가 측면에 따르면, 약제로서 사용하기 위한 본원에 정의된 바와 같은 약학 조성물이 제공된다. 한 구현예에서, 약학 조성물은 치료법에 사용하기 위한, 특히 암, 감염성 질환 또는 염증성 질환의 치료에 사용하기 위한 것이다. 추가 구현예에서, 약학 조성물은 암 치료에 사용하기 위한 것이다.
본 발명의 추가 측면에 따르면, 치료 유효량의 본원에 정의된 바와 같은 단리된 항-Vγ4 항체 또는 이의 단편을 투여하는 단계를 포함하는, 면역 반응의 조절을 필요로 하는 대상체에서 면역 반응을 조절하는 방법이 제공된다. 다양한 구현예에서, 대상체에서 면역 반응을 조절하는 것은 γδ T 세포로의 결합 또는 이의 표적화, γδ T 세포의 활성화, γδ T 세포의 증대 유도 또는 증가, γδ T 세포의 증식 유도 또는 증가, γδ T 세포 탈과립 유도 또는 증가, γδ T 세포-매개 사멸 활성 유도 또는 증가를 포함한다.
본 발명의 추가 측면에 따르면, 치료 유효량의 본원에 정의된 바와 같은 단리된 항-Vγ4 항체 또는 이의 단편을 투여하는 단계를 포함하는, 치료를 필요로 하는 대상체에서 암, 감염성 질환 또는 염증성 질환을 치료하는 방법이 제공된다. 대안적으로, 치료 유효량의 약학 조성물이 투여된다.
본 발명의 추가 측면에 따르면, 예를 들어 암, 감염성 질환 또는 염증성 질환의 치료에서 약제의 제조를 위한 본원에 정의된 바와 같은 항체 또는 이의 단편의 용도가 제공된다.
항체 또는 이의 단편의 용도
본 발명의 추가 측면에 따르면, γδ T 세포(특히 Vγ4 T 세포)의 항원 인식, 활성화, 신호 전달 또는 기능을 연구하기 위한 본원에 기재된 바와 같은 항-Vγ4 항체 또는 이의 단편의 용도가 제공된다. 본원에 기재된 바와 같이, 항체는 γδ T 세포 기능을 조사하기 위해 사용될 수 있는 검정에서 활성인 것으로 나타났다. 이러한 항체는 또한 γδ T 세포의 증대를 유도하는 데 유용할 수 있으므로, γδ T 세포(예를 들어, Vγ4 T 세포)를 증식시키는 방법에 사용될 수 있다.
Vγ4 사슬에 결합하는 항체는 γδ T 세포를 검출하기 위해 사용될 수 있다. 예를 들어, 항체는 검출 가능한 표지 또는 리포터 분자로 표지되거나 샘플에서 Vγ4 T 세포를 선택적으로 검출 및/또는 단리하기 위한 포획 리간드로 사용될 수 있다. 표지된 항체는 당분야에 알려진 많은 방법, 예를 들어 면역조직화학 및 ELISA에서 사용된다.
검출 가능한 표지 또는 리포터 분자는 3H, 14C, 32P, 35S 또는 125I와 같은 방사성동위원소; 플루오레세인 이소티오시아네이트 또는 로다민과 같은 형광 또는 화학발광 모이어티; 또는 알칼리성 포스파타제, β-갈락토시다제, 양고추냉이 퍼옥시다제 또는 루시퍼라제와 같은 효소일 수 있다. 이어서, 본 발명의 항체에 적용된 형광 표지는 형광 활성화 세포 분류(FACS) 방법에 사용될 수 있다.
항체 또는 이의 단편을 생성하는 방법
항체를 생성하는 데 사용하기 위한 가용성 TCR이 본원에 기재되어 있다. 본원에 기재된 바와 같이, 본 발명의 개발 전에는, Vγ4 사슬, 특히 인간 Vγ4 사슬에 특이적으로 결합할 수 있는 항체 또는 이의 단편을 개발하는 것이 통상적으로 불가능할 것이라고 여겨졌다. 이것은 γδ TCR의 인간 Vγ4 사슬 및 인간 Vγ2 사슬 간 고도의 서열 유사성(91%) 때문이었다. 이러한 상당한 난제를 극복하기 위해, 본 발명자들은 특정 항원 및 방법론을 개발하였다. 따라서, 본 발명의 한 측면에 따르면, 항-Vγ4 항체 또는 이의 단편을 생성하는 데 사용하기 위한 서열 번호 256과 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항원이 제공된다.
항원 제조 공정의 또 다른 중요한 측면은 단백질로의 발현하기 적합한 항원을 설계하는 것이었다. γδ TCR은 사슬간 및 사슬내 디설피드 결합이 있는 이종이량체가 관여되는 복합 단백질이다. 류신 지퍼(LZ) 형식 및 Fc 형식이 파지 디스플레이 선택에서 사용될 가용성 TCR 항원을 생성하기 위해 사용되었다. 따라서, 본 발명은 또한 항-Vγ4 항체 또는 이의 단편을 생성하는 데 사용하기 위한 서열 번호 257 또는 258과 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항원을 제공한다.
또한, 감마 델타(γδ) T 세포는 CDR3 폴리클론성을 갖는 폴리클론날 세포이다. 생성된 항체가 CDR3 서열에 대해 선택되는 상황(CDR3 서열은 TCR 클론과 TCR 클론마다 다를 것이기 때문에)을 피하기 위해, 항원 설계에는 상이한 형식으로 일관된 CDR3을 유지하는 것이 관여되었다. 이 설계는 생식계열에서 암호화되므로 모든 클론에서 동일한 감마-4 가변 도메인 내 서열을 인식하는 항체를 생성하여 γδ T 세포의 더 넓은 하위세트를 인식하는 항체를 제공하는 것을 목표로 했다. 따라서, 본 발명의 한 측면에 따르면, 다음 단계를 포함하는 항-Vγ4 항체 또는 이의 단편을 생성하는 방법이 제공된다:
(i) Vγ4의 CDR3 서열이 시리즈의 모든 항원에 대해 동일한, TCR 감마 가변 4(Vγ4) 아미노산 서열을 포함하는 항원 시리즈를 설계하는 단계;
(ii) 단계 (i)에서 설계된 제1 항원을 항체 라이브러리에 노출시키는 단계(예를 들어, 파지 디스플레이에 의해);
(iii) 항원에 결합하는 항체 또는 이의 단편을 단리하는 단계;
(iv) 단리된 항체 또는 이의 단편을 단계 (i)에서 설계된 제2 항원에 노출시키는 단계; 및
(v) 제1 항원 및 제2 항원 모두에 결합하는 항체 또는 이의 단편을 단리하는 단계.
TRGV4 아미노산 서열은 바람직하게는 서열 번호 1의 아미노산 1-99에 상응하는 아미노산 서열을 갖는 인간 TRGV4에 상응한다. 본원에 기재된 항원 시리즈는 또한 상이한 형식의 항원(즉, TCR 감마 가변 4 사슬)을 포함할 수 있다. 따라서, 상기 항원은 합성/재조합 항원일 수 있다. 예를 들어, 항원은 류신 지퍼 또는 Fc 융합체로 제시될 수 있다. 한 구현예에서, TCR 감마 가변 4(Vγ4) 아미노산 서열은 서열 번호 256을 포함한다. 한 구현예에서, TCR Vγ4 아미노산 서열은 서열 번호 257을 포함한다. 한 구현예에서, TCR Vγ4 아미노산 서열은 서열 번호 258을 포함한다.
항원은 또한 단백질 발현을 돕기 위한 추가 특징을 포함할 수 있다. 예를 들어, 본원에 기재된 재조합 TCR 항원은 TCRα 또는 TCRβ 불변 영역에 융합될 수 있다(Xu et al. (2011) PNAS 108: 2414-2419 참조).
한 구현예에서, 방법은 단리된 항체 또는 이의 단편을 상이한 감마 가변 사슬, 예컨대 감마 가변 2(Vγ2) 또는 감마 가변 8(Vγ8)을 갖는 γδ TCR을 포함하는 제2 항원 시리즈에 노출시키는 단계, 및 이어서 제2 항원 시리즈에도 결합하는 항체 또는 이의 단편을 선택해제하는 단계를 추가로 포함한다. 특히, 방법은 감마 가변 2(Vγ2) 사슬을 갖는 γδ TCR을 포함하는 제2 항원 시리즈에 단리된 항체 또는 이의 단편을 노출시키는 단계 및 제2 항원 시리즈에도 결합하는 항체 또는 이의 단편을 선택해제하는 단계를 포함한다. 이미 주지된 바와 같이, Vγ4 및 Vγ2의 서열 간 높은 동일성 백분율(약 91%)이 있으므로, 이는 Vγ4에 특이적인 항체가 선택되도록 보장한다. 한 구현예에서, 제2 항원 시리즈는 Vγ2 사슬을 갖는 γδ TCR을 포함한다. TRGV2 및 TRGV8 아미노산 서열은 바람직하게는 각각 서열 번호 335 및 336에 상응하는 아미노산 서열을 갖는 인간 TRGV2 및 TRGV8에 상응한다. TCR 감마 가변 4 사슬와 관련하여 상기 기재된 바와 같이, 본원에 기재된 TRGV2 및 TRGV8 항원 시리즈는 또한 상이한 형식의 항원을 포함할 수 있다. 따라서, 상기 항원은 합성/재조합 항원일 수 있다. 예를 들어, 항원은 류신 지퍼 또는 Fc 융합체 또는 알파/베타 TCR 불변 도메인(예를 들어, TRAC 및 TRBC 도메인)에 대한 융합체로 제시될 수 있다. 따라서, 추가 구현예에서, 제2 항원 시리즈는 서열 번호 259 및/또는 서열 번호 260(Vγ2 가변 도메인을 포함하는 항원)을 포함한다.
추가 구현예에서, 상이한 감마 가변 사슬을 갖는 γδ TCR을 포함하는 제2 항원 시리즈는 제1 항원 시리즈와 동일한 CDR3 서열을 포함한다. 따라서, 모든 항원은 동일한 CDR3 서열(Vγ4로부터의)을 포함한다.
한 구현예에서, 제1 및/또는 제2 항원 시리즈는 류신 지퍼 및/또는 Fc 융합체로서 제시된다.
한 구현예에서, 항원 시리즈는 이종이량체 및/또는 동종이량체 형식이다.
추가 구현예에서, 항원 시리즈는 표적(즉, TCR 감마 가변 4 사슬)과 함께, 쌍을 이룬 TCR 가변 사슬을 포함한다. 특정 구현예에서, 쌍을 이루는 TCR 가변 사슬은 가변 δ(Vδ) 사슬이다(즉, 항원은 이종이량체 형식임). 한 구현예에서, Vγ4 사슬 및 Vδ 사슬은 적어도 하나의 디설피드 결합에 의해 공유적으로 연결된다. 추가 구현예에서, Vγ4 사슬 및 Vδ 사슬은 특이적 이종이량체화 상호작용(예를 들어, 류신 지퍼)에 의해 쌍을 이룬다. 대안적 구현예에서, Vγ4 사슬 및 Vδ 사슬은 단일쇄 동일-프레임 융합체를 포함한다. 특정 구현예에서, Vγ4 사슬은 Vδ 사슬의 N-말단이다. 대안적인 구현예에서, Vγ4 사슬은 Vδ 사슬의 C-말단이다. 추가 구현예에서, 단일쇄 동일-프레임 융합체는 내부 링커 서열을 포함한다. 대안적인 구현예에서, 쌍을 이루는 TCR 가변 사슬은 또 다른 Vγ 사슬이다. 추가 구현예에서, Vγ 사슬은 표적과 동일하다(즉, 항원은 동종이량체 형식임).
실시예 2는 사용될 수 있는 항원 시리즈의 예를 기재한다. (제1) 항원 시리즈는 Vγ4가 존재하는 항원(예를 들어, L1, L4 및 Fc4/4)을 포함하고 제2 항원 시리즈는 Vγ4가 존재하지 않는 항원(예를 들어, L2, L3)을 포함함이 이해될 것이다.
추가 구현예에서, 항원 시리즈는 TCR 불변 영역에 동일-프레임으로 융합된 표적(즉, TCR 감마 가변 4 사슬)을 포함한다. 예를 들어, 상기 TCR 불변 영역은 Vγ4 사슬의 C-말단에 동일-프레임으로 융합될 수 있다. 한 구현예에서, TCR 불변 영역은 인간 TCR 불변 영역일 수 있다. 한 구현예에서, TCR 불변 영역은 TCRα 또는 TCRβ 불변 영역으로부터 선택된다. 또 다른 구현예에서, 불변 영역은 TCRγ 불변 영역이다. 또 다른 구현예에서, 항원 시리즈는 추가의 제2 TCR 불변 영역을 포함할 수 있고, 제2 TCR 불변 영역은 쌍을 이룬 TCR 가변 사슬에 동일-프레임으로 융합된다. 추가 구현예에서, 제2 TCR 불변 영역은 TCRα 또는 TCRβ 불변 영역으로부터 선택된다. 추가 구현예에서, 불변 영역은 TCRγ 불변 영역이다.
본 발명의 이러한 측면의 방법은 가변 도메인 내 서열을 인식하는 항체(또는 이의 단편)를 단리하는 것을 목표로 하며, 이는 생식계열에서 암호화되어 모든 클론에서 동일하므로, Vγ4 + γδ T 세포의 더 넓은 하위세트를 인식하는 항체를 제공한다.
본원에 기재된 바와 같은 항원 시리즈는 가용성 또는 연결된/융합된 형태로 제시되거나 세포막과 연합될 수 있음이 이해될 것이다. 예를 들어, 디스플레이 목적을 위해 항원 시리즈를 무기 또는 유기 물질(예를 들어, 비드, 플레이트, 컬럼 또는 파지)에 융합 또는 연결되거나 세포 표면 상에서 발현될 수 있다.
본 발명의 다양한 구현예에 따르면, TCR 감마 가변 4(Vγ4) 아미노산 서열을 포함하는 항원 시리즈는 모든 항원에 대해 동일한 Vγ4의 CDR3 서열을 포함한다. 한 구현예에서, CDR3 서열은 RCSB 단백질 데이터 뱅크 엔트리: 4MNH의 CDR3 서열에서 유래된다.
본 발명의 또 다른 측면에 따르면, 다음 단계를 포함하는 방법이 제공된다:
(i) Vγ4 가변 도메인 서열을 포함하는 적어도 하나의 제1 단백질을 설계하는 단계;
(ii) Vγ1, Vγ2, Vγ3, Vγ5, Vγ8, Vγ9, Vγ10 또는 Vγ11 가변 도메인 서열을 포함하는 적어도 하나의 제2 단백질을 설계하는 단계; 및
(iii) 제2 단백질과 비교하여 제1 단백질에 대해 더 강한 결합 신호 또는 강도 또는 특성을 나타내는 항체를 선택, 단리 또는 확인하는 단계.
한 구현예에서, 제2 단백질은 Vγ2 가변 도메인 서열을 포함한다. 추가 구현예에서, 방법은 Vγ2 가변 도메인 서열을 포함하는 단백질 및 Vγ8 가변 도메인 서열을 포함하는 단백질과 같은 적어도 2개의 제2 단백질을 포함한다.
본 발명의 또 다른 측면에 따르면, 다음 단계를 포함하는 방법이 제공된다:
(i) Vγ4 가변 도메인 서열을 포함하는 적어도 하나의 제1 단백질을 설계하는 단계;
(ii) Vγ2 가변 도메인 서열을 포함하는 적어도 하나의 제2 단백질을 설계하는 단계;
(iii) 항체 라이브러리를 제1 단백질에 노출시켜 제1 서열에 결합하는 항체를 선택하는 단계;
(iv) 선택된 항체의 결합 강도 또는 신호 또는 특성을 제2 단백질과 비교하는 단계; 및
(v) 제2 단백질에 대한 결합 신호 또는 강도 또는 특성에 비해 제1 단백질에 대해 더 강한 결합 강도 또는 신호 또는 특성을 나타내는 항체를 선택, 단리 또는 확인하는 단계.
한 구현예에서, 제1 단백질 및/또는 제2 단백질은 다량체 단백질을 포함한다. 추가 구현예에서, 다량체 단백질은 델타 가변 사슬로부터 유래된 TCR 가변 사슬과 같은 쌍을 이루는 TCR 가변 사슬을 포함한다.
한 구현예에서, 제1 단백질 및/또는 제2 단백질은 가용성 단백질이다. 또 다른 구현예에서, 제1 단백질 및/또는 제2 단백질은 세포에 결합된다. 대안적인 구현예에서, 제1 단백질 및/또는 제2 단백질은 플레이트에 결합된다.
한 구현예에서, 특성은 더 많은 TCR 수용체 턴오버(turnover)를 유도하는 항체의 능력이다. 또 다른 구현예에서, 특성은 (예를 들어 Vγ2+ 세포와 비교하여) Vγ4+ 세포 상에서 CD69를 상향조절하는 항체의 능력이다.
본 발명의 추가 측면에 따르면, 본원에 정의된 바와 같은 방법에 의해 수득된 항체가 제공된다.
항목
본 발명 및 그 바람직한 측면을 정의하는 항목 세트는 하기와 같다:
1. γδ T 세포 수용체(TCR)의 감마 가변 4(Vγ4) 사슬에 특이적으로 결합하고 γδ TCR의 감마 가변 2(Vγ2) 사슬에는 결합하지 않는 단리된 항체 또는 이의 단편.
2. 항목 1에 있어서, γδ TCR의 Vγ4 사슬이 인간 Vγ4이고 γδ TCR의 Vγ2 사슬이 인간 Vγ2 인, 단리된 항-Vγ4 항체 또는 이의 단편.
3. 항목 1 또는 2에 있어서, 서열 번호 1의 아미노산 영역 67-82 내의 하나 이상의 아미노산 잔기를 포함하는 γδ TCR의 Vγ4 사슬의 에피토프에 결합하는 단리된 항-Vγ4 항체 또는 이의 단편.
4. 항목 1 내지 3 중 어느 하나에 있어서, 서열 번호 1의 아미노산 영역 71-79 내의 하나 이상의 아미노산 잔기를 포함하는 γδ TCR의 Vγ4 사슬의 에피토프에 결합하는 단리된 항-Vγ4 항체 또는 이의 단편.
5. 항목 4에 있어서, 에피토프가 서열 번호 1의 아미노산 잔기 71, 73, 75, 76, 79 중 적어도 하나를 포함하는, 단리된 항-Vγ4 항체 또는 이의 단편.
6. 항목 1 내지 5 중 어느 하나에 있어서, 에피토프가 서열 번호 1의 아미노산 영역 67-82 내의 하나 이상의 아미노산 잔기로 구성되는, 단리된 항-Vγ4 항체 또는 이의 단편.
7. 항목 1 내지 6 중 어느 하나에 있어서, 에피토프가 서열 번호 1의 K76 및/또는 M80을 포함하거나 이로 구성되는, 단리된 항-Vγ4 항체 또는 이의 단편.
8. 항목 1 내지 7 중 어느 하나에 있어서, 에피토프가 γδ T 세포의 활성화 에피토프인, 단리된 항-Vγ4 항체 또는 이의 단편.
9. 항목 8에 있어서, 활성화 에피토프의 결합이 (i) γδ TCR을 하향조절하고/거나; (ii) γδ T 세포의 탈과립을 활성화하고/거나; (iii) γδ T 세포-매개 사멸을 활성화하고/거나; (iv) Vγ4 사슬-매개 세포 신호전달을 활성화하거나 증가시키는, 단리된 항-Vγ4 항체 또는 이의 단편.
10. 항목 1 내지 9 중 어느 하나에 있어서, γδ TCR의 Vγ4 사슬의 V 영역에 있는 에피토프에만 결합하는 단리된 항-Vγ4 항체 또는 이의 단편.
11. 항목 1 내지 10 중 어느 하나에 있어서, γδ TCR의 Vγ4 사슬의 CDR3에서 발견되는 에피토프에 결합하지 않는 단리된 항-Vγ4 항체 또는 이의 단편.
12. 다음 중 하나 이상을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편:
서열 번호 2-47 중 어느 하나, 바람직하게는 서열 번호 10 및/또는 33과 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3;
서열 번호 48-70 및 서열 A1-A23(도 1) 중 어느 하나, 바람직하게는 서열 번호 56 및/또는 서열 A9와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR2; 및/또는
서열 번호 71 내지 116 중 어느 하나, 바람직하게는 서열 번호 79 및/또는 102와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR1.
13. 항목 12에 있어서, 서열 번호 10, 4, 14, 15, 17, 19 또는 23과 같은 서열 번호 2-24 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VH 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
14. 항목 12 또는 항목 13에 있어서, 서열 번호 56, 50, 60, 61, 63, 65 또는 69와 같은 서열 번호 48-70 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR2를 포함하는 VH 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
15. 항목 12 내지 14 중 어느 하나에 있어서, 서열 번호 79, 73, 83, 84, 86, 88 또는 92와 같은 서열 번호 71-93 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR1을 포함하는 VH 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
16. 항목 12 내지 15 중 어느 하나에 있어서, 서열 번호 10의 서열을 포함하는 CDR3, 서열 번호 56의 서열을 포함하는 CDR2, 및 서열 번호 79의 서열을 포함하는 CDR1을 포함하는 VH 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
17. 항목 12 내지 15 중 어느 하나에 있어서, 서열 번호 4의 서열을 포함하는 CDR3, 서열 번호 50의 서열을 포함하는 CDR2, 및 서열 번호 73의 서열을 포함하는 CDR1을 포함하는 VH 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
18. 항목 12 내지 15 중 어느 하나에 있어서, 서열 번호 14의 서열을 포함하는 CDR3, 서열 번호 60의 서열을 포함하는 CDR2, 및 서열 번호 83의 서열을 포함하는 CDR1을 포함하는 VH 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
19. 항목 12 내지 15 중 어느 하나에 있어서, 서열 번호 15의 서열을 포함하는 CDR3, 서열 번호 61의 서열을 포함하는 CDR2, 및 서열 번호 84의 서열을 포함하는 CDR1을 포함하는 VH 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
20. 항목 12 내지 15 중 어느 하나에 있어서, 서열 번호 17의 서열을 포함하는 CDR3, 서열 번호 63의 서열을 포함하는 CDR2, 및 서열 번호 86의 서열을 포함하는 CDR1을 포함하는 VH 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
21. 항목 12 내지 15 중 어느 하나에 있어서, 서열 번호 19의 서열을 포함하는 CDR3, 서열 번호 65의 서열을 포함하는 CDR2, 및 서열 번호 88의 서열을 포함하는 CDR1을 포함하는 VH 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
22. 항목 12 내지 15 중 어느 하나에 있어서, 서열 번호 23의 서열을 포함하는 CDR3, 서열 번호 69의 서열을 포함하는 CDR2, 및 서열 번호 92의 서열을 포함하는 CDR1을 포함하는 VH 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
23. 항목 12 내지 22 중 어느 하나에 있어서, 서열 번호 33, 27, 37, 38, 40, 42 또는 46과 같은 서열 번호 25-47 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
24. 항목 12 내지 23 중 어느 하나에 있어서, 서열 A9, A3, A13, A14, A16, A18 또는 A22와 같은 서열 A1-A23(도 1) 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR2를 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
25. 항목 12 내지 26 중 어느 하나에 있어서, 서열 번호 102, 96, 106, 107, 109, 111 또는 115와 같은 서열 번호 94-116 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR1을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
26. 항목 12 내지 25 중 어느 하나에 있어서, 서열 번호 33의 서열을 포함하는 CDR3, 서열 A9의 서열을 포함하는 CDR2, 및 서열 번호 102의 서열을 포함하는 CDR1을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
27. 항목 12 내지 25 중 어느 하나에 있어서, 서열 번호 27의 서열을 포함하는 CDR3, 서열 A3의 서열을 포함하는 CDR2, 및 서열 번호 96의 서열을 포함하는 CDR1을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
28. 항목 12 내지 25 중 어느 하나에 있어서, 서열 번호 37의 서열을 포함하는 CDR3, 서열 A13의 서열을 포함하는 CDR2, 및 서열 번호 106의 서열을 포함하는 CDR1을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
29. 항목 12 내지 25 중 어느 하나에 있어서, 서열 번호 38의 서열을 포함하는 CDR3, 서열 A14의 서열을 포함하는 CDR2, 및 서열 번호 107의 서열을 포함하는 CDR1을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
30. 항목 12 내지 25 중 어느 하나에 있어서, 서열 번호 40의 서열을 포함하는 CDR3, 서열 A16의 서열을 포함하는 CDR2, 및 서열 번호 109의 서열을 포함하는 CDR1을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
31. 항목 12 내지 25 중 어느 하나에 있어서, 서열 번호 42의 서열을 포함하는 CDR3, 서열 A18의 서열을 포함하는 CDR2, 및 서열 번호 111의 서열을 포함하는 CDR1을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
32. 항목 12 내지 25 중 어느 하나에 있어서, 서열 번호 46의 서열을 포함하는 CDR3, 서열 A23의 서열을 포함하는 CDR2, 및 서열 번호 115의 서열을 포함하는 CDR1을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
33. 항목 16에 정의된 CDR1, CDR2 및 CDR3 서열을 포함하는 VH 영역 및 항목 26에 정의된 CDR1, CDR2 및 CDR3 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
34. 항목 17에 정의된 CDR1, CDR2 및 CDR3 서열을 포함하는 VH 영역 및 항목 27에 정의된 CDR1, CDR2 및 CDR3 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
35. 항목 18에 정의된 CDR1, CDR2 및 CDR3 서열을 포함하는 VH 영역 및 항목 28에 정의된 CDR1, CDR2 및 CDR3 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
36. 항목 19에 정의된 CDR1, CDR2 및 CDR3 서열을 포함하는 VH 영역 및 항목 29에 정의된 CDR1, CDR2 및 CDR3 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
37. 항목 20에 정의된 CDR1, CDR2 및 CDR3 서열을 포함하는 VH 영역 및 항목 30에 정의된 CDR1, CDR2 및 CDR3 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
38. 항목 21에 정의된 CDR1, CDR2 및 CDR3 서열을 포함하는 VH 영역 및 항목 31에 정의된 CDR1, CDR2 및 CDR3 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
39. 항목 22에 정의된 CDR1, CDR2 및 CDR3 서열을 포함하는 VH 영역 및 항목 32에 정의된 CDR1, CDR2 및 CDR3 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
40. 서열 번호 117-162 또는 261-283 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
41. 항목 40에 있어서, 서열 번호 117-139 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 VH 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
42. 항목 41에 있어서, VH 영역이 서열 번호 125, 119, 129, 130, 132, 134 또는 138 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는, 단리된 항-Vγ4 항체 또는 이의 단편.
43. 항목 40 내지 42 중 어느 하나에 있어서, 서열 번호 140-162 또는 261-283 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
44. 항목 43에 있어서, VL 영역이 다음 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는, 단리된 항-Vγ4 항체 또는 이의 단편:
(a) 서열 번호 148, 142, 152, 153, 155, 157 또는 161; 또는
(b) 서열 번호 269, 263, 273, 274, 276, 278 또는 282.
45. 항목 40 내지 44 중 어느 하나에 있어서, 서열 번호 125의 아미노산 서열을 포함하는 VH 영역 및 서열 번호 148 또는 269의 아미노산 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
46. 항목 40 내지 44 중 어느 하나에 있어서, 서열 번호 119의 아미노산 서열을 포함하는 VH 영역 및 서열 번호 142 또는 263의 아미노산 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
47. 항목 40 내지 44 중 어느 하나에 있어서, 서열 번호 129의 아미노산 서열을 포함하는 VH 영역 및 서열 번호 152 또는 273의 아미노산 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
48. 항목 40 내지 44 중 어느 하나에 있어서, 서열 번호 130의 아미노산 서열을 포함하는 VH 영역 및 서열 번호 153 또는 274의 아미노산 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
49. 항목 40 내지 44 중 어느 하나에 있어서, 서열 번호 132의 아미노산 서열을 포함하는 VH 영역 및 서열 번호 155 또는 276의 아미노산 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
50. 항목 40 내지 44 중 어느 하나에 있어서, 서열 번호 134의 아미노산 서열을 포함하는 VH 영역 및 서열 번호 157 또는 278의 아미노산 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
51. 항목 40 내지 44 중 어느 하나에 있어서, 서열 번호 138의 아미노산 서열을 포함하는 VH 영역 및 서열 번호 161 또는 282의 아미노산 서열을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
52. 다음 중 하나 이상을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편:
(a) 서열 번호 79를 갖는 HCDR1, 서열 번호 56을 갖는 HCDR2 및 서열 번호 10을 갖는 HCDR3을 포함하며, 임의로 서열 번호 125를 포함하는 VH; 및
서열 번호 102를 갖는 LCDR1, 서열 A9(도 1)를 갖는 LCDR2 및 서열 번호 33을 갖는 LCDR3을 포함하며, 임의로 서열 번호 148 또는 269를 포함하는 VL;
(b) 서열 번호 86을 갖는 HCDR1, 서열 번호 63을 갖는 HCDR2 및 서열 번호 17을 갖는 HCDR3을 포함하며, 임의로 서열 번호 132를 포함하는 VH; 및
서열 번호 109를 갖는 LCDR1, 서열 A16(도 1)을 갖는 LCDR2 및 서열 번호 40을 갖는 LCDR3을 포함하며, 임의로 서열 번호 155 또는 276을 포함하는 VL;
(c) 서열 번호 73을 갖는 HCDR1, 서열 번호 50을 갖는 HCDR2 및 서열 번호 4를 갖는 HCDR3을 포함하며, 임의로 서열 번호 119를 포함하는 VH; 및
서열 번호 96을 갖는 LCDR1, 서열 A3(도 1)을 갖는 LCDR2 및 서열 번호 27을 갖는 LCDR3을 포함하며, 임의로 서열 번호 142 또는 263을 포함하는 VL;
(d) 서열 번호 83을 갖는 HCDR1, 서열 번호 60을 갖는 HCDR2 및 서열 번호 14를 갖는 HCDR3을 포함하며, 임의로 서열 번호 129를 포함하는 VH; 및
서열 번호 106을 갖는 LCDR1, 서열 A13(도 1)을 갖는 LCDR2 및 서열 번호 37을 갖는 LCDR3을 포함하며, 임의로 서열 번호 152 또는 273을 포함하는 VL;
(e) 서열 번호 84를 갖는 HCDR1, 서열 번호 61을 갖는 HCDR2 및 서열 번호 15를 갖는 HCDR3을 포함하며, 임의로 서열 번호 130을 포함하는 VH; 및
서열 번호 107을 갖는 LCDR1, 서열 A14(도 1)를 갖는 LCDR2 및 서열 번호 38을 갖는 LCDR3을 포함하며, 임의로 서열 번호 153 또는 274를 포함하는 VL;
(f) 서열 번호 88을 갖는 HCDR1, 서열 번호 65를 갖는 HCDR2 및 서열 번호 19를 갖는 HCDR3을 포함하며, 임의로 서열 번호 134를 포함하는 VH; 및
서열 번호 111을 갖는 LCDR1, 서열 A18(도 1)을 갖는 LCDR2 및 서열 번호 42를 갖는 LCDR3을 포함하며, 임의로 서열 번호 157 또는 278을 포함하는 VL;
(g) 서열 번호 92를 갖는 HCDR1, 서열 번호 69를 갖는 HCDR2 및 서열 번호 23을 갖는 HCDR3을 포함하며, 임의로 서열 번호 138을 포함하는 VH; 및
서열 번호 115를 갖는 LCDR1, 서열 A22(도 1)를 갖는 LCDR2 및 서열 번호 46을 갖는 LCDR3을 포함하며, 임의로 서열 번호 161 또는 282를 포함하는 VL;
(h) 서열 번호 71을 갖는 HCDR1, 서열 번호 48을 갖는 HCDR2 및 서열 번호 2를 갖는 HCDR3을 포함하며, 임의로 서열 번호 117을 포함하는 VH; 및
서열 번호 94를 갖는 LCDR1, 서열 A1(도 1)을 갖는 LCDR2 및 서열 번호 25를 갖는 LCDR3을 포함하며, 임의로 서열 번호 140 또는 261을 포함하는 VL;
(i) 서열 번호 72를 갖는 HCDR1, 서열 번호 49를 갖는 HCDR2 및 서열 번호 3을 갖는 HCDR3을 포함하며, 임의로 서열 번호 118을 포함하는 VH; 및
서열 번호 95를 갖는 LCDR1, 서열 A2(도 1)를 갖는 LCDR2 및 서열 번호 26을 갖는 LCDR3을 포함하며, 임의로 서열 번호 141 또는 262를 포함하는 VL;
(j) 서열 번호 74를 갖는 HCDR1, 서열 번호 51을 갖는 HCDR2 및 서열 번호 5를 갖는 HCDR3을 포함하며, 임의로 서열 번호 120을 포함하는 VH; 및
서열 번호 97을 갖는 LCDR1, 서열 A4(도 1)를 갖는 LCDR2 및 서열 번호 28을 갖는 LCDR3을 포함하며, 임의로 서열 번호 143 또는 264를 포함하는 VL;
(k) 서열 번호 75를 갖는 HCDR1, 서열 번호 52를 갖는 HCDR2 및 서열 번호 6을 갖는 HCDR3을 포함하며, 임의로 서열 번호 121을 포함하는 VH; 및
서열 번호 98을 갖는 LCDR1, 서열 A5(도 1)를 갖는 LCDR2 및 서열 번호 29를 갖는 LCDR3을 포함하며, 임의로 서열 번호 144 또는 265를 포함하는 VL;
(l) 서열 번호 76을 갖는 HCDR1, 서열 번호 53을 갖는 HCDR2 및 서열 번호 7을 갖는 HCDR3을 포함하며, 임의로 서열 번호 122를 포함하는 VH; 및
서열 번호 99를 갖는 LCDR1, 서열 A6(도 1)을 갖는 LCDR2 및 서열 번호 30을 갖는 LCDR3을 포함하며, 임의로 서열 번호 145 또는 266을 포함하는 VL;
(m) 서열 번호 77을 갖는 HCDR1, 서열 번호 54를 갖는 HCDR2 및 서열 번호 8을 갖는 HCDR3을 포함하며, 임의로 서열 번호 123을 포함하는 VH; 및
서열 번호 100을 갖는 LCDR1, 서열 A7(도 1)을 갖는 LCDR2 및 서열 번호 31을 갖는 LCDR3을 포함하며, 임의로 서열 번호 146 또는 267을 포함하는 VL;
(n) 서열 번호 78을 갖는 HCDR1, 서열 번호 55를 갖는 HCDR2 및 서열 번호 9를 갖는 HCDR3을 포함하며, 임의로 서열 번호 124를 포함하는 VH; 및
서열 번호 101을 갖는 LCDR1, 서열 A8(도 1)을 갖는 LCDR2 및 서열 번호 32를 갖는 LCDR3을 포함하며, 임의로 서열 번호 147 또는 268을 포함하는 VL;
(o) 서열 번호 80을 갖는 HCDR1, 서열 번호 57을 갖는 HCDR2 및 서열 번호 11을 갖는 HCDR3을 포함하며, 임의로 서열 번호 126을 포함하는 VH; 및
서열 번호 103을 갖는 LCDR1, 서열 A10(도 1)을 갖는 LCDR2 및 서열 번호 34를 갖는 LCDR3을 포함하며, 임의로 서열 번호 149 또는 270을 포함하는 VL;
(p) 서열 번호 81을 갖는 HCDR1, 서열 번호 58을 갖는 HCDR2 및 서열 번호 12를 갖는 HCDR3을 포함하며, 임의로 서열 번호 127을 포함하는 VH; 및
서열 번호 104를 갖는 LCDR1, 서열 A11(도 1)을 갖는 LCDR2 및 서열 번호 35를 갖는 LCDR3을 포함하며, 임의로 서열 번호 150 또는 271을 포함하는 VL;
(q) 서열 번호 82를 갖는 HCDR1, 서열 번호 59를 갖는 HCDR2 및 서열 번호 13을 갖는 HCDR3을 포함하며, 임의로 서열 번호 128을 포함하는 VH; 및
서열 번호 105를 갖는 LCDR1, 서열 A12(도 1)를 갖는 LCDR2 및 서열 번호 36을 갖는 LCDR3을 포함하며, 임의로 서열 번호 151 또는 272를 포함하는 VL;
(r) 서열 번호 85를 갖는 HCDR1, 서열 번호 62를 갖는 HCDR2 및 서열 번호 16을 갖는 HCDR3을 포함하며, 임의로 서열 번호 131을 포함하는 VH; 및
서열 번호 108을 갖는 LCDR1, 서열 A15(도 1)를 갖는 LCDR2 및 서열 번호 39를 갖는 LCDR3을 포함하며, 임의로 서열 번호 154 또는 275를 포함하는 VL;
(s) 서열 번호 87을 갖는 HCDR1, 서열 번호 64를 갖는 HCDR2 및 서열 번호 18을 갖는 HCDR3을 포함하며, 임의로 서열 번호 133을 포함하는 VH; 및
서열 번호 110을 갖는 LCDR1, 서열 A17(도 1)을 갖는 LCDR2 및 서열 번호 41을 갖는 LCDR3을 포함하며, 임의로 서열 번호 156 또는 277을 포함하는 VL;
(t) 서열 번호 89를 갖는 HCDR1, 서열 번호 66을 갖는 HCDR2 및 서열 번호 20을 갖는 HCDR3을 포함하며, 임의로 서열 번호 135를 포함하는 VH; 및
서열 번호 112를 갖는 LCDR1, 서열 A19(도 1)를 갖는 LCDR2 및 서열 번호 43을 갖는 LCDR3을 포함하며, 임의로 서열 번호 158 또는 279를 포함하는 VL;
(u) 서열 번호 90을 갖는 HCDR1, 서열 번호 67을 갖는 HCDR2 및 서열 번호 21을 갖는 HCDR3을 포함하며, 임의로 서열 번호 136을 포함하는 VH; 및
서열 번호 113을 갖는 LCDR1, 서열 A20(도 1)을 갖는 LCDR2 및 서열 번호 44를 갖는 LCDR3을 포함하며, 임의로 서열 번호 159 또는 280을 포함하는 VL;
(v) 서열 번호 91을 갖는 HCDR1, 서열 번호 68을 갖는 HCDR2 및 서열 번호 22를 갖는 HCDR3을 포함하며, 임의로 서열 번호 137을 포함하는 VH; 및
서열 번호 114를 갖는 LCDR1, 서열 A21(도 1)을 갖는 LCDR2 및 서열 번호 45를 갖는 LCDR3을 포함하며, 임의로 서열 번호 160 또는 281을 포함하는 VL; 및/또는
(w) 서열 번호 93을 갖는 HCDR1, 서열 번호 70을 갖는 HCDR2 및 서열 번호 24를 갖는 HCDR3을 포함하며, 임의로 서열 번호 139를 포함하는 VH; 및
서열 번호 116을 갖는 LCDR1, 서열 A23(도 1)을 갖는 LCDR2 및 서열 번호 47을 갖는 LCDR3을 포함하며, 임의로 서열 번호 162 또는 283을 포함하는 VL.
53. 항목 40 내지 52 중 어느 하나에 있어서, VH 및 VL 영역이 폴리펩티드 링커와 같은 링커에 의해 연결되는, 단리된 항-Vγ4 항체 또는 이의 단편.
54. 항목 53에 있어서, 링커가 (Gly4Ser)n 형식을 포함하고, n = 1 내지 8인, 단리된 항-Vγ4 항체 또는 이의 단편.
55. 항목 53 또는 54에 있어서, 링커가 서열 번호 186을 포함하는, 단리된 항-Vγ4 항체 또는 이의 단편.
56. 항목 55에 있어서, 링커가 서열 번호 186으로 구성되는, 단리된 항-Vγ4 항체 또는 이의 단편.
57. 서열 번호 163-185 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
58. 항목 57에 있어서, 서열 번호 163-185 중 어느 하나의 아미노산 서열을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
59. 항목 57 또는 항목 58에 있어서, 서열 번호 171, 165, 175, 176, 178, 180 또는 184를 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
60. 서열 번호 233-255 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항-Vγ4 항체.
61. 항목 60에 있어서, 서열 번호 233-255 중 어느 하나의 아미노산 서열을 포함하는, 단리된 항-Vγ4 항체.
62. 항목 60 또는 항목 61에 있어서, 서열 번호 235, 241, 245, 246 또는 254를 포함하는 단리된 항-Vγ4 항체.
63. 서열 번호 284-306 중 어느 하나와 적어도 80% 서열 동일성을 갖는 중쇄 아미노산 서열 및/또는 서열 번호 307-329 중 어느 하나와 적어도 80% 서열 동일성을 갖는 경쇄 아미노산 서열을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
64. 항목 63에 있어서, 서열 번호 284-306 중 어느 하나를 포함하는 중쇄 아미노산 서열 및/또는 서열 번호 307-329 중 어느 하나를 포함하는 경쇄 아미노산 서열을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
65. 바람직하게는 항목 1-11 중 어느 하나에 있어서, 항목 12-64 중 어느 하나에 정의된 항체 또는 이의 단편과 동일하거나 본질적으로 동일한 에피토프에 결합하거나 이와 경쟁하는 단리된 항-Vγ4 항체 또는 이의 단편.
66. 항목 1-65 중 어느 하나에 있어서, scFv, Fab, Fab', F(ab')2, Fv, 가변 도메인(예를 들어, VH 또는 VL), 디아바디, 미니바디 또는 전장 항체인 단리된 항-Vγ4 항체 또는 이의 단편.
67. 항목 66에 있어서, scFv 또는 전장 항체인 단리된 항-Vγ4 항체 또는 이의 단편.
68. 항목 67에 있어서, IgG1 항체와 같은 전장 항체인 단리된 항-Vγ4 항체 또는 이의 단편.
69. 항목 1-68 중 어느 하나에 있어서, 인간인 단리된 항-Vγ4 항체 또는 이의 단편.
70. 항목 1-69 중 어느 하나에 있어서, 항체가 Vγ4 T 세포를 조절하는, 단리된 항-Vγ4 항체 또는 이의 단편.
71. 항목 70에 있어서, 조절이 Vγ4 T 세포의 활성화를 포함하는, 단리된 항-Vγ4 항체 또는 이의 단편.
72. 항목 70에 있어서, 조절이 Vγ4 T 세포의 억제를 포함하는, 단리된 항-Vγ4 항체 또는 이의 단편.
73. 항목 70에 있어서, Vγ4 T 세포의 조절이 다음을 포함하는, 단리된 항-Vγ4 항체 또는 이의 단편:
예를 들어, Vγ4 T 세포 수를 선택적으로 증가시키거나 Vγ4 T 세포의 생존 촉진에 의한, Vγ4 T 세포의 증식;
예를 들어, Vγ4 T 세포 역가 증가, 즉 표적 세포 사멸 증가에 의한, Vγ4 T 세포의 자극; 및/또는
Vγ4 T 세포의 탈과립.
74. 항목 1-73 중 어느 하나의 항-Vγ4 항체 또는 이의 단편을 암호화하는 폴리뉴클레오티드 서열.
75. 서열 번호 187-232 중 어느 하나와 적어도 70% 서열 동일성을 갖는 서열을 포함하는 항-Vγ4 항체 또는 이의 단편을 암호화하는 폴리뉴클레오티드 서열.
76. 서열 번호 187-232 중 어느 하나의 서열을 포함하는 항-Vγ4 항체 또는 이의 단편을 암호화하는 폴리뉴클레오티드 서열.
77. 항목 74 내지 76 중 어느 하나의 폴리뉴클레오티드 서열을 포함하는 발현 벡터.
78. 서열 번호 187-209 중 어느 하나의 VH 서열을 포함하는 발현 벡터.
79. 항목 78에 있어서, VH 서열이 서열 번호 195, 189, 199, 200, 202, 204 또는 208을 포함하는, 발현 벡터.
80. 서열 번호 210-232 중 어느 하나의 VL 서열을 포함하는 발현 벡터.
81. 항목 80에 있어서, VL 서열이 서열 번호 218, 212, 222, 223, 225, 227 또는 231을 포함하는, 발현 벡터.
82. 항목 78 또는 항목 79의 VH 서열 및 항목 80 또는 항목 81의 VL 서열을 포함하는 발현 벡터.
83. 항목 74 내지 76 중 어느 하나의 폴리뉴클레오티드 서열 또는 항목 77 내지 82 중 어느 하나의 발현 벡터를 포함하는 세포.
84. 항목 78 또는 항목 79의 제1 발현 벡터 및 항목 80 또는 항목 81의 제2 발현 벡터를 포함하는 세포.
85. 항목 82의 발현 벡터를 포함하는 세포.
86. 항목 83-85 중 어느 하나에 있어서, 폴리뉴클레오티드 또는 발현 벡터가 항체 또는 이의 단편에 융합된 막 앵커 또는 막횡단 도메인을 암호화하고, 항체 또는 이의 단편은 세포의 세포외 표면 상에 제시되는, 세포.
87. 항목 1 내지 73 중 어느 하나의 항체 또는 이의 단편을 포함하는 조성물.
88. 항목 1 내지 73 중 어느 하나의 항체 또는 이의 단편을 약학적으로 허용 가능한 희석제 또는 담체와 함께 포함하는 약학 조성물.
89. 항목 1 내지 73 중 어느 하나 또는 항목 84에 있어서, 약제로서 사용하기 위한 단리된 항-Vγ4 항체 또는 이의 단편 또는 약학 조성물.
90. 항목 89에 있어서, 암, 감염성 질환 또는 염증성 질환의 치료에 사용하기 위한 단리된 항-Vγ4 항체 또는 이의 단편 또는 약학 조성물.
91. 치료 유효량의 항목 1 내지 73 중 어느 하나의 단리된 항-Vγ4 항체 또는 이의 단편 또는 항목 88의 약학 조성물을 투여하는 단계를 포함하는, 치료를 필요로 하는 대상체에서 암, 감염성 질환 또는 염증성 질환을 치료하는 방법.
92. 항-Vγ4 항체 또는 이의 단편을 생성하는 데 사용하기 위한 서열 번호 256-258 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항원.
93. 다음 단계를 포함하는, 항-Vγ4 항체 또는 이의 단편을 생성하는 방법:
(i) TCR 감마 가변 4(Vγ4) 아미노산 서열을 포함하는 항원 시리즈를 설계하는 단계로서, Vγ4의 CDR3 서열은 시리즈의 모든 항원에 대해 동일한, 단계;
(ii) 단계 (i)에서 설계된 제1 항원을 항체 라이브러리에 노출시키는 단계;
(iii) 항원에 결합하는 항체 또는 이의 단편을 단리하는 단계;
(iv) 단리된 항체 또는 이의 단편을 단계 (i)에서 설계된 제2 항원에 노출시키는 단계; 및
(v) 제1 항원 및 제2 항원 모두에 결합하는 항체 또는 이의 단편을 단리하는 단계.
94. 항목 93에 있어서, 단리된 항체 또는 이의 단편을 TCR 감마 가변 2(Vγ2) 또는 TCR 감마 가변 8(Vγ8)과 같은 상이한 감마 가변 사슬을 갖는 γδ TCR을 포함하는 제2 항원 시리즈에 노출시키는 단계, 및 이어서 제2 항원 시리즈에도 결합하는 항체 또는 이의 단편을 선택해제하는 단계를 추가로 포함하는 방법.
95. 항목 93 또는 항목 94에 있어서, 제1 및/또는 제2 항원 시리즈가 류신 지퍼 및/또는 Fc 융합체로 제시되는, 방법.
96. 항목 93-95 중 어느 하나에 있어서, 항원 시리즈가 이종이량체 및/또는 동종이량체 형식인, 방법.
97. 항목 93-96 중 어느 하나의 방법에 의해 수득된 항체.
98. 항목 1 내지 73 중 어느 하나의 항-Vγ4 항체 또는 이의 단편 또는 항목 88의 약학 조성물을 포함하고, 임의로 사용 설명서 및/또는 추가의 치료 활성제를 포함하는 키트.
본 발명의 다른 특징 및 이점은 본원에 제공된 설명으로부터 명백할 것이다. 그러나, 다양한 변경 및 변형이 당업자에게 자명해질 것이므로, 설명 및 특정 실시예는 본 발명의 바람직한 구현예를 나타내지만 단지 예시로서 제공됨이 이해되어야 한다. 본 발명은 이제 하기의 비제한적인 실시예를 사용하여 설명될 것이다:
실시예
실시예 1. 물질 및 방법
항원 제조
하기 실시예에서 사용된 TCRα 및 TCR β 불변 영역을 포함하는 가용성 yδ TCR 이종이량체의 설계는 Xu et al. (2011) PNAS 108: 2414-2419에 따라 생성하였다. Vγ 또는 Vδ 도메인을 막횡단 도메인이 결여된 TCRα 또는 TCRβ 불변 영역에 동일-프레임으로 융합하고, 류신 지퍼 서열 또는 Fc 서열, 및 히스티딘 태그/링커가 뒤따랐다.
발현 구축물은 포유류 EXPI HEK293 현탁 세포에서 일시적으로(이종이량체에 대한 단일 또는 공동-형질감염으로) 형질감염시켰다. 분비된 재조합 단백질을 회수하고 친화도 크로마토그래피에 의해 배양 상청액으로부터 정제하였다. 단량체 항원의 우수한 회수를 보장하기 위해, 샘플을 분취용 크기 배제 크로마토그래피(SEC)를 사용하여 추가로 정제했다. 정제된 항원은 SDS-PAGE에 의해 순도 및 분석용 SEC에 의해 응집 상태에 대해 분석하였다.
선택된 scFv는 상업적으로 이용 가능한 플라스미드를 사용하여 IgG1 프레임워크 내로 서브클로닝하였다. expi293F 현탁 세포를 항체 발현을 위해 상기 플라스미드로 형질감염시켰다. 편의상, 달리 주지되지 않는 한, 이들 실시예에서 특성화된 항체는 scFv로서 파지 디스플레이로부터 선택된 IgG1 형식화된 항체를 지칭한다. 그러나, 본 발명의 항체는 이전에 논의된 바와 같은 임의의 항체 형식일 수 있다.
항체 정제
IgG 항체를 단백질 A 크로마토그래피를 사용하여 상청액으로부터 배치 정제하였다. 정제된 IgG의 품질을 ELISA, SDS-PAGE 및 SEC-HPLC를 사용하여 분석했다.
항원 결합
파지 디스플레이 선택 산출물을 scFv 발현 벡터 pSANG10 내로 서브클로닝하였다(Martin et al. (2006) BMC Biotechnol. 6: 46). 가용성 scFv를 발현시키고 직접 고정된 표적에 대한 해리-증강 란탄족 형광 면역검정(DELFIA)에서 결합에 대해 스크리닝하였다. 히트(hit)는 3000 형광 단위 초과의 DELFIA 신호로 정의되었다.
DELFIA ELISA 결합 방법을 또한 사용하여 항체 상청액 또는 추가 단백질-A 정제 항체의 결합을 평가했다. 간략하게, MaxiSorp 플레이트를 3 μg/ml의 항원 BSA 또는 L1(DV1-GV4), L2(DV1-GV2), L3(DV1-GV8) 또는 L4(DV2-GV4) 재조합 TCR 항원으로 코팅하였다. 그런 다음 플레이트를 PBS로 세척하고, PBS/탈지유로 차단한 다음 시험 물품을 첨가하고 실온에서 1시간 동안 인큐베이션했다. 그 후, 플레이트를 PBS-Tween으로 세척하고 DELFIA Eu-N1-항-인간 IgG(Perkin Elmer #1244-330)를 실온에서 1시간 동안 첨가한 후 추가 세척하고, DELFIA 증강 용액(Perkin Elmer #4001-0010)을 첨가하고, Pherastar 마이크로플레이트 판독기에서 판독하였다.
D1.3 hIgG1(England et al. (1999) J. Immunol. 162: 2129-2136에 기재됨)을 음성 대조군으로 사용하였고 REA173(Miltenyi) 및 TS8.2(ThermoFisher, No. TCR1730)를 비교 항체로 사용했다.
재조합 JRT3-TCR 세포를 이용한 항체 연구
항체 결합, TCR 하향조절 및 CD69 상향조절 연구에 사용된 재조합 JRT3-TCR 세포는 이전에 설명되어 있다(Melandri et al. (2018) Nature Immunology 19(12): 1352-1365, 및 Willcox et al. (2019) Immunity 51(5): 813-825.e4 참조).
항체 결합 연구의 경우, 100,000개의 비형질도입 JRT3 대조군 또는 JRT3-TCR 세포의 1차 염색을 PBS 5% FCS 중 4℃에서 30분 동안, 양이 표시되지 않은 경우 표준 1.0 μg/ml로 또는 각 선도 항체의 도 6에서 0.08, 0.4, 2 또는 10 μg/ml과 같이 표시된 양으로 수행했다. 그런 다음 A647 항-인간 IgG(Biolegend)를 사용하여 2차 염색을 수행했다. 추가로 BV421 항-CD3ε(Biolegend) 또는 PE-Cy7 IMMU510 항-γδTCR(Beckman Coulter) 염색을 표시된 대로 수행했다. 그런 다음 세포를 PBS 5% FCS 중에 두 번 세척하고 FACS Canto II 3L 상에서 유세포 분석을 수행했다.
TCR 하향조절/CD69 상향조절 연구의 경우, 96 평탄 웰 플레이트를 먼저 각 웰에 20 μg/ml 2차 항체, 특히 항-인간 IgG-Fc(인간 D1.3 및 Vγ4 항체의 경우) 또는 항-마우스 IgG(뮤린 항-CD3e 또는 항-범 TCRgd의 경우)를 첨가한 다음 37℃에서 2시간 동안 인큐베이션하여 사전-코팅하였다. 표시된 대로 시험 항체를 먼저 0.01, 0.1, 1 및 10 μg/ml 최종 농도로 희석했다. 각 농도의 50 μl를 사전 코팅된 플레이트의 웰에 첨가한 후 4℃에서 밤새 인큐베이션하였다. 이어서, 결합되지 않은 항체를 PBS로 2회 세척한 후 37℃에서 1시간 동안 포화 PBS 5% FCS를 첨가하였다. 웰당 100,000개의 세포를 400 g 회전에 의해 플레이팅하였다. 그런 다음 세포를 37℃, 5% CO2에서 5시간 동안 인큐베이션한 다음 염색을 위해 96웰 둥근 바닥 플레이트로 옮겼다. 사용된 염색 항체는 1:400으로 희석된 BV421 항-CD3ε(클론 OKT-3 Biolegend); 1:200으로 희석된 PE-Cy7 항-γδTCR(클론 IMMU510 Beckman Coulter); 및 1:200으로 희석된 A647 항-CD69(클론 FN50 Biolegend)를 포함하였다. 모든 염색은 PBS 5% FCS 중 4℃에서 30분 동안 수행하였다.
1차 세포(PBMC)를 이용한 항체 연구
24웰 플레이트를 먼저 각 웰에 20 μg/ml(웰 당 250 μl) 항-인간 IgG-Fc(Biolegend)를 첨가한 다음 37℃에서 2시간 동안 인큐베이션하여 사전-코팅하였다. 미결합 2차 항체를 PBS로 2회 세척하고, 이소형 대조군(인간 IgG1, Biolegend) 또는 항-Vγ4(클론 G4_12)를 먼저 0.1, 1 및 10 μg/ml의 최종 농도로 희석하였다. 이어서 각 농도의 250 μl를 사전 코팅된 플레이트의 웰에 첨가한 후 4℃에서 밤새 인큐베이션하였다. 그 후 미결합 항체를 PBS로 2회 세척한 후 37℃에서 1시간 동안 포화 PBS 5% FCS를 첨가하였다. 이어서 완전 배지(5% 열-불활성화 인간 AB 혈청[PAA laboratories], 피루브산나트륨[1 mM] 및 페니실린/스트렙토마이신[ThermoFisher]이 보충된 RPMI) 중에 106 세포/ml로 재현탁된 500,000개 PBMC를 각각의 웰에 첨가하였다. 다음으로 세포를 37℃, 5% CO2에서 인큐베이션하였다. IL-2 또는 IL-2 + IL-15(각각 100 U/ml 및 10 ng/ml 최종 농도)를 24시간 후에 첨가하고 IL-2 또는 IL-2 + IL-15가 보충된 신선 완전 배지를 2-3일마다 첨가하였다. 배양 제7일 및 제14일에, 세포를 염색을 위해 96웰 둥근-바닥 플레이트로 옮겼다. 사용된 염색 항체는 1 μg/ml로 희석된 비오틴 항-TCRVγ2/3/4(클론 23D12), 1:100 희석된 PE 스트렙타비딘(Biolegend); 1:400 희석된 BV421 항-CD3ε(클론 OKT-3 Biolegend); 1:200 희석된 PE-Cy7 항-TCRγδ(클론 IMMU510 Beckman Coulter); FITC 항-Vδ2(클론 B6 Biolegend); 및 1 μg/ml로 희석된 A647 항-V 4(클론 G4_18)를 포함하였다. 모든 염색은 4℃에서 30분 동안 PBS 5% FCS 중에 수행하였다.
MS 기반 에피토프 매핑
CovalX '초신속 입체형태/선형 에피토프 매핑' 방법론을 사용하였다. 먼저 단백질 항원 L1(DV1-GV4)과 항체 G4_3(1139_P01_A04)을 모두 고질량 MALDI를 사용하여 단백질 온전성 및 응집 수준에 대해 분석했다. 고분해능으로 L1(DV1-GV4)/G4_3 복합체의 결합 에피토프를 결정하기 위해, 복합체를 중수소화된 가교제와 인큐베이션하고 트립신, 키모트립신, Asp-N, 엘라스타제 및 써모라이신을 사용하여 다중 효소 단백분해를 거쳤다. 가교된 펩티드의 농축 후, 샘플을 고분해능 질량 분광기(nLC-LTQ-Orbitrap MS)에 의해 분석하고 생성된 데이터를 XQuest 및 Stavrox 소프트웨어를 사용하여 분석했다.
γδ T 세포 결합 검정
γδ T 세포에 대한 항체의 결합은 고정된 농도의 정제된 항체를 250000개의 γδ T 세포와 인큐베이션함으로써 시험할 수 있다. 이러한 인큐베이션은 Fc 수용체를 통한 항체의 비특이적 결합을 방지하기 위해 huFc 단편 또는 Ig의 첨가와 같은 차단 조건 하에 수행할 수 있다. 검출은 인간 IgG1에 대한 2차, 형광 염료-접합 항체를 첨가하여 수행할 수 있다. 음성 대조군의 경우, 세포를 a) 이소형 항체 단독(재조합 인간 IgG), b) 형광 염료-접합 항-인간 IgG 항체 단독 및 c) a) 및 b)의 조합으로 제조할 수 있다. 완전히 비염색 세포의 대조군 웰도 제조하고 분석할 수 있다. 양성 대조군으로서, 정제된 뮤린 모노클로날 IgG2 항-인간 CD3 항체를 2개의 상이한 농도로 사용하고 형광 염료-접합된 염소 항-마우스 2차 항체로 염색할 수 있다. FITC 채널에서 더 낮은 농도의 양성 대조군 평균 형광 세기가 최고 음성 대조군의 적어도 10배인 경우 검정이 허용될 수 있다.
SPR 분석
아민 고용량 칩이 있는 MASS-2 기기(둘 모두 독일 Sierra Sensors로부터)를 사용하여 SPR 분석을 수행할 수 있다. 15 nM IgG를 단백질 G를 통해 아민 고용량 칩(TS8.2의 경우 100 nM)으로 포획할 수 있다. L1(DV1-GV4) 항원은 다음 매개변수: 180 s 연합, 600 s 해리, 유속 30 μL/분, 실행 완충액 PBS + 0.02% Tween 20을 사용하여 2000 nM부터 15.625 nM까지 1:2 희석 시리즈로 세포 상에 흘릴 수 있다. 모든 실험은 MASS-2 기기 상에서 실온에서 수행하였다. 안정 상태 피팅은 소프트웨어 Sierra Analyzer 3.2를 사용하여 Langmuir 1:1 결합에 따라 결정할 수 있다.
γδ TCR 하향조절 및 탈과립 검정
시험 항체가 로딩되거나 로딩되지 않은 THP-1(TIB-202™, ATCC) 표적 세포를 CellTracker™ Orange CMTMR(ThermoFisher, C2927)로 표지하고 CD107a 항체(항-인간 CD107a BV421(클론 H4A3) BD Biosciences 562623)의 존재 하에 2:1 비로 γδ T 세포와 인큐베이션할 수 있다. 2시간 인큐베이션 후, γδ T 세포 상에서 γδ TCR의 표면 발현(TCR 하향조절을 측정하기 위해) 및 CD107a의 발현(탈과립을 측정하기 위해)을 유세포 분석을 사용하여 평가할 수 있다.
사멸 검정
감마 델타 T 세포-매개 사멸 활성 및 γδ T 세포의 사멸 활성에 대한 시험 항체의 효과를 유세포 분석에 의해 평가할 수 있다. γδ T 세포와 CellTracker™Orange CMTMR(ThermoFisher, C2927)의 20:1 비로의 4시간 시험관 내 공동 배양 후 표지된 THP-1 세포(항체가 로딩되거나 로딩되지 않음)를 생활성 염료 eFluor™ 520(ThermoFisher, 520 65-0867-14)로 염색하여 살아있는 표적 THP-1 세포와 죽은 표적 THP-1 세포를 구별할 수 있다. 샘플 획득 동안, 표적 세포를 CellTracker™ Orange CMTMR 양성에 대해 관문화하고 생활성 염료의 흡수에 기반하여 세포 사멸을 검사할 수 있다. CMTMR 및 eFluor™ 520 이중 양성 세포는 죽은 표적 세포로 인식될 수 있다. γδ T 세포의 사멸 활성은 죽은 표적 세포%로 제시할 수 있다.
실시예 2. 항원 설계
감마 델타(γδ) T 세포는 CDR3 폴리클론성을 갖는 폴리클론날 세포이다. 생성된 항체가 CDR3 서열에 대해 선택되는 상황(CDR3 서열은 TCR 클론과 TCR 클론마다 다를 것이기 때문에)을 피하기 위해, 항원 설계에는 상이한 형식으로 일관된 CDR3을 유지하는 것이 관여되었다. 이 설계는 가변 도메인 내 서열을 인식하는 항체를 생성하는 것을 목표로 하였으며, 이는 생식계열에서 암호화되어 모든 클론에서 동일하므로 γδ T 세포의 더 넓은 하위세트를 인식하는 항체를 제공한다.
항원 제조 과정의 또 다른 중요한 측면은 단백질로의 발현에 적합한 항원을 설계하는 것이었다. γδ TCR은 사슬간 및 사슬내 디설피드 결합이 있는 이종이량체가 관여되는 복합 단백질이다. 류신 지퍼(LZ) 형식 및 Fc 형식을 사용하여 파지 디스플레이 선택에 사용될 가용성 TCR 항원을 생성했다. LZ 및 Fc 형식은 모두 잘 발현되었고 TCR(특히 이종이량체 TCR, 예를 들어, Vδ1Vγ4)을 성공적으로 디스플레이했다.
γδ TCR에 대한 공개 데이터베이스 엔트리로부터의 CDR3 서열이 단백질로서 잘 발현됨이 발견되었다(RCSB 단백질 데이터 뱅크 엔트리: 4MNH). 따라서 이것을 항원 제조를 위해 선택하였다.
감마 가변 4 사슬을 포함하는 항원을 이종이량체로 LZ 형식으로(즉, 상이한 델타 가변 사슬과 조합하여 - 예를 들어, DV1-GV4, 델타 가변 1 사슬 및 감마 가변 4 사슬로 이루어진 이종이량체["L1"로 명명됨] 및 DV2-GV4, 델타 가변 2 사슬 및 감마 가변 4 사슬로 이루어진 이종이량체["L4"로 명명됨]) 및 이종이량체 또는 동종이량체로 Fc 형식으로 발현시켰다(즉, 또 다른 감마 가변 4 사슬과 조합하여 - GV4-GV4, 두 개의 감마 가변 4 사슬로 이루어진 동종이량체["Fc4/4"로 명명됨]). 항원의 모든 감마 가변 4 사슬은 4MNH CDR3을 포함하였다. 유사한 형식을 사용하는 또 다른 γδ TCR 항원 시리즈를 상이한 감마 가변 사슬(예를 들어, 감마 가변 2 및 감마 가변 8)을 포함하도록 설계하였으며 비특이적 또는 표적외 결합을 갖는 항체를 선택해제하기 위해 사용하였다(예를 들어, DV1-GV2, 델타 가변 1 사슬 및 감마 가변 2 사슬로 이루어진 이종이량체["L2"로 명명됨] 또는 DV1-GV8, 델타 가변 1 사슬 및 감마 가변 8 사슬로 이루어진 이종이량체["L3"으로 명명됨]). 이들 항원을 또한 4MNH CDR3을 포함하도록 설계하여 CDR3 영역에서 결합하는 항체도 선택해제되도록 확실히 하였다.
실시예 3. 파지 디스플레이
파지 디스플레이 선택을 라운드 1 및 2에서 이종이량체 LZ TCR 형식을 사용하여 인간 scFv의 라이브러리에 대해 수행하였고, 두 라운드 모두에서 이종이량체 LZ TCR에 대한 선택해제를 수행하였다. 또는 인간 IgG1 Fc에 대한 선택해제와 함께 동종이량체 Fc 융합 TCR을 사용하여 라운드 1을 수행한 후 이종이량체 LZ TCR에 대한 선택해제와 함께 이종이량체 LZ TCR에 대해 라운드 2를 수행했다(표 1 참조).

선택은 100 nM 비오틴화된 단백질을 사용하여 용액상에서 수행하였다. 1 μM 비오틴화 단백질을 사용하여 선택해제를 수행했다.
실시예 4. 항체 선택
실시예 3에서 수득된 히트를 시퀀싱하였다(당분야에 알려진 표준 방법을 사용함). VH 및 VL CDR3의 고유한 조합을 나타내는 130개의 고유한 클론을 확인하였다. 이러한 130개의 고유한 클론 중, 129개는 고유한 VH CDR3을 나타내었고 116개는 고유한 VL CDR3을 나타내었다.
고유한 클론을 재배열하고 특이성을 ELISA(DELFIA)에 의해 분석했다. TRGV4에는 결합하지만 TRGV2 또는 TRGV8에는 결합하지 않는 42개의 고유한 인간 scFv 결합제 패널을 선택으로부터 확인하였다.
전향적인 클론 선택을 돕기 위해 선택한 결합제의 친화도 순위를 포함시켰다. 다수의 결합제가 25 내지 100 nM 비오틴화된 항원(L1)과 반응하여, 나노몰 범위의 친화도를 나타냈다. 소수의 결합제가 5 nM 항원과 강한 반응을 보였으며, 이는 가능한 한 자리 나노몰 친화도를 표시한다. 일부 결합제는 100 nM 항원과 반응을 나타내지 않았으며, 이는 마이크로몰 범위의 친화도를 표시한다.
IgG 전환으로 진행할 클론 선택의 목표는 가능한 한 많은 생식계열 계통과 여러 상이한 CDR3을 포함시키는 것이었다. 또한, 글리코실화, 인테그린 결합 부위, CD11c/CD18 결합 부위, 쌍을 이루지 않은 시스테인과 같은 서열 책임을 피했다. 추가로, 다양한 친화도를 포함시켰다. IgG로 전환되도록 선택된 클론을 도 1에 나타낸다. ELISA 결합으로부터의 결과(형광 단위(FU) 값)를 도 2a에 나타낸다. 결과는 모든 23개의 항체가 파트너 델타 사슬에 관계없이 원하는 감마 4 사슬 특이적 프로파일을 나타냄을 표시한다. 동일한 데이터가 도 2b에도 표현되며, 인간 Vγ2 사슬에 비해 인간 Vγ4 사슬에 대한 각 클론의 결합의 증가 변화 배율을 추가로 나타낸다. 인간 Vγ4 사슬 대 인간 Vγ2 사슬에 대한 결합의 증가 변화 배율은 80배(클론 G4_26) 내지 98387배 증가(클론 G4_18) 범위였다.
항체 결합 연구를 또한 재조합 Jurkat(JRT3-hu17) 세포를 사용하여 수행하였다. ELISA 데이터 및 유세포 분석 데이터로부터의 결과 비교를 도 3a에 나타낸다. Delfia ELISA를 통해 DV1-GV4 항원(Y-축) 및 JRT3-hu17 세포(X-축)에 결합하는 것으로 확인된 항체 클론을 추가 조사를 위해 선택했다.
실시예 5. Vγ4 항체 결합의 조사
상이한 CDR3 서열(hu17 대 hu20, 둘 다 Vγ4Vδ1) 또는 델타 사슬(hu20γ/huPBδ, Vγ4Vδ2; LES, Vγ4Vδ5)를 보유하는 Vγ4 TCR을 염색하는 실시예 4에서 선택된 항체의 능력을 조사하였다. 결과를 도 4a에 나타내며, 시험된 모든 항체가 D1.3 이소형 대조군에 비해 연구에 사용된 Vγ4 TCR 중 하나 이상에 대해 유의하게 증가된 결합을 나타냄을 표시한다. 특히, 5개의 예시적인 항체(G4_3, G4_12, G4_16, G4_18 및 G4_27)는 CDR3 서열 또는 파트너 델타 사슬에 관계없이 이 연구에서 발현된 모든 Vγ4 TCR에 결합하여, D1.3 이소형 대조군 이상으로 현저하게 향상된 결합 신호를 나타낸다. 예를 들어, 이 연구에서 두 개의 항체에 대한 예시적인 흐름 데이터를 도 4b에 나타내며 G4_4 결합(hu17 및 LES 모두에 대해 양성으로 염색되는 반면, hu20[hu17과 비교하여 상이한 CDR3 서열] 및 hu20g/huPBd[Vγ4Vδ2] 둘 모두에 대한 염색은 감소됨) 대비 G4_3 결합(모든 Vγ4 TCR에 대해 양성으로 염색됨) 간 차이를 예시한다.
실시예 6. 키메라 hu17 TCR을 사용한 에피토프 매핑
hu17은 단일 세포 PCR에 의해 BTNL3+8 반응성 인간 결장 상피내 림프구로부터 쌍을 이룬 CDR3 서열이 클로닝된 Vγ4/Vδ1 TCR이다(Melandri et al. (2018) Nat. Immunol. 19: 1352-1365에 기재됨). 상이한 키메라 hu17 TCR 구축물을 도 5a에 요약된 바와 같이 제조하였다. 이들 구축물은 hu17로부터 유래되었으며 모두 Melandri et al. (2018) Nat. Immunol. 19: 1352-1365 및 Willcox et al. (2019) Immunity 51: 813-825에 기재되었다(둘 모두 참조로 본원에 포함됨).
그 다음, JRT3 세포 상에서 발현된 키메라 hu17 TCR에 대한 유세포 분석에 의해 항체 결합을 조사하였다. 표시된 키메라 TCR 구축물에 대한 각 항체의 반응성 요약 표를 도 5b에 나타낸다. 결과는 JRT3 세포 상에서 발현된 개별 TCR에 대한 개별 항체의 상대적 결합 특이성을 강조한다. HV4 영역에서 Vγ2 서열을 포함하는 hu17 TCR 구축물을 사용하는 경우 염색이 관찰되지 않거나 감소된 염색이 관찰되었으므로 항체 G4_3, G4_12, G4_16, G4_18 및 G4_27은 모두 HV4 영역 내 또는 그 주변에 특이적으로 결합하는 것으로 표시되었다.
이 연구에서 관찰된 차별적 결합 신호를 예시하기 위한 에피토프 매핑의 예시적인 흐름 데이터를 도 5c에 나타낸다. 이 경우, 그리고 이 에피토프 매핑 접근의 예로서, 다양한 재조합 키메라 TCR에 결합하는 G4_12를 나타낸다. 첫번째로, G4_12는 시작 hu17 TCR(맨 왼쪽 패널)에 강한 결합을 나타낸다. CDR1+2 서열이 동일-프레임에서 Vγ2 동등 CDR로 교환될 때(중앙 왼쪽 패널) 또는 hu17이 Vγ2 서열 DG>YA로 변형된 HV4일 때(중앙 오른쪽 패널) hu17에 대해 강한 결합이 또한 관찰된다. 그러나 G4_12에 의한 결합의 주목할만한 감소가 대안적인 Vγ4에서 Vγ2로의 아미노산 치환(DGKM>YANL; 중앙 패널) 또는 KM>NL(맨 오른쪽 패널)에서 각각 관찰된다. 따라서 이 경우 G4_12에 의해 인식되는 에피토프는 HV4 영역(서열 번호 1의 아미노산 67-82[KYDTYGSTRKNLRMIL])에 위치하며 밑줄 친 K 및 M 잔기의 Vγ2 HV4 영역의 이 위치에서 발견되는 동등한 잔기로의 변형에 의해 크게 영향을 받는다.
실시예 7. 염색 및 기능적 검정에서 조사된 항체의 적정
JRT3-hu17 세포에 대한 유세포 분석에 의한 염색 및 분석을 위한 조사된 항체의 적정 결과(0.08 내지 10 μg/mL 범위의 농도, 5배 희석 단계)를 도 6a에 나타낸다. 형질도입되지 않은 JRT3 세포(TCR 없음)를 음성 대조군으로 사용하였다. 결과는 모든 항체가 Vγ4 TCR을 발현하는 JRT3 세포에 결합할 수 있었음을 나타낸다.
이어서 적정된 항체에 의한 TCR 턴오버 및 CD69 상향조절 대 항-CD3ε 결합 또는 항-범-TCRγδ 항체에 의해 부여된 턴오버를 조사함으로써 기능적 검정을 수행하였다. 5개의 항체에 대한 결과를 도 6b 및 6c에 나타내며 원래 코호트 내에서 보다 광범위한 항체 선택에 대한 결과를 표 2에 요약한다.

표 2에 나열된 모든 항체는 γδ TCR의 Vγ4 사슬에 결합함을 나타내었다. 그러나, 표에 나타낸 바와 같이, 이들 항체 중 일부는 Vγ4 TCR 하향조절 및/또는 증가된 CD69 발현을 통해 측정된 바와 같이 Vγ4 TCR을 활성화할 수 있는 반면('+', '++' 또는 '+++'로 표시하며 '+++'가 가장 높은 상대적 활성화 수준을 의미함), 다른 항체는 Vγ4 TCR을 활성화하는 인식 가능한 능력을 나타내지 않았다('-'로 표시됨).
실시예 8. MS 기반 에피토프 매핑
고분해능으로 항원/항체 복합체의 에피토프를 결정하기 위해, 단백질 복합체를 중수소화된 가교제와 인큐베이션하고 다중 효소 절단을 거쳤다. 가교된 펩티드의 농축 후, 샘플을 고분해능 질량 분광기(nLC-LTQ-Orbitrap MS)에 의해 분석하고 생성된 데이터를 XQuest(버전 2.0) 및 Stavrox(버전 3.6) 소프트웨어를 사용하여 분석했다.
중수소화 d0d12를 단백질 복합체 L1(DV1-GV4)/1139_P01_A04의 트립신, 키모트립신, Asp-N, 엘라스타제 및 써모라이신 단백분해 후, nLC-orbitrap MS/MS 분석으로 L1(DV1-GV4) 및 항체 1139_P01_A04(G4_3) 간 11개의 가교된 펩티드를 검출하였다. 에피토프 매핑 결과의 결과를 표 3에 나타낸다.

이 에피토프 매핑 데이터는 위의 실험과 상관관계가 있으며, 이 항체가 γ4 사슬의 HV4 영역 내에서 결합함을 표시한다.
실시예 9. 1차 Vγ4-양성 세포의 항-Vγ4 항체 표적화 및 조절.
건강한 및 이환 환자 샘플로부터 유래된 세포를 포함하여 피부, 혈액 및 장으로부터 유래된 1차 Vγ4+ 세포의 항-Vγ4 항체 표적화를 실증하기 위한 추가 연구를 수행하였다.
피부로부터 유래된 1차 Vγ4
+
세포에 대한 결합
먼저, 항-Vγ4 항체를 2명의 개별 공여자의 피부로부터 증식된 1차 Vγ4+ T 세포로의 결합에 대해 시험하였다. 피하 지방을 제거하고 다수의 펀치를 만드기 위해 사용되는 3 mm 생검 펀치로 피부 샘플을 제조했다. 펀치를 탄소 매트릭스 그리드 상에 놓고 G-REX6(Wilson Wolf)의 웰에 배치했다. 각 웰을 AIM-V 배지(Gibco, Life Technologies), CTS 면역 혈청 대체물(Life Technologies), IL-2 및 IL-15를 포함하는 완전 단리 배지로 채웠다. 배양의 처음 7일 동안, 암포테리신 B(Life Technologies)를 포함하는 완전 단리 배지를 사용했다("+AMP"). 상층 배지를 부드럽게 흡인하고 플레이트 또는 생물반응기의 바닥에 있는 세포를 교란하지 않도록 노력하면서 2X 완전 단리 배지(AMP 없음)로 교체함으로써 배지를 매 7일마다 교환하였다. 배양에서 3주 초과부터는 생성된 유출 세포를 신선 조직 배양 용기 및 신선 배지(예를 들어, AIM-V 배지 또는 TexMAX 배지(Miltenyi)) 및 재조합 IL-2, IL-4, IL-15 및 IL-21 내로 계대한 후 수확하였다. 그런 다음 배양 내에 존재하는 αβ T 세포를 Miltenyi에서 제공되는 것과 같은 αβ T 세포 고갈 키트 및 관련 프로토콜의 도움으로 제거했다. 추가 언급은 WO2020/095059를 참조한다.
단리 후, γδ T 세포를 먼저 4℃에서 20분 동안 Fc 블록의 존재하에 생활성 염료로 염색하였다. 그런 다음 γδ T 세포를 고정 농도의 예시적인 항-Vγ4 항체(0.046 - 100 μg/ml) 또는 이소형 대조군(IgG1 항-호흡기 융합 바이러스(RSV) 항체)과 4℃에서 30분 동안 인큐베이션했다. 인간 IgG1(IS11-12E4.23.20)에 대한 2차 형광 염료-접합 항체를 첨가하여 검출을 수행했다. 그런 다음 세포를 고정하고 MACSQuant16 유세포 분석기 상에서 획득했다. 세포를 단일, 살아있는, IgG1(Vγ4)+로 관문화하였다. 나타낸 데이터는 Vγ4+ 세포에 결합하여 검출된 2차 검출 항체의 중앙값 형광 세기(MFI)이다.
결과를 도 7a에 나타낸다. 이들 데이터는 시험된 모든 항-Vγ4 항체가 용량 의존적 방식으로 1차 피부-유래 Vγ4+ T 세포에 결합할 수 있음을 확인시켜 주었다. 이소형 대조군에서는 결합이 관찰되지 않았다.
말초 혈액 단핵 세포(PBMC)로부터 유래된 1차 Vγ4
+
세포에 대한 결합
간략하게, 인간 PBMC(Lonza, 제품 코드 CC-2702)를 먼저 4℃에서 20분 동안 Fc 블록의 존재 하에 생활성 염료로 염색했다. 그런 다음 세포를 10 μg/ml 항-Vγ4 항체 또는 이소형 대조군(RSV)과 4℃에서 30분 동안 인큐베이션했다. 세척하고 항-Vδ1(REA173), 항-Vδ2(REA771), 항-γδ(REA591) 및 항-인간 IgG1(IS11-12E4.23.20)으로 4℃에서 20분 동안 세포외 염색했다. 이어서 세포를 고정하고 MACSQuant16 유세포 분석기 상에서 획득했다. 세포를 단일, 살아있는, γδ+ Vδ2- IgG1(Vγ4)+로 관문화하였다.
결과를 도 7b에 나타낸다. 나타낸 데이터는 접합된 2차 항-인간 IgG1 항체에 의해 결합된 각각의 개별 항체를 사용하여 검출된 γδ+ Vδ2- 세포의 Vγ4+ 세포%이다. 이들 데이터는 1차 혈액-유래 Vγ4+ T 세포에 결합하는 실질적으로 모든 항-Vγ4 항체의 능력을 강조한다. 가장 강한 신호는 항체 G4_23, G4_3, G4_12, G4_18 또는 G4_20을 사용하여 검출되었다.
결장직장암(CRC) 환자로부터 수득된 장 유래 상피내 림프구(IEL)의 1차 Vγ4
+
세포에 대한 결합
이 연구를 위해 인간 CRC 종양 생검을 신선하게 배송받아 수령 즉시 처리하였다. 생검을 약 2 mm2로 측정되는 조각으로 절단하였고 종양-침윤 림프구(TIL)를 원래 Kupper 및 Clarke에 의해 기재된 방법을 응용하여 수득하였다(Clarke et al., 2006, J. Invest. Dermatol. 126, 1059-1070). 구체적으로, 9 mm x 9 mm x 1.5 mm Cellfoam 매트릭스 상에 최대 4개의 2 mm2 생검을 배치하고, 24웰 플레이트 상에 웰당 하나의 매트릭스를 배치했다. 그런 다음 생검을 4% 인간 혈장, β-메르캅토에탄올(50 μM), 페니실린(100 U/ml), 스트렙토마이신(100 μg /ml), 겐타마이신(20 μg/ml), 메트로니다졸(1 μg /ml), 암포테리신 B(2.5 μg /ml), HEPES(10 mM), Na 피루베이트(1 mM), MEM 비필수 아미노산 용액(1X) 및 IL-15(20 ng/ml, Miltenyi Biotech)이 보충된 2 ml 이스코브 변형 둘베코 배지(IMDM) 중에 배양했다. 1 ml의 배지를 3일마다 흡인하고 2x 농축된 IL-15를 포함하는 1 ml의 완전 배지로 교체했다. 10일 후에 TIL을 수확하고, 70 μM 나일론 세포 여과기를 통과시키고, 300 x g에서 5분 동안 원심분리하고, 표현형분석을 위해 완전 배지 중에 재현탁하였다. TIL을 먼저 4℃에서 20분 동안 Fc 블록의 존재 하에 살아있는/죽은 생활성 염료로 염색하였다. 그런 다음 세포를 4℃에서 30분 동안 10 μg/ml 항-Vγ4 항체 또는 이소형 대조군(RSV)과 인큐베이션한 후, 세척하고 항-Vδ1(REA173), 항-γδ(REA591) 및 항-인간 IgG1(IS11-12E4.23.20)으로 4℃에서 20분 동안 세포외 염색하였다. 이어서 세포를 고정하고 MACSQuant16 유세포 분석기 상에서 획득했다. 세포를 단일, 살아있는, γδ+, IgG1+(Vγ4)+로 관문화하였다.
결과를 도 7c에 나타낸다. 나타낸 데이터는 접합된 2차 항-인간 IgG1 항체를 통해 검출된 1차 장-유래 Vγ4+ 세포에 대한 항-Vγ4 항체, G4_3, G4_12 및 G4_18의 결합을 예시하는 FACS 그래프이다. 데이터는 CRC 종양 조직으로부터 수득된 Vγ4+ 세포에 결합하는 본 발명의 항체의 능력을 실증한다.
항-Vγ4 항체에 의해 부여된 인간 장-유래 γδ T 세포의 검출 및 TCR 하향조절
항-Vγ4 항체에 의해 부여된 인간 장-유래 γδ T 세포의 조절을 탐색하기 위한 추가 연구를 수행하였다. 이러한 연구를 위해 CRC 환자의 결장으로부터의 정상 인접 조직(NAT) 생검을 신선하게 배송받아 수령 시 처리하여 단일 세포 현탁액을 수득하였다. 구체적으로, 조직을 약 2 mm2로 측정되는 조각으로 절단하고 최대 1 g의 조직을 관련 세포 표면 분자의 절단을 방지하기 위해 0.2X 농도에서 사용된 효소 R을 제외하고 제조업체에서 권장하는 농도로 Miltenyi 종양 해리 키트로부터의 효소가 포함된 4.7 ml RPMI와 함께 Miltenyi C 튜브 내에 넣었다. C-튜브를 가열 블록이 부착된 GentleMACS™ Octo 해리장치 상에 배치하였다. 연성 종양의 해리를 위해 프로그램 37C_h_TDK_1을 선택하였다. 1시간 후 소화물을 70 μM 필터를 통해 여과하고 4% 인간 혈장을 포함하는 완전 IMDM을 첨가하여 효소 활성을 켄칭하였다. 그런 다음 세포를 두 번 세척하고 계수를 위해 완전 IMDM 중에 재현탁했다. 이 시점에, 세포를 항-Vγ4 항체로의 자극을 위해 플레이팅하거나 표현형분석을 위해 사용하였다.
일련의 실험에서 항-Vγ4 항체로의 자극 전 장 소화물에서의 Vγ4+ γδ T 세포의 표현형을 결정하였다. 간략하게, 세포를 4℃에서 20분 동안 Fc 블록의 존재 하에 살아있는/죽은 생활성 염료로 염색하였다. 그런 다음 세포를 4℃에서 30분 동안 10 μg/ml G4_18 클론과 인큐베이션한 후 세척하고 항-Vδ1(REA173), 항-γδ(REA591), 항-CD69(REA824), 항-CD103(Ber-Act8) 및 항-인간 IgG1(IS11-12E4.23.20)로 4℃에서 20분 동안 세포외 염색했다. 그런 다음 세포를 고정하고 MACSQuant16 유세포 분석기 상에서 획득했다. 도 7d에 나타낸 바와 같이, 살아있는, 단일 세포의 1.4%가 Vδ1+ 이었다. 이들 중 44.2%는 Vγ4와 쌍을 이루었고, 이들 모두는 장으로부터의 γδ T 세포에 대해 예상된 바와 같이 장 조직 잔류 마커(CD69+ CD103+)를 디스플레이했다. 이러한 결과는 본 발명의 항체, 이 경우 항체 G4_18이 인간 장 조직으로부터 단리된 Vγ4+ γδ T 세포를 특이적으로 검출하기 위해 사용될 수 있음을 확인시켜 준다.
다음 일련의 실험은 항-Vγ4 항체로의 세포 자극 효과를 측정했다. 2x106 세포를 48-웰 플레이트에서 웰 당 플레이팅하고 2 ng/ml 농도의 IL-15의 존재 하에 G4_12, G4_18 또는 RSV IgG1 이소형 대조군 항체로 자극하였다. 효소 소화에 의해 단리된 상피내 림프구(IEL)를 mAb 자극 24시간 후 유세포 분석에 의해 분석하였다. 24시간 자극 후, 세포를 4℃에서 20분 동안 Fc 블록의 존재 하에 생활성 염료로 염색하였다. 그런 다음 세포를 γδTCR(REA591)에 대해 세포외 염색하고, 고정하고, MACSQuant16 유세포 분석기 상에서 획득했다. 살아있는, 단일 세포를 γδTCR+로 관문화하였다. 도 7e는 대표적인 FACS 그래프가 동반되는, RSV 이소형 대조군과 비교하여 G4_12 또는 G4_18 클론으로 24시간 자극 후 부여된 γδTCR 하향조절을 나타낸다. 항-Vγ4 항체인 G4_12 및 G4_18 모두 RSV 이소형 대조군에 비해 γδTCR 하향조절을 유도했으며, G4_12로 가장 큰 하향조절이 관찰되었다.
실시예 10. 본 발명의 예시적인 항-Vγ4 항체의 표면 플라즈몬 공명(SPR)에 의해 측정된 인간 Vγ4에 대한 결합 친화도(KD)를 측정하는 추가 연구.
또한, scFv 결합제와 관련하여 실시예 4에 기재된 SPR 결합 연구(실시예 1에 기재된 방법)에 대해, 클론이 완전한 IgG1 모노클로날 항체로 발현될 때 인간 Vγ4 사슬에 대한 선택된 예시적인 클론의 결합 친화도를 측정하기 위해 추가 연구를 수행하였다.
간략하게, 표적(즉, γδ TCR의 인간 Vγ4 사슬)에 대한 항체의 결합 친화도를 Reichert 4SPR 기기(Reichert Technologies)를 사용한 SPR 분석에 의해 확립하였다. 항원(L1(DV1-GV4))을 10 ug/ml의 카복시메틸 덱스트란 칩(Reichert Technologies) 상에 커플링하였고, 이는 기준선으로부터 각각 대략 750 uRIU의 증가를 초래했다. 항체를 하기 매개변수: 180초 연합, 300초 해리, 유속 25 μL/분, 실행 완충액 PBS + 0.05% Tween 20을 사용하여 500 nM 내지 31.25 nM의 1:2 희석 시리즈로 세포 상으로 흘렸다. 모든 실험은 실온에서 수행했고, 칩 상으로 흘리기 전에 샘플을 4℃에서 유지하였다. 안정 상태 피팅을 소프트웨어 TraceDrawer(Reichert Technologies)를 사용하여 Langmuir 1:1 결합에 따라 결정하였다.
결과를 표 4에 나타내며 항체 당 2회 실험의 평균을 나타낸다(표시된 경우 제외).

예상된 대로, 결합 친화도 범위를 결정하여 필요한 결합 친화도에 따라 특정 상황에 대해 특정 항체를 선택할 수 있게 하였다. 특히, 결합 친화도는 나타낸 바와 같이 대략 260 nM - 2.8 nM 범위였다. 이는 실시예 4에 기재된 scFv 연구와 일치하였다.
실시예 11. 1차 인간 Vγ4 T 세포 수를 증가시키기 위한 Vγ4-특이적 항체의 용도
JRT3-hu17 세포 상에서 가장 높은 자극 활성을 나타내는 항체(클론 G4_12, 도 5b, 5c)를 1차 Vγ4+ T 세포를 자극하는 그 능력에 대해 추가 시험하였다. 이소형 대조군 대비 G4_12로의 플레이트-결합 자극 후 PBMC 배양 중 Vγ4 T 세포 백분율의 증가를 A647-접합 항-Vγ4 클론 G4_18을 포함하는 항체 패널을 사용하여 유세포 분석에 의해 분석하였고 도 8에 나타낸다. 제7일 및 제14일에, G4_12 항체의 존재 하에 Vg4 양성 세포의 비율은 이소형 대조군이 존재한 배양에서보다 컸다.
서열






























SEQUENCE LISTING
<110> GammaDelta Therapeutics Limited
<120> Novel Antibodies
<130> P143080WO
<160> 338
<170> PatentIn version 3.5
<210> 1
<211> 256
<212> PRT
<213> Homo sapiens
<220>
<223> V gamma 4 chain of RSCB Protein Data Bank entry: 4MNH
<400> 1
Ser Ser Asn Leu Glu Gly Arg Thr Lys Ser Val Ile Arg Gln Thr Gly
1 5 10 15
Ser Ser Ala Glu Ile Thr Cys Asp Leu Ala Glu Gly Ser Thr Gly Tyr
20 25 30
Ile His Trp Tyr Leu His Gln Glu Gly Lys Ala Pro Gln Arg Leu Leu
35 40 45
Tyr Tyr Asp Ser Tyr Thr Ser Ser Val Val Leu Glu Ser Gly Ile Ser
50 55 60
Pro Gly Lys Tyr Asp Thr Tyr Gly Ser Thr Arg Lys Asn Leu Arg Met
65 70 75 80
Ile Leu Arg Asn Leu Ile Glu Asn Asp Ser Gly Val Tyr Tyr Cys Ala
85 90 95
Thr Trp Asp Glu Lys Tyr Tyr Lys Lys Leu Phe Gly Ser Gly Thr Thr
100 105 110
Leu Val Val Thr Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala
115 120 125
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
130 135 140
Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser
145 150 155 160
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro
165 170 175
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Ala Leu
180 185 190
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
195 200 205
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
210 215 220
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
225 230 235 240
Ala Trp Gly Arg Ala Asp Ser Arg Gly Gly Leu Glu Val Leu Phe Gln
245 250 255
<210> 2
<211> 7
<212> PRT
<213> artificial sequence
<220>
<223> G4_1 Heavy CDR3
<400> 2
Gly His Trp Tyr Phe Asp Leu
1 5
<210> 3
<211> 11
<212> PRT
<213> artificial sequence
<220>
<223> G4_2 Heavy CDR3
<400> 3
Phe Pro Val Ala Gly Phe Tyr Gly Met Asp Val
1 5 10
<210> 4
<211> 7
<212> PRT
<213> artificial sequence
<220>
<223> G4_3 Heavy CDR3
<400> 4
Gly Gly Trp Leu Tyr Asp Tyr
1 5
<210> 5
<211> 10
<212> PRT
<213> artificial sequence
<220>
<223> G4_4 Heavy CDR3
<400> 5
Ser Ser Val Gly Trp Trp Ser Phe Asp Tyr
1 5 10
<210> 6
<211> 11
<212> PRT
<213> artificial sequence
<220>
<223> G4_5 Heavy CDR3
<400> 6
Gly Gly Thr Gly Gly Asp His Val Phe Ala Tyr
1 5 10
<210> 7
<211> 11
<212> PRT
<213> artificial sequence
<220>
<223> G4_6 Heavy CDR3
<400> 7
Ala Asp Tyr Gly Val Val Tyr Tyr Phe Asp Tyr
1 5 10
<210> 8
<211> 10
<212> PRT
<213> artificial sequence
<220>
<223> G4_7 Heavy CDR3
<400> 8
Ile Gly Tyr Ser Ser Ser Ser Phe Asp Tyr
1 5 10
<210> 9
<211> 13
<212> PRT
<213> artificial sequence
<220>
<223> G4_10 Heavy CDR3
<400> 9
Asp Gly Ala Val Asp Phe Trp Arg Asn Gly Met Asp Val
1 5 10
<210> 10
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_12 Heavy CDR3
<400> 10
Val Ala Asn Gly Asp Phe Leu Asp Tyr
1 5
<210> 11
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_13 Heavy CDR3
<400> 11
Gly Gly Leu Gly Met Val Asp Pro
1 5
<210> 12
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_14 Heavy CDR3
<400> 12
Asp Thr Ala His Gly Met Asp Val
1 5
<210> 13
<211> 13
<212> PRT
<213> artificial sequence
<220>
<223> G4_15 Heavy CDR3
<400> 13
Asp Asn Ser His Leu Asp Gln Val Trp Trp Phe Asp Pro
1 5 10
<210> 14
<211> 10
<212> PRT
<213> artificial sequence
<220>
<223> G4_16 Heavy CDR3
<400> 14
Asp Tyr Gly Asp Phe Tyr Gly Met Asp Val
1 5 10
<210> 15
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_18 Heavy CDR3
<400> 15
Asp Leu Asp Leu Ser Ser Leu Asp Tyr
1 5
<210> 16
<211> 12
<212> PRT
<213> artificial sequence
<220>
<223> G4_19 Heavy CDR3
<400> 16
Glu Arg Gly Tyr Ser Tyr Gly Asp Gly Met Asp Val
1 5 10
<210> 17
<211> 10
<212> PRT
<213> artificial sequence
<220>
<223> G4_20 Heavy CDR3
<400> 17
Gly Asn Ser Arg Ser Asp Ala Phe Asp Ile
1 5 10
<210> 18
<211> 11
<212> PRT
<213> artificial sequence
<220>
<223> G4_22 Heavy CDR3
<400> 18
Asp Ser Thr Ala Val Thr Asp Trp Phe Asp Pro
1 5 10
<210> 19
<211> 11
<212> PRT
<213> artificial sequence
<220>
<223> G4_23 Heavy CDR3
<400> 19
Gly Glu Val Ala Ala Leu Tyr Tyr Phe Asp Tyr
1 5 10
<210> 20
<211> 10
<212> PRT
<213> artificial sequence
<220>
<223> G4_24 Heavy CDR3
<400> 20
Asp Trp Ser Ser Thr Arg Ser Phe Asp Tyr
1 5 10
<210> 21
<211> 14
<212> PRT
<213> artificial sequence
<220>
<223> G4_25 Heavy CDR3
<400> 21
Ser Leu Arg Asp Gly Tyr Asn Tyr Ile Gly Ser Leu Gly Tyr
1 5 10
<210> 22
<211> 11
<212> PRT
<213> artificial sequence
<220>
<223> G4_26 Heavy CDR3
<400> 22
Ser Arg Gly Ser Gly Trp Phe Pro Leu Gly Tyr
1 5 10
<210> 23
<211> 13
<212> PRT
<213> artificial sequence
<220>
<223> G4_27 Heavy CDR3
<400> 23
His Gly Ala Tyr Gly Asp Tyr Pro Asp Thr Phe Asp Ile
1 5 10
<210> 24
<211> 16
<212> PRT
<213> artificial sequence
<220>
<223> G4_28 Heavy CDR3
<400> 24
Ser Tyr Val Asp Thr Ala Met Arg Tyr Tyr Tyr Tyr Tyr Met Asp Val
1 5 10 15
<210> 25
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_1 Light CDR3
<400> 25
Gln Gln Ser Tyr Ser Thr Pro Val Thr
1 5
<210> 26
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_2 Light CDR3
<400> 26
Leu Glu Asp Tyr Asn Tyr Leu Trp Thr
1 5
<210> 27
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_3 Light CDR3
<400> 27
Gln Gln Ser Tyr Ser Thr Pro Gln Thr
1 5
<210> 28
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_4 Light CDR3
<400> 28
Gln Gln Tyr Tyr Ser Thr Pro Leu Thr
1 5
<210> 29
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_5 Light CDR3
<400> 29
Gln Gln Ser Tyr Ser Thr Pro Tyr Thr
1 5
<210> 30
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_6 Light CDR3
<400> 30
Gln Gln Ser Tyr Ser Thr Pro Tyr Thr
1 5
<210> 31
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_7 Light CDR3
<400> 31
Met Gln Gly Leu Gln Thr Pro Tyr Thr
1 5
<210> 32
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_10 Light CDR3
<400> 32
Met Gln Gly Thr Leu Trp Pro Pro Thr
1 5
<210> 33
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_12 Light CDR3
<400> 33
Ser Ser His Ala Ser Pro Arg Val
1 5
<210> 34
<211> 10
<212> PRT
<213> artificial sequence
<220>
<223> G4_13 Light CDR3
<400> 34
Gln Ser Tyr Asp Ser Ser Ile Tyr Val Val
1 5 10
<210> 35
<211> 10
<212> PRT
<213> artificial sequence
<220>
<223> G4_14 Light CDR3
<400> 35
Gln Ser Tyr Asp Ser Ser Thr His Val Val
1 5 10
<210> 36
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_15 Light CDR3
<400> 36
Ser Ser Tyr Gly Ser Gly Ser Val
1 5
<210> 37
<211> 10
<212> PRT
<213> artificial sequence
<220>
<223> G4_16 Light CDR3
<400> 37
Thr Ser Tyr Ala Gly Ser Asn Thr Leu Ile
1 5 10
<210> 38
<211> 11
<212> PRT
<213> artificial sequence
<220>
<223> G4_18 Light CDR3
<400> 38
Gln Ser Ala Asp Ser Ser Gly Thr Tyr Thr Val
1 5 10
<210> 39
<211> 10
<212> PRT
<213> artificial sequence
<220>
<223> G4_19 Light CDR3
<400> 39
Gln Ser Tyr Asp Ser Ser Asn His Val Val
1 5 10
<210> 40
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_20 Light CDR3
<400> 40
Gln Ala Trp Asp Ser Ser Thr Val Val
1 5
<210> 41
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_22 Light CDR3
<400> 41
Gln Gln Ser Tyr Ser Ile Pro Trp Thr
1 5
<210> 42
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_23 Light CDR3
<400> 42
Gln Gln Tyr Tyr Ser Thr Pro Arg Thr
1 5
<210> 43
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_24 Light CDR3
<400> 43
Gln Gln Tyr Tyr Ser Thr Pro Pro Thr
1 5
<210> 44
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_25 Light CDR3
<400> 44
Ser Ser Tyr Gly Ser Gly Ser Val
1 5
<210> 45
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_26 Light CDR3
<400> 45
Ser Ser Phe Gly Ser Gly Ser Ile
1 5
<210> 46
<211> 11
<212> PRT
<213> artificial sequence
<220>
<223> G4_27 Light CDR3
<400> 46
Asn Ser Arg Asp Ser Ser Gly Asn His Leu Val
1 5 10
<210> 47
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_28 Light CDR3
<400> 47
Asn Ser Arg Asp Ser Ser Gly Val Val
1 5
<210> 48
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_1 Heavy CDR2
<400> 48
Ile Ser Ser Ser Ser Ser Tyr Ile
1 5
<210> 49
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_2 Heavy CDR2
<400> 49
Val Asp Pro Glu Asp Gly Gln Ser
1 5
<210> 50
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_3 Heavy CDR2
<400> 50
Ile Ser Ser Ser Ser Ser Tyr Ile
1 5
<210> 51
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_4 Heavy CDR2
<400> 51
Ile Ser Gly Ser Gly Gly Ser Thr
1 5
<210> 52
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_5 Heavy CDR2
<400> 52
Ile Gly Ala Tyr Asn Gly Asn Thr
1 5
<210> 53
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_6 Heavy CDR2
<400> 53
Ile Ser Gly Ser Gly Gly Ser Thr
1 5
<210> 54
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_7 Heavy CDR2
<400> 54
Ile Lys Gln Asp Gly Ser Ile Ile
1 5
<210> 55
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_10 Heavy CDR2
<400> 55
Ile Ser Gly Ser Gly Gly Ser Thr
1 5
<210> 56
<211> 7
<212> PRT
<213> artificial sequence
<220>
<223> G4_12 Heavy CDR2
<400> 56
Ile Tyr Ser Gly Gly Ser Thr
1 5
<210> 57
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_13 Heavy CDR2
<400> 57
Ile Ser Gly Thr Ser Ser Tyr Ile
1 5
<210> 58
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_14 Heavy CDR2
<400> 58
Ile Asp Pro Ser Asp Ser Tyr Thr
1 5
<210> 59
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_15 Heavy CDR2
<400> 59
Ile Asn Pro Ser Gly Ser Ser Thr
1 5
<210> 60
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_16 Heavy CDR2
<400> 60
Ile Ser Ala Tyr Asn Gly Asn Thr
1 5
<210> 61
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_18 Heavy CDR2
<400> 61
Ile Asn Pro Asn Ser Gly Gly Thr
1 5
<210> 62
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_19 Heavy CDR2
<400> 62
Ile Asn Pro Ser Gly Gly Ser Thr
1 5
<210> 63
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_20 Heavy CDR2
<400> 63
Ile Ile Pro Ile Phe Gly Thr Ala
1 5
<210> 64
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_22 Heavy CDR2
<400> 64
Val Ser Gly Ser Gly Gly Thr Thr
1 5
<210> 65
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_23 Heavy CDR2
<400> 65
Ile Trp Tyr Asp Gly Ser Asn Lys
1 5
<210> 66
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_24 Heavy CDR2
<400> 66
Thr Tyr Tyr Arg Ser Arg Trp Tyr Asn
1 5
<210> 67
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_25 Heavy CDR2
<400> 67
Ile Ile Pro Ile Phe Gly Thr Ala
1 5
<210> 68
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_26 Heavy CDR2
<400> 68
Ile Ile Pro Ile Phe Gly Thr Ala
1 5
<210> 69
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_27 Heavy CDR2
<400> 69
Ile Tyr Pro Gly Asp Ser Asp Thr
1 5
<210> 70
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_28 Heavy CDR2
<400> 70
Ile Ser Ala Gly Gly Gly Ser Thr
1 5
<210> 71
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_1 Heavy CDR1
<400> 71
Gly Phe Thr Phe Ser Ser Tyr Ser
1 5
<210> 72
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_2 Heavy CDR1
<400> 72
Gly Tyr Pro Phe Thr Asp Tyr Tyr
1 5
<210> 73
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_3 Heavy CDR1
<400> 73
Gly Phe Thr Phe Ser Ser Tyr Ser
1 5
<210> 74
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_4 Heavy CDR1
<400> 74
Gly Phe Thr Phe Ser Ser Tyr Ala
1 5
<210> 75
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_5 Heavy CDR1
<400> 75
Gly Tyr Thr Phe Thr Ser Tyr Gly
1 5
<210> 76
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_6 Heavy CDR1
<400> 76
Gly Phe Thr Phe Ser Ser Tyr Ala
1 5
<210> 77
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_7 Heavy CDR1
<400> 77
Gly Phe Thr Phe Ser His Tyr Trp
1 5
<210> 78
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_10 Heavy CDR1
<400> 78
Gly Phe Thr Phe Ser Ser Tyr Ala
1 5
<210> 79
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_12 Heavy CDR1
<400> 79
Gly Phe Thr Val Ser Ser Asn Tyr
1 5
<210> 80
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_13 Heavy CDR1
<400> 80
Gly Phe Thr Phe Ser Ser Tyr Ser
1 5
<210> 81
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_14 Heavy CDR1
<400> 81
Gly Tyr Ser Phe Thr Ser Tyr Trp
1 5
<210> 82
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_15 Heavy CDR1
<400> 82
Gly Tyr Thr Phe Thr Arg His Tyr
1 5
<210> 83
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_16 Heavy CDR1
<400> 83
Gly Tyr Thr Phe Thr Ser Tyr Gly
1 5
<210> 84
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_18 Heavy CDR1
<400> 84
Gly Tyr Thr Phe Thr Gly Tyr Tyr
1 5
<210> 85
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_19 Heavy CDR1
<400> 85
Gly Tyr Thr Leu Thr Ser Tyr Tyr
1 5
<210> 86
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_20 Heavy CDR1
<400> 86
Gly Gly Thr Phe Ser Ser Tyr Ala
1 5
<210> 87
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_22 Heavy CDR1
<400> 87
Gly Phe Thr Phe Ser Thr Tyr Ala
1 5
<210> 88
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_23 Heavy CDR1
<400> 88
Gly Phe Thr Phe Ser Ser Tyr Gly
1 5
<210> 89
<211> 10
<212> PRT
<213> artificial sequence
<220>
<223> G4_24 Heavy CDR1
<400> 89
Gly Ala Ser Val Ser Ser Asn Ser Val Ala
1 5 10
<210> 90
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_25 Heavy CDR1
<400> 90
Gly Gly Thr Phe Ser Ser Tyr Ala
1 5
<210> 91
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_26 Heavy CDR1
<400> 91
Gly Gly Thr Phe Ser Ser Tyr Ala
1 5
<210> 92
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_27 Heavy CDR1
<400> 92
Gly Tyr Ser Phe Thr Ser Tyr Trp
1 5
<210> 93
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_28 Heavy CDR1
<400> 93
Gly Phe Thr Phe Asp Asp Tyr Ala
1 5
<210> 94
<211> 6
<212> PRT
<213> artificial sequence
<220>
<223> G4_1 Light CDR1
<400> 94
Gln Asp Ile Ser Asn Tyr
1 5
<210> 95
<211> 6
<212> PRT
<213> artificial sequence
<220>
<223> G4_2 Light CDR1
<400> 95
Gln Asp Ile Ser Asn Tyr
1 5
<210> 96
<211> 6
<212> PRT
<213> artificial sequence
<220>
<223> G4_3 Light CDR1
<400> 96
Gln Asp Ile Ser Asn Tyr
1 5
<210> 97
<211> 12
<212> PRT
<213> artificial sequence
<220>
<223> G4_4 Light CDR1
<400> 97
Gln Ser Val Leu Ser Ser Ser Asn Asn Asn Asn Tyr
1 5 10
<210> 98
<211> 6
<212> PRT
<213> artificial sequence
<220>
<223> G4_5 Light CDR1
<400> 98
Gln Ser Ile Ser Ser Tyr
1 5
<210> 99
<211> 6
<212> PRT
<213> artificial sequence
<220>
<223> G4_6 Light CDR1
<400> 99
Gln Ser Ile Ser Thr Tyr
1 5
<210> 100
<211> 11
<212> PRT
<213> artificial sequence
<220>
<223> G4_7 Light CDR1
<400> 100
Gln Ser Leu Leu His Ser Asn Arg Phe Asn Tyr
1 5 10
<210> 101
<211> 11
<212> PRT
<213> artificial sequence
<220>
<223> G4_10 Light CDR1
<400> 101
Gln Ser Leu Glu Tyr Ser Asp Gly Asn Thr Tyr
1 5 10
<210> 102
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_12 Light CDR1
<400> 102
Ser Ser Asp Val Gly Gly Tyr Asn Phe
1 5
<210> 103
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_13 Light CDR1
<400> 103
Ser Gly Ser Ile Ala Ser Asn Tyr
1 5
<210> 104
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_14 Light CDR1
<400> 104
Arg Gly Ser Ile Ala Gly Asn Tyr
1 5
<210> 105
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_15 Light CDR1
<400> 105
Ser Ser Asp Val Gly Gly Tyr Asn Tyr
1 5
<210> 106
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_16 Light CDR1
<400> 106
Ser Ser Asp Ile Gly Ala Phe Asn Ser
1 5
<210> 107
<211> 6
<212> PRT
<213> artificial sequence
<220>
<223> G4_18 Light CDR1
<400> 107
Ala Leu Ala Lys Gln Tyr
1 5
<210> 108
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> G4_19 Light CDR1
<400> 108
Ser Gly Ser Ile Ala Ser Asn Tyr
1 5
<210> 109
<211> 6
<212> PRT
<213> artificial sequence
<220>
<223> G4_20 Light CDR1
<400> 109
Lys Leu Gly Asp Lys Phe
1 5
<210> 110
<211> 6
<212> PRT
<213> artificial sequence
<220>
<223> G4_22 Light CDR1
<400> 110
Gln Asp Ile Ser Asn Tyr
1 5
<210> 111
<211> 6
<212> PRT
<213> artificial sequence
<220>
<223> G4_23 Light CDR1
<400> 111
Gln Gly Ile Ser Asn Ser
1 5
<210> 112
<211> 12
<212> PRT
<213> artificial sequence
<220>
<223> G4_24 Light CDR1
<400> 112
Gln Ser Val Leu Tyr Ser Ser Asn Asn Lys Asn Tyr
1 5 10
<210> 113
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_25 Light CDR1
<400> 113
Ser Ser Asp Val Gly Gly Tyr Asn Tyr
1 5
<210> 114
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> G4_26 Light CDR1
<400> 114
Ser Ser Asp Val Gly Ser Tyr Asn Leu
1 5
<210> 115
<211> 6
<212> PRT
<213> artificial sequence
<220>
<223> G4_27 Light CDR1
<400> 115
Ser Leu Arg Asn Phe Tyr
1 5
<210> 116
<211> 6
<212> PRT
<213> artificial sequence
<220>
<223> G4_28 Light CDR1
<400> 116
Ser Leu Arg Asn Tyr Tyr
1 5
<210> 117
<211> 116
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_1
<400> 117
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ser Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Ser Ser Ser Ser Tyr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly His Trp Tyr Phe Asp Leu Trp Gly Arg Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 118
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_2
<400> 118
Gln Met Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Thr Val Lys Ile Ser Cys Lys Val Ser Gly Tyr Pro Phe Thr Asp Tyr
20 25 30
Tyr Ile His Trp Val Gln Gln Ala Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Leu Val Asp Pro Glu Asp Gly Gln Ser Arg Ser Ala Glu Arg Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Thr Ser Thr Asp Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr Phe Pro Val Ala Gly Phe Tyr Gly Met Asp Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 119
<211> 116
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_3
<400> 119
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ser Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Ser Ser Ser Ser Tyr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Trp Leu Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 120
<211> 119
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_4
<400> 120
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Arg Val Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ser Ser Val Gly Trp Trp Ser Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 121
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_5
<400> 121
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Gly Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Ser Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Pro Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Thr Gly Gly Asp His Val Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 122
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_6
<400> 122
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ala Asp Tyr Gly Val Val Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser
115 120
<210> 123
<211> 119
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_7
<400> 123
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Trp Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Pro Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser His Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Asn Ile Lys Gln Asp Gly Ser Ile Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ile Gly Tyr Ser Ser Ser Ser Phe Asp Tyr Trp Gly Arg Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 124
<211> 122
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_10
<400> 124
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Gly Ala Val Asp Phe Trp Arg Asn Gly Met Asp Val Trp
100 105 110
Gly Arg Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 125
<211> 117
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_12
<400> 125
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Val Ser Ser Asn
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Tyr Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg His Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Val Ala Asn Gly Asp Phe Leu Asp Tyr Trp Gly Arg Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 126
<211> 117
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_13
<400> 126
Gln Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ser Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Thr Ser Ser Tyr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Leu Gly Met Val Asp Pro Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 127
<211> 117
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_14
<400> 127
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Arg Ile Ser Cys Lys Gly Ser Gly Tyr Ser Phe Thr Ser Tyr
20 25 30
Trp Ile Ser Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ser Asp Ser Tyr Thr Asn Tyr Ser Pro Ser Phe
50 55 60
Pro Gly His Val Thr Ile Ser Ala Asp Lys Ser Ile Ser Thr Ala Tyr
65 70 75 80
Leu Gln Trp Ser Ser Leu Lys Ala Ser Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Ala Asp Thr Ala His Gly Met Asp Val Trp Gly Arg Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 128
<211> 122
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_15
<400> 128
Glu Val Gln Leu Val Gln Ser Glu Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg His
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Leu Ile Asn Pro Ser Gly Ser Ser Thr Val Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Leu Thr Arg Asp Thr Ser Thr Ser Thr Asp Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Asn Ser His Leu Asp Gln Val Trp Trp Phe Asp Pro Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 129
<211> 119
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_16
<400> 129
Glu Val Gln Leu Leu Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Tyr Gly Asp Phe Tyr Gly Met Asp Val Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 130
<211> 118
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_18
<400> 130
Glu Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Gly Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asn Pro Asn Ser Gly Gly Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Ala Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Leu Asp Leu Ser Ser Leu Asp Tyr Trp Gly Arg Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 131
<211> 121
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_19
<400> 131
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Leu Thr Ser Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Arg Gly Tyr Ser Tyr Gly Asp Gly Met Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 132
<211> 119
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_20
<400> 132
Gln Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Val Asp Lys Ser Thr Arg Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Lys Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Asn Ser Arg Ser Asp Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 133
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_22
<400> 133
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Thr Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Val Ser Gly Ser Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Ser Thr Ala Val Thr Asp Trp Phe Asp Pro Trp Gly Arg
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 134
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_23
<400> 134
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Trp Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Glu Val Ala Ala Leu Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 135
<211> 122
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_24
<400> 135
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Ala Ser Val Ser Ser Asn
20 25 30
Ser Val Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Arg Trp Tyr Asn Asp Tyr Ala
50 55 60
Leu Ser Val Lys Ser Arg Ile Ile Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Asp Trp Ser Ser Thr Arg Ser Phe Asp Tyr Trp
100 105 110
Gly Arg Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 136
<211> 123
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_25
<400> 136
Glu Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Leu Arg Asp Gly Tyr Asn Tyr Ile Gly Ser Leu Gly Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 137
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_26
<400> 137
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ser Ser Arg Gly Ser Gly Trp Phe Pro Leu Gly Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 138
<211> 122
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_27
<400> 138
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Lys Ile Ser Cys Lys Ser Ser Gly Tyr Ser Phe Thr Ser Tyr
20 25 30
Trp Ile Gly Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Tyr Pro Gly Asp Ser Asp Thr Arg Tyr Ser Pro Ser Phe
50 55 60
Gln Gly Gln Val Thr Phe Ser Ala Asp Glu Ser Ile Ser Thr Ala Tyr
65 70 75 80
Leu Gln Trp Ser Ser Leu Lys Ala Ser Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg His Gly Ala Tyr Gly Asp Tyr Pro Asp Thr Phe Asp Ile Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 139
<211> 125
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full heavy variable sequence G4_28
<400> 139
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Ala Gly Gly Gly Ser Thr Asn Tyr Ala Gly Ser Val
50 55 60
Lys Gly Arg Phe Thr Val Ser Arg Asp Thr Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Lys Ser Tyr Val Asp Thr Ala Met Arg Tyr Tyr Tyr Tyr Tyr Met
100 105 110
Asp Val Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser
115 120 125
<210> 140
<211> 109
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_1
<400> 140
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Val Thr Phe Gly Pro Gly Thr Lys Val Glu Ile Lys
100 105
<210> 141
<211> 109
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_2
<400> 141
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Gly Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Asp Tyr Asn Tyr
85 90 95
Leu Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 142
<211> 109
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_3
<400> 142
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Phe Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Gln Thr Phe Gly Gln Gly Thr Lys Val Asp Ile Lys
100 105
<210> 143
<211> 115
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_4
<400> 143
Ala Ser Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser
1 5 10 15
Leu Gly Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu
20 25 30
Ser Ser Ser Asn Asn Asn Asn Tyr Leu Ala Trp Tyr Gln Gln Arg Pro
35 40 45
Gly Gln Pro Pro Lys Leu Leu Phe Tyr Trp Ala Ser Thr Arg Glu Ser
50 55 60
Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Ser Phe Thr
65 70 75 80
Leu Thr Ile Thr Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys
85 90 95
Gln Gln Tyr Tyr Ser Thr Pro Leu Thr Phe Gly Gly Gly Thr Lys Leu
100 105 110
Glu Ile Lys
115
<210> 144
<211> 109
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_5
<400> 144
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser
20 25 30
Ser Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 145
<211> 109
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_6
<400> 145
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser
20 25 30
Thr Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Pro
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 146
<211> 114
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_7
<400> 146
Ala Ser Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr
1 5 10 15
Pro Gly Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu
20 25 30
His Ser Asn Arg Phe Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly
35 40 45
Gln Ser Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly
50 55 60
Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
65 70 75 80
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met
85 90 95
Gln Gly Leu Gln Thr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Asp
100 105 110
Ile Lys
<210> 147
<211> 114
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_10
<400> 147
Ala Ser Asp Ile Val Met Thr Gln Pro Pro Leu Ser Leu Pro Val Thr
1 5 10 15
Leu Gly His Pro Ala Ser Ile Ser Cys Lys Ser Ser Gln Ser Leu Glu
20 25 30
Tyr Ser Asp Gly Asn Thr Tyr Leu Asn Trp Phe Gln Gln Arg Pro Gly
35 40 45
Gln Ser Pro Arg Arg Leu Ile Tyr Lys Val Ser Asn Arg Asp Ser Gly
50 55 60
Ala Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
65 70 75 80
Glu Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met
85 90 95
Gln Gly Thr Leu Trp Pro Pro Thr Phe Gly Gln Gly Thr Lys Val Asp
100 105 110
Ile Lys
<210> 148
<211> 110
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_12
<400> 148
Ala Ser Gln Ser Val Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly
20 25 30
Gly Tyr Asn Phe Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Met Ile Tyr Glu Val Thr Asn Arg Pro Ser Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser His Ala
85 90 95
Ser Pro Arg Val Phe Gly Thr Gly Thr Lys Val Thr Val Leu
100 105 110
<210> 149
<211> 113
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_13
<400> 149
Ala Ser Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu Ser Pro
1 5 10 15
Gly Lys Thr Val Thr Ile Ser Cys Thr Arg Ser Ser Gly Ser Ile Ala
20 25 30
Ser Asn Tyr Val Gln Trp Tyr Gln Gln Arg Pro Gly Ser Ser Pro Ser
35 40 45
Thr Val Ile Tyr Glu Asp Asn Gln Arg Pro Ser Gly Val Pro Asp Arg
50 55 60
Phe Ser Gly Ser Ile Asp Ser Ser Ser Asn Ser Ala Ser Leu Thr Ile
65 70 75 80
Ser Gly Leu Arg Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr
85 90 95
Asp Ser Ser Ile Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val
100 105 110
Leu
<210> 150
<211> 113
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_14
<400> 150
Ala Ser Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu Ser Pro
1 5 10 15
Gly Lys Thr Val Thr Ile Ser Cys Thr Arg Ser Arg Gly Ser Ile Ala
20 25 30
Gly Asn Tyr Val His Trp Tyr Gln Gln Arg Pro Gly Arg Ala Pro Thr
35 40 45
Thr Val Ile Tyr Arg Asp Lys Glu Arg Pro Ser Gly Val Pro Asp Arg
50 55 60
Ile Ser Gly Ser Ile Asp Ser Ser Ser Asn Ser Ala Ser Leu Thr Ile
65 70 75 80
Ser Gly Leu Lys Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr
85 90 95
Asp Ser Ser Thr His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val
100 105 110
Leu
<210> 151
<211> 110
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_15
<400> 151
Ala Ser Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly
20 25 30
Gly Tyr Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Met Ile Tyr Asp Val Ser Asn Arg Pro Ser Gly Val Ser Asn
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Gly
85 90 95
Ser Gly Ser Val Phe Gly Thr Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 152
<211> 112
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_16
<400> 152
Ala Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Val Thr Phe Ser Cys Thr Gly Thr Ser Ser Asp Ile Gly
20 25 30
Ala Phe Asn Ser Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Leu Ile Tyr Glu Ile Thr Lys Arg Pro Ser Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Val Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Thr Ser Tyr Ala
85 90 95
Gly Ser Asn Thr Leu Ile Phe Gly Gly Gly Thr Lys Val Thr Val Leu
100 105 110
<210> 153
<211> 110
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_18
<400> 153
Ala Ser Ser Tyr Glu Leu Thr Gln Pro Pro Ser Val Thr Glu Ser Pro
1 5 10 15
Gly Gln Thr Ala Arg Ile Thr Cys Ser Gly Asp Ala Leu Ala Lys Gln
20 25 30
Tyr Ala Tyr Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val
35 40 45
Ile Tyr Arg Asp Ser Glu Arg Pro Ser Glu Ile Pro Glu Arg Phe Ser
50 55 60
Gly Ser Ser Ser Gly Thr Thr Val Thr Leu Thr Ile Ser Gly Val Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Ala Asp Ser Ser Gly
85 90 95
Thr Tyr Thr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 154
<211> 113
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_19
<400> 154
Ala Ser Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu Ser Pro
1 5 10 15
Gly Lys Thr Val Thr Ile Ser Cys Thr Arg Ser Ser Gly Ser Ile Ala
20 25 30
Ser Asn Tyr Val Gln Trp Tyr Gln Gln Arg Pro Gly Ser Pro Pro Ile
35 40 45
Thr Leu Ile Tyr Asp Asp Asp Gln Arg Pro Ser Gly Val Pro His Arg
50 55 60
Phe Ser Gly Ser Ile Asp Thr Ser Ser Asn Pro Ala Ser Leu Thr Ile
65 70 75 80
Ser Gly Leu Lys Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr
85 90 95
Asp Ser Ser Asn His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val
100 105 110
Leu
<210> 155
<211> 108
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_20
<400> 155
Ala Ser Ser Tyr Glu Leu Thr His Pro Pro Ser Val Ser Val Ser Pro
1 5 10 15
Gly Gln Thr Ala Ser Ile Thr Cys Ser Gly Asp Lys Leu Gly Asp Lys
20 25 30
Phe Val Ser Trp Tyr His Gln Lys Pro Gly Gln Ser Pro Val Leu Val
35 40 45
Ile Tyr Gln Asp Ser Lys Arg Pro Ser Gly Ile Pro Glu Arg Phe Ser
50 55 60
Gly Ser Asn Ser Gly Asn Thr Ala Thr Leu Thr Ile Ser Gly Thr Arg
65 70 75 80
Ala Met Asp Glu Ala Asp Tyr Tyr Cys Gln Ala Trp Asp Ser Ser Thr
85 90 95
Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105
<210> 156
<211> 109
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_22
<400> 156
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Val Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Asn Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Ile
85 90 95
Pro Trp Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 157
<211> 109
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_23
<400> 157
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser
20 25 30
Asn Ser Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Leu Tyr Ala Ala Ser Arg Leu Glu Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Tyr Ser Thr
85 90 95
Pro Arg Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 158
<211> 115
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_24
<400> 158
Ala Ser Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser
1 5 10 15
Leu Gly Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu
20 25 30
Tyr Ser Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro
35 40 45
Gly Gln Pro Pro Lys Leu Leu Ile Ser Trp Ala Ser Thr Arg Glu Ser
50 55 60
Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
65 70 75 80
Leu Thr Ile Asn Ser Leu Gln Ser Glu Asp Val Ala Ile Tyr Tyr Cys
85 90 95
Gln Gln Tyr Tyr Ser Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu
100 105 110
Glu Ile Lys
115
<210> 159
<211> 110
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_25
<400> 159
Ala Ser Gln Ser Ala Leu Thr Gln Pro Arg Ser Val Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Val Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly
20 25 30
Gly Tyr Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Met Ile Tyr Glu Val Ser Asn Arg Pro Ser Gly Val Ser Asn
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Gly
85 90 95
Ser Gly Ser Val Phe Gly Thr Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 160
<211> 110
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_26
<400> 160
Ala Ser Gln Ser Gly Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly
20 25 30
Ser Tyr Asn Leu Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Met Ile Tyr Glu Val Ser Lys Arg Pro Ser Gly Val Ser Asn
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Phe Gly
85 90 95
Ser Gly Ser Ile Phe Gly Thr Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 161
<211> 110
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_27
<400> 161
Ala Ser Ser Tyr Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu
1 5 10 15
Gly Gln Thr Val Ser Ile Thr Cys Gln Gly Asp Ser Leu Arg Asn Phe
20 25 30
Tyr Ala Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val
35 40 45
Ile Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly
85 90 95
Asn His Leu Val Phe Gly Gly Gly Thr Gln Leu Thr Val Leu
100 105 110
<210> 162
<211> 108
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_28
<400> 162
Ala Ser Ser Tyr Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu
1 5 10 15
Gly Gln Thr Val Thr Ile Thr Cys Gln Gly Asp Ser Leu Arg Asn Tyr
20 25 30
Tyr Ala Ser Trp Tyr Arg Gln Lys Pro Gly Gln Thr Pro Val Leu Val
35 40 45
Val Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser
50 55 60
Val Ser Ala Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln
65 70 75 80
Ala Glu Asp Glu Gly Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly
85 90 95
Val Val Phe Gly Gly Gly Thr Lys Val Thr Val Leu
100 105
<210> 163
<211> 275
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_1
<400> 163
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ser Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Ser Ser Ser Ser Tyr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly His Trp Tyr Phe Asp Leu Trp Gly Arg Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala
130 135 140
Ser Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile
145 150 155 160
Ser Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys
165 170 175
Leu Leu Ile Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg
180 185 190
Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser
195 200 205
Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser
210 215 220
Thr Pro Val Thr Phe Gly Pro Gly Thr Lys Val Glu Ile Lys Arg Thr
225 230 235 240
Ala Ala Ala Ser Ala His His His His His His Lys Leu Asp Tyr Lys
245 250 255
Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp
260 265 270
Asp Asp Lys
275
<210> 164
<211> 279
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_2
<400> 164
Gln Met Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Thr Val Lys Ile Ser Cys Lys Val Ser Gly Tyr Pro Phe Thr Asp Tyr
20 25 30
Tyr Ile His Trp Val Gln Gln Ala Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Leu Val Asp Pro Glu Asp Gly Gln Ser Arg Ser Ala Glu Arg Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Thr Ser Thr Asp Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr Phe Pro Val Ala Gly Phe Tyr Gly Met Asp Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser
130 135 140
Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala
145 150 155 160
Ser Gln Asp Ile Ser Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly
165 170 175
Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly
180 185 190
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
195 200 205
Thr Ile Ser Gly Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu
210 215 220
Glu Asp Tyr Asn Tyr Leu Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu
225 230 235 240
Ile Lys Arg Thr Ala Ala Ala Ser Ala His His His His His His Lys
245 250 255
Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
260 265 270
Tyr Lys Asp Asp Asp Asp Lys
275
<210> 165
<211> 275
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_3
<400> 165
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ser Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Ser Ser Ser Ser Tyr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Trp Leu Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala
130 135 140
Ser Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile
145 150 155 160
Ser Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys
165 170 175
Leu Leu Ile Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg
180 185 190
Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser
195 200 205
Leu Gln Pro Glu Asp Phe Ala Thr Tyr Phe Cys Gln Gln Ser Tyr Ser
210 215 220
Thr Pro Gln Thr Phe Gly Gln Gly Thr Lys Val Asp Ile Lys Arg Thr
225 230 235 240
Ala Ala Ala Ser Ala His His His His His His Lys Leu Asp Tyr Lys
245 250 255
Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp
260 265 270
Asp Asp Lys
275
<210> 166
<211> 284
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_4
<400> 166
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Arg Val Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ser Ser Val Gly Trp Trp Ser Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Ala Ser Asp Ile Val Met Thr Gln Ser Pro Asp Ser
130 135 140
Leu Ala Val Ser Leu Gly Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser
145 150 155 160
Gln Ser Val Leu Ser Ser Ser Asn Asn Asn Asn Tyr Leu Ala Trp Tyr
165 170 175
Gln Gln Arg Pro Gly Gln Pro Pro Lys Leu Leu Phe Tyr Trp Ala Ser
180 185 190
Thr Arg Glu Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Ser Phe Thr Leu Thr Ile Thr Ser Leu Gln Ala Glu Asp Val Ala
210 215 220
Val Tyr Tyr Cys Gln Gln Tyr Tyr Ser Thr Pro Leu Thr Phe Gly Gly
225 230 235 240
Gly Thr Lys Leu Glu Ile Lys Arg Thr Ala Ala Ala Ser Ala His His
245 250 255
His His His His Lys Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys
260 265 270
Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
275 280
<210> 167
<211> 279
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_5
<400> 167
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Gly Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Ser Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Pro Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Thr Gly Gly Asp His Val Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser
130 135 140
Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala
145 150 155 160
Ser Gln Ser Ile Ser Ser Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly
165 170 175
Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly
180 185 190
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
195 200 205
Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln
210 215 220
Gln Ser Tyr Ser Thr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu
225 230 235 240
Ile Lys Arg Thr Ala Ala Ala Ser Ala His His His His His His Lys
245 250 255
Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
260 265 270
Tyr Lys Asp Asp Asp Asp Lys
275
<210> 168
<211> 279
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_6
<400> 168
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ala Asp Tyr Gly Val Val Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser
130 135 140
Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala
145 150 155 160
Ser Gln Ser Ile Ser Thr Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly
165 170 175
Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly
180 185 190
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
195 200 205
Thr Ile Ser Ser Pro Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln
210 215 220
Gln Ser Tyr Ser Thr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu
225 230 235 240
Ile Lys Arg Thr Ala Ala Ala Ser Ala His His His His His His Lys
245 250 255
Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
260 265 270
Tyr Lys Asp Asp Asp Asp Lys
275
<210> 169
<211> 283
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_7
<400> 169
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Trp Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Pro Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser His Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Asn Ile Lys Gln Asp Gly Ser Ile Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ile Gly Tyr Ser Ser Ser Ser Phe Asp Tyr Trp Gly Arg Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Ala Ser Asp Ile Val Met Thr Gln Ser Pro Leu Ser
130 135 140
Leu Pro Val Thr Pro Gly Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser
145 150 155 160
Gln Ser Leu Leu His Ser Asn Arg Phe Asn Tyr Leu Asp Trp Tyr Leu
165 170 175
Gln Lys Pro Gly Gln Ser Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn
180 185 190
Arg Ala Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr
195 200 205
Asp Phe Thr Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val
210 215 220
Tyr Tyr Cys Met Gln Gly Leu Gln Thr Pro Tyr Thr Phe Gly Gln Gly
225 230 235 240
Thr Lys Val Asp Ile Lys Arg Thr Ala Ala Ala Ser Ala His His His
245 250 255
His His His Lys Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp
260 265 270
His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
275 280
<210> 170
<211> 286
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_10
<400> 170
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Gly Ala Val Asp Phe Trp Arg Asn Gly Met Asp Val Trp
100 105 110
Gly Arg Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Ala Ser Asp Ile Val Met Thr Gln Pro
130 135 140
Pro Leu Ser Leu Pro Val Thr Leu Gly His Pro Ala Ser Ile Ser Cys
145 150 155 160
Lys Ser Ser Gln Ser Leu Glu Tyr Ser Asp Gly Asn Thr Tyr Leu Asn
165 170 175
Trp Phe Gln Gln Arg Pro Gly Gln Ser Pro Arg Arg Leu Ile Tyr Lys
180 185 190
Val Ser Asn Arg Asp Ser Gly Ala Pro Asp Arg Phe Ser Gly Ser Gly
195 200 205
Ser Gly Thr Asp Phe Thr Leu Glu Ile Ser Arg Val Glu Ala Glu Asp
210 215 220
Val Gly Val Tyr Tyr Cys Met Gln Gly Thr Leu Trp Pro Pro Thr Phe
225 230 235 240
Gly Gln Gly Thr Lys Val Asp Ile Lys Arg Thr Ala Ala Ala Ser Ala
245 250 255
His His His His His His Lys Leu Asp Tyr Lys Asp His Asp Gly Asp
260 265 270
Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
275 280 285
<210> 171
<211> 277
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_12
<400> 171
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Val Ser Ser Asn
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Tyr Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg His Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Val Ala Asn Gly Asp Phe Leu Asp Tyr Trp Gly Arg Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Ala Ser Gln Ser Val Leu Thr Gln Pro Ala Ser Val Ser Gly
130 135 140
Ser Pro Gly Gln Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp
145 150 155 160
Val Gly Gly Tyr Asn Phe Val Ser Trp Tyr Gln Gln His Pro Gly Lys
165 170 175
Ala Pro Lys Leu Met Ile Tyr Glu Val Thr Asn Arg Pro Ser Gly Val
180 185 190
Pro Asp Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr
195 200 205
Ile Ser Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser
210 215 220
His Ala Ser Pro Arg Val Phe Gly Thr Gly Thr Lys Val Thr Val Leu
225 230 235 240
Arg Thr Ala Ala Ala Ser Ala His His His His His His Lys Leu Asp
245 250 255
Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys
260 265 270
Asp Asp Asp Asp Lys
275
<210> 172
<211> 280
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_13
<400> 172
Gln Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ser Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Thr Ser Ser Tyr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Leu Gly Met Val Asp Pro Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Ala Ser Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu
130 135 140
Ser Pro Gly Lys Thr Val Thr Ile Ser Cys Thr Arg Ser Ser Gly Ser
145 150 155 160
Ile Ala Ser Asn Tyr Val Gln Trp Tyr Gln Gln Arg Pro Gly Ser Ser
165 170 175
Pro Ser Thr Val Ile Tyr Glu Asp Asn Gln Arg Pro Ser Gly Val Pro
180 185 190
Asp Arg Phe Ser Gly Ser Ile Asp Ser Ser Ser Asn Ser Ala Ser Leu
195 200 205
Thr Ile Ser Gly Leu Arg Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln
210 215 220
Ser Tyr Asp Ser Ser Ile Tyr Val Val Phe Gly Gly Gly Thr Lys Leu
225 230 235 240
Thr Val Leu Arg Thr Ala Ala Ala Ser Ala His His His His His His
245 250 255
Lys Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile
260 265 270
Asp Tyr Lys Asp Asp Asp Asp Lys
275 280
<210> 173
<211> 280
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_14
<400> 173
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Arg Ile Ser Cys Lys Gly Ser Gly Tyr Ser Phe Thr Ser Tyr
20 25 30
Trp Ile Ser Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ser Asp Ser Tyr Thr Asn Tyr Ser Pro Ser Phe
50 55 60
Pro Gly His Val Thr Ile Ser Ala Asp Lys Ser Ile Ser Thr Ala Tyr
65 70 75 80
Leu Gln Trp Ser Ser Leu Lys Ala Ser Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Ala Asp Thr Ala His Gly Met Asp Val Trp Gly Arg Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Ala Ser Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu
130 135 140
Ser Pro Gly Lys Thr Val Thr Ile Ser Cys Thr Arg Ser Arg Gly Ser
145 150 155 160
Ile Ala Gly Asn Tyr Val His Trp Tyr Gln Gln Arg Pro Gly Arg Ala
165 170 175
Pro Thr Thr Val Ile Tyr Arg Asp Lys Glu Arg Pro Ser Gly Val Pro
180 185 190
Asp Arg Ile Ser Gly Ser Ile Asp Ser Ser Ser Asn Ser Ala Ser Leu
195 200 205
Thr Ile Ser Gly Leu Lys Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln
210 215 220
Ser Tyr Asp Ser Ser Thr His Val Val Phe Gly Gly Gly Thr Lys Leu
225 230 235 240
Thr Val Leu Arg Thr Ala Ala Ala Ser Ala His His His His His His
245 250 255
Lys Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile
260 265 270
Asp Tyr Lys Asp Asp Asp Asp Lys
275 280
<210> 174
<211> 282
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_15
<400> 174
Glu Val Gln Leu Val Gln Ser Glu Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg His
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Leu Ile Asn Pro Ser Gly Ser Ser Thr Val Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Leu Thr Arg Asp Thr Ser Thr Ser Thr Asp Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Asn Ser His Leu Asp Gln Val Trp Trp Phe Asp Pro Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Ala Ser Gln Ser Ala Leu Thr Gln Pro
130 135 140
Ala Ser Val Ser Gly Ser Pro Gly Gln Ser Ile Thr Ile Ser Cys Thr
145 150 155 160
Gly Thr Ser Ser Asp Val Gly Gly Tyr Asn Tyr Val Ser Trp Tyr Gln
165 170 175
Gln His Pro Gly Lys Ala Pro Lys Leu Met Ile Tyr Asp Val Ser Asn
180 185 190
Arg Pro Ser Gly Val Ser Asn Arg Phe Ser Gly Ser Lys Ser Gly Asn
195 200 205
Thr Ala Ser Leu Thr Ile Ser Gly Leu Gln Ala Glu Asp Glu Ala Asp
210 215 220
Tyr Tyr Cys Ser Ser Tyr Gly Ser Gly Ser Val Phe Gly Thr Gly Thr
225 230 235 240
Lys Leu Thr Val Leu Arg Thr Ala Ala Ala Ser Ala His His His His
245 250 255
His His Lys Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His
260 265 270
Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
275 280
<210> 175
<211> 281
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_16
<400> 175
Glu Val Gln Leu Leu Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Tyr Gly Asp Phe Tyr Gly Met Asp Val Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Ala Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Ala
130 135 140
Ser Gly Ser Pro Gly Gln Ser Val Thr Phe Ser Cys Thr Gly Thr Ser
145 150 155 160
Ser Asp Ile Gly Ala Phe Asn Ser Val Ser Trp Tyr Gln Gln His Pro
165 170 175
Gly Lys Ala Pro Lys Leu Leu Ile Tyr Glu Ile Thr Lys Arg Pro Ser
180 185 190
Gly Val Pro Asp Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser
195 200 205
Leu Thr Ile Ser Val Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys
210 215 220
Thr Ser Tyr Ala Gly Ser Asn Thr Leu Ile Phe Gly Gly Gly Thr Lys
225 230 235 240
Val Thr Val Leu Arg Thr Ala Ala Ala Ser Ala His His His His His
245 250 255
His Lys Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp
260 265 270
Ile Asp Tyr Lys Asp Asp Asp Asp Lys
275 280
<210> 176
<211> 278
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_18
<400> 176
Glu Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Gly Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asn Pro Asn Ser Gly Gly Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Ala Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Leu Asp Leu Ser Ser Leu Asp Tyr Trp Gly Arg Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Ala Ser Ser Tyr Glu Leu Thr Gln Pro Pro Ser Val Thr
130 135 140
Glu Ser Pro Gly Gln Thr Ala Arg Ile Thr Cys Ser Gly Asp Ala Leu
145 150 155 160
Ala Lys Gln Tyr Ala Tyr Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
165 170 175
Val Leu Val Ile Tyr Arg Asp Ser Glu Arg Pro Ser Glu Ile Pro Glu
180 185 190
Arg Phe Ser Gly Ser Ser Ser Gly Thr Thr Val Thr Leu Thr Ile Ser
195 200 205
Gly Val Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Ala Asp
210 215 220
Ser Ser Gly Thr Tyr Thr Val Phe Gly Gly Gly Thr Lys Leu Thr Val
225 230 235 240
Leu Arg Thr Ala Ala Ala Ser Ala His His His His His His Lys Leu
245 250 255
Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr
260 265 270
Lys Asp Asp Asp Asp Lys
275
<210> 177
<211> 284
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_19
<400> 177
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Leu Thr Ser Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Arg Gly Tyr Ser Tyr Gly Asp Gly Met Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Ala Ser Asn Phe Met Leu Thr Gln Pro His
130 135 140
Ser Val Ser Glu Ser Pro Gly Lys Thr Val Thr Ile Ser Cys Thr Arg
145 150 155 160
Ser Ser Gly Ser Ile Ala Ser Asn Tyr Val Gln Trp Tyr Gln Gln Arg
165 170 175
Pro Gly Ser Pro Pro Ile Thr Leu Ile Tyr Asp Asp Asp Gln Arg Pro
180 185 190
Ser Gly Val Pro His Arg Phe Ser Gly Ser Ile Asp Thr Ser Ser Asn
195 200 205
Pro Ala Ser Leu Thr Ile Ser Gly Leu Lys Thr Glu Asp Glu Ala Asp
210 215 220
Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser Asn His Val Val Phe Gly Gly
225 230 235 240
Gly Thr Lys Leu Thr Val Leu Arg Thr Ala Ala Ala Ser Ala His His
245 250 255
His His His His Lys Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys
260 265 270
Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
275 280
<210> 178
<211> 277
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_20
<400> 178
Gln Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Val Asp Lys Ser Thr Arg Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Lys Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Asn Ser Arg Ser Asp Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Ala Ser Ser Tyr Glu Leu Thr His Pro Pro Ser Val
130 135 140
Ser Val Ser Pro Gly Gln Thr Ala Ser Ile Thr Cys Ser Gly Asp Lys
145 150 155 160
Leu Gly Asp Lys Phe Val Ser Trp Tyr His Gln Lys Pro Gly Gln Ser
165 170 175
Pro Val Leu Val Ile Tyr Gln Asp Ser Lys Arg Pro Ser Gly Ile Pro
180 185 190
Glu Arg Phe Ser Gly Ser Asn Ser Gly Asn Thr Ala Thr Leu Thr Ile
195 200 205
Ser Gly Thr Arg Ala Met Asp Glu Ala Asp Tyr Tyr Cys Gln Ala Trp
210 215 220
Asp Ser Ser Thr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
225 230 235 240
Arg Thr Ala Ala Ala Ser Ala His His His His His His Lys Leu Asp
245 250 255
Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys
260 265 270
Asp Asp Asp Asp Lys
275
<210> 179
<211> 279
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_22
<400> 179
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Thr Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Val Ser Gly Ser Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Ser Thr Ala Val Thr Asp Trp Phe Asp Pro Trp Gly Arg
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser
130 135 140
Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala
145 150 155 160
Ser Gln Asp Ile Ser Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly
165 170 175
Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly
180 185 190
Val Pro Ser Arg Phe Ser Val Ser Gly Ser Gly Thr Asp Phe Thr Leu
195 200 205
Thr Ile Ser Asn Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln
210 215 220
Gln Ser Tyr Ser Ile Pro Trp Thr Phe Gly Gln Gly Thr Lys Val Glu
225 230 235 240
Ile Lys Arg Thr Ala Ala Ala Ser Ala His His His His His His Lys
245 250 255
Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
260 265 270
Tyr Lys Asp Asp Asp Asp Lys
275
<210> 180
<211> 279
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_23
<400> 180
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Trp Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Glu Val Ala Ala Leu Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser
130 135 140
Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala
145 150 155 160
Ser Gln Gly Ile Ser Asn Ser Leu Ala Trp Tyr Gln Gln Lys Pro Gly
165 170 175
Lys Ala Pro Lys Leu Leu Leu Tyr Ala Ala Ser Arg Leu Glu Ser Gly
180 185 190
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu
195 200 205
Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln
210 215 220
Gln Tyr Tyr Ser Thr Pro Arg Thr Phe Gly Gly Gly Thr Lys Leu Glu
225 230 235 240
Ile Lys Arg Thr Ala Ala Ala Ser Ala His His His His His His Lys
245 250 255
Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
260 265 270
Tyr Lys Asp Asp Asp Asp Lys
275
<210> 181
<211> 287
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_24
<400> 181
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Ala Ser Val Ser Ser Asn
20 25 30
Ser Val Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Arg Trp Tyr Asn Asp Tyr Ala
50 55 60
Leu Ser Val Lys Ser Arg Ile Ile Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Asp Trp Ser Ser Thr Arg Ser Phe Asp Tyr Trp
100 105 110
Gly Arg Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Ala Ser Asp Ile Val Met Thr Gln Ser
130 135 140
Pro Asp Ser Leu Ala Val Ser Leu Gly Glu Arg Ala Thr Ile Asn Cys
145 150 155 160
Lys Ser Ser Gln Ser Val Leu Tyr Ser Ser Asn Asn Lys Asn Tyr Leu
165 170 175
Ala Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile Ser
180 185 190
Trp Ala Ser Thr Arg Glu Ser Gly Val Pro Asp Arg Phe Ser Gly Ser
195 200 205
Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Asn Ser Leu Gln Ser Glu
210 215 220
Asp Val Ala Ile Tyr Tyr Cys Gln Gln Tyr Tyr Ser Thr Pro Pro Thr
225 230 235 240
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Ala Ala Ala Ser
245 250 255
Ala His His His His His His Lys Leu Asp Tyr Lys Asp His Asp Gly
260 265 270
Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
275 280 285
<210> 182
<211> 283
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_25
<400> 182
Glu Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Leu Arg Asp Gly Tyr Asn Tyr Ile Gly Ser Leu Gly Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Ala Ser Gln Ser Ala Leu Thr Gln
130 135 140
Pro Arg Ser Val Ser Gly Ser Pro Gly Gln Ser Val Thr Ile Ser Cys
145 150 155 160
Thr Gly Thr Ser Ser Asp Val Gly Gly Tyr Asn Tyr Val Ser Trp Tyr
165 170 175
Gln Gln His Pro Gly Lys Ala Pro Lys Leu Met Ile Tyr Glu Val Ser
180 185 190
Asn Arg Pro Ser Gly Val Ser Asn Arg Phe Ser Gly Ser Lys Ser Gly
195 200 205
Asn Thr Ala Ser Leu Thr Ile Ser Gly Leu Gln Ala Glu Asp Glu Ala
210 215 220
Asp Tyr Tyr Cys Ser Ser Tyr Gly Ser Gly Ser Val Phe Gly Thr Gly
225 230 235 240
Thr Lys Leu Thr Val Leu Arg Thr Ala Ala Ala Ser Ala His His His
245 250 255
His His His Lys Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp
260 265 270
His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
275 280
<210> 183
<211> 280
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_26
<400> 183
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ser Ser Arg Gly Ser Gly Trp Phe Pro Leu Gly Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Ala Ser Gln Ser Gly Leu Thr Gln Pro Ala Ser
130 135 140
Val Ser Gly Ser Pro Gly Gln Ser Ile Thr Ile Ser Cys Thr Gly Thr
145 150 155 160
Ser Ser Asp Val Gly Ser Tyr Asn Leu Val Ser Trp Tyr Gln Gln His
165 170 175
Pro Gly Lys Ala Pro Lys Leu Met Ile Tyr Glu Val Ser Lys Arg Pro
180 185 190
Ser Gly Val Ser Asn Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala
195 200 205
Ser Leu Thr Ile Ser Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr
210 215 220
Cys Ser Ser Phe Gly Ser Gly Ser Ile Phe Gly Thr Gly Thr Lys Leu
225 230 235 240
Thr Val Leu Arg Thr Ala Ala Ala Ser Ala His His His His His His
245 250 255
Lys Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile
260 265 270
Asp Tyr Lys Asp Asp Asp Asp Lys
275 280
<210> 184
<211> 282
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_27
<400> 184
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Lys Ile Ser Cys Lys Ser Ser Gly Tyr Ser Phe Thr Ser Tyr
20 25 30
Trp Ile Gly Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Tyr Pro Gly Asp Ser Asp Thr Arg Tyr Ser Pro Ser Phe
50 55 60
Gln Gly Gln Val Thr Phe Ser Ala Asp Glu Ser Ile Ser Thr Ala Tyr
65 70 75 80
Leu Gln Trp Ser Ser Leu Lys Ala Ser Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg His Gly Ala Tyr Gly Asp Tyr Pro Asp Thr Phe Asp Ile Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Ala Ser Ser Tyr Glu Leu Thr Gln Asp
130 135 140
Pro Ala Val Ser Val Ala Leu Gly Gln Thr Val Ser Ile Thr Cys Gln
145 150 155 160
Gly Asp Ser Leu Arg Asn Phe Tyr Ala Asn Trp Tyr Gln Gln Lys Pro
165 170 175
Gly Gln Ala Pro Val Leu Val Ile Tyr Gly Lys Asn Asn Arg Pro Ser
180 185 190
Gly Ile Pro Asp Arg Phe Ser Gly Ser Ser Ser Gly Asn Thr Ala Ser
195 200 205
Leu Thr Ile Thr Gly Ala Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys
210 215 220
Asn Ser Arg Asp Ser Ser Gly Asn His Leu Val Phe Gly Gly Gly Thr
225 230 235 240
Gln Leu Thr Val Leu Arg Thr Ala Ala Ala Ser Ala His His His His
245 250 255
His His Lys Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His
260 265 270
Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
275 280
<210> 185
<211> 283
<212> PRT
<213> artificial sequence
<220>
<223> scFv sequence G4_28
<400> 185
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Ala Gly Gly Gly Ser Thr Asn Tyr Ala Gly Ser Val
50 55 60
Lys Gly Arg Phe Thr Val Ser Arg Asp Thr Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Lys Ser Tyr Val Asp Thr Ala Met Arg Tyr Tyr Tyr Tyr Tyr Met
100 105 110
Asp Val Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Ala Ser Ser Tyr Glu Leu
130 135 140
Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly Gln Thr Val Thr Ile
145 150 155 160
Thr Cys Gln Gly Asp Ser Leu Arg Asn Tyr Tyr Ala Ser Trp Tyr Arg
165 170 175
Gln Lys Pro Gly Gln Thr Pro Val Leu Val Val Tyr Gly Lys Asn Asn
180 185 190
Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Val Ser Ala Ser Gly Asn
195 200 205
Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala Glu Asp Glu Gly Asp
210 215 220
Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Val Val Phe Gly Gly Gly
225 230 235 240
Thr Lys Val Thr Val Leu Arg Thr Ala Ala Ala Ser Ala His His His
245 250 255
His His His Lys Leu Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp
260 265 270
His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
275 280
<210> 186
<211> 13
<212> PRT
<213> artificial sequence
<220>
<223> Linker
<400> 186
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
1 5 10
<210> 187
<211> 348
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_1
<400> 187
gaggtgcagc tgttggagtc tgggggaggc gtggtccagc ctgggaggcc cctgagactc 60
tcctgtgcag cgtctggatt caccttcagt agctatagca tgaactgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcatcc attagtagta gtagtagtta catatactac 180
gcagactcag tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaggacac 300
tggtacttcg atctctgggg ccgtggcacc ctggtcaccg tctcgagt 348
<210> 188
<211> 360
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_2
<400> 188
cagatgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggctac agtgaaaatc 60
tcctgcaagg tttctggata ccctttcacc gactactata tccactgggt gcaacaggcc 120
cctggaaaag ggcttgagtg gatgggactt gttgatcctg aggatgggca aagtagatcc 180
gcggagaggt tccagggcag agtcaccata accgcggaca cgtctacaga cacagcctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc aacattccca 300
gtggctggat tctacggtat ggacgtctgg ggccagggaa ccctggtcac cgtctcgagt 360
<210> 189
<211> 348
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_3
<400> 189
gaggtgcagc tggtggagtc cgggggaggc ttggtccagc cgggggggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt agctatagca tgaactgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcatcc attagtagta gtagtagtta catatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtgt attactgtgc gagaggaggg 300
tggctatatg actactgggg ccaaggaacc ctggtcaccg tctcgagt 348
<210> 190
<211> 357
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_4
<400> 190
caggtgcagc tggtggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc agctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaaaaa caccctgtat 240
ctgcaaatga gcagcctgag agtcgaagac acggccgtat attattgtgc gaaatcgtcg 300
gtgggctggt ggtcttttga ctactggggc caagggacaa tggtcaccgt ctcgagt 357
<210> 191
<211> 360
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_5
<400> 191
gaagtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cttctggtta cacctttacc agctacggta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggatgg atcggcgctt acaatggtaa cacaaactat 180
gcacagaagc tccagggcag agtcaccatg agcacagaca catccacgag cacagcctac 240
atggagctga ggagcccgag atctgacgac acggccgtgt attactgtgc gagaggcggg 300
acggggggtg accacgtctt tgcctactgg gggcaaggga ccacggtcac cgtctcgagt 360
<210> 192
<211> 360
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_6
<400> 192
gaggtgcagc tggtggagtc tgggggaggc ttggtacagc ctggggggcc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc agctatgcca tgaactgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagccgac 300
tacggggtgg tctactactt tgactactgg ggccaaggga caatggtcac cgtctcgagt 360
<210> 193
<211> 357
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_7
<400> 193
gaggtgcagc tggtggagtc tgggggaggc tgggtccagt ctggggggtc cctgagaccc 60
tcctgtgcag cctctggatt cacctttagt cactattgga tgagttgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtggccaac ataaagcaag atggaagtat catatactat 180
gcagactctg tgaagggccg attcaccatc tccagggaca acgccaagaa ctcagtgtat 240
ctgcaaatga acagcctgag agccgaggac acggctgtgt attactgtgc gagaattggg 300
tatagcagct cgtcttttga ctactggggc cgtggcaccc tggtcaccgt ctcgagt 357
<210> 194
<211> 366
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_10
<400> 194
caggtgcagc tggtggagtc tgggggaggc gtggtccagc ctgggaggcc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt agctatgcta tgcactgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagatggg 300
gccgtggatt tttggcgaaa cggtatggac gtctggggcc gtggcaccct ggtcaccgtc 360
tcgagt 366
<210> 195
<211> 351
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_12
<400> 195
gaggtgcagc tgttggagtc tggaggaggc ttggtccagc ctggggggtc cctgagactc 60
tcctgtgcag cctctgggtt caccgtcagt agcaactaca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagtt atttatagcg gtggtagcac atactacgca 180
gactccgtga agggccgatt caccatctcc cgacacaatt ccaagaacac gctgtatctt 240
caaatgaaca gcctgagagc tgaggacacg gccgtgtatt actgtgcgag agtagcgaac 300
ggtgactttc ttgactactg gggccgtggc accctggtca ccgtctcgag t 351
<210> 196
<211> 351
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_13
<400> 196
caggtgcagc tggtggagtc tggggctgag gtgaagaagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt agctatagca tgaactgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcatcc attagtggta ctagtagtta catatactac 180
gcagactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ctcactgtat 240
ctgcaaatga gcagcctgag agccgaggac acggctgttt attactgtgc gagaggaggg 300
ctcgggatgg tcgacccctg gggccaggga accctggtca ccgtctcgag t 351
<210> 197
<211> 351
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_14
<400> 197
gaagtgcagc tggtgcagtc cggagcagag gtgaaaaagc ccggggagtc tctgaggatc 60
tcctgtaagg gttctggata cagctttacc agctactgga tcagctgggt gcgccagatg 120
cccgggaaag gcctggagtg gatggggagg attgatccta gtgactctta taccaactac 180
agcccgtcct tcccaggcca cgtcaccatc tcagctgaca agtccatcag cactgcctac 240
ctgcagtgga gcagcctgaa ggcctcggac accgccatgt attactgtgc ggcggataca 300
gctcacggta tggacgtctg gggccgtggc accctggtca ccgtctcgag t 351
<210> 198
<211> 366
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_15
<400> 198
gaagtgcagc tggtgcagtc tgaggctgag gtgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg cctctggata caccttcacc aggcattata tgcactgggt gcgacaggcc 120
cccggacaag ggcttgagtg gatgggacta atcaacccta gtggtagtag cacagtctac 180
gcacagaagt tccagggcag agtcaccttg accagggaca cgtccacgag cacagactac 240
atggagctga gcagcctgag atctgaggac acggccgtct attattgtgc gagagataat 300
agtcacctcg accaggtttg gtggttcgac ccctggggcc agggcaccct ggtcaccgtc 360
tcgagt 366
<210> 199
<211> 357
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_16
<400> 199
gaggtgcagc tgttggagtc tggagctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta cacctttacc agctatggta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggatgg atcagcgctt acaatggtaa cacaaactat 180
gcacagaagc tccagggcag agtcaccatg accacagaca catccacgag cacagcctac 240
atggagctga ggagcctgag atctgacgac acggccgtgt attactgtgc gagagactac 300
ggtgacttct acggtatgga cgtctggggc caaggaaccc tggtcaccgt ctcgagt 357
<210> 200
<211> 354
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_18
<400> 200
gaggtgcagc tggtggagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggata caccttcacc ggctactata tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggacgg atcaacccta acagtggtgg cacaaactat 180
gcacagaagt ttcagggcag ggtcaccatg accagggacg cgtccatcag cacagcctac 240
atggagctga gcaggctgag atctgacgac acggccgtgt attactgtgc gagagatctt 300
gatctatcct cccttgacta ctggggccgt ggcaccctgg tcaccgtctc gagt 354
<210> 201
<211> 363
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_19
<400> 201
gaagtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg catctggata caccctcacc agctactata tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaata atcaacccta gtggtggtag cacaagctac 180
gcacagaagt tccagggcag agtcaccatg accagggaca cgtccacgag cacagtctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc gagagagcgt 300
ggatacagct atggtgacgg tatggacgtc tgggggcaag ggaccacggt caccgtctcg 360
agt 363
<210> 202
<211> 357
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_20
<400> 202
caggtgcagc tggtggagtc tggagctgag gtgaagaagc ctggggcctc ggtgaaggtc 60
tcctgcaagg cttctggagg caccttcagc agctatgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaggg atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag agtcacgatt accgtggaca aatccacgcg cacagcctac 240
atggagctga gcagcctgag atctaaggac acggccgtgt attactgtgc gagggggaat 300
agcagaagtg atgcttttga tatctggggc caagggacaa tggtcaccgt ctcgagt 357
<210> 203
<211> 360
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_22
<400> 203
caggtgcagt tggtggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc acctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcaact gttagtggta gtggtggtac cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaagac acggccgtat attactgtgc gaaagattca 300
acggcggtga ctgactggtt cgacccctgg ggccgtggca ccctggtcac cgtctcgagt 360
<210> 204
<211> 360
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_23
<400> 204
gaggtgcagc tggtggagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcag cgtctggatt caccttcagt agctatggca tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtggcagtt atatggtatg atggaagtaa taaatactat 180
gcagactccg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggctgtgt attactgtgc gagaggggaa 300
gtggctgcct tgtactactt tgactactgg ggccagggaa ccctggtcac cgtctcgagt 360
<210> 205
<211> 366
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_24
<400> 205
caggtacagc tgcagcagtc aggtccagga ctggtgaagc cctcgcagac cctctcactc 60
acctgtgcca tctccggggc cagtgtctct agcaacagtg ttgcttggaa ctggatcagg 120
cagtccccat cgagaggcct tgagtggctg gggaggacat actacaggtc caggtggtat 180
aatgattatg cattatctgt gaaaagtcga ataatcatca acccagacac atccaagaac 240
cagttctccc tgcagctgaa ctctgtgacc cccgaggaca cggctgtgta ttactgtgca 300
agagattgga gcagcacccg atcctttgac tactggggcc gtggcaccct ggtcaccgtc 360
tcgagt 366
<210> 206
<211> 369
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_25
<400> 206
gaggtgcagc tggtggagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cttctggagg caccttcagc agctatgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaggg atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag agtcacgatt accgcggaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc gagatctctt 300
agagatggct acaattacat cggaagttta ggctactggg gccagggcac cctggtcacc 360
gtctcgagt 369
<210> 207
<211> 360
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_26
<400> 207
caggtccagc ttgtgcagtc tggggctgag gtgaagaagc ctggatcctc ggtgaaggtc 60
tcctgcaagg cttctggagg caccttcagc agctatgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaggg atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag agtcacgatt accgcggacg aatccacgag cacagcttac 240
atggagctga gcagcctgag atctgaagac acggctgtgt attactgtgc gagctcccgg 300
ggcagtggct ggtttccttt gggttactgg ggccaaggaa ccctggtcac cgtctcgagt 360
<210> 208
<211> 366
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_27
<400> 208
caggtccagc tggtacagtc tggagcagag gtgaaaaagc ccggggagtc tctgaagatc 60
tcctgtaaga gttctggata cagctttacc agctactgga tcggctgggt gcgccagatg 120
cccgggaaag gcctggagtg gatggggatc atctatcctg gtgactctga taccagatac 180
agcccgtcct tccaaggcca ggtcaccttc tcagccgacg agtccatcag taccgcctac 240
ctgcagtgga gcagcctgaa ggcctcggac accgccatgt attactgtgc gagacatggc 300
gcctacggtg actacccgga tacttttgat atctggggcc agggcaccct ggtcaccgtc 360
tcgagt 366
<210> 209
<211> 375
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VH sequence G4_28
<400> 209
caggtgcagc tggtggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttgat gattatgcca tgcactgggt ccggcaagct 120
ccagggaagg ggctggagtg ggtctcaggt attagtgctg gtggtggtag cacaaactac 180
gcaggctccg tgaagggccg gttcaccgtc tccagggaca cgtccaagaa cacactttat 240
ctgcaaatga acagcctgag agccgaggac acggccgtgt attactgtgt gaagtcctac 300
gtggatacag ctatgcgcta ctactactac tacatggacg tctggggcca agggacaatg 360
gtcaccgtct cgagt 375
<210> 210
<211> 321
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_1
<400> 210
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc aggcgagtca ggacattagc aactatttaa attggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctacgat gcatccaatt tggaaacagg ggtcccatca 180
aggttcagtg gaagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg caacttacta ctgtcaacag agttacagta cccccgtcac tttcggccct 300
gggaccaagg tggaaatcaa a 321
<210> 211
<211> 321
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_2
<400> 211
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc aggcgagtca ggacattagc aactatttaa attggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatccagtt tgcaaagtgg ggtcccatca 180
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcgg cctgcagcct 240
gaagattttg caacttacta ctgtctagaa gattacaact acctgtggac gttcggccaa 300
gggaccaagc tggagatcaa a 321
<210> 212
<211> 321
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_3
<400> 212
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc aggcgagtca ggacattagc aactatttaa attggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctacgat gcatccaatt tggaaacagg ggtcccatca 180
aggttcagtg gaagtgggtc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg caacttactt ctgtcaacag agttacagta ccccccagac gttcggccaa 300
gggaccaaag tggatatcaa a 321
<210> 213
<211> 339
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_4
<400> 213
gatattgtga tgacccagtc tccagactcc ctggctgtgt ctctgggcga gagggccacc 60
atcaactgca agtccagcca gagtgttttg tccagctcca acaataacaa ctacttagct 120
tggtaccaac agagaccagg acagcctcct aagctgctct tttactgggc atctacccgg 180
gaatcggggg tccctgaccg attcagtggc agcgggtctg gaacatcttt cactctcacc 240
atcaccagcc tgcaggctga agatgtggcg gtttattact gtcagcaata ttattccact 300
cctctcactt tcggcggagg gaccaagctg gagatcaaa 339
<210> 214
<211> 321
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_5
<400> 214
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gagcattagc agctatttaa attggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatccagtt tgcaaagtgg ggtcccatca 180
aggttcagcg gcagtggatc tgggacagat ttcactctca ctatcagcag cctgcagcct 240
gaagattttg caacttacta ctgtcaacag agttacagta ccccctacac ttttggccag 300
gggaccaagg tggaaatcaa a 321
<210> 215
<211> 321
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_6
<400> 215
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gagcattagc acctatttaa attggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatccagtt tgcagagtgg ggtcccatca 180
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tccgcaacct 240
gaagattttg caacttacta ctgtcaacag agttacagta ccccgtacac ttttggccag 300
gggaccaagg tggaaatcaa a 321
<210> 216
<211> 336
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_7
<400> 216
gatattgtga tgacgcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtccagtca gagcctcctg catagtaata gattcaacta tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc taatcgggcc 180
tccggggtcc ctgacaggtt cagtggcagt ggatctggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaaggtct acaaactccg 300
tacacttttg gccaggggac caaagtggat atcaaa 336
<210> 217
<211> 336
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_10
<400> 217
gatattgtga tgacgcagcc tccactctcc ctgcccgtca cccttggaca tccggcctcc 60
atctcctgca agtctagtca aagcctcgaa tatagtgatg gaaacaccta cttgaattgg 120
tttcagcaga ggccaggcca atctccaagg cgcctcattt ataaggtttc taaccgggac 180
tctggggccc ccgacagatt cagcgggagt gggtcaggca ctgatttcac actggaaatc 240
agcagggtgg aggctgagga tgttggagtt tattactgta tgcaaggtac actctggcct 300
cccacgttcg gccaagggac caaagtggat atcaaa 336
<210> 218
<211> 324
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_12
<400> 218
cagtctgtgc tgactcagcc tgcctccgtg tctgggtctc ctggacagtc gatcaccatc 60
tcctgcactg gaaccagcag tgacgttggt ggttataact ttgtctcctg gtaccaacaa 120
cacccaggca aagcccccaa actcatgatt tatgaggtca ctaatcggcc ctcaggggtc 180
cctgatcggt tctctggctc caagtctggc aacacggcct ccctgaccat ctctgggctc 240
caggctgagg acgaggctga ttattactgc agctcacatg caagccccag ggtcttcgga 300
actgggacca aggtcaccgt ccta 324
<210> 219
<211> 333
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_13
<400> 219
aattttatgc tgactcagcc ccactctgtg tcggagtctc cggggaagac ggtaaccatc 60
tcctgcaccc gcagcagtgg cagcattgcc agcaactatg tgcagtggta ccagcagcgc 120
ccgggcagtt cccccagcac tgtgatctat gaggataacc aaagaccctc aggggtccct 180
gatcggttct ctggctccat cgacagctcc tccaactctg cctccctcac catctctgga 240
ctgaggactg aggacgaggc tgactactac tgtcagtctt atgatagcag catttatgtg 300
gtattcggcg gagggaccaa gctgaccgtc cta 333
<210> 220
<211> 333
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_14
<400> 220
aattttatgc tgactcagcc ccactctgtg tcggagtctc cggggaagac ggtaaccata 60
tcctgcaccc gcagccgtgg cagcattgcc ggcaactatg tgcactggta ccagcagcgc 120
ccagggcgtg cccccaccac tgtgatctat cgggataagg aaagaccctc tggggtccct 180
gatcgaatct ctggctccat cgacagctcc tccaactctg cctccctcac catctctgga 240
ctgaagactg aggacgaggc tgattactat tgtcagtctt atgatagcag cacccatgtg 300
gtattcggcg gagggaccaa gctgaccgtc cta 333
<210> 221
<211> 324
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_15
<400> 221
cagtctgcgc tgactcagcc tgcctccgtg tctgggtctc ctggacagtc gatcaccatc 60
tcctgcactg gaaccagcag tgacgttggt ggttataact atgtctcctg gtaccaacaa 120
cacccaggca aagcccccaa actcatgatt tatgacgtca gtaatcggcc ctcaggggtt 180
tctaatcgct tctctggctc caagtctggc aacacggcct ccctgaccat ctctgggctc 240
caggctgagg acgaggctga ttattactgc agctcgtatg gaagcggcag cgtcttcgga 300
actgggacca agctgaccgt ccta 324
<210> 222
<211> 330
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_16
<400> 222
cagtctgtgc tgactcagcc tccctccgcg tccgggtctc ctggacagtc agtcaccttc 60
tcctgcactg gaaccagcag tgacattggt gcttttaact ctgtctcttg gtaccaacag 120
cacccaggca aagcccccaa actcctaatt tatgagatca ctaagcggcc ctcaggggtc 180
cctgatcgct tctctggctc caagtctggc aacacggcct ccctgaccat ctctgtgctc 240
caggctgaag atgaggctga ttattactgc acctcatatg caggcagcaa cactttgatc 300
ttcggcggag ggaccaaggt caccgtccta 330
<210> 223
<211> 324
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_18
<400> 223
tcctatgagc tgacacagcc accctcggtg acagagtccc caggacagac ggccaggatc 60
acctgctctg gagatgcatt ggcaaagcaa tatgcttatt ggtaccagca gaagccaggc 120
caggcccctg tgttggtgat atatagagac agtgagaggc cttcagagat ccctgagcga 180
ttctctggct ccagctcagg gacaacagtc acgttgacca tcagtggagt ccaggcagaa 240
gacgaggctg actattactg tcaatcagca gacagcagtg gtacttatac agtatttggc 300
ggagggacca agctgaccgt ccta 324
<210> 224
<211> 333
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_19
<400> 224
aattttatgc tgactcagcc ccactctgtg tcggagtctc cggggaagac ggtcaccatc 60
tcctgcaccc gcagcagtgg cagcattgcc agcaactatg tacagtggta ccagcagcgc 120
ccgggcagtc cccccatcac tttgatatat gatgatgacc aaagaccctc tggggtccct 180
catcggttct ctggctccat cgacacctca tccaaccctg cctccctcac catctctgga 240
ctgaagactg aggacgaggc tgactactac tgtcagtctt atgatagcag caatcatgtg 300
gtattcggcg gagggaccaa gctgaccgtc cta 333
<210> 225
<211> 318
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_20
<400> 225
tcctatgagc tgactcatcc accctcagtg tccgtgtccc caggacagac agccagcatc 60
acctgctctg gagataaatt gggggataag tttgtttcct ggtatcacca aaagccaggc 120
cagtcccctg tgctggtcat ctatcaagat agcaagcggc cctcagggat ccctgagcgc 180
ttctcaggct ccaattctgg gaacacagcc actctgacca tcagcgggac ccgggctatg 240
gatgaggctg actattactg tcaggcgtgg gacagcagca ctgtggtatt cggcggaggg 300
accaagctga ccgtccta 318
<210> 226
<211> 321
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_22
<400> 226
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc aggcgagtca ggacattagc aactatttaa attggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatccagtc tgcaaagtgg ggtcccatca 180
aggttcagcg tcagtggatc tgggacagat ttcactctca ccatcagcaa cctgcagcct 240
gaagattttg caacttatta ctgtcaacag agttacagta tcccgtggac gttcggccaa 300
gggaccaagg tggagatcaa a 321
<210> 227
<211> 321
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_23
<400> 227
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcgagtca gggcattagc aattctttag cctggtatca gcagaaacca 120
gggaaagccc ctaagctcct gctctatgct gcgtccagat tggaaagtgg ggtcccatcc 180
aggtttagtg gcagtggatc tgggacggat tacaccctca ccatcagcag cctgcagcct 240
gaagattttg caacttatta ctgtcaacag tattatagta cccctcgcac tttcggcgga 300
gggaccaagc tggagatcaa a 321
<210> 228
<211> 339
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_24
<400> 228
gatattgtga tgacccagtc tccagactcc ctggctgtgt ctctgggcga gagggccacc 60
atcaactgca agtccagcca gagtgtttta tacagctcca acaataagaa ctacttagct 120
tggtaccagc agaaaccagg acagcctcct aagttgttga tttcctgggc ttctacccgg 180
gaatctgggg tccctgaccg attcagtggc agcgggtctg ggacagattt cactctcacc 240
atcaacagcc tacagtctga agatgtggca atttattact gtcagcaata ttattctacc 300
cctccgacgt tcggccaggg gaccaagctg gagatcaaa 339
<210> 229
<211> 324
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_25
<400> 229
cagtctgcgc tgactcagcc tcgctcagtg tccgggtctc ctggacagtc agtcaccatc 60
tcctgcactg gaaccagcag tgatgttggt ggttataact atgtctcctg gtaccaacag 120
cacccaggca aagcccccaa actcatgatt tatgaggtca gtaatcggcc ctcaggggtt 180
tctaatcgct tctctggctc caagtctggc aacacggcct ccctgaccat ctctgggctc 240
caggctgagg acgaggctga ttattactgc agctcgtatg gaagcggcag cgtcttcgga 300
actgggacca agctgaccgt ccta 324
<210> 230
<211> 324
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_26
<400> 230
cagtctgggc tgactcagcc tgcctccgtg tctgggtctc ctggacagtc gatcaccatc 60
tcctgcactg gaaccagcag tgatgttggg agttataacc ttgtctcctg gtaccaacag 120
cacccaggca aagcccccaa actcatgatt tatgaggtca gtaagcggcc ctcaggggtt 180
tctaatcgct tctctggctc caagtctggc aacacggcct ccctgaccat ctctgggctc 240
caggctgagg acgaggctga ttattactgc agctcgtttg gaagcggcag catcttcgga 300
actgggacca agctgaccgt ccta 324
<210> 231
<211> 324
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_27
<400> 231
tcctatgagc tgactcagga cccagctgtg tctgtggccc tgggacagac agtcagtatc 60
acatgccaag gagacagcct cagaaacttt tatgcaaact ggtaccagca aaagccagga 120
caggcccctg tacttgtcat ctatggtaaa aacaaccggc cctcagggat cccagaccga 180
ttctctggct ccagctcagg aaacacagct tccttgacca tcactggggc tcaggcggaa 240
gatgaggctg actattactg taactcccgg gacagcagtg gtaaccatct ggtattcggc 300
ggagggaccc agctcaccgt ccta 324
<210> 232
<211> 318
<212> DNA
<213> artificial sequence
<220>
<223> Nucleotide VL sequence G4_28
<400> 232
tcctatgagc tgactcagga ccctgctgtg tctgtggcct tgggacagac agtcacgatc 60
acatgccaag gagacagcct cagaaactat tatgcaagct ggtaccggca gaagccagga 120
cagacccctg tacttgtcgt ctatggtaaa aacaaccggc cctcagggat cccagaccga 180
ttctctgtct ccgcctcagg taacacagct tccttgacca tcactggggc tcaggcggaa 240
gatgagggtg actattactg taactcccgg gacagcagtg gtgtggtttt cggcggaggg 300
accaaggtca ccgtccta 318
<210> 233
<211> 662
<212> PRT
<213> artificial sequence
<220>
<223> G4_1 IgG1 antibody sequence?
<400> 233
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Val Thr Phe Gly Pro Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Leu Glu Ser Gly
210 215 220
Gly Gly Val Val Gln Pro Gly Arg Pro Leu Arg Leu Ser Cys Ala Ala
225 230 235 240
Ser Gly Phe Thr Phe Ser Ser Tyr Ser Met Asn Trp Val Arg Gln Ala
245 250 255
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Ser Ser Ser Ser
260 265 270
Tyr Ile Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
275 280 285
Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Lys Gly His Trp Tyr Phe Asp
305 310 315 320
Leu Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys
325 330 335
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
340 345 350
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
355 360 365
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
370 375 380
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
385 390 395 400
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
405 410 415
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
420 425 430
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
435 440 445
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
450 455 460
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
465 470 475 480
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
485 490 495
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
500 505 510
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
515 520 525
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
530 535 540
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
545 550 555 560
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn
565 570 575
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
580 585 590
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
595 600 605
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
610 615 620
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
625 630 635 640
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
645 650 655
Ser Leu Ser Pro Gly Lys
660
<210> 234
<211> 666
<212> PRT
<213> artificial sequence
<220>
<223> G4_2 IgG1 antibody sequence
<400> 234
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Gly Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Asp Tyr Asn Tyr
85 90 95
Leu Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Gln Met Gln Leu Val Gln Ser Gly
210 215 220
Ala Glu Val Lys Lys Pro Gly Ala Thr Val Lys Ile Ser Cys Lys Val
225 230 235 240
Ser Gly Tyr Pro Phe Thr Asp Tyr Tyr Ile His Trp Val Gln Gln Ala
245 250 255
Pro Gly Lys Gly Leu Glu Trp Met Gly Leu Val Asp Pro Glu Asp Gly
260 265 270
Gln Ser Arg Ser Ala Glu Arg Phe Gln Gly Arg Val Thr Ile Thr Ala
275 280 285
Asp Thr Ser Thr Asp Thr Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Thr Phe Pro Val Ala Gly Phe
305 310 315 320
Tyr Gly Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
325 330 335
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
340 345 350
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
355 360 365
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
370 375 380
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
385 390 395 400
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
405 410 415
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
420 425 430
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
435 440 445
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
450 455 460
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
465 470 475 480
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
485 490 495
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
500 505 510
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
515 520 525
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
530 535 540
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
545 550 555 560
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
565 570 575
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
580 585 590
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
595 600 605
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
610 615 620
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
625 630 635 640
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
645 650 655
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 235
<211> 662
<212> PRT
<213> artificial sequence
<220>
<223> G4_3 IgG1 antibody sequence
<400> 235
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Phe Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Gln Thr Phe Gly Gln Gly Thr Lys Val Asp Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Val Glu Ser Gly
210 215 220
Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
225 230 235 240
Ser Gly Phe Thr Phe Ser Ser Tyr Ser Met Asn Trp Val Arg Gln Ala
245 250 255
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Ser Ser Ser Ser
260 265 270
Tyr Ile Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
275 280 285
Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly Gly Trp Leu Tyr Asp
305 310 315 320
Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys
325 330 335
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
340 345 350
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
355 360 365
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
370 375 380
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
385 390 395 400
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
405 410 415
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
420 425 430
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
435 440 445
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
450 455 460
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
465 470 475 480
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
485 490 495
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
500 505 510
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
515 520 525
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
530 535 540
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
545 550 555 560
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn
565 570 575
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
580 585 590
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
595 600 605
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
610 615 620
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
625 630 635 640
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
645 650 655
Ser Leu Ser Pro Gly Lys
660
<210> 236
<211> 671
<212> PRT
<213> artificial sequence
<220>
<223> G4_4 IgG1 antibody sequence
<400> 236
Ala Ser Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser
1 5 10 15
Leu Gly Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu
20 25 30
Ser Ser Ser Asn Asn Asn Asn Tyr Leu Ala Trp Tyr Gln Gln Arg Pro
35 40 45
Gly Gln Pro Pro Lys Leu Leu Phe Tyr Trp Ala Ser Thr Arg Glu Ser
50 55 60
Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Ser Phe Thr
65 70 75 80
Leu Thr Ile Thr Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys
85 90 95
Gln Gln Tyr Tyr Ser Thr Pro Leu Thr Phe Gly Gly Gly Thr Lys Leu
100 105 110
Glu Ile Lys Arg Thr Ala Ala Ala Pro Ser Val Phe Ile Phe Pro Pro
115 120 125
Ser Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu
130 135 140
Asn Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn
145 150 155 160
Ala Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser
165 170 175
Lys Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala
180 185 190
Asp Tyr Glu Lys His Lys Leu Tyr Ala Cys Glu Val Thr His Gln Gly
195 200 205
Leu Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys Gln Val
210 215 220
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu
225 230 235 240
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr Ala Met
245 250 255
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ala
260 265 270
Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys Gly
275 280 285
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
290 295 300
Met Ser Ser Leu Arg Val Glu Asp Thr Ala Val Tyr Tyr Cys Ala Lys
305 310 315 320
Ser Ser Val Gly Trp Trp Ser Phe Asp Tyr Trp Gly Gln Gly Thr Met
325 330 335
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
340 345 350
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
355 360 365
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
370 375 380
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
385 390 395 400
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
405 410 415
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
420 425 430
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
435 440 445
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
450 455 460
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
465 470 475 480
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
485 490 495
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
500 505 510
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
515 520 525
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
530 535 540
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
545 550 555 560
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
565 570 575
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
580 585 590
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
595 600 605
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
610 615 620
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
625 630 635 640
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
645 650 655
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665 670
<210> 237
<211> 666
<212> PRT
<213> artificial sequence
<220>
<223> G4_5 IgG1 antibody sequence
<400> 237
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser
20 25 30
Ser Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Val Gln Ser Gly
210 215 220
Ala Glu Val Lys Lys Pro Gly Ser Ser Val Lys Val Ser Cys Lys Ala
225 230 235 240
Ser Gly Tyr Thr Phe Thr Ser Tyr Gly Ile Ser Trp Val Arg Gln Ala
245 250 255
Pro Gly Gln Gly Leu Glu Trp Met Gly Trp Ile Gly Ala Tyr Asn Gly
260 265 270
Asn Thr Asn Tyr Ala Gln Lys Leu Gln Gly Arg Val Thr Met Ser Thr
275 280 285
Asp Thr Ser Thr Ser Thr Ala Tyr Met Glu Leu Arg Ser Pro Arg Ser
290 295 300
Asp Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly Gly Thr Gly Gly Asp
305 310 315 320
His Val Phe Ala Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
325 330 335
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
340 345 350
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
355 360 365
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
370 375 380
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
385 390 395 400
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
405 410 415
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
420 425 430
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
435 440 445
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
450 455 460
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
465 470 475 480
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
485 490 495
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
500 505 510
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
515 520 525
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
530 535 540
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
545 550 555 560
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
565 570 575
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
580 585 590
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
595 600 605
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
610 615 620
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
625 630 635 640
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
645 650 655
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 238
<211> 666
<212> PRT
<213> artificial sequence
<220>
<223> G4_6 IgG1 antibody sequence
<400> 238
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser
20 25 30
Thr Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Pro
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Val Glu Ser Gly
210 215 220
Gly Gly Leu Val Gln Pro Gly Gly Pro Leu Arg Leu Ser Cys Ala Ala
225 230 235 240
Ser Gly Phe Thr Phe Ser Ser Tyr Ala Met Asn Trp Val Arg Gln Ala
245 250 255
Pro Gly Lys Gly Leu Glu Trp Val Ser Ala Ile Ser Gly Ser Gly Gly
260 265 270
Ser Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
275 280 285
Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Lys Ala Asp Tyr Gly Val Val
305 310 315 320
Tyr Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser
325 330 335
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
340 345 350
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
355 360 365
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
370 375 380
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
385 390 395 400
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
405 410 415
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
420 425 430
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
435 440 445
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
450 455 460
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
465 470 475 480
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
485 490 495
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
500 505 510
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
515 520 525
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
530 535 540
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
545 550 555 560
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
565 570 575
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
580 585 590
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
595 600 605
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
610 615 620
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
625 630 635 640
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
645 650 655
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 239
<211> 670
<212> PRT
<213> artificial sequence
<220>
<223> G4_7 IgG1 antibody sequence
<400> 239
Ala Ser Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr
1 5 10 15
Pro Gly Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu
20 25 30
His Ser Asn Arg Phe Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly
35 40 45
Gln Ser Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly
50 55 60
Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
65 70 75 80
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met
85 90 95
Gln Gly Leu Gln Thr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Asp
100 105 110
Ile Lys Arg Thr Ala Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
115 120 125
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
130 135 140
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
145 150 155 160
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
165 170 175
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
180 185 190
Tyr Glu Lys His Lys Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu
195 200 205
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys Glu Val Gln
210 215 220
Leu Val Glu Ser Gly Gly Gly Trp Val Gln Ser Gly Gly Ser Leu Arg
225 230 235 240
Pro Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser His Tyr Trp Met Ser
245 250 255
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ala Asn Ile
260 265 270
Lys Gln Asp Gly Ser Ile Ile Tyr Tyr Ala Asp Ser Val Lys Gly Arg
275 280 285
Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Val Tyr Leu Gln Met
290 295 300
Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Ile
305 310 315 320
Gly Tyr Ser Ser Ser Ser Phe Asp Tyr Trp Gly Arg Gly Thr Leu Val
325 330 335
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
340 345 350
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
355 360 365
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
370 375 380
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
385 390 395 400
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
405 410 415
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
420 425 430
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
435 440 445
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
450 455 460
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
465 470 475 480
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
485 490 495
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
500 505 510
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
515 520 525
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
530 535 540
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
545 550 555 560
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
565 570 575
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
580 585 590
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
595 600 605
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
610 615 620
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
625 630 635 640
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
645 650 655
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665 670
<210> 240
<211> 673
<212> PRT
<213> artificial sequence
<220>
<223> G4_10 IgG1 antibody sequence
<400> 240
Ala Ser Asp Ile Val Met Thr Gln Pro Pro Leu Ser Leu Pro Val Thr
1 5 10 15
Leu Gly His Pro Ala Ser Ile Ser Cys Lys Ser Ser Gln Ser Leu Glu
20 25 30
Tyr Ser Asp Gly Asn Thr Tyr Leu Asn Trp Phe Gln Gln Arg Pro Gly
35 40 45
Gln Ser Pro Arg Arg Leu Ile Tyr Lys Val Ser Asn Arg Asp Ser Gly
50 55 60
Ala Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
65 70 75 80
Glu Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met
85 90 95
Gln Gly Thr Leu Trp Pro Pro Thr Phe Gly Gln Gly Thr Lys Val Asp
100 105 110
Ile Lys Arg Thr Ala Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
115 120 125
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
130 135 140
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
145 150 155 160
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
165 170 175
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
180 185 190
Tyr Glu Lys His Lys Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu
195 200 205
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys Gln Val Gln
210 215 220
Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg Pro Leu Arg
225 230 235 240
Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr Ala Met His
245 250 255
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ala Ile
260 265 270
Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg
275 280 285
Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met
290 295 300
Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Lys Asp
305 310 315 320
Gly Ala Val Asp Phe Trp Arg Asn Gly Met Asp Val Trp Gly Arg Gly
325 330 335
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
340 345 350
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
355 360 365
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
370 375 380
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
385 390 395 400
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
405 410 415
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
420 425 430
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys
435 440 445
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
450 455 460
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
465 470 475 480
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
485 490 495
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
500 505 510
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
515 520 525
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
530 535 540
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
545 550 555 560
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
565 570 575
Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr
580 585 590
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
595 600 605
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
610 615 620
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
625 630 635 640
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
645 650 655
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
660 665 670
Lys
<210> 241
<211> 663
<212> PRT
<213> artificial sequence
<220>
<223> G4_12 IgG1 antibody sequence
<400> 241
Ala Ser Gln Ser Val Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly
20 25 30
Gly Tyr Asn Phe Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Met Ile Tyr Glu Val Thr Asn Arg Pro Ser Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser His Ala
85 90 95
Ser Pro Arg Val Phe Gly Thr Gly Thr Lys Val Thr Val Leu Gly Gln
100 105 110
Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Thr Glu Cys Ser Glu Val Gln Leu Leu Glu Ser Gly
210 215 220
Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
225 230 235 240
Ser Gly Phe Thr Val Ser Ser Asn Tyr Met Ser Trp Val Arg Gln Ala
245 250 255
Pro Gly Lys Gly Leu Glu Trp Val Ser Val Ile Tyr Ser Gly Gly Ser
260 265 270
Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg His
275 280 285
Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu
290 295 300
Asp Thr Ala Val Tyr Tyr Cys Ala Arg Val Ala Asn Gly Asp Phe Leu
305 310 315 320
Asp Tyr Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
325 330 335
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
340 345 350
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
355 360 365
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
370 375 380
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
385 390 395 400
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
405 410 415
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
420 425 430
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
435 440 445
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
450 455 460
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
465 470 475 480
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
485 490 495
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
500 505 510
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
515 520 525
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
530 535 540
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
545 550 555 560
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys
565 570 575
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
580 585 590
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
595 600 605
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
610 615 620
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
625 630 635 640
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
645 650 655
Leu Ser Leu Ser Pro Gly Lys
660
<210> 242
<211> 666
<212> PRT
<213> artificial sequence
<220>
<223> G4_13 IgG1 antibody sequence
<400> 242
Ala Ser Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu Ser Pro
1 5 10 15
Gly Lys Thr Val Thr Ile Ser Cys Thr Arg Ser Ser Gly Ser Ile Ala
20 25 30
Ser Asn Tyr Val Gln Trp Tyr Gln Gln Arg Pro Gly Ser Ser Pro Ser
35 40 45
Thr Val Ile Tyr Glu Asp Asn Gln Arg Pro Ser Gly Val Pro Asp Arg
50 55 60
Phe Ser Gly Ser Ile Asp Ser Ser Ser Asn Ser Ala Ser Leu Thr Ile
65 70 75 80
Ser Gly Leu Arg Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr
85 90 95
Asp Ser Ser Ile Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val
100 105 110
Leu Gly Gln Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser
115 120 125
Ser Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser
130 135 140
Asp Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser
145 150 155 160
Pro Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn
165 170 175
Asn Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp
180 185 190
Lys Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr
195 200 205
Val Glu Lys Thr Val Ala Pro Thr Glu Cys Ser Gln Val Gln Leu Val
210 215 220
Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Gly Ser Leu Arg Leu Ser
225 230 235 240
Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr Ser Met Asn Trp Val
245 250 255
Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly
260 265 270
Thr Ser Ser Tyr Ile Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr
275 280 285
Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met Ser Ser
290 295 300
Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly Gly Leu
305 310 315 320
Gly Met Val Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
325 330 335
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
340 345 350
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
355 360 365
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
370 375 380
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
385 390 395 400
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
405 410 415
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
420 425 430
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
435 440 445
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
450 455 460
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
465 470 475 480
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
485 490 495
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
500 505 510
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
515 520 525
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
530 535 540
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
545 550 555 560
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
565 570 575
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
580 585 590
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
595 600 605
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
610 615 620
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
625 630 635 640
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
645 650 655
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 243
<211> 666
<212> PRT
<213> artificial sequence
<220>
<223> G4_14 IgG1 antibody sequence
<400> 243
Ala Ser Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu Ser Pro
1 5 10 15
Gly Lys Thr Val Thr Ile Ser Cys Thr Arg Ser Arg Gly Ser Ile Ala
20 25 30
Gly Asn Tyr Val His Trp Tyr Gln Gln Arg Pro Gly Arg Ala Pro Thr
35 40 45
Thr Val Ile Tyr Arg Asp Lys Glu Arg Pro Ser Gly Val Pro Asp Arg
50 55 60
Ile Ser Gly Ser Ile Asp Ser Ser Ser Asn Ser Ala Ser Leu Thr Ile
65 70 75 80
Ser Gly Leu Lys Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr
85 90 95
Asp Ser Ser Thr His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val
100 105 110
Leu Gly Gln Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser
115 120 125
Ser Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser
130 135 140
Asp Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser
145 150 155 160
Pro Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn
165 170 175
Asn Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp
180 185 190
Lys Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr
195 200 205
Val Glu Lys Thr Val Ala Pro Thr Glu Cys Ser Glu Val Gln Leu Val
210 215 220
Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu Ser Leu Arg Ile Ser
225 230 235 240
Cys Lys Gly Ser Gly Tyr Ser Phe Thr Ser Tyr Trp Ile Ser Trp Val
245 250 255
Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met Gly Arg Ile Asp Pro
260 265 270
Ser Asp Ser Tyr Thr Asn Tyr Ser Pro Ser Phe Pro Gly His Val Thr
275 280 285
Ile Ser Ala Asp Lys Ser Ile Ser Thr Ala Tyr Leu Gln Trp Ser Ser
290 295 300
Leu Lys Ala Ser Asp Thr Ala Met Tyr Tyr Cys Ala Ala Asp Thr Ala
305 310 315 320
His Gly Met Asp Val Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser
325 330 335
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
340 345 350
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
355 360 365
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
370 375 380
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
385 390 395 400
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
405 410 415
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
420 425 430
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
435 440 445
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
450 455 460
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
465 470 475 480
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
485 490 495
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
500 505 510
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
515 520 525
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
530 535 540
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
545 550 555 560
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
565 570 575
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
580 585 590
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
595 600 605
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
610 615 620
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
625 630 635 640
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
645 650 655
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 244
<211> 668
<212> PRT
<213> artificial sequence
<220>
<223> G4_15 IgG1 antibody sequence
<400> 244
Ala Ser Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly
20 25 30
Gly Tyr Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Met Ile Tyr Asp Val Ser Asn Arg Pro Ser Gly Val Ser Asn
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Gly
85 90 95
Ser Gly Ser Val Phe Gly Thr Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Thr Glu Cys Ser Glu Val Gln Leu Val Gln Ser Glu
210 215 220
Ala Glu Val Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala
225 230 235 240
Ser Gly Tyr Thr Phe Thr Arg His Tyr Met His Trp Val Arg Gln Ala
245 250 255
Pro Gly Gln Gly Leu Glu Trp Met Gly Leu Ile Asn Pro Ser Gly Ser
260 265 270
Ser Thr Val Tyr Ala Gln Lys Phe Gln Gly Arg Val Thr Leu Thr Arg
275 280 285
Asp Thr Ser Thr Ser Thr Asp Tyr Met Glu Leu Ser Ser Leu Arg Ser
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Asp Asn Ser His Leu Asp
305 310 315 320
Gln Val Trp Trp Phe Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val
325 330 335
Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser
340 345 350
Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys
355 360 365
Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu
370 375 380
Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu
385 390 395 400
Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr
405 410 415
Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val
420 425 430
Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro
435 440 445
Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
450 455 460
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
465 470 475 480
Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe
485 490 495
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
500 505 510
Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
515 520 525
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
530 535 540
Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala
545 550 555 560
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
565 570 575
Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
580 585 590
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
595 600 605
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
610 615 620
Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
625 630 635 640
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
645 650 655
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 245
<211> 667
<212> PRT
<213> artificial sequence
<220>
<223> G4_16 IgG1 antibody sequence
<400> 245
Ala Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Val Thr Phe Ser Cys Thr Gly Thr Ser Ser Asp Ile Gly
20 25 30
Ala Phe Asn Ser Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Leu Ile Tyr Glu Ile Thr Lys Arg Pro Ser Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Val Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Thr Ser Tyr Ala
85 90 95
Gly Ser Asn Thr Leu Ile Phe Gly Gly Gly Thr Lys Val Thr Val Leu
100 105 110
Gly Gln Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
115 120 125
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
130 135 140
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
145 150 155 160
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
165 170 175
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
180 185 190
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
195 200 205
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser Glu Val Gln Leu Leu Glu
210 215 220
Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys
225 230 235 240
Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Gly Ile Ser Trp Val Arg
245 250 255
Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly Trp Ile Ser Ala Tyr
260 265 270
Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu Gln Gly Arg Val Thr Met
275 280 285
Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr Met Glu Leu Arg Ser Leu
290 295 300
Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys Ala Arg Asp Tyr Gly Asp
305 310 315 320
Phe Tyr Gly Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser
325 330 335
Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser
340 345 350
Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
355 360 365
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
370 375 380
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr
385 390 395 400
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln
405 410 415
Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp
420 425 430
Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
435 440 445
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro
450 455 460
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
465 470 475 480
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
485 490 495
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
500 505 510
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val
515 520 525
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
530 535 540
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
545 550 555 560
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
565 570 575
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
580 585 590
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
595 600 605
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
610 615 620
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
625 630 635 640
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
645 650 655
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 246
<211> 664
<212> PRT
<213> artificial sequence
<220>
<223> G4_18 IgG1 antibody sequence
<400> 246
Ala Ser Ser Tyr Glu Leu Thr Gln Pro Pro Ser Val Thr Glu Ser Pro
1 5 10 15
Gly Gln Thr Ala Arg Ile Thr Cys Ser Gly Asp Ala Leu Ala Lys Gln
20 25 30
Tyr Ala Tyr Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val
35 40 45
Ile Tyr Arg Asp Ser Glu Arg Pro Ser Glu Ile Pro Glu Arg Phe Ser
50 55 60
Gly Ser Ser Ser Gly Thr Thr Val Thr Leu Thr Ile Ser Gly Val Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Ala Asp Ser Ser Gly
85 90 95
Thr Tyr Thr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Thr Glu Cys Ser Glu Val Gln Leu Val Glu Ser Gly
210 215 220
Ala Glu Val Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala
225 230 235 240
Ser Gly Tyr Thr Phe Thr Gly Tyr Tyr Met His Trp Val Arg Gln Ala
245 250 255
Pro Gly Gln Gly Leu Glu Trp Met Gly Arg Ile Asn Pro Asn Ser Gly
260 265 270
Gly Thr Asn Tyr Ala Gln Lys Phe Gln Gly Arg Val Thr Met Thr Arg
275 280 285
Asp Ala Ser Ile Ser Thr Ala Tyr Met Glu Leu Ser Arg Leu Arg Ser
290 295 300
Asp Asp Thr Ala Val Tyr Tyr Cys Ala Arg Asp Leu Asp Leu Ser Ser
305 310 315 320
Leu Asp Tyr Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Ala Ser
325 330 335
Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr
340 345 350
Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro
355 360 365
Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val
370 375 380
His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser
385 390 395 400
Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile
405 410 415
Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val
420 425 430
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
435 440 445
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
450 455 460
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
465 470 475 480
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
485 490 495
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
500 505 510
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
515 520 525
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
530 535 540
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
545 550 555 560
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr
565 570 575
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
580 585 590
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
595 600 605
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
610 615 620
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
625 630 635 640
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
645 650 655
Ser Leu Ser Leu Ser Pro Gly Lys
660
<210> 247
<211> 670
<212> PRT
<213> artificial sequence
<220>
<223> G4_19 IgG1 antibody sequence
<400> 247
Ala Ser Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu Ser Pro
1 5 10 15
Gly Lys Thr Val Thr Ile Ser Cys Thr Arg Ser Ser Gly Ser Ile Ala
20 25 30
Ser Asn Tyr Val Gln Trp Tyr Gln Gln Arg Pro Gly Ser Pro Pro Ile
35 40 45
Thr Leu Ile Tyr Asp Asp Asp Gln Arg Pro Ser Gly Val Pro His Arg
50 55 60
Phe Ser Gly Ser Ile Asp Thr Ser Ser Asn Pro Ala Ser Leu Thr Ile
65 70 75 80
Ser Gly Leu Lys Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr
85 90 95
Asp Ser Ser Asn His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val
100 105 110
Leu Gly Gln Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser
115 120 125
Ser Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser
130 135 140
Asp Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser
145 150 155 160
Pro Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn
165 170 175
Asn Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp
180 185 190
Lys Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr
195 200 205
Val Glu Lys Thr Val Ala Pro Thr Glu Cys Ser Glu Val Gln Leu Val
210 215 220
Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser Val Lys Val Ser
225 230 235 240
Cys Lys Ala Ser Gly Tyr Thr Leu Thr Ser Tyr Tyr Met His Trp Val
245 250 255
Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly Ile Ile Asn Pro
260 265 270
Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe Gln Gly Arg Val Thr
275 280 285
Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr Met Glu Leu Ser Ser
290 295 300
Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Glu Arg Gly
305 310 315 320
Tyr Ser Tyr Gly Asp Gly Met Asp Val Trp Gly Gln Gly Thr Thr Val
325 330 335
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
340 345 350
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
355 360 365
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
370 375 380
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
385 390 395 400
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
405 410 415
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
420 425 430
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
435 440 445
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
450 455 460
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
465 470 475 480
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
485 490 495
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
500 505 510
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
515 520 525
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
530 535 540
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
545 550 555 560
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
565 570 575
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
580 585 590
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
595 600 605
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
610 615 620
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
625 630 635 640
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
645 650 655
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665 670
<210> 248
<211> 663
<212> PRT
<213> artificial sequence
<220>
<223> G4_20 IgG1 antibody sequence
<400> 248
Ala Ser Ser Tyr Glu Leu Thr His Pro Pro Ser Val Ser Val Ser Pro
1 5 10 15
Gly Gln Thr Ala Ser Ile Thr Cys Ser Gly Asp Lys Leu Gly Asp Lys
20 25 30
Phe Val Ser Trp Tyr His Gln Lys Pro Gly Gln Ser Pro Val Leu Val
35 40 45
Ile Tyr Gln Asp Ser Lys Arg Pro Ser Gly Ile Pro Glu Arg Phe Ser
50 55 60
Gly Ser Asn Ser Gly Asn Thr Ala Thr Leu Thr Ile Ser Gly Thr Arg
65 70 75 80
Ala Met Asp Glu Ala Asp Tyr Tyr Cys Gln Ala Trp Asp Ser Ser Thr
85 90 95
Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln Pro Ala
100 105 110
Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu Leu Gln
115 120 125
Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr Pro Gly
130 135 140
Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys Ala Gly
145 150 155 160
Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr Ala Ala
165 170 175
Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His Arg Ser
180 185 190
Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys Thr Val
195 200 205
Ala Pro Thr Glu Cys Ser Gln Val Gln Leu Val Glu Ser Gly Ala Glu
210 215 220
Val Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly
225 230 235 240
Gly Thr Phe Ser Ser Tyr Ala Ile Ser Trp Val Arg Gln Ala Pro Gly
245 250 255
Gln Gly Leu Glu Trp Met Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala
260 265 270
Asn Tyr Ala Gln Lys Phe Gln Gly Arg Val Thr Ile Thr Val Asp Lys
275 280 285
Ser Thr Arg Thr Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser Lys Asp
290 295 300
Thr Ala Val Tyr Tyr Cys Ala Arg Gly Asn Ser Arg Ser Asp Ala Phe
305 310 315 320
Asp Ile Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser Ala Ser Thr
325 330 335
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
340 345 350
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
355 360 365
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
370 375 380
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
385 390 395 400
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
405 410 415
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
420 425 430
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
435 440 445
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
450 455 460
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
465 470 475 480
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
485 490 495
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
500 505 510
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
515 520 525
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
530 535 540
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
545 550 555 560
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys
565 570 575
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
580 585 590
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
595 600 605
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
610 615 620
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
625 630 635 640
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
645 650 655
Leu Ser Leu Ser Pro Gly Lys
660
<210> 249
<211> 666
<212> PRT
<213> artificial sequence
<220>
<223> G4_22 IgG1 antibody sequence
<400> 249
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Val Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Asn Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Ile
85 90 95
Pro Trp Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Gln Val Gln Leu Val Glu Ser Gly
210 215 220
Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
225 230 235 240
Ser Gly Phe Thr Phe Ser Thr Tyr Ala Met Ser Trp Val Arg Gln Ala
245 250 255
Pro Gly Lys Gly Leu Glu Trp Val Ser Thr Val Ser Gly Ser Gly Gly
260 265 270
Thr Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
275 280 285
Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Lys Asp Ser Thr Ala Val Thr
305 310 315 320
Asp Trp Phe Asp Pro Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser
325 330 335
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
340 345 350
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
355 360 365
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
370 375 380
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
385 390 395 400
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
405 410 415
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
420 425 430
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
435 440 445
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
450 455 460
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
465 470 475 480
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
485 490 495
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
500 505 510
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
515 520 525
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
530 535 540
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
545 550 555 560
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
565 570 575
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
580 585 590
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
595 600 605
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
610 615 620
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
625 630 635 640
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
645 650 655
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 250
<211> 666
<212> PRT
<213> artificial sequence
<220>
<223> G4_23 IgG1 antibody sequence
<400> 250
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser
20 25 30
Asn Ser Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Leu Tyr Ala Ala Ser Arg Leu Glu Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Tyr Ser Thr
85 90 95
Pro Arg Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Val Glu Ser Gly
210 215 220
Gly Gly Val Val Gln Pro Gly Arg Ser Leu Arg Leu Ser Cys Ala Ala
225 230 235 240
Ser Gly Phe Thr Phe Ser Ser Tyr Gly Met His Trp Val Arg Gln Ala
245 250 255
Pro Gly Lys Gly Leu Glu Trp Val Ala Val Ile Trp Tyr Asp Gly Ser
260 265 270
Asn Lys Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
275 280 285
Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly Glu Val Ala Ala Leu
305 310 315 320
Tyr Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
325 330 335
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
340 345 350
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
355 360 365
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
370 375 380
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
385 390 395 400
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
405 410 415
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
420 425 430
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
435 440 445
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
450 455 460
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
465 470 475 480
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
485 490 495
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
500 505 510
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
515 520 525
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
530 535 540
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
545 550 555 560
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
565 570 575
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
580 585 590
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
595 600 605
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
610 615 620
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
625 630 635 640
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
645 650 655
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 251
<211> 674
<212> PRT
<213> artificial sequence
<220>
<223> G4_24 IgG1 antibody sequence
<400> 251
Ala Ser Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser
1 5 10 15
Leu Gly Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu
20 25 30
Tyr Ser Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro
35 40 45
Gly Gln Pro Pro Lys Leu Leu Ile Ser Trp Ala Ser Thr Arg Glu Ser
50 55 60
Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
65 70 75 80
Leu Thr Ile Asn Ser Leu Gln Ser Glu Asp Val Ala Ile Tyr Tyr Cys
85 90 95
Gln Gln Tyr Tyr Ser Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu
100 105 110
Glu Ile Lys Arg Thr Ala Ala Ala Pro Ser Val Phe Ile Phe Pro Pro
115 120 125
Ser Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu
130 135 140
Asn Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn
145 150 155 160
Ala Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser
165 170 175
Lys Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala
180 185 190
Asp Tyr Glu Lys His Lys Leu Tyr Ala Cys Glu Val Thr His Gln Gly
195 200 205
Leu Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys Gln Val
210 215 220
Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln Thr Leu
225 230 235 240
Ser Leu Thr Cys Ala Ile Ser Gly Ala Ser Val Ser Ser Asn Ser Val
245 250 255
Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu Trp Leu
260 265 270
Gly Arg Thr Tyr Tyr Arg Ser Arg Trp Tyr Asn Asp Tyr Ala Leu Ser
275 280 285
Val Lys Ser Arg Ile Ile Ile Asn Pro Asp Thr Ser Lys Asn Gln Phe
290 295 300
Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val Tyr Tyr
305 310 315 320
Cys Ala Arg Asp Trp Ser Ser Thr Arg Ser Phe Asp Tyr Trp Gly Arg
325 330 335
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
340 345 350
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
355 360 365
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
370 375 380
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
385 390 395 400
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
405 410 415
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
420 425 430
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
435 440 445
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
450 455 460
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
465 470 475 480
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
485 490 495
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
500 505 510
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
515 520 525
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
530 535 540
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
545 550 555 560
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
565 570 575
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
580 585 590
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
595 600 605
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
610 615 620
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
625 630 635 640
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
645 650 655
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
660 665 670
Gly Lys
<210> 252
<211> 669
<212> PRT
<213> artificial sequence
<220>
<223> G4_25 IgG1 antibody sequence
<400> 252
Ala Ser Gln Ser Ala Leu Thr Gln Pro Arg Ser Val Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Val Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly
20 25 30
Gly Tyr Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Met Ile Tyr Glu Val Ser Asn Arg Pro Ser Gly Val Ser Asn
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Gly
85 90 95
Ser Gly Ser Val Phe Gly Thr Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Thr Glu Cys Ser Glu Val Gln Leu Val Glu Ser Gly
210 215 220
Ala Glu Val Lys Lys Pro Gly Ser Ser Val Lys Val Ser Cys Lys Ala
225 230 235 240
Ser Gly Gly Thr Phe Ser Ser Tyr Ala Ile Ser Trp Val Arg Gln Ala
245 250 255
Pro Gly Gln Gly Leu Glu Trp Met Gly Gly Ile Ile Pro Ile Phe Gly
260 265 270
Thr Ala Asn Tyr Ala Gln Lys Phe Gln Gly Arg Val Thr Ile Thr Ala
275 280 285
Asp Lys Ser Thr Ser Thr Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Ser Leu Arg Asp Gly Tyr
305 310 315 320
Asn Tyr Ile Gly Ser Leu Gly Tyr Trp Gly Gln Gly Thr Leu Val Thr
325 330 335
Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro
340 345 350
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
355 360 365
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala
370 375 380
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly
385 390 395 400
Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
405 410 415
Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
420 425 430
Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys
435 440 445
Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
450 455 460
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
465 470 475 480
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys
485 490 495
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
500 505 510
Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu
515 520 525
Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
530 535 540
Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
545 550 555 560
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
565 570 575
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
580 585 590
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
595 600 605
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly
610 615 620
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
625 630 635 640
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
645 650 655
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 253
<211> 666
<212> PRT
<213> artificial sequence
<220>
<223> G4_26 IgG1 antibody sequence
<400> 253
Ala Ser Gln Ser Gly Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly
20 25 30
Ser Tyr Asn Leu Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Met Ile Tyr Glu Val Ser Lys Arg Pro Ser Gly Val Ser Asn
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Phe Gly
85 90 95
Ser Gly Ser Ile Phe Gly Thr Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Thr Glu Cys Ser Gln Val Gln Leu Val Gln Ser Gly
210 215 220
Ala Glu Val Lys Lys Pro Gly Ser Ser Val Lys Val Ser Cys Lys Ala
225 230 235 240
Ser Gly Gly Thr Phe Ser Ser Tyr Ala Ile Ser Trp Val Arg Gln Ala
245 250 255
Pro Gly Gln Gly Leu Glu Trp Met Gly Gly Ile Ile Pro Ile Phe Gly
260 265 270
Thr Ala Asn Tyr Ala Gln Lys Phe Gln Gly Arg Val Thr Ile Thr Ala
275 280 285
Asp Glu Ser Thr Ser Thr Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Ser Ser Arg Gly Ser Gly Trp
305 310 315 320
Phe Pro Leu Gly Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
325 330 335
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
340 345 350
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
355 360 365
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
370 375 380
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
385 390 395 400
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
405 410 415
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
420 425 430
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
435 440 445
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
450 455 460
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
465 470 475 480
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
485 490 495
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
500 505 510
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
515 520 525
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
530 535 540
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
545 550 555 560
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
565 570 575
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
580 585 590
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
595 600 605
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
610 615 620
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
625 630 635 640
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
645 650 655
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 254
<211> 668
<212> PRT
<213> artificial sequence
<220>
<223> G4_27 IgG1 antibody sequence
<400> 254
Ala Ser Ser Tyr Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu
1 5 10 15
Gly Gln Thr Val Ser Ile Thr Cys Gln Gly Asp Ser Leu Arg Asn Phe
20 25 30
Tyr Ala Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val
35 40 45
Ile Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly
85 90 95
Asn His Leu Val Phe Gly Gly Gly Thr Gln Leu Thr Val Leu Gly Gln
100 105 110
Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Thr Glu Cys Ser Gln Val Gln Leu Val Gln Ser Gly
210 215 220
Ala Glu Val Lys Lys Pro Gly Glu Ser Leu Lys Ile Ser Cys Lys Ser
225 230 235 240
Ser Gly Tyr Ser Phe Thr Ser Tyr Trp Ile Gly Trp Val Arg Gln Met
245 250 255
Pro Gly Lys Gly Leu Glu Trp Met Gly Ile Ile Tyr Pro Gly Asp Ser
260 265 270
Asp Thr Arg Tyr Ser Pro Ser Phe Gln Gly Gln Val Thr Phe Ser Ala
275 280 285
Asp Glu Ser Ile Ser Thr Ala Tyr Leu Gln Trp Ser Ser Leu Lys Ala
290 295 300
Ser Asp Thr Ala Met Tyr Tyr Cys Ala Arg His Gly Ala Tyr Gly Asp
305 310 315 320
Tyr Pro Asp Thr Phe Asp Ile Trp Gly Gln Gly Thr Leu Val Thr Val
325 330 335
Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser
340 345 350
Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys
355 360 365
Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu
370 375 380
Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu
385 390 395 400
Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr
405 410 415
Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val
420 425 430
Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro
435 440 445
Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
450 455 460
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
465 470 475 480
Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe
485 490 495
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
500 505 510
Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
515 520 525
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
530 535 540
Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala
545 550 555 560
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
565 570 575
Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
580 585 590
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
595 600 605
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
610 615 620
Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
625 630 635 640
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
645 650 655
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 255
<211> 669
<212> PRT
<213> artificial sequence
<220>
<223> G4_28 IgG1 antibody sequence
<400> 255
Ala Ser Ser Tyr Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu
1 5 10 15
Gly Gln Thr Val Thr Ile Thr Cys Gln Gly Asp Ser Leu Arg Asn Tyr
20 25 30
Tyr Ala Ser Trp Tyr Arg Gln Lys Pro Gly Gln Thr Pro Val Leu Val
35 40 45
Val Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser
50 55 60
Val Ser Ala Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln
65 70 75 80
Ala Glu Asp Glu Gly Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly
85 90 95
Val Val Phe Gly Gly Gly Thr Lys Val Thr Val Leu Gly Gln Pro Ala
100 105 110
Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu Leu Gln
115 120 125
Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr Pro Gly
130 135 140
Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys Ala Gly
145 150 155 160
Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr Ala Ala
165 170 175
Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His Arg Ser
180 185 190
Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys Thr Val
195 200 205
Ala Pro Thr Glu Cys Ser Gln Val Gln Leu Val Glu Ser Gly Gly Gly
210 215 220
Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly
225 230 235 240
Phe Thr Phe Asp Asp Tyr Ala Met His Trp Val Arg Gln Ala Pro Gly
245 250 255
Lys Gly Leu Glu Trp Val Ser Gly Ile Ser Ala Gly Gly Gly Ser Thr
260 265 270
Asn Tyr Ala Gly Ser Val Lys Gly Arg Phe Thr Val Ser Arg Asp Thr
275 280 285
Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp
290 295 300
Thr Ala Val Tyr Tyr Cys Val Lys Ser Tyr Val Asp Thr Ala Met Arg
305 310 315 320
Tyr Tyr Tyr Tyr Tyr Met Asp Val Trp Gly Gln Gly Thr Met Val Thr
325 330 335
Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro
340 345 350
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
355 360 365
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala
370 375 380
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly
385 390 395 400
Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
405 410 415
Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
420 425 430
Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys
435 440 445
Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
450 455 460
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
465 470 475 480
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys
485 490 495
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
500 505 510
Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu
515 520 525
Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
530 535 540
Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
545 550 555 560
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
565 570 575
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
580 585 590
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
595 600 605
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly
610 615 620
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
625 630 635 640
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
645 650 655
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 256
<211> 270
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4(4MNH) TRAC antigen sequence
<400> 256
Ser Ser Asn Leu Glu Gly Arg Thr Lys Ser Val Ile Arg Gln Thr Gly
1 5 10 15
Ser Ser Ala Glu Ile Thr Cys Asp Leu Ala Glu Gly Ser Thr Gly Tyr
20 25 30
Ile His Trp Tyr Leu His Gln Glu Gly Lys Ala Pro Gln Arg Leu Leu
35 40 45
Tyr Tyr Asp Ser Tyr Thr Ser Ser Val Val Leu Glu Ser Gly Ile Ser
50 55 60
Pro Gly Lys Tyr Asp Thr Tyr Gly Ser Thr Arg Lys Asn Leu Arg Met
65 70 75 80
Ile Leu Arg Asn Leu Ile Glu Asn Asp Ser Gly Val Tyr Tyr Cys Ala
85 90 95
Thr Trp Asp Glu Lys Tyr Tyr Lys Lys Leu Phe Gly Ser Gly Thr Thr
100 105 110
Leu Val Val Thr Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala
115 120 125
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
130 135 140
Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser
145 150 155 160
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro
165 170 175
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Ala Leu
180 185 190
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
195 200 205
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
210 215 220
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
225 230 235 240
Ala Trp Gly Arg Ala Asp Cys Thr Thr Ala Pro Ser Ala Gln Leu Glu
245 250 255
Lys Glu Leu Gln Ala Leu Glu Lys Glu Asn Ala Gln Leu Glu
260 265 270
<210> 257
<211> 282
<212> PRT
<213> artificial sequence
<220>
<223> V gamma 4 (4MNH) GV4TRBC leucine zipper heterodimer antigen
sequence
<400> 257
Ser Ser Asn Leu Glu Gly Arg Thr Lys Ser Val Ile Arg Gln Thr Gly
1 5 10 15
Ser Ser Ala Glu Ile Thr Cys Asp Leu Ala Glu Gly Ser Thr Gly Tyr
20 25 30
Ile His Trp Tyr Leu His Gln Glu Gly Lys Ala Pro Gln Arg Leu Leu
35 40 45
Tyr Tyr Asp Ser Tyr Thr Ser Ser Val Val Leu Glu Ser Gly Ile Ser
50 55 60
Pro Gly Lys Tyr Asp Thr Tyr Gly Ser Thr Arg Lys Asn Leu Arg Met
65 70 75 80
Ile Leu Arg Asn Leu Ile Glu Asn Asp Ser Gly Val Tyr Tyr Cys Ala
85 90 95
Thr Trp Asp Glu Lys Tyr Tyr Lys Lys Leu Phe Gly Ser Gly Thr Thr
100 105 110
Leu Val Val Thr Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala
115 120 125
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
130 135 140
Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser
145 150 155 160
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro
165 170 175
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Ala Leu
180 185 190
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
195 200 205
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
210 215 220
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
225 230 235 240
Ala Trp Gly Arg Ala Asp Cys Thr Thr Ala Pro Ser Ala Gln Leu Glu
245 250 255
Lys Glu Leu Gln Ala Leu Glu Lys Glu Asn Ala Gln Leu Glu Trp Glu
260 265 270
Leu Gln Ala Leu Glu Lys Glu Leu Ala Gln
275 280
<210> 258
<211> 348
<212> PRT
<213> artificial sequence
<220>
<223> V gamma 4 TRGV4(4MNH) Fc heterodimer antigen sequence
<400> 258
Ser Ser Asn Leu Glu Gly Arg Thr Lys Ser Val Ile Arg Gln Thr Gly
1 5 10 15
Ser Ser Ala Glu Ile Thr Cys Asp Leu Ala Glu Gly Ser Thr Gly Tyr
20 25 30
Ile His Trp Tyr Leu His Gln Glu Gly Lys Ala Pro Gln Arg Leu Leu
35 40 45
Tyr Tyr Asp Ser Tyr Thr Ser Ser Val Val Leu Glu Ser Gly Ile Ser
50 55 60
Pro Gly Lys Tyr Asp Thr Tyr Gly Ser Thr Arg Lys Asn Leu Arg Met
65 70 75 80
Ile Leu Arg Asn Leu Ile Glu Asn Asp Ser Gly Val Tyr Tyr Cys Ala
85 90 95
Thr Trp Asp Glu Lys Tyr Tyr Lys Lys Leu Phe Gly Ser Gly Thr Thr
100 105 110
Leu Val Val Thr Glu Asp Ala Ala Ala Asp Lys Thr His Thr Cys Pro
115 120 125
Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
130 135 140
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
145 150 155 160
Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe
165 170 175
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
180 185 190
Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
195 200 205
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
210 215 220
Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala
225 230 235 240
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
245 250 255
Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
260 265 270
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
275 280 285
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
290 295 300
Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
305 310 315 320
Gly Asn Val Phe Ser Cys Ser Val Ser His Glu Ala Leu His Ser His
325 330 335
His Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
340 345
<210> 259
<211> 282
<212> PRT
<213> artificial sequence
<220>
<223> V gamma 2 (4MNH) GV2TRBC leucine zipper heterodimer antigen
sequence
<400> 259
Ser Ser Asn Leu Glu Gly Arg Thr Lys Ser Val Ile Arg Gln Thr Gly
1 5 10 15
Ser Ser Ala Glu Ile Thr Cys Asp Leu Ala Glu Gly Ser Asn Gly Tyr
20 25 30
Ile His Trp Tyr Leu His Gln Glu Gly Lys Ala Pro Gln Arg Leu Gln
35 40 45
Tyr Tyr Asp Ser Tyr Asn Ser Lys Val Val Leu Glu Ser Gly Val Ser
50 55 60
Pro Gly Lys Tyr Tyr Thr Tyr Ala Ser Thr Arg Asn Asn Leu Arg Leu
65 70 75 80
Ile Leu Arg Asn Leu Ile Glu Asn Asp Ser Gly Val Tyr Tyr Cys Ala
85 90 95
Thr Trp Asp Glu Lys Tyr Tyr Lys Lys Leu Phe Gly Ser Gly Thr Thr
100 105 110
Leu Val Val Thr Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala
115 120 125
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
130 135 140
Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser
145 150 155 160
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro
165 170 175
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Ala Leu
180 185 190
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
195 200 205
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
210 215 220
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
225 230 235 240
Ala Trp Gly Arg Ala Asp Cys Thr Thr Ala Pro Ser Ala Gln Leu Glu
245 250 255
Lys Glu Leu Gln Ala Leu Glu Lys Glu Asn Ala Gln Leu Glu Trp Glu
260 265 270
Leu Gln Ala Leu Glu Lys Glu Leu Ala Gln
275 280
<210> 260
<211> 348
<212> PRT
<213> artificial sequence
<220>
<223> V gamma 2 TRGV2(4MNH) Fc heterodimer antigen sequence
<400> 260
Ser Ser Asn Leu Glu Gly Arg Thr Lys Ser Val Ile Arg Gln Thr Gly
1 5 10 15
Ser Ser Ala Glu Ile Thr Cys Asp Leu Ala Glu Gly Ser Asn Gly Tyr
20 25 30
Ile His Trp Tyr Leu His Gln Glu Gly Lys Ala Pro Gln Arg Leu Gln
35 40 45
Tyr Tyr Asp Ser Tyr Asn Ser Lys Val Val Leu Glu Ser Gly Val Ser
50 55 60
Pro Gly Lys Tyr Tyr Thr Tyr Ala Ser Thr Arg Asn Asn Leu Arg Leu
65 70 75 80
Ile Leu Arg Asn Leu Ile Glu Asn Asp Ser Gly Val Tyr Tyr Cys Ala
85 90 95
Thr Trp Asp Glu Lys Tyr Tyr Lys Lys Leu Phe Gly Ser Gly Thr Thr
100 105 110
Leu Val Val Thr Glu Asp Ala Ala Ala Asp Lys Thr His Thr Cys Pro
115 120 125
Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
130 135 140
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
145 150 155 160
Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe
165 170 175
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
180 185 190
Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
195 200 205
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
210 215 220
Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala
225 230 235 240
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
245 250 255
Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
260 265 270
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
275 280 285
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
290 295 300
Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
305 310 315 320
Gly Asn Val Phe Ser Cys Ser Val Ser His Glu Ala Leu His Ser His
325 330 335
His Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
340 345
<210> 261
<211> 107
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_1 no N-terminal AS
<400> 261
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Val
85 90 95
Thr Phe Gly Pro Gly Thr Lys Val Glu Ile Lys
100 105
<210> 262
<211> 107
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_2 no N-terminal AS
<400> 262
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Gly Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Asp Tyr Asn Tyr Leu Trp
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 263
<211> 107
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_3 no N-terminal AS
<400> 263
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Phe Cys Gln Gln Ser Tyr Ser Thr Pro Gln
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Asp Ile Lys
100 105
<210> 264
<211> 113
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_4 no N-terminal AS
<400> 264
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu Ser Ser
20 25 30
Ser Asn Asn Asn Asn Tyr Leu Ala Trp Tyr Gln Gln Arg Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Phe Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Ser Phe Thr Leu Thr
65 70 75 80
Ile Thr Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Thr Pro Leu Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile
100 105 110
Lys
<210> 265
<211> 107
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_5 no N-terminal AS
<400> 265
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 266
<211> 107
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_6 no N-terminal AS
<400> 266
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Thr Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Pro Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 267
<211> 112
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_7 no N-terminal AS
<400> 267
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Arg Phe Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Gly
85 90 95
Leu Gln Thr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Asp Ile Lys
100 105 110
<210> 268
<211> 112
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_10 no N-terminal AS
<400> 268
Asp Ile Val Met Thr Gln Pro Pro Leu Ser Leu Pro Val Thr Leu Gly
1 5 10 15
His Pro Ala Ser Ile Ser Cys Lys Ser Ser Gln Ser Leu Glu Tyr Ser
20 25 30
Asp Gly Asn Thr Tyr Leu Asn Trp Phe Gln Gln Arg Pro Gly Gln Ser
35 40 45
Pro Arg Arg Leu Ile Tyr Lys Val Ser Asn Arg Asp Ser Gly Ala Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Glu Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Gly
85 90 95
Thr Leu Trp Pro Pro Thr Phe Gly Gln Gly Thr Lys Val Asp Ile Lys
100 105 110
<210> 269
<211> 108
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_12 no N-terminal AS
<400> 269
Gln Ser Val Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro Gly Gln
1 5 10 15
Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly Gly Tyr
20 25 30
Asn Phe Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro Lys Leu
35 40 45
Met Ile Tyr Glu Val Thr Asn Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser His Ala Ser Pro
85 90 95
Arg Val Phe Gly Thr Gly Thr Lys Val Thr Val Leu
100 105
<210> 270
<211> 111
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_13 no N-terminal AS
<400> 270
Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu Ser Pro Gly Lys
1 5 10 15
Thr Val Thr Ile Ser Cys Thr Arg Ser Ser Gly Ser Ile Ala Ser Asn
20 25 30
Tyr Val Gln Trp Tyr Gln Gln Arg Pro Gly Ser Ser Pro Ser Thr Val
35 40 45
Ile Tyr Glu Asp Asn Gln Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Ile Asp Ser Ser Ser Asn Ser Ala Ser Leu Thr Ile Ser Gly
65 70 75 80
Leu Arg Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser
85 90 95
Ser Ile Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 271
<211> 111
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_14 no N-terminal AS
<400> 271
Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu Ser Pro Gly Lys
1 5 10 15
Thr Val Thr Ile Ser Cys Thr Arg Ser Arg Gly Ser Ile Ala Gly Asn
20 25 30
Tyr Val His Trp Tyr Gln Gln Arg Pro Gly Arg Ala Pro Thr Thr Val
35 40 45
Ile Tyr Arg Asp Lys Glu Arg Pro Ser Gly Val Pro Asp Arg Ile Ser
50 55 60
Gly Ser Ile Asp Ser Ser Ser Asn Ser Ala Ser Leu Thr Ile Ser Gly
65 70 75 80
Leu Lys Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser
85 90 95
Ser Thr His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 272
<211> 108
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_15 no N-terminal AS
<400> 272
Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro Gly Gln
1 5 10 15
Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly Gly Tyr
20 25 30
Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro Lys Leu
35 40 45
Met Ile Tyr Asp Val Ser Asn Arg Pro Ser Gly Val Ser Asn Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Gly Ser Gly
85 90 95
Ser Val Phe Gly Thr Gly Thr Lys Leu Thr Val Leu
100 105
<210> 273
<211> 110
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_16 no N-terminal AS
<400> 273
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Ser Pro Gly Gln
1 5 10 15
Ser Val Thr Phe Ser Cys Thr Gly Thr Ser Ser Asp Ile Gly Ala Phe
20 25 30
Asn Ser Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Glu Ile Thr Lys Arg Pro Ser Gly Val Pro Asp Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser Val Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Thr Ser Tyr Ala Gly Ser
85 90 95
Asn Thr Leu Ile Phe Gly Gly Gly Thr Lys Val Thr Val Leu
100 105 110
<210> 274
<211> 108
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_18 no N-terminal AS
<400> 274
Ser Tyr Glu Leu Thr Gln Pro Pro Ser Val Thr Glu Ser Pro Gly Gln
1 5 10 15
Thr Ala Arg Ile Thr Cys Ser Gly Asp Ala Leu Ala Lys Gln Tyr Ala
20 25 30
Tyr Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile Tyr
35 40 45
Arg Asp Ser Glu Arg Pro Ser Glu Ile Pro Glu Arg Phe Ser Gly Ser
50 55 60
Ser Ser Gly Thr Thr Val Thr Leu Thr Ile Ser Gly Val Gln Ala Glu
65 70 75 80
Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Ala Asp Ser Ser Gly Thr Tyr
85 90 95
Thr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105
<210> 275
<211> 111
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_19 no N-terminal AS
<400> 275
Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu Ser Pro Gly Lys
1 5 10 15
Thr Val Thr Ile Ser Cys Thr Arg Ser Ser Gly Ser Ile Ala Ser Asn
20 25 30
Tyr Val Gln Trp Tyr Gln Gln Arg Pro Gly Ser Pro Pro Ile Thr Leu
35 40 45
Ile Tyr Asp Asp Asp Gln Arg Pro Ser Gly Val Pro His Arg Phe Ser
50 55 60
Gly Ser Ile Asp Thr Ser Ser Asn Pro Ala Ser Leu Thr Ile Ser Gly
65 70 75 80
Leu Lys Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser
85 90 95
Ser Asn His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 276
<211> 106
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_20 no N-terminal AS
<400> 276
Ser Tyr Glu Leu Thr His Pro Pro Ser Val Ser Val Ser Pro Gly Gln
1 5 10 15
Thr Ala Ser Ile Thr Cys Ser Gly Asp Lys Leu Gly Asp Lys Phe Val
20 25 30
Ser Trp Tyr His Gln Lys Pro Gly Gln Ser Pro Val Leu Val Ile Tyr
35 40 45
Gln Asp Ser Lys Arg Pro Ser Gly Ile Pro Glu Arg Phe Ser Gly Ser
50 55 60
Asn Ser Gly Asn Thr Ala Thr Leu Thr Ile Ser Gly Thr Arg Ala Met
65 70 75 80
Asp Glu Ala Asp Tyr Tyr Cys Gln Ala Trp Asp Ser Ser Thr Val Val
85 90 95
Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105
<210> 277
<211> 107
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_22 no N-terminal AS
<400> 277
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Val
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Asn Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Ile Pro Trp
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 278
<211> 107
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_23 no N-terminal AS
<400> 278
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Asn Ser
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Leu
35 40 45
Tyr Ala Ala Ser Arg Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Tyr Ser Thr Pro Arg
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 279
<211> 113
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_24 no N-terminal AS
<400> 279
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu Tyr Ser
20 25 30
Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Ser Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Asn Ser Leu Gln Ser Glu Asp Val Ala Ile Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile
100 105 110
Lys
<210> 280
<211> 108
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_25 no N-terminal AS
<400> 280
Gln Ser Ala Leu Thr Gln Pro Arg Ser Val Ser Gly Ser Pro Gly Gln
1 5 10 15
Ser Val Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly Gly Tyr
20 25 30
Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro Lys Leu
35 40 45
Met Ile Tyr Glu Val Ser Asn Arg Pro Ser Gly Val Ser Asn Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Gly Ser Gly
85 90 95
Ser Val Phe Gly Thr Gly Thr Lys Leu Thr Val Leu
100 105
<210> 281
<211> 108
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_26 no N-terminal AS
<400> 281
Gln Ser Gly Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro Gly Gln
1 5 10 15
Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly Ser Tyr
20 25 30
Asn Leu Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro Lys Leu
35 40 45
Met Ile Tyr Glu Val Ser Lys Arg Pro Ser Gly Val Ser Asn Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Phe Gly Ser Gly
85 90 95
Ser Ile Phe Gly Thr Gly Thr Lys Leu Thr Val Leu
100 105
<210> 282
<211> 108
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_27 no N-terminal AS
<400> 282
Ser Tyr Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly Gln
1 5 10 15
Thr Val Ser Ile Thr Cys Gln Gly Asp Ser Leu Arg Asn Phe Tyr Ala
20 25 30
Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile Tyr
35 40 45
Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly Ser
50 55 60
Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala Glu
65 70 75 80
Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Asn His
85 90 95
Leu Val Phe Gly Gly Gly Thr Gln Leu Thr Val Leu
100 105
<210> 283
<211> 106
<212> PRT
<213> artificial sequence
<220>
<223> TRGV4 full light variable sequence G4_28 no N-terminal AS
<400> 283
Ser Tyr Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly Gln
1 5 10 15
Thr Val Thr Ile Thr Cys Gln Gly Asp Ser Leu Arg Asn Tyr Tyr Ala
20 25 30
Ser Trp Tyr Arg Gln Lys Pro Gly Gln Thr Pro Val Leu Val Val Tyr
35 40 45
Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Val Ser
50 55 60
Ala Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala Glu
65 70 75 80
Asp Glu Gly Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Val Val
85 90 95
Phe Gly Gly Gly Thr Lys Val Thr Val Leu
100 105
<210> 284
<211> 446
<212> PRT
<213> artificial sequence
<220>
<223> G4_1 IgG1 antibody heavy chain sequence
<400> 284
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ser Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Ser Ser Ser Ser Tyr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly His Trp Tyr Phe Asp Leu Trp Gly Arg Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 285
<211> 450
<212> PRT
<213> artificial sequence
<220>
<223> G4_2 IgG1 antibody heavy chain sequence
<400> 285
Gln Met Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Thr Val Lys Ile Ser Cys Lys Val Ser Gly Tyr Pro Phe Thr Asp Tyr
20 25 30
Tyr Ile His Trp Val Gln Gln Ala Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Leu Val Asp Pro Glu Asp Gly Gln Ser Arg Ser Ala Glu Arg Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Thr Ser Thr Asp Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr Phe Pro Val Ala Gly Phe Tyr Gly Met Asp Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly Lys
450
<210> 286
<211> 446
<212> PRT
<213> artificial sequence
<220>
<223> G4_3 IgG1 antibody heavy chain sequence
<400> 286
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ser Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Ser Ser Ser Ser Tyr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Trp Leu Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 287
<211> 449
<212> PRT
<213> artificial sequence
<220>
<223> G4_4 IgG1 antibody heavy chain sequence
<400> 287
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Arg Val Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ser Ser Val Gly Trp Trp Ser Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys
<210> 288
<211> 450
<212> PRT
<213> artificial sequence
<220>
<223> G4_5 IgG1 antibody heavy chain sequence
<400> 288
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Gly Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Ser Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Pro Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Thr Gly Gly Asp His Val Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly Lys
450
<210> 289
<211> 450
<212> PRT
<213> artificial sequence
<220>
<223> G4_6 IgG1 antibody heavy chain sequence
<400> 289
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ala Asp Tyr Gly Val Val Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly Lys
450
<210> 290
<211> 449
<212> PRT
<213> artificial sequence
<220>
<223> G4_7 IgG1 antibody heavy chain sequence
<400> 290
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Trp Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Pro Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser His Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Asn Ile Lys Gln Asp Gly Ser Ile Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ile Gly Tyr Ser Ser Ser Ser Phe Asp Tyr Trp Gly Arg Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys
<210> 291
<211> 452
<212> PRT
<213> artificial sequence
<220>
<223> G4_10 IgG1 antibody heavy chain sequence
<400> 291
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Gly Ala Val Asp Phe Trp Arg Asn Gly Met Asp Val Trp
100 105 110
Gly Arg Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
210 215 220
Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu
225 230 235 240
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
245 250 255
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
260 265 270
His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu
275 280 285
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
290 295 300
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
305 310 315 320
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro
325 330 335
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
340 345 350
Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val
355 360 365
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
370 375 380
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
385 390 395 400
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
405 410 415
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
420 425 430
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
435 440 445
Ser Pro Gly Lys
450
<210> 292
<211> 447
<212> PRT
<213> artificial sequence
<220>
<223> G4_12 IgG1 antibody heavy chain sequence
<400> 292
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Val Ser Ser Asn
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Tyr Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg His Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Val Ala Asn Gly Asp Phe Leu Asp Tyr Trp Gly Arg Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
210 215 220
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 293
<211> 447
<212> PRT
<213> artificial sequence
<220>
<223> G4_13 IgG1 antibody heavy chain sequence
<400> 293
Gln Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ser Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Thr Ser Ser Tyr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Leu Gly Met Val Asp Pro Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
210 215 220
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 294
<211> 447
<212> PRT
<213> artificial sequence
<220>
<223> G4_14 IgG1 antibody heavy chain sequence
<400> 294
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Arg Ile Ser Cys Lys Gly Ser Gly Tyr Ser Phe Thr Ser Tyr
20 25 30
Trp Ile Ser Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ser Asp Ser Tyr Thr Asn Tyr Ser Pro Ser Phe
50 55 60
Pro Gly His Val Thr Ile Ser Ala Asp Lys Ser Ile Ser Thr Ala Tyr
65 70 75 80
Leu Gln Trp Ser Ser Leu Lys Ala Ser Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Ala Asp Thr Ala His Gly Met Asp Val Trp Gly Arg Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
210 215 220
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 295
<211> 452
<212> PRT
<213> artificial sequence
<220>
<223> G4_15 IgG1 antibody heavy chain sequence
<400> 295
Glu Val Gln Leu Val Gln Ser Glu Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg His
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Leu Ile Asn Pro Ser Gly Ser Ser Thr Val Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Leu Thr Arg Asp Thr Ser Thr Ser Thr Asp Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Asn Ser His Leu Asp Gln Val Trp Trp Phe Asp Pro Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
210 215 220
Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu
225 230 235 240
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
245 250 255
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
260 265 270
His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu
275 280 285
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
290 295 300
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
305 310 315 320
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro
325 330 335
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
340 345 350
Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val
355 360 365
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
370 375 380
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
385 390 395 400
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
405 410 415
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
420 425 430
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
435 440 445
Ser Pro Gly Lys
450
<210> 296
<211> 449
<212> PRT
<213> artificial sequence
<220>
<223> G4_16 IgG1 antibody heavy chain sequence
<400> 296
Glu Val Gln Leu Leu Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Tyr Gly Asp Phe Tyr Gly Met Asp Val Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys
<210> 297
<211> 448
<212> PRT
<213> artificial sequence
<220>
<223> G4_18 IgG1 antibody heavy chain sequence
<400> 297
Glu Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Gly Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asn Pro Asn Ser Gly Gly Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Ala Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Leu Asp Leu Ser Ser Leu Asp Tyr Trp Gly Arg Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro
115 120 125
Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly
130 135 140
Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn
145 150 155 160
Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln
165 170 175
Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser
180 185 190
Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser
195 200 205
Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr
210 215 220
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
225 230 235 240
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
245 250 255
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
260 265 270
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
275 280 285
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
290 295 300
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
305 310 315 320
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
325 330 335
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
340 345 350
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
355 360 365
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
370 375 380
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
385 390 395 400
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
405 410 415
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
420 425 430
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 298
<211> 451
<212> PRT
<213> artificial sequence
<220>
<223> G4_19 IgG1 antibody heavy chain sequence
<400> 298
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Leu Thr Ser Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Arg Gly Tyr Ser Tyr Gly Asp Gly Met Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
225 230 235 240
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
245 250 255
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
260 265 270
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
275 280 285
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
290 295 300
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
305 310 315 320
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
325 330 335
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
340 345 350
Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
355 360 365
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
370 375 380
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
385 390 395 400
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
405 410 415
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
420 425 430
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
435 440 445
Pro Gly Lys
450
<210> 299
<211> 449
<212> PRT
<213> artificial sequence
<220>
<223> G4_20 IgG1 antibody heavy chain sequence
<400> 299
Gln Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Val Asp Lys Ser Thr Arg Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Lys Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Asn Ser Arg Ser Asp Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys
<210> 300
<211> 450
<212> PRT
<213> artificial sequence
<220>
<223> G4_22 IgG1 antibody heavy chain sequence
<400> 300
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Thr Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Val Ser Gly Ser Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Ser Thr Ala Val Thr Asp Trp Phe Asp Pro Trp Gly Arg
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly Lys
450
<210> 301
<211> 450
<212> PRT
<213> artificial sequence
<220>
<223> G4_23 IgG1 antibody heavy chain sequence
<400> 301
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Trp Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Glu Val Ala Ala Leu Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly Lys
450
<210> 302
<211> 452
<212> PRT
<213> artificial sequence
<220>
<223> G4_24 IgG1 antibody heavy chain sequence
<400> 302
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Ala Ser Val Ser Ser Asn
20 25 30
Ser Val Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Arg Trp Tyr Asn Asp Tyr Ala
50 55 60
Leu Ser Val Lys Ser Arg Ile Ile Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Asp Trp Ser Ser Thr Arg Ser Phe Asp Tyr Trp
100 105 110
Gly Arg Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
210 215 220
Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu
225 230 235 240
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
245 250 255
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
260 265 270
His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu
275 280 285
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
290 295 300
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
305 310 315 320
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro
325 330 335
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
340 345 350
Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val
355 360 365
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
370 375 380
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
385 390 395 400
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
405 410 415
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
420 425 430
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
435 440 445
Ser Pro Gly Lys
450
<210> 303
<211> 453
<212> PRT
<213> artificial sequence
<220>
<223> G4_25 IgG1 antibody heavy chain sequence
<400> 303
Glu Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Leu Arg Asp Gly Tyr Asn Tyr Ile Gly Ser Leu Gly Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 304
<211> 450
<212> PRT
<213> artificial sequence
<220>
<223> G4_26 IgG1 antibody heavy chain sequence
<400> 304
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ser Ser Arg Gly Ser Gly Trp Phe Pro Leu Gly Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly Lys
450
<210> 305
<211> 452
<212> PRT
<213> artificial sequence
<220>
<223> G4_27 IgG1 antibody heavy chain sequence
<400> 305
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Lys Ile Ser Cys Lys Ser Ser Gly Tyr Ser Phe Thr Ser Tyr
20 25 30
Trp Ile Gly Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Tyr Pro Gly Asp Ser Asp Thr Arg Tyr Ser Pro Ser Phe
50 55 60
Gln Gly Gln Val Thr Phe Ser Ala Asp Glu Ser Ile Ser Thr Ala Tyr
65 70 75 80
Leu Gln Trp Ser Ser Leu Lys Ala Ser Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg His Gly Ala Tyr Gly Asp Tyr Pro Asp Thr Phe Asp Ile Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
210 215 220
Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu
225 230 235 240
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
245 250 255
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
260 265 270
His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu
275 280 285
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
290 295 300
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
305 310 315 320
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro
325 330 335
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
340 345 350
Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val
355 360 365
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
370 375 380
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
385 390 395 400
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
405 410 415
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
420 425 430
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
435 440 445
Ser Pro Gly Lys
450
<210> 306
<211> 455
<212> PRT
<213> artificial sequence
<220>
<223> G4_28 IgG1 antibody heavy chain sequence
<400> 306
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Ala Gly Gly Gly Ser Thr Asn Tyr Ala Gly Ser Val
50 55 60
Lys Gly Arg Phe Thr Val Ser Arg Asp Thr Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Lys Ser Tyr Val Asp Thr Ala Met Arg Tyr Tyr Tyr Tyr Tyr Met
100 105 110
Asp Val Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser Ala Ser Thr
115 120 125
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
130 135 140
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
145 150 155 160
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
165 170 175
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
180 185 190
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
195 200 205
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
210 215 220
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
225 230 235 240
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
245 250 255
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
260 265 270
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
275 280 285
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
290 295 300
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
305 310 315 320
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
325 330 335
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
340 345 350
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys
355 360 365
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
370 375 380
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
385 390 395 400
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
405 410 415
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
420 425 430
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
435 440 445
Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 307
<211> 216
<212> PRT
<213> artificial sequence
<220>
<223> G4_1 IgG1 antibody light chain sequence
<400> 307
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Val Thr Phe Gly Pro Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 308
<211> 216
<212> PRT
<213> artificial sequence
<220>
<223> G4_2 IgG1 antibody light chain sequence
<400> 308
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Gly Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Asp Tyr Asn Tyr
85 90 95
Leu Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 309
<211> 216
<212> PRT
<213> artificial sequence
<220>
<223> G4_3 IgG1 antibody light chain sequence
<400> 309
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Phe Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Gln Thr Phe Gly Gln Gly Thr Lys Val Asp Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 310
<211> 222
<212> PRT
<213> artificial sequence
<220>
<223> G4_4 IgG1 antibody light chain sequence
<400> 310
Ala Ser Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser
1 5 10 15
Leu Gly Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu
20 25 30
Ser Ser Ser Asn Asn Asn Asn Tyr Leu Ala Trp Tyr Gln Gln Arg Pro
35 40 45
Gly Gln Pro Pro Lys Leu Leu Phe Tyr Trp Ala Ser Thr Arg Glu Ser
50 55 60
Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Ser Phe Thr
65 70 75 80
Leu Thr Ile Thr Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys
85 90 95
Gln Gln Tyr Tyr Ser Thr Pro Leu Thr Phe Gly Gly Gly Thr Lys Leu
100 105 110
Glu Ile Lys Arg Thr Ala Ala Ala Pro Ser Val Phe Ile Phe Pro Pro
115 120 125
Ser Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu
130 135 140
Asn Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn
145 150 155 160
Ala Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser
165 170 175
Lys Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala
180 185 190
Asp Tyr Glu Lys His Lys Leu Tyr Ala Cys Glu Val Thr His Gln Gly
195 200 205
Leu Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 311
<211> 216
<212> PRT
<213> artificial sequence
<220>
<223> G4_5 IgG1 antibody light chain sequence
<400> 311
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser
20 25 30
Ser Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 312
<211> 216
<212> PRT
<213> artificial sequence
<220>
<223> G4_6 IgG1 antibody light chain sequence
<400> 312
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser
20 25 30
Thr Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Pro
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 313
<211> 221
<212> PRT
<213> artificial sequence
<220>
<223> G4_7 IgG1 antibody light chain sequence
<400> 313
Ala Ser Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr
1 5 10 15
Pro Gly Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu
20 25 30
His Ser Asn Arg Phe Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly
35 40 45
Gln Ser Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly
50 55 60
Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
65 70 75 80
Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met
85 90 95
Gln Gly Leu Gln Thr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Asp
100 105 110
Ile Lys Arg Thr Ala Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
115 120 125
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
130 135 140
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
145 150 155 160
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
165 170 175
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
180 185 190
Tyr Glu Lys His Lys Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu
195 200 205
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 314
<211> 221
<212> PRT
<213> artificial sequence
<220>
<223> G4_10 IgG1 antibody light chain sequence
<400> 314
Ala Ser Asp Ile Val Met Thr Gln Pro Pro Leu Ser Leu Pro Val Thr
1 5 10 15
Leu Gly His Pro Ala Ser Ile Ser Cys Lys Ser Ser Gln Ser Leu Glu
20 25 30
Tyr Ser Asp Gly Asn Thr Tyr Leu Asn Trp Phe Gln Gln Arg Pro Gly
35 40 45
Gln Ser Pro Arg Arg Leu Ile Tyr Lys Val Ser Asn Arg Asp Ser Gly
50 55 60
Ala Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
65 70 75 80
Glu Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met
85 90 95
Gln Gly Thr Leu Trp Pro Pro Thr Phe Gly Gln Gly Thr Lys Val Asp
100 105 110
Ile Lys Arg Thr Ala Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
115 120 125
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
130 135 140
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
145 150 155 160
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
165 170 175
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
180 185 190
Tyr Glu Lys His Lys Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu
195 200 205
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 315
<211> 216
<212> PRT
<213> artificial sequence
<220>
<223> G4_12 IgG1 antibody light chain sequence
<400> 315
Ala Ser Gln Ser Val Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly
20 25 30
Gly Tyr Asn Phe Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Met Ile Tyr Glu Val Thr Asn Arg Pro Ser Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser His Ala
85 90 95
Ser Pro Arg Val Phe Gly Thr Gly Thr Lys Val Thr Val Leu Gly Gln
100 105 110
Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 316
<211> 219
<212> PRT
<213> artificial sequence
<220>
<223> G4_13 IgG1 antibody light chain sequence
<400> 316
Ala Ser Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu Ser Pro
1 5 10 15
Gly Lys Thr Val Thr Ile Ser Cys Thr Arg Ser Ser Gly Ser Ile Ala
20 25 30
Ser Asn Tyr Val Gln Trp Tyr Gln Gln Arg Pro Gly Ser Ser Pro Ser
35 40 45
Thr Val Ile Tyr Glu Asp Asn Gln Arg Pro Ser Gly Val Pro Asp Arg
50 55 60
Phe Ser Gly Ser Ile Asp Ser Ser Ser Asn Ser Ala Ser Leu Thr Ile
65 70 75 80
Ser Gly Leu Arg Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr
85 90 95
Asp Ser Ser Ile Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val
100 105 110
Leu Gly Gln Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser
115 120 125
Ser Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser
130 135 140
Asp Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser
145 150 155 160
Pro Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn
165 170 175
Asn Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp
180 185 190
Lys Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr
195 200 205
Val Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 317
<211> 219
<212> PRT
<213> artificial sequence
<220>
<223> G4_14 IgG1 antibody light chain sequence
<400> 317
Ala Ser Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu Ser Pro
1 5 10 15
Gly Lys Thr Val Thr Ile Ser Cys Thr Arg Ser Arg Gly Ser Ile Ala
20 25 30
Gly Asn Tyr Val His Trp Tyr Gln Gln Arg Pro Gly Arg Ala Pro Thr
35 40 45
Thr Val Ile Tyr Arg Asp Lys Glu Arg Pro Ser Gly Val Pro Asp Arg
50 55 60
Ile Ser Gly Ser Ile Asp Ser Ser Ser Asn Ser Ala Ser Leu Thr Ile
65 70 75 80
Ser Gly Leu Lys Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr
85 90 95
Asp Ser Ser Thr His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val
100 105 110
Leu Gly Gln Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser
115 120 125
Ser Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser
130 135 140
Asp Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser
145 150 155 160
Pro Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn
165 170 175
Asn Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp
180 185 190
Lys Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr
195 200 205
Val Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 318
<211> 216
<212> PRT
<213> artificial sequence
<220>
<223> G4_15 IgG1 antibody light chain sequence
<400> 318
Ala Ser Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly
20 25 30
Gly Tyr Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Met Ile Tyr Asp Val Ser Asn Arg Pro Ser Gly Val Ser Asn
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Gly
85 90 95
Ser Gly Ser Val Phe Gly Thr Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 319
<211> 218
<212> PRT
<213> artificial sequence
<220>
<223> G4_16 IgG1 antibody light chain sequence
<400> 319
Ala Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Val Thr Phe Ser Cys Thr Gly Thr Ser Ser Asp Ile Gly
20 25 30
Ala Phe Asn Ser Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Leu Ile Tyr Glu Ile Thr Lys Arg Pro Ser Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Val Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Thr Ser Tyr Ala
85 90 95
Gly Ser Asn Thr Leu Ile Phe Gly Gly Gly Thr Lys Val Thr Val Leu
100 105 110
Gly Gln Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
115 120 125
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
130 135 140
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
145 150 155 160
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
165 170 175
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
180 185 190
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
195 200 205
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 320
<211> 216
<212> PRT
<213> artificial sequence
<220>
<223> G4_18 IgG1 antibody light chain sequence
<400> 320
Ala Ser Ser Tyr Glu Leu Thr Gln Pro Pro Ser Val Thr Glu Ser Pro
1 5 10 15
Gly Gln Thr Ala Arg Ile Thr Cys Ser Gly Asp Ala Leu Ala Lys Gln
20 25 30
Tyr Ala Tyr Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val
35 40 45
Ile Tyr Arg Asp Ser Glu Arg Pro Ser Glu Ile Pro Glu Arg Phe Ser
50 55 60
Gly Ser Ser Ser Gly Thr Thr Val Thr Leu Thr Ile Ser Gly Val Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Ala Asp Ser Ser Gly
85 90 95
Thr Tyr Thr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 321
<211> 219
<212> PRT
<213> artificial sequence
<220>
<223> G4_19 IgG1 antibody light chain sequence
<400> 321
Ala Ser Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu Ser Pro
1 5 10 15
Gly Lys Thr Val Thr Ile Ser Cys Thr Arg Ser Ser Gly Ser Ile Ala
20 25 30
Ser Asn Tyr Val Gln Trp Tyr Gln Gln Arg Pro Gly Ser Pro Pro Ile
35 40 45
Thr Leu Ile Tyr Asp Asp Asp Gln Arg Pro Ser Gly Val Pro His Arg
50 55 60
Phe Ser Gly Ser Ile Asp Thr Ser Ser Asn Pro Ala Ser Leu Thr Ile
65 70 75 80
Ser Gly Leu Lys Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr
85 90 95
Asp Ser Ser Asn His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val
100 105 110
Leu Gly Gln Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser
115 120 125
Ser Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser
130 135 140
Asp Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser
145 150 155 160
Pro Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn
165 170 175
Asn Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp
180 185 190
Lys Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr
195 200 205
Val Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 322
<211> 214
<212> PRT
<213> artificial sequence
<220>
<223> G4_20 IgG1 antibody light chain sequence
<400> 322
Ala Ser Ser Tyr Glu Leu Thr His Pro Pro Ser Val Ser Val Ser Pro
1 5 10 15
Gly Gln Thr Ala Ser Ile Thr Cys Ser Gly Asp Lys Leu Gly Asp Lys
20 25 30
Phe Val Ser Trp Tyr His Gln Lys Pro Gly Gln Ser Pro Val Leu Val
35 40 45
Ile Tyr Gln Asp Ser Lys Arg Pro Ser Gly Ile Pro Glu Arg Phe Ser
50 55 60
Gly Ser Asn Ser Gly Asn Thr Ala Thr Leu Thr Ile Ser Gly Thr Arg
65 70 75 80
Ala Met Asp Glu Ala Asp Tyr Tyr Cys Gln Ala Trp Asp Ser Ser Thr
85 90 95
Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln Pro Ala
100 105 110
Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu Leu Gln
115 120 125
Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr Pro Gly
130 135 140
Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys Ala Gly
145 150 155 160
Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr Ala Ala
165 170 175
Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His Arg Ser
180 185 190
Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys Thr Val
195 200 205
Ala Pro Thr Glu Cys Ser
210
<210> 323
<211> 216
<212> PRT
<213> artificial sequence
<220>
<223> G4_22 IgG1 antibody light chain sequence
<400> 323
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Val Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Asn Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Ile
85 90 95
Pro Trp Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 324
<211> 216
<212> PRT
<213> artificial sequence
<220>
<223> G4_23 IgG1 antibody light chain sequence
<400> 324
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser
20 25 30
Asn Ser Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Leu Tyr Ala Ala Ser Arg Leu Glu Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Tyr Ser Thr
85 90 95
Pro Arg Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 325
<211> 222
<212> PRT
<213> artificial sequence
<220>
<223> G4_24 IgG1 antibody light chain sequence
<400> 325
Ala Ser Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser
1 5 10 15
Leu Gly Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu
20 25 30
Tyr Ser Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro
35 40 45
Gly Gln Pro Pro Lys Leu Leu Ile Ser Trp Ala Ser Thr Arg Glu Ser
50 55 60
Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
65 70 75 80
Leu Thr Ile Asn Ser Leu Gln Ser Glu Asp Val Ala Ile Tyr Tyr Cys
85 90 95
Gln Gln Tyr Tyr Ser Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu
100 105 110
Glu Ile Lys Arg Thr Ala Ala Ala Pro Ser Val Phe Ile Phe Pro Pro
115 120 125
Ser Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu
130 135 140
Asn Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn
145 150 155 160
Ala Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser
165 170 175
Lys Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala
180 185 190
Asp Tyr Glu Lys His Lys Leu Tyr Ala Cys Glu Val Thr His Gln Gly
195 200 205
Leu Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 326
<211> 216
<212> PRT
<213> artificial sequence
<220>
<223> G4_25 IgG1 antibody light chain sequence
<400> 326
Ala Ser Gln Ser Ala Leu Thr Gln Pro Arg Ser Val Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Val Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly
20 25 30
Gly Tyr Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Met Ile Tyr Glu Val Ser Asn Arg Pro Ser Gly Val Ser Asn
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Gly
85 90 95
Ser Gly Ser Val Phe Gly Thr Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 327
<211> 216
<212> PRT
<213> artificial sequence
<220>
<223> G4_26 IgG1 antibody light chain sequence
<400> 327
Ala Ser Gln Ser Gly Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly
20 25 30
Ser Tyr Asn Leu Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Met Ile Tyr Glu Val Ser Lys Arg Pro Ser Gly Val Ser Asn
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Phe Gly
85 90 95
Ser Gly Ser Ile Phe Gly Thr Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 328
<211> 216
<212> PRT
<213> artificial sequence
<220>
<223> G4_27 IgG1 antibody light chain sequence
<400> 328
Ala Ser Ser Tyr Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu
1 5 10 15
Gly Gln Thr Val Ser Ile Thr Cys Gln Gly Asp Ser Leu Arg Asn Phe
20 25 30
Tyr Ala Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val
35 40 45
Ile Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly
85 90 95
Asn His Leu Val Phe Gly Gly Gly Thr Gln Leu Thr Val Leu Gly Gln
100 105 110
Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 329
<211> 214
<212> PRT
<213> artificial sequence
<220>
<223> G4_28 IgG1 antibody light chain sequence
<400> 329
Ala Ser Ser Tyr Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu
1 5 10 15
Gly Gln Thr Val Thr Ile Thr Cys Gln Gly Asp Ser Leu Arg Asn Tyr
20 25 30
Tyr Ala Ser Trp Tyr Arg Gln Lys Pro Gly Gln Thr Pro Val Leu Val
35 40 45
Val Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser
50 55 60
Val Ser Ala Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln
65 70 75 80
Ala Glu Asp Glu Gly Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly
85 90 95
Val Val Phe Gly Gly Gly Thr Lys Val Thr Val Leu Gly Gln Pro Ala
100 105 110
Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu Leu Gln
115 120 125
Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr Pro Gly
130 135 140
Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys Ala Gly
145 150 155 160
Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr Ala Ala
165 170 175
Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His Arg Ser
180 185 190
Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys Thr Val
195 200 205
Ala Pro Thr Glu Cys Ser
210
<210> 330
<211> 107
<212> PRT
<213> artificial sequence
<220>
<223> Human Kappa light constant sequence (preferred allotype and
without cloning artefacts)
<400> 330
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 331
<211> 106
<212> PRT
<213> artificial sequence
<220>
<223> Human Lambda light constant sequence (IGLC2 without cloning
artefacts)
<400> 331
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
20 25 30
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
35 40 45
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
100 105
<210> 332
<211> 330
<212> PRT
<213> artificial sequence
<220>
<223> Human IgG1 constant domain
<400> 332
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
225 230 235 240
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 333
<211> 330
<212> PRT
<213> artificial sequence
<220>
<223> Human IgG1 constant domain with LAGA substitution
<400> 333
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Ala Gly Ala Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
225 230 235 240
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 334
<211> 99
<212> PRT
<213> Homo sapiens
<220>
<223> Human TRGV4
<400> 334
Ser Ser Asn Leu Glu Gly Arg Thr Lys Ser Val Ile Arg Gln Thr Gly
1 5 10 15
Ser Ser Ala Glu Ile Thr Cys Asp Leu Ala Glu Gly Ser Thr Gly Tyr
20 25 30
Ile His Trp Tyr Leu His Gln Glu Gly Lys Ala Pro Gln Arg Leu Leu
35 40 45
Tyr Tyr Asp Ser Tyr Thr Ser Ser Val Val Leu Glu Ser Gly Ile Ser
50 55 60
Pro Gly Lys Tyr Asp Thr Tyr Gly Ser Thr Arg Lys Asn Leu Arg Met
65 70 75 80
Ile Leu Arg Asn Leu Ile Glu Asn Asp Ser Gly Val Tyr Tyr Cys Ala
85 90 95
Thr Trp Asp
<210> 335
<211> 99
<212> PRT
<213> Homo sapiens
<220>
<223> Human TRGV2
<400> 335
Ser Ser Asn Leu Glu Gly Arg Thr Lys Ser Val Ile Arg Gln Thr Gly
1 5 10 15
Ser Ser Ala Glu Ile Thr Cys Asp Leu Ala Glu Gly Ser Asn Gly Tyr
20 25 30
Ile His Trp Tyr Leu His Gln Glu Gly Lys Ala Pro Gln Arg Leu Gln
35 40 45
Tyr Tyr Asp Ser Tyr Asn Ser Lys Val Val Leu Glu Ser Gly Val Ser
50 55 60
Pro Gly Lys Tyr Tyr Thr Tyr Ala Ser Thr Arg Asn Asn Leu Arg Leu
65 70 75 80
Ile Leu Arg Asn Leu Ile Glu Asn Asp Ser Gly Val Tyr Tyr Cys Ala
85 90 95
Thr Trp Asp
<210> 336
<211> 99
<212> PRT
<213> Homo sapiens
<220>
<223> Human TRGV8
<400> 336
Ser Ser Asn Leu Glu Gly Arg Thr Lys Ser Val Thr Arg Pro Thr Gly
1 5 10 15
Ser Ser Ala Val Ile Thr Cys Asp Leu Pro Val Glu Asn Ala Val Tyr
20 25 30
Thr His Trp Tyr Leu His Gln Glu Gly Lys Ala Pro Gln Arg Leu Leu
35 40 45
Tyr Tyr Asp Ser Tyr Asn Ser Arg Val Val Leu Glu Ser Gly Ile Ser
50 55 60
Arg Glu Lys Tyr His Thr Tyr Ala Ser Thr Gly Lys Ser Leu Lys Phe
65 70 75 80
Ile Leu Glu Asn Leu Ile Glu Arg Asp Ser Gly Val Tyr Tyr Cys Ala
85 90 95
Thr Trp Asp
<210> 337
<211> 95
<212> PRT
<213> Homo sapiens
<220>
<223> Human TRDV1
<400> 337
Ala Gln Lys Val Thr Gln Ala Gln Ser Ser Val Ser Met Pro Val Arg
1 5 10 15
Lys Ala Val Thr Leu Asn Cys Leu Tyr Glu Thr Ser Trp Trp Ser Tyr
20 25 30
Tyr Ile Phe Trp Tyr Lys Gln Leu Pro Ser Lys Glu Met Ile Phe Leu
35 40 45
Ile Arg Gln Gly Ser Asp Glu Gln Asn Ala Lys Ser Gly Arg Tyr Ser
50 55 60
Val Asn Phe Lys Lys Ala Ala Lys Ser Val Ala Leu Thr Ile Ser Ala
65 70 75 80
Leu Gln Leu Glu Asp Ser Ala Lys Tyr Phe Cys Ala Leu Gly Glu
85 90 95
<210> 338
<211> 96
<212> PRT
<213> Homo sapiens
<220>
<223> Human TRDV2
<400> 338
Ala Ile Glu Leu Val Pro Glu His Gln Thr Val Pro Val Ser Ile Gly
1 5 10 15
Val Pro Ala Thr Leu Arg Cys Ser Met Lys Gly Glu Ala Ile Gly Asn
20 25 30
Tyr Tyr Ile Asn Trp Tyr Arg Lys Thr Gln Gly Asn Thr Ile Thr Phe
35 40 45
Ile Tyr Arg Glu Lys Asp Ile Tyr Gly Pro Gly Phe Lys Asp Asn Phe
50 55 60
Gln Gly Asp Ile Asp Ile Ala Lys Asn Leu Ala Val Leu Lys Ile Leu
65 70 75 80
Ala Pro Ser Glu Arg Asp Glu Gly Ser Tyr Tyr Cys Ala Cys Asp Thr
85 90 95
Claims (30)
- γδ T 세포 수용체(TCR)의 감마 가변 4(Vγ4) 사슬에 특이적으로 결합하고 γδ TCR의 감마 가변 2(Vγ2) 사슬에는 결합하지 않는, 단리된 항체 또는 이의 단편.
- 제1항에 있어서, γδ TCR의 Vγ4 사슬이 인간 Vγ4이고 γδ TCR의 Vγ2 사슬이 인간 Vγ2 인, 단리된 항-Vγ4 항체 또는 이의 단편.
- 제1항 또는 제2항에 있어서, 서열 번호 1의 아미노산 영역 67-82 내의 하나 이상의 아미노산 잔기를 포함하는 γδ TCR의 Vγ4 사슬의 에피토프에 결합하는, 단리된 항-Vγ4 항체 또는 이의 단편.
- 제3항에 있어서, 에피토프가 서열 번호 1의 아미노산 잔기 71, 73, 75, 76, 79 중 적어도 하나를 포함하는, 단리된 항-Vγ4 항체 또는 이의 단편.
- 제1항 내지 제4항 중 어느 한 항에 있어서, 에피토프가 서열 번호 1의 K76 및/또는 M80을 포함하거나 이로 구성되는, 단리된 항-Vγ4 항체 또는 이의 단편.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 에피토프가 γδ T 세포의 활성화 에피토프인, 단리된 항-Vγ4 항체 또는 이의 단편.
- 제6항에 있어서, 활성화 에피토프의 결합이 (i) γδ TCR을 하향조절하고/거나; (ii) γδ T 세포의 탈과립을 활성화하고/거나; (iii) γδ T 세포-매개 사멸을 활성화하고/거나; (iv) Vγ4 사슬-매개 세포 신호전달을 활성화하거나 증가시키는, 단리된 항-Vγ4 항체 또는 이의 단편.
- 다음 중 하나 이상을 포함하는, 단리된 항-Vγ4 항체 또는 이의 단편:
서열 번호 2-47 중 어느 하나, 바람직하게는 서열 번호 10 및/또는 33과 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3;
서열 번호 48-70 및 서열 A1-A23(도 1) 중 어느 하나, 바람직하게는 서열 번호 56 및/또는 서열 A9와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR2; 및/또는
서열 번호 71-116 중 어느 하나, 바람직하게는 서열 번호 79 및/또는 102와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR1. - 제8항에 있어서, 서열 번호 10, 4, 14, 15, 17, 19 또는 23과 같은 서열 번호 2-24 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VH 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
- 제8항 또는 제9항에 있어서, 서열 번호 33, 27, 37, 38, 40, 42 또는 46과 같은 서열 번호 25-47 중 어느 하나와 적어도 80% 서열 동일성을 갖는 서열을 포함하는 CDR3을 포함하는 VL 영역을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
- 서열 번호 117-162 또는 261-283 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
- 다음 중 하나 이상을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편:
(a) 서열 번호 79를 갖는 HCDR1, 서열 번호 56을 갖는 HCDR2 및 서열 번호 10을 갖는 HCDR3을 포함하며, 임의로 서열 번호 125를 포함하는 VH; 및
서열 번호 102를 갖는 LCDR1, 서열 A9(도 1)를 갖는 LCDR2 및 서열 번호 33을 갖는 LCDR3을 포함하며, 임의로 서열 번호 148 또는 269를 포함하는 VL;
(b) 서열 번호 86을 갖는 HCDR1, 서열 번호 63을 갖는 HCDR2 및 서열 번호 17을 갖는 HCDR3을 포함하며, 임의로 서열 번호 132를 포함하는 VH; 및
서열 번호 109를 갖는 LCDR1, 서열 A16(도 1)을 갖는 LCDR2 및 서열 번호 40을 갖는 LCDR3을 포함하며, 임의로 서열 번호 155 또는 276을 포함하는 VL;
(c) 서열 번호 73을 갖는 HCDR1, 서열 번호 50을 갖는 HCDR2 및 서열 번호 4를 갖는 HCDR3을 포함하며, 임의로 서열 번호 119를 포함하는 VH; 및
서열 번호 96을 갖는 LCDR1, 서열 A3(도 1)을 갖는 LCDR2 및 서열 번호 27을 갖는 LCDR3을 포함하며, 임의로 서열 번호 142 또는 263을 포함하는 VL;
(d) 서열 번호 83을 갖는 HCDR1, 서열 번호 60을 갖는 HCDR2 및 서열 번호 14를 갖는 HCDR3을 포함하며, 임의로 서열 번호 129를 포함하는 VH; 및
서열 번호 106을 갖는 LCDR1, 서열 A13(도 1)을 갖는 LCDR2 및 서열 번호 37을 갖는 LCDR3을 포함하며, 임의로 서열 번호 152 또는 273을 포함하는 VL;
(e) 서열 번호 84를 갖는 HCDR1, 서열 번호 61을 갖는 HCDR2 및 서열 번호 15를 갖는 HCDR3을 포함하며, 임의로 서열 번호 130을 포함하는 VH; 및
서열 번호 107을 갖는 LCDR1, 서열 A14(도 1)를 갖는 LCDR2 및 서열 번호 38을 갖는 LCDR3을 포함하며, 임의로 서열 번호 153 또는 274를 포함하는 VL;
(f) 서열 번호 88을 갖는 HCDR1, 서열 번호 65를 갖는 HCDR2 및 서열 번호 19를 갖는 HCDR3을 포함하며, 임의로 서열 번호 134를 포함하는 VH; 및
서열 번호 111을 갖는 LCDR1, 서열 A18(도 1)을 갖는 LCDR2 및 서열 번호 42를 갖는 LCDR3을 포함하며, 임의로 서열 번호 157 또는 278을 포함하는 VL;
(g) 서열 번호 92를 갖는 HCDR1, 서열 번호 69를 갖는 HCDR2 및 서열 번호 23을 갖는 HCDR3을 포함하며, 임의로 서열 번호 138을 포함하는 VH; 및
서열 번호 115를 갖는 LCDR1, 서열 A22(도 1)를 갖는 LCDR2 및 서열 번호 46을 갖는 LCDR3을 포함하며, 임의로 서열 번호 161 또는 282를 포함하는 VL;
(h) 서열 번호 71을 갖는 HCDR1, 서열 번호 48을 갖는 HCDR2 및 서열 번호 2를 갖는 HCDR3을 포함하며, 임의로 서열 번호 117을 포함하는 VH; 및
서열 번호 94를 갖는 LCDR1, 서열 A1(도 1)을 갖는 LCDR2 및 서열 번호 25를 갖는 LCDR3을 포함하며, 임의로 서열 번호 140 또는 261을 포함하는 VL;
(i) 서열 번호 72를 갖는 HCDR1, 서열 번호 49를 갖는 HCDR2 및 서열 번호 3을 갖는 HCDR3을 포함하며, 임의로 서열 번호 118을 포함하는 VH; 및
서열 번호 95를 갖는 LCDR1, 서열 A2(도 1)를 갖는 LCDR2 및 서열 번호 26을 갖는 LCDR3을 포함하며, 임의로 서열 번호 141 또는 262를 포함하는 VL;
(j) 서열 번호 74를 갖는 HCDR1, 서열 번호 51을 갖는 HCDR2 및 서열 번호 5를 갖는 HCDR3을 포함하며, 임의로 서열 번호 120을 포함하는 VH; 및
서열 번호 97을 갖는 LCDR1, 서열 A4(도 1)를 갖는 LCDR2 및 서열 번호 28을 갖는 LCDR3을 포함하며, 임의로 서열 번호 143 또는 264를 포함하는 VL;
(k) 서열 번호 75를 갖는 HCDR1, 서열 번호 52를 갖는 HCDR2 및 서열 번호 6을 갖는 HCDR3을 포함하며, 임의로 서열 번호 121을 포함하는 VH; 및
서열 번호 98을 갖는 LCDR1, 서열 A5(도 1)를 갖는 LCDR2 및 서열 번호 29를 갖는 LCDR3을 포함하며, 임의로 서열 번호 144 또는 265를 포함하는 VL;
(l) 서열 번호 76을 갖는 HCDR1, 서열 번호 53을 갖는 HCDR2 및 서열 번호 7을 갖는 HCDR3을 포함하며, 임의로 서열 번호 122를 포함하는 VH; 및
서열 번호 99를 갖는 LCDR1, 서열 A6(도 1)을 갖는 LCDR2 및 서열 번호 30을 갖는 LCDR3을 포함하며, 임의로 서열 번호 145 또는 266을 포함하는 VL;
(m) 서열 번호 77을 갖는 HCDR1, 서열 번호 54를 갖는 HCDR2 및 서열 번호 8을 갖는 HCDR3을 포함하며, 임의로 서열 번호 123을 포함하는 VH; 및
서열 번호 100을 갖는 LCDR1, 서열 A7(도 1)을 갖는 LCDR2 및 서열 번호 31을 갖는 LCDR3을 포함하며, 임의로 서열 번호 146 또는 267을 포함하는 VL;
(n) 서열 번호 78을 갖는 HCDR1, 서열 번호 55를 갖는 HCDR2 및 서열 번호 9를 갖는 HCDR3을 포함하며, 임의로 서열 번호 124를 포함하는 VH; 및
서열 번호 101을 갖는 LCDR1, 서열 A8(도 1)을 갖는 LCDR2 및 서열 번호 32를 갖는 LCDR3을 포함하며, 임의로 서열 번호 147 또는 268을 포함하는 VL;
(o) 서열 번호 80을 갖는 HCDR1, 서열 번호 57을 갖는 HCDR2 및 서열 번호 11을 갖는 HCDR3을 포함하며, 임의로 서열 번호 126을 포함하는 VH; 및
서열 번호 103을 갖는 LCDR1, 서열 A10(도 1)을 갖는 LCDR2 및 서열 번호 34를 갖는 LCDR3을 포함하며, 임의로 서열 번호 149 또는 270을 포함하는 VL;
(p) 서열 번호 81을 갖는 HCDR1, 서열 번호 58을 갖는 HCDR2 및 서열 번호 12를 갖는 HCDR3을 포함하며, 임의로 서열 번호 127을 포함하는 VH; 및
서열 번호 104를 갖는 LCDR1, 서열 A11(도 1)을 갖는 LCDR2 및 서열 번호 35를 갖는 LCDR3을 포함하며, 임의로 서열 번호 150 또는 271을 포함하는 VL;
(q) 서열 번호 82를 갖는 HCDR1, 서열 번호 59를 갖는 HCDR2 및 서열 번호 13을 갖는 HCDR3을 포함하며, 임의로 서열 번호 128을 포함하는 VH; 및
서열 번호 105를 갖는 LCDR1, 서열 A12(도 1)를 갖는 LCDR2 및 서열 번호 36을 갖는 LCDR3을 포함하며, 임의로 서열 번호 151 또는 272를 포함하는 VL;
(r) 서열 번호 85를 갖는 HCDR1, 서열 번호 62를 갖는 HCDR2 및 서열 번호 16을 갖는 HCDR3을 포함하며, 임의로 서열 번호 131을 포함하는 VH; 및
서열 번호 108을 갖는 LCDR1, 서열 A15(도 1)를 갖는 LCDR2 및 서열 번호 39를 갖는 LCDR3을 포함하며, 임의로 서열 번호 154 또는 275를 포함하는 VL;
(s) 서열 번호 87을 갖는 HCDR1, 서열 번호 64를 갖는 HCDR2 및 서열 번호 18을 갖는 HCDR3을 포함하며, 임의로 서열 번호 133을 포함하는 VH; 및
서열 번호 110을 갖는 LCDR1, 서열 A17(도 1)을 갖는 LCDR2 및 서열 번호 41을 갖는 LCDR3을 포함하며, 임의로 서열 번호 156 또는 277을 포함하는 VL;
(t) 서열 번호 89를 갖는 HCDR1, 서열 번호 66을 갖는 HCDR2 및 서열 번호 20을 갖는 HCDR3을 포함하며, 임의로 서열 번호 135를 포함하는 VH; 및
서열 번호 112를 갖는 LCDR1, 서열 A19(도 1)를 갖는 LCDR2 및 서열 번호 43을 갖는 LCDR3을 포함하며, 임의로 서열 번호 158 또는 279를 포함하는 VL;
(u) 서열 번호 90을 갖는 HCDR1, 서열 번호 67을 갖는 HCDR2 및 서열 번호 21을 갖는 HCDR3을 포함하며, 임의로 서열 번호 136을 포함하는 VH; 및
서열 번호 113을 갖는 LCDR1, 서열 A20(도 1)을 갖는 LCDR2 및 서열 번호 44를 갖는 LCDR3을 포함하며, 임의로 서열 번호 159 또는 280을 포함하는 VL;
(v) 서열 번호 91을 갖는 HCDR1, 서열 번호 68을 갖는 HCDR2 및 서열 번호 22를 갖는 HCDR3을 포함하며, 임의로 서열 번호 137을 포함하는 VH; 및
서열 번호 114를 갖는 LCDR1, 서열 A21(도 1)을 갖는 LCDR2 및 서열 번호 45를 갖는 LCDR3을 포함하며, 임의로 서열 번호 160 또는 281을 포함하는 VL; 및/또는
(w) 서열 번호 93을 갖는 HCDR1, 서열 번호 70을 갖는 HCDR2 및 서열 번호 24를 갖는 HCDR3을 포함하며, 임의로 서열 번호 139를 포함하는 VH; 및
서열 번호 116을 갖는 LCDR1, 서열 A23(도 1)을 갖는 LCDR2 및 서열 번호 47을 갖는 LCDR3을 포함하며, 임의로 서열 번호 162 또는 283을 포함하는 VL. - 서열 번호 163-185 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
- 서열 번호 233-255 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항-Vγ4 항체.
- 서열 번호 284-306 중 어느 하나와 적어도 80% 서열 동일성을 갖는 중쇄 아미노산 서열 및/또는 서열 번호 307-329 중 어느 하나와 적어도 80% 서열 동일성을 갖는 경쇄 아미노산 서열을 포함하는 단리된 항-Vγ4 항체 또는 이의 단편.
- 바람직하게는 제1항 내지 제7항 중 어느 한 항에 있어서, 제8항 내지 제15항 중 어느 한 항에 정의된 항체 또는 이의 단편과 동일하거나 본질적으로 동일한 에피토프에 결합하거나 이와 경쟁하는, 단리된 항-Vγ4 항체 또는 이의 단편.
- 제1항 내지 제16항 중 어느 한 항에 있어서, 다음과 같은 단리된 항-Vγ4 항체 또는 이의 단편:
(i) scFv 또는 전장 항체; 및/또는
(ii) 인간 항체 또는 이의 단편. - 제1항 내지 제17항 중 어느 한 항에 정의된 항-Vγ4 항체 또는 이의 단편을 암호화하는 폴리뉴클레오티드 서열.
- 서열 번호 187-232 중 어느 하나와 적어도 70% 서열 동일성을 갖는 서열을 포함하는 항-Vγ4 항체 또는 이의 단편을 암호화하는 폴리뉴클레오티드 서열.
- 제18항 또는 제19항에 정의된 폴리뉴클레오티드 서열을 포함하는 발현 벡터.
- 제18항 또는 제19항에 정의된 폴리뉴클레오티드 서열 또는 제20항에 정의된 발현 벡터를 포함하는 세포.
- 제1항 내지 제17항 중 어느 한 항에 정의된 항체 또는 이의 단편을 포함하는 조성물.
- 제1항 내지 제17항 중 어느 한 항에 정의된 항체 또는 이의 단편을 약학적으로 허용 가능한 희석제 또는 담체와 함께 포함하는 약학 조성물.
- 제1항 내지 제17항 중 어느 한 항 또는 제23항에 있어서, 약제로 사용하기 위한 단리된 항-Vγ4 항체 또는 이의 단편 또는 약학 조성물.
- 제24항에 있어서, 암, 감염성 질환 또는 염증성 질환의 치료에 사용하기 위한 단리된 항-Vγ4 항체 또는 이의 단편 또는 약학 조성물.
- 항-Vγ4 항체 또는 이의 단편을 생성하는 데 사용하기 위한 서열 번호 256-258 중 어느 하나와 적어도 80% 서열 동일성을 갖는 아미노산 서열을 포함하는 단리된 항원.
- 다음을 포함하는, 항-Vγ4 항체 또는 이의 단편을 생성하는 방법:
(i) TCR 감마 가변 4(Vγ4) 아미노산 서열을 포함하는 항원 시리즈를 설계하는 단계로서, Vγ4의 CDR3 서열이 시리즈의 모든 항원에 대해 동일한, 단계;
(ii) 단계 (i)에서 설계된 제1 항원을 항체 라이브러리에 노출시키는 단계;
(iii) 항원에 결합하는 항체 또는 이의 단편을 단리하는 단계;
(iv) 단리된 항체 또는 이의 단편을 단계 (i)에서 설계된 제2 항원에 노출시키는 단계; 및
(v) 제1 항원 및 제2 항원 둘 다에 결합하는 항체 또는 이의 단편을 단리하는 단계. - 제27항에 있어서, 단리된 항체 또는 이의 단편을 TCR 감마 가변 2(Vγ2) 또는 TCR 감마 가변 8(Vγ8)과 같은 상이한 감마 가변 사슬을 갖는 γδ TCR을 포함하는 제2 항원 시리즈에 노출시키는 단계 및 이어서 제2 항원 시리즈에도 결합하는 항체 또는 이의 단편을 선택해제하는 단계를 추가로 포함하는 방법.
- 제27항 또는 제28항에 정의된 방법에 의해 수득된 항체.
- 제1항 내지 제17항 중 어느 한 항의 항-Vγ4 항체 또는 이의 단편 또는 제23항의 약학 조성물을 포함하고, 임의로 사용 설명서 및/또는 추가의 치료 활성제를 포함하는 키트.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GBGB2002581.3A GB202002581D0 (en) | 2020-02-24 | 2020-02-24 | Novel antibodies |
| GB2002581.3 | 2020-02-24 | ||
| PCT/GB2021/050459 WO2021171002A1 (en) | 2020-02-24 | 2021-02-24 | Novel antibodies |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220145894A true KR20220145894A (ko) | 2022-10-31 |
Family
ID=70108379
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020227029501A KR20220164473A (ko) | 2020-02-24 | 2021-02-24 | 생체외 감마 델타 t 세포 집단 |
| KR1020227033455A KR20220145894A (ko) | 2020-02-24 | 2021-02-24 | 신규 항체 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020227029501A KR20220164473A (ko) | 2020-02-24 | 2021-02-24 | 생체외 감마 델타 t 세포 집단 |
Country Status (16)
| Country | Link |
|---|---|
| US (2) | US20230090901A1 (ko) |
| EP (2) | EP4110387A1 (ko) |
| JP (2) | JP2023516925A (ko) |
| KR (2) | KR20220164473A (ko) |
| CN (2) | CN115461369A (ko) |
| AU (2) | AU2021225390A1 (ko) |
| BR (2) | BR112022016671A2 (ko) |
| CA (2) | CA3172340A1 (ko) |
| CL (1) | CL2022002296A1 (ko) |
| CO (2) | CO2022013542A2 (ko) |
| EC (1) | ECSP22074030A (ko) |
| GB (1) | GB202002581D0 (ko) |
| IL (2) | IL295696A (ko) |
| MX (2) | MX2022010239A (ko) |
| PE (1) | PE20230438A1 (ko) |
| WO (2) | WO2021171002A1 (ko) |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB201818243D0 (en) | 2018-11-08 | 2018-12-26 | Gammadelta Therapeutics Ltd | Methods for isolating and expanding cells |
| EP4013504A1 (en) * | 2019-08-16 | 2022-06-22 | GammaDelta Therapeutics Limited | Novel anti-tcr delta variable 1 antibodies |
-
2020
- 2020-02-24 GB GBGB2002581.3A patent/GB202002581D0/en not_active Ceased
-
2021
- 2021-02-24 KR KR1020227029501A patent/KR20220164473A/ko unknown
- 2021-02-24 JP JP2022550778A patent/JP2023516925A/ja active Pending
- 2021-02-24 EP EP21709758.3A patent/EP4110387A1/en active Pending
- 2021-02-24 CA CA3172340A patent/CA3172340A1/en active Pending
- 2021-02-24 AU AU2021225390A patent/AU2021225390A1/en active Pending
- 2021-02-24 PE PE2022001812A patent/PE20230438A1/es unknown
- 2021-02-24 US US17/801,786 patent/US20230090901A1/en active Pending
- 2021-02-24 CN CN202180030584.5A patent/CN115461369A/zh active Pending
- 2021-02-24 IL IL295696A patent/IL295696A/en unknown
- 2021-02-24 WO PCT/GB2021/050459 patent/WO2021171002A1/en active Application Filing
- 2021-02-24 US US17/904,890 patent/US20230159638A1/en active Pending
- 2021-02-24 BR BR112022016671A patent/BR112022016671A2/pt unknown
- 2021-02-24 MX MX2022010239A patent/MX2022010239A/es unknown
- 2021-02-24 BR BR112022016894A patent/BR112022016894A2/pt unknown
- 2021-02-24 EP EP21709757.5A patent/EP4110813A1/en active Pending
- 2021-02-24 CN CN202180028136.1A patent/CN115697401A/zh active Pending
- 2021-02-24 KR KR1020227033455A patent/KR20220145894A/ko unknown
- 2021-02-24 WO PCT/GB2021/050460 patent/WO2021171003A1/en active Application Filing
- 2021-02-24 JP JP2022550813A patent/JP2023514437A/ja active Pending
- 2021-02-24 IL IL295852A patent/IL295852A/en unknown
- 2021-02-24 CA CA3168973A patent/CA3168973A1/en active Pending
- 2021-02-24 MX MX2022010383A patent/MX2022010383A/es unknown
- 2021-02-24 AU AU2021228266A patent/AU2021228266A1/en active Pending
-
2022
- 2022-08-23 CL CL2022002296A patent/CL2022002296A1/es unknown
- 2022-09-21 CO CONC2022/0013542A patent/CO2022013542A2/es unknown
- 2022-09-22 EC ECSENADI202274030A patent/ECSP22074030A/es unknown
- 2022-09-22 CO CONC2022/0013633A patent/CO2022013633A2/es unknown
Also Published As
| Publication number | Publication date |
|---|---|
| BR112022016894A2 (pt) | 2023-04-04 |
| CA3168973A1 (en) | 2021-09-02 |
| EP4110387A1 (en) | 2023-01-04 |
| IL295852A (en) | 2022-10-01 |
| CO2022013542A2 (es) | 2022-10-11 |
| IL295696A (en) | 2022-10-01 |
| KR20220164473A (ko) | 2022-12-13 |
| AU2021228266A1 (en) | 2022-10-13 |
| AU2021225390A1 (en) | 2022-09-22 |
| ECSP22074030A (es) | 2022-10-31 |
| GB202002581D0 (en) | 2020-04-08 |
| WO2021171002A1 (en) | 2021-09-02 |
| MX2022010383A (es) | 2022-09-05 |
| CN115461369A (zh) | 2022-12-09 |
| CO2022013633A2 (es) | 2023-02-16 |
| PE20230438A1 (es) | 2023-03-08 |
| CN115697401A (zh) | 2023-02-03 |
| JP2023514437A (ja) | 2023-04-05 |
| CL2022002296A1 (es) | 2023-03-31 |
| BR112022016671A2 (pt) | 2022-11-16 |
| US20230090901A1 (en) | 2023-03-23 |
| CA3172340A1 (en) | 2021-09-02 |
| WO2021171003A1 (en) | 2021-09-02 |
| EP4110813A1 (en) | 2023-01-04 |
| JP2023516925A (ja) | 2023-04-21 |
| MX2022010239A (es) | 2022-11-14 |
| US20230159638A1 (en) | 2023-05-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101516569B1 (ko) | 사람 델타 유사 리간드 4에 대한 사람 항체 | |
| KR101577843B1 (ko) | 인간 ox40 수용체에 대한 결합 분자 | |
| KR101982899B1 (ko) | TL1a에 대한 항체 및 그의 용도 | |
| KR102439395B1 (ko) | Ilt7 결합 분자 및 이의 사용 방법 | |
| KR20200061320A (ko) | 세포독성 t-림프구-관련 단백질 4 (ctla-4)에 대한 신규의 단일클론 항체 | |
| EP3470426A1 (en) | Multispecific antibody | |
| CN114514245A (zh) | 新颖的抗TCRδ可变1抗体 | |
| KR20170108944A (ko) | B-세포 성숙화 항원을 표적화하는 항체 및 사용 방법 | |
| KR102677543B1 (ko) | 항-cd115 항체 | |
| PT2041177E (pt) | Anticorpos com elevada afinidade para o receptor il-6 humano | |
| KR20160090904A (ko) | 치료 펩티드 | |
| KR20140033029A (ko) | 에이치엘에이 에이2에 의해 제공된 더블유티1 펩타이드에 특이적인 티 세포 수용체 유사 항체 | |
| PL217296B1 (pl) | Wyizolowane ludzkie przeciwciało monoklonalne, wytwarzająca je hybrydoma, kodujący to przeciwciało wektor ekspresyjny i zawierająca je kompozycja farmaceutyczna, immunokoniugat, bispecyficzna lub multispecyficzna cząsteczka obejmująca kwasy nukleinowe kodujące ciężki i lekki łańcuch transfektoma, ich zastosowania, zwłaszcza w medycynie, obejmująca te kwasy ex vivo eukariotyczna lub prokariotyczna komórka gospodarza oraz nie będące człowiekiem zwierzę transgeniczne lub roślina, sposób in vitro hamowania wzrostu i/lub proliferacji komórek wyrażających CD25 lub eliminowania komórek wyrażających CD25, sposób wykrywania w próbce obecności antygenu CD25 lub komórki wyrażającej CD25, zestaw diagnostyczny do wykrywania w próbce obecności antygenu CD25 lub komórki wyrażającej CD25 | |
| KR102369118B1 (ko) | 인간화 항-basigin 항체 및 이의 용도 | |
| KR20210049128A (ko) | 항-pd-l1/항-lag3 이중 특이 항체 및 이의 용도 | |
| KR20230017219A (ko) | Sirp 알파, sirp 베타 1, 및 sirp 감마 항체 및 이의 용도 | |
| CN112839963B (zh) | 新型癌症免疫治疗抗体组合物 | |
| KR20230117178A (ko) | T 세포 인게이저 치료제의 개발 및 적용 | |
| KR20220145894A (ko) | 신규 항체 | |
| RU2804490C2 (ru) | Новые композиции антител для иммунотерапии рака | |
| TW202417496A (zh) | 分離的抗原結合蛋白及其用途 | |
| JP2024535834A (ja) | 抗cd40抗体及びその用途 | |
| KR20240021959A (ko) | 항개 cd20 항체 |