KR20180021135A - 인간화 심장 근육 - Google Patents
인간화 심장 근육 Download PDFInfo
- Publication number
- KR20180021135A KR20180021135A KR1020187002387A KR20187002387A KR20180021135A KR 20180021135 A KR20180021135 A KR 20180021135A KR 1020187002387 A KR1020187002387 A KR 1020187002387A KR 20187002387 A KR20187002387 A KR 20187002387A KR 20180021135 A KR20180021135 A KR 20180021135A
- Authority
- KR
- South Korea
- Prior art keywords
- human
- nkx2
- tbx5
- handii
- combination
- Prior art date
Links
- 210000004165 myocardium Anatomy 0.000 title description 6
- 241000282414 Homo sapiens Species 0.000 claims abstract description 130
- 101000632197 Homo sapiens Homeobox protein Nkx-2.5 Proteins 0.000 claims abstract description 105
- 210000004027 cell Anatomy 0.000 claims abstract description 101
- 108010014480 T-box transcription factor 5 Proteins 0.000 claims abstract description 90
- 102100024755 T-box transcription factor TBX5 Human genes 0.000 claims abstract description 80
- 210000002459 blastocyst Anatomy 0.000 claims abstract description 78
- 102100027875 Homeobox protein Nkx-2.5 Human genes 0.000 claims abstract description 75
- -1 HANDII Proteins 0.000 claims abstract description 59
- 210000000130 stem cell Anatomy 0.000 claims abstract description 56
- 101150115978 tbx5 gene Proteins 0.000 claims abstract description 34
- 210000000287 oocyte Anatomy 0.000 claims abstract description 27
- 230000035772 mutation Effects 0.000 claims abstract description 22
- 238000010374 somatic cell nuclear transfer Methods 0.000 claims abstract description 16
- 102000043416 human NKX2-5 Human genes 0.000 claims abstract description 15
- 238000004519 manufacturing process Methods 0.000 claims abstract description 11
- 230000003213 activating effect Effects 0.000 claims abstract description 9
- 210000004102 animal cell Anatomy 0.000 claims abstract description 9
- 108090000623 proteins and genes Proteins 0.000 claims description 105
- 241000282898 Sus scrofa Species 0.000 claims description 90
- 238000000034 method Methods 0.000 claims description 37
- 102000004169 proteins and genes Human genes 0.000 claims description 31
- 210000001161 mammalian embryo Anatomy 0.000 claims description 26
- 108700028369 Alleles Proteins 0.000 claims description 19
- 210000001519 tissue Anatomy 0.000 claims description 19
- 210000002950 fibroblast Anatomy 0.000 claims description 15
- 230000014509 gene expression Effects 0.000 claims description 15
- 210000001778 pluripotent stem cell Anatomy 0.000 claims description 12
- 210000002064 heart cell Anatomy 0.000 claims description 11
- 210000005003 heart tissue Anatomy 0.000 claims description 11
- 241000283690 Bos taurus Species 0.000 claims description 8
- 238000012217 deletion Methods 0.000 claims description 8
- 230000037430 deletion Effects 0.000 claims description 8
- 210000005260 human cell Anatomy 0.000 claims description 8
- 108700026220 vif Genes Proteins 0.000 claims description 8
- 241000283073 Equus caballus Species 0.000 claims description 6
- 241000283707 Capra Species 0.000 claims description 5
- 101000958865 Homo sapiens Myogenic factor 5 Proteins 0.000 claims description 5
- 102100038379 Myogenic factor 6 Human genes 0.000 claims description 5
- 210000004700 fetal blood Anatomy 0.000 claims description 5
- 108010084677 myogenic factor 6 Proteins 0.000 claims description 5
- 210000004287 null lymphocyte Anatomy 0.000 claims description 5
- 101001023043 Homo sapiens Myoblast determination protein 1 Proteins 0.000 claims description 4
- 102100035077 Myoblast determination protein 1 Human genes 0.000 claims description 4
- 102100038380 Myogenic factor 5 Human genes 0.000 claims description 4
- 210000004504 adult stem cell Anatomy 0.000 claims description 3
- 210000003016 hypothalamus Anatomy 0.000 claims description 3
- 210000004263 induced pluripotent stem cell Anatomy 0.000 claims description 3
- 101150047028 MRF4 gene Proteins 0.000 claims description 2
- 101150097771 MYF5 gene Proteins 0.000 claims description 2
- 230000035558 fertility Effects 0.000 claims description 2
- 101150042523 myod gene Proteins 0.000 claims description 2
- 238000003776 cleavage reaction Methods 0.000 claims 1
- 230000037452 priming Effects 0.000 claims 1
- 230000007017 scission Effects 0.000 claims 1
- 150000007523 nucleic acids Chemical group 0.000 description 32
- 101150114527 Nkx2-5 gene Proteins 0.000 description 31
- 210000002216 heart Anatomy 0.000 description 30
- 108020004999 messenger RNA Proteins 0.000 description 26
- 108020004414 DNA Proteins 0.000 description 25
- 210000002257 embryonic structure Anatomy 0.000 description 25
- 210000000056 organ Anatomy 0.000 description 24
- 241000282887 Suidae Species 0.000 description 20
- 230000000747 cardiac effect Effects 0.000 description 20
- 102000039446 nucleic acids Human genes 0.000 description 18
- 108020004707 nucleic acids Proteins 0.000 description 18
- 210000004940 nucleus Anatomy 0.000 description 18
- 102000040430 polynucleotide Human genes 0.000 description 18
- 108091033319 polynucleotide Proteins 0.000 description 18
- 239000002157 polynucleotide Substances 0.000 description 18
- 108091028043 Nucleic acid sequence Proteins 0.000 description 17
- 102100039579 ETS translocation variant 2 Human genes 0.000 description 14
- 101000813735 Homo sapiens ETS translocation variant 2 Proteins 0.000 description 14
- 239000002773 nucleotide Substances 0.000 description 14
- 150000001413 amino acids Chemical class 0.000 description 13
- 125000003729 nucleotide group Chemical group 0.000 description 13
- 150000001875 compounds Chemical class 0.000 description 12
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 12
- 108010026333 seryl-proline Proteins 0.000 description 12
- 241001465754 Metazoa Species 0.000 description 11
- 108010050848 glycylleucine Proteins 0.000 description 11
- 239000000047 product Substances 0.000 description 11
- 208000024172 Cardiovascular disease Diseases 0.000 description 10
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 10
- 238000010362 genome editing Methods 0.000 description 10
- 238000012360 testing method Methods 0.000 description 10
- 238000002054 transplantation Methods 0.000 description 10
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 9
- 206010019280 Heart failures Diseases 0.000 description 9
- 238000010171 animal model Methods 0.000 description 9
- 238000011161 development Methods 0.000 description 9
- 230000018109 developmental process Effects 0.000 description 9
- 108010061238 threonyl-glycine Proteins 0.000 description 9
- 238000013518 transcription Methods 0.000 description 9
- 230000035897 transcription Effects 0.000 description 9
- 239000002299 complementary DNA Substances 0.000 description 8
- 230000002068 genetic effect Effects 0.000 description 8
- 230000012010 growth Effects 0.000 description 8
- 230000009067 heart development Effects 0.000 description 8
- 108010004914 prolylarginine Proteins 0.000 description 8
- 108010020532 tyrosyl-proline Proteins 0.000 description 8
- 239000013598 vector Substances 0.000 description 8
- 241000699666 Mus <mouse, genus> Species 0.000 description 7
- 238000004422 calculation algorithm Methods 0.000 description 7
- 230000004069 differentiation Effects 0.000 description 7
- 230000003511 endothelial effect Effects 0.000 description 7
- 238000005516 engineering process Methods 0.000 description 7
- 108010057821 leucylproline Proteins 0.000 description 7
- 230000002107 myocardial effect Effects 0.000 description 7
- 108090000765 processed proteins & peptides Proteins 0.000 description 7
- 108010031719 prolyl-serine Proteins 0.000 description 7
- 238000002560 therapeutic procedure Methods 0.000 description 7
- 108091026890 Coding region Proteins 0.000 description 6
- 208000002330 Congenital Heart Defects Diseases 0.000 description 6
- IGOYNRWLWHWAQO-JTQLQIEISA-N Gly-Phe-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 IGOYNRWLWHWAQO-JTQLQIEISA-N 0.000 description 6
- 241000124008 Mammalia Species 0.000 description 6
- 241000699670 Mus sp. Species 0.000 description 6
- 241000700159 Rattus Species 0.000 description 6
- KEGBFULVYKYJRD-LFSVMHDDSA-N Thr-Ala-Phe Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KEGBFULVYKYJRD-LFSVMHDDSA-N 0.000 description 6
- 108010005233 alanylglutamic acid Proteins 0.000 description 6
- 238000004458 analytical method Methods 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- 210000000349 chromosome Anatomy 0.000 description 6
- 238000010367 cloning Methods 0.000 description 6
- 208000028831 congenital heart disease Diseases 0.000 description 6
- 201000010099 disease Diseases 0.000 description 6
- 230000000694 effects Effects 0.000 description 6
- 108010077435 glycyl-phenylalanyl-glycine Proteins 0.000 description 6
- 239000013612 plasmid Substances 0.000 description 6
- 230000001850 reproductive effect Effects 0.000 description 6
- 210000001082 somatic cell Anatomy 0.000 description 6
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 5
- NMTANZXPDAHUKU-ULQDDVLXSA-N Arg-Tyr-Lys Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CC=C(O)C=C1 NMTANZXPDAHUKU-ULQDDVLXSA-N 0.000 description 5
- 108091033380 Coding strand Proteins 0.000 description 5
- 102000053602 DNA Human genes 0.000 description 5
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 5
- 101001031594 Homo sapiens Heart- and neural crest derivatives-expressed protein 2 Proteins 0.000 description 5
- HGCNKOLVKRAVHD-UHFFFAOYSA-N L-Met-L-Phe Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 HGCNKOLVKRAVHD-UHFFFAOYSA-N 0.000 description 5
- 241000880493 Leptailurus serval Species 0.000 description 5
- WXZOHBVPVKABQN-DCAQKATOSA-N Leu-Met-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)O)C(=O)O)N WXZOHBVPVKABQN-DCAQKATOSA-N 0.000 description 5
- YKBSXQFZWFXFIB-VOAKCMCISA-N Lys-Thr-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCCN)C(O)=O YKBSXQFZWFXFIB-VOAKCMCISA-N 0.000 description 5
- 101710163270 Nuclease Proteins 0.000 description 5
- GFHXZNVJIKMAGO-IHRRRGAJSA-N Pro-Phe-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O GFHXZNVJIKMAGO-IHRRRGAJSA-N 0.000 description 5
- ADJDNJCSPNFFPI-FXQIFTODSA-N Ser-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO ADJDNJCSPNFFPI-FXQIFTODSA-N 0.000 description 5
- 102000040945 Transcription factor Human genes 0.000 description 5
- 108091023040 Transcription factor Proteins 0.000 description 5
- 230000008901 benefit Effects 0.000 description 5
- 210000004369 blood Anatomy 0.000 description 5
- 239000008280 blood Substances 0.000 description 5
- 239000003814 drug Substances 0.000 description 5
- 230000002526 effect on cardiovascular system Effects 0.000 description 5
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 5
- 108010092114 histidylphenylalanine Proteins 0.000 description 5
- 108010054155 lysyllysine Proteins 0.000 description 5
- 108010068488 methionylphenylalanine Proteins 0.000 description 5
- 239000000203 mixture Substances 0.000 description 5
- 230000001537 neural effect Effects 0.000 description 5
- 108010070643 prolylglutamic acid Proteins 0.000 description 5
- 238000007894 restriction fragment length polymorphism technique Methods 0.000 description 5
- 238000001890 transfection Methods 0.000 description 5
- MQIGTEQXYCRLGK-BQBZGAKWSA-N Ala-Gly-Pro Chemical compound C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O MQIGTEQXYCRLGK-BQBZGAKWSA-N 0.000 description 4
- IUZGUFAJDBHQQV-YUMQZZPRSA-N Gly-Leu-Asn Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IUZGUFAJDBHQQV-YUMQZZPRSA-N 0.000 description 4
- 108010065920 Insulin Lispro Proteins 0.000 description 4
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 4
- WGNOPSQMIQERPK-UHFFFAOYSA-N Leu-Asn-Pro Natural products CC(C)CC(N)C(=O)NC(CC(=O)N)C(=O)N1CCCC1C(=O)O WGNOPSQMIQERPK-UHFFFAOYSA-N 0.000 description 4
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 4
- 108091034117 Oligonucleotide Proteins 0.000 description 4
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 4
- HUPLKEHTTQBXSC-YJRXYDGGSA-N Thr-Ser-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUPLKEHTTQBXSC-YJRXYDGGSA-N 0.000 description 4
- 108700019146 Transgenes Proteins 0.000 description 4
- JIODCDXKCJRMEH-NHCYSSNCSA-N Val-Arg-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N JIODCDXKCJRMEH-NHCYSSNCSA-N 0.000 description 4
- YTNGABPUXFEOGU-SRVKXCTJSA-N Val-Pro-Arg Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O YTNGABPUXFEOGU-SRVKXCTJSA-N 0.000 description 4
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 4
- 108010047495 alanylglycine Proteins 0.000 description 4
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 4
- 238000013459 approach Methods 0.000 description 4
- 108010008355 arginyl-glutamine Proteins 0.000 description 4
- 208000035475 disorder Diseases 0.000 description 4
- 210000001671 embryonic stem cell Anatomy 0.000 description 4
- 239000012634 fragment Substances 0.000 description 4
- 230000004398 heart morphogenesis Effects 0.000 description 4
- 238000000338 in vitro Methods 0.000 description 4
- 230000001404 mediated effect Effects 0.000 description 4
- 238000013310 pig model Methods 0.000 description 4
- 230000008569 process Effects 0.000 description 4
- 230000001172 regenerating effect Effects 0.000 description 4
- 108010005652 splenotritin Proteins 0.000 description 4
- 230000009261 transgenic effect Effects 0.000 description 4
- 238000011830 transgenic mouse model Methods 0.000 description 4
- 108010073969 valyllysine Proteins 0.000 description 4
- 239000013603 viral vector Substances 0.000 description 4
- WXERCAHAIKMTKX-ZLUOBGJFSA-N Ala-Asp-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O WXERCAHAIKMTKX-ZLUOBGJFSA-N 0.000 description 3
- FUSPCLTUKXQREV-ACZMJKKPSA-N Ala-Glu-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O FUSPCLTUKXQREV-ACZMJKKPSA-N 0.000 description 3
- CYBJZLQSUJEMAS-LFSVMHDDSA-N Ala-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C)N)O CYBJZLQSUJEMAS-LFSVMHDDSA-N 0.000 description 3
- XPSGESXVBSQZPL-SRVKXCTJSA-N Arg-Arg-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XPSGESXVBSQZPL-SRVKXCTJSA-N 0.000 description 3
- HJWQFFYRVFEWRM-SRVKXCTJSA-N Arg-Arg-Met Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(O)=O HJWQFFYRVFEWRM-SRVKXCTJSA-N 0.000 description 3
- NKBQZKVMKJJDLX-SRVKXCTJSA-N Arg-Glu-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NKBQZKVMKJJDLX-SRVKXCTJSA-N 0.000 description 3
- WVNFNPGXYADPPO-BQBZGAKWSA-N Arg-Gly-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O WVNFNPGXYADPPO-BQBZGAKWSA-N 0.000 description 3
- CVXXSWQORBZAAA-SRVKXCTJSA-N Arg-Lys-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCN=C(N)N CVXXSWQORBZAAA-SRVKXCTJSA-N 0.000 description 3
- LRPZJPMQGKGHSG-XGEHTFHBSA-N Arg-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)O LRPZJPMQGKGHSG-XGEHTFHBSA-N 0.000 description 3
- MSBDSTRUMZFSEU-PEFMBERDSA-N Asn-Glu-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MSBDSTRUMZFSEU-PEFMBERDSA-N 0.000 description 3
- OPEPUCYIGFEGSW-WDSKDSINSA-N Asn-Gly-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O OPEPUCYIGFEGSW-WDSKDSINSA-N 0.000 description 3
- OOWSBIOUKIUWLO-RCOVLWMOSA-N Asn-Gly-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O OOWSBIOUKIUWLO-RCOVLWMOSA-N 0.000 description 3
- WIDVAWAQBRAKTI-YUMQZZPRSA-N Asn-Leu-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O WIDVAWAQBRAKTI-YUMQZZPRSA-N 0.000 description 3
- XFJKRRCWLTZIQA-XIRDDKMYSA-N Asn-Lys-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)N)N XFJKRRCWLTZIQA-XIRDDKMYSA-N 0.000 description 3
- ZNYKKCADEQAZKA-FXQIFTODSA-N Asn-Ser-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O ZNYKKCADEQAZKA-FXQIFTODSA-N 0.000 description 3
- FRSGNOZCTWDVFZ-ACZMJKKPSA-N Asp-Asp-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O FRSGNOZCTWDVFZ-ACZMJKKPSA-N 0.000 description 3
- XJQRWGXKUSDEFI-ACZMJKKPSA-N Asp-Glu-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O XJQRWGXKUSDEFI-ACZMJKKPSA-N 0.000 description 3
- JXGJJQJHXHXJQF-CIUDSAMLSA-N Asp-Met-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O JXGJJQJHXHXJQF-CIUDSAMLSA-N 0.000 description 3
- 102100021277 Beta-secretase 2 Human genes 0.000 description 3
- 101710150190 Beta-secretase 2 Proteins 0.000 description 3
- 108020004705 Codon Proteins 0.000 description 3
- 206010010356 Congenital anomaly Diseases 0.000 description 3
- ODDOYXKAHLKKQY-MMWGEVLESA-N Cys-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CS)N ODDOYXKAHLKKQY-MMWGEVLESA-N 0.000 description 3
- UKHNKRGNFKSHCG-CUJWVEQBSA-N Cys-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CS)N)O UKHNKRGNFKSHCG-CUJWVEQBSA-N 0.000 description 3
- 230000004568 DNA-binding Effects 0.000 description 3
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 3
- LLVXTGUTDYMJLY-GUBZILKMSA-N Gln-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)N)N LLVXTGUTDYMJLY-GUBZILKMSA-N 0.000 description 3
- IPHGBVYWRKCGKG-FXQIFTODSA-N Gln-Cys-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O IPHGBVYWRKCGKG-FXQIFTODSA-N 0.000 description 3
- NKCZYEDZTKOFBG-GUBZILKMSA-N Gln-Gln-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NKCZYEDZTKOFBG-GUBZILKMSA-N 0.000 description 3
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 3
- QQAPDATZKKTBIY-YUMQZZPRSA-N Gln-Gly-Met Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O QQAPDATZKKTBIY-YUMQZZPRSA-N 0.000 description 3
- IOFDDSNZJDIGPB-GVXVVHGQSA-N Gln-Leu-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IOFDDSNZJDIGPB-GVXVVHGQSA-N 0.000 description 3
- XUMFMAVDHQDATI-DCAQKATOSA-N Gln-Pro-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XUMFMAVDHQDATI-DCAQKATOSA-N 0.000 description 3
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 3
- CUXJIASLBRJOFV-LAEOZQHASA-N Glu-Gly-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O CUXJIASLBRJOFV-LAEOZQHASA-N 0.000 description 3
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 3
- FKJQNJCQTKUBCD-XPUUQOCRSA-N Gly-Ala-His Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O FKJQNJCQTKUBCD-XPUUQOCRSA-N 0.000 description 3
- QXPRJQPCFXMCIY-NKWVEPMBSA-N Gly-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN QXPRJQPCFXMCIY-NKWVEPMBSA-N 0.000 description 3
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 3
- DTPOVRRYXPJJAZ-FJXKBIBVSA-N Gly-Arg-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N DTPOVRRYXPJJAZ-FJXKBIBVSA-N 0.000 description 3
- BUEFQXUHTUZXHR-LURJTMIESA-N Gly-Gly-Pro zwitterion Chemical compound NCC(=O)NCC(=O)N1CCC[C@H]1C(O)=O BUEFQXUHTUZXHR-LURJTMIESA-N 0.000 description 3
- VBOBNHSVQKKTOT-YUMQZZPRSA-N Gly-Lys-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O VBOBNHSVQKKTOT-YUMQZZPRSA-N 0.000 description 3
- DBUNZBWUWCIELX-JHEQGTHGSA-N Gly-Thr-Glu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O DBUNZBWUWCIELX-JHEQGTHGSA-N 0.000 description 3
- SFOXOSKVTLDEDM-HOTGVXAUSA-N Gly-Trp-Leu Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)CN)=CNC2=C1 SFOXOSKVTLDEDM-HOTGVXAUSA-N 0.000 description 3
- PASHZZBXZYEXFE-LSDHHAIUSA-N Gly-Trp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)CN)C(=O)O PASHZZBXZYEXFE-LSDHHAIUSA-N 0.000 description 3
- RYAOJUMWLWUGNW-QMMMGPOBSA-N Gly-Val-Gly Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O RYAOJUMWLWUGNW-QMMMGPOBSA-N 0.000 description 3
- 102100038654 Heart- and neural crest derivatives-expressed protein 2 Human genes 0.000 description 3
- STWGDDDFLUFCCA-GVXVVHGQSA-N His-Glu-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O STWGDDDFLUFCCA-GVXVVHGQSA-N 0.000 description 3
- FYTCLUIYTYFGPT-YUMQZZPRSA-N His-Gly-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FYTCLUIYTYFGPT-YUMQZZPRSA-N 0.000 description 3
- BCZFOHDMCDXPDA-BZSNNMDCSA-N His-Lys-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC2=CN=CN2)N)O BCZFOHDMCDXPDA-BZSNNMDCSA-N 0.000 description 3
- BZAQOPHNBFOOJS-DCAQKATOSA-N His-Pro-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O BZAQOPHNBFOOJS-DCAQKATOSA-N 0.000 description 3
- PLCAEMGSYOYIPP-GUBZILKMSA-N His-Ser-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 PLCAEMGSYOYIPP-GUBZILKMSA-N 0.000 description 3
- MKWSZEHGHSLNPF-NAKRPEOUSA-N Ile-Ala-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O)N MKWSZEHGHSLNPF-NAKRPEOUSA-N 0.000 description 3
- TWPSALMCEHCIOY-YTFOTSKYSA-N Ile-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(=O)O)N TWPSALMCEHCIOY-YTFOTSKYSA-N 0.000 description 3
- CKRFDMPBSWYOBT-PPCPHDFISA-N Ile-Lys-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N CKRFDMPBSWYOBT-PPCPHDFISA-N 0.000 description 3
- RQZFWBLDTBDEOF-RNJOBUHISA-N Ile-Val-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N RQZFWBLDTBDEOF-RNJOBUHISA-N 0.000 description 3
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 3
- PBCHMHROGNUXMK-DLOVCJGASA-N Leu-Ala-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 PBCHMHROGNUXMK-DLOVCJGASA-N 0.000 description 3
- KWTVLKBOQATPHJ-SRVKXCTJSA-N Leu-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N KWTVLKBOQATPHJ-SRVKXCTJSA-N 0.000 description 3
- HASRFYOMVPJRPU-SRVKXCTJSA-N Leu-Arg-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O HASRFYOMVPJRPU-SRVKXCTJSA-N 0.000 description 3
- MMEDVBWCMGRKKC-GARJFASQSA-N Leu-Asp-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N MMEDVBWCMGRKKC-GARJFASQSA-N 0.000 description 3
- VZBIUJURDLFFOE-IHRRRGAJSA-N Leu-His-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VZBIUJURDLFFOE-IHRRRGAJSA-N 0.000 description 3
- KXODZBLFVFSLAI-AVGNSLFASA-N Leu-His-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CN=CN1 KXODZBLFVFSLAI-AVGNSLFASA-N 0.000 description 3
- XQXGNBFMAXWIGI-MXAVVETBSA-N Leu-His-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CN=CN1 XQXGNBFMAXWIGI-MXAVVETBSA-N 0.000 description 3
- FKQPWMZLIIATBA-AJNGGQMLSA-N Leu-Lys-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FKQPWMZLIIATBA-AJNGGQMLSA-N 0.000 description 3
- QNTJIDXQHWUBKC-BZSNNMDCSA-N Leu-Lys-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QNTJIDXQHWUBKC-BZSNNMDCSA-N 0.000 description 3
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 3
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 3
- VQHUBNVKFFLWRP-ULQDDVLXSA-N Leu-Tyr-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=C(O)C=C1 VQHUBNVKFFLWRP-ULQDDVLXSA-N 0.000 description 3
- IWWMPCPLFXFBAF-SRVKXCTJSA-N Lys-Asp-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O IWWMPCPLFXFBAF-SRVKXCTJSA-N 0.000 description 3
- DCRWPTBMWMGADO-AVGNSLFASA-N Lys-Glu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O DCRWPTBMWMGADO-AVGNSLFASA-N 0.000 description 3
- ODUQLUADRKMHOZ-JYJNAYRXSA-N Lys-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)O ODUQLUADRKMHOZ-JYJNAYRXSA-N 0.000 description 3
- PBLLTSKBTAHDNA-KBPBESRZSA-N Lys-Gly-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PBLLTSKBTAHDNA-KBPBESRZSA-N 0.000 description 3
- NCZIQZYZPUPMKY-PPCPHDFISA-N Lys-Ile-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NCZIQZYZPUPMKY-PPCPHDFISA-N 0.000 description 3
- RBEATVHTWHTHTJ-KKUMJFAQSA-N Lys-Leu-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O RBEATVHTWHTHTJ-KKUMJFAQSA-N 0.000 description 3
- GIKFNMZSGYAPEJ-HJGDQZAQSA-N Lys-Thr-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O GIKFNMZSGYAPEJ-HJGDQZAQSA-N 0.000 description 3
- VWPJQIHBBOJWDN-DCAQKATOSA-N Lys-Val-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O VWPJQIHBBOJWDN-DCAQKATOSA-N 0.000 description 3
- TXTZMVNJIRZABH-ULQDDVLXSA-N Lys-Val-Phe Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 TXTZMVNJIRZABH-ULQDDVLXSA-N 0.000 description 3
- RIPJMCFGQHGHNP-RHYQMDGZSA-N Lys-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCCCN)N)O RIPJMCFGQHGHNP-RHYQMDGZSA-N 0.000 description 3
- LMKSBGIUPVRHEH-FXQIFTODSA-N Met-Ala-Asn Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(N)=O LMKSBGIUPVRHEH-FXQIFTODSA-N 0.000 description 3
- VHGIWFGJIHTASW-FXQIFTODSA-N Met-Ala-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O VHGIWFGJIHTASW-FXQIFTODSA-N 0.000 description 3
- RZJOHSFAEZBWLK-CIUDSAMLSA-N Met-Gln-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N RZJOHSFAEZBWLK-CIUDSAMLSA-N 0.000 description 3
- MVMNUCOHQGYYKB-PEDHHIEDSA-N Met-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H](CCSC)N MVMNUCOHQGYYKB-PEDHHIEDSA-N 0.000 description 3
- XPVCDCMPKCERFT-GUBZILKMSA-N Met-Ser-Arg Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O XPVCDCMPKCERFT-GUBZILKMSA-N 0.000 description 3
- WYBVBIHNJWOLCJ-UHFFFAOYSA-N N-L-arginyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCCN=C(N)N WYBVBIHNJWOLCJ-UHFFFAOYSA-N 0.000 description 3
- LSXGADJXBDFXQU-DLOVCJGASA-N Phe-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 LSXGADJXBDFXQU-DLOVCJGASA-N 0.000 description 3
- CYZBFPYMSJGBRL-DRZSPHRISA-N Phe-Ala-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CYZBFPYMSJGBRL-DRZSPHRISA-N 0.000 description 3
- XEXSSIBQYNKFBX-KBPBESRZSA-N Phe-Gly-His Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1N=CNC=1)C(O)=O)C1=CC=CC=C1 XEXSSIBQYNKFBX-KBPBESRZSA-N 0.000 description 3
- DNAXXTQSTKOHFO-QEJZJMRPSA-N Phe-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=CC=C1 DNAXXTQSTKOHFO-QEJZJMRPSA-N 0.000 description 3
- NJJBATPLUQHRBM-IHRRRGAJSA-N Phe-Pro-Ser Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)N)C(=O)N[C@@H](CO)C(=O)O NJJBATPLUQHRBM-IHRRRGAJSA-N 0.000 description 3
- DRVIASBABBMZTF-GUBZILKMSA-N Pro-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@@H]1CCCN1 DRVIASBABBMZTF-GUBZILKMSA-N 0.000 description 3
- NHDVNAKDACFHPX-GUBZILKMSA-N Pro-Arg-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O NHDVNAKDACFHPX-GUBZILKMSA-N 0.000 description 3
- TXPUNZXZDVJUJQ-LPEHRKFASA-N Pro-Asn-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O TXPUNZXZDVJUJQ-LPEHRKFASA-N 0.000 description 3
- QXNSKJLSLYCTMT-FXQIFTODSA-N Pro-Cys-Asp Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O QXNSKJLSLYCTMT-FXQIFTODSA-N 0.000 description 3
- JFNPBBOGGNMSRX-CIUDSAMLSA-N Pro-Gln-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O JFNPBBOGGNMSRX-CIUDSAMLSA-N 0.000 description 3
- UPJGUQPLYWTISV-GUBZILKMSA-N Pro-Gln-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UPJGUQPLYWTISV-GUBZILKMSA-N 0.000 description 3
- LHALYDBUDCWMDY-CIUDSAMLSA-N Pro-Glu-Ala Chemical compound C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1)C(O)=O LHALYDBUDCWMDY-CIUDSAMLSA-N 0.000 description 3
- DMKWYMWNEKIPFC-IUCAKERBSA-N Pro-Gly-Arg Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O DMKWYMWNEKIPFC-IUCAKERBSA-N 0.000 description 3
- FKLSMYYLJHYPHH-UWVGGRQHSA-N Pro-Gly-Leu Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O FKLSMYYLJHYPHH-UWVGGRQHSA-N 0.000 description 3
- ZUZINZIJHJFJRN-UBHSHLNASA-N Pro-Phe-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@H]1NCCC1)C1=CC=CC=C1 ZUZINZIJHJFJRN-UBHSHLNASA-N 0.000 description 3
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 3
- MMGJPDWSIOAGTH-ACZMJKKPSA-N Ser-Ala-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MMGJPDWSIOAGTH-ACZMJKKPSA-N 0.000 description 3
- WXWDPFVKQRVJBJ-CIUDSAMLSA-N Ser-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N WXWDPFVKQRVJBJ-CIUDSAMLSA-N 0.000 description 3
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 3
- VDVYTKZBMFADQH-AVGNSLFASA-N Ser-Gln-Tyr Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 VDVYTKZBMFADQH-AVGNSLFASA-N 0.000 description 3
- UFKPDBLKLOBMRH-XHNCKOQMSA-N Ser-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N)C(=O)O UFKPDBLKLOBMRH-XHNCKOQMSA-N 0.000 description 3
- HDBOEVPDIDDEPC-CIUDSAMLSA-N Ser-Lys-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O HDBOEVPDIDDEPC-CIUDSAMLSA-N 0.000 description 3
- PTWIYDNFWPXQSD-GARJFASQSA-N Ser-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N)C(=O)O PTWIYDNFWPXQSD-GARJFASQSA-N 0.000 description 3
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 3
- FZEUTKVQGMVGHW-AVGNSLFASA-N Ser-Phe-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O FZEUTKVQGMVGHW-AVGNSLFASA-N 0.000 description 3
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 3
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 3
- PAOYNIKMYOGBMR-PBCZWWQYSA-N Thr-Asn-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N)O PAOYNIKMYOGBMR-PBCZWWQYSA-N 0.000 description 3
- KRDSCBLRHORMRK-JXUBOQSCSA-N Thr-Lys-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O KRDSCBLRHORMRK-JXUBOQSCSA-N 0.000 description 3
- TZJSEJOXAIWOST-RHYQMDGZSA-N Thr-Lys-Arg Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N TZJSEJOXAIWOST-RHYQMDGZSA-N 0.000 description 3
- DEGCBBCMYWNJNA-RHYQMDGZSA-N Thr-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O DEGCBBCMYWNJNA-RHYQMDGZSA-N 0.000 description 3
- WPSKTVVMQCXPRO-BWBBJGPYSA-N Thr-Ser-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WPSKTVVMQCXPRO-BWBBJGPYSA-N 0.000 description 3
- SNWIAPVRCNYFNI-SZMVWBNQSA-N Trp-Met-Arg Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N SNWIAPVRCNYFNI-SZMVWBNQSA-N 0.000 description 3
- OHNXAUCZVWGTLL-KKUMJFAQSA-N Tyr-His-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CS)C(=O)O)N)O OHNXAUCZVWGTLL-KKUMJFAQSA-N 0.000 description 3
- HVPPEXXUDXAPOM-MGHWNKPDSA-N Tyr-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 HVPPEXXUDXAPOM-MGHWNKPDSA-N 0.000 description 3
- PMHLLBKTDHQMCY-ULQDDVLXSA-N Tyr-Lys-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O PMHLLBKTDHQMCY-ULQDDVLXSA-N 0.000 description 3
- BIWVVOHTKDLRMP-ULQDDVLXSA-N Tyr-Pro-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O BIWVVOHTKDLRMP-ULQDDVLXSA-N 0.000 description 3
- RWOGENDAOGMHLX-DCAQKATOSA-N Val-Lys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C(C)C)N RWOGENDAOGMHLX-DCAQKATOSA-N 0.000 description 3
- VCIYTVOBLZHFSC-XHSDSOJGSA-N Val-Phe-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N VCIYTVOBLZHFSC-XHSDSOJGSA-N 0.000 description 3
- JSOXWWFKRJKTMT-WOPDTQHZSA-N Val-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N JSOXWWFKRJKTMT-WOPDTQHZSA-N 0.000 description 3
- 108010070944 alanylhistidine Proteins 0.000 description 3
- 108010087924 alanylproline Proteins 0.000 description 3
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 3
- 108010062796 arginyllysine Proteins 0.000 description 3
- 108010077245 asparaginyl-proline Proteins 0.000 description 3
- 230000001746 atrial effect Effects 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 3
- 230000034994 death Effects 0.000 description 3
- 238000010586 diagram Methods 0.000 description 3
- 230000005782 double-strand break Effects 0.000 description 3
- 239000012636 effector Substances 0.000 description 3
- 235000013601 eggs Nutrition 0.000 description 3
- 239000003623 enhancer Substances 0.000 description 3
- 101150003286 gata4 gene Proteins 0.000 description 3
- 108010008237 glutamyl-valyl-glycine Proteins 0.000 description 3
- 108010079547 glutamylmethionine Proteins 0.000 description 3
- JYPCXBJRLBHWME-UHFFFAOYSA-N glycyl-L-prolyl-L-arginine Natural products NCC(=O)N1CCCC1C(=O)NC(CCCN=C(N)N)C(O)=O JYPCXBJRLBHWME-UHFFFAOYSA-N 0.000 description 3
- 108010037850 glycylvaline Proteins 0.000 description 3
- 108010025306 histidylleucine Proteins 0.000 description 3
- 108010018006 histidylserine Proteins 0.000 description 3
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 3
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 3
- 108010003700 lysyl aspartic acid Proteins 0.000 description 3
- 239000000463 material Substances 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 108010056582 methionylglutamic acid Proteins 0.000 description 3
- 210000000496 pancreas Anatomy 0.000 description 3
- 108010074082 phenylalanyl-alanyl-lysine Proteins 0.000 description 3
- 150000008298 phosphoramidates Chemical class 0.000 description 3
- 229920000642 polymer Polymers 0.000 description 3
- 239000002243 precursor Substances 0.000 description 3
- 238000002360 preparation method Methods 0.000 description 3
- 102000004196 processed proteins & peptides Human genes 0.000 description 3
- 230000002062 proliferating effect Effects 0.000 description 3
- 108010077112 prolyl-proline Proteins 0.000 description 3
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 3
- 230000008929 regeneration Effects 0.000 description 3
- 238000011069 regeneration method Methods 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- 125000001424 substituent group Chemical group 0.000 description 3
- 230000008685 targeting Effects 0.000 description 3
- 108010017949 tyrosyl-glycyl-glycine Proteins 0.000 description 3
- 210000005166 vasculature Anatomy 0.000 description 3
- 238000005406 washing Methods 0.000 description 3
- WOVKYSAHUYNSMH-RRKCRQDMSA-N 5-bromodeoxyuridine Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(Br)=C1 WOVKYSAHUYNSMH-RRKCRQDMSA-N 0.000 description 2
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 2
- 229930024421 Adenine Natural products 0.000 description 2
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 2
- BTYTYHBSJKQBQA-GCJQMDKQSA-N Ala-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N)O BTYTYHBSJKQBQA-GCJQMDKQSA-N 0.000 description 2
- 108010011667 Ala-Phe-Ala Proteins 0.000 description 2
- WEZNQZHACPSMEF-QEJZJMRPSA-N Ala-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 WEZNQZHACPSMEF-QEJZJMRPSA-N 0.000 description 2
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 2
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 2
- FEZJJKXNPSEYEV-CIUDSAMLSA-N Arg-Gln-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O FEZJJKXNPSEYEV-CIUDSAMLSA-N 0.000 description 2
- BGDILZXXDJCKPF-CIUDSAMLSA-N Arg-Gln-Cys Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CS)C(O)=O BGDILZXXDJCKPF-CIUDSAMLSA-N 0.000 description 2
- NMRHDSAOIURTNT-RWMBFGLXSA-N Arg-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N NMRHDSAOIURTNT-RWMBFGLXSA-N 0.000 description 2
- VUGWHBXPMAHEGZ-SRVKXCTJSA-N Arg-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N VUGWHBXPMAHEGZ-SRVKXCTJSA-N 0.000 description 2
- AUZAXCPWMDBWEE-HJGDQZAQSA-N Arg-Thr-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O AUZAXCPWMDBWEE-HJGDQZAQSA-N 0.000 description 2
- XTMZYFMTYJNABC-ZLUOBGJFSA-N Asn-Ser-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N XTMZYFMTYJNABC-ZLUOBGJFSA-N 0.000 description 2
- GHWWTICYPDKPTE-NGZCFLSTSA-N Asn-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N GHWWTICYPDKPTE-NGZCFLSTSA-N 0.000 description 2
- 201000001320 Atherosclerosis Diseases 0.000 description 2
- 108091033409 CRISPR Proteins 0.000 description 2
- ZAMOUSCENKQFHK-UHFFFAOYSA-N Chlorine atom Chemical compound [Cl] ZAMOUSCENKQFHK-UHFFFAOYSA-N 0.000 description 2
- CYHMMWIOEUVHHZ-IHRRRGAJSA-N Cys-Met-Tyr Chemical compound SC[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 CYHMMWIOEUVHHZ-IHRRRGAJSA-N 0.000 description 2
- ABLQPNMKLMFDQU-BIIVOSGPSA-N Cys-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CS)N)C(=O)O ABLQPNMKLMFDQU-BIIVOSGPSA-N 0.000 description 2
- KFYPRIGJTICABD-XGEHTFHBSA-N Cys-Thr-Val Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N)O KFYPRIGJTICABD-XGEHTFHBSA-N 0.000 description 2
- 230000007018 DNA scission Effects 0.000 description 2
- 101100481408 Danio rerio tie2 gene Proteins 0.000 description 2
- 108700029231 Developmental Genes Proteins 0.000 description 2
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 2
- 108090000790 Enzymes Proteins 0.000 description 2
- 102000004190 Enzymes Human genes 0.000 description 2
- WOACHWLUOFZLGJ-GUBZILKMSA-N Gln-Arg-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O WOACHWLUOFZLGJ-GUBZILKMSA-N 0.000 description 2
- XWIBVSAEUCAAKF-GVXVVHGQSA-N Gln-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCC(=O)N)N XWIBVSAEUCAAKF-GVXVVHGQSA-N 0.000 description 2
- CAXXTYYGFYTBPV-IUCAKERBSA-N Gln-Leu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CAXXTYYGFYTBPV-IUCAKERBSA-N 0.000 description 2
- SXFPZRRVWSUYII-KBIXCLLPSA-N Gln-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N SXFPZRRVWSUYII-KBIXCLLPSA-N 0.000 description 2
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 2
- ARYKRXHBIPLULY-XKBZYTNZSA-N Gln-Thr-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ARYKRXHBIPLULY-XKBZYTNZSA-N 0.000 description 2
- IESFZVCAVACGPH-PEFMBERDSA-N Glu-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O IESFZVCAVACGPH-PEFMBERDSA-N 0.000 description 2
- KVBPDJIFRQUQFY-ACZMJKKPSA-N Glu-Cys-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O KVBPDJIFRQUQFY-ACZMJKKPSA-N 0.000 description 2
- NKLRYVLERDYDBI-FXQIFTODSA-N Glu-Glu-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKLRYVLERDYDBI-FXQIFTODSA-N 0.000 description 2
- VOORMNJKNBGYGK-YUMQZZPRSA-N Glu-Gly-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)O)N VOORMNJKNBGYGK-YUMQZZPRSA-N 0.000 description 2
- SJJHXJDSNQJMMW-SRVKXCTJSA-N Glu-Lys-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O SJJHXJDSNQJMMW-SRVKXCTJSA-N 0.000 description 2
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 2
- BPLNJYHNAJVLRT-ACZMJKKPSA-N Glu-Ser-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O BPLNJYHNAJVLRT-ACZMJKKPSA-N 0.000 description 2
- RFTVTKBHDXCEEX-WDSKDSINSA-N Glu-Ser-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RFTVTKBHDXCEEX-WDSKDSINSA-N 0.000 description 2
- HVKAAUOFFTUSAA-XDTLVQLUSA-N Glu-Tyr-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O HVKAAUOFFTUSAA-XDTLVQLUSA-N 0.000 description 2
- PYTZFYUXZZHOAD-WHFBIAKZSA-N Gly-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)CN PYTZFYUXZZHOAD-WHFBIAKZSA-N 0.000 description 2
- QSTLUOIOYLYLLF-WDSKDSINSA-N Gly-Asp-Glu Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QSTLUOIOYLYLLF-WDSKDSINSA-N 0.000 description 2
- SOEATRRYCIPEHA-BQBZGAKWSA-N Gly-Glu-Glu Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SOEATRRYCIPEHA-BQBZGAKWSA-N 0.000 description 2
- UUYBFNKHOCJCHT-VHSXEESVSA-N Gly-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN UUYBFNKHOCJCHT-VHSXEESVSA-N 0.000 description 2
- HJARVELKOSZUEW-YUMQZZPRSA-N Gly-Pro-Gln Chemical compound [H]NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O HJARVELKOSZUEW-YUMQZZPRSA-N 0.000 description 2
- HFPVRZWORNJRRC-UWVGGRQHSA-N Gly-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN HFPVRZWORNJRRC-UWVGGRQHSA-N 0.000 description 2
- FMRKUXFLLPKVPG-JYJNAYRXSA-N His-Gln-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC2=CN=CN2)N)O FMRKUXFLLPKVPG-JYJNAYRXSA-N 0.000 description 2
- NTXIJPDAHXSHNL-ONGXEEELSA-N His-Gly-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O NTXIJPDAHXSHNL-ONGXEEELSA-N 0.000 description 2
- JSQIXEHORHLQEE-MEYUZBJRSA-N His-Phe-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JSQIXEHORHLQEE-MEYUZBJRSA-N 0.000 description 2
- DGLAHESNTJWGDO-SRVKXCTJSA-N His-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N DGLAHESNTJWGDO-SRVKXCTJSA-N 0.000 description 2
- 101000625919 Homo sapiens T-box transcription factor TBX5 Proteins 0.000 description 2
- 101000819111 Homo sapiens Trans-acting T-cell-specific transcription factor GATA-3 Proteins 0.000 description 2
- 101000819074 Homo sapiens Transcription factor GATA-4 Proteins 0.000 description 2
- KIAOPHMUNPPGEN-PEXQALLHSA-N Ile-Gly-His Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KIAOPHMUNPPGEN-PEXQALLHSA-N 0.000 description 2
- TWYOYAKMLHWMOJ-ZPFDUUQYSA-N Ile-Leu-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O TWYOYAKMLHWMOJ-ZPFDUUQYSA-N 0.000 description 2
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 2
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 2
- XBBKIIGCUMBKCO-JXUBOQSCSA-N Leu-Ala-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XBBKIIGCUMBKCO-JXUBOQSCSA-N 0.000 description 2
- KVMULWOHPPMHHE-DCAQKATOSA-N Leu-Glu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KVMULWOHPPMHHE-DCAQKATOSA-N 0.000 description 2
- HQUXQAMSWFIRET-AVGNSLFASA-N Leu-Glu-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN HQUXQAMSWFIRET-AVGNSLFASA-N 0.000 description 2
- ZGUMORRUBUCXEH-AVGNSLFASA-N Leu-Lys-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZGUMORRUBUCXEH-AVGNSLFASA-N 0.000 description 2
- AMSSKPUHBUQBOQ-SRVKXCTJSA-N Leu-Ser-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N AMSSKPUHBUQBOQ-SRVKXCTJSA-N 0.000 description 2
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 2
- CLBGMWIYPYAZPR-AVGNSLFASA-N Lys-Arg-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O CLBGMWIYPYAZPR-AVGNSLFASA-N 0.000 description 2
- PBIPLDMFHAICIP-DCAQKATOSA-N Lys-Glu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PBIPLDMFHAICIP-DCAQKATOSA-N 0.000 description 2
- MIROMRNASYKZNL-ULQDDVLXSA-N Lys-Pro-Tyr Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 MIROMRNASYKZNL-ULQDDVLXSA-N 0.000 description 2
- JPCHYAUKOUGOIB-HJGDQZAQSA-N Met-Glu-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPCHYAUKOUGOIB-HJGDQZAQSA-N 0.000 description 2
- NTYQUVLERIHPMU-HRCADAONSA-N Met-Phe-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N NTYQUVLERIHPMU-HRCADAONSA-N 0.000 description 2
- NHXXGBXJTLRGJI-GUBZILKMSA-N Met-Pro-Ser Chemical compound [H]N[C@@H](CCSC)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O NHXXGBXJTLRGJI-GUBZILKMSA-N 0.000 description 2
- 101100481410 Mus musculus Tek gene Proteins 0.000 description 2
- 208000021642 Muscular disease Diseases 0.000 description 2
- 208000023178 Musculoskeletal disease Diseases 0.000 description 2
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 2
- 108010066427 N-valyltryptophan Proteins 0.000 description 2
- 102000019040 Nuclear Antigens Human genes 0.000 description 2
- 108010051791 Nuclear Antigens Proteins 0.000 description 2
- TTZMPOZCBFTTPR-UHFFFAOYSA-N O=P1OCO1 Chemical class O=P1OCO1 TTZMPOZCBFTTPR-UHFFFAOYSA-N 0.000 description 2
- CTNODEMQIKCZGQ-JYJNAYRXSA-N Phe-Gln-His Chemical compound C([C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CC=CC=C1 CTNODEMQIKCZGQ-JYJNAYRXSA-N 0.000 description 2
- KNYPNEYICHHLQL-ACRUOGEOSA-N Phe-Leu-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 KNYPNEYICHHLQL-ACRUOGEOSA-N 0.000 description 2
- AFNJAQVMTIQTCB-DLOVCJGASA-N Phe-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 AFNJAQVMTIQTCB-DLOVCJGASA-N 0.000 description 2
- VFDRDMOMHBJGKD-UFYCRDLUSA-N Phe-Tyr-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N VFDRDMOMHBJGKD-UFYCRDLUSA-N 0.000 description 2
- LCRSGSIRKLXZMZ-BPNCWPANSA-N Pro-Ala-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LCRSGSIRKLXZMZ-BPNCWPANSA-N 0.000 description 2
- ZCXQTRXYZOSGJR-FXQIFTODSA-N Pro-Asp-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZCXQTRXYZOSGJR-FXQIFTODSA-N 0.000 description 2
- FISHYTLIMUYTQY-GUBZILKMSA-N Pro-Gln-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H]1CCCN1 FISHYTLIMUYTQY-GUBZILKMSA-N 0.000 description 2
- PTLOFJZJADCNCD-DCAQKATOSA-N Pro-Glu-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 PTLOFJZJADCNCD-DCAQKATOSA-N 0.000 description 2
- QEWBZBLXDKIQPS-STQMWFEESA-N Pro-Gly-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QEWBZBLXDKIQPS-STQMWFEESA-N 0.000 description 2
- NTXFLJULRHQMDC-GUBZILKMSA-N Pro-Met-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@@H]1CCCN1 NTXFLJULRHQMDC-GUBZILKMSA-N 0.000 description 2
- FHZJRBVMLGOHBX-GUBZILKMSA-N Pro-Pro-Asp Chemical compound OC(=O)C[C@H](NC(=O)[C@@H]1CCCN1C(=O)[C@@H]1CCCN1)C(O)=O FHZJRBVMLGOHBX-GUBZILKMSA-N 0.000 description 2
- SBVPYBFMIGDIDX-SRVKXCTJSA-N Pro-Pro-Pro Chemical compound OC(=O)[C@@H]1CCCN1C(=O)[C@H]1N(C(=O)[C@H]2NCCC2)CCC1 SBVPYBFMIGDIDX-SRVKXCTJSA-N 0.000 description 2
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 2
- LNICFEXCAHIJOR-DCAQKATOSA-N Pro-Ser-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LNICFEXCAHIJOR-DCAQKATOSA-N 0.000 description 2
- UIUWGMRJTWHIJZ-ULQDDVLXSA-N Pro-Tyr-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCCCN)C(=O)O UIUWGMRJTWHIJZ-ULQDDVLXSA-N 0.000 description 2
- FHJQROWZEJFZPO-SRVKXCTJSA-N Pro-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 FHJQROWZEJFZPO-SRVKXCTJSA-N 0.000 description 2
- BRKHVZNDAOMAHX-BIIVOSGPSA-N Ser-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N BRKHVZNDAOMAHX-BIIVOSGPSA-N 0.000 description 2
- UBRXAVQWXOWRSJ-ZLUOBGJFSA-N Ser-Asn-Asp Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N)C(=O)N UBRXAVQWXOWRSJ-ZLUOBGJFSA-N 0.000 description 2
- ZHYMUFQVKGJNRM-ZLUOBGJFSA-N Ser-Cys-Asn Chemical compound OC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CC(N)=O ZHYMUFQVKGJNRM-ZLUOBGJFSA-N 0.000 description 2
- MPPHJZYXDVDGOF-BWBBJGPYSA-N Ser-Cys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CO MPPHJZYXDVDGOF-BWBBJGPYSA-N 0.000 description 2
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 2
- QGAHMVHBORDHDC-YUMQZZPRSA-N Ser-His-Gly Chemical compound OC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CN=CN1 QGAHMVHBORDHDC-YUMQZZPRSA-N 0.000 description 2
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 2
- NLOAIFSWUUFQFR-CIUDSAMLSA-N Ser-Leu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O NLOAIFSWUUFQFR-CIUDSAMLSA-N 0.000 description 2
- UBTNVMGPMYDYIU-HJPIBITLSA-N Ser-Tyr-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O UBTNVMGPMYDYIU-HJPIBITLSA-N 0.000 description 2
- 101710167708 T-box transcription factor TBX5 Proteins 0.000 description 2
- 238000010459 TALEN Methods 0.000 description 2
- DFTCYYILCSQGIZ-GCJQMDKQSA-N Thr-Ala-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DFTCYYILCSQGIZ-GCJQMDKQSA-N 0.000 description 2
- QQWNRERCGGZOKG-WEDXCCLWSA-N Thr-Gly-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O QQWNRERCGGZOKG-WEDXCCLWSA-N 0.000 description 2
- GVMXJJAJLIEASL-ZJDVBMNYSA-N Thr-Pro-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O GVMXJJAJLIEASL-ZJDVBMNYSA-N 0.000 description 2
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 2
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 2
- 102100021386 Trans-acting T-cell-specific transcription factor GATA-3 Human genes 0.000 description 2
- 102100021380 Transcription factor GATA-4 Human genes 0.000 description 2
- NMCBVGFGWSIGSB-NUTKFTJISA-N Trp-Ala-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N NMCBVGFGWSIGSB-NUTKFTJISA-N 0.000 description 2
- OJKVFAWXPGCJMF-BPUTZDHNSA-N Trp-Pro-Ser Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)N[C@@H](CO)C(=O)O OJKVFAWXPGCJMF-BPUTZDHNSA-N 0.000 description 2
- LGEYOIQBBIPHQN-UWJYBYFXSA-N Tyr-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 LGEYOIQBBIPHQN-UWJYBYFXSA-N 0.000 description 2
- RIJPHPUJRLEOAK-JYJNAYRXSA-N Tyr-Gln-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O RIJPHPUJRLEOAK-JYJNAYRXSA-N 0.000 description 2
- HIINQLBHPIQYHN-JTQLQIEISA-N Tyr-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 HIINQLBHPIQYHN-JTQLQIEISA-N 0.000 description 2
- XYBNMHRFAUKPAW-IHRRRGAJSA-N Tyr-Ser-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC1=CC=C(C=C1)O)N XYBNMHRFAUKPAW-IHRRRGAJSA-N 0.000 description 2
- UMSZZGTXGKHTFJ-SRVKXCTJSA-N Tyr-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 UMSZZGTXGKHTFJ-SRVKXCTJSA-N 0.000 description 2
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 2
- REJBPZVUHYNMEN-LSJOCFKGSA-N Val-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N REJBPZVUHYNMEN-LSJOCFKGSA-N 0.000 description 2
- KTEZUXISLQTDDQ-NHCYSSNCSA-N Val-Lys-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)O)C(=O)O)N KTEZUXISLQTDDQ-NHCYSSNCSA-N 0.000 description 2
- IJGPOONOTBNTFS-GVXVVHGQSA-N Val-Lys-Glu Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O IJGPOONOTBNTFS-GVXVVHGQSA-N 0.000 description 2
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 2
- 241000700605 Viruses Species 0.000 description 2
- 230000001133 acceleration Effects 0.000 description 2
- 229960000643 adenine Drugs 0.000 description 2
- 108010045023 alanyl-prolyl-tyrosine Proteins 0.000 description 2
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 2
- 108010044940 alanylglutamine Proteins 0.000 description 2
- 210000001367 artery Anatomy 0.000 description 2
- 108010093581 aspartyl-proline Proteins 0.000 description 2
- 108010047857 aspartylglycine Proteins 0.000 description 2
- 108010092854 aspartyllysine Proteins 0.000 description 2
- 108010068265 aspartyltyrosine Proteins 0.000 description 2
- 230000027455 binding Effects 0.000 description 2
- 230000031018 biological processes and functions Effects 0.000 description 2
- 210000000748 cardiovascular system Anatomy 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 239000000460 chlorine Substances 0.000 description 2
- 229910052801 chlorine Inorganic materials 0.000 description 2
- 230000001684 chronic effect Effects 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 108010016616 cysteinylglycine Proteins 0.000 description 2
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 2
- 230000002498 deadly effect Effects 0.000 description 2
- 230000002950 deficient Effects 0.000 description 2
- 230000011559 double-strand break repair via nonhomologous end joining Effects 0.000 description 2
- 238000002651 drug therapy Methods 0.000 description 2
- 230000008030 elimination Effects 0.000 description 2
- 238000003379 elimination reaction Methods 0.000 description 2
- 230000013020 embryo development Effects 0.000 description 2
- 210000001174 endocardium Anatomy 0.000 description 2
- 210000003038 endothelium Anatomy 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 238000012224 gene deletion Methods 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- 238000011331 genomic analysis Methods 0.000 description 2
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 2
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 2
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 2
- 108010036413 histidylglycine Proteins 0.000 description 2
- 102000048387 human HAND2 Human genes 0.000 description 2
- 238000003364 immunohistochemistry Methods 0.000 description 2
- 230000005764 inhibitory process Effects 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- 210000003734 kidney Anatomy 0.000 description 2
- 239000002502 liposome Substances 0.000 description 2
- 230000007774 longterm Effects 0.000 description 2
- 108010064235 lysylglycine Proteins 0.000 description 2
- 210000004962 mammalian cell Anatomy 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 239000002609 medium Substances 0.000 description 2
- 210000002901 mesenchymal stem cell Anatomy 0.000 description 2
- 239000000178 monomer Substances 0.000 description 2
- 210000003205 muscle Anatomy 0.000 description 2
- 230000005305 organ development Effects 0.000 description 2
- 230000002611 ovarian Effects 0.000 description 2
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 2
- 229920001184 polypeptide Polymers 0.000 description 2
- 108010093296 prolyl-prolyl-alanine Proteins 0.000 description 2
- 108010053725 prolylvaline Proteins 0.000 description 2
- 150000003254 radicals Chemical class 0.000 description 2
- 239000000376 reactant Substances 0.000 description 2
- 238000012216 screening Methods 0.000 description 2
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 2
- 108010071207 serylmethionine Proteins 0.000 description 2
- 210000002027 skeletal muscle Anatomy 0.000 description 2
- 230000000392 somatic effect Effects 0.000 description 2
- 241000894007 species Species 0.000 description 2
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 108010071635 tyrosyl-prolyl-arginine Proteins 0.000 description 2
- 238000011144 upstream manufacturing Methods 0.000 description 2
- IBIDRSSEHFLGSD-UHFFFAOYSA-N valinyl-arginine Natural products CC(C)C(N)C(=O)NC(C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-UHFFFAOYSA-N 0.000 description 2
- 230000002792 vascular Effects 0.000 description 2
- 210000003462 vein Anatomy 0.000 description 2
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- ONEGZXHXCLCVRF-UHFFFAOYSA-N 2-[[2-[[1-(2-amino-3-methylbutanoyl)pyrrolidine-2-carbonyl]amino]-3-methylbutanoyl]amino]-4-methylpentanoic acid Chemical compound CC(C)CC(C(O)=O)NC(=O)C(C(C)C)NC(=O)C1CCCN1C(=O)C(N)C(C)C ONEGZXHXCLCVRF-UHFFFAOYSA-N 0.000 description 1
- FWBHETKCLVMNFS-UHFFFAOYSA-N 4',6-Diamino-2-phenylindol Chemical compound C1=CC(C(=N)N)=CC=C1C1=CC2=CC=C(C(N)=N)C=C2N1 FWBHETKCLVMNFS-UHFFFAOYSA-N 0.000 description 1
- DLFVBJFMPXGRIB-UHFFFAOYSA-N Acetamide Chemical class CC(N)=O DLFVBJFMPXGRIB-UHFFFAOYSA-N 0.000 description 1
- 241000251468 Actinopterygii Species 0.000 description 1
- AAQGRPOPTAUUBM-ZLUOBGJFSA-N Ala-Ala-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O AAQGRPOPTAUUBM-ZLUOBGJFSA-N 0.000 description 1
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 1
- SDMAQFGBPOJFOM-GUBZILKMSA-N Ala-Arg-Arg Chemical compound NC(=N)NCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SDMAQFGBPOJFOM-GUBZILKMSA-N 0.000 description 1
- WDIYWDJLXOCGRW-ACZMJKKPSA-N Ala-Asp-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WDIYWDJLXOCGRW-ACZMJKKPSA-N 0.000 description 1
- LSLIRHLIUDVNBN-CIUDSAMLSA-N Ala-Asp-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN LSLIRHLIUDVNBN-CIUDSAMLSA-N 0.000 description 1
- XYKDZXKKYOOTGC-FXQIFTODSA-N Ala-Cys-Met Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCSC)C(=O)O)N XYKDZXKKYOOTGC-FXQIFTODSA-N 0.000 description 1
- OILNWMNBLIHXQK-ZLUOBGJFSA-N Ala-Cys-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O OILNWMNBLIHXQK-ZLUOBGJFSA-N 0.000 description 1
- ZODMADSIQZZBSQ-FXQIFTODSA-N Ala-Gln-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZODMADSIQZZBSQ-FXQIFTODSA-N 0.000 description 1
- MVBWLRJESQOQTM-ACZMJKKPSA-N Ala-Gln-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O MVBWLRJESQOQTM-ACZMJKKPSA-N 0.000 description 1
- YIGLXQRFQVWFEY-NRPADANISA-N Ala-Gln-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O YIGLXQRFQVWFEY-NRPADANISA-N 0.000 description 1
- NWVVKQZOVSTDBQ-CIUDSAMLSA-N Ala-Glu-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NWVVKQZOVSTDBQ-CIUDSAMLSA-N 0.000 description 1
- HXNNRBHASOSVPG-GUBZILKMSA-N Ala-Glu-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O HXNNRBHASOSVPG-GUBZILKMSA-N 0.000 description 1
- BEMGNWZECGIJOI-WDSKDSINSA-N Ala-Gly-Glu Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O BEMGNWZECGIJOI-WDSKDSINSA-N 0.000 description 1
- PCIFXPRIFWKWLK-YUMQZZPRSA-N Ala-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N PCIFXPRIFWKWLK-YUMQZZPRSA-N 0.000 description 1
- NIZKGBJVCMRDKO-KWQFWETISA-N Ala-Gly-Tyr Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NIZKGBJVCMRDKO-KWQFWETISA-N 0.000 description 1
- FAJIYNONGXEXAI-CQDKDKBSSA-N Ala-His-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CNC=N1 FAJIYNONGXEXAI-CQDKDKBSSA-N 0.000 description 1
- CCDFBRZVTDDJNM-GUBZILKMSA-N Ala-Leu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CCDFBRZVTDDJNM-GUBZILKMSA-N 0.000 description 1
- SDZRIBWEVVRDQI-CIUDSAMLSA-N Ala-Lys-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O SDZRIBWEVVRDQI-CIUDSAMLSA-N 0.000 description 1
- DXTYEWAQOXYRHZ-KKXDTOCCSA-N Ala-Phe-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N DXTYEWAQOXYRHZ-KKXDTOCCSA-N 0.000 description 1
- IPZQNYYAYVRKKK-FXQIFTODSA-N Ala-Pro-Ala Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IPZQNYYAYVRKKK-FXQIFTODSA-N 0.000 description 1
- IORKCNUBHNIMKY-CIUDSAMLSA-N Ala-Pro-Glu Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O IORKCNUBHNIMKY-CIUDSAMLSA-N 0.000 description 1
- OLVCTPPSXNRGKV-GUBZILKMSA-N Ala-Pro-Pro Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OLVCTPPSXNRGKV-GUBZILKMSA-N 0.000 description 1
- CQJHFKKGZXKZBC-BPNCWPANSA-N Ala-Pro-Tyr Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 CQJHFKKGZXKZBC-BPNCWPANSA-N 0.000 description 1
- MSWSRLGNLKHDEI-ACZMJKKPSA-N Ala-Ser-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O MSWSRLGNLKHDEI-ACZMJKKPSA-N 0.000 description 1
- OEVCHROQUIVQFZ-YTLHQDLWSA-N Ala-Thr-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(O)=O OEVCHROQUIVQFZ-YTLHQDLWSA-N 0.000 description 1
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 1
- ZJLORAAXDAJLDC-CQDKDKBSSA-N Ala-Tyr-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O ZJLORAAXDAJLDC-CQDKDKBSSA-N 0.000 description 1
- ZXKNLCPUNZPFGY-LEWSCRJBSA-N Ala-Tyr-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N ZXKNLCPUNZPFGY-LEWSCRJBSA-N 0.000 description 1
- ZCUFMRIQCPNOHZ-NRPADANISA-N Ala-Val-Gln Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N ZCUFMRIQCPNOHZ-NRPADANISA-N 0.000 description 1
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 1
- CLOMBHBBUKAUBP-LSJOCFKGSA-N Ala-Val-His Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N CLOMBHBBUKAUBP-LSJOCFKGSA-N 0.000 description 1
- NLYYHIKRBRMAJV-AEJSXWLSSA-N Ala-Val-Pro Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N NLYYHIKRBRMAJV-AEJSXWLSSA-N 0.000 description 1
- OMSKGWFGWCQFBD-KZVJFYERSA-N Ala-Val-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OMSKGWFGWCQFBD-KZVJFYERSA-N 0.000 description 1
- 108091093088 Amplicon Proteins 0.000 description 1
- VKKYFICVTYKFIO-CIUDSAMLSA-N Arg-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N VKKYFICVTYKFIO-CIUDSAMLSA-N 0.000 description 1
- KWKQGHSSNHPGOW-BQBZGAKWSA-N Arg-Ala-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)NCC(O)=O KWKQGHSSNHPGOW-BQBZGAKWSA-N 0.000 description 1
- OLDOLPWZEMHNIA-PJODQICGSA-N Arg-Ala-Trp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O OLDOLPWZEMHNIA-PJODQICGSA-N 0.000 description 1
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 1
- BHSYMWWMVRPCPA-CYDGBPFRSA-N Arg-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CCCN=C(N)N BHSYMWWMVRPCPA-CYDGBPFRSA-N 0.000 description 1
- HJVGMOYJDDXLMI-AVGNSLFASA-N Arg-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCCNC(N)=N HJVGMOYJDDXLMI-AVGNSLFASA-N 0.000 description 1
- NABSCJGZKWSNHX-RCWTZXSCSA-N Arg-Arg-Thr Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H]([C@H](O)C)C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N NABSCJGZKWSNHX-RCWTZXSCSA-N 0.000 description 1
- DXQIQUIQYAGRCC-CIUDSAMLSA-N Arg-Asp-Gln Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)CN=C(N)N DXQIQUIQYAGRCC-CIUDSAMLSA-N 0.000 description 1
- KMSHNDWHPWXPEC-BQBZGAKWSA-N Arg-Asp-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KMSHNDWHPWXPEC-BQBZGAKWSA-N 0.000 description 1
- PTVGLOCPAVYPFG-CIUDSAMLSA-N Arg-Gln-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O PTVGLOCPAVYPFG-CIUDSAMLSA-N 0.000 description 1
- UBCPNBUIQNMDNH-NAKRPEOUSA-N Arg-Ile-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O UBCPNBUIQNMDNH-NAKRPEOUSA-N 0.000 description 1
- LVMUGODRNHFGRA-AVGNSLFASA-N Arg-Leu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O LVMUGODRNHFGRA-AVGNSLFASA-N 0.000 description 1
- OTZMRMHZCMZOJZ-SRVKXCTJSA-N Arg-Leu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O OTZMRMHZCMZOJZ-SRVKXCTJSA-N 0.000 description 1
- GRRXPUAICOGISM-RWMBFGLXSA-N Arg-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O GRRXPUAICOGISM-RWMBFGLXSA-N 0.000 description 1
- KZXPVYVSHUJCEO-ULQDDVLXSA-N Arg-Phe-Lys Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CC=CC=C1 KZXPVYVSHUJCEO-ULQDDVLXSA-N 0.000 description 1
- WKPXXXUSUHAXDE-SRVKXCTJSA-N Arg-Pro-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O WKPXXXUSUHAXDE-SRVKXCTJSA-N 0.000 description 1
- CGWVCWFQGXOUSJ-ULQDDVLXSA-N Arg-Tyr-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O CGWVCWFQGXOUSJ-ULQDDVLXSA-N 0.000 description 1
- LEFKSBYHUGUWLP-ACZMJKKPSA-N Asn-Ala-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LEFKSBYHUGUWLP-ACZMJKKPSA-N 0.000 description 1
- AKEBUSZTMQLNIX-UWJYBYFXSA-N Asn-Ala-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N AKEBUSZTMQLNIX-UWJYBYFXSA-N 0.000 description 1
- QEYJFBMTSMLPKZ-ZKWXMUAHSA-N Asn-Ala-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O QEYJFBMTSMLPKZ-ZKWXMUAHSA-N 0.000 description 1
- ACRYGQFHAQHDSF-ZLUOBGJFSA-N Asn-Asn-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ACRYGQFHAQHDSF-ZLUOBGJFSA-N 0.000 description 1
- NVGWESORMHFISY-SRVKXCTJSA-N Asn-Asn-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O NVGWESORMHFISY-SRVKXCTJSA-N 0.000 description 1
- QISZHYWZHJRDAO-CIUDSAMLSA-N Asn-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N QISZHYWZHJRDAO-CIUDSAMLSA-N 0.000 description 1
- HPBNLFLSSQDFQW-WHFBIAKZSA-N Asn-Ser-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O HPBNLFLSSQDFQW-WHFBIAKZSA-N 0.000 description 1
- IXIWEFWRKIUMQX-DCAQKATOSA-N Asp-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(O)=O IXIWEFWRKIUMQX-DCAQKATOSA-N 0.000 description 1
- KNMRXHIAVXHCLW-ZLUOBGJFSA-N Asp-Asn-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)C(=O)O KNMRXHIAVXHCLW-ZLUOBGJFSA-N 0.000 description 1
- KIJLEFNHWSXHRU-NUMRIWBASA-N Asp-Gln-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KIJLEFNHWSXHRU-NUMRIWBASA-N 0.000 description 1
- PZXPWHFYZXTFBI-YUMQZZPRSA-N Asp-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O PZXPWHFYZXTFBI-YUMQZZPRSA-N 0.000 description 1
- ICZWAZVKLACMKR-CIUDSAMLSA-N Asp-His-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CN=CN1 ICZWAZVKLACMKR-CIUDSAMLSA-N 0.000 description 1
- CLUMZOKVGUWUFD-CIUDSAMLSA-N Asp-Leu-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O CLUMZOKVGUWUFD-CIUDSAMLSA-N 0.000 description 1
- KPSHWSWFPUDEGF-FXQIFTODSA-N Asp-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(O)=O KPSHWSWFPUDEGF-FXQIFTODSA-N 0.000 description 1
- NAAAPCLFJPURAM-HJGDQZAQSA-N Asp-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O NAAAPCLFJPURAM-HJGDQZAQSA-N 0.000 description 1
- 241000271566 Aves Species 0.000 description 1
- 108010027344 Basic Helix-Loop-Helix Transcription Factors Proteins 0.000 description 1
- 102000018720 Basic Helix-Loop-Helix Transcription Factors Human genes 0.000 description 1
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 1
- 238000010354 CRISPR gene editing Methods 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical group [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- BVKZGUZCCUSVTD-UHFFFAOYSA-L Carbonate Chemical compound [O-]C([O-])=O BVKZGUZCCUSVTD-UHFFFAOYSA-L 0.000 description 1
- 208000015121 Cardiac valve disease Diseases 0.000 description 1
- 241000700198 Cavia Species 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- KRKNYBCHXYNGOX-UHFFFAOYSA-K Citrate Chemical compound [O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O KRKNYBCHXYNGOX-UHFFFAOYSA-K 0.000 description 1
- 208000032170 Congenital Abnormalities Diseases 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- NOCCABSVTRONIN-CIUDSAMLSA-N Cys-Ala-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CS)N NOCCABSVTRONIN-CIUDSAMLSA-N 0.000 description 1
- PKNIZMPLMSKROD-BIIVOSGPSA-N Cys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CS)N PKNIZMPLMSKROD-BIIVOSGPSA-N 0.000 description 1
- SKSJPIBFNFPTJB-NKWVEPMBSA-N Cys-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CS)N)C(=O)O SKSJPIBFNFPTJB-NKWVEPMBSA-N 0.000 description 1
- MKMKILWCRQLDFJ-DCAQKATOSA-N Cys-Lys-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MKMKILWCRQLDFJ-DCAQKATOSA-N 0.000 description 1
- HSAWNMMTZCLTPY-DCAQKATOSA-N Cys-Met-Leu Chemical compound SC[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O HSAWNMMTZCLTPY-DCAQKATOSA-N 0.000 description 1
- NRVQLLDIJJEIIZ-VZFHVOOUSA-N Cys-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CS)N)O NRVQLLDIJJEIIZ-VZFHVOOUSA-N 0.000 description 1
- 206010012289 Dementia Diseases 0.000 description 1
- 108010042407 Endonucleases Proteins 0.000 description 1
- 102000004533 Endonucleases Human genes 0.000 description 1
- 108010067770 Endopeptidase K Proteins 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 101150077461 Etv2 gene Proteins 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- SHERTACNJPYHAR-ACZMJKKPSA-N Gln-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O SHERTACNJPYHAR-ACZMJKKPSA-N 0.000 description 1
- OETQLUYCMBARHJ-CIUDSAMLSA-N Gln-Asn-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OETQLUYCMBARHJ-CIUDSAMLSA-N 0.000 description 1
- VOLVNCMGXWDDQY-LPEHRKFASA-N Gln-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O VOLVNCMGXWDDQY-LPEHRKFASA-N 0.000 description 1
- HYPVLWGNBIYTNA-GUBZILKMSA-N Gln-Leu-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O HYPVLWGNBIYTNA-GUBZILKMSA-N 0.000 description 1
- IHSGESFHTMFHRB-GUBZILKMSA-N Gln-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(N)=O IHSGESFHTMFHRB-GUBZILKMSA-N 0.000 description 1
- YJSCHRBERYWPQL-DCAQKATOSA-N Gln-Pro-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N YJSCHRBERYWPQL-DCAQKATOSA-N 0.000 description 1
- YPFFHGRJCUBXPX-NHCYSSNCSA-N Gln-Pro-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O)C(O)=O YPFFHGRJCUBXPX-NHCYSSNCSA-N 0.000 description 1
- ININBLZFFVOQIO-JHEQGTHGSA-N Gln-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)O ININBLZFFVOQIO-JHEQGTHGSA-N 0.000 description 1
- NHMRJKKAVMENKJ-WDCWCFNPSA-N Gln-Thr-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NHMRJKKAVMENKJ-WDCWCFNPSA-N 0.000 description 1
- MKRDNSWGJWTBKZ-GVXVVHGQSA-N Gln-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MKRDNSWGJWTBKZ-GVXVVHGQSA-N 0.000 description 1
- CSMHMEATMDCQNY-DZKIICNBSA-N Gln-Val-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CSMHMEATMDCQNY-DZKIICNBSA-N 0.000 description 1
- WZZSKAJIHTUUSG-ACZMJKKPSA-N Glu-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O WZZSKAJIHTUUSG-ACZMJKKPSA-N 0.000 description 1
- WOMUDRVDJMHTCV-DCAQKATOSA-N Glu-Arg-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WOMUDRVDJMHTCV-DCAQKATOSA-N 0.000 description 1
- DIXKFOPPGWKZLY-CIUDSAMLSA-N Glu-Arg-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O DIXKFOPPGWKZLY-CIUDSAMLSA-N 0.000 description 1
- LXAUHIRMWXQRKI-XHNCKOQMSA-N Glu-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N)C(=O)O LXAUHIRMWXQRKI-XHNCKOQMSA-N 0.000 description 1
- NUSWUSKZRCGFEX-FXQIFTODSA-N Glu-Glu-Cys Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(O)=O NUSWUSKZRCGFEX-FXQIFTODSA-N 0.000 description 1
- IQACOVZVOMVILH-FXQIFTODSA-N Glu-Glu-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O IQACOVZVOMVILH-FXQIFTODSA-N 0.000 description 1
- VSRCAOIHMGCIJK-SRVKXCTJSA-N Glu-Leu-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VSRCAOIHMGCIJK-SRVKXCTJSA-N 0.000 description 1
- IRXNJYPKBVERCW-DCAQKATOSA-N Glu-Leu-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IRXNJYPKBVERCW-DCAQKATOSA-N 0.000 description 1
- IVGJYOOGJLFKQE-AVGNSLFASA-N Glu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N IVGJYOOGJLFKQE-AVGNSLFASA-N 0.000 description 1
- GJBUAAAIZSRCDC-GVXVVHGQSA-N Glu-Leu-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O GJBUAAAIZSRCDC-GVXVVHGQSA-N 0.000 description 1
- HRBYTAIBKPNZKQ-AVGNSLFASA-N Glu-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(O)=O HRBYTAIBKPNZKQ-AVGNSLFASA-N 0.000 description 1
- FMBWLLMUPXTXFC-SDDRHHMPSA-N Glu-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)O)N)C(=O)O FMBWLLMUPXTXFC-SDDRHHMPSA-N 0.000 description 1
- HQOGXFLBAKJUMH-CIUDSAMLSA-N Glu-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)O)N HQOGXFLBAKJUMH-CIUDSAMLSA-N 0.000 description 1
- QNJNPKSWAHPYGI-JYJNAYRXSA-N Glu-Phe-Leu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=CC=C1 QNJNPKSWAHPYGI-JYJNAYRXSA-N 0.000 description 1
- DXMOIVCNJIJQSC-QEJZJMRPSA-N Glu-Trp-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)O)N DXMOIVCNJIJQSC-QEJZJMRPSA-N 0.000 description 1
- PUUYVMYCMIWHFE-BQBZGAKWSA-N Gly-Ala-Arg Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PUUYVMYCMIWHFE-BQBZGAKWSA-N 0.000 description 1
- JXYMPBCYRKWJEE-BQBZGAKWSA-N Gly-Arg-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O JXYMPBCYRKWJEE-BQBZGAKWSA-N 0.000 description 1
- FZQLXNIMCPJVJE-YUMQZZPRSA-N Gly-Asp-Leu Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O FZQLXNIMCPJVJE-YUMQZZPRSA-N 0.000 description 1
- LXXLEUBUOMCAMR-NKWVEPMBSA-N Gly-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)CN)C(=O)O LXXLEUBUOMCAMR-NKWVEPMBSA-N 0.000 description 1
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 1
- XTQFHTHIAKKCTM-YFKPBYRVSA-N Gly-Glu-Gly Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O XTQFHTHIAKKCTM-YFKPBYRVSA-N 0.000 description 1
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 1
- OLPPXYMMIARYAL-QMMMGPOBSA-N Gly-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)CN OLPPXYMMIARYAL-QMMMGPOBSA-N 0.000 description 1
- YFGONBOFGGWKKY-VHSXEESVSA-N Gly-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)CN)C(=O)O YFGONBOFGGWKKY-VHSXEESVSA-N 0.000 description 1
- FJWSJWACLMTDMI-WPRPVWTQSA-N Gly-Met-Val Chemical compound [H]NCC(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O FJWSJWACLMTDMI-WPRPVWTQSA-N 0.000 description 1
- OOCFXNOVSLSHAB-IUCAKERBSA-N Gly-Pro-Pro Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OOCFXNOVSLSHAB-IUCAKERBSA-N 0.000 description 1
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 1
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 1
- YXTFLTJYLIAZQG-FJXKBIBVSA-N Gly-Thr-Arg Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YXTFLTJYLIAZQG-FJXKBIBVSA-N 0.000 description 1
- HQSKKSLNLSTONK-JTQLQIEISA-N Gly-Tyr-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 HQSKKSLNLSTONK-JTQLQIEISA-N 0.000 description 1
- LYZYGGWCBLBDMC-QWHCGFSZSA-N Gly-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)CN)C(=O)O LYZYGGWCBLBDMC-QWHCGFSZSA-N 0.000 description 1
- DNAZKGFYFRGZIH-QWRGUYRKSA-N Gly-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 DNAZKGFYFRGZIH-QWRGUYRKSA-N 0.000 description 1
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 1
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 1
- 241000282575 Gorilla Species 0.000 description 1
- NYHBQMYGNKIUIF-UUOKFMHZSA-N Guanosine Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NYHBQMYGNKIUIF-UUOKFMHZSA-N 0.000 description 1
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 1
- JWLWNCVBBSBCEM-NKIYYHGXSA-N His-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N)O JWLWNCVBBSBCEM-NKIYYHGXSA-N 0.000 description 1
- HYWZHNUGAYVEEW-KKUMJFAQSA-N His-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N HYWZHNUGAYVEEW-KKUMJFAQSA-N 0.000 description 1
- CHIAUHSHDARFBD-ULQDDVLXSA-N His-Pro-Tyr Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CN=CN1 CHIAUHSHDARFBD-ULQDDVLXSA-N 0.000 description 1
- FLXCRBXJRJSDHX-AVGNSLFASA-N His-Pro-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O FLXCRBXJRJSDHX-AVGNSLFASA-N 0.000 description 1
- KAXZXLSXFWSNNZ-XVYDVKMFSA-N His-Ser-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KAXZXLSXFWSNNZ-XVYDVKMFSA-N 0.000 description 1
- FHKZHRMERJUXRJ-DCAQKATOSA-N His-Ser-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 FHKZHRMERJUXRJ-DCAQKATOSA-N 0.000 description 1
- JGFWUKYIQAEYAH-DCAQKATOSA-N His-Ser-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JGFWUKYIQAEYAH-DCAQKATOSA-N 0.000 description 1
- CMPHFUWXKBPNRS-WDSOQIARSA-N His-Val-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CNC=N1 CMPHFUWXKBPNRS-WDSOQIARSA-N 0.000 description 1
- 102000009331 Homeodomain Proteins Human genes 0.000 description 1
- 108010048671 Homeodomain Proteins Proteins 0.000 description 1
- 241001272567 Hominoidea Species 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101100012008 Homo sapiens ETV2 gene Proteins 0.000 description 1
- 101100338322 Homo sapiens HAND2 gene Proteins 0.000 description 1
- 101000629402 Homo sapiens Mesoderm posterior protein 1 Proteins 0.000 description 1
- 101000574648 Homo sapiens Retinoid-inducible serine carboxypeptidase Proteins 0.000 description 1
- 101100206168 Homo sapiens TBX5 gene Proteins 0.000 description 1
- HERITAGIPLEJMT-GVARAGBVSA-N Ile-Ala-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HERITAGIPLEJMT-GVARAGBVSA-N 0.000 description 1
- TZCGZYWNIDZZMR-NAKRPEOUSA-N Ile-Arg-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](C)C(=O)O)N TZCGZYWNIDZZMR-NAKRPEOUSA-N 0.000 description 1
- TZCGZYWNIDZZMR-UHFFFAOYSA-N Ile-Arg-Ala Natural products CCC(C)C(N)C(=O)NC(C(=O)NC(C)C(O)=O)CCCN=C(N)N TZCGZYWNIDZZMR-UHFFFAOYSA-N 0.000 description 1
- HDODQNPMSHDXJT-GHCJXIJMSA-N Ile-Asn-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O HDODQNPMSHDXJT-GHCJXIJMSA-N 0.000 description 1
- BATWGBRIZANGPN-ZPFDUUQYSA-N Ile-Pro-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BATWGBRIZANGPN-ZPFDUUQYSA-N 0.000 description 1
- FBGXMKUWQFPHFB-JBDRJPRFSA-N Ile-Ser-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N FBGXMKUWQFPHFB-JBDRJPRFSA-N 0.000 description 1
- ZFWISYLMLXFBSX-KKPKCPPISA-N Ile-Trp-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=CC=C3)C(=O)O)N ZFWISYLMLXFBSX-KKPKCPPISA-N 0.000 description 1
- 206010062016 Immunosuppression Diseases 0.000 description 1
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- 229930182816 L-glutamine Natural products 0.000 description 1
- BQSLGJHIAGOZCD-CIUDSAMLSA-N Leu-Ala-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O BQSLGJHIAGOZCD-CIUDSAMLSA-N 0.000 description 1
- HBJZFCIVFIBNSV-DCAQKATOSA-N Leu-Arg-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(N)=O)C(O)=O HBJZFCIVFIBNSV-DCAQKATOSA-N 0.000 description 1
- WUFYAPWIHCUMLL-CIUDSAMLSA-N Leu-Asn-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O WUFYAPWIHCUMLL-CIUDSAMLSA-N 0.000 description 1
- IIKJNQWOQIWWMR-CIUDSAMLSA-N Leu-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(C)C)N IIKJNQWOQIWWMR-CIUDSAMLSA-N 0.000 description 1
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 1
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 1
- DZQMXBALGUHGJT-GUBZILKMSA-N Leu-Glu-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O DZQMXBALGUHGJT-GUBZILKMSA-N 0.000 description 1
- HFBCHNRFRYLZNV-GUBZILKMSA-N Leu-Glu-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HFBCHNRFRYLZNV-GUBZILKMSA-N 0.000 description 1
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 1
- LAPSXOAUPNOINL-YUMQZZPRSA-N Leu-Gly-Asp Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O LAPSXOAUPNOINL-YUMQZZPRSA-N 0.000 description 1
- YFBBUHJJUXXZOF-UWVGGRQHSA-N Leu-Gly-Pro Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O YFBBUHJJUXXZOF-UWVGGRQHSA-N 0.000 description 1
- CFZZDVMBRYFFNU-QWRGUYRKSA-N Leu-His-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)NCC(O)=O CFZZDVMBRYFFNU-QWRGUYRKSA-N 0.000 description 1
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 1
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 1
- SQUFDMCWMFOEBA-KKUMJFAQSA-N Leu-Ser-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 SQUFDMCWMFOEBA-KKUMJFAQSA-N 0.000 description 1
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 1
- FBNPMTNBFFAMMH-UHFFFAOYSA-N Leu-Val-Arg Natural products CC(C)CC(N)C(=O)NC(C(C)C)C(=O)NC(C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-UHFFFAOYSA-N 0.000 description 1
- FDBTVENULFNTAL-XQQFMLRXSA-N Leu-Val-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N FDBTVENULFNTAL-XQQFMLRXSA-N 0.000 description 1
- MPGHETGWWWUHPY-CIUDSAMLSA-N Lys-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN MPGHETGWWWUHPY-CIUDSAMLSA-N 0.000 description 1
- NTEVEUCLFMWSND-SRVKXCTJSA-N Lys-Arg-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O NTEVEUCLFMWSND-SRVKXCTJSA-N 0.000 description 1
- SJNZALDHDUYDBU-IHRRRGAJSA-N Lys-Arg-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(O)=O SJNZALDHDUYDBU-IHRRRGAJSA-N 0.000 description 1
- OVIVOCSURJYCTM-GUBZILKMSA-N Lys-Asp-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(O)=O OVIVOCSURJYCTM-GUBZILKMSA-N 0.000 description 1
- YEIYAQQKADPIBJ-GARJFASQSA-N Lys-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCCN)N)C(=O)O YEIYAQQKADPIBJ-GARJFASQSA-N 0.000 description 1
- ZAWOJFFMBANLGE-CIUDSAMLSA-N Lys-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCCN)N ZAWOJFFMBANLGE-CIUDSAMLSA-N 0.000 description 1
- GFWLIJDQILOEPP-HSCHXYMDSA-N Lys-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCCN)N GFWLIJDQILOEPP-HSCHXYMDSA-N 0.000 description 1
- WRODMZBHNNPRLN-SRVKXCTJSA-N Lys-Leu-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O WRODMZBHNNPRLN-SRVKXCTJSA-N 0.000 description 1
- UQRZFMQQXXJTTF-AVGNSLFASA-N Lys-Lys-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O UQRZFMQQXXJTTF-AVGNSLFASA-N 0.000 description 1
- YXPJCVNIDDKGOE-MELADBBJSA-N Lys-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)N)C(=O)O YXPJCVNIDDKGOE-MELADBBJSA-N 0.000 description 1
- PLDJDCJLRCYPJB-VOAKCMCISA-N Lys-Lys-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PLDJDCJLRCYPJB-VOAKCMCISA-N 0.000 description 1
- JCVOHUKUYSYBAD-DCAQKATOSA-N Lys-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCCCN)N)C(=O)N[C@@H](CS)C(=O)O JCVOHUKUYSYBAD-DCAQKATOSA-N 0.000 description 1
- HKXSZKJMDBHOTG-CIUDSAMLSA-N Lys-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN HKXSZKJMDBHOTG-CIUDSAMLSA-N 0.000 description 1
- CAVRAQIDHUPECU-UVOCVTCTSA-N Lys-Thr-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAVRAQIDHUPECU-UVOCVTCTSA-N 0.000 description 1
- 102100026822 Mesoderm posterior protein 1 Human genes 0.000 description 1
- CHQWUYSNAOABIP-ZPFDUUQYSA-N Met-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCSC)N CHQWUYSNAOABIP-ZPFDUUQYSA-N 0.000 description 1
- KBTQZYASLSUFJR-KKUMJFAQSA-N Met-Phe-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N KBTQZYASLSUFJR-KKUMJFAQSA-N 0.000 description 1
- HLZORBMOISUNIV-DCAQKATOSA-N Met-Ser-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C HLZORBMOISUNIV-DCAQKATOSA-N 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- 241000699660 Mus musculus Species 0.000 description 1
- 101100012009 Mus musculus Etv2 gene Proteins 0.000 description 1
- 208000029578 Muscle disease Diseases 0.000 description 1
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 1
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 1
- 101100068676 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gln-1 gene Proteins 0.000 description 1
- 206010053159 Organ failure Diseases 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 238000002944 PCR assay Methods 0.000 description 1
- 241000282579 Pan Species 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 229930182555 Penicillin Natural products 0.000 description 1
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 1
- 108091093037 Peptide nucleic acid Proteins 0.000 description 1
- 206010057249 Phagocytosis Diseases 0.000 description 1
- BJEYSVHMGIJORT-NHCYSSNCSA-N Phe-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 BJEYSVHMGIJORT-NHCYSSNCSA-N 0.000 description 1
- UMKYAYXCMYYNHI-AVGNSLFASA-N Phe-Gln-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N UMKYAYXCMYYNHI-AVGNSLFASA-N 0.000 description 1
- HNFUGJUZJRYUHN-JSGCOSHPSA-N Phe-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HNFUGJUZJRYUHN-JSGCOSHPSA-N 0.000 description 1
- WEMYTDDMDBLPMI-DKIMLUQUSA-N Phe-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N WEMYTDDMDBLPMI-DKIMLUQUSA-N 0.000 description 1
- MJAYDXWQQUOURZ-JYJNAYRXSA-N Phe-Lys-Gln Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O MJAYDXWQQUOURZ-JYJNAYRXSA-N 0.000 description 1
- GZGPMBKUJDRICD-ULQDDVLXSA-N Phe-Pro-His Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)N)C(=O)N[C@@H](CC3=CN=CN3)C(=O)O GZGPMBKUJDRICD-ULQDDVLXSA-N 0.000 description 1
- HBXAOEBRGLCLIW-AVGNSLFASA-N Phe-Ser-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N HBXAOEBRGLCLIW-AVGNSLFASA-N 0.000 description 1
- GOUWCZRDTWTODO-YDHLFZDLSA-N Phe-Val-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O GOUWCZRDTWTODO-YDHLFZDLSA-N 0.000 description 1
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 1
- 108010039918 Polylysine Chemical class 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- 241000282405 Pongo abelii Species 0.000 description 1
- DZZCICYRSZASNF-FXQIFTODSA-N Pro-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 DZZCICYRSZASNF-FXQIFTODSA-N 0.000 description 1
- VXCHGLYSIOOZIS-GUBZILKMSA-N Pro-Ala-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 VXCHGLYSIOOZIS-GUBZILKMSA-N 0.000 description 1
- CQZNGNCAIXMAIQ-UBHSHLNASA-N Pro-Ala-Phe Chemical compound C[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O CQZNGNCAIXMAIQ-UBHSHLNASA-N 0.000 description 1
- XQLBWXHVZVBNJM-FXQIFTODSA-N Pro-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 XQLBWXHVZVBNJM-FXQIFTODSA-N 0.000 description 1
- HFZNNDWPHBRNPV-KZVJFYERSA-N Pro-Ala-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HFZNNDWPHBRNPV-KZVJFYERSA-N 0.000 description 1
- ICTZKEXYDDZZFP-SRVKXCTJSA-N Pro-Arg-Pro Chemical compound N([C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(O)=O)C(=O)[C@@H]1CCCN1 ICTZKEXYDDZZFP-SRVKXCTJSA-N 0.000 description 1
- CYQQWUPHIZVCNY-GUBZILKMSA-N Pro-Arg-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O CYQQWUPHIZVCNY-GUBZILKMSA-N 0.000 description 1
- ORPZXBQTEHINPB-SRVKXCTJSA-N Pro-Arg-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H]1CCCN1)C(O)=O ORPZXBQTEHINPB-SRVKXCTJSA-N 0.000 description 1
- UTAUEDINXUMHLG-FXQIFTODSA-N Pro-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 UTAUEDINXUMHLG-FXQIFTODSA-N 0.000 description 1
- YFNOUBWUIIJQHF-LPEHRKFASA-N Pro-Asp-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O YFNOUBWUIIJQHF-LPEHRKFASA-N 0.000 description 1
- NOXSEHJOXCWRHK-DCAQKATOSA-N Pro-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@@H]1CCCN1 NOXSEHJOXCWRHK-DCAQKATOSA-N 0.000 description 1
- ZPPVJIJMIKTERM-YUMQZZPRSA-N Pro-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)N)NC(=O)[C@@H]1CCCN1 ZPPVJIJMIKTERM-YUMQZZPRSA-N 0.000 description 1
- HJSCRFZVGXAGNG-SRVKXCTJSA-N Pro-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H]1CCCN1 HJSCRFZVGXAGNG-SRVKXCTJSA-N 0.000 description 1
- ZTVCLZLGHZXLOT-ULQDDVLXSA-N Pro-Glu-Trp Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O ZTVCLZLGHZXLOT-ULQDDVLXSA-N 0.000 description 1
- FEPSEIDIPBMIOS-QXEWZRGKSA-N Pro-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 FEPSEIDIPBMIOS-QXEWZRGKSA-N 0.000 description 1
- SSWJYJHXQOYTSP-SRVKXCTJSA-N Pro-His-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(N)=O)C(O)=O SSWJYJHXQOYTSP-SRVKXCTJSA-N 0.000 description 1
- HOTVCUAVDQHUDB-UFYCRDLUSA-N Pro-Phe-Tyr Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H]1NCCC1)C1=CC=C(O)C=C1 HOTVCUAVDQHUDB-UFYCRDLUSA-N 0.000 description 1
- KDBHVPXBQADZKY-GUBZILKMSA-N Pro-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KDBHVPXBQADZKY-GUBZILKMSA-N 0.000 description 1
- RFWXYTJSVDUBBZ-DCAQKATOSA-N Pro-Pro-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 RFWXYTJSVDUBBZ-DCAQKATOSA-N 0.000 description 1
- LEIKGVHQTKHOLM-IUCAKERBSA-N Pro-Pro-Gly Chemical compound OC(=O)CNC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 LEIKGVHQTKHOLM-IUCAKERBSA-N 0.000 description 1
- POQFNPILEQEODH-FXQIFTODSA-N Pro-Ser-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O POQFNPILEQEODH-FXQIFTODSA-N 0.000 description 1
- BVRBCQBUNGAWFP-KKUMJFAQSA-N Pro-Tyr-Gln Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O BVRBCQBUNGAWFP-KKUMJFAQSA-N 0.000 description 1
- LZHHZYDPMZEMRX-STQMWFEESA-N Pro-Tyr-Gly Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O LZHHZYDPMZEMRX-STQMWFEESA-N 0.000 description 1
- IIRBTQHFVNGPMQ-AVGNSLFASA-N Pro-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 IIRBTQHFVNGPMQ-AVGNSLFASA-N 0.000 description 1
- 101710183548 Pyridoxal 5'-phosphate synthase subunit PdxS Proteins 0.000 description 1
- 108010003201 RGH 0205 Proteins 0.000 description 1
- 102000018120 Recombinases Human genes 0.000 description 1
- 108010091086 Recombinases Proteins 0.000 description 1
- 108700005075 Regulator Genes Proteins 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- FIXILCYTSAUERA-FXQIFTODSA-N Ser-Ala-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FIXILCYTSAUERA-FXQIFTODSA-N 0.000 description 1
- IDQFQFVEWMWRQQ-DLOVCJGASA-N Ser-Ala-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O IDQFQFVEWMWRQQ-DLOVCJGASA-N 0.000 description 1
- NLQUOHDCLSFABG-GUBZILKMSA-N Ser-Arg-Arg Chemical compound NC(N)=NCCC[C@H](NC(=O)[C@H](CO)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NLQUOHDCLSFABG-GUBZILKMSA-N 0.000 description 1
- JJKSSJVYOVRJMZ-FXQIFTODSA-N Ser-Arg-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N)CN=C(N)N JJKSSJVYOVRJMZ-FXQIFTODSA-N 0.000 description 1
- RDFQNDHEHVSONI-ZLUOBGJFSA-N Ser-Asn-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RDFQNDHEHVSONI-ZLUOBGJFSA-N 0.000 description 1
- OHKLFYXEOGGGCK-ZLUOBGJFSA-N Ser-Asp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OHKLFYXEOGGGCK-ZLUOBGJFSA-N 0.000 description 1
- UCOYFSCEIWQYNL-FXQIFTODSA-N Ser-Cys-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCSC)C(O)=O UCOYFSCEIWQYNL-FXQIFTODSA-N 0.000 description 1
- CRZRTKAVUUGKEQ-ACZMJKKPSA-N Ser-Gln-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O CRZRTKAVUUGKEQ-ACZMJKKPSA-N 0.000 description 1
- UOLGINIHBRIECN-FXQIFTODSA-N Ser-Glu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UOLGINIHBRIECN-FXQIFTODSA-N 0.000 description 1
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 1
- HMRAQFJFTOLDKW-GUBZILKMSA-N Ser-His-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O HMRAQFJFTOLDKW-GUBZILKMSA-N 0.000 description 1
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 1
- VIIJCAQMJBHSJH-FXQIFTODSA-N Ser-Met-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(O)=O VIIJCAQMJBHSJH-FXQIFTODSA-N 0.000 description 1
- MQUZANJDFOQOBX-SRVKXCTJSA-N Ser-Phe-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O MQUZANJDFOQOBX-SRVKXCTJSA-N 0.000 description 1
- WBAXJMCUFIXCNI-WDSKDSINSA-N Ser-Pro Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(O)=O WBAXJMCUFIXCNI-WDSKDSINSA-N 0.000 description 1
- BSXKBOUZDAZXHE-CIUDSAMLSA-N Ser-Pro-Glu Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O BSXKBOUZDAZXHE-CIUDSAMLSA-N 0.000 description 1
- RHAPJNVNWDBFQI-BQBZGAKWSA-N Ser-Pro-Gly Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O RHAPJNVNWDBFQI-BQBZGAKWSA-N 0.000 description 1
- DINQYZRMXGWWTG-GUBZILKMSA-N Ser-Pro-Pro Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DINQYZRMXGWWTG-GUBZILKMSA-N 0.000 description 1
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 1
- VLMIUSLQONKLDV-HEIBUPTGSA-N Ser-Thr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VLMIUSLQONKLDV-HEIBUPTGSA-N 0.000 description 1
- VVKVHAOOUGNDPJ-SRVKXCTJSA-N Ser-Tyr-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VVKVHAOOUGNDPJ-SRVKXCTJSA-N 0.000 description 1
- PMTWIUBUQRGCSB-FXQIFTODSA-N Ser-Val-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O PMTWIUBUQRGCSB-FXQIFTODSA-N 0.000 description 1
- YEDSOSIKVUMIJE-DCAQKATOSA-N Ser-Val-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O YEDSOSIKVUMIJE-DCAQKATOSA-N 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- 108091027967 Small hairpin RNA Proteins 0.000 description 1
- 108020004459 Small interfering RNA Proteins 0.000 description 1
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 1
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 1
- 208000006011 Stroke Diseases 0.000 description 1
- 102000052935 T-box transcription factor Human genes 0.000 description 1
- 108700035811 T-box transcription factor Proteins 0.000 description 1
- 108010006785 Taq Polymerase Proteins 0.000 description 1
- 241000255588 Tephritidae Species 0.000 description 1
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 1
- NOWXWJLVGTVJKM-PBCZWWQYSA-N Thr-Asp-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N)O NOWXWJLVGTVJKM-PBCZWWQYSA-N 0.000 description 1
- LIXBDERDAGNVAV-XKBZYTNZSA-N Thr-Gln-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O LIXBDERDAGNVAV-XKBZYTNZSA-N 0.000 description 1
- DKDHTRVDOUZZTP-IFFSRLJSSA-N Thr-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DKDHTRVDOUZZTP-IFFSRLJSSA-N 0.000 description 1
- VGYBYGQXZJDZJU-XQXXSGGOSA-N Thr-Glu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VGYBYGQXZJDZJU-XQXXSGGOSA-N 0.000 description 1
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 1
- BVOVIGCHYNFJBZ-JXUBOQSCSA-N Thr-Leu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O BVOVIGCHYNFJBZ-JXUBOQSCSA-N 0.000 description 1
- HOVLHEKTGVIKAP-WDCWCFNPSA-N Thr-Leu-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HOVLHEKTGVIKAP-WDCWCFNPSA-N 0.000 description 1
- XIULAFZYEKSGAJ-IXOXFDKPSA-N Thr-Leu-His Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CNC=N1 XIULAFZYEKSGAJ-IXOXFDKPSA-N 0.000 description 1
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 1
- BDGBHYCAZJPLHX-HJGDQZAQSA-N Thr-Lys-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BDGBHYCAZJPLHX-HJGDQZAQSA-N 0.000 description 1
- VUXIQSUQQYNLJP-XAVMHZPKSA-N Thr-Ser-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N)O VUXIQSUQQYNLJP-XAVMHZPKSA-N 0.000 description 1
- RVMNUBQWPVOUKH-HEIBUPTGSA-N Thr-Ser-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMNUBQWPVOUKH-HEIBUPTGSA-N 0.000 description 1
- VBMOVTMNHWPZJR-SUSMZKCASA-N Thr-Thr-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VBMOVTMNHWPZJR-SUSMZKCASA-N 0.000 description 1
- VGNKUXWYFFDWDH-BEMMVCDISA-N Thr-Trp-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N3CCC[C@@H]3C(=O)O)N)O VGNKUXWYFFDWDH-BEMMVCDISA-N 0.000 description 1
- 108010073062 Transcription Activator-Like Effectors Proteins 0.000 description 1
- 108700009124 Transcription Initiation Site Proteins 0.000 description 1
- RNDWCRUOGGQDKN-UBHSHLNASA-N Trp-Ser-Asp Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RNDWCRUOGGQDKN-UBHSHLNASA-N 0.000 description 1
- DLZKEQQWXODGGZ-KWQFWETISA-N Tyr-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 DLZKEQQWXODGGZ-KWQFWETISA-N 0.000 description 1
- OOEUVMFKKZYSRX-LEWSCRJBSA-N Tyr-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N OOEUVMFKKZYSRX-LEWSCRJBSA-N 0.000 description 1
- SGFIXFAHVWJKTD-KJEVXHAQSA-N Tyr-Arg-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SGFIXFAHVWJKTD-KJEVXHAQSA-N 0.000 description 1
- NSTPFWRAIDTNGH-BZSNNMDCSA-N Tyr-Asn-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O NSTPFWRAIDTNGH-BZSNNMDCSA-N 0.000 description 1
- NZFCWALTLNFHHC-JYJNAYRXSA-N Tyr-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NZFCWALTLNFHHC-JYJNAYRXSA-N 0.000 description 1
- NMKJPMCEKQHRPD-IRXDYDNUSA-N Tyr-Gly-Tyr Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 NMKJPMCEKQHRPD-IRXDYDNUSA-N 0.000 description 1
- CTDPLKMBVALCGN-JSGCOSHPSA-N Tyr-Gly-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O CTDPLKMBVALCGN-JSGCOSHPSA-N 0.000 description 1
- JHORGUYURUBVOM-KKUMJFAQSA-N Tyr-His-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O JHORGUYURUBVOM-KKUMJFAQSA-N 0.000 description 1
- NSGZILIDHCIZAM-KKUMJFAQSA-N Tyr-Leu-Ser Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N NSGZILIDHCIZAM-KKUMJFAQSA-N 0.000 description 1
- XDGPTBVOSHKDFT-KKUMJFAQSA-N Tyr-Met-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O XDGPTBVOSHKDFT-KKUMJFAQSA-N 0.000 description 1
- ZMKDQRJLMRZHRI-ACRUOGEOSA-N Tyr-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N ZMKDQRJLMRZHRI-ACRUOGEOSA-N 0.000 description 1
- CDBXVDXSLPLFMD-BPNCWPANSA-N Tyr-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=C(O)C=C1 CDBXVDXSLPLFMD-BPNCWPANSA-N 0.000 description 1
- AUZADXNWQMBZOO-JYJNAYRXSA-N Tyr-Pro-Arg Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)C1=CC=C(O)C=C1 AUZADXNWQMBZOO-JYJNAYRXSA-N 0.000 description 1
- ARMNWLJYHCOSHE-KKUMJFAQSA-N Tyr-Pro-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O ARMNWLJYHCOSHE-KKUMJFAQSA-N 0.000 description 1
- VYQQQIRHIFALGE-UWJYBYFXSA-N Tyr-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 VYQQQIRHIFALGE-UWJYBYFXSA-N 0.000 description 1
- GQVZBMROTPEPIF-SRVKXCTJSA-N Tyr-Ser-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GQVZBMROTPEPIF-SRVKXCTJSA-N 0.000 description 1
- BCOBSVIZMQXKFY-KKUMJFAQSA-N Tyr-Ser-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O BCOBSVIZMQXKFY-KKUMJFAQSA-N 0.000 description 1
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 1
- SYFHQHYTNCQCCN-MELADBBJSA-N Tyr-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O SYFHQHYTNCQCCN-MELADBBJSA-N 0.000 description 1
- QGFPYRPIUXBYGR-YDHLFZDLSA-N Val-Asn-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N QGFPYRPIUXBYGR-YDHLFZDLSA-N 0.000 description 1
- ROLGIBMFNMZANA-GVXVVHGQSA-N Val-Glu-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N ROLGIBMFNMZANA-GVXVVHGQSA-N 0.000 description 1
- PIFJAFRUVWZRKR-QMMMGPOBSA-N Val-Gly-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O PIFJAFRUVWZRKR-QMMMGPOBSA-N 0.000 description 1
- URIRWLJVWHYLET-ONGXEEELSA-N Val-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)C(C)C URIRWLJVWHYLET-ONGXEEELSA-N 0.000 description 1
- FXVDGDZRYLFQKY-WPRPVWTQSA-N Val-Gly-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)C(C)C FXVDGDZRYLFQKY-WPRPVWTQSA-N 0.000 description 1
- PTFPUAXGIKTVNN-ONGXEEELSA-N Val-His-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)NCC(=O)O)N PTFPUAXGIKTVNN-ONGXEEELSA-N 0.000 description 1
- DHINLYMWMXQGMQ-IHRRRGAJSA-N Val-His-His Chemical compound C([C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 DHINLYMWMXQGMQ-IHRRRGAJSA-N 0.000 description 1
- AEMPCGRFEZTWIF-IHRRRGAJSA-N Val-Leu-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O AEMPCGRFEZTWIF-IHRRRGAJSA-N 0.000 description 1
- XBJKAZATRJBDCU-GUBZILKMSA-N Val-Pro-Ala Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O XBJKAZATRJBDCU-GUBZILKMSA-N 0.000 description 1
- RYQUMYBMOJYYDK-NHCYSSNCSA-N Val-Pro-Glu Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)O)C(=O)O)N RYQUMYBMOJYYDK-NHCYSSNCSA-N 0.000 description 1
- SJRUJQFQVLMZFW-WPRPVWTQSA-N Val-Pro-Gly Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O SJRUJQFQVLMZFW-WPRPVWTQSA-N 0.000 description 1
- DOFAQXCYFQKSHT-SRVKXCTJSA-N Val-Pro-Pro Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DOFAQXCYFQKSHT-SRVKXCTJSA-N 0.000 description 1
- UJMCYJKPDFQLHX-XGEHTFHBSA-N Val-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N)O UJMCYJKPDFQLHX-XGEHTFHBSA-N 0.000 description 1
- JAIZPWVHPQRYOU-ZJDVBMNYSA-N Val-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O JAIZPWVHPQRYOU-ZJDVBMNYSA-N 0.000 description 1
- 206010047296 Ventricular hypoplasia Diseases 0.000 description 1
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 101150063416 add gene Proteins 0.000 description 1
- 210000001789 adipocyte Anatomy 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 239000011543 agarose gel Substances 0.000 description 1
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 1
- 230000000172 allergic effect Effects 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 239000002870 angiogenesis inducing agent Substances 0.000 description 1
- 208000021623 aortic arch defects Diseases 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- 108010068380 arginylarginine Proteins 0.000 description 1
- 108010060035 arginylproline Proteins 0.000 description 1
- 206010003119 arrhythmia Diseases 0.000 description 1
- 230000006793 arrhythmia Effects 0.000 description 1
- 210000004507 artificial chromosome Anatomy 0.000 description 1
- 108010038633 aspartylglutamate Proteins 0.000 description 1
- 238000003556 assay Methods 0.000 description 1
- 208000010668 atopic eczema Diseases 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 210000000625 blastula Anatomy 0.000 description 1
- 210000000988 bone and bone Anatomy 0.000 description 1
- 210000004271 bone marrow stromal cell Anatomy 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 239000006227 byproduct Substances 0.000 description 1
- 150000004657 carbamic acid derivatives Chemical class 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 125000002057 carboxymethyl group Chemical group [H]OC(=O)C([H])([H])[*] 0.000 description 1
- 210000004413 cardiac myocyte Anatomy 0.000 description 1
- 210000004903 cardiac system Anatomy 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 230000035605 chemotaxis Effects 0.000 description 1
- 239000013611 chromosomal DNA Substances 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 210000004351 coronary vessel Anatomy 0.000 description 1
- 238000005138 cryopreservation Methods 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 239000005549 deoxyribonucleoside Substances 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000009795 derivation Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical compound [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 1
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 1
- KPUWHANPEXNPJT-UHFFFAOYSA-N disiloxane Chemical class [SiH3]O[SiH3] KPUWHANPEXNPJT-UHFFFAOYSA-N 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 210000002308 embryonic cell Anatomy 0.000 description 1
- 231100001129 embryonic lethality Toxicity 0.000 description 1
- 108010026638 endodeoxyribonuclease FokI Proteins 0.000 description 1
- 210000002889 endothelial cell Anatomy 0.000 description 1
- ZMMJGEGLRURXTF-UHFFFAOYSA-N ethidium bromide Chemical compound [Br-].C12=CC(N)=CC=C2C2=CC=C(N)C=C2[N+](CC)=C1C1=CC=CC=C1 ZMMJGEGLRURXTF-UHFFFAOYSA-N 0.000 description 1
- 229960005542 ethidium bromide Drugs 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 239000012091 fetal bovine serum Substances 0.000 description 1
- 230000001605 fetal effect Effects 0.000 description 1
- 210000003754 fetus Anatomy 0.000 description 1
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 1
- 235000013305 food Nutrition 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 238000003209 gene knockout Methods 0.000 description 1
- 238000003205 genotyping method Methods 0.000 description 1
- 210000001654 germ layer Anatomy 0.000 description 1
- 210000004907 gland Anatomy 0.000 description 1
- 108010049041 glutamylalanine Proteins 0.000 description 1
- 108010078326 glycyl-glycyl-valine Proteins 0.000 description 1
- 108010089804 glycyl-threonine Proteins 0.000 description 1
- 108010045126 glycyl-tyrosyl-glycine Proteins 0.000 description 1
- 108010081551 glycylphenylalanine Proteins 0.000 description 1
- 108010087823 glycyltyrosine Proteins 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 238000003306 harvesting Methods 0.000 description 1
- 230000012447 hatching Effects 0.000 description 1
- 208000019622 heart disease Diseases 0.000 description 1
- 210000003709 heart valve Anatomy 0.000 description 1
- 108010028295 histidylhistidine Proteins 0.000 description 1
- 238000009396 hybridization Methods 0.000 description 1
- 230000001506 immunosuppresive effect Effects 0.000 description 1
- 229960003444 immunosuppressant agent Drugs 0.000 description 1
- 239000003018 immunosuppressive agent Substances 0.000 description 1
- 238000002513 implantation Methods 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 238000007901 in situ hybridization Methods 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 238000005462 in vivo assay Methods 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 238000011813 knockout mouse model Methods 0.000 description 1
- 108010053037 kyotorphin Proteins 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 238000011005 laboratory method Methods 0.000 description 1
- 108010034529 leucyl-lysine Proteins 0.000 description 1
- 108010087810 leucyl-seryl-glutamyl-leucine Proteins 0.000 description 1
- 108010091871 leucylmethionine Proteins 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 210000005229 liver cell Anatomy 0.000 description 1
- 244000144972 livestock Species 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 239000006166 lysate Substances 0.000 description 1
- 239000012139 lysis buffer Substances 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical compound CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 1
- 108091070501 miRNA Proteins 0.000 description 1
- 239000002679 microRNA Substances 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 230000002297 mitogenic effect Effects 0.000 description 1
- 230000000394 mitotic effect Effects 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 238000010172 mouse model Methods 0.000 description 1
- 210000000663 muscle cell Anatomy 0.000 description 1
- 210000001665 muscle stem cell Anatomy 0.000 description 1
- 210000000107 myocyte Anatomy 0.000 description 1
- 229910052754 neon Inorganic materials 0.000 description 1
- GKAOGPIIYCISHV-UHFFFAOYSA-N neon atom Chemical compound [Ne] GKAOGPIIYCISHV-UHFFFAOYSA-N 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 238000007899 nucleic acid hybridization Methods 0.000 description 1
- 230000005257 nucleotidylation Effects 0.000 description 1
- 230000015031 pancreas development Effects 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 229940049954 penicillin Drugs 0.000 description 1
- 230000008782 phagocytosis Effects 0.000 description 1
- 239000002831 pharmacologic agent Substances 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 1
- 150000004713 phosphodiesters Chemical group 0.000 description 1
- PTMHPRAIXMAOOB-UHFFFAOYSA-L phosphoramidate Chemical compound NP([O-])([O-])=O PTMHPRAIXMAOOB-UHFFFAOYSA-L 0.000 description 1
- 239000011574 phosphorus Substances 0.000 description 1
- 229910052698 phosphorus Inorganic materials 0.000 description 1
- 230000001766 physiological effect Effects 0.000 description 1
- 210000005059 placental tissue Anatomy 0.000 description 1
- 229920002401 polyacrylamide Polymers 0.000 description 1
- 229920000768 polyamine Polymers 0.000 description 1
- 229920000656 polylysine Chemical class 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000015277 pork Nutrition 0.000 description 1
- 230000002028 premature Effects 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 230000008263 repair mechanism Effects 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 230000003252 repetitive effect Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 210000005132 reproductive cell Anatomy 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 239000002342 ribonucleoside Substances 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 108010048818 seryl-histidine Proteins 0.000 description 1
- 108010007375 seryl-seryl-seryl-arginine Proteins 0.000 description 1
- 230000035939 shock Effects 0.000 description 1
- 210000004927 skin cell Anatomy 0.000 description 1
- 239000004055 small Interfering RNA Substances 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 238000010186 staining Methods 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 229960005322 streptomycin Drugs 0.000 description 1
- 230000009469 supplementation Effects 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 208000024891 symptom Diseases 0.000 description 1
- 208000011580 syndromic disease Diseases 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 101150065190 term gene Proteins 0.000 description 1
- 230000001225 therapeutic effect Effects 0.000 description 1
- 150000003568 thioethers Chemical class 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 229940098465 tincture Drugs 0.000 description 1
- 230000025366 tissue development Effects 0.000 description 1
- 108091006106 transcriptional activators Proteins 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 108010005834 tyrosyl-alanyl-glycine Proteins 0.000 description 1
- 108010051110 tyrosyl-lysine Proteins 0.000 description 1
- 229940035893 uracil Drugs 0.000 description 1
- 210000003708 urethra Anatomy 0.000 description 1
- 210000004291 uterus Anatomy 0.000 description 1
- 108010015385 valyl-prolyl-proline Proteins 0.000 description 1
- 208000019553 vascular disease Diseases 0.000 description 1
- 230000002861 ventricular Effects 0.000 description 1
- 230000035899 viability Effects 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 239000011701 zinc Substances 0.000 description 1
- 229910052725 zinc Inorganic materials 0.000 description 1
Images






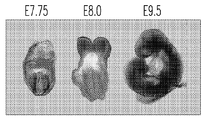
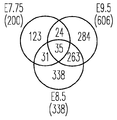

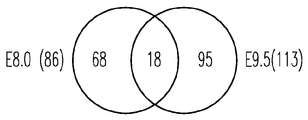





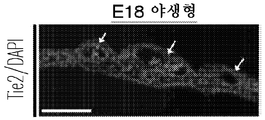



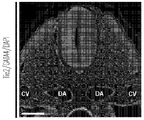
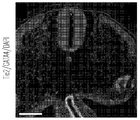


Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; CARE OF BIRDS, FISHES, INSECTS; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K67/00—Rearing or breeding animals, not otherwise provided for; New breeds of animals
- A01K67/027—New breeds of vertebrates
- A01K67/0271—Chimeric animals, e.g. comprising exogenous cells
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; CARE OF BIRDS, FISHES, INSECTS; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K67/00—Rearing or breeding animals, not otherwise provided for; New breeds of animals
- A01K67/027—New breeds of vertebrates
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; CARE OF BIRDS, FISHES, INSECTS; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K67/00—Rearing or breeding animals, not otherwise provided for; New breeds of animals
- A01K67/027—New breeds of vertebrates
- A01K67/0275—Genetically modified vertebrates, e.g. transgenic
- A01K67/0276—Knockout animals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/8509—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells for producing genetically modified animals, e.g. transgenic
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; CARE OF BIRDS, FISHES, INSECTS; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; CARE OF BIRDS, FISHES, INSECTS; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/15—Animals comprising multiple alterations of the genome, by transgenesis or homologous recombination, e.g. obtained by cross-breeding
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; CARE OF BIRDS, FISHES, INSECTS; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
- A01K2227/108—Swine
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; CARE OF BIRDS, FISHES, INSECTS; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2267/00—Animals characterised by purpose
- A01K2267/02—Animal zootechnically ameliorated
- A01K2267/025—Animal producing cells or organs for transplantation
Abstract
본원에서는 a) NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 동물 세포를 생성하는 단계로서, 여기서 비-인간 NKX2-5, HANDII, TBX5 유전자 또는 그의 조합의 양쪽 카피는 상기 비-인간 동물에서 기능적 NKX2-5, HANDII, TBX5 단백질 또는 그의 조합의 생산을 방지하는 돌연변이를 보유하는 것인 단계; b) a)의 상기 NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 동물 세포로부터의 핵을 제핵 비-인간 난모세포 내로 융합시키는 것 및 상기 난모세포를 활성화시켜 NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 배반포를 형성하도록 분열시키는 것을 포함하는 체세포 핵 이식에 의해 NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 배반포를 창출하는 단계; c) 인간 줄기 세포를 b)의 NKX2-5, HANDII, TBX5 또는 조합 널 비-인간 배반포 내로 도입시키는 단계; 및 d) c)로부터의 상기 배반포를 가임신 대리모 비-인간 동물 내로 이식시켜 인간 NKX2-5, HANDII, TBX5 또는 그의 조합을 발현하는 키메라 비-인간 동물을 생성하는 단계를 포함하는, 인간 NKX2-5, HANDII, TBX5 유전자 또는 그의 조합 유전자를 발현하는 키메라 비-인간 동물을 생산하는 방법을 기술한다.
Description
우선권 주장
본 출원은 2015년 6월 30일 출원된 미국 특허 가출원 번호 62/187,040의 우선권의 이익을 주장하고, 본원에서는 그의 우선권의 이익이 주장되며, 상기 출원은 그 전문이 본원에서 참조로 포함된다.
전체 신생아 중 대략 1%가 선천성 심장 질환 (CHD)을 앓고 있으며, 상기 질환은 상당한 질병률과 사망률을 가지고 있다 (1-5). 심혈관 질환이 전 세계 사망 원인의 1위를 차지하고 있으며, 이는 미국에서는 1900년 이래로 매년 가장 흔한 사망 원인이 되고 있다. 오늘날, 성인 3명당 1명이 심혈관 질환을 앓는 채로 살고 있다. 마지막으로, 선천성 심장 결함은 일반 인구에서 가장 흔한 형태의 선천적 결함이며, 소아 및 성인 인구에서의 진행성 또는 말기 심장 부전의 원인이 된다. 선천성 심장 질환 및 다른 심혈관 질환은 심장 부전으로 진행될 수 있다. 말기 심장 부전에 대한 유일한 치유법은 심장 이식이지만, 이식을 위한 기관 부족으로 인해 비교적 적은 환자가 상기 구명 요법을 받고 있다. 심장 이식을 받은 환자는 심장 거부를 방지하기 위해 약물 요법을 필요로 하며, 이러한 약물 요법은 대개, 생존을 제한하기도 하는 장기간의 부작용을 일으킨다.
본원에서는 임상 적용을 위한 개인맞춤형 인간/인간화 심근 조직/심근 세포 생산을 위한 숙주로서의 NKX2-5/HANDII/TBX5 넉아웃 돼지 또는 다른 동물, 예컨대 암소 또는 염소의 개발을 기술한다.
유전자 편집 기술 사용으로 NKX2-5/HANDII/TBX5 널(null) 돼지 배아가 생성되어 왔고, 본 발명자들은 인간 줄기 세포를 사용하여 인간-동물 키메라를 생산하여 왔다. NKX2-5/HANDII/TBX5에 대한 다중 유전자 편집을 수행함으로써 만능성 능력이 있는 인간 세포를 사용하여 심장 재증식을 위한 허용 니치를 제공할 수 있으며, 이로써, 인간화 심장 세포 및/또는 조직 (기관, 예컨대 심장 포함)을 수득할 수 있다.
한 실시양태는, 게놈이 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합의 양쪽 대립유전자에 돌연변이를 보유하여 비-인간 동물 세포, 상실배 또는 배반포에는 기능적 NKX2-5 단백질, HANDII 단백질, TBX5 단백질 또는 그의 조합이 결여된 것인 비-인간 동물 세포, 상실배 또는 배반포를 제공한다. 한 실시양태에서, 돌연변이는 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합의 결실이다. 또 다른 실시양태에서, 비-인간 동물 세포, 상실배 또는 배반포는 돼지, 소, 말 또는 염소이다.
한 실시양태는 인간 NKX2-5, HANDII, TBX5 또는 그의 조합을 발현하며 비-인간 동물 NKX2-5, HANDII, TBX5 또는 그의 조합의 발현이 결여된 키메라 비-인간 동물 상실배 또는 배반포를 제공한다. 한 실시양태에서, 비-인간 동물은 인간화 심장 세포 및/또는 조직을 생산한다.
한 실시양태는 외인성 돼지 NKX2-5, HANDII, TBX5 또는 그의 조합을 발현하며 내인성 돼지 NKX2-5, HANDII, TBX5 또는 그의 조합의 발현이 결여된 키메라 돼지 (돼지-돼지 키메라)를 제공한다. 한 실시양태에서, 비-인간 동물은 돼지, 소, 말 또는 염소이다.
한 실시양태는 a) NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 동물 세포를 생성하는 단계로서, 여기서 비-인간 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합 유전자의 양쪽 카피는 기능적 NKX2-5 단백질, HANDII 단백질, TBX5 단백질 또는 그의 조합의 생산을 방지하는 돌연변이를 보유하는 것인 단계; b) a)의 상기 NKX2-5, HANDI, TBX5 또는 그의 조합 널 비-인간 세포로부터의 핵을 제핵 비-인간 난모세포 내로 융합시키는 것 및 상기 난모세포를 활성화시켜 NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 상실배 또는 배반포를 형성하도록 분열시키는 것을 포함하는 체세포 핵 이식에 의해 NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 상실배 또는 배반포를 창출하는 단계; c) 인간 줄기 세포를 b)의 비-인간 NKX2-5, HANDII, TBX5 또는 그의 조합 널 상실배 또는 배반포 내로 도입시키는 단계; 및 d) c)로부터의 상기 상실배 또는 배반포를 가임신 대리모 비-인간 동물 내로 이식시켜 인간 NKX2-5, HANDII, TBX5 또는 그의 조합을 발현하는 키메라 비-인간 동물을 생성하는 단계를 포함하는, 인간 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합을 발현하는 키메라 비-인간 동물을 생산하는 방법을 제공한다.
또 다른 실시양태는 a) NKX2-5, HANDII, TBX5 또는 그의 조합 널 돼지 세포를 생성하는 단계로서, 여기서 내인성 돼지 MYF5 유전자, MYOD 유전자, MRF4 유전자 또는 그의 조합 유전자의 양쪽 카피는 기능적 내인성 돼지 MYF5 단백질, MYOD 단백질, MRF4 단백질 또는 그의 조합의 생산을 방지하는 돌연변이를 보유하는 것인 단계; b) a)의 상기 NKX2-5, HANDII, TBX5 또는 그의 조합 널 돼지 세포로부터의 핵을 제핵 돼지 난모세포 내로 융합시키는 것 및 상기 난모세포를 활성화시켜 NKX2-5, HANDII, TBX5 또는 그의 조합 널 돼지 상실배 또는 배반포를 형성하도록 분열시키는 것을 포함하는 체세포 핵 이식에 의해 NKX2-5, HANDII, TBX5 또는 그의 조합 널 돼지 상실배 또는 배반포를 창출하는 단계; c) 돼지 줄기 세포를 b)의 돼지 NKX2-5, HANDII, TBX5 또는 그의 조합 널 상실배 또는 배반포 내로 도입시키는 단계; 및 d) c)로부터의 상기 상실배 또는 배반포를 가임신 대리모 돼지 내로 이식시켜 외인성 돼지 NKX2-5, HANDII, TBX5 또는 그의 조합을 발현하는 키메라 돼지를 생성하는 단계를 포함하는, 외인성 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합을 발현하는 키메라 돼지를 생산하는 방법을 제공한다.
또 다른 실시양태는 a) NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 세포를 생성하는 단계로서, 여기서 비-인간 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합의 양쪽 대립유전자는 기능적 비-인간 NKX2-5 단백질, HANDII 단백질, TBX5 단백질 또는 그의 조합의 생산을 방지하는 돌연변이를 보유하는 것인 단계; b) a)의 상기 MYF5, MYOD, MRF4 또는 그의 조합 널 비-인간 세포로부터의 핵을 제핵 비-인간 동물 난모세포 내로 융합시키는 것 및 상기 난모세포를 활성화시켜 NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 동물 상실배 또는 배반포를 형성하도록 분열시키는 것을 포함하는 체세포 핵 이식에 의해 NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 상실배 또는 배반포를 창출하는 단계; c) 인간 줄기 세포를 b)의 NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 동물 배반포 또는 상실배 내로 도입시키는 단계; 및 d) 인간 또는 인간화 심장 세포를 발현하는 비-인간 동물을 생성하도록 c)로부터의 상기 배반포 또는 상실배를 가임신 대리모 돼지 내로 이식시키는 단계를 포함하는, 비-인간 동물에서 인간 또는 인간화 심장 세포를 생산하는 방법을 제공한다.
한 실시양태에서, 비-인간 동물은 돼지, 소, 말 또는 염소이다. 또 다른 실시양태에서, 인간 줄기 세포는 조직 특이적 줄기 세포, 만능성 줄기 세포, 다능성 성체 줄기 세포, 유도된 만능성 줄기 세포 또는 제대혈 줄기 세포 (UCBSC)이다. 또 다른 실시양태에서, 유도된 만능성 세포는 섬유모세포 세포로부터 형성된다.
한 실시양태는, 게놈이 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합의 양쪽 대립유전자에 돌연변이를 보유하여 돼지 세포 또는 배반포에는 기능적 NKX2-5 단백질, HANDII 단백질, TBX5 단백질 또는 그의 조합이 결여된 것인 돼지 세포, 상실배 또는 배반포를 제공한다. 한 실시양태에서, 돌연변이는 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합의 결실이다.
한 실시양태는 인간 NKX2-5, HANDII, TBX5 또는 그의 조합을 발현하며 돼지 NKX2-5, HANDII, TBX5 또는 그의 조합의 발현이 결여된 키메라 돼지를 제공한다. 한 실시양태에서, 키메라 돼지는 인간화 심장 세포 및/또는 조직을 생산한다.
한 실시양태는 a) NKX2-5, HANDII, TBX5 또는 그의 조합 널 돼지 세포를 생성하는 단계로서, 여기서 돼지 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합 유전자의 양쪽 카피는 기능적 돼지 NKX2-5 단백질, HANDII 단백질, TBX5 단백질 또는 그의 조합의 생산을 방지하는 돌연변이를 보유하는 것인 단계; b) a)의 상기 NKX2-5, HANDI, TBX5 또는 그의 조합 널 돼지 세포로부터의 핵을 제핵 돼지 난모세포 내로 융합시키는 것 및 상기 난모세포를 활성화시켜 NKX2-5, HANDII, TBX5 또는 그의 조합 널 돼지 상실배 또는 배반포를 형성하도록 분열시키는 것을 포함하는 체세포 핵 이식에 의해 NKX2-5, HANDII, TBX5 또는 그의 조합 널 돼지 상실배 또는 배반포를 창출하는 단계; c) 인간 줄기 세포를 b)의 돼지 NKX2-5, HANDII, TBX5 또는 그의 조합 널 상실배 또는 배반포 내로 도입시키는 단계; 및 d) c)로부터의 상기 상실배 또는 배반포를 가임신 대리모 돼지 내로 이식시켜 인간 NKX2-5, HANDII, TBX5 또는 그의 조합을 발현하는 키메라 돼지를 생성하는 단계를 포함하는, 인간 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합을 발현하는 키메라 돼지를 생산하는 방법을 제공한다.
또 다른 실시양태는 a) NKX2-5, HANDII, TBX5 또는 그의 조합 널 돼지 세포를 생성하는 단계로서, 여기서 돼지 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합의 양쪽 대립유전자는 기능적 돼지 NKX2-5 단백질, HANDII 단백질, TBX5 단백질 또는 그의 조합의 생산을 방지하는 돌연변이를 보유하는 것인 단계; b) a)의 상기 MYF5, MYOD, MRF4 또는 그의 조합 널 돼지 세포로부터의 핵을 제핵 돼지 난모세포 내로 융합시키는 것 및 상기 난모세포를 활성화시켜 NKX2-5, HANDII, TBX5 또는 그의 조합 널 돼지 상실배 또는 배반포를 형성하도록 분열시키는 것을 포함하는 체세포 핵 이식에 의해 NKX2-5, HANDII, TBX5 또는 그의 조합 널 돼지 상실배 또는 배반포를 창출하는 단계; c) 인간 줄기 세포를 b)의 돼지 NKX2-5, HANDII, TBX5 또는 그의 조합 널 배반포 내로 도입시키는 단계; 및 d) 인간화 심장 세포를 발현하는 돼지를 생성하도록 c)로부터의 상기 배반포를 가임신 대리모 돼지 내로 이식시키는 단계를 포함하는, 돼지에서 인간화 심장 세포를 생산하는 방법을 제공한다. 한 실시양태에서, 인간 줄기 세포는 인간 유도된 만능성 줄기 세포, 인간 만능성 줄기 세포 또는 인간 제대혈 줄기 세포이다. 또 다른 실시양태에서, 인간 유도된 만능성 세포는 섬유모세포 세포로부터 형성된다.
인간 또는 인간화 조직 및 기관을 각 수혜자의 면역 복합체에 맞게 개인맞춤화하는 것이 유용할 것이다. 본원에서 논의되는 바와 같이, 숙주로서 큰 동물을 사용하고, 표적 기관의 성장 및/또는 분화를 담당하는 유전자를 넉 아웃시키거나, 또는 약화시키도록 상기 동물의 게놈을 편집하고, 배반포기 또는 접합기에 상기 동물에 공여자 줄기 세포를 접종하여 기관의 성장 및 발생을 위한 유전적 정보로서 소실된 것을 상보함으로써 상기와 같은 개인맞춤화를 수행할 수 있다. 본 결과는 상보된 조직 (인간/인간화 기관)이 공여자의 유전자형 및 표현형과 매칭되는 것인 키메라 동물이다. 상기 기관은 단일 세대에서 제조될 수 있고, 줄기 세포는 환자 그 자신의 신체로부터 채취될 수 있거나, 또는 생성될 수 있다. 본원에서 논의되는 바와 같이, 이는 한 세포에서 다중 유전자를 동시에 편집함으로써 수행될 수 있다 (예를 들어, WO 2015/168125 (본원에서 참조로 포함됨) 참조). 다중 유전자는 척추동물 세포 또는 배아에서 표적화된 뉴클레아제 및 상동성 지정 수복 (HDR) 주형을 사용하는 편집을 위해 표적화될 수 있다.
도 1은 마우스에서의 심장 형태 발생의 개략도를 도시한 것이다. (좌측에서 우측으로) 심장 반월 (E7.5), 선형 심장 관 (E8.5), 루핑된 심장 (E9.5) 및 4개 챔버로 된 심장 (E10.5)의 형성.
도 2는 Nkx2-5 및 (dHand로도 또한 공지된) HandII 이중 넉아웃에는 양쪽 심실 (rv 및 lv)이 결여되고, 이는 단일의 작은 원시 심방 (dc)을 갖는다는 것을 입증하는 것이다 (Yamagishi 2001).
도 3a-c는 돼지 섬유모세포에서의 NKX2-5, HANDII 및 TBX5의 삼중 넉아웃을 도시한 것이다. a) 각 유전자에 대한 코딩 서열의 개략도를 제시한 것으로; 색 교차부는 엑손 경계부를 나타내고, (하기) 청색 영역은 각 전사 인자의 DNA 결합 도메인을 나타내고, 삼각형 표시는 TALEN 결합 부위 위치를 나타낸다. b) TBX5 및 NKX2-5의 이중대립유전자성 KO에 대한 섬유모세포 콜로니의 RFLP 분석. 별표 표시는 이중의 이중대립유전자성 KO 콜로니를 표시하는 것이다. c) 콜로니 스크리닝의 결과 (n=480). 오직 TBX5 및 NKX2-5 이중 양성 클론에서만 서열분석하여 HANDII 돌연변이율을 분석하였다.
도 4는 Nkx2-5/HANDII/TBX5 삼중 넉아웃 돼지 배아가 무심장증을 갖는다는 것을 도시한 것이다. 삼중 넉아웃 돼지 배아에는 심장이 결여되고, 본질적으로 E18.0에서 (심장을 표시하는) Gata4 면역조직화학적으로 양성인 세포는 없다 (h, 심장 및 fg, 전장).
도 5a-f는 Nkx2-5가 CPC에서 네트워크를 지배하고, 심장 발생을 위한 인자라는 것을 입증하는 것이다. (a) Nkx2-5 유전자의 심장 인핸서 영역을 형광성 리포터 (EYFP)에 융합시키고, 이를 사용하여 트랜스제닉 마우스를 생성하였다. (b) Nkx2-5 인핸서는 트랜스제닉 마우스 배아에서 심장 선조 세포 집단으로의 EYFP 발현을 지시한다. (c) RNA를 분류된 CPC로부터 단리시키고, 증폭시키고, 아피메트릭스(Affymetrix) 어레이 분석을 사용하여 유전자 발현을 평가하였다. 단일 배아로부터의 각 음성 세포 집단 (E7.75-E9.5) 대비 Nkx2-5-EYFP CPC의 아피메트릭스 어레이 분석 결과 심장 발생과 연관된 유전자 발현이 증가되었고, HandII 및 Tbx5가 심장 반월에서 인자인 것으로 확인되었다. Nkx2-5 널 심장 선조 세포 (CPC)에서 상향조절된 유전자 확인. (d) EYFP는 E8.0 및 E9.5의 6kbNkx2-5-EYFP: WT 및 6kbNkx2-5-EYFP: Nkx2-5 널 한배새끼에서 CPC로 유도된다. (e) E8.0 및 E9.5 단계에서 단리된 WT (+/+) CPC 대비 EYFP 양성 Nkx2-5 널 (-/-)에서 유의적으로 상향조절된 유전자에 대한 어레이 분석의 벤 다이어그램. (f) 혈액 형성 억제, (Etv2를 통한) 내피 계통의 촉진 및 (Bnp, Anf, Mlc-2v 및 크립토의 조절에 의한) 심장 계통의 촉진에서의 Nkx2-5의 역할을 입증하는 본 연구의 결과를 요약한 개략도.
도 6은 돼지 모델에서 인간화 심장을 생산하기 위한 전반적인 전략법을 도시한 것이다. 인간화 심장을 포함하는 돼지를 조작하기 위해 NKX2-5/HANDII/TBX5 돌연변이체 돼지 섬유모세포를 생산하는데 뿐만 아니라, SCNT 및 인간 줄기 세포 전달을 위해서도 다중 유전자 편집이 사용될 것이다.
도 7a-b는 ETV2의 TALEN 매개 넉아웃을 도시한 것이다. (a) 유전자 편집을 검출하기 위해 사용된 3 단계로 된 PCR 검정법. 프라이머 a-d로부터의 증폭은 대립유전자 결실이 존재하였다는 것을 나타내었다. 이형접합성 클론과 동형접합성 클론을 구별하기 위해, 프라이머 a-b 및 c-d를 사용하여 야생형 대립유전자를 증폭시켰다. a-d 생성물이 존재하고, a-b, c-d 생성물 둘 다가 부재할 때에만 클론은 대립유전자 결실에 대해 동형접합성인 것으로 간주된다. (b) 상기 기준에 부합하는 클론은 녹색 박스로 인클로징되어 있다.
도 8a-h는 돼지 ETV2 손실이 마우스 Etv2 돌연변이체 표현형을 재현하였다는 것을 입증하는 것이다. 24 체절 단계에서의 야생형 E18.0 돼지 배아 (a) 및 ETV2 넉아웃 배아 (b). 삽도는 요막의 확대도를 보여주는 것이다. 돌연변이체에서의 혈관 얼기 형성의 결여를 갖는 비정상적인 전체 형태에 주목한다 (삽도). (c-h) 각각 a 및 b에 제시된 배아의 요막 (c, d), 심장 수준 (e, f) 및 동맥 수준 (g, h)을 관통하는 섹션을 내피 마커인 Tie2; 심장 계통 마커인 Gata4; 및 핵 대조염색인 DAPI에 대해 염색하였다. 야생형 요막은 Tie2 양성 내피 내층 (c, 화살표 표시)과 함께 고도로 혈관화된 반면 (c), 돌연변이체에는 상기 세포 집단이 결여되었다 (d). 심내막, 주정맥 (CV), 및 등대동맥 (DA)은 야생형 배아에서 뚜렷이 관찰가능하다 (e, g). 그에 반해, Gata4 (녹색)으로 표시된 심장 선조 및 창자가 존재하기는 하지만, ETV2 널 배아에는 상기 구조가 완전히 결여되었다 (각각 f 및 h). 스케일 막대: 1,000 μm (a, b), 200 μm (a, b 중 삽도), 100 μm (c-h).
도 9a-b는 (a) ICM에 DiI 표지된 hiPSC를 포함하는 배반포를 도시한 것이다. 화살표는 DiI 및 HNA에 대해 양성인 세포를 나타낸다. (b) ICM에 EdU 표지된 hiPSC를 포함하는 배반포. hiPSC를 24시간 동안 40 μM EdU로 표지하고, 주사하였다. 배반포를 분열 세포를 표지하기 위해 1시간 동안 10 μM BrdU로 펄싱하였다. 이중 양성 세포는 화살표 표시로 제시되어 있다. BrdU+/EdU- 세포는 분열 숙주 세포이다. 배반포는 부화하기 시작하고 (괄호 표시), 이는 발생 진행을 의미한다는 것에 주목한다. HNA: 인간 핵 항원; OL: 중첩.
도 2는 Nkx2-5 및 (dHand로도 또한 공지된) HandII 이중 넉아웃에는 양쪽 심실 (rv 및 lv)이 결여되고, 이는 단일의 작은 원시 심방 (dc)을 갖는다는 것을 입증하는 것이다 (Yamagishi 2001).
도 3a-c는 돼지 섬유모세포에서의 NKX2-5, HANDII 및 TBX5의 삼중 넉아웃을 도시한 것이다. a) 각 유전자에 대한 코딩 서열의 개략도를 제시한 것으로; 색 교차부는 엑손 경계부를 나타내고, (하기) 청색 영역은 각 전사 인자의 DNA 결합 도메인을 나타내고, 삼각형 표시는 TALEN 결합 부위 위치를 나타낸다. b) TBX5 및 NKX2-5의 이중대립유전자성 KO에 대한 섬유모세포 콜로니의 RFLP 분석. 별표 표시는 이중의 이중대립유전자성 KO 콜로니를 표시하는 것이다. c) 콜로니 스크리닝의 결과 (n=480). 오직 TBX5 및 NKX2-5 이중 양성 클론에서만 서열분석하여 HANDII 돌연변이율을 분석하였다.
도 4는 Nkx2-5/HANDII/TBX5 삼중 넉아웃 돼지 배아가 무심장증을 갖는다는 것을 도시한 것이다. 삼중 넉아웃 돼지 배아에는 심장이 결여되고, 본질적으로 E18.0에서 (심장을 표시하는) Gata4 면역조직화학적으로 양성인 세포는 없다 (h, 심장 및 fg, 전장).
도 5a-f는 Nkx2-5가 CPC에서 네트워크를 지배하고, 심장 발생을 위한 인자라는 것을 입증하는 것이다. (a) Nkx2-5 유전자의 심장 인핸서 영역을 형광성 리포터 (EYFP)에 융합시키고, 이를 사용하여 트랜스제닉 마우스를 생성하였다. (b) Nkx2-5 인핸서는 트랜스제닉 마우스 배아에서 심장 선조 세포 집단으로의 EYFP 발현을 지시한다. (c) RNA를 분류된 CPC로부터 단리시키고, 증폭시키고, 아피메트릭스(Affymetrix) 어레이 분석을 사용하여 유전자 발현을 평가하였다. 단일 배아로부터의 각 음성 세포 집단 (E7.75-E9.5) 대비 Nkx2-5-EYFP CPC의 아피메트릭스 어레이 분석 결과 심장 발생과 연관된 유전자 발현이 증가되었고, HandII 및 Tbx5가 심장 반월에서 인자인 것으로 확인되었다. Nkx2-5 널 심장 선조 세포 (CPC)에서 상향조절된 유전자 확인. (d) EYFP는 E8.0 및 E9.5의 6kbNkx2-5-EYFP: WT 및 6kbNkx2-5-EYFP: Nkx2-5 널 한배새끼에서 CPC로 유도된다. (e) E8.0 및 E9.5 단계에서 단리된 WT (+/+) CPC 대비 EYFP 양성 Nkx2-5 널 (-/-)에서 유의적으로 상향조절된 유전자에 대한 어레이 분석의 벤 다이어그램. (f) 혈액 형성 억제, (Etv2를 통한) 내피 계통의 촉진 및 (Bnp, Anf, Mlc-2v 및 크립토의 조절에 의한) 심장 계통의 촉진에서의 Nkx2-5의 역할을 입증하는 본 연구의 결과를 요약한 개략도.
도 6은 돼지 모델에서 인간화 심장을 생산하기 위한 전반적인 전략법을 도시한 것이다. 인간화 심장을 포함하는 돼지를 조작하기 위해 NKX2-5/HANDII/TBX5 돌연변이체 돼지 섬유모세포를 생산하는데 뿐만 아니라, SCNT 및 인간 줄기 세포 전달을 위해서도 다중 유전자 편집이 사용될 것이다.
도 7a-b는 ETV2의 TALEN 매개 넉아웃을 도시한 것이다. (a) 유전자 편집을 검출하기 위해 사용된 3 단계로 된 PCR 검정법. 프라이머 a-d로부터의 증폭은 대립유전자 결실이 존재하였다는 것을 나타내었다. 이형접합성 클론과 동형접합성 클론을 구별하기 위해, 프라이머 a-b 및 c-d를 사용하여 야생형 대립유전자를 증폭시켰다. a-d 생성물이 존재하고, a-b, c-d 생성물 둘 다가 부재할 때에만 클론은 대립유전자 결실에 대해 동형접합성인 것으로 간주된다. (b) 상기 기준에 부합하는 클론은 녹색 박스로 인클로징되어 있다.
도 8a-h는 돼지 ETV2 손실이 마우스 Etv2 돌연변이체 표현형을 재현하였다는 것을 입증하는 것이다. 24 체절 단계에서의 야생형 E18.0 돼지 배아 (a) 및 ETV2 넉아웃 배아 (b). 삽도는 요막의 확대도를 보여주는 것이다. 돌연변이체에서의 혈관 얼기 형성의 결여를 갖는 비정상적인 전체 형태에 주목한다 (삽도). (c-h) 각각 a 및 b에 제시된 배아의 요막 (c, d), 심장 수준 (e, f) 및 동맥 수준 (g, h)을 관통하는 섹션을 내피 마커인 Tie2; 심장 계통 마커인 Gata4; 및 핵 대조염색인 DAPI에 대해 염색하였다. 야생형 요막은 Tie2 양성 내피 내층 (c, 화살표 표시)과 함께 고도로 혈관화된 반면 (c), 돌연변이체에는 상기 세포 집단이 결여되었다 (d). 심내막, 주정맥 (CV), 및 등대동맥 (DA)은 야생형 배아에서 뚜렷이 관찰가능하다 (e, g). 그에 반해, Gata4 (녹색)으로 표시된 심장 선조 및 창자가 존재하기는 하지만, ETV2 널 배아에는 상기 구조가 완전히 결여되었다 (각각 f 및 h). 스케일 막대: 1,000 μm (a, b), 200 μm (a, b 중 삽도), 100 μm (c-h).
도 9a-b는 (a) ICM에 DiI 표지된 hiPSC를 포함하는 배반포를 도시한 것이다. 화살표는 DiI 및 HNA에 대해 양성인 세포를 나타낸다. (b) ICM에 EdU 표지된 hiPSC를 포함하는 배반포. hiPSC를 24시간 동안 40 μM EdU로 표지하고, 주사하였다. 배반포를 분열 세포를 표지하기 위해 1시간 동안 10 μM BrdU로 펄싱하였다. 이중 양성 세포는 화살표 표시로 제시되어 있다. BrdU+/EdU- 세포는 분열 숙주 세포이다. 배반포는 부화하기 시작하고 (괄호 표시), 이는 발생 진행을 의미한다는 것에 주목한다. HNA: 인간 핵 항원; OL: 중첩.
심혈관 질환은 미국에서 및 전 세계에서 사망 원인의 1위를 차지하고 있다. 현재 성인 3명 중 1명이 심혈관 질환을 앓는 채로 살고 있다. 선천성 심장 결함은 흔하며, 이는 말기 심장 부전으로 진행될 수 있다. 심장 이식이 말기 심장 부전에 대한 유일한 치유법이지만, 공여자 기관의 이용가능성이 제한되어 있기 때문에 비교적 적은 환자가 상기 요법을 받고 있다. 요컨대, 상기 치료 요법을 필요로 하는 환자를 치료하기 위한 심장 공급은 부족한 상태이다. 추가로, 선천성 또는 심장 부전 질환을 위한 새로운 장치, 약리학적 또는 외과적 요법을 시험하기 위한 관련된 인간 모델은 존재하지 않는다. 세 번째로, 심장을 이식할 필요가 없도록 하는 심장 재생을 촉진시키는 인자를 확인, 또는 연구하기 위한 관련된 인간 모델은 존재하지 않는다. 마지막으로, 본원에서는 환자 본인의 줄기 세포를 사용하여 재생될 수 있는 개인맞춤형 인간 조직의 공급원을 제공한다 (이로써, 예컨대 기관 기증 또는 인간 배아 줄기 세포의 사용과 같은 윤리적 문제가 해소된다). 따라서, 본원에서는 큰 동물 모델에서 인간화 심장을 조작함으로써 관련 기술분야에 대혁신을 일으키는 신흥 기술의 이용을 제공한다.
본원에서는 이식을 위한 심장/조직의 무한 공급원으로서의 역할을 하고, 인간 심장의 재생 및/또는 인간 심장의 실험 약물에 대한 반응을 연구하기 위한 큰 동물 모델을 제공하는 돼지에서 인간 기관 (심장)/인간화 조직을 생성하기 위한 조성물 및 방법을 제공한다.
특히, 본원에서는 상기 요법으로부터 이익을 얻게 되는 수백만 명의 사람들에게 개인맞춤형 심장 조직 또는 심장을 제공하기 위한 조성물 및 방법을 제공한다. 상기 전략법은 심혈관 의약에 대혁신을 일으킬 것이며, 이러한 치명적인 질환에 대한 치유법을 제공하게 될 것이다. 개인맞춤형 심장 판막, 심장 조직, 관상 동맥 및 전체 심장이 환자를 위해 이용가능할 수 있고, 이는 면역억제제의 사용을 제거할 것이다. 추가로, 본원에서는 다른 조직, 예컨대 개인맞춤형 혈액, 맥관 구조, 근육, 뼈 및 폐 생성을 위한 플랫폼을 제공한다.
앞서, 심장 발생을 위해 필요하고, 그에 충분한 네트워크를 정의하기 위해 트랜스제닉 및 유전자 파괴 마우스 모델을 조작하였다. 심장 발생의 전사 활성인자로서, 혈액 형성의 억제인자로서, 및 마스터 내피/심장내 인자인 Etv2의 활성인자로서의 Nkx2-5의 역할 (5-21)이 입증되었다. 상기 데이터 및 다른 공개 문헌에 기초하여, Nkx2-5/Hand2/Tbx5에 대한 돌연변이체 동물에는 심장이 완전히 결여되어 있는 것으로 간주되었다 (22-26). 최신의 유전자 편집 기술을 사용하여, 초기 발생 동안 치명적이며, 교란된 심혈관 계통을 가지거나, 또는 심혈관 계통이 없는 돌연변이체 돼지 배아를 생성하였다. 심혈관 질환 치료를 위한 인간 조직의 신규한 공급원으로서의 역할을 하는 것 이외에도, 인간화 돼지는 인간 계통의 재생 또는 약리학적 작용제에 대한 반응(들)을 연구하여 선천성 및 심장 부전 질환을 포함하는 심혈관 질환에 대한 요법을 개선시키는 큰 동물 모델로서의 역할도 할 수 있다. 본 접근법은 혁신적이고, 최신의 첨단 기술을 조합하여 돼지 숙주에서 심혈관 계통을 지배하고, 인간 특이적 조직을 생산하는 네트워크 및 줄기 세포 집단을 해독한다.
정의
하기 정의는 본 명세서 및 특허청구범위에 관한 명확하고 일관된 이해를 제공하기 위해 포함된다. 본원에서 사용되는 바, 언급된 용어는 하기 의미를 갖는다. 본 명세서에서 사용되는 모든 다른 용어 및 어구는 관련 기술분야의 통상의 기술자가 이해하는 것과 같은 그의 일반적인 의미를 갖는다. 그러한 일반적인 의미는 기술 용어 사전, 예컨대 문헌 [Hawley's Condensed Chemical Dictionary 14th Edition, by R.J. Lewis, John Wiley & Sons, New York, N.Y., 2001]을 참조함으로써 얻을 수 있다.
본 명세서에서 "하나의 실시양태", "한 실시양태" 등에 대한 언급은 기술된 실시양태가 특정 측면, 특성, 구조, 모이어티, 또는 특징을 포함할 수 있지만, 모든 실시양태가 반드시 그러한 측면, 특성, 구조, 모이어티, 또는 특징을 포함할 필요는 없다는 것을 나타낸다. 추가로, 상기 어구는 반드시 그러할 필요는 없지만, 본 명세서의 다른 부분에서 언급된 동일한 실시양태를 지칭할 수 있다. 추가로, 특정 측면, 특성, 구조, 모이어티, 또는 특징이 실시양태와 관련하여 기술된 경우, 명백하게 기술되었는지 여부와 상관 없이, 상기 측면, 특성, 구조, 모이어티, 또는 특징은 다른 실시양태에 영향을 줄 수 있거나, 또는 그와 관련시키는 것은 관련 기술분야의 통상의 기술자의 지식 범위 내에 포함되어 있다.
본원에서 사용되는 바, 단수 형태는 하나의, 또는 하나 초과의, 즉, 적어도 하나의 대상을 지칭한다. 예로서, "한 요소"란, 하나의 요소 또는 하나 초과의 요소를 의미한다.
"및/또는"이라는 용어는 상기 용어와 연합된 항목들 중 어느 하나, 항목들의 임의 조합, 또는 항목들을 모두 의미한다. "하나 이상의"라는 어구는 특히 그의 어법과 관련하여 판독될 때에 관련 기술분야의 통상의 기술자에 의해 쉽게 이해될 것이다. 예를 들어, 페닐 고리 상의 하나 이상의 치환기란, 1 내지 5개, 또는 페닐 고리가 이치환된 경우라면, 1 내지 4개를 지칭한다.
본원에서 사용되는 바, "또는"은 상기 정의된 바와 같은 "및/또는"이라는 것과 동일한 의미를 갖는 것으로 이해하여야 한다. 예를 들어, "및/또는" 또는 "또는"이 항목의 목록을 분리한 경우, 이는 다 포함하는 것으로, 예컨대 다수의 항목들 중 적어도 하나를 포함하는 것 뿐만 아니라, 그들 중 하나 초과의 것, 및 임의적으로 열거되지 않은 추가 항목을 포함하는 것으로 해석되어야 한다. 예컨대, "중 단 하나" 또는 "중 정확하게 하나" 또는 특허청구범위에서 사용될 때, "로 이루어진"이라는 용어와 같이, 그에 반하는 것을 명백하게 명시하는 용어만이 다수의 요소들 또는 요소들의 목록에서 정확하게 1개의 요소만을 포함한다는 것을 지칭할 것이다. 일반적으로, 본원에서 사용되는 바, "또는"이라는 용어는 예컨대, "둘 중 어느 하나", "중 하나", "중 단 하나", 또는 "중 정확하게 하나"와 같은 배타적 용어가 앞에 있는 경우, 오직 배타적 대안을 명시하는 것으로만 (즉, "둘 다가 아닌, 하나 또는 다른 하나"인 것으로) 해석되어야 한다.
본원에서 사용되는 바, "수반하는" "수반한다", "가지는", "갖는다", "갖는" 또는 그의 파생어는 "포함하는"이라는 용어와 유사하게 다 포함하는 것으로 의도된다.
"약"이라는 용어는 명시된 값의 ±5%, ±10%, ±20%, 또는 ±25% 변차를 지칭할 수 있다. 예를 들어, 일부 실시양태에서, "약 50" 퍼센트라는 것은 45 내지 55 퍼센트의 변차를 내포할 수 있다. 정수 범위의 경우, "약"이라는 용어는 범위의 각 끝점에 있는 언급된 정수보다 크고/거나, 작은 1 또는 2개의 정수를 포함할 수 있다. 본원에서 달리 명시되지 않는 한, "약"이라는 용어는 개별 성분, 조성물 또는 실시양태의 기능적 면에서 등가인, 언급된 범위에 근접한 값, 예컨대 중량 백분율을 포함하는 것으로 의도된다. 약이라는 용어는 언급된 범위의 종점을 변경시킬 수 있다.
관련 기술분야의 통상의 기술자가 이해하는 바와 같이, 성분의 정량, 특성, 예컨대 분자량, 반응 조건 등을 표현혀는 수치를 포함하는, 모든 수치는 근사치이며, 이는 임의적으로 모든 경우에서 "약"이라는 용어로 수식될 수 있는 것으로 이해된다. 상기 값은 본원의 기술내용의 교시를 사용하는 관련 기술분야의 통상의 기술자가 얻고자 하는 원하는 특성에 의존하여 달라질 수 있다. 상기 값은 내재적으로는 필히 그의 각 시험 측정값에서 발견되는 표준 편차로부터 생성되는 변동성을 함유한다는 것 또한 이해하여야 한다.
관련 기술분야의 통상의 기술자가 이해하는 바와 같이, 임의의 모든 목적을 위해, 특히 작성된 기술내용을 제공한다는 점에서 본원에서 언급된 모든 범위는 또한 하위 범위 및 그의 하위 범위의 조합 뿐만 아니라, 상기 범위를 구성하는 개별 값, 특히, 정수 값도 포함한다. 언급된 범위 (예컨대, 중량 백분율 또는 탄소군)는 각각 상기 범위 내의 특정 값, 정수, 소수, 또는 아이덴티티를 포함한다. 임의의 열거된 범위는 충분히 동일 범위를 기술하고, 이는 적어도 동일한 1/2, 1/3, 1/4, 1/5, 또는 1/10로 분해될 수 있는 것으로 쉽게 인식될 수 있다. 비제한적인 예로서, 본원에서 논의된 각 범위는 하위 1/3, 중간 1/3 및 상위 1/3 등으로 쉽게 분해될 수 있다. 관련 기술분야의 통상의 기술자가 이해하는 바와 같이, 예컨대 "최대", "적어도", "보다 큰", "미만", "초과", "또는 그 초과" 등과 같은 모든 표현은 언급된 수치를 포함하고, 상기 용어는 상기 논의된 바와 같이 후속하여 하위 범위로 분해될 수 있는 범위를 지칭한다. 동일한 방식으로, 본원에서 언급된 모든 비 또한 더 넓은 범위의 비 내에 포함되는 모든 하위 비를 포함한다. 따라서, 라디칼, 치환기, 및 범위에 대해 언급된 특정 값은 단지 예시를 위한 것이며; 이는 라디칼 및 치환기에 대한 다른 정의된 값 또는 정의된 범위 내의 다른 값들을 배제시키지 않는다.
관련 기술분야의 통상의 기술자는 또한 구성원이 함께 일반적인 방식으로, 예컨대 마쿠쉬(Markush) 군으로 함께 분류되어 있는 경우, 본 발명은 열거된 전체 군을 전체로서 뿐만 아니라, 군의 각 구성원을 개별적으로 및 주요 군의 모든 가능한 하위 군을 포함한다는 것도 쉽게 인식하게 될 것이다.
추가로, 모든 목적을 위해, 본 발명은 주요 군 뿐만 아니라, 군 구성원 중 하나 이상의 것이 없는 주요 군도 포함한다. 그러므로, 본 발명은 언급된 군의 구성원 중 임의의 하나 이상의 것의 명백한 배제를 구상한다. 따라서, 개시된 카테고리 또는 실시양태 중 임의의 것에 단서가 적용될 수 있으며, 이로써, 예를 들어, 명백한 부정적 한정에서의 사용을 위해 언급된 요소, 종, 또는 실시양태 중 어느 하나 이상의 것이 상기 카테고리 또는 실시양태로부터 배제될 수 있다.
"단리된"이라는 용어는 생체내에서 인자(들), 세포 또는 세포들과 회합되어 있는 하나 이상의 인자, 세포 또는 하나 이상의 세포 성분과 회합되어 있지 않은 인자(들), 세포 또는 세포들을 지칭한다.
"접촉시키는"이라는 용어는 예컨대, 용액 중, 반응 혼합물 중, 시험관내에서, 또는 생체내에서 세포 또는 분자 수준에서 터치하거나, 접촉하도록 하거나, 바로 옆에 또는 근접하게 위치시켜 생리학적 반응, 화학적 반응, 또는 물리적 변화를 일으키는 행위를 지칭한다.
본원에서 사용되는 바, "세포", "세포주", 및 "세포 배양물"이라는 용어는 상호교환적으로 사용될 수 있다. 상기 용어들은 모두 임의의 모든 후속 세대인, 그의 자손도 포함한다. 모든 자손은 고의적 또는 비고의적 돌연변이에 기인하여 동일하지 않을 수 있다는 것을 이해하여야 한다.
"세포"는 척추동물, 예컨대 인간을 포함하는 포유동물로부터의 세포를 포함하거나, 또는 "대상체"는 척추동물, 예컨대 인간을 포함하는 포유동물이다. 포유동물은 인간, 가축, 스포츠용 동물 및 반려 동물을 포함하나, 이에 제한되지 않는다. "동물"이라는 용어에는 개, 고양이, 어류, 게르빌루스쥐, 기니아 피그, 햄스터, 말, 토끼, 돼지, 마우스, 원숭이 (예컨대, 유인원, 고릴라, 침팬지, 또는 오랑우탄), 래트, 양, 염소, 암소 및 조류가 포함된다.
한 실시양태에서, 줄기, 선조 또는 전구체 세포는 배아 줄기 세포, 성체 줄기 세포, 유도된 만능성 줄기 세포, 및/또는 다능성 줄기 세포 (예컨대, 다능성 중배엽 전구체)이다. 한 실시양태에서, 줄기, 선조 또는 전구체 세포는 포유동물 세포이다. 한 실시양태에서, 줄기 세포로는 유도된 만능성 줄기 세포, 제대혈 줄기 세포, 중간엽 줄기 세포, 만능성 줄기 세포를 포함하나, 이에 제한되지 않는다. 한 실시양태에서, 줄기 세포는 인간 기원의 것이다. 또 다른 실시양태에서, 줄기 세포는 돼지 기원의 것이다.
분화전능성 (일명 전능성) 줄기 세포는 배아 및 배아외 세포 유형으로 분화될 수 있다. 상기 세포가 완전한 생존가능한 유기체를 구축할 수 있다. 상기 세포는 난자 및 정자 세포의 융합으로부터 생산된다. 수정란의 처음 몇회에 걸친 분열에 의해 생산된 세포 또한 분화전능성이다. 만능성 줄기 세포는 분화전능성 세포의 후손이고, 이는 거의 모든 세포로, 즉, 3개의 배엽층 중 임의의 것으로부터 유래된 세포로 분화될 수 있다. 다능성 줄기 세포는 다수의 세포 유형 뿐만 아니라, 세포의 밀접한 관련이 있는 패밀리의 것으로 분화될 수 있다. 소능성 줄기 세포는 단지 몇 세포 유형으로만, 예컨대 림프양 또는 골프양 줄기 세포로 분화될 수 있다. 단능성 세포는 단 하나의 세포 유형인 그 자신을 생산할 수 있지만 [4], 자기 재생 특성을 가지고 있으며, 이를 통해 상기 세포는 비-줄기 세포 (예컨대, 선조 세포, 근육 줄기 세포)와 구별된다.
"확장"이란 분화 없이 이루어지는 세포 증식을 지칭한다.
"선조 세포"는 그의 최종적으로 분화된 자손의 특징들 모두는 아니지만, 그의 일부를 가지는, 줄기 세포의 분화 동안에 생산된 세포이다. 정의된 선조 세포는 특정 또는 최종적으로 분화된 세포 유형으로가 아닌, 계통으로 수임된다. "내피 세포"라는 어구는 최종적으로 분화된 세포 유형 뿐만 아니라, 최종적으로 분화된 것이 아닌, 내피 계통으로 수임된 세포도 포함한다.
"분화 인자"란, 세포 인자, 바람직하게, 계통 수임을 유도하는 성장 인자 또는 혈관신생 인자를 지칭한다.
"피그(pig)" 및 "스와인(swine)" 및 "포사인(porcine)"이라는 용어는 돼지로서 교환가능하게 사용되고, 성별, 크기 또는 품종에 관계 없이 동일한 유형의 동물을 언급하는 총칭이다. "피그", "스와인" 및 "포사인", 예컨대 인간 또는 돼지 유전자로 상보된 널 "피그", "스와인" 및 "포사인", 상기 "피그", "스와인" 및 "포사인"은 배아, 신생 돼지 또는 성체 (갓 태어난 돼지 및 어린 돼지 포함)일 수 있다는 것에도 또한 주목한다.
"Hand2" 및 "HandII"라는 용어는 상호교환적으로 사용된다.
본원에서 사용되는 바, "인간화 골격근", "인간화 심근", 또는 "인간화 근육"이란 하나 이상의 인간 유전자 및/또는 단백질을 발현하는 돼지 또는 다른 비-인간 동물 중의 세포 또는 조직을 지칭한다. 한 실시양태에서, 하나 이상의 인간 유전자/단백질을 발현하는 돼지 세포 또는 조직은 상응하는 기능적 돼지 유전자 및/또는 단백질을 발현하지 않는다.
유전자의 "코딩 영역"은 유전자의 코딩 가닥의 뉴클레오티드 잔기 및 유전자의 전사에 의해 생산되는 mRNA 분자의 코딩 영역과 각각 상동성이거나, 또는 그와 상보적인, 유전자의 비코딩 가닥의 뉴클레오티드로 이루어진다.
"대조군" 세포는 시험 세포와 동일한 세포 유형을 갖는 세포이다. 대조군 세포는 예를 들어, 시험 세포를 검사하는 시점과 정확하게 동일한 시점에 또는 거의 동일한 시점에 검사될 수 있다. 대조군 세포는 또한 예를 들어, 시험 세포를 검사하는 시점과 동떨어진 먼 시점에 검사될 수 있고, 대조군 세포의 검사 결과는 기록된 결과가 시험 세포의 검사에 의해 수득된 결과와 비교될 수 있도록 기록될 수 있다.
본원에서 사용되는 바, "유효량" 또는 "치료학상 유효량"이란, 선택된 효과를 생산하는데, 예컨대 질환 또는 장애의 증상을 완화시키는데 충분한 양을 의미한다. 예컨대, 다중 화합물과 같이, 조합 형태로 화합물을 투여하는 것과 관련하여, 또 다른 화합물(들)과 조합하여 투여될 때, 각 화합물의 양은 상기 화합물이 단독으로 투여될 때와는 상이할 수 있다. 따라서, 비록 각 화합물의 실제 양은 달라질 수 있지만, 화합물의 조합의 유효량은 총칭하여 그 전체로서 조합을 지칭한다. "더욱 효과적인"이라는 용어는 선택된 효과가 그의 비교 대상이 되는 제2 치료법과 비교하였을 때, 한 치료법에 의해 더 큰 정도로 완화되었다는 것을 의미한다.
"코딩하는"이란, 생물학적 프로세스에서 뉴클레오티드 (즉, rRNA, tRNA 및 mRNA)의 정의된 서열 또는 아미노산의 정의된 서열 중 하나를 갖는 다른 중합체 및 거대분자의 합성을 위한 주형으로서의 역할을 하는 폴리뉴클레오티드, 예컨대 유전자, cDNA, 또는 mRNA 중의 뉴클레오티드의 특정 서열의 고유한 특성, 및 그로부터 생성된 생물학적 특성을 지칭한다. 따라서, 유전자에 상응하는 mRNA의 전사 및 번역을 통해 세포 또는 다른 생물학적 시스템에서 단백질이 생산된다면, 유전자는 단백질을 코딩하는 것이다. 그의 뉴클레오티드 서열이 mRNA 서열과 동일하고, 일반적으로 서열 목록에 제공되어 있는 코딩 가닥, 및 유전자 또는 cDNA의 전사를 위한 주형으로서 사용되는 비-코딩 가닥 둘 다는 상기 유전자 또는 cDNA의 단백질 또는 다른 생성물을 코딩하는 것으로서 지칭될 수 있다.
"단편" 또는 "절편"은 적어도 하나의 아미노산을 포함하는 아미노산의 일부분, 또는 적어도 하나의 뉴클레오티드를 포함하는 핵산 서열의 일부분이다. "단편" 및 "절편"이라는 용어는 본원에서 상호교환적으로 사용된다.
본원에서 사용되는 바, "기능적" 생물학적 분자는 특징으로 하는 특성을 보이는 형태의 생물학적 분자이다. 예를 들어, 기능적 효소는 효소가 특징으로 하는 특징적인 촉매성 활성을 보이는 것이다.
본원에서 사용되는 바, "상동성"이란, 2개 중합체 분자 사이의, 예컨대 2개 핵산 분자 사이의, 예컨대 2개 DNA 분자 또는 2개 RNA 분자 사이의, 또는 2개 폴리펩티드 분자 사이의 서브유니트 서열 유사성을 지칭한다. 2개 분자 중 둘 다에서 서브유니트 위치가 동일한 단량체 서브유니트로 점유되어 있을 때, 예컨대 각각의 2개 DNA 분자 중의 위치가 아데닌으로 점유되어 있다면, 이때 그들은 상기 위치에서 상동성을 띠는 것이다. 2개 서열 사이의 상동성은 매칭 또는 상동성 위치의 수의 직접적인 함수이며, 예컨대 2개 화합물 서열 중 위치의 절반 (예컨대, 길이가 10개의 서브유니트로 이루어진 중합체 중의 5개의 위치)이 상동성을 띤다면, 이때 2개 서열은 50% 상동성이고, 위치의 90%, 예컨대 10개 중 9개가 매치되거나, 상동성을 띤다면, 2개 서열은 90%의 상동성을 공유하는 것이다. 예로서, DNA 서열 3'ATTGCC5' 및 3'TATGGC는 50%의 상동성을 공유하는 것이다.
본원에서 사용되는 바, "상동성"은 "동일성"과 동의어로 사용된다.
2개 뉴클레오티드 또는 아미노산 서열 사이의 퍼센트 동일성의 결정은 수학적 알고리즘을 사용하여 달성될 수 있다. 예를 들어, 2개 서열을 비교하는데 유용한 수학적 알고리즘은 문헌 [Karlin and Altschul (1993, Proc. Natl. Acad. Sci. USA 90:5873-5877)]에서 변형된 것과 같은, 카를린(Karlin) 및 알트슐(Altschul)의 알고리즘 (1990, Proc. Natl. Acad. Sci. USA 87:2264-2268)이다. 상기 알고리즘은 문헌 [Altschul, et al. (1990, J. Mol. Biol. 215:403-410)]의 NBLAST 및 XBLAST 프로그램으로 도입되고, 예를 들어, 미국 국립 생물 공학 정보 센터(National Center for Biotechnology Information: NCBI) 웹사이트에서 BLAST 도구를 사용하여 공용 리소스 로케이터를 갖는 NCBI 월드 와이드 웹 사이트에서 액세스가 가능하다. 하기 파라미터: 갭 패널티 = 5; 갭 연장 패널티 = 2; 미스매치 패널티 = 3; 매치 보상 = 1; 기대 값 10.0; 및 워드 크기 = 11을 사용하여 (NCBI 웹사이트에서 "blastn"으로 지정된) NBLAST 프로그램을 이용하여 BLAST 뉴클레오티드 검색을 수행함으로써 본원에 기술된 핵산에 상동성인 뉴클레오티드 서열을 수득할 수 있다. 하기 파라미터: 기대 값 10.0, BLOSUM62 스코어링 행렬을 사용하여 (NCBI 웹사이트에서 "blastn"으로 지정된) XBLAST 프로그램 또는 NCBI "blastp" 프로그램을 이용하여 BLAST 단백질 검색을 수행함으로써 본원에 기술된 단백질 분자에 상동성인 아미노산 서열을 수득할 수 있다. 비교 목적으로 갭이 있는 정렬을 수득하기 위해 문헌 [Altschul et al. (1997, Nucleic Acids Res. 25:3389-3402)]에 기술된 바와 같이 갭드 BLAST(Gapped BLAST)가 사용될 수 있다. 대안적으로, PSI-Blast 또는 PHI-Blast는 분자 사이의 먼 관계 (상기 문헌 동일) 및 공통 패턴을 공유하는 분자 사이의 관계를 검출하는 반복 검색을 수행하는데 사용될 수 있다. BLAST, 갭드 BLAST, PSI-Blast, 및 PHI-Blast 프로그램을 사용할 때, 각 프로그램 (예컨대, XBLAST 및 NBLAST)의 디폴트 파라미터가 사용될 수 있다.
2개 서열 사이의 퍼센트 동일성은 갭을 허용하면서, 또는 허용하지 않으면서, 상기 기술된 것과 유사한 기술을 사용하여 결정될 수 있다. 퍼센트 동일성을 산출할 때, 전형적으로는 정확한 매치가 계수된다.
본원에서 사용되는 바, "설명서"는 본원에서 언급된 각종 질환 또는 장애를 완화시키기 위한 키트에서의 본 발명의 유용성을 전달하는데 사용될 수 있는 간행물, 기록물, 다이어그램, 또는 임의의 다른 표현 매체를 포함한다. 임의적으로, 또는 대안적으로, 설명서는 포유동물의 세포 또는 조직에서의 질환 또는 장애를 완화시키는 하나 이상의 방법을 기술할 수 있다. 본 발명의 키트의 설명서는 예를 들어, 확인된 본 발명, 또는 그의 일부를 함유하는 용기에 부착될 수 있거나, 또는 본 발명, 또는 그의 일부를 함유하는 용기와 함께 수송될 수 있다. 대안적으로, 설명서는 설명서 및 화합물이 수혜자에 의해 협조적으로 사용될 수 있게 하고자 하는 의도로 용기와 따로따로 수송될 수 있다.
본원에서 사용되는 바, "핵산"이라는 용어는 RNA 뿐만 아니라, 단일 및 이중 가닥 DNA 및 cDNA를 포함한다. 추가로, "핵산", "DNA", "RNA"라는 용어 및 유사 용어는 또한 핵산 유사체, 즉, 포스포디에스테르 백본 이외의 것을 갖는 유사체를 포함한다. 예를 들어, 관련 기술분야에 공지되어 있고, 백본 중에 포스포디에스테르 결합 대신 펩티드 결합을 가지는, 소위 "펩티드 핵산"이라고 불리는 것은 본 발명의 범주 내에 포함되는 것으로 간주된다. "핵산"이란, 데옥시리보뉴클레오시드 또는 리보뉴클레오시드로 구성되었는지 여부와 상관 없이, 및 포스포디에스테르 결합 또는 변형된 결합, 예컨대 포스포트리에스테르, 포스포라미데이트, 실록산, 카르보네이트, 카르복시메틸에스테르, 아세트아미데이트, 카르바메이트, 티오에테르, 가교된 포스포라미데이트, 가교된 메틸렌 포스포네이트, 가교된 포스포라미데이트, 가교된 포스포라미데이트, 가교된 메틸렌 포스포네이트, 포스포로티오에이트, 메틸포스포네이트, 포스포로디티오에이트, 가교된 포스포로티오에이트 또는 술폰 결합, 및 상기 결합의 조합으로 구성되었는지 여부와 상관 없이 임의의 핵산을 의미한다. 핵산이라는 용어는 또한 구체적으로 생물학적으로 발생된 5종의 염기 (아데닌, 구아닌, 티민, 시토신, 및 우라실) 이외의 다른 염기로 구성된 핵산을 포함한다. 본원에서는 폴리뉴클레오티드 서열을 기술하는데 관용적 표기법이 사용된다: 단일 가닥 폴리뉴클레오티드 서열의 좌측 단부가 5'-단부이고; 이중 가닥 폴리뉴클레오티드 서열의 좌측 방향은 5'-방향으로 지칭된다. 5'에서 3'으로의, 초기 RNA 전사체에의 뉴클레오티드 부가 방향은 전사 방향으로 지칭된다. mRNA와 동일한 서열을 갖는 DNA 가닥은 "코딩 가닥"으로 지칭되고; DNA 상의 기준점에 대해 5'에 위치하는 DNA 가닥 상의 서열은 "상류 서열"로서 지칭되고; DNA 상의 기준점에 대해 3'에 위치하는 DNA 가닥 상의 서열은 "하류 서열"로서 지칭된다.
본원에서 사용되는 바, "핵산 구축물"이라는 용어는 게놈 또는 합성 방법에 의해 수득되는지 여부와 상관 없이, 원하는 특정 유전자 또는 유전자 단편을 코딩하는 DNA 및 RNA 서열을 포함한다.
달리 언급되지 않는 한, "아미노산 서열을 코딩하는 뉴클레오티드 서열"은 서로의 축퇴성 버전이고, 동일한 아미노산 서열을 코딩하는 모든 뉴클레오티드 서열을 포함한다. 단백질 및 RNA를 코딩하는 뉴클레오티드 서열은 인트론을 포함할 수 있다.
"올리고뉴클레오티드"라는 용어는 전형적으로 짧은 폴리뉴클레오티드, 일반적으로는 약 50개 이하의 뉴클레오티드를 지칭한다. 뉴클레오티드 서열이 DNA 서열 (즉, A, T, G, C)에 의해 표시되는 경우, 이는 "U"가 "T"를 대체하는 것인 RNA 서열 (즉, A, U, G, C)을 포함한다는 것을 이해할 것이다.
전사 활성인자-유사 이펙터 뉴클레아제 (TALEN)는 TAL 이펙터 DNA 결합 도메인을 DNA 절단 도메인에 융합시킴으로써 생성되는 인공 제한 효소이다. 상기 시약을 통해 계내에서 게놈 편집을 위한 효율적이고, 프로그램 가능하고, 특이적인 DNA 절단이 이루어질 수 있다. 전사 활성인자-유사 이펙터 (TALE)는 서열 특이적인 방식으로 DNA에 결합하는 단백질이다. 상기 TALE를 뉴클레아제 (예컨대, FokI 엔도뉴클레아제)에 융합시킴으로써 고도로 특이적인 DNA "가위"가 제조된다 (상기 분자는 임의의 DNA 서열에 결합하도록 조작될 수 있다). 본원에서 사용되는 바, TALEN이라는 용어는 광범위하고, 또 다른 TALEN의 도움 없이 이중 가닥 DNA를 절단할 수 있는 단량체 TALEN을 포함한다. TALEN이라는 용어는 또한 함께 작용하여 같은 부위에서 DNA를 절단하도록 조작된 TALEN 쌍 중 하나 또는 둘 다의 구성원을 지칭하는 것으로 사용된다. 함께 작용하는 TALEN은 DNA의 방향성을 지칭하는 좌측-TALEN 및 우측-TALEN으로서 지칭될 수 있다.
일단 TALEN 유전자를 어셈블리하고 나면, 이를 플라스미드 내로 삽입한 후; 플라스미드를 사용하여 표적 세포를 형질감염시키고, 여기서 유전자 생성물은 발현이 되고, 핵으로 진입하여 게놈에 접근하게 된다. 이중 가닥 파단 (DSB)을 유도하고, 임의적으로, 세포가 수복 기전을 이용하여 반응하게 되는 그 반응 대상인 카르고/미리 선택된 유전자를 삽입함으로써 게놈을 편집하는데 TALEN이 사용될 수 있다. 이러한 방식으로, 예를 들어, 질환을 유발하는 게놈 중의 돌연변이를 교정하는데 사용될 수 있다.
유전자 편집을 포함하는, 유전자 조작은 관련 기술분야의 통상의 기술자에게 이용가능한 임의의 방법에 의해 예를 들어, 표적화된 엔도뉴클레아제, 및 상동성 지정 수복 (HDR), TALEN, CRISPR (예컨대, CAS9/CRISPR), 리콤비나제 융합 분자, 합성 돼지 인공 염색체, 메가뉴클레아제, 아연 핑거 또는 (예컨대, 원하는 표적 유전자를 넉아웃시키기 위한) 유전자 편집을 위한 rAAV 기반 시스템의 사용에 의해 수행될 수 있다. 추가로, 넉아웃 목적으로, 유전자 (예컨대, 간섭 RNA (shRNA, siRNA, dsRNA, RISC, miRNA)의 불활성화를 위해 또는 유전자를 발현시키기 위해서 다양한 핵산이 세포 내로 도입될 수 있다.
체세포 핵 이식 (SCNT)은 체세포 및 난세포로부터 생존가능한 배아를 창출하기 위한 실험실 기술이다. 체세포 핵 이식 프로세스는 2종의 상이한 세포를 포함한다. 첫 번째 것은 난자 (난/난모세포)로 알려져 있는 암컷 생식 세포이다. 두 번째 것은 인간 신체의 세포로 지칭되는 체세포이다. 피부 세포, 지방 세포, 및 간 세포만이 유일의 몇 안 되는 예가 된다. 공여자 난세포의 핵을 제거하고, 폐기하여 '탈프로그램화된' 상태가 되게 남겨 둔다. 체세포의 핵 또한 제거하되, 그대로 남겨 두고, 제핵 체세포를 폐기한다. 남아있는 것은 단독 체세포 핵과 제핵 난세포이다. 이어서, 체세포 핵을 '빈' 난자 내로 스쿼트함으로써 융합시킨다. 체세포 핵은 난 내로 삽입된 후, 그의 숙주 난세포에 의해 재프로그램화된다. 이제 체세포의 핵을 함유하는 난자를 쇼크를 주어 자극시키고, 이는 분열하기 시작할 것이다. 이제 난은 생존가능하고, 오직 한 부모로부터의 모든 필요한 유전 정보를 함유하는 성체 유기체를 생산할 수 있다. 보통은 이어서 발생이 일어나게 될 것이며, 다회에 걸친 유사 분열 후, 상기 단일 세포는 원래의 유기체 (즉, 클론)와 동일한 게놈을 갖는 배반포 (약 100개의 세포를 포함하는 초기 단계의 배아)를 형성한다. 이어서, 치료학적 클로닝에서 사용하기 위해 상기의 클론 배아를 파괴시킴으로써 줄기 세포를 수득할 수 있거나, 재생 클로닝인 경우, 추가 발생을 위해 클론 배아를 숙주 모체 (가임신/대리모) 내로 이식시키고, 분만시킨다.
"키메라"란, 유전적으로 상이한 세포로 구성된 단일 유기체를 지칭한다/유기체이다.
무효접합성 유기체는 동일한 유전자에 대해 2개의 돌연변이체, 또는 결손 대립유전자를 보유한다. 돌연변이체/결손 대립유전자는 둘 다 완전한 기능 상실 또는 '널' 대립유전자인 바, 이에 동형접합성 널 및 무효접합성은 동의어이다.
유전자 넉아웃 (약어: KO)은 유기체의 대립유전자 둘 다를 작동불가능하게 만드는 (유기체를 "넉 아웃시키는") 유전적 기술이다. 이는 또한 넉아웃 유기체 또는 간단하게 넉아웃으로도 알려져 있다. 상기 용어는 또한 유전자를 "넉 아웃시키는 것"에서와 같이 상기와 같은 유기체를 창출하는 프로세스를 지칭한다. 본 기술은 본질적으로 유전자 넉인과 반대되는 것이다.
유전자라는 용어는 광범위하고, 발현되어 기능적 생성물을 생산하는 염색체 DNA를 지칭한다. 유전자는 대립유전자를 갖는다. 유전자 편집은 단일-대립유전자성 또는 이중-대립유전자성일 수 있다.
2개 폴리뉴클레오티드가 "작동가능하게 연결된" 것으로서 기술되어 있는 것은 단일 가닥 또는 이중 가닥 핵산 모이어티가, 2개 폴리뉴클레오티드 중 적어도 하나가 그가 특징으로 하는 생리학적 효과를 그 나머지 하나에서 대해 발휘할 수 있도록 하는 방식으로 핵산 모이어티 내에 배열되어 있는 2개 폴리뉴클레오티드를 포함한다는 것을 의미하는 것이다. 예로서, 유전자의 코딩 영역에 작동가능하게 연결된 프로모터는 코딩 영역의 전사를 촉진시킬 수 있다.
"재조합 폴리뉴클레오티드"란, 천연적으로는 함께 연결되어 있지 않은 서열을 갖는 폴리뉴클레오티드를 지칭한다. 증폭된 또는 어셈블리된 재조합 폴리뉴클레오티드는 적합한 벡터에 포함될 수 있고, 상기 벡터는 적합한 숙주 세포를 형질전환시키는데 사용될 수 있다.
재조합 폴리뉴클레오티드는 또한 비-코딩 기능부 (예컨대, 프로모터, 복제 기점, 리보솜-결합 부위 등)로서의 역할을 할 수 있다.
재조합 폴리뉴클레오티드를 포함하는 숙주 세포는 "재조합 숙주 세포"로서 지칭된다. 유전자가 재조합 폴리뉴클레오티드를 포함하는 경우, 재조합 숙주 세포에서 발현되는 유전자는 "재조합 폴리펩티드"를 생산한다.
"재조합 세포"란, 트랜스진을 포함하는 세포이다. 상기 세포는 진핵 또는 원핵 세포일 수 있다. 또한, 트랜스제닉 세포는 트랜스진을 포함하는 배아 줄기 세포, 세포가 트랜스진을 포함하는 트랜스제닉 배아 줄기 세포로부터 유래된 키메라 포유동물로부터 수득된 세포, 트랜스제닉 포유동물, 또는 그의 태아 또는 태반 조직으로부터 수득된 세포, 및 트랜스진을 포함하는 원핵 세포를 포함하나, 이에 제한되지 않는다.
"조절한다"라는 용어는 관심 기능 또는 활성을 자극시키거나, 또는 억제시키는 것을 지칭한다.
본원에서 사용되는 바, "그를 필요로 하는 대상체"는 본 발명으로부터 이익을 얻게 되는 환자, 동물, 포유동물, 또는 인간이다.
본원에서 사용되는 바, "실질적으로 상동성인 아미노산 서열"은 참조 항체 쇄의 아미노산 서열과 적어도 약 95% 상동성, 바람직하게, 적어도 약 96% 상동성, 더욱 바람직하게, 적어도 약 97% 상동성, 더욱더 바람직하게, 적어도 약 98% 상동성, 및 가장 바람직하게, 적어도 약 99% 이상의 상동성을 갖는 상기 아미노산 서열을 포함한다. 아미노산 서열 유사성 또는 동일성은 BLAST (기본 국소 정렬 검색 도구) 2.0.14 알고리즘을 사용하는 BLASTP 및 TBLASTN 프로그램을 사용함으로써 산출될 수 있다. 상기 프로그램을 위해 사용되는 디폴트 설정 환경은 본 발명의 목적을 위한 실질적으로 유사한 아미노산 서열을 확인하는데 적합하다.
"실질적으로 상동성인 핵산 서열"이란, 상응하는 서열이 참조 핵산 서열에 의해 코딩된 펩티드와 실질적으로 동일한 구조 및 기능을 갖는 펩티드를 코딩하며; 예컨대, 다만 상기 펩티드 기능에 유의적인 영향을 주지 않는 아미노산 변이만이 존재하는 것인, 참조 핵산 서열에 상응하는 핵산 서열을 의미한다. 바람직하게, 실질적으로 동일한 핵산 서열은 참조 핵산 서열에 의해 코딩된 펩티드를 코딩한다. 실질적으로 유사한 핵산 서열과 참조 핵산 서열 사이의 동일성의 백분율은 적어도 약 50%, 65%, 75%, 85%, 95%, 99% 또는 그 초과이다. 핵산 서열의 실질적인 동일성은 예를 들어, 물리적/화학적 방법 (즉, 하이브리드화)에 의해, 또는 컴퓨터 알고리즘을 통한 서열 정렬에 의해 2개 서열의 서열 동일성을 비교함으로써 결정될 수 있다. 뉴클레오티드 서열이 참조 뉴클레오티드 서열과 실질적으로 유사한지 여부를 결정하는데 적합한 핵산 하이브리드화 조건은 하기와 같다: 50℃에서 7% 소듐 도데실 술페이트 SDS, 0.5 M NaPO4, 1 mM EDTA, 50℃에서 2X 표준 염수 시트레이트 (SSC), 0.1% SDS 중에서 세척; 바람직하게, 50℃에서 7% (SDS), 0.5 M NaPO4, 1 mM EDTA, 50℃에서 1X SSC, 0.1% SDS 중에서 세척; 바람직하게, 50℃에서 7% SDS, 0.5 M NaPO4, 1 mM EDTA, 50℃에서 0.5X SSC, 0.1% SDS 중에서 세척; 및 더욱 바람직하게, 50℃에서 7% SDS, 0.5 M NaPO4, 1 mM EDTA, 65℃에서 0.1X SSC, 0.1% SDS 중에서 세척. 2개 핵산 서열 사이의 실질적인 유사성을 결정하는데 적합한 컴퓨터 알고리즘으로는 GCS 프로그램 패키지 (Devereux et al., 1984 Nucl. Acids Res. 12:387), 및 BLASTN 또는 FASTA 프로그램 ([Altschul et al., 1990 Proc. Natl. Acad. Sci. USA. 1990 87:14:5509-13]; [Altschul et al., J. Mol. Biol. 1990 215:3:403-10]; [Altschul et al., 1997 Nucleic Acids Res. 25:3389-3402])을 포함한다. 상기 프로그램과 함께 제공된 디폴트 설정 환경은 본 발명의 목적을 위한 핵산 서열의 실질적인 유사성을 결정하는데 적합하다.
"벡터"는 단리된 핵산을 포함하고, 단리된 핵산을 세포 내부로 전달하는데 사용될 수 있는 물질의 조성물이다. 선형 폴리뉴클레오티드, 이온성 또는 양쪽성 화합물과 회합되어 있는 폴리뉴클레오티드, 플라스미드, 및 바이러스를 포함하나, 이에 제한되지 않는, 다수의 벡터가 관련 기술분야에 공지되어 있다. 따라서, "벡터"라는 용어는 자율 복제 플라스미드 또는 바이러스를 포함한다. 상기 용어는 또한 핵산의 세포로의 이식 또는 전달을 촉진시키는 비-플라스미드 및 비-바이러스 화합물, 예컨대, 예를 들어, 폴리리신 화합물, 리포솜 등을 포함하도록 구축되어야 한다. 바이러스 벡터의 예로는 아데노바이러스 벡터, 아데노-연관 바이러스 벡터, 레트로바이러스 벡터, 재조합 바이러스 벡터 등을 포함하나, 이에 제한되지 않는다. 비-바이러스 벡터의 예로는 리포솜, DNA의 폴리아민 유도체 등을 포함하나, 이에 제한되지 않는다.
종래의 분자생물학 기술을 포함하는 방법이 본원에 기술되어 있다. 상기 기술은 관련 기술분야에 일반적으로 공지되어 있으며, 방법에 관한 논문, 예컨대 [Molecular Cloning: A Laboratory Manual, 2nd ed., vol. 1-3, ed. Sambrook et al., Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., 1989]; 및 [Current Protocols in Molecular Biology, ed. Ausubel et al., Greene Publishing and Wiley-Interscience, New York, 1992] (정기 간행물 최신판 포함)에 상세하게 기술되어 있다. 핵산의 화학적 합성 방법은 예를 들어, 문헌 [Beaucage and Carruthers, Tetra. Letts. 22: 1859-1862, 1981], 및 [Matteucci et al., J. Am. Chem. Soc. 103:3185, 1981]에서 논의되고 있다.
"포함한다", "포함하는"이라는 용어 등은 미국 특허법에 그에 속한다는 의미를 가질 수 있고, 이는 "수반한다", "수반하는"이라는 용어 등을 의미할 수 있다. 본원에서 사용되는 바, "수반하는" 또는 "수반한다" 등은 제한 없이 포함한다는 것을 의미한다.
외인성 기관/조직 생산
인간화 큰 동물 모델은 재생 의학을 위한 자원이며, 이는 개인맞춤형 인간화 돼지 모델을 위한 플랫폼으로서의 역할을 하게 될 것이다. 이러한 전략법은 만성 근골격 질환 및 이식을 위한 현행의 임상 실무 패러다임을 전환시키게 될 것이다. 돼지 심근 제거가 유일한 것인데, 그 이유는 상기 제거가 큰 동물 모델에서의 인간화 심근 발생을 목적으로 할 뿐만 아니라, 이는 면역 거부를 피할 수 있는 신규한 접근법이고, 외인성 기관 발생 전략법을 위해 광범위하게 적용될 수 있기 때문이다.
현재, 진행성 말기 기관 부전을 위한 유일의 최종적인 요법은 이식이다. 수백만 명의 환자가 상기 요법으로부터 이익을 얻을 수는 있지만, 공여자 기관의 이용가능성이 제한되어 있기 때문에 상기 환자들이 이식을 받을 수 있는 자격이 있는 것은 아니다. 그러므로, 시신 또는 생체 관련 공여자 기관이 현저히 부족하다. 추가로, 기관 이식을 위해서는 장기간의 면역억제가 요구되는데, 이는 또한 유해하고, 생활을 제한하는 부작용을 갖는다. 본원에서는 이식을 위한 기관의 비제한적인 공급원으로서의 역할을 하고, 심혈관 질환 치료를 위한 패러다임-전환 플랫폼을 제공하게 될, 돼지에서 생성된 인간화 조직을 기술한다 (도 6).
강렬한 관심이 외인성 이식에 집중되고 있고, 최근의 기술 발전은 상기 전략법이 성공적일 수 있다는 개념을 뒷받침한다. 예를 들어, 래트 췌장은 배반포 상보 프로세스에 의해 마우스에서 생산되었다 (38). 상기 연구에서, 췌장 발생에 대한 마우스 조절 유전자인 Pdx1에 대한 배반포 돌연변이체에 야생형 래트로부터의 만능성 줄기 세포 (rPSC)를 주사하였다 (38). rPSC를 주사맞은 배반포를 마우스 대리모 내로 이식하면 래트 세포로 구성된 기능적 췌장을 갖는 마우스 키메라가 생성된다. 상기 돌연변이체 숙주는 건강한 공여자 줄기 세포가 공여자 유래의 기관을 증식시키고, 그를 생성할 수 있도록 하는 발생 "니치"를 제공한다. 배반포 상보 전략법은 또한 기관, 예컨대 설치류에서 신장 및 간을, 및 최근에서는 돼지에서 췌장을 생산하였다 (39-41). 돼지 모델을 사용한 후자의 상기 보고는 후속하여 이식 또는 진보된 요법을 위해 사용될 수 있는, 돼지에서의 인간 환자 특이적 기관의 발생을 뒷받침한다 (도 6).
인간화 큰 동물 모델은 재생 의학을 위한 자원이며, 이는 개인맞춤형 인간화 돼지 모델을 위한 플랫폼으로서의 역할을 하게 될 것이다. 이러한 전략법은 만성 근골격 질환 및 이식을 위한 현행의 임상 실무 패러다임을 전환시키게 될 것이다. 돼지 심장 조직 제거가 유일한 것인데, 그 이유는 상기 제거가 큰 동물 모델에서의 인간화 심장 조직 발생을 목적으로 할 뿐만 아니라, 이는 면역 거부를 피할 수 있는 신규한 접근법이고, 외인성 기관 발생 전략법을 위해 광범위하게 적용될 수 있기 때문이다.
유전자-편집 플랫폼을 사용하여 각종의 발생 유전자를 돌연변이시켜 기관 및/또는 조직 결손 돼지를 생성할 수 있고, 여기서 외인성 기관 및/또는 조직 생성을 위해 배반포 상보를 사용할 수 있다. 상기 시스템의 효율성을 통해 다수의 유전자를 실험적으로 시험할 수 있다. 다중의 조절 유전자를 동시에 변형시킴으로써 복합 조직 개체 발생을 조정할 수 있다.
근육 질환/장애
심장 조직 및 세포는 심근 세포를 포함하거나, 또는 (심근세포 또는 심장 근세포로도 공지되어 있는) 심근세포는 심근을 구성하는 근육 세포 (근세포)이다. 심혈관 질환 또는 심장 질환은 심장 및 혈관 질환을 포함하며, 그 중 다수는 죽상동맥경화증과 관련이 있다. 질환/장애로는 심장마비, 뇌졸중, 심장 부전, 부정맥, 및 심장 판막 장애를 포함하나, 이에 제한되지 않는다.
정밀
넉아웃
(KO) 돼지의 기관 생산을 위한 생성된 인간-돼지
키메라로의
생성
부위 특이적 뉴클레아제의 사용으로 큰 동물 게놈에서의 정밀 유전자 변경의 도입 효율은 100,000배 초과로 개선되었다. 부위 특이적 뉴클레아제에 의해 절단된 이중 가닥 파단의 비-상동성 단부-연결 (NHEJ)에 의해 유전자를 불활성화시키기는 TALEN 기반 플랫폼을 사용함으로써 가축에서 각각 50% 및 20% 비율의 고도로 효율적인 이형접합성 및 이중-대립유전자성 넉아웃 (KO)이 입증되었다 (27). 유전자-편집 플랫폼을 사용하여 각종의 발생 유전자를 돌연변이시켜 기관-결손 돼지를 생성할 수 있고, 여기서 외인성 기관 생성을 위해 배반포 상보를 사용할 수 있다. 상기 시스템의 효율성을 통해 다수의 유전자를 실험적으로 시험할 수 있다.
ETV2
넉아웃
돼지 배아에는 내피 계통이 결여된
다
Etv2가 결여된 배아는 맥관 구조의 부재와 함께 대략 E9.5에서 치명적인 바, 선행 연구를 통해 Nkx2-5는 Etv2 유전자의 상류 조절인자이며, Etv2는 마우스에서 내피 계통의 마스터 조절인자라는 것이 입증되었다 (8, 10, 12, 13). 돼지에서의 ETV2의 역할을 조사하기 위해, 돼지 섬유모세포에서 유전자에 플랭킹된 2개 TALEN 쌍을 사용하여 전체 ETV2 코딩 서열을 제거하였다 (도 7a). 상기 프로세스는 동형접합성 유전자 제거시에는 15%의 효율성을 띠었고; 유전자형 분석된 클론 528개 중 79개는 ETV2 유전자 결실에 대해 동형접합성을 띠었다 (도 7b). 핵 클로닝 (체세포 핵 이식; SCNT)을 위해 ETV2 동형접합성 넉아웃 섬유모세포 클론을 사용하여 ETV2 널 배아를 생성하였고, 이는 대리모 암퇘지 내로 이식되었다. 클로닝 효율은 29%였으며, 평균 성공률이 20%인 것보다 더 높았다. 배아를 수확하였고, E18.0에서 분석하였다 (도 8). 상기 단계에서, Wt 배아는 요막에 잘 발생된 혈관 얼기를 가지며 혈관화되었다 (도 8a, c). 그에 반해, ETV2 KO에서의 성장은 유의적으로 지연되었고 (도 7b), 이들 배아에는 심장내/내피 계통이 결여되었다 (도 8d, f, h). Wt 배아에서는 확실하게 발생이 이루어지는 주정맥, 등대동맥, 및 심내막이 ETV2 KO 배아에는 결여되었다 (도 8e-h). 본 결과는 마우스 및 돼지 표현형의 유사성을 반영하며, 이는 ETV2의 기능이 이들 종 간에 보존된다는 것을 시사한다. 추가로, 본 데이터는 다중 돌연변이를 돼지 게놈으로 지시함으로써 1종 초과의 세포 유형에서 인간화될 수 있는 키메라 기관의 성장을 지원할 수 있다는 것을 입증한다.
Nkx2
-5,
HandII
및
Tbx5
Nkx2-5, HandII 및 Tbx5를 돌연변이시켜 심장 근육 계통 결손 돼지 배아 (Nkx2-5/HandII/Tbx5 널 돼지 배아)를 생성하였다. Nkx2-5/HandII/Tbx5에 대한 다중의 유전자 편집을 수행함으로써 만능성 능력을 갖는 인간 세포를 사용하여 심장 세포로 재증식되는 허용 니치를 창출하여 인간화 심장/심장 조직 및/또는 심근을 수득하였다. 실시예 2의 상세한 설명을 참조한다.
인간화 큰 동물 모델은 재생 의학을 위한 중요한 자원이 될 것이며, 이는 개인맞춤형 기관 제조를 위한 플랫폼으로서의 역할을 하게 될 것이다. 이러한 전략법은 근육 질환 및 이식을 위한 현행의 임상 실무 패러다임을 전환시킬 수 있다. 현재까지, 기관의 외인성 이식은 마우스와 래트 (27, 29); 및 돼지와 돼지 (31) 사이에서 수행되어 왔으며, 큰 동물 모델에서의 인간화 기관의 성공적인 발생에 대해서는 보고된 바 없다. 미국 가출원 시리얼 번호 62/247,092; 62/247096; 및 62/247,122가 본원에서 참조로 포함된다.
하기 실시예는 본 발명의 특정의 특히 바람직한 실시양태를 추가로 예시하고자 하는 것이며, 이는 어느 방식으로든 본 발명의 범주를 제한하는 것으로 의도되지 않는다.
실시예
실시예
1: 심장 발생의
조절인자로서의
Nkx2
-5,
HandII
및
Tbx5
심장 발생은 전기적으로 커플링되고, 최종적으로는 기능적 합포체를 형성하는 심장 선조의 특수화, 증식, 이동 및 분화를 포함하는, 복잡한 고도로 조직화된 이벤트이다 (도 1). 상기 심장 발생 단계는 유전자 파괴 기술을 사용하여 심장 형성 및 생존가능성을 위해 요구되는 것으로 밝혀진 전사 네트워크에 의해 지배를 받는다 (6, 8, 9, 22-26) (표 1).

Nkx2-5는 초파리(드로소필라(Drosophila)) 호메오도메인 단백질인 틴맨(Tinman) (Csx)의 척추동물 동족체이다. 틴맨 돌연변이 결과 상기 파리에서는 심장 형성이 이루어지지 않게 된다 (35). Nkx2-5는 심장 계통에서 발현되는 가장 초기의 전사 인자 중 하나이다. Nkx2 -5의 표적화된 파괴는 심장 형태 발생을 동요시키고, 성장은 심각하게 지연되고, 대략 E9.5에서 배아 치명성을 띠게 된다 (22, 24). Nkx2-5 상호작용 인자 중 하나는, 함께 복합체를 형성하는 T-박스 전사 인자인 Tbx5이고, 심장 유전자 발현을 전사활성화시킨다 (36). 마우스에서의 Tbx5의 전체적인 결실은 심장 형태 발생을 동요시키고 (중증 심방 및 심실 형성저하증), E10.5까지 배아 치명성을 띠게 된다 (25). 심지어 반수체기능부전 마우스 (Tbx5 +/- )는 중증의 선천성 심장 및 앞다리 기형을 보이고, 환자에서 홀트-오람 증후군을 동반한 결함을 유발하는 것으로 밝혀졌다 (25). HandII (dHand)는 심장 형태 발생을 위해 필요한 것으로도 또한 밝혀진 bHLH 전사 인자이다. HandII 돌연변이체 배아는 조기 배아발생 동안 치명적이고, 중증 우심실 형성저하증 및 대동맥궁 결함을 갖는다 (23). 추가로, Nkx2-5 및 HandII 둘 다가 결여된 마우스는 심실 무발생을 보이며, 오직 단일의 심방 챔버만을 갖는다 (도 2) (26).
돼지
NKX2
-5,
HANDII
및
TBX5
유전자의
다중
넉아웃
심장 선조 세포에서의 Nkx2-5 전사 조절 캐스케이드를 정의하기 위해, 조작된 넉아웃 및 트랜스제닉 마우스 모델을 사용하여 줄기 세포 집단으로부터 심장 계통의 특수화를 지시하는 분자 네트워크를 정의하였다 (8, 9, 37). 심장 발생 동안 Nkx2-5 매개 네트워크를 정의하기 위해, 발생 중인 Nkx2-5 널 심장 (9)에서의 CPC 집단의 분자 시그니처를 조사하였다. 6 kb의 Nkx2-5 인핸서-EYFP 트랜스제닉 마우스 모델을 Nkx2-5 널 배경과 조합 방식으로 매이팅시켜 Nkx2-5 널 CPC에서의 EYFP 발현을 유도하였다. FACS를 사용하여 단계 (연령)가 매칭되는 개별 배아로부터의 Wt 및 Nkx2-5 널 CPC를 단리시키고, RNA를 단리시키고, 증폭시키고, 전체 게놈 분석을 사용하여 각 분자 프로그램에서 정보를 얻었다. 상기 전략법은 하류 Nkx2-5 표적 유전자를 정의하였고, 심장 발생, 내피/심장내 계통 특수화 (Etv2의 유도) 및 혈액 형성의 억제에서의 Nkx2-5의 역할을 밝혀냈다 (도 5f). 본 연구에서는 또한 Nkx2-5, HandII 및 Tbx5를 유도한 조기 CPC 집단에 대한 분자 시그니처가 확인되었다 (37).
돼지에서의 다중
상동성
-의존성 재조합 (
HDR
)
앞서 기술된 바와 같이 (상기 참조), TALEN 특이적 HDR 기술을 사용하여 이중-대립유전자성 넉아웃 (KO)을 돼지 섬유모세포 내로 도입시키는 방법 (28)이 개발되어 있다. 이러한 신흥 기술을 추가로 사용하여 다중 유전자 KO를 수행하였다 (즉, 그를 수행함으로써 NKX2-5/HANDII/TBX5 돌연변이 및 다른 기관 특이적 인자와 함께 ETV2 넉아웃을 조작하였다). 다중의 이중-대립유전자성 유전자 편집을 위한 상기 기술을 확인하기 위해 TALEN 쌍을 사용하였고, 이들 각각을 통해 20% 초과의 HDR/부위를 얻었고, 3가지 조합으로 상기 쌍을 동시에 공동 형질감염시켰으며, 여기서 상기의 각 조합은 돼지 게놈에서 5개의 별개의 유전자를 표적화하였다 (28).
TALEN 유도 HDR 및 (본원에서 논의된) NHEJ에 의한 돌연변이의 조합을 사용하여 NKX2 -5/ HANDII / TBX5 돌연변이체 돼지 배아 섬유모세포를 생성하였다. 각 유전자는 그의 보존 전사 인자/DNA 결합 도메인 내에서 또는 그 바로 앞에서 표적화하였다 (도 3a). 이러한 전략법은 하류 AUG에서의 개시에 의해 기능적 펩티드를 생산할 수 있는 기회를 감소시키기 위해 전사 출발 부위 부근의 유전자를 표적화하는 것보다 바람직하다. TBX5 및 NKX2 -5의 경우, 상동성 주형을 제공하여 신규한 프레임내 정지 코돈, RFLP 스크리닝을 위한 제한 부위, 및 기능적 번역초과 단백질을 방지하기 위해 정지 코돈 뒤의 추가의 5개의 염기 삽입을 생성하였다. HANDII TALEN은 약 10%의 효율성을 띠었고, 그러므로, 본 실험은 돼지 섬유모세포에서 다중 HDR을 사용할 때 관찰된 현상인 TBX5 및 NKX2 -5 HDR 간섭 (비공개 데이터)을 피하기 위해 상동성 주형 없이 수행되었다. 3 단계로 된 접근법을 사용하여 삼중 돌연변이체를 확인하였다. 먼저, RFLP 검정법에 의해 TBX5 및 NKX2 -5의 이중 녹아웃에 대해 콜로니를 스크리닝하였다 (도 3b). 480개의 콜로니로 이루어진 제1 라운드에서, 33개 (7%)가 이중 넉아웃인 것으로 밝혀졌다. 이중 넉아웃 중에서, 4개가 HANDII에 대해서도 또한 돌연변이체인 것으로 확인되었다 (총 1%) (도 3c). 단일 샷으로 삼중 널 돼지 섬유모세포 세포주를 신뢰가능하게 생산할 수 있는 능력은 유일하며, 혁신적인 기술이다.
삼중
넉아웃
돼지 배아 중의 심장 부재
본 실험은 심장 발생을 동요시키는 다수의 전사 인자 (즉, MESP1, GATA4, NKX2-5, HANDII, TBX5 등)를 표적화하였고, 선천성 심장 질환 연구 및 치료를 위한 새로운 모델을 제공한다. NKX2 -5/ HANDII / TBX5 유전자의 결실에 대해 동형접합성을 띠는 클론의 성공적인 표적화 및 생성이 개념 입증으로서 본원에서 증명된다. 핵 클로닝 (SCNT)을 위해 삼중 넉아웃 섬유모세포 클론을 사용하여 NKX2 -5/HANDII/TBX5 널 돼지 배아를 생성하였고, 이는 대리모 암퇘지 내로 이식되었다. 배아를 수확하였고, 마우스의 E11와 등가인 E18에서 분석하였다. E18에서, 삼중 넉아웃 돼지 배아는 맥관 구조, 골격근 및 혈액은 가지지만, 야생형 대조군 돼지 배아와 비교하였을 때, 심장은 결여된다 (최소의 GATA4 면역조직화학적으로 양성인 심근세포) (도 4 참조).
실시예
2 - 인간
줄기 세포는
돼지
반수성개체
(수정 없이
발생되도록
전기적으로 활성화된 배아)의 내부 세포괴 (ICM)로 통합된다.
인간 줄기 세포/선조 세포 집단이 돼지 반수성개체 키메라에 기여하고, 참여할 수 있다. 돼지 반수성개체 발생에 기여할 수 있는 인간 유도성 만능성 줄기 세포 (hiPSC), 인간 중간엽 줄기 세포 (hMSC), 인간 만능성 줄기 세포 및 인간 심장 선조 (hCPC)의 능력을 비교할 것이다. 돼지 단위생식성 배반포를 사용한 데이터 (30)가 hiPSC가 반수성개체의 내부 세포괴로 통합된다는 믿음을 지지한다. 본 실험에서는 hiPSC 세포주, hMSC 세포주, 인간 만능성 줄기 세포 및 hCPC, 및 인간-돼지 키메라를 성공적으로 생산할 수 있는 그의 능력에 대해 돼지 단위생식성 배아를 사용하여 시험관내에서 및 생체내에서 조사할 것이다. 본 연구는 시험관내 분석을 위해 인간 줄기 세포 집단의 증식성 능력, 아폽토시스 및 발생 진행을 조사할 것이다. 생체내 분석은 인간 특이적 항혈청을 이용하는 면역조직화학법 및 이식 후 반수성개체의 계내 하이브리드화를 이용할 것이다.
돼지 배반포로 통합될 수 있고, 배아 발생에 참여할 수 있는 hiPSC의 능력에 대해 평가하였다. 난모세포의 전기 자극을 사용하여 돼지 단위생식성 배반포를 생성하였다 (42). 활성화 후 6일 경과하였을 때, 9-12개의 DiI- 또는 EdU (24 hr)-표지된 hiPSC를 배반포강 내로 주사하였다. 배반포가 배양물 중에서 회복될 수 있도록 2일을 허용한 후, 영상화하였다. 90%의 돼지 배반포의 ICM에서 표지된 hiPSC가 관찰되었다 (도 9a, b, 대표 영상이 제시되어 있음). 인간 핵 항원 특이적 항체 (HNA)를 사용하여 면역조직화학법을 이용함으로써 DiI 분포를 비교한 결과, HNA 항체가 주사된 인간 줄기 세포를 검출한 것으로 나타났다 (도 9a, 화살표 표시). 증식 세포를 검출하기 위하여 수확하기 전 1시간 동안 BrdU를 사용하여 EdU 표지된 hiPSC 주사를 맞은 배반포를 추가로 펄싱하였다. EdU로 이중 표지한 결과, 주사된 인간 줄기 세포가 주사 48 hr 후에도 계속하여 증식한 것으로 나타났다 (도 9b, 화살표 표시). 본 결과는 인간 줄기 세포의 돼지 배반포의 ICM으로의 도입, 및 키메라 배반포의, 자궁 내로의 이식을 위한 준비에서 부화 단계로의 발생 진행을 입증한다.
본 결과는 제안된 전략법의 근거 및 실현 가능성을 뒷받침하고, 인간 줄기 세포 집단이 화합성을 띠고/거나, ICM 발생에 기여하는지 여부를 조사하기 위한 신속한 검정법을 제공한다. 추가로, 단위생식성 배반포의 이식이 인간 줄기 세포의 발생하는 배아로의 조합 및 분화를 조사할 수 있는 고처리량 방법을 제공한다. 본 전략법의 유의적인 이점은 돼지 난모세포가 식품 생산의 부산물로서 풍부하게 이용가능하고, 단위생식성 배아가 정기적으로 대량으로 생성될 수 있다는 점이다. 단위생식성 배아는 8주 경과 후에는 생존하지 못하는 바, 그러므로, 원치않는 인간-돼지 키메라를 의도치 않게 출생시킬 수 있을 것이라는 우려를 무색하게 만든다는 점에 주목하여야 한다.
인간 줄기 세포 집단은 증식되고, 인간-돼지 반수성개체 키메라의 형성에 기여한다. 인간 중간엽 줄기 세포 (hMSC) (46) 및 심장 선조 세포 (hCPC) (47)는 발생하는 돼지에서 배아 계통에 기여할 수 있는 그의 능력에 있어서 더욱 큰 제한을 받게 될 것이다. 추가로, hiPSC 및 돼지 줄기 세포 집단은 동등하게 배아 계통에 기여할 수 있다.
인간 줄기/선조 세포 집단은 NKX2-5/HANDII/TBX5 돌연변이체 돼지 배아를 구제할 것이다. hiPSC는 NKX2-5/HANDII/TBX5 돌연변이체 조산 배아에서 모든 심장 세포에 대한 선조가 될 것이다.
TALEN 매개 기술을 사용하여 (27, 28), 생존불가능하고, 내피 계통이 결여된 ETV2 돌연변이체 돼지 배아를 생성하였다. TALEN 매개 기술을 사용하여 NKX2-5/HANDII/TBX5 돌연변이체 섬유모세포를 생성함으로써, 및 데이터를 통해 상기 돌연변이체 돼지 배아에는 심장이 결여된다는 것을 입증한다. 데이터는 인간 줄기 세포 (인간 제대혈 줄기 세포 및 인간 iPSC)가 돼지 반수성개체의 ICM 내로 통합될 수 있다는 개념을 추가로 뒷받침한다. 인간-돼지 상보 연구에서는 E17 인간 줄기 세포-돼지 키메라에서의 인간 줄기 세포의 생착에 대해 조사할 것이다.
실시예
3
물질 및 방법
TALEN
디자인 및 생산
온라인 도구 "TAL 이펙터 뉴클레오티드 타겟터 2.0(TAL EFFECTOR NUCLEOTIDE TARGETER 2.0)"을 사용하여 후보 TALEN 표적 DNA 서열 및 RVD 서열을 확인하였다. 이어서, 최종 목적 벡터로서 RCI스크립트-GOLDYTALEN (애드진(Addgene) ID 38143)을 사용하여 골든 게이트 어셈블리(Golden Gate Assembly) 프로토콜에 따라 TALEN DNA 형질감염 또는 시험관내 TALEN mRNA 전사를 위한 플라스미드를 구축하였다 (Carlson 2012). QIAPREP SPIN MINIPREP 키트 (퀴아젠(Qiagen))를 사용하여 제조된, 어셈블리된 RCI스크립트 벡터를 SacI에 의해 선형화하여 앞서 명시된 바와 같이 (Carlson, 2009) m메시지 m머신(mMESSAGE mMACHINE)® T3 키트 (앰비온(Ambion))를 사용하는 시험관내 TALEN mRNA 전사를 위한 주형으로서 사용하였다. 생성된 mRNA를 메가클리어 리액션 클린업(MEGACLEAR REACTION CLEANUP) 키트 (어플라이드 바이오사이언시스(Applied Biosciences)) 또는 RN이지(RNeasy) 키트 (퀴아젠)를 사용하여 정제 이전에 DNAse로 처리하였다.
조직 배양 및 형질감염
돼지 섬유모세포를 (명시된 바와 같이) 37 또는 30℃에서 5% CO2하에 10% 우태아 혈청, 100 I.U./mL 페니실린 및 스트렙토마이신, 2 mM L-글루타민 및 10 mM Hepes로 보충된 DMEM 중에서 유지시켰다. 네온 트랜스펙션 시스템(Neon Transfection system) (라이프 테크놀로지스(Life Technologies))을 사용하여 TALEN 및 HDR 올리고를 전달하였다. 전면생장률이 70-100%인, 저계대수의 오사보(Ossabaw) 또는 랜드레이스(Landrace) 돼지 섬유모세포를 1:2로 나누고, 다음날 전면생장률이 70-80%일 때 수확하였다. mRNA TALEN 및 HDR 올리고를 포함하는 "R" 버퍼 (라이프 테크놀로지스) 중에 대략 600,000개의 세포를 재현탁시키고, 하기 파라미터를 사용하여 100 uL 팁에서 전기천공시켰다: 입력 전압: 1800V; 펄스 폭: 20 ms; 펄스 수: 1. 관심의 특이적인 유전자(들)를 위한 0.1-4 ug의 TALEN mRNA 및 0.1-0.4 nmol의 HDR 올리고를 각 형질감염을 위해 포함시켰다. 형질감염된 세포를 30℃에서 2 또는 3일 동안 배양한 후, 유전자 편집 효율에 대해 분석하고, 콜로니를 위해 플레이팅하였다.
희석
클로닝
형질감염 후 2 또는 3일 경과 후, 50 내지 250개의 세포를 10 cm 디쉬 상에 시딩하고, 개별 콜로니의 직경이 대략 5 mm에 도달할 때까지 배양하였다. TrypLE 및 DMEM 배지 (라이프 테크놀로지스)의 1:4 (vol/vol) 혼합물 8 mL를 첨가하고, 콜로니를 흡인시키고, 48 웰 디쉬 및 복제 96 웰 디쉬의 웰로 옮기고, 같은 조건하에서 배양하였다. 냉동보존 및 유전자형 분석을 위한 샘플 제조를 위해 전면생장에 도달한 콜로니를 수집하였다.
샘플 제조
3일 및 10일째에 형질감염된 세포 집단을 6 웰 디쉬의 웰로부터 수집하고, 10-30%를 50 μl의 1X PCR 화합성 용해 완충제: 200 μg/ml 프로테이나제 K로 새로 보충된 10 mM 트리스(Tris)-Cl pH 8.0, 2 mM EDTA, 0.45% 트리톤(Tryton) X-100(vol/vol), 0.45% 트윈(Tween)-20(vol/vol) 중에 재현탁시켰다. 55℃에서 60분, 95℃에서 15분 동안인 프로그램을 사용하여 열 순환기에서 용해물을 프로세싱하였다.
유전자-편집 분석
1 μl의 세포 용해물과 함께 아큐스타트(AccuStart)™ Taq DNA 폴리머라제 하이파이 (콴타 바이오사이언시스(Quanta Biosciences))를 사용하여 제조사의 권고사항에 따라 의도 부위에 플랭킹된 PCR을 수행하였다. 상기 기술된 바와 같은 PCR 생성물 10 ul를 사용하여 서베이어 뮤테이션 디텍션(SURVEYOR MUTATION DETECTION) 키트 (트랜스게노믹(Transgenomic))를 이용함으로써 제조사의 권고사항에 따라 집단 중의 돌연변이의 빈도를 분석하였다. 서베이어(SURVEYOR) 반응물을 10% TBE 폴리아크릴아미드 겔 상에서 분리 분석하고, 에티디움 브로마이드 염색에 의해 시각화하였다. 이미지J(ImageJ)를 사용하여 밴드의 농도계측 측정을 수행하였고; 문헌 (Guschin et al. 2010)에 기술된 바와 같이 서베이어 반응물의 돌연변이율을 산출하였다. 프라이머를 사용하여 HDR 대립유전자의 존재에 대해 개별 콜로니를 스크리닝하였다. 생성된 PCR 앰플리콘을 HindIII으로 분해하여 PCR 생성물에 대해 제한 단편 길이 다형성 분석 (RFLP)을 수행함으로써 대립유전자 중 하나, 둘 다가 절단되었는지 또는 그 어느 것도 절단되지 않았는지 여부, 및 이로써, HDR 대립유전자를 함유하였는지 여부를 결정하였다. 생성물을 아가로스 겔 상에서 분리 분석하였다.
돼지 서열
Nkx2-5: ENSSSCG00000016984
Tbx5: ENSSSCG00000009867
Hand2:ENSSSCG00000009703
돼지 유전자: NKX2-5 유전자 ID: ENSSSCG00000016984
설명: NK2 호메오박스 5 [공급원:HGNC 기호;Acc:HGNC:2488]
동의어: CSX, CSX1, NKX2.5, NKX2E, NKX4-1
위치: 염색체 16: 55,400,561-55,403,626 정방향 가닥.
INSDC 좌표: 염색체:Sscrofa10.2:CM000827.4:55400561:55403626:1
상기 유전자에 대해: 상기 유전자는 1개의 전사체 (스플라이스 변이체), 37개의 오르토로그, 15개의 파라로그를 가지며, 이는 1개의 앙상블 단백질 패밀리의 구성원이다.
돼지 NKX2-5 게놈 서열 ID: CU928102


코드:
돼지 NKX2-5 mRNA 서열: ID ENSSSCT00000018494

돼지 NKX2-5 단백질 서열: F1SJY9-1

돼지 유전자: HAND2 ENSSSCG00000009703 (앙상블)
설명; 심장 및 신경 능선 유도체 발현 2 [공급원:HGNC 기호;Acc: HGNC:4808]
동의어; bHLHa26, dHand, Hed, Thing2
위치; 염색체 14: 17,528,447-17,531,529 역방향 가닥.
INSDC 좌표; 염색체:Sscrofa10.2:CM000825.4:17528447:17531529:1
상기 유전자에 대해: 상기 유전자는 1개의 전사체 (스플라이스 변이체), 54개의 오르토로그, 9개의 파라로그를 가지며, 이는 1개의 앙상블 단백질 패밀리의 구성원이다.
돼지 HAND2 게놈 서열 ID: CU468996
돼지 HAND2-201 mRNA ID: ENSSSCT00000010638 (앙상블) XM_005670479 (NCBI, 예측)
298..767 /유전자="LOC100153751" /표준_명칭="Hand2" /db_xref="UniSTS:238134" 기원

돼지 HAND2 단백질 (예측) XP_005670536.1
1..780 /유전자="LOC100153751" /코돈_개시=1 /생성물="심장- 및 신경 능선 유도체-발현된 단백질 2-유사" /단백질_id="XP_005670536.1" /db_xref="GI:545868321" /db_xref="GeneID:100153751"

유니프롯 ID: F1RJ02-1

돼지 유전자: TBX5 유전자 ID: ENSSSCG00000009867
돼지 TBX5 게놈 서열 ID: CU468413
설명: T-박스 5 [공급원:HGNC 기호;Acc:HGNC:11604]
동의어: HOS
위치: 염색체 14: 40,211,210-40,259,321 정방향 가닥.
INSDC 좌표: 염색체:Sscrofa10.2:CM000825.4:40211210:40259321:1
상기 유전자에 대해: 상기 유전자는 1개의 전사체 (스플라이스 변이체), 61개의 오르토로그, 8개의 파라로그를 가지며, 이는 1개의 앙상블 단백질 패밀리의 구성원이다.
돼지 Tbx5 유전자 ID: ENSSSCG00000009867
돼지 TBX5 mRNA 예측 서열
487..609 /유전자="TBX5" /표준_명칭="MARC_15663-15664:1016570340:1" /db_xref="UniSTS:267858"

돼지 TBX5 단백질 ID: FIRKD2 (앙상블, 예측)
>tr|F1RKD2|F1RKD2_돼지 특징규명되지 않은 단백질 OS=멧돼지 GN=TBX5 PE=4 SV=2

/db_xref="유전자ID:100522280" (NCBI 엔트리, 예측)

호모 사피엔스(Homo sapiens) NK2 전사 인자 관련, 유전자좌 5 (초파리), mRNA (cDNA 클론 MGC:34495 IMAGE:5225103), 완전 cds
인간 NKX2-5 유전자 정보: 진뱅크: BC025711.1
유전자좌 BC025711 1632 bp mRNA 선형 PRI 15-JUL-2006
정의 호모 사피엔스 NK2 전사 인자 관련, 유전자좌 5 (초파리), mRNA (cDNA 클론 MGC:34495 IMAGE:5225103), 완전 cds. 수탁 BC025711 버전 BC025711.1 GI:19343930
단백질 서열 정보
108..1082 /유전자="NKX2-5" /유전자_동의어="CSX1" /유전자_동의어="NKX2.5" /코돈_개시=1 /생성물="NK2 전사 인자 관련, 유전자좌 5 (초파리)" /단백질_id="AAH25711.1" /db_xref="GI:19343931" /db_xref="유전자ID:1482" /db_xref="HGNC:HGNC:2488" /db_xref="MIM:600584"
인간 NKX2-5 단백질 서열

인간 NKX2-5 mRNA 서열

호모 사피엔스 심장 및 신경 능선 유도체 발현 2 (HAND2) mRNA, 완전 cds
진뱅크: FJ226608.1
인간 HAND2 유전자 정보
유전자좌 FJ226608 2351 bp mRNA 선형 PRI 15-APR-2009
정의 호모 사피엔스 심장 및 신경 능선 유도체 발현 2 (HAND2) mRNA, 완전 cds. 수탁 FJ226608 VERSION FJ226608.1 GI:209170693
인간 HAND2 mRNA 정보
2234..2239 /조절_부류="폴리A_신호_서열" /유전자="HAND2" 기원

인간 HAND2 단백질 정보
/생성물="심장 및 신경 능선 유도체 발현 2" /단백질_id="ACI42790.1" /db_xref="GI:209170694"

호모 사피엔스 T-박스 5, mRNA (cDNA 클론 MGC:35581 IMAGE:5204163), 완전 cds
진뱅크: BC027942.1
인간 TBX5 유전자 정보:
유전자좌 BC027942 3748 bp mRNA 선형 PRI 15-JUL-2006
정의 호모 사피엔스 T-박스 5, mRNA (cDNA 클론 MGC:35581 IMAGE:5204163), 완전 cds. 수탁 BC027942 VERSION BC027942.1 GI:20379838
인간 TBX5 mRNA 정보:
기원


인간 TBX5 단백질 정보
/코돈_개시=1 /생성물="T-박스 5" /단백질_id="AAH27942.1" /db_xref="GI:20379839" /db_xref="유전자ID:6910" /db_xref="HGNC:HGNC:11604" /db_xref="MIM:601620"

참고문헌



본원의 개시내용 전역에 걸쳐 언급된 모든 공개문헌, 특허, 및 특허 출원, 진뱅크(진뱅크) 서열, 웹사이트 및 다른 공개된 자료는 마치 각각의 개별 공개문헌, 특허, 또는 특허 출원, 진뱅크 서열, 웹사이트 및 다른 공개된 자료가 참조로 포함되는 것으로 구체적으로 및 개별적으로 명시된 것과 같은 정도로 본원에서 참조로 포함된다. 참조로 포함된 용어 정의가 본원에서 정의된 용어와 상충하는 경우, 본 명세서가 조정하여야 한다.
SEQUENCE LISTING
<110> Garry, Daniel J.
Garry, Mary G.
Koyano-Nakagawa, Naoko
Regents of the University of Minnesota
<120> HUMANIZED HEART MUSCLE
<130> 600.978WO1
<140> PCT/US2016/040431
<141> 2016-06-30
<150> US 62/187,040
<151> 2015-06-30
<160> 15
<170> FastSEQ for Windows Version 4.0
<210> 1
<211> 1725
<212> DNA
<213> Sus scrofa
<400> 1
gtccccctcc tccggcctgg tcccgcctct cctgcccctt gcgccccgca ttacctgccg 60
cctggccaca tcccgagctg gaaggcgggt gcgcgggcgc gcagcgggca ccatgcaggg 120
aggctgccag ggaccgtggg cagcgccgct ctctgccgcc cacctggcgc tgtgagacgc 180
gcgctgccac catgttcccc agccccgcgc tcacgcccac gccgttctcg gtcaaagaca 240
tcttgaacct ggagcaacag cagcgcagcc tggccgccgg ggagctctcc gcgcgcttgg 300
aggccaccct ggcgcccgcc tcctgcatgc tggccgcctt caagcccgag gcctacgcgg 360
ggccggaggc cgcagcgccc ggcctctccg agctgcgcgc cgagctgggc cccgcgccct 420
caccagccaa gtgcgcgccc tccttctcag ccgcccccgc cttctacccg cgtgcctatg 480
gcgaccccga ccccgccaag gaccctcgag ccgataagaa aggtgaggag gaaacacaag 540
cttcttctct gcctctctgt tcccccccgc agagctgtgc gcgctgcaga aggcggtgga 600
gctggagaag ccagaggcgg acagcgccga gagacctcgg gcgcgacgac gaaggaagcc 660
gcgcgtgctc ttttcgcagg cacaggtcta cgagctggag cgacgcttca agcagcagcg 720
gtacctgtcg gctcccgagc gtgaccagtt ggccagcgtg ctgaagctca cgtccacgca 780
ggtcaagatc tggttccaga accggcgcta caagtgcaag cggcaacggc aggaccagac 840
tctggagcta gtggggctgc ccccgccccc gccgccgccg gcccgcagga tcgcggtgcc 900
agtgctggtg cgcgatggca agccttgcct cggggactcc gcgccctacg cgccagccta 960
cggcgtgggc ctcaacgcct acggctataa cgcctacccc gcctacccgg gttacggtgg 1020
cgcggcctgc agccctggct acagctgcac cgctgcgtac ccagccgggc cgcccccggc 1080
gcagtcggct acggccgccg ccaataacaa cttcgtgaac ttcggcgtcg gggacttaaa 1140
cgcggtgcag agcccgggga ttccgcaggg caactcggga gtgtccacgc tgcacggtat 1200
ccgagcctgg tagggaaggg gcctgtctgg ggcacctcta aagaggggca ctaactatcg 1260
gggagaggga gggctcccga tacgatcctg agtccctcag atgtcacatt gactcccacg 1320
gaggcctcgg agctttttcc gtccggtgcg cctttatccc cacgcgcggg agagttcgtg 1380
gcagaggtta cgcagcttgg ggtgagtgat cccgcagccc ggtgccttag ccgtcgcccc 1440
gggagtgccc tccaagcgcc cacgggcatc cccaatcggc tgacaccggc cagttgggac 1500
cgggagcccg agcccaggcg tgccaggctt aagatggggc cgcctttccc cgatcctggg 1560
cccggtgccc ggggcccttg ctgccttgcc gctgccctcc ccacacccgt atttatgttt 1620
ttacttgttt ctgtaagaaa tgagaatctc cttcccatta aagagagtgc gctgatccgc 1680
ctgtgtgctt ctttcagctt gctgtgcttc agaaactgaa atttt 1725
<210> 2
<211> 972
<212> DNA
<213> Sus scrofa
<400> 2
atgttcccca gccccgcgct cacgcccacg ccgttctcgg tcaaagacat cttgaacctg 60
gagcaacagc agcgcagcct ggccgccggg gagctctccg cgcgcttgga ggccaccctg 120
gcgcccgcct cctgcatgct ggccgccttc aagcccgagg cctacgcggg gccggaggcc 180
gcagcgcccg gcctctccga gctgcgcgcc gagctgggcc ccgcgccctc accagccaag 240
tgcgcgccct ccttctcagc cgcccccgcc ttctacccgc gtgcctatgg cgaccccgac 300
cccgccaagg accctcgagc cgataagaaa gagctgtgcg cgctgcagaa ggcggtggag 360
ctggagaagc cagaggcgga cagcgccgag agacctcggg cgcgacgacg aaggaagccg 420
cgcgtgctct tttcgcaggc acaggtctac gagctggagc gacgcttcaa gcagcagcgg 480
tacctgtcgg ctcccgagcg tgaccagttg gccagcgtgc tgaagctcac gtccacgcag 540
gtcaagatct ggttccagaa ccggcgctac aagtgcaagc ggcaacggca ggaccagact 600
ctggagctag tggggctgcc cccgcccccg ccgccgccgg cccgcaggat cgcggtgcca 660
gtgctggtgc gcgatggcaa gccttgcctc ggggactccg cgccctacgc gccagcctac 720
ggcgtgggcc tcaacgccta cggctataac gcctaccccg cctacccggg ttacggtggc 780
gcggcctgca gccctggcta cagctgcacc gctgcgtacc cagccgggcc gcccccggcg 840
cagtcggcta cggccgccgc caataacaac ttcgtgaact tcggcgtcgg ggacttaaac 900
gcggtgcaga gcccggggat tccgcagggc aactcgggag tgtccacgct gcacggtatc 960
cgagcctggt ag 972
<210> 3
<211> 323
<212> PRT
<213> Sus scrofa
<400> 3
Met Phe Pro Ser Pro Ala Leu Thr Pro Thr Pro Phe Ser Val Lys Asp
1 5 10 15
Ile Leu Asn Leu Glu Gln Gln Gln Arg Ser Leu Ala Ala Gly Glu Leu
20 25 30
Ser Ala Arg Leu Glu Ala Thr Leu Ala Pro Ala Ser Cys Met Leu Ala
35 40 45
Ala Phe Lys Pro Glu Ala Tyr Ala Gly Pro Glu Ala Ala Ala Pro Gly
50 55 60
Leu Ser Glu Leu Arg Ala Glu Leu Gly Pro Ala Pro Ser Pro Ala Lys
65 70 75 80
Cys Ala Pro Ser Phe Ser Ala Ala Pro Ala Phe Tyr Pro Arg Ala Tyr
85 90 95
Gly Asp Pro Asp Pro Ala Lys Asp Pro Arg Ala Asp Lys Lys Glu Leu
100 105 110
Cys Ala Leu Gln Lys Ala Val Glu Leu Glu Lys Pro Glu Ala Asp Ser
115 120 125
Ala Glu Arg Pro Arg Ala Arg Arg Arg Arg Lys Pro Arg Val Leu Phe
130 135 140
Ser Gln Ala Gln Val Tyr Glu Leu Glu Arg Arg Phe Lys Gln Gln Arg
145 150 155 160
Tyr Leu Ser Ala Pro Glu Arg Asp Gln Leu Ala Ser Val Leu Lys Leu
165 170 175
Thr Ser Thr Gln Val Lys Ile Trp Phe Gln Asn Arg Arg Tyr Lys Cys
180 185 190
Lys Arg Gln Arg Gln Asp Gln Thr Leu Glu Leu Val Gly Leu Pro Pro
195 200 205
Pro Pro Pro Pro Pro Ala Arg Arg Ile Ala Val Pro Val Leu Val Arg
210 215 220
Asp Gly Lys Pro Cys Leu Gly Asp Ser Ala Pro Tyr Ala Pro Ala Tyr
225 230 235 240
Gly Val Gly Leu Asn Ala Tyr Gly Tyr Asn Ala Tyr Pro Ala Tyr Pro
245 250 255
Gly Tyr Gly Gly Ala Ala Cys Ser Pro Gly Tyr Ser Cys Thr Ala Ala
260 265 270
Tyr Pro Ala Gly Pro Pro Pro Ala Gln Ser Ala Thr Ala Ala Ala Asn
275 280 285
Asn Asn Phe Val Asn Phe Gly Val Gly Asp Leu Asn Ala Val Gln Ser
290 295 300
Pro Gly Ile Pro Gln Gly Asn Ser Gly Val Ser Thr Leu His Gly Ile
305 310 315 320
Arg Ala Trp
<210> 4
<211> 1458
<212> DNA
<213> Sus scrofa
<400> 4
atggagatct tgctgggaaa atccgcttgc tcccctcacg gcgtccagtc ccggagaaca 60
gccgccgccg ccgtcaccca ggagccccca cggccgctgc gcaacagccc tccaagcccc 120
agccgccgcc ttcgcggagc acgagaggag agcggaacac gttactcgct gctaaagtca 180
cattccagga ccaaaacaac aacaaccaaa aatttcatta aaacaataag cgcccaagaa 240
cccagatcag gctggttggg ggaagagatc ggccaccccg agatgtcgcc ccccgactac 300
agcatggccc tgtcctacag tccggagtac gccagcggtg ccgccagcct ggaccactcc 360
cattacgggg gggtgccgcc gggcgccggg cccccgggcc tgggggggcc gcgcccggtg 420
aagcgccggg gcacagccaa ccgcaaggag cggcgcagga ctcagagcat caacagcgcc 480
ttcgccgagc tgcgcgagtg tatccccaat gtgcccgccg acaccaaact ctccaagatc 540
aagacgctgc gcctggccac cagctacatc gcctacctca tggacctgct ggccaaggac 600
gaccagaacg gcgaggcgga ggcctttaag gcggaaatca agaagacaga tgtgaaagaa 660
gagaaaagga agaaggagct gaatgaaatc ttgaaaagca cagtgagcag caacgacaag 720
aaaaccaaag gccggacggg ctggccgcag catgtctggg ccctggagct caagcagtga 780
ggtggagaaa gaggaggtgg aggtggtgga agaggaggag gagagcgcga gccaggccct 840
ggagccggat gcagacccag gactccgggg cgagctctgc gcactccgct ctgaggactt 900
cctgcatttg gatcatccgg tttatttatg tgcaatgtgc ctccctctct ttgcccccct 960
ttgaggcatc cgctccccac caccccctcc aaaaaagtgg atatttgaag aaaagcattc 1020
catattttaa tatgaagagg acactcccgc gtggtaaggg atcccgtcgt cgtcttgtag 1080
attctctgtt tgtgaatgtt tcctcttggc tgtgtagaca ccagcgttgc tccctcccca 1140
cctatccagc cccttacaga taaagacagc tgataatagt gtatttgtga agtgtatctt 1200
taatacctgg cctttggata taaatattcc tggggattat aaagttttat ttcaaagcag 1260
aaaacggggc cgctaacatt tccgttgggg tcggtatcta gtgctgccgt ttcatctgtg 1320
tggttcccta tttgaagatg tttccaacag ctccttgttt tgtgcacttc cgtcctctaa 1380
aactaagtgg aatttaatta atattgaagg tgtaaacgtt gtaagtaatc aataaaccac 1440
tgtgtgtttt tttttttt 1458
<210> 5
<211> 259
<212> PRT
<213> Sus scrofa
<400> 5
Met Glu Ile Leu Leu Gly Lys Ser Ala Cys Ser Pro His Gly Val Gln
1 5 10 15
Ser Arg Arg Thr Ala Ala Ala Ala Val Thr Gln Glu Pro Pro Arg Pro
20 25 30
Leu Arg Asn Ser Pro Pro Ser Pro Ser Arg Arg Leu Arg Gly Ala Arg
35 40 45
Glu Glu Ser Gly Thr Arg Tyr Ser Leu Leu Lys Ser His Ser Arg Thr
50 55 60
Lys Thr Thr Thr Thr Lys Asn Phe Ile Lys Thr Ile Ser Ala Gln Glu
65 70 75 80
Pro Arg Ser Gly Trp Leu Gly Glu Glu Ile Gly His Pro Glu Met Ser
85 90 95
Pro Pro Asp Tyr Ser Met Ala Leu Ser Tyr Ser Pro Glu Tyr Ala Ser
100 105 110
Gly Ala Ala Ser Leu Asp His Ser His Tyr Gly Gly Val Pro Pro Gly
115 120 125
Ala Gly Pro Pro Gly Leu Gly Gly Pro Arg Pro Val Lys Arg Arg Gly
130 135 140
Thr Ala Asn Arg Lys Glu Arg Arg Arg Thr Gln Ser Ile Asn Ser Ala
145 150 155 160
Phe Ala Glu Leu Arg Glu Cys Ile Pro Asn Val Pro Ala Asp Thr Lys
165 170 175
Leu Ser Lys Ile Lys Thr Leu Arg Leu Ala Thr Ser Tyr Ile Ala Tyr
180 185 190
Leu Met Asp Leu Leu Ala Lys Asp Asp Gln Asn Gly Glu Ala Glu Ala
195 200 205
Phe Lys Ala Glu Ile Lys Lys Thr Asp Val Lys Glu Glu Lys Arg Lys
210 215 220
Lys Glu Leu Asn Glu Ile Leu Lys Ser Thr Val Ser Ser Asn Asp Lys
225 230 235 240
Lys Thr Lys Gly Arg Thr Gly Trp Pro Gln His Val Trp Ala Leu Glu
245 250 255
Leu Lys Gln
<210> 6
<211> 176
<212> PRT
<213> Sus scrofa
<400> 6
Gly Trp Leu Gly Glu Glu Ile Gly His Pro Glu Met Ser Pro Pro Asp
1 5 10 15
Tyr Ser Met Ala Leu Ser Tyr Ser Pro Glu Tyr Ala Ser Gly Ala Ala
20 25 30
Ser Leu Asp His Ser His Tyr Gly Gly Val Pro Pro Gly Ala Gly Pro
35 40 45
Pro Gly Leu Gly Gly Pro Arg Pro Val Lys Arg Arg Gly Thr Ala Asn
50 55 60
Arg Lys Glu Arg Arg Arg Thr Gln Ser Ile Asn Ser Ala Phe Ala Glu
65 70 75 80
Leu Arg Glu Cys Ile Pro Asn Val Pro Ala Asp Thr Lys Leu Ser Lys
85 90 95
Ile Lys Thr Leu Arg Leu Ala Thr Ser Tyr Ile Ala Tyr Leu Met Asp
100 105 110
Leu Leu Ala Lys Asp Asp Gln Asn Gly Glu Ala Glu Ala Phe Lys Ala
115 120 125
Glu Ile Lys Lys Thr Asp Val Lys Glu Glu Lys Arg Lys Lys Glu Leu
130 135 140
Asn Glu Ile Leu Lys Ser Thr Val Ser Ser Asn Asp Lys Lys Thr Lys
145 150 155 160
Gly Arg Thr Gly Trp Pro Gln His Val Trp Ala Leu Glu Leu Lys Gln
165 170 175
<210> 7
<211> 2139
<212> DNA
<213> Sus scrofa
<400> 7
actagagttt tcactcgcag ctccaggcgg ggtggcctcc tccatcctcc accccctcaa 60
cccctgcacc gggtacagag ctctcttctg gcaagtttct ccccgagaga gaagaggaag 120
ggagagcagg acccagagcg gtcacagggc cctgggctca ccatggccga cggagacgag 180
ggctttggcc tggctcacac acccctggaa ccagattcaa aggatctacc ctgtgactca 240
aaacccgaga gtgggctagg ggcccccagc aagtccccgt cgtccccgca ggccgccttc 300
acccagcagg gcatggaagg gatcaaggtg tttctccatg aaagagaact gtggctgaaa 360
tttcacgaag tgggcacaga aatgatcata accaaggctg gcaggcggat gtttcccagt 420
tacaaagtga aggtgactgg ccttaatccc aaaaccaagt acattctcct tatggacatc 480
gttcctgccg atgaccacag atacaagttc gccgataata aatggtctgt gacaggcaaa 540
gcggagcctg ccatgccggg ccgcctctac gtgcacccgg actcgccggc cactggagcg 600
cattggatgc ggcagctcgt ctccttccag aaactcaagc tcaccaacaa ccacctggac 660
ccgtttgggc acattattct aaattccatg cacaaatacc agcccagatt acacatcgtg 720
aaagcggacg aaaataatgg atttggctca aaaaatactg cattctgtac ccacgtcttt 780
cctgagacag cgtttattgc agtgacttcc taccagaacc acaagatcac ccaattaaag 840
atcgagaata atccctttgc caaaggattc cggggcagcg atgacatgga actgcacagg 900
atgtcaagga tgcaaagtaa agaatatccc gtggttccca ggagcacagt gagacagaaa 960
gtggcctcca accacagtcc cttcagcagt gagcctcgtg ctctctccac ctcatccaac 1020
ttggggtccc agtatcagtg tgagaatggt gtgtccggcc cctcccagga cctcctgccc 1080
ccacctaacc cgtacccact tccccaggag cacagccaaa tttaccattg caccaagagg 1140
aaagatgaag aatgttccac cacagagcat ccctataaga agccctacat ggagacgtca 1200
cccagtgaag aggacccctt ctaccgagcc ggctaccccc agcagcaggg tctgggtgcc 1260
tcctaccgga cagagtcagc ccagcggcag gcctgcatgt acgccagctc cgcaccgccc 1320
agtgagccgg tgcccagcct ggaggacatt agctgcaaca cgtggcccag catgccttcc 1380
tacagcagct gcacagtcac caccgtgcag cccatggaca ggctacccta ccagcacttc 1440
tctgctcact tcacctcggg gcccctggtc ccccggctgg ctggcatggc caaccacggc 1500
tccccgcagt tgggggaggg aatgttccag caccagacct ccgtggccca ccagcctgtg 1560
gtcaggcagt gtgggcctca gactggcctc cagtccccgg gcagccttca agcgtccgag 1620
ttcctgtact ctcatggcgt gccaaggacc ctgtccccgc atcagtacca ctctgctgtg 1680
cacggggtcg gcatggttcc agagtggagt gacaacagct aaagcgaggc ctgctccttc 1740
actgacgttt ccagagggag gggagagagg gagagagaca gtcgcagaga gaaccccaag 1800
aacgagatgt cgcatttcac tccatgttca cgtctgcact tgagaagccc accctggaca 1860
ctgatgtaat cagtagcttg aaaccacaat tcaaaaaatg tgactttgtt ttgtctcaaa 1920
acttaaaaaa tcgacaagag gcgatgagtc ccaacccccc ctaccccgcc cccaccatcc 1980
accaccacca cagtcatcaa ctggccacat tcacacgacc tccagatgcc ctccgggatt 2040
ccttcttttg gtctccagaa agtcttgcct catggagtgt tttatcccaa aacatagatg 2100
gagtcattcc ctgtcttggt gttactgttg acattgtta 2139
<210> 8
<211> 520
<212> PRT
<213> Sus scrofa
<400> 8
Met Ala Asp Gly Asp Glu Gly Phe Gly Leu Ala His Thr Pro Leu Glu
1 5 10 15
Pro Asp Ser Lys Asp Leu Pro Cys Asp Ser Lys Pro Glu Ser Gly Leu
20 25 30
Gly Ala Pro Ser Lys Ser Pro Ser Ser Pro Gln Ala Ala Phe Thr Gln
35 40 45
Gln Gly Met Glu Gly Ile Lys Val Phe Leu His Glu Arg Glu Leu Trp
50 55 60
Leu Lys Phe His Glu Val Gly Thr Glu Met Ile Ile Thr Lys Ala Gly
65 70 75 80
Arg Arg Met Phe Pro Ser Tyr Lys Val Lys Val Thr Gly Leu Asn Pro
85 90 95
Lys Thr Lys Tyr Ile Leu Leu Met Asp Ile Val Pro Ala Asp Asp His
100 105 110
Arg Tyr Lys Phe Ala Asp Asn Lys Trp Ser Val Thr Gly Lys Ala Glu
115 120 125
Pro Ala Met Pro Gly Arg Leu Tyr Val His Pro Asp Ser Pro Ala Thr
130 135 140
Gly Ala His Trp Met Arg Gln Leu Val Ser Phe Gln Lys Leu Lys Leu
145 150 155 160
Thr Asn Asn His Leu Asp Pro Phe Gly His Ile Ile Leu Asn Ser Met
165 170 175
His Lys Tyr Gln Pro Arg Leu His Ile Val Lys Ala Asp Glu Asn Asn
180 185 190
Gly Phe Gly Ser Lys Asn Thr Ala Phe Cys Thr His Val Phe Pro Glu
195 200 205
Thr Ala Phe Ile Ala Val Thr Ser Tyr Gln Asn His Lys Ile Thr Gln
210 215 220
Leu Lys Ile Glu Asn Asn Pro Phe Ala Lys Gly Phe Arg Gly Ser Asp
225 230 235 240
Asp Met Glu Leu His Arg Met Ser Arg Met Gln Ser Lys Glu Tyr Pro
245 250 255
Val Val Pro Arg Ser Thr Val Arg Gln Lys Val Ala Ser Asn His Ser
260 265 270
Pro Phe Ser Ser Glu Pro Arg Ala Leu Ser Thr Ser Ser Asn Leu Gly
275 280 285
Ser Gln Tyr Gln Cys Glu Asn Gly Val Ser Gly Pro Ser Gln Asp Leu
290 295 300
Leu Pro Pro Pro Asn Pro Tyr Pro Leu Pro Gln Glu His Ser Gln Ile
305 310 315 320
Tyr His Cys Thr Lys Arg Lys Ala Asp Glu Glu Cys Ser Thr Thr Glu
325 330 335
His Pro Tyr Lys Lys Pro Tyr Met Glu Thr Ser Pro Ser Glu Glu Asp
340 345 350
Pro Phe Tyr Arg Ala Gly Tyr Pro Gln Gln Gln Gly Leu Gly Ala Ser
355 360 365
Tyr Arg Thr Glu Ser Ala Gln Arg Gln Ala Cys Met Tyr Ala Ser Ser
370 375 380
Ala Pro Pro Ser Glu Pro Val Pro Ser Leu Glu Asp Ile Ser Cys Asn
385 390 395 400
Thr Trp Pro Ser Met Pro Ser Tyr Ser Ser Cys Thr Val Thr Thr Val
405 410 415
Gln Pro Met Asp Arg Leu Pro Tyr Gln His Phe Ser Ala His Phe Thr
420 425 430
Ser Gly Pro Leu Val Pro Arg Leu Ala Gly Met Ala Asn His Gly Ser
435 440 445
Pro Gln Leu Gly Glu Gly Met Phe Gln His Gln Thr Ser Val Ala His
450 455 460
Gln Pro Val Val Arg Gln Cys Gly Pro Gln Thr Gly Leu Gln Ser Pro
465 470 475 480
Gly Ser Leu Gln Ala Ser Glu Phe Leu Tyr Ser His Gly Val Pro Arg
485 490 495
Thr Leu Ser Pro His Gln Tyr His Ser Ala Val His Gly Val Gly Met
500 505 510
Val Pro Glu Trp Ser Asp Asn Ser
515 520
<210> 9
<211> 519
<212> PRT
<213> Sus scrofa
<400> 9
Met Ala Asp Gly Asp Glu Gly Phe Gly Leu Ala His Thr Pro Leu Glu
1 5 10 15
Pro Asp Ser Lys Asp Leu Pro Cys Asp Ser Lys Pro Glu Ser Gly Leu
20 25 30
Gly Ala Pro Ser Lys Ser Pro Ser Ser Pro Gln Ala Ala Phe Thr Gln
35 40 45
Gln Gly Met Glu Gly Ile Lys Val Phe Leu His Glu Arg Glu Leu Trp
50 55 60
Leu Lys Phe His Glu Val Gly Thr Glu Met Ile Ile Thr Lys Ala Gly
65 70 75 80
Arg Arg Met Phe Pro Ser Tyr Lys Val Lys Val Thr Gly Leu Asn Pro
85 90 95
Lys Thr Lys Tyr Ile Leu Leu Met Asp Ile Val Pro Ala Asp Asp His
100 105 110
Arg Tyr Lys Phe Ala Asp Asn Lys Trp Ser Val Thr Gly Lys Ala Glu
115 120 125
Pro Ala Met Pro Gly Arg Leu Tyr Val His Pro Asp Ser Pro Ala Thr
130 135 140
Gly Ala His Trp Met Arg Gln Leu Val Ser Phe Gln Lys Leu Lys Leu
145 150 155 160
Thr Asn Asn His Leu Asp Pro Phe Gly His Ile Ile Leu Asn Ser Met
165 170 175
His Lys Tyr Gln Pro Arg Leu His Ile Val Lys Ala Asp Glu Asn Asn
180 185 190
Gly Phe Gly Ser Lys Asn Thr Ala Phe Cys Thr His Val Phe Pro Glu
195 200 205
Thr Ala Phe Ile Ala Val Thr Ser Tyr Gln Asn His Lys Ile Thr Gln
210 215 220
Leu Lys Ile Glu Asn Asn Pro Phe Ala Lys Gly Phe Arg Gly Ser Asp
225 230 235 240
Asp Met Glu Leu His Arg Met Ser Arg Met Gln Ser Lys Glu Tyr Pro
245 250 255
Val Val Pro Arg Ser Thr Val Arg Gln Lys Val Ala Ser Asn His Ser
260 265 270
Pro Phe Ser Ser Glu Pro Arg Ala Leu Ser Thr Ser Ser Asn Leu Gly
275 280 285
Ser Gln Tyr Gln Cys Glu Asn Gly Val Ser Gly Pro Ser Gln Asp Leu
290 295 300
Leu Pro Pro Pro Asn Pro Tyr Pro Leu Pro Gln Glu His Ser Gln Ile
305 310 315 320
Tyr His Cys Thr Lys Arg Lys Asp Glu Glu Cys Ser Thr Thr Glu His
325 330 335
Pro Tyr Lys Lys Pro Tyr Met Glu Thr Ser Pro Ser Glu Glu Asp Pro
340 345 350
Phe Tyr Arg Ala Gly Tyr Pro Gln Gln Gln Gly Leu Gly Ala Ser Tyr
355 360 365
Arg Thr Glu Ser Ala Gln Arg Gln Ala Cys Met Tyr Ala Ser Ser Ala
370 375 380
Pro Pro Ser Glu Pro Val Pro Ser Leu Glu Asp Ile Ser Cys Asn Thr
385 390 395 400
Trp Pro Ser Met Pro Ser Tyr Ser Ser Cys Thr Val Thr Thr Val Gln
405 410 415
Pro Met Asp Arg Leu Pro Tyr Gln His Phe Ser Ala His Phe Thr Ser
420 425 430
Gly Pro Leu Val Pro Arg Leu Ala Gly Met Ala Asn His Gly Ser Pro
435 440 445
Gln Leu Gly Glu Gly Met Phe Gln His Gln Thr Ser Val Ala His Gln
450 455 460
Pro Val Val Arg Gln Cys Gly Pro Gln Thr Gly Leu Gln Ser Pro Gly
465 470 475 480
Ser Leu Gln Ala Ser Glu Phe Leu Tyr Ser His Gly Val Pro Arg Thr
485 490 495
Leu Ser Pro His Gln Tyr His Ser Ala Val His Gly Val Gly Met Val
500 505 510
Pro Glu Trp Ser Asp Asn Ser
515
<210> 10
<211> 324
<212> PRT
<213> Homo sapiens
<400> 10
Met Phe Pro Ser Pro Ala Leu Thr Pro Thr Pro Phe Ser Val Lys Asp
1 5 10 15
Ile Leu Asn Leu Glu Gln Gln Gln Arg Ser Leu Ala Ala Ala Gly Glu
20 25 30
Leu Ser Ala Arg Leu Glu Ala Thr Leu Ala Pro Ser Ser Cys Met Leu
35 40 45
Ala Ala Phe Lys Pro Glu Ala Tyr Ala Gly Pro Glu Ala Ala Ala Pro
50 55 60
Gly Leu Pro Glu Leu Arg Ala Glu Leu Gly Arg Ala Pro Ser Pro Ala
65 70 75 80
Lys Cys Ala Ser Ala Phe Pro Ala Ala Pro Ala Phe Tyr Pro Arg Ala
85 90 95
Tyr Ser Asp Pro Asp Pro Ala Lys Asp Pro Arg Ala Glu Lys Lys Glu
100 105 110
Leu Cys Ala Leu Gln Lys Ala Val Glu Leu Glu Lys Thr Glu Ala Asp
115 120 125
Asn Ala Glu Arg Pro Arg Ala Arg Arg Arg Arg Lys Pro Arg Val Leu
130 135 140
Phe Ser Gln Ala Gln Val Tyr Glu Leu Glu Arg Arg Phe Lys Gln Gln
145 150 155 160
Arg Tyr Leu Ser Ala Pro Glu Arg Asp Gln Leu Ala Ser Val Leu Lys
165 170 175
Leu Thr Ser Thr Gln Val Lys Ile Trp Phe Gln Asn Arg Arg Tyr Lys
180 185 190
Cys Lys Arg Gln Arg Gln Asp Gln Thr Leu Glu Leu Val Gly Leu Pro
195 200 205
Pro Pro Pro Pro Pro Pro Ala Arg Arg Ile Ala Val Pro Val Leu Val
210 215 220
Arg Asp Gly Lys Pro Cys Leu Gly Asp Ser Ala Pro Tyr Ala Pro Ala
225 230 235 240
Tyr Gly Val Gly Leu Asn Pro Tyr Gly Tyr Asn Ala Tyr Pro Ala Tyr
245 250 255
Pro Gly Tyr Gly Gly Ala Ala Cys Ser Pro Gly Tyr Ser Cys Thr Ala
260 265 270
Ala Tyr Pro Ala Gly Pro Ser Pro Ala Gln Pro Ala Thr Ala Ala Ala
275 280 285
Asn Asn Asn Phe Val Asn Phe Gly Val Gly Asp Leu Asn Ala Val Gln
290 295 300
Ser Pro Gly Ile Pro Gln Ser Asn Ser Gly Val Ser Thr Leu His Gly
305 310 315 320
Ile Arg Ala Trp
<210> 11
<211> 1632
<212> DNA
<213> Homo sapiens
<400> 11
gacgggtgcg cgggcgggcg gcggcaccat gcagggaagc tgccaggggc cgtgggcagc 60
gccgctttct gccgcccacc tggcgctgtg agactggcgc tgccaccatg ttccccagcc 120
ctgctctcac gcccacgccc ttctcagtca aagacatcct aaacctggaa cagcagcagc 180
gcagcctggc tgccgccgga gagctctctg cccgcctgga ggcgaccctg gcgccctcct 240
cctgcatgct ggccgccttc aagccagagg cctacgctgg gcccgaggcg gctgcgccgg 300
gcctcccaga gctgcgcgca gagctgggcc gcgcgccttc accggccaag tgtgcgtctg 360
cctttcccgc cgcccccgcc ttctatccac gtgcctacag cgaccccgac ccagccaagg 420
accctagagc cgaaaagaaa gagctgtgcg cgctgcagaa ggcggtggag ctggagaaga 480
cagaggcgga caacgcggag cggccccggg cgcgacggcg gaggaagccg cgcgtgctct 540
tctcgcaggc gcaggtctat gagctggagc ggcgcttcaa gcagcagcgg tacctgtcgg 600
cccccgaacg cgaccagctg gccagcgtgc tgaaactcac gtccacgcag gtcaagatct 660
ggttccagaa ccggcgctac aagtgcaagc ggcagcggca ggaccagact ctggagctgg 720
tggggctgcc cccgccgccg ccgccgcctg cccgcaggat cgcggtgcca gtgctggtgc 780
gcgatggcaa gccatgccta ggggactcgg cgccctacgc gcctgcctac ggcgtgggcc 840
tcaatcccta cggttataac gcctaccccg cctatccggg ttacggcggc gcggcctgca 900
gccctggcta cagctgcact gccgcttacc ccgccgggcc ttccccagcg cagccggcca 960
ctgccgccgc caacaacaac ttcgtgaact tcggcgtcgg ggacttgaat gcggttcaga 1020
gccccgggat tccgcagagc aactcgggag tgtccacgct gcatggtatc cgagcctggt 1080
agggaaggga cccgcgtggc gcgaccctga ccgatcccac ctcaacagct ccctgactct 1140
cggggggaga aggggctccc aacatgaccc tgagtcccct ggattttgca ttcactcctg 1200
cggagaccta ggaacttttt ctgtcccacg cgcgtttgtt cttgcgcacg ggagagtttg 1260
tggcggcgat tatgcagcgt gcaatgagtg atcctgcagc ctggtgtctt agctgtcccc 1320
ccaggagtgc cctccgagag tccatgggca cccccggttg gaactgggac tgagctcggg 1380
cacgcagggc ctgagatctg gccgcccatt ccgcgagcca gggccgggcg cccgggcctt 1440
tgctatctcg ccgtcgcccg cccacgcacc cacccgtatt tatgttttta cctattgctg 1500
taagaaatga cgatcccctt cccattaaag agagtgcgtt gaaaaaaaaa aaaaaaaaaa 1560
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 1620
aaaaaaaaaa aa 1632
<210> 12
<211> 2351
<212> DNA
<213> Homo sapiens
<400> 12
agctgtacat ggagatcttg ctgggaaaat ccgcttgctc ccctcacgtc gtccagccca 60
ggagaaccac cgccgtcacc ccggagcttc ctcggccacc gcgcagagcc ctccgagagc 120
ccgagccgcg gtcttcgagc tccaaggctc attcagggcc ccagatcctt gccccgaaag 180
gagaggatct gagaaaatgg atgcactgag acctctctga aaaccctccg agagagcgcg 240
agaggagcga ggacacgtta ctcgcagcta aaatcacatt taaggaccaa aacaacaaca 300
accaaaaatt tcattaaaac aataagcgcc caagaaccca gatcgggctg gtggggggag 360
gggaagaggc gggaagggga gggtcgcacg gaggtagctt tgcagtgagc agtcgacccc 420
gccgcccccc ggcacagctg gaccggctcc tccagccgcg gctcagactc gcccctggat 480
tccgggttag cttcggtgcc aggaccgcgg cccgggcttg gattcccgag actccgcgta 540
ccagcctcgc gggagccccg gcacctttgt atgagcacga gaggattctg cctccgcgca 600
gcagcccggg aagcaggagc cgaagcgcgg gccgtggagc aaggcgggaa ccggaggcgg 660
cggcggcggc ggccaggggc gcacggtgcc aggaccagct cgccgcgccc catggggagc 720
cggcggccgc agcgctgctg aggcgggccc ggctggccag gcggggggac ggggcccggg 780
ctgcagcagc cccctctgcg gctgccgggc gggcccgggc gcccgggggc tggggggtgg 840
ggggtggggg aggacgccga gcgctgaggc aggggcccgg gccgagggcg cggcggggct 900
gcgcgcacgc tggggcgcgt ggaggggcgc ggagggcgaa atgagtctgg taggtggttt 960
tccccaccac ccggtggtgc accacgaggg ctacccgttt gccgccgccg ccgccgcagc 1020
tgccgccgcc gccgccagcc gctgcagcca tgaggagaac ccctacttcc atggctggct 1080
catcggccac cccgagatgt cgccccccga ctacagcatg gccctgtcct acagccccga 1140
gtatgccagc ggcgccgccg gcctggacca ctcccattac gggggggtgc cgccgggcgc 1200
cgggcccccg ggcctggggg ggccgcgccc ggtgaagcgc cgaggcaccg ccaaccgcaa 1260
ggagcggcgc aggactcaga gcatcaacag cgccttcgcc gaactgcgcg agtgcatccc 1320
caacgtaccc gccgacacca aactctccaa aatcaagacc ctgcgcctgg ccaccagcta 1380
catcgcctac ctcatggacc tgctggccaa ggacgaccag aatggcgagg cggaggcctt 1440
caaggcagag atcaagaaga ccgacgtgaa agaggagaag aggaagaagg agctgaacga 1500
aatcttgaaa agcacagtga gcagcaacga caagaaaacc aaaggccgga cgggctggcc 1560
gcagcacgtc tgggccctgg agctcaagca gtgaggagga ggagaaggag gaggaggaga 1620
gcgcgagtga gcaggggcca aggcgccaga tgcagaccca ggactccgga aaagccgtcc 1680
gcgctccgct ctgaggactc cttgcatttg gaatcatccg gtttatttat gtgcaatttc 1740
cttcccctct ctttgacccc ctttgaggca tctgctcccc gtctccccct ccaaaaaaaa 1800
agtggatatt tgaagaaaag cattccatat tttaatacga agaggacact cccgtgtggt 1860
aagggatccc gtcgtctcat agattctgtg tgcgtgaatg ttccctcttg gctgtgtaga 1920
caccagcgtt gccccccgcc aacctactca accccttcca gataaagaca gtgggcacta 1980
gtgcgtttgt gaagtgtatc tttaatactt ggcctttgga tataaatatt cctgggtatt 2040
ataaagtttt atttcaaagc agaaaacagg gccgctaaca tttccgttgg ggtcggtatc 2100
tagtgctatc cattcatctg tggtcgttcc ctctttgaag atgtttccaa cagccacttg 2160
ttttgtgcac ttccgtcctc taaaactaaa tggaatttaa ttaatattga aggtgtaaac 2220
gttgtaagta ttcaataaac cactgtgttt tttttttaca aaaaccttaa tcttttaatg 2280
gctgatacct caaaagagtt ttgaaaacaa agctgttata cttgttttcg taatatttaa 2340
aatattcaga a 2351
<210> 13
<211> 217
<212> PRT
<213> Homo sapiens
<400> 13
Met Ser Leu Val Gly Gly Phe Pro His His Pro Val Val His His Glu
1 5 10 15
Gly Tyr Pro Phe Ala Ala Ala Ala Ala Ala Ala Ala Ala Ala Ala Ala
20 25 30
Ser Arg Cys Ser His Glu Glu Asn Pro Tyr Phe His Gly Trp Leu Ile
35 40 45
Gly His Pro Glu Met Ser Pro Pro Asp Tyr Ser Met Ala Leu Ser Tyr
50 55 60
Ser Pro Glu Tyr Ala Ser Gly Ala Ala Gly Leu Asp His Ser His Tyr
65 70 75 80
Gly Gly Val Pro Pro Gly Ala Gly Pro Pro Gly Leu Gly Gly Pro Arg
85 90 95
Pro Val Lys Arg Arg Gly Thr Ala Asn Arg Lys Glu Arg Arg Arg Thr
100 105 110
Gln Ser Ile Asn Ser Ala Phe Ala Glu Leu Arg Glu Cys Ile Pro Asn
115 120 125
Val Pro Ala Asp Thr Lys Leu Ser Lys Ile Lys Thr Leu Arg Leu Ala
130 135 140
Thr Ser Tyr Ile Ala Tyr Leu Met Asp Leu Leu Ala Lys Asp Asp Gln
145 150 155 160
Asn Gly Glu Ala Glu Ala Phe Lys Ala Glu Ile Lys Lys Thr Asp Val
165 170 175
Lys Glu Glu Lys Arg Lys Lys Glu Leu Asn Glu Ile Leu Lys Ser Thr
180 185 190
Val Ser Ser Asn Asp Lys Lys Thr Lys Gly Arg Thr Gly Trp Pro Gln
195 200 205
His Val Trp Ala Leu Glu Leu Lys Gln
210 215
<210> 14
<211> 3748
<212> DNA
<213> Homo sapiens
<400> 14
ttcagagaga gagagagagg gagagagagt gagagagact gactcttacc tcgaatccgg 60
gaactttaat cctgaaagct gcgctcagaa aggacttcga ccattcactg ggcttccaac 120
tttccctccc tgggggtgta aaggaggagc ggggcactga gattatatgg ttgccggtgc 180
tcttggaggc tattttgtgt tctttggcgc ttgccaactg ggaagtattt agggagagca 240
agcgcacagc agaggaggtg tgtgttggag gtgggcagtc gccgcggagg ctccagcggt 300
aggtgcgccc tagtaggcag cagtagccgc tattctgggt aagcagtaaa ccccgcataa 360
accccggagc caccatgcct gctcccccgc ctcaccgccg gcttccctgc taggagcagc 420
agaggatgtg gtgaatgcac cggcttcacc gaacgagagc agaaccttgc gcgggcacag 480
ggccctgggc gcaccatggc cgacgcagac gagggctttg gcctggcgca cacgcctctg 540
gagcctgacg caaaagacct gccctgcgat tcgaaacccg agagcgcgct cggggccccc 600
agcaagtccc cgtcgtcccc gcaggccgcc ttcacccagc agggcatgga gggaatcaaa 660
gtgtttctcc atgaaagaga actgtggcta aaattccacg aagtgggcac ggaaatgatc 720
ataaccaagg ctggaaggcg gatgtttccc agttacaaag tgaaggtgac gggccttaat 780
cccaaaacga agtacattct tctcatggac attgtacctg ccgacgatca cagatacaaa 840
ttcgcagata ataaatggtc tgtgacgggc aaagctgagc ccgccatgcc tggccgcctg 900
tacgtgcacc cagactcccc cgccaccggg gcgcattgga tgaggcagct cgtctccttc 960
cagaaactca agctcaccaa caaccacctg gacccatttg ggcatattat tctaaattcc 1020
atgcacaaat accagcctag attacacatc gtgaaagcgg atgaaaataa tggatttggc 1080
tcaaaaaata cagcgttctg cactcacgtc tttcctgaga ctgcgtttat agcagtgact 1140
tcctaccaga accacaagat cacgcaatta aagattgaga ataatccctt tgccaaagga 1200
tttcggggca gtgatgacat ggagctgcac agaatgtcaa gaatgcaaag taaagaatat 1260
cccgtggtcc ccaggagcac cgtgaggcaa aaagtggcct ccaaccacag tcctttcagc 1320
agcgagtctc gagctctctc cacctcatcc aatttggggt cccaatacca gtgtgagaat 1380
ggtgtttccg gcccctccca ggacctcctg cctccaccca acccataccc actgccccag 1440
gagcatagcc aaatttacca ttgtaccaag aggaaagagg aagaatgttc caccacagac 1500
catccctata agaagcccta catggagaca tcacccagtg aagaagattc cttctaccgc 1560
tctagctatc cacagcagca gggcctgggt gcctcctaca ggacagagtc ggcacagcgg 1620
caagcttgca tgtatgccag ctctgcgccc cccagcgagc ctgtgcccag cctagaggac 1680
atcagctgca acacgtggcc aagcatgcct tcctacagca gctgcaccgt caccaccgtg 1740
cagcccatgg acaggctacc ctaccagcac ttctccgctc acttcacctc ggggcccctg 1800
gtccctcggc tggctggcat ggccaaccat ggctccccac agctgggaga gggaatgttc 1860
cagcaccaga cctccgtggc ccaccagcct gtggtcaggc agtgtgggcc tcagactggc 1920
ctgcagtccc ctggcaccct tcagccccct gagttcctct actctcatgg cgtgccaagg 1980
actctatccc ctcatcagta ccactctgtg cacggagttg gcatggtgcc agagtggagc 2040
gacaatagct aaagtgaggc ctgcttcaca acagacattt cctagagaaa gagagagaga 2100
gaggagaaag agagagaagg agagagacag tagccaagag aaccccacag acaagatttt 2160
tcatttcacc caatgttcac atctgcactc aaggtcgctg gatgctgatc taatcagtag 2220
cttgaaacca caattttaaa aatgtgactt tcttgttttg tctcaaaact taaaaaaaca 2280
aacacaaaaa gatgagtccc accccccact accaccacac ccatcaacca gccacattca 2340
cgctactccc cagatctctt cccccattcc ttcttttggg ctctagaaag tcttgcctca 2400
ttgagtgttt ttccctagtg cgtagttgga gtctgtccct gtcttggtgt taatgttgac 2460
attgttatat aataaatgat aatatatttt tttctttcaa ttttcttaat gggacccagt 2520
cccttatttg gggggaggtc tgaggcaagt atatttcaaa atatgtactt gcgggattcc 2580
cttcaagtaa accatccctg aaacctaaat tcacgtttcc ccttgactaa gaaaagcacc 2640
tacctctgcc atgtgatgtt tctgaaaagc ctctgtatgt ccccatttgc tttggttttg 2700
tcctgccttc tccaatatca cgtgctcagt tttgcctcta cttacccatg gagtcaggat 2760
aacactgacg ctccctggca tcctatctta ctcagcccta ccatcttgcc agctctgtct 2820
ttccagctgt ctgtcgctaa aacgtggcct atagcttccc ttccggaaag cttgctttga 2880
aaaacttaaa aagcccccgt ttacatgtag gcaggactgt gataacagtg caagctctgt 2940
gttgacaaga gttgtggaca aaaagccaaa ataaatattc ttcctgatta aaaaaatttt 3000
ttttgaaaaa aacaaggcca gccccaacct tccaaacctc catcaccaac aacccaaact 3060
ggatgtcaag caaaatgcac aattcctaca gaagaggcaa gacacagtca ccaatgatat 3120
ctcgccaaag aaaccacgcc cacaccaatg ccgacacaaa actgtgttta ctgaaagccg 3180
aaaacagtat taaaaaaagt gtgtaagtaa agtgttatgg tagggttctt cagatgtaat 3240
attttactgg tactatttat ttataaatag gaattctaat taagtaataa catgaaatga 3300
aacccagcat aggagctggc caagagcttt taattttatt gatactcaaa accaagtttg 3360
tgtttttttg tttttttttg tttttttcct ctttcgaatg tgctttgctt tttttgatta 3420
aaaagaattt ttttttcctt ttttataaac agaccctaat aaagagaaca gggtaagatg 3480
tgaggctgag tgtgtttaag tacgtgagag agtgtgagtg tgtttgtaag tgagtgtccc 3540
tatgcgatta tgtctcttta cgttgctaag gggggagggt gaggattaag tactcgtgcc 3600
ttatatttgt gtgccaatta atgcctaata aataccatgt gcttaaacaa gtaaaaaaaa 3660
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 3720
aaaaaaaaaa aaaaaaaaaa aaaaaaaa 3748
<210> 15
<211> 518
<212> PRT
<213> Homo sapiens
<400> 15
Met Ala Asp Ala Asp Glu Gly Phe Gly Leu Ala His Thr Pro Leu Glu
1 5 10 15
Pro Asp Ala Lys Asp Leu Pro Cys Asp Ser Lys Pro Glu Ser Ala Leu
20 25 30
Gly Ala Pro Ser Lys Ser Pro Ser Ser Pro Gln Ala Ala Phe Thr Gln
35 40 45
Gln Gly Met Glu Gly Ile Lys Val Phe Leu His Glu Arg Glu Leu Trp
50 55 60
Leu Lys Phe His Glu Val Gly Thr Glu Met Ile Ile Thr Lys Ala Gly
65 70 75 80
Arg Arg Met Phe Pro Ser Tyr Lys Val Lys Val Thr Gly Leu Asn Pro
85 90 95
Lys Thr Lys Tyr Ile Leu Leu Met Asp Ile Val Pro Ala Asp Asp His
100 105 110
Arg Tyr Lys Phe Ala Asp Asn Lys Trp Ser Val Thr Gly Lys Ala Glu
115 120 125
Pro Ala Met Pro Gly Arg Leu Tyr Val His Pro Asp Ser Pro Ala Thr
130 135 140
Gly Ala His Trp Met Arg Gln Leu Val Ser Phe Gln Lys Leu Lys Leu
145 150 155 160
Thr Asn Asn His Leu Asp Pro Phe Gly His Ile Ile Leu Asn Ser Met
165 170 175
His Lys Tyr Gln Pro Arg Leu His Ile Val Lys Ala Asp Glu Asn Asn
180 185 190
Gly Phe Gly Ser Lys Asn Thr Ala Phe Cys Thr His Val Phe Pro Glu
195 200 205
Thr Ala Phe Ile Ala Val Thr Ser Tyr Gln Asn His Lys Ile Thr Gln
210 215 220
Leu Lys Ile Glu Asn Asn Pro Phe Ala Lys Gly Phe Arg Gly Ser Asp
225 230 235 240
Asp Met Glu Leu His Arg Met Ser Arg Met Gln Ser Lys Glu Tyr Pro
245 250 255
Val Val Pro Arg Ser Thr Val Arg Gln Lys Val Ala Ser Asn His Ser
260 265 270
Pro Phe Ser Ser Glu Ser Arg Ala Leu Ser Thr Ser Ser Asn Leu Gly
275 280 285
Ser Gln Tyr Gln Cys Glu Asn Gly Val Ser Gly Pro Ser Gln Asp Leu
290 295 300
Leu Pro Pro Pro Asn Pro Tyr Pro Leu Pro Gln Glu His Ser Gln Ile
305 310 315 320
Tyr His Cys Thr Lys Arg Lys Glu Glu Glu Cys Ser Thr Thr Asp His
325 330 335
Pro Tyr Lys Lys Pro Tyr Met Glu Thr Ser Pro Ser Glu Glu Asp Ser
340 345 350
Phe Tyr Arg Ser Ser Tyr Pro Gln Gln Gln Gly Leu Gly Ala Ser Tyr
355 360 365
Arg Thr Glu Ser Ala Gln Arg Gln Ala Cys Met Tyr Ala Ser Ser Ala
370 375 380
Pro Pro Ser Glu Pro Val Pro Ser Leu Glu Asp Ile Ser Cys Asn Thr
385 390 395 400
Trp Pro Ser Met Pro Ser Tyr Ser Ser Cys Thr Val Thr Thr Val Gln
405 410 415
Pro Met Asp Arg Leu Pro Tyr Gln His Phe Ser Ala His Phe Thr Ser
420 425 430
Gly Pro Leu Val Pro Arg Leu Ala Gly Met Ala Asn His Gly Ser Pro
435 440 445
Gln Leu Gly Glu Gly Met Phe Gln His Gln Thr Ser Val Ala His Gln
450 455 460
Pro Val Val Arg Gln Cys Gly Pro Gln Thr Gly Leu Gln Ser Pro Gly
465 470 475 480
Thr Leu Gln Pro Pro Glu Phe Leu Tyr Ser His Gly Val Pro Arg Thr
485 490 495
Leu Ser Pro His Gln Tyr His Ser Val His Gly Val Gly Met Val Pro
500 505 510
Glu Trp Ser Asp Asn Ser
515
Claims (14)
- 게놈이 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합의 양쪽 대립유전자에 돌연변이를 보유하여 비-인간 동물 세포 또는 배반포에는 기능적 NKX2-5 단백질, HANDII 단백질, TBX5 단백질 또는 그의 조합이 결여된 것인 비-인간 동물 세포, 상실배 또는 배반포.
- 제1항에 있어서, 돌연변이가 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합의 결실인 비-인간 동물 세포, 상실배 또는 배반포.
- 제1항 또는 제2항에 있어서, 비-인간 동물 세포 또는 배반포가 돼지, 소, 말 또는 염소인 비-인간 동물 세포, 상실배 또는 배반포.
- 인간 NKX2-5, HANDII, TBX5 또는 그의 조합을 발현하며 비-인간 동물 NKX2-5, HANDII, TBX5 또는 그의 조합의 발현이 결여된 키메라 비-인간 동물, 상실배 또는 배반포.
- 제4항에 있어서, 비-인간 동물이 인간화 심장 세포 및/또는 조직을 생산하는 것인 키메라 비-인간 동물.
- 외인성 돼지 NKX2-5, HANDII, TBX5 또는 그의 조합을 발현하며 내인성 돼지 NKX2-5, HANDII, TBX5 또는 그의 조합의 발현이 결여된 키메라 돼지 (돼지-돼지 키메라).
- 제4항 또는 제5항에 있어서, 비-인간 동물이 돼지, 소, 말 또는 염소인 키메라 비-인간 동물.
- a) NKX2-5, HANDII, TBX5 또는 그의 조합 널(null) 비-인간 동물 세포를 생성하는 단계로서, 여기서 비-인간 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합 유전자의 양쪽 카피는 기능적 NKX2-5 단백질, HANDII 단백질, TBX5 단백질 또는 그의 조합의 생산을 방지하는 돌연변이를 보유하는 것인 단계;
b) a)의 상기 NKX2-5, HANDI, TBX5 또는 그의 조합 널 비-인간 세포로부터의 핵을 제핵 비-인간 난모세포 내로 융합시키는 것 및 상기 난모세포를 활성화시켜 NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 상실배 또는 배반포를 형성하도록 분열시키는 것을 포함하는 체세포 핵 이식에 의해 NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 상실배 또는 배반포를 창출하는 단계;
c) 인간 줄기 세포를 b)의 비-인간 NKX2-5, HANDII, TBX5 또는 그의 조합 널 상실배 또는 배반포 내로 도입시키는 단계; 및
d) c)로부터의 상기 상실배 또는 배반포를 가임신 대리모 비-인간 동물 내로 이식시켜 인간 NKX2-5, HANDII, TBX5 또는 그의 조합을 발현하는 키메라 비-인간 동물을 생성하는 단계
를 포함하는, 인간 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합을 발현하는 키메라 비-인간 동물을 생산하는 방법. - a) NKX2-5, HANDII, TBX5 또는 그의 조합 널 돼지 세포를 생성하는 단계로서, 여기서 내인성 돼지 MYF5 유전자, MYOD 유전자, MRF4 유전자 또는 그의 조합 유전자의 양쪽 카피는 기능적 내인성 돼지 MYF5 단백질, MYOD 단백질, MRF4 단백질 또는 그의 조합의 생산을 방지하는 돌연변이를 보유하는 것인 단계;
b) a)의 상기 NKX2-5, HANDII, TBX5 또는 그의 조합 널 돼지 세포로부터의 핵을 제핵 돼지 난모세포 내로 융합시키는 것 및 상기 난모세포를 활성화시켜 NKX2-5, HANDII, TBX5 또는 그의 조합 널 돼지 상실배 또는 배반포를 형성하도록 분열시키는 것을 포함하는 체세포 핵 이식에 의해 NKX2-5, HANDII, TBX5 또는 그의 조합 널 돼지 상실배 또는 배반포를 창출하는 단계;
c) 돼지 줄기 세포를 b)의 돼지 NKX2-5, HANDII, TBX5 또는 그의 조합 널 상실배 또는 배반포 내로 도입시키는 단계; 및
d) c)로부터의 상기 상실배 또는 배반포를 가임신 대리모 돼지 내로 이식시켜 외인성 돼지 NKX2-5, HANDII, TBX5 또는 그의 조합을 발현하는 키메라 돼지를 생성하는 단계
를 포함하는, 외인성 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합을 발현하는 키메라 돼지를 생산하는 방법. - a) NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 세포를 생성하는 단계로서, 여기서 비-인간 NKX2-5 유전자, HANDII 유전자, TBX5 유전자 또는 그의 조합의 양쪽 대립유전자는 기능적 비-인간 NKX2-5 단백질, HANDII 단백질, TBX5 단백질 또는 그의 조합의 생산을 방지하는 돌연변이를 보유하는 것인 단계;
b) a)의 상기 MYF5, MYOD, MRF4 또는 그의 조합 널 비-인간 세포로부터의 핵을 제핵 비-인간 동물 난모세포 내로 융합시키는 것 및 상기 난모세포를 활성화시켜 NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 동물 배반포를 형성하도록 분열시키는 것을 포함하는 체세포 핵 이식에 의해 NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 상실배 또는 배반포를 창출하는 단계;
c) 인간 줄기 세포를 b)의 NKX2-5, HANDII, TBX5 또는 그의 조합 널 비-인간 동물 배반포 또는 상실배 내로 도입시키는 단계; 및
d) 인간 또는 인간화 심장 세포를 발현하는 비-인간 동물을 생성하도록 c)로부터의 상기 배반포 또는 상실배를 가임신 대리모 비-인간 동물 내로 이식시키는 단계
를 포함하는, 비-인간 동물에서 인간 또는 인간화 심장 세포를 생산하는 방법. - 제8항 또는 제10항에 있어서, 비-인간 동물이 돼지, 소, 말 또는 염소인 방법.
- 제8항 내지 제10항 중 어느 한 항에 있어서, 인간 줄기 세포가 조직 특이적 줄기 세포, 만능성 줄기 세포, 다능성 성체 줄기 세포, 유도된 만능성 줄기 세포 또는 제대혈 줄기 세포 (UCBSC)인 방법.
- 제8항 내지 제10항 중 어느 한 항에 있어서, 유도된 만능성 세포가 섬유모세포 세포로부터 형성된 것인 방법.
- 제8항 내지 제13항 중 어느 한 항의 방법에 의해 생산된 비-인간 동물.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201562187040P | 2015-06-30 | 2015-06-30 | |
| US62/187,040 | 2015-06-30 | ||
| PCT/US2016/040431 WO2017004388A1 (en) | 2015-06-30 | 2016-06-30 | Humanized heart muscle |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20180021135A true KR20180021135A (ko) | 2018-02-28 |
Family
ID=57609529
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020187002387A KR20180021135A (ko) | 2015-06-30 | 2016-06-30 | 인간화 심장 근육 |
Country Status (13)
| Country | Link |
|---|---|
| US (2) | US10897880B2 (ko) |
| EP (1) | EP3316899A4 (ko) |
| JP (1) | JP2018523999A (ko) |
| KR (1) | KR20180021135A (ko) |
| CN (1) | CN108472318A (ko) |
| AU (1) | AU2016288671A1 (ko) |
| BR (1) | BR112017028608A2 (ko) |
| CA (1) | CA2991056A1 (ko) |
| CO (1) | CO2018000859A2 (ko) |
| IL (1) | IL256544A (ko) |
| MX (1) | MX2018000071A (ko) |
| RU (1) | RU2018103234A (ko) |
| WO (1) | WO2017004388A1 (ko) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2016141234A1 (en) | 2015-03-03 | 2016-09-09 | Regents Of The University Of Minnesota | Etv2 and uses thereof |
| CN108472318A (zh) | 2015-06-30 | 2018-08-31 | 明尼苏达大学校董会 | 人源化心脏肌肉 |
| AU2016288196A1 (en) | 2015-06-30 | 2018-02-01 | Regents Of The University Of Minnesota | Humanized skeletal muscle |
Family Cites Families (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0882127A4 (en) * | 1996-01-09 | 2002-09-11 | Univ California | EMBRYONIC STEM CELL-LIKE HOODED CELLS, METHOD FOR THE PRODUCTION AND USE OF THE CELLS FOR THE PRODUCTION OF TRANSGENIC SLEEPING ANIMALS |
| US5994619A (en) | 1996-04-01 | 1999-11-30 | University Of Massachusetts, A Public Institution Of Higher Education Of The Commonwealth Of Massachusetts, As Represented By Its Amherst Campus | Production of chimeric bovine or porcine animals using cultured inner cell mass cells |
| CN1241210A (zh) * | 1996-10-11 | 2000-01-12 | 得克萨斯农业及机械体系综合大学 | 产生原生殖细胞和转基因动物物种的方法 |
| EP1449431A4 (en) | 2001-10-24 | 2007-11-28 | Chugai Pharmaceutical Co Ltd | NON-HUMAN ANIMAL GENETICALLY MODIFIED SRGF ANIMAL |
| US20040133931A1 (en) | 2003-01-08 | 2004-07-08 | Gavin William G. | Method and system for fusion and activation following nuclear transfer in reconstructed embryos |
| US20050125853A1 (en) | 2002-03-22 | 2005-06-09 | St. Jude Children's Resarch Hospital | Method for generating genetically modified animals |
| CA2488725A1 (en) * | 2002-07-03 | 2004-01-15 | Su Qian | Agouti-related protein deficient cells, non-human transgenic animals and methods of selecting compounds which regulate energy metabolism |
| GB2398784B (en) * | 2003-02-26 | 2005-07-27 | Babraham Inst | Removal and modification of the immunoglobulin constant region gene cluster of a non-human mammal |
| US20060008451A1 (en) | 2004-07-06 | 2006-01-12 | Michigan State University | In vivo methods for effecting tissue specific differentiation of embryonic stem cells |
| JP5425641B2 (ja) | 2007-01-11 | 2014-02-26 | ユニバーシティー オブ ピッツバーグ − オブ ザ コモンウェルス システム オブ ハイヤー エデュケーション | 尿路病状の処置のための筋由来細胞ならびにその作製および使用の方法 |
| JP2010516258A (ja) | 2007-01-20 | 2010-05-20 | ベーリンガー インゲルハイム インターナショナル ゲゼルシャフト ミット ベシュレンクテル ハフツング | C反応性タンパク質(crp)ノックアウトマウス |
| JPWO2008102602A1 (ja) * | 2007-02-22 | 2010-05-27 | 国立大学法人 東京大学 | Blastocystcomplementationを利用した臓器再生法 |
| EP2258166A4 (en) | 2008-02-22 | 2013-04-03 | Univ Tokyo | METHOD FOR PRODUCING FOUNDER ANIMAL FOR REPRODUCTIVE ANIMALS HAVING LETHAL PHENOTYPE DUE TO GENE MODIFICATION |
| US20110258715A1 (en) | 2008-08-22 | 2011-10-20 | The University Of Tokyo | ORGAN REGENERATION METHOD UTILIZING iPS CELL AND BLASTOCYST COMPLEMENTATION |
| WO2010108126A2 (en) | 2009-03-19 | 2010-09-23 | Fate Therapeutics, Inc. | Reprogramming compositions and methods of using the same |
| TWI492707B (zh) * | 2009-05-20 | 2015-07-21 | 卡迪歐參生物科技有限公司 | 治療心臟疾病之藥品配方 |
| SG194089A1 (en) | 2011-04-27 | 2013-11-29 | Amyris Inc | Methods for genomic modification |
| AU2012262139B2 (en) | 2011-06-02 | 2017-02-23 | Children's Medical Center Corporation | Methods and uses for ex vivo tissue culture systems |
| US9862929B2 (en) | 2011-11-18 | 2018-01-09 | Kyoto University | Method of inducing differentiation from pluripotent stem cells to skeletal muscle cells |
| IL221187A (en) | 2012-07-30 | 2017-01-31 | Adom Advanced Optical Tech Ltd | A system to perform optical tomography in two 2D beams |
| US20140115728A1 (en) | 2012-10-24 | 2014-04-24 | A. Joseph Tector | Double knockout (gt/cmah-ko) pigs, organs and tissues |
| US11377639B2 (en) * | 2013-11-15 | 2022-07-05 | Wisconsin Alumni Research Foundation | Lineage reprogramming to induced cardiac progenitor cells (iCPC) by defined factors |
| AU2015253352A1 (en) | 2014-04-28 | 2016-12-08 | Recombinetics, Inc. | Multiplex Gene Editing |
| WO2016141234A1 (en) | 2015-03-03 | 2016-09-09 | Regents Of The University Of Minnesota | Etv2 and uses thereof |
| AU2016288196A1 (en) | 2015-06-30 | 2018-02-01 | Regents Of The University Of Minnesota | Humanized skeletal muscle |
| CN108472318A (zh) | 2015-06-30 | 2018-08-31 | 明尼苏达大学校董会 | 人源化心脏肌肉 |
| CA3003652A1 (en) | 2015-10-27 | 2017-05-04 | Regents Of The University Of Minnesota | Compositions and methods for chimeric embryo-assisted organ production |
| CN108125943A (zh) | 2018-01-17 | 2018-06-08 | 云南省第二人民医院 | 前胡醇当归脂作为制备抗动脉粥样硬化药物的应用 |
-
2016
- 2016-06-30 CN CN201680050242.9A patent/CN108472318A/zh active Pending
- 2016-06-30 EP EP16818799.5A patent/EP3316899A4/en active Pending
- 2016-06-30 MX MX2018000071A patent/MX2018000071A/es unknown
- 2016-06-30 WO PCT/US2016/040431 patent/WO2017004388A1/en active Application Filing
- 2016-06-30 RU RU2018103234A patent/RU2018103234A/ru not_active Application Discontinuation
- 2016-06-30 AU AU2016288671A patent/AU2016288671A1/en not_active Abandoned
- 2016-06-30 BR BR112017028608A patent/BR112017028608A2/pt not_active Application Discontinuation
- 2016-06-30 KR KR1020187002387A patent/KR20180021135A/ko not_active Application Discontinuation
- 2016-06-30 JP JP2017568252A patent/JP2018523999A/ja active Pending
- 2016-06-30 US US15/739,066 patent/US10897880B2/en active Active
- 2016-06-30 CA CA2991056A patent/CA2991056A1/en not_active Abandoned
-
2017
- 2017-12-25 IL IL256544A patent/IL256544A/en unknown
-
2018
- 2018-01-29 CO CONC2018/0000859A patent/CO2018000859A2/es unknown
-
2020
- 2020-12-11 US US17/118,981 patent/US20210169054A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| MX2018000071A (es) | 2018-03-16 |
| EP3316899A4 (en) | 2019-04-03 |
| US20180177165A1 (en) | 2018-06-28 |
| CO2018000859A2 (es) | 2018-07-10 |
| RU2018103234A (ru) | 2019-07-31 |
| WO2017004388A1 (en) | 2017-01-05 |
| EP3316899A1 (en) | 2018-05-09 |
| US20210169054A1 (en) | 2021-06-10 |
| AU2016288671A1 (en) | 2018-02-01 |
| CN108472318A (zh) | 2018-08-31 |
| JP2018523999A (ja) | 2018-08-30 |
| US10897880B2 (en) | 2021-01-26 |
| BR112017028608A2 (pt) | 2018-09-04 |
| CA2991056A1 (en) | 2017-01-05 |
| IL256544A (en) | 2018-02-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20220251550A1 (en) | Methods for extending the replicative capacity of somatic cells during an ex vivo cultivation process | |
| JP6480647B1 (ja) | Dnaが編集された真核細胞を製造する方法、および当該方法に用いられるキット | |
| JP6144911B2 (ja) | 遺伝子ベクター | |
| JP2021505187A (ja) | 遺伝子編集のためのcpf1関連方法及び組成物 | |
| Liu et al. | Disruption of the ZBED6 binding site in intron 3 of IGF2 by CRISPR/Cas9 leads to enhanced muscle development in Liang Guang Small Spotted pigs | |
| Zhang et al. | CRISPR/Cas9 mediated chicken Stra8 gene knockout and inhibition of male germ cell differentiation | |
| US20210169054A1 (en) | Humanized heart muscle | |
| CN111549072B (zh) | Vista基因人源化动物细胞及动物模型的构建方法与应用 | |
| Chojnacka-Puchta et al. | CRISPR/Cas9 gene editing in a chicken model: current approaches and applications | |
| JP2019502400A (ja) | キメラ胚補助臓器作製用の組成物及び方法 | |
| JP2016129519A (ja) | 不活化された内因性遺伝子座を有するトランスジェニックニワトリ | |
| JP2021166551A (ja) | 鳥類および卵 | |
| Min et al. | Generation of antiviral transgenic chicken using spermatogonial stem cell transfected in vivo | |
| CN112779284B (zh) | Thpo基因人源化的非人动物的构建方法及应用 | |
| JP2018522553A (ja) | ヒト化骨格筋 | |
| CA2978457A1 (en) | Etv2 and uses thereof | |
| JP2019505218A (ja) | 遺伝子相補によるヒト化腎臓の操作 | |
| EP3311660B1 (en) | Method for producing blood chimeric animal | |
| CN112111511B (zh) | 敲除载体、打靶载体、试剂盒、Prdm16检测用动物模型、检测方法及应用 | |
| KR20180037602A (ko) | Park2 유전자 넉아웃 파킨슨 질환 모델용 돼지 및 이의 용도 | |
| WO2021171688A1 (ja) | 遺伝子ノックイン方法、遺伝子ノックイン細胞作製方法、遺伝子ノックイン細胞、がん化リスク評価方法、がん細胞製造方法、及びこれらに用いるためのキット | |
| KR20220106715A (ko) | 불멸화된 마모셋 세포주 및 이의 제조방법 | |
| WO2024092216A2 (en) | Methods and compositions regarding modulation of poultry genes | |
| EA040859B1 (ru) | Способ получения эукариотических клеток с отредактированной днк и набор, используемый в этом способе | |
| Hossner | Cellular and molecular biology. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal | ||
| E601 | Decision to refuse application |