KR20190071725A - Rna-가이드된 핵산 변형 효소 및 이의 사용 방법 - Google Patents
Rna-가이드된 핵산 변형 효소 및 이의 사용 방법 Download PDFInfo
- Publication number
- KR20190071725A KR20190071725A KR1020197012244A KR20197012244A KR20190071725A KR 20190071725 A KR20190071725 A KR 20190071725A KR 1020197012244 A KR1020197012244 A KR 1020197012244A KR 20197012244 A KR20197012244 A KR 20197012244A KR 20190071725 A KR20190071725 A KR 20190071725A
- Authority
- KR
- South Korea
- Prior art keywords
- casx
- activity
- polypeptide
- nucleic acid
- seq
- Prior art date
Links
- 150000007523 nucleic acids Chemical class 0.000 title claims abstract description 265
- 102000039446 nucleic acids Human genes 0.000 title claims abstract description 262
- 108020004707 nucleic acids Proteins 0.000 title claims abstract description 262
- 238000000034 method Methods 0.000 title claims description 121
- 102000004190 Enzymes Human genes 0.000 title claims description 45
- 108090000790 Enzymes Proteins 0.000 title claims description 45
- 230000004048 modification Effects 0.000 title claims description 36
- 238000012986 modification Methods 0.000 title claims description 36
- 102000004169 proteins and genes Human genes 0.000 claims abstract description 507
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 489
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 305
- 102000004196 processed proteins & peptides Human genes 0.000 claims abstract description 285
- 229920001184 polypeptide Polymers 0.000 claims abstract description 277
- 108020005004 Guide RNA Proteins 0.000 claims abstract description 243
- 210000004027 cell Anatomy 0.000 claims description 216
- 230000000694 effects Effects 0.000 claims description 186
- 239000002773 nucleotide Substances 0.000 claims description 151
- 125000003729 nucleotide group Chemical group 0.000 claims description 151
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 142
- 108091032973 (ribonucleotides)n+m Proteins 0.000 claims description 119
- 108020004414 DNA Proteins 0.000 claims description 109
- 230000004927 fusion Effects 0.000 claims description 98
- 239000012190 activator Substances 0.000 claims description 52
- 239000013604 expression vector Substances 0.000 claims description 51
- 210000004899 c-terminal region Anatomy 0.000 claims description 50
- 102000040650 (ribonucleotides)n+m Human genes 0.000 claims description 48
- 239000000203 mixture Substances 0.000 claims description 42
- 238000003776 cleavage reaction Methods 0.000 claims description 38
- 238000003259 recombinant expression Methods 0.000 claims description 38
- 230000007017 scission Effects 0.000 claims description 38
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 32
- 238000013518 transcription Methods 0.000 claims description 32
- 230000035897 transcription Effects 0.000 claims description 32
- 230000027455 binding Effects 0.000 claims description 30
- 102000053602 DNA Human genes 0.000 claims description 26
- 210000003527 eukaryotic cell Anatomy 0.000 claims description 24
- 239000013598 vector Substances 0.000 claims description 24
- 230000008685 targeting Effects 0.000 claims description 21
- 241000282414 Homo sapiens Species 0.000 claims description 20
- 230000001939 inductive effect Effects 0.000 claims description 17
- 108060004795 Methyltransferase Proteins 0.000 claims description 16
- 101710163270 Nuclease Proteins 0.000 claims description 16
- 108020004999 messenger RNA Proteins 0.000 claims description 15
- 108010033040 Histones Proteins 0.000 claims description 14
- 101000615488 Homo sapiens Methyl-CpG-binding domain protein 2 Proteins 0.000 claims description 12
- 102100021299 Methyl-CpG-binding domain protein 2 Human genes 0.000 claims description 12
- 102000016397 Methyltransferase Human genes 0.000 claims description 12
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 12
- 210000003763 chloroplast Anatomy 0.000 claims description 12
- 230000015572 biosynthetic process Effects 0.000 claims description 11
- 210000001236 prokaryotic cell Anatomy 0.000 claims description 10
- 210000004962 mammalian cell Anatomy 0.000 claims description 9
- 230000002255 enzymatic effect Effects 0.000 claims description 8
- 239000002245 particle Substances 0.000 claims description 8
- 230000032258 transport Effects 0.000 claims description 8
- 241000238631 Hexapoda Species 0.000 claims description 7
- 108020004682 Single-Stranded DNA Proteins 0.000 claims description 7
- 210000005260 human cell Anatomy 0.000 claims description 7
- 230000001177 retroviral effect Effects 0.000 claims description 7
- 102100034343 Integrase Human genes 0.000 claims description 6
- 108010061833 Integrases Proteins 0.000 claims description 6
- 102000005421 acetyltransferase Human genes 0.000 claims description 6
- 108020002494 acetyltransferase Proteins 0.000 claims description 6
- 230000018044 dehydration Effects 0.000 claims description 6
- 238000006297 dehydration reaction Methods 0.000 claims description 6
- 238000001727 in vivo Methods 0.000 claims description 6
- 230000035772 mutation Effects 0.000 claims description 6
- 210000001519 tissue Anatomy 0.000 claims description 6
- 230000009261 transgenic effect Effects 0.000 claims description 6
- 239000013603 viral vector Substances 0.000 claims description 6
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 claims description 5
- 150000002632 lipids Chemical class 0.000 claims description 5
- 238000012360 testing method Methods 0.000 claims description 5
- 108091006107 transcriptional repressors Proteins 0.000 claims description 5
- 108091092194 transporter activity Proteins 0.000 claims description 5
- 102000040811 transporter activity Human genes 0.000 claims description 5
- 241000238421 Arthropoda Species 0.000 claims description 4
- 230000005778 DNA damage Effects 0.000 claims description 4
- 231100000277 DNA damage Toxicity 0.000 claims description 4
- 230000033616 DNA repair Effects 0.000 claims description 4
- 102100025169 Max-binding protein MNT Human genes 0.000 claims description 4
- 241001465754 Metazoa Species 0.000 claims description 4
- 108090000608 Phosphoric Monoester Hydrolases Proteins 0.000 claims description 4
- 102000004160 Phosphoric Monoester Hydrolases Human genes 0.000 claims description 4
- 108091000080 Phosphotransferase Proteins 0.000 claims description 4
- 102000018120 Recombinases Human genes 0.000 claims description 4
- 108010091086 Recombinases Proteins 0.000 claims description 4
- 102000006275 Ubiquitin-Protein Ligases Human genes 0.000 claims description 4
- 108010083111 Ubiquitin-Protein Ligases Proteins 0.000 claims description 4
- 230000004913 activation Effects 0.000 claims description 4
- 102000020233 phosphotransferase Human genes 0.000 claims description 4
- 108090000364 Ligases Proteins 0.000 claims description 3
- 102000003960 Ligases Human genes 0.000 claims description 3
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 claims description 3
- 230000006154 adenylylation Effects 0.000 claims description 3
- 230000009615 deamination Effects 0.000 claims description 3
- 238000006481 deamination reaction Methods 0.000 claims description 3
- 230000022811 deglycosylation Effects 0.000 claims description 3
- 229910052698 phosphorus Inorganic materials 0.000 claims description 3
- 239000011574 phosphorus Substances 0.000 claims description 3
- 102000004357 Transferases Human genes 0.000 claims description 2
- 108090000992 Transferases Proteins 0.000 claims description 2
- 239000000872 buffer Substances 0.000 claims description 2
- 241000288906 Primates Species 0.000 claims 6
- 230000002538 fungal effect Effects 0.000 claims 6
- 241000251539 Vertebrata <Metazoa> Species 0.000 claims 4
- 241000251468 Actinopterygii Species 0.000 claims 3
- 241000271566 Aves Species 0.000 claims 3
- 210000004102 animal cell Anatomy 0.000 claims 3
- 244000045947 parasite Species 0.000 claims 3
- 108091092566 Extrachromosomal DNA Proteins 0.000 claims 2
- 241000270322 Lepidosauria Species 0.000 claims 2
- 108091093078 Pyrimidine dimer Proteins 0.000 claims 2
- 230000006240 deamidation Effects 0.000 claims 2
- 230000007423 decrease Effects 0.000 claims 2
- 230000009504 deubiquitination Effects 0.000 claims 2
- 230000001590 oxidative effect Effects 0.000 claims 2
- 238000006303 photolysis reaction Methods 0.000 claims 2
- 230000015843 photosynthesis, light reaction Effects 0.000 claims 2
- 239000013635 pyrimidine dimer Substances 0.000 claims 2
- 208000008822 Ankylosis Diseases 0.000 claims 1
- 241000239223 Arachnida Species 0.000 claims 1
- 241000938605 Crocodylia Species 0.000 claims 1
- 206010023198 Joint ankylosis Diseases 0.000 claims 1
- 108010077991 O-GlcNAc transferase Proteins 0.000 claims 1
- 102000005520 O-GlcNAc transferase Human genes 0.000 claims 1
- 241001494479 Pecora Species 0.000 claims 1
- 229940124158 Protease/peptidase inhibitor Drugs 0.000 claims 1
- 241000283984 Rodentia Species 0.000 claims 1
- 108700019146 Transgenes Proteins 0.000 claims 1
- 210000000576 arachnoid Anatomy 0.000 claims 1
- 238000005828 desilylation reaction Methods 0.000 claims 1
- 238000010362 genome editing Methods 0.000 claims 1
- 239000003112 inhibitor Substances 0.000 claims 1
- 239000002502 liposome Substances 0.000 claims 1
- 239000011159 matrix material Substances 0.000 claims 1
- 239000008267 milk Substances 0.000 claims 1
- 210000004080 milk Anatomy 0.000 claims 1
- 235000013336 milk Nutrition 0.000 claims 1
- 238000002715 modification method Methods 0.000 claims 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 claims 1
- 229920001864 tannin Polymers 0.000 claims 1
- 239000001648 tannin Substances 0.000 claims 1
- 235000018553 tannin Nutrition 0.000 claims 1
- 108091033409 CRISPR Proteins 0.000 abstract description 58
- 235000018102 proteins Nutrition 0.000 description 496
- 150000001413 amino acids Chemical class 0.000 description 274
- 235000001014 amino acid Nutrition 0.000 description 257
- 229940024606 amino acid Drugs 0.000 description 245
- 108020001580 protein domains Proteins 0.000 description 57
- 206010057190 Respiratory tract infections Diseases 0.000 description 49
- 108010077850 Nuclear Localization Signals Proteins 0.000 description 47
- 108091079001 CRISPR RNA Proteins 0.000 description 46
- -1 and the like Proteins 0.000 description 46
- 108091033319 polynucleotide Chemical group 0.000 description 36
- 102000040430 polynucleotide Human genes 0.000 description 36
- 239000002157 polynucleotide Chemical group 0.000 description 35
- 229940088598 enzyme Drugs 0.000 description 31
- 230000001105 regulatory effect Effects 0.000 description 31
- 230000003197 catalytic effect Effects 0.000 description 26
- 125000005647 linker group Chemical group 0.000 description 26
- 238000010354 CRISPR gene editing Methods 0.000 description 25
- 125000006850 spacer group Chemical group 0.000 description 25
- 230000000295 complement effect Effects 0.000 description 24
- 230000036961 partial effect Effects 0.000 description 24
- 108091034117 Oligonucleotide Proteins 0.000 description 21
- 238000003780 insertion Methods 0.000 description 18
- 230000037431 insertion Effects 0.000 description 18
- 150000001875 compounds Chemical class 0.000 description 17
- 239000002777 nucleoside Substances 0.000 description 17
- 108020001507 fusion proteins Proteins 0.000 description 16
- 102000037865 fusion proteins Human genes 0.000 description 16
- 241000894006 Bacteria Species 0.000 description 14
- 238000010586 diagram Methods 0.000 description 14
- 230000014509 gene expression Effects 0.000 description 14
- 238000006467 substitution reaction Methods 0.000 description 14
- 230000014616 translation Effects 0.000 description 13
- 239000012634 fragment Substances 0.000 description 12
- 239000013612 plasmid Substances 0.000 description 12
- 238000013519 translation Methods 0.000 description 12
- 239000004098 Tetracycline Substances 0.000 description 11
- 229960002180 tetracycline Drugs 0.000 description 11
- 229930101283 tetracycline Natural products 0.000 description 11
- 235000019364 tetracycline Nutrition 0.000 description 11
- 150000003522 tetracyclines Chemical class 0.000 description 11
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 11
- 238000001890 transfection Methods 0.000 description 11
- 241000196324 Embryophyta Species 0.000 description 10
- 241000588724 Escherichia coli Species 0.000 description 10
- 108091093037 Peptide nucleic acid Proteins 0.000 description 10
- 235000009697 arginine Nutrition 0.000 description 10
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 10
- 201000010099 disease Diseases 0.000 description 10
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 10
- 238000000338 in vitro Methods 0.000 description 10
- 229920000642 polymer Polymers 0.000 description 10
- 238000003786 synthesis reaction Methods 0.000 description 10
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 9
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 9
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 9
- 239000005090 green fluorescent protein Substances 0.000 description 9
- 125000000623 heterocyclic group Chemical group 0.000 description 9
- 150000003833 nucleoside derivatives Chemical class 0.000 description 9
- 210000004940 nucleus Anatomy 0.000 description 9
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 9
- 230000003612 virological effect Effects 0.000 description 9
- 239000004475 Arginine Substances 0.000 description 8
- 241000700605 Viruses Species 0.000 description 8
- 150000001408 amides Chemical class 0.000 description 8
- 238000004458 analytical method Methods 0.000 description 8
- 238000003556 assay Methods 0.000 description 8
- 230000002829 reductive effect Effects 0.000 description 8
- 102100031780 Endonuclease Human genes 0.000 description 7
- 108010042407 Endonucleases Proteins 0.000 description 7
- 102000004389 Ribonucleoproteins Human genes 0.000 description 7
- 108010081734 Ribonucleoproteins Proteins 0.000 description 7
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 7
- 125000000217 alkyl group Chemical group 0.000 description 7
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 7
- 125000000637 arginyl group Chemical class N[C@@H](CCCNC(N)=N)C(=O)* 0.000 description 7
- 230000015556 catabolic process Effects 0.000 description 7
- 238000006731 degradation reaction Methods 0.000 description 7
- 238000002474 experimental method Methods 0.000 description 7
- 230000002441 reversible effect Effects 0.000 description 7
- 241000894007 species Species 0.000 description 7
- RAVVEEJGALCVIN-AGVBWZICSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-5-amino-2-[[(2s)-2-[[(2s)-2-[[(2s)-6-amino-2-[[(2s)-6-amino-2-[[(2s)-2-[[2-[[(2s)-2-amino-3-(4-hydroxyphenyl)propanoyl]amino]acetyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]hexanoyl]amino]hexanoyl]amino]-5-(diamino Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 RAVVEEJGALCVIN-AGVBWZICSA-N 0.000 description 6
- 108091026890 Coding region Proteins 0.000 description 6
- 244000089409 Erythrina poeppigiana Species 0.000 description 6
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 6
- 108700000788 Human immunodeficiency virus 1 tat peptide (47-57) Proteins 0.000 description 6
- 235000009776 Rathbunia alamosensis Nutrition 0.000 description 6
- 230000006870 function Effects 0.000 description 6
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 6
- 238000009396 hybridization Methods 0.000 description 6
- 230000001965 increasing effect Effects 0.000 description 6
- 230000002401 inhibitory effect Effects 0.000 description 6
- 150000002500 ions Chemical class 0.000 description 6
- 238000004519 manufacturing process Methods 0.000 description 6
- 238000004806 packaging method and process Methods 0.000 description 6
- 239000000047 product Substances 0.000 description 6
- 238000011160 research Methods 0.000 description 6
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 6
- 238000010361 transduction Methods 0.000 description 6
- 230000026683 transduction Effects 0.000 description 6
- 229940035893 uracil Drugs 0.000 description 6
- 241000699666 Mus <mouse, genus> Species 0.000 description 5
- 108010029485 Protein Isoforms Proteins 0.000 description 5
- 102000001708 Protein Isoforms Human genes 0.000 description 5
- 238000010521 absorption reaction Methods 0.000 description 5
- 230000000692 anti-sense effect Effects 0.000 description 5
- 125000002091 cationic group Chemical group 0.000 description 5
- 229940104302 cytosine Drugs 0.000 description 5
- 102000034287 fluorescent proteins Human genes 0.000 description 5
- 108091006047 fluorescent proteins Proteins 0.000 description 5
- 230000003993 interaction Effects 0.000 description 5
- 230000001404 mediated effect Effects 0.000 description 5
- 238000000520 microinjection Methods 0.000 description 5
- 239000000178 monomer Substances 0.000 description 5
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 5
- 230000000638 stimulation Effects 0.000 description 5
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 4
- 229930024421 Adenine Natural products 0.000 description 4
- 108010051109 Cell-Penetrating Peptides Proteins 0.000 description 4
- 102000020313 Cell-Penetrating Peptides Human genes 0.000 description 4
- 102100036279 DNA (cytosine-5)-methyltransferase 1 Human genes 0.000 description 4
- 108010024491 DNA Methyltransferase 3A Proteins 0.000 description 4
- 108010024985 DNA methyltransferase 3B Proteins 0.000 description 4
- 241001135761 Deltaproteobacteria Species 0.000 description 4
- 108060002716 Exonuclease Proteins 0.000 description 4
- 239000004471 Glycine Substances 0.000 description 4
- 102100022846 Histone acetyltransferase KAT2B Human genes 0.000 description 4
- 102100022893 Histone acetyltransferase KAT5 Human genes 0.000 description 4
- 102100033071 Histone acetyltransferase KAT6A Human genes 0.000 description 4
- 102100033070 Histone acetyltransferase KAT6B Human genes 0.000 description 4
- 102100038720 Histone deacetylase 9 Human genes 0.000 description 4
- 102000006947 Histones Human genes 0.000 description 4
- 101000931098 Homo sapiens DNA (cytosine-5)-methyltransferase 1 Proteins 0.000 description 4
- 101001047006 Homo sapiens Histone acetyltransferase KAT2B Proteins 0.000 description 4
- 101000944179 Homo sapiens Histone acetyltransferase KAT6A Proteins 0.000 description 4
- 101000613625 Homo sapiens Lysine-specific demethylase 4A Proteins 0.000 description 4
- 101001088893 Homo sapiens Lysine-specific demethylase 4C Proteins 0.000 description 4
- 101001088887 Homo sapiens Lysine-specific demethylase 5C Proteins 0.000 description 4
- 101001088879 Homo sapiens Lysine-specific demethylase 5D Proteins 0.000 description 4
- 241000725303 Human immunodeficiency virus Species 0.000 description 4
- 102100040863 Lysine-specific demethylase 4A Human genes 0.000 description 4
- 102100033230 Lysine-specific demethylase 4C Human genes 0.000 description 4
- 102100033246 Lysine-specific demethylase 5A Human genes 0.000 description 4
- 102100033247 Lysine-specific demethylase 5B Human genes 0.000 description 4
- 102100033249 Lysine-specific demethylase 5C Human genes 0.000 description 4
- 102100033143 Lysine-specific demethylase 5D Human genes 0.000 description 4
- 241001529936 Murinae Species 0.000 description 4
- 230000021736 acetylation Effects 0.000 description 4
- 238000006640 acetylation reaction Methods 0.000 description 4
- 229960000643 adenine Drugs 0.000 description 4
- 125000000539 amino acid group Chemical group 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 4
- 230000002759 chromosomal effect Effects 0.000 description 4
- 210000000349 chromosome Anatomy 0.000 description 4
- 239000000412 dendrimer Substances 0.000 description 4
- 229920000736 dendritic polymer Polymers 0.000 description 4
- 230000009977 dual effect Effects 0.000 description 4
- 239000012636 effector Substances 0.000 description 4
- 238000004520 electroporation Methods 0.000 description 4
- 239000003623 enhancer Substances 0.000 description 4
- 102000013165 exonuclease Human genes 0.000 description 4
- 230000013595 glycosylation Effects 0.000 description 4
- 238000006206 glycosylation reaction Methods 0.000 description 4
- 238000010348 incorporation Methods 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- 230000000670 limiting effect Effects 0.000 description 4
- 229920002521 macromolecule Polymers 0.000 description 4
- 239000012528 membrane Substances 0.000 description 4
- 210000004379 membrane Anatomy 0.000 description 4
- 230000011987 methylation Effects 0.000 description 4
- 238000007069 methylation reaction Methods 0.000 description 4
- 239000003607 modifier Substances 0.000 description 4
- 230000000149 penetrating effect Effects 0.000 description 4
- 125000004437 phosphorous atom Chemical group 0.000 description 4
- 238000002360 preparation method Methods 0.000 description 4
- 238000012545 processing Methods 0.000 description 4
- 238000000746 purification Methods 0.000 description 4
- YGSDEFSMJLZEOE-UHFFFAOYSA-N salicylic acid Chemical compound OC(=O)C1=CC=CC=C1O YGSDEFSMJLZEOE-UHFFFAOYSA-N 0.000 description 4
- 150000003431 steroids Chemical class 0.000 description 4
- 230000001052 transient effect Effects 0.000 description 4
- FNQJDLTXOVEEFB-UHFFFAOYSA-N 1,2,3-benzothiadiazole Chemical compound C1=CC=C2SN=NC2=C1 FNQJDLTXOVEEFB-UHFFFAOYSA-N 0.000 description 3
- LRSASMSXMSNRBT-UHFFFAOYSA-N 5-methylcytosine Chemical compound CC1=CNC(=O)N=C1N LRSASMSXMSNRBT-UHFFFAOYSA-N 0.000 description 3
- 239000005964 Acibenzolar-S-methyl Substances 0.000 description 3
- 102000011727 Caspases Human genes 0.000 description 3
- 108010076667 Caspases Proteins 0.000 description 3
- 108020004705 Codon Proteins 0.000 description 3
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 3
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 101710091919 Eukaryotic translation initiation factor 4G Proteins 0.000 description 3
- 108010016918 Histone-Lysine N-Methyltransferase Proteins 0.000 description 3
- 102000000581 Histone-lysine N-methyltransferase Human genes 0.000 description 3
- 102100035042 Histone-lysine N-methyltransferase EHMT2 Human genes 0.000 description 3
- 101000877312 Homo sapiens Histone-lysine N-methyltransferase EHMT2 Proteins 0.000 description 3
- 101001050886 Homo sapiens Lysine-specific histone demethylase 1A Proteins 0.000 description 3
- 241000713772 Human immunodeficiency virus 1 Species 0.000 description 3
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 3
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 3
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 3
- 239000004472 Lysine Substances 0.000 description 3
- 102100024985 Lysine-specific histone demethylase 1A Human genes 0.000 description 3
- 108700026244 Open Reading Frames Proteins 0.000 description 3
- 102000035195 Peptidases Human genes 0.000 description 3
- 108091005804 Peptidases Proteins 0.000 description 3
- 229920002873 Polyethylenimine Polymers 0.000 description 3
- 239000004365 Protease Substances 0.000 description 3
- 108020005067 RNA Splice Sites Proteins 0.000 description 3
- 102000015097 RNA Splicing Factors Human genes 0.000 description 3
- 108010039259 RNA Splicing Factors Proteins 0.000 description 3
- 241000714474 Rous sarcoma virus Species 0.000 description 3
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 3
- 238000009825 accumulation Methods 0.000 description 3
- 239000002253 acid Substances 0.000 description 3
- 230000009471 action Effects 0.000 description 3
- 230000003213 activating effect Effects 0.000 description 3
- 235000004279 alanine Nutrition 0.000 description 3
- 125000003342 alkenyl group Chemical group 0.000 description 3
- 125000000304 alkynyl group Chemical group 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 239000001506 calcium phosphate Substances 0.000 description 3
- 229910000389 calcium phosphate Inorganic materials 0.000 description 3
- 235000011010 calcium phosphates Nutrition 0.000 description 3
- 238000010367 cloning Methods 0.000 description 3
- 239000002299 complementary DNA Substances 0.000 description 3
- 210000000805 cytoplasm Anatomy 0.000 description 3
- 210000000172 cytosol Anatomy 0.000 description 3
- 230000003247 decreasing effect Effects 0.000 description 3
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 3
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 3
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 3
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 3
- 230000004807 localization Effects 0.000 description 3
- 230000014759 maintenance of location Effects 0.000 description 3
- 239000000463 material Substances 0.000 description 3
- 235000013372 meat Nutrition 0.000 description 3
- 229910052751 metal Inorganic materials 0.000 description 3
- 239000002184 metal Substances 0.000 description 3
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 3
- 125000000325 methylidene group Chemical group [H]C([H])=* 0.000 description 3
- 229910052750 molybdenum Inorganic materials 0.000 description 3
- 239000011733 molybdenum Substances 0.000 description 3
- 230000025308 nuclear transport Effects 0.000 description 3
- 125000003835 nucleoside group Chemical group 0.000 description 3
- 230000008488 polyadenylation Effects 0.000 description 3
- 230000029279 positive regulation of transcription, DNA-dependent Effects 0.000 description 3
- 238000001556 precipitation Methods 0.000 description 3
- 108091008146 restriction endonucleases Proteins 0.000 description 3
- 230000000717 retained effect Effects 0.000 description 3
- 239000000523 sample Substances 0.000 description 3
- 230000035939 shock Effects 0.000 description 3
- 230000009870 specific binding Effects 0.000 description 3
- 125000001424 substituent group Chemical group 0.000 description 3
- 229940113082 thymine Drugs 0.000 description 3
- 230000002103 transcriptional effect Effects 0.000 description 3
- 230000009466 transformation Effects 0.000 description 3
- 230000005945 translocation Effects 0.000 description 3
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 3
- 241000701161 unidentified adenovirus Species 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- PIINGYXNCHTJTF-UHFFFAOYSA-N 2-(2-azaniumylethylamino)acetate Chemical group NCCNCC(O)=O PIINGYXNCHTJTF-UHFFFAOYSA-N 0.000 description 2
- ICSNLGPSRYBMBD-UHFFFAOYSA-N 2-aminopyridine Chemical compound NC1=CC=CC=N1 ICSNLGPSRYBMBD-UHFFFAOYSA-N 0.000 description 2
- RYVNIFSIEDRLSJ-UHFFFAOYSA-N 5-(hydroxymethyl)cytosine Chemical compound NC=1NC(=O)N=CC=1CO RYVNIFSIEDRLSJ-UHFFFAOYSA-N 0.000 description 2
- OSXFATOLZGZLSK-UHFFFAOYSA-N 6,7-dimethoxy-2-(4-methyl-1,4-diazepan-1-yl)-N-[1-(phenylmethyl)-4-piperidinyl]-4-quinazolinamine Chemical compound C=12C=C(OC)C(OC)=CC2=NC(N2CCN(C)CCC2)=NC=1NC(CC1)CCN1CC1=CC=CC=C1 OSXFATOLZGZLSK-UHFFFAOYSA-N 0.000 description 2
- PEHVGBZKEYRQSX-UHFFFAOYSA-N 7-deaza-adenine Chemical compound NC1=NC=NC2=C1C=CN2 PEHVGBZKEYRQSX-UHFFFAOYSA-N 0.000 description 2
- HCGHYQLFMPXSDU-UHFFFAOYSA-N 7-methyladenine Chemical compound C1=NC(N)=C2N(C)C=NC2=N1 HCGHYQLFMPXSDU-UHFFFAOYSA-N 0.000 description 2
- MSSXOMSJDRHRMC-UHFFFAOYSA-N 9H-purine-2,6-diamine Chemical compound NC1=NC(N)=C2NC=NC2=N1 MSSXOMSJDRHRMC-UHFFFAOYSA-N 0.000 description 2
- LRFVTYWOQMYALW-UHFFFAOYSA-N 9H-xanthine Chemical compound O=C1NC(=O)NC2=C1NC=N2 LRFVTYWOQMYALW-UHFFFAOYSA-N 0.000 description 2
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 2
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 2
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 2
- 101100443354 Arabidopsis thaliana DME gene Proteins 0.000 description 2
- 101100331657 Arabidopsis thaliana DML2 gene Proteins 0.000 description 2
- 101100091498 Arabidopsis thaliana ROS1 gene Proteins 0.000 description 2
- 241000203069 Archaea Species 0.000 description 2
- 102100026596 Bcl-2-like protein 1 Human genes 0.000 description 2
- 229920001661 Chitosan Polymers 0.000 description 2
- 150000008574 D-amino acids Chemical class 0.000 description 2
- 101150064551 DML1 gene Proteins 0.000 description 2
- 101150117307 DRM3 gene Proteins 0.000 description 2
- 241000702421 Dependoparvovirus Species 0.000 description 2
- 101001095965 Dictyostelium discoideum Phospholipid-inositol phosphatase Proteins 0.000 description 2
- 108700006830 Drosophila Antp Proteins 0.000 description 2
- 102100038595 Estrogen receptor Human genes 0.000 description 2
- VGGSQFUCUMXWEO-UHFFFAOYSA-N Ethene Chemical compound C=C VGGSQFUCUMXWEO-UHFFFAOYSA-N 0.000 description 2
- 239000005977 Ethylene Substances 0.000 description 2
- 108010015776 Glucose oxidase Proteins 0.000 description 2
- 239000004366 Glucose oxidase Substances 0.000 description 2
- HVLSXIKZNLPZJJ-TXZCQADKSA-N HA peptide Chemical compound C([C@@H](C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 HVLSXIKZNLPZJJ-TXZCQADKSA-N 0.000 description 2
- 108091005772 HDAC11 Proteins 0.000 description 2
- 101000969370 Haemophilus parahaemolyticus Type II methyltransferase M.HhaI Proteins 0.000 description 2
- 102100031573 Hematopoietic progenitor cell antigen CD34 Human genes 0.000 description 2
- 102000006479 Heterogeneous-Nuclear Ribonucleoproteins Human genes 0.000 description 2
- 108010019372 Heterogeneous-Nuclear Ribonucleoproteins Proteins 0.000 description 2
- 108010074870 Histone Demethylases Proteins 0.000 description 2
- 102000008157 Histone Demethylases Human genes 0.000 description 2
- 108010036115 Histone Methyltransferases Proteins 0.000 description 2
- 102000011787 Histone Methyltransferases Human genes 0.000 description 2
- 101710116149 Histone acetyltransferase KAT5 Proteins 0.000 description 2
- 102100033068 Histone acetyltransferase KAT7 Human genes 0.000 description 2
- 108090000246 Histone acetyltransferases Proteins 0.000 description 2
- 102000003893 Histone acetyltransferases Human genes 0.000 description 2
- 102000003964 Histone deacetylase Human genes 0.000 description 2
- 108090000353 Histone deacetylase Proteins 0.000 description 2
- 102100039996 Histone deacetylase 1 Human genes 0.000 description 2
- 102100039385 Histone deacetylase 11 Human genes 0.000 description 2
- 102100039999 Histone deacetylase 2 Human genes 0.000 description 2
- 102100021455 Histone deacetylase 3 Human genes 0.000 description 2
- 102100021454 Histone deacetylase 4 Human genes 0.000 description 2
- 102100021453 Histone deacetylase 5 Human genes 0.000 description 2
- 102100038715 Histone deacetylase 8 Human genes 0.000 description 2
- 102100029768 Histone-lysine N-methyltransferase SETD1A Human genes 0.000 description 2
- 102100030095 Histone-lysine N-methyltransferase SETD1B Human genes 0.000 description 2
- 102100023696 Histone-lysine N-methyltransferase SETDB1 Human genes 0.000 description 2
- 102100028998 Histone-lysine N-methyltransferase SUV39H1 Human genes 0.000 description 2
- 101000741445 Homo sapiens Calcitonin Proteins 0.000 description 2
- 101000882584 Homo sapiens Estrogen receptor Proteins 0.000 description 2
- 101000777663 Homo sapiens Hematopoietic progenitor cell antigen CD34 Proteins 0.000 description 2
- 101001046967 Homo sapiens Histone acetyltransferase KAT2A Proteins 0.000 description 2
- 101001046996 Homo sapiens Histone acetyltransferase KAT5 Proteins 0.000 description 2
- 101000944174 Homo sapiens Histone acetyltransferase KAT6B Proteins 0.000 description 2
- 101000944166 Homo sapiens Histone acetyltransferase KAT7 Proteins 0.000 description 2
- 101000882390 Homo sapiens Histone acetyltransferase p300 Proteins 0.000 description 2
- 101001035024 Homo sapiens Histone deacetylase 1 Proteins 0.000 description 2
- 101001035011 Homo sapiens Histone deacetylase 2 Proteins 0.000 description 2
- 101000899282 Homo sapiens Histone deacetylase 3 Proteins 0.000 description 2
- 101000899259 Homo sapiens Histone deacetylase 4 Proteins 0.000 description 2
- 101000899255 Homo sapiens Histone deacetylase 5 Proteins 0.000 description 2
- 101001032113 Homo sapiens Histone deacetylase 7 Proteins 0.000 description 2
- 101001032118 Homo sapiens Histone deacetylase 8 Proteins 0.000 description 2
- 101001032092 Homo sapiens Histone deacetylase 9 Proteins 0.000 description 2
- 101000865038 Homo sapiens Histone-lysine N-methyltransferase SETD1A Proteins 0.000 description 2
- 101000864672 Homo sapiens Histone-lysine N-methyltransferase SETD1B Proteins 0.000 description 2
- 101000696705 Homo sapiens Histone-lysine N-methyltransferase SUV39H1 Proteins 0.000 description 2
- 101100019690 Homo sapiens KAT6B gene Proteins 0.000 description 2
- 101000613629 Homo sapiens Lysine-specific demethylase 4B Proteins 0.000 description 2
- 101001088895 Homo sapiens Lysine-specific demethylase 4D Proteins 0.000 description 2
- 101001088892 Homo sapiens Lysine-specific demethylase 5A Proteins 0.000 description 2
- 101001088883 Homo sapiens Lysine-specific demethylase 5B Proteins 0.000 description 2
- 101001025967 Homo sapiens Lysine-specific demethylase 6A Proteins 0.000 description 2
- 101001025971 Homo sapiens Lysine-specific demethylase 6B Proteins 0.000 description 2
- 101000653360 Homo sapiens Methylcytosine dioxygenase TET1 Proteins 0.000 description 2
- 101001017254 Homo sapiens Myb-binding protein 1A Proteins 0.000 description 2
- 101000602926 Homo sapiens Nuclear receptor coactivator 1 Proteins 0.000 description 2
- 101000687346 Homo sapiens PR domain zinc finger protein 2 Proteins 0.000 description 2
- 101000738757 Homo sapiens Phosphatidylglycerophosphatase and protein-tyrosine phosphatase 1 Proteins 0.000 description 2
- 101000686031 Homo sapiens Proto-oncogene tyrosine-protein kinase ROS Proteins 0.000 description 2
- 101000651467 Homo sapiens Proto-oncogene tyrosine-protein kinase Src Proteins 0.000 description 2
- 101000755643 Homo sapiens RIMS-binding protein 2 Proteins 0.000 description 2
- 101000756365 Homo sapiens Retinol-binding protein 2 Proteins 0.000 description 2
- 101000596093 Homo sapiens Transcription initiation factor TFIID subunit 1 Proteins 0.000 description 2
- 108700003968 Human immunodeficiency virus 1 tat peptide (49-57) Proteins 0.000 description 2
- 102100037924 Insulin-like growth factor 2 mRNA-binding protein 1 Human genes 0.000 description 2
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 2
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 2
- 241000713666 Lentivirus Species 0.000 description 2
- 239000000232 Lipid Bilayer Substances 0.000 description 2
- 102100040860 Lysine-specific demethylase 4B Human genes 0.000 description 2
- 102100033231 Lysine-specific demethylase 4D Human genes 0.000 description 2
- 101710105712 Lysine-specific demethylase 5B Proteins 0.000 description 2
- 102100037462 Lysine-specific demethylase 6A Human genes 0.000 description 2
- 102100037461 Lysine-specific demethylase 6B Human genes 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- 102100030819 Methylcytosine dioxygenase TET1 Human genes 0.000 description 2
- ZOKXTWBITQBERF-UHFFFAOYSA-N Molybdenum Chemical compound [Mo] ZOKXTWBITQBERF-UHFFFAOYSA-N 0.000 description 2
- 101100219625 Mus musculus Casd1 gene Proteins 0.000 description 2
- 102100034005 Myb-binding protein 1A Human genes 0.000 description 2
- 102100031455 NAD-dependent protein deacetylase sirtuin-1 Human genes 0.000 description 2
- 102100022913 NAD-dependent protein deacetylase sirtuin-2 Human genes 0.000 description 2
- 108700019961 Neoplasm Genes Proteins 0.000 description 2
- 102000048850 Neoplasm Genes Human genes 0.000 description 2
- 238000000636 Northern blotting Methods 0.000 description 2
- 108090001145 Nuclear Receptor Coactivator 3 Proteins 0.000 description 2
- 102100022883 Nuclear receptor coactivator 3 Human genes 0.000 description 2
- 108091005461 Nucleic proteins Proteins 0.000 description 2
- 102100024885 PR domain zinc finger protein 2 Human genes 0.000 description 2
- 102000005877 Peptide Initiation Factors Human genes 0.000 description 2
- 108010044843 Peptide Initiation Factors Proteins 0.000 description 2
- 108010039918 Polylysine Proteins 0.000 description 2
- 108010076504 Protein Sorting Signals Proteins 0.000 description 2
- 101710149951 Protein Tat Proteins 0.000 description 2
- 102100023347 Proto-oncogene tyrosine-protein kinase ROS Human genes 0.000 description 2
- 102100027384 Proto-oncogene tyrosine-protein kinase Src Human genes 0.000 description 2
- 230000014632 RNA localization Effects 0.000 description 2
- 230000007022 RNA scission Effects 0.000 description 2
- 102000044126 RNA-Binding Proteins Human genes 0.000 description 2
- 230000004570 RNA-binding Effects 0.000 description 2
- 241000700159 Rattus Species 0.000 description 2
- 101001023863 Rattus norvegicus Glucocorticoid receptor Proteins 0.000 description 2
- 238000012300 Sequence Analysis Methods 0.000 description 2
- 108010041191 Sirtuin 1 Proteins 0.000 description 2
- 108010041216 Sirtuin 2 Proteins 0.000 description 2
- 101710192266 Tegument protein VP22 Proteins 0.000 description 2
- 108010022394 Threonine synthase Proteins 0.000 description 2
- 102000040945 Transcription factor Human genes 0.000 description 2
- 108091023040 Transcription factor Proteins 0.000 description 2
- 102100035222 Transcription initiation factor TFIID subunit 1 Human genes 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- 208000036142 Viral infection Diseases 0.000 description 2
- 238000003914 acid mine drainage Methods 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- DZBUGLKDJFMEHC-UHFFFAOYSA-N acridine Chemical compound C1=CC=CC2=CC3=CC=CC=C3N=C21 DZBUGLKDJFMEHC-UHFFFAOYSA-N 0.000 description 2
- 125000001931 aliphatic group Chemical group 0.000 description 2
- 150000001345 alkine derivatives Chemical class 0.000 description 2
- 125000003282 alkyl amino group Chemical group 0.000 description 2
- 125000003277 amino group Chemical group 0.000 description 2
- 239000005557 antagonist Substances 0.000 description 2
- 230000001640 apoptogenic effect Effects 0.000 description 2
- PYMYPHUHKUWMLA-WDCZJNDASA-N arabinose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)C=O PYMYPHUHKUWMLA-WDCZJNDASA-N 0.000 description 2
- 125000004429 atom Chemical group 0.000 description 2
- 108010051210 beta-Fructofuranosidase Proteins 0.000 description 2
- 210000001185 bone marrow Anatomy 0.000 description 2
- 238000004422 calculation algorithm Methods 0.000 description 2
- 210000000234 capsid Anatomy 0.000 description 2
- 150000001720 carbohydrates Chemical class 0.000 description 2
- 235000014633 carbohydrates Nutrition 0.000 description 2
- 229910052799 carbon Inorganic materials 0.000 description 2
- 125000004432 carbon atom Chemical group C* 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 101150055766 cat gene Proteins 0.000 description 2
- 210000000170 cell membrane Anatomy 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- BHONFOAYRQZPKZ-LCLOTLQISA-N chembl269478 Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCCNC(N)=N)[C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O)C1=CC=CC=C1 BHONFOAYRQZPKZ-LCLOTLQISA-N 0.000 description 2
- 239000003795 chemical substances by application Substances 0.000 description 2
- 235000012000 cholesterol Nutrition 0.000 description 2
- HISOCSRUFLPKDE-KLXQUTNESA-N cmt-2 Chemical compound C1=CC=C2[C@](O)(C)C3CC4C(N(C)C)C(O)=C(C#N)C(=O)[C@@]4(O)C(O)=C3C(=O)C2=C1O HISOCSRUFLPKDE-KLXQUTNESA-N 0.000 description 2
- 239000000356 contaminant Substances 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- ZYGHJZDHTFUPRJ-UHFFFAOYSA-N coumarin Chemical compound C1=CC=C2OC(=O)C=CC2=C1 ZYGHJZDHTFUPRJ-UHFFFAOYSA-N 0.000 description 2
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 2
- 235000018417 cysteine Nutrition 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 206010012601 diabetes mellitus Diseases 0.000 description 2
- ANCLJVISBRWUTR-UHFFFAOYSA-N diaminophosphinic acid Chemical compound NP(N)(O)=O ANCLJVISBRWUTR-UHFFFAOYSA-N 0.000 description 2
- 239000010432 diamond Substances 0.000 description 2
- 102000004419 dihydrofolate reductase Human genes 0.000 description 2
- 239000000539 dimer Substances 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 230000005782 double-strand break Effects 0.000 description 2
- 239000000975 dye Substances 0.000 description 2
- 238000005538 encapsulation Methods 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000007613 environmental effect Effects 0.000 description 2
- 239000003687 estradiol congener Substances 0.000 description 2
- 108010038795 estrogen receptors Proteins 0.000 description 2
- 210000001723 extracellular space Anatomy 0.000 description 2
- 238000007667 floating Methods 0.000 description 2
- 108010021843 fluorescent protein 583 Proteins 0.000 description 2
- 125000001153 fluoro group Chemical group F* 0.000 description 2
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 2
- 125000003843 furanosyl group Chemical group 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- 229940116332 glucose oxidase Drugs 0.000 description 2
- 235000019420 glucose oxidase Nutrition 0.000 description 2
- 125000001475 halogen functional group Chemical group 0.000 description 2
- 125000005842 heteroatom Chemical group 0.000 description 2
- 229920001519 homopolymer Polymers 0.000 description 2
- FDGQSTZJBFJUBT-UHFFFAOYSA-N hypoxanthine Chemical compound O=C1NC=NC2=C1NC=N2 FDGQSTZJBFJUBT-UHFFFAOYSA-N 0.000 description 2
- 150000002484 inorganic compounds Chemical class 0.000 description 2
- 229910010272 inorganic material Inorganic materials 0.000 description 2
- 210000003093 intracellular space Anatomy 0.000 description 2
- 239000001573 invertase Substances 0.000 description 2
- 235000011073 invertase Nutrition 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- 210000003734 kidney Anatomy 0.000 description 2
- 238000001638 lipofection Methods 0.000 description 2
- 239000002479 lipoplex Substances 0.000 description 2
- 239000006166 lysate Substances 0.000 description 2
- 108010021853 m(5)C rRNA methyltransferase Proteins 0.000 description 2
- 238000012423 maintenance Methods 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 239000000693 micelle Substances 0.000 description 2
- 125000004573 morpholin-4-yl group Chemical group N1(CCOCC1)* 0.000 description 2
- 210000003463 organelle Anatomy 0.000 description 2
- 150000002894 organic compounds Chemical class 0.000 description 2
- 229910052760 oxygen Inorganic materials 0.000 description 2
- FJKROLUGYXJWQN-UHFFFAOYSA-N papa-hydroxy-benzoic acid Natural products OC(=O)C1=CC=C(O)C=C1 FJKROLUGYXJWQN-UHFFFAOYSA-N 0.000 description 2
- 230000035515 penetration Effects 0.000 description 2
- 230000003285 pharmacodynamic effect Effects 0.000 description 2
- RDOWQLZANAYVLL-UHFFFAOYSA-N phenanthridine Chemical compound C1=CC=C2C3=CC=CC=C3C=NC2=C1 RDOWQLZANAYVLL-UHFFFAOYSA-N 0.000 description 2
- 150000004713 phosphodiesters Chemical class 0.000 description 2
- 150000003904 phospholipids Chemical class 0.000 description 2
- 150000008300 phosphoramidites Chemical class 0.000 description 2
- 108010054442 polyalanine Proteins 0.000 description 2
- 229920000768 polyamine Polymers 0.000 description 2
- 229920001223 polyethylene glycol Polymers 0.000 description 2
- 229920000656 polylysine Polymers 0.000 description 2
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 2
- 230000001737 promoting effect Effects 0.000 description 2
- 238000000159 protein binding assay Methods 0.000 description 2
- 150000003212 purines Chemical class 0.000 description 2
- 150000003230 pyrimidines Chemical class 0.000 description 2
- 102000005912 ran GTP Binding Protein Human genes 0.000 description 2
- 230000006798 recombination Effects 0.000 description 2
- 238000005215 recombination Methods 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 150000004492 retinoid derivatives Chemical class 0.000 description 2
- 125000000548 ribosyl group Chemical group C1([C@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 2
- 229960004889 salicylic acid Drugs 0.000 description 2
- 150000003839 salts Chemical class 0.000 description 2
- 210000000130 stem cell Anatomy 0.000 description 2
- 230000004936 stimulating effect Effects 0.000 description 2
- 230000004960 subcellular localization Effects 0.000 description 2
- 229910052717 sulfur Inorganic materials 0.000 description 2
- 150000003568 thioethers Chemical class 0.000 description 2
- 108091006106 transcriptional activators Proteins 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 230000014621 translational initiation Effects 0.000 description 2
- 241001430294 unidentified retrovirus Species 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- 230000009385 viral infection Effects 0.000 description 2
- DIGQNXIGRZPYDK-WKSCXVIASA-N (2R)-6-amino-2-[[2-[[(2S)-2-[[2-[[(2R)-2-[[(2S)-2-[[(2R,3S)-2-[[2-[[(2S)-2-[[2-[[(2S)-2-[[(2S)-2-[[(2R)-2-[[(2S,3S)-2-[[(2R)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[2-[[(2S)-2-[[(2R)-2-[[2-[[2-[[2-[(2-amino-1-hydroxyethylidene)amino]-3-carboxy-1-hydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1,5-dihydroxy-5-iminopentylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]hexanoic acid Chemical compound C[C@@H]([C@@H](C(=N[C@@H](CS)C(=N[C@@H](C)C(=N[C@@H](CO)C(=NCC(=N[C@@H](CCC(=N)O)C(=NC(CS)C(=N[C@H]([C@H](C)O)C(=N[C@H](CS)C(=N[C@H](CO)C(=NCC(=N[C@H](CS)C(=NCC(=N[C@H](CCCCN)C(=O)O)O)O)O)O)O)O)O)O)O)O)O)O)O)N=C([C@H](CS)N=C([C@H](CO)N=C([C@H](CO)N=C([C@H](C)N=C(CN=C([C@H](CO)N=C([C@H](CS)N=C(CN=C(C(CS)N=C(C(CC(=O)O)N=C(CN)O)O)O)O)O)O)O)O)O)O)O)O DIGQNXIGRZPYDK-WKSCXVIASA-N 0.000 description 1
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 1
- JARGNLJYKBUKSJ-KGZKBUQUSA-N (2r)-2-amino-5-[[(2r)-1-(carboxymethylamino)-3-hydroxy-1-oxopropan-2-yl]amino]-5-oxopentanoic acid;hydrobromide Chemical compound Br.OC(=O)[C@H](N)CCC(=O)N[C@H](CO)C(=O)NCC(O)=O JARGNLJYKBUKSJ-KGZKBUQUSA-N 0.000 description 1
- YIMATHOGWXZHFX-WCTZXXKLSA-N (2r,3r,4r,5r)-5-(hydroxymethyl)-3-(2-methoxyethoxy)oxolane-2,4-diol Chemical compound COCCO[C@H]1[C@H](O)O[C@H](CO)[C@H]1O YIMATHOGWXZHFX-WCTZXXKLSA-N 0.000 description 1
- BEJKOYIMCGMNRB-GRHHLOCNSA-N (2s)-2-amino-3-(4-hydroxyphenyl)propanoic acid;(2s)-2-amino-3-phenylpropanoic acid Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1.OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 BEJKOYIMCGMNRB-GRHHLOCNSA-N 0.000 description 1
- KUHSEZKIEJYEHN-BXRBKJIMSA-N (2s)-2-amino-3-hydroxypropanoic acid;(2s)-2-aminopropanoic acid Chemical compound C[C@H](N)C(O)=O.OC[C@H](N)C(O)=O KUHSEZKIEJYEHN-BXRBKJIMSA-N 0.000 description 1
- BHQCQFFYRZLCQQ-UHFFFAOYSA-N (3alpha,5alpha,7alpha,12alpha)-3,7,12-trihydroxy-cholan-24-oic acid Natural products OC1CC2CC(O)CCC2(C)C2C1C1CCC(C(CCC(O)=O)C)C1(C)C(O)C2 BHQCQFFYRZLCQQ-UHFFFAOYSA-N 0.000 description 1
- QGVQZRDQPDLHHV-DPAQBDIFSA-N (3s,8s,9s,10r,13r,14s,17r)-10,13-dimethyl-17-[(2r)-6-methylheptan-2-yl]-2,3,4,7,8,9,11,12,14,15,16,17-dodecahydro-1h-cyclopenta[a]phenanthrene-3-thiol Chemical compound C1C=C2C[C@@H](S)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 QGVQZRDQPDLHHV-DPAQBDIFSA-N 0.000 description 1
- SGKRLCUYIXIAHR-AKNGSSGZSA-N (4s,4ar,5s,5ar,6r,12ar)-4-(dimethylamino)-1,5,10,11,12a-pentahydroxy-6-methyl-3,12-dioxo-4a,5,5a,6-tetrahydro-4h-tetracene-2-carboxamide Chemical compound C1=CC=C2[C@H](C)[C@@H]([C@H](O)[C@@H]3[C@](C(O)=C(C(N)=O)C(=O)[C@H]3N(C)C)(O)C3=O)C3=C(O)C2=C1O SGKRLCUYIXIAHR-AKNGSSGZSA-N 0.000 description 1
- 125000000008 (C1-C10) alkyl group Chemical group 0.000 description 1
- PTFYZDMJTFMPQW-UHFFFAOYSA-N 1,10-dihydropyrimido[5,4-b][1,4]benzoxazin-2-one Chemical compound O1C2=CC=CC=C2N=C2C1=CNC(=O)N2 PTFYZDMJTFMPQW-UHFFFAOYSA-N 0.000 description 1
- FYADHXFMURLYQI-UHFFFAOYSA-N 1,2,4-triazine Chemical class C1=CN=NC=N1 FYADHXFMURLYQI-UHFFFAOYSA-N 0.000 description 1
- JKMPXGJJRMOELF-UHFFFAOYSA-N 1,3-thiazole-2,4,5-tricarboxylic acid Chemical group OC(=O)C1=NC(C(O)=O)=C(C(O)=O)S1 JKMPXGJJRMOELF-UHFFFAOYSA-N 0.000 description 1
- UHDGCWIWMRVCDJ-UHFFFAOYSA-N 1-beta-D-Xylofuranosyl-NH-Cytosine Natural products O=C1N=C(N)C=CN1C1C(O)C(O)C(CO)O1 UHDGCWIWMRVCDJ-UHFFFAOYSA-N 0.000 description 1
- WJFKNYWRSNBZNX-UHFFFAOYSA-N 10H-phenothiazine Chemical compound C1=CC=C2NC3=CC=CC=C3SC2=C1 WJFKNYWRSNBZNX-UHFFFAOYSA-N 0.000 description 1
- UHUHBFMZVCOEOV-UHFFFAOYSA-N 1h-imidazo[4,5-c]pyridin-4-amine Chemical compound NC1=NC=CC2=C1N=CN2 UHUHBFMZVCOEOV-UHFFFAOYSA-N 0.000 description 1
- VEPOHXYIFQMVHW-XOZOLZJESA-N 2,3-dihydroxybutanedioic acid (2S,3S)-3,4-dimethyl-2-phenylmorpholine Chemical compound OC(C(O)C(O)=O)C(O)=O.C[C@H]1[C@@H](OCCN1C)c1ccccc1 VEPOHXYIFQMVHW-XOZOLZJESA-N 0.000 description 1
- QSHACTSJHMKXTE-UHFFFAOYSA-N 2-(2-aminopropyl)-7h-purin-6-amine Chemical compound CC(N)CC1=NC(N)=C2NC=NC2=N1 QSHACTSJHMKXTE-UHFFFAOYSA-N 0.000 description 1
- JRYMOPZHXMVHTA-DAGMQNCNSA-N 2-amino-7-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-1h-pyrrolo[2,3-d]pyrimidin-4-one Chemical compound C1=CC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O JRYMOPZHXMVHTA-DAGMQNCNSA-N 0.000 description 1
- WKMPTBDYDNUJLF-UHFFFAOYSA-N 2-fluoroadenine Chemical compound NC1=NC(F)=NC2=C1N=CN2 WKMPTBDYDNUJLF-UHFFFAOYSA-N 0.000 description 1
- 125000004200 2-methoxyethyl group Chemical group [H]C([H])([H])OC([H])([H])C([H])([H])* 0.000 description 1
- 125000003903 2-propenyl group Chemical group [H]C([*])([H])C([H])=C([H])[H] 0.000 description 1
- 102100039377 28 kDa heat- and acid-stable phosphoprotein Human genes 0.000 description 1
- 101710176122 28 kDa heat- and acid-stable phosphoprotein Proteins 0.000 description 1
- FHSQHXGZAXPNBF-UHFFFAOYSA-N 3,4-dihydro-1,4-benzothiazin-2-one Chemical compound C1=CC=C2SC(=O)CNC2=C1 FHSQHXGZAXPNBF-UHFFFAOYSA-N 0.000 description 1
- MCSXGCZMEPXKIW-UHFFFAOYSA-N 3-hydroxy-4-[(4-methyl-2-nitrophenyl)diazenyl]-N-(3-nitrophenyl)naphthalene-2-carboxamide Chemical compound Cc1ccc(N=Nc2c(O)c(cc3ccccc23)C(=O)Nc2cccc(c2)[N+]([O-])=O)c(c1)[N+]([O-])=O MCSXGCZMEPXKIW-UHFFFAOYSA-N 0.000 description 1
- OVONXEQGWXGFJD-UHFFFAOYSA-N 4-sulfanylidene-1h-pyrimidin-2-one Chemical compound SC=1C=CNC(=O)N=1 OVONXEQGWXGFJD-UHFFFAOYSA-N 0.000 description 1
- 101710169336 5'-deoxyadenosine deaminase Proteins 0.000 description 1
- ZLAQATDNGLKIEV-UHFFFAOYSA-N 5-methyl-2-sulfanylidene-1h-pyrimidin-4-one Chemical compound CC1=CNC(=S)NC1=O ZLAQATDNGLKIEV-UHFFFAOYSA-N 0.000 description 1
- UJBCLAXPPIDQEE-UHFFFAOYSA-N 5-prop-1-ynyl-1h-pyrimidine-2,4-dione Chemical compound CC#CC1=CNC(=O)NC1=O UJBCLAXPPIDQEE-UHFFFAOYSA-N 0.000 description 1
- KXBCLNRMQPRVTP-UHFFFAOYSA-N 6-amino-1,5-dihydroimidazo[4,5-c]pyridin-4-one Chemical compound O=C1NC(N)=CC2=C1N=CN2 KXBCLNRMQPRVTP-UHFFFAOYSA-N 0.000 description 1
- DCPSTSVLRXOYGS-UHFFFAOYSA-N 6-amino-1h-pyrimidine-2-thione Chemical compound NC1=CC=NC(S)=N1 DCPSTSVLRXOYGS-UHFFFAOYSA-N 0.000 description 1
- QNNARSZPGNJZIX-UHFFFAOYSA-N 6-amino-5-prop-1-ynyl-1h-pyrimidin-2-one Chemical compound CC#CC1=CNC(=O)N=C1N QNNARSZPGNJZIX-UHFFFAOYSA-N 0.000 description 1
- LOSIULRWFAEMFL-UHFFFAOYSA-N 7-deazaguanine Chemical compound O=C1NC(N)=NC2=C1CC=N2 LOSIULRWFAEMFL-UHFFFAOYSA-N 0.000 description 1
- HRYKDUPGBWLLHO-UHFFFAOYSA-N 8-azaadenine Chemical compound NC1=NC=NC2=NNN=C12 HRYKDUPGBWLLHO-UHFFFAOYSA-N 0.000 description 1
- LPXQRXLUHJKZIE-UHFFFAOYSA-N 8-azaguanine Chemical compound NC1=NC(O)=C2NN=NC2=N1 LPXQRXLUHJKZIE-UHFFFAOYSA-N 0.000 description 1
- 229960005508 8-azaguanine Drugs 0.000 description 1
- 239000013607 AAV vector Substances 0.000 description 1
- 102000012758 APOBEC-1 Deaminase Human genes 0.000 description 1
- 108010079649 APOBEC-1 Deaminase Proteins 0.000 description 1
- 101710159080 Aconitate hydratase A Proteins 0.000 description 1
- 101710159078 Aconitate hydratase B Proteins 0.000 description 1
- 241000186045 Actinomyces naeslundii Species 0.000 description 1
- 102100036664 Adenosine deaminase Human genes 0.000 description 1
- 241001136782 Alca Species 0.000 description 1
- 102000007698 Alcohol dehydrogenase Human genes 0.000 description 1
- 108010021809 Alcohol dehydrogenase Proteins 0.000 description 1
- 241000242757 Anthozoa Species 0.000 description 1
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 1
- 229940088872 Apoptosis inhibitor Drugs 0.000 description 1
- 101100219315 Arabidopsis thaliana CYP83A1 gene Proteins 0.000 description 1
- 101100137444 Arabidopsis thaliana PCMP-H40 gene Proteins 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 241000714230 Avian leukemia virus Species 0.000 description 1
- 108091032955 Bacterial small RNA Proteins 0.000 description 1
- 206010061692 Benign muscle neoplasm Diseases 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 101500025162 Bos taurus Inter-alpha-trypsin inhibitor light chain Proteins 0.000 description 1
- 241000219198 Brassica Species 0.000 description 1
- 235000003351 Brassica cretica Nutrition 0.000 description 1
- 235000003343 Brassica rupestris Nutrition 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- 108010014064 CCCTC-Binding Factor Proteins 0.000 description 1
- 101100014712 Caenorhabditis elegans gld-2 gene Proteins 0.000 description 1
- 101100421200 Caenorhabditis elegans sep-1 gene Proteins 0.000 description 1
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 1
- 101000909256 Caldicellulosiruptor bescii (strain ATCC BAA-1888 / DSM 6725 / Z-1320) DNA polymerase I Proteins 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 101710132601 Capsid protein Proteins 0.000 description 1
- 102000053642 Catalytic RNA Human genes 0.000 description 1
- 108090000994 Catalytic RNA Proteins 0.000 description 1
- 108091005944 Cerulean Proteins 0.000 description 1
- 239000004380 Cholic acid Substances 0.000 description 1
- 108010077544 Chromatin Proteins 0.000 description 1
- 102000011591 Cleavage And Polyadenylation Specificity Factor Human genes 0.000 description 1
- 108010076130 Cleavage And Polyadenylation Specificity Factor Proteins 0.000 description 1
- 102000005221 Cleavage Stimulation Factor Human genes 0.000 description 1
- 108010081236 Cleavage Stimulation Factor Proteins 0.000 description 1
- 101710094648 Coat protein Proteins 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 108020004394 Complementary RNA Proteins 0.000 description 1
- 108091005943 CyPet Proteins 0.000 description 1
- 102100026810 Cyclin-dependent kinase 7 Human genes 0.000 description 1
- UHDGCWIWMRVCDJ-PSQAKQOGSA-N Cytidine Natural products O=C1N=C(N)C=CN1[C@@H]1[C@@H](O)[C@@H](O)[C@H](CO)O1 UHDGCWIWMRVCDJ-PSQAKQOGSA-N 0.000 description 1
- 102000000311 Cytosine Deaminase Human genes 0.000 description 1
- 108010080611 Cytosine Deaminase Proteins 0.000 description 1
- 101710177611 DNA polymerase II large subunit Proteins 0.000 description 1
- 101710184669 DNA polymerase II small subunit Proteins 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 102000052510 DNA-Binding Proteins Human genes 0.000 description 1
- 101710096438 DNA-binding protein Proteins 0.000 description 1
- 108010053770 Deoxyribonucleases Proteins 0.000 description 1
- 102000016911 Deoxyribonucleases Human genes 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 108010028143 Dioxygenases Proteins 0.000 description 1
- 102000016680 Dioxygenases Human genes 0.000 description 1
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 1
- 108091005942 ECFP Proteins 0.000 description 1
- 241000991587 Enterovirus C Species 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 108090000331 Firefly luciferases Proteins 0.000 description 1
- 235000014820 Galium aparine Nutrition 0.000 description 1
- 240000005702 Galium aparine Species 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 1
- 108010014458 Gin recombinase Proteins 0.000 description 1
- 108010063907 Glutathione Reductase Proteins 0.000 description 1
- 102100036442 Glutathione reductase, mitochondrial Human genes 0.000 description 1
- BCCRXDTUTZHDEU-VKHMYHEASA-N Gly-Ser Chemical compound NCC(=O)N[C@@H](CO)C(O)=O BCCRXDTUTZHDEU-VKHMYHEASA-N 0.000 description 1
- 235000010469 Glycine max Nutrition 0.000 description 1
- 244000068988 Glycine max Species 0.000 description 1
- 102100021181 Golgi phosphoprotein 3 Human genes 0.000 description 1
- 101150010036 HNT3 gene Proteins 0.000 description 1
- 102100032510 Heat shock protein HSP 90-beta Human genes 0.000 description 1
- 101710154606 Hemagglutinin Proteins 0.000 description 1
- 108010068250 Herpes Simplex Virus Protein Vmw65 Proteins 0.000 description 1
- 101001023784 Heteractis crispa GFP-like non-fluorescent chromoprotein Proteins 0.000 description 1
- 102000017013 Heterogeneous Nuclear Ribonucleoprotein A1 Human genes 0.000 description 1
- 108010014594 Heterogeneous Nuclear Ribonucleoprotein A1 Proteins 0.000 description 1
- 102100033069 Histone acetyltransferase KAT8 Human genes 0.000 description 1
- 102100038885 Histone acetyltransferase p300 Human genes 0.000 description 1
- 102100022103 Histone-lysine N-methyltransferase 2A Human genes 0.000 description 1
- 102100026265 Histone-lysine N-methyltransferase ASH1L Human genes 0.000 description 1
- 102100038970 Histone-lysine N-methyltransferase EZH2 Human genes 0.000 description 1
- 101710168120 Histone-lysine N-methyltransferase SETDB1 Proteins 0.000 description 1
- 102100028988 Histone-lysine N-methyltransferase SUV39H2 Human genes 0.000 description 1
- 102100029239 Histone-lysine N-methyltransferase, H3 lysine-36 specific Human genes 0.000 description 1
- 102100039489 Histone-lysine N-methyltransferase, H3 lysine-79 specific Human genes 0.000 description 1
- 241001272567 Hominoidea Species 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000901099 Homo sapiens Achaete-scute homolog 1 Proteins 0.000 description 1
- 101000911952 Homo sapiens Cyclin-dependent kinase 7 Proteins 0.000 description 1
- 101001016856 Homo sapiens Heat shock protein HSP 90-beta Proteins 0.000 description 1
- 101000944170 Homo sapiens Histone acetyltransferase KAT8 Proteins 0.000 description 1
- 101001045846 Homo sapiens Histone-lysine N-methyltransferase 2A Proteins 0.000 description 1
- 101000785963 Homo sapiens Histone-lysine N-methyltransferase ASH1L Proteins 0.000 description 1
- 101000882127 Homo sapiens Histone-lysine N-methyltransferase EZH2 Proteins 0.000 description 1
- 101000684609 Homo sapiens Histone-lysine N-methyltransferase SETDB1 Proteins 0.000 description 1
- 101000696699 Homo sapiens Histone-lysine N-methyltransferase SUV39H2 Proteins 0.000 description 1
- 101000634050 Homo sapiens Histone-lysine N-methyltransferase, H3 lysine-36 specific Proteins 0.000 description 1
- 101000963360 Homo sapiens Histone-lysine N-methyltransferase, H3 lysine-79 specific Proteins 0.000 description 1
- 101000599778 Homo sapiens Insulin-like growth factor 2 mRNA-binding protein 1 Proteins 0.000 description 1
- 101000988591 Homo sapiens Minor histocompatibility antigen H13 Proteins 0.000 description 1
- 101000864039 Homo sapiens Nonsense-mediated mRNA decay factor SMG5 Proteins 0.000 description 1
- 101000912957 Homo sapiens Protein DEK Proteins 0.000 description 1
- 101000668140 Homo sapiens RNA-binding protein 8A Proteins 0.000 description 1
- 101000579423 Homo sapiens Regulator of nonsense transcripts 1 Proteins 0.000 description 1
- 101001090935 Homo sapiens Regulator of nonsense transcripts 3A Proteins 0.000 description 1
- 101000829211 Homo sapiens Serine/arginine repetitive matrix protein 1 Proteins 0.000 description 1
- 101001063514 Homo sapiens Telomerase-binding protein EST1A Proteins 0.000 description 1
- 101000964436 Homo sapiens Z-DNA-binding protein 1 Proteins 0.000 description 1
- 101000818735 Homo sapiens Zinc finger protein 10 Proteins 0.000 description 1
- 108700020121 Human Immunodeficiency Virus-1 rev Proteins 0.000 description 1
- UGQMRVRMYYASKQ-UHFFFAOYSA-N Hypoxanthine nucleoside Natural products OC1C(O)C(CO)OC1N1C(NC=NC2=O)=C2N=C1 UGQMRVRMYYASKQ-UHFFFAOYSA-N 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 102100023408 KH domain-containing, RNA-binding, signal transduction-associated protein 1 Human genes 0.000 description 1
- 101710094958 KH domain-containing, RNA-binding, signal transduction-associated protein 1 Proteins 0.000 description 1
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 1
- 150000008575 L-amino acids Chemical class 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 1
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 108010021099 Lamin Type A Proteins 0.000 description 1
- 102000008201 Lamin Type A Human genes 0.000 description 1
- 108010021101 Lamin Type B Proteins 0.000 description 1
- 101000988090 Leishmania donovani Heat shock protein 83 Proteins 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 101710125418 Major capsid protein Proteins 0.000 description 1
- 102000003792 Metallothionein Human genes 0.000 description 1
- 108090000157 Metallothionein Proteins 0.000 description 1
- 241000713333 Mouse mammary tumor virus Species 0.000 description 1
- 108010085220 Multiprotein Complexes Proteins 0.000 description 1
- 102000007474 Multiprotein Complexes Human genes 0.000 description 1
- 241000714177 Murine leukemia virus Species 0.000 description 1
- 101100269674 Mus musculus Alyref2 gene Proteins 0.000 description 1
- 101000969137 Mus musculus Metallothionein-1 Proteins 0.000 description 1
- 101100078999 Mus musculus Mx1 gene Proteins 0.000 description 1
- 101000978776 Mus musculus Neurogenic locus notch homolog protein 1 Proteins 0.000 description 1
- 101100046352 Mus musculus Tjap1 gene Proteins 0.000 description 1
- 102100038895 Myc proto-oncogene protein Human genes 0.000 description 1
- 101710135898 Myc proto-oncogene protein Proteins 0.000 description 1
- 241000713883 Myeloproliferative sarcoma virus Species 0.000 description 1
- 201000004458 Myoma Diseases 0.000 description 1
- OVBPIULPVIDEAO-UHFFFAOYSA-N N-Pteroyl-L-glutaminsaeure Natural products C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-UHFFFAOYSA-N 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 102100029940 Nonsense-mediated mRNA decay factor SMG5 Human genes 0.000 description 1
- 102000002488 Nucleoplasmin Human genes 0.000 description 1
- 101710141454 Nucleoprotein Proteins 0.000 description 1
- XDMCWZFLLGVIID-SXPRBRBTSA-N O-(3-O-D-galactosyl-N-acetyl-beta-D-galactosaminyl)-L-serine Chemical compound CC(=O)N[C@H]1[C@H](OC[C@H]([NH3+])C([O-])=O)O[C@H](CO)[C@H](O)[C@@H]1OC1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 XDMCWZFLLGVIID-SXPRBRBTSA-N 0.000 description 1
- BZQFBWGGLXLEPQ-UHFFFAOYSA-N O-phosphoryl-L-serine Natural products OC(=O)C(N)COP(O)(O)=O BZQFBWGGLXLEPQ-UHFFFAOYSA-N 0.000 description 1
- REYJJPSVUYRZGE-UHFFFAOYSA-N Octadecylamine Chemical compound CCCCCCCCCCCCCCCCCCN REYJJPSVUYRZGE-UHFFFAOYSA-N 0.000 description 1
- 101710093908 Outer capsid protein VP4 Proteins 0.000 description 1
- 101710135467 Outer capsid protein sigma-1 Proteins 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 102100026450 POU domain, class 3, transcription factor 4 Human genes 0.000 description 1
- 101710133389 POU domain, class 3, transcription factor 4 Proteins 0.000 description 1
- 108010043958 Peptoids Proteins 0.000 description 1
- 102000003992 Peroxidases Human genes 0.000 description 1
- PCNDJXKNXGMECE-UHFFFAOYSA-N Phenazine Natural products C1=CC=CC2=NC3=CC=CC=C3N=C21 PCNDJXKNXGMECE-UHFFFAOYSA-N 0.000 description 1
- ABLZXFCXXLZCGV-UHFFFAOYSA-N Phosphorous acid Chemical class OP(O)=O ABLZXFCXXLZCGV-UHFFFAOYSA-N 0.000 description 1
- 235000010582 Pisum sativum Nutrition 0.000 description 1
- 240000004713 Pisum sativum Species 0.000 description 1
- 102000012338 Poly(ADP-ribose) Polymerases Human genes 0.000 description 1
- 108010061844 Poly(ADP-ribose) Polymerases Proteins 0.000 description 1
- 229920000776 Poly(Adenosine diphosphate-ribose) polymerase Polymers 0.000 description 1
- 102100026090 Polyadenylate-binding protein 1 Human genes 0.000 description 1
- 101710103012 Polyadenylate-binding protein, cytoplasmic and nuclear Proteins 0.000 description 1
- 239000004952 Polyamide Substances 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- 101710083689 Probable capsid protein Proteins 0.000 description 1
- 101710176177 Protein A56 Proteins 0.000 description 1
- 108700040121 Protein Methyltransferases Proteins 0.000 description 1
- 102000055027 Protein Methyltransferases Human genes 0.000 description 1
- 101000902592 Pyrococcus furiosus (strain ATCC 43587 / DSM 3638 / JCM 8422 / Vc1) DNA polymerase Proteins 0.000 description 1
- 238000010357 RNA editing Methods 0.000 description 1
- 230000026279 RNA modification Effects 0.000 description 1
- 230000021839 RNA stabilization Effects 0.000 description 1
- 108700020471 RNA-Binding Proteins Proteins 0.000 description 1
- 101710105008 RNA-binding protein Proteins 0.000 description 1
- 241000220259 Raphanus Species 0.000 description 1
- 235000006140 Raphanus sativus var sativus Nutrition 0.000 description 1
- 101000599776 Rattus norvegicus Insulin-like growth factor 2 mRNA-binding protein 1 Proteins 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 102100028287 Regulator of nonsense transcripts 1 Human genes 0.000 description 1
- 102100021087 Regulator of nonsense transcripts 2 Human genes 0.000 description 1
- 102100035026 Regulator of nonsense transcripts 3A Human genes 0.000 description 1
- 241000242739 Renilla Species 0.000 description 1
- 108010034634 Repressor Proteins Proteins 0.000 description 1
- 102000009661 Repressor Proteins Human genes 0.000 description 1
- 102000003661 Ribonuclease III Human genes 0.000 description 1
- 108010057163 Ribonuclease III Proteins 0.000 description 1
- 102000006382 Ribonucleases Human genes 0.000 description 1
- 108010083644 Ribonucleases Proteins 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- GEASJBKJVYIJPW-UHFFFAOYSA-N S1CCN(CC1)C12N(C=NC1=NC(=NC2=O)N)C Chemical compound S1CCN(CC1)C12N(C=NC1=NC(=NC2=O)N)C GEASJBKJVYIJPW-UHFFFAOYSA-N 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 101100069498 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) MGE1 gene Proteins 0.000 description 1
- 101100140580 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) REF2 gene Proteins 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- 102100023664 Serine/arginine repetitive matrix protein 1 Human genes 0.000 description 1
- 101710140159 She2p Proteins 0.000 description 1
- 108020004459 Small interfering RNA Proteins 0.000 description 1
- 101800001707 Spacer peptide Proteins 0.000 description 1
- 102100038020 Speckle targeted PIP5K1A-regulated poly(A) polymerase Human genes 0.000 description 1
- 101710140499 Speckle targeted PIP5K1A-regulated poly(A) polymerase Proteins 0.000 description 1
- 241000713896 Spleen necrosis virus Species 0.000 description 1
- 241000193996 Streptococcus pyogenes Species 0.000 description 1
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 1
- UCKMPCXJQFINFW-UHFFFAOYSA-N Sulphide Chemical compound [S-2] UCKMPCXJQFINFW-UHFFFAOYSA-N 0.000 description 1
- OUUQCZGPVNCOIJ-UHFFFAOYSA-M Superoxide Chemical compound [O-][O] OUUQCZGPVNCOIJ-UHFFFAOYSA-M 0.000 description 1
- 101710137500 T7 RNA polymerase Proteins 0.000 description 1
- 108010076818 TEV protease Proteins 0.000 description 1
- 102000018679 Tacrolimus Binding Proteins Human genes 0.000 description 1
- 108010027179 Tacrolimus Binding Proteins Proteins 0.000 description 1
- 102100031022 Telomerase-binding protein EST1A Human genes 0.000 description 1
- 241000204668 Thermoplasmatales Species 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 102000006601 Thymidine Kinase Human genes 0.000 description 1
- 108020004440 Thymidine kinase Proteins 0.000 description 1
- 108091028113 Trans-activating crRNA Proteins 0.000 description 1
- 101710195626 Transcriptional activator protein Proteins 0.000 description 1
- 101710150448 Transcriptional regulator Myc Proteins 0.000 description 1
- 102100027671 Transcriptional repressor CTCF Human genes 0.000 description 1
- 102000008579 Transposases Human genes 0.000 description 1
- 108010020764 Transposases Proteins 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 101710028540 UPF2 Proteins 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- 108010067390 Viral Proteins Proteins 0.000 description 1
- 108010093894 Xanthine oxidase Proteins 0.000 description 1
- 102100033220 Xanthine oxidase Human genes 0.000 description 1
- 101000771024 Zea mays DNA (cytosine-5)-methyltransferase 1 Proteins 0.000 description 1
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 1
- 102100021112 Zinc finger protein 10 Human genes 0.000 description 1
- SIIZPVYVXNXXQG-KGXOGWRBSA-N [(2r,3r,4r,5r)-5-(6-aminopurin-9-yl)-4-[[(3s,4r)-5-(6-aminopurin-9-yl)-3,4-dihydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-3-hydroxyoxolan-2-yl]methyl [(2r,4r,5r)-2-(6-aminopurin-9-yl)-4-hydroxy-5-(phosphonooxymethyl)oxolan-3-yl] hydrogen phosphate Polymers C1=NC2=C(N)N=CN=C2N1[C@@H]1O[C@H](COP(O)(=O)OC2[C@@H](O[C@H](COP(O)(O)=O)[C@H]2O)N2C3=NC=NC(N)=C3N=C2)[C@@H](O)[C@H]1OP(O)(=O)OCC([C@@H](O)[C@H]1O)OC1N1C(N=CN=C2N)=C2N=C1 SIIZPVYVXNXXQG-KGXOGWRBSA-N 0.000 description 1
- RLXCFCYWFYXTON-JTTSDREOSA-N [(3S,8S,9S,10R,13S,14S,17R)-3-hydroxy-10,13-dimethyl-17-[(2R)-6-methylheptan-2-yl]-2,3,4,7,8,9,11,12,14,15,16,17-dodecahydro-1H-cyclopenta[a]phenanthren-16-yl] N-hexylcarbamate Chemical group C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC(OC(=O)NCCCCCC)[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 RLXCFCYWFYXTON-JTTSDREOSA-N 0.000 description 1
- XVIYCJDWYLJQBG-UHFFFAOYSA-N acetic acid;adamantane Chemical compound CC(O)=O.C1C(C2)CC3CC1CC2C3 XVIYCJDWYLJQBG-UHFFFAOYSA-N 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 230000010933 acylation Effects 0.000 description 1
- 238000005917 acylation reaction Methods 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 101150084233 ago2 gene Proteins 0.000 description 1
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 1
- 150000001336 alkenes Chemical class 0.000 description 1
- 125000005083 alkoxyalkoxy group Chemical group 0.000 description 1
- 125000002877 alkyl aryl group Chemical group 0.000 description 1
- 230000029936 alkylation Effects 0.000 description 1
- 238000005804 alkylation reaction Methods 0.000 description 1
- 238000007844 allele-specific PCR Methods 0.000 description 1
- 108010004469 allophycocyanin Proteins 0.000 description 1
- 230000009435 amidation Effects 0.000 description 1
- 238000007112 amidation reaction Methods 0.000 description 1
- 150000001450 anions Chemical class 0.000 description 1
- PYKYMHQGRFAEBM-UHFFFAOYSA-N anthraquinone Natural products CCC(=O)c1c(O)c2C(=O)C3C(C=CC=C3O)C(=O)c2cc1CC(=O)OC PYKYMHQGRFAEBM-UHFFFAOYSA-N 0.000 description 1
- 150000004056 anthraquinones Chemical class 0.000 description 1
- 230000000843 anti-fungal effect Effects 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 239000000427 antigen Substances 0.000 description 1
- 108091007433 antigens Proteins 0.000 description 1
- 102000036639 antigens Human genes 0.000 description 1
- 239000000074 antisense oligonucleotide Substances 0.000 description 1
- 238000012230 antisense oligonucleotides Methods 0.000 description 1
- 239000000158 apoptosis inhibitor Substances 0.000 description 1
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 1
- 229910052785 arsenic Inorganic materials 0.000 description 1
- RQNWIZPPADIBDY-UHFFFAOYSA-N arsenic atom Chemical compound [As] RQNWIZPPADIBDY-UHFFFAOYSA-N 0.000 description 1
- 125000003710 aryl alkyl group Chemical group 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 108010028263 bacteriophage T3 RNA polymerase Proteins 0.000 description 1
- 230000037429 base substitution Effects 0.000 description 1
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 125000002619 bicyclic group Chemical group 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 239000013060 biological fluid Substances 0.000 description 1
- 230000031018 biological processes and functions Effects 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- QKSKPIVNLNLAAV-UHFFFAOYSA-N bis(2-chloroethyl) sulfide Chemical compound ClCCSCCCl QKSKPIVNLNLAAV-UHFFFAOYSA-N 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- UORVGPXVDQYIDP-BJUDXGSMSA-N borane Chemical compound [10BH3] UORVGPXVDQYIDP-BJUDXGSMSA-N 0.000 description 1
- 229910000085 borane Inorganic materials 0.000 description 1
- 238000010804 cDNA synthesis Methods 0.000 description 1
- 239000001110 calcium chloride Substances 0.000 description 1
- 229910001628 calcium chloride Inorganic materials 0.000 description 1
- 230000001914 calming effect Effects 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 125000001369 canonical nucleoside group Chemical group 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 230000021523 carboxylation Effects 0.000 description 1
- 238000006473 carboxylation reaction Methods 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 229920006317 cationic polymer Polymers 0.000 description 1
- 210000003855 cell nucleus Anatomy 0.000 description 1
- 230000004700 cellular uptake Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 230000011088 chloroplast localization Effects 0.000 description 1
- BHQCQFFYRZLCQQ-OELDTZBJSA-N cholic acid Chemical compound C([C@H]1C[C@H]2O)[C@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@@H](CCC(O)=O)C)[C@@]2(C)[C@@H](O)C1 BHQCQFFYRZLCQQ-OELDTZBJSA-N 0.000 description 1
- 229960002471 cholic acid Drugs 0.000 description 1
- 235000019416 cholic acid Nutrition 0.000 description 1
- 210000003483 chromatin Anatomy 0.000 description 1
- 238000012761 co-transfection Methods 0.000 description 1
- 230000001332 colony forming effect Effects 0.000 description 1
- 238000004737 colorimetric analysis Methods 0.000 description 1
- 238000010959 commercial synthesis reaction Methods 0.000 description 1
- 239000003184 complementary RNA Substances 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 229960000956 coumarin Drugs 0.000 description 1
- 235000001671 coumarin Nutrition 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 238000005520 cutting process Methods 0.000 description 1
- 125000001995 cyclobutyl group Chemical group [H]C1([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- 125000000596 cyclohexenyl group Chemical group C1(=CCCCC1)* 0.000 description 1
- UHDGCWIWMRVCDJ-ZAKLUEHWSA-N cytidine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O1 UHDGCWIWMRVCDJ-ZAKLUEHWSA-N 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 230000017858 demethylation Effects 0.000 description 1
- 238000010520 demethylation reaction Methods 0.000 description 1
- KXGVEGMKQFWNSR-UHFFFAOYSA-N deoxycholic acid Natural products C1CC2CC(O)CCC2(C)C2C1C1CCC(C(CCC(O)=O)C)C1(C)C(O)C2 KXGVEGMKQFWNSR-UHFFFAOYSA-N 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000001212 derivatisation Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- UREBDLICKHMUKA-CXSFZGCWSA-N dexamethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O UREBDLICKHMUKA-CXSFZGCWSA-N 0.000 description 1
- 229960003957 dexamethasone Drugs 0.000 description 1
- 229950006137 dexfosfoserine Drugs 0.000 description 1
- 229910003460 diamond Inorganic materials 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical compound [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 1
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 1
- 229960003722 doxycycline Drugs 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 238000009710 electro sinter forging Methods 0.000 description 1
- 230000013020 embryo development Effects 0.000 description 1
- 230000012202 endocytosis Effects 0.000 description 1
- 210000001163 endosome Anatomy 0.000 description 1
- 230000000021 endosomolytic effect Effects 0.000 description 1
- 238000001952 enzyme assay Methods 0.000 description 1
- CHNUOJQWGUIOLD-NFZZJPOKSA-N epalrestat Chemical compound C=1C=CC=CC=1\C=C(/C)\C=C1/SC(=S)N(CC(O)=O)C1=O CHNUOJQWGUIOLD-NFZZJPOKSA-N 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- 229940011871 estrogen Drugs 0.000 description 1
- 238000002270 exclusion chromatography Methods 0.000 description 1
- 230000029142 excretion Effects 0.000 description 1
- 238000013401 experimental design Methods 0.000 description 1
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 1
- 229910052731 fluorine Inorganic materials 0.000 description 1
- 239000011737 fluorine Substances 0.000 description 1
- 229960000304 folic acid Drugs 0.000 description 1
- 235000019152 folic acid Nutrition 0.000 description 1
- 239000011724 folic acid Substances 0.000 description 1
- 239000012737 fresh medium Substances 0.000 description 1
- 125000000524 functional group Chemical group 0.000 description 1
- 108010044804 gamma-glutamyl-seryl-glycine Proteins 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 238000012239 gene modification Methods 0.000 description 1
- 102000034356 gene-regulatory proteins Human genes 0.000 description 1
- 108091006104 gene-regulatory proteins Proteins 0.000 description 1
- 231100000118 genetic alteration Toxicity 0.000 description 1
- 230000004077 genetic alteration Effects 0.000 description 1
- 239000003862 glucocorticoid Substances 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 108700026078 glutathione trisulfide Proteins 0.000 description 1
- 125000003827 glycol group Chemical group 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 101150118163 h gene Proteins 0.000 description 1
- 230000009931 harmful effect Effects 0.000 description 1
- 230000035876 healing Effects 0.000 description 1
- 238000003505 heat denaturation Methods 0.000 description 1
- 239000000185 hemagglutinin Substances 0.000 description 1
- 210000003958 hematopoietic stem cell Anatomy 0.000 description 1
- 230000002440 hepatic effect Effects 0.000 description 1
- 208000006454 hepatitis Diseases 0.000 description 1
- 231100000283 hepatitis Toxicity 0.000 description 1
- 125000000592 heterocycloalkyl group Chemical group 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 238000003364 immunohistochemistry Methods 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 238000000126 in silico method Methods 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 206010022000 influenza Diseases 0.000 description 1
- 108700032552 influenza virus INS1 Proteins 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 108091006086 inhibitor proteins Proteins 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 239000000138 intercalating agent Substances 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 230000002427 irreversible effect Effects 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 230000001535 kindling effect Effects 0.000 description 1
- 238000011005 laboratory method Methods 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 230000033001 locomotion Effects 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 239000002609 medium Substances 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 229910021645 metal ion Inorganic materials 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 1
- 125000000956 methoxy group Chemical group [H]C([H])([H])O* 0.000 description 1
- 238000002406 microsurgery Methods 0.000 description 1
- VKHAHZOOUSRJNA-GCNJZUOMSA-N mifepristone Chemical compound C1([C@@H]2C3=C4CCC(=O)C=C4CC[C@H]3[C@@H]3CC[C@@]([C@]3(C2)C)(O)C#CC)=CC=C(N(C)C)C=C1 VKHAHZOOUSRJNA-GCNJZUOMSA-N 0.000 description 1
- 229960003248 mifepristone Drugs 0.000 description 1
- 238000010232 migration assay Methods 0.000 description 1
- 230000002438 mitochondrial effect Effects 0.000 description 1
- 230000025608 mitochondrion localization Effects 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 238000003032 molecular docking Methods 0.000 description 1
- 235000010460 mustard Nutrition 0.000 description 1
- 230000007498 myristoylation Effects 0.000 description 1
- 239000002114 nanocomposite Substances 0.000 description 1
- 239000002105 nanoparticle Substances 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 230000006780 non-homologous end joining Effects 0.000 description 1
- 231100000252 nontoxic Toxicity 0.000 description 1
- 230000003000 nontoxic effect Effects 0.000 description 1
- 108060005597 nucleoplasmin Proteins 0.000 description 1
- 108010038765 octaarginine Proteins 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 125000001181 organosilyl group Chemical group [SiH3]* 0.000 description 1
- 239000001301 oxygen Substances 0.000 description 1
- 125000004430 oxygen atom Chemical group O* 0.000 description 1
- 125000000913 palmityl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- MCYTYTUNNNZWOK-LCLOTLQISA-N penetratin Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCCNC(N)=N)[C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=CC=C1 MCYTYTUNNNZWOK-LCLOTLQISA-N 0.000 description 1
- 108010043655 penetratin Proteins 0.000 description 1
- ONTNXMBMXUNDBF-UHFFFAOYSA-N pentatriacontane-17,18,19-triol Chemical compound CCCCCCCCCCCCCCCCC(O)C(O)C(O)CCCCCCCCCCCCCCCC ONTNXMBMXUNDBF-UHFFFAOYSA-N 0.000 description 1
- 210000005259 peripheral blood Anatomy 0.000 description 1
- 239000011886 peripheral blood Substances 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 230000004526 pharmaceutical effect Effects 0.000 description 1
- 229950000688 phenothiazine Drugs 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- PTMHPRAIXMAOOB-UHFFFAOYSA-L phosphoramidate Chemical compound NP([O-])([O-])=O PTMHPRAIXMAOOB-UHFFFAOYSA-L 0.000 description 1
- 150000008298 phosphoramidates Chemical class 0.000 description 1
- BZQFBWGGLXLEPQ-REOHCLBHSA-N phosphoserine Chemical compound OC(=O)[C@@H](N)COP(O)(O)=O BZQFBWGGLXLEPQ-REOHCLBHSA-N 0.000 description 1
- USRGIUJOYOXOQJ-GBXIJSLDSA-N phosphothreonine Chemical compound OP(=O)(O)O[C@H](C)[C@H](N)C(O)=O USRGIUJOYOXOQJ-GBXIJSLDSA-N 0.000 description 1
- DCWXELXMIBXGTH-UHFFFAOYSA-N phosphotyrosine Chemical compound OC(=O)C(N)CC1=CC=C(OP(O)(O)=O)C=C1 DCWXELXMIBXGTH-UHFFFAOYSA-N 0.000 description 1
- 230000001766 physiological effect Effects 0.000 description 1
- 210000000745 plant chromosome Anatomy 0.000 description 1
- 210000002706 plastid Anatomy 0.000 description 1
- 102000015585 poly-pyrimidine tract binding protein Human genes 0.000 description 1
- 108010063723 poly-pyrimidine tract binding protein Proteins 0.000 description 1
- 229920002647 polyamide Polymers 0.000 description 1
- 108010011110 polyarginine Proteins 0.000 description 1
- 229920000570 polyether Polymers 0.000 description 1
- 230000001124 posttranscriptional effect Effects 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 230000002062 proliferating effect Effects 0.000 description 1
- 230000000069 prophylactic effect Effects 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 230000004952 protein activity Effects 0.000 description 1
- 230000009145 protein modification Effects 0.000 description 1
- 230000002797 proteolythic effect Effects 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- IGFXRKMLLMBKSA-UHFFFAOYSA-N purine Chemical compound N1=C[N]C2=NC=NC2=C1 IGFXRKMLLMBKSA-UHFFFAOYSA-N 0.000 description 1
- UBQKCCHYAOITMY-UHFFFAOYSA-N pyridin-2-ol Chemical compound OC1=CC=CC=N1 UBQKCCHYAOITMY-UHFFFAOYSA-N 0.000 description 1
- SRBUGYKMBLUTIS-UHFFFAOYSA-N pyrrolo[2,3-d]pyrimidin-2-one Chemical compound O=C1N=CC2=CC=NC2=N1 SRBUGYKMBLUTIS-UHFFFAOYSA-N 0.000 description 1
- 239000002096 quantum dot Substances 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 102000005962 receptors Human genes 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 108010054624 red fluorescent protein Proteins 0.000 description 1
- 230000037425 regulation of transcription Effects 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 125000006853 reporter group Chemical group 0.000 description 1
- 102000027483 retinoid hormone receptors Human genes 0.000 description 1
- 108091008679 retinoid hormone receptors Proteins 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 108091092562 ribozyme Proteins 0.000 description 1
- 229910052594 sapphire Inorganic materials 0.000 description 1
- 239000010980 sapphire Substances 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 238000013207 serial dilution Methods 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- 230000003584 silencer Effects 0.000 description 1
- 230000005783 single-strand break Effects 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 102000005969 steroid hormone receptors Human genes 0.000 description 1
- 108020003113 steroid hormone receptors Proteins 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- IIACRCGMVDHOTQ-UHFFFAOYSA-N sulfamic acid Chemical group NS(O)(=O)=O IIACRCGMVDHOTQ-UHFFFAOYSA-N 0.000 description 1
- 125000000565 sulfonamide group Chemical group 0.000 description 1
- BDHFUVZGWQCTTF-UHFFFAOYSA-M sulfonate Chemical compound [O-]S(=O)=O BDHFUVZGWQCTTF-UHFFFAOYSA-M 0.000 description 1
- 150000003457 sulfones Chemical group 0.000 description 1
- 150000003462 sulfoxides Chemical class 0.000 description 1
- 239000011593 sulfur Substances 0.000 description 1
- 125000004434 sulfur atom Chemical group 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 208000024891 symptom Diseases 0.000 description 1
- 108010066587 tRNA Methyltransferases Proteins 0.000 description 1
- 102000018477 tRNA Methyltransferases Human genes 0.000 description 1
- 101150024821 tetO gene Proteins 0.000 description 1
- 101150061166 tetR gene Proteins 0.000 description 1
- ZEMGGZBWXRYJHK-UHFFFAOYSA-N thiouracil Chemical compound O=C1C=CNC(=S)N1 ZEMGGZBWXRYJHK-UHFFFAOYSA-N 0.000 description 1
- 210000001685 thyroid gland Anatomy 0.000 description 1
- 102000004217 thyroid hormone receptors Human genes 0.000 description 1
- 108090000721 thyroid hormone receptors Proteins 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 230000037426 transcriptional repression Effects 0.000 description 1
- ZMANZCXQSJIPKH-UHFFFAOYSA-O triethylammonium ion Chemical compound CC[NH+](CC)CC ZMANZCXQSJIPKH-UHFFFAOYSA-O 0.000 description 1
- UORVGPXVDQYIDP-UHFFFAOYSA-N trihydridoboron Substances B UORVGPXVDQYIDP-UHFFFAOYSA-N 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
- 229940075420 xanthine Drugs 0.000 description 1
- 229910052725 zinc Inorganic materials 0.000 description 1
- 239000011701 zinc Substances 0.000 description 1
Images



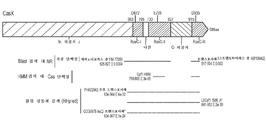
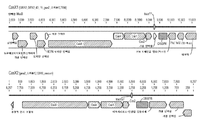

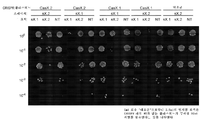

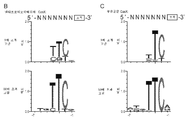
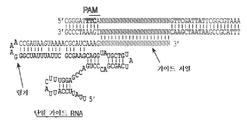





















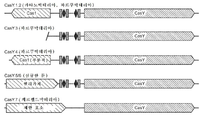







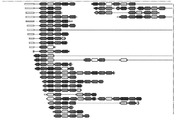





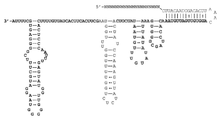
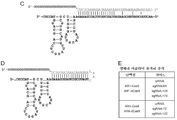
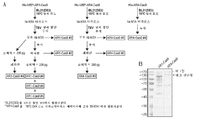
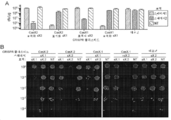


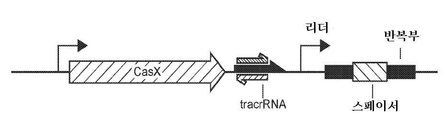

Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/8509—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells for producing genetically modified animals, e.g. transgenic
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K19/00—Hybrid peptides, i.e. peptides covalently bound to nucleic acids, or non-covalently bound protein-protein complexes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/102—Mutagenizing nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/52—Genes encoding for enzymes or proenzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/74—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/88—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation using microencapsulation, e.g. using amphiphile liposome vesicle
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
- C12N15/902—Stable introduction of foreign DNA into chromosome using homologous recombination
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/1003—Transferases (2.) transferring one-carbon groups (2.1)
- C12N9/1007—Methyltransferases (general) (2.1.1.)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/1025—Acyltransferases (2.3)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases RNAses, DNAses
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/03—Fusion polypeptide containing a localisation/targetting motif containing a transmembrane segment
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/06—Fusion polypeptide containing a localisation/targetting motif containing a lysosomal/endosomal localisation signal
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/09—Fusion polypeptide containing a localisation/targetting motif containing a nuclear localisation signal
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/20—Fusion polypeptide containing a tag with affinity for a non-protein ligand
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPRs]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2740/00—Reverse transcribing RNA viruses
- C12N2740/00011—Details
- C12N2740/10011—Retroviridae
- C12N2740/13011—Gammaretrovirus, e.g. murine leukeamia virus
- C12N2740/13041—Use of virus, viral particle or viral elements as a vector
- C12N2740/13043—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2740/00—Reverse transcribing RNA viruses
- C12N2740/00011—Details
- C12N2740/10011—Retroviridae
- C12N2740/16011—Human Immunodeficiency Virus, HIV
- C12N2740/16041—Use of virus, viral particle or viral elements as a vector
- C12N2740/16043—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14141—Use of virus, viral particle or viral elements as a vector
- C12N2750/14143—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
Abstract
본 개시내용은 CasX 단백질, CasX 단백질을 암호화하는 핵산, 및 CasX 단백질 및/또는 이를 암호화하는 핵산을 포함하는 변형된 숙주 세포를 제공한다. 제공된 CasX 단백질은 다양한 적용분야에서 유용하다. 본 개시내용은 CasX 단백질에 결합하고 이에 대한 서열 특이성을 제공하는 CasX 가이드 RNA; CasX 가이드 RNA를 암호화하는 핵산; 및 CasX 가이드 RNA 및/또는 이를 암호화하는 핵산을 포함하는 변형된 숙주 세포를 제공한다. 제공된 CasX 가이드 RNA는 다양한 적용분야에서 유용하다. 본 개시내용은 고세균 Cas9 폴리펩타이드 및 이를 암호화하는 핵산뿐만 아니라 이와 회합된 고세균 Cas9 가이드 RNA 및 이를 암호화하는 핵산을 제공한다.
Description
상호 참조
본 출원은 2016년 9월 30일자로 출원된 미국 가출원 특허 제62/402,846호의 유익을 주장하며, 이 기초출원은 그의 전문이 본 명세서에 참고로 포함된다.
텍스트 파일로서 제공된 서열목록의 참고에 의한 편입
서열목록은 2017년 9월 28일자에 생성되고, 용량이 135 KB인 텍스트 파일 "BERK-342WO_SeqList_ST25.txt"로서 본 명세서에 제공된다. 텍스트 파일의 내용은 그 전체가 본 명세서에 참고로 편입된다.
DNA 서열분석 시대 전의 과학에 알려지지 않은 경로의 예인 CRISPR-Cas 시스템은 이제 파지 및 바이러스에 대해 획득된 면역을 박테리아 및 고세균에 부여하는 것으로 이해된다. 과거 십년에 걸쳐 광대한 연구는 이 생화학 시스템을 발견하지 못하였다. CRISPR-Cas 시스템은 외래 DNA 또는 RNA의 획득, 표적화 및 절단에 연루된 Cas 단백질, 및 Cas 단백질을 그들의 표적에 가이드하는 짧은 스페이서 서열에 측접하는 직접 반복부를 포함하는 CRISPR 어레이로 이루어진다. RNA에 결합된 단일 Cas 단백질이 표적화된 서열에 대한 결합 및 절단을 초래하는 클래스 2 CRISPR-Cas는 최신식의 형태이다. 이들 최소 시스템의 프로그램 가능한 특성은 그들의 용도를 게놈 조작 분야의 혁명을 일으키는 다재다능한 기술로서 용이하게 하였다.
현재의 CRISPR-Cas 기술은 아직 손대지 않은 단리되지 않은 방대한 유기체를 떠나서 배양 박테리아로부터의 시스템에 기반한다. 지금까지, 소수의 클래스 2 CRISPR/Cas 시스템만이 발견되었다. 추가적인 클래스 2 CRISPR/Cas 시스템(예를 들어, Cas 단백질 + 가이드 RNA 조합)에 대한 당업계의 필요가 있다.
본 발명의 개시내용은 본 명세서에서 "CasX" 폴리펩타이드로서 지칭되는(또한 "CasX 단백질"로서 지칭됨) RNA-가이드 엔도뉴클레아제 폴리펩타이드; CasX 폴리펩타이드를 암호화하는 핵산; 및 CasX 폴리펩타이드를 포함하는 변형된 숙주 세포 및/또는 이를 암호화하는 핵산을 제공한다. 제공되는 CasX 폴리펩타이드는 다양한 적용분야에서 유용하다.
본 개시내용은 CasX 단백질에 결합하고 이에 대한 서열 특이성을 제공하는 가이드 RNA(본 명세서에서 "CasX 가이드 RNA"로서 지칭됨); CasX 가이드 RNA를 암호화하는 핵산; 및 CasX 가이드 RNA 및/또는 이를 암호화하는 핵산을 포함하는 변형된 숙주 세포를 제공한다. 제공되는 CasX 가이드 RNA는 다양한 적용분야에서 유용하다.
본 개시내용은 고세균 Cas9 폴리펩타이드 및 이를 암호화하는 핵산뿐만 아니라 이와 회합된 가이드 RNA(고세균 Cas9 가이드 RNA) 및 이를 암호화하는 핵산을 제공한다.
도 1은 2개의 천연 유래 CasX 단백질 서열을 도시한 도면.
도 2는 2개의 동정된 천연 유래 CasX 단백질 서열의 정렬을 도시한 도면.
도 3(패널 a 내지 b)은 CasX에 대한 개략적 도메인 제시를 도시한 도면. 또한 CasX의 상동체를 동정하기 위한 다양한 검색 시도로부터의 결과를 나타낸다. 또한 두 상이한 종으로부터 동정된 CasX-함유 CRISPR 좌위의 부분이 도시된다.
도 4(패널 a 내지 c)는 에스케리키아 콜라이(Escherichia coli)에서 발현된 CasX에 의한 플라스미드 간섭을 입증하기 위해 수행한 실험을 도시한 도면.
도 5(패널 a 내지 b)는 CasX에 대한 PAM 서열을 결정하기 위해 수행된 실험(CasX에 의한 PAM 의존적 플라스미드 간섭)을 도시한 도면.
도 6(패널 a 내지 c)은 CasX가 이중-가이드된 CRISPR-Cas 효과기 복합체라는 것을 결정하기 위해 수행한 실험을 도시한 도면.
도 7은 CasX RNA 가이드된 DNA 간섭의 개략도를 도시한 도면.
도 8은 CasX를 이용하여 인간 세포에서 편집을 입증하는 일 실시형태에 대한 실험 설계의 개략도를 제시한 도면.
도 9는 CasX의 재조합 발현 및 정제를 나타내는 데이터를 제시한 도면.
도 10은 절단 활성에 대해 다양한 상이한 tracrRNA 서열(상이한 서열 길이)을 이용하는 데이터를 제시한 도면.
도 11은 실온 대 37℃에서 작용하는 CasX에 관한 데이터를 제시한 도면.
도 12(패널 a 내지 e)는 고세균 Cas9 CRISPR 시스템(ARMAN-1 II형 CRISPR-cas 시스템)에 관한 정보를 제시한 도면.
도 13은 고세균 Cas9 단백질(ARMAN-1 및 ARMAN-4, 각각 서열번호 71 및 72)을 제시한 도면. 스트렙토코코스 피오게네스(S. pyogenes)의 D10 및 H840에 대응하는 촉매적 잔기는 볼드체이고 밑줄 표시되어 있다.
도 14는 고세균 Cas9 단백질(예를 들어, ARMAN-1 Cas9)과 함께 사용될 수 있는 예시적 이중 가이드(상부 패널)(상부 RNA-서열번호 73, 하부 RNA-서열번호 77) 및 단일 가이드(하부 패널)(서열번호 79) 형식을 제시한 도면.
도 15는 고세균 Cas9 단백질(예를 들어, ARMAN-4 Cas9)과 함께 사용될 수 있는 예시적 이중 가이드(상부 패널)(상부 RNA-서열번호 74, 하부 RNA-서열번호 78) 및 단일 가이드(하부 패널)(서열번호 80) 형식을 제시한 도면.
도 16은 2개의 새로 동정된 비-고세균 Cas9 단백질을 도시한 도면.
도 17은 (i) 2개의 새로 동정된 비-고세균 Cas9 단백질과 ARMAN-1 및 ARMAN-4 Cas9 단백질의 정렬; 및 (ii) ARMAN-1 및 ARMAN-4로부터의 Cas9 단백질뿐만 아니라 구조가 밝혀진 악티노마이세스 나이슬런디(Actinomyces naeslundii) Cas9에 대해 비배양 박테리아로부터의 2가지의 밀접하게 관련된 Cas9 단백질의 정렬을 도시한 도면.
도 18(패널 a 내지 b)은 비배양 유기체로부터의 신규한 동정된 CRISPR-Cas 시스템을 제시한 도면. a, Hug et al.32의 데이터에 기반하여 모든 박테리아 및 고세균에서 단리된 대표자가 있는 그리고 대표자가 없는 주된 계통의 비. 결과는 이들 도메인에서 대규모의 아직 거의 연구되지 않은 생물학을 강조한다. 고세균 Cas9 및 신규한 CRISPR-CasY는 단리된 대표자가 없는 계통에서 배타적으로 발견되었다. b, 새로 발견된 CRISPR-Cas 시스템의 국소 조직화.
도 19(패널 a 내지 b)는 ARMAN-1 Cas9 PAM 서열의 ARMAN-1 CRISPR 어레이 다양성 및 동정을 제시한 도면. a, 15개의 상이한 AMD 샘플로부터 재구성한 CRISPR 어레이. 백색 박스는 반복부를 나타내고, 색이 있는 다이아몬드는 스페이서를 나타낸다(동일한 스페이서는 동일하게 색칠하고; 독특한 스페이서는 검정색이다). 어레이의 보존된 영역을 강조한다(우측 상에서). 최근에 획득된 스페이서의 다양성은(좌측 상에서) 시스템이 활성이라는 것을 나타낸다. 또한 판독 데이터로부터의 CRISPR 단편을 포함하는 분석을 도 25에 제시한다. b, AMD 메가게놈 데이터로부터 재구성된 단일 추정 바이러스 콘틱은 ARMAN-1 CRISPR 어레이로부터의 56개 프로토스페이서(적색 수직 막대)를 함유한다. c, 서열분석은 비표적 가닥 상에서 프로토스페이서 하류의 보존된 'NGG' PAM 모티프를 나타내었다.
도 20(패널 a 내지 d)는 이콜라이에서 프로그램 가능한 DNA 간섭을 매개한다는 것을 나타내는 데이터를 제시한 도면. a, CasX 플라스미드 간섭 분석의 다이어그램. 최소 CasX 좌위를 발현시키는 이콜라이는 CRISPR 어레이(표적)에서 서열을 매칭시키는 스페이서를 함유하는 플라스미드 또는 비-매칭 스페이서(비표적)를 함유하는 플라스미드로 형질전환된다. 형질전환된 후에, 배양물을 플레이팅하고, 콜로니 형성 단위(colony forming unit: cfu)를 정량화하였다. b, 부유균문 CasX 좌위 표적화 스페이서 1(sX.1)을 발현시키고 구체화된 표적(sX1, CasX 스페이서 1; sX2, CasX 스페이서 2; NT, 비-표적)으로 형질전환된 이콜라이의 연속 희석. c, 델타프로테오박테리아 CasX에 의한 플라스미드 간섭. 실험을 3회 중복하여 수행하고 평균 ± s.d.를 나타낸다. d, 이콜라이에서 발현시킨 부유균문 CasX 좌위에 대한 PAM 고갈 분석. 대조군 라이브러리에 비해 30배 초과로 고갈된 PAM 서열을 사용하여 웹로고(WebLogo)를 생성하였다.
도 21(패널 a 내지 c)은 CasX를 나타내는 데이터가 이중-가이드 CRISPR 복합체라는 것을 제시한 도면. a, 아래쪽 다이어그램의 CasX CRISPR 좌위에 대한 환경 RNA 서열(메타전사체 데이터)의 맵핑(적색 화살표, 추정적 tracrRNA; 백색 박스, 반복부 서열; 녹색 다이아몬드, 스페이서 서열). 삽도는 제1 반복부 및 스페이서의 상세한 관점을 나타낸다. b, CasX 이중-가닥 DNA 간섭의 다이어그램. RNA 가공 부위는 검정색 화살표로 나타낸다. c, CasX 좌위의 추정적 tracrRNA 넉아웃 및 crRNA 단독과 함께 공동발현된 CasX, 절단된 sgRNA 또는 전장sgRNA에 의한 플라스미드 간섭 분석 결과(T, 표적; NT, 비-표적). 실험을 3회 중복하여 수행하고 평균 ± s.d.를 나타낸다.
도 22(패널 a 내지 c)는 이콜라이에서 CasY 좌위의 발현이 DNA 간섭에 충분하다는 것을 나타내는 데이터를 제시한 도면. a, CasY 좌위 및 이웃하는 단백질의 다이어그램. b, 대조군 라이브러리에 비해 CasY에 의해 3배 초과로 고갈된 5' PAM 서열의 웹로고. c, 이콜라이 발현 CasY.1에 의한 그리고 표시된 PAM을 함유하는 표적으로 형질전화된 플라스미드 간섭. 실험을 3회 중복하여 수행하고 평균 ± s.d.를 나타낸다.
도 23(패널 a 내지 b)은 공지된 시스템과 관련하여 새로 동정된 CRISPR-Cas를 제시한 도면. a, 보편적 Cas1 단백질의 단순화된 계통수. 공지된 시스템의 CRISPR 유형은 쐐기와 분지로 나타내고; 새로 기재한 시스템은 볼드체이다. 상술한 Cas1 계통발생을 보조 데이터 2에 제시한다. b, II-B형과 II-C형 좌위 사이의 재조합 결과로서 고세균 II형 시스템에 생기는 제안된 진화 시나리오.
도 24는 ARMAN-4로부터의 고세균 Cas9가 축퇴 CRISPR 어레이에 의해 수많은 콘틱 상에서 발견된다는 것을 나타내는 도면. ARMAN-4로부터의 Cas9는 16개의 상이한 콘틱 상에서 진한 적색으로 강조한다. 추정적 도메인 또는 기능을 갖는 단백질을 표지한 반면, 가설 단백질을 표지하지 않는다. 15개의 콘틱은 2개의 축퇴 직접 반복부(1개는 bp 미스매치) 및 단일, 보존된 스페이서를 함유한다. 남아있는 콘틱은 단지 하나의 직접 반복부를 함유한다. ARMAN-1과 달리, 추가적인 Cas 단백질은 ARMAN-4에서 Cas9에 인접하여 발견되지 않는다.
도 25는 ARMAN-1 CRISPR 어레이의 완전한 재구성을 제시한 도면. 기준 조립 서열뿐만 아니라 짧은 DNA 판독으로부터 재구성된 어레이 세그먼트를 포함하는 CRISPR 어레이의 재구성. 녹색 화살표는 반복부를 나타내고, 색이 있는 화살표는 CRISPR 스페이서를 나타낸다(동일한 스페이서는 동일하게 색칠한 반면, 독특한 스페이서는 검정색으로 색칠한다). CRISPR 시스템에서, 스페이서는 전형적으로 일방향성으로 첨가되고, 따라서 좌측 상에서 매우 다양한 스페이서는 최근의 획득에 기인한다.
도 26(패널 a 내지 b)은 ARMAN-1 스페이서가 고세균 군집 구성원의 게놈에 맵핑된다는 것을 도시한 도면. a, 동일한 환경으로부터의 나노고세균인 ARMAN-2의 게놈에 대한 ARMAN-1 맵으로부터의 프로토스페이서(적색 화살표). 6개의 프로토스페이서는 2개의 긴-말단 반복부(long-terminal repeat: LTR)에 의해 측접된 게놈의 부분에 독특하게 맵핑되고, 2개의 추가적인 프로토스페이서는 LTR(청색 및 녹색) 내에서 완전하게 매칭된다. 이 영역은 트랜스포존일 가능성이 있는데, ARMAN-1의 CRISPR-Cas 시스템은 이 요소의 이동을 억제하는 역할을 한다는 것을 시사한다. b, 프로토스페이서는 또한 ARMAN 유기체와 동일한 샘플에서 발견된 리치몬드 마인 에코시스템(Richmond Mine ecosystem)의 다른 구성원인 써모플라즈마탈레스(Thermoplasmatales) 고세균(I-플라즈마)에 대해 맵핑한다. 프로토스페이서는 짧은, 가설 단백질을 암호화하는 게놈 영역 내에서 클러스터링하는데, 이것이 또한 이동 요소를 나타낼 수 있다는 것을 시사한다.
도 27(패널 a 내지 e)은 ARMAN-1 crRNA 및 tracrRNA의 예측된 2차 구조를 제시한 도면. a, CRISPR 반복부 및 tracrRNA 항-반복부를 검정색으로 도시한 반면, 스페이서-유래 서열을 일련의 녹색 N으로 나타낸다. 좌위로부터 분명한 종결 신호를 예측할 수 없고, 따라서 3개의 상이한 tracrRNA 길이는 그들의 2차 구조(각각 적색, 청색 및 핑크색인 69, 104 및 179)에 기반하여 시험하였다. b, a. c에서 이중-가이드에 대응하는 조작된 단일-가이드 RNA, tracrRNA의 3' 말단 상에서 2개의 상이한 헤어핀(75 및 122)을 갖는 ARMAN-4 Cas9에 대한 이중-가이드. d, c에서의 이중-가이드에 대응하는 조작된 단일-가이드 RNA. e, 이콜라이 생체내 표적화 분석에서 시험한 조건.
도 28(패널 a 내지 b)은 시험관내 생화학 연구를 위한 정제 계획을 제시한 도면. a, ARMAN-1(AR1) 및 ARMAN-4(AR4) Cas9를 발현시키고 나서, 보충 물질에서 약술할 바와 같이 다양한 조건 하에 정제하였다. 청색 박스로 윤곽을 나타낸 단백질을 시험관내 절단 활성에 대해 시험하였다. b, AR1-Cas9 및 AR4-Cas9 정제 분획을 10% SDS-PAGE 겔 상에서 분리하였다.
도 29는 공지된 단백질에 비교하여 새로 동정된 CRISPR-Cas 시스템을 제시한 도면. 다음의 검색에 기반하여 알려진 단백질에 대한 CasX 및 CasY의 유사성: (1) NCBI의 흔하지 않은(non-redundant: NR) 단백질 데이터베이스에 대한 Blast 검색, (2) 모든 공지된 단백질의 HMM 데이터베이스에 대한 히든 마르코브 모델(Hidden markov model: HMM) 검색 및 (3) HHpred30을 이용하는 원위 상동성 검색.
도 30(패널 a 내지 f)는 CasX에 의한 프로그래밍된 DNA 간섭과 관련된 데이터를 제시한 도면. a, 도 20, 패널 c로부터 계속된 CasX2 (부유균문) 및 CasX1(델타프로테오박테리아)에 대한 플라스미드 간섭 분석(sX1, CasX 스페이서 1; sX2, CasX 스페이서 2; NT, 비-표적). 실험을 3회 중복하여 수행하고 평균 ± s.d.를 나타낸다. b, 도 20, 패널 b로부터 계속된, CasX 좌위를 발현시키고 구체화된 표적으로 형질감염된 이콜라이의 연속 희석. c, 델타프로테오박테리아 CasX에 대한 PAM 고갈 분석 및 d, 이콜라이에서 발현된 부유균문 CasX. 대조군 라이브러리에 비교하여 나타낸 PAM 고갈 값 역치(PDVT) 초과로 고갈된 PAM 서열을 사용하여 웹로고를 생성하였다. e, CasX.1에 대한 노던 블롯 프로브의 위치를 도시하는 다이어그램. f, CasX.1 좌위를 발현시키는 이콜라이로부터 추출된 총 RNA에서 CasX.1 tracrRNA에 대한 노던 블롯.
도 31은 Cas9 상동체의 진화계통수를 제시한 도면. 유형에 기반하여 색칠한 앞서 기재한 시스템을 나타내는 Cas9 단백질의 최대-가능성 계통수: II-A(청색), II-B(녹색) 및 II-C(보라색). 비배양 박테리아로부터의 2개의 새로 기재된 박테리아 Cas9와 함께 II-C형 CRISPR-Cas 시스템에 의한 클러스터인 고세균 Cas9.
도 32은 ARMAN-1 및 ARMAN-4로부터의 Cas9에 대해 분석한 절단 조건 표를 제시한 도면.
도 2는 2개의 동정된 천연 유래 CasX 단백질 서열의 정렬을 도시한 도면.
도 3(패널 a 내지 b)은 CasX에 대한 개략적 도메인 제시를 도시한 도면. 또한 CasX의 상동체를 동정하기 위한 다양한 검색 시도로부터의 결과를 나타낸다. 또한 두 상이한 종으로부터 동정된 CasX-함유 CRISPR 좌위의 부분이 도시된다.
도 4(패널 a 내지 c)는 에스케리키아 콜라이(Escherichia coli)에서 발현된 CasX에 의한 플라스미드 간섭을 입증하기 위해 수행한 실험을 도시한 도면.
도 5(패널 a 내지 b)는 CasX에 대한 PAM 서열을 결정하기 위해 수행된 실험(CasX에 의한 PAM 의존적 플라스미드 간섭)을 도시한 도면.
도 6(패널 a 내지 c)은 CasX가 이중-가이드된 CRISPR-Cas 효과기 복합체라는 것을 결정하기 위해 수행한 실험을 도시한 도면.
도 7은 CasX RNA 가이드된 DNA 간섭의 개략도를 도시한 도면.
도 8은 CasX를 이용하여 인간 세포에서 편집을 입증하는 일 실시형태에 대한 실험 설계의 개략도를 제시한 도면.
도 9는 CasX의 재조합 발현 및 정제를 나타내는 데이터를 제시한 도면.
도 10은 절단 활성에 대해 다양한 상이한 tracrRNA 서열(상이한 서열 길이)을 이용하는 데이터를 제시한 도면.
도 11은 실온 대 37℃에서 작용하는 CasX에 관한 데이터를 제시한 도면.
도 12(패널 a 내지 e)는 고세균 Cas9 CRISPR 시스템(ARMAN-1 II형 CRISPR-cas 시스템)에 관한 정보를 제시한 도면.
도 13은 고세균 Cas9 단백질(ARMAN-1 및 ARMAN-4, 각각 서열번호 71 및 72)을 제시한 도면. 스트렙토코코스 피오게네스(S. pyogenes)의 D10 및 H840에 대응하는 촉매적 잔기는 볼드체이고 밑줄 표시되어 있다.
도 14는 고세균 Cas9 단백질(예를 들어, ARMAN-1 Cas9)과 함께 사용될 수 있는 예시적 이중 가이드(상부 패널)(상부 RNA-서열번호 73, 하부 RNA-서열번호 77) 및 단일 가이드(하부 패널)(서열번호 79) 형식을 제시한 도면.
도 15는 고세균 Cas9 단백질(예를 들어, ARMAN-4 Cas9)과 함께 사용될 수 있는 예시적 이중 가이드(상부 패널)(상부 RNA-서열번호 74, 하부 RNA-서열번호 78) 및 단일 가이드(하부 패널)(서열번호 80) 형식을 제시한 도면.
도 16은 2개의 새로 동정된 비-고세균 Cas9 단백질을 도시한 도면.
도 17은 (i) 2개의 새로 동정된 비-고세균 Cas9 단백질과 ARMAN-1 및 ARMAN-4 Cas9 단백질의 정렬; 및 (ii) ARMAN-1 및 ARMAN-4로부터의 Cas9 단백질뿐만 아니라 구조가 밝혀진 악티노마이세스 나이슬런디(Actinomyces naeslundii) Cas9에 대해 비배양 박테리아로부터의 2가지의 밀접하게 관련된 Cas9 단백질의 정렬을 도시한 도면.
도 18(패널 a 내지 b)은 비배양 유기체로부터의 신규한 동정된 CRISPR-Cas 시스템을 제시한 도면. a, Hug et al.32의 데이터에 기반하여 모든 박테리아 및 고세균에서 단리된 대표자가 있는 그리고 대표자가 없는 주된 계통의 비. 결과는 이들 도메인에서 대규모의 아직 거의 연구되지 않은 생물학을 강조한다. 고세균 Cas9 및 신규한 CRISPR-CasY는 단리된 대표자가 없는 계통에서 배타적으로 발견되었다. b, 새로 발견된 CRISPR-Cas 시스템의 국소 조직화.
도 19(패널 a 내지 b)는 ARMAN-1 Cas9 PAM 서열의 ARMAN-1 CRISPR 어레이 다양성 및 동정을 제시한 도면. a, 15개의 상이한 AMD 샘플로부터 재구성한 CRISPR 어레이. 백색 박스는 반복부를 나타내고, 색이 있는 다이아몬드는 스페이서를 나타낸다(동일한 스페이서는 동일하게 색칠하고; 독특한 스페이서는 검정색이다). 어레이의 보존된 영역을 강조한다(우측 상에서). 최근에 획득된 스페이서의 다양성은(좌측 상에서) 시스템이 활성이라는 것을 나타낸다. 또한 판독 데이터로부터의 CRISPR 단편을 포함하는 분석을 도 25에 제시한다. b, AMD 메가게놈 데이터로부터 재구성된 단일 추정 바이러스 콘틱은 ARMAN-1 CRISPR 어레이로부터의 56개 프로토스페이서(적색 수직 막대)를 함유한다. c, 서열분석은 비표적 가닥 상에서 프로토스페이서 하류의 보존된 'NGG' PAM 모티프를 나타내었다.
도 20(패널 a 내지 d)는 이콜라이에서 프로그램 가능한 DNA 간섭을 매개한다는 것을 나타내는 데이터를 제시한 도면. a, CasX 플라스미드 간섭 분석의 다이어그램. 최소 CasX 좌위를 발현시키는 이콜라이는 CRISPR 어레이(표적)에서 서열을 매칭시키는 스페이서를 함유하는 플라스미드 또는 비-매칭 스페이서(비표적)를 함유하는 플라스미드로 형질전환된다. 형질전환된 후에, 배양물을 플레이팅하고, 콜로니 형성 단위(colony forming unit: cfu)를 정량화하였다. b, 부유균문 CasX 좌위 표적화 스페이서 1(sX.1)을 발현시키고 구체화된 표적(sX1, CasX 스페이서 1; sX2, CasX 스페이서 2; NT, 비-표적)으로 형질전환된 이콜라이의 연속 희석. c, 델타프로테오박테리아 CasX에 의한 플라스미드 간섭. 실험을 3회 중복하여 수행하고 평균 ± s.d.를 나타낸다. d, 이콜라이에서 발현시킨 부유균문 CasX 좌위에 대한 PAM 고갈 분석. 대조군 라이브러리에 비해 30배 초과로 고갈된 PAM 서열을 사용하여 웹로고(WebLogo)를 생성하였다.
도 21(패널 a 내지 c)은 CasX를 나타내는 데이터가 이중-가이드 CRISPR 복합체라는 것을 제시한 도면. a, 아래쪽 다이어그램의 CasX CRISPR 좌위에 대한 환경 RNA 서열(메타전사체 데이터)의 맵핑(적색 화살표, 추정적 tracrRNA; 백색 박스, 반복부 서열; 녹색 다이아몬드, 스페이서 서열). 삽도는 제1 반복부 및 스페이서의 상세한 관점을 나타낸다. b, CasX 이중-가닥 DNA 간섭의 다이어그램. RNA 가공 부위는 검정색 화살표로 나타낸다. c, CasX 좌위의 추정적 tracrRNA 넉아웃 및 crRNA 단독과 함께 공동발현된 CasX, 절단된 sgRNA 또는 전장sgRNA에 의한 플라스미드 간섭 분석 결과(T, 표적; NT, 비-표적). 실험을 3회 중복하여 수행하고 평균 ± s.d.를 나타낸다.
도 22(패널 a 내지 c)는 이콜라이에서 CasY 좌위의 발현이 DNA 간섭에 충분하다는 것을 나타내는 데이터를 제시한 도면. a, CasY 좌위 및 이웃하는 단백질의 다이어그램. b, 대조군 라이브러리에 비해 CasY에 의해 3배 초과로 고갈된 5' PAM 서열의 웹로고. c, 이콜라이 발현 CasY.1에 의한 그리고 표시된 PAM을 함유하는 표적으로 형질전화된 플라스미드 간섭. 실험을 3회 중복하여 수행하고 평균 ± s.d.를 나타낸다.
도 23(패널 a 내지 b)은 공지된 시스템과 관련하여 새로 동정된 CRISPR-Cas를 제시한 도면. a, 보편적 Cas1 단백질의 단순화된 계통수. 공지된 시스템의 CRISPR 유형은 쐐기와 분지로 나타내고; 새로 기재한 시스템은 볼드체이다. 상술한 Cas1 계통발생을 보조 데이터 2에 제시한다. b, II-B형과 II-C형 좌위 사이의 재조합 결과로서 고세균 II형 시스템에 생기는 제안된 진화 시나리오.
도 24는 ARMAN-4로부터의 고세균 Cas9가 축퇴 CRISPR 어레이에 의해 수많은 콘틱 상에서 발견된다는 것을 나타내는 도면. ARMAN-4로부터의 Cas9는 16개의 상이한 콘틱 상에서 진한 적색으로 강조한다. 추정적 도메인 또는 기능을 갖는 단백질을 표지한 반면, 가설 단백질을 표지하지 않는다. 15개의 콘틱은 2개의 축퇴 직접 반복부(1개는 bp 미스매치) 및 단일, 보존된 스페이서를 함유한다. 남아있는 콘틱은 단지 하나의 직접 반복부를 함유한다. ARMAN-1과 달리, 추가적인 Cas 단백질은 ARMAN-4에서 Cas9에 인접하여 발견되지 않는다.
도 25는 ARMAN-1 CRISPR 어레이의 완전한 재구성을 제시한 도면. 기준 조립 서열뿐만 아니라 짧은 DNA 판독으로부터 재구성된 어레이 세그먼트를 포함하는 CRISPR 어레이의 재구성. 녹색 화살표는 반복부를 나타내고, 색이 있는 화살표는 CRISPR 스페이서를 나타낸다(동일한 스페이서는 동일하게 색칠한 반면, 독특한 스페이서는 검정색으로 색칠한다). CRISPR 시스템에서, 스페이서는 전형적으로 일방향성으로 첨가되고, 따라서 좌측 상에서 매우 다양한 스페이서는 최근의 획득에 기인한다.
도 26(패널 a 내지 b)은 ARMAN-1 스페이서가 고세균 군집 구성원의 게놈에 맵핑된다는 것을 도시한 도면. a, 동일한 환경으로부터의 나노고세균인 ARMAN-2의 게놈에 대한 ARMAN-1 맵으로부터의 프로토스페이서(적색 화살표). 6개의 프로토스페이서는 2개의 긴-말단 반복부(long-terminal repeat: LTR)에 의해 측접된 게놈의 부분에 독특하게 맵핑되고, 2개의 추가적인 프로토스페이서는 LTR(청색 및 녹색) 내에서 완전하게 매칭된다. 이 영역은 트랜스포존일 가능성이 있는데, ARMAN-1의 CRISPR-Cas 시스템은 이 요소의 이동을 억제하는 역할을 한다는 것을 시사한다. b, 프로토스페이서는 또한 ARMAN 유기체와 동일한 샘플에서 발견된 리치몬드 마인 에코시스템(Richmond Mine ecosystem)의 다른 구성원인 써모플라즈마탈레스(Thermoplasmatales) 고세균(I-플라즈마)에 대해 맵핑한다. 프로토스페이서는 짧은, 가설 단백질을 암호화하는 게놈 영역 내에서 클러스터링하는데, 이것이 또한 이동 요소를 나타낼 수 있다는 것을 시사한다.
도 27(패널 a 내지 e)은 ARMAN-1 crRNA 및 tracrRNA의 예측된 2차 구조를 제시한 도면. a, CRISPR 반복부 및 tracrRNA 항-반복부를 검정색으로 도시한 반면, 스페이서-유래 서열을 일련의 녹색 N으로 나타낸다. 좌위로부터 분명한 종결 신호를 예측할 수 없고, 따라서 3개의 상이한 tracrRNA 길이는 그들의 2차 구조(각각 적색, 청색 및 핑크색인 69, 104 및 179)에 기반하여 시험하였다. b, a. c에서 이중-가이드에 대응하는 조작된 단일-가이드 RNA, tracrRNA의 3' 말단 상에서 2개의 상이한 헤어핀(75 및 122)을 갖는 ARMAN-4 Cas9에 대한 이중-가이드. d, c에서의 이중-가이드에 대응하는 조작된 단일-가이드 RNA. e, 이콜라이 생체내 표적화 분석에서 시험한 조건.
도 28(패널 a 내지 b)은 시험관내 생화학 연구를 위한 정제 계획을 제시한 도면. a, ARMAN-1(AR1) 및 ARMAN-4(AR4) Cas9를 발현시키고 나서, 보충 물질에서 약술할 바와 같이 다양한 조건 하에 정제하였다. 청색 박스로 윤곽을 나타낸 단백질을 시험관내 절단 활성에 대해 시험하였다. b, AR1-Cas9 및 AR4-Cas9 정제 분획을 10% SDS-PAGE 겔 상에서 분리하였다.
도 29는 공지된 단백질에 비교하여 새로 동정된 CRISPR-Cas 시스템을 제시한 도면. 다음의 검색에 기반하여 알려진 단백질에 대한 CasX 및 CasY의 유사성: (1) NCBI의 흔하지 않은(non-redundant: NR) 단백질 데이터베이스에 대한 Blast 검색, (2) 모든 공지된 단백질의 HMM 데이터베이스에 대한 히든 마르코브 모델(Hidden markov model: HMM) 검색 및 (3) HHpred30을 이용하는 원위 상동성 검색.
도 30(패널 a 내지 f)는 CasX에 의한 프로그래밍된 DNA 간섭과 관련된 데이터를 제시한 도면. a, 도 20, 패널 c로부터 계속된 CasX2 (부유균문) 및 CasX1(델타프로테오박테리아)에 대한 플라스미드 간섭 분석(sX1, CasX 스페이서 1; sX2, CasX 스페이서 2; NT, 비-표적). 실험을 3회 중복하여 수행하고 평균 ± s.d.를 나타낸다. b, 도 20, 패널 b로부터 계속된, CasX 좌위를 발현시키고 구체화된 표적으로 형질감염된 이콜라이의 연속 희석. c, 델타프로테오박테리아 CasX에 대한 PAM 고갈 분석 및 d, 이콜라이에서 발현된 부유균문 CasX. 대조군 라이브러리에 비교하여 나타낸 PAM 고갈 값 역치(PDVT) 초과로 고갈된 PAM 서열을 사용하여 웹로고를 생성하였다. e, CasX.1에 대한 노던 블롯 프로브의 위치를 도시하는 다이어그램. f, CasX.1 좌위를 발현시키는 이콜라이로부터 추출된 총 RNA에서 CasX.1 tracrRNA에 대한 노던 블롯.
도 31은 Cas9 상동체의 진화계통수를 제시한 도면. 유형에 기반하여 색칠한 앞서 기재한 시스템을 나타내는 Cas9 단백질의 최대-가능성 계통수: II-A(청색), II-B(녹색) 및 II-C(보라색). 비배양 박테리아로부터의 2개의 새로 기재된 박테리아 Cas9와 함께 II-C형 CRISPR-Cas 시스템에 의한 클러스터인 고세균 Cas9.
도 32은 ARMAN-1 및 ARMAN-4로부터의 Cas9에 대해 분석한 절단 조건 표를 제시한 도면.
정의
본 명세서에서 사용되는 바와 같은 "이종성"은 각각 천연 핵산 또는 단백질에서 발견되지 않는 뉴클레오타이드 또는 폴리뉴클레오타이드 서열을 의미한다. 예를 들어, CasX 폴리펩타이드에 대해, 이종성 폴리펩타이드는 CasX 폴리펩타이드 이외의 단백질로부터의 아미노산 서열을 포함한다. 일부 경우에, 하나의 종으로부터의 CasX 단백질 부분은 상이한 종으로부터의 CasX 단백질 부분에 융합된다. 따라서 각각의 종으로부터의 CasX 서열은 서로에 대해 이종성인 것으로 고려될 수 있었다. 다른 예로서, CasX 단백질(예를 들어, dCasX 단백질)은 비-CasX 단백질(예를 들어, 히스톤 데아세틸라제)로부터의 활성 도메인에 융합될 수 있고, 활성 도메인의 서열은 이종성 폴리펩타이드로 고려될 수 있었다(이는 CasX 단백질에 대해 이종성이다).
본 명세서에서 상호 호환적으로 사용되는 용어 "폴리뉴클레오타이드" 및 "핵산"은 리보뉴클레오타이드 또는 데옥시뉴클레오타이드 중 하나의 임의의 길이 뉴클레오타이드의 중합체 형태를 지칭한다. 따라서, 이 용어는 단일-, 이중-, 또는 다중-가닥 DNA 또는 RNA, 게놈 DNA, cDNA, DNA-RNA 혼성체, 또는 퓨린 및 피리미딘 염기 또는 다른 천연, 화학적 또는 생화학적으로 변형된, 비천연 또는 유도체화된 뉴클레오타이드 염기를 포함하는 중합체를 포함하지만, 이들로 제한되지 않는다. 용어 "폴리뉴클레오타이드" 및 "핵산"은 기재 중인 실시형태에 적용 가능한, 단일-가닥(예컨대 센스 또는 안티센스) 및 이중-가닥 폴리뉴클레오타이드를 포함하는 것으로 이해되어야 한다.
용어 "폴리펩타이드", "펩타이드" 및 "단백질"은 본 명세서에서 상호 호환적으로 사용되고, 유전적으로 암호화된 그리고 비유전적으로 암호화된 아미노산, 화학적으로 또는 생화학적으로 변형 또는 유도체화된 아미노산, 및 변형된 펩타이드 골격을 갖는 폴리펩타이드를 포함할 수 있는 임의의 길이의 아미노산의 중합체 형태를 지칭한다. 상기 용어는 N-말단의 메티오닌 잔기가 있거나 또는 없는, 이종성 아미노산 서열과의 융합 단백질, 이종성 및 상동성 리더 서열과의 융합; 면역학적으로 태그된 단백질 등을 포함하지만, 이들로 제한되지 않는 융합 단백질을 포함한다.
핵산, 단백질, 세포 또는 유기체에 적용되는 본 명세서에서 사용되는 용어 "천연 유래"는 천연에서 발견되는 핵산, 세포, 단백질 또는 유기체를 지칭한다.
본 명세서에서 사용되는 용어 "단리된"은 폴리뉴클레오타이드, 폴리펩타이드 또는 세포가 자연적으로 생기는 환경과 상이한 환경에 있는 폴리뉴클레오타이드, 폴리펩타이드 또는 세포를 설명하는 것을 의미한다. 단리된 유전자 변형된 숙주 세포는 유전자 변형된 숙주 세포의 혼합 집단으로 제공될 수 있다.
본 명세서에 사용되는 바와 같은 용어 "외인성 핵산"은 천연에서 주어진 박테리아, 유기체 또는 세포에서 정상적으로 또는 자연적으로 발견되지 않고/않거나 생성되지 않는 핵산을 지칭한다. 본 명세서에 사용되는 바와 같은 용어 "내인성 핵산"은 천연에서 주어진 박테리아, 유기체 또는 세포에서 정상적으로 또는 자연적으로 발견되고/되거나 생성된 핵산을 지칭한다. "내인성 핵산"은 또한 "천연 핵산" 또는 주어진 박테리아, 유기체 또는 세포에 대해 "천연"인 핵산으로서 지칭된다.
본 명세서에서 사용되는 "재조합체"는 특정 핵산(DNA 또는 RNA)이 천연 시스템에서 발견되는 내인성 핵산과 구별 가능한 구조적 암호 또는 비-암호 서열을 갖는 작제물을 초래하는 클로닝, 제한 및/또는 결찰 단계의 다양한 조합의 생성물이라는 것을 의미한다. 일반적으로, 구조적 암호 서열을 암호화하는 DNA 서열은 세포에 또는 무세포 전사 및 번역 시스템에 함유된 재조합 전사 단위로부터 발현될 수 있는 합성 핵산을 제공하기 위해 cDNA 단편 및 짧은 올리고뉴클레오타이드 링커로부터, 또는 일련의 합성 올리고뉴클레오타이드로부터 조립될 수 있다. 이러한 서열은 전형적으로 진핵 유전자에 존재하는 내부 비-번역 서열 또는 인트론에 의해 중단되지 않는 오픈 리딩 프레임 형태로 제공될 수 있다. 적절한 서열을 포함하는 게놈 DNA는 또한 재조합 유전자 또는 전사 단위의 형태로 사용될 수 있다. 비번역 DNA의 서열은 오픈 리딩 프레임으로부터의 5' 또는 3'에 존재할 수 있으며, 여기서 이러한 서열은 암호 영역의 조작 또는 발현을 방해하지 않고, 정말로 다양한 메커니즘에 의해 목적으로 하는 생성물의 생성물을 조작하도록 작용할 수 있다("DNA 조절 서열" 참조, 이하).
따라서, 예를 들어, 용어 "재조합" 폴리뉴클레오타이드 또는 "재조합" 핵산은 천연 유래가 아닌 것, 예를 들어, 인간 개입을 통해 서열의 2개의 다르게 분리된 세그먼트의 인공 조합에 의해 만들어진 것을 지칭한다. 이 인공 조합은 종종 화학적 합성 수단에 의해, 또는 핵산의 단리된 세그먼트의 인공 조작에 의해, 예를 들어, 유전자 조작 기법에 의해 수행된다. 이는 보통 코돈을 동일한 또는 보존적 아미노산을 암호화하는 풍부한 코돈으로 대체하는 한편, 전형적으로 서열 인식 부위를 도입하거나 또는 제거하기 위해 행한다. 대안적으로, 목적으로 하는 기능의 조합을 생성하기 위해 목적으로 하는 기능의 핵산 세그먼트를 함께 결합하도록 수행된다. 이 인공 조합은 종종 화학적 합성 수단에 의해, 또는 핵산의 단리된 세그먼트의 인공 조작에 의해, 예를 들어, 유전자 조작 기법에 의해 수행된다.
유사하게, 용어 "재조합" 폴리펩타이드는 천연 유래가 아니며, 예를 들어, 인간 개입을 통해 아미노 서열의 2개의 다르게 분리된 세그먼트의 인공 조합물에 의해 제조된 폴리펩타이드를 지칭한다. 따라서, 예를 들어, 이종성 아미노산 서열을 포함하는 폴리펩타이드는 재조합이다.
"작제물" 또는 "벡터"는 특정 뉴클레오타이드 서열(들)의 발현 및/또는 증식의 목적을 위해 생성된, 또는 다른 재조합 뉴클레오타이드 서열의 작제물에서 사용될 재조합 핵산, 일반적으로 재조합 DNA를 의미한다.
본 명세서에서 상호 호환적으로 사용되는 용어 "DNA 조절 서열", "제어 요소" 및 "조절 요소"는 암호 서열의 발현 및/또는 숙주 세포에서 암호화된 폴리펩타이드의 생성을 제공하고/하거나 조절하는 전사 및 번역 제어 서열, 예컨대 프로모터, 인핸서, 폴리아데닐화 신호, 종결자, 단백질 분해 신호 등을 지칭한다.
용어 "형질전환"은 본 명세서에서 "유전자 변형"과 상호 호환적으로 사용되고, 세포 내로 새로운 핵산(예를 들어, 세포에 외인성인 DNA)의 도입 후 세포에 유도된 영구한 또는 일시적 유전자 변화를 지칭한다. 유전자 변화("변형")는 숙주 세포의 게놈 내로 새로운 핵산의 혼입에 의해, 또는 에피솜 요소로서 새로운 핵산의 일시적 또는 안정한 유지에 의해 달성될 수 있다. 세포가 진핵 세포인 경우에, 영구한 유전자 변화는 일반적으로 세포 게놈 내로 새로운 DNA의 도입에 의해 달성된다. 원핵세포에서, 염색체 내로 또는 염색체외 요소, 예컨대 플라스미드 및 발현 벡터를 통해 영구적 변화가 도입될 수 있는데, 이는 재조합 숙주 세포에서 그들의 유지에 도움을 주는 하나 이상의 선택 가능한 마커를 함유할 수 있다. 유전자 변형의 적합한 방법은 바이러스 감염, 형질감염, 접합, 원형질체 융합, 전기천공법, 입자총 기법, 인산칼슘 침전, 직접 마이크로주사 등을 포함한다. 방법의 선택은 일반적으로 형질감염 중인 세포의 유형 및 형질감염이 일어나는 환경(즉, 시험관내, 생체외 또는 생체내)에 의존한다. 이들 방법의 일반적 논의는 문헌[Ausubel, et al, Short Protocols in Molecular Biology, 3rd ed., Wiley & Sons, 1995]에서 찾을 수 있다.
"작동 가능하게 연결된"은 이렇게 기재된 성분이 그들의 의도된 방식으로 작용하도록 허용하는 관계인 병치를 지칭한다. 예를 들어, 프로모터가 그의 전사 또는 발현에 영향을 미친다면 프로모터는 암호 서열에 작동 가능하게 연결된다. 본 명세서에서 사용되는 용어 "이종성 프로모터" 및 "이종성 제어 영역"은 천연에서 특정 핵산과 정상적으로 결합되지 않은 프로모터 및 다른 제어 영역을 지칭한다. 예를 들어, "암호 영역에 대해 이종성인 전사 제어 영역"은 천연에서 암호 영역과 정상적으로 결합되지 않은 전사 제어 영역이다.
본 명세서에서 사용되는 "숙주 세포"는 진핵 또는 원핵 세포가 핵산에 대한 수용자(예를 들어, 발현 벡터)로서 사용될 수 있거나 또는 사용되고, 핵산에 의해 유전자 변형된 본래의 세포의 자손을 포함하는, 생체내 또는 시험관내 진핵 세포, 원핵 세포 또는 단세포 독립체로서 배양시킨 다세포 유기체로부터의 세포(예를 들어, 세포주)를 나타낸다. 단일 세포의 자손은 단일 세포의 자손은 천연, 우연한 또는 의도적인 돌연변이에 기인하여, 본래의 모체와 형태가 또는 게놈 또는 총 DNA 상보체와 완전히 동일할 필요는 없다는 것이 이해된다. "재조합 숙주 세포"(또한 "유전자 변형된 숙주 세포"로서 지칭됨)는 이종성 핵산, 예를 들어, 발현 벡터가 도입된 숙주 세포이다. 예를 들어, 대상 원핵 숙주 세포는 이종성 핵산, 예를 들어, 원핵 숙주 세포에서 정상적으로 발견되지 않는 원핵 숙주 세포 또는 재조합 핵산에 대해 외래인(그리고 천연에서 정상적으로 발견되지 않는) 외인성 핵산의 적합한 원핵 숙주 세포 내로의 도입에 의한 유전자 변형된 원핵 숙주 세포(예를 들어, 박테리아)이고; 그리고 대상 진핵 숙주 세포는 이종성 핵산, 예를 들어, 진핵 숙주 세포에 정상적으로 발견되지 않는 진핵 숙주 세포, 또는 재조합 핵산에 대해 외래인 외인성 핵산의 적합한 진핵 숙주 세포 내로 도입에 의한 유전자 변형된 진핵 숙주 세포이다.
용어 "보존적 아미노산 치환"은 유사한 측쇄를 갖는 아미노산 잔기의 단백질에서의 상호 호환성을 지칭한다. 예를 들어, 지방족 측쇄를 갖는 아미노산의 그룹은 글리신, 알라닌, 발린, 류신, 및 아이소류신으로 이루어지며; 지방족-하이드록실 측쇄를 갖는 아미노산의 그룹은 세린 및 트레오닌으로 이루어지고; 아마이드-함유 측쇄를 갖는 아미노산의 그룹은 아스파라긴 및 글루타민으로 이루어지며; 방향족 측쇄를 갖는 아미노산 그룹은 페닐알라닌, 타이로신 및 트립토판으로 이루어지고; 염기성 측쇄를 갖는 아미노산의 그룹은 라이신, 알기닌 및 히스티딘으로 이루어지며; 그리고 황-함유 측쇄를 갖는 아미노기의 그룹은 시스테인 및 메티오닌으로 이루어진다. 예시적인 보존적 아미노산 치환 그룹은 발린-류신-아이소류신, 페닐알라닌-타이로신, 라이신-알기닌, 알라닌-발린, 및 아스파라긴-글루타민이다.
폴리뉴클레오타이드 또는 폴리펩타이드는 다른 폴리뉴클레오타이드 또는 폴리펩타이드에 대한 특정 "서열 동일성" 백분율을 갖는데, 이는 정렬될 때, 염기 또는 아미노산의 백분율이 동일하고, 두 서열을 비교할 때 동일한 상대적 위치에 있다는 것을 의미한다. 서열 유사성은 다수의 상이한 방식으로 결정될 수 있다. 서열 동일성을 결정하기 위해, 서열은 ncbi.nlm.nih.gov/BLAST에서 월드 와이드 웹에 대해 이용 가능한 BLAST를 포함하는 방법 및 컴퓨터 프로그램을 이용하여 정렬될 수 있다. 예를 들어, 문헌[Altschul et al. (1990), J. Mol . Biol . 215:403-10] 참조. 다른 정렬 알고리즘은 옥스퍼드 몰레큘러 그룹, 인코포레이티드(Oxford Molecular Group, Inc.)의 전액 출자된 자회사인 미국 위스콘신주 메디슨에 소재한 제네틱스 컴퓨팅 그룹(Genetics Computing Group: GCG) 패키지에서 이용 가능한 FASTA이다. 정렬을 위한 다른 기법은 문헌[Methods in Enzymology, vol. 266: Computer Methods for Macromolecular Sequence Analysis (1996), ed. Doolittle, Academic Press, Inc., a division of Harcourt Brace & Co., San Diego, California, USA]에 기재되어 있다. 특정 관심 대상 중에서 서열 내 갭을 허용하는 정렬 프로그램이다. 스미스-워터만(Smith-Waterman)은 서열 정렬에서 갭을 허용하는 알고리즘 중 하나의 유형이다. 문헌[Meth . Mol . Biol . 70: 173-187 (1997)] 참조. 또한, 니들만(Needleman) 및 분쉬(Wunsch) 정렬 방법을 이용하는 GAP 프로그램은 서열을 정렬하기 위해 이용될 수 있다. 문헌[J. Mol . Biol. 48: 443-453 (1970)] 참조.
본 명세서에서 사용되는 용어 "치료", "치료하는" 등은 목적으로 하는 약학적 및/또는 생리적 효과를 얻는 것을 지칭한다. 효과는 질환 또는 이의 증상을 완전히 또는 부분적으로 방지하는 것에 관해 예방적일 수 있고/있거나 질환 및/또는 질환에 기인하는 유해한 효과에 대한 부분적 또는 완전한 치유에 관해 치유적일 수 있다. 본 명세서에서 사용되는 "치료"는 포유류에서, 예를 들어, 인간에서의 질환의 임의의 치료를 아우르며, (a) 질환의 성향이 있을 수 있지만, 그것을 갖는 것으로 아직 진단되지 않은 대상체에서 질환이 생기는 것을 예방하는 것; (b) 질환을 저해하는 것, 즉, 그의 발생을 저지하는 것; 및 (c) 질환을 완화시키는 것, 즉, 질환의 퇴행을 야기하는 것을 포함한다.
본 명세서에서 상호 호환적으로 사용되는 용어 "개체", "대상체", "숙주" 및 "환자"는 뮤린, 유인원, 인간, 포유류 농장 동물, 포유류 스포츠 동물 및 포유류 반려동물을 포함하지만, 이들로 제한되지 않는 개개 유기체, 예를 들어, 포유류를 지칭한다.
본 발명을 추가로 기재하기 전에, 본 발명은 기재한 특정 실시형태로 제한되지 않으며, 그렇게 해서 물론 다를 수 있다는 것이 이해되어야 한다. 또한 본 명세서에 사용되는 용어는 단지 특정 실시형태를 기재할 목적을 위한 것이며, 제한하는 것으로 의도되지 않는데, 본 발명의 범주는 첨부된 청구범위에 의해서만 제한될 것이기 때문이다.
수치의 범위가 제공되는 경우에, 문맥에서 달리 분명하게 나타내지 않는 한, 해당 범위 및 해당 언급된 범위에서의 임의의 다른 언급된 또는 개재된 값의 상한과 하한 사이에서 하한 단위의 1/10까지의 각각의 사이의 값은 본 발명 내에 포함된다는 것이 이해된다. 이들 더 작은 범위의 상한 및 하한은 더 작은 범위에 독립적으로 포함될 수 있고, 또한 본 발명 내에 포함되며, 언급됨 범위 내에서 임의의 구체적으로 제외된 제한이 적용된다. 언급된 범위가 제한 중 하나 또는 둘 다를 포함하는 경우에, 포함된 제한 중 하나 또는 둘 다를 제외한 범위가 또한 본 발명에 포함된다.
달리 정의되지 않는 한, 본 명세서에서 사용되는 모든 기술적 및 과학적 용어는 본 발명이 속하는 기술분야의 당업자에 의해 통상적으로 이해되는 것과 동일한 의미를 가진다. 본 명세서에 기재된 것과 유사하거나 또는 동일한 임의의 방법 및 물질이 또한 본 발명의 실행 또는 시험에서 사용될 수 있지만, 바람직한 방법 및 물질이 이제 기재된다. 본 명세서에서 언급된 모든 간행물은 간행물과 함께 인용된 방법 및/또는 물질을 개시하고 기재하기 위해 본 명세서에 참고로 편입된다.
본 명세서에 사용되고 첨부하는 청구범위에 사용되는 바와 같은 단수 형태는 달리 분명하게 나타내지 않는 한 복수의 대상을 포함하는 것임을 주목하여야 한다. 따라서, 예를 들어, "CasX 폴리펩타이드"에 대한 언급은 복수의 이러한 폴리펩타이드를 포함하고, "가이드 RNA"에 대한 언급은 당업자에게 공지된 하나 이상의 가이드 RNA 및 이의 동등물 등에 대한 언급을 포함한다. 청구범위는 임의의 선택적 요소를 제외하도록 작성될 수 있다는 것을 추가로 주목한다. 이렇게 해서, 이러한 언급은 청구범위 요소의 열거와 관련하여 "유일하게", "단지" 등의 사용 또는 "음성" 제한의 사용을 위한 선행 기준으로서 작용하는 것으로 의도된다.
명확함을 위해 별개의 실시형태와 관련하여 기재된 본 발명의 특정 특징은 또한 단일 실시형태에서 조합하여 제공될 수 있다는 것이 인식된다. 대조적으로, 간결함을 위해 단일 실시형태와 관련하여 기재된 본 발명의 다양한 특징은 또한 별개로 또는 임의의 적합한 하위-조합으로 제공될 수 있다. 본 발명에 관한 실시형태의 모든 조합은 본 발명에 의해 구체적으로 포함되고, 각각의 그리고 모든 조합이 개별적으로 그리고 명확하게 개시되는 것과 같이 본 명세서에 개시된다. 추가로, 다양한 실시형태의 모든 하위 조합 및 이의 요소는 또한 본 발명에 의해 구체적으로 포함되고, 각각의 그리고 모든 이러한 하위 조합이 개별적으로 그리고 명확하게 본 명세서에 개시되는 것과 같이 본 명세서에 개시된다.
본 명세서에서 논의되는 간행물은 본 출원의 출원일 전의 그들의 개시내용에 대해서만 제공된다. 본 명세서의 어떤 것도 본 발명이 선행 발명 때문에 이러한 간행물보다 선행한다는 자격이 부여되지 않는다는 용인으로서 해석되어서는 안 된다. 추가로, 제공된 간행물의 날짜는 독립적으로 확인될 필요가 있을 수 있는 실제 간행물과 상이할 수 있다.
상세한 설명
본 발명의 개시내용은 본 명세서에서 "CasX" 폴리펩타이드로서 지칭되는(또한 "CasX 단백질"로서 지칭됨) RNA-가이드 엔도뉴클레아제 폴리펩타이드; CasX 폴리펩타이드를 암호화하는 핵산; 및 CasX 폴리펩타이드를 포함하는 변형된 숙주 세포 및/또는 이를 암호화하는 핵산을 제공한다. 제공되는 CasX 폴리펩타이드는 다양한 적용분야에서 유용하다.
본 개시내용은 CasX 단백질에 결합하고 이에 대한 서열 특이성을 제공하는 가이드 RNA(본 명세서에서 "CasX 가이드 RNA"로서 지칭됨); CasX 가이드 RNA를 암호화하는 핵산; 및 CasX 가이드 RNA 및/또는 이를 암호화하는 핵산을 포함하는 변형된 숙주 세포를 제공한다. 제공되는 CasX 가이드 RNA는 다양한 적용분야에서 유용하다.
본 개시내용은 고세균 Cas9 폴리펩타이드 및 이를 암호화하는 핵산뿐만 아니라 이와 회합된 가이드 RNA(고세균 Cas9 가이드 RNA) 및 이를 암호화하는 핵산을 제공한다.
조성물
CRISPR
/
CasX
단백질 및 가이드 RNA
CRISPR/Cas 엔도뉴클레아제(예를 들어, CasX 단백질)는 대응하는 가이드 RNA(예를 들어, CasX 가이드 RNA)와 상호작용(결합)하여 표적 핵산 분자 내에서 가이드 RNA와 표적 서열 사이의 염기쌍을 통해 표적 핵산 내 특정 부위로 표적화된 리보뉴클레오단백질(RNP) 복합체를 형성한다. 가이드 RNA는 표적 핵산의 서열(표적 부위)에 상보성인 뉴클레오타이드 서열(가이드 서열)을 포함한다. 따라서, CasX 단백질은 CasX 가이드 RNA와 복합체를 형성하고, 가이드 RNA는 가이드 서열을 통해 RNP 복합체에 서열 특이성을 제공한다. 복합체의 CasX 단백질은 부위-특이적 활성을 제공한다. 다시 말해서, CasX 단백질은 가이드 RNA와 그의 결합 덕분에 표적 핵산 서열(예를 들어, 염색체 서열 또는 염색체외 서열, 예를 들어, 에피솜 서열, 소형 고리형 서열, 미토콘드리아 서열, 엽록체 서열 등) 내에서 표적 부위(예를 들어, 표적 부위에서 안정화됨)로 가이드된다.
본 개시내용은 CasX 폴리펩타이드(및/또는 CasX 폴리펩타이드를 암호화하는 핵산)(예를 들어, CasX 폴리펩타이드가 자연적으로 존재하는 단백질일 수 있는 경우에, 틈내기효소 CasX 단백질, dCasX 단백질, 키메라 CasX 단백질 등)을 포함하는 조성물을 제공한다. 본 개시내용은 CasX 가이드 RNA(및/또는 CasX 가이드 RNA를 암호화하는 핵산)(예를 들어, CasX 가이드 RNA가 이중 또는 단일 가이드 형식일 수 있는 경우)을 포함하는 조성물을 제공한다. 본 개시내용은 (a) CasX 폴리펩타이드(및/또는 CasX 폴리펩타이드를 암호화하는 핵산)(예를 들어, CasX 폴리펩타이드가 자연적으로 존재하는 단백질일 수 있는 경우에, 틈내기효소 CasX 단백질, dCasX 단백질, 키메라 CasX 단백질 등) 및 (b) CasX 가이드 RNA(및/또는 CasX 가이드 RNA를 암호화하는 핵산)(예를 들어, CasX 가이드 RNA가 이중 또는 단일 가이드 형식일 수 있는 경우)을 포함하는 조성물을 제공한다. 본 개시내용은: (a) 본 개시내용의 CasX 폴리펩타이드(예를 들어, CasX 폴리펩타이드가 자연적으로 존재하는 단백질, 틈내기효소 CasX 단백질, dCasX 단백질, 키메라 CasX 단백질 등일 수 있는 경우); 및 (b) CasX 가이드 RNA(예를 들어, CasX 가이드 RNA가 이중 또는 단일 가이드 형식일 수 있는 경우)를 포함하는 핵산/단백질 복합체(RNP 복헵체)를 제공한다.
CasX
단백질
CasX 폴리펩타이드(이 용어는 용어 "CasX 단백질"과 상호 호환적으로 사용됨)는 표적 핵산과 결합된 표적 핵산 및/또는 폴리펩타이드에 결합하고/하거나 변형할 수 있다(예를 들어, 절단, 틈내기, 메틸화, 데메틸화 등)(예를 들어, 히스톤 꼬리의 메틸화 또는 아세틸화)(예를 들어, 일부 경우에, CasX 단백질은 활성을 갖는 융합 상대를 포함하고, 일부 경우에 CasX 단백질은 뉴클레아제 활성을 제공한다). 일부 경우에, CasX 단백질은 천연 유래 단백질이다(예를 들어, 원핵 세포에서 자연적으로 생긴다). 다른 경우에, CasX 단백질은 천연 유래 폴리펩타이드가 아니다(예를 들어, CasX 단백질은 변이체 CasX 단백질, 키메라 단백질 등이다).
주어진 단백질이 CasX 가이드 RNA와 상호작용하는지의 여부를 결정하는 분석은 단백질과 핵산 사이의 결합에 대해 시험하는 임의의 편리한 결합 분석일 수 있다. 적합한 결합 분석(예를 들어, 겔 이동 분석)은 당업자에게 공지될 것이다(예를 들어, CasX 가이드 RNA 및 표적 핵산에 대한 단백질의 첨가를 포함하는 분석). 단백질이 활성을 갖는지의 여부를 결정하는(예를 들어, 단백질이 표적 핵산을 절단하는 뉴클레아제 활성 및/또는 일부 이종성 활성을 갖는지의 여뷰를 결정하는) 분석은 임의의 편리한 분석(예를 들어, 핵산 절단에 대해 시험하는 임의의 편리한 핵산 절단 분석)일 수 있다. 적합한 분석(예를 들어, 절단 분석)은 당업자에게 공지될 것이다.
천연 유래 CasX 단백질은 표적화된 이중 가닥 DNA(dsDNA) 내 특정 서열에서 이중 가닥 파손을 촉매하는 엔도뉴클레아제로서 작용한다. 서열 특이성은 표적 DNA 내에서 표적 서열에 혼성화하는 회합된 가이드 RNA에 의해 제공된다. 천연 유래 가이드 RNA는 crRNA에 혼성화된 tracrRNA를 포함하며, 여기서 crRNA는 표적 DNA에서 표적 서열에 혼성화하는 가이드 서열 포함하는 단백질 결합 세그먼트를 포함한다.
일부 실시형태에서, 대상 방법 및/또는 조성물의 CasX 단백질은 천연 유래(야생형) 단백질이다(또는 이로부터 유래된다). 천연 유래 CasX 단백질의 예는 도 1에 도시하고 서열번호 1 내지 2에 제시한다. 천연 유래 CasX 단백질의 예는 도 1에 도시하고 서열번호 1 내지 3에 제시한다. 2개의 천연 유래 CasX 단백질의 정렬은 도 2에 제시된다('gwa2'는 CasX1이고, 'gwc2'는 CasX2임). 서열분석 데이터로부터(델타프로테오박테리아(Deltaproteobacter)(gwa2 스캐폴드)로부터 그리고 부유균문(gwc2 스캐폴드)으로부터) 조립된 CRISPR 좌위의 부분적 DNA 스캐폴드는 각각 서열번호 51 및 52로서 제시된다. 이 새로 발견된 단백질(CasX)은 이전에 동정된 CRISPR-Cas 엔도뉴클레아제에 비해 짧고, 따라서 대안으로서 이 단백질의 사용은 단백질을 암호화하는 뉴클레오타이드가 상대적으로 짧다는 이점을 제공한다는 것을 주목하는 것은 중요하다. 이는, 예를 들어, 연구 및/또는 임상 적용을 위한 세포, 예컨대 진핵 세포(예를 들어, 시험관내, 생체외, 생체내 포유류 세포, 인간 세포, 마우스 세포)에 대한 전달을 위해 CasX 단백질을 암호화하는 핵산이 바람직한 경우에, 예를 들어, 바이러스 벡터(예를 들어, AAV 벡터)를 사용하는 경우에 유용하다. 또한 CasX CRISPR 좌위를 보유하는 박테리아는 저온(예를 들어, 10 내지 17℃)에서 수집된 환경 샘플에 존재한다는 것이 본 명세서에서 주목된다. 따라서, CasX는 저온(예를 들어, 10 내지 14℃, 10 내지 17℃, 10 내지 20℃)에서 제대로 작용할 수 있는 것으로 예상된다(예를 들어, 지금까지 발견된 다른 Cas 엔도뉴클레아제보다 더 양호함).
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 단백질의 천연 유래 촉매 활성을 감소시키는 아미노산 치환(예를 들어, 1, 2 또는 3개의 아미노산 치환)(예를 들어, 이하에 기재하는 아미노산 위치)을 포함한다는 것을 제외하고, 서열번호 1에 제시된 CasX 단백질 서열을 갖는 아미노산 서열을 포함한다.
일부 경우에, CasX 단백질은 서열번호 2에 제시된 CasX 단백질 서열과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 2에 제시된 CasX 단백질 서열과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 2에 제시된 CasX 단백질 서열과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 2에 제시된 CasX 단백질 서열과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 2에 제시된 CasX 단백질 서열을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 단백질의 천연 유래 촉매 활성을 감소시키는 아미노산 치환(예를 들어, 1, 2 또는 3개의 아미노산 치환)(예를 들어, 이하에 기재하는 아미노산 위치)을 포함한다는 것을 제외하고, 서열번호 2에 제시된 CasX 단백질 서열을 갖는 아미노산 서열을 포함한다.
일부 경우에, CasX 단백질은 서열번호 3에 제시된 CasX 단백질 서열과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 3에 제시된 CasX 단백질 서열과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 3에 제시된 CasX 단백질 서열과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 3에 제시된 CasX 단백질 서열과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 3에 제시된 CasX 단백질 서열을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 단백질의 천연 유래 촉매 활성을 감소시키는 아미노산 치환(예를 들어, 1, 2 또는 3개의 아미노산 치환)(예를 들어, 이하에 기재하는 아미노산 위치)을 포함한다는 것을 제외하고, 서열번호 3에 제시된 CasX 단백질 서열을 갖는 아미노산 서열을 포함한다.
일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나와 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나와 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나와 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나와 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 및 2 중 임의의 하나에 제시된 CasX 단백질 서열을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 단백질의 천연 유래 촉매 활성을 감소시키는 아미노산 치환(예를 들어, 1, 2 또는 3개의 아미노산 치환)(예를 들어, 이하에 기재하는 아미노산 위치)을 포함한다는 것을 제외하고, 서열번호 1 및 2 중 임의의 하나에 제시된 CasX 단백질 서열을 갖는 아미노산 서열을 포함한다.
일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나와 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나와 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나와 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나와 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상, 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 내지 3 중 임의의 하나에 제시된 CasX 단백질 서열을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 단백질의 천연 유래 촉매 활성을 감소시키는 아미노산 치환(예를 들어, 1, 2 또는 3개의 아미노산 치환)(예를 들어, 이하에 기재하는 아미노산 위치)을 포함한다는 것을 제외하고, 서열번호 1 내지 3 중 임의의 하나에 제시된 CasX 단백질 서열을 갖는 아미노산 서열을 포함한다.
CasX
단백질 도메인
CasX 단백질의 도메인을 도 3에 도시한다. 도 3의 개략적 표현에 알 수 있는 바와 같이(아미노산은 CasX1 단백질에 기반하여 넘버링됨(서열번호 1)), CasX 단백질은 길이가 거의 650개의 아미노산인 N-말단의 도메인(예를 들어, CasX1에 대해 약 663 및 CasX2에 대해 약 650), 및 CasX 단백질의 주요 아미노산 서열에 대해 인접하지 않지만, 일단 단백질이 생성되고 폴딩된다면 RuvC 도메인을 형성하는 3개의 부분적 RuvC 도메인(RuvC-I, RuvC-II 및 RuvC-III, 또한 본 명세서에서 서브도메인으로서 지칭됨)을 포함하는 C-말단의 도메인을 포함한다. 따라서, 일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 길이가 500 내지 750개의 아미노산(예를 들어, 550-750, 600-750, 640-750, 650-750, 500-700, 550-700, 600-700, 640-700, 650-700, 500-680, 550-680, 600-680, 640-680, 650-680, 500-670, 550-670, 600-670, 640-670 또는 650-670개의 아미노산) 범위인 N-말단 도메인(예를 들어, 임의의 융합된 이종성 서열, 예컨대 NLS 및/또는 촉매 활성을 갖는 도메인을 포함하지 않음)을 갖는 아미노산 서열을 포함한다. 일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 분할 Ruv C 도메인(예를 들어, 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III)에 대해 N-말단인 500 내지 750개의 아미노산(예를 들어, 550-750, 600-750, 640-750, 650-750, 500-700, 550-700, 600-700, 640-700, 650-700, 500-680, 550-680, 600-680, 640-680, 650-680, 500-670, 550-670, 600-670, 640-670, 또는 650-670개의 아미노산) 범위인(예를 들어, 임의의 융합된 이종성 서열, 예컨대 NLS 및/또는 촉매 활성을 갖는 도메인을 포함하지 않음) 길이를 갖는 아미노산 서열을 포함한다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대해 아미노산 1 내지 663로서 도시된 도메인, 패널 a)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663로서 도시된 도메인, 패널 a)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663으로서 도시된 도메인, 패널 a)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663으로서 도시된 도메인, 패널 a)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 아미노산 1 내지 663을 갖는 아미노산 서열을 포함한다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 2에 제시된 CasX 단백질 서열의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대해 아미노산 1 내지 663로서 도시된 도메인, 패널 a)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 서열번호 2에 제시된 CasX 단백질 서열의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663로서 도시된 도메인, 패널 a)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 2에 제시된 CasX 단백질 서열의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663으로서 도시된 도메인, 패널 a)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 2에 제시된 CasX 단백질 서열의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663으로서 도시된 도메인, 패널 a)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 아미노산 1 내지 663에 대응하는 서열번호 2의 아미노산 서열을 포함한다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 3에 제시된 CasX 단백질 서열의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대해 아미노산 1 내지 663로서 도시된 도메인, 패널 a)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 서열번호 3에 제시된 CasX 단백질 서열의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663로서 도시된 도메인, 패널 a)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 3에 제시된 CasX 단백질 서열의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663으로서 도시된 도메인, 패널 a)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 3에 제시된 CasX 단백질 서열의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663으로서 도시된 도메인, 패널 a)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 아미노산 1 내지 663에 대응하는 서열번호 3의 아미노산 서열을 포함한다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대해 아미노산 1 내지 663로서 도시된 도메인, 패널 a)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663로서 도시된 도메인, 패널 a)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663으로서 도시된 도메인, 패널 a)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663으로서 도시된 도메인, 패널 a)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 아미노산 1 내지 663에 대응하는 아미노산 서열을 포함한다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 분할 Ruv C 도메인(예를 들어, 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III)을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 분할 Ruv C 도메인(예를 들어, 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III)을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 분할 Ruv C 도메인(예를 들어, 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III)을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 분할 Ruv C 도메인(예를 들어, 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III)을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1로서 제시된 CasX 단백질 서열의 아미노산 1 내지 663에 대응하는 아미노산 서열(예를 들어, 서열번호 2에 제시된 CasX 단백질 서열의 아미노산 1 내지 650); 및 분할 Ruv C 도메인(예를 들어, 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II, 및 RuvC-III)을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함한다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대해 아미노산 1 내지 663로서 도시된 도메인, 패널 a)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663로서 도시된 도메인, 패널 a)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663으로서 도시된 도메인, 패널 a)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 1 내지 663으로서 도시된 도메인, 패널 a)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 아미노산 1 내지 663에 대응하는 아미노산 서열을 포함한다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 분할 Ruv C 도메인(예를 들어, 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III)을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 분할 Ruv C 도메인(예를 들어, 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III)을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 분할 Ruv C 도메인(예를 들어, 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III)을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 분할 Ruv C 도메인(예를 들어, 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III)을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1로서 제시된 CasX 단백질 서열의 아미노산 1 내지 663에 대응하는 아미노산 서열(예를 들어, 서열번호 2에 제시된 CasX 단백질 서열의 아미노산 1 내지 650); 및 분할 Ruv C 도메인(예를 들어, 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II, 및 RuvC-III)을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함한다.
일부 실시형태에서, (대상 조성물 및/또는 방법의) CasX 단백질의 분할 RuvC 도메인은 RuvC-III 서브도메인보다 더 큰 RuvC-II와 RuvC-III 서브도메인 사이의 영역을 포함한다. 예를 들어, 일부 경우에, RuvC-III 서브도메인의 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1.1 이상(예를 들어, 1.2)이다. 일부 경우에, RuvC-III 서브도메인의 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이다. 일부 경우에, RuvC-III 서브도메인의 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2)이다.
(대상 조성물 및/또는 방법의 CasX 단백질에 대해) 일부 실시형태에서, RuvC-III 서브도메인의 길이에 대해 RuvC-II 서브도메인 길이비는 2 이하(예를 들어, 1.8 이하, 1.7 이하, 1.6 이하, 1.5 이하 또는 1.4 이하)이다. 예를 들어, 일부 경우에, RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1.5 이하(예를 들어, 1.4 이하)이다. 일부 실시형태에서, RuvC-III 서브도메인의 길이에 대해 RuvC-II 서브도메인의 길이비는 1 내지 2(예를 들어, 1.1 내지 2, 1.2 내지 2, 1 내지 1.8, 1.1 내지 1.8, 1.2 내지 1.8, 1 내지 1.6, 1.1 내지 1.6, 1.2 내지 1.6, 1 내지 14, 1.1 내지 1.4, 또는 1.2 내지 1.4)의 범위이다.
(대상 조성물 및/또는 방법의 CasX 단백질에 대해)일부 경우에, RuvC-III 서브도메인의 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이다. 일부 경우에, RuvC-III 서브도메인의 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2)이다.
(대상 조성물 및/또는 방법의 CasX 단백질에 대해) 일부 경우에, RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 73개의 아미노산(예를 들어, 길이가 적어도 75, 77, 80, 85 또는 87 개의 아미노산)이다. 예를 들어, 일부 경우에, RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 78개의 아미노산(예를 들어, 길이가 적어도 80, 85 또는 87개의 아미노산)이다. 일부 경우에, RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 85개의 아미노산이다. 일부 경우에, RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 75 내지 100개의 아미노산 범위(예를 들어, 75-95, 75-90, 75-88, 78-100, 78-95, 78-90, 78-88, 80-100, 80-95, 80-90, 80-88, 83-100, 83-95, 83-90, 83-88, 85-100, 85-95, 85-90 또는 85-88개의 아미노산의 범위)이다. 일부 경우에, RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 80 내지 95개의 아미노산 범위(예를 들어, 80-90, 80-88, 83-95, 83-90, 83-88, 85-95, 85-90 또는 85-88개의 아미노산의 범위)이다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함하며, 여기서: (i) RuvC-III 서브도메인의 길이에 대해 RuvC-II 대 RuvC-III 서브도메인 사이의 영역 길이비는 1.1 이상(예를 들어, 1.2)이고; (ii) RuvC-III 서브도메인의 길이에 대해 RuvC-II 내지 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이고; (iii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2)이며; (iv) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 2 이하(예를 들어, 1.8 이하, 1.7 이하, 1.6 이하, 1.5 이하 또는 1.4 이하)이고; (v) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1.5 이하(예를 들어, 1.4 이하)이며; (vi) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1 내지 2(예를 들어, 1.1 내지 2, 1.2 내지 2, 1 내지 1.8, 1.1 내지 1.8, 1.2 내지 1.8, 1 내지 1.6, 1.1 내지 1.6, 1.2 내지 1.6, 1 내지 14, 1.1 내지 1.4, 또는 1.2 내지 1.4) 범위이고; (vii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이며; (viii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2) 이고; (ix) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 73개의 아미노산(예를 들어, 길이가 적어도 75, 77, 80, 85 또는 87개의 아미노산)이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 78개의 아미노산(예를 들어, 길이가 적어도 80, 85 또는 87개의 아미노산)이며; (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 85개의 아미노산이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 길이가 75 내지 100개의 아미노산 범위(예를 들어, 75-95, 75-90, 75-88, 78-100, 78-95, 78-90, 78-88, 80-100, 80-95, 80-90, 80-88, 83-100, 83-95, 83-90, 83-88, 85-100, 85-95, 85-90 또는 85-88개의 아미노산 범위)이거나; 또는 (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 80 내지 95개의 아미노산 범위(예를 들어, 80-90, 80-88, 83-95, 83-90, 83-88, 85-95, 85-90 또는 85-88개 아미노산 범위)의 길이를 가진다.
예를 들어, 일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함하며, 여기서: (i) RuvC-III 서브도메인의 길이에 대해 RuvC-II 대 RuvC-III 서브도메인 사이의 영역 길이비는 1.1 이상(예를 들어, 1.2)이고; (ii) RuvC-III 서브도메인의 길이에 대해 RuvC-II 내지 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이고; (iii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2)이며; (iv) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 2 이하(예를 들어, 1.8 이하, 1.7 이하, 1.6 이하, 1.5 이하 또는 1.4 이하)이고; (v) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1.5 이하(예를 들어, 1.4 이하)이며; (vi) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1 내지 2(예를 들어, 1.1 내지 2, 1.2 내지 2, 1 내지 1.8, 1.1 내지 1.8, 1.2 내지 1.8, 1 내지 1.6, 1.1 내지 1.6, 1.2 내지 1.6, 1 내지 14, 1.1 내지 1.4, 또는 1.2 내지 1.4) 범위이고; (vii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이며; (viii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2) 이고; (ix) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 73개의 아미노산(예를 들어, 길이가 적어도 75, 77, 80, 85 또는 87개의 아미노산)이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 78개의 아미노산(예를 들어, 길이가 적어도 80, 85 또는 87개의 아미노산)이며; (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 85개의 아미노산이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 길이가 75 내지 100개의 아미노산 범위(예를 들어, 75-95, 75-90, 75-88, 78-100, 78-95, 78-90, 78-88, 80-100, 80-95, 80-90, 80-88, 83-100, 83-95, 83-90, 83-88, 85-100, 85-95, 85-90 또는 85-88개의 아미노산 범위)이거나; 또는 (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 80 내지 95개의 아미노산 범위(예를 들어, 80-90, 80-88, 83-95, 83-90, 83-88, 85-95, 85-90 또는 85-88개 아미노산 범위)의 길이를 가진다.
일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함하며, 여기서: (i) RuvC-III 서브도메인의 길이에 대해 RuvC-II 대 RuvC-III 서브도메인 사이의 영역 길이비는 1.1 이상(예를 들어, 1.2)이고; (ii) RuvC-III 서브도메인의 길이에 대해 RuvC-II 내지 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이고; (iii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2)이며; (iv) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 2 이하(예를 들어, 1.8 이하, 1.7 이하, 1.6 이하, 1.5 이하 또는 1.4 이하)이고; (v) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1.5 이하(예를 들어, 1.4 이하)이며; (vi) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1 내지 2(예를 들어, 1.1 내지 2, 1.2 내지 2, 1 내지 1.8, 1.1 내지 1.8, 1.2 내지 1.8, 1 내지 1.6, 1.1 내지 1.6, 1.2 내지 1.6, 1 내지 14, 1.1 내지 1.4, 또는 1.2 내지 1.4) 범위이고; (vii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이며; (viii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2) 이고; (ix) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 73개의 아미노산(예를 들어, 길이가 적어도 75, 77, 80, 85 또는 87개의 아미노산)이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 78개의 아미노산(예를 들어, 길이가 적어도 80, 85 또는 87개의 아미노산)이며; (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 85개의 아미노산이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 길이가 75 내지 100개의 아미노산 범위(예를 들어, 75-95, 75-90, 75-88, 78-100, 78-95, 78-90, 78-88, 80-100, 80-95, 80-90, 80-88, 83-100, 83-95, 83-90, 83-88, 85-100, 85-95, 85-90 또는 85-88개의 아미노산 범위)이거나; 또는 (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 80 내지 95개의 아미노산 범위(예를 들어, 80-90, 80-88, 83-95, 83-90, 83-88, 85-95, 85-90 또는 85-88개 아미노산 범위)의 길이를 가진다.
일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함하며, 여기서: (i) RuvC-III 서브도메인의 길이에 대해 RuvC-II 대 RuvC-III 서브도메인 사이의 영역 길이비는 1.1 이상(예를 들어, 1.2)이고; (ii) RuvC-III 서브도메인의 길이에 대해 RuvC-II 내지 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이고; (iii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2)이며; (iv) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 2 이하(예를 들어, 1.8 이하, 1.7 이하, 1.6 이하, 1.5 이하 또는 1.4 이하)이고; (v) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1.5 이하(예를 들어, 1.4 이하)이며; (vi) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1 내지 2(예를 들어, 1.1 내지 2, 1.2 내지 2, 1 내지 1.8, 1.1 내지 1.8, 1.2 내지 1.8, 1 내지 1.6, 1.1 내지 1.6, 1.2 내지 1.6, 1 내지 14, 1.1 내지 1.4, 또는 1.2 내지 1.4) 범위이고; (vii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이며; (viii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2) 이고; (ix) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 73개의 아미노산(예를 들어, 길이가 적어도 75, 77, 80, 85 또는 87개의 아미노산)이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 78개의 아미노산(예를 들어, 길이가 적어도 80, 85 또는 87개의 아미노산)이며; (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 85개의 아미노산이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 길이가 75 내지 100개의 아미노산 범위(예를 들어, 75-95, 75-90, 75-88, 78-100, 78-95, 78-90, 78-88, 80-100, 80-95, 80-90, 80-88, 83-100, 83-95, 83-90, 83-88, 85-100, 85-95, 85-90 또는 85-88개의 아미노산 범위)이거나; 또는 (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 80 내지 95개의 아미노산 범위(예를 들어, 80-90, 80-88, 83-95, 83-90, 83-88, 85-95, 85-90 또는 85-88개 아미노산 범위)의 길이를 가진다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함하고 - 여기서: (i) RuvC-III 서브도메인의 길이에 대해 RuvC-II 대 RuvC-III 서브도메인 사이의 영역 길이비는 1.1 이상(예를 들어, 1.2)이고; (ii) RuvC-III 서브도메인의 길이에 대해 RuvC-II 내지 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이고; (iii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2)이며; (iv) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 2 이하(예를 들어, 1.8 이하, 1.7 이하, 1.6 이하, 1.5 이하 또는 1.4 이하)이고; (v) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1.5 이하(예를 들어, 1.4 이하)이며; (vi) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1 내지 2(예를 들어, 1.1 내지 2, 1.2 내지 2, 1 내지 1.8, 1.1 내지 1.8, 1.2 내지 1.8, 1 내지 1.6, 1.1 내지 1.6, 1.2 내지 1.6, 1 내지 14, 1.1 내지 1.4, 또는 1.2 내지 1.4) 범위이고; (vii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이며; (viii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2) 이고; (ix) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 73개의 아미노산(예를 들어, 길이가 적어도 75, 77, 80, 85 또는 87개의 아미노산)이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 78개의 아미노산(예를 들어, 길이가 적어도 80, 85 또는 87개의 아미노산)이며; (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 85개의 아미노산이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 길이가 75 내지 100개의 아미노산 범위(예를 들어, 75-95, 75-90, 75-88, 78-100, 78-95, 78-90, 78-88, 80-100, 80-95, 80-90, 80-88, 83-100, 83-95, 83-90, 83-88, 85-100, 85-95, 85-90 또는 85-88개의 아미노산 범위)이거나; 또는 (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 80 내지 95개의 아미노산 범위(예를 들어, 80-90, 80-88, 83-95, 83-90, 83-88, 85-95, 85-90 또는 85-88개 아미노산 범위)의 길이를 가진다.
예를 들어, 일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함하며, 여기서: (i) RuvC-III 서브도메인의 길이에 대해 RuvC-II 대 RuvC-III 서브도메인 사이의 영역 길이비는 1.1 이상(예를 들어, 1.2)이고; (ii) RuvC-III 서브도메인의 길이에 대해 RuvC-II 내지 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이고; (iii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2)이며; (iv) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 2 이하(예를 들어, 1.8 이하, 1.7 이하, 1.6 이하, 1.5 이하 또는 1.4 이하)이고; (v) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1.5 이하(예를 들어, 1.4 이하)이며; (vi) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1 내지 2(예를 들어, 1.1 내지 2, 1.2 내지 2, 1 내지 1.8, 1.1 내지 1.8, 1.2 내지 1.8, 1 내지 1.6, 1.1 내지 1.6, 1.2 내지 1.6, 1 내지 14, 1.1 내지 1.4, 또는 1.2 내지 1.4) 범위이고; (vii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이며; (viii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2) 이고; (ix) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 73개의 아미노산(예를 들어, 길이가 적어도 75, 77, 80, 85 또는 87개의 아미노산)이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 78개의 아미노산(예를 들어, 길이가 적어도 80, 85 또는 87개의 아미노산)이며; (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 85개의 아미노산이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 길이가 75 내지 100개의 아미노산 범위(예를 들어, 75-95, 75-90, 75-88, 78-100, 78-95, 78-90, 78-88, 80-100, 80-95, 80-90, 80-88, 83-100, 83-95, 83-90, 83-88, 85-100, 85-95, 85-90 또는 85-88개의 아미노산 범위)이거나; 또는 (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 80 내지 95개의 아미노산 범위(예를 들어, 80-90, 80-88, 83-95, 83-90, 83-88, 85-95, 85-90 또는 85-88개 아미노산 범위)의 길이를 가진다.
일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함하며 여기서: (i) RuvC-III 서브도메인의 길이에 대해 RuvC-II 대 RuvC-III 서브도메인 사이의 영역 길이비는 1.1 이상(예를 들어, 1.2)이고; (ii) RuvC-III 서브도메인의 길이에 대해 RuvC-II 내지 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이고; (iii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2)이며; (iv) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 2 이하(예를 들어, 1.8 이하, 1.7 이하, 1.6 이하, 1.5 이하 또는 1.4 이하)이고; (v) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1.5 이하(예를 들어, 1.4 이하)이며; (vi) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1 내지 2(예를 들어, 1.1 내지 2, 1.2 내지 2, 1 내지 1.8, 1.1 내지 1.8, 1.2 내지 1.8, 1 내지 1.6, 1.1 내지 1.6, 1.2 내지 1.6, 1 내지 14, 1.1 내지 1.4, 또는 1.2 내지 1.4) 범위이고; (vii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이며; (viii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2) 이고; (ix) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 73개의 아미노산(예를 들어, 길이가 적어도 75, 77, 80, 85 또는 87개의 아미노산)이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 78개의 아미노산(예를 들어, 길이가 적어도 80, 85 또는 87개의 아미노산)이며; (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 85개의 아미노산이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 길이가 75 내지 100개의 아미노산 범위(예를 들어, 75-95, 75-90, 75-88, 78-100, 78-95, 78-90, 78-88, 80-100, 80-95, 80-90, 80-88, 83-100, 83-95, 83-90, 83-88, 85-100, 85-95, 85-90 또는 85-88개의 아미노산 범위)이거나; 또는 (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 80 내지 95개의 아미노산 범위(예를 들어, 80-90, 80-88, 83-95, 83-90, 83-88, 85-95, 85-90 또는 85-88개 아미노산 범위)의 길이를 가진다.
일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 N-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대해 아미노산 1 내지 663으로서 도시된 도메인)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 제1 아미노산 서열; 및 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함하며 여기서: (i) RuvC-III 서브도메인의 길이에 대해 RuvC-II 대 RuvC-III 서브도메인 사이의 영역 길이비는 1.1 이상(예를 들어, 1.2)이고; (ii) RuvC-III 서브도메인의 길이에 대해 RuvC-II 내지 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이고; (iii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2)이며; (iv) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 2 이하(예를 들어, 1.8 이하, 1.7 이하, 1.6 이하, 1.5 이하 또는 1.4 이하)이고; (v) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1.5 이하(예를 들어, 1.4 이하)이며; (vi) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1 내지 2(예를 들어, 1.1 내지 2, 1.2 내지 2, 1 내지 1.8, 1.1 내지 1.8, 1.2 내지 1.8, 1 내지 1.6, 1.1 내지 1.6, 1.2 내지 1.6, 1 내지 14, 1.1 내지 1.4, 또는 1.2 내지 1.4) 범위이고; (vii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이며; (viii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2) 이고; (ix) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 73개의 아미노산(예를 들어, 길이가 적어도 75, 77, 80, 85 또는 87개의 아미노산)이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 78개의 아미노산(예를 들어, 길이가 적어도 80, 85 또는 87개의 아미노산)이며; (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 85개의 아미노산이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 길이가 75 내지 100개의 아미노산 범위(예를 들어, 75-95, 75-90, 75-88, 78-100, 78-95, 78-90, 78-88, 80-100, 80-95, 80-90, 80-88, 83-100, 83-95, 83-90, 83-88, 85-100, 85-95, 85-90 또는 85-88개의 아미노산 범위)이거나; 또는 (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 80 내지 95개의 아미노산 범위(예를 들어, 80-90, 80-88, 83-95, 83-90, 83-88, 85-95, 85-90 또는 85-88개 아미노산 범위)의 길이를 가진다.
일부 경우에, CasX 단백질은 서열번호 1로서 제시된 CasX 단백질 서열의 아미노산 1 내지 663에 대응하는 아미노산 서열(예를 들어, 서열번호 2에 제시된 CasX 단백질 서열의 아미노산 1 내지 650); 및 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II, 및 RuvC-III을 포함하는 제1 아미노산 서열에 대해 C-말단인 제2 아미노산 서열을 포함하고- 여기서: (i) RuvC-III 서브도메인의 길이에 대해 RuvC-II 대 RuvC-III 서브도메인 사이의 영역 길이비는 1.1 이상(예를 들어, 1.2)이고; (ii) RuvC-III 서브도메인의 길이에 대해 RuvC-II 내지 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이고; (iii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2)이며; (iv) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 2 이하(예를 들어, 1.8 이하, 1.7 이하, 1.6 이하, 1.5 이하 또는 1.4 이하)이고; (v) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1.5 이하(예를 들어, 1.4 이하)이며; (vi) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1 내지 2(예를 들어, 1.1 내지 2, 1.2 내지 2, 1 내지 1.8, 1.1 내지 1.8, 1.2 내지 1.8, 1 내지 1.6, 1.1 내지 1.6, 1.2 내지 1.6, 1 내지 14, 1.1 내지 1.4, 또는 1.2 내지 1.4) 범위이고; (vii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이며; (viii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2) 이고; (ix) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 73개의 아미노산(예를 들어, 길이가 적어도 75, 77, 80, 85 또는 87개의 아미노산)이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 78개의 아미노산(예를 들어, 길이가 적어도 80, 85 또는 87개의 아미노산)이며; (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 85개의 아미노산이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 길이가 75 내지 100개의 아미노산 범위(예를 들어, 75-95, 75-90, 75-88, 78-100, 78-95, 78-90, 78-88, 80-100, 80-95, 80-90, 80-88, 83-100, 83-95, 83-90, 83-88, 85-100, 85-95, 85-90 또는 85-88개의 아미노산 범위)이거나; 또는 (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 80 내지 95개의 아미노산 범위(예를 들어, 80-90, 80-88, 83-95, 83-90, 83-88, 85-95, 85-90 또는 85-88개 아미노산 범위)의 길이를 가진다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 N-말단인 500 내지 750개의 아미노산(예를 들어, 550-750, 600-750, 640-750, 650-750, 500-700, 550-700, 600-700, 640-700, 650-700, 500-680, 550-680, 600-680, 640-680, 650-680, 500-670, 550-670, 600-670, 640-670, 또는 650-670개의 아미노산) 범위인 길이를 갖는 N-말단 도메인을 갖는 제1 아미노산 서열(예를 들어, 임의의 융합된 이종성 서열, 예컨대 NLS 및/또는 촉매 활성을 갖는 도메인을 포함하지 않음); 및 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III을 갖는 분할 Ruv C 도메인을 갖는 제2 아미노산 서열(제1에 대해 C-말단)을 포함하며, 여기서: (i) RuvC-III 서브도메인의 길이에 대해 RuvC-II 대 RuvC-III 서브도메인 사이의 영역 길이비는 1.1 이상(예를 들어, 1.2)이고; (ii) RuvC-III 서브도메인의 길이에 대해 RuvC-II 내지 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이고; (iii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2)이며; (iv) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 2 이하(예를 들어, 1.8 이하, 1.7 이하, 1.6 이하, 1.5 이하 또는 1.4 이하)이고; (v) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1.5 이하(예를 들어, 1.4 이하)이며; (vi) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1 내지 2(예를 들어, 1.1 내지 2, 1.2 내지 2, 1 내지 1.8, 1.1 내지 1.8, 1.2 내지 1.8, 1 내지 1.6, 1.1 내지 1.6, 1.2 내지 1.6, 1 내지 14, 1.1 내지 1.4, 또는 1.2 내지 1.4) 범위이고; (vii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이며; (viii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2) 이고; (ix) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 73개의 아미노산(예를 들어, 길이가 적어도 75, 77, 80, 85 또는 87개의 아미노산)이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 78개의 아미노산(예를 들어, 길이가 적어도 80, 85 또는 87개의 아미노산)이며; (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 85개의 아미노산이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 길이가 75 내지 100개의 아미노산 범위(예를 들어, 75-95, 75-90, 75-88, 78-100, 78-95, 78-90, 78-88, 80-100, 80-95, 80-90, 80-88, 83-100, 83-95, 83-90, 83-88, 85-100, 85-95, 85-90 또는 85-88개의 아미노산 범위)이거나; 또는 (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 80 내지 95개의 아미노산 범위(예를 들어, 80-90, 80-88, 83-95, 83-90, 83-88, 85-95, 85-90 또는 85-88개 아미노산 범위)의 길이를 가진다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 3개의 부분적 RuvC 도메인 - RuvC-I, RuvC-II 및 RuvC-III을 갖는 분할 Ruv C 도메인에 대해 N-말단인 500 내지 750개의 아미노산(예를 들어, 550-750, 600-750, 640-750, 650-750, 500-700, 550-700, 600-700, 640-700, 650-700, 500-680, 550-680, 600-680, 640-680, 650-680, 500-670, 550-670, 600-670, 640-670, 또는 650-670개의 아미노산) 범위인 길이를 갖는 제1 아미노산 서열(예를 들어, 임의의 융합된 이종성 서열, 예컨대 NLS 및/또는 촉매 활성을 갖는 도메인을 포함하지 않음)을 포함하며, 여기서: (i) RuvC-III 서브도메인의 길이에 대해 RuvC-II 대 RuvC-III 서브도메인 사이의 영역 길이비는 1.1 이상(예를 들어, 1.2)이고; (ii) RuvC-III 서브도메인의 길이에 대해 RuvC-II 내지 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이고; (iii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2)이며; (iv) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 2 이하(예를 들어, 1.8 이하, 1.7 이하, 1.6 이하, 1.5 이하 또는 1.4 이하)이고; (v) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1.5 이하(예를 들어, 1.4 이하)이며; (vi) RuvC-III 서브도메인 길이에 대해 RuvC-II 서브도메인 길이비는 1 내지 2(예를 들어, 1.1 내지 2, 1.2 내지 2, 1 내지 1.8, 1.1 내지 1.8, 1.2 내지 1.8, 1 내지 1.6, 1.1 내지 1.6, 1.2 내지 1.6, 1 내지 14, 1.1 내지 1.4, 또는 1.2 내지 1.4) 범위이고; (vii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과이며; (viii) RuvC-III 서브도메인 길이에 대해 RuvC-II와 RuvC-III 서브도메인 사이의 영역의 길이비는 1 초과 및 1 내지 1.3(예를 들어, 1 내지 1.2) 이고; (ix) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 73개의 아미노산(예를 들어, 길이가 적어도 75, 77, 80, 85 또는 87개의 아미노산)이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 78개의 아미노산(예를 들어, 길이가 적어도 80, 85 또는 87개의 아미노산)이며; (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 85개의 아미노산이고; (x) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 적어도 길이가 75 내지 100개의 아미노산 범위(예를 들어, 75-95, 75-90, 75-88, 78-100, 78-95, 78-90, 78-88, 80-100, 80-95, 80-90, 80-88, 83-100, 83-95, 83-90, 83-88, 85-100, 85-95, 85-90 또는 85-88개의 아미노산 범위)이거나; 또는 (xi) RuvC-II와 RuvC-III 서브도메인 사이의 영역은 길이가 80 내지 95개의 아미노산 범위(예를 들어, 80-90, 80-88, 83-95, 83-90, 83-88, 85-95, 85-90 또는 85-88개 아미노산 범위)의 길이를 가진다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대해 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986로서 도시된 도메인, 패널 a)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 아미노산 664 내지 986을 갖는 아미노산 서열을 포함한다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 2에 제시된 CasX 단백질 서열의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대해 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 서열번호 2에 제시된 CasX 단백질 서열의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986로서 도시된 도메인, 패널 a)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 2에 제시된 CasX 단백질 서열의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 2에 제시된 CasX 단백질 서열의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 아미노산 664 내지 986에 대응하는 서열번호 2의 아미노산 서열을 포함한다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 3에 제시된 CasX 단백질 서열의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대해 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 서열번호 3에 제시된 CasX 단백질 서열의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986로서 도시된 도메인, 패널 a)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 3에 제시된 CasX 단백질 서열의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 3에 제시된 CasX 단백질 서열의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1에 제시된 CasX 단백질 서열의 아미노산 664 내지 986에 대응하는 서열번호 3의 아미노산 서열을 포함한다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대해 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)(예를 들어, 서열번호 2로서 제시된 CasX 단백질에 대해 아미노산 651 내지 978)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 및 2에 제시된 CasX 단백질 서열 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1로서 제시된 CasX 단백질 서열의 아미노산 664 내지 986에 대응하는 아미노산 서열(예를 들어, 서열번호 2에 제시된 CasX 단백질 서열의 아미노산 651 내지 978)을 포함한다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 길이가 500 내지 750개의 아미노산(예를 들어, 550-750, 600-750, 640-750, 650-750, 500-700, 550-700, 600-700, 640-700, 650-700, 500-680, 550-680, 600-680, 640-680, 650-680, 500-670, 550-670, 600-670, 640-670 또는 650-670개의 아미노산) 범위인 제1 아미노산 서열(N-말단 도메인)(예를 들어, 임의의 융합된 이종성 서열, 예컨대 NLS 및/또는 촉매 활성을 갖는 도메인을 포함하지 않음); 및 서열번호 1 내지 2로서 제시된 CasX 단백질 서열(예를 들어, 서열번호 2로서 제시된 CasX 단백질에 대한 아미노산 651 내지 978) 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대한 아미노산 664 내지 986로서 도시된 도메인)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는, 제1 아미노산 서열에 대해 C-말단에 위치된 제2 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 길이가 500 내지 750개의 아미노산(예를 들어, 550-750, 600-750, 640-750, 650-750, 500-700, 550-700, 600-700, 640-700, 650-700, 500-680, 550-680, 600-680, 640-680, 650-680, 500-670, 550-670, 600-670, 640-670 또는 650-670개의 아미노산) 범위인 제1 아미노산 서열(N-말단 도메인)(예를 들어, 임의의 융합된 이종성 서열, 예컨대 NLS 및/또는 촉매 활성을 갖는 도메인을 포함하지 않음); 및 서열번호 1 내지 2로서 제시된 CasX 단백질 서열 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대한 아미노산 664 내지 986로서 도시된 도메인)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는, 제1 아미노산 서열에 대해 C-말단에 위치된 제2 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 길이가 500 내지 750개의 아미노산(예를 들어, 550-750, 600-750, 640-750, 650-750, 500-700, 550-700, 600-700, 640-700, 650-700, 500-680, 550-680, 600-680, 640-680, 650-680, 500-670, 550-670, 600-670, 640-670 또는 650-670개의 아미노산) 범위인 제1 아미노산 서열(N-말단 도메인)(예를 들어, 임의의 융합된 이종성 서열, 예컨대 NLS 및/또는 촉매 활성을 갖는 도메인을 포함하지 않음); 및 서열번호 1 내지 2로서 제시된 CasX 단백질 서열 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대한 아미노산 664 내지 986로서 도시된 도메인)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는, 제1 아미노산 서열에 대해 C-말단에 위치된 제2 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 길이가 500 내지 750개의 아미노산(예를 들어, 550-750, 600-750, 640-750, 650-750, 500-700, 550-700, 600-700, 640-700, 650-700, 500-680, 550-680, 600-680, 640-680, 650-680, 500-670, 550-670, 600-670, 640-670 또는 650-670개의 아미노산) 범위인 제1 아미노산 서열(N-말단 도메인)(예를 들어, 임의의 융합된 이종성 서열, 예컨대 NLS 및/또는 촉매 활성을 갖는 도메인을 포함하지 않음); 및 서열번호 1 내지 2로서 제시된 CasX 단백질 서열 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대한 아미노산 664 내지 986로서 도시된 도메인)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는, 제1 아미노산 서열에 대해 C-말단에 위치된 제2 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 길이가 500 내지 750개의 아미노산(예를 들어, 550-750, 600-750, 640-750, 650-750, 500-700, 550-700, 600-700, 640-700, 650-700, 500-680, 550-680, 600-680, 640-680, 650-680, 500-670, 550-670, 600-670, 640-670 또는 650-670개의 아미노산) 범위인 제1 아미노산 서열(N-말단 도메인)(예를 들어, 임의의 융합된 이종성 서열, 예컨대 NLS 및/또는 촉매 활성을 갖는 도메인을 포함하지 않음); 및 서열번호 1에 제시된 CasX 단백질 서열의 아미노산 664 내지 986에 대응하는 아미노산 서열(예를 들어, 서열번호 2에 제시된 CasX 단백질의 아미노산 651 내지 978)을 갖는, 제1 아미노산 서열에 대해 C-말단에 위치된 제2 아미노산 서열을 포함한다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대해 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)(예를 들어, 서열번호 2로서 제시된 CasX 단백질에 대해 아미노산 651 내지 978)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986로서 도시된 도메인, 패널 a)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1 내지 3에 제시된 CasX 단백질 서열 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3의 CasX1에 대한 아미노산 664 내지 986으로서 도시된 도메인, 패널 a)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 서열번호 1로서 제시된 CasX 단백질 서열의 아미노산 664 내지 986에 대응하는 아미노산 서열(예를 들어, 서열번호 2에 제시된 CasX 단백질 서열의 아미노산 651 내지 978)을 포함한다.
일부 경우에, (대상 조성물 및/또는 방법의) CasX 단백질은 길이가 500 내지 750개의 아미노산(예를 들어, 550-750, 600-750, 640-750, 650-750, 500-700, 550-700, 600-700, 640-700, 650-700, 500-680, 550-680, 600-680, 640-680, 650-680, 500-670, 550-670, 600-670, 640-670 또는 650-670개의 아미노산) 범위인 제1 아미노산 서열(N-말단 도메인)(예를 들어, 임의의 융합된 이종성 서열, 예컨대 NLS 및/또는 촉매 활성을 갖는 도메인을 포함하지 않음); 및 서열번호 1 내지 3으로서 제시된 CasX 단백질 서열(예를 들어, 서열번호 2로서 제시된 CasX 단백질에 대한 아미노산 651 내지 978) 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대한 아미노산 664 내지 986로서 도시된 도메인)과 20% 이상의 서열 동일성(예를 들어, 30% 이상, 40% 이상, 50% 이상, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는, 제1 아미노산 서열에 대해 C-말단에 위치된 제2 아미노산 서열을 포함한다. 예를 들어, 일부 경우에, CasX 단백질은 길이가 500 내지 750개의 아미노산(예를 들어, 550-750, 600-750, 640-750, 650-750, 500-700, 550-700, 600-700, 640-700, 650-700, 500-680, 550-680, 600-680, 640-680, 650-680, 500-670, 550-670, 600-670, 640-670 또는 650-670개의 아미노산) 범위인 제1 아미노산 서열(N-말단 도메인)(예를 들어, 임의의 융합된 이종성 서열, 예컨대 NLS 및/또는 촉매 활성을 갖는 도메인을 포함하지 않음); 및 서열번호 1 내지 3으로서 제시된 CasX 단백질 서열 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대한 아미노산 664 내지 986로서 도시된 도메인)과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는, 제1 아미노산 서열에 대해 C-말단에 위치된 제2 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 길이가 500 내지 750개의 아미노산(예를 들어, 550-750, 600-750, 640-750, 650-750, 500-700, 550-700, 600-700, 640-700, 650-700, 500-680, 550-680, 600-680, 640-680, 650-680, 500-670, 550-670, 600-670, 640-670 또는 650-670개의 아미노산) 범위인 제1 아미노산 서열(N-말단 도메인)(예를 들어, 임의의 융합된 이종성 서열, 예컨대 NLS 및/또는 촉매 활성을 갖는 도메인을 포함하지 않음); 및 서열번호 1 내지 3으로서 제시된 CasX 단백질 서열 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대한 아미노산 664 내지 986로서 도시된 도메인)과 80% 이상의 서열 동일성(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는, 제1 아미노산 서열에 대해 C-말단에 위치된 제2 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 길이가 500 내지 750개의 아미노산(예를 들어, 550-750, 600-750, 640-750, 650-750, 500-700, 550-700, 600-700, 640-700, 650-700, 500-680, 550-680, 600-680, 640-680, 650-680, 500-670, 550-670, 600-670, 640-670 또는 650-670개의 아미노산) 범위인 제1 아미노산 서열(N-말단 도메인)(예를 들어, 임의의 융합된 이종성 서열, 예컨대 NLS 및/또는 촉매 활성을 갖는 도메인을 포함하지 않음); 및 서열번호 1 내지 3으로서 제시된 CasX 단백질 서열 중 임의의 하나의 C-말단 도메인(예를 들어, 도 3, 패널 a에서 CasX1에 대한 아미노산 664 내지 986로서 도시된 도메인)과 90% 이상의 서열 동일성(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 서열 동일성)을 갖는, 제1 아미노산 서열에 대해 C-말단에 위치된 제2 아미노산 서열을 포함한다. 일부 경우에, CasX 단백질은 길이가 500 내지 750개의 아미노산(예를 들어, 550-750, 600-750, 640-750, 650-750, 500-700, 550-700, 600-700, 640-700, 650-700, 500-680, 550-680, 600-680, 640-680, 650-680, 500-670, 550-670, 600-670, 640-670 또는 650-670개의 아미노산) 범위인 제1 아미노산 서열(N-말단 도메인)(예를 들어, 임의의 융합된 이종성 서열, 예컨대 NLS 및/또는 촉매 활성을 갖는 도메인을 포함하지 않음); 및 서열번호 1에 제시된 CasX 단백질 서열의 아미노산 664 내지 986에 대응하는 아미노산 서열(예를 들어, 서열번호 2에 제시된 CasX 단백질의 아미노산 651 내지 978)을 갖는, 제1 아미노산 서열에 대해 C-말단에 위치된 제2 아미노산 서열을 포함한다.
CasX
변이체
변이체 CasX 단백질은 대응하는 야생형 CasX 단백질의 아미노산 서열에 비교할 때 적어도 하나의 아미노산만큼 상이한 아미노산 서열을 가진다(예를 들어, 결실, 삽입, 치환, 융합을 가진다). 이중 가닥 표적 핵산 중 한 가닥을 절단하지만, 다른 한 가닥은 절단하지 않는 CasX 단백질은 본 명세서에서 "틈내기효소"(예를 들어, "틈내기효소 CasX"로서 지칭된다. 뉴클레아제 활성이 실질적으로 없는 CasX 단백질은 본 명세서에서 사멸 CasX 단백질("dCasX")로서 지칭된다(뉴클레아제 활성이 이하에 상세하게 기재되는 키메라 CasX 단백질의 경우에 이종성 폴리펩타이드(융합 상대)에 의해 제공될 수 있다는 경고가 있음). 본 명세서에 기재된 임의의 CasX 변이체 단백질(예를 들어, 틈내기효소 CasX, dCasX, 키메라 CasX)에 대해, CasX 변이체는 상기 기재된 것과 동일한 매개변수(예를 들어, 존재하는 도메인, 동일성 백분율 등)를 갖는 CasX 단백질 서열을 포함할 수 있다.
변이체
- 촉매 활성
일부 경우에, CasX 단백질은, 예를 들어, 천연 유래 촉매적으로 활성인 서열에 대해 돌연변이된 변이체 CasX 단백질이고, 대응하는 천연 유래 서열에 비교할 때 감소된 절단 활성을 나타낸다(예를 들어, 90%, 이하, 80% 이하, 70% 이하, 60% 이하, 50% 이하, 40% 이하 또는 30% 이하의 절단 활성을 나타낸다). 일부 경우에, 이러한 변이체 CasX 단백질은 촉매적으로 '사멸' 단백질이고(절단 활성이 실질적으로 없음) 'dCasX'로서 지칭될 수 있다. 일부 경우에, 변이체 CasX 단백질은 틈내기효소이다(이중 가닥 표적 핵산, 예를 들어, 이중 가닥 표적 DNA의 단지 하나의 가닥을 절단함). 본 명세서에서 더 상세하게 기재되는 바와 같이, 일부 경우에, CasX 단백질(일부 경우에, 야생형 절단 활성을 갖는 CasX 단백질 및 일부 경우에 감소된 절단 활성을 갖는 변이체 CasX, 예를 들어, dCasX 또는 틈내기효소 CasX)은 융합 단백질(키메라 CasX 단백질)을 형성하기 위해 관심 대상의 활성(예를 들어, 관심 대상의 촉매 활성)을 갖는 이종성 폴리펩타이드에 융합된다(접합된다).
CasX의 보존된 촉매적 잔기는 CasX1(서열번호 1)에 따라 넘버링될 때 D672, E769, D935 및 CasX2(서열번호 2)에 따라 넘버링될 때 659D, 756E, 및 922D를 포함한다(이들 잔기를 도 1에 밑줄 표시함). (도 2의 배열에서, 넘버링은 CasX 단백질로 추적하지 않지만, 대신에 그 자체의 정렬로 추적한다는 것을 주목한다. 이 단락에서 상기 언급한 보존된 잔기는 도면에 표시하며, CasX2는 상부 서열('gwc2')이고, CasX1은 하부 서열('gwa2')임).
따라서, 일부 경우에, CasX 단백질은 감소된 활성을 가지고, 상기 기재된 아미노산 중 하나 이상(또는 임의의 CasX 단백질의 하나 이상의 대응하는 아미노산)이 돌연변이된다(예를 들어, 알라닌으로 치환된다). 일부 경우에, 변이체 CasX 단백질은 촉매적으로 '사멸' 단백질이고(촉매적으로 비활성임), 'dCasX'로서 지칭된다. dCasX 단백질은 활성을 제공하는 융합 상대에 융합될 수 있고, 그리고 일부 경우에, dCasX(예를 들어, 촉매 활성을 제공하지만, 진핵 세포에서 발현될 때 NLS를 가질 수 있는 융합 상대가 없는 하나)는 표적 DNA에 결합할 수 있고, 표적 DNA로부터의 번역으로부터 RNA 중합효소를 차단할 수 있다. 일부 경우에, 변이체 CasX 단백질은 틈내기효소이다(이중 가닥 표적 핵산, 예를 들어, 이중 가닥 표적 DNA의 단지 하나의 가닥을 절단함).
변이체
-
키메라
CasX
(즉, 융합 단백질)
상기 언급한 바와 같이, 일부 경우에, CasX 단백질(일부 경우에, 야생형 절단 활성을 갖는 CasX 단백질 및 일부 경우에 감소된 절단 활성을 갖는 변이체 CasX, 예를 들어, dCasX 또는 틈내기효소 CasX)은 융합 단백질(키메라 CasX 단백질)을 형성하기 위해 관심 대상의 활성(예를 들어, 관심 대상의 촉매 활성)을 갖는 이종성 폴리펩타이드에 융합된다(접합된다). CasX 단백질이 융합될 수 있는 이종성 폴리펩타이드는 본 명세서에서 '융합 상대'로서 지칭된다.
일부 경우에, 융합 상대는 표적 DNA의 전사를 조절할 수 있다(예를 들어, 전사를 저해, 전사를 증가시킬 수 있다). 예를 들어, 일부 경우에 융합 상대는 전사를 저해하는 단백질(또는 단백질로부터의 도메인)(예를 들어, 전사 리프레서, 전사 저해제 단백질의 보충을 통해 작용하는 단백질, 표적 DNA의 변형, 예컨대 메틸화, DNA 변형제의 보충, 표적 DNA와 회합된 히스톤의 조절, 히스톤 변형제, 예컨대 히스톤의 아세틸화 및/또는 메틸화를 변형시키는 것의 보충 등)이다. 일부 경우에 융합 상대는 전사를 증가시키는 단백질(또는 단백질로부터의 도메인)(예를 들어, 전사 활성체, 전사 활성체 단백질의 보충을 통해 작용하는 단백질, 표적 DNA의 변형, 예컨대 탈메틸화의 변형, DNA 변형제의 보충, 표적 DNA와 회합된 히스톤의 조절, 히스톤 변형제, 예컨대 히스톤의 아세틸화 및/또는 메틸화를 변형시키는 것의 보충 등)이다.
일부 경우에, 키메라 CasX 단백질은 표적 핵산을 변형시키는 효소 활성(예를 들어, 뉴클레아제 활성, 메틸트랜스퍼라제 활성, 데메틸라제 활성, DNA 수선 활성, DNA 손상 활성, 탈아미노화 활성, 디스무타제 활성, 알킬화 활성, 탈퓨린화 활성, 산화 활성, 피리미딘 이량체 형성 활성, 인테그라제 활성, 트랜스포사제 활성, 재조합효소 활성, 중합효소 활성, 리가제 활성, 헬리카제 활성, 광분해효소 활성 또는 글리코실라제 활성)을 갖는 이종성 폴리펩타이드를 포함한다.
일부 경우에, 키메라 CasX 단백질은 표적 핵산과 회합된 폴리펩타이드(예를 들어, 히스톤)를 변형하는 효소 활성(예를 들어, 메틸트랜스퍼라제 활성, 데메틸라제 활성, 아세틸트랜스퍼라제 활성, 데아세틸라제 활성, 키나제 활성, 포스파타제 활성, 유비퀴틴 리가제 활성, 데유비퀴틴화 활성, 아데닐화 활성, 탈아데닐화 활성, 수모일화(SUMOylating) 활성, 탈수모일화(deSUMOylating) 활성, 리보실화 활성, 탈리보실화 활성, 미리스토일화 활성 또는 탈미리스토일화 활성)을 갖는 이종성 폴리펩타이드를 포함한다.
전사 증가에서 사용될 수 있는 단백질(또는 이의 단편)의 예는 전사 활성체, 예컨대 VP16, VP64, VP48, VP160, p65 서브도메인(예를 들어, NFkB로부터 유래), 및 EDLL의 활성화 도메인 및/또는 TAL 활성화 도메인(예를 들어, 식물의 활성에 대해); 히스톤 라이신 메틸트랜스퍼라제, 예컨대 SET1A, SET1B, MLL1 내지 5, ASH1, SYMD2, NSD1 등; 히스톤 라이신 데메틸라제, 예컨대 JHDM2a/b, UTX, JMJD3 등; 히스톤 아세틸트랜스퍼라제, 예컨대 GCN5, PCAF, CBP, p300, TAF1, TIP60/PLIP, MOZ/MYST3, MORF/MYST4, SRC1, ACTR, P160, CLOCK 등; 및 DNA 데메틸라제, 예컨대 염색체 10번과 11번 사이의 전좌(Ten-Eleven Translocation: TET) 다이옥시게나제 1(TET1CD), TET1, DME, DML1, DML2, ROS1 등을 포함하지만, 이들로 제한되지 않는다.
전사 감소에서 사용될 수 있는 단백질(또는 이의 단편)의 예는 전사 리프레서, 예컨대 쿠루펠( ) 관련 박스(KRAB 또는 SKD); KOX1 억제 도메인; Mad mSIN3 상호작용 도메인(SID); ERF 리프레서 도메인(ERD), SRDX 억제 도메인(예를 들어, 식물에서의 억제를 위해) 등; 히스톤 라이신 메틸트랜스퍼라제, 예컨대 Pr-SET7/8, SUV4-20H1, RIZ1 등; 히스톤 라이신 데메틸라제, 예컨대 JMJD2A/JHDM3A, JMJD2B, JMJD2C/GASC1, JMJD2D, JARID1A/RBP2, JARID1B/PLU-1, JARID1C/SMCX, JARID1D/SMCY 등; 히스톤 라이신 데아세틸라제, 예컨대 HDAC1, HDAC2, HDAC3, HDAC8, HDAC4, HDAC5, HDAC7, HDAC9, SIRT1, SIRT2, HDAC11 등; DNA 메틸라제, 예컨대 HhaI DNA m5c-메틸트랜스퍼라제(M.HhaI), DNA 메틸트랜스퍼라제 1(DNMT1), DNA 메틸트랜스퍼라제 3a(DNMT3a), DNA 메틸트랜스퍼라제 3b(DNMT3b), METI, DRM3(식물), ZMET2, CMT1, CMT2(식물) 등; 및 주변 보충 요소, 예컨대 라민(Lamin) A, 라민 B 등을 포함하지만, 이들로 제한되지 않는다.
) 관련 박스(KRAB 또는 SKD); KOX1 억제 도메인; Mad mSIN3 상호작용 도메인(SID); ERF 리프레서 도메인(ERD), SRDX 억제 도메인(예를 들어, 식물에서의 억제를 위해) 등; 히스톤 라이신 메틸트랜스퍼라제, 예컨대 Pr-SET7/8, SUV4-20H1, RIZ1 등; 히스톤 라이신 데메틸라제, 예컨대 JMJD2A/JHDM3A, JMJD2B, JMJD2C/GASC1, JMJD2D, JARID1A/RBP2, JARID1B/PLU-1, JARID1C/SMCX, JARID1D/SMCY 등; 히스톤 라이신 데아세틸라제, 예컨대 HDAC1, HDAC2, HDAC3, HDAC8, HDAC4, HDAC5, HDAC7, HDAC9, SIRT1, SIRT2, HDAC11 등; DNA 메틸라제, 예컨대 HhaI DNA m5c-메틸트랜스퍼라제(M.HhaI), DNA 메틸트랜스퍼라제 1(DNMT1), DNA 메틸트랜스퍼라제 3a(DNMT3a), DNA 메틸트랜스퍼라제 3b(DNMT3b), METI, DRM3(식물), ZMET2, CMT1, CMT2(식물) 등; 및 주변 보충 요소, 예컨대 라민(Lamin) A, 라민 B 등을 포함하지만, 이들로 제한되지 않는다.
일부 경우에, 융합 상대는 표적 핵산(예를 들어, ssRNA, dsRNA, ssDNA, dsDNA)을 변형시키는 효소 활성을 가진다. 융합 상대에 의해 제공될 수 있는 효소 활성의 예는 뉴클레아제 활성, 예컨대 제한 효소(예를 들어, FokI 뉴클레아제)에 의해 제공되는 것, 메틸트랜스퍼라제 활성, 예컨대 메틸트랜스퍼라제(예를 들어, HhaI DNA m5c-메틸트랜스퍼라제(M.HhaI), DNA 메틸트랜스퍼라제 1(DNMT1), DNA 메틸트랜스퍼라제 3a (DNMT3a), DNA 메틸트랜스퍼라제 3b(DNMT3b), METI, DRM3(식물), ZMET2, CMT1, CMT2(식물) 등)에 의해 제공되는 것; 데메틸라제 활성, 예컨대 데메틸라제(예를 들어, 염색체 10번과 11번 사이의 전좌(TET) 다이옥시게나제 1(TET1CD), TET1, DME, DML1, DML2, ROS1 등)에 의해 제공되는 것, DNA 수선 활성, DNA 손상 활성, 탈아미노화 활성, 예컨대 데아미나제(예를 들어, 사이토신 데아미나제 효소, 예컨대 래트 APOBEC1)에 의해 제공되는 것, 디스무타제 활성, 알킬화 활성, 탈퓨린화 활성, 산화 활성, 피리미딘 이량체 형성 활성, 인테그라제 활성, 예컨대 인테그라제 및/또는 레솔바제(예를 들어, Gin 인버타제, 예컨대 Gin 인버타제의 과활성 돌연변이체, GinH106Y; 인간 면역결핍 바이러스 1형 인테그라제(IN); Tn3 레솔바제; 등)에 의해 제공되는 것, 트랜스포사제 활성, 재조합효소 활성, 예컨대 재조합효소(예를 들어, Gin 재조합효소의 촉매 도메인)에 의해 제공되는 것, 중합효소 활성, 리가제 활성, 헬리카제 활성, 광분해효소 활성, 및 글리코실라제 활성)를 포함하지만, 이들로 제한되지 않는다.
일부 경우에, 융합 상대는 표적 핵산(예를 들어, ssRNA, dsRNA, ssDNA, dsDNA)과 회합되는 단백질(예를 들어, 히스톤, RNA 결합 단백질, DNA 결합 단백질 등)을 변형시키는 효소 활성을 가진다. 융합 상대에 의해 제공될 수 있는 (표적 핵산과 회합된 단백질을 변형시키는) 효소 활성의 예는 메틸트랜스퍼라제 활성, 예컨대 히스톤 메틸트랜스퍼라제(HMT)에 의해 제공되는 것(예를 들어, 얼룩 3-9 상동체 1의 억제자(SUV39H1, 또한 KMT1A로서 알려짐), 진정염색성 히스톤 라이신 메틸트랜스퍼라제 2(G9A, 또한 KMT1C 및 EHMT2로서 알려짐), SUV39H2, ESET/SETDB1 등, SET1A, SET1B, MLL1 내지 5, ASH1, SYMD2, NSD1, DOT1L, Pr-SET7/8, SUV4-20H1, EZH2, RIZ1), 데메틸라제 활성, 예컨대 히스톤 데메틸라제(예를 들어, 라이신 데메틸라제 1A(또한 LSD1로서 알려진 KDM1A), JHDM2a/b, JMJD2A/JHDM3A, JMJD2B, JMJD2C/GASC1, JMJD2D, JARID1A/RBP2, JARID1B/PLU-1, JARID1C/SMCX, JARID1D/SMCY, UTX, JMJD3 등)에 의해 제공되는 것, 아세틸트랜스퍼라제 활성, 예컨대 히스톤 아세틸라제 트랜스퍼라제에 의해 제공되는 것(예를 들어, 촉매 코어/인간 아세틸트랜스퍼라제 p300, GCN5, PCAF, CBP, TAF1, TIP60/PLIP, MOZ/MYST3, MORF/MYST4, HBO1/MYST2, HMOF/MYST1, SRC1, ACTR, P160, CLOCK 등의 단편), 데아세틸라제 활성, 예컨대 히스톤 데아세틸라제(예를 들어, HDAC1, HDAC2, HDAC3, HDAC8, HDAC4, HDAC5, HDAC7, HDAC9, SIRT1, SIRT2, HDAC11 등)에 의해 제공되는 것, 키나제 활성, 포스파타제 활성, 유비퀴틴 리가제 활성, 탈유비퀴틴화 활성, 아데닐화 활성, 탈아데닐화 활성, 수모일화 활성, 탈수모일화 활성, 리보실화 활성, 데리보실화 활성, 미리스토일화 활성, 및 데미리스토일화 활성을 포함하지만, 이들로 제한되지 않는다.
적합한 융합 상대의 추가적인 예는 다이하이드로엽산 환원효소(DHFR) 탈안정화 도메인(예를 들어, 화학적으로 제어 가능한 키메라 키메라 CasX 단백질을 생성), 및 엽록체 수송 펩타이드이다. 적합한 엽록체 수송 펩타이드는 하기를 포함하지만, 이들로 제한되지 않는다:

일부 경우에, 본 개시내용의 CasX 융합 폴리펩타이드는 a) 본 개시내용의 CasX 폴리펩타이드; 및 b) 엽록체 수송 펩타이드를 포함한다. 따라서, 예를 들어, CRISPR-CasX 복합체는 엽록체에 표적화될 수 있다. 일부 경우에, 이 표적화는 엽록체 수송 펩타이드(CTP) 또는 색소체 수송 펩타이드로 불리는 N-말단 연장의 존재에 의해 달성될 수 있다. 발현된 폴리펩타이드가 식물 색소체(예를 들어, 엽록체)에서 구획화된다면, 박테리아 공급원으로부터의 염색체 이식유전자는 발현된 폴리펩타이드를 암호화하는 서열에 융합된 CTP 서열을 암호화하는 서열을 가져야 한다. 따라서, 엽록체에 대한 외인성 폴리펩타이드의 국소화는 종종 외인성 폴리펩타이드를 암호화하는 폴리뉴클레오타이드의 5' 영역에 CTP 서열을 암호화하는 폴리뉴클레오타이드 서열을 작동 가능하게 연결함으로써 1 달성된다. CTP는 색소체 내로 전좌 동안 가공 단계에서 제거된다. 그러나, 가공 효율은 펩타이드의 CTP의 서열 그리고 NH 2 말단에서 근처의 서열에 의해 영향받을 수 있다. 기재된 엽록체에 대한 표적화를 위한 다른 선택은 마이스 cab-m7 신호 서열(미국 특허 제7,022,896호, WO 97/41228) 완두콩 글루타티온 환원효소 신호 서열(WO 97/41228) 및 미국 특허 제2009029861호에 기재된 CTP이다.
일부 경우에, 본 개시내용의 CasX 융합 폴리펩타이드는 a) 본 개시내용의 CasX 폴리펩타이드; 및 b) 엔도솜 탈출 펩타이드를 포함할 수 있다. 일부 경우에, 엔도솜 탈출 폴리펩타이드는 아미노산 서열 GLFXALLXLLXSLWXLLLXA(서열번호 94)을 포함하되, 각각의 X는 라이신, 히스티딘 및 알기닌으로부터 독립적으로 선택된다. 일부 경우에, 엔도솜 탈출 폴리펩타이드는 아미노산 서열 GLFHALLHLLHSLWHLLLHA(서열번호 95)을 포함한다.
(부위 특이적 표적 변형, 전사의 조절 및/또는 표적 단백질 변형, 예를 들어, 히스톤 변형에 대해) Cas9, 아연 핑거 및/또는 TALE 단백질과의 융합과 관련하여 사용되는 상기 융합 상대의 일부(그리고 더 많은) 예는, 예를 들어, 문헌[Nomura et al,, J Am Chem Soc. 2007 Jul 18;129(28):8676-7; Rivenbark et al., Epigenetics. 2012 Apr;7(4):350-60; Nucleic Acids Res. 2016 Jul 8;44(12):5615-28; Gilbert et. al., Cell. 2013 Jul 18;154(2):442-51; Kearns et al., Nat Methods. 2015 May;12(5):401-3; Mendenhall et. al., Nat Biotechnol. 2013 Dec;31(12):1133-6; Hilton et. al., Nat Biotechnol. 2015 May;33(5):510-7; Gordley et. al., Proc Natl Acad Sci U S A. 2009 Mar 31;106(13):5053-8; Akopian et. al., Proc Natl Acad Sci U S A. 2003 Jul 22;100(15):8688-91; Tan et., al., J Virol. 2006 Feb;80(4):1939-48; Tan et. al., Proc Natl Acad Sci U S A. 2003 Oct 14;100(21):11997-2002; Papworth et. al., Proc Natl Acad Sci U S A. 2003 Feb 18;100(4):1621-6; Sanjana et. al., Nat Protoc. 2012 Jan 5;7(1):171-92; Beerli et. al., Proc Natl Acad Sci U S A. 1998 Dec 8;95(25):14628-33; Snowden et. al., Curr Biol. 2002 Dec 23;12(24):2159-66; Xu et.al., Xu et. al., Cell Discov. 2016 May 3;2:16009; Komor et al., Nature. 2016 Apr 20;533(7603):420-4; Chaikind et. al., Nucleic Acids Res. 2016 Aug 11; Choudhury at. al., Oncotarget. 2016 Jun 23; Du et. al., Cold Spring Harb Protoc. 2016 Jan 4; Pham et. al., Methods Mol Biol. 2016;1358:43-57; Balboa et al., Stem Cell Reports. 2015 Sep 8;5(3):448-59; Hara et. al., Sci Rep. 2015 Jun 9;5:11221; Piatek et. al., Plant Biotechnol J. 2015 May;13(4):578-89; Hu et al., Nucleic Acids Res. 2014 Apr;42(7):4375-90; Cheng et. al., Cell Res. 2013 Oct;23(10):1163-71; cheng et. al., Cell Res. 2013 Oct;23(10):1163-71; 및 Maeder et. al., Nat Methods. 2013 Oct;10(10):977-9] 참조.
추가적인 적합한 이종성 폴리펩타이드는 표적 핵산의 증가된 전사 및/또는 번역을 직접적으로 그리고/또는 간접적으로 제공하는 폴리펩타이드(예를 들어, 전사 활성체 또는 이의 단편, 전사 활성체를 보충하는 단백질 또는 이의 단편, 소분자/약물-반응성 전사 및/또는 번역 조절제, 번역-조절 단백질 등)를 포함하지만, 이들로 제한되지 않는다. 증가된 또는 감소된 전사를 달성하기 위한 이종성 폴리펩타이드의 비제한적 예는 전사 활성체 및 전사 리프레서 도메인을 포함한다. 일부 이러한 경우에, 키메라 CasX 폴리펩타이드는 표적 핵산에서 특정 위치(즉, 서열)에 대해 가이드 핵산(가이드 RNA)에 의해 표적화되고, (예를 들어, 표적 핵산을 변형시키거나 또는 표적 핵산과 회합된 폴리펩타이드를 변형시키는 융합 서열이 사용될 때) 프로모터(전사 활성체 기능을 선택적으로 저해)에 대한 RNA 중합효소 결합을 차단하고/하거나 국소 염색질 상태를 변형시키는 것과 같은 좌위-특이적 조절을 발휘한다. 일부 경우에, 변화는 일시적이다(예를 들어, 전사 억제 또는 활성화). 일부 경우에, 변화는 유전성이다(예를 들어, 표적 핵산에 대해 또는 표적 핵산과 회합된 단백질, 예를 들어, 뉴클레오솜 히스톤에 대해 후성적 변형이 만들어질 때).
ssRNA 표적 핵산을 표적화할 때 사용하기 위한 이종성 폴리펩타이드의 비제한적 예는 스플라이싱 인자(예를 들어, RS 도메인); 단백질 번역 성분(예를 들어, 번역 개시, 신장 및/또는 방출 인자; 예를 들어, eIF4G); RNA 메틸라제; RNA 편집 효소(예를 들어, RNA 탈아미나제, 예를 들어, RNA 상에서 작용하는 아데노신 데아미나제(ADAR)(A 내지 I 및/또는 C 내지 U 편집 효소를 포함)); 헬리카제; RNA-결합 단백질 등을 포함한다(그러나 이들로 제한되지 않음). 이종성 폴리펩타이드는 전체 단백질을 포함할 수 있거나 또는 일부 경우에 단백질(예를 들어, 기능성 도메인)의 단편을 포함할 수 있다는 것이 이해된다.
대상 키메라 CasX 폴리펩타이드의 이종성 폴리펩타이드는 일시적이든 또는 비가역적이든, 직접적이든 또는 간접적이든; 엔도뉴클레아제(예를 들어, SMG5 및 SMG6과 같은 단백질로부터의 RNase III, CRR22 DYW 도메인, Dicer, 및 PIN(PilT N-말단) 도메인); RNA 절단의 자극을 초래하는 단백질 및 단백질 도메인(예를 들어, CPSF, CstF, CFIm 및 CFIIm); 엑소뉴클레아제(예를 들어, XRN-1 또는 엑소뉴클레아제 T); 데아데닐라제(예를 들어, HNT3); 넌센스 매개된 RNA 붕괴를 초래하는 단백질 및 단백질 도메인(예를 들어, UPF1, UPF2, UPF3, UPF3b, RNP S1, Y14, DEK, REF2, 및 SRm160); RNA 안정화를 초래하는 단백질 및 단백질 도메인(예를 들어, PABP); 번역 억제를 초래하는 단백질 및 단백질 도메인(예를 들어, Ago2 및 Ago4); 번역 자극을 초래하는 단백질 및 단백질 도메인(예를 들어, Staufen); 번역 조절을 초래하는(예를 들어, 초래할 수 있는) 단백질 및 단백질 도메인(예를 들어, 번역 인자, 예컨대 개시 인자, 신장 인자, 방출 인자 등, 예를 들어, eIF4G); RNA의 폴리아데닐화를 초래하는 단백질 및 단백질 도메인(예를 들어, PAP1, GLD-2, 및 Star- PAP); RNA의 폴리유리딘일화를 초래하는 단백질 및 단백질 도메인(예를 들어, CI D1 및 말단의 유리딜레이트 트랜스퍼라제); RNA 국소화를 초래하는 단백질 및 단백질 도메인(예를 들어, IMP1, ZBP1, She2p, She3p 및 Bicaudal-D로부터의); RNA의 핵 보유를 초래하는 단백질 및 단백질 도메인(예를 들어, Rrp6); RNA의 핵 수송을 초래하는 단백질 및 단백질 도메인(예를 들어, TAP, NXF1, THO, TREX, REF 및 Aly); RNA 스플라이싱의 억제를 초래하는 단백질 및 단백질 도메인(예를 들어, PTB, Sam68 및 hnRNP A1); RNA 스플라이싱의 자극을 초래하는 단백질 및 단백질 도메인(예를 들어, 세린/알기닌-풍부(SR) 도메인); 전사 효율 감소를 초래하는 단백질 및 단백질 도메인(예를 들어, FUS (TLS)); 및 전사 자극을 초래하는 단백질 및 단백질 도메인(예를 들어, CDK7 및 HIV Tat)을 포함하는 군으로부터 선택된 효과기 도메인을 포함하지만, 이들로 제한되지 않는, ssRNA와 상호작용할 수 있는 임의의 도메인(본 개시내용의 목적을 위해, 분자내 및/또는 분자간 2차 구조, 예를 들어, 이중-가닥 RNA 듀플렉스, 예컨대 헤어핀, 줄기-루프 등을 포함함)일 수 있다. 대안적으로, 효과기 도메인은 엔도뉴클레아제; RNA 절단을 자극할 수 있는 단백질 및 단백질 도메인; 엑소뉴클레아제; 데아데닐라제; 넌센스 매개된 RNA 붕괴 활성을 갖는 단백질 및 단백질 도메인; RNA를 안정화시킬 수 있는 단백질 및 단백질 도메인; 번역을 억제할 수 있는 단백질 및 단백질 도메인; 번역을 자극할 수 있는 단백질 및 단백질 도메인; 번역을 조절할 수 있는 단백질 및 단백질 도메인(예를 들어, 번역 인자, 예컨대 개시 인자, 신장 인자, 방출 인자 등, 예를 들어, eIF4G); RNA의 폴리아데닐화를 가능하게 하는 단백질 및 단백질 도메인; RNA의 폴리유리딘일화를 가능하게 하는 단백질 및 단백질 도메인; RNA 국소화 활성을 갖는 단백질 및 단백질 도메인; RNA의 핵 보유를 가능하게 하는 단백질 및 단백질 도메인; RNA 핵 수송 활성을 갖는 단백질 및 단백질 도메인; RNA 스플라이싱의 억제를 가능하게 하는 단백질 및 단백질 도메인; RNA 스플라이싱의 자극을 가능하게 하는 단백질 및 단백질 도메인; 전사 효율을 감소시킬 수 있는 단백질 및 단백질 도메인; 및 전사를 자극할 수 있는 단백질 및 단백질 도메인을 포함하는 군으로부터 선택될 수 있다. 다른 적합한 이종성 폴리펩타이드는 본 명세서에 전문이 참고로 편입된 WO2012068627에서 더 상세하게 기재되는 PUF RNA-결합 도메인이다.
키메라 CasX 폴리펩타이드에 대한 이종성 폴리펩타이드로서 사용될 수 있는(전체로 또는 이의 단편으로서) 일부 RNA 스플라이싱 인자는 별개의 서열-특이적 RNA 결합 분자 및 스플라이싱 효과기 도메인과 함께 모듈 조직화를 가진다. 예를 들어, 세린/알기닌-풍부(SR) 단백질 패밀리의 구성원은 엑손 혼입을 촉진하는 프레-mRNA 및 C-말단의 RS 도메인에서 엑손 스플라이싱 인핸서(ESE)에 결합하는 N-말단의 RNA 인식 모티프(RRM)를 함유한다. 다른 예로서, hnRNP 단백질 hnRNP Al는 그의 RRM 도메인을 통해 엑손 스플라이싱 사일런서(ESS)에 결합하고 C-말단의 글리신-풍부 도메인을 통해 엑손 포함을 저해한다. 일부 스플라이싱 인자는 두 대안의 부위 사이의 조절 서열에 대한 결합에 의해 스플라이스 부위(ss)의 대안의 사용을 조절할 수 있다. 예를 들어, ASF/SF2는 ESE를 인식하고 인트론 근위 부위의 사용을 촉진시킬 수 있는 반면, hnRNP ESS에 결합하고 Al은 인트론 원위 부위의 사용에 대해 스플라이싱을 이동시킬 수 있다. 이러한 인자의 한 가지 적용은 내인성 유전자, 특히 질환 관련 유전자의 대안의 스플라이싱을 조절하는 ESF를 생성하는 것이다. 예를 들어, Bcl-x 프레-mRNA는 반대 기능의 단백질을 암호화하기 위해 2개의 대안의 5' 스플라이스 부위를 갖는 2개의 스플라이싱 아이소폼을 생성한다. 긴 스플라이싱 아이소폼 Bcl-xL은 장기간 생존된 유사분열후(postmitotic) 세포에서 발현된 강력한 세포자멸사 저해제이고, 다수의 암세포, 세포자멸사 신호에 대한 보호 세포에서 상향조절된다. 짧은 아이소폼 Bcl-xS는 세포자멸사전 아이소폼이고, 높음 전환율을 갖는 세포(예를 들어, 발생 중인 림프구)에서 고수준으로 발현된다. 2개의 Bcl-x 스플라이싱 아이소폼의 비는 코어 엑손 영역 또는 엑손 연장 영역 중 하나에(즉, 두 대안의 5' 스플라이스 부위 사이에) 위치된 다중  -요소에 의해 조절된다. 더 많은 예에 대해, 본 명세서에 전문이 참고로 편입된 WO2010075303 참조.
-요소에 의해 조절된다. 더 많은 예에 대해, 본 명세서에 전문이 참고로 편입된 WO2010075303 참조.
추가적인 적합한 융합 상대는 경계 요소인 단백질(또는 이의 단편)(예를 들어, CTCF), 주변 보충을 제공하는 단백질 및 이의 단편(예를 들어, 라민 A, 라민 B 등), 단백질 도킹 요소(예를 들어, FKBP/FRB, Pil1/Aby1 등)를 포함하지만, 이들로 제한되지 않는다.
대상 키메라 CasX 폴리펩타이드에 대한 다양한 추가적인 적합한 이종성 폴리펩타이드(또는 이의 단편)의 예는 다음의 요소에 기재된 것을 포함하지만, 이들로 제한되지 않는다(이들 간행물은 다른 CRISPR 엔도뉴클레아제, 예컨대 Cas9와 관련되지만, 기재된 융합 상대는 또한 CasX 대신 사용될 수 있다): PCT 특허 출원: WO2010075303, WO2012068627, 및 WO2013155555, 그리고, 예를 들어 미국 특허 및 특허 출원에서 찾을 수 있다: 8,906,616; 8,895,308; 8,889,418; 8,889,356; 8,871,445; 8,865,406; 8,795,965; 8,771,945; 8,697,359; 20140068797; 20140170753; 20140179006; 20140179770; 20140186843; 20140186919; 20140186958; 20140189896; 20140227787; 20140234972; 20140242664; 20140242699; 20140242700; 20140242702; 20140248702; 20140256046; 20140273037; 20140273226; 20140273230; 20140273231; 20140273232; 20140273233; 20140273234; 20140273235; 20140287938; 20140295556; 20140295557; 20140298547; 20140304853; 20140309487; 20140310828; 20140310830; 20140315985; 20140335063; 20140335620; 20140342456; 20140342457; 20140342458; 20140349400; 20140349405; 20140356867; 20140356956; 20140356958; 20140356959; 20140357523; 20140357530; 20140364333; 및 20140377868; 이들 모두는 본 명세서에 그들의 전문이 참고로 편입된다.
일부 경우에, 이종성 폴리펩타이드(융합 상대)는 세포하 국소화를 제공하고, 즉, 이종성 폴리펩타이드는 핵에 대한 표적화를 위한 세포하 국소화 서열(예를 들어, 핵에 대한 국소화를 위한 핵 국소화 신호(NLS), 핵 밖에서 융합 단백질을 유지하기 위한 서열, 예를 들어, 핵 수송 서열(NES), 세포질에 보유된 융합 단백질을 유지하기 위한 서열, 미노콘드리아에 대한 표적화를 위한 미토콘드리아 국소화 신호, 엽록체, ER 체류 신호 등에 대한 표적화를 위한 엽록체 국소화 신호)을 함유한다. 일부 실시형태에서, CasX 융합 폴리펩타이드는 NLS를 포함하지 않으며, 따라서 단백질은 핵에 대해 표적화되지 않는다(이는, 예를 들어, 표적 핵산이 사이토졸에 존재하는 RNA일 때 유리할 수 있다). 일부 실시형태에서, 이종성 폴리펩타이드는 수송 및/또는 정제의 용이함을 위한 태그(즉, 이종성 폴리펩타이드는 검출 가능한 표지임)(예를 들어, 형광 단백질, 예를 들어, 녹색 형광 단백질(GFP), YFP, RFP, CFP, mCherry, tdTomato 등; 히스티딘 태그, 예를 들어, 6XHis 태그; 혈구응집소(HA) 태그; FLAG 태그; Myc 태그; 등)을 제공할 수 있다.
일부 경우에 CasX 단백질(예를 들어, 야생형 CasX 단백질, 변이체 CasX 단백질, 키메라 CasX 단백질, dCasX 단백질, 키메라 CasX 단백질, 여기서 CasX 부분은 감소된 뉴클레아제 활성을 가짐 - 예컨대 융합상대에 융합된 dCasX 단백질 등)은 핵 국소화 신호(NLS)(예를 들어, 일부 경우에 2개 이상, 3개 이상, 4개 이상 또는 5개 이상의 NLS)를 포함한다(이에 융합된다). 따라서, 일부 경우에, CasX 폴리펩타이드는 1개 이상의 NLS(예를 들어, 2개 이상, 3개 이상, 4개 이상 또는 5개 이상의 NLS)를 포함한다. 일부 경우에, 1개 이상의 NLS(2개 이상, 3개 이상, 4개 이상 또는 5개 이상의 NLS)는 N-말단 및/또는 C-말단에 또는 근처에(예를 들어, 이의 50개 아미노산 내에) 위치된다. 일부 경우에, 1개 이상의 NLS(2개 이상, 3개 이상, 4개 이상 또는 5개 이상의 NLS)는 N-말단에 또는 근처에(예를 들어, 이의 50개 아미노산 내에) 위치된다. 일부 경우에, 1개 이상의 NLS(2개 이상, 3개 이상, 4개 이상 또는 5개 이상의 NLS)는 C-말단에 또는 근처에(예를 들어, 이의 50개 아미노산 내에) 위치된다. 일부 경우에, 1개 이상의 NLS(3개 이상, 4개 이상 또는 5개 이상의 NLS)는 N-말단과 C-말단 둘 다에 또는 근처에(예를 들어, 이의 50개 아미노산 내에) 위치된다. 일부 경우에, NLS는 N-말단에 위치되고, NLS는 C-말단에 위치된다.
일부 경우에 CasX 단백질(예를 들어, 야생형 CasX 단백질, 변이체 CasX 단백질, 키메라 CasX 단백질, dCasX 단백질, 키메라 CasX 단백질, 여기서 CasX 부분은 감소된 뉴클레아제 활성 - 예컨대 융합 상대에 융합된 dCasX 단백질 등을 가짐)은 1 내지 10개의 NLS(예를 들어, 1-9, 1-8, 1-7, 1-6, 1-5, 2-10, 2-9, 2-8, 2-7, 2-6 또는 2-5개의 NLS)를 포함한다(이에 융합된다). 일부 경우에 CasX 단백질(예를 들어, 야생형 CasX 단백질, 변이체 CasX 단백질, 키메라 CasX 단백질, dCasX 단백질, 키메라 CasX 단백질, 여기서 CasX 부분은 감소된 뉴클레아제 활성 - 예컨대 융합 상대에 융합된 dCasX 단백질 등을 가짐)은 2 내지 5개의 NLS(예를 들어, 2 내지 4 또는 2 내지 3개의 NLS)를 포함한다(이에 융합된다).
NLS의 비제한적 예는 아미노산 서열 PKKKRKV(서열번호 96)를 갖는 SV40 바이러스 거대 T-항원의 NLS; 뉴클레오플라스민으로부터의 NLS(예를 들어, 서열 KRPAATKKAGQAKKKK(서열번호 97)을 갖는 뉴클레오플라스민 이분(bipartite) NLS)로부터 유래된 NLS 서열; 아미노산 서열 PAAKRVKLD(서열번호 98) 또는 RQRRNELKRSP(서열번호 99)를 갖는 c-myc NLS; 서열 NQSSNFGPMKGGNFGGRSSGPYGGGGQYFAKPRNQGGY(서열번호 100)을 갖는 hRNPA1 M9 NLS; 임포틴-알파로부터의 IBB 도메인의 서열 RMRIZFKNKGKDTAELRRRRVEVSVELRKAKKDEQILKRRNV(서열번호 101); 근종 T 단백질의 서열 VSRKRPRP(서열번호 102) 및 PPKKARED(서열번호 103); 인간 p53의 서열 PQPKKKPL(서열번호 104); 마우스 c-abl IV의 서열 SALIKKKKKMAP(서열번호 105); 인플루엔자 바이러스 NS1의 서열 DRLRR(서열번호 106) 및 PKQKKRK(서열번호 107); 간염 바이러스 델타 항원의 서열 RKLKKKIKKL(서열번호 108); 마우스 Mx1 단백질의 서열 REKKKFLKRR(서열번호 109); 인간 폴리(ADP-리보스) 중합효소의 서열 KRKGDEVDGVDEVAKKKSKK(서열번호 110); 및 스테로이드 호르몬 수용체(인간) 글루코코르티코이드의 서열 RKCLQAGMNLEARKTKK(서열번호 111)을 포함한다. 일반적으로, NLS(또는 다중 NLS)는 진핵 세포의 핵에서 검출 가능한 양으로 CasX 단백질의 축적을 유도하기에 충분한 강도를 가진다. 핵에서 축적의 검출은 임의의 적합한 기법에 의해 수행될 수 있다. 예를 들어, 검출 가능한 마커는 세포 내의 위치가 시각화될 수 있도록 CasX 단백질에 융합될 수 있다. 세포 핵은 또한 세포로부터 단리될 수 있고, 이어서, 이의 내용은 단백질을 검출하기 위한 임의의 적합한 방법, 예컨대 면역조직화학, 웨스턴 블롯, 또는 효소 활성 분석에 의해 분석될 수 있다. 핵에서의 축적은 또한 간접적으로 결정될 수 있다.
일부 경우에, CasX 융합 폴리펩타이드는 "단백질 형질도입 도메인" 또는 PTD(또한 CPP - 세포 침투성 펩타이드로서 알려짐)를 포함하는데, 이는 지질 이중층, 마이셀, 세포막, 세포소기관 막 또는 소수포 막을 가로지르는 것을 용이하게 하는 폴리펩타이드, 폴리뉴클레오타이드, 탄수화물 또는 유기 또는 무기 화합물을 지칭한다. 거대 분자 및/또는 나노분자의 범위일 수 있는 다른 분자에 부착된 PTD는 분자가 막을 가로지르는 것, 예를 들어, 세포외 공간으로부터 세포내 공간 또는 사이토졸을 세포소기관 내로 이동하는 것을 용이하게 한다. 일부 실시형태에서, PTD는 아미노 말단 폴리펩타이드에 공유적으로 연결된다(예를 들어, 융합 단백질을 생성하기 위해 야생형 CasX에 연결되거나, 또는 융합 단백질을 생성하기 위해 변이체 CasX 단백질, 예컨대 dCasX, 틈내기효소 CasX, 또는 키메라 CasX 단백질에 연결됨). 일부 실시형태에서, PTD는 폴리펩타이드의 카복실 말단 공유적으로 연결된다(예를 들어, 융합 단백질을 생성하기 위해 야생형 CasX에 연결되거나, 또는 융합 단백질을 생성하기 위해 변이체 CasX 단백질, 예컨대 dCasX, 틈내기효소 CasX, 또는 키메라 CasX 단백질에 연결됨). 일부 경우에, PTD는 적합한 삽입 부위에서 CasX 융합 폴리펩타이드에서 내부로 삽입된다(즉, CasX 융합 폴리펩타이드의 N- 또는 C-말단에서가 아님). 일부 경우에, 대상 CasX 융합 폴리펩타이드는 1개 이상의 PTD(예를 들어, 2개 이상, 3개 이상, 4개 이상의 PTD)를 포함한다(이에 접합되고, 융합된다). 일부 경우에, PTD는 핵 국소화 신호(NLS)(예를 들어, 일부 경우에 2개 이상, 3개 이상, 4개 이상 또는 5개 이상의 NLS)를 포함한다. 따라서, 일부 경우에, CasX 융합 폴리펩타이드는 1개 이상의 NLS(예를 들어, 2개 이상, 3개 이상, 4개 이상 또는 5개 이상의 NLS)를 포함한다. 일부 실시형태에서, PTD는 핵산(예를 들어, CasX 가이드 핵산, CasX 가이드 핵산을 암호화하는 폴리뉴클레오타이드, CasX 융합 폴리펩타이드를 암호화하는 폴리뉴클레오타이드, 공여자 폴리뉴클레오타이드 등)에 공유적으로 연결된다. PTD의 예는 최소 운데카펩타이드 단백질 형질도입 도메인(YGRKKRRQRRR; 서열번호 112를 포함하는 HIV-1 TAT의 잔기 47 내지 57에 대응); 세포 내로 유입을 지시하기에 충분한 다수의 알기닌을 포함하는 폴리알기닌 서열(예를 들어, 3, 4, 5, 6, 7, 8, 9, 10 또는 10 내지 50개의 알기닌); VP22 도메인(Zender et al. (2002) Cancer Gene Ther. 9(6):489-96); 초파리 안테나페디아(Antennapedia) 단백질 형질도입 도메인(Noguchi et al. (2003) Diabetes 52(7):1732-1737); 절단된 인간 칼시토닌 펩타이드(Trehin et al. (2004) Pharm . Research 21:1248-1256); 폴리라이신(Wender et al. (2000) Proc . Natl . Acad . Sci. USA 97:13003-13008); RRQRRTSKLMKR(서열번호 113); 트랜스포탄 GWTLNSAGYLLGKINLKALAALAKKIL(서열번호 114); KALAWEAKLAKALAKALAKHLAKALAKALKCEA(서열번호 115); 및 RQIKIWFQNRRMKWKK(서열번호 116)을 포함하지만, 이들로 제한되지 않는다. 예시적인 PTD는 YGRKKRRQRRR(서열번호 117), RKKRRQRRR(서열번호 118); 3개의 알기닌 잔기 내지 50개의 알기닌 잔기의 알기닌 동종중합체를 포함하지만, 이들로 제한되지 않고; 예시적인 PTD 도메인 아미노산 서열은 다음 중 어떤 것을 포함하지만, 이들로 제한되지 않는다: YGRKKRRQRRR(서열번호 119); RKKRRQRR(서열번호 120); YARAAARQARA(서열번호 121); THRLPRRRRRR(서열번호 122); 및 GGRRARRRRRR(서열번호 123). 일부 실시형태에서, PTD는 활성화 가능한 CPP(ACPP)이다(Aguilera et al. (2009) Integr Biol ( Camb ) June; 1(5-6): 371-381). ACPP는 매칭 절단 가능한 링커를 통해 다음이온(예를 들어, Glu9 또는 "E9")에 연결된 다양이온 CPP(예를 들어, Arg9 또는 "R9")를 포함하는데, 이는 순전하를 거의 0으로 감소시키고, 이에 의해 세포에 대한 접착 및 흡수를 저해한다. 링커의 절단 시, 다음이온이 방출되며, 다알기닌 및 그의 고유한 부착성을 국소로 가리며, 따라서 막을 가로지르도록 ACPP를 "활성화시킨다".
링커(예를 들어, 융합 상대에 대해)
일부 실시형태에서, 대상 CasX 단백질은 링커 폴리펩타이드(예를 들어, 하나 이상의 링커 폴리펩타이드)를 통해 융합 상대에 융합될 수 있다. 링커 폴리펩타이드는 임의의 다양한 아미노산 서열을 가질 수 있다. 다른 화학적 결합이 제외되지는 않지만, 단백질은 일반적으로 가요성 특성의 스페이서 펩타이드에 의해 결합될 수 있다. 적합한 링커는 길이가 4개의 아미노산 내지 40개의 아미노산, 또는 길이가 4개의 아미노산 내지 25개의 아미노산인 폴리펩타이드를 포함한다. 이들 링커는 단백질을 결합하기 위해 합성, 링커-암호화 올리고뉴클레오타이드를 이용함으로써 생성될 수 있거나, 또는 융합 단백질을 암호화하는 핵산 서열에 의해 암호화될 수 있다. 일정 정도의 가요성이 있는 펩타이드 링커가 사용될 수 있다. 연결 펩타이드는 사실상 임의의 아미노산 서열을 가질 수 있고, 바람직한 링커는 일반적으로 가요성 펩타이드를 초래하는 서열을 가질 것임을 유념한다. 작은 아미노산, 예컨대 글리신 및 알라닌의 사용은 가요성 펩타이드를 생성하는 용도를 가진다. 이러한 서열의 생성은 당업자에게 일상적이다. 다양한 상이한 링커가 상업적으로 입수 가능하고, 사용에 적합한 것으로 고려된다.
링커 폴리펩타이드의 예는 글리신 중합체(G)n, 글리신-세린 중합체(예를 들어, (GS)n, GSGGSn(서열번호 124), GGSGGSn(서열번호 125) 및 GGGSn(서열번호 126)을 포함, 여기서 n은 적어도 하나의 정수임), 글리신-알라닌 중합체, 알라닌-세린 중합체를 포함한다. 예시적인 링커는 GGSG(서열번호 127), GGSGG(서열번호 128), GSGSG(서열번호 129), GSGGG(서열번호 130), GGGSG(서열번호 131), GSSSG(서열번호 132) 등을 포함하지만, 이들로 제한되지 않는 아미노산 서열을 포함할 수 있다. 당업자는 링커가 가요성 링커뿐만 아니라 덜 가요성인 구조를 부여하는 하나 이상의 부분을 포함할 수 있도록 임의의 목적으로 하는 요소에 접합된 펩타이드의 설계가 모두 또는 부분적으로 가요성인 링커를 포함할 수 있다는 것을 인식할 것이다.
검출 가능한 표지
일부 경우에, 본 개시내용의 CasX 폴리펩타이드는 검출 가능한 표지를 포함한다. 적합한 검출 가능한 표지 및/또는 검출 가능한 신호를 제공할 수 있는 모이어티는 효소, 방사성 동위 원소, 특정 결합쌍의 구성원; 형광단; 형광 단백질; 양자점 등을 포함할 수 있지만, 이들로 제한되지 않는다.
적합한 형광 단백질은 녹색 형광 단백질(GFP) 또는 이의 변이체, GFP의 청색 형광 변이체(BFP), GFP의 사이안 형광 변이체(CFP), GFP의 황색 형광 변이체(YFP), 증강된 GFP(EGFP), 증강된 CFP(ECFP), 증강된 YFP(EYFP), GFPS65T, 에메랄드, 토파즈(TYFP), 비너스, 시트린, 엠시트린(mCitrine), GFPuv, 불안정 EGFP (dEGFP), 불안정 ECFP (dECFP), 불안정 EYFP (dEYFP), mCFPm, 세룰리언, T-사파이어, CyPet, YPet, mKO, HcRed, t-HcRed, DsRed, DsRed2, DsRed-단량체, J-Red, 이량체2, t-이량체2(12), mRFP1, 포실로포린, 레닐라 GFP, 몬스터 GFP, paGFP, Kaede 단백질 및 킨들링 단백질, 피코빌리단백질 및 피코빌리단백질 접합체(B-피코에리트린, R-피코에리트린 및 알로피코사이아닌을 포함)를 포함하지만, 이들로 제한되지 않는다. 형광 단백질의 다른 예는 mHoneydew, mBanana, mOrange, dTomato, tdTomato, mTangerine, mStrawberry, mCherry, mGrape1, mRaspberry, mGrape2, mPlum(Shaner et al. (2005) Nat. Methods 2:905-909) 등을 포함한다. 예를 들어, 문헌[Matz et al. (1999) Nature Biotechnol . 17:969-973]에 기재된 바와 같은 화충류(Anthozoan) 종으로부터의 임의의 다양한 형광 및 착색 단백질이 사용에 적합하다.
적합한 효소는 겨자무과산화효소(HRP), 알칼리성 포스파타제(AP), 베타-갈락토시다제(GAL), 글루코스-6-인산 탈수소효소, 베타-N-아세틸글루코사미니다제, β-글루쿠로니다제, 인버타제, 잔틴 옥시다제, 반딧불이 루시퍼라제, 글루코스 옥시다제(GO) 등을 포함하지만, 이들로 제한되지 않는다.
프로토스페이서
인접 모티프(PAM)
CasX 단백질은 DNA-표적화 RNA와 표적 DNA 사이의 상보성 영역에 의해 정해지는 표적 서열에서 표적 DNA에 결합한다. 다수의 CRISPR 엔도뉴클레아제에 대한 경우에서와 같이, 이중 가닥 표적 DNA의 부위-특이적 결합(및/또는 절단)은 (i) 가이드 RNA와 표적 DNA 사이의 염기쌍 상보성; 그리고 (ii) 표적 DNA 내 짧은 모티프[프로토스페이서 인접 모티프(PAM)로서 지칭됨]에 의해 결정된 위치에서 생긴다.
일부 실시형태에서, CasX 단백질에 대한 PAM은 표적 DNA의 비상보성 가닥의 표적 서열의 5' 바로 옆이다(상보성 가닥은 가이드 RNA의 가이드 서열에 혼성화되는 한편, 비-상보성 가닥은 가이드 RNA에 직접 혼성화하지 않으며, 비-상보성 가닥의 역상보체이다). 일부 실시형태에서(예를 들어, 본 명세서에 기재된 바와 같은 CasX1이 사용될 때), 비-상보성 가닥의 PAM 서열은 5'-TCN-3'이며(그리고 일부 경우에 TTCN), 여기서 N은 임의의 DNA 뉴클레오타이드이다. 예로서, 도 6, 패널 c, 및 도 7을 참조하며, 이때 PAM(TCN)(비상보적 가닥 상에서)은 TCA이고(도면에서 나타낸 PAM은 TTCA임), PAM은 표적 서열의 5'이다.
일부 경우에, 상이한 CasX 단백질(즉, 다양한 종으로부터의 CasX 단백질)은 상이한 CasX 단백질의 다양한 효소 특징을 활용하기 위해(예를 들어, 상이한 PAM 서열 선호도에 대해; 증가된 또는 감소된 효소 활성에 대해; 세포 독성의 증가된 또는 감소된 수준에 대해; NHEJ, 상동성-직접 수선, 단일 가닥 파손, 이중 가닥 파손 등 사이의 균형 변화를 위해; 짧은 총 서열의 이점을 취하기 위해; 등) 다양한 제공된 방법으로 사용하는 것이 유리할 수 있다. 상이한 종으로부터의 CasX 단백질은 표적 DNA에서 상이한 PAM 서열을 필요로 할 수 있다. 따라서, 특정 선택 CasX 단백질에 대해, PAM 서열 필요는 상기 기재한 5'-TCN-3' 서열과 상이할 수 있다. 적절한 PAM 서열의 동정을 위한 다양한 방법(인실리코 및/또는 습식 실험실 방법을 포함)은 당업계에 공지되어 있고, 일상적이며, 임의의 편리한 방법이 사용될 수 있다. 본 명세서에 기재된 TCN PAM 서열은 PAM 고갈 분석(예를 들어, 이하의 작업 실시예의 도 5 참조)을 이용하여 동정되었다.
CasX
가이드 RNA
리보뉴클레오단백질 복합체(RNP)를 형성하고, 표적 핵산(예를 들어, 표적 DNA) 내의 특정 위치에 대해 복합체를 표적화하는 CasX 단백질에 결합하는 핵산은 본 명세서에서 "CasX 가이드 RNA"로서 또는 단순히 "가이드 RNA"로서 지칭된다. 일부 경우에, CasX 가이드 RNA가 RNA 염기에 추가로 DNA 염기를 포함하도록 혼성 DNA/RNA가 만들어질 수 있지만, 용어 "CasX 가이드 RNA"는 여전히 본 명세서의 이러한 분자를 포함하기 위해 사용된다는 것이 이해되어야 한다.
CasX 가이드 RNA는 2개의 세그먼트, 표적화 세그먼트 및 단백질-결합 세그먼트를 포함하는 것으로 언급될 수 있다. CasX 가이드 RNA의 표적화 세그먼트는 표적 핵산(예를 들어, 표적 ssRNA, 표적 ssDNA, 이중 가닥 표적 DNA의 상보성 가닥 등) 내의 특정 서열(표적 부위)에 상보성인(그리고 따라서 이에 혼성화하는) 뉴클레오타이드 서열(가이드 서열)을 포함한다. 단백질-결합 세그먼트(또는 "단백질-결합 서열")는 CasX 폴리펩타이드에 상호작용한다(이에 결합한다). 대상 CasX 가이드 RNA의 단백질의 단백질-결합 세그먼트는 이중 가닥 RNA 듀플렉스(dsRNA 듀플렉스)을 형성하기 위해 서로 혼성화하는 뉴클레오타이드의 2개의 상보적 신장을 포함한다. 표적 핵산(예를 들어, 게놈 DNA)의 부위-특이적 결합 및/또는 절단은 CasX 가이드 RNA(CasX 가이드 RNA의 가이드 서열 )와 표적 핵산 사이의 염기쌍 상보성에 의해 결정되는 위치(예를 들어, 표적 좌위의 표적 서열)에서 일어날 수 있다.
CasX 가이드 RNA 및 CasX 단백질, 예를 들어, 융합 CasX 폴리펩타이드는 복합체를 형성한다(예를 들어, 비공유 상호작용을 통해 결합한다). CasX 가이드 RNA는 가이드 서열(표적 핵산의 서열에 상보성인 뉴클레오타이드 서열)을 포함하는 표적화 세그먼트를 포함함으로써 복합체에 표적 특이성을 제공한다. 복합체의 CasX 단백질은 부위-특이적 활성(예를 들어, CasX 단백질에 의해 제공된 절단 활성 및/또는 키메라 CasX 단백질의 경우에 융합 상대에 의해 제공된 활성)을 제공한다. 다시 말해서, CasX 단백질은 CasX 가이드 RNA와 그의 회합 때문에 표적 핵산 서열(예를 들어, 표적 서열)로 가이드된다.
CasX 가이드 RNA의 "표적화 서열"로서도 지칭되는 "가이드 서열"은 PAM 서열을 고려할 수 있다는 것을 제외하고(예를 들어, 본 명세서에 기재된 바와 같이), CasX 가이드 RNA가 임의의 목적으로 하는 표적 핵산의 임의의 목적으로 하는 서열에 대해 CasX 단백질(예를 들어, 천연 유래 CasX 단백질, 융합 CasX 폴리펩타이드(키메라 CasX) 등)을 표적화할 수 있도록 변형될 수 있다. 따라서, 예를 들어, CasX 가이드 RNA는 진핵 세포 내 핵산, 예를 들어, 바이러스 핵산, 진핵 핵산(예를 들어, 진핵 염색체, 염색체 서열, 진핵 RNA 등) 등에서의 서열에 대해 상보성인(예를 들어, 혼성화할 수 있는) 가이드 서열을 가질 수 있다.
대상 CasX 가이드 RNA는 또한 "활성체(activator)" 및 "표적자(targeter)"(예를 들어, 각각 "활성체-RNA" 및 "표적자-RNA")를 포함하는 것으로 언급될 수 있다. "활성체" 및 "표적자"가 2개의 별개의 분자일 때, 가이드 RNA는 본 명세서에서 "이중 가이드 RNA", "dgRNA", "이중-분자 가이드 RNA" 또는 "2-분자 가이드 RNA", 예를 들어, "CasX 이중 가이드 RNA"로서 지칭된다. 일부 실시형태에서, 활성체 및 표적자는 서로에 대해(예를 들어, 개재 뉴클레오타이드를 통해) 공유결합되고, 가이드 RNA는 본 명세서에서 "단일 가이드 RNA", "sgRNA", "단일-분자 가이드 RNA" 또는 "1-분자 가이드 RNA"(예를 들어, "CasX 단일 가이드 RNA")로서 지칭된다. 따라서, 대상 CasX 단일 가이드 RNA는 서로에 대해(예를 들어, 개재 뉴클레오타이드에 의해) 연결된 표적자(예를 즐어, 표적자-RNA) 및 활성체(예를 들어, 활성체-RNA)를 포함하고, 서로 혼성화되어 가이드 RNA의 단백질-결합 세그먼트의 이중 가닥 RNA 듀플렉스(dsRNA 듀플렉스)를 형성하고, 따라서, 줄기-루프 구조를 초래한다(도 6, 패널 c). 따라서, 표적자 및 활성체는 각각 듀플렉스-형성 세그먼트를 가지며, 여기서, 표적자의 듀플렉스 형성 세그먼트 및 활성체의 듀플렉스-형성 세그먼트는 서로 상보성을 가지며, 서로에 대해 혼성화된다.
일부 실시형태에서, CasX 단일 가이드 RNA의 링커는 뉴클레오타이드의 스트레치이다(도 6, 패널 c에서 GAAA로서 도시됨). 일부 경우에, CasX 단일 가이드 RNA의 표적자 및 활성체는 개재 뉴클레오타이드에 의해 서로에 대해 연결되고, 링커는 3 내지 20개의 뉴클레오타이드(nt)(예를 들어, 3 내지 15, 3 내지 12, 3 내지 10, 3 내지 8, 3 내지 6, 3 내지 5, 3 내지 4, 4 내지 20, 4 내지 15, 4 내지 12, 4 내지 10, 4 내지 8, 4 내지 6, 또는 4 내지 5개의 nt)의 길이를 가질 수 있다. 일부 실시형태에서, CasX 단일 가이드 RNA의 링커는 3 내지 100개의 뉴클레오타이드(nt)(예를 들어, 3 내지 80, 3 내지 50, 3 내지 30, 3 내지 25, 3 내지 20, 3 내지 15, 3 내지 12, 3 내지 10, 3 내지 8, 3 내지 6, 3 내지 5, 3 내지 4, 4 내지 100, 4 내지 80, 4 내지 50, 4 내지 30, 4 내지 25, 4 내지 20, 4 내지 15, 4 내지 12, 4 내지 10, 4 내지 8, 4 내지 6, 또는 4 내지 5개의 nt)의 길이를 가질 수 있다. 일부 실시형태에서, CasX 단일 가이드 RNA의 링커는 3 내지 10개의 뉴클레오타이드(nt)(예를 들어, 3 내지 9, 3 내지 8, 3 내지 7, 3 내지 6, 3 내지 5, 3 내지 4, 4 내지 10, 4 내지 9, 4 내지 8, 4 내지 7, 4 내지 6, 또는 4 내지 5개의 nt)의 길이를 가질 수 있다.
CasX
가이드 RNA의 가이드 서열
대상 CasX 가이드 RNA의 표적화 세그먼트는 표적 핵산 내 서열(표적 부위)에 대해 상보성은 뉴클레오타이드 서열인 가이드 서열(즉, 표적화 서열)을 포함한다. 다시 말해서, CasX 가이드 RNA의 표적화 세그먼트는 혼성화(즉, 염기쌍)를 통해 서열 특이적 방식으로 표적 핵산(예를 들어, 이중 가닥 DNA(dsDNA), 단일 가닥 DNA(ssDNA), 단일 가닥 RNA(ssRNA) 또는 이중 가닥 RNA(dsRNA))과 상호작용할 수 있다. CasX 가이드 RNA의 가이드 서열은 표적 핵산(예를 들어, 진핵 표적 핵산, 예컨대 게놈 DNA) 내에서 임의의 목적으로 하는 표적 서열(예를 들어, PAM을 고려하는 동안, 예를 들어, dsDNA 표적을 표적화할 때)에 혼성화하도록 변형(예를 들어, 유전자 조작에 의해)/설계될 수 있다.
일부 실시형태에서, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 60% 이상(예를 들어, 65% 이상, 70% 이상, 75% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 80% 이상(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 90% 이상(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 100% 이상이다.
일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 표적 핵산의 7개의 인접한 가장 3'의 뉴클레오타이드에 대해 100%이다.
일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 19개 이상의(예를 들어, 20개 이상, 21개 이상, 22개 이상) 인접한 뉴클레오타이드에 대해 60% 이상(예를 들어, 70% 이상, 75% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 19개 이상의(예를 들어, 20개 이상, 21개 이상, 22개 이상) 인접한 뉴클레오타이드에 대해 80% 이상(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 19개 이상의(예를 들어, 20개 이상, 21개 이상, 22개 이상) 인접한 뉴클레오타이드에 대해 90% 이상(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 19개 이상의(예를 들어, 20개 이상, 21개 이상, 22개 이상)의 인접한 뉴클레오타이드에 대해 100%이다.
일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 19 내지 25개의 인접한 뉴클레오타이드에 대해 60% 이상(예를 들어, 70% 이상, 75% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 19 내지 25개의 인접한 뉴클레오타이드에 대해 80% 이상(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 19 내지 25개의 인접한 뉴클레오타이드에 대해 90% 이상(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 19 내지 25개의 인접한 뉴클레오타이드에 대해 100% 이상이다.
일부 경우에, 가이드 서열은 길이가 19 내지 30개의 뉴클레오타이드(nt)(예를 들어, 19-25, 19-22, 19-20, 20-30, 20-25 또는 20-22 nt) 범위이다. 일부 경우에, 가이드 서열은 길이가 19 내지 25개의 뉴클레오타이드(nt)(예를 들어, 19-22, 19-20, 20-25, 20-25 또는 20-22 nt) 범위이다. 일부 경우에, 가이드 서열은 길이가 19개 이상의 nt(예를 들어, 20개 이상, 21개 이상 또는 22개 이상의 nt; 19 nt, 20 nt, 21 nt, 22 nt, 23 nt, 24 nt, 25 nt 등)를 가진다. 일부 경우에, 가이드 서열은 길이가 19 nt이다. 일부 경우에, 가이드 서열은 길이가 20 nt이다. 일부 경우에, 가이드 서열은 길이가 21 nt이다. 일부 경우에, 가이드 서열은 길이가 22 nt이다. 일부 경우에, 가이드 서열은 길이가 23 nt이다.
CasX
가이드 RNA의 단백질-결합
세그먼트
대상 CasX 가이드 RNA의 단백질-결합 세그먼트는 CasX 단백질과 상호작용한다. CasX 가이드 RNA는 결합된 CasX 단백질을 상기 언급한 가이드 서열을 통해 표적 핵산 내의 특정 뉴클레오타이드 서열로 가이드한다. CasX 가이드 RNA의 단백질-결합 세그먼트는 서로에 대해 상보성이고 이중 가닥 RNA 듀플렉스(dsRNA 듀플렉스)을 형성하도록 혼성화되는 뉴클레오타이드의 2개의 신장(활성체의 듀플렉스-형성 세그먼트 및 표적자의 듀플렉스-형성 세그먼트)을 포함한다. 따라서, 단백질-결합 세그먼트는 dsRNA 듀플렉스를 포함한다.
일부 경우에, 활성체와 표적자 사이에 형성된 dsRNA 듀플렉스 영역(즉, 활성체/표적자 dsRNA 듀플렉스)(예를 들어, 이중 또는 단일 가이드 RNA 형식에서)은 8 내지 25개의 염기쌍(bp)의 범위(예를 들어, 8-22, 8-18, 8-15, 8-12, 12-25, 12-22, 12-18, 12-15, 13-25, 13-22, 13-18, 13-15, 14-25, 14-22, 14-18, 14-15, 15-25, 15-22, 15-18, 17-25, 17-22 또는 17-18 bp, 예를 들어, 15 bp, 16 bp, 17 bp, 18 bp, 19 bp, 20 bp, 21 bp 등)를 포함한다. 일부 경우에, 듀플렉스 영역(예를 들어, 이중 또는 단일 가이드 RNA 형식으로)은 8개 이상의 bp(예를 들어, 10개 이상, 12개 이상, 15개 이상 또는 17개 이상의 bp)를 포함한다. 일부 경우에, 듀플렉스 영역의 모든 뉴클레오타이드가 짝지어지지는 않으며, 따라서 듀플렉스 형성 영역은 벌지(bulge)를 포함할 수 있다(예를 들어, 도 6, 패널 c 및 도 7 참조). 본 명세서의 용어 "벌지"는 이중 가닥 듀플렉스에 기여하지 않지만, 기여하는 뉴클레오타이드에 의해 5' 및 3'을 둘러싸는 뉴클레오타이드의 신장(하나의 뉴클레오타이드일 수 있음)을 의미하기 위해 사용되며, 이러한 벌지는 듀플렉스 영역의 부분으로 고려된다. 일부 경우에, 활성체와 표적자 사이에 형성된 dsRNA 이중가닥(즉, 활성체/표적자 dsRNA 듀플렉스)는 1개 이상의 벌지(예를 들어, 2개 이상, 3개 이상, 4개 이상의 벌지)를 포함한다. 일부 경우에, 활성체와 표적자 사이에 형성된 dsRNA 이중가닥(즉, 활성체/표적자 dsRNA 듀플렉스)는 2개 이상의 벌지(예를 들어, 3개 이상, 4개 이상의 벌지)를 포함한다. 일부 경우에, 활성체와 표적자 사이에 형성된 dsRNA 이중가닥(즉, 활성체/표적자 dsRNA 듀플렉스)는 1 내지 5개의 벌지(예를 들어, 1-4, 1-3, 2-5, 2-4, 또는 2-3개의 벌지)를 포함한다.
따라서, 일부 경우에, 활성체 및 표적자의 듀플렉스-형성 세그먼트는 서로 70% 내지 100% 상보성(예를 들어, 75%-100%, 80%-10%, 85%-100%, 90%-100%, 95%-100% 상보성)을 가진다. 일부 경우에, 활성체 및 표적자의 듀플렉스-형성 세그먼트는 서로 70% 내지 100% 상보성(예를 들어, 75%-100%, 80%-10%, 85%-100%, 90%-100%, 95%-100% 상보성)을 가진다. 일부 경우에, 활성체 및 표적자의 듀플렉스-형성 세그먼트는 서로 85% 내지 100% 상보성(예를 들어, 90%-100%, 95%-100% 상보성)을 가진다. 일부 경우에, 활성체 및 표적자의 듀플렉스-형성 세그먼트는 서로 70% 내지 95% 상보성(예를 들어, 75%-95%, 80%-95%, 85%-95%, 90%-95% 상보성)을 가진다.
다시 말해서, 일부 실시형태에서, 활성체와 표적자 사이에 형성된 dsRNA 듀플렉스(즉, 활성체/표적자 dsRNA 이중가닥)는dsRNA 듀플렉스는 서로 70%-100% 상보성(예를 들어, 75%-100%, 80%-10%, 85%-100%, 90%-100%, 95%-100% 상보성)을 갖는 뉴클레오타이드의 2개 신장을 포함한다. 일부 경우에, 활성체/표적자 dsRNA 듀플렉스는 서로 85%-100% 상보성(예를 들어, 90%-100%, 95%-100% 상보성)을 갖는 뉴클레오타이드의 2개 신장을 포함한다. 일부 경우에, 활성체/표적자 dsRNA 듀플렉스는 서로 70%-95% 상보성(예를 들어, 75%-95%, 80%-95%, 85%-95%, 90%-95% 상보성)을 갖는 뉴클레오타이드의 2개 신장을 포함한다.
대상 CasX 가이드 RNA의 듀플렉스 영역은 (이중 가이드 또는 단일 가이드 RNA 형식에서) 천연 유래 듀플렉스 영역에 비해 하나 이상(1, 2, 3, 4, 5 등)의 돌연변이를 포함할 수 있다. 예를 들어, 일부 경우에 염기쌍은 유지될 수 있는 한편 각각의 세그먼트(표적자 및 활성체)로부터의 염기쌍에 기여하는 뉴클레오타이드는 상이할 수 있다. 일부 경우에, 대상 CasX 가이드 RNA의 이중가닥 영역은 (천연 유래 CasX 가이드 RNA의) 천연 유래 이중가닥 영역에 비교할 때 더 짝지어진 염기, 덜 짝지어진 염기, 더 작은 벌지, 더 큰 벌지, 소수의 벌지, 더 많은 벌지, 또는 이들의 임의의 편리한 조합을 포함한다.
일부 경우에, 대상 CasX 가이드 RNA의 활성체(예를 들어, 활성체-RNA)는 (이중 또는 단일 가이드 RNA 형식에서) 적어도 2개의 내부 RNA 듀플렉스(즉, 활성체/표적자 dsRNA에 추가로 2개의 내부 헤어핀)를 포함한다. 활성체의 내부 RNA 듀플렉스(헤어핀)는 활성체/표적자 dsRNA 듀플렉스의 5'에 위치될 수 있다(예를 들어, 도 6, 패널 c, 및 도 7 참조, 이들 둘 다 활성체/표적자 dsRNA 듀플렉스의 2개의 내부 헤어핀이 위치된 5'을 갖는 활성체를 포함함). 일부 경우에, 활성체는 활성체/표적자 dsRNA 듀플렉스의 1개의 헤어핀이 위치된 5'을 포함한다. 일부 경우에, 활성체는 활성체/표적자 dsRNA 듀플렉스의 2개의 헤어핀이 위치된 5'을 포함한다. 일부 경우에, 활성체는 활성체/표적자 dsRNA 듀플렉스의 3개의 헤어핀이 위치된 5'을 포함한다. 일부 경우에, 활성체는 활성체/표적자 dsRNA 듀플렉스의 2개 이상의 헤어핀(예를 들어, 3개 이상 또는 4개 이상의 헤어핀)이 위치된 5'을 포함한다. 일부 경우에, 활성체는 활성체/표적자 dsRNA 듀플렉스의 2 내지 5개의 헤어핀(예를 들어, 2 내지 4개 또는 2 내지 3개의 헤어핀)이 위치된 5'을 포함한다.
일부 경우에, 활성체-RNA는(예를 들어, 이중 또는 단일 가이드 RNA 형식으로), 예를 들어, 도 6 및 도 7의 tracrRNA에 도시한 바와 같이, 가장 5'의 헤어핀 줄기의 적어도 2개의 뉴클레오타이드(nt)(예를 들어, 적어도 3 또는 적어도 4 nt) 5'을 포함한다. 일부 경우에, 활성체-RNA는(예를 들어, 이중 또는 단일 가이드 RNA 형식으로), 예를 들어, 도 6 및 도 7의 tracrRNA에 도시한 바와 같이, 가장 5'의 헤어핀 줄기의 적어도 4개의 nt 5'를 포함한다.
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 형식으로) 65개 이상의 뉴클레오타이드(nt)(예를 들어, 66개 이상, 67개 이상, 68개 이상, 69개 이상, 70개 이상 또는 75개 이상의 nt)의 길이를 가진다. 일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 형식으로) 66개 이상의 nt(예를 들어, 67개 이상, 68개 이상, 69개 이상, 70개 이상 또는 75개 이상의 nt)의 길이를 가진다. 일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 형식으로) 67개 이상의 nt(예를 들어, 68개 이상, 69개 이상, 70개 이상 또는 75개 이상의 nt)의 길이를 가진다.
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 형식으로) 활성체와 표적자 사이에 형성된 dsRNA 듀플렉스(활성체/표적자 dsRNA 듀플렉스)의 45개 이상의 뉴클레오타이드(nt)(예를 들어, 46개 이상, 47개 이상, 48개 이상, 49개 이상, 50개 이상, 51개 이상, 52개 이상, 53개 이상, 54개 이상 또는 55개 이상의 nt) 5'을 포함한다. 일부 경우에, 활성체는 천연 유래 CasX 활성체에 대해 5' 단부에서 절단된다. 일부 경우에, 활성체는 천연 유래 CasX 활성체에 대해 5' 단부에서 연장된다.
다양한 Cas9 가이드 RNA의 예는 당업계에서 찾을 수 있고, 그리고 일부 경우에 Cas9 가이드 RNA 내로 도입된 것과 유사한 변형이 또한 본 개시내용의 CasX 가이드 RNA 내로 도입될 수 있다. 예를 들어, 문헌[Jinek et al., Science. 2012 Aug 17;337(6096):816-21; Chylinski et al., RNA Biol. 2013 May; 10(5):726-37; Ma et al., Biomed Res Int. 2013;2013:270805; Hou et al., Proc Natl Acad Sci U S A. 2013 Sep 24;110(39):15644-9; Jinek et al., Elife. 2013;2:e00471; Pattanayak et al., Nat Biotechnol. 2013 Sep;31(9):839-43; Qi et al, Cell. 2013 Feb 28;152(5):1173-83; Wang et al., Cell. 2013 May 9;153(4):910-8; Auer et al., Genome Res. 2013 Oct 31; Chen et al., Nucleic Acids Res. 2013 Nov 1;41(20):e19; Cheng et al., Cell Res. 2013 Oct;23(10):1163-71; Cho et al., Genetics. 2013 Nov;195(3):1177-80; DiCarlo et al., Nucleic Acids Res. 2013 Apr;41(7):4336-43; Dickinson et al., Nat Methods. 2013 Oct;10(10):1028-34; Ebina et al., Sci Rep. 2013;3:2510; Fujii et. al, Nucleic Acids Res. 2013 Nov 1;41(20):e187; Hu et al., Cell Res. 2013 Nov;23(11):1322-5; Jiang et al., Nucleic Acids Res. 2013 Nov 1;41(20):e188; Larson et al., Nat Protoc. 2013 Nov;8(11):2180-96; Mali et. at., Nat Methods. 2013 Oct;10(10):957-63; Nakayama et al., Genesis. 2013 Dec;51(12):835-43; Ran et al., Nat Protoc. 2013 Nov;8(11):2281-308; Ran et al., Cell. 2013 Sep 12;154(6):1380-9; Upadhyay et al., G3 (Bethesda). 2013 Dec 9;3(12):2233-8; Walsh et al., Proc Natl Acad Sci U S A. 2013 Sep 24;110(39):15514-5; Xie et al., Mol Plant. 2013 Oct 9; Yang et al., Cell. 2013 Sep 12;154(6):1370-9; Briner et al., Mol Cell. 2014 Oct 23;56(2):333-9]; 및 미국 특허 및 특허 출원: 8,906,616; 8,895,308; 8,889,418; 8,889,356; 8,871,445; 8,865,406; 8,795,965; 8,771,945; 8,697,359; 20140068797; 20140170753; 20140179006; 20140179770; 20140186843; 20140186919; 20140186958; 20140189896; 20140227787; 20140234972; 20140242664; 20140242699; 20140242700; 20140242702; 20140248702; 20140256046; 20140273037; 20140273226; 20140273230; 20140273231; 20140273232; 20140273233; 20140273234; 20140273235; 20140287938; 20140295556; 20140295557; 20140298547; 20140304853; 20140309487; 20140310828; 20140310830; 20140315985; 20140335063; 20140335620; 20140342456; 20140342457; 20140342458; 20140349400; 20140349405; 20140356867; 20140356956; 20140356958; 20140356959; 20140357523; 20140357530; 20140364333; 및 20140377868을 참조하며; 이들 모두는 본 명세서에 그들의 전문이 참고로 편입된다.
용어 "활성체" 또는 "활성체 RNA"는 본 명세서에서 CasX 이중 가이드 RNA의 (그리고 따라서 "활성체" 및 "표적자"가, 예를 들어, 개재 뉴클레오타이드에 의해 함께 연결될 때, CasX 단일 가이드 RNA의) tracrRNA-유사 분자(tracrRNA: "전사 촉진성 CRISPR RNA"를 의미하기 위해 사용된다. 따라서, 예를 들어, CasX 가이드 RNA(dgRNA 또는 sgRNA)는 활성체 서열(예를 들어, tracrRNA 서열)을 포함한다. tracr 분자(tracrRNA)는 CRISPR RNA 분자(crRNA)와 혼성화하여 CasX 이중 가이드 RNA를 형성하는 천연 유래 분자이다. 용어 "활성체"는 본 명세서에서 천연 유래 tracrRNA를 포함할 뿐만 아니라, 변형(예를 들어, 절단, 연장, 서열 변화, 염기 변형, 골격 변형, 결합 변형 등)을 갖는 tracrRNA를 포함하기 위해 사용되며, 여기서, 활성체는 tracrRNA의 적어도 하나의 기능을 보유한다(예를 들어, CasX 단백질이 결합하는 dsRNA 듀플렉스에 기여한다). 일부 경우에, 활성체는 CasX 단백질과 상호작용할 수 있는 하나 이상의 줄기 루프를 제공한다. 활성체는 tracr 서열(tracrRNA 서열)을 갖는 것으로 언급될 수 있고, 일부 경우에, tracrRNA이지만, 용어 "활성체"는 천연 유래 tracrRNA로 제한되지 않는다.
일부 경우에(예를 들어, 일부 경우에 가이드 RNA가 단일 가이드 형식인 경우), 활성체-RNA는 대응하는 야생형 tracrRNA에 대해 절단된다(더 짧아진다). 일부 경우에(예를 들어, 일부 경우에 가이드 RNA가 단일 가이드 형식인 경우), 활성체-RNA는 대응하는 야생형 tracrRNA에 대해 절단되지(더 짧아지지) 않는다. 일부 경우에(예를 들어, 일붑 경우에 가이드 RNA가 단일 가이드 형식인 경우에) 활성체-RNA는 50 초과의 nt (예를 들어, 55 초과의 nt, 60 초과의 nt, 65 초과의 nt, 70 초과의 nt, 75 초과의 nt, 80 초과의 nt)인 길이를 가진다. 일부 경우에(예를 들어, 일부 경우에 가이드 RNA가 단일 가이드 형식인 경우) 활성체-RNA는 80 초과의 nt인 길이를 가진다. 일부 경우에(예를 들어, 일부 경우에 가이드 RNA가 단일 가이드 형식인 경우) 활성체-RNA는 51 내지 90 nt(예를 들어, 51-85, 51-84, 55-90, 55-85, 55-84, 60-90, 60-85, 60-84, 65-90, 65-85, 65-84, 70-90, 70-85, 70-84, 75-90, 75-85, 75-84, 80-90, 80-85 또는 80-84 nt) 범위의 길이를 가진다. 일부 경우에(예를 들어, 일부 경우에 가이드 RNA가 단일 가이드 형식인 경우) 활성체-RNA는 80 내지 90nt 범위의 길이를 가진다.
용어 "표적자" 또는 "표적자 RNA"는 본 명세서에서 CasX 이중 가이드 RNA의(따라서 "활성체" 및 "표적자"가, 예를 들어, 개재 뉴클레오타이드에 의해 함께 연결될 때, CasX 단일 가이드 RNA의) crRNA-유사 분자(crRNA: "CRISPR RNA")를 지칭하기 위해 사용된다. 따라서, 예를 들어, CasX 가이드 RNA(dgRNA 또는 sgRNA)는 가이드 서열 및 듀플렉스-형성 세그먼트(예를 들어, crRNA 반복부로서도 지칭될 수 있는 crRNA의 듀플렉스 형성 세그먼트)를 포함한다. 표적자의 표적화 세그먼트(표적 핵산의 표적 서열과 혼성화하는 세그먼트)의 서열은 요망되는 표적 핵산과 혼성화하기 위해 사용자에 의해 변형되기 때문에, 표적자의 서열은 종종 비천연 유래 서열일 것이다. 그러나, 활성체의 듀플렉스-형성 세그먼트와 혼성화하는 표적자의 듀플렉스-형성 세그먼트(본 명세서에서 더 상세하게 기재함)는 천연 유래 서열을 포함할 수 있다(예를 들어, crRNA 반복부로서도 지칭될 수 있는 천연 유래 crRNA의 듀플렉스-형성 세그먼트 서열을 포함할 수 있다). 따라서, 용어 표적자는 본 명세서에서 crRNA로부터의 천연 유래 서열을 포함한다는 사실에도 불구하고, 천연 유래 crRNA를 구별하기 위해 사용된다. 그러나, 용어 "표적자"는 천연 유래 crRNA를 포함한다.
상기 언급한 바와 같이, 표적자는 CasX 가이드 RNA의 가이드 서열과 CasX 가이드 RNA의 단백질-결합 세그먼트의 dsRNA 듀플렉스의 1/2을 형성하는 뉴클레오타이드의 신장부("듀플렉스-형성 세그먼트")를 둘 다 포함한다. 대응하는 tracrRNA-유사 분자(활성체)는 CasX 가이드 RNA의 단백질-결합 세그먼트의 dsRNA 듀플렉스의 다른 1/2을 형성하는 뉴클레오타이드의 신장부(듀플렉스-형성 세그먼트)를 포함한다. 다시 말해서, 표적자의 뉴클레오타이드의 신장부는 CasX 가이드 RNA의 단백질-결합 세그먼트의 dsRNA 듀플렉스를 형성하기 위해 활성체의 뉴클레오타이드의 신장부에 대해 상보성이며 이에 혼성화한다. 이렇게 해서, 각각의 표적자는 대응하는 활성체(표적자와 혼성화하는 영역을 가짐)를 갖도록 언급될 수 있다. 표적자 분자는 가이드 서열을 추가적으로 제공한다. 따라서, 표적자 및 활성체(대응하는 쌍으로서)는 CasX 가이드 RNA를 형성하기 위해 혼성화된다. 주어진 천연 유래 crRNA 또는 tracrRNA 분자의 특정 서열은 RNA 분자가 발견된 종의 특징일 수 있다. 적합한 활성체 및 표적자의 예가 본 명세서에 제공된다.
가이드 RNA 서열의 예
도 6 (이중 가이드 형식) 및 도 7 (이중 가이드 형식)
에 도시된 가이드 RNA는 CasX1에 대한 천연 좌위로부터 유래된다. 이하의 단란에서 논의되는 서열 및 이하의 작업 실시예에 기재하고 시험하는 서열에 대해, tracrRNA 및 crRNA 서열은 CasX1 좌위로부터 유래되었다. 가능한 표적자-RNA 및 활성체-RNA의 동일한 매개변수 및 세트가 예상되며, CasX1 좌위에 대한 서열을 CasX2 좌위의 서열과 비교하는 것으로부터 유래될 수 있다. 예를 들어, CasX1 tracrRNA 서열:

CasX3 좌위에 대해, tracr는 이들 230개의 nt 내일 가능성이 있다(상보성 영역을 밑줄 표시함):

마찬가지로, CasX1 crRNA
CCGAUAAGUAAAACGCAUCAAAGNNNNNNNNNNNNNNNNNNNN(Ns가 없는 서열번호 11, Ns가 있는 서열번호 61)은 CasX2 crRNA 서열 UCUCCGAUAAAUAAGAAGCAUCAAAGNNNNNNNNNNNNNNNNNNNN(Ns가 없는 서열번호 13, Ns가 있는 서열번호 69)과 비교될 수 있다.
CasX3 좌위로부터의 crRNA 반복부는 GTTTACACACTCCCTCTCATAGGGT(서열번호 54), GTTTACACACTCCCTCTCATGAGGT(서열번호 55), TTTTACATACCCCCTCTCATGGGAT(서열번호 56) 및 GTTTACACACTCCCTCTCATGGGGG(서열번호 57)이다. 따라서 crRNA 서열(예를 들어, CasX3 좌위)은
GUUUACACACUCCCUCUCAUAGGGUNNNNNNNNNNNNNNNNNNNN (Ns가 없는 서열번호 14, Ns가 있는 서열번호 31), GUUUACACACUCCCUCUCAUGAGGUNNNNNNNNNNNNNNNNNNNN (Ns가 없는 서열번호 15, Ns가 있는 서열번호 32), UUUUACAUACCCCCUCUCAUGGGAUNNNNNNNNNNNNNNNNNNNN (Ns가 없는 서열번호 16, Ns가 있는 서열번호 33) 및/또는 GUUUACACACUCCCUCUCAUGGGGGNNNNNNNNNNNNNNNNNNNN (Ns가 없는 서열번호 17, Ns가 있는 서열번호 34)를 포함할 수 있다.
예시적
표적자
-RNA(예를 들어,
crRNA
) 서열
일부 경우에, 표적자-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로)(예를 들어, 가이드 서열에 추가로) crRNA 서열 CCGAUAAGUAAAACGCAUCAAAG(서열번호 11)(예를 들어, 도 6, 패널 c의 sgRNA 참조)를 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) crRNA 서열 CCGAUAAGUAAAACGCAUCAAAG(서열번호 11)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 표적자-RNA는 (예를 들어, 가이드 서열에 추가로) crRNA 서열 AUUUGAAGGUAUCUCCGAUAAGUAAAACGCAUCAAAG(서열번호 12)을 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) crRNA 서열 AUUUGAAGGUAUCUCCGAUAAGUAAAACGCAUCAAAG(서열번호 12)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 표적자-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로)(예를 들어, 가이드 서열에 추가로) crRNA 서열 UCUCCGAUAAAUAAGAAGCAUCAAAG(서열번호 13)를 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) crRNA 서열 UCUCCGAUAAAUAAGAAGCAUCAAAG(서열번호 13)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 표적자-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로)(예를 들어, 가이드 서열에 추가로) crRNA 서열 GUUUACACACUCCCUCUCAUAGGGU(서열번호 14)를 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) crRNA 서열 GUUUACACACUCCCUCUCAUAGGGU(서열번호 14)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 표적자-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로)(예를 들어, 가이드 서열에 추가로) crRNA 서열 GUUUACACACUCCCUCUCAUGAGGU(서열번호 15)를 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) crRNA 서열 GUUUACACACUCCCUCUCAUGAGGU(서열번호 15)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 표적자-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로)(예를 들어, 가이드 서열에 추가로) crRNA 서열 UUUUACAUACCCCCUCUCAUGGGAU(서열번호 16)를 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) crRNA 서열 UUUUACAUACCCCCUCUCAUGGGAU(서열번호 16)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 표적자-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로)(예를 들어, 가이드 서열에 추가로) crRNA 서열 GUUUACACACUCCCUCUCAUGGGGG(서열번호 17)를 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) crRNA 서열 GUUUACACACUCCCUCUCAUGGGGG(서열번호 17)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 표적자-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로)(예를 들어, 가이드 서열에 추가로) 서열번호 11 및 13 중 임의의 하나에 제시된 crRNA 서열을 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) 서열번호 11 및 13 중 임의의 하나에 제시된 crRNA 서열과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 표적자-RNA는 (예를 들어, 가이드 서열에 추가로) 서열번호 11 내지 13 중 임의의 하나에 제시된 crRNA 서열을 포함한다. 일부 경우에, 표적자-RNA는 서열번호 11 내지 13 중 임의의 하나에 제시된 crRNA 서열 crRNA 서열과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 표적자-RNA는 (예를 들어, 가이드 서열에 추가로) 서열번호 14 내지 17 중 임의의 하나에 제시된 crRNA 서열을 포함한다. 일부 경우에, 표적자-RNA는 서열번호 14 내지 17 중 임의의 하나에 제시된 crRNA 서열 crRNA 서열과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 표적자-RNA는 (예를 들어, 가이드 서열에 추가로) 서열번호 11 내지 17 중 임의의 하나에 제시된 crRNA 서열을 포함한다. 일부 경우에, 표적자-RNA는 서열번호 11 내지 17 중 임의의 하나에 제시된 crRNA 서열 crRNA 서열과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
예시적인 활성체-RNA(예를 들어,
tracrRNA
) 서열
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 ACAUCUGGCGCGUUUAUUCCAUUACUUUGGAGCCAGUCCCAGCGACUAUGUCGUAUGGACGAAGCGCUUAUUUAUCGGAGA(서열번호 21)을 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 ACAUCUGGCGCGUUUAUUCCAUUACUUUGGAGCCAGUCCCAGCGACUAUGUCGUAUGGACGAAGCGCUUAUUUAUCGGAGA(서열번호 21)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 ACAUCUGGCGCGUUUAUUCCAUUACUUUGGAGCCAGUCCCAGCGACUAUGUCGUAUGGACGAAGCGCUUAUUUAUCGG(서열번호 22)을 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 ACAUCUGGCGCGUUUAUUCCAUUACUUUGGAGCCAGUCCCAGCGACUAUGUCGUAUGGACGAAGCGCUUAUUUAUCGG(서열번호 22)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 UUAUUCCAUUACUUUGGAGCCAGUCCCAGCGACUAUGUCGUAUGGACGAAGCGCUUAUUUAUCGG(서열번호 23)을 포함한다(예를 들어, 도 6의 sgRNA를 참조). 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 UUAUUCCAUUACUUUGGAGCCAGUCCCAGCGACUAUGUCGUAUGGACGAAGCGCUUAUUUAUCGG(서열번호 23)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 AAGUAGUAAAUUACAUCUGGCGCGUUUAUUCCAUUACUUUGGAGCCAGUCCCAGCGACUAUGUCGUAUGGACGAAGCGCUUAUUUAUCGGAGA(서열번호 24)을 포함한다(예를 들어, 도 6의 sgRNA를 참조). 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 AAGUAGUAAAUUACAUCUGGCGCGUUUAUUCCAUUACUUUGGAGCCAGUCCCAGCGACUAUGUCGUAUGGACGAAGCGCUUAUUUAUCGGAGA(서열번호 24)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 UUAUUCCAUUACUUUGGAGCCAGUCCCAGCGACUAUGUCGUAUGGACGAAGCGCUUAUUUAUCGGAGA(서열번호 25)을 포함한다(예를 들어, 도 6의 sgRNA를 참조). 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 UUAUUCCAUUACUUUGGAGCCAGUCCCAGCGACUAUGUCGUAUGGACGAAGCGCUUAUUUAUCGGAGA(서열번호 25)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 UUAUCUCAUUACUUUGAGAGCCAUCACCAGCGACUAUGUCGUAUGGGUAAAGCGCUUAUUUAUCGGAGA(서열번호 26)을 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 UUAUCUCAUUACUUUGAGAGCCAUCACCAGCGACUAUGUCGUAUGGGUAAAGCGCUUAUUUAUCGGAGA(서열번호 26)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 UUAUCUCAUUACUUUGAGAGCCAUCACCAGCGACUAUGUCGUAUGGGUAAAGCGCUUAUUUAUCGG(서열번호 27)을 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 UUAUCUCAUUACUUUGAGAGCCAUCACCAGCGACUAUGUCGUAUGGGUAAAGCGCUUAUUUAUCGG(서열번호 27)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식에서) 다음의 서열 내로부터 tracrRNA 서열을 포함한다: UAAAUUUUUUGAGCCCUAUCUCCGCGAGGAAGACAGGGCUCUUUUCAUGAGAGGAAGCUUUUAUACCCGACCGGUAAUCCGGUCGGGGGAUUGGCCGUUGAAACGAUUUUAAAGCGGCCAAUGGGCCCCUCUAUAUGGAUACUACUUAUAUAAGGAGCUUGGGGAAGAAGAUAGCUUAAUCCCGCUAUCUUGUCAAGGGGUUGGGGGAGUAUCAGUAUCCGGCAGGCGCC(서열번호 28). 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 UAAAUUUUUUGAGCCCUAUCUCCGCGAGGAAGACAGGGCUCUUUUCAUGAGAGGAAGCUUUUAUACCCGACCGGUAAUCCGGUCGGGGGAUUGGCCGUUGAAACGAUUUUAAAGCGGCCAAUGGGCCCCUCUAUAUGGAUACUACUUAUAUAAGGAGCUUGGGGAAGAAGAUAGCUUAAUCCCGCUAUCUUGUCAAGGGGUUGGGGGAGUAUCAGUAUCCGGCAGGCGCC(서열번호 28)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) 서열번호 21 내지 27 중 임의의 하나에 제시된 tracrRNA를 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) 서열번호 21 및 27 중 임의의 하나에 제시된 tracrRNA 서열과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) 서열번호 21 내지 27 중 임의의 하나에 제시된 tracrRNA를 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) 서열번호 21 및 28 중 임의의 하나에 제시된 tracrRNA 서열과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, CasX 단일 가이드 RNA는 서열 UUAUUCCAUUACUUUGGAGCCAGUCCCAGCGACUAUGUCGUAUGGACGAAGCGCUUAUUUAUCGGgaaaCCGAUAAGUAAAACGCAUCAAAG(서열번호 41)을 포함한다. 일부 경우에, 표적자-RNA는 tracrRNA 서열 UUAUUCCAUUACUUUGGAGCCAGUCCCAGCGACUAUGUCGUAUGGACGAAGCGCUUAUUUAUCGGgaaaCCGAUAAGUAAAACGCAUCAAAG(서열번호 41)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, CasX 단일 가이드 RNA는 서열 ACAUCUGGCGCGUUUAUUCCAUUACUUUGGAGCCAGUCCCAGCGACUAUGUCGUAUGGACGAAGCGCUUAUUUAUCGGAGAgaaaCCGAUAAGUAAAACGCAUCAAAG(서열번호 42)을 포함한다. 일부 경우에, 표적자-RNA는 tracrRNA 서열 ACAUCUGGCGCGUUUAUUCCAUUACUUUGGAGCCAGUCCCAGCGACUAUGUCGUAUGGACGAAGCGCUUAUUUAUCGGAGAgaaaCCGAUAAGUAAAACGCAUCAAAG(서열번호 42)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, CasX 단일 가이드 RNA는 서열 UUAUCUCAUUACUUUGAGAGCCAUCACCAGCGACUAUGUCGUAUGGGUAAAGCGCUUAUUUAUCGGgaaaUCUCCGAUAAAUAAGAAGCAUCAAAG(서열번호 43)을 포함한다. 일부 경우에, 표적자-RNA는 tracrRNA 서열 UUAUCUCAUUACUUUGAGAGCCAUCACCAGCGACUAUGUCGUAUGGGUAAAGCGCUUAUUUAUCGGgaaaUCUCCGAUAAAUAAGAAGCAUCAAAG(서열번호 43)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, CasX 단일 가이드 RNA는 서열번호 41 내지 43 중 임의의 하나에 제시된 서열을 포함한다. 일부 경우에, 표적자-RNA는 서열번호 41 내지 43 중 임의의 하나에 제시된 tracrRNA 서열과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
CasX
시스템
본 개시내용은 CasX 시스템을 개시한다. 본 개시내용의 CasX 시스템은 a) 본 개시내용의 CasX 폴리펩타이드 및 CasX 가이드 RNA; b) 본 개시내용의 CasX 폴리펩타이드, CasX 가이드 RNA, 및 공여자 주형 핵산; c) 본 개시내용의 CasX 융합 폴리펩타이드 및 CasX 가이드 RNA; d) 본 개시내용의 CasX 융합 폴리펩타이드, CasX 가이드 RNA, 및 공여자 주형 핵산; e) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 mRNA; 및 CasX 가이드 RNA; f) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 mRNA, CasX 가이드 RNA, 및 공여자 주형 핵산; g) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 mRNA; 및 CasX 가이드 RNA; h) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 mRNA, CasX 가이드 RNA, 및 공여자 주형 핵산; i) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; j) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 공여자 주형 핵산을 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; k) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; l) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 공여자 주형 핵산을 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; m) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; n) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; 및 공여자 주형 핵산; o) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; p) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; 및 공여자 주형 핵산; q) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, 제1 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 제2 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; 또는 r) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, 제1 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 제2 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; 또는 (a) 내지 (r) 중 하나의 일부 변형을 포함할 수 있다.
핵산
본 개시내용은 공여자 폴리뉴클레오타이드 서열, CasX 폴리펩타이드(예를 들어, 야생형 CasX 단백질, 틈내기효소 CasX 단백질, dCasX 단백질, 키메라 CasX 단백질 등)을 암호화하는 뉴클레오타이드 서열, CasX 가이드 RNA, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열(이는 이중 가이드 RNA 형식의 경우에 2개의 별개의 뉴클레오타이드 서열을 포함하거나 또는 단일 가이드 RNA 형식의 경우에 단일 뉴클레오타이드 서열을 포함할 수 있음) 중 하나 이상의 포함하는 하나 이상의 핵산을 제공한다. 본 개시내용은 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산을 제공한다. 본 개시내용은 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터를 제공한다. 본 개시내용은 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터를 제공한다. 본 개시내용은 a) CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; 및 b) CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열(들)을 포함하는, 재조합 발현 벡터를 제공한다. 본 개시내용은 a) CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; 및 b) CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열(들)을 포함하는, 재조합 발현 벡터를 제공한다. 일부 경우에, CasX 단백질을 암호화하는 뉴클레오타이드 서열 및/또는 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열은 선택 세포 유형(예를 들어, 원핵 세포, 진핵 세포, 식물 세포, 동물 세포, 포유류 세포, 영장류 세포, 설치류 세포, 인간 세포 등)에서 작동 가능한 프로모터에 작동 가능하게 연결된다.
일부 경우에, 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열은 코돈 최적화된다. 이런 최적화 유형은 의도된 숙주 유기체 또는 세포의 코돈 선호도를 모방하는 한편, 동일한 단백질을 암호화하는 CasX-암호화 뉴클레오타이드 서열의 돌연변이를 수반한다. 따라서, 코돈은 변할 수 있지만, 암호화된 단백질은 변하지 않고 남아있다. 예를 들어, 의도된 표적 세포가 인간 세포라면, 인간 코돈 최적화된 CasX-암호화 뉴클레오타이드 서열이 사용될 수 있었다. 다른 비제한적 예로서, 의도된 숙주 세포가 마우스 세포였다면, 마우스 코돈-최적화된 CasX-암호화 뉴클레오타이드 서열이 생성될 수 있었다. 다른 비제한적 예로서, 의도된 숙주 세포가 식물 세포였다면, 식물 코돈-최적화된 CasX-암호화 뉴클레오타이드 서열이 생성될 수 있었다. 다른 비제한적 예로서, 의도된 숙주 세포가 곤충 세포였다면, 곤충 코돈-최적화된 CasX-암호화 뉴클레오타이드 서열이 생성될 수 있었다.
본 개시내용은 (일부 경우에 상이한 재조합 발현 벡터에서, 그리고 일부 경우에 동일한 재조합 발현 벡터에서): (i) 공여자 주형 핵산의 뉴클레오타이드 서열(공여자 주형이 표적 핵산(예를 들어, 표적 게놈)의 표적 서열에 대해 상동성을 갖는 뉴클레오타이드 서열을 포함하는 경우); (ii) 표적화된 게놈의 표적 좌위의 표적 서열에 혼성화되는 CasX 가이드 RNA(예를 들어, 단일 또는 이중 가이드 RNA)를 암호화하는 뉴클레오타이드 서열(예를 들어, 표적 세포, 예컨대 진핵 세포에서 작동 가능한 프로모터에 작동 가능하게 연결됨); 및 (iii) CasX 단백질을 암호화하는 뉴클레오타이드 서열(예를 들어, 표적 세포, 예컨대 진핵 세포에서 작동 가능한 프로모터에 작동 가능하게 연결됨)을 포함하는 하나 이상의 재조합 발현 벡터를 제공한다. 본 개시내용은 (일부 경우에 상이한 재조합 발현 벡터에서, 그리고 일부 경우에 동일한 재조합 발현 벡터에서): (i) 공여자 주형 핵산의 뉴클레오타이드 서열(공여자 주형이 표적 핵산(예를 들어, 표적 게놈)의 표적 서열에 대해 상동성을 갖는 뉴클레오타이드 서열을 포함하는 경우); 및 (ii) 표적화된 게놈의 표적 좌위의 표적 서열에 혼성화되는 CasX 가이드 RNA(예를 들어, 단일 또는 이중 가이드 RNA)를 암호화하는 뉴클레오타이드 서열(예를 들어, 표적 세포, 예컨대 진핵 세포에서 작동 가능한 프로모터에 작동 가능하게 연결됨)을 포함하는 하나 이상의 재조합 발현 벡터를 제공한다. 본 개시내용은 (일부 경우에 상이한 재조합 발현 벡터에서, 그리고 일부 경우에 동일한 재조합 발현 벡터에서): (i) 표적화된 게놈의 표적 좌위의 표적 서열에 혼성화되는 CasX 가이드 RNA(예를 들어, 단일 또는 이중 가이드 RNA)를 암호화하는 뉴클레오타이드 서열(예를 들어, 표적 세포, 예컨대 진핵 세포에서 작동 가능한 프로모터에 작동 가능하게 연결됨); 및 (ii) CasX 단백질을 암호화하는 뉴클레오타이드 서열(예를 들어, 표적 세포, 예컨대 진핵 세포에서 작동 가능한 프로모터에 작동 가능하게 연결됨)을 포함하는 하나 이상의 재조합 발현 벡터를 제공한다.
적합한 발현 벡터는 바이러스 발현 벡터(예를 들어, 백시니아 바이러스; 폴리오 바이러스; 아데노바이러스에 기반한 바이러스 벡터(예를 들어, 문헌[Li et al., Invest Opthalmol Vis Sci 35:2543 2549, 1994; Borras et al., Gene Ther 6:515 524, 1999; Li and Davidson, PNAS 92:7700 7704, 1995; Sakamoto et al., H Gene Ther 5:1088 1097, 1999]; WO 94/12649, WO 93/03769; WO 93/19191; WO 94/28938; WO 95/11984 및 WO 95/00655); 아데노-연관 바이러스(AAV)(예를 들어, 문헌[Ali et al., Hum Gene Ther 9:81 86, 1998, Flannery et al., PNAS 94:6916 6921, 1997; Bennett et al., Invest Opthalmol Vis Sci 38:2857 2863, 1997; Jomary et al., Gene Ther 4:683 690, 1997, Rolling et al., Hum Gene Ther 10:641 648, 1999; Ali et al., Hum Mol Genet 5:591 594, 1996; Srivastava in WO 93/09239, Samulski et al., J. Vir. (1989) 63:3822-3828; Mendelson et al., Virol. (1988) 166:154-165; 및 Flotte et al., PNAS (1993) 90:10613-10617] 참조); SV40; 단순포진 바이러스; 인간 면역결핍 바이러스(예를 들어, 문헌[Miyoshi et al., PNAS 94:10319 23, 1997; Takahashi et al., J Virol 73:7812 7816, 1999]); 레트로바이러스 벡터(예를 들어, 뮤린 백혈병 바이러스, 비장 괴사 바이러스, 및 레트로바이러스, 예컨대 라우스 육종 바이러스, 하비 육종 바이러스, 조류 백혈병 바이러스, 렌티바이러스, 인간 면역결핍 바이러스, 골수증식성 육종 바이러스 및 유방암 바이러스로부터 유래된 벡터); 등을 포함한다. 일부 경우에, 본 개시내용의 재조합 발현 벡터는 재조합 아데노-연관 바이러스(AAV) 벡터이다. 일부 경우에, 본 개시내용의 재조합 발현 벡터는 재조합 렌티바이러스 벡터이다. 일부 경우에, 본 개시내용의 재조합 발현 벡터는 재조합 레트로바이러스 벡터이다.
이용되는 숙주/벡터 시스템에 따라서, 다수의 적합한 전사 및 번역 제어 요소(구성적 및 유도성 프로모터, 전사 인핸서 요소, 전사 종결자 등을 포함)가 발현 벡터에서 사용될 수 있다.
일부 실시형태에서, CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열은 제어 요소, 예를 들어, 전사 제어 요소, 예컨대 프로모터에 작동 가능하게 연결된다. 일부 실시형태에서, CasX 단백질 또는 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열은 제어 요소, 예를 들어, 전사 제어 요소, 예컨대 프로모터에 작동 가능하게 연결된다.
전사 제어 요소는 프로모터일 수 있다. 일부 경우에, 프로모터는 구성적으로 활성인 프로모터이다. 일부 경우에, 프로모터는 조절 가능한 프로모터이다. 일부 경우에, 프로모터는 유도성 프로모터이다. 일부 경우에, 프로모터는 조직-특이적 프로모터이다. 일부 경우에, 프로모터는 세포 유형-특이적 프로모터이다. 일부 경우에, 전사 제어 요소(예를 들어, 프로모터)는 표적화된 세포 유형 또는 표적화된 세포 집단에서 기능성이다. 예를 들어, 일부 경우에, 전사 제어 요소는 진핵 세포, 예를 들어, 조혈모세포(예를 들어, 이동 말초 혈액(mobilized peripheral blood: mPB) CD34(+) 세포, 골수(BM) CD34(+) 세포 등)에서 기능성일 수 있다.
진핵 프로모터(진핵 세포에서 프로모터 기능성)인 비제한적 예는 EF1α, 거대세포바이러스(CMV) 급초기, 단순포진 바이러스(HSV) 티미딘 키나제, 초기 및 후기 SV40, 레트로바이러스로부터의 긴 말단 반복부(LTR) 및 마우스 메탈로티오네인-I로부터의 프로모터를 포함한다. 적절한 벡터 및 프로모터의 선택은 당업자 수준 내에서 매우 용이하다. 발현 벡터는 또한 번역 개시 및 전사 종결자에 대한 리보솜 결합 부위를 함유할 수 있다. 발현 벡터는 또한 발현을 증폭시키기 위한 적절한 서열을 포함할 수 있다. 발현 벡터는 또한 CasX 단백질에 융합되어, 키메라 CasX 폴리펩타이드를 생성할 수 있는 단백질 태그(예를 들어, 6xHis 태그, 혈구응집소 태그, 형광 단백질 등)를 암호화하는 뉴클레오타이드 서열을 포함할 수 있다.
일부 실시형태에서, CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열 및/또는 CasX 융합 폴리펩타이드는 유도성 프로모터에 작동 가능하게 연결된다. 일부 실시형태에서, CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열 및/또는 CasX 융합 단백질은 구성적 프로모터에 작동 가능하게 연결된다.
프로모터는 구성적으로 활성인 프로모터(즉, 구성적으로 활성인/"온(ON)" 상태인 프로모터)일 수 있고, 유도성 프로모터(즉, 상태가 활성/"온" 또는 비활성/"오프"인 프로모터, 외부 자극, 예를 들어, 특정 온도, 화합물 또는 단백질의 존재에 의해 제어됨)일 수 있으며, 공간적으로 제한된 프로모터(즉, 전사 제어 요소, 인핸서 등)(예를 들어, 조직 특이적 프로모터, 세포 유형 특이적 프로모터 등)일 수 있고, 그리고 일시적으로 제한된 프로모터일 수 있다(즉, 프로모터는 배아 발생의 특정 단계 동안에 또는 생물학적 과정(예를 들어, 마우스에서의 모낭 주기)의 특정 단계 동안에 "온" 상태 또는 "오프" 상태이다.
적합한 프로모터는 바이러스로부터 유래될 수 있고, 따라서 바이러스 프로모터로서 지칭될 수 있거나, 또는 그들은 원핵 또는 진핵 유기체를 포함하는 임의의 유기체로부터 유래될 수 있다. 적합한 프로모터는 임의의 RNA 중합효소(예를 들어, pol I, pol II, pol III)에 의해 발현을 유도하는 데 사용될 수 있다. 예시적인 프로모터는 SV40 초기 프로모터, 마우스 유방 종양 바이러스 긴 말단 반복부(LTR) 프로모터; 아데노바이러스 주요 후기 프로모터(Ad MLP); 단순포진 바이러스(HSV) 프로모터, 거대세포바이러스(CMV) 프로모터, 예컨대 CMV 급초기 프로모터 영역(CMVIE), 라우스 육종 바이러스(RSV) 프로모터, 인간 U6 소핵 프로모터(U6)(Miyagishi et al., Nature Biotechnology 20, 497 - 500 (2002)), 증강된 U6 프로모터(예를 들어, Xia et al., Nucleic Acids Res. 2003 Sep 1;31(17)), 인간 H1 프로모터(H1) 등을 포함하지만, 이들로 제한되지 않는다.
일부 경우에, CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열은 진핵 세포에서 작동 가능한 프로모터(예를 들어, U6 프로모터, 증강된 U6 프로모터, H1 프로모터 등)(의 제어 하에서) 작동 가능하게 연결된다. 당업자에 의해 이해될 바와 같이, U6 프로모터(예를 들어, 진핵 세포에서), 또는 다른 PolIII 프로모터를 이용하여 핵산(예를 들어, 발현 벡터)로부터 RNA(예를 들어, 가이드 RNA)를 발현시킬 때, 행에 몇 개의 T이 있다면(RNA에서 U에 대한 암호) RNA는 돌연변이될 필요가 있을 수 있다. 이는 DNA 내 T(예를 들어, 5개의 T)의 문자열이 중합효소 III(PolIII)에 대한 종결자로서 작용할 수 있기 때문이다. 따라서, 진핵 세포 내 가이드 RNA(예를 들어, 이중 가이드 또는 단일 가이드 형식에서 활성체 부분 및/또는 표적자 부분)의 전사를 보장하기 위해, 때때로 T의 실행을 제거하는 가이드 RNA를 암호화하는 서열을 변형할 필요가 있을 수 있다. 일부 경우에, CasX 단백질(예를 들어, 야생형 CasX 단백질, 틈내기효소 CasX 단백질, dCasX 단백질, 키메라 CasX 단백질 등)을 암호화하는 뉴클레오타이드 서열은 진핵 세포에서 작동 가능한 프로모터(예를 들어, CMV 프로모터, EF1α 프로모터, 에스트로겐 수용체-조절 프로모터 등)에 작동 가능하게 연결된다.
유도성 프로모터의 예는 T7 RNA 중합효소 프로모터, T3 RNA 중합효소 프로모터, 아이소프로필-베타-D-티오갈락토피라노사이드(IPTG)-조절된 프로모터, 락토스 유도된 프로모터, 열 충격 프로모터, 테트라사이클린-조절 프로모터, 스테로이드-조절 프로모터, 금속-조절 프로모터, 에스트로겐 수용체-조절 프로모터 등을 포함하지만, 이들로 제한되지 않는다. 따라서 유도성 프로모터는 독시사이클린; 에스트로겐 및/또는 에스트로겐 유사체; IPTG 등을 포함하지만, 이들로 제한되지 않는 분자에 의해 조절될 수 있다.
사용에 적합한 유도성 프로모터는 본 명세서에 기재되거나 또는 당업자에게 공지된 임의의 유도성 프로모터를 포함한다. 유도성 프로모터의 예는 화학적으로/생화학적으로-조절된 그리고 물리적으로 조절된 프로모터, 예컨대 알코올-조절된 프로모터, 테트라사이클린-조절된 프로모터 (예를 들어, 테트라사이클린 리프레서 단백질(tetR), 테트라사이클린 오퍼레이터 서열(tetO) 및 테트라사이클린 트랜스작용인자 융합 단백질(tTA)을 포함하는, 안하이드로테트라사이클린 (aTc)-반응성 프로모터 및 다른 테트라사이클린-반응성 프로모터 시스템), 스테로이드-조절된 프로모터(예를 들어, 래트 글루코코르티코이드 수용체에 기반한 프로모터, 인간 에스트로겐 수용체, 나방 엑디손 수용체, 및 스테로이드/레티노이드/갑상선 수용체 슈퍼패밀리로부터의 프로모터), 금속-조절된 프로모터(예를 들어, 효모, 마우스 및 인간으로부터의 메탈로티오네인으로부터 유래된 프로모터(금속 이온에 결합하고 격리시키는 단백질) 유전자), 발병-조절된 프로모터(예를 들어, 살리실산, 에틸렌 또는 벤조티아다이아졸(BTH)에 의해 유도), 온도/열-유도성 프로모터(예를 들어, 열 충격 프로모터), 및 광-조절된 프로모터(예를 들어, 식물 세포로부터의 광 반응성 프로모터)를 포함하지만, 이들로 제한되지 않는다.
일부 경우에, 다세포 유기체에서, 프로모터가 특정 세포의 서브세트에서 활성(즉, "온")이 되도록 프로모터는 공간적으로 제한된 프로모터(즉, 세포 유형 특이적 프로모터, 조직 특이적 프로모터 등)이다. 공간적으로 제한된 프로모터는 또한 인핸서, 전사 제어 요소, 제어 서열 등으로서 지칭될 수 있다. 프로모터가 표적화된 숙주 세포(예를 들어, 진핵 세포; 원핵 세포)에서 기능성이라면, 임의의 편리한 공간적으로 제한된 프로모터가 사용될 수 있다.
일부 경우에, 프로모터는 가역적 프로모터이다. 가역적 유도성 프로모터를 포함하는 적합한 가역적 프로모터는 당업계에 공지되어 있다. 이러한 가역적 프로모터는 다수의 유기체, 예컨대 진핵생물 및 원핵생물로부터 단리 및 유래될 수 있다. 제2 유기체, 예를 들어, 제1 원핵생물 및 제2 진핵생물, 제1 진핵생물 및 제2 원핵생물에서 사용하기 위한 제1 유기체로부터 유래된 가역적 프로모터의 변형은 당업계에 잘 공지되어 있다. 이러한 가역적 프로모터, 및 이러한 가역적 프로모터에 기반할 뿐만 아니라 추가적인 제어 단백질을 포함하는 시스템은 알코올 조절된 프로모터(예를 들어, 알코올 탈수소효소 I(alcA) 유전자 프로모터, 알코올 트랜스작용인자 단백질(AlcR)에 반응성인 프로모터 등), 테트라사이클린 조절된 프로모터, (예를 들어, 테트라사이클린활성체(TetActivator), 테트라사이클린온(TetON), 테트라사이클린오프(TetOFF) 등을 포함하는 프로모터 시스템), 스테로이드 조절된 프로모터(예를 들어, 래트 글루코코르티코이드 수용체 프로모터 시스템, 인간 에스트로겐 수용체 프로모터 시스템, 레티노이드 프로모터 시스템, 갑상선 프로모터 시스템, 엑디손 프로모터 시스템, 미페프리스톤 프로모터 시스템 등), 금속 조절된 프로모터(예를 들어, 메탈로티오네인 프로모터 시스템 등), 발병-관련 조절 프로모터(예를 들어, 살리실산 조절 프로모터, 에틸렌 조절 프로모터, 벤조티아다이아졸 조절 프로모터 등), 온도 조절 프로모터(예를 들어, 열 충격 유도성 프로모터(예를 들어, HSP-70, HSP-90, 대두 열 충격 프로모터 등), 광 조절 프로모터, 합성 유도성 프로모터 등을 포함하지만, 이들로 제한되지 않는다.
핵산(예를 들어, 공여자 폴리뉴클레오타이드 서열을 포함하는 핵산, CasX 단백질 및/또는 CasX 가이드 RNA를 암호화하는 하나 이상의 핵산 등)을 숙주 세포 내로 도입하는 방법은 당업계에 공지되어 있고, 핵산(예를 들어, 발현 작제물)을 세포 내로 도입하기 위해 임의의 편리한 방법이 사용될 수 있다. 적합한 방법은, 예를 들어, 바이러스 감염, 형질감염, 리포펙션, 전기천공법, 인산칼슘 침전, 폴리에틸렌이민(PEI)-매개 형질감염, DEAE-덱스트란 매개 형질감염, 리포좀-매개 형질감염, 입자총 기법, 인산칼슘 침전, 직접 미량주사법, 나노입자-매개 핵산 전달 등을 포함한다.
재조합 발현 벡터를 세포 내로 도입하는 것은 임의의 배양 배지에서 그리고 세포 생존을 촉진시키는 임의의 배양 조건 하에 생길 수 있다. 표적 세포 내로 재조합 발현 벡터를 도입하는 것은 생체내 또는 생체외에서 수행될 수 있다. 표적 세포 내로 재조합 발현 벡터를 도입하는 것은 시험관외에서 수행될 수 있다.
일부 실시형태에서, CasX 단백질은 RNA로서 제공될 수 있다. RNA는 직접 화학 합성에 의해 제공될 수 있거나 또는 DNA(예를 들어, CasX 단백질을 암호화)로부터 시험관외에서 전사될 수 있다. 일단 합성되면, RNA는 핵산을 세포 내로 도입하기 위한 임의의 잘 공지된 기법(예를 들어, 미량주사법, 전기천공법, 형질감염 등)에 의해 세포 내로 도입될 수 있다.
핵산은 잘 개발된 형질감염 기법(예를 들어, 문헌[Angel and Yanik (2010) PLoS ONE 5(7): e11756] 참조), 및 퀴아젠사(Qiagen)로부터의 상업적으로 입수 가능한 TransMessenger(등록상표) 시약, 스템젠트사(Stemgent)로부터의 Stemfect(상표명) RNA 형질감염 키트, 및 미루스 바이오 엘엘씨(Mirus Bio LLC)로부터의 TransIT(등록상표)-mRNA 형질감염 키트를 이용하여 세포에 제공될 수 있다. 또한 문헌[Beumer et al. (2008) PNAS 105(50):19821-19826] 참조.
벡터는 표적 숙주 세포에 직접 제공될 수 있다. 다시 말해서, 벡터가 세포에 의해 취해지도록, 세포는 대상 핵산을 포함하는 벡터(예를 들어, 공여자 주형 서열을 갖고 CasX 가이드 RNA를 암호화하는 재조합 발현 벡터; CasX 단백질을 암호화하는 재조합 발현 벡터 등)와 접촉된다. 세포를 플라스미드인 핵산 벡터와 접촉시키는 방법은 당업계에 잘 공지되어 있는 전기천공법, 염화칼슘 형질감염, 미량주사법, 및 리포펙션을 포함한다. 바이러스 벡터 전달을 위해, 세포는 대상 바이러스 발현 벡터를 포함하는 바이러스 입자와 접촉될 수 있다.
레트로바이러스, 예를 들어, 렌티바이러스는 본 개시내용의 방법에서 사용하기에 적합하다. 통상적으로 사용되는 레트로바이러스 벡터는 "결함성"이며, 즉, 증식성 감염에 필요한 바이러스 단백질을 생성할 수 없다. 오히려, 벡터의 복제는 패키징 세포주에서의 성장을 필요로 한다. 관심 대상을 포함하는 바이러스 입자를 생성하기 위해, 핵산을 포함하는 레트로바이러스 핵산은 패키징 세포주에 의해 바이러스 캡시드 내로 패키징된다. 상이한 패키징 세포주는캡시드 내로 혼입될 상이한 외피 단백질(동종숙주성(ecotropic), 양쪽성 또는 이종향성(xenotropic))을 제공하는데, 이 외피 단백질은 세포에 대한 바이러스 입자의 특이성(뮤린 및 래트에 대한 동종숙주; 인간, 개 및 마우스를 포함하는 대부분의 포유류 세포 유형에 대해 양쪽성; 및 뮤린 세포를 제외한 대부분의 포유류 세포에 대해 이종향성)을 결정한다. 적절한 패키징 세포주를 사용하여 세포가 패키징된 바이러스 입자에 의해 표적화되는 것을 보장할 수 있다. 대상 벡터 발현 벡터를 패키징 세포주에 도입하고 패키징 세포주에 의해 생성된 바이러스 입자를 수집하는 방법은 당업계에 잘 공지되어 있다. 핵산은 또한 직접 미량주사법(예를 들어, RNA의 주사)에 의해 도입될 수 있다.
CasX 가이드 RNA 및/또는 CasX 폴리펩타이드를 암호화하는 핵산을 표적 숙주 세포에 제공하기 위해 사용되는 벡터는 발현을 유도하기 위한, 즉, 관심 대상의 핵산의 전사 활성화를 위한 적합한 프로모터를 포함할 수 있다. 다시 말해서, 일부 경우에, 관심 대상의 핵산은 프로모터에 작동 가능하게 연결될 것이다. 이는 편재하는 작용 프로모터, 예를 들어, CMV-β-액틴 프로모터, 또는 유도성 프로모터, 예컨대 특정 세포 집단에서 활성이거나 또는 테트라사이클린과 같은 약물의 존재에 반응하는 프로모터를 포함할 수 있다. 전사 활성화에 의해, 전사는 10배, 100배만큼, 더 보통으로는 1000배만큼 표적 세포에서 기준 수준 초과로 증가될 것이 의도된다. 추가로, CasX 가이드 RNA 및/또는 CasX 단백질을 암호화하는 핵산을 세포에 제공하기 위해 사용되는 벡터는 CasX 가이드 RNA 및/또는 CasX 단백질을 취한 세포를 동정하기 위해 표적 세포에서 선택 가능한 마커를 암호화하는 핵산 서열을 포함할 수 있다.
CasX 폴리펩타이드, 또는 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산은 일부 경우에 RNA이다. 따라서, CasX 융합 단백질은 RNA로서 세포 내로 도입될 수 있다. 세포 내로 RNA를 도입하는 방법은 당업계에 공지되어 있고, 예를 들어, 직접 미량주사법, 형질감염, 또는 DNA의 도입을 위해 사용되는 임의의 다른 방법을 포함할 수 있다. CasX 단백질은 대신에 폴리펩타이드로서 세포에 제공될 수 있다. 이러한 폴리펩타이드는 생성물의 용해도를 증가시키는 폴리펩타이드에 선택적으로 융합될 수 있다. 도메인은 정해진 프로테아제 절단 부위, 예를 들어, TEV 프로테아제에 의해 절단되는 TEV 서열을 통해 폴리펩타이드에 연결될 수 있다. 링커는 또한 하나 이상의 가요성 서열, 예를 들어, 1 내지 10개의 글리신 잔기를 포함할 수 있다. 일부 실시형태에서, 융합 단백질의 절단은 생성물의 용해도를 유지하는 완충제에서, 예를 들어, 0.5 내지 2 M 유레아의 존재 하에, 용해도 등을 증가시키는 폴리펩타이드 및/또는 폴리뉴클레오타이드의 존재 하에 수행된다. 관심 대상의 도메인은 엔도솜 용해성 도메인, 예를 들어, 인플루엔자 HA 도메인; 및 생성에 도움을 주는 다른 폴리펩타이드, 예를 들어, IF2 도메인, GST 도메인, GRPE 도메인 등을 포함한다. 폴리펩타이드는 개선된 안정성을 위해 제형화될 수 있다. 예를 들어, 펩타이드는 페길화될 수 있으며(PEGylated), 여기서 폴리에틸렌옥시기는 혈류에서 증강된 수명을 제공한다.
추가적으로 또는 대안적으로, 본 개시내용의 CasX 폴리펩타이드는 세포에 의한 흡수를 촉진하기 위해 폴리펩타이드 침투 도메인에 융합될 수 있다. 다수의 침투 도메인이 당업계에 공지되어 있고, 펩타이드, 펩타이드 모방체 및 비-펩타이드 담체를 포함하는 본 개시내용의 비통합 폴리펩타이드에서 사용될 수 있다. 예를 들어, 침투 펩타이드는 아미노산 서열 RQIKIWFQNRRMKWKK(서열번호 133)를 포함하는, 페너트라틴(penetratin)으로서 지칭되는 노랑초파리 전사 인자 안테나피디어(Antennapaedia)의 세 번째 알파 나선으로부터 유래될 수 있다. 다른 예로서, 침투 펩타이드는, 예를 들어, 천연 유래 tat 단백질의 아미노산 49 내지 57을 포함할 수 있는 HIV-1 tat 염기성 영역 아미노산 서열을 포함한다. 다른 침투 도메인은 폴리-알기닌 모티프, 예를 들어, HIV-1 rev 단백질, 노나-알기닌, 옥타-알기닌 등의 아미노산 34 내지 56의 영역을 포함한다. (예를 들어, 전좌 펩타이드 및 펩토이드의 교시에 대해 본 명세서에 구체적으로 참고로 편입된 문헌[Futaki et al. (2003) Curr Protein Pept Sci. 2003 Apr; 4(2): 87-9 및 446; 및 Wender et al. (2000) Proc. Natl. Acad. Sci. U.S.A 2000 Nov. 21; 97(24):13003-8]; 공개된 미국 특허 출원 제20030220334호; 제20030083256호; 제20030032593호; 및 제20030022831호를 참조). 노나-알기닌(R9) 서열은 특성규명된 더 효율적인 PTD 중 하나이다(Wender et al. 2000; Uemura et al. 2002). 융합이 이루어지는 부위는 폴리펩타이드의 생물학적 활성, 분비 또는 결합 특징을 최적화하기 위해 선택될 수 있다. 최적의 부위는 일상적인 실험에 의해 결정될 것이다.
본 개시내용의 CasX 폴리펩타이드는 시험관내에서 또는 진핵세포에 의해 또는 원핵 세포에 의해 생성될 수 있고, 비폴딩, 예를 들어, 열 변성, 다이티오트레이톨 환원 등에 의해 추가로 가공될 수 있고, 당업계에 공지된 방법을 이용하여 추가로 재폴딩될 수 있다.
1차 서열을 변경시키지 않는 관심 대상의 변형은 폴리펩타이드의 화학적 유도체화, 예를 들어, 아실화, 아세틸화, 카복실화, 아마이드화 등을 포함한다. 또한 글리코실화의 변형, 예를 들어, 합성 및 가공 동안 또는 추가 가공 단계에서 폴리펩타이드의 글리코실화 패턴을 변형시킴으로써; 예를 들어, 글리코실화, 예컨대 포유류 글리코실화 또는 탈글리코실화 효소에 영향을 미치는 효소에 폴리펩타이드를 노출시킴으로써 만들어지는 것이 포함된다. 또한 포스포릴화된 아미노산 잔기, 예를 들어, 포스포타이로신, 포스포세린 또는 포스포트레오닌을 갖는 서열이 포함된다.
또한 단백질 분해에 대한 그들의 내성을 개선시키기 위해, 표적 서열 특이성을 변화시키기 위해, 용해도 특성을 최적화하기 위해, 단백질 활성(예를 들어, 전사 조절 활성, 효소 활성 등)을 변경하기 위해 또는 그들을 더 적합하게 제공하기 위해 보통의 분자 생물학 기법 및 합성 화학을 이용하여 변형된 핵산(예를 들어, CasX 가이드 RNA를 암호화, CasX 융합 단백질을 암호화 등) 및 단백질(예를 들어, 야생형 단백질 또는 변이체 단백질로부터 유래된 CasX 융합 단백질)이 본 개시내용의 실시형태에 포함하기에 적합하다. 이러한 폴리펩타이드의 유사체는 천연 유래 L-아미노산, 예를 들어, D-아미노산 또는 비천연 유래 합성 아미노산 이외의 잔기를 함유하는 것을 포함한다. D-아미노산은 일부 또는 모든 아미노산 잔기로 치환될 수 있다.
본 개시내용의 CasX 폴리펩타이드는 당업계에 공지된 통상적인 방법을 이용하여 시험관내 합성에 의해 제조될 수 있다. 다양한 상업적 합성 장치, 예를 들어, 어플라이드 바이오시스템즈, 인코포레이티드(Applied Biosystems, Inc.), 베크만(Beckman) 등에 의한 자동화된 합성기를 이용 가능하다. 합성기를 이용함으로써, 천연 유래 아미노산은 비천연 아미노산으로 치환될 수 있다. 특정 서열 및 제조 방식은 편리함, 경제성, 필요한 순도 등에 의해 결정될 것이다.
원한다면, 합성 동안 또는 발현 동안에 다양한 기가 펩타이드 내로 도입되는데, 이는 다른 분자에 또는 표면에 대한 연결을 허용한다. 따라서 티오에터, 금속 이온 복합체에 대한 연결을 위한 히스티딘, 아마이드 또는 에스터를 형성하기 위한 카복실기 또는 아마이드를 형성하기 위한 아미노기 등을 만들기 위해 시스테인이 사용될 수 있다.
본 개시내용의 CasX 폴리펩타이드는 또한 단리될 수 있고, 재조합 합성의 통상적인 방법에 따라 정제될 수 있다. 발현 숙주의 용해물이 제조될 수 있고, 용해물은 고성능 액체 크로마토그래피(HPLC), 배제 크로마토그래피, 겔 전기영동, 친화도 크로마토그래피 또는 다른 정제 기법을 이용하여 정제된다. 대부분에 대해, 사용되는 조성물은 생성물의 제조 및 그의 정제 방법과 관련된 오염물질에 대해 20중량% 이상의 목적으로 하는 생성물, 더 보통으로는 75중량% 이상, 바람직하게는 95중량% 이상, 그리고 치료적 목적을 위해, 보통 99.5중량% 이상을 포함할 것이다. 보통, 백분율은 총 단백질을 기준으로 할 것이다. 따라서, 일부 경우에, 본 개시내용의 CasX 폴리펩타이드, 또는 CasX 융합 폴리펩타이드는 적어도 80% 순수, 적어도 85% 순수, 적어도 90% 순수, 적어도 95% 순수, 적어도 98% 순수 또는 적어도 99% 순수(예를 들어, 오염물질, 비-CasX 단백질 또는 다른 거대분자 등이 없음)이다.
표적 핵산(예를 들어, 게놈 DNA)에 대한 절단 또는 임의의 목적으로 하는 변형, 또는 표적 핵산, 본 개시내용의 CasX 가이드 RNA 및/또는 CasX 폴리펩타이드 및/또는 공여자 주형 서열과 관련된 폴리펩타이드에 대한 임의의 목적으로 하는 변형을 유도하기 위해, 그들이 핵산으로서 도입되든 또는 폴리펩타이드로서 도입되든, 약 30분 내지 약 24시간, 예를 들어, 1시간, 1.5시간, 2시간, 2.5시간, 3시간, 3.5시간 4시간, 5시간, 6시간, 7시간, 8시간, 12시간, 16시간, 18시간, 20시간, 또는 약 30분 내지 약 24시간의 임의의 다른 기간 동안 세포에 제공되는데, 이는 대략 매일 내지 약 4일마다, 예를 들어, 1.5일마다, 2일마다, 3일마다의 빈도로, 또는 대략 매일 내지 약 4일마다의 임의의 다른 빈도로 반복될 수 있다. 제제(들)는 대상 세포에 1회 이상, 예를 들어, 1회, 2회, 3회, 3회 초과로 제공될 수 있고, 세포는 각각의 접촉 사건 후 일정한 시간 동안, 예를 들어, 16 내지 24시간 동안 제제(들)와 함께 인큐베이션되도록 허용되며, 이 시간 후에 배지는 신선한 배지로 대체되고, 세포는 추가로 배양된다.
2 이상의 상이한 표적화 복합체가 세포(예를 들어, 동일 또는 상이한 표적 핵산 내에서 상이한 서열에 상보성인 2개의 상이한 CasX 가이드 RNA)에 제공되는 경우에, 복합체는 동시에(예를 들어, 2개의 폴리펩타이드 및/또는 핵산으로서) 제공될 수 있거나, 또는 동시에 전달될 수 있다. 대안적으로, 그들은 연속적으로, 예를 들어, 제1의 제공된 표적화 복합체, 다음에 제2 표적화 복합체 등 또는 그 반대로 제공될 수 있다.
DNA 벡터의 표적 세포의 전달을 개선시키기 위해, DNA는 손상으로부터 보호될 수 있고, 세포 내로 그의 유입은, 예를 들어, 리포플렉스(lipoplex) 및 폴리플렉스(polyplex)를 이용함으로써 용이하게 된다. 따라서, 일부 경우에, 본 개시내용의 핵산(예를 들어, 본 개시내용의 재조합 발현 벡세포 유형-특이적는 마이셀 또는 리포좀과 같이 조직화된 구조에서 지질로 뒤덮일 수 있다. 조직화된 구조가 DNA와 함께 복합체화될 때, 이는 리포플렉스로 불린다. 3가지 유형의 지질, 음이온(음으로 하전됨), 중성 또는 양이온성(양으로 하전됨)이 있다. 양이온성 지질을 이용하는 리포플렉스는 유전자 전달을 위한 증명된 효용을 가진다. 양전하 지질은 그들의 양전하에 기인하여 음으로 하전된 DNA와 자연적으로 복합체화된다. 또한 그들의 하전의 결과로서, 그들은 세포막과 상호작용한다. 이어서, 리포플렉스의 내포작용이 일어나고, DNA는 세포질 내로 방출된다. 양이온성 지질은 또한 세포에 의해 DNA의 분해에 대해 보호한다.
DNA와 중합체의 복합체는 폴리플렉스로 불린다. 대부분의 폴리플렉스는 양이온성 중합체로 이루어지고, 그들의 생성은 이온 상호작용에 의해 조절된다. 폴리플렉스와 리포플렉스의 작용 방법 간의 한 가지 큰 차이는 폴리플렉스는 세포질 내로 그들의 DNA 부하를 방출할 수 없고, 이를 위하여, 엔도솜-용해제(내포작용 동안 만들어진 엔도솜을 용해시키기 위함), 예컨대 비활성화 아데노바이러스와의 공동형질감염이 일어나야 한다는 것이다. 그러나, 이는 항상 그런 것은 아니며; 중합체, 예컨대 폴리에틸렌이민은 키토산 및 트라이메틸키토산과 같이 엔도솜 붕괴의 그 자체의 방법을 가진다.
구체 형태를 갖는 상당히 분지형인 거대분자인 덴드리머는 또한 줄기 세포를 유전적으로 변형하기 위해 사용될 수 있다. 덴드리머 입자의 표면은 그의 특성을 변경시키도록 작용화될 수 있다. 특히, 양이온성 덴드리머(즉, 양성 표면 전하를 갖는 것)를 작제하는 것이 가능하다. 유전자 물질, 예컨대 DNA 플라스미드의 존재 하에 있을 때, 전하 상보성은 양이온성 덴드리머와 핵산의 일시적 회합을 야기한다. 그의 목적에 도달되었을 때, 덴드리머-핵산 복합체는 내포작용에 의해 세포 내로 흡수될 수 있다.
일부 경우에, 개시내용의 핵산(예를 들어, 발현 벡터)은 관심 대상의 가이드 서열에 대한 삽입 부위를 포함한다. 예를 들어, 핵산은 관심 대상의 가이드 서열에 대한 삽입 부위를 포함할 수 있으며, 여기서 삽입 부위는 가이드 서열이 목적으로 하는 표적 서열(예를 들어, 가이드 RNA의 CasX 결합 양상에 기여하는 서열, 예를 들어, CasX 가이드 RNA의 dsRNA 듀플렉스(들)에 기여하는 서열 - 가이드 RNA의 이 부분은 또한 가이드 RNA의 '스캐폴드' 또는 '불변 영역'으로서 지칭될 수 있음)에 혼성화하도록 변할 때 변하지 않는 CasX 가이드 RNA의 일부를 암호화하는 뉴클레오타이드 서열에 바로 인접한다. 따라서, 일부 경우에, 가이드 RNA의 가이드 서열을 암호화하는 부분이 삽입 서열(삽입 부위)라는 것을 제외하고, 대상 핵산(예를 들어, 발현 벡터)는 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함한다. 삽입 부위는 목적으로 하는 서열의 삽입을 위해 사용되는 임의의 뉴클레오타이드 서열이다. 다양한 기법과 함께 사용하기 위한 "삽입 부위"는 당업자에게 공지되어 있고, 임의의 편리한 삽입 부위가 사용될 수 있다. 삽입 부위는 핵산 서열을 조작하기 위한 임의의 방법에 대한 것일 수 있다. 예를 들어, 일부 경우에 삽입 부위는 다중 클로닝 부위(MCS)(예를 들어, 하나 이상의 제한 효소 인식 서열을 포함하는 부위), 결찰 독립적 클로닝을 위한 부위, 재조합 기반 클로닝을 위한 부위(예를 들어, att 부위에 기반한 재조합), CRISPR/Cas(예를 들어, Cas9) 기반 기법에 의해 인식되는 뉴클레오타이드 서열 등이다.
삽입 부위는 임의의 바람직한 길이일 수 있고, 삽입 부위 유형에 의존할 수 있다(예를 들어, 부위가 하나 이상의 제한 효소 인식 서열을 포함하는지의 여부(및 얼마나 많이 포함하는지), 부위가 CRISPR/Cas 단백질에 대한 표적 부위를 포함하는지의 여부 등에 의존할 수 있다). 일부 경우에, 대상 핵산의 삽입 부위는 길이가 3개 이상의 뉴클레오타이드(nt)이다(예를 들어, 길이가 5개 이상, 8개 이상, 10개 이상, 15개 이상, 17개 이상, 18개 이상, 19개 이상, 20개 이상 또는 25개 이상 또는 30개 이상의 nt). 일부 경우에, 대상 핵산의 삽입 부위 길이는 길이가 2 내지 50개의 뉴클레오타이드(nt)(예를 들어, 2 내지 40 nt, 2 내지 30개의 nt, 2 내지 25개의 nt, 2 내지 20개의 nt, 5 내지 50개의 nt, 5 내지 40개의 nt, 5 내지 30개의 nt, 5 내지 25개의 nt, 5 내지 20개의 nt, 10 내지 50개의 nt, 10 내지 40개의 nt, 10 내지 30개의 nt, 10 내지 25개의 nt, 10 내지 20개의 nt, 17 내지 50개의 nt, 17 내지 40개의 nt, 17 내지 30개의 nt, 17 내지 25 nt) 범위이다. 일부 경우에, 대상 핵산의 삽입 부위 길이는 길이가 5 내지 40 nt이다.
핵산 변형
일부 실시형태에서, 새로운 또는 증강된 특징(예를 들어, 개선된 안정성)을 갖는 핵산을 제공하기 위해 대상 핵산(예를 들어, CasX 가이드 RNA)는 하나 이상의 변형, 예를 들어, 염기 변형, 골격 변형 등을 가진다. 뉴클레오사이드는 염기-당 조합이다. 뉴클레오사이드의 염기 부분은 정상적으로 복소환식 염기이다. 이러한 복소환식 염기의 2가지 가장 통상적인 부류는 퓨린 및 피리미딘이다. 뉴클레오타이드는 뉴클레오사이드의 당 부분에 공유적으로 연결된 인산염기를 추가로 포함하는 뉴클레오사이드이다. 펜토퓨라노실 당을 포함하는 해당 뉴클레오사이드에 대해, 인산염기는 당의 2', 3' 또는 5' 하이드록실 모이어티에 연결될 수 있다. 올리고뉴클레오타이드를 형성함에 있어서, 인산염기는 서로 인접한 뉴클레오사이드에 공유적으로 연결되어 선형 중합체 화합물을 형성한다. 결국, 이 선형 중합체 화합물의 각각의 단부는 추가로 결합되어 원형 화합물을 형성할 수 있지만, 그러나, 선형 화합물이 적합하다. 추가로, 선형 화합물은 내부 뉴클레오타이드 염기 상보성을 가질 수 있으며, 따라서 완전히 또는 부분적으로 이중-가닥 화합물을 생성하기 위한 방식으로 폴딩될 수 있다. 올리고뉴클레오타이드 내에서, 인산염기는 통상적으로 올리고뉴클레오타이드의 뉴클레오사이드간 골격을 형성하는 것으로 지칭된다. RNA 및 DNA의 정상 결합 또는 골격은 3' 내지 5' 포스포다이에스터 결합이다.
적합한 핵산 변형은 하기를 포함하지만, 이들로 제한되지 않는다: 2'O메틸 변형된 뉴클레오타이드, 2' 플루오로 변형된 뉴클레오타이드, 잠금 핵산(locked nucleic acid: LNA) 변형된 뉴클레오타이드, 펩타이드 핵산(peptide nucleic acid: PNA) 변형된 뉴클레오타이드, 포스포로티오에이트 결합을 갖는 뉴클레오타이드 및 5' 캡(예를 들어, 7-메틸구아닐레이트 캡(m7G)). 추가적인 상세한 설명 및 추가적인 변형을 이하에 기재한다.
2'-O-메틸 변형된 뉴클레오타이드(또한 2'-O-메틸 RNA로서 지칭됨)는 tRNA에서 발견되는 RNA 및 전사후 변형으로서 생기는 다른 작은 RNA의 천연 유래 변형이다. 2'-O-메틸 RNA를 함유하는 올리고뉴클레오타이드가 직접적으로 합성될 수 있다. 이 변형은 RNA:RNA 듀플렉스의 Tm을 증가시키지만 RNA:DNA 안정성의 작은 변화만을 초래한다. 이는 단일-가닥 리보뉴클레아제에 의한 공격에 대해 안정하며 전형적으로 DNA보다 DNase에 대해 5 내지 10배 덜 민감하다. 이는 표적 전령에 대한 안정성 및 결합 친화도를 증가시키기 위한 수단으로서 안티센스 올리고에서 통상적으로 사용된다.
2' 플루오로 변형된 뉴클레오타이드(예를 들어, 2' 플루오로 염기)는 결합 친화도(Tm)를 증가시키는 플루오린 변형된 리보스를 가지며, 또한 천연 RNA에 비해 일부 상대적 뉴클레아제 내성을 부여한다. 이들 변형은 혈청 또는 다른 생물학적 유체에서의 안정성을 개선시키기 위해 리보자임 및 siRNA에서 통상적으로 사용된다.
LNA 염기는 RNA A-형 나선 듀플렉스 기하학을 선호하는 C3'-엔도 위치에서 염기를 잠그는 리보스 골격에 대한 변형을 가진다. 이 변형은 Tm을 상당히 증가시키며, 또한 매우 뉴클레아제 내성이다. 다중 LNA 삽입은 3'-단부를 제외한 임의의 위치에서 올리고에 위치될 수 있다. 적용은 혼성화 프로프에 대한 안티센스 올리고로부터 SNP 검출 및 대립유전자 특이적 PCR까지의 범위로 기재되었다. LNA에 의해 부여되는 Tm의 큰 증가에 기인하여, 그들은 또한 프라이머 이량체 형성뿐만 아니라 자기-헤어핀 형성의 증가를 야기할 수 있다. 일부 경우에, 단일 올리고 내로 혼입된 LNA의 수는 10개 이하의 염기이다.
포스포로티오에이트(PS) 결합(즉, 포스포로티오에이트 결합)은 핵산(예를 들어, 올리고)의 인산염 골격에서 황 원자를 비-브리징 산소로 치환한다. 이 변형은 뉴클레아제 분해에 내성이 있는 뉴클레오타이드간 결합을 제공한다. 포스포로티오에이트 결합은 엑소뉴클레아제 분해를 저해하기 위해 올리고의 5'- 또는 3'-단부에서 마지막 3 내지 5개 뉴클레오타이드 사이에 도입될 수 있다. 올리고 내에서(예를 들어, 전체 올리고를 전체적으로) 포스포로티오에이트 결합을 포함하는 것은 마찬가지로 엔도뉴클레아제에 의한 공격을 감소시킬 수 있다.
일부 실시형태에서, 대상 핵산은 2'-O-메틸 변형된 뉴클레오타이드인 하나 이상의 뉴클레오타이드이다. 일부 실시형태에서, 대상 핵산(예를 들어, dsRNA, siNA 등)은 하나 이상의 2' 플루오로 변형된 뉴클레오타이드를 가진다. 일부 실시형태에서, 대상 핵산(예를 들어, dsRNA, siNA 등)은 하나 이상의 LNA 염기를 가진다. 일부 실시형태에서, 대상 핵산(예를 들어, dsRNA, siNA 등)은 포스포로티오에이트 결합에 의해 연결된 하나 이상의 뉴클레오타이드를 가진다(즉, 대상 핵산은 하나 이상의 포스포로티오에이트 결합을 가진다). 일부 실시형태에서, 대상 핵산(예를 들어, dsRNA, siNA 등)은 5' 캡(예를 들어, 7-메틸구아닐레이트 캡(m7G))을 가진다. 일부 실시형태에서, 대상 핵산(예를 들어, dsRNA, siNA 등)은 변형된 뉴클레오타이드의 조합을 가진다. 예를 들어, 대상 핵산(예를 들어, dsRNA, siNA 등)은 다른 변형을 갖는 하나 이상의 뉴클레오타이드(예를 들어, 2'-O-메틸 뉴클레오타이드 및/또는 2' 플루오로 변형된 뉴클레오타이드 및/또는 LNA 염기 및/또는 포스포로티오에이트 결합)를 갖는 것에 추가로 5' 캡(예를 들어, 7-메틸구아닐레이트 캡(m7G))을 가질 수 있다.
변형된 골격 및 변형된
뉴클레오사이드간
결합
변형을 함유하는 적합한 핵산(예를 들어, CasX 가이드 RNA)의 예는 변형된 골격 또는 비천연 뉴클레오사이드간 결합을 함유하는 핵산을 포함한다. 변형된 골격을 갖는 핵산은 골격에 인 원자를 보유하는 것 및 골격에 인 원자를 갖지 않는 것을 포함한다.
인 원자를 함유하는 적합한 변형된 올리고뉴클레오타이드 골격은, 예를 들어, 포스포로티오에이트, 카이랄 포스포로티오에이트, 포스포로다이티오에이트, 포스포트라이에스터, 아미노알킬포스포트라이에스터, 메틸 및 다른 알킬 포스포네이트(3'-알킬렌 포스포네이트, 5'-알킬렌 포스포네이트 및 카이랄 포스포네이트를 포함), 포스피네이트, 포스포르아미데이트(3'-아미노 포스포르아미데이트 및 아미노알킬포스포르아미데이트, 포스포로다이아미데이트, 티오노포스포르아미데이트를 포함), 티오노알킬포스포네이트, 티오노알킬포스포트라이에스터, 셀레노포스페이트 및 정상 3'-5' 결합을 갖는 보라노포스페이트, 이들의 2'-5'연결된 유사체, 및 반전된 극성을 갖는 것을 포함하되, 하나 이상의 뉴클레오타이드간 결합은 3' 내지 3', 5' 내지 5' 또는 2' 내지 2' 결합이다. 반전된 극성을 갖는 적합한 올리고뉴클레오타이드는 가장 3'의 뉴클레오타이드간 결합에서 단일 3' 내지 3' 결합, 즉, 염기성일 수 있는 단일 반전 뉴클레오사이드 잔기를 포함한다(뉴클레오염기는 그 대신에 상실되거나 하이드록실기를 가짐). 다양한 염(예컨대, 칼륨 또는 나트륨), 혼합된 염 및 유리 산 형태가 또한 포함된다.
일부 실시형태에서, 대상 핵산은 하나 이상의 포스포로티오에이트 및/또는 헤테로원자 뉴클레오사이드간 결합, 특히 -CH2-NH-O-CH2-, -CH2-N(CH3)-O-CH2-(메틸렌(메틸이미노) 또는 MMI 골격으로서 알려짐), -CH2-O-N(CH3)-CH2-, -CH2-N(CH3)-N(CH3)-CH2- 및 -O-N(CH3)-CH2-CH2-를 포함한다(천연 포스포다이에스터 뉴클레오타이드간 결합은 -O-P(=O)(OH)-O-CH2-로서 나타냄). MMI 유형 뉴클레오사이드간 결합은 상기 언급된 미국 특허 제5,489,677호에 개시되어 있으며, 이의 개시내용은 본 명세서에 그의 전문이 참고로 편입된다. 적합한 아마이드 뉴클레오사이드간 결합은 미국 특허 제5,602,240호에 개시되어 있으며, 이의 개시내용은 전문이 본 명세서에 참고로 편입된다.
또한, 예를 들어, 미국 특허 제5,034,506호에 기재된 바와 같은 몰폴리노 골격 구조를 갖는 핵산이 적합하다. 예를 들어, 일부 실시형태에서, 대상 핵산은 리보스 고리 대신에 6-원 몰폴리노 고리를 포함한다. 일부 이들 실시형태에서, 포스포로다이아미데이트 또는 다른 비-포스포다이에스터 뉴클레오사이드간 결합은 포스포다이에스터 결합을 대체한다.
인 원자를 포함하지 않는 적합한 변형된 폴리뉴클레오타이드 골격은 짧은 쇄알킬 또는 사이클로알킬 뉴클레오사이드간 결합, 혼합된 헤테로원자 및 알킬 또는 사이클로알킬 뉴클레오사이드간 결합 또는 하나 이상의 짧은 쇄 헤테로원자 또는 복소환식 뉴클레오사이드간 결합에 의해 형성된 골격을 가진다. 이들은 몰폴리노 결합을 갖는 것(뉴클레오사이드의 당 부분으로부터 부분적으로 형성됨); 실록산 골격; 설파이드, 설폭사이드 및 설폰 골격; 폼아세틸 및 티오폼아세틸 골격; 메틸렌 폼아세틸 및 티오폼아세틸 골격; 리보아세틸 골격; 알켄 함유 골격; 설파메이트 골격; 메틸렌이미노 및 메틸렌하이드라지노 골격; 설포네이트 및 설폰아마이드 골격; 아마이드 골격; 및 혼합된 N, O, S 및 CH2 성분 부분을 갖는 다른 것을 포함한다.
모방체
대상 핵산은 핵산 모방체일 수 있다. 폴리뉴클레오타이드에 적용되는 용어 "모방체"는 폴리뉴클레오타이드를 포함하는 것으로 의도되되, 푸라노스 고리만 또는 푸라노스 고리와 뉴클레오타이드가나 결합 둘 다는 비-푸라노스 기로 대체되며, 푸라노스 고리만의 대체는 또한 본 명세서에서 당 대용물로서 지칭된다. 복소환식 염기 모이어티 또는 변형된 복소환식 염기 모이어티는 적절한 표적 핵산과의 혼성화를 위해 유지된다. 우수한 혼성화 특성을 갖는 것을 나타난 하나의 이러한 핵산, 폴리뉴클레오타이드 모방체는 펩타이드 핵산(PNA)으로서 지칭된다. PNA에서, 폴리뉴클레오타이드의 당-골격은 골격, 특히 아미노에틸글리신 골격을 함유하는 아마이드로 대체된다. 뉴클레오타이드가 보유되며, 골격의 아마이드 부분의 아자 질소 원자에 직접 또는 간접적으로 결합된다.
우수한 혼성화 특성을 갖는 것으로 보고된 하나의 폴리뉴클레오타이드 모방체는 펩타이드 핵산(PNA)이다. PNA 화합물의 골격은 PNA에 아마이드 함유 골격을 제공하는 2 이상의 연결된 아미노에틸 글리신 단위이다. 복소환식 염기 모이어티는 골격의 아마이드 부분의 아자 질소 원자에 직접 또는 간접적으로 결합된다. PNA 화합물의 제조를 기재하는 대표적인 미국 특허는 미국 특허 제5,539,082호; 제5,714,331호; 및 제5,719,262호를 포함하지만, 이들로 제한되지 않으며, 이의 개시내용은 본 명세서에 전문이 참고로 포함된다.
연구된 다른 부류의 폴리뉴클레오타이드 모방체는 몰폴리노 고리에 부착된 복소환식 염기를 갖는 연결된 몰폴리노 단위(몰폴리노 핵산)에 기반한다. 몰폴리노 핵산에서 몰폴리노 단량체 단위를 연결하는 다수의 연결기가 보고되었다. 비이온성 올리고머 화합물을 제공하기 위한 연결기의 한 가지 부류가 선택되었다. 비-이온성 몰폴리노계 올리고머 화합물은 세포 단백질과의 원치않는 상호작용을 가질 가능성이 더 적다. 몰폴리노계 폴리뉴클레오타이드는 세포 단백질과의 원치않는 상호작용을 형성할 가능성이 더 적은 올리고뉴클레오타이드의 비이온성 모방체이다(Dwaine A. Braasch and David R. Corey, Biochemistry, 2002, 41(14), 4503-4510). 몰폴리노계 폴리뉴클레오타이드는 미국 특허 제5,034,506호에 개시되어 있고, 이의 개시내용은 본 명세서에 그의 전문이 참고로 편입된다. 단량체 서브유닛을 결합하는 다양한 상이한 연결기를 갖는 폴리뉴클레오타이드의 몰폴리노 부류 내의 다양한 화합물이 제조되었다.
추가적인 부류의 폴리뉴클레오타이드 모방체는 사이클로헥센일 핵산(CeNA)으로서 지칭된다. DNA/RNA 분자에 정상적으로 존재하는 푸라노스 고리는 사이클로헥센일 고리로 대체된다. CeNA DMT 보호된 포스포르아미다이트 단량체가 제조되었고, 고전적 포스포르아미다이트 화학 다음의 올리고머 화합물 합성을 위해 사용되었다. CeNA로 변형된 특정 위치를 갖는 완전히 변형된 CeNA 올리고머 화합물 및 올리고뉴클레오타이드가 제조되고, 연구되었다(문헌[Wang et al., J. Am. Chem . Soc., 2000, 122, 8595-8602]을 참조하며, 이의 개시내용은 본 명세서에 그의 전문이 참고로 편입됨). 일반적으로 DNA 쇄에 대한 CeNA 단량체의 편입은 DNA/RNA 혼성체의 그의 안정성을 증가시킨다. CeNA 올리고아데닐레이트는 천연 복합체와 유사한 안정성을 갖는 RNA 및 DNA 상보체와의 복합체를 형성하였다. 천연 핵산 구조에 CeNA 구조를 혼입하는 연구는 용이한 입체배좌 적용에 의해 진행되는 NMR 및 원이색법에 의해 나타낸다.
추가적인 변형은 잠금 핵산(LNA)을 포함하며, 이때 2'-하이드록실기는 당 고리의 4' 탄소 원자에 연결됨으로써, 2'-C,4'-C-옥시메틸렌 결합을 형성하고, 이에 의해 이환식 당 모이어티를 형성한다. 결합은 2' 산소 원자와 4' 탄소 원자를 브리징하는 기인 메틸렌(-CH2-)일 수 있되, n은 1 또는 2이다(문헌[Singh et al., Chem. Commun., 1998, 4, 455-456], 이의 개시내용은 본 명세서에 그의 전문이 참고로 편입됨). LNA 및 LNA 유사체는 상보성 DNA 및 RNA에 의한 매우 높은 듀플렉스 열 안정성(Tm=+3 내지 +10℃), 3'-핵산외부 분해 및 양호한 용해도 특성에 대한 안정성을 나타낸다. LNA를 함유하는 강력한 그리고 비독성의 안티센스 올리고뉴클레오타이드가 기재되었다(예를 들어, 문헌[Wahlestedt et al., Proc . Natl . Acad . Sci. U.S.A., 2000, 97, 5633-5638] 참조, 이의 개시내용은 본 명세서에 그의 전문이 참고로 편입됨).
LNA 단량체 아데닌, 사이토신, 구아닌, 5-메틸-사이토신, 티민 및 유라실의 합성 및 제조는, 그들의 올리고머, 및 핵산 인식 특성과 함께 기재되었다(예를 들어, 문헌[Koshkin et al., Tetrahedron, 1998, 54, 3607-3630] 참조, 이의 개시내용은 본 명세서에 그의 전문이 참고로 편입됨). LNA 및 이의 제조는 또한 WO 98/39352 및 WO 99/14226뿐만 아니라 미국 특허 출원 제20120165514호, 제20100216983호, 제20090041809호, 제20060117410호, 제20040014959호, 제20020094555호 및 제20020086998호에 기재되어 있고, 이의 개시내용은 그들의 전문이 본 명세서에 참고로 포함된다.
변형된 당
모이어티
대상 핵산은 또한 하나 이상의 치환된 당 모이어티를 포함할 수 있다. 적합한 폴리뉴클레오타이드는 OH; F; O-, S-, 또는 N-알킬; O-, S- 또는 N-알켄일; O-, S- 또는 N-알킨일; 또는 O-알킬-O-알킬로부터 선택된 당 치환체기를 포함하되, 알킬, 알켄일 및 알킨일은 치환된 또는 비치환된 C1 내지 C10 알킬 또는 C2 내지 C10 알켄일 및 알킨일일 수 있다. O((CH2)nO) mCH3, O(CH2)nOCH3, O(CH2)nNH2, O(CH2)nCH3, O(CH2)nONH2 및 O(CH2)nON((CH2)nCH3)2가 특히 적합하며, n 및 m은 1 내지 약 10이다. 다른 적합한 폴리뉴클레오타이드는 C1 내지 C10 저급 알킬, 치환된 저급 알킬, 알켄일, 알킨일, 알카릴, 아르알킬, O-알카릴 또는 O-아르알킬, SH, SCH3, OCN, Cl, Br, CN, CF3, OCF3, SOCH3, SO2CH3, ONO2, NO2, N3, NH2, 헤테로사이클로알킬, 헤테로사이클로알카릴, 아미노알킬아미노, 폴리알킬아미노, 치환된 실릴, RNA 절단기, 리포터기, 삽입제(intercalator), 올리고뉴클레오타이드의 약물동력학 특성을 개선시키기 위한 기, 또는 올리고뉴클레오타이드의 약물동력학 특성을 개선시키기 위한 기 및 유사한 특성을 갖는 다른 치환체로부터 선택된 당 치환체기를 포함한다. 적합한 변형은 2'-메톡시에톡시(2'-O-CH2 CH2OCH3, 또한 2'-O-(2-메톡시에틸) 또는 2'-MOE로서 알려짐)(Martin et al., Helv . Chim . Acta, 1995, 78, 486-504, 이의 개시내용은 본 명세서에 그의 전문이 참고로 편입됨) 즉, 알콕시알콕시기를 포함한다. 추가적인 적합한 변형은 본 명세서의 이하의 실시예에 기재된 바와 같은 2'-DMAOE로서도 알려진 2'-다이메틸아미노옥시에톡시, 즉, O(CH2)2ON(CH3)2 기, 및 2'-다이메틸아미노에톡시에톡시(또한 당업계에서 2'-O-다이메틸-아미노-에톡시-에틸 또는 2'-DMAEOE로서 알려짐), 즉, 2'-O-CH2-O-CH2-N(CH3)2를 포함한다.
다른 적합한 당 치환체기는 메톡시 (-O-CH3), 아미노프로폭시(--O CH2 CH2 CH2NH2), 알릴(-CH2-CH=CH2), -O-알릴(--O-- CH2―CH=CH2) 및 플루오로(F)를 포함한다. 2'-당 치환체기는 아라비노(위) 위치 또는 리보(아래) 위치일 수 있다. 적합한 2'-아라비노 변형은 2'-F이다. 유사한 변형은 또한 올리고머 화합물 상의 다른 위치에서, 특히 3' 말단의 뉴클레오사이드 상의 당의 3' 위치에서 또는 2'-5' 연결된 올리고뉴클레오타이드 및 5' 말단 뉴클레오타이드의 5' 위치에서 만들어질 수 있다. 올리고머 화합물은 또한 펜토퓨라노실 당 대신 당 모방체, 예컨대 사이클로뷰틸 모이어티를 가질 수 있다.
염기 변형 및 치환
대상 핵산은 또한 핵염기(종종 본 명세서에서 단순히 "염기"로서 지칭됨) 변형 또는 치환을 포함할 수 있다. 본 명세서에서 사용되는 바와 같은, "비변형" 또는 "천연" 핵염기는 퓨린 염기 아데닌(A) 및 구아닌(G), 및 피리미딘 염기 티민(T), 사이토신(C) 및 유라실(U)을 포함한다. 변형된 핵염기는 다른 합성 및 천연 핵염기, 예컨대 5-메틸사이토신(5-me-C), 5-하이드록시메틸 사이토신, 잔틴, 하이포잔틴, 2-아미노아데닌, 아데닌 및 구아닌의 6-메틸 및 기타 알킬 유도체, 아데닌 및 구아닌의 2-프로필 및 기타 알킬 유도체, 2-티오유라실, 2-티오티민 및 2-티오사이토신, 5-할로유라실 및 사이토신, 5-프로핀일 (-C=C-CH3) 유라실 및 피리미딘 염기의 사이토신 및 다른 알킨일 유도체, 6-아조 유라실, 사이토신 및 티민, 5-유라실 (슈도유라실), 4-티오유라실, 8-할로, 8-아미노, 8-티올, 8-티오알킬, 8-하이드록실 및 다른 8-치환된 아데닌 및 구아닌, 5-할로, 특히 5-브로모, 5-트라이플루오로메틸 및 다른 5-치환된 유라실 및 사이토신, 7-메틸구아닌 및 7-메틸아데닌, 2-F-아데닌, 2-아미노-아데닌, 8-아자구아닌 및 8-아자아데닌, 7-데아자구아닌 및 7-데아자아데닌 및 3-데아자구아닌 및 3-데아자아데닌을 포함한다. 추가로 변형된 핵염기는 삼환식 피리미딘, 예컨대 페녹사진 사이티딘(1H-피리미도(5,4-b)(1,4)벤족사진-2(3H)-온), 페노티아진 사이티딘 (1H-피리미도(5,4-b)(1,4)벤조티아진-2(3H)-온), G-클램프, 예컨대 치환된 페녹사진 사이티딘(예를 들어, 9-(2-아미노에톡시)-H-피리미도(5,4-(b)(1,4)벤족사진-2(3H)-온), 카바졸 사이티딘(2H-피리미도(4,5-b)인돌-2-온), 피리도인돌 사이티딘(H-피리도(3',2':4,5)피롤로(2,3-d)피리미딘-2-온)을 포함한다.
복소환식 염기 모이어티는 또한 퓨린 또는 피리미딘 염기가 다른 헤테로사이클, 예를 들어, 7-데아자-아데닌, 7-데아자구아노신, 2-아미노피리딘 및 2-피리돈으로 대체되는 것을 포함할 수 있다. 추가로 핵염기는 미국 특허 제3,687,808호에 개시된 것, 문헌[The Concise Encyclopedia Of Polymer Science And Engineering, 페이지 858-859, Kroschwitz, J. I., ed. John Wiley & Sons, 1990]에 개시된 것, 문헌[Englisch et al., Angewandte Chemie , International Edition, 1991, 30, 613]에 의해 개시된 것, 및 문헌[Sanghvi, Y. S., Chapter 15, Antisense Research and Applications, 페이지 289-302, Crooke, S. T. and Lebleu, B., ed., CRC Press, 1993]에 의해 개시된 것을 포함하며; 이의 개시내용은 본 명세서에 그들의 전문이 참고로 편입된다. 특정 이들 핵염기는 올리고머 화합물의 결합 친화도를 증가시키는 데 유용하다. 이들은 5-치환된 피리미딘, 6-아자피리미딘 및 N-2, N-6 및 O-6 치환된 퓨린(2-아미노프로필아데닌, 5-프로핀일유라실 및 5-프로핀일사이토신을 포함)을 포함한다. 5-메틸사이토신 치환은 0.6 내지 1.2℃만큼 핵산 듀플렉스 안정성을 증가시키는 것으로 나타났고(Sanghvi et al., eds., Antisense Research and Applications, CRC Press, Boca Raton, 1993, pp. 276-278; 이의 개시내용은 본 명세서에 그의 전문이 참고로 편입됨), 예를 들어, 2'-O-메톡시에틸 당 변형과 조합될 때, 적합한 염기 치환이다.
접합체
대상 핵산의 다른 가능한 변형은 올리고뉴클레오타이드의 활성, 세포 분포 또는 세포 흡수를 향상시키는 하나 이상의 모이어티 또는 접합체를 폴리뉴클레오타이드에 화학적으로 연결하는 것을 수반한다. 이들 모이어티 또는 접합체는 작용기, 예컨대 1차 또는 2차 하이드록실기에 공유 결합된 접합체기를 포함할 수 있다. 접합체기는 삽입제, 리포터 분자, 폴리아민, 폴리아마이드, 폴리에틸렌 글리콜, 폴리에터, 올리고머의 약력학적 특성을 향상시키는 기, 및 올리고머의 약물동력학적 특성을 향상시키는 기를 포함하지만, 이들로 제한되지 않는다. 적합한 접합기는 콜레스테롤, 지질, 인지질, 바이오틴, 페나진, 엽산, 페난트리딘, 안트라퀴논, 아크리딘, 플루오레세인, 로다민, 쿠마린 및 염료를 포함하지만, 이들로 제한되지 않는다. 약력학적 특성을 향상시키는 기는 흡수를 개선시키고/시키거나, 분해에 대한 내성을 향상시키고/시키거나 표적 핵산과의 서열-특이적 혼성화를 강화시키는 기를 포함한다. 약물동태학적 특성을 향상시키는 기는 대상 핵산의 흡수, 분포, 대사 또는 배설을 개선시키는 기를 포함한다.
접합 모이어티는 지질 모이어티, 예컨대 콜레스테롤 모이어티(Letsinger et al., Proc . Natl . Acad . Sci. USA, 1989, 86, 6553-6556), 콜산(Manoharan et al., Bioorg . Med . Chem . Let., 1994, 4, 1053-1060), 티오에터, 예를 들어, 헥실-S-트라이틸티올(Manoharan et al., Ann. N.Y . Acad . Sci., 1992, 660, 306-309; Manoharan et al., Bioorg. Med . Chem . Let., 1993, 3, 2765-2770), 티오콜레스테롤(Oberhauser et al., Nucl . Acids Res., 1992, 20, 533-538), 지방족 쇄, 예를 들어, 도데칸다이올 또는 운데실 잔기(Saison-Behmoaras et al., EMBO J., 1991, 10, 1111-1118; Kabanov et al., FEBS Lett., 1990, 259, 327-330; Svinarchuk et al., Biochimie, 1993, 75, 49-54), 인지질, 예를 들어, 다이-헥사데실-rac-글리세롤 또는 트라이에틸암모늄 1,2-다이-O-헥사데실-rac-글리세로-3-H-포스포네이트(Manoharan et al., Tetrahedron Lett., 1995, 36, 3651-3654; Shea et al., Nucl . Acids Res., 1990, 18, 3777-3783), 폴리아민 또는 폴리에틸렌 글리콜 쇄(Manoharan et al., Nucleosides & Nucleotides, 1995, 14, 969-973), 또는 아다만탄 아세트산(Manoharan et al., Tetrahedron Lett., 1995, 36, 3651-3654), 팔미틸 모이어티(Mishra et al., Biochim . Biophys . Acta, 1995, 1264, 229-237), 또는 옥타데실아민 또는 헥실아미노-카보닐-옥시콜레스테롤 모이어티(Crooke et al., J. Pharmacol . Exp . Ther., 1996, 277, 923-937)를 포함하지만, 이들로 제한되지 않는다.
접합체는 "단백질 형질도입 도메인" 또는 PTD(또한 CPP - 세포 침투성 펩타이드로서 알려짐)를 포함하는데, 이는 지질 이중층, 마이셀, 세포막, 세포소기관 막 또는 소수포 막을 가로지르는 것을 용이하게 하는 폴리펩타이드, 폴리뉴클레오타이드, 탄수화물 또는 유기 또는 무기 화합물을 지칭할 수 있다. 거대 분자 및/또는 나노분자의 범위일 수 있는 다른 분자에 부착된 PTD는 분자가 막을 가로지르는 것, 예를 들어, 세포외 공간으로부터 세포내 공간 또는 사이토졸을 세포소기관(예를 들어, 핵) 내로 이동하는 것을 용이하게 한다. 일부 실시형태에서, PTD는 외인성 폴리뉴클레오타이드의 3' 단부에 공유적으로 연결된다. 일부 실시형태에서, PTD는 외인성 폴리뉴클레오타이드의 5' 단부에 공유적으로 연결된다. 예시적인 PTD는 최소 운데카펩타이드 단백질 형질도입 도메인(YGRKKRRQRRR; 서열번호 112를 포함하는 HIV-1 TAT의 잔기 47 내지 57에 대응); 세포 내로 유입을 지시하기에 충분한 다수의 알기닌을 포함하는 폴리알기닌 서열(예를 들어, 3, 4, 5, 6, 7, 8, 9, 10 또는 10-50 알기닌); VP22 도메인(Zender et al. (2002) Cancer Gene Ther. 9(6):489-96); 초파리 안테나페디아(Antennapedia) 단백질 형질도입 도메인(Noguchi et al. (2003) Diabetes 52(7):1732-1737); 절단된 인간 칼시토닌 펩타이드(Trehin et al. (2004) Pharm . Research 21:1248-1256); 폴리라이신(Wender et al. (2000) Proc . Natl . Acad . Sci . USA 97:13003-13008); RRQRRTSKLMKR 서열번호 113); 트랜스포탄 GWTLNSAGYLLGKINLKALAALAKKIL 서열번호 114); KALAWEAKLAKALAKALAKHLAKALAKALKCEA 서열번호 115); 및 RQIKIWFQNRRMKWKK 서열번호 116)을 포함하지만, 이들로 제한되지 않는다. 예시적인 PTD는 YGRKKRRQRRR 서열번호 117), RKKRRQRRR 서열번호 118); 3개의 알기닌 잔기 내지 50개의 알기닌 잔기의 알기닌 동종중합체를 포함하지만, 이들로 제한되지 않고; 예시적인 PTD 도메인 아미노산 서열은 다음 중 어떤 것을 포함하지만, 이들로 제한되지 않는다: YGRKKRRQRRR 서열번호 119); RKKRRQRR 서열번호 120); YARAAARQARA 서열번호 121); THRLPRRRRRR 서열번호 122); 및 GGRRARRRRRR 서열번호 123). 일부 실시형태에서, PTD는 활성화 가능한 CPP(ACPP)이다(Aguilera et al. (2009) Integr Biol ( Camb ) June; 1(5-6): 371-381). ACPP는 매칭 절단 가능한 링커를 통해 다음이온(예를 들어, Glu9 또는 "E9")에 연결된 다양이온 CPP(예를 들어, Arg9 또는 "R9")를 포함하는데, 이는 순전하를 거의 0으로 감소시키고, 이에 의해 세포에 대한 접착 및 흡수를 저해한다. 링커의 절단 시, 다음이온이 방출되며, 다알기닌 및 그의 고유한 부착성을 국소로 가리며, 따라서 막을 가로지르도록 ACPP를 "활성화시킨다".
표적 세포 내로의 성분의 도입
본 개시내용의 CasX 가이드 RNA(또는 이를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산) 및/또는 CasX 폴리펩타이드(또는 이를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산) 및/또는 본 개시내용의 CasX 융합 폴리펩타이드(또는 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산) 및/또는 공여자 폴리뉴클레오타이드(공여자 주형)는 임의의 다양한 잘 공지된 방법에 의해 숙주 세포 내로 도입될 수 있다.
본 개시내용의 CasX 시스템을 표적 세포에 전달하기 위해 임의의 다양한 화합물 및 방법이 사용될 수 있으며, 예를 들어, CasX 시스템은 a) 본 개시내용의 CasX 폴리펩타이드 및 CasX 가이드 RNA; b) 본 개시내용의 CasX 폴리펩타이드, CasX 가이드 RNA, 및 공여자 주형 핵산; c) 본 개시내용의 CasX 융합 폴리펩타이드 및 CasX 가이드 RNA; d) 본 개시내용의 CasX 융합 폴리펩타이드, CasX 가이드 RNA, 및 공여자 주형 핵산; e) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 mRNA; 및 CasX 가이드 RNA; f) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 mRNA, CasX 가이드 RNA, 및 공여자 주형 핵산; g) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 mRNA; 및 CasX 가이드 RNA; h) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 mRNA, CasX 가이드 RNA, 및 공여자 주형 핵산; i) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; j) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 공여자 주형 핵산을 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; k) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; l) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 공여자 주형 핵산을 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; m) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; n) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; 및 공여자 주형 핵산; o) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; p) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; 및 공여자 주형 핵산; q) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, 제1 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 제2 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; 또는 r) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, 제1 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 제2 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; 또는 (a) 내지 (r) 중 하나의 일부 변형을 포함한다. 비제한적 예로서, 본 개시내용의 CasX 시스템은 지질과 조합될 수 있다. 다른 비제한적 예로서, 본 개시내용의 CasX 시스템은 입자와 조합될 수 있거나 또는 입자 내로 제형화될 수 있다.
숙주 세포 내로 핵산을 도입하는 방법은 당업계에 공지되어 있고, 임의의 편리한 방법은 대상 핵산(예를 들어, 발현 작제물/벡터)을 표적 세포(예를 들어, 원핵 세포, 진핵 세포, 식물 세포, 동물 세포, 포유류 세포, 인간 세포 등) 내로 도입하는 데 사용될 수 있다. 적합한 방법은, 예를 들어, 바이러스 감염, 형질감염, 접합, 프로토플라스트 융합, 리포펙션, 전기천공법, 인산칼슘 침전, 폴리에틸렌이민(PEI)-매개 형질감염, DEAE-덱스트란 매개 형질감염, 리포좀-매개 형질감염, 입자총 기법, 인산칼슘 침전, 직접 미량주사법, 나노입자-매개 핵산 전달(예를 들어, 문헌[Panyam et., al Adv Drug Deliv Rev. 2012 Sep 13. pii: S0169-409X(12)00283-9. doi: 10.1016/j.addr.2012.09.023] 참조)등을 포함한다.
일부 경우에, 본 개시내용의 CasX 폴리펩타이드는 CasX 폴리펩타이드를 암호화하는 핵산(예를 들어, mRNA, DNA, 플라스미드, 발현 벡터, 바이러스 벡터 등)으로서 제공된다. 일부 경우에, 본 개시내용의 CasX 폴리펩타이드는 단백질로서(예를 들어, 관련된 가이드 RNA 없이 또는 회합 가이드 RNA와 함께, 즉, 리보핵단백질로서) 직접 제공된다. 본 개시내용의 CasX 폴리펩타이드는 임의의 편리한 방법에 의해 세포 내로 도입될 수 있으며(세포에 제공되며); 이러한 방법은 당업자에게 공지되어 있다. 예시적 예로서, 본 개시내용의 CasX 폴리펩타이드는 (예를 들어, CasX 가이드 RNA 또는 CasX 가이드 RNA를 암호화하는 핵산과 함께 또는 이들 없이, 그리고 공여자 폴리뉴클레오타이드와 함께 또는 이것 없이) 세포 내로 직접 주사될 수 있다. 다른 예로서, 본 개시내용의 CasX 폴리펩타이드 및 CasX 가이드 RNA(RNP)의 수행된 복합체는 (예를 들어, 주사를 통해, 뉴클레오펙션을 통해; 하나 이상의 성분에 접합된, 예를 들어, CasX 단백질에 접합된, 가이드 RNA 등에 접합된, 본 개시내용의 CasX 폴리펩타이드 및 가이드 RNA에 접합된 단백질 형질도입 도메인(PTD)을 통해) 세포(예를 들어, 진핵 세포) 내로 도입될 수 있다.
일부 경우에, 본 개시내용의 CasX 융합 폴리펩타이드(예를 들어, 융합 상대에 융합된 dCasX, 융합 상대에 융합된 틈내기효소 CasX 등)는 CasX 폴리펩타이드를 암호화하는 핵산(예를 들어, mRNA, DNA, 플라스미드, 발현 벡터, 바이러스 벡터 등)으로서 제공된다. 일부 경우에, 본 개시내용의 CasX 융합 폴리펩타이드는 단백질로서(예를 들어, 관련된 가이드 RNA 없이 또는 회합 가이드 RNA와 함께, 즉, 리보핵단백질로서) 직접 제공된다. 본 개시내용의 CasX 융합 폴리펩타이드는 임의의 편리한 방법에 의해 세포 내로 도입될 수 있으며(세포에 제공되며); 이러한 방법은 당업자에게 공지되어 있다. 예시적 예로서, 본 개시내용의 CasX 융합 폴리펩타이드는 (예를 들어, CasX 가이드 RNA를 암호화하는 핵산과 함께 또는 이들 없이, 그리고 공여자 폴리뉴클레오타이드와 함께 또는 이것 없이) 세포 내로 직접 주사될 수 있다. 다른 예로서, 본 개시내용의 CasX 융합 폴리펩타이드 및 CasX 가이드 RNA(RNP)의 수행된 복합체는 (예를 들어, 주사를 통해, 뉴클레오펙션을 통해; 하나 이상의 성분에 접합된, 예를 들어, CasX 융합 단백질에 접합된, 가이드 RNA 등에 접합된, 본 개시내용의 CasX 융합 폴리펩타이드 및 가이드 RNA에 접합된 단백질 형질도입 도메인(PTD)을 통해) 세포 내로 도입될 수 있다.
일부 경우에, 핵산(예를 들어, CasX 가이드 RNA; 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산; 등)은 입자 내 또는 입자와 회합된 세포(예를 들어, 표적 숙주 세포) 및/또는 폴리펩타이드(예를 들어, CasX 폴리펩타이드; CasX 융합 폴리펩타이드)에 전달된다. 일부 경우에, 본 개시내용의 CasX 시스템은 입자 내 세포에 전달되거나 또는 입자와 회합된다. 용어 "입자" 및 나노입자"는 적절하다면, 상호 호환적으로 사용될 수 있다. 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열 및/또는 CasX 가이드 RNA, 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 mRNA, 및 가이드 RNA를 포함하는 재조합 발현 벡터는 입자 또는 지질 외피를 이용하여 동시에 전달될 수 있고; 예를 들어, CasX 폴리펩타이드 및 예를 들어, 복합체(예를 들어, 리보뉴클레오단백질(RNP) 복합체)로서 CasX 가이드 RNA가 입자, 예를 들어, 지질 또는 리피도이드 및 친수성 중합체, 예를 들어, 양이온성 지질 및 친수성 중합체를 포함하는 전달 입자를 통해 전달될 수 있되, 예를 들어, 양이온성 지질은 1,2-다이올레오일-3-트라이메틸암모늄-프로판(DOTAP) 또는 1,2-다이테트라데칸오일-sn-글리세로-3-포스포콜린(DMPC)을 포함하고/하거나 친수성 중합체는 에틸렌 글리콜 또는 폴리에틸렌 글리콜(PEG)을 포함하고; 그리고/또는 입자는 추가로 콜레스테롤을 포함한다(예를 들어, 제형 1로부터의 입자=DOTAP 100, DMPC 0, PEG 0, 콜레스테롤 0; 제형 번호 2=DOTAP 90, DMPC 0, PEG 10, 콜레스테롤 0; 제형 번호 3=DOTAP 90, DMPC 0, PEG 5, 콜레스테롤 5). 예를 들어, 입자는 CasX 폴리펩타이드 및 CasX 가이드RNA가, 예를 들어, 1:1 몰비에서, 예를 들어, 실온에서, 예를 들어, 30분 동안, 예를 들어, 멸균, 무 뉴클레아제 1 x 인산염-완충 식염수(PBS) 중에서 함께 혼합되고; 그리고 별개로, 제형에 대해 적용 가능하다면 DOTAP, DMPC, PEG 및 콜레스테롤은 알코올, 예를 들어, 100% 에탄올 중에서 용해되고; 그리고, 두 용액은 함께 혼합되어 복합체를 함유하는 입자를 형성하는 다단계 공정을 이용하여 형성될 수 있다.
본 개시내용의 CasX 폴리펩타이드(또는 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 mRNA; 또는 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터) 및/또는 CasX 가이드 RNA(또는 CasX 가이드 RNA를 암호화하는 하나 이상의 발현 벡터와 같은 핵산)는 입자 또는 지질 외피를 이용하여 동시에 전달될 수 있다. 예를 들어, 인지질 이중층 껍질로 뒤덮인 폴리(β-아미노 에스터)(PBAE) 코어를 갖는 생분해성 코어 껍질 구조의 나노입자를 사용할 수 있다. 일부 경우에, 자가 조립 생접착성 중합체에 기반한 입자/나노입자가 사용되고; 이러한 입자/나노입자는, 예를 들어, 뇌에 대해, 펩타이드의 경구 전달, 펩타이드의 정맥내 전달 및 펩타이드의 비강 전달에 적용될 수 있다. 다른 실시형태, 예컨대 경구 흡수 및 소수성 약물의 눈 전달이 또한 상정된다. 보호되고 질환 부위로 전달되는 조작된 중합체를 수반하는 분자 외피 기법이 사용될 수 있다. 약 5㎎/㎏의 용량은 다양한 인자, 예를 들어, 표적 조직에 따라서 단일 또는 다회 용량으로 사용될 수 있다.
리피도이드 화합물(예를 들어, 미국 특허 출원 제20110293703호에 기재된 바와 같음)은 또한 폴리뉴클레오타이드의 투여에 유용하고, 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산 또는 본 개시내용의 CasX 시스템을 전달하기 위해 사용될 수 있다(예를 들어, CasX 시스템은 a) 본 개시내용의 CasX 폴리펩타이드 및 CasX 가이드 RNA; b) 본 개시내용의 CasX 폴리펩타이드, CasX 가이드 RNA, 및 공여자 주형 핵산; c) 본 개시내용의 CasX 융합 폴리펩타이드 및 CasX 가이드 RNA; d) 본 개시내용의 CasX 융합 폴리펩타이드, CasX 가이드 RNA, 및 공여자 주형 핵산; e) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 mRNA; 및 CasX 가이드 RNA; f) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 mRNA, CasX 가이드 RNA, 및 공여자 주형 핵산; g) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 mRNA; 및 CasX 가이드 RNA; h) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 mRNA, CasX 가이드 RNA, 및 공여자 주형 핵산; i) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; j) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 공여자 주형 핵산을 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; k) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; l) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 공여자 주형 핵산을 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; m) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; n) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; 및 공여자 주형 핵산; o) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; p) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; 및 공여자 주형 핵산; q) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, 제1 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 제2 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; 또는 r) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, 제1 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 제2 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; 또는 (a) 내지 (r) 중 하나의 일부 변형을 포함한다. 일 양상에서, 아미노알코올 리피도이드 화합물은 세포 또는 대상에 전달될 제제와 조합되어 마이크로입자, 나노입자, 리포좀 또는 마이셀을 형성한다. 아미노알코올 리피도이드 화합물은 다른 아미노알코올 리피도이드 화합물, 중합체(합성 또는 천연), 계면활성제, 콜레스테롤, 탄수화물, 단백질, 지질 등과 조합되어 입자를 형성할 수 있다. 이어서, 이들 입자는 선택적으로 약제학적 부형제와 조합되어 약제학적 조성물을 형성할 수 있다.
폴리(베타-아미노 알코올)(PBAA)은 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하는 데 사용될 수 있다. 미국 특허 공개 제20130302401호는 조합적 중합을 이용하여 제조된 폴리(베타-아미노 알코올)(PBAA) 부류에 관한 것이다.
당-기반 입자는, 예를 들어, 참고로 WO2014118272(본 명세서에 참고로 편입됨) 및 문헌[Nair, J K et al., 2014, Journal of the American Chemical Society 136 (49), 16958-16961]에 기재된 바와 같은 GalNAc이 사용될 수 있고, 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하기 위해 사용될 수 있다.
일부 경우에, 지질 나노입자(LNP)는 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하는 데 사용될 수 있다. 음으로 하전된 중합체, 예컨대 RNA는 낮은 pH 값(예를 들어, pH 4)에서 LNP에 부하될 수 있고, 여기서 이온화 가능한 지질은 양전하를 나타낸다. 그러나, 생리적 pH 값에서, LNP는 더 긴 순환 시간에 적합한 낮은 표면 전하를 나타낸다. 이온화 가능한 양이온성 지질의 4가지 종, 즉, 1,2-다이리놀레일-3-다이메틸암모늄-프로판(DLinDAP), 1,2-다이리놀레일옥시-3-N,N-다이메틸아미노프로판(DLinDMA), 1,2-다이리놀레일옥시-케토-N,N-다이메틸-3-아미노프로판(DLinKDMA), 및 1,2-다이리놀레일-4-(2-다이메틸아미노에틸)-[1,3]-다이옥솔란(DLinKC2-DMA)에 중점을 두었다. LNP의 제조는, 예를 들어, 문헌[Rosin et al. (2011) Molecular Therapy 19:1286-2200)]에 기재되어 있다. 양이온성 지질 1,2-다이리놀레일-3-다이메틸암모늄-프로판(DLinDAP), 1,2-다이리놀레일옥시-3-N,N-다이메틸아미노프로판(DLinDMA), 1,2-다이리놀레일옥시케토-N,N-다이메틸-3-아미노프로판(DLinK-DMA), 1,2-다이리놀레일-4-(2-다이메틸아미노에틸)-[1,3]-다이옥솔란 (DLinKC2-DMA), (3-o-[2''-(메톡시폴리에틸렌글리콜 2000) 숙신오일]-1,2-다이미리스토일-sn-글리콜 (PEG-S-DMG), 및 R-3-[(.오메가.-메톡시-폴리(에틸렌 글리콜)2000) 카바모일]-1,2-다이미리스틸옥실프로필-3-아민(PEG-C-DOMG)이 사용될 수 있다. 핵산(예를 들어, CasX 가이드 RNA; 본 개시내용의 핵산 등)은 DLinDAP, DLinDMA, DLinK-DMA 및 DLinKC2-DMA(40:10:40:10 몰비로 양이온성 지질:DSPC:CHOL: PEGS-DMG 또는 PEG-C-DOMG)를 함유하는 LNP에서 캡슐화될 수 있다. 일부 경우에, 0.2% SP-DiOC18이 혼입된다.
구체 핵산(SNA(상표명)) 작제물 및 다른 나노입자(특히 금 나노입자)는 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하는 데 사용될 수 있다. 예를 들어, 문헌[Cutler et al., J. Am. Chem. Soc. 2011 133:9254-9257, Hao et al., Small. 2011 7:3158-3162, Zhang et al., ACS Nano. 2011 5:6962-6970, Cutler et al., J. Am. Chem. Soc. 2012 134:1376-1391, Young et al., Nano Lett. 2012 12:3867-71, Zheng et al., Proc. Natl. Acad. Sci. USA. 2012 109:11975-80, Mirkin, Nanomedicine 2012 7:635-638 Zhang et al., J. Am. Chem. Soc. 2012 134:16488-1691, Weintraub, Nature 2013 495:S14-S16, Choi et al., Proc. Natl. Acad. Sci. USA. 2013 110(19): 7625-7630, Jensen et al., Sci. Transl. Med. 5, 209ra152 (2013) 및 Mirkin, et al., Small, 10:186-192] 참조.
RNA를 갖는 자기-조립 나노입자는 폴리에틸렌 글리콜(PEG)의 원위 단부에 부착된 Arg-Gly-Asp (RGD)펩타이드 리간드로 페길화된 폴리에틸렌이민(PEI)에 의해 작제될 수 있다.
일반적으로, "나노입자"는 직경이 1000㎚ 미만인 임의의 입자를 지칭한다. 일부 경우에, 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산, 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하는 데 사용하기에 적합한 나노입자는 직경이 500㎚ 이하, 예를 들어, 25㎚ 내지 35㎚, 35㎚ 내지 50㎚, 50㎚ 내지 75㎚, 75㎚ 내지 100㎚, 100㎚ 내지 150㎚, 150㎚ 내지 200㎚, 200㎚ 내지 300㎚, 300㎚ 내지 400㎚, 또는 400㎚ 내지 500㎚이다. 일부 경우에, 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하는 데 사용하기에 적합한 나노입자는 직경이 25㎚ 내지 200㎚이다. 일부 경우에, 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산, 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하는 데 사용하기에 적합한 나노입자는 직경이 100㎚ 이하이고, 일부 경우에, 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산, 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하는 데 사용하기에 적합한 나노입자는 직경이 35㎚ 내지 60㎚이다.
본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산, 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하는 데 사용하기에 적합한 나노입자는 상이한 형태, 예를 들어, 고체 나노입자(예를 들어, 금속, 예컨대 은, 금, 철, 티타늄), 비-금속, 지질계 고체, 중합체), 나노입자의 현탁액 또는 이들의 조합물로 제공될 수 있다. 금속, 유전체 및 반도체 나노입자뿐만 아니라 혼성 구조(예를 들어, 코어-껍질 나노입자)가 제조될 수 있다. 반도체 물질로 만들어진 나노입자는 또한, 그들이 전자 에너지 준위의 양자화가 일어나기에 충분히 작다면(전형적으로 10㎚ 미만), 표지된 양자점일 수 있다. 이러한 나노규모 입자는 약물 담체 또는 영상화제로서의 생의학적 적용분야에서 사용되고, 본 개시내용에서 유사한 목적을 위해 채택될 수 있다.
반고체 및 연질 나노입자는 또한 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하는 데 사용하기에 적합하다. 반고체 특성의 원형 나노입자는 리포좀이다.
일부 경우에, 엑소좀은 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하는 데 사용될 수 있다. 엑소좀은 RNA 및 단백질을 수송하고, RNA를 뇌 및 다른 표적 기관에 전달할 수 있는 내인성 나노소포체이다.
일부 경우에, 리포좀은 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하는 데 사용될 수 있다. 리포좀은 내부 수성 구획을 둘러싸는 단층 또는 다층 지질 이중층 및 상대적으로 불침투성의 외부 친유성 인지질 이중층으로 구성된 구체 소수포 구조이다. 리포좀은 몇몇 상이한 유형의 지질로부터 이루어질 수 있지만, 그러나 인지질은 리포좀을 생성하는 데 가장 통상적으로 사용된다. 지질막이 수성 용액과 혼합될 때 리포좀 제형은 자발적이지만, 이는 또한 균질기, 초음파분해기 또는 압출 장치를 이용함으로써 진탕 형태로 힘을 적용함으로써 촉진될 수 있다. 이 구조 및 특성을 변형시키기 위래 몇몇 다른 첨가제가 리포좀에 첨가될 수 있다. 예를 들어, 리포좀 구조를 안정화시키기 위해 그리고 리포좀 내부 내용물의 누출을 방지하기 위해 콜레스테롤 또는 스핑고마이엘린 중 하나가 리포좀 혼합물에 첨가될 수 있다. 리포좀 제형은 주로 천연 인지질 및 지질, 예컨대 1,2-다이스테아릴-sn-글리세로-3-포스파티딜 콜린(DSPC), 스핑고마이엘린, 난황 포스파티딜콜린 및 모노시알로강글리오사이드를 포함할 수 있다.
안정한 핵산-지질 입자(SNALP)는 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하는 데 사용될 수 있다. SNALP 제형은 2:40:10:48 몰 백분율 비로 지질 3-N-[(메톡시폴리(에틸렌 글리콜) 2000) 카바모일]-1,2-다이미리스틸옥시-프로필아민(PEG-C-DMA), 1,2-다이리놀레일옥시-N,N-다이메틸-3-아미노프로판(DLinDMA), 1,2-다이스테아로일-sn-글리세로-3-포스포콜린(DSPC) 및 콜레스테롤을 함유할 수 있다. SNALP 리포좀은 콜레스테롤/D-Lin-DMA/DSPC/PEG-C-DMA의 25:1 지질/siRNA 비 및 48/40/10/2 몰비를 이용하여 다이스테아로일포스파티딜콜린(DSPC), 콜레스테롤 및 siRNA와 함께 D-Lin-DMA 및 PEG-C-DMA를 제형화함으로써 제조될 수 있다. 얻어진 SNALP 리포좀은 크기가 약 80 내지 100㎚일 수 있다. SNALP는 합성 콜레스테롤(시그마-알드리치(Sigma-Aldrich), 미국 미주리주 세인트루이스에 소재), 다이팔미토일포스파티딜콜린(아반티 폴라 인코포레이티드(Avanti Polar Lipids), 미국 앨리버마주 알라바스터에 소재), 3-N-[(w-메톡시 폴리(에틸렌 글리콜)2000)카바모일]-1,2-다이미리스틸옥시프로필아민 및 양이온성 1,2-다이리놀레일옥시-3-N,N-다이메틸아미노프로판을 포함할 수 있다. SNALP는 합성 콜레스테롤(시그마-알드리치), 1,2-다이스테아로일-sn-글리세로-3-포스포콜린(DSPC; 아반티 폴라 리피트 인코포레이티드), PEG-cDMA, 및 1,2-다이리놀레일옥시-3-(N;N-다이메틸)아미노프로판(DLinDMA)을 포함할 수 있다.
다른 양이온성 지질, 예컨대 아미노 지질 2,2-다이리놀레일-4-다이메틸아미노에틸-[1,3]-다이옥솔란(DLin-KC2-DMA)은 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산, 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하기 위해 사용될 수 있다. 다음의 지질 조성으로 수행된 소수포가 상정될 수 있다: 각각 몰비 40/10/40/10로 아미노 지질, 다이스테아로일포스파티딜콜린(DSPC), 콜레스테롤 및 (R)-2,3-비스(옥타데실옥시) 프로필-1-(메톡시 폴리(에틸렌 글리콜)2000)프로필카바메이트(PEG-지질), 및 대략 0.05(w/w)의 FVII siRNA/총 지질비. 70 내지 90㎚ 범위의 좁은 입자 크기 분포 및 0.11.+-.0.04(n=56)의 낮은 다분산지수를 보장하기 위해, 입자는 가이드 RNA를 첨가하기 전에 80㎚ 막을 통해 3회까지 압출될 수 있다. 상당히 강한 아미노 지질 16을 함유하는 입자가 사용될 수 있으며, 이때 4가지 지질 성분 16, DSPC, 콜레스테롤 및 PEG-지질(50/10/38.5/1.5)의 몰비는 생체내 활성을 향상시키도록 추가로 최적화될 수 있다.
지질은 본 개시내용의 CasX 시스템 또는 이의 성분(들) 또는 이를 암호화하는 핵산으로 제형화되어 지질 나노입자(LNP)를 형성할 수 있다. 적합한 지질은 DLin-KC2-DMA4, C12-200 및 코지질(colipid) 다이스테로일포스파티딜 콜린, 콜레스테롤 및 PEG-DMG를 포함하지만, 이들로 제한되지 않으며, 자발적 소수포 제형화 절차를 이용하여 본 개시내용의 CasX 시스템, 또는 이의 성분으로 제형화될 수 있다. 성분 몰비는 약 50/10/38.5/1.5(DLin-KC2-DMA 또는 C12-200/다이스테로일포스파티딜 콜린/콜레스테롤/PEG-DMG)일 수 있다.
미국 특허 공개 제20130252281호 및 제20130245107호 및 제20130244279호에서 추가로 기재된 것과 같이 PLGA 마이크로스피어에서 캡슐화된 본 개시내용의 CasX 시스템, 또는 이의 성분이 전달될 수 있다.
과급된 단백질이 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하는 데 사용될 수 있다. 과급된 단백질은 흔치 않게 높은 양성 또는 음성 이론적 순전하를 갖는 조작된 또는 천연 유래 단백질의 부류이다. 초음성과 초양성으로 하전된 단백질은 둘 다 열적으로 또는 화학적으로 유도된 응집을 견뎌내는 능력을 나타낸다. 초양성으로 하전된 단백질은 또한 포유류 세포를 침투할 수 있다. 이들 단백질, 예컨대 플라스미드 DNA, RNA 또는 다른 단백질과 화물의 회합은 시험관내 그리고 생체내 둘 다에서 포유류 세포 내로 이들 거대분자의 기능적 전달을 용이하게 할 수 있다.
세포 침투성 펩타이드(Cell Penetrating Peptide: CPP)가 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산 또는 본 개시내용의 CasX 시스템을 표적 세포에 전달하는 데 사용될 수 있다. CPP는 전형적으로 양으로 하전된 아미노산, 예컨대 라이신 또는 알기닌의 낮은 상대적 존재비를 함유하거나 또는 극성/하전된 아미노산 및 비극성, 소수성 아미노산의 교번의 패턴을 함유하는 서열을 갖는 아미노산 조성물을 가진다.
이식 가능한 장치는 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산(예를 들어, CasX 가이드 RNA, CasX 가이드 RNA를 암호화하는 핵산, CasX 폴리펩타이드를 암호화하는 핵산, 공여자 주형 등), 또는 본 개시내용의 CasX 시스템을 표적 세포(예를 들어, 생체내 표적 세포, 여기서 표적 세포는 순환에서의 표적 세포, 조직 내 표적 세포, 기관 내 표적 세포임)에 전달하는 데 사용될 수 있다. 본 개시내용의 CasX 폴리펩타이드, 본 개시내용의 CasX 융합 폴리펩타이드, 본 개시내용의 RNP, 본 개시내용의 핵산, 또는 본 개시내용의 CasX 시스템을 표적 세포(예를 들어, 생체내 표적 세포, 여기서 표적 세포는 순환에서의 표적 세포, 조직 내 표적 세포, 기관 내 표적 세포 등임)에 전달하는 데 사용하기에 적합한 이식 가능한 장치는 CasX 폴리펩타이드, CasX 융합 폴리펩타이드, RNP, 또는 CasX 시스템(또는 이의 성분, 예를 들어, 본 개시내용의 핵산)을 포함하는 용기(예를 들어, 저장소, 매트릭스 등)를 포함할 수 있다.
적합한 이식 가능한 장치는 중합체 기질, 예컨대 매트릭스(예를 들어, 장치 본체로서 사용됨), 및 일부 경우에 추가적인 스캐폴드 물질, 예컨대 금속 또는 추가적인 중합체, 및 가시성 및 이미징을 향상시키기 위한 물질을 포함할 수 있다. 이식 가능한 전달 장치는 국소로 그리고 장기간에 걸쳐 방출을 제공하는 데 유리할 수 있고, 여기서 전달될 폴리펩타이드 및/또는 핵산은 표적 부위, 예를 들어, 세포외 기질(ECM), 종양을 둘러싸는 혈관, 질병 조직 등으로 직접 방출된다. 적합한 이식 가능한 전달 장치는 복강과 같은 내강에 대한 전달 및/또는 임의의 다른 유형의 투여에서 사용하기에 적합한 장치를 포함하며, 이때 생체 안정성 및/또는 분해성 및/또는 생체 흡수성 중합체 기질(예를 들어, 선택적으로 매트릭스일 수 있음)을 포함하는 약물 전달 시스템은 고정 또는 부착되지 않는다. 일부 경우에, 적합한 이식 가능한 약물 전달 장치는 분해성 중합체를 포함하되, 주요 방출 메커니즘은 벌크 침식(bulk erosion)이다. 일부 경우에, 적합한 이식 가능한 약물 전달 장치는 비분해성 또는 느리게 분해되는 중합체를 포함하되, 주요 방출 메커니즘은 벌크 침식보다는 확산성이며, 따라서 외부 부분은 막으로서 작용하고, 그의 내부 부분은 약물 저장소로서 작용하는데, 이는 사실상 장기간 동안(예를 들어, 약 1주 내지 약 몇 개월) 주변에 의해 영향받지 않는다. 상이한 중합체와 상이한 방출 메커니즘의 조합이 또한 선택적으로 사용될 수 있다. 농도 구배는 총 방출 기간의 상당한 기간 동안 효과적으로 유지될 수 있고, 따라서 확산 속도는 효과적으로 일정하다("제로 방식(zero mode)" 확산으로 칭해짐). 용어 "일정한"은 치료적 유효성의 하부 역치 초과로 유지되지만, 여전히 선택적으로 초기 버스트 확산 속도를 특징으로 할 수 있고/있거나, 예를 들어, 특정 정도로 증가 및 감소하면서 변동할 수 있는 확산 속도를 의미한다. 확산 속도는 장기간 동안 그렇게 유지될 수 있고, 이는 치료적으로 유효한 기간, 예를 들어, 유효한 침묵 기간을 최적화하기 위해 특정 수준에 대해 일정하게 고려될 수 있다.
일부 경우에, 이식 가능한 전달 시스템은, 천연에서 화학물질이든 또는 대상체의 신체에서 효소 및 다른 인자로부터의 공격에 기인하든 뉴클레오타이드계 치료제가 분해되는 것을 막도록 설계된다.
장치의 이식을 위한 부위 또는 표적 부위는 최대 치료 효능을 위해 선택될 수 있다. 예를 들어, 전달 장치는 종양 환경, 또는 종양과 관련된 혈액 공급 내에서 또는 이의 근위에 이식될 수 있다. 표적 위치는, 예를 들어 하기일 수 있다: 1) 기저핵, 백질 및 회백질에서 파킨슨 또는 알츠하이머병에서와 같이 퇴행성 부위에서의 뇌; 2) 근위축성측색경화증(ALS)의 경우에 척추; 3) 자궁경부; 4) 활성 및 만성 염증성 관절염; 5) 건선의 경우에 피부; 7) 알레르기 효과에 대한 교감신경성 및 감각 신경 부위; 7) 뼈; 8) 급성 또는 만성 감염 부위; 9) 질내; 10) 내이--청각계, 내이의 미로, 전정계; 11) 기관내; 12) 심장내; 관상동맥, 심외막; 13) 비뇨기관 또는 방광; 14) 담도계; 15) 신장, 표, 비장을 포함하지만, 이들로 제한되지 않는 실질세포; 16) 림프절; 17) 침샘; 18) 덴탈검(dental gum); 19) 관절강내(관절내); 20) 안구내; 21) 뇌조직; 22) 뇌실; 23) 복강을 포함하는 강(예를 들어, 제한되는 것은 아니지만, 난소암에 대해); 24) 식도내; 및 25) 직장내; 및 26) 혈관구조내.
삽입, 예컨대 이식 방법은 선택적으로 변형 없이 또는 대안적으로 선택적으로 이러한 방법에서 중요하지 않은 변형만으로 다른 유형의 조직 이식을 위해 그리고/또는 삽입을 위해 그리고/또는 조직 샘플링을 위해 선택적으로 이미 사용될 수 있다. 이러한 방법은 선택적으로 브라키테라피 방법, 생검, 초음파와 함께 그리고/또는 초음파 없이 내시경검사, 예컨대 뇌 조직 내로 주촉성 방법, 관절, 복부 기관, 방광벽 및 체강 내로 복강경의 이식을 포함하는 복강경검사를 포함하지만, 이들로 제한되지 않는다.
변형된 숙주 세포
본 개시내용은 본 개시내용의 CasX 폴리펩타이드를 포함하는 변형된 세포 및/또는 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산을 제공한다. 본 개시내용은 본 개시내용의 CasX 폴리펩타이드를 포함하는 변형된 세포를 제공하며, 여기서 변형된 세포는 본 개시내용의 CasX 폴리펩타이드를 정상적으로 포함하지 않는 세포이다. 본 개시내용은 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산을 포함하는 변형된 세포(예를 들어, 유전자 변형된 세포)를 제공한다. 본 개시내용은 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 mRNA로 유전자 변형된 유전자 변형 세포를 제공한다. 본 개시내용은 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터로 유전자 변형된 유전자 변형 세포를 제공한다. 본 개시내용은: a) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; 및 b) 본 개시내용의 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터로 유전자 변형된 유전자 변형 세포를 제공한다. 본 개시내용은: a) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; b) 본 개시내용의 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열; 및 c) 공여자 주형을 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터로 유전자 변형된 유전자 변형 세포를 제공한다.
본 개시내용의 CasX 폴리펩타이드 및/또는 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산 및/또는 본 개시내용의 CasX 가이드 RNA에 대한 수용자로서 작용하는 세포는, 예를 들어, 시험관내 세포; 생체내 세포; 생체외 세포; 1차 세포; 암 세포; 동물 세포; 식물 세포; 조류 세포; 진균 세포 등을 포함하는 임의의 다양한 세포일 수 있다. 본 개시내용의 CasX 폴리펩타이드 및/또는 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산 및/또는 본 개시내용의 CasX 가이드 RNA에 대한 수용자로서 작용하는 세포는 "숙주 세포" 또는 "표적 세포"로서 지칭된다. 숙주 세포 또는 표적 세포는 본 개시내용의 CasX 시스템의 수용자일 수 있다. 숙주 세포 또는 표적 세포는 본 개시내용의 CasX RNP의 수용자일 수 있다. 숙주 세포 또는 표적 세포는 본 개시내용의 CasX 시스템의 단일 성분의 수용자일 수 있다.
세포(표적 세포)의 비제한적 예는 원핵 세포, 진핵 세포, 박테리아 세포, 고세균 세포, 단세포 진핵 유기체의 세포, 원생동물 세포, 식물로부터의 세포(예를 들어, 식물 작물, 과일, 채소, 곡물, 대두, 옥수수, 마이스, 밀, 종자, 토마토, 벼, 카사바, 사탕수수, 호박, 건초, 감자, 목화, 대마초, 담배, 하훼, 구과 식물, 겉씨식물, 속씨식물, 양치식물, 석송, 뿔이끼류, 우산이끼류, 선태식물, 쌍떡잎식물, 외떡잎식물 등), 조류 세포, (예를 들어, 보트리오코쿠스 브라우니(Botryococcus braunii), 칼라마이도모나스 레인하르티(Chlamydomonas reinhardtii), 난노클로롭시스 가디타나(Nannochloropsis gaditana), 클로렐라 피레노이도사(Chlorella pyrenoidosa), 모자반속(Sargassum patens, C. agardh) 등), 해초(예를 들어, 켈프) 진균 세포 (예를 들어, 효모 세포, 버섯으로부터의 세포), 동물 세포, 무척추동물(예를 들어, 과실파리, 강장동물, 극피동물, 선충 등)으로부터의 세포, 척추동물(예를 들어, 어류, 양서류, 파충류, 조류, 포유류)로부터의 세포, 포유류 (예를 들어, 유제류(예를 들어, 돼지, 소, 염소, 양)로부터의 세포; 설치류(예를 들어, 래트, 마우스); 비-인간 영장류; 인간; 고양이과(예를 들어, 고양이); 갯과(예를 들어, 개); 등) 등을 포함한다. 일부 경우에, 세포는 천연 유기체로부터 유래되지 않은 세포이다(예를 들어, 세포는 합성으로 만들어진 세포일 수 있고; 또한 인공 세포로서 지칭된다).
세포는 시험관내 세포일 수 있다(예를 들어, 확립된 배양 세포주). 세포는 생체외 세포일 수 있다(개체로부터의 배양 세포). 세포는 생체내 세포(예를 들어, 개체 내 세포)일 수 있다. 세포는 단리된 세포일 수 있다. 세포는 유기체 내부의 세포일 수 있다. 세포는 유기체일 수 있다. 세포는 세포 배양물 내 세포일 수 있다(예를 들어, 시험관내 세포 배양물). 세포는 세포 수집물 중 하나일 수 있다. 세포는 원핵 세포이거나 또는 원핵 세포로부터 유래될 수 있다. 세포는 박테리아 세포일 수 있거나 또는 박테리아 세포로부터 유래될 수 있다. 세포는 고세균 세포일 수 있거나 또는 고세균 세포로부터 유래될 수 있다. 세포는 진핵 세포일 수 있거나 또는 진핵 세포로부터 유래될 수 있다. 세포는 식물 세포일 수 있거나 또는 식물 세포로부터 유래될 수 있다. 세포는 동물 세포일 수 있거나 또는 동물 세포로부터 유래될 수 있다. 세포는 무척추동물 세포일 수 있거나 또는 무척추동물 세포로부터 유래될 수 있다. 세포는 척추동물 세포일 수 있거나 또는 척추동물 세포로부터 유래될 수 있다. 세포는 포유류 세포일 수 있거나 또는 포유류 세포로부터 유래될 수 있다. 세포는 설치류 세포일 수 있거나 또는 설치류 세포로부터 유래될 수 있다. 세포는 인간 세포일 수 있거나 또는 인간 세포로부터 유래될 수 있다. 세포는 미생물 세포일 수 있거나 또는 미생물 세포로부터 유래될 수 있다. 세포는 진균 세포일 수 있거나 또는 진균 세포로부터 유래될 수 있다. 세포는 곤충 세포일 수 있다. 세포는 절지동물 세포일 수 있다. 세포는 원생동물 세포일 수 있다. 세포는 유충 세포일 수 있다.
적합한 세포는 줄기 세포(예를 들어, 배아 줄기(ES) 세포, 유도 만능 줄기(iPS) 세포; 생식세포(예를 들어, 난모세포, 정자, 난원세포, 정원세포 등); 체세포, 예를 들어, 섬유아세포, 희소돌기신경교, 교세포, 조혈모세포, 뉴런, 근육 세포, 골세포, 간세포, 췌장 세포 등을 포함한다.
적합한 세포는 인간 배아 줄기 세포, 태아 심장 근육 세포, 근육섬유아세포, 간충직 줄기 세포, 자가이식 확장된 심장 근육 세포, 지방세포, 전분화 세포, 만능 세포, 혈액 줄기 세포, 근아세포, 성체 줄기 세포, 골수 세포, 간충직 세포, 배아 줄기 세포, 실질 세포, 상피세포, 내피세포, 중피세포, 섬유아세포, 조골세포, 연골세포, 외인성 세포, 내인성 세포, 줄기 세포, 조혈모세포, 골수 유래 전구체 세포, 심근세포, 골격 세포, 태아 세포, 미분화 세포, 다능 전구체 세포, 단분화능 전구체 세포, 단핵구, 심장 근아세포, 골격 근아세포, 대식세포, 모세혈관 내피세포, 이종 세포, 동종 세포 및 출산후 줄기 세포를 포함한다.
일부 경우에, 세포는 면역세포, 뉴런, 상피세포 및 내피세포 또는 줄기 세포이다. 일부 경우에, 면역세포는 T 세포, B 세포, 단핵구, 자연살해 세포, 수지상 세포 또는 대식세포이다. 일부 경우에, 면역세포는 세포독성 T 세포이다. 일부 경우에, 면역세포는 헬퍼 T 세포이다. 일부 경우에, 면역세포는 조절 T 세포(Treg)이다.
일부 경우에, 세포는 줄기 세포이다. 줄기 세포는 성체 줄기 세포를 포함한다. 성체 줄기 세포는 또한 체세포 줄기 세포로서 지칭된다.
성체 줄기 세포는 분화된 조직 내에 존재하지만, 자기 재생 특성 및 다중 세포 유형, 보통 줄기 세포가 발견된 전형적인 조직의 세포 유형이 생기게 하는 능력을 보유한다. 체세포 줄기 세포의 수많은 예는 당업자에게 공지되어 있으며, 근육 줄기 세포; 조혈모세포; 상피 줄기 세포; 신경 줄기 세포; 간충직 줄기 세포; 유방 줄기 세포; 장 줄기 세포; 중배엽 줄기 세포; 내피 줄기 세포; 후각 줄기 세포; 신경 능선 줄기 세포 등을 포함한다.
관심 대상의 줄기 세포는 포유류 줄기 세포를 포함하며, 용어 "포유류"는 인간; 비-인간 영장류; 가축 및 농장 동물; 및 동물원, 실험실, 운동 또는 반려 동물, 예컨대 개, 말, 고양이, 소, 마우스, 래트, 토끼 등을 포함하는 포유류로서 분류된 임의의 동물을 지칭한다. 일부 경우에, 줄기 세포는 인간 줄기 세포이다. 일부 경우에, 줄기 세포는 설치류(예를 들어, 마우스; 래트) 줄기 세포이다. 일부 경우에, 줄기 세포는 비-인간 영장류 줄기 세포이다.
줄기 세포는 하나 이상의 줄기 세포 마커, 예를 들어, SOX9, KRT19, KRT7, LGR5, CA9, FXYD2, CDH6, CLDN18, TSPAN8, BPIFB1, OLFM4, CDH17 및 PPARGC1A를 발현시킬 수 있다.
일부 실시형태에서, 줄기 세포는 조혈모세포(HSC)이다. HSC는 골수, 혈액, 제대혈, 태아간 및 난황낭으로부터 단리될 수 있는 중배엽-유래 세포이다. HSC는 CD34+ 및 CD3-으로서 특성규명된다. HSC는 생체내 적혈구, 호중성-대식세포, 거핵구 및 림프계 조혈세포 계통을 재생시킬 수 있다. 시험관내에서, HSC는 적어도 일부의 자기-재생 세포 분열을 겪도록 유도될 수 있고, 생체내에서 알 수 있는 바와 같이 동일한 계통으로 분화되도록 유도될 수 있다. 이렇게 해서, HSC는 적혈구 세포, 거핵구, 호중구, 대식세포 및 림프구 세포 중 하나 이상으로 분화되도록 유도될 수 있다.
다른 실시형태에서, 줄기 세포는 신경 줄기 세포(NSC)이다. 신경 줄기 세포(NSC)는 뉴런, 및 교세포(희소돌기신경교 및 성상교세포를 포함)로 분화할 수 있다. 신경 줄기 세포는 다회 분열할 수 있는 다능성 줄기 세포이고, 특정 조건 하에서 신경아세포 또는 아교모세포, 예를 들어, 각각 뉴런 및 교세포 중 하나 이상의 유형이 되도록 기여하는 세포일 수 있는 신경 줄기 세포 또는 신경 전구체 세포인 딸 세포를 생성할 수 있다. NSC를 얻는 방법은 당업계에 공지되어 있다.
다른 실시형태에서, 줄기 세포는 간충직 줄기 세포(MSC)이다. MSC는 본래 배아 중배엽으로부터 유래되고, 성체 골수로부터 단리되며, 근육, 뼈, 연골, 지방, 골수 기질 및 힘줄을 형성하도록 분화될 수 있다. MSC를 단리시키는 방법은 당업계에 공지되어 있으며; MSC를 얻기 위한 임의의 공지된 방법이 사용될 수 있다. 예를 들어, 인간 MSC의 단리를 기재하는 미국 특허 제5,736,396호 참조.
세포는 일부 경우에 식물 세포이다. 식물 세포는 외떡잎식물의 세포일 수 있다. 세포는 쌍떡잎식물의 세포일 수 있다.
일부 경우에, 세포는 식물 세포이다. 예를 들어, 세포는 주요 농작물, 예를 들어, 보리, 콩류(건조 식용), 카놀라, 옥수수, 목화(피마), 목화(업랜드), 아마씨, 건초(알팔파), 건초(비-알팔파), 귀리, 땅콩, 벼, 수수, 대두, 사탕무, 사탕수수, 해바라기(오일), 해바라기(비-오일), 고구마, 담배(벌리), 담배(연관처리(Flue-cured)), 토마토, 밀(듀럼), 밀(봄), 밀(겨울) 등의 세포일 수 있다. 다른 예로서, 세포는, 예를 들어, 알팔파, 알로에 잎, 애로루트, 벗풀, 아티초크, 아스파라거스, 죽순, 바나나꽃, 콩나물, 콩류, 비이트톱, 근대, 비타멜론, 청경채, 브로콜리, 브로콜리 라베(엽경채), 방울다다기 양배추, 양배추, 방울 양배추, 가재발 선인장(노팔), 호리병박 열매, 카르둔, 당근, 콜리플라워, 셀러리, 차요테, 중국 아티초크(두루미냉이), 중국 양배추, 중국 셀러리, 중국 차이브, 채심, 국화잎(퉁호), 콜라드 그린, 옥수수대, 단옥수수, 오이, 대컨, 단데리온 그린, 타로토란, 다우 무에(dau mue)(피 팁(pea tip)), 동과(겨울멜론), 가지, 엔다이브, 에스카롤, 선수 장식 양치식물, 갓류 식물, 치커리, 갓 (중국 겨자), 가일론(gailon), 갈랑가(시암, 태국 생강), 마늘, 생강 뿌리, 우엉, 나물, 하노버 샐러드 나물, 후아우존틀, 예루살렘 아티초크, 히카마, 케일 나물, 콜라비, 명아주(?리떼), 상추(비브), 상추(보스턴), 상추 (보스턴 레드), 상추(녹색잎), 상추(아이스버그), 상추(롤라로사), 상추(오크리프 - 녹색), 상추 (오크리프 - 적색), 상추(가공처리), 상추(적색잎), 상추(로메인), 상추(루비 로메인), 상추(러시안 레드 겨자), 린쿡, 로 복, 긴콩류, 연근, 마하, 용설란 (아가베) 잎, 말랑가, 메스꿀랭 믹스, 겨자과, 모압(수세미오이), 무(moo), 모쿠아(moqua)(동과), 버섯, 겨자, 참마, 오크라, 옹초이, 그린 어니언, 오포(opo)(롱 스쿼시), 장식용 옥수수, 관상용 호박, 파슬리, 파스닙, 완두콩, 후추(벨형), 후추, 호박, 라디키오, 무순, 무, 레이프 그린(rape greens),레이프 그린, 대황, 로메인(베이비 레드), 루타베가, 함초(씨빈), 신쿠아(앵글드/줄기가 선 수세미), 시금치, 스쿼시, 짚 더미, 사탕수수, 고구마, 근대, 타마린드, 타로, 타로잎, 타로 슈트, 탓소이, 테페구아헤(tepeguaje)(구아헤), 빔바, 토마틸로, 토마토, 토마토 (체리), 토마토(포도형), 토마토 (자두형), 강황, 순무 어린잎 나물, 순무, 마름, 얌피, 얌스(네임스), 유초이, 유카(카사바) 등을 포함하지만, 이들로 제한되지 않는 채소 작물의 세포이다.
세포는 일부 경우에 절지동물 세포이다. 예를 들어, 세포는, 예를 들어, 협각류, 다지류, 헥시포디아(Hexipodia), 거미강, 곤충강, 돌좀목, 좀류, 구시아강, 하루살이목, 잠자리목, 잠자리하목, 실잠자리아목, 신시류, 외시류, 강도래목, 흰개미붙이목, 메뚜기, 민벌레목, 집게벌레목, 바퀴목, 귀뚜라미붙이목, 갈르와벌레과, 만토파스마토데과, 대벌레목, 바퀴목, 흰개미목, 사마귀목, 책좀, 다듬이벌레목, 총채벌레목, 이목, 반시목, 내시류 또는 완전변태류, 막시류, 초시류, 부채벌레목, 약대벌레목, 뱀잠자리목, 풀잠자리목, 밑드리목, 버룩목, 파리목, 날도래류 또는 인시목의 아목, 과, 아과, 군, 하위군, 또는 종의 세포일 수 있다.
세포는 일부 경우에 곤충 세포이다. 예를 들어, 일부 경우에, 세포는 모기, 메뚜기, 노린재류, 파리, 벼룩, 벌, 말벌, 개미, 이, 나방 또는 딱정벌레의 세포이다.
키트
본 개시내용은 본 개시내용의 CasX 시스템 또는 본 개시내용의 CasX 시스템의 성분을 포함하는 키트를 제공한다.
본 개시내용의 키트는 a) 본 개시내용의 CasX 폴리펩타이드 및 CasX 가이드 RNA; b) 본 개시내용의 CasX 폴리펩타이드, CasX 가이드 RNA, 및 공여자 주형 핵산; c) 본 개시내용의 CasX 융합 폴리펩타이드 및 CasX 가이드 RNA; d) 본 개시내용의 CasX 융합 폴리펩타이드, CasX 가이드 RNA, 및 공여자 주형 핵산; e) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 mRNA; 및 CasX 가이드 RNA; f) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 mRNA, CasX 가이드 RNA, 및 공여자 주형 핵산; g) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 mRNA; 및 CasX 가이드 RNA; h) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 mRNA, CasX 가이드 RNA, 및 공여자 주형 핵산; i) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; j) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 공여자 주형 핵산을 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; k) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; l) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 공여자 주형 핵산을 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; m) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; n) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; 및 공여자 주형 핵산; o) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; p) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 제1 재조합 발현 벡터, 및 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 제2 재조합 발현 벡터; 및 공여자 주형 핵산; q) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, 제1 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 제2 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; 또는 r) 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열, 제1 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열, 및 제2 CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터; 또는 (a) 내지 (r) 중 하나의 일부 변형을 포함할 수 있다.
본 개시내용의 키트는 a) 본 개시내용의 CasX 시스템, 또는 본 개시내용의 CasX 시스템의 상기 기재한 바와 같은 성분; 및 b) 1종 이상의 추가적인 시약, 예를 들어, i) 완충제; ii) 프로테아제 저해제; iii) 뉴클레아제 저해제; iv) 검출 가능한 표지를 개발하거나 또는 시각화하는 데 필요한 시약; v) 양성 및/또는 음성 대조군 표적 DNA; vi) 양성 및/또는 음성 대조군 CasX 가이드 RNA 등을 포함할 수 있다. 본 개시내용의 키트는 a) 상기 기재한 바와 같은 본 개시내용의 CasX 시스템의 성분, 또는 본 개시내용의 CasX 시스템; 및 b) 치료제를 포함할 수 있다.
본 개시내용의 키트는 a) 표적 핵산에서 표적 뉴클레오타이드 서열에 혼성화하는 CasX 가이드 RNA의 일부를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산을 삽입하기 위한 삽입 부위; 및 b) CasX 가이드 RNA의 CasX-결합 부분을 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터를 포함할 수 있다. 본 개시내용의 키트는 a) 표적 핵산에서 표적 뉴클레오타이드 서열에 혼성화하는 CasX 가이드 RNA의 일부를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산을 삽입하기 위한 삽입 부위; b) CasX 가이드 RNA의 CasX-결합 부분을 암호화하는 뉴클레오타이드 서열 및 c) 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터를 포함할 수 있다.
효용
본 개시내용의 CasX 폴리펩타이드, 또는 본 개시내용의 CasX 융합 폴리펩타이드는 다양한 방법에서의(예를 들어, CasX 가이드 RNA와 조합하여 그리고 일부 경우에 추가로 공여자 주형과 조합하여) 용도를 발견한다. 예를 들어, 본 개시내용의 CasX 폴리펩타이드는 (i) 표적 핵산(DNA 또는 RNA; 단일 가닥 또는 이중 가닥)을 변형(예를 들어, 절단, 예를 들어, 틈내기; 메틸화 등); (ii) 표적 핵산의 전사를 조절; (iii) 표적 핵산을 표지; (iv)(예를 들어, 단리, 표지, 영상화, 추적 등의 목적을 위해) 표적 핵산에 결합; (v) 표적 핵산과 회합된 폴리펩타이드(예를 들어, 히스톤)를 변형 등을 위해 사용될 수 있다. 따라서, 본 개시내용은 표적 핵산을 변형시키는 방법을 제공한다. 일부 경우에, 표적 핵산을 변형시키기 위한 본 개시내용의 방법은 표적 핵산을: a) 본 개시내용의 CasX 폴리펩타이드; 및 b) 하나 이상의(예를 들어, 2개의) CasX 가이드 RNA와 접촉시키는 단계를 포함한다. 일부 경우에, 표적 핵산을 변형시키기 위한 본 개시내용의 방법은 표적 핵산을 a) 본 개시내용의 CasX 폴리펩타이드; b) CasX 가이드 RNA; 및 c) 공여자 핵산(예를 들어, 공여자 주형)과 접촉시키는 단계를 포함한다. 일부 경우에, 접촉시키는 단계는 시험관내 세포에서 수행된다. 일부 경우에, 접촉시키는 단계는 생체내 세포에서 수행된다. 일부 경우에, 접촉시키는 단계는 생체외 세포에서 수행된다.
CasX 폴리펩타이드를 사용하는 방법은 (회합된 CasX 가이드 RNA에 의해 거기서 표적화한 덕분에) 표적 핵산 내 특정 영역에 대한 CasX 폴리펩타이드의 결합을 포함하기 때문에, 상기 방법은 일반적으로 본 명세서에서 결합 방법(예를 들어, 표적 핵산의 결합 방법)으로서 지칭된다. 그러나, 일부 경우에, 결합 방법이 표적 핵산의 결합에 불과할 수 있지만, 다른 경우에, 상기 방법은 상이한 최종 결과를 가질 수 있다는 것이 이해되어야 한다(예를 들어, 상기 방법은 표적 핵산의 변형, 예를 들어, 절단/메틸화/등, 표적 핵산으로부터의 전사의 조절; 표적 핵산의 번역의 조절; 게놈 편집; 표적 핵산과 회합된 단백질의 조절; 표적 핵산의 단리 등을 초래할 수 있다).
적합한 방법의 예에 대해, 예를 들어, 문헌[Jinek et al., Science. 2012 Aug 17;337(6096):816-21; Chylinski et al., RNA Biol. 2013 May;10(5):726-37; Ma et al., Biomed Res Int. 2013;2013:270805; Hou et al., Proc Natl Acad Sci U S A. 2013 Sep 24;110(39):15644-9; Jinek et al., Elife. 2013;2:e00471; Pattanayak et al., Nat Biotechnol. 2013 Sep;31(9):839-43; Qi et al, Cell. 2013 Feb 28;152(5):1173-83; Wang et al., Cell. 2013 May 9;153(4):910-8; Auer et al., Genome Res. 2013 Oct 31; Chen et al., Nucleic Acids Res. 2013 Nov 1;41(20):e19; Cheng et al., Cell Res. 2013 Oct;23(10):1163-71; Cho et al., Genetics. 2013 Nov;195(3):1177-80; DiCarlo et al., Nucleic Acids Res. 2013 Apr;41(7):4336-43; Dickinson et al., Nat Methods. 2013 Oct;10(10):1028-34; Ebina et al., Sci Rep. 2013;3:2510; Fujii et al, Nucleic Acids Res. 2013 Nov 1;41(20):e187; Hu et al., Cell Res. 2013 Nov;23(11):1322-5; Jiang et al., Nucleic Acids Res. 2013 Nov 1;41(20):e188; Larson et al., Nat Protoc. 2013 Nov;8(11):2180-96; Mali et. at., Nat Methods. 2013 Oct;10(10):957-63; Nakayama et al., Genesis. 2013 Dec;51(12):835-43; Ran et al., Nat Protoc. 2013 Nov;8(11):2281-308; Ran et al., Cell. 2013 Sep 12;154(6):1380-9; Upadhyay et al., G3 (Bethesda). 2013 Dec 9;3(12):2233-8; Walsh et al., Proc Natl Acad Sci U S A. 2013 Sep 24;110(39):15514-5; Xie et al., Mol Plant. 2013 Oct 9; Yang et al., Cell. 2013 Sep 12;154(6):1370-9]; 및 미국 특허 및 특허 출원 8,906,616; 8,895,308; 8,889,418; 8,889,356; 8,871,445; 8,865,406; 8,795,965; 8,771,945; 8,697,359; 20140068797; 20140170753; 20140179006; 20140179770; 20140186843; 20140186919; 20140186958; 20140189896; 20140227787; 20140234972; 20140242664; 20140242699; 20140242700; 20140242702; 20140248702; 20140256046; 20140273037; 20140273226; 20140273230; 20140273231; 20140273232; 20140273233; 20140273234; 20140273235; 20140287938; 20140295556; 20140295557; 20140298547; 20140304853; 20140309487; 20140310828; 20140310830; 20140315985; 20140335063; 20140335620; 20140342456; 20140342457; 20140342458; 20140349400; 20140349405; 20140356867; 20140356956; 20140356958; 20140356959; 20140357523; 20140357530; 20140364333; 및 20140377868를 참조하며; 이들 각각은 본 명세서에 그들의 전문이 참고로 포함된다.
예를 들어, 본 개시내용은 표적 핵산의 절단 방법; 표적 핵산의 편집 방법; 표적 핵산으로부터 전사를 조절하는 방법; 표적 핵산을 단리시키는 방법, 표적 핵산을 결합시키는 방법, 표적 핵산의 영상화 방법, 표적 핵산을 변형시키는 방법 등을 제공한다(그러나 이들로 제한되지 않는다).
본 명세서에서 사용되는 바와 같은, 예를 들어, CasX 폴리펩타이드와 또는 CasX 융합 폴리펩타이드 등과 "표적 핵산을 접촉시키다" 및 "표적 핵산을 접촉시키는"이라는 용어/어구는 표적 핵산을 접촉시키기 위한 모든 방법을 포함한다. 예를 들어, CasX 폴리펩타이드는 단백질, RNA(CasX 폴리펩타이드를 암호화) 또는 DNA(CasX 폴리펩타이드를 암호화)로서 세포에 제공될 수 있는 반면; CasX 가이드 RNA는 가이드 RNA로서 또는 가이드 RNA를 암호화하는 핵산으로서 제공될 수 있다. 이렇게 해서, 예를 들어, 세포에서(예를 들어, 시험관내 세포 내에서, 생체내 세포 내에서, 생체외 세포 내에서) 방법을 수행할 때, 표적 핵산을 접촉시키는 단계를 포함하는 방법은 그들의 활성/최종 상태에서(예를 들어, CasX 폴리펩타이드에 대한 단백질(들)의 형태로; CasX 융합 폴리펩타이드에 대한 단백질의 형태로; 일부 경우에 가이드 RNA에 대한 RNA의 형태로) 임의의 또는 모든 성분의 세포 내로의 도입을 포함하고, 그리고 또한 하나 이상의 성분을 암호화하는 하나 이상의 핵산(예를 들어, CasX 폴리펩타이드 또는 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열(들)을 포함하는 핵산(들), 가이드 RNA(들)를 암호화하는 뉴클레오타이드 서열(들)을 포함하는 핵산(들), 공여자 주형을 암호화하는 뉴클레오타이드 서열을 포함하는 핵산 등)의 세포 내로의 도입을 포함한다. 상기 방법은 또한 세포밖 시험관내에서 수행될 수 있기 때문에, 표적 핵산을 접촉시키는 단계를 포함하는 방법은, (달리 구체화되지 않는 한) 시험관내 세포 밖에서, 시험관내 세포 내에서, 생체내 세포 내에서, 생체외 세포 내 등에서 접촉시키는 단계를 포함한다.
일부 경우에, 표적 핵산을 변형시키기 위한 본 개시내용의 방법은 표적 핵산을 본 개시내용의 CasX 폴리펩타이드와, 또는 본 개시내용의 CasX 융합 폴리펩타이드와 접촉시키는 단계를 포함한다. 일부 경우에, 표적 핵산을 변형시키기 위한 본 개시내용의 방법은 표적 핵산을 CasX 폴리펩타이드 및 CasX 가이드 RNA와 접촉시키는 단계를 포함한다. 일부 경우에, 표적 핵산을 변형시키기 위한 본 개시내용의 방법은 표적 핵산을 CasX 폴리펩타이드, 제1 CasX 가이드 RNA, 및 제2 CasX 가이드 RNA와 접촉시키는 단계를 포함한다. 일부 경우에, 표적 핵산을 변형시키기 위한 본 개시내용의 방법은 표적 핵산을 본 개시내용의 CasX 폴리펩타이드 및 CasX 가이드 RNA 및 공여자 DNA 주형과 접촉시키는 단계를 포함한다.
관심 대상의 표적 핵산
및 표적
세포
CasX 가이드 RNA에 결합될 때, 본 개시내용의 CasX 폴리펩타이드, 또는 본 개시내용의 CasX 융합 폴리펩타이드는 표적 핵산에 결합할 수 있고, 일부 경우에, 표적 핵산에 결합하고 이를 변형시킬 수 있다. 표적 핵산은 임의의 핵산(예를 들어, DNA, RNA)일 수 있고, 이중 가닥 또는 단일 가닥일 수 있으며, 임의의 유형의 핵산(예를 들어, 염색체(게놈 DNA), 염색체로부터 유래, 염색체 DNA, 플라스미드, 바이러스, 세포외, 세포내, 미토콘드리아, 엽록체, 선형, 원형 등)일 수 있고, (예를 들어, 표적 핵산이 표적화될 수 있도록 CasX 가이드 RNA가 표적 핵산 내 표적 서열에 혼성화하는 뉴클레오타이드 서열을 포함하는 한) 임의의 유기체로부터 유래될 수 있다.
표적 핵산은 DNA 또는 RNA일 수 있다. 표적 핵산은 이중 가닥(예를 들어, dsDNA, dsRNA) 또는 단일 가닥(예를 들어, ssRNA, ssDNA)일 수 있다. 일부 경우에, 표적 핵산은 단일 가닥이다. 일부 경우에, 표적 핵산은 단일 가닥 RNA(ssRNA)이다. 일부 경우에, 표적 ssRNA(예를 들어, 표적 세포 ssRNA, 바이러스 ssRNA 등)는 mRNA, rRNA, tRNA, 비-암호 RNA(ncRNA), 긴 비-암호 RNA(lncRNA) 및 마이크로RNA(miRNA)로부터 선택된다. 일부 경우에, 표적 핵산은 단일 가닥 DNA(ssDNA)(예를 들어, 바이러스 DNA)이다. 상기 언급한 바와 같이, 일부 경우에, 표적 핵산은 단일 가닥이다.
표적 핵산은 어디에서나, 예를 들어, 시험관내 세포 밖에서, 시험관내 세포 내에서, 생체내 세포 내에서, 생체외 세포 내 등에 위치될 수 있다. 적합한 표적 세포(표적 핵산, 예컨대 게놈 DNA를 포함할 수 있음)는 박테리아 세포; 고세균 세포; 단세포 진핵 유기체의 세포; 식물 세포; 조류 세포, 예를 들어, 보트리오코쿠스 브라우니, 칼라마이도모나스 레인하르티, 난노클로롭시스 가디타나, 클로렐라 피레노이도사, 모자반속 등; 진균 세포(예를 들어, 효모 세포); 동물 세포; 무척추동물(예를 들어, 과실파리, 강장동물, 극피동물, 선충 등)로부터의 세포; 곤충(예를 들어, 모기; 벌; 해충 등)의 세포; 거미류(예를 들어, 거미; 진드기 등)의 세포; 척추동물 (예를 들어, 어류, 양서류, 파충류, 조류, 포유류)로부터의 세포; 포유류(예를 들어, 설치류로부터의 세포; 인간으로부터의 세포; 비-인간 포유류의 세포; 설치류(예를 들어, 마우스, 래트)의 세포; 토끼목(예를 들어, 토끼)의 세포; 유제류(예를 들어, 소, 말, 낙타, 라마, 비쿠냐, 양, 염소 등)의 세포; 해양 포유류(예를 들어, 고래, 바다표범, 바다 코끼리, 돌고래, 바다사자 등) 등을 포함하지만, 이들로 제한되지 않는다. 임의의 유형의 세포에 관심이 있을 수 있다(예를 들어, 줄기 세포, 예를 들어, 배아 줄기(ES) 세포, 유도 만능 줄기(iPS) 세포, 생식세포(예를 들어, 난모세포, 정자, 난원세포, 정원세포 등), 성체 줄기 세포, 체세포, 예를 들어, 섬유아세포, 조혈모세포, 뉴런, 근육 세포, 골세포, 간세포, 췌장 세포; 임의의 단계에서 배아의 시험관내 또는 생체내 배아 세포, 예를 들어, 1-세포, 2-세포, 4-세포, 8-세포 등 단계 제브라피쉬 배아 등).
세포는 확립된 세포주로부터 유래될 수 있거나 또는 그들은 1차 세포일 수 있고, 여기서 "1차 세포", "1차 세포주" 및 "1차 배양물"은 대상으로부터 유래되고 배양물의 제한된 수의 계대, 즉, 분할 동안 시험관내에서 성장이 허용되는 세포 및 세포 배양물을 지칭하기 위해 본 명세서에서 상호 호환적으로 사용된다. 예를 들어, 1차 배양물은 0회, 1회, 2회, 4회, 5회, 10회 또는 15회(그러나, 위기의 단계를 통과하기에 충분한 시간은 아님) 계대될 수 있는 배양물이다. 전형적으로, 1차 세포주는 시험관내에서 10회보다 더 적은 계대 동안 유지된다. 표적 세포는 단세포 유기체일 수 있고/있거나 배양물에서 성장될 수 있다. 세포가 1차 세포라면, 그들은 임의의 편리한 방법에 의해 개체로부터 채취될 수 있다. 예를 들어, 백혈구는 분리반출법, 백혈구분리반출법, 밀도 구배 분리 등에 의해 편리하게 채취될 수 있는 한편, 조직, 예컨대 피부, 근육, 골수, 비장, 간, 췌장, 폐, 장, 위 등으로부터의 세포는 생검에 의해 편리하게 채취될 수 있다.
일부 상기 적용에서, 대상 방법은 (예를 들어, 표적화된 mRNA에 의해 암호화된 단백질의 생성을 파괴하기 위해, 표적 DNA를 절단하거나 또는 달리 변형시키기 위해, 표적 세포 등을 유전적으로 변형시키기 위해) 생체내 및/또는 생체외 및/또는 시험관내 유사분열 또는 유사분열후 세포에서 표적 핵산 절단, 표적 핵산 변형을 유도하기 위해, 그리고/또는 표적 핵산에 결합하기 위해(예를 들어, 수집 및/또는 분석 등을 위한 시각화를 위해) 사용될 수 있다. 가이드 RNA는 표적 핵산에 혼성화함으로써 특이성을 제공하기 때문에, 개시된 방법에서 관심 대상의 유사분열 및/또는 유사분열후 세포는 임의의 유기체로부터의 세포(예를 들어, 박테리아 세포, 고세균 세포, 단일 세포 진핵 유기체의 세포, 식물 세포, 조류 세포, 예를 들어, 보트리오코쿠스 브라우니, 칼라마이도모나스 레인하르티, 난노클로롭시스 가디타나, 클로렐라 피레노이도사, 모자반속 등, 진균 세포(예를 들어, 효모 세포), 동물 세포, 무척추동물(예를 들어, 과실파리, 강장동물, 극피동물, 선충 등)으로부터의 세포, 척추동물(예를 들어, 어류, 양서류, 파충류, 조류, 포유류)로부터의 세포, 포유류로부터의 세포, 설치류로부터의 세포, 인간으로부터의 세포 등)을 포함할 수 있다. 일부 경우에, 대상 CasX 단백질(및/또는 단백질을 암호화하는 핵산, 예컨대 DNA 및/또는 RNA), 및/또는 CasX 가이드 RNA(및/또는 가이드 RNA를 암호화하는 DNA), 및/또는 공여자 주형, 및/또는 RNP는 개체에게 도입될 수 있다(즉, 표적 세포는 생체내일 수 있다)(예를 들어, 포유류, 래트, 마우스, 돼지, 영장류, 비-인간 영장류, 인간 등). 일부 경우에, 이러한 투여는, 예를 들어, 표적화된 세포의 게놈을 편집함으로써 질환을 치료하고/하거나 예방하는 목적을 위한 것일 수 있다.
식물 세포는 외떡잎식물의 세포, 및 쌍떡잎식물의 세포를 포함한다. 세포는 뿌리 세포, 잎 세포, 물관부의 세포, 체관부의 세포, 형성층의 세포, 정단분열조직 세포, 격벽 유세포, 후각조직, 후막조직 세포 등일 수 있다. 식물 세포는 농작물, 예컨대 밀, 옥수수, 벼, 수수, 조, 대두 등의 세포를 포함한다. 식물 세포는 농업 과일 및 견과 식물, 예를 들어, 살구, 오렌지, 레놈, 사과, 자두, 배, 아몬드 등을 생산하는 식물을 포함한다.
표적 세포의 추가적인 예는 상기 표제 "변형 세포" 부문에서 열거된다. 세포(표적 세포)의 비제한적 예는 원핵 세포, 진핵 세포, 박테리아 세포, 고세균 세포, 단세포 진핵 유기체의 세포, 원생동물 세포, 식물로부터의 세포(예를 들어, 식물 작물, 과일, 채소, 곡물, 대두, 옥수수, 마이스, 밀, 종자, 토마토, 벼, 카사바, 사탕수수, 호박, 건초, 감자, 목화, 대마초, 담배, 하훼, 구과 식물, 겉씨식물, 속씨식물, 양치식물, 석송, 뿔이끼류, 우산이끼류, 선태식물, 쌍떡잎식물, 외떡잎식물 등), 조류 세포, (예를 들어, 보트리오코쿠스 브라우니(Botryococcus braunii), 칼라마이도모나스 레인하르티(Chlamydomonas reinhardtii), 난노클로롭시스 가디타나(Nannochloropsis gaditana), 클로렐라 피레노이도사(Chlorella pyrenoidosa), 모자반속(Sargassum patens, C. agardh) 등), 해초(예를 들어, 켈프) 진균 세포 (예를 들어, 효모 세포, 버섯으로부터의 세포), 동물 세포, 무척추동물(예를 들어, 과실파리, 강장동물, 극피동물, 선충 등)으로부터의 세포, 척추동물(예를 들어, 어류, 양서류, 파충류, 조류, 포유류)로부터의 세포, 포유류 (예를 들어, 유제류(예를 들어, 돼지, 소, 염소, 양)로부터의 세포; 설치류(예를 들어, 래트, 마우스); 비-인간 영장류; 인간; 고양이과(예를 들어, 고양이); 갯과(예를 들어, 개); 등) 등을 포함한다. 일부 경우에, 세포는 천연 유기체로부터 유래되지 않은 세포이다(예를 들어, 세포는 합성으로 만들어진 세포일 수 있고; 또한 인공 세포로서 지칭된다).
세포는 시험관내 세포일 수 있다(예를 들어, 확립된 배양 세포주). 세포는 생체외 세포일 수 있다(개체로부터의 배양 세포). 세포는 생체내 세포(예를 들어, 개체 내 세포)일 수 있다. 세포는 단리된 세포일 수 있다. 세포는 유기체 내부의 세포일 수 있다. 세포는 유기체일 수 있다. 세포는 세포 배양물 내 세포일 수 있다(예를 들어, 시험관내 세포 배양물). 세포는 세포 수집물 중 하나일 수 있다. 세포는 원핵 세포이거나 또는 원핵 세포로부터 유래될 수 있다. 세포는 박테리아 세포일 수 있거나 또는 박테리아 세포로부터 유래될 수 있다. 세포는 고세균 세포일 수 있거나 또는 고세균 세포로부터 유래될 수 있다. 세포는 진핵 세포일 수 있거나 또는 진핵 세포로부터 유래될 수 있다. 세포는 식물 세포일 수 있거나 또는 식물 세포로부터 유래될 수 있다. 세포는 동물 세포일 수 있거나 또는 동물 세포로부터 유래될 수 있다. 세포는 무척추동물 세포일 수 있거나 또는 무척추동물 세포로부터 유래될 수 있다. 세포는 척추동물 세포일 수 있거나 또는 척추동물 세포로부터 유래될 수 있다. 세포는 포유류 세포일 수 있거나 또는 포유류 세포로부터 유래될 수 있다. 세포는 설치류 세포일 수 있거나 또는 설치류 세포로부터 유래될 수 있다. 세포는 인간 세포일 수 있거나 또는 인간 세포로부터 유래될 수 있다. 세포는 미생물 세포일 수 있거나 또는 미생물 세포로부터 유래될 수 있다. 세포는 진균 세포일 수 있거나 또는 진균 세포로부터 유래될 수 있다. 세포는 곤충 세포일 수 있다. 세포는 절지동물 세포일 수 있다. 세포는 원생동물 세포일 수 있다. 세포는 유충 세포일 수 있다.
적합한 세포는 줄기 세포(예를 들어, 배아 줄기(ES) 세포, 유도 만능 줄기(iPS) 세포; 생식세포(예를 들어, 난모세포, 정자, 난원세포, 정원세포 등); 체세포, 예를 들어, 섬유아세포, 희소돌기신경교, 교세포, 조혈모세포, 뉴런, 근육 세포, 골세포, 간세포, 췌장 세포 등을 포함한다.
적합한 세포는 인간 배아 줄기 세포, 태아 심장 근육 세포, 근육섬유아세포, 간충직 줄기 세포, 자가이식 확장된 심장 근육 세포, 지방세포, 전분화 세포, 만능 세포, 혈액 줄기 세포, 근아세포, 성체 줄기 세포, 골수 세포, 간충직 세포, 배아 줄기 세포, 실질 세포, 상피세포, 내피세포, 중피세포, 섬유아세포, 조골세포, 연골세포, 외인성 세포, 내인성 세포, 줄기 세포, 조혈모세포, 골수 유래 전구체 세포, 심근세포, 골격 세포, 태아 세포, 미분화 세포, 다능 전구체 세포, 단분화능 전구체 세포, 단핵구, 심장 근아세포, 골격 근아세포, 대식세포, 모세혈관 내피세포, 이종 세포, 동종 세포 및 출산후 줄기 세포를 포함한다.
일부 경우에, 세포는 면역세포, 뉴런, 상피세포 및 내피세포 또는 줄기 세포이다. 일부 경우에, 면역세포는 T 세포, B 세포, 단핵구, 자연살해 세포, 수지상 세포 또는 대식세포이다. 일부 경우에, 면역세포는 세포독성 T 세포이다. 일부 경우에, 면역세포는 헬퍼 T 세포이다. 일부 경우에, 면역세포는 조절 T 세포(Treg)이다.
일부 경우에, 세포는 줄기 세포이다. 줄기 세포는 성체 줄기 세포를 포함한다. 성체 줄기 세포는 또한 체세포 줄기 세포로서 지칭된다.
성체 줄기 세포는 분화된 조직 내에 존재하지만, 자기 재생 특성 및 다중 세포 유형, 보통 줄기 세포가 발견된 전형적인 조직의 세포 유형이 생기게 하는 능력을 보유한다. 체세포 줄기 세포의 수많은 예는 당업자에게 공지되어 있으며, 근육 줄기 세포; 조혈모세포; 상피 줄기 세포; 신경 줄기 세포; 간충직 줄기 세포; 유방 줄기 세포; 장 줄기 세포; 중배엽 줄기 세포; 내피 줄기 세포; 후각 줄기 세포; 신경 능선 줄기 세포 등을 포함한다.
관심 대상의 줄기 세포는 포유류 줄기 세포를 포함하며, 용어 "포유류"는 인간; 비-인간 영장류; 가축 및 농장 동물; 및 동물원, 실험실, 운동 또는 반려 동물, 예컨대 개, 말, 고양이, 소, 마우스, 래트, 토끼 등을 포함하는 포유류로서 분류된 임의의 동물을 지칭한다. 일부 경우에, 줄기 세포는 인간 줄기 세포이다. 일부 경우에, 줄기 세포는 설치류(예를 들어, 마우스; 래트) 줄기 세포이다. 일부 경우에, 줄기 세포는 비-인간 영장류 줄기 세포이다.
줄기 세포는 하나 이상의 줄기 세포 마커, 예를 들어, SOX9, KRT19, KRT7, LGR5, CA9, FXYD2, CDH6, CLDN18, TSPAN8, BPIFB1, OLFM4, CDH17 및 PPARGC1A를 발현시킬 수 있다.
일부 실시형태에서, 줄기 세포는 조혈모세포(HSC)이다. HSC는 골수, 혈액, 제대혈, 태아간 및 난황낭으로부터 단리될 수 있는 중배엽-유래 세포이다. HSC는 CD34+ 및 CD3-로서 특성규명된다. HSC는 생체내 적혈구, 호중성-대식세포, 거핵구 및 림프계 조혈세포 계통을 재생시킬 수 있다. 시험관내에서, HSC는 적어도 일부의 자기-재생 세포 분열을 겪도록 유도될 수 있고, 생체내에서 알 수 있는 바와 같이 동일한 계통으로 분화되도록 유도될 수 있다. 이렇게 해서, HSC는 적혈구 세포, 거핵구, 호중구, 대식세포 및 림프구 세포 중 하나 이상으로 분화되도록 유도될 수 있다.
다른 실시형태에서, 줄기 세포는 신경 줄기 세포(NSC)이다. 신경 줄기 세포(NSC)는 뉴런, 및 교세포(희소돌기신경교 및 성상교세포를 포함)로 분화할 수 있다. 신경 줄기 세포는 다회 분열할 수 있는 다능성 줄기 세포이고, 특정 조건 하에서 신경아세포 또는 아교모세포, 예를 들어, 각각 뉴런 및 교세포 중 하나 이상의 유형이 되도록 기여하는 세포일 수 있는 신경 줄기 세포 또는 신경 전구체 세포인 딸 세포를 생성할 수 있다. NSC를 얻는 방법은 당업계에 공지되어 있다.
다른 실시형태에서, 줄기 세포는 간충직 줄기 세포(MSC)이다. MSC는 본래 배아 중배엽으로부터 유래되고, 성체 골수로부터 단리되며, 근육, 뼈, 연골, 지방, 골수 기질 및 힘줄을 형성하도록 분화될 수 있다. MSC를 단리시키는 방법은 당업계에 공지되어 있으며; MSC를 얻기 위한 임의의 공지된 방법이 사용될 수 있다. 예를 들어, 인간 MSC의 단리를 기재하는 미국 특허 제5,736,396호 참조.
세포는 일부 경우에 식물 세포이다. 식물 세포는 외떡잎식물의 세포일 수 있다. 세포는 쌍떡잎식물의 세포일 수 있다.
일부 경우에, 세포는 식물 세포이다. 예를 들어, 세포는 주요 농작물, 예를 들어, 보리, 콩류(건조 식용), 카놀라, 옥수수, 목화(피마), 목화(업랜드), 아마씨, 건초(알팔파), 건초(비-알팔파), 귀리, 땅콩, 벼, 수수, 대두, 사탕무, 사탕수수, 해바라기(오일), 해바라기(비-오일), 고구마, 담배(벌리), 담배(연관처리(Flue-cured)), 토마토, 밀(듀럼), 밀(봄), 밀(겨울) 등의 세포일 수 있다. 다른 예로서, 세포는, 예를 들어, 알팔파, 알로에 잎, 애로루트, 벗풀, 아티초크, 아스파라거스, 죽순, 바나나꽃, 콩나물, 콩류, 비이트톱, 근대, 비타멜론, 청경채, 브로콜리, 브로콜리 라베(엽경채), 방울다다기 양배추, 양배추, 방울 양배추, 가재발 선인장(노팔), 호리병박 열매, 카르둔, 당근, 콜리플라워, 셀러리, 차요테, 중국 아티초크(두루미냉이), 중국 양배추, 중국 셀러리, 중국 차이브, 채심, 국화잎(퉁호), 콜라드 그린, 옥수수대, 단옥수수, 오이, 대컨, 단데리온 그린, 타로토란, 다우 무에(피 팁), 동과(겨울멜론), 가지, 엔다이브, 에스카롤, 선수 장식 양치식물, 갓류 식물, 치커리, 갓 (중국 겨자), 가일론, 갈랑가(시암, 태국 생강), 마늘, 생강 뿌리, 우엉, 나물, 하노버 샐러드 나물, 후아우존틀, 예루살렘 아티초크, 히카마, 케일 나물, 콜라비, 명아주(?리떼), 상추(비브), 상추(보스턴), 상추(보스턴 레드), 상추(녹색잎), 상추(아이스버그), 상추(롤라로사), 상추(오크리프 - 녹색), 상추(오크리프 - 적색), 상추(가공처리), 상추(적색잎), 상추(로메인), 상추(루비 로메인), 상추(러시안 레드 겨자), 린쿡, 로 복, 긴콩류, 연근, 마하, 용설란(아가베) 잎, 말랑가, 메스꿀랭 믹스, 겨자과, 모압(수세미오이), 무, 모쿠아(동과), 버섯, 겨자, 참마, 오크라, 옹초이, 그린 어니언, 오포(롱 스쿼시), 장식용 옥수수, 관상용 호박, 파슬리, 파스닙, 완두콩, 후추(벨형), 후추, 호박, 라디키오, 무순, 무, 레이프 그린, 레이프 그린, 대황, 로메인(베이비 레드), 루타베가, 함초(씨빈), 신쿠아(앵글드/줄기가 선 수세미), 시금치, 스쿼시, 짚 더미, 사탕수수, 고구마, 근대, 타마린드, 타로, 타로잎, 타로 슈트, 탓소이, 테페구아헤(구아헤), 빔바, 토마틸로, 토마토, 토마토(체리), 토마토(포도형), 토마토(자두형), 강황, 순무 어린잎 나물, 순무, 마름, 얌피, 얌스(네임스), 유초이, 유카(카사바) 등을 포함하지만, 이들로 제한되지 않는 채소 작물의 세포이다.
세포는 일부 경우에 절지동물 세포이다. 예를 들어, 세포는, 예를 들어, 협각류, 다지류, 헥시포디아), 거미강, 곤충강, 돌좀목, 좀류, 구시아강, 하루살이목, 잠자리목, 잠자리하목, 실잠자리아목, 신시류, 외시류, 강도래목, 흰개미붙이목, 메뚜기, 민벌레목, 집게벌레목, 바퀴목, 귀뚜라미붙이목, 갈르와벌레과, 만토파스마토데과, 대벌레목, 바퀴목, 흰개미목, 사마귀목, 책좀, 다듬이벌레목, 총채벌레목, 이목, 반시목, 내시류 또는 완전변태류, 막시류, 초시류, 부채벌레목, 약대벌레목, 뱀잠자리목, 풀잠자리목, 밑드리목, 버룩목, 파리목, 날도래류 또는 인시목의 아목, 과, 아과, 군, 하위군, 또는 종의 세포일 수 있다.
세포는 일부 경우에 곤충 세포이다. 예를 들어, 일부 경우에, 세포는 모기, 메뚜기, 노린재류, 파리, 벼룩, 벌, 말벌, 개미, 이, 나방 또는 딱정벌레의 세포이다.
표적 세포 내로의 성분의 도입
Cas9 가이드 RNA(또는 이를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산), 및/또는 Cas9 융합 폴리펩타이드(또는 이를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산) 및/또는 공여자 폴리뉴클레오타이드는 임의의 다양한 잘 공지된 방법에 의해 숙주 세포 내로 도입될 수 있다.
핵산을 세포 내로 도입하는 방법은 당업계에 공지되어 있고, 임의의 편리한 방법을 사용하여 핵산(예를 들어, 발현 작제물)을 표적 세포(예를 들어, 진핵 세포, 인간 세포, 줄기 세포, 전구체 세포 등) 내로 도입할 수 있다. 적합한 방법은 본 명세서의 다른 곳에 더 상세하게 기재되어 있으며, 예를 들어, 바이러스 또는 박테리오파지 감염, 형질감염, 접합, 프로토플라스트 융합, 리포펙션, 전기천공법, 인산칼슘 침전, 폴리에틸렌이민(PEI)-매개 형질감염, DEAE-덱스트란 매개 형질감염, 리포좀-매개 형질감염, 입자총 기법, 인산칼슘 침전, 직접 미량주사법, 나노입자-매개 핵산 전달(예를 들어, 문헌[Panyam et., al Adv Drug Deliv Rev. 2012 Sep 13. pii: S0169-409X(12)00283-9. doi: 10.1016/j.addr.2012.09.023] 참조)등을 포함한다. 임의의 또는 모든 성분이 공지된 방법, 예를 들어, 뉴클레오펙션을 이용하여 조성물(예를 들어, CasX 폴리펩타이드, CasX 가이드 RNA, 공여자 폴리뉴클레오타이드 등의 임의의 편리한 조합을 포함)로서 세포 내로 도입될 수 있다.
공여자
폴리뉴클레오타이드
(공여자 주형)
CasX 이중 또는 단일 가이드 RNA에 의해 가이드된, CasX 단백질은 일부 경우에 비-상동성 말단 접합(NHEJ) 또는 상동성-관련 재조합(HDR) 중 하나에 의해 수선된 이중-가닥 DNA(dsDNA) 표적 핵산 내에서 부위-특이적 이중 가닥 파손(double strand break: DSB) 또는 단일 가닥 파손(SSB)(예를 들어, CasX 단백질이 틈내기효소 변이체일 때)을 생성한다.
일부 경우에, 표적 DNA를 (CasX 단백질 및 CasX 가이드 RNA와) 접촉시키는 것은 비상동성 말단 결합 또는 상동 직접 수선을 허용하는 조건 하에서 일어난다. 따라서, 일부 경우에, 대상 방법은 표적 DNA를 공여자 폴리뉴클레오타이드와 (예를 들어, 공여자 폴리뉴클레오타이드를 세포 내로 도입함으로써) 접촉시키는 단계를 포함하되, 공여자 폴리뉴클레오타이드, 공여자 폴리뉴클레오타이드의 일부, 공여자 폴리뉴클레오타이드의 복제물, 또는 공여자 폴리뉴클레오타이드 복제물의 일부가 표적 DNA 내로 통합된다. 일부 경우에, 상기 방법은 세포를 공여자 폴리뉴클레오타이드와 접촉시키는 단계를 포함하지 않으며, 표적 DNA 내의 뉴클레오타이드가 결실되도록 표적 DNA는 변형된다.
일부 경우에, CasX 가이드 RNA(또는 이를 암호화하는 DNA) 및 CasX 단백질(또는 이를 암호화하는 핵산, 예컨대 RNA 또는 DNA, 예를 들어, 하나 이상의 발현 벡터)는 적어도 표적 DNA 서열에 상동성인 세그먼트를 포함하는 공여자 폴리뉴클레오타이드 서열과 함께 공동투여되며(예를 들어, 표적 핵산과 접촉되고, 세포에 투여됨 등), 대상 방법은 핵산 물질을 표적 DNA 서열에 첨가하기 위해, 즉, 삽입 또는 대체하기 위해(예를 들어, 핵산, 예를 들어, 단백질을 암호화하는 것, siRNA, miRNA 등을 "넉인"하기 위해), 태그(예를 들어, 6xHis, 형광 단백질(예를 들어, 녹색 형광 단백질; 황색형광 단백질 등), 혈구응집소(HA), FLAG 등)를 첨가하기 위해, 조절 서열을 유전자(예를 들어, 프로모터, 폴리아데닐화 신호, 내부 리보솜 유입 서열(IRES), 2A 펩타이드, 개시 코돈, 정지 코돈, 스플라이스 신호, 국소화 신호 등)를 첨가하기 위해, 핵산 서열(예를 들어, 돌연변이를 도입하기 위해, 정확한 서열을 도입함으로써 돌연변이를 야기하는 질환을 제거하기 위해) 등을 변형시키기 위해 사용될 수 있다. 이렇게 해서, CasX 가이드 RNA 및 CasX 단백질을 포함하는 복합체는 부위-특이적, 즉, "표적화된" 방법으로 DNA를 변형시키는 것이 바람직한 임의의 시험관내 또는 생체내 적용, 예를 들어, 유전자 요법에서 사용되는 바와 같은, 예를 들어, 유전자 넉인, 유전자 편집, 유전자 태깅 등에서, 예를 들어, 질환을 치료하거나 또는 항바이러스, 항병원성 또는 항암 치료제로서, 농업에서 유전자 변형된 유기체의 생산, 치료적, 진단적 또는 연구적 목적을 위한 세포에 의한 단백질의 생성, iPS 세포의 유도, 생물학적 연구, 검출 또는 대체 등을 위한 병원균 유전자의 표적화에서 유용하다.
폴리뉴클레오타이드 서열을 표적 서열이 절단되는 게놈 내로 삽입하는 것이 바람직한 적용에서, 공여자 폴리뉴클레오타이드(공여자 서열을 포함하는 핵산)는 또한 세포에 제공될 수 있다. "공여자 서열" 또는 "공여자 폴리뉴클레오타이드" 또는 "공여자 주형"은 (예를 들어, dsDNA 절단 후에, 표적 DNA의 틈내기 후에, 표적 DNA의 이중 틈내기 후에 등) CasX 단백질에 의해 절단된 부위에 삽입될 핵산 서열을 의미한다. 공여자 폴리뉴클레오타이드는 그것과 상동성을 보유하는 게놈 서열 사이의 상동 직접 수선을 뒷받침하기 위해, 예를 들어, 표적 부위의 약 50개 이하의 염기 이내, 예를 들어, 약 30개의 염기 이내, 약 15개의 염기 이내, 약 10개의 염기 이내, 약 5개의 염기 이내, 또는 표적 부위에 바로 측접하여 표적 부위에서 게놈 서열에 대한 충분한 상동성, 예를 들어, 표적 부위에 측접하는 뉴클레오타이드 서열과 70%, 80%, 85%, 90%, 95% 또는 100% 상동성을 함유할 수 있다. 공여자와 게놈 서열 사이의 서열 상동성의 대략 25, 50, 100 또는 200개 이상의 뉴클레오타이드, 또는 200개 초과의 뉴클레오타이드(또는 10 내지 200개 이상의 뉴클레오타이드의 임의의 정수값)는 상동 직접 수선을 뒷받침할 수 있다. 공여자 폴리뉴클레오타이드는 임의의 길이, 예를 들어, 10개 이상의 뉴클레오타이드, 50개 이상의 뉴클레오타이드, 100개 이상의 뉴클레오타이드,250개 이상의 뉴클레오타이드, 500개 이상의 뉴클레오타이드, 1000개 이상의 뉴클레오타이드, 5000개 이상의 뉴클레오타이드 등을 가질 수 있다.
공여자 서열은 전형적으로 그것이 대체하는 게놈 서열과 동일하지 않다. 오히려, 상동 직접 수선을 뒷받침하기 위해(예를 들어, 유전자 보정을 위해, 예를 들어, 질환 원인 염기쌍을 비질환 원인 염기쌍으로 전환시키기 위해) 충분한 상동성이 존재한다면 공여자 서열은 게놈 서열에 대해 적어도 하나 이상의 단일 염기 변화, 삽입, 결실, 역위 또는 재배열을 함유할 수 있다. 일부 실시형태에서, 표적 DNA 영역과 두 측접 서열 사이의 상동 직접 수선이 표적 영역에서 비상동성 서열의 삽입을 초래하도록 공여자 서열은 상동체의 두 영역에 의해 측접되는 비상동성 서열을 포함한다. 공여자 서열은 또한 관심 대상의 DNA 영역에 상동성이 아니고 관심 대상의 DNA 영역 내로의 삽입에 대해 의도되지 않는 서열을 함유하는 벡터 골격을 포함할 수 있다. 일반적으로, 공여자 서열의 상동성 영역(들)은 재조합이 요망되는 게놈 서열에 대해 적어도 50%의 서열 동일성을 가질 것이다. 특정 실시형태에서, 60%, 70%, 80%, 90%, 95%, 98%, 99% 또는 99.9%의 서열 동일성이 존재한다. 공여자 폴리뉴클레오타이드의 길이에 따라서 1% 내지 100%의 서열 동일성의 임의의 값이 존재할 수 있다.
공여자 서열은 게놈 서열, 예를 들어, 제한 부위, 뉴클레오타이드 다형성, 선택 가능한 마커(예를 들어, 약물 내성 유전자, 형광 단백질, 효소 등) 등에 비교하여 특정 서열 차이를 포함할 수 있는데, 이는 절단 부위에서 공여자 서열의 성공적인 삽입에 대한 평가를 위해 사용될 수 있거나 또는 일부 경우에 다른 목적을 위해(예를 들어, 표적화된 게놈 좌위에서 발현을 나타내기 위해) 사용될 수 있다. 일부 경우에, 암호 영역에 위치된다면, 이러한 뉴클레오타이드 서열 차이는 아미노산 서열을 변화시키지 않을 것이고, 또는 침묵 아미노산 변화(즉, 단백질의 구조 또는 기능에 영향을 미치지 않는 변화)를 만들 것이다. 대안적으로, 이들 서열 차이는 측접하는 재조합 서열, 예컨대 FLP, loxP 서열 등을 포함할 수 있는데, 이는 마커 서열의 제거를 위해 이후의 시간에 활성화될 수 있다.
일부 경우에, 공여자 서열은 단일-가닥 DNA로서 세포에 제공된다. 일부 경우에, 공여자 서열은 이중-가닥 DNA로서 세포에 제공된다. 이는 선형 또는 원형 형태로 세포에 도입될 수 있다. 선형 형태로 도입된다면, 공여자 서열의 말단은 임의의 편리한 방법에 의해 (예를 들어, 핵산외부분해로부터) 보호될 수 있고, 이러한 방법은 당업자에게 공지되어 있다. 예를 들어, 하나 이상의 다이데옥시뉴클레오타이드 잔기가 선형 분자의 3' 말단에 첨가될 수 있고/있거나 자기-상보성 올리고뉴클레오타이드가 단부 중 하나 또는 둘 다에 결찰될 수 있다. 예를 들어, 문헌[Chang et al. (1987) Proc. Natl. Acad Sci USA 84:4959-4963; Nehls et al. (1996) Science 272:886-889] 참조. 분해로부터 외인성 폴리뉴클레오타이드를 보호하기 위한 추가적인 방법은 말단 아미노기(들)의 첨가 및 변형된 뉴클레오타이드간 결합, 예를 들어, 포스포로티오에이트, 포스포르아미데이트 및 O-메틸 리보스 또는 데옥시리보스 잔기의 사용을 포함하지만, 이들로 제한되지 않는다. 선형 공여자 서열 말단 보호에 대한 대안으로서, 서열의 추가적인 길이가 재조합에 영향을 미치는 일 없이 분해될 수 있는 영역 외부에 포함될 수 있다. 공여자 서열은 추가적인 서열, 예를 들어, 복제 기점, 프로모터 및 항생제 내성을 암호화하는 유전자를 갖는 벡터의 부분으로서 세포 내로 도입될 수 있다. 게다가, 공여자 서열은 네이키드 핵산으로서, 리포좀 또는 폴록사머와 같은 제제와 복합체화된 핵산으로서 도입될 수 있거나, 또는 CasX 가이드 RNA 및/또는 CasX 융합 폴리펩타이드 및/또는 공여자 폴리뉴클레오타이드를 암호화하는 핵산에 대해 본 명세서의 다른 곳에 기재된 바와 같이, 바이러스(예를 들어, 아데노바이러스, AAV)에 의해 전달될 수 있다.
유전자이식, 비인간 유기체
상기 기재한 바와 같이, 일부 경우에, 본 개시내용(예를 들어, 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산; 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산 등)의 핵산(예를 들어, 재조합 발현 벡터)은 본 개시내용의 CasX 폴리펩타이드 또는 CasX 융합 폴리펩타이드를 생성하는 유전자이식 비-인간 유기체를 생성하기 위해 이식유전자로서 사용된다. 본 개시내용은 본 개시내용의 CasX 폴리펩타이드, 또는 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 유전자이식 비인간 유기체를 제공한다.
유전자이식, 비-인간 동물
본 개시내용은 유전자이식 비-인간 동물을 제공하는데, 이 동물은 CasX 폴리펩타이드 또는 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산을 포함하는 이식유전자를 포함한다. 일부 실시형태에서, 유전자이식 비-인간 동물의 게놈은 본 개시내용의 CasX 폴리펩타이드 또는 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함한다. 일부 경우에, 유전자이식 비-인간 동물은 유전자 변형에 대해 동형접합적이다. 일부 경우에, 유전자이식 비-인간 동물은 유전자 변형에 대해 이형접합적이다. 일부 실시형태에서, 유전자이식 비-인간 동물은 척추동물, 예를 들어, 어류(예를 들어, 연어, 송어, 제브라피쉬, 금붕어, 복어, 동굴어 등), 양서류(개구리, 영원, 도롱뇽 등), 조류(예를 들어, 닭, 칠면조 등), 파충류(예를 들어, 뱀, 도마뱀 등), 비-인간 포유류(예를 들어, 유제류, 예를 들어, 돼지, 소, 염소, 양 등; 토끼목(예를 들어, 토끼); 설치류(예를 들어, 래트, 마우스); 비-인간 영장류 등) 등이다. 일부 경우에, 유전자이식 비-인간 동물은 무척추동물이다. 일부 경우에, 유전자이식 비-인간 동물은 곤충(예를 들어, 모기; 해충 등)이다. 일부 경우에, 유전자이식 비-인간 동물은 거미류이다.
본 개시내용의 CasX 폴리펩타이드, 또는 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열은 미공지 프로모터(예를 들어, 핵산이 숙주 세포 게놈 내로 무작위로 통합될 때) 제어 하에 있을 수 있거나(즉, 이에 작동 가능하게 연결됨) 또는 알려진 프로모터의 제어 하에 있을 수 있다(즉, 이에 작동 가능하게 연결됨). 적합한 알려진 프로모터는 임의의 알려진 프로모터일 수 있고, 구성적으로 활성인 프로모터(예를 들어, CMV 프로모터), 유도성 프로모터(예를 들어, 열 충격 프로모터, 테트라사이클린-조절된 프로모터, 스테로이드-조절된 프로모터, 금속-조절된 프로모터, 에스트로겐 수용체-조절 프로모터 등), 공간적으로 제한된 그리고/또는 일시적으로 제한된 프로모터(예를 들어, 조직 특이적 프로모터, 세포 유형 특이적 프로모터 등) 등을 포함한다.
유전자이식 식물
상기 기재한 바와 같이, 일부 경우에, 본 개시내용(예를 들어, 본 개시내용의 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산; 본 개시내용의 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산 등)의 핵산(예를 들어, 재조합 발현 벡터)은 본 개시내용의 CasX 폴리펩타이드 또는 CasX 융합 폴리펩타이드를 생성하는 유전자이식 식물을 생성하기 위해 이식유전자로서 사용된다. 본 개시내용은 본 개시내용의 CasX 폴리펩타이드, 또는 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 유전자이식 식물을 제공한다. 일부 실시형태에서, 유전자이식 식물의 게놈은 대상 핵산을 포함한다. 일부 실시형태에서, 유전자이식 식물은 유전자 변형에 대해 동형접합적이다. 일부 실시형태에서, 유전자이식 식물은 유전자 변형에 대해 이형접합적이다.
식물 세포 내로 외인성 핵산을 도입하는 방법은 당업계에 잘 공지되어 있다. 이러한 식물 세포는 상기 정의한 바와 같이 "형질전환되는" 것으로 고려된다. 적합한 방법은 바이러스 감염(예컨대 이중 가닥 DNA 바이러스), 형질감염, 접합, 원형질체 융합, 전기천공법, 입자총법, 인산칼슘 침전, 직접 미량주사법, 탄화규소 위스커 기법, 아그로박테륨-매개 형질전환 등을 포함한다. 방법의 선택은 일반적으로 형질감염 중인 세포의 유형 및 형질감염이 일어나는 환경(즉, 시험관내, 생체외 또는 생체내)에 의존한다.
토양 박테리아 아그로박테륨 투메파시엔스(Agrobacterium tumefaciens)에 기반한 형질전환 방법은 외인성 핵산 분자를 관다발 식물 내로 도입하는 데 특히 유용하다. 아그로박테륨의 야생형 형태는 숙주 식물 상에서 종양형성성 뿌리혹병 성장의 생산을 지시하는 Ti(종양-유도성) 플라스미드를 함유한다. 식물 게놈에 대한 Ti 플라스미드의 종양 유도성 T-DNA 영역의 전달은 Ti 플라스미드-암호화된 독력 유전자뿐만 아니라 T-DNA 경계를 필요로 하는데, 이는 전달될 영역을 설명하는 직접 DNA 반복부의 세트이다. 아그로벡테리움계 벡터는 Ti 플라스미드의 변형된 형태인데, 이때 종양 유도성 작용은 식물 숙주 내로 도입될 관심 대상의 핵산 서열에 의해 대체된다.
아그로박테륨-매개 형질전환은 일반적으로 합체 벡터 또는 바이너리 벡터 시스템을 사용하는데, 이때 Ti 플라스미드의 성분은 아그로박테륨 숙주에서 영구적으로 체류하고 독력 유전자를 운반하는 헬퍼 벡터와 T-DNA 서열에 의해 결합되는 관심 대상의 유전자를 함유하는 셔틀 벡터 사이에서 분할된다. 다양한 바이너리 벡터는 당업계에 잘 공지되어 있고, 예를 들어, 클론테크(Clontech)(캘리포니아주 팔로알토에 소재)로부터 상업적으로 입수 가능하다. 배양된 식물 세포 또는 상처 조직, 예컨대 잎 조직, 뿌리 외식편, 배축, 줄기 조각 또는 덩이줄기와 함께 아그로박테륨을 배양시키는 방법은, 예를 들어, 또한 당업계에 잘 공지되어 있다. 예를 들어, 문헌[Glick and Thompson, (eds.), Methods in Plant Molecular Biology and Biotechnology, Boca Raton, Fla.: CRC Press (1993)] 참조.
미세투사물-매개 형질전환이 또한 대상 유전자이식 식물을 생산하는 데 사용될 수 있다. 문헌[Klein et al. (Nature 327:70-73 (1987))]에 의해 처음 기재된 이 방법은 염화칼슘, 스퍼미딘 또는 폴리에틸렌 글리콜에 의한 침전에 의해 목적으로 하는 핵산 분자로 코팅된 금 또는 텅스텐과 같은 미세투사물에 의존한다. 미세투사물 입자는 BIOLISTIC PD-1000(바이오래드(Biorad); 캘리포니아주 허큘레스에 소재)와 같은 장치를 이용하여 속씨식물 내로 고속으로 가속화된다.
핵산이, 예를 들어 생체내 또는 생체외 프로토콜을 통해 식물 세포(들) 내로 들어갈 수 있는 방식으로 본 개시내용의 핵산(예를 들어, 본 개시내용의 CasX 폴리펩타이드 또는 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산(예를 들어, 재조합 발현 벡터))은 식물 내로 도입될 수 있다. "생체내"는 핵산이 식물의 살아있는 몸체에 투여되는 것, 예를 들어, 침윤을 의미한다. "생체외"는 세포 또는 외식편이 식물 외부에서 변형되고, 이어서, 이러한 세포 또는 기관이 식물에 대해 재생된다는 것을 의미한다. 문헌[Weissbach and Weissbach, (1989) Methods for Plant Molecular Biology Academic Press, 및 Gelvin et al., (1990) Plant Molecular Biology Manual, Kluwer Academic Publishers]에 기재된 것을 포함하는 식물 세포의 안정한 형질전환 또는 유전자이식 식물의 확립에 적합한 다수의 벡터가 기재되었다. 구체적 예는 아그로박테륨 투메파시엔스의 Ti 플라스미드로부터 유래된 것뿐만 아니라 문헌[Herrera-Estrella et al. (1983) Nature 303: 209, Bevan (1984) Nucl Acid Res. 12: 8711-8721, Klee (1985) Bio/Technolo 3: 637-642]에 의해 개시된 것을 포함한다. 대안적으로, 비-Ti 벡터는 유리 DNA 전달 기법을 이용함으로써 식물 및 세포에 대한 DNA의 전달을 위해 사용될 수 있다. 이들 방법을 이용함으로써, 유전자이식 식물, 예컨대, 밀, 벼(Christou (1991) Bio/Technology 9:957-9 및 4462) 및 옥수수(Gordon-Kamm (1990) Plant Cell 2: 603-618)가 생산될 수 있다. 미성숙 배아는 또한 입자총(문헌[Weeks et al. (1993) Plant Physiol 102: 1077-1084; Vasil (1993) Bio/Technolo 10: 667-674; Wan and Lemeaux (1994) Plant Physiol 104: 37-48]을 이용함으로써 직접 DNA 전달 기법을 위한 그리고 아그로박테륨-매개 DNA 전달(Ishida et al. (1996) Nature Biotech 14: 745-750)을 위한 외떡잎식물에 대한 양호한 표적 조직일 수 있다. 엽록체 내로 DNA의 도입을 위한 예시적인 방법은 유전자충격, 프로토플라스트의 폴리에틸렌 글리콜 형질전환, 및 미량주사법이다(문헌[Danieli et al Nat. Biotechnol 16:345-348, 1998; Staub et al Nat. Biotechnol 18: 333-338, 2000; O'Neill et al Plant J. 3:729-738, 1993; Knoblauch et al Nat. Biotechnol 17: 906-909]; 미국 특허 제5,451,513호, 제5,545,817호, 제5,545,818호 및 제5,576,198호; 국제 특허 출원 WO 95/16783; 및 문헌[Boynton et al., Methods in Enzymology 217: 510-536 (1993), Svab et al., Proc. Natl. Acad. Sci. USA 90: 913-917 (1993), 및 McBride et al., Proc. Natl. Acad. Sci. USA 91: 7301-7305 (1994)]). 유전자충격, 프로토플라스트의 폴리에틸렌 글리콜 형질전환 및 미량주사법의 방법에 적합한 임의의 벡터는 엽록체 형질전환을 위한 표적화 벡터로서 적합할 것이다. 임의의 이중 가닥 DNA 벡터는 형질전환 벡터, 특히 도입 방법이 아그로박테륨을 이용하지 않을 때 사용될 수 있다.
유전자 변형될 수 있는 식물은 곡물, 사료용 작물, 과일, 채소, 오일시드 작물, 야자나무, 삼림 및 덩굴식물을 포함한다. 변형될 수 있는 식물의 구체적 예는 다음에 따를 수 있다: 마이스, 바나나, 땅콩, 경협종완두, 해바라기, 토마토, 카놀라, 담배, 밀, 보리, 귀리, 감자, 대두, 목화, 카네이션, 수수, 루핀 및 벼.
본 개시내용은 형질전환된 식물 세포, 조직, 식물 및 형질전환 식물 세포를 함유하는 생성물을 제공한다. 대상 형질전환 세포, 및 조직 및 이를 포함하는 생성물의 특징은 게놈 내로 통합되는 대상 핵산의 존재, 및 본 개시내용의 CasX 폴리펩타이드, 또는 CasX 융합 폴리펩타이드의 식물 세포에 의한 생성이다. 본 발명의 재조합 식물 세포는 재조합 세포의 집단으로서, 또는 조직, 종자, 전체 식물, 줄기, 열매, 잎, 뿌리, 꽃, 줄기, 덩이줄기, 곡물, 동물 사료, 식물의 밭 등으로서 유용하다.
본 개시내용의 CasX 폴리펩타이드, 또는 CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열은 미공지 프로모터(예를 들어, 핵산이 숙주 세포 게놈 내로 무작위로 통합될 때) 제어 하에 있을 수 있거나(즉, 이에 작동 가능하게 연결됨) 또는 알려진 프로모터의 제어 하에 있을 수 있다(즉, 이에 작동 가능하게 연결됨). 적합한 알려진 프로모터는 임의의 알려진 프로모터일 수 있고 구성적으로 활성인 프로모터, 유도성 프로모터, 공간적으로 제한된 그리고/또는 일시적으로 제한된 프로모터 등을 포함한다.
고세균
Cas9
폴리펩타이드
및 가이드 RNA
본 발명자들은 처음에 고세균 세포 내 II형 CRISPR/Cas 좌위를 발견하였다. 고세균 세포는 I형 및/또는 III형 CRISPR/cas 시스템만을 포함하지만, II형 시스템은 포함하지 않으며, Cas9는 II형 CRISPR 시스템의 서명 단백질인 것이 이전에 생각되었다. 다시 말해서, 본 개시내용 전에 당업계에서 고세균에 속하는 유기체가 Cas9 단백질을 포함하지 않는 것으로 교시되었다. 고세균 Cas9 단백질(또는 이를 암호화하는 핵산)(예를 들어, ARMAN-1 Cas9 단백질, ARMAN-4 Cas9 단백질, 이들의 변이체 등), 및/또는 고세균 Cas9 가이드 RNA(이중 또는 단일 가이드 RNA 형식)(또는 이를 암호화하는 DNA, 예를 들어, 하나 이상의 발현 벡터), 및/또는 공여자 주형을 포함하는 방법 및 조성물이 제공된다.
용어 ARMAN은 "고세균 리치몬드 광산 호산성 나노유기체(archaeal Richmond Mine acidophilic nanoorganism)"를 지칭하며, 예를 들어, 문헌[Baker et. al., Proc Natl Acad Sci U S A. 2010 May 11; 107(19): 8806-8811; Baker et. al., Science. 2006 Dec 22;314(5807):1933-5]을 참조한다. ARMAN-1은 또한 "칸디다투스 마이크라카에움(Candidatus Micrarchaeum) 호산성 ARMAN-1"로서 지칭될 수 있는 한편; ARMAN-4는 또한 "칸디다투스 파르바카에움(Candidatus Parvarchaeum) 호산성 ARMAN-4"로서 지칭될 수 있다. ARMAN-2 및 ARMAN-5가 또한 동정되었고, "칸디다투스 마이크라카에움 호산성 ARMAN-2"로서 지칭될 수 있는 한편, ARMAN-5는 "칸디다투스 파바카에움(Candidatus Parvarchaeum) 호산성 ARMAN-5"로서 지칭될 수 있다 따라서, 용어 "칸디다투스 마이크라카에움 호산성"은 적어도 칸디다투스 마이크라카에움 호산성 ARMAN-1 및 칸디다투스 마이크라카에움 호산성 ARMAN-2를 포함하는 일반적 용어인 반면, 용어 "칸디다투스 마이크라카에움 호산성"은 적어도 칸디다투스 파바카에움 호산성 ARMAN-4 및 칸디다투스 파바카에움 호산성 ARMAN-5를 포함하는 일반적 용어이다. 따라서 고세균 Cas9 단백질(또는 이를 암호화하는 핵산)(예를 들어, 칸디다투스 마이크라카에움 호산성 Cas9 단백질, 칸디다투스 파바카에움 호산성 Cas9 단백질, ARMAN-1 Cas9 단백질, ARMAN-4 Cas9 단백질, 이들의 변이체 등), 및/또는 고세균 Cas9 가이드 RNA(이중 또는 단일 가이드 RNA 형식)(또는 이를 암호화하는 DNA, 예를 들어, 하나 이상의 발현 벡터), 및/또는 공여자 주형을 포함하는 방법 및 조성물이 제공된다.
본 명세서에 기재된 임의의 실시형태에서(예를 들어, 모든 기재된 조성물 및 방법, 예를 들어, 핵산, 결합 방법, 이미징 방법, 변형 방법, 게놈 편집 등을 포함), CasX 단백질 대신에, 고세균 Cas9 단백질(예를 들어, ARMAN-1 Cas9 단백질, ARMAN-4 Cas9 단백질 등)이 사용될 수 있다. 다시 말해서, 고세균 Cas9 단백질(예를 들어, ARMAN-1 Cas9 단백질, ARMAN-4 Cas9 단백질 등)은 CasX 단백질을 대체할 수 있다. 이러한 경우에, 적절하다면, 대응하는 가이드 RNA는 (고세균 Cas9 가이드 RNA, 예를 들어, 이중 또는 단일 가이드 형식으로) CasX 가이드 RNA 대신 사용되어야 한다. 고세균 Cas9 단백질 및 고세균 Cas9 가이드 RNA의 예는 도 13(ARMAN-1 및 ARMAN-4 Cas9 단백질), 도 14(ARMAN-1 Cas9 가이드 RNAs), 및 도 15(ARMAN-4 Cas9 가이드 RNA)에 도시되어 있다. 가이드 RNA의 나머지에 대해(예를 들어, 표적자의 듀플렉스-형성 세그먼트에 대해) 고세균 Cas9 가이드 RNA의 가이드 서열의 배향은 CasX 가이드 RNA의 반대인 한편(예를 들어, 가이드 서열이 CasX 가이드 RNA에 대해 3' 단부에 있는 도 6 및 도 7의 Ns를 가이드 서열이 고세균 Cas9 가이드 RNA의 5' 단부에 있는 도 14 및 도 15의 Ns와 비교); 표적 dsDNA 상에서 PAM의 위치는 또한 CasX 단백질에 비교되는 고세균 Cas9 단백질에 대해 반대라는 것을 주목한다(더 상세하게는 이하를 참조).
고세균
Cas9
단백질
비-고세균 Cas9 단백질(즉, 박테리아로부터의 Cas9 단백질이지만, 고세균으로부터는 아님)은 당업계에 공지되어 있으며, 대상 고세균 Cas9 단백질은 유사한 도메인 구조를 가진다. 그러나, 고세균 Cas9 단백질의 전반적인 서열은 고도로 분기성이며, 전반적 서열 상동성을 매우 조금 공유한다.
천연 유래 고세균 Cas9 단백질은 표적화된 이중 가닥 DNA(dsDNA) 내 특정 서열에서 이중 가닥 파손을 촉매하는 엔도뉴클레아제로서 작용한다. 서열 특이성은 표적 DNA 내에서 표적 서열에 혼성화하는 회합된 가이드 RNA에 의해 제공된다. 천연 유래 가이드 RNA는 crRNA에 혼성화된 tracrRNA를 포함하며, 여기서 crRNA는 표적 DNA에서 표적 서열에 혼성화하는 가이드 서열 포함하는 단백질 결합 세그먼트를 포함한다.
일부 실시형태에서, 대상 방법 및/또는 조성물의 고세균 Cas9 단백질은 천연 유래(야생형) 단백질이다(또는 이로부터 유래된다). 천연 유래 고세균 Cas9 단백질의 예는 도 13에 도시하고 서열번호 71 및 72에 제시한다. 새로 발견된 고세균 Cas9 단백질(예를 들어, 도 13 참조)은 이전에 동정된 CRISPR-Cas 엔도뉴클레아제에 비해 짧고(예를 들어, 그들은 가장 짧은 것으로 알려진 Cas9 단백질임), 따라서 대안으로서 고세균 Cas9 단백질의 사용은 단백질을 암호화하는 뉴클레오타이드가 상대적으로 짧다는 이점을 제공한다는 것을 주목하는 것은 중요하다. 이는, 예를 들어, 연구 및/또는 임상 적용을 위한 세포, 예컨대 진핵 세포(예를 들어, 시험관내, 생체외, 생체내 포유류 세포, 인간 세포, 마우스 세포)에 대한 전달을 위해 CasX 단백질을 암호화하는 핵산이 바람직한 경우에, 예를 들어, 바이러스 벡터(예를 들어, AAV 벡터)를 사용하는 경우에 유용하다.
비-고세균 Cas9 단백질이지만, 계통수 상에서 고세균 Cas9와 군집을 이루고, 따라서 고세균 Cas9에 대한 서열에서 관련된 2개의 추가적인 Cas9 단백질(도 16 참조)이 본 발명자들에 의해 동정되었다(예를 들어, 도 16의 델타프로테오박테리아 Cas9는 도 12, 패널 d의 계통수에 RBG_프로테오박테리아|RBG_16_델타프로테오박테리아_42_7_큐레이트|991aa로서 나타내는 한편; 도 16의 린도우박테리아 Cas9는 도 12, 패널 d의 계통수에 RIF2_CPR|RIFCSPLOWO2_12_FULL_린도우박테리아_62_27_큐레이트|RIF2|1044aa로서 나타낸다). ARMAN-1 Cas9 및 ARMAN-4 Cas9에 대해 도 16의 서열의 정렬을 도 17에 제공한다.
일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 71(ARMAN-1)로서 제시된 아미노산 서열과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 71(ARMAN-1)로서 제시된 아미노산 서열과 70% 이상의 서열 동일성(예를 들어, 80% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 71(ARMAN-1)로서 제시된 아미노산 서열과 80% 이상의 서열 동일성(예를 들어, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 71(ARMAN-1)로서 제시된 아미노산 서열과 95% 이상의 서열 동일성(예를 들어, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 71에 제시된 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 칸디다투스 마이크라카에움 호산성 Cas9 단백질이다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 ARMAN-1 Cas9 단백질이다.
일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 72(ARMAN-4)로서 제시된 아미노산 서열과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 72(ARMAN-4)로서 제시된 아미노산 서열과 70% 이상의 서열 동일성(예를 들어, 80% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 72(ARMAN-4)로서 제시된 아미노산 서열과 80% 이상의 서열 동일성(예를 들어, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 72(ARMAN-4)로서 제시된 아미노산 서열과 95% 이상의 서열 동일성(예를 들어, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 72에 제시된 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 칸디다투스 파바카에움 호산성 Cas9 단백질이다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 ARMAN-4 Cas9 단백질이다.
일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 71 및 72(각각 ARMAN-1 및 ARMAN-4) 중 임의의 하나에 제시된 아미노산 서열과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 71 및 72(각각 ARMAN-1 및 ARMAN-4) 중 임의의 하나에 제시된 아미노산 서열과 70% 이상의 서열 동일성(예를 들어, 80% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 71 및 72(각각 ARMAN-1 및 ARMAN-4) 중 임의의 하나에 제시된 아미노산 서열과 80% 이상의 서열 동일성(예를 들어, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 71 및 72(각각 ARMAN-1 및 ARMAN-4) 중 임의의 하나에 제시된 아미노산 서열과 95% 이상의 서열 동일성(예를 들어, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 서열번호 71 및 72 중 임의의 하나에 제시된 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)은 칸디다투스 마이크라카에움 호산성 Cas9 단백질(예를 들어, ARMAN-1 Cas9 단백질) 또는 칸디다투스 파바카에움 호산성 Cas9 단백질(예를 들어, ARMAN-4 Cas9 단백질)이다.
일부 경우에, 대상 Cas9 단백질은 서열번호 135로서 제시된 아미노산 서열과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 135로서 제시된 아미노산 서열과 70% 이상의 서열 동일성(예를 들어, 80% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 135로서 제시된 아미노산 서열과 80% 이상의 서열 동일성(예를 들어, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 135로서 제시된 아미노산 서열과 95% 이상의 서열 동일성(예를 들어, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 135에 제시된 아미노산 서열을 포함한다.
일부 경우에, 대상 Cas9 단백질은 서열번호 136으로서 제시된 아미노산 서열과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 136으로서 제시된 아미노산 서열과 70% 이상의 서열 동일성(예를 들어, 80% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 136으로서 제시된 아미노산 서열과 80% 이상의 서열 동일성(예를 들어, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 136으로서 제시된 아미노산 서열과 95% 이상의 서열 동일성(예를 들어, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 136에 제시된 아미노산 서열을 포함한다.
일부 경우에, 대상 Cas9 단백질은 서열번호 135 및 136 중 임의의 하나에 제시된 아미노산 서열과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 135 및 136 중 임의의 하나에 제시된 아미노산 서열과 70% 이상의 서열 동일성(예를 들어, 80% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 135 및 136 중 임의의 하나에 제시된 아미노산 서열과 80% 이상의 서열 동일성(예를 들어, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 135 및 136 중 임의의 하나의 아미노산 서열과 95% 이상의 서열 동일성(예를 들어, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 135 및 136 중 임의의 하나에 제시된 아미노산 서열을 포함한다.
일부 경우에, 대상 Cas9 단백질은 서열번호 71, 72, 135 및 136 중 임의의 하나에 제시된 아미노산 서열과 50% 이상의 서열 동일성(예를 들어, 60% 이상, 70% 이상, 80% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 71, 72, 135 및 136 중 임의의 하나에 제시된 아미노산 서열과 70% 이상의 서열 동일성(예를 들어, 80% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 71, 72, 135 및 136 중 임의의 하나에 제시된 아미노산 서열과 80% 이상의 서열 동일성(예를 들어, 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 71, 72, 135 및 136 중 임의의 하나의 아미노산 서열과 95% 이상의 서열 동일성(예를 들어, 98% 이상, 99% 이상 또는 100% 서열 동일성)을 갖는 아미노산 서열을 포함한다. 일부 경우에, 대상 Cas9 단백질은 서열번호 71, 72, 135 및 136 중 임의의 하나에 제시된 아미노산 서열을 포함한다.
변이체
(
틈내기효소
,
dCas9
및
키메라
Cas9
단백질을 포함)
사용될 수 있는 변이체에 대한 명명법 및 용도에 대해 CasX 단백질의 변이체에 대한 부문을 참조한다(예를 들어, CasX 단백질에 대해 고세균 Cas9 단백질로 교체하고, CasX 단백질 등에 대해 2가지의 새로 동정된 비-고세균 Cas9 단백질 중 하나로 교체함). 대상 Cas9 단백질(예를 들어, 고세균 Cas9 단백질)에 대해, 예를 들어, 상기 동일성% 매개변수를 포함하는, 임의의 상기 매개변수는 ARMAN-1 Cas9 단백질, ARMAN-4 Cas9 단백질, 칸디다투스 마이크라카에움 호산성 Cas9 단백질, 칸디다투스 파바카에움 호산성 Cas9 단백질 등으로 교체될 수 있다.
Cas9 단백질(예를 들어, 고세균 Cas9 단백질)의 촉매 잔기는 비-고세균 Cas9 단백질과의 극도로 낮은 전반적 서열 동일성에도 불구하고 용이하게 동정 가능하다. 예를 들어, 서열번호 71(ARMAN-1)로서 제시된 고세균 Cas9의 D30(RuvC 도메인) 및 H506 (HNH 도메인)은 각각 스트렙토코커스 피오게네스(S. pyogenes) Cas9의 D10 및 H840에 대응하는 한편; 서열번호 72(ARMAN-4)에 제시된 고세균 Cas9의 D58(RuvC 도메인) 및 H514(HNH 도메인)는 각각 스트렙토코커스 피오게네스 Cas9의 D10 및 H840에 대응한다. 이들 잔기는 도 13에서 볼드체이며 밑줄 표시되어 있다.
Cas9 틈내기효소(예를 들어, 고세균 Cas9 틈내기효소)는 RuvC 도메인(예를 들어, ARMAN-1 Cas9의 D30; ARMAN-4 Cas9 단백질의 D58을 돌연변이시킴으로써) 또는 HNH 도메인(예를 들어, ARMAN-1 Cas9의 H506; ARMAN-4 Cas9 단백질의 H514를 돌연변이시킴으로써) 중 하나의 촉매 활성을 제거함으로써(예를 들어, 촉매적 잔기를 돌연변이시킴으로써) 생성될 수 있다(예를 들어, 각각의 도메인은 표적 이중 가닥 DNA의 하나의 가닥을 절단한다). Cas9 단백질(예를 들어, 고세균 Cas9 단백질)(예를 들어, dCas9, 고세균 dCas9)의 사멸 형태는 RuvC 도메인과 HNH 도메인 둘 다의 촉매 활성을 제거함으로써(예를 들어, 촉매 잔기를 돌연변이시킴으로써) 생성될 수 있다.
고세균 Cas9(또는 새로 동정된 비-고세균 Cas9의 하나)가 CasX에 대해 교체될 수 있다는 것을 제외하고, 모든 동일한 융합 단백질이 사용될 수 있다. 비제한적 예는 NLS(들)를 갖는 고세균 Cas9 또는 dCas9 또는 틈내기효소 Cas9, (예를 들어, 표적 DNA를 변형시키기 위해, 표적 DNA와 회합된 히스톤과 같은 단백질을 변형시키기 위해, 표적 DNA로부터 전사를 조절하기 위해 등) 촉매적 활성 및/또는 전사 억제 또는 활성화 활성을 갖는 융합 상대 고세균 Cas9 또는 dCas9 또는 틈내기효소 Cas9, 검출 가능한 표지 등을 갖는 고세균 Cas9 또는 dCas9 또는 틈내기효소 Cas9를 포함한다. 고세균 Cas9에 대해 사용될 수 있는 융합 상태의 목록은 CasX 단백질에 대해 사용될 수 있는 목록과 동일하다(본 명세서에서 더 상세하게 논의됨).
고세균
Cas9
단백질에 대한
프로토스페이서
인접 모티프(PAM)
고세균 Cas9 단백질에 대한 PAM은 표적 DNA의 비상보성 가닥의 표적 서열의 3' 바로 옆이다(상보성 가닥은 가이드 RNA의 가이드 서열에 혼성화되는 한편, 비-상보성 가닥은 가이드 RNA에 직접 혼성화하지 않으며, 비-상보성 가닥의 역상보체이다). 따라서, 고세균 Cas9 단백질에 대한 PAM은 CasX 단백질에 대한 PAM에 비교하여 표적 서열의 반대측 상에 있다(예를 들어, CasX 단백질에 대한 PAM의 5' 배향을 나타내는 도 6, 패널 c, 및 도 7 참조). 일부 실시형태에서(예를 들어, 본 명세서에 기재된 바와 같은 고세균 Cas9 단백질이 사용될 때), 비-상보성 가닥의 PAM 서열은 5'-NGG-3'이며, 여기서 N은 임의의 DNA 뉴클레오타이드이다.
일부 경우에, 상이한 고세균 Cas9 단백질(즉, 다양한 고세균 종으로부터의 고세균 Cas9 단백질, 고세균 Cas9 단백질의 변이체, 여기서 PAM 선호도는 변화됨)은 상이한 고세균 Cas9 단백질의 다양한 효소 특징을 활용하기 위해(예를 들어, 상이한 PAM 서열 선호도에 대해; 증가된 또는 감소된 효소 활성에 대해; 세포 독성의 증가된 또는 감소된 수준에 대해; NHEJ, 상동성-직접 수선, 단일 가닥 파손, 이중 가닥 파손 등 사이의 균형 변화를 위해; 짧은 총 서열의 이점을 취하기 위해; 등) 다양한 제공된 방법으로 사용하는 것이 유리할 수 있다. 상이한 종으로부터의 고세균 Cas9 단백질(또는 이의 변이체)은 표적 DNA에서 상이한 PAM 서열을 선호할 수 있다. 따라서, 선택의 특정 고세균 Cas9 단백질에 대해, PAM 서열 선호도는 상기 기재한 5'-NGG-3' 서열과 상이할 수 있다. 적절한 PAM 서열의 동정을 위한 다양한 방법(인실리코 및/또는 습식 실험실 방법을 포함)은 당업계에 공지되어 있고, 일상적이며, 임의의 편리한 방법이 사용될 수 있다. 본 명세서에 기재된 NGG PAM 서열은 인실리코 서열 분석 기법을 이용하여 동정되었다(예를 들어, 이하의 작업 실시예의 도 12, 패널 b 참조).
고세균
Cas9
가이드 RNA
비-고세균 Cas9 가이드 RNA(즉, 박테리아로부터 유래된 Cas9 가이드 RNA, 그러나 고세균으로부터 유래된 것은 아님)는 당업계에 공지되어 있고, 대상 고세균 Cas9 가이드 RNA는 비-고세균 Cas9 가이드 RNA와 유사한 구조를 가진다. 고세균 Cas9 가이드 RNA에 대해, 가이드 서열은 표적자 RNA의 듀플렉스-형성 세그먼트의 5'에 위치되는 반면, CasX 가이드 RNA 내 듀플렉스-형성 세그먼트의 3'에 위치된다는 것을 주목한다(예를 들어, 예시적 고세균 Cas9 가이드 RNA를 도시하는 도 14 및 도 15를 예시적 CasX 가이드 RNA를 도시하는 도 6, 패널 c 및 도 7과 비교함).
일부 경우에, 고세균 Cas9 가이드 RNA(dgRNA 또는 sgRNA)의 활성체(예를 들어, tracr 서열)는 (i) 단백질-결합 세그먼트의 dsRNA 듀플렉스에 기여하는 듀플렉스 형성 세그먼트; 및 (ii) 듀플렉스 형성 세그먼트의 뉴클레오타이드 신장부(예를 들어, 본 명세서에서 3' 꼬리로서 지칭됨) 3'를 포함한다. 일부 경우에, 듀플렉스 형성 세그먼트의 추가적인 뉴클레오타이드 3'은 하나 이상의 줄기 루프(예를 들어, 2 이상, 3 이상, 1, 2 또는 3)를 형성한다. 일부 경우에, 고세균 Cas9 가이드 RNA(dgRNA 또는 sgRNA)의 활성체(예를 들어, tracr 서열)는 (i) 단백질-결합 세그먼트의 dsRNA 듀플렉스에 기여하는 듀플렉스 형성 세그먼트; 및 (ii) 듀플렉스 형성 세그먼트의 5개 이상의 뉴클레오타이드(예를 들어, 6개 이상, 7개 이상, 8개 이상, 9개 이상, 10개 이상, 11개 이상, 12개 이상, 13개 이상, 14개 이상, 15개 이상, 20개 이상, 25개 이상, 30개 이상, 35개 이상의, 40개 이상의, 45개 이상, 50개 이상, 60개 이상, 70개 이상 또는 75개 이상의 뉴클레오타이드) 3'을 포함한다. 일부 경우에, 고세균 Cas9 가이드 RNA(dgRNA 또는 sgRNA)의 활성체(활성체 RNA)는 (i) 단백질-결합 세그먼트의 dsRNA 듀플렉스에 기여하는 듀플렉스 형성 세그먼트; 및 (ii) 듀플렉스 형성 세그먼트의 5개 이상의 뉴클레오타이드(예를 들어, 6개 이상, 7개 이상, 8개 이상, 9개 이상, 10개 이상, 11개 이상, 12개 이상, 13개 이상, 14개 이상, 15개 이상, 20개 이상, 25개 이상, 30개 이상, 35개 이상의, 40개 이상의, 45개 이상, 50개 이상, 60개 이상, 70개 이상 또는 75개 이상의 뉴클레오타이드) 3'을 포함한다.
일부 경우에, 고세균 Cas9 가이드 RNA(dgRNA 또는 sgRNA)의 활성체(예를 들어, tracr 서열)는 (i) 단백질-결합 세그먼트의 dsRNA 듀플렉스에 기여하는 듀플렉스 형성 세그먼트; 및 (ii) 듀플렉스 형성 세그먼트의 뉴클레오타이드 신장부(예를 들어, 본 명세서에서 3' 꼬리로서 지칭됨) 3'를 포함한다. 일부 경우에, 듀플렉스 형성 세그먼트의 뉴클레오타이드 3'의 신장부는 5 내지 200개의 뉴클레오타이드(nt)(예를 들어, 5 내지 150개의 nt, 5 내지 130개의 nt, 5 내지 120개의 nt, 5 내지 100개의 nt, 5 내지 80개의 nt, 10 내지 200개의 nt, 10 내지 150개의 nt, 10 내지 130개의 nt, 10 내지 120개의 nt, 10 내지 100개의 nt, 10 내지 80개의 nt, 12 내지 200개의 nt, 12 내지 150개의 nt, 12 내지 130개의 nt, 12 내지 120개의 nt, 12 내지 100개의 nt, 12 내지 80개의 nt, 15 내지 200개의 nt, 15 내지 150개의 nt, 15 내지 130개의 nt, 15 내지 120개의 nt, 15 내지 100개의 nt, 15 내지 80개의 nt, 20 내지 200개의 nt, 20 내지 150개의 nt, 20 내지 130개의 nt, 20 내지 120개의 nt, 20 내지 100개의 nt, 20 내지 80개의 nt, 30 내지 200개의 nt, 30 내지 150개의 nt, 30 내지 130개의 nt, 30 내지 120개의 nt, 30 내지 100 nt, 또는 30 내지 80 nt) 범위의 길이를 가진다. 일부 경우에, 활성체 RNA의 3' 꼬리의 뉴클레오타이드는 야생형 서열이다.
다수의 상이한 대안의 서열이 사용될 수 있다면, 예시적 고세균 Cas9 가이드 RNA 서열은 서열번호 75 내지 76(예시적 crRNA 서열 - 가이드 서열), 77 내지 78(예시적 tracrRNA 서열) 및 81 내지 82(예시적 단일 가이드 RNA 서열 - 가이드 서열)에 제시된 서열 중 하나 이상을 포함할 수 있다.
일부 경우에, 활성체와 표적자 사이에 형성된 dsRNA 듀플렉스 영역(즉, 활성체/표적자 dsRNA 듀플렉스)(예를 들어, 이중 또는 단일 가이드 RNA 형식에서)은 8 내지 25개의 염기쌍(bp)의 범위(예를 들어, 8-22, 8-18, 8-15, 8-12, 12-25, 12-22, 12-18, 12-15, 13-25, 13-22, 13-18, 13-15, 14-25, 14-22, 14-18, 14-15, 15-25, 15-22, 15-18, 17-25, 17-22 또는 17-18 bp, 예를 들어, 15 bp, 16 bp, 17 bp, 18 bp, 19 bp, 20 bp, 21 bp 등)를 포함한다. 일부 경우에, 듀플렉스 영역(예를 들어, 이중 또는 단일 가이드 RNA 형식으로)은 8개 이상의 bp(예를 들어, 10개 이상, 12개 이상, 15개 이상 또는 17개 이상의 bp)를 포함한다. 일부 경우에, 듀플렉스 영역의 모든 뉴클레오타이드가 짝지어지지는 않으며, 따라서 듀플렉스 형성 영역은 벌지(bulge)를 포함할 수 있다(예를 들어, 도 6, 패널 c 및 도 7 참조). 본 명세서의 용어 "벌지"는 이중 가닥 듀플렉스에 기여하지 않지만, 기여하는 뉴클레오타이드에 의해 5' 및 3'을 둘러싸는 뉴클레오타이드의 신장(하나의 뉴클레오타이드일 수 있음)을 의미하기 위해 사용되며, 이러한 벌지는 듀플렉스 영역의 부분으로 고려된다. 일부 경우에, 활성체와 표적자 사이에 형성된 dsRNA 이중가닥(즉, 활성체/표적자 dsRNA 듀플렉스)는 1개 이상의 벌지(예를 들어, 2개 이상, 3개 이상, 4개 이상의 벌지)를 포함한다. 일부 경우에, 활성체와 표적자 사이에 형성된 dsRNA 이중가닥(즉, 활성체/표적자 dsRNA 듀플렉스)는 2개 이상의 벌지(예를 들어, 3개 이상, 4개 이상의 벌지)를 포함한다. 일부 경우에, 활성체와 표적자 사이에 형성된 dsRNA 이중가닥(즉, 활성체/표적자 dsRNA 듀플렉스)는 1 내지 5개의 벌지(예를 들어, 1-4, 1-3, 2-5, 2-4, 또는 2-3개의 벌지)를 포함한다.
따라서, 일부 경우에, 활성체 및 표적자의 듀플렉스-형성 세그먼트는 서로 70% 내지 100% 상보성(예를 들어, 75%-100%, 80%-10%, 85%-100%, 90%-100%, 95%-100% 상보성)을 가진다. 일부 경우에, 활성체 및 표적자의 듀플렉스-형성 세그먼트는 서로 70% 내지 100% 상보성(예를 들어, 75%-100%, 80%-10%, 85%-100%, 90%-100%, 95%-100% 상보성)을 가진다. 일부 경우에, 활성체 및 표적자의 듀플렉스-형성 세그먼트는 서로 85% 내지 100% 상보성(예를 들어, 90%-100%, 95%-100% 상보성)을 가진다. 일부 경우에, 활성체 및 표적자의 듀플렉스-형성 세그먼트는 서로 70% 내지 95% 상보성(예를 들어, 75%-95%, 80%-95%, 85%-95%, 90%-95% 상보성)을 가진다.
다시 말해서, 일부 실시형태에서, 활성체와 표적자 사이에 형성된 dsRNA 듀플렉스(즉, 활성체/표적자 dsRNA 이중가닥)는dsRNA 듀플렉스는 서로 70%-100% 상보성(예를 들어, 75%-100%, 80%-10%, 85%-100%, 90%-100%, 95%-100% 상보성)을 갖는 뉴클레오타이드의 2개 신장을 포함한다. 일부 경우에, 활성체/표적자 dsRNA 듀플렉스는 서로 85%-100% 상보성(예를 들어, 90%-100%, 95%-100% 상보성)을 갖는 뉴클레오타이드의 2개 신장을 포함한다. 일부 경우에, 활성체/표적자 dsRNA 듀플렉스는 서로 70%-95% 상보성(예를 들어, 75%-95%, 80%-95%, 85%-95%, 90%-95% 상보성)을 갖는 뉴클레오타이드의 2개 신장을 포함한다.
대상 고세균 Cas9 가이드 RNA의 듀플렉스 영역은 (이중 가이드 또는 단일 가이드 RNA 형식에서) 천연 유래 듀플렉스 영역에 비해 하나 이상(1, 2, 3, 4, 5 등)의 돌연변이를 포함할 수 있다. 예를 들어, 일부 경우에 염기쌍은 유지될 수 있는 한편 각각의 세그먼트(표적자 및 활성체)로부터의 염기쌍에 기여하는 뉴클레오타이드는 상이할 수 있다. 일부 경우에, 대상 고세균 Cas9 가이드 RNA의 이중가닥 영역은 (천연 유래 고세균 Cas9 가이드 RNA의) 천연 유래 이중가닥 영역에 비교할 때 더 짝지어진 염기, 덜 짝지어진 염기, 더 작은 벌지, 더 큰 벌지, 소수의 벌지, 더 많은 벌지, 또는 이들의 임의의 편리한 조합을 포함한다.
고세균
Cas9
가이드 RNA에 대한 예시적 서열
일부 경우에, 표적자-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) crRNA 서열 CCUUACAAUCGACACUUAAAUAAUUUGCAUGUGUAAG(서열번호 75)(예를 들어, 도 6, 패널 c의 sgRNA 참조)를 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) crRNA 서열 CUUACAAUCGACACUUAAAUAAUUUGCAUGUGUAAG(서열번호 75)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다. 일부 경우에, 표적자-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) crRNA 서열 CCUUACAAUCGACACUUAAAUAAUUUGCAUGUGUAAG(서열번호 75)를 포함한다.
일부 경우에, 표적자-RNA는 crRNA 서열 CUUUCAAUAAACAAAUAAAUCUUAGUAAUAUGUAAC(서열번호 76)을 포함한다. 일부 경우에, 표적자-RNA crRNA 서열 CUUUCAAUAAACAAAUAAAUCUUAGUAAUAUGUAAC(서열번호 76)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다. 일부 경우에, 표적자-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) crRNA 서열 CUUUCAAUAAACAAAUAAAUCUUAGUAAUAUGUAAC(서열번호 76)를 포함한다.
일부 경우에, 표적자-RNA는 서열번호 75 내지 76 중 임의의 하나에 제시된 crRNA 서열을 포함한다. 일부 경우에, 표적자-RNA는 서열번호 75 내지 76 중 임의의 하나에 제시된 crRNA 서열과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 GGCAUGGACCAUAUCCAGGUGUUGAUUGUAAACACCUAGCGGGGAAAUUAUAUAUGUUUGUAAUAUCUUCACUAUCCAAAGUUAUCUCUGGUUUUGGUUUGGUAAGCUUCACUUCACUAUUGUUUUCACUCCCAAUUUGAGUAUGGUUGGGGGUAAGGAUGCUUUCGGGGAGUGCUUUUA(서열번호 77)을 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 GGCAUGGACCAUAUCCAGGUGUUGAUUGUAAACACCUAGCGGGGAAAUUAUAUAUGUUUGUAAUAUCUUCACUAUCCAAAGUUAUCUCUGGUUUUGGUUUGGUAAGCUUCACUUCACUAUUGUUUUCACUCCCAAUUUGAGUAUGGUUGGGGGUAAGGAUGCUUUCGGGGAGUGCUUUUA(서열번호 77)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 AACUGGCUAUUGCUAAUAUUAUUUGUUUAUUGAAAGAAGCCUAGACGUUAGGGUUCGCGUGCAUGUAGGCUCCAGCAGGUACCUC(서열번호 78)을 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) tracrRNA 서열 AACUGGCUAUUGCUAAUAUUAUUUGUUUAUUGAAAGAAGCCUAGACGUUAGGGUUCGCGUGCAUGUAGGCUCCAGCAGGUACCUC(서열번호 78)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 활성체-RNA는 (예를 들어, 이중 또는 단일 가이드 RNA 형식으로) 서열번호 77 내지 78 중 임의의 하나에 제시된 tracrRNA를 포함한다. 일부 경우에, 표적자-RNA(예를 들어, 이중 또는 단일 가이드 RNA 형식으로) 서열번호 77 및 78 중 임의의 하나에 제시된 tracrRNA 서열과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 고세균 Cas9 단일 가이드 RNA는 서열 CUUACAAUCGACACUUaaacAGGUGUUGAUUGUAAACACCUAGCGGGGAAAUUAUAUAUGUUUGUAAUAUCUUCACUAUCCAAAGUUAUCUCUGGUUUUGGUUUGGUAAGCUUCACUUCACUAUUGUUUUCACUCCCAAUUUGAGUAUGGUUGGGGGUAAGGAUGCUUUCGGGGAGUGCUUUUA(서열번호 81)을 포함한다. 일부 경우에, 표적자-RNA는 tracrRNA 서열 CUUACAAUCGACACUUaaacAGGUGUUGAUUGUAAACACCUAGCGGGGAAAUUAUAUAUGUUUGUAAUAUCUUCACUAUCCAAAGUUAUCUCUGGUUUUGGUUUGGUAAGCUUCACUUCACUAUUGUUUUCACUCCCAAUUUGAGUAUGGUUGGGGGUAAGGAUGCUUUCGGGGAGUGCUUUUA(서열번호 81)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 고세균 Cas9 단일 가이드 RNA는 서열 CUUUCAAUAAACAAAUAAaaacUUAUUUGUUUAUUGAAAGAAGCCUAGACGUUAGGGUUCGCGUGCAUGUAGGCUCCAGCAGGUACCUC(서열번호 82)을 포함한다. 일부 경우에, 표적자-RNA는 tracrRNA 서열 CUUUCAAUAAACAAAUAAaaacUUAUUUGUUUAUUGAAAGAAGCCUAGACGUUAGGGUUCGCGUGCAUGUAGGCUCCAGCAGGUACCUC(서열번호 82)과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
일부 경우에, 고세균 Cas9 단일 가이드 RNA는 서열번호 81 내지 82 중 임의의 하나에 제시된 서열을 포함한다. 일부 경우에, 표적자-RNA는 서열번호 81 내지 82 중 임의의 하나에 제시된 tracrRNA 서열과 80% 이상의 동일성(예를 들어, 85% 이상, 90% 이상, 93% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%의 동일성)을 갖는 뉴클레오타이드 서열을 포함한다.
고세균
Cas9
가이드 RNA의 가이드 서열
일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 17개 이상의(예를 들어, 18개 이상, 19개 이상, 20개 이상, 21개 이상, 22개 이상) 인접한 뉴클레오타이드에 대해 60% 이상(예를 들어, 70% 이상, 75% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 17개 이상의(예를 들어, 18개 이상, 19개 이상, 20개 이상, 21개 이상, 22개 이상) 인접한 뉴클레오타이드에 대해 80% 이상(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 17개 이상의(예를 들어, 18개 이상, 19개 이상, 20개 이상, 21개 이상, 22개 이상) 인접한 뉴클레오타이드에 대해 90% 이상(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 17개 이상의(예를 들어, 18개 이상, 19개 이상, 20개 이상, 21개 이상, 22개 이상)의 인접한 뉴클레오타이드에 대해 100%이다.
일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 17 내지 25개의 인접한 뉴클레오타이드에 대해 60% 이상(예를 들어, 70% 이상, 75% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 17 내지 25개의 인접한 뉴클레오타이드에 대해 80% 이상(예를 들어, 85% 이상, 90% 이상, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 17 내지 25개의 인접한 뉴클레오타이드에 대해 90% 이상(예를 들어, 95% 이상, 97% 이상, 98% 이상, 99% 이상 또는 100%)이다. 일부 경우에, 표적 핵산의 가이드 서열과 표적 부위 사이의 상보성 백분율은 17 내지 25개의 인접한 뉴클레오타이드에 대해 100% 이상이다.
일부 경우에, 가이드 서열은 길이가 17 내지 30개의 뉴클레오타이드(nt)(예를 들어, 17-25, 17-22, 17-20, 19-30, 19-25, 19-22, 19-20, 20-30, 20-25 또는 20-22 nt) 범위이다. 일부 경우에, 가이드 서열은 길이가 17 내지 25개의 뉴클레오타이드(nt)(예를 들어, 17-22, 17-20, 19-25, 19-22, 19-20, 20-25, 20-25 또는 20-22 nt) 범위이다. 일부 경우에, 가이드 서열은 길이가 17개 이상의 nt(예를 들어, 18개 이상, 19개 이상, 20개 이상, 21개 이상 또는 22개 이상의 nt; 17 nt, 18nt, 19 nt, 20 nt, 21 nt, 22 nt, 23 nt, 24 nt, 25 nt 등)를 가진다. 일부 경우에, 가이드 서열은 길이가 17 nt이다. 일부 경우에, 가이드 서열은 길이가 18 nt이다. 일부 경우에, 가이드 서열은 길이가 19 nt이다. 일부 경우에, 가이드 서열은 길이가 20 nt이다. 일부 경우에, 가이드 서열은 길이가 21 nt이다. 일부 경우에, 가이드 서열은 길이가 22 nt이다. 일부 경우에, 가이드 서열은 길이가 23 nt이다.
다양한 Cas 단백질 및 Cas9 가이드 RNA의 예는 (비록 비-고세균 Cas9 단백질 및 가이드 RNA일지라도) 당업계에서 발견할 수 있으며, 일부 경우에, 예를 들어, Cas9의 높은 충실도 형태를 포함하여, 비고세균 Cas9 단백질 및 가이드 RNA 내로 도입된 것과 유사한 변형이 또한 고세균 Cas9 단백질 및 본 개시내용의 가이드 RNA 내로 도입될 수 있다. 예를 들어, 고충실도 Cas9를 생성하기 위해 이전에 공지된 Cas9 단백질 내로 도입될 수 있는 돌연변이는 또한 동일 또는 유사한 목적을 위해 고세균 Cas9 단백질 내로 도입될 수 있다(예를 들어, 대상 고세균 Cas9 단백질에서의 돌연변이를 위한 적절한 아미노산(예를 들어, 고세균 Cas9 단백질이 아닌 스트렙코코커스 피오게네스 Cas9 단백질의 아미노산 N497, R661, Q695 및 Q926)을 결정하기 위해 서열 및/또는 구조적 정렬이 수행될 수 있다)(예를 들어, 문헌[Kleinstiver et al. (2016) Nature529:490] 참조). 예를 들어, 문헌[Jinek et al., Science. 2012 Aug 17;337(6096):816-21; Chylinski et al., RNA Biol. 2013 May;10(5):726-37; Ma et al., Biomed Res Int. 2013;2013:270805; Hou et al., Proc Natl Acad Sci U S A. 2013 Sep 24;110(39):15644-9; Jinek et al., Elife. 2013;2:e00471; Pattanayak et al., Nat Biotechnol. 2013 Sep;31(9):839-43; Qi et al, Cell. 2013 Feb 28;152(5):1173-83; Wang et al., Cell. 2013 May 9;153(4):910-8; Auer et al., Genome Res. 2013 Oct 31; Chen et al., Nucleic Acids Res. 2013 Nov 1;41(20):e19; Cheng et al., Cell Res. 2013 Oct;23(10):1163-71; Cho et al., Genetics. 2013 Nov;195(3):1177-80; DiCarlo et al., Nucleic Acids Res. 2013 Apr;41(7):4336-43; Dickinson et al., Nat Methods. 2013 Oct;10(10):1028-34; Ebina et al., Sci Rep. 2013;3:2510; Fujii et. al, Nucleic Acids Res. 2013 Nov 1;41(20):e187; Hu et al., Cell Res. 2013 Nov;23(11):1322-5; Jiang et al., Nucleic Acids Res. 2013 Nov 1;41(20):e188; Larson et al., Nat Protoc. 2013 Nov;8(11):2180-96; Mali et. at., Nat Methods. 2013 Oct;10(10):957-63; Nakayama et al., Genesis. 2013 Dec;51(12):835-43; Ran et al., Nat Protoc. 2013 Nov;8(11):2281-308; Ran et al., Cell. 2013 Sep 12;154(6):1380-9; Upadhyay et al., G3 (Bethesda). 2013 Dec 9;3(12):2233-8; Walsh et al., Proc Natl Acad Sci U S A. 2013 Sep 24;110(39):15514-5; Xie et al., Mol Plant. 2013 Oct 9; Yang et al., Cell. 2013 Sep 12;154(6):1370-9; Briner et al., Mol Cell. 2014 Oct 23;56(2):333-9]; 및 미국 특허 및 특허 출원: 8,906,616; 8,895,308; 8,889,418; 8,889,356; 8,871,445; 8,865,406; 8,795,965; 8,771,945; 8,697,359; 20140068797; 20140170753; 20140179006; 20140179770; 20140186843; 20140186919; 20140186958; 20140189896; 20140227787; 20140234972; 20140242664; 20140242699; 20140242700; 20140242702; 20140248702; 20140256046; 20140273037; 20140273226; 20140273230; 20140273231; 20140273232; 20140273233; 20140273234; 20140273235; 20140287938; 20140295556; 20140295557; 20140298547; 20140304853; 20140309487; 20140310828; 20140310830; 20140315985; 20140335063; 20140335620; 20140342456; 20140342457; 20140342458; 20140349400; 20140349405; 20140356867; 20140356956; 20140356958; 20140356959; 20140357523; 20140357530; 20140364333; 및 20140377868을 참조하며; 이들 모두는 본 명세서에 그들의 전문이 참고로 편입된다.
개시내용의
비제한적
양상의 예
상기 기재한 본 대상의 실시형태를 포함하는 양상은 단독으로 또는 하나 이상의 다른 양상 또는 실시형태와 조합하여 유리하게 될 수 있다. 앞서 언급한 설명을 제한하는 일 없이, 1 내지 131로 넘버링된 개시내용의 특정 비제한적 양상(세트 A - CasX에 관련됨) 및 1 내지 133으로 넘버링된 양상(세트 B - 고세균 Cas9에 관련됨)을 이하에 제공한다. 본 개시내용을 읽을 때 당업자에게 명백할 바와 같이, 각각의 개별적으로 넘버링된 양상은 임의의 앞서 선행하는 또는 뒤에 오는 개개로 넘버링된 양상과 함께 사용되거나 또는 조합될 수 있다. 이는 모든 이러한 조합에 대한 근거를 제공하는 것으로 의도되며, 이하에 명확하게 제공되는 양상의 조합으로 제한되지 않는다:
세트 A
CasX와
관련
1.
조성물로서,
a) CasX 폴리펩타이드, 또는 상기 CasX 폴리펩타이드를 암호화하는 핵산 분자; 및
b) CasX 가이드 RNA, 또는 상기 CasX 가이드 RNA를 암호화하는 하나 이상의 DNA 분자
를 포함하는, 조성물.
2.
1에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 50% 이상의 동일성을 갖는 아미노산 서열을 포함하는, 조성물.
3.
1 또는 2에 있어서, 상기 CasX 가이드 RNA는 단일 가이드 RNA인, 조성물.
4.
1 또는 2에 있어서, 상기 CasX 가이드 RNA는 이중-가이드 RNA인, 조성물.
5.
1 내지 4 중 어느 하나에 있어서, 상기 조성물은 지질을 포함하는, 조성물.
6.
1 내지 4 중 어느 하나에 있어서, a) 및 b)는 리포좀 내에 있는, 조성물.
7.
1 내지 4 중 어느 하나에 있어서, a) 및 b)는 입자 내에 있는, 조성물.
8.
1 내지 7 중 어느 하나에 있어서, 완충제, 뉴클레아제 저해제, 및 프로테아제 저해제 중 하나 이상을 포함하는, 조성물.
9.
1 내지 8 중 어느 하나에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 85% 이상의 동일성을 갖는 아미노산 서열을 포함하는, 조성물.
10.
1 내지 9 중 어느 하나에 있어서, 상기 CasX 폴리펩타이드는 이중-가닥 표적 핵산 분자의 하나의 가닥만을 절단할 수 있는 틈내기효소인, 조성물.
11.
1 내지 9 중 어느 하나에 있어서, 상기 CasX 폴리펩타이드는 촉매적으로 비활성인 CasX 폴리펩타이드(dCasX)인, 조성물.
12.
10 또는 11에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1의 D672, E769 및 D935로부터 선택된 것에 대응하는 위치에서 하나 이상의 돌연변이를 포함하는, 조성물.
13.
1 내지 12 중 어느 하나에 있어서, DNA 공여자 주형을 더 포함하는, 조성물.
14.
CasX 단일 가이드 RNA 분자로서,
a) 표적 핵산에 혼성화하는 가이드 서열, 및 듀플렉스-형성 세그먼트를 포함하는 표적자 서열; 및
b) 표적자 서열의 듀플렉스-형성 세그먼트와 혼성화하여 CasX 폴리펩타이드에 결합할 수 있는 이중 가닥 RNA(dsRNA) 듀플렉스를 형성하는 활성체 서열
을 포함하는, CasX 단일 가이드 RNA 분자.
15.
14에 있어서, 상기 가이드 서열은 길이가 19 내지 30개의 뉴클레오타이드를 갖는, CasX 단일 가이드 RNA 분자.
16.
14 또는 15의 CasX 단일 가이드 RNA 분자를 암호화하는 뉴클레오타이드 서열을 포함하는 DNA 분자.
17.
16에 있어서, 상기 CasX 단일 가이드 RNA를 암호화하는 상기 뉴클레오타이드 서열은 프로모터에 작동 가능하게 연결된, DNA 분자.
18.
17에 있어서, 상기 프로모터는 진핵 세포에서 기능성인, DNA 분자.
19.
18에 있어서, 상기 프로모터는 식물 세포, 진균 세포, 동물 세포, 무척추동물의 세포, 파리 세포, 척추동물의 세포, 포유류 세포, 영장류 세포, 비-인간 영장류 세포 및 인간 세포 중 하나 이상에서 기능성인, DNA 분자.
20.
17 내지 19 중 어느 하나에 있어서, 상기 프로모터는 구성적 프로모터, 유도성 프로모터, 세포 유형-특이적 프로모터, 및 조직-특이적 프로모터 중 하나 이상인, DNA 분자.
21.
16 내지 20 중 어느 하나에 있어서, 상기 DNA 분자는 재조합 발현 벡터인, DNA 분자.
22.
21에 있어서, 상기 재조합 발현 벡터는 재조합 아데노연관 바이러스 벡터, 재조합 레트로바이러스 벡터 또는 재조합 렌티바이러스 벡터인, DNA 분자.
23.
17에 있어서, 상기 프로모터는 원핵 세포에서 기능성인, DNA 분자.
24.
이종성 폴리펩타이드에 융합된 CasX 폴리펩타이드를 포함하는, CasX 융합 폴리펩타이드.
25.
24에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 50% 이상의 동일성을 갖는 아미노산 서열을 포함하는, CasX 융합 폴리펩타이드.
26.
24에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 85% 이상의 동일성을 갖는 아미노산 서열을 포함하는, CasX 융합 폴리펩타이드.
27.
24 내지 27 중 어느 하나에 있어서, 상기 CasX 폴리펩타이드는 이중-가닥 표적 핵산 분자의 하나의 가닥만을 절단할 수 있는 틈내기효소인, CasX 융합 폴리펩타이드.
28.
24 내지 27 중 어느 하나에 있어서, 상기 CasX 폴리펩타이드는 촉매적으로 비활성인 CasX 폴리펩타이드(dCasX)인, CasX 융합 폴리펩타이드.
29.
27 또는 28에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1의 D672, E769 및 D935로부터 선택된 것에 대응하는 위치에서 하나 이상의 돌연변이를 포함하는, CasX 융합 폴리펩타이드.
30.
24 내지 29 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 상기 CasX 폴리펩타이드의 N-말단 및/또는 C-말단에 융합된, CasX 융합 폴리펩타이드.
31.
24 내지 30 중 어느 하나에 있어서, NLS를 포함하는, CasX 융합 폴리펩타이드.
32.
24 내지 31 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 표적 세포 또는 표적 세포 유형 상의 세포 표면 모이어티에 대한 결합을 제공하는 표적화 폴리펩타이드인, CasX 융합 폴리펩타이드.
33.
24 내지 31 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 표적 DNA를 변형시키는 효소 활성을 나타내는, CasX 융합 폴리펩타이드.
34.
33에 있어서, 상기 이종성 폴리펩타이드는 뉴클레아제 활성, 메틸트랜스퍼라제 활성, 데메틸라제 활성, DNA 수선 활성, DNA 손상 활성, 탈아미노화 활성, 디스무타제 활성, 알킬화 활성, 탈퓨린화 활성, 산화 활성, 피리미딘 이량체 형성 활성, 인테그라제 활성, 트랜스포사제 활성, 재조합효소 활성, 중합효소 활성, 리가제 활성, 헬리카제 활성, 광분해효소 활성 및 글리코실라제 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, CasX 융합 폴리펩타이드.
35.
34에 있어서, 상기 이종성 폴리펩타이드는 뉴클레아제 활성, 메틸트랜스퍼라제 활성, 데메틸라제 활성, 탈아미노화 활성, 탈퓨린화 활성, 인테그라제 활성, 트랜스포사제 활성 및 재조합효소 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, CasX 융합 폴리펩타이드.
36.
24 내지 31 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 표적 핵산과 회합된 표적 폴리펩타이드를 변형시키는 효소 활성을 나타내는, CasX 융합 폴리펩타이드.
37.
36에 있어서, 상기 이종성 폴리펩타이드는 히스톤 변형 활성을 나타내는, CasX 융합 폴리펩타이드.
38.
36 또는 37에 있어서, 상기 이종성 폴리펩타이드는 메틸트랜스퍼라제 활성, 데메틸라제 활성, 아세틸트랜스퍼라제 활성, 데아세틸라제 활성, 키나제 활성, 포스파타제 활성, 유비퀴틴 리가제 활성, 데유비퀴틴화 활성, 아데닐화 활성, 탈아데닐화 활성, 수모일화 활성, 탈수모일화활성, 리보실화 활성, 탈리보실화 활성, 미리스토일화 활성, 탈미리스토일화 활성, 글리코실화 활성(예를 들어, O-GlcNAc 트랜스퍼라제로부터의 활성) 및 탈글리코실화 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, CasX 융합 폴리펩타이드.
39.
38에 있어서, 상기 이종성 폴리펩타이드는 메틸트랜스퍼라제 활성, 데메틸라제 활성, 아세틸트랜스퍼라제 활성 및 데아세틸라제 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, CasX 융합 폴리펩타이드.
40.
24 내지 31 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 엔도솜 탈출 폴리펩타이드인, CasX 융합 폴리펩타이드.
41.
40에 있어서, 상기 엔도솜 탈출 폴리펩타이드는 하기로부터 선택된 아미노산 서열을 포함하는, CasX 융합 폴리펩타이드: GLFXALLXLLXSLWXLLLXA(서열번호 94), 및 GLFHALLHLLHSLWHLLLHA(서열번호 95), 여기서, 각각의 X는 라이신, 히스티딘 및 알기닌으로부터 독립적으로 선택된다.
42.
24 내지 31 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 엽록체 수송 펩타이드인, CasX 융합 폴리펩타이드.
43.
42에 있어서, 상기 엽록체 수송 펩타이드는,

44.
24 내지 31 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 전사를 증가 또는 감소시키는 단백질인, CasX 융합 폴리펩타이드.
45.
44에 있어서, 상기 이종성 폴리펩타이드는 전사 리프레서 도메인인, CasX 융합 폴리펩타이드.
46.
44에 있어서, 상기 이종성 폴리펩타이드는 전사 활성화 도메인인, CasX 융합 폴리펩타이드.
47.
24 내지 31 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 단백질 결합 도메인인, CasX 융합 폴리펩타이드.
48.
제24항 내지 제47항 중 어느 하나의 CasX 융합 폴리펩타이드를 암호화하는 핵산 분자.
49.
48에 있어서, 상기 CasX 융합 폴리펩타이드를 암호화하는 상기 뉴클레오타이드 서열은 프로모터에 작동 가능하게 연결된, 핵산 분자.
50.
49에 있어서, 상기 프로모터는 진핵 세포에서 기능성인, 핵산 분자.
51.
50에 있어서, 상기 프로모터는 식물 세포, 진균 세포, 동물 세포, 무척추동물의 세포, 파리 세포, 척추동물의 세포, 포유류 세포, 영장류 세포, 비-인간 영장류 세포 및 인간 세포 중 하나 이상에서 기능성인, 핵산.
52.
49 내지 51 중 어느 하나에 있어서, 상기 프로모터는 구성적 프로모터, 유도성 프로모터, 세포 유형-특이적 프로모터, 및 조직-특이적 프로모터 중 하나 이상인, 핵산 분자.
53.
48 내지 52 중 어느 하나에 있어서, 상기 DNA 분자는 재조합 발현 벡터인, 핵산 분자.
54.
53에 있어서, 상기 재조합 발현 벡터는 재조합 아데노연관 바이러스 벡터, 재조합 레트로바이러스 벡터 또는 재조합 렌티바이러스 벡터인, 핵산 분자.
55.
49에 있어서, 상기 프로모터는 원핵 세포에서 기능성인, 핵산 분자.
56.
48에 있어서, 상기 핵산 분자는 mRNA인, 핵산 분자.
57.
하나 이상의 핵산 분자로서,
(a) 활성체 RNA 및 표적자 RNA를 포함하는 CasX 가이드 RNA; 및
(b) CasX 폴리펩타이드
를 암호화하는, 하나 이상의 핵산 분자.
58.
57에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 50% 이상의 동일성을 갖는 아미노산 서열을 포함하는, 하나 이상의 핵산 분자.
59.
57에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 85% 이상의 동일성을 갖는 아미노산 서열을 포함하는, 하나 이상의 핵산 분자.
60.
57 내지 59 중 어느 하나에 있어서, 상기 CasX 가이드 RNA는 단일 가이드 RNA인, 하나 이상의 핵산 분자.
61.
57 내지 59 중 어느 하나에 있어서, 상기 CasX 가이드 RNA는 이중-가이드 RNA인, 하나 이상의 핵산 분자.
62.
61에 있어서, 상기 하나 이상의 핵산 분자는 상기 활성체를 암호화하는 제1 뉴클레오타이드 서열 및 상기 표적자를 암호화화는 제2 뉴클레오타이드 서열을 포함하되, 상기 제1 및 제2 뉴클레오타이드 서열은 상이한 DNA 분자 상에 존재하는, 하나 이상의 핵산 분자.
63.
57 내지 62 중 어느 하나에 있어서, 상기 하나 이상의 핵산 분자는 프로모터에 작동 가능하게 연결된 상기 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는, 하나 이상의 핵산 분자.
64.
63에 있어서, 상기 프로모터는 진핵 세포에서 기능성인, 하나 이상의 핵산 분자.
65.
64에 있어서, 상기 프로모터는 식물 세포, 진균 세포, 동물 세포, 무척추동물의 세포, 파리 세포, 척추동물의 세포, 포유류 세포, 영장류 세포, 비-인간 영장류 세포 및 인간 세포 중 하나 이상에서 기능성인, 하나 이상의 핵산 분자.
66.
63 내지 65 중 어느 하나에 있어서, 상기 프로모터는 구성적 프로모터, 유도성 프로모터, 세포 유형-특이적 프로모터, 및 조직-특이적 프로모터 중 하나 이상인, 하나 이상의 핵산 분자.
67.
57 내지 66 중 어느 하나에 있어서, 상기 하나 이상의 핵산 분자는 하나 이상의 재조합 발현 벡터인, 하나 이상의 핵산 분자.
68.
67에 있어서, 상기 하나 이상의 재조합 발현 벡터는 하나 이상의 아데노연관 바이러스 벡터, 하나 이상의 재조합 레트로바이러스 벡터, 또는 하나 이상의 재조합 렌티바이러스 벡터로부터 선택되는, 하나 이상의 핵산 분자.
69.
63에 있어서, 상기 프로모터는 원핵 세포에서 기능성인, 하나 이상의 핵산 분자.
70.
진핵 세포로서,
a) CasX 폴리펩타이드, 또는 상기 CasX 폴리펩타이드를 암호화하는 핵산 분자,
b) CasX 융합 폴리펩타이드, 또는 상기 CasX 융합 폴리펩타이드를 암호화하는 핵산 분자, 및
c) CasX 가이드 RNA, 또는 상기 CasX 가이드 RNA를 암호화하는 핵산 분자
중 하나 이상을 포함하는, 진핵 세포.
71.
70에 있어서, 상기 CasX 폴리펩타이드를 암호화하는 핵산 분자를 포함하되, 상기 핵산 분자는 상기 세포의 상기 게놈 DNA 내로 통합된, 진핵 세포.
72.
70 또는 71에 있어서, 상기 진핵 세포는 식물 세포, 포유류 세포, 곤충 세포, 거미류 세포, 진균 세포, 조류 세포, 파충류 세포, 양서류 세포, 무척추동물 세포, 마우스 세포, 래트 세포, 영장류 세포, 비-인간 영장류 세포, 또는 인간 세포인, 진핵 세포.
73.
CasX 융합 폴리펩타이드, 또는 상기 CasX 융합 폴리펩타이드를 암호화하는 핵산 분자를 포함하는 세포.
74.
73에 있어서, 상기 세포는 원핵 세포인, 세포.
75.
73 또는 74에 있어서, 상기 CasX 융합 폴리펩타이드를 암호화하는 핵산 분자를 포함하되, 상기 핵산 분자는 상기 세포의 상기 게놈 DNA 내로 통합된, 세포.
76.
표적 핵산의 변형 방법으로서, 상기 표적 핵산을,
a) CasX 폴리펩타이드; 및
b) 상기 표적 핵산의 표적 서열에 혼성화하는 가이드 서열을 포함하는 CasX 가이드 RNA
와 접촉시키는 단계를 포함하되,
상기 접촉시키는 단계는 상기 CasX 폴리펩타이드에 의해 상기 표적 핵산의 변형을 초래하는, 표적 핵산의 변형 방법.
77.
76에 있어서, 상기 변형은 상기 표적 핵산의 절단인, 방법.
78.
76 또는 77에 있어서, 상기 표적 핵산은 이중 가닥 DNA, 단일 가닥 DNA, RNA, 게놈 DNA, 및 염색체외 DNA로부터 선택된, 방법.
79.
76 내지 78 중 어느 하나에 있어서, 상기 접촉시키는 단계는 세포 외부의 시험관내에서 일어나는, 방법.
80.
76 내지 78 중 어느 하나에 있어서, 상기 접촉시키는 단계는 배양물 내 세포의 내부에서 일어나는, 방법.
81.
76 내지 78 중 어느 하나에 있어서, 상기 접촉시키는 단계는 생체내 세포의 내부에서 일어나는, 방법.
82.
80 또는 81에 있어서, 상기 세포는 진핵 세포인, 방법.
83.
82에 있어서, 상기 세포는 식물 세포, 진균 세포, 포유류 세포, 파충류 세포, 곤충 세포, 조류 세포, 어류 세포, 기생충 세포, 절지동물 세포, 무척추동물의 세포, 척추동물의 세포, 설치류 세포, 마우스 세포, 래트 세포, 영장류 세포, 비-인간 영장류 세포, 및 인간 세포로부터 선택된, 방법.
84.
80 또는 81에 있어서, 상기 세포는 원핵 세포인, 방법.
85.
76 내지 84 중 어느 하나에 있어서, 상기 접촉시키는 단계는 게놈 편집을 초래하는, 방법.
86.
76 내지 85 중 어느 하나에 있어서, 상기 접촉시키는 단계는 세포 내로: (a) 상기 CasX 폴리펩타이드, 또는 상기 CasX 폴리펩타이드를 암호화하는 핵산 분자, 및 (b) 상기 CasX 가이드 RNA, 또는 상기 CasX 가이드 RNA를 암호화하는 핵산 분자를 도입하는 것을 포함하는, 방법.
87.
86에 있어서, 상기 접촉시키는 단계는 DNA 공여자 주형을 상기 세포 내로 도입하는 것을 더 포함하는, 방법.
88.
76 내지 87 중 어느 하나에 있어서, 상기 CasX 가이드 RNA는 단일 가이드 RNA인, 방법.
89.
76 내지 87 중 어느 하나에 있어서, 상기 CasX 가이드 RNA는 이중 가이드 RNA인, 방법.
90.
표적 DNA로부터 전사를 조절하거나, 표적 핵산을 변형시키거나, 또는 표적 핵산과 회합된 단백질을 변형시키는 방법으로서, 상기 표적 핵산을,
a) 이종성 폴리펩타이드에 융합된 CasX 폴리펩타이드를 포함하는, CasX 융합 폴리펩타이드; 및
b) 상기 표적 핵산의 표적 서열에 혼성화하는 가이드 서열을 포함하는 CasX 가이드 RNA
와 접촉시키는 단계를 포함하는, 방법.
91.
90에 있어서, 상기 CasX 가이드 RNA는 단일 가이드 RNA인, 방법.
92.
90에 있어서, 상기 CasX 가이드 RNA는 이중 가이드 RNA인, 방법.
93.
90 내지 92 중 어느 하나에 있어서, 상기 변형은 상기 표적 핵산의 절단이 아닌, 방법.
94.
90 또는 93 중 어느 하나에 있어서, 상기 표적 핵산은 이중 가닥 DNA, 단일 가닥 DNA, RNA, 게놈 DNA, 및 염색체외 DNA로부터 선택된, 방법.
95.
90 내지 94 중 어느 하나에 있어서, 상기 접촉시키는 단계는 세포 외부의 시험관내에서 일어나는, 방법.
96.
90 내지 94 중 어느 하나에 있어서, 상기 접촉시키는 단계는 배양물 내 세포의 내부에서 일어나는, 방법.
97.
90 내지 94 중 어느 하나에 있어서, 상기 접촉시키는 단계는 생체내 세포의 내부에서 일어나는, 방법.
98.
96 또는 97에 있어서, 상기 세포는 진핵 세포인, 방법.
99.
98에 있어서, 상기 세포는 식물 세포, 진균 세포, 포유류 세포, 파충류 세포, 곤충 세포, 조류 세포, 어류 세포, 기생충 세포, 절지동물 세포, 무척추동물의 세포, 척추동물의 세포, 설치류 세포, 마우스 세포, 래트 세포, 영장류 세포, 비-인간 영장류 세포, 및 인간 세포로부터 선택된, 방법.
100.
96 또는 97에 있어서, 상기 세포는 원핵 세포인, 방법.
101.
90 내지 100 중 어느 하나에 있어서, 상기 접촉시키는 단계는 세포 내로: (a) 상기 CasX 융합 폴리펩타이드, 또는 상기 CasX 융합 폴리펩타이드를 암호화하는 핵산 분자, 및 (b) 상기 CasX 가이드 RNA, 또는 상기 CasX 가이드 RNA를 암호화하는 핵산 분자를 도입하는 것을 포함하는, 방법.
102.
90 내지 101 중 어느 하나에 있어서, 상기 CasX 폴리펩타이드는 촉매적으로 비활성인 CasX 폴리펩타이드(dCasX)인, 조성물.
103.
90 또는 102에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1의 D672, E769 및 D935로부터 선택된 것에 대응하는 위치에서 하나 이상의 돌연변이를 포함하는, 방법.
104.
90 내지 103 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 표적 DNA를 변형시키는 효소 활성을 나타내는, 방법.
105.
104에 있어서, 상기 이종성 폴리펩타이드는 뉴클레아제 활성, 메틸트랜스퍼라제 활성, 데메틸라제 활성, DNA 수선 활성, DNA 손상 활성, 탈아미노화 활성, 디스무타제 활성, 알킬화 활성, 탈퓨린화 활성, 산화 활성, 피리미딘 이량체 형성 활성, 인테그라제 활성, 트랜스포사제 활성, 재조합효소 활성, 중합효소 활성, 리가제 활성, 헬리카제 활성, 광분해효소 활성 및 글리코실라제 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 방법.
106.
105에 있어서, 상기 이종성 폴리펩타이드는 뉴클레아제 활성, 메틸트랜스퍼라제 활성, 데메틸라제 활성, 탈아미노화 활성, 탈퓨린화 활성, 인테그라제 활성, 트랜스포사제 활성 및 재조합효소 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 방법.
107.
90 내지 103 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 표적 핵산과 회합된 표적 폴리펩타이드를 변형시키는 효소 활성을 나타내는, 방법.
108.
107에 있어서, 상기 이종성 폴리펩타이드는 히스톤 변형 활성을 나타내는, 방법.
109.
107 또는 108에 있어서, 상기 이종성 폴리펩타이드는 메틸트랜스퍼라제 활성, 데메틸라제 활성, 아세틸트랜스퍼라제 활성, 데아세틸라제 활성, 키나제 활성, 포스파타제 활성, 유비퀴틴 리가제 활성, 데유비퀴틴화 활성, 아데닐화 활성, 탈아데닐화 활성, 수모일화 활성, 탈수모일화활성, 리보실화 활성, 탈리보실화 활성, 미리스토일화 활성, 탈미리스토일화 활성, 글리코실화 활성(예를 들어, O-GlcNAc 트랜스퍼라제로부터의 활성) 및 탈글리코실화 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 방법.
110.
109에 있어서, 상기 이종성 폴리펩타이드는 메틸트랜스퍼라제 활성, 데메틸라제 활성, 아세틸트랜스퍼라제 활성 및 데아세틸라제 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 방법.
111.
90 내지 103 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 전사를 증가 또는 감소시키는 단백질인, 방법.
112.
111에 있어서, 상기 이종성 폴리펩타이드는 전사 리프레서 도메인인, 방법.
113.
111에 있어서, 상기 이종성 폴리펩타이드는 전사 활성화 도메인인, 방법.
114.
90 내지 103 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 단백질 결합 도메인인, 방법.
115.
유전자이식, 다세포, 비인간 유기체로서, 게놈이,
a) CasX 폴리펩타이드,
b) CasX 융합 폴리펩타이드, 및
c) CasX 가이드 RNA
중 하나 이상을 암호화하는 뉴클레오타이드 서열을 포함하는 이식유전자를 포함하는, 유전자이식, 다세포, 비인간 유기체.
116.
제115항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 50% 이상의 아미노산 서열 동일성을 갖는 아미노산 서열을 포함하는, 유전자이식, 다세포, 비인간 유기체.
117.
제115항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 85% 이상의 아미노산 서열 동일성을 갖는 아미노산 서열을 포함하는, 유전자이식, 다세포, 비인간 유기체.
118.
115 내지 117 중 어느 하나에 있어서, 상기 유기체는 식물, 외떡잎식물, 쌍떡잎식물, 무척추동물, 곤충, 절지동물, 거미류, 기생충, 벌레, 강장동물, 척추동물, 어류, 파충류, 양서류, 유제류, 조류, 돼지, 말, 양, 설치류, 마우스, 래트 또는 비 인간 영장류인, 유전자이식, 다세포, 비인간 유기체.
119.
시스템으로서,
a) CasX 폴리펩타이드 및 CasX 단일 가이드 RNA;
b) CasX 폴리펩타이드, CasX 가이드 RNA, 및 DNA 공여자 주형;
c) CasX 융합 폴리펩타이드 및 CasX 가이드 RNA;
d) CasX 융합 폴리펩타이드, CasX 가이드 RNA, 및 DNA 공여자 주형;
e) CasX 폴리펩타이드를 암호화하는 mRNA 및 CasX 단일 가이드 RNA;
f) CasX 폴리펩타이드를 암호화하는 mRNA; CasX 가이드 RNA, 및 DNA 공여자 주형;
g) CasX 융합 폴리펩타이드를 암호화하는 mRNA 및 CasX 가이드 RNA;
h) CasX 융합 폴리펩타이드를 암호화하는 mRNA; CasX 가이드 RNA, 및 DNA 공여자 주형;
i) i) CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; 및 ii) CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 하나 이상의 재조합 발현 벡터;
j) i) CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; ii) CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열; 및 iii) DNA 공여자 주형을 포함하는 하나 이상의 재조합 발현 벡터;
k) i) CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; 및 ii) CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 하나 이상의 재조합 발현 벡터; 및
l) i) CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; ii) CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열; 및 iii) DNA 공여자 주형을 포함하는 하나 이상의 재조합 발현 벡터
를 포함하는, 시스템.
120.
119에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 50% 이상의 아미노산 서열 동일성을 갖는 아미노산 서열을 포함하는, CasX 시스템.
121.
119에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 85% 이상의 아미노산 서열 동일성을 갖는 아미노산 서열을 포함하는, CasX 시스템.
122.
119 내지 121 중 어느 하나에 있어서, 상기 공여자 주형 핵산은 길이가 8개의 뉴클레오타이드 내지 1000개의 뉴클레오타이드인, CasX 시스템.
123.
119 내지 121 중 어느 하나에 있어서, 상기 공여자 주형 핵산은 길이가 25개의 뉴클레오타이드 내지 500개의 뉴클레오타이드인, CasX 시스템.
124.
119 내지 123 중 어느 하나의 CasX 시스템을 포함하는 키트.
125.
124에 있어서, 상기 키트의 부품은 동일한 용기에 있는, 키트.
126.
124에 있어서, 상기 키트의 부품은 별개의 용기에 있는, 키트.
127.
119 내지 126 중 어느 하나의 CasX 시스템을 포함하는 멸균 용기.
128.
127에 있어서, 상기 용기는 주사기인, 멸균 용기.
129.
119 내지 126 중 어느 하나의 CasX 시스템을 포함하는 이식 가능한 장치.
130.
129에 있어서, 상기 CasX 시스템은 기질 내인, 이식 가능한 장치.
131.
129에 있어서, 상기 CasX 시스템은 저장소 내인, 이식 가능한 장치.
세트 B
고세균
Cas9와
관련
1. 조성물로서,
a) 고세균 Cas9 폴리펩타이드, 또는 상기 고세균 Cas9 폴리펩타이드를 암호화하는 핵산 분자; 및
b) 고세균 Cas9 가이드 RNA, 또는 상기 고세균 Cas9 가이드 RNA를 암호화하는 하나 이상의 DNA 분자
를 포함하는, 조성물.
2.
1에 있어서, 상기 고세균 Cas9 폴리펩타이드는 서열번호 71 또는 서열번호 72에 제시된 아미노산 서열에 대해 50% 이상의 동일성을 갖는 아미노산 서열을 포함하는, 조성물.
3.
1 또는 2에 있어서, 상기 고세균 Cas9 가이드 RNA는 단일 가이드 RNA인, 조성물.
4.
1 또는 2에 있어서, 상기 고세균 Cas9 가이드 RNA는 이중 가이드 RNA인, 조성물.
5.
1 내지 4 중 어느 하나에 있어서, 상기 조성물은 지질을 포함하는, 조성물.
6.
1 내지 4 중 어느 하나에 있어서, a) 및 b)는 리포좀 내에 있는, 조성물.
7.
1 내지 4 중 어느 하나에 있어서, a) 및 b)는 입자 내에 있는, 조성물.
8.
1 내지 7 중 어느 하나에 있어서, 완충제, 뉴클레아제 저해제, 및 프로테아제 저해제 중 하나 이상을 포함하는, 조성물.
9.
1 내지 8 중 어느 하나에 있어서, 상기 고세균 Cas9 폴리펩타이드는 서열번호 71 또는 서열번호 72에 제시된 아미노산 서열에 대해 85% 이상의 동일성을 갖는 아미노산 서열을 포함하는, 조성물.
10.
1 내지 9 중 어느 하나에 있어서, 상기 고세균 Cas9 폴리펩타이드는 이중-가닥 표적 핵산 분자의 하나의 가닥만을 절단할 수 있는 틈내기효소인, 조성물.
11.
1 내지 9 중 어느 하나에 있어서, 상기 고세균 Cas9 폴리펩타이드는 촉매적으로 비활성인 고세균 Cas9 폴리펩타이드(사멸 고세균 Cas9)인, 조성물.
12.
10 또는 11에 있어서, 상기 고세균 Cas9 폴리펩타이드는 서열번호 71의 D672, E769 및 D935로부터 선택된 것에 대응하는 위치에서 하나 이상의 돌연변이를 포함하는, 조성물.
13.
1 내지 12 중 어느 하나에 있어서, DNA 공여자 주형을 더 포함하는, 조성물.
14.
고세균 Cas9 단일 가이드 RNA 분자로서,
a) 표적 핵산에 혼성화하는 가이드 서열, 및 듀플렉스-형성 세그먼트를 포함하는 표적자 서열; 및
b) 표적자 서열의 듀플렉스-형성 세그먼트와 혼성화하여 고세균 Cas9 폴리펩타이드에 결합할 수 있는 이중 가닥 RNA(dsRNA) 듀플렉스를 형성하는 활성체 서열
을 포함하는, 고세균 Cas9 단일 가이드 RNA 분자.
15.
14에 있어서, 상기 가이드 서열은 길이가 19 내지 30개의 뉴클레오타이드를 갖는, 고세균 Cas9 단일 가이드 RNA 분자.
16.
14 또는 15의 고세균 Cas9 단일 가이드 RNA 분자를 암호화하는 뉴클레오타이드 서열을 포함하는 DNA 분자.
17.
16에 있어서, 상기 고세균 Cas9 단일 가이드 RNA를 암호화하는 상기 뉴클레오타이드 서열은 프로모터에 작동 가능하게 연결된, DNA 분자.
18.
17에 있어서, 상기 프로모터는 진핵 세포에서 기능성인, DNA 분자.
19.
18에 있어서, 상기 프로모터는 식물 세포, 진균 세포, 동물 세포, 무척추동물의 세포, 파리 세포, 척추동물의 세포, 포유류 세포, 영장류 세포, 비-인간 영장류 세포 및 인간 세포 중 하나 이상에서 기능성인, DNA 분자.
20.
17 내지 19 중 어느 하나에 있어서, 상기 프로모터는 구성적 프로모터, 유도성 프로모터, 세포 유형-특이적 프로모터, 및 조직-특이적 프로모터 중 하나 이상인, DNA 분자.
21.
16 내지 20 중 어느 하나에 있어서, 상기 DNA 분자는 재조합 발현 벡터인, DNA 분자.
22.
21에 있어서, 상기 재조합 발현 벡터는 재조합 아데노연관 바이러스 벡터, 재조합 레트로바이러스 벡터 또는 재조합 렌티바이러스 벡터인, DNA 분자.
23.
17에 있어서, 상기 프로모터는 원핵 세포에서 기능성인, DNA 분자.
24.
이종성 폴리펩타이드에 융합된 고세균 Cas9 폴리펩타이드를 포함하는, 고세균 Cas9 융합 폴리펩타이드.
25.
24에 있어서, 상기 고세균 Cas9 폴리펩타이드는 서열번호 71 또는 서열번호 72에 제시된 아미노산 서열에 대해 50% 이상의 동일성을 갖는 아미노산 서열을 포함하는, 고세균 Cas9 융합 폴리펩타이드.
26.
24에 있어서, 상기 고세균 Cas9 폴리펩타이드는 서열번호 71 또는 서열번호 72에 제시된 아미노산 서열에 대해 85% 이상의 동일성을 갖는 아미노산 서열을 포함하는, 고세균 Cas9 융합 폴리펩타이드.
27.
24 내지 27 중 어느 하나에 있어서, 상기 고세균 Cas9 폴리펩타이드는 이중-가닥 표적 핵산 분자의 하나의 가닥만을 절단할 수 있는 틈내기효소인, 고세균 Cas9 융합 폴리펩타이드.
28.
24 내지 27 중 어느 하나에 있어서, 상기 고세균 Cas9 폴리펩타이드는 촉매적으로 비활성인 고세균 Cas9 폴리펩타이드(사멸 고세균 Cas9)인, 고세균 Cas9 융합 폴리펩타이드.
29.
27 또는 28에 있어서, 상기 고세균 Cas9 폴리펩타이드는 서열번호 71의 D672, E769 및 D935로부터 선택된 것에 대응하는 위치에서 하나 이상의 돌연변이를 포함하는, 고세균 Cas9 융합 폴리펩타이드.
30.
24 내지 29 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 상기 고세균 Cas9 폴리펩타이드의 N-말단 및/또는 C-말단에 융합된, 고세균 Cas9 융합 폴리펩타이드.
31.
24 내지 30 중 어느 하나에 있어서, NLS를 포함하는, 고세균 Cas9 융합 폴리펩타이드.
32.
24 내지 31 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 표적 세포 또는 표적 세포 유형 상의 세포 표면 모이어티에 대한 결합을 제공하는 표적화 폴리펩타이드인, 고세균 Cas9 융합 폴리펩타이드.
33.
24 내지 31 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 표적 DNA를 변형시키는 효소 활성을 나타내는, 고세균 Cas9 융합 폴리펩타이드.
34.
33에 있어서, 상기 이종성 폴리펩타이드는 뉴클레아제 활성, 메틸트랜스퍼라제 활성, 데메틸라제 활성, DNA 수선 활성, DNA 손상 활성, 탈아미노화 활성, 디스무타제 활성, 알킬화 활성, 탈퓨린화 활성, 산화 활성, 피리미딘 이량체 형성 활성, 인테그라제 활성, 트랜스포사제 활성, 재조합효소 활성, 중합효소 활성, 리가제 활성, 헬리카제 활성, 광분해효소 활성 및 글리코실라제 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 고세균 Cas9 융합 폴리펩타이드.
35.
34에 있어서, 상기 이종성 폴리펩타이드는 뉴클레아제 활성, 메틸트랜스퍼라제 활성, 데메틸라제 활성, 탈아미노화 활성, 탈퓨린화 활성, 인테그라제 활성, 트랜스포사제 활성 및 재조합효소 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 고세균 Cas9 융합 폴리펩타이드.
36.
24 내지 31 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 표적 핵산과 회합된 표적 폴리펩타이드를 변형시키는 효소 활성을 나타내는, 고세균 Cas9 융합 폴리펩타이드.
37.
36에 있어서, 상기 이종성 폴리펩타이드는 히스톤 변형 활성을 나타내는, 고세균 Cas9 융합 폴리펩타이드.
38.
36 또는 37에 있어서, 상기 이종성 폴리펩타이드는 메틸트랜스퍼라제 활성, 데메틸라제 활성, 아세틸트랜스퍼라제 활성, 데아세틸라제 활성, 키나제 활성, 포스파타제 활성, 유비퀴틴 리가제 활성, 데유비퀴틴화 활성, 아데닐화 활성, 탈아데닐화 활성, 수모일화 활성, 탈수모일화활성, 리보실화 활성, 탈리보실화 활성, 미리스토일화 활성, 탈미리스토일화 활성, 글리코실화 활성(예를 들어, O-GlcNAc 트랜스퍼라제로부터의 활성) 및 탈글리코실화 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 고세균 Cas9 융합 폴리펩타이드.
39.
38에 있어서, 상기 이종성 폴리펩타이드는 메틸트랜스퍼라제 활성, 데메틸라제 활성, 아세틸트랜스퍼라제 활성 및 데아세틸라제 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 고세균 Cas9 융합 폴리펩타이드.
40.
24 내지 31 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 엔도솜 탈출 폴리펩타이드인, 고세균 Cas9 융합 폴리펩타이드.
41.
40에 있어서, 상기 엔도솜 탈출 폴리펩타이드는 GLFXALLXLLXSLWXLLLXA(서열번호 94), 및 GLFHALLHLLHSLWHLLLHA(서열번호 95)로부터 선택된 아미노산 서열을 포함하되, 각각의 X는 라이신, 히스티딘 및 알기닌으로부터 독립적으로 선택되는, 고세균 Cas9 융합 폴리펩타이드.
42.
24 내지 31 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 엽록체 수송 펩타이드인, 고세균 Cas9 융합 폴리펩타이드.
43.
42에 있어서, 상기 엽록체 수송 펩타이드는,

44.
24 내지 31 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 전사를 증가 또는 감소시키는 단백질인, 고세균 Cas9 융합 폴리펩타이드.
45.
44에 있어서, 상기 이종성 폴리펩타이드는 전사 리프레서 도메인인, 고세균 Cas9 융합 폴리펩타이드.
46.
44에 있어서, 상기 이종성 폴리펩타이드는 전사 활성화 도메인인, 고세균 Cas9 융합 폴리펩타이드.
47.
24 내지 31 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 단백질 결합 도메인인, 고세균 Cas9 융합 폴리펩타이드.
48.
제24항 내지 제47항 중 어느 하나의 고세균 Cas9 융합 폴리펩타이드를 암호화하는 핵산 분자.
49.
48에 있어서, 상기 고세균 Cas9 융합 폴리펩타이드를 암호화하는 상기 뉴클레오타이드 서열은 프로모터에 작동 가능하게 연결된, 핵산 분자.
50.
49에 있어서, 상기 프로모터는 진핵 세포에서 기능성인, 핵산 분자.
51.
50에 있어서, 상기 프로모터는 식물 세포, 진균 세포, 동물 세포, 무척추동물의 세포, 파리 세포, 척추동물의 세포, 포유류 세포, 영장류 세포, 비-인간 영장류 세포 및 인간 세포 중 하나 이상에서 기능성인, 핵산.
52.
49 내지 51 중 어느 하나에 있어서, 상기 프로모터는 구성적 프로모터, 유도성 프로모터, 세포 유형-특이적 프로모터, 및 조직-특이적 프로모터 중 하나 이상인, 핵산 분자.
53.
48 내지 52 중 어느 하나에 있어서, 상기 DNA 분자는 재조합 발현 벡터인, 핵산 분자.
54.
53에 있어서, 상기 재조합 발현 벡터는 재조합 아데노연관 바이러스 벡터, 재조합 레트로바이러스 벡터 또는 재조합 렌티바이러스 벡터인, 핵산 분자.
55.
49에 있어서, 상기 프로모터는 원핵 세포에서 기능성인, 핵산 분자.
56.
48에 있어서, 상기 핵산 분자는 mRNA인, 핵산 분자.
57.
하나 이상의 핵산 분자로서,
(a) 활성체 RNA 및 표적자 RNA를 포함하는 고세균 Cas9 가이드 RNA; 및
(b) 고세균 Cas9 폴리펩타이드
를 암호화하는, 하나 이상의 핵산 분자.
58.
57에 있어서, 상기 고세균 Cas9 폴리펩타이드는 서열번호 71 또는 서열번호 72에 제시된 아미노산 서열에 대해 50% 이상의 동일성을 갖는 아미노산 서열을 포함하는, 하나 이상의 핵산 분자.
59.
57에 있어서, 상기 고세균 Cas9 폴리펩타이드는 서열번호 71 또는 서열번호 72에 제시된 아미노산 서열에 대해 85% 이상의 동일성을 갖는 아미노산 서열을 포함하는, 하나 이상의 핵산 분자.
60.
57 내지 59 중 어느 하나에 있어서, 상기 고세균 Cas9 가이드 RNA는 단일 가이드 RNA인, 하나 이상의 핵산 분자.
61.
57 내지 59 중 어느 하나에 있어서, 상기 고세균 Cas9 가이드 RNA는 이중-가이드 RNA인, 하나 이상의 핵산 분자.
62.
61에 있어서, 상기 하나 이상의 핵산 분자는 상기 활성체를 암호화하는 제1 뉴클레오타이드 서열 및 상기 표적자를 암호화화는 제2 뉴클레오타이드 서열을 포함하되, 상기 제1 및 제2 뉴클레오타이드 서열은 상이한 DNA 분자 상에 존재하는, 하나 이상의 핵산 분자.
63.
57 내지 62 중 어느 하나에 있어서, 상기 하나 이상의 핵산 분자는 프로모터에 작동 가능하게 연결된 상기 고세균 Cas9 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는, 하나 이상의 핵산 분자.
64.
63에 있어서, 상기 프로모터는 진핵 세포에서 기능성인, 하나 이상의 핵산 분자.
65.
64에 있어서, 상기 프로모터는 식물 세포, 진균 세포, 동물 세포, 무척추동물의 세포, 파리 세포, 척추동물의 세포, 포유류 세포, 영장류 세포, 비-인간 영장류 세포 및 인간 세포 중 하나 이상에서 기능성인, 하나 이상의 핵산 분자.
66.
63 내지 65 중 어느 하나에 있어서, 상기 프로모터는 구성적 프로모터, 유도성 프로모터, 세포 유형-특이적 프로모터, 및 조직-특이적 프로모터 중 하나 이상인, 하나 이상의 핵산 분자.
67.
57 내지 66 중 어느 하나에 있어서, 상기 하나 이상의 핵산 분자는 하나 이상의 재조합 발현 벡터인, 하나 이상의 핵산 분자.
68.
67에 있어서, 상기 하나 이상의 재조합 발현 벡터는 하나 이상의 아데노연관 바이러스 벡터, 하나 이상의 재조합 레트로바이러스 벡터, 또는 하나 이상의 재조합 렌티바이러스 벡터로부터 선택되는, 하나 이상의 핵산 분자.
69.
63에 있어서, 상기 프로모터는 원핵 세포에서 기능성인, 하나 이상의 핵산 분자.
70.
진핵 세포로서,
a) 고세균 Cas9 폴리펩타이드, 또는 상기 고세균 Cas9 폴리펩타이드를 암호화하는 핵산 분자,
b) 고세균 융합 Cas9 폴리펩타이드, 또는 상기 고세균 Cas9 융합 폴리펩타이드를 암호화하는 핵산 분자, 및
c) 고세균 Cas9 가이드 RNA 폴리펩타이드, 또는 상기 고세균 Cas9 가이드 RNA 폴리펩타이드를 암호화하는 핵산 분자
중 하나 이상을 포함하는, 진핵 세포.
71.
70에 있어서, 상기 고세균 Cas9 폴리펩타이드를 암호화하는 핵산 분자를 포함하되, 상기 핵산 분자는 상기 세포의 상기 게놈 DNA 내로 통합된, 진핵 세포.
72.
70 또는 71에 있어서, 상기 진핵 세포는 식물 세포, 포유류 세포, 곤충 세포, 거미류 세포, 진균 세포, 조류 세포, 파충류 세포, 양서류 세포, 무척추동물 세포, 마우스 세포, 래트 세포, 영장류 세포, 비-인간 영장류 세포, 또는 인간 세포인, 진핵 세포.
73.
고세균 융합 Cas9 폴리펩타이드, 또는 상기 고세균 Cas9 융합 폴리펩타이드를 암호화하는 핵산 분자를 포함하는 세포.
74.
73에 있어서, 상기 세포는 원핵 세포인, 세포.
75.
73 또는 74에 있어서, 상기 고세균 Cas9 융합 폴리펩타이드를 암호화하는 핵산 분자를 포함하되, 상기 핵산 분자는 상기 세포의 상기 게놈 DNA 내로 통합된, 세포.
76.
표적 핵산의 변형 방법으로서, 상기 표적 핵산을,
a) 고세균 Cas9 폴리펩타이드; 및
b) 상기 표적 핵산의 표적 서열에 혼성화하는 가이드 서열을 포함하는 고세균 Cas9 가이드 RNA
와 접촉시키는 단계를 포함하되,
상기 접촉시키는 단계는 상기 고세균 Cas9 폴리펩타이드에 의해 상기 표적 핵산의 변형을 초래하는, 방법.
77.
76에 있어서, 상기 변형은 상기 표적 핵산의 절단인, 방법.
78.
76 또는 77에 있어서, 상기 표적 핵산은 이중 가닥 DNA, 단일 가닥 DNA, RNA, 게놈 DNA, 및 염색체외 DNA로부터 선택된, 방법.
79.
76 내지 78 중 어느 하나에 있어서, 상기 접촉시키는 단계는 세포 외부의 시험관내에서 일어나는, 방법.
80.
76 내지 78 중 어느 하나에 있어서, 상기 접촉시키는 단계는 배양물 내 세포의 내부에서 일어나는, 방법.
81.
76 내지 78 중 어느 하나에 있어서, 상기 접촉시키는 단계는 생체내 세포의 내부에서 일어나는, 방법.
82.
80 또는 81에 있어서, 상기 세포는 진핵 세포인, 방법.
83.
82에 있어서, 상기 세포는 식물 세포, 진균 세포, 포유류 세포, 파충류 세포, 곤충 세포, 조류 세포, 어류 세포, 기생충 세포, 절지동물 세포, 무척추동물의 세포, 척추동물의 세포, 설치류 세포, 마우스 세포, 래트 세포, 영장류 세포, 비-인간 영장류 세포, 및 인간 세포로부터 선택된, 방법.
84.
80 또는 81에 있어서, 상기 세포는 원핵 세포인, 방법.
85.
76 내지 84 중 어느 하나에 있어서, 상기 접촉시키는 단계는 게놈 편집을 초래하는, 방법.
86.
76 내지 85 중 어느 하나에 있어서, 상기 접촉시키는 단계는 세포 내로: (a) 상기 고세균 Cas9 폴리펩타이드, 또는 상기 고세균 Cas9 폴리펩타이드를 암호화하는 핵산 분자, 및 (b) 상기 고세균 Cas9 가이드 RNA, 또는 상기 고세균 Cas9 가이드 RNA를 암호화하는 핵산 분자를 도입하는 것을 포함하는, 방법.
87.
86에 있어서, 상기 접촉시키는 단계는 DNA 공여자 주형을 상기 세포 내로 도입하는 것을 더 포함하는, 방법.
88.
76 내지 87 중 어느 하나에 있어서, 상기 고세균 Cas9 가이드 RNA는 단일 가이드 RNA인, 방법.
89.
76 내지 87 중 어느 하나에 있어서, 상기 고세균 Cas9 가이드 RNA는 이중 가이드 RNA인, 방법.
90.
표적 DNA로부터 전사를 조절하거나, 표적 핵산을 변형시키거나, 또는 표적 핵산과 회합된 단백질을 변형시키는 방법으로서, 상기 표적 핵산을,
a) 이종성 폴리펩타이드에 융합된 고세균 Cas9 폴리펩타이드를 포함하는, 고세균 Cas9 융합 폴리펩타이드; 및
b) 상기 표적 핵산의 표적 서열에 혼성화하는 가이드 서열을 포함하는 고세균 Cas9 가이드 RNA
와 접촉시키는 단계를 포함하는, 방법.
91.
90에 있어서, 상기 고세균 Cas9 가이드 RNA는 단일 가이드 RNA인, 방법.
92.
90에 있어서, 상기 고세균 Cas9 가이드 RNA는 이중 가이드 RNA인, 방법.
93.
90 내지 92 중 어느 하나에 있어서, 상기 변형은 상기 표적 핵산의 절단이 아닌, 방법.
94.
90 또는 93 중 어느 하나에 있어서, 상기 표적 핵산은 이중 가닥 DNA, 단일 가닥 DNA, RNA, 게놈 DNA, 및 염색체외 DNA로부터 선택된, 방법.
95.
90 내지 94 중 어느 하나에 있어서, 상기 접촉시키는 단계는 세포 외부의 시험관내에서 일어나는, 방법.
96.
90 내지 94 중 어느 하나에 있어서, 상기 접촉시키는 단계는 배양물 내 세포의 내부에서 일어나는, 방법.
97.
90 내지 94 중 어느 하나에 있어서, 상기 접촉시키는 단계는 생체내 세포의 내부에서 일어나는, 방법.
98.
96 또는 97에 있어서, 상기 세포는 진핵 세포인, 방법.
99.
98에 있어서, 상기 세포는 식물 세포, 진균 세포, 포유류 세포, 파충류 세포, 곤충 세포, 조류 세포, 어류 세포, 기생충 세포, 절지동물 세포, 무척추동물의 세포, 척추동물의 세포, 설치류 세포, 마우스 세포, 래트 세포, 영장류 세포, 비-인간 영장류 세포, 및 인간 세포로부터 선택된, 방법.
100.
96 또는 97에 있어서, 상기 세포는 원핵 세포인, 방법.
101.
90 내지 100 중 어느 하나에 있어서, 상기 접촉시키는 단계는 세포 내로: (a) 상기 고세균 Cas9 융합 폴리펩타이드, 또는 상기 고세균 Cas9 융합 폴리펩타이드를 암호화하는 핵산 분자, 및 (b) 상기 고세균 Cas9 가이드 RNA, 또는 상기 고세균 Cas9 가이드 RNA를 암호화하는 핵산 분자를 도입하는 것을 포함하는, 방법.
102.
90 내지 101 중 어느 하나에 있어서, 상기 고세균 Cas9 폴리펩타이드는 촉매적으로 비활성인 고세균 Cas9 폴리펩타이드(사멸 고세균 Cas9)인, 방법.
103.
90 또는 102에 있어서, 상기 고세균 Cas9 폴리펩타이드는 서열번호 71의 D672, E769 및 D935로부터 선택된 것에 대응하는 위치에서 하나 이상의 돌연변이를 포함하는, 방법.
104.
90 내지 103 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 표적 DNA를 변형시키는 효소 활성을 나타내는, 방법.
105.
104에 있어서, 상기 이종성 폴리펩타이드는 뉴클레아제 활성, 메틸트랜스퍼라제 활성, 데메틸라제 활성, DNA 수선 활성, DNA 손상 활성, 탈아미노화 활성, 디스무타제 활성, 알킬화 활성, 탈퓨린화 활성, 산화 활성, 피리미딘 이량체 형성 활성, 인테그라제 활성, 트랜스포사제 활성, 재조합효소 활성, 중합효소 활성, 리가제 활성, 헬리카제 활성, 광분해효소 활성 및 글리코실라제 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 방법.
106.
105에 있어서, 상기 이종성 폴리펩타이드는 뉴클레아제 활성, 메틸트랜스퍼라제 활성, 데메틸라제 활성, 탈아미노화 활성, 탈퓨린화 활성, 인테그라제 활성, 트랜스포사제 활성 및 재조합효소 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 방법.
107.
90 내지 103 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 표적 핵산과 회합된 표적 폴리펩타이드를 변형시키는 효소 활성을 나타내는, 방법.
108.
107에 있어서, 상기 이종성 폴리펩타이드는 히스톤 변형 활성을 나타내는, 방법.
109.
107 또는 108에 있어서, 상기 이종성 폴리펩타이드는 메틸트랜스퍼라제 활성, 데메틸라제 활성, 아세틸트랜스퍼라제 활성, 데아세틸라제 활성, 키나제 활성, 포스파타제 활성, 유비퀴틴 리가제 활성, 데유비퀴틴화 활성, 아데닐화 활성, 탈아데닐화 활성, 수모일화 활성, 탈수모일화활성, 리보실화 활성, 탈리보실화 활성, 미리스토일화 활성, 탈미리스토일화 활성, 글리코실화 활성(예를 들어, O-GlcNAc 트랜스퍼라제로부터의 활성) 및 탈글리코실화 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 방법.
110.
109에 있어서, 상기 이종성 폴리펩타이드는 메틸트랜스퍼라제 활성, 데메틸라제 활성, 아세틸트랜스퍼라제 활성 및 데아세틸라제 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 방법.
111.
90 내지 103 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 전사를 증가 또는 감소시키는 단백질인, 방법.
112.
111에 있어서, 상기 이종성 폴리펩타이드는 전사 리프레서 도메인인, 방법.
113.
111에 있어서, 상기 이종성 폴리펩타이드는 전사 활성화 도메인인, 방법.
114.
90 내지 103 중 어느 하나에 있어서, 상기 이종성 폴리펩타이드는 단백질 결합 도메인인, 방법.
115.
유전자이식, 다세포, 비인간 유기체로서, 게놈이,
a) 고세균 Cas9 폴리펩타이드,
b) 고세균 융합 Cas9 폴리펩타이드; 및
c) 고세균 Cas9 가이드 RNA
중 하나 이상을 암호화하는 뉴클레오타이드 서열을 포함하는 이식유전자를 포함하는, 유전자이식, 다세포, 비인간 유기체.
116.
제115항에 있어서, 상기 고세균 Cas9 폴리펩타이드는 서열번호 71 또는 서열번호 72에 제시된 아미노산 서열에 대해 50% 이상의 아미노산 서열 동일성을 갖는 아미노산 서열을 포함하는, 유전자이식, 다세포, 비인간 유기체.
117.
제115항에 있어서, 상기 고세균 Cas9 폴리펩타이드는 서열번호 71 또는 서열번호 72에 제시된 아미노산 서열에 대해 85% 이상의 아미노산 서열 동일성을 갖는 아미노산 서열을 포함하는, 유전자이식, 다세포, 비인간 유기체.
118.
115 내지 117 중 어느 하나에 있어서, 상기 유기체는 식물, 외떡잎식물, 쌍떡잎식물, 무척추동물, 곤충, 절지동물, 거미류, 기생충, 벌레, 강장동물, 척추동물, 어류, 파충류, 양서류, 유제류, 조류, 돼지, 말, 양, 설치류, 마우스, 래트 또는 비 인간 영장류인, 유전자이식, 다세포, 비인간 유기체.
119.
시스템으로서,
a) 고세균 Cas9 폴리펩타이드 및 고세균 Cas9 단일 가이드 RNA;
b) 고세균 Cas9 폴리펩타이드, 고세균 Cas9 가이드 RNA, 및 DNA 공여자 주형;
c) 고세균 Cas9 융합 폴리펩타이드 및 고세균 Cas9 가이드 RNA;
d) 고세균 Cas9 융합 폴리펩타이드, 고세균 Cas9 가이드 RNA, 및 DNA 공여자 주형;
e) 고세균 Cas9 폴리펩타이드를 암호화하는 mRNA, 및 고세균 Cas9 단일 가이드 RNA;
f) 고세균 Cas9 폴리펩타이드를 암호화하는 mRNA; 고세균 Cas9 가이드 RNA, 및 DNA 공여자 주형;
g) 고세균 Cas9 융합 폴리펩타이드를 암호화하는 mRNA, 및 고세균 Cas9 가이드 RNA;
h) 고세균 Cas9 융합 폴리펩타이드를 암호화하는 mRNA, 고세균 Cas9 가이드 RNA, 및 DNA 공여자 주형;
i) i) 고세균 Cas9 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; 및 ii) 고세균 Cas9 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 하나 이상의 재조합 발현 벡터;
j) i) 고세균 Cas9 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; ii) 고세균 Cas9 가이드 RNA를 암호화하는 뉴클레오타이드 서열; 및 iii) DNA 공여자 주형을 포함하는 하나 이상의 재조합 발현 벡터;
k) i) 고세균 Cas9 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; 및 ii) 고세균 Cas9 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 하나 이상의 재조합 발현 벡터; 및
l) i) 고세균 Cas9 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; ii) 고세균 Cas9 가이드 RNA를 암호화하는 뉴클레오타이드 서열; 및 DNA 공여자 주형을 포함하는 하나 이상의 재조합 발현 벡터
를 포함하는, 시스템.
120.
제119항에 있어서, 상기 고세균 Cas9 폴리펩타이드는 서열번호 71 또는 서열번호 72에 제시된 아미노산 서열에 대해 50% 이상의 아미노산 서열 동일성을 갖는 아미노산 서열을 포함하는, 고세균 Cas9 시스템.
121.
제119항에 있어서, 상기 고세균 Cas9 폴리펩타이드는 서열번호 71 또는 서열번호 72에 제시된 아미노산 서열에 대해 85% 이상의 아미노산 서열 동일성을 갖는 아미노산 서열을 포함하는, 고세균 Cas9 시스템.
122.
119 내지 121 중 어느 하나에 있어서, 상기 공여자 주형 핵산은 길이가 8개의 뉴클레오타이드 내지 1000개의 뉴클레오타이드인, 고세균 Cas9 시스템.
123.
119 내지 121 중 어느 하나에 있어서, 상기 공여자 주형 핵산은 길이가 25개의 뉴클레오타이드 내지 500개의 뉴클레오타이드인, 고세균 Cas9 시스템.
124.
119 내지 123 중 어느 하나의 고세균 Cas9 시스템을 포함하는 키트.
125.
124에 있어서, 상기 키트의 부품은 동일한 용기에 있는, 키트.
126.
124에 있어서, 상기 키트의 부품은 별개의 용기에 있는, 키트.
127.
119 내지 126 중 어느 하나의 고세균 Cas9 시스템을 포함하는 멸균 용기.
128.
127에 있어서, 상기 용기는 주사기인, 멸균 용기.
129.
119 내지 126 중 어느 하나의 고세균 Cas9 시스템을 포함하는 이식 가능한 장치.
130.
129에 있어서, 상기 고세균 Cas9 시스템은 기질 내인, 이식 가능한 장치.
131.
129에 있어서, 상기 고세균 Cas9 시스템은 저장소 내인, 이식 가능한 장치.
132.
1 내지 131(세트 B) 중 어느 하나에 있어서, 고세균 Cas9 단백질이 ARMAN-1 Cas9 단백질 또는 ARMAN-4 Cas9 단백질인 것.
133.
1 내지 131(세트 B) 중 어느 하나에 있어서, 고세균 Cas9 단백질이 칸디다투스 마이크라카에움 호산성 Cas9 단백질 또는 칸디다투스 파바카에움 호산성 Cas9 단백질인 것.
실시예
다음의 실시예는 당업자에게 본 발명의 제조하고 사용하는 방법의 완전한 개시내용 및 설명을 제공하기 위해 제시하며, 본 발명자들이 본 발명으로서 간주하는 것의 범주를 제한하는 것으로 의도되지도 또는 이하의 실험이 모든 또는 수행되는 실험만을 나타내는 것으로 의도하지도 않는다. 사용한 숫자(예를 들어, 양, 온도 등)에 관한 정확성을 보장하기 위한 노력을 하였지만, 일부 실험적 오차 및 편차를 고려하여야 한다. 달리 나타내지 않는 한, 부분은 중량부이고, 분자량은 중량 평균 분자량이며, 온도는 섭씨이고, 압력은 대기압에서 또는 대기압 근처이다. 표준 약어, 예를 들어, bp, 염기쌍(들); kb, 킬로베이스(들); pl, 피코리터(들); s 또는 sec, 초(들); min, 분(들); h 또는 hr, 시간(들); aa, 아미노산(들); kb, 킬로베이스(들); bp, 염기쌍(들); nt, 뉴클레오타이드(들); i.m., 근육내(로); i.p., 복강내(로); s.c., 피하(로); 등.
실시예
1
본 명세서에 기재된 작업은 지하수, 퇴적물 및 산성 광산 배수로부터의 미생물 군집의 메타게놈 샘플 분석을 포함한다. 배양 유기체 중에서 나타나지 않은 뉴 클래스 2 CRISPR-Cas 시스템을 동정하였다.
도 3. CasX 도메인 및 유사성 검색. (패널 a) HHpred를 이용하여 AcCpf1이 있는 원위 상동체 정렬로부터 추론되는 CasX에 대한 개략적 도메인 표현. 보존된 촉매적 잔기를 단백질 위의 적색 막대로 표시한다. CasX는 C-말단 영역에서 RuvC 분할 도메인(RuvC-I, RuvC-II 및 RuvC-III), 및 거대 신규한 N-말단 도메인을 함유한다. 이하의 개략도는 다음의 검색에 기반하여 상부 히트를 나타낸다: (1) NCBI(모델 및 환경 단백질을 포함하는 NR 데이터베이스)에서 모든 단백질에 대한 BLAST 검색. (2) 문헌[Makarova et al. Nat Rev Microbiol. 2015 Nov;13(11):722-36, 및 Shmakov et al. Mol Cell. 2015 Nov 5;60(3):385-97)]에서 기재한 모든 Cas 단백질을 이용하여 구성한 모델에 기반한 프로파일 은닉 마르코브 모델(hidden markov model: HMM) 검색. (3) HHpred에 기반한 원위 상동체 검색. 히트는 그들의 유의도에 기반하여 색-암호화하고, 히트 범위 및 E-값을 제공한다. 특히, CasX는 국소 히트만을 가졌다. CasX의 620개의 N-말단 아미노산은 임의의 검색 개략도에서 히트가 없었다. 종합하면, 이들 발견은 CasX가 새로운 Cas 단백질이라는 것을 나타낸다. (패널 b) 두 상이한 CasX-함유 CRISPR 좌위 스캐폴드를 서열 데이터로부터 구성하였고, 상부는 델타프로테오박터(CasX1)로부터 유래되며, 하부는 부유균문(CasX2)이다. 대응하는 DNA 서열은 각각 서열번호 51 및 52에 제시한다.
실시예
2
도 4(패널 a 내지 c). 이콜라이에서 발현된 CasX에 의한 플라스미드 간섭. (패널 a) CasX 플라스미드 간섭의 실험 설계. 최소 간섭 CasX 좌위(제거된 획득 단백질)을 발현시키는 적격 이콜라이 세포를 제조하였다. 이들 세포를 CasX CRISPR 좌위에서 스페이서에 대한 매칭을 함유하는 플라스미드(표적) 또는 그렇지 않은 것(비-표적)으로 형질전환시키고 나서, CRISPR 및 표적 플라스미드에 대한 항생제 선택을 함유하는 배지 상에서 플레이팅하였다. 성공적인 플라스미드 간섭은 표적 플라스미드에 대해 감소된 수의 형질전환 콜로니를 초래한다. (패널 b) CasX1로부터의 스페이서(sX1), CasX2로부터의 스페이서(sX2)를 함유하는 형질전환된 플라스미드 또는 무작위 30nt 서열을 함유하는 비표적 플라스미드의 cfu/㎍. (패널 c) CRISPR과 표적 플라스미드 둘 다에 대해 항생제 선택을 함유하는 배지 상에서 패널 b로부터의 형질전환체의 연속 희석을 수행하였다.
도 5 (패널 a 내지 b) CasX에 의한 PAM 의존적 플라스미드 간섭. (패널 a) CasX를 이용하여 PAM 고갈 분석을 수행하였다. CasX CRISPR 좌위를 함유하는 이콜라이를 표적 서열의 7개 뉴클레오타이드 무작위화된 5' 또는 3'을 갖는 플라스미드 라이브러리로 형질전환시켰다. 표적 플라스미드를 선택하고 형질전환체를 모았다. 무작위화된 영역을 증폭시키고 나서, 심층 서열분석을 위해 제조하였다. 고갈된 서열을 동정하고 나서, PAM 로고를 생성하는 데 사용하였다. (패널 b) 델타프로테오박테리아 CasX에 대해 생성된 PAM 로고는 표적의 5'-TTCN-3' 측접 서열 5'을 함유하는 서열에 대한 강한 선호도를 나타내었다. 3' PAM은 검출되지 않았다. c, 부유균 CasX에 대해 생성된 PAM 로고는 첫 번째 T에서 더 낮은 엄격함을 갖는 표적의 5'-TTCN-3' 측접 서열 5'을 함유하는 서열에 대해 강한 선호도를 나타내었다. 3' PAM은 검출되지 않았다.
도 6(패널 a 내지 c). CasX는 이중 가이드된 CRISPR - Cas 효과기 복합체이다. (패널 a) tracrRNA 넉아웃 실험 및 sgRNA 시험에 대한 CRISPR 좌위. (패널 b) 표적 또는 비표적 서열을 함유하는 형질전환 플라스미드의 ㎍ 당 콜로니 형성 단위(cfu). tracrRNA의 결실은 플라스미드 간섭의 제거를 초래하였다. tracrRNA 및 CRISPR 어레이 대신에 합성 shRNA의 발현은 CasX에 의한 강한 플라스미드 간섭을 초래하였다. (패널 c) sgRNA 설계의 다이어그램(CasX1에 대한 tracrRNA 및 crRNA 서열로부터 유래됨). tracrRNA(녹색)을 테트라루프(GAAA)에 의해 crRNA(반복부, 검정색; 스페이서, 적색)에 결합시켰다.
도 7. CasX RNA 가이드된 DNA 간섭의 개략도. CasX는 tracrRNA(녹색) 및 crRNA(검정색, 반복부; 적색, 스페이서)에 결합한다. 정확한 프로토스페이서 인접 모티프(황색)를 함유하는 표적 서열(청색)에 대한 가이드 RNA의 염기쌍은 표적 DNA의 이중 가닥 절단을 초래한다. 도시한 서열은 CasX1에 대한 tracrRNA 및 crRNA 서열로부터 유래된다.
실시예
3
도 8. CasX를 이용하여 인간 세포를 편집하기 위한 실험 설계. 탈안정화된 GFP를 발현시키는 HEK293 세포를 플라스미드 발현 CasX 및 그의 가이드 RNA의 리포펙션 또는 가이드 RNA와 함께 사전 조립된 CasX의 뉴클레오펙션을 이용하여 CasX로 처리하였다. 성공적인 게놈 절단은 유세포분석 및/또는 서베이어 분석(예를 들어, T7E1 분석)에 의해 검출될 수 있는 형광 신호의 상실을 야기하는 GFP 좌위에서 삽입결실을 초래할 것이다.
실시예
4
도 9. CasX의 재조합 발현 및 정제. CasX를 말토스 결합 단백질에 융합시켰고, 이콜라이에서 발현시켰다. 용해물을 Ni-NTA 수지에 대해 정제하고 나서, TEV로 처리하고, 헤파린 칼럼 및 크기 배제 칼럼에 대해 정제하였다. 크기 배제 칼럼으로부터의 분획을 참조를 위해 분자량 마커로 나타낸다. CasX의 계산된 크기는 대략 110kDa이었다.
실시예
5
도 10. 다양한 tracrRNA 서열의 시험. 시험한 tracrRNA 서열은 다음과 같다(CasX 이중 가이드 RNA의 개략도에 대해 도 7을 참조한다):

추가로, 다음의 crRNA 서열을 기능에 대해 시험하였다:
crRNA 1(crRNA의 가공 형태 - sgRNA와 이중 가이드 형식 둘 다에서 활성임):
CCGAUAAGUAAAACGCAUCAAAGNNNNNNNNNNNNNNNNNNNN(서열번호 61)
crRNA 2(이중 가이드 형식에서 활성임):
AUUUGAAGGUAUCUCCGAUAAGUAAAACGCAUCAAAGNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN(서열번호 62)
추가로, 다음의 sgRNA 서열을 기능에 대해 시험하였다(CasX 가이드 RNA의 개략적 표현에 대해 도 6 및 도 7을 참조한다):
sgRNA1(은 활성, 센스, 가공됨):

sgRNA2(는 비활성, 센스, 사전가공, 밑줄 표시 서열은 sgRNA1에 대해 상이함):

sgRNA3(은 비활성, 안티센스, 가공됨):

sgRNA4(는 비활성):

실시예
6
도 11. CasX 시스템(CasX 단백질 및 가이드 RNA)은 실온 및 37℃에서 박테리아 세포에서의 기능에 대해 시험하였다. 형질전환 플라스미드의 ㎍ 당 콜로니 형성 단위(cfu)를 표적 또는 비표적 서열을 함유하는 플라스미드에 대해 분석하였다. 분석을 실온 또는 37℃에서 수행하였다. 데이터는 CasX 시스템은 실온 또는 37℃에서 유사한 정도로 작용하였다.
실시예
7 -
고세균
Cas9
도 12. ARMAN -1 II형 CRISPR -cas 시스템. (패널 a), ARMAN-1 CRISPR-Cas 좌위 개요. (패널 b) NGG 3' PAM에 대한 강한 선호도는 240개의 프로토스페이서의 분석으로부터 추론하였다. (패널 c) 리치몬드 광산 생태계로부터 샘플링한 ARMAN-1 게놈에서 CRISPR 어레이의 재구성. 녹색 화살표는 반복부를 나타내고, 색이 있는 화살표는 CRISPR 스페이서를 나타낸다(동일한 스페이서는 동일하게 색칠한 반면, 독특한 스페이서는 검정색으로 색칠한다). 콘틱(회색 막대)은 메타게놈 콘틱 상의 스페이서 순서를 기준으로 정렬한다. 회색 배경은 어레이의 보존된 그리고 추정적으로 오래된 영역을 나타낸다. CRISPR 시스템에서, 스페이서는 전형적으로 편방향으로 첨가되고, 따라서 좌위의 좌측에서 매우 다양한 스페이서가 최근의 획득이 일어난 경우라는 것을 나타낸다. 최근에 획득된 스페이서의 다양성의 존재뿐만 아니라 상이한 부위에서 그리고 상이한 시간에 수집한 데이터세트로부터 조립된 게놈 단편에서 반복부 및 스페이서 서열의 보존은 시스템이 활성이라는 것을 나타낸다. (패널 d) ARMAN-1 Cas9의 계통발생은 그것을 ARMAN-4 Cas9 및 본 명세서에 처음 보고된 2종의 새로운 박테리아 Cas9와 함께 클러스터링하였다(검정색). 이들 Cas9는 좌위가 Cas4를 함유한다고 해도, II-B형 시스템에서 전형적으로 발견되는 II-C형 시스템과 진화적으로 관련되는 것으로 여겨진다. (패널 e) 상이한 세트의 II-B형과 함께 클러스터링된 ARMAN-1 Cas1의 계통발생. 종합하면, 패널 (d) 및 (e)에서 계통수는 ARMAN-1 II형 시스템이 II-B 및 II-C형 CRSIPR-Cas 시스템의 재조합 결과일 수 있다는 것을 시사한다.
도 14. (상부 패널) ARMAN-1 Cas9에 대한 crRNA:tracrRNA 이중-가이드 RNA의 예측된 2차 구조. crRNA(상부 가닥)와 다양한 길이의 예측된 tracrRNA 서열(하부 가닥) 사이의 2차 구조 및 염기쌍을 도시한다. "crRNA"는 ARMAN-1로부터의 직접 반복부 서열을 나타내는 반면, 녹색의 N20은 사용자-정의 서열(가이드 서열)이다. TracrRNA-69를 적색으로 나타낸 한편, tracrRNA-104 및 tracrRNA-179는 각각 청색 및 핑크색 서열에 의해 연장된다. (하부 패널) ARMAN-1 Cas9에 대한 예시적 단일-가이드 RNA의 예측 구조. sgRNA의 2차 구조를 도시한다. "표적자"는 부분 직접 반복부(절단됨) 및 표적자를 활성체에 연결하는(또한 절단됨) 조작된 테트라루프(링커)를 나타낸다. 녹색의 N20은 사용자-정의 서열(가이드 서열)이다. tracrRNA-69, tracrRNA-104 및 tracrRNA-179를 포함하는 SgRNA를 도시한다.
도 15. (상부 패널) ARMAN-4 Cas9에 대한 crRNA:tracrRNA 이중-가이드 RNA의 예측된 2차 구조. crRNA(상부 가닥)와 예측된 tracrRNA 서열(하부 가닥) 사이의 2차 구조 및 염기쌍을 도시한다. "crRNA"는 ARMAN-4로부터의 직접 반복부 서열을 나타내는 반면, 녹색의 N20은 사용자-정의 서열(가이드 서열)이다. (하부 패널) ARMAN-4 Cas9에 대한 예시적 단일-가이드 RNA의 예측 구조. sgRNA의 2차 구조를 도시한다. "표적자"는 부분 직접 반복부(절단됨) 및 표적자를 활성체에 연결하는(또한 절단됨) 조작된 테트라루프(링커)를 나타낸다. 녹색의 N20은 사용자-정의 서열(가이드 서열)이다.
실시예
8:
비배양
미생물로부터의 새로운
CRISPR
-
Cas
시스템
CRISPR-Cas 적응 면역계는 부위-특이적 DNA 절단을 할 수 있는 프로그램 가능한 효소를 제공함으로써 게놈에 혁신을 일으켰다. 그러나, 현재의 CRISPR-Cas 기술은 아직 손대지 않은 단리되지 않은 유기체로부터의 방대한 효소를 떠나서 배양 박테리아로부터의 시스템에만 기반한다. 본 명세서의 데이터는 배양-독립적 게놈-해결 메타게노믹스를 이용하여, 고세균의 생활 도메인에서 처음 보고된 Cas9를 포함하는 새로운 CRISPR-Cas 시스템의 동정을 나타낸다. 이런 분기하는 Cas9 효소는 활성 CRISPR-Cas 시스템의 부분으로서 거의 연구되지 않은 나노고세균에서 발견되었다. 박테리아에서, 2개의 이전에 알려지지 않은 시스템, 즉, 아직 동정되지 않은 가장 최신의 시스템 중에서 CRISPR-CasX 및 CRISPR-CasY가 발견되었다. 특히, 모든 필요한 기능성 성분을 메타게노믹스에 의해 동정하였는데, 이는 이콜라이에서 강한 RNA-가이드 DNA 간섭의 확인을 허용하였다. 본 명세서의 데이터는 살아있는 세포에서의 실험과 조합된 환경적 미생물 군집의 의문이 내용이 미생물계 생물기법의 레퍼토리를 확장하는 게놈의 전례없는 다양성에 대한 접근을 허용한다는 것을 나타낸다.
결과
지하수, 퇴적물, 및 산성 광산 배수 미생물 군집으로부터의 테라베이스-규모의 메타게놈 데이터세트를 분석하였고, 배양 유기체 중에서 나타내지 않은 클래스 2 CRISPR-Cas 시스템을 탐색하였다. 도메인 고세균에서 제1 Cas9 단백질을 동정하였고, 비배양 박테리아에서 2개의 새로운 CRISPR-Cas 시스템, 즉, CRISPR-CasX 및 CRISPR-CasY를 발견하였다(도 18). 특히, 고세균 Cas9와 CasY는 둘 다 알려진 단리된 대표물이 없는 계통으로부터의 유기체 게놈에서 배타적으로 암호화되었다.
고세균
Cas9의
제1 동정
CRISPR-Cas9의 특징 중 하나는 박테리아 도메인에서만의 그의 추정적 존재였다. 따라서 산성 광산 배수(AMD) 메타게놈 데이터세트에서 나노고세균 ARMAN-1(칸디다투스 마이크라카에움(Candidatus Micrarchaeum) 호산성 ARMAN-1) 및 ARMAN-4(칸디다투스 파르바카에움(Candidatus Parvarchaeum) 호산성 ARMAN-4) 게놈에서 암호화된 Cas9 단백질을 발견한 것은 놀라웠다. 이들 발견은 Cas9-함유 CRISPR 시스템의 발생을 다른 생활 도메인으로 확장시킨다.
ARMAN-4 cas9 유전자는 동일한 게놈 내용의 16개의 상이한 샘플에서 발견되었지만, 다른 인접한 cas 유전자는 없었고(25 kbp 초과로 몇몇 DNA 서열 콘틱에서 중심에 위치됨에도 불구하고), 하나의 인접한 CRISPR 반복-스페이서 단위만을 가진다(도 24). 보편적인 CRISPR 인테그라제를 암호화하는 전형적인 CRISPR 어레이 및 cas1의 결여는 새로운 스페이서를 획득하는 능력이 없는 시스템을 시사한다. 표적은 스페이서 서열에 대해 동정될 수 없었지만, 몇년에 걸쳐 수집한 샘플 내 좌위의 보존을 제공하였으며, "단일-표적" CRISPR-Cas 시스템에서 그의 기능은 이때에 제외할 수 없다.
대조적으로, 15개의 상이한 샘플로부터 회수한 ARMAN-1에서 CRISPR-Cas 좌위는 cas1, cas2, cas4 및 cas9 유전자에 인접한 거대 CRISPR 어레이를 포함한다. 대체로 보존된 말단(가장 오래된 스페이서를 포함할 가능성이 있음) 및 다수의 별개의 스페이서가 혼입된 가변 영역을 갖는 수많은 대안의 ARMAN-1 CRISPR 어레이를 재구성하였다(도 19a 및 도 25). 스페이서 내용에서 이 초가변성에 기반하여, 이들 데이터는 ARMAN-1 CRISPR-Cas9 시스템이 샘플링한 집단에서 활성이라는 것을 나타낸다.
현저하게는, ARMAN-1 CRISPR-Cas9 시스템의 추정적 스페이서 표적(프로토스페이서) 중 56개를, 그것이 고밀도의 짧은 가설 단백질을 암호화한다는 것을 고려하여 ARMAN-1 바이러스일 가능성이 있는 단일 10 kbp 게놈 단편에 위치시켰다(도 19b). 사실, 극저온 전자 단층 촬영 재구성은 종종 ARMAN 세포에 부착된 바이러스 입자를 동정하였다. ARMAN-1 프로토스페이서는 또한 동일한 생태계로부터의 I-플라즈마를 포함하는, ARMAN-2(다른 나노고세균)의 게놈 내에서 추정적 트랜스포존 및 써모플라스마탈레스(Thermoplasmatales) 고세균의 게놈 내 추정적 이동 요소로부터 유래되었다(도 26). ARMAN과 써모플라스마탈레스 세포 사이에 직접 세포질 "브리지"가 관찰되었는데, 이는 그들 사이의 밀접한 관계를 나타낸다. 따라서 ARMAN-1 CRISPR-Cas9는 진핵 생식 계통에서 piRNA-매개 방어를 연상시키는 역할인 이들 유기체 사이의 트랜스포존 증식에 대해 방어될 수 있다.
활성 DNA-표적화 CRISPR-Cas 시스템은 자기 대 비자기 차별에 대해 표적 서열 다음에 위치된 2 내지 4개의 bp 프로토스페이서-인접 모티프(PAM)를 사용한다. 게놈 표적 서열에 인접한 서열의 시험은 사실 ARMAN-1에서의 강한 'NGG' PAM 선호도를 나타내었다(도 19c). Cas9는 또한 RNA-가이드 DNA 절단을 위해 2개의 별개의 전사체, 즉, CRISPR RNA(crRNA) 및 전사 촉진 CRISPR RNA(tracrRNA)를 사용한다. ARMAN-1과 ARMAN-4 CRISPR-Cas9 시스템 둘 다의 근처에서 추정적 tracrRNA를 동정하였다(도 27). 이전에, 고세균에서는 숙주 인자인 RNase III의 결여에 기인하여 II형 CRISPR 시스템이 없고, 이는 crRNA-tracrRNA 가이드 복합체 성숙을 초래하였다는 것을 시사하였다. 특히, RNase III 상동체는 ARMAN-1 게놈(95% 완전한 것으로 추정됨)에서 동정되지 않았고, 내부 프로모터는 CRISPR 어레이에 대해 예측되지 않았는데, 이는 가이드 RNA 생산의 아직 결정되지 않은 메커니즘을 시사한다. 이콜라이와 효모 둘 다로부터 정제된 ARMAN-1 및 ARMAN-4 Cas9 단백질의 절단 활성을 시험하기 위한 생화학적 실험 및 생체내 이콜라이 표적화 분석은 임의의 검출 가능한 활성을 나타내지 않았다(도 32 및 도 28 참조).
CRISPR
-
CasX는
새로운 이중-RNA-가이드
CRISPR
시스템이다
Cas9에 추가로, 클래스 2 Cas 효과기 단백질의 3가지 패밀리만을 발견하였고, 실험적으로 확인하였다: Cpf1, C2c1 및 C2c2. 작은 DNA 단편 상에서만 동정된 다른 유전자인 c2c3은 또한 이러한 단백질 패밀리를 암호화하는 것으로 시사되었다. 새로운 유형의 클래스 2 CRISPR-Cas 시스템은 지하수 및 퇴적물 샘플로부터 반복적으로 회수한 2종의 박테리아의 게놈에서 발견되었다. 상이한 문에 속하는 2종의 유기체, 즉, 델타프로테오박테리아 및 부유균문에서 이 시스템의 높은 보존은 최근의 문 간의 전달을 시사한다. 이 새로 기재된 시스템은 본 명세서에서 CasX로서 지칭되는 Cas1, Cas2, Cas4 및 비특성규명된 대략 980개의 aa 단백질을 포함한다. 각각의 CasX와 회합된 CRISPR 어레이는 37개의 염기쌍의 고도로 유사한 반복부, 33 내지 34개 염기쌍의 스페이서, 및 Cas 오페론과 CRISPR 어레이 사이의 추정적 tracrRNA를 가졌다(도 18b). BLAST 검색은 CasX C-말단의 특정 영역으로 제한된 유사성으로, 트랜스포사제에 대해 약한 유사성만을 나타내었다(e-값 > 1×10-4). 원위 상동성 검출 및 단백질 모델링은 V형 CRISPR-Cas 시스템에서 발견된 조직화를 연상시키는 CasX C-말단 단부 근처의 RuvC 도메인을 동정하였다(도 29). CasX 단백질의 나머지(630 N-말단의 아미노산)은 임의의 공지된 단백질에 대해 검출 가능한 유사성을 나타내지 않았는데, 이는 신규한 클래스 2 효과기라는 것을 시사한다. tracrRNA와 별개의 Cas1, Cas2 및 Cas4 단백질의 조합은 V형 시스템 중에서 독특하다. 추가로, CasX는 임의의 공지된 V 단백질보다 상당히 더 작다: Cpf1, C2c1 및 C2c3에 대해 980 aa은 1,200 aa보다 더 큰 전형적인 크기와 비교됨.
다음에, 그의 작은 크기 및 비정규 좌위 내용에도 불구하고, CasX는 Cas9 및 Cpf1 효소와 유사한 RNA-가이드 DNA 표적화를 할 수 있는지의 여부를 생각하였다. 이 가능성을 시험하기 위해, casX, 짧은 반복부-스페이서 어레이 및 간접 비암호 영역을 포함하는 최소 CRISPR-CasX 좌위를 암호화하는 플라스미드를 합성하였다. 이콜라이에서 발현될 때, 이런 최소 좌위는 메타게놈 분석에 의해 동정된 플라스미드 보유 표적 서열에 의한 형질전환을 차단하였다(도 20a 내지 도 20c, 도 30). 더 나아가, 최소-좌위에서 스페이서 서열이 플라스미드 표적 내 프로토스페이서 서열에 매칭될 때에만 형질전환에 의한 간섭이 일어났다. CasX에 대한 PAM 서열을 동정하기 위해, 표적 부위에 인접한 5' 또는 3' 무작위화 서열 중 하나를 함유하는 플라스미드를 사용하여 형질전환 분석을 이콜라이에서 반복하였다. 이 분석은 프로토스페이서 서열의 5' 바로 옆에 위치된 서열 'TTCN'에 대한 엄격한 선호도를 나타내었다(도 20d). 3' PAM 선호도는 관찰되지 않았다(도 30). 이 발견과 일치되게, 'TTCA'는 환경 샘플에서 동정한 추정적 델타프로테오박테리아 CRISPR-CasX 프로토스페이서 상류에서 발견된 서열이었다. 특히, CRISPR-CasX 좌위는 동일한 PAM 서열을 공유하는데, 이는 그들의 높은 정도의 CasX 단백질 상동성과 연결된다.
단일-RNA와 이중-RNA 가이드 시스템 둘 다의 예는 V형 CRISPR 좌위에 존재한다. 실험적 메타-전사체 데이터를 사용하여 CasX가 DNA 표적화 활성에 대해 tracrRNA를 필요로 하는지의 여부를 결정하였다. 이 분석은 Cas2 오픈 리딩 프레임과 CRISPR 어레이 사이에 암호화된 CRISPR 반복부에 상보성인 서열을 갖는 비-암호 RNA 전사체를 나타내었다(도 21a). CasX 좌위를 발현시키는 이콜라이에서 이 비-암호 RNA의 발현에 대해 확인하기 위해, 방향 둘 다에서 이 전사체에 대해 노덧 블롯을 수행하였다(도 30). 결과는 대략 60 내지 70개의 nt의 더 이종성의 전사체에 의한, casX 유전자와 동일한 가닥 상에서 암호화된 대략 110개의 nt의 전사체의 발현을 나타내었고, 이는 CRISPR 어레이에 대한 리더 서열이 tracrRNA와 어레이 사이에 있다는 것을 시사한다. 전사체 맵핑은 추가로 CRISPR RNA(crRNA)가 CRISPR-Cas9 시스템에서 생긴 crRNA 가공과 유사하게 반복부의 22 nt(또는 약 23 nt) 및 인접한 스페이서의 20nt를 포함하도록 가공된다는 것을 시사한다(도 21a). 더 나아가, 2-nt 3' 돌출부를 동정하였는데, 이는 crRNA-tracrRNA 듀플렉스의 RNase III-매개 가공과 일치된다(도 21b). 추정적 tracrRNA에 대한 CasX 활성의 의존도를 결정하기 위해, 이 영역을 상기 기재한 최소 CRISPR-CasX 좌위로부터 결실시키고, 플라스미드 간섭 분석을 반복하였다. CasX 플라스미드로부터의 추정적 tracrRNA-암호화 서열의 결실은 그의 존재에서 관찰된 강한 형질전환 간섭이 없었다(도 21c). 단일-가이드 RNA(sgRNA)를 형성하기 위해 테트라루프를 이용하여 가공된 crRNA와 이 추정적 tracrRNA를 결합하였다. crRNA 단독의 이종성 프로모터 또는 sgRNA의 단축 형태를 이용하는 발현이 임의의 상당한 플라스미드 간섭을 나타내지 않았다면, 전장 sgRNA의 발현은 플라스미드 형질전환에 대한 내성을 부여하였다(도 21c). 종합하면, 이들 결과는 새로운 기능성 DNA-표적화, 이중-RNA 가이드 CRISPR 효소로서 CasX를 확립한다. 이들 결과는 CasX가 단일-RNA 가이드 CRISPR 효소로서 작용할 수 있다는 것을 추가로 입증한다.
단리물이
없는 박테리아 계통에서 배타적으로 발견된 시스템인
CRISPR
-
CasY
특정 후보 문 방사선(candidate phyla radiation: CPR) 박테리아의 게놈에서 암호화된 다른 새로운 클래스 2 Cas 단백질을 동정하였다. 이들 박테리아는 전형적으로 작은 세포 크기(크라이오-TEM 데이터 및 여과를 통한 농축에 기반함), 매우 작은 게놈 및 제한된 생합성 능력을 갖는데, 이는 그들이 공생자일 가능성이 있다는 것을 나타낸다. 본 명세서에서 CasY로서 지칭되는 새로운 대략 1,200 aa Cas 단백질은 기껏해야, Cas1 및 CRISPR 어레이를 포함하는 최소 CRISPR-Cas 시스템의 부분인 것으로 나타났다(도 22a). 대부분의 CRISPR 어레이는 보통 17 내지 19 nt의 짧은 스페이서를 갖지만, Cas1을 결여하는 하나의 시스템(CasY.5)은 더 긴 스페이서(27 내지 29 nt)를 가진다. 동정된 CasY 단백질의 6가지 예는 공공의 데이터베이스에서 임의의 단백질에 대해 상당한 서열 유사성이 없었다. 공개된 Cas 단백질3,4로부터 구성된 프로파일 모델(HMM)을 이용하는 민감한 검색은 6개의 CasY 단백질 중 4개는 RuvC 도메인과 중복되는 C-말단 영역 및 N-말단의 작은 영역(대략 45aa)에서 C2c3에 대해 국소 유사성(e-값 4×10-11 내지 3×10- 18)을 가진다는 것을 나타내었다(도 29 참조). C2c3은 분류학상의 소속 없이 짧은 콘틱에 대해 동정된 추정적 V형 Cas 효과기이며, 실험적으로 입증되지 않았다. CasY와 같이, C2c3는 짧은 스페이서 및 Cas1를 갖지만, 다른 Cas 단백질이 없는 어레이 옆에서 발견되었다. 특히, 현재의 연구에서 동정된 CasY 단백질 중 둘은 다른 CasY 단백질과 상당한 서열 유사성(최고 Blast 히트: e-값 6×10-85, 7×10-75)을 공유함에도 불구하고, C2c3에 대해 상당한 유사성이 없었다.
임의의 실험적으로 확인된 CRISPR 좌위에 대한 CRISPR-CasY의 낮은 상동성을 고려하여, 다음에 이 시스템이 RNA-가이드 DNA 간섭을 부여하는지의 여부를 생각하였지만, 짧은 스페이서 길이 때문에 이러한 활성에 필요할 수 있는 가능한 PAM 모티프에 관해 신뢰 가능한 정보는 존재하지 않았다. 이것에 착수하기 위해, 단축된 CRISPR 어레이로 전체 CRISPR-CasY.1 좌위를 합성하고 나서, 플라스미드 벡터 상에서 이콜라이에 도입하였다. 이어서, 가능한 PAM을 동정하기 위해 어레이에서 스페이서 서열에 매칭되고 인접한 무작위화 5' 또는 3'영역을 함유하는 서열을 갖는 플라스미드를 이용하여 형질전환 분석에서 이들 세포에 도전하였다. 형질전환체의 분석은 표적화된 서열에 직접적으로 인접한 5' TA를 함유하는 서열의 고갈을 나타내었다(도 22b). 이 동정된 PAM 서열을 이용하여, CasY.1 좌위를 단일 PAM을 함유하는 플라스미드에 대해 시험하였다. 플라스미드 간섭은 동정된 5'TA PAM 서열을 함유하는 표적의 존재에서만 입증되었다(도 22c). 따라서, 이들 데이터는 CRISPR-CasY가 DNA 간섭 활성을 가진다는 것을 나타낸다.
논의
비배양 박테리아 및 고세균으로부터의 게놈에서 새로운 클래스 2 CRISPR-Cas 적응 면역계를 동정하였고 특성규명하였다. 활성 CRISPR 좌위에 대해 보편적인 Cas1의 진화 분석(도 23a)은 본 명세서에 기재된 고세균 Cas9 시스템이 임의의 존재하는 II형 서브타입에 명확하게 속하지 않았다는 것을 시사하였다. Cas1 계통발생(뿐만 아니라 cas4의 존재)을 야생형 II-B 시스템과 함께 클러스터링시켰고, 아직 Cas9의 서열은 II-C형 단백질과 더 유사하였다(도 31). 따라서, 고세균 II형 시스템은 II-C형 및 II-B형 시스템의 융합으로서 생길 수 있다(도 23b). 마찬가지로, Cas1 계통발생 분석은 CRISPR-CasX 시스템으로부터의 Cas1인 임의의 다른 공지된 V형 시스템으로부터 원위에 있다는 것을 나타내었다. V형 시스템은 조상 I형 시스템으로부터의 적응 모듈(Cas1 내지 Cas2)과 트랜스포존의 융합 결과가 되는 것으로 시사되었다. 따라서 CRISPR-CasX 시스템이 이전에 기재된 V형 시스템에 생기는 것과 상이한 융합 사건 후에 나타났다는 가설을 세운다. 현저하게, CRISPR-CasY와 추정적 C2c3 시스템은 둘 다 CRISPR 좌위 내로 DNA를 통합하는 데 필수적인 것으로 생각되는 단백질인 Cas2를 결여하는 것으로 보인다. 모든 CRISPR-Cas 시스템이 Cas1과 Cas2를 둘 다 함유한 조상 I형 시스템의 후속인 것으로 생각되는 것을 고려하면, CRISPR-CasY 및 C2c3 시스템은 CRISPR-Cas 시스템의 나머지와 상이한 혈통을 가질 수 있거나, 또는 대안적으로, Cas2는 그들의 진화 이력 동안 상실될 수 있었다.
고세균에서 Cas9의 본 명세서에 기재된 발견 및 박테리아에서 2가지의 이전에 미공지 CRISPR-Cas 시스템은 복잡한 천연 미생물 군집으로부터 얻은 광대한 DNA 및 RNA 서열을 사용하였다. CasX 및 CasY의 경우에, 게놈 내용은 결집되지 않은 서열 정보로부터 명백하지 않은 기능의 예측에 대해 중요하였다. 추가로, 추정적 tracrRNA뿐만 아니라 표적화된 바이러스 서열의 동정은 메타게놈 데이터 가이드된 기능성 시험의 분석을 통해 다루지 않았다. 흥미롭게도, 지금까지 동정된 가장 빽빽한 CRISPR-Cas 좌위의 일부는 매우 작은 게놈을 갖는 유기체에서 발견되었다. 작은 게놈 크기의 결과는 기본적 대사 필요를 위해 다른 군집 구성원에 의존할 가능성이 있으며, 따라서 그들은 대체로 전통적 배양-기반 방법의 범주 밖에서 남아있었다. 간섭에 필요한 제한된 수의 단백질은 이들 최소 시스템이 새로운 게놈 편집 도구의 개발에 특히 가치 있게 만든다. 중요하게는, CRISPR-Cas 시스템과 관련된 메타게놈 발견이 인실리코 관찰로 제한되지 않지만, 그들의 기능이 시험될 수 있는 실험 환경에 도입될 수 있다는 것을 본 명세서에 나타낸다. 생명이 존재하는 사실상 모든 환경이 현재 게놈-해결 메타게놈 방법에 의해 프로빙될 수 있다는 것을 고려하면, 본 명세서에 기재된 조합된 컴퓨터-실험 접근은 공지된 CRISPR-Cas 시스템의 다양성을 크게 확장시켜, 생물학적 연구 및 임상 용도를 위한 새로운 기법을 제공한다는 것이 예상된다.
방법
메타게놈
및
메타전사체분석
3개의 상이한 부위로부터의 메타게놈 샘플을 분석하였다: (1) 캘리포니아주 아이언 마운틴에 소재한 리치몬드 광산으로부터 2006년과 2010년 사이에 수집한 산성 광산 배수(AMD) 샘플 (2) 콜로라도주 라이플 근처의 콜로라도강에 인접한 라이플 인터그레이티드 필드 리서치(Rifle Integrated Field Research: IFRC) 현장으로부터의 2007년과 2013년 사이에 수집한 지하수 및 퇴적물 샘플. (3) 유타주 콜로라도 고원에서 크리스탈 가이저(Crystal Geyser)로부터 2009년과 2014년에 수집한 지하수, 차가운, CO2-유도 간헐천.
AMD 데이터에 대해, 문헌[Denef and Banfield (2012) 및 Miller et al. (2011)]에 의해 DNA 추출 방법 및 짧은 판독 서열분석을 보고하였다. 라이플 데이터에 대해, DNA 및 RNA 추출뿐만 아니라 서열분석, 조립체 및 재구성된 게놈을 문헌[Anantharaman et al. (2016) 및 Brown et al. (2015)]에 의해 기재하였다. 크리스탈 가이저로부터의 샘플에 대해, 방법은 문헌[Probst et al (2016) 및 Emerson et al. (2015)]에 의해 기재된 것에 따른다. 간략하게, 파워소일(PowerSoil) DNA 단리 키트(미국 캘리포니아주 칼스베드에 소재한 모바이오 래버러토리즈 인코포레이티드(MoBio Laboratories Inc.))를 이용하여 DNA를 샘플로부터 추출하였다. 문헌[Brown et al. (2015)]에 의해 기재된 바와 같은 6개의 2011 라이플 지하수로부터 수집된 0.2㎛ 필터로부터 RNA를 추출하였다. DNA를 일루미나(Illumina) HiSeq2000 플랫폼 상에서, 그리고 메타전사체 cDNA를 5500XL SOLiD 플랫폼 상에서 서열분석하였다. 새로 보고된 크리스탈 가이저 데이터 및 AMD 데이터의 재분석을 위해, IDBA-UD를 이용하여 서열을 조립하였다. Bowtie2를 이용하여 서열분석 범위 및 유전자 발현을 각각 결정하기 위해 사용한 DNA 및 RNA(cDNA) 판독-맵핑을 수행하였다. 프로디갈(Prodigal)을 이용하여 조립 스캐폴드에 대해 오픈 리딩 프레임(Open reading frame: ORF)을 예측하였다. 출현 자기-조직화 맵(Emergent Self-Organizing Map: ESOM)을 이용하여 ABAWACA, ABAWACA2(https://github.com/CK7) Maxbin2, 및 테트라뉴클레오타이드 빈도의 조합을 이용하는 차별적 범위 존재비 패턴에 기반하여 크리스탈 가이저 데이터세트로부터의 스캐폴드를 버렸다. GC 함량%, 분류학상의 소속 및 게놈 완전성을 이용하여 게놈을 수동으로 만들었다. ra2.py를 이용하여 스캐폴딩 오차를 수정하였다(https://github.com/christophertbrown).
CRISPR
-
Cas
계산 분석
문헌[Makarova et al. 및 Shmakov et al.]으로부터의 정렬에 기반하여 허머(HMMer) 스위트를 이용하여 구성한 은닉 마르코프 모델(HMM) 프로파일을 이용하여 공지된 Cas 단백질에 대해 다양한 샘플로부터의 조립 콘틱을 스캐닝하였다. CrisprFinder 소프트웨어의 국소 형태를 이용하여 CRISPR 어레이를 동정하였다. cas1 유전자에 인접한 10개의 ORF 중 하나가 800 aa보다 더 큰 비특성규명 단백질에 대해 암호화되었다면 Cas1과 CRISPR 어레이를 둘 다 함유한 좌위를 추가로 분석하였고, 동일한 콘틱 상에서 cas 간섭 유전자는 동정되지 않았다. 이들 거대 단백질을 잠재적 클래스 2 Cas 효과기로서 추가로 분석하였다. MCL을 이용하여 서열 유사상에 기반하여 단백질 패밀리에 대해 잠재적 효과기를 클러스터링하였다. 각각의 이들 패밀리를 나타내는 HMM을 구성함으로써, 그리고 유사한 Cas 단백질에 대해 메타게놈 데이터세트를 검색하기 위해 그들을 이용함으로써 이들 단백질 패밀리를 확장시켰다. 단백질 패밀리가 정말로 새롭게 되도록 하기 위해, NCBI의 흔치않은(nr) 및 메타게놈(env_nr) 단백질 데이터베이스에 대한 BLAST뿐만 아니라 UniProt KnowledegeBase에 대한 HMM 검색을 이용하여 공지된 상동체를 검색하였다. 전장 히트가(단백질 길이의 25% 초과) 없는 단백질만을 신규한 단백질로 고려하였다. HH-스위트로부터의 HHpred를 이용하여 추정적 Cas 단백질의 원위 상동성 검색을 수행하였다. 해결된 결정 구조, 및 JPred4에 의해 예측된 2차 구조와의 비교에 기반하여 도메인 구조를 추론하기 위해 고스코어링 HHpred 히트를 사용하였다. 새로 발견된 Cas 단백질을 포함하는 HMM 데이터베이스를 보조 데이터 1에서 이용 가능하다.
CrisprFinder를 이용하여 조립 데이터로부터 스페이서 서열을 결정하였다. 적절한 샘플의 짧은 DNA 판독에서 추가적인 스페이서를 위치시키기 위해 CRASS를 사용하였다. 스페이서에 대해 미스매치가 1 이하인 히트에 대한 적절한 메타게놈 조립체에 대해 BLAST 검색에 의해("-task blastn-short"를 이용) 스페이서 표적(프로토스페이서)을 동정하였다. (프로토스페이서로서 CRISPR 어레이 동정을 피하기 위해) 관련된 반복부를 함유한 콘틱에 속하는 히트를 여과시켰다. 프로토스페이서에 측접하는 영역을 정렬함으로써 그리고 웹로고(WebLogo)를 이용하여 시각화함으로써 프로토스페이서 인접 모티프(PAM)를 동정하였다. mFold를 이용하여 RNA 구조를 예측하였다. 조립 데이터로부터 스페이서, 반복부 및 측접 서열을 수동으로 정렬함으로써 CRISPR 어레이 다양성을 분석하였다. 제네이오스(Geneious) 9.1을 이용하여 수동 정렬 및 콘틱 시각화를 수행하였다.
새로 동정된 시스템의 Cas1 및 Cas9 단백질의 계통발생학적 분석을 위해 문헌[Makarova et al. 및 Shmakov et al.]으로부터의 단백질과 함께 사용하였다. CD-HIT를 이용하여 90% 이상의 동일성을 갖는 단백질을 함께 클러스터링함으로써 비중복 세트에 따랐다. MAFFT를 이용하여 정렬을 생성하였고, 그리고 치환 모델로서 PROTGAMMALG를 이용하는 RAxML 및 100 부트스트랩(bootstrap) 샘플링을 이용하여 최대-가능성 계통발생을 작제하였다. 카스포존(casposon)을 야기하는 분지를 이용하여 Cas1 나무의 뿌리를 고정시켰다. FigTree 1.4.1 (http://tree.bio.ed.ac.uk/software/figtree/) 및 iTOL v3을 이용하여 나무를 시각화하였다.
이종성
플라스미드의 생성
CasX에 대한 획득과 관련된 단백질을 제거함으로써 그리고 CasX와 CasY 둘 다에 대해 CRISPR 어레이 크기를 감소시킴으로써 메타게놈 콘틱을 최소 CRISPR 간섭 플라스미드로 만들었다. 최소 좌위를 Gblocks(인테그레이티드 DNA 테크놀로지)로서 합성하고 나서, 깁슨 어셈블리(Gibson Assembly)를 이용하여 조립하였다.
PAM 고갈 분석
변형에 의해 앞서 기재한 바와 같이 PAM 고갈 분석을 수행하였다. 무작위화된 PAM 서열을 함유하는 플라스미드 라이브러리를 프라이머를 이용하여 7 nt 무작위화된 PAM 영역을 함유하는 DNA 올리고뉴클레오타이드를 어닐링함으로써 조립하고 나서, 클레노브단편(Klenow Fragment: NEB)으로 연장시켰다. EcoRI 및 NcoI로 이중 가닥 DNA를 분해시키고 나서, pUC19 골격에 결찰시켰다. 결찰된 라이브러리를 DH5α로 형질전환시키고, 108개 초과의 세포를 채취하고 나서, 플라스미드를 추출하고, 정제하였다. 200ng의 풀링 라이브러리를 CRISPR 좌위 또는 좌위가 없는 대조군 플라스미드를 보유하는 전기천공적격 이콜라이로 형질전환시켰다. 형질전환 세포를 30시간 동안 25℃에서 카베니실린(100㎎ ℓ-1) 및 클로람페니콜(30㎎ ℓ-1)을 함유하는 선택 배지 상에서 플레이팅하였다. 플라스미드 DNA를 추출하고 나서, 일루미나 서열분석을 위한 어댑터를 이용하여 PAM 서열을 증폭시켰다. 7 nt PAM 영역을 추출하고 나서, 각각의 7nt 서열에 대해 PAM 빈도를 계산하였다. 명시된 역치 초과에서 고갈된 PAM 서열을 사용하여 웹로고(WebLogo)를 생성하였다.
플라스미드 간섭
메타게놈 서열 분석 또는 PAM 고갈 분석으로부터 동정된 추정적 표적을 pUC19 플라스미드 내로 클로닝시켰다. 10ng의 표적 플라스미드를 CRISPR 좌위 플라스미드를 함유하는 전기천공적격 이콜라이(NEB 안정성)로 형질전환시켰다. 세포를 2시간 동안 25℃에서 회수하고 나서, 선택 배지 상에서 적절한 희석물을 플레이팅하였다. 플레이트를 25℃에서 인큐베이션하고 나서, 콜로니 형성 단위를 계수화하였다. 모든 플라스미드 간섭 실험을 3회 수행하고 나서, 전기천공적격 세포를 각각의 복제물에 대해 독립적으로 제조하였다.
ARMAN
-
Cas9
단백질 발현 및 정제
ARMAN-1(AR1) 및 ARMAN-4(AR4)로부터의 Cas9에 대한 발현 작제물을 이콜라이에 대해 코돈 최적화된 gBlocks(인터그레이티드 DNA 테크놀로지즈)으로부터 조립하였다. N-말단 His6-MBP 또는 His6 융합 단백질로서 pET-기반 발현 벡터에 조립 유전자를 클로닝하였다. 발현 벡터를 BL21(DE3) 이콜라이 세포로 형질전환시키고 나서, 37℃에서 LB 브로스에서 성장시켰다. 단백질 발현을 위해, 0.4mM IPTG(아이소프로필 β-D-1-티오갈락토피라노사이드)를 이용하여 중간-대수기 동안 세포를 유도하고 나서, 16℃에서 밤새 인큐베이션시켰다. 모든 후속적 단계를 4℃에서 수행하였다. 세포 펠렛을 용해 완충제(50mM 트리스(Tris)-HCl pH 8, 500mM NaCl, 1mM TCEP, 10mM 이미다졸) 0.5% 트리톤 X-100 중에서 재현탁시키고, 초음파처리에 의한 용해 전에 적격 프로테아제 저해제 혼합물(로슈(Roche))로 보충하였다. 용해물을 15000g에서 40분 동안 원심분리에 의해 정화시키고 나서, 배취에서 슈퍼플로우(Superflow) Ni-NTA 아가로스(퀴아젠(Qiagen))에 적용하였다. 세척 완충제 A(50mM 트리스-HCl pH 8, 500mM NaCl, 1mM TCEP, 10mM 이미다졸)를 이용하여 수지를 광범위하게 세척한 후에, 5개 칼럼 용적의 세척 완충제 B(50mM 트리스-HCl pH 8, 1M NaCl, 1mM TCEP, 10mM 이미다졸)로 세척하였다. 용해 완충제(50mM 트리스-HCl pH 8, 500mM NaCl, 1mM TCEP, 300mM 이미다졸)를 이용하여 Ni-NTA 수지의 단백질을 용리시켰다. 세척 완충제 A에 대해 밤새 투석 동안 TEV 프로테아제에 의해 His6-MBP 태그를 제거하였다. 제2 Ni-NTA 아가로스 칼럼을 통해 친화도 태그로부터 절단된 Cas9를 제거하였다. 5㎖ 헤파린 HiTrap 칼럼(GE 라이프 사이언시즈(GE Life Sciences))에 대한 적용 전에 IEX 완충제 A(50mM 트리스-HCl pH 7.5, 300mM NaCl, 1mM TCEP, 5% 글리세롤)에 단백질을 투석하였다. 선형 NaCl(0.3 내지 1.5 M) 구배로 Cas9를 용리시켰다. 분획을 풀링하고 나서, 30kDa 스핀 농축기(써모 피셔(Thermo Fisher))를 이용하여 농축시켰다. 적용 가능할 때, 슈퍼덱스(Superdex) 200pg 칼럼(GE 라이프 사이언시즈) 상에서 크기-배제 크로마토그래피를 통해 Cas9를 추가로 정제하였고, 후속적 절단 분석을 위해 IEX 완충제 A에서 저장하였다. 효모 발현을 위해, AR1-Cas9를 Gal1/10 His6-MBP TEV Ura 사카로마이세스 세레비시애(S. cerevisiae) 발현 벡터(애드진 플라스미드(Addgene plasmid) # 48305)에 클로닝시켰다. 벡터를 BY4741 URA3 균주에 형질전환시키고 나서, 배양물을 30℃로 배지에서 성장시켰다. 대략 0.6의 OD600에서, 2% w/v 갈락토스를 이용하여 단백질 발현을 유도하고 나서, 16℃에서 밤새 인큐베이션시켰다. 상기와 같이 단백질 정제를 수행하였다.
RNA
시험관내
전사 및
올리고뉴클레오타이드
정제
T7 프로모터 서열을 함유하는 합성 DNA 주형을 이용하여 앞서 기재한 바와 같이 시험관내 전사 반응을 수행하였다65. 변성 PAGE를 통해 모든 시험관내 전사된 가이드 RNA 및 표적 RNA 또는 DNA를 정제하였다. 95℃에서 1분 동안 인큐베이션에 의해 20mM 트리스 HCl pH 7.5 및 100mM NaCl 중에서 이중-가닥 표적 RNA 및 DNA를 혼성화시킨 후에, 실온으로 서서히 냉각시켰다. 천연 PAGE에 의해 혼성체를 정제하였다.
시험관내
절단 분석
1x PNK 완충제 중에서 37℃에서 30분 동안 T4 폴리뉴클레오타이드 키나제(NEB) 및 [γ-32P] ATP(퍼킨-엘머)를 이용하여 정제된 DNA 및 RNA 올리고뉴클레오타이드를 방사성표지하였다. 65℃에서 20분 동안 PNK를 열 불활성화시키고 나서, 일러스트라 마이크로스핀(illustra Microspin) G-25 칼럼(GE 라이프 사이언시즈)를 이용하여 표지 반응으로부터 유리 ATP를 제거하였다). CrRNA와 tracrRNA를 1x 재폴딩 완충제(50mM 트리스 HCl pH 7.5, 300mM NaCl, 1mM TCEP, 5% 글리세롤) 중에서 등몰량으로 혼합하고 나서, 70℃에서 5분 동안 인큐베이션시키고, 이어서, 실온으로 서서히 냉각시켰다. 반응물을 1mM 최종 금속 농도로 보충하고, 후속적으로 50℃에서 5분 동안 가열하였다. 실온으로 서서히 냉각시킨 후에, 재폴딩된 가이드를 얼음에 위치시켰다. 완충제, 염 농도에 대해 언급되지 않는 한, Cas9를 37℃에서 10분 동안 1x 절단 완충제(50mM 트리스 HCl pH 7.5, 300mM NaCl, 1mM TCEP, 5% 글리세롤, 5mM 2가 금속) 중에서 등몰량의 가이드로 재구성하였다. 37℃또는 표시된 온도에서 방사성표지 표적에 대해 10x 과량의 Cas9-가이드 복합체를 갖는 1x 절단 완충제에서 절단 반응을 수행하였다. 50mM EDTA로 보충한 동일 용적의 겔 부하 완충제에서 반응을 퀀칭시켰다. 10% 변성 PAGE 상에서 절단 생성물을 분해하고 나서, 포스포르이미징에 의해 시각화하였다.
생체내
이콜라이
간섭 분석
AR1- 및 AR4-Cas9에 대한 이콜라이 형질전환 분석을 앞서 공개된 바와 같이 수행하였다. 간략하게, 가이드 RNA에 의해 형질전환된 이콜라이는 전기천공적격으로 만들어졌다. 이어서, 세포를 야생형 또는 촉매적으로 비활성인 Cas9(dCas9)를 암호화하는 플라스미드의 9 fmol로 형질전환시켰다. 회수한 세포의 연속 희석물을 선택적 항생제와 함께 LB 플레이트 상에 플레이팅하였다. 37℃에서 16시간 후에 콜로니를 계수하였다.
| CRISPR-Cas 시스템을 동정한 유기체 및 게놈 위치에 관한 상세한 설명뿐만 아니라 재구성된 스페이서의 수 및 평균 길이 및 반복부 길이에 대한 정보(NA, 이용 가능하지 않음). ARMAN-1 스페이서를 16개의 샘플로부터 재구성하였다. | ||||||
| 분류학적 그룹 | Cas 효과기 | NCBI 접근 | 좌표 | 반복부 길이 | 스페이서 수 | 스페이서 평균 길이 |
| ARMAN-1 | Cas9 | MOEG01000017 | 1827..7130 | 36 | 271 | 34.5 |
| ARMAN-4 | Cas9 | KY040241 | 11779..14900 | 36 | 1 | 36 |
| 델타프로테오박테리아 | CasX | MGPG01000094 | 4319..9866 | 37 | 5 | 33.6 |
| 부유균문 | CasX | MHYZ01000150 | 1..5586 | 37 | 7 | 32.3 |
| 칸디다투스 칸타노박테리아(Candidatus Katanobacteria) | CasY.1 | MOEH01000029 | 459..5716 | 26 | 14 | 17.1 |
| 칸디다투스 보겔박테리아(Candidatus Vogelbacteria) | CasY.2 | MOEJ01000028 | 7322..13087 | 26 | 18 | 17.3 |
| 칸디다투스 보겔박테리아(Candidatus Vogelbacteria) | CasY.3 | MOEK01000006 | 1..4657 | 26 | 12 | 17.3 |
| 칸디다투스 파르쿠박테리아(Candidatus Parcubacteria) | CasY.4 | KY040242 | 1..5193 | 25 | 13 | 18.4 |
| 칸디다투스 코메일리박테리아(Candidatus Komeilibacteria) | CasY.5 | MOEI01000022 | 2802..7242 | 36 | 8 | 26 |
| 칸디다투스 케르펠드박테리아(Candidatus Kerfeldbacteria) | CasY.6 | MHKD01000036 | 11503..15366 | NA | NA | NA |
본 발명을 이의 구체적 실시형태를 참고로 하여 기재하였지만, 본 발명의 진정한 정신과 범주로부터 벗어나는 일 없이 다양한 변화가 이루어질 수 있고 동등물이 치환될 수 있다는 것이 이해되어야 한다. 추가로, 본 발명의 객관적 정신 및 범주에 대해 특정 상황, 물질, 대상 조성물, 공정, 공정 단계 또는 단계들을 적용하여 다수의 변형이 이루어질 수 있다. 모든 이러한 변형은 본 명세서에 첨부하는 청구범위의 범주 내인 것으로 의도된다.
SEQUENCE LISTING
<110> THE REGENTS OF THE UNIVERSITY OF CALIFORNIA
<120> RNA-GUIDED NUCLEIC ACID MODIFYING ENZYMES AND METHODS OF USE
THEREOF
<130> WO/2018/064371
<140> PCT/US2017/054081
<141> 2017-09-28
<150> US 62/402,846
<151> 2016-09-30
<160> 136
<170> PatentIn version 3.5
<210> 1
<211> 986
<212> PRT
<213> Unknown
<220>
<223> identified from meta-transcriptomics sequence data from unknown
deltaproteobacter
<400> 1
Met Glu Lys Arg Ile Asn Lys Ile Arg Lys Lys Leu Ser Ala Asp Asn
1 5 10 15
Ala Thr Lys Pro Val Ser Arg Ser Gly Pro Met Lys Thr Leu Leu Val
20 25 30
Arg Val Met Thr Asp Asp Leu Lys Lys Arg Leu Glu Lys Arg Arg Lys
35 40 45
Lys Pro Glu Val Met Pro Gln Val Ile Ser Asn Asn Ala Ala Asn Asn
50 55 60
Leu Arg Met Leu Leu Asp Asp Tyr Thr Lys Met Lys Glu Ala Ile Leu
65 70 75 80
Gln Val Tyr Trp Gln Glu Phe Lys Asp Asp His Val Gly Leu Met Cys
85 90 95
Lys Phe Ala Gln Pro Ala Ser Lys Lys Ile Asp Gln Asn Lys Leu Lys
100 105 110
Pro Glu Met Asp Glu Lys Gly Asn Leu Thr Thr Ala Gly Phe Ala Cys
115 120 125
Ser Gln Cys Gly Gln Pro Leu Phe Val Tyr Lys Leu Glu Gln Val Ser
130 135 140
Glu Lys Gly Lys Ala Tyr Thr Asn Tyr Phe Gly Arg Cys Asn Val Ala
145 150 155 160
Glu His Glu Lys Leu Ile Leu Leu Ala Gln Leu Lys Pro Glu Lys Asp
165 170 175
Ser Asp Glu Ala Val Thr Tyr Ser Leu Gly Lys Phe Gly Gln Arg Ala
180 185 190
Leu Asp Phe Tyr Ser Ile His Val Thr Lys Glu Ser Thr His Pro Val
195 200 205
Lys Pro Leu Ala Gln Ile Ala Gly Asn Arg Tyr Ala Ser Gly Pro Val
210 215 220
Gly Lys Ala Leu Ser Asp Ala Cys Met Gly Thr Ile Ala Ser Phe Leu
225 230 235 240
Ser Lys Tyr Gln Asp Ile Ile Ile Glu His Gln Lys Val Val Lys Gly
245 250 255
Asn Gln Lys Arg Leu Glu Ser Leu Arg Glu Leu Ala Gly Lys Glu Asn
260 265 270
Leu Glu Tyr Pro Ser Val Thr Leu Pro Pro Gln Pro His Thr Lys Glu
275 280 285
Gly Val Asp Ala Tyr Asn Glu Val Ile Ala Arg Val Arg Met Trp Val
290 295 300
Asn Leu Asn Leu Trp Gln Lys Leu Lys Leu Ser Arg Asp Asp Ala Lys
305 310 315 320
Pro Leu Leu Arg Leu Lys Gly Phe Pro Ser Phe Pro Val Val Glu Arg
325 330 335
Arg Glu Asn Glu Val Asp Trp Trp Asn Thr Ile Asn Glu Val Lys Lys
340 345 350
Leu Ile Asp Ala Lys Arg Asp Met Gly Arg Val Phe Trp Ser Gly Val
355 360 365
Thr Ala Glu Lys Arg Asn Thr Ile Leu Glu Gly Tyr Asn Tyr Leu Pro
370 375 380
Asn Glu Asn Asp His Lys Lys Arg Glu Gly Ser Leu Glu Asn Pro Lys
385 390 395 400
Lys Pro Ala Lys Arg Gln Phe Gly Asp Leu Leu Leu Tyr Leu Glu Lys
405 410 415
Lys Tyr Ala Gly Asp Trp Gly Lys Val Phe Asp Glu Ala Trp Glu Arg
420 425 430
Ile Asp Lys Lys Ile Ala Gly Leu Thr Ser His Ile Glu Arg Glu Glu
435 440 445
Ala Arg Asn Ala Glu Asp Ala Gln Ser Lys Ala Val Leu Thr Asp Trp
450 455 460
Leu Arg Ala Lys Ala Ser Phe Val Leu Glu Arg Leu Lys Glu Met Asp
465 470 475 480
Glu Lys Glu Phe Tyr Ala Cys Glu Ile Gln Leu Gln Lys Trp Tyr Gly
485 490 495
Asp Leu Arg Gly Asn Pro Phe Ala Val Glu Ala Glu Asn Arg Val Val
500 505 510
Asp Ile Ser Gly Phe Ser Ile Gly Ser Asp Gly His Ser Ile Gln Tyr
515 520 525
Arg Asn Leu Leu Ala Trp Lys Tyr Leu Glu Asn Gly Lys Arg Glu Phe
530 535 540
Tyr Leu Leu Met Asn Tyr Gly Lys Lys Gly Arg Ile Arg Phe Thr Asp
545 550 555 560
Gly Thr Asp Ile Lys Lys Ser Gly Lys Trp Gln Gly Leu Leu Tyr Gly
565 570 575
Gly Gly Lys Ala Lys Val Ile Asp Leu Thr Phe Asp Pro Asp Asp Glu
580 585 590
Gln Leu Ile Ile Leu Pro Leu Ala Phe Gly Thr Arg Gln Gly Arg Glu
595 600 605
Phe Ile Trp Asn Asp Leu Leu Ser Leu Glu Thr Gly Leu Ile Lys Leu
610 615 620
Ala Asn Gly Arg Val Ile Glu Lys Thr Ile Tyr Asn Lys Lys Ile Gly
625 630 635 640
Arg Asp Glu Pro Ala Leu Phe Val Ala Leu Thr Phe Glu Arg Arg Glu
645 650 655
Val Val Asp Pro Ser Asn Ile Lys Pro Val Asn Leu Ile Gly Val Asp
660 665 670
Arg Gly Glu Asn Ile Pro Ala Val Ile Ala Leu Thr Asp Pro Glu Gly
675 680 685
Cys Pro Leu Pro Glu Phe Lys Asp Ser Ser Gly Gly Pro Thr Asp Ile
690 695 700
Leu Arg Ile Gly Glu Gly Tyr Lys Glu Lys Gln Arg Ala Ile Gln Ala
705 710 715 720
Ala Lys Glu Val Glu Gln Arg Arg Ala Gly Gly Tyr Ser Arg Lys Phe
725 730 735
Ala Ser Lys Ser Arg Asn Leu Ala Asp Asp Met Val Arg Asn Ser Ala
740 745 750
Arg Asp Leu Phe Tyr His Ala Val Thr His Asp Ala Val Leu Val Phe
755 760 765
Glu Asn Leu Ser Arg Gly Phe Gly Arg Gln Gly Lys Arg Thr Phe Met
770 775 780
Thr Glu Arg Gln Tyr Thr Lys Met Glu Asp Trp Leu Thr Ala Lys Leu
785 790 795 800
Ala Tyr Glu Gly Leu Thr Ser Lys Thr Tyr Leu Ser Lys Thr Leu Ala
805 810 815
Gln Tyr Thr Ser Lys Thr Cys Ser Asn Cys Gly Phe Thr Ile Thr Thr
820 825 830
Ala Asp Tyr Asp Gly Met Leu Val Arg Leu Lys Lys Thr Ser Asp Gly
835 840 845
Trp Ala Thr Thr Leu Asn Asn Lys Glu Leu Lys Ala Glu Gly Gln Ile
850 855 860
Thr Tyr Tyr Asn Arg Tyr Lys Arg Gln Thr Val Glu Lys Glu Leu Ser
865 870 875 880
Ala Glu Leu Asp Arg Leu Ser Glu Glu Ser Gly Asn Asn Asp Ile Ser
885 890 895
Lys Trp Thr Lys Gly Arg Arg Asp Glu Ala Leu Phe Leu Leu Lys Lys
900 905 910
Arg Phe Ser His Arg Pro Val Gln Glu Gln Phe Val Cys Leu Asp Cys
915 920 925
Gly His Glu Val His Ala Asp Glu Gln Ala Ala Leu Asn Ile Ala Arg
930 935 940
Ser Trp Leu Phe Leu Asn Ser Asn Ser Thr Glu Phe Lys Ser Tyr Lys
945 950 955 960
Ser Gly Lys Gln Pro Phe Val Gly Ala Trp Gln Ala Phe Tyr Lys Arg
965 970 975
Arg Leu Lys Glu Val Trp Lys Pro Asn Ala
980 985
<210> 2
<211> 978
<212> PRT
<213> Unknown
<220>
<223> identified from meta-transcriptomics sequence data from unknown
Planctomycetes
<400> 2
Met Gln Glu Ile Lys Arg Ile Asn Lys Ile Arg Arg Arg Leu Val Lys
1 5 10 15
Asp Ser Asn Thr Lys Lys Ala Gly Lys Thr Gly Pro Met Lys Thr Leu
20 25 30
Leu Val Arg Val Met Thr Pro Asp Leu Arg Glu Arg Leu Glu Asn Leu
35 40 45
Arg Lys Lys Pro Glu Asn Ile Pro Gln Pro Ile Ser Asn Thr Ser Arg
50 55 60
Ala Asn Leu Asn Lys Leu Leu Thr Asp Tyr Thr Glu Met Lys Lys Ala
65 70 75 80
Ile Leu His Val Tyr Trp Glu Glu Phe Gln Lys Asp Pro Val Gly Leu
85 90 95
Met Ser Arg Val Ala Gln Pro Ala Pro Lys Asn Ile Asp Gln Arg Lys
100 105 110
Leu Ile Pro Val Lys Asp Gly Asn Glu Arg Leu Thr Ser Ser Gly Phe
115 120 125
Ala Cys Ser Gln Cys Cys Gln Pro Leu Tyr Val Tyr Lys Leu Glu Gln
130 135 140
Val Asn Asp Lys Gly Lys Pro His Thr Asn Tyr Phe Gly Arg Cys Asn
145 150 155 160
Val Ser Glu His Glu Arg Leu Ile Leu Leu Ser Pro His Lys Pro Glu
165 170 175
Ala Asn Asp Glu Leu Val Thr Tyr Ser Leu Gly Lys Phe Gly Gln Arg
180 185 190
Ala Leu Asp Phe Tyr Ser Ile His Val Thr Arg Glu Ser Asn His Pro
195 200 205
Val Lys Pro Leu Glu Gln Ile Gly Gly Asn Ser Cys Ala Ser Gly Pro
210 215 220
Val Gly Lys Ala Leu Ser Asp Ala Cys Met Gly Ala Val Ala Ser Phe
225 230 235 240
Leu Thr Lys Tyr Gln Asp Ile Ile Leu Glu His Gln Lys Val Ile Lys
245 250 255
Lys Asn Glu Lys Arg Leu Ala Asn Leu Lys Asp Ile Ala Ser Ala Asn
260 265 270
Gly Leu Ala Phe Pro Lys Ile Thr Leu Pro Pro Gln Pro His Thr Lys
275 280 285
Glu Gly Ile Glu Ala Tyr Asn Asn Val Val Ala Gln Ile Val Ile Trp
290 295 300
Val Asn Leu Asn Leu Trp Gln Lys Leu Lys Ile Gly Arg Asp Glu Ala
305 310 315 320
Lys Pro Leu Gln Arg Leu Lys Gly Phe Pro Ser Phe Pro Leu Val Glu
325 330 335
Arg Gln Ala Asn Glu Val Asp Trp Trp Asp Met Val Cys Asn Val Lys
340 345 350
Lys Leu Ile Asn Glu Lys Lys Glu Asp Gly Lys Val Phe Trp Gln Asn
355 360 365
Leu Ala Gly Tyr Lys Arg Gln Glu Ala Leu Leu Pro Tyr Leu Ser Ser
370 375 380
Glu Glu Asp Arg Lys Lys Gly Lys Lys Phe Ala Arg Tyr Gln Phe Gly
385 390 395 400
Asp Leu Leu Leu His Leu Glu Lys Lys His Gly Glu Asp Trp Gly Lys
405 410 415
Val Tyr Asp Glu Ala Trp Glu Arg Ile Asp Lys Lys Val Glu Gly Leu
420 425 430
Ser Lys His Ile Lys Leu Glu Glu Glu Arg Arg Ser Glu Asp Ala Gln
435 440 445
Ser Lys Ala Ala Leu Thr Asp Trp Leu Arg Ala Lys Ala Ser Phe Val
450 455 460
Ile Glu Gly Leu Lys Glu Ala Asp Lys Asp Glu Phe Cys Arg Cys Glu
465 470 475 480
Leu Lys Leu Gln Lys Trp Tyr Gly Asp Leu Arg Gly Lys Pro Phe Ala
485 490 495
Ile Glu Ala Glu Asn Ser Ile Leu Asp Ile Ser Gly Phe Ser Lys Gln
500 505 510
Tyr Asn Cys Ala Phe Ile Trp Gln Lys Asp Gly Val Lys Lys Leu Asn
515 520 525
Leu Tyr Leu Ile Ile Asn Tyr Phe Lys Gly Gly Lys Leu Arg Phe Lys
530 535 540
Lys Ile Lys Pro Glu Ala Phe Glu Ala Asn Arg Phe Tyr Thr Val Ile
545 550 555 560
Asn Lys Lys Ser Gly Glu Ile Val Pro Met Glu Val Asn Phe Asn Phe
565 570 575
Asp Asp Pro Asn Leu Ile Ile Leu Pro Leu Ala Phe Gly Lys Arg Gln
580 585 590
Gly Arg Glu Phe Ile Trp Asn Asp Leu Leu Ser Leu Glu Thr Gly Ser
595 600 605
Leu Lys Leu Ala Asn Gly Arg Val Ile Glu Lys Thr Leu Tyr Asn Arg
610 615 620
Arg Thr Arg Gln Asp Glu Pro Ala Leu Phe Val Ala Leu Thr Phe Glu
625 630 635 640
Arg Arg Glu Val Leu Asp Ser Ser Asn Ile Lys Pro Met Asn Leu Ile
645 650 655
Gly Ile Asp Arg Gly Glu Asn Ile Pro Ala Val Ile Ala Leu Thr Asp
660 665 670
Pro Glu Gly Cys Pro Leu Ser Arg Phe Lys Asp Ser Leu Gly Asn Pro
675 680 685
Thr His Ile Leu Arg Ile Gly Glu Ser Tyr Lys Glu Lys Gln Arg Thr
690 695 700
Ile Gln Ala Ala Lys Glu Val Glu Gln Arg Arg Ala Gly Gly Tyr Ser
705 710 715 720
Arg Lys Tyr Ala Ser Lys Ala Lys Asn Leu Ala Asp Asp Met Val Arg
725 730 735
Asn Thr Ala Arg Asp Leu Leu Tyr Tyr Ala Val Thr Gln Asp Ala Met
740 745 750
Leu Ile Phe Glu Asn Leu Ser Arg Gly Phe Gly Arg Gln Gly Lys Arg
755 760 765
Thr Phe Met Ala Glu Arg Gln Tyr Thr Arg Met Glu Asp Trp Leu Thr
770 775 780
Ala Lys Leu Ala Tyr Glu Gly Leu Pro Ser Lys Thr Tyr Leu Ser Lys
785 790 795 800
Thr Leu Ala Gln Tyr Thr Ser Lys Thr Cys Ser Asn Cys Gly Phe Thr
805 810 815
Ile Thr Ser Ala Asp Tyr Asp Arg Val Leu Glu Lys Leu Lys Lys Thr
820 825 830
Ala Thr Gly Trp Met Thr Thr Ile Asn Gly Lys Glu Leu Lys Val Glu
835 840 845
Gly Gln Ile Thr Tyr Tyr Asn Arg Tyr Lys Arg Gln Asn Val Val Lys
850 855 860
Asp Leu Ser Val Glu Leu Asp Arg Leu Ser Glu Glu Ser Val Asn Asn
865 870 875 880
Asp Ile Ser Ser Trp Thr Lys Gly Arg Ser Gly Glu Ala Leu Ser Leu
885 890 895
Leu Lys Lys Arg Phe Ser His Arg Pro Val Gln Glu Lys Phe Val Cys
900 905 910
Leu Asn Cys Gly Phe Glu Thr His Ala Asp Glu Gln Ala Ala Leu Asn
915 920 925
Ile Ala Arg Ser Trp Leu Phe Leu Arg Ser Gln Glu Tyr Lys Lys Tyr
930 935 940
Gln Thr Asn Lys Thr Thr Gly Asn Thr Asp Lys Arg Ala Phe Val Glu
945 950 955 960
Thr Trp Gln Ser Phe Tyr Arg Lys Lys Leu Lys Glu Val Trp Lys Pro
965 970 975
Ala Val
<210> 3
<211> 855
<212> PRT
<213> unknown
<220>
<223> identified from meta-transcriptomics sequence data from
Candidatus Sungbacteria bacterium
<400> 3
Met Asp Asn Ala Asn Lys Pro Ser Thr Lys Ser Leu Val Asn Thr Thr
1 5 10 15
Arg Ile Ser Asp His Phe Gly Val Thr Pro Gly Gln Val Thr Arg Val
20 25 30
Phe Ser Phe Gly Ile Ile Pro Thr Lys Arg Gln Tyr Ala Ile Ile Glu
35 40 45
Arg Trp Phe Ala Ala Val Glu Ala Ala Arg Glu Arg Leu Tyr Gly Met
50 55 60
Leu Tyr Ala His Phe Gln Glu Asn Pro Pro Ala Tyr Leu Lys Glu Lys
65 70 75 80
Phe Ser Tyr Glu Thr Phe Phe Lys Gly Arg Pro Val Leu Asn Gly Leu
85 90 95
Arg Asp Ile Asp Pro Thr Ile Met Thr Ser Ala Val Phe Thr Ala Leu
100 105 110
Arg His Lys Ala Glu Gly Ala Met Ala Ala Phe His Thr Asn His Arg
115 120 125
Arg Leu Phe Glu Glu Ala Arg Lys Lys Met Arg Glu Tyr Ala Glu Cys
130 135 140
Leu Lys Ala Asn Glu Ala Leu Leu Arg Gly Ala Ala Asp Ile Asp Trp
145 150 155 160
Asp Lys Ile Val Asn Ala Leu Arg Thr Arg Leu Asn Thr Cys Leu Ala
165 170 175
Pro Glu Tyr Asp Ala Val Ile Ala Asp Phe Gly Ala Leu Cys Ala Phe
180 185 190
Arg Ala Leu Ile Ala Glu Thr Asn Ala Leu Lys Gly Ala Tyr Asn His
195 200 205
Ala Leu Asn Gln Met Leu Pro Ala Leu Val Lys Val Asp Glu Pro Glu
210 215 220
Glu Ala Glu Glu Ser Pro Arg Leu Arg Phe Phe Asn Gly Arg Ile Asn
225 230 235 240
Asp Leu Pro Lys Phe Pro Val Ala Glu Arg Glu Thr Pro Pro Asp Thr
245 250 255
Glu Thr Ile Ile Arg Gln Leu Glu Asp Met Ala Arg Val Ile Pro Asp
260 265 270
Thr Ala Glu Ile Leu Gly Tyr Ile His Arg Ile Arg His Lys Ala Ala
275 280 285
Arg Arg Lys Pro Gly Ser Ala Val Pro Leu Pro Gln Arg Val Ala Leu
290 295 300
Tyr Cys Ala Ile Arg Met Glu Arg Asn Pro Glu Glu Asp Pro Ser Thr
305 310 315 320
Val Ala Gly His Phe Leu Gly Glu Ile Asp Arg Val Cys Glu Lys Arg
325 330 335
Arg Gln Gly Leu Val Arg Thr Pro Phe Asp Ser Gln Ile Arg Ala Arg
340 345 350
Tyr Met Asp Ile Ile Ser Phe Arg Ala Thr Leu Ala His Pro Asp Arg
355 360 365
Trp Thr Glu Ile Gln Phe Leu Arg Ser Asn Ala Ala Ser Arg Arg Val
370 375 380
Arg Ala Glu Thr Ile Ser Ala Pro Phe Glu Gly Phe Ser Trp Thr Ser
385 390 395 400
Asn Arg Thr Asn Pro Ala Pro Gln Tyr Gly Met Ala Leu Ala Lys Asp
405 410 415
Ala Asn Ala Pro Ala Asp Ala Pro Glu Leu Cys Ile Cys Leu Ser Pro
420 425 430
Ser Ser Ala Ala Phe Ser Val Arg Glu Lys Gly Gly Asp Leu Ile Tyr
435 440 445
Met Arg Pro Thr Gly Gly Arg Arg Gly Lys Asp Asn Pro Gly Lys Glu
450 455 460
Ile Thr Trp Val Pro Gly Ser Phe Asp Glu Tyr Pro Ala Ser Gly Val
465 470 475 480
Ala Leu Lys Leu Arg Leu Tyr Phe Gly Arg Ser Gln Ala Arg Arg Met
485 490 495
Leu Thr Asn Lys Thr Trp Gly Leu Leu Ser Asp Asn Pro Arg Val Phe
500 505 510
Ala Ala Asn Ala Glu Leu Val Gly Lys Lys Arg Asn Pro Gln Asp Arg
515 520 525
Trp Lys Leu Phe Phe His Met Val Ile Ser Gly Pro Pro Pro Val Glu
530 535 540
Tyr Leu Asp Phe Ser Ser Asp Val Arg Ser Arg Ala Arg Thr Val Ile
545 550 555 560
Gly Ile Asn Arg Gly Glu Val Asn Pro Leu Ala Tyr Ala Val Val Ser
565 570 575
Val Glu Asp Gly Gln Val Leu Glu Glu Gly Leu Leu Gly Lys Lys Glu
580 585 590
Tyr Ile Asp Gln Leu Ile Glu Thr Arg Arg Arg Ile Ser Glu Tyr Gln
595 600 605
Ser Arg Glu Gln Thr Pro Pro Arg Asp Leu Arg Gln Arg Val Arg His
610 615 620
Leu Gln Asp Thr Val Leu Gly Ser Ala Arg Ala Lys Ile His Ser Leu
625 630 635 640
Ile Ala Phe Trp Lys Gly Ile Leu Ala Ile Glu Arg Leu Asp Asp Gln
645 650 655
Phe His Gly Arg Glu Gln Lys Ile Ile Pro Lys Lys Thr Tyr Leu Ala
660 665 670
Asn Lys Thr Gly Phe Met Asn Ala Leu Ser Phe Ser Gly Ala Val Arg
675 680 685
Val Asp Lys Lys Gly Asn Pro Trp Gly Gly Met Ile Glu Ile Tyr Pro
690 695 700
Gly Gly Ile Ser Arg Thr Cys Thr Gln Cys Gly Thr Val Trp Leu Ala
705 710 715 720
Arg Arg Pro Lys Asn Pro Gly His Arg Asp Ala Met Val Val Ile Pro
725 730 735
Asp Ile Val Asp Asp Ala Ala Ala Thr Gly Phe Asp Asn Val Asp Cys
740 745 750
Asp Ala Gly Thr Val Asp Tyr Gly Glu Leu Phe Thr Leu Ser Arg Glu
755 760 765
Trp Val Arg Leu Thr Pro Arg Tyr Ser Arg Val Met Arg Gly Thr Leu
770 775 780
Gly Asp Leu Glu Arg Ala Ile Arg Gln Gly Asp Asp Arg Lys Ser Arg
785 790 795 800
Gln Met Leu Glu Leu Ala Leu Glu Pro Gln Pro Gln Trp Gly Gln Phe
805 810 815
Phe Cys His Arg Cys Gly Phe Asn Gly Gln Ser Asp Val Leu Ala Ala
820 825 830
Thr Asn Leu Ala Arg Arg Ala Ile Ser Leu Ile Arg Arg Leu Pro Asp
835 840 845
Thr Asp Thr Pro Pro Thr Pro
850 855
<210> 4
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 4
Ala Ala Ala Ala
1
<210> 5
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 5
Ala Ala Ala Ala
1
<210> 6
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 6
Ala Ala Ala Ala
1
<210> 7
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 7
Ala Ala Ala Ala
1
<210> 8
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 8
Ala Ala Ala Ala
1
<210> 9
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 9
Ala Ala Ala Ala
1
<210> 10
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 10
Ala Ala Ala Ala
1
<210> 11
<211> 23
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 11
ccgauaagua aaacgcauca aag 23
<210> 12
<211> 37
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 12
auuugaaggu aucuccgaua aguaaaacgc aucaaag 37
<210> 13
<211> 26
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 13
ucuccgauaa auaagaagca ucaaag 26
<210> 14
<211> 25
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 14
guuuacacac ucccucucau agggu 25
<210> 15
<211> 25
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 15
guuuacacac ucccucucau gaggu 25
<210> 16
<211> 25
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 16
uuuuacauac ccccucucau gggau 25
<210> 17
<211> 25
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 17
guuuacacac ucccucucau ggggg 25
<210> 18
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 18
aaaaaaaaaa 10
<210> 19
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 19
aaaaaaaaaa 10
<210> 20
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 20
aaaaaaaaaa 10
<210> 21
<211> 81
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 21
acaucuggcg cguuuauucc auuacuuugg agccaguccc agcgacuaug ucguauggac 60
gaagcgcuua uuuaucggag a 81
<210> 22
<211> 78
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 22
acaucuggcg cguuuauucc auuacuuugg agccaguccc agcgacuaug ucguauggac 60
gaagcgcuua uuuaucgg 78
<210> 23
<211> 65
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 23
uuauuccauu acuuuggagc cagucccagc gacuaugucg uauggacgaa gcgcuuauuu 60
aucgg 65
<210> 24
<211> 93
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 24
aaguaguaaa uuacaucugg cgcguuuauu ccauuacuuu ggagccaguc ccagcgacua 60
ugucguaugg acgaagcgcu uauuuaucgg aga 93
<210> 25
<211> 68
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 25
uuauuccauu acuuuggagc cagucccagc gacuaugucg uauggacgaa gcgcuuauuu 60
aucggaga 68
<210> 26
<211> 69
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 26
uuaucucauu acuuugagag ccaucaccag cgacuauguc guauggguaa agcgcuuauu 60
uaucggaga 69
<210> 27
<211> 66
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 27
uuaucucauu acuuugagag ccaucaccag cgacuauguc guauggguaa agcgcuuauu 60
uaucgg 66
<210> 28
<211> 230
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 28
uaaauuuuuu gagcccuauc uccgcgagga agacagggcu cuuuucauga gaggaagcuu 60
uuauacccga ccgguaaucc ggucggggga uuggccguug aaacgauuuu aaagcggcca 120
augggccccu cuauauggau acuacuuaua uaaggagcuu ggggaagaag auagcuuaau 180
cccgcuaucu ugucaagggg uugggggagu aucaguaucc ggcaggcgcc 230
<210> 29
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 29
aaaaaaaaaa 10
<210> 30
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 30
aaaaaaaaaa 10
<210> 31
<211> 45
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (26)..(45)
<223> n is a, c, g, or u
<400> 31
guuuacacac ucccucucau agggunnnnn nnnnnnnnnn nnnnn 45
<210> 32
<211> 45
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (26)..(45)
<223> n is a, c, g, or u
<400> 32
guuuacacac ucccucucau gaggunnnnn nnnnnnnnnn nnnnn 45
<210> 33
<211> 45
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (26)..(45)
<223> n is a, c, g, or u
<400> 33
uuuuacauac ccccucucau gggaunnnnn nnnnnnnnnn nnnnn 45
<210> 34
<211> 45
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (26)..(45)
<223> n is a, c, g, or u
<400> 34
guuuacacac ucccucucau gggggnnnnn nnnnnnnnnn nnnnn 45
<210> 35
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 35
aaaaaaaaaa 10
<210> 36
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 36
aaaaaaaaaa 10
<210> 37
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 37
aaaaaaaaaa 10
<210> 38
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 38
aaaaaaaaaa 10
<210> 39
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 39
aaaaaaaaaa 10
<210> 40
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 40
aaaaaaaaaa 10
<210> 41
<211> 92
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 41
uuauuccauu acuuuggagc cagucccagc gacuaugucg uauggacgaa gcgcuuauuu 60
aucgggaaac cgauaaguaa aacgcaucaa ag 92
<210> 42
<211> 108
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 42
acaucuggcg cguuuauucc auuacuuugg agccaguccc agcgacuaug ucguauggac 60
gaagcgcuua uuuaucggag agaaaccgau aaguaaaacg caucaaag 108
<210> 43
<211> 96
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 43
uuaucucauu acuuugagag ccaucaccag cgacuauguc guauggguaa agcgcuuauu 60
uaucgggaaa ucuccgauaa auaagaagca ucaaag 96
<210> 44
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 44
aaaaaaaaaa 10
<210> 45
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 45
aaaaaaaaaa 10
<210> 46
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 46
aaaaaaaaaa 10
<210> 47
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 47
aaaaaaaaaa 10
<210> 48
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 48
aaaaaaaaaa 10
<210> 49
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 49
aaaaaaaaaa 10
<210> 50
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 50
aaaaaaaaaa 10
<210> 51
<211> 25368
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 51
ctggaaggac gcatggcaga aatcgttttt tactgttttt gccgataggg atagtttttg 60
cttcttgaca tgctttttca tagatgacag attaaggact tttacaagag gctaacattg 120
ctttgttttt caaaaacaac ttaagaagat agtctatcat gcaaaaatct atagaggtta 180
ttgatgttat aaagatatac aagatgggag atgtagattt tccagcgctt caaggggttt 240
ctcttgagat agacaaaggg gaattcgtgg cagtaatggg gccgtcaggt tctggaaaat 300
ctacattcat gaacatcata ggctgtctcg atacgcctac tgccggaaaa tattggttgg 360
ataggcagga agtcgggcaa ttaagcaaag atgtgttggc aattatacgc aataaaaata 420
tagggtttgt atttcagagc tttaacctgc tgccaaggat aactgcaatg gaaaatgttg 480
aactccccct tttgtataac ggtttgccgt caagggagag aagacaaagg tctctttcag 540
cattgaggtc tgttgggctt gaagggaggg aatatcacaa atccaatcaa ttatcaggcg 600
ggcagcaaca gagggttgcc atagcaaggg cattggtaaa taatccatct ctcattctgg 660
ctgatgaacc aaccggcaat cttgattccc aaacaagcaa tgaacttatg acgcttttta 720
agcggctcaa taaggaaaac ggcataacta ttgttatggt aacccatgag gcagatgttg 780
cccggtatgc tgacaggcat attgttttta aggacggaag ggtggtaaaa gacgataaaa 840
ttacgaatta atcttgcaat tccctgtagc ttgctgcagg gttactttat agttccctcc 900
cccttgatgg gggagggtta gggtgggggt gatagaatgt tgtttccacc ctcccctttg 960
tcccctcccg tcaagagagg ggagatttta ggataccccg cagcttgccg cggggaggtt 1020
cattaactac gaattttaaa aaaaccattc agatgtctta gcaggctgtt gaaaaagtca 1080
tcaacagcct tgattacaca gattataaaa aatgattaca cagatatttc aaggagtttc 1140
aatctgtgta atccaatctt ttctctgtgt aatcagagat tgttgagttt ttcaacaatc 1200
tgttaatttt taattcttac ttcataattg ctttcctatg aacataatcg caaccattaa 1260
aatagccgcc aatgccctgg gcataaataa aatgaggtca ggccttacca tgcttggcat 1320
aataatcggc gtggccgctg ttatagccat gctctctgta ggctcaggcg caaggactca 1380
gatttctaaa gagattgcca gcctcggctc caaccttttg ataattctgc ctggcgcgcc 1440
caccagcggc ggactcagaa tgggttttgg aacagcgccc acgttgacat ccgatgatgc 1500
aaaggcaata cctcaggaaa tatctaatgt tgcatttgca gcgccgattt taggcggcac 1560
agcgcagata gtatacggaa atcaaaactg gagcaccatt gtgacaggca caacaccggg 1620
tttttttgat atacgggaat ggcagcttga ctcaggcgct ctgtttaccc agaaggatgt 1680
tgatggcgca acaaaggttg cattggttgg ccagactgtt acggaaaacc tttttggata 1740
tgaggaccca ttgggaaaga ttataagaat aaaaaagata ccatttagag tcatcggggt 1800
cttatccaga aaagggcagt ctcctattgg ccaggatcag gatgacagca tatatatacc 1860
ggtaacaact gcgcaaaaga ggctttttgg cacaacattt cccggcatgg tgaggatgat 1920
aaccgtaaag gcgaaaacct ctgatgcaat caaagatgct gaaaaggaga ttgcggcatt 1980
actgagacag agacatcata ttacagccgg gagggacgaa gatgatttca gcgtccgcaa 2040
tcttagtgaa atgatggctg catctgaaca ggcggcaaaa atcatgtcca tcctcctcgg 2100
ctctattgcg tcggtatctt taatagtcgg cggcataggc attatgaaca tcatgcttgt 2160
ctctgtaaca gaaaggacaa gagagatagg catccgcatg gcagtcggcg caaggcccag 2220
agatatactc atgcagtttc ttatagaagc catagtcctt gctgtcattg gcggcagtat 2280
aggtattctg tgcggcgccg gaggctcatg gcttatttca tactttgccg gctgggagat 2340
agccatatcc tctgttgcta tagttcttgc attcggtttt tccgcgttag tcggaatatt 2400
cttcggtttt tatccggcca gaaaggcgtc ccgccttgcg ccggtggagt gtttgaggta 2460
tgaataagtt gtggtttgca ggcaaactcc attttcgttt tataatccgg agcggactgg 2520
gtttgtctgg ctgggttgcg gcattacaga ggaagtaaat ttgggaaact gttataaaaa 2580
aggttgaaat acatatctgt tctgcttata ataagaatat cagataatca gaaaggagga 2640
atttatatgc ctgttgtcaa aatgagggaa aggggacaac taaccatccc atacgaatac 2700
aggaaagatc tcggcattgg caaggaagat atgctcaatg tcttaaaaat cggcgatgtg 2760
cttatccttg tgccgaaaca gcttgccgga gatatcgtat ccaagaaaat tgaagggacg 2820
atgaagaaaa aagggctgac acttgataac cttctaagca atctcaggga gcagagaaaa 2880
agatattcca aagagacata tgccaaagca aagacctaaa gtttttcttg acacaagcgc 2940
attgattgcc ggcatagcat cttcaagggg cgcagcaagg gctgtgctgc agcttgctga 3000
aatcggtttg atacaggtct ttgtctcaag gcaggtcatt gtggaagcag acaggaatat 3060
tgaagaaaaa ctgccggaga tgctgaatga atacagagaa tttatcaaac tcctatcacc 3120
cgtgttagtt gatgacccaa gccacaagga agttgcaaaa tatttatcag taatcaattc 3180
ggatgacgcg cctatccttg cctctgcaat aacctcacac gctgatttcc ttatcacatg 3240
ggacagaaag catttcatcg gcaaaaatat ccgtatccac ttaaacctga aaatcgttac 3300
tccgggagat tttttgaagt atttcaggaa atatattgag taaaagccca cctctttggc 3360
aaagagggga atggcatttg tttgagggac gaggggactg tcccagacaa aataaattat 3420
ttttaaccgt tttttggatg tgtgttatat tctgtgaata aggagggatt gccatggatg 3480
ataaagacaa ggatttaatg ctggaattta gaaaaaggct ttcatcggat ttagcaaatc 3540
atataacacg tctcatagta ttcgggtcaa gggcgaaagg tgaagtagca gaggattctg 3600
atcttgatgt aattgccata gttgatgaaa aaaactctgc gattgaaaaa agtcttgaag 3660
atatagcgta tcggattatg tgggatcatg acttcaggcc aatcatatca ctcaaagtgc 3720
tctctgaagc ccaattcagt gacgcccttc gtagagggtt ttctttttac aggcatgtgg 3780
aaaaagaggg ggttttggta tgaccgagga agtaaaaaag ctgattgaaa aagctgaaca 3840
cgcccttgag gtagccgaaa agttaatgaa tgacggttat ccatcagatg ccgcaagcaa 3900
aatctattat tcaatgtatt atgcagcaca tgccccttta aaatcagaag gaattgatgt 3960
catcaagcac tcagccgttg aatcagcctt cgggtattac tttgcgaaga ctggaaagat 4020
taatcccaaa caccacagga tgctaataga cgcaagaaag attcgtgaaa tagccgatta 4080
tgatattcag gaagagattg ttgagccaac tgcatcgcta aaaattaaag aggggaagtc 4140
ttttttgtct gcaatcagaa aaattcttgg cagcctgtag caatggactt gacaagcgaa 4200
gtgggactgt ccaggattta cggacagagc gaagcggagt cccgaatcca atggttgtgg 4260
tttgcgggca ggcattattt tcgttttata atctggaaag aaaaaaggaa aaccccttat 4320
ggaaaagaga ataaacaaga tacgaaagaa actatcggcc gataatgcca caaagcctgt 4380
gagcaggagc ggccccatga aaacactcct tgtccgggtc atgacggacg acttgaaaaa 4440
aagactggag aagcgtcgga aaaagccgga agttatgccg caggttattt caaataacgc 4500
agcaaacaat cttagaatgc tccttgatga ctatacaaag atgaaggagg cgatactaca 4560
agtttactgg caggaattta aggacgacca tgtgggcttg atgtgcaaat ttgcccagcc 4620
tgcttccaaa aaaattgacc agaacaaact aaaaccggaa atggatgaaa aaggaaatct 4680
aacaactgcc ggttttgcat gttctcaatg cggtcagccg ctatttgttt ataagcttga 4740
acaggtgagt gaaaaaggca aggcttatac aaattacttc ggccggtgta atgtggccga 4800
gcatgagaaa ttgattcttc ttgctcaatt aaaacctgaa aaagacagtg acgaagcagt 4860
gacatactcc cttggcaaat tcggccagag ggcattggac ttttattcaa tccacgtaac 4920
aaaagaatcc acccatccag taaagcccct ggcacagatt gcgggcaacc gctatgcaag 4980
cggacctgtt ggcaaggccc tttccgatgc ctgtatgggc actatagcca gttttctttc 5040
gaaatatcaa gacatcatca tagaacatca aaaggttgtg aagggtaatc aaaagaggtt 5100
agagagtctc agggaattgg cagggaaaga aaatcttgag tacccatcgg ttacactgcc 5160
gccgcagccg catacgaaag aaggggttga cgcttataac gaagttattg caagggtacg 5220
tatgtgggtt aatcttaatc tgtggcaaaa gctgaagctc agccgtgatg acgcaaaacc 5280
gctactgcgg ctaaaaggat tcccatcttt ccctgttgtg gagcggcgtg aaaacgaagt 5340
tgactggtgg aatacgatta atgaagtaaa aaaactgatt gacgctaaac gagatatggg 5400
acgggtattc tggagcggcg ttaccgcaga aaagagaaat accatccttg aaggatacaa 5460
ctatctgcca aatgagaatg accataaaaa gagagagggc agtttggaaa accctaagaa 5520
gcctgccaaa cgccagtttg gagacctctt gctgtatctt gaaaagaaat atgccggaga 5580
ctggggaaag gtcttcgatg aggcatggga gaggatagat aagaaaatag ccggactcac 5640
aagccatata gagcgcgaag aagcaagaaa cgcggaagac gctcaatcca aagccgtact 5700
tacagactgg ctaagggcaa aggcatcatt tgttcttgaa agactgaagg aaatggatga 5760
aaaggaattc tatgcgtgtg aaatccaact tcaaaaatgg tatggcgatc ttcgaggcaa 5820
cccgtttgcc gttgaagctg agaatagagt tgttgatata agcgggtttt ctatcggaag 5880
cgatggccat tcaatccaat acagaaatct ccttgcctgg aaatatctgg agaacggcaa 5940
gcgtgaattc tatctgttaa tgaattatgg caagaaaggg cgcatcagat ttacagatgg 6000
aacagatatt aaaaagagcg gcaaatggca gggactatta tatggcggtg gcaaggcaaa 6060
ggttattgat ctgactttcg accccgatga tgaacagttg ataatcctgc cgctggcctt 6120
tggcacaagg caaggccgcg agtttatctg gaacgatttg ctgagtcttg aaacaggcct 6180
gataaagctc gcaaacggaa gagttatcga aaaaacaatc tataacaaaa aaatagggcg 6240
ggatgaaccg gctctattcg ttgccttaac atttgagcgc cgggaagttg ttgatccatc 6300
aaatataaag cctgtaaacc ttataggcgt tgaccgcggc gaaaacatcc cggcggttat 6360
tgcattgaca gaccctgaag gttgtccttt accggaattc aaggattcat cagggggccc 6420
aacagacatc ctgcgaatag gagaaggata taaggaaaag cagagggcta ttcaggcagc 6480
aaaggaggta gagcaaaggc gggctggcgg ttattcacgg aagtttgcat ccaagtcgag 6540
gaacctggcg gacgacatgg tgagaaattc agcgcgagac cttttttacc atgccgttac 6600
ccacgatgcc gtccttgtct ttgaaaacct gagcaggggt tttggaaggc agggcaaaag 6660
gaccttcatg acggaaagac aatatacaaa gatggaagac tggctgacag cgaagctcgc 6720
atacgaaggt cttacgtcaa aaacctacct ttcaaagacg ctggcgcaat atacgtcaaa 6780
aacatgctcc aactgcgggt ttactataac gactgccgat tatgacggga tgttggtaag 6840
gcttaaaaag acttctgatg gatgggcaac taccctcaac aacaaagaat taaaagccga 6900
aggccagata acgtattata accggtataa aaggcaaacc gtggaaaaag aactctccgc 6960
agagcttgac aggctttcag aagagtcggg caataatgat atttctaagt ggaccaaggg 7020
tcgccgggac gaggcattat ttttgttaaa gaaaagattc agccatcggc ctgttcagga 7080
acagtttgtt tgcctcgatt gcggccatga agtccacgcc gatgaacagg cagccttgaa 7140
tattgcaagg tcatggcttt ttctaaactc aaattcaaca gaattcaaaa gttataaatc 7200
gggtaaacag cccttcgttg gtgcttggca ggccttttac aaaaggaggc ttaaagaggt 7260
atggaagccc aacgcctgat attgccgata agcaccgtaa tggaatccat ctactgcccg 7320
cgcaacgcat ggtatgcctt tgtgggcgag cggcggaata tggctaaaag cgttcacttt 7380
acggaggccg tccatgcaca cagggcggtg gatgaatcca cgcagagaat ccgcactgat 7440
tgcaagcaga ttacagggat gtatatttat agcaataagc ttggcctgac agggcgggcg 7500
gatacagttg agtggctgta tggaatccct ataccggttg agacaaagac cggcgcaatc 7560
agggattttg agaacttccg ggtacagatt gcattacagg ccttgtgcct ggaagagatg 7620
tttaatgtga acatcccata cggtgagata tttttctgtg aaaccatgcg gcggcacgaa 7680
atagctgtag acgaagacct tagaacgcat agcacggcaa ttgtggtgga gttgagagaa 7740
aggtttctgt cttttgacat caaccgcttc caaagggtaa atgaccatag atgcccaaag 7800
tgtcaatatt tggagtcatg ccttcctccg agtcttgagt tgtgaggttc ctttatgacg 7860
gcgataacag acaggataac cctttacatc acagcggatg aatccagcat ttcacgccga 7920
ggcgatgcat tcctgatcca aaaggcaggc gaggaaaaag ggcaaaagat accagcgatg 7980
aaagtaaaag atatagtagt cgttggtcac gttacgcttg acagccgtct gattggactt 8040
tgcagggaag agtcaattcc gatccatttt ctaagcggaa ggtgggaata tcagggtagc 8100
cttcagttcg agccggtcaa gaatctattt atccgcaggg cgcagataaa aaaacatttc 8160
gacccggaaa agaaactgga tatatccaaa aaaatagtcg gtggaaaaat ccgaaatcag 8220
caggccatgc tggataaata ccggaaaaat ctgaagttgg cgtgcccgca aattgattca 8280
gtgggcgata tggaaaccct gcgagggatt gagggtgtgg tggcaaagga gtattacggc 8340
ttctatcccg ccataataaa aaattcggag ttcacgttta cacgcaggac aaagcgtccg 8400
ccggaggatg aaataaacgc gctcctaagc ctgctgtata ccctcatttt caacgagata 8460
cactctaccg cattgctcgt agggctggac ccggcctttg ggtatctcca cgacgtctat 8520
tacggacgac catcgttgat ttgcgatctt cttgaagaat ggcggccatt ggccgaccgg 8580
tttgtgctga atatgataaa caggaaagag gtcacaccgg aagatttcag gaaagagacc 8640
gaccaaaagg gcgtgtggtt aagcaaggac ggatatccaa aggtgataaa gaaatggcac 8700
cagtttttca agatggatga acaaaacaca agcattctga gccgccccat aacatatcaa 8760
cacgcaattg aaaggcaggt caggaccttc agccagtatc tcatggatga caaagacaat 8820
tataagacga tagagctttg ataatgcgcc atctcatctg ttatgacata gaggaggata 8880
aggtaagggc acggcttgta aagctcttgg aagcctacgg cgtcaggatt caatattctg 8940
tttttgaatt caacctttca aaggcgcgct ggacagacct taagctgaat ttgaaagaaa 9000
aagggttcct tgacggctcc attagcattg tcatctatcc attatccgca gaggcttatg 9060
agctggtgga acgttatggc gctgcctcta tatgggatga gggggatatg gttttcgatt 9120
gatttttctt gactgcaatc tgtcataagt agtaaattac atctggcgcg tttattccat 9180
tactttggag ccagtcccag cgactatgtc gtatggacga agcgcttatt tatcggagat 9240
agctccgggt gcaaactcgg agctgttttt ttacgaaaca gctaatttta gccaaaagtt 9300
ctttgaaaac ctgatattac ggtttttttg tttgtaaaag ggtttacagt gcagatctcc 9360
ttataattat tgaaaatgtg tttcgttact cttaatattc gagaatttcg acttccggaa 9420
ctcattgata tatctgggtt gttggtattt gaaggtatct ccgataagta aaacgcatca 9480
aaggtctcac tcaagatgac gaggagatac ttgagaattt gaaggtatct ccgataagta 9540
aaacgcatca aagatccaga aaaatacggc cttctttacc atttcctatt tgaaggtatc 9600
tccgataagt aaaacgcatc aaagtacccc tgcacccatt agatttagat gcaggataat 9660
ttgaaggtat ctccgataag taaaacgcat caaagagctc tgctttgtag atgcctgctg 9720
caagggttga tttgaaggta tctccgataa gtaaaacgca tcaaagtcct gcagcagaaa 9780
atcaaagaca atgaatatta tttgaaggta tctccgataa gtaaaacgca tcaaaggccg 9840
ctctgaaaaa ggaaaagctc ggactaaaat tatatttggg cgggaagcaa cgtaaagcct 9900
tcttttcttg ctgcatctct cagttttgaa tcaaggcaga cgaaataatg accttttggc 9960
ctttttcctg cccatacgag cgcggcagat agttgcaagg catctgcggc acggagaggg 10020
tgcagcataa gaagtcttcc tgcaatatcc cgtatgtctt cgccgggttc aatctctgtc 10080
catgtatccg aaagaagggt gaggagatgc cgcacaccgt cttcttcctc aggtttgagg 10140
aatcccttgc gccgcaagcg ggcaaaggct gaacagcact ctatgaagct gccccaccat 10200
actgcaatag cgtgatcttt tctcacaagc tgttagacag cctttgtttg tggttcgtca 10260
atgcataatg ggatgatagc agaagaatcc cagaacatca tcttccttcc tcccgttccc 10320
gtaaaagggc attaagagcc cgtccttttt tatcctttgg tctgggcata ttccaaaaat 10380
ctgccggcag tctgcctgcg ccgatgcgga caagccctgc cttctccaac gttaatagat 10440
gcgccggtat ttcaatatct cctcttttca aaggaataat cttggctata ggctttcccc 10500
tgtcagtgac aagaacctct tctccagcct ttacctttga caggtattcg ctgatagatg 10560
cctttaattc agaaaccttt gcggtcttca tagggttatc ctccgtgact atatggatat 10620
gaccgatata gtcttattcc atagccctgt caaatgaaaa aaacgaataa cagttacttt 10680
atcgtatgaa acataagctc agcatgattt aatgaaccgc ttttatcaag aatgagtttc 10740
aggagaaaag ggcgtcttgg cggaagcgag ttaaaccgca ggtcaaaata ttccaccata 10800
tatccttcgc cctcctcttt tacggttacc acaggaaatc tggcaaacca gagatatgtc 10860
tttacaatct ccagtttttc aaccttttca ataatgttat ttccctccgg tccctgattt 10920
aagccttcag ggagatgctt tttctcaaag gaattaaatg gcgagatgct tttcagcgca 10980
tcaacatcaa cctgataaaa ccttttatca tcctctatat acacagacca tctgaaaggg 11040
gagaagggga ggggaattgc ctcaactctt ttgccggtta tgccaagttt ttgagcctcg 11100
gccttagcgc tttcaatagc aatggttctc catgtgtagg caatccccag atagattatt 11160
atacctgcaa cagaactcaa ggctataacc tttgtccatt cccgtttgaa ctttattatg 11220
accaatggga taagcatcaa ggcggtgaaa taaaaatcta tgataaagac aaggtcaaga 11280
gagtatcttt tgtcggtgaa aggaaagaaa actaaagtcc cgtaagatgt gatgaggtca 11340
aggaagatat gggtgtatat gcctaataaa aacaggccaa aggttgttag atagcctaat 11400
ttttctctaa atcgttctat tgaacagaca atacctgcca tgatagcggc gattacaaaa 11460
ctgccgataa tggagtgcgt aaatccccga tggtatttga gataggcgag gggacctgca 11520
agcctcaggg ttaagtggtc aatatcaggt attagtgcgg caacaataaa gattatggtg 11580
gcaggtctgc caaatctctg atagaatcct gttctggaca gaacgacacc ggagaggccg 11640
tgtgttattg gatccatagg tttagataag tatattatat ataatggtat taaacaacag 11700
gggattttat cgttaccttt ttatgagaac aattaaaaga acagtttgtt cagcctttgt 11760
tttatttatc ttattctcgt cagatgctgt tgccgacctt tatcagtggc aggatgaaaa 11820
aggggatatc catgttgtag atgatatgct cctggttccg ccgcaatata aagataaggc 11880
aaagaaatta aaggcaaggc cttcaaggca aaccccttct ccccaacaaa atgttcaacc 11940
ccctgtgccg cctcaaacat cttcagaaca agaagagctg tatggggatt atcctttgag 12000
ttggtggaaa aatgagttca gcagtaaaaa aaacgagatt tctaaacttg aaaatactat 12060
aaaagagcag aaaaatttta tagctgatta tgaaagaggg aggaggcttt atcgattata 12120
cagcaaggaa gatacggata aatacgaaac ctataaaaaa gagctgtctg ataatgagaa 12180
ccaattgaac aaactcaaaa cagatttgga cgaattcagg cgcaaggcgc aaatctacgg 12240
cgttccgagg gcaatcagag aatagtaatt aacaggctgt tgaaaaaggc atcaacagcc 12300
ttgattacac agattaggaa aaacgattac acagatattt caatgagttt taatctgtga 12360
aatctaatct tttatccgtg taattgaagt ttgttgagtt tttcaacaaa ctgttaatat 12420
ggtaaaacct gttatcagtt gtagggcaag ccttcaggct tgcttatttg cagggctaaa 12480
gccctgccct acatcaagtt atttatcaag ttatttattg ccttcactat aatatggtaa 12540
aacctattat cagaaatagc attgcatatc tcttatgttt atgcctcctt taccccgtga 12600
ctaaggtttt tggtgtggat gacgatgcta taacaatagt ggcagcagga gacctttatc 12660
ttggaggctc tgccaatcca tacttaaaac agcgcggata ttcatatcca tttgaatcaa 12720
ccaaggatgt tttgcatagc gcggatatcg cagttgtcaa tctcgaagcg cccttgacca 12780
acaagacgga aatatttatg aataaagagt ttgtccttaa ggctaaccct gattcaagtg 12840
aggcgataaa ggctgtgggt tttgatgtgg cgacattggc aaataatcac attatggatt 12900
acgggcaaga gggattgaaa gatacgataa ccgcacttaa taagagaggg gtaagctata 12960
ctggcgcagg agaagactta aataatgcaa ggaagcctgc catccttaat gttaaaaata 13020
aaaagattgc ctttcttgca tattccaggg tctttccaga agaattctat gctaccgata 13080
tctctggcgg aacagcgccc ggtttatttg aatatataag ggacgatatt aaaaagataa 13140
agaaagatgc tgatattgtt gttgtttctt ttcactggag tgaagagctg ttgaaatatc 13200
ccaaagaata ccaaattaaa cttgcccatc ttgccattga cagcggggca aatctaatca 13260
taggccatca cccgcatgtg attcagggta tagagaaata taaaaacggc ctcatctttt 13320
acagtcttgg gaattttgcc tttggatcta tcagccaatc atcgccagag ggtatattgg 13380
ccgctgtccg gtttaagggt aaccaaatca tctcggctga gataattcca ttaaatgtca 13440
ataataaaga ggtttttttt cagccaaagg ttttggaagg agaaagggcg gaagttgcaa 13500
tgaggaatat tcaagaaata tcagacagat tcaaattaac cattatggct agggaaggaa 13560
agggctacat acagcttaac gaggagttaa aatcagcctc gcttccgtga ataggggttg 13620
ttgttacaag tagagttaag tcagatatta tgtaaacgtg tgatcccttg ctatgcaagt 13680
ttacataata tatcttatgc gacaataaaa tttagttagc cttaatggcc tgtttgggct 13740
aaaaatccct atattccatt cgttttgccc cctgttatct ttatcccgct tttctttatt 13800
gcgcttttta tcatctttag tttccaatcc ctatgcgcat taattgtaga gagaacctct 13860
ctggggttat cggttatttt aacgaggtct aaatcttccg gagatattgt atcttccttt 13920
aacatcgttg ttttcatcca gtggataaga ccattccaat aatccttgcc aaccagaatt 13980
aaaggcaatg gatatatctt atgagtctga acaagcgtaa gcgcctcaaa aaattcatca 14040
agggttccaa atccgccagg catacagaca tagcccatgg catactttat aaacatcacc 14100
tttctggcaa aaaagtattt aaaggttaat gatttattct gaaatgggtt cggcttctgc 14160
tcctttggca gaaggatgtt gagtcctacc gaacctccgc cattcttggc agcgcctctg 14220
ttggcagcct ccataatgcc gggaccgccg ccggttatga tggtatagcc atcctttgca 14280
agcagtgtgg ctatatcttc ggccattttg tagtatgtat gatttttagg aaatcttgcg 14340
gagccgaata tagatacagc cggccctatg gcagaaagtt cttcaaaacc ctccacgaac 14400
tcgctcatta ttttaaatat acgccatgtt tcctgacctc ttaaatcttc aaccattttt 14460
atttactccc attctatagt actcgggggt tttgtgctga tatcataaac caccctgttg 14520
atgccgcgca cttcatttat aatccttgag gagatccttg ccattaaatc atagggaagc 14580
tttacccagt ctgccgtcat tccatccatg ctttctacag cccttattgc ggcaacattc 14640
tcatatgtcc tctcatcacc catgacaccc actgtcctta cgggcaaaag cactgcaaac 14700
gcctgccaca tctttgtgta aaggccggcc ttttttatct cttcaagcac aatactgtct 14760
gcctttctta gtatatcaca tctctctttt gtaacctcgc ctaaaattct tatagcaagg 14820
cctgggcctg gaaatgggtg tctgtttatt atttcctcag acatgccaag ttctttaccc 14880
agtatccgca cttcatcctt aaacaattcg cgaagaggtt cgacaagttt gagtttcatt 14940
ttttttagaa gaccgccgac attatggtgg ctttttattg tcgctgaagg gcctttgaag 15000
gatacactct caatcacatc cggataaaga gtgccttgtc caagaaagct cacttcctgc 15060
cttttgcctc cgcctctggc ggatgaggcg gatgccccct gttttaactt catggcctct 15120
tcttcaaaga cccttacaaa ttcattgcct attatttttc tcttcttttc agggtcctcg 15180
atacctttga gcttgtttaa aaatctttga gaggcgtcaa tacatttaaa attcatacga 15240
aaatgcttct ttaatgtctc ttcaaccttc tttgcctcac cctgcctcaa tacgccgttg 15300
tctacaaaga tacaggtaag tttgtttcct atggccttat gcattaatac cgctgcaact 15360
gctgaatcca cacccccgct tatgccgcat accacccccc tgccccctac cctttccctt 15420
atatccttta cagcagtgtc tacaaatgcc tccatggtcc agataggttt gcatccacat 15480
atcttgaaaa ggaaatttct aattatctgc aagccctttg gcgtatgaac tacttccgga 15540
tgaaactgca cgccaaagat ttttcttttg gcatccttca tagcacagat tggagaatta 15600
ctactgcggg caatagatgt gaatccatta ggcatctttc ttacacggtc gccgtggctc 15660
atccatacag gcgtgaggtg tgaggcgtaa ggcgtgaggc gtgacaacaa atcattacta 15720
tcatcaatta ccagttcagc gcttccgtat tctctgtgtg atgatttttc aacctttccg 15780
cctaaaaggt aggctgtaag ctgcatgccg tagcatatgc cgaggattgg aatgtccaga 15840
ttgaagagtt cttttggaat aagaggggcg tttttatcgt agacgcttga cggcccgccg 15900
gagaggatta tgccttttgg gtgaaaagcc ctgatctttt caaggcctat attataagga 15960
tgtatctcgc agtagacctt ttgttcccgc accctccttg caataagctg ggtatattgg 16020
gaaccaaagt ctaaaataag gattttttgc tgatgtatgt tttgcattag gggaatattt 16080
tattaaagtt aaaaaaatat atcttaaaaa aaccaaatag acaatagaaa aatcatgcgt 16140
gtaaaaaacc tctttcttga cagtatccat tctgttatga taagaacagc tcttttttta 16200
tacagaacaa gactgaatct tacgatagaa tcattaagca aatcatatag tttaataggt 16260
aggacacttc atgtttcaat ttgttaagat agcagcgcta tcctttataa taattatagc 16320
accttgggat tcatttaaac caacatataa tagcgatata tttcagttta taataacctc 16380
tttcagttca gttgacctgc catttgtatc aagcagtctg catagagagg aattggaaca 16440
agcctctgtc ttttggaagt atttctttct attaatcttt ttcctgtctg ttgatggatt 16500
caaaatattg attgaaattt ataaacgtcc ggtcttacgg acttatactt ccaaccctca 16560
ggatgtaaca gcattaatcg catgctacaa tagcgctaaa acaataaagt ttacgattga 16620
tgaccttcaa aagattttgt ctaatgatag gattattgtt gtggatgacg gcagcactga 16680
taatacattt aatattgcaa agaatatggg cgttcaggta tatcggtttg aaatgaataa 16740
aggaaaagtt gcagccatta attttggaat ctaccgtgtt aaaactaagt atactttgct 16800
attagatgat gatacaaggg taggcccttt gtctcctcca acctctttgc tggaggaagg 16860
gtacaccgga gtggccttta accttttacc ttgccgtaga acacgagact tgactaatgg 16920
gaaaaacttt gtaagctgcc ttcagagata cgagtacagt aaatccatgg agattggcaa 16980
aagattccaa gacggcgcat tgagcgtcag ctgcatatcc ggcgcagtag gcctgttttt 17040
gacttcacgg ctcaattctt tccatcattt acactcaacg gtatttcagg gagaagattt 17100
ggagagaacc ttaatagatt tattaaaagg cggaaaggtt gcctttgtaa atcaaaatgt 17160
ttggaccttt gccccggata actggttgag tctcacaaag caacggcttt ttaactggta 17220
ccctgggttt taccgcaata tagaccattt cttccatata ctctttgaca aacaacttcc 17280
gttaaggctc aaaggtgaaa tgttttataa catctttgta attctgactg atcctctaag 17340
gatatattca ttttttgccc tgtttattta taagcagtgg gctatgcttc ttttcgtata 17400
tctcttttat ttagctatag agatataccc ctttattgta gtggaaaaat atcttcctgt 17460
cgcaagatat tatatgcccg ccctcatcgc atatcccata tatggaattt ataataccct 17520
attgcgctct cttgctttat tcgtatggtt gtataataga tttataacaa aacggatgag 17580
accaaaagga cgcccggggg atagaattgc ttaggaatgc ctttctgatt gctgtatttc 17640
tactatggct gccaaatgtt gtaatgggcg ctgacagctt aactatcaca aatgattata 17700
ttatagatat caaagatggc ggggataaaa catataacga cacatatatc cgcttagatt 17760
ataaacagct ctacgcagtg ggctatcttg gagagtggca gcatggcttt gaaataggcg 17820
ggtttataaa agatgaacgg atgtctgcgt atagcgcaat gttgcgggct cgtggaaatg 17880
atcagaccta tcaggtggga accgatcagg tgttaggaat gggttttgtg ggaaaggttg 17940
atttacgata catccatatt gaagaattag aaaaaaccgg agataaacac gacctttttg 18000
tttatggttt gggatttgat aaatattatg gtgattacaa ctatttgact gctgtgattt 18060
ataacgaccc ccggaagagt gatagattct ctgtagtcat cagtaacacc cttgccaatc 18120
agaactctta tctgagatta ggtgtcgttc cgagaagcga cggcacattg ggctattttg 18180
gaacaataaa ataccactgg attgtggccg gatatgccta tacgcgagaa tttgacttta 18240
ctacccttga taggaaggtt tttaccttag cgctccagat accctttgat ttaaagtgga 18300
acagagaaga acaataaccc gaaaagtgca taatgcctgt ctgcaaacaa ctactccacc 18360
accttataat tcggcgcctc ttttgtgatt acgacatcat ggacatgact ttcacgaagc 18420
cctgcaatgc ttattctgac taatttggca ttctttctaa gctcagaaat agtcctgcac 18480
ccgcaataac ccataccgga ttttaggccg cctataagct gaaatatact tgaagatacc 18540
ggccccttgt gaggcaccct cccctcaatg ccttccggca caagcttaag ctcgctctca 18600
acatcatcct gaaagtatct gtctttgctc cctttcttca tagcttcaat agatcccatt 18660
cctctataca tcttataggt tcgcccttga taaagaactg tctccccagg gctttcatct 18720
gtgcctgcaa ataaccctcc tatcataacc gaatcagcgc cggcagcgag ggcctttaca 18780
atatcgcctg aaaactttat gccgccgtcg gcaataaccg gtatgttctt ttttctggca 18840
acagccgcac aatccatgat ggctgttatc tgcggaacgc ctacccctgt cactatcctg 18900
gtggtgcata ttgagccggg gccaatgcca atctttacag catcaacgtc agcctttatc 18960
agagcatttg cgccatcgga tgtcccaaca ttgcctgcta tcagctggca ttttggaaag 19020
tttttcttgg tatctttaac agcggtgagc acccctttgc tgtggccgtg ggctgtatca 19080
ataacaataa catcagcgcc tgcctttaaa agcgcatcta tccttgcctc gcggtcaaat 19140
gatacgccaa ctgcagcgcc aaccattaat cgcccgagtt tatccttgca agagtttgga 19200
tatttttccc gtttttctat gtcagagatg gttatcaggc ctttcaactg cccattttta 19260
tcaattaacg gcagtttttc tatcctgtgg cggtgaagca tatcctttgc cttttctatt 19320
gatgtgccgg ccggagctgt tacaagtttt tttgtcatta cctcggatat ttttttgtta 19380
gggttcttct caaatcttaa gtccctgttg gtaaggatgc cgaccaatac cccgttttta 19440
actataggga aactggatat ctgctctatt tttttaatct gcaatgcatc ggcaatgcgc 19500
tggtctggct ccagtgtcct tggtttcatt attacaacac tttcgtattt ttttactttg 19560
tcaacctcta tggcctgttc ttctatggtc aggtttttat ggattatgcc cataccgcct 19620
tcctgggcta ttgcaattgc catgcgggat tccgttactg tatccatagc ggagcttaaa 19680
agaggtatat ttaatctgat ggtatttgta aggcgggtag aggtatctac atccctcggc 19740
aaagcttccg aaaatgccgg tatcagtaaa acatcgtcaa aggcaagacc ttgtttaata 19800
tttttttctg gcataaataa aacctccaac agaaattgat tgaggctgga ggcaagaggt 19860
gcgaggcaaa cgacactacc tccatcctcc aacctctaac ctgtcttctc caatagtatc 19920
ccttccaaaa gccccgcatc gcttaccgtc attttatcaa aaccaaaacc ttccattgcc 19980
tttaaaacaa tagctgcgcc tgggattatt atgtcttccc tccccttttc aagagagaga 20040
atttcctctc tctgttttaa aggcaataag gcaaggtgtt gatatatctt tctgatagcc 20100
tcataactta atatgtaatt gtttatcttg cctgactcat atttctcaag tccctgatca 20160
atagcagcaa gcgtggtaat agtacctgct gttcctacaa ataaggcgga ggctgaaggt 20220
aaacagccat ctcttttcat caaatccttt aaatctgcaa taacacctct tatctcattt 20280
tccattgcgt ctaactcact gtgagtcggc gggtctgtct tgagataatt ttctgtgaga 20340
tgcaccaccc ccatctcaag actccacgca ccaagcatcc ttccggcatc tgttgcaata 20400
aactcggtgc tccctccgcc aatatcaacg acaaggcatt tggggataga ttttaaatct 20460
gtccccactt ttatgactga cagaacccca agcaaagaaa gccttgcctc ttcatcgcct 20520
gatattatct ttatctctat ccctgtcctt ttcaggacac tgttcagaaa ttcttccctg 20580
ttctttgccc tgcgtaccac actggttgca actgccctta cctcttttat atcatactct 20640
tttatctttt cagaaaaaaa ctcaagcgcc tttattgtcc tttcctgagc cttcctgttt 20700
atgccaatat cttctttata accgccgcca agccttgtga tggttcgttt taagtaaaca 20760
ggctgaaggt ttttattatc tatctctgca atcagtaacc ttaaggtgtt tgtgccaata 20820
tcaatggagg cgtattttgt tgacatagct gtatcattgc ttaattcagt ttatgctcaa 20880
aaatatccca gatgcaaggc gccgaggagc gagcagcgga gcatacgccc tcaggtatgt 20940
gagcagcgca gtgacgaagg caacgtagca gatgggtatt tttcagcata aactatttcc 21000
tttccggctc tattgcgata gataacttct ctgccccggc gcgcttggca atatccaaaa 21060
cctttacaac tatgccgtgg agaacatctt tatctgcctt tattattacg attttatcag 21120
ctcgagatgt aatatctgtt tttatagcgt caaaaagcat ttctatgccg attgttttgt 21180
tgttaatata tataatacct cccggagcaa tggagatagt tatacccttc cctgtttcag 21240
tgtctgccgt aaccgccttt ggcagcttta ttttgaatga ttccattatc agaagcggcg 21300
ttgtcaccat aaaaatcaca agcaagacaa gcatgacatc agtcaatgga gtgatattta 21360
tctcagagat aatcttatcc ctattacctg caagactcca ttttttcatt tattgtcctc 21420
aaaaagcgca tcaataaatt ctgctgccct gccttctatt tcaactgccg cgctgtttat 21480
ttttcttgta aagtaattat atgcaataac cgccggcaca gccacaaaaa gacctgctgc 21540
ggttgccaca agggcctctg caatcccatc tgccacaaca gaaggccctg ccccctctgc 21600
tatggcgagg tcatggaatg ccctgataat tccaagcact gtgccaaaga gccccacaaa 21660
gggggctgtg cttccagtgg ttccaagaac gcctaaatac cgctctaaat aaagaagctc 21720
ttgttttgct gccagctcca ttgcctctcc aaccgctgtt ttgccttctt tatattttgt 21780
aagccctgcc ttaaaaatcc ttgccagagg ttcttccttc ccgcagatgg taaatgccgc 21840
ctccctgtta ccatccctta aagccttttc aatttgcaaa gaaaatattt tagaacctct 21900
tcggaattta aataaagccc aaagtctctc catcatcacg ccgacagaga gaacagaaaa 21960
gaaggcgagg acaattaccg taacgccgcc tttttgaagc agggatataa gaccaagatt 22020
atcaaacata tttatatttc taaacctaat gtaatctgcc gatttatcgg ctattcaaag 22080
ttacgcaata gaaatacgcc cataaatggg caactacctt ttatactcct tagaatattc 22140
aatgtagttt tttgcggatt tcaaaatcct tgccacttct tcatctttaa gctgtcggac 22200
aacctttccc ggcagcccca tgacaaggct tttcggcggg attatgctct tttcagtaac 22260
gagtgcgccc gctcctatga tggaatcttc gccgatggta acgccatcaa gtattattga 22320
acccatgccg atgaggcacc tatctttgat cacacagccg tgcagcgtaa cattgtgccc 22380
gacagtaata tcattgccaa gcatcacagg ccaaacacct tttgtgccgt gaaggacgca 22440
attatcctgg atatttgtcc ttgcgccaag cttaatatga tgaacatcgc ctctcagaac 22500
agcgttgcac caaatgctgg aatattcgcc tatctccaca tcgccgatta cctgggcgct 22560
gtcttcaata taggctgtag catgtatttt tggatttatg tttttgtaag gtcttatcat 22620
aagaaattac agattgtgat atgccttata aatatagtat aaggtctttt cttcggtaga 22680
tattctcttc attaacgccg ctcttattgc aataatgcca tttataaaac cggtttcgtc 22740
tgctgtaatg gctttttcat tttcatacct tgaaagaaaa tcaaaaatat tcttggaaat 22800
atctttcatg ccgtctataa aaatatcaag cgcaggcagc agtgcgtctt gtttaagctc 22860
tatggccttt tgcctcatag cagggtaaaa cttattgtcc tcatcccgga gatgattaat 22920
gaggatagtt ttaagctgtt caataatttt caatacataa gcagtgtcac ggatgtcctt 22980
gttttctata ataggctcta atttcttgaa tgccttctct atcattgcat gttctttttc 23040
taaaccctta ataaattttt catgctccat aacaatgccc ctctaaataa agacaccaat 23100
aaaggtgtaa aactataaca aaaacaccca tctttgcgca agattttgct gccacccaga 23160
aaatcaaagt ctattttttt gtatcacttt ctgggcgtct ttacagatgc gataaattca 23220
gcgctgaaaa gcaatataac tgccgaataa aatatccata aaagcattat cataatagcg 23280
ccaagagagc catacatctt attaaaactc ccaaagtgtg cgaggtataa ggcaaagagg 23340
tgttttgctg tctcccataa aacagagaat attacgctgc ctaaaatagc atgtcttgcc 23400
tttatgttct tcccggccat tattttgaat ataaaggcga cggcaataat cataattaca 23460
actggcagga aatatttaaa ggttatactc tttgcaacat agtaggatat atctatgccc 23520
aagacagcta tttttactct gcctaaaatc tctgcggcaa tcggaagacc tatagaaata 23580
agaaaaactg cgcaccagat aaaaaataca ccccatacaa ctatcctggt ttttatgaag 23640
cccatcttct ctgcttctcc aaaaatgagg ttcattgcat cccttatcgc gagtattaca 23700
aactcagcgc tccagatgag cgtgataatg ccaatccagc caaaaacctt tctgttagct 23760
ataagccctt taatatcatc tacgatgctg tcgctcaaat atggaaggct ctcctttaca 23820
aattctaaaa tccgttcaaa aagccgtgtc tccgttccga gaatagagcc tataaaagag 23880
aagagcagaa acatgagcgg gagcagagag aataaggcat aaaatgatat tgccgcagcc 23940
atagtaagac aattatcata agaaaatgcc ctaatgctgt cagttataat tacaaaaagt 24000
cgtttcataa ttatttctgc ctctttctaa aataaagccg tatgacaacc ttatcaaggc 24060
caaaggcctc tctcatttga tttacaagga accgttcata ggaaaagtga ataccttccg 24120
ggtaattggc aaagccgaca aatgtaggcg gttttatgtc agtctgggtt atataataaa 24180
ttttcagcaa tttcccctta tacatcggag gctgatggtg cttattgaag gtgctaaaaa 24240
atttgttaag ctgtgcagtt ggtatccttt tcgtaagctg cgccaatacc tcttctacca 24300
attcaaggat tttaaaaatc ctctggcctg taagcgctga cacaaagatg acaggggcga 24360
actgcaaaaa ttttaccttc caccgtatac gttctgcata ttgttttgcc gtgtttgtct 24420
ctttttcagg caaatcccat ttattgacaa caataataca tcccttaccc ctttcatagg 24480
caaggcctgc tatcttttca tcctgctctg tcatgccgct cattgcatct ataaccaata 24540
atgcaacatc gcatctatca atacacttga ttgccgacat aactgaatac tgttcaagcg 24600
ccatgcctat ccttgccttt tttcttatac cggctgtatc aacaagcaga taatttttct 24660
tattataatt gaattgcgta tcaatggcat ctctggttgt gccaggaata tcgcttacca 24720
caaccctctc atagccgaga agcctgttaa caagggaaga cttgccgaca tttggtcttc 24780
caactactgc caattttatc ctctcttctt tttcttcttt gacagcagcc cttggaataa 24840
ggcttattgc tttatctaat aattcatcaa ccccccttcc ctgttcagat gaaacgagaa 24900
agagattttc catgccgaga ctgaagaaat cagaaacccc ctgttcttgc ttggtagtat 24960
ctattttatt cacagcataa actattggtt tgccggattt tctcagtatg tctgccacat 25020
ccctatctga cggaagaaat ccatctctgc catccatgag aagtataata acatcagcct 25080
cctcaatggc gagcatggcc tgctctctta ccttggcagg gatagttaaa tccctcctat 25140
caccctttct ggggacagtc cgcatttggc ggatgaaatc tgttcccata gggcgagcgg 25200
ggattgcctc gaaaccgcct gtgtcaataa gggtaaatgt tgttcctcgt tcaaccacat 25260
ccccataatt caagtctctg gttacaccag gctcattttt tacaatggcc tttcttttcc 25320
caatgagacg gttgaagagg gttgacttgc cgacattcgg cctgccta 25368
<210> 52
<211> 7832
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 52
gctatcttta atctcaattc ttttcataca cgcataatac cataaatctg tattatgcgc 60
aatatattat gtcgttatgt ataataagct gataaatacc gatccgagac ccatttcatg 120
taaaaaggca catatttttc tttaactagt ggcttctgaa tgagatgctc tttaaaagcc 180
aaaagcataa caggatcaaa caattatcgt aattcagtat aataataaat atcctatttc 240
ttatctaaaa tatctccaag ttttcaacat aatgctgtcg attttggatt gacatccgct 300
aagtaatacg atattcctta acacttcaat ctctttctga aaattttatc tctttatggt 360
cttgccattg ctctatactt tatctatttc tcattgcttg caattgaaat atgaaggtga 420
ccccaatctc ccgccatgaa aacttagtca aatatattta ttgcatggag atttcatctg 480
tagtaaaatc ctgaaaatgc tgggatgaaa gatatttatc gaattttgcc atctatttaa 540
atagccacca aactatatac ttattaaaga attgggggta aagatgcagg aaataaaaag 600
gataaataaa atacgaagga gattggtaaa ggatagcaac acgaaaaaag ccggcaaaac 660
cggccctatg aaaaccttgc tcgttcgggt tatgacacct gacctgagag aaaggttaga 720
gaatcttcgc aaaaagccgg aaaacattcc tcagcccatt tcaaatactt cacgtgcaaa 780
tttaaataaa ctcctcactg actatacgga aatgaagaaa gcaatcctgc atgtttattg 840
ggaagagttc caaaaagacc ctgtcggatt gatgagcagg gttgcacaac cagcgcccaa 900
gaatattgat cagagaaaat tgattccggt gaaggacgga aatgagagac taacaagttc 960
tggatttgcc tgttctcagt gctgtcaacc cctctatgtt tataagcttg aacaagtgaa 1020
tgacaagggt aagccccata caaattactt tggccgttgt aatgtctccg agcatgaacg 1080
tttgatattg ctctcgccgc ataaaccgga ggcaaatgac gagctagtaa cgtattcgtt 1140
ggggaagttc ggtcaaaggg cattggactt ttattcaatc cacgtaacaa gagaatcgaa 1200
ccatcctgta aagccgctag aacagatcgg tggcaatagc tgcgcaagtg gtcccgttgg 1260
taaggcttta tctgatgcct gtatgggagc agtagccagt ttccttacaa agtaccagga 1320
catcatcctc gaacaccaaa aggttataaa aaaaaacgaa aagagattgg caaatctaaa 1380
ggatatagca agtgcaaacg ggcttgcatt tcctaaaatc actcttccac cgcaaccgca 1440
tacaaaagaa gggattgaag cttataacaa tgttgttgct cagatagtga tctgggtaaa 1500
cctgaatctt tggcagaaac tcaaaattgg cagggatgag gcaaagccct tacagcggct 1560
taagggtttt ccgtccttcc ctcttgttga acgccaggcg aatgaggttg attggtggga 1620
tatggtctgt aatgtcaaaa agttgattaa cgaaaagaaa gaggacggga aggtcttctg 1680
gcaaaatctt gctggatata aaaggcagga agccttgctt ccatatcttt cgtctgaaga 1740
agaccgtaaa aaaggaaaaa agtttgcgcg ttatcagttt ggtgaccttt tgcttcacct 1800
tgaaaagaaa cacggtgaag attggggcaa agtttatgat gaggcatggg aaagaataga 1860
taaaaaagtt gaaggtctga gtaagcacat aaagttggag gaagaaagaa ggtctgaaga 1920
tgctcaatca aaggctgccc tcactgattg gctcagggca aaggcctctt ttgttattga 1980
agggctcaaa gaagctgata aggatgagtt ttgcaggtgt gagttaaagc ttcaaaagtg 2040
gtatggagat ttgagaggaa aaccatttgc tatagaagca gagaacagca ttttagatat 2100
aagcggattt tctaaacagt ataattgtgc atttatatgg cagaaagacg gcgtaaagaa 2160
gttaaatctt tatttaataa taaattactt caaaggtggt aagctacgct tcaaaaaaat 2220
caagccagaa gcttttgaag caaataggtt ttatacagta attaataaaa aaagcggtga 2280
gattgtgcct atggaggtca acttcaattt tgatgacccg aatttgataa ttctgccttt 2340
ggcctttgga aaaaggcagg ggagggagtt tatctggaac gacctattga gccttgagac 2400
gggttcattg aaactcgcca atggcagggt tattgaaaaa acgctctata acagaaggac 2460
gagacaggat gaaccagcac tttttgttgc cctgacattt gaaagaagag aggtgcttga 2520
ctcatcgaat ataaaaccga tgaatctgat aggaatagac cggggagaaa atatcccggc 2580
agtcatagca ttaacagacc cggaaggatg ccccttgtca agattcaaag attcattggg 2640
caatccaacg catattttgc gaataggaga aagttataag gaaaaacaac ggactattca 2700
ggctgctaaa gaagttgaac aaaggcgggc aggcggatat tcgagaaaat atgcatcaaa 2760
ggcgaagaat ctggcggacg atatggtaag aaatacagct cgtgacctct tatattatgc 2820
tgttactcaa gatgcaatgc tcatttttga aaatctttcc cgcggttttg gtagacaagg 2880
caagaggact tttatggcgg aaaggcagta cacgaggatg gaagactggc tgactgcaaa 2940
gcttgcctat gaaggtctgc catcaaaaac ctatctttca aagactctgg cacagtatac 3000
ctcaaagaca tgttctaatt gtggttttac aatcacaagt gcagattatg acagggtgct 3060
cgaaaagctc aagaagacgg ctactggatg gatgactaca atcaatggaa aagagttaaa 3120
agttgaagga cagataacat actataaccg gtataaaagg cagaatgtgg taaaagacct 3180
ctctgtagag ctggatagac tttcggaaga gtcggtaaat aatgatattt ctagttggac 3240
aaaaggccgc agtggtgaag ctttatctct gctaaaaaag agatttagtc acaggccggt 3300
gcaggaaaag tttgtttgcc tgaactgtgg ttttgaaacc catgcagacg aacaagcagc 3360
actgaatatt gcaaggtcgt ggctctttct ccgttctcaa gaatataaga agtatcaaac 3420
caataaaacg accggaaata ctgacaaaag ggcatttgtt gaaacatggc aatcctttta 3480
cagaaagaag ctcaaagaag tatggaaacc agccgtctga tattgcacat cagcacggta 3540
atggagtcaa tctattgtcc gcgcaatgca tggtatgcct ttgttggaga acggcgtaat 3600
atggctaaga gcatccactt tacagaggcc atacacgcgc acagggcggt ggataaatca 3660
tcgcagagaa gctgccctga ttgtaagcag gtaacaggcg tgtatcttta cagcaataag 3720
ctcggtttgg caggccgggc agaccttatc gagtggaggg atgggatacc gattcctatc 3780
gaaacaaaga cagggaaggt aagggatttt gagaacttcc acgttcagat tgggttacag 3840
gcaatttgcc ttgaagagat gtataatgtc aatataccag ttggtgaaat atttttctgt 3900
gaaacacgga gacggaaaga aattgttata gataaaaccc tgaaagtgcg ttgtgtagaa 3960
gttgttacaa atctgcgaga ctgcttcttg tcctttgata taagcaggtt tcccaaggtt 4020
gatgaccata ggtgtccgca gtgccagtat agtgaatcgt gtcttccttc aatacttggt 4080
tagaaaaata aaaggcttac tgatgaccgc tataaccgac aggataaccc tctatctcac 4140
gggtgatgaa ttcattttgg attgtcgtgg tcgggcattt ctcataaaaa aggacaatga 4200
agagaagggg cagaagattc ccgcaatgaa ggtaaaagat atcgtggtag ttggccgggt 4260
taccctcgat agccgtgtta ttagcctttg cagagaagaa tctataccga tacatttctt 4320
tagcggcaga tgggaatatc aagggagcct tcaatttgaa cccgtcaaaa atctgtttat 4380
tcgtcgggcg caaattcata agcattttga tccccacaaa aaacttgaaa ttgcaaaaag 4440
tatcgttgcc ggtaagatca aaaaccagca atcattactt gataaatata gacttggttt 4500
gagaatcgag tgtaccgaaa tcaacgccgt cactgattta gagaccttgc gtggaataga 4560
aggcgcaaca acaaggcagt attatggcaa tttttcggct atcttaaagc atccaagctt 4620
tgtttttgtg cgccgtacca agagacctcc tgaggatgaa atcaacgcca tgatgagcct 4680
tatctacacc ctcctgttca acgaaataca ttcgactgca ttactcgtcg gttttgaccc 4740
ggcctttggt tacttgcatg acgtctatta tggtcgtccc tctttaatat gcgatcttct 4800
ggaggagtgg cggccgttgg ctgaccgttt tgtgatcaat ttgataaata gaagggaagt 4860
ggatacagac gatttcagga aagaaactga ccaaaaaggt gtttggctga ataaggatgc 4920
ctatccaaaa gtaatcaaaa aatggcatca attctttaag gtagatgagc agaaaaccaa 4980
tttacttatc caatcaataa cgtatcagca cgcagttgag cggcaggtta ggttgtttag 5040
ccagcatatt caagatgata gggaatgtta taagcctata gagctttaaa atgcgacatc 5100
tcatttgtta tgatattgaa gatgataagg tcagggcacg gttagttaaa cttctggaag 5160
cctatggtgt tcggattcaa tattctgtct ttgagtttaa cctttcaaaa gcaaggtggg 5220
ctgatctaaa gctcaacctt aaagaaaaag gatttatgga tggctctata agtctggtaa 5280
tttatcctct ctcagaggag atatatgaac ggatagaaag gtacggaagc gctgctattt 5340
ggaatgaagg ggatatggtc tttgattgat tttaagcttg acgaaaggat ttgtgaatag 5400
taaattatta ctggcgcttt tatctcatta ctttgagagc catcaccagc gactatgtcg 5460
tatgggtaaa gcgcttattt atcggagagt tctggatgca aacccagagc tgttttttta 5520
gattcttata aattacataa gaagttcttt gaaaatctga tgttaaagct ttttgtgaga 5580
agaacaggtt tacagtgcgt aactctgcta aattattaaa ggtatcctcc gcaacttgta 5640
aaatattgaa aatacaattt ccagaagtca ttgaaaaatc tggatatgcg gggtttgaag 5700
atatctccga taaataagaa gcatcaaagt taatccccaa atagacgggc taaaatacgt 5760
atcgtttgaa gatatctccg ataaataaga agcatcaaag cttatatata tacaatcttt 5820
gcaggtttct gtgtttgaag atatctccga taaataagaa gcatcaaagt tatctaatct 5880
tgatgtcttt ctcaatacat tacgtttgaa gatatctccg ataaataaga agcatcaaag 5940
agccagaaga tatgcctgta aaatgggcaa tgtttgaaga tatctccgat aaataagaag 6000
catcaaagaa tattaatggt tcaccattgc catgttgatg gtgtttgaag atatctccga 6060
taaataagaa gcatcaaaga aataataggc gcataattcc acgatttcag tttgaagata 6120
tctccgataa ataagaagca tcaaagtatt aaatactcgt attgctgttc gattatgttt 6180
gaagatatct ccgataaata agaagcatca aagaacaaag cagaatatat tacacggaca 6240
aatcatgtga ttaggaagat aaaggctttg gggtagatat aatgagcttt acacgagtag 6300
attgcctttc cttgattcaa aagatttcag aagagatagg cgctttgtgc cttaaatccc 6360
cagaatcaac aattcagaga cacgtggaaa aacccagccc cataaaaaat cctttagact 6420
tagccccatt aattgagcat accttattga aaccggaggc aacccatagg gatataacga 6480
ggctttgcga tgaggcaagg cgattccatt ttcgtggcgt ctgtgtgaat cctgtctttg 6540
ttaaagaagt ccaaaaccaa ttagcaggaa cagattgttt gattgttact gttgtgggtt 6600
tcccactagg tgctaattta acagctacaa aggttgagga aacgaaacat gttataaatc 6660
taggtgcgaa tgaggtggat atggttattg cactcggtgc attgaaagag ggcaattaca 6720
aaactgtcta taatgacatc cgtgcggtcg ttaaatctgt agaatcaata cctgttaagg 6780
taattgtaga ggcaggactt ctgaatgaaa gagaaaagat agccgcttgt ctgttagcag 6840
aacgggctgg cgcatcgttt gttaaaacct ctactggttt tactgcacgt agtgcgacgg 6900
taggagatgt cagattaatg aaggcagtag taggagacag actcggcata aaagccgcag 6960
gtgggatacg tgattttcag actgcctgcg ctatggtgga ggcaggggca gtgcgtttgg 7020
gctgttcggc atcggtagca attgtgacag aacacatata aaaaagcatt gtgagatatt 7080
tttgtatata atgtttaaca atagaatttt ttaaatattt ctgtttgttt actattttgg 7140
caagtttaag tatgtatctt ttgttatttc ttcttcgtgc tgaacaagct atattgacca 7200
tctttaaaac agtatgtccc tataacattg ggagcttctg gatttttaaa ggatatgaca 7260
aatttaagac gtgaataacc agcggtttca gatgaaggtt ctacctctac gtaggtcaag 7320
tgcgccttat gctcaaggct aatgatattc cactgaattc ccttattatc gggaaactca 7380
gcttctgcca acctggtaat attgtctttc agaaacgatt ccctctttgc ctcttcgctg 7440
acaaaggttg tttcctgttt tggttgcaca atgtcgggct ttgcctcgct agtctgcgtt 7500
atttcttcag tagctttctg caaatcttcg gacttagtct gttcactgat tacggctgtt 7560
tcctcttttg gtggtgcgat atcagtattt acttcgccgg tctgtgttgt ttcttcaaga 7620
ccttcctgtg tattttcagc cattgccttt tctatttcct cgatgccttt cttgattccc 7680
tctcccacag ccttgccaag acctttcacc atctcaccca ctgcgcctcc aaacattgac 7740
atcattgtct tgtcagcatc aaccttccac tgtccgcctt cttttacaag aatagtctgc 7800
atctggactt caaattccgt tgtctcgtta tg 7832
<210> 53
<211> 10
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 53
aaaaaaaaaa 10
<210> 54
<211> 25
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 54
gtttacacac tccctctcat agggt 25
<210> 55
<211> 25
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 55
gtttacacac tccctctcat gaggt 25
<210> 56
<211> 25
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 56
ttttacatac cccctctcat gggat 25
<210> 57
<211> 25
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 57
gtttacacac tccctctcat ggggg 25
<210> 58
<211> 10
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 58
aaaaaaaaaa 10
<210> 59
<211> 10
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 59
aaaaaaaaaa 10
<210> 60
<211> 10
<212> DNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 60
aaaaaaaaaa 10
<210> 61
<211> 43
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (24)..(43)
<223> n is a, c, g, or u
<400> 61
ccgauaagua aaacgcauca aagnnnnnnn nnnnnnnnnn nnn 43
<210> 62
<211> 70
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (38)..(70)
<223> n is a, c, g, or u
<400> 62
auuugaaggu aucuccgaua aguaaaacgc aucaaagnnn nnnnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn 70
<210> 63
<211> 174
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (142)..(174)
<223> n is a, c, g, or u
<400> 63
aaguaguaaa uuacaucugg cgcguuuauu ccauuacuuu ggagccaguc ccagcgacua 60
ugucguaugg acgaagcgcu uauuuaucgg agauagcucc gaaaauuuga agguaucucc 120
gauaaguaaa acgcaucaaa gnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnn 174
<210> 64
<211> 128
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (1)..(20)
<223> n is a, c, g, or u
<400> 64
nnnnnnnnnn nnnnnnnnnn cuuugaugcg uuuuacuuau cgggaaaucu ccgauaaaua 60
agcgcuucgu ccauacgaca uagucgcugg gacuggcucc aaaguaaugg aauaaacgcg 120
ccagaugu 128
<210> 65
<211> 171
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (1)..(30)
<223> n is a, c, g, or u
<400> 65
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn cuuugaugcg uuuuacuuau cggagauacc 60
uucaaaugaa aggagcuauc uccgauaaau aagcgcuucg uccauacgac auagucgcug 120
ggacuggcuc caaaguaaug gaauaaacgc gccagaugua auuuacuacu u 171
<210> 66
<211> 65
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 66
uuccauuacu uuggagccag ucccagcgac uaugucguau ggacgaagcg cuuauuuauc 60
ggaga 65
<210> 67
<211> 46
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 67
gucccagcga cuaugucgua uggacgaagc gcuuauuuau cggaga 46
<210> 68
<211> 21
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 68
gaagcgcuua uuuaucggag a 21
<210> 69
<211> 46
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (27)..(46)
<223> n is a, c, g, or u
<400> 69
ucuccgauaa auaagaagca ucaaagnnnn nnnnnnnnnn nnnnnn 46
<210> 70
<211> 10
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 70
aaaaaaaaaa 10
<210> 71
<211> 949
<212> PRT
<213> Unknown
<220>
<223> Synthetic sequence
<400> 71
Met Arg Asp Ser Ile Thr Ala Pro Arg Tyr Ser Ser Ala Leu Ala Ala
1 5 10 15
Arg Ile Lys Glu Phe Asn Ser Ala Phe Lys Leu Gly Ile Asp Leu Gly
20 25 30
Thr Lys Thr Gly Gly Val Ala Leu Val Lys Asp Asn Lys Val Leu Leu
35 40 45
Ala Lys Thr Phe Leu Asp Tyr His Lys Gln Thr Leu Glu Glu Arg Arg
50 55 60
Ile His Arg Arg Asn Arg Arg Ser Arg Leu Ala Arg Arg Lys Arg Ile
65 70 75 80
Ala Arg Leu Arg Ser Trp Ile Leu Arg Gln Lys Ile Tyr Gly Lys Gln
85 90 95
Leu Pro Asp Pro Tyr Lys Ile Lys Lys Met Gln Leu Pro Asn Gly Val
100 105 110
Arg Lys Gly Glu Asn Trp Ile Asp Leu Val Val Ser Gly Arg Asp Leu
115 120 125
Ser Pro Glu Ala Phe Val Arg Ala Ile Thr Leu Ile Phe Gln Lys Arg
130 135 140
Gly Gln Arg Tyr Glu Glu Val Ala Lys Glu Ile Glu Glu Met Ser Tyr
145 150 155 160
Lys Glu Phe Ser Thr His Ile Lys Ala Leu Thr Ser Val Thr Glu Glu
165 170 175
Glu Phe Thr Ala Leu Ala Ala Glu Ile Glu Arg Arg Gln Asp Val Val
180 185 190
Asp Thr Asp Lys Glu Ala Glu Arg Tyr Thr Gln Leu Ser Glu Leu Leu
195 200 205
Ser Lys Val Ser Glu Ser Lys Ser Glu Ser Lys Asp Arg Ala Gln Arg
210 215 220
Lys Glu Asp Leu Gly Lys Val Val Asn Ala Phe Cys Ser Ala His Arg
225 230 235 240
Ile Glu Asp Lys Asp Lys Trp Cys Lys Glu Leu Met Lys Leu Leu Asp
245 250 255
Arg Pro Val Arg His Ala Arg Phe Leu Asn Lys Val Leu Ile Arg Cys
260 265 270
Asn Ile Cys Asp Arg Ala Thr Pro Lys Lys Ser Arg Pro Asp Val Arg
275 280 285
Glu Leu Leu Tyr Phe Asp Thr Val Arg Asn Phe Leu Lys Ala Gly Arg
290 295 300
Val Glu Gln Asn Pro Asp Val Ile Ser Tyr Tyr Lys Lys Ile Tyr Met
305 310 315 320
Asp Ala Glu Val Ile Arg Val Lys Ile Leu Asn Lys Glu Lys Leu Thr
325 330 335
Asp Glu Asp Lys Lys Gln Lys Arg Lys Leu Ala Ser Glu Leu Asn Arg
340 345 350
Tyr Lys Asn Lys Glu Tyr Val Thr Asp Ala Gln Lys Lys Met Gln Glu
355 360 365
Gln Leu Lys Thr Leu Leu Phe Met Lys Leu Thr Gly Arg Ser Arg Tyr
370 375 380
Cys Met Ala His Leu Lys Glu Arg Ala Ala Gly Lys Asp Val Glu Glu
385 390 395 400
Gly Leu His Gly Val Val Gln Lys Arg His Asp Arg Asn Ile Ala Gln
405 410 415
Arg Asn His Asp Leu Arg Val Ile Asn Leu Ile Glu Ser Leu Leu Phe
420 425 430
Asp Gln Asn Lys Ser Leu Ser Asp Ala Ile Arg Lys Asn Gly Leu Met
435 440 445
Tyr Val Thr Ile Glu Ala Pro Glu Pro Lys Thr Lys His Ala Lys Lys
450 455 460
Gly Ala Ala Val Val Arg Asp Pro Arg Lys Leu Lys Glu Lys Leu Phe
465 470 475 480
Asp Asp Gln Asn Gly Val Cys Ile Tyr Thr Gly Leu Gln Leu Asp Lys
485 490 495
Leu Glu Ile Ser Lys Tyr Glu Lys Asp His Ile Phe Pro Asp Ser Arg
500 505 510
Asp Gly Pro Ser Ile Arg Asp Asn Leu Val Leu Thr Thr Lys Glu Ile
515 520 525
Asn Ser Asp Lys Gly Asp Arg Thr Pro Trp Glu Trp Met His Asp Asn
530 535 540
Pro Glu Lys Trp Lys Ala Phe Glu Arg Arg Val Ala Glu Phe Tyr Lys
545 550 555 560
Lys Gly Arg Ile Asn Glu Arg Lys Arg Glu Leu Leu Leu Asn Lys Gly
565 570 575
Thr Glu Tyr Pro Gly Asp Asn Pro Thr Glu Leu Ala Arg Gly Gly Ala
580 585 590
Arg Val Asn Asn Phe Ile Thr Glu Phe Asn Asp Arg Leu Lys Thr His
595 600 605
Gly Val Gln Glu Leu Gln Thr Ile Phe Glu Arg Asn Lys Pro Ile Val
610 615 620
Gln Val Val Arg Gly Glu Glu Thr Gln Arg Leu Arg Arg Gln Trp Asn
625 630 635 640
Ala Leu Asn Gln Asn Phe Ile Pro Leu Lys Asp Arg Ala Met Ser Phe
645 650 655
Asn His Ala Glu Asp Ala Ala Ile Ala Ala Ser Met Pro Pro Lys Phe
660 665 670
Trp Arg Glu Gln Ile Tyr Arg Thr Ala Trp His Phe Gly Pro Ser Gly
675 680 685
Asn Glu Arg Pro Asp Phe Ala Leu Ala Glu Leu Ala Pro Gln Trp Asn
690 695 700
Asp Phe Phe Met Thr Lys Gly Gly Pro Ile Ile Ala Val Leu Gly Lys
705 710 715 720
Thr Lys Tyr Ser Trp Lys His Ser Ile Ile Asp Asp Thr Ile Tyr Lys
725 730 735
Pro Phe Ser Lys Ser Ala Tyr Tyr Val Gly Ile Tyr Lys Lys Pro Asn
740 745 750
Ala Ile Thr Ser Asn Ala Ile Lys Val Leu Arg Pro Lys Leu Leu Asn
755 760 765
Gly Glu His Thr Met Ser Lys Asn Ala Lys Tyr Tyr His Gln Lys Ile
770 775 780
Gly Asn Glu Arg Phe Leu Met Lys Ser Gln Lys Gly Gly Ser Ile Ile
785 790 795 800
Thr Val Lys Pro His Asp Gly Pro Glu Lys Val Leu Gln Ile Ser Pro
805 810 815
Thr Tyr Glu Cys Ala Val Leu Thr Lys His Asp Gly Lys Ile Ile Val
820 825 830
Lys Phe Lys Pro Ile Lys Pro Leu Arg Asp Met Tyr Ala Arg Gly Val
835 840 845
Ile Lys Ala Met Asp Lys Glu Leu Glu Thr Ser Leu Ser Ser Met Ser
850 855 860
Lys His Ala Lys Tyr Lys Glu Leu His Thr His Asp Ile Ile Tyr Leu
865 870 875 880
Pro Ala Thr Lys Lys His Val Asp Gly Tyr Phe Ile Ile Thr Lys Leu
885 890 895
Ser Ala Lys His Gly Ile Lys Ala Leu Pro Glu Ser Met Val Lys Val
900 905 910
Lys Tyr Thr Gln Ile Gly Ser Glu Asn Asn Ser Glu Val Lys Leu Thr
915 920 925
Lys Pro Lys Pro Glu Ile Thr Leu Asp Ser Glu Asp Ile Thr Asn Ile
930 935 940
Tyr Asn Phe Thr Arg
945
<210> 72
<211> 967
<212> PRT
<213> Unknown
<220>
<223> Synthetic sequence
<400> 72
Met Leu Gly Ser Ser Arg Tyr Leu Arg Tyr Asn Leu Thr Ser Phe Glu
1 5 10 15
Gly Lys Glu Pro Phe Leu Ile Met Gly Tyr Tyr Lys Glu Tyr Asn Lys
20 25 30
Glu Leu Ser Ser Lys Ala Gln Lys Glu Phe Asn Asp Gln Ile Ser Glu
35 40 45
Phe Asn Ser Tyr Tyr Lys Leu Gly Ile Asp Leu Gly Asp Lys Thr Gly
50 55 60
Ile Ala Ile Val Lys Gly Asn Lys Ile Ile Leu Ala Lys Thr Leu Ile
65 70 75 80
Asp Leu His Ser Gln Lys Leu Asp Lys Arg Arg Glu Ala Arg Arg Asn
85 90 95
Arg Arg Thr Arg Leu Ser Arg Lys Lys Arg Leu Ala Arg Leu Arg Ser
100 105 110
Trp Val Met Arg Gln Lys Val Gly Asn Gln Arg Leu Pro Asp Pro Tyr
115 120 125
Lys Ile Met His Asp Asn Lys Tyr Trp Ser Ile Tyr Asn Lys Ser Asn
130 135 140
Ser Ala Asn Lys Lys Asn Trp Ile Asp Leu Leu Ile His Ser Asn Ser
145 150 155 160
Leu Ser Ala Asp Asp Phe Val Arg Gly Leu Thr Ile Ile Phe Arg Lys
165 170 175
Arg Gly Tyr Leu Ala Phe Lys Tyr Leu Ser Arg Leu Ser Asp Lys Glu
180 185 190
Phe Glu Lys Tyr Ile Asp Asn Leu Lys Pro Pro Ile Ser Lys Tyr Glu
195 200 205
Tyr Asp Glu Asp Leu Glu Glu Leu Ser Ser Arg Val Glu Asn Gly Glu
210 215 220
Ile Glu Glu Lys Lys Phe Glu Gly Leu Lys Asn Lys Leu Asp Lys Ile
225 230 235 240
Asp Lys Glu Ser Lys Asp Phe Gln Val Lys Gln Arg Glu Glu Val Lys
245 250 255
Lys Glu Leu Glu Asp Leu Val Asp Leu Phe Ala Lys Ser Val Asp Asn
260 265 270
Lys Ile Asp Lys Ala Arg Trp Lys Arg Glu Leu Asn Asn Leu Leu Asp
275 280 285
Lys Lys Val Arg Lys Ile Arg Phe Asp Asn Arg Phe Ile Leu Lys Cys
290 295 300
Lys Ile Lys Gly Cys Asn Lys Asn Thr Pro Lys Lys Glu Lys Val Arg
305 310 315 320
Asp Phe Glu Leu Lys Met Val Leu Asn Asn Ala Arg Ser Asp Tyr Gln
325 330 335
Ile Ser Asp Glu Asp Leu Asn Ser Phe Arg Asn Glu Val Ile Asn Ile
340 345 350
Phe Gln Lys Lys Glu Asn Leu Lys Lys Gly Glu Leu Lys Gly Val Thr
355 360 365
Ile Glu Asp Leu Arg Lys Gln Leu Asn Lys Thr Phe Asn Lys Ala Lys
370 375 380
Ile Lys Lys Gly Ile Arg Glu Gln Ile Arg Ser Ile Val Phe Glu Lys
385 390 395 400
Ile Ser Gly Arg Ser Lys Phe Cys Lys Glu His Leu Lys Glu Phe Ser
405 410 415
Glu Lys Pro Ala Pro Ser Asp Arg Ile Asn Tyr Gly Val Asn Ser Ala
420 425 430
Arg Glu Gln His Asp Phe Arg Val Leu Asn Phe Ile Asp Lys Lys Ile
435 440 445
Phe Lys Asp Lys Leu Ile Asp Pro Ser Lys Leu Arg Tyr Ile Thr Ile
450 455 460
Glu Ser Pro Glu Pro Glu Thr Glu Lys Leu Glu Lys Gly Gln Ile Ser
465 470 475 480
Glu Lys Ser Phe Glu Thr Leu Lys Glu Lys Leu Ala Lys Glu Thr Gly
485 490 495
Gly Ile Asp Ile Tyr Thr Gly Glu Lys Leu Lys Lys Asp Phe Glu Ile
500 505 510
Glu His Ile Phe Pro Arg Ala Arg Met Gly Pro Ser Ile Arg Glu Asn
515 520 525
Glu Val Ala Ser Asn Leu Glu Thr Asn Lys Glu Lys Ala Asp Arg Thr
530 535 540
Pro Trp Glu Trp Phe Gly Gln Asp Glu Lys Arg Trp Ser Glu Phe Glu
545 550 555 560
Lys Arg Val Asn Ser Leu Tyr Ser Lys Lys Lys Ile Ser Glu Arg Lys
565 570 575
Arg Glu Ile Leu Leu Asn Lys Ser Asn Glu Tyr Pro Gly Leu Asn Pro
580 585 590
Thr Glu Leu Ser Arg Ile Pro Ser Thr Leu Ser Asp Phe Val Glu Ser
595 600 605
Ile Arg Lys Met Phe Val Lys Tyr Gly Tyr Glu Glu Pro Gln Thr Leu
610 615 620
Val Gln Lys Gly Lys Pro Ile Ile Gln Val Val Arg Gly Arg Asp Thr
625 630 635 640
Gln Ala Leu Arg Trp Arg Trp His Ala Leu Asp Ser Asn Ile Ile Pro
645 650 655
Glu Lys Asp Arg Lys Ser Ser Phe Asn His Ala Glu Asp Ala Val Ile
660 665 670
Ala Ala Cys Met Pro Pro Tyr Tyr Leu Arg Gln Lys Ile Phe Arg Glu
675 680 685
Glu Ala Lys Ile Lys Arg Lys Val Ser Asn Lys Glu Lys Glu Val Thr
690 695 700
Arg Pro Asp Met Pro Thr Lys Lys Ile Ala Pro Asn Trp Ser Glu Phe
705 710 715 720
Met Lys Thr Arg Asn Glu Pro Val Ile Glu Val Ile Gly Lys Val Lys
725 730 735
Pro Ser Trp Lys Asn Ser Ile Met Asp Gln Thr Phe Tyr Lys Tyr Leu
740 745 750
Leu Lys Pro Phe Lys Asp Asn Leu Ile Lys Ile Pro Asn Val Lys Asn
755 760 765
Thr Tyr Lys Trp Ile Gly Val Asn Gly Gln Thr Asp Ser Leu Ser Leu
770 775 780
Pro Ser Lys Val Leu Ser Ile Ser Asn Lys Lys Val Asp Ser Ser Thr
785 790 795 800
Val Leu Leu Val His Asp Lys Lys Gly Gly Lys Arg Asn Trp Val Pro
805 810 815
Lys Ser Ile Gly Gly Leu Leu Val Tyr Ile Thr Pro Lys Asp Gly Pro
820 825 830
Lys Arg Ile Val Gln Val Lys Pro Ala Thr Gln Gly Leu Leu Ile Tyr
835 840 845
Arg Asn Glu Asp Gly Arg Val Asp Ala Val Arg Glu Phe Ile Asn Pro
850 855 860
Val Ile Glu Met Tyr Asn Asn Gly Lys Leu Ala Phe Val Glu Lys Glu
865 870 875 880
Asn Glu Glu Glu Leu Leu Lys Tyr Phe Asn Leu Leu Glu Lys Gly Gln
885 890 895
Lys Phe Glu Arg Ile Arg Arg Tyr Asp Met Ile Thr Tyr Asn Ser Lys
900 905 910
Phe Tyr Tyr Val Thr Lys Ile Asn Lys Asn His Arg Val Thr Ile Gln
915 920 925
Glu Glu Ser Lys Ile Lys Ala Glu Ser Asp Lys Val Lys Ser Ser Ser
930 935 940
Gly Lys Glu Tyr Thr Arg Lys Glu Thr Glu Glu Leu Ser Leu Gln Lys
945 950 955 960
Leu Ala Glu Leu Ile Ser Ile
965
<210> 73
<211> 56
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (1)..(20)
<223> n is a, c, g, or u
<400> 73
nnnnnnnnnn nnnnnnnnnn cuuacaaucg acacuuaaau aauuugcaug uguaag 56
<210> 74
<211> 56
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (1)..(20)
<223> n is a, c, g, or u
<400> 74
nnnnnnnnnn nnnnnnnnnn cuuucaauaa acaaauaaau cuuaguaaua uguaac 56
<210> 75
<211> 36
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 75
cuuacaaucg acacuuaaau aauuugcaug uguaag 36
<210> 76
<211> 36
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 76
cuuucaauaa acaaauaaau cuuaguaaua uguaac 36
<210> 77
<211> 180
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 77
ggcauggacc auauccaggu guugauugua aacaccuagc ggggaaauua uauauguuug 60
uaauaucuuc acuauccaaa guuaucucug guuuugguuu gguaagcuuc acuucacuau 120
uguuuucacu cccaauuuga guaugguugg ggguaaggau gcuuucgggg agugcuuuua 180
<210> 78
<211> 85
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 78
aacuggcuau ugcuaauauu auuuguuuau ugaaagaagc cuagacguua ggguucgcgu 60
gcauguaggc uccagcaggu accuc 85
<210> 79
<211> 204
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (1)..(20)
<223> n is a, c, g, or u
<400> 79
nnnnnnnnnn nnnnnnnnnn cuuacaaucg acacuuaaac agguguugau uguaaacacc 60
uagcggggaa auuauauaug uuuguaauau cuucacuauc caaaguuauc ucugguuuug 120
guuugguaag cuucacuuca cuauuguuuu cacucccaau uugaguaugg uuggggguaa 180
ggaugcuuuc ggggagugcu uuua 204
<210> 80
<211> 109
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (1)..(20)
<223> n is a, c, g, or u
<400> 80
nnnnnnnnnn nnnnnnnnnn cuuucaauaa acaaauaaaa acuuauuugu uuauugaaag 60
aagccuagac guuaggguuc gcgugcaugu aggcuccagc agguaccuc 109
<210> 81
<211> 184
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 81
cuuacaaucg acacuuaaac agguguugau uguaaacacc uagcggggaa auuauauaug 60
uuuguaauau cuucacuauc caaaguuauc ucugguuuug guuugguaag cuucacuuca 120
cuauuguuuu cacucccaau uugaguaugg uuggggguaa ggaugcuuuc ggggagugcu 180
uuua 184
<210> 82
<211> 89
<212> RNA
<213> Artificial sequence
<220>
<223> Synthetic sequence
<400> 82
cuuucaauaa acaaauaaaa acuuauuugu uuauugaaag aagccuagac guuaggguuc 60
gcgugcaugu aggcuccagc agguaccuc 89
<210> 83
<211> 84
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 83
Met Ala Ser Met Ile Ser Ser Ser Ala Val Thr Thr Val Ser Arg Ala
1 5 10 15
Ser Arg Gly Gln Ser Ala Ala Met Ala Pro Phe Gly Gly Leu Lys Ser
20 25 30
Met Thr Gly Phe Pro Val Arg Lys Val Asn Thr Asp Ile Thr Ser Ile
35 40 45
Thr Ser Asn Gly Gly Arg Val Lys Cys Met Gln Val Trp Pro Pro Ile
50 55 60
Gly Lys Lys Lys Phe Glu Thr Leu Ser Tyr Leu Pro Pro Leu Thr Arg
65 70 75 80
Asp Ser Arg Ala
<210> 84
<211> 57
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 84
Met Ala Ser Met Ile Ser Ser Ser Ala Val Thr Thr Val Ser Arg Ala
1 5 10 15
Ser Arg Gly Gln Ser Ala Ala Met Ala Pro Phe Gly Gly Leu Lys Ser
20 25 30
Met Thr Gly Phe Pro Val Arg Lys Val Asn Thr Asp Ile Thr Ser Ile
35 40 45
Thr Ser Asn Gly Gly Arg Val Lys Ser
50 55
<210> 85
<211> 85
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 85
Met Ala Ser Ser Met Leu Ser Ser Ala Thr Met Val Ala Ser Pro Ala
1 5 10 15
Gln Ala Thr Met Val Ala Pro Phe Asn Gly Leu Lys Ser Ser Ala Ala
20 25 30
Phe Pro Ala Thr Arg Lys Ala Asn Asn Asp Ile Thr Ser Ile Thr Ser
35 40 45
Asn Gly Gly Arg Val Asn Cys Met Gln Val Trp Pro Pro Ile Glu Lys
50 55 60
Lys Lys Phe Glu Thr Leu Ser Tyr Leu Pro Asp Leu Thr Asp Ser Gly
65 70 75 80
Gly Arg Val Asn Cys
85
<210> 86
<211> 76
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 86
Met Ala Gln Val Ser Arg Ile Cys Asn Gly Val Gln Asn Pro Ser Leu
1 5 10 15
Ile Ser Asn Leu Ser Lys Ser Ser Gln Arg Lys Ser Pro Leu Ser Val
20 25 30
Ser Leu Lys Thr Gln Gln His Pro Arg Ala Tyr Pro Ile Ser Ser Ser
35 40 45
Trp Gly Leu Lys Lys Ser Gly Met Thr Leu Ile Gly Ser Glu Leu Arg
50 55 60
Pro Leu Lys Val Met Ser Ser Val Ser Thr Ala Cys
65 70 75
<210> 87
<211> 76
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 87
Met Ala Gln Val Ser Arg Ile Cys Asn Gly Val Trp Asn Pro Ser Leu
1 5 10 15
Ile Ser Asn Leu Ser Lys Ser Ser Gln Arg Lys Ser Pro Leu Ser Val
20 25 30
Ser Leu Lys Thr Gln Gln His Pro Arg Ala Tyr Pro Ile Ser Ser Ser
35 40 45
Trp Gly Leu Lys Lys Ser Gly Met Thr Leu Ile Gly Ser Glu Leu Arg
50 55 60
Pro Leu Lys Val Met Ser Ser Val Ser Thr Ala Cys
65 70 75
<210> 88
<211> 72
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 88
Met Ala Gln Ile Asn Asn Met Ala Gln Gly Ile Gln Thr Leu Asn Pro
1 5 10 15
Asn Ser Asn Phe His Lys Pro Gln Val Pro Lys Ser Ser Ser Phe Leu
20 25 30
Val Phe Gly Ser Lys Lys Leu Lys Asn Ser Ala Asn Ser Met Leu Val
35 40 45
Leu Lys Lys Asp Ser Ile Phe Met Gln Leu Phe Cys Ser Phe Arg Ile
50 55 60
Ser Ala Ser Val Ala Thr Ala Cys
65 70
<210> 89
<211> 69
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 89
Met Ala Ala Leu Val Thr Ser Gln Leu Ala Thr Ser Gly Thr Val Leu
1 5 10 15
Ser Val Thr Asp Arg Phe Arg Arg Pro Gly Phe Gln Gly Leu Arg Pro
20 25 30
Arg Asn Pro Ala Asp Ala Ala Leu Gly Met Arg Thr Val Gly Ala Ser
35 40 45
Ala Ala Pro Lys Gln Ser Arg Lys Pro His Arg Phe Asp Arg Arg Cys
50 55 60
Leu Ser Met Val Val
65
<210> 90
<211> 77
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 90
Met Ala Ala Leu Thr Thr Ser Gln Leu Ala Thr Ser Ala Thr Gly Phe
1 5 10 15
Gly Ile Ala Asp Arg Ser Ala Pro Ser Ser Leu Leu Arg His Gly Phe
20 25 30
Gln Gly Leu Lys Pro Arg Ser Pro Ala Gly Gly Asp Ala Thr Ser Leu
35 40 45
Ser Val Thr Thr Ser Ala Arg Ala Thr Pro Lys Gln Gln Arg Ser Val
50 55 60
Gln Arg Gly Ser Arg Arg Phe Pro Ser Val Val Val Cys
65 70 75
<210> 91
<211> 57
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 91
Met Ala Ser Ser Val Leu Ser Ser Ala Ala Val Ala Thr Arg Ser Asn
1 5 10 15
Val Ala Gln Ala Asn Met Val Ala Pro Phe Thr Gly Leu Lys Ser Ala
20 25 30
Ala Ser Phe Pro Val Ser Arg Lys Gln Asn Leu Asp Ile Thr Ser Ile
35 40 45
Ala Ser Asn Gly Gly Arg Val Gln Cys
50 55
<210> 92
<211> 65
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 92
Met Glu Ser Leu Ala Ala Thr Ser Val Phe Ala Pro Ser Arg Val Ala
1 5 10 15
Val Pro Ala Ala Arg Ala Leu Val Arg Ala Gly Thr Val Val Pro Thr
20 25 30
Arg Arg Thr Ser Ser Thr Ser Gly Thr Ser Gly Val Lys Cys Ser Ala
35 40 45
Ala Val Thr Pro Gln Ala Ser Pro Val Ile Ser Arg Ser Ala Ala Ala
50 55 60
Ala
65
<210> 93
<211> 72
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 93
Met Gly Ala Ala Ala Thr Ser Met Gln Ser Leu Lys Phe Ser Asn Arg
1 5 10 15
Leu Val Pro Pro Ser Arg Arg Leu Ser Pro Val Pro Asn Asn Val Thr
20 25 30
Cys Asn Asn Leu Pro Lys Ser Ala Ala Pro Val Arg Thr Val Lys Cys
35 40 45
Cys Ala Ser Ser Trp Asn Ser Thr Ile Asn Gly Ala Ala Ala Thr Thr
50 55 60
Asn Gly Ala Ser Ala Ala Ser Ser
65 70
<210> 94
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (8)..(8)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (11)..(11)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (15)..(15)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (19)..(19)
<223> Xaa can be any naturally occurring amino acid
<400> 94
Gly Leu Phe Xaa Ala Leu Leu Xaa Leu Leu Xaa Ser Leu Trp Xaa Leu
1 5 10 15
Leu Leu Xaa Ala
20
<210> 95
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 95
Gly Leu Phe His Ala Leu Leu His Leu Leu His Ser Leu Trp His Leu
1 5 10 15
Leu Leu His Ala
20
<210> 96
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 96
Pro Lys Lys Lys Arg Lys Val
1 5
<210> 97
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 97
Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1 5 10 15
<210> 98
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 98
Pro Ala Ala Lys Arg Val Lys Leu Asp
1 5
<210> 99
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 99
Arg Gln Arg Arg Asn Glu Leu Lys Arg Ser Pro
1 5 10
<210> 100
<211> 38
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 100
Asn Gln Ser Ser Asn Phe Gly Pro Met Lys Gly Gly Asn Phe Gly Gly
1 5 10 15
Arg Ser Ser Gly Pro Tyr Gly Gly Gly Gly Gln Tyr Phe Ala Lys Pro
20 25 30
Arg Asn Gln Gly Gly Tyr
35
<210> 101
<211> 42
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 101
Arg Met Arg Ile Glx Phe Lys Asn Lys Gly Lys Asp Thr Ala Glu Leu
1 5 10 15
Arg Arg Arg Arg Val Glu Val Ser Val Glu Leu Arg Lys Ala Lys Lys
20 25 30
Asp Glu Gln Ile Leu Lys Arg Arg Asn Val
35 40
<210> 102
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 102
Val Ser Arg Lys Arg Pro Arg Pro
1 5
<210> 103
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 103
Pro Pro Lys Lys Ala Arg Glu Asp
1 5
<210> 104
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 104
Pro Gln Pro Lys Lys Lys Pro Leu
1 5
<210> 105
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 105
Ser Ala Leu Ile Lys Lys Lys Lys Lys Met Ala Pro
1 5 10
<210> 106
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 106
Asp Arg Leu Arg Arg
1 5
<210> 107
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 107
Pro Lys Gln Lys Lys Arg Lys
1 5
<210> 108
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 108
Arg Lys Leu Lys Lys Lys Ile Lys Lys Leu
1 5 10
<210> 109
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 109
Arg Glu Lys Lys Lys Phe Leu Lys Arg Arg
1 5 10
<210> 110
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 110
Lys Arg Lys Gly Asp Glu Val Asp Gly Val Asp Glu Val Ala Lys Lys
1 5 10 15
Lys Ser Lys Lys
20
<210> 111
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 111
Arg Lys Cys Leu Gln Ala Gly Met Asn Leu Glu Ala Arg Lys Thr Lys
1 5 10 15
Lys
<210> 112
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 112
Tyr Gly Arg Lys Lys Arg Arg Gln Arg Arg Arg
1 5 10
<210> 113
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 113
Arg Arg Gln Arg Arg Thr Ser Lys Leu Met Lys Arg
1 5 10
<210> 114
<211> 27
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 114
Gly Trp Thr Leu Asn Ser Ala Gly Tyr Leu Leu Gly Lys Ile Asn Leu
1 5 10 15
Lys Ala Leu Ala Ala Leu Ala Lys Lys Ile Leu
20 25
<210> 115
<211> 33
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 115
Lys Ala Leu Ala Trp Glu Ala Lys Leu Ala Lys Ala Leu Ala Lys Ala
1 5 10 15
Leu Ala Lys His Leu Ala Lys Ala Leu Ala Lys Ala Leu Lys Cys Glu
20 25 30
Ala
<210> 116
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 116
Arg Gln Ile Lys Ile Trp Phe Gln Asn Arg Arg Met Lys Trp Lys Lys
1 5 10 15
<210> 117
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 117
Tyr Gly Arg Lys Lys Arg Arg Gln Arg Arg Arg
1 5 10
<210> 118
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 118
Arg Lys Lys Arg Arg Gln Arg Arg Arg
1 5
<210> 119
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 119
Tyr Gly Arg Lys Lys Arg Arg Gln Arg Arg Arg
1 5 10
<210> 120
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 120
Arg Lys Lys Arg Arg Gln Arg Arg
1 5
<210> 121
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 121
Tyr Ala Arg Ala Ala Ala Arg Gln Ala Arg Ala
1 5 10
<210> 122
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 122
Thr His Arg Leu Pro Arg Arg Arg Arg Arg Arg
1 5 10
<210> 123
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 123
Gly Gly Arg Arg Ala Arg Arg Arg Arg Arg Arg
1 5 10
<210> 124
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 124
Gly Ser Gly Gly Ser
1 5
<210> 125
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 125
Gly Gly Ser Gly Gly Ser
1 5
<210> 126
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 126
Gly Gly Gly Ser
1
<210> 127
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 127
Gly Gly Ser Gly
1
<210> 128
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 128
Gly Gly Ser Gly Gly
1 5
<210> 129
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 129
Gly Ser Gly Ser Gly
1 5
<210> 130
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 130
Gly Ser Gly Gly Gly
1 5
<210> 131
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 131
Gly Gly Gly Ser Gly
1 5
<210> 132
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 132
Gly Ser Ser Ser Gly
1 5
<210> 133
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 133
Arg Gln Ile Lys Ile Trp Phe Gln Asn Arg Arg Met Lys Trp Lys Lys
1 5 10 15
<210> 134
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic sequence
<400> 134
Tyr Gly Arg Lys Lys Arg Arg Gln Arg Arg Arg
1 5 10
<210> 135
<211> 1067
<212> PRT
<213> Unknown
<220>
<223> sequence from metagenomic data - from unidentified Lindow
bacteria
<400> 135
Val Ser Ala Thr Arg Lys Gly Gln Gly Ser Gly Ala Pro Ile Ser Arg
1 5 10 15
Thr Glu Ala Pro Gln Ile Ala Leu Met Ala Thr Glu Leu Glu Gln Arg
20 25 30
Leu Asn Glu Phe Leu Asp Ser Leu Arg Leu Gly Ile Asp Phe Gly Glu
35 40 45
Asp Tyr Gly Gly Ile Ala Leu Val Gln Ala Asn Arg Val Leu His Ala
50 55 60
Glu Thr Phe Val Asp Phe His Gln Ala Thr Leu Lys Asp Arg Arg Arg
65 70 75 80
Asn Arg Arg Gly Arg Arg Thr Arg His Ala Arg Lys Met Arg Leu Ala
85 90 95
Arg Leu Arg Ser Trp Ile Leu Arg Gln Lys Leu Pro Gly Gly Gln Arg
100 105 110
Leu Pro Asp Pro Tyr Gly Val Met His Trp Pro Phe Lys Thr Lys Lys
115 120 125
Gly His Thr Ile Lys Thr Gly Leu Ala Ser Arg Gln Asp Gly Lys Arg
130 135 140
Thr Ile Ile Gln Lys Cys Lys Ile Gly Thr Ala Thr Pro Glu Glu Phe
145 150 155 160
Val Cys Ser Leu Thr Leu Leu Phe Gln Lys Arg Gly Phe Val Trp Glu
165 170 175
Gly Ser Asp Leu Cys Glu Leu Ser Asp Gln Glu Leu Ala Glu Glu Leu
180 185 190
Met Thr Val Arg Ile Thr Glu Ala Val Ala Ala Ala Ile Lys Glu Glu
195 200 205
Ile Glu Arg Arg Lys Lys Glu Pro Glu Asp Asn Lys Glu Gly Glu Ile
210 215 220
Glu Asn Leu Glu Thr Val Leu Cys Asp Ala Val Lys Arg Ala Arg Ser
225 230 235 240
Pro Arg Thr Pro Glu His Arg Ser Ile Val Glu Ser Asp Leu Lys Asp
245 250 255
Ile Val Asp Gly Trp Thr Arg Lys Asn Cys Pro Gln Met Thr Asp Met
260 265 270
Trp Lys Lys Glu Leu Ser Cys Leu Leu Asn Lys His Val Arg Pro Ala
275 280 285
Arg Phe Glu Asn Arg Ile Val Ala Gly Cys Ser Trp Cys Gly Lys Met
290 295 300
Val Pro Arg Lys Ser Lys Val Arg Glu Leu Ala Tyr Lys Val Val Val
305 310 315 320
Lys Asn Ile Arg Val Glu Asp Phe Thr Ser Arg Gln Pro Leu Thr Ala
325 330 335
Gln Glu Ala Glu Tyr Phe Ser Gln Leu Trp Val Asp Lys Glu Ala Lys
340 345 350
Pro Pro Ala Arg Thr Ala Ile Glu Asn Lys Leu Lys Lys Leu Lys Ala
355 360 365
Ser Pro Lys Met Ala Asn Gln Leu Tyr Glu Leu Leu Ala Pro Ser Glu
370 375 380
Pro Lys Gly His Thr Asn Leu Cys Gln Gln His Leu Glu Met Ala Ala
385 390 395 400
Arg Gly Ala Phe Met Cys Asn Arg His His Ala Ile Cys Glu Asn Asn
405 410 415
Asn Gly Asp His Gln Thr Ile Asp Ser Val Lys Glu Gly Arg Lys Arg
420 425 430
Ala Gly Pro Arg Asn Pro Cys Arg Glu Asp Arg Asp Arg Arg Met Ile
435 440 445
Arg Arg Leu Glu Gln Ile Leu Phe Glu Thr Pro Gly Lys Pro Gly Lys
450 455 460
Pro Ser His Ser Ile Pro Arg Leu Ile Thr Ile Glu Phe Pro Lys Pro
465 470 475 480
Asn Thr Ala Gln Thr Ala Gly Cys Pro His Cys Lys Glu Lys Leu Ser
485 490 495
Leu Asp Ala Arg Val Arg Trp Lys Met Ala Arg Pro Met Lys Leu Glu
500 505 510
Ala Ser Asn Asp Ser Thr Pro Phe Phe Cys Pro Ser Cys Ala Ala Gly
515 520 525
Ile Lys Ile Thr Leu Tyr Lys Lys Met Arg Ile Lys Glu Lys Glu Ile
530 535 540
Val Gln Lys Tyr Ser Pro Lys Asp Thr Asp Val Leu Val Arg Lys Thr
545 550 555 560
Ala Ala Gly Gly Leu Lys Lys Leu Lys Tyr Asp Met Tyr Leu Lys Glu
565 570 575
Thr Asp Gly Thr Cys Val Tyr Cys Gly Thr Ser Ile Gly Ser Gly Gln
580 585 590
Ile Asp His Ile Phe Pro Gln Ser Arg Gly Gly Pro Asn Ile Asp Tyr
595 600 605
Asn Leu Ile Ser Cys Cys Arg Thr Cys Asn Gly Asn Leu Lys Lys Asn
610 615 620
Lys Ser Pro Trp Glu Trp Phe Gly Asn Ile Asp Gln Arg Trp Arg Glu
625 630 635 640
Phe Glu Asp Arg Val Lys Lys Leu Pro Ala Pro Gln Arg Lys Lys Ala
645 650 655
Ile Leu Leu Ser Arg Glu Ser Ala Tyr Pro Glu Asn Pro Thr Ala Leu
660 665 670
Ala Arg Val Gly Ala Arg Thr Lys Glu Phe Ile Gly Arg Ile Lys Gln
675 680 685
Met Leu Leu Ala Asn Gly Val Lys Glu Asn Glu Ile Ala Asp Asn Tyr
690 695 700
Glu Lys Asp Lys Ile Val Ile Gln Thr Ile Asp Gly Trp Met Thr Ser
705 710 715 720
Arg Leu Arg Gly Cys Trp Arg Thr Phe Pro Asp Gly Thr Ala Asn Phe
725 730 735
Pro Pro Lys Asn Asp Ala Asp Lys Arg Asn His Ala Gln Asp Ala Val
740 745 750
Leu Ile Ala Ala Cys Pro Pro His Thr Trp Arg Glu Arg Ile Phe Thr
755 760 765
Trp Lys Pro Glu Asn Pro Tyr Phe Ser Val Leu Gln Lys Ile Ala Pro
770 775 780
Arg Trp Lys Asp His Gln Ala Thr Met Lys Ile Leu Gly Arg Tyr Phe
785 790 795 800
Pro Arg Trp His Asn Gln Asn Ser Asp Ile Gln Phe Val His Gln His
805 810 815
Lys Thr Gln Asn Gly Thr Ser Tyr Thr Met Arg Asp Thr Val Glu Ser
820 825 830
Ile Asp Val Gly Thr Asp Lys Lys Gly Gly Ser Ile Glu Arg Ile Tyr
835 840 845
Ser Lys Ser Phe Arg Asp Phe Phe Ser Arg Thr Phe Lys Ser Leu Gly
850 855 860
Ile Lys Met Ala Met Asn Glu Ile Pro Lys Leu Lys Ser Gln Trp Leu
865 870 875 880
Asn Glu Arg Arg Ala Ala Trp Met Lys Lys Asn Pro Ala Thr Pro Val
885 890 895
Pro Asn Gln Arg Glu Arg Ala Trp Glu Ala Ser Phe Pro Arg Arg Leu
900 905 910
Gln Phe Asp Met Gly Tyr Gly Glu Asp Val Ala Glu Val Asn Pro Lys
915 920 925
Asn Gly Pro Ser Arg Phe Val Arg Ala Gln Pro Val Asn Asp Arg Ile
930 935 940
Glu Val Trp Thr Asn Asp Val Arg Gln Ala Gln Ile Arg Thr Val Lys
945 950 955 960
Asn Arg Ile Leu Phe Arg His Ile Gln Asp Asn Ser Pro Gln Gly Arg
965 970 975
Thr Leu Glu Arg Ile Phe Arg Arg Asn Asp Met Ile Gln Leu Asp Ala
980 985 990
Val Gln Lys Arg Gly Arg Lys Gly Ile Thr Gly Lys Ser Tyr Glu Ala
995 1000 1005
Gly Glu Tyr Met Val Val Lys Ile Glu Lys Gly Gly Lys Phe Thr
1010 1015 1020
Ala Val Pro Ala His Arg Gly Lys Gly Arg Glu Asn Gln Arg Gln
1025 1030 1035
Val Ser Gln Arg Glu Ile Ala Lys Leu Cys Gly Val Ser Leu Ser
1040 1045 1050
Pro Lys Arg Arg Lys Pro Ser Arg Ser Thr Ser Glu Ser Gly
1055 1060 1065
<210> 136
<211> 990
<212> PRT
<213> Unknown
<220>
<223> sequence from metagenomic data - from unidentified Delta
proteobacteria
<400> 136
Val Ala Ala Ala Ser Leu Ile Leu Gln Arg Gly Gly Leu Val Ala Leu
1 5 10 15
His Pro Arg Leu Glu Arg Lys Ile Lys Glu Phe Leu Pro Thr Tyr Arg
20 25 30
Leu Gly Val Asp Leu Gly Glu Ala Ala Gly Gly Leu Ala Leu Ile His
35 40 45
Asn Asn Asn Ile Leu His Ala Glu Thr Phe Thr Asp Phe His Glu Ala
50 55 60
Thr Leu Glu Thr Lys Arg Ala Leu Arg Arg Gly Arg Arg Thr Arg His
65 70 75 80
Ala Lys Lys Met Arg Leu Ala Arg Leu Arg Ser Trp Ile Leu Arg Gln
85 90 95
Cys Ile Pro Ala His Val Thr Gly Ala Glu Ile Lys Asp Ser Tyr Ser
100 105 110
Arg Leu Pro Asp Pro Tyr Arg Leu Met Lys Asp Lys Lys Tyr Gln Thr
115 120 125
Leu Pro Gly Phe Tyr Glu Val Lys Gly Gln Asn Pro Glu Lys Ser Pro
130 135 140
Thr Trp Ile Asp Lys Ala Lys Ala Gly Glu Val Asp Ala Glu Gly Phe
145 150 155 160
Val Ile Ala Leu Thr His Ile Leu Gln Lys Arg Gly Tyr Lys Tyr Asp
165 170 175
Gly Lys Glu Phe Ser Asp Tyr Asp Asp Ser Arg Leu Ile Asp Phe Ile
180 185 190
Asp Ser Cys Ala Met Leu Ala Glu Ala Pro Glu Met Arg Lys Ala Leu
195 200 205
Glu Asp Glu Ile Met Arg Arg Glu Val Gly Glu Lys Glu Lys Pro Lys
210 215 220
Leu His Glu Ala Phe Asp Asn Ala Leu Asn Arg Gln Arg Glu Arg Lys
225 230 235 240
Lys Ala Leu Pro Arg Gln Val Arg Glu Lys Asp Met Glu Asp Met Val
245 250 255
Asp Val Phe Gly Arg Arg Trp Gln Leu Ser Gln Glu Ile Ile Ala Asn
260 265 270
Trp Lys Ser Gln Leu Thr Gly Leu Leu Asn Lys Val Val Arg Glu Ala
275 280 285
Arg Tyr Asp Asn Arg Leu Lys Ser Gly Cys Ser Trp Cys Gly Lys Lys
290 295 300
Thr Pro Arg Leu Ala Lys Pro Glu Ile Arg Glu Leu Ala Phe Glu Ala
305 310 315 320
Ala Val Gly Asn Leu Arg Ile Arg Glu Arg Asp Gly Arg Asp Arg Pro
325 330 335
Ile Ser Asp Glu Glu Arg Asn Pro Leu Arg Gly Trp Phe Gln Arg Arg
340 345 350
Arg Glu Asn His Asp Tyr Ser Arg Ala Thr Lys Asn Thr Pro Ile Glu
355 360 365
Glu Arg Ala Pro Ser Glu Asp Asn Ile Arg Thr Tyr Leu Glu Gln Ile
370 375 380
Gly Val Lys Lys Ala Trp Ile Arg Lys Lys Lys Gly Lys Glu Lys Trp
385 390 395 400
Lys Phe Asp Phe Ala Met Leu Pro Gln Leu Asp Asn Leu Ile Asn Lys
405 410 415
Glu Ala Arg Lys Gly Arg Ala Arg Leu Cys Val Glu His Met Arg Met
420 425 430
Gln Ala Glu Gly Lys Thr Met Lys Asp Ala Asp Val Asp Trp Gln Ser
435 440 445
Met Arg Lys Arg Asn Ala Pro Asn Pro Arg Arg Glu Gln His Asp Ala
450 455 460
Arg Val Leu Lys Arg Ile Glu Arg Leu Ile Phe Asn Arg Gly Lys Lys
465 470 475 480
Gly Thr Asp Ala Trp Arg His Gly Pro Ile Ala Val Ile Thr Leu Glu
485 490 495
Val Pro Met Pro Val Asp Leu Glu Arg Ala Arg Glu Lys Glu Gln Val
500 505 510
Glu Arg Lys Pro Leu Asn Leu Arg Gln Arg Leu His Ala Glu Thr Glu
515 520 525
Gly Val Cys Ile Tyr Cys Gly Glu Asn Val His Asp Arg Thr Met His
530 535 540
Leu Glu His Ile Val Pro Gln Ala Lys Gly Gly Pro Asp Val Gln Met
545 550 555 560
Asn Arg Ile Ala Ser Cys Pro Lys Cys Asn Ala Asp Arg Asp Thr Gly
565 570 575
Lys Lys Asp Met Leu Pro Ser Glu Trp Leu Thr Gly Asp Lys Trp Asn
580 585 590
Val Phe Lys Ser Arg Val Met Ser Leu Asn Leu Pro Pro Leu Lys Lys
595 600 605
Gln Leu Leu Leu Leu Glu Pro Gly Ser Lys Tyr Pro Asn Asp Pro Thr
610 615 620
Pro Leu Ala Arg Val Ser Ala Arg Trp Arg Ala Phe Ala Ala Asp Ile
625 630 635 640
Met Trp Leu Phe Asp Glu Tyr Ser Val Pro Val Pro Thr Leu Asn Tyr
645 650 655
Glu Lys Asp Lys Pro His Ile Gln Val Val Arg Gly Asn Leu Thr Ser
660 665 670
Arg Leu Arg Arg Asp Trp Arg Trp Lys Asp His Glu Ala Thr Val Glu
675 680 685
Asn Phe Pro Asp Lys Arg Arg Thr Asp Leu Tyr Asn His Ala Gln Asp
690 695 700
Ala Ala Ile Leu Ala Ala Ile Pro Pro His Thr Trp Gln Glu Gln Ile
705 710 715 720
Phe Ser Asp Met Ala Val Arg Pro Cys Ala Lys Lys Asp Glu Gln Gly
725 730 735
Asn Ile Leu Lys Asn Glu Lys Glu Met Arg Pro Arg Pro Gly Ile Ala
740 745 750
Ala Leu Ala Leu Ala Pro Glu Trp Ala Asp Tyr Glu Arg Thr Gln Lys
755 760 765
Glu Leu Lys Arg Pro Met Val His Thr Leu Gly Lys Leu Lys Ala Thr
770 775 780
Trp Arg Arg Gln Ile Met Asp Leu Ser Phe Tyr Gln Asn Pro Thr Asp
785 790 795 800
Asn Asp Gly Pro Leu Phe Ile Arg Lys Val Asp Ala Lys Thr Gly Lys
805 810 815
Arg Glu Thr Lys Glu Val Gln Lys Gly Gly Leu Val Val Gln Val Pro
820 825 830
His Tyr Asp Gly Thr Ser Gly Lys Arg Lys Val Gln Ile Lys Pro Ile
835 840 845
Gln Ser Asn Ala Ile Ile Leu Trp His Asp Pro Ser Gly Arg Lys Asp
850 855 860
Asn Leu Asn Ile Ser Ile Glu Arg Pro Ala Ala Ile Lys Lys Phe Val
865 870 875 880
Lys His Pro Val Asp Pro Pro Ile Ala Ser Asp Ala Ile Ile Leu Gly
885 890 895
Arg Ile Glu Arg Ala Ser Thr Leu Trp Leu Arg Glu Gly Lys Gly Thr
900 905 910
Val Glu Leu Lys Ala Asp Lys Lys Ser Val Arg Ser Ser Val Val Met
915 920 925
Pro Glu Gly Ile Tyr Arg Val Lys Glu Leu Gly Ser Asn Gly Val Ile
930 935 940
Val Val Gln Glu Asn Ala Val Ser Lys Glu Leu Ala Asn Lys Leu Gly
945 950 955 960
Ile Ser Asp Asp Gln Phe Ser Lys Val Pro Glu Arg Ala Leu Gly Lys
965 970 975
Lys Glu Leu Ala Glu Tyr Phe Lys Gly Asn Gln Arg Ser Gly
980 985 990
Claims (131)
- 조성물로서,
a) CasX 폴리펩타이드, 또는 상기 CasX 폴리펩타이드를 암호화하는 핵산 분자; 및
b) CasX 가이드 RNA, 또는 상기 CasX 가이드 RNA를 암호화하는 하나 이상의 DNA 분자
를 포함하는 조성물. - 제1항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 50% 이상의 동일성을 갖는 아미노산 서열을 포함하는, 조성물.
- 제1항 또는 제2항에 있어서, 상기 CasX 가이드 RNA는 단일 가이드 RNA인, 조성물.
- 제1항 또는 제2항에 있어서, 상기 CasX 가이드 RNA는 이중-가이드 RNA인, 조성물.
- 제1항 내지 제4항 중 어느 한 항에 있어서, 상기 조성물은 지질을 포함하는, 조성물.
- 제1항 내지 제4항 중 어느 한 항에 있어서, a) 및 b)는 리포좀 내에 있는, 조성물.
- 제1항 내지 제4항 중 어느 한 항에 있어서, a) 및 b)는 입자 내에 있는, 조성물.
- 제1항 내지 제7항 중 어느 한 항에 있어서, 완충제, 뉴클레아제 저해제, 및 프로테아제 저해제 중 하나 이상을 포함하는, 조성물.
- 제1항 내지 제8항 중 어느 한 항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 85% 이상의 동일성을 갖는 아미노산 서열을 포함하는, 조성물.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 상기 CasX 폴리펩타이드는 이중-가닥 표적 핵산 분자의 하나의 가닥만을 절단할 수 있는 틈내기효소인, 조성물.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 상기 CasX 폴리펩타이드는 촉매적으로 비활성인 CasX 폴리펩타이드(dCasX)인, 조성물.
- 제10항 또는 제11항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1의 D672, E769 및 D935로부터 선택된 것에 대응하는 위치에서 하나 이상의 돌연변이를 포함하는, 조성물.
- 제1항 내지 제12항 중 어느 한 항에 있어서, DNA 공여자 주형을 더 포함하는, 조성물.
- CasX 단일 가이드 RNA 분자로서,
a) 표적 핵산에 혼성화하는 가이드 서열, 및 듀플렉스-형성 세그먼트를 포함하는 표적자 서열; 및
b) 상기 표적자 서열의 상기 듀플렉스-형성 세그먼트와 혼성화하여 CasX 폴리펩타이드에 결합할 수 있는 이중 가닥 RNA(dsRNA) 듀플렉스를 형성하는 활성체 서열
을 포함하는, CasX 단일 가이드 RNA 분자. - 제14항에 있어서, 상기 가이드 서열은 길이가 19 내지 30개의 뉴클레오타이드를 갖는, CasX 단일 가이드 RNA 분자.
- 제14항 또는 제15항의 CasX 단일 가이드 RNA 분자를 암호화하는 뉴클레오타이드 서열을 포함하는 DNA 분자.
- 제16항에 있어서, 상기 CasX 단일 가이드 RNA를 암호화하는 상기 뉴클레오타이드 서열은 프로모터에 작동 가능하게 연결된, DNA 분자.
- 제17항에 있어서, 상기 프로모터는 진핵 세포에서 기능성인, DNA 분자.
- 제18항에 있어서, 상기 프로모터는 식물 세포, 진균 세포, 동물 세포, 무척추동물의 세포, 파리 세포, 척추동물의 세포, 포유류 세포, 영장류 세포, 비-인간 영장류 세포 및 인간 세포 중 하나 이상에서 기능성인, DNA 분자.
- 제17항 내지 제19항 중 어느 한 항에 있어서, 상기 프로모터는 구성적 프로모터, 유도성 프로모터, 세포 유형-특이적 프로모터, 및 조직-특이적 프로모터 중 하나 이상인, DNA 분자.
- 제16항 내지 제20항 중 어느 한 항에 있어서, 상기 DNA 분자는 재조합 발현 벡터인, DNA 분자.
- 제21항에 있어서, 상기 재조합 발현 벡터는 재조합 아데노연관 바이러스 벡터, 재조합 레트로바이러스 벡터 또는 재조합 렌티바이러스 벡터인, DNA 분자.
- 제17항에 있어서, 상기 프로모터는 원핵 세포에서 기능성인, DNA 분자.
- 이종성 폴리펩타이드에 융합된 CasX 폴리펩타이드를 포함하는, CasX 융합 폴리펩타이드.
- 제24항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 50% 이상의 동일성을 갖는 아미노산 서열을 포함하는, CasX 융합 폴리펩타이드.
- 제24항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 85% 이상의 동일성을 갖는 아미노산 서열을 포함하는, CasX 융합 폴리펩타이드.
- 제24항 내지 제26항 중 어느 한 항에 있어서, 상기 CasX 폴리펩타이드는 이중-가닥 표적 핵산 분자의 하나의 가닥만을 절단할 수 있는 틈내기효소인, CasX 융합 폴리펩타이드.
- 제24항 내지 제27항 중 어느 한 항에 있어서, 상기 CasX 폴리펩타이드는 촉매적으로 비활성인 CasX 폴리펩타이드(dCasX)인, CasX 융합 폴리펩타이드.
- 제27항 또는 제28항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1의 D672, E769 및 D935로부터 선택된 것에 대응하는 위치에서 하나 이상의 돌연변이를 포함하는, CasX 융합 폴리펩타이드.
- 제24항 내지 제29항 중 어느 한 항에 있어서, 상기 이종성 폴리펩타이드는 상기 CasX 폴리펩타이드의 N-말단 및/또는 C-말단에 융합된, CasX 융합 폴리펩타이드.
- 제24항 내지 제30항 중 어느 한 항에 있어서, NLS를 포함하는, CasX 융합 폴리펩타이드.
- 제24항 내지 제31항 중 어느 한 항에 있어서, 상기 이종성 폴리펩타이드는 표적 세포 또는 표적 세포 유형 상의 세포 표면 모이어티에 대한 결합을 제공하는 표적화 폴리펩타이드인, CasX 융합 폴리펩타이드.
- 제24항 내지 제31항 중 어느 한 항에 있어서, 상기 이종성 폴리펩타이드는 표적 DNA를 변형시키는 효소 활성을 나타내는, CasX 융합 폴리펩타이드.
- 제33항에 있어서, 상기 이종성 폴리펩타이드는 뉴클레아제 활성, 메틸트랜스퍼라제 활성, 데메틸라제 활성, DNA 수선 활성, DNA 손상 활성, 탈아미노화 활성, 디스무타제 활성, 알킬화 활성, 탈퓨린화 활성, 산화 활성, 피리미딘 이량체 형성 활성, 인테그라제 활성, 트랜스포사제 활성, 재조합효소 활성, 중합효소 활성, 리가제 활성, 헬리카제 활성, 광분해효소 활성 및 글리코실라제 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, CasX 융합 폴리펩타이드.
- 제34항에 있어서, 상기 이종성 폴리펩타이드는 뉴클레아제 활성, 메틸트랜스퍼라제 활성, 데메틸라제 활성, 탈아미노화 활성, 탈퓨린화 활성, 인테그라제 활성, 트랜스포사제 활성 및 재조합효소 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, CasX 융합 폴리펩타이드.
- 제24항 내지 제31항 중 어느 한 항에 있어서, 상기 이종성 폴리펩타이드는 표적 핵산과 회합된 표적 폴리펩타이드를 변형시키는 효소 활성을 나타내는, CasX 융합 폴리펩타이드.
- 제36항에 있어서, 상기 이종성 폴리펩타이드는 히스톤 변형 활성을 나타내는, CasX 융합 폴리펩타이드.
- 제36항 또는 제37항에 있어서, 상기 이종성 폴리펩타이드는 메틸트랜스퍼라제 활성, 데메틸라제 활성, 아세틸트랜스퍼라제 활성, 데아세틸라제 활성, 키나제 활성, 포스파타제 활성, 유비퀴틴 리가제 활성, 데유비퀴틴화 활성, 아데닐화 활성, 탈아데닐화 활성, 수모일화(SUMOylating) 활성, 탈수모일화(deSUMOylating) 활성, 리보실화 활성, 탈리보실화 활성, 미리스토일화 활성, 탈미리스토일화 활성, 글리코실화 활성(예를 들어, O-GlcNAc 트랜스퍼라제로부터의 활성) 및 탈글리코실화 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, CasX 융합 폴리펩타이드.
- 제38항에 있어서, 상기 이종성 폴리펩타이드는 메틸트랜스퍼라제 활성, 데메틸라제 활성, 아세틸트랜스퍼라제 활성 및 데아세틸라제 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, CasX 융합 폴리펩타이드.
- 제24항 내지 제31항 중 어느 한 항에 있어서, 상기 이종성 폴리펩타이드는 엔도솜 탈출 폴리펩타이드인, CasX 융합 폴리펩타이드.
- 제40항에 있어서, 상기 엔도솜 탈출 폴리펩타이드는 GLFXALLXLLXSLWXLLLXA(서열번호 94) 및 GLFHALLHLLHSLWHLLLHA(서열번호 95)로부터 선택된 아미노산 서열을 포함하되, 각각의 X는 라이신, 히스티딘 및 알기닌으로부터 독립적으로 선택된, CasX 융합 폴리펩타이드.
- 제24항 내지 제31항 중 어느 한 항에 있어서, 상기 이종성 폴리펩타이드는 엽록체 수송 펩타이드인, CasX 융합 폴리펩타이드.
- 제42항에 있어서, 상기 엽록체 수송 펩타이드는,
으로부터 선택된 아미노산 서열을 포함하는, CasX 융합 폴리펩타이드.
- 제24항 내지 제31항 중 어느 한 항에 있어서, 상기 이종성 폴리펩타이드는 전사를 증가 또는 감소시키는 단백질인, CasX 융합 폴리펩타이드.
- 제44항에 있어서, 상기 이종성 폴리펩타이드는 전사 리프레서 도메인인, CasX 융합 폴리펩타이드.
- 제44항에 있어서, 상기 이종성 폴리펩타이드는 전사 활성화 도메인인, CasX 융합 폴리펩타이드.
- 제24항 내지 제31항 중 어느 한 항에 있어서, 상기 이종성 폴리펩타이드는 단백질 결합 도메인인, CasX 융합 폴리펩타이드.
- 제24항 내지 제47항 중 어느 한 항의 CasX 융합 폴리펩타이드를 암호화하는 핵산 분자.
- 제48항에 있어서, 상기 CasX 융합 폴리펩타이드를 암호화하는 상기 뉴클레오타이드 서열은 프로모터에 작동 가능하게 연결된, 핵산 분자.
- 제49항에 있어서, 상기 프로모터는 진핵 세포에서 기능성인, 핵산 분자.
- 제50항에 있어서, 상기 프로모터는 식물 세포, 진균 세포, 동물 세포, 무척추동물의 세포, 파리 세포, 척추동물의 세포, 포유류 세포, 영장류 세포, 비-인간 영장류 세포 및 인간 세포 중 하나 이상에서 기능성인, 핵산.
- 제49항 내지 제51항 중 어느 한 항에 있어서, 상기 프로모터는 구성적 프로모터, 유도성 프로모터, 세포 유형-특이적 프로모터, 및 조직-특이적 프로모터 중 하나 이상인, 핵산 분자.
- 제48항 내지 제52항 중 어느 한 항에 있어서, 상기 DNA 분자는 재조합 발현 벡터인, 핵산 분자.
- 제53항에 있어서, 상기 재조합 발현 벡터는 재조합 아데노연관 바이러스 벡터, 재조합 레트로바이러스 벡터 또는 재조합 렌티바이러스 벡터인, 핵산 분자.
- 제49항에 있어서, 상기 프로모터는 원핵 세포에서 기능성인, 핵산 분자.
- 제48항에 있어서, 상기 핵산 분자는 mRNA인, 핵산 분자.
- 하나 이상의 핵산 분자로서,
(a) 활성체 RNA 및 표적자 RNA를 포함하는 CasX 가이드 RNA; 및
(b) CasX 폴리펩타이드
를 암호화하는, 하나 이상의 핵산 분자. - 제57항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 50% 이상의 동일성을 갖는 아미노산 서열을 포함하는, 하나 이상의 핵산 분자.
- 제57항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 85% 이상의 동일성을 갖는 아미노산 서열을 포함하는, 하나 이상의 핵산 분자.
- 제57항 내지 제59항 중 어느 한 항에 있어서, 상기 CasX 가이드 RNA는 단일 가이드 RNA인, 하나 이상의 핵산 분자.
- 제57항 내지 제59항 중 어느 한 항에 있어서, 상기 CasX 가이드 RNA는 이중-가이드 RNA인, 하나 이상의 핵산 분자.
- 제61항에 있어서, 상기 하나 이상의 핵산 분자는 상기 활성체를 암호화하는 제1 뉴클레오타이드 서열 및 상기 표적자를 암호화화는 제2 뉴클레오타이드 서열을 포함하되, 상기 제1 및 제2 뉴클레오타이드 서열은 상이한 DNA 분자 상에 존재하는, 하나 이상의 핵산 분자.
- 제57항 내지 제62항 중 어느 한 항에 있어서, 상기 하나 이상의 핵산 분자는 프로모터에 작동 가능하게 연결된 상기 CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는, 하나 이상의 핵산 분자.
- 제63항에 있어서, 상기 프로모터는 진핵 세포에서 기능성인, 하나 이상의 핵산 분자.
- 제64항에 있어서, 상기 프로모터는 식물 세포, 진균 세포, 동물 세포, 무척추동물의 세포, 파리 세포, 척추동물의 세포, 포유류 세포, 영장류 세포, 비-인간 영장류 세포 및 인간 세포 중 하나 이상에서 기능성인, 하나 이상의 핵산 분자.
- 제63항 내지 제65항 중 어느 한 항에 있어서, 상기 프로모터는 구성적 프로모터, 유도성 프로모터, 세포 유형-특이적 프로모터, 및 조직-특이적 프로모터 중 하나 이상인, 하나 이상의 핵산 분자.
- 제57항 내지 제66항 중 어느 한 항에 있어서, 상기 하나 이상의 핵산 분자는 하나 이상의 재조합 발현 벡터인, 하나 이상의 핵산 분자.
- 제67항에 있어서, 상기 하나 이상의 재조합 발현 벡터는 하나 이상의 아데노연관 바이러스 벡터, 하나 이상의 재조합 레트로바이러스 벡터, 또는 하나 이상의 재조합 렌티바이러스 벡터로부터 선택된, 하나 이상의 핵산 분자.
- 제63항에 있어서, 상기 프로모터는 원핵 세포에서 기능성인, 하나 이상의 핵산 분자.
- 진핵 세포로서,
a) CasX 폴리펩타이드, 또는 상기 CasX 폴리펩타이드를 암호화하는 핵산 분자,
b) CasX 융합 폴리펩타이드, 또는 상기 CasX 융합 폴리펩타이드를 암호화하는 핵산 분자, 및
c) CasX 가이드 RNA, 또는 상기 CasX 가이드 RNA를 암호화하는 핵산 분자
중 하나 이상을 포함하는, 진핵 세포. - 제70항에 있어서, 상기 CasX 폴리펩타이드를 암호화하는 핵산 분자를 포함하되, 상기 핵산 분자는 상기 세포의 상기 게놈 DNA 내로 통합된, 진핵 세포.
- 제70항 또는 제71항에 있어서, 상기 진핵 세포는 식물 세포, 포유류 세포, 곤충 세포, 거미류 세포, 진균 세포, 조류 세포, 파충류 세포, 양서류 세포, 무척추동물 세포, 마우스 세포, 래트 세포, 영장류 세포, 비-인간 영장류 세포, 또는 인간 세포인, 진핵 세포.
- CasX 융합 폴리펩타이드, 또는 상기 CasX 융합 폴리펩타이드를 암호화하는 핵산 분자를 포함하는 세포.
- 제73항에 있어서, 상기 세포는 원핵 세포인, 세포.
- 제73항 또는 제74항에 있어서, 상기 CasX 융합 폴리펩타이드를 암호화하는 핵산 분자를 포함하되, 상기 핵산 분자는 상기 세포의 상기 게놈 DNA 내로 통합된, 세포.
- 표적 핵산의 변형 방법으로서, 상기 표적 핵산을
a) CasX 폴리펩타이드; 및
b) 상기 표적 핵산의 표적 서열에 혼성화하는 가이드 서열을 포함하는 CasX 가이드 RNA
와 접촉시키는 단계를 포함하되,
상기 접촉시키는 단계는 상기 CasX 폴리펩타이드에 의해 상기 표적 핵산의 변형을 초래하는, 표적 핵산의 변형 방법. - 제76항에 있어서, 상기 변형은 상기 표적 핵산의 절단인, 표적 핵산의 변형 방법.
- 제76항 또는 제77항에 있어서, 상기 표적 핵산은 이중 가닥 DNA, 단일 가닥 DNA, RNA, 게놈 DNA, 및 염색체외 DNA로부터 선택된, 표적 핵산의 변형 방법.
- 제76항 내지 제78항 중 어느 한 항에 있어서, 상기 접촉시키는 단계는 세포 외부의 시험관내에서 일어나는, 방법.
- 제76항 내지 제78항 중 어느 한 항에 있어서, 상기 접촉시키는 단계는 배양물 내 세포의 내부에서 일어나는, 표적 핵산의 변형 방법.
- 제76항 내지 제78항 중 어느 한 항에 있어서, 상기 접촉시키는 단계는 생체내 세포의 내부에서 일어나는, 표적 핵산의 변형 방법.
- 제80항 또는 제81항에 있어서, 상기 세포는 진핵 세포인, 표적 핵산의 변형 방법.
- 제82항에 있어서, 상기 세포는 식물 세포, 진균 세포, 포유류 세포, 파충류 세포, 곤충 세포, 조류 세포, 어류 세포, 기생충 세포, 절지동물 세포, 무척추동물의 세포, 척추동물의 세포, 설치류 세포, 마우스 세포, 래트 세포, 영장류 세포, 비-인간 영장류 세포, 및 인간 세포로부터 선택된, 표적 핵산의 변형 방법.
- 제80항 또는 제81항에 있어서, 상기 세포는 원핵 세포인, 표적 핵산의 변형 방법.
- 제76항 내지 제84항 중 어느 한 항에 있어서, 상기 접촉시키는 단계는 게놈 편집을 초래하는, 표적 핵산의 변형 방법.
- 제76항 내지 제85항 중 어느 한 항에 있어서, 상기 접촉시키는 단계는 세포 내로: (a) 상기 CasX 폴리펩타이드, 또는 상기 CasX 폴리펩타이드를 암호화하는 핵산 분자, 및 (b) 상기 CasX 가이드 RNA, 또는 상기 CasX 가이드 RNA를 암호화하는 핵산 분자를 도입하는 것을 포함하는, 표적 핵산의 변형 방법.
- 제86항에 있어서, 상기 접촉시키는 단계는 DNA 공여자 주형을 상기 세포 내로 도입하는 것을 더 포함하는, 표적 핵산의 변형 방법.
- 제76항 내지 제87항 중 어느 한 항에 있어서, 상기 CasX 가이드 RNA는 단일 가이드 RNA인, 표적 핵산의 변형 방법.
- 제76항 내지 제87항 중 어느 한 항에 있어서, 상기 CasX 가이드 RNA는 이중 가이드 RNA인, 표적 핵산의 변형 방법.
- 표적 DNA로부터 전사를 조절하거나, 표적 핵산을 변형시키거나, 또는 표적 핵산과 회합된 단백질을 변형시키는 방법으로서, 상기 표적 핵산을,
a) 이종성 폴리펩타이드에 융합된 CasX 폴리펩타이드를 포함하는, CasX 융합 폴리펩타이드; 및
b) 상기 표적 핵산의 표적 서열에 혼성화하는 가이드 서열을 포함하는 CasX 가이드 RNA
와 접촉시키는 단계를 포함하는, 방법. - 제90항에 있어서, 상기 CasX 가이드 RNA는 단일 가이드 RNA인, 방법.
- 제90항에 있어서, 상기 CasX 가이드 RNA는 이중 가이드 RNA인, 방법.
- 제90항 내지 제92항 중 어느 한 항에 있어서, 상기 변형은 상기 표적 핵산의 절단이 아닌, 방법.
- 제90항 내지 제93항 중 어느 한 항에 있어서, 상기 표적 핵산은 이중 가닥 DNA, 단일 가닥 DNA, RNA, 게놈 DNA, 및 염색체외 DNA로부터 선택된, 방법.
- 제90항 내지 제94항 중 어느 한 항에 있어서, 상기 접촉시키는 단계는 세포 외부의 시험관내에서 일어나는, 방법.
- 제90항 내지 제94항 중 어느 한 항에 있어서, 상기 접촉시키는 단계는 배양물 내 세포의 내부에서 일어나는, 방법.
- 제90항 내지 제94항 중 어느 한 항에 있어서, 상기 접촉시키는 단계는 생체내 세포의 내부에서 일어나는, 방법.
- 제96항 또는 제97항에 있어서, 상기 세포는 진핵 세포인, 방법.
- 제98항에 있어서, 상기 세포는 식물 세포, 진균 세포, 포유류 세포, 파충류 세포, 곤충 세포, 조류 세포, 어류 세포, 기생충 세포, 절지동물 세포, 무척추동물의 세포, 척추동물의 세포, 설치류 세포, 마우스 세포, 래트 세포, 영장류 세포, 비-인간 영장류 세포, 및 인간 세포로부터 선택된, 방법.
- 제96항 또는 제97항에 있어서, 상기 세포는 원핵 세포인, 방법.
- 제90항 내지 제100항 중 어느 한 항에 있어서, 상기 접촉시키는 단계는 세포 내로: (a) 상기 CasX 융합 폴리펩타이드, 또는 상기 CasX 융합 폴리펩타이드를 암호화하는 핵산 분자, 및 (b) 상기 CasX 가이드 RNA, 또는 상기 CasX 가이드 RNA를 암호화하는 핵산 분자를 도입하는 것을 포함하는, 방법.
- 제90항 내지 제101항 중 어느 한 항에 있어서, 상기 CasX 폴리펩타이드는 촉매적으로 비활성인 CasX 폴리펩타이드(dCasX)인, 조성물.
- 제90항 내지 제102항 중 어느 한 항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1의 D672, E769 및 D935로부터 선택된 것에 대응하는 위치에서 하나 이상의 돌연변이를 포함하는, 방법.
- 제90항 내지 제103항 중 어느 한 항에 있어서, 상기 이종성 폴리펩타이드는 표적 DNA를 변형시키는 효소 활성을 나타내는, 방법.
- 제104항에 있어서, 상기 이종성 폴리펩타이드는 뉴클레아제 활성, 메틸트랜스퍼라제 활성, 데메틸라제 활성, DNA 수선 활성, DNA 손상 활성, 탈아미노화 활성, 디스무타제 활성, 알킬화 활성, 탈퓨린화 활성, 산화 활성, 피리미딘 이량체 형성 활성, 인테그라제 활성, 트랜스포사제 활성, 재조합효소 활성, 중합효소 활성, 리가제 활성, 헬리카제 활성, 광분해효소 활성 및 글리코실라제 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 방법.
- 제105항에 있어서, 상기 이종성 폴리펩타이드는 뉴클레아제 활성, 메틸트랜스퍼라제 활성, 데메틸라제 활성, 탈아미노화 활성, 탈퓨린화 활성, 인테그라제 활성, 트랜스포사제 활성 및 재조합효소 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 방법.
- 제90항 내지 제103항 중 어느 한 항에 있어서, 상기 이종성 폴리펩타이드는 표적 핵산과 회합된 표적 폴리펩타이드를 변형시키는 효소 활성을 나타내는, 방법.
- 제107항에 있어서, 상기 이종성 폴리펩타이드는 히스톤 변형 활성을 나타내는, 방법.
- 제107항 또는 제108항에 있어서, 상기 이종성 폴리펩타이드는 메틸트랜스퍼라제 활성, 데메틸라제 활성, 아세틸트랜스퍼라제 활성, 데아세틸라제 활성, 키나제 활성, 포스파타제 활성, 유비퀴틴 리가제 활성, 데유비퀴틴화 활성, 아데닐화 활성, 탈아데닐화 활성, 수모일화 활성, 탈수모일화활성, 리보실화 활성, 탈리보실화 활성, 미리스토일화 활성, 탈미리스토일화 활성, 글리코실화 활성(예를 들어, O-GlcNAc 트랜스퍼라제로부터의 활성) 및 탈글리코실화 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 방법.
- 제109항에 있어서, 상기 이종성 폴리펩타이드는 메틸트랜스퍼라제 활성, 데메틸라제 활성, 아세틸트랜스퍼라제 활성 및 데아세틸라제 활성으로부터 선택된 하나 이상의 효소 활성을 나타내는, 방법.
- 제90항 내지 제103항 중 어느 한 항에 있어서, 상기 이종성 폴리펩타이드는 전사를 증가 또는 감소시키는 단백질인, 방법.
- 제111항에 있어서, 상기 이종성 폴리펩타이드는 전사 리프레서 도메인인, 방법.
- 제111항에 있어서, 상기 이종성 폴리펩타이드는 전사 활성화 도메인인, 방법.
- 제90항 내지 제103항 중 어느 한 항에 있어서, 상기 이종성 폴리펩타이드는 단백질 결합 도메인인, 방법.
- 유전자이식, 다세포, 비인간 유기체로서, 게놈이,
a) CasX 폴리펩타이드,
b) CasX 융합 폴리펩타이드, 및
c) CasX 가이드 RNA
중 하나 이상을 암호화하는 뉴클레오타이드 서열을 포함하는 이식유전자를 포함하는, 유전자이식, 다세포, 비인간 유기체. - 제115항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 50% 이상의 아미노산 서열 동일성을 갖는 아미노산 서열을 포함하는, 유전자이식, 다세포, 비인간 유기체.
- 제115항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 85% 이상의 아미노산 서열 동일성을 갖는 아미노산 서열을 포함하는, 유전자이식, 다세포, 비인간 유기체.
- 제115항 내지 제117항 중 어느 한 항에 있어서, 상기 유기체는 식물, 외떡잎식물, 쌍떡잎식물, 무척추동물, 곤충, 절지동물, 거미류, 기생충, 벌레, 강장동물, 척추동물, 어류, 파충류, 양서류, 유제류, 조류, 돼지, 말, 양, 설치류, 마우스, 래트 또는 비 인간 영장류인, 유전자이식, 다세포, 비인간 유기체.
- 시스템으로서,
a) CasX 폴리펩타이드 및 CasX 단일 가이드 RNA;
b) CasX 폴리펩타이드, CasX 가이드 RNA, 및 DNA 공여자 주형;
c) CasX 융합 폴리펩타이드 및 CasX 가이드 RNA;
d) CasX 융합 폴리펩타이드, CasX 가이드 RNA, 및 DNA 공여자 주형;
e) CasX 폴리펩타이드를 암호화하는 mRNA 및 CasX 단일 가이드 RNA;
f) CasX 폴리펩타이드를 암호화하는 mRNA; CasX 가이드 RNA, 및 DNA 공여자 주형;
g) CasX 융합 폴리펩타이드를 암호화하는 mRNA 및 CasX 가이드 RNA;
h) CasX 융합 폴리펩타이드를 암호화하는 mRNA; CasX 가이드 RNA, 및 DNA 공여자 주형;
i) i) CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; 및 ii) CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 하나 이상의 재조합 발현 벡터;
j) i) CasX 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; ii) CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열; 및 iii) DNA 공여자 주형을 포함하는 하나 이상의 재조합 발현 벡터;
k) i) CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; 및 ii) CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 포함하는 하나 이상의 재조합 발현 벡터; 및
l) i) CasX 융합 폴리펩타이드를 암호화하는 뉴클레오타이드 서열; ii) CasX 가이드 RNA를 암호화하는 뉴클레오타이드 서열; 및 DNA 공여자 주형을 포함하는 하나 이상의 재조합 발현 벡터
를 포함하는, 시스템. - 제119항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 50% 이상의 아미노산 서열 동일성을 갖는 아미노산 서열을 포함하는, CasX 시스템.
- 제119항에 있어서, 상기 CasX 폴리펩타이드는 서열번호 1 또는 서열번호 2 또는 서열번호 3에 제시된 아미노산 서열에 대해 85% 이상의 아미노산 서열 동일성을 갖는 아미노산 서열을 포함하는, CasX 시스템.
- 제119항 내지 제121항 중 어느 한 항에 있어서, 상기 공여자 주형 핵산은 길이가 8개의 뉴클레오타이드 내지 1000개의 뉴클레오타이드인, CasX 시스템.
- 제119항 내지 제121항 중 어느 한 항에 있어서, 상기 공여자 주형 핵산은 길이가 25개의 뉴클레오타이드 내지 500개의 뉴클레오타이드인, CasX 시스템.
- 제119항 내지 제123항 중 어느 한 항의 CasX 시스템을 포함하는 키트.
- 제124항에 있어서, 상기 키트의 부품은 동일한 용기에 있는, 키트.
- 제124항에 있어서, 상기 키트의 부품은 별개의 용기에 있는, 키트.
- 제119항 내지 제126항 중 어느 한 항의 CasX 시스템을 포함하는 멸균 용기.
- 제127항에 있어서, 상기 용기는 주사기인, 멸균 용기.
- 제119항 내지 제126항 중 어느 한 항의 CasX 시스템을 포함하는 이식 가능한 장치.
- 제129항에 있어서, 상기 CasX 시스템은 기질 내인, 이식 가능한 장치.
- 제129항에 있어서, 상기 CasX 시스템은 저장소 내인, 이식 가능한 장치.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020237041555A KR20230170126A (ko) | 2016-09-30 | 2017-09-28 | Rna-가이드된 핵산 변형 효소 및 이의 사용 방법 |
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201662402846P | 2016-09-30 | 2016-09-30 | |
| US62/402,846 | 2016-09-30 | ||
| PCT/US2017/054081 WO2018064371A1 (en) | 2016-09-30 | 2017-09-28 | Rna-guided nucleic acid modifying enzymes and methods of use thereof |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237041555A Division KR20230170126A (ko) | 2016-09-30 | 2017-09-28 | Rna-가이드된 핵산 변형 효소 및 이의 사용 방법 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20190071725A true KR20190071725A (ko) | 2019-06-24 |
Family
ID=61760962
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020197012244A KR20190071725A (ko) | 2016-09-30 | 2017-09-28 | Rna-가이드된 핵산 변형 효소 및 이의 사용 방법 |
| KR1020237041555A KR20230170126A (ko) | 2016-09-30 | 2017-09-28 | Rna-가이드된 핵산 변형 효소 및 이의 사용 방법 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237041555A KR20230170126A (ko) | 2016-09-30 | 2017-09-28 | Rna-가이드된 핵산 변형 효소 및 이의 사용 방법 |
Country Status (13)
| Country | Link |
|---|---|
| US (3) | US11873504B2 (ko) |
| EP (1) | EP3523426A4 (ko) |
| JP (2) | JP2019532644A (ko) |
| KR (2) | KR20190071725A (ko) |
| CN (1) | CN110023494A (ko) |
| AU (1) | AU2017335890A1 (ko) |
| BR (1) | BR112019006384A2 (ko) |
| CA (1) | CA3038960A1 (ko) |
| EA (1) | EA201990861A1 (ko) |
| GB (1) | GB2569733B (ko) |
| IL (1) | IL265598A (ko) |
| MX (1) | MX2019003674A (ko) |
| WO (1) | WO2018064371A1 (ko) |
Families Citing this family (79)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA2853829C (en) | 2011-07-22 | 2023-09-26 | President And Fellows Of Harvard College | Evaluation and improvement of nuclease cleavage specificity |
| US20150044192A1 (en) | 2013-08-09 | 2015-02-12 | President And Fellows Of Harvard College | Methods for identifying a target site of a cas9 nuclease |
| US9359599B2 (en) | 2013-08-22 | 2016-06-07 | President And Fellows Of Harvard College | Engineered transcription activator-like effector (TALE) domains and uses thereof |
| US9526784B2 (en) | 2013-09-06 | 2016-12-27 | President And Fellows Of Harvard College | Delivery system for functional nucleases |
| US9322037B2 (en) | 2013-09-06 | 2016-04-26 | President And Fellows Of Harvard College | Cas9-FokI fusion proteins and uses thereof |
| US9228207B2 (en) | 2013-09-06 | 2016-01-05 | President And Fellows Of Harvard College | Switchable gRNAs comprising aptamers |
| US11053481B2 (en) | 2013-12-12 | 2021-07-06 | President And Fellows Of Harvard College | Fusions of Cas9 domains and nucleic acid-editing domains |
| WO2016022363A2 (en) | 2014-07-30 | 2016-02-11 | President And Fellows Of Harvard College | Cas9 proteins including ligand-dependent inteins |
| EP3215617A2 (en) | 2014-11-07 | 2017-09-13 | Editas Medicine, Inc. | Methods for improving crispr/cas-mediated genome-editing |
| WO2016182959A1 (en) | 2015-05-11 | 2016-11-17 | Editas Medicine, Inc. | Optimized crispr/cas9 systems and methods for gene editing in stem cells |
| WO2016201047A1 (en) | 2015-06-09 | 2016-12-15 | Editas Medicine, Inc. | Crispr/cas-related methods and compositions for improving transplantation |
| CA2999500A1 (en) | 2015-09-24 | 2017-03-30 | Editas Medicine, Inc. | Use of exonucleases to improve crispr/cas-mediated genome editing |
| US10167457B2 (en) | 2015-10-23 | 2019-01-01 | President And Fellows Of Harvard College | Nucleobase editors and uses thereof |
| WO2017165826A1 (en) | 2016-03-25 | 2017-09-28 | Editas Medicine, Inc. | Genome editing systems comprising repair-modulating enzyme molecules and methods of their use |
| US11236313B2 (en) | 2016-04-13 | 2022-02-01 | Editas Medicine, Inc. | Cas9 fusion molecules, gene editing systems, and methods of use thereof |
| US10337051B2 (en) | 2016-06-16 | 2019-07-02 | The Regents Of The University Of California | Methods and compositions for detecting a target RNA |
| IL308426A (en) | 2016-08-03 | 2024-01-01 | Harvard College | Adenosine nuclear base editors and their uses |
| CN109804066A (zh) | 2016-08-09 | 2019-05-24 | 哈佛大学的校长及成员们 | 可编程cas9-重组酶融合蛋白及其用途 |
| WO2018039438A1 (en) | 2016-08-24 | 2018-03-01 | President And Fellows Of Harvard College | Incorporation of unnatural amino acids into proteins using base editing |
| EA201990861A1 (ru) | 2016-09-30 | 2019-09-30 | Те Риджентс Оф Те Юниверсити Оф Калифорния | Рнк-направляемые модифицирующие нуклеиновые кислоты ферменты и способы их применения |
| KR20230169449A (ko) | 2016-09-30 | 2023-12-15 | 더 리젠츠 오브 더 유니버시티 오브 캘리포니아 | Rna-가이드된 핵산 변형 효소 및 이의 사용 방법 |
| AU2017342543A1 (en) | 2016-10-14 | 2019-05-02 | President And Fellows Of Harvard College | AAV delivery of nucleobase editors |
| WO2018119359A1 (en) | 2016-12-23 | 2018-06-28 | President And Fellows Of Harvard College | Editing of ccr5 receptor gene to protect against hiv infection |
| WO2018136396A2 (en) * | 2017-01-18 | 2018-07-26 | Excision Biotherapeutics, Inc. | Crisprs |
| US20190367924A1 (en) * | 2017-02-17 | 2019-12-05 | Temple University - Of The Commonwealth System Of Higher Education | Gene editing therapy for hiv infection via dual targeting of hiv genome and ccr5 |
| US11898179B2 (en) | 2017-03-09 | 2024-02-13 | President And Fellows Of Harvard College | Suppression of pain by gene editing |
| US11542496B2 (en) | 2017-03-10 | 2023-01-03 | President And Fellows Of Harvard College | Cytosine to guanine base editor |
| JP7191388B2 (ja) | 2017-03-23 | 2022-12-19 | プレジデント アンド フェローズ オブ ハーバード カレッジ | 核酸によってプログラム可能なdna結合蛋白質を含む核酸塩基編集因子 |
| WO2018201086A1 (en) | 2017-04-28 | 2018-11-01 | Editas Medicine, Inc. | Methods and systems for analyzing guide rna molecules |
| WO2018202800A1 (en) * | 2017-05-03 | 2018-11-08 | Kws Saat Se | Use of crispr-cas endonucleases for plant genome engineering |
| US11560566B2 (en) | 2017-05-12 | 2023-01-24 | President And Fellows Of Harvard College | Aptazyme-embedded guide RNAs for use with CRISPR-Cas9 in genome editing and transcriptional activation |
| AU2018279829B2 (en) | 2017-06-09 | 2024-01-04 | Editas Medicine, Inc. | Engineered Cas9 nucleases |
| US11866726B2 (en) | 2017-07-14 | 2024-01-09 | Editas Medicine, Inc. | Systems and methods for targeted integration and genome editing and detection thereof using integrated priming sites |
| EP3658573A1 (en) | 2017-07-28 | 2020-06-03 | President and Fellows of Harvard College | Methods and compositions for evolving base editors using phage-assisted continuous evolution (pace) |
| US11319532B2 (en) | 2017-08-30 | 2022-05-03 | President And Fellows Of Harvard College | High efficiency base editors comprising Gam |
| EP3697906A1 (en) | 2017-10-16 | 2020-08-26 | The Broad Institute, Inc. | Uses of adenosine base editors |
| US11578334B2 (en) * | 2017-10-25 | 2023-02-14 | Monsanto Technology Llc | Targeted endonuclease activity of the RNA-guided endonuclease CasX in eukaryotes |
| RU2020117711A (ru) | 2017-11-01 | 2021-12-02 | Те Риджентс Оф Те Юниверсити Оф Калифорния | КОМПОЗИЦИИ И СПОСОБЫ ПРИМЕНЕНИЯ CasZ |
| US11661599B1 (en) | 2017-12-14 | 2023-05-30 | National Technology & Engineering Solutions Of Sandia, Llc | CRISPR-Cas based system for targeting single-stranded sequences |
| US11807877B1 (en) | 2018-03-22 | 2023-11-07 | National Technology & Engineering Solutions Of Sandia, Llc | CRISPR/Cas activity assays and compositions thereof |
| CA3101648A1 (en) | 2018-06-07 | 2019-12-12 | Arc Bio, Llc | Compositions and methods for making guide nucleic acids |
| US20190390193A1 (en) * | 2018-06-23 | 2019-12-26 | John Lawrence Mee | Reversible method for sustainable human cognitive enhancement |
| WO2020023529A1 (en) * | 2018-07-24 | 2020-01-30 | The Regents Of The University Of California | Rna-guided nucleic acid modifying enzymes and methods of use thereof |
| WO2020028729A1 (en) | 2018-08-01 | 2020-02-06 | Mammoth Biosciences, Inc. | Programmable nuclease compositions and methods of use thereof |
| WO2020041456A1 (en) * | 2018-08-22 | 2020-02-27 | The Regents Of The University Of California | Variant type v crispr/cas effector polypeptides and methods of use thereof |
| KR20210104068A (ko) * | 2018-12-14 | 2021-08-24 | 파이어니어 하이 부렛드 인터내쇼날 인코포레이팃드 | 게놈 편집을 위한 신규한 crispr-cas 시스템 |
| EP3931313A2 (en) | 2019-01-04 | 2022-01-05 | Mammoth Biosciences, Inc. | Programmable nuclease improvements and compositions and methods for nucleic acid amplification and detection |
| KR20210126014A (ko) * | 2019-01-14 | 2021-10-19 | 유니버시티 오브 로체스터 | CRISPR-Cas로 표적화된 핵 RNA 분열 및 폴리아데닐화 |
| WO2020181101A1 (en) | 2019-03-07 | 2020-09-10 | The Regents Of The University Of California | Crispr-cas effector polypeptides and methods of use thereof |
| CA3133226A1 (en) | 2019-03-11 | 2020-09-17 | Sorrento Therapeutics, Inc. | Improved process for integration of dna constructs using rna-guided endonucleases |
| DE112020001342T5 (de) | 2019-03-19 | 2022-01-13 | President and Fellows of Harvard College | Verfahren und Zusammensetzungen zum Editing von Nukleotidsequenzen |
| EP3945801A4 (en) * | 2019-04-03 | 2023-06-07 | University of Georgia Research Foundation, Inc. | CRISPR/MCAS9 DELIVERY THROUGH EXTRACELLULAR VESICLES FOR GENOMIC EDITING |
| AU2020289591A1 (en) * | 2019-06-07 | 2021-12-23 | Scribe Therapeutics Inc. | Engineered CasX systems |
| AU2020311438A1 (en) * | 2019-07-11 | 2021-12-16 | Arbor Biotechnologies, Inc. | Novel CRISPR DNA targeting enzymes and systems |
| JP2021016370A (ja) * | 2019-07-23 | 2021-02-15 | 株式会社東芝 | 核酸導入キャリア、核酸導入キャリアセット、核酸導入組成物及び核酸導入方法 |
| US20220348925A1 (en) | 2019-09-09 | 2022-11-03 | Scribe Therapeutics Inc. | Compositions and methods for the targeting of sod1 |
| CN114729368A (zh) * | 2019-09-09 | 2022-07-08 | 斯克里贝治疗公司 | 用于免疫疗法的组合物和方法 |
| CN110669795A (zh) * | 2019-10-18 | 2020-01-10 | 福州大学 | 一种在鱼类胚胎中实现精确定点rna剪切的技术 |
| CA3159320A1 (en) | 2019-12-06 | 2021-06-10 | Scribe Therapeutics Inc. | Particle delivery systems |
| CA3159316A1 (en) | 2019-12-06 | 2021-06-10 | Benjamin OAKES | Compositions and methods for the targeting of rhodopsin |
| EP4069846A1 (en) | 2019-12-07 | 2022-10-12 | Scribe Therapeutics Inc. | Compositions and methods for the targeting of htt |
| AU2020412714A1 (en) * | 2019-12-23 | 2022-05-26 | The Regents Of The University Of California | CRISPR-Cas effector polypeptides and methods of use thereof |
| EP4085132A1 (en) * | 2019-12-30 | 2022-11-09 | DSM IP Assets B.V. | Lipase-modified strain |
| US20230167424A1 (en) | 2020-01-10 | 2023-06-01 | Scribe Therapeutics Inc. | Compositions and methods for the targeting of pcsk9 |
| WO2021152402A1 (en) * | 2020-01-29 | 2021-08-05 | Jenthera Therapeutics Inc. | Nuclease-scaffold composition delivery platform |
| CN115485300A (zh) | 2020-02-26 | 2022-12-16 | 索伦托药业有限公司 | 具有通用掩蔽部分的可活化的抗原结合蛋白 |
| WO2021182474A1 (ja) * | 2020-03-12 | 2021-09-16 | 株式会社Frest | オリゴヌクレオチド及び標的rnaの部位特異的編集方法 |
| MX2022011460A (es) * | 2020-03-18 | 2022-12-15 | Scribe Therapeutics Inc | Composiciones y métodos para el direccionamiento de c9orf72. |
| WO2021217083A1 (en) | 2020-04-24 | 2021-10-28 | Sorrento Therapeutics, Inc. | Memory dimeric antigen receptors |
| JP2023525304A (ja) | 2020-05-08 | 2023-06-15 | ザ ブロード インスティテュート,インコーポレーテッド | 標的二本鎖ヌクレオチド配列の両鎖同時編集のための方法および組成物 |
| BR112023001641A2 (pt) * | 2020-07-30 | 2023-04-04 | Adarx Pharmaceuticals Inc | Composições de edição dependentes de adar e métodos de uso das mesmas |
| US20220162625A1 (en) * | 2020-11-11 | 2022-05-26 | Monsanto Technology Llc | Methods to improve site-directed integration frequency |
| EP4256054A1 (en) * | 2020-12-03 | 2023-10-11 | Scribe Therapeutics Inc. | Engineered class 2 type v crispr systems |
| US20240100185A1 (en) * | 2020-12-03 | 2024-03-28 | Scribe Therapeutics Inc. | Compositions and methods for the targeting of ptbp1 |
| WO2022125843A1 (en) * | 2020-12-09 | 2022-06-16 | Scribe Therapeutics Inc. | Aav vectors for gene editing |
| AU2021409729A1 (en) | 2020-12-22 | 2023-07-13 | Chroma Medicine, Inc. | Compositions and methods for epigenetic editing |
| IL308806A (en) | 2021-06-01 | 2024-01-01 | Arbor Biotechnologies Inc | Gene editing systems including nuclease crisper and their uses |
| WO2023049742A2 (en) * | 2021-09-21 | 2023-03-30 | Scribe Therapeutics Inc. | Engineered casx repressor systems |
| CN113969281B (zh) * | 2021-12-24 | 2022-04-01 | 汕头大学 | 经修饰的CrRNA片段及非洲猪瘟病毒试剂盒 |
Family Cites Families (85)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5034506A (en) | 1985-03-15 | 1991-07-23 | Anti-Gene Development Group | Uncharged morpholino-based polymers having achiral intersubunit linkages |
| JP2004521606A (ja) | 2000-05-24 | 2004-07-22 | サード・ウェーブ・テクノロジーズ・インク | Rnaの検出法 |
| US6773885B1 (en) | 2000-09-29 | 2004-08-10 | Integrated Dna Technologies, Inc. | Compositions and methods for visual ribonuclease detection assays |
| CN1886512A (zh) * | 2002-04-23 | 2006-12-27 | 斯克里普斯研究所 | 多肽在叶绿体中的表达以及用于表达多肽的组合物和方法 |
| EP1580273A1 (en) | 2004-03-26 | 2005-09-28 | Friedrich-Alexander-Universität Erlangen-Nürnberg | Peptide-based method for monitoring gene expression in a host cell |
| CN101283089A (zh) | 2005-10-07 | 2008-10-08 | 加利福尼亚大学董事会 | 修饰细胞色素p450酶的编码核酸和其应用方法 |
| US9689031B2 (en) | 2007-07-14 | 2017-06-27 | Ionian Technologies, Inc. | Nicking and extension amplification reaction for the exponential amplification of nucleic acids |
| WO2010075303A1 (en) | 2008-12-23 | 2010-07-01 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Splicing factors with a puf protein rna-binding domain and a splicing effector domain and uses of same |
| EP2536846B1 (en) | 2010-02-15 | 2016-10-05 | Cascade Biosystems, Inc. | Methods and materials for detecting viral or microbial infections |
| US20130261196A1 (en) | 2010-06-11 | 2013-10-03 | Lisa Diamond | Nucleic Acids For Multiplex Organism Detection and Methods Of Use And Making The Same |
| WO2012027675A2 (en) | 2010-08-26 | 2012-03-01 | Massachusetts Institute Of Technology | Poly(beta-amino alcohols), their preparation, and uses thereof |
| US9580714B2 (en) | 2010-11-24 | 2017-02-28 | The University Of Western Australia | Peptides for the specific binding of RNA targets |
| US9730967B2 (en) * | 2011-02-04 | 2017-08-15 | Katherine Rose Kovarik | Method and system for treating cancer cachexia |
| US8815782B2 (en) | 2011-11-11 | 2014-08-26 | Agilent Technologies, Inc. | Use of DNAzymes for analysis of an RNA sample |
| EP2838912A4 (en) | 2012-04-16 | 2015-11-18 | Univ Western Australia | PEPTIDES FOR BINDING NUCLEOTIDE TARGETS |
| PE20190844A1 (es) | 2012-05-25 | 2019-06-17 | Emmanuelle Charpentier | Modulacion de transcripcion con arn de direccion a adn generico |
| SG10202107423UA (en) * | 2012-12-06 | 2021-08-30 | Sigma Aldrich Co Llc | Crispr-based genome modification and regulation |
| SG10201801969TA (en) | 2012-12-12 | 2018-04-27 | Broad Inst Inc | Engineering and Optimization of Improved Systems, Methods and Enzyme Compositions for Sequence Manipulation |
| EP2931899A1 (en) | 2012-12-12 | 2015-10-21 | The Broad Institute, Inc. | Functional genomics using crispr-cas systems, compositions, methods, knock out libraries and applications thereof |
| EP2848690B1 (en) | 2012-12-12 | 2020-08-19 | The Broad Institute, Inc. | Crispr-cas component systems, methods and compositions for sequence manipulation |
| US8697359B1 (en) | 2012-12-12 | 2014-04-15 | The Broad Institute, Inc. | CRISPR-Cas systems and methods for altering expression of gene products |
| US20140310830A1 (en) | 2012-12-12 | 2014-10-16 | Feng Zhang | CRISPR-Cas Nickase Systems, Methods And Compositions For Sequence Manipulation in Eukaryotes |
| US20140242664A1 (en) | 2012-12-12 | 2014-08-28 | The Broad Institute, Inc. | Engineering of systems, methods and optimized guide compositions for sequence manipulation |
| EP3252160B1 (en) | 2012-12-12 | 2020-10-28 | The Broad Institute, Inc. | Crispr-cas component systems, methods and compositions for sequence manipulation |
| US8993233B2 (en) | 2012-12-12 | 2015-03-31 | The Broad Institute Inc. | Engineering and optimization of systems, methods and compositions for sequence manipulation with functional domains |
| ES2883590T3 (es) | 2012-12-12 | 2021-12-09 | Broad Inst Inc | Suministro, modificación y optimización de sistemas, métodos y composiciones para la manipulación de secuencias y aplicaciones terapéuticas |
| KR102240135B1 (ko) | 2012-12-13 | 2021-04-14 | 다우 아그로사이언시즈 엘엘씨 | 부위 특이적 뉴클레아제 활성에 대한 dna 검출 방법 |
| SG11201504621RA (en) | 2012-12-17 | 2015-07-30 | Harvard College | Rna-guided human genome engineering |
| WO2014118272A1 (en) | 2013-01-30 | 2014-08-07 | Santaris Pharma A/S | Antimir-122 oligonucleotide carbohydrate conjugates |
| WO2014130955A1 (en) | 2013-02-25 | 2014-08-28 | Sangamo Biosciences, Inc. | Methods and compositions for enhancing nuclease-mediated gene disruption |
| NZ712727A (en) | 2013-03-14 | 2017-05-26 | Caribou Biosciences Inc | Compositions and methods of nucleic acid-targeting nucleic acids |
| US11332719B2 (en) | 2013-03-15 | 2022-05-17 | The Broad Institute, Inc. | Recombinant virus and preparations thereof |
| US20140273230A1 (en) | 2013-03-15 | 2014-09-18 | Sigma-Aldrich Co., Llc | Crispr-based genome modification and regulation |
| JP6980380B2 (ja) | 2013-03-15 | 2021-12-15 | ザ ジェネラル ホスピタル コーポレイション | 短縮ガイドRNA(tru−gRNA)を用いたRNA誘導型ゲノム編集の特異性の増大 |
| US10760064B2 (en) | 2013-03-15 | 2020-09-01 | The General Hospital Corporation | RNA-guided targeting of genetic and epigenomic regulatory proteins to specific genomic loci |
| US9234213B2 (en) | 2013-03-15 | 2016-01-12 | System Biosciences, Llc | Compositions and methods directed to CRISPR/Cas genomic engineering systems |
| US20140349400A1 (en) | 2013-03-15 | 2014-11-27 | Massachusetts Institute Of Technology | Programmable Modification of DNA |
| BR112015022522B1 (pt) | 2013-03-15 | 2023-09-26 | Regents Of The University Of Minnesota | Método para a modificação do material genômico em uma célula vegetal e vetor viral |
| US20140364333A1 (en) | 2013-03-15 | 2014-12-11 | President And Fellows Of Harvard College | Methods for Live Imaging of Cells |
| US10501748B2 (en) | 2013-04-05 | 2019-12-10 | Dow Agrosciences Llc | Methods and compositions for integration of an exogenous sequence within the genome of plants |
| PT3456831T (pt) | 2013-04-16 | 2021-09-10 | Regeneron Pharma | Modificação alvejada do genoma de rato |
| AU2014262867B2 (en) | 2013-05-10 | 2019-12-05 | Sangamo Therapeutics, Inc. | Delivery methods and compositions for nuclease-mediated genome engineering |
| WO2014190181A1 (en) | 2013-05-22 | 2014-11-27 | Northwestern University | Rna-directed dna cleavage and gene editing by cas9 enzyme from neisseria meningitidis |
| US9873907B2 (en) | 2013-05-29 | 2018-01-23 | Agilent Technologies, Inc. | Method for fragmenting genomic DNA using CAS9 |
| US9267135B2 (en) | 2013-06-04 | 2016-02-23 | President And Fellows Of Harvard College | RNA-guided transcriptional regulation |
| CA2930877A1 (en) * | 2013-11-18 | 2015-05-21 | Crispr Therapeutics Ag | Crispr-cas system materials and methods |
| EP3835419A1 (en) | 2013-12-12 | 2021-06-16 | The Regents of The University of California | Methods and compositions for modifying a single stranded target nucleic acid |
| US9850525B2 (en) | 2014-01-29 | 2017-12-26 | Agilent Technologies, Inc. | CAS9-based isothermal method of detection of specific DNA sequence |
| WO2015139139A1 (en) | 2014-03-20 | 2015-09-24 | UNIVERSITé LAVAL | Crispr-based methods and products for increasing frataxin levels and uses thereof |
| US10253311B2 (en) | 2014-04-10 | 2019-04-09 | The Regents Of The University Of California | Methods and compositions for using argonaute to modify a single stranded target nucleic acid |
| CA2951707A1 (en) | 2014-06-10 | 2015-12-17 | Massachusetts Institute Of Technology | Method for gene editing |
| JP6806668B2 (ja) | 2014-08-19 | 2021-01-06 | プレジデント アンド フェローズ オブ ハーバード カレッジ | 核酸をプロービングおよびマッピングするためのrna誘導型システム |
| WO2016094872A1 (en) | 2014-12-12 | 2016-06-16 | The Broad Institute Inc. | Dead guides for crispr transcription factors |
| WO2016094867A1 (en) | 2014-12-12 | 2016-06-16 | The Broad Institute Inc. | Protected guide rnas (pgrnas) |
| WO2016106236A1 (en) | 2014-12-23 | 2016-06-30 | The Broad Institute Inc. | Rna-targeting system |
| WO2016123243A1 (en) | 2015-01-28 | 2016-08-04 | The Regents Of The University Of California | Methods and compositions for labeling a single-stranded target nucleic acid |
| US9790490B2 (en) | 2015-06-18 | 2017-10-17 | The Broad Institute Inc. | CRISPR enzymes and systems |
| EP3666895A1 (en) | 2015-06-18 | 2020-06-17 | The Broad Institute, Inc. | Novel crispr enzymes and systems |
| WO2016205749A1 (en) | 2015-06-18 | 2016-12-22 | The Broad Institute Inc. | Novel crispr enzymes and systems |
| IL284808B (en) | 2015-06-18 | 2022-07-01 | Broad Inst Inc | Mutations in the crispr enzyme that reduce unintended effects |
| US9580727B1 (en) | 2015-08-07 | 2017-02-28 | Caribou Biosciences, Inc. | Compositions and methods of engineered CRISPR-Cas9 systems using split-nexus Cas9-associated polynucleotides |
| WO2017070605A1 (en) | 2015-10-22 | 2017-04-27 | The Broad Institute Inc. | Type vi-b crispr enzymes and systems |
| US11193127B2 (en) | 2016-01-08 | 2021-12-07 | University Of Georgia Research Foundation, Inc. | Methods for cleaving DNA and RNA molecules |
| US11441146B2 (en) * | 2016-01-11 | 2022-09-13 | Christiana Care Health Services, Inc. | Compositions and methods for improving homogeneity of DNA generated using a CRISPR/Cas9 cleavage system |
| US9896696B2 (en) | 2016-02-15 | 2018-02-20 | Benson Hill Biosystems, Inc. | Compositions and methods for modifying genomes |
| CA3015360A1 (en) | 2016-02-23 | 2017-08-31 | Arc Bio, Llc | Methods and compositions for target detection |
| US20190093091A1 (en) | 2016-04-06 | 2019-03-28 | Temple University - Of The Commonwealth System Of Higher Education | Compositions for eradicating flavivirus infections in subjects |
| WO2017205668A1 (en) | 2016-05-25 | 2017-11-30 | Arizona Board Of Regents On Behalf Of Arizona State University | Portable, low-cost pathogen detection and strain identification platform |
| US10337051B2 (en) | 2016-06-16 | 2019-07-02 | The Regents Of The University Of California | Methods and compositions for detecting a target RNA |
| KR20230156150A (ko) | 2016-06-17 | 2023-11-13 | 더 브로드 인스티튜트, 인코퍼레이티드 | 제vi형 crispr 오솔로그 및 시스템 |
| US10017760B2 (en) * | 2016-06-24 | 2018-07-10 | Inscripta, Inc. | Methods for generating barcoded combinatorial libraries |
| EP3500967A1 (en) | 2016-08-17 | 2019-06-26 | The Broad Institute, Inc. | Methods for identifying class 2 crispr-cas systems |
| EA201990861A1 (ru) | 2016-09-30 | 2019-09-30 | Те Риджентс Оф Те Юниверсити Оф Калифорния | Рнк-направляемые модифицирующие нуклеиновые кислоты ферменты и способы их применения |
| KR20230169449A (ko) | 2016-09-30 | 2023-12-15 | 더 리젠츠 오브 더 유니버시티 오브 캘리포니아 | Rna-가이드된 핵산 변형 효소 및 이의 사용 방법 |
| CN106701830B (zh) | 2016-12-07 | 2020-01-03 | 湖南人文科技学院 | 一种敲除猪胚胎p66shc基因的方法 |
| BR122021009064B1 (pt) | 2016-12-09 | 2022-04-12 | The Broad Institute, Inc. | Sistema, método e dispositivo para detectar a presença de um ou mais polipeptídeos em uma amostra |
| WO2018172556A1 (en) | 2017-03-24 | 2018-09-27 | Curevac Ag | Nucleic acids encoding crispr-associated proteins and uses thereof |
| US11591589B2 (en) | 2017-04-21 | 2023-02-28 | The General Hospital Corporation | Variants of Cpf1 (Cas12a) with altered PAM specificity |
| CN111373040A (zh) | 2017-08-09 | 2020-07-03 | 本森希尔股份有限公司 | 修饰基因组的组合物和方法 |
| US20200255858A1 (en) | 2017-11-01 | 2020-08-13 | Jillian F. Banfield | Casy compositions and methods of use |
| WO2019089808A1 (en) | 2017-11-01 | 2019-05-09 | The Regents Of The University Of California | Class 2 crispr/cas compositions and methods of use |
| EP3704254A4 (en) | 2017-11-01 | 2021-09-01 | The Regents of The University of California | CAS12C COMPOSITIONS AND METHOD OF USE |
| RU2020117711A (ru) | 2017-11-01 | 2021-12-02 | Те Риджентс Оф Те Юниверсити Оф Калифорния | КОМПОЗИЦИИ И СПОСОБЫ ПРИМЕНЕНИЯ CasZ |
| US10253365B1 (en) | 2017-11-22 | 2019-04-09 | The Regents Of The University Of California | Type V CRISPR/Cas effector proteins for cleaving ssDNAs and detecting target DNAs |
| CA3086550A1 (en) | 2017-12-22 | 2019-06-27 | The Broad Institute, Inc. | Crispr effector system based multiplex diagnostics |
-
2017
- 2017-09-28 EA EA201990861A patent/EA201990861A1/ru unknown
- 2017-09-28 BR BR112019006384A patent/BR112019006384A2/pt unknown
- 2017-09-28 KR KR1020197012244A patent/KR20190071725A/ko not_active IP Right Cessation
- 2017-09-28 US US16/335,516 patent/US11873504B2/en active Active
- 2017-09-28 CN CN201780074116.1A patent/CN110023494A/zh active Pending
- 2017-09-28 EP EP17857442.2A patent/EP3523426A4/en active Pending
- 2017-09-28 WO PCT/US2017/054081 patent/WO2018064371A1/en unknown
- 2017-09-28 GB GB1905575.5A patent/GB2569733B/en active Active
- 2017-09-28 MX MX2019003674A patent/MX2019003674A/es unknown
- 2017-09-28 CA CA3038960A patent/CA3038960A1/en active Pending
- 2017-09-28 AU AU2017335890A patent/AU2017335890A1/en active Pending
- 2017-09-28 JP JP2019517305A patent/JP2019532644A/ja active Pending
- 2017-09-28 KR KR1020237041555A patent/KR20230170126A/ko active Search and Examination
-
2018
- 2018-08-03 US US16/054,513 patent/US10570415B2/en active Active
-
2019
- 2019-03-25 IL IL265598A patent/IL265598A/en unknown
- 2019-05-24 US US16/422,824 patent/US11795472B2/en active Active
-
2022
- 2022-12-14 JP JP2022199477A patent/JP2023027277A/ja active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| GB201905575D0 (en) | 2019-06-05 |
| JP2019532644A (ja) | 2019-11-14 |
| WO2018064371A1 (en) | 2018-04-05 |
| GB2569733B (en) | 2022-09-14 |
| EP3523426A4 (en) | 2020-01-22 |
| EP3523426A1 (en) | 2019-08-14 |
| US11873504B2 (en) | 2024-01-16 |
| US20200017879A1 (en) | 2020-01-16 |
| KR20230170126A (ko) | 2023-12-18 |
| US20190276842A1 (en) | 2019-09-12 |
| CN110023494A (zh) | 2019-07-16 |
| CA3038960A1 (en) | 2018-04-05 |
| US11795472B2 (en) | 2023-10-24 |
| JP2023027277A (ja) | 2023-03-01 |
| MX2019003674A (es) | 2021-01-08 |
| IL265598A (en) | 2019-05-30 |
| US20180346927A1 (en) | 2018-12-06 |
| EA201990861A1 (ru) | 2019-09-30 |
| AU2017335890A1 (en) | 2019-04-11 |
| GB2569733A (en) | 2019-06-26 |
| BR112019006384A2 (pt) | 2019-06-25 |
| US10570415B2 (en) | 2020-02-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7306696B2 (ja) | Rna誘導型核酸修飾酵素及びその使用方法 | |
| US11795472B2 (en) | RNA-guided nucleic acid modifying enzymes and methods of use thereof | |
| US11453866B2 (en) | CASZ compositions and methods of use | |
| US20200339967A1 (en) | Cas12c compositions and methods of use | |
| WO2019089808A1 (en) | Class 2 crispr/cas compositions and methods of use | |
| US20210284981A1 (en) | Rna-guided nucleic acid modifying enzymes and methods of use thereof | |
| JP2022522650A (ja) | Crispr-casエフェクターポリペプチド及びその使用方法 | |
| US20230407276A1 (en) | Crispr-cas effector polypeptides and methods of use thereof | |
| EA045278B1 (ru) | Рнк-направляемые модифицирующие нуклеиновые кислоты ферменты и способы их применения |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AMND | Amendment | ||
| A201 | Request for examination | ||
| AMND | Amendment | ||
| E902 | Notification of reason for refusal | ||
| AMND | Amendment | ||
| E601 | Decision to refuse application | ||
| AMND | Amendment | ||
| X601 | Decision of rejection after re-examination |