KR20200120649A - 비-바이러스 dna 벡터 및 항체 및 융합 단백질 생산을 위한 이의 용도 - Google Patents
비-바이러스 dna 벡터 및 항체 및 융합 단백질 생산을 위한 이의 용도 Download PDFInfo
- Publication number
- KR20200120649A KR20200120649A KR1020207024274A KR20207024274A KR20200120649A KR 20200120649 A KR20200120649 A KR 20200120649A KR 1020207024274 A KR1020207024274 A KR 1020207024274A KR 20207024274 A KR20207024274 A KR 20207024274A KR 20200120649 A KR20200120649 A KR 20200120649A
- Authority
- KR
- South Korea
- Prior art keywords
- antibody
- itr
- cedna
- cedna vector
- sequence
- Prior art date
Links
Images




































Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/02—Drugs for skeletal disorders for joint disorders, e.g. arthritis, arthrosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/28—Drugs for disorders of the nervous system for treating neurodegenerative disorders of the central nervous system, e.g. nootropic agents, cognition enhancers, drugs for treating Alzheimer's disease or other forms of dementia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/22—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against growth factors ; against growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/24—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against cytokines, lymphokines or interferons
- C07K16/241—Tumor Necrosis Factors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/53—DNA (RNA) vaccination
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2710/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA dsDNA viruses
- C12N2710/00011—Details
- C12N2710/14011—Baculoviridae
- C12N2710/14111—Nucleopolyhedrovirus, e.g. autographa californica nucleopolyhedrovirus
- C12N2710/14141—Use of virus, viral particle or viral elements as a vector
- C12N2710/14143—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2710/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA dsDNA viruses
- C12N2710/00011—Details
- C12N2710/14011—Baculoviridae
- C12N2710/14111—Nucleopolyhedrovirus, e.g. autographa californica nucleopolyhedrovirus
- C12N2710/14141—Use of virus, viral particle or viral elements as a vector
- C12N2710/14144—Chimeric viral vector comprising heterologous viral elements for production of another viral vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14141—Use of virus, viral particle or viral elements as a vector
- C12N2750/14143—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14141—Use of virus, viral particle or viral elements as a vector
- C12N2750/14144—Chimeric viral vector comprising heterologous viral elements for production of another viral vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2830/00—Vector systems having a special element relevant for transcription
- C12N2830/50—Vector systems having a special element relevant for transcription regulating RNA stability, not being an intron, e.g. poly A signal
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Medicinal Chemistry (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- General Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Biotechnology (AREA)
- Immunology (AREA)
- Veterinary Medicine (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- Neurosurgery (AREA)
- Neurology (AREA)
- Psychiatry (AREA)
- Hospice & Palliative Care (AREA)
- Virology (AREA)
- Physical Education & Sports Medicine (AREA)
- Rheumatology (AREA)
- Orthopedic Medicine & Surgery (AREA)
- Dermatology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
Abstract
본 출원은 이식유전자의 전달 및 발현을 위한 선형 및 연속 구조를 갖는 ceDNA 벡터를 기술한다. ceDNA 벡터는 2개의 ITR 서열이 측면에 있는 발현 카세트를 포함하며, 여기서 발현 카세트는 이식유전자를 인코딩한다. 일부 ceDNA 벡터는 조절 스위치를 포함하여, 시스 조절-요소를 추가로 포함한다. 추가로 ceDNA 벡터를 사용하여 시험관내, 생체외 및 생체내에서 신뢰할 수 있는 유전자 발현을 위한 방법 및 세포주가 본원에 제공된다. 세포, 조직 또는 대상체에서 항체 또는 융합 단백질의 발현에 유용한 ceDNA 벡터를 포함하는 방법 및 조성물이 본원에 제공된다. 이러한 항체 또는 융합 단백질은 질환을 치료하기 위해 또는 대안적으로 상업적인 환경에서 항체 또는 융합 단백질의 생산을 위해 발현될 수 있다.
Description
관련 출원에 대한 상호 참조
본 출원은 2018년 2월 14일에 제출된 미국 가출원 62/630,670, 2018년 6월 4일에 제출된 미국 가출원 62/680,087, 2018년 2월 14일에 제출된 미국 가출원 62/630,676 및 미국 가출원 2018년 6월 4일에 제출된 62/680,092의 35 U.S.C. 119 (e)에 따른 이익을 주장하며, 각각의 내용은 그 전문이 본원에 참고로 포함된다.
서열 목록
본 출원은 ASCII 형식으로 전자적으로 제출된 시퀀스 목록을 포함하며, 그 전문이 본원에 참고로 포함된다. 2019년 2월 13일에 작성된 상기 ASCII 사본의 이름은 080170-091100-WOPT_SL.txt이며 크기는 128,788 바이트이다.
기술 분야
본 발명은 대상체 또는 세포에서 이식유전자 또는 단리된 폴리뉴클레오티드를 발현하기 위한 비-바이러스 벡터를 포함하는 유전자 요법 분야에 관한 것이다. 본 개시는 또한 폴리뉴클레오티드를 포함하는 핵산 작제물, 프로모터, 벡터 및 숙주 세포뿐만 아니라 외인성 DNA 서열을 표적 세포, 조직, 기관 또는 유기체에 전달하는 방법에 관한 것이다. 예를 들어, 본 발명은 비-바이러스성 DNA 벡터를 사용하여 세포로부터 치료 항체와 같은 항체를 발현시키는 방법을 제공한다. 본 개시내용은 또한 비-바이러스성 DNA 벡터를 사용하여 세포로부터 치료 단백질, 예컨대 치료 융합 단백질을 발현시키는 방법을 제공한다. 상기 방법 및 조성물은 예를 들어, 상업적 항체 또는 융합 단백질 생산 또는 이를 필요로 하는 대상체의 세포 또는 조직에서 치료적 항체 또는 융합 단백질을 발현시킴으로써 질환을 치료하기 위해 적용될 수 있다.
유전자 요법은 유전자 돌연변이 또는 유전자 발현 프로파일의 이상(aberration)에 의해 유발된 후천성 질환을 앓고 있는 환자의 임상 결과를 개선시키는 것을 목표로 한다. 유전자 요법은 장애, 질환, 악성 종양 등을 초래할 수 있는, 결함 유전자, 또는 비정상적 조절 또는 발현, 예를 들어 저발현(underexpression) 또는 과발현으로 인한 의학적 상태의 치료 또는 예방을 포함한다. 예를 들어, 결함 유전자에 의해 야기된 질환 또는 장애는 교정 유전 물질을 환자에게 전달함으로써 치료 예방 또는 개선될 수 있거나, 예를 들어 교정 유전 물질을 시용하여 결함 유전자를 환자에게 변경 또는 침묵시킴으로써 환자 내에서 유전 물질의 치료적 발현을 초래함으로써 치료, 예방 또는 개선될 수 있다.
유전자 요법의 기초는, 예를 들어, 긍정적인 기능 획득 효과, 부정적인 기능 손실 효과, 또는 다른 결과를 초래할 수 있는 활성 유전자 산물 (때로는 이식유전자으로 지칭됨)을 전사 카세트에 공급하는 것이다. 이러한 결과는 활성화 항체 또는 융합 단백질 또는 억제성 (중화) 항체 또는 융합 단백질의 발현에 기인할 수 있다. 유전자 요법은 또한 다른 요인들에 의해 야기된 질환 또는 악성 종양을 치료하는 데 사용될 수 있다. 인간 단일유전인자 장애는 표적 세포로의 정상 유전자의 전달 및 발현에 의해 치료될 수 있다. 환자의 표적 세포에서 교정 유전자의 전달 및 발현은 조작된 바이러스 및 바이러스 유전자 전달 벡터의 사용을 포함하여 수많은 방법을 통해 수행될 수 있다. 이용 가능한 많은 바이러스-유래 벡터 (예를 들어, 재조합 레트로바이러스, 재조합 렌티바이러스, 재조합 아데노바이러스 등) 중에서, 재조합 아데노-관련 바이러스 (rAAV)는 유전자 요법에서 다용도 벡터로서 인기를 얻고 있다.
아데노-관련 바이러스 (AAV)는 파보비리다에(parvoviridae) 패밀리에 속하고 보다 구체적으로 데펜도파보바이러스(dependoparvovirus) 속을 구성한다. AAV로부터 유래된 벡터 (즉, 재조합 AAV (rAVV) 또는 AAV 벡터)는 (i) 근세포 및 뉴런을 포함하는 다양한 비-분열 및 분열 세포 유형을 감염 (형질도입)시킬 수 있고; (ii) 바이러스 구조 유전자가 결여되어 바이러스 감염에 대한 숙주 세포 반응, 예를 들어 인터페론-매개 반응을 감소시키고; (iii) 야생형 바이러스는 인간에서 비-병리학적인 것으로 간주되고; (iv) 숙주 세포 게놈 내로 통합될 수 있는 야생형 AAV와 달리, 복제-결함 AAV 벡터는 rep 유전자가 결여되고 일반적으로 에피솜으로서 지속되므로, 삽입 돌연변이유발 또는 유전독성의 위험을 제한하고; (v) 다른 벡터 시스템과 비교하여, AAV 벡터는 일반적으로 상대적으로 열악한 면역원으로 간주되고 따라서 상당한 면역 반응을 유발하지 않으며 (ii 참조), 따라서 벡터 DNA의 지속성 및 잠재적으로 치료적 이식유전자(transgene)의 장기간 발현을 얻게 되기 때문에 유전 물질을 전달하는 데 매력적이다.
그러나, AAV 입자를 유전자 전달 벡터로서 사용하는 데에는 몇 가지 주요 결점이 있다. rAAV와 관련된 하나의 주요 단점은 약 4.5 kb의 이종 DNA의 제한된 바이러스 패키징 용량이고 (Dong et al., 1996; Athanasopoulos et al., 2004; Lai et al., 2010), 그리고 결과적으로, AAV 벡터의 사용은 150,000 Da 미만의 단백질 코딩 능력으로 제한되었다. 두 번째 단점은 개체군에서 야생형 AAV 감염의 유병률로 인해 rAAV 유전자 요법 후보가 환자로부터 벡터를 제거하는 중화 항체의 존재에 대해 스크리닝되어야 한다는 점이다. 세 번째 단점은 초기 치료에서 배제되지 않은 환자에게 재투여를 방지하는 캡시드 면역원성과 관련이 있다. 환자의 면역계는 향후 치료를 배제하는 높은 역가 항-AAV 항체를 생성하는 면역계를 자극하기 위해 "부스터"샷으로서 효과적으로 작용하는 벡터에 반응할 수 있다. 일부 최근 보고는 고용량 상황에서 면역원성에 대한 우려를 나타낸다. 또 다른 주목할 만한 단점은 단일-가닥 AAV DNA가 이종 유전자 발현 전에 이중 가닥 DNA로 전환되어야 하기 때문에 AAV 매개 유전자 발현의 개시가 상대적으로 느리다는 점이다.
또한, 캡시드를 갖는 통상적인 AAV 비리온은 AAV 게놈, rep 유전자 및 cap 유전자를 함유하는 플라스미드 또는 플라스미드들을 도입함으로써 생성된다 (Grimm et al., 1998). 그러나, 이러한 캡시드로 이입된 AAV 바이러스 벡터는 특정 세포 및 조직 유형을 비효율적으로 형질도입시키는 것으로 밝혀졌고 그리고 캡시드는 또한 면역 반응을 유도한다.
따라서, 유전자 치료를 위한 아데노-관련 바이러스 (AAV) 벡터의 사용은 (환자 면역 반응으로 인해) 환자에 대한 단일 투여, 최소 바이러스 패키징 용량 (약 4.5 kb)으로 인한 AAV 벡터로의 전달에 적합한 이식유전자 유전 물질의 제한된 범위, 및 느린 AAV-매개 유전자 발현으로 인해 제한된다.
세포, 조직 또는 대상체에서 또는, 대안적으로, 정제 및/또는 상업적 생산을 위해 시험관내 또는 생체내에서 항체 또는 융합 단백질을 생성하기 위해 치료 항체 (예를 들어, 분비된 항체 또는 인트라바디(intrabody)) 또는 융합 단백질 (예를 들어, 수용체 세포외 도메인-Fc 융합물)의 발현을 가능하게 하는 기술에 대한 당해 분야에서의 필요성이 존재한다. 또한, 기존 또는 통상적인 방법 또는 벡터와 비교하여 항체 (예를 들어, 치료 항체) 및 융합 단백질 (예를 들어, 치료 융합 단백질)의 생산 개선을 위한 생산 및/또는 발현 특성이 개선된 제어 가능한 재조합 DNA 벡터에 대한 충족되지 않은 중요한 필요성이 여전히 남아있다.
발명의 간단한 설명
본원에 기재된 기술은 공유적으로-폐쇄된 말단을 갖는 캡시드-비함유 (예를 들어, 비-바이러스) DNA 벡터 (본원에서는 "폐쇄된-말단 DNA 벡터" 또는 "ceDNA 벡터"로 지칭됨)를 사용하는 항체 및 융합 단백질 (예컨대 치료 항체 및 융합 단백질)의 발현을 위한 방법 및 조성물에 관한 것이다. 이들 ceDNA 벡터는 질환 치료, 악성 종양 치료, 모니터링 및 진단, 뿐만 아니라 상업적 항체 또는 융합 단백질 생산을 위한 항체 및 융합 단백질을 생성하는데 사용될 수 있다. 하나의 예시적인 항체는 본원에 기재된 ceDNA 벡터를 사용하여 대상체의 세포 또는 조직에서 발현될 수 있는 모노클로날 항체 아달리무맙(Humira™)을 포함하지만 이에 제한되지 않는 항종양 괴사 인자 항체 또는 이의 항체-결합 단편이다. 이러한 치료 항체는 류마티스 관절염, 건선성 관절염, 강직성 척추염 및 크론병의 치료 목적으로 사용될 수 있다.
따라서, 본원에 기재된 본 발명은 세포, 예를 들어, 분비된 항체 또는 인트라바디 내에서 항체의 발현을 가능하게 하기 위해 항체 (예를 들어, 경쇄, 중쇄, 프레임워크, Fab', 단일쇄 항체) 또는 이의 항원-결합 단편을 인코딩하는 이종 유전자를 포함하는 공유적으로-폐쇄된 말단을 갖는 캡시드-비함유 (예를 들어, 비-바이러스) DNA 벡터 (본원에서는 "폐쇄된-말단 DNA 벡터" 또는 "ceDNA 벡터"로 지칭됨)에 관한 것이다. 본 발명은 또한 세포 내에서 융합 단백질의 발현을 가능하게 하기 위해 융합 단백질을 인코딩하는 이종 유전자를 포함하는 ceDNA 벡터에 관한 것이다. 발현될 이러한 항체 또는 융합 단백질은 치료 항체 또는 융합 단백질일 수 있고/있거나 적용된 기술은 상업적 목적을 위한 항체 또는 융합 단백질의 생성에 사용될 수 있다. 특히, 본원에 기재된 기술은 ceDNA 벡터를 사용하는 항체 및 융합 단백질의 생산 개선에 관한 것이다.
본원에 기재된 바와 같이 항체 및 융합 단백질 생산에 대한 ceDNA 벡터는 5' 역 말단 반복 (ITR) 서열 및 3' ITR 서열을 포함하는 공유적으로 폐쇄된 말단 (선형, 연속 및 비-캡슐화된 구조)을 갖는 상보성 DNA의 연속 가닥으로부터 형성된 캡시드-비함유 선형 듀플렉스 DNA 분자이며, 여기서 5' ITR 및 3' ITR은 서로 동일한 대칭 3차원 구성을 가질 수 있거나 (즉, 대칭 또는 실질적으로 대칭), 또는 대안적으로 5' ITR 및 3' ITR은 서로 상이한 3차원 구성 (즉, 비대칭 ITR)을 가질 수 있다. 또한, ITR은 동일하거나 상이한 혈청형으로부터 유래될 수 있다. 일부 구현예에서, ceDNA 벡터는 구조가 기하학적 공간에서 동일한 형상이거나 3D 공간에서 동일한 A, C-C' 및 B-B' 루프를 갖도록 대칭 3차원 공간 구성을 갖는 ITR 서열을 포함할 수 있다 (즉, 이들은 동일하거나 서로 거울상임). 일부 구현예에서, 하나의 ITR은 하나의 AAV 혈청형으로부터 유래될 수 있고, 다른 ITR은 상이한 AAV 혈청형으로부터 유래될 수 있다.
따라서, 본원에 기재된 기술의 일부 측면은 (i) 적어도 하나의 WT ITR 및 적어도 하나의 변형된 AAV 역 말단 반복부 (ITR) (예를 들어, 비대칭인 변형된 ITR); (ii) 모드-ITR 쌍이 서로 상이한 3차원 공간 구성을 갖는 2개의 변형된 ITR (예를 들어, 비대칭인 변형된 ITR), 또는 (iii) 각각의 WT-ITR이 동일한 3차원 공간 구성을 갖는 대칭 또는 실질적으로 대칭인 WT-WT ITR 쌍, 또는 (iv) 각각의 모드-ITR이 동일한 3차원 공간 구성을 갖는 대칭 또는 실질적으로 대칭인 변형된 ITR 쌍 중 어느 것으로부터 선택된 ITR 서열을 포함하는 개선된 항체 또는 융합 단백질 발현 및/또는 생산용 ceDNA 벡터에 관한 것이다. 본원에 개시된 ceDNA 벡터는 진핵 세포에서 생성될 수 있으며, 따라서 곤충 세포에서 원핵생물 DNA 변형 및 박테리아 내독소 오염이 없다.
본원에 기재된 방법 및 조성물은, 부분적으로, 세포로부터 적어도 하나의 항체 및/또는 융합 단백질, 또는 하나 초과의 항체 및/또는 융합 단백질을 발현시키는데 사용될 수 있는 공유적으로-폐쇄된 말단을 갖는 비-바이러스 캡시드-비함유 DNA 벡터(ceDNA 벡터)의 발견에 관한 것이다. 상기 방법 및 조성물은 예를 들어, 상업적 항체 또는 융합 단백질 생산에 또는 치료 항체 또는 융합 단백질로 질환을 치료하기 위해 적용될 수 있다.
따라서, 일 측면에서 2개의 상이한 AAV 역 말단 반복 서열 (ITR) 사이에 위치한 프로모터에 작동 가능하게 연결된 항체 또는 이의 항원-결합 단편 또는 융합 단백질을 인코딩하는 적어도 하나의 이식유전자를 인코딩하는 적어도 하나의 이종 핵산 서열을 포함하는 DNA 벡터 (예를 들어, ceDNA 벡터)가 본원에 제공되며, 상기 ITR 중 하나는 기능적 AAV 말단 분해 부위 및 Rep 결합 부위를 포함하고, 상기 ITR 중 하나는 다른 ITR에 대한 결실, 삽입 또는 치환을 포함하고; 여기서 이식유전자는 항체 또는 이의 단편(예를 들어, 이의 항원-결합 단편) 또는 융합 단백질이고; DNA는, DNA 벡터 상에 단일 인식 부위를 갖는 제한 효소로 소화될 때, 비-변성 겔 상에서 분석되는 경우 선형 및 비-연속 DNA 대조군과 비교하여 선형 및 연속 DNA의 특징적인 밴드가 존재한다. 다른 측면은 본원에 기재된 바와 같은 ceDNA 벡터로부터 생체내에서 발현시킴으로써 치료 항체 또는 융합 단백질의 전달 및 추가로 이러한 항체 또는 융합 단백질을 사용한 다양한 질환의 치료를 포함한다. 본원에 기재된 바와 같은 ceDNA 벡터를 포함하는 세포가 또한 본 명세서에서 고려된다.
본 발명의 측면은 본원에 기재된 바와 같은 세포에서 항체 또는 융합 단백질 생산 또는 항체 또는 융합 단백질 발현에 유용한 ceDNA 벡터를 생성하는 방법에 관한 것이다. 다른 구현예는 본원에 제공된 방법에 의해 생성된 ceDNA 벡터에 관한 것이다. 일 구현예에서, 항체 또는 융합 단백질 생산을 위한 캡시드 비함유 (예를 들어, 비-바이러스) DNA 벡터 (ceDNA 벡터)는 다음의 순서로 포함되는 폴리뉴클레오티드 발현 작제물 주형을 포함하는 플라스미드 (본 명세서에서 "ceDNA-플라스미드"로 지칭됨)로부터 수득되며: 처음 5' 역 말단 반복부 (예를 들어, AAV ITR); 이종 핵산 서열; 및 3' ITR (예를 들어, AAV ITR), 여기서 5' ITR 및 3' ITR은 서로 비대칭일 수 있거나, 또는 본원에 정의된 바와 같은 대칭 (예를 들어, WT-ITR 또는 변형된 대칭 ITR)일 수 있다.
본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 본 개시내용을 읽은 후에 당업자에게 공지될 수 있는 수많은 수단들에 의해 수득될 수 있다. 예를 들어, 본 발명의 ceDNA 벡터를 생성하는 데 사용된 폴리뉴클레오티드 발현 작제물 주형은 ceDNA-플라스미드, ceDNA-박미드(bacmid) 및/또는 ceDNA-바쿨로바이러스일 수 있다. 일 구현예에서, ceDNA-플라스미드는 예를 들어, 이식유전자, 예를 들어, 항체 또는 이의 항원 결합 단편 또는 융합 단백질 및/또는 리포터 유전자를 코딩하는 핵산)에 작동적으로 연결된 프로모터를 포함하는 발현 카세트가 삽입될 수 있는 ITR들 사이에 작동 가능하게 위치한 제한 클로닝 부위 (예를 들어, 서열 번호: 123 및/또는 124)를 포함한다. 일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 대칭 또는 비대칭 ITR (변형된 또는 WT ITR)을 함유하는 폴리뉴클레오티드 주형 (예를 들어, ceDNA-플라스미드, ceDNA-박미드, ceDNA-바쿨로바이러스)으로부터 생성된다.
허용 숙주 세포에서, 예를 들어, Rep의 존재하에, 적어도 2개의 ITR을 갖는 폴리뉴클레오티드 주형이 복제되어 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 생성한다. ceDNA 벡터 생산은 두 단계, 즉 우선, Rep 단백질을 통한 주형 골격 (예를 들어 ceDNA-플라스미드, ceDNA-박미드, ceDNA-바쿨로바이러스 게놈 등)으로부터 주형의 절제 ("구조") 단계 및 둘째, 절제된 ceDNA 벡터의 Rep 매개 복제 단계를 거친다. 다양한 AAV 혈청형의 Rep 단백질 및 Rep 결합 부위는 당업자에게 널리 공지되어 있다. 당업자는 적어도 하나의 기능성 ITR에 기초하여 핵산 서열에 결합하고 이를 복제하는 혈청형으로부터 Rep 단백질을 선택하는 것을 이해한다. 예를 들어, 복제 적격 ITR이 AAV 혈청형 2에서 유래한 경우, 상응하는 Rep는 AAV2 또는 AAV4 Rep를 갖는 AAV2 ITR과 같은 혈청형과 작동하는 AAV 혈청형에서 유래하지만 AAV5 Rep는 그렇지 않다. 복제시, 공유-폐쇄된 말단 ceDNA 벡터는 허용 세포에 계속 축적되고, ceDNA 벡터는 바람직하게는 표준 복제 조건 하에서 Rep 단백질의 존재하에 시간 경과에 따라 충분히 안정적이어서, 예를 들어, 적어도 1 pg/세포, 바람직하게는 적어도 2 pg/세포, 바람직하게는 적어도 3 pg/세포, 보다 바람직하게는 적어도 4 pg/세포, 더욱 더 바람직하게는 적어도 5 pg/세포의 양으로 축적된다.
따라서, 본 발명의 일 측면은 a) 숙주 세포 내에서 ceDNA 벡터의 생성을 유도하는데 효과적인 조건 하에서 및 충분한 시간 동안 Rep 단백질의 존재하에서 바이러스 캡시드 코딩 서열이 없는, 폴리뉴클레오티드 발현 작제물 주형 (예를 들어, ceDNA-플라스미드, ceDNA-박미드 및/또는 ceDNA-바쿨로바이러스)을 보유하는 숙주 세포 (예를 들어, 곤충 세포)의 개체군을 인큐베이션하는 단계로서, 숙주 세포는 바이러스 캡시드 코딩 서열을 포함하지 않는, 상기 단계; 및 b) 숙주 세포로부터 ceDNA 벡터를 수거하고 단리하는 단계를 포함하는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 제조 방법에 관한 것이다. Rep 단백질의 존재는 숙주 세포에서 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 생성하기 위해 변형된 ITR로 벡터 폴리뉴클레오티드의 복제를 유도한다. 그러나, 바이러스 입자 (예를 들어, AAV 비리온)는 발현되지 않는다. 따라서, 비리온-적용 크기 제한은 없다.
항체 또는 융합 단백질 생산에 유용한 ceDNA 벡터의 존재는 숙주 세포로부터 단리되어 ceDNA 벡터 상에 단일 인식 부위를 갖는 제한 효소로 숙주 세포로부터 단리된 DNA를 소화시키고 선형 및 비-연속 DNA와 비교하여 선형 및 연속 DNA의 특징적인 밴드의 존재를 확인하기 위해 변성 및 비-변성 겔에서 소화된 DNA 물질을 분석함으로써 확인될 수 있다.
본 개시의 목적을 위해, ceDNA에 의해 발현된 이식유전자는 항체 또는 항체 결합 단편 또는 융합 단백질을 인코딩한다. 항체 및 융합 단백질은 당 업계에 잘 알려져 있으며, 리간드, 수용체, 독소, 호르몬, 효소, 또는 세포 표면 단백질, 또는 병원체 또는 바이러스 단백질 또는 항원, 뿐만 아니라 번역 전 및 번역 후 변형된 단백질, 예컨대 당단백질 또는 수모화(SUMOylated) 단백질 (예를 들어, ant-SUMO2/3 항체) 등을 포함하지만, 이에 제한되지 않는 임의의 관심 단백질에 결합할 수 있다. 항체 및 항원 결합 단편은 또한 핵산, 예를 들어, DNA (예를 들어, 항-dsDNA 항체), RNA (예를 들어, 항-RNA 결합 항체)를 포함하지만 이에 제한되지 않는, 임의의 항원에 결합하는 항체를 포함한다. 일부 구현예에서, 본원에 개시된 ceDNA 벡터에 의해 생성된 항체는 중화 항체 또는 이의 항원-결합 단편이다. 표적화될 예시적인 유전자 및 관심 단백질은 본원의 사용 방법 및 치료 방법 섹션에 상세히 기재되어 있다.
세포 또는 대상체에서 ceDNA 벡터를 사용하는, 치료 용도를 갖는 항체 또는 융합 단백질을 발현시키는 방법이 또한 본원에 제공된다. 이러한 항체 또는 융합 단백질은 질환의 치료에 사용될 수 있다. 따라서, 치료 항체 또는 융합 단백질을 인코딩하는 ceDNA 벡터를 이를 필요로 하는 대상체에게 투여하는 것을 포함하는 질환의 치료 방법이 본원에 제공된다. 다른 구현예에서 치료 항체 또는 융합 단백질은 악성 세포를 표적화하거나, 특정 단백질을 모니터링하거나, 또는 진단 목적으로 사용될 수 있다.
일부 구현예에서, 본 출원은 하기 단락 중 임의의 단락에서 정의될 수 있다:
1. 플랭킹 역 말단 반복부 (ITR) 사이의 적어도 하나의 이종 뉴클레오티드 서열을 포함하는 캡시드-비함유 폐쇄된-말단 DNA (ceDNA) 벡터로서, 적어도 하나의 이종 뉴클레오티드 서열은 적어도 하나의 항체 및/또는 융합 단백질을 인코딩하는, 캡시드-비함유 폐쇄된-말단 DNA (ceDNA) 벡터.
1. 제1항에 있어서, 적어도 하나의 이종 뉴클레오티드 서열은 항체를 인코딩하는, ceDNA 벡터.
2. 제2항에 있어서, 상기 항체는 전장 항체, Fab, Fab', 단일-도메인 항체, 또는 단일쇄 항체 (scFv)인, ceDNA 벡터.
3. 제3항에 있어서, 적어도 하나의 이종 뉴클레오티드 서열은 단일-도메인 항체 또는 단일쇄 항체를 인코딩하는, ceDNA 벡터.
4. 제4항에 있어서, 상기 적어도 하나의 이종 뉴클레오티드 서열은 단일-도메인 항체 또는 단일쇄 항체의 상류에 있는 분비 리더 서열(secretory leader sequence)을 추가로 인코딩하는, ceDNA 벡터.
5. 제1항 내지 제3항 중 어느 한 항에 있어서, 제1 이종 뉴클레오티드 서열은 중쇄 가변 영역을 인코딩하고, 제2 이종 뉴클레오티드 서열은 경쇄 가변 영역을 인코딩하는, ceDNA 벡터.
6. 제4항에 있어서, 상기 제1 이종 뉴클레오티드 서열은 중쇄 가변 영역 및 중쇄 불변 영역 또는 이의 일부를 인코딩하고, 상기 제2 이종 뉴클레오티드 서열은 경쇄 가변 영역 및 경쇄 불변 영역 또는 이의 일부를 인코딩하는, cDNA 벡터.
7. 제6항 또는 제7항에 있어서, 상기 제1 이종 뉴클레오티드 서열 및/또는 상기 제2 이종 뉴클레오티드 서열은 상기 중쇄 가변 영역 및/또는 경쇄 가변 영역의 상류에 있는 분비 리더 서열을 추가로 인코딩하는, ceDNA 벡터.
8. 제1항 내지 제8항 중 어느 한 항에 있어서, 상기 항체는 인간 또는 인간화된 항체인, ceDNA 벡터.
9. 제1항 내지 제9항 중 어느 한 항에 있어서, 상기 항체는 IgG, IgA, IgD, IgM, 또는 IgE 항체인, ceDNA 벡터.
10. 제10항에 있어서, 상기 항체는 IgG 항체인, ceDNA 벡터.
11. 제11항에 있어서, 상기 IgG 항체는 IgG1, IgG2, IgG3, 또는 IgG4 항체인, ceDNA 벡터.
12. 제1항 내지 제12항 중 어느 한 항에 있어서, 상기 항체는 표 1, 2, 3a, 3b, 4, 및 5에 열거된 표적으로부터 선택된 적어도 하나의 표적에 결합하는, ceDNA 벡터.
13. 제1항에 있어서, 적어도 하나의 이종 뉴클레오티드 서열은 융합 단백질을 인코딩하는, ceDNA 벡터.
14. 제14항에 있어서, 상기 적어도 하나의 이종 뉴클레오티드 서열은 상기 융합 단백질의 상류에 있는 분비 리더 서열을 추가로 인코딩하는, ceDNA 벡터.
15. 제14항 또는 제15항에 있어서, 상기 융합 단백질은 Fc 영역에 융합된 적어도 하나의 수용체 세포외 도메인을 포함하는, ceDNA 벡터.
16. 제16항에 있어서, 상기 수용체 세포외 도메인은 CTLA-4, VEGFR1, VEGFR2, LFA-3, TNFR, IL-1R1, IL-1R1, IL-1RAcP, 및 ACVR2A로부터 선택된 수용체의 세포외 도메인인, ceDNA 벡터.
17. 제1항 내지 제17항 중 어느 한 항에 있어서, 상기 항체 또는 융합 단백질은 표 1, 2, 3A, 3B, 4, 또는 5의 항체 및 융합 단백질로부터 선택되는, ceDNA 벡터.
18. 제1항 내지 제18항 중 어느 한 항에 있어서, 상기 ceDNA 벡터는 하나 이상의 폴리-A 부위를 포함하는, ceDNA 벡터.
19. 제1항 내지 제19항 중 어느 한 항에 있어서, 상기 ceDNA 벡터는 적어도 하나의 이종 뉴클레오티드 서열에 작동 가능하게 연결된 적어도 하나의 프로모터를 포함하는, ceDNA 벡터.
20. 제1항 내지 제20항 중 어느 한 항에 있어서, 적어도 하나의 이종 뉴클레오티드 서열은 cDNA인, ceDNA 벡터.
21. 제1항 내지 제21항 중 어느 한 항에 있어서, 적어도 하나의 ITR은 기능적 말단 분해 부위 및 Rep 결합 부위를 포함하는, ceDNA 벡터.
22. 제1항 내지 제22항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 파보바이러스(parvovirus), 데펜도바이러스(dependovirus), 및 아데노-관련 바이러스 (AAV)로부터 선택된 바이러스로부터 유래되는, ceDNA 벡터.
23. 제1항 내지 제23항 중 어느 한 항에 있어서, 상기 플랭킹 ITR은 대칭 또는 비대칭인, ceDNA 벡터.
24. 제24항에 있어서, 상기 플랭킹 ITR은 대칭이거나 실질적으로 대칭인, ceDNA 벡터.
25. 제24항에 있어서, 상기 플랭킹 ITR은 비대칭인, ceDNA 벡터.
26. 제1항 내지 제26항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 야생형이거나, 두 ITR 모두 야생형인, ceDNA 벡터.
27. 제1항 내지 제27항 중 어느 한 항에 있어서, 상기 플랭킹 ITR은 상이한 바이러스 혈청형으로부터 유래하는, ceDNA 벡터.
28. 제1항 내지 제28항 중 어느 한 항에 있어서, 상기 플랭킹 ITR은 표 6에 나타낸 한 쌍의 바이러스 혈청형으로부터 유래하는, ceDNA 벡터.
29. 제1항 내지 제29항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 표 7의 서열로부터 선택된 서열을 포함하는, ceDNA 벡터.
30. 제1항 내지 제30항 중 어느 한 항에 있어서, 상기 ITR 중 적어도 하나는 상기 ITR의 전체 3차원 입체 형태에 영향을 주는 결실, 첨가 또는 치환에 의해 야생형 AAV ITR 서열로부터 변경되는, ceDNA 벡터.
31. 제1항 내지 제31항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 AAV1, AAV2, AAV3, AAV4, AAV5, AAV6, AAV7, AAV8, AAV9, AAV10, AAV11, 및 AAV12로부터 선택된 AAV 혈청형으로부터 유래되는, ceDNA 벡터.
32. 제1항 내지 제32항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 합성인, ceDNA 벡터.
33. 제1항 내지 제33항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 야생형 ITR이 아니거나, 두 ITR 모두가 야생형이 아닌, ceDNA 벡터.
34. 제1항 내지 제34항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 A, A', B, B', C, C', D, 및 D'로부터 선택된 ITR 영역 중 적어도 하나에서 결실, 삽입 및/또는 치환에 의해 변형되는, ceDNA 벡터.
35. 제35항에 있어서, 상기 결실, 삽입 및/또는 치환이 A, A', B, B' C 또는 C' 영역에 의해 일반적으로 형성된 스템-루프 구조의 전부 또는 일부를 결실시키는, ceDNA 벡터.
36. 제1항 내지 제36항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 B 및 B' 영역에 의해 일반적으로 형성된 스템-루프 구조의 전부 또는 일부를 결실시키는 결실, 삽입 및/또는 치환에 의해 변형되는, ceDNA 벡터.
37. 제1항 내지 제37항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 C 및 C' 영역에 의해 일반적으로 형성된 스템-루프 구조의 전부 또는 일부를 결실시키는 결실, 삽입 및/또는 치환에 의해 변형되는, ceDNA 벡터.
38. 제1항 내지 제38항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 B 및 B' 영역에 의해 일반적으로 형성된 스템-루프 구조의 일부 및/또는 C 및 C' 영역에 의해 일반적으로 형성된 스템-루프 구조의 일부를 결실시키는 결실, 삽입 및/또는 치환에 의해 변형되는, ceDNA 벡터.
39. 제1항 내지 제39항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 B 및 B' 영역에 의해 형성된 제1 스템-루프 구조 및 C 및 C' 영역에 의해 형성된 제2 스템-루프 구조를 일반적으로 포함하는 영역에서 단일 스템-루프 구조를 포함하는, ceDNA 벡터.
40. 제1항 내지 제40항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 B 및 B' 영역에 의해 형성된 제1 스템-루프 구조 및 C 및 C' 영역에 의해 형성된 제2 스템-루프 구조를 일반적으로 포함하는 영역에서 단일 스템 및 2개의 루프를 포함하는, ceDNA 벡터.
41. 제1항 내지 제41항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 B 및 B' 영역에 의해 형성된 제1 스템-루프 구조 및 C 및 C' 영역에 의해 형성된 제2 스템-루프 구조를 일반적으로 포함하는 영역에서 단일 스템 및 단일 루프를 포함하는, ceDNA 벡터.
42. 제1항 내지 제42항 중 어느 한 항에 있어서, 상기 ITR이 서로 반전될 때 두 ITR이 전체적으로 3차원 대칭이 되는 방식으로 변경되는, ceDNA 벡터.
43. 제1항 내지 제43항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 표 7, 9a, 9b, 및 10의 서열로부터 선택된 서열을 포함하는, ceDNA 벡터.
44. 제1항 내지 제44항 중 어느 한 항에 있어서, 적어도 하나의 이종 뉴클레오티드 서열은 적어도 하나의 조절 스위치의 제어하에 있는, ceDNA 벡터.
45. 제45항에 있어서, 적어도 하나의 조절 스위치는 이진 조절 스위치, 소분자 조절 스위치, 패스코드(passcode) 조절 스위치, 핵산-기반 조절 스위치, 전사 후 조절 스위치, 방사선-제어 또는 초음파 제어 조절 스위치, 저산소증-매개 조절 스위치, 염증 반응 조절 스위치, 전단-활성화 조절 스위치, 및 사멸 스위치로부터 선택되는, ceDNA 벡터.
46. 상기 세포를 제1항 내지 제46항 중 어느 한 항의 ceDNA 벡터와 접촉시키는 것을 포함하는 세포에서 항체 또는 융합 단백질을 발현시키는 방법.
47. 제47항에 있어서, 접촉된 세포가 진핵 세포인, 방법.
48. 제47항 또는 제48항에 있어서, 상기 세포는 시험관내 또는 생체내인, 방법.
49. 제47항 내지 제49항 중 어느 한 항에 있어서, 상기 적어도 하나의 이종 뉴클레오티드 서열은 상기 진핵 세포에서의 발현에 대해 코돈 최적화된, 방법.
50. 제47항 내지 제50항 중 어느 한 항에 있어서, 상기 항체 또는 융합 단백질은 상기 세포로부터 분비되는, 방법.
51. 제47항 내지 제50항 중 어느 한 항에 있어서, 상기 항체 또는 융합 단백질은 세포에서 유지되는, 방법.
52. 대상체를 치료 항체 또는 치료 융합 단백질로 치료하는 방법으로서, 상기 대상체에게 제1항 내지 제46항 중 어느 한 항의 ceDNA 벡터를 투여하는 것을 포함하고, 여기서 적어도 하나의 이종 뉴클레오티드 서열은 상기 치료 항체 또는 치료 융합 단백질을 인코딩하는, 방법.
53. 제53항에 있어서, 상기 대상체는 암, 자가면역 질환, a 신경퇴행성 장애, 고콜레스테롤혈증, 급성 기관 거부, 다발성 경화증, 폐경기후 골다공증, 피부 병태, 천식, 또는 혈우병으로부터 선택된 질환 또는 장애를 갖는, 방법.
54. 제53항에 있어서, 상기 암은 고형 종양, 연조직 육종, 림프종 및 백혈병으로부터 선택되는, 방법.
55. 제53항에 있어서, 상기 자가면역 질환은 류마티스 관절염 및 크론병으로부터 선택되는, 방법.
56. 제53항에 있어서, 상기 피부 병태는 건선 및 아토피 피부염으로부터 선택되는, 방법.
57. 제53항에 있어서, 상기 신경퇴행성 장애는 알츠하이머병인, 방법.
58. 제1항 내지 제46항 중 어느 한 항의 ceDNA 벡터를 포함하는 약제학적 조성물.
59. 제1항 내지 제46항 중 어느 한 항의 ceDNA 벡터를 함유하는 세포.
60. 제1항 내지 제46항 중 어느 한 항의 ceDNA 벡터 및 지질을 포함하는 조성물.
61. 제61항에 있어서, 상기 지질은 지질 나노입자 (LNP)인, 조성물.
62. 제1항 내지 제46항 중 어느 한 항의 ceDNA 벡터 또는 제61항 또는 제62항의 조성물 또는 제60항의 세포를 포함하는 키트.
63. 제60항의 세포를 항체 또는 융합 단백질을 생성하기에 적합한 조건하에서 배양하는 것을 포함하는 항체 또는 융합 단백질의 생산 방법.
64. 제64항에 있어서, 상기 항체 또는 융합 단백질의 단리를 추가로 포함하는, 방법.
일부 구현예에서, 본원에 기재된 기술의 일 측면은 공유적으로 폐쇄된 말단을 갖는 비-바이러스 캡시드 비함유 DNA 벡터 (ceDNA 벡터)에 관한 것이며, 여기서 ceDNA 벡터는 비대칭 역 말단 반복 서열 사이에 작동 가능하게 위치된 적어도 하나의 이종 뉴클레오티드 서열을 포함하고, ITR 서열이 이들 용어가 본원에 정의된 바와 같이 비대칭, 또는 대칭 또는 실질적으로 대칭일 수 있고, ITR 중 적어도 하나는 기능성 말단 분해 부위 및 Rep 결합 부위를 포함하고, 임의로 이종 핵산 서열이 이식유전자(예를 들어, 항체 또는 융합 단백질)를 인코딩하고, 벡터가 바이러스 캡시드에 있지 않다.
본 발명의 이들 및 다른 측면은 아래에 더 상세히 설명된다.
위에서 간략하게 요약되고 아래에서 더 상세히 논의되는 본 개시의 구현예는 첨부된 도면에 도시된 본 개시의 예시적인 구현예를 참조하여 이해될 수 있다. 그러나, 첨부된 도면은 본 개시의 전형적인 구현예만을 도시하며, 따라서 본 개시는 다른 동등하게 유효한 구현예를 인정할 수 있기 때문에 범위를 제한하는 것으로 간주되지 않아야 한다.
위에서 간략하게 요약되고 아래에서 더 상세히 논의되는 본 개시의 구현예는 첨부된 도면에 도시된 본 개시의 예시적인 구현예를 참조하여 이해될 수 있다. 그러나, 첨부된 도면은 본 개시의 전형적인 구현예만을 도시하며, 따라서 본 개시는 다른 동등하게 유효한 구현예를 인정할 수 있기 때문에 범위를 제한하는 것으로 간주되지 않아야 한다.
도 1a는 비대칭 ITR을 포함하는, 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적인 구조를 도시한다. 이 구현예에서, 예시적인 ceDNA 벡터는 CAG 프로모터, WPRE 및 BGHpA를 함유하는 발현 카세트를 포함한다. 이식유전자, 예를 들어, 항체 또는 융합 단백질을 인코딩하는 핵산을 인코딩하는 오픈 리딩 프레임 (ORF)이 CAG 프로모터와 WPRE 사이의 클로닝 부위 (R3/R4)에 삽입된다. 발현 카세트는 2개의 역 말단 반복부 (ITR), 즉 발현 카세트의 상류 (5'-말단)의 야생형 AAV2 ITR 및 하류 (3'-말단)의 변형된 ITR에 의해 플랭킹되며, 따라서 발현 카세트 측면에 있는 2개의 ITR은 서로 비대칭이다.
도 1b는 CAG 프로모터, WPRE 및 BGHpA를 함유하는 발현 카세트를 이용한 비대칭 ITR을 포함하는, 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적인 구조를 도시한다. 이식유전자 항체 또는 융합 단백질을 인코딩하는 핵산을 인코딩하는 오픈 리딩 프레임 (ORF)이 CAG 프로모터와 WPRE 사이의 클로닝 부위에 삽입된다. 발현 카세트는 발현 카세트의 상류 (5'-말단)의 변형된 ITR 및 하류 (3'-말단)의 야생형 ITR인, 2개의 역 말단 반복부 (ITR)에 의해 플랭킹된다.
도 1c는 인핸서/프로모터, 이식유전자, 전사 후 요소 (WPRE) 및 폴리 A 신호를 함유하는 발현 카세트를 갖는, 비대칭 ITR을 포함하는 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적인 구조를 도시한다. 오픈 리딩 프레임 (ORF)은 이식유전자, 예를 들어 항체 또는 융합 단백질을 인코딩하는 핵산을 CAG 프로모터와 WPRE 사이의 클로닝 부위 내로의 삽입을 허용한다. 발현 카세트는 서로 비대칭인 2개의 역 말단 반복부 (ITR); 발현 카세트의 상류 (5'-말단)의 변형된 ITR 및 하류 (3'-말단)의 변형된 ITR에 의해 플랭킹되고, 여기서 5' ITR 및 3' ITR은 모두 변형된 ITR이지만 상이한 변형을 갖는다 (즉, 이들은 동일한 변형을 갖지 않는다).
도 1d는 CAG 프로모터, WPRE, 및 BGHpA를 함유하는 발현 카세트를 갖는, 본원에 정의된 바와 같은 대칭 변형된 ITR 또는 실질적으로 대칭 변형된 ITR을 포함하는, 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적인 구조를 도시한다. 이식유전자, 예를 들어, 항체 또는 융합 단백질을 인코딩하는 핵산을 인코딩하는 오픈 리딩 프레임 (ORF)이 CAG 프로모터와 WPRE 사이의 클로닝 부위에 삽입된다. 상기 발현 카세트는 2개의 변형된 역 말단 반복부 (ITR)의 측면에 있으며, 여기서 5' 변형된 ITR 및 3' 변형된 ITR은 대칭이거나 실질적으로 대칭이다.
도 1e는 인핸서/프로모터, 이식유전자, 전사 후 요소 (WPRE), 및 폴리A 신호를 함유하는 발현 카세트를 갖는, 본원에 정의된 바와 같은 대칭 변형된 ITR 또는 실질적으로 대칭 변형된 ITR을 포함하는 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적인 구조를 도시한다. 오픈 리딩 프레임 (ORF)은 이식유전자, 예를 들어, 항체 또는 융합 단백질을 인코딩하는 핵산을 CAG 프로모터와 WPRE 사이의 클로닝 부위에 삽입할 수 있게 한다. 상기 발현 카세트는 2개의 변형된 역 말단 반복부 (ITR)의 측면에 있으며, 여기서 5' 변형된 ITR 및 3' 변형된 ITR은 대칭이거나 실질적으로 대칭이다.
도 1f는 CAG 프로모터, WPRE, 및 BGHpA를 함유하는 발현 카세트를 갖는, 본원에 정의된 바와 같은 대칭 WT-ITR 또는 실질적으로 대칭 WT-ITR을 포함하는, 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적인 구조를 도시한다. 이식유전자, 예를 들어, 항체 또는 융합 단백질을 인코딩하는 핵산을 인코딩하는 오픈 리딩 프레임 (ORF)이 CAG 프로모터와 WPRE 사이의 클로닝 부위에 삽입된다. 상기 발현 카세트는 2개의 야생형 역 말단 반복부 (WT-ITR)의 측면에 있으며, 여기서 5' WT-ITR 및 3' WT-ITR은 대칭이거나 실질적으로 대칭이다.
도 1g는 인핸서/프로모터, 이식유전자, 전사 후 요소(WPRE) 및 폴리A 신호를 함유하는 발현 카세트와 함께, 본원에 개시된 바와 같은 대칭 변형된 ITR 또는 실질적으로 대칭인 변형된 ITR을 포함하는, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적 구조를 도시한다. 오픈 리딩 프레임 (ORF)은 이식유전자, 예를 들어 항체 또는 융합 단백질을 인코딩하는 핵산을 CAG 프로모터와 WPRE 사이의 클로닝 부위에 삽입할 수 있게 한다. 발현 카세트는 2 개의 야생형 역 말단 반복 (WT-ITR)에 의해 측면(flanked) 위치하며, 여기서 5' WT-ITR 및 3' WT ITR은 대칭 또는 실질적으로 대칭이다.
도 2a는 A-A' 아암, B-B' 아암, C-C' 아암, 2개의 Rep 결합 부위 (RBE 및 RBE')의 확인과 함께 AAV2의 야생형 좌측 ITR (서열 번호: 52)의 T형 스템-루프 구조를 제공하며, 말단 분해 부위 (trs)도 도시된다. RBE는 Rep 78 또는 Rep 68과 상호 작용하는 것으로 여겨지는 일련의 4개의 듀플렉스 사량체를 포함한다. 또한, RBE'는 또한 작제물에서 야생형 ITR 또는 돌연변이된 ITR 상에 조립된 Rep 복합체와 상호 작용하는 것으로 여겨진다. D 및 D' 영역은 전사 인자 결합 부위 및 다른 보존된 구조를 함유한다. 도 2b는 A-A' 아암, B-B' 아암, C-C' 아암, 2개의 Rep 결합 부위 (RBE 및 RBE')의 확인과 함께 AAV2의 야생형 좌측 ITR의 T형 스템-루프 구조를 포함하는, 야생형 좌측 ITR (서열 번호: 53)에서 제안된 Rep-촉매화된 닉킹 및 결찰 활성을 도시하며, 또한 말단 분해 부위 (trs) 및 여러 전사 인자 결합 부위 및 다른 보존된 구조를 포함하는 D 및 D' 영역을 보여준다.
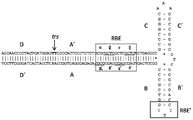
도 3a는 A-A' 아암, 및 야생형 좌측 AAV2 ITR (서열 번호: 54)의 C-C' 및 B-B' 아암의 RBE-함유 부분의 1차 구조 (폴리뉴클레오티드 서열) (왼쪽) 및 2차 구조 (오른쪽)를 제공한다. 도 3b는 좌측 ITR에 대한 예시적인 돌연변이된 ITR (또한 변형된 ITR이라고도 지칭됨) 서열을 도시한다. 예시적인 돌연변이된 좌측 ITR (ITR-1, 왼쪽) (서열 번호: 113)의 A-A' 아암, C 아암 및 B-B' 아암의 RBE 부분의 1차 구조 (왼쪽) 및 예측된 2차 구조 (오른쪽)가 도시되어 있다. 도 3c는 A-A' 루프 및 야생형 우측 AAV2 ITR (서열 번호: 55)의 B-B' 및 C-C' 아암의 RBE-함유 부분의 1차 구조 (왼쪽) 및 2차 구조 (오른쪽)를 도시한다. 도 3d는 예시적인 우측 변형된 ITR을 도시한다. 예시적인 돌연변이체 우측 ITR (ITR-1, 오른쪽) (서열 번호: 114)의 A-A' 아암, B-B' 및 C 아암의 일부를 함유하는 RBE의 1차 구조 (왼쪽) 및 예측된 2차 구조 (오른쪽)가 도시된다. 좌우 ITR (예를 들어, AAV2 ITR 또는 다른 바이러스 혈청형 또는 합성 ITR)의 임의의 조합이 본원에 교시된 바와 같이 사용될 수 있다. 도 3a-3d 폴리뉴클레오티드 서열 각각은 본원에 기재된 바와 같이 ceDNA를 생성하는 데 사용된 플라스미드 또는 박미드/바쿨로바이러스 게놈에 사용된 서열을 지칭한다. 또한, 도 3a-3d 각각에는 플라스미드 또는 박미드/바쿨로바이러스 게놈의 ceDNA 벡터 구성 및 예측된 깁스 자유 에너지 값으로부터 추론된 상응하는 ceDNA 2차 구조가 포함된다.
도 4a는 도 4b의 개략도에 기술된 과정에서 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA의 생성에 유용한 바쿨로바이러스 감염된 곤충 세포 (BIIC)를 제조하기 위한 상류 공정을 도시한 개략도이다. 도 4b는 ceDNA 생산의 예시적인 방법의 개략도이고, 도 4c는 ceDNA 벡터 생성을 확인하기 위한 생화학적 방법 및 과정을 도시한다. 도 4d 및 도 4e는 도 4b의 ceDNA 생산 공정 동안 수득된 세포 펠렛으로부터 수거된 DNA에서 ceDNA의 존재를 확인하기 위한 과정을 설명하는 개략도이다. 도 4d는 제한 엔도뉴클레아제로 절단되지 않은 상태로 유지되거나 소화된 후 미변성 겔 또는 변성 겔 상에서 전기영동을 거친 예시적인 ceDNA에 대한 개략적인 예상 밴드를 보여준다. 가장 왼쪽의 도식은 미변성 겔이며, 다수의 밴드를 보여주는데, 이는 듀플렉스 및 절단되지 않은 형태에서 ceDNA가, 더 빠르게 이동하는 더 작은 단량체 및 더 느리게 이동하는 이량체 (단량체 크기의 2배임)로 보이는, 적어도 단량체 및 이량체 상태로 존재함을 시사한다. 왼쪽에서 두 번째 도식은 ceDNA가 제한 엔도뉴클레아제로 절단될 때, 원래 밴드가 사라지고 절단 후 남은 예상 단편 크기에 상응하는 더 빠르게 이동하는 (예를 들어, 더 작은) 밴드가 나타난다는 것을 보여준다. 변성 조건 하에서, 원래의 듀플렉스 DNA는 단일 가닥이고 상보적 가닥이 공유적으로 연결되어 있기 때문에 미변성 겔에서 관찰된 것보다 2배 큰 종으로 이동한다. 따라서 오른쪽에서 두 번째 도식에서, 소화된 ceDNA는 미변성 겔에서 관찰된 것과 유사한 밴딩 분포를 나타내지만, 밴드는 미변성 겔 대응물 크기의 두 배의 단편으로 이동한다. 가장 오른쪽 도식은 변성 조건 하에서 절단되지 않은 ceDNA가 단일 가닥 개방 원으로 이동하므로 관찰된 밴드는 원이 열리지 않은 미변성 조건 하에서 관찰된 크기의 두 배라는 것을 보여준다. 이 도면에서, "kb"는, 맥락에 따라, 뉴클레오티드 사슬 길이 (예를 들어, 변성 조건에서 관찰된 단일 가닥 분자의 경우) 또는 염기쌍의 수 (예를 들어, 미변성 조건에서 관찰된 이중 가닥 분자의 경우)에 기초한 뉴클레오티드 분자의 상대적인 크기를 나타내기 위해 사용된다. 도 4e는 비-연속 구조를 갖는 DNA를 도시한다. ceDNA는 ceDNA 벡터 상에 단일 인식 부위를 갖는 제한 엔도뉴클레아제에 의해 절단될 수 있고, 중성 및 변성 조건 모두에서 상이한 크기 (1kb 및 2kb)를 갖는 2개의 DNA 단편을 생성한다. 도 4e는 또한 선형 및 연속 구조를 갖는 ceDNA를 도시한다. ceDNA 벡터는 제한 엔도뉴클레아제에 의해 절단될 수 있고, 중성 조건에서 1kb 및 2kb로 이동하는 2개의 DNA 단편을 생성하지만, 변성 조건에서, 스탠드는 연결된 상태로 유지되고 2kb 및 4kb로 이동하는 단일 가닥을 생성한다.
도 5는 엔도뉴클레아제 (ceDNA 작제물 1 및 2에 대해 EcoRI; ceDNA 작제물 3 및 4에 대해 BamH1; ceDNA 작제물 5 및 6에 대해 SpeI; 및 ceDNA 작제물 7 및 8에 대해 XhoI)로 소화된 (+) 또는 소화되지 않은 (-) ceDNA 벡터의 변성 겔 실행 예의 예시적인 사진이다. 작제물 1-8은 국제 출원 PCT PCT/US18/49996의 실시예 1에 기재되어 있으며, 이는 그 전문이 본원에 참조로 포함된다. 별표로 강조 표시된 밴드의 크기를 결정하고 사진 하단에 제공했다.
도 6a-6c는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 생성하기 위한 예시적인 작제물 및 플라스미드를 나타내고, 예시적인 목적으로 아두카누맙(aducanumab)을 인코딩하는 ceDNA 벡터를 도시한다. 숙련가는 아두카누맙을 인코딩하는 핵산을 상이한 항체 또는 융합 단백질을 인코딩하는 임의의 다른 핵산으로 쉽게 대체할 수 있다. 도 6a는 ceDNA 벡터를 발현시키는 아두카누맙 (전체 IgG1)을 생성하기 위한 예시적인 ceDNA 플라스미드 (pFBdual-ceDNA-아두카누맙; 서열 번호: 56)를 도시한다. 이 ceDNA 플라스미드는 비대칭 ITR 쌍 (즉, WT 5' ITR (wt ITR)과 3' 모드-ITR (R-asym ITR) 사이의 측면에 배치된, 코돈 최적화된 아두카누맙을 발현시키기 위한 핵산 서열을 포함한다. 이 ITR 쌍은 본원에 기재된 바와 같은 또 다른 비대칭 ITR-쌍 또는 대칭 ITR 쌍으로 쉽게 대체될 수 있다. 또한, 이 플라스미드는 5'에서 3'의 방향으로 ITR-쌍 사이의 측면에 배치된, SV40 인핸서 (서열 번호: 126), 인간 EF1 알파 프로모터 (서열 번호: 77) 또는 이의 단편 (서열 번호: 78), 및 VH1-02 분비 리더 서열 (서열 번호: 88), 최적화된 아두카누맙 중쇄 (HC) 핵산 서열 (서열 번호: 57), SV40 폴리A 서열 (서열 번호: 86)을 포함하고, 아두카누맙 경쇄 (LC) 서열의 상류에서 CMV 인핸서 (서열 번호: 83), rEF1 프로모터 (서열 번호: 85 또는 서열 번호: 150), VK A26 리더 서열 (서열 번호: 89), 최적화된 아두카누맙 경쇄 (LC) 핵산 서열 (서열 번호: 58) 및 BGH 폴리아데닐화 서열 (서열 번호: 68 또는 서열 번호: 148)을 포함한다. 최적화된 아두카누맙 중쇄 (HC) 서열 및 최적화된 아두카누맙 경쇄 (LC) 핵산 서열은 본원에 기재된 항체의 임의의 다른 중쇄 또는 경쇄 서열로 쉽게 치환될 수 있으며, 예를 들어, 본원의 표 1-5를 참고한다. 도 6b는 도 6a에서와 같이 플라스미드를 생성하기 위해 원하는 ceDNA 벡터에 삽입될 모듈식 성분으로서 사용될 수 있는 예시적인 삽입물이다. 도 6c는 아두카누맙을 생성하기 위한 서열을 포함하는 ceDNA-Adu-전체-IgG1 플라스미드 영역의 선형도이다.
도 7a-7g는 본원에 개시된 여러 상이한 항체 또는 항원-결합 단편 또는 융합 단백질을 발현시킬 수 있는 예시적인 ceDNA 벡터를 도시한다. 예시된 ceDNA 벡터는 또한 IRES 서열, 프로모터 서열, 인핸서 서열, 링커 서열, 폴리아데닐화 서열의 사용과 관련하여 다수의 구성을 도시한다. 도 7a는 중쇄 서열 다음에 폴리 A 서열, 및 경쇄 핵산 서열의 상류에 있는 선택적 인핸서를 갖는 항체를 생산하기 위한 ceDNA 벡터 작제물의 구현예를 도시한다. 도 7b는 중쇄 서열 다음에 폴리 A 서열, 및 경쇄 핵산 서열의 상류에 있는 IRES를 갖는 항체를 생산하기 위한 ceDNA 벡터 작제물의 구현예를 도시한다. 도 7c는 중쇄 Fab 단편 서열 다음에 폴리 A 서열, 및 경쇄 단편 핵산 서열의 상류에 있는 선택적 인핸서를 포함하는, 도 7a와 유사한 항체 단편 (예를 들어, 항원 결합 단편)을 생산하기 위한 ceDNA 벡터 작제물의 구현예를 도시한다. 도 7d는 경쇄 서열 다음에 폴리A 서열을 포함하는, 본원에 개시된 항체를 생산하기 위한 ceDNA 벡터 작제물의 구현예를 도시한다. 도 7e는 중쇄 서열 다음에 폴리A 서열을 포함하는, 본원에 개시된 항체를 생산하기 위한 ceDNA 벡터 작제물의 구현예를 도시한다. 도 7f는 dAb 서열 다음에 폴리A 서열을 포함하는, 본원에 개시된 단일 도메인 항체 (dAb)를 생산하기 위한 ceDNA 벡터 작제물의 구현예를 도시한다. 도 7g는 단일쇄 항체 서열의 scFv 서열 다음에 폴리A 서열을 포함하는, 본원에 개시된 항체 단편, 예컨대 단일쇄 가변 단편 융합 단백질 (scFv) 또는 단일쇄 항체를 생산하기 위한 ceDNA 벡터 작제물의 구현예를 도시한다. 당업자라면, 본원에 기재된 바와 같은 항체 생산을 위한 ceDNA 벡터를 모듈 방식으로 사용할 수 있어서, 항체 또는 이의 단편을 인코딩하는 원하는 조절 서열 또는 이종 핵산이 다른 원하는 서열과 상호교환될 수 있음을 이해할 것이다. 즉, ceDNA 벡터는 원하는 적용을 위해 맞춤화될 수 있다. 또한, 가변 쇄 (VH 및 VL) 및 불변 쇄 (CH 및 CL)에 대한 핵산 서열, 및 Fc 서열이 서로 인접하게 위치하거나, 대안적으로 Fc가 본원에 개시된 바와 같은 링커 서열을 통해 VH 및 VL을 인코딩하는 서열에 연결될 수 있는 구현예가 도 7a-7g에 도시되어 있다.
도 8a-8b는 발현된 단백질의 일 단계 정제 후 실시예 9에 기재된 바와 같이 ceDNA-IgG1-Adu 작제물로부터 발현된 아두카누맙 (전체 IgG1) 항체의 발현에 대한 예시적인 SDS-Page (도 8a) 및 웨스턴 블롯 (도 8b) 분석을 도시한다. 도 8a는 발현된 항체의 SDS-PAGE 겔 이미지를 보여준다. 레인은 다음과 같다: M1은 단백질 마커 (Takara cat. no. 3452)이고, 정제된 아두카누맙은 환원 조건 (레인 1) 및 비-환원 (레인 2) 조건으로 보여준다. 환원 조건에서 2개의 밴드 및 비-환원 조건에서 단 1개의 밴드의 존재는 비환원 조건에서 단일 밴드로 이동하고, 환원 조건하에 구성 성분인 중쇄 및 경쇄로 이동하는 중쇄 및 경쇄를 갖는 항체인 단백질과 일치한다. 도 8b는 항-인간 IgG 항체로 면역염색된 웨스턴 블롯 이미지를 보여준다. 레인은 다음과 같다: M2는 단백질 마커 (GenScript, cat. no. M00521)이고, P는 양성 대조군 인간 IgG1 항체 (Sigma)이다.
도 9a-9b는 ceDNA-IgG1-Adu 벡터로부터 발현된 ceDNA 발현 GFP 또는 아두카누맙 (전체 IgG1) 항체의 발현을 보여준다. 도 9a는 실시예 8에 기재된 바와 같이, ceDNA-GFP 플라스미드 (상단 패널) 및 ceDNA-GFP 벡터 (하단 패널)로 형질감염된 HEK293T 세포의 형광 현미경 이미지를 제공한다. 두 이미지에서 풍부한 형광의 존재는 각각의 ceDNA 처리로 세포에서 이식유전자 GFP의 상당한 형질감염 및 발현이 발생했음을 보여준다. 도 9b는 실시예 8에 기재된 바와 같이, SDS-PAGE에 의해 전기영동적으로 분리된 세포 샘플의 동일한 막 전달의 2개의 상이한 이미지를 제공한다. 하단 패널은 모든 단백질 함량을 나타내는 폰소(Ponceau) 염색된 막이고; 상단 패널은 가시적인 밴드가 인간 항체의 존재를 반영하는 웨스턴 블롯이다. 레인 7-10에서 항체 중쇄는 대략 50 kDa으로 이동하고, 항체 경쇄는 대략 25 kDa으로 이동하고; 두 쇄는 모두 4개의 모든 레인에서 볼 수 있다.
도 10a-10b는 ceDNA 생산된 아두카누맙 항체의 특성화를 보여준다. 도 10a는 ceDNA-생산된 아두카누맙에 상응하는 단일 피크를 보여주는, 실시예 9에 기재된 HPLC 분석 결과를 도시한다. 도 10b는 실시예 9에 기재된 바와 같이, 정제된 아두카누맙 항체가 고정된 베타-아밀로이드 (1-42) 리간드를 인식하는 능력을 평가하는 ELISA 분석 결과를 도시한다.
도 11은 실시예 10에 기재된 실험 결과를 그래프로 도시한다. 아두카누맙 이식유전자가 결여된 ceDNA 작제물로 처리된 마우스로부터의 음성 대조군 샘플 (ceDNA 음성 대조군으로 표지됨)은 분석에서 정량 하한 또는 그 미만이었다. 대조적으로, ceDNA-IgG 작제물로 처리된 마우스의 혈청에는 3일 및 7일 시점 모두에 존재하는 인간 면역글로불린 수준이 높았다.
도 12는 실시예 12에 기재된 바와 같이, SDS-PAGE에 의해 전기영동적으로 분리된 세포 샘플의 동일한 막 전달의 2개의 상이한 시간 노출을 제공한다. 상단 패널은 6초 노출시 촬영되고, 하단 패널은 20초 노출 후 촬영되었다. 온전한 항체에 상응하는 밴드가 겔의 상단에 보이고 (각각 ~50 kDa 및 ~25 kDa으로 이동한 제한된 양의 환원된 중쇄 및 경쇄) 레인 5, 7 (둘 다 아두카누맙), 및 11 (베바시주맙) (화살표 참고)에서 볼 수 있다. 레인 9에서, Fc 융합 단백질의 존재는 레인의 상단 근처에서 관찰되고, 예상되는 바와 같이, 더 낮은 분자량의 구성 성분 생성물은 관찰되지 않는다.
위에서 간략하게 요약되고 아래에서 더 상세히 논의되는 본 개시의 구현예는 첨부된 도면에 도시된 본 개시의 예시적인 구현예를 참조하여 이해될 수 있다. 그러나, 첨부된 도면은 본 개시의 전형적인 구현예만을 도시하며, 따라서 본 개시는 다른 동등하게 유효한 구현예를 인정할 수 있기 때문에 범위를 제한하는 것으로 간주되지 않아야 한다.
도 1a는 비대칭 ITR을 포함하는, 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적인 구조를 도시한다. 이 구현예에서, 예시적인 ceDNA 벡터는 CAG 프로모터, WPRE 및 BGHpA를 함유하는 발현 카세트를 포함한다. 이식유전자, 예를 들어, 항체 또는 융합 단백질을 인코딩하는 핵산을 인코딩하는 오픈 리딩 프레임 (ORF)이 CAG 프로모터와 WPRE 사이의 클로닝 부위 (R3/R4)에 삽입된다. 발현 카세트는 2개의 역 말단 반복부 (ITR), 즉 발현 카세트의 상류 (5'-말단)의 야생형 AAV2 ITR 및 하류 (3'-말단)의 변형된 ITR에 의해 플랭킹되며, 따라서 발현 카세트 측면에 있는 2개의 ITR은 서로 비대칭이다.
도 1b는 CAG 프로모터, WPRE 및 BGHpA를 함유하는 발현 카세트를 이용한 비대칭 ITR을 포함하는, 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적인 구조를 도시한다. 이식유전자 항체 또는 융합 단백질을 인코딩하는 핵산을 인코딩하는 오픈 리딩 프레임 (ORF)이 CAG 프로모터와 WPRE 사이의 클로닝 부위에 삽입된다. 발현 카세트는 발현 카세트의 상류 (5'-말단)의 변형된 ITR 및 하류 (3'-말단)의 야생형 ITR인, 2개의 역 말단 반복부 (ITR)에 의해 플랭킹된다.
도 1c는 인핸서/프로모터, 이식유전자, 전사 후 요소 (WPRE) 및 폴리 A 신호를 함유하는 발현 카세트를 갖는, 비대칭 ITR을 포함하는 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적인 구조를 도시한다. 오픈 리딩 프레임 (ORF)은 이식유전자, 예를 들어 항체 또는 융합 단백질을 인코딩하는 핵산을 CAG 프로모터와 WPRE 사이의 클로닝 부위 내로의 삽입을 허용한다. 발현 카세트는 서로 비대칭인 2개의 역 말단 반복부 (ITR); 발현 카세트의 상류 (5'-말단)의 변형된 ITR 및 하류 (3'-말단)의 변형된 ITR에 의해 플랭킹되고, 여기서 5' ITR 및 3' ITR은 모두 변형된 ITR이지만 상이한 변형을 갖는다 (즉, 이들은 동일한 변형을 갖지 않는다).
도 1d는 CAG 프로모터, WPRE, 및 BGHpA를 함유하는 발현 카세트를 갖는, 본원에 정의된 바와 같은 대칭 변형된 ITR 또는 실질적으로 대칭 변형된 ITR을 포함하는, 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적인 구조를 도시한다. 이식유전자, 예를 들어, 항체 또는 융합 단백질을 인코딩하는 핵산을 인코딩하는 오픈 리딩 프레임 (ORF)이 CAG 프로모터와 WPRE 사이의 클로닝 부위에 삽입된다. 상기 발현 카세트는 2개의 변형된 역 말단 반복부 (ITR)의 측면에 있으며, 여기서 5' 변형된 ITR 및 3' 변형된 ITR은 대칭이거나 실질적으로 대칭이다.
도 1e는 인핸서/프로모터, 이식유전자, 전사 후 요소 (WPRE), 및 폴리A 신호를 함유하는 발현 카세트를 갖는, 본원에 정의된 바와 같은 대칭 변형된 ITR 또는 실질적으로 대칭 변형된 ITR을 포함하는 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적인 구조를 도시한다. 오픈 리딩 프레임 (ORF)은 이식유전자, 예를 들어, 항체 또는 융합 단백질을 인코딩하는 핵산을 CAG 프로모터와 WPRE 사이의 클로닝 부위에 삽입할 수 있게 한다. 상기 발현 카세트는 2개의 변형된 역 말단 반복부 (ITR)의 측면에 있으며, 여기서 5' 변형된 ITR 및 3' 변형된 ITR은 대칭이거나 실질적으로 대칭이다.
도 1f는 CAG 프로모터, WPRE, 및 BGHpA를 함유하는 발현 카세트를 갖는, 본원에 정의된 바와 같은 대칭 WT-ITR 또는 실질적으로 대칭 WT-ITR을 포함하는, 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적인 구조를 도시한다. 이식유전자, 예를 들어, 항체 또는 융합 단백질을 인코딩하는 핵산을 인코딩하는 오픈 리딩 프레임 (ORF)이 CAG 프로모터와 WPRE 사이의 클로닝 부위에 삽입된다. 상기 발현 카세트는 2개의 야생형 역 말단 반복부 (WT-ITR)의 측면에 있으며, 여기서 5' WT-ITR 및 3' WT-ITR은 대칭이거나 실질적으로 대칭이다.
도 1g는 인핸서/프로모터, 이식유전자, 전사 후 요소(WPRE) 및 폴리A 신호를 함유하는 발현 카세트와 함께, 본원에 개시된 바와 같은 대칭 변형된 ITR 또는 실질적으로 대칭인 변형된 ITR을 포함하는, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적 구조를 도시한다. 오픈 리딩 프레임 (ORF)은 이식유전자, 예를 들어 항체 또는 융합 단백질을 인코딩하는 핵산을 CAG 프로모터와 WPRE 사이의 클로닝 부위에 삽입할 수 있게 한다. 발현 카세트는 2 개의 야생형 역 말단 반복 (WT-ITR)에 의해 측면(flanked) 위치하며, 여기서 5' WT-ITR 및 3' WT ITR은 대칭 또는 실질적으로 대칭이다.
도 2a는 A-A' 아암, B-B' 아암, C-C' 아암, 2개의 Rep 결합 부위 (RBE 및 RBE')의 확인과 함께 AAV2의 야생형 좌측 ITR (서열 번호: 52)의 T형 스템-루프 구조를 제공하며, 말단 분해 부위 (trs)도 도시된다. RBE는 Rep 78 또는 Rep 68과 상호 작용하는 것으로 여겨지는 일련의 4개의 듀플렉스 사량체를 포함한다. 또한, RBE'는 또한 작제물에서 야생형 ITR 또는 돌연변이된 ITR 상에 조립된 Rep 복합체와 상호 작용하는 것으로 여겨진다. D 및 D' 영역은 전사 인자 결합 부위 및 다른 보존된 구조를 함유한다. 도 2b는 A-A' 아암, B-B' 아암, C-C' 아암, 2개의 Rep 결합 부위 (RBE 및 RBE')의 확인과 함께 AAV2의 야생형 좌측 ITR의 T형 스템-루프 구조를 포함하는, 야생형 좌측 ITR (서열 번호: 53)에서 제안된 Rep-촉매화된 닉킹 및 결찰 활성을 도시하며, 또한 말단 분해 부위 (trs) 및 여러 전사 인자 결합 부위 및 다른 보존된 구조를 포함하는 D 및 D' 영역을 보여준다.
도 3a는 A-A' 아암, 및 야생형 좌측 AAV2 ITR (서열 번호: 54)의 C-C' 및 B-B' 아암의 RBE-함유 부분의 1차 구조 (폴리뉴클레오티드 서열) (왼쪽) 및 2차 구조 (오른쪽)를 제공한다. 도 3b는 좌측 ITR에 대한 예시적인 돌연변이된 ITR (또한 변형된 ITR이라고도 지칭됨) 서열을 도시한다. 예시적인 돌연변이된 좌측 ITR (ITR-1, 왼쪽) (서열 번호: 113)의 A-A' 아암, C 아암 및 B-B' 아암의 RBE 부분의 1차 구조 (왼쪽) 및 예측된 2차 구조 (오른쪽)가 도시되어 있다. 도 3c는 A-A' 루프 및 야생형 우측 AAV2 ITR (서열 번호: 55)의 B-B' 및 C-C' 아암의 RBE-함유 부분의 1차 구조 (왼쪽) 및 2차 구조 (오른쪽)를 도시한다. 도 3d는 예시적인 우측 변형된 ITR을 도시한다. 예시적인 돌연변이체 우측 ITR (ITR-1, 오른쪽) (서열 번호: 114)의 A-A' 아암, B-B' 및 C 아암의 일부를 함유하는 RBE의 1차 구조 (왼쪽) 및 예측된 2차 구조 (오른쪽)가 도시된다. 좌우 ITR (예를 들어, AAV2 ITR 또는 다른 바이러스 혈청형 또는 합성 ITR)의 임의의 조합이 본원에 교시된 바와 같이 사용될 수 있다. 도 3a-3d 폴리뉴클레오티드 서열 각각은 본원에 기재된 바와 같이 ceDNA를 생성하는 데 사용된 플라스미드 또는 박미드/바쿨로바이러스 게놈에 사용된 서열을 지칭한다. 또한, 도 3a-3d 각각에는 플라스미드 또는 박미드/바쿨로바이러스 게놈의 ceDNA 벡터 구성 및 예측된 깁스 자유 에너지 값으로부터 추론된 상응하는 ceDNA 2차 구조가 포함된다.
도 4a는 도 4b의 개략도에 기술된 과정에서 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA의 생성에 유용한 바쿨로바이러스 감염된 곤충 세포 (BIIC)를 제조하기 위한 상류 공정을 도시한 개략도이다. 도 4b는 ceDNA 생산의 예시적인 방법의 개략도이고, 도 4c는 ceDNA 벡터 생성을 확인하기 위한 생화학적 방법 및 과정을 도시한다. 도 4d 및 도 4e는 도 4b의 ceDNA 생산 공정 동안 수득된 세포 펠렛으로부터 수거된 DNA에서 ceDNA의 존재를 확인하기 위한 과정을 설명하는 개략도이다. 도 4d는 제한 엔도뉴클레아제로 절단되지 않은 상태로 유지되거나 소화된 후 미변성 겔 또는 변성 겔 상에서 전기영동을 거친 예시적인 ceDNA에 대한 개략적인 예상 밴드를 보여준다. 가장 왼쪽의 도식은 미변성 겔이며, 다수의 밴드를 보여주는데, 이는 듀플렉스 및 절단되지 않은 형태에서 ceDNA가, 더 빠르게 이동하는 더 작은 단량체 및 더 느리게 이동하는 이량체 (단량체 크기의 2배임)로 보이는, 적어도 단량체 및 이량체 상태로 존재함을 시사한다. 왼쪽에서 두 번째 도식은 ceDNA가 제한 엔도뉴클레아제로 절단될 때, 원래 밴드가 사라지고 절단 후 남은 예상 단편 크기에 상응하는 더 빠르게 이동하는 (예를 들어, 더 작은) 밴드가 나타난다는 것을 보여준다. 변성 조건 하에서, 원래의 듀플렉스 DNA는 단일 가닥이고 상보적 가닥이 공유적으로 연결되어 있기 때문에 미변성 겔에서 관찰된 것보다 2배 큰 종으로 이동한다. 따라서 오른쪽에서 두 번째 도식에서, 소화된 ceDNA는 미변성 겔에서 관찰된 것과 유사한 밴딩 분포를 나타내지만, 밴드는 미변성 겔 대응물 크기의 두 배의 단편으로 이동한다. 가장 오른쪽 도식은 변성 조건 하에서 절단되지 않은 ceDNA가 단일 가닥 개방 원으로 이동하므로 관찰된 밴드는 원이 열리지 않은 미변성 조건 하에서 관찰된 크기의 두 배라는 것을 보여준다. 이 도면에서, "kb"는, 맥락에 따라, 뉴클레오티드 사슬 길이 (예를 들어, 변성 조건에서 관찰된 단일 가닥 분자의 경우) 또는 염기쌍의 수 (예를 들어, 미변성 조건에서 관찰된 이중 가닥 분자의 경우)에 기초한 뉴클레오티드 분자의 상대적인 크기를 나타내기 위해 사용된다. 도 4e는 비-연속 구조를 갖는 DNA를 도시한다. ceDNA는 ceDNA 벡터 상에 단일 인식 부위를 갖는 제한 엔도뉴클레아제에 의해 절단될 수 있고, 중성 및 변성 조건 모두에서 상이한 크기 (1kb 및 2kb)를 갖는 2개의 DNA 단편을 생성한다. 도 4e는 또한 선형 및 연속 구조를 갖는 ceDNA를 도시한다. ceDNA 벡터는 제한 엔도뉴클레아제에 의해 절단될 수 있고, 중성 조건에서 1kb 및 2kb로 이동하는 2개의 DNA 단편을 생성하지만, 변성 조건에서, 스탠드는 연결된 상태로 유지되고 2kb 및 4kb로 이동하는 단일 가닥을 생성한다.
도 5는 엔도뉴클레아제 (ceDNA 작제물 1 및 2에 대해 EcoRI; ceDNA 작제물 3 및 4에 대해 BamH1; ceDNA 작제물 5 및 6에 대해 SpeI; 및 ceDNA 작제물 7 및 8에 대해 XhoI)로 소화된 (+) 또는 소화되지 않은 (-) ceDNA 벡터의 변성 겔 실행 예의 예시적인 사진이다. 작제물 1-8은 국제 출원 PCT PCT/US18/49996의 실시예 1에 기재되어 있으며, 이는 그 전문이 본원에 참조로 포함된다. 별표로 강조 표시된 밴드의 크기를 결정하고 사진 하단에 제공했다.
도 6a-6c는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 생성하기 위한 예시적인 작제물 및 플라스미드를 나타내고, 예시적인 목적으로 아두카누맙(aducanumab)을 인코딩하는 ceDNA 벡터를 도시한다. 숙련가는 아두카누맙을 인코딩하는 핵산을 상이한 항체 또는 융합 단백질을 인코딩하는 임의의 다른 핵산으로 쉽게 대체할 수 있다. 도 6a는 ceDNA 벡터를 발현시키는 아두카누맙 (전체 IgG1)을 생성하기 위한 예시적인 ceDNA 플라스미드 (pFBdual-ceDNA-아두카누맙; 서열 번호: 56)를 도시한다. 이 ceDNA 플라스미드는 비대칭 ITR 쌍 (즉, WT 5' ITR (wt ITR)과 3' 모드-ITR (R-asym ITR) 사이의 측면에 배치된, 코돈 최적화된 아두카누맙을 발현시키기 위한 핵산 서열을 포함한다. 이 ITR 쌍은 본원에 기재된 바와 같은 또 다른 비대칭 ITR-쌍 또는 대칭 ITR 쌍으로 쉽게 대체될 수 있다. 또한, 이 플라스미드는 5'에서 3'의 방향으로 ITR-쌍 사이의 측면에 배치된, SV40 인핸서 (서열 번호: 126), 인간 EF1 알파 프로모터 (서열 번호: 77) 또는 이의 단편 (서열 번호: 78), 및 VH1-02 분비 리더 서열 (서열 번호: 88), 최적화된 아두카누맙 중쇄 (HC) 핵산 서열 (서열 번호: 57), SV40 폴리A 서열 (서열 번호: 86)을 포함하고, 아두카누맙 경쇄 (LC) 서열의 상류에서 CMV 인핸서 (서열 번호: 83), rEF1 프로모터 (서열 번호: 85 또는 서열 번호: 150), VK A26 리더 서열 (서열 번호: 89), 최적화된 아두카누맙 경쇄 (LC) 핵산 서열 (서열 번호: 58) 및 BGH 폴리아데닐화 서열 (서열 번호: 68 또는 서열 번호: 148)을 포함한다. 최적화된 아두카누맙 중쇄 (HC) 서열 및 최적화된 아두카누맙 경쇄 (LC) 핵산 서열은 본원에 기재된 항체의 임의의 다른 중쇄 또는 경쇄 서열로 쉽게 치환될 수 있으며, 예를 들어, 본원의 표 1-5를 참고한다. 도 6b는 도 6a에서와 같이 플라스미드를 생성하기 위해 원하는 ceDNA 벡터에 삽입될 모듈식 성분으로서 사용될 수 있는 예시적인 삽입물이다. 도 6c는 아두카누맙을 생성하기 위한 서열을 포함하는 ceDNA-Adu-전체-IgG1 플라스미드 영역의 선형도이다.
도 7a-7g는 본원에 개시된 여러 상이한 항체 또는 항원-결합 단편 또는 융합 단백질을 발현시킬 수 있는 예시적인 ceDNA 벡터를 도시한다. 예시된 ceDNA 벡터는 또한 IRES 서열, 프로모터 서열, 인핸서 서열, 링커 서열, 폴리아데닐화 서열의 사용과 관련하여 다수의 구성을 도시한다. 도 7a는 중쇄 서열 다음에 폴리 A 서열, 및 경쇄 핵산 서열의 상류에 있는 선택적 인핸서를 갖는 항체를 생산하기 위한 ceDNA 벡터 작제물의 구현예를 도시한다. 도 7b는 중쇄 서열 다음에 폴리 A 서열, 및 경쇄 핵산 서열의 상류에 있는 IRES를 갖는 항체를 생산하기 위한 ceDNA 벡터 작제물의 구현예를 도시한다. 도 7c는 중쇄 Fab 단편 서열 다음에 폴리 A 서열, 및 경쇄 단편 핵산 서열의 상류에 있는 선택적 인핸서를 포함하는, 도 7a와 유사한 항체 단편 (예를 들어, 항원 결합 단편)을 생산하기 위한 ceDNA 벡터 작제물의 구현예를 도시한다. 도 7d는 경쇄 서열 다음에 폴리A 서열을 포함하는, 본원에 개시된 항체를 생산하기 위한 ceDNA 벡터 작제물의 구현예를 도시한다. 도 7e는 중쇄 서열 다음에 폴리A 서열을 포함하는, 본원에 개시된 항체를 생산하기 위한 ceDNA 벡터 작제물의 구현예를 도시한다. 도 7f는 dAb 서열 다음에 폴리A 서열을 포함하는, 본원에 개시된 단일 도메인 항체 (dAb)를 생산하기 위한 ceDNA 벡터 작제물의 구현예를 도시한다. 도 7g는 단일쇄 항체 서열의 scFv 서열 다음에 폴리A 서열을 포함하는, 본원에 개시된 항체 단편, 예컨대 단일쇄 가변 단편 융합 단백질 (scFv) 또는 단일쇄 항체를 생산하기 위한 ceDNA 벡터 작제물의 구현예를 도시한다. 당업자라면, 본원에 기재된 바와 같은 항체 생산을 위한 ceDNA 벡터를 모듈 방식으로 사용할 수 있어서, 항체 또는 이의 단편을 인코딩하는 원하는 조절 서열 또는 이종 핵산이 다른 원하는 서열과 상호교환될 수 있음을 이해할 것이다. 즉, ceDNA 벡터는 원하는 적용을 위해 맞춤화될 수 있다. 또한, 가변 쇄 (VH 및 VL) 및 불변 쇄 (CH 및 CL)에 대한 핵산 서열, 및 Fc 서열이 서로 인접하게 위치하거나, 대안적으로 Fc가 본원에 개시된 바와 같은 링커 서열을 통해 VH 및 VL을 인코딩하는 서열에 연결될 수 있는 구현예가 도 7a-7g에 도시되어 있다.
도 8a-8b는 발현된 단백질의 일 단계 정제 후 실시예 9에 기재된 바와 같이 ceDNA-IgG1-Adu 작제물로부터 발현된 아두카누맙 (전체 IgG1) 항체의 발현에 대한 예시적인 SDS-Page (도 8a) 및 웨스턴 블롯 (도 8b) 분석을 도시한다. 도 8a는 발현된 항체의 SDS-PAGE 겔 이미지를 보여준다. 레인은 다음과 같다: M1은 단백질 마커 (Takara cat. no. 3452)이고, 정제된 아두카누맙은 환원 조건 (레인 1) 및 비-환원 (레인 2) 조건으로 보여준다. 환원 조건에서 2개의 밴드 및 비-환원 조건에서 단 1개의 밴드의 존재는 비환원 조건에서 단일 밴드로 이동하고, 환원 조건하에 구성 성분인 중쇄 및 경쇄로 이동하는 중쇄 및 경쇄를 갖는 항체인 단백질과 일치한다. 도 8b는 항-인간 IgG 항체로 면역염색된 웨스턴 블롯 이미지를 보여준다. 레인은 다음과 같다: M2는 단백질 마커 (GenScript, cat. no. M00521)이고, P는 양성 대조군 인간 IgG1 항체 (Sigma)이다.
도 9a-9b는 ceDNA-IgG1-Adu 벡터로부터 발현된 ceDNA 발현 GFP 또는 아두카누맙 (전체 IgG1) 항체의 발현을 보여준다. 도 9a는 실시예 8에 기재된 바와 같이, ceDNA-GFP 플라스미드 (상단 패널) 및 ceDNA-GFP 벡터 (하단 패널)로 형질감염된 HEK293T 세포의 형광 현미경 이미지를 제공한다. 두 이미지에서 풍부한 형광의 존재는 각각의 ceDNA 처리로 세포에서 이식유전자 GFP의 상당한 형질감염 및 발현이 발생했음을 보여준다. 도 9b는 실시예 8에 기재된 바와 같이, SDS-PAGE에 의해 전기영동적으로 분리된 세포 샘플의 동일한 막 전달의 2개의 상이한 이미지를 제공한다. 하단 패널은 모든 단백질 함량을 나타내는 폰소(Ponceau) 염색된 막이고; 상단 패널은 가시적인 밴드가 인간 항체의 존재를 반영하는 웨스턴 블롯이다. 레인 7-10에서 항체 중쇄는 대략 50 kDa으로 이동하고, 항체 경쇄는 대략 25 kDa으로 이동하고; 두 쇄는 모두 4개의 모든 레인에서 볼 수 있다.
도 10a-10b는 ceDNA 생산된 아두카누맙 항체의 특성화를 보여준다. 도 10a는 ceDNA-생산된 아두카누맙에 상응하는 단일 피크를 보여주는, 실시예 9에 기재된 HPLC 분석 결과를 도시한다. 도 10b는 실시예 9에 기재된 바와 같이, 정제된 아두카누맙 항체가 고정된 베타-아밀로이드 (1-42) 리간드를 인식하는 능력을 평가하는 ELISA 분석 결과를 도시한다.
도 11은 실시예 10에 기재된 실험 결과를 그래프로 도시한다. 아두카누맙 이식유전자가 결여된 ceDNA 작제물로 처리된 마우스로부터의 음성 대조군 샘플 (ceDNA 음성 대조군으로 표지됨)은 분석에서 정량 하한 또는 그 미만이었다. 대조적으로, ceDNA-IgG 작제물로 처리된 마우스의 혈청에는 3일 및 7일 시점 모두에 존재하는 인간 면역글로불린 수준이 높았다.
도 12는 실시예 12에 기재된 바와 같이, SDS-PAGE에 의해 전기영동적으로 분리된 세포 샘플의 동일한 막 전달의 2개의 상이한 시간 노출을 제공한다. 상단 패널은 6초 노출시 촬영되고, 하단 패널은 20초 노출 후 촬영되었다. 온전한 항체에 상응하는 밴드가 겔의 상단에 보이고 (각각 ~50 kDa 및 ~25 kDa으로 이동한 제한된 양의 환원된 중쇄 및 경쇄) 레인 5, 7 (둘 다 아두카누맙), 및 11 (베바시주맙) (화살표 참고)에서 볼 수 있다. 레인 9에서, Fc 융합 단백질의 존재는 레인의 상단 근처에서 관찰되고, 예상되는 바와 같이, 더 낮은 분자량의 구성 성분 생성물은 관찰되지 않는다.
항체 (예를 들어, 중쇄, 경쇄, 프레임워크, Fab', scAb)를 인코딩하는 하나 이상의 이종성 핵산을 포함하는 본원에 기재된 바와 같은 항체 생산을 위한 ceDNA 벡터가 본원에 제공된다. 융합 단백질을 인코딩하는 하나 이상의 이종성 핵산을 포함하는 본원에 기재된 바와 같은 융합 단백질 생산을 위한 ceDNA 벡터가 본원에 제공된다. 이러한 벡터는 ceDNA 벡터로부터 세포 내 발현에 의해, 상업적 항체 또는 융합 단백질 생산 또는 본원에 기재된 바와 같은 치료용 항체 또는 융합 단백질의 전달에 사용될 수 있다. 일부 구현예에서, 항체 또는 융합 단백질의 발현은 항체 또는 융합 단백질이 발현되는 세포 밖으로 항체 또는 융합 단백질의 분비를 포함 할 수 있거나 또는 일부 구현예에서, 발현된 항체 또는 융합 단백질은 이것이 발현되는 세포 내의 단백질을 표적화할 수 있다 (예를 들어, 항체는 체내이다). 일부 구현예에서, ceDNA 벡터는 대상체의 근육 (예를 들어, 골격근)에서 항체 또는 그의 항원-결합 단편 또는 융합 단백질을 발현하며, 이는 항체 또는 융합 단백질 생성 및 다수의 전신 구획에 대한 분비를 위한 저장소로서 작용할 수 있다.
I. 정의
본 명세서에서 달리 정의되지 않는 한, 본 출원과 관련하여 사용된 과학 및 기술 용어는 본 발명이 속하는 기술 분야의 숙련가에 의해 일반적으로 이해되는 의미를 가질 것이다. 본 발명은 본원에 기술된 특정 방법론, 프로토콜 및 시약 등에 제한되지 않으며, 다양할 수 있음을 이해해야 한다. 본원에 사용된 용어는 단지 특정한 구현예를 설명하기 위한 것으로, 본 발명의 범위를 한정하려는 의도가 아니며, 본 발명의 범위는 청구범위에 의해서만 정의된다. 면역학 및 분자 생물학에서 일반적인 용어의 정의는 하기에서 찾을 수 있다: The Merck Manual of Diagnosis and Therapy, 19th Edition, published by Merck Sharp & Dohme Corp., 2011 (ISBN 978-0-911910-19-3); Robert S. Porter et al. (eds.), Fields Virology, 6th Edition, published by Lippincott Williams & Wilkins, Philadelphia, PA, USA (2013), Knipe, D.M. and Howley, P.M. (ed.), The Encyclopedia of Molecular Cell Biology and Molecular Medicine, published by Blackwell Science Ltd., 1999-2012 (ISBN 9783527600908); 및 Robert A. Meyers (ed.), Molecular Biology and Biotechnology: a Comprehensive Desk Reference, published by VCH Publishers, Inc., 1995 (ISBN 1-56081-569-8); Immunology by Werner Luttmann, published by Elsevier, 2006; Janeway's Immunobiology, Kenneth Murphy, Allan Mowat, Casey Weaver (eds.), Taylor & Francis Limited, 2014 (ISBN 0815345305, 9780815345305); Lewin's Genes XI, published by Jones & Bartlett Publishers, 2014 (ISBN-1449659055); Michael Richard Green and Joseph Sambrook, Molecular Cloning: A Laboratory Manual, 4th ed., Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., USA (2012) (ISBN 1936113414); Davis et al., Basic Methods in Molecular Biology, Elsevier Science Publishing, Inc., New York, USA (2012) (ISBN 044460149X); Laboratory Methods in Enzymology: DNA, Jon Lorsch (ed.) Elsevier, 2013 (ISBN 0124199542); Current Protocols in Molecular Biology (CPMB), Frederick M. Ausubel (ed.), John Wiley and Sons, 2014 (ISBN047150338X, 9780471503385), Current Protocols in Protein Science (CPPS), John E. Coligan (ed.), John Wiley and Sons, Inc., 2005; and Current Protocols in Immunology (CPI) (John E. Coligan, ADA M Kruisbeek, David H Margulies, Ethan M Shevach, Warren Strobe, (eds.) John Wiley and Sons, Inc., 2003 (ISBN 0471142735, 9780471142737) (이들의 내용은 그 전문이 본원에 참고로 포함됨).
본원에 사용된 용어 "이종 뉴클레오티드 서열" 및 "이식유전자"은 상호 교환적으로 사용되며, 본 명세서에 개시된 바와 같은 ceDNA 벡터에 통합되고 ceDNA 벡터에 의해 전달되고 발현될 수 있는 관심 핵산 (캡시드 폴리펩티드를 인코딩하는 핵산 이외)을 지칭한다.
본원에 사용된 용어 "발현 카세트" 및 "전사 카세트"는 상호 교환적으로 사용되며, 하나 이상의 프로모터 또는 이식유전자의 전사를 지시하기에 충분한 다른 조절 서열에 작동 가능하게 연결되지만, 캡시드-인코딩 서열, 다른 벡터 서열 또는 역 말단 반복 영역을 포함하지 않는 이식유전자를 포함하는 핵산의 선형 스트레치를 지칭한다. 발현 카세트는 하나 이상의 시스 -작용 서열 (예를 들어, 프로모터, 인핸서 또는 리프레서), 하나 이상의 인트론 및 하나 이상의 전사 후 조절 요소를 추가로 포함할 수 있다.
본원에서 상호 교환적으로 사용되는 용어 "폴리뉴클레오티드" 및 "핵산"은 리보뉴클레오티드 또는 데옥시리보뉴클레오티드인, 임의의 길이의 뉴클레오티드의 폴리머 형태를 지칭한다. 따라서, 이 용어는 단일, 이중 또는 다중 가닥 DNA 또는 RNA, 게놈 DNA, cDNA, DNA-RNA 하이브리드, 또는 퓨린 및 피리미딘 염기 또는 다른 천연, 화학적 또는 생화학적으로 변형된, 비-천연 또는 유도체화된 뉴클레오티드 염기를 포함하는 폴리머를 포함한다. "올리고뉴클레오티드"는 일반적으로 단일 가닥 또는 이중 가닥 DNA의 약 5개 내지 약 100개의 뉴클레오티드의 폴리뉴클레오티드를 지칭한다. 그러나, 본 개시의 목적상, 올리고뉴클레오티드의 길이에 대한 상한은 없다. 올리고뉴클레오티드는 또한 "올리고머" 또는 "올리고"로 공지되어 있으며, 유전자로부터 단리되거나, 당 업계에 공지된 방법에 의해 화학적으로 합성될 수 있다. 용어 "폴리뉴클레오티드" 및 "핵산"은, 기술된 구현예에 적용 가능한, 단일 가닥 (예컨대 센스 또는 안티센스) 및 이중 가닥 폴리뉴클레오티드를 포함하는 것으로 이해되어야 한다.
본원에 사용된 용어 "핵산 작제물"은 단일 가닥 또는 이중 가닥의 핵산 분자를 말하며, 이는 천연 발생 유전자로부터 단리되거나 또는 달리 자연적으로 존재하지 않거나 합성되는 방식으로 핵산 세그먼트를 함유하도록 변형된다. 핵산 작제물이라는 용어는 핵산 작제물이 본 개시내용의 코딩 서열의 발현에 필요한 조절 서열을 함유할 때 "발현 카세트"라는 용어와 동의어이다. "발현 카세트"는 프로모터에 작동 가능하게 연결된 DNA 코딩 서열을 포함한다.
"하이브리드화 가능" 또는 "상보적" 또는 "실질적으로 상보적"이란 핵산 (예를 들어, RNA)이 적절한 시험관내 및/또는 생체내 조건의 온도 및 용액 이온 강도 하에서 서열 특이적 역평행 방식으로 (즉, 핵산은 상보적인 핵산에 특이적으로 결합함) 또 다른 핵산에 비-공유적으로 결합하거나, 즉 왓슨-크릭(Watson-Crick) 염기쌍 및/또는 G/U 염기쌍을 형성하거나, "어닐링"하거나 "하이브리드화"될 수 있는 뉴클레오티드 서열을 포함함을 의미한다. 당 업계에 공지된 바와 같이, 표준 왓슨-크릭 염기쌍은 티미딘 (T)과 쌍을 이루는 아데닌 (A), 우라실 (U)과 쌍을 이루는 아데닌 (A) 및 시토신 (C)과 쌍을 이루는 구아닌 (G)을 포함한다. 또한, 2개의 RNA 분자 (예를 들어, dsRNA) 간의 하이브리드화, 우라실 (U)과 구아닌 (G)의 염기쌍에 대해 당 업계에 공지되어 있다. 예를 들어, G/U 염기 짝짓기는 mRNA 내 코돈과 tRNA 항-코돈 염기 짝짓기의 맥락에서 유전자 코드의 축퇴 (즉 , 중복)를 부분적으로 담당한다. 본 개시의 맥락에서, 대상 DNA-표적화 RNA 분자의 단백질-결합 세그먼트 (dsRNA 듀플렉스)의 구아닌 (G)은 우라실 (U)과 상보적인 것으로 간주되고, 그 반대도 마찬가지이다. 이와 같이, G/U 염기쌍이 주어진 뉴클레오티드 위치 대상 DNA-표적화 RNA 분자의 단백질-결합 세그먼트 (dsRNA 듀플렉스)에서 만들어질 수 있는 경우, 위치는 비-상보적인 것으로 간주되지 않고, 대신에 상보적인 것으로 간주된다.
용어 "펩티드", "폴리펩티드" 및 "단백질"은 본원에서 상호 교환적으로 사용되며, 코딩된 및 코딩되지 않은 아미노산, 화학적으로 또는 생화학적으로 변형되거나 유도체화된 아미노산, 및 변형된 펩티드 골격을 갖는 폴리펩티드를 포함할 수 있는, 임의의 길이의 아미노산의 폴리머 형태를 지칭한다.
본원에 사용된 용어 "항체"는 원하는 항원 또는 에피토프에 대한 항원-결합 활성을 보유하는 임의의 항체 또는 항체 단편 (즉, 기능성 항체 단편), 또는 항원-결합 단편을 포함한다. 일 구현예에서, 항체 또는 이의 항원-결합 단편은 면역글로불린 쇄 또는 이의 단편 및 적어도 하나의 면역글로불린 가변 도메인 서열을 포함한다. 항체의 예는 scFv, Fab 단편, Fab', F(ab')2, 단일 도메인 항체 (dAb), 중쇄, 경쇄, 중쇄 및 경쇄, 전체 항체 (예를 들어, 각각의 Fc, Fab, 중쇄, 경쇄, 가변 영역 등을 포함함), 이중특이적 항체, 디아바디, 선형 항체, 단일쇄 항체, 인트라바디, 모노클로날 항체, 키메라 항체, 또는 다량체 항체를 포함하지만, 이에 제한되지 않는다. 또한, 항체는 임의의 포유동물, 예를 들어, 영장류, 인간, 랫트, 마우스, 말, 염소 등으로부터 유래될 수 있다. 일 구현예에서, 항체는 인간 또는 인간화된 항체이다. 일부 구현예에서, 항체는 변형된 항체이다. 일부 구현예에서, 항체의 성분은 단백질 성분의 발현 후에 항체가 자가-조립되도록 개별적으로 발현될 수 있다. 일부 구현예에서, 항체는 질환 또는 질환의 증상을 치료할 목적으로 원하는 기능, 예를 들어, 원하는 단백질의 상호작용 및 억제를 갖는다. 일 구현예에서, 항체 또는 이의 항원-결합 단편은 프레임워크 영역 또는 Fc 영역을 포함한다. 항체 단편은 완전한 항체의 활성의 10-99% (예를 들어, 10-90%, 10-80%, 10-70%, 10-60%, 10-50%, 10-40%, 10-30%, 10-20%, 50-99%, 50-90%, 50-80%, 50-70%, 50-60%, 20-99%, 30-99%, 40-99%, 60-99%, 70-99%, 80-99% 90-99% 또는 그 사이의 임의의 활성)를 보유할 수 있다. 또한, 기능성 항체 단편은 온전한 항체의 활성보다 큰 활성 (예를 들어, 적어도 2배 이상)을 포함하는 것으로 고려된다. 또 다른 구현예에서, 항체 단편은 동일한 표적 (예를 들어, 에피토프)에 대한 온전한 항체의 친화도와 실질적으로 유사한 이의 표적에 대한 친화도를 포함한다. 항체는 표적 단백질의 활성을 증가시키도록 "활성화" 항체일 수 있거나, 또는 표적 단백질의 활성을 감소시키도록 "억제" 항체 (예를 들어, 중화 또는 차단 항체)일 수 있다.
본원에 사용된 용어 항체 분자의 "항원-결합 도메인"은 항원 결합에 참여하는 항체 분자, 예를 들어, 면역글로불린 (Ig) 분자의 일부를 지칭한다. 구현예에서, 항원 결합 부위는 무거운 (H) 및 가벼운 (L) 쇄의 가변 (V) 영역의 아미노산 잔기에 의해 형성된다. 초가변 영역으로 지칭되는, 중쇄 및 경쇄의 가변 영역 내의 3개의 고도로 분기된 확장부는 "프레임워크 영역" (FR)으로 불리는 보다 보존된 플랭킹 확장부 사이에 배치된다. FR은 면역글로불린에서 초가변 영역 사이에 및 이에 인접하여 자연적으로 발견되는 아미노산 서열이다. 구현예에서, 항체 분자에서, 경쇄의 3개의 초가변 영역 및 중쇄의 3개의 초가변 영역은 3차원 공간에서 서로에 대해 배치되어 항원-결합 표면을 형성하며, 이는 결합된 항원의 3차원 표면에 상보적이다. 각각의 중쇄 및 경쇄의 3개의 초가변 영역은 "상보성-결정 영역" 또는 "CDR"로 지칭된다. 프레임워크 영역 및 CDR은, 예를 들어, 하기에서 정의되고 설명되었다: Kabat, E. A., et al. (1991) Sequences of 단백질 of Immunological Interest, Fifth Edition, U.S. Department of Health and Human Services, NIH Publication No. 91-3242, 및 Chothia, C. et al. (1987) J. Mol. Biol. 196:901-917. 각각의 가변 사슬 (예를 들어, 가변 중쇄 및 가변 경쇄)은 전형적으로, 아미노산 순서로 아미노-말단에서 카복시-말단으로 배열된 3개의 CDR 및 4개의 FR, 즉 FR1, CDR1, FR2, CDR2, FR3, CDR3, 및 FR4로 구성된다. 본원에 사용된 용어 "상보성 결정 영역" 및 "CDR"은 항원 특이성 및 결합 친화성을 부여하는 항체 가변 영역 내의 아미노산 서열을 지칭한다. 일반적으로, 각각의 중쇄 가변 영역 내 3개의 CDR (HCDR1, HCDR2, HCDR3)이 있고, 각각의 경쇄 가변 영역 내 3개의 CDR (LCDR1, LCDR2, LCDR3)이 있다. 주어진 CDR의 정확한 아미노산 서열 경계는 카밧 등 (Kabat et al. (1991), "Sequences of 단백질 of Immunological Interest," 5th Ed. Public Health Service, National Institutes of Health, Bethesda, Md.) ("카밧" 넘버링 방식), 알-라지카니 등(Al-Lazikani et al., (1997) JMB 273,927-948) ("초티아(Chothia)" 넘버링 방식)에 의해 기재된 것들을 포함하여, 다수의 공지된 임의의 방식을 사용하여 결정될 수 있다. 본원에 사용된 "초티아" 번호 방식에 따라 정의된 CDR은 때때로 "초가변 루프"로도 지칭된다. 예를 들어, 카밧 하에, 중쇄 가변 도메인 (VH) 내 CDR 아미노산 잔기는 31-35 (HCDR1), 50-65 (HCDR2), 및 95-102 (HCDR3)로 넘버링되고; 경쇄 가변 도메인 (VL) 내 CDR 아미노산 잔기는 24-34 (LCDR1), 50-56 (LCDR2), 및 89-97 (LCDR3)로 넘버링된다. 초티아 하에, VH 내 CDR 아미노산은 26-32 (HCDR1), 52-56 (HCDR2), 및 95-102 (HCDR3)로 넘버링되고; VL 내 아미노산 잔기는 26-32 (LCDR1), 50-52 (LCDR2), 및 91-96 (LCDR3)으로 넘버링된다. 각각의 VH 및 VL은 전형적으로 다음 순서로 아미노-말단에서 카복시-말단으로 배열된 3개의 CDR 및 4개의 FR, 즉 FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4를 포함한다.
본원에 사용된 용어 "전장 항체"는 예를 들어, 자연적으로 발생하고, 정상적인 면역글로불린 유전자 단편 재조합 과정에 의해 형성된 면역글로불린 (Ig) 분자 (예를 들어, IgG, IgE, IgM 항체)를 지칭한다.
본원에 사용된 용어 "기능성 항체 단편" 또는 "항원-결합 단편"은 상호 교환적으로 사용되며, 온전한 (예를 들어, 전장) 항체에 의해 인식되는 것과 동일한 항원 또는 에피토프에 결합하는 항체 단편을 지칭한다. 용어 "항체 단편" 또는 "기능적 단편"은 또한 가변 영역으로 구성된 단리된 단편, 예컨대 중쇄 및 경쇄의 가변 영역으로 구성된 "Fv" 단편 또는 경쇄 및 중쇄 가변 영역이 펩티드 링커 ("scFv 단백질")에 의해 연결되는 재조합 단일쇄 폴리펩티드 분자를 포함한다. 일부 구현예에서, 항체 단편은 항원 결합 활성이 없는 항체의 일부, 예컨대 Fc 단편 또는 단일 아미노산 잔기를 포함하지 않는다. 일부 구현예에서, 기능성 항체 단편은, 예를 들어, 표적 단백질의 활성화 또는 억제 정도를 측정함으로써 평가된 바와 같이, 온전한 또는 전장 항체의 활성의 적어도 20%를 보유한다. 다른 구현예에서, 기능성 항체 단편은 온전한 항체에 대해 적어도 30%, 적어도 40%, 적어도 50%, 적어도 60%, 적어도 70%, 적어도 80%, 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99%, 또는 심지어 100% (즉, 실질적으로 유사한) 활성을 보유한다. 기능성 항체 단편은 온전한 항체와 비교하여 증가된 활성 (예를 들어, 적어도 1배, 적어도 2배, 적어도 5배, 적어도 10배, 적어도 100배 이상)을 포함할 것으로 본 명세서에서 또한 고려된다.
본원에 사용된 바와 같이, "면역글로불린 가변 도메인 서열"은 면역글로불린 가변 도메인의 구조를 형성할 수 있는 아미노산 서열을 지칭한다. 예를 들어, 상기 서열은 자연 발생 가변 도메인의 아미노산 서열의 전부 또는 일부를 포함할 수 있다. 예를 들어, 상기 서열은 1개, 2개 또는 그 이상의 N-말단 또는 C-말단 아미노산을 포함할 수 있거나 포함하지 않을 수 있거나, 또는 단백질 구조의 형성에 적합한 다른 변경을 포함할 수 있다.
본원에 사용된 용어 "프레임워크" 또는 "프레임워크 서열"은 CDR을 뺀 가변 영역의 나머지 서열을 지칭한다. CDR 서열의 정확한 정의는 상이한 시스템에 의해 결정될 수 있기 때문에, 프레임워크 서열의 의미는 상응하는 상이한 해석의 대상이된다. 6개의 CDR (경쇄의 CDR-L1, CDR-L2 및 CDR-L3, 및 중쇄의 CDR-H1, CDR-H2 및 CDR-H3)은 또한 경쇄 및 중쇄 상의 프레임워크 영역을 각각의 사슬 상의 4개의 하위-영역 (FR1, FR2, FR3 및 FR4)으로 분할하며, 여기서 CDR1은 FR1과 FR2 사이에 위치하고, CDR2는 FR2와 FR3 사이에 위치하며, CDR3은 FR3과 FR4 사이에 위치한다. 특정 하위-영역을 FR1, FR2, FR3 또는 FR4로 지정하지 않고, 프레임워크 영역은, 다른 것으로 언급되는 바와 같이, 단일의 자연 발생 면역글로불린 사슬의 가변 영역 내에서 결합된 FR을 나타낸다. 본원에 사용된 바와 같이, FR은 4개의 하위-영역 중 하나를 나타내고, FR은 프레임워크 영역을 구성하는 4개의 하위-영역 중 2개 이상을 나타낸다.
특정 항체 또는 항원-결합 단편을 "인코딩"하는 DNA 서열은 특정 RNA 및/또는 단백질로 전사되는 DNA 핵산 서열이다. DNA 폴리뉴클레오티드는 단백질로 번역되는 RNA (mRNA)를 인코딩할 수 있거나, DNA 폴리뉴클레오티드는 단백질로 번역되지 않는 RNA (예를 들어, tRNA, rRNA 또는 DNA-표적화 RNA; "비-코딩" RNA 또는 "ncRNA"라고도 함)를 인코딩할 수 있다.
본원에 사용된 바와 같이, 본원에 사용된 용어 "융합 단백질"은 적어도 2개의 상이한 단백질로부터의 단백질 도메인을 포함하는 폴리펩티드를 지칭한다. 예를 들어, 융합 단백질은 (i) 항체 또는 이의 단편 (예를 들어, 항체의 항원-결합 부분 또는 항원-결합 단편) 또는 리간드 결합 도메인 및 (ii) 적어도 하나의 비-항체 단백질을 포함할 수 있다. 본원에 포함된 융합 단백질은 항체, 또는 관심 단백질에 융합된 항체의 Fc 또는 항원-결합 단편, 예를 들어, 수용체, 리간드, 효소 또는 펩티드의 세포외 도메인을 포함하지만, 이에 제한되지 않는다. 융합 단백질의 일부인 항체 또는 이의 항원-결합 단편은 단일특이적 항체 또는 이중특이적 또는 다중특이적 항체일 수 있다.
본원에 사용된 용어 "게놈 세이프 하버 유전자" 또는 "세이프 하버 유전자"는 내인성 유전자 활성에 중대한 부정적인 영향 없이 또는 암의 촉진 없이 서열이 예측 가능한 방식으로 통합되고 기능할 수 있도록 (예를 들어, 관심 단백질을 발현하도록) 핵산 서열이 삽입될 수 있는 유전자 또는 유전자좌를 지칭한다. 일부 구현예에서, 세이프 하버 유전자는 또한 삽입된 핵산 서열이 비-세이프 하버 부위보다 효율적으로 그리고 더 높은 수준으로 발현될 수 있는 유전자좌 또는 유전자이다.
본원에 사용된 용어 "유전자 전달"은 외래 DNA가 유전자 요법 적용을 위해 숙주 세포로 전달되는 과정을 의미한다.
본원에 사용된 용어 "말단 반복부" 또는 "TR"은 적어도 하나의 최소 요구된 복제 기원 및 회문 헤어핀 구조를 포함하는 영역을 포함하는 임의의 바이러스 말단 반복 또는 합성 서열을 포함한다. Rep-결합 서열 ("RBS") (RBE (Rep-결합 요소)로도 지칭됨) 및 말단 분해 부위 ("TRS")는 함께 "최소 요구된 복제 기원"을 구성하므로 TR은 적어도 하나의 RBS 및 적어도 하나의 TRS를 포함한다. 주어진 폴리뉴클레오티드 서열의 스트레치 내에서 서로의 역 보체인 TR은 전형적으로 각각 "역 말단 반복" 또는 "ITR"로 지칭된다. 바이러스와 관련하여, ITR은 복제, 바이러스 패키징, 통합 및 프로바이러스 구조를 중재한다. 본 발명에서 예기치 않게 발견된 바와 같이, 전장에 걸쳐 역 보체가 아닌 TR은 여전히 ITR의 전통적인 기능을 수행할 수 있으므로, ITR이라는 용어는 본원에서 ceDNA 벡터의 복제를 매개할 수 있는 ceDNA 게놈 또는 ceDNA 벡터 내의 TR을 지칭하는데 사용된다. 복잡한 ceDNA 벡터 구성에서 2개 이상의 ITR 또는 비대칭 ITR 쌍이 존재할 수 있음을 당업자는 이해할 것이다. ITR은 AAV ITR 또는 비-AAV ITR일 수 있거나, AAV ITR 또는 비-AAV ITR로부터 유도될 수 있다. 예를 들어, ITR은 파보바이러스 및 데펜도바이러스 (예를 들어, 개 파보바이러스, 소 파보바이러스, 마우스 파보바이러스, 돼지 파보바이러스, 인간 파보바이러스 B-19)를 포함하는 파보비리다에 패밀리로부터 유래될 수 있거나, SV40 복제 기원으로 사용되는 SV40 헤어핀을 ITR로 사용할 수 있으며, 이는 절단, 치환, 결실, 삽입 및/또는 첨가에 의해 추가로 변형될 수 있다. 파보비리다에 패밀리 바이러스는 척추동물을 감염시키는 파보비리나에(Parvovirinae), 및 무척추동물을 감염시키는 덴소비리나에(Densovirinae)의 2개의 하위패밀리로 구성된다. 데펜도파보바이러스는 인간, 영장류, 소, 개, 말 및 양 종을 포함하지만 이에 제한되지 않는 척추동물 숙주에서 복제할 수 있는 아데노-관련 바이러스 (AAV)의 바이러스 패밀리를 포함한다. 본원의 편의를 위해, ceDNA 벡터에서 발현 카세트의 5'에 (상류에) 위치한 ITR은 "5' ITR" 또는 "좌측 ITR"로 지칭되고, ceDNA 벡터에서 발현 카세트의 3'에 (하류에) 위치한 ITR은 "3' ITR" 또는 "우측 ITR"로 지칭된다.
"야생형 ITR" 또는 "WT-ITR"은, 예를 들어, Rep 결합 활성 및 Rep 닉킹 능력을 보유하는 AAV 또는 다른 데펜도바이러스에서 천연 발생 ITR 서열의 서열을 지칭한다. 임의의 AAV 혈청형으로부터의 WT-ITR의 뉴클레오티드 서열은 유전자 코드 또는 드리프트의 축퇴로 인해 정규 천연 발생 서열과 약간 다를 수 있으므로, 본원에 사용하기 위해 포함된 WT-ITR 서열은 생성 과정 중에 발생하는 천연 발생 변화 (예를 들어, 복제 오류)의 결과로서 WT-ITR 서열을 포함한다.
본원에 사용된 용어 "실질적으로 대칭인 WT-ITR" 또는 "실질적으로 대칭인 WT-ITR 쌍"은 둘 다 전체 길이에 걸쳐 역 보체 서열을 갖는 야생형 ITR인 단일 ceDNA 게놈 또는 ceDNA 벡터 내의 한 쌍의 WT-ITR을 지칭한다. 예를 들어, ITR은 변화가 서열의 특성 및 전체 3차원 구조에 영향을 미치지 않는 한, 정규 천연 발생 서열로부터 벗어난 하나 이상의 뉴클레오티드를 갖는 경우에도 야생형 서열로 간주될 수 있다. 일부 측면에서, 변형 뉴클레오티드는 보존적 서열 변화를 나타낸다. 하나의 비제한적인 예로서, 정규 서열과 적어도 95%, 96%, 97%, 98% 또는 99%의 서열 동일성을 갖고 (예를 들어, 디폴트 설정에서 BLAST를 사용하여 측정됨), 또한 3D 구조가 기하학적 공간에서 동일한 형상이 되도록 다른 WT-ITR에 대해 대칭 3차원 공간 구성을 갖는 서열. 실질적으로 대칭인 WT-ITR은 3D 공간에서 동일한 A, C-C' 및 B-B' 루프를 갖는다. 실질적으로 대칭인 WT-ITR은 그것이 적절한 Rep 단백질과 쌍을 이루는 작동 가능한 Rep 결합 부위 (RBE 또는 RBE') 및 말단 분해 부위 (trs)를 갖는 것으로 결정함으로써 WT로서 기능적으로 확인될 수 있다. 허용 조건 하에서 이식유전자 발현을 포함하여, 다른 기능을 선택적으로 시험할 수 있다.
본원에 사용된 "변형된 ITR" 또는 "모드-ITR" 또는 "돌연변이 ITR"의 문구는 본원에서 상호 교환적으로 사용되며, 동일한 혈청형으로부터의 WT-ITR과 비교하여 적어도 하나 이상의 뉴클레오티드 내의 돌연변이를 갖는 ITR을 지칭한다. 돌연변이는 ITR에서 A, C, C', B, B' 영역 중 하나 이상에서의 변화를 초래할 수 있고, 동일한 혈청형의 WT-ITR의 3D 공간 구성과 비교하여 3차원 공간 구성 (즉, 기하학적 공간에서의 3D 구조)의 변화를 초래할 수 있다.
본원에서 사용되는 용어 "비대칭 ITR"은 "비대칭 ITR 쌍"으로도 지칭되고, 전체 길이에 걸쳐 역 보체가 아닌 단일 ceDNA 게놈 또는 ceDNA 벡터 내의 한 쌍의 ITR을 지칭한다. 하나의 비제한적인 예로서, 비대칭 ITR 쌍은 3D 구조가 기하학적 공간에서 상이한 형상이 되도록 동족 ITR에 대해 대칭인 3차원 공간 구성을 갖지 않는다. 다르게 말하면, 비대칭 ITR 쌍은 전체적인 기하학적 구조가 다르며, 즉, 3D 공간에서 A, C-C' 및 B-B' 루프의 구성이 다르다 (예를 들어, 하나의 ITR은 동족 ITR과 비교하여 짧은 C-C' 아암 및/또는 짧은 B-B' 아암을 가질 수 있음). 두 ITR 사이의 서열 차이는 하나 이상의 뉴클레오티드 첨가, 결실, 절단 또는 점 돌연변이에 기인할 수 있다. 일 구현예에서, 비대칭 ITR 쌍의 하나의 ITR은 야생형 AAV ITR 서열일 수 있고, 다른 ITR은 본원에 정의된 변형된 ITR (예를 들어, 비-야생형 또는 합성 ITR 서열)일 수 있다. 또 다른 구현예에서, 비대칭 ITR 쌍의 모든 ITR은 야생형 AAV 서열이 아니며, 2개의 ITR은 기하학적 공간에서 상이한 형상 (즉, 상이한 전체 기하학적 구조)을 갖는 변형된 ITR이다. 일부 구현예에서, 비대칭 ITR 쌍의 하나의 모드-ITR은 짧은 C-C' 아암을 가질 수 있고 다른 ITR은 상이한 변형 (예를 들어, 단일 암 또는 짧은 B-B' 아암 등)을 가질 수 있으므로 동족 비대칭 모드-ITR과 비교하여 상이한 3차원 공간 구성을 갖는다.
본원에 사용된 용어 "대칭 ITR"은 야생형 데펜도바이러스 ITR 서열에 대해 돌연변이되거나 변형되고 전장에 걸쳐 역 보체인 단일 ceDNA 게놈 또는 ceDNA 벡터 내의 한 쌍의 ITR을 지칭한다. ITR은 모두 야생형 ITR AAV2 서열이 아니며 (즉, 돌연변이 ITR이라고도 하는 변형된 ITR임), 뉴클레오티드 첨가, 결실, 치환, 절단 또는 점 돌연변이로 인해 야생형 ITR과 서열상 차이가 있을 수 있다. 본원의 편의를 위해, ceDNA 벡터에서 발현 카세트의 5'에 (상류에) 위치한 ITR은 "5' ITR" 또는 "좌측 ITR"로 지칭되고, ceDNA 벡터에서 발현 카세트의 3'에 (하류에) 위치한 ITR은 "3' ITR" 또는 "우측 ITR"로 지칭된다.
본원에 사용된 용어 "실질적으로 대칭인 변형된-ITR" 또는 "실질적으로 대칭인 모드-ITR 쌍"은 둘 다 전체 길이에 걸쳐 역 보체 서열을 갖는 단일 ceDNA 게놈 또는 ceDNA 벡터 내의 한 쌍의 변형된-ITR을 지칭한다. 예를 들어, 변형된 ITR은 변화가 특성 및 전체 형상에 영향을 미치지 않는 한, 역 보체 서열로부터 벗어난 일부 뉴클레오티드 서열을 가지더라도 실질적으로 대칭인 것으로 간주될 수 있다. 하나의 비제한적인 예로서, 정규 서열과 적어도 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 서열 동일성을 갖고 (디폴트 설정에서 BLAST를 사용하여 측정됨), 또한 3D 구조가 기하학적 공간에서 동일한 형상이 되도록 동족 변형된 ITR에 대해 대칭 3차원 공간 구성을 갖는 서열. 다르게 말하면, 실질적으로 대칭인 변형된-ITR 쌍은 3D 공간에서 구성된 동일한 A, C-C' 및 B-B' 루프를 갖는다. 일부 구현예에서, 모드-ITR 쌍으로부터의 ITR은 상이한 역 보체 뉴클레오티드 서열을 가질 수 있지만 여전히 동일한 대칭 3차원 공간 구성을 가질 수 있으며 - 즉, 두 ITR은 모두 동일한 전체 3D 형상을 초래하는 돌연변이를 갖는다. 예를 들어, 모드-ITR 쌍에서 하나의 ITR (예를 들어, 5' ITR)은 하나의 혈청형으로부터 유래될 수 있고, 다른 ITR (예를 들어, 3' ITR)은 상이한 혈청형으로부터 유래될 수 있지만, 둘 모두 동일한 상응하는 돌연변이를 가질 수 있으므로 (예를 들어, 5'ITR이 C 영역에서 결실을 갖는 경우, 상이한 혈청형으로부터의 동족 변형된 3'ITR은 C '영역 내 상응하는 위치에서 결실을 가짐) 변형된 ITR 쌍은 동일한 대칭 3차원 공간 구성을 갖는다. 이러일 구현예에서, 변형된 ITR 쌍의 각각의 ITR은 AAV2 및 AAV6의 조합과 같은 다른 혈청형 (예를 들어 AAV1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 및 12)으로부터 유래할 수 있으며, 하나의 ITR에서의 변형은 다른 혈청형으로부터의 동족 ITR의 상응하는 위치에 반영된다. 일 구현예에서, 실질적으로 대칭인 변형된 ITR 쌍은 ITR 사이의 뉴클레오티드 서열의 차이가 특성 또는 전체 형상에 영향을 미치지 않고 3D 공간에서 실질적으로 동일한 형상을 갖는 한 변형된 ITR (모드-ITR)의 쌍을 지칭한다. 비제한적인 예로서, BLAST(기본 지역 정렬 검색 도구(Basic Local Alignment Search Tool)) 또는 디폴트 설정의 BLASTN과 같이 당 업계에 잘 알려진 표준 수단에 의해 결정된 정규 모드-ITR과 적어도 95%, 96%, 97%, 98% 또는 99% 서열 동일성을 갖고, 또한 3D 구조가 기하학적 공간에서 동일한 형상이 되도록 대칭 3차원 공간 구성을 갖는, 모드-ITR. 실질적으로 대칭인 모드-ITR 쌍은 3D 공간에서 동일한 A, C-C' 및 B-B' 루프를 가지며, 예를 들어, 실질적으로 대칭인 모드-ITR 쌍의 변형된 ITR이 C-C' 아암의 결실을 갖는다면, 동족 모드-ITR은 상응하는 C-C' 루프의 결실을 가지며 또한 동족 모드-ITR의 기하학적 공간에서 동일한 형태로 남은 A 및 B-B' 루프의 유사한 3D 구조를 갖는다.
용어 "플랭킹"은 또 다른 핵산 서열에 대한 하나의 핵산 서열의 상대적 위치를 지칭한다. 일반적으로, 서열 ABC에서, B는 A 및 C에 의해 플랭킹된다. 배열 AxBxC에 대해서도 동일하다. 따라서, 플랭킹 서열은 플랭킹된 서열에 선행하거나 후속하지만 플랭킹된 서열에 근접하거나 또는 바로 인접할 필요는 없다. 일 구현예에서, 용어 플랭킹은 선형 듀플렉스 ceDNA 벡터의 각 말단에서의 말단 반복부를 지칭한다.
본원에 사용된 용어 "ceDNA 게놈"은 적어도 하나의 역 말단 반복 영역을 추가로 포함하는 발현 카세트를 지칭한다. ceDNA 게놈은 하나 이상의 스페이서 영역을 추가로 포함할 수 있다. 일부 구현예에서, ceDNA 게놈은 DNA의 분자간 듀플렉스 폴리뉴클레오티드로서 플라스미드 또는 바이러스 게놈에 통합된다.
본원에 사용된 용어 "ceDNA 스페이서 영역"은 ceDNA 벡터 또는 ceDNA 게놈에서 기능적 요소를 분리하는 개재 서열을 지칭한다. 일부 구현예에서, ceDNA 스페이서 영역은 최적의 기능성을 위해 2개의 기능성 요소를 원하는 거리로 유지한다. 일부 구현예에서, ceDNA 스페이서 영역은 예를 들어, 플라스미드 또는 바쿨로바이러스 내에서 ceDNA 게놈의 유전자 안정성을 제공하거나 추가한다. 일부 구현예에서, ceDNA 스페이서 영역은 클로닝 부위 등을 위한 편리한 위치를 제공함으로써 ceDNA 게놈의 준비된 유전자 조작을 용이하게 한다. 예를 들어, 특정 측면에서, 몇몇 제한 엔도뉴클레아제 부위를 함유하는 올리고뉴클레오티드 "폴리링커", 또는 공지된 단백질 (예를 들어, 전사 인자) 결합 부위를 갖지 않도록 설계된 비-오픈 리딩 프레임 서열은, 예를 들어, 말단 분해 부위와 상류 전사 조절 요소 사이에 6mer, 12mer, 18mer, 24mer, 48mer, 86mer, 176mer 등을 삽입하여 시스 - 작용 인자를 분리하도록 ceDNA 게놈에 위치할 수 있다. 유사하게, 스페이서는 폴리아데닐화 신호 서열과 3'-말단 분해 부위 사이에 포함될 수 있다.
본원에 사용된 용어 "Rep 결합 부위, "Rep 결합 요소, "RBE" 및 "RBS"는 상호 교환적으로 사용되며, Rep 단백질에 의해 결합될 때 Rep 단백질이 RBS를 포함하는 서열에서 이의 부위-특이적 엔도뉴클레아제 활성을 수행할 수 있도록 하는 Rep 단백질 (예를 들어, AAV Rep 78 또는 AAV Rep 68)에 대한 결합 부위를 지칭한다. RBS 서열 및 이의 역 보체는 함께 단일 RBS를 형성한다. RBS 서열은 당 업계에 공지되어 있으며, 예를 들어, AAV2에서 확인된 RBS 서열인, 5'-GCGCGCTCGCTCGCTC-3' (서열 번호: 60)를 포함한다. 다른 공지된 AAV RBS 서열 및 다른 자연적으로 알려진 또는 합성 RBS 서열을 포함하는, 임의의 공지된 RBS 서열이 본 발명의 구현예에서 사용될 수 있다. 이론에 구속되지 않고, Rep 단백질의 뉴클레아제 도메인은 듀플렉스 뉴클레오티드 서열 GCTC에 결합하고, 따라서 공지된 2개의 AAV Rep 단백질은 듀플렉스 올리고뉴클레오티드, 5'-(GCGC)(GCTC)(GCTC)(GCTC)-3' (서열 번호: 60)에 직접 결합하고 안정적으로 조립된다고 생각된다. 또한, 가용성 응집된 컨포머 (즉, 정의되지 않은 수의 상호 연관된 Rep 단백질)는 해리되어 Rep 결합 부위를 함유하는 올리고뉴클레오티드에 결합한다. 각각의 Rep 단백질은 각 가닥에서 질소 염기 및 포스포디에스테르 골격 둘 다와 상호 작용한다. 질소 염기와의 상호 작용은 서열 특이성을 제공하는 반면, 포스포디에스테르 골격과의 상호 작용은 서열에 특이적이지 않거나 덜 특이적이고, 단백질-DNA 복합체를 안정화시킨다.
본원에 사용된 용어 "말단 분해 부위" 및 "TRS"는 본원에서 상호 교환적으로 사용되며, Rep가 DNA 중합 효소, 예를 들어, DNA pol 델타 또는 DNA pol 엡실론을 통해 DNA 확장을 위한 기질로 작용하는 3' OH를 생성하는 5' 티미딘과 티로신-포스포디에스테르 결합을 형성하여 영역을 지칭한다. 대안적으로, Rep-티미딘 복합체는 조정된 결찰 반응에 참여할 수 있다. 일부 구현예에서, TRS는 비-염기쌍을 이루는 티미딘을 최소로 포함한다. 일부 구현예에서, TRS의 닉킹 효율은 RBS로부터 동일한 분자 내에서의 거리에 의해 적어도 부분적으로 제어될 수 있다. 수용체 기질이 상보적 ITR인 경우, 생성된 생성물은 분자내 듀플렉스이다. TRS 서열은 당 업계에 공지되어 있으며, 예를 들어, AAV2에서 확인된 헥사뉴클레오티드 서열인, 5'-GGTTGA-3' (서열 번호: 61)를 포함한다. 다른 공지된 AAV TRS 서열 및 다른 자연적으로 알려진 또는 합성 TRS 서열 예컨대 AGTT (서열 번호: 62), GGTTGG (서열 번호: 63), AGTTGG (서열 번호: 64), AGTTGA (서열 번호: 65), 및 RRTTRR (서열 번호: 66)과 같은 다른 모티프를 포함하는, 임의의 공지된 TRS 서열이 본 발명의 구현예에서 사용될 수 있다.
본원에 사용된 용어 "ceDNA-플라스미드"는 분자간 듀플렉스로서 ceDNA 게놈을 포함하는 플라스미드를 지칭한다.
본원에 사용된 용어 "ceDNA-박미드"는 이. 콜라이에서 플라스미드로서 증식할 수 있는 분자간 듀플렉스로서 ceDNA 게놈을 포함하는 감염성 바쿨로바이러스 게놈을 지칭하며, 따라서 바쿨로바이러스에 대한 셔틀 벡터로서 작용할 수 있다.
본원에 사용된 용어 "ceDNA- 바쿨로바이러스"는 바쿨로바이러스 게놈 내의 분자간 듀플렉스로서 ceDNA 게놈을 포함하는 바쿨로바이러스를 지칭한다.
본원에 사용된 용어 "ceDNA-바쿨로바이러스 감염된 곤충 세포" 및 "ceDNA-BIIC"는 상호 교환적으로 사용되며, ceDNA-바쿨로바이러스로 감염된 무척추동물 숙주 세포 (곤충 세포 (예를 들어, Sf9 세포)를 포함하지만 이에 제한되지 않음)를 지칭한다.
본원에 사용된 용어 "폐쇄 말단 DNA 벡터"는 적어도 하나의 공유적으로 폐쇄된 말단을 갖는 캡시드 비함유 DNA 벡터 (즉, 분자내 듀플렉스)를 지칭하고, 벡터의 적어도 일부는 분자 내 듀플렉스를 갖는다.
본원에 사용된 용어 "ceDNA 벡터" 및 "ceDNA"는 상호교환 가능하게 사용되고 적어도 하나의 말단 회문을 포함하는 폐쇄 말단 DNA 벡터를 지칭한다. 일부 구현예에서, ceDNA는 2개의 공유적으로 폐쇄된 말단을 포함한다.
본원에 정의된 바와 같이, "리포터"는 검출 가능한 판독을 제공하는데 사용될 수 있는 단백질을 지칭한다. 리포터는 일반적으로 형광, 색 또는 발광과 같은 측정 가능한 신호를 생성한다. 리포터 단백질 코딩 서열은 세포 또는 유기체에서의 존재가 쉽게 관찰되는 단백질을 인코딩한다. 예를 들어, 형광 단백질은 특정 파장의 빛으로 여기될 때 세포가 형광을 일으키고, 루시퍼라제는 세포가 빛을 생성하는 반응을 촉매하게 하며, β-갈락토시다제와 같은 효소는 기질을 착색된 생성물로 전환시킨다. 실험 또는 진단 목적에 유용한 예시적인 리포터 폴리펩티드는 β-락타마제, β-갈락토시다제 (LacZ), 알칼리 포스파타제 (AP), 티미딘 키나제 (TK), 녹색 형광 단백질 (GFP) 및 기타 형광 단백질, 클로람페니콜 아세틸트랜스퍼라제 (CAT), 루시퍼라제 및 당 업계에 잘 알려진 다른 것들을 포함하지만, 이에 제한되지는 않는다.
본원에 사용된 용어 "이펙터 단백질"은, 예를 들어, 리포터 폴리펩티드로서 또는 보다 적절하게는, 세포를 사멸시키는 폴리펩티드, 예를 들어 독소, 또는 세포를 선택된 제제로의 사멸 또는 이의 결핍에 민감하게 하는 제제로서 검출 가능한 판독을 제공하는 폴리펩티드를 지칭한다. 이펙터 단백질은 숙주 세포의 DNA 및/또는 RNA를 직접 표적화하거나 손상시키는 임의의 단백질 또는 펩티드를 포함한다. 예를 들어, 이펙터 단백질은 숙주 세포 DNA 서열 (게놈 또는 염색체외 요소에 관계없이)을 표적화하는 제한 엔도뉴클레아제, 세포 생존에 필요한 폴리펩티드 표적을 분해하는 프로테아제, DNA 자이레이스 억제제, 및 리보뉴클레아제-타입 독소를 포함할 수 있지만, 이에 제한되지는 않는다. 일부 구현예에서, 본원에 기재된 합성 생물학적 회로에 의해 제어되는 이펙터 단백질의 발현은 또 다른 합성 생물학적 회로의 인자로서 참여하여 생물학적 회로 시스템의 반응성의 범위 및 복잡성을 확장시킬 수 있다.
전사 조절제는 관심 유전자의 전사를 활성화시키거나 억제하는 전사 활성화제 및 억제제를 지칭한다. 프로모터는 특정 유전자의 전사를 개시하는 핵산의 영역이다. 전사 활성화제는 전형적으로 전사 프로모터 인근에 결합하고 전사를 직접 개시하기 위해 RNA 폴리머라제를 동원한다. 억제제는 전사 프로모터에 결합하고 RNA 폴리머라제에 의한 전사 개시를 입체적으로 방해한다. 다른 전사 조절제는 이들이 결합하는 위치 및 세포 및 환경 조건에 따라 활성화제 또는 억제제로서 작용할 수 있다. 전사 조절제 부류의 비제한적인 예는 호메오도메인 단백질, 아연-핑거 단백질, 윙드(winged)-헬릭스 (포크헤드) 단백질 및 류신-지퍼 단백질을 포함하지만, 이에 제한되지는 않는다.
본원에 사용된 "억제 단백질" 또는 "유도 단백질"은 조절 서열 요소에 결합하고 조절 서열 요소에 작동적으로 연결된 서열의 전사를 각각 억제하거나 활성화시키는 단백질이다. 본원에 기술된 바람직한 억제 및 유도 단백질은 적어도 하나의 투입 제제 또는 환경 투입의 존재 또는 부재에 민감하다. 본원에 기재된 바와 같은 바람직한 단백질은, 예를 들어, 분리 가능한 DNA-결합 및 투입 제제-결합 또는 반응성 요소 또는 도메인을 포함하는 형태의 모듈이다.
본원에 사용된 "담체"는 임의의 및 모든 용매, 분산 매질, 비히클, 코팅, 희석제, 항균제 및 항진균제, 등장제 및 흡수 지연제, 완충제, 담체 용액, 현탁액, 콜로이드 등을 포함한다. 약제학적 활성 물질을 위한 이러한 매질 및 제제의 사용은 당 업계에 잘 알려져 있다. 보충 활성 성분이 또한 조성물에 혼입될 수 있다. 문구 "약제학적으로 허용되는"은 숙주에 투여될 때 독성, 알레르기성 또는 유사한 유해 반응을 일으키지 않는 분자 엔티티 및 조성물을 지칭한다.
본원에 사용된 "입력 제제 반응 도메인"은 연결된 DNA 결합 융합 도메인이 그 조건 또는 입력의 존재에 반응하도록 하는 방식으로 조건 또는 입력 제제에 결합하거나 달리 반응하는 전사 인자의 도메인이다. 일 구현예에서, 조건 또는 투입의 존재는 전사 인자의 전사-조절 활성을 변형시키는, 투입 제제 반응 도메인 또는 그것이 융합된 단백질에서 형태적 변화를 초래한다.
"생체내"라는 용어는 유기체, 예컨대 다세포 동물에서 또는 내에서 발생하는 분석 또는 과정을 지칭한다. 본원에 기재된 일부 측면에서, 박테리아와 같은 단세포 유기체가 사용될 때 방법 또는 사용이 "생체내"에서 발생한다고 말할 수 있다. "생체외"라는 용어는 다세포 동물 또는 식물의 몸체 외부, 예를 들어, 외식편, 일차 세포 및 세포주를 비롯한 배양 세포, 형질전환 세포주, 및 추출된 조직 또는 특히 혈액 세포를 포함하는 세포의 외부인 온전한 막을 갖는 살아있는 세포를 사용하여 수행되는 방법 및 사용을 지칭한다. "시험관내"라는 용어는 세포 추출물과 같은 온전한 막을 갖는 세포의 존재를 필요로 하지 않는 분석 및 방법을 지칭하고, 비-세포 시스템, 예컨대 세포 추출물과 같이 세포 또는 세포 시스템을 포함하지 않는 배지에서 프로그램 가능한 합성 생물학적 회로의 도입을 지칭할 수 있다.
본원에 사용된 용어 "프로모터"는 단백질 또는 RNA를 인코딩하는 이종 표적 유전자일 수 있는, 핵산 서열의 전사를 유도함으로써 또 다른 핵산 서열의 발현을 조절하는 임의의 핵산 서열을 지칭한다. 프로모터는 구성적, 유도성, 억제성, 조직-특이적, 또는 이들의 임의의 조합일 수 있다. 프로모터는 핵산 서열의 나머지 부분의 개시 및 전사 속도를 제어하는 핵산 서열의 제어 영역이다. 프로모터는 또한 조절 단백질 및 분자가 결합할 수 있는 유전자 요소, 예컨대 RNA 폴리머라제 및 다른 전사 인자를 함유할 수 있다. 본원에 기재된 측면의 일부 구현예에서, 프로모터는 프로모터 자체의 발현을 조절하는 전사 인자의 발현을 구동할 수 있다. 프로모터 서열 내에서 전사 개시 부위 및 RNA 폴리머라제의 결합을 담당하는 단백질 결합 도메인이 발견될 것이다. 진핵생물 프로모터는 종종 "TATA" 박스 및 "CAT" 박스를 포함하지만, 항상 그런 것은 아니다. 유도성 프로모터를 포함하는 다양한 프로모터가 본원에 개시된 ceDNA 벡터에서 이식유전자의 발현을 유도하는데 사용될 수 있다. 프로모터 서열은 전사 개시 부위에 의해 이의 3' 말단에 결합될 수 있고, 배경 이상의 검출 가능한 수준으로 전사를 개시하는데 필요한 최소 수의 염기 또는 요소를 포함하도록 상류 (5' 방향)로 연장된다.
본원에 사용된 용어 "인핸서"는 핵산 서열의 전사 활성화를 증가시키기 위해 하나 이상의 단백질 (예를 들어, 활성화제 단백질 또는 전사 인자)에 결합하는 시스-작용 조절 서열 (예를 들어, 50-1,500 염기쌍)을 지칭한다. 인핸서는 이들이 조절하는 유전자 개시 부위의 상류 또는 유전자 개시 부위의 하류에서 최대 1,000,000개의 염기 파스(base pars)에 위치할 수 있다. 인핸서는 인트론 영역 내에 또는 관련되지 않은 유전자의 엑손 영역에 위치할 수 있다.
프로모터는 그것이 조절하는 핵산 서열의 발현 또는 전사를 유도한다고 할 수 있다. "작동 가능하게 연결된", "작동적으로 위치된", "작동적으로 연결된", "제어 하" 및 "전사적 제어 하"라는 문구는 프로모터가 핵산 서열과 관련하여 해당 서열의 전사 개시 및/또는 발현을 제어하도록 조절하는 올바른 기능적 위치 및/또는 배향에 있음을 나타낸다. 본원에 사용된 "역 프로모터"는 핵산 서열이 역 배향으로 되어, 코딩 가닥이 이제 비-코딩 가닥이 되거나 그 반대인 프로모터를 지칭한다. 역 프로모터 서열은 스위치의 상태를 조절하기 위해 다양한 구현예에서 사용될 수 있다. 또한, 다양일 구현예에서, 프로모터는 인핸서와 함께 사용될 수 있다.
프로모터는 주어진 유전자 또는 서열의 코딩 세그먼트 및/또는 엑손의 상류에 위치한 5' 비-코딩 서열을 단리함으로써 수득될 수 있는 바와 같이 유전자 또는 서열과 자연적으로 관련된 것일 수 있다. 이러한 프로모터는 "내인성"으로 지칭될 수 있다. 유사하게, 일부 구현예에서, 인핸서는 그 서열의 하류 또는 상류에 위치한 핵산 서열과 자연적으로 관련된 것일 수 있다.
일부 구현예에서, 코딩 핵산 세그먼트는 "재조합 프로모터" 또는 "이종 프로모터"의 제어 하에 위치되며, 이들 둘 모두는 천연 환경에서 작동 가능하게 연결되는 인코딩된 핵산 서열과 정상적으로 연관되지 않은 프로모터를 지칭한다. 재조합 또는 이종 인핸서는 천연 환경에서 주어진 핵산 서열과 정상적으로 관련되지 않은 인핸서를 지칭한다. 이러한 프로모터 또는 인핸서는 다른 유전자의 프로모터 또는 인핸서; 임의의 다른 원핵생물, 바이러스 또는 진핵생물 세포로부터 단리된 프로모터 또는 인핸서; 및 "천연 발생"이 아닌 합성 프로모터 또는 인핸서를 포함할 수 있으며, 즉, 상이한 전사 조절 영역의 상이한 요소, 및/또는 당 업계에 공지된 유전 공학 방법을 통해 발현을 변경시키는 돌연변이를 포함한다. 프로모터 및 인핸서의 핵산 서열을 합성적으로 생성하는 것에 더하여, 프로모터 서열은 본원에 개시된 합성 생물학적 회로 및 모듈과 관련하여, PCR을 포함하는 재조합 클로닝 및/또는 핵산 증폭 기술을 사용하여 생성될 수 있다 (예를 들어, 미국 특허 번호 4,683,202, 미국 특허 번호 5,928,906 참조, 각각 본원에 참고로 포함됨). 또한, 미토콘드리아, 엽록체 등과 같은 비-핵 소기관 내에서 서열의 전사 및/또는 발현을 지시하는 제어 서열도 사용될 수 있는 것으로 고려된다.
본원에 기재된 바와 같이, "유도성 프로모터"는 유도제 또는 유도 제제의 존재하, 이에 영향을 받거나 이에 의해 접촉될 때 전사 활성을 개시 또는 향상시키는 것을 특징으로 하는 것이다. 본원에 정의된 "유도제" 또는 "유도 제제"는 유도성 프로모터로부터 전사 활성을 유도하는데 활성이 있는 방식으로 투여되는 내인성, 또는 일반적으로 외인성 화합물 또는 단백질일 수 있다. 일부 구현예에서, 유도제 또는 유도 제제, 즉, 화학 물질, 화합물 또는 단백질 자체는 핵산 서열의 전사 또는 발현 결과일 수 있으며 (즉, 유도제는 또 다른 성분 또는 모듈에 의해 발현된 유도 단백질일 수 있음), 이는 그 자체로 제어 하에 있거나 유도성 프로모터일 수 있다. 일부 구현예에서, 유도성 프로모터는 특정 작용제, 예컨대 억제제의 부재 하에 유도된다. 유도성 프로모터의 예는 테트라사이클린, 메탈로티오닌, 엑디손, 포유동물 바이러스 (예를 들어, 아데노바이러스 후기 프로모터; 및 마우스 유방 종양 바이러스 긴 말단 반복부 (MMTV-LTR)) 및 다른 스테로이드-반응성 프로모터인, 라파마이신 반응성 프로모터 등을 포함하지만, 이에 제한되지는 않는다.
본원에서 상호 교환적으로 사용되는 용어 "DNA 조절 서열", "제어 요소" 및 "조절 요소"는 전사 및 번역 제어 서열, 예컨대 프로모터, 인핸서, 폴리아데닐화 신호, 종결자, 단백질 분해 신호 등을 지칭하고, 비-코딩 서열 (예를 들어, DNA-표적화 RNA) 또는 코딩 서열 (예를 들어, 부위 지향적 변형 폴리펩티드, 또는 Cas9/Csn1 폴리펩티드)의 전사를 제공 및/또는 조절하고/하거나 인코딩된 폴리펩티드의 번역을 조절한다.
"작동 가능하게 연결된"은 설명된 구성 요소들이 의도된 방식으로 기능할 수 있게 하는 관계에 있는 근접부위(juxtaposition)를 지칭한다. 예를 들어, 프로모터가 이의 전사 또는 발현에 영향을 미치는 경우, 프로모터는 코딩 서열에 작동 가능하게 연결된다. "발현 카세트"는 ceDNA 벡터에서 이식유전자의 전사를 지시하기에 충분한 프로모터 또는 다른 조절 서열에 작동 가능하게 연결된 이종 DNA 서열을 포함한다. 적합한 프로모터는, 예를 들어, 조직 특이적 프로모터를 포함한다. 프로모터는 또한 AAV 기원일 수 있다.
본원에 사용된 용어 "대상체"는 예방적 치료를 포함하여, 본 발명에 따른 ceDNA 벡터를 사용한 치료가 제공되는 인간 또는 동물을 지칭한다. 일반적으로 동물은 영장류, 설치류, 가축 또는 게임 동물과 같은 척추동물이다. 영장류는 침팬지, 사이노몰구스 원숭이(cynomologous monkey), 거미 원숭이 및 마카크(macaque), 예를 들어 레소스(Rhesus)를 포함하지만 이에 제한되지 않는다. 설치류에는 마우스, 랫트, 우드척(woodchuck), 흰 족제비, 토끼 및 햄스터가 포함된다. 가축 및 게임 동물에는 소, 말, 돼지, 사슴, 들소, 버팔로, 고양이과 종, 예를 들어, 집고양이, 개과 종, 예를 들어, 개, 여우, 늑대, 조류 종, 예를 들어, 닭, 에뮤, 타조 및 어류, 예를 들어, 송어, 메기 및 연어가 포함되지만 이에 제한되지 않는다. 본원에 기재된 측면의 특정 구현예에서, 대상체는 포유동물, 예를 들어, 영장류 또는 인간이다. 대상체는 남성 또는 여성일 수 있다. 또한, 대상체는 유아 또는 소아일 수 있다. 일부 구현예에서, 대상체는 신생아 또는 태어나지 않은 대상체일 수 있으며, 예를 들어, 대상체는 자궁 내에 있다. 바람직하게는, 대상체는 포유동물이다. 포유동물은 인간, 비인간 영장류, 마우스, 랫트, 개, 고양이, 말 또는 소일 수 있지만, 이들 예에 제한되지는 않는다. 인간 이외의 포유동물이 질환 및 장애의 동물 모델을 나타내는 대상체로서 유리하게 사용될 수 있다. 또한, 본원에 기술된 방법 및 조성물은 길들여진 동물 및/또는 애완 동물을 위해 사용될 수 있다. 인간 대상체는 임의의 연령, 성별, 인종 또는 민족 그룹, 예를 들어, 코카서스(백인), 아시아인, 아프리카인, 흑인, 아프리카계 미국인, 아프리카계 유럽인, 히스패닉계, 중동인 등일 수 있다. 일부 구현예에서, 대상체는 임상 환경의 환자 또는 다른 대상체일 수 있다. 일부 구현예에서, 대상체는 이미 치료 중이다. 일부 구현예에서, 대상체는 배아, 태아, 신생아, 유아, 소아, 청소년 또는 성인이다. 일부 구현예에서, 대상체는 인간 태아, 인간 신생아, 인간 유아, 인간 소아, 인간 청소년 또는 인간 성인이다. 일부 구현예에서, 대상체는 동물 배아, 또는 비인간 배아 또는 비인간 영장류 배아이다. 일부 구현예에서, 대상체는 인간 배아이다.
본원에 사용된 용어 "숙주 세포"는 본 개시내용의 핵산 작제물 또는 ceDNA 발현 벡터에 의한 형질전환, 형질감염, 형질도입 등에 민감한 임의의 세포 유형을 포함한다. 비제한적인 예로서, 숙주 세포는 단리된 1차 세포, 다능성 줄기세포, CD34+ 세포), 유도된 다능성 줄기세포, 또는 임의의 다수의 불멸화 세포주 (예를 들어, HepG2 세포)일 수 있다. 대안적으로, 숙주 세포는 조직, 기관 또는 유기체 내의 동일계 또는 생체내 세포일 수 있다.
용어 "외인성"은 천연 공급원이 아닌 세포에 존재하는 물질을 지칭한다. 본원에서 사용될 때 용어 "외인성"은 인간의 손을 포함하는 과정에 의해 세포 또는 유기체와 같은 생물학적 시스템으로 도입된 핵산 (예를 들어, 폴리펩티드를 인코딩하는 핵산) 또는 폴리펩티드를 지칭할 수 있으며, 이는 정상적으로는 발견되지 않으며, 그러한 세포 또는 유기체 내로 핵산 또는 폴리펩티드를 도입하고자 하는 것이다. 대안적으로, "외인성"은 인간의 손을 포함하는 과정에 의해 세포 또는 유기체와 같은 생물학적 시스템으로 도입된 핵산 또는 폴리펩티드를 지칭할 수 있으며, 이는 비교적 적은 양으로 발견되고 세포 또는 유기체에서 핵산 또는 폴리펩티드의 양을 증가시키고자 하는 것, 예를 들어, 이소성 발현 또는 수준을 생성하고자 하는 것이다. 대조적으로, 용어 "내인성"은 생물학적 시스템 또는 세포에 자생하는 물질을 지칭한다.
용어 "서열 동일성"은 두 뉴클레오티드 서열 사이의 관련성을 지칭한다. 본 개시의 목적을 위해, 2개의 데옥시리보뉴클레오티드 서열 사이의 서열 동일성 정도는 EMBOSS 패키지 (EMBOSS: 유럽 분자 생물학 개방 소프트웨어 스위트, Rice et al., 2000, 상기)의 니들 프로그램, 바람직하게는 버전 3.0.0 이상에서 구현된 바와 같이 니들맨-운쉬 알고리즘 (Needleman and Wunsch, 1970, 상기)을 사용하여 결정된다. 사용되는 선택적 파라미터는 갭 오픈 페널티(gap open penalty) 10, 갭 연장 페널티(gap extension penalty) 0.5, 및 EDNAFULL (NCBI NUC4.4의 EMBOSS 버전) 치환 매트릭스이다. "가장 긴 동일성"으로 표시된 니들의 출력 (-nobrief 옵션을 사용하여 획득)은 백분율 동일성으로 사용되며 다음과 같이 계산된다: (동일한 데옥시리보뉴클레오티드.횟수.100)/(정렬의 길이-정렬에서의 총 갭의 수). 정렬의 길이는 바람직하게는 적어도 10개의 뉴클레오티드, 바람직하게는 적어도 25개의 뉴클레오티드, 보다 바람직하게는 적어도 50개의 뉴클레오티드, 가장 바람직하게는 적어도 100개의 뉴클레오티드이다.
본원에 사용된 용어 "상동성" 또는 "상동"은 서열을 정렬하고, 필요한 경우, 최대 퍼센트 서열 동일성을 달성하기 위해 갭을 도입한 후 표적 염색체 상의 상응하는 서열의 뉴클레오티드 잔기와 동일한 뉴클레오티드 잔기의 백분율로 정의된다. 뉴클레오티드 서열 상동성 백분율을 결정하기 위한 정렬은, 예를 들어, BLAST, BLAST-2, ALIGN, ClustalW2 또는 Megalign (DNASTAR) 소프트웨어와 같은 공개적으로 이용 가능한 컴퓨터 소프트웨어를 사용하여 당 업계의 기술 내에 있는 다양한 방식으로 달성될 수 있다. 당업자는 비교되는 서열의 전체 길이에 걸쳐 최대 정렬을 달성하는데 필요한 임의의 알고리즘을 포함하여, 서열을 정렬하기 위한 적절한 파라미터를 결정할 수 있다. 일부 구현예에서, 서열이 숙주 세포의 상응하는 천연 또는 편집되지 않은 핵산 서열 (예를 들어, 게놈 서열)과 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 91%, 적어도 92%, 적어도 93%, 적어도 94%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99% 이상 동일한 경우, 예를 들어 상동성 아암의 핵산 서열 (예를 들어, DNA 서열)은 "상동성"인 것으로 간주된다.
본원에 사용된 용어 "이종"은 각각 고유 핵산 또는 단백질에서 발견되지 않는 뉴클레오티드 또는 폴리펩티드 서열을 의미한다. 이종 핵산 서열은 (예를 들어, 유전 공학에 의해) 천연 발생 핵산 서열 (또는 이의 변이체)에 연결되어 키메라 폴리펩티드를 인코딩하는 키메라 뉴클레오티드 서열을 생성할 수 있다. 이종 핵산 서열은 (예를 들어, 유전 공학에 의해) 변이체 폴리펩티드에 연결되어 융합 변이체 폴리펩티드를 인코딩하는 뉴클레오티드 서열을 생성할 수 있다.
"벡터" 또는 "발현 벡터"는 또 다른 DNA 세그먼트, 즉 "삽입물"이 세포에 부착된 세그먼트의 복제를 야기하도록 부착될 수 있는 플라스미드, 박미드, 파지, 바이러스, 비리온 또는 코스미드와 같은 레플리콘이다. 벡터는 숙주 세포로의 전달 또는 상이한 숙주 세포 사이의 이동을 위해 설계된 핵산 작제물일 수 있다. 본원에 사용된 벡터는 최초 및/또는 최종 형태의 바이러스성 또는 비-바이러스성일 수 있지만, 본 개시의 목적상, "벡터"는 일반적으로 그 용어가 본원에 사용된 바와 같이 ceDNA 벡터를 지칭한다. 용어 "벡터"는 적절한 제어 요소와 관련될 때 복제될 수 있고 유전자 서열을 세포로 전달할 수 있는 임의의 유전자 요소를 포함한다. 일부 구현예에서, 벡터는 발현 벡터 또는 재조합 벡터일 수 있다.
본원에 사용된 용어 "발현 벡터"는 벡터 상의 전사 조절 서열에 연결된 서열로부터 RNA 또는 폴리펩티드의 발현을 지시하는 벡터를 지칭한다. 발현된 서열은 종종 세포에 대해 이종성일 수 있지만, 반드시 그런 것은 아니다. 발현 벡터는 추가 요소를 포함할 수 있으며, 예를 들어, 발현 벡터는 2개의 복제 시스템을 가질 수 있고, 따라서 2개의 유기체, 예를 들어 발현을 위한 인간 세포 및 클로닝 및 증폭을 위한 원핵생물 숙주에서 유지될 수 있도록 한다. 용어 "발현"은, 적용 가능한 경우, 예를 들어, 전사, 전사체 프로세싱, 번역 및 단백질 폴딩, 변형 및 프로세싱을 포함하지만, 이에 제한되지 않는, RNA 및 단백질 및 적절한 경우, 분비 단백질을 생산하는데 관여하는 세포 과정을 지칭한다. "발현 산물"은 유전자로부터 전사된 RNA, 및 유전자로부터 전사된 mRNA의 번역에 의해 수득된 폴리펩티드를 포함한다. 용어 "유전자"는 적절한 조절 서열에 작동 가능하게 연결된 경우 시험관내 또는 생체내에서 (DNA가) RNA로 전사되는 핵산 서열을 의미한다. 유전자는 코딩 영역의 앞뒤에 있는 영역, 예를 들어, 5' 비번역 (5'UTR) 또는 "리더" 서열 및 3' UTR 또는 "트레일러" 서열뿐만 아니라 개별 코딩 세그먼트 (엑손) 간의 개재 서열 (인트론)을 포함하거나 포함하지 않을 수 있다.
"재조합 벡터"는 이종 핵산 서열, 또는 생체내에서 발현될 수 있는 "이식유전자"을 포함하는 벡터를 의미한다. 본원에 기술된 벡터는, 일부 구현예에서, 다른 적합한 조성물 및 요법과 조합될 수 있음을 이해해야 한다. 일부 구현예에서, 벡터는 에피솜이다. 적합한 에피솜 벡터의 사용은 대상체에서 관심 뉴클레오티드를 높은 카피 수의 추가 염색체 DNA로 유지하여 염색체 통합의 잠재적 영향을 제거하는 수단을 제공한다.
본원에 사용된 문구 "유전 질환"은 게놈에서 하나 이상의 이상, 특히 출생시 존재하는 상태에 의해 부분적으로 또는 전적으로, 직접적으로 또는 간접적으로 유발되는 질환을 지칭한다. 이상은 돌연변이, 삽입 또는 결실일 수 있다. 이상은 유전자의 코딩 서열 또는 이의 조절 서열에 영향을 줄 수 있다. 유전 질환은 DMD, 혈우병, 낭포성 섬유증, 헌팅턴 무도병, 가족성 고콜레스테롤혈증 (LDL 수용체 결함), 간모세포종, 윌슨병(Wilson's disease), 선천성 간성 포르피린증, 간 대사의 유전성 장애, 레쉬 니한 증후군(Lesch Nyhan syndrome), 겸상 적혈구 빈혈, 지중해빈혈, 색소피부건조증, 판코니 빈혈(Fanconi's anemia), 망막색소변성증, 모세혈관확장성 실조증, 블룸 증후군(Bloom's syndrome), 망막모세포종 및 테이-삭스병(Tay-Sachs disease)일 수 있지만, 이에 제한되지는 않는다.
본원에 사용된 용어 "포함하는" 또는 "포함하다"는 방법 또는 조성물에 필수적인 조성물, 방법 및 이의 각각의 성분(들)을 언급하는데 사용되지만, 필수적인지 여부에 관계없이, 특정되지 않은 요소의 포함에도 개방적이다.
본원에 사용된 용어 "본질적으로 구성되는"은 주어진 구현예에 필요한 요소들을 지칭한다. 상기 용어는 그 구현예의 기본 및 신규 또는 기능적 특성(들)에 실질적으로 영향을 미치지 않는 요소의 존재를 허용한다. "포함하는"의 사용은 제한이 아니라 포함을 나타낸다.
"구성되는"이라는 용어는 구현예의 설명에서 언급되지 않은 임의의 요소를 배제한, 본원에 기재된 조성물, 방법 및 이들의 각각의 구성 요소를 지칭한다.
본 명세서 및 첨부된 청구범위에 사용된 바와 같이, 단수 형태 "a", "an" 및 "the"는 문맥상 명백하게 달리 지시되지 않는 한 복수의 지시대상을 포함한다. 따라서, 예를 들어, "방법"에 대한 언급은 하나 이상의 방법, 및/또는 여기에 설명된 유형의 단계를 포함하고/하거나 본 개시내용 등을 읽을 때 당업자에게 명백할 것이다. 유사하게, 용어 "또는"은 문맥상 명백하게 달리 나타내지 않는 한 "및"을 포함하는 것으로 의도된다. 본 명세서에 기술된 것과 유사하거나 동등한 방법 및 재료가 본 개시의 실시 또는 시험에 사용될 수 있지만, 적합한 방법 및 재료가 후술된다. 약어 "예를 들어(e.g.)"는 라틴어 예컨대(Latin exempli gratia)로부터 유래되며, 비제한적인 예를 나타내기 위해 본원에서 사용된다. 따라서, 약어 "예를 들어(e.g.)"는 "예를 들어(for example)"라는 용어와 동의어이다.
작동 실시예 이외의, 또는 달리 지시된 경우에, 본원에 사용된 성분 또는 반응 조건의 양을 나타내는 모든 수는 모든 경우에 용어 "약"에 의해 수식되는 것으로 이해되어야 한다. 백분율과 관련하여 사용될 때 "약"이라는 용어는 ±1%를 의미할 수 있다. 이하의 실시예에 의해 본 발명을 더욱 상세하게 추가로 설명하지만, 본 발명의 범위가 이것에 한정되는 것은 아니다.
본원에 개시된 본 발명의 대안적인 요소 또는 구현예의 그룹핑은 제한으로서 해석되지 않아야 한다. 각각의 그룹 구성원은 개별적으로 또는 그룹의 다른 구성원 또는 본원에서 발견된 다른 요소와의 임의의 조합으로 언급되고 청구될 수 있다. 편의성 및/또는 특허성의 이유로 그룹의 하나 이상의 구성원이 그룹에 포함되거나 그룹에서 삭제될 수 있다. 그러한 포함 또는 삭제가 발생할 때, 본 명세서는 본원에서 수정된 그룹을 포함하는 것으로 간주되어 첨부된 청구범위에 사용된 모든 마쿠시 그룹의 서면 설명을 충족시킨다.
임의의 측면의 일부 구현예에서, 본원에 기재된 개시내용은 인간을 클로닝하는 과정, 인간의 생식선 유전자 동일성을 변형시키는 공정, 산업 또는 상업적 목적을 위한 인간 배아의 사용 또는 사람이나 동물에게 어떠한 실질적인 의학적 이익 없이 고통을 유발할 수 있는 동물의 유전적 정체성을 변경시키는 과정, 및 그러한 과정으로 얻어진 동물에 관한 것이 아니다.
다른 용어는 본 발명의 다양한 측면의 설명 내에서 본원에 정의된다.
문헌 참조, 발행된 특허, 공개된 특허 출원 및 동시 계류중인 특허 출원을 포함하고; 본원 전체에 걸쳐 인용된 모든 특허 및 기타 출판물은, 예를 들어, 본원에 설명된 기술과 관련하여 사용될 수 있는 그러한 공보에 기술된 방법론을 기술하고 개시할 목적으로 명백히 본원에 참고로 포함된다. 이들 간행물은 본 출원의 출원일 이전에 그들의 공개만을 위해 제공된다. 이와 관련하여 어떠한 것도 발명자가 선행 발명에 의해 또는 임의의 다른 이유로 그러한 개시를 앞당길 자격이 없다는 것을 인정하는 것으로 해석되어서는 안된다. 이 문서의 날짜 또는 내용에 대한 표현에 관한 모든 진술은 출원인이 이용할 수 있는 정보를 기반으로 하며 이 문서의 날짜 또는 내용의 정확성에 대한 어떠한 입장을 의미하지 않는다.
본 개시의 구현예의 설명은 완전하거나 본 개시내용을 개시된 정확한 형태로 제한하려는 것이 아니다. 본 개시의 특정 구현예 및 본 개시에 대한 예가 예시적인 목적으로 본 명세서에 기술되었지만, 관련 기술 분야의 숙련가들이 인식할 수 있는 바와 같이, 본 개시의 범위 내에서 다양한 등가의 변형들이 가능하다. 예를 들어, 방법 단계 또는 기능이 주어진 순서로 제시되지만, 대안적인 구현예가 다른 순서로 기능을 수행할 수 있거나, 기능이 실질적으로 동시에 수행될 수 있다. 본원에 제공된 개시내용의 교시는 다른 절차 또는 방법에 적절하게 적용될 수 있다. 본원에 기재된 다양한 구현예는 추가 구현예를 제공하기 위해 조합될 수 있다. 본 개시의 측면은, 필요하다면, 본 개시의 추가 구현예를 제공하기 위해 상기 참조 및 적용의 조성물, 기능 및 개념을 사용하도록 변형될 수 있다. 또한, 생물학적 기능적 동등성 고려 사항으로 인해, 생물학적 또는 화학적 작용의 종류 또는 양에 영향을 미치지 않으면서 단백질 구조에서 약간의 변화가 이루어질 수 있다. 상세한 설명에 비추어 본 개시내용에 대한 이들 및 다른 변경이 이루어질 수 있다. 이러한 모든 변형은 첨부된 청구범위의 범위 내에 포함되도록 의도된다.
임의의 전술한 구현예의 특정 요소는 조합되거나 다른 구현예의 요소를 대체할 수 있다. 또한, 본 개시내용의 특정 구현예와 관련된 이점이 이들 구현예의 맥락에서 설명되었지만, 다른 구현예도 그러한 이점을 나타낼 수 있으며, 모든 구현예가 본 개시내용의 범위 내에 있도록 반드시 이러한 이점을 나타낼 필요는 없다.
본원에 기재된 기술은 하기 실시예에 의해 추가로 설명되며, 이는 결코 추가로 제한되는 것으로 해석되어서는 안된다.
본 발명은 본원에 기재된 특정 방법론, 프로토콜 및 시약 등에 제한되지 않으며, 다양할 수 있음을 이해해야 한다. 본원에서 사용된 용어는 단지 특정한 구현예를 설명하기 위한 것으로, 본 발명의 범위를 한정하려는 의도가 아니며, 본 발명의 범위는 청구범위에 의해서만 정의된다.
II. ceDNA 벡터로부터 항체 또는 융합 단백질의 발현
본원에 기재된 기술은 일반적으로 비-바이러스 DNA 벡터, 예를 들어, 본원에 기재된 ceDNA 벡터로부터의 세포에서 항체 또는 융합 단백질의 발현 및/또는 생산에 관한 것이다. 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 "일반적인 ceDNA 벡터"라는 제목의 섹션에서 본원에 기재되어 있다. 특히, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 한 쌍의 ITR (예를 들어, 본원에 기재된 바와 같이 대칭 또는 비대칭), 및 ITR 쌍 사이에, 프로모터 또는 조절 서열에 작동 가능하게 연결된, 본원에 기재된 항체 또는 융합 단백질을 인코딩하는 핵산을 포함한다. 전통적인 AAV 벡터, 및 심지어 렌티바이러스 벡터에 비해 항체 또는 융합 단백질 생산에 대한 ceDNA 벡터의 뚜렷한 이점은 원하는 단백질을 인코딩하는 이종 핵산 서열에 대한 크기 제약이 없다는 것이다. 따라서, 예를 들어, 2개의 중쇄 Fc 영역, 링커 및 Fab 단편을 포함하는 전장 항체조차 단일 ceDNA 벡터로부터 발현될 수 있다. 특히 항체의 발현 및/또는 생산에 있어서, 이의 크기가 주어지면, ceDNA 벡터는 사용 용이성으로 인해 전통적인 벡터보다 유리할 수 있으며, 크기 제약의 결여로 상이한 도메인 구조를 갖는 항체 (다량체 항체 포함)를 제어된 방식으로 쉽게 발현시킬 수 있다. 또한, 상이한 항체 또는 융합 단백질을 발현시키는 상이한 ceDNA 벡터의 칵테일(coctail)이 투여될 수 있도록 다수의 투여가 이루어질 수 있다. 따라서, 본원에 기재된 ceDNA 벡터는 치료 항체 또는 융합 단백질을 이를 필요로 하는 대상체에서 발현시키기 위해 사용될 수 있다. 대안적으로, ceDNA 벡터는 상업적 환경에서, 예를 들어, 생물반응기(bioreactor)를 사용하여 또는 원하는 숙주에서의 생산을 위한 항체 또는 융합 단백질의 생산에 사용될 수 있다.
알 수 있는 바와 같이, 본원에 기재된 ceDNA 벡터 기술은 임의의 수준의 복잡성에 적응될 수 있거나 항체 또는 융합 단백질의 상이한 성분의 발현이 독립적인 방식으로 제어될 수 있는 모듈 방식으로 사용될 수 있다. 예를 들어, 본원에 설계된 ceDNA 벡터 기술은 단일 이종 유전자 서열 (예를 들어, 원하는 항체의 중쇄 또는 경쇄)을 발현시키기 위해 단일 ceDNA 벡터를 사용하는 것만큼 단순할 수 있거나 또는 다수의 ceDNA 벡터를 사용하는 것과 같이 복잡할 수 있는 것으로 구체적으로 고려되며, 여기서 각각의 벡터는 상이한 프로모터에 의해 각각 독립적으로 제어되는 다수의 항체 또는 항체 성분을 발현시킨다. 하기 구현예는 본원에서 구체적으로 고려되며, 원하는 바에 따라 당업자에 의해 조정될 수 있다.
일 구현예에서, 단일 ceDNA 벡터는 항체 또는 융합 단백질의 단일 성분, 예를 들어, 중쇄 또는 경쇄를 발현시키는데 사용될 수 있다. 대안적으로, 단일 ceDNA 벡터는, 선택적으로 각 성분의 적절한 발현을 보장하기 위해 IRES 서열(들)을 사용하여 단일 프로모터 (예를 들어, 강력한 프로모터)의 제어하에 항체 또는 융합 단백질의 다수의 성분 (예를 들어, 적어도 2개)을 발현시키는데 사용될 수 있다.
또 다른 구현예에서, 적어도 2개의 삽입물 (예를 들어, 중쇄 또는 경쇄를 발현시킴)을 포함하는 단일 ceDNA 벡터가 또한 본 명세서에서 고려되며, 여기서 각각의 삽입물의 발현은 그 자신의 프로모터의 제어하에 있다. 프로모터는 동일한 프로모터의 다수의 카피, 다수의 상이한 프로모터, 또는 이들의 임의의 조합을 포함할 수 있다. 당업자라면, 상이한 발현 수준으로 항체의 성분을 발현시켜 세포에서 효율적인 항체 폴딩 및 조합을 보장하도록 발현된 개별 성분의 화학량론을 제어하는 것이 종종 바람직할 수 있음을 이해할 것이다.
ceDNA 벡터 기술의 추가 변형은 당업자에 의해 구상될 수 있거나 통상적인 벡터를 사용하는 항체 생산 방법으로부터 조정될 수 있다.
A. 항체 또는 융합 단백질을 발현시키기 위한 이종 서열
본질적으로 임의의 항체 또는 이의 항원-결합 단편 (예를 들어, 기능적 단편) 또는 융합 단백질은 본원에 기재된 ceDNA 벡터로부터 발현될 수 있다. 당업자는 항체 단편이 최소한 항원 또는 에피토프 결합에 필요한 아미노산 (예를 들어, scAb, Fab, F(ab')2, dAb 및 Fv)을 포함한다는 것을 이해할 것이다. 예를 들어, 항체 분자는 무거운 (H) 사슬 가변 도메인 서열 (본원에서 VH로 약칭됨), 및 가벼운 (L) 사슬 가변 도메인 서열 (본원에서 VL로 약칭됨)을 포함할 수 있다. 일 구현예에서, 항체 분자는 중쇄 및 경쇄를 포함하거나 이로 구성된다 (본원에서 반 항체(half antibody)로 지칭됨). 또 다른 예에서, 항체 분자는 2개의 무거운 (H) 사슬 가변 도메인 서열 및 2개의 가벼운 (L) 사슬 가변 도메인 서열을 포함하여 2개의 항원 결합 부위, 예컨대 Fab, Fab', F(ab')2, Fc, Fd, Fd', Fv, 단일쇄 항체 (예를 들어 scFv), 단일 가변 도메인 항체, 디아바디 (Dab) (2가 및 이중특이적), 및 키메라 (예를 들어, 인간화된) 항체를 형성하며, 이는 전체 항체 또는 재조합 DNA 기술을 사용하여 새로 합성된 것들의 변형에 의해 생성될 수 있다. 이러한 기능성 항체 단편은 이의 각각의 항원 또는 에피토프와 선택적으로 결합하고, 표적 단백질을 활성화 또는 억제하는 능력을 보유한다.
또한, 융합 단백질을 발현시키는 ceDNA 벡터가 본원에 포함된다. 일부 구현예에서, 융합 단백질은 생체기능성(biofunctional) 융합 단백질이다. 일부 구현예에서, 융합 단백질은 트랩(trap) 기술, 예를 들어, 항체-리간드 트랩에 유용하며, 여기서 융합 단백질은 펩티드에 융합된 항체 (예를 들어, 단일특이적 또는 이중특이적 항체) 또는 항체 단편 (예를 들어, 항원-결합 단편), 또는 리간드를 포획하여 리간드의 활성을 억제하는 리간드 결합 도메인 또는 수용체 도메인을 포함한다. 따라서, 일부 구현예에서 ceDNA 벡터는 당 업계에서 트랩 또는 Y-트랩으로 지칭되는 융합 단백질을 인코딩하고 발현시킬 수 있다. 일부 구현예에서, 본원에 기재된 ceDNA 벡터는 융합 단백질, 예를 들어, VEGF-트랩 융합 단백질, IGF-트랩 융합 단백질 (Vaniotis et al., Sci Rep, 2018, 8(1), 17361 참조) 또는 TGFβ-트랩 융합 단백질을 발현시키는데 사용된다. 예시적인 TGFβ-트랩은 Y-트랩, 예를 들어, 표적 세포 미세환경에서 자가분비/주변분비 TGFβ (a-CTLA4-TGFβRIIecd 및 a-PDL1-TGFβRIIecd)를 동시에 무력화시키는 TGFβ 수용체 II 엑토도메인 서열에 융합된 CTLA-4 및/또는 PD-L1을 표적화하는 항체를 포함하는 이작용성 항체-리간드 트랩 (Y-트랩)이다 (예를 들어, Ravi et al., Nat Comm 2018, 9(1);741 참조). 일부 구현예에서, 본원에 사용하기 위해 포함되고, ceDNA 벡터에 의해 발현되는 융합 단백질은 항체-리간드 트랩이고, 여기서 융합 단백질은 리간드를 포획하는 리간드 결합 도메인 또는 수용체 도메인 (예를 들어, 세포외 수용체 도메인)에 융합된 항체 또는 항체 단편 (예를 들어, 항원-결합 단편)을 포함하며, 여기서 리간드는 IGF, VEGF, TGFβ, TNFα, EGF, NGF, PDGF, LFA-3, CTLA-4, IL-1, TPO를 포함하지만 이에 제한되지 않는 임의의 통상적으로 공지된 성장 인자 또는 리간드로부터 선택된다.
예시적인 융합 단백질은 인간 IgG1 Fc에 융합된 종양 괴사 인자 (TNF) 수용체 II의 75 kDa 가용성 세포외 도메인 (ECD)을 포함하는 에타너셉트 (ENBREL®); 인간 IgG1 Fc에 융합된 림프구 기능-관련 항원 3 (LFA-3)의 제1 ECD를 포함하는 알레파셉트 (AMEVIVE®); 인간 IgG1 Fc에 융합된 인간 세포독성 T 림프구 관련 분자-4 (CTLA-4)의 ECD를 포함하는 아바타셉트 (ORENCIA®); 인간 IgG1 Fc에 융합된, IL-1RI ECD의 N-말단에 융합된 IL-1R 보조 단백질 리간드 결합 영역의 C-말단을 각각 포함하는 2개의 사슬을 포함하는 릴로나셉트 (ARCALYST®); 아글리코실화 인간 IgG1 Fc의 C-말단에 융합된 펩티드 트롬보포이에틴 (TPO) 모방체를 포함하는 로미플로스팀 (NPLATE®); 인간 IgG1 Fc에 융합된 CTLA-4의 ECD를 포함하고, CTLA-4 영역에서 2개의 아미노산 치환 (L104E, A29Y)에 의해 아바타셉트와 상이한 벨라타셉트 (NULOJIX®)를 포함하지만, 이에 제한되지 않는다.
항체 및 항체 단편은 IgG, IgA, IgM, IgD 및 IgE를 포함하지만, 이에 제한되지 않는 임의의 클래스의 항체, 및 항체의 임의의 서브클래스 (예를 들어, IgG1, IgG2, IgG3 및 IgG4)로부터 유래할 수 있다. 항체는 모노클로날일 수 있다. 본원에 기재된 방법을 사용하여 생산된 항체는 인간, 인간화된, CDR-그래프팅된, 또는 시험관내 생성된 항체일 수 있다. 항체는, 예를 들어, IgG1, IgG2, IgG3, 또는 IgG4로부터 선택된 중쇄 불변 영역을 가질 수 있다. 항체는 또한 예를 들어, 카파 또는 람다로부터 선택된 경쇄를 가질 수 있다. 용어 "면역글로불린" (Ig)은 본원에서 용어 "항체"와 상호 교환적으로 사용된다. 이러한 항체에 대한 코딩 서열을 ceDNA 벡터에 삽입함으로써 사실상 임의의 항체가 생성될 수 있다. 일 구현예에서, 경쇄 및 중쇄 유전자는 조절 스위치의 제어하에 있다. 동일한 또는 대안적인 구현예에서, 경쇄 및 중쇄 유전자는 IRES 서열 (예를 들어, 서열 번호: 190)과 연결된다.
전형적으로, 항체 또는 융합 단백질 유전자는 또한 분비 서열을 인코딩하여 항체가 ER을 통과하고 세포 밖으로 빠져나갈 때 샤페론 분자에 의해 항체가 올바른 형태로 폴딩되는 곳에서 골지체 및 소포체로 향하게 될 것이다. 예시적인 분비 서열은 VH-02 (서열 번호: 88) abd VK-A26 (서열 번호: 89) 및 Igκ 신호 서열 (서열 번호: 126), 뿐만 아니라 태그된 단백질이 시토졸 밖으로 분비될 수 있도록 하는 Gluc 분비 신호 (서열 번호: 188), 태그된 단백질이 골지로 향하게 하는 TMD-ST 분비 서열 (서열 번호: 189)을 포함하지만, 이에 제한되지 않는다.
인트라바디가 필요한 경우, 항체를 인코딩하는 핵산 또는 유전자는 전형적으로 분비 서열을 코딩하지 않는다. 일부 경우에, 이는 분비 서열을 인코딩할 수 있지만, 비제한적으로 세포 내에 이를 유지하기 위한 KDEL 서열과 같은 의도된 표적화 서열을 또한 갖는다. 다른 구현예에서, 인트라바디 유전자는 또 다른 세포내 표적화 서열, 예를 들어, 핵 국재화 서열을 인코딩한다.
조절 스위치는, 원하는 발현 수준 또는 양으로의 항체 또는 융합 단백질의 발현을 비제한적으로 포함하거나, 또는 대안적으로, 특정 신호의 존재 또는 부재가 있을 때, 세포 시그널링 사건을 포함하여, 항체가 원하는 대로 발현되도록 항체 (인트라바디 포함) 또는 융합 단백질의 발현을 미세 조정하기 위해 사용될 수 있다. 예를 들어, 본원에 기재된 바와 같이, ceDNA 벡터로부터 항체 또는 융합 단백질의 발현은 본원에서 조절 스위치라는 제목의 섹션에 기재된 바와 같이, 특정 조건이 발생할 때 켜지거나 꺼질 수 있다.
예를 들어, 그리고 예시의 목적으로만, 항체 또는 융합 단백질은 항-TNFα 항체, 예컨대 아달리무맙과 같은 바람직하지 않은 반응을 끄는 데 사용될 수 있다. 다른 경우에, 항체 또는 융합 단백질은 면역 반응을 증대시키는 것을 도울 수 있다. 예를 들어, 악성 세포, 예를 들어, 종양과 관련하여. 항체 유전자는 종양-관련 마커를 함유하여 항체를 원하는 세포로 가져올 수 있다. 그러나, 어느 상황에서도 항체 또는 융합 단백질의 발현을 조절하는 것이 바람직할 수 있다. ceDNA 벡터는 항체와 함께 조절 스위치의 사용을 쉽게 수용한다. ceDNA 벡터는 또한 중쇄 및 경쇄의 화학량론의 제어를 가능하게 한다. 융합 단백질의 예는 VEGF-트랩 및 TGFβ-트랩 기술을 포함하지만, 이에 제한되지 않는다.
항체 분자는 온전한 분자뿐만 아니라 항원-결합 단편 및 이의 기능적 단편을 포함한다. 항체 분자의 불변 영역은 항체의 특성을 변형시키기 위해 (예를 들어, Fc 수용체 결합, 시스테인 잔기의 수 등 중 하나 이상을 증가 또는 감소시키기 위해) 변경, 예를 들어, 돌연변이될 수 있다. 항체 분자의 항원-결합 단편의 예는 다음을 포함하지만, 이에 제한되지 않는다: (i) VL, VH, CL 및 CH1 도메인으로 구성된 1가 단편인, Fab 단편; (ii) 힌지 영역에서 이황화 브릿지에 의해 연결된 2개의 Fab 단편을 포함하는 2가 단편인, F(ab')2 단편; (iii) VH 및 CH1 도메인으로 구성된 Fd 단편; (iv) 항체의 단일 아암의 VL 및 VH 도메인으로 구성된 Fv 단편, (v) VH 도메인으로 구성된 디아바디 (dAb) 단편; (vi) 낙타 또는 낙타화(camelized) 가변 도메인; (vii) 단일쇄 Fv (scFv), 예를 들어, Bird et al. (1988) Science 242:423-426; 및 Huston et al. (1988) Proc. Natl. Acad. Sci. USA 85:5879-5883 참조); (viii) 단일 도메인 항체. 이들 항체 단편은 ceDNA 벡터를 사용하여 수득되며 온전한 항체와 동일한 방식으로 유용성에 대해 스크리닝될 수 있다.
전통적인 AAV 벡터, 및 심지어 렌티바이러스 벡터에 비해 ceDNA 벡터의 뚜렷한 이점은 원하는 단백질을 인코딩하는 이종 핵산 서열에 대한 크기 제약이 없다는 것이다. 따라서, 2개의 중쇄 Fc 영역, 링커 및 Fab 단편을 포함하는 전장 항체조차 단일 ceDNA 벡터로부터 발현될 수 있다. 또한, 필요한 스티오케미스트리(stiochemistry)에 따라, 동일한 항체 또는 융합 단백질의 다중 세그먼트, 예를 들어, 경쇄 및 중쇄를 발현시킬 수 있고, 동일하거나 상이한 프로모터를 사용할 수 있으며, 또한 조절 스위치를 사용하여 각 영역의 발현을 미세 조정할 수 있다. 예를 들어, 실시예에 나타난 바와 같이, 이중 프로모터 시스템을 포함하는 ceDNA 벡터가 사용될 수 있어서, 상이한 프로모터가 아두카누맙 항체의 중쇄 및 경쇄 각각에 대해 사용된다. 항체 또는 융합 단백질을 생성하기 위한 ceDNA 플라스미드의 사용은 기능성 항체 또는 융합 단백질의 형성을 위한 중쇄 및 경쇄의 적절한 비율을 초래하는 중쇄 및 경쇄의 발현을 위한 독특한 프로모터 조합을 포함할 수 있다. 따라서, 일부 구현예에서, ceDNA 벡터를 사용하여 항체 또는 융합 단백질의 상이한 영역을 개별적으로 (예를 들어, 상이한 프로모터의 제어하에) 발현시킬 수 있다. 일부 구현예에서, 중쇄를 인코딩하는 핵산은 제1 프로모터 또는 제1 조절 스위치에 작동 가능하게 연결될 수 있고, 경쇄를 인코딩하는 핵산은 제2 프로모터 또는 제2 조절 스위치에 작동 가능하게 연결될 수 있어서, 서로 독립적으로 중쇄 및 경쇄의 제어되거나 조정 가능한 발현을 가능하게 하여 기능성 항체 또는 융합 단백질의 생산을 위한 중쇄 및 경쇄의 비의 제어를 가능하게 한다.
ceDNA 벡터로부터의 항체 또는 융합 단백질의 발현은 하나 이상의 유도성 또는 억제성 프로모터를 사용하여 공간적으로 및 시간적으로 달성될 수 있다.
항체 분자는 또한 단일 도메인 항체일 수 있다. 단일 도메인 항체는 상보적 결정 영역이 단일 도메인 폴리펩티드의 일부인 항체를 포함할 수 있다. 예로는 중쇄 항체, 경쇄가 자연적으로 결여된 항체, 통상적인 4-쇄 항체로부터 유래된 단일 도메인 항체, 조작된 항체 및 항체로부터 유래된 것 이외의 단일 도메인 스캐폴드를 포함하지만, 이에 제한되지 않는다. 단일 도메인 항체는 당 업계의 임의의 것, 또는 임의의 향후 단일 도메인 항체일 수 있다. 단일 도메인 항체는 마우스, 인간, 낙타, 라마, 어류, 상어, 염소, 토끼 및 소를 포함하지만, 이에 제한되지 않는 임의의 종으로부터 유래될 수 있다.
일부 구현예에서, 항체는 다중특이적 항체로서, 2개 이상의 가변 영역을 포함하여, 예를 들어, 동일한 표적 단백질 상에서 적어도 2개의 상이한 에피토프에 결합하거나 동시에 적어도 2개의 상이한 단백질을 표적화한다. 즉, 다중특이적 항체에 의해 인식되는 에피토프는 동일하거나 상이한 표적 상에 있을 수 있다.
다른 구현예에서, 항체는 이중특이적 항체로서, 적어도 2개의 상이한 에피토프 또는 표적을 인식하고 이에 결합할 수 있다 (예를 들어, 예시적인 이중특이적 항체 구조에 대해서는 Riethmuller, G Cancer Immunity (2012) 12:12-18; Schaefer w et al. PNAS (2011) 108(27):11187-92 참조). 2세대 이중특이적 항체, 예를 들어, "삼작용성 이중특이적" 항체도 본원에 기재된 방법 및 조성물로 고려된다.
특정 구현예에서, 제공된 항체는 이중특이적 항체를 포함하는 다중특이적 항체이다. 다중특이적 항체는 적어도 2개의 상이한 부위에 대한 결합 특이성을 갖는 모노클로날 항체이다. 예시적인 이중특이적 항체는 결합 특이성 중 하나가 A베타에 대한 것이고 다른 하나는 임의의 다른 항원에 대한 것이다. 특정 구현예에서, 이중특이적 항체는 A베타의 2개의 상이한 에피토프에 결합할 수 있다. 이중특이적 항체는 또한 세포독성제를 세포에 국한시키는데 사용될 수 있다. 이중특이적 항체는 전장 항체 또는 항체 단편으로 제조될 수 있다.
일부 구현예에서, 다중특이적 항체를 생산하기 위한 ceDNA 벡터는 특이성이 상이한 2개의 면역글로불린 중쇄-경쇄 쌍의 공동-발현 (Milstein and Cuello, Nature 305: 537 (1983)), WO 93/08829, 및 Traunecker et al., EMBO J. 10: 3655 (1991) 참조), 및 "놉-인-홀(knob-in-hole)" 엔지니어링 (예를 들어, 미국 특허 번호 5,731,168 참조)을 포함한다. 다중특이적 항체는 또한 항체 Fc-이종이량체 분자를 제조하기 위한 정전기적 스티어링 효과(electrostatic steering effect)를 조작하고 (WO 2009/089004A1); 2개 이상의 항체 또는 단편을 가교하고 (예를 들어, 미국 특허 번호 4,676,980, 및 Brennan et al., Science, 229: 81 (1985) 참조); 이중특이적 항체를 생성하기 위해 류신 지퍼를 사용하고 (예를 들어, Kostelny et al., J. Immunol., 148(5):1547-1553 (1992) 참조); 이중특이적 항체 단편을 제조하기 위해 "디아바디" 기술을 사용하고 (예를 들어, Hollinger et al., Proc. Natl. Acad. Sci. USA, 90:6444-6448 (1993) 참조); 단일쇄 Fv (sFv) 이량체를 사용하고 (예를 들어 Gruber et al., J. Immunol., 152:5368 (1994) 참조); 예를 들어, 문헌[Tutt et al. J. Immunol. 147: 60 (1991)]에 기재된 바와 같은 삼중특이적 항체를 제조함으로써 제조될 수 있다.
일부 구현예에서, ceDNA 벡터는 본원에 또한 포함되는, "옥토퍼스 항체(Octopus antibody)"를 포함하여, 3개 이상의 기능성 항원 결합 부위를 갖는 조작된 항체를 인코딩한다 (예를 들어, US 2006/0025576A1 참조). 일부 구현예에서, ceDNA 벡터는 A베타뿐만 아니라 다른 상이한 항원에 결합하는 항원 결합 부위를 포함하는 "이중 작용 FAb" 또는 "DAF"인 항체 또는 융합 단백질을 인코딩한다 (예를 들어, US 2008/0069820 참조).
일 구현예에서, 항체는 "항체 변이체"로, 이의 상응하는 천연 항체와 비교하여 변경된 아미노산 서열, 조성 또는 구조를 갖는 항체를 지칭한다. 예를 들어, 항체 변이체는 비-천연 분비 신호를 포함하여 항체가 숙주 세포로부터 분비되도록 할 수 있다.
특정 구현예에서, ceDNA 벡터는 시스테인 조작된 항체 변이체, 예를 들어, "티오MAb"를 인코딩하고, 여기서 항체의 하나 이상의 잔기는 시스테인 잔기로 치환된다. 특정 구현예에서, 치환된 잔기는 항체의 접근 가능한 부위에서 발생한다. 이들 잔기를 시스테인으로 치환함으로써, 반응성 티올 기는 항체의 접근 가능한 부위에 위치되고, 본원에서 추가로 기재된 면역접합체를 생성하기 위해 약물 모이어티 또는 링커-약물 모이어티와 같이, 항체를 다른 모이어티에 접합시키는데 사용될 수 있다. 특정 구현예에서, 다음의 잔기 중 임의의 하나 이상이 시스테인으로 치환될 수 있다: 경쇄의 V205 (카밧 넘버링); 중쇄의 A118 (EU 넘버링); 및 중쇄 Fc 영역의 S400 (EU 넘버링). 시스테인 조작된 항체는, 예를 들어, 미국 특허 번호 7,521,541에 기재된 바와 같이 생성될 수 있다.
또 다른 구현예에서, 항체는 가변 경쇄, 가변 무거운 항원 결합 도메인 및, 선택적으로, 하나 이상의 이펙터 도메인 (예를 들어, 조직-특이적 표적화)을 포함하는 1가 또는 2가 항체인, 소형화된 항체일 수 있다. 소형화된 항체의 사용이 본원에서 구체적으로 고려되지만, ceDNA 벡터는 이종 핵산 서열과 관련하여 크기에 의해 제한되지 않으므로 전장 항체도 발현시킬 수 있는 이점이 있다.
또 다른 구현예에서, ceDNA 벡터로부터 발현된 항체 또는 융합 단백질은 추가의 기능성, 예컨대 형광, 효소 활성, 분비 신호 또는 면역 세포 활성화제를 추가로 포함한다.
일부 구현예에서, ceDNA 벡터에 의해 인코딩된 항체는 디아바디 (이중특이적 단일쇄 항체) 또는 유니바디(unibody) (면역 활성화의 위험을 감소시키기 위해 힌지 영역이 없는 IgG4 분자)를 포함한다.
항체 생산을 위한 본원에 기재된 ceDNA 벡터는 또한 세포 기능 (예를 들어, 대사, 세포 분열, 전사, 번역 등)에 영향을 미치는 세포내 단백질을 표적화할 수 있는 융합 단백질 또는 인트라바디 (즉, 세포내 항체)의 발현에 유용하다. 인트라바디는 scFv일 수 있다. 인트라바디는 C-말단 ER 체류 신호 (예를 들어, KDEL), 미토콘드리아 표적화 서열, 핵 국재화 서열 등과 같은 시그널링 모티프를 통합함으로써 특정 세포 구획으로 향할 수 있다.
인트라바디는 미스폴딩된 단백질과 관련된 질환, 예를 들어, 알츠하이머병, 파킨슨병, 프라이온병, 헌팅턴병 등의 치료에 특히 적합하다.
일부 구현예에서, 항체 또는 융합 단백질은, 예를 들어, 링커 도메인을 추가로 포함할 수 있다. 본원에 사용된 "링커 도메인"은 본원에 기재된 바와 같은 항체의 임의의 도메인/영역을 함께 연결하는, 약 2 내지 100개 아미노산 길이의 올리고펩티드 또는 폴리펩티드 영역을 지칭한다. 일부 구현예에서, 링커는 인접한 단백질 도메인이 서로에 대해 자유롭게 이동할 수 있도록 글리신 및 세린과 같은 가요성 잔기를 포함하거나 이로 구성될 수 있다. 인접한 두 도메인이 서로 입체적으로 간섭하지 않도록 하는 것이 바람직한 경우 더 긴 링커가 사용될 수 있다. 링커는 절단 가능하거나 절단 불가능할 수 있다. 절단 가능한 링커의 예는 2A 링커 (예를 들어 T2A), 2A-유사 링커 또는 이의 기능적 등가물 및 이들의 조합을 포함한다. 링커는 토세아 어사이나(Thosea asigna) 바이러스로부터 유래된 T2A인 링커 영역일 수 있다.
예를 들어, 융합 단백질, 중쇄, 경쇄, 가변 영역 등의 공지된 및/또는 공개적으로 이용 가능한 단백질 서열을 취하고, 이러한 단백질 (예를 들어, 융합 단백질) 또는 항체를 인코딩하기 위해 cDNA 서열을 역 엔지니어링하는 것은 당업자의 능력 내에 있다. 이어서, cDNA는 의도된 숙주 세포와 매칭되도록 코돈 최적화되고 본원에 기재된 바와 같이 ceDNA 벡터에 삽입될 수 있다.
일 구현예에서, 항체-인코딩 서열은, 예를 들어, 하이브리도마 세포주로부터 수득된 mRNA를 역전사시키고 PCR을 사용하여 서열을 증폭시킴으로써 기존의 하이브리도마 세포주로부터 유래될 수 있다.
B. 항체 또는 융합 단백질을 발현시키는 ceDNA 벡터
원하는 항체를 인코딩하는 하나 이상의 서열을 갖는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 조절 서열, 예컨대 프로모터, 분비 신호, 폴리A 영역, 및 인핸서를 포함할 수 있다. 최소한, ceDNA 벡터는 항체 또는 융합 단백질을 인코딩하는 하나 이상의 이종 서열을 포함한다. 항체 또는 융합 단백질 생산을 위한 예시적인 ceDNA 벡터가 도 7a-7g에 도시되어 있다.
매우 효율적이고 정확한 항체 또는 융합 단백질 어셈블리를 달성하기 위해, 일부 구현예에서, 항체, 융합 단백질 또는 개별 항체 도메인은 소포체 ER 리더 서열을 포함하여 단백질 폴딩이 일어나는 ER로 유도하는 것이 구체적으로 고려된다. 예를 들어, 폴딩을 위해 발현된 단백질(들)을 ER로 유도하는 서열.
일부 구현예에서, ceDNA 벡터에 세포 또는 세포외 국재화 신호 (예를 들어, 분비 신호, 핵 국재화 신호, 미토콘드리아 국재화 신호 등)가 포함되어 (예를 들어, 도 10g 참조) 항체 또는 융합 단백질이 세포내 표적(들) (예를 들어, 인트라바디) 또는 세포외 표적(들)에 결합할 수 있도록 항체 또는 융합 단백질의 분비 또는 원하는 세포하 국재화를 유도한다.
특정 구현예에서, 항체 생산을 위한 ceDNA 벡터는 인트라바디를 인코딩할 수 있으며, 일부 구현예에서, 인트라바디는 전장 항체뿐만 아니라 단일쇄일 수 있다. 인트라바디는 바이러스 장애, 및 세포 장애 예컨대 암을 치료하는 것을 포함하여 광범위한 영역에 사용될 수 있으며, 예를 들어 미국 특허 번호: 6,004,940을 참조한다.
일부 구현예에서, 본원에 기재된 바와 같이 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터 (예를 들어 도 6a에 도시된 예시적인 ceDNA 벡터 참조)는 모듈 방식으로 임의의 원하는 항체 또는 융합 단백질의 어셈블리 및 발현을 가능하게 한다. 본원에 사용된 용어 "모듈"은 작제물로부터 쉽게 제거될 수 있는 ceDNA 발현 플라스미드의 요소를 지칭한다. 예를 들어, ceDNA-생성 플라스미드의 모듈 요소는 작제물 내에서 각 요소의 측면에 있는 고유한 제한 부위 쌍을 포함하여, 개별 요소의 배타적 조작을 가능하게 한다 (예를 들어, 도 7a-7g 참조). 따라서, ceDNA 벡터 플랫폼은 임의의 원하는 항체 또는 융합 단백질 구성의 발현 및 어셈블리를 허용할 수 있다. 다양한 구현예에서, 항체 또는 융합 단백질을 인코딩하는 원하는 ceDNA 벡터를 조립하는데 필요한 조작량을 감소 및/또는 최소화할 수 있는 ceDNA 플라스미드 벡터가 본원에 제공된다.
C. ceDNA 벡터에 의해 발현된 예시적인 항체 및 융합 단백질
특히, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는, 예를 들어, 비제한적으로, 질환, 기능 장애, 손상 및/또는 장애의 하나 이상의 증상의 치료, 예방 및/또는 개선에 사용하기 위한 항체, 항원 결합 단편, 융합 단백질뿐만 아니라 변이체 및/또는 이의 활성 단편을 인코딩할 수 있다. 일 측면에서, 질환, 기능 장애, 외상, 손상 및/또는 장애는 인간 질환, 기능 장애, 외상, 손상 및/또는 장애이다.
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 또한, ceDNA로부터 발현된 항체 또는 융합 단백질과 함께 사용될 수 있는 보조-인자 또는 다른 폴리펩티드, 센스 또는 안티센스 올리고뉴클레오티드, 또는 RNA (코딩 또는 비-코딩; 예를 들어, siRNA, shRNA, 마이크로-RNA, 및 이들의 안티센스 대응물 (예를 들어, antagoMiR))를 인코딩할 수 있다. 또한, 항체 또는 융합 단백질을 인코딩하는 서열을 포함하는 발현 카세트는 또한, β-락타마제, β-갈락토시다제 (LacZ), 알칼리 포스파타제, 티미딘 키나제, 녹색 형광 단백질 (GFP), 클로람페니콜 아세틸트랜스퍼라제 (CAT), 루시퍼라제, 및 당 업계에 잘 알려진 다른 것들과 같이, 실험적 또는 진단 목적에 사용되는 리포터 단백질을 인코딩하는 외인성 서열을 포함할 수 있다.
특정 구현예에서, 다수의 상이한 항체 및/또는 융합 단백질은 하나 이상의 ceDNA 벡터를 사용하여 투여될 수 있다. 따라서, 세포, 조직 또는 대상체에서 "칵테일"로 원하는 수의 항체 및/또는 융합 단백질을 발현시킬 수 있는 것으로 구체적으로 고려된다.
본원에 기재된 ceDNA 벡터는 예를 들어, 암, 자가면역 질환 (예를 들어, 류마티스 관절염, 크론병), 알츠하이머병, 고콜레스테롤혈증, 급성 기관 거부, 다발성 경화증, 폐경기후 골다공증, 피부 병태 (예를 들어, 건선, 아토피 피부염), 천식, 또는 혈우병의 치료를 위한 항체 및 융합 단백질을 전달하기 위해 사용될 수 있다.
본원에 기재된 ceDNA 벡터는 임의의 원하는 치료 항체 또는 융합 단백질을 발현시키는데 사용될 수 있다. 예시적인 치료 항체 및 융합 단백질은 아브시시맙, 아발로파라티드, 아달리무맙, 아달리무맙-아토(adalimumab-atto), 아도-트라스투주맙 엠탄신, 아두카누맙, 알렘투주맙, 알리로쿠맙, 아테졸리주맙, 아벨루맙, 바피뉴주맙, 바실리시맙, 벨리무맙, 베바시주맙, 베즐로톡수맙, 블리나투모맙, 블로소주맙, 보코시주맙, 브렌툭시맙 베도틴, 브로달루맙, 카나키누맙, 카프로맙 펜데티드, 세르톨리주맙 페골, 세툭시맙, 콘시주맙, 다클리주맙, 다라투무맙, 데노수맙, 디누툭시맙, 두필루맙, 더발루맙, 에칼란티드, 에쿨리주맙, 엘로투주맙, 엠탄신, 에미시주맙, 에볼로쿠맙, 에비나쿠맙, 인자 IX-Fc 항체, 인자 VIII-Fc 항체, 골리무맙, 이브리투모맙 튜세탄, 이다루시주맙, 인클라쿠맙, 인플리시맙, 인플리시맙-abda, 인플리시맙-dyyb, 이필리무맙, 익세키주맙, 라나델루맙, 로델시주맙, 메폴리주맙, 나탈리주맙, 네시투무맙, 니볼루맙, 오빌톡사시맙(obiltoxaximab), 오비누투주맙, 오크렐리주맙, 오파투무맙, 올라라투맙, 오말리주맙, 오르티쿠맙, 팔리비주맙, 파니투무맙, 펨브로리주맙, 퍼투주맙, 페셀리주맙, 랄판시주맙, 라무시루맙, 라니비주맙, 락시바쿠맙, 레슬리주맙, 리툭시맙, 롤레두맙, 로모소주맙, 세쿠키누맙, 실툭시맙, 솔라네주맙, 소타터셉트, 타도시주맙, 토실리주맙, 트라스투주맙, 우스테키누맙, 베돌리주맙, 사릴루맙, 리툭시맙, 구셀쿠맙, 이노투주맙 오조가미신, 아달리무맙-adbm, 젬투주맙 오조가미신, 베바시주맙-awwb, 벤랄리주맙, 에미시주맙-kxwh, 트라스투주맙-dkst를 포함하지만, 이에 제한되지 않는다.
일 구현예에서, ceDNA 벡터는 질환의 치료에 기능적인 치료 항체 또는 융합 단백질을 발현시키는 핵산 서열을 포함한다. 바람직한 구현예에서, 치료 항체 또는 융합 단백질은, 원치 않는 한, 면역계 반응을 일으키지 않는다.
일 구현예에서, 항체는 면역 체크포인트 억제제 (예를 들어, PDL1)를 표적화하고, 예를 들어, 암 (예를 들어, 고형 종양, 유방암, 림프종, 간암, 난소암, 폐암, 결장직장암, 백혈병, 혈액암, 피부암, 다발성 골수종 등)의 치료에 사용될 수 있는 ceDNA 벡터에 의해 발현된 치료 항체 또는 융합 단백질이다. 일 구현예에서, 치료 항체 또는 융합 단백질은 체크포인트 억제제 예컨대 PDL1, CD47, 메소텔린, 강글리오시드 2 (GD2), 전립선 줄기세포 항원 (PSCA), 전립선 특이적 막 항원 (PMSA), 전립선-특이적 항원 (PSA), 암배아 항원 (CEA), Ron 키나제, c-Met, 미성숙 라미닌 수용체, TAG-72, BING-4, 칼슘-활성화 클로라이드 채널 2, 사이클린-B1, 9D7, Ep-CAM, EphA3, Her2/neu, 텔로머라제, SAP-1, 서바이빈(Survivin), NY-ESO-1/LAGE-1, PRAME, SSX-2, 멜란-A/MART-1, Gp100/pmel17, 티로시나제, TRP-1/-2, MC1R, β-카테닌, BRCA1/2, CDK4, CML66, 피브로넥틴, p53, Ras, TGF-B 수용체, AFP, ETA, MAGE, MUC-1, CA-125, BAGE, GAGE, NY-ESO-1, β-카테닌, CDK4, CDC27, CD47, α 액티닌-4, TRP1/gp75, TRP2, gp100, 멜란-A/MART1, 강글리오시드, WT1, EphA3, 표피 성장 인자 수용체 (EGFR), CD20, MART-2, MART-1, MUC1, MUC2, MUC16, MUM1, MUM2, MUMS, NA88-1, NPM, OA1, OGT, RCC, RUI1, RUI2, SAGE, TRG, TRP1, TSTA, 폴레이트 수용체 알파, L1-CAM, CAIX, EGFRvIII, gpA33, GD3, GM2, VEGFR, 인터그린(Intergrin) (인테그린 알파V베타3, 인테그린 알파5베타1), 탄수화물 (Le), IGF1R, EPHA3, TRAILR1, TRAILR2, RANKL, 섬유아세포 활성화 프로테아제 (FAP), TGF-베타, 히알루론산, 콜라겐 (예를 들어, 콜라겐 IV, 테나신 C, 또는 테나신 W), CD19, CD33, CD47, CD123, CD20, CD99, CD30, BCMA, CD38, CD22, SLAMF7, 또는 NY-ESO1을 표적화한다.
일 구현예에서, ceDNA 벡터는 에볼로쿠맙 모노클로날 항체를 발현시키고, 고지혈증의 치료에 사용된다. 에볼로쿠맙은 전구단백질 전환 효소 서브틸리신/켁신 유형 9 (PCSK9)를 억제한다. PCSK9는 분해를 위해 LDL 수용체를 표적화하여 혈액에서 LDL-C 또는 "나쁜" 콜레스테롤을 제거하는 간 기능을 감소시키는 단백질이다. 에볼로쿠맙은 그 전문이 본원에 참고로 포함된, US8,999,341에 추가로 기재되어 있다.
본원에 개시된 방법 및 조성물에 사용하기 위한 ceDNA 벡터로부터 발현된 예시적인 항체 및 융합 단백질은 본원의 표 1, 표 2, 표 3a, 표 3b, 표 4 또는 표 5에 열거된 임의의 항체 또는 융합 단백질일 수 있다.
표 1: 예시적인 항체 및 융합 단백질로서 FDA-승인된 항체 및 융합 단백질.




표 2: 본원에 기재된 방법 및 조성물에 유용한 ceDNA 벡터에 의한 발현을 위한 예시적인 항체 및 융합 단백질.






표 3a: ceDNA 벡터에 의해 발현되는 예시적인 항체는 유럽 연합 또는 미국에서 승인된 항체 치료제를 포함하지만, 이에 제한되지는 않는다.

표 3b: ceDNA 벡터에 의해 발현되는 예시적인 항체는 유럽 연합 또는 미국에서 규제 검토중인 항체 치료제를 포함하지만, 이에 제한되지는 않는다

표 4: ceDNA 벡터에 의해 발현되는 예시적인 항체는 말기 임상 연구에서 비암 적응증에 대한 항체 치료제를 포함하지만, 이에 제한되지 않는다. 항체를 상업적으로 개발하거나 임상적으로 시험하고 있는 회사는 다음과 같다: 1. Novartis, 2. LFB Group, 3. Shire, 4. Prothena Therapeutics Ltd., 5. Omeros Corporation, 6. Alexion Pharmaceuticals Inc., 7. AstraZeneca/ MedImmune LLC, 8. Boehringer Ingelheim Pharmaceuticals, AbbVie, 9. Genentech, 10. Shire, 11. R-Pharm, 12. Chugai Pharmaceuticals/Roche, 13. NovImmune SA, 14. CytoDyn, 15. Biogen, 16. Hoffmann-La Roche, 17. Alder Biopharmaceuticals, 18. Regeneron Pharmaceuticals, 19. Pfizer; Eli Lilly & Company, 20. Horizon Pharma USA


표 5: ceDNA 벡터에 의해 발현되는 예시적인 항체는 말기 임상 연구에서 암 적응증에 대한 항체 치료제를 포함하지만 이에 제한되지 않는다. 표 4의 항체를 상업적으로 개발하거나 임상적으로 시험하고 있는 회사는 다음과 같다: 1. Actinium Pharmaceuticals, 2. Sanofi, 3. TG Therapeutics, , 5. MorphoSys, 6. Pfizer, 8. Viventia Bio, 10. Jiangsu HengRui Medicine Co., Ltd, 11. MacroGenics, 16. Gilead Sciences, 18. AstraZeneca/ MedImmune LLC, 19. Recombio SL, 20. Regeneron Pharmaceuticals, 21. Innovent Biologics (Suzhou) Co. Ltd., 22. BeiGene, 24. Biocad, 25. Novartis, 26. Philogen SpA, 27.Tracon.

ceDNA 벡터에 의해 발현되는 추가의 예시적인 항체 및 융합 단백질은 하기 기재된 것들을 포함하지만, 이에 제한되지 않는다:
브로달루맙 (SILIQ®, LUMICEF®, KYNTHEUM®, AMG-827)은 IL-17 수용체 A (IL-17RA)를 표적화하고, IL-17RA를 통한 IL-17A, IL-17F 및 IL-17C 전염증성 사이토카인의 염증 시그널링을 방지하는 인간 IgG2 항체이다. 브로달루맙은 미국 (SILIQ®), EU (KYNTHEUM®), 및 일본 (LUMICEF®)에서 승인되었다. 브로달루맙은 전신 요법 또는 광선 요법의 후보이며, 다른 전신 요법에 반응을 나타내지 않거나 다른 전신 요법에 대한 반응이 중단된, 중등도 내지 중증의 판상형 건선을 갖는 성인 환자의 치료에 권고된다.
두필루맙 (DUPIXENT®, REGN668/SAR231893)은 IL-4 수용체 (IL4R)를 표적화하여 IL-4 및 IL-13에 의해 매개된 염증 반응을 차단하는 인간 IgG4 mAb이다. mAb는 아토피 피부염 환자에 대해 미국 및 EU에서 승인되었다.
오크렐리주맙 (OCREVUS®)은 CD20-양성 B 세포를 표적화하는 인간화된 IgG1 항체이다. 이러한 B 세포는 미엘린 손상 및 다발성 경화증 발병에서 역할을 한다.
오크렐리주맙은 미국에서 재발 다발성 경화증 (RMS) 및 일차 진행성 다발성 경화증 (PPMS)의 치료에 대한 승인을 받았다.
사릴루맙 (KEVZARA®, SAR153191, REGN88)은 IL-6 수용체 (IL-6R)를 표적화하는 인간 IgG1 항체이고, 캐나다, 미국 및 EU에서 메토트렉세이트 (MTX)와 같은 하나 이상의 질환 변형 항-류마티스 약물 (DMARD)에 대한 반응이 불충분하거나 불내성인 중등도 내지 중증의 활성 류마티스 관절염 (RA) 환자에 대해 승인되었다.
벤랄리주맙 (FASENRA®, MEDI-563)은 호산구에서 발견되는 IL-5R의 α-서브유닛을 표적화하는 비푸코실화된 IgG1 mAb로, 12세 이상의 중증 천식 환자의 추가 유지 치료에 대한 FDA 승인을 받았다.
에미시주맙 (HEMLIBRA®, 에미시주맙-kxwh, ACE910, RO5534262)은 인자 IXa 및 X를 표적화하는 이중특이적 IgG4 mAb로, FDA에 의해 승인되었다. 이 약물은 인자 VIII 억제제가 발달한 혈우병 A를 갖는 성인 및 소아 환자에서 출혈 에피소드를 예방하거나 이의 빈도를 감소시키는 것으로 승인되었다. 2017년 12월 1일 현재, 총 9개의 항체 치료제가 미국 또는 EU에서 규제 검토를 받고 있다. 이들 중, 8개 (이발리주맙, 부로수맙, 틸드라키주맙, 카플라시주맙, 에레누맙, 프레마네주맙, 갈카네주맙, 로모소주맙)는 아직 판매 승인을 받지 못했다. 모가물리주맙은 2012년 3월 20일자로 일본에서 세계 최초의 승인을 받았다.
이발리주맙은 CD4를 표적화하는 IgG4 mAb이고, 다제내성 인간 면역결핍 바이러스 (HIV) 감염에 대한 치료제로서 FDA에 의해 평가되고 있다.
부로수맙 (KRN23)은 신장에 의한 인산염 배출 및 활성 비타민 D 생성을 조절하는 호르몬인, 섬유아세포 성장 인자 23 (FGF23)을 표적화하는 인간 IgG1 mAb이다.
틸드라키주맙 (SCH 900222/MK-3222)은 IL-23p19를 표적화하는 인간화된 IgG1 mAb이다. 중등도 내지 중증 판상형 건선 치료제로서 틸드라키주맙의 판매 신청서가 EU 및 미국에 제출되었다.
카플라시주맙 (ALX-0081)은 폰 빌레브란트 인자를 표적화하는 2가 단일-도메인 항체 (Nanobody®)로, aTTP 환자에서 낮은 혈소판 수, 조직 허혈 및 장기 부전을 유발하는 미세혈전(microclot)의 형성을 수반하는, 희귀한, 생명을 위협하는 혈액 응고 장애인 후천성 혈전성 혈소판감소성 자반증 (aTTP)에 대한 치료제로서 규제 검토를 받고 있다.
에레누맙 (AIMOVIG™, AMG 334)은 감작된 침해 수용성 뉴런의 발달에 관여하는 칼시토닌 유전자-관련 펩티드 (CGRP)에 대한 수용체를 표적화하는 IgG2 mAb이다. 한 달에 4일 이상 편두통을 경험한 환자의 편두통 예방을 위한 에레누맙의 판매 신청서가 EU 및 미국에 제출되었다.
프레마네주맙 (TEV-48125)은 편두통 예방 치료에 대한 규제 검토를 받고 있는 CGRP를 표적화하는 IgG2 mAb이다.
갈카네주맙 (LY2951742)은 CGRP를 표적화하는 IgG4 mAb로, 성인의 발작적 편두통 및 만성 편두통 예방에 대한 규제 검토를 받고 있다.
로모소주맙 (EVENITY™, AMG785)은 스클레로스틴을 표적화하는 인간화된 IgG2 mAb로, 여성 및 남성의 골다공증 치료제로서 평가되고 있다.
모가물리주맙 (KW-0761, POTELIGEo®)은 균상식육종 및 세자리( ) 증후군을 포함하는, 피부 T 세포 백혈병 림프종 (CTCL)을 갖는 환자의 종양 세포에서 발현된 CC 케모카인 수용체 4 (CCR4)를 표적화하는 IgG1 비푸코실화된 인간화된 mAb이다.
) 증후군을 포함하는, 피부 T 세포 백혈병 림프종 (CTCL)을 갖는 환자의 종양 세포에서 발현된 CC 케모카인 수용체 4 (CCR4)를 표적화하는 IgG1 비푸코실화된 인간화된 mAb이다.
라나델루맙 (SHP643, DX-2930)은 혈장 칼리크레인을 표적화하여 브라디키닌의 생성을 방지하는 인간 IgG1 mAb이다.
크리잔리주맙 (SEG101)은 CD62로도 알려진 P-셀렉틴을 표적화하는 인간화된 mAb이고, 겸상 적혈구 질환 환자에서 혈관 폐쇄에 의해 유발된 겸상 적혈구-관련 통증 위기 (SCPC)의 치료제로서 평가를 받고 있다.
라불리주맙 (ALXN1210)은 발작성 야간혈색뇨 (PNH) 환자의 두 3상 연구에서 평가를 받고 있는 보체 성분 5 (C5)를 표적화하는 인간화된 mAb이다.
엡티네주맙 (ALD403)은 칼시토닌 유전자-관련 펩티드 (CGRP)를 표적화하는 IgG1 mAb이고, 편두통 예방에 대해 평가되고 있다.
리산키주맙 (ABBV066, BI655066)은 건선의 발병에 연루된 IL-23의 p19 서브유닛을 표적화하는 IgG1 mAb이다.
사트랄리주맙 (SA237)은 IL-6R을 표적화하는 인간화된 IgG2로, 시신경 척수염 (NMO) 또는 NMO 스펙트럼 장애가 있는 환자의 두 3상 연구에서 평가되고 있다.
브롤루시주맙 (RTH258)은 혈관 내피 성장 인자 (VEGF)-A를 표적화하는 단일쇄 가변 단편 (scFv)이다.
PRO140은 인간화된 IgG4 mAb로, T 세포에서 인간 면역결핍 바이러스 (HIV) 공동-수용체 CCR5를 차단하여 바이러스 진입을 방지한다.
람팔리주맙 (RG7417, FCFD4514S)은 인간화 항원-결합 단편 (Fab)으로, 보체 인자 D에 결합함으로써 대안적인 보체 경로의 활성화 및 증폭을 억제한다.
롤레두맙 (LFB-R593)은 LFB S.A.의 EMABLING® 기술 플랫폼으로부터 유래된 인간 IgG1 항-레수스 (Rh)D mAb로, 푸코실화를 변경시켜 항체를 이펙터 세포에 보다 효과적으로 결합시킨다. 상기 항체는 일부 태아모체 동종면역 상태, 즉, RhD-양성 태아를 임신한 RhD-음성 임산부에서 일부 태아모체 동종면역 상태를 예방하도록 설계된다.
파시누맙 (REGN475)은 신경 성장 인자를 표적화하는 인간 IgG4 mAb로, 많은 말기 연구에서 엉덩이 또는 무릎의 중등도 내지 중증의 골관절염 통증 및 만성 요통에 대한 치료제로서 평가되고 있다.
에트롤리주맙 (RH7413)은 α4β7 및 αEβ7 인테그린 이종이량체의 β7 서브유닛에 결합하여 이들의 리간드 MAdCAM-1 및 E-카드헤린과의 상호작용을 각각 억제하는 인간화된 mAb이다.
NEOD001은 인간화된 IgG1 mAb로, 심장, 신장 및 간을 포함하는 조직 및 기관에 단백질 응집체가 과도하게 축적되는 것을 특징으로 하는 장애인, 아밀로이드 경쇄 (AL) 아밀로이드증을 유발하는 가용성 및 불용성 경쇄 응집체를 표적화한다.
간테네루맙 (RO4909832)은 알츠하이머병의 치료제로서 조사되고 있는 원섬유 아밀로이드-β를 표적화하는 인간 mAb이다.
아니프롤루맙 (MEDI-546)은 SLE의 치료제로서 평가되고 있는 I형 인터페론 (IFN) 수용체 서브유닛 1을 표적화하는 인간 IgG1 mAb이다.
목세투모맙 파수도톡스 (HA22, CAT- 8015)는 CD22를 표적화하는 항체 가변 단편에 융합된 슈도모나스 외독소 A의 38-kDa 세포독성 부분을 함유하는 재조합 면역독소이다.
프로그램된 사멸-1 (PD1)을 표적화하는 인간 항체인, 세미플리맙 (REGN2810, SAR439684)은 전이성 또는 절제 불가능한 피부 편평세포 암종 (CSCC)의 치료제로서 평가를 받고 있다.
유블리툭시맙 (LFB-R603, TGT-1101, TGTX-1101)은 CD20을 표적화하는 당조작된(glycoengineered) 키메라 mAb이다.
트레멜리무맙 (CP-675,206)은 세포독성 T 림프구-관련 항원-4 (CTLA-4)를 표적화하는 인간 IgG2 항체이다. 생리학적 조건에서, CD28은 B7 리간드 (CD80, CD86)와 상호작용하여 T 세포 활성화, 증식 및 CTLA-4 상향조절을 초래한다. CTLA-4는 CD28보다 높은 친화도로 B7 리간드에 결합하고 T-세포 반응을 종결시킨다.
이사툭시맙 (SAR650984)은 재발성 및 불응성 다발성 골수종 (MM) 환자의 치료에 대해 평가되고 있는 항-CD38 IgG1 키메라 항체이다.
BCD-100은 프로그램된 세포 사멸-1 (PD-1)을 표적화하는 인간 항체이다.
카로툭시맙 (TRC105)은 혈관 신생 및 증식성 내피세포에서 고도로 발현된 단백질인, 엔도글린 (CD105)을 표적화하는 키메라 IgG1 항체이다. mAb는 1-2 ng/mL의 KD로 증식하는 내피에서 인간 CD105에 결합하고 인간 제정맥 내피세포의 ADCC를 유도한다.
캄렐리주맙 (INCSHR-1210, SHR-1210)은 PD-1을 표적화하는 IgG4κ 인간화된 항체이다.
글렘바투무맙 베도틴 (CDX-011, CR011-vcMMAE)은 암 세포에서 방출될 때, 종양 세포 사멸을 유도할 수 있는 세포독성 약물인, 모노메틸 아우리스타틴 E에 접합된 막횡단 당단백질 비-전이성 유전자 B (gpNMB)를 표적화하는 IgG2 인간 항체이다.
미르베툭시맙 소라브탄신 (IMGN853)은 항-유사분열제인, 메이탄시노이드 약물 DM4의 3-4 분자에 접합된 폴레이트 수용체 알파 (FRα)를 표적화하는 항체이다.
오포르투주납 모나톡스 (VICINIUM™, VB4-845)는 슈도모나스 아에루기노사(Pseudomonas aeruginosa) 외독소 A에 접합된 항-상피 세포 접착 분자 (EpCAM) 재조합 인간화된 항체 scFv 단편이다.
L19IL2/L19TNF (DAROMUN)는 인간 IL2 또는 인간 TNF에 융합된 피브로넥틴의 엑스트라도메인 B를 표적화하는, L19 항체의 scFv로 구성된 융합 단백질이다.
더 추가의 예시적인 항체 및 융합 단백질은 다음 중 임의의 것으로부터 선택될 수 있다: AstraZeneca 및 MedImmune의 벤랄리주맙, MEDI-8968, 아니프롤루맙, MEDI7183, 시팔리무맙, MEDI-575, 트라로키누맙; Biogen Idec/Eisai Co. LTD ("Eisai")/BioArctic Neuroscience AB의 BAN2401; Biogen의 CDP7657 항-CD40L 1가 페길화된 Fab 항체 단편, STX-100 항-avB6 mAb, BIIB059, 항-TWEAK (BIIB023), 및 BIIB022; Janssen 및 Amgen의 풀라누맙; BioInvent International/Genentech의 BI-204/RG7418; Biotest Pharmaceuticals Corporation의 BT-062 (인다툭시맙 라브탄신); Boehringer Ingelheim/Xencor의 XmAb; Bristol-Myers Squibb의 항-IP10; BZL Biologics LLC의 J 591 Lu-177; CDX-011 (글렘바투무맙 베도틴), Celldex Therapeutics의 CDX-0401; Crucell의 포라비루맙; Daiichi Sankyo Company Limited의 티가투주맙; Eisai의 MORAb-004, MORAb-009 (아마툭시맙); Eli Lilly의 LY2382770; EMD Serono Inc의 DI17E6; Emergent BioSolutions, Inc.의 자놀리무맙; FibroGen, Inc.의 FG-3019; Fresenius SE & Co. KGaA의 카투막소맙; Genentech의 파테클리주맙, 론탈리주맙; Genzyme & Sanofi의 프레솔리무맙; Gilead의 GS-6624 (심투주맙); Janssen의 CNTO-328, 바피뉴주맙 (AAB-001), 카를루맙, CNTO-136; KaloBios Pharmaceuticals, Inc.의 KB003; Kyowa의 ASKP1240; Labrys Biologics Inc.의 RN-307; Life Science Pharmaceuticals의 에크로멕시맙; Eli Lilly의 LY2495655, LY2928057, LY3015014, LY2951742; MassBiologics의 MBL-HCV1; MENTRIK Biotech, LLC의 AME-133v; Merck KGaA의 아비투주맙; Merrimack Pharmaceuticals, Inc.의 MM-121; Novartis AG의 MCS 110, QAX576, QBX258, QGE031; Novartis AG and XOMA Corporation ("XOMA")의 HCD122; Novo Nordisk의 NN8555; Peregrine Pharmaceuticals, Inc.의 바비툭시맙, 코타라; Progenies Pharmaceuticals, Inc.의 PSMA-ADC; Quest Pharmatech, Inc.의 오레고보맙; Regeneron의 파시누맙 (REGN475), REGN1033, SAR231893, REGN846; Roche의 RG7160, CIM331, RG7745; TaiMed Biologics Inc.의 이발리주맙 (TMB-355); Theraclone Sciences의 TCN-032; TRACON Pharmaceuticals, Inc.의 TRC105; United Biomedical Inc.의 UB-421; Viventia Bio, Inc.의 VB4-845; AbbVie의 ABT-110; Ablynx의 카플라시주맙, 오조랄리주맙; CytoDyn, Inc.의 PRO 140; Medarex, Inc.의 GS-CDA1, MDX-1388; Amgen의 AMG 827, AMG 888; TG Therapeutics Inc.의 유블리툭시맙; Tolera Therapeutics, Inc.의 TOL101; ImmunoGen Inc.의 huN901-DM1 (로르보투주맙 머탄신); Immunomedics, Inc.의 에프라투주맙 Y-90/벨투주맙 조합 (IMMU-102); Agenix, Limited의 항-피브린 mAb/3B6/22 Tc-99m; Alder Biopharmaceuticals, Inc.의 ALD403; Pfizer의 RN6G/PF-04382923; CG Therapeutics, Inc.의 CG201; KaloBios Pharmaceuticals/Sanofi의 KB001-A; Kyowa.의 KRN-23; Immunomedics, Inc.의 Y-90 hPAM 4; Morphosys AG & OncoMed Pharmaceuticals, Inc.의 타렉스투맙; Morphosys AG & Novartis AG의 LFG316; Morphosys AG & Jannsen의 CNTO3157, CNTO6785; Roche & Chugai의 RG6013; Merrimack Pharmaceuticals, Inc. ("Merrimack")의 MM-111; GlaxoSmithKline의 GSK2862277; Amgen의 AMG 282, AMG 172, AMG 595, AMG 745, AMG 761; Biocon의 BVX-20; Celltrion의 CT-P19, CT-P24, CT-P25, CT-P26, CT-P27, CT-P4; GlaxoSmithKline의 GSK284933, GSK2398852, GSK2618960, GSK1223249, GSK933776A; Morphosys AG & Bayer AG의 아네투맙 라브탄신; Morphosys AG & Boehringer Ingelheim의 BI-836845; Morphosys AG & Novartis AG의 NOV-7, NOV-8; Merrimack의 MM-302, MM-310, MM-141, MM-131, MM-151, Roche & Seattle Genetics의 RG7882; Roche/Genentech의 RG7841; Pfizer의 PF-06410293, PF-06438179, PF-06439535, PF-04605412, PF-05280586; Roche의 RG7716, RG7936, 젠테네루맙, RG7444; Astrazeneca의 MEDI-547, MEDI-565, MEDI1814, MEDI4920, MEDI8897, MEDI-4212, MEDI-5117, MEDI-7814; Bristol-Myers Squibb의 울로쿠플루맙, PCSK9 아드넥틴; FivePrime Therapeutics, Inc.의 FPA009, FPA145; Gilead의 GS-5745; Kyowa Hakko Kirin의 BIW-8962, KHK4083, KHK6640; Merck KGaA의 MM-141; Regeneron의 REGN1154, REGN1193, REGN1400, REGN1500, REGN1908-1909, REGN2009, REGN2176-3, REGN728; Sanofi의 SAR307746; Seattle Genetics의 SGN-CD70A; Ablynx의 ALX-0141, ALX-0171; Immunomedics, Inc.의 밀라투주맙-DOX, 밀라투주맙, TF2; Millennium의 MLNO264; AbbVie의 ABT-981; AbGenomics International Inc.의 AbGn-168H; AVEO의 피클라투주맙; BioInvent International의 BI-505; Celldex Therapeutics의 CDX-1127, CDX-301; Cellerant Therapeutics Inc.의 CLT-008; Circadian의 VGX-100; Daiichi Sankyo Company Limited의 U3-1565; Dekkun Corp.의 DKN-01; Eli Lilly의 플란보투맙 (TYRP1 단백질), IL-1β 항체, IMC-CS4; Eli Lilly 및 ImClone, LLC의 VEGFR3 mAb, IMC-TR1 (LY3022859); Elusys Therapeutics Inc.의 앤심; Galaxy Biotech LLC의 HuL2G7; ImmunoGen Inc.의 IMGB853, IMGN529; Janssen의 CNTO-5, CNTO-5825; Kaketsuken의 KD-247; KaloBios Pharmaceuticals의 KB004; MacroGenics, Inc.의 MGA271, MGAH22; MorphoSys AG/Xencor의 XmAb5574; Neogenix Oncology, Inc.의 엔시툭시맙; Novartis AG and XOMA의 LFA102; Novartis AG의 ATI355; Santarus Inc.의 SAN-300; Selexys의 SelG1; Targa Therapeutics, Corp.의 HuM195/rGel; Teva Pharmaceuticals, Industries Ltd. ("Teva") 및 Vaccinex Inc.의 VX15; Theraclone Sciences의 TCN-202; Xencor의 XmAb2513, XmAb5872; XOMA 및 미국 국립 알레르기 및 전염병 연구소(National Institute for Allergy and Infectious Diseases)의 XOMA 3AB; MabVax Therapeutics의 신경아세포종 항체 백신; CytoDyn, Inc.의 사이톨린; Emergent BioSolutions Inc.의 트라빅사(Thravixa); 및 Cytovance Biologics의 FB 301; Janssen 및 Sanofi의 광견병 mAb; 미국국립보건원(National Institutes of Health)이 일부 기금을 제공한, Janssen의 flu mAb; Mapp Biopharmaceutical, Inc.의 MB-003 및 ZMapp; 및 Defyrus IncG의 ZMAb
III. 항체 및 융합 단백질의 생산에 사용하기 위한 일반적인 ceDNA 벡터
본 발명의 구현예는 이식유전자 (예를 들어, 항체 또는 융합 단백질)를 발현시킬 수 있는 폐쇄 말단 선형 듀플렉스 (ceDNA) 벡터를 포함하는 방법 및 조성물에 기반한다. 일부 구현예에서, 이식유전자는 항체 또는 융합 단백질을 인코딩하는 서열이다. 본원에 기재된 바와 같이 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 크기에 의해 제한되지 않으므로, 예를 들어, 단일 벡터로부터 이식유전자의 발현에 필요한 모든 성분의 발현을 허용한다. 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 바람직하게는 듀플렉스, 예를 들어 발현 카세트와 같은 분자의 적어도 일부에 대해 자가-상보적이다 (예를 들어 ceDNA는 이중 가닥 원형 분자가 아님). ceDNA 벡터는 공유적으로 폐쇄된 말단을 가지므로 예를 들어 37℃에서 1시간 이상 동안 엑소뉴클레아제 소화 (예를 들어 엑소뉴클레아제 I 또는 엑소뉴클레아제 III)에 내성이 있다.
일반적으로, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 5'에서 3'의 방향으로 제1 아데노-관련 바이러스 (AAV) 역 말단 반복부 (ITR), 관심 뉴클레오티드 서열 (예를 들어 본원에 기재된 발현 카세트) 및 제2 AAV ITR을 포함한다. ITR 서열은 다음 중 어느 것으로부터 선택된다: (i) 적어도 하나의 WT ITR 및 적어도 하나의 변형된 AAV 역 말단 반복부 (모드-ITR) (예를 들어, 비대칭 변형된 ITR); (ii) 모드-ITR 쌍이 서로에 대해 상이한 3차원 공간 구성을 갖는 2개의 변형된 ITR (예를 들어, 비대칭 변형된 ITR), 또는 (iii) 각각의 WT-ITR이 동일한 3차원 공간 구성을 갖는 대칭 또는 실질적으로 대칭인 WT-WT ITR 쌍, 또는 (iv) 각각의 모드-ITR이 동일한 3차원 공간 구성을 갖는 대칭 또는 실질적으로 대칭인 변형된 ITR 쌍.
비제한적으로, 리포좀 나노입자 전달 시스템과 같은 전달 시스템을 추가로 포함할 수 있는, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 포함하는 방법 및 조성물이 본원에 포함된다. 사용을 위해 포함되는 비제한적인 예시적인 리포좀 나노입자 시스템이 본원에 개시되어 있다. 일부 측면에서, 본 개시내용은 ceDNA 및 이온화 가능한 지질을 포함하는 지질 나노입자를 제공한다. 예를 들어, 본 방법에 의해 수득된 ceDNA 벡터로 제조되고 로딩된 지질 나노입자 제형은 2018년 9월 7일자로 출원된 국제 출원 PCT/US2018/050042에 개시되어 있으며, 이는 본원에 포함된다.
본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 바이러스 캡시드 내의 제한 공간에 의해 부과되는 패키징 제약이 없다. ceDNA 벡터는 캡슐화된 AAV 게놈과 대조적으로, 원핵생물-생산 플라스미드 DNA 벡터에 대한 생존가능 진핵생물적으로-생산된 대안을 나타낸다. 이는 제어 요소, 예를 들어, 본원에 개시된 조절 스위치, 대형 이식유전자, 다중 이식유전자 등의 삽입을 허용한다.
도 1a-1e는 항체 또는 융합 단백질 생산을 위한 비제한적인, 예시적인 ceDNA 벡터, 또는 상응하는 ceDNA 플라스미드 서열의 개략도를 보여준다. 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 캡시드가 없고, 제1 ITR, 이식유전자를 포함하는 발현 카세트 및 제2 ITR 순으로 인코딩된 플라스미드로부터 수득될 수 있다. 발현 카세트는 이식유전자의 발현을 허용 및/또는 통제하는 하나 이상의 조절 서열을 포함할 수 있고, 예를 들어, 여기서 발현 카세트는 다음 순서로, 인핸서/프로모터, ORF 리포터 (이식유전자), 전사 후 조절 요소 (예를 들어, WPRE), 및 폴리아데닐화 및 종결 신호 (예를 들어, BGH 폴리A) 중 하나 이상을 포함할 수 있다.
발현 카세트는 또한 내부 리보솜 진입 부위 (IRES) 및/또는 2A 요소를 포함할 수 있다. 시스-조절 요소는 프로모터, 리보스위치(riboswitch), 절연체, mir-조절 가능 요소, 전사 후 조절 요소, 조직- 및 세포 유형-특이적 프로모터 및 인핸서를 포함하지만, 이에 제한되지 않는다. 일부 구현예에서, ITR은 이식유전자, 예를 들어, 항체 또는 융합 단백질에 대한 프로모터로서 작용할 수 있다. 일부 구현예에서, ceDNA 벡터는 이식유전자의 발현을 조절하기 위한 추가 성분, 예를 들어, 항체 또는 융합 단백질의 발현을 제어 및 조절하기 위한 "조절 스위치"라는 제목의 섹션에서 본원에 기재된 조절 스위치를 포함하고, 원한다면, ceDNA 벡터를 포함하는 세포의 제어된 세포 사멸을 가능하게 하는 사멸 스위치인, 조절 스위치를 포함할 수 있다.
발현 카세트는 4000개 초과의 뉴클레오티드, 5000개의 뉴클레오티드, 10,000개의 뉴클레오티드 또는 20,000개의 뉴클레오티드, 또는 30,000개의 뉴클레오티드, 또는 40,000개의 뉴클레오티드 또는 50,000개의 뉴클레오티드, 또는 약 4000-10,000개의 뉴클레오티드 또는 10,000-50,000개의 뉴클레오티드 사이의 임의의 범위, 또는 50,000개 초과의 뉴클레오티드를 포함할 수 있다. 일부 구현예에서, 발현 카세트는 500 내지 50,000개의 뉴클레오티드 길이 범위의 이식유전자를 포함할 수 있다. 일부 구현예에서, 발현 카세트는 500 내지 75,000개의 뉴클레오티드 길이 범위의 이식유전자를 포함할 수 있다. 일부 구현예에서, 발현 카세트는 500 내지 10,000개의 뉴클레오티드 길이 범위의 이식유전자를 포함할 수 있다. 일부 구현예에서, 발현 카세트는 1000 내지 10,000개의 뉴클레오티드 길이 범위의 이식유전자를 포함할 수 있다. 일부 구현예에서, 발현 카세트는 500 내지 5,000개의 뉴클레오티드 길이 범위의 이식유전자를 포함할 수 있다. ceDNA 벡터는 캡시드로 둘러싸인 AAV 벡터의 크기 제한이 없으므로, 효율적인 이식유전자 발현을 제공하기 위해 대형 발현 카세트의 전달을 가능하게 한다. 일부 구현예에서, ceDNA 벡터는 원핵생물-특이적 메틸화가 없다.
ceDNA 발현 카세트는, 예를 들어, 수용 대상체에서 부재하거나, 비활성이거나 활성이 불충분한 단백질을 인코딩하는 발현 가능한 외인성 서열 (예를 들어, 오픈 리딩 프레임) 또는 원하는 생물학적 또는 치료적 효과를 갖는 단백질을 인코딩하는 유전자를 포함할 수 있다. 이식유전자는 결함 유전자 또는 전사체의 발현을 교정하는 기능을 할 수 있는 유전자 산물을 인코딩할 수 있다. 원칙적으로, 발현 카세트는 돌연변이로 인해 감소되거나 부재하거나, 과발현될 때 치료적 이점을 전달하는 단백질, 폴리펩티드 또는 RNA를 인코딩하는 임의의 유전자를 포함할 수 있으며, 이는 본 개시의 범위 내에 있는 것으로 간주된다.
발현 카세트는 임의의 이식유전자 (예를 들어, 항체 또는 융합 단백질을 인코딩하는), 예를 들어, 대상체에서 질환 또는 장애의 치료에 유용한 항체 또는 융합 단백질, 즉, 치료 항체 또는 융합 단백질을 포함할 수 있다. ceDNA 벡터는 단독으로 또는 폴리펩티드를 인코딩하는 핵산, 또는 비-코딩 핵산 (예를 들어, RNAi, miR 등), 뿐만 아니라 대상체의 게놈 내의 바이러스 서열, 예를 들어, HIV 바이러스 서열 등을 포함하는 외인성 유전자 및 뉴클레오티드 서열과 함께, 대상체에서 임의의 관심 항체 또는 융합 단백질을 전달하고 발현시키는데 사용될 수 있다. 바람직하게는 본원에 개시된 ceDNA 벡터는 치료 목적 (예를 들어, 의학적, 진단 또는 수의학적 용도) 또는 면역원성 폴리펩티드에 사용된다. 특정 구현예에서, ceDNA 벡터는, 하나 이상의 폴리펩티드, 펩티드, 리보자임, 펩티드 핵산, siRNA, RNAis, 안티센스 올리고뉴클레오티드, 안티센스 폴리뉴클레오티드, 또는 RNA (코딩 또는 비-코딩; 예를 들어, siRNA, shRNA, 마이크로-RNA, 및 이들의 안티센스 대응물 (예를 들어, antagoMiR)), 항체, 융합 단백질, 또는 이들의 임의의 조합을 포함하여, 대상체에서 임의의 관심 유전자를 발현시키는데 유용하다.
발현 카세트는 또한 폴리펩티드, 센스 또는 안티센스 올리고뉴클레오티드, 또는 RNA (코딩 또는 비-코딩; 예를 들어, siRNA, shRNA, 마이크로-RNA, 및 이들의 안티센스 대응물 (예를 들어, antagoMiR))를 인코딩할 수 있다. 발현 카세트는 β-락타마제, β-갈락토시다제 (LacZ), 알칼리성 포스파타제, 티미딘 키나제, 녹색 형광 단백질 (GFP), 클로람페니콜 아세틸트랜스퍼라제 (CAT), 루시퍼라제 및 당 업계에 잘 알려진 다른 것들과 같은 실험 또는 진단 목적으로 사용되는 리포터 단백질을 인코딩하는 외인성 서열을 포함할 수 있다.
본원에 기재된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 발현 카세트, 발현 작제물에 제공된 서열은 표적 숙주 세포에 대해 코돈 최적화될 수 있다. 본원에 사용된 용어 "코돈 최적화된" 또는 "코돈 최적화"는 천연 서열 (예를 들어, 원핵생물 서열)의 적어도 하나, 하나 초과 또는 상당한 수의 코돈을 척추동물의 유전자에서 보다 빈번하게 또는 가장 빈번하게 사용되는 코돈으로 대체함으로써 관심 척추동물 세포, 예를 들어, 마우스 또는 인간의 세포에서 발현을 향상시키기 위해 핵산 서열을 변형시키는 과정을 지칭한다. 다양한 종은 특정 아미노산의 특정 코돈에 대해 특정한 편향을 나타낸다. 전형적으로, 코돈 최적화는 원래 번역된 단백질의 아미노산 서열을 변경시키지 않는다. 최적화된 코돈은 예를 들어, Aptagen's Gene Forge® 코돈 최적화 및 맞춤형 유전자 합성 플랫폼 (Aptagen, Inc., 2190 Fox Mill Rd. Suite 300, Herndon, Va. 20171) 또는 또 다른 공개적으로 이용 가능한 데이터베이스를 사용하여 결정될 수 있다. 일부 구현예에서, 항체 또는 융합 단백질을 인코딩하는 핵산은 인간 발현을 위해 최적화되고/되거나 당 분야에 공지된 바와 같이, 인간 항체 또는 인간화된 항체, 또는 이의 항원-결합 단편이다.
일부 구현예에서, ceDNA 벡터에 의해 발현된 항체 또는 융합 단백질은 치료 활성화 항체 또는 융합 단백질 또는 치료 중화 (예를 들어, 차단 또는 억제) 항체 또는 융합 단백질을 포함하는 치료 항체 또는 융합 단백질이다.
본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터에 의해 발현된 이식유전자는 항체 또는 융합 단백질을 인코딩한다. 항체 및 융합 단백질은 당 업계에 잘 알려져 있으며, 리간드, 수용체, 독소, 호르몬, 효소 또는 세포 표면 단백질, 또는 병원체 또는 바이러스 단백질 또는 항원, 뿐만 아니라 번역 전 및 번역 후 변형된 단백질, 예컨대 당단백질 또는 수모화(SUMOylated) 단백질 (예를 들어, ant-SUMO2/3 항체) 등을 포함하지만, 이에 제한되지 않는, 임의의 관심 단백질에 결합할 수 있다. 항체는 또한, 핵산, 예를 들어, DNA (예를 들어, 항-dsDNA 항체), RNA (예를 들어, 항-RNA 결합 항체)를 포함하지만, 이에 제한되지 않는, 임의의 항원에 결합하는 항체를 포함한다. 일부 구현예에서, 본원에 개시된 ceDNA 벡터에 의해 생성된 항체 또는 융합 단백질은 중화 항체 또는 융합 단백질이다. 표적화되는 예시적인 유전자 및 관심 단백질은 본원의 사용 방법 및 치료 방법 섹션에 상세히 기재되어 있다. 질환, 기능 장애, 손상 및/또는 장애의 하나 이상의 증상의 치료, 예방 및/또는 개선에 사용하기 위한, 항체, 융합 단백질, 뿐만 아니라 변이체 및/또는 이의 활성 단편은 본원에 개시된 항체 또는 융합 단백질 생산을 위해 ceDNA 벡터에서 사용되는 것이 포함된다. 예시적인 치료 유전자는 "치료 방법"이라는 제목의 섹션에서 본원에 기재되어 있다.
플라스미드 기반 발현 벡터와 상이한 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 많은 구조적 특징이 있다. ceDNA 벡터는 다음의 특징들 중 하나 이상을 가질 수 있다: 원래 (즉, 삽입되지 않은) 박테리아 DNA의 결핍, 원핵생물 복제 기원의 결핍, 자가-포함(being self-containing), 즉, 이들은 Rep 결합 및 말단 분해 부위 (RBS 및 TRS)를 포함하는 2개의 ITR, 및 ITR들 사이의 외인성 서열 이외의 임의의 서열을 요구하지 않음, 헤어핀을 형성하는 ITR 서열의 존재 및 박테리아 유형 DNA 메틸화 또는 실제로 포유동물 숙주에 의해 비정상적인 것으로 간주되는 임의의 다른 메틸화의 부재. 일반적으로, 본 벡터는 임의의 원핵생물 DNA를 함유하지 않는 것이 바람직하지만, 일부 원핵생물 DNA는 프로모터 또는 인핸서 영역에서 비-제한적인 예로서 외인성 서열로서 삽입될 수 있는 것으로 고려된다. 플라스미드 발현 벡터로부터 ceDNA 벡터를 구별하는 또 다른 중요한 특징은 ceDNA 벡터가 폐쇄 말단을 갖는 단일 가닥 선형 DNA인 반면, 플라스미드는 항상 이중 가닥 DNA라는 것이다.
본원에 제공된 방법에 의해 생성된, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 바람직하게는 제한 효소 소화 분석에 의해 결정된 바와 같이, 비-연속 구조보다는 선형 및 연속 구조를 갖는다 (도 4d). 선형 및 연속 구조는 세포 엔도뉴클레아제에 의한 공격으로부터 보다 안정할뿐만 아니라 재조합되고 돌연변이를 유발할 가능성이 적은 것으로 여겨진다. 따라서, 선형 및 연속 구조에서 ceDNA 벡터는 바람직일 구현예이다. 연속적인, 선형의 단일 가닥 분자내 듀플렉스 ceDNA 벡터는 AAV 캡시드 단백질을 인코딩하는 서열 없이 공유 결합된 말단을 가질 수 있다. 이들 ceDNA 벡터는 박테리아 기원의 원형 듀플렉스 핵산 분자인 플라스미드 (본원에 기재된 ceDNA 플라스미드 포함)와 구조적으로 구별된다. 상보적인 플라스미드 가닥은 변성 후에 분리되어 2개의 핵산 분자를 생성할 수 있는 반면, 대조적으로, 상보적인 가닥을 가지면서 ceDNA 벡터는 단일 DNA 분자이고, 따라서 변성되더라도 단일 분자로 남아있다. 일부 구현예에서, 본원에 기재된 바와 같은 ceDNA 벡터는 플라스미드와 달리, 원핵생물 유형의 DNA 염기 메틸화 없이 생성될 수 있다. 따라서, ceDNA 벡터 및 ceDNA-플라스미드는 둘 모두 구조 측면에서 (특히 선형 대 원형) 및 또한 이들 상이한 대상을 생성 및 정제하는데 사용된 방법의 관점에서 (아래 참조), 및 ceDNA-플라스미드에 대해 원핵생물 유형이고 ceDNA 벡터에 대해 진핵생물 유형인 DNA 메틸화의 관점에서 상이하다.
플라스미드-기반 발현 벡터에 비해 본원에 기재된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 사용하는 것의 몇 가지 이점이 있으며, 이러한 이점은 다음을 포함하지만, 이에 제한되지는 않는다: 1) 플라스미드는 박테리아 DNA 서열을 함유하고 원핵생물-특이적 메틸화, 예를 들어, 6-메틸 아데노신 및 5-메틸 시토신 메틸화를 거친 박테리아 DNA 서열을 함유하고, 반면 캡시드-비함유 AAV 벡터 서열은 진핵생물 기원이고 원핵생물-특이적 메틸화를 겪지 않으며; 결과적으로, 캡시드-비함유 AAV 벡터는 플라스미드와 비교하여 염증 및 면역 반응을 유발할 가능성이 적고; 2) 플라스미드는 생산 공정 동안 저항성 유전자의 존재를 요구하지만, ceDNA 벡터는 그렇지 않고; 3) 원형 플라스미드가 세포 내로 도입될 때 핵으로 전달되지 않고, 세포 뉴클레아제에 의한 분해를 우회하기 위해 과부하가 필요한 반면, ceDNA 벡터는 바이러스성 시스-요소, 즉, 클레아제에 대한 저항성을 부여하고 핵으로 표적화되고 전달되도록 설계될 수 있는 ITR을 함유한다. ITR 기능에 없어서는 안 될 최소 정의 요소는 Rep-결합 부위 (RBS; AAV2의 경우 5'-GCGCGCTCGCTCGCTC-3' (서열 번호: 60)) 및 말단 분해 부위 (TRS; AAV2의 경우 5'-AGTTGG-3' (서열 번호: 64)) 및 헤어핀 형성을 허용하는 가변 팔린드롬 서열인 것으로 가정되고; 4) ceDNA 벡터는 T 세포-매개 면역 반응을 유발하는, 톨-유사 수용체 패밀리의 일원에 결합하는 것으로 보고된 원핵생물-유래 플라스미드에서 종종 발견되는 CpG 디뉴클레오티드의 과다-표현(over-representation)을 갖지 않는다. 대조적으로, 본원에 개시된 캡시드-비함유 AAV 벡터를 이용한 형질도입은 다양한 전달 시약을 사용하여 통상적인 AAV 비리온으로 형질도입하기 어려운 세포 및 조직 유형을 효율적으로 표적화할 수 있다.
IV.
ITR
본원에 개시된 바와 같이, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 2개의 역 말단 반복 (ITR) 서열 사이에 위치된 이식유전자 EH는 이종 핵산 서열을 함유하며, 여기서 ITR 서열은 이 용어가 본원에 정의된 바와 같이, 비대칭 ITR 쌍 또는 대칭 또는 실질적으로 대칭 ITR 쌍일 수 있다. 본원에 개시된 ceDNA 벡터는 (i) 적어도 하나의 WT ITR 및 적어도 하나의 변형된 AAV 역 말단 반복부 (모드-ITR) (예를 들어, 비대칭인 변형된 ITR); (ii) 모드-ITR 쌍이 서로 상이한 3차원 공간 구성을 갖는 2개의 변형된 ITR (예를 들어, 비대칭인 변형된 ITR), 또는 (iii) 대칭 또는 실질적으로 대칭인 WT-WT ITR 쌍 (여기서 각각의 WT-ITR은 동일한 3차원 공간 구성을 가짐), 또는 (iv) 대칭 또는 실질적으로 대칭인 변형된 ITR 쌍 (여기서 각각의 모드-ITR은 동일한 3차원 공간 구성을 가짐) 중 어느 것으로부터 선택된 ITR 서열을 포함할 수 있으며, 여기서 본 개시의 방법은 비제한적으로 리포좀 나노입자 전달 시스템과 같은 전달 시스템을 추가로 포함할 수 있다.
일부 구현예에서, ITR 서열은 2개의 서브패밀리: 척추동물을 감염시키는 파보비리나에, 및 곤충을 감염시키는 덴소비리나에를 포함하는 파보비리다에 패밀리의 바이러스로부터 유래될 수 있다. 파보비리나에 서브패밀리 (파보바이러스라고 함)에는 데펜도바이러스 속이 포함되는데, 대부분의 조건에서, 이의 구성원은 생산적인 감염을 위해 아데노바이러스 또는 헤르페스 바이러스와 같은 헬퍼 바이러스로 동시 감염이 필요하다. 데펜도바이러스 속에는 일반적으로 사람 (예를 들어, 혈청형 2, 3A, 3B, 5 및 6) 또는 영장류 (예를 들어, 혈청형 1 및 4)를 감염시키는 아데노 관련 바이러스 (AAV) 및 다른 온혈 동물 (예를 들어, 소, 개, 말 및 양 아데노-관련 바이러스)을 감염시키는 관련 바이러스가 포함한다. 파보바이러스 및 파보비리다에 패밀리의 다른 구성원은 일반적으로 하기에 기재되어 있다: Kenneth I. Berns, "Parvoviridae: The Viruses and Their Replication," Chapter 69 in FIELDS VIROLOGY (3d Ed. 1996).
본원의 명세서 및 실시예에서 예시된 ITR은 AAV2 WT-ITR이지만, 당업자는, 상기 언급된 바와 같이, 임의의 공지된 파보바이러스, 예를 들어 데펜도바이러스 예컨대 AAV (예를 들어, AAV1, AAV2, AAV3, AAV4, AAV5, AAV 5, AAV7, AAV8, AAV9, AAV10, AAV 11, AAV12, AAVrh8, AAVrh10, AAV-DJ 및 AAV-DJ8 게놈. 예를 들어, NCBI:NC 002077; NC 001401; NC001729; NC001829; NC006152; NC 006260; NC 006261)로부터의 ITR, 키메라 ITR 또는 임의의 합성 AAV로부터의 ITR을 사용할 수 있다는 것을 알고 있다. 일부 구현예에서, AAV는 온혈 동물, 예를 들어, 조류 (AAAV), 소 (BAAV), 개, 말 및 양 아데노-관련 바이러스를 감염시킬 수 있다. 일부 구현예에서, ITR은 B19 파보바이러스 (GenBank 수탁 번호: NC 000883), 마우스로부터의 미세 바이러스 (Minute Virus from Mouse; MVM) (GenBank 수탁 번호 NC 001510); 거위 파보바이러스 (GenBank 수탁 번호 NC 001701); 뱀 파보바이러스 1 (GenBank 수탁 번호 NC 006148)에서 유래된다. 일부 구현예에서, 5' WT-ITR은 본원에 논의된 바와 같이, 하나의 혈청형으로부터 유래될 수 있고, 3' WT-ITR은 상이한 혈청형으로부터 유래될 수 있다.
통상의 숙련가는 ITR 서열이 이중 가닥 홀리데이 접합의 공통 구조를 가지며, 이는 전형적으로 T형 또는 Y형 헤어핀 구조 (예를 들어, 도 2a 및 도 3a 참조)임을 알고 있으며, 여기서 각각의 WT-ITR은 더 큰 팔린드롬 아암 (A-A')에 포매된 2개의 팔린드롬 아암 또는 루프 (B-B' 및 C-C')와 단일 가닥 D 서열 (여기서 이러한 팔린드롬 서열의 순서는 ITR의 플립 또는 플롭 배향을 한정함)에 의해 형성된다. 예를 들어, 하기에 기재된, 상이한 AAV 혈청형 (AAV1-AAV6)으로부터의 ITR의 구조 분석 및 서열 비교를 참조한다: Grimm et al., J. Virology, 2006; 80(1); 426-439; Yan et al., J. Virology, 2005; 364-379; Duan et al., Virology 1999; 261; 8-14. 당업자는 본원에 제공된 예시적인 AAV2 ITR 서열에 기초하여 ceDNA 벡터 또는 ceDNA-플라스미드에 사용하기 위한 임의의 AAV 혈청형으로부터 WT-ITR 서열을 쉽게 결정할 수 있다. 예를 들어, AAV2의 좌측 ITR과 다른 혈청형으로부터의 좌측 ITR의% 동일성: AAV-1 (84%), AAV-3 (86%), AAV-4 (79%), AAV-5 (58%), AAV-6 (좌측 ITR) (100%) 및 AAV-6 (우측 ITR) (82%)을 보여주는, 문헌(Grimm et al., J. Virology, 2006; 80(1); 426-439)에 기재된 상이한 AAV 혈청형 (AAV1-AAV6, 및 조류 AAV (AAAV) 및 소 AAV (BAAV))으로부터의 ITR의 서열 비교를 참조한다.
A. 대칭 ITR 쌍
일부 구현예에서, 본원에 기재된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 5 '내지 3'방향으로: 제1 아데노 관련 바이러스 (AAV) 역 말단 반복 (ITR), 관심대상의 뉴클레오티드 서열 (예를 들어, 본원에 기재된 바와 같은 발현 카세트) 및 제2 AAV ITR을 포함하며, 여기서 제1 ITR (5' ITR)과 제2 ITR (3' ITR)이 서로에 대해 대칭이거나 실질적으로 대칭이며, 즉, ceDNA 벡터는 그들의 구조가 기하학적 공간에서 동일한 형상이거나 3D 공간에서 동일한 A, C-C' 및 B-B' 루프를 갖도록 대칭 3 차원 공간 구성을 갖는 ITR 서열을 포함할 수 있다. 이러한 구현예에서, 대칭 ITR 쌍, 또는 실질적으로 대칭 ITR 쌍은 야생형 ITR이 아닌 변형된 ITR (예를 들어, 모드-ITR)일 수 있다. 모드-ITR 쌍은 야생형 ITR로부터 하나 이상의 변형을 갖고 서로의 역 보체 (역상)인 동일한 서열을 가질 수 있다. 대안적인 구현예에서, 변형된 ITR 쌍은 본 명세서에 정의된 바와 같이 실질적으로 대칭이고, 즉, 변형된 ITR 쌍은 상이한 서열을 가질 수 있지만 상응하는 또는 동일한 대칭 3차원 형상을 가질 수 있다.
(i) 야생형
ITR
일부 구현예에서, 대칭 ITR 또는 실질적으로 대칭 ITR은 본원에 기재된 야생형 (WT-ITR)이다. 즉, 두 ITR 모두 야생형 서열을 갖지만 반드시 동일한 AAV 혈청형으로부터의 WT-ITR일 필요는 없다. 즉, 일부 구현예에서, 하나의 WT-ITR은 하나의 AAV 혈청형으로부터 유래될 수 있고, 다른 WT-ITR은 상이한 AAV 혈청형으로부터 유래될 수 있다. 이러일 구현예에서, WT-ITR 쌍은 본원에 정의된 바와 같이 실질적으로 대칭이며, 즉, 대칭인 3차원 공간 구성을 여전히 유지하면서 하나 이상의 보존적 뉴클레오티드 변형을 가질 수 있다.
따라서, 본원에 개시된 바와 같이, 이식유전자 또는 이종 핵산을 함유하는 ceDNA 벡터는 2개의 플랭킹 야생형 역 말단 반복 (WT-ITR) 서열 사이에 위치된 이식유전자 또는 이종 핵산 서열을 함유하며, 이는 서로의 역 보체 (역상)이거나 또는 대안적으로는 서로 실질적으로 대칭이고, 즉, WT-ITR 쌍이 대칭인 3차원 공간 구성을 갖는다. 일부 구현예에서, 야생형 ITR 서열 (예를 들어, AAV WT-ITR)은 기능적 Rep 결합 부위 (RBS; 예를 들어, AAV2에 대한 5'-GCGCGCTCGCTCGCTC-3', 서열 번호: 60) 및 기능성 말단 분해 부위 (TRS; 예를 들어 5'-AGTT-3', 서열 번호: 62)를 포함한다.
일 측면에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 2개의 WT 역 말단 반복 서열 (WT-ITR) (예를 들어 AAV WT-ITR) 사이에 작동적으로 위치된 이종 핵산을 인코딩하는 벡터 폴리뉴클레오티드로부터 얻을 수 있다. 즉, 두 ITR 모두 야생형 서열을 갖지만, 반드시 동일한 AAV 혈청형으로부터의 WT-ITR일 필요는 없다. 즉, 일부 구현예에서, 하나의 WT-ITR은 하나의 AAV 혈청형으로부터 유래될 수 있고, 다른 WT-ITR은 상이한 AAV 혈청형으로부터 유래될 수 있다. 이러일 구현예에서, WT-ITR 쌍은 본원에 정의된 바와 같이 실질적으로 대칭이며, 즉, 대칭인 3차원 공간 구성을 여전히 유지하면서 하나 이상의 보존적 뉴클레오티드 변형을 가질 수 있다. 일부 구현예에서, 5' WT-ITR은 하나의 AAV 혈청형으로부터 유래되고, 3' WT-ITR은 동일하거나 상이한 AAV 혈청형으로부터 유래된다. 일부 구현예에서, 5' WT-ITR 및 3'WT-ITR은 서로의 거울상이고, 즉 대칭이다. 일부 구현예에서, 5' WT-ITR 및 3' WT-ITR은 동일한 AAV 혈청형으로부터 유래된다.
WT ITR은 잘 알려져 있다. 일 구현예에서, 2개의 ITR은 동일한 AAV2 혈청형으로부터 유래된다. 특정 구현예에서, 다른 혈청형으로부터의 WT를 사용할 수 있다. 상동성인 다수의 혈청형, 예를 들어 AAV2, AAV4, AAV6, AAV8이 있다. 일 구현예에서, 밀접한 상동성 ITR (예를 들어, 유사한 루프 구조를 갖는 ITR)이 사용될 수 있다. 또 다른 구현예에서, 보다 다양한 AAV WT ITR, 예를 들어, AAV2 및 AAV5를 사용할 수 있고, 또 다른 구현예에서, 실질적으로 WT인 ITR을 사용할 수 있으며, 즉, 그것은 WT의 기본 루프 구조를 갖지만 특성을 변경하거나 특성에 영향을 미치지 않는 일부 보존적 뉴클레오티드 변화를 갖는다. 동일한 바이러스 혈청형으로부터 WT-ITR을 사용할 때, 하나 이상의 조절 서열이 추가로 사용될 수 있다. 특정 구현예에서, 조절 서열은 ceDNA의 활성의 조절, 예를 들어 인코딩된 항체 또는 융합 단백질의 발현을 허용하는 조절 스위치이다.
일부 구현예에서, 본원에 기재된 기술의 한 측면은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터에 관한 것이며, 여기서 ceDNA 벡터는 2개의 야생형 역 말단 반복 서열 (WT-ITR) 사이에 작동 가능하게 위치된 적어도 하나의 이종 뉴클레오티드 서열을 포함하며, WT-ITR은 동일한 혈청형, 상이한 혈청형으로부터 유래될 수 있거나 서로 실질적으로 대칭일 수 있다 (즉, 이들의 구조가 기하학적 공간에서 동일한 형상이거나 3D 공간에서 동일한 A, C-C' 및 B-B' 루프를 가짐). 일부 구현예에서, 대칭 WT-ITR은 기능성 말단 분해 부위 및 Rep 결합 부위를 포함한다. 일부 구현예에서, 이종 핵산 서열은 이식유전자를 인코딩하고, 벡터는 바이러스 캡시드에 있지 않다.
일부 구현예에서, WT-ITR은 동일하지만 서로의 역 보체이다. 예를 들어, 5' ITR에서 서열 AACG는 상응하는 부위에서 3' ITR에서 CGTT (즉, 역 보체)일 수 있다. 일례에서, 5' WT-ITR 센스 가닥은 ATCGATCG의 서열을 포함하고 상응하는 3' WT-ITR 센스 가닥은 CGATCGAT (즉, ATCGATCG의 역 보체)를 포함한다. 일부 구현예에서, WT-ITR ceDNA는 말단 분해 부위 및 복제 단백질 결합 부위 (RPS) (때로는 복제 단백질 결합 부위로 지칭됨), 예를 들어 Rep 결합 부위를 추가로 포함한다.
WT-ITR을 포함하는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터에 사용하기 위한 예시적인 WT-ITR 서열은 본원의 표 7에 도시되어 있으며, 이는 WT-ITR의 쌍 (5' WT-ITR 및 3' WT-ITR)을 나타낸다.
예시적인 예로서, 본 개시내용은 조절 스위치의 존재 또는 부재 하에 이식유전자 (예를 들어, 이종 핵산 서열)에 작동 가능하게 연결된 프로모터를 포함하는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 제공하며, 여기서 ceDNA는 캡시드 단백질이 없고, (a) ceDNA는 WT-ITR을 인코딩하는 ceDNA-플라스미드 (예를 들어, 도 1f-1g 참조)로부터 생성되며, 여기서 각각의 WT-ITR은 이의 헤어핀 이차 구성에서 동일한 수의 분자내 이중화 염기쌍을 갖고 (바람직하게는 이러한 참조 서열과 비교하여 이 구성에서 임의의 AAA 또는 TTT 말단 루프의 결실을 배제함), (b) ceDNA는 미변성 겔 및 실시예 1의 변성 조건 하에서 아가로스 겔 전기영동에 의해 ceDNA 식별을 위한 분석을 사용하여 ceDNA로서 식별된다.
일부 구현예에서, 플랭킹 WT-ITR은 서로 실질적으로 대칭이다. 이 구현예에서, 5' WT-ITR은 AAV의 하나의 혈청형으로부터 유래될 수 있고, 3' WT-ITR은 AAV의 상이한 혈청형으로부터 유래될 수 있으므로 WT-ITR은 동일한 역 보체가 아니다. 예를 들어, 5' WT-ITR은 AAV2로부터 유래될 수 있고, 3' WT-ITR은 상이한 혈청형 (예를 들어, AAV1, 3, 4, 5, 6, 7, 8, 9, 10, 11 및 12)으로부터 유래될 수 있다. 일부 구현예에서, WT-ITR은 AAV1, AAV2, AAV3, AAV4, AAV5, AAV6, AAV7, AAV8, AAV9, AAV10, AAV11, AAV12, AAV13, 뱀 파보바이러스 (예를 들어, 로얄 피톤(royal python) 파보바이러스), 소 파보바이러스, 염소 파보바이러스, 조류 파보바이러스, 개 파보바이러스, 말 파보바이러스, 새우 파보바이러스, 돼지 파보바이러스 또는 곤충 AAV 중 어느 것으로부터 선택된 2개의 상이한 파보바이러스로부터 선택될 수 있다. 일부 구현예에서, 이러한 WT ITR의 조합은 AAV2 및 AAV6으로부터의 WT-ITR의 조합이다. 일 구현예에서, 실질적으로 대칭인 WT-ITR은 하나가 다른 ITR에 대해 반전될 때, 적어도 90% 동일하고, 적어도 95% 동일하고, 적어도 96% ... 97% ... 98% ... 99% .... 99.5% 및 그 사이의 모든 포인트 동일하고, 동일한 대칭 3차원 공간 구성을 갖는다. 일부 구현예에서, WT-ITR 쌍은 대칭인 3차원 공간 구성, 예를 들어, A, C-C'. B-B' 및 D 아암의 동일한 3D 구성을 갖기 때문에 실질적으로 대칭이다. 일 구현예에서, 실질적으로 대칭인 WT-ITR 쌍은 다른 것에 대해 반전되고, 서로 적어도 95% 동일하고, 적어도 96% ... 97% ... 98% ... 99% .... 99.5% 및 그 사이의 모든 포인트 동일하고, 하나의 WT-ITR은 5'-GCGCGCTCGCTCGCTC-3'(서열 번호: 60)의 Rep-결합 부위 (RBS) 및 말단 분해 부위 (trs)를 보유한다. 일부 구현예에서, 실질적으로 대칭인 WT-ITR 쌍은 서로 반전되고, 서로 적어도 95% 동일하고, 적어도 96% ... 97% ... 98% ... 99% .... 99.5% 및 그 사이의 모든 포인트 동일하고, 하나의 WT-ITR은 헤어핀 이차 구조 형성을 허용하는 가변 팔린드롬 서열에 추가하여 5'-GCGCGCTCGCTCGCTC-3' (서열 번호: 60)의 Rep-결합 부위 (RBS) 및 말단 분해 부위 (trs)를 보유한다. 상동성은 디폴트 설정에서 BLAST (기본 지역 정렬 검색 도구), BLASTN과 같은 당 업계에 잘 알려진 표준 수단에 의해 결정될 수 있다.
일부 구현예에서, ITR의 구조적 요소는 큰 Rep 단백질 (예를 들어, Rep 78 또는 Rep 68)과 ITR의 기능적 상호 작용에 관여하는 임의의 구조적 요소일 수 있다. 특정 구현예에서, 구조적 요소는 큰 Rep 단백질과 ITR의 상호 작용에 대한 선택성을 제공하고, 즉, Rep 단백질이 ITR과 기능적으로 상호 작용하는 것을 적어도 부분적으로 결정한다. 다른 구현예에서, Rep 단백질이 ITR에 결합될 때 구조적 요소는 큰 Rep 단백질과 물리적으로 상호 작용한다. 각각의 구조적 요소는, 예를 들어, ITR의 2차 구조, ITR의 뉴클레오티드 서열, 2개 이상의 요소 사이의 간격, 또는 임의의 상기의 조합일 수 있다. 일 구현예에서, 구조적 요소는 A 및 A' 아암, B 및 B' 아암, C 및 C' 아암, D 아암, Rep 결합 부위 (RBE) 및 RBE' (즉, 상보적인 RBE 서열) 및 말단 분해 부위 (trs)로 구성된 군으로부터 선택된다.
단지 예로서, 표 6은 WT-ITR의 예시적인 조합을 나타낸다.
표 6: 동일한 혈청형 또는 상이한 혈청형 또는 상이한 파로바이러스로부터의 WT-ITR의 예시적인 조합. 표시된 순서는 ITR 위치를 나타내지 않으며, 예를 들어, "AAV1, AAV2"는 ceDNA가 5' 위치에 WT-AAV1 ITR을, 3' 위치에 WT-AAV2 ITR을 포함할 수 있고, 반대로, 5' 위치에 WT-AAV2 ITR 및 3' 위치에 WT-AAV1 ITR을 포함할 수 있음을 나타낸다. 약어: AAV 혈청형 1 (AAV1), AAV 혈청형 2 (AAV2), AAV 혈청형 3 (AAV3), AAV 혈청형 4 (AAV4), AAV 혈청형 5 (AAV5), AAV 혈청형 6 (AAV6), AAV 혈청형 7 (AAV7) AAV 혈청형 8 (AAV8), AAV 혈청형 9 (AAV9), AAV 혈청형 10 (AAV10), AAV 혈청형 11 (AAV11) 또는 AAV 혈청형 12 (AAV12); AAVrh8, AAVrh10, AAV-DJ 및 AAV-DJ8 게놈 (예를 들어, NCBI: NC 002077; NC 001401; NC001729; NC001829; NC006152; NC 006260; NC 006261), 온혈 동물로부터의 ITR (조류 AAV (AAAV), 소 AAV (BAAV), 개, 말 및 양 AAV), B19 파보비리스로부터의 ITR (GenBank 수탁 번호: NC 000883), 마우스로부터의 미세 바이러스 (MVM) (GenBank 수탁 번호 NC 001510); 거위: 거위 파보바이러스 (GenBank 수탁 번호 NC 001701); 뱀: 뱀 파보바이러스 1 (GenBank 수탁 번호 NC 006148).
표 6:



단지 예로서, 표 7은 일부 상이한 AAV 혈청형으로부터의 예시적인 WT-ITR의 서열을 보여준다.
표 7


일부 구현예에서, WT-ITR 서열의 뉴클레오티드 서열은 (예를 들어, 1, 2, 3, 4 또는 5개 이상의 뉴클레오티드 또는 그 안의 임의의 범위의 뉴클레오티드를 변형시킴으로써) 변형될 수 있는데, 변형은 상보적 뉴클레오티드에 대한 치환이고, 예를 들어, C 대신 G, 및 그 반대, 및 A 대신 T, 및 그 반대이다.
본 발명의 특정 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 서열 번호: 1, 2, 5-14 중 임의의 것으로부터 선택된 뉴클레오티드 서열로 구성된 WT-ITR을 갖지 않는다. 본 발명의 대안의 구현예에서, ceDNA 벡터가 서열 번호: 1, 2, 5-14 중 임의의 것으로부터 선택된 뉴클레오티드 서열을 포함하는 WT-ITR을 갖는 경우, 플랭킹 ITR은 또한 WT이고, ceDNA 벡터는 예를 들어, 본원 및 PCT/US18/49996 (예를 들어, PCT/US18/49996의 표 11 참조)에 개시된 바와 같은 조절 스위치를 포함한다. 일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 본원에 개시된 바와 같은 조절 스위치 및 서열 번호: 1, 2, 5-14로 구성된 군 중 어느 것으로부터 선택된 뉴클레오티드 서열을 갖는 선택된 WT-ITR을 포함한다.
본원에 기재된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 작동 가능한 RBE, trs 및 RBE' 부분을 보유하는 WT-ITR 구조를 포함할 수 있다. 도 2a 및 도 2b는 예시적인 목적으로 야생형 ITR을 사용하여 ceDNA 벡터의 야생형 ITR 구조 부분 내에서 trs 부위의 작동을 위한 하나의 가능한 메커니즘을 보여준다. 일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 Rep-결합 부위 (RBS; AAV2에 대해 5'-GCGCGCTCGCTCGCTC-3'(서열 번호: 60)) 및 말단 분해 부위 (TRS; 5'-AGTT (서열 번호: 62))를 포함하는 하나 이상의 기능성 WT-ITR 폴리뉴클레오티드 서열을 함유한다. 일부 구현예에서, 적어도 하나의 WT-ITR은 기능적이다. 대안적인 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터가 서로 실질적으로 대칭인 2개의 WT-ITR을 포함하는 경우, 적어도 하나의 WT-ITR은 기능적이고 적어도 하나의 WT-ITR은 비-기능적이다.
B. 비대칭
ITR
쌍 또는 대칭
ITR
쌍을 포함하는
ceDNA
벡터에 대한 일반적으로 변형된
ITR
(모드-
ITR
)
본원에서 논의된 바와 같이, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 대칭 ITR 쌍 또는 비대칭 ITR 쌍을 포함할 수 있다. 두 경우 모두에서, ITR의 하나 또는 둘 모두는 변형된 ITR일 수 있으며, 차이점은 첫 번째 경우 (즉, 대칭 모드-ITR), 모드-ITR은 동일한 3차원 공간 구성을 가지며 (즉, 동일한 A-A', C-C' 및 B-B' 아암 구성를 가짐), 반면 두 번째 경우 (즉, 비대칭 모드-ITR), 모드-ITR은 다른 3차원 공간 구성을 갖는다 (즉, A-A', C-C' 및 B-B' 아암의 다른 구성을 가짐).
일부 구현예에서, 변형된 ITR은 야생형 ITR 서열 (예를 들어 AAV ITR)과 비교하여 결실, 삽입 및/또는 치환에 의해 변형된 ITR이다. 일부 구현예에서, ceDNA 벡터의 ITR 중 적어도 하나는 기능적 Rep 결합 부위 (RBS; 예를 들어, AAV2에 대해 5'-GCGCGCTCGCTCGCTC-3', 서열 번호: 60) 및 기능성 말단 분해 부위 (TRS; 5'-AGTT-3', 서열 번호: 62)를 포함한다. 일 구현예에서, ITR 중 적어도 하나는 비-기능적 ITR이다. 일 구현예에서, 상이한 또는 변형된 ITR은 각각 상이한 혈청형으로부터의 야생형 ITR이 아니다.
ITR에서의 특정 변경 및 돌연변이는 본원에 상세하게 기술되어 있지만, ITR의 맥락에서, "변경된" 또는 "돌연변이된" 또는 "변형된"은, 뉴클레오티드가 야생형, 참조 또는 원래 ITR 서열에 대해 삽입, 결실 및/또는 치환된 것을 나타낸다. 변경된 또는 돌연변이된 ITR은 조작된 ITR일 수 있다. 본원에 사용된 "조작된"은 인간의 손에 의해 조작된 측면을 지칭한다. 예를 들어, 폴리펩티드의 적어도 하나의 측면, 예를 들어, 이의 서열이 사람의 손에 의해 조작되어 자연에 존재하는 측면과 상이할 때 폴리펩티드가 "조작된" 것으로 간주된다.
일부 구현예에서, 모드-ITR은 합성일 수 있다. 일 구현예에서, 합성 ITR은 하나 초과의 AAV 혈청형으로부터의 ITR 서열에 기초한다. 또 다른 구현예에서, 합성 ITR은 AAV 기반 서열을 포함하지 않는다. 또 다른 구현예에서, 합성 ITR은 AAV에서 얻어진 서열의 일부만을 갖거나 갖지 않더라도 상기 기술된 ITR 구조를 보존한다. 일부 측면에서, 합성 ITR은 야생형 Rep 또는 특정 혈청형의 Rep와 우선적으로 상호 작용할 수 있거나, 일부 경우 야생형 Rep에 의해 인식되지 않고 돌연변이된 Rep에 의해서만 인식될 것이다.
당업자는 공지된 수단에 의해 다른 혈청형에서 상응하는 서열을 결정할 수 있다. 예를 들어, 변화가 A, A', B, B', C, C' 또는 D 영역에 있는지 확인하고 또 다른 혈청형에서 해당 영역을 결정한다. BLAST® (기본 지역 정렬 검색 도구) 또는 다른 상동성 정렬 프로그램을 디폴트 상태로 사용하여 상응하는 서열을 결정할 수 있다. 본 발명은 또한 상이한 AAV 혈청형의 조합으로부터의 모드-ITR을 포함하는 ceDNA 벡터의 집단 및 복수의 ceDNA 벡터를 제공하고, 즉, 하나의 모드-ITR은 하나의 AAV 혈청형으로부터 유래될 수 있고, 다른 모드-ITR은 상이한 혈청형으로부터 유래될 수 있다. 이론에 구속되지 않고, 일 구현예에서 하나의 ITR은 AAV2 ITR 서열로부터 유래하거나 이를 기초로 할 수 있고, ceDNA 벡터의 다른 ITR은 AAV 혈청형 1 (AAV1), AAV 혈청형 4 (AAV4), AAV 혈청형 5 (AAV5), AAV 혈청형 6 (AAV6), AAV 혈청형 7 (AAV7), AAV 혈청형 8 (AAV8), AAV 혈청형 9 (AAV9), AAV 혈청형 10 (AAV10) , AAV 혈청형 11 (AAV11), 또는 AAV 혈청형 12 (AAV12)의 임의의 하나 이상의 ITR 서열로부터 유래하거나 이를 기초로 할 수 있다.
임의의 파보바이러스 ITR은 변형을 위해 ITR 또는 기본 ITR로 사용될 수 있다. 바람직하게는, 파보바이러스는 데펜도바이러스이다. 보다 바람직하게는 AAV. 선택된 혈청형은 혈청형의 조직 향성(tropism)에 기초할 수 있다. AAV2는 광범위한 조직 향성을 가지며, AAV1은 뉴런 및 골격근을 우선적으로 표적화하고, AAV5는 뉴런, 망막 색소 상피 및 광수용체를 우선적으로 표적화한다. AAV6은 골격근 및 폐를 우선적으로 표적화한다. AAV8은 간, 골격근, 심장 및 췌장 조직을 우선적으로 표적화한다. AAV9는 간, 골격 및 폐 조직을 우선적으로 표적화한다. 일 구현예에서, 변형된 ITR은 AAV2 ITR에 기초한다.
보다 구체적으로, 구조적 요소가 특정한 큰 Rep 단백질과 기능적으로 상호 작용하는 능력은 구조적 요소를 변형시킴으로써 변경될 수 있다. 예를 들어, 구조적 요소의 뉴클레오티드 서열은 ITR의 야생형 서열과 비교하여 변형될 수 있다. 일 구현예에서, ITR의 구조적 요소 (예를 들어, A 아암, A' 아암, B 아암, B' 아암, C 아암, C' 아암, D 아암, RBE, RBE' 및 trs)는 제거되고 다른 파보바이러스로부터의 야생형 구조적 요소로 대체될 수 있다. 예를 들어, 대체 구조는 AAV1, AAV2, AAV3, AAV4, AAV5, AAV6, AAV7, AAV8, AAV9, AAV10, AAV11, AAV12, AAV13, 뱀 파보바이러스 (예를 들어, 로얄 피톤 파보바이러스), 소 파보바이러스, 염소 파보바이러스, 조류 파보바이러스, 개 파보바이러스, 말 파보바이러스, 새우 파보바이러스, 돼지 파보바이러스 또는 곤충 AAV로부터 유래될 수 있다. 예를 들어, ITR은 AAV2 ITR일 수 있고, A 또는 A' 아암 또는 RBE는 AAV5로부터의 구조적 요소로 대체될 수 있다. 또 다른 예에서, ITR은 AAV5 ITR일 수 있고, C 또는 C' 아암, RBE, 및 trs는 AAV2로부터의 구조적 요소로 대체될 수 있다. 또 다른 예에서, AAV ITR은 AAV2 ITR B 및 B' 아암으로 대체된 B 및 B' 아암을 갖는 AAV5 ITR일 수 있다.
단지 예로서, 표 8은 변형된 ITR의 영역에서 적어도 하나의 뉴클레오티드의 예시적인 변형 (예를 들어, 결실, 삽입 및/또는 치환)을 나타내며, 여기서 X는 상응하는 야생형 ITR에 대한 해당 섹션에서의 적어도 하나의 핵산의 변형 (예를 들어, 결실, 삽입 및/또는 치환)을 나타낸다. 일부 구현예에서, C 및/또는 C' 및/또는 B 및/또는 B'의 임의의 영역에서 적어도 하나의 뉴클레오티드의 임의의 변형 (예를 들어, 결실, 삽입 및/또는 치환)은 적어도 하나의 말단 루프에서 3개의 순차적인 T 뉴클레오티드 (즉, TTT)를 보유한다. 예를 들어, 변형 결과, 단일 아암 ITR (예를 들어, 단일 C-C' 아암 또는 단일 B-B' 아암) 또는 변형된 C-B' 아암 또는 C'-B 아암, 또는 적어도 하나의 절단된 아암 (예를 들어, 절단된 C-C' 아암 및/또는 절단된 B-B' 아암)을 갖는 2개의 아암 ITR 중 어느 것이 된다면, 적어도 하나의 단일 아암 또는 2개의 아암 ITR 중 적어도 하나의 아암 (하나의 아암이 절단될 수 있는 경우)은 적어도 하나의 말단 루프에서 순차적인 T 뉴클레오티드 (즉, TTT)를 보유한다. 일부 구현예에서, 절단된 C-C' 아암 및/또는 절단된 B-B' 아암은 말단 루프에서 3개의 순차적인 T 뉴클레오티드 (즉, TTT)를 갖는다.
표 8: ITR의 상이한 B-B' 및 C-C' 영역 또는 아암에 대한 적어도 하나의 뉴클레오티드 변형 (예를 들어, 결실, 삽입 및/또는 치환)의 예시적인 조합 (X는 뉴클레오티드 변형, 예를 들어, 상기 영역에서 적어도 하나의 뉴클레오티드의 첨가, 결실 또는 치환을 나타냄).

일부 구현예에서, 비대칭 ITR 쌍, 또는 본원에 개시된 바와 같은 대칭 모드-ITR 쌍을 포함하는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터에 사용하기 위한 모드-ITR은 표 8에 나타낸 변형, 및 또한 A'와 C 사이, C와 C' 사이, C'와 B 사이, B와 B' 사이, 및 B'와 A 사이에서 선택된 영역 중 어느 하나 이상에서 적어도 하나의 뉴클레오티드의 변형의 조합 중 어느 하나를 포함할 수 있다. 일부 구현예에서, C 또는 C' 또는 B 또는 B' 영역에서 적어도 하나의 뉴클레오티드의 임의의 변형 (예를 들어, 결실, 삽입 및/또는 치환)은 여전히 스템-루프의 말단 루프를 보존한다. 일부 구현예에서, C 및 C' 및/또는 B 및 B' 사이의 적어도 하나의 뉴클레오티드의 임의의 변형 (예를 들어, 결실, 삽입 및/또는 치환)은 적어도 하나의 말단 루프에 3개의 순차적인 T 뉴클레오티드 (즉, TTT)를 보유한다. 대안적인 구현예에서, C 및 C' 및/또는 B 및 B' 사이의 적어도 하나의 뉴클레오티드의 임의의 변형 (예를 들어, 결실, 삽입 및/또는 치환)은 적어도 하나의 말단 루프에 3개의 순차적인 A 뉴클레오티드 (즉, AAA)를 보유한다 일부 구현예에서, 본원에 사용하기 위한 변형된 ITR은 표 8에 나타낸 변형, 및 또한 A', A 및/또는 D로부터 선택된 영역 중 임의의 하나에서 적어도 하나의 뉴클레오티드의 변형 (예를 들어, 결실, 삽입 및/또는 치환)의 조합 중 임의의 하나를 포함할 수 있다. 예를 들어, 일부 구현예에서, 본원에 사용하기 위한 변형된 ITR은 표 8에 나타낸 변형, 및 또한 A 영역에서 적어도 하나의 뉴클레오티드 변형 (예를 들어, 결실, 삽입 및/또는 치환)의 조합 중 임의의 하나를 포함할 수 있다. 일부 구현예에서, 본원에 사용하기 위한 변형된 ITR은 표 8에 나타낸 변형, 및 또한 A' 영역에서 적어도 하나의 뉴클레오티드 변형 (예를 들어, 결실, 삽입 및/또는 치환)의 조합 중 임의의 하나를 포함할 수 있다. 일부 구현예에서, 본원에 사용하기 위한 변형된 ITR은 표 8에 나타낸 변형, 및 또한 A 및/또는 A' 영역에서 적어도 하나의 뉴클레오티드 변형 (예를 들어, 결실, 삽입 및/또는 치환)의 조합 중 임의의 하나를 포함할 수 있다. 일부 구현예에서, 본원에 사용하기 위한 변형된 ITR은 표 8에 나타낸 변형, 및 또한 D 영역에서 적어도 하나의 뉴클레오티드 변형 (예를 들어, 결실, 삽입 및/또는 치환)의 조합 중 임의의 하나를 포함할 수 있다.
일 구현예에서, 구조적 요소의 뉴클레오티드 서열을 (예를 들어, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 또는 20개 이상의 뉴클레오티드 또는 그 안의 임의의 범위의 뉴클레오티드를 변형함으로써) 변형시켜 변형된 구조적 요소를 생성할 수 있다. 일 구현예에서, ITR에 대한 특정 변형은 본원에 예시되어 있거나 (예를 들어, 2018년 12월 6일에 출원된 PCT/US2018/064242의 서열 번호: 3, 4, 15-47, 101-116 또는 165-187, 또는 도 7a-7b에 도시됨 (예를 들어, PCT/US2018/064242 중의 서열번호: 97-98, 101-103, 105-108, 111-112, 117-134, 545-54)에 도시되어 있다. 일부 구현예에서, ITR은 (예를 들어, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 또는 20개 이상의 뉴클레오티드 또는 그 안의 임의의 범위의 뉴클레오티드를 변형시킴으로써) 변형될 수 있다. 다른 구현예에서, ITR은 서열 번호: 3, 4, 15-47, 101-116 또는 165-187의 변형된 ITR, 또는 서열 번호: 3, 4, 15-47, 101-116 또는 165-187의 A-A' 아암 및 C-C' 및 B-B' 아암의 RBE-함유 섹션, 또는 국제 출원 PCT/US18/49996 (이는 그 전문이 본원에 참고로 포함됨)의 표 2-9 (즉, 서열 번호: 110-112, 115-190, 200-468)에 나타낸 것 중 하나와 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99% 또는 그 이상의 서열 동일성을 가질 수 있다.
일부 구현예에서, 변형된 ITR은 예를 들어 특정 아암의 전부, 예를 들어, A-A' 아암의 전부 또는 일부, 또는 B-B' 아암의 전부 또는 일부 또는 C-C' 아암의 전부 또는 일부의 제거 또는 결실, 또는 대안적으로, 스템 (예를 들어, 단일 아암)을 캡핑하는 최종 루프가 존재하는 한 루프의 스템을 형성하는 1, 2, 3, 4, 5, 6, 7, 8, 9개 이상의 염기쌍의 제거를 포함할 수 있다 (예를 들어, 2018년 12월 6일에 출원된 PCT/US2018/064242의 도 7a의 ITR-21 참조). 일부 구현예에서, 변형된 ITR은 B-B' 아암으로부터 1, 2, 3, 4, 5, 6, 7, 8, 9개 이상의 염기쌍의 제거를 포함할 수 있다. 일부 구현예에서, 변형된 ITR은 C-C' 아암으로부터 1, 2, 3, 4, 5, 6, 7, 8, 9개 이상의 염기쌍의 제거를 포함할 수 있다 (예를 들어, 2018년 12월 6일에 출원된 PCT/US2018/064242의 도 3b의 ITR-1 또는 도 7a의 ITR-45 참조). 일부 구현예에서, 변형된 ITR은 C-C' 아암으로부터 1, 2, 3, 4, 5, 6, 7, 8, 9개 이상의 염기쌍의 제거 및 B-B' 아암으로부터 1, 2, 3, 4, 5, 6, 7, 8, 9개 이상의 염기쌍의 제거를 포함할 수 있다. 염기쌍의 제거의 임의의 조합이 구상되며, 예를 들어, C-C' 아암에서 6개의 염기쌍이 제거될 수 있고, B-B' 아암에서 2개의 염기쌍이 제거될 수 있다. 예시적인 예로서, 도 3b는 각각의 C 부분 및 C' 부분으로부터 결실된 적어도 7개의 염기쌍, C 및 C' 영역 사이의 루프에서 뉴클레오티드의 치환, 및 변형된 ITR이 적어도 하나의 아암 (예를 들어, C-C')이 절단된 2개의 아암을 포함하도록 B 영역 및 B' 영역 각각으로부터 적어도 하나의 염기쌍 결실을 갖는 예시적인 변형된 ITR을 보여준다. 일부 구현예에서, 변형된 ITR은 또한, B-B' 아암이 WT ITR에 대해 또한 절단되도록 B 영역 및 B' 영역 각각으로부터 적어도 하나의 염기쌍 결실을 포함한다.
일부 구현예에서, 변형된 ITR은 전장 야생형 ITR 서열에 대해 1 내지 50개 (예를 들어, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49 또는 50개)의 뉴클레오티드 결실을 가질 수 있다. 일부 구현예에서, 변형된 ITR은 전장 WT ITR 서열에 대해 1 내지 30개의 뉴클레오티드 결실을 가질 수 있다. 일부 구현예에서, 변형된 ITR은 전장 야생형 ITR 서열에 대해 2 내지 20개의 뉴클레오티드 결실을 갖는다.
일부 구현예에서, 변형된 ITR은 A 또는 A' 영역의 RBE-함유 부분에서 임의의 뉴클레오티드 결실을 함유하지 않아서 DNA 복제 (예를 들어, Rep 단백질에 의한 RBE에의 결합 또는 말단 분해 부위에서의 닉킹)를 방해하지 않는다. 일부 구현예에서, 본원에 사용하기 위해 포함된 변형된 ITR은 본원에 기재된 바와 같이 B, B', C 및/또는 C 영역에서 하나 이상의 결실을 갖는다.
일부 구현예에서, 대칭 ITR 쌍 또는 비대칭 ITR 쌍을 포함하는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 본원에 개시된 바와 같은 조절 스위치 및 서열 번호: 3, 4, 15-47, 101-116 또는 165-187로 구성된 군 중 어느 것으로부터 선택된 뉴클레오티드 서열을 갖는 선택된 적어도 하나의 변형된 ITR을 포함한다.
또 다른 구현예에서, 구조적 요소의 구조는 변형될 수 있다. 예를 들어, 구조적 요소는 스템의 높이 및/또는 루프에서 뉴클레오티드 수의 변화이다. 예를 들어, 스템의 높이는 약 2, 3, 4, 5, 6, 7, 8 또는 9개 이상의 뉴클레오티드 또는 그 안의 임의의 범위일 수 있다. 일 구현예에서, 스템 높이는 약 5개의 뉴클레오티드 내지 약 9개의 뉴클레오티드일 수 있고, Rep와 기능적으로 상호 작용할 수 있다. 또 다른 구현예에서, 스템 높이는 약 7개의 뉴클레오티드일 수 있고, Rep와 기능적으로 상호 작용할 수 있다. 또 다른 예에서, 루프는 3, 4, 5, 6, 7, 8, 9 또는 10개 이상의 뉴클레오티드 또는 그 안의 임의의 범위를 가질 수 있다.
또 다른 구현예에서, RBE 또는 확장된 RBE 내의 GAGY 결합 부위 또는 GAGY 관련 결합 부위의 수는 증가 또는 감소될 수 있다. 일 예에서, RBE 또는 확장된 RBE는 1, 2, 3, 4, 5 또는 6개 이상의 GAGY 결합 부위 또는 그 안의 임의의 범위를 포함할 수 있다. 서열이 Rep 단백질에 결합하기에 충분하다면, 각각의 GAGY 결합 부위는 독립적으로 정확한 GAGY 서열 또는 GAGY와 유사한 서열일 수 있다.
또 다른 구현예에서, 두 요소 (예컨대 비제한적으로 RBE 및 헤어핀) 사이의 간격은 큰 Rep 단백질과의 기능적 상호 작용을 변경하기 위해 변경 (예를 들어, 증가 또는 감소)될 수 있다. 예를 들어, 간격은 약 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 또는 21개 이상의 뉴클레오티드 또는 그 안의 임의의 범위일 수 있다.
본원에 기재된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 본원에 개시된 야생형 AAV2 ITR 구조와 관련하여 변형된 ITR 구조를 포함할 수 있지만 여전히 작동 가능한 RBE, trs 및 RBE' 부분을 보유한다. 도 2a 및 도 2b는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 야생형 ITR 구조 부분 내에서 trs 부위의 작동을 위한 하나의 가능한 메커니즘을 보여준다. 일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 Rep-결합 부위 (RBS; 5'-GCGCGCTCGCTCGCTC-3' (AAV2의 경우 서열번호 60)) 및 말단 확인 부위 (TRS; 5'-AGTT (서열 번호 62))를 포함하는 하나 이상의 기능성 ITR 폴리뉴클레오티드 서열 를 함유한다. 일부 구현예에서, 하나 이상의 ITR (wt 또는 변형된 ITR)은 기능적이다. 대안적 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터가 서로 상이하거나 비대칭인 2 개의 변형된 ITR을 포함하는 경우, 하나 이상의 변형된 ITR은 기능적이고 하나 이상의 변형된 ITR은 비-기능적이다.
일부 구현예에서, 본원에 기재된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 변형된 ITR (예를 들어, 좌측 또는 우측 ITR)은 루프 아암, 절단된 아암 또는 스페이서 내에서 변형을 갖는다. 루프 암, 절단된 암 또는 스페이서 내에서 변형을 갖는 ITR의 예시적인 서열은 국제 출원 PCT/US18/49996의 표 2 (즉, 서열 번호: 135-190, 200-233); 표 3 (예를 들어, 서열 번호: 234-263); 표 4 (예를 들어, 서열 번호: 264-293); 표 5 (예를 들어, 본원의 서열 번호: 294-318); 표 6 (예를 들어, 서열 번호: 319-468; 및 표 7-9 (예를 들어, 서열 번호: 101-110, 111-112, 115-134)) 또는 표 10A 또는 10B (예를 들어, 서열 번호: 9, 100, 469-483, 484-499)에 열거되어 있으며, 이는 그 전문이 본원에 참조로 포함된다.
일부 구현예에서, 비대칭 ITR 쌍 또는 대칭 mod-ITR 쌍을 포함하는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터에 사용하기 위한 변형된 ITR은 국제 출원 PCT/US18/49996의 표 2, 3, 4, 5, 6, 7, 8, 9 및 10A-10B에 나타나며, 본원에 그 전체가 참조로 포함된다.
상기 클래스 각각에서 비대칭 ITR 쌍, 또는 대칭 mod-ITR 쌍을 포함하는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터에 사용하기 위한 추가의 예시적인 변형된 ITR이 표 9A 및 9B에 제공되어 있다. 표 9A에서 우측 변형된 ITR의 예측된 이차 구조는 2018년 12월 6일에 출원된 국제 출원 PCT/US2018/064242의 도 7A 및 표 9B에서 좌측 변형된 ITR의 예측된 2차 구조가 2018년 12월 6일에 출원된 국제 출원 PCT/US2018/064242의 도 7B에 도시되며, 본원에 그 전체가 참조로 포함된다.
표 9A 및 표 9B는 예시적인 우측 및 좌측 변형된 ITR을 나타낸다.
표 9A: 예시적인 변형된 우측 ITR. 이러한 예시적인 변형된 우측 ITR은 GCGCGCTCGCTCGCTC-3'의 RBE (서열 번호: 60), ACTGAGGC의 스페이서 (서열 번호: 69), 스페이서 보체 GCCTCAGT (서열 번호: 70) 및 RBE' (즉, GAGCGAGCGAGCGCGC (서열 번호 71)의 RBE에 대한 보체).


표 9B : 예시적인 변형된 좌측 ITR. 이러한 예시적인 변형된 좌측 ITR은 GCGCGCTCGCTCGCTC-3'의 RBE (서열 번호: 60), ACTGAGGC의 스페이서 (서열 번호: 69), 스페이서 보체 GCCTCAGT (서열 번호: 70) 및 GAGCGAGCGAGCGCGC (서열 번호 71)의 RBE 보체 (RBE')을 포함할 수 있다.


일 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 5'에서 3'의 방향으로 제1 아데노-관련 바이러스 (AAV) 역 말단 반복부 (ITR), 관심 뉴클레오티드 서열 (예를 들어 본원에 기재된 발현 카세트) 및 제2 AAV ITR을 포함하고, 여기서 제1 ITR (5' ITR) 및 제2 ITR (3' ITR)은 서로 비대칭이고, 즉, 이들은 서로 상이한 3차원 구성을 갖는다. 예시적인 구현예로서, 제1 ITR은 야생형 ITR일 수 있고, 제2 ITR은 돌연변이되거나 변형된 ITR일 수 있거나, 반대로, 제1 ITR이 돌연변이되거나 변형된 ITR이고, 제2 ITR이 야생형 ITR일 수 있다. 일부 구현예에서, 제1 ITR 및 제2 ITR은 둘 다 모드-ITR이지만, 상이한 서열, 또는 상이한 변형을 갖고, 따라서 동일한 변형된 ITR이 아니며, 상이한 3D 공간 구성을 갖는다. 다르게 말하면, 비대칭 ITR을 갖는 ceDNA 벡터는 WT-ITR에 대해 하나의 ITR에서의 임의의 변화가 다른 ITR에 반영되지 않거나; 또는 대안적으로, 비대칭 ITR이, 서로 상이한 서열 및 상이한 3차원 형상을 가질 수 있는 변형된 비대칭 ITR 쌍을 갖는 ITR을 포함한다. 항체 또는 융합 단백질 생산 및 ceDNA-플라스미드를 생성하는데 사용하기 위한 ceDNA 벡터 내의 예시적인 비대칭 ITR은 표 9A 및 9B에서 보여준다.
대안적 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 2개의 대칭인 모드-ITR을 포함하며, 즉, 두 ITR은 동일한 서열을 갖지만, 서로의 역 보체 (역상)이다. 일부 구현예에서, 대칭 모드-ITR 쌍은 동일한 AAV 혈청형으로부터의 야생형 ITR 서열에 대한 결실, 삽입 또는 치환 중 적어도 하나 또는 임의의 조합을 포함한다. 대칭 ITR에서의 첨가, 결실 또는 치환은 동일하지만 서로의 역 보체이다. 예를 들어, 5' ITR의 C 영역에서 3개의 뉴클레오티드의 삽입은 3' ITR의 C' 영역에서의 상응하는 섹션에서 3개의 역 보체 뉴클레오티드의 삽입에 반영될 것이다. 단지 설명의 목적으로만, 5' ITR에서 첨가가 AACG인 경우, 상응하는 부위에서의 3' ITR에서 첨가는 CGTT이다. 예를 들어, 5' ITR 센스 가닥이 ATCGATCG인 경우, G와 A 사이에 AACG가 첨가되어 ATCG AACG ATCG 서열 (서열번호: 51)이 생성된다. 상응하는 3' ITR 센스 가닥은 CGATCGAT (ATCGATCG의 역 보체)이고, T와 C 사이에 CGTT (즉, AACG의 역 보체)를 첨가하여 CGAT CGTT CGAT (서열번호: 49) (ATCG AACG ATCG의 역 보체) 서열 (서열번호: 51)이 생성된다.
대안적인 구현예에서, 변형된 ITR 쌍은 본원에 정의된 바와 같이 실질적으로 대칭이고, 즉, 변형된 ITR 쌍은 상이한 서열을 가질 수 있지만 대응하는 또는 동일한 대칭 3차원 형상을 가질 수 있다. 예를 들어, 하나의 변형된 ITR은 하나의 혈청형으로부터 유래될 수 있고, 다른 변형된 ITR은 상이한 혈청형으로부터 유래될 수 있지만, 이들은 동일한 영역에서 동일한 돌연변이 (예를 들어, 뉴클레오티드 삽입, 결실 또는 치환)를 갖는다. 달리 언급하면, 단지 설명의 목적으로, 5' 모드-ITR은 AAV2로부터 유래될 수 있고, C 영역에서 결실을 가질 수 있으며, 3' 모드-ITR은 AAV5로부터 유래될 수 있고, C' 영역에서 상응하는 결실을 가질 수 있으며, 5' 모드-ITR 및 3' 모드-ITR이 동일하거나 대칭인 3차원 공간 구성을 갖는 경우, 이들은 본 명세서에서 변형된 ITR 쌍으로 사용하기 위해 포함된다.
일부 구현예에서, 실질적으로 대칭인 모드-ITR 쌍은 3D 공간에서 동일한 A, C-C' 및 B-B' 루프를 가지며, 예를 들어, 실질적으로 대칭인 모드-ITR 쌍에서 변형된 ITR이 C-C' 아암의 결실을 갖는 경우, 동족 모드-ITR은 C-C' 루프의 상응하는 결실을 가지며 또한 이의 동족 모드-ITR의 기하학적 공간에서 동일한 형태로 나머지 A 및 B-B' 루프의 유사한 3D 구조를 갖는다. 단지 예로서, 실질적으로 대칭인 ITR은 그 구조가 기하학적 공간에서 동일한 형상이 되도록 대칭 공간 구성을 가질 수 있다. 이것은, 예를 들어, G-C 쌍이, 예를 들어, C-G 쌍으로 또는 그 반대로 변형될 때, 또는 A-T 쌍이 T-A 쌍으로 또는 그 반대로 변형될 때 발생할 수 있다. 따라서, ATCG AACG ATCG (서열 번호: 51)로서 변형된 5' ITR 및 CGAT CGTT CGAT (서열 번호: 49) (즉, ATCG AACG ATCG (서열 번호: 51)의 역 보체)로서 변형된 3' ITR의 상기 예시적인 예를 사용하면, 예를 들어, 5' ITR이 ATCG AAC C ATCG (서열 번호: 50)의 서열을 갖는 경우, 이러한 변형된 ITR은 여전히 대칭일 것이며, 여기서 첨가에서 G는 C로 변형되고, 실질적으로 대칭인 3' ITR은 A로의 첨가에서 T의 상응하는 변형 없이 CGATCGTT CGAT (서열 번호: 49)의 서열을 갖는다. 일부 구현예에서, 이러한 변형된 ITR 쌍은 변형된 ITR 쌍이 대칭 입체화학을 갖기 때문에 실질적으로 대칭이다.
표 10은 항체 또는 융합 단백질 생산을 위한 ceDAN 벡터에서 사용하기 위한 예시적인 대칭 변형된 ITR 쌍 (즉, 좌측 변형된 ITR 및 대칭 우측 변형된 ITR)을 보여준다. 서열의 굵은 체 (빨간색) 부분은 도 31a-46b에 또한 도시된 부분 ITR 서열 (즉, A-A', C-C' 및 B-B' 루프의 서열)을 식별한다. 이러한 예시적인 변형된 ITR은 GCGCGCTCGCTCGCTC-3' (서열 번호: 60)의 RBE, ACTGAGGC (서열 번호: 69)의 스페이서, 스페이서 보체 GCCTCAGT (서열 번호: 70) 및 GAGCGAGCGAGCGCGC (서열 번호: 71)의 RBE' (즉, RBE에 대한 보체)를 포함할 수 있다.






일부 구현예에서, 비대칭 ITR 쌍을 포함하는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 본원의 표 9A-9B 중 임의의 하나 이상에 나타낸 ITR 서열 또는 ITR 부분 서열 또는 2018년 12월 6일에 출원된 국제 출원 PCT/US2018/064242의 도 7a-도 7b에 도시된 서열(이는 그 전문이 본원에 참고로 포함), 또는 2018년 9월 7일에 출원된 국제 출원 PCT/US18/49996의 표 2, 3, 4, 5, 6, 7, 8, 9 또는 10A-10B에 개시된 서열에서의 임의의 변형에 상응하는 변형을 갖는 ITR을 포함할 수 있다.
V. 예시적인
ceDNA
벡터
상술한 바와 같이, 본 개시내용은 비대칭 ITR 쌍, 대칭 ITR 쌍, 또는 전술한 바와 같이 실질적으로 대칭인 ITR 쌍 중 임의의 하나를 포함하는 재조합 ceDNA 발현 벡터 및 항체 및 융합 단백질 생산을 위한 항체 및 융합 단백질을 인코딩하는 ceDNA 벡터에 관한 것이다. 특정 구현예에서, 본 개시내용은 플랭킹 ITR 서열 및 이식유전자를 갖는 항체 또는 융합 단백질 생산을 위한 재조합 ceDNA 벡터에 관한 것으로, 여기서 ITR 서열은 본원에 정의된 바와 같이 서로 비대칭, 대칭 또는 실질적으로 대칭이며, ceDNA는 플랭킹 ITR 사이에 위치한 관심 뉴클레오티드 서열 (예를 들어 이식유전자의 핵산을 포함하는 발현 카세트)을 추가로 포함하며, 여기서 상기 핵산 분자는 바이러스 캡시드 단백질 코딩 서열이 없다.
항체 또는 융합 단백질 생산을 위한 ceDNA 발현 벡터는 적어도 하나의 ITR이 변경된 경우 본원에 기재된 바와 같은 뉴클레오티드 서열(들)을 포함하는 재조합 DNA 절차에 편리하게 적용될 수 있는 임의의 ceDNA 벡터일 수 있다. 본 개시내용의 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 ceDNA 벡터가 도입될 숙주 세포와 양립 가능하다. 특정 구현예에서, ceDNA 벡터는 선형일 수 있다. 특정 구현예에서, ceDNA 벡터는 염색체외 엔티티로서 존재할 수 있다. 특정 구현예에서, 본 개시내용의 ceDNA 벡터는 공여체 서열을 숙주 세포의 게놈으로 통합시킬 수 있는 요소(들)를 함유할 수 있다. 본원에 사용된 "이식유전자" 및 "이종 뉴클레오티드 서열"은 동의어고, 본원에 기재된 항체 또는 융합 단백질을 인코딩한다.
이제 도 1a-1g를 참조하면, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 제조하는데 유용한 2개의 비제한적 플라스미드의 기능적 성분의 개략도가 도시되어 있다. 도 1a, 1b, 1d, 1f는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터 또는 상응하는 ceDNA 플라스미드 서열의 작제물을 보여준다. ceDNA 벡터는 캡시드가 없고, 제1 ITR, 발현성 이식유전자 카세트 및 제2 ITR의 순서로 인코딩된 플라스미드로부터 수득될 수 있으며, 여기서 제1 및 제2 ITR 서열은 본 명세서에서 정의된 바와 같이 서로 비대칭, 대칭 또는 실질적으로 대칭이다. 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 캡시드가 없고, 하기 순서로 코딩하는 플라스미드로부터 얻을 수 있다: 제1 ITR, 발현성 이식유전자 (단백질 또는 핵산) 및 제2 ITR, 여기서 제1 및 제2 ITR 서열은 본원에 정의된 바와 같이 서로에 대해 비대칭, 대칭 또는 실질적으로 대칭이다. 일부 구현예에서, 발현성 이식유전자 카세트는 필요에 따라 인핸서/프로모터, 하나 이상의 상동성 아암, 공여체 서열, 전사 후 조절 요소 (예를 들어, WPRE, 예를 들어, 서열번호 67)) 및 폴리아데닐화 및 종결 신호 (예를 들어, BGH 폴리A, 예를 들어, 서열번호 68)를 포함한다.
도 5는 실시예에 기재된 방법을 사용하여 다중 플라스미드 작제물로부터 ceDNA의 생성을 확인하는 겔이다. ceDNA는 상기 도 4a와 관련하여 그리고 실시예에서 논의된 바와 같이, 겔에서의 특징적인 밴드 패턴에 의해 확인된다.
A. 조절 요소.
본원에 정의된 비대칭 ITR 쌍 또는 대칭 ITR 쌍을 포함하는 본원에 기재된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 시스-조절 요소의 특정 조합을 추가로 포함한다. 시스-조절 요소는 프로모터, 리보스위치, 절연체, 미르-조절 가능 요소, 전사 후 조절 요소, 조직- 및 세포 유형-특이적 프로모터 및 인핸서를 포함하지만, 이에 제한되지는 않는다. 일부 구현예에서, ITR은 이식유전자, 예를 들어 항체 또는 융합 단백질의 프로모터로서 작용할 수 있다. 일부 구현예에서, 본원에 기재된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 이식유전자의 발현을 조절하기 위한 추가 성분, 예를 들어, 이식유전자의 발현을 조절하기 위한 본원에 기재된 조절 스위치, 또는 항체 또는 그의 항원 결합 단편을 인코딩하는 ceDNA 벡터를 포함하는 세포를 사멸시킬 수 있는 사멸 스위치를 포함한다. 본 발명에서 사용될 수 있는 조절 스위치를 포함하는 조절 요소는 국제 출원 PCT/US18/49996에 보다 상세하게 논의되어 있으며, 이의 전문이 본원에 참고로 포함된다.
구현예에서, 제2 뉴클레오티드 서열은 조절 서열, 및 뉴클레아제를 인코딩하는 뉴클레오티드 서열을 포함한다. 특정 구현예에서, 유전자 조절 서열은 뉴클레아제를 인코딩하는 뉴클레오티드 서열에 작동 가능하게 연결된다. 특정 구현예에서, 조절 서열은 숙주 세포에서 뉴클레아제의 발현을 제어하기에 적합하다. 특정 구현예에서, 조절 서열은 프로모터 서열에 작동 가능하게 연결된 유전자, 예컨대 본 개시내용의 뉴클레아제(들)를 인코딩하는 뉴클레오티드 서열의 전사를 지시할 수 있는, 적합한 프로모터 서열을 포함한다. 특정 구현예에서, 제2 뉴클레오티드 서열은 뉴클레아제를 인코딩하는 뉴클레오티드 서열의 5' 말단에 연결된 인트론 서열을 포함한다. 특정 구현예에서, 프로모터의 효능을 증가시키기 위해 인핸서 서열이 프로모터의 상류에 제공된다. 특정 구현예에서, 조절 서열은 인핸서 및 프로모터를 포함하고, 여기서 제2 뉴클레오티드 서열은 뉴클레아제를 인코딩하는 뉴클레오티드 서열의 상류에 있는 인트론 서열을 포함하고, 상기 인트론은 하나 이상의 뉴클레아제 절단 부위(들)를 포함하고, 상기 프로모터는 뉴클레아제를 인코딩하는 뉴클레오티드 서열에 작동 가능하게 연결된다.
합성적으로 또는 실시예에서 본원에 기재된 바와 같은 세포-기반 생산 방법을 사용하여 생산된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 시스-조절 요소, 예컨대 WHP 전사 후 조절 요소 (WPRE) (예를 들어, 서열 번호: 67) 및 BGH 폴리A (서열 번호: 68)의 특정 조합을을 추가로 포함할 수 있다. 발현 작제물에 사용하기에 적합한 발현 카세트는 바이러스 캡시드에 의해 부과된 패키징 제약에 의해 제한되지 않는다.
(i). 프로모터:
본원에 개시된 바와 같이 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터에 사용된 프로모터는 이들이 촉진하는 특정 서열에 적합하게 맞추어져야 한다는 것이 당업자에게 이해될 것이다.
항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 발현 카세트는 세포-특이성뿐만 아니라 전체 발현 수준에 영향을 줄 수 있는 프로모터를 포함한다. 이식유전자 발현 예를 들어, 항체 또는 항원-결합 단편 발현을 위해, 이들은 매우 활성인 바이러스-유래 즉각적인 조기 프로모터를 포함할 수 있다. 발현 카세트는 조직 특이적 진핵생물 프로모터를 함유하여 이식유전자 발현을 특정 세포 유형으로 제한하고 조절되지 않은 이소성 발현으로 인한 독성 효과 및 면역 반응을 감소시킬 수 있다. 특정 구현예에서, 발현 카세트는 합성 조절 요소, 예컨대 CAG 프로모터 (서열 번호: 72)를 함유할 수 있다. CAG 프로모터는 (i) 사이토메갈로바이러스 (CMV) 조기 인핸서 요소, (ii) 치킨 베타-액틴 유전자의 프로모터, 제1 엑손 및 제1 인트론, 및 (iii) 토끼 베타-글로빈 유전자의 스플라이스 수용체를 포함한다. 대안적으로, 발현 카세트는 알파-1-항트립신 (AAT) 프로모터 (서열 번호: 73 또는 서열 번호: 74), 간 특이적 (LP1) 프로모터 (서열 번호: 75 또는 서열 번호: 76), 또는 인간 신장 인자-1 알파 (EF1a) 프로모터 (예를 들어, 서열 번호: 77 또는 서열 번호: 78)를 함유할 수 있다. 일부 구현예에서, 발현 카세트는 하나 이상의 구성적 프로모터, 예를 들어, 레트로바이러스 라우스 육종 바이러스 (RSV) LTR 프로모터 (선택적으로 RSV 인핸서를 가짐) 또는 사이토메갈로바이러스 (CMV) 즉각적인 조기 프로모터 (선택적으로 CMV 인핸서, 예를 들어, 서열 번호: 79를 가짐)를 포함한다. 대안적으로, 유도성 프로모터, 이식유전자를 위한 천연 프로모터, 조직-특이적 프로모터, 또는 당 업계에 공지된 다양한 프로모터가 사용될 수 있다.
상기 기재된 것들을 포함하여, 적합한 프로모터는 바이러스로부터 유래될 수 있으며 따라서 바이러스 프로모터로 지칭될 수 있거나, 원핵생물 또는 진핵생물 유기체를 포함하는 임의의 유기체로부터 유래될 수 있다. 적합한 프로모터를 사용하여 임의의 RNA 폴리머라제 (예를 들어, pol I, pol II, pol III)에 의한 발현을 구동시킬 수 있다. 예시적인 프로모터는 SV40 조기 프로모터, 마우스 유방 종양 바이러스 긴 말단 반복 (LTR) 프로모터; 아데노바이러스 주요 후기 프로모터 (Ad MLP); 단순 포진 바이러스 (HSV) 프로모터, CMV 즉각적인 조기 프로모터 영역 (CMVIE)과 같은 사이토메갈로바이러스 (CMV) 프로모터, 라우스 육종 바이러스 (RSV) 프로모터, 인간 U6 소형 핵 프로모터 (U6, 예를 들어, 서열 번호: 80) (Miyagishi et al., Nature Biotechnology 20, 497-500 (2002)), 향상된 U6 프로모터 (예를 들어, Xia et al., Nucleic Acids Res. 2003 Sep. 1; 31(17)), 인간 H1 프로모터 (H1) (예를 들어, 서열 번호: 81 또는 서열번호: 155), CAG 프로모터, 인간 알파 1-안티팁신(antitypsin) (HAAT) 프로모터 (예를 들어, 서열 번호: 82) 등을 포함하지만, 이에 제한되지 않는다. 특정 구현예에서, 이들 프로모터는 하나 이상의 뉴클레아제 절단 부위를 포함하도록 하류 인트론 함유 말단에서 변경된다. 특정 구현예에서, 뉴클레아제 절단 부위(들)를 함유하는 DNA는 프로모터 DNA에 이질적이다.
일 구현예에서, 사용된 프로모터는 치료 단백질을 인코딩하는 유전자의 천연 프로모터이다. 치료 단백질을 인코딩하는 각각의 유전자에 대한 프로모터 및 다른 조절 서열은 공지되어 있고 특성화되어 있다. 사용된 프로모터 영역은 SV40 인핸서 (서열 번호 126)를 포함하는, 하나 이상의 추가 조절 서열 (예를 들어, 천연), 예를 들어 인핸서 (예를 들어, 서열 번호: 79 및 서열 번호: 83)를 추가로 포함할 수 있다.
일부 구현예에서, 프로모터는 또한 인간 유비퀴틴 C (hUbC), 인간 액틴, 인간 미오신, 인간 헤모글로빈, 인간 근육 크레아틴 또는 인간 메탈로티오네인과 같은 인간 유전자로부터의 프로모터일 수 있다. 프로모터는 또한 조직 특이적 프로모터, 예컨대 간 특이적 프로모터, 예컨대 인간 알파 1-안티팁신 (HAAT), 천연 또는 합성일 수 있다. 일 구현예에서, 간으로의 전달은 간세포 표면에 존재하는 저밀도 지단백질 (LDL) 수용체를 통해 간세포에 대한 ceDNA 벡터를 포함하는 조성물의 내인성 ApoE 특이적 표적화를 사용하여 달성될 수 있다.
본 발명에 따라 사용하기에 적합한 프로모터의 비제한적인 예는, 예를 들어, (서열 번호: 72)의 CAG 프로모터, HAAT 프로모터 (서열 번호: 82), 인간 EF1-α 프로모터 (서열 번호: 77) 또는 EF1a 프로모터의 단편 (서열 번호: 78), IE2 프로모터 (예를 들어, 서열 번호: 84) 및 랫트 EF1-α 프로모터 (서열 번호: 85), mEF1 프로모터 (서열 번호: 59) 또는 1E1 프로모터 단편 (서열 번호: 125)를 포함한다.
(ii).
폴리아데닐화
서열:
ceDNA 벡터로부터 발현된 mRNA를 안정화시키고 핵 수출 및 번역을 돕기 위해 폴리아데닐화 서열을 인코딩하는 서열이 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터에 포함될 수 있다. 일 구현예에서, ceDNA 벡터는 폴리아데닐화 서열을 포함하지 않는다. 다른 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 적어도 1, 적어도 2, 적어도 3, 적어도 4, 적어도 5, 적어도 10, 적어도 15, 적어도 20, 적어도 25, 적어도 30, 적어도 40, 적어도 45, 적어도 50개 또는 그 이상의 아데닌 디뉴클레오티드를 포함한다. 일부 구현예에서, 폴리아데닐화 서열은 약 43개 뉴클레오티드, 약 40-50개 뉴클레오티드, 약 40-55개 뉴클레오티드, 약 45-50개 뉴클레오티드, 약 35-50개 뉴클레오티드, 또는 이들 사이의 임의의 범위를 포함한다. 도 10a-10g에 도시된 바와 같이, 폴리아데닐화 서열은 항체 또는 항체 단편을 인코딩하는 이식유전자의 3'에 위치할 수 있다. 일부 구현예에서, 전체 IgG 또는 전체 항체를 인코딩하는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 IRES (내부 리보솜 진입 부위) 서열 (서열 번호 190)을 포함 할 수 있으며, 예를 들어, 상기 IRES 서열이 폴리아데닐화 서열의 3'에 위치함으로써, 제1 이식유전자의 3'에 위치한 제2 이식유전자 (예를 들어, 항체 또는 항원-결합 단편)가 동일한 ceDNA 벡터에 의해 번역되고 발현되며, 이로써 ceDNA 벡터는 완전한 항체를 발현할 수 있다. (예를 들어, 도 10b 참조).
발현 카세트는 당 업계에 공지된 폴리아데닐화 서열 또는 이의 변형, 예컨대 소 BGHpA (예를 들어, 서열 번호: 68) 또는 바이러스 SV40pA (예를 들어, 서열 번호: 86), 또는 합성 서열 (예를 들어, 서열 번호: 87)로부터 단리된 천연 발생 서열을 포함할 수 있다. 일부 발현 카세트는 또한 SV40 후기 폴리 A 신호 상류 인핸서 (USE) 서열을 포함할 수 있다. 일부 구현예에서, USE는 SV40pA 또는 이종 폴리-A 신호와 조합하여 사용될 수 있다.
발현 카세트는 또한 이식유전자의 발현을 증가시키기 위해 전사 후 요소를 포함할 수 있다. 일부 구현예에서, 우드척 간염 바이러스 (WHP) 전사 후 조절 요소 (WPRE) (예를 들어, 서열 번호: 67)는 이식유전자의 발현을 증가시키는 데 사용된다. 단순 포진 바이러스 또는 B형 간염 바이러스 (HBV)의 티미딘 키나제 유전자로부터의 전사 후 요소와 같은 다른 전사 후 처리 요소가 사용될 수 있다. 분비 서열은 이식유전자, 예를 들어, VH-02 및 VK-A26 서열, 예를 들어, 서열 번호: 88 및 서열 번호: 89에 연결될 수 있다.
(iii). 핵
국재화
서열
일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 하나 이상의 핵 국재화 서열 (NLS), 예를 들어, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개 또는 그 이상의 NLS를 포함한다. 일부 구현예에서, 하나 이상의 NLS는 아미노-말단에 또는 그 근처, 카복시-말단에 또는 그 근처에 위치하거나, 또는 이들의 조합 (예를 들어, 아미노-말단에서 하나 이상의 NLS 및/또는 카복시 말단에서 하나 이상의 NLS)에 위치한다. 하나 초과의 NLS가 존재하는 경우, 단일 NLS가 하나 초과의 카피에 존재하고/하거나 하나 이상의 다른 NLS와 조합하여 하나 이상의 카피에 존재하도록 다른 것과 독립적으로 선택될 수 있다. NLS의 비제한적인 예는 표 11에 제시되어 있다.
표 11: 핵 국재화 신호

B.
ceDNA 벡터의 추가 성분
본 개시내용의 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 유전자 발현을 위해 다른 성분을 인코딩하는 뉴클레오티드를 함유할 수 있다. 예를 들어, 특정 유전자 표적화 사건을 선택하기 위해, 보호 shRNA가 마이크로RNA에 포매되어 알부민 유전자좌와 같은 고도로 활성인 유전자좌에 부위 특이적으로 통합되도록 설계된 재조합 ceDNA 벡터에 삽입될 수 있다. 이러일 구현예는 하기에 기재된 바와 같은 임의의 유전자 배경에서 유전자 변형 간세포의 생체내 선택 및 확장을 위한 시스템을 제공할 수 있다: Nygaard et al., A universal system to select gene-modified hepatocytes in vivo , Gene Therapy, June 8, 2016. 본 개시내용의 ceDNA 벡터는 형질전환, 형질감염, 형질도입 또는 이와 유사한 세포의 선택을 허용하는 하나 이상의 선택 가능한 마커를 함유할 수 있다. 선택 가능한 마커는 그 산물이 살생물제 또는 바이러스 내성, 중금속에 대한 내성, 영양요구성에 대한 프로토트로피(prototrophy), NeoR 등을 제공하는 유전자이다. 특정 구현예에서, 양성 선별 마커는 NeoR과 같은 공여체 서열에 포함된다. 음성 선별 마커는 공여체 서열의 하류에 통합될 수 있으며, 예를 들어 음성 선별 마커를 인코딩하는 핵산 서열 HSV-tk는 공여체 서열의 하류에 있는 핵산 작제물에 통합될 수 있다.
C. 조절 스위치
분자 조절 스위치는 신호에 응답하여 측정 가능한 상태 변화를 생성하는 스위치이다. 이러한 조절 스위치는 ceDNA 벡터로부터 항체 또는 항원-결합 단편의 발현의 출력을 제어하기 위해 본원에 기재된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터와 유용하게 결합될 수 있다. 일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 항체 또는 항원-결합 단편의 발현을 미세 조정하는 역할을 하는 조절 스위치를 포함한다. 예를 들어, 이는 ceDNA 벡터의 생화학적 봉쇄(biocontainment) 기능으로 작용할 수 있다. 일부 구현예에서, 스위치는 제어 가능하고 조절 가능한 방식으로 ceDNA 벡터에서 항체 또는 항원-결합 단편의 발현을 시작 또는 중지 (즉, 셧다운)하도록 설계된 "ON/OFF" 스위치이다. 일부 구현예에서, 스위치는 스위치가 활성화되면 ceDNA 벡터를 포함하는 세포가 세포 프로그래밍된 사멸을 겪도록 지시할 수 있는 "사멸 스위치"를 포함할 수 있다. 항체 또는 융합 단백질 생산을 위한 ceDNA에 사용하기 위해 포함된 예시적인 조절 스위치는 이식유전자의 발현을 조절하는데 이용될 수 있고 국제 출원 PCT/US18/49996 (이는 그 전문이 본원에 참고로 포함됨)에서 보다 상세히 논의된다.
(i) 이진 조절 스위치
일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 항체 또는 항원-결합 단편의 발현을 제어 가능하게 조절하는 역할을 할 수 있는 조절 스위치를 포함한다. 예를 들어, ceDNA 벡터의 ITR 사이에 위치한 발현 카세트는 항원-결합 단편에 작동적으로 연결된, 조절 영역, 예를 들어, 프로모터, 시스-요소, 리프레서, 인핸서 등을 추가로 포함할 수 있으며, 여기서 조절 영역은 하나 이상의 보조 인자 또는 외인성 제제에 의해 조절된다. 단지 예로서, 조절 영역은 소분자 스위치 또는 유도성 또는 억제성 프로모터에 의해 조절될 수 있다. 유도성 프로모터의 비-제한적인 예는 호르몬-유도성 또는 금속-유도성 프로모터이다. 다른 예시적인 유도성 프로모터/인핸서 요소는 RU486-유도성 프로모터, 엑디손-유도성 프로모터, 라파마이신-유도성 프로모터 및 메탈로티오네인 프로모터를 포함하지만, 이에 제한되지는 않는다.
(ii)
소분자
조절 스위치
다양한 당 업계에 공지된 소분자 기반 조절 스위치가 당 업계에 공지되어 있고, 조절 스위치 제어 ceDNA 벡터를 형성하기 위해 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터와 조합될 수 있다. 일부 구현예에서, 조절 스위치는 문헌(Taylor, et al. BMC Biotechnology 10 (2010): 15)에 기재된 것과 같이, 작동적으로 연결된 이식유전자의 발현을 제어하는 인공 프로모터와 함께, 직교 리간드/핵 수용체 쌍, 예를 들어 레티노이드 수용체 변이체/LG335 및 GRQCIMFI; 조작된 스테로이드 수용체, 예를 들어, 프로게스테론에 결합할 수 없지만 RU486 (미페프리스톤)에 결합하는 C-말단 절단을 갖는 변형된 프로게스테론 수용체 (미국 특허 번호 5,364,791); 드로소필라(Drosophila) 유래 엑디손 수용체 및 이의 엑디스테로이드 리간드 (Saez, et al., PNAS, 97(26)(2000), 14512-14517; 또는 문헌(Sando R 3rd; Nat Methods. 2013, 10(11):1085-8)에 개시된 바와 같은 항생제 트리메토프림 (TMP)에 의해 제어되는 스위치 중 임의의 하나 또는 조합으로부터 선택될 수 있다. 일부 구현예에서, 이식유전자를 제어하거나 ceDNA 벡터에 의해 발현되는 조절 스위치는 미국 특허 8,771,679 및 6,339,070에 개시된 것과 같은 전구 약물 활성화 스위치이다.
(iii) "패스코드(
Passcode
)" 조절 스위치
일부 구현예에서, 조절 스위치는 "패스코드 스위치" 또는 "패스코드 회로"일 수 있다. 패스코드 스위치는 특정 조건이 발생할 때 ceDNA 벡터에서 이식유전자의 발현 제어를 미세 조정할 수 있도록 하며, 즉, 이식유전자 발현 및/또는 억제가 발생하려면 조건의 조합이 필요한다. 예를 들어, 이식유전자의 발현이 발생하기 위해서는 적어도 조건 A 및 B가 발생해야 한다. 패스코드 조절 스위치는 이식유전자 발현이 발생하기 위해 임의의 수의 조건, 예를 들어, 적어도 2, 적어도 3, 적어도 4, 적어도 5, 적어도 6 또는 적어도 7개 또는 그 이상의 조건이 존재할 수 있다. 일부 구현예에서, 적어도 2개의 조건 (예를 들어, A, B 조건)이 발생해야 하고, 일부 구현예에서, 적어도 3개의 조건 (예를 들어, A, B 및 C, 또는 A, B 및 D)이 발생해야 한다. 단지 예로서, 패스코드 "ABC" 조절 스위치를 갖는 ceDNA로부터의 유전자 발현이 발생하기 위해서는 조건 A, B 및 C가 존재해야 한다. 조건 A, B 및 C는 다음과 같을 수 있다; 조건 A는 병태 또는 질환의 존재이고, 조건 B는 호르몬 반응이고, 조건 C는 이식유전자 발현에 대한 반응이다. 예를 들어, 이식유전자이 결함 있는 EPO 유전자를 편집하는 경우, 조건 A는 만성 신장 질환 (CKD)의 존재이고, 조건 B는 대상체가 신장에 저산소 상태에 있는 경우 발생하고, 조건 C는 신장에서 에리스로포이에틴 생성 세포 (EPC) 동원이 손상된 것이거나; 또는 대안적으로, HIF-2 활성화가 손상된 것이다. 산소 수준이 증가하거나 원하는 수준의 EPO에 도달하면, 3가지 조건이 발생할 때까지 이식유전자이 다시 꺼지고, 다시 켜진다.
일부 구현예에서, ceDNA 벡터에 사용하기 위해 포함된 패스코드 조절 스위치 또는 "패스코드 회로"는 생화학적 봉쇄 조건을 정의하는데 사용되는 환경 신호의 범위 및 복잡성을 확장시키기 위해 하이브리드 전사 인자 (TF)를 포함한다. 미리 결정된 조건의 존재하에 세포 사멸을 유발하는 데드맨 스위치(deadman switch)와는 달리, "패스코드 회로"는 특정 "패스코드"의 존재하에서 세포 생존 또는 이식유전자 발현을 허용하고, 미리 결정된 환경 조건 또는 패스코드가 존재하는 경우에만 이식유전자 발현 및/또는 세포 생존을 허용하도록 쉽게 재프로그래밍될 수 있다.
본원에 개시된 조절 스위치의 임의의 및 모든 조합, 예를 들어, 소분자 스위치, 핵산-기반 스위치, 소분자-핵산 하이브리드 스위치, 전사 후 이식유전자 조절 스위치, 번역 후 조절, 방사선-제어 스위치, 저산소증-매개 스위치 및 본원에 개시된 바와 같은 당업자에게 공지된 다른 조절 스위치는 본원에 개시된 바와 같은 패스코드 조절 스위치에 사용될 수 있다. 사용을 위해 포함된 조절 스위치는 리뷰 논문 (Kis et al., J R Soc Interface. 12: 20141000 (2015))에서 또한 논의되며, Kis의 표 1에 요약되어 있다. 일부 구현예에서, 패스코드 시스템에 사용하기 위한 조절 스위치는 본원에 그 전체가 참고로 포함된 국제 특허 출원 PCT/US18/49996의 표 11에 개시된 스위치 중 임의의 것 또는 조합으로부터 선택될 수 있다.
(iv). 이식유전자 발현을 제어하기 위한 핵산 기반 조절 스위치
일부 구현예에서, ceDNA에 의해 발현된 항체 또는 항원-결합 단편을 제어하기 위한 조절 스위치는 핵산 기반 제어 메커니즘에 기초한다. 예시적인 핵산 제어 메카니즘이 당 업계에 공지되어 있으며 사용이 구상된다. 예를 들어, 이러한 메커니즘은, 예를 들어, US2009/0305253, US2008/0269258, US2017/0204477, WO2018026762A1, 미국 특허 9,222,093 및 EP 출원 EP288071에 개시되고, 또한 문헌(Villa JK et al., Microbiol Spectr. 2018 May;6(3))에 의한 검토에 개시된 것과 같은 리보스위치를 포함한다. 또한, WO2018/075486 및 WO2017/147585에 개시된 것과 같은 대사 물질-반응성 전사 바이오센서가 포함된다. 사용이 구상된 당 업계에 공지된 다른 메커니즘은 siRNA 또는 RNAi 분자 (예를 들어, miR, shRNA)로 이식유전자의 침묵화를 포함한다. 예를 들어, ceDNA 벡터는 ceDNA 벡터에 의해 발현된 이식유전자의 일부에 상보적인 RNAi 분자를 인코딩하는 조절 스위치를 포함할 수 있다. 이식유전자(예를 들어, 항체 또는 항원-결합 단편)가 ceDNA 벡터에 의해 발현되더라도 이러한 RNAi가 발현될 때, 상보적 RNAi 분자에 의해 침묵화될 것이고, 이식유전자이 ceDNA 벡터에 의해 발현될 때 RNAi가 발현되지 않을 때 이식유전자(예를 들어, 항체 또는 항원-결합 단편)는 RNAi에 의해 침묵화되지 않는다.
일부 구현예에서, 조절 스위치는, 예를 들어 US2002/0022018에 개시된 바와 같은 조직-특이적 자가-활성화 조절 스위치이며, 따라서 조절 스위치는 이식유전자 발현이 그렇지 않으면 불리할 수 있는 부위에서 이식유전자(예를 들어, 항체 또는 항원-결합 단편) 발현을 의도적으로 차단한다. 일부 구현예에서, 조절 스위치는, 예를 들어 US2014/0127162 및 미국 특허 8,324,436에 개시된 바와 같은 재조합 효소 가역 유전자 발현 시스템이다.
(V). 전사 후 및 번역 후 조절 스위치.
일부 구현예에서, ceDNA 벡터에 의해 발현된 항체 또는 항원-결합 단편을 제어하기 위한 조절 스위치는 전사 후 변형 시스템이다. 예를 들어, 이러한 조절 스위치는 US2018/0119156, GB201107768, WO2001/064956A3, EP 특허 2707487 및 문헌(Beilstein et al., ACS Synth. Biol., 2015, 4 (5), pp 526-534; Zhong et al., Elife. 2016 Nov 2;5. pii: e18858)에 개시된 바와 같이 테트라사이클린 또는 테오필린에 민감한 압타자임(aptazyme) 리보스위치일 수 있다. 일부 구현예에서, 당업자는 리간드 감수성 (OFF-스위치) 압타머를 함유하는 억제성 siRNA 및 이식유전자 둘 다를 인코딩할 수 있으며, 최종 결과는 리간드 감수성 ON-스위치인 것으로 예상된다.
(vi). 다른 예시적인 조절 스위치
환경 변화에 의해 유발된 것들을 포함하여, ceDNA 벡터에 의해 발현된 항체 또는 항원-결합 단편의 유전자 발현을 제어하기 위해 임의의 공지된 조절 스위치가 ceDNA 벡터에서 사용될 수 있다. 추가의 예는 다음을 포함하지만, 이에 제한되지 않는다; 문헌(Suzuki et al., Scientific Reports 8; 10051 (2018))의 BOC 방법; 유전자 코드 확장 및 비-생리적 아미노산; 방사선 제어 또는 초음파 제어 온/오프 스위치 (예를 들어, Scott S et al., Gene Ther. 2000 Jul;7(13):1121-5; 미국 특허 5,612,318; 5,571,797; 5,770,581; 5,817,636; 및 WO1999/025385A1 참조. 일부 구현예에서, 조절 스위치는, 예를 들어, 미국 특허 7,840,263; US2007/0190028A1 (여기서 유전자 발현은 ceDNA 벡터의 이식유전자에 작동적으로 연결된 프로모터를 활성화시키는 전자기 에너지를 포함하는 하나 이상의 형태의 에너지에 의해 제어됨)에 개시된 바와 같은 이식 가능한 시스템에 의해 제어된다.
일부 구현예에서, ceDNA 벡터에 사용하기 위해 구상된 조절 스위치는 저산소증-매개 또는 스트레스-활성화 스위치, 예를 들어, WO1999060142A2, 미국 특허 5,834,306; 6,218,179; 6,709,858; US2015/0322410; 문헌(Greco et al., (2004) Targeted Cancer Therapies 9, S368)에 기재된 것, 뿐만 아니라, 예를 들어, 미국 특허 9,394,526에 개시된 바와 같은, FROG, TOAD 및 NRSE 요소 및 저산소증 반응 요소 (HRE), 염증 반응 요소 (IRE) 및 전단 응력 활성화 요소 (SSAE)를 포함한 조건부로 유도 가능한 침묵 요소이다. 이러한 구현예는 허혈 후 또는 허혈성 조직 및/또는 종양에서 ceDNA 벡터로부터 이식유전자의 발현을 켜는데 유용하다.
(iv). 사멸 스위치
본원에 기재된 다른 구현예는 사멸 스위치를 포함하는 본원에 기재된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터에 관한 것이다. 본원에 개시된 사멸 스위치는 ceDNA 벡터를 포함하는 세포가 대상체 시스템으로부터 도입된 ceDNA 벡터를 영구적으로 제거하기 위한 수단으로 사멸되거나 프로그래밍된 세포 사멸을 겪도록 할 수 있다. 당업자는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터에서 사멸 스위치의 사용이 전형적으로 대상체가 수용 가능하게 상실할 수 있는 제한된 수의 세포 또는 아폽토시스가 바람직한 세포 유형 (예를 들어, 암 세포)에 대한 ceDNA 벡터의 표적화와 결합될 수 있음을 이해할 것이다. 모든 측면에서, 본원에 개시된 바와 같은 "사멸 스위치"는 입력 생존 신호 또는 다른 특정 조건이 없는 경우 ceDNA 벡터를 포함하는 세포의 빠르고 강력한 세포 사멸을 제공하도록 설계된다. 달리 말하면, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터에 의해 인코딩된 사멸 스위치는 ceDNA 벡터를 포함하는 세포의 세포 생존을 특정 입력 신호에 의해 정의된 환경으로 제한할 수 있다. 이러한 사멸 스위치는 대상체로부터 항체 또는 항원-결합 단편을 발현하는 ceDNA 벡터를 제거하거나 그것이 인코딩된 항체 또는 항원-결합 단편을 발현하지 않도록 보장하는 것이 바람직한 경우 생물학적 봉쇄 기능을 한다.
당업자에게 공지된 다른 사멸 스위치, 뿐만 아니라 문헌[Jusiak et al, Reviews in Cell Biology and molecular Medicine; 2014; 1-56; Kobayashi et al., PNAS, 2004; 101; 8419-9; Marchisio et al., Int. Journal of Biochem and Cell Biol., 2011; 43; 310-319; 및 Reinshagen et al., Science Translational Medicine, 2018, 11]에 개시된 사멸 스위치는 본원에 개시된 바와 같이, 예를 들어, US2010/0175141; US2013/0009799; US2011/0172826; US2013/0109568에 개시된 바와 같이, 항체 또는 융합 단백질 생산을 위해 ceDNA 벡터에서 사용되는 것이 포함된다.
따라서, 일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 이펙터 독소 또는 리포터 단백질을 인코딩하는 핵산을 포함하는, 사멸 스위치 핵산 작제물을 포함할 수 있고, 여기서 이펙터 독소 (예를 들어, 사멸 단백질) 또는 리포터 단백질의 발현은 미리 결정된 조건에 의해 제어된다. 예를 들어, 미리 결정된 조건은 예를 들어, 외인성 인자와 같은 환경 인자의 존재일 수 있으며, 상기 환경 인자가 없다면 세포는 이펙터 독소 (예를 들어, 사멸 단백질)의 발현에 대해 디폴트되거나 사멸될 것이다. 대안적인 구현예에서, 미리 결정된 조건은 2가지 이상의 환경 인자의 존재이며, 예를 들어, 세포는 2가지 이상의 필수적인 외인성 인자가 공급되는 경우에만 생존할 것이며, 이들 중 어느 하나라도 없다면, ceDNA 벡터를 포함하는 세포는 사멸된다.
일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 ceDNA 벡터에 의해 발현되는 이식유전자 (예를 들어, 전장 항체, Fab, scAb)의 생체내 발현을 효과적으로 종결시키기 위해 ceDNA 벡터를 포함하는 세포를 파괴하는 사멸-스위치를 포함하도록 변형된다. 구체적으로, ceDNA 벡터는 정상 생리학적 조건하에 포유동물 세포에서 기능하지 않는 스위치-단백질을 발현시키도록 추가로 유전자 조작된다. 이 스위치-단백질을 특이적으로 표적화하는 약물 또는 환경 조건의 투여시에만, 스위치-단백질을 발현시키는 세포가 파괴되어 치료 단백질 또는 펩티드의 발현이 종결될 것이다. 예를 들어, HSV-티미딘 키나제를 발현시키는 세포는 간시클로비르 및 시토신 데아미나제와 같은 약물의 투여시 사멸될 수 있는 것으로 보고되었다. 예를 들어, 하기를 참조한다: Dey and Evans, Suicide Gene Therapy by Herpes Simplex Virus-1 Thymidine Kinase (HSV-TK), in Targets in Gene Therapy, edited by You (2011); 및 Beltinger et al., Proc. Natl. Acad. Sci. USA 96(15):8699-8704 (1999). 일부 구현예에서 ceDNA 벡터는 DISE (생존 유전자 제거로 인한 사망)로 지칭되는 siRNA 사멸 스위치를 포함할 수 있다 (Murmann et al., Oncotarget. 2017; 8:84643-84658. Induction of DISE in ovarian cancer cells in vivo).
VI. ceDNA 벡터의 상세한 생산 방법
A. 일반적인 생산
본원에 기재된 바와 같이 비대칭 ITR 쌍 또는 대칭 ITR 쌍을 포함하는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 특정 생산 방법은 2018년 9월 7일자로 출원된 국제 출원 PCT/US18/49996의 섹션 IV에 기재되어 있으며, 이는 그 전문이 본원에 참고로 포함되어 있다. 일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 본원에 기재된 바와 같이, 곤충 세포를 사용하여 생성될 수 있다. 대안적인 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 합성적으로 그리고 일부 구현예에서, 그 전문이 본원에 참고로 포함된, 2019년 1월 18일자로 출원된 국제 출원 PCT/US19/14122에 개시된 바와 같은 무세포 방법으로 생성될 수 있다.
본원에 기재된 바와 같이, 일 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는, 예를 들어, a) 숙주 세포 내에서 ceDNA 벡터의 생성을 유도하기에 효과적인 조건 하에서 및 충분한 시간 동안 Rep 단백질의 존재하에, 바이러스 캡시드 코딩 서열이 없는, 폴리뉴클레오티드 발현 작제물 주형 (예를 들어, ceDNA-플라스미드, ceDNA-박미드 및/또는 ceDNA-바쿨로바이러스)을 보유하는 숙주 세포 (예를 들어, 곤충 세포) 집단을 인큐베이션하는 단계로서, 상기 숙주 세포는 바이러스 캡시드 코딩 서열을 포함하지 않는, 상기 단계; 및 b) 숙주 세포로부터 ceDNA 벡터를 수거하고 분리하는 단계를 포함하는 과정에 의해 얻어질 수 있다. Rep 단백질의 존재는 변형된 ITR로 벡터 폴리뉴클레오티드의 복제를 유도하여 숙주 세포에서 ceDNA 벡터를 생성한다. 그러나, 바이러스 입자 (예를 들어 AAV 비리온)는 발현되지 않는다. 따라서, AAV 또는 다른 바이러스 기반 벡터에 자연적으로 부과되는 것과 같은 크기 제한은 없다.
숙주 세포로부터 단리된 ceDNA 벡터의 존재는 ceDNA 벡터 상에 단일 인식 부위를 갖는 제한 효소로 숙주 세포로부터 단리된 DNA를 소화하고 비-변성 겔 상에서 소화된 DNA 물질을 분석하여 선형 및 비연속 DNA와 비교하여 선형 및 연속 DNA의 특징적인 밴드의 존재를 확인함으로써 확인될 수 있다.
또 다른 측면에서, 본 발명은, 예를 들어, 하기에 기재된 바와 같이, 비-바이러스성 DNA 벡터의 생산에서 DNA 벡터 폴리뉴클레오티드 발현 주형 (ceDNA 주형)을 그들 자신의 게놈에 안정적으로 통합시킨 숙주 세포주의 사용을 제공한다: Lee, L. et al. (2013) Plos One 8(8): e69879. 바람직하게는, Rep는 약 3의 MOI에서 숙주 세포에 첨가된다. 숙주 세포주가 포유동물 세포주, 예를 들어, HEK293 세포인 경우, 세포주는 안정적으로 통합된 폴리뉴클레오티드 벡터 주형을 가질 수 있고, 헤르페스 바이러스와 같은 제2 벡터를 사용하여 Rep 단백질을 세포 내로 도입할 수 있으며, 이는 Rep 및 헬퍼 바이러스의 존재하에 ceDNA의 절제 및 증폭을 허용한다.
일 구현예에서, 본원에 기재된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 제조하는데 사용된 숙주 세포는 곤충 세포이고, 바쿨로바이러스는 Rep 단백질을 인코딩하는 폴리뉴클레오티드 및, 예를 들어, 도 4a-4c 및 실시예 1에 기재된 바와 같이, ceDNA에 대한 비-바이러스성 DNA 벡터 폴리뉴클레오티드 발현 작제물 주형 둘 다를 전달하는데 사용된다. 일부 구현예에서, 숙주 세포는 Rep 단백질을 발현하도록 조작된다.
이어서 ceDNA 벡터를 수거하고 숙주 세포로부터 단리한다. 세포로부터 본원에 기재된 ceDNA 벡터를 수거하고 수집하는 시간은 ceDNA 벡터의 고-수율 생산을 달성하도록 선택되고 최적화될 수 있다. 예를 들어, 수거 시간은 세포 생존력, 세포 형태, 세포 성장 등을 고려하여 선택될 수 있다. 일 구현예에서, 세포는 충분한 조건 하에서 성장하고, ceDNA 벡터를 생성하기 위해 바쿨로바이러스 감염 후 그러나 바쿨로바이러스 독성으로 인해 대부분의 세포가 죽기 시작하기 전에 충분한 시간 수거한다. Qiagen Endo-Free Plasmid 키트와 같은 플라스미드 정제 키트를 사용하여 DNA 벡터를 분리할 수 있다. 플라스미드 분리를 위해 개발된 다른 방법도 DNA 벡터에 적용될 수 있다. 일반적으로, 임의의 핵산 정제 방법이 채택될 수 있다.
DNA 벡터는 DNA의 정제를 위해 당업자에게 공지된 임의의 수단에 의해 정제될 수 있다. 일 구현예에서, ceDNA 벡터는 DNA 분자로서 정제된다. 또 다른 구현예에서, ceDNA 벡터는 엑소좀 또는 미세입자로서 정제된다.
항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 존재는 DNA 벡터 상에 단일 인식 부위를 갖는 제한 효소로 세포로부터 단리된 벡터 DNA를 소화시키고, 겔 전기영동을 사용하여 소화된 및 소화되지 않은 DNA 물질 모두를 분석하여, 선형 및 비-연속 DNA와 비교하여 선형 및 연속 DNA의 특징적인 밴드의 존재를 확인함으로써 확인할 수 있다. 도 4c 및 도 4d는 본원의 공정에 의해 생성된 폐쇄 말단 ceDNA 벡터의 존재를 확인하기 위한 일 구현예를 도시한다.
B.
ceDNA
플라스미드
ceDNA-플라스미드는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 추후 생산에 사용되는 플라스미드이다. 일부 구현예에서, ceDNA-플라스미드는 적어도 다음을 전사 방향으로 작동적으로 연결된 성분으로서 제공하기 위해 공지된 기술을 사용하여 구축될 수 있다: (1) 변형된 5' ITR 서열; (2) 시스-조절 요소, 예를 들어, 프로모터, 유도성 프로모터, 조절 스위치, 인핸서 등을 함유하는 발현 카세트; 및 (3) 3' ITR 서열이 5' ITR 서열에 대해 대칭인 변형된 3' ITR 서열. 일부 구현예에서, ITR이 측면에 있는 발현 카세트는 외인성 서열을 도입하기 위한 클로닝 부위를 포함한다. 발현 카세트는 AAV 게놈의 rep 및 cap 코딩 영역을 대체한다.
일 측면에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 본원에서, 제1 아데노-관련 바이러스 (AAV) 역 말단 반복부 (ITR), 이식유전자를 포함하는 발현 카세트, 및 돌연변이 또는 변형된 AAV ITR 순서로 인코딩하는 "ceDNA-플라스미드"로 지칭되는 플라스미드로부터 수득되며, 여기서 상기 ceDNA-플라스미드는 AAV 캡시드 단백질 코딩 서열이 없다. 대안적인 구현예에서, ceDNA-플라스미드는 제1 (또는 5') 변형 또는 돌연변이된 AAV ITR, 이식유전자를 포함하는 발현 카세트, 및 제2 (또는 3') 변형된 AAV ITR 순서로 인코딩하며, 여기서 상기 ceDNA-플라스미드 AAV 캡시드 단백질 코딩 서열이 없고, 5' 및 3' ITR은 서로 대칭이다. 대안적인 구현예에서, ceDNA-플라스미드는 제1 (또는 5') 변형 또는 돌연변이된 AAV ITR, 이식유전자를 포함하는 발현 카세트, 및 제2 (또는 3') 돌연변이 또는 변형된 AAV ITR 순서로 인코딩하며, 여기서 상기 ceDNA-플라스미드는 AAV 캡시드 단백질 코딩 서열이 없고, 5' 및 3' 변형된 ITR은 동일한 변형을 갖는다 (즉, 이들은 서로 역 보체이거나 대칭이다).
추가의 구현예에서, ceDNA-플라스미드 시스템은 바이러스 캡시드 단백질 코딩 서열이 없다 (즉, AAV 캡시드 유전자가 없고 다른 바이러스의 캡시드 유전자도 없다). 또한, 특정 구현예에서, ceDNA-플라스미드는 또한 AAV Rep 단백질 코딩 서열이 없다. 따라서, 바람직한 구현예에서, ceDNA-플라스미드는 AAV2)에 대한 기능성 AAV 캡 및 AAV rep 유전자 GG-3', 및 헤어핀 형성을 허용하는 가변 팔린드롬 서열이 없다.
본 발명의 ceDNA-플라스미드는 당 업계에 널리 공지된 임의의 AAV 혈청형의 게놈의 천연 뉴클레오티드 서열을 사용하여 생성될 수 있다. 일 구현예에서, ceDNA-플라스미드 골격은 AAV1, AAV2, AAV3, AAV4, AAV5, AAV 5, AAV7, AAV8, AAV9, AAV10, AAV 11, AAV12, AAVrh8, AAVrh10, AAV-DJ 및 AAV-DJ8 게놈으로부터 유도된다. 예를 들어, NCBI: NC 002077; NC 001401; NC001729; NC001829; NC006152; NC 006260; NC 006261; Kotin and Smith, The Springer Index of Viruses, Springer가 유지 관리하는 URL에서 이용 가능 (www 웹 주소: oesys.springer.de/viruses/database/mkchapter.asp?virID=42.04.)(참고 -URL 또는 데이터베이스에 대한 참조는 본 출원의 유효 출원일자의 URL 또는 데이터베이스의 내용을 지칭함). 특정 구현예에서, ceDNA-플라스미드 골격은 AAV2 게놈으로부터 유래된다. 또 다른 특정 구현예에서, ceDNA-플라스미드 골격은 이들 AAV 게놈 중 하나로부터 유래된 5' 및 3' ITR을 포함하도록 유전자 조작된 합성 골격이다.
ceDNA-플라스미드는 선택적으로 ceDNA 벡터-생성 세포주의 확립에 사용하기 위한 선택 가능한 또는 선별 마커를 포함할 수 있다. 일 구현예에서, 선별 마커는 3' ITR 서열의 하류 (즉 , 3')에 삽입될 수 있다. 또 다른 구현예에서, 선별 마커는 5' ITR 서열의 상류 (즉 , 5')에 삽입될 수 있다. 적절한 선별 마커는, 예를 들어, 약물 내성을 부여하는 마커를 포함한다. 선별 마커는, 예를 들어, 블라스티시딘 S-저항성 유전자, 카나마이신, 제네티신 등일 수 있다. 바람직일 구현예에서, 약물 선별 마커는 블라스티시딘 S-저항성 유전자이다.
항체 또는 융합 단백질 생산을 위한 예시적인 ceDNA (예를 들어, rAAV0) 벡터는 rAAV 플라스미드로부터 생성된다. rAAV 벡터의 생산 방법은 (a) 상기 기재된 바와 같은 rAAV 플라스미드를 숙주 세포에 제공하는 단계로서, 상기 숙주 세포 및 상기 플라스미드 둘 다는 캡시드 단백질 코딩 유전자가 없는, 상기 단계, (b) 숙주 세포를 ceDNA 게놈의 생성을 허용하는 조건 하에 배양하는 단계, 및 (c) 세포를 수거하고 상기 세포로부터 생성된 AAV 게놈을 분리하는 단계를 포함한다.
C.
ceDNA
플라스미드로부터
ceDNA
벡터를 제조하는 예시적인 방법
항체 또는 융합 단백질 생산을 위한 캡시드가 없는 ceDNA 벡터를 제조하는 방법, 특히 생체내 실험에 충분한 벡터를 제공하기 위해 충분히 높은 수율을 갖는 방법이 또한 본원에 제공된다.
일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 생산 방법은 (1) 발현 카세트 및 2개의 대칭 ITR 서열을 포함하는 핵산 작제물을 숙주 세포 (예를 들어, Sf9 세포)에 도입하는 단계, (2) 선택적으로, 예를 들어, 플라스미드 상에 존재하는 선별 마커를 사용하여 클론 세포주를 확립하는 단계, (3) Rep 코딩 유전자를 상기 곤충 세포 내로 (상기 유전자를 운반하는 바쿨로바이러스에 의한 형질감염 또는 감염에 의해) 도입하는 단계; 및 (4) 세포를 수거하고 ceDNA 벡터를 정제하는 단계를 포함한다. ceDNA 벡터의 생성을 위해 상기 기술된 발현 카세트 및 2개의 ITR 서열을 포함하는 핵산 작제물은 ceDNA 플라스미드, 또는 하기 기재된 바와 같이 ceDNA 플라스미드로 생성된 박미드 또는 바쿨로바이러스의 형태일 수 있다. 핵산 작제물은 형질감염, 바이러스 형질도입, 안정적인 통합 또는 당 업계에 공지된 다른 방법에 의해 숙주 세포로 도입될 수 있다.
D. 세포주
:
항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 생산에 사용되는 숙주 세포주는 Sf9 Sf21과 같은 스포도프테라 프루기페르다(Spodoptera frugiperda), 또는 트리코플루시아 니(Trichoplusia ni) 세포, 또는 기타 무척추동물, 척추동물 또는 포유동물 세포를 포함하는 다른 진핵 세포주로부터 유래된 곤충 세포주를 포함할 수 있다. HEK293, Huh-7, HeLa, HepG2, HeplA, 911, CHO, COS, MeWo, NIH3T3, A549, HT1 180, 단핵구 및 성숙 및 미성숙 수지상 세포과 같은, 당업자에게 공지된 다른 세포주가 또한 사용될 수 있다. 높은 수율의 ceDNA 벡터 생산을 위해 ceDNA-플라스미드의 안정적인 발현을 위해 숙주 세포주를 형질감염시킬 수 있다.
CeDNA-플라스미드는 당 업계에 공지된 시약 (예를 들어, 리포좀, 인산칼슘) 또는 물리적 수단 (예를 들어, 전기천공)을 사용하여 일시적 형질감염에 의해 Sf9 세포 내로 도입될 수 있다. 대안적으로, ceDNA-플라스미드를 게놈에 안정적으로 통합시킨 안정적인 Sf9 세포주가 확립될 수 있다. 이러한 안정적인 세포주는 상기 기술된 바와 같이 선별 마커를 ceDNA-플라스미드에 통합시킴으로써 확립될 수 있다. 세포주를 형질감염시키기 위해 사용된 ceDNA-플라스미드가 항생제와 같은 선별 마커를 포함하는 경우, ceDNA-플라스미드로 형질감염되고 ceDNA-플라스미드 DNA를 게놈에 통합시킨 세포는 세포 성장 배지에 항생제의 첨가에 의해 선별될 수 있다. 이어서, 세포의 내성 클론을 단일 세포 희석 또는 콜로니 전달 기술에 의해 단리하고 증식시킬 수 있다.
E.
ceDNA
벡터 분리 및 정제
:
ceDNA 벡터를 수득 및 분리하는 과정의 예는 도 4a-4e 및 아래의 특정 예에 기재되어 있다. 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA-벡터는 ceDNA-플라스미드, ceDNA-박미드 또는 ceDNA-바쿨로바이러스로 추가로 형질전환된, AAV Rep 단백질(들)을 발현하는 생산 세포로부터 얻을 수 있다. ceDNA 벡터의 생산에 유용한 플라스미드는 항체 중쇄 및/또는 항체 경쇄, 또는 하나 이상의 REP 단백질을 인코딩하는 플라스미드를 포함한다. 예시적인 ceDNA 플라스미드가 도 6a에 도시되어 있으며, 아두카누맙 HC를 인코딩하는 이식유전자 및 아두카누만 LC를 인코딩하는 이식유전자는 관심있는 항체 또는 융합 단백질의 중쇄 및/또는 경쇄를 갖는 핵산 서열로 대체될 수 있으며, 예를 들어 표 1-5를 참조한다.
일 측면에서, 폴리뉴클레오티드는 플라스미드 (Rep-플라스미드), 박미드 (Rep-박미드) 또는 바쿨로바이러스 (Rep-바쿨로바이러스)에서 생산 세포로 전달된 AAV Rep 단백질 (Rep 78 또는 68)을 인코딩한다. Rep-플라스미드, Rep-박미드 및 Rep-바쿨로바이러스는 위에서 설명한 방법으로 생성될 수 있다.
항체 또는 융합 단백질 생산을 위한 ceDNA-벡터를 생성하는 방법이 본원에 기재되어 있다. 본원에 기재된 바와 같이 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 생성하기 위해 사용되는 발현 작제물은 플라스미드 (예를 들어, ceDNA-플라스미드), 박미드 (예를 들어, ceDNA-박미드) 및/또는 바쿨로바이러스 (예를 들어, ceDNA-바쿨로바이러스)일 수 있다. 단지 예로서, ceDNA-벡터는 ceDNA-바쿨로바이러스 및 Rep-바쿨로바이러스로 공동 감염된 세포로부터 생성될 수 있다. Rep-바쿨로바이러스로부터 생산된 Rep 단백질은 ceDNA-바쿨로바이러스를 복제하여 ceDNA-벡터를 생성할 수 있다. 대안적으로, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 Rep-플라스미드, Rep-박미드 또는 Rep-바쿨로바이러스로 전달된 AAV Rep 단백질 (Rep78/52)을 인코딩하는 서열을 포함하는 작제물로 안정적으로 형질감염된 세포로부터 생성될 수 있다. ceDNA-바쿨로바이러스는 세포로 일시적으로 형질감염될 수 있고, Rep 단백질에 의해 복제되고 ceDNA 벡터를 생성할 수 있다.
박미드 (예를 들어, ceDNA- 박미드)는 Sf9, Sf21, Tni (트리코플루시아 니) 세포, 하이 파이브(High Five) 세포와 같은 허용 곤충 세포로 형질감염될 수 있고, ceDNA-바쿨로바이러스를 생성할 수 있으며, 이는 대칭 ITR 및 발현 카세트를 포함하는 서열을 포함하는 재조합 바쿨로바이러스이다. ceDNA-바쿨로바이러스는 곤충 세포 내로 다시 감염되어 차세대 재조합 바쿨로바이러스를 수득할 수 있다. 선택적으로, 단계는 재조합 바쿨로바이러스를 대량으로 생성하기 위해 한 번 또는 여러 번 반복될 수 있다.
세포로부터 본원에 기재된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 수거하고 수집하는 시간은 ceDNA 벡터의 고수율 생산을 달성하도록 선택되고 최적화될 수 있다. 예를 들어, 수거 시간은 세포 생존력, 세포 형태, 세포 성장 등을 고려하여 선택될 수 있다. 일반적으로, 세포는 ceDNA 벡터 (예를 들어, ceDNA 벡터)를 생성하기 위해 바쿨로바이러스 감염 후 충분한 시간 후에 그러나 바이러스 독성으로 인해 대부분의 세포가 죽기 시작하기 전에 수거될 수 있다. ceDNA-벡터는 Qiagen ENDO-FREE PLASMID® 키트와 같은 플라스미드 정제 키트를 사용하여 Sf9 세포로부터 분리될 수 있다. 플라스미드 단리를 위해 개발된 다른 방법들도 ceDNA 벡터에 적용될 수 있다. 일반적으로, 상업적으로 입수 가능한 DNA 추출 키트뿐만 아니라 임의의 당 업계에 공지된 핵산 정제 방법이 채택될 수 있다.
대안적으로, 정제는 세포 펠릿을 알칼리 용해 공정에 적용하고, 생성된 용해물을 원심분리하고 크로마토그래피 분리를 수행함으로써 구현될 수 있다. 하나의 비-제한적인 예로서, 상기 공정은 핵산을 보유하는 이온 교환 컬럼 (예를 들어, SARTOBIND Q®) 상에 상청액을 로딩한 후 (예를 들어 1.2 M NaCl 용액으로) 용리하고 겔 여과 칼럼 (예를 들어, 6 빠른 흐름 GE) 상에서 추가 크로마토그래피 정제를 수행함으로써 수행될 수 있다. 이어서, 캡시드-비함유 AAV 벡터는, 예를 들어, 침전에 의해 회수된다.
일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 또한 엑소좀 또는 미세입자 형태로 정제될 수 있다. 많은 세포 유형이 막 미세소포 쉐딩(membrane microvesicle shedding)을 통해 가용성 단백질뿐만 아니라 복잡한 단백질/핵산 카고도 방출한다는 것이 당 업계에 공지되어 있다 (Cocucci et al, 2009; EP 10306226.1) 이러한 소포는 미세소포 (미세입자로도 지칭됨) 및 엑소좀 (나노소포로도 지칭됨)을 포함하는데, 이 둘은 모두 단백질 및 RNA를 카고로서 포함한다. 미세소포는 원형질막의 직접 버딩(budding)으로부터 생성되고, 엑소좀은 다소포성 엔도좀과 원형질막의 융합시 세포외 환경으로 방출된다. 따라서, ceDNA 벡터-함유 미세소포 및/또는 엑소좀은 ceDNA-플라스미드 또는 ceDNA-플라스미드로 생성된 박미드 또는 바쿨로바이러스로 형질도입된 세포로부터 단리될 수 있다.
미세소포는 배양 배지를 여과하거나 20,000 x g에서, 엑소좀은 100,000 x g에서 초원심분리함으로써 단리될 수 있다. 초원심분리의 최적 지속 시간은 실험적으로 결정될 수 있으며, 소포가 분리되는 특정 세포 유형에 의존할 것이다. 바람직하게는, 배양 배지는 먼저 저속 원심분리 (예를 들어, 2000 x g에서 5-20분 동안)로 제거되고, 예를 들어, AMICON® 스핀 컬럼 (Millipore, Watford, UK)을 사용하여 스핀 농축된다. 미세소포 및 엑소좀은 미세소포 및 엑소좀 상에 존재하는 특정 표면 항원을 인식하는 특정 항체를 사용함으로써 FACS 또는 MACS를 통해 추가로 정제될 수 있다. 다른 미세소포 및 엑소좀 정제 방법은 면역침전, 친화성 크로마토그래피, 여과 및 특정 항체 또는 압타머로 코팅된 자성 비드를 포함하지만, 이에 제한되지는 않는다. 정제시, 소포는, 예를 들어, 포스페이트-완충 염수로 세척된다. ceDNA-함유 소포를 전달하기 위해 미세소포 또는 엑소좀을 사용하는 것의 하나의 이점은 이들 소포가 각각의 세포 유형 상의 특정 수용체에 의해 인식되는 막 단백질을 포함하여 다양한 세포 유형에 표적화될 수 있다는 것이다. (또한 EP 10306226 참조)
본원의 또 다른 측면은 ceDNA 작제물을 자신의 게놈에 안정적으로 통합한 숙주 세포주로부터 ceDNA 벡터를 정제하는 방법에 관한 것이다. 일 구현예에서, ceDNA 벡터는 DNA 분자로서 정제된다. 또 다른 구현예에서, ceDNA 벡터는 엑소좀 또는 미세입자로서 정제된다.
국제 출원 PCT/US18/49996의 도 5는 실시예에 기재된 방법을 사용하여 다수의 ceDNA-플라스미드 작제물로부터 ceDNA의 생성을 확인하는 겔을 보여준다. ceDNA는 실시예에서 도 4d와 관련하여 논의된 바와 같이, 겔에서 특징적인 밴드 패턴에 의해 확인된다.
VII. 약제학적 조성물
또 다른 측면에서, 약제학적 조성물이 제공된다. 약제학적 조성물은 본원에 기재된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터 및 약제학적으로 허용되는 담체 또는 희석제를 포함한다.
본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA-벡터는 대상체의 세포, 조직 또는 기관으로의 생체내 전달을 위해 대상체에게 투여하기에 적합한 약제학적 조성물에 포함될 수 있다. 전형적으로, 약제학적 조성물은 본원에 개시된 바와 같은 ceDNA-벡터 및 약제학적으로 허용되는 담체를 포함한다. 예를 들어, 본원에 기재된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 원하는 치료적 투여 경로 (예를 들어, 비경구 투여)에 적합한 약제학적 조성물에 포함될 수 있다. 고압 정맥내 또는 동맥내 주입, 및 세포내 주사, 예컨대 핵내 미세주입 또는 세포질내 주사를 통한 수동적인 조직 형질도입이 또한 고려된다. 치료 목적을 위한 약제학적 조성물은 용액, 마이크로에멀젼, 분산액, 리포좀 또는 높은 ceDNA 벡터 농도에 적합한 다른 정렬된 구조로서 제형화될 수 있다. 멸균 주사용 용액은 ceDNA 벡터 화합물을 필요한 양으로, 필요에 따라, 상기 열거된 성분 중 하나 또는 조합과 함께 적절한 완충제에 혼입한 후 멸균 여과함으로써 제조될 수 있으며, ceDNA 벡터를 포함하여 제형화하여 핵 내의 이식유전자를 수용자의 유전자에 전달하여, 그 안의 이식유전자 또는 공여체 서열의 치료적 발현을 초래한다. 상기 조성물은 또한 약제학적으로 허용되는 담체를 포함할 수 있다.
항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 포함하는 약제학적 활성 조성물은 다양한 목적을 위해 이식유전자를 세포, 예를 들어, 대상체의 세포로 전달하도록 제형화될 수 있다.
치료 목적을 위한 약제학적 조성물은 전형적으로 제조 및 저장 조건 하에서 멸균되고 안정적이어야 한다. 조성물은 용액, 마이크로에멀젼, 분산액, 리포좀 또는 높은 ceDNA 벡터 농도에 적합한 다른 정렬 구조로 제형화될 수 있다. 멸균 주사용 용액은 ceDNA 벡터 화합물을 필요한 양으로, 필요에 따라, 상기 열거된 성분 중 하나 또는 조합과 함께 적절한 완충제에 혼입한 후 멸균 여과함으로써 제조될 수 있다.
본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 국소, 전신, 양막내, 경막내, 두개내, 동맥내, 정맥내, 림프내, 복강내, 피하, 기관, 조직내 (예를 들어, 근육내, 심장내, 간내, 신장내, 뇌내), 경막내, 방광내, 결막 (예를 들어, 안와외(extra-orbital), 안와내, 안와후(retroorbital), 망막내, 망막하, 맥락막, 맥락막하, 간질내, 전방내 및 유리체내), 달팽이관내 및 점막 (예를 들어, 구강, 직장, 코) 투여에 적합한 약제학적 조성물에 포함될 수 있다. 고압 정맥내 또는 동맥내 주입, 및 세포내 주사, 예컨대 핵내 미세주입 또는 세포질내 주사를 통한 수동 조직 형질도입이 또한 고려된다.
일부 측면에서, 본원에 제공된 방법은 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 하나 이상의 ceDNA 벡터를 숙주 세포로 전달하는 것을 포함한다. 또한, 이러한 방법에 의해 생성된 세포, 및 이러한 세포를 포함하거나 이로부터 생성된 유기체 (예컨대 동물, 식물 또는 진균)가 본원에 제공된다. 핵산의 전달 방법은 리포펙션, 뉴클레오펙션, 마이크로인젝션, 유전자총법(biolistics), 리포좀, 면역리포좀, 다가 양이온 또는 지질:핵산 접합체, 네이키드 DNA, 및 작용제-강화된 DNA 흡수를 포함할 수 있다. 리포펙션은 예를 들어, 미국 특허 번호 5,049,386, 4,946,787; 및 4,897,355)에 기재되어 있으며, 리포펙션 시약은 상업적으로 판매된다 (예를 들어, Transfectam™ 및 Lipofectin™). 전달은 세포 (예를 들어, 시험관 내 또는 생체외 투여) 또는 표적 조직 (예를 들어, 생체내 투여)으로의 전달일 수 있다.
핵산을 세포로 전달하기 위한 다양한 기술 및 방법이 당 업계에 공지되어 있다. 예를 들어, 항체 또는 융합 단백질 생산을 위한 ceDNA와 같은 핵산은 지질 나노입자 (LNP), 리피도이드, 리포좀, 지질 나노입자, 리포플렉스 또는 코어-쉘 나노입자로 제형화될 수 있다. 전형적으로, LNP는 핵산 (예를 들어, ceDNA) 분자, 하나 이상의 이온화 가능한 또는 양이온성 지질 (또는 이의 염), 하나 이상의 비이온성 또는 중성 지질 (예를 들어, 인지질), 응집을 방지하는 분자 (예를 들어, PEG 또는 PEG-지질 접합체), 및 임의로 스테롤 (예를 들어, 콜레스테롤)로 구성된다.
항체 또는 융합 단백질 생산을 위한 ceDNA와 같은 핵산을 세포로 전달하는 또 다른 방법은 세포에 의해 내재화된 리간드와 핵산을 접합시키는 것이다. 예를 들어, 리간드는 세포 표면상의 수용체에 결합하고 세포내이입을 통해 내재화될 수 있다. 리간드는 핵산에서 뉴클레오티드에 공유적으로 연결될 수 있다. 핵산을 세포 내로 전달하기 위한 예시적인 접합체는, 예를 들어, WO2015/006740, WO2014/025805, WO2012/037254, WO2009/082606, WO2009/073809, WO2009/018332, WO2006/112872, WO2004/090108, WO2004/091515 및 WO2017/177326에 기재되어 있다.
항체 또는 융합 단백질 생산을 위한 ceDNA 벡터와 같은 핵산은 또한 형질감염에 의해 세포로 전달될 수 있다. 유용한 형질감염 방법은 지질-매개 형질감염, 양이온성 폴리머-매개 형질감염 또는 인산칼슘 침전을 포함하지만, 이에 제한되지는 않는다. 형질감염 시약은 당 업계에 잘 알려져 있으며, TurboFect 형질감염 시약 (Thermo Fisher Scientific), Pro-Ject 시약 (Thermo Fisher Scientific), TRANSPASS™ P 단백질 형질감염 시약 (New England Biolabs), CHARIOT™ 단백질 전달 시약 (Active Motif), PROTEOJUICE™ 단백질 형질감염 시약 (EMD Millipore), 293fectin, LIPOFECTAMINE™ 2000, LIPOFECTAMINE™ 3000 (Thermo Fisher Scientific), LIPOFECTAMINE™ (Thermo Fisher Scientific), LIPOFECTIN™ (Thermo Fisher Scientific), DMRIE-C, CELLFECTIN™ (Thermo Fisher Scientific), OLIGOFECTAMINE™ (Thermo Fisher Scientific), LIPOFECTACE™, FUGENE™ (Roche, Basel, Switzerland), FUGENE™ HD (Roche), TRANSFECTAM™ (Transfectam, Pr오메가, Madison, Wis.), TFX-10™ (Pr오메가), TFX-20™ (Pr오메가), TFX-50™ (Pr오메가), TRANSFECTIN™ (BioRad, Hercules, Calif.), SILENTFECT™ (Bio-Rad), Effectene™ (Qiagen, Valencia, Calif.), DC-chol (Avanti Polar Lipids), GENEPORTER™ (Gene Therapy Systems, San Diego, Calif.), DHARMAFECT 1™ (Dharmacon, Lafayette, Colo.), DHARMAFECT 2™ (Dharmacon), DHARMAFECT 3™ (Dharmacon), DHARMAFECT 4™ (Dharmacon), ESCORT™ III (Sigma, St. Louis, Mo.) 및 ESCORT™ IV (Sigma Chemical Co.)를 포함하지만, 이에 제한되지 않는다. ceDNA와 같은 핵산은 또한 당업자에게 공지된 미세유체 방법을 통해 세포로 전달될 수 있다.
본원에 기재된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 또한 생체내에서 세포의 형질도입을 위해 유기체에 직접 투여될 수 있다. 투여는 주사, 주입, 국소 적용 및 전기천공을 포함하지만, 이에 제한되지 않는, 분자를 혈액 또는 조직 세포와 궁극적으로 접촉되게 도입하기 위해 통상적으로 사용되는 임의의 경로에 의해 이루어진다. 이러한 핵산을 투여하는 적합한 방법은 이용 가능하고 당업자에게 잘 알려져 있으며, 하나 초과의 경로가 특정 조성물을 투여하는데 사용될 수 있지만, 특정 경로는 종종 또 다른 경로보다 더 즉각적이고 보다 효과적인 반응을 제공할 수 있다.
본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 핵산 벡터 ceDNA 벡터의 도입 방법은, 예를 들어, 미국 특허 번호 5,928,638에 기재된 바와 같은 방법에 의해 조혈 줄기세포로 전달될 수 있다.
본 발명에 따른 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 대상체에서 세포 또는 표적 기관으로 전달하기 위해 리포좀에 첨가될 수 있다. 리포좀은 적어도 하나의 지질 이중층을 갖는 소포이다. 리포좀은 약학 개발의 맥락에서 약물/치료적 전달을 위한 담체로서 전형적으로 사용된다. 그들은 세포막과 융합하고 그의 지질 구조를 재배치하여 약물 또는 활성 제약 성분 (API)을 전달함으로써 작동한다. 이러한 전달을 위한 리포좀 조성물은 인지질, 특히 포스파티딜콜린기를 갖는 화합물로 구성되지만, 이들 조성물은 또한 다른 지질을 포함할 수 있다. 폴리에틸렌글리콜 (PEG)-작용기 함유 화합물을 포함하나 이에 제한되지 않는 예시적인 리포좀 및 리포좀 제형은 2018년 9월 7일에 출원된 국제 출원 PCT/US2018/050042 및 2018년 12월 6일에 출원된 국제 출원 PCT/US2018/064242에 개시되어 있으며, 예를 들어, "제약 제형" 섹션을 참조한다.
당 업계에 공지된 다양한 전달 방법 또는 이의 변형을 사용하여 시험관내 또는 생체내에서 ceDNA 벡터를 전달할 수 있다. 예를 들어, 일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 표적화된 세포로의 DNA 유입이 촉진되도록 기계적, 전기, 초음파, 유체 역학적 또는 레이저-기반 에너지에 의해 세포막에 일시적 침투를 함으로써 전달된다. 예를 들어, ceDNA 벡터는 크기 제한 채널을 통해 또는 당 업계에 공지된 다른 수단을 통해 세포를 압착함으로써 일시적으로 세포막을 파괴함으로써 전달될 수 있다. 일부 경우에, ceDNA 벡터는 단독으로 피부, 흉선, 심장 근육, 골격근 또는 간 세포에 네이키드 DNA로서 직접 주사된다. 일부 경우에, ceDNA 벡터는 유전자 총에 의해 전달된다. 캡시드가 없는 AAV 벡터로 코팅된 금 또는 텅스텐 구형 입자 (1-3 μm 직경)는 가압된 가스를 통해 표적 조직 세포로 침투하기 위해 고속으로 가속화될 수 있다.
항체 또는 융합 단백질 생산을 위한 ceDNA 벡터 및 약제학적으로 허용되는 담체를 포함하는 조성물이 본원에서 구체적으로 고려된다. 일부 구현예에서, ceDNA 벡터는 지질 전달 시스템, 예를 들어, 본원에 기재된 리포좀으로 제형화된다. 일부 구현예에서, 이러한 조성물은 숙련된 전문가가 원하는 임의의 경로로 투여된다. 상기 조성물은 경구, 비경구, 설하, 경피, 직장, 경점막, 국소, 흡입, 협측 투여, 흉막내, 정맥내, 동맥내, 복강내, 피하, 근육내, 비강내 경막내, 및 관절내 또는 이들의 조합을 포함하여 상이한 경로로 대상체에게 투여될 수 있다. 수의용으로, 조성물은 정상적인 수의학적 실무에 따라 적합하게 허용되는 제형으로 투여될 수 있다. 수의사는 특정 동물에 가장 적합한 투여 요법 및 투여 경로를 쉽게 결정할 수 있다. 조성물은 전통적인 주사기, 바늘이 없는 주입 장치, "미세발사체 충격 유전자 건(mjicroprojectile bombardment gene gun)" 또는 전기천공 ("EP"), 유체 역학적 방법 또는 초음파와 같은 다른 물리적 방법에 의해 투여될 수 있다.
일부 경우에, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 유체 역학적 주사에 의해 전달되는데, 이는 임의의 수용성 화합물 및 입자를 사지 전체의 내부 기관 및 골격근으로 직접 세포내로 전달하기 위한 간단하고 매우 효율적인 방법이다.
일부 경우에, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 내부 장기 또는 종양의 세포 내로 DNA 입자의 세포내 전달을 용이하게 하기 위해 막에 나노스코픽 공극을 만들어 초음파에 의해 전달되므로, 플라스미드 DNA의 크기 및 농도는 시스템의 효율에 큰 역할을 한다. 일부 경우에, ceDNA 벡터는 핵산을 함유하는 입자를 표적 세포 내로 농축시키기 위해 자기장을 사용하여 자기감염에 의해 전달된다.
일부 경우에, 화학적 전달 시스템은, 예를 들어, 나노머 복합체를 사용함으로써 사용될 수 있으며, 이는 양이온성 리포좀/미쉘 또는 양이온성 폴리머에 속하는, 다가 양이온 나노머 입자에 의한 음전하 핵산의 압축을 포함한다. 전달 방법에 사용되는 양이온성 지질은 1가 양이온성 지질, 다가 양이온성 지질, 구아니딘 함유 화합물, 콜레스테롤 유도체 화합물, 양이온성 폴리머 (예를 들어, 폴리(에틸렌이민), 폴리-L-리신, 프로타민, 기타 양이온성 폴리머), 및 지질-폴리머 하이브리드를 포함하지만, 이에 제한되지 않는다.
A. 엑소좀:
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 엑소좀에 패키징되어 전달된다. 엑소좀은 다소포체와 원형질막의 융합 후 세포외 환경으로 방출되는 식작용 기원의 작은 막 소포이다. 이들의 표면은 공여체 세포의 세포막으로부터의 지질 이중층으로 구성되며, 이들은 엑소좀을 생성하는 세포로부터의 시토졸을 함유하고, 표면상의 모 세포로부터 막 단백질을 나타낸다. 엑소좀은 상피 세포, B 및 T 림프구, 비만 세포 (MC) 및 수지상 세포 (DC)를 포함하는 다양한 세포 유형에 의해 생성된다. 일부 구현예, 직경이 10nm 내지 1μm, 20nm 내지 500nm, 30nm 내지 250nm, 50nm 내지 100nm인 엑소좀이 사용되는 것으로 예상된다. 공여체 세포를 사용하거나 특정 핵산을 이들에 도입함으로써 표적 세포로의 전달을 위한 엑소좀을 단리할 수 있다. 당 업계에 공지된 다양한 접근법을 사용하여 본 발명의 캡시드-비함유 AAV 벡터를 함유하는 엑소좀을 생성할 수 있다.
B. 미세입자/나노입자:
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 지질 나노입자에 의해 전달된다. 일반적으로, 지질 나노입자는 예를 들어 하기에 개시된 바와 같이, 이온화 가능한 아미노 지질 (예를 들어, 헵타트리아콘타-6,9,28,31-테트라엔-19-일 4-(디메틸아미노)부타노에이트, DLin-MC3-DMA, 포스파티딜콜린 (1,2-디스테아로일-sn-글리세로-3-포스포콜린, DSPC), 콜레스테롤 및 코트 지질 (폴리에틸렌 글리콜-디미리스토글리세롤, PEG-DMG)을 포함한다: Tam et al. (2013). Advances in Lipid Nanoparticles for siRNA delivery. Pharmaceuticals 5(3): 498-507.
일부 구현예에서, 지질 나노입자는 약 10 내지 약 1000 nm의 평균 직경을 갖는다. 일부 구현예에서, 지질 나노입자는 300 nm 미만의 직경을 갖는다. 일부 구현예에서, 지질 나노입자는 약 10 내지 약 300 nm의 직경을 갖는다. 일부 구현예에서, 지질 나노입자는 200 nm 미만의 직경을 갖는다. 일부 구현예에서, 지질 나노입자는 약 25 내지 약 200 nm의 직경을 갖는다. 일부 구현예에서, 지질 나노입자 제제 (예를 들어, 복수의 지질 나노입자를 포함하는 조성물)는 평균 크기 (예를 들어, 직경)가 약 70 nm 내지 약 200 nm이고, 보다 전형적으로 평균 크기가 약 100nm 이하인 크기 분포를 갖는다.
당 업계에 공지된 다양한 지질 나노입자가 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 전달하는데 사용될 수 있다. 예를 들어, 지질 나노입자를 사용한 다양한 전달 방법은 미국 특허 번호 9,404,127, 9,006,417 및 9,518,272에 기재되어 있다.
일부 구현예에서, 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 금 나노입자에 의해 전달된다. 일반적으로, 핵산은, 예를 들어, 하기에 기재된 바와 같이, 금 나노입자에 공유 결합될 수 있거나 금 나노입자에 비공유 결합 (예를 들어, 전하-전하 상호작용에 의해 결합)될 수 있다: Ding et al. (2014). Gold Nanoparticles for Nucleic Acid Delivery. Mol. Ther. 22(6); 1075-1083. 일부 구현예에서, 금 나노입자-핵산 접합체는, 예를 들어, 미국 특허 번호 6,812,334에 기재된 방법을 사용하여 제조된다.
C. 접합체
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 접합된다 (예를 들어, 세포 흡수를 증가시키는 작용제에 공유 결합됨). "세포 흡수를 증가시키는 작용제"는 지질 막을 통한 핵산의 수송을 용이하게 하는 분자이다. 예를 들어, 핵산은 친유성 화합물 (예를 들어, 콜레스테롤, 토코페롤 등), 세포 침투 펩티드 (CPP) (예를 들어, 페네트라틴, TAT, Syn1B 등) 및 폴리아민 (예를 들어, 스퍼민)에 접합될 수 있다. 세포 흡수를 증가시키는 작용제의 추가 예는, 예를 들어, 하기에 개시되어 있다: Winkler (2013). Oligonucleotide conjugates for therapeutic applications. Ther. Deliv. 4(7); 791-809.
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 폴리머 (예를 들어, 폴리머 분자) 또는 폴레이트 분자 (예를 들어, 엽산 분자)에 접합된다. 일반적으로, 폴리머에 접합된 핵산의 전달은, 예를 들어 WO2000/34343 및 WO2008/022309에 기재된 바와 같이, 당 업계에 공지되어 있다. 일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는, 예를 들어 미국 특허 번호 8,987,377에 기재된 바와 같은 폴리(아미드) 폴리머에 접합된다. 일부 구현예에서, 본 개시내용에 기재된 핵산은 미국 특허 번호 8,507,455에 기재된 바와 같은 엽산 분자에 접합된다.
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는, 예를 들어, 미국 특허 번호 8,450,467에 기재된 바와 같이 탄수화물에 접합된다.
D. 나노캡슐
대안적으로, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 나노캡슐 제형이 사용될 수 있다. 나노캡슐은 일반적으로 물질을 안정적이고 재현 가능한 방식으로 포획할 수 있다. 세포내 폴리머 과부하로 인한 부작용을 피하기 위해, 이러한 초미립자 (약 0.1 μm 크기)는 생체내에서 분해될 수 있는 폴리머를 사용하여 설계되어야 한다. 이들 요건을 충족시키는 생분해성 폴리알킬-시아노아크릴레이트 나노입자가 사용될 것으로 고려된다.
E. 리포솜
본 개시내용에 따른 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 대상체에서 세포 또는 표적 기관으로 전달하기 위해 리포좀에 첨가될 수 있다. 리포좀은 적어도 하나의 지질 이중층을 갖는 소포이다. 리포좀은 제약 개발의 맥락에서 약물/치료적 전달을 위한 담체로서 전형적으로 사용된다. 이들은 세포막과 융합하고 이의 지질 구조를 재배치하여 약물 또는 활성 제약 성분 (API)을 전달함으로써 작동한다. 이러한 전달을 위한 리포좀 조성물은 인지질, 특히 포스파티딜콜린 기를 갖는 화합물로 구성되지만, 이들 조성물은 또한 다른 지질을 포함할 수 있다.
리포좀의 형성 및 사용은 일반적으로 당업자에게 공지되어 있다. 리포좀은 개선된 혈청 안정성 및 순환 하프-타임(half-time)으로 개발되었다 (미국 특허 번호 5,741,516). 또한, 잠재적 약물 담체로서의 리포좀 및 리포좀 유사 제제의 다양한 방법이 기술되어 있다 (미국 특허 번호 5,567,434; 5,552,157; 5,565,213; 5,738,868 및 5,795,587).
F. 예시적인 리포좀 및 지질 나노입자 (LNP) 조성물
본 발명에 따른 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 이식유전자의 발현이 필요한 세포, 예를 들어 세포로 전달하기 위해 리포좀에 첨가될 수 있다. 리포좀은 적어도 하나의 지질 이중층을 갖는 소포이다. 리포좀은 제약 개발의 맥락에서 약물/치료적 전달을 위한 담체로서 전형적으로 사용된다. 이들은 세포막과 융합하고 이의 지질 구조를 재배치하여 약물 또는 활성 제약 성분 (API)을 전달함으로써 작동한다. 이러한 전달을 위한 리포좀 조성물은 인지질, 특히 포스파티딜콜린 기를 갖는 화합물로 구성되지만, 이들 조성물은 또한 다른 지질을 포함할 수 있다.
ceDNA 벡터를 포함하는 지질 나노 입자 (LNP)는 2018년 9월 7일에 출원된 국제 출원 PCT/US2018/050042 및 2018년 12월 6일에 출원된 국제 출원 PCT/US2018/064242에 개시되어 있으며, 이들은 전체가 본원에 포함되고 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 방법 및 조성물에 사용되도록 계획된다.
일부 측면에서, 본 개시내용은 화합물(들)의 면역원성/항원성을 감소시키고, 친수성 및 소수성을 제공하고, 투여 빈도를 감소시킬 수 있는 폴리에틸렌 글리콜 (PEG) 작용기를 갖는 하나 이상의 화합물 (소위 "PEG화 화합물")을 포함하는 리포좀 제형을 제공한다. 또는 리포좀 제형은 단순히 추가 성분으로서 폴리에틸렌 글리콜 (PEG) 폴리머를 포함한다. 이러한 측면에서, PEG 또는 PEG 작용기의 분자량은 62 Da 내지 약 5,000 Da일 수 있다.
일부 측면에서, 본 개시내용은 수 시간 내지 수 주에 걸쳐 연장 방출 또는 제어 방출 프로파일을 갖는 API를 전달할 리포좀 제형을 제공한다. 일부 관련 측면에서, 리포좀 제형은 지질 이중층에 의해 결합된 수성 챔버를 포함할 수 있다. 다른 관련 측면에서, 리포좀 제형은 승온에서 물리적 전이를 겪는 성분으로 API를 캡슐화하여 수 시간 내지 수 주에 걸쳐 API를 방출한다.
일부 측면에서, 리포좀 제형은 스핑고미엘린 및 본원에 개시된 하나 이상의 지질을 포함한다. 일부 측면에서, 리포좀 제형은 옵티좀을 포함한다.
일부 측면에서, 본 개시내용은 N-(카보닐-메톡시폴리에틸렌 글리콜 2000)-1,2-디스테아로일-sn-글리세로-3-포스포에탄올아민 나트륨염 (디스테아로일-sn-글리세로-포스포에탄올아민), MPEG (메톡시 폴리에틸렌 글리콜)-공액 지질, HSPC (수소화 대두 포스파티딜콜린); PEG (폴리에틸렌 글리콜); DSPE (디스테아로일-sn-글리세로-포스포에탄올아민); DSPC (디스테아로일포스파티딜콜린); DOPC (디올레오일포스파티딜콜린); DPPG (디팔미토일포스파티딜글리세롤); EPC (계란 포스파티딜콜린); DOPS (디올레오일포스파티딜세린); POPC (팔미토일로레오일포스파티딜콜린); SM (스핑고미엘린); MPEG (메톡시 폴리에틸렌 글리콜); DMPC (디미리스토일 포스파티딜콜린); DMPG (디미리스토일 포스파티딜글리세롤); DSPG (디스테아로일포스파티딜글리세롤); DEPC (디에루코일포스파티딜콜린); DOPE (디올레올리-sn-글리세로-포스포에탄올아민). 콜레스테릴 설페이트 (CS), 디팔미토일포스파티딜글리세롤 (DPPG), DOPC (디오롤리-sn-글리세로-포스파티딜콜린) 또는 이들의 임의의 조합으로부터 선택된 하나 이상의 지질을 포함하는 리포좀 제형을 제공한다.
일부 측면에서, 본 개시내용은 인지질, 콜레스테롤 및 PEG화 지질을 56:38:5의 몰비로 포함하는 리포좀 제형을 제공한다. 일부 측면에서, 리포좀 제형의 전체 지질 함량은 2-16 mg/mL이다. 일부 측면에서, 본 개시내용은 포스파티딜콜린 작용기를 함유하는 지질, 에탄올아민 작용기를 함유하는 지질 및 PEG화 지질을 포함하는 리포좀 제형을 제공한다. 일부 측면에서, 본 개시내용은 포스파티딜콜린 작용기를 함유하는 지질, 에탄올아민 작용기를 함유하는 지질 및 PEG화 지질을 각각 3:0.015:2의 몰비로 포함하는 리포좀 제형을 제공한다. 일부 측면에서, 본 개시내용은 포스파티딜콜린 작용기를 함유하는 지질, 콜레스테롤 및 PEG화 지질을 포함하는 리포좀 제형을 제공한다. 일부 측면에서, 본 개시내용은 포스파티딜콜린 작용기를 함유하는 지질 및 콜레스테롤을 포함하는 리포좀 제형을 제공한다. 일부 측면에서, PEG화 지질은 PEG-2000-DSPE이다. 일부 측면에서, 본 개시내용은 DPPG, 대두 PC, MPEG-DSPE 지질 접합체 및 콜레스테롤을 포함하는 리포좀 제형을 제공한다.
일부 측면에서, 본 개시내용은 포스파티딜콜린 작용기를 함유하는 하나 이상의 지질 및 에탄올아민 작용기를 함유하는 하나 이상의 지질을 포함하는 리포좀 제형을 제공한다. 일부 측면에서, 본 개시내용은 포스파티딜콜린 작용기를 함유하는 지질, 에탄올아민 작용기를 함유하는 지질 및 스테롤, 예를 들어 콜레스테롤 중 하나 이상을 포함하는 리포좀 제형을 제공한다. 일부 측면에서, 리포좀 제형은 DOPC/DEPC; 및 DOPE를 포함한다.
일부 측면에서, 본 개시내용은 하나 이상의 약제학적 부형제, 예를 들어, 수 크로스 및/또는 글리신을 추가로 포함하는 리포좀 제형을 제공한다.
일부 측면에서, 본 개시내용은 구조상 단일 라멜라 또는 다중 라멜라인 리포좀 제형을 제공한다. 일부 측면에서, 본 개시내용은 다중 소포성 입자 및/또는 발포체 기반 입자를 포함하는 리포좀 제형을 제공한다. 일부 측면에서, 본 개시내용은 일반적인 나노입자에 비해 크기가 크고 크기가 약 150 내지 250 nm인 리포좀 제형을 제공한다. 일부 측면에서, 리포좀 제형은 동결 건조된 분말이다.
일부 측면에서, 본 개시내용은 리포좀 외부에 단리된 ceDNA를 갖는 혼합물에 약한 염기를 첨가함으로써 본원에 개시되거나 기재된 ceDNA 벡터로 제조되고 로딩된 리포좀 제형을 제공한다. 이 첨가는 리포좀 외부의 pH를 약 7.3으로 증가시키고 API를 리포좀으로 유도한다. 일부 측면에서, 본 개시내용은 리포좀 내부에서 산성인 pH를 갖는 리포좀 제형을 제공한다. 이러한 경우, 리포좀 내부는 pH 4-6.9, 보다 바람직하게는 pH 6.5일 수 있다. 다른 측면에서, 본 개시내용은 리포좀내 약물 안정화 기술을 사용하여 제조된 리포좀 제형을 제공한다. 이러한 경우에, 폴리머 또는 비-폴리머 고도로 하전된 음이온 및 리포좀내 포획제, 예를 들어 폴리포스페이트 또는 수크로스 옥타설페이트가 사용된다.
일부 측면에서, 본 개시내용은 ceDNA 및 이온화 가능한 지질을 포함하는 지질 나노입자를 제공한다. 예를 들어, 본원에 포함된, 2018년 9월 7일자로 출원된 국제 출원 PCT/US2018/050042에 개시된 바와 같은 방법에 의해 수득된 ceDNA로 제조되고 로딩된 지질 나노입자 제형. 이는 이온화 가능한 지질을 양성화하고 ceDNA/지질 회합 및 입자의 핵 형성에 유리한 에너지학을 제공하는 낮은 pH에서 에탄올성 지질과 수성 ceDNA의 고에너지 혼합에 의해 달성될 수 있다. 입자는 유기 용매의 수성 희석 및 제거를 통해 추가로 안정화될 수 있다. 입자는 원하는 수준으로 농축될 수 있다.
일반적으로, 지질 입자는 약 10:1 내지 30:1의 총 지질 대 ceDNA (질량 또는 중량) 비로 제조된다. 일부 구현예에서, 지질 대 ceDNA 비 (질량/질량 비; w/w 비)는 약 1:1 내지 약 25:1, 약 10:1 내지 약 14:1, 약 3:1 내지 약 15:1, 약 4:1 내지 약 10:1, 약 5:1 내지 약 9:1, 또는 약 6:1 내지 약 9:1의 범위일 수 있다. 지질 및 ceDNA의 양은 원하는 N/P 비, 예를 들어, 3, 4, 5, 6, 7, 8, 9, 10 이상의 N/P 비를 제공하도록 조정될 수 있다. 일반적으로, 지질 입자 제형의 전체 지질 함량은 약 5 mg/ml 내지 약 30 mg/mL의 범위일 수 있다.
이온화 가능한 지질은 전형적으로 핵산 카고, 예를 들어, ceDNA를 낮은 pH에서 응축시키고 막 회합 및 융합유도성(fusogenicity)을 유도하기 위해 사용된다. 일반적으로, 이온화 가능한 지질은 산성 조건, 예를 들어 pH 6.5 이하에서 양으로 하전되거나 양성화되는 적어도 하나의 아미노기를 포함하는 지질이다. 이온화 가능한 지질은 또한 본원에서 양이온성 지질로 지칭된다.
예시적인 이온화 가능한 지질은 국제 PCT 특허 공보 WO2015/095340, WO2015/199952, WO2018/011633, WO2017/049245, WO2015/061467, WO2012/040184, WO2012/000104, WO2015/074085, WO2016/081029, WO2017/004143, WO2017/075531, WO2017/117528, WO2011/022460, WO2013/148541, WO2013/116126, WO2011/153120, WO2012/044638, WO2012/054365, WO2011/090965, WO2013/016058, WO2012/162210, WO2008/042973, WO2010/129709, WO2010/144740 , WO2012/099755, WO2013/049328, WO2013/086322, WO2013/086373, WO2011/071860, WO2009/132131, WO2010/048536, WO2010/088537, WO2010/054401, WO2010/054406 , WO2010/054405, WO2010/054384, WO2012/016184, WO2009/086558, WO2010/042877, WO2011/000106, WO2011/000107, WO2005/120152, WO2011/141705, WO2013/126803, WO2006/007712, WO2011/038160, WO2005/121348, WO2011/066651, WO2009/127060, WO2011/141704, WO2006/069782, WO2012/031043, WO2013/006825, WO2013/033563, WO2013/089151, WO2017/099823, WO2015/095346, 및 WO2013/086354, 및 미국 특허 공보 US2016/0311759, US2015/0376115, US2016/0151284, US2017/0210697, US2015/0140070, US2013/0178541, US2013/0303587, US2015/0141678, US2015/0239926, US2016/0376224, US2017/0119904, US2012/0149894, US2015/0057373, US2013/0090372, US2013/0274523, US2013/0274504, US2013/0274504, US2009/0023673, US2012/0128760, US2010/0324120, US2014/0200257, US2015/0203446, US2018/0005363, US2014/0308304, US2013/0338210, US2012/0101148, US2012/0027796, US2012/0058144, US2013/0323269, US2011/0117125, US2011/0256175, US2012/0202871, US2011/0076335, US2006/0083780, US2013/0123338, US2015/0064242, US2006/0051405, US2013/0065939, US2006/0008910, US2003/0022649, US2010/0130588, US2013/0116307, US2010/0062967, US2013/0202684, US2014/0141070, US2014/0255472, US2014/0039032, US2018/0028664, US2016/0317458, 및 US2013/0195920 (이들 내용은 모두 그 전문이 본원에 참고로 포함됨)에 기재되어 있다.
일부 구현예에서, 이온화 가능한 지질은 다음 구조를 갖는 MC3 (6Z,9Z,28Z,31Z)-헵타트리아콘타-6,9,28,31-테트라엔-19-일-4-(디메틸아미노) 부타노에이트 (DLin-MC3-DMA 또는 MC3)이다.

지질 DLin-MC3-DMA는 Jayaraman et al., Angew. Chem. Int. Ed Engl. (2012), 51(34): 8529-8533에 기재되어 있으며, 이의 내용은 그 전문이 본원에 참고로 포함된다.
일부 구현예에서, 이온화 가능한 지질은 WO2015/074085에 기재된 지질 ATX-002이며, 이의 내용은 그 전문이 본원에 참고로 포함된다.
일부 구현예에서, 이온화 가능한 지질은 WO2012/040184에 기재된 (13Z,16Z)-N,N-디메틸-3-노닐도코사-13,16-디엔-1-아민 (화합물 32)이며, 이의 내용은 그 전문이 본원에 참고로 포함된다.
일부 구현예에서, 이온 가능한 지질은 WO2015/199952에 기재된 화합물 6 또는 화합물 22이며, 이의 내용은 그 전문이 본원에 참고로 포함된다.
제한 없이, 이온화 가능한 지질은 지질 나노입자에 존재하는 총 지질의 20-90% (mol)를 포함할 수 있다. 예를 들어, 이온화 가능한 지질 몰 함량은 지질 나노입자에 존재하는 총 지질의 20-70% (mol), 30-60% (mol) 또는 40-50% (mol)일 수 있다. 일부 구현예에서, 이온화 가능한 지질은 지질 나노입자에 존재하는 총 지질의 약 50 mol% 내지 약 90 mol%를 포함한다.
일부 측면에서, 지질 나노입자는 비-양이온성 지질을 추가로 포함할 수 있다. 비이온성 지질은 양친매성 지질, 중성 지질 및 음이온성 지질을 포함한다. 따라서, 비-양이온성 지질은 중성, 하전된, 양쪽이온성 또는 음이온성 지질일 수 있다. 비양이온성 지질은 전형적으로 융합유도성을 향상시키기 위해 사용된다.
본원에 개시된 바와 같은 방법 및 조성물에 사용하기 위해 계획된 예시적인 비-양이온성 지질은 2018년 9월 7일 출원된 국제 출원 PCT/US2018/050042 및 2018년 12월 6일 출원된 PCT/US2018/064242에 기재되어 있으며, 이는 그 전체가 본원에 포함된다. 예시적인 비-양이온성 지질은 국제 출원 공개 WO2017/099823 및 미국 특허 공개 US2018/0028664에 기재되어 있으며, 이들의 내용은 그 전문이 본원에 참조로 포함된다.
비-양이온성 지질은 지질 나노입자에 존재하는 총 지질의 0-30% (mol)를 포함할 수 있다. 예를 들어, 비-양이온성 지질 함량은 지질 나노입자에 존재하는 총 지질의 5-20% (mol) 또는 10-15% (mol)이다. 다양일 구현예에서, 이온화 가능한 지질 대 중성 지질의 몰비는 약 2:1 내지 약 8:1의 범위이다.
일부 구현예에서, 지질 나노입자는 임의의 인지질을 포함하지 않는다. 일부 측면에서, 지질 나노입자는 막 완전성을 제공하기 위해 스테롤과 같은 성분을 추가로 포함할 수 있다.
지질 나노입자에 사용될 수 있는 하나의 예시적인 스테롤은 콜레스테롤 및 이의 유도체이다. 예시적인 콜레스테롤 유도체는 국제 출원 WO2009/127060 및 미국 특허 공보 US2010/0130588에 기재되어 있으며, 이들의 내용은 모두 그 전문이 본원에 참고로 포함된다.
스테롤과 같은 막 완전성을 제공하는 성분은 지질 나노입자에 존재하는 총 지질의 0-50% (mol)를 포함할 수 있다. 일부 구현예에서, 이러한 성분은 지질 나노입자의 총 지질 함량의 20-50% (mol) 30-40% (mol)이다.
일부 측면에서, 지질 나노입자는 폴리에틸렌 글리콜 (PEG) 또는 공액 지질 분자를 추가로 포함할 수 있다. 일반적으로, 이들은 지질 나노입자의 응집을 억제하고/하거나 입체 안정화를 제공하는데 사용된다. 예시적인 공액 지질은 PEG-지질 접합체, 폴리옥사졸린 (POZ)-지질 접합체, 폴리아미드-지질 접합체 (예컨대 ATTA-지질 접합체) , 양이온-폴리머 지질 (CPL) 접합체, 및 이들의 혼합물을 포함하지만, 이에 제한되지 않는다. 일부 구현예에서, 접합된 지질 분자는 PEG-지질 접합체, 예를 들어 (메톡시 폴리에틸렌 글리콜)-접합된 지질이다. 예시적인 PEG-지질 접합체는 PEG-디아실글리세롤 (DAG) (예컨대 1-(모노메톡시-폴리에틸렌글리콜)-2,3-디미리스토일글리세롤 (PEG-DMG)), PEG-디알킬옥시프로필 (DAA), PEG-인지질, PEG-세라마이드 (Cer), 페길화된 포스파티딜에탄올로아민 (PEG-PE), PEG 석시네이트 디아실글리세롤 (PEGS-DAG) (예컨대 4-O-(2',3'-디(테트라데카노일옥시)프로필-1-O-(w-메톡시(폴리에톡시)에틸) 부탄디오에이트 (PEG-S-DMG)), PEG 디알콕시프로필카밤, N-(카보닐-메톡시폴리에틸렌 글리콜 2000)-1,2-디스테아로일-sn-글리세로-3-포스포에탄올아민 나트륨염, 또는 이들의 혼합물을 포함하지만, 이에 제한되지는 않는다. 추가의 예시적인 PEG-지질 접합체는 US5,885,613, US6,287,591, US2003/0077829, US2003/0077829, US2005/0175682, US2008/0020058, US2011/0117125, US2010/0130588, US2016/0376224, 및 US2017/0119904에 기재되어 있으며, 이들의 내용은 그 전문이 본원에 참고로 포함된다.
일부 구현예에서, PEG-지질은 US2018/0028664(이의 내용은 그 전문이 본원에 참고로 포함됨)에 정의된 바와 같은 화합물이다. 일부 구현예에서, PEG-지질은 US20150376115 또는 US2016/0376224 (이들 내용은 모두 그 전문이 본원에 참고로 포함됨)에 개시된다.
PEG-DAA 접합체는, 예를 들어, PEG-디라우릴옥시프로필, PEG-디미리스틸옥시프로필, PEG-디팔미틸옥시프로필 또는 PEG-디스테아릴옥시프로필일 수 있다. PEG-지질은 PEG-DMG, PEG-디라우릴글리세롤, PEG-디팔미토일글리세롤, PEG-디스테릴글리세롤, PEG-디라우릴글리카미드, PEG-디미리스틸글리카미드, PEG-디팔미토일글리카미드, PEG-디스테릴글리카미드, PEG-콜레스테롤 (1-[8'-(콜레스트-5-엔-3[베타]-옥시)카복사미도-3',6'-디옥사옥타닐] 카바모일-[오메가]-메틸-폴리(에틸렌 글리콜), PEG-DMB (3,4-디테트라데콕실벤질- [오메가]-메틸-폴리(에틸렌 글리콜) 에테르), 및 1,2-디미리스토일-sn-글리세로-3-포스포에탄올아민-N-[메톡시(폴리에틸렌 글리콜)-2000] 중 하나 이상일 수 있다. 일부 구현예에서, PEG-지질은 PEG-DMG, 1,2-디미리스토일-sn-글리세로-3-포스포에탄올아민-N-[메톡시(폴리에틸렌 글리콜) -2000]로 구성된 군으로부터 선택될 수 있다.
PEG 이외의 분자와 접합된 지질도 PEG-지질 대신 사용될 수 있다. 예를 들어, 폴리옥사졸린 (POZ)-지질 접합체, 폴리아미드-지질 접합체 (예컨대 ATTA-지질 접합체), 및 양이온성-폴리머 지질 (CPL) 접합체가 PEG-지질 대신에 또는 이에 더하여 사용될 수 있다. 예시적인 접합된 지질, 즉, PEG-지질, (POZ)-지질 접합체, ATTA-지질 접합체 및 양이온성 폴리머-지질은 국제 특허 출원 공보 WO1996/010392, WO1998/051278, WO2002/087541, WO2005/026372, WO2008/147438, WO2009/086558, WO2012/000104, WO2017/117528, WO2017/099823, WO2015/199952, WO2017/004143, WO2015/095346, WO2012/000104, WO2012/000104, 및 WO2010/006282, 미국 특허 출원 공보 US2003/0077829, US2005/0175682, US2008/0020058, US2011/0117125, US2013/0303587, US2018/0028664, US2015/0376115, US2016/0376224, US2016/0317458, US2013/0303587, US2013/0303587, 및 US20110123453 및 미국 특허 US5,885,613, US6,287,591, US6,320,017, 및 US6,586,559 (이들 내용은 모두 그 전문이 본원에 참고로 포함됨)에 기재되어 있다.
일부 구현예에서, 하나 이상의 추가 화합물은 치료제일 수 있다. 치료제는 치료 목적에 적합한 임의의 부류로부터 선택될 수 있다. 다시 말해, 치료제는 치료 목적에 적합한 임의의 부류로부터 선택될 수 있다. 즉, 치료제는 원하는 치료 목적 및 생물학적 작용에 따라 선택될 수 있다. 예를 들어, LNP 내의 ceDNA가 암 치료에 유용한 경우, 추가의 화합물은 항암제 (예를 들어, 화학요법제, 표적화된 암 요법 (소분자 또는 항체를 포함하지만, 이에 제한되지 않음)일 수 있다. 또 다른 예에서, ceDNA를 함유하는 LNP가 감염 치료에 유용한 경우, 추가의 화합물은 항균제 (예를 들어, 항생제 또는 항바이러스 화합물)일 수 있다. 또 다른 예에서, ceDNA를 함유하는 LNP가 면역 질환 또는 장애의 치료에 유용한 경우, 추가 화합물은 면역 반응을 조절하는 화합물 (예를 들어, 면역억제제, 면역자극 화합물, 또는 하나 이상의 특정 면역 경로를 조절하는 화합물일 수 있다. 일부 구현예에서, 상이한 단백질을 인코딩하는 ceDNA와 같은 상이한 화합물, 또는 치료제와 같은 상이한 화합물을 함유하는 상이한 지질 나노입자의 상이한 칵테일이 본 발명의 조성물 및 방법에 사용될 수 있다.
일부 구현예에서, 추가의 화합물은 면역 조절제이다. 예를 들어, 추가 화합물은 면역억제제이다. 일부 구현예에서, 추가의 화합물은 면역자극제이다. 생산된 지질 나노 입자-캡슐화된 곤충 세포 또는 본원에 기재된 바와 같은 항체 또는 융합 단백질 생산을 위한 합성적으로 생산된 ceDNA 벡터 및 약제학적으로 허용되는 담체 또는 부형제를 포함하는 약제학적 조성물이 본원에 또한 제공된다.
일부 측면에서, 본 개시내용은 하나 이상의 약제학적 부형제를 추가로 포함하는 지질 나노입자 제형을 제공한다. 일부 구현예에서, 지질 나노입자 제형은 수크로스, 트리스, 트레할로스 및/또는 글리신을 추가로 포함한다.
ceDNA 벡터는 입자의 지질 부분과 복합체화되거나 지질 나노입자의 지질 부분에서 캡슐화될 수 있다. 일부 구현예에서, ceDNA는 지질 나노입자의 지질 위치에서 완전히 캡슐화될 수 있으며, 이에 의해, 예를 들어, 수용액에서 뉴클레아제에 의한 분해로부터 보호할 수 있다. 일부 구현예에서, 지질 나노입자 중의 ceDNA는 지질 나노입자를 37℃에서 적어도 약 20, 30, 45 또는 60분 동안 뉴클레아제에 노출시킨 후 실질적으로 분해되지 않는다. 일부 구현예에서, 지질 나노입자의 ceDNA는 37℃에서 적어도 약 30, 45 또는 60분 또는 적어도 약 2, 3, 4, 5, 6, 7, 8, 9, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34 또는 36시간 동안 혈청에서 입자의 인큐베이션 후 실질적으로 분해되지 않는다.
특정 구현예에서, 지질 나노입자는 대상체, 예를 들어, 인간과 같은 포유동물에 실질적으로 비-독성이다. 일부 측면에서, 지질 나노입자 제형은 동결 건조된 분말이다.
일부 구현예에서, 지질 나노입자는 적어도 하나의 지질 이중층을 갖는 고체 코어 입자이다. 다른 구현예에서, 지질 나노입자는 비-이중층 구조, 즉, 비-라멜라 (즉, 비-이중층) 형태를 갖는다. 제한 없이, 비-이중층 형태는, 예를 들어, 3차원 튜브, 막대, 입방체 대칭 등을 포함할 수 있다. 예를 들어, 지질 나노입자의 형태 (라멜라 대 비-라멜라)는, 예를 들어, US2010/0130588 (이의 내용은 그 전문이 본원에 참조로 포함됨)에 기재된 바와 같은 Cryo-TEM 분석을 사용하여 쉽게 평가되고 특성화될 수 있다.
일부 추가의 구현예에서, 비-라멜라 형태를 갖는 지질 나노입자는 고전자밀도이다. 일부 측면에서, 본 개시내용은 구조상 단일 라멜라 또는 다중 라멜라인 지질 나노입자를 제공한다. 일부 측면에서, 본 개시내용은 다중-소포성 입자 및/또는 발포체-기반 입자를 포함하는 지질 나노입자 제형을 제공한다.
지질 성분의 조성 및 농도를 제어함으로써, 지질 접합체가 지질 입자로부터 교환되는 속도, 및 이어서 지질 나노입자가 융합유도성이 되는 속도를 제어할 수 있다. 또한, 예를 들어, pH, 온도 또는 이온 강도를 포함하는 다른 변수를 사용하여 지질 나노입자가 융합유도성이 되는 속도를 변화 및/또는 제어할 수 있다. 지질 나노입자가 융합유도성이 되는 속도를 제어하는데 사용될 수 있는 다른 방법은 본 개시내용에 기초하여 당업자에게 명백할 것이다. 지질 접합체의 조성 및 농도를 제어함으로써 지질 입자 크기를 제어할 수 있음이 또한 명백할 것이다.
제형화된 양이온성 지질의 pKa는 핵산의 전달을 위한 LNP의 효과와 상관관계가 있을 수 있다 (Jayaraman et al, Angewandte Chemie, International Edition (2012), 51(34), 8529-8533; Semple et al, Nature Biotechnology 28, 172-176 (20l0) 참조, 둘 다 그 전문이 참고로 포함됨). pKa의 바람직한 범위는 약 5 내지 약 7이다. 양이온성 지질의 pKa는 2-(p-톨루이디노)-6-나프탈렌 설폰산 (TNS)의 형광에 기초한 검정을 사용하여 지질 나노입자에서 측정될 수 있다.
VIII. 사용 방법
본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 또한 표적 세포 (예를 들어, 숙주 세포)에 관심 뉴클레오티드 서열 (예를 들어, 항체 또는 융합 단백질을 인코딩함)을 전달하는 방법에 사용될 수 있다. 상기 방법은 특히 항체 또는 항원-결합 단편을 이를 필요로 하는 대상체의 세포로 전달하고 관심 질환을 치료하는 방법일 수 있다. 본 발명은 항체 또는 융합 단백질의 발현의 치료 효과가 발생하도록 대상체의 세포에서 ceDNA 벡터에 인코딩된 항체 또는 융합 단백질의 생체내 발현을 가능하게 한다. 이러한 결과는 ceDNA 벡터의 생체내 및 시험관내 전달 방식 둘 다에서 관찰된다.
또한, 본 발명은 이를 필요로 하는 대상체의 세포에서 항체 또는 융합 단백질을 전달하는 방법으로, 상기 항체 또는 융합 단백질을 인코딩하는 본 발명의 ceDNA 벡터의 다중 투여를 포함하는 방법이 제공된다. 본 발명의 ceDNA 벡터가 캡시드로 둘러싸인 바이러스 벡터에 대해 전형적으로 관찰되는 것과 같은 면역 반응을 유도하지 않기 때문에, 이러한 다중 투여 전략은 ceDNA-기반 시스템에서 더 큰 성공을 거둘 것이다.
ceDNA 벡터는 원하는 조직의 세포를 형질감염시키고, 과도한 부작용 없이 항체 또는 융합 단백질의 충분한 수준의 유전자 전달 및 발현을 제공하기에 충분한 양으로 투여된다. 통상적이고 약제학적으로 허용되는 투여 경로는 정맥내 (예를 들어, 리포좀 제형으로), 선택된 기관으로의 직접 전달 (예를 들어, 간으로의 문맥내 전달), 근육내 및 기타 모 투여 경로를 포함하지만, 이에 제한되지는 않는다. 원하는 경우, 투여 경로가 조합될 수 있다.
본원에 기재된 바와 같이 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 전달은 발현된 항체 또는 항원-결합 단편의 전달로 제한되지 않는다. 예를 들어, 통상적으로 생성된 (예를 들어, 세포-기반 생산 방법 (예를 들어, 곤충-세포 생산 방법)을 사용하여) 또는 본원에 기재된 바와 같이 합성적으로 생산된 ceDNA 벡터는 유전자 요법의 일부를 제공하기 위해 제공된 다른 전달 시스템과 함께 사용될 수 있다. 본 개시내용에 따른 ceDNA 벡터와 조합될 수 있는 시스템의 비제한적인 일 예는 항체 또는 융합 단백질을 발현시키는 ceDNA 벡터의 효과적인 유전자 발현을 위해 하나 이상의 보조-인자 또는 면역 억제제를 개별적으로 전달하는 시스템을 포함한다.
본 발명은 또한 선택적으로 약제학적으로 허용되는 담체와 함께, 치료적 유효량의 ceDNA 벡터를 대상체의 이를 필요로 하는 표적 세포 (특히 근육 세포 또는 조직)에 도입하는 것을 포함하는 대상체에서 질환을 치료하는 방법을 제공한다. ceDNA 벡터는 캐리어의 존재하에 도입될 수 있지만, 이러한 캐리어는 필수가 아니다. 선택된 ceDNA 벡터는 질환을 치료하는데 유용한 항체 또는 융합 단백질을 인코딩하는 뉴클레오티드 서열을 포함한다. 특히, ceDNA 벡터는 대상체에 도입될 때 외인성 DNA 서열에 의해 인코딩된 원하는 항체 또는 융합 단백질의 전사를 지시할 수 있는 제어 요소에 작동 가능하게 연결된 원하는 항체 또는 융합 단백질 서열을 포함할 수 있다. ceDNA 벡터는 상기 및 본원의 다른 곳에 제공된 임의의 적합한 경로를 통해 투여될 수 있다.
본원에 제공된 조성물 및 벡터는 다양한 목적으로 항체 또는 융합 단백질을 전달하는데 사용될 수 있다. 일부 구현예에서, 이식유전자는 연구 목적으로, 예를 들어, 항체 또는 융합 단백질 산물의 기능을 연구하기 위한, 예를 들어, 이식유전자를 보유한 체세포성 형질전환 동물 모델을 생성하기 위해 사용하고자 하는 항체 또는 융합 단백질을 인코딩한다. 또 다른 예에서, 이식유전자는 동물 질환 모델을 생성하기 위해 사용하고자 하는 항체 또는 융합 단백질을 인코딩한다. 일부 구현예에서, 인코딩된 항체 또는 융합 단백질은 포유동물 대상체에서 질환 상태의 치료 또는 예방에 유용하다. 항체 또는 융합 단백질은 유전자의 발현 감소, 발현 결핍 또는 기능 장애와 관련된 질환을 치료하기에 충분한 양으로 환자에게 전달 (예를 들어, 환자에서 발현)될 수 있다.
원칙적으로, 발현 카세트는 돌연변이로 인해 감소되거나 부재하거나 또는 과발현될 때 치료적 이점을 전달하는 항체 또는 융합 단백질을 인코딩하는 핵산 또는 임의의 이식유전자를 포함할 수 있으며, 이는 본 발명의 범위 내에 있는 것으로 간주된다. 바람직하게는, 비삽입된 박테리아 DNA는 존재하지 않으며, 바람직하게는 박테리아 DNA가 본원에 제공된 ceDNA 조성물에 존재하지 않는다.
ceDNA 벡터는 한 종의 ceDNA 벡터로 제한되지 않는다. 이와 같이, 또 다른 측면에서, 상이한 항체 또는 융합 단백질 또는 동일한 항체 또는 융합 단백질을 발현시키지만 상이한 프로모터 또는 시스-조절 요소에 작동 가능하게 연결된 다수의 ceDNA 벡터는 표적 세포, 조직, 기관 또는 대상체에게 동시에 또는 순차적으로 전달될 수 있다. 따라서, 이 전략은 다수의 항체 및/또는 융합 단백질의 유전자 요법 또는 유전자 전달을 동시에 허용할 수 있다. 항체의 상이한 부분을, 동시에 또는 상이한 시간에 투여될 수 있고, 개별적으로 조절 가능하여 항체 또는 융합 단백질의 발현의 추가 수준의 제어를 부가할 수 있는 별도의 ceDNA 벡터 (예를 들어, 항체 또는 항원-결합 단편의 기능성에 필요한 상이한 도메인 및/또는 보조-인자)로 분리하는 것이 또한 가능하다. 전달은 또한 여러 번, 중요하게는 바이러스 캡시드의 부재로 인한 항-캡시드 숙주 면역 반응의 부족을 고려하여, 후속적으로 증가하거나 감소하는 용량으로 임상 환경에서 유전자 요법에 대해 수행될 수 있다. 캡시드가 없으므로 항-캡시드 반응이 일어나지 않을 것으로 예상된다.
본 발명은 또한 선택적으로 약제학적으로 허용되는 담체와 함께, 치료적 유효량의 본원에 개시된 ceDNA 벡터를 대상체의 이를 필요로 하는 표적 세포 (특히 근육 세포 또는 조직)에 도입하는 것을 포함하는 대상체에서 질환을 치료하는 방법을 제공한다. ceDNA 벡터는 캐리어의 존재하에 도입될 수 있지만, 이러한 캐리어는 필수가 아니다. 구현된 ceDNA 벡터는 질환을 치료하는데 유용한 관심 뉴클레오티드 서열을 포함한다. 특히, ceDNA 벡터는 대상체에 도입될 때 외인성 DNA 서열에 의해 인코딩된 원하는 폴리펩티드, 단백질 또는 올리고뉴클레오티드의 전사를 지시할 수 있는 제어 요소에 작동 가능하게 연결된 원하는 외인성 DNA 서열을 포함할 수 있다. ceDNA 벡터는 상기 및 본원의 다른 곳에 제공된 임의의 적합한 경로를 통해 투여될 수 있다.
IX. 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 전달하는 방법
일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 다양한 적합한 방법에 의해 시험관내 또는 생체내에서 표적 세포에 전달될 수 있다. ceDNA 벡터는 단독으로 적용되거나 주사될 수 있다. ceDNA 벡터는 형질감염 시약 또는 기타 물리적 수단의 도움 없이 세포에 전달될 수 있다. 대안적으로, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 DNA의 세포로의 진입을 촉진시키는 임의의 당 업계에 공지된 형질감염 시약 또는 기타 당 업계에 공지된 물리적 수단, 예를 들어, 리포좀, 알코올, 폴리리신-풍부 화합물, 아르기닌-풍부 화합물, 인산칼슘, 미세소포, 미세주사, 전기천공 등을 사용하여 전달될 수 있다.
본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 다양한 전달 시약을 사용하여 통상적인 AAV 비리온으로 형질도입하는 것이 일반적으로 어려운 세포 및 조직-유형을 효율적으로 표적화할 수 있다.
본원에 기재된 기술의 일 측면은 항체 또는 항원-결합 단편을 세포에 전달하는 방법에 관한 것이다. 전형적으로, 생체내 및 시험관내 방법의 경우, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 본원에 개시된 바와 같은 방법뿐만 아니라 당 업계에 공지된 다른 방법을 사용하여 세포에 도입될 수 있다. 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 바람직하게는 생물학적 유효량으로 세포에 투여된다. ceDNA 벡터가 생체내에서 세포에 (예를 들어, 대상체에게) 투여되는 경우, 생물학적 유효량의 ceDNA 벡터는 표적 세포에서 항체 또는 항원-결합 단편의 형질도입 및 발현을 초래하기에 충분한 양이다.
본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 예시적인 투여 방식은 경구, 직장, 경점막, 비강내, 흡입 (예를 들어, 에어로졸을 통한), 협측 (예를 들어, 설하), 질, 경막내, 안내, 경피, 내피내, 자궁 내 (또는 난(ovo) 내), 비경구 (예를 들어, 정맥내, 피하, 피내, 두개내, 근육내 [골격, 횡격막 및/또는 심장 근육으로의 투여 포함], 흉막내, 뇌내 및 관절내), 국소 (예를 들어, 기도 표면, 및 경피 투여를 포함하는, 피부 및 점막 표면 모두에), 림프내 등, 뿐만 아니라 직접 조직 또는 기관 주사 (예를 들어, 비제한적으로, 간, 눈, 골격근, 심장 근육, 횡격막 근육을 포함하는 근육, 또는 뇌)를 포함한다.
ceDNA 벡터의 투여는 뇌, 골격근, 평활근, 심장, 횡격막, 기도 상피, 간, 신장, 비장, 췌장, 피부 및 눈으로 구성된 군으로부터 선택된 부위를 포함하지만, 이에 제한되지 않는, 대상체의 임의의 부위에 투여될 수 있다. ceDNA 벡터의 투여는 또한 종양 (예를 들어, 종양 또는 림프절 내 또는 그 근처)으로의 투여일 수 있다.
임의의 주어진 경우에 가장 적합한 경로는 치료, 개선 및/또는 예방되는 상태의 성질 및 중증도 및 사용되는 특정 ceDNA 벡터의 성질에 따라 달라질 것이다. 또한, ceDNA는 단일 벡터 또는 다수의 ceDNA 벡터 (예를 들어 ceDNA 칵테일)에서 하나 초과의 항체를 투여할 수 있게 한다.
A. ceDNA 벡터의 근육내 투여
일부 구현예에서, 대상체에서 질환을 치료하는 방법은 선택적으로 약제학적으로 허용되는 담체와 함께, 항체 또는 이의 항원 결합 단편을 인코딩하는 ceDNA 벡터의 치료적 유효량을 대상체의 이를 필요로 하는 표적 세포 (특히 근육 세포 또는 조직)에 도입하는 것을 포함한다. 일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 대상체의 근육 조직에 투여된다.
일부 구현예에서, ceDNA 벡터의 투여는 골격근, 평활근, 심장, 횡경막 또는 눈 근육으로 구성된 군으로부터 선택된 부위를 포함하지만, 이에 제한되지 않는 대상체의 임의의 부위에 투여될 수 있다. 일부 구현예에서, 본 발명에 따른 ceDNA 벡터는 골격근, 횡격막 근육 및/또는 심장 근육에 투여된다 (예를 들어, 근이영양증 또는 심장병 (예를 들어, PAD 또는 울혈성 심부전)을 치료, 개선 및/또는 예방하기 위해).
본 발명에 따른 골격근으로 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 투여는 사지 (예를 들어, 상완, 하완, 상부 다리 및/또는 하부 다리), 등, 목, 머리 (예를 들어, 혀), 흉부, 복부, 골반/회음 및/또는 손발가락의 골격근으로의 투여를 포함하지만 이에 제한되지 않는다. 본원에 개시된 바와 같은 ceDNA 벡터는 정맥내 투여, 동맥내 투여, 복강내 투여, 사지 관류, (선택적으로, 다리 및/또는 팔의 고립된 사지 관류; 예를 들어, Arruda et al., (2005) Blood 105: 3458-3464 참조), 및/또는 직접 근육내 주사에 의해 골격근으로 전달될 수 있다. 특정 구현예에서, 본원에 개시된 바와 같은 ceDNA 벡터는 사지 관류, 선택적으로 고립된 사지 관류 (예를 들어, 정맥내 또는 관절내 투여에 의해 대상체 (예를 들어, DMD와 같은 근이영양증을 갖는 대상체)의 사지 (팔 및/또는 다리)에 투여된다. 구현예에서, 본원에 개시된 바와 같은 ceDNA 벡터는 "유체 역학적" 기술을 사용하지 않고 투여될 수 있다. 예를 들어, 통상적인 바이러스 벡터의 조직 전달 (예를 들어, 근육으로)은 종종 유체 역학적 기술 (예를 들어, 대량으로 정맥내/정맥내 투여)에 의해 향상되고, 이는 혈관계 내 압력을 증가시키고 내피 세포 장벽을 가로지르는 바이러스 벡터의 능력을 촉진시킨다. 특정 구현예에서, 본원에 기재된 ceDNA 벡터는 유체 역학적 기술 예컨대 다량의 주입 및/또는 상승된 혈관내 압력 (예를 들어, 정상 수축기압보다 큰, 예를 들어, 정상 수축기압에 비해 혈관내 압력의 5%, 10%, 15%, 20%, 25% 이하의 증가)의 부재하에 투여될 수 있다. 이러한 방법은 부종, 신경 손상 및/또는 구획 증후군과 같은 유체 역학적 기술과 관련된 부작용을 줄이거나 피할 수 있다.
또한, 골격근으로 투여되는 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 포함하는 조성물은 사지 (예를 들어, 상완, 하완, 상부 다리 및/또는 하부 다리), 등, 목, 머리 (예를 들어, 혀), 흉부, 복부, 골반/회음 및/또는 손발가락의 골격근으로 투여될 수 있다. 적합한 골격근은 소지외전근 (손에서), 소지외전근 (발에서), 무지외전근, 애브덕터 오시스 메타타르시 퀸티(abductor ossis metatarsi quinti), 단무지외전근, 장무지외전근, 단내전근, 무지내전근, 장내전근, 대내전근, 엄지내전근, 주근, 전사각근, 슬관절근, 상완이두근, 대퇴이두근, 상완신근, 상완요근, 협근, 오훼완근, 추미근, 델토이드, 구각하체근, 하순하체근, 이복근, 배측골간근 (손에서), 배측골간근 (발에서), 단요측수근신근, 장요측수근신근, 척측수근신근, 소지신근, 지신근, 단지신근, 장지신근, 단무지신근, 장무지신근, 시지신근, 짧은엄지폄근, 긴엄지폄근, 요측수근굴근, 척측수근굴근, 단소지굴근 (손에서), 단소지굴근 (발에서), 단지굴근, 장지굴근, 심지굴근, 천지굴근, 짧은엄지발가락굽힘근, 긴엄지발가락굽힘근, 짧은엄지손가락굽힘근, 긴엄지손가락굽힘근, 전두근, 비복근, 이설골근, 대둔근, 중둔근, 소둔근, 대퇴박근, 경장늑근, 요장늑근, 흉장늑근, 장근(illiacus), 아래쌍동이근, 하사근, 하직근, 극하근, 가시사이근육(interspinalis), 가로돌기사이근육(intertransversi), 외측익돌근, 외직근, 광배근, 구각거근, 상순거근, 상순비익거근, 상안검거근, 견갑거근, 긴 돌림근육(long rotators), 두최장근, 경최장근, 흉최장근, 두장근, 경장근, 충양근 (손에서), 충양근 (발에서), 교근, 내측날개근, 내측곧은근, 중사각근, 다열근, 악설골근, 하두사근, 상두사근, 외폐쇄근, 내폐쇄근, 후두근, 견갑설골근, 새끼맞섬근, 무지대립근, 안륜근, 구륜근, 장측골간근, 단수장근, 장수장근, 치골근, 대흉근, 소흉근, 단비골근, 장비골근, 제삼비골근, 이상근, 저측골간근, 족척근, 광경근, 슬와근, 후사각근, 방형회내근, 원회내근, 대요근, 대퇴방형근, 족척방형근, 전두직근, 외측두직근, 대후두직근, 소후두직근, 대퇴직근, 대능형근, 소능형근, 소근, 봉공근, 최소사각근, 반막양근, 두반극근, 경반극근, 흉반극근, 반건형근, 전거근, 짧은 돌림근육(short rotators), 가자미근, 두극근, 경극근, 흉극근, 두판상근, 경판상근, 흉쇄유돌근, 흉설골근, 복장방패근, 경돌설골근, 쇄골하근, 견갑하근, 상쌍자근, 상사근, 상직근, 회외근, 극상근, 측두근, 대퇴근막장근, 대원근, 소원근, 가슴근육, 갑상설골근, 전경골근, 후경골근, 승모근, 상완삼두근, 중간광근, 외측광근, 내측광근, 대관골근, 및 소관골근, 및 당 업계에 공지된 바와 같은 임의의 다른 적합한 골격근을 포함하지만 이에 제한되지 않는다.
횡격막 근육으로 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 투여는 정맥내 투여, 동맥내 투여 및/또는 복강내 투여를 포함하는 임의의 적합한 방법에 의해 투여될 수 있다. 일부 구현예에서, ceDNA 벡터에서 표적 조직으로 발현된 이식유전자의 전달은 또한 ceDNA 벡터를 포함하는 합성 데포를 전달함으로써 달성될 수 있으며, 여기서 ceDNA 벡터를 포함하는 데포는 골격, 평활, 심장 및/또는 횡격막 근육 조직에 이식되거나 근육 조직은 본원에 기재된 바와 같은 ceDNA 벡터를 포함하는 필름 또는 다른 매트릭스와 접촉될 수 있다. 이러한 이식 가능한 매트릭스 또는 기재는 미국 특허 번호 7,201,898에 기재되어 있다.
심장 근육으로 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 투여는 좌심방, 우심방, 좌심실, 우심실 및/또는 격막으로의 투여를 포함한다. 본원에 기재된 바와 같은 ceDNA 벡터는 정맥내 투여, 동맥내 투여 예컨대 대동맥내 투여, 직접 심장 주사 (예를 들어, 좌심방, 우심방, 좌심실, 우심실 내로), 및/또는 관상동맥 관류에 의해 심장 근육으로 전달될 수 있다.
평활근으로 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 투여는 정맥내 투여, 동맥내 투여 및/또는 복강내 투여를 포함하는 임의의 적합한 방법에 의해 투여될 수 있다. 일 구현예에서, 투여는 평활근 내, 평활근 인근에 및/또는 평활근 상에 존재하는 내피세포로의 투여일 수 있다. 평활근의 비제한적인 예는 눈의 홍채, 폐의 세기관지, 후두 근육 (성대), 위 근육층, 식도, 위장관의 소장 및 대장, 요관, 방광의 배뇨근, 자궁근층, 음경 또는 전립선을 포함한다.
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 골격근, 횡격막 근육 및/또는 심장 근육에 투여된다 (예를 들어, 근이영양증 또는 심장병 (예를 들어, PAD 또는 울혈성 심부전)을 치료, 개선 및/또는 예방하기 위해). 대표적인 구현예에서, 본 발명에 따른 ceDNA 벡터는 골격, 심장 및/또는 횡격막 근육의 장애를 치료 및/또는 예방하는데 사용된다.
구체적으로, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 포함하는 조성물은 하나 이상의 눈의 근육 (예를 들어, 외직근, 내측곧은근, 상직근, 하직근, 상사근, 하사근), 안면 근육 (예를 들어, 후두전두근, 관자마루근, 눈살근, 코근, 비중격하체근, 안륜근, 추미근, 미모하체근, 이개근, 구륜근, 구각하체근, 소근, 대관골근, 소관골근, 상순거근, 상순비익거근, 하순하체근, 구각거근, 협근, 턱끝근) 또는 혀 근육 (예를 들어, 턱끝혀근, 부대설근, 소각설근, 경돌설근, 구개설근, 상종설근, 하종설근, 수직근, 및 횡근)으로 전달될 수 있다.
(i) 근육내 주사: 일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 포함하는 조성물은 바늘을 사용하여 대상체의 소정의 근육, 예를 들어, 골격근 (예를 들어, 델토이드, 외측광근, 배둔근(dorsogluteal muscle)의 복둔근(ventrogluteal muscle), 또는 영아의 경우 전외측대퇴)의 하나 이상의 부위에 주사될 수 있다. ceDNA를 포함하는 조성물은 근육 세포의 다른 하위 유형에 도입될 수 있다. 근육 세포 하위 유형의 비제한적인 예는 골격근 세포, 심장 근육 세포, 평활근 세포 및/또는 횡격막 근육 세포를 포함한다.
근육내 주사 방법은 당업자에게 공지되어 있으며, 따라서 본원에 상세하게 기술되지 않았다. 그러나, 근육내 주사를 수행할 때, 환자의 연령 및 크기, 조성물의 점도, 뿐만 아니라 주사 부위에 기초하여 적절한 바늘 크기가 결정되어야 한다. 표 12는 예시적인 주사 부위 및 상응하는 바늘 크기에 대한 지침을 제공한다.
표 12: 인간 환자에서 근육내 주사를 위한 지침

특정 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 소량, 예를 들어, 소정의 대상체에 대해 표 12에 개괄된 예시적인 용적으로 제형화된다. 일부 구현예에서, 원하는 경우, 대상체는 주사 전에 전신 또는 국소 마취제를 투여받을 수 있다. 이것은 상기 언급된 일반적인 주사 부위보다는 다수의 주사가 요구되거나 더 깊은 근육이 주사되는 경우에 특히 바람직하다.
일부 구현예에서, 근육내 주사는 전기천공, 전달 압력 또는 형질감염 시약의 사용과 조합되어 ceDNA 벡터의 세포 흡수를 향상시킬 수 있다.
(ii) 형질감염 시약: 일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 근관 또는 근육 조직으로의 벡터의 흡수를 촉진시키기 위해 하나 이상의 형질감염 시약을 포함하는 조성물로 제형화된다. 따라서, 일 구현예에서, 본원에 기재된 핵산은 본원의 다른 곳에 기재된 방법을 사용하여 형질감염에 의해 근육 세포, 근관 또는 근육 조직에 투여된다.
(iii) 전기천공: 특정 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 세포 내로 ceDNA의 진입을 용이하게 하기 위한 담체의 부재하에 또는 생리학적으로 불활성인 약제학적으로 허용되는 담체 (즉, 캡시드 비함유, 비-바이러스 벡터의 근관으로의 흡수를 개선 또는 향상시키지 않는 임의의 담체)에서 투여된다. 이러한 구현예에서, 캡시드 비함유, 비-바이러스 벡터의 흡수는 세포 또는 조직의 전기천공에 의해 촉진될 수 있다.
세포막은 자연적으로 세포외의 세포 세포질 내로의 통과에 저항한다. 이러한 저항을 일시적으로 감소시키는 한 가지 방법은 "전기천공"으로, 전기장을 사용하여 세포에 영구적인 손상을 주지 않으면서 세포에 기공을 생성한다. 이들 기공은 DNA 벡터, 약제, DNA 및 다른 극성 화합물이 세포 내부에 접근할 수 있을 정도로 충분히 크다. 시간이 지남에 따라 세포막의 기공이 닫히고 세포가 또 다시 불투과성이 된다.
전기천공은 시험관내 및 생체내 적용에서 모두 사용되어 예를 들어, 외인성 DNA를 살아있는 세포에 도입할 수 있다. 시험관내 적용은 전형적으로 살아있는 세포 샘플을 예를 들어, DNA를 포함하는 조성물과 혼합한다. 이어서, 세포를 평행 플레이트와 같은 전극 사이에 놓고 전기장을 세포/조성물 혼합물에 적용한다.
생체내 전기천공에 대한 다수의 방법이 있으며; 전극은, 예를 들어, 치료될 세포 영역 위에 가로놓인 표피를 파지하는 캘리퍼와 같은 다양한 구성으로 제공될 수 있다. 대안적으로, 바늘 모양의 전극은 조직에 삽입되어 보다 깊게 위치한 세포에 접근할 수 있다. 어느 경우이든, 예를 들어, 핵산을 포함하는 조성물을 치료 부위에 주사한 후, 전극은 상기 부위에 전기장을 인가한다. 일부 전기천공 적용에서, 이 전기장은 약 10 내지 60 ms 지속 시간의 100 내지 500 V/cm 정도의 단일 구형파 펄스를 포함한다. 이러한 펄스는, 예를 들어, Genetronics, Inc.의 BTX 사업부에 의해 제작된, Electro Square Porator T820의 공지된 어플리케이션에서 생성될 수 있다.
전형적으로, 예를 들어, 핵산의 성공적인 흡수는 근육이, 예를 들어, 근육에 주사에 의해 조성물의 투여 즉시 또는 직후에 근육이 전기적으로 자극되는 경우에만 발생한다.
특정 구현예에서, 전기천공은 전기장의 펄스를 사용하거나 저전압/장 펄스 치료 요법 (예를 들어, 구형파 펄스 전기천공 시스템을 사용)을 사용하여 달성된다. 펄스 전기장을 생성할 수 있는 예시적인 펄스 발생기는, 예를 들어, 지수 파형(exponential wave form)을 생성할 수 있는 ECM600, 및 구형파형(square wave form)을 생성할 수 있는 ElectroSquarePorator (T820)를 포함하며, 둘 다 Genetronics, Inc.의 사업부인, BTX (San Diego, Calif.)로부터 입수 가능하다. 구형파 전기천공 시스템은 설정된 전압으로 빠르게 상승하는 제어된 전기 펄스를 제공하고, 설정된 시간 (펄스 길이) 동안 해당 레벨을 유지한 다음 빠르게 0으로 떨어진다.
일부 구현예에서, 국소 마취제는, 예를 들어, 본원에 기재된 바와 같이 캡시드 비함유, 비-바이러스 벡터를 포함하는 조성물의 존재하에 조직의 전기천공과 관련될 수 있는 통증을 감소시키기 위한 치료 부위에의 주사에 의해 투여된다. 또한, 당업자는 근육의 섬유증, 괴사 또는 염증을 유발하는 과도한 조직 손상을 최소화 및/또는 방지하는 조성물의 용량이 선택되어야 한다는 것을 이해할 것이다.
(iv) 전달 압력 : 일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 근육 조직으로 전달하는 것은 전달 압력에 의해 촉진되는데, 이는 사지에 공급되는 동맥 (예를 들어, 장골동맥)으로의 대량 및 빠른 주사의 조합을 사용한다. 이러한 투여 방식은, 전형적으로 근육이 혈관 클램프의 지혈대를 사용하여 전신 순환으로부터 단리되는 동안, ceDNA 벡터를 포함하는 조성물을 사지 혈관계에 주입하는 것을 포함하는 다양한 방법을 통해 달성될 수 있다. 일 방법에서, 조성물은 사지 혈관계를 통해 순환되어 세포로의 혈관외 유출을 가능하게 한다. 또 다른 방법에서, 혈관내 유체 역학적 압력은 혈관 층을 확장시키고 ceDNA 벡터의 근육 세포 또는 조직으로의 흡수를 증가시키기 위해 증가된다. 일 구현예에서, ceDNA 조성물은 동맥으로 투여된다.
(v) 지질 나노입자 조성물: 일부 구현예에서, 근육내 전달을 위한 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 본원의 다른 곳에 기재된 바와 같은 리포좀을 포함하는 조성물로 제형화된다.
(vi) 근육 조직을 표적화하는 ceDNA 벡터의 전신 투여: 일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 간접 전달 투여를 통해 근육을 표적화하도록 제형화되며, 여기서 ceDNA는 간이 아닌 근육으로 운반된다. 따라서, 본원에 기재된 기술은, 예를 들어, 전신 투여에 의해 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 포함하는 조성물을 근육 조직에 간접적으로 투여하는 것을 포함한다. 이러한 조성물은 국소, 정맥내 (볼루스 또는 연속 주입에 의해), 세포내 주사, 조직내 주사, 경구, 흡입, 복강내, 피하내, 공동내(intracavity)로 투여될 수 있고, 원한다면, 연동 수단에 의해 또는 당업자에게 알려진 다른 수단에 의해 전달될 수 있다. 제제는, 원하는 경우, 전신 투여, 예를 들어, 정맥내 주입에 의해 투여될 수 있다.
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 근육 세포/조직으로의 흡수는 벡터를 근육 조직으로 우선적으로 지시하는 표적화 제제 또는 모이어티를 사용함으로써 증가된다. 따라서, 일부 구현예에서, 캡시드 비함유 ceDNA 벡터는 신체의 다른 세포 또는 조직에 존재하는 캡시드 비함유 ceDNA 벡터의 양과 비교하여 근육 조직에서 농축될 수 있다.
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 포함하는 조성물은 근육 세포에 대한 표적화 모이어티를 추가로 포함한다. 다른 구현예에서, 발현된 유전자 산물은 작용하고자 하는 조직에 특이적인 표적화 모이어티를 포함한다. 표적화 모이어티는 세포 또는 조직의 세포내, 세포 표면 또는 세포외 바이오마커를 표적화, 상호작용, 커플링 및/또는 결합할 수 있는 임의의 분자 또는 분자 복합체를 포함할 수 있다. 바이오마커는, 예를 들어, 세포 프로테아제, 키나제, 단백질, 세포 표면 수용체, 지질 및/또는 지방산을 포함할 수 있다. 표적화 모이어티가 표적화, 상호작용, 커플링 및/또는 결합할 수 있는 바이오마커의 다른 예는 특정 질환과 관련된 분자를 포함한다. 예를 들어, 바이오마커는 표피 성장 인자 수용체 및 트랜스페린 수용체와 같이 암 발달에 연루된 세포 표면 수용체를 포함할 수 있다. 표적화 모이어티는 표적 근육 조직에서 발현된 분자에 결합하는 합성 화합물, 천연 화합물 또는 생성물, 거대분자 개체, 생체공학적 분자 (예를 들어, 폴리펩티드, 지질, 폴리뉴클레오티드, 항체, 항체 단편), 및 작은 개체 (예를 들어, 소분자, 신경전달물질, 기질, 리간드, 호르몬 및 원소 화합물)를 포함할 수 있지만, 이에 제한되지 않는다.
특정 구현예에서, 표적화 분자는, 예를 들어, 표적 세포의 특정한 원하는 분자를 자연적으로 인식하는 수용체를 포함하는 수용체 분자를 추가로 포함할 수 있다. 이러한 수용체 분자는 표적 분자와의 상호작용의 특이성을 증가시키도록 변형된 수용체, 수용체에 의해 자연적으로 인식되지 않는 원하는 표적 분자와 상호작용하도록 변형된 수용체, 및 이러한 수용체의 단편을 포함한다 (예를 들어, Skerra, 2000, J. Molecular Recognition, 13:167-187 참조). 바람직한 수용체는 케모카인 수용체이다. 예시적인 케모카인 수용체는, 예를 들어, 하기에 기재되었다: Lapidot et al, 2002, Exp Hematol, 30:973-81 및 Onuffer et al, 2002, Trends Pharmacol Sci, 23:459-67.
다른 구현예에서, 추가의 표적화 모이어티는, 예를 들어, 트랜스페린 (Tf) 리간드와 같은 표적 세포의 원하는 특정 수용체를 자연적으로 인식하는 리간드를 포함하는 리간드 분자를 포함할 수 있다. 이러한 리간드 분자는 표적 수용체와의 상호작용의 특이성을 증가시키기 위해 변형된 리간드, 리간드에 의해 자연적으로 인식되지 않는 원하는 수용체와 상호작용하도록 변형된 리간드, 및 이러한 리간드의 단편을 포함한다.
또 다른 구현예에서, 표적화 모이어티는 압타머를 포함할 수 있다. 압타머는 표적 세포의 원하는 분자 구조에 특이적으로 결합하도록 선택된 올리고뉴클레오티드이다. 압타머는 전형적으로 파지 디스플레이의 친화도 선택 (시험관내 분자 진화로도 알려져 있음)과 유사한 친화도 선택 과정의 산물이다. 상기 방법은, 예를 들어, 병에 걸린 면역원이 결합된 고체 지지체를 사용하여 친화도 분리의 여러 탠덤 반복을 수행한 후, 면역원에 결합된 핵산을 증폭시키기 위한 중합효소 연쇄 반응 (PCR)을 수반한다. 따라서 각 친화도 분리 라운드는 원하는 면역원에 성공적으로 결합하는 분자에 대한 핵산 집단을 풍부하게 한다. 이러한 방식으로, 랜덤 핵산 풀이 "교육(educated)"되어 표적 분자에 특이적으로 결합하는 압타머를 생성할 수 있다. 압타머는 전형적으로 RNA이지만, 비제한적으로, 펩티드 핵산 (PNA) 및 포스포로티오에이트 핵산과 같은, DNA 또는 이의 유사체 또는 유도체일 수 있다.
일부 구현예에서, 표적화 모이어티는 캡시드 비함유, 비-바이러스 벡터 또는 유전자 산물이 특정 조직으로 표적화되도록, 예를 들어, 집속 광 빔(focused beam of light)으로부터 방출되는 광분해성 리간드 (즉, '케이지드(caged)' 리간드)를 포함할 수 있다.
본 명세서에서 조성물은 대상체의 하나 이상의 근육에서 다수의 부위로 전달되는 것이 또한 고려된다. 즉, 주사는 적어도 2, 적어도 3, 적어도 4, 적어도 5, 적어도 6, 적어도 7, 적어도 8, 적어도 9, 적어도 10, 적어도 15, 적어도 20, 적어도 25, 적어도 30, 적어도 35, 적어도 40, 적어도 45, 적어도 50, 적어도 55, 적어도 60, 적어도 65, 적어도 70, 적어도 75, 적어도 80, 적어도 85, 적어도 90, 적어도 95, 적어도 100개의 주사 부위에서 수행될 수 있다. 이러한 부위는 단일 근육의 영역에 퍼지거나 여러 근육에 분산될 수 있다.
B.
비-근육 위치에 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 투여
또 다른 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 CNS (예를 들어, 뇌 또는 눈)에 투여된다. ceDNA 벡터는 척수, 뇌간 (숨뇌, 뇌교), 중뇌 (시상하부, 시상, 시상상부, 뇌하수체, 흑질, 송과선), 소뇌, 종뇌(선조체, 후두를 포함한 대뇌, 측두엽, 두정엽, 전두엽, 피질, 기저핵, 해마 및 포르타아미달라(portaamygdala)), 변연계, 신피질, 선조체, 대뇌 및 하구로 도입될 수 있다. ceDNA 벡터는 또한 망막, 각막 및/또는 시신경과 같은 눈의 다른 영역에 투여될 수 있다. 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 뇌척수액 내로 전달될 수 있다 (예를 들어, 요추 천자에 의해). ceDNA 벡터는 혈액-뇌 장벽이 교란된 상황 (예를 들어, 뇌종양 또는 뇌경색)에서 CNS에 혈관내로 추가로 투여될 수 있다.
일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 경막내, 안구내, 뇌내, 심실내, 정맥내 (예를 들어, 만니톨과 같은 당의 존재하에), 비강내, 귀내, 안구내 (예를 들어, 유리체내, 망막하, 전방) 및 안구주위 (예를 들어, 서브-테논 부위(sub-Tenon's region)) 전달뿐만 아니라 운동 뉴런으로 역행 전달을 통한 근육내 전달을 포함하지만 이에 제한되지 않는, 당 업계에 공지된 임의의 경로에 의해 CNS의 원하는 영역(들)에 투여될 수 있다.
일부 구현예에서, 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 CNS의 원하는 영역 또는 구획에 직접 주사 (예를 들어, 정위 주사)에 의해 액체 제형으로 투여된다. 다른 구현예에서, ceDNA 벡터는 원하는 영역에 국소 적용하거나 에어로졸 제형의 비강내 투여에 의해 제공될 수 있다. 눈에의 투여는 액체 액적의 국소 적용에 의한 것일 수 있다. 추가의 대안으로서, ceDNA 벡터는 고체, 서방형 제형으로서 투여될 수 있다 (예를 들어, 미국 특허 번호 7,201,898 참조). 또 다른 추가의 구현예에서, ceDNA 벡터는 운동 뉴런 (예를 들어, 근위축성 측삭 경화증 (ALS); 척수 근육 위축 (SMA) 등)을 포함하는 질환 및 장애를 치료, 개선 및/또는 예방하기 위해 역행 수송에 사용될 수 있다. 예를 들어, ceDNA 벡터는 뉴런으로 이동할 수 있는 근육 조직으로 전달될 수 있다.
C. 생체외
치료
일부 구현예에서, 대상체로부터 세포를 제거하고, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터가 그 안에 도입되고, 이어서 세포는 대상체 내로 다시 교체된다. 생체외 치료를 위해 대상체로부터 세포를 제거한 후 대상체로 다시 도입하는 방법은 당 업계에 공지되어 있다 (예를 들어, 미국 특허 번호 5,399,346 참조; 이의 개시내용은 그 전문이 본원에 포함됨). 대안적으로, ceDNA 벡터는 또 다른 대상체 유래 세포, 배양 세포, 또는 임의의 다른 적합한 공급원 유래 세포 내로 도입되고, 세포는 이를 필요로 하는 대상체에게 투여된다.
본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터로 형질도입된 세포는 바람직하게는 약제학적 담체와 함께 "치료적 유효량"으로 대상체에게 투여된다. 당업자는 치료 효과가 대상체에게 약간의 이점이 제공되는 한 완전하거나 치유력이 있을 필요는 없음을 이해할 것이다.
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 시험관내, 생체외 또는 생체내 세포에서 생산되는 본원에 기재된 바와 같은 항체 또는 융합 단백질 (때로는 이식유전자 또는 이종 뉴클레오티드 서열이라고도 함)을 인코딩할 수 있다. 예를 들어, 본원에 논의된 바와 같은 치료 방법에서 본원에 기재된 ceDNA 벡터의 사용과 대조적으로, 일부 구현예에서 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는, 예를 들어, 항체 및 융합 단백질의 생산을 위해 배양 세포 및 상기 세포로부터 단리된 발현된 항체 또는 융합 단백질 내로 도입될 수 있다. 일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 포함하는 배양 세포는, 예를 들어, 항체 또는 융합 단백질의 소규모 또는 대규모 바이오 제조(biomanufacturing)를 위한 세포 공급원으로서 제공되는, 항체 또는 융합 단백질의 상업적 생산에 사용될 수 있다. 대안적인 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 소규모 생산뿐만 아니라 상업적인 대규모 항체 또는 융합 단백질 생산을 포함하여, 항체 또는 융합 단백질의 생체내 생산을 위해 숙주 비-인간 대상체의 세포로 도입된다.
본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 수의학 및 의학적 용도 둘 모두에서 사용될 수 있다. 상기 기재된 바와 같은 생체외 유전자 전달 방법에 적합한 대상체는 조류 (예를 들어, 닭, 오리, 거위, 메추라기, 칠면조 및 꿩) 및 포유동물 (예를 들어, 인간, 소, 양, 염소, 말, 고양이, 개 및 토끼목) 둘 다를 포함하며, 포유동물이 바람직하다. 인간 대상체가 가장 바람직하다. 인간 대상체에는 신생아, 유아, 청소년 및 성인이 포함된다.
D. 투여 범위
본원에 기재된 바와 같은 항체 또는 융합 단백질을 인코딩하는 ceDNA 벡터를 포함하는 조성물의 유효량을 대상체에게 투여하는 것을 포함하는 치료 방법이 본원에 제공된다. 숙련가에 의해 이해되는 바와 같이, 용어 "유효량"은 질환의 치료를 위해 "치료적 유효량"으로 항체 또는 융합 단백질을 발현시키는 투여된 ceDNA 조성물의 양을 지칭한다.
생체내 및/또는 시험관내 분석은 선택적으로 사용을 위한 최적의 투약 범위를 식별하는데 도움을 주기 위해 사용될 수 있다. 제형에 사용될 정확한 용량은 또한 투여 경로 및 상태의 심각성에 따라 달라질 것이며, 당업자의 판단 및 각 대상체의 상황에 따라 결정되어야 한다. 시험관내 또는 동물 모델 시험 시스템으로부터 유도된 용량-반응 곡선으로부터 유효 용량이 추론될 수 있다.
본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 원하는 조직의 세포를 형질감염시키고 과도한 부작용 없이 충분한 수준의 유전자 전달 및 발현을 제공하기에 충분한 양으로 투여된다. 통상적이고 약제학적으로 허용되는 투여 경로는 선택된 기관으로의 직접 전달 (예를 들어, 간으로의 문맥내 전달), 경구, 흡입 (비강내 및 기관내 전달 포함), 안내, 정맥내, 근육내, 피하, 피내, 종양내 및 기타 모 투여 경로와 같이 상기 "투여" 섹션에서 기재된 것을 포함하지만, 이에 제한되지 않는다. 원하는 경우, 투여 경로를 조합할 수 있다.
특정 "치료 효과"를 달성하기 위해 요구되는 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 양의 용량은 핵산 투여 경로, 치료 효과를 달성하기 위해 요구되는 유전자 또는 RNA 발현 수준, 치료되는 특정 질환 또는 장애, 및 유전자(들), RNA 산물(들), 또는 생성된 발현 단백질(들)의 안정성을 포함하지만, 이에 제한되지 않는 몇몇 요인에 기초하여 달라질 것이다. 당업자는 상기 언급된 인자, 및 당 업계에 잘 알려진 다른 인자에 기초하여 특정 질환 또는 장애를 갖는 환자를 치료하기 위한 ceDNA 벡터 용량 범위를 쉽게 결정할 수 있다.
투약 요법은 최적의 치료 반응을 제공하도록 조정될 수 있다. 예를 들어, 올리고뉴클레오티드는 반복적으로 투여될 수 있으며, 예를 들어, 수회 용량이 매일 투여될 수 있거나, 치료 상황의 긴급성으로 지시되는 바와 같이 용량을 비례적으로 감소시킬 수 있다. 당업자는 올리고 뉴클레오티드가 세포 또는 대상체에게 투여되는지에 관계없이 대상 올리고뉴클레오티드의 적절한 용량 및 투여 스케줄을 쉽게 결정할 수 있을 것이다.
"치료적 유효 용량"은 임상 시험을 통해 결정될 수 있는 비교적 넓은 범위에 속할 것이고, 특정 적용에 따라 달라질 것이다 (신경 세포는 매우 소량을 필요로 하는 한편, 전신 주사는 다량을 필요로 할 것임). 예를 들어, 인간 대상체의 골격 또는 심장 근육으로의 생체내 직접 주사의 경우, 치료적 유효 용량은 약 1 μg 내지 100 g 정도의 ceDNA 벡터일 것이다. 엑소좀 또는 미세입자가 ceDNA 벡터를 전달하기 위해 사용되는 경우, 치료적 유효 용량은 실험적으로 결정될 수 있지만, 1 μg 내지 약 100 g의 벡터를 전달할 것으로 예상된다. 또한, 치료적 유효 용량은 질환의 하나 이상의 증상을 감소시키지만, 상당한 오프-표적 또는 상당한 부작용을 초래하지 않는, 대상체에게 영향을 미치기에 충분한 양의 이식유전자를 발현시키는 ceDNA 벡터의 양이다. 일 구현예에서, "치료적 유효량"은 질환 바이오마커의 발현 또는 주어진 질환 증상의 감소에서 통계적으로 유의하고, 측정 가능한 변화를 생성하기에 충분한 발현된 항체 또는 융합 단백질의 양이다. 이러한 유효량은 주어진 ceDNA 벡터 조성물에 대한 동물 연구뿐만 아니라 임상 시험에서 측정될 수 있다.
약제학적으로-허용되는 부형제 및 담체 용액의 제형은 다양한 치료 요법에서 본원에 기재된 특정 조성물을 사용하기 위한 적합한 투여 및 치료 요법의 개발과 같이 당업자에게 잘 알려져 있다.
시험관내 형질감염의 경우, 세포 (1x106 세포)로 전달될 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 유효량은 0.1 내지 100 μg ceDNA 벡터, 바람직하게는 1 내지 20 μg, 보다 바람직하게는 1 내지 15 μg 또는 8 내지 10 μg 정도일 것이다. 더 큰 ceDNA 벡터는 더 높은 용량을 요구할 것이다. 엑소좀 또는 미세입자가 사용되는 경우, 효과적인 시험관내 용량은 실험적으로 결정될 수 있지만 일반적으로 동일한 양의 ceDNA 벡터를 전달하도록 의도될 것이다.
질환의 치료를 위해, 본원에 개시된 바와 같은 항체 또는 융합 단백질을 발현시키는 ceDNA 벡터의 적절한 투여량은 치료될 특정 질환 유형, 항체 유형, 질환의 중증도 및 과정, 이전 요법, 환자의 임상 병력 및 항체에 대한 반응, 및 주치의의 재량에 따라 달라질 것이다. 항체는 한번에 또는 일련의 치료에 걸쳐 환자에게 적합하게 투여된다. 다양한 시점에 걸친 단일 또는 다중 투여, 볼루스 투여 및 펄스 주입을 포함하지만, 이에 제한되지 않는 다양한 투여 스케줄이 본원에서 고려된다.
질환의 유형 및 중증도에 따라, ceDNA 벡터는 인코딩된 항체 또는 융합 단백질이 1회 이상의 개별 투여 또는 연속 주입에 의해 약 0.3 mg/kg 내지 100 mg/kg (예를 들어 15 mg/kg-100 mg/kg, 또는 그 범위 내의 임의의 투여량)에서 발현되는 양으로 투여된다. ceDNA 벡터의 하나의 전형적인 1일 투여량은 상기 언급된 인자에 따라, 약 15 mg/kg 내지 100 mg/kg 이상의 범위에서 인코딩된 항체 또는 융합 단백질의 발현을 초래하기에 충분하다. ceDNA 벡터의 하나의 예시적인 용량은 약 10 mg/kg 내지 약 50 mg/kg의 범위에서 본원에 개시된 바와 같은 인코딩된 항체 또는 융합 단백질의 발현을 초래하기에 충분한 양이다. 따라서, 약 0.5 mg/kg, 1 mg/kg, 1.5 mg/kg, 2.0 mg/kg, 3 mg/kg, 4.0 mg/kg, 5 mg/kg, 10 mg/kg, 15 mg/kg, 20 mg/kg, 25 mg/kg, 30 mg/kg, 35 mg/kg, 40 mg/kg, 50 mg/kg, 60 mg/kg, 70 mg/kg, 80 mg/kg, 90 mg/kg, 또는 100 mg/kg (또는 이들의 임의의 조합)에서 인코딩된 항체 또는 융합 단백질의 발현을 초래하기에 충분한 양의 ceDNA 벡터의 하나 이상의 용량이 환자에게 투여될 수 있다. 일부 구현예에서, ceDNA 벡터는 50 mg 내지 2500 mg의 범위의 총 용량에 대해 인코딩된 항체 또는 융합 단백질의 발현을 초래하기에 충분한 양이다. ceDNA 벡터의 예시적인 용량은 약 50 mg, 약 100 mg, 200 mg, 300 mg, 400 mg, 약 500 mg, 약 600 mg, 약 700 mg, 약 720 mg, 약 1000 mg, 약 1050 mg, 약 1100 mg, 약 1200 mg, 약 1300 mg, 약 1400 mg, 약 1500 mg, 약 1600 mg, 약 1700 mg, 약 1800 mg, 약 1900 mg, 약 2000 mg, 약 2050 mg, 약 2100 mg, 약 2200 mg, 약 2300 mg, 약 2400 mg, 또는 약 2500 mg (또는 이들의 임의의 조합)에서 인코딩된 항체 또는 융합 단백질의 전체 발현을 초래하기에 충분한 양이다. ceDNA 벡터로부터의 항체 또는 융합 단백질의 발현은 본원의 조절 스위치, 또는 대안적으로 대상체에게 투여되는 ceDNA 벡터의 다중 용량에 의해 조심스럽게 제어될 수 있으므로, ceDNA 벡터로부터의 항체 또는 융합 단백질의 발현은 발현된 항체 또는 융합 단백질의 용량이 간헐적으로, 예를 들어 ceDNA 벡터로부터 매주, 2주마다, 3주마다, 4주마다, 매월, 2개월마다, 3개월마다 또는 6개월마다 투여될 수 있는 방식으로 제어될 수 있다. 이 요법의 진행은 통상적인 기술 및 분석에 의해 모니터링될 수 있다.
특정 구현예에서, ceDNA 벡터는 15 mg/kg, 30 mg/kg, 40 mg/kg, 45 mg/kg, 50 mg/kg, 60 mg/kg의 용량 또는 예를 들어, 300 mg, 500 mg, 700 mg, 800 mg 이상의 균일한 용량에서 인코딩된 항체 또는 융합 단백질의 발현을 초래하기에 충분한 양으로 투여된다. 일부 구현예에서, ceDNA 벡터로부터 항체 또는 융합 단백질의 발현은, 항체 또는 융합 단백질이 일정 기간 동안 매일, 격일마다, 매주, 2주마다 또는 4주마다 발현되도록 제어된다. 일부 구현예에서, ceDNA 벡터로부터 항체 또는 융합 단백질의 발현은, 항체 또는 융합 단백질이 일정 기간 동안 2주마다 또는 4주마다 발현되도록 제어된다. 특정 구현예에서, 일정 기간은 6개월, 1년, 18개월, 2년, 5년, 10년, 15년, 20년 또는 환자의 수명이다.
치료는 단일 용량 또는 다중 용량의 투여를 수반할 수 있다. 일부 구현예에서, 하나 초과의 용량이 대상체에게 투여될 수 있고; 실제로, ceDNA 벡터는 바이러스 캡시드의 부재로 인해 항-캡시드 숙주 면역 반응을 유발하고 유발하지 않기 때문에, 필요에 따라 다중 용량이 투여될 수 있다. 이와 같이, 당업자는 적절한 수의 용량을 쉽게 결정할 수 있다. 투여되는 용량의 수는, 예를 들어, 1 내지 100, 바람직하게는 2 내지 20개 정도의 용량일 수 있다.
임의의 특정 이론에 구속되지 않고, 본 개시내용에 기재된 바와 같은 ceDNA 벡터의 투여에 의해 유발된 전형적인 항-바이러스 면역 반응의 부재 (즉, 캡시드 성분의 부재)는 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터가 숙주에 여러 번 투여될 수 있게 한다. 일부 구현예에서, 이종 핵산이 대상체에게 전달되는 경우의 수는 2 내지 10배 (예를 들어, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10배)의 범위이다. 일부 구현예에서, ceDNA 벡터는 10회 넘게 대상체에게 전달된다.
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 용량은 캘린더 일(calendar day) (예를 들어, 24시간 기간)당 1회 이하로 대상체에게 투여된다. 일부 구현예에서, ceDNA 벡터의 용량은 2, 3, 4, 5, 6 또는 7 캘린더 일당 1회 이하로 대상체에게 투여된다. 일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 용량은 캘린더 주(calendar week) (예를 들어, 7 캘린더 일)당 1회 이하로 대상체에게 투여된다. 일부 구현예에서, ceDNA 벡터의 용량은 격주 이내에 (예를 들어, 2 캘린더 주 주기 내에 1회) 대상체에게 투여된다. 일부 구현예에서, ceDNA 벡터의 용량은 캘린더 개월(calendar month)당 1회 이하로 (예를 들어, 30 캘린더 일 내에 1회) 대상체에게 투여된다. 일부 구현예에서, ceDNA 벡터의 용량은 6 캘린더 개월당 1회 이하로 대상체에게 투여된다. 일부 구현예에서, ceDNA 벡터의 용량은 캘린더 년(calendar year) (예를 들어, 365일 또는 윤년에는 366일)당 1회 이하로 대상체에게 투여된다.
특정 구현예에서, 예를 들어, 매일, 매주, 매달, 매년 등과 같이 다양한 간격의 기간 동안 원하는 수준의 유전자 발현을 달성하기 위해 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 1회 이상 투여 (예를 들어, 2, 3, 4회 이상의 투여)가 이용될 수 있다.
일부 구현예에서, 본원에 개시된 바와 같은 ceDNA 벡터에 의해 인코딩된 치료 항체는, 그것이 적어도 1시간, 적어도 2시간, 적어도 5시간, 적어도 10시간, 적어도 12시간, 적어도 18시간, 적어도 24시간, 적어도 36시간, 적어도 48시간, 적어도 72시간, 적어도 1주, 적어도 2주, 적어도 1개월, 적어도 2개월, 적어도 6개월, 적어도 12개월/1년, 적어도 2년, 적어도 5년, 적어도 10년, 적어도 15년, 적어도 20년, 적어도 30년, 적어도 40년, 적어도 50년 이상 동안 대상체에서 발현되도록 조절 스위치, 유도 가능한 또는 억제 가능한 프로모터에 의해 조절될 수 있다. 일 구현예에서, 발현은 미리 결정된 또는 원하는 간격으로 본원에 기재된 ceDNA 벡터의 반복 투여에 의해 달성될 수 있다. 대안적으로, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 질환의 실질적으로 영구적인 치료 또는 "치유"를 위해 유전자 편집 시스템의 성분 (예를 들어, CRISPR/Cas, TALEN, 아연 핑거 엔도뉴클레아제 등)을 추가로 포함하여 항체를 인코딩하는 하나 이상의 핵산 서열의 삽입을 가능하게 할 수 있다. 유전자 편집 성분을 포함하는 이러한 ceDNA 벡터는 국제 출원 PCT/US18/64242에 개시되어 있고, 알부민 유전자 또는 CCR5 유전자를 포함하지 않는, 세이프 하버 영역에 항체를 인코딩하는 핵산을 삽입하기 위한 5' 및 3' 상동성 아암 (예를 들어, 서열 번호: 151-154, 또는 이에 적어도 40%, 50%, 60%, 70% 또는 80% 상동성을 갖는 서열)을 포함할 수 있다.
치료 기간은 대상체의 임상 진행 및 치료에 대한 반응성에 따라 달라진다. 초기의 더 높은 치료 용량 후에는 지속적이고 비교적 낮은 유지 용량이 고려된다.
E. 단위 투여 형태
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 포함하는 약제학적 조성물은 단위 투여 형태로 편리하게 제공될 수 있다. 단위 투여 형태는 전형적으로 약제학적 조성물의 하나 이상의 특정 투여 경로에 적합할 것이다. 일부 구현예에서, 단위 투여 형태는 흡입에 의한 투여에 적합하다. 일부 구현예에서, 단위 투여 형태는 기화기에 의한 투여에 적합하다. 일부 구현예에서, 단위 투여 형태는 네불라이저(nebulizer)에 의한 투여에 적합하다. 일부 구현예에서, 단위 투여 형태는 분무기(aerosolizer)에 의한 투여에 적합하다. 일부 구현예에서, 단위 투여 형태는 경구 투여, 협측 투여 또는 설하 투여에 적합하다. 일부 구현예에서, 단위 투여 형태는 정맥내, 근육내 또는 피하 투여에 적합하다. 일부 구현예에서, 단위 투여 형태는 경막내 또는 뇌실내 투여에 적합하다. 일부 구현예에서, 약제학적 조성물은 국소 투여용으로 제형화된다. 단일 투여 형태를 생성하기 위해 담체 물질과 조합될 수 있는 활성 성분의 양은 일반적으로 치료 효과를 생성하는 화합물의 양일 것이다.
X. 치료 방법
본원에 기재된 기술은 또한, 예를 들어, 생체외, 현장외(ex situ), 시험관내 및 생체내 적용, 방법론, 진단 절차 및/또는 유전자 치료 요법을 포함하는 다양한 방식으로 항체 또는 융합 단백질 생산을 위해 개시된 ceDNA 벡터를 사용하는 방법뿐만 아니라 제조 방법을 입증한다.
일 구현예에서, 본원에 개시된 바와 같은 ceDNA 벡터로부터 발현된, 발현된 치료 항체는 질환의 치료에 기능적이다. 바람직한 구현예에서, 치료 항체는 원하지 않는 한 면역계 반응을 일으키지 않는다.
선택적으로 약제학적으로 허용되는 담체와 함께, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 치료적 유효량을 대상체의 이를 필요로 하는 표적 세포 (예를 들어, 근육 세포 또는 조직, 또는 다른 병든 세포 유형)에 도입하는 것을 포함하는 대상체에서 질환 또는 장애를 치료하는 방법이 본원에 제공된다. ceDNA 벡터는 담체의 존재하에 도입될 수 있지만, 이러한 담체는 필수가 아니다. 구현된 ceDNA 벡터는 질환을 치료하는데 유용한 본원에 기재된 바와 같은 항체 또는 항원-결합 단편을 인코딩하는 뉴클레오티드 서열을 포함한다. 특히, ceDNA 벡터는 대상체에 도입될 때 외인성 DNA 서열에 의해 인코딩된 원하는 항체 또는 항원-결합 단편의 전사를 지시할 수 있는 제어 요소에 작동 가능하게 연결된 원하는 항체 또는 항원-결합 단편 DNA 서열을 포함할 수 있다. 본원에 개시된 바와 같이 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 상기 및 본원의 다른 곳에 제공된 임의의 적합한 경로를 통해 투여될 수 있다.
본원에는, 본 발명의 ceDNA 벡터 중 하나 이상을, 하나 이상의 약제학적으로 허용되는 완충제, 희석제 또는 부형제와 함께 포함하는 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터 조성물 및 제형이 개시된다. 질환, 손상, 장애, 외상 또는 기능 장애의 하나 이상의 증상을 진단, 예방, 치료 또는 개선하기 위한 이러한 조성물은 하나 이상의 진단 또는 치료 키트에 포함될 수 있다. 일 측면에서, 질환, 손상, 장애, 외상 또는 기능 장애는 인간 질환, 손상, 장애, 외상 또는 기능 장애이다.
본원에 기재된 기술의 또 다른 측면은 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터의 진단적 또는 치료적 유효량을 이를 필요로 하는 대상체에게 제공하는 방법을 제공하며, 상기 방법은 이를 필요로 하는 대상체의 세포, 조직 또는 기관에, 본원에 개시된 바와 같은 ceDNA 벡터의 양을; ceDNA 벡터로부터 항체 또는 항원-결합 단편의 발현을 가능하게 하기에 효과적인 시간 동안 제공하여 ceDNA 벡터에 의해 발현된 항체 또는 항원-결합 단편의 진단적 또는 치료적 유효량을 대상체에게 제공하는 단계를 포함한다. 추가 측면에서, 대상체는 인간이다.
본원에 기재된 기술의 또 다른 측면은 대상체에서 질환, 장애, 기능 장애, 손상, 비정상적 상태 또는 외상의 적어도 하나 이상의 증상을 진단, 예방, 치료 또는 개선하는 방법을 제공한다. 전체적이고 일반적인 의미에서, 상기 방법은 적어도, 이를 필요로 하는 대상체에게 항체 또는 융합 단백질 생산을 위한 하나 이상의 개시된 ceDNA 벡터를, 상기 대상체의 질환, 장애, 기능 장애, 손상, 비정상적 상태 또는 외상의 하나 이상의 증상을 진단, 예방, 치료 또는 개선하기에 충분한 양으로 그리고 시간 동안 투여하는 단계를 포함한다. 이러한 구현예에서, 대상체는 항체/항원-결합 단편의 효능, 또는 대안적으로 대상체에서 특정 단백질 또는 조직 위치 (세포 및 세포하 위치 포함)에 대한 항원 또는 항원-결합 단편의 검출에 대해 평가될 수 있다. 이와 같이, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는, 예를 들어, 암 또는 다른 징후의 검출을 위한 생체내 진단 도구로서 사용될 수 있다. 추가 측면에서, 대상체는 인간이다.
또 다른 측면은 질환 또는 질환 상태의 하나 이상의 증상을 치료 또는 감소시키기 위한 도구로서 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 사용하는 것이다. 결함이 있는 유전자가 알려져 있고, 전형적으로 다음의 두 가지 부류에 속하는 수많은 유전 질환이 있다: 일반적으로 열성 방식으로 유전되는, 일반적으로 효소의 결핍 상태, 및 조절 또는 구조 단백질을 수반할 수 있고, 전형적으로 우성 방식으로 유전되지만 항상 그런 것은 아닌 불균형 상태. 결핍 상태 질환의 경우, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 대체 요법을 위한 정상 유전자의 발현을 증가시키는 경로에서 단백질을 중화시키는 항체 또는 융합 단백질을 전달할 뿐만 아니라, 일부 구현예에서, 중화 항체 또는 융합 단백질을 발현시키는 ceDNA 벡터를 사용하여 질환에 대한 동물 모델을 생성하기 위해 사용될 수 있다. 불균형 질환 상태의 경우, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 사용하여 모델 시스템에서 질환 상태를 생성한 다음 질환 상태를 저지하기 위한 노력에 사용할 수 있다. 따라서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 유전병의 치료를 가능하게 한다. 본원에 사용된 바와 같이, 질환 상태는 질환을 유발하거나 더 심각하게 만드는 결핍 또는 불균형을 부분적으로 또는 전체적으로 개선함으로써 치료된다.
일 구현예에서, 근육내 전달 및 근육에서 항체에 대한 이식유전자의 발현이 근육-특이적 질환을 치료하는데, 또는 대안적으로, 치료적 이식유전자 산물이 원위 부위에서 작용하기 위한 단백질 생산을 위한 데포로서 작용하는데 사용될 수 있음이 본원에서 고려된다. 본원에 기재된 ceDNA 벡터는 근육에서 항체 또는 융합 단백질을 발현시키는데 사용될 수 있다. 일부 구현예에서, 유전자 산물은 표적 유전자의 발현 및/또는 활성을 증가시킨다. 다른 구현예에서, 유전자 산물은 표적 유전자의 발현 및/또는 활성을 감소시킨다.
A. 숙주 세포:
일부 구현예에서, 본원에 기재된 바와 같이 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 항체 또는 항원-결합 단편 이식유전자를 대상체 숙주 세포 내로 전달한다. 일부 구현예에서, 본 발명의 숙주 세포는, 예를 들어 혈액 세포, 줄기세포, 조혈 세포, CD34+ 세포, 간 세포, 암 세포, 혈관 세포, 근육 세포, 췌장 세포, 신경 세포, 눈 또는 망막 세포, 상피 또는 내피 세포, 수지상 세포, 섬유 모세포, 또는, 제한 없이, 간(hepatic) (즉, 간(liver)) 세포, 폐 세포, 심장 세포, 췌장 세포, 장 세포, 횡격막 세포, 신장(renal) (즉, 신장(kidney)) 세포, 신경 세포, 혈액 세포, 골수 세포, 또는 유전자 요법이 고려되는 대상체의 임의의 하나 이상의 선택된 조직을 포함하는 포유동물 기원의 임의의 다른 세포를 포함하는 인간 숙주 세포이다. 일 측면에서, 본 발명의 숙주 세포는 인간 숙주 세포이다.
본 개시내용은 또한, 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 포함하여, 상기 언급된 바와 같은 재조합 숙주 세포에 관한 것이다. 따라서, 숙련가에게 명백한 목적에 따라 다수의 숙주 세포를 사용할 수 있다. 공여체 서열을 포함하는, 본원에 개시된 바와 같이 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터 또는 작제물이 숙주 세포 내로 도입되어 공여체 서열이 전술한 바와 같이 염색체 구성 요소로 유지된다. 용어 숙주 세포는 복제 동안 발생하는 돌연변이로 인해 모 세포와 동일하지 않은 모 세포의 임의의 자손을 포함한다. 숙주 세포의 선택은 공여체 서열 및 그 공급원에 크게 좌우될 것이다.
숙주 세포는 또한 포유동물, 곤충, 식물 또는 진균 세포와 같은 진핵생물일 수 있다. 일 구현예에서, 숙주 세포는 인간 세포 (예를 들어, 1차 세포, 줄기세포 또는 불멸화된 세포주)이다. 일부 구현예에서, 숙주 세포는 생체 외에서 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위해 ceDNA 벡터를 투여한 후 유전자 요법 이벤트 후 대상에게 전달될 수 있다. 숙주 세포는 임의의 세포 유형, 예를 들어, 체세포 또는 줄기세포, 유도된 다능성 줄기세포, 또는 혈액 세포, 예를 들어, T-세포 또는 B-세포, 또는 골수 세포일 수 있다. 특정 구현예에서, 숙주 세포는 동종이계 세포이다. 예를 들어, T-세포 게놈 조작은 암 면역요법, HIV 요법과 같은 질환 조절 (예를 들어, 수용체 녹아웃, 예컨대 CXCR4 및 CCR5) 및 면역결핍 요법에 유용하다. B-세포 상의 MHC 수용체는 면역요법에 대해 표적화될 수 있다. 일부 구현예에서, 유전자 변형된 숙주 세포, 예를 들어, 골수 줄기세포, 예를 들어, CD34+ 세포, 또는 유도된 다능성 줄기세포는 치료 단백질의 발현을 위해 환자에게 다시 이식될 수 있다.
C. 유전자 치료를 위한 추가 질환:
일반적으로, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 대상체의 유산 단백질 발현 또는 유전자 발현과 관련된 임의의 장애와 관련된 증상을 치료, 예방 또는 개선하기 위해 상기 설명에 따라 임의의 항체 또는 항원-결합 단편을 전달하는데 사용될 수 있다. 예시적인 질환 상태는 낭포성 섬유증 (및 폐의 다른 질환), 혈우병 A, 혈우병 B, 지중해 빈혈, 빈혈 및 기타 혈액 장애, AIDS, 알츠하이머병, 파킨슨병, 헌팅턴병, 근위축성 측삭 경화증, 간질 및 기타 신경계 장애, 암, 당뇨병, 근위축증 (예를 들어, 뒤센느, 베커), 헐러병(Hurler's disease), 아데노신 데아미나제 결핍, 대사 결함, 망막 퇴행성 질환 (및 눈의 다른 질환), 미토콘드리아증 (예를 들어, 레버의 유전성 시신경병증 (LHON), 리 증후군 및 아급성 경화성 뇌병증), 근병증 (예를 들어, 안면견갑상완 근병증 (FSHD) 및 심근병증), 고형 장기 (예를 들어, 뇌, 간, 신장, 심장) 질환 등을 포함하지만, 이에 제한되지는 않는다. 일부 구현예에서, 본원에 개시된 바와 같은 ceDNA 벡터는 대사 장애 (예를 들어, 오르니틴 트랜스카바밀라제 결핍)를 갖는 개체의 치료에 유리하게 사용될 수 있다.
일부 구현예에서, 본원에 개시된 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 유전자 또는 유전자 산물에서의 돌연변이에 의해 야기된 질환 또는 장애를 치료, 개선 및/또는 예방하는데 사용될 수 있다. ceDNA 벡터로 치료될 수 있는 예시적인 질환 또는 장애는 대사 질환 또는 장애 (예를 들어, 파브리병, 고셔병, 페닐케톤뇨증 (PKU), 글리코겐 저장병); 우레아 사이클 질환 또는 장애 (예를 들어, 오르니틴 트랜스카바밀라제 (OTC) 결핍); 리소좀 저장 질환 또는 장애 (예를 들어, 이염성백질디스트로피 (MLD), 점막다당류증 II형 (MPSII; 헌터 증후군)); 간 질환 또는 장애 (예를 들어, 진행 가족성 간내담즙정체 (PFIC); 혈액 질환 또는 장애 (예를 들어, 혈우병 (A 및 B), 지중해 빈혈 및 빈혈); 암 및 종양, 및 유전 질환 또는 장애 (예를 들어, 낭포성 섬유증)를 포함하지만, 이에 제한되지 않는다.
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 항체 또는 융합 단백질을 골격, 심장 또는 다이어프램 근육에 전달하여 혈액에서 분비 및 순환을 위해, 또는 장애 (예를 들어, 대사 장애, 예컨대 당뇨병 (예를 들어, 인슐린), 혈우병 (예를 들어, VIII), 무코다당류 장애 (예를 들어, Sly 증후군, 헐러 증후군, 샤이 증후군(Scheie Syndrome), 헐러-샤이 증후군, 헌터 증후군, 산필리포 증후군(Sanfilippo Syndrome) A, B, C, D, 모르키오 증후군(Morquio Syndrome), 마로토-라미 증후군(Maroteaux-Lamy Syndrome) 등) 또는 리소좀 저장 장애 (예컨대 고셔병 [글루코세레브로시다제], 폼페병 [리소좀산 .알파-글루코시다제] 또는 파브리병 [.알파-갈락토시다제 A]) 또는 글리코겐 저장 장애 (예컨대, 폼페병 [리소좀산 글루코시다제])를 치료, 개선 및/또는 예방하기 위해 다른 조직으로 전신 전달하기 위해 골격, 심장 또는 횡격막 근육에 항체 또는 융합 단백질을 전달하는데 사용될 수 있다. 대사 장애를 치료, 개선 및/또는 예방하기 위한 다른 적합한 단백질이 상기 기재되어 있다.
다른 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 이를 필요로 하는 대상체에서 대사 장애를 치료, 개선 및/또는 예방하는 방법으로 항체 또는 항원-결합 단편을 전달하는데 사용될 수 있다. 예시적인 대사 장애 및 항체 또는 항원-결합 단편은 본원에 기재되어 있다. 선택적으로, 폴리펩티드는 분비된다 (예를 들어, 천연 상태의 분비된 폴리펩티드이거나, 예를 들어, 당 업계에 공지된 바와 같은 분비 신호 서열과의 작동 가능한 회합에 의해 분비되도록 조작된 폴리펩티드).
본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 임의의 적합한 수단에 의해, 선택적으로 대상체가 흡입하는, ceDNA 벡터를 포함하는 호흡 가능한 입자의 에어로졸 현탁액을 투여함으로써 대상체의 폐에 투여될 수 있다. 호흡 가능한 입자는 액체 또는 고체일 수 있다. ceDNA 벡터를 포함하는 액체 입자의 에어로졸은 당업자에게 공지된 바와 같이, 임의의 적합한 수단, 예컨대 압력 구동식 에어로졸 분무기 또는 초음파 분무기를 사용하여 제조될 수 있다. 예를 들어, 미국 특허 번호 4,501,729 호를 참조한다. ceDNA 벡터를 포함하는 고체 입자의 에어로졸도 마찬가지로 제약 분야에 공지된 기술에 의해 임의의 고체 미립자 의약 에어로졸 발생기로 제조될 수 있다.
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 CNS의 조직 (예를 들어, 뇌, 눈)에 투여될 수 있다. 특정 구현예에서, 본원에 개시된 바와 같은 ceDNA 벡터는 유전 장애, 신경퇴행성 장애, 정신 장애 및 종양을 포함하는, CNS 질환을 치료, 개선 또는 예방하기 위해 투여될 수 있다. CNS의 예시적인 질환은 알츠하이머병, 파킨슨병, 헌팅턴병, 카나반병(Canavan disease), 라이병(Leigh's disease), 레프숨병(Refsum disease), 투렛 증후군, 1차 측삭 경화증, 근위축성 측삭 경화증, 진행성 근위축증, 피크병(Pick's disease), 근위축증, 다발성 경화증, 중증 근무력증, 빈스완거병(Binswanger's disease), 척수 또는 두부 손상으로 인한 외상, 테이 삭스병, 레쉬-나이안병(Lesch-Nyan disease), 간질, 뇌경색, 기분 장애 (예를 들어, 우울증, 양극성 정동 장애, 지속성 정동 장애, 2차 기분 장애)를 포함한 정신 장애, 조현병, 약물 의존성 (예를 들어, 알코올 중독 및 기타 물질 의존성), 신경증 (예를 들어, 불안, 강박 장애, 신체형 장애, 해리성 장애, 비탄, 산후 우울증), 정신병 (예를 들어, 환각 및 망상), 치매, 편집증, 주의력 결핍 장애, 정신성적 장애, 수면 장애, 통증 장애, 식이 또는 체중 장애 (예를 들어, 비만, 악액질, 신경성 식욕부진 및 폭식증(bulemia)) 및 CNS의 암 및 종양 (예를 들어, 뇌하수체 종양)을 포함하지만, 이에 제한되지는 않는다.
본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터로 치료, 개선 또는 예방될 수 있는 안구 장애에는 망막, 후관(posterior tract) 및 시신경을 포함하는 안과 질환 (예를 들어, 망막색소변성증, 당뇨병성 망막병증 및 기타 망막 퇴행성 질환, 포도막염, 연령-관련 황반 변성, 녹내장)을 포함한다. 많은 안과 질환 및 장애는 3가지 유형의 징후 중 하나 이상과 관련이 있다: (1) 혈관 신생, (2) 염증 및 (3) 변성. 일부 구현예에서, 본원에 개시된 바와 같은 ceDNA 벡터는 항-혈관 신생 인자; 항염증 인자; 세포 변성을 지연시키거나, 세포 스페어링(cell sparing)을 촉진시키거나, 또는 세포 성장를 촉진시키는 인자 및 상기의 조합을 전달하기 위해 사용될 수 있다. 예를 들어, 당뇨병성 망막병증은 혈관 신생을 특징으로 한다. 당뇨병성 망막병증은 안구 내로 (예를 들어, 유리체에서) 또는 안구 주위로 (예를 들어, 서브-테논 부위에서) 하나 이상의 항-혈관 신생 항체 또는 융합 단백질을 전달함으로써 치료될 수 있다. 본 발명의 ceDNA 벡터로 치료, 개선 또는 예방될 수 있는 추가의 안 질환은 지도모양 위축(geographic atrophy), 혈관 또는 "습성" 황반 변성, 스타가르트, 질환(Stargardt disease), 레베르 선천성 흑암시 (LCA), 어셔 증후군(Usher syndrome), 탄력섬유성 가황색종 (PXE), x-연관 망막색소변성증 (XLRP), x-연관 망막층간분리증 (XLRS), 맥락막결손, 레베르 유전성 시신경병증 (LHON), 아코마톱시아(Archomatopsia), 추체-간체 이영양증, 퓨크스 내피 각막 이영양증(Fuchs endothelial corneal dystrophy), 당뇨병성 황반 부종 및 안암 및 안 종양을 포함한다.
일부 구현예에서, 염증성 안 질환 또는 장애 (예를 들어, 포도막염)는 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터에 의해 치료, 개선 또는 예방될 수 있다. 하나 이상의 항-염증성 항체 또는 융합 단백질이 본원에 개시된 바와 같은 ceDNA 벡터의 안내 (예를 들어, 유리체 또는 전방) 투여에 의해 발현될 수 있다.
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 리포터 폴리펩티드 (예를 들어, 효소 예컨대 녹색 형광 단백질 또는 알칼리 포스파타제)를 인코딩하는 이식유전자와 관련된 항체 또는 항원-결합 단편을 인코딩할 수 있다. 일부 구현예에서, 실험 또는 진단 목적에 유용한 리포터 단백질을 인코딩하는 이식유전자는 β-락타마제, β-갈락토시다제 (LacZ), 알칼리 포스파타제 (AP), 티미딘 키나제, 녹색 형광 단백질 (GFP), 클로람페니콜 아세틸트랜스퍼라제 (CAT), 루시퍼라제, 및 당 업계에 잘 알려진 다른 것들 중 어느 것으로부터 선택된다. 일부 측면에서, 리포터 폴리펩티드에 연결된 항체 또는 항원-결합 단편을 발현시키는 ceDNA 벡터는 진단 목적뿐만 아니라 효능을 결정하거나 그것이 투여되는 대상체에서 ceDNA 벡터의 활성 마커로서 사용될 수 있다.
일부 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 대상체에서 면역원성 폴리펩티드 또는 면역원에 특이적으로 결합하는 항체 또는 항원-결합 단편을 발현시킬 수 있다. 항체 또는 항원-결합 단편은 인간 면역결핍 바이러스, 인플루엔자 바이러스, gag 단백질, 종양 항원, 암 항원, 박테리아 항원, 바이러스 항원 등으로부터의 면역원을 포함하지만, 이에 제한되지 않는 당 업계에 공지된 임의의 관심 면역원에 특이적으로 결합할 수 있다.
D. ceDNA 벡터를 사용한 성공적인 유전자 발현 시험
ceDNA 벡터에 의한 항체 또는 항원-결합 단편의 유전자 전달 효율을 시험하기 위해 당 업계에 잘 알려진 분석법이 시험관내 및 생체내 모델 둘 다에서 수행될 수 있다. ceDNA에 의한 항체 또는 항원-결합 단편의 발현 수준은 항체 또는 항원-결합 단편의 mRNA 및 단백질 수준을 측정 (예를 들어, 역전사 PCR, 웨스턴 블롯 분석 및 효소-결합 면역흡착 분석법 (ELISA))함으로써 당업자에 의해 평가될 수 있다. 일 구현예에서, ceDNA는, 예를 들어 형광 현미경 또는 발광 플레이트 판독기에 의해 리포터 단백질의 발현을 조사함으로써, 항체 또는 항원-결합 단편의 발현을 평가하는데 사용될 수 있는 리포터 단백질을 포함한다. 생체내 적용의 경우, 단백질 기능 분석을 사용하여 유전자 발현이 성공적으로 일어났는지 결정하기 위해 주어진 항체 또는 항원-결합 단편의 기능성을 시험할 수 있다. 당업자는 시험관내 또는 생체내에서 ceDNA 벡터에 의해 발현된 항체 또는 항원-결합 단편의 기능성을 측정하기 위한 최상의 시험을 결정할 수 있을 것이다.
세포 또는 대상체에서 ceDNA 벡터로부터 항체 또는 항원-결합 단편의 유전자 발현의 효과는 적어도 1개월, 적어도 2개월, 적어도 3개월, 적어도 4개월, 적어도 5개월, 적어도 6개월, 적어도 10개월, 적어도 12개월, 적어도 18개월, 적어도 2년, 적어도 5년, 적어도 10년, 적어도 20년 동안 지속되거나 영구적일 수 있음이 고려된다.
일부 구현예에서, 본원에 기재된 발현 카세트, 발현 작제물 또는 ceDNA 벡터의 항체 또는 항원-결합 단편은 숙주 세포에 대해 코돈 최적화될 수 있다. 본원에 사용된 용어 "코돈 최적화된" 또는 "코돈 최적화"는 천연 서열 (예를 들어, 원핵생물 서열)의 적어도 하나, 하나 초과 또는 상당수의 코돈을 척추동물의 유전자에서 보다 빈번하게 또는 가장 빈번하게 사용되는 코돈으로 대체함으로써, 관심 척추동물의 세포, 예를 들어 마우스 또는 인간 (예를 들어, 인간화된)의 세포에서 발현을 향상시키기 위해 핵산 서열을 변형시키는 과정을 지칭한다. 다양한 종은 특정 아미노산의 특정 코돈에 대해 특정한 편향을 나타낸다. 전형적으로, 코돈 최적화는 원래 번역된 단백질의 아미노산 서열을 변경시키지 않는다. 최적화된 코돈은 예를 들어, Aptagen's Gene Forge® 코돈 최적화 및 맞춤형 유전자 합성 플랫폼 (Aptagen, Inc.) 또는 또 다른 공개적으로 이용 가능한 데이터베이스를 사용하여 결정될 수 있다.
E. ceDNA 벡터로부터 항체 발현을 평가함으로써 효능 결정
본질적으로 단백질 발현을 결정하기 위한 당 업계에 공지된 임의의 방법을 사용하여 ceDNA 벡터로부터 원하는 항체의 발현을 분석할 수 있다. 이러한 방법/분석법의 비제한적인 예는 효소-결합 면역분석법 (ELISA), 친화성 ELISA, ELISPOT, 연속 희석, 유세포 분석, 표면 플라즈몬 공명 분석, 동역학 배제 분석법, 질량 분석법, 웨스턴 블롯, 면역침전 및 PCR을 포함한다.
생체내 항체 발현을 평가하기 위해, 분석을 위한 대상체로부터의 생물학적 샘플이 수득될 수 있다. 예시적인 생물학적 샘플은 생체 유체 샘플, 체액 샘플, 혈액 (전혈 포함), 혈청, 혈장, 소변, 타액, 생검 및/또는 조직 샘플 등을 포함한다. 생물학적 샘플 또는 조직 샘플은 또한, 종양 생검, 대변, 척수액, 흉수, 유두 흡인물, 림프액, 피부의 외부 섹션, 기도, 장관, 및 비뇨생식관, 누액, 타액, 모유, 세포 (혈액 세포를 포함하지만, 이에 제한되지 않음), 종양, 기관을 포함하지만, 이에 제한되지 않는 개체로부터 단리된 조직 또는 유체 샘플, 및 또한 시험관내 세포 배양 성분의 샘플을 지칭할 수 있다. 상기 용어는 또한 상기 언급된 샘플의 혼합물을 포함한다. 용어 "샘플"은 또한 처리되지 않은 또는 전처리된 (또는 사전 프로세싱된) 생물학적 샘플을 포함한다. 일부 구현예에서, 본원에 기재된 분석법 및 방법에 사용된 샘플은 시험될 대상체에서 수집된 혈청 샘플을 포함한다.
F. 임상 파라미터에 의한 발현된 항체의 효능 결정
류마티스 관절염 또는 암 (유방암, 흑색종 등을 포함하지만, 이에 제한되지 않음)과 같은 주어진 질환에 대해 ceDNA 벡터에 의해 발현된 (즉, 기능적 발현) 주어진 항체 또는 항원-결합 단편의 효능은 숙련된 임상의에 의해 결정될 수 있다. 그러나, 암의 징후 또는 증상 중 임의의 하나 또는 전부가 유익한 방식으로 변경되거나, 또는 질환의 임상적으로 허용되는 다른 증상 또는 마커가, 예를 들어, 본원에 기재된 바와 같은 치료 항체를 인코딩하는 ceDNA 벡터로 치료 후 적어도 10% 향상되거나 개선된다면, 치료는 그 용어가 본원에 사용된 바와 같이 "효과적인 치료"로 간주된다. 효능은 또한 질환의 안정화, 또는 의학적 개입의 필요성에 의해 평가된 바와 같이 개체가 악화되지 않음 (즉, 질환의 진행이 정지되거나 적어도 둔화됨)에 의해 측정될 수 있다. 이들 지표를 측정하는 방법은 당업자에게 공지되어 있고/있거나 본원에 기재되어 있다. 치료는 개체 또는 동물 (일부 비제한적인 예로는 인간 또는 포유동물이 포함됨)에서 질환의 임의의 치료를 포함하고, 다음을 포함한다: (1) 질환의 억제, 예를 들어, 질환 (예를 들어, 관절염, 암) 진행의 저지 또는 둔화; 또는 (2) 예를 들어, 질환의 퇴행을 유발하는 질환의 완화; 및 (3) 질환의 발병 가능성 예방 또는 감소, 또는 질환관 관련된 이차 질환/장애 (예를 들어, 류마티스 관절염으로 인한 손 기형, 또는 암 전이)의 예방.
질환의 치료를 위한 유효량은, 이를 필요로 하는 포유동물에게 투여될 때, 그 용어가 본원에서 정의된 바와 같이, 그 질환에 대해 효과적인 치료를 하기에 충분한 양을 의미한다. 제제의 효능은 주어진 질환에 특정한 물리적 지표를 평가함으로써 결정될 수 있다. 예를 들어, 암의 물리적 지표에는 통증, 종양 크기, 종양 성장 속도, 혈액 세포 수 등이 포함되지만, 이에 제한되지 않는다.
XI. 항체 또는 융합 단백질을 발현시키는 ceDNA 벡터의 다양한 적용
본원에 개시된 바와 같이, 본원에 기재된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터 및 조성물은 다양한 목적으로 항체 또는 융합 단백질을 발현시키는데 사용될 수 있다. 일 구현예에서, 항체 또는 융합 단백질을 발현시키는 ceDNA 벡터는, 예를 들어, 항체 또는 융합 단백질의 표적의 기능을 연구하기 위해 이식유전자를 보유한 체세포성 형질전환 동물 모델을 생성하는데 사용될 수 있다. 일부 구현예에서, 항체 또는 융합 단백질을 발현시키는 ceDNA 벡터는 포유동물 대상체에서 질환 상태 또는 장애의 치료, 예방 또는 개선에 유용하다.
일부 구현예에서 항체 또는 융합 단백질은 발현 증가, 유전자 산물의 활성 증가 또는 유전자의 부적절한 상향조절과 관련된 질환을 치료하는데 충분한 양으로 대상체에서 ceDNA 벡터로부터 발현될 수 있다. 이러한 구현예에서, 발현된 항체 또는 융합 단백질은 표적이거나 항체 또는 융합 단백질이 특이적으로 결합하는 단백질 또는 유전자 산물의 활성을 저해 또는 억제 또는 달리 감소시키는 기능을 하는 차단 또는 중화 항체 또는 융합 단백질일 수 있다.
일부 구현예에서 항체 또는 융합 단백질은 단백질의 발현 감소, 발현 부족 또는 기능 장애와 관련된 질환을 치료하기에 충분한 양으로 대상체에서 ceDNA 벡터로부터 발현될 수 있다. 예를 들어, 발현된 항체 또는 융합 단백질은 활성화 항체 또는 융합 단백질이고, 예를 들어, 단백질을 작용시키거나 단백질의 억제자를 억제함으로써 대상체에서 발현 및/또는 활성이 감소된 단백질의 활성 또는 기능을 증가시킬 수 있다.
이식유전자는 그 자체로 전사될 유전자의 오픈 리딩 프레임이 아닐 수 있음을 당업자는 인식할 것이며; 대신에, 그것은 표적 유전자의 프로모터 영역 또는 억제 영역일 수 있고, ceDNA 벡터는 관심 유전자의 발현을 조절하는 결과로 이러한 영역을 변형시킬 수 있다.
본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터 및 조성물은 상기 기재된 바와 같이 다양한 목적으로 항체 또는 항원-결합 단편을 전달하는데 사용될 수 있다.
일부 구현예에서, 이식유전자는 포유동물 대상체에서 질환 상태의 치료, 개선 또는 예방에 유용한 하나 이상의 항체 또는 융합 단백질을 인코딩한다. ceDNA 벡터에 의해 발현된 항체 또는 융합 단백질은 비정상적인 유전자 서열과 관련된 질환을 치료하는데 충분한 양으로 환자에게 투여되며, 이는 다음 중 임의의 하나 이상을 초래할 수 있다: 단백질 발현 증가, 단백질의 과잉 활성, 발현 감소, 표적 유전자 또는 단백질의 발현 부족 또는 기능 장애.
일부 구현예에서, 진단 및 스크리닝 방법에 사용하기 위해, 항체 또는 항원-결합 단편이 세포 배양 시스템, 또는 대안적으로 형질전환 동물 모델에서 일시적으로 또는 안정적으로 발현되는, 본원에 개시된 바와 같이 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터가 구상된다.
본원에 기재된 기술의 또 다른 측면은 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 갖는 포유동물 세포 집단을 형질도입시키는 방법을 제공한다. 전체적이고 일반적인 의미에서, 본 방법은 적어도, 집단의 하나 이상의 세포에, 본원에 개시된 바와 같이 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터 중 하나 이상의 유효량을 포함하는 조성물을 도입하는 단계를 포함한다.
추가로, 본 발명은 하나 이상의 개시된, 본원에 개시된 바와 같이 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터 또는 ceDNA 조성물을 포함하거나, 하나 이상의 추가 성분으로 제형화되거나, 또는 이들의 사용을 위한 하나 이상의 설명서와 함께 준비된 조성물, 및 치료 및/또는 진단 키트를 제공한다.
본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터가 투여되는 세포는 신경 세포 (말초 및 중추 신경계 세포, 특히 뇌 세포 포함), 폐 세포, 망막 세포, 상피 세포 (예를 들어, 장 및 호흡기 상피 세포), 근육 세포, 수지상 세포, 췌장 세포 (섬 세포 포함), 간 세포, 심근 세포, 골 세포 (예를 들어, 골수 줄기세포), 조혈 줄기세포, 비장 세포, 각질 세포, 섬유 모세포, 내피 세포, 전립선 세포, 생식 세포 등을 포함하지만 이에 제한되지 않는 임의의 유형일 수 있다. 대안적으로, 세포는 임의의 전구 세포일 수 있다. 추가의 대안으로서, 세포는 줄기세포 (예를 들어, 신경 줄기세포, 간 줄기세포)일 수 있다. 또 다른 대안으로서, 세포는 암 또는 종양 세포일 수 있다. 더욱이, 세포는, 상기 나타낸 바와 같이, 임의의 기원의 종으로부터 유래될 수 있다.
A. 상업적 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터
일부 구현예에서, 본원에 개시된 바와 같은 ceDNA 벡터는 상업적 환경에서, 예를 들어, 생물반응기를 사용하여 또는 원하는 숙주에서의 생산을 위해 항체 또는 융합 단백질의 생산에 사용될 수 있다.
예를 들어, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터를 포함하는 세포는, 예를 들어, 항체 또는 융합 단백질의 소규모 또는 대규모 바이오 제조를 위한 세포 공급원으로서 제공되는, 항체 또는 융합 단백질의 상업적 생산에 사용될 수 있다. 대안적인 구현예에서, 본원에 개시된 바와 같은 항체 또는 융합 단백질 생산을 위한 ceDNA 벡터는 소규모 생산뿐만 아니라 상업적 대규모 항체 또는 융합 단백질 생산을 포함하여, 항체 또는 융합 단백질의 생체내 생산을 위해 숙주 비-인간 대상체의 세포에 도입된다. 예를 들어, 일부 구현예에서, 본원에 기재된 ceDNA 벡터는, 예를 들어, 복수 종양을 사용하여 랫트, 마우스, 말, 염소 등에서 항체 또는 융합 단백질을 생체내에서 생성하는데 사용될 수 있다.
일부 구현예에서, 항체 또는 융합 단백질을 인코딩하는 ceDNA 벡터는, 예를 들어, 키메라 항원 수용체 (CAR)를 생성하는데 사용될 수 있으며, 이는 이어서 CAR T 세포를 생성하는데 사용될 수 있다. CAR은 특정 모노클로날 항체 및 하나 이상의 T-세포 수용체 세포내 시그널링 도메인으로부터 선택된 단일쇄 단편 변수의 융합 단백질이다. 이 T-세포 유전자 변형은 본원에 기재된 바와 같은 ceDNA 벡터를 사용하여 발생할 수 있다. 따라서, 키메라 항원 수용체를 발현시키는 ceDNA 벡터는 예를 들어, 생체외 T 세포에 투여되어 암, 예컨대, 비제한적으로 백혈병, 유방암, 폐암, 난소암 등의 치료를 위해 CAR T 세포를 조작할 수 있는 것으로 구체적으로 고려된다.
B. 항체 또는 융합 단백질 생산 및 정제
본원에 개시된 ceDNA 벡터는 시험관내 또는 생체내에서 항체 또는 융합 단백질을 생성하는데 사용된다. 이러한 방식으로 생성된 항체 또는 융합 단백질은 단리되고, 원하는 기능에 대해 시험되고, 연구에서 또는 치료적 처치로서 추가로 사용하기 위해 정제될 수 있다. 각각의 항체 또는 융합 단백질 생산 시스템은 그 자체의 장점/단점을 갖는다. 시험관내에서 생성된 항체 또는 융합 단백질은 쉽게 정제될 수 있고, 단시간에 항체 또는 융합 단백질을 생성할 수 있지만, 생체내에서 생성된 항체 또는 융합 단백질은 글리코실화와 같은 번역 후 변형을 가질 수 있다.
면역화 및 라이브러리 디스플레이 (예를 들어, 파지 디스플레이)와 같은 항체를 생성하기 위한 종래의 기술은 항체 또는 항체 성분을 인코딩하기 위해 전통적인 벡터 (예를 들어, 플라스미드, 바이러스 등) 대신에 ceDNA를 사용함으로써 조정될 수 있다. 또한, 본원에 기재된 바와 같은 ceDNA 벡터는 생물반응기, 생물반응기 생성 또는 원하는 숙주, 세포, 조직 또는 기관에서의 항체 생산에서 전통적인 벡터를 대체할 수 있다. 이러한 기술은 당업자에게 공지되어 있으며, 본원에서 상세하게 설명되지 않는다.
본원에 기재된 ceDNA 벡터는 하이브리도마 세포주에서 원하는 항체를 발현시키는데 사용될 수 있다. 하이브리도마 세포주의 생성 방법은 당 분야에 공지되어 있다. 대규모 항체 생산을 위해, 하이브리도마 세포는 정적 또는 교반된 세포 현탁 배양, 롤러-병 배양 또는 생물반응기 (예를 들어, 중공 섬유 생물반응기)에서 성장할 수 있다. 막-기반 배양 시스템은 또한 시험관내에서 항체를 생성하는데 사용될 수 있으며, 여기서 세포 배양물은 산소 및 가스 전달을 높이는 특수 가스화 막(special gassing membrane)을 통해 영양소로부터 분리된다. 대안적으로, 하이브리도마 세포가 매트릭스 상에 고정되고 새로운 배양 배지가 연속적으로 공급되는 매트릭스-기반 배양 시스템.
ceDNA 벡터를 사용하여 생성된 항체는 당업자에게 공지된 임의의 방법, 예를 들어, 이온 교환 크로마토그래피, 친화성 크로마토그래피, 침전 또는 전기영동법을 사용하여 정제될 수 있다.
본원에 기재된 방법 및 조성물에 의해 생성된 항체는 원하는 표적 단백질과의 결합에 대해 시험될 수 있다.
XIII. 기타 다양한 구현예
일부 구현예에서, 본 출원은 하기 단락 중 임의의 단락에서 정의될 수 있다:
1. 2개의 AAV 역 말단 반복 서열 (ITR) 사이에 위치한 프로모터에 작동 가능하게 연결된 적어도 하나의 이식유전자를 인코딩하는 적어도 하나의 이종 핵산 서열을 포함하는 DNA 벡터로서, 상기 ITR은 선택적으로 동일하거나 상이한 ITR일 수 있고, 이들이 상이한 ITR인 경우, ITR 중 하나는 기능적 AAV 말단 분해 부위 및 Rep 결합 부위를 포함하고, ITR 중 하나는 다른 ITR에 대한 결실, 삽입, 또는 치환을 포함하고; 상기 이식유전자는 항체 또는 이의 단편 또는 융합 단백질이고; 상기 DNA는 DNA 벡터 상에 단일 인식 부위를 갖는 제한 효소로 소화될 때 비-변성 겔 상에서 분석되는 경우 선형 및 비-연속 DNA 대조군과 비교하여 선형 및 연속 DNA의 특징적인 밴드가 존재하는, DNA 벡터.
2. 항체는 전장 항체 또는 이의 단편인, 단락 1의 벡터.
3. 항체는 모노클로날 항체, 단일쇄 항체, Fab' 단편 또는 단일 도메인 항체 (dAb)인, 단락 2의 벡터.
4. DNA 벡터는 분비 서열 및 중쇄 단백질을 인코딩하는 제1 이식유전자에 작동 가능하게 연결된 프로모터, 및 경쇄 단백질을 인코딩하는 제2 이식유전자에 작동 가능하게 연결된 제2 프로모터를 함유하는, 단락 1-3 중 어느 하나의 벡터.
5. 이식유전자는 융합 단백질을 인코딩하고, 상기 융합 단백질은 단일쇄 가변 단편 (scFv)인, 단락 1-4 중 어느 하나의 벡터.
6. 항체는 표 1-5로부터 선택된 항체인, 단락 1-5 중 어느 하나의 벡터.
7. ITR은 기능적 말단 분해 부위 및 Rep 결합 부위를 포함하고, 야생형 AAV ITR이거나, 2개의 ITR은 대칭이거나 실질적으로 대칭이거나, 2개의 ITR은 비대칭이거나, 2개의 ITR은 표 7, 9a, 9b 및 10에 열거된 어느 것으로부터 선택되는, 단락 1-6 중 어느 하나의 벡터.
8. 항체는 아두카누맙인, 단락 1의 벡터.
9. 항체는 인간 또는 인간화된 항체인, 상기 단락 중 어느 하나의 벡터.
10. 항체는 IgG, IgA, IgD, IgM, 또는 IgE 항체인, 상기 단락 중 어느 하나의 벡터.
11. 단락 1-10의 DNA 벡터의 유효량을 세포 또는 이의 집단에 투여하고, 세포에서 항체를 발현시키는 조건하에 세포 또는 이의 집단을 배양하는 것을 포함하는, 세포 또는 이의 집단에서 항체를 발현시키는 방법.
12. DNA 벡터 또는 ceDNA 벡터는 약제학적으로 허용되는 담체와 함께 투여되는, 단락 11의 방법.
13. 항체 또는 이의 단편은 세포로부터 분비되는, 단락 11 또는 12의 방법.
14. 항체 또는 이의 단편은 인트라바디로서 세포내 유지되는, 단락 11-13 중 어느 하나의 방법.
15. 세포는 포유동물 세포인, 단락 11-14 중 어느 하나의 방법.
16. 세포는 인간 세포인, 단락 15의 방법.
17. 항체는 세포로부터 단리되고 정제되는, 단락 15의 방법.
18. 대상체에게 치료 항체를 전달하는 방법으로서, 대상체에게 단락 1-10의 DNA 벡터를 포함하는 조성물을 투여하는 것을 포함하는, 방법.
19. 대상체에서 질환을 치료하는 방법으로서, 대상체에게 단락 1-10의 DNA 벡터를 포함하는 조성물을 투여하여 대상체에서 치료 항체를 발현시키고 질환을 치료하는 것을 포함하는, 방법.
20. ceDNA 벡터는 약제학적으로 허용되는 담체와 함께 투여되는, 단락 18 또는 19의 방법.
21. 치료 항체는 그것이 발현된 세포로부터 분비되는, 단락 18-20 중 어느 하나의 방법.
22. 치료 항체는 그것이 발현되는 세포에서 유지되는, 단락 18-22 중 어느 하나의 방법.
23. 세포 또는 이의 집단은 생물반응기에서 배양되는, 단락 11-17 중 어느 하나의 방법.
24. 대상체의 질환 치료에 사용하기 위한 단락 1-10 중 어느 하나에 따른 벡터를 포함하는 조성물.
25. 대상체의 질환 치료에서 단락 1-10 중 어느 하나에 따른 벡터를 포함하는 조성물의 용도.
26. 대상체의 질환 치료를 위한 약제의 제조에서 단락 1-10 중 어느 하나에 따른 벡터를 포함하는 조성물의 용도.
실시예
하기 실시예는 제한이 아닌 예시로서 제공된다. 당업자는 ceDNA 벡터가 본원에 기재된 임의의 야생형 또는 변형된 ITR로부터 구축될 수 있고, 하기 예시적인 방법이 이러한 ceDNA 벡터의 활성을 구축 및 평가하는데 사용될 수 있음을 이해할 것이다. 상기 방법은 특정 ceDNA 벡터로 예시되지만, 설명에 따라 임의의 ceDNA 벡터에 적용 가능하다.
실시예
1: 곤충 세포-기반 방법을 사용하는
ceDNA
벡터의 구축
폴리뉴클레오티드 작제 주형을 사용한 ceDNA 벡터의 생성은 PCT/US18/49996의 실시예 1에 기재되어 있으며, 이는 본원에 그 전체가 참조된다. 예를 들어, 본 발명의 ceDNA 벡터를 생성하는데 사용되는 폴리뉴클레오티드 작제 주형은 ceDNA-플라스미드, ceDNA-박미드 및/또는 ceDNA-바쿨로바이러스일 수 있다. 이론에 제한되지 않고, 허용 숙주 세포에서, 예를 들어, Rep의 존재하에, 2개의 대칭 ITR 및 발현 작제물을 갖는 폴리뉴클레오티드 작제 주형 (여기서 ITR 중 적어도 하나는 야생형 ITR 서열에 대해 변형됨)은 ceDNA 벡터를 생성하기 위해 복제된다. ceDNA 벡터 생산은 두 단계, 즉, 우선, Rep 단백질을 통한 주형 골격 (예를 들어 ceDNA-플라스미드, ceDNA-박미드, ceDNA-배큘로바이러스(baculovirus) 게놈 등)으로부터 주형의 절제 ("구조") 단계 및 둘째, 절제된 ceDNA 벡터의 Rep 매개 복제 단계를 거친다.
ceDNA 벡터를 생성하는 예시적인 방법은 본원에 기재된 ceDNA-플라스미드로부터의 방법이다. 도 1a 및 1b를 참조하면, 각각의 ceDNA-플라스미드의 폴리뉴클레오티드 작제 주형은 ITR 서열 사이에 다음을 갖는 좌측 변형된 ITR 및 우측 변형된 ITR 둘 모두를 포함한다: (i) 인핸서/프로모터; (ii) 이식유전자의 클로닝 부위; (iii) 전사 후 반응 요소 (예를 들어, 우드척 간염 바이러스 전사 후 조절 요소 (WPRE)); 및 (iv) 폴리아데닐화 신호 (예를 들어, 소 성장 호르몬 유전자 (BGHpA)로부터). 작제물 내의 특정 부위에 새로운 유전자 성분의 도입을 용이하게 하기 위해 고유한 제한 엔도뉴클레아제 인식 부위 (R1-R6) (도 1a 및 도 1b에 도시됨)가 또한 각 성분 사이에 도입되었다. R3 (PmeI) GTTTAAAC (서열 번호: 123) 및 R4 (PacI) TTAATTAA (서열 번호: 124) 효소 부위는 클로닝 부위로 조작되어 이식유전자의 오픈 리딩 프레임을 도입한다. 이들 서열을 ThermoFisher Scientific으로부터 입수한 pFastBac HT B 플라스미드 내로 클로닝하였다.
ceDNA-박미드의 생산:
DH10Bac 적격 세포 (MAX EFFICIENCY® DH10Bac™ 적격 세포, Thermo Fisher)를 제조사의 지시에 따른 프로토콜에 따라 시험 또는 대조군 플라스미드로 형질전환시켰다. DH10Bac 세포에서 플라스미드와 바쿨로바이러스 셔틀 벡터 간의 재조합을 유도하여 재조합 ceDNA-박미드를 생성하였다. 박미드 및 트랜스포사제 플라스미드를 유지 및 형질전환체를 선택하기 위해 항생제와 함께 X-gal 및 IPTG를 함유하는 박테리아 한천 플레이트 상에서 이. 콜라이(E. coli)에서의 청색-백색 스크리닝 (Φ80dlacZΔM15 마커는 박미드 벡터로부터 β-갈락토시다제 유전자의 α-상보성을 제공함)에 기초한 양성 선별을 스크리닝함으로써 재조합 박미드를 선별하였다. β-갈락토시드 지표 유전자를 파괴하는 전위에 의해 야기된 백색 콜로니를 선별하여 10 ml의 배지에서 배양하였다.
재조합 ceDNA-박미드를 이. 콜라이로부터 단리하고 FugeneHD를 사용하여 Sf9 또는 Sf21 곤충 세포로 형질감염시켜 감염성 바쿨로바이러스를 생성하였다. 부착성 Sf9 또는 Sf21 곤충 세포를 25℃에서 T25 플라스크 중의 50 ml의 배지에서 배양하였다. 4일 후, 배양 배지 (P0 바이러스 함유)를 세포로부터 제거하고, 0.45 μm 필터를 통해 여과하여, 감염성 바쿨로바이러스 입자를 세포 또는 세포 잔해로부터 분리하였다.
선택적으로, 제1 세대의 바쿨로바이러스 (P0)는 50 내지 500 ml의 배지에서 나이브 Sf9 또는 Sf21 곤충 세포를 감염시킴으로써 증폭되었다. 세포가 직경 18-19 nm (나이브 직경 14-15 nm), 및 밀도 ~4.0E+6 세포/mL에 도달할 때까지, 세포 직경 및 생존력을 모니터링하면서, 25℃에서 130 rpm으로 궤도 진탕기 인큐베이터에서 현탁 배양으로 세포를 유지시켰다. 감염 후 3일에서 8일 사이에, 배지에서 P1 바쿨로바이러스 입자를 원심분리 후 수집하여 세포 및 잔해물을 제거한 다음 0.45 μm 필터를 통해 여과하였다.
시험 작제물을 포함하는 ceDNA-바쿨로바이러스를 수집하고, 바쿨로바이러스의 감염성 활성 또는 역가를 측정하였다. 구체적으로, 2.5E+6 세포/ml에서 4 x 20 ml Sf9 세포 배양물을 다음 희석에서 P1 바쿨로바이러스로 처리하고: 1/1000, 1/10,000, 1/50,000, 1/100,000, 25-27℃에서 인큐베이션하였다. 감염력은 4 내지 5일 동안 매일, 세포 직경 증가율 및 세포주기 정지율, 및 세포 생존력의 변화에 의해 결정되었다.
전체적으로 본 명세서에 참고로 포함된 PCT/US18/49996의 도 8a에 개시된 "Rep-플라스미드"는 Rep78 (서열 번호: 131 또는 133) 및 Rep52 (서열 번호: 132) 또는 Rep68 (서열 번호: 130) 및 Rep40 (서열 번호: 129) 둘 모두를 포함하는 pFASTBAC™-이중 발현 벡터 (ThermoFisher)에서 생성되었다. Rep-플라스미드를 제조자가 제공한 프로토콜에 따라 DH10Bac 적격 세포 (MAX EFFICIENCY® DH10Bac™ Competent Cells (Thermo Fisher)로 형질전환시켰다. DH10Bac 세포에서 Rep-플라스미드와 바쿨로바이러스 셔틀 벡터 간의 재조합을 유도하여 재조합 박미드 ("Rep-박미드")를 생성하였다. X-gal 및 IPTG를 함유하는 박테리아 한천 플레이트 상의 이. 콜라이에서의 청색-백색 스크리닝 (Φ80dlacZΔM15 마커는 박미드 벡터로부터 β-갈락토시다제 유전자의 α-상보성을 제공함)을 포함하는 양성 선별에 의해 재조합 박미드를 선별하였다. 단리된 백색 콜로니를 선별하고 10 ml의 선별 배지 (LB 브로쓰 중의 카나마이신, 겐타마이신, 테트라사이클린)에 접종하였다. 재조합 박미드 (Rep-박미드)를 이. 콜라이로부터 단리하고, Rep-박미드를 Sf9 또는 Sf21 곤충 세포에 형질감염시켜 감염성 바쿨로바이러스를 생성하였다.
Sf9 또는 Sf21 곤충 세포를 4일 동안 50 ml의 배지에서 배양하고, 감염성 재조합 바쿨로바이러스 ("Rep-바쿨로바이러스")를 배양물로부터 단리하였다. 선택적으로, 제1 세대의 렙-바쿨로바이러스 (P0)는 나이브 Sf9 또는 Sf21 곤충 세포를 감염시켜 증폭되고 50 내지 500 ml의 배지에서 배양되었다. 감염 후 3일 내지 8일 사이에, 배지에서 P1 바쿨로바이러스 입자를 원심분리 또는 여과 또는 또 다른 분별 공정에 의해 세포를 분리함으로써 수집하였다. Rep-바쿨로바이러스를 수집하고 바쿨로바이러스의 감염 활성을 측정하였다. 구체적으로, 2.5x106 세포/mL에서 4 x 20 mL Sf9 세포 배양물을 다음 희석, 1/1000, 1/10,000, 1/50,000, 1/100,000에서 P1 바쿨로바이러스로 처리하고, 인큐베이션하였다. 감염력은 4 내지 5일 동안 매일, 세포 직경 증가율 및 세포주기 정지율, 및 세포 생존력의 변화에 의해 결정되었다.
ceDNA 벡터 생성 및 특성화
도 4b를 참조하면, (1) ceDNA-박미드 또는 ceDNA-바쿨로바이러스를 함유하는 샘플 및 (2) 상기 기재된 Rep-바쿨로바이러스를 함유하는 Sf9 곤충 세포 배양 배지를 각각 1:1000 및 1:10,000의 비율로 Sf9 세포의 새로운 배양액 (2.5E+6 세포/ml, 20ml)에 첨가하였다. 이어서, 세포를 25℃에서 130 rpm으로 배양하였다. 공동 감염 후 4-5일 후에, 세포 직경 및 생존력이 검출된다. 세포 직경이 ~70-80%의 생존력으로 18-20nm에 도달하면, 세포 배양물을 원심분리하고, 배지를 제거하고, 세포 펠릿을 수집하였다. 세포 펠릿은 먼저 물 또는 완충제 중 적절한 부피의 수성 매질에 재현탁된다. ceDNA 벡터는 Qiagen MIDI PLUS™ 정제 프로토콜 (Qiagen, 컬럼당 처리되는 세포 펠릿 덩어리 0.2mg)을 사용하여 세포로부터 단리 및 정제되었다.
Sf9 곤충 세포로부터 생성되고 정제된 ceDNA 벡터의 수율은 260nm에서의 UV 흡광도에 기초하여 초기에 결정되었다.
ceDNA 벡터는 도 4d에 도시된 바와 같이 비변성 또는 변성 조건 하에서 아가로스 겔 전기영동에 의해 동정함으로써 평가될 수 있으며, 여기서 (a) 제한 엔도뉴클레아제 절단 및 겔 전기영동 분석 후 변성 겔 대 비변성 겔 상에서 크기의 2배로 이동하는 특징적인 밴드의 존재 및 (b) 비절단 물질에 대한 변성 겔 상의 단량체 및 이량체 (2x) 밴드의 존재는 ceDNA 벡터의 존재의 특징이다.
단리된 ceDNA 벡터의 구조는 a) ceDNA 벡터 내에 단일 절단 부위만 존재, 및 b) 0.8% 변성 아가로스 겔 상에서 분별될 때 명확하게 보일 정도로 충분히 큰 생성 단편 (>800 bp)에 대해 선택된 제한 엔도뉴클레아제를 사용하여 공동-감염된 Sf9 세포 (본원에 기재된 바와 같음)로부터 수득된 DNA를 소화함으로써 추가로 분석되었다. 도 4d 및 4e에 도시된 바와 같이, 비-연속 구조를 갖는 선형 DNA 벡터 및 선형 및 연속 구조를 갖는 ceDNA 벡터는 반응 생성물의 크기에 의해 구별될 수 있고, 예를 들어, 비-연속 구조를 갖는 DNA 벡터는 1kb 및 2kb 단편을 생성할 것으로 예상되고, 연속 구조를 갖는 비-캡슐화된 벡터는 2kb 및 4kb 단편을 생성할 것으로 예상된다.
따라서, 단리된 ceDNA 벡터가 정의에 의해 요구되는 바와 같이 공유적으로 폐쇄된-말단이라는 것을 정성적인 방식으로 입증하기 위해, 샘플을 단일 제한 부위를 갖는 것으로 특정 DNA 벡터 서열의 맥락에서 확인된 제한 엔도뉴클레아제로 소화하여, 바람직하게는 동일하지 않은 크기 (예를 들어, 1000 bp 및 2000 bp)의 2개의 절단 산물을 생성한다. 소화 및 변성 겔 (2개의 상보적 DNA 가닥을 분리함) 상에서 전기영동 후, 선형의 비공유적으로 폐쇄된 DNA는 1000 bp 및 2000 bp 크기로 분해되며, 공유적으로 폐쇄된 DNA (즉, ceDNA 벡터)는, 2개의 DNA 가닥이 연결되고 현재 펼쳐져(unfolded) 길이가 2배 (단일 가닥을 통해)이므로 2배 크기 (2000 bp 및 4000 bp)로 분해될 것이다. 또한, DNA 벡터의 단량체, 이량체 및 n-머릭(meric) 형태의 소화는 다량체 DNA 벡터의 말단-대-말단 연결로 인해 동일한 크기의 단편으로 모두 분해될 것이다 (도 4d 참조).
본원에 사용된 문구 "비변성 겔 및 변성 조건 하에서 아가로스 겔 전기영동에 의한 DNA 벡터의 동정을 위한 분석"은 제한 엔도뉴클레아제 소화를 수행한 후 소화 생성물의 전기영동 평가를 수행하여 ceDNA의 폐쇄-말단성(close-endedness)을 평가하기 위한 분석을 지칭한다. 하나의 이러한 예시적인 분석이 뒤따르지만, 당업자는 이 예에서 많은 당 업계 공지된 변형이 가능하다는 것을 이해할 것이다. 제한 엔도뉴클레아제는 DNA 벡터 길이의 대략 1/3x 및 2/3x의 생성물을 생성하는 관심 ceDNA 벡터에 대한 단일 절단 효소로 선택된다. 이것은 비변성 겔과 변성 겔 상의 밴드를 분해한다. 변성 전에, 샘플에서 완충제를 제거하는 것이 중요한다. Qiagen PCR 클린-업 키트 또는 탈염 "스핀 컬럼", 예를 들어 GE HEALTHCARE ILUSTRA™ MICROSPIN™ G-25 컬럼이 엔도뉴클레아제 소화를 위해 당 업계에 공지된 일부 옵션이다. 분석은 예를 들어, i) 적절한 제한 엔도뉴클레아제(들)를 사용하여 DNA 소화시키고, 2) 예를 들어, Qiagen PCR 클린-업 키트에 적용하고, 증류수로 용리하고, iii) 10x 변성 용액 (10x = 0.5M NaOH, 10mM EDTA)을 첨가하고, 완충되지 않은 10X 염료를 첨가하고, NaOH 농도가 겔 및 겔 박스에서 균일하도록 보장하기 위해 1mM EDTA 및 200mM NaOH와 함께 사전 인큐베이션된 0.8 - 1.0% 겔 상에서 10X 변성 용액을 4x로 첨가하여 제조된 DNA 레더와 함께 분석하고, 1x 변성 용액 (50 mM NaOH, 1mM EDTA)의 존재하에 겔을 작동시키는 것을 포함한다. 당업자는 크기 및 원하는 결과 타이밍에 기초하여 전기영동을 작동시키기 위해 어떤 전압을 사용할 것인지 이해할 것이다. 전기영동 후, 겔을 배수하고 1x TBE 또는 TAE로 중화시키고 1x SYBR Gold를 사용하여 증류수 또는 1x TBE/TAE로 옮긴다. 그런 다음 밴드를 예를 들어 Thermo Fisher, SYBR® Gold Nucleic Acid Gel Stain (DMSO 중 10,000X 농축물) 및 에피플루오레센트 빛(epifluorescent light) (청색) 또는 UV (312nm)로 시각화할 수 있다.
생성된 ceDNA 벡터의 순도는 임의의 당 업계에 공지된 방법을 사용하여 평가될 수 있다. 하나의 예시적이고 비제한적인 방법으로서, ceDNA 벡터의 형광 강도를 표준과 비교함으로써 샘플의 전체 UV 흡광도에 대한 ceDNA-플라스미드의 기여를 추정할 수 있다. 예를 들어, UV 흡광도를 기준으로 4μg의 ceDNA 벡터가 겔에 로딩되고, ceDNA 벡터 형광 강도가 1μg인 것으로 알려진 2kb 밴드에 해당하는 경우, 1μg의 ceDNA 벡터가 있으며, ceDNA 벡터는 총 UV 흡수 물질의 25%이다. 그런 다음 겔 상의 밴드 강도는 밴드가 나타내는 계산된 입력에 대해 플로팅되며, 예를 들어, 총 ceDNA 벡터가 8kb이고, 절단된 비교 밴드가 2kb인 경우, 밴드 강도는 전체 입력의 25%로 플롯팅될 것이며, 이 경우 1.0μg 입력에 대해 .25μg일 것이다. 이어서 ceDNA 벡터 플라스미드 적정을 사용하여 표준 곡선을 플롯팅하면, 회귀선 방정식은 ceDNA 벡터 밴드의 양을 계산하는데 사용되고, 그런 다음 ceDNA 벡터로 표시되는 총 입력 백분율 또는 순도 백분율을 결정하는데 사용될 수 있다.
비교 목적으로, 실시예 1은 곤충 세포 기반 방법 및 폴리뉴클레오티드 작제물 주형을 사용하여 ceDNA 벡터의 생성을 기술하고, 또한 PCT/US18/49996의 실시예 1에 기재되어 있으며, 이는 그 전문이 본원에 참고로 포함된다. 예를 들어, 실시예 1에 따른 본 발명의 ceDNA 벡터를 생성하는데 사용되는 폴리뉴클레오티드 작제 주형은 ceDNA-플라스미드, ceDNA-박미드 및/또는 ceDNA-바쿨로바이러스일 수 있다. 이론에 제한되지 않고, 허용 숙주 세포에서, 예를 들어, Rep의 존재하에, 2개의 대칭 ITR 및 발현 작제물을 갖는 폴리뉴클레오티드 작제 주형 (여기서 ITR 중 적어도 하나는 야생형 ITR 서열에 대해 변형됨)은 ceDNA 벡터를 생성하기 위해 복제된다. ceDNA 벡터 생산은 두 단계, 즉, 우선, Rep 단백질을 통해 주형 골격 (예를 들어 ceDNA-플라스미드, ceDNA-박미드, ceDNA-바쿨로바이러스 게놈 등)으로부터 주형의 절제 ("구조") 단계 및 둘째, 절제된 ceDNA 벡터의 Rep 매개 복제 단계를 거친다.
곤충 세포를 사용하는 방법에서 ceDNA 벡터를 생성하는 예시적인 방법은 본원에 기재된 ceDNA-플라스미드로부터의 방법이다. 도 1a 및 1b를 참조하면, 각각의 ceDNA-플라스미드의 폴리뉴클레오티드 작제 주형은 ITR 서열 사이에 다음을 갖는 좌측 변형된 ITR 및 우측 변형된 ITR 둘 모두를 포함한다: (i) 인핸서/프로모터; (ii) 이식유전자의 클로닝 부위; (iii) 전사 후 반응 요소 (예를 들어 우드척 간염 바이러스 전사 후 조절 요소 (WPRE)); 및 (iv) 폴리아데닐화 신호 (예를 들어, 소 성장 호르몬 유전자 (BGHpA)로부터). 작제물 내의 특정 부위에 새로운 유전자 성분의 도입을 용이하게 하기 위해 고유한 제한 엔도뉴클레아제 인식 부위 (R1-R6) (도 1a 및 도 1b에 도시됨)가 또한 각 성분 사이에 도입되었다. R3 (PmeI) GTTTAAAC (서열 번호: 123) 및 R4 (PacI) TTAATTAA (서열 번호: 124) 효소 부위는 이식유전자의 오픈 리딩 프레임을 도입하기 위해 클로닝 부위로 조작된다. 이들 서열을 ThermoFisher Scientific으로부터 입수한 pFastBac HT B 플라스미드 내로 클로닝하였다.
ceDNA-박미드의 생산:
DH10Bac 적격 세포 (MAX EFFICIENCY® DH10Bac™ 적격 세포, Thermo Fisher)를 제조사의 지시에 따른 프로토콜에 따라 시험 또는 대조군 플라스미드로 형질전환시켰다. DH10Bac 세포에서 플라스미드와 바쿨로바이러스 셔틀 벡터 간의 재조합을 유도하여 재조합 ceDNA-박미드를 생성하였다. 박미드 및 트랜스포사제 플라스미드를 유지 및 형질전환체를 선택하기 위해 항생제와 함께 X-gal 및 IPTG를 함유하는 박테리아 한천 플레이트 상에서 이. 콜라이에서의 청색-백색 스크리닝 (Φ80dlacZΔM15 마커는 박미드 벡터로부터 β-갈락토시다제 유전자의 α-상보성을 제공함)에 기초한 양성 선별을 스크리닝함으로써 재조합 박미드를 선별하였다. β-갈락토시드 지표 유전자를 파괴하는 전위에 의해 야기된 백색 콜로니를 선별하여 10 ml의 배지에서 배양하였다.
재조합 ceDNA-박미드를 이. 콜라이로부터 단리하고 FugeneHD를 사용하여 Sf9 또는 Sf21 곤충 세포로 형질감염시켜 감염성 바쿨로바이러스를 생성하였다. 부착성 Sf9 또는 Sf21 곤충 세포를 25℃에서 T25 플라스크 중의 50 ml의 배지에서 배양하였다. 4일 후, 배양 배지 (P0 바이러스 함유)를 세포로부터 제거하고, 0.45 μm 필터를 통해 여과하여, 감염성 바쿨로바이러스 입자를 세포 또는 세포 잔해물로부터 분리하였다.
선택적으로, 제1 세대의 바쿨로바이러스 (P0)는 50 내지 500 ml의 배지에서 나이브 Sf9 또는 Sf21 곤충 세포를 감염시킴으로써 증폭되었다. 세포가 직경 18-19 nm (나이브 직경 14-15 nm), 및 밀도 ~4.0E+6 세포/mL에 도달할 때까지, 세포 직경 및 생존력을 모니터링하면서, 25℃에서 130 rpm으로 궤도 진탕기 인큐베이터에서 현탁 배양으로 세포를 유지시켰다. 감염 후 3일에서 8일 사이에, 배지에서 P1 바쿨로바이러스 입자를 원심분리 후 수집하여 세포 및 잔해물을 제거한 다음 0.45 μm 필터를 통해 여과하였다.
시험 작제물을 포함하는 ceDNA-바쿨로바이러스를 수집하고, 바쿨로바이러스의 감염성 활성 또는 역가를 측정하였다. 구체적으로, 2.5E+6 세포/ml에서 4 x 20 ml Sf9 세포 배양물을 다음 희석에서 P1 바쿨로바이러스로 처리하고: 1/1000, 1/10,000, 1/50,000, 1/100,000, 25-27℃에서 인큐베이션하였다. 감염력은 4 내지 5일 동안 매일, 세포 직경 증가율 및 세포주기 정지율, 및 세포 생존력의 변화에 의해 결정되었다.
"Rep-플라스미드"는 Rep 78 (서열 번호: 131 또는 133) 또는 Rep68 (서열 번호: 130) 및 Rep52 (서열 번호: 132) 또는 Rep40 (서열 번호: 129) 둘 다를 포함하는 pFASTBAC™-이중 발현 벡터 (ThermoFisher)에서 생성되었다. Rep-플라스미드를 제조자가 제공한 프로토콜에 따라 DH10Bac 적격 세포 (MAX EFFICIENCY® DH10Bac™ 적격 세포 (Thermo Fisher)로 형질전환시켰다. DH10Bac 세포에서 Rep-플라스미드와 바쿨로바이러스 셔틀 벡터 간의 재조합을 유도하여 재조합 박미드 ("Rep-박미드")를 생성하였다. X-gal 및 IPTG를 함유하는 박테리아 한천 플레이트 상의 이. 콜라이에서의 청색-백색 스크리닝 (Φ80dlacZΔM15 마커는 박미드 벡터로부터 β-갈락토시다제 유전자의 α-상보성을 제공함)을 포함하는 양성 선별에 의해 재조합 박미드를 선별하였다. 단리된 백색 콜로니를 선별하고 10 ml의 선별 배지 (LB 브로쓰 중의 카나마이신, 겐타마이신, 테트라사이클린)에 접종하였다. 재조합 박미드 (Rep-박미드)를 이. 콜라이로부터 단리하고, Rep-박미드를 Sf9 또는 Sf21 곤충 세포로 형질감염시켜 감염성 바쿨로바이러스를 생성하였다.
Sf9 또는 Sf21 곤충 세포를 4일 동안 50 ml의 배지에서 배양하고, 감염성 재조합 바쿨로바이러스 ("Rep-바쿨로바이러스")를 배양물로부터 단리하였다. 선택적으로, 제1 세대 Rep-바쿨로바이러스 (P0)는 50 내지 500 ml의 배지에서 나이브 Sf9 또는 Sf21 곤충 세포를 감염시킴으로써 증폭되었다. 감염 후 3일에서 8일 사이에, 배지에서 P1 바쿨로바이러스 입자를, 원심분리 또는 여과 또는 또 다른 분별 공정에 의해 세포를 분리함으로써 수집하였다. Rep-바쿨로바이러스를 수집하고, 바쿨로바이러스의 감염성 활성을 측정하였다. 구체적으로, 2.5x106 세포/ml에서 4 x 20 ml Sf9 세포 배양물을 다음 희석에서 P1 바쿨로바이러스로 처리하고: 1/1000, 1/10,000, 1/50,000, 1/100,000, 인큐베이션하였다. 감염력은 4 내지 5일 동안 매일, 세포 직경 증가율 및 세포주기 정지율, 및 세포 생존력의 변화에 의해 결정되었다.
ceDNA 벡터 생성 및 특성화
이어서, (1) ceDNA-박미드 또는 ceDNA-바쿨로바이러스를 함유하는 샘플 및 (2) 상기 기재된 Rep-바쿨로바이러스를 함유하는 Sf9 곤충 세포 배양 배지를 각각 1:1000 및 1:10,000의 비율로 Sf9 세포의 새로운 배양액 (2.5E+6 세포/ml, 20ml)에 첨가하였다. 이어서, 세포를 25℃에서 130 rpm으로 배양하였다. 공동-감염 후 4-5일 후에, 세포 직경 및 생존력을 검출한다. 세포 직경이 ~70-80%의 생존력으로 18-20nm에 도달하면, 세포 배양물을 원심분리하고, 배지를 제거하고, 세포 펠릿을 수집하였다. 세포 펠릿은 먼저 물 또는 완충제 중 적절한 부피의 수성 매질에 재현탁된다. ceDNA 벡터는 Qiagen MIDI PLUS™ 정제 프로토콜 (Qiagen, 컬럼당 처리되는 세포 펠릿 덩어리 0.2mg)을 사용하여 세포로부터 단리 및 정제되었다.
Sf9 곤충 세포로부터 생성되고 정제된 ceDNA 벡터의 수율은 260nm에서의 UV 흡광도에 기초하여 초기에 결정되었다. 정제된 ceDNA 벡터는 실시예 5에 기재된 전기영동 방법론을 사용하여 적절한 폐쇄-말단 구성에 대해 평가될 수 있다.
실시예 2: 이중 가닥 DNA 분자로부터 절제를 통한 합성 ceDNA 생산
ceDNA 벡터의 합성적 생산은 2019년 1월 18일자로 출원된 국제 출원 PCT/US19/14122의 실시예 2-6에 기재되어 있으며, 이는 그 전문이 본원에 참고로 포함된다. 이중 가닥 DNA 분자의 절제를 포함하는 합성 방법을 사용하여 ceDNA 벡터를 생성하는 하나의 예시적인 방법. 간략하게, ceDNA 벡터는 이중 가닥 DNA 작 제물을 사용하여 생성될 수 있으며, 예를 들어, PCT/US19/14122의 도 7a-8e를 참조한다. 일부 구현예에서, 이중 가닥 DNA 작제물은 ceDNA 플라스미드이고, 예를 들어, 2018년 12월 6일자로 출원된 국제 특허 출원 PCT/US2018/064242의 도 6을 참조한다.
일부 구현예에서, ceDNA 벡터를 제조하기 위한 작제물은 본원에 기재된 바와 같은 조절 스위치를 포함한다.
예시적인 목적으로, 실시예 2는 이 방법을 사용하여 생성된 예시적인 폐쇄된-말단 DNA 벡터로서 ceDNA 벡터를 생성하는 것을 기술한다. 그러나, ITR 및 발현 카세트 (예를 들어, 이종 핵산 서열)를 포함하는 이중 가닥 폴리뉴클레오티드의 절제에 이어서 본원에 기재된 바와 같이 유리 3' 및 5' 말단의 결찰에 의해 폐쇄된-말단 DNA 벡터를 생성하기 위한 시험관내 합성적 생산 방법을 설명하기 위해 ceDNA 벡터가 본 실시예에서 예시되어 있지만, 당업자는, 상기 예시된 바와 같이, 도기본(doggybone) DNA, 덤벨 DNA 등을 포함하지만, 이에 제한되지 않는 임의의 원하는 폐쇄된-말단 DNA 벡터가 생성되도록 이중 가닥 DNA 폴리뉴클레오티드 분자가 변형될 수 있다는 것을 알고 있다. 실시예 2에 기재된 합성적 생산 방법에 의해 생성될 수 있는 항체 또는 융합 단백질의 생산을 위한 예시적인 DNA 벡터는 "III 일반적인 ceDNA 벡터"라는 제목의 섹션에서 논의된다. ceDNA 벡터에 의해 발현된 예시적인 항체 및 융합 단백질은 "IIC ceDNA 벡터에 의해 발현된 예시적인 항체 및 융합 단백질"이라는 제목의 섹션에 기재되어 있다.
상기 방법은 (i) 이중 가닥 DNA 작제물로부터 발현 카세트를 인코딩하는 서열을 절제하는 단계 및 (ii) 하나 이상의 ITR에서 헤어핀 구조를 형성하는 단계 및 (iii) 유리 5' 및 3' 말단을 결찰, 예를 들어, T4 DNA 리가아제에 의한 결찰에 의해 연결하는 단계를 포함한다.
이중 가닥 DNA 작제물은 5'에서 3' 순서로 제1 제한 엔도뉴클레아제 부위; 상류 ITR; 발현 카세트; 하류 ITR; 및 제2 제한 엔도뉴클레아제 부위를 포함한다. 이어서, 이중 가닥 DNA 작제물을 하나 이상의 제한 엔도뉴클레아제와 접촉시켜 제한 엔도뉴클레아제 부위의 양쪽에서 이중 가닥 파괴물을 생성한다. 하나의 엔도뉴클레아제는 양쪽 부위를 표적화할 수 있거나, 제한 부위가 ceDNA 벡터 주형에 존재하지 않는 한 각각의 부위는 상이한 엔도뉴클레아제에 의해 표적화될 수 있다. 이는 나머지 이중 가닥 DNA 작제물로부터 제한 엔도뉴클레아제 부위들 사이의 서열을 절제한다 (PCT/US19/14122의 도 9 참조). 결찰될 때 폐쇄된-말단 DNA 벡터가 형성된다.
본 방법에 사용된 ITR 중 하나 또는 둘 다는 야생형 ITR일 수 있다. 변형된 ITR이 또한 사용될 수 있으며, 여기서 변형은 B 및 B' 아암 및/또는 C 및 C' 아암을 형성하는 서열에서 야생형 ITR로부터 하나 이상의 뉴클레오티드의 결실, 삽입 또는 치환을 포함할 수 있고 (예를 들어, 도 6-8 및 10 PCT/US19/14122의 도 11b 참조), 2개 이상의 헤어핀 루프 (예를 들어, 도 6-8 PCT/US19/14122의 도 11b 참조) 또는 단일 헤어핀 루프 (예를 들어, 도 10a-10b PCT/US19/14122의 도 11b 참조)를 가질 수 있다. 헤어핀 루프 변형된 ITR은 기존 올리고의 유전자 변형에 의해 또는 새로운 생물학적 및/또는 화학적 합성에 의해 생성될 수 있다.
비제한적인 예로, ITR-6 좌측 및 우측 (서열 번호: 111 및 112)은 AAV2의 야생형 ITR로부터의 B-B' 및 C-C' 아암 내 40개의 뉴클레오티드 결실을 포함한다. 변형된 ITR에 남아있는 뉴클레오티드는 단일 헤어핀 구조를 형성할 것으로 예측된다. 구조를 언폴딩(unfolding)하는 깁스 자유 에너지는 약 -54.4 kcal/mol이다. 기능적 Rep 결합 부위 또는 Trs 부위의 선택적 결실을 포함하여, ITR에 대한 다른 변형이 또한 이루어질 수 있다.
실시예 3: 올리고뉴클레오티드 구축을 통한 ceDNA 생산
다양한 올리고뉴클레오티드의 어셈블리를 포함하는 합성 방법을 사용하여 ceDNA 벡터를 생성하는 또 다른 예시적인 방법이 PCT/US19/14122의 실시예 3에서 제공되고, 여기서 ceDNA 벡터는 5' 올리고뉴클레오티드 및 3' ITR 올리고뉴클레오티드를 합성하고 ITR 올리고뉴클레오티드를, 발현 카세트를 포함하는 이중 가닥 폴리뉴클레오티드에 결찰함으로써 생성된다. PCT/US19/14122의 도 11b는 5' ITR 올리고뉴클레오티드 및 3' ITR 올리고뉴클레오티드를, 발현 카세트를 포함하는 이중 가닥 폴리뉴클레오티드에 결찰하는 예시적인 방법을 도시한다.
본원에 개시된 바와 같이, ITR 올리고뉴클레오티드는 WT-ITR (예를 들어, 도 3a, 도 3c 참조), 또는 변형된 ITR (예를 들어, 도 3b 및 도 3d 참조)을 포함할 수 있다. (또한, 예를 들어, 그 전문이 본원에 포함된, PCT/US19/14122의 도 6a, 6b, 7a 및 7b 참조). 예시적인 ITR 올리고뉴클레오티드는 서열 번호: 134-145를 포함하지만, 이에 제한되지 않는다 (예를 들어, PCT/US19/14122의 표 7 참조). 변형된 ITR은 B 및 B' 아암 및/또는 C 및 C' 아암을 형성하는 서열에서 야생형 ITR로부터 하나 이상의 뉴클레오티드의 결실, 삽입, 또는 치환을 포함할 수 있다. 무세포 합성에서 사용되는 본원에 기재된 바와 같은 WT-ITR 또는 모드-ITR을 포함하는 ITR 올리고뉴클레오티드는 유전자 변형 또는 생물학적 및/또는 화학적 합성에 의해 생성될 수 있다. 본원에 논의된 바와 같이, 실시예 2 및 3의 ITR 올리고뉴클레오티드는 본원에 논의된 바와 같이, 대칭 또는 비대칭 구성으로 WT-ITR 또는 변형된 ITR (모드-ITR)을 포함할 수 있다.
실시예 4: 단일 가닥 DNA 분자를 통한 ceDNA 생산
합성 방법을 사용하여 ceDNA 벡터를 생성하는 또 다른 예시적인 방법은 PCT/US19/14122의 실시예 4에 제공되고, 센스 발현 카세트 서열의 측면에 있고, 안티센스 발현 카세트의 측면에 있는 2개의 안티센스 ITR에 공유적으로 부착되는 2개의 센스 ITR을 포함하는 단일 가닥 선형 DNA를 사용하며, 이후 이 단일 가닥 선형 DNA의 말단이 결찰되어 폐쇄된-말단 단일 가닥 분자를 형성한다. 하나의 비제한적인 예는 단일 가닥 DNA 분자를 합성 및/또는 생성하고, 분자의 일부를 어닐링하여 2차 구조의 하나 이상의 염기쌍 영역을 갖는 단일 선형 DNA 분자를 형성한 다음, 유리 5' 및 3' 말단을 서로 결찰하여 폐쇄된 단일 가닥 분자를 형성하는 것을 포함한다.
ceDNA 벡터의 생산을 위한 예시적인 단일 가닥 DNA 분자는 5'에서 3'로 다음을 포함한다:
센스 제1 ITR;
센스 발현 카세트 서열;
센스 제2 ITR;
안티센스 제2 ITR;
안티센스 발현 카세트 서열; 및
안티센스 제1 ITR.
실시예 4의 예시적인 방법에 사용하기 위한 단일 가닥 DNA 분자는 본원에 기재된 임의의 DNA 합성 방법, 예를 들어, 시험관내 DNA 합성에 의해 형성될 수 있거나, DNA 작제물 (예를 들어, 플라스미드)을 뉴클레아제로 절단하고 생성된 dsDNA 단편을 용융시켜 ssDNA 단편을 제공함으로써 제공된다.
어닐링은 온도를 센스 및 안티센스 서열 쌍의 계산된 용융 온도 아래로 낮춤으로써 달성될 수 있다. 용융 온도는 특정 뉴클레오티드 염기 함량 및 사용된 용액의 특성, 예를 들어, 염 농도에 의존한다. 임의의 주어진 서열 및 용액 조합에 대한 용융 온도는 당업자에 의해 쉽게 계산된다.
어닐링된 분자의 유리 5' 및 3' 말단은 서로 결찰되거나 헤어핀 분자에 결찰되어 ceDNA 벡터를 형성할 수 있다. 예시적인 적합한 결찰 방법 및 헤어핀 분자는 실시예 2 및 3에 기재되어 있다.
실시예 5: ceDNA의 정제 및/또는 생성 확인
예를 들어, 실시예 1에 기재된 곤충 세포 기반 생산 방법, 또는 실시예 2-4에 기재된 합성적 생산 방법을 포함하여, 본원에 기재된 방법에 의해 생성된 임의의 DNA 벡터 산물은, 예를 들어, 불순물, 미사용 성분 또는 부산물을, 숙련가에게 흔히 알려진 방법을 사용하여 제거하기 위해 정제될 수 있고; 및/또는 생성된 DNA 벡터 (이 경우에, ceDNA 벡터)가 원하는 분자임을 확인하기 위해 분석될 수 있다. DNA 벡터, 예를 들어, ceDNA의 정제를 위한 예시적인 방법은 Qiagen Midi Plus 정제 프로토콜 (Qiagen) 및/또는 겔 정제를 사용하는 것이다.
다음은 ceDNA 벡터의 정체(identity)를 확인하기 위한 예시적인 방법이다.
ceDNA 벡터는 도 4d에 도시된 바와 같이 비변성 또는 변성 조건하에 아가로스 겔 전기영동에 의해 동정함으로써 평가될 수 있으며, 여기서 (a) 제한 엔도뉴클레아제 절단 및 겔 전기영동 분석 후 변성 겔 대 비변성 겔 상에서 크기의 2배로 이동하는 특징적인 밴드의 존재 및 (b) 비절단 물질에 대한 변성 겔 상의 단량체 및 이량체 (2x) 밴드의 존재는 ceDNA 벡터의 존재의 특징이다.
단리된 ceDNA 벡터의 구조는 a) ceDNA 벡터 내에 단일 절단 부위만 존재, 및 b) 0.8% 변성 아가로스 겔 상에서 분별될 때 명확하게 보일 정도로 충분히 큰 생성 단편 (>800 bp)을 위해 선택된 제한 엔도뉴클레아제로 정제된 DNA를 소화시킴으로써 추가로 분석되었다. 도 4d 및 4e에 도시된 바와 같이, 비-연속 구조를 갖는 선형 DNA 벡터 및 선형 및 연속 구조를 갖는 ceDNA 벡터는 반응 생성물의 크기에 의해 구별될 수 있고, 예를 들어, 비-연속 구조를 갖는 DNA 벡터는 1kb 및 2kb 단편을 생성할 것으로 예상되고, 한편 연속 구조를 갖는 ceDNA 벡터는 2kb 및 4kb 단편을 생성할 것으로 예상된다.
따라서, 단리된 ceDNA 벡터가 정의상 요구되는 바와 같이 공유적으로 폐쇄된-말단이라는 것을 정성적인 방식으로 입증하기 위해, 샘플을 단일 제한 부위를 갖는 것으로 특정 DNA 벡터 서열의 맥락에서 확인된 제한 엔도뉴클레아제로 소화시켜, 바람직하게는 크기가 동일하지 않은 (예를 들어, 1000 bp 및 2000 bp) 2개의 절단 산물을 생성한다. 소화 및 변성 겔 상에서 전기영동 (2개의 상보적 DNA 가닥을 분리함) 후, 선형의 비공유적으로 폐쇄된 DNA는 1000 bp 및 2000 bp 크기로 분해될 것이며, 한편 공유적으로 폐쇄된 DNA (즉, ceDNA 벡터)는, 2개의 DNA 가닥이 연결되고 이제 언폴딩되어(unfolded) 길이가 2배 (단일 가닥을 통해)가 되므로 2배 크기 (2000 bp 및 4000 bp)로 분해될 것이다. 또한, DNA 벡터의 단량체, 이량체 및 n-머릭(meric) 형태의 소화는 다량체 DNA 벡터의 말단-대-말단 연결로 인해 동일한 크기의 단편으로 모두 분해될 것이다 (도 4e 참조).
본원에 사용된 문구 "비변성 겔 및 변성 조건하에 아가로스 겔 전기영동에 의한 DNA 벡터의 동정을 위한 분석"은 제한 엔도뉴클레아제 소화를 수행한 후 소화 생성물의 전기영동 평가를 수행하여 ceDNA의 폐쇄-말단성(close-endedness)을 평가하기 위한 분석을 지칭한다. 이러한 하나의 예시적인 분석이 뒤따르지만, 당업자는 이 예에서 많은 당 업계에 공지된 변형이 가능하다는 것을 이해할 것이다. 제한 엔도뉴클레아제는 DNA 벡터 길이의 대략 1/3x 및 2/3x의 생성물을 생성하는 관심 ceDNA 벡터에 대한 단일 절단 효소인 것으로 선택된다. 이것은 비변성 겔과 변성 겔 상의 밴드를 분해한다. 변성 전에, 샘플에서 완충제를 제거하는 것이 중요하다. Qiagen PCR 클린-업 키트 또는 탈염 "스핀 컬럼", 예를 들어 GE HEALTHCARE ILUSTRA™ MICROSPIN™ G-25 컬럼이 엔도뉴클레아제 소화를 위해 당 업계에 공지된 일부 옵션이다. 분석은 예를 들어, i) 적절한 제한 엔도뉴클레아제(들)로 DNA를 소화시키고, 2) 예를 들어, Qiagen PCR 클린-업 키트에 적용하고, 증류수로 용리하고, iii) 10x 변성 용액 (10x = 0.5 M NaOH, 10mM EDTA)을 첨가하고, 완충되지 않은 10X 염료를 첨가하고, NaOH 농도가 겔 및 겔 박스에서 균일하도록 보장하기 위해 1mM EDTA 및 200mM NaOH와 함께 사전 인큐베이션된 0.8 - 1.0% 겔 상에서 10X 변성 용액을 4x로 첨가하여 제조된 DNA 레더와 함께 분석하고, 1x 변성 용액 (50 mM NaOH, 1mM EDTA)의 존재하에 겔을 작동시키는 것을 포함한다. 당업자는 크기 및 원하는 결과 타이밍에 기초하여 전기영동을 작동시키기 위해 어떤 전압을 사용할 것인지 이해할 것이다. 전기영동 후, 겔을 배수하고 1x TBE 또는 TAE로 중화시키고 1x SYBR Gold를 사용하여 증류수 또는 1x TBE/TAE로 옮긴다. 그런 다음 밴드를 예를 들어 Thermo Fisher, SYBR® Gold Nucleic Acid Gel Stain (DMSO 중 10,000X 농축물) 및 에피플루오레센트 빛(epifluorescent light) (청색) 또는 UV (312nm)로 시각화할 수 있다. 상기 겔-기반 방법은 겔 밴드로부터 ceDNA 벡터를 동정하고 그것이 재생되도록 함으로써 정제 목적에 적합할 수 있다.
생성된 ceDNA 벡터의 순도는 임의의 당 업계에 공지된 방법을 사용하여 평가될 수 있다. 하나의 예시적이고 비제한적인 방법으로서, ceDNA 벡터의 형광 강도를 표준과 비교함으로써 샘플의 전체 UV 흡광도에 대한 ceDNA-플라스미드의 기여를 추정할 수 있다. 예를 들어, UV 흡광도를 기준으로 4μg의 ceDNA 벡터가 겔에 로딩되고, ceDNA 벡터 형광 강도가 1μg인 것으로 알려진 2kb 밴드에 해당하는 경우, 1μg의 ceDNA 벡터가 있으며, ceDNA 벡터는 총 UV 흡수 물질의 25%이다. 그런 다음 겔 상의 밴드 강도는 밴드가 나타내는 계산된 입력에 대해 플로팅되며, 예를 들어 총 ceDNA 벡터가 8kb이고, 절제된 비교 밴드가 2kb인 경우, 밴드 강도는 전체 입력의 25%로 플롯팅될 것이며, 이 경우 1.0μg 입력에 대해 .25μg일 것이다. 이어서, ceDNA 벡터 플라스미드 적정을 사용하여 표준 곡선을 플롯팅하면, 회귀선 방정식이 ceDNA 벡터 밴드의 양을 계산하는데 사용되고, 그런 다음 ceDNA 벡터로 표시되는 총 입력 백분율 또는 순도 백분율을 결정하는데 사용될 수 있다.
실시예 6: ceDNA 플라스미드로부터 항체 또는 융합 단백질 생산
항체를 발현시키는 ceDNA 벡터의 능력을 입증하기 위해, 모노클로날 항체 아두카누맙을 인코딩하는 ceDNA 플라스미드가 생성되었다.
아두카누맙은 응집된 형태의 베타-아밀로이드 단백질을 표적화함으로써 알츠하이머병의 치료를 위해 연구되고 있는 인간 모노클로날 항체이다. 도 6a는 전장 아두카누맙을 발현시키도록 생성되고 결정된 예시적인 플라스미드를 도시한다. 도 6b는 도 6a의 ceDNA 플라스미드를 사용하여 수득될 수 있는 ceDNA 벡터의 개략도이다. 도 6b의 발현 카세트는 아두카누맙 항체의 중쇄 및 경쇄 각각에 대해 상이한 프로모터가 사용되는 이중 프로모터 시스템을 도시한다. 아두카누맙 항체를 생성하는데 사용된 ceDNA 플라스미드는 기능성 항체의 형성을 위한 중쇄 및 경쇄의 적절한 비율을 초래하는 중쇄 및 경쇄의 발현을 위한 독특한 프로모터 조합을 포함한다. 당업자는 온전한 항체의 효율적인 형성을 촉진하기 위해 원하는 비율의 발현된 중쇄 및/또는 경쇄를 생성하도록 원하는 항체의 각각의 경쇄 및 중쇄에 대한 프로모터를 선택하는 방법을 이해할 것이다.
도 6a에 도시된 바와 같은 "pFB이중-ceDNA-아두카누맙 플라스미드" 또는 "ceDNA-IgG-플라스미드"로 지칭되는 ceDNA 플라스미드는 실시예 1에 기재된 바와 같이 제조되고, 293 세포의 일시적 형질감염에 사용되었다. 293-6E 세포를 무혈청 FreeStyle™ 293 발현 배지 (Life Technologies, Carlsbad, CA, USA)에서 성장시켰다. 세포를 궤도 진탕기 (VWR Scientific, Chester, PA) 상의 삼각 플라스크 (Corning Inc., Acton, MA)에서 37℃에서 5% CO2로 유지시켰다. 형질감염 하루 전에, 세포를 코닝 삼각 플라스크에 적절한 밀도로 시딩하였다. 형질감염 당일, DNA 및 형질감염 시약을 최적의 비율로 혼합한 후 형질감염을 위해 준비된 세포와 함께 플라스크에 첨가하였다. 표적 단백질을 인코딩하는 재조합 플라스미드를 현탁액 293-6E 세포 배양물로 일시적으로 형질감염시켰다. 형질감염 후 2일, 4일 및 5일째의 세포 밀도 및 생존력이 표 13에 열거되어 있다. 2일, 4일 및 5일째에 수집된 세포 배양 상청액 샘플을 단백질 발현 평가에 사용하였다. 형질감염 후 6일째에 수확된 세포 배양 상청액을 정제에 사용하였다.
표 13: 293-6E 세포에서 ceTTX-IgG1-Adu의 세포 밀도 및 생존력

항체의 발현 및 정제: 단백질 발현 수준을 추정하기 위해, 형질감염 후 2, 4 및 5일째에 세포 배양 상청액을 수집하고, SDS-PAGE 및 웨스턴 블롯으로 분석하였다 (데이터는 표시되지 않음). 단백질 정제를 위해, 세포 배양 브로쓰를 원심분리하고 상청액을 여과하였다. 여과된 상청액을 1.0 ml/분으로 Monofinity A 수지 사전 패킹된 컬럼 1 ml (GenScript) 상에 로딩한 다음 적절한 완충제로 세척하고 용리하였다. 용리된 분획을 풀링하고 PBS pH7.2로 완충제 교환하였다. 정제된 단백질을 분자량, 수율 및 순도 측정을 위해 표준 프로토콜을 사용하여 SDS-PAGE (도 8a), 웨스턴 블롯 (도 8b) 및 SEC-HPLC (데이터는 표시되지 않음)로 분석하였다.
요약하면, 현탁 배양으로 성장한 293-6E 세포에서 pFB이중-ceDNA-아두카누맙 플라스미드로부터 생성된 ceDNA 벡터로부터 아두카누맙을 발현시켰다. 항체는 SDS-PAGE 분석을 사용하여 식별될 수 있는 수준으로 발현되었다 (도 8a). 한 단계 정제 후, 추정된 분자량이 환원 조건하에 ~55 kDa 및 ~25 kDa이고, 비-환원 조건하에 ~150 kDa인 항체가 검출되었다 (도 8b). 이 데이터는 항체의 중쇄 및 경쇄가 이 시스템에서 전체 항체로 자가-조립되었음을 나타낸다.
실시예 7: 체외 재조합 항체의 대규모 생산
아두카누맙 중쇄 및 경쇄를 인코딩하는 서열을 포함하는 ceDNA 플라스미드는 실시예 1 및 5에서 이전에 기재된 바와 같이 생성될 수 있고, 예를 들어 무혈청 조건에서 성장하도록 적응된 FreeStyle™ 293-F 세포 (R790-07, Life Technologies)의 대규모 현탁 배양으로 형질감염될 수 있다. 현탁 및 무혈청 적응된 FreeStyleTM293-F 세포 (Life Technologies)는, 궤도 진탕기 플랫폼에서 135 rpm으로 회전시키면서, 벤트 캡(vented cap) (Sigma)이 있는 125mL 멸균 삼각 플라스크 내의 FreeStyleTM293 발현 배지 (Life Technologies)에서 1 X 105-5 X 105 생존 세포/mL 사이의 밀도로 배양된다. 1 X 106 생존 세포/mL에서 30 mL의 세포를 함유하는 각각의 125 mL 플라스크를 제조사의 지시에 따라 ceDNA Fugene6 형질감염 시약 (3:1 Fugene6:ceDNA)으로 형질감염시켰다. 형질감염 24시간 후, 선별 (50 mg/mL)을 세포에 첨가하고 세포를 2 X 105 - 5 X 105 생존 세포/mL 사이의 밀도에서 2주 동안 선별하에 유지한 후 1 L 진탕기 플라스크 (Sigma), 1 L 스피너 병 (Sigma) 또는 5 L WAVE 생물반응기 (GE Healthcare)로 확장시켰다. 샘플은 48시간마다 수집되고 IgG 발현 수준은 항-인간 IgG ELISA에 의해 결정된다. 피크 발현에서, 배양된 상청액을 수거하고, 1000 X g에서 15분 동안 원심분리하고, 0.45 mm 필터 (Sartorius)를 통과시키고, 사용할 때까지 0.1% 아지드화나트륨 (Sigma)과 함께 4℃에서 저장한다.  Prime 시스템 (GE Healthcare) 및 0.2 μm 여과 완충액을 사용하여 5 mL HiTrap Protein-G HP 컬럼 (GE Healthcare)이 구비된 친화성 크로마토그래피로 항체를 정제할 수 있다. 예를 들어, 칼럼은 10 컬럼 용적 (CV)의 포스페이트 완충 염수 (PBS) 세척 완충제 (pH 7.0)로 평형화되고, 상청액을 2 mL/분의 유속으로 로딩하고, 이어서 10 CV의 세척 완충제를 로딩한다. 항체를 0.2 M 글리신 완충제 (pH 2.3)로 용리시키고, 2.5 mL 분획을 중화를 위해 0.5 mL 1 M 트리스-HCl pH 8.6을 함유하는 튜브에 수집하였다.
Prime 시스템 (GE Healthcare) 및 0.2 μm 여과 완충액을 사용하여 5 mL HiTrap Protein-G HP 컬럼 (GE Healthcare)이 구비된 친화성 크로마토그래피로 항체를 정제할 수 있다. 예를 들어, 칼럼은 10 컬럼 용적 (CV)의 포스페이트 완충 염수 (PBS) 세척 완충제 (pH 7.0)로 평형화되고, 상청액을 2 mL/분의 유속으로 로딩하고, 이어서 10 CV의 세척 완충제를 로딩한다. 항체를 0.2 M 글리신 완충제 (pH 2.3)로 용리시키고, 2.5 mL 분획을 중화를 위해 0.5 mL 1 M 트리스-HCl pH 8.6을 함유하는 튜브에 수집하였다.
실시예 8: 전장 아두카누맙을 발현시키는 ceDNA 벡터의 제조 및
시험관내
에서 항체의 ceDNA 발현
아두카누맙 또는 GFP를 발현시키는 ceDNA 플라스미드 또는 ceDNA 벡터는 실시예 1에서 제조된 바와 같은 ceDNA Adu-전체-IgG1 플라스미드 (pFB이중-ceDNA-아두카누맙 플라스미드 또는 ceDNA-IgG-플라스미드) (도 6a)를 사용하여 실시예 1 및 5에 기재된 바와 같이 제조하였다. 생성되고 정제된 ceDNA 벡터 ("ceDNA IgG"로 지칭됨) 또는 ceDNA 플라스미드의 수율은 260nm에서의 UV 흡광도에 기초하여 결정되었다. ceDNA 벡터 또는 ceDNA 플라스미드를 제조사의 지시에 따라 Lipofectamine™ 3000 형질감염 시약 (Invitrogen)을 사용하여 HEK293T 세포로 형질감염시켰다. 72시간 후, 세포를 RIPA 완충제에 용해시키고, 전체 세포 상청액을 수집하고 필터 (Amicon)를 사용하여 농축시켰다. 생성된 항체 생산을 웨스턴 블롯으로 검사하였다. 세포 상청액 및 용해물 샘플을, 동일한 양의 단백질이 로딩되도록 하는 농도로 정규화하였다. 제조된 샘플을 70℃에서 10분 동안 열 블록에서 비등시킨 후 얼음 위에 두었다. 샘플을 200V에서 32분 동안 SDS-PAGE 겔에서 작동시킨 후 표준 기술을 사용하여 니트로셀룰로오스 막으로 옮겼다. 상업적으로 입수 가능한 인간 IgG를 양성 대조군 (Abcam, Sigma)으로 사용하였다. 막을 실온에서 30분 동안 차단 완충제 (Odyssey)로 차단하였다. 폰소 S 염색으로 막을 5분 동안 염색한 후 증류수로 세척하고 TBST로 디스테이닝(destaining)하여 단백질 밴드를 시각화하였다. 이어서 막을 차단 완충액에 1:5000으로 희석된, 호스래디시 페록시다제에 접합된 1차 항-인간 IgG 항체 (Genscript)로 가볍게 교반하면서 4℃에서 밤새 프로빙(probed)하였다. 이어서, 블롯을 TBST로 매번 5분 동안 3회 세척하고, ECL 키트 (SuperSignal West Femto Substrate)로 현상하고 겔 이미징 시스템 (Syngene Box Mini)을 사용하여 영상화하였다.
Lipofectamine™ 3000 형질감염 절차의 형질감염 효율은 ceDNA-GFP 플라스미드 (도 9a, 상단 패널) 또는 ceDNA-GFP 벡터 (도 9a, 하단 패널)로 형질감염된 293T 세포의 형광을 검사함으로써 평가되었다. 두 샘플 모두 도 9a에 도시된 바와 같이 상당한 형광을 나타냈고, 이는 형질감염이 두 경우에 모두 성공했음을 나타낸다. 각각의 샘플에서 상당한 단백질 함량 (도 9b, 하단 패널)에도 불구하고, 발현된 아두카누맙의 존재는 ceDNA-IgG 플라스미드 또는 ceDNA-IgG 작제물로 형질감염된 세포로부터의 샘플에서만 검출되었다 (도 9b, 상단 패널, 중쇄 및 경쇄 모두 관찰됨). 이는 ceDNA 벡터가 293T 세포에서 아두카누맙을 발현시켰음을 나타냈다.
실시예 9: 발현된 항체의 정체 확인
인간 배아 신장 세포 (HEK293-6E) 세포에서의 발현을 위해 아두카누맙을 인코딩하는 관심 핵산을 포함하는 플라스미드를 제조하였다. HEK293-6E 세포를 무혈청 배지 (FreeStyle™ 293 발현 배지, Thermo Fisher Scientific)에서 성장시켰다. 세포를 궤도 진탕기 상에서 5% CO2로 37℃의 삼각 플라스크에 유지시켰다. 형질감염 하루 전, 세포를 삼각 플라스크에 적절한 밀도로 시딩하였다. 형질감염 당일, DNA 및 형질감염 시약을 최적의 비율로 혼합한 후 형질감염을 위해 준비된 세포와 함께 플라스크에 첨가하였다. 표적 단백질을 인코딩하는 재조합 플라스미드를 현탁 HEK293-6E 세포 배양물로 일시적으로 형질감염시켰다. 6일째에 수집된 세포 배양 상청액을 정제에 사용하였다.
세포 배양 브로스를 원심분리하고, 여과하고, 적절한 유속으로 친화성 정제 컬럼 (Monofinity A Resin™ Prepacked Column, GenScript) 상에 로딩하였다. 세척 및 용리 후, 용리된 분획을 풀링하고 최종 제형 완충제로 완충제 교환하였다. 정제된 단백질은 (a) 환원 및 비-환원 조건하에 SDS-폴리아크릴아미드 겔 전기영동, (b) 염소-항-인간 IgG-HRP (GenScript) 및 염소 항-인간 카파-HRP를 1차 항체로 사용하고, 화학발광 검출된, 웨스턴 블롯팅, 및 (c) 분자량 및 순도를 결정하기 위해 TSKgel G3000SWxl (Tosoh Bioscience) 고성능 액체 크로마토그래피를 사용한 크기 배제 크로마토그래피로 분석되었다. 단백질 농도는 A260/280에서의 흡수에 의해 결정되었다. 결과는 도 10a에 도시되어 있다. HPLC 분석 결과 단일 피크가 나타났다 (도 10a). 이 단백질의 샘플이 SDS-PAGE 겔에서 실행될 때 (도 8a), 비-환원 조건에서 단일 밴드가 명백하였고 (레인 2), 반면 샘플이 환원 조건에 노출되었을 때 2개의 밴드가 관찰되었다 (레인 1). 이는 경쇄 및 중쇄 서브유닛이 비환원 조건하에서 이황화-결합된 상태로 유지되고 단일 밴드로 이동하지만, 환원 조건하에서 이들의 개별 서브유닛으로 분리되어 2개의 밴드로 이동하는 항체인, 단백질과 일치한다. 웨스턴 블롯은 유사한 밴딩 패턴을 나타내었고 (도 8b), 인간 IgG 및 인간 카파 경쇄에 특이적인 1차 항체에 의한 검출이기 때문에 항체의 존재를 추가로 확인하였다.
정제된 아두카누맙이 이의 리간드 베타-아밀로이드 (1-42) ("A베타")를 인식하는 능력을 ELISA로 평가하였다. 아밀로이드를 시험관내에서 응집시키고 플레이트에 부착시킨 후 다양한 농도 및 시간에서 아두카누맙 또는 대조군 항체에 노출시킨 다음 비색계 노출시켰다. 합성 Aβ1-42 펩티드 (AnaSpec, Fremont, California, USA)를 헥사플루오로-이소프로판올에서 1 mg/ml의 농도로 재구성하고, 공기 건조시키고 진공 농축하여 필름을 형성하였다. 필름을 DMSO에 용해시키고, DMSO 재구성된 단량체를 100 μg/mL의 농도로 PBS에 희석하고, 각각 37℃에서 적어도 3일 및 1주 동안 인큐베이션함으로써 AB42 올리고머 및 AB42 피브릴을 제조하였다. ELISA 플레이트를 응집된 아밀로이드로 코팅하였다.
간략하게, 문헌[Stine et al., Methods Mol. Biol. (2011) 670: 13-32]에 기재된 방법에 따라 A베타를 제조하고 웨스턴 블롯을 실행하고 염색하였다. 동등한 양의 A베타를 겔 상의 각각의 레인 3, 4 및 5에서 실행시켰다. 니트로셀룰로스로 옮긴 후, 각각의 레인을 분리하고, 상이한 1차 항체로 프로빙하였다: 레인 3에는 본원에 기재된 정제된 아두카누맙, 레인 4에는 정제된 항-베타-아밀로이드 (17-24) (BioLegend, 클론 4G8), 및 레인 5에는 정제된 항-베타-아밀로이드 (1-16) (BioLegend, 클론 6E10). 세척 후, 각각 2차 항체로서 염소 항-인간 IgG-HRP (레인 3) (GenScript) 또는 염소 항-마우스 IgG-HRP (레인 4 및 5) (GenScript)로 프로빙하고, HRP 기질로 현상하였다. 결과는 도 10b에 도시되어 있다. 플라스미드-발현된 아두카누맙은, 다른 2개의 항-A베타 항체와 같이, 니트로셀룰로스-고정된 A베타 단량체에 결합하고, 이는 정제된 아두카누맙이 예상대로 이의 리간드를 인식할 수 있었음을 나타낸다.
실시예 10: 야생형 마우스에서 항체의 생체내 발현
야생형 좌측 ITR 및 절단 돌연변이 우측 ITR을 갖고 각각 자체 EF1 프로모터의 제어하에 아두카누맙 중쇄 및 경쇄를 인코딩하는 이식유전자 영역을 갖는 ceDNA 벡터를 상기 실시예 1 및 5에 기재된 바와 같이 제조하고 정제하였다("ceDNA IgG 벡터"). 간-특이적 hAAT 프로모터의 제어하에 루시퍼라제 이식유전자를 포함하는 ceDNA IgG 벡터 또는 ceDNA 제어 벡터를 대략 6주령의 수컷 C57bl/6J 마우스에 투여하였다. 캡슐화되지 않은 ceDNA 벡터는 2.2 mL 용적의 측면 꼬리 정맥을 통한 유체 역학적 정맥내 주사에 의해 동물당 0.005 mg (그룹당 4마리의 동물)으로 투여되었다. 3일, 7일, 14일, 21일 및 28일 종료일에 각각의 처리된 동물로부터 혈액 샘플을 수집하였다. 혈청 샘플에서 발현된 아두카누맙의 존재는 제조사의 지시에 따라 상업적으로 입수 가능한 Discovery Human/NHP IgG 키트 (Meso Scale Discovery) 중의 임의의 특이성을 갖는 인간 항체를 인식하는 폴리클로날 항-인간 면역글로불린 항체를 사용하여 ELISA에 의해 측정되었다.
도 11에 도시된 바와 같이, 인간 항체는 ceDNA IgG 벡터로 처리된 마우스로부터 3일 및 7일째 혈청 샘플에서 쉽게 검출되었지만, 인간 항체가 아닌 루시퍼라제를 발현시키는 ceDNA로 처리된 마우스에서는 관찰되지 않았다. 이 특정 벡터에 대해 이들 두 시점에서 관찰된 최대 혈청 발현 수준은 대략 500 ng/mL였다.
실시예 11: 알츠하이머병 마우스 모델에서 항체의
생체내
발현
아두카누맙 중쇄 및 경쇄를 인코딩하는 서열을 갖는 ceDNA 벡터는 실시예 1 및 5에서 이전에 기재된 바와 같이 생성될 수 있다. ceDNA 벡터는 지질 나노입자와 함께 제형화되어 Tg2576 마우스 (Kawarabayashi et al, J. Neurosci 21(2):372-381 (2001)) 및 정상 마우스에게 투여될 것이다. LNP-ceDNA 벡터는 1.2 mL 용적으로 0.3 내지 5 mg/kg의 용량으로 각각의 마우스에게 투여된다. 각 용량은 i.v. 유체 역학적 투여를 통해 투여되거나, 또는 예를 들어 복강내 주사에 의해 투여될 것이다. 정상 마우스로의 투여는 대조군으로서 제공되고, 또한 아두카누맙 mAb의 존재 및 양을 검출하는데 사용될 수 있다. 본 명세서 및 실시예 6에 기재된 바와 같이, 각각 응집된 아밀로이드 및 뇌 절편 IHC를 사용한 시험관내 및 생체외 결합 분석 (ELISA이 수행될 것이다.
급성 투약 후, 예를 들어 a., 단일 용량의 LNP-TTX-Adu ceDNA 혈장 및 뇌 농도는 다양한 시점, 예를 들어, 10, 20, 30, 40, 50, 1000 및 200일 이상의 시점에 ELISA에 의해 결정될 것이다. 구체적으로, 프로테아제 억제제와 함께, 50 mM NaCl, 0.2% 디에틸아민 (DEA)을 함유하는 용액의 10 용적으로 동결된 뇌 (10 mL/g의 습성 조직)를 균질화하고, 얼음 위에서 대략 15-20초 동안 초음파처리한다. 샘플을 4℃에서 100,000 g로 30분 동안 원심분리하고, 상청액을 DEA 추출된 가용성 Aβ 분획으로서 유지시킨다. 나머지 펠릿을 10 용적의 5M 구아니딘-염산염 (Gu-HCl)에 재현탁시키고, 초음파 처리하고, 상기와 같이 원심분리한다. 생성된 상청액은 구아니딘-추출된 불용성 Aβ 분획으로서 유지되고, 나머지 펠릿은 폐기된다. 혈장 및 뇌 항체 농도의 경우, 96 웰 마이크로플레이트 (Nunc Maxisorp, Corning Costar)를 4℃에서 밤새 차가운 코팅 완충제에서 5 ug/mL의 농도로 Aβ(1-42) 펩티드 (Αβ42)로 코팅하였다. 혈장 또는 DEA 추출된 (즉, 세제가 없는) 뇌 균질액 샘플을 최종 작업 농도로 희석하고, 실온에서 2시간 동안 인큐베이션한다. 결합은 리포터 항체, 예를 들어 호스래디시 페록시다제 (HRP)-접합된 염소 항-인간 폴리클로날 항체 (Jackson ImmunoResearch)를 사용하여 결정되고, 이어서 기질 TMB를 사용하여 HRP 활성을 측정한다. 정제된 항체를 사용하여 생성된 표준 곡선과 비교하여 농도를 결정한다. 대안적으로, 혈장 중 Ab는 기재된 바와 같은 웨스턴 블롯을 사용하여 확인된다.
Tg2576 마우스에서 단일 용량 후 Aβ 침착물에 대한 항체의 생체내 결합은 또한 비오티닐화된 항-인간 2차 항체를 사용하여 결정될 수 있고, 양성 대조군으로서 연속 섹션에서 생체외에서 수행된 pan-Aβ 항체 5F3에 의한 염색과 비교될 수 있다. 조직은 포르말린-고정된 파라핀 포매되고, 5 μm로 절편화되고, 파라핀이 제거되고, EDTA-보레이트 기반 열-유도된 에피토프 검색 (Ventana CC1)이 사용될 수 있다. 이어서, 염소 항-인간 2차 항체를 1:500 희석으로 조직에 적용하고 헤마톡실린으로 염색된 조직에 적용할 수 있다.
전신 투여된 LNP-TTX-Adu ceDNA는 혈장 및 뇌에서 발현될 것이고, 높은 친화도로 실질 아밀로이드 플라크에 결합할 것으로 예상된다.
실시예 12: ceDNA로 투여 후 아밀로이드 부담 감소 분석
아밀로이드 부담을 감소시키는 데 있어서 ceDNA 발현된 아두카누맙의 효능은 Tg2576 형질전환 마우스에서 만성 투여 후 평가될 것이다. 예를 들어, 0.3, 1, 3, 10, 내지 30 mg/kg 등의 용량 또는 PBS는 주어진 시간 프레임에, 예를 들어 매주 또는 매월 투여될 것이다. 혈장 및 뇌 약물 수준은 상기 실시예 8에 기재된 바와 같이 ELISA에 의해 측정될 것이다. 혈장 샘플을 마지막 투약 후 24시간-72시간에 수집하고, 항체 수준을 측정하여 용량 반응을 결정할 것이다.
피질 및 해마에서의 총 뇌 아밀로이드 로드는 면역조직화학에 의해 밝혀질 것이다. 구체적으로, 뇌를 해부하고, 48 내지 72시간 동안 10% 중성 완충 포르말린에 침지시켜 고정시킨다. 이어서 고정된 뇌를 수평 방향으로 처리하고 포매한다. 각 블록은 해마가 식별될 때까지 섹셔닝되며, 이 시점에서 300개의 연속 5μm 섹션 (슬라이드당 3개의 섹션)이 수득된다. 6E10 및 티오플라빈-S 염색 둘 다에 대해, 매 14번째 슬라이드가 염색되었다 (225 μm마다 대략 1개의 섹션). 뇌 아밀로이드를 규정하는 면역조직화학은 예를 들어 1 :750 희석으로 1차 항체로서 마우스 항-Aβ 1-16 모노클로날 항체 (클론 6E10, Covance, Princeton, NJ), 및 Ultramap 항-마우스 알칼리성 포스파타제 키트 (Ventana Medical Systems, Tucson, AZ)를 사용할 것이고, 본원에 기재된 바와 같은 VISIOPHARM® 소프트웨어를 사용하여 정량화된다. Ventana Discovery XT 면역염색제(immunostainer) 위에 놓기 전에 슬라이드를 88% 포름산 용액으로 전처리한다. 슬라이드를 Ventana Hematoxylin (Ventana Medical Systems, Tucson, AZ)으로 대비염색하고, 커버슬립하고, 밤새 공기 건조시킨다.
6E10 면역염색 후, 슬라이드를 제조사의 지시에 따라 20x 배율로 Aperio XT (Aperio Technologies, Inc., Vista, CA) 전체 슬라이드 이미징 시스템에서 스캐닝한다. 이어서 디지털 이미지를 검토하고, 개별 마스크로 수동으로 주석을 달고(annotated), VISIOPHARM'^ 소프트웨어로 작성된 알고리즘을 사용하여 분석할 수 있다. 이 알고리즘은 이러한 해부학적 영역에서 주석이 달린 해마 또는 피질의 영역과 실질 및 혈관 아밀로이드의 영역을 10X 가상 배율로 결정한다. 예를 들어, 소프트웨어의 트레이닝은 50개의 슬라이드 세트에서 수행된다. 슬라이드를 또한 (Bussiere et ah, Am J Pathol 165:987-995 (2004))에 기재된 바와 같이 티오플라빈-S (Thio-S)로 염색하고, DAPI를 갖춘 VECTASHIELD® Mounting Media (Vector Laboratories Burlingame, CA)로 커버슬립한다. 티오플라빈-S 염색 후, 슬라이드는 영상화 시스템, 예를 들어 Aperio FL (Aperio Technologies, Inc., Vista, CA) 형광 전체 슬라이드 영상화 시스템으로 제조사의 지시에 따라 20x 배율로 검토 및 스캐닝된다. 6E10과 마찬가지로, 해마 또는 피질을 개별 마스크로 수동으로 주석을 달고, 이어서 VISIOPHARM® 소프트웨어로 작성된 알고리즘을 사용하여 분석하고, 형광에 대해 조정된다. 이 알고리즘은 이러한 해부학적 영역에서 해마 및 피질의 영역과 실질 및 혈관 아밀로이드의 영역을 10X 가상 배율로 결정한다. 소프트웨어의 트레이닝은 10개의 슬라이드 세트에서 수행될 수 있다. 염색된 침착물이 차지하는 총 면적은 PBS 대조군과 비교하여 상당히 감소될 것으로 예상된다.
실시예 13:
시험관내
에서 항체 및 Fc-융합 단백질의 ceDNA-기반 발현
아두카누맙을 제외하고 다른 항체 및 면역글로불린-유사 분자를 발현시키는 ceDNA의 능력을 평가하기 위해, 유전자 카세트에서 베바시주맙의 경쇄 및 중쇄 (혈관 내피 성장 인자 ("VEGF")에 특이적으로 결합하는 항체)를 인코딩하는 것 및 Fc 융합 단백질 아플리버셉트 (인간 VEGF 수용체 1 및 2의 세포외 도메인의 VEGF-결합 부분에 융합된 인간 IgG1 Fc)를 인코딩하는 것인, 2개의 추가 ceDNA 작제물로 실시예 8의 실험을 반복하였다. 비-환원 샘플에 대한 웨스턴 블롯의 결과는 도 12에 도시되어 있다 (6초 및 12초의 상이한 노출 시간에서 동일한 블롯의 두 이미지가 도시됨). 아두카누맙은 실시예 8에서 이전에 발견된 바와 같이 ceDNA-Adu-플라스미드에서 그리고 ceDNA-Adu 벡터-형질감염된 세포로부터 다시 발현되었다 (레인 5 및 7). 베바시주맙은 ceDNA-베바시주맙 벡터-형질감염된 세포에서 유사하게 발현되었다 (레인 11). 아플리버셉트는 또한 ceDNA-아플리버셉트 벡터-형질감염된 세포에서 발현되었다 (레인 9). 이는 ceDNA 작제물로부터 다양한 IgG 및 면역글로불린-유사 분자의 세포에서의 발현이 얻어질 수 있음을 입증한다.
참조
본 출원 및 본원의 실시예에 인용된 특허 및 특허 출원을 포함하지만 이에 제한되지 않는 모든 간행물 및 참고 문헌은, 각각의 개별 간행물 또는 참고 문헌이 본 명세서에 완전히 제시된 것으로 본원에 참고로 포함되는 것으로 구체적이고 개별적으로 표시된 것처럼 그 전문이 참고로 포함된다. 본 출원이 우선권을 주장하는 임의의 특허 출원도 간행물 및 참고 문헌에 대해 전술한 방식으로 본원에 참고로 포함된다.
SEQUENCE LISTING
<110> GENERATION BIO INC.
<120> NON-VIRAL DNA VECTORS AND USES THEREOF FOR ANTIBODY PRODUCTION
<130> 080170-091100-WOPT
<140>
<141>
<150> 62/680,087
<151> 2018-06-04
<150> 62/680,092
<151> 2018-06-04
<150> 62/630,670
<151> 2018-02-14
<150> 62/630,676
<151> 2018-02-14
<160> 190
<170> PatentIn version 3.5
<210> 1
<211> 141
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 1
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgacc aaaggtcgcc cgacgcccgg gctttgcccg ggcggcctca gtgagcgagc 120
gagcgcgcag ctgcctgcag g 141
<210> 2
<211> 141
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 2
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc ccgggcaaag cccgggcgtc 60
gggcgacctt tggtcgcccg gcctcagtga gcgagcgagc gcgcagagag ggagtggcca 120
actccatcac taggggttcc t 141
<210> 3
<211> 130
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 3
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgacc aaaggtcgcc cgacgcccgg gcggcctcag tgagcgagcg agcgcgcagc 120
tgcctgcagg 130
<210> 4
<211> 130
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 4
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc ccgggcgtcg ggcgaccttt 60
ggtcgcccgg cctcagtgag cgagcgagcg cgcagagagg gagtggccaa ctccatcact 120
aggggttcct 130
<210> 5
<211> 143
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 5
ttgcccactc cctctctgcg cgctcgctcg ctcggtgggg cctgcggacc aaaggtccgc 60
agacggcaga ggtctcctct gccggcccca ccgagcgagc gacgcgcgca gagagggagt 120
gggcaactcc atcactaggg taa 143
<210> 6
<211> 144
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 6
ttggccactc cctctatgcg cactcgctcg ctcggtgggg cctggcgacc aaaggtcgcc 60
agacggacgt gggtttccac gtccggcccc accgagcgag cgagtgcgca tagagggagt 120
ggccaactcc atcactagag gtat 144
<210> 7
<211> 127
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 7
ttggccactc cctctatgcg cgctcgctca ctcactcggc cctggagacc aaaggtctcc 60
agactgccgg cctctggccg gcagggccga gtgagtgagc gagcgcgcat agagggagtg 120
gccaact 127
<210> 8
<211> 166
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 8
tcccccctgt cgcgttcgct cgctcgctgg ctcgtttggg ggggcgacgg ccagagggcc 60
gtcgtctggc agctctttga gctgccaccc ccccaaacga gccagcgagc gagcgaacgc 120
gacagggggg agagtgccac actctcaagc aagggggttt tgtaag 166
<210> 9
<211> 144
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 9
ttgcccactc cctctaatgc gcgctcgctc gctcggtggg gcctgcggac caaaggtccg 60
cagacggcag aggtctcctc tgccggcccc accgagcgag cgagcgcgca tagagggagt 120
gggcaactcc atcactaggg gtat 144
<210> 10
<211> 143
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 10
ttaccctagt gatggagttg cccactccct ctctgcgcgc gtcgctcgct cggtggggcc 60
ggcagaggag acctctgccg tctgcggacc tttggtccgc aggccccacc gagcgagcga 120
gcgcgcagag agggagtggg caa 143
<210> 11
<211> 144
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 11
atacctctag tgatggagtt ggccactccc tctatgcgca ctcgctcgct cggtggggcc 60
ggacgtggaa acccacgtcc gtctggcgac ctttggtcgc caggccccac cgagcgagcg 120
agtgcgcata gagggagtgg ccaa 144
<210> 12
<211> 127
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 12
agttggccac attagctatg cgcgctcgct cactcactcg gccctggaga ccaaaggtct 60
ccagactgcc ggcctctggc cggcagggcc gagtgagtga gcgagcgcgc atagagggag 120
tggccaa 127
<210> 13
<211> 166
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 13
cttacaaaac ccccttgctt gagagtgtgg cactctcccc cctgtcgcgt tcgctcgctc 60
gctggctcgt ttgggggggt ggcagctcaa agagctgcca gacgacggcc ctctggccgt 120
cgccccccca aacgagccag cgagcgagcg aacgcgacag ggggga 166
<210> 14
<211> 144
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 14
atacccctag tgatggagtt gcccactccc tctatgcgcg ctcgctcgct cggtggggcc 60
ggcagaggag acctctgccg tctgcggacc tttggtccgc aggccccacc gagcgagcga 120
gcgcgcatta gagggagtgg gcaa 144
<210> 15
<211> 120
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 15
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
cgcacgcccg ggtttcccgg gcggcctcag tgagcgagcg agcgcgcagc tgcctgcagg 120
<210> 16
<211> 122
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 16
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgacgcccg ggctttgccc gggcggcctc agtgagcgag cgagcgcgca gctgcctgca 120
gg 122
<210> 17
<211> 129
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 17
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgacc aaaggtcgcc cgacgcccgg gcgcctcagt gagcgagcga gcgcgcagct 120
gcctgcagg 129
<210> 18
<211> 101
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 18
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ctttgcctca gtgagcgagc gagcgcgcag ctgcctgcag g 101
<210> 19
<211> 139
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 19
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgaca aagtcgcccg acgcccgggc tttgcccggg cggcctcagt gagcgagcga 120
gcgcgcagct gcctgcagg 139
<210> 20
<211> 137
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 20
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgaaa atcgcccgac gcccgggctt tgcccgggcg gcctcagtga gcgagcgagc 120
gcgcagctgc ctgcagg 137
<210> 21
<211> 135
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 21
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgaaa cgcccgacgc ccgggctttg cccgggcggc ctcagtgagc gagcgagcgc 120
gcagctgcct gcagg 135
<210> 22
<211> 133
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 22
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcaaag cccgacgccc gggctttgcc cgggcggcct cagtgagcga gcgagcgcgc 120
agctgcctgc agg 133
<210> 23
<211> 139
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 23
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgacc aaaggtcgcc cgacgcccgg gtttcccggg cggcctcagt gagcgagcga 120
gcgcgcagct gcctgcagg 139
<210> 24
<211> 137
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 24
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgacc aaaggtcgcc cgacgcccgg tttccgggcg gcctcagtga gcgagcgagc 120
gcgcagctgc ctgcagg 137
<210> 25
<211> 135
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 25
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgacc aaaggtcgcc cgacgcccgt ttcgggcggc ctcagtgagc gagcgagcgc 120
gcagctgcct gcagg 135
<210> 26
<211> 133
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 26
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgacc aaaggtcgcc cgacgccctt tgggcggcct cagtgagcga gcgagcgcgc 120
agctgcctgc agg 133
<210> 27
<211> 131
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 27
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgacc aaaggtcgcc cgacgccttt ggcggcctca gtgagcgagc gagcgcgcag 120
ctgcctgcag g 131
<210> 28
<211> 129
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 28
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgacc aaaggtcgcc cgacgctttg cggcctcagt gagcgagcga gcgcgcagct 120
gcctgcagg 129
<210> 29
<211> 127
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 29
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgacc aaaggtcgcc cgacgtttcg gcctcagtga gcgagcgagc gcgcagctgc 120
ctgcagg 127
<210> 30
<211> 122
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 30
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgacc aaaggtcgcc cgacggcctc agtgagcgag cgagcgcgca gctgcctgca 120
gg 122
<210> 31
<211> 130
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 31
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgacc aaaggtcgcc cgacgcccgg gcggcctcag tgagcgagcg agcgcgcagc 120
tgcctgcagg 130
<210> 32
<211> 120
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 32
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc ccgggaaacc cgggcgtgcg 60
cctcagtgag cgagcgagcg cgcagagagg gagtggccaa ctccatcact aggggttcct 120
<210> 33
<211> 122
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 33
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgt cgggcgacct ttggtcgccc 60
ggcctcagtg agcgagcgag cgcgcagaga gggagtggcc aactccatca ctaggggttc 120
ct 122
<210> 34
<211> 122
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 34
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc ccgggcaaag cccgggcgtc 60
ggcctcagtg agcgagcgag cgcgcagaga gggagtggcc aactccatca ctaggggttc 120
ct 122
<210> 35
<211> 129
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 35
cctgcaggca gctgcgcgct cgctcgctca ctgaggcgcc cgggcgtcgg gcgacctttg 60
gtcgcccggc ctcagtgagc gagcgagcgc gcagagaggg agtggccaac tccatcacta 120
ggggttcct 129
<210> 36
<211> 101
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 36
cctgcaggca gctgcgcgct cgctcgctca ctgaggcaaa gcctcagtga gcgagcgagc 60
gcgcagagag ggagtggcca actccatcac taggggttcc t 101
<210> 37
<211> 139
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 37
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc ccgggcaaag cccgggcgtc 60
gggcgacttt gtcgcccggc ctcagtgagc gagcgagcgc gcagagaggg agtggccaac 120
tccatcacta ggggttcct 139
<210> 38
<211> 137
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 38
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc ccgggcaaag cccgggcgtc 60
gggcgatttt cgcccggcct cagtgagcga gcgagcgcgc agagagggag tggccaactc 120
catcactagg ggttcct 137
<210> 39
<211> 135
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 39
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc ccgggcaaag cccgggcgtc 60
gggcgtttcg cccggcctca gtgagcgagc gagcgcgcag agagggagtg gccaactcca 120
tcactagggg ttcct 135
<210> 40
<211> 133
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 40
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc ccgggcaaag cccgggcgtc 60
gggctttgcc cggcctcagt gagcgagcga gcgcgcagag agggagtggc caactccatc 120
actaggggtt cct 133
<210> 41
<211> 139
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 41
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc ccgggaaacc cgggcgtcgg 60
gcgacctttg gtcgcccggc ctcagtgagc gagcgagcgc gcagagaggg agtggccaac 120
tccatcacta ggggttcct 139
<210> 42
<211> 137
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 42
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc ccggaaaccg ggcgtcgggc 60
gacctttggt cgcccggcct cagtgagcga gcgagcgcgc agagagggag tggccaactc 120
catcactagg ggttcct 137
<210> 43
<211> 135
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 43
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc ccgaaacggg cgtcgggcga 60
cctttggtcg cccggcctca gtgagcgagc gagcgcgcag agagggagtg gccaactcca 120
tcactagggg ttcct 135
<210> 44
<211> 133
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 44
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc ccaaagggcg tcgggcgacc 60
tttggtcgcc cggcctcagt gagcgagcga gcgcgcagag agggagtggc caactccatc 120
actaggggtt cct 133
<210> 45
<211> 131
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 45
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc caaaggcgtc gggcgacctt 60
tggtcgcccg gcctcagtga gcgagcgagc gcgcagagag ggagtggcca actccatcac 120
taggggttcc t 131
<210> 46
<211> 129
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 46
cctgcaggca gctgcgcgct cgctcgctca ctgaggccgc aaagcgtcgg gcgacctttg 60
gtcgcccggc ctcagtgagc gagcgagcgc gcagagaggg agtggccaac tccatcacta 120
ggggttcct 129
<210> 47
<211> 127
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 47
cctgcaggca gctgcgcgct cgctcgctca ctgaggccga aacgtcgggc gacctttggt 60
cgcccggcct cagtgagcga gcgagcgcgc agagagggag tggccaactc catcactagg 120
ggttcct 127
<210> 48
<211> 122
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 48
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgggcgacc aaaggtcgcc cgacggcctc agtgagcgag cgagcgcgca gctgcctgca 120
gg 122
<210> 49
<211> 12
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 49
cgatcgttcg at 12
<210> 50
<211> 12
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 50
atcgaaccat cg 12
<210> 51
<211> 12
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 51
atcgaacgat cg 12
<210> 52
<211> 165
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 52
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg 60
ccgcccgggc aaagcccggg cgtcgggcga cctttggtcg cccggcctca gtgagcgagc 120
gagcgcgcag agagggagtg gccaactcca tcactagggg ttcct 165
<210> 53
<211> 140
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 53
cccctagtga tggagttggc cactccctct ctgcgcgctc gctcgctcac tgaggccgcc 60
cgggcaaagc ccgggcgtcg ggcgaccttt ggtcgcccgg cctcagtgag cgagcgagcg 120
cgcagagaga tcactagggg 140
<210> 54
<211> 91
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 54
gcgcgctcgc tcgctcactg aggccgcccg ggcaaagccc gggcgtcggg cgacctttgg 60
tcgcccggcc tcagtgagcg agcgagcgcg c 91
<210> 55
<211> 91
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 55
gcgcgctcgc tcgctcactg aggccgggcg accaaaggtc gcccgacgcc cgggctttgc 60
ccgggcggcc tcagtgagcg agcgagcgcg c 91
<210> 56
<211> 10808
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 56
aaagtagccg aagatgacgg tttgtcacat ggagttggca ggatgtttga ttaaaaacat 60
aacaggaaga aaaatgcccc gctgtgggcg gacaaaatag ttgggaactg ggaggggtgg 120
aaatggagtt tttaaggatt atttagggaa gagtgacaaa atagatggga actgggtgta 180
gcgtcgtaag ctaatacgaa aattaaaaat gacaaaatag tttggaacta gatttcactt 240
atctggttcg gatctcctag gcggccggcc cctgcaggca gctgcgcgct cgctcgctca 300
ctgaggccgc ccgggcaaag cccgggcgtc gggcgacctt tggtcgcccg gcctcagtga 360
gcgagcgagc gcgcagagag ggagtggcca actccatcac taggggttcc ttgtagttaa 420
tgattaaccc gccatgctac ttatctacgt agccatgcgc ggccgcggcc tgaaataacc 480
tctgaaagag gaacttggtt aggtaccttc tgaggcggaa agaaccagct gtggaatgtg 540
tgtcagttag ggtgtggaaa gtccccaggc tccccagcag gcagaagtat gcaaagcatg 600
catctcaatt agtcagcaac caggtgtgga aagtccccag gctccccagc aggcagaagt 660
atgcaaagca tgcatctcaa ttagtcagca accatagtcc cactagtgga gccgagagta 720
attcatacaa aaggagggat cgccttcgca aggggagagc ccagggaccg tccctaaatt 780
ctcacagacc caaatccctg tagccgcccc acgacagcgc gaggagcatg cgctcagggc 840
tgagcgcggg gagagcagag cacacaagct catagaccct ggtcgtgggg gggaggaccg 900
gggagctggc gcggggcaaa ctgggaaagc ggtgtcgtgt gctggctccg ccctcttccc 960
gagggtgggg gagaacggta tataagtgcg gcagtcgcct tggacgttct ttttcgcaac 1020
gggtttgccg tcagaacgca ggtgaggggc gggtgtggct tccgcgggcc gccgagctgg 1080
aggtcctgct ccgagcgggc cgggccccgc tgtcgtcggc ggggattagc tgcgagcatt 1140
cccgcttcga gttgcgggcg gcgcgggagg cagagtgcga ggcctagcgg caaccccgta 1200
gcctcgcctc gtgtccggct tgaggcctag cgtggtgtcc gcgccgccgc cgcgtgctac 1260
tccggccgca ctctggtctt tttttttttt gttgttgttg ccctgctgcc ttcgattgcc 1320
gttcagcaat aggggctaac aaagggaggg tgcggggctt gctcgcccgg agcccggaga 1380
ggtcatggtt ggggaggaat ggagggacag gagtggcggc tggggcccgc ccgccttcgg 1440
agcacatgtc cgacgccacc tggatggggc gaggcctggg gtttttcccg aagcaaccag 1500
gctggggtta gcgtgccgag gccatgtggc cccagcaccc ggcacgatct ggcttggcgg 1560
cgccgcgttg ccctgcctcc ctaactaggg tgaggccatc ccgtccggca ccagttgcgt 1620
gcgtggaaag atggccgctc ccgggccctg ttgcaaggag ctcaaaatgg aggacgcggc 1680
agcccggtgg agcgggcggg tgagtcaccc acacaaagga agagggcctg gtccctcacc 1740
ggctgctgct tcctgtgacc ccgtggtcct atcggccgca atagtcacct cgggcttttg 1800
agcacggcta gtcgcggcgg ggggagggga tgtaatggcg ttggagtttg ttcacatttg 1860
gtgggtggag actagtcagg ccagcctggc gctggaagtc atttttggaa tttgtcccct 1920
tgagttttga gcggagctaa ttctcgggct tcttagcggt tcaaaggtat cttttaaacc 1980
cttttttagg tgttgtgaaa accaccgcta attcaaagca accggtatgg actggacctg 2040
gcgaattctt ttccttgtag cagcggctac tggtgcacat tcattggttg agtcaggcgg 2100
tggggtagta cagcctggcc ggtcccttag gctctcctgc gccgcgtccg ggttcgcgtt 2160
tagctcctac gggatgcact gggttagaca ggctcctgga aagggactgg aatgggttgc 2220
agtcatttgg tttgacggga ccaaaaaata ctatacagat tccgttaagg ggaggtttac 2280
aatcagtaga gataatagta aaaacacgtt gtatcttcaa atgaatactc tcagagccga 2340
agatacagca gtatattact gcgcccgcga tcggggaata ggcgctcgga ggggacccta 2400
ctatatggat gtgtggggta aaggtacgac cgtgactgtg agctctgcgt ccaccaaagg 2460
tccaagtgtt tttcccctcg ccccttcaag caagtcaacc tcaggcggta ctgctgcttt 2520
gggatgtctg gttaaagatt actttccaga gcctgtgact gtgagttgga attcaggcgc 2580
tcttaccagc ggtgttcaca cattccccgc agtcttgcaa tcctctggtt tgtattccct 2640
gagtagcgta gtcacggtgc ctagcagtag cctcgggaca caaacgtaca tttgcaatgt 2700
gaatcacaaa cccagtaata ccaaggttga taagcgggtc gaacctaaat cctgtgacaa 2760
gacccacaca tgtcctccgt gcccggctcc cgagctgctg ggcgggccgt ccgtattcct 2820
gtttccccct aaaccgaaag acactttgat gatatcacgg acacccgagg ttacgtgtgt 2880
ggtcgtcgat gtttctcacg aggaccccga agtcaaattc aattggtacg tggatggtgt 2940
tgaggttcac aacgccaaaa ctaaaccccg cgaggagcag tacaattcaa cctatagggt 3000
tgtgagtgtc cttactgtcc tccatcaaga ttggctgaac ggcaaagaat ataaatgcaa 3060
agtctcaaac aaagctctgc cagccccgat agaaaagacc atctccaaag ctaaggggca 3120
acccagagaa cctcaagtgt acaccctccc tccatcaagg gaggagatga cgaaaaatca 3180
agtaagcttg acctgtcttg taaaagggtt ctacccaagt gatatagctg tagaatggga 3240
gagtaatggg cagcccgaga ataattacaa aacgacaccg cccgtgctgg actcagacgg 3300
tagctttttc ctctacagca aacttactgt agataaaagt aggtggcagc agggaaatgt 3360
tttttcctgt tcagtcatgc atgaagcatt gcacaaccat tacacccaga agtctctcag 3420
tttgagcccg ggcaagtaat gaccagacat gataagatac attgatgagt ttggacaaac 3480
cacaactaga atgcagtgaa aaaaatgctt tatttgtgaa atttgtgatg ctattgcttt 3540
atttgtaacc attataagct gcaataaaca agttaacaac aacaattgca ttcattttat 3600
gtttcaggtt cagggggagg tgtgggaggt tttttaaagc aagtaaaacc tctacaaatg 3660
tggtatggcg ttacataact tacggtaaat ggcccgcctg gctgaccgcc caacgacccc 3720
cgcccattga cgtcaataat gacgtatgtt cccatagtaa cgccaatagg gactttccat 3780
tgacgtcaat gggtggagta tttacggtaa actgcccact tggcagtaca tcaagtgtat 3840
catatgccaa gtacgccccc tattgacgtc aatgacggta aatggcccgc ctggcattat 3900
gcccagtaca tgaccttatg ggactttcct acttggcagt acatctacgt attagtcatc 3960
gctattacca tgatgatgcg gttttggcag tacatcaatg ggcgtggata gcggtttgac 4020
tcacggggat ttccaagtct ccaccccatt gacgtcaatg ggagtttgtt ttgactagtg 4080
gagccgagag taattcatac aaaaggaggg atcgccttcg caaggggaga gcccagggac 4140
cgtccctaaa ttctcacaga cccaaatccc tgtagccgcc ccacgacagc gcgaggagca 4200
tgcgcccagg gctgagcgcg ggtagatcag agcacacaag ctcacagtcc ccggcggtgg 4260
ggggaggggc gcgctgagcg ggggccaggg agctggcgcg gggcaaactg ggaaagtggt 4320
gtcgtgtgct ggctccgccc tcttcccgag ggtgggggag aacggtatat aagtgcggta 4380
gtcgccttgg acgttctttt tcgcaacggg tttgccgtca gaacgcaggt gagtggcggg 4440
tgtggcttcc gcgggccccg gagctggagc cctgctctga gcgggccggg ctgatatgcg 4500
agtgtcgtcc gcagggttta gctgtgagca ttcccacttc gagtggcggg cggtgcgggg 4560
gtgagagtgc gaggcctagc ggcaaccccg tagcctcgcc tcgtgtccgg cttgaggcct 4620
agcgtggtgt ccgccgccgc gtgccactcc ggccgcacta tgcgtttttt gtccttgctg 4680
ccctcgattg ccttccagca gcatgggcta acaaagggag ggtgtggggc tcactcttaa 4740
ggagcccatg aagcttacgt tggataggaa tggaagggca ggaggggcga ctggggcccg 4800
cccgccttcg gagcacatgt ccgacgccac ctggatgggg cgaggcctgt ggctttccga 4860
agcaatcggg cgtgagttta gcctacctgg gccatgtggc cctagcactg ggcacggtct 4920
ggcctggcgg tgccgcgttc ccttgcctcc caacaagggt gaggccgtcc cgcccggcac 4980
cagttgcttg cgcggaaaga tggccgctcc cggggccctg ttgcaaggag ctcaaaatgg 5040
aggacgcggc agcccggtgg agcgggcggg tgagtcaccc acacaaagga agagggcctt 5100
gcccctcgcc ggccgctgct tcctgtgacc ccgtggtcta tcggccgcat agtcacctcg 5160
ggcttctctt gagcaccgct cgtcgcggcg gggggagggg atctaatggc gttggagttt 5220
gttcacattt ggtgggtgga gactagtcag gccagcctgg cgctggaagt cattcttgga 5280
atttgcccct ttgagtttgg agcgaggcta attctcaagc ctcttagcgg ttcaaaggta 5340
ttttctaaac ccgtttccag gtgttgtgaa agccaccgct aattcaaagc aatccggaat 5400
gcttccaagt cagttgatag ggtttttgct gctgtgggtg cctgcttcaa gaggtattca 5460
gatgactcaa tctccttctt ctctgtcagc cagcgtaggt gatcgcgtca ccatcacctg 5520
tcgagcctca cagtccattt ctagctatct caattggtat cagcagaagc caggaaaagc 5580
ccctaaactt ctcatatacg ccgcctctag tctccaaagt ggggtgccca gtcggttcag 5640
tggctccgga tctgggactg atttcacttt gactatatct agtctccagc ctgaggattt 5700
tgctacatat tattgtcaac aatcctactc tacacccctg acgttcggtg gcggaacgaa 5760
ggttgaaata aagaggactg tggccgcccc atcagttttc attttcccgc cgtctgatga 5820
acaactcaaa agcggcacag catctgtagt ctgccttttg aacaactttt atccacggga 5880
ggcaaaagtg caatggaaag tggataatgc tctgcaaagt ggtaacagcc aagaaagtgt 5940
aaccgaacag gattccaaag actcaaccta ttccctcagt tccacactca cactgtctaa 6000
ggctgattac gagaagcata aggtttacgc ctgtgaagtt acgcaccaag gactctctag 6060
tccagttact aaaagcttta atcgggggga atgttagtga tgtgccttct agttgccagc 6120
catctgttgt ttgcccctcc cccgtgcctt ccttgaccct ggaaggtgcc actcccactg 6180
tcctttccta ataaaatgag gaaattgcat cgcattgtct gagtaggtgt cattctattc 6240
tggggggtgg ggtggggcag gacagcaagg gggaggattg ggaagacaat agcaggcatg 6300
ctggggatgc ggtgggctct atggcggcgc gccgcatggc tacgtagata agtagcatgg 6360
cgggttaatc attaactaca cctgcaggag gaacccctag tgatggagtt ggccactccc 6420
tctctgcgcg ctcgctcgct cactgaggcc gggcgaccaa aggtcgcccg acgcccgggc 6480
ggcctcagtg agcgagcgag cgcgcagctg cctgcaggtc gacgcatgcg gtaccgggag 6540
atgggggagg ctaactgaaa cacggaagga gacaataccg gaaggaaccc gcgctatgac 6600
ggcaataaaa agacagaata aaacgcacgg gtgttgggtc gtttgttcat aaacgcgggg 6660
ttcggtccca gggctggcac tctgtcgata ccccaccgag accccattgg gaccaatacg 6720
cccgcgtttc ttccttttcc ccaccccaac ccccaagttc gggtgaaggc ccagggctcg 6780
cagccaacgt cggggcggca agccctgcca tagccactac gggtacgtag gccaaccact 6840
agaactatag ctagagtcct gggcgaacaa acgatgctcg ccttccagaa aaccgaggat 6900
gcgaaccact tcatccgggg tcagcaccac cggcaagcgc cgcgacggcc gaggtctacc 6960
gatctcctga agccagggca gatccgtgca cagcaccttg ccgtagaaga acagcaaggc 7020
cgccaatgcc tgacgatgcg tggagaccga aaccttgcgc tcgttcgcca gccaggacag 7080
aaatgcctcg acttcgctgc tgcccaaggt tgccgggtga cgcacaccgt ggaaacggat 7140
gaaggcacga acccagttga cataagcctg ttcggttcgt aaactgtaat gcaagtagcg 7200
tatgcgctca cgcaactggt ccagaacctt gaccgaacgc agcggtggta acggcgcagt 7260
ggcggttttc atggcttgtt atgactgttt ttttgtacag tctatgcctc gggcatccaa 7320
gcagcaagcg cgttacgccg tgggtcgatg tttgatgtta tggagcagca acgatgttac 7380
gcagcagcaa cgatgttacg cagcagggca gtcgccctaa aacaaagtta ggtggctcaa 7440
gtatgggcat cattcgcaca tgtaggctcg gccctgacca agtcaaatcc atgcgggctg 7500
ctcttgatct tttcggtcgt gagttcggag acgtagccac ctactcccaa catcagccgg 7560
actccgatta cctcgggaac ttgctccgta gtaagacatt catcgcgctt gctgccttcg 7620
accaagaagc ggttgttggc gctctcgcgg cttacgttct gcccaggttt gagcagccgc 7680
gtagtgagat ctatatctat gatctcgcag tctccggcga gcaccggagg cagggcattg 7740
ccaccgcgct catcaatctc ctcaagcatg aggccaacgc gcttggtgct tatgtgatct 7800
acgtgcaagc agattacggt gacgatcccg cagtggctct ctatacaaag ttgggcatac 7860
gggaagaagt gatgcacttt gatatcgacc caagtaccgc cacctaacaa ttcgttcaag 7920
ccgagatcgg cttcccggcc gcggagttgt tcggtaaatt gtcacaacgc cgcgaatata 7980
gtctttacca tgcccttggc cacgcccctc tttaatacga cgggcaattt gcacttcaga 8040
aaatgaagag tttgctttag ccataacaaa agtccagtat gctttttcac agcataactg 8100
gactgatttc agtttacaac tattctgtct agtttaagac tttattgtca tagtttagat 8160
ctattttgtt cagtttaaga ctttattgtc cgcccacacc cgcttacgca gggcatccat 8220
ttattactca accgtaaccg attttgccag gttacgcggc tggtctgcgg tgtgaaatac 8280
cgcacagatg cgtaaggaga aaataccgca tcaggcgctc ttccgcttcc tcgctcactg 8340
actcgctgcg ctcggtcgtt cggctgcggc gagcggtatc agctcactca aaggcggtaa 8400
tacggttatc cacagaatca ggggataacg caggaaagaa catgtgagca aaaggccagc 8460
aaaaggccag gaaccgtaaa aaggccgcgt tgctggcgtt tttccatagg ctccgccccc 8520
ctgacgagca tcacaaaaat cgacgctcaa gtcagaggtg gcgaaacccg acaggactat 8580
aaagatacca ggcgtttccc cctggaagct ccctcgtgcg ctctcctgtt ccgaccctgc 8640
cgcttaccgg atacctgtcc gcctttctcc cttcgggaag cgtggcgctt tctcaatgct 8700
cacgctgtag gtatctcagt tcggtgtagg tcgttcgctc caagctgggc tgtgtgcacg 8760
aaccccccgt tcagcccgac cgctgcgcct tatccggtaa ctatcgtctt gagtccaacc 8820
cggtaagaca cgacttatcg ccactggcag cagccactgg taacaggatt agcagagcga 8880
ggtatgtagg cggtgctaca gagttcttga agtggtggcc taactacggc tacactagaa 8940
ggacagtatt tggtatctgc gctctgctga agccagttac cttcggaaaa agagttggta 9000
gctcttgatc cggcaaacaa accaccgctg gtagcggtgg tttttttgtt tgcaagcagc 9060
agattacgcg cagaaaaaaa ggatctcaag aagatccttt gatcttttct acggggtctg 9120
acgctcagtg gaacgaaaac tcacgttaag ggattttggt catgagatta tcaaaaagga 9180
tcttcaccta gatcctttta aattaaaaat gaagttttaa atcaatctaa agtatatatg 9240
agtaaacttg gtctgacagt taccaatgct taatcagtga ggcacctatc tcagcgatct 9300
gtctatttcg ttcatccata gttgcctgac tccccgtcgt gtagataact acgatacggg 9360
agggcttacc atctggcccc agtgctgcaa tgataccgcg agacccacgc tcaccggctc 9420
cagatttatc agcaataaac cagccagccg gaagggccga gcgcagaagt ggtcctgcaa 9480
ctttatccgc ctccatccag tctattaatt gttgccggga agctagagta agtagttcgc 9540
cagttaatag tttgcgcaac gttgttgcca ttgctacagg catcgtggtg tcacgctcgt 9600
cgtttggtat ggcttcattc agctccggtt cccaacgatc aaggcgagtt acatgatccc 9660
ccatgttgtg caaaaaagcg gttagctcct tcggtcctcc gatcgttgtc agaagtaagt 9720
tggccgcagt gttatcactc atggttatgg cagcactgca taattctctt actgtcatgc 9780
catccgtaag atgcttttct gtgactggtg agtactcaac caagtcattc tgagaatagt 9840
gtatgcggcg accgagttgc tcttgcccgg cgtcaatacg ggataatacc gcgccacata 9900
gcagaacttt aaaagtgctc atcattggaa aacgttcttc ggggcgaaaa ctctcaagga 9960
tcttaccgct gttgagatcc agttcgatgt aacccactcg tgcacccaac tgatcttcag 10020
catcttttac tttcaccagc gtttctgggt gagcaaaaac aggaaggcaa aatgccgcaa 10080
aaaagggaat aagggcgaca cggaaatgtt gaatactcat actcttcctt tttcaatatt 10140
attgaagcat ttatcagggt tattgtctca tgagcggata catatttgaa tgtatttaga 10200
aaaataaaca aataggggtt ccgcgcacat ttccccgaaa agtgccacct gaaattgtaa 10260
acgttaatat tttgttaaaa ttcgcgttaa atttttgtta aatcagctca ttttttaacc 10320
aataggccga aatcggcaaa atcccttata aatcaaaaga atagaccgag atagggttga 10380
gtgttgttcc agtttggaac aagagtccac tattaaagaa cgtggactcc aacgtcaaag 10440
ggcgaaaaac cgtctatcag ggcgatggcc cactacgtga accatcaccc taatcaagtt 10500
ttttggggtc gaggtgccgt aaagcactaa atcggaaccc taaagggagc ccccgattta 10560
gagcttgacg gggaaagccg gcgaacgtgg cgagaaagga agggaagaaa gcgaaaggag 10620
cgggcgctag ggcgctggca agtgtagcgg tcacgctgcg cgtaaccacc acacccgccg 10680
cgcttaatgc gccgctacag ggcgcgtccc attcgccatt caggctgcaa ataagcgttg 10740
atattcagtc aattacaaac attaataacg aagagatgac agaaaaattt tcattctgtg 10800
acagagaa 10808
<210> 57
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<221> MOD_RES
<222> (1)..(1)
<223> Any amino acid
<400> 57
Xaa Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Trp Phe Asp Gly Thr Lys Lys Tyr Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Thr Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Gly Ile Gly Ala Arg Arg Gly Pro Tyr Tyr Met Asp
100 105 110
Val Trp Gly Lys Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
130 135 140
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
195 200 205
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro
210 215 220
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
225 230 235 240
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
245 250 255
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
260 265 270
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
275 280 285
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
290 295 300
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
305 310 315 320
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
325 330 335
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
340 345 350
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn
355 360 365
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
370 375 380
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
385 390 395 400
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
405 410 415
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
420 425 430
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
435 440 445
Ser Leu Ser Pro Gly
450
<210> 58
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 58
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 59
<211> 1310
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 59
ggagccgaga gtaattcata caaaaggagg gatcgccttc gcaaggggag agcccaggga 60
ccgtccctaa attctcacag acccaaatcc ctgtagccgc cccacgacag cgcgaggagc 120
atgcgctcag ggctgagcgc ggggagagca gagcacacaa gctcatagac cctggtcgtg 180
ggggggagga ccggggagct ggcgcggggc aaactgggaa agcggtgtcg tgtgctggct 240
ccgccctctt cccgagggtg ggggagaacg gtatataagt gcggcagtcg ccttggacgt 300
tctttttcgc aacgggtttg ccgtcagaac gcaggtgagg ggcgggtgtg gcttccgcgg 360
gccgccgagc tggaggtcct gctccgagcg ggccgggccc cgctgtcgtc ggcggggatt 420
agctgcgagc attcccgctt cgagttgcgg gcggcgcggg aggcagagtg cgaggcctag 480
cggcaacccc gtagcctcgc ctcgtgtccg gcttgaggcc tagcgtggtg tccgcgccgc 540
cgccgcgtgc tactccggcc gcactctggt cttttttttt tttgttgttg ttgccctgct 600
gccttcgatt gccgttcagc aataggggct aacaaaggga gggtgcgggg cttgctcgcc 660
cggagcccgg agaggtcatg gttggggagg aatggaggga caggagtggc ggctggggcc 720
cgcccgcctt cggagcacat gtccgacgcc acctggatgg ggcgaggcct ggggtttttc 780
ccgaagcaac caggctgggg ttagcgtgcc gaggccatgt ggccccagca cccggcacga 840
tctggcttgg cggcgccgcg ttgccctgcc tccctaacta gggtgaggcc atcccgtccg 900
gcaccagttg cgtgcgtgga aagatggccg ctcccgggcc ctgttgcaag gagctcaaaa 960
tggaggacgc ggcagcccgg tggagcgggc gggtgagtca cccacacaaa ggaagagggc 1020
ctggtccctc accggctgct gcttcctgtg accccgtggt cctatcggcc gcaatagtca 1080
cctcgggctt ttgagcacgg ctagtcgcgg cggggggagg ggatgtaatg gcgttggagt 1140
ttgttcacat ttggtgggtg gagactagtc aggccagcct ggcgctggaa gtcatttttg 1200
gaatttgtcc ccttgagttt tgagcggagc taattctcgg gcttcttagc ggttcaaagg 1260
tatcttttaa accctttttt aggtgttgtg aaaaccaccg ctaattcaaa 1310
<210> 60
<211> 16
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 60
gcgcgctcgc tcgctc 16
<210> 61
<211> 6
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 61
ggttga 6
<210> 62
<211> 4
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 62
agtt 4
<210> 63
<211> 6
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 63
ggttgg 6
<210> 64
<211> 6
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 64
agttgg 6
<210> 65
<211> 6
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 65
agttga 6
<210> 66
<211> 6
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 66
rrttrr 6
<210> 67
<211> 581
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 67
gagcatctta ccgccattta ttcccatatt tgttctgttt ttcttgattt gggtatacat 60
ttaaatgtta ataaaacaaa atggtggggc aatcatttac atttttaggg atatgtaatt 120
actagttcag gtgtattgcc acaagacaaa catgttaaga aactttcccg ttatttacgc 180
tctgttcctg ttaatcaacc tctggattac aaaatttgtg aaagattgac tgatattctt 240
aactatgttg ctccttttac gctgtgtgga tatgctgctt tatagcctct gtatctagct 300
attgcttccc gtacggcttt cgttttctcc tccttgtata aatcctggtt gctgtctctt 360
ttagaggagt tgtggcccgt tgtccgtcaa cgtggcgtgg tgtgctctgt gtttgctgac 420
gcaaccccca ctggctgggg cattgccacc acctgtcaac tcctttctgg gactttcgct 480
ttccccctcc cgatcgccac ggcagaactc atcgccgcct gccttgcccg ctgctggaca 540
ggggctaggt tgctgggcac tgataattcc gtggtgttgt c 581
<210> 68
<211> 225
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 68
tgtgccttct agttgccagc catctgttgt ttgcccctcc cccgtgcctt ccttgaccct 60
ggaaggtgcc actcccactg tcctttccta ataaaatgag gaaattgcat cgcattgtct 120
gagtaggtgt cattctattc tggggggtgg ggtggggcag gacagcaagg gggaggattg 180
ggaagacaat agcaggcatg ctggggatgc ggtgggctct atggc 225
<210> 69
<211> 8
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 69
actgaggc 8
<210> 70
<211> 8
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 70
gcctcagt 8
<210> 71
<211> 16
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 71
gagcgagcga gcgcgc 16
<210> 72
<211> 1923
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 72
tcaatattgg ccattagcca tattattcat tggttatata gcataaatca atattggcta 60
ttggccattg catacgttgt atctatatca taatatgtac atttatattg gctcatgtcc 120
aatatgaccg ccatgttggc attgattatt gactagttat taatagtaat caattacggg 180
gtcattagtt catagcccat atatggagtt ccgcgttaca taacttacgg taaatggccc 240
gcctggctga ccgcccaacg acccccgccc attgacgtca ataatgacgt atgttcccat 300
agtaacgcca atagggactt tccattgacg tcaatgggtg gagtatttac ggtaaactgc 360
ccacttggca gtacatcaag tgtatcatat gccaagtccg ccccctattg acgtcaatga 420
cggtaaatgg cccgcctggc attatgccca gtacatgacc ttacgggact ttcctacttg 480
gcagtacatc tacgtattag tcatcgctat taccatggtc gaggtgagcc ccacgttctg 540
cttcactctc cccatctccc ccccctcccc acccccaatt ttgtatttat ttatttttta 600
attattttgt gcagcgatgg gggcgggggg gggggggggg cgcgcgccag gcggggcggg 660
gcggggcgag gggcggggcg gggcgaggcg gagaggtgcg gcggcagcca atcagagcgg 720
cgcgctccga aagtttcctt ttatggcgag gcggcggcgg cggcggccct ataaaaagcg 780
aagcgcgcgg cgggcgggag tcgctgcgac gctgccttcg ccccgtgccc cgctccgccg 840
ccgcctcgcg ccgcccgccc cggctctgac tgaccgcgtt actcccacag gtgagcgggc 900
gggacggccc ttctcctccg ggctgtaatt agcgcttggt ttaatgacgg cttgtttctt 960
ttctgtggct gcgtgaaagc cttgaggggc tccgggaggg ccctttgtgc gggggggagc 1020
ggctcggggg gtgcgtgcgt gtgtgtgtgc gtggggagcg ccgcgtgcgg cccgcgctgc 1080
ccggcggctg tgagcgctgc gggcgcggcg cggggctttg tgcgctccgc agtgtgcgcg 1140
aggggagcgc ggccgggggc ggtgccccgc ggtgcggggg gggctgcgag gggaacaaag 1200
gctgcgtgcg gggtgtgtgc gtgggggggt gagcaggggg tgtgggcgcg gcggtcgggc 1260
tgtaaccccc ccctgcaccc ccctccccga gttgctgagc acggcccggc ttcgggtgcg 1320
gggctccgta cggggcgtgg cgcggggctc gccgtgccgg gcggggggtg gcggcaggtg 1380
ggggtgccgg gcggggcggg gccgcctcgg gccggggagg gctcggggga ggggcgcggc 1440
ggcccccgga gcgccggcgg ctgtcgaggc gcggcgagcc gcagccattg ccttttatgg 1500
taatcgtgcg agagggcgca gggacttcct ttgtcccaaa tctgtgcgga gccgaaatct 1560
gggaggcgcc gccgcacccc ctctagcggg cgcggggcga agcggtgcgg cgccggcagg 1620
aaggaaatgg gcggggaggg ccttcgtgcg tcgccgcgcc gccgtcccct tctccctctc 1680
cagcctcggg gctgtccgcg gggggacggc tgccttcggg ggggacgggg cagggcgggg 1740
ttcggcttct ggcgtgtgac cggcggctct agagcctctg ctaaccatgt tttagccttc 1800
ttctttttcc tacagctcct gggcaacgtg ctggttattg tgctgtctca tcatttgtcg 1860
acagaattcc tcgaagatcc gaaggggttc aagcttggca ttccggtact gttggtaaag 1920
cca 1923
<210> 73
<211> 1272
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 73
aggctcagag gcacacagga gtttctgggc tcaccctgcc cccttccaac ccctcagttc 60
ccatcctcca gcagctgttt gtgtgctgcc tctgaagtcc acactgaaca aacttcagcc 120
tactcatgtc cctaaaatgg gcaaacattg caagcagcaa acagcaaaca cacagccctc 180
cctgcctgct gaccttggag ctggggcaga ggtcagagac ctctctgggc ccatgccacc 240
tccaacatcc actcgacccc ttggaatttc ggtggagagg agcagaggtt gtcctggcgt 300
ggtttaggta gtgtgagagg gtccgggttc aaaaccactt gctgggtggg gagtcgtcag 360
taagtggcta tgccccgacc ccgaagcctg tttccccatc tgtacaatgg aaatgataaa 420
gacgcccatc tgatagggtt tttgtggcaa ataaacattt ggtttttttg ttttgttttg 480
ttttgttttt tgagatggag gtttgctctg tcgcccaggc tggagtgcag tgacacaatc 540
tcatctcacc acaaccttcc cctgcctcag cctcccaagt agctgggatt acaagcatgt 600
gccaccacac ctggctaatt ttctattttt agtagagacg ggtttctcca tgttggtcag 660
cctcagcctc ccaagtaact gggattacag gcctgtgcca ccacacccgg ctaatttttt 720
ctatttttga cagggacggg gtttcaccat gttggtcagg ctggtctaga ggtaccggat 780
cttgctacca gtggaacagc cactaaggat tctgcagtga gagcagaggg ccagctaagt 840
ggtactctcc cagagactgt ctgactcacg ccaccccctc caccttggac acaggacgct 900
gtggtttctg agccaggtac aatgactcct ttcggtaagt gcagtggaag ctgtacactg 960
cccaggcaaa gcgtccgggc agcgtaggcg ggcgactcag atcccagcca gtggacttag 1020
cccctgtttg ctcctccgat aactggggtg accttggtta atattcacca gcagcctccc 1080
ccgttgcccc tctggatcca ctgcttaaat acggacgagg acagggccct gtctcctcag 1140
cttcaggcac caccactgac ctgggacagt gaatccggac tctaaggtaa atataaaatt 1200
tttaagtgta taatgtgtta aactactgat tctaattgtt tctctctttt agattccaac 1260
ctttggaact ga 1272
<210> 74
<211> 1177
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 74
ggctcagagg ctcagaggca cacaggagtt tctgggctca ccctgccccc ttccaacccc 60
tcagttccca tcctccagca gctgtttgtg tgctgcctct gaagtccaca ctgaacaaac 120
ttcagcctac tcatgtccct aaaatgggca aacattgcaa gcagcaaaca gcaaacacac 180
agccctccct gcctgctgac cttggagctg gggcagaggt cagagacctc tctgggccca 240
tgccacctcc aacatccact cgaccccttg gaatttcggt ggagaggagc agaggttgtc 300
ctggcgtggt ttaggtagtg tgagagggtc cgggttcaaa accacttgct gggtggggag 360
tcgtcagtaa gtggctatgc cccgaccccg aagcctgttt ccccatctgt acaatggaaa 420
tgataaagac gcccatctga tagggttttt gtggcaaata aacatttggt ttttttgttt 480
tgttttgttt tgttttttga gatggaggtt tgctctgtcg cccaggctgg agtgcagtga 540
cacaatctca tctcaccaca accttcccct gcctcagcct cccaagtagc tgggattaca 600
agcatgtgcc accacacctg gctaattttc tatttttagt agagacgggt ttctccatgt 660
tggtcagcct cagcctccca agtaactggg attacaggcc tgtgccacca cacccggcta 720
attttttcta tttttgacag ggacggggtt tcaccatgtt ggtcaggctg gtctagaggt 780
accggatctt gctaccagtg gaacagccac taaggattct gcagtgagag cagagggcca 840
gctaagtggt actctcccag agactgtctg actcacgcca ccccctccac cttggacaca 900
ggacgctgtg gtttctgagc caggtacaat gactcctttc ggtaagtgca gtggaagctg 960
tacactgccc aggcaaagcg tccgggcagc gtaggcgggc gactcagatc ccagccagtg 1020
gacttagccc ctgtttgctc ctccgataac tggggtgacc ttggttaata ttcaccagca 1080
gcctcccccg ttgcccctct ggatccactg cttaaatacg gacgaggaca gggccctgtc 1140
tcctcagctt caggcaccac cactgacctg ggacagt 1177
<210> 75
<211> 547
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 75
ccctaaaatg ggcaaacatt gcaagcagca aacagcaaac acacagccct ccctgcctgc 60
tgaccttgga gctggggcag aggtcagaga cctctctggg cccatgccac ctccaacatc 120
cactcgaccc cttggaattt ttcggtggag aggagcagag gttgtcctgg cgtggtttag 180
gtagtgtgag aggggaatga ctcctttcgg taagtgcagt ggaagctgta cactgcccag 240
gcaaagcgtc cgggcagcgt aggcgggcga ctcagatccc agccagtgga cttagcccct 300
gtttgctcct ccgataactg gggtgacctt ggttaatatt caccagcagc ctcccccgtt 360
gcccctctgg atccactgct taaatacgga cgaggacagg gccctgtctc ctcagcttca 420
ggcaccacca ctgacctggg acagtgaatc cggactctaa ggtaaatata aaatttttaa 480
gtgtataatg tgttaaacta ctgattctaa ttgtttctct cttttagatt ccaacctttg 540
gaactga 547
<210> 76
<211> 556
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 76
ccctaaaatg ggcaaacatt gcaagcagca aacagcaaac acacagccct ccctgcctgc 60
tgaccttgga gctggggcag aggtcagaga cctctctggg cccatgccac ctccaacatc 120
cactcgaccc cttggaattt cggtggagag gagcagaggt tgtcctggcg tggtttaggt 180
agtgtgagag gggaatgact cctttcggta agtgcagtgg aagctgtaca ctgcccaggc 240
aaagcgtccg ggcagcgtag gcgggcgact cagatcccag ccagtggact tagcccctgt 300
ttgctcctcc gataactggg gtgaccttgg ttaatattca ccagcagcct cccccgttgc 360
ccctctggat ccactgctta aatacggacg aggacactcg agggccctgt ctcctcagct 420
tcaggcacca ccactgacct gggacagtga atccggacat cgattctaag gtaaatataa 480
aatttttaag tgtataattt gttaaactac tgattctaat tgtttctctc ttttagattc 540
caacctttgg aactga 556
<210> 77
<211> 1179
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 77
ggctccggtg cccgtcagtg ggcagagcgc acatcgccca cagtccccga gaagttgggg 60
ggaggggtcg gcaattgaac cggtgcctag agaaggtggc gcggggtaaa ctgggaaagt 120
gatgtcgtgt actggctccg cctttttccc gagggtgggg gagaaccgta tataagtgca 180
gtagtcgccg tgaacgttct ttttcgcaac gggtttgccg ccagaacaca ggtaagtgcc 240
gtgtgtggtt cccgcgggcc tggcctcttt acgggttatg gcccttgcgt gccttgaatt 300
acttccacct ggctgcagta cgtgattctt gatcccgagc ttcgggttgg aagtgggtgg 360
gagagttcga ggccttgcgc ttaaggagcc ccttcgcctc gtgcttgagt tgaggcctgg 420
cctgggcgct ggggccgccg cgtgcgaatc tggtggcacc ttcgcgcctg tctcgctgct 480
ttcgataagt ctctagccat ttaaaatttt tgatgacctg ctgcgacgct ttttttctgg 540
caagatagtc ttgtaaatgc gggccaagat ctgcacactg gtatttcggt ttttggggcc 600
gcgggcggcg acggggcccg tgcgtcccag cgcacatgtt cggcgaggcg gggcctgcga 660
gcgcggccac cgagaatcgg acgggggtag tctcaagctg gccggcctgc tctggtgcct 720
ggtctcgcgc cgccgtgtat cgccccgccc tgggcggcaa ggctggcccg gtcggcacca 780
gttgcgtgag cggaaagatg gccgcttccc ggccctgctg cagggagctc aaaatggagg 840
acgcggcgct cgggagagcg ggcgggtgag tcacccacac aaaggaaaag ggcctttccg 900
tcctcagccg tcgcttcatg tgactccacg gagtaccggg cgccgtccag gcacctcgat 960
tagttctcga gcttttggag tacgtcgtct ttaggttggg gggaggggtt ttatgcgatg 1020
gagtttcccc acactgagtg ggtggagact gaagttaggc cagcttggca cttgatgtaa 1080
ttctccttgg aatttgccct ttttgagttt ggatcttggt tcattctcaa gcctcagaca 1140
gtggttcaaa gtttttttct tccatttcag gtgtcgtga 1179
<210> 78
<211> 141
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 78
aataaacgat aacgccgttg gtggcgtgag gcatgtaaaa ggttacatca ttatcttgtt 60
cgccatccgg ttggtataaa tagacgttca tgttggtttt tgtttcagtt gcaagttggc 120
tgcggcgcgc gcagcacctt t 141
<210> 79
<211> 317
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 79
ggtgtggaaa gtccccaggc tccccagcag gcagaagtat gcaaagcatg catctcaatt 60
agtcagcaac caggtgtgga aagtccccag gctccccagc aggcagaagt atgcaaagca 120
tgcatctcaa ttagtcagca accatagtcc cgcccctaac tccgcccatc ccgcccctaa 180
ctccgcccag ttccgcccat tctccgcccc atggctgact aatttttttt atttatgcag 240
aggccgaggc cgcctcggcc tctgagctat tccagaagta gtgaggaggc ttttttggag 300
gcctaggctt ttgcaaa 317
<210> 80
<211> 241
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 80
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
c 241
<210> 81
<211> 215
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 81
gaacgctgac gtcatcaacc cgctccaagg aatcgcgggc ccagtgtcac taggcgggaa 60
cacccagcgc gcgtgcgccc tggcaggaag atggctgtga gggacagggg agtggcgccc 120
tgcaatattt gcatgtcgct atgtgttctg ggaaatcacc ataaacgtga aatgtctttg 180
gatttgggaa tcgtataaga actgtatgag accac 215
<210> 82
<211> 546
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 82
ccctaaaatg ggcaaacatt gcaagcagca aacagcaaac acacagccct ccctgcctgc 60
tgaccttgga gctggggcag aggtcagaga cctctctggg cccatgccac ctccaacatc 120
cactcgaccc cttggaattt ttcggtggag aggagcagag gttgtcctgg cgtggtttag 180
gtagtgtgag aggggaatga ctcctttcgg taagtgcagt ggaagctgta cactgcccag 240
gcaaagcgtc cgggcagcgt aggcgggcga ctcagatccc agccagtgga cttagcccct 300
gtttgctcct ccgataactg gggtgacctt ggttaatatt caccagcagc ctcccccgtt 360
gcccctctgg atccactgct taaatacgga cgaggacagg gccctgtctc ctcagcttca 420
ggcaccacca ctgacctggg acagtgaatc cggactctaa ggtaaatata aaatttttaa 480
gtgtataatg tgttaaacta ctgattctaa ttgtttctct cttttagatt ccaacctttg 540
gaactg 546
<210> 83
<211> 576
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 83
tagtaatcaa ttacggggtc attagttcat agcccatata tggagttccg cgttacataa 60
cttacggtaa atggcccgcc tggctgaccg cccaacgacc cccgcccatt gacgtcaata 120
atgacgtatg ttcccatagt aacgccaata gggactttcc attgacgtca atgggtggag 180
tatttacggt aaactgccca cttggcagta catcaagtgt atcatatgcc aagtacgccc 240
cctattgacg tcaatgacgg taaatggccc gcctggcatt atgcccagta catgacctta 300
tgggactttc ctacttggca gtacatctac gtattagtca tcgctattac catggtgatg 360
cggttttggc agtacatcaa tgggcgtgga tagcggtttg actcacgggg atttccaagt 420
ctccacccca ttgacgtcaa tgggagtttg ttttggcacc aaaatcaacg ggactttcca 480
aaatgtcgta acaactccgc cccattgacg caaatgggcg gtaggcgtgt acggtgggag 540
gtctatataa gcagagctgg tttagtgaac cgtcag 576
<210> 84
<211> 150
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 84
ataaacgata acgccgttgg tggcgtgagg catgtaaaag gttacatcat tatcttgttc 60
gccatccggt tggtataaat agacgttcat gttggttttt gtttcagttg caagttggct 120
gcggcgcgcg cagcaccttt gcggccatct 150
<210> 85
<211> 1313
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 85
ggagccgaga gtaattcata caaaaggagg gatcgccttc gcaaggggag agcccaggga 60
ccgtccctaa attctcacag acccaaatcc ctgtagccgc cccacgacag cgcgaggagc 120
atgcgcccag ggctgagcgc gggtagatca gagcacacaa gctcacagtc cccggcggtg 180
gggggagggg cgcgctgagc gggggccagg gagctggcgc ggggcaaact gggaaagtgg 240
tgtcgtgtgc tggctccgcc ctcttcccga gggtggggga gaacggtata taagtgcggt 300
agtcgccttg gacgttcttt ttcgcaacgg gtttgccgtc agaacgcagg tgagtggcgg 360
gtgtggcttc cgcgggcccc ggagctggag ccctgctctg agcgggccgg gctgatatgc 420
gagtgtcgtc cgcagggttt agctgtgagc attcccactt cgagtggcgg gcggtgcggg 480
ggtgagagtg cgaggcctag cggcaacccc gtagcctcgc ctcgtgtccg gcttgaggcc 540
tagcgtggtg tccgccgccg cgtgccactc cggccgcact atgcgttttt tgtccttgct 600
gccctcgatt gccttccagc agcatgggct aacaaaggga gggtgtgggg ctcactctta 660
aggagcccat gaagcttacg ttggatagga atggaagggc aggaggggcg actggggccc 720
gcccgccttc ggagcacatg tccgacgcca cctggatggg gcgaggcctg tggctttccg 780
aagcaatcgg gcgtgagttt agcctacctg ggccatgtgg ccctagcact gggcacggtc 840
tggcctggcg gtgccgcgtt cccttgcctc ccaacaaggg tgaggccgtc ccgcccggca 900
ccagttgctt gcgcggaaag atggccgctc ccggggccct gttgcaagga gctcaaaatg 960
gaggacgcgg cagcccggtg gagcgggcgg gtgagtcacc cacacaaagg aagagggcct 1020
tgcccctcgc cggccgctgc ttcctgtgac cccgtggtct atcggccgca tagtcacctc 1080
gggcttctct tgagcaccgc tcgtcgcggc ggggggaggg gatctaatgg cgttggagtt 1140
tgttcacatt tggtgggtgg agactagtca ggccagcctg gcgctggaag tcattcttgg 1200
aatttgcccc tttgagtttg gagcgaggct aattctcaag cctcttagcg gttcaaaggt 1260
attttctaaa cccgtttcca ggtgttgtga aagccaccgc taattcaaag caa 1313
<210> 86
<211> 213
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 86
taagatacat tgatgagttt ggacaaacca caactagaat gcagtgaaaa aaatgcttta 60
tttgtgaaat ttgtgatgct attgctttat ttgtaaccat tataagctgc aataaacaag 120
ttaacaacaa caattgcatt cattttatgt ttcaggttca gggggaggtg tgggaggttt 180
tttaaagcaa gtaaaacctc tacaaatgtg gta 213
<210> 87
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 87
Pro Lys Lys Lys Arg Lys Val
1 5
<210> 88
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 88
Met Asp Trp Thr Trp Arg Ile Leu Phe Leu Val Ala Ala Ala Thr Gly
1 5 10 15
Ala His Ser
<210> 89
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 89
Met Leu Pro Ser Gln Leu Ile Gly Phe Leu Leu Leu Trp Val Pro Ala
1 5 10 15
Ser Arg Gly
<210> 90
<211> 7
<212> PRT
<213> Simian virus 40
<400> 90
Pro Lys Lys Lys Arg Lys Val
1 5
<210> 91
<211> 21
<212> DNA
<213> Simian virus 40
<400> 91
cccaagaaga agaggaaggt g 21
<210> 92
<211> 16
<212> PRT
<213> Unknown
<220>
<223> Description of Unknown:
Nucleoplasmin bipartite NLS sequence
<400> 92
Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1 5 10 15
<210> 93
<211> 9
<212> PRT
<213> Unknown
<220>
<223> Description of Unknown:
C-myc NLS sequence
<400> 93
Pro Ala Ala Lys Arg Val Lys Leu Asp
1 5
<210> 94
<211> 11
<212> PRT
<213> Unknown
<220>
<223> Description of Unknown:
C-myc NLS sequence
<400> 94
Arg Gln Arg Arg Asn Glu Leu Lys Arg Ser Pro
1 5 10
<210> 95
<211> 38
<212> PRT
<213> Homo sapiens
<400> 95
Asn Gln Ser Ser Asn Phe Gly Pro Met Lys Gly Gly Asn Phe Gly Gly
1 5 10 15
Arg Ser Ser Gly Pro Tyr Gly Gly Gly Gly Gln Tyr Phe Ala Lys Pro
20 25 30
Arg Asn Gln Gly Gly Tyr
35
<210> 96
<211> 42
<212> PRT
<213> Unknown
<220>
<223> Description of Unknown:
IBB domain from importin-alpha sequence
<400> 96
Arg Met Arg Ile Glx Phe Lys Asn Lys Gly Lys Asp Thr Ala Glu Leu
1 5 10 15
Arg Arg Arg Arg Val Glu Val Ser Val Glu Leu Arg Lys Ala Lys Lys
20 25 30
Asp Glu Gln Ile Leu Lys Arg Arg Asn Val
35 40
<210> 97
<211> 8
<212> PRT
<213> Unknown
<220>
<223> Description of Unknown:
Myoma T protein sequence
<400> 97
Val Ser Arg Lys Arg Pro Arg Pro
1 5
<210> 98
<211> 8
<212> PRT
<213> Unknown
<220>
<223> Description of Unknown:
Myoma T protein sequence
<400> 98
Pro Pro Lys Lys Ala Arg Glu Asp
1 5
<210> 99
<211> 8
<212> PRT
<213> Homo sapiens
<400> 99
Pro Gln Pro Lys Lys Lys Pro Leu
1 5
<210> 100
<211> 12
<212> PRT
<213> Mus musculus
<400> 100
Ser Ala Leu Ile Lys Lys Lys Lys Lys Met Ala Pro
1 5 10
<210> 101
<211> 70
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 101
gcgcgctcgc tcgctcactg aggccgcccg ggaaacccgg gcgtgcgcct cagtgagcga 60
gcgagcgcgc 70
<210> 102
<211> 70
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 102
gcgcgctcgc tcgctcactg aggcgcacgc ccgggtttcc cgggcggcct cagtgagcga 60
gcgagcgcgc 70
<210> 103
<211> 72
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 103
gcgcgctcgc tcgctcactg aggccgtcgg gcgacctttg gtcgcccggc ctcagtgagc 60
gagcgagcgc gc 72
<210> 104
<211> 72
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 104
gcgcgctcgc tcgctcactg aggccgggcg accaaaggtc gcccgacggc ctcagtgagc 60
gagcgagcgc gc 72
<210> 105
<211> 72
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 105
gcgcgctcgc tcgctcactg aggccgcccg ggcaaagccc gggcgtcggc ctcagtgagc 60
gagcgagcgc gc 72
<210> 106
<211> 72
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 106
gcgcgctcgc tcgctcactg aggccgacgc ccgggctttg cccgggcggc ctcagtgagc 60
gagcgagcgc gc 72
<210> 107
<211> 83
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 107
gcgcgctcgc tcgctcactg aggccgcccg ggcaaagccc gggcgtcggg ctttgcccgg 60
cctcagtgag cgagcgagcg cgc 83
<210> 108
<211> 83
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 108
gcgcgctcgc tcgctcactg aggccgggca aagcccgacg cccgggcttt gcccgggcgg 60
cctcagtgag cgagcgagcg cgc 83
<210> 109
<211> 77
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 109
gcgcgctcgc tcgctcactg aggccgaaac gtcgggcgac ctttggtcgc ccggcctcag 60
tgagcgagcg agcgcgc 77
<210> 110
<211> 77
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 110
gcgcgctcgc tcgctcactg aggccgggcg accaaaggtc gcccgacgtt tcggcctcag 60
tgagcgagcg agcgcgc 77
<210> 111
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 111
gcgcgctcgc tcgctcactg aggcaaagcc tcagtgagcg agcgagcgcg c 51
<210> 112
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 112
gcgcgctcgc tcgctcactg aggctttgcc tcagtgagcg agcgagcgcg c 51
<210> 113
<211> 80
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 113
gcgcgctcgc tcgctcactg aggccgcccg ggcgtcgggc gacctttggt cgcccggcct 60
cagtgagcga gcgagcgcgc 80
<210> 114
<211> 80
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 114
gcgcgctcgc tcgctcactg aggccgggcg accaaaggtc gcccgacgcc cgggcggcct 60
cagtgagcga gcgagcgcgc 80
<210> 115
<211> 79
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 115
gcgcgctcgc tcgctcactg aggcgcccgg gcgtcgggcg acctttggtc gcccggcctc 60
agtgagcgag cgagcgcgc 79
<210> 116
<211> 79
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 116
gcgcgctcgc tcgctcactg aggccgggcg accaaaggtc gcccgacgcc cgggcgcctc 60
agtgagcgag cgagcgcgc 79
<210> 117
<211> 5
<212> PRT
<213> Influenza virus
<400> 117
Asp Arg Leu Arg Arg
1 5
<210> 118
<211> 7
<212> PRT
<213> Influenza virus
<400> 118
Pro Lys Gln Lys Lys Arg Lys
1 5
<210> 119
<211> 10
<212> PRT
<213> Hepatitis delta virus
<400> 119
Arg Lys Leu Lys Lys Lys Ile Lys Lys Leu
1 5 10
<210> 120
<211> 10
<212> PRT
<213> Mus musculus
<400> 120
Arg Glu Lys Lys Lys Phe Leu Lys Arg Arg
1 5 10
<210> 121
<211> 20
<212> PRT
<213> Homo sapiens
<400> 121
Lys Arg Lys Gly Asp Glu Val Asp Gly Val Asp Glu Val Ala Lys Lys
1 5 10 15
Lys Ser Lys Lys
20
<210> 122
<211> 17
<212> PRT
<213> Homo sapiens
<400> 122
Arg Lys Cys Leu Gln Ala Gly Met Asn Leu Glu Ala Arg Lys Thr Lys
1 5 10 15
Lys
<210> 123
<211> 8
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 123
gtttaaac 8
<210> 124
<211> 8
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 124
ttaattaa 8
<210> 125
<211> 141
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 125
aataaacgat aacgccgttg gtggcgtgag gcatgtaaaa ggttacatca ttatcttgtt 60
cgccatccgg ttggtataaa tagacgttca tgttggtttt tgtttcagtt gcaagttggc 120
tgcggcgcgc gcagcacctt t 141
<210> 126
<211> 317
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 126
ggtgtggaaa gtccccaggc tccccagcag gcagaagtat gcaaagcatg catctcaatt 60
agtcagcaac caggtgtgga aagtccccag gctccccagc aggcagaagt atgcaaagca 120
tgcatctcaa ttagtcagca accatagtcc cgcccctaac tccgcccatc ccgcccctaa 180
ctccgcccag ttccgcccat tctccgcccc atggctgact aatttttttt atttatgcag 240
aggccgaggc cgcctcggcc tctgagctat tccagaagta gtgaggaggc ttttttggag 300
gcctaggctt ttgcaaa 317
<210> 127
<211> 72
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 127
gcgcgctcgc tcgctcactg aggccgggcg accaaaggtc gcccgacggc ctcagtgagc 60
gagcgagcgc gc 72
<210> 128
<211> 60
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 128
gagacagaca cactcctgct atgggtactg ctgctctggg ttccaggttc cactggtgac 60
<210> 129
<211> 1260
<212> DNA
<213> Adeno-associated virus - 2
<400> 129
atggagctgg tcgggtggct cgtggacaag gggattacct cggagaagca gtggatccag 60
gaggaccagg cctcatacat ctccttcaat gcggcctcca actcgcggtc ccaaatcaag 120
gctgccttgg acaatgcggg aaagattatg agcctgacta aaaccgcccc cgactacctg 180
gtgggccagc agcccgtgga ggacatttcc agcaatcgga tttataaaat tttggaacta 240
aacgggtacg atccccaata tgcggcttcc gtctttctgg gatgggccac gaaaaagttc 300
ggcaagagga acaccatctg gctgtttggg cctgcaacta ccgggaagac caacatcgcg 360
gaggccatag cccacactgt gcccttctac gggtgcgtaa actggaccaa tgagaacttt 420
cccttcaacg actgtgtcga caagatggtg atctggtggg aggaggggaa gatgaccgcc 480
aaggtcgtgg agtcggccaa agccattctc ggaggaagca aggtgcgcgt ggaccagaaa 540
tgcaagtcct cggcccagat agacccgact cccgtgatcg tcacctccaa caccaacatg 600
tgcgccgtga ttgacgggaa ctcaacgacc ttcgaacacc agcagccgtt gcaagaccgg 660
atgttcaaat ttgaactcac ccgccgtctg gatcatgact ttgggaaggt caccaagcag 720
gaagtcaaag actttttccg gtgggcaaag gatcacgtgg ttgaggtgga gcatgaattc 780
tacgtcaaaa agggtggagc caagaaaaga cccgccccca gtgacgcaga tataagtgag 840
cccaaacggg tgcgcgagtc agttgcgcag ccatcgacgt cagacgcgga agcttcgatc 900
aactacgcag acaggtacca aaacaaatgt tctcgtcacg tgggcatgaa tctgatgctg 960
tttccctgca gacaatgcga gagaatgaat cagaattcaa atatctgctt cactcacgga 1020
cagaaagact gtttagagtg ctttcccgtg tcagaatctc aacccgtttc tgtcgtcaaa 1080
aaggcgtatc agaaactgtg ctacattcat catatcatgg gaaaggtgcc agacgcttgc 1140
actgcctgcg atctggtcaa tgtggatttg gatgactgca tctttgaaca ataaatgatt 1200
taaatcaggt atggctgccg atggttatct tccagattgg ctcgaggaca ctctctctga 1260
<210> 130
<211> 1932
<212> DNA
<213> Adeno-associated virus - 2
<400> 130
atgccggggt tttacgagat tgtgattaag gtccccagcg accttgacga gcatctgccc 60
ggcatttctg acagctttgt gaactgggtg gccgagaagg aatgggagtt gccgccagat 120
tctgacatgg atctgaatct gattgagcag gcacccctga ccgtggccga gaagctgcag 180
cgcgactttc tgacggaatg gcgccgtgtg agtaaggccc cggaggccct tttctttgtg 240
caatttgaga agggagagag ctacttccac atgcacgtgc tcgtggaaac caccggggtg 300
aaatccatgg ttttgggacg tttcctgagt cagattcgcg aaaaactgat tcagagaatt 360
taccgcggga tcgagccgac tttgccaaac tggttcgcgg tcacaaagac cagaaatggc 420
gccggaggcg ggaacaaggt ggtggatgag tgctacatcc ccaattactt gctccccaaa 480
acccagcctg agctccagtg ggcgtggact aatatggaac agtatttaag cgcctgtttg 540
aatctcacgg agcgtaaacg gttggtggcg cagcatctga cgcacgtgtc gcagacgcag 600
gagcagaaca aagagaatca gaatcccaat tctgatgcgc cggtgatcag atcaaaaact 660
tcagccaggt acatggagct ggtcgggtgg ctcgtggaca aggggattac ctcggagaag 720
cagtggatcc aggaggacca ggcctcatac atctccttca atgcggcctc caactcgcgg 780
tcccaaatca aggctgcctt ggacaatgcg ggaaagatta tgagcctgac taaaaccgcc 840
cccgactacc tggtgggcca gcagcccgtg gaggacattt ccagcaatcg gatttataaa 900
attttggaac taaacgggta cgatccccaa tatgcggctt ccgtctttct gggatgggcc 960
acgaaaaagt tcggcaagag gaacaccatc tggctgtttg ggcctgcaac taccgggaag 1020
accaacatcg cggaggccat agcccacact gtgcccttct acgggtgcgt aaactggacc 1080
aatgagaact ttcccttcaa cgactgtgtc gacaagatgg tgatctggtg ggaggagggg 1140
aagatgaccg ccaaggtcgt ggagtcggcc aaagccattc tcggaggaag caaggtgcgc 1200
gtggaccaga aatgcaagtc ctcggcccag atagacccga ctcccgtgat cgtcacctcc 1260
aacaccaaca tgtgcgccgt gattgacggg aactcaacga ccttcgaaca ccagcagccg 1320
ttgcaagacc ggatgttcaa atttgaactc acccgccgtc tggatcatga ctttgggaag 1380
gtcaccaagc aggaagtcaa agactttttc cggtgggcaa aggatcacgt ggttgaggtg 1440
gagcatgaat tctacgtcaa aaagggtgga gccaagaaaa gacccgcccc cagtgacgca 1500
gatataagtg agcccaaacg ggtgcgcgag tcagttgcgc agccatcgac gtcagacgcg 1560
gaagcttcga tcaactacgc agacaggtac caaaacaaat gttctcgtca cgtgggcatg 1620
aatctgatgc tgtttccctg cagacaatgc gagagaatga atcagaattc aaatatctgc 1680
ttcactcacg gacagaaaga ctgtttagag tgctttcccg tgtcagaatc tcaacccgtt 1740
tctgtcgtca aaaaggcgta tcagaaactg tgctacattc atcatatcat gggaaaggtg 1800
ccagacgctt gcactgcctg cgatctggtc aatgtggatt tggatgactg catctttgaa 1860
caataaatga tttaaatcag gtatggctgc cgatggttat cttccagatt ggctcgagga 1920
cactctctct ga 1932
<210> 131
<211> 1876
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 131
cgcagccacc atggcggggt tttacgagat tgtgattaag gtccccagcg accttgacgg 60
gcatctgccc ggcatttctg acagctttgt gaactgggtg gccgagaagg aatgggagtt 120
gccgccagat tctgacatgg atctgaatct gattgagcag gcacccctga ccgtggccga 180
gaagctgcag cgcgactttc tgacggaatg gcgccgtgtg agtaaggccc cggaggccct 240
tttctttgtg caatttgaga agggagagag ctacttccac atgcacgtgc tcgtggaaac 300
caccggggtg aaatccatgg ttttgggacg tttcctgagt cagattcgcg aaaaactgat 360
tcagagaatt taccgcggga tcgagccgac tttgccaaac tggttcgcgg tcacaaagac 420
cagaaatggc gccggaggcg ggaacaaggt ggtggatgag tgctacatcc ccaattactt 480
gctccccaaa acccagcctg agctccagtg ggcgtggact aatatggaac agtatttaag 540
cgcctgtttg aatctcacgg agcgtaaacg gttggtggcg cagcatctga cgcacgtgtc 600
gcagacgcag gagcagaaca aagagaatca gaatcccaat tctgatgcgc cggtgatcag 660
atcaaaaact tcagccaggt acatggagct ggtcgggtgg ctcgtggaca aggggattac 720
ctcggagaag cagtggatcc aggaggacca ggcctcatac atctccttca atgcggcctc 780
caactcgcgg tcccaaatca aggctgcctt ggacaatgcg ggaaagatta tgagcctgac 840
taaaaccgcc cccgactacc tggtgggcca gcagcccgtg gaggacattt ccagcaatcg 900
gatttataaa attttggaac taaacgggta cgatccccaa tatgcggctt ccgtctttct 960
gggatgggcc acgaaaaagt tcggcaagag gaacaccatc tggctgtttg ggcctgcaac 1020
taccgggaag accaacatcg cggaggccat agcccacact gtgcccttct acgggtgcgt 1080
aaactggacc aatgagaact ttcccttcaa cgactgtgtc gacaagatgg tgatctggtg 1140
ggaggagggg aagatgaccg ccaaggtcgt ggagtcggcc aaagccattc tcggaggaag 1200
caaggtgcgc gtggaccaga aatgcaagtc ctcggcccag atagacccga ctcccgtgat 1260
cgtcacctcc aacaccaaca tgtgcgccgt gattgacggg aactcaacga ccttcgaaca 1320
ccagcagccg ttgcaagacc ggatgttcaa atttgaactc acccgccgtc tggatcatga 1380
ctttgggaag gtcaccaagc aggaagtcaa agactttttc cggtgggcaa aggatcacgt 1440
ggttgaggtg gagcatgaat tctacgtcaa aaagggtgga gccaagaaaa gacccgcccc 1500
cagtgacgca gatataagtg agcccaaacg ggtgcgcgag tcagttgcgc agccatcgac 1560
gtcagacgcg gaagcttcga tcaactacgc agacaggtac caaaacaaat gttctcgtca 1620
cgtgggcatg aatctgatgc tgtttccctg cagacaatgc gagagaatga atcagaattc 1680
aaatatctgc ttcactcacg gacagaaaga ctgtttagag tgctttcccg tgtcagaatc 1740
tcaacccgtt tctgtcgtca aaaaggcgta tcagaaactg tgctacattc atcatatcat 1800
gggaaaggtg ccagacgctt gcactgcctg cgatctggtc aatgtggatt tggatgactg 1860
catctttgaa caataa 1876
<210> 132
<211> 1194
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 132
atggagctgg tcgggtggct cgtggacaag gggattacct cggagaagca gtggatccag 60
gaggaccagg cctcatacat ctccttcaat gcggcctcca actcgcggtc ccaaatcaag 120
gctgccttgg acaatgcggg aaagattatg agcctgacta aaaccgcccc cgactacctg 180
gtgggccagc agcccgtgga ggacatttcc agcaatcgga tttataaaat tttggaacta 240
aacgggtacg atccccaata tgcggcttcc gtctttctgg gatgggccac gaaaaagttc 300
ggcaagagga acaccatctg gctgtttggg cctgcaacta ccgggaagac caacatcgcg 360
gaggccatag cccacactgt gcccttctac gggtgcgtaa actggaccaa tgagaacttt 420
cccttcaacg actgtgtcga caagatggtg atctggtggg aggaggggaa gatgaccgcc 480
aaggtcgtgg agtcggccaa agccattctc ggaggaagca aggtgcgcgt ggaccagaaa 540
tgcaagtcct cggcccagat agacccgact cccgtgatcg tcacctccaa caccaacatg 600
tgcgccgtga ttgacgggaa ctcaacgacc ttcgaacacc agcagccgtt gcaagaccgg 660
atgttcaaat ttgaactcac ccgccgtctg gatcatgact ttgggaaggt caccaagcag 720
gaagtcaaag actttttccg gtgggcaaag gatcacgtgg ttgaggtgga gcatgaattc 780
tacgtcaaaa agggtggagc caagaaaaga cccgccccca gtgacgcaga tataagtgag 840
cccaaacggg tgcgcgagtc agttgcgcag ccatcgacgt cagacgcgga agcttcgatc 900
aactacgcag accgctacca aaacaaatgt tctcgtcacg tgggcatgaa tctgatgctg 960
tttccctgca gacaatgcga gagaatgaat cagaattcaa atatctgctt cactcacgga 1020
cagaaagact gtttagagtg ctttcccgtg tcagaatctc aacccgtttc tgtcgtcaaa 1080
aaggcgtatc agaaactgtg ctacattcat catatcatgg gaaaggtgcc agacgcttgc 1140
actgcctgcg atctggtcaa tgtggatttg gatgactgca tctttgaaca ataa 1194
<210> 133
<211> 1876
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 133
cgcagccacc atggcggggt tttacgagat tgtgattaag gtccccagcg accttgacgg 60
gcatctgccc ggcatttctg acagctttgt gaactgggtg gccgagaagg aatgggagtt 120
gccgccagat tctgacatgg atctgaatct gattgagcag gcacccctga ccgtggccga 180
gaagctgcag cgcgactttc tgacggaatg gcgccgtgtg agtaaggccc cggaggccct 240
tttctttgtg caatttgaga agggagagag ctacttccac atgcacgtgc tcgtggaaac 300
caccggggtg aaatccatgg ttttgggacg tttcctgagt cagattcgcg aaaaactgat 360
tcagagaatt taccgcggga tcgagccgac tttgccaaac tggttcgcgg tcacaaagac 420
cagaaatggc gccggaggcg ggaacaaggt ggtggatgag tgctacatcc ccaattactt 480
gctccccaaa acccagcctg agctccagtg ggcgtggact aatatggaac agtatttaag 540
cgcctgtttg aatctcacgg agcgtaaacg gttggtggcg cagcatctga cgcacgtgtc 600
gcagacgcag gagcagaaca aagagaatca gaatcccaat tctgatgcgc cggtgatcag 660
atcaaaaact tcagccaggt acatggagct ggtcgggtgg ctcgtggaca aggggattac 720
ctcggagaag cagtggatcc aggaggacca ggcctcatac atctccttca atgcggcctc 780
caactcgcgg tcccaaatca aggctgcctt ggacaatgcg ggaaagatta tgagcctgac 840
taaaaccgcc cccgactacc tggtgggcca gcagcccgtg gaggacattt ccagcaatcg 900
gatttataaa attttggaac taaacgggta cgatccccaa tatgcggctt ccgtctttct 960
gggatgggcc acgaaaaagt tcggcaagag gaacaccatc tggctgtttg ggcctgcaac 1020
taccgggaag accaacatcg cggaggccat agcccacact gtgcccttct acgggtgcgt 1080
aaactggacc aatgagaact ttcccttcaa cgactgtgtc gacaagatgg tgatctggtg 1140
ggaggagggg aagatgaccg ccaaggtcgt ggagtcggcc aaagccattc tcggaggaag 1200
caaggtgcgc gtggaccaga aatgcaagtc ctcggcccag atagacccga ctcccgtgat 1260
cgtcacctcc aacaccaaca tgtgcgccgt gattgacggg aactcaacga ccttcgaaca 1320
ccagcagccg ttgcaagacc ggatgttcaa atttgaactc acccgccgtc tggatcatga 1380
ctttgggaag gtcaccaagc aggaagtcaa agactttttc cggtgggcaa aggatcacgt 1440
ggttgaggtg gagcatgaat tctacgtcaa aaagggtgga gccaagaaaa gacccgcccc 1500
cagtgacgca gatataagtg agcccaaacg ggtgcgcgag tcagttgcgc agccatcgac 1560
gtcagacgcg gaagcttcga tcaactacgc agacaggtac caaaacaaat gttctcgtca 1620
cgtgggcatg aatctgatgc tgtttccctg cagacaatgc gagagaatga atcagaattc 1680
aaatatctgc ttcactcacg gacagaaaga ctgtttagag tgctttcccg tgtcagaatc 1740
tcaacccgtt tctgtcgtca aaaaggcgta tcagaaactg tgctacattc atcatatcat 1800
gggaaaggtg ccagacgctt gcactgcctg cgatctggtc aatgtggatt tggatgactg 1860
catctttgaa caataa 1876
<210> 134
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 134
ctaggccgcc cgggcaaagc ccgggcgtcg ggcgaccttt ggtcgcccgg c 51
<210> 135
<211> 65
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 135
ctaggactga ggccgcccgg gcaaagcccg ggcgtcgggc gacctttggt cgcccggcct 60
cagtc 65
<210> 136
<211> 67
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 136
ggactgaggc cgcccgggca aagcccgggc gtcgggcgac ctttggtcgc ccggcctcag 60
tcctgca 67
<210> 137
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 137
gtgcgggcga ccaaaggtcg cccgacgccc gggcgcactc a 41
<210> 138
<211> 56
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 138
ggactgaggc cgggcgacca aaggtcgccc gacgcccggg cggcctcagt cctgca 56
<210> 139
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 139
ctaggactga ggccgcccgg gcgtcgggcg acctttggtc gcccggcctc agtc 54
<210> 140
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 140
ggactgaggc cgggcgacca aaggtcgccc gacggcctca gtcctgca 48
<210> 141
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 141
ctaggactga ggccgtcggg cgacctttgg tcgcccggcc tcagtc 46
<210> 142
<211> 67
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 142
ggactgaggc ccgggcgacc aaaggtcgcc cgacgcccgg gctttgcccg ggcgcctcag 60
tcctgca 67
<210> 143
<211> 47
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 143
atacctaggc acgcgtgtta ctagttatta atagtaatca attacgg 47
<210> 144
<211> 29
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 144
atacctaggg gccgcacgcg tgttactag 29
<210> 145
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 145
atacactcag tgcctgcagg cacgtggtcc ggagatccag ac 42
<210> 146
<211> 3754
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 146
cctaggtgag cgagcgagcg cgcagagagg gagtggccaa ctccatcact aggggttcct 60
tgtagttaat gattaacccg ccatgctact tatcgcggcc gctcaatatt ggccattagc 120
catattattc attggttata tagcataaat caatattggc tattggccat tgcatacgtt 180
gtatctatat cataatatgt acatttatat tggctcatgt ccaatatgac cgccatgttg 240
gcattgatta ttgactagtt attaatagta atcaattacg gggtcattag ttcatagccc 300
atatatggag ttccgcgtta cataacttac ggtaaatggc ccgcctggct gaccgcccaa 360
cgacccccgc ccattgacgt caataatgac gtatgttccc atagtaacgc caatagggac 420
tttccattga cgtcaatggg tggagtattt acggtaaact gcccacttgg cagtacatca 480
agtgtatcat atgccaagtc cgccccctat tgacgtcaat gacggtaaat ggcccgcctg 540
gcattatgcc cagtacatga ccttacggga ctttcctact tggcagtaca tctacgtatt 600
agtcatcgct attaccatgg tcgaggtgag ccccacgttc tgcttcactc tccccatctc 660
ccccccctcc ccacccccaa ttttgtattt atttattttt taattatttt gtgcagcgat 720
gggggcgggg gggggggggg ggcgcgcgcc aggcggggcg gggcggggcg aggggcgggg 780
cggggcgagg cggagaggtg cggcggcagc caatcagagc ggcgcgctcc gaaagtttcc 840
ttttatggcg aggcggcggc ggcggcggcc ctataaaaag cgaagcgcgc ggcgggcggg 900
agtcgctgcg acgctgcctt cgccccgtgc cccgctccgc cgccgcctcg cgccgcccgc 960
cccggctctg actgaccgcg ttactcccac aggtgagcgg gcgggacggc ccttctcctc 1020
cgggctgtaa ttagcgcttg gtttaatgac ggcttgtttc ttttctgtgg ctgcgtgaaa 1080
gccttgaggg gctccgggag ggccctttgt gcggggggga gcggctcggg gggtgcgtgc 1140
gtgtgtgtgt gcgtggggag cgccgcgtgc ggcccgcgct gcccggcggc tgtgagcgct 1200
gcgggcgcgg cgcggggctt tgtgcgctcc gcagtgtgcg cgaggggagc gcggccgggg 1260
gcggtgcccc gcggtgcggg gggggctgcg aggggaacaa aggctgcgtg cggggtgtgt 1320
gcgtgggggg gtgagcaggg ggtgtgggcg cggcggtcgg gctgtaaccc ccccctgcac 1380
ccccctcccc gagttgctga gcacggcccg gcttcgggtg cggggctccg tacggggcgt 1440
ggcgcggggc tcgccgtgcc gggcgggggg tggcggcagg tgggggtgcc gggcggggcg 1500
gggccgcctc gggccgggga gggctcgggg gaggggcgcg gcggcccccg gagcgccggc 1560
ggctgtcgag gcgcggcgag ccgcagccat tgccttttat ggtaatcgtg cgagagggcg 1620
cagggacttc ctttgtccca aatctgtgcg gagccgaaat ctgggaggcg ccgccgcacc 1680
ccctctagcg ggcgcggggc gaagcggtgc ggcgccggca ggaaggaaat gggcggggag 1740
ggccttcgtg cgtcgccgcg ccgccgtccc cttctccctc tccagcctcg gggctgtccg 1800
cggggggacg gctgccttcg ggggggacgg ggcagggcgg ggttcggctt ctggcgtgtg 1860
accggcggct ctagagcctc tgctaaccat gttttagcct tcttcttttt cctacagctc 1920
ctgggcaacg tgctggttat tgtgctgtct catcatttgt cgacagaatt cctcgaagat 1980
ccgaaggggt tcaagcttgg cattccggta ctgttggtaa agccagttta aacgccgcca 2040
ccatggtgag caagggcgag gagctgttca ccggggtggt gcccatcctg gtcgagctgg 2100
acggcgacgt aaacggccac aagttcagcg tgtccggcga gggcgagggc gatgccacct 2160
acggcaagct gaccctgaag ttcatctgca ccaccggcaa gctgcccgtg ccctggccca 2220
ccctcgtgac caccctgacc tacggcgtgc agtgcttcag ccgctacccc gaccacatga 2280
agcagcacga cttcttcaag tccgccatgc ccgaaggcta cgtccaggag cgcaccatct 2340
tcttcaagga cgacggcaac tacaagaccc gcgccgaggt gaagttcgag ggcgacaccc 2400
tggtgaaccg catcgagctg aagggcatcg acttcaagga ggacggcaac atcctggggc 2460
acaagctgga gtacaactac aacagccaca acgtctatat catggccgac aagcagaaga 2520
acggcatcaa ggtgaacttc aagatccgcc acaacatcga ggacggcagc gtgcagctcg 2580
ccgaccacta ccagcagaac acccccatcg gcgacggccc cgtgctgctg cccgacaacc 2640
actacctgag cacccagtcc gccctgagca aagaccccaa cgagaagcgc gatcacatgg 2700
tcctgctgga gttcgtgacc gccgccggga tcactctcgg catggacgag ctgtacaagt 2760
aattaattaa gagcatctta ccgccattta ttcccatatt tgttctgttt ttcttgattt 2820
gggtatacat ttaaatgtta ataaaacaaa atggtggggc aatcatttac atttttaggg 2880
atatgtaatt actagttcag gtgtattgcc acaagacaaa catgttaaga aactttcccg 2940
ttatttacgc tctgttcctg ttaatcaacc tctggattac aaaatttgtg aaagattgac 3000
tgatattctt aactatgttg ctccttttac gctgtgtgga tatgctgctt tatagcctct 3060
gtatctagct attgcttccc gtacggcttt cgttttctcc tccttgtata aatcctggtt 3120
gctgtctctt ttagaggagt tgtggcccgt tgtccgtcaa cgtggcgtgg tgtgctctgt 3180
gtttgctgac gcaaccccca ctggctgggg cattgccacc acctgtcaac tcctttctgg 3240
gactttcgct ttccccctcc cgatcgccac ggcagaactc atcgccgcct gccttgcccg 3300
ctgctggaca ggggctaggt tgctgggcac tgataattcc gtggtgttgt ctgtgccttc 3360
tagttgccag ccatctgttg tttgcccctc ccccgtgcct tccttgaccc tggaaggtgc 3420
cactcccact gtcctttcct aataaaatga ggaaattgca tcgcattgtc tgagtaggtg 3480
tcattctatt ctggggggtg gggtggggca ggacagcaag ggggaggatt gggaagacaa 3540
tagcaggcat gctggggatg cggtgggctc tatggctcta gagcatggct acgtagataa 3600
gtagcatggc gggttaatca ttaactacac ctgcagcagg aacccctagt gatggagttg 3660
gccactccct ctctgcgcgc tcgctcgctc cctgcaggac tgaggccggg cgaccaaagg 3720
tcgcccgacg cccgggcggc ctcagtcctg cagg 3754
<210> 147
<211> 8418
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 147
ggcagctgcg cgctcgctcg ctcacctagg ccgcccgggc aaagcccggg cgtcgggcga 60
cctttggtcg cccggcctag gtgagcgagc gagcgcgcag agagggagtg gccaactcca 120
tcactagggg ttccttgtag ttaatgatta acccgccatg ctacttatcg cggccgctca 180
atattggcca ttagccatat tattcattgg ttatatagca taaatcaata ttggctattg 240
gccattgcat acgttgtatc tatatcataa tatgtacatt tatattggct catgtccaat 300
atgaccgcca tgttggcatt gattattgac tagttattaa tagtaatcaa ttacggggtc 360
attagttcat agcccatata tggagttccg cgttacataa cttacggtaa atggcccgcc 420
tggctgaccg cccaacgacc cccgcccatt gacgtcaata atgacgtatg ttcccatagt 480
aacgccaata gggactttcc attgacgtca atgggtggag tatttacggt aaactgccca 540
cttggcagta catcaagtgt atcatatgcc aagtccgccc cctattgacg tcaatgacgg 600
taaatggccc gcctggcatt atgcccagta catgacctta cgggactttc ctacttggca 660
gtacatctac gtattagtca tcgctattac catggtcgag gtgagcccca cgttctgctt 720
cactctcccc atctcccccc cctccccacc cccaattttg tatttattta ttttttaatt 780
attttgtgca gcgatggggg cggggggggg gggggggcgc gcgccaggcg gggcggggcg 840
gggcgagggg cggggcgggg cgaggcggag aggtgcggcg gcagccaatc agagcggcgc 900
gctccgaaag tttcctttta tggcgaggcg gcggcggcgg cggccctata aaaagcgaag 960
cgcgcggcgg gcgggagtcg ctgcgacgct gccttcgccc cgtgccccgc tccgccgccg 1020
cctcgcgccg cccgccccgg ctctgactga ccgcgttact cccacaggtg agcgggcggg 1080
acggcccttc tcctccgggc tgtaattagc gcttggttta atgacggctt gtttcttttc 1140
tgtggctgcg tgaaagcctt gaggggctcc gggagggccc tttgtgcggg ggggagcggc 1200
tcggggggtg cgtgcgtgtg tgtgtgcgtg gggagcgccg cgtgcggccc gcgctgcccg 1260
gcggctgtga gcgctgcggg cgcggcgcgg ggctttgtgc gctccgcagt gtgcgcgagg 1320
ggagcgcggc cgggggcggt gccccgcggt gcgggggggg ctgcgagggg aacaaaggct 1380
gcgtgcgggg tgtgtgcgtg ggggggtgag cagggggtgt gggcgcggcg gtcgggctgt 1440
aacccccccc tgcacccccc tccccgagtt gctgagcacg gcccggcttc gggtgcgggg 1500
ctccgtacgg ggcgtggcgc ggggctcgcc gtgccgggcg gggggtggcg gcaggtgggg 1560
gtgccgggcg gggcggggcc gcctcgggcc ggggagggct cgggggaggg gcgcggcggc 1620
ccccggagcg ccggcggctg tcgaggcgcg gcgagccgca gccattgcct tttatggtaa 1680
tcgtgcgaga gggcgcaggg acttcctttg tcccaaatct gtgcggagcc gaaatctggg 1740
aggcgccgcc gcaccccctc tagcgggcgc ggggcgaagc ggtgcggcgc cggcaggaag 1800
gaaatgggcg gggagggcct tcgtgcgtcg ccgcgccgcc gtccccttct ccctctccag 1860
cctcggggct gtccgcgggg ggacggctgc cttcgggggg gacggggcag ggcggggttc 1920
ggcttctggc gtgtgaccgg cggctctaga gcctctgcta accatgtttt agccttcttc 1980
tttttcctac agctcctggg caacgtgctg gttattgtgc tgtctcatca tttgtcgaca 2040
gaattcctcg aagatccgaa ggggttcaag cttggcattc cggtactgtt ggtaaagcca 2100
gtttaaacgc cgccaccatg gtgagcaagg gcgaggagct gttcaccggg gtggtgccca 2160
tcctggtcga gctggacggc gacgtaaacg gccacaagtt cagcgtgtcc ggcgagggcg 2220
agggcgatgc cacctacggc aagctgaccc tgaagttcat ctgcaccacc ggcaagctgc 2280
ccgtgccctg gcccaccctc gtgaccaccc tgacctacgg cgtgcagtgc ttcagccgct 2340
accccgacca catgaagcag cacgacttct tcaagtccgc catgcccgaa ggctacgtcc 2400
aggagcgcac catcttcttc aaggacgacg gcaactacaa gacccgcgcc gaggtgaagt 2460
tcgagggcga caccctggtg aaccgcatcg agctgaaggg catcgacttc aaggaggacg 2520
gcaacatcct ggggcacaag ctggagtaca actacaacag ccacaacgtc tatatcatgg 2580
ccgacaagca gaagaacggc atcaaggtga acttcaagat ccgccacaac atcgaggacg 2640
gcagcgtgca gctcgccgac cactaccagc agaacacccc catcggcgac ggccccgtgc 2700
tgctgcccga caaccactac ctgagcaccc agtccgccct gagcaaagac cccaacgaga 2760
agcgcgatca catggtcctg ctggagttcg tgaccgccgc cgggatcact ctcggcatgg 2820
acgagctgta caagtaatta attaagagca tcttaccgcc atttattccc atatttgttc 2880
tgtttttctt gatttgggta tacatttaaa tgttaataaa acaaaatggt ggggcaatca 2940
tttacatttt tagggatatg taattactag ttcaggtgta ttgccacaag acaaacatgt 3000
taagaaactt tcccgttatt tacgctctgt tcctgttaat caacctctgg attacaaaat 3060
ttgtgaaaga ttgactgata ttcttaacta tgttgctcct tttacgctgt gtggatatgc 3120
tgctttatag cctctgtatc tagctattgc ttcccgtacg gctttcgttt tctcctcctt 3180
gtataaatcc tggttgctgt ctcttttaga ggagttgtgg cccgttgtcc gtcaacgtgg 3240
cgtggtgtgc tctgtgtttg ctgacgcaac ccccactggc tggggcattg ccaccacctg 3300
tcaactcctt tctgggactt tcgctttccc cctcccgatc gccacggcag aactcatcgc 3360
cgcctgcctt gcccgctgct ggacaggggc taggttgctg ggcactgata attccgtggt 3420
gttgtctgtg ccttctagtt gccagccatc tgttgtttgc ccctcccccg tgccttcctt 3480
gaccctggaa ggtgccactc ccactgtcct ttcctaataa aatgaggaaa ttgcatcgca 3540
ttgtctgagt aggtgtcatt ctattctggg gggtggggtg gggcaggaca gcaaggggga 3600
ggattgggaa gacaatagca ggcatgctgg ggatgcggtg ggctctatgg ctctagagca 3660
tggctacgta gataagtagc atggcgggtt aatcattaac tacacctgca gcaggaaccc 3720
ctagtgatgg agttggccac tccctctctg cgcgctcgct cgctccctgc aggactgagg 3780
ccgggcgacc aaaggtcgcc cgacgcccgg gcggcctcag tcctgcaggg agcgagcgag 3840
cgcgcagctg cctgcacggg cgcgccggta ccgggagatg ggggaggcta actgaaacac 3900
ggaaggagac aataccggaa ggaacccgcg ctatgacggc aataaaaaga cagaataaaa 3960
cgcacgggtg ttgggtcgtt tgttcataaa cgcggggttc ggtcccaggg ctggcactct 4020
gtcgataccc caccgagacc ccattgggac caatacgccc gcgtttcttc cttttcccca 4080
ccccaacccc caagttcggg tgaaggccca gggctcgcag ccaacgtcgg ggcggcaagc 4140
cctgccatag ccactacggg tacgtaggcc aaccactaga actatagcta gagtcctggg 4200
cgaacaaacg atgctcgcct tccagaaaac cgaggatgcg aaccacttca tccggggtca 4260
gcaccaccgg caagcgccgc gacggccgag gtctaccgat ctcctgaagc cagggcagat 4320
ccgtgcacag caccttgccg tagaagaaca gcaaggccgc caatgcctga cgatgcgtgg 4380
agaccgaaac cttgcgctcg ttcgccagcc aggacagaaa tgcctcgact tcgctgctgc 4440
ccaaggttgc cgggtgacgc acaccgtgga aacggatgaa ggcacgaacc cagttgacat 4500
aagcctgttc ggttcgtaaa ctgtaatgca agtagcgtat gcgctcacgc aactggtcca 4560
gaaccttgac cgaacgcagc ggtggtaacg gcgcagtggc ggttttcatg gcttgttatg 4620
actgtttttt tgtacagtct atgcctcggg catccaagca gcaagcgcgt tacgccgtgg 4680
gtcgatgttt gatgttatgg agcagcaacg atgttacgca gcagcaacga tgttacgcag 4740
cagggcagtc gccctaaaac aaagttaggt ggctcaagta tgggcatcat tcgcacatgt 4800
aggctcggcc ctgaccaagt caaatccatg cgggctgctc ttgatctttt cggtcgtgag 4860
ttcggagacg tagccaccta ctcccaacat cagccggact ccgattacct cgggaacttg 4920
ctccgtagta agacattcat cgcgcttgct gccttcgacc aagaagcggt tgttggcgct 4980
ctcgcggctt acgttctgcc caggtttgag cagccgcgta gtgagatcta tatctatgat 5040
ctcgcagtct ccggcgagca ccggaggcag ggcattgcca ccgcgctcat caatctcctc 5100
aagcatgagg ccaacgcgct tggtgcttat gtgatctacg tgcaagcaga ttacggtgac 5160
gatcccgcag tggctctcta tacaaagttg ggcatacggg aagaagtgat gcactttgat 5220
atcgacccaa gtaccgccac ctaacaattc gttcaagccg agatcggctt cccggccgcg 5280
gagttgttcg gtaaattgtc acaacgccgc gaatatagtc tttaccatgc ccttggccac 5340
gcccctcttt aatacgacgg gcaatttgca cttcagaaaa tgaagagttt gctttagcca 5400
taacaaaagt ccagtatgct ttttcacagc ataactggac tgatttcagt ttacaactat 5460
tctgtctagt ttaagacttt attgtcatag tttagatcta ttttgttcag tttaagactt 5520
tattgtccgc ccacacccgc ttacgcaggg catccattta ttactcaacc gtaaccgatt 5580
ttgccaggtt acgcggctgg tctgcggtgt gaaataccgc acagatgcgt aaggagaaaa 5640
taccgcatca ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg 5700
ctgcggcgag cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg 5760
gataacgcag gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag 5820
gccgcgttgc tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga 5880
cgctcaagtc agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct 5940
ggaagctccc tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc 6000
tttctccctt cgggaagcgt ggcgctttct caatgctcac gctgtaggta tctcagttcg 6060
gtgtaggtcg ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc 6120
tgcgccttat ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca 6180
ctggcagcag ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag 6240
ttcttgaagt ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct 6300
ctgctgaagc cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc 6360
accgctggta gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga 6420
tctcaagaag atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca 6480
cgttaaggga ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat 6540
taaaaatgaa gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac 6600
caatgcttaa tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt 6660
gcctgactcc ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt 6720
gctgcaatga taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag 6780
ccagccggaa gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct 6840
attaattgtt gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt 6900
gttgccattg ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc 6960
tccggttccc aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt 7020
agctccttcg gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg 7080
gttatggcag cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg 7140
actggtgagt actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct 7200
tgcccggcgt caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc 7260
attggaaaac gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt 7320
tcgatgtaac ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt 7380
tctgggtgag caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg 7440
aaatgttgaa tactcatact cttccttttt caatattatt gaagcattta tcagggttat 7500
tgtctcatga gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg 7560
cgcacatttc cccgaaaagt gccacctgaa attgtaaacg ttaatatttt gttaaaattc 7620
gcgttaaatt tttgttaaat cagctcattt tttaaccaat aggccgaaat cggcaaaatc 7680
ccttataaat caaaagaata gaccgagata gggttgagtg ttgttccagt ttggaacaag 7740
agtccactat taaagaacgt ggactccaac gtcaaagggc gaaaaaccgt ctatcagggc 7800
gatggcccac tacgtgaacc atcaccctaa tcaagttttt tggggtcgag gtgccgtaaa 7860
gcactaaatc ggaaccctaa agggagcccc cgatttagag cttgacgggg aaagccggcg 7920
aacgtggcga gaaaggaagg gaagaaagcg aaaggagcgg gcgctagggc gctggcaagt 7980
gtagcggtca cgctgcgcgt aaccaccaca cccgccgcgc ttaatgcgcc gctacagggc 8040
gcgtcccatt cgccattcag gctgcaaata agcgttgata ttcagtcaat tacaaacatt 8100
aataacgaag agatgacaga aaaattttca ttctgtgaca gagaaaaagt agccgaagat 8160
gacggtttgt cacatggagt tggcaggatg tttgattaaa aacataacag gaagaaaaat 8220
gccccgctgt gggcggacaa aatagttggg aactgggagg ggtggaaatg gagtttttaa 8280
ggattattta gggaagagtg acaaaataga tgggaactgg gtgtagcgtc gtaagctaat 8340
acgaaaatta aaaatgacaa aatagtttgg aactagattt cacttatctg gttcggatct 8400
cctagtgagc tccctgca 8418
<210> 148
<211> 225
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 148
tgtgccttct agttgccagc catctgttgt ttgcccctcc cccgtgcctt ccttgaccct 60
ggaaggtgcc actcccactg tcctttccta ataaaatgag gaaattgcat cgcattgtct 120
gagtaggtgt cattctattc tggggggtgg ggtggggcag gacagcaagg gggaggattg 180
ggaagacaat agcaggcatg ctggggatgc ggtgggctct atggc 225
<210> 149
<211> 1177
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 149
ggctcagagg ctcagaggca cacaggagtt tctgggctca ccctgccccc ttccaacccc 60
tcagttccca tcctccagca gctgtttgtg tgctgcctct gaagtccaca ctgaacaaac 120
ttcagcctac tcatgtccct aaaatgggca aacattgcaa gcagcaaaca gcaaacacac 180
agccctccct gcctgctgac cttggagctg gggcagaggt cagagacctc tctgggccca 240
tgccacctcc aacatccact cgaccccttg gaatttcggt ggagaggagc agaggttgtc 300
ctggcgtggt ttaggtagtg tgagagggtc cgggttcaaa accacttgct gggtggggag 360
tcgtcagtaa gtggctatgc cccgaccccg aagcctgttt ccccatctgt acaatggaaa 420
tgataaagac gcccatctga tagggttttt gtggcaaata aacatttggt ttttttgttt 480
tgttttgttt tgttttttga gatggaggtt tgctctgtcg cccaggctgg agtgcagtga 540
cacaatctca tctcaccaca accttcccct gcctcagcct cccaagtagc tgggattaca 600
agcatgtgcc accacacctg gctaattttc tatttttagt agagacgggt ttctccatgt 660
tggtcagcct cagcctccca agtaactggg attacaggcc tgtgccacca cacccggcta 720
attttttcta tttttgacag ggacggggtt tcaccatgtt ggtcaggctg gtctagaggt 780
accggatctt gctaccagtg gaacagccac taaggattct gcagtgagag cagagggcca 840
gctaagtggt actctcccag agactgtctg actcacgcca ccccctccac cttggacaca 900
ggacgctgtg gtttctgagc caggtacaat gactcctttc ggtaagtgca gtggaagctg 960
tacactgccc aggcaaagcg tccgggcagc gtaggcgggc gactcagatc ccagccagtg 1020
gacttagccc ctgtttgctc ctccgataac tggggtgacc ttggttaata ttcaccagca 1080
gcctcccccg ttgcccctct ggatccactg cttaaatacg gacgaggaca gggccctgtc 1140
tcctcagctt caggcaccac cactgacctg ggacagt 1177
<210> 150
<211> 1326
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 150
ctgcagggcc cactagtgga gccgagagta attcatacaa aaggagggat cgccttcgca 60
aggggagagc ccagggaccg tccctaaatt ctcacagacc caaatccctg tagccgcccc 120
acgacagcgc gaggagcatg cgcccagggc tgagcgcggg tagatcagag cacacaagct 180
cacagtcccc ggcggtgggg ggaggggcgc gctgagcggg ggccagggag ctggcgcggg 240
gcaaactggg aaagtggtgt cgtgtgctgg ctccgccctc ttcccgaggg tgggggagaa 300
cggtatataa gtgcggtagt cgccttggac gttctttttc gcaacgggtt tgccgtcaga 360
acgcaggtga gtggcgggtg tggcttccgc gggccccgga gctggagccc tgctctgagc 420
gggccgggct gatatgcgag tgtcgtccgc agggtttagc tgtgagcatt cccacttcga 480
gtggcgggcg gtgcgggggt gagagtgcga ggcctagcgg caaccccgta gcctcgcctc 540
gtgtccggct tgaggcctag cgtggtgtcc gccgccgcgt gccactccgg ccgcactatg 600
cgttttttgt ccttgctgcc ctcgattgcc ttccagcagc atgggctaac aaagggaggg 660
tgtggggctc actcttaagg agcccatgaa gcttacgttg gataggaatg gaagggcagg 720
aggggcgact ggggcccgcc cgccttcgga gcacatgtcc gacgccacct ggatggggcg 780
aggcctgtgg ctttccgaag caatcgggcg tgagtttagc ctacctgggc catgtggccc 840
tagcactggg cacggtctgg cctggcggtg ccgcgttccc ttgcctccca acaagggtga 900
ggccgtcccg cccggcacca gttgcttgcg cggaaagatg gccgctcccg gggccctgtt 960
gcaaggagct caaaatggag gacgcggcag cccggtggag cgggcgggtg agtcacccac 1020
acaaaggaag agggccttgc ccctcgccgg ccgctgcttc ctgtgacccc gtggtctatc 1080
ggccgcatag tcacctcggg cttctcttga gcaccgctcg tcgcggcggg gggaggggat 1140
ctaatggcgt tggagtttgt tcacatttgg tgggtggaga ctagtcaggc cagcctggcg 1200
ctggaagtca ttcttggaat ttgccccttt gagtttggag cgaggctaat tctcaagcct 1260
cttagcggtt caaaggtatt ttctaaaccc gtttccaggt gttgtgaaag ccaccgctaa 1320
ttcaaa 1326
<210> 151
<211> 573
<212> DNA
<213> Mus musculus
<400> 151
gtaagagttt tatgtttttt catctctgct tgtatttttc tagtaatgga agcctggtat 60
tttaaaatag ttaaattttc ctttagtgct gatttctaga ttattattac tgttgttgtt 120
gttattattg tcattatttg catctgagaa cccttaggtg gttatattat tgatatattt 180
ttggtatctt tgatgacaat aatgggggat tttgaaagct tagctttaaa tttcttttaa 240
ttaaaaaaaa atgctaggca gaatgactca aattacgttg gatacagttg aatttattac 300
ggtctcatag ggcctgcctg ctcgaccatg ctatactaaa aattaaaagt gtgtgttact 360
aattttataa atggagtttc catttatatt tacctttatt tcttatttac cattgtctta 420
gtagatattt acaaacatga cagaaacact aaatcttgag tttgaatgca cagatataaa 480
cacttaacgg gttttaaaaa taataatgtt ggtgaaaaaa tataactttg agtgtagcag 540
agaggaacca ttgccacctt cagattttcc tgt 573
<210> 152
<211> 1993
<212> DNA
<213> Mus musculus
<400> 152
acgatcggga actggcatct tcagggagta gcttaggtca gtgaagagaa gaacaaaaag 60
cagcatatta cagttagttg tcttcatcaa tctttaaata tgttgtgtgg tttttctctc 120
cctgtttcca cagacaagag tgagatcgcc catcggtata atgatttggg agaacaacat 180
ttcaaaggcc tgtaagttat aatgctgaaa gcccacttaa tatttctggt agtattagtt 240
aaagttttaa aacacctttt tccaccttga gtgtgagaat tgtagagcag tgctgtccag 300
tagaaatgtg tgcattgaca gaaagactgt ggatctgtgc tgagcaatgt ggcagccaga 360
gatcacaagg ctatcaagca ctttgcacat ggcaagtgta actgagaagc acacattcaa 420
ataatagtta attttaattg aatgtatcta gccatgtgtg gctagtagct cctttcctgg 480
agagagaatc tggagcccac atctaacttg ttaagtctgg aatcttattt tttatttctg 540
gaaaggtcta tgaactatag ttttgggggc agctcactta ctaactttta atgcaataag 600
atctcatggt atcttgagaa cattattttg tctctttgta gtactgaaac cttatacatg 660
tgaagtaagg ggtctatact taagtcacat ctccaacctt agtaatgttt taatgtagta 720
aaaaaatgag taattaattt atttttagaa ggtcaatagt atcatgtatt ccaaataaca 780
gaggtatatg gttagaaaag aaacaattca aaggacttat ataatatcta gccttgacaa 840
tgaataaatt tagagagtag tttgcctgtt tgcctcatgt tcataaatct attgacacat 900
atgtgcatct gcacttcagc atggtagaag tccatattcc tttgcttgga aaggcaggtg 960
ttcccattac gcctcagaga atagctgacg ggaagaggct ttctagatag ttgtatgaaa 1020
gatatacaaa atctcgcagg tatacacagg catgatttgc tggttgggag agccacttgc 1080
ctcatactga ggtttttgtg tctgcttttc agagtcctga ttgccttttc ccagtatctc 1140
cagaaatgct catacgatga gcatgccaaa ttagtgcagg aagtaacaga ctttgcaaag 1200
acgtgtgttg ccgatgagtc tgccgccaac tgtgacaaat cccttgtgag taccttctga 1260
ttttgtggat ctactttcct gctttctgga actctgtttc aaagccaatc atgactccat 1320
cacttaaggc cccgggaaca ctgtggcaga gggcagcaga gagattgata aagccagggt 1380
gatgggaatt ttctgtggga ctccatttca tagtaattgc agaagctaca atacactcaa 1440
aaagtctcac cacatgactg cccaaatggg agcttgacag tgacagtgac agtagatatg 1500
ccaaagtgga tgagggaaag accacaagag ctaaaccctg taaaaagaac tgtaggcaac 1560
taaggaatgc agagagaaga agttgccttg gaagagcata ccaactgcct ctccaatacc 1620
aatggtcatc cctaaaacat acgtatgaat aacatgcaga ctaagcaggc tacatttagg 1680
aatatacatg tatttacata aatgtatatg catgtaacaa caatgaatga aaactgaggt 1740
catggatctg aaagagagca agggggctta catgagaggg tttggaggga ggggttggag 1800
ggagggaggt attattcttt agttttacag ggaacgtagt aaaaacatag gcttctccca 1860
aaggagcaga gcccatgagg agctgtgcaa ggttccccag cttgatttta cctgctcctc 1920
aaattccctt gatttgtttt tattataatg actttactcc tagcttttag tgtcagatag 1980
aaaacatgga agg 1993
<210> 153
<211> 1350
<212> DNA
<213> Homo sapiens
<400> 153
taggaggctg aggcaggagg atcgcttgag cccaggagtt cgagaccagc ctgggcaaca 60
tagtgtgatc ttgtatctat aaaaataaac aaaattagct tggtgtggtg gcgcctgtag 120
tccccagcca cttggagggg tgaggtgaga ggattgcttg agcccgggat ggtccaggct 180
gcagtgagcc atgatcgtgc cactgcactc cagcctgggc gacagagtga gaccctgtct 240
cacaacaaca acaacaacaa caaaaaggct gagctgcacc atgcttgacc cagtttctta 300
aaattgttgt caaagcttca ttcactccat ggtgctatag agcacaagat tttatttggt 360
gagatggtgc tttcatgaat tcccccaaca gagccaagct ctccatctag tggacaggga 420
agctagcagc aaaccttccc ttcactacaa aacttcattg cttggccaaa aagagagtta 480
attcaatgta gacatctatg taggcaatta aaaacctatt gatgtataaa acagtttgca 540
ttcatggagg gcaactaaat acattctagg actttataaa agatcacttt ttatttatgc 600
acagggtgga acaagatgga ttatcaagtg tcaagtccaa tctatgacat caattattat 660
acatcggagc cctgccaaaa aatcaatgtg aagcaaatcg cagcccgcct cctgcctccg 720
ctctactcac tggtgttcat ctttggtttt gtgggcaaca tgctggtcat cctcatcctg 780
ataaactgca aaaggctgaa gagcatgact gacatctacc tgctcaacct ggccatctct 840
gacctgtttt tccttcttac tgtccccttc tgggctcact atgctgccgc ccagtgggac 900
tttggaaata caatgtgtca actcttgaca gggctctatt ttataggctt cttctctgga 960
atcttcttca tcatcctcct gacaatcgat aggtacctgg ctgtcgtcca tgctgtgttt 1020
gctttaaaag ccaggacggt cacctttggg gtggtgacaa gtgtgatcac ttgggtggtg 1080
gctgtgtttg cgtctctccc aggaatcatc tttaccagat ctcaaaaaga aggtcttcat 1140
tacacctgca gctctcattt tccatacagt cagtatcaat tctggaagaa tttccagaca 1200
ttaaagatag tcatcttggg gctggtcctg ccgctgcttg tcatggtcat ctgctactcg 1260
ggaatcctaa aaactctgct tcggtgtcga aatgagaaga agaggcacag ggctgtgagg 1320
cttatcttca ccatcatgat tgtttatttt 1350
<210> 154
<211> 1223
<212> DNA
<213> Homo sapiens
<400> 154
tgacagagac tcttgggatg acgcactgct gcatcaaccc catcatctat gcctttgtcg 60
gggagaagtt cagaaactac ctcttagtct tcttccaaaa gcacattgcc aaacgcttct 120
gcaaatgctg ttctattttc cagcaagagg ctcccgagcg agcaagctca gtttacaccc 180
gatccactgg ggagcaggaa atatctgtgg gcttgtgaca cggactcaag tgggctggtg 240
acccagtcag agttgtgcac atggcttagt tttcatacac agcctgggct gggggtgggg 300
tgggagaggt cttttttaaa aggaagttac tgttatagag ggtctaagat tcatccattt 360
atttggcatc tgtttaaagt agattagatc ttttaagccc atcaattata gaaagccaaa 420
tcaaaatatg ttgatgaaaa atagcaacct ttttatctcc ccttcacatg catcaagtta 480
ttgacaaact ctcccttcac tccgaaagtt ccttatgtat atttaaaaga aagcctcaga 540
gaattgctga ttcttgagtt tagtgatctg aacagaaata ccaaaattat ttcagaaatg 600
tacaactttt tacctagtac aaggcaacat ataggttgta aatgtgttta aaacaggtct 660
ttgtcttgct atggggagaa aagacatgaa tatgattagt aaagaaatga cacttttcat 720
gtgtgatttc ccctccaagg tatggttaat aagtttcact gacttagaac caggcgagag 780
acttgtggcc tgggagagct ggggaagctt cttaaatgag aaggaatttg agttggatca 840
tctattgctg gcaaagacag aagcctcact gcaagcactg catgggcaag cttggctgta 900
gaaggagaca gagctggttg ggaagacatg gggaggaagg acaaggctag atcatgaaga 960
accttgacgg cattgctccg tctaagtcat gagctgagca gggagatcct ggttggtgtt 1020
gcagaaggtt tactctgtgg ccaaaggagg gtcaggaagg atgagcattt agggcaagga 1080
gaccaccaac agccctcagg tcagggtgag gatggcctct gctaagctca aggcgtgagg 1140
atgggaagga gggaggtatt cgtaaggatg ggaaggaggg aggtattcgt gcagcatatg 1200
aggatgcaga gtcagcagaa ctg 1223
<210> 155
<211> 215
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 155
gaacgctgac gtcatcaacc cgctccaagg aatcgcgggc ccagtgtcac taggcgggaa 60
cacccagcgc gcgtgcgccc tggcaggaag atggctgtga gggacagggg agtggcgccc 120
tgcaatattt gcatgtcgct atgtgttctg ggaaatcacc ataaacgtga aatgtctttg 180
gatttgggaa tcttataagt tctgtatgag accac 215
<210> 156
<211> 141
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 156
cctgcaggca gctgcgcgct cgctcgctca cctaggccgc ccgggcaaag cccgggcgtc 60
gggcgacctt tggtcgcccg gcctaggtga gcgagcgagc gcgcagagag ggagtggcca 120
actccatcac taggggttcc t 141
<210> 157
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 157
gcgcgctcgc tcgctcacc 19
<210> 158
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 158
ctaggtgagc gagcgagcgc gc 22
<210> 159
<211> 75
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 159
cctgcaggac tgaggccgcc cgggcaaagc ccgggcgtcg ggcgaccttt ggtcgcccgg 60
cctcagtcct gcagg 75
<210> 160
<211> 130
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 160
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagt 60
gcgggcgacc aaaggtcgcc cgacgcccgg gcgcactcag tgagcgagcg agcgcgcagc 120
tgcctgcagg 130
<210> 161
<211> 142
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 161
cctgcaggca gctgcgcgct cgctcgctcc ctaggactga ggccgcccgg gcgtcgggcg 60
acctttggtc gcccggcctc agtcctaggg agcgagcgag cgcgcagaga gggagtggcc 120
aactccatca ctaggggttc ct 142
<210> 162
<211> 80
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 162
gcgcgctcgc tcgctcactg agtgcgggcg accaaaggtc gcccgacgcc cgggcgcact 60
cagtgagcga gcgagcgcgc 80
<210> 163
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 163
gcgcgctcgc tcgctcactg a 21
<210> 164
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 164
gtgagcgagc gagcgcgc 18
<210> 165
<211> 89
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 165
gcgcgctcgc tcgctcactg aggccgcccg ggcaaagccc gggcgtcggg cgactttgtc 60
gcccggcctc agtgagcgag cgagcgcgc 89
<210> 166
<211> 89
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 166
gcgcgctcgc tcgctcactg aggccgggcg acaaagtcgc ccgacgcccg ggctttgccc 60
gggcggcctc agtgagcgag cgagcgcgc 89
<210> 167
<211> 87
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 167
gcgcgctcgc tcgctcactg aggccgcccg ggcaaagccc gggcgtcggg cgattttcgc 60
ccggcctcag tgagcgagcg agcgcgc 87
<210> 168
<211> 87
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 168
gcgcgctcgc tcgctcactg aggccgggcg aaaatcgccc gacgcccggg ctttgcccgg 60
gcggcctcag tgagcgagcg agcgcgc 87
<210> 169
<211> 85
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 169
gcgcgctcgc tcgctcactg aggccgcccg ggcaaagccc gggcgtcggg cgtttcgccc 60
ggcctcagtg agcgagcgag cgcgc 85
<210> 170
<211> 85
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 170
gcgcgctcgc tcgctcactg aggccgggcg aaacgcccga cgcccgggct ttgcccgggc 60
ggcctcagtg agcgagcgag cgcgc 85
<210> 171
<211> 89
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 171
gcgcgctcgc tcgctcactg aggccgcccg ggaaacccgg gcgtcgggcg acctttggtc 60
gcccggcctc agtgagcgag cgagcgcgc 89
<210> 172
<211> 89
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 172
gcgcgctcgc tcgctcactg aggccgggcg accaaaggtc gcccgacgcc cgggtttccc 60
gggcggcctc agtgagcgag cgagcgcgc 89
<210> 173
<211> 87
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 173
gcgcgctcgc tcgctcactg aggccgcccg gaaaccgggc gtcgggcgac ctttggtcgc 60
ccggcctcag tgagcgagcg agcgcgc 87
<210> 174
<211> 87
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 174
gcgcgctcgc tcgctcactg aggccgggcg accaaaggtc gcccgacgcc cggtttccgg 60
gcggcctcag tgagcgagcg agcgcgc 87
<210> 175
<211> 85
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 175
gcgcgctcgc tcgctcactg aggccgcccg aaacgggcgt cgggcgacct ttggtcgccc 60
ggcctcagtg agcgagcgag cgcgc 85
<210> 176
<211> 85
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 176
gcgcgctcgc tcgctcactg aggccgggcg accaaaggtc gcccgacgcc cgtttcgggc 60
ggcctcagtg agcgagcgag cgcgc 85
<210> 177
<211> 83
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 177
gcgcgctcgc tcgctcactg aggccgccca aagggcgtcg ggcgaccttt ggtcgcccgg 60
cctcagtgag cgagcgagcg cgc 83
<210> 178
<211> 83
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 178
gcgcgctcgc tcgctcactg aggccgggcg accaaaggtc gcccgacgcc ctttgggcgg 60
cctcagtgag cgagcgagcg cgc 83
<210> 179
<211> 81
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 179
gcgcgctcgc tcgctcactg aggccgccaa aggcgtcggg cgacctttgg tcgcccggcc 60
tcagtgagcg agcgagcgcg c 81
<210> 180
<211> 81
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 180
gcgcgctcgc tcgctcactg aggccgggcg accaaaggtc gcccgacgcc tttggcggcc 60
tcagtgagcg agcgagcgcg c 81
<210> 181
<211> 79
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 181
gcgcgctcgc tcgctcactg aggccgcaaa gcgtcgggcg acctttggtc gcccggcctc 60
agtgagcgag cgagcgcgc 79
<210> 182
<211> 79
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 182
gcgcgctcgc tcgctcactg aggccgggcg accaaaggtc gcccgacgct ttgcggcctc 60
agtgagcgag cgagcgcgc 79
<210> 183
<211> 81
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 183
ctgcgcgctc gctcgctcac tgaggccgaa acgtcgggcg acctttggtc gcccggcctc 60
agtgagcgag cgagcgcgca g 81
<210> 184
<211> 81
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 184
ctgcgcgctc gctcgctcac tgaggccggg cgaccaaagg tcgcccgacg tttcggcctc 60
agtgagcgag cgagcgcgca g 81
<210> 185
<211> 72
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 185
gcgcgctcgc tcgctcactg aggccgggcg accaaaggtc gcccgacggc ctcagtgagc 60
gagcgagcgc gc 72
<210> 186
<211> 80
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 186
gcgcgctcgc tcgctcactg aggccgggcg accaaaggtc gcccgacgcc cgggcggcct 60
cagtgagcga gcgagcgcgc 80
<210> 187
<211> 79
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 187
gcgcgctcgc tcgctcactg aggcgcccgg gcgtcgggcg acctttggtc gcccggcctc 60
agtgagcgag cgagcgcgc 79
<210> 188
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 188
ggagtcaaag ttctgtttgc cctgatctgc atcgctgtgg ccgaggcc 48
<210> 189
<211> 99
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 189
attcatacca acttgaagaa aaagttcagc ctcttcatcc tggtctttct cctgttcgca 60
gtcatctgtg tttggaagaa agggagcgac tatgaggcc 99
<210> 190
<211> 588
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 190
gcccctctcc ctcccccccc cctaacgtta ctggccgaag ccgcttggaa taaggccggt 60
gtgcgtttgt ctatatgtta ttttccacca tattgccgtc ttttggcaat gtgagggccc 120
ggaaacctgg ccctgtcttc ttgacgagca ttcctagggg tctttcccct ctcgccaaag 180
gaatgcaagg tctgttgaat gtcgtgaagg aagcagttcc tctggaagct tcttgaagac 240
aaacaacgtc tgtagcgacc ctttgcaggc agcggaaccc cccacctggc gacaggtgcc 300
tctgcggcca aaagccacgt gtataagata cacctgcaaa ggcggcacaa ccccagtgcc 360
acgttgtgag ttggatagtt gtggaaagag tcaaatggct ctcctcaagc gtattcaaca 420
aggggctgaa ggatgcccag aaggtacccc attgtatggg atctgatctg gggcctcggt 480
gcacatgctt tacatgtgtt tagtcgaggt taaaaaaacg tctaggcccc ccgaaccacg 540
gggacgtggt tttcctttga aaaacacgat gataatatgg ccacaacc 588
Claims (65)
- 플랭킹 역 말단 반복부 (ITR) 사이의 적어도 하나의 이종 뉴클레오티드 서열을 포함하는 캡시드-비함유 폐쇄된-말단 DNA (ceDNA) 벡터로서, 적어도 하나의 이종 뉴클레오티드 서열은 적어도 하나의 항체 및/또는 융합 단백질을 인코딩하는, 캡시드-비함유 폐쇄된-말단 DNA (ceDNA) 벡터.
- 제1항에 있어서, 적어도 하나의 이종 뉴클레오티드 서열은 항체를 인코딩하는, ceDNA 벡터.
- 제2항에 있어서, 상기 항체는 전장 항체, Fab, Fab', 단일-도메인 항체, 또는 단일쇄 항체 (scFv)인, ceDNA 벡터.
- 제3항에 있어서, 적어도 하나의 이종 뉴클레오티드 서열은 단일-도메인 항체 또는 단일쇄 항체를 인코딩하는, ceDNA 벡터.
- 제4항에 있어서, 상기 적어도 하나의 이종 뉴클레오티드 서열은 단일-도메인 항체 또는 단일쇄 항체의 상류에 있는 분비 리더 서열(secretory leader sequence)을 추가로 인코딩하는, ceDNA 벡터.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 제1 이종 뉴클레오티드 서열은 중쇄 가변 영역을 인코딩하고, 제2 이종 뉴클레오티드 서열은 경쇄 가변 영역을 인코딩하는, ceDNA 벡터.
- 제4항에 있어서, 상기 제1 이종 뉴클레오티드 서열은 중쇄 가변 영역 및 중쇄 불변 영역 또는 이의 일부를 인코딩하고, 상기 제2 이종 뉴클레오티드 서열은 경쇄 가변 영역 및 경쇄 불변 영역 또는 이의 일부를 인코딩하는, cDNA 벡터.
- 제6항 또는 제7항에 있어서, 상기 제1 이종 뉴클레오티드 서열 및/또는 상기 제2 이종 뉴클레오티드 서열은 상기 중쇄 가변 영역 및/또는 경쇄 가변 영역의 상류에 있는 분비 리더 서열을 추가로 인코딩하는, ceDNA 벡터.
- 제1항 내지 제8항 중 어느 한 항에 있어서, 상기 항체는 인간 또는 인간화된 항체인, ceDNA 벡터.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 상기 항체는 IgG, IgA, IgD, IgM, 또는 IgE 항체인, ceDNA 벡터.
- 제10항에 있어서, 상기 항체는 IgG 항체인, ceDNA 벡터.
- 제11항에 있어서, 상기 IgG 항체는 IgG1, IgG2, IgG3, 또는 IgG4 항체인, ceDNA 벡터.
- 제1항 내지 제12항 중 어느 한 항에 있어서, 상기 항체는 표 2, 3a, 3b, 4, 및 5에 열거된 표적으로부터 선택된 적어도 하나의 표적에 결합하는, ceDNA 벡터.
- 제1항에 있어서, 적어도 하나의 이종 뉴클레오티드 서열은 융합 단백질을 인코딩하는, ceDNA 벡터.
- 제14항에 있어서, 상기 적어도 하나의 이종 뉴클레오티드 서열은 상기 융합 단백질의 상류에 있는 분비 리더 서열을 추가로 인코딩하는, ceDNA 벡터.
- 제14항 또는 제15항에 있어서, 상기 융합 단백질은 Fc 영역에 융합된 적어도 하나의 수용체 세포외 도메인을 포함하는, ceDNA 벡터.
- 제16항에 있어서, 상기 수용체 세포외 도메인은 CTLA-4, VEGFR1, VEGFR2, LFA-3, TNFR, IL-1R1, IL-1R1, IL-1RAcP, 및 ACVR2A로부터 선택된 수용체의 세포외 도메인인, ceDNA 벡터.
- 제1항 내지 제17항 중 어느 한 항에 있어서, 상기 항체 또는 융합 단백질은 표 1, 2, 3A, 3B, 4, 또는 5의 항체 및 융합 단백질로부터 선택되는, ceDNA 벡터.
- 제1항 내지 제18항 중 어느 한 항에 있어서, 상기 ceDNA 벡터는 하나 이상의 폴리-A 부위를 포함하는, ceDNA 벡터.
- 제1항 내지 제19항 중 어느 한 항에 있어서, 상기 ceDNA 벡터는 적어도 하나의 이종 뉴클레오티드 서열에 작동 가능하게 연결된 적어도 하나의 프로모터를 포함하는, ceDNA 벡터.
- 제1항 내지 제20항 중 어느 한 항에 있어서, 적어도 하나의 이종 뉴클레오티드 서열은 cDNA인, ceDNA 벡터.
- 제1항 내지 제21항 중 어느 한 항에 있어서, 적어도 하나의 ITR은 기능적 말단 분해 부위 및 Rep 결합 부위를 포함하는, ceDNA 벡터.
- 제1항 내지 제22항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 파보바이러스(parvovirus), 데펜도바이러스(dependovirus), 및 아데노-관련 바이러스 (AAV)로부터 선택된 바이러스로부터 유래되는, ceDNA 벡터.
- 제1항 내지 제23항 중 어느 한 항에 있어서, 상기 플랭킹 ITR은 대칭 또는 비대칭인, ceDNA 벡터.
- 제24항에 있어서, 상기 플랭킹 ITR은 대칭이거나 실질적으로 대칭인, ceDNA 벡터.
- 제24항에 있어서, 상기 플랭킹 ITR은 비대칭인, ceDNA 벡터.
- 제1항 내지 제26항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 야생형이거나, 두 ITR 모두 야생형인, ceDNA 벡터.
- 제1항 내지 제27항 중 어느 한 항에 있어서, 상기 플랭킹 ITR은 상이한 바이러스 혈청형으로부터 유래하는, ceDNA 벡터.
- 제1항 내지 제28항 중 어느 한 항에 있어서, 상기 플랭킹 ITR은 표 6에 나타낸 한 쌍의 바이러스 혈청형으로부터 유래하는, ceDNA 벡터.
- 제1항 내지 제29항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 표 7의 서열로부터 선택된 서열을 포함하는, ceDNA 벡터.
- 제1항 내지 제30항 중 어느 한 항에 있어서, 상기 ITR 중 적어도 하나는 상기 ITR의 전체 3차원 입체 형태에 영향을 주는 결실, 첨가 또는 치환에 의해 야생형 AAV ITR 서열로부터 변경되는, ceDNA 벡터.
- 제1항 내지 제31항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 AAV1, AAV2, AAV3, AAV4, AAV5, AAV6, AAV7, AAV8, AAV9, AAV10, AAV11, 및 AAV12로부터 선택된 AAV 혈청형으로부터 유래되는, ceDNA 벡터.
- 제1항 내지 제32항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 합성인, ceDNA 벡터.
- 제1항 내지 제33항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 야생형 ITR이 아니거나, 두 ITR 모두가 야생형이 아닌, ceDNA 벡터.
- 제1항 내지 제34항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 A, A', B, B', C, C', D, 및 D'로부터 선택된 ITR 영역 중 적어도 하나에서 결실, 삽입 및/또는 치환에 의해 변형되는, ceDNA 벡터.
- 제35항에 있어서, 상기 결실, 삽입 및/또는 치환이 A, A', B, B' C 또는 C' 영역에 의해 일반적으로 형성된 스템-루프 구조의 전부 또는 일부를 결실시키는, ceDNA 벡터.
- 제1항 내지 제36항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 B 및 B' 영역에 의해 일반적으로 형성된 스템-루프 구조의 전부 또는 일부를 결실시키는 결실, 삽입 및/또는 치환에 의해 변형되는, ceDNA 벡터.
- 제1항 내지 제37항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 C 및 C' 영역에 의해 일반적으로 형성된 스템-루프 구조의 전부 또는 일부를 결실시키는 결실, 삽입 및/또는 치환에 의해 변형되는, ceDNA 벡터.
- 제1항 내지 제38항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 B 및 B' 영역에 의해 일반적으로 형성된 스템-루프 구조의 일부 및/또는 C 및 C' 영역에 의해 일반적으로 형성된 스템-루프 구조의 일부를 결실시키는 결실, 삽입 및/또는 치환에 의해 변형되는, ceDNA 벡터.
- 제1항 내지 제39항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 B 및 B' 영역에 의해 형성된 제1 스템-루프 구조 및 C 및 C' 영역에 의해 형성된 제2 스템-루프 구조를 일반적으로 포함하는 영역에서 단일 스템-루프 구조를 포함하는, ceDNA 벡터.
- 제1항 내지 제40항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 B 및 B' 영역에 의해 형성된 제1 스템-루프 구조 및 C 및 C' 영역에 의해 형성된 제2 스템-루프 구조를 일반적으로 포함하는 영역에서 단일 스템 및 2개의 루프를 포함하는, ceDNA 벡터.
- 제1항 내지 제41항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 B 및 B' 영역에 의해 형성된 제1 스템-루프 구조 및 C 및 C' 영역에 의해 형성된 제2 스템-루프 구조를 일반적으로 포함하는 영역에서 단일 스템 및 단일 루프를 포함하는, ceDNA 벡터.
- 제1항 내지 제42항 중 어느 한 항에 있어서, 상기 ITR가 서로 반전될 때 두 ITR이 전체적으로 3차원 대칭이 되는 방식으로 변경되는, ceDNA 벡터.
- 제1항 내지 제43항 중 어느 한 항에 있어서, 상기 ITR 중 하나 또는 둘 모두는 표 7, 9a, 9b, 및 10의 서열로부터 선택된 서열을 포함하는, ceDNA 벡터.
- 제1항 내지 제44항 중 어느 한 항에 있어서, 적어도 하나의 이종 뉴클레오티드 서열은 적어도 하나의 조절 스위치의 제어하에 있는, ceDNA 벡터.
- 제45항에 있어서, 적어도 하나의 조절 스위치는 이진 조절 스위치, 소분자 조절 스위치, 패스코드(passcode) 조절 스위치, 핵산-기반 조절 스위치, 전사 후 조절 스위치, 방사선-제어 또는 초음파 제어 조절 스위치, 저산소증-매개 조절 스위치, 염증 반응 조절 스위치, 전단-활성화 조절 스위치, 및 사멸 스위치로부터 선택되는, ceDNA 벡터.
- 상기 세포를 제1항 내지 제46항 중 어느 한 항의 ceDNA 벡터와 접촉시키는 단계를 포함하는 세포에서 항체 또는 융합 단백질을 발현시키는 방법.
- 제47항에 있어서, 상기 접촉된 세포가 진핵 세포인, 방법.
- 제47항 또는 제48항에 있어서, 상기 세포는 시험관내 또는 생체내에 존재하는, 방법.
- 제47항 내지 제49항 중 어느 한 항에 있어서, 상기 적어도 하나의 이종 뉴클레오티드 서열은 상기 진핵 세포에서의 발현에 대해 코돈 최적화된, 방법.
- 제47항 내지 제50항 중 어느 한 항에 있어서, 상기 항체 또는 융합 단백질은 상기 세포로부터 분비되는, 방법.
- 제47항 내지 제50항 중 어느 한 항에 있어서, 상기 항체 또는 융합 단백질은 세포에서 유지되는, 방법.
- 대상체를 치료 항체 또는 치료 융합 단백질로 치료하는 방법으로서, 상기 대상체에게 제1항 내지 제46항 중 어느 한 항의 ceDNA 벡터를 투여하는 단계를 포함하며, 여기서 적어도 하나의 이종 뉴클레오티드 서열은 상기 치료 항체 또는 치료 융합 단백질을 인코딩하는, 방법.
- 제53항에 있어서, 상기 대상체는 암, 자가면역 질환, 신경퇴행성 장애, 고콜레스테롤혈증, 급성 기관 거부, 다발성 경화증, 폐경기후 골다공증, 피부 병태, 천식, 또는 혈우병으로부터 선택된 질환 또는 장애를 갖는, 방법.
- 제53항에 있어서, 상기 암은 고형 종양, 연조직 육종, 림프종 및 백혈병으로부터 선택되는, 방법.
- 제53항에 있어서, 상기 자가면역 질환은 류마티스 관절염 및 크론병으로부터 선택되는, 방법.
- 제53항에 있어서, 상기 피부 병태는 건선 및 아토피 피부염으로부터 선택되는, 방법.
- 제53항에 있어서, 상기 신경퇴행성 장애는 알츠하이머병인, 방법.
- 제1항 내지 제46항 중 어느 한 항의 ceDNA 벡터를 포함하는 약제학적 조성물.
- 제1항 내지 제46항 중 어느 한 항의 ceDNA 벡터를 함유하는 세포.
- 제1항 내지 제46항 중 어느 한 항의 ceDNA 벡터 및 지질을 포함하는 조성물.
- 제61항에 있어서, 상기 지질은 지질 나노입자 (LNP)인, 조성물.
- 제1항 내지 제46항 중 어느 한 항의 ceDNA 벡터 또는 제61항 또는 제62항의 조성물 또는 제60항의 세포를 포함하는 키트.
- 제60항의 세포를 항체 또는 융합 단백질을 생성하기에 적합한 조건하에서 배양하는 것을 포함하는 항체 또는 융합 단백질의 생산 방법.
- 제64항에 있어서, 상기 항체 또는 융합 단백질의 단리시키는 단계를 추가로 포함하는, 방법.
Applications Claiming Priority (9)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862630670P | 2018-02-14 | 2018-02-14 | |
| US201862630676P | 2018-02-14 | 2018-02-14 | |
| US62/630,670 | 2018-02-14 | ||
| US62/630,676 | 2018-02-14 | ||
| US201862680087P | 2018-06-04 | 2018-06-04 | |
| US201862680092P | 2018-06-04 | 2018-06-04 | |
| US62/680,087 | 2018-06-04 | ||
| US62/680,092 | 2018-06-04 | ||
| PCT/US2019/018016 WO2019161059A1 (en) | 2018-02-14 | 2019-02-14 | Non-viral dna vectors and uses thereof for antibody and fusion protein production |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20200120649A true KR20200120649A (ko) | 2020-10-21 |
Family
ID=67619630
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020207024274A KR20200120649A (ko) | 2018-02-14 | 2019-02-14 | 비-바이러스 dna 벡터 및 항체 및 융합 단백질 생산을 위한 이의 용도 |
Country Status (14)
| Country | Link |
|---|---|
| US (1) | US20220042035A1 (ko) |
| EP (1) | EP3752191A4 (ko) |
| JP (1) | JP2021513355A (ko) |
| KR (1) | KR20200120649A (ko) |
| CN (1) | CN111818942A (ko) |
| AU (1) | AU2019221642A1 (ko) |
| BR (1) | BR112020016288A2 (ko) |
| CA (1) | CA3091250A1 (ko) |
| IL (1) | IL276469A (ko) |
| MA (1) | MA51842A (ko) |
| MX (1) | MX2020008470A (ko) |
| PH (1) | PH12020551039A1 (ko) |
| SG (1) | SG11202006431WA (ko) |
| WO (1) | WO2019161059A1 (ko) |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| BR112020013319A2 (pt) * | 2018-01-19 | 2020-12-01 | Generation Bio Co. | vetores de dna de extremidade fechada obteníveis a partir de síntese livre de células e processo para obter vetores de cedna |
| WO2021046265A1 (en) * | 2019-09-06 | 2021-03-11 | Generation Bio Co. | Lipid nanoparticle compositions comprising closed-ended dna and cleavable lipids and methods of use thereof |
| WO2021169167A1 (en) * | 2020-02-29 | 2021-09-02 | Nanjing GenScript Biotech Co., Ltd. | Method for treating coronavirus infections |
| DE102020111571A1 (de) | 2020-03-11 | 2021-09-16 | Immatics US, Inc. | Wpre-mutantenkonstrukte, zusammensetzungen und zugehörige verfahren |
| CA3172591A1 (en) * | 2020-03-24 | 2021-09-30 | Douglas Anthony KERR | Non-viral dna vectors and uses thereof for expressing gaucher therapeutics |
| BR112023001648A2 (pt) | 2020-07-27 | 2023-04-04 | Anjarium Biosciences Ag | Moléculas de dna de fita dupla, veículo de entrega e método para preparar uma molécula de dna com extremidade em grampo |
| US20240066149A1 (en) * | 2021-01-12 | 2024-02-29 | Jcr Pharmaceuticals Co., Ltd. | Nucleic Acid Molecule Containing Incorporated Gene Encoding Fused Protein of Ligand and Protein Having Physiological Activity |
| US20240092885A1 (en) * | 2021-01-26 | 2024-03-21 | Kriya Therapeutics, Inc. | Vector constructs for delivery of nucleic acids encoding therapeutic anti-tnf antibodies and methods of using the same |
| WO2023091708A1 (en) * | 2021-11-18 | 2023-05-25 | The Brigham And Women's Hospital, Inc. | Induced proteinopathy models |
| TW202423974A (zh) * | 2022-12-12 | 2024-06-16 | 大陸商蘇州荷光科匯生物科技有限公司 | 一種感染視網膜的aav載體、阿達木單抗及其應用 |
| US11993783B1 (en) * | 2023-03-27 | 2024-05-28 | Genecraft Inc. | Nucleic acid molecule comprising asymmetrically modified ITR for improving expression rate of inserted gene, and use thereof |
| CN116549632B (zh) * | 2023-03-28 | 2024-09-10 | 中国人民解放军军事科学院军事医学研究院 | 抗Lingo-1抗体Opicinumab的新用途及针对新用途的药物 |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2001092551A2 (en) * | 2000-06-01 | 2001-12-06 | University Of North Carolina At Chapel Hill | Duplexed parvovirus vectors |
| CA2454731C (en) * | 2001-08-27 | 2010-11-02 | Genentech, Inc. | A system for antibody expression and assembly |
| CN103492574B (zh) * | 2011-02-22 | 2015-12-09 | 加州理工学院 | 使用腺相关病毒(aav)载体递送蛋白 |
| EP2500434A1 (en) * | 2011-03-12 | 2012-09-19 | Association Institut de Myologie | Capsid-free AAV vectors, compositions, and methods for vector production and gene delivery |
| MX2016010215A (es) * | 2014-02-06 | 2016-11-15 | Genzyme Corp | Composiciones y metodos de tratamiento y prevencion de degeneracion macular. |
| US10577627B2 (en) * | 2014-06-09 | 2020-03-03 | Voyager Therapeutics, Inc. | Chimeric capsids |
| SG10201913688TA (en) * | 2016-03-03 | 2020-03-30 | Univ Massachusetts | Closed-ended linear duplex dna for non-viral gene transfer |
| WO2019032102A1 (en) * | 2017-08-09 | 2019-02-14 | The Usa, As Represented By The Secretary, Dept. Of Health And Human Services | LINEAR DUPLEX DNA, WITH CLOSED ENDS OF ADENO-ASSOCIATED VIRUSES AND USES THEREOF |
| SG11202000765PA (en) * | 2017-09-08 | 2020-03-30 | Generation Bio Co | Lipid nanoparticle formulations of non-viral, capsid-free dna vectors |
| CN111132699A (zh) * | 2017-09-08 | 2020-05-08 | 世代生物公司 | 修饰的封闭端dna(cedna) |
| SG11202003479TA (en) * | 2017-10-18 | 2020-05-28 | Regenxbio Inc | Fully-human post-translationally modified antibody therapeutics |
| MA51113A (fr) * | 2017-12-06 | 2020-10-14 | Generation Bio Co | Édition de gène à l'aide d'un adn modifié à extrémités fermées (adnce) |
| BR112020013319A2 (pt) * | 2018-01-19 | 2020-12-01 | Generation Bio Co. | vetores de dna de extremidade fechada obteníveis a partir de síntese livre de células e processo para obter vetores de cedna |
| AU2019226527A1 (en) * | 2018-03-02 | 2020-10-01 | Generation Bio Co. | Closed-ended DNA (ceDNA) vectors for insertion of transgenes at genomic safe harbors (GSH) in humans and murine genomes |
-
2019
- 2019-02-14 SG SG11202006431WA patent/SG11202006431WA/en unknown
- 2019-02-14 CA CA3091250A patent/CA3091250A1/en active Pending
- 2019-02-14 MX MX2020008470A patent/MX2020008470A/es unknown
- 2019-02-14 JP JP2020543344A patent/JP2021513355A/ja active Pending
- 2019-02-14 US US16/968,990 patent/US20220042035A1/en active Pending
- 2019-02-14 EP EP19753655.0A patent/EP3752191A4/en active Pending
- 2019-02-14 MA MA051842A patent/MA51842A/fr unknown
- 2019-02-14 WO PCT/US2019/018016 patent/WO2019161059A1/en active Application Filing
- 2019-02-14 AU AU2019221642A patent/AU2019221642A1/en active Pending
- 2019-02-14 KR KR1020207024274A patent/KR20200120649A/ko unknown
- 2019-02-14 BR BR112020016288-4A patent/BR112020016288A2/pt unknown
- 2019-02-14 CN CN201980013028.XA patent/CN111818942A/zh active Pending
-
2020
- 2020-07-03 PH PH12020551039A patent/PH12020551039A1/en unknown
- 2020-08-03 IL IL276469A patent/IL276469A/en unknown
Also Published As
| Publication number | Publication date |
|---|---|
| WO2019161059A1 (en) | 2019-08-22 |
| EP3752191A1 (en) | 2020-12-23 |
| CA3091250A1 (en) | 2019-08-22 |
| US20220042035A1 (en) | 2022-02-10 |
| EP3752191A4 (en) | 2021-12-22 |
| PH12020551039A1 (en) | 2021-08-23 |
| RU2020130010A (ru) | 2022-03-14 |
| AU2019221642A1 (en) | 2020-07-09 |
| BR112020016288A2 (pt) | 2020-12-15 |
| MA51842A (fr) | 2020-12-23 |
| MX2020008470A (es) | 2020-09-25 |
| CN111818942A (zh) | 2020-10-23 |
| IL276469A (en) | 2020-09-30 |
| JP2021513355A (ja) | 2021-05-27 |
| SG11202006431WA (en) | 2020-08-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20200120649A (ko) | 비-바이러스 dna 벡터 및 항체 및 융합 단백질 생산을 위한 이의 용도 | |
| KR20200111726A (ko) | 무세포 합성으로부터 수득된 폐쇄 말단 DNA 벡터 및 ceDNA 벡터를 수득하는 방법 | |
| AU2018211212B2 (en) | Treatment of amd using AAV sFlt-1 | |
| KR102696307B1 (ko) | 비-바이러스성 캡시드-비함유 dna 벡터의 지질 나노입자 제형 | |
| KR20200051011A (ko) | 변형된 폐쇄-종결된 dna(cedna) | |
| KR20210119416A (ko) | 폐쇄-말단 dna (cedna), 및 유전자 또는 핵산 치료 관련 면역 반응을 감소시키는 방법에서의 이의 용도 | |
| JP2024028931A (ja) | 閉端dna(cedna)ベクターを使用した導入遺伝子の制御された発現 | |
| KR20210090619A (ko) | 대칭인 변형된 역말단반복을 포함하는 변형된 폐쇄형 DNA(ceDNA) | |
| KR20210127935A (ko) | 폐쇄형 DNA(ceDNA) 생산에서의 Rep 단백질 활성의 변형 | |
| KR20210149702A (ko) | 비바이러스성 dna 벡터 및 페닐알라닌 히드록실라아제(pah) 치료제 발현을 위한 이의 용도 | |
| KR20230003477A (ko) | 비-바이러스성 dna 벡터 및 인자 ix 치료제 발현을 위한 이의 용도 | |
| KR20230117179A (ko) | 청신경초종 연관 증상을 치료하기 위한 항-vegf 항체작제물 및 관련된 방법 | |
| KR20230003478A (ko) | 비-바이러스성 dna 벡터 및 고셰 치료제 발현을 위한 이의 용도 | |
| JP2022524434A (ja) | Fviii治療薬を発現するための非ウイルス性dnaベクターおよびその使用 | |
| KR20220007601A (ko) | 치료제 투여를 위한 조성물 및 방법 | |
| RU2800914C2 (ru) | Невирусные днк-векторы и их применение для продуцирования антител и слитых белков | |
| RU2800914C9 (ru) | Невирусные днк-векторы и их применение для продуцирования антител и слитых белков | |
| RU2820586C2 (ru) | ДНК-ВЕКТОРЫ С ЗАМКНУТЫМИ КОНЦАМИ, ПОЛУЧАЕМЫЕ ПУТЕМ БЕСКЛЕТОЧНОГО СИНТЕЗА, И СПОСОБ ПОЛУЧЕНИЯ зкДНК-ВЕКТОРОВ | |
| RU2816871C2 (ru) | КОНТРОЛИРУЕМАЯ ЭКСПРЕССИЯ ТРАНСГЕНОВ С ИСПОЛЬЗОВАНИЕМ ДНК-ВЕКТОРОВ С ЗАМКНУТЫМИ КОНЦАМИ (зкДНК) | |
| RU2816963C2 (ru) | МОДИФИЦИРОВАННАЯ ДНК С ЗАМКНУТЫМИ КОНЦАМИ (зкДНК), СОДЕРЖАЩАЯ СИММЕТРИЧНЫЕ МОДИФИЦИРОВАННЫЕ ИНВЕРТИРОВАННЫЕ КОНЦЕВЫЕ ПОВТОРЫ | |
| RU2800026C2 (ru) | МОДИФИЦИРОВАННАЯ ДНК С ЗАМКНУТЫМИ КОНЦАМИ (зкДНК) | |
| RU2814137C2 (ru) | Невирусные днк-векторы и варианты их применения для экспрессии терапевтического средства на основе фенилаланингидроксилазы (pah) | |
| RU2812850C2 (ru) | Модуляция активности rep белка при получении днк с замкнутыми концами (зкднк) | |
| KR20240011714A (ko) | 치료용 항체를 발현하는 비바이러스성 dna 벡터 및 이의 용도 | |
| CN116568283A (zh) | 用于治疗前庭神经鞘瘤相关症状的抗vegf抗体构建体和相关方法 |