KR20140008295A - 돌연변이 델타-9 연장효소 및 다중불포화 지방산의 제조에서의 그들의 용도 - Google Patents
돌연변이 델타-9 연장효소 및 다중불포화 지방산의 제조에서의 그들의 용도 Download PDFInfo
- Publication number
- KR20140008295A KR20140008295A KR1020137007483A KR20137007483A KR20140008295A KR 20140008295 A KR20140008295 A KR 20140008295A KR 1020137007483 A KR1020137007483 A KR 1020137007483A KR 20137007483 A KR20137007483 A KR 20137007483A KR 20140008295 A KR20140008295 A KR 20140008295A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- delta
- leu
- phe
- mutations
- Prior art date
Links
- 235000020777 polyunsaturated fatty acids Nutrition 0.000 title claims abstract description 69
- 239000004606 Fillers/Extenders Substances 0.000 claims abstract description 164
- 238000000034 method Methods 0.000 claims abstract description 80
- 240000004808 Saccharomyces cerevisiae Species 0.000 claims abstract description 52
- OYHQOLUKZRVURQ-IXWMQOLASA-N linoleic acid Natural products CCCCC\C=C/C\C=C\CCCCCCCC(O)=O OYHQOLUKZRVURQ-IXWMQOLASA-N 0.000 claims abstract description 17
- OYHQOLUKZRVURQ-HZJYTTRNSA-N Linoleic acid Chemical compound CCCCC\C=C/C\C=C/CCCCCCCC(O)=O OYHQOLUKZRVURQ-HZJYTTRNSA-N 0.000 claims abstract description 16
- 235000020778 linoleic acid Nutrition 0.000 claims abstract description 16
- XSXIVVZCUAHUJO-AVQMFFATSA-N (11e,14e)-icosa-11,14-dienoic acid Chemical compound CCCCC\C=C\C\C=C\CCCCCCCCCC(O)=O XSXIVVZCUAHUJO-AVQMFFATSA-N 0.000 claims abstract description 15
- 235000021297 Eicosadienoic acid Nutrition 0.000 claims abstract description 14
- 229960004488 linolenic acid Drugs 0.000 claims abstract description 10
- 235000020978 long-chain polyunsaturated fatty acids Nutrition 0.000 claims abstract description 6
- 108090000623 proteins and genes Proteins 0.000 claims description 230
- 230000035772 mutation Effects 0.000 claims description 212
- 238000006243 chemical reaction Methods 0.000 claims description 114
- 235000014113 dietary fatty acids Nutrition 0.000 claims description 94
- 229930195729 fatty acid Natural products 0.000 claims description 94
- 239000000194 fatty acid Substances 0.000 claims description 94
- 150000004665 fatty acids Chemical class 0.000 claims description 93
- 108090000790 Enzymes Proteins 0.000 claims description 89
- 102000004190 Enzymes Human genes 0.000 claims description 88
- 230000000694 effects Effects 0.000 claims description 80
- 150000001413 amino acids Chemical class 0.000 claims description 76
- 241000235013 Yarrowia Species 0.000 claims description 65
- 102000004169 proteins and genes Human genes 0.000 claims description 60
- 229920001184 polypeptide Polymers 0.000 claims description 52
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 52
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 52
- 125000003729 nucleotide group Chemical group 0.000 claims description 49
- 239000002773 nucleotide Substances 0.000 claims description 48
- 239000000758 substrate Substances 0.000 claims description 45
- 102220414503 c.62C>T Human genes 0.000 claims description 43
- JAZBEHYOTPTENJ-JLNKQSITSA-N all-cis-5,8,11,14,17-icosapentaenoic acid Chemical compound CC\C=C/C\C=C/C\C=C/C\C=C/C\C=C/CCCC(O)=O JAZBEHYOTPTENJ-JLNKQSITSA-N 0.000 claims description 42
- 235000020673 eicosapentaenoic acid Nutrition 0.000 claims description 42
- JAZBEHYOTPTENJ-UHFFFAOYSA-N eicosapentaenoic acid Natural products CCC=CCC=CCC=CCC=CCC=CCCCC(O)=O JAZBEHYOTPTENJ-UHFFFAOYSA-N 0.000 claims description 42
- 229960005135 eicosapentaenoic acid Drugs 0.000 claims description 42
- 102200072413 rs121917964 Human genes 0.000 claims description 42
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 40
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 34
- 102220517500 PAN2-PAN3 deadenylation complex subunit PAN3_L108G_mutation Human genes 0.000 claims description 33
- 230000001105 regulatory effect Effects 0.000 claims description 31
- 102000040430 polynucleotide Human genes 0.000 claims description 25
- 108091033319 polynucleotide Proteins 0.000 claims description 25
- 239000002157 polynucleotide Substances 0.000 claims description 25
- 102220528496 Myelin protein P0_V32F_mutation Human genes 0.000 claims description 24
- 230000000813 microbial effect Effects 0.000 claims description 24
- 102200108135 rs121912661 Human genes 0.000 claims description 21
- 239000002253 acid Substances 0.000 claims description 20
- 230000000295 complement effect Effects 0.000 claims description 20
- 102220311624 rs1211419981 Human genes 0.000 claims description 19
- HOBAELRKJCKHQD-UHFFFAOYSA-N (8Z,11Z,14Z)-8,11,14-eicosatrienoic acid Natural products CCCCCC=CCC=CCC=CCCCCCCC(O)=O HOBAELRKJCKHQD-UHFFFAOYSA-N 0.000 claims description 18
- HOBAELRKJCKHQD-QNEBEIHSSA-N dihomo-γ-linolenic acid Chemical compound CCCCC\C=C/C\C=C/C\C=C/CCCCCCC(O)=O HOBAELRKJCKHQD-QNEBEIHSSA-N 0.000 claims description 18
- 102220223286 rs1060501211 Human genes 0.000 claims description 18
- 102200156952 rs1799807 Human genes 0.000 claims description 18
- 102220103817 rs878853955 Human genes 0.000 claims description 18
- 241000196324 Embryophyta Species 0.000 claims description 17
- 102220483782 Myb/SANT-like DNA-binding domain-containing protein 1_A21D_mutation Human genes 0.000 claims description 17
- 102220227884 rs1064793082 Human genes 0.000 claims description 17
- DTOSIQBPPRVQHS-PDBXOOCHSA-N alpha-linolenic acid Chemical compound CC\C=C/C\C=C/C\C=C/CCCCCCCC(O)=O DTOSIQBPPRVQHS-PDBXOOCHSA-N 0.000 claims description 16
- MBMBGCFOFBJSGT-KUBAVDMBSA-N all-cis-docosa-4,7,10,13,16,19-hexaenoic acid Chemical compound CC\C=C/C\C=C/C\C=C/C\C=C/C\C=C/C\C=C/CCC(O)=O MBMBGCFOFBJSGT-KUBAVDMBSA-N 0.000 claims description 15
- YUFFSWGQGVEMMI-JLNKQSITSA-N (7Z,10Z,13Z,16Z,19Z)-docosapentaenoic acid Chemical compound CC\C=C/C\C=C/C\C=C/C\C=C/C\C=C/CCCCCC(O)=O YUFFSWGQGVEMMI-JLNKQSITSA-N 0.000 claims description 12
- 241000195493 Cryptophyta Species 0.000 claims description 11
- 108010073542 Delta-5 Fatty Acid Desaturase Proteins 0.000 claims description 11
- 241000233866 Fungi Species 0.000 claims description 11
- 235000020669 docosahexaenoic acid Nutrition 0.000 claims description 11
- 108020004511 Recombinant DNA Proteins 0.000 claims description 10
- 102100034544 Acyl-CoA 6-desaturase Human genes 0.000 claims description 9
- 108010037138 Linoleoyl-CoA Desaturase Proteins 0.000 claims description 9
- 239000011159 matrix material Substances 0.000 claims description 9
- 101000912235 Rebecca salina Acyl-lipid (7-3)-desaturase Proteins 0.000 claims description 8
- 101000877236 Siganus canaliculatus Acyl-CoA Delta-4 desaturase Proteins 0.000 claims description 8
- 235000020661 alpha-linolenic acid Nutrition 0.000 claims description 8
- YZXBAPSDXZZRGB-DOFZRALJSA-N arachidonic acid Chemical group CCCCC\C=C/C\C=C/C\C=C/C\C=C/CCCC(O)=O YZXBAPSDXZZRGB-DOFZRALJSA-N 0.000 claims description 8
- 102100034542 Acyl-CoA (8-3)-desaturase Human genes 0.000 claims description 7
- 108010087894 Fatty acid desaturases Proteins 0.000 claims description 7
- 241000235015 Yarrowia lipolytica Species 0.000 claims description 7
- -1 delta-12 desaturase Proteins 0.000 claims description 7
- 241000894006 Bacteria Species 0.000 claims description 6
- 241000222120 Candida <Saccharomycetales> Species 0.000 claims description 6
- 102000016553 Stearoyl-CoA Desaturase Human genes 0.000 claims description 6
- 241001527609 Cryptococcus Species 0.000 claims description 5
- 241000223252 Rhodotorula Species 0.000 claims description 5
- 230000014759 maintenance of location Effects 0.000 claims description 5
- 235000021294 Docosapentaenoic acid Nutrition 0.000 claims description 4
- 235000021342 arachidonic acid Nutrition 0.000 claims description 4
- 229940114079 arachidonic acid Drugs 0.000 claims description 4
- 229940090949 docosahexaenoic acid Drugs 0.000 claims description 4
- HJOVHMDZYOCNQW-UHFFFAOYSA-N isophorone Chemical compound CC1=CC(=O)CC(C)(C)C1 HJOVHMDZYOCNQW-UHFFFAOYSA-N 0.000 claims description 4
- 241000195623 Euglenida Species 0.000 claims description 3
- 241001149698 Lipomyces Species 0.000 claims description 3
- 241000316848 Rhodococcus <scale insect> Species 0.000 claims description 3
- 241000223230 Trichosporon Species 0.000 claims description 3
- 108010011713 delta-15 desaturase Proteins 0.000 claims description 3
- 240000000073 Achillea millefolium Species 0.000 claims description 2
- 235000007754 Achillea millefolium Nutrition 0.000 claims description 2
- 235000021298 Dihomo-γ-linolenic acid Nutrition 0.000 claims description 2
- WHXSMMKQMYFTQS-UHFFFAOYSA-N Lithium Chemical compound [Li] WHXSMMKQMYFTQS-UHFFFAOYSA-N 0.000 claims description 2
- 241001466451 Stramenopiles Species 0.000 claims description 2
- 229910052744 lithium Inorganic materials 0.000 claims description 2
- 150000007523 nucleic acids Chemical group 0.000 abstract description 34
- 239000012634 fragment Substances 0.000 abstract description 15
- AHANXAKGNAKFSK-PDBXOOCHSA-N all-cis-icosa-11,14,17-trienoic acid Chemical compound CC\C=C/C\C=C/C\C=C/CCCCCCCCCC(O)=O AHANXAKGNAKFSK-PDBXOOCHSA-N 0.000 abstract description 2
- PRHHYVQTPBEDFE-UHFFFAOYSA-N eicosatrienoic acid Natural products CCCCCC=CCC=CCCCCC=CCCCC(O)=O PRHHYVQTPBEDFE-UHFFFAOYSA-N 0.000 abstract description 2
- 210000004027 cell Anatomy 0.000 description 122
- 235000001014 amino acid Nutrition 0.000 description 95
- 230000014509 gene expression Effects 0.000 description 76
- 108020004414 DNA Proteins 0.000 description 71
- 235000018102 proteins Nutrition 0.000 description 55
- 150000002632 lipids Chemical class 0.000 description 49
- 239000000047 product Substances 0.000 description 45
- KFKWRHQBZQICHA-STQMWFEESA-N L-leucyl-L-phenylalanine Natural products CC(C)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KFKWRHQBZQICHA-STQMWFEESA-N 0.000 description 44
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 44
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 43
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 39
- 238000006467 substitution reaction Methods 0.000 description 36
- 239000013615 primer Substances 0.000 description 35
- 238000003556 assay Methods 0.000 description 34
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 33
- 239000013612 plasmid Substances 0.000 description 33
- 235000019387 fatty acid methyl ester Nutrition 0.000 description 32
- 239000003921 oil Substances 0.000 description 32
- 239000013598 vector Substances 0.000 description 30
- QNTJIDXQHWUBKC-BZSNNMDCSA-N Leu-Lys-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QNTJIDXQHWUBKC-BZSNNMDCSA-N 0.000 description 29
- 238000004458 analytical method Methods 0.000 description 29
- ZGNITFSDLCMLGI-UHFFFAOYSA-N flubendiamide Chemical compound CC1=CC(C(F)(C(F)(F)F)C(F)(F)F)=CC=C1NC(=O)C1=CC=CC(I)=C1C(=O)NC(C)(C)CS(C)(=O)=O ZGNITFSDLCMLGI-UHFFFAOYSA-N 0.000 description 29
- 208000016444 Benign adult familial myoclonic epilepsy Diseases 0.000 description 28
- 241000195619 Euglena gracilis Species 0.000 description 28
- 208000016427 familial adult myoclonic epilepsy Diseases 0.000 description 28
- 108010050848 glycylleucine Proteins 0.000 description 28
- 108010057821 leucylproline Proteins 0.000 description 28
- BYSKNUASOAGJSS-NQCBNZPSSA-N Trp-Ile-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N BYSKNUASOAGJSS-NQCBNZPSSA-N 0.000 description 27
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 26
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 25
- 101100382243 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) YAT1 gene Proteins 0.000 description 25
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 25
- ZYNBEWGJFXTBDU-ACRUOGEOSA-N Phe-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC2=CC=CC=C2)N ZYNBEWGJFXTBDU-ACRUOGEOSA-N 0.000 description 24
- 125000000539 amino acid group Chemical group 0.000 description 23
- 108010068265 aspartyltyrosine Proteins 0.000 description 23
- 108010028295 histidylhistidine Proteins 0.000 description 22
- 235000020660 omega-3 fatty acid Nutrition 0.000 description 22
- 108091026890 Coding region Proteins 0.000 description 21
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 21
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 21
- 108010047857 aspartylglycine Proteins 0.000 description 21
- 238000004519 manufacturing process Methods 0.000 description 21
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 20
- FZADUTOCSFDBRV-RNXOBYDBSA-N Tyr-Tyr-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=C(O)C=C1 FZADUTOCSFDBRV-RNXOBYDBSA-N 0.000 description 20
- 108010022240 delta-8 fatty acid desaturase Proteins 0.000 description 20
- 108010081551 glycylphenylalanine Proteins 0.000 description 20
- 230000009466 transformation Effects 0.000 description 20
- GJLXVWOMRRWCIB-MERZOTPQSA-N (2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-acetamido-5-(diaminomethylideneamino)pentanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]-3-(1H-indol-3-yl)propanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanamide Chemical compound C([C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=C(O)C=C1 GJLXVWOMRRWCIB-MERZOTPQSA-N 0.000 description 19
- PTVGLOCPAVYPFG-CIUDSAMLSA-N Arg-Gln-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O PTVGLOCPAVYPFG-CIUDSAMLSA-N 0.000 description 19
- ZAESWDKAMDVHLL-RCOVLWMOSA-N Asn-Val-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O ZAESWDKAMDVHLL-RCOVLWMOSA-N 0.000 description 19
- ZQFRDAZBTSFGGW-SRVKXCTJSA-N Asp-Ser-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ZQFRDAZBTSFGGW-SRVKXCTJSA-N 0.000 description 19
- HJTSRYLPAYGEEC-SIUGBPQLSA-N Glu-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCC(=O)O)N HJTSRYLPAYGEEC-SIUGBPQLSA-N 0.000 description 19
- BBTCXWTXOXUNFX-IUCAKERBSA-N Gly-Met-Arg Chemical compound CSCC[C@H](NC(=O)CN)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O BBTCXWTXOXUNFX-IUCAKERBSA-N 0.000 description 19
- JSLVAHYTAJJEQH-QWRGUYRKSA-N Gly-Ser-Phe Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JSLVAHYTAJJEQH-QWRGUYRKSA-N 0.000 description 19
- BALLIXFZYSECCF-QEWYBTABSA-N Ile-Gln-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N BALLIXFZYSECCF-QEWYBTABSA-N 0.000 description 19
- HNDWYLYAYNBWMP-AJNGGQMLSA-N Leu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N HNDWYLYAYNBWMP-AJNGGQMLSA-N 0.000 description 19
- QLFAPXUXEBAWEK-NHCYSSNCSA-N Lys-Val-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QLFAPXUXEBAWEK-NHCYSSNCSA-N 0.000 description 19
- AWOMRHGUWFBDNU-ZPFDUUQYSA-N Met-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCSC)N AWOMRHGUWFBDNU-ZPFDUUQYSA-N 0.000 description 19
- SMVTWPOATVIXTN-NAKRPEOUSA-N Met-Ser-Ile Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SMVTWPOATVIXTN-NAKRPEOUSA-N 0.000 description 19
- OOXVBECOTYHTCK-WDSOQIARSA-N Met-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCSC)N OOXVBECOTYHTCK-WDSOQIARSA-N 0.000 description 19
- 101100005882 Mus musculus Cel gene Proteins 0.000 description 19
- 101100289046 Mus musculus Lias gene Proteins 0.000 description 19
- MMPBPRXOFJNCCN-ZEWNOJEFSA-N Phe-Tyr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MMPBPRXOFJNCCN-ZEWNOJEFSA-N 0.000 description 19
- YKQNVTOIYFQMLW-IHRRRGAJSA-N Pro-Cys-Tyr Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H]1NCCC1)C1=CC=C(O)C=C1 YKQNVTOIYFQMLW-IHRRRGAJSA-N 0.000 description 19
- RFKVQLIXNVEOMB-WEDXCCLWSA-N Thr-Leu-Gly Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)O)N)O RFKVQLIXNVEOMB-WEDXCCLWSA-N 0.000 description 19
- AKFLVKKWVZMFOT-IHRRRGAJSA-N Tyr-Arg-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O AKFLVKKWVZMFOT-IHRRRGAJSA-N 0.000 description 19
- ARJASMXQBRNAGI-YESZJQIVSA-N Tyr-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N ARJASMXQBRNAGI-YESZJQIVSA-N 0.000 description 19
- KZKMBGXCNLPYKD-YEPSODPASA-N Val-Gly-Thr Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O KZKMBGXCNLPYKD-YEPSODPASA-N 0.000 description 19
- QTXGUIMEHKCPBH-FHWLQOOXSA-N Val-Trp-Lys Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 QTXGUIMEHKCPBH-FHWLQOOXSA-N 0.000 description 19
- 108010011559 alanylphenylalanine Proteins 0.000 description 19
- 230000001965 increasing effect Effects 0.000 description 19
- 101150091094 lipA gene Proteins 0.000 description 19
- YAFQFNOUYXZVPZ-UHFFFAOYSA-N liproxstatin-1 Chemical compound ClC1=CC=CC(CNC=2C3(CCNCC3)NC3=CC=CC=C3N=2)=C1 YAFQFNOUYXZVPZ-UHFFFAOYSA-N 0.000 description 19
- 235000020665 omega-6 fatty acid Nutrition 0.000 description 19
- BHTBAVZSZCQZPT-GUBZILKMSA-N Ala-Pro-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N BHTBAVZSZCQZPT-GUBZILKMSA-N 0.000 description 18
- HJDNZFIYILEIKR-OSUNSFLBSA-N Arg-Ile-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HJDNZFIYILEIKR-OSUNSFLBSA-N 0.000 description 18
- NJIKKGUVGUBICV-ZLUOBGJFSA-N Asp-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O NJIKKGUVGUBICV-ZLUOBGJFSA-N 0.000 description 18
- XKPACHRGOWQHFH-IRIUXVKKSA-N Gln-Thr-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XKPACHRGOWQHFH-IRIUXVKKSA-N 0.000 description 18
- IBYOLNARKHMLBG-WHOFXGATSA-N Gly-Phe-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 IBYOLNARKHMLBG-WHOFXGATSA-N 0.000 description 18
- AIPUZFXMXAHZKY-QWRGUYRKSA-N His-Leu-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AIPUZFXMXAHZKY-QWRGUYRKSA-N 0.000 description 18
- CSRRMQFXMBPSIL-SIXJUCDHSA-N His-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CN=CN3)N CSRRMQFXMBPSIL-SIXJUCDHSA-N 0.000 description 18
- WCNWGAUZWWSYDG-SVSWQMSJSA-N Ile-Thr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)O)N WCNWGAUZWWSYDG-SVSWQMSJSA-N 0.000 description 18
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 18
- TXJJXEXCZBHDNA-ACRUOGEOSA-N Phe-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)N TXJJXEXCZBHDNA-ACRUOGEOSA-N 0.000 description 18
- ANESFYPBAJPYNJ-SDDRHHMPSA-N Pro-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 ANESFYPBAJPYNJ-SDDRHHMPSA-N 0.000 description 18
- RKDFEMGVMMYYNG-WDCWCFNPSA-N Thr-Gln-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O RKDFEMGVMMYYNG-WDCWCFNPSA-N 0.000 description 18
- XLMDWQNAOKLKCP-XDTLVQLUSA-N Tyr-Ala-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N XLMDWQNAOKLKCP-XDTLVQLUSA-N 0.000 description 18
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 18
- 239000000203 mixture Substances 0.000 description 18
- 108010018625 phenylalanylarginine Proteins 0.000 description 18
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 17
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 17
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 17
- 108010066427 N-valyltryptophan Proteins 0.000 description 17
- 230000015572 biosynthetic process Effects 0.000 description 17
- 101150099000 EXPA1 gene Proteins 0.000 description 16
- JGKHAFUAPZCCDU-BZSNNMDCSA-N Leu-Tyr-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=C(O)C=C1 JGKHAFUAPZCCDU-BZSNNMDCSA-N 0.000 description 16
- WLXGMVVHTIUPHE-ULQDDVLXSA-N Lys-Phe-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O WLXGMVVHTIUPHE-ULQDDVLXSA-N 0.000 description 16
- OOSPRDCGTLQLBP-NHCYSSNCSA-N Met-Glu-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OOSPRDCGTLQLBP-NHCYSSNCSA-N 0.000 description 16
- CULGJGUDIJATIP-STQMWFEESA-N Met-Tyr-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 CULGJGUDIJATIP-STQMWFEESA-N 0.000 description 16
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 16
- ZOGICTVLQDWPER-UFYCRDLUSA-N Phe-Tyr-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O ZOGICTVLQDWPER-UFYCRDLUSA-N 0.000 description 16
- 101100119348 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) EXP1 gene Proteins 0.000 description 16
- 101100269618 Streptococcus pneumoniae serotype 4 (strain ATCC BAA-334 / TIGR4) aliA gene Proteins 0.000 description 16
- CDRYEAWHKJSGAF-BPNCWPANSA-N Tyr-Ala-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O CDRYEAWHKJSGAF-BPNCWPANSA-N 0.000 description 16
- 108700002148 exportin 1 Proteins 0.000 description 16
- 108010084389 glycyltryptophan Proteins 0.000 description 16
- QPOARHANPULOTM-GMOBBJLQSA-N Arg-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N QPOARHANPULOTM-GMOBBJLQSA-N 0.000 description 15
- GLWFAWNYGWBMOC-SRVKXCTJSA-N Asn-Leu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GLWFAWNYGWBMOC-SRVKXCTJSA-N 0.000 description 15
- 102100029095 Exportin-1 Human genes 0.000 description 15
- 102220480533 GSK3B-interacting protein_S9A_mutation Human genes 0.000 description 15
- NCWOMXABNYEPLY-NRPADANISA-N Glu-Ala-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O NCWOMXABNYEPLY-NRPADANISA-N 0.000 description 15
- VIPDPMHGICREIS-GVXVVHGQSA-N Glu-Val-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VIPDPMHGICREIS-GVXVVHGQSA-N 0.000 description 15
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 15
- XKIYNCLILDLGRS-QWRGUYRKSA-N His-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CC1=CN=CN1 XKIYNCLILDLGRS-QWRGUYRKSA-N 0.000 description 15
- SRBFZHDQGSBBOR-HWQSCIPKSA-N L-arabinopyranose Chemical compound O[C@H]1COC(O)[C@H](O)[C@H]1O SRBFZHDQGSBBOR-HWQSCIPKSA-N 0.000 description 15
- YFBBUHJJUXXZOF-UWVGGRQHSA-N Leu-Gly-Pro Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O YFBBUHJJUXXZOF-UWVGGRQHSA-N 0.000 description 15
- DRWMRVFCKKXHCH-BZSNNMDCSA-N Leu-Phe-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=CC=C1 DRWMRVFCKKXHCH-BZSNNMDCSA-N 0.000 description 15
- GOFJOGXGMPHOGL-DCAQKATOSA-N Leu-Ser-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(C)C GOFJOGXGMPHOGL-DCAQKATOSA-N 0.000 description 15
- WBRJVRXEGQIDRK-XIRDDKMYSA-N Leu-Trp-Ser Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 WBRJVRXEGQIDRK-XIRDDKMYSA-N 0.000 description 15
- XNKDCYABMBBEKN-IUCAKERBSA-N Lys-Gly-Gln Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O XNKDCYABMBBEKN-IUCAKERBSA-N 0.000 description 15
- LNMKRJJLEFASGA-BZSNNMDCSA-N Lys-Phe-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O LNMKRJJLEFASGA-BZSNNMDCSA-N 0.000 description 15
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 15
- KRLKICLNEICJGV-STQMWFEESA-N Met-Phe-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 KRLKICLNEICJGV-STQMWFEESA-N 0.000 description 15
- OWSLLRKCHLTUND-BZSNNMDCSA-N Phe-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OWSLLRKCHLTUND-BZSNNMDCSA-N 0.000 description 15
- GTMSCDVFQLNEOY-BZSNNMDCSA-N Phe-Tyr-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N GTMSCDVFQLNEOY-BZSNNMDCSA-N 0.000 description 15
- BQMFWUKNOCJDNV-HJWJTTGWSA-N Phe-Val-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BQMFWUKNOCJDNV-HJWJTTGWSA-N 0.000 description 15
- RZUOXAKGNHXZTB-GUBZILKMSA-N Ser-Arg-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(O)=O RZUOXAKGNHXZTB-GUBZILKMSA-N 0.000 description 15
- SFTZTYBXIXLRGQ-JBDRJPRFSA-N Ser-Ile-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O SFTZTYBXIXLRGQ-JBDRJPRFSA-N 0.000 description 15
- PHKQVWWHRYUCJL-HJOGWXRNSA-N Tyr-Phe-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O PHKQVWWHRYUCJL-HJOGWXRNSA-N 0.000 description 15
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 15
- PAPWZOJOLKZEFR-AVGNSLFASA-N Val-Arg-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N PAPWZOJOLKZEFR-AVGNSLFASA-N 0.000 description 15
- ZMDCGGKHRKNWKD-LAEOZQHASA-N Val-Asn-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZMDCGGKHRKNWKD-LAEOZQHASA-N 0.000 description 15
- 108010087823 glycyltyrosine Proteins 0.000 description 15
- 230000037361 pathway Effects 0.000 description 15
- VCSABYLVNWQYQE-SRVKXCTJSA-N Ala-Lys-Lys Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O VCSABYLVNWQYQE-SRVKXCTJSA-N 0.000 description 14
- KBQOUDLMWYWXNP-YDHLFZDLSA-N Asn-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KBQOUDLMWYWXNP-YDHLFZDLSA-N 0.000 description 14
- MUZAUPFGPMMZSS-GUBZILKMSA-N Cys-Glu-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N MUZAUPFGPMMZSS-GUBZILKMSA-N 0.000 description 14
- MUGLKCQHTUFLGF-WPRPVWTQSA-N Gly-Val-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)CN MUGLKCQHTUFLGF-WPRPVWTQSA-N 0.000 description 14
- CYHWWHKRCKHYGQ-GUBZILKMSA-N His-Cys-Glu Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N CYHWWHKRCKHYGQ-GUBZILKMSA-N 0.000 description 14
- IGJWJGIHUFQANP-LAEOZQHASA-N Ile-Gly-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N IGJWJGIHUFQANP-LAEOZQHASA-N 0.000 description 14
- JZBVBOKASHNXAD-NAKRPEOUSA-N Ile-Val-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N JZBVBOKASHNXAD-NAKRPEOUSA-N 0.000 description 14
- FLNPJLDPGMLWAU-UWVGGRQHSA-N Leu-Met-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC(C)C FLNPJLDPGMLWAU-UWVGGRQHSA-N 0.000 description 14
- JHSRGEODDALISP-XVSYOHENSA-N Phe-Thr-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O JHSRGEODDALISP-XVSYOHENSA-N 0.000 description 14
- OHKLFYXEOGGGCK-ZLUOBGJFSA-N Ser-Asp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OHKLFYXEOGGGCK-ZLUOBGJFSA-N 0.000 description 14
- YVXIAOOYAKBAAI-SZMVWBNQSA-N Trp-Leu-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 YVXIAOOYAKBAAI-SZMVWBNQSA-N 0.000 description 14
- NZBSVMQZQMEUHI-WZLNRYEVSA-N Tyr-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N NZBSVMQZQMEUHI-WZLNRYEVSA-N 0.000 description 14
- BMOFUVHDBROBSE-DCAQKATOSA-N Val-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C(C)C)N BMOFUVHDBROBSE-DCAQKATOSA-N 0.000 description 14
- 108010015792 glycyllysine Proteins 0.000 description 14
- 229940033080 omega-6 fatty acid Drugs 0.000 description 14
- 108010048818 seryl-histidine Proteins 0.000 description 14
- 238000009482 thermal adhesion granulation Methods 0.000 description 14
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 13
- 230000012010 growth Effects 0.000 description 13
- 239000002609 medium Substances 0.000 description 13
- 102000039446 nucleic acids Human genes 0.000 description 13
- 108020004707 nucleic acids Proteins 0.000 description 13
- 108020004705 Codon Proteins 0.000 description 12
- 241000588724 Escherichia coli Species 0.000 description 12
- CNPNWGHRMBQHBZ-ZKWXMUAHSA-N Ile-Gln Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(O)=O)CCC(N)=O CNPNWGHRMBQHBZ-ZKWXMUAHSA-N 0.000 description 12
- WMGVYPPIMZPWPN-SRVKXCTJSA-N Phe-Asp-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N WMGVYPPIMZPWPN-SRVKXCTJSA-N 0.000 description 12
- 108020004999 messenger RNA Proteins 0.000 description 12
- 244000005700 microbiome Species 0.000 description 12
- 229940012843 omega-3 fatty acid Drugs 0.000 description 12
- 238000002741 site-directed mutagenesis Methods 0.000 description 12
- 241000195620 Euglena Species 0.000 description 11
- 241000282326 Felis catus Species 0.000 description 11
- 238000010276 construction Methods 0.000 description 11
- 230000006872 improvement Effects 0.000 description 11
- 229920006395 saturated elastomer Polymers 0.000 description 11
- 241000894007 species Species 0.000 description 11
- 238000003786 synthesis reaction Methods 0.000 description 11
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 11
- 241001517212 Euglenaria anabaena Species 0.000 description 10
- VTFXTWDFPTWNJY-RHYQMDGZSA-N Pro-Leu-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VTFXTWDFPTWNJY-RHYQMDGZSA-N 0.000 description 10
- 102220474092 Protection of telomeres protein 1_S9D_mutation Human genes 0.000 description 10
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 9
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 9
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 9
- 238000012790 confirmation Methods 0.000 description 9
- 238000002474 experimental method Methods 0.000 description 9
- 238000000855 fermentation Methods 0.000 description 9
- 230000004151 fermentation Effects 0.000 description 9
- 230000006870 function Effects 0.000 description 9
- 108010034529 leucyl-lysine Proteins 0.000 description 9
- 239000012528 membrane Substances 0.000 description 9
- 229910052757 nitrogen Inorganic materials 0.000 description 9
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 8
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 8
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 8
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 8
- WTPKKLMBNBCCNL-ACZMJKKPSA-N Ser-Cys-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N WTPKKLMBNBCCNL-ACZMJKKPSA-N 0.000 description 8
- WQDUMFSSJAZKTM-UHFFFAOYSA-N Sodium methoxide Chemical compound [Na+].[O-]C WQDUMFSSJAZKTM-UHFFFAOYSA-N 0.000 description 8
- 108010092854 aspartyllysine Proteins 0.000 description 8
- 108700012830 rat Lip2 Proteins 0.000 description 8
- 239000000523 sample Substances 0.000 description 8
- 238000013518 transcription Methods 0.000 description 8
- 230000035897 transcription Effects 0.000 description 8
- 108010044292 tryptophyltyrosine Proteins 0.000 description 8
- 108700010070 Codon Usage Proteins 0.000 description 7
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 7
- LIINDKYIGYTDLG-PPCPHDFISA-N Leu-Ile-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LIINDKYIGYTDLG-PPCPHDFISA-N 0.000 description 7
- 108091005804 Peptidases Proteins 0.000 description 7
- 108010044940 alanylglutamine Proteins 0.000 description 7
- 230000006696 biosynthetic metabolic pathway Effects 0.000 description 7
- 238000004422 calculation algorithm Methods 0.000 description 7
- 230000008859 change Effects 0.000 description 7
- 230000001086 cytosolic effect Effects 0.000 description 7
- 230000002255 enzymatic effect Effects 0.000 description 7
- 235000013305 food Nutrition 0.000 description 7
- 235000013350 formula milk Nutrition 0.000 description 7
- VZCCETWTMQHEPK-QNEBEIHSSA-N gamma-linolenic acid Chemical compound CCCCC\C=C/C\C=C/C\C=C/CCCCC(O)=O VZCCETWTMQHEPK-QNEBEIHSSA-N 0.000 description 7
- 230000002068 genetic effect Effects 0.000 description 7
- 239000008103 glucose Substances 0.000 description 7
- 230000002209 hydrophobic effect Effects 0.000 description 7
- 239000007788 liquid Substances 0.000 description 7
- 108010009298 lysylglutamic acid Proteins 0.000 description 7
- 238000002703 mutagenesis Methods 0.000 description 7
- 231100000350 mutagenesis Toxicity 0.000 description 7
- 102220045402 rs41294986 Human genes 0.000 description 7
- WYMDDFRYORANCC-UHFFFAOYSA-N 2-[[3-[bis(carboxymethyl)amino]-2-hydroxypropyl]-(carboxymethyl)amino]acetic acid Chemical compound OC(=O)CN(CC(O)=O)CC(O)CN(CC(O)=O)CC(O)=O WYMDDFRYORANCC-UHFFFAOYSA-N 0.000 description 6
- SEHFUALWMUWDKS-UHFFFAOYSA-N 5-fluoroorotic acid Chemical compound OC(=O)C=1NC(=O)NC(=O)C=1F SEHFUALWMUWDKS-UHFFFAOYSA-N 0.000 description 6
- PVQLRJRPUTXFFX-CIUDSAMLSA-N Ala-Met-Gln Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O PVQLRJRPUTXFFX-CIUDSAMLSA-N 0.000 description 6
- FTTHLXOMDMLKKW-FHWLQOOXSA-N Gln-Phe-Phe Chemical compound C([C@H](NC(=O)[C@H](CCC(N)=O)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 FTTHLXOMDMLKKW-FHWLQOOXSA-N 0.000 description 6
- PTRKPHUGYULXPU-KKUMJFAQSA-N Leu-Phe-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O PTRKPHUGYULXPU-KKUMJFAQSA-N 0.000 description 6
- 102000035195 Peptidases Human genes 0.000 description 6
- 238000012300 Sequence Analysis Methods 0.000 description 6
- NWEGIYMHTZXVBP-JSGCOSHPSA-N Tyr-Val-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O NWEGIYMHTZXVBP-JSGCOSHPSA-N 0.000 description 6
- 238000005119 centrifugation Methods 0.000 description 6
- 238000012217 deletion Methods 0.000 description 6
- 230000037430 deletion Effects 0.000 description 6
- 238000004925 denaturation Methods 0.000 description 6
- 230000036425 denaturation Effects 0.000 description 6
- 238000004817 gas chromatography Methods 0.000 description 6
- VLKZOEOYAKHREP-UHFFFAOYSA-N n-Hexane Chemical compound CCCCCC VLKZOEOYAKHREP-UHFFFAOYSA-N 0.000 description 6
- SECPZKHBENQXJG-FPLPWBNLSA-N palmitoleic acid Chemical compound CCCCCC\C=C/CCCCCCCC(O)=O SECPZKHBENQXJG-FPLPWBNLSA-N 0.000 description 6
- 108010051242 phenylalanylserine Proteins 0.000 description 6
- 230000008569 process Effects 0.000 description 6
- 239000011541 reaction mixture Substances 0.000 description 6
- 238000011160 research Methods 0.000 description 6
- 230000008685 targeting Effects 0.000 description 6
- 238000005809 transesterification reaction Methods 0.000 description 6
- 238000013519 translation Methods 0.000 description 6
- 108010003137 tyrosyltyrosine Proteins 0.000 description 6
- WRIDQFICGBMAFQ-UHFFFAOYSA-N (E)-8-Octadecenoic acid Natural products CCCCCCCCCC=CCCCCCCC(O)=O WRIDQFICGBMAFQ-UHFFFAOYSA-N 0.000 description 5
- LQJBNNIYVWPHFW-UHFFFAOYSA-N 20:1omega9c fatty acid Natural products CCCCCCCCCCC=CCCCCCCCC(O)=O LQJBNNIYVWPHFW-UHFFFAOYSA-N 0.000 description 5
- QSBYPNXLFMSGKH-UHFFFAOYSA-N 9-Heptadecensaeure Natural products CCCCCCCC=CCCCCCCCC(O)=O QSBYPNXLFMSGKH-UHFFFAOYSA-N 0.000 description 5
- 241000024188 Andala Species 0.000 description 5
- HZZIFFOVHLWGCS-KKUMJFAQSA-N Asn-Phe-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O HZZIFFOVHLWGCS-KKUMJFAQSA-N 0.000 description 5
- FTNRWCPWDWRPAV-BZSNNMDCSA-N Asn-Phe-Phe Chemical compound C([C@H](NC(=O)[C@H](CC(N)=O)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 FTNRWCPWDWRPAV-BZSNNMDCSA-N 0.000 description 5
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical group [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 5
- 108091035707 Consensus sequence Proteins 0.000 description 5
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 5
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 5
- 241001245610 Eutreptiella Species 0.000 description 5
- YQAQQKPWFOBSMU-WDCWCFNPSA-N Glu-Thr-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O YQAQQKPWFOBSMU-WDCWCFNPSA-N 0.000 description 5
- TVYWVSJGSHQWMT-AJNGGQMLSA-N Ile-Leu-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N TVYWVSJGSHQWMT-AJNGGQMLSA-N 0.000 description 5
- NAFIFZNBSPWYOO-RWRJDSDZSA-N Ile-Thr-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N NAFIFZNBSPWYOO-RWRJDSDZSA-N 0.000 description 5
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 5
- 241000880493 Leptailurus serval Species 0.000 description 5
- UCNNZELZXFXXJQ-BZSNNMDCSA-N Leu-Leu-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCNNZELZXFXXJQ-BZSNNMDCSA-N 0.000 description 5
- FYPWFNKQVVEELI-ULQDDVLXSA-N Leu-Phe-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=CC=C1 FYPWFNKQVVEELI-ULQDDVLXSA-N 0.000 description 5
- 241000196329 Marchantia polymorpha Species 0.000 description 5
- UYAKZHGIPRCGPF-CIUDSAMLSA-N Met-Glu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCSC)N UYAKZHGIPRCGPF-CIUDSAMLSA-N 0.000 description 5
- 108010021466 Mutant Proteins Proteins 0.000 description 5
- 102000008300 Mutant Proteins Human genes 0.000 description 5
- 108010079364 N-glycylalanine Proteins 0.000 description 5
- 239000005642 Oleic acid Substances 0.000 description 5
- ZQPPMHVWECSIRJ-UHFFFAOYSA-N Oleic acid Natural products CCCCCCCCC=CCCCCCCCC(O)=O ZQPPMHVWECSIRJ-UHFFFAOYSA-N 0.000 description 5
- 108091034117 Oligonucleotide Proteins 0.000 description 5
- KIQUCMUULDXTAZ-HJOGWXRNSA-N Phe-Tyr-Tyr Chemical compound N[C@@H](Cc1ccccc1)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](Cc1ccc(O)cc1)C(O)=O KIQUCMUULDXTAZ-HJOGWXRNSA-N 0.000 description 5
- 239000004365 Protease Substances 0.000 description 5
- UPLYXVPQLJVWMM-KKUMJFAQSA-N Ser-Phe-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O UPLYXVPQLJVWMM-KKUMJFAQSA-N 0.000 description 5
- BKVICMPZWRNWOC-RHYQMDGZSA-N Thr-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O BKVICMPZWRNWOC-RHYQMDGZSA-N 0.000 description 5
- AYHSJESDFKREAR-KKUMJFAQSA-N Tyr-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AYHSJESDFKREAR-KKUMJFAQSA-N 0.000 description 5
- URIRWLJVWHYLET-ONGXEEELSA-N Val-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)C(C)C URIRWLJVWHYLET-ONGXEEELSA-N 0.000 description 5
- HQPCSDADVLFHHO-LTKCOYKYSA-N all-cis-8,11,14,17-icosatetraenoic acid Chemical compound CC\C=C/C\C=C/C\C=C/C\C=C/CCCCCCC(O)=O HQPCSDADVLFHHO-LTKCOYKYSA-N 0.000 description 5
- 238000000137 annealing Methods 0.000 description 5
- 229910052799 carbon Inorganic materials 0.000 description 5
- 238000011156 evaluation Methods 0.000 description 5
- 235000021588 free fatty acids Nutrition 0.000 description 5
- 238000003780 insertion Methods 0.000 description 5
- 230000037431 insertion Effects 0.000 description 5
- 230000010354 integration Effects 0.000 description 5
- 239000000543 intermediate Substances 0.000 description 5
- QXJSBBXBKPUZAA-UHFFFAOYSA-N isooleic acid Natural products CCCCCCCC=CCCCCCCCCC(O)=O QXJSBBXBKPUZAA-UHFFFAOYSA-N 0.000 description 5
- 108010030617 leucyl-phenylalanyl-valine Proteins 0.000 description 5
- 239000000463 material Substances 0.000 description 5
- 108010005942 methionylglycine Proteins 0.000 description 5
- 230000004048 modification Effects 0.000 description 5
- 238000012986 modification Methods 0.000 description 5
- 238000010369 molecular cloning Methods 0.000 description 5
- 230000007935 neutral effect Effects 0.000 description 5
- ZQPPMHVWECSIRJ-KTKRTIGZSA-N oleic acid Chemical compound CCCCCCCC\C=C/CCCCCCCC(O)=O ZQPPMHVWECSIRJ-KTKRTIGZSA-N 0.000 description 5
- 238000012545 processing Methods 0.000 description 5
- 108091008146 restriction endonucleases Proteins 0.000 description 5
- 108010026333 seryl-proline Proteins 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- 230000009261 transgenic effect Effects 0.000 description 5
- 230000014621 translational initiation Effects 0.000 description 5
- 238000011144 upstream manufacturing Methods 0.000 description 5
- 229920001817 Agar Polymers 0.000 description 4
- LXAARTARZJJCMB-CIQUZCHMSA-N Ala-Ile-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LXAARTARZJJCMB-CIQUZCHMSA-N 0.000 description 4
- MFMDKJIPHSWSBM-GUBZILKMSA-N Ala-Lys-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O MFMDKJIPHSWSBM-GUBZILKMSA-N 0.000 description 4
- BFMIRJBURUXDRG-DLOVCJGASA-N Ala-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 BFMIRJBURUXDRG-DLOVCJGASA-N 0.000 description 4
- IHMCQESUJVZTKW-UBHSHLNASA-N Ala-Phe-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=CC=C1 IHMCQESUJVZTKW-UBHSHLNASA-N 0.000 description 4
- WQLDNOCHHRISMS-NAKRPEOUSA-N Ala-Pro-Ile Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WQLDNOCHHRISMS-NAKRPEOUSA-N 0.000 description 4
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 4
- SAHQGRZIQVEJPF-JXUBOQSCSA-N Ala-Thr-Lys Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN SAHQGRZIQVEJPF-JXUBOQSCSA-N 0.000 description 4
- ITVINTQUZMQWJR-QXEWZRGKSA-N Arg-Asn-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O ITVINTQUZMQWJR-QXEWZRGKSA-N 0.000 description 4
- JSHVMZANPXCDTL-GMOBBJLQSA-N Arg-Asp-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JSHVMZANPXCDTL-GMOBBJLQSA-N 0.000 description 4
- OGSQONVYSTZIJB-WDSOQIARSA-N Arg-Leu-Trp Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CCCN=C(N)N)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O OGSQONVYSTZIJB-WDSOQIARSA-N 0.000 description 4
- GXMSVVBIAMWMKO-BQBZGAKWSA-N Asn-Arg-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N GXMSVVBIAMWMKO-BQBZGAKWSA-N 0.000 description 4
- JQSWHKKUZMTOIH-QWRGUYRKSA-N Asn-Gly-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N JQSWHKKUZMTOIH-QWRGUYRKSA-N 0.000 description 4
- ZJIFRAPZHAGLGR-MELADBBJSA-N Asn-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC(=O)N)N)C(=O)O ZJIFRAPZHAGLGR-MELADBBJSA-N 0.000 description 4
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 4
- CGYKCTPUGXFPMG-IHPCNDPISA-N Asn-Tyr-Trp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O CGYKCTPUGXFPMG-IHPCNDPISA-N 0.000 description 4
- RNAQPBOOJRDICC-BPUTZDHNSA-N Asp-Met-Trp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N RNAQPBOOJRDICC-BPUTZDHNSA-N 0.000 description 4
- LGGHQRZIJSYRHA-GUBZILKMSA-N Asp-Pro-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC(=O)O)N LGGHQRZIJSYRHA-GUBZILKMSA-N 0.000 description 4
- KGHLGJAXYSVNJP-WHFBIAKZSA-N Asp-Ser-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O KGHLGJAXYSVNJP-WHFBIAKZSA-N 0.000 description 4
- OYSYWMMZGJSQRB-AVGNSLFASA-N Asp-Tyr-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O OYSYWMMZGJSQRB-AVGNSLFASA-N 0.000 description 4
- SFJUYBCDQBAYAJ-YDHLFZDLSA-N Asp-Val-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SFJUYBCDQBAYAJ-YDHLFZDLSA-N 0.000 description 4
- 239000002028 Biomass Substances 0.000 description 4
- FWYBFUDWUUFLDN-FXQIFTODSA-N Cys-Asp-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N)CN=C(N)N FWYBFUDWUUFLDN-FXQIFTODSA-N 0.000 description 4
- BDWIZLQVVWQMTB-XKBZYTNZSA-N Cys-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N)O BDWIZLQVVWQMTB-XKBZYTNZSA-N 0.000 description 4
- 102000053602 DNA Human genes 0.000 description 4
- UBRQJXFDVZNYJP-AVGNSLFASA-N Gln-Tyr-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O UBRQJXFDVZNYJP-AVGNSLFASA-N 0.000 description 4
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 4
- HILMIYALTUQTRC-XVKPBYJWSA-N Glu-Gly-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HILMIYALTUQTRC-XVKPBYJWSA-N 0.000 description 4
- FBEJIDRSQCGFJI-GUBZILKMSA-N Glu-Leu-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FBEJIDRSQCGFJI-GUBZILKMSA-N 0.000 description 4
- KXTAGESXNQEZKB-DZKIICNBSA-N Glu-Phe-Val Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=CC=C1 KXTAGESXNQEZKB-DZKIICNBSA-N 0.000 description 4
- QSVCIFZPGLOZGH-WDSKDSINSA-N Gly-Glu-Ser Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QSVCIFZPGLOZGH-WDSKDSINSA-N 0.000 description 4
- UESJMAMHDLEHGM-NHCYSSNCSA-N Gly-Ile-Leu Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O UESJMAMHDLEHGM-NHCYSSNCSA-N 0.000 description 4
- QAMMIGULQSIRCD-IRXDYDNUSA-N Gly-Phe-Tyr Chemical compound C([C@H](NC(=O)C[NH3+])C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C([O-])=O)C1=CC=CC=C1 QAMMIGULQSIRCD-IRXDYDNUSA-N 0.000 description 4
- UIQGJYUEQDOODF-KWQFWETISA-N Gly-Tyr-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 UIQGJYUEQDOODF-KWQFWETISA-N 0.000 description 4
- PMWSGVRIMIFXQH-KKUMJFAQSA-N His-His-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1NC=NC=1)C1=CN=CN1 PMWSGVRIMIFXQH-KKUMJFAQSA-N 0.000 description 4
- YOTNPRLPIPHQSB-XUXIUFHCSA-N Ile-Arg-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N YOTNPRLPIPHQSB-XUXIUFHCSA-N 0.000 description 4
- DCQMJRSOGCYKTR-GHCJXIJMSA-N Ile-Asp-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O DCQMJRSOGCYKTR-GHCJXIJMSA-N 0.000 description 4
- CCYGNFBYUNHFSC-MGHWNKPDSA-N Ile-His-Phe Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O CCYGNFBYUNHFSC-MGHWNKPDSA-N 0.000 description 4
- IDMNOFVUXYYZPF-DKIMLUQUSA-N Ile-Lys-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N IDMNOFVUXYYZPF-DKIMLUQUSA-N 0.000 description 4
- OTSVBELRDMSPKY-PCBIJLKTSA-N Ile-Phe-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OTSVBELRDMSPKY-PCBIJLKTSA-N 0.000 description 4
- VISRCHQHQCLODA-NAKRPEOUSA-N Ile-Pro-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CS)C(=O)O)N VISRCHQHQCLODA-NAKRPEOUSA-N 0.000 description 4
- NGKPIPCGMLWHBX-WZLNRYEVSA-N Ile-Tyr-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N NGKPIPCGMLWHBX-WZLNRYEVSA-N 0.000 description 4
- AUIYHFRUOOKTGX-UKJIMTQDSA-N Ile-Val-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N AUIYHFRUOOKTGX-UKJIMTQDSA-N 0.000 description 4
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 4
- DQPQTXMIRBUWKO-DCAQKATOSA-N Leu-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(C)C)N DQPQTXMIRBUWKO-DCAQKATOSA-N 0.000 description 4
- IBMVEYRWAWIOTN-RWMBFGLXSA-N Leu-Arg-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(O)=O IBMVEYRWAWIOTN-RWMBFGLXSA-N 0.000 description 4
- MDVZJYGNAGLPGJ-KKUMJFAQSA-N Leu-Asn-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MDVZJYGNAGLPGJ-KKUMJFAQSA-N 0.000 description 4
- DLCOFDAHNMMQPP-SRVKXCTJSA-N Leu-Asp-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O DLCOFDAHNMMQPP-SRVKXCTJSA-N 0.000 description 4
- VFQOCUQGMUXTJR-DCAQKATOSA-N Leu-Cys-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCSC)C(=O)O)N VFQOCUQGMUXTJR-DCAQKATOSA-N 0.000 description 4
- LLBQJYDYOLIQAI-JYJNAYRXSA-N Leu-Glu-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LLBQJYDYOLIQAI-JYJNAYRXSA-N 0.000 description 4
- UBZGNBKMIJHOHL-BZSNNMDCSA-N Leu-Leu-Phe Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 UBZGNBKMIJHOHL-BZSNNMDCSA-N 0.000 description 4
- CPONGMJGVIAWEH-DCAQKATOSA-N Leu-Met-Ala Chemical compound CSCC[C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](C)C(O)=O CPONGMJGVIAWEH-DCAQKATOSA-N 0.000 description 4
- WXZOHBVPVKABQN-DCAQKATOSA-N Leu-Met-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)O)C(=O)O)N WXZOHBVPVKABQN-DCAQKATOSA-N 0.000 description 4
- SYRTUBLKWNDSDK-DKIMLUQUSA-N Leu-Phe-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SYRTUBLKWNDSDK-DKIMLUQUSA-N 0.000 description 4
- SNOUHRPNNCAOPI-SZMVWBNQSA-N Leu-Trp-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N SNOUHRPNNCAOPI-SZMVWBNQSA-N 0.000 description 4
- NTEVEUCLFMWSND-SRVKXCTJSA-N Lys-Arg-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O NTEVEUCLFMWSND-SRVKXCTJSA-N 0.000 description 4
- FACUGMGEFUEBTI-SRVKXCTJSA-N Lys-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCCCN FACUGMGEFUEBTI-SRVKXCTJSA-N 0.000 description 4
- UGTZHPSKYRIGRJ-YUMQZZPRSA-N Lys-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(O)=O)CCC(O)=O UGTZHPSKYRIGRJ-YUMQZZPRSA-N 0.000 description 4
- GAHJXEMYXKLZRQ-AJNGGQMLSA-N Lys-Lys-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O GAHJXEMYXKLZRQ-AJNGGQMLSA-N 0.000 description 4
- HVAUKHLDSDDROB-KKUMJFAQSA-N Lys-Lys-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O HVAUKHLDSDDROB-KKUMJFAQSA-N 0.000 description 4
- QQPSCXKFDSORFT-IHRRRGAJSA-N Lys-Lys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN QQPSCXKFDSORFT-IHRRRGAJSA-N 0.000 description 4
- HYSVGEAWTGPMOA-IHRRRGAJSA-N Lys-Pro-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O HYSVGEAWTGPMOA-IHRRRGAJSA-N 0.000 description 4
- YRAWWKUTNBILNT-FXQIFTODSA-N Met-Ala-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YRAWWKUTNBILNT-FXQIFTODSA-N 0.000 description 4
- AFFKUNVPPLQUGA-DCAQKATOSA-N Met-Leu-Ala Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O AFFKUNVPPLQUGA-DCAQKATOSA-N 0.000 description 4
- ZRACLHJYVRBJFC-ULQDDVLXSA-N Met-Lys-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ZRACLHJYVRBJFC-ULQDDVLXSA-N 0.000 description 4
- MIAZEQZXAFTCCG-UBHSHLNASA-N Met-Phe-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 MIAZEQZXAFTCCG-UBHSHLNASA-N 0.000 description 4
- WXXNVZMWHOLNRJ-AVGNSLFASA-N Met-Pro-Lys Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O WXXNVZMWHOLNRJ-AVGNSLFASA-N 0.000 description 4
- 241000907999 Mortierella alpina Species 0.000 description 4
- IMNFDUFMRHMDMM-UHFFFAOYSA-N N-Heptane Chemical compound CCCCCCC IMNFDUFMRHMDMM-UHFFFAOYSA-N 0.000 description 4
- 238000012408 PCR amplification Methods 0.000 description 4
- GNUCSNWOCQFMMC-UFYCRDLUSA-N Phe-Arg-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 GNUCSNWOCQFMMC-UFYCRDLUSA-N 0.000 description 4
- HTTYNOXBBOWZTB-SRVKXCTJSA-N Phe-Asn-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N HTTYNOXBBOWZTB-SRVKXCTJSA-N 0.000 description 4
- CDNPIRSCAFMMBE-SRVKXCTJSA-N Phe-Asn-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CDNPIRSCAFMMBE-SRVKXCTJSA-N 0.000 description 4
- JIYJYFIXQTYDNF-YDHLFZDLSA-N Phe-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CC=CC=C1)N JIYJYFIXQTYDNF-YDHLFZDLSA-N 0.000 description 4
- NAOVYENZCWFBDG-BZSNNMDCSA-N Phe-His-His Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CC=CC=C1 NAOVYENZCWFBDG-BZSNNMDCSA-N 0.000 description 4
- RSPUIENXSJYZQO-JYJNAYRXSA-N Phe-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RSPUIENXSJYZQO-JYJNAYRXSA-N 0.000 description 4
- WZEWCHQHNCMBEN-PMVMPFDFSA-N Phe-Lys-Trp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N WZEWCHQHNCMBEN-PMVMPFDFSA-N 0.000 description 4
- FQUUYTNBMIBOHS-IHRRRGAJSA-N Phe-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N FQUUYTNBMIBOHS-IHRRRGAJSA-N 0.000 description 4
- JXQVYPWVGUOIDV-MXAVVETBSA-N Phe-Ser-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JXQVYPWVGUOIDV-MXAVVETBSA-N 0.000 description 4
- GMWNQSGWWGKTSF-LFSVMHDDSA-N Phe-Thr-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O GMWNQSGWWGKTSF-LFSVMHDDSA-N 0.000 description 4
- QTDBZORPVYTRJU-KKXDTOCCSA-N Phe-Tyr-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O QTDBZORPVYTRJU-KKXDTOCCSA-N 0.000 description 4
- DBNGDEAQXGFGRA-ACRUOGEOSA-N Phe-Tyr-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCCCN)C(=O)O)N DBNGDEAQXGFGRA-ACRUOGEOSA-N 0.000 description 4
- CDHURCQGUDNBMA-UBHSHLNASA-N Phe-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 CDHURCQGUDNBMA-UBHSHLNASA-N 0.000 description 4
- QSKCKTUQPICLSO-AVGNSLFASA-N Pro-Arg-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O QSKCKTUQPICLSO-AVGNSLFASA-N 0.000 description 4
- FKYKZHOKDOPHSA-DCAQKATOSA-N Pro-Leu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FKYKZHOKDOPHSA-DCAQKATOSA-N 0.000 description 4
- ULWBBFKQBDNGOY-RWMBFGLXSA-N Pro-Lys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@@H]2C(=O)O ULWBBFKQBDNGOY-RWMBFGLXSA-N 0.000 description 4
- WOIFYRZPIORBRY-AVGNSLFASA-N Pro-Lys-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O WOIFYRZPIORBRY-AVGNSLFASA-N 0.000 description 4
- QGLFRQCECIWXFA-RCWTZXSCSA-N Pro-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@@H]1CCCN1)O QGLFRQCECIWXFA-RCWTZXSCSA-N 0.000 description 4
- 108010003201 RGH 0205 Proteins 0.000 description 4
- MUARUIBTKQJKFY-WHFBIAKZSA-N Ser-Gly-Asp Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MUARUIBTKQJKFY-WHFBIAKZSA-N 0.000 description 4
- WGDYNRCOQRERLZ-KKUMJFAQSA-N Ser-Lys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N WGDYNRCOQRERLZ-KKUMJFAQSA-N 0.000 description 4
- PMTWIUBUQRGCSB-FXQIFTODSA-N Ser-Val-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O PMTWIUBUQRGCSB-FXQIFTODSA-N 0.000 description 4
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- 235000021355 Stearic acid Nutrition 0.000 description 4
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 4
- VFEHSAJCWWHDBH-RHYQMDGZSA-N Thr-Arg-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VFEHSAJCWWHDBH-RHYQMDGZSA-N 0.000 description 4
- TVOGEPLDNYTAHD-CQDKDKBSSA-N Tyr-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 TVOGEPLDNYTAHD-CQDKDKBSSA-N 0.000 description 4
- GFZQWWDXJVGEMW-ULQDDVLXSA-N Tyr-Arg-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O GFZQWWDXJVGEMW-ULQDDVLXSA-N 0.000 description 4
- HSBZWINKRYZCSQ-KKUMJFAQSA-N Tyr-Lys-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O HSBZWINKRYZCSQ-KKUMJFAQSA-N 0.000 description 4
- SOAUMCDLIUGXJJ-SRVKXCTJSA-N Tyr-Ser-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O SOAUMCDLIUGXJJ-SRVKXCTJSA-N 0.000 description 4
- HRHYJNLMIJWGLF-BZSNNMDCSA-N Tyr-Ser-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 HRHYJNLMIJWGLF-BZSNNMDCSA-N 0.000 description 4
- RZAGEHHVNYESNR-RNXOBYDBSA-N Tyr-Trp-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RZAGEHHVNYESNR-RNXOBYDBSA-N 0.000 description 4
- NVJCMGGZHOJNBU-UFYCRDLUSA-N Tyr-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N NVJCMGGZHOJNBU-UFYCRDLUSA-N 0.000 description 4
- UEOOXDLMQZBPFR-ZKWXMUAHSA-N Val-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N UEOOXDLMQZBPFR-ZKWXMUAHSA-N 0.000 description 4
- VXDSPJJQUQDCKH-UKJIMTQDSA-N Val-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N VXDSPJJQUQDCKH-UKJIMTQDSA-N 0.000 description 4
- JAKHAONCJJZVHT-DCAQKATOSA-N Val-Lys-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N JAKHAONCJJZVHT-DCAQKATOSA-N 0.000 description 4
- ILMVQSHENUZYIZ-JYJNAYRXSA-N Val-Met-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N ILMVQSHENUZYIZ-JYJNAYRXSA-N 0.000 description 4
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 4
- KISFXYYRKKNLOP-IHRRRGAJSA-N Val-Phe-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N KISFXYYRKKNLOP-IHRRRGAJSA-N 0.000 description 4
- HOZAIQIEJTWWDG-HJOGWXRNSA-N Val-Trp-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)O)N HOZAIQIEJTWWDG-HJOGWXRNSA-N 0.000 description 4
- 239000008272 agar Substances 0.000 description 4
- 108010070944 alanylhistidine Proteins 0.000 description 4
- 125000001931 aliphatic group Chemical group 0.000 description 4
- 230000004075 alteration Effects 0.000 description 4
- 230000003321 amplification Effects 0.000 description 4
- 230000008901 benefit Effects 0.000 description 4
- 239000000872 buffer Substances 0.000 description 4
- 108010069495 cysteinyltyrosine Proteins 0.000 description 4
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 4
- 238000007429 general method Methods 0.000 description 4
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 4
- 108010074027 glycyl-seryl-phenylalanine Proteins 0.000 description 4
- 108010089804 glycyl-threonine Proteins 0.000 description 4
- 230000007407 health benefit Effects 0.000 description 4
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 4
- 108010054155 lysyllysine Proteins 0.000 description 4
- 108010017391 lysylvaline Proteins 0.000 description 4
- 239000003550 marker Substances 0.000 description 4
- 238000003199 nucleic acid amplification method Methods 0.000 description 4
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 4
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 4
- 108010072637 phenylalanyl-arginyl-phenylalanine Proteins 0.000 description 4
- 108010084572 phenylalanyl-valine Proteins 0.000 description 4
- 230000008488 polyadenylation Effects 0.000 description 4
- 239000002243 precursor Substances 0.000 description 4
- 230000002441 reversible effect Effects 0.000 description 4
- 235000003441 saturated fatty acids Nutrition 0.000 description 4
- 150000004671 saturated fatty acids Chemical class 0.000 description 4
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 4
- 239000000243 solution Substances 0.000 description 4
- 239000008117 stearic acid Substances 0.000 description 4
- 108010061238 threonyl-glycine Proteins 0.000 description 4
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 4
- 230000001131 transforming effect Effects 0.000 description 4
- 108010080629 tryptophan-leucine Proteins 0.000 description 4
- AVKOENOBFIYBSA-WMPRHZDHSA-N (4Z,7Z,10Z,13Z,16Z)-docosa-4,7,10,13,16-pentaenoic acid Chemical compound CCCCC\C=C/C\C=C/C\C=C/C\C=C/C\C=C/CCC(O)=O AVKOENOBFIYBSA-WMPRHZDHSA-N 0.000 description 3
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 3
- HHRAXZAYZFFRAM-CIUDSAMLSA-N Ala-Leu-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O HHRAXZAYZFFRAM-CIUDSAMLSA-N 0.000 description 3
- RBOBTTLFPRSXKZ-BZSNNMDCSA-N Asn-Phe-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RBOBTTLFPRSXKZ-BZSNNMDCSA-N 0.000 description 3
- CBHVAFXKOYAHOY-NHCYSSNCSA-N Asn-Val-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O CBHVAFXKOYAHOY-NHCYSSNCSA-N 0.000 description 3
- 239000003155 DNA primer Substances 0.000 description 3
- 238000001712 DNA sequencing Methods 0.000 description 3
- SBJKKFFYIZUCET-JLAZNSOCSA-N Dehydro-L-ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(=O)C1=O SBJKKFFYIZUCET-JLAZNSOCSA-N 0.000 description 3
- FHQRLHFYVZAQHU-IUCAKERBSA-N Gly-Lys-Gln Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O FHQRLHFYVZAQHU-IUCAKERBSA-N 0.000 description 3
- 241001501873 Isochrysis galbana Species 0.000 description 3
- VQPPIMUZCZCOIL-GUBZILKMSA-N Leu-Gln-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O VQPPIMUZCZCOIL-GUBZILKMSA-N 0.000 description 3
- LXKNSJLSGPNHSK-KKUMJFAQSA-N Leu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N LXKNSJLSGPNHSK-KKUMJFAQSA-N 0.000 description 3
- WPIKRJDRQVFRHP-TUSQITKMSA-N Leu-Trp-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O WPIKRJDRQVFRHP-TUSQITKMSA-N 0.000 description 3
- WSXTWLJHTLRFLW-SRVKXCTJSA-N Lys-Ala-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O WSXTWLJHTLRFLW-SRVKXCTJSA-N 0.000 description 3
- BXPHMHQHYHILBB-BZSNNMDCSA-N Lys-Lys-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BXPHMHQHYHILBB-BZSNNMDCSA-N 0.000 description 3
- 235000021319 Palmitoleic acid Nutrition 0.000 description 3
- 241000206766 Pavlova Species 0.000 description 3
- WPTYDQPGBMDUBI-QWRGUYRKSA-N Phe-Gly-Asn Chemical compound N[C@@H](Cc1ccccc1)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O WPTYDQPGBMDUBI-QWRGUYRKSA-N 0.000 description 3
- HTXVATDVCRFORF-MGHWNKPDSA-N Phe-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N HTXVATDVCRFORF-MGHWNKPDSA-N 0.000 description 3
- ZKBKUWQVDWWSRI-BZSNNMDCSA-N Ser-Phe-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKBKUWQVDWWSRI-BZSNNMDCSA-N 0.000 description 3
- PLQWGQUNUPMNOD-KKUMJFAQSA-N Ser-Tyr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O PLQWGQUNUPMNOD-KKUMJFAQSA-N 0.000 description 3
- 241000970807 Thermoanaerobacterales Species 0.000 description 3
- YXFVVABEGXRONW-UHFFFAOYSA-N Toluene Chemical compound CC1=CC=CC=C1 YXFVVABEGXRONW-UHFFFAOYSA-N 0.000 description 3
- NMKJPMCEKQHRPD-IRXDYDNUSA-N Tyr-Gly-Tyr Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 NMKJPMCEKQHRPD-IRXDYDNUSA-N 0.000 description 3
- PQPWEALFTLKSEB-DZKIICNBSA-N Tyr-Val-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O PQPWEALFTLKSEB-DZKIICNBSA-N 0.000 description 3
- HPOSMQWRPMRMFO-GUBZILKMSA-N Val-Pro-Cys Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CS)C(=O)O)N HPOSMQWRPMRMFO-GUBZILKMSA-N 0.000 description 3
- QZKVWWIUSQGWMY-IHRRRGAJSA-N Val-Ser-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QZKVWWIUSQGWMY-IHRRRGAJSA-N 0.000 description 3
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 3
- 150000007513 acids Chemical class 0.000 description 3
- 108010047495 alanylglycine Proteins 0.000 description 3
- 108010062796 arginyllysine Proteins 0.000 description 3
- 108010093581 aspartyl-proline Proteins 0.000 description 3
- 230000009286 beneficial effect Effects 0.000 description 3
- 230000033228 biological regulation Effects 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- SECPZKHBENQXJG-UHFFFAOYSA-N cis-palmitoleic acid Natural products CCCCCCC=CCCCCCCCC(O)=O SECPZKHBENQXJG-UHFFFAOYSA-N 0.000 description 3
- 239000002299 complementary DNA Substances 0.000 description 3
- 235000015872 dietary supplement Nutrition 0.000 description 3
- 238000004520 electroporation Methods 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- 239000013604 expression vector Substances 0.000 description 3
- 239000000284 extract Substances 0.000 description 3
- 238000000605 extraction Methods 0.000 description 3
- 125000000524 functional group Chemical group 0.000 description 3
- 108010037850 glycylvaline Proteins 0.000 description 3
- 239000001963 growth medium Substances 0.000 description 3
- IPCSVZSSVZVIGE-UHFFFAOYSA-M hexadecanoate Chemical compound CCCCCCCCCCCCCCCC([O-])=O IPCSVZSSVZVIGE-UHFFFAOYSA-M 0.000 description 3
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 3
- 235000020667 long-chain omega-3 fatty acid Nutrition 0.000 description 3
- 238000012423 maintenance Methods 0.000 description 3
- 235000012162 pavlova Nutrition 0.000 description 3
- 239000008188 pellet Substances 0.000 description 3
- 238000003752 polymerase chain reaction Methods 0.000 description 3
- 239000011535 reaction buffer Substances 0.000 description 3
- 230000010076 replication Effects 0.000 description 3
- 238000012552 review Methods 0.000 description 3
- 238000012216 screening Methods 0.000 description 3
- 238000010561 standard procedure Methods 0.000 description 3
- 238000003860 storage Methods 0.000 description 3
- 230000002194 synthesizing effect Effects 0.000 description 3
- DCXXMTOCNZCJGO-UHFFFAOYSA-N tristearoylglycerol Chemical compound CCCCCCCCCCCCCCCCCC(=O)OCC(OC(=O)CCCCCCCCCCCCCCCCC)COC(=O)CCCCCCCCCCCCCCCCC DCXXMTOCNZCJGO-UHFFFAOYSA-N 0.000 description 3
- 108010045269 tryptophyltryptophan Proteins 0.000 description 3
- 235000021122 unsaturated fatty acids Nutrition 0.000 description 3
- 150000004670 unsaturated fatty acids Chemical class 0.000 description 3
- 108010009962 valyltyrosine Proteins 0.000 description 3
- 210000005253 yeast cell Anatomy 0.000 description 3
- YUFFSWGQGVEMMI-UHFFFAOYSA-N (7Z,10Z,13Z,16Z,19Z)-7,10,13,16,19-docosapentaenoic acid Natural products CCC=CCC=CCC=CCC=CCC=CCCCCCC(O)=O YUFFSWGQGVEMMI-UHFFFAOYSA-N 0.000 description 2
- UHPMCKVQTMMPCG-UHFFFAOYSA-N 5,8-dihydroxy-2-methoxy-6-methyl-7-(2-oxopropyl)naphthalene-1,4-dione Chemical compound CC1=C(CC(C)=O)C(O)=C2C(=O)C(OC)=CC(=O)C2=C1O UHPMCKVQTMMPCG-UHFFFAOYSA-N 0.000 description 2
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 2
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 2
- GFBLJMHGHAXGNY-ZLUOBGJFSA-N Ala-Asn-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O GFBLJMHGHAXGNY-ZLUOBGJFSA-N 0.000 description 2
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 2
- BEMGNWZECGIJOI-WDSKDSINSA-N Ala-Gly-Glu Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O BEMGNWZECGIJOI-WDSKDSINSA-N 0.000 description 2
- QUIGLPSHIFPEOV-CIUDSAMLSA-N Ala-Lys-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O QUIGLPSHIFPEOV-CIUDSAMLSA-N 0.000 description 2
- DXTYEWAQOXYRHZ-KKXDTOCCSA-N Ala-Phe-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N DXTYEWAQOXYRHZ-KKXDTOCCSA-N 0.000 description 2
- YXXPVUOMPSZURS-ZLIFDBKOSA-N Ala-Trp-Leu Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@H](C)N)=CNC2=C1 YXXPVUOMPSZURS-ZLIFDBKOSA-N 0.000 description 2
- MTDDMSUUXNQMKK-BPNCWPANSA-N Ala-Tyr-Arg Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N MTDDMSUUXNQMKK-BPNCWPANSA-N 0.000 description 2
- JNJHNBXBGNJESC-KKXDTOCCSA-N Ala-Tyr-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JNJHNBXBGNJESC-KKXDTOCCSA-N 0.000 description 2
- MUGAESARFRGOTQ-IGNZVWTISA-N Ala-Tyr-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N MUGAESARFRGOTQ-IGNZVWTISA-N 0.000 description 2
- OMSKGWFGWCQFBD-KZVJFYERSA-N Ala-Val-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OMSKGWFGWCQFBD-KZVJFYERSA-N 0.000 description 2
- 108010039224 Amidophosphoribosyltransferase Proteins 0.000 description 2
- 102100039239 Amidophosphoribosyltransferase Human genes 0.000 description 2
- 108020005544 Antisense RNA Proteins 0.000 description 2
- DBKNLHKEVPZVQC-LPEHRKFASA-N Arg-Ala-Pro Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O DBKNLHKEVPZVQC-LPEHRKFASA-N 0.000 description 2
- MUXONAMCEUBVGA-DCAQKATOSA-N Arg-Arg-Gln Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O MUXONAMCEUBVGA-DCAQKATOSA-N 0.000 description 2
- FEZJJKXNPSEYEV-CIUDSAMLSA-N Arg-Gln-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O FEZJJKXNPSEYEV-CIUDSAMLSA-N 0.000 description 2
- CFGHCPUPFHWMCM-FDARSICLSA-N Arg-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N CFGHCPUPFHWMCM-FDARSICLSA-N 0.000 description 2
- GRRXPUAICOGISM-RWMBFGLXSA-N Arg-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O GRRXPUAICOGISM-RWMBFGLXSA-N 0.000 description 2
- SLQQPJBDBVPVQV-JYJNAYRXSA-N Arg-Phe-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O SLQQPJBDBVPVQV-JYJNAYRXSA-N 0.000 description 2
- PNHQRQTVBRDIEF-CIUDSAMLSA-N Asn-Leu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(=O)N)N PNHQRQTVBRDIEF-CIUDSAMLSA-N 0.000 description 2
- HPBNLFLSSQDFQW-WHFBIAKZSA-N Asn-Ser-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O HPBNLFLSSQDFQW-WHFBIAKZSA-N 0.000 description 2
- JPPLRQVZMZFOSX-UWJYBYFXSA-N Asn-Tyr-Ala Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=C(O)C=C1 JPPLRQVZMZFOSX-UWJYBYFXSA-N 0.000 description 2
- LBOVBQONZJRWPV-YUMQZZPRSA-N Asp-Lys-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O LBOVBQONZJRWPV-YUMQZZPRSA-N 0.000 description 2
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 2
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 2
- 241000251571 Ciona intestinalis Species 0.000 description 2
- UIKLEGZPIOXFHJ-DLOVCJGASA-N Cys-Phe-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O UIKLEGZPIOXFHJ-DLOVCJGASA-N 0.000 description 2
- SWJYSDXMTPMBHO-FXQIFTODSA-N Cys-Pro-Ser Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SWJYSDXMTPMBHO-FXQIFTODSA-N 0.000 description 2
- 102000004594 DNA Polymerase I Human genes 0.000 description 2
- 108010017826 DNA Polymerase I Proteins 0.000 description 2
- 238000002965 ELISA Methods 0.000 description 2
- 241000223218 Fusarium Species 0.000 description 2
- LKUWAWGNJYJODH-KBIXCLLPSA-N Gln-Ala-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LKUWAWGNJYJODH-KBIXCLLPSA-N 0.000 description 2
- IOFDDSNZJDIGPB-GVXVVHGQSA-N Gln-Leu-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IOFDDSNZJDIGPB-GVXVVHGQSA-N 0.000 description 2
- OQXDUSZKISQQSS-GUBZILKMSA-N Glu-Lys-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OQXDUSZKISQQSS-GUBZILKMSA-N 0.000 description 2
- QXPRJQPCFXMCIY-NKWVEPMBSA-N Gly-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN QXPRJQPCFXMCIY-NKWVEPMBSA-N 0.000 description 2
- UFPXDFOYHVEIPI-BYPYZUCNSA-N Gly-Gly-Asp Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O UFPXDFOYHVEIPI-BYPYZUCNSA-N 0.000 description 2
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 2
- LHYJCVCQPWRMKZ-WEDXCCLWSA-N Gly-Leu-Thr Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LHYJCVCQPWRMKZ-WEDXCCLWSA-N 0.000 description 2
- CLNSYANKYVMZNM-UWVGGRQHSA-N Gly-Lys-Arg Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N CLNSYANKYVMZNM-UWVGGRQHSA-N 0.000 description 2
- JPVGHHQGKPQYIL-KBPBESRZSA-N Gly-Phe-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 JPVGHHQGKPQYIL-KBPBESRZSA-N 0.000 description 2
- JYPCXBJRLBHWME-IUCAKERBSA-N Gly-Pro-Arg Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JYPCXBJRLBHWME-IUCAKERBSA-N 0.000 description 2
- LLWQVJNHMYBLLK-CDMKHQONSA-N Gly-Thr-Phe Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LLWQVJNHMYBLLK-CDMKHQONSA-N 0.000 description 2
- GULGDABMYTYMJZ-STQMWFEESA-N Gly-Trp-Asp Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(O)=O)C(O)=O GULGDABMYTYMJZ-STQMWFEESA-N 0.000 description 2
- KYMUEAZVLPRVAE-GUBZILKMSA-N His-Asn-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KYMUEAZVLPRVAE-GUBZILKMSA-N 0.000 description 2
- SGLXGEDPYJPGIQ-ACRUOGEOSA-N His-Phe-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)NC(=O)[C@H](CC3=CN=CN3)N SGLXGEDPYJPGIQ-ACRUOGEOSA-N 0.000 description 2
- ILUVWFTXAUYOBW-CUJWVEQBSA-N His-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC1=CN=CN1)N)O ILUVWFTXAUYOBW-CUJWVEQBSA-N 0.000 description 2
- DMAPKBANYNZHNR-ULQDDVLXSA-N His-Val-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N DMAPKBANYNZHNR-ULQDDVLXSA-N 0.000 description 2
- NKVZTQVGUNLLQW-JBDRJPRFSA-N Ile-Ala-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)O)N NKVZTQVGUNLLQW-JBDRJPRFSA-N 0.000 description 2
- WECYRWOMWSCWNX-XUXIUFHCSA-N Ile-Arg-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O WECYRWOMWSCWNX-XUXIUFHCSA-N 0.000 description 2
- FHCNLXMTQJNJNH-KBIXCLLPSA-N Ile-Cys-Gln Chemical compound N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)O FHCNLXMTQJNJNH-KBIXCLLPSA-N 0.000 description 2
- SVBAHOMTJRFSIC-SXTJYALSSA-N Ile-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SVBAHOMTJRFSIC-SXTJYALSSA-N 0.000 description 2
- TWYOYAKMLHWMOJ-ZPFDUUQYSA-N Ile-Leu-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O TWYOYAKMLHWMOJ-ZPFDUUQYSA-N 0.000 description 2
- GAZGFPOZOLEYAJ-YTFOTSKYSA-N Ile-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N GAZGFPOZOLEYAJ-YTFOTSKYSA-N 0.000 description 2
- PELCGFMHLZXWBQ-BJDJZHNGSA-N Ile-Ser-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)O)N PELCGFMHLZXWBQ-BJDJZHNGSA-N 0.000 description 2
- MITYXXNZSZLHGG-OBAATPRFSA-N Ile-Trp-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N MITYXXNZSZLHGG-OBAATPRFSA-N 0.000 description 2
- 108010065920 Insulin Lispro Proteins 0.000 description 2
- HGCNKOLVKRAVHD-UHFFFAOYSA-N L-Met-L-Phe Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 HGCNKOLVKRAVHD-UHFFFAOYSA-N 0.000 description 2
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 2
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 2
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 2
- XIRYQRLFHWWWTC-QEJZJMRPSA-N Leu-Ala-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XIRYQRLFHWWWTC-QEJZJMRPSA-N 0.000 description 2
- SGIIOQQGLUUMDQ-IHRRRGAJSA-N Leu-His-Val Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](C(C)C)C(=O)O)N SGIIOQQGLUUMDQ-IHRRRGAJSA-N 0.000 description 2
- QJXHMYMRGDOHRU-NHCYSSNCSA-N Leu-Ile-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O QJXHMYMRGDOHRU-NHCYSSNCSA-N 0.000 description 2
- DSFYPIUSAMSERP-IHRRRGAJSA-N Leu-Leu-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DSFYPIUSAMSERP-IHRRRGAJSA-N 0.000 description 2
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 2
- YESNGRDJQWDYLH-KKUMJFAQSA-N Leu-Phe-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CS)C(=O)O)N YESNGRDJQWDYLH-KKUMJFAQSA-N 0.000 description 2
- YWKNKRAKOCLOLH-OEAJRASXSA-N Leu-Phe-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CC1=CC=CC=C1 YWKNKRAKOCLOLH-OEAJRASXSA-N 0.000 description 2
- MVVSHHJKJRZVNY-ACRUOGEOSA-N Leu-Phe-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MVVSHHJKJRZVNY-ACRUOGEOSA-N 0.000 description 2
- UFPLDOKWDNTTRP-ULQDDVLXSA-N Leu-Tyr-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CC=C(O)C=C1 UFPLDOKWDNTTRP-ULQDDVLXSA-N 0.000 description 2
- RDFIVFHPOSOXMW-ACRUOGEOSA-N Leu-Tyr-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O RDFIVFHPOSOXMW-ACRUOGEOSA-N 0.000 description 2
- MSFITIBEMPWCBD-ULQDDVLXSA-N Leu-Val-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 MSFITIBEMPWCBD-ULQDDVLXSA-N 0.000 description 2
- LLSUNJYOSCOOEB-GUBZILKMSA-N Lys-Glu-Asp Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O LLSUNJYOSCOOEB-GUBZILKMSA-N 0.000 description 2
- RBEATVHTWHTHTJ-KKUMJFAQSA-N Lys-Leu-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O RBEATVHTWHTHTJ-KKUMJFAQSA-N 0.000 description 2
- YUAXTFMFMOIMAM-QWRGUYRKSA-N Lys-Lys-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O YUAXTFMFMOIMAM-QWRGUYRKSA-N 0.000 description 2
- VHTOGMKQXXJOHG-RHYQMDGZSA-N Lys-Thr-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O VHTOGMKQXXJOHG-RHYQMDGZSA-N 0.000 description 2
- MIMXMVDLMDMOJD-BZSNNMDCSA-N Lys-Tyr-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O MIMXMVDLMDMOJD-BZSNNMDCSA-N 0.000 description 2
- VVURYEVJJTXWNE-ULQDDVLXSA-N Lys-Tyr-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O VVURYEVJJTXWNE-ULQDDVLXSA-N 0.000 description 2
- QEVRUYFHWJJUHZ-DCAQKATOSA-N Met-Ala-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(C)C QEVRUYFHWJJUHZ-DCAQKATOSA-N 0.000 description 2
- MCNGIXXCMJAURZ-VEVYYDQMSA-N Met-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCSC)N)O MCNGIXXCMJAURZ-VEVYYDQMSA-N 0.000 description 2
- XZFYRXDAULDNFX-UHFFFAOYSA-N N-L-cysteinyl-L-phenylalanine Natural products SCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XZFYRXDAULDNFX-UHFFFAOYSA-N 0.000 description 2
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 2
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 2
- 241000277275 Oncorhynchus mykiss Species 0.000 description 2
- 108700026244 Open Reading Frames Proteins 0.000 description 2
- 241001221668 Ostreococcus tauri Species 0.000 description 2
- LXVFHIBXOWJTKZ-BZSNNMDCSA-N Phe-Asn-Tyr Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O LXVFHIBXOWJTKZ-BZSNNMDCSA-N 0.000 description 2
- APJPXSFJBMMOLW-KBPBESRZSA-N Phe-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 APJPXSFJBMMOLW-KBPBESRZSA-N 0.000 description 2
- SMFGCTXUBWEPKM-KBPBESRZSA-N Phe-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 SMFGCTXUBWEPKM-KBPBESRZSA-N 0.000 description 2
- METZZBCMDXHFMK-BZSNNMDCSA-N Phe-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N METZZBCMDXHFMK-BZSNNMDCSA-N 0.000 description 2
- KZRQONDKKJCAOL-DKIMLUQUSA-N Phe-Leu-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KZRQONDKKJCAOL-DKIMLUQUSA-N 0.000 description 2
- YCCUXNNKXDGMAM-KKUMJFAQSA-N Phe-Leu-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YCCUXNNKXDGMAM-KKUMJFAQSA-N 0.000 description 2
- OHIYMVFLQXTZAW-UFYCRDLUSA-N Phe-Met-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O OHIYMVFLQXTZAW-UFYCRDLUSA-N 0.000 description 2
- FSXRLASFHBWESK-HOTGVXAUSA-N Phe-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 FSXRLASFHBWESK-HOTGVXAUSA-N 0.000 description 2
- XALFIVXGQUEGKV-JSGCOSHPSA-N Phe-Val-Gly Chemical compound OC(=O)CNC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 XALFIVXGQUEGKV-JSGCOSHPSA-N 0.000 description 2
- 241000195887 Physcomitrella patens Species 0.000 description 2
- DRKAXLDECUGLFE-ULQDDVLXSA-N Pro-Leu-Phe Chemical compound CC(C)C[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O DRKAXLDECUGLFE-ULQDDVLXSA-N 0.000 description 2
- AIOWVDNPESPXRB-YTWAJWBKSA-N Pro-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2)O AIOWVDNPESPXRB-YTWAJWBKSA-N 0.000 description 2
- MTMJNKFZDQEVSY-BZSNNMDCSA-N Pro-Val-Trp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O MTMJNKFZDQEVSY-BZSNNMDCSA-N 0.000 description 2
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 2
- XUDRHBPSPAPDJP-SRVKXCTJSA-N Ser-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO XUDRHBPSPAPDJP-SRVKXCTJSA-N 0.000 description 2
- HNDMFDBQXYZSRM-IHRRRGAJSA-N Ser-Val-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HNDMFDBQXYZSRM-IHRRRGAJSA-N 0.000 description 2
- BSNZTJXVDOINSR-JXUBOQSCSA-N Thr-Ala-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O BSNZTJXVDOINSR-JXUBOQSCSA-N 0.000 description 2
- NFMPFBCXABPALN-OWLDWWDNSA-N Thr-Ala-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N)O NFMPFBCXABPALN-OWLDWWDNSA-N 0.000 description 2
- BWUHENPAEMNGQJ-ZDLURKLDSA-N Thr-Gln Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(O)=O)CCC(N)=O BWUHENPAEMNGQJ-ZDLURKLDSA-N 0.000 description 2
- NIEWSKWFURSECR-FOHZUACHSA-N Thr-Gly-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NIEWSKWFURSECR-FOHZUACHSA-N 0.000 description 2
- LCCSEJSPBWKBNT-OSUNSFLBSA-N Thr-Ile-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N LCCSEJSPBWKBNT-OSUNSFLBSA-N 0.000 description 2
- ISLDRLHVPXABBC-IEGACIPQSA-N Thr-Leu-Trp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O ISLDRLHVPXABBC-IEGACIPQSA-N 0.000 description 2
- MGJLBZFUXUGMML-VOAKCMCISA-N Thr-Lys-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MGJLBZFUXUGMML-VOAKCMCISA-N 0.000 description 2
- LKJCABTUFGTPPY-HJGDQZAQSA-N Thr-Pro-Gln Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O LKJCABTUFGTPPY-HJGDQZAQSA-N 0.000 description 2
- GVMXJJAJLIEASL-ZJDVBMNYSA-N Thr-Pro-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O GVMXJJAJLIEASL-ZJDVBMNYSA-N 0.000 description 2
- XZUBGOYOGDRYFC-XGEHTFHBSA-N Thr-Ser-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O XZUBGOYOGDRYFC-XGEHTFHBSA-N 0.000 description 2
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 2
- 108700009124 Transcription Initiation Site Proteins 0.000 description 2
- XNRJFXBORWMIPY-DCPHZVHLSA-N Trp-Ala-Phe Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XNRJFXBORWMIPY-DCPHZVHLSA-N 0.000 description 2
- RERIQEJUYCLJQI-QRTARXTBSA-N Trp-Asp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N RERIQEJUYCLJQI-QRTARXTBSA-N 0.000 description 2
- VRTMYQGKPQZAPO-SBCJRHGPSA-N Trp-Trp-Ile Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VRTMYQGKPQZAPO-SBCJRHGPSA-N 0.000 description 2
- NGALWFGCOMHUSN-AVGNSLFASA-N Tyr-Gln-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NGALWFGCOMHUSN-AVGNSLFASA-N 0.000 description 2
- FMOSEWZYZPMJAL-KKUMJFAQSA-N Tyr-Glu-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N FMOSEWZYZPMJAL-KKUMJFAQSA-N 0.000 description 2
- HDSKHCBAVVWPCQ-FHWLQOOXSA-N Tyr-Glu-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HDSKHCBAVVWPCQ-FHWLQOOXSA-N 0.000 description 2
- QAYSODICXVZUIA-WLTAIBSBSA-N Tyr-Gly-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O QAYSODICXVZUIA-WLTAIBSBSA-N 0.000 description 2
- LFCQXIXJQXWZJI-BZSNNMDCSA-N Tyr-His-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)N)O LFCQXIXJQXWZJI-BZSNNMDCSA-N 0.000 description 2
- NXRGXTBPMOGFID-CFMVVWHZSA-N Tyr-Ile-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O NXRGXTBPMOGFID-CFMVVWHZSA-N 0.000 description 2
- WSFXJLFSJSXGMQ-MGHWNKPDSA-N Tyr-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N WSFXJLFSJSXGMQ-MGHWNKPDSA-N 0.000 description 2
- BSCBBPKDVOZICB-KKUMJFAQSA-N Tyr-Leu-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BSCBBPKDVOZICB-KKUMJFAQSA-N 0.000 description 2
- DWAMXBFJNZIHMC-KBPBESRZSA-N Tyr-Leu-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O DWAMXBFJNZIHMC-KBPBESRZSA-N 0.000 description 2
- KHCSOLAHNLOXJR-BZSNNMDCSA-N Tyr-Leu-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KHCSOLAHNLOXJR-BZSNNMDCSA-N 0.000 description 2
- DMWNPLOERDAHSY-MEYUZBJRSA-N Tyr-Leu-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DMWNPLOERDAHSY-MEYUZBJRSA-N 0.000 description 2
- CWVHKVVKAQIJKY-ACRUOGEOSA-N Tyr-Lys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC2=CC=C(C=C2)O)N CWVHKVVKAQIJKY-ACRUOGEOSA-N 0.000 description 2
- NHOVZGFNTGMYMI-KKUMJFAQSA-N Tyr-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NHOVZGFNTGMYMI-KKUMJFAQSA-N 0.000 description 2
- MQUYPYFPHIPVHJ-MNSWYVGCSA-N Tyr-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)O MQUYPYFPHIPVHJ-MNSWYVGCSA-N 0.000 description 2
- HZDQUVQEVVYDDA-ACRUOGEOSA-N Tyr-Tyr-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 HZDQUVQEVVYDDA-ACRUOGEOSA-N 0.000 description 2
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- DRTQHJPVMGBUCF-XVFCMESISA-N Uridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-XVFCMESISA-N 0.000 description 2
- VLOYGOZDPGYWFO-LAEOZQHASA-N Val-Asp-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VLOYGOZDPGYWFO-LAEOZQHASA-N 0.000 description 2
- YODDULVCGFQRFZ-ZKWXMUAHSA-N Val-Asp-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YODDULVCGFQRFZ-ZKWXMUAHSA-N 0.000 description 2
- PYXQBKJPHNCTNW-CYDGBPFRSA-N Val-Ile-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](C(C)C)N PYXQBKJPHNCTNW-CYDGBPFRSA-N 0.000 description 2
- AEMPCGRFEZTWIF-IHRRRGAJSA-N Val-Leu-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O AEMPCGRFEZTWIF-IHRRRGAJSA-N 0.000 description 2
- BTWMICVCQLKKNR-DCAQKATOSA-N Val-Leu-Ser Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C([O-])=O BTWMICVCQLKKNR-DCAQKATOSA-N 0.000 description 2
- YDVDTCJGBBJGRT-GUBZILKMSA-N Val-Met-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)O)N YDVDTCJGBBJGRT-GUBZILKMSA-N 0.000 description 2
- CEKSLIVSNNGOKH-KZVJFYERSA-N Val-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](C(C)C)N)O CEKSLIVSNNGOKH-KZVJFYERSA-N 0.000 description 2
- SUGRIIAOLCDLBD-ZOBUZTSGSA-N Val-Trp-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC(=O)O)C(=O)O)N SUGRIIAOLCDLBD-ZOBUZTSGSA-N 0.000 description 2
- WFTKOJGOOUJLJV-VKOGCVSHSA-N Val-Trp-Ile Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C([O-])=O)NC(=O)[C@@H]([NH3+])C(C)C)=CNC2=C1 WFTKOJGOOUJLJV-VKOGCVSHSA-N 0.000 description 2
- 238000009825 accumulation Methods 0.000 description 2
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 2
- 108010087924 alanylproline Proteins 0.000 description 2
- 108010070783 alanyltyrosine Proteins 0.000 description 2
- 229960000723 ampicillin Drugs 0.000 description 2
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 2
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 2
- 125000003118 aryl group Chemical group 0.000 description 2
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 2
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 2
- 239000012620 biological material Substances 0.000 description 2
- 102220364220 c.103C>T Human genes 0.000 description 2
- 229940041514 candida albicans extract Drugs 0.000 description 2
- 125000004432 carbon atom Chemical group C* 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- 239000006285 cell suspension Substances 0.000 description 2
- 239000007795 chemical reaction product Substances 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 239000003184 complementary RNA Substances 0.000 description 2
- 239000013078 crystal Substances 0.000 description 2
- 108010060199 cysteinylproline Proteins 0.000 description 2
- 229940104302 cytosine Drugs 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 150000001982 diacylglycerols Chemical class 0.000 description 2
- XIVFQYWMMJWUCD-UHFFFAOYSA-N dihydrophaseic acid Natural products C1C(O)CC2(C)OCC1(C)C2(O)C=CC(C)=CC(O)=O XIVFQYWMMJWUCD-UHFFFAOYSA-N 0.000 description 2
- 239000003814 drug Substances 0.000 description 2
- 230000009088 enzymatic function Effects 0.000 description 2
- 239000003925 fat Substances 0.000 description 2
- 235000019197 fats Nutrition 0.000 description 2
- 238000010230 functional analysis Methods 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- 239000006481 glucose medium Substances 0.000 description 2
- JYPCXBJRLBHWME-UHFFFAOYSA-N glycyl-L-prolyl-L-arginine Natural products NCC(=O)N1CCCC1C(=O)NC(CCCN=C(N)N)C(O)=O JYPCXBJRLBHWME-UHFFFAOYSA-N 0.000 description 2
- 108010078326 glycyl-glycyl-valine Proteins 0.000 description 2
- 108010025801 glycyl-prolyl-arginine Proteins 0.000 description 2
- 239000003102 growth factor Substances 0.000 description 2
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 2
- IPCSVZSSVZVIGE-UHFFFAOYSA-N hexadecanoic acid Chemical compound CCCCCCCCCCCCCCCC(O)=O IPCSVZSSVZVIGE-UHFFFAOYSA-N 0.000 description 2
- 108010092114 histidylphenylalanine Proteins 0.000 description 2
- 229910052739 hydrogen Inorganic materials 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 229910052500 inorganic mineral Inorganic materials 0.000 description 2
- 108010078274 isoleucylvaline Proteins 0.000 description 2
- 108010076756 leucyl-alanyl-phenylalanine Proteins 0.000 description 2
- 108010000761 leucylarginine Proteins 0.000 description 2
- 108010068488 methionylphenylalanine Proteins 0.000 description 2
- 239000011707 mineral Substances 0.000 description 2
- 239000006014 omega-3 oil Substances 0.000 description 2
- 239000003960 organic solvent Substances 0.000 description 2
- 229910052760 oxygen Inorganic materials 0.000 description 2
- 239000001301 oxygen Substances 0.000 description 2
- 150000003904 phospholipids Chemical class 0.000 description 2
- 229950004354 phosphorylcholine Drugs 0.000 description 2
- PYJNAPOPMIJKJZ-UHFFFAOYSA-N phosphorylcholine chloride Chemical compound [Cl-].C[N+](C)(C)CCOP(O)(O)=O PYJNAPOPMIJKJZ-UHFFFAOYSA-N 0.000 description 2
- 239000013600 plasmid vector Substances 0.000 description 2
- 229920000642 polymer Polymers 0.000 description 2
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 2
- 108010090894 prolylleucine Proteins 0.000 description 2
- 238000002708 random mutagenesis Methods 0.000 description 2
- 239000006152 selective media Substances 0.000 description 2
- 238000002864 sequence alignment Methods 0.000 description 2
- 238000012163 sequencing technique Methods 0.000 description 2
- 230000037432 silent mutation Effects 0.000 description 2
- NDVLTYZPCACLMA-UHFFFAOYSA-N silver oxide Chemical compound [O-2].[Ag+].[Ag+] NDVLTYZPCACLMA-UHFFFAOYSA-N 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 229940113082 thymine Drugs 0.000 description 2
- 230000002103 transcriptional effect Effects 0.000 description 2
- 230000007704 transition Effects 0.000 description 2
- 150000003626 triacylglycerols Chemical class 0.000 description 2
- CSRZQMIRAZTJOY-UHFFFAOYSA-N trimethylsilyl iodide Substances C[Si](C)(C)I CSRZQMIRAZTJOY-UHFFFAOYSA-N 0.000 description 2
- 108010038745 tryptophylglycine Proteins 0.000 description 2
- 238000011311 validation assay Methods 0.000 description 2
- 108010073969 valyllysine Proteins 0.000 description 2
- 238000001262 western blot Methods 0.000 description 2
- 239000012138 yeast extract Substances 0.000 description 2
- KHWCHTKSEGGWEX-RRKCRQDMSA-N 2'-deoxyadenosine 5'-monophosphate Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@H]1C[C@H](O)[C@@H](COP(O)(O)=O)O1 KHWCHTKSEGGWEX-RRKCRQDMSA-N 0.000 description 1
- LTFMZDNNPPEQNG-KVQBGUIXSA-N 2'-deoxyguanosine 5'-monophosphate Chemical compound C1=2NC(N)=NC(=O)C=2N=CN1[C@H]1C[C@H](O)[C@@H](COP(O)(O)=O)O1 LTFMZDNNPPEQNG-KVQBGUIXSA-N 0.000 description 1
- ONEGZXHXCLCVRF-UHFFFAOYSA-N 2-[[2-[[1-(2-amino-3-methylbutanoyl)pyrrolidine-2-carbonyl]amino]-3-methylbutanoyl]amino]-4-methylpentanoic acid Chemical compound CC(C)CC(C(O)=O)NC(=O)C(C(C)C)NC(=O)C1CCCN1C(=O)C(N)C(C)C ONEGZXHXCLCVRF-UHFFFAOYSA-N 0.000 description 1
- 108010054662 2-acylglycerophosphate acyltransferase Proteins 0.000 description 1
- TWJNQYPJQDRXPH-UHFFFAOYSA-N 2-cyanobenzohydrazide Chemical compound NNC(=O)C1=CC=CC=C1C#N TWJNQYPJQDRXPH-UHFFFAOYSA-N 0.000 description 1
- 102100022089 Acyl-[acyl-carrier-protein] hydrolase Human genes 0.000 description 1
- HHGYNJRJIINWAK-FXQIFTODSA-N Ala-Ala-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N HHGYNJRJIINWAK-FXQIFTODSA-N 0.000 description 1
- SSSROGPPPVTHLX-FXQIFTODSA-N Ala-Arg-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSROGPPPVTHLX-FXQIFTODSA-N 0.000 description 1
- KVWLTGNCJYDJET-LSJOCFKGSA-N Ala-Arg-His Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KVWLTGNCJYDJET-LSJOCFKGSA-N 0.000 description 1
- TTXMOJWKNRJWQJ-FXQIFTODSA-N Ala-Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N TTXMOJWKNRJWQJ-FXQIFTODSA-N 0.000 description 1
- NJIFPLAJSVUQOZ-JBDRJPRFSA-N Ala-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C)N NJIFPLAJSVUQOZ-JBDRJPRFSA-N 0.000 description 1
- CXZFXHGJJPVUJE-CIUDSAMLSA-N Ala-Cys-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)O)N CXZFXHGJJPVUJE-CIUDSAMLSA-N 0.000 description 1
- YEVZMOUUZINZCK-LKTVYLICSA-N Ala-Glu-Trp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O YEVZMOUUZINZCK-LKTVYLICSA-N 0.000 description 1
- PNALXAODQKTNLV-JBDRJPRFSA-N Ala-Ile-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O PNALXAODQKTNLV-JBDRJPRFSA-N 0.000 description 1
- TZDNWXDLYFIFPT-BJDJZHNGSA-N Ala-Ile-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O TZDNWXDLYFIFPT-BJDJZHNGSA-N 0.000 description 1
- XCZXVTHYGSMQGH-NAKRPEOUSA-N Ala-Ile-Met Chemical compound C[C@H]([NH3+])C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCSC)C([O-])=O XCZXVTHYGSMQGH-NAKRPEOUSA-N 0.000 description 1
- VNYMOTCMNHJGTG-JBDRJPRFSA-N Ala-Ile-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O VNYMOTCMNHJGTG-JBDRJPRFSA-N 0.000 description 1
- LNNSWWRRYJLGNI-NAKRPEOUSA-N Ala-Ile-Val Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O LNNSWWRRYJLGNI-NAKRPEOUSA-N 0.000 description 1
- WUHJHHGYVVJMQE-BJDJZHNGSA-N Ala-Leu-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WUHJHHGYVVJMQE-BJDJZHNGSA-N 0.000 description 1
- RGQCNKIDEQJEBT-CQDKDKBSSA-N Ala-Leu-Tyr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 RGQCNKIDEQJEBT-CQDKDKBSSA-N 0.000 description 1
- XHNLCGXYBXNRIS-BJDJZHNGSA-N Ala-Lys-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O XHNLCGXYBXNRIS-BJDJZHNGSA-N 0.000 description 1
- PMQXMXAASGFUDX-SRVKXCTJSA-N Ala-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CCCCN PMQXMXAASGFUDX-SRVKXCTJSA-N 0.000 description 1
- VCSABYLVNWQYQE-UHFFFAOYSA-N Ala-Lys-Lys Natural products NCCCCC(NC(=O)C(N)C)C(=O)NC(CCCCN)C(O)=O VCSABYLVNWQYQE-UHFFFAOYSA-N 0.000 description 1
- FUKFQILQFQKHLE-DCAQKATOSA-N Ala-Lys-Met Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(O)=O FUKFQILQFQKHLE-DCAQKATOSA-N 0.000 description 1
- CHFFHQUVXHEGBY-GARJFASQSA-N Ala-Lys-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N CHFFHQUVXHEGBY-GARJFASQSA-N 0.000 description 1
- JWUZOJXDJDEQEM-ZLIFDBKOSA-N Ala-Lys-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C)C(O)=O)=CNC2=C1 JWUZOJXDJDEQEM-ZLIFDBKOSA-N 0.000 description 1
- IHRGVZXPTIQNIP-NAKRPEOUSA-N Ala-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C)N IHRGVZXPTIQNIP-NAKRPEOUSA-N 0.000 description 1
- CJQAEJMHBAOQHA-DLOVCJGASA-N Ala-Phe-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CJQAEJMHBAOQHA-DLOVCJGASA-N 0.000 description 1
- CQJHFKKGZXKZBC-BPNCWPANSA-N Ala-Pro-Tyr Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 CQJHFKKGZXKZBC-BPNCWPANSA-N 0.000 description 1
- DYXOFPBJBAHWFY-JBDRJPRFSA-N Ala-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N DYXOFPBJBAHWFY-JBDRJPRFSA-N 0.000 description 1
- HOVPGJUNRLMIOZ-CIUDSAMLSA-N Ala-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N HOVPGJUNRLMIOZ-CIUDSAMLSA-N 0.000 description 1
- OMCKWYSDUQBYCN-FXQIFTODSA-N Ala-Ser-Met Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O OMCKWYSDUQBYCN-FXQIFTODSA-N 0.000 description 1
- XQNRANMFRPCFFW-GCJQMDKQSA-N Ala-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C)N)O XQNRANMFRPCFFW-GCJQMDKQSA-N 0.000 description 1
- VQBULXOHAZSTQY-GKCIPKSASA-N Ala-Trp-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O VQBULXOHAZSTQY-GKCIPKSASA-N 0.000 description 1
- AOAKQKVICDWCLB-UWJYBYFXSA-N Ala-Tyr-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N AOAKQKVICDWCLB-UWJYBYFXSA-N 0.000 description 1
- BHFOJPDOQPWJRN-XDTLVQLUSA-N Ala-Tyr-Gln Chemical compound C[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CCC(N)=O)C(O)=O BHFOJPDOQPWJRN-XDTLVQLUSA-N 0.000 description 1
- VYMJAWXRWHJIMS-LKTVYLICSA-N Ala-Tyr-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N VYMJAWXRWHJIMS-LKTVYLICSA-N 0.000 description 1
- DEAGTWNKODHUIY-MRFFXTKBSA-N Ala-Tyr-Trp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O DEAGTWNKODHUIY-MRFFXTKBSA-N 0.000 description 1
- 241000192542 Anabaena Species 0.000 description 1
- KWKQGHSSNHPGOW-BQBZGAKWSA-N Arg-Ala-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)NCC(O)=O KWKQGHSSNHPGOW-BQBZGAKWSA-N 0.000 description 1
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 1
- XPSGESXVBSQZPL-SRVKXCTJSA-N Arg-Arg-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XPSGESXVBSQZPL-SRVKXCTJSA-N 0.000 description 1
- VWVPYNGMOCSSGK-GUBZILKMSA-N Arg-Arg-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O VWVPYNGMOCSSGK-GUBZILKMSA-N 0.000 description 1
- HJVGMOYJDDXLMI-AVGNSLFASA-N Arg-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCCNC(N)=N HJVGMOYJDDXLMI-AVGNSLFASA-N 0.000 description 1
- PVSNBTCXCQIXSE-JYJNAYRXSA-N Arg-Arg-Phe Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PVSNBTCXCQIXSE-JYJNAYRXSA-N 0.000 description 1
- JCAISGGAOQXEHJ-ZPFDUUQYSA-N Arg-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N JCAISGGAOQXEHJ-ZPFDUUQYSA-N 0.000 description 1
- QAODJPUKWNNNRP-DCAQKATOSA-N Arg-Glu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O QAODJPUKWNNNRP-DCAQKATOSA-N 0.000 description 1
- CYXCAHZVPFREJD-LURJTMIESA-N Arg-Gly-Gly Chemical compound NC(=N)NCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O CYXCAHZVPFREJD-LURJTMIESA-N 0.000 description 1
- NVCIXQYNWYTLDO-IHRRRGAJSA-N Arg-His-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCCN=C(N)N)N NVCIXQYNWYTLDO-IHRRRGAJSA-N 0.000 description 1
- HCIUUZGFTDTEGM-NAKRPEOUSA-N Arg-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N HCIUUZGFTDTEGM-NAKRPEOUSA-N 0.000 description 1
- FSNVAJOPUDVQAR-AVGNSLFASA-N Arg-Lys-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FSNVAJOPUDVQAR-AVGNSLFASA-N 0.000 description 1
- BTJVOUQWFXABOI-IHRRRGAJSA-N Arg-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCNC(N)=N BTJVOUQWFXABOI-IHRRRGAJSA-N 0.000 description 1
- LXMKTIZAGIBQRX-HRCADAONSA-N Arg-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O LXMKTIZAGIBQRX-HRCADAONSA-N 0.000 description 1
- UIUXXFIKWQVMEX-UFYCRDLUSA-N Arg-Phe-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O UIUXXFIKWQVMEX-UFYCRDLUSA-N 0.000 description 1
- OWSMKCJUBAPHED-JYJNAYRXSA-N Arg-Pro-Tyr Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 OWSMKCJUBAPHED-JYJNAYRXSA-N 0.000 description 1
- ADPACBMPYWJJCE-FXQIFTODSA-N Arg-Ser-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O ADPACBMPYWJJCE-FXQIFTODSA-N 0.000 description 1
- FRBAHXABMQXSJQ-FXQIFTODSA-N Arg-Ser-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FRBAHXABMQXSJQ-FXQIFTODSA-N 0.000 description 1
- LRPZJPMQGKGHSG-XGEHTFHBSA-N Arg-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)O LRPZJPMQGKGHSG-XGEHTFHBSA-N 0.000 description 1
- CGWVCWFQGXOUSJ-ULQDDVLXSA-N Arg-Tyr-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O CGWVCWFQGXOUSJ-ULQDDVLXSA-N 0.000 description 1
- QHUOOCKNNURZSL-IHRRRGAJSA-N Arg-Tyr-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O QHUOOCKNNURZSL-IHRRRGAJSA-N 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- XYOVHPDDWCEUDY-CIUDSAMLSA-N Asn-Ala-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O XYOVHPDDWCEUDY-CIUDSAMLSA-N 0.000 description 1
- QEYJFBMTSMLPKZ-ZKWXMUAHSA-N Asn-Ala-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O QEYJFBMTSMLPKZ-ZKWXMUAHSA-N 0.000 description 1
- AYZAWXAPBAYCHO-CIUDSAMLSA-N Asn-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N AYZAWXAPBAYCHO-CIUDSAMLSA-N 0.000 description 1
- DAPLJWATMAXPPZ-CIUDSAMLSA-N Asn-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(N)=O DAPLJWATMAXPPZ-CIUDSAMLSA-N 0.000 description 1
- QHBMKQWOIYJYMI-BYULHYEWSA-N Asn-Asn-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O QHBMKQWOIYJYMI-BYULHYEWSA-N 0.000 description 1
- CTQIOCMSIJATNX-WHFBIAKZSA-N Asn-Gly-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O CTQIOCMSIJATNX-WHFBIAKZSA-N 0.000 description 1
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 1
- UDSVWSUXKYXSTR-QWRGUYRKSA-N Asn-Gly-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O UDSVWSUXKYXSTR-QWRGUYRKSA-N 0.000 description 1
- OOWSBIOUKIUWLO-RCOVLWMOSA-N Asn-Gly-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O OOWSBIOUKIUWLO-RCOVLWMOSA-N 0.000 description 1
- JEEFEQCRXKPQHC-KKUMJFAQSA-N Asn-Leu-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JEEFEQCRXKPQHC-KKUMJFAQSA-N 0.000 description 1
- NTWOPSIUJBMNRI-KKUMJFAQSA-N Asn-Lys-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NTWOPSIUJBMNRI-KKUMJFAQSA-N 0.000 description 1
- NLDNNZKUSLAYFW-NHCYSSNCSA-N Asn-Lys-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLDNNZKUSLAYFW-NHCYSSNCSA-N 0.000 description 1
- UYCPJVYQYARFGB-YDHLFZDLSA-N Asn-Phe-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O UYCPJVYQYARFGB-YDHLFZDLSA-N 0.000 description 1
- VHQSGALUSWIYOD-QXEWZRGKSA-N Asn-Pro-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O VHQSGALUSWIYOD-QXEWZRGKSA-N 0.000 description 1
- VLDRQOHCMKCXLY-SRVKXCTJSA-N Asn-Ser-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O VLDRQOHCMKCXLY-SRVKXCTJSA-N 0.000 description 1
- HPNDKUOLNRVRAY-BIIVOSGPSA-N Asn-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N)C(=O)O HPNDKUOLNRVRAY-BIIVOSGPSA-N 0.000 description 1
- LRCIOEVFVGXZKB-BZSNNMDCSA-N Asn-Tyr-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LRCIOEVFVGXZKB-BZSNNMDCSA-N 0.000 description 1
- SOYOSFXLXYZNRG-CIUDSAMLSA-N Asp-Arg-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O SOYOSFXLXYZNRG-CIUDSAMLSA-N 0.000 description 1
- MUWDILPCTSMUHI-ZLUOBGJFSA-N Asp-Asn-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N)C(=O)O MUWDILPCTSMUHI-ZLUOBGJFSA-N 0.000 description 1
- UGIBTKGQVWFTGX-BIIVOSGPSA-N Asp-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N)C(=O)O UGIBTKGQVWFTGX-BIIVOSGPSA-N 0.000 description 1
- IJHUZMGJRGNXIW-CIUDSAMLSA-N Asp-Glu-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IJHUZMGJRGNXIW-CIUDSAMLSA-N 0.000 description 1
- KHBLRHKVXICFMY-GUBZILKMSA-N Asp-Glu-Lys Chemical compound N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O KHBLRHKVXICFMY-GUBZILKMSA-N 0.000 description 1
- AYFVRYXNDHBECD-YUMQZZPRSA-N Asp-Leu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AYFVRYXNDHBECD-YUMQZZPRSA-N 0.000 description 1
- CJUKAWUWBZCTDQ-SRVKXCTJSA-N Asp-Leu-Lys Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O CJUKAWUWBZCTDQ-SRVKXCTJSA-N 0.000 description 1
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 1
- OZBXOELNJBSJOA-UBHSHLNASA-N Asp-Ser-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N OZBXOELNJBSJOA-UBHSHLNASA-N 0.000 description 1
- NAAAPCLFJPURAM-HJGDQZAQSA-N Asp-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O NAAAPCLFJPURAM-HJGDQZAQSA-N 0.000 description 1
- ITGFVUYOLWBPQW-KKHAAJSZSA-N Asp-Thr-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O ITGFVUYOLWBPQW-KKHAAJSZSA-N 0.000 description 1
- 108010023063 Bacto-peptone Proteins 0.000 description 1
- 241000219198 Brassica Species 0.000 description 1
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 1
- 101100512078 Caenorhabditis elegans lys-1 gene Proteins 0.000 description 1
- 101100315624 Caenorhabditis elegans tyr-1 gene Proteins 0.000 description 1
- 244000020518 Carthamus tinctorius Species 0.000 description 1
- 235000003255 Carthamus tinctorius Nutrition 0.000 description 1
- 229920000742 Cotton Polymers 0.000 description 1
- 241000223233 Cutaneotrichosporon cutaneum Species 0.000 description 1
- 241000235646 Cyberlindnera jadinii Species 0.000 description 1
- 241001042096 Cyberlindnera tropicalis Species 0.000 description 1
- CEZSLNCYQUFOSL-BQBZGAKWSA-N Cys-Arg-Gly Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O CEZSLNCYQUFOSL-BQBZGAKWSA-N 0.000 description 1
- IIGHQOPGMGKDMT-SRVKXCTJSA-N Cys-Asp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N IIGHQOPGMGKDMT-SRVKXCTJSA-N 0.000 description 1
- KXUKWRVYDYIPSQ-CIUDSAMLSA-N Cys-Leu-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O KXUKWRVYDYIPSQ-CIUDSAMLSA-N 0.000 description 1
- IZUNQDRIAOLWCN-YUMQZZPRSA-N Cys-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N IZUNQDRIAOLWCN-YUMQZZPRSA-N 0.000 description 1
- SRIRHERUAMYIOQ-CIUDSAMLSA-N Cys-Leu-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SRIRHERUAMYIOQ-CIUDSAMLSA-N 0.000 description 1
- FCXJJTRGVAZDER-FXQIFTODSA-N Cys-Val-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O FCXJJTRGVAZDER-FXQIFTODSA-N 0.000 description 1
- DGQJGBDBFVGLGL-ZKWXMUAHSA-N Cys-Val-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CS)N DGQJGBDBFVGLGL-ZKWXMUAHSA-N 0.000 description 1
- AZDQAZRURQMSQD-XPUUQOCRSA-N Cys-Val-Gly Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AZDQAZRURQMSQD-XPUUQOCRSA-N 0.000 description 1
- 108010090461 DFG peptide Proteins 0.000 description 1
- 102000012410 DNA Ligases Human genes 0.000 description 1
- 108010061982 DNA Ligases Proteins 0.000 description 1
- 230000033616 DNA repair Effects 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- 101710088194 Dehydrogenase Proteins 0.000 description 1
- 108010042407 Endonucleases Proteins 0.000 description 1
- 102000004533 Endonucleases Human genes 0.000 description 1
- 241000588722 Escherichia Species 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 108010039731 Fatty Acid Synthases Proteins 0.000 description 1
- 229930091371 Fructose Natural products 0.000 description 1
- 239000005715 Fructose Substances 0.000 description 1
- RFSUNEUAIZKAJO-ARQDHWQXSA-N Fructose Chemical compound OC[C@H]1O[C@](O)(CO)[C@@H](O)[C@@H]1O RFSUNEUAIZKAJO-ARQDHWQXSA-N 0.000 description 1
- 241000233732 Fusarium verticillioides Species 0.000 description 1
- 108700007698 Genetic Terminator Regions Proteins 0.000 description 1
- KVYVOGYEMPEXBT-GUBZILKMSA-N Gln-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O KVYVOGYEMPEXBT-GUBZILKMSA-N 0.000 description 1
- PRBLYKYHAJEABA-SRVKXCTJSA-N Gln-Arg-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O PRBLYKYHAJEABA-SRVKXCTJSA-N 0.000 description 1
- CRRFJBGUGNNOCS-PEFMBERDSA-N Gln-Asp-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CRRFJBGUGNNOCS-PEFMBERDSA-N 0.000 description 1
- UICOTGULOUGGLC-NUMRIWBASA-N Gln-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N)O UICOTGULOUGGLC-NUMRIWBASA-N 0.000 description 1
- MCAVASRGVBVPMX-FXQIFTODSA-N Gln-Glu-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O MCAVASRGVBVPMX-FXQIFTODSA-N 0.000 description 1
- XJKAKYXMFHUIHT-AUTRQRHGSA-N Gln-Glu-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N XJKAKYXMFHUIHT-AUTRQRHGSA-N 0.000 description 1
- ORYMMTRPKVTGSJ-XVKPBYJWSA-N Gln-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O ORYMMTRPKVTGSJ-XVKPBYJWSA-N 0.000 description 1
- FTIJVMLAGRAYMJ-MNXVOIDGSA-N Gln-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(N)=O FTIJVMLAGRAYMJ-MNXVOIDGSA-N 0.000 description 1
- ZNTDJIMJKNNSLR-RWRJDSDZSA-N Gln-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N ZNTDJIMJKNNSLR-RWRJDSDZSA-N 0.000 description 1
- QDXMSSWCEVYOLZ-SZMVWBNQSA-N Gln-Leu-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCC(=O)N)N QDXMSSWCEVYOLZ-SZMVWBNQSA-N 0.000 description 1
- ILKYYKRAULNYMS-JYJNAYRXSA-N Gln-Lys-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ILKYYKRAULNYMS-JYJNAYRXSA-N 0.000 description 1
- FALJZCPMTGJOHX-SRVKXCTJSA-N Gln-Met-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O FALJZCPMTGJOHX-SRVKXCTJSA-N 0.000 description 1
- DFRYZTUPVZNRLG-KKUMJFAQSA-N Gln-Met-Phe Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N DFRYZTUPVZNRLG-KKUMJFAQSA-N 0.000 description 1
- DBNLXHGDGBUCDV-KKUMJFAQSA-N Gln-Phe-Met Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(O)=O DBNLXHGDGBUCDV-KKUMJFAQSA-N 0.000 description 1
- QFXNFFZTMFHPST-DZKIICNBSA-N Gln-Phe-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CCC(=O)N)N QFXNFFZTMFHPST-DZKIICNBSA-N 0.000 description 1
- ZGHMRONFHDVXEF-AVGNSLFASA-N Gln-Ser-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ZGHMRONFHDVXEF-AVGNSLFASA-N 0.000 description 1
- OEIDWQHTRYEYGG-QEJZJMRPSA-N Gln-Trp-Asp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N OEIDWQHTRYEYGG-QEJZJMRPSA-N 0.000 description 1
- FITIQFSXXBKFFM-NRPADANISA-N Gln-Val-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FITIQFSXXBKFFM-NRPADANISA-N 0.000 description 1
- JJKKWYQVHRUSDG-GUBZILKMSA-N Glu-Ala-Lys Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O JJKKWYQVHRUSDG-GUBZILKMSA-N 0.000 description 1
- KBKGRMNVKPSQIF-XDTLVQLUSA-N Glu-Ala-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KBKGRMNVKPSQIF-XDTLVQLUSA-N 0.000 description 1
- VTTSANCGJWLPNC-ZPFDUUQYSA-N Glu-Arg-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VTTSANCGJWLPNC-ZPFDUUQYSA-N 0.000 description 1
- CKRUHITYRFNUKW-WDSKDSINSA-N Glu-Asn-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O CKRUHITYRFNUKW-WDSKDSINSA-N 0.000 description 1
- LXAUHIRMWXQRKI-XHNCKOQMSA-N Glu-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N)C(=O)O LXAUHIRMWXQRKI-XHNCKOQMSA-N 0.000 description 1
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 1
- PJBVXVBTTFZPHJ-GUBZILKMSA-N Glu-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N PJBVXVBTTFZPHJ-GUBZILKMSA-N 0.000 description 1
- MWMJCGBSIORNCD-AVGNSLFASA-N Glu-Leu-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O MWMJCGBSIORNCD-AVGNSLFASA-N 0.000 description 1
- WNRZUESNGGDCJX-JYJNAYRXSA-N Glu-Leu-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WNRZUESNGGDCJX-JYJNAYRXSA-N 0.000 description 1
- NJCALAAIGREHDR-WDCWCFNPSA-N Glu-Leu-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NJCALAAIGREHDR-WDCWCFNPSA-N 0.000 description 1
- ZQYZDDXTNQXUJH-CIUDSAMLSA-N Glu-Met-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(=O)O)N ZQYZDDXTNQXUJH-CIUDSAMLSA-N 0.000 description 1
- CHDWDBPJOZVZSE-KKUMJFAQSA-N Glu-Phe-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(O)=O CHDWDBPJOZVZSE-KKUMJFAQSA-N 0.000 description 1
- QJVZSVUYZFYLFQ-CIUDSAMLSA-N Glu-Pro-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O QJVZSVUYZFYLFQ-CIUDSAMLSA-N 0.000 description 1
- LPHGXOWFAXFCPX-KKUMJFAQSA-N Glu-Pro-Phe Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O LPHGXOWFAXFCPX-KKUMJFAQSA-N 0.000 description 1
- BPLNJYHNAJVLRT-ACZMJKKPSA-N Glu-Ser-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O BPLNJYHNAJVLRT-ACZMJKKPSA-N 0.000 description 1
- HMJULNMJWOZNFI-XHNCKOQMSA-N Glu-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N)C(=O)O HMJULNMJWOZNFI-XHNCKOQMSA-N 0.000 description 1
- MWTGQXBHVRTCOR-GLLZPBPUSA-N Glu-Thr-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MWTGQXBHVRTCOR-GLLZPBPUSA-N 0.000 description 1
- RGJKYNUINKGPJN-RWRJDSDZSA-N Glu-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(=O)O)N RGJKYNUINKGPJN-RWRJDSDZSA-N 0.000 description 1
- OVSKVOOUFAKODB-UWVGGRQHSA-N Gly-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N OVSKVOOUFAKODB-UWVGGRQHSA-N 0.000 description 1
- MXXXVOYFNVJHMA-IUCAKERBSA-N Gly-Arg-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CN MXXXVOYFNVJHMA-IUCAKERBSA-N 0.000 description 1
- XUORRGAFUQIMLC-STQMWFEESA-N Gly-Arg-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CN)O XUORRGAFUQIMLC-STQMWFEESA-N 0.000 description 1
- UXJHNZODTMHWRD-WHFBIAKZSA-N Gly-Asn-Ala Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O UXJHNZODTMHWRD-WHFBIAKZSA-N 0.000 description 1
- DWUKOTKSTDWGAE-BQBZGAKWSA-N Gly-Asn-Arg Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DWUKOTKSTDWGAE-BQBZGAKWSA-N 0.000 description 1
- NZAFOTBEULLEQB-WDSKDSINSA-N Gly-Asn-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)CN NZAFOTBEULLEQB-WDSKDSINSA-N 0.000 description 1
- GGEJHJIXRBTJPD-BYPYZUCNSA-N Gly-Asn-Gly Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GGEJHJIXRBTJPD-BYPYZUCNSA-N 0.000 description 1
- JVACNFOPSUPDTK-QWRGUYRKSA-N Gly-Asn-Phe Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JVACNFOPSUPDTK-QWRGUYRKSA-N 0.000 description 1
- QGZSAHIZRQHCEQ-QWRGUYRKSA-N Gly-Asp-Tyr Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QGZSAHIZRQHCEQ-QWRGUYRKSA-N 0.000 description 1
- MOJKRXIRAZPZLW-WDSKDSINSA-N Gly-Glu-Ala Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O MOJKRXIRAZPZLW-WDSKDSINSA-N 0.000 description 1
- MBOAPAXLTUSMQI-JHEQGTHGSA-N Gly-Glu-Thr Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MBOAPAXLTUSMQI-JHEQGTHGSA-N 0.000 description 1
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 1
- GDOZQTNZPCUARW-YFKPBYRVSA-N Gly-Gly-Glu Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O GDOZQTNZPCUARW-YFKPBYRVSA-N 0.000 description 1
- OLPPXYMMIARYAL-QMMMGPOBSA-N Gly-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)CN OLPPXYMMIARYAL-QMMMGPOBSA-N 0.000 description 1
- FSPVILZGHUJOHS-QWRGUYRKSA-N Gly-His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CNC=N1 FSPVILZGHUJOHS-QWRGUYRKSA-N 0.000 description 1
- LPCKHUXOGVNZRS-YUMQZZPRSA-N Gly-His-Ser Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O LPCKHUXOGVNZRS-YUMQZZPRSA-N 0.000 description 1
- ALOBJFDJTMQQPW-ONGXEEELSA-N Gly-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)CN ALOBJFDJTMQQPW-ONGXEEELSA-N 0.000 description 1
- SWQALSGKVLYKDT-UHFFFAOYSA-N Gly-Ile-Ala Natural products NCC(=O)NC(C(C)CC)C(=O)NC(C)C(O)=O SWQALSGKVLYKDT-UHFFFAOYSA-N 0.000 description 1
- COVXELOAORHTND-LSJOCFKGSA-N Gly-Ile-Val Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O COVXELOAORHTND-LSJOCFKGSA-N 0.000 description 1
- UUYBFNKHOCJCHT-VHSXEESVSA-N Gly-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN UUYBFNKHOCJCHT-VHSXEESVSA-N 0.000 description 1
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 1
- NTBOEZICHOSJEE-YUMQZZPRSA-N Gly-Lys-Ser Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O NTBOEZICHOSJEE-YUMQZZPRSA-N 0.000 description 1
- OQQKUTVULYLCDG-ONGXEEELSA-N Gly-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)CN)C(O)=O OQQKUTVULYLCDG-ONGXEEELSA-N 0.000 description 1
- GAAHQHNCMIAYEX-UWVGGRQHSA-N Gly-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN GAAHQHNCMIAYEX-UWVGGRQHSA-N 0.000 description 1
- ZLCLYFGMKFCDCN-XPUUQOCRSA-N Gly-Ser-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CO)NC(=O)CN)C(O)=O ZLCLYFGMKFCDCN-XPUUQOCRSA-N 0.000 description 1
- GNNJKUYDWFIBTK-QWRGUYRKSA-N Gly-Tyr-Asp Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O GNNJKUYDWFIBTK-QWRGUYRKSA-N 0.000 description 1
- NGBGZCUWFVVJKC-IRXDYDNUSA-N Gly-Tyr-Tyr Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 NGBGZCUWFVVJKC-IRXDYDNUSA-N 0.000 description 1
- JZNWSCPGTDBMEW-UHFFFAOYSA-N Glycerophosphorylethanolamin Natural products NCCOP(O)(=O)OCC(O)CO JZNWSCPGTDBMEW-UHFFFAOYSA-N 0.000 description 1
- 244000068988 Glycine max Species 0.000 description 1
- 235000010469 Glycine max Nutrition 0.000 description 1
- 229930186217 Glycolipid Natural products 0.000 description 1
- VPZXBVLAVMBEQI-VKHMYHEASA-N Glycyl-alanine Chemical compound OC(=O)[C@H](C)NC(=O)CN VPZXBVLAVMBEQI-VKHMYHEASA-N 0.000 description 1
- 244000299507 Gossypium hirsutum Species 0.000 description 1
- 244000020551 Helianthus annuus Species 0.000 description 1
- 235000003222 Helianthus annuus Nutrition 0.000 description 1
- HTZKFIYQMHJWSQ-INTQDDNPSA-N His-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N HTZKFIYQMHJWSQ-INTQDDNPSA-N 0.000 description 1
- HDXNWVLQSQFJOX-SRVKXCTJSA-N His-Arg-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N HDXNWVLQSQFJOX-SRVKXCTJSA-N 0.000 description 1
- MWAJSVTZZOUOBU-IHRRRGAJSA-N His-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC1=CN=CN1 MWAJSVTZZOUOBU-IHRRRGAJSA-N 0.000 description 1
- CJGDTAHEMXLRMB-ULQDDVLXSA-N His-Arg-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O CJGDTAHEMXLRMB-ULQDDVLXSA-N 0.000 description 1
- MAABHGXCIBEYQR-XVYDVKMFSA-N His-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N MAABHGXCIBEYQR-XVYDVKMFSA-N 0.000 description 1
- JWTKVPMQCCRPQY-SRVKXCTJSA-N His-Asn-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JWTKVPMQCCRPQY-SRVKXCTJSA-N 0.000 description 1
- VYMGAXSNYUFVCK-GUBZILKMSA-N His-Gln-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N VYMGAXSNYUFVCK-GUBZILKMSA-N 0.000 description 1
- KWBISLAEQZUYIC-UWJYBYFXSA-N His-His-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC2=CN=CN2)N KWBISLAEQZUYIC-UWJYBYFXSA-N 0.000 description 1
- BZKDJRSZWLPJNI-SRVKXCTJSA-N His-His-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O BZKDJRSZWLPJNI-SRVKXCTJSA-N 0.000 description 1
- ORZGPQXISSXQGW-IHRRRGAJSA-N His-His-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(O)=O ORZGPQXISSXQGW-IHRRRGAJSA-N 0.000 description 1
- SKOKHBGDXGTDDP-MELADBBJSA-N His-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N SKOKHBGDXGTDDP-MELADBBJSA-N 0.000 description 1
- TWROVBNEHJSXDG-IHRRRGAJSA-N His-Leu-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O TWROVBNEHJSXDG-IHRRRGAJSA-N 0.000 description 1
- KAXZXLSXFWSNNZ-XVYDVKMFSA-N His-Ser-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KAXZXLSXFWSNNZ-XVYDVKMFSA-N 0.000 description 1
- VIJMRAIWYWRXSR-CIUDSAMLSA-N His-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 VIJMRAIWYWRXSR-CIUDSAMLSA-N 0.000 description 1
- KFQDSSNYWKZFOO-LSJOCFKGSA-N His-Val-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O KFQDSSNYWKZFOO-LSJOCFKGSA-N 0.000 description 1
- WSAILOWUJZEAGC-DCAQKATOSA-N His-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N WSAILOWUJZEAGC-DCAQKATOSA-N 0.000 description 1
- FFYYUUWROYYKFY-IHRRRGAJSA-N His-Val-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O FFYYUUWROYYKFY-IHRRRGAJSA-N 0.000 description 1
- 101150017040 I gene Proteins 0.000 description 1
- JXUGDUWBMKIJDC-NAKRPEOUSA-N Ile-Ala-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JXUGDUWBMKIJDC-NAKRPEOUSA-N 0.000 description 1
- HERITAGIPLEJMT-GVARAGBVSA-N Ile-Ala-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HERITAGIPLEJMT-GVARAGBVSA-N 0.000 description 1
- MKWSZEHGHSLNPF-NAKRPEOUSA-N Ile-Ala-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O)N MKWSZEHGHSLNPF-NAKRPEOUSA-N 0.000 description 1
- FVEWRQXNISSYFO-ZPFDUUQYSA-N Ile-Arg-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N FVEWRQXNISSYFO-ZPFDUUQYSA-N 0.000 description 1
- LOXMWQOKYBGCHF-JBDRJPRFSA-N Ile-Cys-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O LOXMWQOKYBGCHF-JBDRJPRFSA-N 0.000 description 1
- VCYVLFAWCJRXFT-HJPIBITLSA-N Ile-Cys-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N VCYVLFAWCJRXFT-HJPIBITLSA-N 0.000 description 1
- JRYQSFOFUFXPTB-RWRJDSDZSA-N Ile-Gln-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N JRYQSFOFUFXPTB-RWRJDSDZSA-N 0.000 description 1
- FUOYNOXRWPJPAN-QEWYBTABSA-N Ile-Glu-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N FUOYNOXRWPJPAN-QEWYBTABSA-N 0.000 description 1
- SPQWWEZBHXHUJN-KBIXCLLPSA-N Ile-Glu-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O SPQWWEZBHXHUJN-KBIXCLLPSA-N 0.000 description 1
- UCGDDTHMMVWVMV-FSPLSTOPSA-N Ile-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(O)=O UCGDDTHMMVWVMV-FSPLSTOPSA-N 0.000 description 1
- GQKSJYINYYWPMR-NGZCFLSTSA-N Ile-Gly-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N1CCC[C@@H]1C(=O)O)N GQKSJYINYYWPMR-NGZCFLSTSA-N 0.000 description 1
- JLWLMGADIQFKRD-QSFUFRPTSA-N Ile-His-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CN=CN1 JLWLMGADIQFKRD-QSFUFRPTSA-N 0.000 description 1
- AFERFBZLVUFWRA-HTFCKZLJSA-N Ile-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CS)C(=O)O)N AFERFBZLVUFWRA-HTFCKZLJSA-N 0.000 description 1
- HUWYGQOISIJNMK-SIGLWIIPSA-N Ile-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N HUWYGQOISIJNMK-SIGLWIIPSA-N 0.000 description 1
- OVDKXUDMKXAZIV-ZPFDUUQYSA-N Ile-Lys-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OVDKXUDMKXAZIV-ZPFDUUQYSA-N 0.000 description 1
- GLYJPWIRLBAIJH-UHFFFAOYSA-N Ile-Lys-Pro Natural products CCC(C)C(N)C(=O)NC(CCCCN)C(=O)N1CCCC1C(O)=O GLYJPWIRLBAIJH-UHFFFAOYSA-N 0.000 description 1
- UOPBQSJRBONRON-STECZYCISA-N Ile-Met-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UOPBQSJRBONRON-STECZYCISA-N 0.000 description 1
- USXAYNCLFSUSBA-MGHWNKPDSA-N Ile-Phe-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N USXAYNCLFSUSBA-MGHWNKPDSA-N 0.000 description 1
- ZDNNDIJTUHQCAM-MXAVVETBSA-N Ile-Ser-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N ZDNNDIJTUHQCAM-MXAVVETBSA-N 0.000 description 1
- QGXQHJQPAPMACW-PPCPHDFISA-N Ile-Thr-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)O)N QGXQHJQPAPMACW-PPCPHDFISA-N 0.000 description 1
- JJQQGCMKLOEGAV-OSUNSFLBSA-N Ile-Thr-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(=O)O)N JJQQGCMKLOEGAV-OSUNSFLBSA-N 0.000 description 1
- QHUREMVLLMNUAX-OSUNSFLBSA-N Ile-Thr-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)O)N QHUREMVLLMNUAX-OSUNSFLBSA-N 0.000 description 1
- XDVKZSJODLMNLJ-GGQYPGDFSA-N Ile-Trp-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 XDVKZSJODLMNLJ-GGQYPGDFSA-N 0.000 description 1
- JSLIXOUMAOUGBN-JUKXBJQTSA-N Ile-Tyr-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N JSLIXOUMAOUGBN-JUKXBJQTSA-N 0.000 description 1
- REXAUQBGSGDEJY-IGISWZIWSA-N Ile-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N REXAUQBGSGDEJY-IGISWZIWSA-N 0.000 description 1
- DLEBSGAVWRPTIX-PEDHHIEDSA-N Ile-Val-Ile Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)[C@@H](C)CC DLEBSGAVWRPTIX-PEDHHIEDSA-N 0.000 description 1
- 229930010555 Inosine Natural products 0.000 description 1
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 1
- 102100034343 Integrase Human genes 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 1
- 108091026898 Leader sequence (mRNA) Proteins 0.000 description 1
- QPRQGENIBFLVEB-BJDJZHNGSA-N Leu-Ala-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O QPRQGENIBFLVEB-BJDJZHNGSA-N 0.000 description 1
- CNNQBZRGQATKNY-DCAQKATOSA-N Leu-Arg-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N CNNQBZRGQATKNY-DCAQKATOSA-N 0.000 description 1
- GRZSCTXVCDUIPO-SRVKXCTJSA-N Leu-Arg-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRZSCTXVCDUIPO-SRVKXCTJSA-N 0.000 description 1
- YOZCKMXHBYKOMQ-IHRRRGAJSA-N Leu-Arg-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N YOZCKMXHBYKOMQ-IHRRRGAJSA-N 0.000 description 1
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 1
- OXKYZSRZKBTVEY-ZPFDUUQYSA-N Leu-Asn-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O OXKYZSRZKBTVEY-ZPFDUUQYSA-N 0.000 description 1
- JKGHDYGZRDWHGA-SRVKXCTJSA-N Leu-Asn-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JKGHDYGZRDWHGA-SRVKXCTJSA-N 0.000 description 1
- OGCQGUIWMSBHRZ-CIUDSAMLSA-N Leu-Asn-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OGCQGUIWMSBHRZ-CIUDSAMLSA-N 0.000 description 1
- ZURHXHNAEJJRNU-CIUDSAMLSA-N Leu-Asp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZURHXHNAEJJRNU-CIUDSAMLSA-N 0.000 description 1
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 1
- GLBNEGIOFRVRHO-JYJNAYRXSA-N Leu-Gln-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O GLBNEGIOFRVRHO-JYJNAYRXSA-N 0.000 description 1
- HFBCHNRFRYLZNV-GUBZILKMSA-N Leu-Glu-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HFBCHNRFRYLZNV-GUBZILKMSA-N 0.000 description 1
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 1
- OXRLYTYUXAQTHP-YUMQZZPRSA-N Leu-Gly-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(O)=O OXRLYTYUXAQTHP-YUMQZZPRSA-N 0.000 description 1
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 1
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 1
- VGPCJSXPPOQPBK-YUMQZZPRSA-N Leu-Gly-Ser Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O VGPCJSXPPOQPBK-YUMQZZPRSA-N 0.000 description 1
- PBGDOSARRIJMEV-DLOVCJGASA-N Leu-His-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(O)=O PBGDOSARRIJMEV-DLOVCJGASA-N 0.000 description 1
- VZBIUJURDLFFOE-IHRRRGAJSA-N Leu-His-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VZBIUJURDLFFOE-IHRRRGAJSA-N 0.000 description 1
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 1
- JKSIBWITFMQTOA-XUXIUFHCSA-N Leu-Ile-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O JKSIBWITFMQTOA-XUXIUFHCSA-N 0.000 description 1
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 1
- FAELBUXXFQLUAX-AJNGGQMLSA-N Leu-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C FAELBUXXFQLUAX-AJNGGQMLSA-N 0.000 description 1
- FOBUGKUBUJOWAD-IHPCNDPISA-N Leu-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FOBUGKUBUJOWAD-IHPCNDPISA-N 0.000 description 1
- RTIRBWJPYJYTLO-MELADBBJSA-N Leu-Lys-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N RTIRBWJPYJYTLO-MELADBBJSA-N 0.000 description 1
- GSSMYQHXZNERFX-WDSOQIARSA-N Leu-Met-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N GSSMYQHXZNERFX-WDSOQIARSA-N 0.000 description 1
- LQUIENKUVKPNIC-ULQDDVLXSA-N Leu-Met-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LQUIENKUVKPNIC-ULQDDVLXSA-N 0.000 description 1
- INCJJHQRZGQLFC-KBPBESRZSA-N Leu-Phe-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O INCJJHQRZGQLFC-KBPBESRZSA-N 0.000 description 1
- WXDRGWBQZIMJDE-ULQDDVLXSA-N Leu-Phe-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(O)=O WXDRGWBQZIMJDE-ULQDDVLXSA-N 0.000 description 1
- MJWVXZABPOKJJF-ACRUOGEOSA-N Leu-Phe-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MJWVXZABPOKJJF-ACRUOGEOSA-N 0.000 description 1
- MAXILRZVORNXBE-PMVMPFDFSA-N Leu-Phe-Trp Chemical compound C([C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=CC=C1 MAXILRZVORNXBE-PMVMPFDFSA-N 0.000 description 1
- UCBPDSYUVAAHCD-UWVGGRQHSA-N Leu-Pro-Gly Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UCBPDSYUVAAHCD-UWVGGRQHSA-N 0.000 description 1
- YUTNOGOMBNYPFH-XUXIUFHCSA-N Leu-Pro-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YUTNOGOMBNYPFH-XUXIUFHCSA-N 0.000 description 1
- KWLWZYMNUZJKMZ-IHRRRGAJSA-N Leu-Pro-Leu Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O KWLWZYMNUZJKMZ-IHRRRGAJSA-N 0.000 description 1
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 1
- RGUXWMDNCPMQFB-YUMQZZPRSA-N Leu-Ser-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RGUXWMDNCPMQFB-YUMQZZPRSA-N 0.000 description 1
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 1
- PPGBXYKMUMHFBF-KATARQTJSA-N Leu-Ser-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PPGBXYKMUMHFBF-KATARQTJSA-N 0.000 description 1
- URHJPNHRQMQGOZ-RHYQMDGZSA-N Leu-Thr-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(O)=O URHJPNHRQMQGOZ-RHYQMDGZSA-N 0.000 description 1
- LXGSOEPHQJONMG-PMVMPFDFSA-N Leu-Trp-Tyr Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N LXGSOEPHQJONMG-PMVMPFDFSA-N 0.000 description 1
- TUIOUEWKFFVNLH-DCAQKATOSA-N Leu-Val-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O TUIOUEWKFFVNLH-DCAQKATOSA-N 0.000 description 1
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 1
- LMDVGHQPPPLYAR-IHRRRGAJSA-N Leu-Val-His Chemical compound N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O LMDVGHQPPPLYAR-IHRRRGAJSA-N 0.000 description 1
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 1
- 235000004431 Linum usitatissimum Nutrition 0.000 description 1
- 240000006240 Linum usitatissimum Species 0.000 description 1
- 239000000232 Lipid Bilayer Substances 0.000 description 1
- 239000006142 Luria-Bertani Agar Substances 0.000 description 1
- WXJKFRMKJORORD-DCAQKATOSA-N Lys-Arg-Ala Chemical compound NC(=N)NCCC[C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CCCCN WXJKFRMKJORORD-DCAQKATOSA-N 0.000 description 1
- ALSRJRIWBNENFY-DCAQKATOSA-N Lys-Arg-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O ALSRJRIWBNENFY-DCAQKATOSA-N 0.000 description 1
- IWWMPCPLFXFBAF-SRVKXCTJSA-N Lys-Asp-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O IWWMPCPLFXFBAF-SRVKXCTJSA-N 0.000 description 1
- NTBFKPBULZGXQL-KKUMJFAQSA-N Lys-Asp-Tyr Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NTBFKPBULZGXQL-KKUMJFAQSA-N 0.000 description 1
- DFXQCCBKGUNYGG-GUBZILKMSA-N Lys-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCCCN DFXQCCBKGUNYGG-GUBZILKMSA-N 0.000 description 1
- IMAKMJCBYCSMHM-AVGNSLFASA-N Lys-Glu-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN IMAKMJCBYCSMHM-AVGNSLFASA-N 0.000 description 1
- PAMDBWYMLWOELY-SDDRHHMPSA-N Lys-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)C(=O)O PAMDBWYMLWOELY-SDDRHHMPSA-N 0.000 description 1
- ODUQLUADRKMHOZ-JYJNAYRXSA-N Lys-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)O ODUQLUADRKMHOZ-JYJNAYRXSA-N 0.000 description 1
- ITWQLSZTLBKWJM-YUMQZZPRSA-N Lys-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCCCN ITWQLSZTLBKWJM-YUMQZZPRSA-N 0.000 description 1
- NKKFVJRLCCUJNA-QWRGUYRKSA-N Lys-Gly-Lys Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN NKKFVJRLCCUJNA-QWRGUYRKSA-N 0.000 description 1
- PBLLTSKBTAHDNA-KBPBESRZSA-N Lys-Gly-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PBLLTSKBTAHDNA-KBPBESRZSA-N 0.000 description 1
- FGMHXLULNHTPID-KKUMJFAQSA-N Lys-His-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CN=CN1 FGMHXLULNHTPID-KKUMJFAQSA-N 0.000 description 1
- JYXBNQOKPRQNQS-YTFOTSKYSA-N Lys-Ile-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JYXBNQOKPRQNQS-YTFOTSKYSA-N 0.000 description 1
- ZXFRGTAIIZHNHG-AJNGGQMLSA-N Lys-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CCCCN)N ZXFRGTAIIZHNHG-AJNGGQMLSA-N 0.000 description 1
- MYZMQWHPDAYKIE-SRVKXCTJSA-N Lys-Leu-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O MYZMQWHPDAYKIE-SRVKXCTJSA-N 0.000 description 1
- NJNRBRKHOWSGMN-SRVKXCTJSA-N Lys-Leu-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O NJNRBRKHOWSGMN-SRVKXCTJSA-N 0.000 description 1
- VMTYLUGCXIEDMV-QWRGUYRKSA-N Lys-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCCN VMTYLUGCXIEDMV-QWRGUYRKSA-N 0.000 description 1
- XIZQPFCRXLUNMK-BZSNNMDCSA-N Lys-Leu-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCCCN)N XIZQPFCRXLUNMK-BZSNNMDCSA-N 0.000 description 1
- NVGBPTNZLWRQSY-UWVGGRQHSA-N Lys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(O)=O)CCCCN NVGBPTNZLWRQSY-UWVGGRQHSA-N 0.000 description 1
- PYFNONMJYNJENN-AVGNSLFASA-N Lys-Lys-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PYFNONMJYNJENN-AVGNSLFASA-N 0.000 description 1
- ZJSZPXISKMDJKQ-JYJNAYRXSA-N Lys-Phe-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCC(O)=O)C(O)=O)CC1=CC=CC=C1 ZJSZPXISKMDJKQ-JYJNAYRXSA-N 0.000 description 1
- AFLBTVGQCQLOFJ-AVGNSLFASA-N Lys-Pro-Arg Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O AFLBTVGQCQLOFJ-AVGNSLFASA-N 0.000 description 1
- WQDKIVRHTQYJSN-DCAQKATOSA-N Lys-Ser-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N WQDKIVRHTQYJSN-DCAQKATOSA-N 0.000 description 1
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 1
- ZUGVARDEGWMMLK-SRVKXCTJSA-N Lys-Ser-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN ZUGVARDEGWMMLK-SRVKXCTJSA-N 0.000 description 1
- CUHGAUZONORRIC-HJGDQZAQSA-N Lys-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N)O CUHGAUZONORRIC-HJGDQZAQSA-N 0.000 description 1
- ZFNYWKHYUMEZDZ-WDSOQIARSA-N Lys-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCCCN)N ZFNYWKHYUMEZDZ-WDSOQIARSA-N 0.000 description 1
- IMDJSVBFQKDDEQ-MGHWNKPDSA-N Lys-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCCCN)N IMDJSVBFQKDDEQ-MGHWNKPDSA-N 0.000 description 1
- OHXUUQDOBQKSNB-AVGNSLFASA-N Lys-Val-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O OHXUUQDOBQKSNB-AVGNSLFASA-N 0.000 description 1
- UGCIQUYEJIEHKX-GVXVVHGQSA-N Lys-Val-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O UGCIQUYEJIEHKX-GVXVVHGQSA-N 0.000 description 1
- IKXQOBUBZSOWDY-AVGNSLFASA-N Lys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CCCCN)N IKXQOBUBZSOWDY-AVGNSLFASA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 108091027974 Mature messenger RNA Proteins 0.000 description 1
- HUKLXYYPZWPXCC-KZVJFYERSA-N Met-Ala-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HUKLXYYPZWPXCC-KZVJFYERSA-N 0.000 description 1
- YNOVBMBQSQTLFM-DCAQKATOSA-N Met-Asn-Leu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O YNOVBMBQSQTLFM-DCAQKATOSA-N 0.000 description 1
- CAODKDAPYGUMLK-FXQIFTODSA-N Met-Asn-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CAODKDAPYGUMLK-FXQIFTODSA-N 0.000 description 1
- FVKRQMQQFGBXHV-QXEWZRGKSA-N Met-Asp-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O FVKRQMQQFGBXHV-QXEWZRGKSA-N 0.000 description 1
- YKWHHKDMBZBMLG-GUBZILKMSA-N Met-Cys-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCSC)N YKWHHKDMBZBMLG-GUBZILKMSA-N 0.000 description 1
- JPCHYAUKOUGOIB-HJGDQZAQSA-N Met-Glu-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPCHYAUKOUGOIB-HJGDQZAQSA-N 0.000 description 1
- LRALLISKBZNSKN-BQBZGAKWSA-N Met-Gly-Ser Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LRALLISKBZNSKN-BQBZGAKWSA-N 0.000 description 1
- CUICVBQQHMKBRJ-LSJOCFKGSA-N Met-His-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](C)C(O)=O CUICVBQQHMKBRJ-LSJOCFKGSA-N 0.000 description 1
- ABHVWYPPHDYFNY-WDSOQIARSA-N Met-His-Trp Chemical compound C([C@H](NC(=O)[C@@H](N)CCSC)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CN=CN1 ABHVWYPPHDYFNY-WDSOQIARSA-N 0.000 description 1
- RVYDCISQIGHAFC-ZPFDUUQYSA-N Met-Ile-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O RVYDCISQIGHAFC-ZPFDUUQYSA-N 0.000 description 1
- WPTDJKDGICUFCP-XUXIUFHCSA-N Met-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CCSC)N WPTDJKDGICUFCP-XUXIUFHCSA-N 0.000 description 1
- ZIIMORLEZLVRIP-SRVKXCTJSA-N Met-Leu-Gln Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZIIMORLEZLVRIP-SRVKXCTJSA-N 0.000 description 1
- WTHGNAAQXISJHP-AVGNSLFASA-N Met-Lys-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O WTHGNAAQXISJHP-AVGNSLFASA-N 0.000 description 1
- WUYLWZRHRLLEGB-AVGNSLFASA-N Met-Met-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O WUYLWZRHRLLEGB-AVGNSLFASA-N 0.000 description 1
- XOFDBXYPKZUAAM-GUBZILKMSA-N Met-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)O)N XOFDBXYPKZUAAM-GUBZILKMSA-N 0.000 description 1
- LQTGGXSOMDSWTQ-UNQGMJICSA-N Met-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CCSC)N)O LQTGGXSOMDSWTQ-UNQGMJICSA-N 0.000 description 1
- LXCSZPUQKMTXNW-BQBZGAKWSA-N Met-Ser-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O LXCSZPUQKMTXNW-BQBZGAKWSA-N 0.000 description 1
- DSZFTPCSFVWMKP-DCAQKATOSA-N Met-Ser-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN DSZFTPCSFVWMKP-DCAQKATOSA-N 0.000 description 1
- CIIJWIAORKTXAH-FJXKBIBVSA-N Met-Thr-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O CIIJWIAORKTXAH-FJXKBIBVSA-N 0.000 description 1
- PESQCPHRXOFIPX-RYUDHWBXSA-N Met-Tyr Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-RYUDHWBXSA-N 0.000 description 1
- LIIXIZKVWNYQHB-STECZYCISA-N Met-Tyr-Ile Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LIIXIZKVWNYQHB-STECZYCISA-N 0.000 description 1
- FZDOBWIKRQORAC-ULQDDVLXSA-N Met-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCSC)N FZDOBWIKRQORAC-ULQDDVLXSA-N 0.000 description 1
- PNHRPOWKRRJATF-IHRRRGAJSA-N Met-Tyr-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CC=C(O)C=C1 PNHRPOWKRRJATF-IHRRRGAJSA-N 0.000 description 1
- JHVNNUIQXOGAHI-KJEVXHAQSA-N Met-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCSC)N)O JHVNNUIQXOGAHI-KJEVXHAQSA-N 0.000 description 1
- QAVZUKIPOMBLMC-AVGNSLFASA-N Met-Val-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(C)C QAVZUKIPOMBLMC-AVGNSLFASA-N 0.000 description 1
- LBSWWNKMVPAXOI-GUBZILKMSA-N Met-Val-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O LBSWWNKMVPAXOI-GUBZILKMSA-N 0.000 description 1
- 241000235575 Mortierella Species 0.000 description 1
- 235000021360 Myristic acid Nutrition 0.000 description 1
- TUNFSRHWOTWDNC-UHFFFAOYSA-N Myristic acid Natural products CCCCCCCCCCCCCC(O)=O TUNFSRHWOTWDNC-UHFFFAOYSA-N 0.000 description 1
- AUEJLPRZGVVDNU-UHFFFAOYSA-N N-L-tyrosyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CC1=CC=C(O)C=C1 AUEJLPRZGVVDNU-UHFFFAOYSA-N 0.000 description 1
- 101100068676 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gln-1 gene Proteins 0.000 description 1
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 1
- 108091092724 Noncoding DNA Proteins 0.000 description 1
- 108020005187 Oligonucleotide Probes Proteins 0.000 description 1
- 235000021314 Palmitic acid Nutrition 0.000 description 1
- LSXGADJXBDFXQU-DLOVCJGASA-N Phe-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 LSXGADJXBDFXQU-DLOVCJGASA-N 0.000 description 1
- BBDSZDHUCPSYAC-QEJZJMRPSA-N Phe-Ala-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O BBDSZDHUCPSYAC-QEJZJMRPSA-N 0.000 description 1
- LGBVMDMZZFYSFW-HJWJTTGWSA-N Phe-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC1=CC=CC=C1)N LGBVMDMZZFYSFW-HJWJTTGWSA-N 0.000 description 1
- AGYXCMYVTBYGCT-ULQDDVLXSA-N Phe-Arg-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O AGYXCMYVTBYGCT-ULQDDVLXSA-N 0.000 description 1
- CPTJPDZTFNKFOU-MXAVVETBSA-N Phe-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=CC=C1)N CPTJPDZTFNKFOU-MXAVVETBSA-N 0.000 description 1
- RJYBHZVWJPUSLB-QEWYBTABSA-N Phe-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=CC=C1)N RJYBHZVWJPUSLB-QEWYBTABSA-N 0.000 description 1
- GDBOREPXIRKSEQ-FHWLQOOXSA-N Phe-Gln-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O GDBOREPXIRKSEQ-FHWLQOOXSA-N 0.000 description 1
- FMMIYCMOVGXZIP-AVGNSLFASA-N Phe-Glu-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O FMMIYCMOVGXZIP-AVGNSLFASA-N 0.000 description 1
- XEXSSIBQYNKFBX-KBPBESRZSA-N Phe-Gly-His Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1N=CNC=1)C(O)=O)C1=CC=CC=C1 XEXSSIBQYNKFBX-KBPBESRZSA-N 0.000 description 1
- HNFUGJUZJRYUHN-JSGCOSHPSA-N Phe-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HNFUGJUZJRYUHN-JSGCOSHPSA-N 0.000 description 1
- MJQFZGOIVBDIMZ-WHOFXGATSA-N Phe-Ile-Gly Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)O MJQFZGOIVBDIMZ-WHOFXGATSA-N 0.000 description 1
- NRKNYPRRWXVELC-NQCBNZPSSA-N Phe-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC3=CC=CC=C3)N NRKNYPRRWXVELC-NQCBNZPSSA-N 0.000 description 1
- KXUZHWXENMYOHC-QEJZJMRPSA-N Phe-Leu-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O KXUZHWXENMYOHC-QEJZJMRPSA-N 0.000 description 1
- KBVJZCVLQWCJQN-KKUMJFAQSA-N Phe-Leu-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O KBVJZCVLQWCJQN-KKUMJFAQSA-N 0.000 description 1
- TXKWKTWYTIAZSV-KKUMJFAQSA-N Phe-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N TXKWKTWYTIAZSV-KKUMJFAQSA-N 0.000 description 1
- MSHZERMPZKCODG-ACRUOGEOSA-N Phe-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MSHZERMPZKCODG-ACRUOGEOSA-N 0.000 description 1
- DNAXXTQSTKOHFO-QEJZJMRPSA-N Phe-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=CC=C1 DNAXXTQSTKOHFO-QEJZJMRPSA-N 0.000 description 1
- IEOHQGFKHXUALJ-JYJNAYRXSA-N Phe-Met-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IEOHQGFKHXUALJ-JYJNAYRXSA-N 0.000 description 1
- OAOLATANIHTNCZ-IHRRRGAJSA-N Phe-Met-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N OAOLATANIHTNCZ-IHRRRGAJSA-N 0.000 description 1
- FENSZYFJQOFSQR-FIRPJDEBSA-N Phe-Phe-Ile Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FENSZYFJQOFSQR-FIRPJDEBSA-N 0.000 description 1
- GRVMHFCZUIYNKQ-UFYCRDLUSA-N Phe-Phe-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O GRVMHFCZUIYNKQ-UFYCRDLUSA-N 0.000 description 1
- FKFCKDROTNIVSO-JYJNAYRXSA-N Phe-Pro-Met Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(O)=O FKFCKDROTNIVSO-JYJNAYRXSA-N 0.000 description 1
- AFNJAQVMTIQTCB-DLOVCJGASA-N Phe-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 AFNJAQVMTIQTCB-DLOVCJGASA-N 0.000 description 1
- YDUGVDGFKNXFPL-IXOXFDKPSA-N Phe-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N)O YDUGVDGFKNXFPL-IXOXFDKPSA-N 0.000 description 1
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 1
- ZVJGAXNBBKPYOE-HKUYNNGSSA-N Phe-Trp-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(O)=O)C1=CC=CC=C1 ZVJGAXNBBKPYOE-HKUYNNGSSA-N 0.000 description 1
- AGTHXWTYCLLYMC-FHWLQOOXSA-N Phe-Tyr-Glu Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 AGTHXWTYCLLYMC-FHWLQOOXSA-N 0.000 description 1
- GCFNFKNPCMBHNT-IRXDYDNUSA-N Phe-Tyr-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)NCC(=O)O)N GCFNFKNPCMBHNT-IRXDYDNUSA-N 0.000 description 1
- ZTVSVSFBHUVYIN-UFYCRDLUSA-N Phe-Tyr-Met Chemical compound C([C@@H](C(=O)N[C@@H](CCSC)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC=CC=1)C1=CC=C(O)C=C1 ZTVSVSFBHUVYIN-UFYCRDLUSA-N 0.000 description 1
- VDTYRPWRWRCROL-UFYCRDLUSA-N Phe-Val-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 VDTYRPWRWRCROL-UFYCRDLUSA-N 0.000 description 1
- IEIFEYBAYFSRBQ-IHRRRGAJSA-N Phe-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N IEIFEYBAYFSRBQ-IHRRRGAJSA-N 0.000 description 1
- MWQXFDIQXIXPMS-UNQGMJICSA-N Phe-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CC1=CC=CC=C1)N)O MWQXFDIQXIXPMS-UNQGMJICSA-N 0.000 description 1
- 244000298647 Poinciana pulcherrima Species 0.000 description 1
- 108010021757 Polynucleotide 5'-Hydroxyl-Kinase Proteins 0.000 description 1
- 102000008422 Polynucleotide 5'-hydroxyl-kinase Human genes 0.000 description 1
- BNBBNGZZKQUWCD-IUCAKERBSA-N Pro-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H]1CCCN1 BNBBNGZZKQUWCD-IUCAKERBSA-N 0.000 description 1
- CYQQWUPHIZVCNY-GUBZILKMSA-N Pro-Arg-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O CYQQWUPHIZVCNY-GUBZILKMSA-N 0.000 description 1
- ORPZXBQTEHINPB-SRVKXCTJSA-N Pro-Arg-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H]1CCCN1)C(O)=O ORPZXBQTEHINPB-SRVKXCTJSA-N 0.000 description 1
- OBVCYFIHIIYIQF-CIUDSAMLSA-N Pro-Asn-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O OBVCYFIHIIYIQF-CIUDSAMLSA-N 0.000 description 1
- FUVBEZJCRMHWEM-FXQIFTODSA-N Pro-Asn-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O FUVBEZJCRMHWEM-FXQIFTODSA-N 0.000 description 1
- YSUZKYSRAFNLRB-ULQDDVLXSA-N Pro-Gln-Trp Chemical compound N([C@@H](CCC(=O)N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C(=O)[C@@H]1CCCN1 YSUZKYSRAFNLRB-ULQDDVLXSA-N 0.000 description 1
- NMELOOXSGDRBRU-YUMQZZPRSA-N Pro-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 NMELOOXSGDRBRU-YUMQZZPRSA-N 0.000 description 1
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 1
- JRQCDSNPRNGWRG-AVGNSLFASA-N Pro-His-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@@H]2CCCN2 JRQCDSNPRNGWRG-AVGNSLFASA-N 0.000 description 1
- AUQGUYPHJSMAKI-CYDGBPFRSA-N Pro-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 AUQGUYPHJSMAKI-CYDGBPFRSA-N 0.000 description 1
- FMLRRBDLBJLJIK-DCAQKATOSA-N Pro-Leu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FMLRRBDLBJLJIK-DCAQKATOSA-N 0.000 description 1
- HFNPOYOKIPGAEI-SRVKXCTJSA-N Pro-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 HFNPOYOKIPGAEI-SRVKXCTJSA-N 0.000 description 1
- BRJGUPWVFXKBQI-XUXIUFHCSA-N Pro-Leu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRJGUPWVFXKBQI-XUXIUFHCSA-N 0.000 description 1
- JUJCUYWRJMFJJF-AVGNSLFASA-N Pro-Lys-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]1CCCN1 JUJCUYWRJMFJJF-AVGNSLFASA-N 0.000 description 1
- XQPHBAKJJJZOBX-SRVKXCTJSA-N Pro-Lys-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O XQPHBAKJJJZOBX-SRVKXCTJSA-N 0.000 description 1
- MHHQQZIFLWFZGR-DCAQKATOSA-N Pro-Lys-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O MHHQQZIFLWFZGR-DCAQKATOSA-N 0.000 description 1
- AUYKOPJPKUCYHE-SRVKXCTJSA-N Pro-Met-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@@H]1CCCN1 AUYKOPJPKUCYHE-SRVKXCTJSA-N 0.000 description 1
- RCYUBVHMVUHEBM-RCWTZXSCSA-N Pro-Pro-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O RCYUBVHMVUHEBM-RCWTZXSCSA-N 0.000 description 1
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 1
- CHYAYDLYYIJCKY-OSUNSFLBSA-N Pro-Thr-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CHYAYDLYYIJCKY-OSUNSFLBSA-N 0.000 description 1
- CNUIHOAISPKQPY-HSHDSVGOSA-N Pro-Thr-Trp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O CNUIHOAISPKQPY-HSHDSVGOSA-N 0.000 description 1
- FYXCBXDAMPEHIQ-FHWLQOOXSA-N Pro-Trp-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N[C@@H](CCCCN)C(=O)O FYXCBXDAMPEHIQ-FHWLQOOXSA-N 0.000 description 1
- OOZJHTXCLJUODH-QXEWZRGKSA-N Pro-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 OOZJHTXCLJUODH-QXEWZRGKSA-N 0.000 description 1
- FIODMZKLZFLYQP-GUBZILKMSA-N Pro-Val-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FIODMZKLZFLYQP-GUBZILKMSA-N 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- 241000825199 Rebecca salina Species 0.000 description 1
- 241001149408 Rhodotorula graminis Species 0.000 description 1
- 241000221523 Rhodotorula toruloides Species 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- 241000233671 Schizochytrium Species 0.000 description 1
- ZUGXSSFMTXKHJS-ZLUOBGJFSA-N Ser-Ala-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O ZUGXSSFMTXKHJS-ZLUOBGJFSA-N 0.000 description 1
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 1
- BRKHVZNDAOMAHX-BIIVOSGPSA-N Ser-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N BRKHVZNDAOMAHX-BIIVOSGPSA-N 0.000 description 1
- HQTKVSCNCDLXSX-BQBZGAKWSA-N Ser-Arg-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O HQTKVSCNCDLXSX-BQBZGAKWSA-N 0.000 description 1
- XVAUJOAYHWWNQF-ZLUOBGJFSA-N Ser-Asn-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O XVAUJOAYHWWNQF-ZLUOBGJFSA-N 0.000 description 1
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 1
- ICHZYBVODUVUKN-SRVKXCTJSA-N Ser-Asn-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ICHZYBVODUVUKN-SRVKXCTJSA-N 0.000 description 1
- KNZQGAUEYZJUSQ-ZLUOBGJFSA-N Ser-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N KNZQGAUEYZJUSQ-ZLUOBGJFSA-N 0.000 description 1
- BYIROAKULFFTEK-CIUDSAMLSA-N Ser-Asp-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO BYIROAKULFFTEK-CIUDSAMLSA-N 0.000 description 1
- INCNPLPRPOYTJI-JBDRJPRFSA-N Ser-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N INCNPLPRPOYTJI-JBDRJPRFSA-N 0.000 description 1
- CRZRTKAVUUGKEQ-ACZMJKKPSA-N Ser-Gln-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O CRZRTKAVUUGKEQ-ACZMJKKPSA-N 0.000 description 1
- VMVNCJDKFOQOHM-GUBZILKMSA-N Ser-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N VMVNCJDKFOQOHM-GUBZILKMSA-N 0.000 description 1
- BQWCDDAISCPDQV-XHNCKOQMSA-N Ser-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N)C(=O)O BQWCDDAISCPDQV-XHNCKOQMSA-N 0.000 description 1
- KJMOINFQVCCSDX-XKBZYTNZSA-N Ser-Gln-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KJMOINFQVCCSDX-XKBZYTNZSA-N 0.000 description 1
- SNVIOQXAHVORQM-WDSKDSINSA-N Ser-Gly-Gln Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O SNVIOQXAHVORQM-WDSKDSINSA-N 0.000 description 1
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 1
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 1
- LOKXAXAESFYFAX-CIUDSAMLSA-N Ser-His-Cys Chemical compound OC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CS)C(O)=O)CC1=CN=CN1 LOKXAXAESFYFAX-CIUDSAMLSA-N 0.000 description 1
- UGHCUDLCCVVIJR-VGDYDELISA-N Ser-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CO)N UGHCUDLCCVVIJR-VGDYDELISA-N 0.000 description 1
- UIPXCLNLUUAMJU-JBDRJPRFSA-N Ser-Ile-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UIPXCLNLUUAMJU-JBDRJPRFSA-N 0.000 description 1
- KCNSGAMPBPYUAI-CIUDSAMLSA-N Ser-Leu-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O KCNSGAMPBPYUAI-CIUDSAMLSA-N 0.000 description 1
- GVIGVIOEYBOTCB-XIRDDKMYSA-N Ser-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CC(C)C)C(O)=O)=CNC2=C1 GVIGVIOEYBOTCB-XIRDDKMYSA-N 0.000 description 1
- JWOBLHJRDADHLN-KKUMJFAQSA-N Ser-Leu-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JWOBLHJRDADHLN-KKUMJFAQSA-N 0.000 description 1
- SBMNPABNWKXNBJ-BQBZGAKWSA-N Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](N)CO SBMNPABNWKXNBJ-BQBZGAKWSA-N 0.000 description 1
- SRKMDKACHDVPMD-SRVKXCTJSA-N Ser-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N SRKMDKACHDVPMD-SRVKXCTJSA-N 0.000 description 1
- LRWBCWGEUCKDTN-BJDJZHNGSA-N Ser-Lys-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LRWBCWGEUCKDTN-BJDJZHNGSA-N 0.000 description 1
- PPQRSMGDOHLTBE-UWVGGRQHSA-N Ser-Phe Chemical compound OC[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PPQRSMGDOHLTBE-UWVGGRQHSA-N 0.000 description 1
- FZEUTKVQGMVGHW-AVGNSLFASA-N Ser-Phe-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O FZEUTKVQGMVGHW-AVGNSLFASA-N 0.000 description 1
- KZPRPBLHYMZIMH-MXAVVETBSA-N Ser-Phe-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KZPRPBLHYMZIMH-MXAVVETBSA-N 0.000 description 1
- MQUZANJDFOQOBX-SRVKXCTJSA-N Ser-Phe-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O MQUZANJDFOQOBX-SRVKXCTJSA-N 0.000 description 1
- FLONGDPORFIVQW-XGEHTFHBSA-N Ser-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FLONGDPORFIVQW-XGEHTFHBSA-N 0.000 description 1
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 1
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 1
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 1
- HAUVENOGHPECML-BPUTZDHNSA-N Ser-Trp-Val Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CO)=CNC2=C1 HAUVENOGHPECML-BPUTZDHNSA-N 0.000 description 1
- GSCVDSBEYVGMJQ-SRVKXCTJSA-N Ser-Tyr-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N)O GSCVDSBEYVGMJQ-SRVKXCTJSA-N 0.000 description 1
- SYCFMSYTIFXWAJ-DCAQKATOSA-N Ser-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CO)N SYCFMSYTIFXWAJ-DCAQKATOSA-N 0.000 description 1
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 1
- LSHUNRICNSEEAN-BPUTZDHNSA-N Ser-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CO)N LSHUNRICNSEEAN-BPUTZDHNSA-N 0.000 description 1
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- 238000002105 Southern blotting Methods 0.000 description 1
- 108091081024 Start codon Proteins 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 108700005078 Synthetic Genes Proteins 0.000 description 1
- 241001491687 Thalassiosira pseudonana Species 0.000 description 1
- LHUBVKCLOVALIA-HJGDQZAQSA-N Thr-Arg-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O LHUBVKCLOVALIA-HJGDQZAQSA-N 0.000 description 1
- CEXFELBFVHLYDZ-XGEHTFHBSA-N Thr-Arg-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O CEXFELBFVHLYDZ-XGEHTFHBSA-N 0.000 description 1
- JVTHIXKSVYEWNI-JRQIVUDYSA-N Thr-Asn-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JVTHIXKSVYEWNI-JRQIVUDYSA-N 0.000 description 1
- OYTNZCBFDXGQGE-XQXXSGGOSA-N Thr-Gln-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C)C(=O)O)N)O OYTNZCBFDXGQGE-XQXXSGGOSA-N 0.000 description 1
- ZQUKYJOKQBRBCS-GLLZPBPUSA-N Thr-Gln-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O ZQUKYJOKQBRBCS-GLLZPBPUSA-N 0.000 description 1
- MQUZMZBFKCHVOB-HJGDQZAQSA-N Thr-Gln-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O MQUZMZBFKCHVOB-HJGDQZAQSA-N 0.000 description 1
- XXNLGZRRSKPSGF-HTUGSXCWSA-N Thr-Gln-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O XXNLGZRRSKPSGF-HTUGSXCWSA-N 0.000 description 1
- BECPPKYKPSRKCP-ZDLURKLDSA-N Thr-Glu Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(O)=O)CCC(O)=O BECPPKYKPSRKCP-ZDLURKLDSA-N 0.000 description 1
- DJDSEDOKJTZBAR-ZDLURKLDSA-N Thr-Gly-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O DJDSEDOKJTZBAR-ZDLURKLDSA-N 0.000 description 1
- URPSJRMWHQTARR-MBLNEYKQSA-N Thr-Ile-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O URPSJRMWHQTARR-MBLNEYKQSA-N 0.000 description 1
- GMXIJHCBTZDAPD-QPHKQPEJSA-N Thr-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N GMXIJHCBTZDAPD-QPHKQPEJSA-N 0.000 description 1
- ADPHPKGWVDHWML-PPCPHDFISA-N Thr-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N ADPHPKGWVDHWML-PPCPHDFISA-N 0.000 description 1
- FLPZMPOZGYPBEN-PPCPHDFISA-N Thr-Leu-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FLPZMPOZGYPBEN-PPCPHDFISA-N 0.000 description 1
- JLNMFGCJODTXDH-WEDXCCLWSA-N Thr-Lys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O JLNMFGCJODTXDH-WEDXCCLWSA-N 0.000 description 1
- KKPOGALELPLJTL-MEYUZBJRSA-N Thr-Lys-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KKPOGALELPLJTL-MEYUZBJRSA-N 0.000 description 1
- SIEZEMFJLYRUMK-YTWAJWBKSA-N Thr-Met-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N)O SIEZEMFJLYRUMK-YTWAJWBKSA-N 0.000 description 1
- NWECYMJLJGCBOD-UNQGMJICSA-N Thr-Phe-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O NWECYMJLJGCBOD-UNQGMJICSA-N 0.000 description 1
- DEGCBBCMYWNJNA-RHYQMDGZSA-N Thr-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O DEGCBBCMYWNJNA-RHYQMDGZSA-N 0.000 description 1
- ZMYCLHFLHRVOEA-HEIBUPTGSA-N Thr-Thr-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ZMYCLHFLHRVOEA-HEIBUPTGSA-N 0.000 description 1
- ZOCJFNXUVSGBQI-HSHDSVGOSA-N Thr-Trp-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O ZOCJFNXUVSGBQI-HSHDSVGOSA-N 0.000 description 1
- ZEJBJDHSQPOVJV-UAXMHLISSA-N Thr-Trp-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZEJBJDHSQPOVJV-UAXMHLISSA-N 0.000 description 1
- RPECVQBNONKZAT-WZLNRYEVSA-N Thr-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H]([C@@H](C)O)N RPECVQBNONKZAT-WZLNRYEVSA-N 0.000 description 1
- DIHPMRTXPYMDJZ-KAOXEZKKSA-N Thr-Tyr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N)O DIHPMRTXPYMDJZ-KAOXEZKKSA-N 0.000 description 1
- SBYQHZCMVSPQCS-RCWTZXSCSA-N Thr-Val-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O SBYQHZCMVSPQCS-RCWTZXSCSA-N 0.000 description 1
- SPIFGZFZMVLPHN-UNQGMJICSA-N Thr-Val-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SPIFGZFZMVLPHN-UNQGMJICSA-N 0.000 description 1
- 241001467333 Thraustochytriaceae Species 0.000 description 1
- 241000233675 Thraustochytrium Species 0.000 description 1
- 108700019146 Transgenes Proteins 0.000 description 1
- BRBCKMMXKONBAA-KWBADKCTSA-N Trp-Ala-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 BRBCKMMXKONBAA-KWBADKCTSA-N 0.000 description 1
- LTLBNCDNXQCOLB-UBHSHLNASA-N Trp-Asp-Ser Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 LTLBNCDNXQCOLB-UBHSHLNASA-N 0.000 description 1
- OFCKFBGRYHOKFP-IHPCNDPISA-N Trp-Asp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N OFCKFBGRYHOKFP-IHPCNDPISA-N 0.000 description 1
- IQLVYVFBJUWZNT-BPUTZDHNSA-N Trp-Cys-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N IQLVYVFBJUWZNT-BPUTZDHNSA-N 0.000 description 1
- FNOQJVHFVLVMOS-AAEUAGOBSA-N Trp-Gly-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N FNOQJVHFVLVMOS-AAEUAGOBSA-N 0.000 description 1
- WLBZWXXGSOLJBA-HOCLYGCPSA-N Trp-Gly-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 WLBZWXXGSOLJBA-HOCLYGCPSA-N 0.000 description 1
- KIMOCKLJBXHFIN-YLVFBTJISA-N Trp-Ile-Gly Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O)=CNC2=C1 KIMOCKLJBXHFIN-YLVFBTJISA-N 0.000 description 1
- LDMUNXDDIDAPJH-VMBFOHBNSA-N Trp-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N LDMUNXDDIDAPJH-VMBFOHBNSA-N 0.000 description 1
- ILDJYIDXESUBOE-HSCHXYMDSA-N Trp-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N ILDJYIDXESUBOE-HSCHXYMDSA-N 0.000 description 1
- CCZXBOFIBYQLEV-IHPCNDPISA-N Trp-Leu-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(O)=O CCZXBOFIBYQLEV-IHPCNDPISA-N 0.000 description 1
- MEZCXKYMMQJRDE-PMVMPFDFSA-N Trp-Leu-Tyr Chemical compound C([C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)CC(C)C)C(O)=O)C1=CC=C(O)C=C1 MEZCXKYMMQJRDE-PMVMPFDFSA-N 0.000 description 1
- IQIRAJGHFRVFEL-UBHSHLNASA-N Trp-Ser-Cys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N IQIRAJGHFRVFEL-UBHSHLNASA-N 0.000 description 1
- YCQXZDHDSUHUSG-FJHTZYQYSA-N Trp-Thr-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 YCQXZDHDSUHUSG-FJHTZYQYSA-N 0.000 description 1
- SEXRBCGSZRCIPE-LYSGOOTNSA-N Trp-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O SEXRBCGSZRCIPE-LYSGOOTNSA-N 0.000 description 1
- HTGJDTPQYFMKNC-VFAJRCTISA-N Trp-Thr-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)[C@@H](C)O)=CNC2=C1 HTGJDTPQYFMKNC-VFAJRCTISA-N 0.000 description 1
- DYIXEGROAOVQPK-VFAJRCTISA-N Trp-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O DYIXEGROAOVQPK-VFAJRCTISA-N 0.000 description 1
- WNGMGTMSUBARLB-RXVVDRJESA-N Trp-Trp-Gly Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)N)C(=O)NCC(O)=O)=CNC2=C1 WNGMGTMSUBARLB-RXVVDRJESA-N 0.000 description 1
- AOLQJUGGZLTUBD-WIRXVTQYSA-N Trp-Trp-Phe Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O AOLQJUGGZLTUBD-WIRXVTQYSA-N 0.000 description 1
- ZGTKIODEJMUQOT-WIRXVTQYSA-N Trp-Trp-Tyr Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(O)=O)C1=CC=C(O)C=C1 ZGTKIODEJMUQOT-WIRXVTQYSA-N 0.000 description 1
- VNRTXOUAOUZCFW-WDSOQIARSA-N Trp-Val-His Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O VNRTXOUAOUZCFW-WDSOQIARSA-N 0.000 description 1
- ZWZOCUWOXSDYFZ-CQDKDKBSSA-N Tyr-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 ZWZOCUWOXSDYFZ-CQDKDKBSSA-N 0.000 description 1
- XGEUYEOEZYFHRL-KKXDTOCCSA-N Tyr-Ala-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 XGEUYEOEZYFHRL-KKXDTOCCSA-N 0.000 description 1
- ONWMQORSVZYVNH-UWVGGRQHSA-N Tyr-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 ONWMQORSVZYVNH-UWVGGRQHSA-N 0.000 description 1
- PZXUIGWOEWWFQM-SRVKXCTJSA-N Tyr-Asn-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O PZXUIGWOEWWFQM-SRVKXCTJSA-N 0.000 description 1
- XMNDQSYABVWZRK-BZSNNMDCSA-N Tyr-Asn-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XMNDQSYABVWZRK-BZSNNMDCSA-N 0.000 description 1
- VTFWAGGJDRSQFG-MELADBBJSA-N Tyr-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O VTFWAGGJDRSQFG-MELADBBJSA-N 0.000 description 1
- YRBHLWWGSSQICE-IHRRRGAJSA-N Tyr-Asp-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O YRBHLWWGSSQICE-IHRRRGAJSA-N 0.000 description 1
- SMLCYZYQFRTLCO-UWJYBYFXSA-N Tyr-Cys-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O SMLCYZYQFRTLCO-UWJYBYFXSA-N 0.000 description 1
- KEHKBBUYZWAMHL-DZKIICNBSA-N Tyr-Gln-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O KEHKBBUYZWAMHL-DZKIICNBSA-N 0.000 description 1
- CNLKDWSAORJEMW-KWQFWETISA-N Tyr-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O CNLKDWSAORJEMW-KWQFWETISA-N 0.000 description 1
- KCPFDGNYAMKZQP-KBPBESRZSA-N Tyr-Gly-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O KCPFDGNYAMKZQP-KBPBESRZSA-N 0.000 description 1
- CVXURBLRELTJKO-BWAGICSOSA-N Tyr-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)O CVXURBLRELTJKO-BWAGICSOSA-N 0.000 description 1
- HFJJDMOFTCQGEI-STECZYCISA-N Tyr-Ile-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N HFJJDMOFTCQGEI-STECZYCISA-N 0.000 description 1
- AZZLDIDWPZLCCW-ZEWNOJEFSA-N Tyr-Ile-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O AZZLDIDWPZLCCW-ZEWNOJEFSA-N 0.000 description 1
- BJCILVZEZRDIDR-PMVMPFDFSA-N Tyr-Leu-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=C(O)C=C1 BJCILVZEZRDIDR-PMVMPFDFSA-N 0.000 description 1
- OLYXUGBVBGSZDN-ACRUOGEOSA-N Tyr-Leu-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 OLYXUGBVBGSZDN-ACRUOGEOSA-N 0.000 description 1
- ZOBLBMGJKVJVEV-BZSNNMDCSA-N Tyr-Lys-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N)O ZOBLBMGJKVJVEV-BZSNNMDCSA-N 0.000 description 1
- BBSPTGPYIPGTKH-JYJNAYRXSA-N Tyr-Met-Arg Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N BBSPTGPYIPGTKH-JYJNAYRXSA-N 0.000 description 1
- CYTJBBNFJIWKGH-STECZYCISA-N Tyr-Met-Ile Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CYTJBBNFJIWKGH-STECZYCISA-N 0.000 description 1
- OGPKMBOPMDTEDM-IHRRRGAJSA-N Tyr-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N OGPKMBOPMDTEDM-IHRRRGAJSA-N 0.000 description 1
- OKDNSNWJEXAMSU-IRXDYDNUSA-N Tyr-Phe-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)NCC(O)=O)C1=CC=C(O)C=C1 OKDNSNWJEXAMSU-IRXDYDNUSA-N 0.000 description 1
- NVZVJIUDICCMHZ-BZSNNMDCSA-N Tyr-Phe-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O NVZVJIUDICCMHZ-BZSNNMDCSA-N 0.000 description 1
- ARMNWLJYHCOSHE-KKUMJFAQSA-N Tyr-Pro-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O ARMNWLJYHCOSHE-KKUMJFAQSA-N 0.000 description 1
- FRMFMFNMGQGMNB-BVSLBCMMSA-N Tyr-Pro-Trp Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=C(O)C=C1 FRMFMFNMGQGMNB-BVSLBCMMSA-N 0.000 description 1
- LUMQYLVYUIRHHU-YJRXYDGGSA-N Tyr-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUMQYLVYUIRHHU-YJRXYDGGSA-N 0.000 description 1
- MDXLPNRXCFOBTL-BZSNNMDCSA-N Tyr-Ser-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MDXLPNRXCFOBTL-BZSNNMDCSA-N 0.000 description 1
- XFEMMSGONWQACR-KJEVXHAQSA-N Tyr-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O XFEMMSGONWQACR-KJEVXHAQSA-N 0.000 description 1
- GAKBTSMAPGLQFA-JNPHEJMOSA-N Tyr-Thr-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 GAKBTSMAPGLQFA-JNPHEJMOSA-N 0.000 description 1
- JAQGKXUEKGKTKX-HOTGVXAUSA-N Tyr-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 JAQGKXUEKGKTKX-HOTGVXAUSA-N 0.000 description 1
- WYOBRXPIZVKNMF-IRXDYDNUSA-N Tyr-Tyr-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)NCC(O)=O)C1=CC=C(O)C=C1 WYOBRXPIZVKNMF-IRXDYDNUSA-N 0.000 description 1
- KRXFXDCNKLANCP-CXTHYWKRSA-N Tyr-Tyr-Ile Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 KRXFXDCNKLANCP-CXTHYWKRSA-N 0.000 description 1
- BUPRFDPUIJNOLS-UFYCRDLUSA-N Tyr-Tyr-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCSC)C(O)=O BUPRFDPUIJNOLS-UFYCRDLUSA-N 0.000 description 1
- TYGHOWWWMTWVKM-HJOGWXRNSA-N Tyr-Tyr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 TYGHOWWWMTWVKM-HJOGWXRNSA-N 0.000 description 1
- KHPLUFDSWGDRHD-SLFFLAALSA-N Tyr-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)C(=O)O KHPLUFDSWGDRHD-SLFFLAALSA-N 0.000 description 1
- GOPQNCQSXBJAII-ULQDDVLXSA-N Tyr-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N GOPQNCQSXBJAII-ULQDDVLXSA-N 0.000 description 1
- RVGVIWNHABGIFH-IHRRRGAJSA-N Tyr-Val-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O RVGVIWNHABGIFH-IHRRRGAJSA-N 0.000 description 1
- DDRBQONWVBDQOY-GUBZILKMSA-N Val-Ala-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O DDRBQONWVBDQOY-GUBZILKMSA-N 0.000 description 1
- JFAWZADYPRMRCO-UBHSHLNASA-N Val-Ala-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JFAWZADYPRMRCO-UBHSHLNASA-N 0.000 description 1
- COYSIHFOCOMGCF-WPRPVWTQSA-N Val-Arg-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N COYSIHFOCOMGCF-WPRPVWTQSA-N 0.000 description 1
- COYSIHFOCOMGCF-UHFFFAOYSA-N Val-Arg-Gly Natural products CC(C)C(N)C(=O)NC(C(=O)NCC(O)=O)CCCN=C(N)N COYSIHFOCOMGCF-UHFFFAOYSA-N 0.000 description 1
- CVUDMNSZAIZFAE-UHFFFAOYSA-N Val-Arg-Pro Natural products NC(N)=NCCCC(NC(=O)C(N)C(C)C)C(=O)N1CCCC1C(O)=O CVUDMNSZAIZFAE-UHFFFAOYSA-N 0.000 description 1
- XLDYBRXERHITNH-QSFUFRPTSA-N Val-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)C(C)C XLDYBRXERHITNH-QSFUFRPTSA-N 0.000 description 1
- OVLIFGQSBSNGHY-KKHAAJSZSA-N Val-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N)O OVLIFGQSBSNGHY-KKHAAJSZSA-N 0.000 description 1
- CFSSLXZJEMERJY-NRPADANISA-N Val-Gln-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O CFSSLXZJEMERJY-NRPADANISA-N 0.000 description 1
- XEYUMGGWQCIWAR-XVKPBYJWSA-N Val-Gln-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)NCC(=O)O)N XEYUMGGWQCIWAR-XVKPBYJWSA-N 0.000 description 1
- VFOHXOLPLACADK-GVXVVHGQSA-N Val-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N VFOHXOLPLACADK-GVXVVHGQSA-N 0.000 description 1
- ZEVNVXYRZRIRCH-GVXVVHGQSA-N Val-Gln-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N ZEVNVXYRZRIRCH-GVXVVHGQSA-N 0.000 description 1
- PGBJAZDAEWPDAA-NHCYSSNCSA-N Val-Gln-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCSC)C(=O)O)N PGBJAZDAEWPDAA-NHCYSSNCSA-N 0.000 description 1
- BRPKEERLGYNCNC-NHCYSSNCSA-N Val-Glu-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N BRPKEERLGYNCNC-NHCYSSNCSA-N 0.000 description 1
- PMDOQZFYGWZSTK-LSJOCFKGSA-N Val-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)C(C)C PMDOQZFYGWZSTK-LSJOCFKGSA-N 0.000 description 1
- XBRMBDFYOFARST-AVGNSLFASA-N Val-His-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](C(C)C)C(=O)O)N XBRMBDFYOFARST-AVGNSLFASA-N 0.000 description 1
- CPGJELLYDQEDRK-NAKRPEOUSA-N Val-Ile-Ala Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](C)C(O)=O CPGJELLYDQEDRK-NAKRPEOUSA-N 0.000 description 1
- MYLNLEIZWHVENT-VKOGCVSHSA-N Val-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](C(C)C)N MYLNLEIZWHVENT-VKOGCVSHSA-N 0.000 description 1
- FEXILLGKGGTLRI-NHCYSSNCSA-N Val-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N FEXILLGKGGTLRI-NHCYSSNCSA-N 0.000 description 1
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 1
- BZOSBRIDWSSTFN-AVGNSLFASA-N Val-Leu-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](C(C)C)N BZOSBRIDWSSTFN-AVGNSLFASA-N 0.000 description 1
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 1
- WDIWOIRFNMLNKO-ULQDDVLXSA-N Val-Leu-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 WDIWOIRFNMLNKO-ULQDDVLXSA-N 0.000 description 1
- SVFRYKBZHUGKLP-QXEWZRGKSA-N Val-Met-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SVFRYKBZHUGKLP-QXEWZRGKSA-N 0.000 description 1
- WHVSJHJTMUHYBT-SRVKXCTJSA-N Val-Met-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCSC)C(=O)O)N WHVSJHJTMUHYBT-SRVKXCTJSA-N 0.000 description 1
- VNGKMNPAENRGDC-JYJNAYRXSA-N Val-Phe-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=CC=C1 VNGKMNPAENRGDC-JYJNAYRXSA-N 0.000 description 1
- XBJKAZATRJBDCU-GUBZILKMSA-N Val-Pro-Ala Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O XBJKAZATRJBDCU-GUBZILKMSA-N 0.000 description 1
- DEGUERSKQBRZMZ-FXQIFTODSA-N Val-Ser-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DEGUERSKQBRZMZ-FXQIFTODSA-N 0.000 description 1
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 1
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 1
- YQYFYUSYEDNLSD-YEPSODPASA-N Val-Thr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O YQYFYUSYEDNLSD-YEPSODPASA-N 0.000 description 1
- PDDJTOSAVNRJRH-UNQGMJICSA-N Val-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](C(C)C)N)O PDDJTOSAVNRJRH-UNQGMJICSA-N 0.000 description 1
- YLBNZCJFSVJDRJ-KJEVXHAQSA-N Val-Thr-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](Cc1ccc(O)cc1)C(O)=O YLBNZCJFSVJDRJ-KJEVXHAQSA-N 0.000 description 1
- POFQRHFHYPSCOI-FHWLQOOXSA-N Val-Trp-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)N POFQRHFHYPSCOI-FHWLQOOXSA-N 0.000 description 1
- RFZFBOQPPFCOKG-BZSNNMDCSA-N Val-Trp-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCSC)C(=O)O)N RFZFBOQPPFCOKG-BZSNNMDCSA-N 0.000 description 1
- KJFBXCFOPAKPTM-BZSNNMDCSA-N Val-Trp-Val Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O)=CNC2=C1 KJFBXCFOPAKPTM-BZSNNMDCSA-N 0.000 description 1
- MIAZWUMFUURQNP-YDHLFZDLSA-N Val-Tyr-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N MIAZWUMFUURQNP-YDHLFZDLSA-N 0.000 description 1
- JPBGMZDTPVGGMQ-ULQDDVLXSA-N Val-Tyr-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N JPBGMZDTPVGGMQ-ULQDDVLXSA-N 0.000 description 1
- AEFJNECXZCODJM-UWVGGRQHSA-N Val-Val-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)NCC([O-])=O AEFJNECXZCODJM-UWVGGRQHSA-N 0.000 description 1
- WHNSHJJNWNSTSU-BZSNNMDCSA-N Val-Val-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 WHNSHJJNWNSTSU-BZSNNMDCSA-N 0.000 description 1
- YKZVPMUGEJXEOR-JYJNAYRXSA-N Val-Val-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N YKZVPMUGEJXEOR-JYJNAYRXSA-N 0.000 description 1
- 240000008042 Zea mays Species 0.000 description 1
- 235000005824 Zea mays ssp. parviglumis Nutrition 0.000 description 1
- 235000002017 Zea mays subsp mays Nutrition 0.000 description 1
- 108010081404 acein-2 Proteins 0.000 description 1
- FKNHDDTXBWMZIR-GEMLJDPKSA-N acetic acid;(2s)-1-[(2r)-2-amino-3-sulfanylpropanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(O)=O.SC[C@H](N)C(=O)N1CCC[C@H]1C(O)=O FKNHDDTXBWMZIR-GEMLJDPKSA-N 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 229960005305 adenosine Drugs 0.000 description 1
- UDMBCSSLTHHNCD-KQYNXXCUSA-N adenosine 5'-monophosphate Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@H]1O UDMBCSSLTHHNCD-KQYNXXCUSA-N 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 1
- 108010045023 alanyl-prolyl-tyrosine Proteins 0.000 description 1
- 108010045350 alanyl-tyrosyl-alanine Proteins 0.000 description 1
- 108010005233 alanylglutamic acid Proteins 0.000 description 1
- 150000001298 alcohols Chemical class 0.000 description 1
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 1
- 229910052782 aluminium Inorganic materials 0.000 description 1
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 230000003698 anagen phase Effects 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 108010008355 arginyl-glutamine Proteins 0.000 description 1
- 108010001271 arginyl-glutamyl-arginine Proteins 0.000 description 1
- 108010072041 arginyl-glycyl-aspartic acid Proteins 0.000 description 1
- 108010077245 asparaginyl-proline Proteins 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 238000002869 basic local alignment search tool Methods 0.000 description 1
- 238000007630 basic procedure Methods 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- DRTQHJPVMGBUCF-PSQAKQOGSA-N beta-L-uridine Natural products O[C@H]1[C@@H](O)[C@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-PSQAKQOGSA-N 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 230000008238 biochemical pathway Effects 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 230000001851 biosynthetic effect Effects 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 239000001569 carbon dioxide Substances 0.000 description 1
- 229910002092 carbon dioxide Inorganic materials 0.000 description 1
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 238000006555 catalytic reaction Methods 0.000 description 1
- 230000010261 cell growth Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 238000004140 cleaning Methods 0.000 description 1
- 239000013599 cloning vector Substances 0.000 description 1
- 238000010959 commercial synthesis reaction Methods 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 108091036078 conserved sequence Proteins 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 235000005822 corn Nutrition 0.000 description 1
- 239000010779 crude oil Substances 0.000 description 1
- 230000001351 cycling effect Effects 0.000 description 1
- 108010004073 cysteinylcysteine Proteins 0.000 description 1
- 108010016616 cysteinylglycine Proteins 0.000 description 1
- IERHLVCPSMICTF-XVFCMESISA-N cytidine 5'-monophosphate Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](COP(O)(O)=O)O1 IERHLVCPSMICTF-XVFCMESISA-N 0.000 description 1
- GYOZYWVXFNDGLU-XLPZGREQSA-N dTMP Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)C1 GYOZYWVXFNDGLU-XLPZGREQSA-N 0.000 description 1
- 235000013365 dairy product Nutrition 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 239000008367 deionised water Substances 0.000 description 1
- 229910021641 deionized water Inorganic materials 0.000 description 1
- CYQFCXCEBYINGO-IAGOWNOFSA-N delta1-THC Chemical compound C1=C(C)CC[C@H]2C(C)(C)OC3=CC(CCCCC)=CC(O)=C3[C@@H]21 CYQFCXCEBYINGO-IAGOWNOFSA-N 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 239000012153 distilled water Substances 0.000 description 1
- 101150036185 dnaQ gene Proteins 0.000 description 1
- 238000011143 downstream manufacturing Methods 0.000 description 1
- 239000012636 effector Substances 0.000 description 1
- 229940096118 ella Drugs 0.000 description 1
- 210000002472 endoplasmic reticulum Anatomy 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 238000001976 enzyme digestion Methods 0.000 description 1
- 230000032050 esterification Effects 0.000 description 1
- 238000005886 esterification reaction Methods 0.000 description 1
- 235000019441 ethanol Nutrition 0.000 description 1
- 150000002190 fatty acyls Chemical group 0.000 description 1
- 230000002538 fungal effect Effects 0.000 description 1
- 239000005350 fused silica glass Substances 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 238000012268 genome sequencing Methods 0.000 description 1
- 229930195712 glutamate Natural products 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 125000000404 glutamine group Chemical group N[C@@H](CCC(N)=O)C(=O)* 0.000 description 1
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 1
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 1
- 108010049041 glutamylalanine Proteins 0.000 description 1
- 108010079547 glutamylmethionine Proteins 0.000 description 1
- 235000011187 glycerol Nutrition 0.000 description 1
- HPAIKDPJURGQLN-UHFFFAOYSA-N glycyl-L-histidyl-L-phenylalanine Natural products C=1C=CC=CC=1CC(C(O)=O)NC(=O)C(NC(=O)CN)CC1=CN=CN1 HPAIKDPJURGQLN-UHFFFAOYSA-N 0.000 description 1
- 108010019832 glycyl-asparaginyl-glycine Proteins 0.000 description 1
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 1
- 108010010147 glycylglutamine Proteins 0.000 description 1
- 108010077515 glycylproline Proteins 0.000 description 1
- 235000011868 grain product Nutrition 0.000 description 1
- RQFCJASXJCIDSX-UUOKFMHZSA-N guanosine 5'-monophosphate Chemical compound C1=2NC(N)=NC(=O)C=2N=CN1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@H]1O RQFCJASXJCIDSX-UUOKFMHZSA-N 0.000 description 1
- 108010040030 histidinoalanine Proteins 0.000 description 1
- 108010036413 histidylglycine Proteins 0.000 description 1
- 229930195733 hydrocarbon Natural products 0.000 description 1
- 150000002430 hydrocarbons Chemical class 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- 125000001165 hydrophobic group Chemical group 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-M hydroxide Chemical compound [OH-] XLYOFNOQVPJJNP-UHFFFAOYSA-M 0.000 description 1
- 238000007901 in situ hybridization Methods 0.000 description 1
- 229960003786 inosine Drugs 0.000 description 1
- 239000013067 intermediate product Substances 0.000 description 1
- 238000011835 investigation Methods 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 108010027338 isoleucylcysteine Proteins 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- 108010053037 kyotorphin Proteins 0.000 description 1
- 108010051673 leucyl-glycyl-phenylalanine Proteins 0.000 description 1
- 108010091871 leucylmethionine Proteins 0.000 description 1
- 108010012058 leucyltyrosine Proteins 0.000 description 1
- GZQKNULLWNGMCW-PWQABINMSA-N lipid A (E. coli) Chemical compound O1[C@H](CO)[C@@H](OP(O)(O)=O)[C@H](OC(=O)C[C@@H](CCCCCCCCCCC)OC(=O)CCCCCCCCCCCCC)[C@@H](NC(=O)C[C@@H](CCCCCCCCCCC)OC(=O)CCCCCCCCCCC)[C@@H]1OC[C@@H]1[C@@H](O)[C@H](OC(=O)C[C@H](O)CCCCCCCCCCC)[C@@H](NC(=O)C[C@H](O)CCCCCCCCCCC)[C@@H](OP(O)(O)=O)O1 GZQKNULLWNGMCW-PWQABINMSA-N 0.000 description 1
- XIXADJRWDQXREU-UHFFFAOYSA-M lithium acetate Chemical compound [Li+].CC([O-])=O XIXADJRWDQXREU-UHFFFAOYSA-M 0.000 description 1
- 150000004668 long chain fatty acids Chemical class 0.000 description 1
- 235000010598 long-chain omega-6 fatty acid Nutrition 0.000 description 1
- 108010075702 lysyl-valyl-aspartyl-leucine Proteins 0.000 description 1
- 108010064235 lysylglycine Proteins 0.000 description 1
- 108010089734 malonyl-CoA synthetase Proteins 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 235000013622 meat product Nutrition 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 229910021645 metal ion Inorganic materials 0.000 description 1
- 108700023046 methionyl-leucyl-phenylalanine Proteins 0.000 description 1
- 108010034507 methionyltryptophan Proteins 0.000 description 1
- 150000004702 methyl esters Chemical class 0.000 description 1
- 238000009629 microbiological culture Methods 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 239000006151 minimal media Substances 0.000 description 1
- 150000002759 monoacylglycerols Chemical class 0.000 description 1
- 231100000219 mutagenic Toxicity 0.000 description 1
- 239000003471 mutagenic agent Substances 0.000 description 1
- 230000003505 mutagenic effect Effects 0.000 description 1
- WQEPLUUGTLDZJY-UHFFFAOYSA-N n-Pentadecanoic acid Natural products CCCCCCCCCCCCCCC(O)=O WQEPLUUGTLDZJY-UHFFFAOYSA-N 0.000 description 1
- 239000002417 nutraceutical Substances 0.000 description 1
- 235000015097 nutrients Nutrition 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 239000002751 oligonucleotide probe Substances 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 235000015927 pasta Nutrition 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 210000001322 periplasm Anatomy 0.000 description 1
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 1
- 108010065135 phenylalanyl-phenylalanyl-phenylalanine Proteins 0.000 description 1
- 108010024607 phenylalanylalanine Proteins 0.000 description 1
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 1
- 108010083476 phenylalanyltryptophan Proteins 0.000 description 1
- WTJKGGKOPKCXLL-RRHRGVEJSA-N phosphatidylcholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCC=CCCCCCCCC WTJKGGKOPKCXLL-RRHRGVEJSA-N 0.000 description 1
- 150000008104 phosphatidylethanolamines Chemical class 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 230000001124 posttranscriptional effect Effects 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 238000004321 preservation Methods 0.000 description 1
- 230000019525 primary metabolic process Effects 0.000 description 1
- 239000002987 primer (paints) Substances 0.000 description 1
- 108010025826 prolyl-leucyl-arginine Proteins 0.000 description 1
- 108010029020 prolylglycine Proteins 0.000 description 1
- 108010015796 prolylisoleucine Proteins 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 230000004853 protein function Effects 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 230000008929 regeneration Effects 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 238000007127 saponification reaction Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 108010071207 serylmethionine Proteins 0.000 description 1
- 230000035939 shock Effects 0.000 description 1
- 150000004666 short chain fatty acids Chemical class 0.000 description 1
- 229910001923 silver oxide Inorganic materials 0.000 description 1
- 235000011888 snacks Nutrition 0.000 description 1
- 238000000527 sonication Methods 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 108010005652 splenotritin Proteins 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 150000003463 sulfur Chemical class 0.000 description 1
- 238000000194 supercritical-fluid extraction Methods 0.000 description 1
- 150000005672 tetraenes Chemical class 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 238000000844 transformation Methods 0.000 description 1
- 150000005691 triesters Chemical class 0.000 description 1
- MDTPTXSNPBAUHX-UHFFFAOYSA-M trimethylsulfanium;hydroxide Chemical compound [OH-].C[S+](C)C MDTPTXSNPBAUHX-UHFFFAOYSA-M 0.000 description 1
- VFJYIHQDILEQNR-UHFFFAOYSA-M trimethylsulfanium;iodide Chemical compound [I-].C[S+](C)C VFJYIHQDILEQNR-UHFFFAOYSA-M 0.000 description 1
- 108010084932 tryptophyl-proline Proteins 0.000 description 1
- 108010029599 tyrosyl-glutamyl-tryptophan Proteins 0.000 description 1
- 108010051110 tyrosyl-lysine Proteins 0.000 description 1
- 108010077037 tyrosyl-tyrosyl-phenylalanine Proteins 0.000 description 1
- 108010078580 tyrosylleucine Proteins 0.000 description 1
- OOLLAFOLCSJHRE-ZHAKMVSLSA-N ulipristal acetate Chemical compound C1=CC(N(C)C)=CC=C1[C@@H]1C2=C3CCC(=O)C=C3CC[C@H]2[C@H](CC[C@]2(OC(C)=O)C(C)=O)[C@]2(C)C1 OOLLAFOLCSJHRE-ZHAKMVSLSA-N 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 229940035893 uracil Drugs 0.000 description 1
- DRTQHJPVMGBUCF-UHFFFAOYSA-N uracil arabinoside Natural products OC1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-UHFFFAOYSA-N 0.000 description 1
- 229940045145 uridine Drugs 0.000 description 1
- 108010003885 valyl-prolyl-glycyl-glycine Proteins 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 239000002023 wood Substances 0.000 description 1
Images

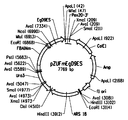















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/1025—Acyltransferases (2.3)
- C12N9/1029—Acyltransferases (2.3) transferring groups other than amino-acyl groups (2.3.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/52—Genes encoding for enzymes or proenzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/80—Vectors or expression systems specially adapted for eukaryotic hosts for fungi
- C12N15/81—Vectors or expression systems specially adapted for eukaryotic hosts for fungi for yeasts
- C12N15/815—Vectors or expression systems specially adapted for eukaryotic hosts for fungi for yeasts for yeasts other than Saccharomyces
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/64—Fats; Fatty oils; Ester-type waxes; Higher fatty acids, i.e. having at least seven carbon atoms in an unbroken chain bound to a carboxyl group; Oxidised oils or fats
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/64—Fats; Fatty oils; Ester-type waxes; Higher fatty acids, i.e. having at least seven carbon atoms in an unbroken chain bound to a carboxyl group; Oxidised oils or fats
- C12P7/6436—Fatty acid esters
- C12P7/6445—Glycerides
- C12P7/6458—Glycerides by transesterification, e.g. interesterification, ester interchange, alcoholysis or acidolysis
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/64—Fats; Fatty oils; Ester-type waxes; Higher fatty acids, i.e. having at least seven carbon atoms in an unbroken chain bound to a carboxyl group; Oxidised oils or fats
- C12P7/6436—Fatty acid esters
- C12P7/6445—Glycerides
- C12P7/6472—Glycerides containing polyunsaturated fatty acid [PUFA] residues, i.e. having two or more double bonds in their backbone
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y203/00—Acyltransferases (2.3)
- C12Y203/01—Acyltransferases (2.3) transferring groups other than amino-acyl groups (2.3.1)
- C12Y203/01016—Acetyl-CoA C-acyltransferase (2.3.1.16)
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Mycology (AREA)
- Oil, Petroleum & Natural Gas (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Plant Pathology (AREA)
- Biophysics (AREA)
- Medicinal Chemistry (AREA)
- Physics & Mathematics (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Enzymes And Modification Thereof (AREA)
- Fats And Perfumes (AREA)
Abstract
리놀레산[18:2, LA]으로부터 에이코사다이엔산[20:2, EDA] 및/또는 α-리놀렌산[18:3, ALA]으로부터 에이코사트라이엔산[20:3, ETrA]으로의 전환 능력을 갖는 돌연변이 델타-9 연장효소가 본 명세서에 개시된다. 돌연변이 델타-9 연장효소를 암호화하는 분리된 핵산 단편 및 이들 단편을 포함하는 재조합 구축물과 함께, 유지성 효모 내에서 이들 돌연변이 델타-9 연장효소를 사용한 장쇄 다중불포화 지방산["PUFA"]의 생성 방법이 또한 개시된다.
Description
본 출원은 본 명세서에 그 전체가 참고로 포함되는 미국 가출원 제61/377,248호(출원일: 2010년 8월 26일)에 대한 우선권을 주장한다.
본 발명은 생명공학의 기술 분야이다. 더욱 자세하게는, 본 발명은 돌연변이 델타-9 지방산 연장효소를 암호화하는 폴리뉴클레오티드 서열의 생성 및 장쇄 다중불포화 지방산["PUFA"]의 제조에서의 이들 연장효소의 용도에 관한 것이다.
식물, 조류, 진균류, 부등편모조류(stramenopiles) 및 효모를 비롯한 다양한 상이한 숙주는 상용의 다중불포화 지방산["PUFA"] 생성의 수단으로서 조사되고 있다. 유전 공학(genetic engineering)에 의해, 일부 숙주의 천연의 능력(심지어 선천적으로 리놀레산["LA"; 18:2 오메가-6] 및 α-리놀렌산["ALA"; 18:3 오메가-3] 지방산 생성으로 제한되는 숙주)이 실질적으로 높은 수준의 다양한 장쇄 오메가-3/오메가-6 PUFA의 생성을 야기하도록 변경될 수 있는 것으로 입증되었다. 이것이 천연의 능력의 결과이든 재조합 기술의 결과이든, 아라키돈산["ARA"; 20:4 오메가-6], 에이코사펜타엔산["EPA"; 20:5 오메가-3], 도코사펜타엔산["DPA"; 22:5 오메가-3] 및 도코사헥사엔산["DHA"; 22:6 오메가-3]의 생성은 모두 델타-9 연장효소 유전자의 발현을 필요로 할 수 있다.
특성화된 델타-9 연장효소는 LA로부터 에이코사다이엔산["EDA"; 20:2 오메가-6]으로의 전환 능력 및 ALA로부터 에이코사트라이엔산["ETrA"; 20:3 오메가-3]으로의 전환 능력을 갖는다. 그러나, 오직 소수의 델타-9 연장효소만이 동정되었다. 이들에는 아이소크라이시스 갈바나(Isochrysis galbana)로부터의 델타-9 연장효소["IgD9e"](서열 번호 1 및 2; PCT 공개 WO 2002/077213호, WO 2005/083093호, WO 2005/012316호 및 WO 2004/057001호; 진뱅크(GenBank) 수탁 번호 AAL37626), 유트렙티엘라(Eutreptiella) 종 CCMP389로부터의 델타-9 연장효소["E389D9e"](서열 번호 3 및 4; 미국 특허 제7,645,604호), 유글레나 그라실리스(Euglena gracilis)로부터의 델타-9 연장효소["EgD9e"](서열 번호 7 및 8; 미국 특허 제7,645,604호) 및 유글레나 아나바에나(Euglena anabaena)로부터의 델타-9 연장효소["EaD9e"](서열 번호 11 및 12; 미국 특허 제7,794,701호)가 포함된다. 미국 특허 제7,645,604호에는 EgD9e, E389D9e와 IgD9e 연장효소 간에, 그리고 그들 중에 보존되었던 7개의 모티프가 동정되어 있지만, 델타-9 연장효소 기능에 중요한 아미노산 잔기를 동정하기 위한 시도로, 오직 단일의 연구가 IgD9e를 사용하여 수행되었다(문헌[Qi, B., et al., FEBS Lett., 547:137-139 (2003)]). 단백질의 유전적 진화를 설명하기 위한 델타-9 연장효소로부터의 결정 구조가 이용가능하지 않으며, 델타-9 연장효소 서열, 구조와 기능 간의 관계에 대하여 거의 알려져 있지 않다. 이러한 지식이 없음에도 불구하고, PUFA를 생성할 수 있는 생성 숙주 세포에서 높은 효소 활성으로 효율적으로 발현되는 델타-9 연장효소 유전자가 필요하다.
상업적으로 유용한 숙주 세포에서 PUFA 생합성 경로로의 통합에 매우 적절한 활성이 높은 신규한 델타-9 연장효소 돌연변이체가 발견되었다. 놀랍게도, 그리고 예기치 않게, 특정 점 돌연변이에 의해, LA로부터 EDA로의 전환에 기초하여, 효소 활성이 야생형 효소의 96% 내지 145%인 델타-9 연장효소 돌연변이체가 야기됨이 관찰되었다.
제1 실시형태에서, 본 발명은
(a) 델타-9 연장효소 활성을 가지며, 서열 번호 22에 기재된 아미노산 서열을 갖는 돌연변이 폴리펩티드를 암호화하는 뉴클레오티드 서열로서, 서열 번호 22는 적어도 하나의 아미노산 돌연변이에 의해 서열 번호 10과 상이하며, 상기 돌연변이(들)가
i) L35F 돌연변이;
ii) L35M 돌연변이;
iii) L35G 돌연변이;
iv) L35G 돌연변이, 및 S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, Q107E, L108G, G127L, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, Q244N, A254W 및 A254Y로 이루어진 군으로부터 선택되는 적어도 하나의 다른 돌연변이;
v) L35G, W132T 및 I179R 돌연변이;
vi) L35G, S9D, Y84C 및 I179R 돌연변이;
vii) L35G, A21V, L108G 및 I179R 돌연변이;
viii) L35G, Y84C, I179R 및 Q244N 돌연변이;
ix) L35G, A21V, W132T, I179R 및 Q244N 돌연변이;
x) K58R 및 I257T 돌연변이;
xi) D98G 돌연변이;
xii) L130M 및 V243A 돌연변이; 및
xiii) K58R, L35F, L35G, L35M, S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, D98G, Q107E, L108G, G127L, L130M, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, V243A, Q244N, A254W, A254Y 및 I257T로 이루어진 군으로부터 선택되는 적어도 2개의 돌연변이를 포함하는 임의의 조합으로 이루어진 군으로부터 선택되는 뉴클레오티드 서열; 및
(b) 파트 (a)의 뉴클레오티드 서열의 상보체로서, 상보체와 파트 (a)의 뉴클레오티드 서열이 동일한 개수의 뉴클레오티드로 이루어져 있으며, 100% 상보성인 파트 (a)의 뉴클레오티드 서열의 상보체를 포함하는 분리된 폴리뉴클레오티드에 관한 것이다.
분리된 폴리뉴클레오티드는 서열 번호 28, 서열 번호 31, 서열 번호 34, 서열 번호 37, 서열 번호 40, 서열 번호 58, 서열 번호 61, 서열 번호 86, 서열 번호 95, 서열 번호 96, 서열 번호 97, 서열 번호 100, 서열 번호 103, 서열 번호 106 및 서열 번호 109로 이루어진 군으로부터 선택되는 뉴클레오티드 서열을 가질 수 있다.
제2 실시형태에서, 본 발명은 특허청구범위 제1항의 분리된 폴리뉴클레오티드에 의해 암호화되는 델타-9 연장효소 활성을 갖는 돌연변이 폴리펩티드에 관한 것이다. 돌연변이 폴레펩티드는 서열 번호 29, 서열 번호 32, 서열 번호 35, 서열 번호 38, 서열 번호 41, 서열 번호 59, 서열 번호 62, 서열 번호 87, 서열 번호 101, 서열 번호 104, 서열 번호 107 및 서열 번호 110으로 이루어진 군으로부터 선택되는 단백질 서열을 가질 수 있다.
제3 실시형태에서, 돌연변이 폴리펩티드는 서열 번호 10에 기재된 폴리펩티드의 델타-9 연장효소 활성과 적어도 대략 기능적으로 동등한 델타-9 연장효소 활성을 가질 것이다. 바람직하게는, 돌연변이 폴리펩티드의 리놀레산으로부터 에이코사다이엔산으로의 기질 전환 백분율은 서열 번호 10에 기재된 폴리펩티드의 리놀레산으로부터 에이코사다이엔산으로의 기질 전환 백분율에 비하여 적어도 110%이며(즉, 적어도 10%의 활성의 향상에 상응), 더욱 바람직하게는, 돌연변이 폴리펩티드의 리놀레산으로부터 에이코사다이엔산으로의 기질 전환 백분율은 적어도 120%이다(즉, 적어도 20%의 활성의 향상에 상응). 제4 실시형태에서, 본 발명은 적어도 하나의 조절 서열에 작동가능하게 연결된 특허청구범위 제1항의 분리된 폴리뉴클레오티드를 포함하는 재조합 구축물(construct)에 관한 것이다.
제5 실시형태에서, 본 발명은 본 발명의 분리된 폴리뉴클레오티드를 포함하는 형질전환된 세포에 관한 것이다. 형질전환된 세포는 바람직하게는 식물, 박테리아, 효모, 조류, 유글레나류(euglenoids), 부등편모조류, 난균류 및 진균류로 이루어진 군으로부터 선택될 수 있다.
제6 실시형태에서, 본 발명은
(a) 본 발명의 분리된 폴리뉴클레오티드를 포함하는 적어도 하나의 재조합 DNA 구축물; 및
(b) 적어도 하나의 조절 서열에 작동가능하게 연결된 분리된 폴리뉴클레오티드를 포함하는 적어도 하나의 재조합 DNA 구축물로서, 델타-4 불포화화효소(desaturase), 델타-5 불포화화효소, 델타-8 불포화화효소, 델타-6 불포화화효소, 델타-9 불포화화효소, 델타-12 불포화화효소, 델타-15 불포화화효소, 델타-17 불포화화효소, C14 /16 연장효소, C16 /18 연장효소, C18 /20 연장효소 및 C20 /22 연장효소로 이루어진 군으로부터 선택되는 폴리펩티드를 암호화하는 구축물을 포함하며, 건조 세포 중량의 적어도 약 25%를 오일로 생성하는 형질전환된 유지성(oleaginous) 효모에 관한 것이며;
여기서, 형질전환된 유지성 효모는 아라키돈산, 에이코사다이엔산, 에이코사펜타엔산, 에이코사테트라엔산, 에이코사트라이엔산, 다이호모-γ-리놀렌산, 도코사테트라엔산, 도코사펜타엔산 및 도코사헥사엔산으로 이루어진 군으로부터 선택되는 장쇄 다중불포화 지방산을 생성할 수 있다.
더욱 자세하게는, 본 발명의 트랜스제닉(transgenic) 유지성 효모는 야로위아 리폴리티카(Yarrowia lipolytica)이다.
제7 실시형태에서, 본 발명은
a) i) 적어도 하나의 조절 서열에 작동가능하게 연결되는 재조합 구축물로서, 상기 재조합 구축물이 델타-9 연장효소 활성을 가지며, 서열 번호 22에 기재된 아미노산 서열을 갖는 돌연변이 폴리펩티드를 암호화하는 분리된 폴리뉴클레오티드를 포함하며, 서열 번호 22가 적어도 하나의 아미노산 돌연변이에 의해 서열 번호 10과 상이하며, 상기 돌연변이(들)가
(a) L35F 돌연변이;
(b) L35M 돌연변이;
(c) L35G 돌연변이;
(d) L35G 돌연변이, 및 S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, Q107E, L108G, G127L, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, Q244N, A254W 및 A254Y로 이루어진 군으로부터 선택되는 적어도 하나의 다른 돌연변이;
(e) L35G, W132T 및 I179R 돌연변이;
(f) L35G, S9D, Y84C 및 I179R 돌연변이;
(g) L35G, A21V, L108G 및 I179R 돌연변이;
(h) L35G, Y84C, I179R 및 Q244N 돌연변이;
(i) L35G, A21V, W132T, I179R 및 Q244N 돌연변이;
(j) K58R 및 I257T 돌연변이;
(k) D98G 돌연변이;
(l) L130M 및 V243A 돌연변이; 및
(m) K58R, L35F, L35G, L35M, S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, D98G, Q107E, L108G, G127L, L130M, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, V243A, Q244N, A254W, A254Y 및 I257T로 이루어진 군으로부터 선택되는 적어도 2개의 돌연변이를 포함하는 임의의 조합으로 이루어진 군으로부터 선택되는 재조합 구축물; 및
ii) 리놀레산 및 알파-리놀렌산으로 이루어진 군으로부터 선택되는 기질 지방산의 공급원을 포함하는 유지성 효모를 제공하는 단계;
b) 델타-9 연장효소 활성을 갖는 돌연변이 폴리펩티드를 암호화하는 재조합 구축물이 발현되고, 기질 지방산이 생성물 지방산으로 전환되는 조건 하에서 단계 (a)의 효모를 성장시키는 단계로서, 리놀레산이 에이코사다이엔산으로 전환되고, 알파-리놀렌산이 에이코사트라이엔산으로 전환되는 단계; 및
c) 임의로, 단계 (b)의 생성물 지방산을 회수하는 단계를 포함하는 다중불포화 지방산의 생성 방법에 관한 것이다.
제8 실시형태에서, 본 발명은 본 발명의 유지성 효모로부터 수득되는 미생물 오일에 관한 것이다.
제9 실시형태에서, 본 발명은 건조 세포 중량의 중량 백분율로 측정시 적어도 22.5 중량%의 에이코사펜타엔산을 포함하는 오일을 생성하는 재조합 미생물 숙주 세포로서, 본 발명의 적어도 하나의 돌연변이 델타-9 연장효소 폴리펩티드를 포함하는 재조합 미생물 숙주 세포에 관한 것이다.
생물학적 기탁
하기의 생물학적 물질은 미국 버지니아주 20110-2209, 머내서스 볼리바드 대학 10801 아메리칸 타입 컬쳐 콜렉션(ATCC)에 기탁되어 있으며, 하기에 명칭, 수탁 번호 및 기탁일이 있다.

상술된 생물학적 물질은 특허 절차 상의 미생물 기탁의 국제적 승인에 관한 부다페스트 조약 하에 기탁되었다. 열거된 기탁물은 적어도 30년간 표시된 국제기탁기관에 유지될 것이며, 그것을 개시한 특허의 허여시 공중에게 이용가능하게 될 것이다. 기탁물의 입수가능성은 정부 조치에 의해 허여된 특허권을 침해하는 방식으로 대상 발명이 실시되는 허가를 이루는 것은 아니다.
야로위아 리폴리티카 Y9502는 미국 특허 출원 공개 제2010-0317072-A1호에 기재된 방법에 따라, 야로위아 리폴리티카 Y8412로부터 유래된 것이다.
도면 및 서열 목록의 간단한 설명
<도 1>
도 1은 벡터 엔티아이(Vector NTI)(등록 상표)의 얼라인엑스(AlignX) 프로그램(미국 캘리포니아주 칼스배드 소재의 인비트로겐 코포레이션(Invitrogen Corporation))을 사용한 아이소크라이시스 갈바나의 델타-9 연장효소["IgD9e"](서열 번호 2), 유트렙티엘라 종 CCMP389의 델타-9 연장효소["E389D9e"](서열 번호 4), 유글레나 그라실리스의 델타-9 연장효소["EgD9e"](서열 번호 8) 및 유글레나 아나바에나의 델타-9 연장효소["EaD9e"](서열 번호 12)의 정렬이다.
<도 2>
도 2는 pZUFmEgD9ES의 플라스미드 맵이다.
<도 3a, 3b, 3c, 3d, 3e, 3f, 3g 및 3h>
도 3a, 3b, 3c, 3d, 3e, 3f, 3g 및 3h는 클러스탈더블유(ClustalW) 정렬 방법을 사용한 키오나 인테스티날리스(Ciona intestinalis)(서열 번호 43), 온코린처스 마이키스(Oncorhynchus mykiss)(서열 번호 44), 마르찬티아 폴리모르파(Marchantia polymorpha)(서열 번호 45), 피스코미트렐라 파텐스(Physcomitrella patens)(서열 번호 46), 마르찬티아 폴리모르파(서열 번호 47), 오스트레오코커스 타우리(Ostreococcus tauri)(서열 번호 48), 파블로바(Pavlova) 종 CCMP459(서열 번호 49), 파블로바 살리나(Pavlova salina)(서열 번호 50), 오스트레오코커스 타우리(서열 번호 51), 유글레나 아나바에나(서열 번호 12), 유글레나 그라실리스(서열 번호 8), 유트렙티엘라 종 CCMP389(서열 번호 4), 아이소크라이시스 갈바나(서열 번호 2), 탈라시오시라 슈도나나(Thalassiosira pseudonana)(서열 번호 52), 탈라시오시라 슈도나나(서열 번호 53), 모르티에렐라 알피나(Mortierella alpina)(서열 번호 54) 및 트라우스토키트리움(Thraustochytrium) 종 FJN-10(서열 번호 55)으로부터의 17개 지방산 연장효소의 정렬이다.
<도 4a>
도 4a는 EgD9eS의 막 위상 모델을 보여주며; 각각의 수직의 원통은 막-스패닝 세그먼트(membrane-spanning segment)를 나타내는 한편, 각각의 수평의 원통은 내막 리플릿(leaflet) 내의 또는 그 근처의 소수성 스트레치(stretch)를 나타낸다.
<도 4b>
도 4b는 임의로 L35F 돌연변이; L35M 돌연변이; L35G 돌연변이; L35G 돌연변이, 및 S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, Q107E, L108G, G127L, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, Q244N, A254W 및 A254Y로 이루어진 군으로부터 선택되는 적어도 하나의 다른 돌연변이; L35G, A21V, L108G 및 I179R 돌연변이; L35G, W132T 및 I179R 돌연변이; L35G, S9D, Y84C 및 I179R 돌연변이; L35G, Y84C, I179R 및 Q244N 돌연변이; L35G, A21V, W132T, I179R 및 Q244N 돌연변이; K58R 및 I257T 돌연변이; D98G 돌연변이; L130M 및 V243A 돌연변이; 및 K58R, L35F, L35G, L35M, S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, D98G, Q107E, L108G, G127L, L130M, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, V243A, Q244N, A254W, A254Y 및 I257T로 이루어진 군으로부터 선택되는 적어도 2개의 돌연변이를 포함하는 임의의 조합을 포함하는 유글레나 그라실리스 유래의 합성 돌연변이 델타-9 연장효소(즉, "EgD9eS-돌연변이체 공통서열(consensus)"; 서열 번호 22)의 도식을 보여준다.
<도 5a 및 도 5b>
도 5a 및 도 5b는 오메가-3 및 오메가-6 지방산 생합성 경로를 예시한 것이며, 함께 고려해야 한다.
<도 6>
도 6은 전체 지질 분획 중에서 58.7% 초과의 EPA를 생성하는 야로위아 리폴리티카 균주 Z1978의 개발을 도시한다.
<도 7>
도 7은 (a) pZKUM; 및 (b) pZKL3-9DP9N에 대한 플라스미드 맵을 제공한다.
본 발명은 하기의 상세한 설명 및 첨부된 서열 설명으로부터 더욱 완전하게 이해될 수 있으며, 이들은 본 출원의 일부를 형성한다.
하기의 서열들은 37 C.F.R. §1.821-1.825("뉴클레오티드 서열 및/또는 아미노산 서열 개시를 포함하는 특허출원에 관한 요건 - 서열 규정")를 따르며 세계지적재산권기구(World Intellectual Property Organization, WIPO) 표준 ST.25(1998), 및 EPO 및 PCT의 서열 목록 요건(규정 5.2 및 49.5(a-bis), 및 시행세칙의 섹션 208 및 부칙 C)에 부합한다. 뉴클레오티드 및 아미노산 서열 데이터에 사용된 기호 및 체제는 37 C.F.R. §1.822에 제시된 규정을 준수한다.
서열 번호 1 내지 111은 표 1에 확인된 바와 같은 ORF 암호화 유전자, 단백질(또는 그의 부분), 프라이머 또는 플라스미드이다.




본 명세서에 개시된 모든 특허, 특허 출원서 및 공개문헌은 그들 전문이 참고로 포함된다.
본 개시내용에서, 다수의 용어 및 약어가 사용된다. 아미노산은 아미노산에 대한 1-문자 코드 또는 3-문자 코드로 표기되며, 문헌[Nucleic Acids Research , 13:3021-3030 (1985)] 및 문헌[Biochemical Journal , 219 (2):345-373 (1984)]에 기재된 IUPAC-IYUB 기준에 부합되며, 상기 문헌은 본 명세서에 참고로 포함된다.
하기의 정의가 제공된다.
"오픈 리딩 프레임(open reading frame)"은 "ORF"로 약칭된다.
"중합효소 연쇄 반응"은 "PCR"로 약칭된다.
"아메리칸 타입 컬쳐 콜렉션(American Type Culture Collection)"은 "ATCC"로 약칭된다.
"다중불포화 지방산(들)"은 "PUFA(들)"로 약칭된다.
"트라이아실글리세롤"은 "TAG"로 약칭된다.
"전체 지방산"은 "TFA"로 약칭된다.
"지방산 메틸 에스테르"는 "FAME"로 약칭된다.
본 명세서에서 사용되는 용어 "발명" 또는 "본 발명"은 본 명세서의 특허청구범위 및 상세한 설명에 기재된 본 발명의 모든 태양 및 실시형태를 지칭하고자 하며, 임의의 특정 실시형태 또는 태양에 제한되는 것으로 해석되어서는 안된다.
용어 "지방산"은 약 C12 내지 C22의 다양한 쇄 길이의 장쇄 지방족 산(알칸산)을 지칭하지만, 더 긴 쇄 길이의 산과 더 짧은 쇄 길이의 산이 둘 모두 공지되어 있다. 주된 쇄 길이는 C16 내지 C22이다. 지방산의 구조는 "X:Y"의 단순한 표기 체계로 표현되며, 여기서, X는 특정 지방산에서의 전체 탄소 원자["C"]의 개수이고, Y는 이중 결합의 개수이다. "포화 지방산" 대 "불포화 지방산", "단일불포화 지방산" 대 "다중불포화 지방산"["PUFA"] 및 "오메가-6 지방산"["ω-6" 또는 "n-6"] 대 "오메가-3 지방산"["ω-3" 또는 "n-3"] 간의 구별에 관한 추가의 상세사항은 본 명세서에 참고로 포함되는 미국 특허 제7,238,482호에 제공되어 있다.
본 명세서에서 PUFA를 기재하는데 사용되는 명명법은 표 2에 제공되어 있다. "약칭 표기"라는 표제의 열에서, 오메가-참조 체계는 탄소의 개수, 이중 결합의 개수 및 오메가 탄소와 가장 가까운 이중 결합의 위치를 오메가 탄소(이러한 목적을 위해 1로 번호를 매김)로부터 카운팅하여, 표시하기 위해 사용된다. 표의 나머지는 오메가-3 및 오메가-6 지방산의 일반명 및 그들의 전구체, 본 명세서에서 사용될 약어 및 각 화합물의 화학명을 요약한 것이다.

본 명세서에 기재된 방법을 사용하여 표 2에 기재된 오메가-3/오메가-6 PUFA가 미생물 및 식물 숙주의 오일 분획에 축적될 것 같지만, 이러한 목록은 제한하거나 완전한 것으로 간주되어서는 안된다.
용어 "오일"은 25℃에서 액체인 지질 물질을 말하며; 오일은 소수성이나 유기 용매 중에서 용해성이다. 유지성 유기체에서, 오일은 전체 지질의 주요 부분을 구성한다. "오일"은 주로 트라이아실글리세롤["TAG"]로 이루어지나, 다른 중성 지질, 인지질 및 유리 지방산도 또한 함유할 수 있다. 오일 중의 지방산 조성 및 전체 지질의 지방산 조성은 일반적으로 유사하며; 이에 따라, 전체 지질 중의 PUFA의 농도의 증가 또는 감소는 오일 중의 PUFA의 농도의 증가 또는 감소와 부합할 것이며, 그 역도 또한 그러하다.
"중성 지질"은 저장 지방으로서 지질체 중의 세포에서 통상적으로 관찰되는 지질을 지칭하고, 이렇게 지칭되는 것은 세포 pH에서 지질이 전하를 띠지 않은 기를 보유하기 때문이다. 일반적으로, 이들은 물에 대한 친화성이 없이 완전히 비-극성이다. 중성 지질은 일반적으로, 글리세롤과 지방산의 모노-, 다이-, 및/또는 트라이에스테르를 지칭하고, 또한 모노아실글리세롤["MAG"], 다이아실글리세롤["DAG"] 또는 트라이아실글리세롤로 각각 지칭되거나, 집합적으로 아실글리세롤로 지칭된다. 아실글리세롤로부터 유리 지방산을 유리시키기 위해서는 가수분해 반응이 일어나야만 한다.
용어 "트라이아실글리세롤"["TAG"]은 글리세롤 분자에 에스테르화된 3개의 지방 아실 잔기로 구성된 중성 지질을 지칭한다. TAG는 장쇄 PUFA 및 포화 지방산뿐 아니라 보다 짧은 쇄의 포화 및 불포화 지방산을 포함할 수 있다.
본 명세서에서, 용어 "전체 지방산"["TFA"]은 예를 들어, 바이오매스 또는 오일일 수 있는 주어진 시료에서 염기 에스테르 교환 방법(당업계에 공지되어 있는)에 의해 지방산 메틸 에스테르["FAME"]로 유도체화될 수 있는 모든 세포 지방산의 합을 말한다. 따라서, 전체 지방산은 중성 지질 분획(DAG, MAG 및 TAG 포함) 및 극성 지질 분획(예컨대, 포스파티딜콜린["PC"] 및 포스파티딜에탄올아민["PE"] 분획 포함)으로부터의 지방산을 포함하나, 유리 지방산은 포함하지 않는다.
용어 세포의 "전체 지질 함량"은 건조 세포 중량["DCW"]의 백분율로서의 TFA의 측정치이지만, 전체 지질 함량은 DCW의 백분율로서의 FAME["FAME % DCW"]의 측정치로 근사치를 계산할 수 있다. 따라서, 전체 지질 함량["TFA % DCW"]은 예를 들어, 100 밀리그램의 DCW당 전체 지방산의 밀리그램과 등가이다.
전체 지질 중의 지방산의 농도는 본 명세서에서 TFA의 중량 백분율["% TFA"], 예컨대, 100 밀리그램의 TFA당 주어진 지방산의 밀리그램으로 표현된다. 본 명세서의 개시내용에서 구체적으로 달리 기재되지 않는 한, 전체 지질에 대한 주어진 지방산의 백분율에 대한 참조는 % TFA로서의 지방산의 농도와 등가이다(예컨대, 전체 지질의 EPA%는 EPA % TFA와 등가이다).
일부 경우에, 건조 세포 중량의 그의 중량 백분율["% DCW"]로서 세포 중의 주어진 지방산(들)의 함량을 표현하는 것이 유용하다. 따라서, 예를 들어, EPA % DCW는 하기의 식에 따라 결정할 것이다: (EPA % TFA) * (TFA % DCW)]/100. 그러나, 세포 중의 주어진 지방산(들)의 함량은 건조 세포 중량의 그의 중량 백분율["% DCW"]로서 하기의 식으로 근사치를 계산할 수 있다: (EPA % TFA) * (FAME % DCW)]/100.
용어 "지질 프로파일" 및 "지질 조성"은 상호교환가능하며, 특정 지질 분획, 예컨대 전체 지질 또는 오일에 함유되는 개별 지방산의 양을 지칭하며, 여기서 이러한 양은 TFA의 중량 백분율로 표현된다. 혼합물에 존재하는 각 개별 지방산의 합은 100이어야 한다.
용어 "PUFA 생합성 경로"는 올레산을 오메가-6 지방산, 예컨대 LA, EDA, GLA, DGLA, ARA, DTA 및 DPAn-6, 및 오메가-3 지방산, 예컨대 ALA, STA, ETrA, ETA, EPA, DPA 및 DHA로 전환시키는 대사 과정을 지칭한다. 이러한 과정은 문헌에 널리 기재되어 있다(예컨대, 미국 특허 제7,932,077호 참조). 간단하게 설명하자면, 이 과정은 소포체 막에 존재하는 "PUFA 생합성 경로 효소"로 지칭되는 일련의 특별한 연장 및 불포화 효소를 통하여, 탄소 원자의 부가를 통한 탄소 쇄의 연장 및 이중 결합의 부가를 통한 분자의 불포화화를 수반한다. 더욱 구체적으로, "PUFA 생합성 경로 효소"는 PUFA의 생합성과 관련이 있는 다음을 포함하는 효소(및 상기 효소를 암호화하는 유전자) 중 임의의 것을 지칭한다: 델타-4 불포화화효소, 델타-5 불포화화효소, 델타-6 불포화화효소, 델타-12 불포화화효소, 델타-15 불포화화효소, 델타-17 불포화화효소, 델타-9 불포화화효소, 델타-8 불포화화효소, 델타-9 연장효소, C14/16 연장효소, C16/18 연장효소, C18/20 연장효소 및/또는 C20/22 연장효소.
용어 "델타-9 연장효소/델타-8 불포화화효소 경로"는 최소한 적어도 하나의 델타-9 연장효소 및 적어도 하나의 델타-8 불포화화효소를 포함하여, 중간체 지방산으로서 EDA 및/또는 ETrA와 함께, 각각 LA 및 ALA로부터 DGLA 및/또는 ETA의 생합성을 가능하게 하는 PUFA 생합성 경로를 지칭할 것이다. 다른 불포화화효소 및 연장효소의 발현과 함께, ARA, DTA, DPAn-6, EPA, DPA 및 DHA도 합성될 수 있다.
용어 "불포화화효소"는 하나 이상의 지방산을 불포화화시켜, 즉, 하나 이상의 지방산에 이중 결합을 도입시켜, 대상 지방산 또는 전구체를 생성할 수 있는 폴리펩티드를 지칭한다. 본 명세서에서 특정 지방산을 언급하기 위해 오메가-참조 체계가 사용되고는 있지만, 델타-체계를 사용하여 기질의 카복실 말단으로부터 카운팅하여 불포화화효소의 활성을 표시하는 것이 보다 편리하다. 본 명세서에서, 델타-8 불포화화효소, 델타-5 불포화화효소, 델타-17 불포화화효소, 델타-12 불포화화효소, 델타-4 불포화화효소, 델타-6 불포화화효소, 델타-15 불포화화효소 및 델타-9 불포화화효소가 특히 흥미로운 것이다.
용어 "연장효소"는 기질 지방산 탄소 쇄를 연장시켜, 연장효소가 작용하는 지방산 기질보다 2개의 탄소가 더 긴 지방산을 생성할 수 있는 폴리펩티드를 지칭한다. 이러한 연장 과정은 미국 특허 제7,659,120호에 기재된 바와 같이, 지방산 신타아제(synthase)와 연계된 다단계 메카니즘에서 발생한다. 연장효소 계에 의해 촉매작용되는 반응의 예에는 LA로부터 EDA로의 전환, ALA로부터 ETrA로의 전환, GLA로부터 DGLA로의 전환, STA로부터 ETA로의 전환, ARA로부터 DTA로의 전환 및 EPA로부터 DPA로의 전환이 있다. 일반적으로, 연장효소의 기질 선택성은 다소 광범위하나, 쇄 길이, 및 불포화 정도 및 유형 둘 모두에 의해 구분된다. 예를 들어, C14 /16 연장효소는 C14 기질(예컨대, 미리스트산)을 사용할 것이며, C16 /18 연장효소는 C16 기질(예컨대, 팔미테이트)을 사용할 것이며, C18 /20 연장효소는 C18 기질(예컨대, GLA, STA, LA 및 ALA)을 사용할 것이며, C20 /22 연장효소[델타-5 연장효소 또는 C20 연장효소로도 지칭됨]는 C20 기질(예컨대, ARA, EPA)을 사용할 것이다. 본 명세서의 목적을 위하여, 2가지의 별개의 C18 /20 연장효소의 유형을 규정할 수 있다: 델타-6 연장효소는 각각 GLA 및 STA로부터 DGLA 및 ETA로의 전환을 촉매작용시킬 것이나, 델타-9 연장효소는 각각 LA 및 ALA로부터 EDA 및 ETrA로의 전환을 촉매작용시킬 수 있다.
용어 "EgD9e"는 본 명세서에서 서열 번호 7에 의해 암호화되는 유글레나 그라실리스로부터 분리된 델타-9 연장효소(서열 번호 8)를 지칭한다. 유사하게, 용어 "EgD9eS"는 야로위아 리폴리티카에서의 발현을 위해 코돈-최적화된 유글레나 그라실리스 유래의 합성 델타-9 연장효소(즉, 서열 번호 9 및 10)를 지칭한다. EgD9e 및 EgD9eS와 관련된 추가의 상세사항은 미국 특허 제7,645,604호에 기재되어 있다.
본 명세서의 목적을 위하여, 용어 "EaD9e"는 본 명세서에서 서열 번호 11에 의해 암호화된, 유글레나 아나바에나로부터 분리된 델타-9 연장효소(서열 번호 12)를 지칭한다. 유사하게, 용어 "EaD9eS"는 야로위아 리폴리티카에서의 발현을 위해 코돈-최적화된 유글레나 아나바에나 유래의 합성 델타-9 연장효소(즉, 서열 번호 13 및 14)를 지칭한다. EaD9e 및 EaD9eS와 관련된 추가의 상세사항은 미국 특허 제7,794,701호에 기재되어 있다.
용어 "E389D9e"는 본 명세서에서 서열 번호 3에 의해 암호화된 유트렙티엘라 종 CCMP389로부터 분리된 델타-9 연장효소(서열 번호 4)를 지칭한다. 유사하게, 용어 "E389S9eS"는 야로위아 리폴리티카에서의 발현을 위해 코돈-최적화된 유트렙티엘라 종 CCMP389 유래의 합성 델타-9 연장효소(즉, 서열 번호 5 및 6)를 지칭한다. E389D9e 및 E389D9eS와 관련된 추가의 상세사항은 미국 특허 제7,645,604호에 기재되어 있다.
용어 "IgD9e"는 본 명세서에서 서열 번호 1에 의해 암호화된 아이소크라이시스 갈바나로부터 분리된 델타-9 연장효소(서열 번호 2; NCBI 수탁 번호 AAL37626(GI 17226123))를 지칭한다.
용어 "보존된 도메인" 또는 "모티프"는 진화적으로 관련된 단백질의 정렬된 서열을 따라 특정 위치에서 보존된 일련의 아미노산을 의미한다. 다른 위치의 아미노산은 상동 단백질들 간에 달라질 수 있는 반면에, 특정 위치에서 고도로 보존된 아미노산은 이들 아미노산이 단백질의 구조, 안정성, 또는 활성에 있어서 중요할 수 있음을 나타낸다. 이들은 단백질 상동체의 패밀리의 정렬된 서열에서의 이들의 높은 보존도에 의해 확인되기 때문에, 이들은 새로 결정된 서열을 갖는 단백질이 이전에 동정된 단백질 패밀리에 속하는지 여부를 결정하기 위한 식별자(identifier) 또는 "표시자(signature)"로 사용될 수 있다.
델타-9 연장효소 모티프는 미국 특허 제7,645,604호에 기재되어 있으며, Y-N-X-(L 또는 F)-X4-S-X2-S-F(서열 번호 15); F-Y-X-S-K-X2-(E 또는 D)-Y-X-D-(T 또는 S)-X2-L(서열 번호 16); L-(Q 또는 H)-X-F-H-H-X-G-A(서열 번호 17); M-Y-X-Y-Y-X7-(K 또는 R 또는 N)-F(서열 번호 18); K-X-L-(I 또는 L 또는 M)-T-X2-Q(서열 번호 19); W-X-F-N-Y-X-Y(서열 번호 20); 및 Y-X-G-X-V-X2-L-F(서열 번호 21)를 포함하며; 여기서, X는 임의의 아미노산일 수 있으며, 밑줄이 그어진 아미노산은 델타-9 연장효소에 독특한 것일 수 있다. 벡터 엔티아이(등록 상표)의 얼라인엑스 프로그램(미국 캘리포니아주 칼스배드 소재의 인비트로겐 코포레이션)의 디폴트 파라미터를 사용한 IgD9e(서열 번호 2), EgD9e(서열 번호 8), E389D9e(서열 번호 4) 및 EaD9e(서열 번호 12)의 아미노산 서열의 다중의 정렬은 도 1에 나타나 있다. 모든 정렬된 서열 간에 보존된 미국 특허 제7,645,604호의 델타-9 연장효소 모티프는 공통 서열 내의 밑줄이 그어진 굵은 문자로 도면에 나타나 있다.
용어 "돌연변이 EgD9eS"는 야로위아 리폴리티카에서의 발현을 위해 코돈-최적화된 유글레나 그라실리스 유래의 합성 델타-9 연장효소(즉, EgD9eS[서열 번호 9 및 10])에 대하여 적어도 하나의 뉴클레오티드 또는 아미노산 돌연변이를 갖는 본 발명의 델타-9 연장효소를 지칭한다. "돌연변이"가 임의의 결실, 삽입 및 점 돌연변이(또는 그들의 조합)를 포함할 수 있지만, 바람직한 실시형태에서, 돌연변이 EgD9eS는 서열 번호 22에 기재되어 있으며(도 4b), 여기서 서열 번호 22는 적어도 하나의 아미노산 돌연변이에 의해 서열 번호 10과 상이하며, 상기 돌연변이(들)는 a) L35F 돌연변이; b) L35M 돌연변이; c) L35G 돌연변이; d) L35G 돌연변이 및 S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, Q107E, L108G, G127L, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, Q244N, A254W 및 A254Y로 이루어진 군으로부터 선택되는 적어도 하나의 다른 돌연변이; e) L35G, A21V, L108G 및 I179R 돌연변이; f) L35G, W132T 및 I179R 돌연변이; g) L35G, S9D, Y84C 및 I179R 돌연변이; h) L35G, Y84C, I179R 및 Q244N 돌연변이; i) L35G, A21V, W132T, I179R 및 Q244N 돌연변이; j) K58R 및 I257T 돌연변이; k) D98G 돌연변이; l) L130M 및 V243A 돌연변이; 및 m) K58R, L35F, L35G, L35M, S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, D98G, Q107E, L108G, G127L, L130M, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, V243A, Q244N, A254W, A254Y 및 I257T로 이루어진 군으로부터 선택되는 적어도 2개의 돌연변이를 포함하는 임의의 조합으로 이루어진 군으로부터 선택된다. 열거된 각각의 치환에 대하여, 처음의 문자는 EgD9eS의 아미노산(서열 번호 10)에 해당하며, 두번째 문자는 돌연변이체에서 동일한 위치에서 관찰되는 아미노산(서열 번호 22)에 해당하며, 즉, L35F는 위치 35에서 EgD9eS의 Leu[L]로부터 EgD9eS 돌연변이체의 Phe[F]로의 변화를 나타낸다. 이러한 명명법은 본 명세서에 기재된 델타-9 연장효소 단백질 내의 돌연변이를 지칭하기 위해 본 명세서에 사용되며; 유사한 명명법을 사용하여 뉴클레오티드 서열 내의 치환을 기재한다(즉, C62T는 위치 62에서 EgD9eS(서열 번호 9)의 시토신[C]으로부터 EgD9eS 돌연변이체의 티민[T]으로의 변화를 나타낸다).
돌연변이 EgD9eS는 돌연변이 EgD9eS 서열의 효소 활성(및 임의로, 특이적 선택성)이 상이한 폴리펩티드 서열에도 불구하고, EgD9eS의 효소 활성과 유사한 경우, EgD9eS와 "적어도 대략 기능적으로 동등"하다. 따라서, 기능적으로 동등한 돌연변이 EgD9eS 서열은 각 효소의 "전환 효율"을 비교하는 경우, EgD9eS의 활성에 대하여 실질적으로 감소되지 않은 델타-9 연장효소 활성을 보유할 것이다(즉, 돌연변이 EgD9eS는 EgD9eS의 적어도 약 50%, 바람직하게는 적어도 약 75%, 더욱 바람직하게는 적어도 약 85%, 가장 바람직하게는 적어도 약 95%의 효소 활성을 가질 것이다). 더욱 바람직한 실시형태에서, 돌연변이 EgD9eS는 EgD9eS의 효소 활성에 비해 증가된 효소 활성(및 임의로, 특이적 선택성)을 가질 것이다(즉, EgD9eS의 적어도 약 101-150%, 더욱 바람직하게는 적어도 약 151-200%, 가장 바람직하게는 적어도 약 201-250%의 효소 활성). 바람직한 범위가 상술되어 있지만, EgD9eS와 비교한 전환 효율의 유용한 예에는 50% 내지 적어도 250%, 예컨대 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 100%, 101%, 102%, 103%, 104%, 105%, 106%, 107%, 108%, 109%, 110%, 111%, 112%, 113%, 114%, 115%, 116%, 117%, 118%, 119%, 120%, 121%, 122%, 123%, 124%, 125%, 126%, 127%, 128%, 129%, 130%, 131%, 132%, 133%, 134%, 135%, 136%, 137%, 138%, 139%, 140%, 141%, 142%, 143%, 144%, 145%, 146%, 147%, 148%, 149%, 150%, 250% 이하의 기타의 임의의 정수 백분율이 포함된다.
용어 "전환 효율" 및 "기질 전환 백분율"은 특정 효소(예컨대, 델타-9 연장효소)가 기질을 생성물로 전환시킬 수 있는 효율을 지칭한다. 전환 효율은 하기의 식에 따라 측정된다: ([생성물]/[기질 + 생성물])*100, 여기서, '생성물'은 중간 생성물 및 그로부터 유래된 경로에서의 모든 생성물을 포함한다. 따라서, "LA로부터 EDA로의 전환 효율"은 기질, 즉, LA가 생성물, 즉, EDA로 전환되는 전환 효율을 지칭한다.
일반적으로, 용어 "유지성"은 유기체의 에너지원을 오일의 형태로 저장하는 경향이 있는 유기체를 지칭한다(문헌[Weete, In: Fungal Lipid Biochemistry, 2nd Ed., Plenum, 1980]). 이러한 과정 동안, 유지성 미생물의 세포 오일 함량은 일반적으로 S자 모양의 곡선을 따르며, 여기서, 지질의 농도는 그것이 후기 대수 성장기 또는 초기 정지 성장기에서 최대에 도달할 때까지 증가하였다가 후기 정지기 및 사멸기 동안에 점차적으로 감소한다(문헌[Yongmanitchai and Ward, Appl. Environ. Microbiol., 57:419-25 (1991)]). 용어 "유지성"은 본 출원의 목적을 위해, 그리고 미생물에 관하여 사용되는 경우, 미생물의 DCW의 적어도 약 25%를 오일로 축적할 수 있는 미생물을 지칭한다.
용어 "유지성 효모"는 오일을 만들 수 있는 효모로 분류되는 이러한 유지성 미생물을 지칭하며, 다시 말하면, 여기서, 효모의 DCW의 약 25%의 과량으로 오일이 축적될 수 있다. 유지성 효모의 예에는 하기의 속이 포함되나, 이에 제한되는 것을 의미하는 것은 아니다: 야로위아, 칸디다(Candida), 로도토룰라(Rhodotorula), 로도스포리듐(Rhodosporidium), 크립토코커스(Cryptococcus), 트리코스포론(Trichosporon) 및 리포마이세스(Lipomyces). 효모의 DCW의 약 25% 과량의 오일을 축적하는 능력은 재조합 엔지니어링(engineering)의 결과를 통하여 또는 유기체의 천연의 능력을 통하여 이루어질 수 있다.
용어 "보존적 아미노산 치환"은 주어진 단백질 중의 아미노산 잔기가 다른 아미노산으로 치환되면서, 그 단백질의 화학적 또는 기능적 성질은 변경시키지 않는 치환을 말한다. 예를 들어, 주어진 부위에서 화학적으로 동등한 아미노산의 생성을 야기하는(그러나, 암호화되는 폴딩(folding)된 단백질의 구조적 및 기능적 특성에는 영향을 주지 않는) 유전자의 변경이 일반적이라는 것은 당업계에 널리 공지되어 있다. 본 발명의 목적을 위하여, "보존적 아미노산 치환"은 하기 5개 그룹 중 하나 내에서의 교환으로 정의된다:
1. 비극성 또는 약간 극성인 작은 지방족 잔기: Ala[A], Ser[S], Thr[T](Pro[P], Gly[G]);
2. 음으로 하전된 극성 잔기 및 그들의 아미드: Asp[D], Asn[N], Glu[E], Gln[Q];
3. 양으로 하전된 극성 잔기: His[H], Arg[R], Lys[K];
4. 비극성인 큰 지방족 잔기: Met[M], Leu[L], Ile[I], Val[V](Cys[C]); 및
5. 큰 방향족 잔기: Phe[F], Tyr[Y], Trp[W].
따라서, 알라닌, 즉, 약간 소수성인 아미노산은 다른 소수성이 더 작은 잔기(예컨대, Gly)로 치환될 수 있다. 유사하게, 음으로 하전된 하나의 잔기로 다른 하나를(예를 들어 아스파르트산으로 글루탐산을) 치환하거나 양으로 하전된 하나의 잔기로 다른 하나를(예를 들어, 라이신으로 아르기닌을) 치환하는 변화도 기능적으로 동등한 생성물을 생성하는 것으로 예상될 수 있다. 이와 같이, 보존적 아미노산 치환은 일반적으로 1) 치환 영역에서의 폴리펩티드 백본(backbone) 구조; 2) 표적 부위에서의 분자의 전하 또는 소수성; 또는, 3) 측쇄의 규모(bulk)를 유지한다. 추가로, 많은 경우에서, 단백질 분자의 N-말단부 및 C-말단부의 변경도 또한 단백질의 활성을 변경시키는 것으로 예상되지 않을 것이다.
용어 "비-보존적 아미노산 치환"은 일반적으로 단백질 특성에 있어서 가장 큰 변화를 생성할 것으로 예상되는 아미노산 치환을 지칭한다. 따라서, 예를 들어, 비-보존적 아미노산 치환은 1) 친수성 잔기가 소수성 잔기로 치환되거나 그 반대의 경우(예컨대, Ser 또는 Thr이 Leu, Ile, Val으로 치환되거나 그 반대의 경우); 2) Cys 또는 Pro가 임의의 다른 잔기로 치환되거나 그 반대의 경우; 3) 전기양성 측쇄를 갖는 잔기가 전기음성 잔기로 치환되거나 그 반대의 경우(예컨대, Lys, Arg 또는 His이 Asp 또는 Glu으로 치환되거나 그 반대의 경우); 또는 4) 부피가 큰 측쇄를 갖는 잔기가 측쇄를 갖지 않는 것으로 치환되거나 그 반대의 경우(예컨대, Phe이 Gly으로 치환되거나 그 반대의 경우)에 의한 것일 것이다. 때때로, 5개 그룹 중 2개 간의 비-보존적 아미노산 치환은 암호화되는 단백질의 활성에 영향을 주지 않을 것이다.
용어 "침묵(silent) 돌연변이"는 암호화되는 폴리펩티드의 아미노산 변화를 야기하지 않는 DNA 서열의 돌연변이를 지칭한다. 이들 돌연변이는 종종 1개 초과의 코돈이 하나의 아미노산을 명시할 수 있는 유전자 코드의 축퇴성(degeneracy)의 결과로 발생한다. 예를 들어, TCT, TCA, TCG 및 TCC는 모두 아미노산 Ser을 암호화하며; 이에 따라, DNA 서열 내의 TCT로부터 TCA로의 돌연변이는 유전자(또는 그의 mRNA)의 시퀀싱(sequencing)에 의해서만 검출될 수 있을 것인데, 이는 합성된 단백질 내의 아미노산(즉, Ser)의 변경이 없기 때문이다.
용어 "폴리뉴클레오티드", "폴리뉴클레오티드 서열", "핵산 서열", "핵산 단편" 및 "분리된 핵산 단편"은 본 명세서에서 상호교환가능하게 사용된다. 이들 용어는 뉴클레오티드 서열 등을 포함한다. 폴리뉴클레오티드는 합성, 비-천연 뉴클레오티드 염기 또는 변경된 뉴클레오티드 염기를 임의로 함유하는 단일- 또는 이중-가닥인 RNA 또는 DNA의 폴리머일 수 있다. DNA의 폴리머 형태인 폴리뉴클레오티드는 cDNA, 게놈 DNA, 합성 DNA, 또는 그들의 혼합물의 하나 이상의 세그먼트로 이루어질 수 있다. 뉴클레오티드(통상적으로, 그들의 5'-모노포스페이트 형태로 관찰됨)는 다음과 같은 1-문자 표시로 언급된다: 아데닐레이트 또는 데옥시아데닐레이트(각각 RNA 또는 DNA에 대한 것)는 "A", 시티딜레이트 또는 데옥시시티딜레이트는 "C", 구아닐레이트 또는 데옥시구아닐레이트는 "G", 유리딜레이트는 "U", 데옥시티미딜레이트는 "T", 퓨린(A 또는 G)은 "R", 피리미딘(C 또는 T)은 "Y", G 또는 T는 "K", A 또는 C 또는 T는 "H", 이노신은 "I", 및 임의의 뉴클레오티드는 "N".
아미노산 또는 뉴클레오티드 서열의 "상당한 부분"은, 당업자에 의한 서열의 수동 평가에 의해, 또는 BLAST(기본 국소 정렬 검색 도구(Basic Local Alignment Search Tool); 문헌[Altschul, S. F., et al., J. Mol . Biol ., 215:403-410(1993)])와 같은 알고리듬을 사용하는 컴퓨터-자동화 서열 비교 및 동정에 의해, 폴리펩티드 또는 유전자를 추정상으로 동정하기에 충분한 폴리펩티드의 아미노산 서열 또는 유전자의 뉴클레오티드 서열을 포함하는 부분이다. 일반적으로, 폴리펩티드 또는 핵산 서열을 공지의 단백질 또는 유전자와 상동성인 것으로 추정상 동정하기 위해서는 10 개 이상 연속되는 아미노산 또는 30 개 이상의 뉴클레오티드의 서열이 필요하다. 더욱이, 뉴클레오티드 서열에 있어서는, 서열-의존적인 유전자 동정(예를 들어, 서던 혼성화(Southern hybridization)) 및 분리(예를 들어, 박테리아 콜로니 또는 박테리오파아지 플라크의 동소 혼성화(in situ hybridization)) 방법에 20 내지 30개의 연속된 뉴클레오티드를 포함하는 유전자 특이적 올리고뉴클레오티드 프로브가 사용될 수 있다. 또한, 12 내지 15개 염기의 짧은 올리고뉴클레오티드를 PCR에서 증폭 프라이머로 사용하여, 프라이머를 포함하는 특정 핵산 단편을 얻을 수 있다. 따라서, 뉴클레오티드 서열의 "상당한 부분"은, 서열을 포함하는 핵산 단편을 특이적으로 동정 및/또는 분리하기에 충분한 서열을 포함한다. 본 명세서의 개시내용은 특정 연장효소를 암호화하는 뉴클레오티드 서열 및 완전한 아미노산을 교시하고 있다. 본 명세서에 기록된 서열의 이익을 갖는 당업자는 이제 당업자에게 알려져 있는 목적을 위하여 개시된 서열의 모든 또는 상당한 부분을 사용할 수 있다. 따라서, 첨부하는 서열 목록에 보고된 완전 서열뿐 아니라 상기 정의된 서열들의 상당한 부분이 본 개시내용에 포함된다.
용어 "상보성"은 서로 혼성화될 수 있는 뉴클레오티드 염기 간의 관계를 기술하기 위해 사용된다. 예를 들어, DNA에 있어서 아데노신은 티민에 상보성이고 시토신은 구아닌에 상보성이다. 따라서, 첨부된 서열 목록에 기록된 완전한 서열뿐 아니라 실질적으로 유사한 핵산 서열에 대하여 상보성인 분리된 핵산 단편은 본 발명의 개시내용에 포함된다.
용어 "상동성, "상동성인", "실질적으로 유사한" 및 "실질적으로 상응하는"은 본 명세서에서 상호교환가능하게 사용된다. 그들은 유사하나 동일하지 않은 서열을 갖는 핵산 단편 또는 폴리펩티드를 지칭한다. 또한, 이들 용어는 때때로 초기의 변형되지 않은 단편에 비하여 생성된 핵산 단편의 기능적 특성을 실질적으로 변경시키지 않는 핵산 단편의 변형(예를 들어, 하나 이상의 뉴클레오티드의 결실 또는 삽입을 통한)을 말한다. 그러므로, 당업자가 인식할 바와 같이, 본 발명은 특정 예시적 서열을 초과하여 포괄한다는 것이 이해된다.
핵산 또는 폴리펩티드 서열과 관련하여 "서열 동일성" 또는 "동일성"은, 특정 비교창에 걸쳐 최대 상응도로 정렬되는 경우에 2개 서열 중의 동일한 핵산 염기 또는 아미노산 잔기를 지칭한다.
따라서, "서열 동일성의 백분율" 또는 "동일성 백분율"은 비교창에 걸쳐 최적으로 정렬된 2개의 서열을 비교함으로써 결정된 값을 지칭하며, 여기서 비교창 내의 폴리뉴클레오티드 또는 폴리펩티드 서열의 부분은 2개 서열의 최적 정렬을 위한 기준 서열(삽입 또는 결실을 포함하지 않음)과 비교하여 삽입 또는 결실(즉, 갭)을 포함할 수 있다. 양자 모두의 서열 내에서 동일한 핵산 염기 또는 아미노산 잔기가 나타나는 위치의 개수를 결정하여 일치하는 위치의 개수를 산출하고, 일치하는 위치의 개수를 비교창 내의 위치의 총 개수로 나누고, 그 결과에 100을 곱하여 서열 동일성의 백분율을 산출함으로써 백분율을 계산한다.
"동일성 백분율" 및 "유사성 백분율"의 결정 방법은 공중 이용가능한 컴퓨터 프로그램에 코드화되어 있다. 동일성 백분율 및 유사성 백분율은 하기의 문헌에 기재된 것을 포함하나 이에 한정되지 않는 공지의 방법에 의해 용이하게 계산될 수 있다: 1) 문헌[Computational Molecular Biology (Lesk, A. M., Ed.) Oxford University: NY (1988)]; 2) 문헌[Biocomputing : Informatics and Genome Projects (Smith, D. W., Ed.) Academic: NY (1993)]; 3) 문헌[Computer Analysis of Sequence Data , Part I (Griffin, A. M., and Griffin, H. G., Eds.) Humania: NJ (1994)]; 4) 문헌[Sequence Analysis in Molecular Biology (von Heinje, G., Ed.) Academic (1987)]; 및 5) 문헌[Sequence Analysis Primer (Gribskov, M. and Devereux, J., Eds.) Stockton: NY (1991)].
서열 정렬 및 동일성 또는 유사성 백분율 계산은, 레이저진 바이오인포매틱스 컴퓨팅 스위트(LASERGENE bioinformatics computing suite)(미국 위스콘신주 메디슨 소재의 디엔에이스타 인코포레이티드(DNASTAR Inc.))의 멕얼라인(MegAlign)(상표명) 프로그램을 포함하나 이에 한정되지 않는, 상동성 서열을 검출하도록 고안된 다양한 비교 방법을 사용하여 결정할 수 있다. 서열의 다중 정렬은 "클러스탈 브이 정렬 방법" 및 "클러스탈 더블유 정렬 방법"(문헌[Higgins and Sharp, CABIOS, 5:151-153 (1989)]; 문헌[Higgins, D.G. et al., Comput. Appl. Biosci., 8:189-191(1992)]에 기재)을 포함하는 몇가지 종류의 알고리듬을 포함하는 "클러스탈 정렬 방법"을 사용하여 수행되며, 레이저진 바이오인포매틱스 컴퓨팅 스위트(디엔에이 스타 인코포레이티드)의 멕얼라인(상표명)(버젼 8.0.2) 프로그램에서 관찰된다. 클러스탈 프로그램 중 어느 하나를 사용한 서열의 정렬 후에, 프로그램 내의 "서열 거리" 표를 봄으로써 "동일성 백분율"을 수득할 수 있다.
클러스털 브이 정렬 방법을 사용한 다중 정렬에 대하여 디폴트 값은 갭 페널티(GAP PENALTY)=10 및 갭 길이 페널티(GAP LENGTH PENALTY)=10에 해당한다. 클러스탈 브이 방법을 사용하는 단백질 서열의 동일성 백분율의 계산 및 쌍정렬을 위한 디폴트 파라미터는 케이터플(KTUPLE)=1, 갭 페널티=3, 윈도우(WINDOW)=5 및 다이아고날스 세이브드(DIAGONALS SAVED)=5이다. 핵산의 경우, 이들 파라미터는 케이터플=2, 갭 페널티=5, 윈도우=4 및 다이아고날스 세이브드=4이다.
클러스털 더블유 정렬 방법을 사용한 다중 정렬을 위한 디폴트 파라미터는 갭 페널티=10, 갭 길이 페널티=0.2, 딜레이 디버전트 시퀀스(Delay Divergent Seqs)(%)=30, DNA 전이 중량(DNA Transition Weight)=0.5, 단백질 중량 매트릭스(Protein Weight Matrix)=고넷 시리즈(Gonnet Series), DNA 중량 매트릭스(DNA Weight Matrix)=IUB에 해당한다.
"BLASTN 정렬 방법"은 디폴트 파라미터를 사용하여 뉴클레오티드 서열을 비교하기 위해 국립생물정보센터["NCBI"]에 의해 제공되는 알고리듬이며, "BLASTP 정렬 방법"은 디폴트 파라미터를 사용하여 단백질 서열을 비교하기 위해 NCBI에 의해 제공되는 알고리듬이다.
동일하거나 유사한 기능 또는 활성을 가진 폴리펩티드를 다른 종으로부터 동정함에 있어서 여러 수준의 서열 동일성이 유용하다는 것이 당업자에게 주지되어 있다. 본 명세서의 개시내용에 따른 적절한 핵산 단편, 즉, 분리된 폴리뉴클레오티드는 적어도 약 70-85% 동일한 폴리펩티드를 암호화하는 한편, 더욱 바람직한 핵산 단편은 본 명세서에 기록된 아미노산 서열과 적어도 약 85-95% 동일한 아미노산 서열을 암호화한다. 바람직한 범위가 상술되어 있지만, 유용한 동일성 백분율의 예에는 70% 내지 100%, 예컨대 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%의 임의의 정수 백분율이 포함된다. 또한, 이러한 분리된 뉴클레오티드 단편의 임의의 전장 또는 부분 상보체도 관심대상이다.
적절한 핵산 단편은 상기 상동성을 가질 뿐 아니라 전형적으로, 적어도 50개 아미노산, 바람직하게는 적어도 100개 아미노산, 더욱 바람직하게는 적어도 150개 아미노산, 더더욱 바람직하게는 적어도 200개 아미노산, 가장 바람직하게는 적어도 250개 아미노산을 갖는 폴리펩티드를 암호화한다.
"코돈 축퇴성"은 암호화된 폴리펩티드의 아미노산 서열에 영향을 주지 않으면서 뉴클레오티드 서열의 변이를 허용하는 유전자 코드의 성질을 지칭한다. 따라서, EgD9eS-L35F(서열 번호 29), EgD9eS-K58R/I257T(서열 번호 32), EgD9eS-L130M/V243A1(서열 번호 35), EgD9eS-D98G(서열 번호 38), EgD9eS-L130M/V243A2(서열 번호 41), EgD9eS-L35G(서열 번호 59), EgD9eS-L35M/Q107E(서열 번호 62), EgD9eS-A21V/L35G/L108G/I179R(서열 번호 87), EgD9eS-L35G/W132T/I179R(서열 번호 101), EgD9eS-L35G/S9D/Y84C/I179R(서열 번호 104), EgD9eS-L35G/Y84C/I179R/Q244N(서열 번호 107), EgD9eS-L35G/A21V/W132T/I179R/Q244N(서열 번호 110) 및 EgD9eS-돌연변이체 공통서열(서열 번호 22)에 기재된 본 발명의 델타-9 연장효소 폴리펩티드를 암호화하는 아미노산 서열의 모든 또는 상당한 부분을 암호화하는 임의의 핵산 단편이 본 명세서에 기재된다. 주어진 아미노산을 특정하기 위한 뉴클레오티드 코돈의 사용에 있어서 특정 숙주 세포에서 나타나는 "코돈-편향(codon-bias)"이 당업자에게 주지되어 있다. 그러므로, 숙주 세포 내의 발현을 향상시키기 위해 유전자를 합성할 경우에는, 그의 코돈 사용 빈도가 숙주 세포가 선호하는 코돈의 사용 빈도에 근접하도록 유전자를 고안하는 것이 바람직하다.
"합성 유전자"는 당업자에게 공지되어 있는 절차를 사용하여 화학적으로 합성된 올리고뉴클레오티드 빌딩 블록(building block)으로부터 조립될 수 있다. 이들 올리고뉴클레오티드 빌딩 블록을 어닐링시킨 다음, 라이게이션시켜, 유전자 세그먼트를 형성하며, 이어서, 효소적으로 조립하여 전체 유전자를 구축한다. 따라서, 유전자는 숙주 세포의 코돈 편향을 반영하기 위하여 뉴클레오티드 서열의 최적화에 기초하여 최적의 유전자 발현을 위해 맞춤화될 수 있다. 당업자는 코돈 사용이 숙주가 선호하는 코돈에 편향된다면, 성공적인 유전자 발현이 가능함을 인식한다. 바람직한 코돈의 결정은 서열 정보를 이용할 수 있는 숙주 세포로부터 유래된 유전자의 조사에 기초할 수 있다. 예를 들어, 야로위아 리폴리티카에 대한 코돈 사용 프로파일은 미국 특허 제7,125,672호에 제공되어 있다.
"유전자"는 특정 단백질을 발현하며, 단독의 암호화 영역을 지칭하거나 암호화 영역 업스트림 및/또는 다운스트림의 조절 서열(예컨대, 암호화 영역의 전사 시작 부위의 업스트림 5' 미번역 영역, 3' 비-암호화 영역)을 포함할 수 있는 핵산 단편을 지칭한다. "천연 유전자"는 그 자신의 조절 서열과 함께 자연에서 발견되는 유전자를 지칭한다. "키메라 유전자"는 자연에서 함께 발견되지 않는 조절 및 암호화 서열을 포함하는, 천연 유전자가 아닌 임의의 유전자를 지칭한다. 따라서, 키메라 유전자는 상이한 공급원으로부터 유래된 조절 서열과 암호화 서열, 또는 동일한 공급원으로부터 유래되었지만, 자연에서 발견되는 것과 상이한 방식으로 배열된 조절 서열과 암호화 서열을 포함할 수 있다. "내인성 유전자"는 유기체의 게놈에서 그의 자연의 위치에 있는 천연 유전자를 지칭한다. "외래" 유전자는 유전자 전달에 의해 숙주 유기체 내로 도입된 유전자를 지칭한다. 외래 유전자는 비-천연 유기체에 삽입된 천연 유전자, 천연 숙주 내의 새로운 위치에 도입된 천연 유전자, 또는 키메라 유전자를 포함할 수 있다. "트랜스유전자(transgene)"는 형질전환 절차에 의해 게놈 내로 도입된 유전자이다. "코돈-최적화된 유전자"는 그의 코돈 사용 빈도가 숙주 세포의 선호하는 코돈 사용의 빈도를 모방하도록 설계된 유전자이다.
"암호화 서열"은 특정 아미노산 서열을 암호화하는 DNA 서열을 지칭한다. "조절 서열"은 암호화 서열의 전사 시작 부위의 업스트림, 5' 미번역 영역 및 3' 비암호화 영역에 위치하고, 전사, RNA 프로세싱 또는 안정성, 또는 관련 암호화 서열의 번역에 영향을 미칠 수 있는 뉴클레오티드 서열을 지칭한다. 조절 서열은 프로모터, 인핸서(enhancer), 사일런서(silencer), 5' 미번역 리더 서열(leader sequence), 인트론, 폴리아데닐화 인식 서열, RNA 프로세싱 부위, 이펙터(effector) 결합 부위 및 스템-루프(stem-loop) 구조를 포함할 수 있으나, 이에 한정되지 않는다.
"프로모터"는 암호화 서열 또는 기능적 RNA의 발현을 조절할 수 있는 DNA 서열을 지칭한다. 일반적으로, 프로모터 서열은 암호화 서열의 5' 업스트림이다. 프로모터는 천연 유전자로부터 그 전체가 유래될 수도 있거나, 자연에서 발견되는 상이한 프로모터로부터 유래된 상이한 요소로 구성될 수도 있거나, 심지어 합성 DNA 세그먼트를 포함할 수도 있다. 상이한 프로모터가 상이한 조직 또는 세포 유형에서, 또는 상이한 세포 성장 및/또는 발생 단계에서, 또는 상이한 환경 조건에 반응하여 유전자의 발현을 유도할 수 있음을 당업자는 이해할 것이다. 유전자가 거의 모든 발생 단계에서 발현되게 하는 프로모터는 통상 "구성적(constitutive) 프로모터"로 지칭된다. 대부분의 경우에, 조절 서열의 정확한 경계(특히 그들의 5' 말단에서)가 완벽하게 규정되어 있지 않기 때문에, 일부 변이가 있는 DNA 단편이 동일한 프로모터 활성을 가질 수 있다는 것이 추가로 인식된다.
용어 "3' 비암호화 서열", "전사 종결자(terminator)", "종결자" 및 "종결 서열"은 암호화 서열의 3' 다운스트림에 위치한 DNA 서열을 지칭한다. 이는 폴리아데닐화 인식 서열 및 mRNA 프로세싱 또는 유전자 발현에 영향을 미칠 수 있는 조절 신호를 암호화하는 다른 서열을 포함한다. 폴리아데닐화 신호는 통상적으로 mRNA 전구체의 3' 말단에 폴리아데닐산 트랙트(tract)를 부가하는 데에 영향을 미치는 것을 특징으로 한다. 3' 영역은 전사, RNA 프로세싱 또는 안정성, 또는 관련 암호화 서열의 번역에 영향을 미칠 수 있다.
"RNA 전사체"는 DNA 서열의 RNA 중합효소-촉매작용된 전사로부터 야기된 생성물을 지칭한다. RNA 전사체가 DNA 서열의 완벽한 상보성 카피(copy)인 경우, 그는 1차 전사체로 지칭된다. RNA 전사체가 1차 전사체의 전사후 프로세싱으로부터 유래된 RNA 서열인 경우에, RNA 전사체는 성숙 RNA라고 지칭한다. "메신저 RNA" 또는 "mRNA"는 인트론을 갖고 있지 않으며 세포에 의해 단백질로 번역될 수 있는 RNA를 지칭한다. "cDNA"는 mRNA 주형에 상보성이고 역전사효소를 이용하여 그로부터 합성되는 DNA를 지칭한다. cDNA는 단일-가닥일 수도 있거나, 또는 DNA 중합효소 I의 클레나우(Klenow) 단편을 이용하여 이중-가닥 형태로 전환될 수도 있다. "센스" RNA는 mRNA를 포함하며 세포 내에서 또는 시험관내에서 단백질로 번역될 수 있는 RNA 전사체를 지칭한다. "안티센스 RNA"는 표적 1차 전사체 또는 mRNA의 전부 또는 일부에 상보성이고, 표적 유전자의 발현을 차단시키는 RNA 전사체를 지칭한다(미국 특허 제5,107,065호).
용어 "작동가능하게 연결된"은 하나의 기능이 나머지에 의해 영향을 받도록 하는, 단일 핵산 단편 상에서의 핵산 서열의 연계를 지칭한다. 예를 들어, 프로모터는 그것이 암호화 서열의 발현에 영향을 미칠 수 있는 경우에, 암호화 서열에 작동가능하게 연결되며, 다시 말하면, 암호화 서열은 프로모터의 전사 조절 하에 있다. 암호화 서열은 센스 또는 안티센스 배향으로 조절 서열에 작동가능하게 연결될 수 있다.
용어 "재조합"은, 예를 들어 유전 공학 기술에 의한 분리된 핵산 세그먼트의 조작에 의하거나 화학적 합성에 의한, 다르게 분리되어 있는 2개의 서열 세그먼트의 인공의 조합을 지칭한다.
본 명세서에 사용되는 용어 "발현"은 센스(mRNA) 또는 안티센스 RNA의 전사 및 안정적인 축적을 지칭한다. 또한, 발현은 mRNA의 단백질(전구체 또는 성숙체 중 어느 하나)로의 번역도 포함한다.
"형질전환"은, 숙주 유기체 내로 핵산 분자를 전달하여 유전적으로 안정적인 유전성을 유발하는 것을 지칭한다. 핵산 분자는 예를 들어, 자가 복제되는 플라스미드일 수 있거나, 그것이 숙주 유기체의 게놈 내로 통합될 수 있다. 형질전환된 핵산 단편을 함유하는 숙주 유기체는 "트랜스제닉" 또는 "재조합" 또는 "형질전환된" 또는 "형질전환체" 유기체로 지칭된다.
용어 "플라스미드" 및 "벡터"는 종종 세포의 중추적 대사의 일부가 아닌 유전자를 운반하는 보통 원형의 이중 가닥 DNA 단편 형태의 염색체 외 요소를 지칭한다. 이러한 요소는 자가 복제되는 서열, 게놈 통합 서열, 파지 또는 뉴클레오티드 서열을 가질 수 있으며, 임의의 공급원으로부터 유래되는 선형 또는 원형의 단일- 또는 이중-가닥 DNA 또는 RNA일 수 있고, 여기서, 다수의 뉴클레오티드 서열은 세포 내로 발현 카세트(들)를 도입할 수 있는 독특한 구축물 내로 결합되거나 재조합된다.
용어 "발현 카세트"는 외래 숙주에서 외래 유전자의 발현을 가능하게 하는 외래 유전자 외의 요소를 가지며, 외래 유전자를 함유하는 DNA의 단편을 지칭한다. 일반적으로, 발현 카세트는 선택된 유전자의 암호화 서열, 및 선택된 유전자 생성물의 발현에 필요한 암호화 서열에 선행하는 조절 서열(5' 비암호화 서열) 및 후행하는 조절 서열(3' 비암호화 서열)을 포함할 것이다. 따라서, 발현 카세트는 전형적으로 1) 프로모터 서열; 2) 암호화 서열(즉, ORF); 및, 3) 통상 진핵생물에서의 폴리아데닐화 부위를 함유하는 종결자로 이루어진다. 발현 카세트(들)는 통상적으로 벡터 내에 포함되어, 클로닝 및 형질전환을 용이하게 한다. 정확한 조절 서열이 각각의 숙주에 대하여 사용되는 한, 상이한 발현 카세트가 박테리아, 효모, 식물 및 포유류 세포를 비롯한 상이한 유기체 내로 형질전환될 수 있다.
용어 "재조합 구축물", "발현 구축물", "키메라 구축물", "구축물" 및 "재조합 DNA 구축물"은 본 명세서에서 상호호환적으로 사용된다. 재조합 구축물은 핵산 단편, 예를 들어, 자연에서는 함께 발견되지 않는 조절 및 암호화 서열의 인공 조합을 포함한다. 예를 들어, 재조합 DNA 구축물은 상이한 공급원으로부터 유래된 조절 서열 및 암호화 서열, 또는 동일한 공급원으로부터 유래되지만, 자연에서 발견되는 것과는 상이한 방식으로 배열된 조절 서열 및 암호화 서열을 포함할 수 있다. 이러한 구축물은 단독으로 사용될 수도 있거나, 벡터와 함께 사용될 수도 있다. 벡터를 사용한다면, 당업자에게 주지된 바와 같이 백터의 선택은 숙주 세포를 형질전환시키기 위해 사용될 방법에 따라 달라진다. 예를 들어, 플라스미드 벡터를 사용할 수 있다. 본 명세서에 기재된 임의의 분리된 핵산 단편을 포함하는 숙주 세포를 성공적으로 형질전환시키고 선택하고 증식시키기 위하여 벡터 상에 존재해야 하는 유전 요소는 당업자에게 주지되어 있다. 또한, 당업자는 상이한 독립적인 형질전환 사건이 상이한 발현 수준 및 패턴을 야기할 것이며(문헌[Jones et al., EMBO J., 4:2411-2418 (1985)]; 문헌[De Almeida et al., Mol. Gen. Genetics, 218:78-86 (1989)]), 이에 따라, 목적하는 발현 수준 및 패턴을 나타내는 균주 또는 세포주를 수득하기 위해서는 그러한 다중의 사건을 스크리닝해야 한다는 것을 인식할 것이다. 이러한 스크리닝은 특히 DNA의 서던(Southern) 분석, mRNA 발현의 노던(Northern) 분석, 단백질 발현의 웨스턴(Western) 및/또는 엘라이자(Elisa) 분석, 특정 생성물의 형성, PUFA 생성물의 표현형 분석 또는 GC 분석에 의해 달성될 수 있다.
용어 "숙주 세포" 및 "숙주 유기체"는 본 명세서에서 상호교환가능하게 사용되며, 외래 또는 이종 유전자를 받아들일 수 있으며 그 유전자를 발현할 수 있는 임의의 유기체, 예컨대 미생물 또는 식물(즉, 유지종자 식물)을 지칭한다. "재조합 숙주 세포"는 재조합으로 엔지니어링되는 숙주 세포를 지칭한다.
용어 "서열 분석 소프트웨어"는 뉴클레오티드 또는 아미노산 서열을 분석하는데 유용한 임의의 컴퓨터 알고리듬 또는 소프트웨어 프로그램을 지칭한다. "서열 분석 소프트웨어"는 상업적으로 입수할 수 있거나 독립적으로 개발할 수 있다. 전형적인 서열 분석 소프트웨어에는 하기의 것이 포함될 것이나, 이에 한정되지 않는다: 1) GCG 프로그램 모음(위스콘신 패키지 버전(Wisconsin Package Version) 9.0, 미국 위스콘신주 매디슨 소재의 제네틱스 컴퓨터 그룹(Genetics Computer Group, GCG)); 2) BLASTP, BLASTN, BLASTX(문헌[Altschul et al., J. Mol . Biol ., 215:403-410 (1990)]); 3) DNASTAR(미국 위스콘신주 매디슨 소재의 디엔에이스타, 인코포레이티드); 4) 시퀀쳐(Sequencher)(미국 미시간주 앤 아버 소재의 진 코즈 코포레이션(Gene Codes Corporation)); 및, 5) 스미스-워터만(Smith-Waterma) 알고리듬을 통합하는 파스타(FASTA) 프로그램(문헌[W. R. Pearson, Comput. Methods Genome Res ., [Proc. Int. Symp.] (1994), Meeting Date 1992, 111-20. Editor (s): Suhai, Sandor. Plenum: New York, NY]). 본 출원 내에서, 서열 분석 소프트웨어를 분석에 이용할 때마다, 달리 특정하지 않는 한, 분석 결과는 인용된 프로그램의 "디폴트 값"에 기초한다. 본 명세서에 사용되는 바와 같이, "디폴트 값"은 최초 초기화할 때에 소프트웨어에 원래 로딩된 값 또는 파라미터의 임의의 세트를 의미할 것이다.
본 명세서에 사용되는 표준 재조합 DNA 및 분자 클로닝 기술은 당업계에 주지되어 있으며, 문헌[Sambrook, J., Fritsch, E.F. and Maniatis, T. Molecular Cloning: A Laboratory Manual; Cold Spring Harbor Laboratory: Cold Spring Harbor, NY (1989)]; 문헌[Silhavy, T. J., Bennan, M. L. and Enquist, L. W., Experiments with Gene Fusions, Cold Spring Harbor Laboratory: Cold Spring Harbor, NY (1984)]; 및 문헌[Ausubel, F. M. et al., Current Protocols in Molecular Biology, published by Greene Publishing Assoc. and Wiley-Interscience, Hoboken, NJ (1987)]에 더욱 완전히 기재되어 있다.
건강에 좋은 PUFA의 생성을 위한 생화학적 경로의 조작에 사용될 수 있는 새로운 돌연변이 델타-9 연장효소 및 이를 암호화하는 유전자가 본 명세서에 개시되어 있다.
도 5a 및 5b에는 특정 오메가-3/오메가-6 지방산(들)의 생성을 위한 다수의 대안적인 경로가 함께 기재되어 있다. 모든 경로는 델타-12 불포화화효소에 의해 올레산이 처음의 오메가-6 지방산인 리놀레산["LA"]으로 초기 전환되는 것을 필요로 한다. 이어서, "델타-9 연장효소/델타-8 불포화화효소 경로" 및 기질로서 LA를 사용하여, 장쇄 오메가-6 지방산이 하기와 같이 형성된다: 1) LA는 델타-9 연장효소에 의해 에이코사다이엔산["EDA"]으로 전환되고; 2) EDA는 델타-8 불포화화효소에 의해 다이호모-γ-리놀렌산["DGLA"]으로 전환되고; 3) DGLA는 델타-5 불포화화효소에 의해 아라키돈산["ARA"]으로 전환되고; 4) ARA는 C20 /22 연장효소에 의해 도코사테트라엔산["DTA"]으로 전환되고; 5) DTA는 델타-4 불포화화효소에 의해 도코사펜타엔산["DPAn-6"]으로 전환된다.
또한, "델타-9 연장효소/델타-8 불포화화효소 경로"는 하기와 같이 기질로서 알파-리놀렌산["ALA"]을 사용하여 장쇄 오메가-3 지방산을 생성할 수 있다: 1) LA는 델타-15 불포화화효소에 의해 처음의 오메가-3 지방산인 ALA로 전환되고; 2) ALA는 델타-9 연장효소에 의해 에이코사트라이엔산["ETrA"]으로 전환되고; 3) ETrA는 델타-8 불포화화효소에 의해 에이코사테트라엔산["ETA"]으로 전환되고; 4) ETA는 델타-5 불포화화효소에 의해 에이코사펜타엔산["EPA"]으로 전환되고; 5) EPA는 C20/22 연장효소에 의해 도코사펜타엔산["DPA"]으로 전환되고; 6) DPA는 델타-4 불포화화효소에 의해 도코사헥사엔산["DHA"]으로 전환된다. 임의로, 오메가-6 지방산은 오메가-3 지방산으로 전환될 수 있다. 예를 들어, ETA 및 EPA는 델타-17 불포화화효소 활성에 의해 각각 DGLA 및 ARA로부터 생성된다.
오메가-3/오메가-6 지방산의 생합성을 위한 대안적인 경로는 델타-6 불포화화효소 및 C18/20 연장효소, 즉, "델타-6 불포화화효소/델타-6 연장효소 경로"를 사용한다. 더욱 구체적으로, LA 및 ALA는 델타-6 불포화화효소에 의해 각각 GLA 및 스테아리돈산["STA"]으로 전환된 다음; C18/20 연장효소에 의해 GLA가 DGLA로 전환되고/거나 STA가 ETA로 전환될 수 있다. 다운스트림 PUFA는 상술된 바와 같이 후속하여 형성된다.
유기체가 오메가-3/오메가-6 지방산을 생성하는 것을 가능하게 하거나 그 능력을 증가시키기 위하여 특정 숙주 유기체 내로 도입될 필요가 있는 특정 기능이 숙주 세포(및 그의 천연 PUFA 프로파일 및/또는 불포화화효소/연장효소 프로파일), 기질의 이용가능성 및 목적하는 최종 생성물(들)에 의해 좌우될 것임이 고려된다. 이들 고려사항뿐 아니라, 불포화화효소 및 연장효소(예컨대, 델타-6 불포화화효소, C18/20 연장효소, 델타-5 불포화화효소, 델타-17 불포화화효소, 델타-15 불포화화효소, 델타-9 불포화화효소, 델타-12 불포화화효소, C14/16 연장효소, C16/18 연장효소, 델타-9 연장효소, 델타-8 불포화화효소, 델타-4 불포화화효소 및 C20/22 연장효소)를 암호화하는 특정 유전자의 동정 및 선택에 영향을 미치는 인자에 대한 검토는 미국 특허 제7,238,482호 및 미국 특허 제7,932,077호에서 찾을 수 있다.
그러나, 본 발명과 특히 관련된 일 태양은 특정 숙주 유기체에서 발현되어야 하는 각각의 특정 불포화화효소 및/또는 연장효소의 전환 효율이다. 더욱 자세하게는, 각각의 효소는 드물게 100%의 효율로 기질을 생성물로 전환시키도록 기능하기 때문에, 숙주 세포에서 생성된 미정제된 오일의 최종 지질 프로파일은 전형적으로, 목적하는 오메가-3/오메가-6 지방산으로 이루어진 다양한 PUFA뿐 아니라 다양한 업스트림 중간 PUFA의 혼합물일 것이다. 따라서, 목적하는 지방산의 생합성의 최적화시에, 각 효소의 전환 효율을 종종 고려한다.
일단 지방산이 유기체 내에서 합성되면(포화 및 불포화 지방산 및 단쇄 및 장쇄 지방산 포함), 그들은 TAG 내로 혼입될 수 있다. TAG는 지방산에 대한 일차 저장 유닛이다.
공동 소유의 미국 특허 공개 제2007-0118929-A1호 및 미국 특허 제7,645,604호는 둘 모두 LA를 EDA로 연장시킬 수 있는 유글레나 그라실리스(Euglena gracilis) 델타-9 연장효소("EgD9e"; 본 명세서에서 서열 번호 7 및 8)를 개시하고 있다. 추가로, 유글레나 그라실리스로부터 유래되고 야로위아 리폴리티카에서의 발현을 위해 코돈-최적화된 합성 델타-9 연장효소가 또한 미국 특허 제7,645,604호("EgD9eS"; 본 명세서에서 서열 번호 9 및 10)에 개시되어 있다. 구체적으로, 번역 개시 부위의 변형에 더하여, 777 bp 암호화 영역의 117 bp를 변형시키고(15.1%), 106개 코돈을 최적화시켰다(그렇지만, 코돈-최적화된 유전자에 의해 암호화되는 단백질 서열(즉, 서열 번호 10)은 야생형 단백질 서열(즉, 서열 번호 8)의 것과 동일하다). EgD9eS는 야로위아 리폴리티카에서 발현시 야생형 EgD9e보다 약 16.2% 더욱 효율적으로 LA를 EDA로 연장시키는 것으로 결정되었다.
서열의 합성 방법 및 서열의 결합 방법은 문헌에 널리 확립되어 있다. 그리고, 자연 발생 유전자의 돌연변이를 수득하기 위한 많은 기술이 통상 사용된다(여기서, 이러한 돌연변이는 결실, 삽입 및 점 돌연변이 또는 그들의 조합을 포함할 수 있다). 본 발명의 연구는 유지성 효모, 즉, 야로위아 리폴리티카에서 발현되는 경우 효소의 LA로부터 EDA로의 전환 효율을 증가시킬 것인 EgD9eS 내의 적절한 돌연변이(들)를 동정하는 목적으로 행하였다. 증가된 전환 효율은 전반적인 PUFA 생합성의 속도 및 질을 증가시키는 수단으로서 바람직하였다. 다양한 돌연변이가 본 명세서에 기재되어 있으며; 야생형(즉, 서열 번호 8)으로부터 유래된 모든 이러한 돌연변이 단백질 및 그들을 암호화하는 뉴클레오티드 서열 및 상술된 합성의 코돈-최적화된(서열 번호 10) 델타-9 연장효소는 본 발명의 범주 내에 있다.
비록 델타-9 연장효소가 몇몇 보존된 서열(도 1; 즉, 서열 번호 15-21)을 함유하지만, 이들 모티프 중 하나의 오직 일부분만이 최적의 효소 기능에서의 그의 역할을 결정하기 위해 이전에 연구되어 왔다. 구체적으로, 퀴, 비.(Qi, B.) 등(문헌[FEBS Lett ., 547:137-139 (2003)])은 델타-9 연장효소 활성을 갖는 것으로 동정된 처음의 PUFA-특이적 연장효소인 아이소크라이시스 갈바나 델타-9 연장효소["IgD9e"]의 다양한 히스티딘-박스["His-box"]를 시험하였다. IgD9e가 델타-6 연장효소에 존재하는 고도로 보존된 His-Xaa-Xaa-His-His["HxxHH"; 서열 번호 24] 모티프 대신에, Gln-Xaa-Xaa-His-His["QxxHH"; 서열 번호 23] 모티프를 갖는 것으로 알려져 있는 유일한 PUFA-특이적 연장효소(그 당시에)였기 때문에, 일련의 돌연변이를 행하여 Gln을 His, Ala 또는 Phe 잔기로 대체하고, 사카로마이세스 세레비지애(Saccharomyces cerevisiae)에서의 발현 시의 활성에 대하여 돌연변이 단백질을 검정하였다. 퀴 등은 모든 치환이 더 낮은 델타-9 연장효소 활성을 야기하는 것으로 결정하였으며, 이에 따라 "히스티딘 박스 내의 글루타민 잔기...가 최적의 효소 촉매작용에 필수적인 것으로 보인다"고 결론지었다.
상기 단독의 연구 및 델타-9 연장효소로부터의 임의의 결정 구조가 없음에 기초하여, 델타-9 연장효소 내의 적절한 돌연변이를 동정하는 방법을 표적화하는 이유는 이상적이지 않았다. 델타-9 연장효소를 암호화하는 돌연변이 서열의 라이브러리를 주형으로서 EgD9eS(서열 번호 9)를 사용하여 오류-유발 PCR(error-prone PCR["ePCR"])에 의해 합성으로 엔지니어링하였으며, 여기서, EgD9eS는 키메라 FBAINm::EgD9eS::Pex20 유전자를 포함하는 플라스미드 구축물 내에 함유되어 있다. 이어서, ePCR 라이브러리를 야로위아 리폴리티카 내로 형질전환시키고, GC 분석 및 EDA의 생성에 기초하여 향상된 델타-9 연장효소 활성에 대하여 스크리닝하였다.
완전히 비-기능성인 돌연변이 델타-9 연장효소(즉, 검출가능한 델타-9 연장효소 활성을 갖지 않는) 또는 비-돌연변이 야생형 효소, EgD9eS에 대하여 델타-9 연장효소 활성이 실질적으로 감소된 돌연변이 델타-9 연장효소를 야기하는 많은 클론을 동정하였다. 그러나, 놀랍게도, LA로부터 EDA로의 향상된 전환 효율[([EDA]/[LA+EDA])*100로 계산]을 야기하는 다양한 돌연변이가 동정되었다. 구체적으로, 4개의 상이한 돌연변이 델타-9 연장효소 유전자를 포함하는(즉, EgD9eS의 단백질 서열[서열 번호 10]과 비교시, 각각 K58R/I257T 돌연변이, L35F 돌연변이, D98G 돌연변이 및 L130M/V243A 돌연변이를 포함하는) 5개의 형질전환 균주가 동정되었으며, 여기서, 델타-9 연장효소 전환 활성은 105% 내지 117% 범위이고(하기 표 3), 이는 5 내지 17% 향상에 상응한다. 따라서, 이러한 연구에 의해, EgD9eS의 델타-9 연장효소 활성이 실제로 단백질 엔지니어링에 의해 향상될 수 있었던 것이 입증되었다.
이어서, 상기 EgD9eS ePCR 라이브러리로부터 수득되는 초기의 데이터를 사용하여, 부위-포화 라이브러리의 생성을 위한 적절한 표적이었던 EgD9eS 내의 2개의 상이한 아미노산 잔기(즉, 잔기 35 및 107)를 합리적으로 동정하였다. 다시, 생성된 돌연변이 EgD9eS 단백질의 델타-9 연장효소 활성에서의 각각의 돌연변이의 영향을 스크리닝하였으며, 이에 따라, LA로부터 EDA로의 전환 효율을 향상시키는 2개의 추가의 돌연변이의 동정이 가능하게 되었다. 구체적으로, 돌연변이 델타-9 연장효소 내의 L35G 돌연변이 또는 L35M/Q107E 돌연변이 중 어느 하나를 포함하는 형질전환 균주가 동정되었으며, 여기서, 델타-9 연장효소 전환 활성은 EgD9eS에 비하여 142% 내지 145% 또는 132% 중 어느 하나였으며(상기 표 3), 이는 32% 내지 45% 향상에 상응한다.
L35G 돌연변이의 동정 후에, 50개의 상이한 아미노산 잔기를 표적화하는 후속의 라이브러리를 슬로노맥스(SlonoMax)(등록 상표) 기술 및 표적으로서 EgD9eS-L35G 유전자를 사용하여 생성하였다. 모 연장효소, 즉, EgD9eS-L35G에 비하여 96% 내지 141%의 델타-9 연장효소 전환 활성을 야기하는(-4% 내지 41%의 향상에 상응)(하기의 표 3) 각각 L35G 돌연변이와 조합된 25개의 상이한 돌연변이를 동정하였다.
마지막으로, 최근의 연구에서, 슬로노맥스(등록 상표) 라이브러리 내에서 동정된 다수의 유익한 돌연변이를 조합(또는 스택킹(stack))하려고 시도하였으며, 이에 의해, 합성의 코돈-최적화된 EgD9eS 서열 내의 적절한 개별 아미노산 돌연변이를 "스택킹"하였다. 이에 따라, 예를 들어, 서열 번호 10[EgD9eS]에 대하여 A21V, L35G, W132T, I179R 및 Q244N 돌연변이를 포함하는 돌연변이 델타-9 연장효소가 EgD9eS에 비하여 123%(23% 향상에 상응)의 델타-9 연장효소 전환 활성을 야기하는 것으로 입증되었다(하기의 표 3).

본 발명의 유용한 돌연변이 델타-9 연장효소가 상술된 37개 돌연변이 조합에 제한되지 않음이 당업자에 의해 인식될 것이다. 대신에, 상기 많은 보존적 및 비-보존적 아미노산 치환(즉, 돌연변이)이 서로의 임의의 조합으로 사용될 수 있는 것으로 고려된다. 그리고, 이러한 모든 돌연변이 단백질 및 본 명세서에 기재된 EgD9e 및/또는 EgD9eS로부터 유래된 그들을 암호화하는 뉴클레오티드 서열은 본 발명의 범주 내에 있다.
예를 들어, 본 발명의 연구에 적용되는 실험 전략은 대부분 EgD9eS-L35G로 "스택킹"될 수 있으며 합성의 코돈-최적화된 EgD9eS 또는 EgD9eS-L35G 중 어느 하나의 것에 비하여 델타-9 연장효소 전환 효율에 대한 추가의 이익을 전할 수 있는 추가의 보존적 및 비-보존적 아미노산 치환을 동정하는 것을 기반으로 한다. 비록 EgD9eS에 대하여 2개의 돌연변이를 포함하는 다양한 돌연변이 델타-9 연장효소가 동정되었지만, 조합 라이브러리로부터 각각이 EgD9eS에 대하여 3개 내지 5개의 돌연변이를 갖는 오직 5개의 돌연변이체를 특성화하였다. EgD9eS 또는 EgD9eS-L35G 중 어느 하나에 대하여 적어도 대략 기능적으로 동등한 활성을 갖거나 향상된 델타-9 연장효소 전환 효율을 가지며, EgD9eS에 대하여 2, 3, 4, 5, 6개 이상의 돌연변이를 갖는 다양한 다른 돌연변이체가 동정될 수 있는 것으로 예상된다.
대안적으로, 당업자는 예를 들어, 주형으로서 EgD9eS-D98G(즉, EgD9eS-L35G 대신에)를 용이하게 이용할 수 있으며, K58R, L35F, L35G, L35M, S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, Q107E, L108G, G127L, L130M, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, V243A, Q244N, A254W, A254Y 및 I257T로 이루어진 군으로부터 선택되는 돌연변이가 유리하게 "스태킹"되어, EgD9eS에 대하여 2, 3, 4, 5, 6개 이상의 돌연변이를 갖는 최종 돌연변이 델타-9 연장효소를 제공할 수 있는지를 결정할 수 있다.
따라서, 일 실시형태에서, 본 발명은
a) 델타-9 연장효소 활성을 가지며, 서열 번호 22에 기재된 아미노산 서열을 갖는 돌연변이 폴리펩티드를 암호화하는 뉴클레오티드 서열로서, 서열 번호 22는 적어도 하나의 아미노산 돌연변이에 의해 서열 번호 10과 상이하며, 상기 돌연변이(들)가
i) L35F 돌연변이;
ii) L35M 돌연변이;
iii) L35G 돌연변이;
iv) L35G 돌연변이, 및 S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, Q107E, L108G, G127L, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, Q244N, A254W 및 A254Y로 이루어진 군으로부터 선택되는 적어도 하나의 다른 돌연변이;
v) L35G, A21V, L108G 및 I179R 돌연변이;
vi) L35G, W132T 및 I179 돌연변이;
vii) L35G, S9D, Y84C 및 I179R 돌연변이;
viii) L35G, Y84C, I179R 및 Q244N 돌연변이;
ix) L35G, A21V, W132T, I179R 및 Q244N 돌연변이;
x) K58R 및 I257T 돌연변이;
xi) D98G 돌연변이;
xii) L130M 및 V243A 돌연변이; 및
xiii) K58R, L35F, L35G, L35M, S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, D98G, Q107E, L108G, G127L, L130M, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, V243A, Q244N, A254W, A254Y 및 I257T로 이루어진 군으로부터 선택되는 적어도 2개의 돌연변이를 포함하는 임의의 조합으로 이루어진 군으로부터 선택되는 뉴클레오티드 서열; 및
b) 파트 (a)의 뉴클레오티드 서열의 상보체로서, 상보체와 파트 (a)의 뉴클레오티드 서열이 동일한 개수의 뉴클레오티드로 이루어져 있으며, 100% 상보성인 파트 (a)의 뉴클레오티드 서열의 상보체를 포함하는 도 4b에 제시된 바와 같은 분리된 폴리뉴클레오티드에 관한 것이다.
일부 실시형태에서, 본 명세서에서 본 발명의 돌연변이 폴리펩티드는 서열 번호 29, 서열 번호 32, 서열 번호 35, 서열 번호 38, 서열 번호 41, 서열 번호 59, 서열 번호 62, 서열 번호 87, 서열 번호 101, 서열 번호 104, 서열 번호 107 및 서열 번호 110으로 이루어진 군으로부터 선택되는 단백질 서열을 가질 수 있지만, 이들 예는 본 명세서에서 본 발명에 제한되지 않는다.
본 발명의 돌연변이 폴리펩티드를 생성하는데 사용되는 방법 또는 본 발명의 돌연변이 폴리펩티드를 동정하는데 사용되는 방법 중 어느 것도 본 명세서에서 제한하는 것으로 고려되어서는 안된다.
예를 들어, 시험관 내 돌연변이유발 및 선택 또는 오류 유발 PCR(문헌[Leung et al., Techniques, 1:11-15 (1989)]; 문헌[Zhou et al., Nucleic Acids Res., 19:6052-6052 (1991)]; 문헌[Spee et al., Nucleic Acids Res., 21:777-778 (1993)]; 문헌[Melnikov et al., Nucleic Acids Res., 27(4):1056-1062(February 15, 1999)])은 자연 발생 델타-9 연장효소 유전자의 돌연변이를 수득하기 위한 수단으로 사용될 수 있으며, 여기서, 돌연변이는 결실, 삽입 및 점 돌연변이 또는 그들의 조합을 포함할 수 있다. 오류-유발 PCR의 주요 이점은 이러한 방법에 의해 도입되는 모든 돌연변이는 목적하는 연장효소 유전자 내에 존재할 것이며, PCR 조건을 변경시킴으로써 임의의 변경을 용이하게 조절할 수 있다. 대안적으로, 생체 내 돌연변이유발은 상업적으로 이용가능한 재료, 예컨대 스트라타진(Stratagene)(미국 캘리포니아주 라 졸라 소재)으로부터의 에스케리키아 콜라이(E. coli) XL1-레드(Red) 균주 및 에피쿠리안 콜라이(Epicurian coli) XL1-레드 뮤테이터(mutator) 균주(또한, 문헌[Greener and Callahan, Strategies, 7:32-34 (1994)] 참조)를 사용하여 활용될 수 있다. 이러한 균주는 주요 DNA 수선 경로 중 3개(mutS, mutD 및 mutT)에 결함이 있어, 야생형의 돌연변이율보다 돌연변이율이 5000배 더 커지게 한다. 생체 내 돌연변이유발은 라이게이션 효율에 좌우되지 않으나(오류-유발 PCR과 같이); 돌연변이는 벡터의 임의의 영역에서 발생할 수 있으며, 돌연변이율은 일반적으로 훨씬 더 낮다.
또한, 델타-9 연장효소 활성이 변경되거나 증가된 돌연변이 델타-9 연장효소가 "유전자 셔플링" 방법을 사용하여 구축될 수 있는 것으로 고려된다(미국 특허 제5,605,793호; 미국 특허 제5,811,238호; 미국 특허 제5,830,721호; 및 미국 특허 제5,837,458호). 유전자 셔플링 방법은 그의 수월한 이행 및 높은 돌연변이유발률 때문에 특히 매력적이다. 유전자 셔플링 방법은 둘 다 대상 유전자에 유사한(또는 상이한) DNA 영역의 부가적인 집단의 존재 하에 대상 유전자를 특정 크기의 단편으로 제한하는 것을 포함한다. 이러한 푸울(pool)의 단편은 변성된 다음 재어닐링되어 돌연변이된 유전자를 생성할 것이다. 그 다음 돌연변이된 유전자를 변경된 활성에 대해 스크리닝한다. 이들 방법 중 임의의 것을 사용하여 활성이 향상된 델타-9 연장효소 돌연변이 효소를 생성할 수 있다.
대안적으로, 당업자는 델타-9 연장효소 활성을 갖는 단백질을 암호화하는 유전자의 선택을 위한 추가의 스크리닝을 계획할 수 있을 것이다. 예를 들어, 연장효소 활성은 효소를 함유하는 제제를 적절한 형태의 기질 지방산과 함께 인큐베이션시키고, 이러한 기질로부터 예측되는 지방산 생성물로의 전환에 대하여 분석하는 검정에 의해 입증될 수 있다. 대안적으로, 연장효소 단백질을 암호화하도록 제시된 DNA 서열은 적절한 벡터 구축물 내로 혼입될 수 있으며, 이에 의해, 통상은 특정 지방산 기질을 연장시키는 능력을 갖지 않는 유형의 세포에서 발현될 수 있다. 이어서, DNA 서열에 의해 암호화되는 연장효소의 활성은 적절한 형태의 기질 지방산을 연장효소-암호화 DNA 서열을 함유하는 벡터로 형질전환된 세포 및 적절한 대조군 세포(단독의 빈(empty) 벡터로 형질전환된)에 공급함으로써 입증될 수 있다. 이러한 실험에서, 연장효소-암호화 DNA 서열을 함유하는 세포에서의 예측되는 지방산 생성물의 검출 및 대조군 세포에서의 미검출에 의해 연장효소 활성을 확립한다.
유용한 돌연변이 델타-9 연장효소가 상술된 돌연변이에 제한되지 않음이 당업자에 의해 인식될 것이다. 실제로, 결과에 의해, 모체(즉, 다양한 종, 속 등으로부터의)로서 다양한 대안의 델타-9 연장효소를 사용하는 유사한 실험을 수행하여 그에 의해 델타-9 연장효소 활성이 증가된 다양한 돌연변이 델타-9 연장효소를 엔지니어링할 수 있음이 제시된다. 바람직하게는, 돌연변이유발로 처리되는 델타-9 연장효소는 미국 특허 제7,645,604호에 기재되고 서열 번호 15, 16, 17, 18, 19, 20 및 21에 기재된 7개의 델타-9 연장효소 모티프 중 적어도 하나를 포함할 것이다. 아마도, 적절한 모체 델타-9 연장효소는 EgD9eS와 적어도 약 35% 내지 50% 동일할 것이며, 여기서, 적어도 약 50% 내지 65% 동일한 서열이 특히 적절하며, 적어도 약 65% 내지 80% 동일한 서열이 가장 바람직하다. 비록 바람직한 범위가 상술되어 있지만, 서열 동일성 백분율의 유용한 예에는 35% 내지 100%의 임의의 정수 백분율, 예컨대 36%, 37%, 38%, 39%, 40%, 41%, 42%, 43%, 44%, 45%, 46%, 47%, 48%, 49%, 50%, 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%가 포함된다. 델타-9 연장효소 활성이 증가된 돌연변이 효소가 오메가-3/오메가-6 지방산의 생성의 증가를 가능하게 하기에 유용할 수 있음이 인식될 것이다.
예를 들어, 아이소크라이시스 갈바나의 델타-9 연장효소(즉, IgD9e[서열 번호 2]; EgD9eS에 대하여 약 35% 서열 동일성), 유트렙티엘라 종 CCMP389의 델타-9 연장효소(즉, E389D9e[서열 번호 4]; EgD9eS에 대하여 약 60% 서열 동일성) 및 유글레나 아나바에나의 델타-9 연장효소(즉, EaD9e[서열 번호 12]; EgD9eS에 대하여 약 60% 서열 동일성)의 델타-9 연장효소 활성을 용이하게 향상시킬 수 있었으며, 이는 이들 유전자가 유글레나 그라실리스에서 관찰되는 것과 유사한 방식으로 돌연변이를 허용할 것 같기 때문이다. 비록 이들 모체 분자의 임의의 것에 대한 예컨대, 오류 유발 PCR 라이브러리의 생성에 의해 돌연변이유발을 개시하는 것이 바람직할 수 있지만, EgD9eS 내의 그 부위와 상동성을 공유하는 아미노산 잔기의 돌연변이에 기초하여 향상된 돌연변이체를 동정할 수 있는 것을 합리적으로 예측할 수 있다. 벡터 엔티아이(등록 상표) 얼라인엑스 프로그램(미국 캘리포니아주 칼스배드 소재의 인비트로겐 코포레이션)의 디폴트 파라미터를 사용하여 준비된 IgD9e, E389D9e, EgD9e 및 EaD9e의 정렬이 도 1에 나타나 있다. 공통 서열에서의 밑줄이 그어진 굵은 문자는 델타-9 연장효소 활성을 나타낼 수 있는 모티프 서열에 관하여 이전에 기재되어 있다. 서열 번호 8의 EgD9e 서열 내의 굵은 문자의 잔기(서열이 서열 번호 10에 기재된 EgD9eS의 서열과 동일)는 본 출원에서 돌연변이되어 델타-9 연장효소 활성이 향상된 돌연변이 연장효소를 야기하는 잔기를 나타낸다. 또한, 이들 돌연변이의 위치는 각각의 정렬의 열에 걸쳐 별표로 강조표시되어 있다. 이러한 정렬의 분석에 기초하여, 당업자는 표 4에서 후술되는 임의의 잔기에서의 변형이 또한 각각 EaD9e, E389D9e 및 IgD9e에서 향상된 델타-9 연장효소 활성을 야기할 수 있는 것으로 가정할 것이다. 따라서, 예를 들어, 서열 번호 4[E389D9e]의 아미노산 잔기 13(즉, Ala [A])을 서열 번호 10[EgD9eS]의 아미노산 잔기 9(즉, Ser [S])와 정렬시키고; 이에 따라, E389D9e에서의 Ala의 치환이 Ser을 Ala, Asp, Gly, Ile, Lys 또는 Gln으로 치환하는 경우, EgD9eS에서 관찰되는 것과 유사한 방식으로, 델타-9 활성이 증가된 돌연변이 E389D9e 연장효소를 야기할 수 있는 것이 예측될 것이다. 각각의 아미노산 잔기에서의 가장 바람직한 치환의 동정은 실험적으로 결정될 수 있다.

적절한 프로모터의 조절 하에서 EgD9eS의 델타-9 연장효소 활성에 대하여 델타-9 연장효소 활성이 증가된 본 명세서에 기재된 돌연변이 델타-9 연장효소를 암호화하는 키메라 유전자를 도입하는 것이 형질전환된 숙주 유기체에서 각각 EDA 및/또는 ETrA의 생성의 증가를 야기할 것이 예상된다. 이와 같이, PUFA의 직접적인 생성 방법이 본 명세서에 기재되어 있으며, 여기서, 상기 방법은 지방산 기질(즉, LA 및/또는 ALA)을 본 명세서에 기재된 돌연변이 연장효소(예컨대, 서열 번호 22)에 노출시켜, 기질이 목적 지방산 생성물(즉, 각각 EDA 및/또는 ETrA)로 전환되게 하는 것을 포함한다.
더욱 구체적으로,
a) i) 적어도 하나의 조절 서열에 작동가능하게 연결되는 재조합 구축물로서, 상기 재조합 구축물이 델타-9 연장효소 활성을 가지며, 서열 번호 22에 기재된 아미노산 서열을 갖는 돌연변이 폴리펩티드를 암호화하는 분리된 뉴클레오티드를 포함하며, 서열 번호 22는 적어도 하나의 아미노산 돌연변이에 의해 서열 번호 10[EgD9eS]과 상이하며, 상기 돌연변이(들)가
(a) L35F 돌연변이;
(b) L35M 돌연변이;
(c) L35G 돌연변이;
(d) L35G 돌연변이, 및 S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, Q107E, L108G, G127L, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, Q244N, A254W 및 A254Y로 이루어진 군으로부터 선택되는 적어도 하나의 다른 돌연변이;
(e) L35G, A21V, L108G 및 I179R 돌연변이;
(f) L35G, W132T 및 I179 돌연변이;
(g) L35G, S9D, Y84C 및 I179R 돌연변이;
(h) L35G, Y84C, I179R 및 Q244N 돌연변이;
(i) L35G, A21V, W132T, I179R 및 Q244N 돌연변이;
(j) K58R 및 I257T 돌연변이;
(k) D98G 돌연변이;
(l) L130M 및 V243A 돌연변이; 및
(m) K58R, L35F, L35G, L35M, S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, D98G, Q107E, L108G, G127L, L130M, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, V243A, Q244N, A254W, A254Y 및 I257T로 이루어진 군으로부터 선택되는 적어도 2개의 돌연변이를 포함하는 임의의 조합으로 이루어진 군으로부터 선택되는 재조합 구축물; 및
ii) 리놀레산 및 알파-리놀렌산으로 이루어진 군으로부터 선택되는 기질 지방산의 공급원을 포함하는 유지성 효모를 제공하는 단계;
b) 델타-9 연장효소 활성을 갖는 돌연변이 폴리펩티드를 암호화하는 재조합 구축물이 발현되고, 기질 지방산이 생성물 지방산으로 전환되는 조건 하에서 단계 (a)의 효모를 성장시키는 단계로서, 리놀레산이 에이코사다이엔산으로 전환되고, 알파-리놀렌산이 에이코사트라이엔산으로 전환되는 단계; 및
c) 임의로, 단계 (b)의 생성물 지방산을 회수하는 단계를 포함하는 다중불포화 지방산의 생성 방법이 본 명세서에 기재된다.
대안적으로, 본 명세서에 기재된 각각의 돌연변이 델타-9 연장효소 유전자 및 그의 상응하는 효소 생성물을 사용하여 다양한 오메가-6 및 오메가-3 PUFA의 생성을 증가시킬 수 있다(도 5a 및 도 5b; 미국 특허 제7,238,482호 및 미국 특허 공개 제2009-0093543-A1호 참조). 오메가-3/오메가-6 PUFA의 생성의 증가가 발생하며, 여기서, 지방산 기질은 중간 단계(들) 또는 경로 중간체(들)의 수단을 통하여 목적하는 지방산 생성물로 전환된다. 따라서, 본 명세서에 기재된 돌연변이 델타-9 연장효소가 PUFA 생합성 경로의 효소(예컨대, 델타-6 불포화화효소, C18/20 연장효소, 델타-17 불포화화효소, 델타-8 불포화화효소, 델타-15 불포화화효소, 델타-9 불포화화효소, 델타-12 불포화화효소, C14 /16 연장효소, C16 /18 연장효소, 델타-9 연장효소, 델타-5 불포화화효소, 델타-4 불포화화효소, C20/22 연장효소)를 암호화하는 추가의 유전자와 결합하여 발현되어, 더 높은 수준의 장쇄 오메가-3/오메가-6 지방산(예컨대, DGLA, ETA, ARA, EPA, DTA, DPAn-6, DPA 및/또는 DHA)의 생성 수준을 야기할 수 있는 것이 고려된다.
바람직하게는, 본 명세서에 기재된 델타-9 연장효소는 적어도 하나의 델타-8 불포화화효소와 결합되어 발현될 것이다. 그러나, 특정 발현 카세트에 포함되는 특정 유전자는 숙주 세포(및 그의 PUFA 프로파일 및/또는 불포화화효소/연장효소 프로파일), 기질의 이용가능성 및 목적하는 최종 생성물(들)에 좌우될 것이다.
오메가-3/오메가-6 PUFA의 증가된 생성을 위한 돌연변이 델타-9 연장효소의 이용이 실시예 11에서 본 명세서에 입증되어 있으며, 야로위아 리폴리티카의 균주 Z1978을 구축하여, 38.3% 전체 지질 함량["TFA % DCW"]을 갖는 전체 지질에 비하여 약 58.7% EPA를 생성하였다. 이러한 특정 예에서, 돌연변이 델타-9 연장효소는 델타-9 연장효소/델타-8 불포화화효소 경로에서 델타-9 연장효소 활성을 증가시키도록 기능하는 것으로 추정된다.
따라서, 본 명세서에서 본 발명의 일 태양은 DCW의 중량 백분율로 측정시 적어도 22.5 중량 백분율의 EPA를 포함하는 오일을 생성하는 재조합 미생물 숙주 세포에 관한 것이며, 상기 재조합 미생물 숙주 세포는 본 발명의 적어도 하나의 돌연변이 델타-9 연장효소 폴리펩티드를 포함한다.
본 명세서에 기재된 돌연변이 델타-9 연장효소 유전자 및 유전자 생성물은 다양한 이종 숙주 세포, 특히 식물, 박테리아, 효모, 조류, 유글레나조류, 부등편모조류, 난균류 및 진균류로 이루어진 군으로부터 선택되는 세포에서 생성될 수 있다. 일반적으로, 당업자는 본 발명의 돌연변이 델타-9 연장효소가 야생형 EgD9e 또는 돌연변이체가 유래되는 코돈-최적화된 EgD9eS 델타-9 연장효소를 발현할 수 있는 임의의 숙주 세포, 또는 델타-9 연장효소의 상동체가 발현되는 숙주에서의 발현에 적절할 것으로 가정할 수 있다.
미국 특허 제7,645,604호에는 EgD9e 및 EgD9eS의 발현을 위한 식물 발현 체계, 카세트, 벡터 및 그의 형질전환 방법이 기재되어 있으며, 그의 논의는 본 명세서에 그 전문이 참고로 포함되어 있다. 돌연변이 델타-9 연장효소가 발현될 수 있는 특히 바람직한 식물은 유지종자 식물(예컨대, 대두, 브라시카(Brassica) 종, 해바라기, 옥수수, 목화, 아마 및 홍화)을 포함한다.
유사하게, 미국 특허 제7,645,604호에는 또한 EgD9e 및 EgD9eS의 발현을 위한 미생물 발현 체계, 카세트, 벡터 및 그의 형질전환 방법이 기재되어 있다. 상기 문헌의 논의는 하기의 것과 조합하여 고려되어야 한다. 특히, 본 명세서에 기재된 돌연변이 델타-9 연장효소 유전자 및 유전자 생성물은 또한 이종 미생물 숙주 세포에서, 특히 유지성 효모(예컨대, 야로위아 리폴리티카)의 세포에서 생성될 수 있다. 재조합 미생물 숙주에서의 발현은 다양한 PUFA 경로 중간체의 생성 또는 이전에는 숙주를 사용하여 가능하지 않았던 새로운 생성물의 합성을 위한 숙주에 이미 존재하는 PUFA 경로의 조절에 유용할 수 있다.
외래 유전자의 높은 수준의 발현을 지시하는 조절 서열을 함유하는 미생물 발현 체계 및 발현 벡터가 당업자에게 잘 알려져 있다. 이들 중 임의의 것을 사용하여 본 발명의 서열의 유전자 생성물 중 임의의 것의 생성을 위한 키메라 유전자를 구축할 수 있었다. 그 다음, 이들 키메라 유전자를 형질전환을 통하여 적절한 미생물 내로 도입시켜, 암호화된 단백질의 높은 수준의 발현을 제공할 수 있다.
적절한 미생물 또는 식물 숙주 세포의 형질전환에 유용한 벡터(예컨대, 구축물, 플라스미드) 및 DNA 발현 카세트는 당업계에 잘 알려져 있다. 구축물에 존재하는 서열의 특이적 선택은 목적하는 발현 생성물(상기), 숙주 세포의 성질 및 형질전환된 세포를 형질전환되지 않은 세포에 대하여 분리하기 위한 제안된 수단에 좌우된다. 그러나, 전형적으로, 벡터는 적어도 하나의 발현 카세트, 선택가능한 마커 및 자가 복제 또는 염색체 통합을 가능하게 하는 서열을 함유한다. 적절한 발현 카세트는 전형적으로 프로모터, 선택된 유전자의 암호화 서열 및 종결자를 포함한다. 둘 모두의 조절 영역이 형질전환된 숙주 세포로부터의 유전자로부터 유래되는 경우가 가장 바람직하다.
목적하는 미생물 숙주 세포 또는 식물 세포에서 본 발명의 델타-9 연장효소 ORF가 발현되게 하기에 유용한 프로모터는 다양하며 당업자에 공지되어 있다. 사실상, 선택된 숙주 세포에서 이들 유전자가 발현되게 할 수 있는 임의의 프로모터(즉, 천연, 합성 또는 키메라)가 적절하다. 숙주 세포에서의 발현은 유도된 방식 또는 구성적 방식으로 달성될 수 있다. 유도된 발현은 대상 유전자에 작동가능하게 연결된 조절가능한 프로모터의 활성을 유도함으로써 달성될 수 있으며, 구성적 발현은 대상 유전자에 작동가능하게 연결된 구성적 프로모터의 사용에 의해 달성될 수 있다.
일 예로서, 미국 특허 공개 제2009-0093543-A1호에는 야로위아 리폴리티카에서의 사용을 위한 프로모터가 기재되어 있다. 구성적 또는 유도된 전사의 필요 여부, 대상 ORF를 발현하는 데에서의 프로모터의 효율, 구축의 용이성 등에 따라, 다수의 프로모터 중 임의의 것이 사용될 수 있다.
번역 개시 코돈 'ATG' 주위의 뉴클레오티드 서열은 효모 세포에서의 발현에 영향을 미치는 것으로 관찰되었다. 목적 폴리펩티드가 효모에서 약하게 발현된다면, 외인성 유전자의 암호화 영역을 효율적인 효모 번역 개시 서열을 포함하도록 변형시켜 최적의 유전자 발현을 얻을 수 있다. 이는 효모에서의 발현을 위하여, 비효율적으로 발현되는 유전자를 프레임 내에서(in-frame) 내인성 효모 프로모터, 바람직하게는 고도로 발현되는 프로모터와 융합시킴으로써, 또는 이러한 불충분하게 발현되는 유전자의 부위-지정 돌연변이유발에 의해 수행될 수 있다. 대안적으로, 숙주의 공통 번역 개시 서열은 그들의 최적의 발현을 위하여 이종 유전자 내로 엔지니어링될 수 있다.
종결자는 프로모터가 수득되는 유전자의 3' 영역 또는 상이한 유전자로부터 유래될 수 있다. 매우 다수의 종결자가 공지되어 있으며, 그들이 유래된 것과 동일한 속과 종, 및 그와 상이한 속과 종에서 이용하는 경우 둘 모두에 다양한 숙주에서 만족스럽게 기능한다. 종결자는 통상 임의의 특정 특성 때문이 아니라, 편의성의 문제로 선택된다. 종결자는 바람직한 숙주에 고유한 다양한 유전자로부터 유래될 수 있다. 또한, 종결자는 당업자가 종결자를 설계하고 합성하기 위하여 입수할 수 있는 정보를 이용할 수 있음에 따라, 합성일 수 있다. 종결자는 불필요할 수 있지만, 매우 바람직하다.
유전자를 클로닝 벡터에 단지 삽입하는 것으로는 그것이 필요한 수준, 농도, 양 등으로 그것이 발현하는 것을 보장하지 않는다. 높은 수준의 발현에 대한 필요에 따라, 전사, RNA 안정성, 번역, 단백질 안정성 및 위치, 산소 제한 및 미생물 숙주 세포 또는 식물 세포로부터의 분비를 관리하는 소정의 특성을 조정함으로써 많은 특수 발현 벡터를 생성하였다. 이들 특성은 관련 전사 프로모터 및 종결자 서열의 성질; 클로닝된 유전자의 카피수(여기서, 플라스미드 카피수를 증가시키거나, 클로닝된 유전자를 게놈 내로 다수 통합시킴으로써 추가의 카피는 단일의 발현 구축물 내에 클로닝될 수 있고/거나 추가의 카피는 숙주 세포에 도입될 수 있다); 유전자가 플라스미드-운반형(plasmid-borne)인지 숙주 세포 게놈 내로 통합된 것인지의 여부; 합성된 외래 단백질의 최종 세포 위치; 숙주 유기체에서의 단백질의 올바른 폴딩 및 번역의 효율; 숙주 세포 내의 클로닝된 유전자의 mRNA 및 단백질의 내재적 안정성; 및 클로닝된 유전자 내의 코돈 사용을 포함한다. 이들 각각을 본 명세서에 기재된 방법 및 숙주 세포에 사용하여, 본 명세서에 기재된 돌연변이 델타-9 연장효소의 발현을 추가로 최적화시킬 수 있다.
일단 적절한 숙주 세포에서의 발현에 적절한 DNA 카세트(예컨대, 프로모터, ORF 및 종결자를 포함하는 키메라 유전자 포함)가 수득되면, 그를 숙주 세포에서 자가 복제될 수 있는 플라스미드 벡터 내에 배치하거나, 또는 숙주 세포의 게놈 내로 직접 통합시킨다. 발현 카세트의 통합은 숙주 게놈 내에서 무작위로 발생할 수 있거나, 숙주 유전자좌와의 재조합을 표적화하기에 충분한 숙주 게놈과의 상동성 영역을 함유하는 구축물의 사용을 통하여 표적화시킬 수 있다. 전사 및 번역 조절 영역의 전부 또는 일부가 구축물이 표적화되는 내인성 유전자좌에 의해 제공될 수 있다.
둘 이상의 유전자를 별개의 복제 벡터로부터 발현시키는 경우에는, 각 벡터가 상이한 선별 수단을 갖는 것이 바람직하며, 안정적인 발현을 유지하고 구축물들 사이에서의 요소의 재배열을 방지하기 위해 다른 구축물(들)과의 상동성은 결여되어야 한다. 조절 영역, 선별 수단 및 도입된 구축물(들)을 증가시키는 방법의 현명한 선택은, 도입된 모든 유전자가 원하는 생성물의 합성을 제공하는데 필요한 수준으로 발현되도록 실험적으로 결정할 수 있다.
대상 유전자(들)를 포함하는 구축물은 임의의 표준 기술에 의해 미생물 숙주 세포 또는 식물 숙주 세포내로 도입될 수 있다. 이들 기술로는 형질전환(예컨대, 아세트산리튬 형질전환(문헌[Methods in Enzymology, 194:186-187 (1991)])), 원형질체 형질전환, 바이올리스틱 충격, 전기천공, 미세주입, 또는 대상 유전자(들)를 숙주 세포 내로 도입하는 임의의 다른 방법이 포함된다.
편의상, DNA 서열을 취하는 임의의 방법에 의해, 예를 들어, 발현 카세트에서 조작되는 숙주 세포는 본 명세서에서 "형질전환된", "형질전환체" 또는 "재조합체"라고 지칭된다(이들 용어는 본 명세서에서 상호교환가능하게 사용될 것이다). 형질전환된 숙주는 적어도 하나의 카피의 발현 구축물을 가질 것이며, 발현 카세트가 게놈 내로 통합되는지, 증폭되는지 아니면 다중 카피수를 갖는 염색체외 요소 상에 존재하는 지의 여부에 따라 2개 이상을 가질 수 있다.
형질전환된 숙주 세포는 도입된 구축물에 함유되는 마커에 대한 선택에 의해 동정될 수 있다. 대안적으로, 개별 마커 구축물은 많은 형질전환 기술에 의해 많은 DNA 분자가 숙주 세포 내로 도입됨에 따라 원하는 구축물과 함께 공동-형질전환될 수 있다.
전형적으로, 형질전환된 숙주는 항생제가 도입되거나 형질전환되지 않은 숙주의 성장에 필요한 인자, 예컨대 영양소 또는 성장 인자가 결여될 수 있는 선택적 배지에서 그들이 성장하는 능력에 대하여 선택된다. 도입된 마커 유전자는 항생제 내성을 부여하거나 필수 성장 인자 또는 효소를 암호화하여, 형질전환된 숙주에서 발현되는 경우 선택적 배지에서의 성장을 가능하게 할 수 있다. 또한, 형질전환된 숙주의 선택은 발현된 마커가 직접적으로 또는 간접적으로 검출될 수 있는 경우에 발생할 수 있다. 추가의 선택 기술은 미국 특허 제7,238,482호, 미국 특허 제7,259,255호 및 미국 특허 제7,932,077호에 기재되어 있다.
형질전환 후, 본 발명의 돌연변이 델타-9 연장효소(및 임의로는 숙주 세포 내에서 동시 발현되는 다른 PUFA 효소)에 적절한 기질은 천연적 또는 트랜스제닉으로 숙주에 의해 생성될 수도 있거나, 또는 이들이 외적으로 제공될 수도 있다.
본 발명의 유전자 및 핵산 단편의 발현을 위한 미생물 숙주 세포는 광범위한 온도 및 pH 값에 걸쳐, 단순 또는 복합 탄수화물, 지방산, 유기산, 오일, 글리세롤 및 알코올, 및/또는 탄화수소를 비롯한 다양한 공급원료 상에서 성장하는 숙주를 포함할 수 있다. 본 출원인의 양수인의 요구에 기초하여, 본 발명에 기재된 연장효소는 유지성 효모 및 특히 야로위아 리폴리티카에서 발현되어 왔다. 전사, 번역 및 단백질 생합성 기구가 고도로 보존되는 것이기 때문에, 임의의 박테리아, 효모, 조류, 유글레나조류, 부등편모조류, 난균류 및/또는 진균류가 본 발명의 핵산 단편을 발현하는데 적절한 미생물 숙주일 것으로 여겨진다.
그러나, 바람직한 미생물 숙주는 유지성 유기체, 예컨대 유지성 효모이다. 이들 유기체는 천연적으로 오일을 합성하고 축적할 수 있는데, 여기서, 오일은 건조 세포 중량["DCW"]의 약 25% 초과, 더욱 바람직하게는 DCW의 약 30% 초과, 더욱 바람직하게는 DCW의 약 40% 초과, 더욱 바람직하게는 DCW의 약 50% 초과, 가장 바람직하게는 DCW의 약 60% 초과로 포함될 수 있다. 전형적으로 유지성 효모로 동정되는 속에는 야로위아, 칸디다, 로도토룰라, 로도스포리듐, 크립토코커스, 트리코스포론 및 리포마이세스가 포함되나 이에 한정되지 않는다. 더욱 자세하게, 예시적인 오일-합성 효모에는 로도스포리듐 토룰로이데스(Rhodosporidium toruloides), 리포마이세스 스타케이이(Lipomyces starkeyii), 엘. 리포페러스(L. lipoferus), 칸디다 레브카우피(Candida revkaufi), 씨. 풀케리마(C. pulcherrima), 씨. 트로피칼리스(C. tropicalis), 씨. 유틸리스(C. utilis), 트리코스포론 풀란스(Trichosporon pullans), 티. 쿠타네움(T. cutaneum), 로도토룰라 글루티누스(Rhodotorula glutinus), 알. 그라미니스(R. graminis) 및 야로위아 리폴리티카(Yarrowia lipolytica)(이전에 칸디다 리폴리티카로 분류)가 포함된다. 대안적인 실시형태에서, 비-유지성 유기체는 유지성, 예컨대 사카로마이세스 세레비지애와 같은 효모가 되도록 유전적으로 변형될 수 있다(국제 출원 공개 WO 2006/102342호 참조).
따라서, 본 명세서의 일 실시형태에서, (a) 적어도 하나의 조절 서열에 작동가능하게 연결된, 돌연변이 델타-9 연장효소 폴리펩티드를 암호화하는 분리된 폴리뉴클레오티드를 포함하는 제1 재조합 DNA 구축물; 및 (b) 델타-4 불포화화효소, 델타-5 불포화화효소, 델타-8 불포화화효소, 델타-6 불포화화효소, 델타-9 불포화화효소, 델타-12 불포화화효소, 델타-15 불포화화효소, 델타-17 불포화화효소, C14 /16 연장효소, C16 /18 연장효소, C18 /20 연장효소 및 C20 /22 연장효소로 이루어진 군으로부터 선택되는 폴리펩티드를 암호화하는, 적어도 하나의 조절 서열에 작동가능하게 연결된 분리된 폴리뉴클레오티드를 포함하는 적어도 하나의 추가의 재조합 DNA 구축물을 포함하는 유지성 효모가 제공된다.
유지성 효모 야로위아 리폴리티카가 가장 바람직하다. 추가의 실시형태에서, ATCC #20362, ATCC #8862, ATCC #18944, ATCC #76982 및/또는 LGAM S(7)1로 명명된 야로위아 리폴리티카 균주가 가장 바람직하다(문헌[Papanikolaou S., and Aggelis G., Bioresour . Technol., 82(1):43-9 (2002)]).
선형화된 DNA의 단편에 기초한 통합 기술을 통한 유지성 효모(즉, 야로위아 리폴리티카)의 형질전환에 적용가능한 구체적인 교시는 미국 특허 제4,880,741호 및 미국 특허 제5,071,764호 및 문헌[Chen, D. C. et al. (Appl. Microbiol. Biotechnol., 48(2):232-235 (1997))]을 포함한다. 야로위아 리폴리티카에서 ARA, EPA 및 DHA 생성을 엔지니어링하는데 적용가능한 구체적인 교시는 각각 미국 특허 제7,588,931호, 미국 특허 제7,932,077호 및 미국 특허 공개 제2009-0093543-A1호 및 미국 특허 제7,550,286호에 제공되어 있다.
다른 바람직한 미생물 숙주는 유지성 박테리아, 조류, 유글레나조류, 부등편모조류, 난균류 및/또는 진균류를 포함한다. 이러한 광범위한 군의 미생물 숙주에서 특히 관심이 있는 것은 오메가-3/오메가-6 지방산을 합성하는 미생물 또는 이러한 목적을 위해 유전적으로 엔지니어링될 수 있는 것들(예컨대, 다른 효모, 예컨대 사카로마이세스 세레비지애)이다. 따라서, 예를 들어, 유도가능하거나 조절되는 프로모터의 조절 하의 본 발명의 임의의 델타-9 연장효소 유전자로 모르티에렐라 알피나(ARA의 생성을 위해 상업적으로 사용됨)를 형질전환시키면, 증가된 양의 EDA를 합성할 수 있는 형질전환 유기체가 생성될 수 있으며; 델타-8 불포화화효소 유전자가 동시 발현된다면, 이것이 증가된 양의 DGLA로 전환될 수 있다. 모르티에렐라 알피나의 형질전환 방법은 문헌[Mackenzie et al. (Appl . Environ . Microbiol., 66:4655 (2000))]에 기재되어 있다. 유사하게, 트라우스토키트리알레스(Thraustochytriales) 미생물(예컨대, 트라우스토키트리움, 스키조키트리움(Schizochytrium))의 형질전환 방법이 미국 특허 제7,001,772호에 기재되어 있다.
본 명세서에 기재된 돌연변이 델타-9 연장효소의 발현을 위해 선택되는 숙주와 관계 없이, 원하는 발현 수준 및 패턴을 나타내는 균주를 수득하기 위하여 다수의 형질전환체를 스크리닝하여야 한다. 이러한 스크리닝은 DNA 블롯의 서던 분석(문헌[Southern, J. Mol. Biol., 98:503 (1975)]), mRNA 발현의 노던 분석(문헌[Kroczek, J. Chromatogr. Biomed. Appl., 618(1-2):133-145 (1993)]), 단백질 발현의 웨스턴 및/또는 엘라이자 분석, PUFA 생성물의 표현형 분석 또는 GC 분석에 의해 달성될 수 있다.
형질전환된 미생물 숙주 세포는 키메라 탈불포화화효소 및 연장효소 유전자의 발현을 최적화하는 조건 하에서 성장하며, 가장 크고 가장 경제적인 수율의 원하는 PUFA를 생성한다. 일반적으로, 탄소원의 유형 및 양, 질소원의 유형 및 양, 탄소-대-질소 비, 상이한 미네랄 이온의 양, 산소 수준, 성장 온도, pH, 바이오매스 생성 단계의 기간, 오일 축적 단계의 기간 및 세포 수집 시간 및 방법을 변경함으로써 배지 조건을 최적화시킬 수 있다. 대상 미생물, 예컨대 유지성 효모(예컨대, 야로위아 리폴리티카)는 일반적으로 복합 배지, 예컨대 효모 추출물-펩톤-덱스트로스 브로쓰["YPD"] 또는 성장에 필수적인 성분이 결여되어 목적하는 발현 카세트가 선택되게 하는 정의된 최소 배지(예컨대, 이스트 니트로겐 베이스(Yeast Nitrogen Base)(미국 미시간주 디트로이트 소재의 디프코 래보러터리즈(DIFCO Laboratories)))에서 성장시킨다.
본 명세서에 기재된 방법 및 숙주 세포를 위한 발효 배지는 적절한 탄소원, 예컨대 미국 특허 제7,238,482호 및 미국 특허 공개 제2011-0059204-A1호에 교시된 것을 함유해야 한다. 본 명세서에 기재된 방법 및 숙주 세포에 적절한 탄소원에는 다양한 공급원이 포함되며, 당(예컨대, 글루코스, 전화당(invert sucrose), 프룩토스 및 그들의 조합), 글리세롤 및/또는 지방산이 바람직하다.
질소는 무기 공급원(예컨대, (NH4)2SO4) 또는 유기 공급원(예컨대, 우레아 또는 글루타메이트)으로부터 공급될 수 있다. 적절한 탄소원과 질소원에 더하여, 발효 배지는 적절한 미네랄, 염, 보조인자, 완충제, 비타민 및 유지성 숙주의 성장과 PUFA 생성에 필요한 효소 경로의 촉진에 적절한 것으로 당업자에게 공지된 다른 구성성분도 함유해야 한다. 지질과 PUFA의 합성을 촉진시키는 몇가지 금속 이온, 예를 들어 Fe+2, Cu+2, Mn+2, Co+2, Zn+2 및 Mg+2에 특히 주목한다(문헌[Nakahara, T. et al., Ind . Appl . Single Cell Oils , D. J. Kyle and R. Colin, eds. pp 61-97 (1992)]).
본 명세서에 기재된 방법 및 숙주 세포에 바람직한 성장 배지는 통상적인 상업적으로 제조된 통상의 배지, 예를 들어 이스트 니트로겐 베이스(미국 미시간주 디트로이트 소재의 디프코 래보러터리즈)이다. 다른 정의된 성장 배지 또는 합성 성장 배지를 사용할 수도 있고, 형질전환체 숙주 세포의 성장에 적절한 배지는 미생물학 또는 발효 과학 분야의 전문가에게 공지되어 있을 것이다. 전형적으로, 발효에 적절한 pH 범위는 약 pH 4.0 내지 pH 8.0이며, pH 5.5 내지 pH 7.5가 초기 성장 조건의 범위로서 바람직하다. 발효는 호기성 또는 혐기성 조건 하에 행해질 수 있으며, 미세호기성(microaerobic) 조건이 바람직하다.
전형적으로, 높은 수준의 PUFA가 유지성 효모 세포에 축적되기 위해서는 2-단계 공정이 필요한데, 이는 대사 상태가 성장과 지방의 합성/저장 간에 "균형을 이루어야" 하기 때문이다. 따라서, 가장 바람직하게는, 유지성 효모(예컨대, 야로위아 리폴리티카)에서 PUFA를 생성시키기 위해 2-단계 발효 공정이 필요하다. 이러한 접근법은 다양한 적합한 발효 공정 설계(즉, 회분식, 유가식(fed-batch) 및 연속식) 및 성장 동안의 고려사항으로서, 미국 특허 제7,238,482호에 기재되어 있다.
PUFA는 숙주 미생물 및 식물에서 유리 지방산으로, 또는 아실글리세롤, 인지질, 황지질 또는 당지질과 같은 에스테르화 형태로 관찰될 수 있으며, 당업계에 널리 공지된 각종 수단을 통해 숙주 세포로부터 추출할 수 있다. 효모 지질에 대한 추출 기술, 품질 분석 및 허용 기준에 관한 하나의 검토는 문헌[Z. Jacobs(Critical Reviews in Biotechnology , 12(5/6):463-491 (1992))]의 것이다. 하류 가공에 관한 간단한 검토는 또한 문헌[A. Singh and O. Ward (Adv . Appl . Microbiol., 45:271-312 (1997))]에서 입수할 수 있다.
일반적으로, PUFA를 정제하기 위한 수단으로는 유기 용매를 사용한 추출(예컨대, 미국 특허 제6,797,303호 및 미국 특허 제5,648,564호), 초음파처리, 초임계 유체 추출(예를 들어, 이산화탄소를 사용함), 비누화 및 물리적 수단, 예를 들어 압착, 비드 비터(bead beater) 또는 그들의 조합이 포함될 수 있다. 추가의 상세사항에 대해서는 미국 특허 제7,238,482호를 참조한다.
시장에서는 현재 오메가-3 및/또는 오메가-6 지방산(특히, 예컨대 ALA, GLA, ARA, EPA, DPA 및 DHA)을 혼입하는 매우 다양한 식품 및 사료 제품을 지원하고 있다. 장쇄 PUFA를 포함하는 미생물 또는 식물 바이오매스, PUFA를 포함하는 부분 정제된 바이오매스, PUFA를 포함하는 정제유 및/또는 본 명세서에 기재된 방법 및 숙주 세포에 의해 제조되는 정제된 PUFA가 그들의 첨가에 의해 향상되는 식품 또는 사료의 섭취 시에 건강상 이익을 부여할 것으로 여겨진다. 더욱 구체적으로, 오메가-3 및/또는 오메가-6 지방산을 함유하는 이들 오일은 몇가지 예를 들면, 식품 유사물, 육류 제품, 시리얼 제품, 베이킹 식품, 스낵 식품 및 유제품에 첨가될 수 있다. 본 명세서에 참고로 포함되는 미국 특허 공개 제2009-0093543-A1호를 참조한다.
또한, 이들 조성물은 의료용 영양제, 식이 보조제, 유아용 조제식 및 약제를 비롯한 의료용 식품에 첨가함으로써 건강상 이점을 부여할 수 있다. 당업자는 건강상의 이점을 부여하기 위하여 식품, 사료, 식이 보조제, 기능성식품(nutriceutical), 약제 및 다른 섭취가능한 제품에 첨가될 이들 오일의 양을 이해할 것이다. 이들 오일의 섭취로부터의 건강상의 이점은 해당 분야에 기재되어 있으며, 당업자에게 공지되어 있고, 지속적으로 연구되고 있다. 이러한 양을 본 명세서에서는 "유효량"이라 지칭할 것이고, 다른 것 중에, 이들 오일을 함유하는 섭취되는 제품의 성질 및 이들이 처치하고자 하는 신체 병상(condition)에 좌우될 것이다.
실시예
본 발명은 하기의 실시예에 추가로 기재되어 있으며, 이는 본 발명을 실시하기 위한 축소판을 예시하나 그의 가능한 모든 변이형을 완전하게 정의하지 않는다.
일반 방법
본 실시예들에서 사용된 표준 재조합 DNA 및 분자 클로닝 기술은 당업계에 주지되어 있으며, 1) 문헌[Sambrook, J., Fritsch, E. F. and Maniatis, T., Molecular Cloning : A Laboratory Manual; Cold Spring Harbor Laboratory: Cold Spring Harbor, NY (1989) (Maniatis)]; 2) 문헌[T. J. Silhavy, M. L. Bennan, and L. W. Enquist, Experiments with Gene Fusions; Cold Spring Harbor Laboratory: Cold Spring Harbor, NY (1984)]; 및 3) 문헌[Ausubel, F. M. et al., Current Protocols in Molecular Biology, Greene Publishing Assoc. and Wiley-Interscience (1987)]에 기재되어 있다.
미생물 배양의 유지 및 성장에 적절한 재료 및 방법은 당업계에 잘 알려져 있다. 하기의 실시예에 사용하기에 적절한 기술은 문헌[Manual of Methods for General Bacteriology (P. Gerhardt, R.G.E. Murray, R.N. Costilow, E.W. Nester, W.A. Wood, N.R. Krieg and G.B. Phillips, Eds), American Society for Microbiology: Washington, D.C. (1994))]; 또는 문헌[Thomas D. Brock in Biotechnology: A Textbook of Industrial Microbiology, 2nd ed., Sinauer Associates: Sunderland, MA (1989)]에 기재된 바와 같이 찾을 수 있다. 미생물 세포의 성장 및 유지에 사용되는 모든 시약, 제한 효소 및 재료는 달리 특정되지 않는 한, 알드리치 케미컬즈(Aldrich Chemicals)(미국 위스콘신주 밀워키 소재), 디프코 래보러터리즈(미국 미시간주 디트로이트 소재), 지브코(GIBCO)/BRL(미국 메릴랜드주 게이더스버그 소재), 뉴 잉글랜드 바이오랩스(New England Biolabs)(미국 매사추세츠주 입스위치 소재), 또는 시그마 케미컬 컴퍼니(Sigma Chemical Company)(미국 미주리주 세인트 루이스 소재)로부터 수득하였다. 에스케리키아 콜라이 균주를 전형적으로 루리아-베르타니(Luria Bertani)["LB"] 플레이트 상에서 37℃에서 성장시켰다.
일반적 분자 클로닝을 표준 방법에 따라 수행하였다(상기 문헌[Sambrook et al.]). 서열 교정(editing)은 시퀀처(Sequencher)(미국 미시간주 앤 아버 소재의 진 코즈 코포레이션(Gene Codes Corp.))에서 수행하였다. 모든 서열은 양 방향으로 적어도 2배의 적용 범위를 나타낸다. 유전 서열의 비교는 디엔에이스타(DNASTAR) 소프트웨어(미국 위스콘신주 매디슨 소재의 디엔에이스타 인코포레이티드(DNASTAR Inc.)) 또는 사내에서(in-house) 생성한 유사 소프트웨어(미국 델라웨어주 윌밍턴 소재의 이.아이. 듀폰 드 네무어 앤드 컴퍼니 인코포레이티드(E.I. duPont de Nemours & Co., Inc.))를 사용하여 달성하였다.
약어의 의미는 다음과 같다: "sec"는 초를 의미하고, "min"은 분을 의미하며, "h"는 시간을 의미하고, "d"는 일을 의미하며, "㎕"은 마이크로리터를 의미하고, "㎖"은 밀리리터를 의미하며, "ℓ"은 리터를 의미하며, "μM"은 마이크로몰을 의미하고, "mM"은 밀리몰을 의미하며, "M"은 몰을 의미하고, "mmol"은 밀리몰을 의미하며, "μmole"는 마이크로몰을 의미하고, "g"는 그램을 의미하며, "㎍"는 마이크로그램을 의미하고, "ng"는 나노그램을 의미하며, "U"는 유닛을 의미하고, "bp"는 염기쌍을 의미하며, "kB"는 킬로베이스를 의미한다.
발현 카세트에 대한 명명법: 발현 카세트의 구조는 "X::Y::Z"의 간단한 표기 체계에 의해 나타낼 것이며, 여기서, X는 프로모터 단편을 말하며, Y는 유전자 단편을 말하고, Z는 종결자 단편을 기재하며, 이들 모두는 서로 작동가능하게 연결된다.
야로위아 리폴리티카의 형질전환 및 배양: ATCC 수탁 번호가 #20362, #76982 및 #90812인 야로위아 리폴리티카 균주를 아메리칸 타입 컬쳐 콜렉션(미국 메릴랜드주 록빌 소재)으로부터 구입하였다. 야로위아 리폴리티카 균주를 전형적으로 하기에 나타낸 방법에 따라 몇몇 배지에서 28 내지 30℃에서 성장시켰다. 아가 플레이트를 표준 방법에 따라, 각 액체 배지에 20 g/ℓ의 아가를 첨가함으로써 요구되는 바와 같이 준비하였다.
YPD 아가 배지(리터당): 10 g의 효모 추출물[디프코], 20 g의 박토(Bacto) 펩톤[디프코] 및 20 g의 글루코스.
기본 최소 배지[" MM "](리터당): 20 g의 글루코스, 1.7 g의 이스트 니트로겐 베이스(아미노산 없음), 1.0 g의 프롤린 및 pH 6.1(조정할 필요 없음).
최소 배지 + 5-플루오로오로트산[" MM + 5- FOA "](리터당): 20 g의 글루코스, 6.7 g의 이스트 니트로겐 베이스, 75 mg의 우라실, 75 mg의 우리딘 및 100 mg/ℓ 내지 1000 mg/ℓ 범위의 농도에 대한 FOA 활성 시험에 기초하여(공급처로부터 받은 각각의 배치에서 변이가 발생하기 때문에), 적절한 양의 FOA(미국 캘리포니아주 오렌지 소재의 자이모 리서치 코포레이션(Zymo Research Corp.)).
고 글루코스 배지[" HGM "](리터당): 80의 글루코스, 2.58 g의 KH2PO4 및 5.36 g의 K2HPO4, pH 7.5(조정할 필요가 없음).
발효 배지[" FM "](리터당): 6.70 g/ℓ의 이스트 니트로겐 베이스, 6.00 g의 KH2PO4, 2.00 g의 K2HPO4, 1.50 g의 MgSO4*7H2O, 20 g의 글루코스 및 5.00g의 효모 추출물(BBL).
야로위아 리폴리티카의 형질전환을 본 명세서에 참고로 포함되는 미국 특허 공개 제 2009-0093543-A1호에 기재된 바와 같이 수행하였다.
실시예 1
야로위아
리폴리티카에서의
발현을 위해 코돈-최적화된 합성 델타-9 연장효소 유전자(유글레나
그라실리스로부터
유래)["
EgD9eS
"]를 포함하는
야로위아
리폴리티카
발현 벡터
pZuFmEgD9ES
의 구축
키메라 FBAINm::EgD9eS::Pex20 유전자(여기서, EgD9eS는 유글레나 그라실리스로부터 유래되고 야로위아에서의 발현을 위해 코돈-최적화된 합성 델타-9 연장효소이다)를 포함하는 야로위아 리폴리티카 벡터 pZuFmEgD9ES(도 2; 서열 번호 25)의 구축은 본 명세서에 참고로 포함되는 미국 특허 제7,645,604호의 실시예 8에 기재되어 있다. EgD9eS의 뉴클레오티드 서열(서열 번호 9)은 야생형 유글레나 그라실리스 델타-9 연장효소의 뉴클레오티드 서열("EgD9e"; 서열 번호 7)과 상이한데, 이는 번역 개시 부위의 변형에 더하여 777 bp 암호화 영역 중 117 bp를 변형시키고(15.1%) 106개 코돈을 최적화시켰기 때문이다(40.9%)(그렇지만, 코돈-최적화된 유전자에 의해 암호화되는 단백질 서열[즉, 서열 번호 10]은 야생형 단백질 서열[즉, 서열 번호 8]의 것과 동일하다).
실시예 2
델타-9 연장효소 전환 효율이 증가된 돌연변이 델타-9 연장효소를 포함하는 야로위아 리폴리티카 형질전환체를 분석하기 위한 일반 방법
본 실시예는 오류 유발 중합효소 연쇄 반응["ePCR"] 라이브러리(실시예 3), 부위-포화 라이브러리(실시예 5), 슬로노맥스(등록 상표) 라이브러리(실시예 7) 또는 조합 라이브러리(실시예 9)(상기 기재)에서 생성된 다양한 돌연변이된 EgD9eS 유전자 또는 비-돌연변이 EgD9eS 유전자(서열 번호 9)("대조군" 또는 "야생형" 중 어느 하나로 지칭) 중 어느 하나를 발현하는 야로위아 리폴리티카 균주 Y2224의 pZUFmEgD9ES 형질전환 유기체(야생형 야로위아 균주 ATCC #20362의 Ura3 유전자의 자가 돌연변이로부터의 FOA 내성 돌연변이체[국제 특허 출원 공개 WO 2008/073367호의 실시예 7에 기재된 분리])에서의 지질 프로파일을 분석하기 위한 일반적인 수단을 기재하고 있다.
돌연변이 라이브러리의 에스케리키아
콜라이
(
Escherichia
coli
) 및
야로위아
리폴리티카로의
형질전환
각각의 돌연변이 라이브러리로부터의 DNA를 전기천공법에 의해 에스케리키아 콜라이 탑(Top) 10 일렉트로-컴피턴트(electro-competent) 세포(카달로그 번호 C404052, 미국 캘리포니아주 칼스배드 소재의 인비트로겐(Invitrogen))로 형질전환시켰다. 형질전환된 세포를 100 mg/ℓ 앰피실린이 있는 루리아-베르타니["LB"] 아가 플레이트로 스프레딩하고, 37℃ 인큐베이터에서 하룻밤 성장시켰다. 플라스미드 DNA를 제조처의 프로토콜에 따라 퀴아프렙(QIAprep)(등록 상표) 스핀 미니프렙(Spin Miniprep) 키트(미국 캘리포니아주 발렌시아 소재의 퀴아젠 인코포레이티드(Qiagen Inc.))를 사용하여 형질전환체 에스케리키아 콜라이 세포로부터 추출하였다.
이어서, DNA 분자를 일반 방법에 기재된 바와 같이 야로위아 리폴리티카 균주 Y2224로 형질전환시키고, 형질전환체를 MM 플레이트 상에서 선택하였다. 30℃에서의 2일의 성장 후에, MM 플레이트 상에서 선택한 형질전환체를 픽킹하고(picked) 새로운 MM 플레이트 상으로 다시 스트리킹(streaked)하였다.
퀵 스크린 플레이트 검정법(Quick Screen Plate Assay)
퀵 스크린 "플레이트 검정법"을 각각의 돌연변이 라이브러리의 예비 기능 분석을 위해 사용하였다. 이러한 플레이트 검정법을 위하여, 상기 다시 스트리킹한 MM 플레이트로부터의 형질전환체 야로위아 세포를 배지 플레이트로부터 직접 분석하였다. 지방산 메틸 에스테르["FAME"]를 트라이메틸설포늄 하이드록시드["TMSH"]를 사용하여 제조하였다.
TMSH를 메탄올 중의 산화은과의 반응에 의한 하이드록시드 용액으로의 전환 후에 트라이메틸설포늄 아이오다이드["TMSI"]로부터 제조하였다. 구체적으로, 4.4 g의 TMSI를 100 ㎖의 MeOH에서 혼합하고, 50℃ 수조에서 1시간 동안 인큐베이션되게 한 다음; 5 g의 Ag2O를 용액에 첨가하고, 실온에서 4시간 동안 교반하였다. 최종 용액을 사용 전에 여과하였다. TMSH는 염기-촉매작용된 O-아실 지질(즉, TAG)의 에스테르 교환 및 유리 지방산의 에스테르화를 야기한다(문헌[A. H. El-Hamdy & W. W. Christie, J. of Chromatography , 630:438-441 (1993)]).
1 ㎕ 루프(loop)를 사용하여, 세포를 다시 스트리킹한 MM 플레이트로부터 직접 취하고, 0.35 ㎖ 인서트(insert)가 있는 기체 크로마토그램["GC"] 바이얼에서 50 ㎕의 TMSH에 현탁화시켰다. 이어서, 헵탄(150 ㎕)을 바이얼 인서트에 첨가하고, 바이얼을 캡핑한 다음, 진탕시키면서 실온에서 20분 동안 인큐베이션시켰다. 이후에, 헵탄층으로부터의 1 ㎕를 FAME의 GC 분석을 위하여 오메가왁스(Omegawax) 320 융합 실리카 모세관 컬럼(미국 펜실베니아주 벨폰테 소재의 수펠코 인코포레이티드(Supelco Inc.))이 장착된 휴렛 팩커드(Hewlett Packard) 7890 GC로 주입하였다. 정체 시간을 상용의 표준물질(표준물질 #461, 미국 미네소타주 엘리시안 소재의 누-체크 프렙 인코포레이티드(Nu-Chek Prep, Inc.))로부터의 메틸 에스테르에 대한 것과 비교하였다.
EgD9eS 돌연변이체를 포함하는 세포로부터 수득한 FAME 프로파일을 비-돌연변이 EgD9eS 대조군의 것과 비교하였다. 이러한 일차 스크린의 결과는 이차 확인 검정법으로 처리할 돌연변이체의 선택을 위한 기준으로 삼았다. 확인 검정법을 위한 돌연변이체를 선택하기 위해 사용되는 기준은 지질 프로파일, 특히 모든 적분된 피크의 합에 비한 백분율로서 해당하는 FAME의 GC 피크 영역으로 계산 시의 EDA의 농도["EDA % TFA"] 및/또는 LA로부터 EDA로의 전환 효율에 기초한 것이었다. LA로부터 EDA로의 전환 효율["전환%"]을 하기의 식에 따라 각각의 형질전환체에 대하여 계산하였다: ([생성물]/[기질 + 생성물])*100(여기서, 생성물은 EDA % TFA였으며, 기질은 TFA의 영역 백분율로서의 LA의 농도["LA % TFA"]였다).
"확인" 검정법
퀵 스크린 "플레이트 검정법"을 통하여 대조군에 비한 델타-9 연장효소 활성의 향상을 나타내는 돌연변이체를 이후의 확인 검정법을 위해 선택하였다.
돌연변이체로 형질전환된 야로위아를 먼저 다시 스트리킹한 MM 플레이트로부터 성장시킨 다음, 각각의 돌연변이체를 30℃에서 3 ㎖ 액체 MM을 포함하는 3벌의 배양물로 개별적으로 접종하고, 250 rpm/분에서 2일 동안 쉐이킹하였다. 세포를 원심분리에 의해 수집하고, 지질을 추출하고, FAME를 소듐 메톡시드를 사용한 지질 추출물의 에스테르 교환에 의해 제조하고(문헌[Roughan, G., and Nishida I., Arch. Biochem. Biophys., 276(1):38-46 (1990)]), 이후에 플레이트 검정법(상기)에 대해 기재된 바와 같이 GC에 의해 분석하였다.
향상된 델타-9 연장효소 활성의 확인 후에, 각각의 돌연변이체 pZUFmEgD9ES 플라스미드를 자이모프렙(Zymoprep)(상표명) 이스트 플라스미드 미니프렙(Yeast Plasmid Miniprep) II 키트(카달로그 번호 D2004, 미국 캘리포니아주 오렌지 소재의 자이모 리서치)를 제조처에 의해 권고되는 바와 같이 사용하여 그것이 발현되는 형질전환된 야로위아 리폴리티카 균주 Y2224로부터 회수하였다.
복원된 플라스미드의 서열을 표준 DNA 시퀀싱 방법을 사용하여 특성화하였다. 약술하면, DNA 서열을 염료 종결 기술(dye terminator technology)(미국 특허 제5,366,860호; 유럽 특허 제272,007호)을 사용하는 ABI 자동 시퀀서(sequencer)에서, 벡터 및 삽입물-특이적 프라이머의 조합을 사용하여 생성하였다. 유전 서열의 비교를 당업자에게 잘 알려져 있는 표준 도구를 사용하여 달성하였다.
실시예 3
2개의
EgD9eS
오류 유발
PCR
라이브러리의 구축
본 실시예는 2개의 델타-9 연장효소 오류 유발 중합효소 연쇄 반응["ePCR"] 라이브러리의 합성에 대해 기재하고 있다. 먼저 주형 내의 무작위 돌연변이를 포함하는 메가프라이머의 모음의 생성을 필요로 하며, pZuFmEgD9ES로 점 돌연변이를 만들기 위한 이들 메가프라이머의 이용으로 이어지는 2-단계 방법에서 2개의 ePCR 라이브러리를 생성하였다. 구축물 pZuFmEgD9ES(서열 번호 25)(실시예 1)를 제1 ePCR 라이브러리를 위한 DNA 주형으로 사용하였다. 제2 ePCR 라이브러리는 DNA 주형으로서 제1 ePCR 라이브러리로부터의 힛트(hit)를 사용하였다.
무작위 돌연변이유발
키트를
사용한
메가프라이머의
생성
진모르프(GeneMorph) II 랜덤 뮤타지네시스(Random Mutagenesis) 키트(카달로그 번호 200550, 미국 캘리포니아주 라 졸라 소재의 스트라타진)를 사용하여 표적 단백질 내에 무작위 아미노산 치환을 생성하였다. 이는 A 및 T 대 G 및 C에서 동등한 돌연변이률을 갖는 덜 편향된 돌연변이 스펙트럼을 생성하도록 2개의 상이한 중합효소의 조합을 포함하는 신규한 오류 유발 PCR 효소 배합된 조성을 사용하여 오류-유발 PCR 동안 표적 유전자 내로 돌연변이를 도입함으로써 기능한다. 높은 생성물 수율을 위해 최적화된 단일의 세트의 완충액 조건을 사용하여 kB당 1 내지 16개 돌연변이의 돌연변이율이 달성될 수 있는 것으로 언급되었다. 바람직한 돌연변이율은 단순하게 반응 내의 처음의 주형 DNA의 양 및/또는 수행되는 증폭 사이클의 횟수를 다양하게 함으로써 조절할 수 있다.
상기 키트를 사용하여 제조처에 의해 권고되는 프로토콜을 사용하여 EgD9eS "메가프라이머"를 생성하였다. 이들 메가프라이머는 약 930 bp 길이였으며, EgD9eS를 암호화하는 777 bp(서열 번호 9)를 포함한다. 반응 혼합물은 제1 ePCR 라이브러리를 위하여 ㎕당 16 ng의 DNA 주형 또는 제2 라이브러리를 위하여 ㎕당 2.0 ng의 DNA 주형 중 어느 하나를 함유한다. 이는 또한 반응 완충액, dNTP(0.8 mM), 프라이머 pZUFm_6980_012208f(서열 번호 26)(2 μM), 프라이머 pZUFm_210_012208r(서열 번호 27)(2 μM) 및 뮤타자임(Mutazyme)(등록 상표) II DNA 중합효소(0.25 U/㎕)를 포함한다. PCR 반응을 마스터사이클러 구배 장비(Mastercycler gradient equipment)(미국 뉴욕주 웨스트버리 소재의 브린크만 인스트루먼츠, 인코포레이티드(Brinkmann Instruments, Inc.))에서 얇은 벽의 200 ㎕ 튜브에서 수행하였다. PCR 증폭을 하기의 조건을 사용하여 수행하였다: 2분 동안 95℃에 이어서, 30초 동안 95℃에서의 변성, 30초 동안 55℃에서의 어닐링(annealing) 및 90초 동안 72℃에서의 연장의 30 사이클. 72℃에서 4분 동안의 최종 연장 사이클에 이어서 4℃에서의 반응 종결을 수행하였다.
PCR 생성물을 제조처에 의해 권고되는 바와 같이, 디엔에이 클린 앤드 컨센트레이터(DNA Clean & Concentrator)(상표명)-5 키트(카달로그 번호 D4003, 미국 캘리포니아주 오렌지 소재의 자이모 리서치)를 사용하여 정제하였다. 정제된 이중-가닥 PCR 생성물을 "메가프라이머"로 사용하였으며, 각각은 EgD9eS 내의 다양한 돌연변이를 함유한다.
EgD9eS의 ePCR 돌연변이 유전자를 생성하기 위한 표준 클로닝 방법
제1 ePCR 라이브러리를 위하여, "메가프라이머"를 NcoI 및 NotI 제한 효소로 분해하였다. 그 다음, 겔 정제된 NcoI/NotI 유전자 단편을 실온에서 5시간 동안의 라이게이션 반응을 통하여 T4 DNA 리가아제(ligase)(미국 위스콘신주 매디슨 소재의 프로메가(Promega))를 사용하여, 겔 정제된 NcoI/NotI pZUFmEgD9ES 벡터(서열 번호 25)로 직접 라이게이션시켰다.
EgD9eS
의
ePCR
돌연변이 유전자를 생성하기 위한 부위-지정 돌연변이유발
제2 ePCR 라이브러리를 생성하기 위하여, "메가프라이머" 내의 EgD9eS 돌연변이를 pZuFmEgD9ES(도 2; 서열 번호 25)로 도입하여, 이에 의해 비-돌연변이 EgD9eS 유전자를 다양한 돌연변이 EgD9eS 유전자로 대체하도록 설계된 반응에서 상술된 "메가프라이머"를 사용하였다. 이는 퀵체인지(QuikChange)(등록 상표) II XL 부위 지정 돌연변이유발 키트(카달로그 번호 200524, 미국 캘리포니아주 라 졸라 소재의 스트라타진)를 사용하여 달성하였다.
둘 모두의 플라스미드 가닥의 돌연변이 유발 프라이머-지시 복제를 위한 하이-피델리티(high-fidelity) PfuUltra DNA 중합효소를 사용하여 이중 가닥 벡터 내의 대상 삽입물 내에서 점 돌연변이를 생성하고, 아미노산을 대체하고, 단일/다수의 인접 아미노산을 결실시키거나 삽입하기 위하여, 퀵체인지(QuikChange)(등록 상표) II 부위-지정 돌연변이유발 키트를 사용하였다. 키트는 특수 벡터, 독특한 제한 부위 또는 다수의 형질전환을 필요로 하지 않으며, 사실상 임의의 이중-가닥 플라스미드 내의 부위-특이적 돌연변이가 가능하게 된다. 기본적인 절차는 2개의 합성 올리고뉴클레오티드 프라이머를 사용하며, 둘 모두는 목적하는 돌연변이를 함유하며, 벡터의 반대 가닥에 상보적이며, 이는 프라이머 대체 없이 하이-피델리티 DNA 중합효소에 의해 온도 사이클링 동안 연장된다. 올리고뉴클레오티드 프라이머의 연장에 의해, 스태거드 닉(staggered nick)을 함유하는 돌연변이된 플라스미드를 생성하였으며, 이어서 이를 Dpn I 엔도뉴클레아제(endonuclease)로 처리하였다. 이러한 제한 효소는 메틸화된 DNA 및 반-메틸화 DNA에 대하여 특이적이며, 이에 의해, 모 DNA 주형의 분해 및 돌연변이를 함유하는 합성 DNA에 대한 선택이 가능하게 된다. 이어서, 목적 돌연변이를 함유하는 닉이 있는 벡터 DNA를 에스케리키아 콜라이 숙주에서 형질전환시키고 증식시켰다.
그러나, 본 방법에서, 다양한 돌연변이 EgD9eS 유전자를 포함하는 이중 가닥 메가프라이머를 통상적인 합성 올리고뉴클레오티드 프라이머 대신에 사용하였다. 구체적으로, 5.0 ㎕의 키트-제공되는 10x 반응 완충액, 1.0 ㎕의 50 ng/㎕ pZUFmEgD9ES 주형(서열 번호 25), 42 ㎕의 메가프라이머, 1.0 ㎕의 40 mM 키트-제공된 dNTP 믹스(mix) 및 1.0 ㎕의 키트-제공된 Pfu -Ultra DNA 중합효소를 포함하는 50 ㎕의 반응물을 제조하였다. 이러한 반응 혼합물을 얇은 벽 200 ㎕-용량 PCR 튜브에 두고, 하기의 조건을 사용하여 PCR 증폭으로 처리하였다: 30초 동안 95℃에 이어서, 30초 동안 95℃에서의 변성, 1분 동안 55℃에서의 어닐링 및 6분 동안 68℃에서의 연장의 25 사이클. 8분 동안 68℃에서의 최종 연장 사이클을 수행하고, 4℃에서의 반응 종결로 이어졌다.
키트-제공된 DpnI 제한 효소(1.0 ㎕)를 완성된 부위-지정 돌연변이유발 반응 혼합물에 직접 첨가하고, 효소 분해를 37℃에서 1시간 동안 수행하여, DNA 주형을 제거하였다. 분해된 생성물을 DNA 클리닝(cleaning) 키트(자이모 리서치)를 사용하여 정제하고, 용리시켜, pZUFmEgD9ES 벡터 백본에 함유되는 다양한 돌연변이 EgD9eS 유전자를 포함하는 10 ㎕의 정제된 DNA를 제공하였다.
실시예 4
델타-9 연장효소 전환 효율이 향상된 ePCR EgD9eS 라이브러리 돌연변이체의 동정
본 실시예는 1) 야생형 단백질 EgD9eS(서열 번호 10)의 전환 효율에 비하여 LA로부터 EDA로의 델타-9 연장효소 전환 효율이 향상된 EgD9eS ePCR 라이브러리 돌연변이체의 동정; 및 2) 이들 EgD9eS ePCR 라이브러리 돌연변이체의 서열 분석.
EgD9eS ePCR 돌연변이체의 동정
실시예 3에서 제조된 ePCR 유전자 라이브러리 돌연변이체를 에스케리키아 콜라이 탑 10 일렉트로-컴피턴트 세포로 형질전환시키고, 정제하고, 이후에 실시예 2에 기재된 바와 같이 야로위아 리폴리티카 균주 Y2224로 형질전환시켰다. 1,724개의 야로위아 형질전환체의 지방산 프로파일을 실시예 2의 퀵 스크린 "플레이트 검정법"을 사용하여 스크리닝하였다. 대부분의 이들 돌연변이체는 대조군에 비하여 감소된 활성을 나타내었다. 그러나, 5개의 돌연변이체는 실시예 2의 확인 검정법에 기초하여, 대조군에 비하여 향상된 델타-9 연장효소 활성을 나타내는 것으로 확인되었다.
2개의 독립적인 확인 검정법으로부터의 데이터는 표 5 및 표 6에 제공되어 있으며, 개별 pZuFmEgD9ES 대조군 형질전환체의 FAME 프로파일을 ePCR 돌연변이체의 프로파일과 비교하였다. 더욱 구체적으로, 각각의 균주에 대한 모든 적분된 피크의 합과 비교한 백분율["% TFA"]로서 해당하는 FAME의 GC 피크 영역으로부터 계산시 각각의 지방산의 농도 및 LA로부터 EDA로의 전환%(실시예 2에 기재된 바와 같이 결정)는 하기의 표 5 및 표 6에 나타나 있으며, 평균은 회색으로 강조표시하였고, "평균"으로 나타내었다. 지방산을 16:0(팔미트산), 16:1(팔미톨레산), 18:0(스테아르산), 18:1(올레산), LA 및 EDA로 동정하였다. EgD9eS 대조군에 대한 각각의 돌연변이체의 성능의 비교는 각각의 돌연변이체가 분석되는 특정 확인 검정법에서만 이루어져야 한다(즉, 검정법 #1과 검정법 #2 간의 비교는 이루어질 수 없다).


확인 검정법 #1에서의 상술된 데이터의 요약에 있어서, 비-돌연변이 코돈-최적화된 EgD9eS 유전자를 포함하는 pZuFmEgD9ES로 형질전환된 야로위아 리폴리티카 균주 Y2224의 클론이 평균 3.1 EDA % TFA를 생성하였으며, 여기서, 이들 5개의 클론에서의 LA로부터 EDA로의 평균 전환 효율["전환%"]은 약 15.5%인 것으로 결정되었다. 대조적으로, 돌연변이 균주 1.2ep-8에 대한 LA로부터 EDA로의 평균 전환%는 17.8%(또는 대조군에 비해서는 115%)였고; 돌연변이 균주 1.9ep-63에 대한 평균 전환%는 16.3%(또는 대조군에 비해서는 105%)였고; 돌연변이 균주 1.4ep-161에 대한 평균 전환%는 16.4%(또는 대조군에 비해서는 106%)였다.
확인 검정법 #2에서, pZuFmEgD9ES로 형질전환된 야로위아 리폴리티카 균주 Y2224의 클론은 2.9 EDA % TFA를 생성하였으며, 이들 4개의 균주에서의 LA로부터 EDA로의 평균 전환%는 약 16.9%인 것으로 결정되었다. 돌연변이 균주 2.1ep-94에 대한 LA로부터 EDA로의 평균 전환%는 19.8%(또는 대조군에 비해서는 117%)였으며; 돌연변이 균주 2.1ep-95에 대한 평균 전환%는 18.8%(또는 대조군에 비해서는 111%)였다.
따라서, 이들 실험에 의해, EgD9eS ePCR 돌연변이체 1.2ep-8, 1.9ep-63, 1.4ep-161, 2.1ep-94 및 2.1ep-95에 의해 향상된 델타-9 연장효소 전환 효율이 나타나는 것이 확인되었다.
EgD9eS ePCR 돌연변이체의 서열
돌연변이체 1.2ep-8, 1.9ep-63, 1.4ep-161, 2.1ep-94 및 2.1ep-95로부터 복원된 플라스미드를 DNA 시퀀싱에 의해 특성화하였으며, 분석에 의해, 표 7에 나타낸 바와 같이, 돌연변이 EgD9eS 유전자 내에서 다양한 뉴클레오티드 치환이 드러났고, 아미노산 치환이 발현되었다. 아미노산 치환을 나타내는 명칭은 각 돌연변이 EgD9eS 유전자 및 돌연변이 EgD9eS 유전자를 포함하는 각각의 돌연변이 pZuFmEgD9ES 플라스미드에 제공하였다. 열거된 각각의 치환(즉, L35G)에 대하여, 처음의 문자는 비-돌연변이 EgD9eS(즉, 서열 번호 10) 내의 아미노산에 해당하며, 두번째 문자는 돌연변이체 내의 동일한 위치에서 관찰되는 아미노산에 해당하며, 다시 말하면, L35G는 EgD9eS 돌연변이체에서 위치 35의 Leu로부터 Gly로의 변화를 나타낸다.

따라서, 예를 들어, 돌연변이 1.2ep-8로부터 복원된 플라스미드는 2개의 뉴클레오티드 치환(즉, C103T 및 A654G)을 포함한다. 이들 2개의 뉴클레오티드 치환은 하나의 발현된 아미노산 치환(즉, L35F) 및 하나의 침묵 아미노산 돌연변이(즉, G218G; GGA 및 GGG 둘 모두가 Gly를 암호화하기 때문에, 이러한 아미노산은 A654G 뉴클레오티드 치환의 결과로서 돌연변이 단백질에서 변경되지 않았다)에 해당한다. 아미노산 변화 L35F를 야기하는 C103T 및 A654G 돌연변이를 포함하는 플라스미드는 pZuFmEgD9ES-L35F(서열 번호 30)로 명명하는 한편, 거기에서 돌연변이 델타-9 연장효소의 뉴클레오티드 서열은 "EgD9eS-L35F"(서열 번호 28)로 명명하고, 이는 서열 번호 29에 기재된 단백질 서열을 갖는다.
실시예 5
2-부위 포화
EgD9eS
유전자 라이브러리의 구축
본 실시예는 EgD9eS(서열 번호 10) 내의 아미노산 위치 35 및 107을 표적화함으로써 만들어지는 부위-포화["SS"] 라이브러리의 합성을 기재하고 있다. 위치 35를 표적화하는 이유는 실시예 4의 결과에 기초한 것이며, 위치 107을 표적화하는 이유는 후술된다. 먼저 주형 내의 표적화된 돌연변이를 포함하는 메가프라이머의 생성에 이어서, pZuFmEgD9ES로 점 돌연변이를 만들기 위한 이들 메가프라이머의 이용을 필요로 하는 2-단계 방법에서 SS 라이브러리를 생성하였다.
EgD9eS
의 위치 107을
표적화하는
이유
먼저, 하기 표 8에 기재된 바와 같은 17개 지방산 연장효소의 아미노산 서열을 클러스털더블유 정렬 방법을 사용하여 정렬하였다.

톰슨(Thompson) 등에 의해 기재된 클러스털 더블유 정렬 방법(문헌[Nucleic Acids Res . 22:4673-4680 (1994)])을 디폴트 파라미터(즉, 단백질 중량 매트릭스 = 고넷 250, 갭 개방 페널티(gap opening penalty) = 10, 갭 연장 페널티 = 0.2 및 전체 정렬 알고리듬)와 함께 클러스털더블유 패키지(버전 1.83)를 사용하여 수행하였다. 정렬의 결과는 도 3(도 3a, 3b, 3c, 3d, 3e, 3f, 3g 및 3h)에 나타나 있다. "Trace_1", "Trace_2", "Trace_3" 및 "Trace_4"는 하기에 정의되는 바와 같은 기능성 그룹 I, 그룹 II, 그룹 III 및 그룹 IV에 대한 각각의 열의 공통서열을 나타내며, 다시 말하면, Trace 1은 Ci_elo, Om_elo, Mp_elo1, Pp_elo1, Mp_d5e 및 Ot_elo1을 포함하는 그룹 I에서의 단백질 공통 서열을 나타낸다. 각 열의 공통서열은 하기에 정의되어 있다. 구체적으로, 열이 완전히 보존되었다면, 공통서열은 대문자로 나타낸 보존된 아미노산으로 표시하였다. 열이 물리-화학적 특성의 면에서 보존되었다면, 공통서열은 소문자로 표시하였으며, 여기서, "k"는 아미노산 D 및 E(음으로 하전)를 나타내며, "q"는 아미노산 H, K 및 R(양으로 하전)을 나타내고, "p"는 아미노산 N 및 Q(극성)를 나타내며, "a"는 아미노산 I, L 및 V(지방족)를 나타내고, "d"는 아미노산 F, W 및 Y(방향족)를 나타내며, "h"는 아미노산 A 및 G(아주 작은)를 나타내고, "s"는 아미노산 D, E, N, Q, H, K, R, S 및 T(친수성)를 나타내며, "f"는 아미노산 I, L, V, F, W, Y, C 및 M(소수성)을 나타낸다. 열이 보존되지 않았다면, 공통서열은 대문자 "X"로 나타내었다.
이웃-연결수(Neighbor-joining tree)를 클러스털 더블유 정렬로부터 생성하였다. 이웃-연결수 토폴로지(topology)에 기초하여, 17개의 서열을 4개의 그룹으로 분배하였으며, 이는 상이한 기질 특이성의 기능성 그룹에 해당하는 것으로 가정된다: 그룹 I은 Ci_elo, Om_elo, Mp_elo1, Pp_elo1, Mp_d5e 및 Ot_elo1을 포함하고; 그룹 II는 Pav_elo2, Ps_elo2 및 Ot_elo2를 포함하며; 그룹 III은 Ea_d9e, Eg_d9e, E398_d9e 및 Ig_d9e를 포함하고; 그룹 IV는 Tp_elo2, Tp_elo1, Ma_d6e 및 Th_elo2를 포함한다.
도 3의 정렬 및 이웃-연결수의 그룹화를 고려하여, 하기의 결론을 도출하였다. 먼저, 몇몇 위치는 그룹 I, II, III 및 IV 내의 모든 17개 서열에 걸쳐 완전히 보존된다. 이들 위치는 연장효소의 촉매적 활성에 필수적일 것 같다고 여겨졌으며, 이에 따라 돌연변이에 대한 표적으로 배제하였다. 몇몇 위치는 그룹 I, II, III 및 IV 내의 오직 일부의 서열에서만 보존되었다(즉, 완전하게 보존되지 않았다). 이들 위치는 그룹 I, II, III 또는 IV의 기능성 그룹 내에서 연장효소에 의해 나타나는 기질 특이성에 중요할 것 같다고 여겨졌다. 몇몇 위치는 그룹 III(모든 4개의 공지되어 있는 델타-9 연장효소 포함) 내에서 상대적으로 보존되었으나, 변이도 또한 나타났고; EgD9e의 넘버링에 기초하여 아미노산 위치 22, 47, 54, 101, 107, 111, 115, 161, 182, 192 및 242를 확인하길 바란다. 이들 위치는 델타-9 연장효소의 활성에 중요할 것 같다고 여겨졌으며, Ea_d9e(서열 번호 12), Eg_d9e(서열 번호 8), E398_d9e(서열 번호 4) 및 Ig_d9e(서열 번호 2)의 기질 특이성의 차이를 조절하는 것으로 가정되었다.
EgD9eS 내의 막관통(transmembrane)["TM"] 도메인의 분석을 TMHMM 프로그램("단백질 내의 막관통 헬릭스의 예측(Prediction of transmembrane helices in proteins)"; TMHMM Server v. 2.0, 덴마크 DK-2800 링비 소재의 덴마크 공과 대학 바이오센트럼(BioCentrum)-DTU 생물 서열 분석 센터(Center for Biological Sequence Analysis))을 사용하여 수행하였다. 예측에 의해, N- 및 C-말단 둘 모두가 세포질 측에 위치하는 6개의 막-스패닝 헬릭스(아미노산 잔기 32-51, 66-88, 114-136, 156-175, 188-206, 221-243에 해당)가 나타났다. Ot_elo2, Ig_elo1, Pav_elo2 및 Tp_elo2를 TMHMM 프로그램을 사용하여 유사하게 분석하는 경우, 막-스패닝 헬릭스의 개수는 4 내지 8로 달라졌다. 따라서, 이들 달라지는 예측을 확실히 하기 위하여, 하기의 기능 정보의 부분을 사용하였다.
1. 고도로 보존된 히스티딘-풍부 모티프[Q/H]xxHH("His-box")는 Ig_d9e(서열 번호 2)의 최적의 효소 활성에 필수적인 것으로 관찰되었으나, 기질 특이성의 직접적인 원인인 것은 아니다(문헌[Qi et al., FEBS Letters, 547:137-139 (2003)]). 따라서, His-box(EgD9eS 내의 아미노산 잔기 134-138에 해당)가 활성 부위에 수반되는 것이 강력하게 제시되었으며; 이는 폴딩된 단백질의 세포질 측 내에 또는 그 근처에 위치하여 기질이 활성 부위에 접근할 수 있도록 해야 한다.
2. 하전된 잔기를 갖는 몇몇의 고도로 보존된 위치는 EgD9eS의 C-말단에 존재한다. 그들은 활성에 관련이 있을 것 같으며, 이에 따라, C-말단은 아마도 폴딩된 단백질의 세포질 측에 위치할 것이다.
아미노산 잔기 114-136 및 아미노산 잔기 156-175에서 막-스패닝 헬릭스를 예측한 TMHMM 결과와 대조적으로, 상기 고려사항에 의해 잔기 114-136의 서열 영역이 막을 스패닝하지 않는 것이 나타났는데, 이는 His-box가 막의 외면에 위치할 수 없기 때문이다. C-말단이 세포질 측에 위치한다면, 156-175의 예측된 TM 도메인도 또한 막을 스패닝하지 않는다. 연장효소에 대한 기질이 고도로 소수성이기 때문에, 그는 아마도 지질 이중층으로 분배될 것이다. 활성 부위(His-box 포함)는 막 표면에서 또는 그의 바로 근처에서 나타날 수 있다.
따라서, 이들 2개의 소수성 영역(즉, 아미노산 잔기 114-136 및 아미노산 잔기 156-175에 해당)이 내막 리플릿 내에 또는 그 근처에 놓여 있어, 활성 부위가 막 근처에서 자리잡게 하는 것으로 본 명세서에서 예측되었다. EgD9eS에 대해 예측된 최종 막 토폴로지 모델은 도 4a에 나타나 있다. 구체적으로, 각각의 수직의 원통은 막-스패닝 세그먼트를 나타내는 한편, 각각의 수평의 원통은 내막 리플릿 내에 또는 그 근처에 놓여 있는 소수성 스트레치를 나타낸다. His-box(즉, 아미노산 잔기 134-138에 해당) 내의 보존된 글루타민[Q] 및 히스티딘[H]은 작은 원으로 표시되어 있다. 마지막으로, "내부"는 세포질 공간에 해당하고, "외부"는 주변세포질 공간에 해당한다.
보존 패턴 분석에 의해, 효소 활성에 영향을 미치는 것으로 예측되었던 그룹 III 델타-9 지방산 연장효소(즉, Ea_d9e[서열 번호 12], Eg_d9e[서열 번호 8], E398_d9e[서열 번호 4] 및 Ig_d9e[서열 번호 2]) 내에서 11개의 상이한 아미노산 잔기가 동정되었으나, 예측되는 토폴로지 모델로부터의 결과에 의해 후보 잔기가 추가로 제한되었다. 구체적으로, 효소 활성에 중요한 위치는 활성 부위가 놓여 있는 세포질 측에 또는 그 근처에 존재하여야 하는 것으로 추론되었다. 아미노산 잔기 47, 54 및 192는 이러한 기준을 만족시키지 못하였으며, 이에 따라, 그들이 델타-9 연장효소의 활성을 조절하는데 중요할 리가 없는 것으로 추정되었다.
상기 이유에 기초하여, EgD9eS의 델타-9 연장효소 활성에 유의미하게 영향을 미칠 것 같은 후보 잔기는 서열 번호 10의 전장 단백질 내의 258개 잔기로부터 위치 22, 101, 107, 111, 115, 161, 182 및 242에 해당하는 오직 8개의 잔기로 줄었다. 이들 8개의 위치는 EgD9eS의 기질 전환율을 향상시키기 위한 부위-지정 돌연변이유발에 대한 표적으로 권고되었다. 하기의 실험 데이터는 위치 107을 표적화한 것이다.
부위-포화 라이브러리의 구축을 위한 메가프라이머의 생성
올리고뉴클레오티드 EgD9E_102_053008f(서열 번호 56) 및 EgD9E_760_053008r(서열 번호 57)을 각각 EgD9eS(서열 번호 10)의 아미노산 잔기 35 및 107을 표적화하도록 설계하였다. 이들 올리고뉴클레오티드의 상업적 합성 후에, 그들을 PCR 반응에서 사용하여 SS 라이브러리의 구축에 사용하기에 적절한 메가프라이머를 생성하였다. 구체적으로, 50 ㎕ 반응 혼합물이 Pfu-Ultra 중합효소(스트라타진)가 제공된 5.0 ㎕의 10x 반응 완충액, 1.0 ㎕의 50 ng/㎕ EgD9eS(서열 번호 10), 1.0 ㎕의 10 pmol/㎕ 프라이머 EgD9E_102_053008f(서열 번호 56), 1.0 ㎕의 10 pmol/㎕ 프라이머 EgD9E_760_053008r(서열 번호 57), 1.0 ㎕의 40 mM dNTP 믹스(미국 위스콘신주 매디슨 소재의 프로메가), 1.0 ㎕의 하이 피델리티(high fidelity) Pfu-Ultra DNA 중합효소(스트라타진) 및 40 ㎕의 물을 함유하도록 제조하였다. 혼합물을 마스터사이클러 구배 장비(미국 뉴욕주 웨스트버리 소재의 브린크만 인스트루먼츠, 인코포레이티드)에서 PCR 반응을 위하여 얇은 벽의 200 ㎕ 튜브에 배치하였다. PCR 증폭을 하기의 조건을 사용하여 수행하였다: 30초 동안 95℃에 이어서, 30초 동안 95℃에서의 변성, 1분 동안 54℃에서의 어닐링 및 2분 동안 72℃에서의 연장의 30 사이클. 4분 동안 72℃에서 최종 연장 사이클을 수행하고, 4℃에서의 반응 종결로 이어졌다.
PCR 생성물을 제조처에 의해 권고되는 바와 같이, 디엔에이 클린 앤드 컨센트레이터(상표명)-5 키트(카달로그 번호 D4003, 미국 캘리포니아주 오렌지 소재의 자이모 리서치)를 사용하여 정제하였다. 정제된 이중-가닥 PCR 생성물은 각각이 EgD9eS 내의 다양한 돌연변이를 함유하는 "메가프라이머"로 사용하였다.
EgD9eS의 부위-포화 돌연변이 유전자를 생성하기 위한 부위-지정 돌연변이유발
이어서, "메가프라이머" 내의 EgD9eS 돌연변이를 pZuFmEgD9ES(도 2; 서열 번호 25)로 도입하여, 이에 의해 비-돌연변이 EgD9eS 유전자를 다양한 돌연변이 EgD9eS 유전자로 대체하도록 설계된 반응에서 상술된 "메가프라이머"를 사용하였다. 이는 실시예 3에 기재된 바와 같이 퀵체인지(등록 상표) II XL 부위 지정 돌연변이유발 키트(카달로그 번호 200524, 미국 캘리포니아주 라 졸라 소재의 스트라타진)를 사용하여 달성하였다. 구체적으로, 부위 지정 돌연변이유발 반응의 조성 및 증폭 조건은 DpnI 제한효소 및 DNA 클린-업(clean-up) 방법과 같이, 실시예 3에 기재된 것과 동일하였다.
실시예 6
델타-9 연장효소 전환 효율이 향상된 EgD9eS 부위-포화 라이브러리 돌연변이체의 동정
본 실시예는 1) 야생형 단백질 EgD9eS(서열 번호 10)의 전환 효율에 비하여 LA로부터 EDA로의 델타-9 연장효소 전환 효율이 향상된 EgD9eS 돌연변이체의 동정; 및 2) 이들 EgD9eS 돌연변이체의 서열 분석을 기재하고 있다.
EgD9eS 부위-포화 돌연변이체의 동정
실시예 5에서 제조된 SS 라이브러리를 에스케리키아 콜라이 탑 10 일렉트로-컴피턴트 세포로 형질전환시키고, 정제하고, 이후에 실시예 2에 기재된 바와 같이 야로위아 리폴리티카 균주 Y2224로 형질전환시켰다. SS 라이브러리로부터의 구축물을 갖는 510개의 야로위아 형질전환체의 지방산 프로파일을 실시예 2의 퀵 스크린 "플레이트 검정법"을 사용하여 분석하였다. 3개의 돌연변이체는 실시예 2의 확인 검정법에 기초하여 대조군에 비하여 향상된 델타-9 연장효소 활성을 나타내는 것으로 확인되었다.
확인 검정법으로부터의 데이터는 표 9에 제시되어 있으며, 개별 pZuFmEgD9ES 대조군 형질전환체의 FAME 프로파일을 SS 라이브러리 돌연변이체의 FAME 프로파일과 비교하였다. 더욱 구체적으로, 각각의 균주에 대한 TFA의 영역 백분율["TFA%"]로서의 각각의 지방산의 농도 및 LA로부터 EDA로의 전환%(실시예 2에 기재된 바와 같이 결정)는 하기의 표 9에 나타나 있으며, 평균은 회색으로 강조표시하였고, "평균"으로 나타내었다. 지방산을 실시예 4의 약어에 기초하여 나타내었다.

확인 검정법에서, 비-돌연변이 코돈-최적화된 EgD9eS 유전자를 포함하는 pZuFmEgD9ES로 형질전환된 야로위아 리폴리티카 균주 Y2224의 클론이 평균 3.5 EDA % TFA를 생성하였으며, 여기서, 이들 4개의 균주에서의 LA로부터 EDA로의 평균 전환 효율["전환%"]은 약 18.7%인 것으로 결정되었다. 그에 비해, 돌연변이 균주 2.4sd2-24에 대한 LA로부터 EDA로의 평균 전환%는 27.2%(또는 대조군에 비해서는 145%)였고; 돌연변이 균주 2.4sd2-52에 대한 평균 전환%는 26.6%(또는 대조군에 비해서는 142%)였고; 돌연변이 균주 2.4sd2-53에 대한 평균 전환%는 24.6%(또는 대조군에 비해서는 132%)였다. 따라서 이러한 검정법에 의해, 부위-포화 돌연변이체 2.4sd2-24, 2.4sd2-52 및 22.4sd2-53에 의해 향상된 델타-9 연장효소 전환 효율이 나타나는 것이 확인되었다.
EgD9eS 부위-포화 돌연변이체의 서열
돌연변이 2.4sd-24, 2.4sd-52 및 2.4sd-53으로부터 복원된 플라스미드를 DNA 시퀀싱에 의해 특성화하였으며, 분석에 의해, 표 10에 나타낸 바와 같이, 돌연변이 EgD9eS 유전자 내에서 다양한 뉴클레오티드 치환이 드러났고, 아미노산 치환이 발현되었다. 아미노산 치환을 나타내는 명칭은 각 돌연변이 EgD9eS 유전자 및 돌연변이 EgD9eS 유전자를 포함하는 각각의 돌연변이 pZuFmEgD9ES 플라스미드에 제공하였다.

당업자에게 명백할 것처럼, 출원인은 다양한 뉴클레오티드 서열이 유전자 코드의 축퇴성에 기초하여, 예를 들어 EgD9eS-L35G에 기재된 단백질을 암호화할 수 있음을 인식한다. 따라서, 예를 들어, 아미노산 잔기 위치 35에서 서열 번호 59에 기재된 돌연변이 단백질에 암호화되는 Gly는 GGG(서열 번호 58에 기재된 델타-9 연장효소 오픈 리딩 프레임["ORF"]에서와 같이), GGA(서열 번호 95에 기재된 델타-9 연장효소 ORF에서와 같이), GGC(서열 번호 96에 기재된 델타-9 연장효소 ORF에서와 같이) 및 GGT(서열 번호 97에 기재된 델타-9 연장효소 ORF에서와 같이)에 의해 암호화될 수 있다. 암호화되는 단백질에서 침묵 돌연변이를 야기하는 다양한 다른 뉴클레오티드 치환도 또한 고려되며, 이에 따라, EgD9eS-L35G를 암호화하는 본 명세서에 제공되는 뉴클레오티드 서열(서열 번호 59)은 본 개시물에 대한 제한으로 간주되어서는 안된다. 본 발명의 돌연변이 단백질을 암호화하며 델타-9 연장효소 활성을 갖는 본 명세서에 기재된 임의의 뉴클레오티드 서열 내의 유사한 변이가 고려된다.
실시예 7
EgD9eS
-
L35G
슬로노맥스
(등록 상표) 라이브러리의 생성
본 실시예는 모 효소에 비하여 LA로부터 EDA로의 전환 효율의 42-45% 향상을 나타내는 EgD9eS-L35G 돌연변이체(서열 번호 59; 실시예 6) 내의 50개의 별개의 아미노산 위치를 표적화함으로써 제조되는 슬로노맥스(등록 상표) 라이브러리의 합성을 기재하고 있다. 따라서, 본 실시예는 L35 돌연변이를 포함하는 EgD9eS 돌연변이체로 "스태킹"될 수 있는 추가의 유익한 돌연변이를 동정하고자 한다.
하기에 추가로 상세히 기재되는 자동화 로봇식 플랫폼인 슬로노믹스(Slonomics)(등록 상표)에 의해, 슬로노맥스(등록 상표) 라이브러리를 생성하였으며, 여기서, 서열 위치마다의 돌연변이체의 개수 및 그들의 비는 매우 정밀하게 조절될 수 있다. 따라서, 자동화 과정은 부위-포화 라이브러리의 생성 시에 고려되는 제한되는 잔기와 대조적으로(실시예 5), 델타-9 연장효소 활성에서의 그들의 영향을 결정하기 위하여 실험적으로 시험할 수 있는 후보 잔기의 개수가 크게 증가될 수 있다는 점에서 이점을 제공한다.
기능적 부위 평가를 위한
EgD9eS
내의 50개의 별개의
잔기의
표적화의
이유
델타-9 연장효소를 동정하였으며, 아이소크라이시스 갈바나["IgD9e"](서열 번호 2; PCT 공개 WO 2002/077213호, WO 2005/083093호, WO 2005/012316호 및 WO 2004/057001호; 진뱅크 수탁 번호 AAL37626), 유트렙티엘라 종 CCMP389["E389D9e"](서열 번호 4; 미국 특허 제7,645,604호), 유글레나 그라실리스["EgD9e"](서열 번호 8; 미국 특허 제7,645,604호) 및 유글레나 아나바에나["EaD9e"](서열 번호 12; 미국 특허 제7,794,701호)로부터 기능적으로 특성화하였다. 각각의 이들 연장효소는 LA를 EDA로 전환시킬 수 있는 것으로 보인다. EgD9e, EaD9e 및 E389D9e는 서로 60% 초과의 서열 유사성을 공유하는 한편, IgD9E는 EgD9e, EaD9e 및 E389D9e 중 임의의 것과 약 35%의 서열 유사성만을 공유한다(디폴트 파라미터(즉, 단백질 중량 매트릭스 = 고넷 250, 갭 개방 페널티 = 10, 갭 연장 페널티 = 0.2 및 전체 정렬 알고리듬)를 사용하는 클러스털 더블유(버전 1.83) 분석에 기초하여).
델타-9 연장효소 전환 효율이 향상된 돌연변이체를 야기하는 위치(예컨대, D98G[실시예 4] 및 L35G[실시예 6])가 중등의 서열 보존성을 갖는 것으로 관찰되었다. IgD9e, EgD9e, EaD9e 및 E389D9e의 아미노산 서열 정렬을 생성하여, 벡터 엔티아이(등록 상표)의 얼라인엑스 프로그램(미국 캘리포니아주 칼스배드 소재의 인비트로겐 코포레이션)의 디폴트 파라미터를 사용하여, 다른 중등으로 보존된 잔기를 동정하였다(도 1). 이들 중등으로 보존된 잔기가 아미노산 치환에 대한 표적으로서의 우수한 후보여서, 비-돌연변이 EgD9eS 대조군에 비하여 활성이 증가된 제2 세대의 돌연변이 효소를 제공할 가능성이 있을 수 있는 것으로 가정되었다.
이들 4개의 상동성 효소의 서열을 비교하여, 258개 아미노산 위치 중 58개가 모든 4개의 연장효소 중에 보존되는 것으로 결정되었으며; 이에 따라, 이들 잔기를 고려대상으로부터 배제하였다. 추가로, 92개의 위치가 EgD9e, EaD9e 및 E389D9e 간에 보존되는 것으로 결정되었으며; 이들 위치도 또한 고려대상으로부터 배제하였다. 마지막으로, 상동체 간에 무작위 아미노산 변화를 갖는 위치는 통상 단백질 기능에 유의미한 역할을 수행하지 않기 때문에, 이에 따라 모든 4개의 연장효소 간에 4가지 상이한 아미노산 잔기를 갖는 것으로 결정된 추가의 22개 위치를 기능 평가를 위한 표적화된 위치로서의 고려대상으로부터 배제하였다.
서열 번호 8 내의 나머지 86개 위치(즉, 위치 1, 3, 4, 5, 9, 12, 21, 22, 27, 28, 29, 32, 35, 37, 41, 42, 45, 47, 48, 51, 52, 53, 54, 57, 58, 60, 62, 63, 66, 67, 70, 71, 73, 74, 80, 83, 84, 85, 89, 94, 98, 101, 104, 105, 107, 108, 111, 115, 127, 131, 132, 143, 149, 152, 153, 155, 156, 161, 168, 169, 179, 181, 182, 192, 196, 204, 207, 209, 210, 211, 216, 218, 222, 223, 225, 229, 236, 239, 242, 244, 245, 247, 250, 254, 257 및 258)를 기능적 부위 평가에 대한 유력한 표적으로 고려하였다. EgD9e(서열 번호 8), EaD9e(서열 번호 12) 및 E389E9e(서열 번호 4) 내의 이들 각각의 하나의 위치에서 암호화된 아미노산 잔기의 비교를 하기 표 11에 나타내었다.

표 11에서 상기 동정된 86개 위치 중에, 도 4a의 막 토폴로지 모델에 기초하여, 주변세포질 공간에 가장 근접한 부위는 추가의 고려대상으로부터 배제하였다(즉, 위치 45, 47, 48, 51, 52, 53, 54, 57, 58, 60, 62, 63, 66, 67, 70, 71, 73, 74, 204, 207, 209, 210, 211, 216, 218, 222, 223, 225 및 229). 회색의 굵은 문자로 강조표시된 부위(즉, EgD9eS의 위치 3, 5, 9, 12, 21, 22, 27, 28, 32, 37, 41, 42, 80, 84, 85, 94, 98, 101, 104, 105, 107, 108, 111, 115, 127, 131, 132, 143, 149, 152, 153, 156, 161, 168, 169, 179, 181, 182, 192, 196, 236, 239, 242, 244, 245, 247, 250, 254, 257 및 258)를 추가의 실험적 평가를 위해 선택하였다.
EgD9eS
-
L35G
의
슬로노맥스
(등록 상표) 돌연변이 유전자를 생성하기 위한
슬로노믹스
(등록 상표)
슬로노믹스(등록 상표)(미국 특허 제7,695,906호)는 "한번에 하나의 코돈"의 조합 라이브러리 합성을 위한 보편적인 빌딩 블록(universal building block)(독일 푸하임 소재의 슬로닝 바이오테크놀로지(Sloning BioTechnology))으로서 일련의 이중 가닥의 DNA 트리플렛(triplet)을 사용한다. 라이브러리 생성을 위하여, 임의의 원하는 서열 위치에서 동시에 다수의 코돈을 도입할 수 있다. 임의의 비로 최대 20개의 코돈의 전달을 선택하고 정확하게 조절하는 능력 및 기능적 편향의 부재에 의해 완전한 목적하는 돌연변이체 세트를 함유하는 특별히 고 품질의 라이브러리가 야기된다.
이에 따라, 슬로노맥스(등록 상표) 유전자 라이브러리(총 50개)를 주형으로서 pZuFmEgD9ES-L35G(서열 번호 60)를 사용하여 슬로닝 바이오테크놀로지에 의해 생성하였으며, 각각의 유전자 라이브러리는 표적화된 위치(다시 말하면, EgD9eS의 위치 3, 5, 9, 12, 21, 22, 27, 28, 32, 37, 41, 42, 80, 84, 85, 94, 98, 101, 104, 105, 107, 108, 111, 115, 127, 131, 132, 143, 149, 152, 153, 156, 161, 168, 169, 179, 181, 182, 192, 196, 236, 239, 242, 244, 245, 247, 250, 254, 257 또는 258)에서 적어도 16개의 독립적이고 독특한 서열 돌연변이를 갖는다.
실시예 2에 기재된 바와 같이, 모든 EgD9eS-L35G 돌연변이체를 pZuFmEgD9ES-L35G에 의해 제공되는 벡터 백본으로 클로닝하고, 이후에 야로위아 리폴리티카 균주 Y2224로 형질전환시키고, 배양하였다. 형질전환된 세포(동결된 글리세롤 스톡(stock)으로 제공) 및 DNA를 슬로닝 바이오테크놀로지로부터 수득하였다. 약간의 형질전환된 세포 및 DNA를 시퀀싱하고 확인하였다.
실시예 8
델타-9 연장효소 전환 효율이 향상된
EgD9eS
-
L35G
슬로노맥스
(등록 상표) 라이브러리 돌연변이체의 동정
본 실시예는 실시예 6에서 동정된 변이체 단백질 EgD9eS-L35G(서열 번호 59)의 LA로부터 EDA로의 델타-9 연장효소 전환 효율에 비하여 전환 효율이 향상된 EgD9eS-L35G 슬로노맥스(등록 상표) 돌연변이체의 동정을 기재하고 있다.
슬로노맥스(등록 상표) 라이브러리로부터의 구축물을 갖는 807개의 야로위아 형질전환체의 지방산 프로파일을 실시예 2의 "확인 검정" 방법을 사용하여 스크리닝하여, 신선한 다시-스트리킹된 MM 플레이트에서 성장한 세포를 사용하여 3 ㎖ 액체 MM을 포함하는 3벌의 배양물을 개별 접종하였다. 807개의 돌연변이체에 더하여, pZuFmEgD9ES-L35G(서열 번호 60)를 포함하는 야로위아 균주 Y2224를 실험 대조군으로서 3벌로 접종하였다.
확인 검정법에서 선택된 돌연변이체로부터의 데이터는 표 12에 제시되어 있으며, 3개의 대표적인 EgD9eS-L35G 대조군의 FAME 프로파일을 슬로노맥스(등록 상표) 라이브러리 돌연변이체의 것과 비교하여, LA로부터 EDA로의 평균 전환%의 증가가 나타났다. 더욱 구체적으로 각각의 균주에 대한 TFA의 영역 백분율["% TFA"]로서의 각각의 지방산의 평균("평균"으로 나타냄) 농도 및 LA로부터 EDA로의 평균 전환%(실시예 2에 기재된 바와 같이 결정)는 하기 표 12에 나타나 있다. 지방산은 실시예 4의 약어에 기초하여 나타나 있다. 각각의 균주 설명은 돌연변이 EgD9eS 유전자 각각에 존재하는 특정 아미노산 치환을 나타낸다. 따라서, 균주 EgD9eS-L35G/S9A는 서열 번호 10에 기재된 EgD9eS의 서열에 비하여 L35G 돌연변이 및 S9A 돌연변이를 갖는 돌연변이 EgD9eS 유전자를 포함하는 돌연변이 pZuFmEgD9ES 플라스미드를 포함한다.


표 12에 제시된 반복 EgD9eS-L35G 대조군의 지방산 프로파일 및 LA로부터 EDA로의 전환%가 이전에 제시된 EgD9eS-L35G 프로파일과 다소 상이한 것은 주목할 만한 것이다. 본 실험 세트에서, EgD9eS-L35G 대조군은 이전 분석에 비하여 "저조하였다"(즉, 상기에서 LA로부터 EDA로의 평균 전환%는 약 18.1%인 것으로 결정되었으며, 실시예 6, 표 9에서 LA로부터 EDA로의 평균 전환%는 약 26.6% 및 27.2%인 것으로 결정되었다). 그러나, EgD9eS-L35G가 있는 형질전환체는 4.3 EDA % TFA(상기의 평균)를 생성하였으며, 이는 EgD9eS가 있는 형질전환체에서 생성되는 것보다 유의미하게 더 컸다(즉, 3.1 EDA % TFA[실시예 4, 표 5], 2.9 EDA % TFA[실시예 4, 표 6] 및 3.5 EDA % TFA[실시예 6, 표 9]). 이러한 이유로, EgD9eS-L35G의 기능 분석을 반복한 이전의 실험으로부터의 성능(데이터 미도시)을 표 12에 제시되는 EgD9eS 부위-평가 라이브러리로부터의 돌연변이체의 비교를 위한 기준으로서 본 실험에서 EgD9eS-L35G 성능에 더하여 사용하였다.
표 12에 제시된 26개의 선택된 연장효소 변이체 중에, 표 12의 대조군 데이터와 비교하여 유사하거나 향상된 델타-9 연장효소 전환 활성을 나타내는 11개를 동정하였다(굵은 문자로 강조표시). 이들 돌연변이체에는 EgD9eS-L35G/S9D(141%), EgD9eS-L35G/A21V(118%), EgD9eS-L35G/V32F(104%), EgD9eS-L35G/Y84C(144%), EgD9eS-L35G/L108G(104%), EgD9eS-L35G/W132T(100%), EgD9eS-L35G/M143N(96%), EgD9eS-L35G/L161T(131%), EgD9eS-L35G/I179R(141%), EgD9eS-L35G/C236N(102%) 및 EgD9eS-L35G/Q244N(134%)이 포함되며, 여기서, EgD9eS에 비한 델타-9 연장효소 전환 활성이 괄호 안에 나타나 있다. 따라서, 최대 44%의 LA로부터 EDA로의 전환 효율의 향상이 입증되었다.
실시예 9
EgD9eS
-L35G/S9D/A21V/V32F/Y84C/L108G/W132T/M143N/L161T/I179R/C236N/Q244N 조합 라이브러리의 생성
본 실시예는 돌연변이 EgD9eS 조합 라이브러리의 합성을 기재하고 있으며, 여기서, 상기 실시예 8에서 동정된 유익한 돌연변이의 다양한 조합(즉, S9D, A21V, V32F, Y84C, L108G, W132T, M143N, L161T, I179R, C236N 및 Q244N)을 L35G 돌연변이를 포함하는 EgD9eS 돌연변이체로 함께 "스태킹"하였다.
조합 라이브러리의 구축을 위한 합성 프라이머의 생성
11쌍의 프라이머를 서열 번호 64-85에 기재된 바와 같이 상업적으로 합성하였다(하기 표 13 참조). 하기의 돌연변이 중 하나를 EgD9eS-L35G 유전자로 도입하도록 각 프라이머 쌍을 설계하였다: S9D, A21V, V32F, Y84C, L108G, W132T, M143N, L161T, I179R, C236N 및 Q244N.
프라이머를 T4 폴리뉴클레오티드 키나제["PNK"](카달로그 번호 70031Z, 유에스비 코포레이션(USB Corp.))를 사용하여 37℃에서 60분 동안 인산화시킨 다음, 65℃에서 20분 동안 불활성화시켰다. 각 20 ㎕의 인산화 반응 혼합물은 2.0 ㎕의 10x T4 PNK 완충액, 15.0 ㎕의 프라이머 DNA(약 7 μM), 0.6 ㎕의 100 mM ATP, 0.4 ㎕의 T4 PNK 및 2.0 ㎕의 물을 함유한다.
EgD9eS
-
L35G
의 조합 돌연변이 유전자를 생성하기 위한 다수의 돌연변이 부위 돌연변이유발
체인지(Change)-IT(상표명) 다중 돌연변이 부위 지정 돌연변이유발 키트(카달로그 번호 78480, 미국 오하이오주 클리블랜드 소재의 유에스비 코포레이션)를 사용하여 일련의 6개의 반응에서 S9D, A21V, V32F, Y84C, L108G, W132T, M143N, L161T, I179R, C236N 및 Q244N 돌연변이를 EgD9eS-L35G 내로 도입하고, 각 반응(최종 반응을 제외하고)에서 프라이머 세트 "A"의 정방향 프라이머 및 역방향 프라이머, 및 프라이머 세트 "B"의 정방향 프라이머 및 역방향 프라이머의 포함에 기초하여 2개의 새로운 돌연변이를 도입하였다(표 13). 일련의 반응에서의 초기의 주형이 EgD9eS-L35G였지만, 체인지-IT(상표명) 반응 1의 생성물은 체인지-IT(상표명) 반응 2의 주형으로 소용되는 등등이었다.

더욱 구체적으로, 2개의 25 ㎕ PCR 반응 혼합물을 준비하였으며, 각각의 것은 2.5 ㎕의 10x 체인지-IT(상표명) 완충액, 2.5 ㎕의 인산화된 정방향 프라이머, 2.5 ㎕의 인산화된 역방향 프라이머, 1.0 ㎕의 주형(50 ng/㎕), 15.5 ㎕의 뉴클레아제-미함유 물 및 1.0 ㎕의 체인지-IT(상표명) 피델리택(FideliTaq) 효소를 포함한다. 제1 반응에서는 프라이머 세트 "A"로부터의 프라이머를 사용하는 한편, 제2 반응에서는 프라이머 세트 "B" 프라이머를 사용하였다. PCR 증폭을 하기의 조건을 사용하여 수행하였다: 2분 동안 95℃에 이어서, 30초 동안 95℃에서의 변성, 30초 동안 55℃에서의 어닐링 및 25분 동안 68℃에서의 연장/라이게이션의 30 사이클. 30분 동안 68℃에서 최종 연장/라이게이션 사이클을 수행하고, 4℃에서의 반응 종결로 이어졌다.
증폭 후에, DpnI 효소를 첨가함으로써 주형을 제거하고, 37℃에서 3시간 동안 분해를 수행하였다. PCR DNA를 사용하여 에스케리키아 콜라이 탑 10 일렉트로-컴피턴트 세포(카달로그 번호 C404052, 미국 캘리포니아주 칼스배드 소재의 인비트로겐)를 전기천공법에 의해 형질전환시켰다. 형질전환된 세포를 100 mg/L 앰피실린이 있는 LB 아가 플레이트로 스프레딩하고, 37℃ 인큐베이터에서 하룻밤 성장시켰다. 플라스미드 DNA를 제조처의 프로토콜에 따라 퀴아프렙(등록 상표) 스핀 미니프렙 키트(미국 캘리포니아주 발렌시아 소재의 퀴아젠 인코포레이티드)를 사용하여 형질전환체 에스케리키아 콜라이 세포로부터 추출하였다. 그 다음, 정제된 DNA를 다음의 체인지-IT(상표명) 반응에서 주형으로 사용하였다. 11개의 돌연변이 중 마지막을 원래의 EgD9eS-L35G 주형에 도입하는 6번째 반응 후에, 상술된 바와 같이 DNA를 형질전환체 에스케리키아 콜라이 세포로부터 정제하였다. 이어서, DNA를 야로위아 리폴리티카 균주 Y2224(상기 실시예 2)로 형질전환시켰다.
실시예 10
델타-9 연장효소 전환 효율이 향상된
EgD9eS
-
L35G
/
S9D
/ A21V/
V32F
/
Y84C
/
L108G
/ W132T/
M143N
/
L161T
/
I179R
/
C236N
/
Q244N
조합 라이브러리 돌연변이체의 동정
본 실시예는 1) 야생형 단백질 EgD9eS(서열 번호 10)에 비하여 향상된 LA로부터 EDA로의 델타-9 연장효소 전환 효율을 갖는 EgD9eS-L35G/ S9D/ A21V/ V32F/ Y84C/ L108G/ W132T/ M143N/ L161T/ I179R/ C236N/ Q244N 조합 라이브러리 돌연변이체의 동정; 2) 이들 EgD9eS 돌연변이체의 서열 분석; 및 3) 향상된 델타-9 연장효소 전환 효율을 확인하기 위한 시퀀싱된 EgD9eS 돌연변이체의 재생성을 기재하고 있다.
조합 라이브러리(실시예 9)로부터의 구축물을 갖는 2,388가지 야로위아 형질전환체의 지방산 프로파일을 실시예 2의 퀵 스크린 "플레이트 검정법"을 사용하여 스크리닝하였다. 이들 대부분의 돌연변이체는 야생형 대조군, EgD9eS(서열 번호 10)에 비하여 감소된 LA로부터 EDA로의 전환을 나타내었다. 그러나, 5개의 돌연변이체는 실시예 2의 확인 검정법에 기초하여, 대조군에 비하여 향상된 델타-9 연장효소 활성을 나타내는 것으로 확인되었다.
돌연변이 EgD9eS 유전자의 DNA 서열을 콜로니 PCR을 사용하여 결정하였다. 약술하면, 소량의 효모 세포를 멸균 피펫 팁(pipette tip)을 사용하여, 새로이 스트리킹된 플레이트로부터 시료 추출하고, 세포를 20 ㎕의 분자 등급의 물에서 현탁화시켰다. 세포 현탁액(2 ㎕)을 제조처(타카라 바이오테크놀로지 컴퍼니, 리미티드(Takara Biotechnology Co., LTD.))의 권고에 따라 제조한 타카라(TaKaRa) Ex Taq PCR 믹스로 옮겼다. 콜로니 PCR을 위해 사용한 프라이머는 정방향 프라이머 FBAIN-F(서열 번호 98) 및 역방향 프라이머 Y1026(서열 번호 99)이었다. 써멀 사이클러(thermal cycler) 프로그램에는 5분 동안 94℃에서의 주형의 초기 변성에 이은, 30초 동안 94℃에서의 변성, 30초 동안 56℃에서의 어닐링 및 3분 동안 72℃에서의 연장의 40 사이클이 포함되었다. 6분 동안 72℃에서의 최종 연장을 수행하였다.
PCR 생성물을 프라이머 FBAIN-F(서열 번호 98) 및 Y1026(서열 번호 99)을 사용하여 시퀀싱하였다. DNA 서열 데이터의 분석에 의해, 돌연변이 EgD9eS 유전자 내에서 뉴클레오티드 치환이 드러났으며, 아미노산 치환이 발현되었다. 아미노산 치환을 나타내는 명칭을 표 14에 나타낸 바와 같이, 돌연변이 EgD9eS 유전자 및 돌연변이 EgD9eS 유전자를 포함하는 돌연변이 pZuFmEgD9ES 플라스미드에 제공하였다.

부위-지정 돌연변이유발을 위한 새로운 프라이머를 표 14의 아미노산 치환에 기초하여 설계하였다. 이어서, 이들 프라이머를 "메가프라이머" 내의 EgD9eS 돌연변이를 pZuFmEgD9ES(도 2; 서열 번호 25)로 도입하도록 설계된 반응에서 사용하고, 이에 의해, 비-돌연변이 EgD9eS 유전자를 표 14에 열거된 다양한 돌연변이 EgD9eS 유전자로 대체하였다.
이는 실시예 3에 기재된 바와 같이, 퀵체인지(등록 상표) II XL 부위 지정 돌연변이유발 키트(카달로그 번호 200524, 미국 캘리포니아주 라 졸라 소재의 스트라타진)를 사용하여 달성하였다. 이들 돌연변이 유전자를 실시예 2에 기재된 바와 같이 에스케리키아 콜라이 탑 10 일렉트로-컴피턴트 세포로 형질전환시키고, 정제하고, 시퀀싱하고, 이후에 야로위아 리폴리티카 균주 Y2224로 형질전환시켰다. 이러한 방식으로, 표 14에 나타낸 돌연변이 EgD9eS 유전자를 플라스미드 상에 재생성하였으며, 균주 Y2224 내로 다시 도입하여, EgD9eS 조합 돌연변이체에 의해 나타나는 향상된 델타-9 연장효소 전환 효율이 동정된 아미노산 치환에 기인함을 확인하였다.
이들 확인 검정법으로부터의 데이터는 표 15에 제시되어 있으며, 개별 pZuFmEgD9ES 대조군 형질전환체의 FAME 프로파일을 조합 라이브러리의 돌연변이체와 비교하였다. 줄잡아 비교하기 위하여, 각 균주에 대하여 나타낸 데이터는 각 균주에 대하여 LA로부터 EDA로의 가장 높은 전환%를 갖는 3개의 분리주에 대한 FAME 프로파일을 나타낸다. 더욱 구체적으로, 각각의 균주에 대한 TFA의 영역 백분율["% TFA"]로서의 각각의 지방산의 농도 및 LA로부터 EDA로의 전환%(실시예 2에 기재된 바와 같이 결정)는 하기에 나타나 있으며, 평균은 회색으로 강조표시하였고, "평균"으로 나타내었다. 지방산을 실시예 4의 약어에 기초하여 나타내었다.

서열 번호 10(비-돌연변이체)의 코돈-최적화된 EgD9eS 유전자를 포함하는 pZuFmEgD9ES로 형질전환된 야로위아 리폴리티카 균주 Y2224의 클론은 평균 2.5 EDA % TFA를 생성하였으며, 여기서, 이들 3개의 클론에서의 LA로부터 EDA로의 평균 전환 효율["전환%"]은 약 16.1%인 것으로 결정되었다. 대조적으로, 돌연변이 균주 EgD9EN-427에 대한 LA로부터 EDA로의 평균 전환%는 17.8%(또는 대조군에 비해서는 110%)였다. 유사하게, 돌연변이 균주 EgD9EN-1043에 대한 LA로부터 EDA로의 평균 전환%는 17.5%(또는 대조군에 비해서는 108%)였다. 돌연변이 균주 EgD9EN-1534에 대한 LA로부터 EDA로의 평균 전환%는 16.8%(또는 대조군에 비해서는 104%)였으며; 돌연변이 균주 EgD9EN-1635에 대한 평균 EgD9EN 전환%는 18.0%(또는 대조군에 비해서는 111%)였고; 돌연변이 균주 EgD9EN-1734에 대한 평균 전환%는 20.0%(또는 대조군에 비해서는 123%)였다.
따라서, 이들 실험에 의해, EgD9eS 조합 라이브러리 돌연변이체 EgD9EN-427, EgD9EN-1043, EgD9EN-1534, EgD9EN-1635 및 EgD9EN-1734에 의해 나타나는 향상된 델타-9 연장효소 전환 효율이 확인되었으며, 여기서, 향상은 4 내지 23% 범위였다.
실시예 11
전체 지방산의 약 58.7% EPA를 생성하기 위한 야로위아 리폴리티카 균주 Z1978의 생성
본 실시예는 델타-9 연장효소/델타-8 불포화화효소 경로의 발현을 통하여 38.3% 전체 지질 함량["TFA % DCW"]을 갖는 전체 지질에 비하여 약 58.7% EPA를 생성할 수 있는 야로위아 리폴리티카 ATCC #20362로부터 유래된 균주 Z1978의 구축을 기재하고 있다. 이러한 균주는 L35G 돌연변이(즉, EgD9eS-L35G[서열 번호 58 및 59])를 포함하는 실시예 5 및 6의 델타-9 연장효소 부위-포화 돌연변이체를 포함한다.
균주 Z1978(도 6)의 개발은 균주 Y2224, Y4001, Y4001U, Y4036, Y4036U, L135, L135U9, Y8002, Y8006U6, Y8069, Y8069U, Y8154, Y8154U, Y8269, Y8269U, Y8412U6, Y8647, Y8467U, Y9028, Y9028U, Y9502 및 균주 Y9502U의 구축을 필요로 한다.
균주 구축 동안의 야로위아 리폴리티카의 지방산 분석
지방산["FA"] 분석을 위하여, 세포를 원심분리에 의해 수집하고, 지질을 문헌[Bligh, E. G. & Dyer, W. J. (Can . J. Biochem . Physiol., 37:911-917 (1959))]에 기재된 바와 같이 추출하였다. 지방산 메틸 에스테르["FAME"]를 소듐 메톡시드를 사용한 지질 추출물의 에스테르 교환에 의해 제조하고(문헌[Roughan, G., and Nishida I., Arch Biochem Biophys., 276(1):38-46 (1990)]), 이어서 30-m X 0.25 mm(내경) HP-INNOWAX(휴렛-패카드)(Hewlett-Packard) 컬럼이 장착된 휴렛-패카드 6890 GC로 분석하였다. 오븐 온도는 3.5℃/분에서 170℃(25분 유지)로부터 185℃까지였다.
직접적인 염기 에스테르 교환을 위하여, 야로위아 세포(0.5 ㎖ 배양물)를 수집하고, 증류수에 1회 세정하고, 스피드-백(Speed-Vac)에서 5 내지 10분 동안 진공 하에 건조시켰다. 소듐 메톡시드(1%의 100 ㎕) 및 공지된 양의 C15:0 트라이아실글리세롤(C15:0 TAG; 카탈로그 번호 T-145, 미국 미네소타주 엘리시안 소재의 누-체크 프렙)을 시료에 첨가한 다음, 시료를 볼텍싱(vortexed)하고, 50℃에서 30분 동안 흔들었다. 3방울의 1 M NaCl 및 400 ㎕의 헥산을 첨가한 후에, 시료를 볼텍싱하고, 회전시켰다. 상층을 제거하고, GC로 분석하였다.
대안적으로, 문헌[Lipid Analysis, William W. Christie, 2003]에 기재된 염기-촉매작용된 에스테르 교환 방법의 변형법을 발효 또는 플라스크 시료 중 어느 하나로부터의 브로쓰(broth) 시료의 통상적인 분석을 위해 사용하였다. 구체적으로, 브로쓰 시료를 실온의 물에서 빠르게 해동시킨 다음, 0.22 ㎛ 코닝(Corning)(등록 상표) 코스타(Costar)(등록 상표) 스핀(Spin)-X(등록 상표) 원심분리용 튜브 필터(카달로그 번호 8161)가 있는 타르를 칠한 2 ㎖ 미량 원심분리용 튜브에 칭량해 넣었다(0.1 mg까지). 이전에 결정된 DCW에 따라 시료(75 - 800 ㎕)를 사용하였다. 에펜도르프(Eppendorf) 5430 원심분리기를 사용하여, 시료를 14,000 rpm에서 5 내지 7분 동안 또는 브로쓰를 제거하는데 필요한 만큼 원심분리하였다. 필터를 제거하고, 액체를 빼내고, 약 500 ㎕의 탈이온수를 필터에 첨가하여 시료를 세정하였다. 물을 제거하기 위한 원심분리 후에, 필터를 다시 제거하고, 액체를 빼내고, 필터를 다시 삽입하였다. 그 다음, 튜브를 원심분리기에 다시 삽입하고, 이번에는 상측을 개방하여 약 3 내지 5분 동안 건조시켰다. 이어서, 필터를 튜브의 대략 절반에서 절단하고, 새로운 2 ㎖ 둥근 바닥 에펜도르프 튜브(카달로그 번호 22 36 335-2)에 삽입하였다.
필터를 오직 절단된 필터 용기의 가장자리와 접촉하며 시료 또는 필터 물질과는 접촉하지 않는 적절한 도구를 사용하여 튜브의 바닥으로 압축시켰다. 톨루엔 중의 공지되어 있는 양의 C15:0 TAG(상기)를 첨가하고, 새로 제조한 메탄올 용액 중의 1% 소듐 메톡시드 500 ㎕를 첨가하였다. 시료 펠렛을 적절한 도구를 사용하여 철저히 부수고, 튜브를 닫고, 30분 동안 50℃ 히트 블록(heat block)(VWR 카달로그 번호 12621-088)에 배치하였다. 이어서, 튜브가 적어도 5분 동안 냉각되게 하였다. 이어서, 헥산 400 ㎕ 및 수용액 중의 1 M NaCl 500 ㎕을 첨가하고, 튜브를 6초 동안 2회 볼텍싱시키고, 1분 동안 원심분리하였다. 대략 150 ㎕의 상(유기)층을 인서트(insert)가 있는 GC 바이얼에 두고, GC로 분석하였다.
GC 분석을 통해 기록된 FAME 피크를 공지되어 있는 지방산의 피크와 비교시 그들의 정체 시간에 의해 확인하고, FAME 피크 영역을 공지되어 있는 양의 내부 표준물질(C15:0 TAG)의 피크 영역과 비교함으로써 정량화하였다. 따라서, 임의의 지방산 FAME의 근사량(㎍)["FAME ㎍"]은 식: (특정 지방산에 대한 FAME 피크의 영역/표준물질 FAME 피크의 영역) * (표준물질 C15:0 TAG의 ㎍)에 따라 계산하고, 임의의 지방산의 양(㎍)["FA ㎍"]은 식: (특정 지방산에 대한 FAME 피크의 영역/표준물질 FAME 피크의 영역) * (표준물질 C15:0 TAG의 ㎍) * 0.9503에 따라 계산하는데, 이는 1 ㎍의 C15:0 TAG가 0.9503 ㎍의 지방산과 같기 때문이다. 0.9503 전환 인자가 0.95 내지 0.96 범위인 대부분의 지방산에 대하여 결정된 값의 대략치임을 주목해야 한다.
TFA의 중량 백분율로서 각각의 개별 지방산의 양을 요약하는 지질 프로파일을 개별 FAME 피크 영역을 모든 FAME 피크 영역의 합으로 나누고 이에 100을 곱함으로써 결정하였다.
플라스크 검정법에 의한 균주 구축 동안의 야로위아 리폴리티카에서의 전체 지질 함량 및 조성의 분석
야로위아 리폴리티카의 특정 균주에서의 전체 지질 함량 및 조성의 상세한 분석을 위하여, 플라스크 검정법을 하기와 같이 행하였다. 구체적으로, 하나의 루프의 새로 스트리킹된 세포를 3 ㎖ FM 배지에 접종하고, 250 rpm 및 30℃에서 하룻밤 성장시켰다. OD600nm를 측정하고, 세포의 분취물을 125 ㎖ 플라스크에서 25 ㎖ FM 배지 중에 최종 0.3의 OD600nm로 첨가하였다. 250 rpm 및 30℃의 쉐이커 인큐베이터에서 2일 후에, 6 ㎖의 배양물을 원심분리에 의해 수집하고, 125 ㎖ 플라스크에서 25 ㎖ HGM에 재현탁화시켰다. 250 rpm 및 30℃의 쉐이커 인큐베이터에서 5일 후에, 1 ㎖ 분취물을 지방산 분석(상기)을 위해 사용하고, 건조 세포 중량["DCW"] 결정을 위하여 10 ㎖을 건조시켰다.
DCW 결정을 위하여, 10 ㎖ 배양물을 베크만(Beckman) GS-6R 원심분리기 내의 베크만 GH-3.8 로터에서 4000 rpm에서 5분 동안 원심분리함으로써 수집하였다. 펠렛을 25 ㎖의 물에 재현탁화시키고, 상술된 바와 같이 다시 수집하였다. 세정된 펠렛을 20 ㎖의 물에 재현탁화시키고, 사전-칭량된 알루미늄 팬으로 옮겼다. 세포 현탁액을 80℃에서 진공 오븐에서 하룻밤 건조시켰다. 세포의 중량을 결정하였다.
세포의 전체 지질 함량["TFA % DCW"]을 계산하고, TFA의 중량 백분율["% TFA"]로서의 각각의 지방산의 농도 및 건조 세포 중량의 백분율로서의 EPA 함량["EPA % DCW"]을 표로 만든 데이터와 함께 고려하였다. 플라스크 검정법으로부터의 데이터는 세포의 전체 건조 세포 중량["DCW"], 세포의 전체 지질 함량["TFA % DCW"], TFA의 중량 백분율["% TFA"]로서의 각 지방산의 농도 및 건조 세포 중량의 백분율로서의 EPA 함량["EPA % DCW"]을 요약한 표에 제시되어 있다. 더욱 구체적으로, 지방산은 16:0(팔미테이트), 16:1(팔미톨레산), 18:0(스테아르산), 18:1(올레산), 18:2(LA), ALA, EDA, DGLA, ARA, ETrA, ETA, EPA 및 다른 것으로 동정하였다.
야로위아 리폴리티카 균주 Y9502의 유전형
균주 Y9502의 생성은 미국 특허 공개 제2010-0317072-A1호에 기재되어 있다. 야로위아 리폴리티카 ATCC #20362로부터 유래된 균주 Y9502는 델타-9 연장효소/델타-8 불포화화효소 경로의 발현을 통하여 전체 지질에 비하여 약 57.0% EPA를 생성할 수 있었다(도 6).
야생형 야로위아 리폴리티카 ATCC #20362에 대한 균주 Y9502의 최종 유전형은 Ura+, Pex3-, unknown 1-, unknown 2-, unknown 3-, unknown 4-, unknown 5-, unknown6-, unknown 7-, unknown 8-, unknown9-, unknown 10-, YAT1::ME3S::Pex16, GPD::ME3S::Pex20, YAT1::ME3S::Lip1, FBAINm::EgD9eS::Lip2, EXP1::EgD9eS::Lip1, GPAT::EgD9e::Lip2, YAT1::EgD9eS::Lip2, FBAINm::EgD8M::Pex20, EXP1::EgD8M::Pex16, FBAIN::EgD8M::Lip1, GPD::EaD8S::Pex16 (2 copies), YAT1::E389D9eS/EgD8M::Lip1, YAT1::EgD9eS/EgD8M::Aco, FBAINm::EaD9eS/EaD8S::Lip2, GPD::FmD12::Pex20, YAT1::FmD12::Oct, EXP1::FmD12S::Aco, GPDIN::FmD12::Pex16, EXP1::EgD5M::Pex16, FBAIN::EgD5SM::Pex20, GPDIN::EgD5SM::Aco, GPM::EgD5SM::Oct, EXP1::EgD5SM::Lip1, YAT1::EaD5SM::Oct, FBAINm::PaD17::Aco, EXP1::PaD17::Pex16, YAT1::PaD17S::Lip1, YAT1::YlCPT1::Aco, YAT1::MCS::Lip1, FBA::MCS::Lip1, YAT1::MaLPAAT1S::Pex16이었다. 약어는 하기와 같다: FmD12는 푸사리움 모닐리포르메(Fusarium moniliforme) 델타-12 불포화화효소 유전자이고[미국 특허 제7,504,259호]; FmD12S는 푸사리움 모닐리포르메 유래의 코돈-최적화된 델타-12 불포화화효소 유전자이고[미국 특허 제7,504,259호]; ME3S는 모르티에렐라 알피나 유래의 코돈-최적화된 C16 /18 연장효소 유전자이고[미국 특허 제7,470,532호]; EgD9e는 유글레나 그라실리스 델타-9 연장효소 유전자이고[미국 특허 제7,645,604호]; EgD9eS는 유글레나 그라실리스 유래의 코돈-최적화된 델타-9 연장효소 유전자이고[미국 특허 제7,645,604호]; EgD8M은 유글레나 그라실리스 유래의[미국 특허 제7,256,033호] 합성 돌연변이 델타-8 불포화화효소 유전자[미국 특허 제7,709,239호]이고; EaD8S는 유글레나 아나바에나 유래의 코돈-최적화된 델타-8 불포화화효소 유전자이고[미국 특허 제7,790,156호]; E389D9eS/EgD8M은 유트렙티엘라 종 CCMP389 델타-9 연장효소 유래의 코돈-최적화된 델타-9 연장효소 유전자("E389D9eS")(미국 특허 제7,645,604호)를 델타-8 불포화화효소 "EgD8M"(상기)[미국 특허 공개 제2008-0254191-A1호]에 연결함으로써 생성되는 DGLA 신타아제이고; EgD9eS/EgD8M은 델타-9 연장효소 "EgD9eS"(상기)를 델타-8 불포화화효소 "EgD8M"(상기)[미국 특허 공개 제2008-0254191-A1호]에 연결함으로써 생성된 DGLA 신타아제이고; EaD9eS/EgD8M은 유글레나 아나바에나 델타-9 연장효소 유래의 코돈-최적화된 델타-9 연장효소 유전자("EaD9eS")[미국 특허 제7,794,701호]를 델타-8 불포화화효소 "EgD8M"(상기)[미국 특허 공개 제2008-0254191-A1호]에 연결함으로써 생성되는 DGLA 신타아제이고; EgD5M 및 EgD5SM은 유글레나 그라실리스 유래의[미국 특허 제7,678,560호] 합성 돌연변이 델타-5 불포화화효소 유전자[미국 특허 공개 제2010-0075386-A1호]이고; EaD5SM은 유글레나 아나바에나 유래의[미국 특허 제7,943,365호] 합성 돌연변이 델타-5 불포화화효소 유전자[미국 특허 공개 제2010-0075386-A1호]이고; PaD17은 피티움 아파니더마툼(Pythium aphanidermatum) 델타-17 불포화화효소 유전자이고[미국 특허 제7,556,949호]; PaD17S는 피티움 아파니더마툼 유래의 코돈-최적화된 델타-17 불포화화효소 유전자이고[미국 특허 제7,556,949호]; YlCPT1은 야로위아 리폴리티카 다이아실글리세롤 콜린포스포트랜스퍼라제 유전자이고[미국 특허 제7,932,077호]; MCS는 리조비움 레구미노사룸(Rhizobium leguminosarum) 생물변이형 비시애(bv. viciae) 3841 유래의 코돈-최적화된 말로닐-CoA 신테타제(synthetase) 유전자이며[미국 특허 공개 제2010-0159558-A1호], MaLPAAT1S는 모르티에렐라 알피나 유래의 코돈-최적화된 라이소포스파티드산 아실트랜스퍼라제 유전자이다[미국 특허 제7,879,591호].
균주 Y9502 내의 전체 지질 함량 및 조성의 상세한 분석을 위하여, 세포를 총 7일 동안 2단계로 성장시키는 플라스크 검정법을 행하였다. 분석에 기초하여, 균주 Y9502는 3.8 g/L DCW, 37.1 TFA % DCW, 21.3 EPA % DCW를 생성하였으며, 지질 프로파일은 하기와 같았고, 여기서, 각 지방산의 농도는 TFA의 중량 백분율["% TFA"]로서의 것이다: 16:0(팔미테이트)-2.5, 16:1(팔미톨레산)-0.5, 18:0(스테아르산)-2.9, 18:1(올레산)-5.0, 18:2(LA)-12.7, ALA-0.9, EDA-3.5, DGLA-3.3, ARA-0.8, ETrA-0.7, ETA-2.4, EPA-57.0, 기타-7.5.
균주
Y9502U
(
Ura3
-
)의 생성
균주 Y9502에서 Ura3 유전자를 파괴하기 위하여, SalI/ PacI -분해된 구축물 pZKUM(도 7a; 서열 번호 89; 본 명세서에 참고로 포함되는 미국 특허 공개 제2009-0093543-A1호의 표 15에 기재)을 사용하여 일반 방법에 따라 Ura3 돌연변이 유전자를 균주 Y9502의 Ura3 유전자 내로 통합시켰다. 총 27개의 돌연변이체(8개의 형질전환체를 포함하는 제1 그룹, 8개의 형질전환체를 포함하는 제2 그룹 및 11개의 형질전환체를 포함하는 제3 그룹으로부터 선택되는)를 최소 배지 + 5-플루오로오로트산["MM + 5-FOA"] 선택 플레이트에서 성장시키고, 30℃에서 2 내지 5일 동안 유지시켰다. 추가의 실험에 의해, 오직 제3 형질전환체 그룹만이 실제 Ura - 표현형을 갖는 것으로 결정되었다.
Ura - 세포를 MM + 5-FOA 플레이트로부터 긁어내고, 일반 방법에 따라 지방산 분석으로 처리하였다. 이러한 방식으로, GC 분석에 의해, 각각 그룹 3의 MM + 5-FOA 플레이트 상에서 성장시킨 pZKUM-형질전환체 #1, #3, #6, #7, #8, #10 및 #11에서 TFA 중 28.5%, 28.5%, 27.4%, 28.6%, 29.2%, 30.3% 및 29.6% EPA가 있는 것으로 나타났다. 이들 7개의 균주를 각각 균주 Y9502U12, Y9502U14, Y9502U17, Y9502U18, Y9502U19, Y9502U21 및 Y9502U22(집합하여, Y9502U)로 명명하였다.
균주 Z1978의 생성
이어서, 하나의 델타-9 불포화화효소 유전자, 하나의 콜린-포스페이트 시티딜릴-트랜스퍼라제 유전자 및 하나의 델타-9 연장효소 돌연변이 유전자가 균주 Y9502U의 야로위아 YALI0F32131p 유전자좌(진뱅크 수탁 번호 XM_506121) 내로 통합되도록 구축물 pZKL3-9DP9N(도 7b; 서열 번호 90)을 생성하였다. pZKL3-9DP9N 플라스미드에는 하기의 성분이 포함되어 있다:

pZKL3-9DP9N 플라스미드를 AscI/SphI로 분해한 다음, 균주 Y9502U17의 형질전환을 위해 사용하였다. 형질전환체 세포를 최소 배지["MM"] 플레이트 상에 플레이팅하고, 30℃에서 3 내지 4일 동안 유지시켰다. 단일의 콜로니를 MM 플레이트 상으로 다시 스트리킹한 다음, 30℃에서 액체 MM으로 접종하고, 250 rpm/분으로 2일 동안 쉐이킹하였다. 세포를 원심분리에 의해 수집하고, 고 글루코스 배지["HGM"] 에 재현탁화시킨 다음, 250 rpm/분에서 5일 동안 쉐이킹하였다. 세포를 상기 지방산 분석으로 처리하였다.
GC 분석에 의해, pZKL3-9DP9N을 갖는 선택된 96개의 Y9502U17 균주의 대부분이 TFA 중 50-56% EPA를 생성하는 것으로 나타났다. TFA 중 약 59.0%, 56.6%, 58.9%, 56.5% 및 57.6% EPA를 생성하였던 5개의 균주(즉, #31, #32, #35, #70 및 #80)를 각각 균주 Z1977, Z1978, Z1979, Z1980 및 Z1981로 명명하였다.
야생형 야로위아 리폴리티카 ATCC #20362에 대한 이들 pZKL3-9DP9N 형질전환체 균주의 최종 유전형은 Ura+, Pex3-, unknown 1-, unknown 2-, unknown 3-, unknown 4-, unknown 5-, unknown6-, unknown 7-, unknown 8-, unknown9-, unknown 10-, unknown 11-, YAT1::ME3S::Pex16, GPD::ME3S::Pex20, YAT1::ME3S::Lip1, FBAINm::EgD9eS::Lip2, EXP1::EgD9eS::Lip1, GPAT::EgD9e::Lip2, YAT1::EgD9eS::Lip2, YAT1::EgD9eS-L35G::Pex20, FBAINm::EgD8M::Pex20, EXP1::EgD8M::Pex16, FBAIN::EgD8M::Lip1, GPD::EaD8S::Pex16 (2 copies), YAT1::E389D9eS/EgD8M::Lip1, YAT1::EgD9eS/EgD8M::Aco, FBAINm::EaD9eS/EaD8S::Lip2, GPDIN::YlD9::Lip1, GPD::FmD12::Pex20, YAT1::FmD12::Oct, EXP1::FmD12S::Aco, GPDIN::FmD12::Pex16, EXP1::EgD5M::Pex16, FBAIN::EgD5SM::Pex20, GPDIN::EgD5SM::Aco, GPM::EgD5SM::Oct, EXP1::EgD5SM::Lip1, YAT1::EaD5SM::Oct, FBAINm::PaD17::Aco, EXP1::PaD17::Pex16, YAT1::PaD17S::Lip1, YAT1::YlCPT1::Aco, YAT1::MCS::Lip1, FBA::MCS::Lip1, YAT1::MaLPAAT1S::Pex16, EXP1::YlPCT::Pex16이었다.
균주 Z1977, Z1978, Z1979, Z1980 및 Z1981에서의 YALI0F32131p 유전자좌(진뱅크 수탁 번호 XM_50612)의 낙아웃(Knockout)은 pZKL3-9DP9N으로의 형질전환에 의해 생성되는 이들 임의의 EPA 균주에서 확인되지 않았다.
균주 Z1977, Z1978, Z1979, Z1980 및 Z1981의 YPD 플레이트로부터의 세포를 성장시키고, 플라스크 검정법에 의해 전체 지질 함량 및 조성에 대하여 분석하였다. 하기의 표 17에는 이들 각각의 균주에서의 전체 지질 함량 및 조성이 요약되어 있다. 구체적으로, 표에는 전체 DCW, TFA % DCW, TFA의 중량 백분율["% TFA"]로서의 각 지방산의 농도 및 EPA % DCW가 요약되어 있다.

균주 Z1978을 이후에 부분 게놈 시퀀싱으로 처리하였다. 미국 가출원 제61/428,277호(이.아이. 듀폰 드 네무어 앤드 컴퍼니, 인코포레이티드, 대리인 문서 번호 CL5267USPRV(출원일: 2010년 12월 30일))에 기재된 바와 같은 이러한 작업에 의해, 야로위아 게놈 내로 도입된 6개의 델타-5 불포화화효소 유전자(즉, 키메라 유전자 EXP1::EgD5M::Pex16, FBAIN::EgD5SM::Pex20, GPDIN::EgD5SM::Aco, GPM::EgD5SM::Oct, EXP1::EgD5SM::Lip1, YAT1::EaD5SM::Oct) 대신에, 엔지니어링된 균주는 실제로 오직 4개의 델타-5 불포화화효소 유전자(즉, EXP1::EgD5M::Pex16, FBAIN::EgD5SM::Pex20, EXP1::EgD5SM::Lip1 및 YAT1::EaD5SM::Oct)만을 갖는 것이 결정되었다.
야로위아 리폴리티카 균주 Y9502 및 균주 Z1978의 비교
균주 Z1978에서 발현되는 이종 유전자는 하나의 델타-9 불포화화효소 유전자, 하나의 콜린포스페이트 시티딜릴트랜스퍼라제 유전자 및 하나의 델타-9 연장효소 돌연변이체(즉, 서열 번호 58 및 59에 기재된 EgD9eS-L35G)의 추가의 발현만이 균주 Y9502에서 발현되는 것과 상이하다. LA 및 ALA로부터 EPA로의 전체 델타-9 연장효소 전환 효율["전환%"]을 Y9502 및 Z1978 균주에 대하여 하기의 식에 따라 표 18에서 계산하였다: ([생성물]/[기질 + 생성물])*100, 여기서, 생성물은 EDA % TFA, ETrA % TFA, DGLA % TFA, ETA % TFA, ARA % TFA 및 EPA % TFA의 합이며, 기질은 LA % TFA, ALA % TFA, EDA % TFA, ETrA % TFA, DGLA % TFA, ETA % TFA, ARA % TFA 및 EPA % TFA의 합이다.

상술된 바와 같이, 전체 델타-9 연장효소 전환 효율이 균주 Y9502에서 83.3%인 것으로 결정된 한편, 효율은 균주 Z1978에서 향상되었다(즉, 85.3%). 이러한 델타-9 연장효소 활성의 향상에 기초하여, EgD9eS-L35G는 PUFA의 생합성을 위한 기능성 델타-9 연장효소/델타-8 탈포화화효소 경로에서 사용할 유용한 돌연변이 유전자로 여겨진다.
본 명세서에서 본 발명의 임의의 돌연변이 델타-9 연장효소는 본 실시예에서 입증된 바와 같이 바람직한 야로위아 리폴리티카 균주 내에서의 발현을 위한 적절한 벡터 내로 유사하게 도입될 수 있다.
SEQUENCE LISTING
<110> E.I. duPont de Nemours and Company, Inc.
Li, Yougen
Bostick, Michael
Zhu, Quinn
<120> MUTANT DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED
<130> CL4783
<150> US 61/377,248
<151> 2010-08-26
<160> 111
<170> PatentIn version 3.5
<210> 1
<211> 1064
<212> DNA
<213> Isochrysis galbana (GenBank Accession No. AF390174)
<220>
<221> CDS
<222> (2)..(793)
<223> delta-9 elongase (IgD9e)
<400> 1
g atg gcc ctc gca aac gac gcg gga gag cgc atc tgg gcg gct gtg acc 49
Met Ala Leu Ala Asn Asp Ala Gly Glu Arg Ile Trp Ala Ala Val Thr
1 5 10 15
gac ccg gaa atc ctc att ggc acc ttc tcg tac ttg cta ctc aaa ccg 97
Asp Pro Glu Ile Leu Ile Gly Thr Phe Ser Tyr Leu Leu Leu Lys Pro
20 25 30
ctg ctc cgc aat tcc ggg ctg gtg gat gag aag aag ggc gca tac agg 145
Leu Leu Arg Asn Ser Gly Leu Val Asp Glu Lys Lys Gly Ala Tyr Arg
35 40 45
acg tcc atg atc tgg tac aac gtt ctg ctg gcg ctc ttc tct gcg ctg 193
Thr Ser Met Ile Trp Tyr Asn Val Leu Leu Ala Leu Phe Ser Ala Leu
50 55 60
agc ttc tac gtg acg gcg acc gcc ctc ggc tgg gac tat ggt acg ggc 241
Ser Phe Tyr Val Thr Ala Thr Ala Leu Gly Trp Asp Tyr Gly Thr Gly
65 70 75 80
gcg tgg ctg cgc agg caa acc ggc gac aca ccg cag ccg ctc ttc cag 289
Ala Trp Leu Arg Arg Gln Thr Gly Asp Thr Pro Gln Pro Leu Phe Gln
85 90 95
tgc ccg tcc ccg gtt tgg gac tcg aag ctc ttc aca tgg acc gcc aag 337
Cys Pro Ser Pro Val Trp Asp Ser Lys Leu Phe Thr Trp Thr Ala Lys
100 105 110
gca ttc tat tac tcc aag tac gtg gag tac ctc gac acg gcc tgg ctg 385
Ala Phe Tyr Tyr Ser Lys Tyr Val Glu Tyr Leu Asp Thr Ala Trp Leu
115 120 125
gtg ctc aag ggc aag agg gtc tcc ttt ctc cag gcc ttc cac cac ttt 433
Val Leu Lys Gly Lys Arg Val Ser Phe Leu Gln Ala Phe His His Phe
130 135 140
ggc gcg ccg tgg gat gtg tac ctc ggc att cgg ctg cac aac gag ggc 481
Gly Ala Pro Trp Asp Val Tyr Leu Gly Ile Arg Leu His Asn Glu Gly
145 150 155 160
gta tgg atc ttc atg ttt ttc aac tcg ttc att cac acc atc atg tac 529
Val Trp Ile Phe Met Phe Phe Asn Ser Phe Ile His Thr Ile Met Tyr
165 170 175
acc tac tac ggc ctc acc gcc gcc ggg tat aag ttc aag gcc aag ccg 577
Thr Tyr Tyr Gly Leu Thr Ala Ala Gly Tyr Lys Phe Lys Ala Lys Pro
180 185 190
ctc atc acc gcg atg cag atc tgc cag ttc gtg ggc ggc ttc ctg ttg 625
Leu Ile Thr Ala Met Gln Ile Cys Gln Phe Val Gly Gly Phe Leu Leu
195 200 205
gtc tgg gac tac atc aac gtc ccc tgc ttc aac tcg gac aaa ggg aag 673
Val Trp Asp Tyr Ile Asn Val Pro Cys Phe Asn Ser Asp Lys Gly Lys
210 215 220
ttg ttc agc tgg gct ttc aac tat gca tac gtc ggc tcg gtc ttc ttg 721
Leu Phe Ser Trp Ala Phe Asn Tyr Ala Tyr Val Gly Ser Val Phe Leu
225 230 235 240
ctc ttc tgc cac ttt ttc tac cag gac aac ttg gca acg aag aaa tcg 769
Leu Phe Cys His Phe Phe Tyr Gln Asp Asn Leu Ala Thr Lys Lys Ser
245 250 255
gcc aag gcg ggc aag cag ctc tag gcctcgagcc ggctcgcggg ttcaaggagg 823
Ala Lys Ala Gly Lys Gln Leu
260
gcgacacggg ggtgggacgt ttgcatggag atggattgtg gatgtcctta cgccttactc 883
atcaatgtcc tcccatctct cccctctaga ccttctacta gccatctaga agggcagctc 943
agagacggat accgttcccc ctccccttcc ttttcgtctt tgctttgcca ttgtttgttt 1003
gtctctattt tttaaactat tgacgctaac gcgttacgct cgcaaaaaaa aaaaaaaaaa 1063
a 1064
<210> 2
<211> 263
<212> PRT
<213> Isochrysis galbana (GenBank Accession No. AF390174)
<400> 2
Met Ala Leu Ala Asn Asp Ala Gly Glu Arg Ile Trp Ala Ala Val Thr
1 5 10 15
Asp Pro Glu Ile Leu Ile Gly Thr Phe Ser Tyr Leu Leu Leu Lys Pro
20 25 30
Leu Leu Arg Asn Ser Gly Leu Val Asp Glu Lys Lys Gly Ala Tyr Arg
35 40 45
Thr Ser Met Ile Trp Tyr Asn Val Leu Leu Ala Leu Phe Ser Ala Leu
50 55 60
Ser Phe Tyr Val Thr Ala Thr Ala Leu Gly Trp Asp Tyr Gly Thr Gly
65 70 75 80
Ala Trp Leu Arg Arg Gln Thr Gly Asp Thr Pro Gln Pro Leu Phe Gln
85 90 95
Cys Pro Ser Pro Val Trp Asp Ser Lys Leu Phe Thr Trp Thr Ala Lys
100 105 110
Ala Phe Tyr Tyr Ser Lys Tyr Val Glu Tyr Leu Asp Thr Ala Trp Leu
115 120 125
Val Leu Lys Gly Lys Arg Val Ser Phe Leu Gln Ala Phe His His Phe
130 135 140
Gly Ala Pro Trp Asp Val Tyr Leu Gly Ile Arg Leu His Asn Glu Gly
145 150 155 160
Val Trp Ile Phe Met Phe Phe Asn Ser Phe Ile His Thr Ile Met Tyr
165 170 175
Thr Tyr Tyr Gly Leu Thr Ala Ala Gly Tyr Lys Phe Lys Ala Lys Pro
180 185 190
Leu Ile Thr Ala Met Gln Ile Cys Gln Phe Val Gly Gly Phe Leu Leu
195 200 205
Val Trp Asp Tyr Ile Asn Val Pro Cys Phe Asn Ser Asp Lys Gly Lys
210 215 220
Leu Phe Ser Trp Ala Phe Asn Tyr Ala Tyr Val Gly Ser Val Phe Leu
225 230 235 240
Leu Phe Cys His Phe Phe Tyr Gln Asp Asn Leu Ala Thr Lys Lys Ser
245 250 255
Ala Lys Ala Gly Lys Gln Leu
260
<210> 3
<211> 792
<212> DNA
<213> Eutreptiella sp. CCMP389
<220>
<221> CDS
<222> (1)..(792)
<223> delta-9 elongase
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> WO 2007/061742
<311> 2006-11-16
<312> 2007-05-31
<313> (1)..(792)
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> US 7,645,604
<311> 2006-11-16
<312> 2010-01-12
<313> (1)..(792)
<400> 3
atg gct gcg gtg ata gag gtc gcc aac gag ttt gta gcc atc acg gca 48
Met Ala Ala Val Ile Glu Val Ala Asn Glu Phe Val Ala Ile Thr Ala
1 5 10 15
gaa acg ctc ccc aaa gtt gac tat caa cga cta tgg cga gac att tac 96
Glu Thr Leu Pro Lys Val Asp Tyr Gln Arg Leu Trp Arg Asp Ile Tyr
20 25 30
agt tgt gag cta ctg tat ttc tcc att gcc ttc gtg atc ttg aag ttt 144
Ser Cys Glu Leu Leu Tyr Phe Ser Ile Ala Phe Val Ile Leu Lys Phe
35 40 45
acg ttg ggc gag ttg agc gac agc gga aaa aag att ttg aga gtg ttg 192
Thr Leu Gly Glu Leu Ser Asp Ser Gly Lys Lys Ile Leu Arg Val Leu
50 55 60
ttc aag tgg tac aat ctc ttc atg tcc gtg ttc tcc ttg gtg tct ttc 240
Phe Lys Trp Tyr Asn Leu Phe Met Ser Val Phe Ser Leu Val Ser Phe
65 70 75 80
ctt tgc atg ggc tat gcc att tat acc gtg ggc cta tac tct aac gaa 288
Leu Cys Met Gly Tyr Ala Ile Tyr Thr Val Gly Leu Tyr Ser Asn Glu
85 90 95
tgc gac agg gct ttc gac aac tcg ttg ttc cgc ttt gca aca aag gtg 336
Cys Asp Arg Ala Phe Asp Asn Ser Leu Phe Arg Phe Ala Thr Lys Val
100 105 110
ttc tac tac agt aag ttt ttg gag tac atc gac tct ttt tat ctt ccg 384
Phe Tyr Tyr Ser Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro
115 120 125
ctc atg gcc aag ccg ctg tct ttc ctg caa ttc ttc cat cac ttg gga 432
Leu Met Ala Lys Pro Leu Ser Phe Leu Gln Phe Phe His His Leu Gly
130 135 140
gcc ccc atg gac atg tgg ctc ttt gtc caa tat tct ggg gaa tct att 480
Ala Pro Met Asp Met Trp Leu Phe Val Gln Tyr Ser Gly Glu Ser Ile
145 150 155 160
tgg atc ttt gtg ttt ttg aat ggg ttc att cac ttt gtt atg tac ggg 528
Trp Ile Phe Val Phe Leu Asn Gly Phe Ile His Phe Val Met Tyr Gly
165 170 175
tac tac tgg act cgg ctg atg aag ttc aat ttc cca atg ccc aag cag 576
Tyr Tyr Trp Thr Arg Leu Met Lys Phe Asn Phe Pro Met Pro Lys Gln
180 185 190
ttg att acc gcg atg cag atc acg cag ttc aac gtt ggt ttc tac ctc 624
Leu Ile Thr Ala Met Gln Ile Thr Gln Phe Asn Val Gly Phe Tyr Leu
195 200 205
gtg tgg tgg tac aaa gat att ccc tgc tac cga aag gat ccc atg cga 672
Val Trp Trp Tyr Lys Asp Ile Pro Cys Tyr Arg Lys Asp Pro Met Arg
210 215 220
atg ttg gcc tgg atc ttc aat tac tgg tat gtt ggg act gtc ttg ctg 720
Met Leu Ala Trp Ile Phe Asn Tyr Trp Tyr Val Gly Thr Val Leu Leu
225 230 235 240
ctg ttc att aat ttc ttc gtc aaa tcc tat gtg ttc cca aag ccg aag 768
Leu Phe Ile Asn Phe Phe Val Lys Ser Tyr Val Phe Pro Lys Pro Lys
245 250 255
act gca gat aaa aag gtc caa tag 792
Thr Ala Asp Lys Lys Val Gln
260
<210> 4
<211> 263
<212> PRT
<213> Eutreptiella sp. CCMP389
<400> 4
Met Ala Ala Val Ile Glu Val Ala Asn Glu Phe Val Ala Ile Thr Ala
1 5 10 15
Glu Thr Leu Pro Lys Val Asp Tyr Gln Arg Leu Trp Arg Asp Ile Tyr
20 25 30
Ser Cys Glu Leu Leu Tyr Phe Ser Ile Ala Phe Val Ile Leu Lys Phe
35 40 45
Thr Leu Gly Glu Leu Ser Asp Ser Gly Lys Lys Ile Leu Arg Val Leu
50 55 60
Phe Lys Trp Tyr Asn Leu Phe Met Ser Val Phe Ser Leu Val Ser Phe
65 70 75 80
Leu Cys Met Gly Tyr Ala Ile Tyr Thr Val Gly Leu Tyr Ser Asn Glu
85 90 95
Cys Asp Arg Ala Phe Asp Asn Ser Leu Phe Arg Phe Ala Thr Lys Val
100 105 110
Phe Tyr Tyr Ser Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro
115 120 125
Leu Met Ala Lys Pro Leu Ser Phe Leu Gln Phe Phe His His Leu Gly
130 135 140
Ala Pro Met Asp Met Trp Leu Phe Val Gln Tyr Ser Gly Glu Ser Ile
145 150 155 160
Trp Ile Phe Val Phe Leu Asn Gly Phe Ile His Phe Val Met Tyr Gly
165 170 175
Tyr Tyr Trp Thr Arg Leu Met Lys Phe Asn Phe Pro Met Pro Lys Gln
180 185 190
Leu Ile Thr Ala Met Gln Ile Thr Gln Phe Asn Val Gly Phe Tyr Leu
195 200 205
Val Trp Trp Tyr Lys Asp Ile Pro Cys Tyr Arg Lys Asp Pro Met Arg
210 215 220
Met Leu Ala Trp Ile Phe Asn Tyr Trp Tyr Val Gly Thr Val Leu Leu
225 230 235 240
Leu Phe Ile Asn Phe Phe Val Lys Ser Tyr Val Phe Pro Lys Pro Lys
245 250 255
Thr Ala Asp Lys Lys Val Gln
260
<210> 5
<211> 792
<212> DNA
<213> Eutreptiella sp. CCMP389
<220>
<221> CDS
<222> (1)..(792)
<223> synthetic delta-9 elongase (codon-optimized for Yarrowia
lipolytica)
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> WO 2007/061742
<311> 2006-11-16
<312> 2007-05-31
<313> (1)..(792)
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> US 7,645,604
<311> 2006-11-16
<312> 2010-01-12
<313> (1)..(792)
<400> 5
atg gct gcc gtc atc gag gtg gcc aac gag ttc gtc gct atc act gcc 48
Met Ala Ala Val Ile Glu Val Ala Asn Glu Phe Val Ala Ile Thr Ala
1 5 10 15
gag acc ctt ccc aag gtg gac tat cag cga ctc tgg cga gac atc tac 96
Glu Thr Leu Pro Lys Val Asp Tyr Gln Arg Leu Trp Arg Asp Ile Tyr
20 25 30
tcc tgc gag ctc ctg tac ttc tcc att gct ttc gtc atc ctc aag ttt 144
Ser Cys Glu Leu Leu Tyr Phe Ser Ile Ala Phe Val Ile Leu Lys Phe
35 40 45
acc ctt ggc gag ctc tcg gat tct ggc aaa aag att ctg cga gtg ctg 192
Thr Leu Gly Glu Leu Ser Asp Ser Gly Lys Lys Ile Leu Arg Val Leu
50 55 60
ttc aag tgg tac aac ctc ttc atg tcc gtc ttt tcg ctg gtg tcc ttc 240
Phe Lys Trp Tyr Asn Leu Phe Met Ser Val Phe Ser Leu Val Ser Phe
65 70 75 80
ctc tgt atg ggt tac gcc atc tac acc gtt gga ctg tac tcc aac gaa 288
Leu Cys Met Gly Tyr Ala Ile Tyr Thr Val Gly Leu Tyr Ser Asn Glu
85 90 95
tgc gac aga gct ttc gac aac agc ttg ttc cga ttt gcc acc aag gtc 336
Cys Asp Arg Ala Phe Asp Asn Ser Leu Phe Arg Phe Ala Thr Lys Val
100 105 110
ttc tac tat tcc aag ttt ctg gag tac atc gac tct ttc tac ctt ccc 384
Phe Tyr Tyr Ser Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro
115 120 125
ctc atg gcc aag cct ctg tcc ttt ctg cag ttc ttt cat cac ttg gga 432
Leu Met Ala Lys Pro Leu Ser Phe Leu Gln Phe Phe His His Leu Gly
130 135 140
gct cct atg gac atg tgg ctc ttc gtg cag tac tct ggc gaa tcc att 480
Ala Pro Met Asp Met Trp Leu Phe Val Gln Tyr Ser Gly Glu Ser Ile
145 150 155 160
tgg atc ttt gtg ttc ctg aac gga ttc att cac ttt gtc atg tac ggc 528
Trp Ile Phe Val Phe Leu Asn Gly Phe Ile His Phe Val Met Tyr Gly
165 170 175
tac tat tgg aca cgg ctg atg aag ttc aac ttt ccc atg ccc aag cag 576
Tyr Tyr Trp Thr Arg Leu Met Lys Phe Asn Phe Pro Met Pro Lys Gln
180 185 190
ctc att acc gca atg cag atc acc cag ttc aac gtt ggc ttc tac ctc 624
Leu Ile Thr Ala Met Gln Ile Thr Gln Phe Asn Val Gly Phe Tyr Leu
195 200 205
gtg tgg tgg tac aag gac att ccc tgt tac cga aag gat ccc atg cga 672
Val Trp Trp Tyr Lys Asp Ile Pro Cys Tyr Arg Lys Asp Pro Met Arg
210 215 220
atg ctg gcc tgg atc ttc aac tac tgg tac gtc ggt acc gtt ctt ctg 720
Met Leu Ala Trp Ile Phe Asn Tyr Trp Tyr Val Gly Thr Val Leu Leu
225 230 235 240
ctc ttc atc aac ttc ttt gtc aag tcc tac gtg ttt ccc aag cct aag 768
Leu Phe Ile Asn Phe Phe Val Lys Ser Tyr Val Phe Pro Lys Pro Lys
245 250 255
act gcc gac aaa aag gtc cag tag 792
Thr Ala Asp Lys Lys Val Gln
260
<210> 6
<211> 263
<212> PRT
<213> Eutreptiella sp. CCMP389
<400> 6
Met Ala Ala Val Ile Glu Val Ala Asn Glu Phe Val Ala Ile Thr Ala
1 5 10 15
Glu Thr Leu Pro Lys Val Asp Tyr Gln Arg Leu Trp Arg Asp Ile Tyr
20 25 30
Ser Cys Glu Leu Leu Tyr Phe Ser Ile Ala Phe Val Ile Leu Lys Phe
35 40 45
Thr Leu Gly Glu Leu Ser Asp Ser Gly Lys Lys Ile Leu Arg Val Leu
50 55 60
Phe Lys Trp Tyr Asn Leu Phe Met Ser Val Phe Ser Leu Val Ser Phe
65 70 75 80
Leu Cys Met Gly Tyr Ala Ile Tyr Thr Val Gly Leu Tyr Ser Asn Glu
85 90 95
Cys Asp Arg Ala Phe Asp Asn Ser Leu Phe Arg Phe Ala Thr Lys Val
100 105 110
Phe Tyr Tyr Ser Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro
115 120 125
Leu Met Ala Lys Pro Leu Ser Phe Leu Gln Phe Phe His His Leu Gly
130 135 140
Ala Pro Met Asp Met Trp Leu Phe Val Gln Tyr Ser Gly Glu Ser Ile
145 150 155 160
Trp Ile Phe Val Phe Leu Asn Gly Phe Ile His Phe Val Met Tyr Gly
165 170 175
Tyr Tyr Trp Thr Arg Leu Met Lys Phe Asn Phe Pro Met Pro Lys Gln
180 185 190
Leu Ile Thr Ala Met Gln Ile Thr Gln Phe Asn Val Gly Phe Tyr Leu
195 200 205
Val Trp Trp Tyr Lys Asp Ile Pro Cys Tyr Arg Lys Asp Pro Met Arg
210 215 220
Met Leu Ala Trp Ile Phe Asn Tyr Trp Tyr Val Gly Thr Val Leu Leu
225 230 235 240
Leu Phe Ile Asn Phe Phe Val Lys Ser Tyr Val Phe Pro Lys Pro Lys
245 250 255
Thr Ala Asp Lys Lys Val Gln
260
<210> 7
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> delta-9 elongase
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> WO 2007/061742
<311> 2006-11-16
<312> 2007-05-31
<313> (1)..(777)
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> US 7,645,604
<311> 2006-11-16
<312> 2010-01-12
<313> (1)..(777)
<400> 7
atg gag gtg gtg aat gaa ata gtc tca att ggg cag gaa gtt tta ccc 48
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aaa gtt gat tat gcc caa ctc tgg agt gat gcc agt cac tgt gag gtg 96
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctt tac ttg tcc atc gca ttt gtc atc ttg aag ttc act ctt ggc ccc 144
Leu Tyr Leu Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctt ggt cca aaa ggt cag tct cgt atg aag ttt gtt ttc acc aat tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
aac ctt ctc atg tcc att tat tcg ttg gga tca ttc ctc tca atg gca 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tat gcc atg tac acc atc ggt gtt atg tct gac aac tgc gag aag gct 288
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttt gac aac aac gtc ttc agg atc acc acg cag ttg ttc tat ttg agc 336
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc ctg gag tat att gac tcc ttc tat ttg cca ctg atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct ctg acc tgg ttg caa ttc ttc cat cat ttg ggg gca ccg atg gat 432
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tat aat tac cga aat gaa gct gtt tgg att ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ttg aat ggt ttc atc cac tgg atc atg tac ggt tat tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
aga ttg atc aag ctg aag ttc ccc atg cca aaa tcc ctg att aca tca 576
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att caa ttc aat gtt ggt ttc tac att gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
agg aac att ccc tgt tat cgc caa gat ggg atg agg atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttc ttc aat tac ttt tat gtt ggc aca gtc ttg tgt ttg ttc ttg aat 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tat gtg caa acg tat atc gtc agg aag cac aag gga gcc aaa aag 768
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
att cag tga 777
Ile Gln
<210> 8
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 8
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Leu Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 9
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> synthetic delta-9 elongase (codon-optimized for Yarrowia
lipolytica)
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> WO 2007/061742
<311> 2006-11-16
<312> 2007-05-31
<313> (1)..(777)
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> US 7,645,604
<311> 2006-11-16
<312> 2010-01-12
<313> (1)..(777)
<400> 9
atg gag gtc gtg aac gaa atc gtc tcc att ggc cag gag gtt ctt ccc 48
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aag gtc gac tat gct cag ctc tgg tct gat gcc tcg cac tgc gag gtg 96
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctg tac ctc tcc atc gcc ttc gtc atc ctg aag ttc acc ctt ggt cct 144
Leu Tyr Leu Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctc gga ccc aag ggt cag tct cga atg aag ttt gtg ttc acc aac tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
aac ctg ctc atg tcc atc tac tcg ctg ggc tcc ttc ctc tct atg gcc 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tac gcc atg tac acc att ggt gtc atg tcc gac aac tgc gag aag gct 288
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttc gac aac aat gtc ttc cga atc acc act cag ctg ttc tac ctc agc 336
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc ctc gag tac att gac tcc ttc tat ctg ccc ctc atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct ctg acc tgg ttg cag ttc ttt cac cat ctc gga gct cct atg gac 432
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tac aac tac cga aac gaa gcc gtt tgg atc ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggc tac tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctg atc aag ctc aag ttc cct atg ccc aag tcc ctg att act tct 576
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att cag ttc aac gtt ggc ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgg aac att ccc tgc tac cga caa gat gga atg aga atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttt ttc aac tac ttc tac gtt ggt act gtc ctg tgt ctg ttc ctc aac 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tac gtg cag acc tac atc gtc cga aag cac aag gga gcc aaa aag 768
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
att cag tga 777
Ile Gln
<210> 10
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 10
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Leu Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 11
<211> 774
<212> DNA
<213> Euglena anabaena UTEX 373
<220>
<221> CDS
<222> (1)..(774)
<223> delta-9 elongase
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> U.S. 7,794,701
<311> 2008-04-15
<312> 2010-09-14
<313> (1)..(774)
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> WO 2008/128241
<311> 2008-04-16
<312> 2008-10-23
<313> (1)..(774)
<400> 11
atg gaa gca gcc aaa gaa ttg gtt tcc atc gtc caa gag gag ctc ccc 48
Met Glu Ala Ala Lys Glu Leu Val Ser Ile Val Gln Glu Glu Leu Pro
1 5 10 15
aag gtg gac tat gcc cag ctt tgg cag gat gcc agc agc tgt gag gtc 96
Lys Val Asp Tyr Ala Gln Leu Trp Gln Asp Ala Ser Ser Cys Glu Val
20 25 30
ctt tac ctc tcg gtg gca ttc gtg gcg atc aag ttc atg ctg cgc cca 144
Leu Tyr Leu Ser Val Ala Phe Val Ala Ile Lys Phe Met Leu Arg Pro
35 40 45
ctg gac ctg aag cgc cag gcc acc ttg aag aag ctg ttc aca gca tac 192
Leu Asp Leu Lys Arg Gln Ala Thr Leu Lys Lys Leu Phe Thr Ala Tyr
50 55 60
aac ttc ctc atg tcg atc tat tcc ttt ggc tcc ttc ctg gcc atg gcc 240
Asn Phe Leu Met Ser Ile Tyr Ser Phe Gly Ser Phe Leu Ala Met Ala
65 70 75 80
tat gcc cta tca gta act ggc atc ctc tcc ggc gac tgt gag acg gcg 288
Tyr Ala Leu Ser Val Thr Gly Ile Leu Ser Gly Asp Cys Glu Thr Ala
85 90 95
ttc aac aac gat gtg ttc agg atc aca act cag ctg ttc tac ctc agc 336
Phe Asn Asn Asp Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc gta gag tac atc gac tcc ttc tac ctt ccc ctt atg gac aag 384
Lys Phe Val Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Asp Lys
115 120 125
cca ctg tcg ttc ctt cag ttc ttc cat cat ttg ggg gcc ccc att gac 432
Pro Leu Ser Phe Leu Gln Phe Phe His His Leu Gly Ala Pro Ile Asp
130 135 140
atg tgg cta ttc tac aaa tac cgc aac gaa gga gtc tgg atc ttt gtc 480
Met Trp Leu Phe Tyr Lys Tyr Arg Asn Glu Gly Val Trp Ile Phe Val
145 150 155 160
ctg ttg aat ggg ttc att cac tgg atc atg tac ggt tac tat tgg acg 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cgg ctc atc aag ctg aac ttc ccc atg ccc aag aac ctg atc acc tcc 576
Arg Leu Ile Lys Leu Asn Phe Pro Met Pro Lys Asn Leu Ile Thr Ser
180 185 190
atg cag atc atc cag ttc aat gtc ggg ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgc aat gtg cca tgc tac cgc cag gat ggg atg cgc atg ttt gcc tgg 672
Arg Asn Val Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Ala Trp
210 215 220
atc ttc aac tac tgg tat gtc ggg acg gtc ttg ctg ctg ttc ctc aac 720
Ile Phe Asn Tyr Trp Tyr Val Gly Thr Val Leu Leu Leu Phe Leu Asn
225 230 235 240
ttt tac gtg cag acg tac atc cgg aag ccg agg aag aac cga ggg aag 768
Phe Tyr Val Gln Thr Tyr Ile Arg Lys Pro Arg Lys Asn Arg Gly Lys
245 250 255
aag gag 774
Lys Glu
<210> 12
<211> 258
<212> PRT
<213> Euglena anabaena UTEX 373
<400> 12
Met Glu Ala Ala Lys Glu Leu Val Ser Ile Val Gln Glu Glu Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Gln Asp Ala Ser Ser Cys Glu Val
20 25 30
Leu Tyr Leu Ser Val Ala Phe Val Ala Ile Lys Phe Met Leu Arg Pro
35 40 45
Leu Asp Leu Lys Arg Gln Ala Thr Leu Lys Lys Leu Phe Thr Ala Tyr
50 55 60
Asn Phe Leu Met Ser Ile Tyr Ser Phe Gly Ser Phe Leu Ala Met Ala
65 70 75 80
Tyr Ala Leu Ser Val Thr Gly Ile Leu Ser Gly Asp Cys Glu Thr Ala
85 90 95
Phe Asn Asn Asp Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Val Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Asp Lys
115 120 125
Pro Leu Ser Phe Leu Gln Phe Phe His His Leu Gly Ala Pro Ile Asp
130 135 140
Met Trp Leu Phe Tyr Lys Tyr Arg Asn Glu Gly Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Ile Lys Leu Asn Phe Pro Met Pro Lys Asn Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Val Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Ala Trp
210 215 220
Ile Phe Asn Tyr Trp Tyr Val Gly Thr Val Leu Leu Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Gln Thr Tyr Ile Arg Lys Pro Arg Lys Asn Arg Gly Lys
245 250 255
Lys Glu
<210> 13
<211> 774
<212> DNA
<213> Euglena anabaena UTEX 373
<220>
<221> CDS
<222> (1)..(774)
<223> synthetic delta-9 elongase (codon-optimized for Yarrowia
lipolytica)
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> U.S. 7,794,701
<311> 2008-04-15
<312> 2010-09-14
<313> (1)..(774)
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> WO 2008/128241
<311> 2008-04-16
<312> 2008-10-23
<313> (1)..(774)
<400> 13
atg gag gct gcc aag gag ctg gtc tcc atc gtc cag gag gaa ctt ccc 48
Met Glu Ala Ala Lys Glu Leu Val Ser Ile Val Gln Glu Glu Leu Pro
1 5 10 15
aag gtg gac tac gcc cag ctc tgg cag gac gcc tcc tct tgc gag gtt 96
Lys Val Asp Tyr Ala Gln Leu Trp Gln Asp Ala Ser Ser Cys Glu Val
20 25 30
ctg tac ctc tcg gtc gct ttc gtg gcc atc aag ttc atg ctt cga cct 144
Leu Tyr Leu Ser Val Ala Phe Val Ala Ile Lys Phe Met Leu Arg Pro
35 40 45
ctg gac ctc aag cga caa gcc acc ctc aaa aag ctg ttc acc gca tac 192
Leu Asp Leu Lys Arg Gln Ala Thr Leu Lys Lys Leu Phe Thr Ala Tyr
50 55 60
aac ttt ctc atg tcc atc tac tcg ttc ggc tcc ttc ctg gcg atg gcc 240
Asn Phe Leu Met Ser Ile Tyr Ser Phe Gly Ser Phe Leu Ala Met Ala
65 70 75 80
tac gct ctc tct gtc act ggt att ctt tcc ggc gat tgt gag act gcc 288
Tyr Ala Leu Ser Val Thr Gly Ile Leu Ser Gly Asp Cys Glu Thr Ala
85 90 95
ttc aac aat gac gtg ttc cga atc acc act cag ctg ttc tac ctc agc 336
Phe Asn Asn Asp Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc gtc gag tac atc gac tcc ttc tac ctt ccc ctc atg gac aag 384
Lys Phe Val Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Asp Lys
115 120 125
ccc ttg tcg ttt ctg cag ttc ttt cac cat ctc gga gct ccc atc gac 432
Pro Leu Ser Phe Leu Gln Phe Phe His His Leu Gly Ala Pro Ile Asp
130 135 140
atg tgg ctg ttc tac aag tat cga aac gaa ggc gtc tgg atc ttt gtt 480
Met Trp Leu Phe Tyr Lys Tyr Arg Asn Glu Gly Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggt tac tat tgg acg 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctc atc aag ctg aac ttc cct atg ccc aag aac ctc att acc tcc 576
Arg Leu Ile Lys Leu Asn Phe Pro Met Pro Lys Asn Leu Ile Thr Ser
180 185 190
atg caa att atc cag ttc aac gtc gga ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cga aac gtg ccc tgc tac cgg cag gac ggt atg cga atg ttt gcc tgg 672
Arg Asn Val Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Ala Trp
210 215 220
atc ttc aac tac tgg tat gtc ggc acg gtg ctg ctt ctg ttc ctc aac 720
Ile Phe Asn Tyr Trp Tyr Val Gly Thr Val Leu Leu Leu Phe Leu Asn
225 230 235 240
ttc tac gtc cag acc tac att cgg aag cct cga aag aac cga ggc aaa 768
Phe Tyr Val Gln Thr Tyr Ile Arg Lys Pro Arg Lys Asn Arg Gly Lys
245 250 255
aag gag 774
Lys Glu
<210> 14
<211> 258
<212> PRT
<213> Euglena anabaena UTEX 373
<400> 14
Met Glu Ala Ala Lys Glu Leu Val Ser Ile Val Gln Glu Glu Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Gln Asp Ala Ser Ser Cys Glu Val
20 25 30
Leu Tyr Leu Ser Val Ala Phe Val Ala Ile Lys Phe Met Leu Arg Pro
35 40 45
Leu Asp Leu Lys Arg Gln Ala Thr Leu Lys Lys Leu Phe Thr Ala Tyr
50 55 60
Asn Phe Leu Met Ser Ile Tyr Ser Phe Gly Ser Phe Leu Ala Met Ala
65 70 75 80
Tyr Ala Leu Ser Val Thr Gly Ile Leu Ser Gly Asp Cys Glu Thr Ala
85 90 95
Phe Asn Asn Asp Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Val Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Asp Lys
115 120 125
Pro Leu Ser Phe Leu Gln Phe Phe His His Leu Gly Ala Pro Ile Asp
130 135 140
Met Trp Leu Phe Tyr Lys Tyr Arg Asn Glu Gly Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Ile Lys Leu Asn Phe Pro Met Pro Lys Asn Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Val Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Ala Trp
210 215 220
Ile Phe Asn Tyr Trp Tyr Val Gly Thr Val Leu Leu Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Gln Thr Tyr Ile Arg Lys Pro Arg Lys Asn Arg Gly Lys
245 250 255
Lys Glu
<210> 15
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> delta-9 elongase motif
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> MISC_FEATURE
<222> (4)..(4)
<223> X = L or F
<220>
<221> misc_feature
<222> (5)..(8)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (10)..(11)
<223> Xaa can be any naturally occurring amino acid
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> US 7,645,604
<311> 2006-11-16
<312> 2010-01-12
<313> (1)..(13)
<400> 15
Tyr Asn Xaa Xaa Xaa Xaa Xaa Xaa Ser Xaa Xaa Ser Phe
1 5 10
<210> 16
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> delta-9 elongase motif
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (6)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> MISC_FEATURE
<222> (8)..(8)
<223> X = E or D
<220>
<221> misc_feature
<222> (10)..(10)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> MISC_FEATURE
<222> (12)..(12)
<223> X = T or S
<220>
<221> misc_feature
<222> (13)..(14)
<223> Xaa can be any naturally occurring amino acid
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> U.S. 7,645,604
<311> 2006-11-16
<312> 2010-01-12
<313> (1)..(15)
<400> 16
Phe Tyr Xaa Ser Lys Xaa Xaa Xaa Tyr Xaa Asp Xaa Xaa Xaa Leu
1 5 10 15
<210> 17
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> delta-9 elongase motif
<220>
<221> MISC_FEATURE
<222> (2)..(2)
<223> X = Q or H
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (7)..(7)
<223> Xaa can be any naturally occurring amino acid
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> U.S. 7,645,604
<311> 2006-11-16
<312> 2010-01-12
<313> (1)..(9)
<400> 17
Leu Xaa Xaa Phe His His Xaa Gly Ala
1 5
<210> 18
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> delta-9 elongase motif
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (6)..(12)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> MISC_FEATURE
<222> (13)..(13)
<223> X = K or R or N
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> U.S. 7,645,604
<311> 2006-11-16
<312> 2010-01-12
<313> (1)..(14)
<400> 18
Met Tyr Xaa Tyr Tyr Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Phe
1 5 10
<210> 19
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> delta-9 elongase motif
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> MISC_FEATURE
<222> (4)..(4)
<223> X = I or L or M
<220>
<221> misc_feature
<222> (6)..(7)
<223> Xaa can be any naturally occurring amino acid
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> U.S. 7,645,604
<311> 2006-11-16
<312> 2010-01-12
<313> (1)..(8)
<400> 19
Lys Xaa Leu Xaa Thr Xaa Xaa Gln
1 5
<210> 20
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> delta-9 elongase motif
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (6)..(6)
<223> Xaa can be any naturally occurring amino acid
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> U.S. 7,645,604
<311> 2006-11-16
<312> 2010-01-12
<313> (1)..(7)
<400> 20
Trp Xaa Phe Asn Tyr Xaa Tyr
1 5
<210> 21
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> delta-9 elongase motif
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (6)..(7)
<223> Xaa can be any naturally occurring amino acid
<300>
<302> DELTA-9 ELONGASES AND THEIR USE IN MAKING POLYUNSATURATED FATTY
ACIDS
<310> U.S. 7,645,604
<311> 2006-11-16
<312> 2010-01-12
<313> (1)..(9)
<400> 21
Tyr Xaa Gly Xaa Val Xaa Xaa Leu Phe
1 5
<210> 22
<211> 258
<212> PRT
<213> Euglena gracilis
<220>
<221> MISC_FEATURE
<222> (1)..(258)
<223> mutant delta-9 elongase; EgD9eS-mutant consensus
<220>
<221> MISC_FEATURE
<222> (9)..(9)
<223> Xaa = Ser [S] (synthetic codon-optimized) or (Ala [A] or Asp [D]
or Gly [G] or Ile [I] or Lys [K] or Gln [Q]) (mutant)
<220>
<221> MISC_FEATURE
<222> (12)..(12)
<223> Xaa = Gln [Q] (synthetic codon-optimized) or Lys [K] (mutant)
<220>
<221> MISC_FEATURE
<222> (21)..(21)
<223> Xaa = Ala [A] (synthetic codon-optimized) or (Asp [D] or Thr [T]
or Val [V]) (mutant)
<220>
<221> MISC_FEATURE
<222> (32)..(32)
<223> Xaa = Val [V] (synthetic codon-optimized) or Phe [F] (mutant)
<220>
<221> MISC_FEATURE
<222> (35)..(35)
<223> Xaa = Leu [L] (synthetic codon-optimized) or (Phe [F] or Gly [G]
or Met [M]) (mutant)
<220>
<221> MISC_FEATURE
<222> (58)..(58)
<223> Xaa = Lys [K] (synthetic codon-optimized) or Arg [R] (mutant)
<220>
<221> MISC_FEATURE
<222> (84)..(84)
<223> Xaa = Tyr [Y] (synthetic codon-optimized) or Cys [C] (mutant)
<220>
<221> MISC_FEATURE
<222> (98)..(98)
<223> Xaa = Asp [D] (synthetic codon-optimized) or Gly [G] (mutant)
<220>
<221> MISC_FEATURE
<222> (107)..(107)
<223> Xaa = Gln [Q] (synthetic codon-optimized) or Glu [E] (mutant)
<220>
<221> MISC_FEATURE
<222> (108)..(108)
<223> Xaa = Leu [L] (synthetic codon-optimized) or Gly [G] (mutant)
<220>
<221> MISC_FEATURE
<222> (127)..(127)
<223> Xaa = Gly [G] (synthetic codon-optimized) or Leu [L] (mutant)
<220>
<221> MISC_FEATURE
<222> (130)..(130)
<223> Xaa = Leu [L] (synthetic codon-optimized) or Met [M] (mutant)
<220>
<221> MISC_FEATURE
<222> (132)..(132)
<223> Xaa = Trp [W] (synthetic codon-optimized) or Thr [T] (mutant)
<220>
<221> MISC_FEATURE
<222> (143)..(143)
<223> Xaa = Met [M] (synthetic codon-optimized) or (Asn [N] or Trp
[W]) (mutant)
<220>
<221> MISC_FEATURE
<222> (161)..(161)
<223> Xaa = Leu [L] (synthetic codon-optimized) or (Thr [T] or Tyr
[Y]) (mutant)
<220>
<221> MISC_FEATURE
<222> (168)..(168)
<223> Xaa = Trp [W] (synthetic codon-optimized) or Gly [G] (mutant)
<220>
<221> MISC_FEATURE
<222> (179)..(179)
<223> Xaa = Ile [I] (synthetic codon-optimized) or (Met [M] or Arg
[R]) (mutant)
<220>
<221> MISC_FEATURE
<222> (236)..(236)
<223> Xaa = Cys [C] (synthetic codon-optimized) or Asn [N] (mutant)
<220>
<221> MISC_FEATURE
<222> (243)..(243)
<223> Xaa = Val [V] (synthetic codon-optimized) or Ala [A] (mutant)
<220>
<221> MISC_FEATURE
<222> (244)..(244)
<223> Xaa = Gln [Q] (synthetic codon-optimized) or Asn [N] (mutant)
<220>
<221> MISC_FEATURE
<222> (254)..(254)
<223> Xaa = Ala [A] (synthetic codon-optimized) or (Trp [W] or Tyr
[Y]) (mutant)
<220>
<221> MISC_FEATURE
<222> (257)..(257)
<223> Xaa = Ile [I] (synthetic codon-optimized) or Thr [T] (mutant)
<400> 22
Met Glu Val Val Asn Glu Ile Val Xaa Ile Gly Xaa Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Xaa Gln Leu Trp Ser Asp Ala Ser His Cys Glu Xaa
20 25 30
Leu Tyr Xaa Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Xaa Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Xaa Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Xaa Asn Asn Val Phe Arg Ile Thr Thr Xaa Xaa Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Xaa Lys
115 120 125
Pro Xaa Thr Xaa Leu Gln Phe Phe His His Leu Gly Ala Pro Xaa Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Xaa Leu Asn Gly Phe Ile His Xaa Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Xaa Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Xaa Leu Phe Leu Asn
225 230 235 240
Phe Tyr Xaa Xaa Thr Tyr Ile Val Arg Lys His Lys Gly Xaa Lys Lys
245 250 255
Xaa Gln
<210> 23
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Variant His box
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 23
Gln Xaa Xaa His His
1 5
<210> 24
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> His box
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 24
His Xaa Xaa His His
1 5
<210> 25
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZUFmEgD9E
<400> 25
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtcg tgaacgaaat cgtctccatt 7020
ggccaggagg ttcttcccaa ggtcgactat gctcagctct ggtctgatgc ctcgcactgc 7080
gaggtgctgt acctctccat cgccttcgtc atcctgaagt tcacccttgg tcctctcgga 7140
cccaagggtc agtctcgaat gaagtttgtg ttcaccaact acaacctgct catgtccatc 7200
tactcgctgg gctccttcct ctctatggcc tacgccatgt acaccattgg tgtcatgtcc 7260
gacaactgcg agaaggcttt cgacaacaat gtcttccgaa tcaccactca gctgttctac 7320
ctcagcaagt tcctcgagta cattgactcc ttctatctgc ccctcatggg caagcctctg 7380
acctggttgc agttctttca ccatctcgga gctcctatgg acatgtggct gttctacaac 7440
taccgaaacg aagccgtttg gatctttgtg ctgctcaacg gcttcattca ctggatcatg 7500
tacggctact attggacccg actgatcaag ctcaagttcc ctatgcccaa gtccctgatt 7560
acttctatgc agatcattca gttcaacgtt ggcttctaca tcgtctggaa gtaccggaac 7620
attccctgct accgacaaga tggaatgaga atgtttggct ggtttttcaa ctacttctac 7680
gttggtactg tcctgtgtct gttcctcaac ttctacgtgc agacctacat cgtccgaaag 7740
cacaagggag ccaaaaagat tcagtgagc 7769
<210> 26
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer pZUFm_6980_012208f
<400> 26
gctctggtac catggaggtc 20
<210> 27
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer pZUFm_40_012208r
<400> 27
acagaaccgg gcactcactt 20
<210> 28
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-L35F"
<400> 28
atg gag gtc gtg aac gaa atc gtc tcc att ggc cag gag gtt ctt ccc 48
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aag gtc gac tat gct cag ctc tgg tct gat gcc tcg cac tgc gag gtg 96
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctg tac ttc tcc atc gcc ttc gtc atc ctg aag ttc acc ctt ggt cct 144
Leu Tyr Phe Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctc gga ccc aag ggt cag tct cga atg aag ttt gtg ttc acc aac tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
aac ctg ctc atg tcc atc tac tcg ctg ggc tcc ttc ctc tct atg gcc 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tac gcc atg tac acc att ggt gtc atg tcc gac aac tgc gag aag gct 288
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttc gac aac aat gtc ttc cga atc acc act cag ctg ttc tac ctc agc 336
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc ctc gag tac att gac tcc ttc tat ctg ccc ctc atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct ctg acc tgg ttg cag ttc ttt cac cat ctc gga gct cct atg gac 432
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tac aac tac cga aac gaa gcc gtt tgg atc ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggc tac tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctg atc aag ctc aag ttc cct atg ccc aag tcc ctg att act tct 576
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att cag ttc aac gtt ggc ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgg aac att ccc tgc tac cga caa gat ggg atg aga atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttt ttc aac tac ttc tac gtt ggt act gtc ctg tgt ctg ttc ctc aac 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tac gtg cag acc tac atc gtc cga aag cac aag gga gcc aaa aag 768
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
att cag tga 777
Ile Gln
<210> 29
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 29
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Phe Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 30
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZUFmEgD9eS-L35F
<400> 30
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtcg tgaacgaaat cgtctccatt 7020
ggccaggagg ttcttcccaa ggtcgactat gctcagctct ggtctgatgc ctcgcactgc 7080
gaggtgctgt acttctccat cgccttcgtc atcctgaagt tcacccttgg tcctctcgga 7140
cccaagggtc agtctcgaat gaagtttgtg ttcaccaact acaacctgct catgtccatc 7200
tactcgctgg gctccttcct ctctatggcc tacgccatgt acaccattgg tgtcatgtcc 7260
gacaactgcg agaaggcttt cgacaacaat gtcttccgaa tcaccactca gctgttctac 7320
ctcagcaagt tcctcgagta cattgactcc ttctatctgc ccctcatggg caagcctctg 7380
acctggttgc agttctttca ccatctcgga gctcctatgg acatgtggct gttctacaac 7440
taccgaaacg aagccgtttg gatctttgtg ctgctcaacg gcttcattca ctggatcatg 7500
tacggctact attggacccg actgatcaag ctcaagttcc ctatgcccaa gtccctgatt 7560
acttctatgc agatcattca gttcaacgtt ggcttctaca tcgtctggaa gtaccggaac 7620
attccctgct accgacaaga tgggatgaga atgtttggct ggtttttcaa ctacttctac 7680
gttggtactg tcctgtgtct gttcctcaac ttctacgtgc agacctacat cgtccgaaag 7740
cacaagggag ccaaaaagat tcagtgagc 7769
<210> 31
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-K58R/I257T"
<400> 31
atg gag gtc gtg aac gaa atc gtc tcc att ggc cag gag gtt ctt ccc 48
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aag gtc gac tat gct cag ctc tgg tct gat gcc tcg cac tgc gag gtg 96
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctg tac ctc tcc atc gcc ttc gtc atc ctg aag ttc acc ctt ggt cct 144
Leu Tyr Leu Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctc gga ccc aag ggt cag tct cga atg agg ttt gtg ttc acc aac tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Arg Phe Val Phe Thr Asn Tyr
50 55 60
aac ctg ctc atg tcc atc tac tcg ctg ggc tcc ttc ctc tcg atg gcc 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tac gcc atg tac acc att ggt gtc atg tcc gac aac tgc gag aag gct 288
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttc gac aac aat gtc ttc cga atc acc act cag ctg ttc tac ctc agc 336
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc ctc gag tac att gac tcc ttc tat ctg ccc ctc atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct ctg acc tgg ttg caa ttc ttt cac cat ctc gga gct cct atg gac 432
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tac aac tac cga aac gaa gcc gtt tgg atc ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggc tac tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctg atc aag ctc aag ttc cct atg ccc aag tcc ctg att act tct 576
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att cag ttc aac gtt ggc ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgg aac att ccc tgc tac cga caa gat gga atg aga atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttt ttc aac tac ttc tac gtt ggt act gtc ctg tgt ctg ttc ctc aac 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tac gtg cag acc tac atc gtc cga aag cac aag gga gcc aaa aag 768
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
act cag tga 777
Thr Gln
<210> 32
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 32
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Leu Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Arg Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Thr Gln
<210> 33
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZuFmEgD9eS-K58R/I257T
<400> 33
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtcg tgaacgaaat cgtctccatt 7020
ggccaggagg ttcttcccaa ggtcgactat gctcagctct ggtctgatgc ctcgcactgc 7080
gaggtgctgt acctctccat cgccttcgtc atcctgaagt tcacccttgg tcctctcgga 7140
cccaagggtc agtctcgaat gaggtttgtg ttcaccaact acaacctgct catgtccatc 7200
tactcgctgg gctccttcct ctcgatggcc tacgccatgt acaccattgg tgtcatgtcc 7260
gacaactgcg agaaggcttt cgacaacaat gtcttccgaa tcaccactca gctgttctac 7320
ctcagcaagt tcctcgagta cattgactcc ttctatctgc ccctcatggg caagcctctg 7380
acctggttgc aattctttca ccatctcgga gctcctatgg acatgtggct gttctacaac 7440
taccgaaacg aagccgtttg gatctttgtg ctgctcaacg gcttcattca ctggatcatg 7500
tacggctact attggacccg actgatcaag ctcaagttcc ctatgcccaa gtccctgatt 7560
acttctatgc agatcattca gttcaacgtt ggcttctaca tcgtctggaa gtaccggaac 7620
attccctgct accgacaaga tggaatgaga atgtttggct ggtttttcaa ctacttctac 7680
gttggtactg tcctgtgtct gttcctcaac ttctacgtgc agacctacat cgtccgaaag 7740
cacaagggag ccaaaaagac tcagtgagc 7769
<210> 34
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-L130M/V243A1"
<400> 34
atg gag gtc gtg aac gaa atc gtc tcc att ggc cag gag gtt ctt ccc 48
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aag gtc gac tat gct cag ctc tgg tct gat gcc tcg cac tgc gag gtg 96
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctg tac ctc tcc atc gcc ttc gtc atc ctg aag ttc acc ctt ggt cct 144
Leu Tyr Leu Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctc gga ccc aag ggt cag tct cga atg aag ttt gtg ttc acc aac tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
aac ctg ctc atg tcc atc tac tcg ctg ggc tcc ttc ctc tct atg gcc 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tac gcc atg tac acc att ggt gtc atg tcc gac aac tgc gag aag gct 288
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttc gac aac aat gtc ttc cga atc acc act cag ctg ttc tac ctc agc 336
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc ctc gag tac att gac tcc ttc tat ctg ccc ctc atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct atg acc tgg ttg cag ttc ttt cac cat ctc gga gct cct atg gac 432
Pro Met Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tac aat tac cga aac gaa gcc gtt tgg atc ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggc tac tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctg atc aag ctc aag ttc cct atg ccc aag tcc ctg att act tct 576
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att cag ttc aac gtt ggc ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgg aac att ccc tgc tac cga caa gat gga atg aga atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttt ttc aac tac ttc tac gtt ggt act gtc ctg tgt ctg ttc ctc aac 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tac gcg cag acc tac atc gtc cga aag cac aag gga gcc aaa aag 768
Phe Tyr Ala Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
att cag tga 777
Ile Gln
<210> 35
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 35
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Leu Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Met Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Ala Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 36
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZuFmEgD9eS-L130M/V243A1
<400> 36
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtcg tgaacgaaat cgtctccatt 7020
ggccaggagg ttcttcccaa ggtcgactat gctcagctct ggtctgatgc ctcgcactgc 7080
gaggtgctgt acctctccat cgccttcgtc atcctgaagt tcacccttgg tcctctcgga 7140
cccaagggtc agtctcgaat gaagtttgtg ttcaccaact acaacctgct catgtccatc 7200
tactcgctgg gctccttcct ctctatggcc tacgccatgt acaccattgg tgtcatgtcc 7260
gacaactgcg agaaggcttt cgacaacaat gtcttccgaa tcaccactca gctgttctac 7320
ctcagcaagt tcctcgagta cattgactcc ttctatctgc ccctcatggg caagcctatg 7380
acctggttgc agttctttca ccatctcgga gctcctatgg acatgtggct gttctacaat 7440
taccgaaacg aagccgtttg gatctttgtg ctgctcaacg gcttcattca ctggatcatg 7500
tacggctact attggacccg actgatcaag ctcaagttcc ctatgcccaa gtccctgatt 7560
acttctatgc agatcattca gttcaacgtt ggcttctaca tcgtctggaa gtaccggaac 7620
attccctgct accgacaaga tggaatgaga atgtttggct ggtttttcaa ctacttctac 7680
gttggtactg tcctgtgtct gttcctcaac ttctacgcgc agacctacat cgtccgaaag 7740
cacaagggag ccaaaaagat tcagtgagc 7769
<210> 37
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-D98G"
<400> 37
atg gag gtc gtg aac gaa atc gtc tcc att ggc cag gag gtt ctt ccc 48
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aag gtc gac tat gct cag ctc tgg tct gat gcc tcg cac tgc gag gtg 96
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctg tac ctc tcc atc gcc ttc gtc atc ctg aag ttc acc ctt ggt cct 144
Leu Tyr Leu Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctc gga ccc aag ggt cag tct cga atg aag ttt gtg ttc acc aac tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
aac ctg ctc atg tcc atc tac tcg ctg ggc tcc ttc ctc tct atg gcc 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tac gcc atg tac acc att ggt gtc atg tcc gac aac tgc gag aag gct 288
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttc ggc aac aat gtc ttc cga atc acc act cag ctg ttc tac ctc agc 336
Phe Gly Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc ctc gag tac att gac tcc ttc tat ctg ccc ctc atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct ctg acc tgg ttg cag ttc ttt cac cat ctc gga gct cct atg gac 432
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tac aac tac cga aac gaa gcc gtt tgg atc ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggc tac tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctg atc aag ctc aag ttc cct atg ccc aag tcc ctg att act tct 576
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att cag ttc aac gtt ggc ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgg aac att ccc tgc tac cga caa gat gga atg aga atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttt ttc aac tac ttc tac gtt ggt act gtc ctg tgt ctg ttc ctc aac 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tac gtg cag acc tac atc gtc cga aag cac aag gga gcc aaa aag 768
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
att cag tga 777
Ile Gln
<210> 38
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 38
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Leu Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Gly Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 39
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZuFmEgD9eS-D98G
<400> 39
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtcg tgaacgaaat cgtctccatt 7020
ggccaggagg ttcttcccaa ggtcgactat gctcagctct ggtctgatgc ctcgcactgc 7080
gaggtgctgt acctctccat cgccttcgtc atcctgaagt tcacccttgg tcctctcgga 7140
cccaagggtc agtctcgaat gaagtttgtg ttcaccaact acaacctgct catgtccatc 7200
tactcgctgg gctccttcct ctctatggcc tacgccatgt acaccattgg tgtcatgtcc 7260
gacaactgcg agaaggcttt cggcaacaat gtcttccgaa tcaccactca gctgttctac 7320
ctcagcaagt tcctcgagta cattgactcc ttctatctgc ccctcatggg caagcctctg 7380
acctggttgc agttctttca ccatctcgga gctcctatgg acatgtggct gttctacaac 7440
taccgaaacg aagccgtttg gatctttgtg ctgctcaacg gcttcattca ctggatcatg 7500
tacggctact attggacccg actgatcaag ctcaagttcc ctatgcccaa gtccctgatt 7560
acttctatgc agatcattca gttcaacgtt ggcttctaca tcgtctggaa gtaccggaac 7620
attccctgct accgacaaga tggaatgaga atgtttggct ggtttttcaa ctacttctac 7680
gttggtactg tcctgtgtct gttcctcaac ttctacgtgc agacctacat cgtccgaaag 7740
cacaagggag ccaaaaagat tcagtgagc 7769
<210> 40
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-L130M/V243A2"
<400> 40
atg gag gtc gtg aac gaa att gtc tcc att ggc cag gag gtt ctt ccc 48
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aag gtc gac tat gct cag ctc tgg tct gat gcc tcg cac tgc gag gtg 96
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctg tac ctc tcc atc gcc ttc gtc atc ctg aag ttc acc ctt ggt cct 144
Leu Tyr Leu Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctc gga ccc aag ggt cag tct cga atg aag ttt gtg ttc acc aac tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
aac ctg ctc atg tcc atc tac tcg ctg ggc tcc ttc ctc tct atg gcc 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tac gcc atg tac acc att ggt gtc atg tcc gac aac tgc gag aag gct 288
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttc gac aac aat gtc ttc cga atc acc act cag ctg ttc tac ctc agc 336
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc ctc gag tac att gac tcc ttc tat ctg ccc ctc atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct atg acc tgg ttg cag ttc ttt cac cat ctc gga gct cct atg gac 432
Pro Met Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tac aat tac cga aac gaa gcc gtt tgg atc ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggc tac tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctg atc aag ctc aag ttc cct atg ccc aag tcc ctg att act tct 576
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att cag ttc aac gtt ggc ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgg aac att ccc tgc tac cga caa gat gga atg aga atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttt ttc aac tac ttc tac gtt ggt act gtc ctg tgt ctg ttc ctc aac 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tac gcg cag acc tac atc gtc cga aag cac aag gga gcc aaa aag 768
Phe Tyr Ala Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
att cag tga 777
Ile Gln
<210> 41
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 41
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Leu Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Met Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Ala Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 42
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZuFmEgD9eS-L130M/V243A2
<400> 42
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtcg tgaacgaaat tgtctccatt 7020
ggccaggagg ttcttcccaa ggtcgactat gctcagctct ggtctgatgc ctcgcactgc 7080
gaggtgctgt acctctccat cgccttcgtc atcctgaagt tcacccttgg tcctctcgga 7140
cccaagggtc agtctcgaat gaagtttgtg ttcaccaact acaacctgct catgtccatc 7200
tactcgctgg gctccttcct ctctatggcc tacgccatgt acaccattgg tgtcatgtcc 7260
gacaactgcg agaaggcttt cgacaacaat gtcttccgaa tcaccactca gctgttctac 7320
ctcagcaagt tcctcgagta cattgactcc ttctatctgc ccctcatggg caagcctatg 7380
acctggttgc agttctttca ccatctcgga gctcctatgg acatgtggct gttctacaat 7440
taccgaaacg aagccgtttg gatctttgtg ctgctcaacg gcttcattca ctggatcatg 7500
tacggctact attggacccg actgatcaag ctcaagttcc ctatgcccaa gtccctgatt 7560
acttctatgc agatcattca gttcaacgtt ggcttctaca tcgtctggaa gtaccggaac 7620
attccctgct accgacaaga tggaatgaga atgtttggct ggtttttcaa ctacttctac 7680
gttggtactg tcctgtgtct gttcctcaac ttctacgcgc agacctacat cgtccgaaag 7740
cacaagggag ccaaaaagat tcagtgagc 7769
<210> 43
<211> 289
<212> PRT
<213> Ciona intestinalis
<400> 43
Met Asp Val Leu His Arg Phe Leu Gly Phe Tyr Glu Trp Thr Leu Thr
1 5 10 15
Phe Ala Asp Pro Arg Val Ala Lys Trp Pro Leu Ile Glu Asn Pro Leu
20 25 30
Pro Thr Ile Ala Ile Val Leu Leu Tyr Leu Ala Phe Val Leu Tyr Ile
35 40 45
Gly Pro Arg Phe Met Arg Lys Arg Ala Pro Val Asp Phe Gly Leu Phe
50 55 60
Leu Pro Gly Tyr Asn Phe Ala Leu Val Ala Leu Asn Tyr Tyr Ile Leu
65 70 75 80
Gln Glu Val Val Thr Gly Ser Tyr Gly Ala Gly Tyr Asp Leu Val Cys
85 90 95
Thr Pro Leu Arg Ser Asp Ser Tyr Asp Pro Asn Glu Met Lys Val Ala
100 105 110
Asn Ala Val Trp Trp Tyr Tyr Val Ser Lys Ile Ile Glu Leu Phe Asp
115 120 125
Thr Val Leu Phe Thr Leu Arg Lys Arg Asp Arg Gln Val Thr Phe Leu
130 135 140
His Val Tyr His His Ser Thr Met Pro Leu Leu Trp Trp Ile Gly Ala
145 150 155 160
Lys Trp Val Pro Gly Gly Gln Ser Phe Val Gly Ile Ile Leu Asn Ser
165 170 175
Ser Val His Val Ile Met Tyr Thr Tyr Tyr Gly Leu Ser Ala Leu Gly
180 185 190
Pro His Met Gln Lys Phe Leu Trp Trp Lys Lys Tyr Ile Thr Met Leu
195 200 205
Gln Leu Val Gln Phe Val Leu Ala Ile Tyr His Thr Ala Arg Ser Leu
210 215 220
Tyr Val Lys Cys Pro Ser Pro Val Trp Met His Trp Ala Leu Ile Leu
225 230 235 240
Tyr Ala Phe Ser Phe Ile Leu Leu Phe Ser Asn Phe Tyr Met His Ala
245 250 255
Tyr Ile Lys Lys Ser Arg Lys Gly Lys Glu Asn Gly Ser Arg Gly Lys
260 265 270
Gly Gly Val Ser Asn Gly Lys Glu Lys Leu His Ala Asn Gly Lys Thr
275 280 285
Asp
<210> 44
<211> 295
<212> PRT
<213> Oncorhynchus mykiss
<400> 44
Met Glu Thr Phe Asn Tyr Lys Leu Asn Met Tyr Ile Asp Ser Trp Met
1 5 10 15
Gly Pro Arg Asp Glu Arg Val Gln Gly Trp Leu Leu Leu Asp Asn Tyr
20 25 30
Pro Pro Thr Phe Ala Leu Thr Val Met Tyr Leu Leu Ile Val Trp Met
35 40 45
Gly Pro Lys Tyr Met Arg His Arg Gln Pro Val Ser Cys Arg Gly Leu
50 55 60
Leu Leu Val Tyr Asn Leu Gly Leu Thr Ile Leu Ser Phe Tyr Met Phe
65 70 75 80
Tyr Glu Met Val Ser Ala Val Trp His Gly Asp Tyr Asn Phe Phe Cys
85 90 95
Gln Asp Thr His Ser Ala Gly Glu Thr Asp Thr Lys Ile Ile Asn Val
100 105 110
Leu Trp Trp Tyr Tyr Phe Ser Lys Leu Ile Glu Phe Met Asp Thr Phe
115 120 125
Phe Phe Ile Leu Arg Lys Asn Asn His Gln Ile Thr Phe Leu His Ile
130 135 140
Tyr His His Ala Ser Met Leu Asn Ile Trp Trp Phe Val Met Asn Trp
145 150 155 160
Val Pro Cys Gly His Ser Tyr Phe Gly Ala Ser Leu Asn Ser Phe Ile
165 170 175
His Val Leu Met Tyr Ser Tyr Tyr Gly Leu Ser Ala Val Pro Ala Leu
180 185 190
Arg Pro Tyr Leu Trp Trp Lys Lys Tyr Ile Thr Gln Val Gln Leu Ile
195 200 205
Gln Phe Phe Leu Thr Met Ser Gln Thr Ile Cys Ala Val Ile Trp Pro
210 215 220
Cys Asp Phe Pro Arg Gly Trp Leu Tyr Phe Gln Ile Phe Tyr Val Ile
225 230 235 240
Thr Leu Ile Ala Leu Phe Ser Asn Phe Tyr Ile Gln Thr Tyr Lys Lys
245 250 255
His Leu Val Ser Gln Lys Lys Glu Tyr His Gln Asn Gly Ser Val Ala
260 265 270
Ser Leu Asn Gly His Val Asn Gly Val Thr Pro Thr Glu Thr Ile Thr
275 280 285
His Arg Lys Val Arg Gly Asp
290 295
<210> 45
<211> 290
<212> PRT
<213> Marchantia polymorpha
<400> 45
Met Glu Ala Tyr Glu Met Val Asp Ser Phe Val Ser Lys Thr Val Phe
1 5 10 15
Glu Thr Leu Gln Arg Leu Arg Gly Gly Val Val Leu Thr Glu Ser Ala
20 25 30
Ile Thr Lys Gly Leu Pro Cys Val Asp Ser Pro Thr Pro Ile Val Leu
35 40 45
Gly Leu Ser Ser Tyr Leu Thr Phe Val Phe Leu Gly Leu Ile Val Ile
50 55 60
Lys Ser Leu Asp Leu Lys Pro Arg Ser Lys Glu Pro Ala Ile Leu Asn
65 70 75 80
Leu Phe Val Ile Phe His Asn Phe Val Cys Phe Ala Leu Ser Leu Tyr
85 90 95
Met Cys Val Gly Ile Val Arg Gln Ala Ile Leu Asn Arg Tyr Ser Leu
100 105 110
Trp Gly Asn Ala Tyr Asn Pro Lys Glu Val Gln Met Gly His Leu Leu
115 120 125
Tyr Ile Phe Tyr Met Ser Lys Tyr Ile Glu Phe Met Asp Thr Val Ile
130 135 140
Met Ile Leu Lys Arg Asn Thr Arg Gln Ile Thr Val Leu His Val Tyr
145 150 155 160
His His Ala Ser Ile Ser Phe Ile Trp Trp Ile Ile Ala Tyr His Ala
165 170 175
Pro Gly Gly Glu Ala Tyr Phe Ser Ala Ala Leu Asn Ser Gly Val His
180 185 190
Val Leu Met Tyr Leu Tyr Tyr Leu Leu Ala Ala Thr Leu Gly Lys Asn
195 200 205
Glu Lys Ala Arg Arg Lys Tyr Leu Trp Trp Gly Lys Tyr Leu Thr Gln
210 215 220
Leu Gln Met Phe Gln Phe Val Leu Asn Met Ile Gln Ala Tyr Tyr Asp
225 230 235 240
Ile Lys Asn Asn Ser Pro Tyr Pro Gln Phe Leu Ile Gln Ile Leu Phe
245 250 255
Tyr Tyr Met Ile Ser Leu Leu Ala Leu Phe Gly Asn Phe Tyr Val His
260 265 270
Lys Tyr Val Ser Ala Pro Ala Lys Pro Ala Lys Ile Lys Ser Lys Lys
275 280 285
Ala Glu
290
<210> 46
<211> 290
<212> PRT
<213> Physcomitrella patens
<400> 46
Met Glu Val Val Glu Arg Phe Tyr Gly Glu Leu Asp Gly Lys Val Ser
1 5 10 15
Gln Gly Val Asn Ala Leu Leu Gly Ser Phe Gly Val Glu Leu Thr Asp
20 25 30
Thr Pro Thr Thr Lys Gly Leu Pro Leu Val Asp Ser Pro Thr Pro Ile
35 40 45
Val Leu Gly Val Ser Val Tyr Leu Thr Ile Val Ile Gly Gly Leu Leu
50 55 60
Trp Ile Lys Ala Arg Asp Leu Lys Pro Arg Ala Ser Glu Pro Phe Leu
65 70 75 80
Leu Gln Ala Leu Val Leu Val His Asn Leu Phe Cys Phe Ala Leu Ser
85 90 95
Leu Tyr Met Cys Val Gly Ile Ala Tyr Gln Ala Ile Thr Trp Arg Tyr
100 105 110
Ser Leu Trp Gly Asn Ala Tyr Asn Pro Lys His Lys Glu Met Ala Ile
115 120 125
Leu Val Tyr Leu Phe Tyr Met Ser Lys Tyr Val Glu Phe Met Asp Thr
130 135 140
Val Ile Met Ile Leu Lys Arg Ser Thr Arg Gln Ile Ser Phe Leu His
145 150 155 160
Val Tyr His His Ser Ser Ile Ser Leu Ile Trp Trp Ala Ile Ala His
165 170 175
His Ala Pro Gly Gly Glu Ala Tyr Trp Ser Ala Ala Leu Asn Ser Gly
180 185 190
Val His Val Leu Met Tyr Ala Tyr Tyr Phe Leu Ala Ala Cys Leu Arg
195 200 205
Ser Ser Pro Lys Leu Lys Asn Lys Tyr Leu Phe Trp Gly Arg Tyr Leu
210 215 220
Thr Gln Phe Gln Met Phe Gln Phe Met Leu Asn Leu Val Gln Ala Tyr
225 230 235 240
Tyr Asp Met Lys Thr Asn Ala Pro Tyr Pro Gln Trp Leu Ile Lys Ile
245 250 255
Leu Phe Tyr Tyr Met Ile Ser Leu Leu Phe Leu Phe Gly Asn Phe Tyr
260 265 270
Val Gln Lys Tyr Ile Lys Pro Ser Asp Gly Lys Gln Lys Gly Ala Lys
275 280 285
Thr Glu
290
<210> 47
<211> 348
<212> PRT
<213> Marchantia polymorpha
<400> 47
Met Ala Thr Lys Ser Gly Ser Gly Leu Leu Glu Trp Ile Ala Val Ala
1 5 10 15
Ala Lys Met Lys Gln Ala Arg Ser Ser Pro Glu Gly Glu Ile Val Gly
20 25 30
Gly Asn Arg Met Gly Ser Gly Asn Gly Ala Glu Trp Thr Thr Ser Leu
35 40 45
Ile His Ala Phe Leu Asn Ala Thr Asn Gly Lys Ser Gly Gly Ala Ser
50 55 60
Lys Val Arg Pro Leu Glu Glu Arg Ile Gly Glu Ala Val Phe Arg Val
65 70 75 80
Leu Glu Asp Val Val Gly Val Asp Ile Arg Lys Pro Asn Pro Val Thr
85 90 95
Lys Asp Leu Pro Met Val Glu Ser Pro Val Pro Val Leu Ala Cys Ile
100 105 110
Ser Leu Tyr Leu Leu Val Val Trp Leu Trp Ser Ser His Ile Lys Ala
115 120 125
Ser Gly Gln Lys Pro Arg Lys Glu Asp Pro Leu Ala Leu Arg Cys Leu
130 135 140
Val Ile Ala His Asn Leu Phe Leu Cys Cys Leu Ser Leu Phe Met Cys
145 150 155 160
Val Gly Leu Ile Ala Ala Ala Arg His Tyr Gly Tyr Ser Val Trp Gly
165 170 175
Asn Tyr Tyr Arg Glu Arg Glu Pro Ala Met Asn Leu Leu Ile Tyr Val
180 185 190
Phe Tyr Met Ser Lys Leu Tyr Glu Phe Met Asp Thr Ala Ile Met Leu
195 200 205
Phe Arg Arg Asn Leu Arg Gln Val Thr Tyr Leu His Val Tyr His His
210 215 220
Ala Ser Ile Ala Met Ile Trp Trp Ile Ile Cys Tyr Arg Phe Pro Gly
225 230 235 240
Ala Asp Ser Tyr Phe Ser Ala Ala Phe Asn Ser Cys Ile His Val Ala
245 250 255
Met Tyr Leu Tyr Tyr Leu Leu Ala Ala Thr Val Ala Arg Asp Glu Lys
260 265 270
Arg Arg Arg Lys Tyr Leu Phe Trp Gly Lys Tyr Leu Thr Ile Ile Gln
275 280 285
Met Leu Gln Phe Leu Ser Phe Ile Gly Gln Ala Ile Tyr Ala Met Trp
290 295 300
Lys Phe Glu Tyr Tyr Pro Lys Gly Phe Gly Arg Met Leu Phe Phe Tyr
305 310 315 320
Ser Val Ser Leu Leu Ala Phe Phe Gly Asn Phe Phe Val Lys Lys Tyr
325 330 335
Ser Asn Ala Ser Gln Pro Lys Thr Val Lys Val Glu
340 345
<210> 48
<211> 292
<212> PRT
<213> Ostreococcus tauri
<400> 48
Met Ser Gly Leu Arg Ala Pro Asn Phe Leu His Arg Phe Trp Thr Lys
1 5 10 15
Trp Asp Tyr Ala Ile Ser Lys Val Val Phe Thr Cys Ala Asp Ser Phe
20 25 30
Gln Trp Asp Ile Gly Pro Val Ser Ser Ser Thr Ala His Leu Pro Ala
35 40 45
Ile Glu Ser Pro Thr Pro Leu Val Thr Ser Leu Leu Phe Tyr Leu Val
50 55 60
Thr Val Phe Leu Trp Tyr Gly Arg Leu Thr Arg Ser Ser Asp Lys Lys
65 70 75 80
Ile Arg Glu Pro Thr Trp Leu Arg Arg Phe Ile Ile Cys His Asn Ala
85 90 95
Phe Leu Ile Val Leu Ser Leu Tyr Met Cys Leu Gly Cys Val Ala Gln
100 105 110
Ala Tyr Gln Asn Gly Tyr Thr Leu Trp Gly Asn Glu Phe Lys Ala Thr
115 120 125
Glu Thr Gln Leu Ala Leu Tyr Ile Tyr Ile Phe Tyr Val Ser Lys Ile
130 135 140
Tyr Glu Phe Val Asp Thr Tyr Ile Met Leu Leu Lys Asn Asn Leu Arg
145 150 155 160
Gln Val Ser Phe Leu His Ile Tyr His His Ser Thr Ile Ser Phe Ile
165 170 175
Trp Trp Ile Ile Ala Arg Arg Ala Pro Gly Gly Asp Ala Tyr Phe Ser
180 185 190
Ala Ala Leu Asn Ser Trp Val His Val Cys Met Tyr Thr Tyr Tyr Leu
195 200 205
Leu Ser Thr Leu Ile Gly Lys Glu Asp Pro Lys Arg Ser Asn Tyr Leu
210 215 220
Trp Trp Gly Arg His Leu Thr Gln Met Gln Met Leu Gln Phe Phe Phe
225 230 235 240
Asn Val Leu Gln Ala Leu Tyr Cys Ala Ser Phe Ser Thr Tyr Pro Lys
245 250 255
Phe Leu Ser Lys Ile Leu Leu Val Tyr Met Met Ser Leu Leu Gly Leu
260 265 270
Phe Gly His Phe Tyr Tyr Ser Lys His Ile Ala Ala Ala Lys Leu Gln
275 280 285
Lys Lys Gln Gln
290
<210> 49
<211> 277
<212> PRT
<213> Pavlova sp.
<400> 49
Met Met Leu Ala Ala Gly Tyr Leu Leu Val Leu Ser Ala Ala Arg Gln
1 5 10 15
Ser Phe Gln Gln Asp Ile Asp Asn Pro Asn Gly Ala Tyr Ser Thr Ser
20 25 30
Trp Thr Gly Leu Pro Ile Val Met Ser Val Val Tyr Leu Ser Gly Val
35 40 45
Phe Gly Leu Thr Lys Tyr Phe Glu Asn Arg Lys Pro Met Thr Gly Leu
50 55 60
Lys Asp Tyr Met Phe Thr Tyr Asn Leu Tyr Gln Val Ile Ile Asn Val
65 70 75 80
Trp Cys Val Val Ala Phe Leu Leu Glu Val Arg Arg Ala Gly Met Ser
85 90 95
Leu Ile Gly Asn Lys Val Asp Leu Gly Pro Asn Ser Phe Arg Leu Gly
100 105 110
Phe Val Thr Trp Val His Tyr Asn Asn Lys Tyr Val Glu Leu Leu Asp
115 120 125
Thr Leu Trp Met Val Leu Arg Lys Lys Thr Gln Gln Val Ser Phe Leu
130 135 140
His Val Tyr His His Val Leu Leu Met Trp Ala Trp Phe Val Val Val
145 150 155 160
Lys Leu Gly Asn Gly Gly Asp Ala Tyr Phe Gly Gly Leu Met Asn Ser
165 170 175
Ile Ile His Val Met Met Tyr Ser Tyr Tyr Thr Met Ala Leu Leu Gly
180 185 190
Trp Ser Cys Pro Trp Lys Arg Tyr Leu Thr Gln Ala Gln Leu Val Gln
195 200 205
Phe Cys Ile Cys Leu Ala His Ser Thr Trp Ala Ala Val Thr Gly Ala
210 215 220
Tyr Pro Trp Arg Ile Cys Leu Val Glu Val Trp Val Met Val Ser Met
225 230 235 240
Leu Val Leu Phe Thr Arg Phe Tyr Arg Gln Ala Tyr Ala Lys Glu Ala
245 250 255
Lys Ala Lys Glu Ala Lys Lys Leu Ala Gln Glu Ala Ser Gln Ala Lys
260 265 270
Ala Val Lys Ala Glu
275
<210> 50
<211> 302
<212> PRT
<213> Rebecca salina
<400> 50
Met Lys Ala Ala Ala Gly Lys Val Gln Gln Glu Ala Glu Arg Leu Thr
1 5 10 15
Ala Gly Leu Trp Leu Pro Met Met Leu Ala Ala Gly Tyr Leu Leu Val
20 25 30
Leu Ser Ala Asn Arg Ala Ser Phe Tyr Glu Asn Ile Asn Asn Glu Lys
35 40 45
Gly Ala Tyr Ser Thr Ser Trp Phe Ser Leu Pro Cys Val Met Thr Ala
50 55 60
Val Tyr Leu Gly Gly Val Phe Gly Leu Thr Lys Tyr Phe Glu Gly Arg
65 70 75 80
Lys Pro Met Gln Gly Leu Lys Asp Tyr Met Phe Thr Tyr Asn Leu Tyr
85 90 95
Gln Val Ile Ile Asn Val Trp Cys Ile Ala Ala Phe Val Val Glu Val
100 105 110
Arg Arg Ala Gly Met Ser Ala Val Gly Asn Lys Val Asp Leu Gly Pro
115 120 125
Asn Ser Phe Arg Leu Gly Phe Val Thr Trp Val His Tyr Asn Asn Lys
130 135 140
Tyr Val Glu Leu Leu Asp Thr Leu Trp Met Val Leu Arg Lys Lys Thr
145 150 155 160
Gln Gln Val Ser Phe Leu His Val Tyr His His Val Leu Leu Ile Trp
165 170 175
Ala Trp Phe Cys Val Val Lys Phe Cys Asn Gly Gly Asp Ala Tyr Phe
180 185 190
Gly Gly Met Leu Asn Ser Ile Ile His Val Met Met Tyr Ser Tyr Tyr
195 200 205
Thr Met Ala Leu Leu Gly Trp Ser Cys Pro Trp Lys Arg Tyr Leu Thr
210 215 220
Gln Ala Gln Leu Val Gln Phe Cys Ile Cys Leu Ala His Ala Thr Trp
225 230 235 240
Ala Ala Ala Thr Gly Val Tyr Pro Phe His Ile Cys Leu Val Glu Ile
245 250 255
Trp Val Met Val Ser Met Leu Tyr Leu Phe Thr Lys Phe Tyr Asn Ser
260 265 270
Ala Tyr Lys Gly Ala Ala Lys Gly Ala Ala Ala Ser Ser Asn Gly Ala
275 280 285
Ala Ala Pro Ser Gly Ala Lys Pro Lys Ser Ile Lys Ala Asn
290 295 300
<210> 51
<211> 300
<212> PRT
<213> Ostreococcus tauri
<400> 51
Met Ser Ala Ser Gly Ala Leu Leu Pro Ala Ile Ala Ser Ala Ala Tyr
1 5 10 15
Ala Tyr Ala Thr Tyr Ala Tyr Ala Phe Glu Trp Ser His Ala Asn Gly
20 25 30
Ile Asp Asn Val Asp Ala Arg Glu Trp Ile Gly Ala Leu Ser Leu Arg
35 40 45
Leu Pro Ala Ile Ala Thr Thr Met Tyr Leu Leu Phe Cys Leu Val Gly
50 55 60
Pro Arg Leu Met Ala Lys Arg Glu Ala Phe Asp Pro Lys Gly Phe Met
65 70 75 80
Leu Ala Tyr Asn Ala Tyr Gln Thr Ala Phe Asn Val Val Val Leu Gly
85 90 95
Met Phe Ala Arg Glu Ile Ser Gly Leu Gly Gln Pro Val Trp Gly Ser
100 105 110
Thr Met Pro Trp Ser Asp Arg Lys Ser Phe Lys Ile Leu Leu Gly Val
115 120 125
Trp Leu His Tyr Asn Asn Lys Tyr Leu Glu Leu Leu Asp Thr Val Phe
130 135 140
Met Val Ala Arg Lys Lys Thr Lys Gln Leu Ser Phe Leu His Val Tyr
145 150 155 160
His His Ala Leu Leu Ile Trp Ala Trp Trp Leu Val Cys His Leu Met
165 170 175
Ala Thr Asn Asp Cys Ile Asp Ala Tyr Phe Gly Ala Ala Cys Asn Ser
180 185 190
Phe Ile His Ile Val Met Tyr Ser Tyr Tyr Leu Met Ser Ala Leu Gly
195 200 205
Ile Arg Cys Pro Trp Lys Arg Tyr Ile Thr Gln Ala Gln Met Leu Gln
210 215 220
Phe Val Ile Val Phe Ala His Ala Val Phe Val Leu Arg Gln Lys His
225 230 235 240
Cys Pro Val Thr Leu Pro Trp Ala Gln Met Phe Val Met Thr Asn Met
245 250 255
Leu Val Leu Phe Gly Asn Phe Tyr Leu Lys Ala Tyr Ser Asn Lys Ser
260 265 270
Arg Gly Asp Gly Ala Ser Ser Val Lys Pro Ala Glu Thr Thr Arg Ala
275 280 285
Pro Ser Val Arg Arg Thr Arg Ser Arg Lys Ile Asp
290 295 300
<210> 52
<211> 358
<212> PRT
<213> Thalassiosira pseudonana
<400> 52
Met Cys Ser Ser Pro Pro Ser Gln Ser Lys Thr Thr Ser Leu Leu Ala
1 5 10 15
Arg Tyr Thr Thr Ala Ala Leu Leu Leu Leu Thr Leu Thr Thr Trp Cys
20 25 30
His Phe Ala Phe Pro Ala Ala Thr Ala Thr Pro Gly Leu Thr Ala Glu
35 40 45
Met His Ser Tyr Lys Val Pro Leu Gly Leu Thr Val Phe Tyr Leu Leu
50 55 60
Ser Leu Pro Ser Leu Lys Tyr Val Thr Asp Asn Tyr Leu Ala Lys Lys
65 70 75 80
Tyr Asp Met Lys Ser Leu Leu Thr Glu Ser Met Val Leu Tyr Asn Val
85 90 95
Ala Gln Val Leu Leu Asn Gly Trp Thr Val Tyr Ala Ile Val Asp Ala
100 105 110
Val Met Asn Arg Asp His Pro Phe Ile Gly Ser Arg Ser Leu Val Gly
115 120 125
Ala Ala Leu His Ser Gly Ser Ser Tyr Ala Val Trp Val His Tyr Cys
130 135 140
Asp Lys Tyr Leu Glu Phe Phe Asp Thr Tyr Phe Met Val Leu Arg Gly
145 150 155 160
Lys Met Asp Gln Val Ser Phe Leu His Ile Tyr His His Thr Thr Ile
165 170 175
Ala Trp Ala Trp Trp Ile Ala Leu Arg Phe Ser Pro Gly Gly Asp Ile
180 185 190
Tyr Phe Gly Ala Leu Leu Asn Ser Ile Ile His Val Leu Met Tyr Ser
195 200 205
Tyr Tyr Ala Leu Ala Leu Leu Lys Val Ser Cys Pro Trp Lys Arg Tyr
210 215 220
Leu Thr Gln Ala Gln Leu Leu Gln Phe Thr Ser Val Val Val Tyr Thr
225 230 235 240
Gly Cys Thr Gly Tyr Thr His Tyr Tyr His Thr Lys His Gly Ala Asp
245 250 255
Glu Thr Gln Pro Ser Leu Gly Thr Tyr Tyr Phe Cys Cys Gly Val Gln
260 265 270
Val Phe Glu Met Val Ser Leu Phe Val Leu Phe Ser Ile Phe Tyr Lys
275 280 285
Arg Ser Tyr Ser Lys Lys Asn Lys Ser Gly Gly Lys Asp Ser Lys Lys
290 295 300
Asn Asp Asp Gly Asn Asn Glu Asp Gln Cys His Lys Ala Met Lys Asp
305 310 315 320
Ile Ser Glu Gly Ala Lys Glu Val Val Gly His Ala Ala Lys Asp Ala
325 330 335
Gly Lys Leu Val Ala Thr Ala Ser Lys Ala Val Lys Arg Lys Gly Thr
340 345 350
Arg Val Thr Gly Ala Met
355
<210> 53
<211> 272
<212> PRT
<213> Thalassiosira pseudonana
<400> 53
Met Asp Ala Tyr Asn Ala Ala Met Asp Lys Ile Gly Ala Ala Ile Ile
1 5 10 15
Asp Trp Ser Asp Pro Asp Gly Lys Phe Arg Ala Asp Arg Glu Asp Trp
20 25 30
Trp Leu Cys Asp Phe Arg Ser Ala Ile Thr Ile Ala Leu Ile Tyr Ile
35 40 45
Ala Phe Val Ile Leu Gly Ser Ala Val Met Gln Ser Leu Pro Ala Met
50 55 60
Asp Pro Tyr Pro Ile Lys Phe Leu Tyr Asn Val Ser Gln Ile Phe Leu
65 70 75 80
Cys Ala Tyr Met Thr Val Glu Ala Gly Phe Leu Ala Tyr Arg Asn Gly
85 90 95
Tyr Thr Val Met Pro Cys Asn His Phe Asn Val Asn Asp Pro Pro Val
100 105 110
Ala Asn Leu Leu Trp Leu Phe Tyr Ile Ser Lys Val Trp Asp Phe Trp
115 120 125
Asp Thr Ile Phe Ile Val Leu Gly Lys Lys Trp Arg Gln Leu Ser Phe
130 135 140
Leu His Val Tyr His His Thr Thr Ile Phe Leu Phe Tyr Trp Leu Asn
145 150 155 160
Ala Asn Val Leu Tyr Asp Gly Asp Ile Phe Leu Thr Ile Leu Leu Asn
165 170 175
Gly Phe Ile His Thr Val Met Tyr Thr Tyr Tyr Phe Ile Cys Met His
180 185 190
Thr Lys Asp Ser Lys Thr Gly Lys Ser Leu Pro Ile Trp Trp Lys Ser
195 200 205
Ser Leu Thr Ala Phe Gln Leu Leu Gln Phe Thr Ile Met Met Ser Gln
210 215 220
Ala Thr Tyr Leu Val Phe His Gly Cys Asp Lys Val Ser Leu Arg Ile
225 230 235 240
Thr Ile Val Tyr Phe Val Ser Leu Leu Ser Leu Phe Phe Leu Phe Ala
245 250 255
Gln Phe Phe Val Gln Ser Tyr Met Ala Pro Lys Lys Lys Lys Ser Ala
260 265 270
<210> 54
<211> 318
<212> PRT
<213> Mortierella alpina
<400> 54
Met Glu Ser Ile Ala Pro Phe Leu Pro Ser Lys Met Pro Gln Asp Leu
1 5 10 15
Phe Met Asp Leu Ala Thr Ala Ile Gly Val Arg Ala Ala Pro Tyr Val
20 25 30
Asp Pro Leu Glu Ala Ala Leu Val Ala Gln Ala Glu Lys Tyr Ile Pro
35 40 45
Thr Ile Val His His Thr Arg Gly Phe Leu Val Ala Val Glu Ser Pro
50 55 60
Leu Ala Arg Glu Leu Pro Leu Met Asn Pro Phe His Val Leu Leu Ile
65 70 75 80
Val Leu Ala Tyr Leu Val Thr Val Phe Val Gly Met Gln Ile Met Lys
85 90 95
Asn Phe Glu Arg Phe Glu Val Lys Thr Phe Ser Leu Leu His Asn Phe
100 105 110
Cys Leu Val Ser Ile Ser Ala Tyr Met Cys Gly Gly Ile Leu Tyr Glu
115 120 125
Ala Tyr Gln Ala Asn Tyr Gly Leu Phe Glu Asn Ala Ala Asp His Thr
130 135 140
Phe Lys Gly Leu Pro Met Ala Lys Met Ile Trp Leu Phe Tyr Phe Ser
145 150 155 160
Lys Ile Met Glu Phe Val Asp Thr Met Ile Met Val Leu Lys Lys Asn
165 170 175
Asn Arg Gln Ile Ser Phe Leu His Val Tyr His His Ser Ser Ile Phe
180 185 190
Thr Ile Trp Trp Leu Val Thr Phe Val Ala Pro Asn Gly Glu Ala Tyr
195 200 205
Phe Ser Ala Ala Leu Asn Ser Phe Ile His Val Ile Met Tyr Gly Tyr
210 215 220
Tyr Phe Leu Ser Ala Leu Gly Phe Lys Gln Val Ser Phe Ile Lys Phe
225 230 235 240
Tyr Ile Thr Arg Ser Gln Met Thr Gln Phe Cys Met Met Ser Val Gln
245 250 255
Ser Ser Trp Asp Met Tyr Ala Met Lys Val Leu Gly Arg Pro Gly Tyr
260 265 270
Pro Phe Phe Ile Thr Ala Leu Leu Trp Phe Tyr Met Trp Thr Met Leu
275 280 285
Gly Leu Phe Tyr Asn Phe Tyr Arg Lys Asn Ala Lys Leu Ala Lys Gln
290 295 300
Ala Lys Ala Asp Ala Ala Lys Glu Lys Ala Arg Lys Leu Gln
305 310 315
<210> 55
<211> 271
<212> PRT
<213> Thraustochytrium sp.
<400> 55
Met Met Glu Pro Leu Asp Arg Tyr Arg Ala Leu Ala Glu Leu Ala Ala
1 5 10 15
Arg Tyr Ala Ser Ser Ala Ala Phe Lys Trp Gln Val Thr Tyr Asp Ala
20 25 30
Lys Asp Ser Phe Val Gly Pro Leu Gly Ile Arg Glu Pro Leu Gly Leu
35 40 45
Leu Val Gly Ser Val Val Leu Tyr Leu Ser Leu Gln Ala Val Val Tyr
50 55 60
Ala Leu Arg Asn Tyr Leu Gly Gly Leu Met Ala Leu Arg Ser Val His
65 70 75 80
Asn Leu Gly Leu Cys Leu Phe Ser Gly Ala Val Trp Ile Tyr Thr Ser
85 90 95
Tyr Leu Met Ile Gln Asp Gly His Phe Arg Ser Leu Glu Ala Ala Thr
100 105 110
Cys Glu Pro Leu Lys His Pro His Phe Gln Leu Ile Ser Leu Leu Phe
115 120 125
Ala Leu Ser Lys Ile Trp Glu Trp Phe Asp Thr Val Leu Leu Ile Val
130 135 140
Lys Gly Asn Lys Leu Arg Phe Leu His Val Leu His His Ala Thr Thr
145 150 155 160
Phe Trp Leu Tyr Ala Ile Asp His Ile Phe Leu Ser Ser Ile Lys Tyr
165 170 175
Gly Val Ala Val Asn Ala Phe Ile His Thr Val Met Tyr Ala His Tyr
180 185 190
Phe Arg Pro Phe Pro Lys Gly Leu Arg Pro Leu Ile Thr Gln Leu Gln
195 200 205
Ile Val Gln Phe Ile Phe Ser Ile Gly Ile His Thr Ala Ile Tyr Trp
210 215 220
His Tyr Asp Cys Glu Pro Leu Val His Thr His Phe Trp Glu Tyr Val
225 230 235 240
Thr Pro Tyr Leu Phe Val Val Pro Phe Leu Ile Leu Phe Leu Asn Phe
245 250 255
Tyr Leu Gln Gln Tyr Val Leu Ala Pro Ala Lys Thr Lys Lys Ala
260 265 270
<210> 56
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer EgD9E_102_053008f
<220>
<221> misc_feature
<222> (10)..(11)
<223> n is a, c, g, or t
<400> 56
gtgctgtacn nktccatcgc ctt 23
<210> 57
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer EgD9E_760_053008r
<400> 57
tcccttgtgc tttcggacga tgta 24
<210> 58
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-L35G"
<400> 58
atg gag gtc gtg aac gaa atc gtc tcc att ggc cag gag gtt ctt ccc 48
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aag gtc gac tat gct cag ctc tgg tct gat gcc tcg cac tgc gag gtg 96
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctg tac ggg tcc atc gcc ttc gtc atc ctg aag ttc acc ctt ggt cct 144
Leu Tyr Gly Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctc gga ccc aag ggt cag tct cga atg aag ttt gtg ttc acc aac tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
aac ctg ctc atg tcc atc tac tcg ctg ggc tcc ttc ctc tct atg gcc 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tac gcc atg tac acc att ggt gtc atg tcc gac aac tgc gag aag gct 288
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttc gac aac aat gtc ttc cga atc acc act cag ctg ttc tac ctc agc 336
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc ctc gag tac att gac tcc ttc tat ctg ccc ctc atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct ctg acc tgg ttg cag ttc ttt cac cat ctc gga gct cct atg gac 432
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tac aac tac cga aac gaa gcc gtt tgg atc ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggc tac tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctg atc aag ctc aag ttc cct atg ccc aag tcc ctg att act tct 576
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att cag ttc aac gtt ggc ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgg aac att ccc tgc tac cga caa gat gga atg aga atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttt ttc aac tac ttc tac gtt ggt act gtc ctg tgt ctg ttc ctc aac 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tac gtg cag acc tac atc gtc cga aag cac aag gga gcc aaa aag 768
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
att cag tga 777
Ile Gln
<210> 59
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 59
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Gly Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 60
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZuFmEgD9ES-L35G
<400> 60
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtcg tgaacgaaat cgtctccatt 7020
ggccaggagg ttcttcccaa ggtcgactat gctcagctct ggtctgatgc ctcgcactgc 7080
gaggtgctgt acgggtccat cgccttcgtc atcctgaagt tcacccttgg tcctctcgga 7140
cccaagggtc agtctcgaat gaagtttgtg ttcaccaact acaacctgct catgtccatc 7200
tactcgctgg gctccttcct ctctatggcc tacgccatgt acaccattgg tgtcatgtcc 7260
gacaactgcg agaaggcttt cgacaacaat gtcttccgaa tcaccactca gctgttctac 7320
ctcagcaagt tcctcgagta cattgactcc ttctatctgc ccctcatggg caagcctctg 7380
acctggttgc agttctttca ccatctcgga gctcctatgg acatgtggct gttctacaac 7440
taccgaaacg aagccgtttg gatctttgtg ctgctcaacg gcttcattca ctggatcatg 7500
tacggctact attggacccg actgatcaag ctcaagttcc ctatgcccaa gtccctgatt 7560
acttctatgc agatcattca gttcaacgtt ggcttctaca tcgtctggaa gtaccggaac 7620
attccctgct accgacaaga tggaatgaga atgtttggct ggtttttcaa ctacttctac 7680
gttggtactg tcctgtgtct gttcctcaac ttctacgtgc agacctacat cgtccgaaag 7740
cacaagggag ccaaaaagat tcagtgagc 7769
<210> 61
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-L35M/Q107E"
<400> 61
atg gag gtc gtg aac gaa atc gtc tcc att ggc cag gag gtt ctt ccc 48
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aag gtc gac tat gct cag ctc tgg tct gat gcc tcg cac tgc gag gtg 96
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctg tac atg tcc atc gcc ttc gtc atc ctg aag ttc acc ctt ggt cct 144
Leu Tyr Met Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctc gga ccc aag ggt cag tct cga atg aag ttt gtg ttc acc aac tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
aac ctg ctc atg tcc atc tac tcg ctg ggc tcc ttc ctc tct atg gcc 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tac gcc atg tac acc att ggt gtc atg tcc gac aac tgc gag aag gct 288
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttc gac aac aat gtc ttc cga atc acc act gag ctg ttc tac ctc agc 336
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Glu Leu Phe Tyr Leu Ser
100 105 110
aag ttc ctc gag tac att gac tcc ttc tat ctg ccc ctc atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct ctg acc tgg ttg cag ttc ttt cac cat ctc gga gct cct atg gac 432
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tac aac tac cga aac gaa gcc gtt tgg atc ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggc tac tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctg atc aag ctc aag ttc cct atg ccc aag tcc ctg att act tct 576
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att cag ttc aac gtt ggc ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgg aac att ccc tgc tac cga caa gat gga atg aga atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttt ttc aac tac ttc tac gtt ggt act gtc ctg tgt ctg ttc ctc aac 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tac gtg cag acc tac atc gtc cga aag cac aag gga gcc aaa aag 768
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
att cag tga 777
Ile Gln
<210> 62
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 62
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Met Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Glu Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 63
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZuFmEgD9ES-L35M/Q107E
<400> 63
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtcg tgaacgaaat cgtctccatt 7020
ggccaggagg ttcttcccaa ggtcgactat gctcagctct ggtctgatgc ctcgcactgc 7080
gaggtgctgt acatgtccat cgccttcgtc atcctgaagt tcacccttgg tcctctcgga 7140
cccaagggtc agtctcgaat gaagtttgtg ttcaccaact acaacctgct catgtccatc 7200
tactcgctgg gctccttcct ctctatggcc tacgccatgt acaccattgg tgtcatgtcc 7260
gacaactgcg agaaggcttt cgacaacaat gtcttccgaa tcaccactga gctgttctac 7320
ctcagcaagt tcctcgagta cattgactcc ttctatctgc ccctcatggg caagcctctg 7380
acctggttgc agttctttca ccatctcgga gctcctatgg acatgtggct gttctacaac 7440
taccgaaacg aagccgtttg gatctttgtg ctgctcaacg gcttcattca ctggatcatg 7500
tacggctact attggacccg actgatcaag ctcaagttcc ctatgcccaa gtccctgatt 7560
acttctatgc agatcattca gttcaacgtt ggcttctaca tcgtctggaa gtaccggaac 7620
attccctgct accgacaaga tggaatgaga atgtttggct ggtttttcaa ctacttctac 7680
gttggtactg tcctgtgtct gttcctcaac ttctacgtgc agacctacat cgtccgaaag 7740
cacaagggag ccaaaaagat tcagtgagc 7769
<210> 64
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_9D_122709f
<400> 64
gaaatcgtcg acattggcca gg 22
<210> 65
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_84C_122709r
<400> 65
gacaccaatg gtacacatgg cgtaggc 27
<210> 66
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_84C_122709f
<400> 66
gcctacgcca tgtgtaccat tggtgtc 27
<210> 67
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_9D_122709r
<400> 67
cctggccaat gtcgacgatt tc 22
<210> 68
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_161T_122709f
<400> 68
gatctttgtg accctcaacg gcttc 25
<210> 69
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_179R_122709r
<400> 69
gaacttgagc tttcgcagtc gggtc 25
<210> 70
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_179R_122709f
<400> 70
gacccgactg cgaaagctca agttc 25
<210> 71
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_161T_122709r
<400> 71
gaagccgttg agggtcacaa agatc 25
<210> 72
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_244N_122709f
<400> 72
cttctacgtg aacacctaca tc 22
<210> 73
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_21V_010710r
<400> 73
gaccagagct gcacatagtc gac 23
<210> 74
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_21V_010710f
<400> 74
gtcgactatg tgcagctctg gtc 23
<210> 75
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_244N_122709r
<400> 75
gatgtaggtg ttcacgtaga ag 22
<210> 76
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_32F_010710f
<400> 76
gcactgcgag tttctgtacc tc 22
<210> 77
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_108G_010710r
<400> 77
gaggtagaaa ccctgagtgg tg 22
<210> 78
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_108G_010710f
<400> 78
caccactcag ggtttctacc tc 22
<210> 79
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_32F_010710r
<400> 79
gaggtacaga aactcgcagt gc 22
<210> 80
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_132T_010710f
<400> 80
gcctctgacc accttgcagt tc 22
<210> 81
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_143N_010710r
<400> 81
gccacatgtc gttaggagct cc 22
<210> 82
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_143N_010710f
<400> 82
ggagctccta acgacatgtg gc 22
<210> 83
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_132T_010710r
<400> 83
gaactgcaag gtggtcagag gc 22
<210> 84
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_236N_010710f
<400> 84
gtactgtcct gaacctgttc ctc 23
<210> 85
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Eg_236N_010710r
<400> 85
gaggaacagg ttcaggacag tac 23
<210> 86
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-A21V/L35G/L108G/I179R"
<400> 86
atg gag gtc gtg aac gaa atc gtc tcc att ggc cag gag gtt ctt ccc 48
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aag gtc gac tat gtg cag ctc tgg tct gat gcc tcg cac tgc gag gtg 96
Lys Val Asp Tyr Val Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctg tac ggg tcc atc gcc ttc gtc atc ctg aag ttc acc ctt ggt cct 144
Leu Tyr Gly Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctc gga ccc aag ggt cag tct cga atg aag ttt gtg ttc acc aac tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
aac ctg ctc atg tcc atc tac tcg ctg ggc tcc ttc ctc tct atg gcc 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tac gcc atg tac acc att ggt gtc atg tcc gac aac tgc gag aag gct 288
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttc gac aac aat gtc ttc cga atc acc act cag ggt ttc tac ctc agc 336
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Gly Phe Tyr Leu Ser
100 105 110
aag ttc ctc gag tac att gac tcc ttc tat ctg ccc ctc atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct ctg acc tgg ttg cag ttc ttt cac cat ctc gga gct cct atg gac 432
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tac aac tac cga aac gaa gcc gtt tgg atc ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggc tac tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctg cga aag ctc aag ttc cct atg ccc aag tcc ctg att act tct 576
Arg Leu Arg Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att cag ttc aac gtt ggc ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgg aac att ccc tgc tac cga caa gat gga atg aga atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttt ttc aac tac ttc tac gtt ggt act gtc ctg tgt ctg ttc ctc aac 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tac gtg cag acc tac atc gtc cga aag cac aag gga gcc aaa aag 768
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
att cag tga 777
Ile Gln
<210> 87
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 87
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Val Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Gly Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Gly Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Arg Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 88
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZuFmEgD9ES-A21V/L35G/L108G/I179R
<400> 88
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtcg tgaacgaaat cgtctccatt 7020
ggccaggagg ttcttcccaa ggtcgactat gtgcagctct ggtctgatgc ctcgcactgc 7080
gaggtgctgt acgggtccat cgccttcgtc atcctgaagt tcacccttgg tcctctcgga 7140
cccaagggtc agtctcgaat gaagtttgtg ttcaccaact acaacctgct catgtccatc 7200
tactcgctgg gctccttcct ctctatggcc tacgccatgt acaccattgg tgtcatgtcc 7260
gacaactgcg agaaggcttt cgacaacaat gtcttccgaa tcaccactca gggtttctac 7320
ctcagcaagt tcctcgagta cattgactcc ttctatctgc ccctcatggg caagcctctg 7380
acctggttgc agttctttca ccatctcgga gctcctatgg acatgtggct gttctacaac 7440
taccgaaacg aagccgtttg gatctttgtg ctgctcaacg gcttcattca ctggatcatg 7500
tacggctact attggacccg actgcgaaag ctcaagttcc ctatgcccaa gtccctgatt 7560
acttctatgc agatcattca gttcaacgtt ggcttctaca tcgtctggaa gtaccggaac 7620
attccctgct accgacaaga tggaatgaga atgtttggct ggtttttcaa ctacttctac 7680
gttggtactg tcctgtgtct gttcctcaac ttctacgtgc agacctacat cgtccgaaag 7740
cacaagggag ccaaaaagat tcagtgagc 7769
<210> 89
<211> 4313
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZKUM
<400> 89
taatcgagct tggcgtaatc atggtcatag ctgtttcctg tgtgaaattg ttatccgctc 60
acaattccac acaacatacg agccggaagc ataaagtgta aagcctgggg tgcctaatga 120
gtgagctaac tcacattaat tgcgttgcgc tcactgcccg ctttccagtc gggaaacctg 180
tcgtgccagc tgcattaatg aatcggccaa cgcgcgggga gaggcggttt gcgtattggg 240
cgctcttccg cttcctcgct cactgactcg ctgcgctcgg tcgttcggct gcggcgagcg 300
gtatcagctc actcaaaggc ggtaatacgg ttatccacag aatcagggga taacgcagga 360
aagaacatgt gagcaaaagg ccagcaaaag gccaggaacc gtaaaaaggc cgcgttgctg 420
gcgtttttcc ataggctccg cccccctgac gagcatcaca aaaatcgacg ctcaagtcag 480
aggtggcgaa acccgacagg actataaaga taccaggcgt ttccccctgg aagctccctc 540
gtgcgctctc ctgttccgac cctgccgctt accggatacc tgtccgcctt tctcccttcg 600
ggaagcgtgg cgctttctca tagctcacgc tgtaggtatc tcagttcggt gtaggtcgtt 660
cgctccaagc tgggctgtgt gcacgaaccc cccgttcagc ccgaccgctg cgccttatcc 720
ggtaactatc gtcttgagtc caacccggta agacacgact tatcgccact ggcagcagcc 780
actggtaaca ggattagcag agcgaggtat gtaggcggtg ctacagagtt cttgaagtgg 840
tggcctaact acggctacac tagaaggaca gtatttggta tctgcgctct gctgaagcca 900
gttaccttcg gaaaaagagt tggtagctct tgatccggca aacaaaccac cgctggtagc 960
ggtggttttt ttgtttgcaa gcagcagatt acgcgcagaa aaaaaggatc tcaagaagat 1020
cctttgatct tttctacggg gtctgacgct cagtggaacg aaaactcacg ttaagggatt 1080
ttggtcatga gattatcaaa aaggatcttc acctagatcc ttttaaatta aaaatgaagt 1140
tttaaatcaa tctaaagtat atatgagtaa acttggtctg acagttacca atgcttaatc 1200
agtgaggcac ctatctcagc gatctgtcta tttcgttcat ccatagttgc ctgactcccc 1260
gtcgtgtaga taactacgat acgggagggc ttaccatctg gccccagtgc tgcaatgata 1320
ccgcgagacc cacgctcacc ggctccagat ttatcagcaa taaaccagcc agccggaagg 1380
gccgagcgca gaagtggtcc tgcaacttta tccgcctcca tccagtctat taattgttgc 1440
cgggaagcta gagtaagtag ttcgccagtt aatagtttgc gcaacgttgt tgccattgct 1500
acaggcatcg tggtgtcacg ctcgtcgttt ggtatggctt cattcagctc cggttcccaa 1560
cgatcaaggc gagttacatg atcccccatg ttgtgcaaaa aagcggttag ctccttcggt 1620
cctccgatcg ttgtcagaag taagttggcc gcagtgttat cactcatggt tatggcagca 1680
ctgcataatt ctcttactgt catgccatcc gtaagatgct tttctgtgac tggtgagtac 1740
tcaaccaagt cattctgaga atagtgtatg cggcgaccga gttgctcttg cccggcgtca 1800
atacgggata ataccgcgcc acatagcaga actttaaaag tgctcatcat tggaaaacgt 1860
tcttcggggc gaaaactctc aaggatctta ccgctgttga gatccagttc gatgtaaccc 1920
actcgtgcac ccaactgatc ttcagcatct tttactttca ccagcgtttc tgggtgagca 1980
aaaacaggaa ggcaaaatgc cgcaaaaaag ggaataaggg cgacacggaa atgttgaata 2040
ctcatactct tcctttttca atattattga agcatttatc agggttattg tctcatgagc 2100
ggatacatat ttgaatgtat ttagaaaaat aaacaaatag gggttccgcg cacatttccc 2160
cgaaaagtgc cacctgacgc gccctgtagc ggcgcattaa gcgcggcggg tgtggtggtt 2220
acgcgcagcg tgaccgctac acttgccagc gccctagcgc ccgctccttt cgctttcttc 2280
ccttcctttc tcgccacgtt cgccggcttt ccccgtcaag ctctaaatcg ggggctccct 2340
ttagggttcc gatttagtgc tttacggcac ctcgacccca aaaaacttga ttagggtgat 2400
ggttcacgta gtgggccatc gccctgatag acggtttttc gccctttgac gttggagtcc 2460
acgttcttta atagtggact cttgttccaa actggaacaa cactcaaccc tatctcggtc 2520
tattcttttg atttataagg gattttgccg atttcggcct attggttaaa aaatgagctg 2580
atttaacaaa aatttaacgc gaattttaac aaaatattaa cgcttacaat ttccattcgc 2640
cattcaggct gcgcaactgt tgggaagggc gatcggtgcg ggcctcttcg ctattacgcc 2700
agctggcgaa agggggatgt gctgcaaggc gattaagttg ggtaacgcca gggttttccc 2760
agtcacgacg ttgtaaaacg acggccagtg aattgtaata cgactcacta tagggcgaat 2820
tgggtaccgg gccccccctc gaggtcgacg agtatctgtc tgactcgtca ttgccgcctt 2880
tggagtacga ctccaactat gagtgtgctt ggatcacttt gacgatacat tcttcgttgg 2940
aggctgtggg tctgacagct gcgttttcgg cgcggttggc cgacaacaat atcagctgca 3000
acgtcattgc tggctttcat catgatcaca tttttgtcgg caaaggcgac gcccagagag 3060
ccattgacgt tctttctaat ttggaccgat agccgtatag tccagtctat ctataagttc 3120
aactaactcg taactattac cataacatat acttcactgc cccagataag gttccgataa 3180
aaagttctgc agactaaatt tatttcagtc tcctcttcac caccaaaatg ccctcctacg 3240
aagctcgagt gctcaagctc gtggcagcca agaaaaccaa cctgtgtgct tctctggatg 3300
ttaccaccac caaggagctc attgagcttg ccgataaggt cggaccttat gtgtgcatga 3360
tcaaaaccca tatcgacatc attgacgact tcacctacgc cggcactgtg ctccccctca 3420
aggaacttgc tcttaagcac ggtttcttcc tgttcgagga cagaaagttc gcagatattg 3480
gcaacactgt caagcaccag taccggtgtc accgaatcgc cgagtggtcc gatatcacca 3540
acgcccacgg tgtacccgga accggaatcg attgctggcc tgcgagctgg tgcgtacgag 3600
gaaactgtct ctgaacagaa gaaggaggac gtctctgact acgagaactc ccagtacaag 3660
gagttcctag tcccctctcc caacgagaag ctggccagag gtctgctcat gctggccgag 3720
ctgtcttgca agggctctct ggccactggc gagtactcca agcagaccat tgagcttgcc 3780
cgatccgacc ccgagtttgt ggttggcttc attgcccaga accgacctaa gggcgactct 3840
gaggactggc ttattctgac ccccggggtg ggtcttgacg acaagggaga cgctctcgga 3900
cagcagtacc gaactgttga ggatgtcatg tctaccggaa cggatatcat aattgtcggc 3960
cgaggtctgt acggccagaa ccgagatcct attgaggagg ccaagcgata ccagaaggct 4020
ggctgggagg cttaccagaa gattaactgt tagaggttag actatggata tgtaatttaa 4080
ctgtgtatat agagagcgtg caagtatgga gcgcttgttc agcttgtatg atggtcagac 4140
gacctgtctg atcgagtatg tatgatactg cacaacctgt gtatccgcat gatctgtcca 4200
atggggcatg ttgttgtgtt tctcgatacg gagatgctgg gtacagtgct aatacgttga 4260
actacttata cttatatgag gctcgaagaa agctgacttg tgtatgactt aat 4313
<210> 90
<211> 13565
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZKL3-9DP9N
<400> 90
gtacggattg tgtatgtccc tgtacctgca tcttgatgga gagagctccg gaaagcggat 60
caggagctgt ccaattttaa ttttataaca tggaaacgag tccttggagc tagaagacca 120
ttttttcaac tgccctatcg actatattta tctactccaa aaccgactgc ttcccaagaa 180
tcttcagcca aggcttccaa agtaacccct cgcttcccga cacttaattg aaaccttaga 240
tgcagtcact gcgagtgaag tggactctaa catctccaac atagcgacga tattgcgagg 300
gtttgaatat aactaagatg catgatccat tacatttgta gaaatatcat aaacaacgaa 360
gcacatagac agaatgctgt tggttgttac atctgaagcc gaggtaccga tgtcattttc 420
agctgtcact gcagagacag gggtatgtca catttgaaga tcatacaacc gacgtttatg 480
aaaaccagag atatagagaa tgtattgacg gttgtggcta tgtcataagt gcagtgaagt 540
gcagtgatta taggtatagt acacttactg tagctacaag tacatactgc tacagtaata 600
ctcatgtatg caaaccgtat tctgtgtcta cagaaggcga tacggaagag tcaatctctt 660
atgtagagcc atttctataa tcgaaggggc cttgtaattt ccaaacgagt aattgagtaa 720
ttgaagagca tcgtagacat tacttatcat gtattgtgag agggaggaga tgcagctgta 780
gctactgcac atactgtact cgcccatgca gggataatgc atagcgagac ttggcagtag 840
gtgacagttg ctagctgcta cttgtagtcg ggtgggtgat agcatggcgc gccagctgca 900
ttaatgaatc ggccaacgcg cggggagagg cggtttgcgt attgggcgct cttccgcttc 960
ctcgctcact gactcgctgc gctcggtcgt tcggctgcgg cgagcggtat cagctcactc 1020
aaaggcggta atacggttat ccacagaatc aggggataac gcaggaaaga acatgtgagc 1080
aaaaggccag caaaaggcca ggaaccgtaa aaaggccgcg ttgctggcgt ttttccatag 1140
gctccgcccc cctgacgagc atcacaaaaa tcgacgctca agtcagaggt ggcgaaaccc 1200
gacaggacta taaagatacc aggcgtttcc ccctggaagc tccctcgtgc gctctcctgt 1260
tccgaccctg ccgcttaccg gatacctgtc cgcctttctc ccttcgggaa gcgtggcgct 1320
ttctcatagc tcacgctgta ggtatctcag ttcggtgtag gtcgttcgct ccaagctggg 1380
ctgtgtgcac gaaccccccg ttcagcccga ccgctgcgcc ttatccggta actatcgtct 1440
tgagtccaac ccggtaagac acgacttatc gccactggca gcagccactg gtaacaggat 1500
tagcagagcg aggtatgtag gcggtgctac agagttcttg aagtggtggc ctaactacgg 1560
ctacactaga agaacagtat ttggtatctg cgctctgctg aagccagtta ccttcggaaa 1620
aagagttggt agctcttgat ccggcaaaca aaccaccgct ggtagcggtg gtttttttgt 1680
ttgcaagcag cagattacgc gcagaaaaaa aggatctcaa gaagatcctt tgatcttttc 1740
tacggggtct gacgctcagt ggaacgaaaa ctcacgttaa gggattttgg tcatgagatt 1800
atcaaaaagg atcttcacct agatcctttt aaattaaaaa tgaagtttta aatcaatcta 1860
aagtatatat gagtaaactt ggtctgacag ttaccaatgc ttaatcagtg aggcacctat 1920
ctcagcgatc tgtctatttc gttcatccat agttgcctga ctccccgtcg tgtagataac 1980
tacgatacgg gagggcttac catctggccc cagtgctgca atgataccgc gagacccacg 2040
ctcaccggct ccagatttat cagcaataaa ccagccagcc ggaagggccg agcgcagaag 2100
tggtcctgca actttatccg cctccatcca gtctattaat tgttgccggg aagctagagt 2160
aagtagttcg ccagttaata gtttgcgcaa cgttgttgcc attgctacag gcatcgtggt 2220
gtcacgctcg tcgtttggta tggcttcatt cagctccggt tcccaacgat caaggcgagt 2280
tacatgatcc cccatgttgt gcaaaaaagc ggttagctcc ttcggtcctc cgatcgttgt 2340
cagaagtaag ttggccgcag tgttatcact catggttatg gcagcactgc ataattctct 2400
tactgtcatg ccatccgtaa gatgcttttc tgtgactggt gagtactcaa ccaagtcatt 2460
ctgagaatag tgtatgcggc gaccgagttg ctcttgcccg gcgtcaatac gggataatac 2520
cgcgccacat agcagaactt taaaagtgct catcattgga aaacgttctt cggggcgaaa 2580
actctcaagg atcttaccgc tgttgagatc cagttcgatg taacccactc gtgcacccaa 2640
ctgatcttca gcatctttta ctttcaccag cgtttctggg tgagcaaaaa caggaaggca 2700
aaatgccgca aaaaagggaa taagggcgac acggaaatgt tgaatactca tactcttcct 2760
ttttcaatat tattgaagca tttatcaggg ttattgtctc atgagcggat acatatttga 2820
atgtatttag aaaaataaac aaataggggt tccgcgcaca tttccccgaa aagtgccacc 2880
tgatgcggtg tgaaataccg cacagatgcg taaggagaaa ataccgcatc aggaaattgt 2940
aagcgttaat attttgttaa aattcgcgtt aaatttttgt taaatcagct cattttttaa 3000
ccaataggcc gaaatcggca aaatccctta taaatcaaaa gaatagaccg agatagggtt 3060
gagtgttgtt ccagtttgga acaagagtcc actattaaag aacgtggact ccaacgtcaa 3120
agggcgaaaa accgtctatc agggcgatgg cccactacgt gaaccatcac cctaatcaag 3180
ttttttgggg tcgaggtgcc gtaaagcact aaatcggaac cctaaaggga gcccccgatt 3240
tagagcttga cggggaaagc cggcgaacgt ggcgagaaag gaagggaaga aagcgaaagg 3300
agcgggcgct agggcgctgg caagtgtagc ggtcacgctg cgcgtaacca ccacacccgc 3360
cgcgcttaat gcgccgctac agggcgcgtc cattcgccat tcaggctgcg caactgttgg 3420
gaagggcgat cggtgcgggc ctcttcgcta ttacgccagc tggcgaaagg gggatgtgct 3480
gcaaggcgat taagttgggt aacgccaggg ttttcccagt cacgacgttg taaaacgacg 3540
gccagtgaat tgtaatacga ctcactatag ggcgaattgg gcccgacgtc gcatgcagga 3600
atagacatct tcaataggag cattaatacc tgtgggatca ctgatgtaaa cttctcccag 3660
agtatgtgaa taaccagcgg gccatccaac aaagaagtcg ttccagtgag tgactcggta 3720
catccgtctt tcggggttga tggtaagtcc gtcgtctcct tgcttaaaga acagagcgtc 3780
cacgtagtct gcaaaagcct tgtttccaag tcgaggctgc ccatagttga ttagcgttgg 3840
atcatatcca agattcttca ggttgatgcc catgaataga gcagtgacag ctcctagaga 3900
gtggccagtt acgatcaatt tgtagtcagt gttgtttcca aggaagtcga ccagacgatc 3960
ctgtacgttc accatagtct ctctgtatgc cttctgaaag ccatcatgaa cttggcagcc 4020
aggacaattg atactggcag aagggtttgt ggagtttatg tcagtagtgt taagaggagg 4080
gatactggtc atgtagggtt gttggatcgt ttggatgtca gtaatagcgt ctgcaatgga 4140
gaaagtgcct cggaaaacaa tatacttttc ctttttggtg tgatcgtggg ccaaaaatcc 4200
agtaactgaa gtcgagaaga aatttcctcc aaactggtag tcaagagtca catcgggaaa 4260
atgagcgcaa gagtttccac aggtaaaatc gctctgcagg gcaaatgggc caggggctct 4320
gacacaatag gccacgttag atagccatcc gtacttgaga acaaagtcgt atgtctcctg 4380
ggtgatagga gccgttaatt aagttgcgac acatgtcttg atagtatctt gaattctctc 4440
tcttgagctt ttccataaca agttcttctg cctccaggaa gtccatgggt ggtttgatca 4500
tggttttggt gtagtggtag tgcagtggtg gtattgtgac tggggatgta gttgagaata 4560
agtcatacac aagtcagctt tcttcgagcc tcatataagt ataagtagtt caacgtatta 4620
gcactgtacc cagcatctcc gtatcgagaa acacaacaac atgccccatt ggacagatca 4680
tgcggataca caggttgtgc agtatcatac atactcgatc agacaggtcg tctgaccatc 4740
atacaagctg aacaagcgct ccatacttgc acgctctcta tatacacagt taaattacat 4800
atccatagtc taacctctaa cagttaatct tctggtaagc ctcccagcca gccttctggt 4860
atcgcttggc ctcctcaata ggatctcggt tctggccgta cagacctcgg ccgacaatta 4920
tgatatccgt tccggtagac atgacatcct caacagttcg gtactgctgt ccgagagcgt 4980
ctcccttgtc gtcaagaccc accccggggg tcagaataag ccagtcctca gagtcgccct 5040
taggtcggtt ctgggcaatg aagccaacca caaactcggg gtcggatcgg gcaagctcaa 5100
tggtctgctt ggagtactcg ccagtggcca gagagccctt gcaagacagc tcggccagca 5160
tgagcagacc tctggccagc ttctcgttgg gagaggggac taggaactcc ttgtactggg 5220
agttctcgta gtcagagacg tcctccttct tctgttcaga gacagtttcc tcggcaccag 5280
ctcgcaggcc agcaatgatt ccggttccgg gtacaccgtg ggcgttggtg atatcggacc 5340
actcggcgat tcggtgacac cggtactggt gcttgacagt gttgccaata tctgcgaact 5400
ttctgtcctc gaacaggaag aaaccgtgct taagagcaag ttccttgagg gggagcacag 5460
tgccggcgta ggtgaagtcg tcaatgatgt cgatatgggt tttgatcatg cacacataag 5520
gtccgacctt atcggcaagc tcaatgagct ccttggtggt ggtaacatcc agagaagcac 5580
acaggttggt tttcttggct gccacgagct tgagcactcg agcggcaaag gcggacttgt 5640
ggacgttagc tcgagcttcg taggagggca ttttggtggt gaagaggaga ctgaaataaa 5700
tttagtctgc agaacttttt atcggaacct tatctggggc agtgaagtat atgttatggt 5760
aatagttacg agttagttga acttatagat agactggact atacggctat cggtccaaat 5820
tagaaagaac gtcaatggct ctctgggcgt cgcctttgcc gacaaaaatg tgatcatgat 5880
gaaagccagc aatgacgttg cagctgatat tgttgtcggc caaccgcgcc gaaaacgcag 5940
ctgtcagacc cacagcctcc aacgaagaat gtatcgtcaa agtgatccaa gcacactcat 6000
agttggagtc gtactccaaa ggcggcaatg acgagtcaga cagatactcg tcgacctttt 6060
ccttgggaac caccaccgtc agcccttctg actcacgtat tgtagccacc gacacaggca 6120
acagtccgtg gatagcagaa tatgtcttgt cggtccattt ctcaccaact ttaggcgtca 6180
agtgaatgtt gcagaagaag tatgtgcctt cattgagaat cggtgttgct gatttcaata 6240
aagtcttgag atcagtttgg ccagtcatgt tgtggggggt aattggattg agttatcgcc 6300
tacagtctgt acaggtatac tcgctgccca ctttatactt tttgattccg ctgcacttga 6360
agcaatgtcg tttaccaaaa gtgagaatgc tccacagaac acaccccagg gtatggttga 6420
gcaaaaaata aacactccga tacggggaat cgaaccccgg tctccacggt tctcaagaag 6480
tattcttgat gagagcgtat cgatggttaa tgctgctgtg tgctgtgtgt gtgtgttgtt 6540
tggcgctcat tgttgcgtta tgcagcgtac accacaatat tggaagctta ttagcctttc 6600
tattttttcg tttgcaaggc ttaacaacat tgctgtggag agggatgggg atatggaggc 6660
cgctggaggg agtcggagag gcgttttgga gcggcttggc ctggcgccca gctcgcgaaa 6720
cgcacctagg accctttggc acgccgaaat gtgccacttt tcagtctagt aacgccttac 6780
ctacgtcatt ccatgcgtgc atgtttgcgc cttttttccc ttgcccttga tcgccacaca 6840
gtacagtgca ctgtacagtg gaggttttgg gggggtctta gatgggagct aaaagcggcc 6900
tagcggtaca ctagtgggat tgtatggagt ggcatggagc ctaggtggag cctgacagga 6960
cgcacgaccg gctagcccgt gacagacgat gggtggctcc tgttgtccac cgcgtacaaa 7020
tgtttgggcc aaagtcttgt cagccttgct tgcgaaccta attcccaatt ttgtcacttc 7080
gcacccccat tgatcgagcc ctaacccctg cccatcaggc aatccaatta agctcgcatt 7140
gtctgccttg tttagtttgg ctcctgcccg tttcggcgtc cacttgcaca aacacaaaca 7200
agcattatat ataaggctcg tctctccctc ccaaccacac tcactttttt gcccgtcttc 7260
ccttgctaac acaaaagtca agaacacaaa caaccacccc aaccccctta cacacaagac 7320
atatctacag caatggccat ggccaaaagc aaacgacggt cggaggctgt ggaagagcac 7380
gtgaccggct cggacgaggg cttgaccgat acttcgggtc acgtgagccc tgccgccaag 7440
aagcagaaga actcggagat tcatttcacc acccaggctg cccagcagtt ggatcgggag 7500
cgcaaggagg agtatctgga ctcgctgatc gacaacaagg actatctcaa gtaccgtcct 7560
cgaggctgga agctcaacaa cccgcctacc gaccgacctg tgcgaatcta cgccgatgga 7620
gtgtttgatt tgttccatct gggacacatg cgtcagctgg agcagtccaa gaaggccttc 7680
cccaacgcag tgttgattgt gggcattccc agcgacaagg agacccacaa gcggaaggga 7740
ttgaccgtgc tgagtgacgt ccagcggtac gagacggtgc gacactgcaa gtgggtggac 7800
gaggtggtgg aggatgctcc ctggtgtgtc accatggact ttctggaaaa acacaaaatc 7860
gactacgtgg cccatgacga tctgccctac gcttccggca acgacgatga tatctacaag 7920
cccatcaagg agaagggcat gtttctggcc acccagcgaa ccgagggcat ttccacctcg 7980
gacatcatca ccaagattat ccgagactac gacaagtatt taatgcgaaa ctttgcccgg 8040
ggtgctaacc gaaaggatct caacgtctcg tggctcaaga agaacgagct ggacttcaag 8100
cgtcatgtgg ccgagttccg aaactcgttc aagcgaaaga aggtcggtaa ggatctctac 8160
ggcgagattc gcggtctgct gcagaatgtg ctcatttgga acggcgacaa ctccggcact 8220
tccactcccc agcgaaagac gctgcagacc aacgccaaga agatgtacat gaacgtgctc 8280
aagactctgc aggctcctga cgctgttgac gtggactcct cggagaacgt gtctgagaac 8340
gtcactgatg aggaggagga agacgacgac gaggttgatg aggacgaaga agccgacgac 8400
gacgacgaag acgacgaaga cgaggaagac gacgagtagg cggccgcatt gatgattgga 8460
aacacacaca tgggttatat ctaggtgaga gttagttgga cagttatata ttaaatcagc 8520
tatgccaacg gtaacttcat tcatgtcaac gaggaaccag tgactgcaag taatatagaa 8580
tttgaccacc ttgccattct cttgcactcc tttactatat ctcatttatt tcttatatac 8640
aaatcacttc ttcttcccag catcgagctc ggaaacctca tgagcaataa catcgtggat 8700
ctcgtcaata gagggctttt tggactcctt gctgttggcc accttgtcct tgctgtttaa 8760
acacgcagta ggatgtcctg cacgggtctt tttgtggggt gtggagaaag gggtgcttgg 8820
agatggaagc cggtagaacc gggctgcttg tgcttggaga tggaagccgg tagaaccggg 8880
ctgcttgggg ggatttgggg ccgctgggct ccaaagaggg gtaggcattt cgttggggtt 8940
acgtaattgc ggcatttggg tcctgcgcgc atgtcccatt ggtcagaatt agtccggata 9000
ggagacttat cagccaatca cagcgccgga tccacctgta ggttgggttg ggtgggagca 9060
cccctccaca gagtagagtc aaacagcagc agcaacatga tagttggggg tgtgcgtgtt 9120
aaaggaaaaa aaagaagctt gggttatatt cccgctctat ttagaggttg cgggatagac 9180
gccgacggag ggcaatggcg ctatggaacc ttgcggatat ccatacgccg cggcggactg 9240
cgtccgaacc agctccagca gcgttttttc cgggccattg agccgactgc gaccccgcca 9300
acgtgtcttg gcccacgcac tcatgtcatg ttggtgttgg gaggccactt tttaagtagc 9360
acaaggcacc tagctcgcag caaggtgtcc gaaccaaaga agcggctgca gtggtgcaaa 9420
cggggcggaa acggcgggaa aaagccacgg gggcacgaat tgaggcacgc cctcgaattt 9480
gagacgagtc acggccccat tcgcccgcgc aatggctcgc caacgcccgg tcttttgcac 9540
cacatcaggt taccccaagc caaacctttg tgttaaaaag cttaacatat tataccgaac 9600
gtaggtttgg gcgggcttgc tccgtctgtc caaggcaaca tttatataag ggtctgcatc 9660
gccggctcaa ttgaatcttt tttcttcttc tcttctctat attcattctt gaattaaaca 9720
cacatcaaca tggccatcaa agtcggtatt aacggattcg ggcgaatcgg acgaattgtg 9780
agtaccatag aaggtgatgg aaacatgacc caacagaaac agatgacaag tgtcatcgac 9840
ccaccagagc ccaattgagc tcatactaac agtcgacaac ctgtcgaacc aattgatgac 9900
tccccgacaa tgtactaaca caggtcctgc ccatggtgaa aaacgtggac caagtggatc 9960
tctcgcaggt cgacaccatt gcctccggcc gagatgtcaa ctacaaggtc aagtacacct 10020
ccggcgttaa gatgagccag ggcgcctacg acgacaaggg ccgccacatt tccgagcagc 10080
ccttcacctg ggccaactgg caccagcaca tcaactggct caacttcatt ctggtgattg 10140
cgctgcctct gtcgtccttt gctgccgctc ccttcgtctc cttcaactgg aagaccgccg 10200
cgtttgctgt cggctattac atgtgcaccg gtctcggtat caccgccggc taccaccgaa 10260
tgtgggccca tcgagcctac aaggccgctc tgcccgttcg aatcatcctt gctctgtttg 10320
gaggaggagc tgtcgagggc tccatccgat ggtgggcctc gtctcaccga gtccaccacc 10380
gatggaccga ctccaacaag gacccttacg acgcccgaaa gggattctgg ttctcccact 10440
ttggctggat gctgcttgtg cccaacccca agaacaaggg ccgaactgac atttctgacc 10500
tcaacaacga ctgggttgtc cgactccagc acaagtacta cgtttacgtt ctcgtcttca 10560
tggccattgt tctgcccacc ctcgtctgtg gctttggctg gggcgactgg aagggaggtc 10620
ttgtctacgc cggtatcatg cgatacacct ttgtgcagca ggtgactttc tgtgtcaact 10680
cccttgccca ctggattgga gagcagccct tcgacgaccg acgaactccc cgagaccacg 10740
ctcttaccgc cctggtcacc tttggagagg gctaccacaa cttccaccac gagttcccct 10800
cggactaccg aaacgccctc atctggtacc agtacgaccc caccaagtgg ctcatctgga 10860
ccctcaagca ggttggtctc gcctgggacc tccagacctt ctcccagaac gccatcgagc 10920
agggtctcgt gcagcagcga cagaagaagc tggacaagtg gcgaaacaac ctcaactggg 10980
gtatccccat tgagcagctg cctgtcattg agtttgagga gttccaagag caggccaaga 11040
cccgagatct ggttctcatt tctggcattg tccacgacgt gtctgccttt gtcgagcacc 11100
accctggtgg aaaggccctc attatgagcg ccgtcggcaa ggacggtacc gctgtcttca 11160
acggaggtgt ctaccgacac tccaacgctg gccacaacct gcttgccacc atgcgagttt 11220
cggtcattcg aggcggcatg gaggttgagg tgtggaagac tgcccagaac gaaaagaagg 11280
accagaacat tgtctccgat gagagtggaa accgaatcca ccgagctggt ctccaggcca 11340
cccgggtcga gaaccccggt atgtctggca tggctgctta ggcggccgca tgagaagata 11400
aatatataaa tacattgaga tattaaatgc gctagattag agagcctcat actgctcgga 11460
gagaagccaa gacgagtact caaaggggat tacaccatcc atatccacag acacaagctg 11520
gggaaaggtt ctatatacac tttccggaat accgtagttt ccgatgttat caatgggggc 11580
agccaggatt tcaggcactt cggtgtctcg gggtgaaatg gcgttcttgg cctccatcaa 11640
gtcgtaccat gtcttcattt gcctgtcaaa gtaaaacaga agcagatgaa gaatgaactt 11700
gaagtgaagg aatttaaata gttggagcaa gggagaaatg tagagtgtga aagactcact 11760
atggtccggg cttatctcga ccaatagcca aagtctggag tttctgagag aaaaaggcaa 11820
gatacgtatg taacaaagcg acgcatggta caataatacc ggaggcatgt atcatagaga 11880
gttagtggtt cgatgatggc actggtgcct ggtatgactt tatacggctg actacatatt 11940
tgtcctcaga catacaatta cagtcaagca cttacccttg gacatctgta ggtacccccc 12000
ggccaagacg atctcagcgt gtcgtatgtc ggattggcgt agctccctcg ctcgtcaatt 12060
ggctcccatc tactttcttc tgcttggcta cacccagcat gtctgctatg gctcgttttc 12120
gtgccttatc tatcctccca gtattaccaa ctctaaatga catgatgtga ttgggtctac 12180
actttcatat cagagataag gagtagcaca gttgcataaa aagcccaact ctaatcagct 12240
tcttcctttc ttgtaattag tacaaaggtg attagcgaaa tctggaagct tagttggccc 12300
taaaaaaatc aaaaaaagca aaaaacgaaa aacgaaaaac cacagttttg agaacaggga 12360
ggtaacgaag gatcgtatat atatatatat atatatatac ccacggatcc cgagaccggc 12420
ctttgattct tccctacaac caaccattct caccacccta attcacaacc atggaggtcg 12480
tgaacgaaat cgtctccatt ggccaggagg ttcttcccaa ggtcgactat gctcagctct 12540
ggtctgatgc ctcgcactgc gaggtgctgt acctctccat cgccttcgtc atcctgaagt 12600
tcacccttgg tcctctcgga cccaagggtc agtctcgaat gaagtttgtg ttcaccaact 12660
acaacctgct catgtccatc tactcgctgg gctccttcct ctctatggcc tacgccatgt 12720
acaccattgg tgtcatgtcc gacaactgcg agaaggcttt cgacaacaat gtcttccgaa 12780
tcaccactca gctgttctac ctcagcaagt tcctcgagta cattgactcc ttctatctgc 12840
ccctcatggg caagcctctg acctggttgc agttctttca ccatctcgga gctcctatgg 12900
acatgtggct gttctacaac taccgaaacg aagccgtttg gatctttgtg ctgctcaacg 12960
gcttcattca ctggatcatg tacggctact attggacccg actgatcaag ctcaagttcc 13020
ctatgcccaa gtccctgatt acttctatgc agatcattca gttcaacgtt ggcttctaca 13080
tcgtctggaa gtaccggaac attccctgct accgacaaga tggaatgaga atgtttggct 13140
ggtttttcaa ctacttctac gttggtactg tcctgtgtct gttcctcaac ttctacgtgc 13200
agacctacat cgtccgaaag cacaagggag ccaaaaagat tcagtgagcg gccgcaagtg 13260
tggatgggga agtgagtgcc cggttctgtg tgcacaattg gcaatccaag atggatggat 13320
tcaacacagg gatatagcga gctacgtggt ggtgcgagga tatagcaacg gatatttatg 13380
tttgacactt gagaatgtac gatacaagca ctgtccaagt acaatactaa acatactgta 13440
catactcata ctcgtacccg gcaacggttt cacttgagtg cagtggctag tgctcttact 13500
cgtacagtgt gcaatactgc gtatcatagt ctttgatgta tatcgtattc attcatgtta 13560
gttgc 13565
<210> 91
<211> 1449
<212> DNA
<213> Yarrowia lipolytica
<220>
<221> CDS
<222> (1)..(1449)
<223> delta-9 desaturase; GenBank Accession No. XM_501496
<400> 91
atg gtg aaa aac gtg gac caa gtg gat ctc tcg cag gtc gac acc att 48
Met Val Lys Asn Val Asp Gln Val Asp Leu Ser Gln Val Asp Thr Ile
1 5 10 15
gcc tcc ggc cga gat gtc aac tac aag gtc aag tac acc tcc ggc gtt 96
Ala Ser Gly Arg Asp Val Asn Tyr Lys Val Lys Tyr Thr Ser Gly Val
20 25 30
aag atg agc cag ggc gcc tac gac gac aag ggc cgc cac att tcc gag 144
Lys Met Ser Gln Gly Ala Tyr Asp Asp Lys Gly Arg His Ile Ser Glu
35 40 45
cag ccc ttc acc tgg gcc aac tgg cac cag cac atc aac tgg ctc aac 192
Gln Pro Phe Thr Trp Ala Asn Trp His Gln His Ile Asn Trp Leu Asn
50 55 60
ttc att ctg gtg att gcg ctg cct ctg tcg tcc ttt gct gcc gct ccc 240
Phe Ile Leu Val Ile Ala Leu Pro Leu Ser Ser Phe Ala Ala Ala Pro
65 70 75 80
ttc gtc tcc ttc aac tgg aag acc gcc gcg ttt gct gtc ggc tat tac 288
Phe Val Ser Phe Asn Trp Lys Thr Ala Ala Phe Ala Val Gly Tyr Tyr
85 90 95
atg tgc acc ggt ctc ggt atc acc gcc ggc tac cac cga atg tgg gcc 336
Met Cys Thr Gly Leu Gly Ile Thr Ala Gly Tyr His Arg Met Trp Ala
100 105 110
cat cga gcc tac aag gcc gct ctg ccc gtt cga atc atc ctt gct ctg 384
His Arg Ala Tyr Lys Ala Ala Leu Pro Val Arg Ile Ile Leu Ala Leu
115 120 125
ttt gga gga gga gct gtc gag ggc tcc atc cga tgg tgg gcc tcg tct 432
Phe Gly Gly Gly Ala Val Glu Gly Ser Ile Arg Trp Trp Ala Ser Ser
130 135 140
cac cga gtc cac cac cga tgg acc gac tcc aac aag gac cct tac gac 480
His Arg Val His His Arg Trp Thr Asp Ser Asn Lys Asp Pro Tyr Asp
145 150 155 160
gcc cga aag gga ttc tgg ttc tcc cac ttt ggc tgg atg ctg ctt gtg 528
Ala Arg Lys Gly Phe Trp Phe Ser His Phe Gly Trp Met Leu Leu Val
165 170 175
ccc aac ccc aag aac aag ggc cga act gac att tct gac ctc aac aac 576
Pro Asn Pro Lys Asn Lys Gly Arg Thr Asp Ile Ser Asp Leu Asn Asn
180 185 190
gac tgg gtt gtc cga ctc cag cac aag tac tac gtt tac gtt ctc gtc 624
Asp Trp Val Val Arg Leu Gln His Lys Tyr Tyr Val Tyr Val Leu Val
195 200 205
ttc atg gcc att gtt ctg ccc acc ctc gtc tgt ggc ttt ggc tgg ggc 672
Phe Met Ala Ile Val Leu Pro Thr Leu Val Cys Gly Phe Gly Trp Gly
210 215 220
gac tgg aag gga ggt ctt gtc tac gcc ggt atc atg cga tac acc ttt 720
Asp Trp Lys Gly Gly Leu Val Tyr Ala Gly Ile Met Arg Tyr Thr Phe
225 230 235 240
gtg cag cag gtg act ttc tgt gtc aac tcc ctt gcc cac tgg att gga 768
Val Gln Gln Val Thr Phe Cys Val Asn Ser Leu Ala His Trp Ile Gly
245 250 255
gag cag ccc ttc gac gac cga cga act ccc cga gac cac gct ctt acc 816
Glu Gln Pro Phe Asp Asp Arg Arg Thr Pro Arg Asp His Ala Leu Thr
260 265 270
gcc ctg gtc acc ttt gga gag ggc tac cac aac ttc cac cac gag ttc 864
Ala Leu Val Thr Phe Gly Glu Gly Tyr His Asn Phe His His Glu Phe
275 280 285
ccc tcg gac tac cga aac gcc ctc atc tgg tac cag tac gac ccc acc 912
Pro Ser Asp Tyr Arg Asn Ala Leu Ile Trp Tyr Gln Tyr Asp Pro Thr
290 295 300
aag tgg ctc atc tgg acc ctc aag cag gtt ggt ctc gcc tgg gac ctc 960
Lys Trp Leu Ile Trp Thr Leu Lys Gln Val Gly Leu Ala Trp Asp Leu
305 310 315 320
cag acc ttc tcc cag aac gcc atc gag cag ggt ctc gtg cag cag cga 1008
Gln Thr Phe Ser Gln Asn Ala Ile Glu Gln Gly Leu Val Gln Gln Arg
325 330 335
cag aag aag ctg gac aag tgg cga aac aac ctc aac tgg ggt atc ccc 1056
Gln Lys Lys Leu Asp Lys Trp Arg Asn Asn Leu Asn Trp Gly Ile Pro
340 345 350
att gag cag ctg cct gtc att gag ttt gag gag ttc caa gag cag gcc 1104
Ile Glu Gln Leu Pro Val Ile Glu Phe Glu Glu Phe Gln Glu Gln Ala
355 360 365
aag acc cga gat ctg gtt ctc att tct ggc att gtc cac gac gtg tct 1152
Lys Thr Arg Asp Leu Val Leu Ile Ser Gly Ile Val His Asp Val Ser
370 375 380
gcc ttt gtc gag cac cac cct ggt gga aag gcc ctc att atg agc gcc 1200
Ala Phe Val Glu His His Pro Gly Gly Lys Ala Leu Ile Met Ser Ala
385 390 395 400
gtc ggc aag gac ggt acc gct gtc ttc aac gga ggt gtc tac cga cac 1248
Val Gly Lys Asp Gly Thr Ala Val Phe Asn Gly Gly Val Tyr Arg His
405 410 415
tcc aac gct ggc cac aac ctg ctt gcc acc atg cga gtt tcg gtc att 1296
Ser Asn Ala Gly His Asn Leu Leu Ala Thr Met Arg Val Ser Val Ile
420 425 430
cga ggc ggc atg gag gtt gag gtg tgg aag act gcc cag aac gaa aag 1344
Arg Gly Gly Met Glu Val Glu Val Trp Lys Thr Ala Gln Asn Glu Lys
435 440 445
aag gac cag aac att gtc tcc gat gag agt gga aac cga atc cac cga 1392
Lys Asp Gln Asn Ile Val Ser Asp Glu Ser Gly Asn Arg Ile His Arg
450 455 460
gct ggt ctc cag gcc acc cgg gtc gag aac ccc ggt atg tct ggc atg 1440
Ala Gly Leu Gln Ala Thr Arg Val Glu Asn Pro Gly Met Ser Gly Met
465 470 475 480
gct gct tag 1449
Ala Ala
<210> 92
<211> 482
<212> PRT
<213> Yarrowia lipolytica
<400> 92
Met Val Lys Asn Val Asp Gln Val Asp Leu Ser Gln Val Asp Thr Ile
1 5 10 15
Ala Ser Gly Arg Asp Val Asn Tyr Lys Val Lys Tyr Thr Ser Gly Val
20 25 30
Lys Met Ser Gln Gly Ala Tyr Asp Asp Lys Gly Arg His Ile Ser Glu
35 40 45
Gln Pro Phe Thr Trp Ala Asn Trp His Gln His Ile Asn Trp Leu Asn
50 55 60
Phe Ile Leu Val Ile Ala Leu Pro Leu Ser Ser Phe Ala Ala Ala Pro
65 70 75 80
Phe Val Ser Phe Asn Trp Lys Thr Ala Ala Phe Ala Val Gly Tyr Tyr
85 90 95
Met Cys Thr Gly Leu Gly Ile Thr Ala Gly Tyr His Arg Met Trp Ala
100 105 110
His Arg Ala Tyr Lys Ala Ala Leu Pro Val Arg Ile Ile Leu Ala Leu
115 120 125
Phe Gly Gly Gly Ala Val Glu Gly Ser Ile Arg Trp Trp Ala Ser Ser
130 135 140
His Arg Val His His Arg Trp Thr Asp Ser Asn Lys Asp Pro Tyr Asp
145 150 155 160
Ala Arg Lys Gly Phe Trp Phe Ser His Phe Gly Trp Met Leu Leu Val
165 170 175
Pro Asn Pro Lys Asn Lys Gly Arg Thr Asp Ile Ser Asp Leu Asn Asn
180 185 190
Asp Trp Val Val Arg Leu Gln His Lys Tyr Tyr Val Tyr Val Leu Val
195 200 205
Phe Met Ala Ile Val Leu Pro Thr Leu Val Cys Gly Phe Gly Trp Gly
210 215 220
Asp Trp Lys Gly Gly Leu Val Tyr Ala Gly Ile Met Arg Tyr Thr Phe
225 230 235 240
Val Gln Gln Val Thr Phe Cys Val Asn Ser Leu Ala His Trp Ile Gly
245 250 255
Glu Gln Pro Phe Asp Asp Arg Arg Thr Pro Arg Asp His Ala Leu Thr
260 265 270
Ala Leu Val Thr Phe Gly Glu Gly Tyr His Asn Phe His His Glu Phe
275 280 285
Pro Ser Asp Tyr Arg Asn Ala Leu Ile Trp Tyr Gln Tyr Asp Pro Thr
290 295 300
Lys Trp Leu Ile Trp Thr Leu Lys Gln Val Gly Leu Ala Trp Asp Leu
305 310 315 320
Gln Thr Phe Ser Gln Asn Ala Ile Glu Gln Gly Leu Val Gln Gln Arg
325 330 335
Gln Lys Lys Leu Asp Lys Trp Arg Asn Asn Leu Asn Trp Gly Ile Pro
340 345 350
Ile Glu Gln Leu Pro Val Ile Glu Phe Glu Glu Phe Gln Glu Gln Ala
355 360 365
Lys Thr Arg Asp Leu Val Leu Ile Ser Gly Ile Val His Asp Val Ser
370 375 380
Ala Phe Val Glu His His Pro Gly Gly Lys Ala Leu Ile Met Ser Ala
385 390 395 400
Val Gly Lys Asp Gly Thr Ala Val Phe Asn Gly Gly Val Tyr Arg His
405 410 415
Ser Asn Ala Gly His Asn Leu Leu Ala Thr Met Arg Val Ser Val Ile
420 425 430
Arg Gly Gly Met Glu Val Glu Val Trp Lys Thr Ala Gln Asn Glu Lys
435 440 445
Lys Asp Gln Asn Ile Val Ser Asp Glu Ser Gly Asn Arg Ile His Arg
450 455 460
Ala Gly Leu Gln Ala Thr Arg Val Glu Asn Pro Gly Met Ser Gly Met
465 470 475 480
Ala Ala
<210> 93
<211> 1101
<212> DNA
<213> Yarrowia lipolytica
<220>
<221> CDS
<222> (1)..(1101)
<223> choline-phosphate cytidylyl-transferase; GenBank Accession No.
XM_502978
<400> 93
atg gcc aaa agc aaa cga cgg tcg gag gct gtg gaa gag cac gtg acc 48
Met Ala Lys Ser Lys Arg Arg Ser Glu Ala Val Glu Glu His Val Thr
1 5 10 15
ggc tcg gac gag ggc ttg acc gat act tcg ggt cac gtg agc cct gcc 96
Gly Ser Asp Glu Gly Leu Thr Asp Thr Ser Gly His Val Ser Pro Ala
20 25 30
gcc aag aag cag aag aac tcg gag att cat ttc acc acc cag gct gcc 144
Ala Lys Lys Gln Lys Asn Ser Glu Ile His Phe Thr Thr Gln Ala Ala
35 40 45
cag cag ttg gat cgg gag cgc aag gag gag tat ctg gac tcg ctg atc 192
Gln Gln Leu Asp Arg Glu Arg Lys Glu Glu Tyr Leu Asp Ser Leu Ile
50 55 60
gac aac aag gac tat ctc aag tac cgt cct cga ggc tgg aag ctc aac 240
Asp Asn Lys Asp Tyr Leu Lys Tyr Arg Pro Arg Gly Trp Lys Leu Asn
65 70 75 80
aac ccg cct acc gac cga cct gtg cga atc tac gcc gat gga gtg ttt 288
Asn Pro Pro Thr Asp Arg Pro Val Arg Ile Tyr Ala Asp Gly Val Phe
85 90 95
gat ttg ttc cat ctg gga cac atg cgt cag ctg gag cag tcc aag aag 336
Asp Leu Phe His Leu Gly His Met Arg Gln Leu Glu Gln Ser Lys Lys
100 105 110
gcc ttc ccc aac gca gtg ttg att gtg ggc att ccc agc gac aag gag 384
Ala Phe Pro Asn Ala Val Leu Ile Val Gly Ile Pro Ser Asp Lys Glu
115 120 125
acc cac aag cgg aag gga ttg acc gtg ctg agt gac gtc cag cgg tac 432
Thr His Lys Arg Lys Gly Leu Thr Val Leu Ser Asp Val Gln Arg Tyr
130 135 140
gag acg gtg cga cac tgc aag tgg gtg gac gag gtg gtg gag gat gct 480
Glu Thr Val Arg His Cys Lys Trp Val Asp Glu Val Val Glu Asp Ala
145 150 155 160
ccc tgg tgt gtc acc atg gac ttt ctg gaa aaa cac aaa atc gac tac 528
Pro Trp Cys Val Thr Met Asp Phe Leu Glu Lys His Lys Ile Asp Tyr
165 170 175
gtg gcc cat gac gat ctg ccc tac gct tcc ggc aac gac gat gat atc 576
Val Ala His Asp Asp Leu Pro Tyr Ala Ser Gly Asn Asp Asp Asp Ile
180 185 190
tac aag ccc atc aag gag aag ggc atg ttt ctg gcc acc cag cga acc 624
Tyr Lys Pro Ile Lys Glu Lys Gly Met Phe Leu Ala Thr Gln Arg Thr
195 200 205
gag ggc att tcc acc tcg gac atc atc acc aag att atc cga gac tac 672
Glu Gly Ile Ser Thr Ser Asp Ile Ile Thr Lys Ile Ile Arg Asp Tyr
210 215 220
gac aag tat tta atg cga aac ttt gcc cgg ggt gct aac cga aag gat 720
Asp Lys Tyr Leu Met Arg Asn Phe Ala Arg Gly Ala Asn Arg Lys Asp
225 230 235 240
ctc aac gtc tcg tgg ctc aag aag aac gag ctg gac ttc aag cgt cat 768
Leu Asn Val Ser Trp Leu Lys Lys Asn Glu Leu Asp Phe Lys Arg His
245 250 255
gtg gcc gag ttc cga aac tcg ttc aag cga aag aag gtc ggt aag gat 816
Val Ala Glu Phe Arg Asn Ser Phe Lys Arg Lys Lys Val Gly Lys Asp
260 265 270
ctc tac ggc gag att cgc ggt ctg ctg cag aat gtg ctc att tgg aac 864
Leu Tyr Gly Glu Ile Arg Gly Leu Leu Gln Asn Val Leu Ile Trp Asn
275 280 285
ggc gac aac tcc ggc act tcc act ccc cag cga aag acg ctg cag acc 912
Gly Asp Asn Ser Gly Thr Ser Thr Pro Gln Arg Lys Thr Leu Gln Thr
290 295 300
aac gcc aag aag atg tac atg aac gtg ctc aag act ctg cag gct cct 960
Asn Ala Lys Lys Met Tyr Met Asn Val Leu Lys Thr Leu Gln Ala Pro
305 310 315 320
gac gct gtt gac gtg gac tcc tcg gag aac gtg tct gag aac gtc act 1008
Asp Ala Val Asp Val Asp Ser Ser Glu Asn Val Ser Glu Asn Val Thr
325 330 335
gat gag gag gag gaa gac gac gac gag gtt gat gag gac gaa gaa gcc 1056
Asp Glu Glu Glu Glu Asp Asp Asp Glu Val Asp Glu Asp Glu Glu Ala
340 345 350
gac gac gac gac gaa gac gac gaa gac gag gaa gac gac gag tag 1101
Asp Asp Asp Asp Glu Asp Asp Glu Asp Glu Glu Asp Asp Glu
355 360 365
<210> 94
<211> 366
<212> PRT
<213> Yarrowia lipolytica
<400> 94
Met Ala Lys Ser Lys Arg Arg Ser Glu Ala Val Glu Glu His Val Thr
1 5 10 15
Gly Ser Asp Glu Gly Leu Thr Asp Thr Ser Gly His Val Ser Pro Ala
20 25 30
Ala Lys Lys Gln Lys Asn Ser Glu Ile His Phe Thr Thr Gln Ala Ala
35 40 45
Gln Gln Leu Asp Arg Glu Arg Lys Glu Glu Tyr Leu Asp Ser Leu Ile
50 55 60
Asp Asn Lys Asp Tyr Leu Lys Tyr Arg Pro Arg Gly Trp Lys Leu Asn
65 70 75 80
Asn Pro Pro Thr Asp Arg Pro Val Arg Ile Tyr Ala Asp Gly Val Phe
85 90 95
Asp Leu Phe His Leu Gly His Met Arg Gln Leu Glu Gln Ser Lys Lys
100 105 110
Ala Phe Pro Asn Ala Val Leu Ile Val Gly Ile Pro Ser Asp Lys Glu
115 120 125
Thr His Lys Arg Lys Gly Leu Thr Val Leu Ser Asp Val Gln Arg Tyr
130 135 140
Glu Thr Val Arg His Cys Lys Trp Val Asp Glu Val Val Glu Asp Ala
145 150 155 160
Pro Trp Cys Val Thr Met Asp Phe Leu Glu Lys His Lys Ile Asp Tyr
165 170 175
Val Ala His Asp Asp Leu Pro Tyr Ala Ser Gly Asn Asp Asp Asp Ile
180 185 190
Tyr Lys Pro Ile Lys Glu Lys Gly Met Phe Leu Ala Thr Gln Arg Thr
195 200 205
Glu Gly Ile Ser Thr Ser Asp Ile Ile Thr Lys Ile Ile Arg Asp Tyr
210 215 220
Asp Lys Tyr Leu Met Arg Asn Phe Ala Arg Gly Ala Asn Arg Lys Asp
225 230 235 240
Leu Asn Val Ser Trp Leu Lys Lys Asn Glu Leu Asp Phe Lys Arg His
245 250 255
Val Ala Glu Phe Arg Asn Ser Phe Lys Arg Lys Lys Val Gly Lys Asp
260 265 270
Leu Tyr Gly Glu Ile Arg Gly Leu Leu Gln Asn Val Leu Ile Trp Asn
275 280 285
Gly Asp Asn Ser Gly Thr Ser Thr Pro Gln Arg Lys Thr Leu Gln Thr
290 295 300
Asn Ala Lys Lys Met Tyr Met Asn Val Leu Lys Thr Leu Gln Ala Pro
305 310 315 320
Asp Ala Val Asp Val Asp Ser Ser Glu Asn Val Ser Glu Asn Val Thr
325 330 335
Asp Glu Glu Glu Glu Asp Asp Asp Glu Val Asp Glu Asp Glu Glu Ala
340 345 350
Asp Asp Asp Asp Glu Asp Asp Glu Asp Glu Glu Asp Asp Glu
355 360 365
<210> 95
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> misc_feature
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-L35G"
<400> 95
atggaggtcg tgaacgaaat cgtctccatt ggccaggagg ttcttcccaa ggtcgactat 60
gctcagctct ggtctgatgc ctcgcactgc gaggtgctgt acggatccat cgccttcgtc 120
atcctgaagt tcacccttgg tcctctcgga cccaagggtc agtctcgaat gaagtttgtg 180
ttcaccaact acaacctgct catgtccatc tactcgctgg gctccttcct ctctatggcc 240
tacgccatgt acaccattgg tgtcatgtcc gacaactgcg agaaggcttt cgacaacaat 300
gtcttccgaa tcaccactca gctgttctac ctcagcaagt tcctcgagta cattgactcc 360
ttctatctgc ccctcatggg caagcctctg acctggttgc agttctttca ccatctcgga 420
gctcctatgg acatgtggct gttctacaac taccgaaacg aagccgtttg gatctttgtg 480
ctgctcaacg gcttcattca ctggatcatg tacggctact attggacccg actgatcaag 540
ctcaagttcc ctatgcccaa gtccctgatt acttctatgc agatcattca gttcaacgtt 600
ggcttctaca tcgtctggaa gtaccggaac attccctgct accgacaaga tggaatgaga 660
atgtttggct ggtttttcaa ctacttctac gttggtactg tcctgtgtct gttcctcaac 720
ttctacgtgc agacctacat cgtccgaaag cacaagggag ccaaaaagat tcagtga 777
<210> 96
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> misc_feature
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-L35G"
<400> 96
atggaggtcg tgaacgaaat cgtctccatt ggccaggagg ttcttcccaa ggtcgactat 60
gctcagctct ggtctgatgc ctcgcactgc gaggtgctgt acggctccat cgccttcgtc 120
atcctgaagt tcacccttgg tcctctcgga cccaagggtc agtctcgaat gaagtttgtg 180
ttcaccaact acaacctgct catgtccatc tactcgctgg gctccttcct ctctatggcc 240
tacgccatgt acaccattgg tgtcatgtcc gacaactgcg agaaggcttt cgacaacaat 300
gtcttccgaa tcaccactca gctgttctac ctcagcaagt tcctcgagta cattgactcc 360
ttctatctgc ccctcatggg caagcctctg acctggttgc agttctttca ccatctcgga 420
gctcctatgg acatgtggct gttctacaac taccgaaacg aagccgtttg gatctttgtg 480
ctgctcaacg gcttcattca ctggatcatg tacggctact attggacccg actgatcaag 540
ctcaagttcc ctatgcccaa gtccctgatt acttctatgc agatcattca gttcaacgtt 600
ggcttctaca tcgtctggaa gtaccggaac attccctgct accgacaaga tggaatgaga 660
atgtttggct ggtttttcaa ctacttctac gttggtactg tcctgtgtct gttcctcaac 720
ttctacgtgc agacctacat cgtccgaaag cacaagggag ccaaaaagat tcagtga 777
<210> 97
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> misc_feature
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-L35G"
<400> 97
atggaggtcg tgaacgaaat cgtctccatt ggccaggagg ttcttcccaa ggtcgactat 60
gctcagctct ggtctgatgc ctcgcactgc gaggtgctgt acggttccat cgccttcgtc 120
atcctgaagt tcacccttgg tcctctcgga cccaagggtc agtctcgaat gaagtttgtg 180
ttcaccaact acaacctgct catgtccatc tactcgctgg gctccttcct ctctatggcc 240
tacgccatgt acaccattgg tgtcatgtcc gacaactgcg agaaggcttt cgacaacaat 300
gtcttccgaa tcaccactca gctgttctac ctcagcaagt tcctcgagta cattgactcc 360
ttctatctgc ccctcatggg caagcctctg acctggttgc agttctttca ccatctcgga 420
gctcctatgg acatgtggct gttctacaac taccgaaacg aagccgtttg gatctttgtg 480
ctgctcaacg gcttcattca ctggatcatg tacggctact attggacccg actgatcaag 540
ctcaagttcc ctatgcccaa gtccctgatt acttctatgc agatcattca gttcaacgtt 600
ggcttctaca tcgtctggaa gtaccggaac attccctgct accgacaaga tggaatgaga 660
atgtttggct ggtttttcaa ctacttctac gttggtactg tcctgtgtct gttcctcaac 720
ttctacgtgc agacctacat cgtccgaaag cacaagggag ccaaaaagat tcagtga 777
<210> 98
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer FBAIN-F
<400> 98
caagcggggg gcttgtctag ggtat 25
<210> 99
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer Y1026
<400> 99
tttgcggccg ctcactgaat ctttttggct cccttgtgct 40
<210> 100
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-L35G/W132T/I179R"
<400> 100
atg gag gtc gtg aac gaa atc gtc tcc att ggc cag gag gtt ctt ccc 48
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aag gtc gac tat gct cag ctc tgg tct gat gcc tcg cac tgc gag gtg 96
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctg tac ggg tcc atc gcc ttc gtc atc ctg aag ttc acc ctt ggt cct 144
Leu Tyr Gly Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctc gga ccc aag ggt cag tct cga atg aag ttt gtg ttc acc aac tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
aac ctg ctc atg tcc atc tac tcg ctg ggc tcc ttc ctc tct atg gcc 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tac gcc atg tac acc att ggt gtc atg tcc gac aac tgc gag aag gct 288
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttc gac aac aat gtc ttc cga atc acc act cag ctg ttc tac ctc agc 336
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc ctc gag tac att gac tcc ttc tat ctg ccc ctc atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct ctg acc acc ttg cag ttc ttt cac cat ctc gga gct cct atg gac 432
Pro Leu Thr Thr Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tac aac tac cga aac gaa gcc gtt tgg atc ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggc tac tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctg cga aag ctc aag ttc cct atg ccc aag tcc ctg att act tct 576
Arg Leu Arg Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att cag ttc aac gtt ggc ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgg aac att ccc tgc tac cga caa gat gga atg aga atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttt ttc aac tac ttc tac gtt ggt act gtc ctg tgt ctg ttc ctc aac 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tac gtg cag acc tac atc gtc cga aag cac aag gga gcc aaa aag 768
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
att cag tga 777
Ile Gln
<210> 101
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 101
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Gly Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Leu Thr Thr Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Arg Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 102
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid EgD9eS-L35G/W132T/I179R
<400> 102
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtcg tgaacgaaat cgtctccatt 7020
ggccaggagg ttcttcccaa ggtcgactat gctcagctct ggtctgatgc ctcgcactgc 7080
gaggtgctgt acgggtccat cgccttcgtc atcctgaagt tcacccttgg tcctctcgga 7140
cccaagggtc agtctcgaat gaagtttgtg ttcaccaact acaacctgct catgtccatc 7200
tactcgctgg gctccttcct ctctatggcc tacgccatgt acaccattgg tgtcatgtcc 7260
gacaactgcg agaaggcttt cgacaacaat gtcttccgaa tcaccactca gctgttctac 7320
ctcagcaagt tcctcgagta cattgactcc ttctatctgc ccctcatggg caagcctctg 7380
accaccttgc agttctttca ccatctcgga gctcctatgg acatgtggct gttctacaac 7440
taccgaaacg aagccgtttg gatctttgtg ctgctcaacg gcttcattca ctggatcatg 7500
tacggctact attggacccg actgcgaaag ctcaagttcc ctatgcccaa gtccctgatt 7560
acttctatgc agatcattca gttcaacgtt ggcttctaca tcgtctggaa gtaccggaac 7620
attccctgct accgacaaga tggaatgaga atgtttggct ggtttttcaa ctacttctac 7680
gttggtactg tcctgtgtct gttcctcaac ttctacgtgc agacctacat cgtccgaaag 7740
cacaagggag ccaaaaagat tcagtgagc 7769
<210> 103
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-S9D/L35G/Y84C/I179R"
<400> 103
atg gag gtc gtg aac gaa atc gtc gac att ggc cag gag gtt ctt ccc 48
Met Glu Val Val Asn Glu Ile Val Asp Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aag gtc gac tat gct cag ctc tgg tct gat gcc tcg cac tgc gag gtg 96
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctg tac ggg tcc atc gcc ttc gtc atc ctg aag ttc acc ctt ggt cct 144
Leu Tyr Gly Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctc gga ccc aag ggt cag tct cga atg aag ttt gtg ttc acc aac tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
aac ctg ctc atg tcc atc tac tcg ctg ggc tcc ttc ctc tct atg gcc 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tac gcc atg tgt acc att ggt gtc atg tcc gac aac tgc gag aag gct 288
Tyr Ala Met Cys Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttc gac aac aat gtc ttc cga atc acc act cag ctg ttc tac ctc agc 336
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc ctc gag tac att gac tcc ttc tat ctg ccc ctc atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct ctg acc tgg ttg cag ttc ttt cac cat ctc gga gct cct atg gac 432
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tac aac tac cga aac gaa gcc gtt tgg atc ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggc tac tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctg cga aag ctc aag ttc cct atg ccc aag tcc ctg att act tct 576
Arg Leu Arg Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att cag ttc aac gtt ggc ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgg aac att ccc tgc tac cga caa gat gga atg aga atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttt ttc aac tac ttc tac gtt ggt act gtc ctg tgt ctg ttc ctc aac 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tac gtg cag acc tac atc gtc cga aag cac aag gga gcc aaa aag 768
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
att cag tga 777
Ile Gln
<210> 104
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 104
Met Glu Val Val Asn Glu Ile Val Asp Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Gly Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Cys Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Arg Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 105
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid EgD9eS-S9D/L35G/Y84C/I179R
<400> 105
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtcg tgaacgaaat cgtcgacatt 7020
ggccaggagg ttcttcccaa ggtcgactat gctcagctct ggtctgatgc ctcgcactgc 7080
gaggtgctgt acgggtccat cgccttcgtc atcctgaagt tcacccttgg tcctctcgga 7140
cccaagggtc agtctcgaat gaagtttgtg ttcaccaact acaacctgct catgtccatc 7200
tactcgctgg gctccttcct ctctatggcc tacgccatgt gtaccattgg tgtcatgtcc 7260
gacaactgcg agaaggcttt cgacaacaat gtcttccgaa tcaccactca gctgttctac 7320
ctcagcaagt tcctcgagta cattgactcc ttctatctgc ccctcatggg caagcctctg 7380
acctggttgc agttctttca ccatctcgga gctcctatgg acatgtggct gttctacaac 7440
taccgaaacg aagccgtttg gatctttgtg ctgctcaacg gcttcattca ctggatcatg 7500
tacggctact attggacccg actgcgaaag ctcaagttcc ctatgcccaa gtccctgatt 7560
acttctatgc agatcattca gttcaacgtt ggcttctaca tcgtctggaa gtaccggaac 7620
attccctgct accgacaaga tggaatgaga atgtttggct ggtttttcaa ctacttctac 7680
gttggtactg tcctgtgtct gttcctcaac ttctacgtgc agacctacat cgtccgaaag 7740
cacaagggag ccaaaaagat tcagtgagc 7769
<210> 106
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-L35G/Y84C/I179R/Q244N"
<400> 106
atg gag gtc gtg aac gaa atc gtc tcc att ggc cag gag gtt ctt ccc 48
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aag gtc gac tat gct cag ctc tgg tct gat gcc tcg cac tgc gag gtg 96
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctg tac ggg tcc atc gcc ttc gtc atc ctg aag ttc acc ctt ggt cct 144
Leu Tyr Gly Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctc gga ccc aag ggt cag tct cga atg aag ttt gtg ttc acc aac tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
aac ctg ctc atg tcc atc tac tcg ctg ggc tcc ttc ctc tct atg gcc 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tac gcc atg tgt acc att ggt gtc atg tcc gac aac tgc gag aag gct 288
Tyr Ala Met Cys Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttc gac aac aat gtc ttc cga atc acc act cag ctg ttc tac ctc agc 336
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc ctc gag tac att gac tcc ttc tat ctg ccc ctc atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct ctg acc tgg ttg cag ttc ttt cac cat ctc gga gct cct atg gac 432
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tac aac tac cga aac gaa gcc gtt tgg atc ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggc tac tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctg cga aag ctc aag ttc cct atg ccc aag tcc ctg att act tct 576
Arg Leu Arg Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att cag ttc aac gtt ggc ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgg aac att ccc tgc tac cga caa gat gga atg aga atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttt ttc aac tac ttc tac gtt ggt act gtc ctg tgt ctg ttc ctc aac 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tac gtg aac acc tac atc gtc cga aag cac aag gga gcc aaa aag 768
Phe Tyr Val Asn Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
att cag tga 777
Ile Gln
<210> 107
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 107
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Gly Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Cys Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Arg Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Asn Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 108
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid EgD9eS-L35G/Y84C/I179R/Q244N
<400> 108
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtcg tgaacgaaat cgtctccatt 7020
ggccaggagg ttcttcccaa ggtcgactat gctcagctct ggtctgatgc ctcgcactgc 7080
gaggtgctgt acgggtccat cgccttcgtc atcctgaagt tcacccttgg tcctctcgga 7140
cccaagggtc agtctcgaat gaagtttgtg ttcaccaact acaacctgct catgtccatc 7200
tactcgctgg gctccttcct ctctatggcc tacgccatgt gtaccattgg tgtcatgtcc 7260
gacaactgcg agaaggcttt cgacaacaat gtcttccgaa tcaccactca gctgttctac 7320
ctcagcaagt tcctcgagta cattgactcc ttctatctgc ccctcatggg caagcctctg 7380
acctggttgc agttctttca ccatctcgga gctcctatgg acatgtggct gttctacaac 7440
taccgaaacg aagccgtttg gatctttgtg ctgctcaacg gcttcattca ctggatcatg 7500
tacggctact attggacccg actgcgaaag ctcaagttcc ctatgcccaa gtccctgatt 7560
acttctatgc agatcattca gttcaacgtt ggcttctaca tcgtctggaa gtaccggaac 7620
attccctgct accgacaaga tggaatgaga atgtttggct ggtttttcaa ctacttctac 7680
gttggtactg tcctgtgtct gttcctcaac ttctacgtga acacctacat cgtccgaaag 7740
cacaagggag ccaaaaagat tcagtgagc 7769
<210> 109
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-A21V/L35G/W132T/I179R/Q244N"
<400> 109
atg gag gtc gtg aac gaa atc gtc tcc att ggc cag gag gtt ctt ccc 48
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aag gtc gac tat gtg cag ctc tgg tct gat gcc tcg cac tgc gag gtg 96
Lys Val Asp Tyr Val Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctg tac ggg tcc atc gcc ttc gtc atc ctg aag ttc acc ctt ggt cct 144
Leu Tyr Gly Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctc gga ccc aag ggt cag tct cga atg aag ttt gtg ttc acc aac tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
aac ctg ctc atg tcc atc tac tcg ctg ggc tcc ttc ctc tct atg gcc 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tac gcc atg tac acc att ggt gtc atg tcc gac aac tgc gag aag gct 288
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttc gac aac aat gtc ttc cga atc acc act cag ctg ttc tac ctc agc 336
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc ctc gag tac att gac tcc ttc tat ctg ccc ctc atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct ctg acc acc ttg cag ttc ttt cac cat ctc gga gct cct atg gac 432
Pro Leu Thr Thr Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tac aac tac cga aac gaa gcc gtt tgg atc ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggc tac tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctg cga aag ctc aag ttc cct atg ccc aag tcc ctg att act tct 576
Arg Leu Arg Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att cag ttc aac gtt ggc ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgg aac att ccc tgc tac cga caa gat gga atg aga atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttt ttc aac tac ttc tac gtt ggt act gtc ctg tgt ctg ttc ctc aac 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tac gtg aac acc tac atc gtc cga aag cac aag gga gcc aaa aag 768
Phe Tyr Val Asn Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
att cag tga 777
Ile Gln
<210> 110
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 110
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Val Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Gly Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Leu Thr Thr Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Arg Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Asn Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 111
<211> 7769
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid EgD9eS-A21V/L35G/W132T/I179R/Q244N
<400> 111
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgagccggaa gcataaagtg taaagcctgg ggtgcctaat 360
gagtgagcta actcacatta attgcgttgc gctcactgcc cgctttccag tcgggaaacc 420
tgtcgtgcca gctgcattaa tgaatcggcc aacgcgcggg gagaggcggt ttgcgtattg 480
ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg ctgcggcgag 540
cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg gataacgcag 600
gaaagaacat gtgagcaaaa ggccagcaaa aggccaggaa ccgtaaaaag gccgcgttgc 660
tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga cgctcaagtc 720
agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggaagctccc 780
tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc tttctccctt 840
cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg gtgtaggtcg 900
ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc tgcgccttat 960
ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca ctggcagcag 1020
ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag ttcttgaagt 1080
ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct ctgctgaagc 1140
cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc accgctggta 1200
gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga tctcaagaag 1260
atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca cgttaaggga 1320
ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat taaaaatgaa 1380
gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac caatgcttaa 1440
tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt gcctgactcc 1500
ccgtcgtgta gataactacg atacgggagg gcttaccatc tggccccagt gctgcaatga 1560
taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag ccagccggaa 1620
gggccgagcg cagaagtggt cctgcaactt tatccgcctc catccagtct attaattgtt 1680
gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt gttgccattg 1740
ctacaggcat cgtggtgtca cgctcgtcgt ttggtatggc ttcattcagc tccggttccc 1800
aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt agctccttcg 1860
gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg gttatggcag 1920
cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg actggtgagt 1980
actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct tgcccggcgt 2040
caatacggga taataccgcg ccacatagca gaactttaaa agtgctcatc attggaaaac 2100
gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt tcgatgtaac 2160
ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt tctgggtgag 2220
caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg aaatgttgaa 2280
tactcatact cttccttttt caatattatt gaagcattta tcagggttat tgtctcatga 2340
gcggatacat atttgaatgt atttagaaaa ataaacaaat aggggttccg cgcacatttc 2400
cccgaaaagt gccacctgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg 2460
ttacgcgcag cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct 2520
tcccttcctt tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc 2580
ctttagggtt ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg 2640
atggttcacg tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt 2700
ccacgttctt taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg 2760
tctattcttt tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc 2820
tgatttaaca aaaatttaac gcgaatttta acaaaatatt aacgcttaca atttccattc 2880
gccattcagg ctgcgcaact gttgggaagg gcgatcggtg cgggcctctt cgctattacg 2940
ccagctggcg aaagggggat gtgctgcaag gcgattaagt tgggtaacgc cagggttttc 3000
ccagtcacga cgttgtaaaa cgacggccag tgaattgtaa tacgactcac tatagggcga 3060
attgggtacc gggccccccc tcgaggtcga tggtgtcgat aagcttgata tcgaattcat 3120
gtcacacaaa ccgatcttcg cctcaaggaa acctaattct acatccgaga gactgccgag 3180
atccagtcta cactgattaa ttttcgggcc aataatttaa aaaaatcgtg ttatataata 3240
ttatatgtat tatatatata catcatgatg atactgacag tcatgtccca ttgctaaata 3300
gacagactcc atctgccgcc tccaactgat gttctcaata tttaaggggt catctcgcat 3360
tgtttaataa taaacagact ccatctaccg cctccaaatg atgttctcaa aatatattgt 3420
atgaacttat ttttattact tagtattatt agacaactta cttgctttat gaaaaacact 3480
tcctatttag gaaacaattt ataatggcag ttcgttcatt taacaattta tgtagaataa 3540
atgttataaa tgcgtatggg aaatcttaaa tatggatagc ataaatgata tctgcattgc 3600
ctaattcgaa atcaacagca acgaaaaaaa tcccttgtac aacataaata gtcatcgaga 3660
aatatcaact atcaaagaac agctattcac acgttactat tgagattatt attggacgag 3720
aatcacacac tcaactgtct ttctctcttc tagaaataca ggtacaagta tgtactattc 3780
tcattgttca tacttctagt catttcatcc cacatattcc ttggatttct ctccaatgaa 3840
tgacattcta tcttgcaaat tcaacaatta taataagata taccaaagta gcggtatagt 3900
ggcaatcaaa aagcttctct ggtgtgcttc tcgtatttat ttttattcta atgatccatt 3960
aaaggtatat atttatttct tgttatataa tccttttgtt tattacatgg gctggataca 4020
taaaggtatt ttgatttaat tttttgctta aattcaatcc cccctcgttc agtgtcaact 4080
gtaatggtag gaaattacca tacttttgaa gaagcaaaaa aaatgaaaga aaaaaaaaat 4140
cgtatttcca ggttagacgt tccgcagaat ctagaatgcg gtatgcggta cattgttctt 4200
cgaacgtaaa agttgcgctc cctgagatat tgtacatttt tgcttttaca agtacaagta 4260
catcgtacaa ctatgtacta ctgttgatgc atccacaaca gtttgttttg tttttttttg 4320
tttttttttt ttctaatgat tcattaccgc tatgtatacc tacttgtact tgtagtaagc 4380
cgggttattg gcgttcaatt aatcatagac ttatgaatct gcacggtgtg cgctgcgagt 4440
tacttttagc ttatgcatgc tacttgggtg taatattggg atctgttcgg aaatcaacgg 4500
atgctcaatc gatttcgaca gtaattaatt aagtcataca caagtcagct ttcttcgagc 4560
ctcatataag tataagtagt tcaacgtatt agcactgtac ccagcatctc cgtatcgaga 4620
aacacaacaa catgccccat tggacagatc atgcggatac acaggttgtg cagtatcata 4680
catactcgat cagacaggtc gtctgaccat catacaagct gaacaagcgc tccatacttg 4740
cacgctctct atatacacag ttaaattaca tatccatagt ctaacctcta acagttaatc 4800
ttctggtaag cctcccagcc agccttctgg tatcgcttgg cctcctcaat aggatctcgg 4860
ttctggccgt acagacctcg gccgacaatt atgatatccg ttccggtaga catgacatcc 4920
tcaacagttc ggtactgctg tccgagagcg tctcccttgt cgtcaagacc caccccgggg 4980
gtcagaataa gccagtcctc agagtcgccc ttaggtcggt tctgggcaat gaagccaacc 5040
acaaactcgg ggtcggatcg ggcaagctca atggtctgct tggagtactc gccagtggcc 5100
agagagccct tgcaagacag ctcggccagc atgagcagac ctctggccag cttctcgttg 5160
ggagagggga ctaggaactc cttgtactgg gagttctcgt agtcagagac gtcctccttc 5220
ttctgttcag agacagtttc ctcggcacca gctcgcaggc cagcaatgat tccggttccg 5280
ggtacaccgt gggcgttggt gatatcggac cactcggcga ttcggtgaca ccggtactgg 5340
tgcttgacag tgttgccaat atctgcgaac tttctgtcct cgaacaggaa gaaaccgtgc 5400
ttaagagcaa gttccttgag ggggagcaca gtgccggcgt aggtgaagtc gtcaatgatg 5460
tcgatatggg ttttgatcat gcacacataa ggtccgacct tatcggcaag ctcaatgagc 5520
tccttggtgg tggtaacatc cagagaagca cacaggttgg ttttcttggc tgccacgagc 5580
ttgagcactc gagcggcaaa ggcggacttg tggacgttag ctcgagcttc gtaggagggc 5640
attttggtgg tgaagaggag actgaaataa atttagtctg cagaactttt tatcggaacc 5700
ttatctgggg cagtgaagta tatgttatgg taatagttac gagttagttg aacttataga 5760
tagactggac tatacggcta tcggtccaaa ttagaaagaa cgtcaatggc tctctgggcg 5820
tcgcctttgc cgacaaaaat gtgatcatga tgaaagccag caatgacgtt gcagctgata 5880
ttgttgtcgg ccaaccgcgc cgaaaacgca gctgtcagac ccacagcctc caacgaagaa 5940
tgtatcgtca aagtgatcca agcacactca tagttggagt cgtactccaa aggcggcaat 6000
gacgagtcag acagatactc gtcgacgttt aaacagtgta cgcagatcta ctatagagga 6060
acatttaaat tgccccggag aagacggcca ggccgcctag atgacaaatt caacaactca 6120
cagctgactt tctgccattg ccactagggg ggggcctttt tatatggcca agccaagctc 6180
tccacgtcgg ttgggctgca cccaacaata aatgggtagg gttgcaccaa caaagggatg 6240
ggatgggggg tagaagatac gaggataacg gggctcaatg gcacaaataa gaacgaatac 6300
tgccattaag actcgtgatc cagcgactga caccattgca tcatctaagg gcctcaaaac 6360
tacctcggaa ctgctgcgct gatctggaca ccacagaggt tccgagcact ttaggttgca 6420
ccaaatgtcc caccaggtgc aggcagaaaa cgctggaaca gcgtgtacag tttgtcttaa 6480
caaaaagtga gggcgctgag gtcgagcagg gtggtgtgac ttgttatagc ctttagagct 6540
gcgaaagcgc gtatggattt ggctcatcag gccagattga gggtctgtgg acacatgtca 6600
tgttagtgta cttcaatcgc cccctggata tagccccgac aataggccgt ggcctcattt 6660
ttttgccttc cgcacatttc cattgctcga tacccacacc ttgcttctcc tgcacttgcc 6720
aaccttaata ctggtttaca ttgaccaaca tcttacaagc ggggggcttg tctagggtat 6780
atataaacag tggctctccc aatcggttgc cagtctcttt tttcctttct ttccccacag 6840
attcgaaatc taaactacac atcacagaat tccgagccgt gagtatccac gacaagatca 6900
gtgtcgagac gacgcgtttt gtgtaatgac acaatccgaa agtcgctagc aacacacact 6960
ctctacacaa actaacccag ctctggtacc atggaggtcg tgaacgaaat cgtctccatt 7020
ggccaggagg ttcttcccaa ggtcgactat gtgcagctct ggtctgatgc ctcgcactgc 7080
gaggtgctgt acgggtccat cgccttcgtc atcctgaagt tcacccttgg tcctctcgga 7140
cccaagggtc agtctcgaat gaagtttgtg ttcaccaact acaacctgct catgtccatc 7200
tactcgctgg gctccttcct ctctatggcc tacgccatgt acaccattgg tgtcatgtcc 7260
gacaactgcg agaaggcttt cgacaacaat gtcttccgaa tcaccactca gctgttctac 7320
ctcagcaagt tcctcgagta cattgactcc ttctatctgc ccctcatggg caagcctctg 7380
accaccttgc agttctttca ccatctcgga gctcctatgg acatgtggct gttctacaac 7440
taccgaaacg aagccgtttg gatctttgtg ctgctcaacg gcttcattca ctggatcatg 7500
tacggctact attggacccg actgcgaaag ctcaagttcc ctatgcccaa gtccctgatt 7560
acttctatgc agatcattca gttcaacgtt ggcttctaca tcgtctggaa gtaccggaac 7620
attccctgct accgacaaga tggaatgaga atgtttggct ggtttttcaa ctacttctac 7680
gttggtactg tcctgtgtct gttcctcaac ttctacgtga acacctacat cgtccgaaag 7740
cacaagggag ccaaaaagat tcagtgagc 7769
Claims (18)
- (a) 델타-9 연장효소(elongase) 활성을 가지며, 서열 번호 22에 기재된 아미노산 서열을 갖는 돌연변이 폴리펩티드를 암호화하는 뉴클레오티드 서열로서, 서열 번호 22가 적어도 하나의 아미노산 돌연변이에 의해 서열 번호 10과 상이하며, 상기 돌연변이(들)가
i) L35F 돌연변이;
ii) L35M 돌연변이;
iii) L35G 돌연변이;
iv) L35G 돌연변이, 및 S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, Q107E, L108G, G127L, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, Q244N, A254W 및 A254Y로 이루어진 군으로부터 선택되는 적어도 하나의 다른 돌연변이;
v) L35G, A21V, L108G 및 I179R 돌연변이;
vi) L35G, W132T 및 I179 돌연변이;
vii) L35G, S9D, Y84C 및 I179R 돌연변이;
viii) L35G, Y84C, I179R 및 Q244N 돌연변이;
ix) L35G, A21V, W132T, I179R 및 Q244N 돌연변이;
x) K58R 및 I257T 돌연변이;
xi) D98G 돌연변이;
xii) L130M 및 V243A 돌연변이; 및
i) K58R, L35F, L35G, L35M, S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, D98G, Q107E, L108G, G127L, L130M, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, V243A, Q244N, A254W, A254Y 및 I257T로 이루어진 군으로부터 선택되는 적어도 2개의 돌연변이를 포함하는 임의의 조합으로 이루어진 군으로부터 선택되는 뉴클레오티드 서열; 및
(b) 파트 (a)의 뉴클레오티드 서열의 상보체로서, 상보체와 파트 (a)의 뉴클레오티드 서열이 동일한 개수의 뉴클레오티드로 이루어져 있으며, 100% 상보성인 파트 (a)의 뉴클레오티드 서열의 상보체를 포함하는 분리된 폴리뉴클레오티드. - 제1항에 있어서, 뉴클레오티드 서열이 서열 번호 28, 서열 번호 31, 서열 번호 34, 서열 번호 37, 서열 번호 40, 서열 번호 58, 서열 번호 61, 서열 번호 86, 서열 번호 95, 서열 번호 96, 서열 번호 97, 서열 번호 100, 서열 번호 103, 서열 번호 106 및 서열 번호 109로 이루어진 군으로부터 선택되는 분리된 폴리뉴클레오티드.
- 제1항의 분리된 폴리뉴클레오티드에 의해 암호화되는 델타-9 연장효소 활성을 갖는 돌연변이 폴리펩티드.
- 제3항에 있어서, 단백질 서열이 서열 번호 29, 서열 번호 32, 서열 번호 35, 서열 번호 38, 서열 번호 41, 서열 번호 59, 서열 번호 62, 서열 번호 87, 서열 번호 101, 서열 번호 104, 서열 번호 107 및 서열 번호 110으로 이루어진 군으로부터 선택되는 돌연변이 폴리펩티드.
- 제3항 또는 제4항에 있어서, 델타-9 연장효소 활성이 서열 번호 10에 기재된 폴리펩티드의 델타-9 연장효소 활성과 적어도 대략 기능적으로 동등한 돌연변이 폴리펩티드.
- 제5항에 있어서, 리놀레산으로부터 에이코사다이엔산으로의 기질 전환 백분율이 서열 번호 10에 기재된 폴리펩티드의 리놀레산으로부터 에이코사다이엔산으로의 기질 전환 백분율에 비하여 적어도 110%인 돌연변이 폴리펩티드.
- 제6항에 있어서, 리놀레산으로부터 에이코사다이엔산으로의 기질 전환 백분율이 서열 번호 10에 기재된 폴리펩티드의 리놀레산으로부터 에이코사다이엔산으로의 기질 전환 백분율에 비하여 적어도 120%인 돌연변이 폴리펩티드.
- 적어도 하나의 조절 서열에 작동가능하게 연결된 제1항의 분리된 폴리뉴클레오티드를 포함하는 재조합 구축물(construct).
- 제1항의 분리된 폴리뉴클레오티드를 포함하는 형질전환된 세포.
- 제9항에 있어서, 상기 세포가 식물, 박테리아, 효모, 조류, 유글레나조류(euglenoids), 부등편모조류(stramenopiles), 난균류 및 진균류로 이루어진 군으로부터 선택되는 형질전환된 세포.
- 제10항에 있어서, 세포가 건조 세포 중량의 적어도 약 25%를 오일로 생성하는 유지성(oleaginous) 효모인 형질전환된 세포.
- 제11항에 있어서, 유지성 효모가
적어도 하나의 조절 서열에 작동가능하게 연결된 분리된 폴리뉴클레오티드를 포함하는 적어도 하나의 재조합 DNA 구축물 - 재조합 DNA 구축물은 델타-4 불포화화효소(desaturase), 델타-5 불포화화효소, 델타-8 불포화화효소, 델타-6 불포화화효소, 델타-9 불포화화효소, 델타-12 불포화화효소, 델타-15 불포화화효소, 델타-17 불포화화효소, C14/16 연장효소, C16/18 연장효소, C18/20 연장효소 및 C20/22 연장효소로 이루어진 군으로부터 선택되는 폴리펩티드를 암호화한다 - 을 추가로 포함하는 형질전환된 세포. - 제12항에 있어서, 유지성 효모에 의해 생성되는 오일이 아라키돈산, 에이코사다이엔산, 에이코사펜타엔산, 에이코사테트라엔산, 에이코사트라이엔산, 다이호모-γ-리놀렌산, 도코사테트라엔산, 도코사펜타엔산 및 도코사헥사엔산으로 이루어진 군으로부터 선택되는 장쇄 다중불포화 지방산을 포함하는 형질전환된 세포.
- 제10항 또는 제11항에 있어서, 유지성 효모가 야로위아(Yarrowia), 칸디다(Candida), 로도토룰라(Rhodotorula), 로도스포리듐(Rhodosporidium), 크립토코커스(Cryptococcus), 트리코스포론(Trichosporon) 및 리포마이세스(Lipomyces)로 이루어진 군으로부터 선택되는 형질전환된 세포.
- 제14항에 있어서, 세포가 야로위아 리폴리티카(Yarrowia lipolytica)인 형질전환된 세포.
- a) i) 적어도 하나의 조절 서열에 작동가능하게 연결되는 재조합 구축물로서, 상기 재조합 구축물이 델타-9 연장효소 활성을 가지며, 서열 번호 22에 기재된 아미노산 서열을 갖는 돌연변이 폴리펩티드를 암호화하는 분리된 폴리뉴클레오티드를 포함하며, 서열 번호 22는 적어도 하나의 아미노산 돌연변이에 의해 서열 번호 10과 상이하며, 상기 돌연변이(들)가
(a) L35F 돌연변이;
(b) L35M 돌연변이;
(c) L35G 돌연변이;
(d) L35G 돌연변이, 및 S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, Q107E, L108G, G127L, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, Q244N, A254W 및 A254Y로 이루어진 군으로부터 선택되는 적어도 하나의 다른 돌연변이;
(e) L35G, A21V, L108G 및 I179R 돌연변이;
(f) L35G, W132T 및 I179 돌연변이;
(g) L35G, S9D, Y84C 및 I179R 돌연변이;
(h) L35G, Y84C, I179R 및 Q244N 돌연변이;
(i) L35G, A21V, W132T, I179R 및 Q244N 돌연변이;
(j) K58R 및 I257T 돌연변이;
(k) D98G 돌연변이;
(l) L130M 및 V243A 돌연변이; 및
(m) K58R, L35F, L35G, L35M, S9A, S9D, S9G, S9I, S9K, S9Q, Q12K, A21D, A21T, A21V, V32F, Y84C, D98G, Q107E, L108G, G127L, L130M, W132T, M143N, M143W, L161T, L161Y, W168G, I179M, I179R, C236N, V243A, Q244N, A254W, A254Y 및 I257T로 이루어진 군으로부터 선택되는 적어도 2개의 돌연변이를 포함하는 임의의 조합으로 이루어진 군으로부터 선택되는 재조합 구축물; 및
ii) 리놀레산 및 알파-리놀렌산으로 이루어진 군으로부터 선택되는 기질 지방산의 공급원을 포함하는 유지성 효모를 제공하는 단계;
b) 델타-9 연장효소 활성을 갖는 돌연변이 폴리펩티드를 암호화하는 재조합 구축물이 발현되고, 기질 지방산이 생성물 지방산으로 전환되는 조건 하에서 단계 (a)의 효모를 성장시키는 단계로서, 리놀레산이 에이코사다이엔산으로 전환되고, 알파-리놀렌산이 에이코사트라이엔산으로 전환되는 단계; 및
c) 임의로, 단계 (b)의 생성물 지방산을 회수하는 단계를 포함하는 다중불포화 지방산의 생성 방법. - 제9항의 유지성 효모로부터 수득되는 미생물 오일.
- 건조 세포 중량의 중량 백분율로 측정시 적어도 22.5 중량 백분율의 에이코사펜타엔산을 포함하는 오일을 생성하는 재조합 미생물 숙주 세포로서, 상기 재조합 미생물 숙주 세포가 적어도 하나의 돌연변이 델타-9 연장효소 폴리펩티드를 포함하며, 상기 돌연변이 델타-9 연장효소 폴리펩티드가 서열 번호 59에 기재된 아미노산 서열을 포함하는 재조합 미생물 숙주 세포.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US37724810P | 2010-08-26 | 2010-08-26 | |
| US61/377,248 | 2010-08-26 | ||
| PCT/US2011/049361 WO2012027676A1 (en) | 2010-08-26 | 2011-08-26 | Mutant delta-9 elongases and their use in making polyunsaturated fatty acids |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20140008295A true KR20140008295A (ko) | 2014-01-21 |
Family
ID=44534726
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020137007483A KR20140008295A (ko) | 2010-08-26 | 2011-08-26 | 돌연변이 델타-9 연장효소 및 다중불포화 지방산의 제조에서의 그들의 용도 |
Country Status (11)
| Country | Link |
|---|---|
| US (1) | US8980589B2 (ko) |
| EP (1) | EP2609201B1 (ko) |
| JP (1) | JP5963749B2 (ko) |
| KR (1) | KR20140008295A (ko) |
| CN (1) | CN103080316B (ko) |
| AU (1) | AU2011293167B2 (ko) |
| BR (1) | BR112013004356A2 (ko) |
| CA (1) | CA2808000A1 (ko) |
| CL (1) | CL2013000507A1 (ko) |
| DK (1) | DK2609201T3 (ko) |
| WO (1) | WO2012027676A1 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102085555B1 (ko) * | 2018-08-27 | 2020-03-06 | 대한민국(농촌진흥청장) | 아라키돈산 생합성을 위한 신규 델타-5 불포화효소 및 이의 용도 |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| MX2009009304A (es) * | 2007-03-01 | 2009-11-18 | Novartis Ag | Inhibidores de cinasa pim y metodos para su uso. |
| CN102978177B (zh) * | 2012-11-09 | 2015-06-03 | 浙江工业大学 | 冬虫夏草合成代谢二十碳五烯酸的△-5-脱氢酶、基因及应用 |
| WO2014100061A1 (en) | 2012-12-21 | 2014-06-26 | E. I. Du Pont De Nemours And Company | Down-regulation of a polynucleotide encoding a sou2 sorbitol utilization protein to modify lipid production in microbial cells |
| CN110358692B (zh) * | 2018-04-09 | 2021-07-27 | 中国科学院青岛生物能源与过程研究所 | 生产神经酸的重组酵母菌株及其应用 |
Family Cites Families (41)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4880741A (en) | 1983-10-06 | 1989-11-14 | Pfizer Inc. | Process for transformation of Yarrowia lipolytica |
| US5071764A (en) | 1983-10-06 | 1991-12-10 | Pfizer Inc. | Process for integrative transformation of yarrowia lipolytica |
| US5107065A (en) | 1986-03-28 | 1992-04-21 | Calgene, Inc. | Anti-sense regulation of gene expression in plant cells |
| JP2527340B2 (ja) | 1986-12-15 | 1996-08-21 | アプライド バイオシステムズ インコーポレイテッド | ロ―ダミン染料の5−及び6−スクシニミジルカルボキシレ―ト異性体 |
| US5366860A (en) | 1989-09-29 | 1994-11-22 | Applied Biosystems, Inc. | Spectrally resolvable rhodamine dyes for nucleic acid sequence determination |
| US5605793A (en) | 1994-02-17 | 1997-02-25 | Affymax Technologies N.V. | Methods for in vitro recombination |
| US5837458A (en) | 1994-02-17 | 1998-11-17 | Maxygen, Inc. | Methods and compositions for cellular and metabolic engineering |
| US5648564A (en) | 1995-12-21 | 1997-07-15 | Kemin Industries, Inc. | Process for the formation, isolation and purification of comestible xanthophyll crystals from plants |
| GB0107510D0 (en) | 2001-03-26 | 2001-05-16 | Univ Bristol | New elongase gene and a process for the production of -9-polyunsaturated fatty acids |
| TWI324181B (en) | 2001-04-16 | 2010-05-01 | Martek Biosciences Corp | Product and process for transformation of thraustochytriales microorganisms |
| US6797303B2 (en) | 2001-09-04 | 2004-09-28 | Lycored Natural Products Industries Ltd. | Carotenoid extraction process |
| ATE400650T1 (de) | 2002-10-18 | 2008-07-15 | Sloning Biotechnology Gmbh | Verfahren zur herstellung von nukleinsäuremolekülen |
| WO2004057001A2 (en) | 2002-12-19 | 2004-07-08 | University Of Bristol | Method for the production of polyunsaturated fatty acids |
| US7125672B2 (en) | 2003-05-07 | 2006-10-24 | E. I. Du Pont De Nemours And Company | Codon-optimized genes for the production of polyunsaturated fatty acids in oleaginous yeasts |
| US7238482B2 (en) | 2003-05-07 | 2007-07-03 | E. I. Du Pont De Nemours And Company | Production of polyunsaturated fatty acids in oleaginous yeasts |
| US8313911B2 (en) | 2003-05-07 | 2012-11-20 | E I Du Pont De Nemours And Company | Production of polyunsaturated fatty acids in oleaginous yeasts |
| US7259255B2 (en) | 2003-06-25 | 2007-08-21 | E. I. Du Pont De Nemours And Company | Glyceraldehyde-3-phosphate dehydrogenase and phosphoglycerate mutase promoters for gene expression in oleaginous yeast |
| EP3395945A1 (de) | 2003-08-01 | 2018-10-31 | BASF Plant Science GmbH | Verfahren zur herstellung mehrfach ungesättigter fettsäuren in transgenen organismen |
| CA2542564A1 (en) | 2003-11-12 | 2005-05-26 | E.I. Du Pont De Nemours And Company | Delta-15 desaturases suitable for altering levels of polyunsaturated fatty acids in oilseed plants and oleaginous yeast |
| US7504259B2 (en) | 2003-11-12 | 2009-03-17 | E. I. Du Pont De Nemours And Company | Δ12 desaturases suitable for altering levels of polyunsaturated fatty acids in oleaginous yeast |
| EP4219670A3 (de) | 2004-02-27 | 2023-08-09 | BASF Plant Science GmbH | Verfahren zur herstellung mehrfach ungesättigter fettsäuren in transgenen pflanzen |
| BRPI0512481A (pt) | 2004-06-25 | 2008-03-11 | Du Pont | polinucleotìdeo isolado, polipeptìdeo, construção recombinante, célula, yarrowia sp.transformada, métodos para transformar uma célula, produzir uma planta transformada, produzir levedura, produzir ácidos graxos poliinsaturados e produzir pelo menos um ácido graxo poliinsaturados, sementes, óleos, plantas de sementes oleaginosa e alimentos ou rações |
| US7550286B2 (en) | 2004-11-04 | 2009-06-23 | E. I. Du Pont De Nemours And Company | Docosahexaenoic acid producing strains of Yarrowia lipolytica |
| US7879591B2 (en) | 2004-11-04 | 2011-02-01 | E.I. Du Pont De Nemours And Company | High eicosapentaenoic acid producing strains of Yarrowia lipolytica |
| CN101218352B (zh) | 2005-03-18 | 2013-09-04 | 米克罗比亚公司 | 产油酵母和真菌中类胡萝卜素的产生 |
| US7470532B2 (en) | 2005-10-19 | 2008-12-30 | E.I. Du Pont De Nemours And Company | Mortierella alpina C16/18 fatty acid elongase |
| US7645604B2 (en) * | 2005-11-23 | 2010-01-12 | E.I. Du Pont De Nemours And Company | Delta-9 elongases and their use in making polyunsaturated fatty acids |
| US7465793B2 (en) * | 2006-04-20 | 2008-12-16 | E.I. Du Pont De Nemours And Company | Synthetic Δ17 desaturase derived from Phytophthora ramourum and its use in making polyunsaturated fatty acids |
| US7678560B2 (en) | 2006-05-17 | 2010-03-16 | E.I. Du Pont De Nemours And Company | Δ 5 desaturase and its use in making polyunsaturated fatty acids |
| AU2007314481B2 (en) | 2006-10-30 | 2012-11-29 | E. I. Du Pont De Nemours And Company | Delta17 desaturase and its use in making polyunsaturated fatty acids |
| US7709239B2 (en) | 2006-12-07 | 2010-05-04 | E.I. Du Pont De Nemours And Company | Mutant Δ8 desaturase genes engineered by targeted mutagenesis and their use in making polyunsaturated fatty acids |
| US8846374B2 (en) | 2006-12-12 | 2014-09-30 | E I Du Pont De Nemours And Company | Carotenoid production in a recombinant oleaginous yeast |
| EP2129777B1 (en) * | 2007-04-03 | 2015-10-28 | E. I. du Pont de Nemours and Company | Multizymes and their use in making polyunsaturated fatty acids |
| US8188338B2 (en) | 2007-04-10 | 2012-05-29 | E. I. Du Pont De Nemours And Company | Delta-8 desaturases and their use in making polyunsaturated fatty acids |
| US7794701B2 (en) * | 2007-04-16 | 2010-09-14 | E.I. Du Pont De Nemours And Company | Δ-9 elongases and their use in making polyunsaturated fatty acids |
| US8957280B2 (en) | 2007-05-03 | 2015-02-17 | E. I. Du Pont De Nemours And Company | Delta-5 desaturases and their use in making polyunsaturated fatty acids |
| EP2195415A1 (en) | 2007-10-03 | 2010-06-16 | E. I. du Pont de Nemours and Company | Optimized strains of yarrowia lipolytica for high eicosapentaenoic acid production |
| US8168858B2 (en) | 2008-06-20 | 2012-05-01 | E. I. Du Pont De Nemours And Company | Delta-9 fatty acid elongase genes and their use in making polyunsaturated fatty acids |
| WO2010033753A2 (en) | 2008-09-19 | 2010-03-25 | E. I. Du Pont De Nemours And Company | Mutant delta5 desaturases and their use in making polyunsaturated fatty acids |
| EP2358862B1 (en) | 2008-12-18 | 2017-08-02 | E. I. du Pont de Nemours and Company | Reducing byproduction of malonates in a fermentation process |
| US8524485B2 (en) | 2009-06-16 | 2013-09-03 | E I Du Pont De Nemours And Company | Long chain omega-3 and omega-6 polyunsaturated fatty acid biosynthesis by expression of acyl-CoA lysophospholipid acyltransferases |
-
2011
- 2011-08-26 CA CA2808000A patent/CA2808000A1/en not_active Abandoned
- 2011-08-26 US US13/218,591 patent/US8980589B2/en active Active
- 2011-08-26 CN CN201180040811.9A patent/CN103080316B/zh not_active Expired - Fee Related
- 2011-08-26 EP EP11750066.0A patent/EP2609201B1/en not_active Not-in-force
- 2011-08-26 BR BR112013004356A patent/BR112013004356A2/pt not_active Application Discontinuation
- 2011-08-26 AU AU2011293167A patent/AU2011293167B2/en not_active Ceased
- 2011-08-26 JP JP2013526175A patent/JP5963749B2/ja not_active Expired - Fee Related
- 2011-08-26 WO PCT/US2011/049361 patent/WO2012027676A1/en active Application Filing
- 2011-08-26 DK DK11750066.0T patent/DK2609201T3/en active
- 2011-08-26 KR KR1020137007483A patent/KR20140008295A/ko not_active Application Discontinuation
-
2013
- 2013-02-22 CL CL2013000507A patent/CL2013000507A1/es unknown
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102085555B1 (ko) * | 2018-08-27 | 2020-03-06 | 대한민국(농촌진흥청장) | 아라키돈산 생합성을 위한 신규 델타-5 불포화효소 및 이의 용도 |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2012027676A1 (en) | 2012-03-01 |
| AU2011293167B2 (en) | 2016-12-08 |
| CN103080316B (zh) | 2016-08-31 |
| JP2013541328A (ja) | 2013-11-14 |
| DK2609201T3 (en) | 2016-06-06 |
| BR112013004356A2 (pt) | 2017-06-27 |
| CA2808000A1 (en) | 2012-03-01 |
| CL2013000507A1 (es) | 2014-03-28 |
| AU2011293167A1 (en) | 2013-01-24 |
| US20120226062A1 (en) | 2012-09-06 |
| CN103080316A (zh) | 2013-05-01 |
| JP5963749B2 (ja) | 2016-08-03 |
| US8980589B2 (en) | 2015-03-17 |
| EP2609201B1 (en) | 2016-03-02 |
| EP2609201A1 (en) | 2013-07-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| AU2018220469B2 (en) | Method and cell line for production of phytocannabinoids and phytocannabinoid analogues in yeast | |
| KR102370675B1 (ko) | 표적 핵산의 변형을 위한 개선된 방법 | |
| CN101848996B (zh) | △9延伸酶及其在制备多不饱和脂肪酸中的用途 | |
| CA2683497C (en) | .delta.8 desaturases and their use in making polyunsaturated fatty acids | |
| AU2023226754A1 (en) | Compositions and methods for modifying genomes | |
| DK2140006T3 (en) | DELTA-5 desaturases AND USE THEREOF FOR THE PRODUCTION OF polyunsaturated fatty acids | |
| CN108138121B (zh) | 用微生物高水平生产长链二羧酸 | |
| CN101365788B (zh) | Δ-9延伸酶及其在制备多不饱和脂肪酸中的用途 | |
| DK2087105T3 (da) | Delta 17-desaturase og anvendelse heraf ved fremstilling af flerumættede fedtsyrer | |
| DK2443248T3 (en) | IMPROVEMENT OF LONG-CHAIN POLYUM Saturated OMEGA-3 AND OMEGA-6 FATTY ACID BIOS SYNTHESIS BY EXPRESSION OF ACYL-CoA LYSOPHOSPHOLIPID ACYL TRANSFERASES | |
| DK2576605T3 (en) | PREPARATION OF METABOLITES | |
| KR20140007430A (ko) | 에이코사펜타엔산 농축물 | |
| KR20130138760A (ko) | 고농도의 에이코사펜타엔산 생성을 위한 재조합 미생물 숙주 세포 | |
| DK2609201T3 (en) | Mutant DELTA-9 elongases AND USE THEREOF FOR THE PRODUCTION OF polyunsaturated fatty acids | |
| CN107868780B (zh) | 在大于10kb环状DNA分子上实现定点突变的方法 | |
| KR102096592B1 (ko) | 신규한 crispr 연관 단백질 및 이의 용도 | |
| CN109996874A (zh) | 10-甲基硬脂酸的异源性产生 | |
| DK2475679T3 (da) | Forbedrede, optimerede stammer af yarrowia lipolytica til fremstilling af højkoncentreret eicosapentaensyre | |
| KR20140000711A (ko) | 수크로스 이용에 있어서의 야로위아 리포라이티카에서의 사카로마이세스 세레비지애 suc2 유전자의 용도 | |
| CN113039278A (zh) | 通过指导的内切核酸酶和单链寡核苷酸进行基因组编辑 | |
| KR101566371B1 (ko) | 구제역 아시아1 혈청형의 표준백신 바이러스의 방어항원을 발현하는 재조합 구제역 바이러스 및 이의 제조 방법 | |
| US20030185851A1 (en) | Tet transactivator system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |