KR20110026529A - 종양에서 특이적으로 발현되는 유전자 산물 및 이의 용도 - Google Patents
종양에서 특이적으로 발현되는 유전자 산물 및 이의 용도 Download PDFInfo
- Publication number
- KR20110026529A KR20110026529A KR1020117004206A KR20117004206A KR20110026529A KR 20110026529 A KR20110026529 A KR 20110026529A KR 1020117004206 A KR1020117004206 A KR 1020117004206A KR 20117004206 A KR20117004206 A KR 20117004206A KR 20110026529 A KR20110026529 A KR 20110026529A
- Authority
- KR
- South Korea
- Prior art keywords
- nucleic acid
- leu
- tumor
- ser
- associated antigen
- Prior art date
Links
- 206010028980 Neoplasm Diseases 0.000 title claims abstract description 387
- 230000002068 genetic effect Effects 0.000 title description 3
- 150000007523 nucleic acids Chemical class 0.000 claims abstract description 379
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 352
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 352
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 169
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 86
- 102000004169 proteins and genes Human genes 0.000 claims abstract description 85
- 102000004196 processed proteins & peptides Human genes 0.000 claims abstract description 63
- 229920001184 polypeptide Polymers 0.000 claims abstract description 49
- 201000010099 disease Diseases 0.000 claims abstract description 48
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims abstract description 48
- 238000011282 treatment Methods 0.000 claims abstract description 25
- 239000000427 antigen Substances 0.000 claims description 340
- 102000036639 antigens Human genes 0.000 claims description 340
- 108091007433 antigens Proteins 0.000 claims description 340
- 210000004027 cell Anatomy 0.000 claims description 195
- 230000014509 gene expression Effects 0.000 claims description 121
- 238000000034 method Methods 0.000 claims description 111
- 239000003795 chemical substances by application Substances 0.000 claims description 68
- 241000282414 Homo sapiens Species 0.000 claims description 66
- 210000001519 tissue Anatomy 0.000 claims description 62
- 239000008194 pharmaceutical composition Substances 0.000 claims description 58
- 102000053602 DNA Human genes 0.000 claims description 55
- 239000000523 sample Substances 0.000 claims description 38
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 36
- 239000012634 fragment Substances 0.000 claims description 35
- 101000679365 Homo sapiens Putative tyrosine-protein phosphatase TPTE Proteins 0.000 claims description 33
- 102100022578 Putative tyrosine-protein phosphatase TPTE Human genes 0.000 claims description 33
- 230000002159 abnormal effect Effects 0.000 claims description 33
- 230000000692 anti-sense effect Effects 0.000 claims description 31
- 201000011510 cancer Diseases 0.000 claims description 31
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 29
- 230000000295 complement effect Effects 0.000 claims description 28
- 238000001514 detection method Methods 0.000 claims description 27
- 125000003729 nucleotide group Chemical group 0.000 claims description 22
- 230000001225 therapeutic effect Effects 0.000 claims description 22
- 230000000694 effects Effects 0.000 claims description 21
- 239000002773 nucleotide Substances 0.000 claims description 21
- 208000026310 Breast neoplasm Diseases 0.000 claims description 20
- 230000028993 immune response Effects 0.000 claims description 20
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 18
- 210000004443 dendritic cell Anatomy 0.000 claims description 17
- 102000004127 Cytokines Human genes 0.000 claims description 16
- 108090000695 Cytokines Proteins 0.000 claims description 16
- 201000001441 melanoma Diseases 0.000 claims description 16
- 239000000126 substance Substances 0.000 claims description 16
- 206010027476 Metastases Diseases 0.000 claims description 15
- 208000029742 colonic neoplasm Diseases 0.000 claims description 15
- 206010006187 Breast cancer Diseases 0.000 claims description 14
- 238000004519 manufacturing process Methods 0.000 claims description 14
- 238000012544 monitoring process Methods 0.000 claims description 13
- 239000002671 adjuvant Substances 0.000 claims description 12
- 210000000612 antigen-presenting cell Anatomy 0.000 claims description 12
- 239000013604 expression vector Substances 0.000 claims description 12
- 230000009401 metastasis Effects 0.000 claims description 12
- 239000013598 vector Substances 0.000 claims description 12
- 108020004511 Recombinant DNA Proteins 0.000 claims description 11
- 239000003814 drug Substances 0.000 claims description 11
- 210000004698 lymphocyte Anatomy 0.000 claims description 11
- 102000040430 polynucleotide Human genes 0.000 claims description 10
- 108091033319 polynucleotide Proteins 0.000 claims description 10
- 239000002157 polynucleotide Substances 0.000 claims description 10
- 230000003321 amplification Effects 0.000 claims description 9
- 201000008275 breast carcinoma Diseases 0.000 claims description 9
- 239000000032 diagnostic agent Substances 0.000 claims description 9
- 229940039227 diagnostic agent Drugs 0.000 claims description 9
- 238000003199 nucleic acid amplification method Methods 0.000 claims description 9
- 229940124597 therapeutic agent Drugs 0.000 claims description 9
- 239000012472 biological sample Substances 0.000 claims description 8
- 210000000170 cell membrane Anatomy 0.000 claims description 8
- 230000002062 proliferating effect Effects 0.000 claims description 8
- 238000013518 transcription Methods 0.000 claims description 8
- 230000035897 transcription Effects 0.000 claims description 8
- 208000019065 cervical carcinoma Diseases 0.000 claims description 7
- 230000001461 cytolytic effect Effects 0.000 claims description 7
- 230000001472 cytotoxic effect Effects 0.000 claims description 7
- 206010009944 Colon cancer Diseases 0.000 claims description 6
- 102000004190 Enzymes Human genes 0.000 claims description 6
- 108090000790 Enzymes Proteins 0.000 claims description 6
- 208000006265 Renal cell carcinoma Diseases 0.000 claims description 6
- 210000003719 b-lymphocyte Anatomy 0.000 claims description 6
- 231100000433 cytotoxic Toxicity 0.000 claims description 6
- 210000002540 macrophage Anatomy 0.000 claims description 6
- 241001430294 unidentified retrovirus Species 0.000 claims description 6
- 230000015572 biosynthetic process Effects 0.000 claims description 5
- 238000011161 development Methods 0.000 claims description 5
- 108020003175 receptors Proteins 0.000 claims description 5
- 102000005962 receptors Human genes 0.000 claims description 5
- 239000003053 toxin Substances 0.000 claims description 5
- 231100000765 toxin Toxicity 0.000 claims description 5
- 108700012359 toxins Proteins 0.000 claims description 5
- 108010021625 Immunoglobulin Fragments Proteins 0.000 claims description 4
- 102000008394 Immunoglobulin Fragments Human genes 0.000 claims description 4
- 230000005867 T cell response Effects 0.000 claims description 4
- 230000003213 activating effect Effects 0.000 claims description 4
- 230000003013 cytotoxicity Effects 0.000 claims description 4
- 231100000135 cytotoxicity Toxicity 0.000 claims description 4
- 230000002163 immunogen Effects 0.000 claims description 4
- 150000003384 small molecules Chemical class 0.000 claims description 4
- 102000004457 Granulocyte-Macrophage Colony-Stimulating Factor Human genes 0.000 claims description 3
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 claims description 3
- 230000036755 cellular response Effects 0.000 claims description 3
- 238000012258 culturing Methods 0.000 claims description 3
- 230000006378 damage Effects 0.000 claims description 3
- 230000002349 favourable effect Effects 0.000 claims description 3
- 208000015181 infectious disease Diseases 0.000 claims description 3
- 230000002401 inhibitory effect Effects 0.000 claims description 3
- 238000013508 migration Methods 0.000 claims description 3
- 230000005012 migration Effects 0.000 claims description 3
- 239000013603 viral vector Substances 0.000 claims description 3
- 102000019034 Chemokines Human genes 0.000 claims description 2
- 108010012236 Chemokines Proteins 0.000 claims description 2
- 210000001124 body fluid Anatomy 0.000 claims description 2
- 230000010261 cell growth Effects 0.000 claims description 2
- 238000002372 labelling Methods 0.000 claims description 2
- 208000020816 lung neoplasm Diseases 0.000 claims description 2
- 208000037841 lung tumor Diseases 0.000 claims description 2
- 230000002934 lysing effect Effects 0.000 claims description 2
- 230000001404 mediated effect Effects 0.000 claims description 2
- 230000001394 metastastic effect Effects 0.000 claims description 2
- 206010061289 metastatic neoplasm Diseases 0.000 claims description 2
- 239000001397 quillaja saponaria molina bark Substances 0.000 claims description 2
- 229930182490 saponin Natural products 0.000 claims description 2
- 150000007949 saponins Chemical group 0.000 claims description 2
- 108091027967 Small hairpin RNA Proteins 0.000 claims 4
- 239000004055 small Interfering RNA Substances 0.000 claims 4
- 108091032973 (ribonucleotides)n+m Proteins 0.000 claims 2
- 108050001049 Extracellular proteins Proteins 0.000 claims 1
- 230000030833 cell death Effects 0.000 claims 1
- 230000007402 cytotoxic response Effects 0.000 claims 1
- 239000003937 drug carrier Substances 0.000 claims 1
- 208000023958 prostate neoplasm Diseases 0.000 claims 1
- 230000002100 tumorsuppressive effect Effects 0.000 claims 1
- 241001515965 unidentified phage Species 0.000 claims 1
- 238000003745 diagnosis Methods 0.000 abstract description 8
- 108020004414 DNA Proteins 0.000 description 48
- 210000001550 testis Anatomy 0.000 description 44
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 39
- 239000000047 product Substances 0.000 description 33
- 108091034117 Oligonucleotide Proteins 0.000 description 23
- 238000003752 polymerase chain reaction Methods 0.000 description 23
- 108700018351 Major Histocompatibility Complex Proteins 0.000 description 22
- 150000001413 amino acids Chemical class 0.000 description 22
- 230000020382 suppression by virus of host antigen processing and presentation of peptide antigen via MHC class I Effects 0.000 description 22
- 101000759808 Homo sapiens Testis-expressed basic protein 1 Proteins 0.000 description 18
- 102100023292 Testis-expressed basic protein 1 Human genes 0.000 description 18
- 108010009298 lysylglutamic acid Proteins 0.000 description 18
- 210000004881 tumor cell Anatomy 0.000 description 18
- 101000746142 Homo sapiens RNA polymerase-associated protein CTR9 homolog Proteins 0.000 description 17
- 238000013519 translation Methods 0.000 description 17
- DSFYPIUSAMSERP-IHRRRGAJSA-N Leu-Leu-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DSFYPIUSAMSERP-IHRRRGAJSA-N 0.000 description 16
- 108010050848 glycylleucine Proteins 0.000 description 16
- 108091060211 Expressed sequence tag Proteins 0.000 description 15
- 102100031357 L-lactate dehydrogenase C chain Human genes 0.000 description 15
- 239000002299 complementary DNA Substances 0.000 description 15
- 208000003362 bronchogenic carcinoma Diseases 0.000 description 14
- 210000001072 colon Anatomy 0.000 description 14
- 108010049041 glutamylalanine Proteins 0.000 description 14
- 108010064235 lysylglycine Proteins 0.000 description 14
- 229920002477 rna polymer Polymers 0.000 description 14
- 206010006417 Bronchial carcinoma Diseases 0.000 description 13
- KTSZUNRRYXPZTK-BQBZGAKWSA-N Gly-Gln-Glu Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KTSZUNRRYXPZTK-BQBZGAKWSA-N 0.000 description 13
- 101001130171 Homo sapiens L-lactate dehydrogenase C chain Proteins 0.000 description 13
- 108010093581 aspartyl-proline Proteins 0.000 description 13
- 210000002443 helper t lymphocyte Anatomy 0.000 description 13
- 239000000203 mixture Substances 0.000 description 13
- 108010073969 valyllysine Proteins 0.000 description 13
- 101000578853 Homo sapiens Membrane-spanning 4-domains subfamily A member 12 Proteins 0.000 description 12
- 102100028425 Membrane-spanning 4-domains subfamily A member 12 Human genes 0.000 description 12
- 238000009396 hybridization Methods 0.000 description 12
- 108010054155 lysyllysine Proteins 0.000 description 12
- -1 10 to 30 Chemical class 0.000 description 11
- 108700024394 Exon Proteins 0.000 description 11
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 11
- QPRQGENIBFLVEB-BJDJZHNGSA-N Leu-Ala-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O QPRQGENIBFLVEB-BJDJZHNGSA-N 0.000 description 11
- 238000001727 in vivo Methods 0.000 description 11
- 108010034529 leucyl-lysine Proteins 0.000 description 11
- 150000003839 salts Chemical class 0.000 description 11
- 241000880493 Leptailurus serval Species 0.000 description 10
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 10
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 10
- 108010092854 aspartyllysine Proteins 0.000 description 10
- 238000010367 cloning Methods 0.000 description 10
- 230000006870 function Effects 0.000 description 10
- 108010037850 glycylvaline Proteins 0.000 description 10
- 230000001105 regulatory effect Effects 0.000 description 10
- 108010061238 threonyl-glycine Proteins 0.000 description 10
- CGHXMODRYJISSK-NHCYSSNCSA-N Leu-Val-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O CGHXMODRYJISSK-NHCYSSNCSA-N 0.000 description 9
- 108010087924 alanylproline Proteins 0.000 description 9
- 230000003053 immunization Effects 0.000 description 9
- 238000000338 in vitro Methods 0.000 description 9
- 230000003993 interaction Effects 0.000 description 9
- 210000001165 lymph node Anatomy 0.000 description 9
- 238000003757 reverse transcription PCR Methods 0.000 description 9
- 108010026333 seryl-proline Proteins 0.000 description 9
- 238000012360 testing method Methods 0.000 description 9
- 102100027350 Cysteine-rich secretory protein 2 Human genes 0.000 description 8
- CGOHAEBMDSEKFB-FXQIFTODSA-N Glu-Glu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O CGOHAEBMDSEKFB-FXQIFTODSA-N 0.000 description 8
- 101000726255 Homo sapiens Cysteine-rich secretory protein 2 Proteins 0.000 description 8
- HPCFRQWLTRDGHT-AJNGGQMLSA-N Ile-Leu-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O HPCFRQWLTRDGHT-AJNGGQMLSA-N 0.000 description 8
- LVTJJOJKDCVZGP-QWRGUYRKSA-N Leu-Lys-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O LVTJJOJKDCVZGP-QWRGUYRKSA-N 0.000 description 8
- YDDDRTIPNTWGIG-SRVKXCTJSA-N Lys-Lys-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O YDDDRTIPNTWGIG-SRVKXCTJSA-N 0.000 description 8
- FTKXYXACXYOHND-XUXIUFHCSA-N Val-Ile-Leu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O FTKXYXACXYOHND-XUXIUFHCSA-N 0.000 description 8
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 8
- 241000700605 Viruses Species 0.000 description 8
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 8
- 238000007418 data mining Methods 0.000 description 8
- 230000004069 differentiation Effects 0.000 description 8
- 238000002649 immunization Methods 0.000 description 8
- 238000003780 insertion Methods 0.000 description 8
- 230000037431 insertion Effects 0.000 description 8
- 108020004999 messenger RNA Proteins 0.000 description 8
- 230000004044 response Effects 0.000 description 8
- VWWKKDNCCLAGRM-GVXVVHGQSA-N (2s)-2-[[2-[[(2s)-2-[[(2s)-2-amino-4-methylpentanoyl]amino]propanoyl]amino]acetyl]amino]-3-methylbutanoic acid Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O VWWKKDNCCLAGRM-GVXVVHGQSA-N 0.000 description 7
- YIGLXQRFQVWFEY-NRPADANISA-N Ala-Gln-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O YIGLXQRFQVWFEY-NRPADANISA-N 0.000 description 7
- VYLVOMUVLMGCRF-ZLUOBGJFSA-N Asn-Asp-Ser Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O VYLVOMUVLMGCRF-ZLUOBGJFSA-N 0.000 description 7
- CBWCQCANJSGUOH-ZKWXMUAHSA-N Asn-Val-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O CBWCQCANJSGUOH-ZKWXMUAHSA-N 0.000 description 7
- MCAVASRGVBVPMX-FXQIFTODSA-N Gln-Glu-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O MCAVASRGVBVPMX-FXQIFTODSA-N 0.000 description 7
- 101001028659 Homo sapiens MORC family CW-type zinc finger protein 1 Proteins 0.000 description 7
- SJLVSMMIFYTSGY-GRLWGSQLSA-N Ile-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N SJLVSMMIFYTSGY-GRLWGSQLSA-N 0.000 description 7
- YFBBUHJJUXXZOF-UWVGGRQHSA-N Leu-Gly-Pro Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O YFBBUHJJUXXZOF-UWVGGRQHSA-N 0.000 description 7
- PDQDCFBVYXEFSD-SRVKXCTJSA-N Leu-Leu-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O PDQDCFBVYXEFSD-SRVKXCTJSA-N 0.000 description 7
- ITWQLSZTLBKWJM-YUMQZZPRSA-N Lys-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCCCN ITWQLSZTLBKWJM-YUMQZZPRSA-N 0.000 description 7
- 102100037200 MORC family CW-type zinc finger protein 1 Human genes 0.000 description 7
- IYXDSYWCVVXSKB-CIUDSAMLSA-N Met-Asn-Glu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O IYXDSYWCVVXSKB-CIUDSAMLSA-N 0.000 description 7
- 108700026244 Open Reading Frames Proteins 0.000 description 7
- 206010033128 Ovarian cancer Diseases 0.000 description 7
- FYQSMXKJYTZYRP-DCAQKATOSA-N Pro-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 FYQSMXKJYTZYRP-DCAQKATOSA-N 0.000 description 7
- XZONQWUEBAFQPO-HJGDQZAQSA-N Pro-Gln-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XZONQWUEBAFQPO-HJGDQZAQSA-N 0.000 description 7
- QUBVFEANYYWBTM-VEVYYDQMSA-N Pro-Thr-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O QUBVFEANYYWBTM-VEVYYDQMSA-N 0.000 description 7
- 206010060862 Prostate cancer Diseases 0.000 description 7
- GRSLLFZTTLBOQX-CIUDSAMLSA-N Ser-Glu-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N GRSLLFZTTLBOQX-CIUDSAMLSA-N 0.000 description 7
- DSGYZICNAMEJOC-AVGNSLFASA-N Ser-Glu-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O DSGYZICNAMEJOC-AVGNSLFASA-N 0.000 description 7
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 7
- PJIQEIFXZPCWOJ-FXQIFTODSA-N Ser-Pro-Asp Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O PJIQEIFXZPCWOJ-FXQIFTODSA-N 0.000 description 7
- YEDSOSIKVUMIJE-DCAQKATOSA-N Ser-Val-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O YEDSOSIKVUMIJE-DCAQKATOSA-N 0.000 description 7
- AEMPCGRFEZTWIF-IHRRRGAJSA-N Val-Leu-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O AEMPCGRFEZTWIF-IHRRRGAJSA-N 0.000 description 7
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 7
- 108010008355 arginyl-glutamine Proteins 0.000 description 7
- 210000000481 breast Anatomy 0.000 description 7
- 150000001875 compounds Chemical class 0.000 description 7
- 238000012217 deletion Methods 0.000 description 7
- 230000037430 deletion Effects 0.000 description 7
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 7
- 108010080575 glutamyl-aspartyl-alanine Proteins 0.000 description 7
- 108010092114 histidylphenylalanine Proteins 0.000 description 7
- 230000001965 increasing effect Effects 0.000 description 7
- 108010009932 leucyl-alanyl-glycyl-valine Proteins 0.000 description 7
- 108010083708 leucyl-aspartyl-valine Proteins 0.000 description 7
- 230000007246 mechanism Effects 0.000 description 7
- 238000000392 pressure-controlled scanning calorimetry Methods 0.000 description 7
- 108010004914 prolylarginine Proteins 0.000 description 7
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 7
- 238000006467 substitution reaction Methods 0.000 description 7
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 6
- CPTXATAOUQJQRO-GUBZILKMSA-N Arg-Val-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O CPTXATAOUQJQRO-GUBZILKMSA-N 0.000 description 6
- 108091026890 Coding region Proteins 0.000 description 6
- MKRDNSWGJWTBKZ-GVXVVHGQSA-N Gln-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MKRDNSWGJWTBKZ-GVXVVHGQSA-N 0.000 description 6
- WOMUDRVDJMHTCV-DCAQKATOSA-N Glu-Arg-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WOMUDRVDJMHTCV-DCAQKATOSA-N 0.000 description 6
- RBXSZQRSEGYDFG-GUBZILKMSA-N Glu-Lys-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O RBXSZQRSEGYDFG-GUBZILKMSA-N 0.000 description 6
- JRDYDYXZKFNNRQ-XPUUQOCRSA-N Gly-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN JRDYDYXZKFNNRQ-XPUUQOCRSA-N 0.000 description 6
- ZNOBVZFCHNHKHA-KBIXCLLPSA-N Ile-Ser-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZNOBVZFCHNHKHA-KBIXCLLPSA-N 0.000 description 6
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 6
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 6
- FIXILCYTSAUERA-FXQIFTODSA-N Ser-Ala-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FIXILCYTSAUERA-FXQIFTODSA-N 0.000 description 6
- HVKMTOIAYDOJPL-NRPADANISA-N Ser-Gln-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVKMTOIAYDOJPL-NRPADANISA-N 0.000 description 6
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 6
- 208000024770 Thyroid neoplasm Diseases 0.000 description 6
- 108010077245 asparaginyl-proline Proteins 0.000 description 6
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 6
- 238000007796 conventional method Methods 0.000 description 6
- 230000037433 frameshift Effects 0.000 description 6
- 108010078144 glutaminyl-glycine Proteins 0.000 description 6
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 6
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 6
- 210000000987 immune system Anatomy 0.000 description 6
- 108010000761 leucylarginine Proteins 0.000 description 6
- 239000003446 ligand Substances 0.000 description 6
- 239000002502 liposome Substances 0.000 description 6
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 6
- 230000035755 proliferation Effects 0.000 description 6
- 108010070643 prolylglutamic acid Proteins 0.000 description 6
- 201000001514 prostate carcinoma Diseases 0.000 description 6
- FBLMOFHNVQBKRR-IHRRRGAJSA-N Arg-Asp-Tyr Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FBLMOFHNVQBKRR-IHRRRGAJSA-N 0.000 description 5
- XEDQMTWEYFBOIK-ACZMJKKPSA-N Asp-Ala-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O XEDQMTWEYFBOIK-ACZMJKKPSA-N 0.000 description 5
- DAHLWSFUXOHMIA-FXQIFTODSA-N Glu-Ser-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O DAHLWSFUXOHMIA-FXQIFTODSA-N 0.000 description 5
- YQAQQKPWFOBSMU-WDCWCFNPSA-N Glu-Thr-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O YQAQQKPWFOBSMU-WDCWCFNPSA-N 0.000 description 5
- ZQIMMEYPEXIYBB-IUCAKERBSA-N Gly-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)CN ZQIMMEYPEXIYBB-IUCAKERBSA-N 0.000 description 5
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 5
- OOCFXNOVSLSHAB-IUCAKERBSA-N Gly-Pro-Pro Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OOCFXNOVSLSHAB-IUCAKERBSA-N 0.000 description 5
- OEROYDLRVAYIMQ-YUMQZZPRSA-N His-Gly-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O OEROYDLRVAYIMQ-YUMQZZPRSA-N 0.000 description 5
- GUXQAPACZVVOKX-AVGNSLFASA-N His-Lys-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N GUXQAPACZVVOKX-AVGNSLFASA-N 0.000 description 5
- UWSMZKRTOZEGDD-CUJWVEQBSA-N His-Thr-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O UWSMZKRTOZEGDD-CUJWVEQBSA-N 0.000 description 5
- AUIYHFRUOOKTGX-UKJIMTQDSA-N Ile-Val-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N AUIYHFRUOOKTGX-UKJIMTQDSA-N 0.000 description 5
- HQUXQAMSWFIRET-AVGNSLFASA-N Leu-Glu-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN HQUXQAMSWFIRET-AVGNSLFASA-N 0.000 description 5
- QLDHBYRUNQZIJQ-DKIMLUQUSA-N Leu-Ile-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QLDHBYRUNQZIJQ-DKIMLUQUSA-N 0.000 description 5
- FKQPWMZLIIATBA-AJNGGQMLSA-N Leu-Lys-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FKQPWMZLIIATBA-AJNGGQMLSA-N 0.000 description 5
- NTEVEUCLFMWSND-SRVKXCTJSA-N Lys-Arg-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O NTEVEUCLFMWSND-SRVKXCTJSA-N 0.000 description 5
- HKXSZKJMDBHOTG-CIUDSAMLSA-N Lys-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN HKXSZKJMDBHOTG-CIUDSAMLSA-N 0.000 description 5
- JMNRXRPBHFGXQX-GUBZILKMSA-N Lys-Ser-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JMNRXRPBHFGXQX-GUBZILKMSA-N 0.000 description 5
- MIXPUVSPPOWTCR-FXQIFTODSA-N Met-Ser-Ser Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MIXPUVSPPOWTCR-FXQIFTODSA-N 0.000 description 5
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical group OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 5
- 208000033781 Thyroid carcinoma Diseases 0.000 description 5
- KZKMBGXCNLPYKD-YEPSODPASA-N Val-Gly-Thr Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O KZKMBGXCNLPYKD-YEPSODPASA-N 0.000 description 5
- YKNOJPJWNVHORX-UNQGMJICSA-N Val-Phe-Thr Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CC1=CC=CC=C1 YKNOJPJWNVHORX-UNQGMJICSA-N 0.000 description 5
- BGXVHVMJZCSOCA-AVGNSLFASA-N Val-Pro-Lys Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)O)N BGXVHVMJZCSOCA-AVGNSLFASA-N 0.000 description 5
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 5
- 239000000556 agonist Substances 0.000 description 5
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 5
- 108010047495 alanylglycine Proteins 0.000 description 5
- 108010068380 arginylarginine Proteins 0.000 description 5
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 5
- 238000006243 chemical reaction Methods 0.000 description 5
- 210000000349 chromosome Anatomy 0.000 description 5
- 238000010195 expression analysis Methods 0.000 description 5
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 5
- 108010089804 glycyl-threonine Proteins 0.000 description 5
- 108010018006 histidylserine Proteins 0.000 description 5
- 210000003734 kidney Anatomy 0.000 description 5
- 108010057821 leucylproline Proteins 0.000 description 5
- 108010012058 leucyltyrosine Proteins 0.000 description 5
- 210000004185 liver Anatomy 0.000 description 5
- 210000004072 lung Anatomy 0.000 description 5
- 108010038320 lysylphenylalanine Proteins 0.000 description 5
- 210000001672 ovary Anatomy 0.000 description 5
- 108010031719 prolyl-serine Proteins 0.000 description 5
- 210000002307 prostate Anatomy 0.000 description 5
- 210000003491 skin Anatomy 0.000 description 5
- 210000001541 thymus gland Anatomy 0.000 description 5
- 201000002510 thyroid cancer Diseases 0.000 description 5
- 208000013077 thyroid gland carcinoma Diseases 0.000 description 5
- 238000001890 transfection Methods 0.000 description 5
- 108020004463 18S ribosomal RNA Proteins 0.000 description 4
- HHGYNJRJIINWAK-FXQIFTODSA-N Ala-Ala-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N HHGYNJRJIINWAK-FXQIFTODSA-N 0.000 description 4
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 4
- IMMKUCQIKKXKNP-DCAQKATOSA-N Ala-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CCCN=C(N)N IMMKUCQIKKXKNP-DCAQKATOSA-N 0.000 description 4
- NJPMYXWVWQWCSR-ACZMJKKPSA-N Ala-Glu-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O NJPMYXWVWQWCSR-ACZMJKKPSA-N 0.000 description 4
- PNALXAODQKTNLV-JBDRJPRFSA-N Ala-Ile-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O PNALXAODQKTNLV-JBDRJPRFSA-N 0.000 description 4
- CFPQUJZTLUQUTJ-HTFCKZLJSA-N Ala-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@H](C)N CFPQUJZTLUQUTJ-HTFCKZLJSA-N 0.000 description 4
- VNYMOTCMNHJGTG-JBDRJPRFSA-N Ala-Ile-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O VNYMOTCMNHJGTG-JBDRJPRFSA-N 0.000 description 4
- AWZKCUCQJNTBAD-SRVKXCTJSA-N Ala-Leu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN AWZKCUCQJNTBAD-SRVKXCTJSA-N 0.000 description 4
- DHBKYZYFEXXUAK-ONGXEEELSA-N Ala-Phe-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 DHBKYZYFEXXUAK-ONGXEEELSA-N 0.000 description 4
- NUBPTCMEOCKWDO-DCAQKATOSA-N Arg-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N NUBPTCMEOCKWDO-DCAQKATOSA-N 0.000 description 4
- KMSHNDWHPWXPEC-BQBZGAKWSA-N Arg-Asp-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KMSHNDWHPWXPEC-BQBZGAKWSA-N 0.000 description 4
- WVNFNPGXYADPPO-BQBZGAKWSA-N Arg-Gly-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O WVNFNPGXYADPPO-BQBZGAKWSA-N 0.000 description 4
- SLNCSSWAIDUUGF-LSJOCFKGSA-N Arg-His-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(O)=O SLNCSSWAIDUUGF-LSJOCFKGSA-N 0.000 description 4
- OFIYLHVAAJYRBC-HJWJTTGWSA-N Arg-Ile-Phe Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)CCCNC(N)=N)C(=O)N[C@@H](Cc1ccccc1)C(O)=O OFIYLHVAAJYRBC-HJWJTTGWSA-N 0.000 description 4
- DNUKXVMPARLPFN-XUXIUFHCSA-N Arg-Leu-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DNUKXVMPARLPFN-XUXIUFHCSA-N 0.000 description 4
- UGZUVYDKAYNCII-ULQDDVLXSA-N Arg-Phe-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O UGZUVYDKAYNCII-ULQDDVLXSA-N 0.000 description 4
- DRDWXKWUSIKKOB-PJODQICGSA-N Arg-Trp-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O DRDWXKWUSIKKOB-PJODQICGSA-N 0.000 description 4
- AZHXYLJRGVMQKW-UMPQAUOISA-N Arg-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCCN=C(N)N)N)O AZHXYLJRGVMQKW-UMPQAUOISA-N 0.000 description 4
- UVTGNSWSRSCPLP-UHFFFAOYSA-N Arg-Tyr Natural products NC(CCNC(=N)N)C(=O)NC(Cc1ccc(O)cc1)C(=O)O UVTGNSWSRSCPLP-UHFFFAOYSA-N 0.000 description 4
- QHUOOCKNNURZSL-IHRRRGAJSA-N Arg-Tyr-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O QHUOOCKNNURZSL-IHRRRGAJSA-N 0.000 description 4
- IZSMEUDYADKZTJ-KJEVXHAQSA-N Arg-Tyr-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IZSMEUDYADKZTJ-KJEVXHAQSA-N 0.000 description 4
- LTZIRYMWOJHRCH-GUDRVLHUSA-N Asn-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N LTZIRYMWOJHRCH-GUDRVLHUSA-N 0.000 description 4
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 4
- YFSLJHLQOALGSY-ZPFDUUQYSA-N Asp-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N YFSLJHLQOALGSY-ZPFDUUQYSA-N 0.000 description 4
- DWOGMPWRQQWPPF-GUBZILKMSA-N Asp-Leu-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O DWOGMPWRQQWPPF-GUBZILKMSA-N 0.000 description 4
- ORRJQLIATJDMQM-HJGDQZAQSA-N Asp-Leu-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O ORRJQLIATJDMQM-HJGDQZAQSA-N 0.000 description 4
- HJCGDIGVVWETRO-ZPFDUUQYSA-N Asp-Lys-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC(O)=O)C(O)=O HJCGDIGVVWETRO-ZPFDUUQYSA-N 0.000 description 4
- 102100021277 Beta-secretase 2 Human genes 0.000 description 4
- 101710150190 Beta-secretase 2 Proteins 0.000 description 4
- 201000009030 Carcinoma Diseases 0.000 description 4
- VNCLJDOTEPPBBD-GUBZILKMSA-N Gln-Cys-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCC(=O)N)N VNCLJDOTEPPBBD-GUBZILKMSA-N 0.000 description 4
- MAGNEQBFSBREJL-DCAQKATOSA-N Gln-Glu-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N MAGNEQBFSBREJL-DCAQKATOSA-N 0.000 description 4
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 4
- PSERKXGRRADTKA-MNXVOIDGSA-N Gln-Leu-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O PSERKXGRRADTKA-MNXVOIDGSA-N 0.000 description 4
- ZGHMRONFHDVXEF-AVGNSLFASA-N Gln-Ser-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ZGHMRONFHDVXEF-AVGNSLFASA-N 0.000 description 4
- QXQDADBVIBLBHN-FHWLQOOXSA-N Gln-Tyr-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QXQDADBVIBLBHN-FHWLQOOXSA-N 0.000 description 4
- OGMQXTXGLDNBSS-FXQIFTODSA-N Glu-Ala-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O OGMQXTXGLDNBSS-FXQIFTODSA-N 0.000 description 4
- VTTSANCGJWLPNC-ZPFDUUQYSA-N Glu-Arg-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VTTSANCGJWLPNC-ZPFDUUQYSA-N 0.000 description 4
- RJONUNZIMUXUOI-GUBZILKMSA-N Glu-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N RJONUNZIMUXUOI-GUBZILKMSA-N 0.000 description 4
- RDDSZZJOKDVPAE-ACZMJKKPSA-N Glu-Asn-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RDDSZZJOKDVPAE-ACZMJKKPSA-N 0.000 description 4
- DSPQRJXOIXHOHK-WDSKDSINSA-N Glu-Asp-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O DSPQRJXOIXHOHK-WDSKDSINSA-N 0.000 description 4
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 4
- ZGKXAUIVGIBISK-SZMVWBNQSA-N Glu-His-Trp Chemical compound N[C@@H](CCC(O)=O)C(=O)N[C@@H](Cc1c[nH]cn1)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O ZGKXAUIVGIBISK-SZMVWBNQSA-N 0.000 description 4
- ILWHFUZZCFYSKT-AVGNSLFASA-N Glu-Lys-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O ILWHFUZZCFYSKT-AVGNSLFASA-N 0.000 description 4
- ZIYGTCDTJJCDDP-JYJNAYRXSA-N Glu-Phe-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZIYGTCDTJJCDDP-JYJNAYRXSA-N 0.000 description 4
- RFTVTKBHDXCEEX-WDSKDSINSA-N Glu-Ser-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RFTVTKBHDXCEEX-WDSKDSINSA-N 0.000 description 4
- HMJULNMJWOZNFI-XHNCKOQMSA-N Glu-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N)C(=O)O HMJULNMJWOZNFI-XHNCKOQMSA-N 0.000 description 4
- NTHIHAUEXVTXQG-KKUMJFAQSA-N Glu-Tyr-Arg Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O NTHIHAUEXVTXQG-KKUMJFAQSA-N 0.000 description 4
- SOYWRINXUSUWEQ-DLOVCJGASA-N Glu-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O SOYWRINXUSUWEQ-DLOVCJGASA-N 0.000 description 4
- AFWYPMDMDYCKMD-KBPBESRZSA-N Gly-Leu-Tyr Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AFWYPMDMDYCKMD-KBPBESRZSA-N 0.000 description 4
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 4
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 4
- WUEIUSDAECDLQO-NAKRPEOUSA-N Ile-Ala-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)O)N WUEIUSDAECDLQO-NAKRPEOUSA-N 0.000 description 4
- KIMHKBDJQQYLHU-PEFMBERDSA-N Ile-Glu-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N KIMHKBDJQQYLHU-PEFMBERDSA-N 0.000 description 4
- KLBVGHCGHUNHEA-BJDJZHNGSA-N Ile-Leu-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)O)N KLBVGHCGHUNHEA-BJDJZHNGSA-N 0.000 description 4
- PHRWFSFCNJPWRO-PPCPHDFISA-N Ile-Leu-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N PHRWFSFCNJPWRO-PPCPHDFISA-N 0.000 description 4
- DSDPLOODKXISDT-XUXIUFHCSA-N Ile-Leu-Val Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O DSDPLOODKXISDT-XUXIUFHCSA-N 0.000 description 4
- ADDYYRVQQZFIMW-MNXVOIDGSA-N Ile-Lys-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ADDYYRVQQZFIMW-MNXVOIDGSA-N 0.000 description 4
- GVNNAHIRSDRIII-AJNGGQMLSA-N Ile-Lys-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N GVNNAHIRSDRIII-AJNGGQMLSA-N 0.000 description 4
- CIDLJWVDMNDKPT-FIRPJDEBSA-N Ile-Phe-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N CIDLJWVDMNDKPT-FIRPJDEBSA-N 0.000 description 4
- IVXJIMGDOYRLQU-XUXIUFHCSA-N Ile-Pro-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O IVXJIMGDOYRLQU-XUXIUFHCSA-N 0.000 description 4
- PELCGFMHLZXWBQ-BJDJZHNGSA-N Ile-Ser-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)O)N PELCGFMHLZXWBQ-BJDJZHNGSA-N 0.000 description 4
- HJDZMPFEXINXLO-QPHKQPEJSA-N Ile-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N HJDZMPFEXINXLO-QPHKQPEJSA-N 0.000 description 4
- JCGMFFQQHJQASB-PYJNHQTQSA-N Ile-Val-His Chemical compound N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O JCGMFFQQHJQASB-PYJNHQTQSA-N 0.000 description 4
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 4
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 4
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 4
- ZURHXHNAEJJRNU-CIUDSAMLSA-N Leu-Asp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZURHXHNAEJJRNU-CIUDSAMLSA-N 0.000 description 4
- MYGQXVYRZMKRDB-SRVKXCTJSA-N Leu-Asp-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN MYGQXVYRZMKRDB-SRVKXCTJSA-N 0.000 description 4
- CLVUXCBGKUECIT-HJGDQZAQSA-N Leu-Asp-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CLVUXCBGKUECIT-HJGDQZAQSA-N 0.000 description 4
- QLQHWWCSCLZUMA-KKUMJFAQSA-N Leu-Asp-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QLQHWWCSCLZUMA-KKUMJFAQSA-N 0.000 description 4
- YVKSMSDXKMSIRX-GUBZILKMSA-N Leu-Glu-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O YVKSMSDXKMSIRX-GUBZILKMSA-N 0.000 description 4
- HPBCTWSUJOGJSH-MNXVOIDGSA-N Leu-Glu-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HPBCTWSUJOGJSH-MNXVOIDGSA-N 0.000 description 4
- AVEGDIAXTDVBJS-XUXIUFHCSA-N Leu-Ile-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AVEGDIAXTDVBJS-XUXIUFHCSA-N 0.000 description 4
- IEWBEPKLKUXQBU-VOAKCMCISA-N Leu-Leu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IEWBEPKLKUXQBU-VOAKCMCISA-N 0.000 description 4
- WXZOHBVPVKABQN-DCAQKATOSA-N Leu-Met-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)O)C(=O)O)N WXZOHBVPVKABQN-DCAQKATOSA-N 0.000 description 4
- PJWOOBTYQNNRBF-BZSNNMDCSA-N Leu-Phe-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)O)N PJWOOBTYQNNRBF-BZSNNMDCSA-N 0.000 description 4
- MJWVXZABPOKJJF-ACRUOGEOSA-N Leu-Phe-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MJWVXZABPOKJJF-ACRUOGEOSA-N 0.000 description 4
- MVHXGBZUJLWZOH-BJDJZHNGSA-N Leu-Ser-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MVHXGBZUJLWZOH-BJDJZHNGSA-N 0.000 description 4
- CLBGMWIYPYAZPR-AVGNSLFASA-N Lys-Arg-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O CLBGMWIYPYAZPR-AVGNSLFASA-N 0.000 description 4
- LMVOVCYVZBBWQB-SRVKXCTJSA-N Lys-Asp-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN LMVOVCYVZBBWQB-SRVKXCTJSA-N 0.000 description 4
- ULUQBUKAPDUKOC-GVXVVHGQSA-N Lys-Glu-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O ULUQBUKAPDUKOC-GVXVVHGQSA-N 0.000 description 4
- GPJGFSFYBJGYRX-YUMQZZPRSA-N Lys-Gly-Asp Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O GPJGFSFYBJGYRX-YUMQZZPRSA-N 0.000 description 4
- XNKDCYABMBBEKN-IUCAKERBSA-N Lys-Gly-Gln Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O XNKDCYABMBBEKN-IUCAKERBSA-N 0.000 description 4
- NKKFVJRLCCUJNA-QWRGUYRKSA-N Lys-Gly-Lys Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN NKKFVJRLCCUJNA-QWRGUYRKSA-N 0.000 description 4
- KYNNSEJZFVCDIV-ZPFDUUQYSA-N Lys-Ile-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O KYNNSEJZFVCDIV-ZPFDUUQYSA-N 0.000 description 4
- ZXFRGTAIIZHNHG-AJNGGQMLSA-N Lys-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CCCCN)N ZXFRGTAIIZHNHG-AJNGGQMLSA-N 0.000 description 4
- VUTWYNQUSJWBHO-BZSNNMDCSA-N Lys-Leu-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VUTWYNQUSJWBHO-BZSNNMDCSA-N 0.000 description 4
- JQSIGLHQNSZZRL-KKUMJFAQSA-N Lys-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)N JQSIGLHQNSZZRL-KKUMJFAQSA-N 0.000 description 4
- ZJSZPXISKMDJKQ-JYJNAYRXSA-N Lys-Phe-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCC(O)=O)C(O)=O)CC1=CC=CC=C1 ZJSZPXISKMDJKQ-JYJNAYRXSA-N 0.000 description 4
- QRHWTCJBCLGYRB-FXQIFTODSA-N Met-Ala-Cys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CS)C(O)=O QRHWTCJBCLGYRB-FXQIFTODSA-N 0.000 description 4
- DBMLDOWSVHMQQN-XGEHTFHBSA-N Met-Ser-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DBMLDOWSVHMQQN-XGEHTFHBSA-N 0.000 description 4
- ZBLSZPYQQRIHQU-RCWTZXSCSA-N Met-Thr-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O ZBLSZPYQQRIHQU-RCWTZXSCSA-N 0.000 description 4
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 4
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 4
- 108010066427 N-valyltryptophan Proteins 0.000 description 4
- KIEPQOIQHFKQLK-PCBIJLKTSA-N Phe-Asn-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KIEPQOIQHFKQLK-PCBIJLKTSA-N 0.000 description 4
- RIYZXJVARWJLKS-KKUMJFAQSA-N Phe-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 RIYZXJVARWJLKS-KKUMJFAQSA-N 0.000 description 4
- HNFUGJUZJRYUHN-JSGCOSHPSA-N Phe-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HNFUGJUZJRYUHN-JSGCOSHPSA-N 0.000 description 4
- PPHFTNABKQRAJV-JYJNAYRXSA-N Phe-His-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PPHFTNABKQRAJV-JYJNAYRXSA-N 0.000 description 4
- NGNNPLJHUFCOMZ-FXQIFTODSA-N Pro-Asp-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 NGNNPLJHUFCOMZ-FXQIFTODSA-N 0.000 description 4
- LXLFEIHKWGHJJB-XUXIUFHCSA-N Pro-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 LXLFEIHKWGHJJB-XUXIUFHCSA-N 0.000 description 4
- GOMUXSCOIWIJFP-GUBZILKMSA-N Pro-Ser-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GOMUXSCOIWIJFP-GUBZILKMSA-N 0.000 description 4
- KWMZPPWYBVZIER-XGEHTFHBSA-N Pro-Ser-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWMZPPWYBVZIER-XGEHTFHBSA-N 0.000 description 4
- 238000012300 Sequence Analysis Methods 0.000 description 4
- BGOWRLSWJCVYAQ-CIUDSAMLSA-N Ser-Asp-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BGOWRLSWJCVYAQ-CIUDSAMLSA-N 0.000 description 4
- SWSRFJZZMNLMLY-ZKWXMUAHSA-N Ser-Asp-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O SWSRFJZZMNLMLY-ZKWXMUAHSA-N 0.000 description 4
- YQQKYAZABFEYAF-FXQIFTODSA-N Ser-Glu-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQQKYAZABFEYAF-FXQIFTODSA-N 0.000 description 4
- SVWQEIRZHHNBIO-WHFBIAKZSA-N Ser-Gly-Cys Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CS)C(O)=O SVWQEIRZHHNBIO-WHFBIAKZSA-N 0.000 description 4
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 4
- DOSZISJPMCYEHT-NAKRPEOUSA-N Ser-Ile-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O DOSZISJPMCYEHT-NAKRPEOUSA-N 0.000 description 4
- RWDVVSKYZBNDCO-MELADBBJSA-N Ser-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CO)N)C(=O)O RWDVVSKYZBNDCO-MELADBBJSA-N 0.000 description 4
- ILZAUMFXKSIUEF-SRVKXCTJSA-N Ser-Ser-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ILZAUMFXKSIUEF-SRVKXCTJSA-N 0.000 description 4
- GSCVDSBEYVGMJQ-SRVKXCTJSA-N Ser-Tyr-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N)O GSCVDSBEYVGMJQ-SRVKXCTJSA-N 0.000 description 4
- 108091008874 T cell receptors Proteins 0.000 description 4
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 4
- TYVAWPFQYFPSBR-BFHQHQDPSA-N Thr-Ala-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)NCC(O)=O TYVAWPFQYFPSBR-BFHQHQDPSA-N 0.000 description 4
- OHAJHDJOCKKJLV-LKXGYXEUSA-N Thr-Asp-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O OHAJHDJOCKKJLV-LKXGYXEUSA-N 0.000 description 4
- BVOVIGCHYNFJBZ-JXUBOQSCSA-N Thr-Leu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O BVOVIGCHYNFJBZ-JXUBOQSCSA-N 0.000 description 4
- MEJHFIOYJHTWMK-VOAKCMCISA-N Thr-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)[C@@H](C)O MEJHFIOYJHTWMK-VOAKCMCISA-N 0.000 description 4
- AKFLVKKWVZMFOT-IHRRRGAJSA-N Tyr-Arg-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O AKFLVKKWVZMFOT-IHRRRGAJSA-N 0.000 description 4
- QYSBJAUCUKHSLU-JYJNAYRXSA-N Tyr-Arg-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O QYSBJAUCUKHSLU-JYJNAYRXSA-N 0.000 description 4
- AYHSJESDFKREAR-KKUMJFAQSA-N Tyr-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AYHSJESDFKREAR-KKUMJFAQSA-N 0.000 description 4
- VFJIWSJKZJTQII-SRVKXCTJSA-N Tyr-Asp-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O VFJIWSJKZJTQII-SRVKXCTJSA-N 0.000 description 4
- FJBCEFPCVPHPPM-STECZYCISA-N Tyr-Ile-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O FJBCEFPCVPHPPM-STECZYCISA-N 0.000 description 4
- ABSXSJZNRAQDDI-KJEVXHAQSA-N Tyr-Val-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ABSXSJZNRAQDDI-KJEVXHAQSA-N 0.000 description 4
- ASQFIHTXXMFENG-XPUUQOCRSA-N Val-Ala-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O ASQFIHTXXMFENG-XPUUQOCRSA-N 0.000 description 4
- AZSHAZJLOZQYAY-FXQIFTODSA-N Val-Ala-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O AZSHAZJLOZQYAY-FXQIFTODSA-N 0.000 description 4
- GBESYURLQOYWLU-LAEOZQHASA-N Val-Glu-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N GBESYURLQOYWLU-LAEOZQHASA-N 0.000 description 4
- ZXAGTABZUOMUDO-GVXVVHGQSA-N Val-Glu-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N ZXAGTABZUOMUDO-GVXVVHGQSA-N 0.000 description 4
- WNZSAUMKZQXHNC-UKJIMTQDSA-N Val-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N WNZSAUMKZQXHNC-UKJIMTQDSA-N 0.000 description 4
- UKEVLVBHRKWECS-LSJOCFKGSA-N Val-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](C(C)C)N UKEVLVBHRKWECS-LSJOCFKGSA-N 0.000 description 4
- IJGPOONOTBNTFS-GVXVVHGQSA-N Val-Lys-Glu Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O IJGPOONOTBNTFS-GVXVVHGQSA-N 0.000 description 4
- MJOUSKQHAIARKI-JYJNAYRXSA-N Val-Phe-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=CC=C1 MJOUSKQHAIARKI-JYJNAYRXSA-N 0.000 description 4
- YTNGABPUXFEOGU-SRVKXCTJSA-N Val-Pro-Arg Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O YTNGABPUXFEOGU-SRVKXCTJSA-N 0.000 description 4
- GBIUHAYJGWVNLN-AEJSXWLSSA-N Val-Ser-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N GBIUHAYJGWVNLN-AEJSXWLSSA-N 0.000 description 4
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 4
- RTJPAGFXOWEBAI-SRVKXCTJSA-N Val-Val-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RTJPAGFXOWEBAI-SRVKXCTJSA-N 0.000 description 4
- 108010005233 alanylglutamic acid Proteins 0.000 description 4
- 238000013459 approach Methods 0.000 description 4
- 108010013835 arginine glutamate Proteins 0.000 description 4
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 4
- 108010038850 arginyl-isoleucyl-tyrosine Proteins 0.000 description 4
- 108010036533 arginylvaline Proteins 0.000 description 4
- 239000000969 carrier Substances 0.000 description 4
- 230000001413 cellular effect Effects 0.000 description 4
- 230000008045 co-localization Effects 0.000 description 4
- 230000018109 developmental process Effects 0.000 description 4
- 210000003038 endothelium Anatomy 0.000 description 4
- 210000003238 esophagus Anatomy 0.000 description 4
- 210000004602 germ cell Anatomy 0.000 description 4
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 4
- 108010010147 glycylglutamine Proteins 0.000 description 4
- 108010015792 glycyllysine Proteins 0.000 description 4
- 108010036413 histidylglycine Proteins 0.000 description 4
- 238000009169 immunotherapy Methods 0.000 description 4
- 239000000463 material Substances 0.000 description 4
- 210000005087 mononuclear cell Anatomy 0.000 description 4
- 108010024607 phenylalanylalanine Proteins 0.000 description 4
- 108010051242 phenylalanylserine Proteins 0.000 description 4
- 108010077112 prolyl-proline Proteins 0.000 description 4
- 238000012216 screening Methods 0.000 description 4
- 108010071207 serylmethionine Proteins 0.000 description 4
- 210000000952 spleen Anatomy 0.000 description 4
- 235000000346 sugar Nutrition 0.000 description 4
- 210000001685 thyroid gland Anatomy 0.000 description 4
- 238000012546 transfer Methods 0.000 description 4
- 238000002255 vaccination Methods 0.000 description 4
- 229960005486 vaccine Drugs 0.000 description 4
- IBIDRSSEHFLGSD-UHFFFAOYSA-N valinyl-arginine Natural products CC(C)C(N)C(=O)NC(C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-UHFFFAOYSA-N 0.000 description 4
- GJLXVWOMRRWCIB-MERZOTPQSA-N (2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-acetamido-5-(diaminomethylideneamino)pentanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]-3-(1H-indol-3-yl)propanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanamide Chemical compound C([C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=C(O)C=C1 GJLXVWOMRRWCIB-MERZOTPQSA-N 0.000 description 3
- BRPMXFSTKXXNHF-IUCAKERBSA-N (2s)-1-[2-[[(2s)-pyrrolidine-2-carbonyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound OC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H]1NCCC1 BRPMXFSTKXXNHF-IUCAKERBSA-N 0.000 description 3
- GVJHHUAWPYXKBD-UHFFFAOYSA-N (±)-α-Tocopherol Chemical compound OC1=C(C)C(C)=C2OC(CCCC(C)CCCC(C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-UHFFFAOYSA-N 0.000 description 3
- TVEXGJYMHHTVKP-UHFFFAOYSA-N 6-oxabicyclo[3.2.1]oct-3-en-7-one Chemical compound C1C2C(=O)OC1C=CC2 TVEXGJYMHHTVKP-UHFFFAOYSA-N 0.000 description 3
- NKJBKNVQHBZUIX-ACZMJKKPSA-N Ala-Gln-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKJBKNVQHBZUIX-ACZMJKKPSA-N 0.000 description 3
- NMXKFWOEASXOGB-QSFUFRPTSA-N Ala-Ile-His Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 NMXKFWOEASXOGB-QSFUFRPTSA-N 0.000 description 3
- VHVVPYOJIIQCKS-QEJZJMRPSA-N Ala-Leu-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 VHVVPYOJIIQCKS-QEJZJMRPSA-N 0.000 description 3
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 3
- VCSABYLVNWQYQE-UHFFFAOYSA-N Ala-Lys-Lys Natural products NCCCCC(NC(=O)C(N)C)C(=O)NC(CCCCN)C(O)=O VCSABYLVNWQYQE-UHFFFAOYSA-N 0.000 description 3
- VEAPAYQQLSEKEM-GUBZILKMSA-N Ala-Met-Met Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCSC)C(O)=O VEAPAYQQLSEKEM-GUBZILKMSA-N 0.000 description 3
- ZBLQIYPCUWZSRZ-QEJZJMRPSA-N Ala-Phe-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=CC=C1 ZBLQIYPCUWZSRZ-QEJZJMRPSA-N 0.000 description 3
- WQLDNOCHHRISMS-NAKRPEOUSA-N Ala-Pro-Ile Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WQLDNOCHHRISMS-NAKRPEOUSA-N 0.000 description 3
- YYAVDNKUWLAFCV-ACZMJKKPSA-N Ala-Ser-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O YYAVDNKUWLAFCV-ACZMJKKPSA-N 0.000 description 3
- YCTIYBUTCKNOTI-UWJYBYFXSA-N Ala-Tyr-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCTIYBUTCKNOTI-UWJYBYFXSA-N 0.000 description 3
- BHSYMWWMVRPCPA-CYDGBPFRSA-N Arg-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CCCN=C(N)N BHSYMWWMVRPCPA-CYDGBPFRSA-N 0.000 description 3
- KBBKCNHWCDJPGN-GUBZILKMSA-N Arg-Gln-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KBBKCNHWCDJPGN-GUBZILKMSA-N 0.000 description 3
- VDBKFYYIBLXEIF-GUBZILKMSA-N Arg-Gln-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VDBKFYYIBLXEIF-GUBZILKMSA-N 0.000 description 3
- UFBURHXMKFQVLM-CIUDSAMLSA-N Arg-Glu-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O UFBURHXMKFQVLM-CIUDSAMLSA-N 0.000 description 3
- URAUIUGLHBRPMF-NAKRPEOUSA-N Arg-Ser-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O URAUIUGLHBRPMF-NAKRPEOUSA-N 0.000 description 3
- FRBAHXABMQXSJQ-FXQIFTODSA-N Arg-Ser-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FRBAHXABMQXSJQ-FXQIFTODSA-N 0.000 description 3
- XEOXPCNONWHHSW-AVGNSLFASA-N Arg-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N XEOXPCNONWHHSW-AVGNSLFASA-N 0.000 description 3
- OOWSBIOUKIUWLO-RCOVLWMOSA-N Asn-Gly-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O OOWSBIOUKIUWLO-RCOVLWMOSA-N 0.000 description 3
- GQRDIVQPSMPQME-ZPFDUUQYSA-N Asn-Ile-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O GQRDIVQPSMPQME-ZPFDUUQYSA-N 0.000 description 3
- JLNFZLNDHONLND-GARJFASQSA-N Asn-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N JLNFZLNDHONLND-GARJFASQSA-N 0.000 description 3
- ZYPWIUFLYMQZBS-SRVKXCTJSA-N Asn-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N ZYPWIUFLYMQZBS-SRVKXCTJSA-N 0.000 description 3
- GHWWTICYPDKPTE-NGZCFLSTSA-N Asn-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N GHWWTICYPDKPTE-NGZCFLSTSA-N 0.000 description 3
- ZCKYZTGLXIEOKS-CIUDSAMLSA-N Asp-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)O)N ZCKYZTGLXIEOKS-CIUDSAMLSA-N 0.000 description 3
- HKEZZWQWXWGASX-KKUMJFAQSA-N Asp-Leu-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 HKEZZWQWXWGASX-KKUMJFAQSA-N 0.000 description 3
- UAXIKORUDGGIGA-DCAQKATOSA-N Asp-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O UAXIKORUDGGIGA-DCAQKATOSA-N 0.000 description 3
- GIKOVDMXBAFXDF-NHCYSSNCSA-N Asp-Val-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GIKOVDMXBAFXDF-NHCYSSNCSA-N 0.000 description 3
- ZUNMTUPRQMWMHX-LSJOCFKGSA-N Asp-Val-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O ZUNMTUPRQMWMHX-LSJOCFKGSA-N 0.000 description 3
- LKHMGNHQULEPFY-ACZMJKKPSA-N Cys-Ser-Glu Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O LKHMGNHQULEPFY-ACZMJKKPSA-N 0.000 description 3
- 241000701022 Cytomegalovirus Species 0.000 description 3
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 3
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 3
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 3
- 102100037981 Dickkopf-like protein 1 Human genes 0.000 description 3
- 101710125833 Dickkopf-like protein 1 Proteins 0.000 description 3
- DTMLKCYOQKZXKZ-HJGDQZAQSA-N Gln-Arg-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DTMLKCYOQKZXKZ-HJGDQZAQSA-N 0.000 description 3
- ORYMMTRPKVTGSJ-XVKPBYJWSA-N Gln-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O ORYMMTRPKVTGSJ-XVKPBYJWSA-N 0.000 description 3
- GURIQZQSTBBHRV-SRVKXCTJSA-N Gln-Lys-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GURIQZQSTBBHRV-SRVKXCTJSA-N 0.000 description 3
- RWCBJYUPAUTWJD-NHCYSSNCSA-N Gln-Met-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O RWCBJYUPAUTWJD-NHCYSSNCSA-N 0.000 description 3
- DRNMNLKUUKKPIA-HTUGSXCWSA-N Gln-Phe-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@@H](N)CCC(N)=O)C(O)=O DRNMNLKUUKKPIA-HTUGSXCWSA-N 0.000 description 3
- AVZHGSCDKIQZPQ-CIUDSAMLSA-N Glu-Arg-Ala Chemical compound C[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AVZHGSCDKIQZPQ-CIUDSAMLSA-N 0.000 description 3
- BUZMZDDKFCSKOT-CIUDSAMLSA-N Glu-Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BUZMZDDKFCSKOT-CIUDSAMLSA-N 0.000 description 3
- WNRZUESNGGDCJX-JYJNAYRXSA-N Glu-Leu-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WNRZUESNGGDCJX-JYJNAYRXSA-N 0.000 description 3
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 3
- ZSIDREAPEPAPKL-XIRDDKMYSA-N Glu-Trp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N ZSIDREAPEPAPKL-XIRDDKMYSA-N 0.000 description 3
- UZWUBBRJWFTHTD-LAEOZQHASA-N Glu-Val-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O UZWUBBRJWFTHTD-LAEOZQHASA-N 0.000 description 3
- LZEUDRYSAZAJIO-AUTRQRHGSA-N Glu-Val-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LZEUDRYSAZAJIO-AUTRQRHGSA-N 0.000 description 3
- QSDKBRMVXSWAQE-BFHQHQDPSA-N Gly-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN QSDKBRMVXSWAQE-BFHQHQDPSA-N 0.000 description 3
- TVUWMSBGMVAHSJ-KBPBESRZSA-N Gly-Leu-Phe Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 TVUWMSBGMVAHSJ-KBPBESRZSA-N 0.000 description 3
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 3
- SSFWXSNOKDZNHY-QXEWZRGKSA-N Gly-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN SSFWXSNOKDZNHY-QXEWZRGKSA-N 0.000 description 3
- WTUSRDZLLWGYAT-KCTSRDHCSA-N Gly-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)CN WTUSRDZLLWGYAT-KCTSRDHCSA-N 0.000 description 3
- QSLKWWDKIXMWJV-SRVKXCTJSA-N His-Cys-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N QSLKWWDKIXMWJV-SRVKXCTJSA-N 0.000 description 3
- CUEQQFOGARVNHU-VGDYDELISA-N His-Ser-Ile Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CUEQQFOGARVNHU-VGDYDELISA-N 0.000 description 3
- 102000008949 Histocompatibility Antigens Class I Human genes 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- 101000757191 Homo sapiens Ankyrin repeat domain-containing protein 30A Proteins 0.000 description 3
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 description 3
- VAXBXNPRXPHGHG-BJDJZHNGSA-N Ile-Ala-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)O)N VAXBXNPRXPHGHG-BJDJZHNGSA-N 0.000 description 3
- DMZOUKXXHJQPTL-GRLWGSQLSA-N Ile-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N DMZOUKXXHJQPTL-GRLWGSQLSA-N 0.000 description 3
- LPFBXFILACZHIB-LAEOZQHASA-N Ile-Gly-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)O)C(=O)O)N LPFBXFILACZHIB-LAEOZQHASA-N 0.000 description 3
- BBQABUDWDUKJMB-LZXPERKUSA-N Ile-Ile-Ile Chemical compound CC[C@H](C)[C@H]([NH3+])C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C([O-])=O BBQABUDWDUKJMB-LZXPERKUSA-N 0.000 description 3
- PFPUFNLHBXKPHY-HTFCKZLJSA-N Ile-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)O)N PFPUFNLHBXKPHY-HTFCKZLJSA-N 0.000 description 3
- TVYWVSJGSHQWMT-AJNGGQMLSA-N Ile-Leu-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N TVYWVSJGSHQWMT-AJNGGQMLSA-N 0.000 description 3
- IOVUXUSIGXCREV-DKIMLUQUSA-N Ile-Leu-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IOVUXUSIGXCREV-DKIMLUQUSA-N 0.000 description 3
- RFMDODRWJZHZCR-BJDJZHNGSA-N Ile-Lys-Cys Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(O)=O RFMDODRWJZHZCR-BJDJZHNGSA-N 0.000 description 3
- MSASLZGZQAXVFP-PEDHHIEDSA-N Ile-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N MSASLZGZQAXVFP-PEDHHIEDSA-N 0.000 description 3
- BATWGBRIZANGPN-ZPFDUUQYSA-N Ile-Pro-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BATWGBRIZANGPN-ZPFDUUQYSA-N 0.000 description 3
- NURNJECQNNCRBK-FLBSBUHZSA-N Ile-Thr-Thr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NURNJECQNNCRBK-FLBSBUHZSA-N 0.000 description 3
- YJRSIJZUIUANHO-NAKRPEOUSA-N Ile-Val-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(=O)O)N YJRSIJZUIUANHO-NAKRPEOUSA-N 0.000 description 3
- DLEBSGAVWRPTIX-PEDHHIEDSA-N Ile-Val-Ile Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)[C@@H](C)CC DLEBSGAVWRPTIX-PEDHHIEDSA-N 0.000 description 3
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 3
- 108010065805 Interleukin-12 Proteins 0.000 description 3
- 102000013462 Interleukin-12 Human genes 0.000 description 3
- 102000003855 L-lactate dehydrogenase Human genes 0.000 description 3
- 108700023483 L-lactate dehydrogenases Proteins 0.000 description 3
- KFKWRHQBZQICHA-STQMWFEESA-N L-leucyl-L-phenylalanine Natural products CC(C)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KFKWRHQBZQICHA-STQMWFEESA-N 0.000 description 3
- LJHGALIOHLRRQN-DCAQKATOSA-N Leu-Ala-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N LJHGALIOHLRRQN-DCAQKATOSA-N 0.000 description 3
- ZRLUISBDKUWAIZ-CIUDSAMLSA-N Leu-Ala-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O ZRLUISBDKUWAIZ-CIUDSAMLSA-N 0.000 description 3
- DUBAVOVZNZKEQQ-AVGNSLFASA-N Leu-Arg-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CCCN=C(N)N DUBAVOVZNZKEQQ-AVGNSLFASA-N 0.000 description 3
- OGCQGUIWMSBHRZ-CIUDSAMLSA-N Leu-Asn-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OGCQGUIWMSBHRZ-CIUDSAMLSA-N 0.000 description 3
- CIVKXGPFXDIQBV-WDCWCFNPSA-N Leu-Gln-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CIVKXGPFXDIQBV-WDCWCFNPSA-N 0.000 description 3
- LLBQJYDYOLIQAI-JYJNAYRXSA-N Leu-Glu-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LLBQJYDYOLIQAI-JYJNAYRXSA-N 0.000 description 3
- BABSVXFGKFLIGW-UWVGGRQHSA-N Leu-Gly-Arg Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N BABSVXFGKFLIGW-UWVGGRQHSA-N 0.000 description 3
- KOSWSHVQIVTVQF-ZPFDUUQYSA-N Leu-Ile-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O KOSWSHVQIVTVQF-ZPFDUUQYSA-N 0.000 description 3
- WXUOJXIGOPMDJM-SRVKXCTJSA-N Leu-Lys-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O WXUOJXIGOPMDJM-SRVKXCTJSA-N 0.000 description 3
- AMSSKPUHBUQBOQ-SRVKXCTJSA-N Leu-Ser-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N AMSSKPUHBUQBOQ-SRVKXCTJSA-N 0.000 description 3
- DEFGUIIUYAUEDU-ZPFDUUQYSA-N Lys-Asn-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DEFGUIIUYAUEDU-ZPFDUUQYSA-N 0.000 description 3
- QUCDKEKDPYISNX-HJGDQZAQSA-N Lys-Asn-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QUCDKEKDPYISNX-HJGDQZAQSA-N 0.000 description 3
- IWWMPCPLFXFBAF-SRVKXCTJSA-N Lys-Asp-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O IWWMPCPLFXFBAF-SRVKXCTJSA-N 0.000 description 3
- VEGLGAOVLFODGC-GUBZILKMSA-N Lys-Glu-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VEGLGAOVLFODGC-GUBZILKMSA-N 0.000 description 3
- OJDFAABAHBPVTH-MNXVOIDGSA-N Lys-Ile-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O OJDFAABAHBPVTH-MNXVOIDGSA-N 0.000 description 3
- WAIHHELKYSFIQN-XUXIUFHCSA-N Lys-Ile-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O WAIHHELKYSFIQN-XUXIUFHCSA-N 0.000 description 3
- QQPSCXKFDSORFT-IHRRRGAJSA-N Lys-Lys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN QQPSCXKFDSORFT-IHRRRGAJSA-N 0.000 description 3
- ULNXMMYXQKGNPG-LPEHRKFASA-N Met-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCSC)N ULNXMMYXQKGNPG-LPEHRKFASA-N 0.000 description 3
- OSOLWRWQADPDIQ-DCAQKATOSA-N Met-Asp-Leu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O OSOLWRWQADPDIQ-DCAQKATOSA-N 0.000 description 3
- JHDNAOVJJQSMMM-GMOBBJLQSA-N Met-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCSC)N JHDNAOVJJQSMMM-GMOBBJLQSA-N 0.000 description 3
- CQRGINSEMFBACV-WPRPVWTQSA-N Met-Val-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O CQRGINSEMFBACV-WPRPVWTQSA-N 0.000 description 3
- 241000699670 Mus sp. Species 0.000 description 3
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 3
- 108010065395 Neuropep-1 Proteins 0.000 description 3
- 108010038807 Oligopeptides Proteins 0.000 description 3
- 102000015636 Oligopeptides Human genes 0.000 description 3
- LBSARGIQACMGDF-WBAXXEDZSA-N Phe-Ala-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 LBSARGIQACMGDF-WBAXXEDZSA-N 0.000 description 3
- ZLGQEBCCANLYRA-RYUDHWBXSA-N Phe-Gly-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O ZLGQEBCCANLYRA-RYUDHWBXSA-N 0.000 description 3
- RVRRHFPCEOVRKQ-KKUMJFAQSA-N Phe-His-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CC(=O)N)C(=O)O)N RVRRHFPCEOVRKQ-KKUMJFAQSA-N 0.000 description 3
- KPEIBEPEUAZWNS-ULQDDVLXSA-N Phe-Leu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 KPEIBEPEUAZWNS-ULQDDVLXSA-N 0.000 description 3
- RAGOJJCBGXARPO-XVSYOHENSA-N Phe-Thr-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RAGOJJCBGXARPO-XVSYOHENSA-N 0.000 description 3
- 108090000608 Phosphoric Monoester Hydrolases Proteins 0.000 description 3
- 102000004160 Phosphoric Monoester Hydrolases Human genes 0.000 description 3
- OZAPWFHRPINHND-GUBZILKMSA-N Pro-Cys-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O OZAPWFHRPINHND-GUBZILKMSA-N 0.000 description 3
- CDGABSWLRMECHC-IHRRRGAJSA-N Pro-Lys-His Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O CDGABSWLRMECHC-IHRRRGAJSA-N 0.000 description 3
- RMODQFBNDDENCP-IHRRRGAJSA-N Pro-Lys-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O RMODQFBNDDENCP-IHRRRGAJSA-N 0.000 description 3
- OFOBLEOULBTSOW-UHFFFAOYSA-N Propanedioic acid Natural products OC(=O)CC(O)=O OFOBLEOULBTSOW-UHFFFAOYSA-N 0.000 description 3
- BYIROAKULFFTEK-CIUDSAMLSA-N Ser-Asp-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO BYIROAKULFFTEK-CIUDSAMLSA-N 0.000 description 3
- RNMRYWZYFHHOEV-CIUDSAMLSA-N Ser-Gln-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RNMRYWZYFHHOEV-CIUDSAMLSA-N 0.000 description 3
- OWCVUSJMEBGMOK-YUMQZZPRSA-N Ser-Lys-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O OWCVUSJMEBGMOK-YUMQZZPRSA-N 0.000 description 3
- LRWBCWGEUCKDTN-BJDJZHNGSA-N Ser-Lys-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LRWBCWGEUCKDTN-BJDJZHNGSA-N 0.000 description 3
- XUDRHBPSPAPDJP-SRVKXCTJSA-N Ser-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO XUDRHBPSPAPDJP-SRVKXCTJSA-N 0.000 description 3
- KZPRPBLHYMZIMH-MXAVVETBSA-N Ser-Phe-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KZPRPBLHYMZIMH-MXAVVETBSA-N 0.000 description 3
- ANOQEBQWIAYIMV-AEJSXWLSSA-N Ser-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N ANOQEBQWIAYIMV-AEJSXWLSSA-N 0.000 description 3
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 3
- MQCPGOZXFSYJPS-KZVJFYERSA-N Thr-Ala-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MQCPGOZXFSYJPS-KZVJFYERSA-N 0.000 description 3
- PXQUBKWZENPDGE-CIQUZCHMSA-N Thr-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H]([C@@H](C)O)N PXQUBKWZENPDGE-CIQUZCHMSA-N 0.000 description 3
- OJRNZRROAIAHDL-LKXGYXEUSA-N Thr-Asn-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OJRNZRROAIAHDL-LKXGYXEUSA-N 0.000 description 3
- FHDLKMFZKRUQCE-HJGDQZAQSA-N Thr-Glu-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FHDLKMFZKRUQCE-HJGDQZAQSA-N 0.000 description 3
- UDQBCBUXAQIZAK-GLLZPBPUSA-N Thr-Glu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UDQBCBUXAQIZAK-GLLZPBPUSA-N 0.000 description 3
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 3
- RRRRCRYTLZVCEN-HJGDQZAQSA-N Thr-Leu-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O RRRRCRYTLZVCEN-HJGDQZAQSA-N 0.000 description 3
- XIULAFZYEKSGAJ-IXOXFDKPSA-N Thr-Leu-His Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CNC=N1 XIULAFZYEKSGAJ-IXOXFDKPSA-N 0.000 description 3
- OHOVFPKXPZODHS-SJWGOKEGSA-N Tyr-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N OHOVFPKXPZODHS-SJWGOKEGSA-N 0.000 description 3
- QARCDOCCDOLJSF-HJPIBITLSA-N Tyr-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QARCDOCCDOLJSF-HJPIBITLSA-N 0.000 description 3
- NVZVJIUDICCMHZ-BZSNNMDCSA-N Tyr-Phe-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O NVZVJIUDICCMHZ-BZSNNMDCSA-N 0.000 description 3
- YYLHVUCSTXXKBS-IHRRRGAJSA-N Tyr-Pro-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YYLHVUCSTXXKBS-IHRRRGAJSA-N 0.000 description 3
- LUMQYLVYUIRHHU-YJRXYDGGSA-N Tyr-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUMQYLVYUIRHHU-YJRXYDGGSA-N 0.000 description 3
- TYGHOWWWMTWVKM-HJOGWXRNSA-N Tyr-Tyr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 TYGHOWWWMTWVKM-HJOGWXRNSA-N 0.000 description 3
- LABUITCFCAABSV-UHFFFAOYSA-N Val-Ala-Tyr Natural products CC(C)C(N)C(=O)NC(C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LABUITCFCAABSV-UHFFFAOYSA-N 0.000 description 3
- BRPKEERLGYNCNC-NHCYSSNCSA-N Val-Glu-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N BRPKEERLGYNCNC-NHCYSSNCSA-N 0.000 description 3
- YMTOEGGOCHVGEH-IHRRRGAJSA-N Val-Lys-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O YMTOEGGOCHVGEH-IHRRRGAJSA-N 0.000 description 3
- VPGCVZRRBYOGCD-AVGNSLFASA-N Val-Lys-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O VPGCVZRRBYOGCD-AVGNSLFASA-N 0.000 description 3
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 3
- KISFXYYRKKNLOP-IHRRRGAJSA-N Val-Phe-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N KISFXYYRKKNLOP-IHRRRGAJSA-N 0.000 description 3
- 239000002253 acid Substances 0.000 description 3
- 230000004913 activation Effects 0.000 description 3
- 238000004458 analytical method Methods 0.000 description 3
- 239000002246 antineoplastic agent Substances 0.000 description 3
- 239000000074 antisense oligonucleotide Substances 0.000 description 3
- 238000012230 antisense oligonucleotides Methods 0.000 description 3
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 3
- 108010091092 arginyl-glycyl-proline Proteins 0.000 description 3
- 238000003556 assay Methods 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 239000006172 buffering agent Substances 0.000 description 3
- 210000001638 cerebellum Anatomy 0.000 description 3
- 230000002490 cerebral effect Effects 0.000 description 3
- 108010016616 cysteinylglycine Proteins 0.000 description 3
- 230000018732 detection of tumor cell Effects 0.000 description 3
- 108010054813 diprotin B Proteins 0.000 description 3
- 238000009826 distribution Methods 0.000 description 3
- 238000000605 extraction Methods 0.000 description 3
- 238000009472 formulation Methods 0.000 description 3
- 108010079547 glutamylmethionine Proteins 0.000 description 3
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 3
- 108010066198 glycyl-leucyl-phenylalanine Proteins 0.000 description 3
- 108010079413 glycyl-prolyl-glutamic acid Proteins 0.000 description 3
- 108010085325 histidylproline Proteins 0.000 description 3
- 230000005764 inhibitory process Effects 0.000 description 3
- 229940117681 interleukin-12 Drugs 0.000 description 3
- 238000002955 isolation Methods 0.000 description 3
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 3
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 3
- 210000000265 leukocyte Anatomy 0.000 description 3
- 108010003700 lysyl aspartic acid Proteins 0.000 description 3
- 210000005075 mammary gland Anatomy 0.000 description 3
- 239000003550 marker Substances 0.000 description 3
- 230000035772 mutation Effects 0.000 description 3
- 239000002777 nucleoside Substances 0.000 description 3
- 210000000496 pancreas Anatomy 0.000 description 3
- 238000002823 phage display Methods 0.000 description 3
- 238000002360 preparation method Methods 0.000 description 3
- 239000003755 preservative agent Substances 0.000 description 3
- 108010014614 prolyl-glycyl-proline Proteins 0.000 description 3
- 108010090894 prolylleucine Proteins 0.000 description 3
- 108010053725 prolylvaline Proteins 0.000 description 3
- 238000000746 purification Methods 0.000 description 3
- 230000002285 radioactive effect Effects 0.000 description 3
- 239000011541 reaction mixture Substances 0.000 description 3
- 238000003753 real-time PCR Methods 0.000 description 3
- 230000010076 replication Effects 0.000 description 3
- 239000000243 solution Substances 0.000 description 3
- 230000004936 stimulating effect Effects 0.000 description 3
- 150000008163 sugars Chemical class 0.000 description 3
- 108010031491 threonyl-lysyl-glutamic acid Proteins 0.000 description 3
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 3
- 241000701161 unidentified adenovirus Species 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- OTLLEIBWKHEHGU-UHFFFAOYSA-N 2-[5-[[5-(6-aminopurin-9-yl)-3,4-dihydroxyoxolan-2-yl]methoxy]-3,4-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-3,5-dihydroxy-4-phosphonooxyhexanedioic acid Chemical compound C1=NC=2C(N)=NC=NC=2N1C(C(C1O)O)OC1COC1C(CO)OC(OC(C(O)C(OP(O)(O)=O)C(O)C(O)=O)C(O)=O)C(O)C1O OTLLEIBWKHEHGU-UHFFFAOYSA-N 0.000 description 2
- WYWHKKSPHMUBEB-UHFFFAOYSA-N 6-Mercaptoguanine Natural products N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 description 2
- TTXMOJWKNRJWQJ-FXQIFTODSA-N Ala-Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N TTXMOJWKNRJWQJ-FXQIFTODSA-N 0.000 description 2
- FXKNPWNXPQZLES-ZLUOBGJFSA-N Ala-Asn-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O FXKNPWNXPQZLES-ZLUOBGJFSA-N 0.000 description 2
- 108010040956 Ala-Asp-Glu-Leu Proteins 0.000 description 2
- ZODMADSIQZZBSQ-FXQIFTODSA-N Ala-Gln-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZODMADSIQZZBSQ-FXQIFTODSA-N 0.000 description 2
- LMFXXZPPZDCPTA-ZKWXMUAHSA-N Ala-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N LMFXXZPPZDCPTA-ZKWXMUAHSA-N 0.000 description 2
- NBTGEURICRTMGL-WHFBIAKZSA-N Ala-Gly-Ser Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O NBTGEURICRTMGL-WHFBIAKZSA-N 0.000 description 2
- SMCGQGDVTPFXKB-XPUUQOCRSA-N Ala-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N SMCGQGDVTPFXKB-XPUUQOCRSA-N 0.000 description 2
- JEPNLGMEZMCFEX-QSFUFRPTSA-N Ala-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C)N JEPNLGMEZMCFEX-QSFUFRPTSA-N 0.000 description 2
- LNNSWWRRYJLGNI-NAKRPEOUSA-N Ala-Ile-Val Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O LNNSWWRRYJLGNI-NAKRPEOUSA-N 0.000 description 2
- MFMDKJIPHSWSBM-GUBZILKMSA-N Ala-Lys-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O MFMDKJIPHSWSBM-GUBZILKMSA-N 0.000 description 2
- MAZZQZWCCYJQGZ-GUBZILKMSA-N Ala-Pro-Arg Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MAZZQZWCCYJQGZ-GUBZILKMSA-N 0.000 description 2
- MSWSRLGNLKHDEI-ACZMJKKPSA-N Ala-Ser-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O MSWSRLGNLKHDEI-ACZMJKKPSA-N 0.000 description 2
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 2
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 2
- 108091093088 Amplicon Proteins 0.000 description 2
- 102100023003 Ankyrin repeat domain-containing protein 30A Human genes 0.000 description 2
- 108010032595 Antibody Binding Sites Proteins 0.000 description 2
- HJVGMOYJDDXLMI-AVGNSLFASA-N Arg-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCCNC(N)=N HJVGMOYJDDXLMI-AVGNSLFASA-N 0.000 description 2
- NABSCJGZKWSNHX-RCWTZXSCSA-N Arg-Arg-Thr Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H]([C@H](O)C)C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N NABSCJGZKWSNHX-RCWTZXSCSA-N 0.000 description 2
- QPOARHANPULOTM-GMOBBJLQSA-N Arg-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N QPOARHANPULOTM-GMOBBJLQSA-N 0.000 description 2
- OTCJMMRQBVDQRK-DCAQKATOSA-N Arg-Asp-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O OTCJMMRQBVDQRK-DCAQKATOSA-N 0.000 description 2
- SVHRPCMZTWZROG-DCAQKATOSA-N Arg-Cys-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCN=C(N)N)N SVHRPCMZTWZROG-DCAQKATOSA-N 0.000 description 2
- PNQWAUXQDBIJDY-GUBZILKMSA-N Arg-Glu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNQWAUXQDBIJDY-GUBZILKMSA-N 0.000 description 2
- PBSOQGZLPFVXPU-YUMQZZPRSA-N Arg-Glu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O PBSOQGZLPFVXPU-YUMQZZPRSA-N 0.000 description 2
- FNXCAFKDGBROCU-STECZYCISA-N Arg-Ile-Tyr Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FNXCAFKDGBROCU-STECZYCISA-N 0.000 description 2
- LLUGJARLJCGLAR-CYDGBPFRSA-N Arg-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N LLUGJARLJCGLAR-CYDGBPFRSA-N 0.000 description 2
- PZBSKYJGKNNYNK-ULQDDVLXSA-N Arg-Leu-Tyr Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CCCN=C(N)N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(O)=O PZBSKYJGKNNYNK-ULQDDVLXSA-N 0.000 description 2
- RIIVUOJDDQXHRV-SRVKXCTJSA-N Arg-Lys-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O RIIVUOJDDQXHRV-SRVKXCTJSA-N 0.000 description 2
- INXWADWANGLMPJ-JYJNAYRXSA-N Arg-Phe-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)CC1=CC=CC=C1 INXWADWANGLMPJ-JYJNAYRXSA-N 0.000 description 2
- JOTRDIXZHNQYGP-DCAQKATOSA-N Arg-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N JOTRDIXZHNQYGP-DCAQKATOSA-N 0.000 description 2
- UZSQXCMNUPKLCC-FJXKBIBVSA-N Arg-Thr-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UZSQXCMNUPKLCC-FJXKBIBVSA-N 0.000 description 2
- XMZZGVGKGXRIGJ-JYJNAYRXSA-N Arg-Tyr-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O XMZZGVGKGXRIGJ-JYJNAYRXSA-N 0.000 description 2
- BDMIFVIWCNLDCT-CIUDSAMLSA-N Asn-Arg-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O BDMIFVIWCNLDCT-CIUDSAMLSA-N 0.000 description 2
- MFFOYNGMOYFPBD-DCAQKATOSA-N Asn-Arg-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O MFFOYNGMOYFPBD-DCAQKATOSA-N 0.000 description 2
- JEPNYDRDYNSFIU-QXEWZRGKSA-N Asn-Arg-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(N)=O)C(O)=O JEPNYDRDYNSFIU-QXEWZRGKSA-N 0.000 description 2
- QISZHYWZHJRDAO-CIUDSAMLSA-N Asn-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N QISZHYWZHJRDAO-CIUDSAMLSA-N 0.000 description 2
- SPIPSJXLZVTXJL-ZLUOBGJFSA-N Asn-Cys-Ser Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O SPIPSJXLZVTXJL-ZLUOBGJFSA-N 0.000 description 2
- GYOHQKJEQQJBOY-QEJZJMRPSA-N Asn-Glu-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)N)N GYOHQKJEQQJBOY-QEJZJMRPSA-N 0.000 description 2
- SPCONPVIDFMDJI-QSFUFRPTSA-N Asn-Ile-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O SPCONPVIDFMDJI-QSFUFRPTSA-N 0.000 description 2
- NLRJGXZWTKXRHP-DCAQKATOSA-N Asn-Leu-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NLRJGXZWTKXRHP-DCAQKATOSA-N 0.000 description 2
- BXUHCIXDSWRSBS-CIUDSAMLSA-N Asn-Leu-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BXUHCIXDSWRSBS-CIUDSAMLSA-N 0.000 description 2
- MYCSPQIARXTUTP-SRVKXCTJSA-N Asn-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)N)N MYCSPQIARXTUTP-SRVKXCTJSA-N 0.000 description 2
- PBFXCUOEGVJTMV-QXEWZRGKSA-N Asn-Met-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O PBFXCUOEGVJTMV-QXEWZRGKSA-N 0.000 description 2
- NJSNXIOKBHPFMB-GMOBBJLQSA-N Asn-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC(=O)N)N NJSNXIOKBHPFMB-GMOBBJLQSA-N 0.000 description 2
- VHQSGALUSWIYOD-QXEWZRGKSA-N Asn-Pro-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O VHQSGALUSWIYOD-QXEWZRGKSA-N 0.000 description 2
- NYLBGYLHBDFRHL-VEVYYDQMSA-N Asp-Arg-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NYLBGYLHBDFRHL-VEVYYDQMSA-N 0.000 description 2
- MUWDILPCTSMUHI-ZLUOBGJFSA-N Asp-Asn-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N)C(=O)O MUWDILPCTSMUHI-ZLUOBGJFSA-N 0.000 description 2
- BUVNWKQBMZLCDW-UGYAYLCHSA-N Asp-Asn-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BUVNWKQBMZLCDW-UGYAYLCHSA-N 0.000 description 2
- UGKZHCBLMLSANF-CIUDSAMLSA-N Asp-Asn-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O UGKZHCBLMLSANF-CIUDSAMLSA-N 0.000 description 2
- PXLNPFOJZQMXAT-BYULHYEWSA-N Asp-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O PXLNPFOJZQMXAT-BYULHYEWSA-N 0.000 description 2
- KHGPWGKPYHPOIK-QWRGUYRKSA-N Asp-Gly-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O KHGPWGKPYHPOIK-QWRGUYRKSA-N 0.000 description 2
- POTCZYQVVNXUIG-BQBZGAKWSA-N Asp-Gly-Pro Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O POTCZYQVVNXUIG-BQBZGAKWSA-N 0.000 description 2
- NHSDEZURHWEZPN-SXTJYALSSA-N Asp-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H](CC(=O)O)N NHSDEZURHWEZPN-SXTJYALSSA-N 0.000 description 2
- HOBNTSHITVVNBN-ZPFDUUQYSA-N Asp-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N HOBNTSHITVVNBN-ZPFDUUQYSA-N 0.000 description 2
- PAYPSKIBMDHZPI-CIUDSAMLSA-N Asp-Leu-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O PAYPSKIBMDHZPI-CIUDSAMLSA-N 0.000 description 2
- XWSIYTYNLKCLJB-CIUDSAMLSA-N Asp-Lys-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O XWSIYTYNLKCLJB-CIUDSAMLSA-N 0.000 description 2
- VSMYBNPOHYAXSD-GUBZILKMSA-N Asp-Lys-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O VSMYBNPOHYAXSD-GUBZILKMSA-N 0.000 description 2
- LBOVBQONZJRWPV-YUMQZZPRSA-N Asp-Lys-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O LBOVBQONZJRWPV-YUMQZZPRSA-N 0.000 description 2
- DONWIPDSZZJHHK-HJGDQZAQSA-N Asp-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)O DONWIPDSZZJHHK-HJGDQZAQSA-N 0.000 description 2
- MYLZFUMPZCPJCJ-NHCYSSNCSA-N Asp-Lys-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O MYLZFUMPZCPJCJ-NHCYSSNCSA-N 0.000 description 2
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 2
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 2
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 2
- GGBQDSHTXKQSLP-NHCYSSNCSA-N Asp-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N GGBQDSHTXKQSLP-NHCYSSNCSA-N 0.000 description 2
- 101150013553 CD40 gene Proteins 0.000 description 2
- 101100512078 Caenorhabditis elegans lys-1 gene Proteins 0.000 description 2
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 2
- 241000283707 Capra Species 0.000 description 2
- JWBOIMRXGHLCPP-UHFFFAOYSA-N Chloditan Chemical compound C=1C=CC=C(Cl)C=1C(C(Cl)Cl)C1=CC=C(Cl)C=C1 JWBOIMRXGHLCPP-UHFFFAOYSA-N 0.000 description 2
- FMDCYTBSPZMPQE-JBDRJPRFSA-N Cys-Ala-Ile Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FMDCYTBSPZMPQE-JBDRJPRFSA-N 0.000 description 2
- ISWAQPWFWKGCAL-ACZMJKKPSA-N Cys-Cys-Glu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISWAQPWFWKGCAL-ACZMJKKPSA-N 0.000 description 2
- PFAQXUDMZVMADG-AVGNSLFASA-N Cys-Gln-Tyr Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O PFAQXUDMZVMADG-AVGNSLFASA-N 0.000 description 2
- ABLJDBFJPUWQQB-DCAQKATOSA-N Cys-Leu-Arg Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CS)N ABLJDBFJPUWQQB-DCAQKATOSA-N 0.000 description 2
- WZJLBUPPZRZNTO-CIUDSAMLSA-N Cys-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CS)N WZJLBUPPZRZNTO-CIUDSAMLSA-N 0.000 description 2
- DQGIAOGALAQBGK-BWBBJGPYSA-N Cys-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CS)N)O DQGIAOGALAQBGK-BWBBJGPYSA-N 0.000 description 2
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 2
- 108060002716 Exonuclease Proteins 0.000 description 2
- 108010008177 Fd immunoglobulins Proteins 0.000 description 2
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 2
- RMOCFPBLHAOTDU-ACZMJKKPSA-N Gln-Asn-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RMOCFPBLHAOTDU-ACZMJKKPSA-N 0.000 description 2
- XEYMBRRKIFYQMF-GUBZILKMSA-N Gln-Asp-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O XEYMBRRKIFYQMF-GUBZILKMSA-N 0.000 description 2
- XFKUFUJECJUQTQ-CIUDSAMLSA-N Gln-Gln-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XFKUFUJECJUQTQ-CIUDSAMLSA-N 0.000 description 2
- ZNZPKVQURDQFFS-FXQIFTODSA-N Gln-Glu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZNZPKVQURDQFFS-FXQIFTODSA-N 0.000 description 2
- DRDSQGHKTLSNEA-GLLZPBPUSA-N Gln-Glu-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DRDSQGHKTLSNEA-GLLZPBPUSA-N 0.000 description 2
- XJKAKYXMFHUIHT-AUTRQRHGSA-N Gln-Glu-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N XJKAKYXMFHUIHT-AUTRQRHGSA-N 0.000 description 2
- QKCZZAZNMMVICF-DCAQKATOSA-N Gln-Leu-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O QKCZZAZNMMVICF-DCAQKATOSA-N 0.000 description 2
- IULKWYSYZSURJK-AVGNSLFASA-N Gln-Leu-Lys Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O IULKWYSYZSURJK-AVGNSLFASA-N 0.000 description 2
- TWIAMTNJOMRDAK-GUBZILKMSA-N Gln-Lys-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O TWIAMTNJOMRDAK-GUBZILKMSA-N 0.000 description 2
- CELXWPDNIGWCJN-WDCWCFNPSA-N Gln-Lys-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CELXWPDNIGWCJN-WDCWCFNPSA-N 0.000 description 2
- FTTHLXOMDMLKKW-FHWLQOOXSA-N Gln-Phe-Phe Chemical compound C([C@H](NC(=O)[C@H](CCC(N)=O)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 FTTHLXOMDMLKKW-FHWLQOOXSA-N 0.000 description 2
- OSCLNNWLKKIQJM-WDSKDSINSA-N Gln-Ser-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O OSCLNNWLKKIQJM-WDSKDSINSA-N 0.000 description 2
- JTWZNMUVQWWGOX-SOUVJXGZSA-N Gln-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O JTWZNMUVQWWGOX-SOUVJXGZSA-N 0.000 description 2
- HNAUFGBKJLTWQE-IFFSRLJSSA-N Gln-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCC(=O)N)N)O HNAUFGBKJLTWQE-IFFSRLJSSA-N 0.000 description 2
- WZZSKAJIHTUUSG-ACZMJKKPSA-N Glu-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O WZZSKAJIHTUUSG-ACZMJKKPSA-N 0.000 description 2
- CGYDXNKRIMJMLV-GUBZILKMSA-N Glu-Arg-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O CGYDXNKRIMJMLV-GUBZILKMSA-N 0.000 description 2
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 2
- XHUCVVHRLNPZSZ-CIUDSAMLSA-N Glu-Gln-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XHUCVVHRLNPZSZ-CIUDSAMLSA-N 0.000 description 2
- PJBVXVBTTFZPHJ-GUBZILKMSA-N Glu-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N PJBVXVBTTFZPHJ-GUBZILKMSA-N 0.000 description 2
- IVGJYOOGJLFKQE-AVGNSLFASA-N Glu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N IVGJYOOGJLFKQE-AVGNSLFASA-N 0.000 description 2
- CUPSDFQZTVVTSK-GUBZILKMSA-N Glu-Lys-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(O)=O CUPSDFQZTVVTSK-GUBZILKMSA-N 0.000 description 2
- BCYGDJXHAGZNPQ-DCAQKATOSA-N Glu-Lys-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O BCYGDJXHAGZNPQ-DCAQKATOSA-N 0.000 description 2
- OCJRHJZKGGSPRW-IUCAKERBSA-N Glu-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O OCJRHJZKGGSPRW-IUCAKERBSA-N 0.000 description 2
- HRBYTAIBKPNZKQ-AVGNSLFASA-N Glu-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(O)=O HRBYTAIBKPNZKQ-AVGNSLFASA-N 0.000 description 2
- ZGEJRLJEAMPEDV-SRVKXCTJSA-N Glu-Lys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)O)N ZGEJRLJEAMPEDV-SRVKXCTJSA-N 0.000 description 2
- MFNUFCFRAZPJFW-JYJNAYRXSA-N Glu-Lys-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFNUFCFRAZPJFW-JYJNAYRXSA-N 0.000 description 2
- QDMVXRNLOPTPIE-WDCWCFNPSA-N Glu-Lys-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QDMVXRNLOPTPIE-WDCWCFNPSA-N 0.000 description 2
- JHSRJMUJOGLIHK-GUBZILKMSA-N Glu-Met-Glu Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N JHSRJMUJOGLIHK-GUBZILKMSA-N 0.000 description 2
- QMOSCLNJVKSHHU-YUMQZZPRSA-N Glu-Met-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O QMOSCLNJVKSHHU-YUMQZZPRSA-N 0.000 description 2
- MCGNJCNXIMQCMN-DCAQKATOSA-N Glu-Met-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CCC(O)=O MCGNJCNXIMQCMN-DCAQKATOSA-N 0.000 description 2
- GMVCSRBOSIUTFC-FXQIFTODSA-N Glu-Ser-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMVCSRBOSIUTFC-FXQIFTODSA-N 0.000 description 2
- IDEODOAVGCMUQV-GUBZILKMSA-N Glu-Ser-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IDEODOAVGCMUQV-GUBZILKMSA-N 0.000 description 2
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 2
- PUUYVMYCMIWHFE-BQBZGAKWSA-N Gly-Ala-Arg Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PUUYVMYCMIWHFE-BQBZGAKWSA-N 0.000 description 2
- GZUKEVBTYNNUQF-WDSKDSINSA-N Gly-Ala-Gln Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GZUKEVBTYNNUQF-WDSKDSINSA-N 0.000 description 2
- RQZGFWKQLPJOEQ-YUMQZZPRSA-N Gly-Arg-Gln Chemical compound C(C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)CN)CN=C(N)N RQZGFWKQLPJOEQ-YUMQZZPRSA-N 0.000 description 2
- CIMULJZTTOBOPN-WHFBIAKZSA-N Gly-Asn-Asn Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CIMULJZTTOBOPN-WHFBIAKZSA-N 0.000 description 2
- QPDUVFSVVAOUHE-XVKPBYJWSA-N Gly-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)CN)C(O)=O QPDUVFSVVAOUHE-XVKPBYJWSA-N 0.000 description 2
- MBOAPAXLTUSMQI-JHEQGTHGSA-N Gly-Glu-Thr Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MBOAPAXLTUSMQI-JHEQGTHGSA-N 0.000 description 2
- ITZOBNKQDZEOCE-NHCYSSNCSA-N Gly-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)CN ITZOBNKQDZEOCE-NHCYSSNCSA-N 0.000 description 2
- UUYBFNKHOCJCHT-VHSXEESVSA-N Gly-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN UUYBFNKHOCJCHT-VHSXEESVSA-N 0.000 description 2
- CLNSYANKYVMZNM-UWVGGRQHSA-N Gly-Lys-Arg Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N CLNSYANKYVMZNM-UWVGGRQHSA-N 0.000 description 2
- PTIIBFKSLCYQBO-NHCYSSNCSA-N Gly-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)CN PTIIBFKSLCYQBO-NHCYSSNCSA-N 0.000 description 2
- DBJYVKDPGIFXFO-BQBZGAKWSA-N Gly-Met-Ala Chemical compound [H]NCC(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O DBJYVKDPGIFXFO-BQBZGAKWSA-N 0.000 description 2
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 2
- BXDLTKLPPKBVEL-FJXKBIBVSA-N Gly-Thr-Met Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(O)=O BXDLTKLPPKBVEL-FJXKBIBVSA-N 0.000 description 2
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 2
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 2
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 2
- CIWILNZNBPIHEU-DCAQKATOSA-N His-Arg-Asn Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O CIWILNZNBPIHEU-DCAQKATOSA-N 0.000 description 2
- MDBYBTWRMOAJAY-NHCYSSNCSA-N His-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N MDBYBTWRMOAJAY-NHCYSSNCSA-N 0.000 description 2
- LPZUKJALYGXBIE-SRVKXCTJSA-N His-Gln-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N LPZUKJALYGXBIE-SRVKXCTJSA-N 0.000 description 2
- JSHOVJTVPXJFTE-HOCLYGCPSA-N His-Gly-Trp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O JSHOVJTVPXJFTE-HOCLYGCPSA-N 0.000 description 2
- VUUFXXGKMPLKNH-BZSNNMDCSA-N His-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CC3=CN=CN3)N VUUFXXGKMPLKNH-BZSNNMDCSA-N 0.000 description 2
- OWYIDJCNRWRSJY-QTKMDUPCSA-N His-Pro-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O OWYIDJCNRWRSJY-QTKMDUPCSA-N 0.000 description 2
- JMSONHOUHFDOJH-GUBZILKMSA-N His-Ser-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 JMSONHOUHFDOJH-GUBZILKMSA-N 0.000 description 2
- FRDFAWHTPDKRHG-ULQDDVLXSA-N His-Tyr-Arg Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)C1=CN=CN1 FRDFAWHTPDKRHG-ULQDDVLXSA-N 0.000 description 2
- JATYGDHMDRAISQ-KKUMJFAQSA-N His-Tyr-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O JATYGDHMDRAISQ-KKUMJFAQSA-N 0.000 description 2
- 108010088652 Histocompatibility Antigens Class I Proteins 0.000 description 2
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 2
- HDOYNXLPTRQLAD-JBDRJPRFSA-N Ile-Ala-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)O)N HDOYNXLPTRQLAD-JBDRJPRFSA-N 0.000 description 2
- UAVQIQOOBXFKRC-BYULHYEWSA-N Ile-Asn-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O UAVQIQOOBXFKRC-BYULHYEWSA-N 0.000 description 2
- DURWCDDDAWVPOP-JBDRJPRFSA-N Ile-Cys-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N DURWCDDDAWVPOP-JBDRJPRFSA-N 0.000 description 2
- BEWFWZRGBDVXRP-PEFMBERDSA-N Ile-Glu-Asn Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O BEWFWZRGBDVXRP-PEFMBERDSA-N 0.000 description 2
- LWWILHPVAKKLQS-QXEWZRGKSA-N Ile-Gly-Met Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCSC)C(=O)O)N LWWILHPVAKKLQS-QXEWZRGKSA-N 0.000 description 2
- WIZPFZKOFZXDQG-HTFCKZLJSA-N Ile-Ile-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O WIZPFZKOFZXDQG-HTFCKZLJSA-N 0.000 description 2
- YNMQUIVKEFRCPH-QSFUFRPTSA-N Ile-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)O)N YNMQUIVKEFRCPH-QSFUFRPTSA-N 0.000 description 2
- CSQNHSGHAPRGPQ-YTFOTSKYSA-N Ile-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCCN)C(=O)O)N CSQNHSGHAPRGPQ-YTFOTSKYSA-N 0.000 description 2
- UWLHDGMRWXHFFY-HPCHECBXSA-N Ile-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1CCC[C@@H]1C(=O)O)N UWLHDGMRWXHFFY-HPCHECBXSA-N 0.000 description 2
- YTRFFJUOYBMLPN-UHFFFAOYSA-N Ile-Lys-Lys-Ser Chemical compound CCC(C)C(N)C(=O)NC(CCCCN)C(=O)NC(CCCCN)C(=O)NC(CO)C(O)=O YTRFFJUOYBMLPN-UHFFFAOYSA-N 0.000 description 2
- ZUPJCJINYQISSN-XUXIUFHCSA-N Ile-Met-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)O)N ZUPJCJINYQISSN-XUXIUFHCSA-N 0.000 description 2
- USXAYNCLFSUSBA-MGHWNKPDSA-N Ile-Phe-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N USXAYNCLFSUSBA-MGHWNKPDSA-N 0.000 description 2
- KBDIBHQICWDGDL-PPCPHDFISA-N Ile-Thr-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N KBDIBHQICWDGDL-PPCPHDFISA-N 0.000 description 2
- WCNWGAUZWWSYDG-SVSWQMSJSA-N Ile-Thr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)O)N WCNWGAUZWWSYDG-SVSWQMSJSA-N 0.000 description 2
- APQYGMBHIVXFML-OSUNSFLBSA-N Ile-Val-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N APQYGMBHIVXFML-OSUNSFLBSA-N 0.000 description 2
- 108060003951 Immunoglobulin Proteins 0.000 description 2
- 108090001005 Interleukin-6 Proteins 0.000 description 2
- 108010044467 Isoenzymes Proteins 0.000 description 2
- KFZMGEQAYNKOFK-UHFFFAOYSA-N Isopropanol Chemical compound CC(C)O KFZMGEQAYNKOFK-UHFFFAOYSA-N 0.000 description 2
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 2
- 108010028554 LDL Cholesterol Proteins 0.000 description 2
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 2
- PPBKJAQJAUHZKX-SRVKXCTJSA-N Leu-Cys-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CC(C)C PPBKJAQJAUHZKX-SRVKXCTJSA-N 0.000 description 2
- PNUCWVAGVNLUMW-CIUDSAMLSA-N Leu-Cys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O PNUCWVAGVNLUMW-CIUDSAMLSA-N 0.000 description 2
- BOFAFKVZQUMTID-AVGNSLFASA-N Leu-Gln-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N BOFAFKVZQUMTID-AVGNSLFASA-N 0.000 description 2
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 2
- POZULHZYLPGXMR-ONGXEEELSA-N Leu-Gly-Val Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O POZULHZYLPGXMR-ONGXEEELSA-N 0.000 description 2
- OHZIZVWQXJPBJS-IXOXFDKPSA-N Leu-His-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OHZIZVWQXJPBJS-IXOXFDKPSA-N 0.000 description 2
- DBSLVQBXKVKDKJ-BJDJZHNGSA-N Leu-Ile-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O DBSLVQBXKVKDKJ-BJDJZHNGSA-N 0.000 description 2
- QJXHMYMRGDOHRU-NHCYSSNCSA-N Leu-Ile-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O QJXHMYMRGDOHRU-NHCYSSNCSA-N 0.000 description 2
- SEMUSFOBZGKBGW-YTFOTSKYSA-N Leu-Ile-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SEMUSFOBZGKBGW-YTFOTSKYSA-N 0.000 description 2
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 2
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 2
- DCGXHWINSHEPIR-SRVKXCTJSA-N Leu-Lys-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)O)N DCGXHWINSHEPIR-SRVKXCTJSA-N 0.000 description 2
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 2
- INCJJHQRZGQLFC-KBPBESRZSA-N Leu-Phe-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O INCJJHQRZGQLFC-KBPBESRZSA-N 0.000 description 2
- KTOIECMYZZGVSI-BZSNNMDCSA-N Leu-Phe-His Chemical compound C([C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CC=CC=C1 KTOIECMYZZGVSI-BZSNNMDCSA-N 0.000 description 2
- PWPBLZXWFXJFHE-RHYQMDGZSA-N Leu-Pro-Thr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O PWPBLZXWFXJFHE-RHYQMDGZSA-N 0.000 description 2
- SVBJIZVVYJYGLA-DCAQKATOSA-N Leu-Ser-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O SVBJIZVVYJYGLA-DCAQKATOSA-N 0.000 description 2
- VDIARPPNADFEAV-WEDXCCLWSA-N Leu-Thr-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O VDIARPPNADFEAV-WEDXCCLWSA-N 0.000 description 2
- HGLKOTPFWOMPOB-MEYUZBJRSA-N Leu-Thr-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HGLKOTPFWOMPOB-MEYUZBJRSA-N 0.000 description 2
- WUHBLPVELFTPQK-KKUMJFAQSA-N Leu-Tyr-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O WUHBLPVELFTPQK-KKUMJFAQSA-N 0.000 description 2
- ISSAURVGLGAPDK-KKUMJFAQSA-N Leu-Tyr-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O ISSAURVGLGAPDK-KKUMJFAQSA-N 0.000 description 2
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 2
- RVOMPSJXSRPFJT-DCAQKATOSA-N Lys-Ala-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RVOMPSJXSRPFJT-DCAQKATOSA-N 0.000 description 2
- MPOHDJKRBLVGCT-CIUDSAMLSA-N Lys-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N MPOHDJKRBLVGCT-CIUDSAMLSA-N 0.000 description 2
- WXJKFRMKJORORD-DCAQKATOSA-N Lys-Arg-Ala Chemical compound NC(=N)NCCC[C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CCCCN WXJKFRMKJORORD-DCAQKATOSA-N 0.000 description 2
- JGAMUXDWYSXYLM-SRVKXCTJSA-N Lys-Arg-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O JGAMUXDWYSXYLM-SRVKXCTJSA-N 0.000 description 2
- YEIYAQQKADPIBJ-GARJFASQSA-N Lys-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCCN)N)C(=O)O YEIYAQQKADPIBJ-GARJFASQSA-N 0.000 description 2
- NTBFKPBULZGXQL-KKUMJFAQSA-N Lys-Asp-Tyr Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NTBFKPBULZGXQL-KKUMJFAQSA-N 0.000 description 2
- QQUJSUFWEDZQQY-AVGNSLFASA-N Lys-Gln-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCCN QQUJSUFWEDZQQY-AVGNSLFASA-N 0.000 description 2
- DRCILAJNUJKAHC-SRVKXCTJSA-N Lys-Glu-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DRCILAJNUJKAHC-SRVKXCTJSA-N 0.000 description 2
- PAMDBWYMLWOELY-SDDRHHMPSA-N Lys-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)C(=O)O PAMDBWYMLWOELY-SDDRHHMPSA-N 0.000 description 2
- QZONCCHVHCOBSK-YUMQZZPRSA-N Lys-Gly-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O QZONCCHVHCOBSK-YUMQZZPRSA-N 0.000 description 2
- ISHNZELVUVPCHY-ZETCQYMHSA-N Lys-Gly-Gly Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O ISHNZELVUVPCHY-ZETCQYMHSA-N 0.000 description 2
- RFQATBGBLDAKGI-VHSXEESVSA-N Lys-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCCCN)N)C(=O)O RFQATBGBLDAKGI-VHSXEESVSA-N 0.000 description 2
- FHIAJWBDZVHLAH-YUMQZZPRSA-N Lys-Gly-Ser Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FHIAJWBDZVHLAH-YUMQZZPRSA-N 0.000 description 2
- CANPXOLVTMKURR-WEDXCCLWSA-N Lys-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN CANPXOLVTMKURR-WEDXCCLWSA-N 0.000 description 2
- ZMMDPRTXLAEMOD-BZSNNMDCSA-N Lys-His-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ZMMDPRTXLAEMOD-BZSNNMDCSA-N 0.000 description 2
- PRSBSVAVOQOAMI-BJDJZHNGSA-N Lys-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN PRSBSVAVOQOAMI-BJDJZHNGSA-N 0.000 description 2
- VMTYLUGCXIEDMV-QWRGUYRKSA-N Lys-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCCN VMTYLUGCXIEDMV-QWRGUYRKSA-N 0.000 description 2
- WVJNGSFKBKOKRV-AJNGGQMLSA-N Lys-Leu-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WVJNGSFKBKOKRV-AJNGGQMLSA-N 0.000 description 2
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 2
- WRODMZBHNNPRLN-SRVKXCTJSA-N Lys-Leu-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O WRODMZBHNNPRLN-SRVKXCTJSA-N 0.000 description 2
- UQRZFMQQXXJTTF-AVGNSLFASA-N Lys-Lys-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O UQRZFMQQXXJTTF-AVGNSLFASA-N 0.000 description 2
- PIXVFCBYEGPZPA-JYJNAYRXSA-N Lys-Phe-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N PIXVFCBYEGPZPA-JYJNAYRXSA-N 0.000 description 2
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 2
- XABXVVSWUVCZST-GVXVVHGQSA-N Lys-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN XABXVVSWUVCZST-GVXVVHGQSA-N 0.000 description 2
- OZVXDDFYCQOPFD-XQQFMLRXSA-N Lys-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N OZVXDDFYCQOPFD-XQQFMLRXSA-N 0.000 description 2
- 108091054437 MHC class I family Proteins 0.000 description 2
- 102000018697 Membrane Proteins Human genes 0.000 description 2
- 108010052285 Membrane Proteins Proteins 0.000 description 2
- KUQWVNFMZLHAPA-CIUDSAMLSA-N Met-Ala-Gln Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O KUQWVNFMZLHAPA-CIUDSAMLSA-N 0.000 description 2
- CGUYGMFQZCYJSG-DCAQKATOSA-N Met-Lys-Ser Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O CGUYGMFQZCYJSG-DCAQKATOSA-N 0.000 description 2
- FIZZULTXMVEIAA-IHRRRGAJSA-N Met-Ser-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FIZZULTXMVEIAA-IHRRRGAJSA-N 0.000 description 2
- GWADARYJIJDYRC-XGEHTFHBSA-N Met-Thr-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GWADARYJIJDYRC-XGEHTFHBSA-N 0.000 description 2
- MFDDVIJCQYOOES-GUBZILKMSA-N Met-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCSC)N MFDDVIJCQYOOES-GUBZILKMSA-N 0.000 description 2
- LPNWWHBFXPNHJG-AVGNSLFASA-N Met-Val-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN LPNWWHBFXPNHJG-AVGNSLFASA-N 0.000 description 2
- 241001465754 Metazoa Species 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- 238000012408 PCR amplification Methods 0.000 description 2
- 229910019142 PO4 Inorganic materials 0.000 description 2
- 108010067902 Peptide Library Proteins 0.000 description 2
- AJOKKVTWEMXZHC-DRZSPHRISA-N Phe-Ala-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 AJOKKVTWEMXZHC-DRZSPHRISA-N 0.000 description 2
- IWRZUGHCHFZYQZ-UFYCRDLUSA-N Phe-Arg-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 IWRZUGHCHFZYQZ-UFYCRDLUSA-N 0.000 description 2
- IUVYJBMTHARMIP-PCBIJLKTSA-N Phe-Asp-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O IUVYJBMTHARMIP-PCBIJLKTSA-N 0.000 description 2
- MPFGIYLYWUCSJG-AVGNSLFASA-N Phe-Glu-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 MPFGIYLYWUCSJG-AVGNSLFASA-N 0.000 description 2
- WEMYTDDMDBLPMI-DKIMLUQUSA-N Phe-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N WEMYTDDMDBLPMI-DKIMLUQUSA-N 0.000 description 2
- GPLWGAYGROGDEN-BZSNNMDCSA-N Phe-Phe-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O GPLWGAYGROGDEN-BZSNNMDCSA-N 0.000 description 2
- GMWNQSGWWGKTSF-LFSVMHDDSA-N Phe-Thr-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O GMWNQSGWWGKTSF-LFSVMHDDSA-N 0.000 description 2
- JHSRGEODDALISP-XVSYOHENSA-N Phe-Thr-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O JHSRGEODDALISP-XVSYOHENSA-N 0.000 description 2
- VFDRDMOMHBJGKD-UFYCRDLUSA-N Phe-Tyr-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N VFDRDMOMHBJGKD-UFYCRDLUSA-N 0.000 description 2
- FRMKIPSIZSFTTE-HJOGWXRNSA-N Phe-Tyr-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O FRMKIPSIZSFTTE-HJOGWXRNSA-N 0.000 description 2
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 2
- FZHBZMDRDASUHN-NAKRPEOUSA-N Pro-Ala-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1)C(O)=O FZHBZMDRDASUHN-NAKRPEOUSA-N 0.000 description 2
- BNBBNGZZKQUWCD-IUCAKERBSA-N Pro-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H]1CCCN1 BNBBNGZZKQUWCD-IUCAKERBSA-N 0.000 description 2
- NUZHSNLQJDYSRW-BZSNNMDCSA-N Pro-Arg-Trp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O NUZHSNLQJDYSRW-BZSNNMDCSA-N 0.000 description 2
- LXVLKXPFIDDHJG-CIUDSAMLSA-N Pro-Glu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O LXVLKXPFIDDHJG-CIUDSAMLSA-N 0.000 description 2
- SRBFGSGDNNQABI-FHWLQOOXSA-N Pro-Leu-Trp Chemical compound N([C@@H](CC(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C(=O)[C@@H]1CCCN1 SRBFGSGDNNQABI-FHWLQOOXSA-N 0.000 description 2
- CPRLKHJUFAXVTD-ULQDDVLXSA-N Pro-Leu-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CPRLKHJUFAXVTD-ULQDDVLXSA-N 0.000 description 2
- JUJCUYWRJMFJJF-AVGNSLFASA-N Pro-Lys-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]1CCCN1 JUJCUYWRJMFJJF-AVGNSLFASA-N 0.000 description 2
- SXMSEHDMNIUTSP-DCAQKATOSA-N Pro-Lys-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O SXMSEHDMNIUTSP-DCAQKATOSA-N 0.000 description 2
- XQPHBAKJJJZOBX-SRVKXCTJSA-N Pro-Lys-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O XQPHBAKJJJZOBX-SRVKXCTJSA-N 0.000 description 2
- ABSSTGUCBCDKMU-UWVGGRQHSA-N Pro-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H]1CCCN1 ABSSTGUCBCDKMU-UWVGGRQHSA-N 0.000 description 2
- SEZGGSHLMROBFX-CIUDSAMLSA-N Pro-Ser-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O SEZGGSHLMROBFX-CIUDSAMLSA-N 0.000 description 2
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 2
- FDMCIBSQRKFSTJ-RHYQMDGZSA-N Pro-Thr-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O FDMCIBSQRKFSTJ-RHYQMDGZSA-N 0.000 description 2
- OOZJHTXCLJUODH-QXEWZRGKSA-N Pro-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 OOZJHTXCLJUODH-QXEWZRGKSA-N 0.000 description 2
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 2
- FHJQROWZEJFZPO-SRVKXCTJSA-N Pro-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 FHJQROWZEJFZPO-SRVKXCTJSA-N 0.000 description 2
- 238000012228 RNA interference-mediated gene silencing Methods 0.000 description 2
- 238000010240 RT-PCR analysis Methods 0.000 description 2
- 108091028664 Ribonucleotide Proteins 0.000 description 2
- BTPAWKABYQMKKN-LKXGYXEUSA-N Ser-Asp-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BTPAWKABYQMKKN-LKXGYXEUSA-N 0.000 description 2
- COLJZWUVZIXSSS-CIUDSAMLSA-N Ser-Cys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N COLJZWUVZIXSSS-CIUDSAMLSA-N 0.000 description 2
- MOVJSUIKUNCVMG-ZLUOBGJFSA-N Ser-Cys-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N)O MOVJSUIKUNCVMG-ZLUOBGJFSA-N 0.000 description 2
- BRGQQXQKPUCUJQ-KBIXCLLPSA-N Ser-Glu-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRGQQXQKPUCUJQ-KBIXCLLPSA-N 0.000 description 2
- LALNXSXEYFUUDD-GUBZILKMSA-N Ser-Glu-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LALNXSXEYFUUDD-GUBZILKMSA-N 0.000 description 2
- HBTCFCHYALPXME-HTFCKZLJSA-N Ser-Ile-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HBTCFCHYALPXME-HTFCKZLJSA-N 0.000 description 2
- RIAKPZVSNBBNRE-BJDJZHNGSA-N Ser-Ile-Leu Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O RIAKPZVSNBBNRE-BJDJZHNGSA-N 0.000 description 2
- MOINZPRHJGTCHZ-MMWGEVLESA-N Ser-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N MOINZPRHJGTCHZ-MMWGEVLESA-N 0.000 description 2
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 2
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 2
- JWOBLHJRDADHLN-KKUMJFAQSA-N Ser-Leu-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JWOBLHJRDADHLN-KKUMJFAQSA-N 0.000 description 2
- PPCZVWHJWJFTFN-ZLUOBGJFSA-N Ser-Ser-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPCZVWHJWJFTFN-ZLUOBGJFSA-N 0.000 description 2
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 2
- BEBVVQPDSHHWQL-NRPADANISA-N Ser-Val-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O BEBVVQPDSHHWQL-NRPADANISA-N 0.000 description 2
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 2
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 2
- 241000282887 Suidae Species 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 2
- ZUXQFMVPAYGPFJ-JXUBOQSCSA-N Thr-Ala-Lys Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN ZUXQFMVPAYGPFJ-JXUBOQSCSA-N 0.000 description 2
- VXMHQKHDKCATDV-VEVYYDQMSA-N Thr-Asp-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VXMHQKHDKCATDV-VEVYYDQMSA-N 0.000 description 2
- GNHRVXYZKWSJTF-HJGDQZAQSA-N Thr-Asp-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N)O GNHRVXYZKWSJTF-HJGDQZAQSA-N 0.000 description 2
- BNGDYRRHRGOPHX-IFFSRLJSSA-N Thr-Glu-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O BNGDYRRHRGOPHX-IFFSRLJSSA-N 0.000 description 2
- KBBRNEDOYWMIJP-KYNKHSRBSA-N Thr-Gly-Thr Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KBBRNEDOYWMIJP-KYNKHSRBSA-N 0.000 description 2
- AYCQVUUPIJHJTA-IXOXFDKPSA-N Thr-His-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O AYCQVUUPIJHJTA-IXOXFDKPSA-N 0.000 description 2
- KRGDDWVBBDLPSJ-CUJWVEQBSA-N Thr-His-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O KRGDDWVBBDLPSJ-CUJWVEQBSA-N 0.000 description 2
- VTVVYQOXJCZVEB-WDCWCFNPSA-N Thr-Leu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O VTVVYQOXJCZVEB-WDCWCFNPSA-N 0.000 description 2
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 2
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 2
- KERCOYANYUPLHJ-XGEHTFHBSA-N Thr-Pro-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O KERCOYANYUPLHJ-XGEHTFHBSA-N 0.000 description 2
- NBIIPOKZPUGATB-BWBBJGPYSA-N Thr-Ser-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N)O NBIIPOKZPUGATB-BWBBJGPYSA-N 0.000 description 2
- IQPWNQRRAJHOKV-KATARQTJSA-N Thr-Ser-Lys Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN IQPWNQRRAJHOKV-KATARQTJSA-N 0.000 description 2
- WKGAAMOJPMBBMC-IXOXFDKPSA-N Thr-Ser-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WKGAAMOJPMBBMC-IXOXFDKPSA-N 0.000 description 2
- YRJOLUDFVAUXLI-GSSVUCPTSA-N Thr-Thr-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(O)=O YRJOLUDFVAUXLI-GSSVUCPTSA-N 0.000 description 2
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 2
- 108700009124 Transcription Initiation Site Proteins 0.000 description 2
- 108091023040 Transcription factor Proteins 0.000 description 2
- 102000040945 Transcription factor Human genes 0.000 description 2
- LAIUAVGWZYTBKN-VHWLVUOQSA-N Trp-Asn-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(O)=O LAIUAVGWZYTBKN-VHWLVUOQSA-N 0.000 description 2
- IQXWAJUIAQLZNX-IHPCNDPISA-N Trp-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N IQXWAJUIAQLZNX-IHPCNDPISA-N 0.000 description 2
- OSYOKZZRVGUDMO-HSCHXYMDSA-N Trp-Lys-Ile Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O OSYOKZZRVGUDMO-HSCHXYMDSA-N 0.000 description 2
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 2
- QHLIUFUEUDFAOT-MGHWNKPDSA-N Tyr-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QHLIUFUEUDFAOT-MGHWNKPDSA-N 0.000 description 2
- ARJASMXQBRNAGI-YESZJQIVSA-N Tyr-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N ARJASMXQBRNAGI-YESZJQIVSA-N 0.000 description 2
- YSGAPESOXHFTQY-IHRRRGAJSA-N Tyr-Met-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N YSGAPESOXHFTQY-IHRRRGAJSA-N 0.000 description 2
- PLXQRTXVLZUNMU-RNXOBYDBSA-N Tyr-Phe-Trp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)NC(=O)[C@H](CC4=CC=C(C=C4)O)N PLXQRTXVLZUNMU-RNXOBYDBSA-N 0.000 description 2
- SZEIFUXUTBBQFQ-STQMWFEESA-N Tyr-Pro-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O SZEIFUXUTBBQFQ-STQMWFEESA-N 0.000 description 2
- SOAUMCDLIUGXJJ-SRVKXCTJSA-N Tyr-Ser-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O SOAUMCDLIUGXJJ-SRVKXCTJSA-N 0.000 description 2
- ITDWWLTTWRRLCC-KJEVXHAQSA-N Tyr-Thr-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 ITDWWLTTWRRLCC-KJEVXHAQSA-N 0.000 description 2
- OJCISMMNNUNNJA-BZSNNMDCSA-N Tyr-Tyr-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 OJCISMMNNUNNJA-BZSNNMDCSA-N 0.000 description 2
- 241000700618 Vaccinia virus Species 0.000 description 2
- LABUITCFCAABSV-BPNCWPANSA-N Val-Ala-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 LABUITCFCAABSV-BPNCWPANSA-N 0.000 description 2
- PFNZJEPSCBAVGX-CYDGBPFRSA-N Val-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](C(C)C)N PFNZJEPSCBAVGX-CYDGBPFRSA-N 0.000 description 2
- IVXJODPZRWHCCR-JYJNAYRXSA-N Val-Arg-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N IVXJODPZRWHCCR-JYJNAYRXSA-N 0.000 description 2
- YODDULVCGFQRFZ-ZKWXMUAHSA-N Val-Asp-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YODDULVCGFQRFZ-ZKWXMUAHSA-N 0.000 description 2
- CWSIBTLMMQLPPZ-FXQIFTODSA-N Val-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N CWSIBTLMMQLPPZ-FXQIFTODSA-N 0.000 description 2
- VCAWFLIWYNMHQP-UKJIMTQDSA-N Val-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N VCAWFLIWYNMHQP-UKJIMTQDSA-N 0.000 description 2
- OQWNEUXPKHIEJO-NRPADANISA-N Val-Glu-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N OQWNEUXPKHIEJO-NRPADANISA-N 0.000 description 2
- XWYUBUYQMOUFRQ-IFFSRLJSSA-N Val-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N)O XWYUBUYQMOUFRQ-IFFSRLJSSA-N 0.000 description 2
- LAYSXAOGWHKNED-XPUUQOCRSA-N Val-Gly-Ser Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LAYSXAOGWHKNED-XPUUQOCRSA-N 0.000 description 2
- YTUABZMPYKCWCQ-XQQFMLRXSA-N Val-His-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N2CCC[C@@H]2C(=O)O)N YTUABZMPYKCWCQ-XQQFMLRXSA-N 0.000 description 2
- ZIGZPYJXIWLQFC-QTKMDUPCSA-N Val-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C(C)C)N)O ZIGZPYJXIWLQFC-QTKMDUPCSA-N 0.000 description 2
- JPPXDMBGXJBTIB-ULQDDVLXSA-N Val-His-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N JPPXDMBGXJBTIB-ULQDDVLXSA-N 0.000 description 2
- XXWBHOWRARMUOC-NHCYSSNCSA-N Val-Lys-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)N)C(=O)O)N XXWBHOWRARMUOC-NHCYSSNCSA-N 0.000 description 2
- WMRWZYSRQUORHJ-YDHLFZDLSA-N Val-Phe-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)O)C(=O)O)N WMRWZYSRQUORHJ-YDHLFZDLSA-N 0.000 description 2
- KSFXWENSJABBFI-ZKWXMUAHSA-N Val-Ser-Asn Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O KSFXWENSJABBFI-ZKWXMUAHSA-N 0.000 description 2
- LTTQCQRTSHJPPL-ZKWXMUAHSA-N Val-Ser-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N LTTQCQRTSHJPPL-ZKWXMUAHSA-N 0.000 description 2
- QTPQHINADBYBNA-DCAQKATOSA-N Val-Ser-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN QTPQHINADBYBNA-DCAQKATOSA-N 0.000 description 2
- UJMCYJKPDFQLHX-XGEHTFHBSA-N Val-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N)O UJMCYJKPDFQLHX-XGEHTFHBSA-N 0.000 description 2
- MNSSBIHFEUUXNW-RCWTZXSCSA-N Val-Thr-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N MNSSBIHFEUUXNW-RCWTZXSCSA-N 0.000 description 2
- MIAZWUMFUURQNP-YDHLFZDLSA-N Val-Tyr-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N MIAZWUMFUURQNP-YDHLFZDLSA-N 0.000 description 2
- JXWGBRRVTRAZQA-ULQDDVLXSA-N Val-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N JXWGBRRVTRAZQA-ULQDDVLXSA-N 0.000 description 2
- WBPFYNYTYASCQP-CYDGBPFRSA-N Val-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N WBPFYNYTYASCQP-CYDGBPFRSA-N 0.000 description 2
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 2
- YKZVPMUGEJXEOR-JYJNAYRXSA-N Val-Val-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N YKZVPMUGEJXEOR-JYJNAYRXSA-N 0.000 description 2
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 2
- 102000013814 Wnt Human genes 0.000 description 2
- 108050003627 Wnt Proteins 0.000 description 2
- 230000005856 abnormality Effects 0.000 description 2
- 238000010521 absorption reaction Methods 0.000 description 2
- 238000009825 accumulation Methods 0.000 description 2
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 239000004480 active ingredient Substances 0.000 description 2
- 239000013543 active substance Substances 0.000 description 2
- 238000007792 addition Methods 0.000 description 2
- 108010044940 alanylglutamine Proteins 0.000 description 2
- 125000001931 aliphatic group Chemical group 0.000 description 2
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 2
- 125000000539 amino acid group Chemical group 0.000 description 2
- 108010001271 arginyl-glutamyl-arginine Proteins 0.000 description 2
- 108010038633 aspartylglutamate Proteins 0.000 description 2
- 108010047857 aspartylglycine Proteins 0.000 description 2
- TZCXTZWJZNENPQ-UHFFFAOYSA-L barium sulfate Chemical compound [Ba+2].[O-]S([O-])(=O)=O TZCXTZWJZNENPQ-UHFFFAOYSA-L 0.000 description 2
- 239000002585 base Substances 0.000 description 2
- 238000001574 biopsy Methods 0.000 description 2
- 210000001185 bone marrow Anatomy 0.000 description 2
- 125000003636 chemical group Chemical group 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- OSASVXMJTNOKOY-UHFFFAOYSA-N chlorobutanol Chemical compound CC(C)(O)C(Cl)(Cl)Cl OSASVXMJTNOKOY-UHFFFAOYSA-N 0.000 description 2
- 101150070926 ct gene Proteins 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 239000002552 dosage form Substances 0.000 description 2
- 230000005014 ectopic expression Effects 0.000 description 2
- 238000001962 electrophoresis Methods 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 230000002708 enhancing effect Effects 0.000 description 2
- 210000003527 eukaryotic cell Anatomy 0.000 description 2
- 102000013165 exonuclease Human genes 0.000 description 2
- 231100000776 exotoxin Toxicity 0.000 description 2
- 239000002095 exotoxin Substances 0.000 description 2
- 239000013613 expression plasmid Substances 0.000 description 2
- 210000003754 fetus Anatomy 0.000 description 2
- 230000009368 gene silencing by RNA Effects 0.000 description 2
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 2
- 210000003958 hematopoietic stem cell Anatomy 0.000 description 2
- 230000002998 immunogenetic effect Effects 0.000 description 2
- 102000018358 immunoglobulin Human genes 0.000 description 2
- 229940072221 immunoglobulins Drugs 0.000 description 2
- 230000002055 immunohistochemical effect Effects 0.000 description 2
- 238000000126 in silico method Methods 0.000 description 2
- 230000006698 induction Effects 0.000 description 2
- 239000003112 inhibitor Substances 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 238000001990 intravenous administration Methods 0.000 description 2
- 108010027338 isoleucylcysteine Proteins 0.000 description 2
- 230000004807 localization Effects 0.000 description 2
- 210000004962 mammalian cell Anatomy 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 2
- 229960001428 mercaptopurine Drugs 0.000 description 2
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 2
- 108010056582 methionylglutamic acid Proteins 0.000 description 2
- 229960000485 methotrexate Drugs 0.000 description 2
- 229960000350 mitotane Drugs 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 238000010369 molecular cloning Methods 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 239000013642 negative control Substances 0.000 description 2
- 125000003835 nucleoside group Chemical group 0.000 description 2
- 239000003921 oil Substances 0.000 description 2
- 229940124276 oligodeoxyribonucleotide Drugs 0.000 description 2
- 210000003463 organelle Anatomy 0.000 description 2
- 230000036961 partial effect Effects 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- 210000005259 peripheral blood Anatomy 0.000 description 2
- 239000011886 peripheral blood Substances 0.000 description 2
- 108010073101 phenylalanylleucine Proteins 0.000 description 2
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 2
- 108010083476 phenylalanyltryptophan Proteins 0.000 description 2
- 235000021317 phosphate Nutrition 0.000 description 2
- 230000004962 physiological condition Effects 0.000 description 2
- 239000013612 plasmid Substances 0.000 description 2
- 229960000624 procarbazine Drugs 0.000 description 2
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 description 2
- 210000001236 prokaryotic cell Anatomy 0.000 description 2
- 108010079317 prolyl-tyrosine Proteins 0.000 description 2
- 108010029020 prolylglycine Proteins 0.000 description 2
- 238000011002 quantification Methods 0.000 description 2
- 102000037983 regulatory factors Human genes 0.000 description 2
- 108091008025 regulatory factors Proteins 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 230000001177 retroviral effect Effects 0.000 description 2
- 239000002336 ribonucleotide Substances 0.000 description 2
- 125000002652 ribonucleotide group Chemical group 0.000 description 2
- YGSDEFSMJLZEOE-UHFFFAOYSA-N salicylic acid Chemical compound OC(=O)C1=CC=CC=C1O YGSDEFSMJLZEOE-UHFFFAOYSA-N 0.000 description 2
- 238000007423 screening assay Methods 0.000 description 2
- 230000028327 secretion Effects 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 241000894007 species Species 0.000 description 2
- 230000002269 spontaneous effect Effects 0.000 description 2
- 230000000638 stimulation Effects 0.000 description 2
- 239000000725 suspension Substances 0.000 description 2
- 208000024891 symptom Diseases 0.000 description 2
- 230000008685 targeting Effects 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 2
- MNRILEROXIRVNJ-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=NC=N[C]21 MNRILEROXIRVNJ-UHFFFAOYSA-N 0.000 description 2
- 229960003087 tioguanine Drugs 0.000 description 2
- 230000005748 tumor development Effects 0.000 description 2
- 108010078580 tyrosylleucine Proteins 0.000 description 2
- 238000011144 upstream manufacturing Methods 0.000 description 2
- 229960004982 vinblastine sulfate Drugs 0.000 description 2
- KDQAABAKXDWYSZ-PNYVAJAMSA-N vinblastine sulfate Chemical compound OS(O)(=O)=O.C([C@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 KDQAABAKXDWYSZ-PNYVAJAMSA-N 0.000 description 2
- AQTQHPDCURKLKT-JKDPCDLQSA-N vincristine sulfate Chemical compound OS(O)(=O)=O.C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C=O)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 AQTQHPDCURKLKT-JKDPCDLQSA-N 0.000 description 2
- 229960002110 vincristine sulfate Drugs 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- XVZCXCTYGHPNEM-IHRRRGAJSA-N (2s)-1-[(2s)-2-[[(2s)-2-amino-4-methylpentanoyl]amino]-4-methylpentanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(O)=O XVZCXCTYGHPNEM-IHRRRGAJSA-N 0.000 description 1
- YYGNTYWPHWGJRM-UHFFFAOYSA-N (6E,10E,14E,18E)-2,6,10,15,19,23-hexamethyltetracosa-2,6,10,14,18,22-hexaene Chemical compound CC(C)=CCCC(C)=CCCC(C)=CCCC=C(C)CCC=C(C)CCC=C(C)C YYGNTYWPHWGJRM-UHFFFAOYSA-N 0.000 description 1
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 1
- PNDPGZBMCMUPRI-HVTJNCQCSA-N 10043-66-0 Chemical compound [131I][131I] PNDPGZBMCMUPRI-HVTJNCQCSA-N 0.000 description 1
- BFSVOASYOCHEOV-UHFFFAOYSA-N 2-diethylaminoethanol Chemical compound CCN(CC)CCO BFSVOASYOCHEOV-UHFFFAOYSA-N 0.000 description 1
- WUIABRMSWOKTOF-OYALTWQYSA-N 3-[[2-[2-[2-[[(2s,3r)-2-[[(2s,3s,4r)-4-[[(2s,3r)-2-[[6-amino-2-[(1s)-3-amino-1-[[(2s)-2,3-diamino-3-oxopropyl]amino]-3-oxopropyl]-5-methylpyrimidine-4-carbonyl]amino]-3-[(2r,3s,4s,5s,6s)-3-[(2r,3s,4s,5r,6r)-4-carbamoyloxy-3,5-dihydroxy-6-(hydroxymethyl)ox Chemical compound OS([O-])(=O)=O.N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1NC=NC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C WUIABRMSWOKTOF-OYALTWQYSA-N 0.000 description 1
- BMYNFMYTOJXKLE-UHFFFAOYSA-N 3-azaniumyl-2-hydroxypropanoate Chemical compound NCC(O)C(O)=O BMYNFMYTOJXKLE-UHFFFAOYSA-N 0.000 description 1
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 1
- 108091027075 5S-rRNA precursor Proteins 0.000 description 1
- FVFVNNKYKYZTJU-UHFFFAOYSA-N 6-chloro-1,3,5-triazine-2,4-diamine Chemical group NC1=NC(N)=NC(Cl)=N1 FVFVNNKYKYZTJU-UHFFFAOYSA-N 0.000 description 1
- ZCYVEMRRCGMTRW-UHFFFAOYSA-N 7553-56-2 Chemical compound [I] ZCYVEMRRCGMTRW-UHFFFAOYSA-N 0.000 description 1
- 108010066676 Abrin Proteins 0.000 description 1
- DLFVBJFMPXGRIB-UHFFFAOYSA-N Acetamide Chemical class CC(N)=O DLFVBJFMPXGRIB-UHFFFAOYSA-N 0.000 description 1
- YAXNATKKPOWVCP-ZLUOBGJFSA-N Ala-Asn-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O YAXNATKKPOWVCP-ZLUOBGJFSA-N 0.000 description 1
- GORKKVHIBWAQHM-GCJQMDKQSA-N Ala-Asn-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GORKKVHIBWAQHM-GCJQMDKQSA-N 0.000 description 1
- IKKVASZHTMKJIR-ZKWXMUAHSA-N Ala-Asp-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O IKKVASZHTMKJIR-ZKWXMUAHSA-N 0.000 description 1
- CXQODNIBUNQWAS-CIUDSAMLSA-N Ala-Gln-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N CXQODNIBUNQWAS-CIUDSAMLSA-N 0.000 description 1
- FVSOUJZKYWEFOB-KBIXCLLPSA-N Ala-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)N FVSOUJZKYWEFOB-KBIXCLLPSA-N 0.000 description 1
- CZPAHAKGPDUIPJ-CIUDSAMLSA-N Ala-Gln-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CZPAHAKGPDUIPJ-CIUDSAMLSA-N 0.000 description 1
- HMRWQTHUDVXMGH-GUBZILKMSA-N Ala-Glu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN HMRWQTHUDVXMGH-GUBZILKMSA-N 0.000 description 1
- YEVZMOUUZINZCK-LKTVYLICSA-N Ala-Glu-Trp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O YEVZMOUUZINZCK-LKTVYLICSA-N 0.000 description 1
- OMMDTNGURYRDAC-NRPADANISA-N Ala-Glu-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OMMDTNGURYRDAC-NRPADANISA-N 0.000 description 1
- WMYJZJRILUVVRG-WDSKDSINSA-N Ala-Gly-Gln Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O WMYJZJRILUVVRG-WDSKDSINSA-N 0.000 description 1
- FAJIYNONGXEXAI-CQDKDKBSSA-N Ala-His-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CNC=N1 FAJIYNONGXEXAI-CQDKDKBSSA-N 0.000 description 1
- DVJSJDDYCYSMFR-ZKWXMUAHSA-N Ala-Ile-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O DVJSJDDYCYSMFR-ZKWXMUAHSA-N 0.000 description 1
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 1
- OYJCVIGKMXUVKB-GARJFASQSA-N Ala-Leu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N OYJCVIGKMXUVKB-GARJFASQSA-N 0.000 description 1
- VCSABYLVNWQYQE-SRVKXCTJSA-N Ala-Lys-Lys Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O VCSABYLVNWQYQE-SRVKXCTJSA-N 0.000 description 1
- KLALXKYLOMZDQT-ZLUOBGJFSA-N Ala-Ser-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(N)=O KLALXKYLOMZDQT-ZLUOBGJFSA-N 0.000 description 1
- QKHWNPQNOHEFST-VZFHVOOUSA-N Ala-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C)N)O QKHWNPQNOHEFST-VZFHVOOUSA-N 0.000 description 1
- BGGAIXWIZCIFSG-XDTLVQLUSA-N Ala-Tyr-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O BGGAIXWIZCIFSG-XDTLVQLUSA-N 0.000 description 1
- JNJHNBXBGNJESC-KKXDTOCCSA-N Ala-Tyr-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JNJHNBXBGNJESC-KKXDTOCCSA-N 0.000 description 1
- 108020005544 Antisense RNA Proteins 0.000 description 1
- VBFJESQBIWCWRL-DCAQKATOSA-N Arg-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCNC(N)=N VBFJESQBIWCWRL-DCAQKATOSA-N 0.000 description 1
- XPSGESXVBSQZPL-SRVKXCTJSA-N Arg-Arg-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XPSGESXVBSQZPL-SRVKXCTJSA-N 0.000 description 1
- MUXONAMCEUBVGA-DCAQKATOSA-N Arg-Arg-Gln Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O MUXONAMCEUBVGA-DCAQKATOSA-N 0.000 description 1
- RWCLSUOSKWTXLA-FXQIFTODSA-N Arg-Asp-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O RWCLSUOSKWTXLA-FXQIFTODSA-N 0.000 description 1
- NAARDJBSSPUGCF-FXQIFTODSA-N Arg-Cys-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)CN=C(N)N NAARDJBSSPUGCF-FXQIFTODSA-N 0.000 description 1
- YUGFLWBWAJFGKY-BQBZGAKWSA-N Arg-Cys-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)NCC(O)=O YUGFLWBWAJFGKY-BQBZGAKWSA-N 0.000 description 1
- GOWZVQXTHUCNSQ-NHCYSSNCSA-N Arg-Glu-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O GOWZVQXTHUCNSQ-NHCYSSNCSA-N 0.000 description 1
- OOIMKQRCPJBGPD-XUXIUFHCSA-N Arg-Ile-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O OOIMKQRCPJBGPD-XUXIUFHCSA-N 0.000 description 1
- GNYUVVJYGJFKHN-RVMXOQNASA-N Arg-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N GNYUVVJYGJFKHN-RVMXOQNASA-N 0.000 description 1
- BTJVOUQWFXABOI-IHRRRGAJSA-N Arg-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCNC(N)=N BTJVOUQWFXABOI-IHRRRGAJSA-N 0.000 description 1
- QBQVKUNBCAFXSV-ULQDDVLXSA-N Arg-Lys-Tyr Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QBQVKUNBCAFXSV-ULQDDVLXSA-N 0.000 description 1
- VRTWYUYCJGNFES-CIUDSAMLSA-N Arg-Ser-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O VRTWYUYCJGNFES-CIUDSAMLSA-N 0.000 description 1
- LFAUVOXPCGJKTB-DCAQKATOSA-N Arg-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N LFAUVOXPCGJKTB-DCAQKATOSA-N 0.000 description 1
- ICRHGPYYXMWHIE-LPEHRKFASA-N Arg-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ICRHGPYYXMWHIE-LPEHRKFASA-N 0.000 description 1
- ASQKVGRCKOFKIU-KZVJFYERSA-N Arg-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ASQKVGRCKOFKIU-KZVJFYERSA-N 0.000 description 1
- WCZXPVPHUMYLMS-VEVYYDQMSA-N Arg-Thr-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O WCZXPVPHUMYLMS-VEVYYDQMSA-N 0.000 description 1
- HZPSDHRYYIORKR-WHFBIAKZSA-N Asn-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CC(N)=O HZPSDHRYYIORKR-WHFBIAKZSA-N 0.000 description 1
- DQTIWTULBGLJBL-DCAQKATOSA-N Asn-Arg-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)N)N DQTIWTULBGLJBL-DCAQKATOSA-N 0.000 description 1
- HAJWYALLJIATCX-FXQIFTODSA-N Asn-Asn-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N)CN=C(N)N HAJWYALLJIATCX-FXQIFTODSA-N 0.000 description 1
- ZWASIOHRQWRWAS-UGYAYLCHSA-N Asn-Asp-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZWASIOHRQWRWAS-UGYAYLCHSA-N 0.000 description 1
- VWJFQGXPYOPXJH-ZLUOBGJFSA-N Asn-Cys-Asp Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)C(=O)N VWJFQGXPYOPXJH-ZLUOBGJFSA-N 0.000 description 1
- FAEFJTCTNZTPHX-ACZMJKKPSA-N Asn-Gln-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O FAEFJTCTNZTPHX-ACZMJKKPSA-N 0.000 description 1
- HJRBIWRXULGMOA-ACZMJKKPSA-N Asn-Gln-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJRBIWRXULGMOA-ACZMJKKPSA-N 0.000 description 1
- JREOBWLIZLXRIS-GUBZILKMSA-N Asn-Glu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JREOBWLIZLXRIS-GUBZILKMSA-N 0.000 description 1
- GFFRWIJAFFMQGM-NUMRIWBASA-N Asn-Glu-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GFFRWIJAFFMQGM-NUMRIWBASA-N 0.000 description 1
- OPEPUCYIGFEGSW-WDSKDSINSA-N Asn-Gly-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O OPEPUCYIGFEGSW-WDSKDSINSA-N 0.000 description 1
- PHJPKNUWWHRAOC-PEFMBERDSA-N Asn-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N PHJPKNUWWHRAOC-PEFMBERDSA-N 0.000 description 1
- KMCRKVOLRCOMBG-DJFWLOJKSA-N Asn-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KMCRKVOLRCOMBG-DJFWLOJKSA-N 0.000 description 1
- TZFQICWZWFNIKU-KKUMJFAQSA-N Asn-Leu-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 TZFQICWZWFNIKU-KKUMJFAQSA-N 0.000 description 1
- FBODFHMLALOPHP-GUBZILKMSA-N Asn-Lys-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O FBODFHMLALOPHP-GUBZILKMSA-N 0.000 description 1
- RZNAMKZJPBQWDJ-SRVKXCTJSA-N Asn-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)N)N RZNAMKZJPBQWDJ-SRVKXCTJSA-N 0.000 description 1
- GMUOCGCDOYYWPD-FXQIFTODSA-N Asn-Pro-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O GMUOCGCDOYYWPD-FXQIFTODSA-N 0.000 description 1
- OOXUBGLNDRGOKT-FXQIFTODSA-N Asn-Ser-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OOXUBGLNDRGOKT-FXQIFTODSA-N 0.000 description 1
- GZXOUBTUAUAVHD-ACZMJKKPSA-N Asn-Ser-Glu Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O GZXOUBTUAUAVHD-ACZMJKKPSA-N 0.000 description 1
- WLVLIYYBPPONRJ-GCJQMDKQSA-N Asn-Thr-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O WLVLIYYBPPONRJ-GCJQMDKQSA-N 0.000 description 1
- ZUFPUBYQYWCMDB-NUMRIWBASA-N Asn-Thr-Glu Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZUFPUBYQYWCMDB-NUMRIWBASA-N 0.000 description 1
- WUQXMTITJLFXAU-JIOCBJNQSA-N Asn-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N)O WUQXMTITJLFXAU-JIOCBJNQSA-N 0.000 description 1
- UXHYOWXTJLBEPG-GSSVUCPTSA-N Asn-Thr-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UXHYOWXTJLBEPG-GSSVUCPTSA-N 0.000 description 1
- QTKYFZCMSQLYHI-UBHSHLNASA-N Asn-Trp-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O QTKYFZCMSQLYHI-UBHSHLNASA-N 0.000 description 1
- DPWDPEVGACCWTC-SRVKXCTJSA-N Asn-Tyr-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O DPWDPEVGACCWTC-SRVKXCTJSA-N 0.000 description 1
- HPNDBHLITCHRSO-WHFBIAKZSA-N Asp-Ala-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)NCC(O)=O HPNDBHLITCHRSO-WHFBIAKZSA-N 0.000 description 1
- SDHFVYLZFBDSQT-DCAQKATOSA-N Asp-Arg-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)O)N SDHFVYLZFBDSQT-DCAQKATOSA-N 0.000 description 1
- GHODABZPVZMWCE-FXQIFTODSA-N Asp-Glu-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O GHODABZPVZMWCE-FXQIFTODSA-N 0.000 description 1
- VILLWIDTHYPSLC-PEFMBERDSA-N Asp-Glu-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VILLWIDTHYPSLC-PEFMBERDSA-N 0.000 description 1
- JOCQXVJCTCEFAZ-CIUDSAMLSA-N Asp-His-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O JOCQXVJCTCEFAZ-CIUDSAMLSA-N 0.000 description 1
- RQHLMGCXCZUOGT-ZPFDUUQYSA-N Asp-Leu-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RQHLMGCXCZUOGT-ZPFDUUQYSA-N 0.000 description 1
- TZBJAXGYGSIUHQ-XUXIUFHCSA-N Asp-Leu-Leu-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O TZBJAXGYGSIUHQ-XUXIUFHCSA-N 0.000 description 1
- UMHUHHJMEXNSIV-CIUDSAMLSA-N Asp-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O UMHUHHJMEXNSIV-CIUDSAMLSA-N 0.000 description 1
- KPSHWSWFPUDEGF-FXQIFTODSA-N Asp-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(O)=O KPSHWSWFPUDEGF-FXQIFTODSA-N 0.000 description 1
- BWJZSLQJNBSUPM-FXQIFTODSA-N Asp-Pro-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O BWJZSLQJNBSUPM-FXQIFTODSA-N 0.000 description 1
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 1
- RVMXMLSYBTXCAV-VEVYYDQMSA-N Asp-Pro-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMXMLSYBTXCAV-VEVYYDQMSA-N 0.000 description 1
- BPAUXFVCSYQDQX-JRQIVUDYSA-N Asp-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC(=O)O)N)O BPAUXFVCSYQDQX-JRQIVUDYSA-N 0.000 description 1
- SFJUYBCDQBAYAJ-YDHLFZDLSA-N Asp-Val-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SFJUYBCDQBAYAJ-YDHLFZDLSA-N 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 1
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 1
- 101710117545 C protein Proteins 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 108090000565 Capsid Proteins Proteins 0.000 description 1
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 description 1
- 108090000994 Catalytic RNA Proteins 0.000 description 1
- 102000053642 Catalytic RNA Human genes 0.000 description 1
- 102100023321 Ceruloplasmin Human genes 0.000 description 1
- 108010049048 Cholera Toxin Proteins 0.000 description 1
- 102000009016 Cholera Toxin Human genes 0.000 description 1
- GUTLYIVDDKVIGB-OUBTZVSYSA-N Cobalt-60 Chemical compound [60Co] GUTLYIVDDKVIGB-OUBTZVSYSA-N 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 1
- PMATZTZNYRCHOR-CGLBZJNRSA-N Cyclosporin A Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O PMATZTZNYRCHOR-CGLBZJNRSA-N 0.000 description 1
- 108010036949 Cyclosporine Proteins 0.000 description 1
- AEJSNWMRPXAKCW-WHFBIAKZSA-N Cys-Ala-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O AEJSNWMRPXAKCW-WHFBIAKZSA-N 0.000 description 1
- YFXFOZPXVFPBDH-VZFHVOOUSA-N Cys-Ala-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)CS)C(O)=O YFXFOZPXVFPBDH-VZFHVOOUSA-N 0.000 description 1
- YMBAVNPKBWHDAW-CIUDSAMLSA-N Cys-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N YMBAVNPKBWHDAW-CIUDSAMLSA-N 0.000 description 1
- DZLQXIFVQFTFJY-BYPYZUCNSA-N Cys-Gly-Gly Chemical compound SC[C@H](N)C(=O)NCC(=O)NCC(O)=O DZLQXIFVQFTFJY-BYPYZUCNSA-N 0.000 description 1
- IZUNQDRIAOLWCN-YUMQZZPRSA-N Cys-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N IZUNQDRIAOLWCN-YUMQZZPRSA-N 0.000 description 1
- CIVXDCMSSFGWAL-YUMQZZPRSA-N Cys-Lys-Gly Chemical compound C(CCN)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N CIVXDCMSSFGWAL-YUMQZZPRSA-N 0.000 description 1
- SMEYEQDCCBHTEF-FXQIFTODSA-N Cys-Pro-Ala Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O SMEYEQDCCBHTEF-FXQIFTODSA-N 0.000 description 1
- VCPHQVQGVSKDHY-FXQIFTODSA-N Cys-Ser-Met Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O VCPHQVQGVSKDHY-FXQIFTODSA-N 0.000 description 1
- HJXSYJVCMUOUNY-SRVKXCTJSA-N Cys-Ser-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CS)N HJXSYJVCMUOUNY-SRVKXCTJSA-N 0.000 description 1
- NDNZRWUDUMTITL-FXQIFTODSA-N Cys-Ser-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NDNZRWUDUMTITL-FXQIFTODSA-N 0.000 description 1
- IRKLTAKLAFUTLA-KATARQTJSA-N Cys-Thr-Lys Chemical compound C[C@@H](O)[C@H](NC(=O)[C@@H](N)CS)C(=O)N[C@@H](CCCCN)C(O)=O IRKLTAKLAFUTLA-KATARQTJSA-N 0.000 description 1
- MHYHLWUGWUBUHF-GUBZILKMSA-N Cys-Val-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CS)N MHYHLWUGWUBUHF-GUBZILKMSA-N 0.000 description 1
- KZZYVYWSXMFYEC-DCAQKATOSA-N Cys-Val-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KZZYVYWSXMFYEC-DCAQKATOSA-N 0.000 description 1
- 102000000634 Cytochrome c oxidase subunit IV Human genes 0.000 description 1
- 108090000365 Cytochrome-c oxidases Proteins 0.000 description 1
- 102000018832 Cytochromes Human genes 0.000 description 1
- 108010052832 Cytochromes Proteins 0.000 description 1
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 1
- 108010092160 Dactinomycin Proteins 0.000 description 1
- 241000702421 Dependoparvovirus Species 0.000 description 1
- 206010061818 Disease progression Diseases 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 241000701959 Escherichia virus Lambda Species 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 229920001917 Ficoll Polymers 0.000 description 1
- PXGOKWXKJXAPGV-UHFFFAOYSA-N Fluorine Chemical compound FF PXGOKWXKJXAPGV-UHFFFAOYSA-N 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- 229910052688 Gadolinium Inorganic materials 0.000 description 1
- 108700004714 Gelonium multiflorum GEL Proteins 0.000 description 1
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 1
- 206010018338 Glioma Diseases 0.000 description 1
- NNQHEEQNPQYPGL-FXQIFTODSA-N Gln-Ala-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O NNQHEEQNPQYPGL-FXQIFTODSA-N 0.000 description 1
- CXFUMJQFZVCETK-FXQIFTODSA-N Gln-Cys-Gln Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O CXFUMJQFZVCETK-FXQIFTODSA-N 0.000 description 1
- VSXBYIJUAXPAAL-WDSKDSINSA-N Gln-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O VSXBYIJUAXPAAL-WDSKDSINSA-N 0.000 description 1
- CLPQUWHBWXFJOX-BQBZGAKWSA-N Gln-Gly-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O CLPQUWHBWXFJOX-BQBZGAKWSA-N 0.000 description 1
- SBHVGKBYOQKAEA-SDDRHHMPSA-N Gln-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SBHVGKBYOQKAEA-SDDRHHMPSA-N 0.000 description 1
- ICDIMQAMJGDHSE-GUBZILKMSA-N Gln-His-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O ICDIMQAMJGDHSE-GUBZILKMSA-N 0.000 description 1
- GQZDDFRXSDGUNG-YVNDNENWSA-N Gln-Ile-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O GQZDDFRXSDGUNG-YVNDNENWSA-N 0.000 description 1
- HXOLDXKNWKLDMM-YVNDNENWSA-N Gln-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N HXOLDXKNWKLDMM-YVNDNENWSA-N 0.000 description 1
- LGIKBBLQVSWUGK-DCAQKATOSA-N Gln-Leu-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LGIKBBLQVSWUGK-DCAQKATOSA-N 0.000 description 1
- IOFDDSNZJDIGPB-GVXVVHGQSA-N Gln-Leu-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IOFDDSNZJDIGPB-GVXVVHGQSA-N 0.000 description 1
- IHSGESFHTMFHRB-GUBZILKMSA-N Gln-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(N)=O IHSGESFHTMFHRB-GUBZILKMSA-N 0.000 description 1
- DOMHVQBSRJNNKD-ZPFDUUQYSA-N Gln-Met-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DOMHVQBSRJNNKD-ZPFDUUQYSA-N 0.000 description 1
- VLOLPWWCNKWRNB-LOKLDPHHSA-N Gln-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O VLOLPWWCNKWRNB-LOKLDPHHSA-N 0.000 description 1
- STHSGOZLFLFGSS-SUSMZKCASA-N Gln-Thr-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O STHSGOZLFLFGSS-SUSMZKCASA-N 0.000 description 1
- BBFCMGBMYIAGRS-AUTRQRHGSA-N Gln-Val-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O BBFCMGBMYIAGRS-AUTRQRHGSA-N 0.000 description 1
- QZQYITIKPAUDGN-GVXVVHGQSA-N Gln-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N QZQYITIKPAUDGN-GVXVVHGQSA-N 0.000 description 1
- UTKUTMJSWKKHEM-WDSKDSINSA-N Glu-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O UTKUTMJSWKKHEM-WDSKDSINSA-N 0.000 description 1
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 1
- JJKKWYQVHRUSDG-GUBZILKMSA-N Glu-Ala-Lys Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O JJKKWYQVHRUSDG-GUBZILKMSA-N 0.000 description 1
- AFODTOLGSZQDSL-PEFMBERDSA-N Glu-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N AFODTOLGSZQDSL-PEFMBERDSA-N 0.000 description 1
- HJIFPJUEOGZWRI-GUBZILKMSA-N Glu-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N HJIFPJUEOGZWRI-GUBZILKMSA-N 0.000 description 1
- QQLBPVKLJBAXBS-FXQIFTODSA-N Glu-Glu-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QQLBPVKLJBAXBS-FXQIFTODSA-N 0.000 description 1
- KUTPGXNAAOQSPD-LPEHRKFASA-N Glu-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O KUTPGXNAAOQSPD-LPEHRKFASA-N 0.000 description 1
- WRNAXCVRSBBKGS-BQBZGAKWSA-N Glu-Gly-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O WRNAXCVRSBBKGS-BQBZGAKWSA-N 0.000 description 1
- KRGZZKWSBGPLKL-IUCAKERBSA-N Glu-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)O)N KRGZZKWSBGPLKL-IUCAKERBSA-N 0.000 description 1
- RAUDKMVXNOWDLS-WDSKDSINSA-N Glu-Gly-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O RAUDKMVXNOWDLS-WDSKDSINSA-N 0.000 description 1
- CXRWMMRLEMVSEH-PEFMBERDSA-N Glu-Ile-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O CXRWMMRLEMVSEH-PEFMBERDSA-N 0.000 description 1
- YVYVMJNUENBOOL-KBIXCLLPSA-N Glu-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N YVYVMJNUENBOOL-KBIXCLLPSA-N 0.000 description 1
- QXDXIXFSFHUYAX-MNXVOIDGSA-N Glu-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O QXDXIXFSFHUYAX-MNXVOIDGSA-N 0.000 description 1
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 1
- HVYWQYLBVXMXSV-GUBZILKMSA-N Glu-Leu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O HVYWQYLBVXMXSV-GUBZILKMSA-N 0.000 description 1
- DNPCBMNFQVTHMA-DCAQKATOSA-N Glu-Leu-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DNPCBMNFQVTHMA-DCAQKATOSA-N 0.000 description 1
- DXVOKNVIKORTHQ-GUBZILKMSA-N Glu-Pro-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O DXVOKNVIKORTHQ-GUBZILKMSA-N 0.000 description 1
- BXSZPACYCMNKLS-AVGNSLFASA-N Glu-Ser-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O BXSZPACYCMNKLS-AVGNSLFASA-N 0.000 description 1
- JSIQVRIXMINMTA-ZDLURKLDSA-N Glu-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](N)CCC(O)=O JSIQVRIXMINMTA-ZDLURKLDSA-N 0.000 description 1
- MWTGQXBHVRTCOR-GLLZPBPUSA-N Glu-Thr-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MWTGQXBHVRTCOR-GLLZPBPUSA-N 0.000 description 1
- UMZHHILWZBFPGL-LOKLDPHHSA-N Glu-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O UMZHHILWZBFPGL-LOKLDPHHSA-N 0.000 description 1
- BKMOHWJHXQLFEX-IRIUXVKKSA-N Glu-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCC(=O)O)N)O BKMOHWJHXQLFEX-IRIUXVKKSA-N 0.000 description 1
- QXUPRMQJDWJDFR-NRPADANISA-N Glu-Val-Ser Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXUPRMQJDWJDFR-NRPADANISA-N 0.000 description 1
- MFVQGXGQRIXBPK-WDSKDSINSA-N Gly-Ala-Glu Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O MFVQGXGQRIXBPK-WDSKDSINSA-N 0.000 description 1
- XUDLUKYPXQDCRX-BQBZGAKWSA-N Gly-Arg-Asn Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O XUDLUKYPXQDCRX-BQBZGAKWSA-N 0.000 description 1
- KFMBRBPXHVMDFN-UWVGGRQHSA-N Gly-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCNC(N)=N KFMBRBPXHVMDFN-UWVGGRQHSA-N 0.000 description 1
- BGVYNAQWHSTTSP-BYULHYEWSA-N Gly-Asn-Ile Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BGVYNAQWHSTTSP-BYULHYEWSA-N 0.000 description 1
- MHHUEAIBJZWDBH-YUMQZZPRSA-N Gly-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN MHHUEAIBJZWDBH-YUMQZZPRSA-N 0.000 description 1
- XXGQRGQPGFYECI-WDSKDSINSA-N Gly-Cys-Glu Chemical compound NCC(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCC(O)=O XXGQRGQPGFYECI-WDSKDSINSA-N 0.000 description 1
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 1
- DHDOADIPGZTAHT-YUMQZZPRSA-N Gly-Glu-Arg Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DHDOADIPGZTAHT-YUMQZZPRSA-N 0.000 description 1
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 1
- INLIXXRWNUKVCF-JTQLQIEISA-N Gly-Gly-Tyr Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 INLIXXRWNUKVCF-JTQLQIEISA-N 0.000 description 1
- FSPVILZGHUJOHS-QWRGUYRKSA-N Gly-His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CNC=N1 FSPVILZGHUJOHS-QWRGUYRKSA-N 0.000 description 1
- SWQALSGKVLYKDT-ZKWXMUAHSA-N Gly-Ile-Ala Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O SWQALSGKVLYKDT-ZKWXMUAHSA-N 0.000 description 1
- SWQALSGKVLYKDT-UHFFFAOYSA-N Gly-Ile-Ala Natural products NCC(=O)NC(C(C)CC)C(=O)NC(C)C(O)=O SWQALSGKVLYKDT-UHFFFAOYSA-N 0.000 description 1
- FCKPEGOCSVZPNC-WHOFXGATSA-N Gly-Ile-Phe Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FCKPEGOCSVZPNC-WHOFXGATSA-N 0.000 description 1
- BHPQOIPBLYJNAW-NGZCFLSTSA-N Gly-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN BHPQOIPBLYJNAW-NGZCFLSTSA-N 0.000 description 1
- COVXELOAORHTND-LSJOCFKGSA-N Gly-Ile-Val Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O COVXELOAORHTND-LSJOCFKGSA-N 0.000 description 1
- YIFUFYZELCMPJP-YUMQZZPRSA-N Gly-Leu-Cys Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(O)=O YIFUFYZELCMPJP-YUMQZZPRSA-N 0.000 description 1
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 1
- LOEANKRDMMVOGZ-YUMQZZPRSA-N Gly-Lys-Asp Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(O)=O)C(O)=O LOEANKRDMMVOGZ-YUMQZZPRSA-N 0.000 description 1
- VLIJYPMATZSOLL-YUMQZZPRSA-N Gly-Lys-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN VLIJYPMATZSOLL-YUMQZZPRSA-N 0.000 description 1
- SJLKKOZFHSJJAW-YUMQZZPRSA-N Gly-Met-Glu Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)CN SJLKKOZFHSJJAW-YUMQZZPRSA-N 0.000 description 1
- YYXJFBMCOUSYSF-RYUDHWBXSA-N Gly-Phe-Gln Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O YYXJFBMCOUSYSF-RYUDHWBXSA-N 0.000 description 1
- VNNRLUNBJSWZPF-ZKWXMUAHSA-N Gly-Ser-Ile Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNNRLUNBJSWZPF-ZKWXMUAHSA-N 0.000 description 1
- POJJAZJHBGXEGM-YUMQZZPRSA-N Gly-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)CN POJJAZJHBGXEGM-YUMQZZPRSA-N 0.000 description 1
- JSLVAHYTAJJEQH-QWRGUYRKSA-N Gly-Ser-Phe Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JSLVAHYTAJJEQH-QWRGUYRKSA-N 0.000 description 1
- ABPRMMYHROQBLY-NKWVEPMBSA-N Gly-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)CN)C(=O)O ABPRMMYHROQBLY-NKWVEPMBSA-N 0.000 description 1
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 1
- MYXNLWDWWOTERK-BHNWBGBOSA-N Gly-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN)O MYXNLWDWWOTERK-BHNWBGBOSA-N 0.000 description 1
- IHDKKJVBLGXLEL-STQMWFEESA-N Gly-Tyr-Met Chemical compound CSCC[C@H](NC(=O)[C@H](Cc1ccc(O)cc1)NC(=O)CN)C(O)=O IHDKKJVBLGXLEL-STQMWFEESA-N 0.000 description 1
- DUAWRXXTOQOECJ-JSGCOSHPSA-N Gly-Tyr-Val Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O DUAWRXXTOQOECJ-JSGCOSHPSA-N 0.000 description 1
- YDIDLLVFCYSXNY-RCOVLWMOSA-N Gly-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN YDIDLLVFCYSXNY-RCOVLWMOSA-N 0.000 description 1
- 102100031573 Hematopoietic progenitor cell antigen CD34 Human genes 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- QZAFGJNKLMNDEM-DCAQKATOSA-N His-Asn-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CN=CN1 QZAFGJNKLMNDEM-DCAQKATOSA-N 0.000 description 1
- FIMNVXRZGUAGBI-AVGNSLFASA-N His-Glu-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O FIMNVXRZGUAGBI-AVGNSLFASA-N 0.000 description 1
- QMUHTRISZMFKAY-MXAVVETBSA-N His-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N QMUHTRISZMFKAY-MXAVVETBSA-N 0.000 description 1
- ORERHHPZDDEMSC-VGDYDELISA-N His-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N ORERHHPZDDEMSC-VGDYDELISA-N 0.000 description 1
- KHUFDBQXGLEIHC-BZSNNMDCSA-N His-Leu-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CN=CN1 KHUFDBQXGLEIHC-BZSNNMDCSA-N 0.000 description 1
- HJUPAYWVVVRYFQ-PYJNHQTQSA-N His-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CC1=CN=CN1)N HJUPAYWVVVRYFQ-PYJNHQTQSA-N 0.000 description 1
- YXXKBPJEIYFGOD-MGHWNKPDSA-N His-Phe-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CC2=CN=CN2)N YXXKBPJEIYFGOD-MGHWNKPDSA-N 0.000 description 1
- XVZJRZQIHJMUBG-TUBUOCAGSA-N His-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC1=CN=CN1)N XVZJRZQIHJMUBG-TUBUOCAGSA-N 0.000 description 1
- AHEBIAHEZWQVHB-QTKMDUPCSA-N His-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O AHEBIAHEZWQVHB-QTKMDUPCSA-N 0.000 description 1
- CSTDQOOBZBAJKE-BWAGICSOSA-N His-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC2=CN=CN2)N)O CSTDQOOBZBAJKE-BWAGICSOSA-N 0.000 description 1
- 102000018713 Histocompatibility Antigens Class II Human genes 0.000 description 1
- 108010027412 Histocompatibility Antigens Class II Proteins 0.000 description 1
- 101000690301 Homo sapiens Aldo-keto reductase family 1 member C4 Proteins 0.000 description 1
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 1
- 101000935587 Homo sapiens Flavin reductase (NADPH) Proteins 0.000 description 1
- 101000777663 Homo sapiens Hematopoietic progenitor cell antigen CD34 Proteins 0.000 description 1
- 101001116548 Homo sapiens Protein CBFA2T1 Proteins 0.000 description 1
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 1
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 description 1
- 102000009438 IgE Receptors Human genes 0.000 description 1
- 108010073816 IgE Receptors Proteins 0.000 description 1
- JRHFQUPIZOYKQP-KBIXCLLPSA-N Ile-Ala-Glu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O JRHFQUPIZOYKQP-KBIXCLLPSA-N 0.000 description 1
- ATXGFMOBVKSOMK-PEDHHIEDSA-N Ile-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N ATXGFMOBVKSOMK-PEDHHIEDSA-N 0.000 description 1
- LLZLRXBTOOFODM-QSFUFRPTSA-N Ile-Asp-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N LLZLRXBTOOFODM-QSFUFRPTSA-N 0.000 description 1
- LKACSKJPTFSBHR-MNXVOIDGSA-N Ile-Gln-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N LKACSKJPTFSBHR-MNXVOIDGSA-N 0.000 description 1
- YBJWJQQBWRARLT-KBIXCLLPSA-N Ile-Gln-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O YBJWJQQBWRARLT-KBIXCLLPSA-N 0.000 description 1
- TVSPLSZTKTUYLV-ZPFDUUQYSA-N Ile-Glu-Met Chemical compound N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCSC)C(=O)O TVSPLSZTKTUYLV-ZPFDUUQYSA-N 0.000 description 1
- ODPKZZLRDNXTJZ-WHOFXGATSA-N Ile-Gly-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N ODPKZZLRDNXTJZ-WHOFXGATSA-N 0.000 description 1
- VOBYAKCXGQQFLR-LSJOCFKGSA-N Ile-Gly-Val Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O VOBYAKCXGQQFLR-LSJOCFKGSA-N 0.000 description 1
- DMSVBUWGDLYNLC-IAVJCBSLSA-N Ile-Ile-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 DMSVBUWGDLYNLC-IAVJCBSLSA-N 0.000 description 1
- GLLAUPMJCGKPFY-BLMTYFJBSA-N Ile-Ile-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 GLLAUPMJCGKPFY-BLMTYFJBSA-N 0.000 description 1
- KBAPKNDWAGVGTH-IGISWZIWSA-N Ile-Ile-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KBAPKNDWAGVGTH-IGISWZIWSA-N 0.000 description 1
- WMDZARSFSMZOQO-DRZSPHRISA-N Ile-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 WMDZARSFSMZOQO-DRZSPHRISA-N 0.000 description 1
- SVZFKLBRCYCIIY-CYDGBPFRSA-N Ile-Pro-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SVZFKLBRCYCIIY-CYDGBPFRSA-N 0.000 description 1
- NLZVTPYXYXMCIP-XUXIUFHCSA-N Ile-Pro-Lys Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O NLZVTPYXYXMCIP-XUXIUFHCSA-N 0.000 description 1
- YKZAMJXNJUWFIK-JBDRJPRFSA-N Ile-Ser-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)O)N YKZAMJXNJUWFIK-JBDRJPRFSA-N 0.000 description 1
- XMYURPUVJSKTMC-KBIXCLLPSA-N Ile-Ser-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N XMYURPUVJSKTMC-KBIXCLLPSA-N 0.000 description 1
- ZLFNNVATRMCAKN-ZKWXMUAHSA-N Ile-Ser-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZLFNNVATRMCAKN-ZKWXMUAHSA-N 0.000 description 1
- CNMOKANDJMLAIF-CIQUZCHMSA-N Ile-Thr-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O CNMOKANDJMLAIF-CIQUZCHMSA-N 0.000 description 1
- BZUOLKFQVVBTJY-SLBDDTMCSA-N Ile-Trp-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC(=O)N)C(=O)O)N BZUOLKFQVVBTJY-SLBDDTMCSA-N 0.000 description 1
- XVUAQNRNFMVWBR-BLMTYFJBSA-N Ile-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N XVUAQNRNFMVWBR-BLMTYFJBSA-N 0.000 description 1
- ZGKVPOSSTGHJAF-HJPIBITLSA-N Ile-Tyr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CO)C(=O)O)N ZGKVPOSSTGHJAF-HJPIBITLSA-N 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102100037850 Interferon gamma Human genes 0.000 description 1
- 102000006992 Interferon-alpha Human genes 0.000 description 1
- 108010047761 Interferon-alpha Proteins 0.000 description 1
- 108010074328 Interferon-gamma Proteins 0.000 description 1
- ZCYVEMRRCGMTRW-AHCXROLUSA-N Iodine-123 Chemical compound [123I] ZCYVEMRRCGMTRW-AHCXROLUSA-N 0.000 description 1
- OIRFJRBSRORBCM-UHFFFAOYSA-N Iopanoic acid Chemical compound CCC(C(O)=O)CC1=C(I)C=C(I)C(N)=C1I OIRFJRBSRORBCM-UHFFFAOYSA-N 0.000 description 1
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 1
- JVTAAEKCZFNVCJ-UHFFFAOYSA-M Lactate Chemical compound CC(O)C([O-])=O JVTAAEKCZFNVCJ-UHFFFAOYSA-M 0.000 description 1
- 108010088350 Lactate Dehydrogenase 5 Proteins 0.000 description 1
- KWTVLKBOQATPHJ-SRVKXCTJSA-N Leu-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N KWTVLKBOQATPHJ-SRVKXCTJSA-N 0.000 description 1
- XIRYQRLFHWWWTC-QEJZJMRPSA-N Leu-Ala-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XIRYQRLFHWWWTC-QEJZJMRPSA-N 0.000 description 1
- JQSXWJXBASFONF-KKUMJFAQSA-N Leu-Asp-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JQSXWJXBASFONF-KKUMJFAQSA-N 0.000 description 1
- KWURTLAFFDOTEQ-GUBZILKMSA-N Leu-Cys-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N KWURTLAFFDOTEQ-GUBZILKMSA-N 0.000 description 1
- NHHKSOGJYNQENP-SRVKXCTJSA-N Leu-Cys-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N NHHKSOGJYNQENP-SRVKXCTJSA-N 0.000 description 1
- LAGPXKYZCCTSGQ-JYJNAYRXSA-N Leu-Glu-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LAGPXKYZCCTSGQ-JYJNAYRXSA-N 0.000 description 1
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 1
- KVOFSTUWVSQMDK-KKUMJFAQSA-N Leu-His-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CN=CN1 KVOFSTUWVSQMDK-KKUMJFAQSA-N 0.000 description 1
- HVHRPWQEQHIQJF-AVGNSLFASA-N Leu-Lys-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O HVHRPWQEQHIQJF-AVGNSLFASA-N 0.000 description 1
- FIICHHJDINDXKG-IHPCNDPISA-N Leu-Lys-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O FIICHHJDINDXKG-IHPCNDPISA-N 0.000 description 1
- ONPJGOIVICHWBW-BZSNNMDCSA-N Leu-Lys-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 ONPJGOIVICHWBW-BZSNNMDCSA-N 0.000 description 1
- POMXSEDNUXYPGK-IHRRRGAJSA-N Leu-Met-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N POMXSEDNUXYPGK-IHRRRGAJSA-N 0.000 description 1
- DRWMRVFCKKXHCH-BZSNNMDCSA-N Leu-Phe-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=CC=C1 DRWMRVFCKKXHCH-BZSNNMDCSA-N 0.000 description 1
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 1
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 1
- YRRCOJOXAJNSAX-IHRRRGAJSA-N Leu-Pro-Lys Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)O)N YRRCOJOXAJNSAX-IHRRRGAJSA-N 0.000 description 1
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 1
- JDBQSGMJBMPNFT-AVGNSLFASA-N Leu-Pro-Val Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O JDBQSGMJBMPNFT-AVGNSLFASA-N 0.000 description 1
- IDGZVZJLYFTXSL-DCAQKATOSA-N Leu-Ser-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IDGZVZJLYFTXSL-DCAQKATOSA-N 0.000 description 1
- AKVBOOKXVAMKSS-GUBZILKMSA-N Leu-Ser-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O AKVBOOKXVAMKSS-GUBZILKMSA-N 0.000 description 1
- KLSUAWUZBMAZCL-RHYQMDGZSA-N Leu-Thr-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(O)=O KLSUAWUZBMAZCL-RHYQMDGZSA-N 0.000 description 1
- GZRABTMNWJXFMH-UVOCVTCTSA-N Leu-Thr-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZRABTMNWJXFMH-UVOCVTCTSA-N 0.000 description 1
- YWFZWQKWNDOWPA-XIRDDKMYSA-N Leu-Trp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O YWFZWQKWNDOWPA-XIRDDKMYSA-N 0.000 description 1
- WBRJVRXEGQIDRK-XIRDDKMYSA-N Leu-Trp-Ser Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 WBRJVRXEGQIDRK-XIRDDKMYSA-N 0.000 description 1
- WFCKERTZVCQXKH-KBPBESRZSA-N Leu-Tyr-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O WFCKERTZVCQXKH-KBPBESRZSA-N 0.000 description 1
- JGKHAFUAPZCCDU-BZSNNMDCSA-N Leu-Tyr-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=C(O)C=C1 JGKHAFUAPZCCDU-BZSNNMDCSA-N 0.000 description 1
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 1
- GQYIWUVLTXOXAJ-UHFFFAOYSA-N Lomustine Chemical compound ClCCN(N=O)C(=O)NC1CCCCC1 GQYIWUVLTXOXAJ-UHFFFAOYSA-N 0.000 description 1
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 1
- IRNSXVOWSXSULE-DCAQKATOSA-N Lys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN IRNSXVOWSXSULE-DCAQKATOSA-N 0.000 description 1
- GGAPIOORBXHMNY-ULQDDVLXSA-N Lys-Arg-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)N)O GGAPIOORBXHMNY-ULQDDVLXSA-N 0.000 description 1
- BYPMOIFBQPEWOH-CIUDSAMLSA-N Lys-Asn-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N BYPMOIFBQPEWOH-CIUDSAMLSA-N 0.000 description 1
- QYOXSYXPHUHOJR-GUBZILKMSA-N Lys-Asn-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QYOXSYXPHUHOJR-GUBZILKMSA-N 0.000 description 1
- RLZDUFRBMQNYIJ-YUMQZZPRSA-N Lys-Cys-Gly Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)NCC(=O)O)N RLZDUFRBMQNYIJ-YUMQZZPRSA-N 0.000 description 1
- SSYOBDBNBQBSQE-SRVKXCTJSA-N Lys-Cys-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O SSYOBDBNBQBSQE-SRVKXCTJSA-N 0.000 description 1
- MWVUEPNEPWMFBD-SRVKXCTJSA-N Lys-Cys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCCCN MWVUEPNEPWMFBD-SRVKXCTJSA-N 0.000 description 1
- BYEBKXRNDLTGFW-CIUDSAMLSA-N Lys-Cys-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O BYEBKXRNDLTGFW-CIUDSAMLSA-N 0.000 description 1
- XFBBBRDEQIPGNR-KATARQTJSA-N Lys-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCCN)N)O XFBBBRDEQIPGNR-KATARQTJSA-N 0.000 description 1
- NDORZBUHCOJQDO-GVXVVHGQSA-N Lys-Gln-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O NDORZBUHCOJQDO-GVXVVHGQSA-N 0.000 description 1
- GJJQCBVRWDGLMQ-GUBZILKMSA-N Lys-Glu-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O GJJQCBVRWDGLMQ-GUBZILKMSA-N 0.000 description 1
- DCRWPTBMWMGADO-AVGNSLFASA-N Lys-Glu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O DCRWPTBMWMGADO-AVGNSLFASA-N 0.000 description 1
- IMAKMJCBYCSMHM-AVGNSLFASA-N Lys-Glu-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN IMAKMJCBYCSMHM-AVGNSLFASA-N 0.000 description 1
- NNKLKUUGESXCBS-KBPBESRZSA-N Lys-Gly-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O NNKLKUUGESXCBS-KBPBESRZSA-N 0.000 description 1
- OWRUUFUVXFREBD-KKUMJFAQSA-N Lys-His-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O OWRUUFUVXFREBD-KKUMJFAQSA-N 0.000 description 1
- IVFUVMSKSFSFBT-NHCYSSNCSA-N Lys-Ile-Gly Chemical compound OC(=O)CNC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN IVFUVMSKSFSFBT-NHCYSSNCSA-N 0.000 description 1
- NCZIQZYZPUPMKY-PPCPHDFISA-N Lys-Ile-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NCZIQZYZPUPMKY-PPCPHDFISA-N 0.000 description 1
- XREQQOATSMMAJP-MGHWNKPDSA-N Lys-Ile-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XREQQOATSMMAJP-MGHWNKPDSA-N 0.000 description 1
- ZJWIXBZTAAJERF-IHRRRGAJSA-N Lys-Lys-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N ZJWIXBZTAAJERF-IHRRRGAJSA-N 0.000 description 1
- YXPJCVNIDDKGOE-MELADBBJSA-N Lys-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)N)C(=O)O YXPJCVNIDDKGOE-MELADBBJSA-N 0.000 description 1
- PLDJDCJLRCYPJB-VOAKCMCISA-N Lys-Lys-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PLDJDCJLRCYPJB-VOAKCMCISA-N 0.000 description 1
- IPSDPDAOSAEWCN-RHYQMDGZSA-N Lys-Met-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IPSDPDAOSAEWCN-RHYQMDGZSA-N 0.000 description 1
- DNWBUCHHMRQWCZ-GUBZILKMSA-N Lys-Ser-Gln Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O DNWBUCHHMRQWCZ-GUBZILKMSA-N 0.000 description 1
- ZUGVARDEGWMMLK-SRVKXCTJSA-N Lys-Ser-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN ZUGVARDEGWMMLK-SRVKXCTJSA-N 0.000 description 1
- MEQLGHAMAUPOSJ-DCAQKATOSA-N Lys-Ser-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O MEQLGHAMAUPOSJ-DCAQKATOSA-N 0.000 description 1
- QVTDVTONTRSQMF-WDCWCFNPSA-N Lys-Thr-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CCCCN QVTDVTONTRSQMF-WDCWCFNPSA-N 0.000 description 1
- IEVXCWPVBYCJRZ-IXOXFDKPSA-N Lys-Thr-His Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 IEVXCWPVBYCJRZ-IXOXFDKPSA-N 0.000 description 1
- DLCAXBGXGOVUCD-PPCPHDFISA-N Lys-Thr-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DLCAXBGXGOVUCD-PPCPHDFISA-N 0.000 description 1
- CAVRAQIDHUPECU-UVOCVTCTSA-N Lys-Thr-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAVRAQIDHUPECU-UVOCVTCTSA-N 0.000 description 1
- ZJSXCIMWLPSTMG-HSCHXYMDSA-N Lys-Trp-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZJSXCIMWLPSTMG-HSCHXYMDSA-N 0.000 description 1
- YUTZYVTZDVZBJJ-IHPCNDPISA-N Lys-Trp-Lys Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 YUTZYVTZDVZBJJ-IHPCNDPISA-N 0.000 description 1
- PELXPRPDQRFBGQ-KKUMJFAQSA-N Lys-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N)O PELXPRPDQRFBGQ-KKUMJFAQSA-N 0.000 description 1
- UGCIQUYEJIEHKX-GVXVVHGQSA-N Lys-Val-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O UGCIQUYEJIEHKX-GVXVVHGQSA-N 0.000 description 1
- NYTDJEZBAAFLLG-IHRRRGAJSA-N Lys-Val-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(O)=O NYTDJEZBAAFLLG-IHRRRGAJSA-N 0.000 description 1
- IKXQOBUBZSOWDY-AVGNSLFASA-N Lys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CCCCN)N IKXQOBUBZSOWDY-AVGNSLFASA-N 0.000 description 1
- 102000043129 MHC class I family Human genes 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 101710127721 Membrane protein Proteins 0.000 description 1
- 102100032517 Membrane-spanning 4-domains subfamily A member 3 Human genes 0.000 description 1
- 108050001411 Membrane-spanning 4-domains subfamily A member 3 Proteins 0.000 description 1
- QEVRUYFHWJJUHZ-DCAQKATOSA-N Met-Ala-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(C)C QEVRUYFHWJJUHZ-DCAQKATOSA-N 0.000 description 1
- QXEVZBXTDTVPCP-GMOBBJLQSA-N Met-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCSC)N QXEVZBXTDTVPCP-GMOBBJLQSA-N 0.000 description 1
- GODBLDDYHFTUAH-CIUDSAMLSA-N Met-Asp-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(O)=O GODBLDDYHFTUAH-CIUDSAMLSA-N 0.000 description 1
- TZLYIHDABYBOCJ-FXQIFTODSA-N Met-Asp-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O TZLYIHDABYBOCJ-FXQIFTODSA-N 0.000 description 1
- GTRWUQSSISWRTL-NAKRPEOUSA-N Met-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCSC)N GTRWUQSSISWRTL-NAKRPEOUSA-N 0.000 description 1
- VZBXCMCHIHEPBL-SRVKXCTJSA-N Met-Glu-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN VZBXCMCHIHEPBL-SRVKXCTJSA-N 0.000 description 1
- YAWKHFKCNSXYDS-XIRDDKMYSA-N Met-Glu-Trp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N YAWKHFKCNSXYDS-XIRDDKMYSA-N 0.000 description 1
- KMSMNUFBNCHMII-IHRRRGAJSA-N Met-Leu-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN KMSMNUFBNCHMII-IHRRRGAJSA-N 0.000 description 1
- WXUUEPIDLLQBLJ-DCAQKATOSA-N Met-Met-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N WXUUEPIDLLQBLJ-DCAQKATOSA-N 0.000 description 1
- XOFDBXYPKZUAAM-GUBZILKMSA-N Met-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)O)N XOFDBXYPKZUAAM-GUBZILKMSA-N 0.000 description 1
- SMVTWPOATVIXTN-NAKRPEOUSA-N Met-Ser-Ile Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SMVTWPOATVIXTN-NAKRPEOUSA-N 0.000 description 1
- XTSBLBXAUIBMLW-KKUMJFAQSA-N Met-Tyr-Glu Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N XTSBLBXAUIBMLW-KKUMJFAQSA-N 0.000 description 1
- IQJMEDDVOGMTKT-SRVKXCTJSA-N Met-Val-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IQJMEDDVOGMTKT-SRVKXCTJSA-N 0.000 description 1
- BAQCROVBDNBEEB-UBYUBLNFSA-N Metrizamide Chemical compound CC(=O)N(C)C1=C(I)C(NC(C)=O)=C(I)C(C(=O)N[C@@H]2[C@H]([C@H](O)[C@@H](CO)OC2O)O)=C1I BAQCROVBDNBEEB-UBYUBLNFSA-N 0.000 description 1
- 241000108056 Monas Species 0.000 description 1
- 108700005084 Multigene Family Proteins 0.000 description 1
- 241000699666 Mus <mouse, genus> Species 0.000 description 1
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 1
- WYBVBIHNJWOLCJ-UHFFFAOYSA-N N-L-arginyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCCN=C(N)N WYBVBIHNJWOLCJ-UHFFFAOYSA-N 0.000 description 1
- 238000005481 NMR spectroscopy Methods 0.000 description 1
- GRYLNZFGIOXLOG-UHFFFAOYSA-N Nitric acid Chemical compound O[N+]([O-])=O GRYLNZFGIOXLOG-UHFFFAOYSA-N 0.000 description 1
- 238000000636 Northern blotting Methods 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 206010061535 Ovarian neoplasm Diseases 0.000 description 1
- 238000010222 PCR analysis Methods 0.000 description 1
- 108010011536 PTEN Phosphohydrolase Proteins 0.000 description 1
- 102000014160 PTEN Phosphohydrolase Human genes 0.000 description 1
- 229930012538 Paclitaxel Natural products 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 108010081690 Pertussis Toxin Proteins 0.000 description 1
- UHRNIXJAGGLKHP-DLOVCJGASA-N Phe-Ala-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O UHRNIXJAGGLKHP-DLOVCJGASA-N 0.000 description 1
- SEPNOAFMZLLCEW-UBHSHLNASA-N Phe-Ala-Val Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O SEPNOAFMZLLCEW-UBHSHLNASA-N 0.000 description 1
- MPGJIHFJCXTVEX-KKUMJFAQSA-N Phe-Arg-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O MPGJIHFJCXTVEX-KKUMJFAQSA-N 0.000 description 1
- CSYVXYQDIVCQNU-QWRGUYRKSA-N Phe-Asp-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O CSYVXYQDIVCQNU-QWRGUYRKSA-N 0.000 description 1
- KRYSMKKRRRWOCZ-QEWYBTABSA-N Phe-Ile-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O KRYSMKKRRRWOCZ-QEWYBTABSA-N 0.000 description 1
- GXDPQJUBLBZKDY-IAVJCBSLSA-N Phe-Ile-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O GXDPQJUBLBZKDY-IAVJCBSLSA-N 0.000 description 1
- WLYPRKLMRIYGPP-JYJNAYRXSA-N Phe-Lys-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=CC=C1 WLYPRKLMRIYGPP-JYJNAYRXSA-N 0.000 description 1
- RBRNEFJTEHPDSL-ACRUOGEOSA-N Phe-Phe-Lys Chemical compound C([C@@H](C(=O)N[C@@H](CCCCN)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 RBRNEFJTEHPDSL-ACRUOGEOSA-N 0.000 description 1
- DSXPMZMSJHOKKK-HJOGWXRNSA-N Phe-Phe-Tyr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O DSXPMZMSJHOKKK-HJOGWXRNSA-N 0.000 description 1
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 1
- IAOZOFPONWDXNT-IXOXFDKPSA-N Phe-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IAOZOFPONWDXNT-IXOXFDKPSA-N 0.000 description 1
- APMXLWHMIVWLLR-BZSNNMDCSA-N Phe-Tyr-Ser Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(O)=O)C1=CC=CC=C1 APMXLWHMIVWLLR-BZSNNMDCSA-N 0.000 description 1
- CDHURCQGUDNBMA-UBHSHLNASA-N Phe-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 CDHURCQGUDNBMA-UBHSHLNASA-N 0.000 description 1
- 102000045595 Phosphoprotein Phosphatases Human genes 0.000 description 1
- 108700019535 Phosphoprotein Phosphatases Proteins 0.000 description 1
- 108091000080 Phosphotransferase Proteins 0.000 description 1
- 108010004729 Phycoerythrin Proteins 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- LNLNHXIQPGKRJQ-SRVKXCTJSA-N Pro-Arg-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 LNLNHXIQPGKRJQ-SRVKXCTJSA-N 0.000 description 1
- OYEUSRAZOGIDBY-JYJNAYRXSA-N Pro-Arg-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OYEUSRAZOGIDBY-JYJNAYRXSA-N 0.000 description 1
- MTHRMUXESFIAMS-DCAQKATOSA-N Pro-Asn-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O MTHRMUXESFIAMS-DCAQKATOSA-N 0.000 description 1
- TXPUNZXZDVJUJQ-LPEHRKFASA-N Pro-Asn-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O TXPUNZXZDVJUJQ-LPEHRKFASA-N 0.000 description 1
- AHXPYZRZRMQOAU-QXEWZRGKSA-N Pro-Asn-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1)C(O)=O AHXPYZRZRMQOAU-QXEWZRGKSA-N 0.000 description 1
- ILMLVTGTUJPQFP-FXQIFTODSA-N Pro-Asp-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ILMLVTGTUJPQFP-FXQIFTODSA-N 0.000 description 1
- ZPPVJIJMIKTERM-YUMQZZPRSA-N Pro-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)N)NC(=O)[C@@H]1CCCN1 ZPPVJIJMIKTERM-YUMQZZPRSA-N 0.000 description 1
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 1
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 1
- DXTOOBDIIAJZBJ-BQBZGAKWSA-N Pro-Gly-Ser Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CO)C(O)=O DXTOOBDIIAJZBJ-BQBZGAKWSA-N 0.000 description 1
- LNOWDSPAYBWJOR-PEDHHIEDSA-N Pro-Ile-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LNOWDSPAYBWJOR-PEDHHIEDSA-N 0.000 description 1
- FKVNLUZHSFCNGY-RVMXOQNASA-N Pro-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 FKVNLUZHSFCNGY-RVMXOQNASA-N 0.000 description 1
- FXGIMYRVJJEIIM-UWVGGRQHSA-N Pro-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FXGIMYRVJJEIIM-UWVGGRQHSA-N 0.000 description 1
- YYARMJSFDLIDFS-FKBYEOEOSA-N Pro-Phe-Trp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O YYARMJSFDLIDFS-FKBYEOEOSA-N 0.000 description 1
- JLMZKEQFMVORMA-SRVKXCTJSA-N Pro-Pro-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 JLMZKEQFMVORMA-SRVKXCTJSA-N 0.000 description 1
- CGSOWZUPLOKYOR-AVGNSLFASA-N Pro-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 CGSOWZUPLOKYOR-AVGNSLFASA-N 0.000 description 1
- QAAYIXYLEMRULP-SRVKXCTJSA-N Pro-Pro-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 QAAYIXYLEMRULP-SRVKXCTJSA-N 0.000 description 1
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 1
- POQFNPILEQEODH-FXQIFTODSA-N Pro-Ser-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O POQFNPILEQEODH-FXQIFTODSA-N 0.000 description 1
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 1
- VVAWNPIOYXAMAL-KJEVXHAQSA-N Pro-Thr-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VVAWNPIOYXAMAL-KJEVXHAQSA-N 0.000 description 1
- FIODMZKLZFLYQP-GUBZILKMSA-N Pro-Val-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FIODMZKLZFLYQP-GUBZILKMSA-N 0.000 description 1
- 101710093543 Probable non-specific lipid-transfer protein Proteins 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 241000589516 Pseudomonas Species 0.000 description 1
- LCTONWCANYUPML-UHFFFAOYSA-M Pyruvate Chemical compound CC(=O)C([O-])=O LCTONWCANYUPML-UHFFFAOYSA-M 0.000 description 1
- 238000002123 RNA extraction Methods 0.000 description 1
- 239000013614 RNA sample Substances 0.000 description 1
- 238000011529 RT qPCR Methods 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 1
- 108010039491 Ricin Proteins 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 201000010208 Seminoma Diseases 0.000 description 1
- 241000710961 Semliki Forest virus Species 0.000 description 1
- DWUIECHTAMYEFL-XVYDVKMFSA-N Ser-Ala-His Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 DWUIECHTAMYEFL-XVYDVKMFSA-N 0.000 description 1
- WTWGOQRNRFHFQD-JBDRJPRFSA-N Ser-Ala-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WTWGOQRNRFHFQD-JBDRJPRFSA-N 0.000 description 1
- BRKHVZNDAOMAHX-BIIVOSGPSA-N Ser-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N BRKHVZNDAOMAHX-BIIVOSGPSA-N 0.000 description 1
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 1
- PZZJMBYSYAKYPK-UWJYBYFXSA-N Ser-Ala-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O PZZJMBYSYAKYPK-UWJYBYFXSA-N 0.000 description 1
- JJKSSJVYOVRJMZ-FXQIFTODSA-N Ser-Arg-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N)CN=C(N)N JJKSSJVYOVRJMZ-FXQIFTODSA-N 0.000 description 1
- XVAUJOAYHWWNQF-ZLUOBGJFSA-N Ser-Asn-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O XVAUJOAYHWWNQF-ZLUOBGJFSA-N 0.000 description 1
- FIDMVVBUOCMMJG-CIUDSAMLSA-N Ser-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO FIDMVVBUOCMMJG-CIUDSAMLSA-N 0.000 description 1
- DKKGAAJTDKHWOD-BIIVOSGPSA-N Ser-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N)C(=O)O DKKGAAJTDKHWOD-BIIVOSGPSA-N 0.000 description 1
- OLIJLNWFEQEFDM-SRVKXCTJSA-N Ser-Asp-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 OLIJLNWFEQEFDM-SRVKXCTJSA-N 0.000 description 1
- KNCJWSPMTFFJII-ZLUOBGJFSA-N Ser-Cys-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O KNCJWSPMTFFJII-ZLUOBGJFSA-N 0.000 description 1
- OJPHFSOMBZKQKQ-GUBZILKMSA-N Ser-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CO OJPHFSOMBZKQKQ-GUBZILKMSA-N 0.000 description 1
- VMVNCJDKFOQOHM-GUBZILKMSA-N Ser-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N VMVNCJDKFOQOHM-GUBZILKMSA-N 0.000 description 1
- SMIDBHKWSYUBRZ-ACZMJKKPSA-N Ser-Glu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O SMIDBHKWSYUBRZ-ACZMJKKPSA-N 0.000 description 1
- PVDTYLHUWAEYGY-CIUDSAMLSA-N Ser-Glu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PVDTYLHUWAEYGY-CIUDSAMLSA-N 0.000 description 1
- HJEBZBMOTCQYDN-ACZMJKKPSA-N Ser-Glu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJEBZBMOTCQYDN-ACZMJKKPSA-N 0.000 description 1
- QKQDTEYDEIJPNK-GUBZILKMSA-N Ser-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CO QKQDTEYDEIJPNK-GUBZILKMSA-N 0.000 description 1
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 1
- IOVHBRCQOGWAQH-ZKWXMUAHSA-N Ser-Gly-Ile Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOVHBRCQOGWAQH-ZKWXMUAHSA-N 0.000 description 1
- WSTIOCFMWXNOCX-YUMQZZPRSA-N Ser-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N WSTIOCFMWXNOCX-YUMQZZPRSA-N 0.000 description 1
- LQESNKGTTNHZPZ-GHCJXIJMSA-N Ser-Ile-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O LQESNKGTTNHZPZ-GHCJXIJMSA-N 0.000 description 1
- NNFMANHDYSVNIO-DCAQKATOSA-N Ser-Lys-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NNFMANHDYSVNIO-DCAQKATOSA-N 0.000 description 1
- PTWIYDNFWPXQSD-GARJFASQSA-N Ser-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N)C(=O)O PTWIYDNFWPXQSD-GARJFASQSA-N 0.000 description 1
- BUYHXYIUQUBEQP-AVGNSLFASA-N Ser-Phe-Glu Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CO)N BUYHXYIUQUBEQP-AVGNSLFASA-N 0.000 description 1
- MQUZANJDFOQOBX-SRVKXCTJSA-N Ser-Phe-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O MQUZANJDFOQOBX-SRVKXCTJSA-N 0.000 description 1
- ZKBKUWQVDWWSRI-BZSNNMDCSA-N Ser-Phe-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKBKUWQVDWWSRI-BZSNNMDCSA-N 0.000 description 1
- JLKWJWPDXPKKHI-FXQIFTODSA-N Ser-Pro-Asn Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CO)N)C(=O)N[C@@H](CC(=O)N)C(=O)O JLKWJWPDXPKKHI-FXQIFTODSA-N 0.000 description 1
- DINQYZRMXGWWTG-GUBZILKMSA-N Ser-Pro-Pro Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DINQYZRMXGWWTG-GUBZILKMSA-N 0.000 description 1
- JCLAFVNDBJMLBC-JBDRJPRFSA-N Ser-Ser-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JCLAFVNDBJMLBC-JBDRJPRFSA-N 0.000 description 1
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 1
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 1
- ZWSZBWAFDZRBNM-UBHSHLNASA-N Ser-Trp-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(O)=O ZWSZBWAFDZRBNM-UBHSHLNASA-N 0.000 description 1
- RTXKJFWHEBTABY-IHPCNDPISA-N Ser-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CO)N RTXKJFWHEBTABY-IHPCNDPISA-N 0.000 description 1
- 241000700584 Simplexvirus Species 0.000 description 1
- 241000710960 Sindbis virus Species 0.000 description 1
- 108091081024 Start codon Proteins 0.000 description 1
- KDYFGRWQOYBRFD-UHFFFAOYSA-N Succinic acid Natural products OC(=O)CCC(O)=O KDYFGRWQOYBRFD-UHFFFAOYSA-N 0.000 description 1
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 1
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 description 1
- 210000000173 T-lymphoid precursor cell Anatomy 0.000 description 1
- 108700026226 TATA Box Proteins 0.000 description 1
- 108010006785 Taq Polymerase Proteins 0.000 description 1
- GKLVYJBZJHMRIY-OUBTZVSYSA-N Technetium-99 Chemical compound [99Tc] GKLVYJBZJHMRIY-OUBTZVSYSA-N 0.000 description 1
- 206010043276 Teratoma Diseases 0.000 description 1
- BHEOSNUKNHRBNM-UHFFFAOYSA-N Tetramethylsqualene Natural products CC(=C)C(C)CCC(=C)C(C)CCC(C)=CCCC=C(C)CCC(C)C(=C)CCC(C)C(C)=C BHEOSNUKNHRBNM-UHFFFAOYSA-N 0.000 description 1
- XSLXHSYIVPGEER-KZVJFYERSA-N Thr-Ala-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O XSLXHSYIVPGEER-KZVJFYERSA-N 0.000 description 1
- WFUAUEQXPVNAEF-ZJDVBMNYSA-N Thr-Arg-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CCCN=C(N)N WFUAUEQXPVNAEF-ZJDVBMNYSA-N 0.000 description 1
- QNJZOAHSYPXTAB-VEVYYDQMSA-N Thr-Asn-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O QNJZOAHSYPXTAB-VEVYYDQMSA-N 0.000 description 1
- NLSNVZAREYQMGR-HJGDQZAQSA-N Thr-Asp-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NLSNVZAREYQMGR-HJGDQZAQSA-N 0.000 description 1
- VGYBYGQXZJDZJU-XQXXSGGOSA-N Thr-Glu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VGYBYGQXZJDZJU-XQXXSGGOSA-N 0.000 description 1
- KCRQEJSKXAIULJ-FJXKBIBVSA-N Thr-Gly-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O KCRQEJSKXAIULJ-FJXKBIBVSA-N 0.000 description 1
- MSIYNSBKKVMGFO-BHNWBGBOSA-N Thr-Gly-Pro Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N1CCC[C@@H]1C(=O)O)N)O MSIYNSBKKVMGFO-BHNWBGBOSA-N 0.000 description 1
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 1
- FIFDDJFLNVAVMS-RHYQMDGZSA-N Thr-Leu-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O FIFDDJFLNVAVMS-RHYQMDGZSA-N 0.000 description 1
- SCSVNSNWUTYSFO-WDCWCFNPSA-N Thr-Lys-Glu Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O SCSVNSNWUTYSFO-WDCWCFNPSA-N 0.000 description 1
- JLNMFGCJODTXDH-WEDXCCLWSA-N Thr-Lys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O JLNMFGCJODTXDH-WEDXCCLWSA-N 0.000 description 1
- YJVJPJPHHFOVMG-VEVYYDQMSA-N Thr-Met-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O YJVJPJPHHFOVMG-VEVYYDQMSA-N 0.000 description 1
- GUHLYMZJVXUIPO-RCWTZXSCSA-N Thr-Met-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O GUHLYMZJVXUIPO-RCWTZXSCSA-N 0.000 description 1
- XKWABWFMQXMUMT-HJGDQZAQSA-N Thr-Pro-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XKWABWFMQXMUMT-HJGDQZAQSA-N 0.000 description 1
- BCYUHPXBHCUYBA-CUJWVEQBSA-N Thr-Ser-His Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O BCYUHPXBHCUYBA-CUJWVEQBSA-N 0.000 description 1
- VUXIQSUQQYNLJP-XAVMHZPKSA-N Thr-Ser-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N)O VUXIQSUQQYNLJP-XAVMHZPKSA-N 0.000 description 1
- WPSKTVVMQCXPRO-BWBBJGPYSA-N Thr-Ser-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WPSKTVVMQCXPRO-BWBBJGPYSA-N 0.000 description 1
- RVMNUBQWPVOUKH-HEIBUPTGSA-N Thr-Ser-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMNUBQWPVOUKH-HEIBUPTGSA-N 0.000 description 1
- GQPQJNMVELPZNQ-GBALPHGKSA-N Thr-Ser-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N)O GQPQJNMVELPZNQ-GBALPHGKSA-N 0.000 description 1
- AAZOYLQUEQRUMZ-GSSVUCPTSA-N Thr-Thr-Asn Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O AAZOYLQUEQRUMZ-GSSVUCPTSA-N 0.000 description 1
- CSNBWOJOEOPYIJ-UVOCVTCTSA-N Thr-Thr-Lys Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O CSNBWOJOEOPYIJ-UVOCVTCTSA-N 0.000 description 1
- KAJRRNHOVMZYBL-IRIUXVKKSA-N Thr-Tyr-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAJRRNHOVMZYBL-IRIUXVKKSA-N 0.000 description 1
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 1
- BDWDMRSGCXEDMR-WFBYXXMGSA-N Trp-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N BDWDMRSGCXEDMR-WFBYXXMGSA-N 0.000 description 1
- MJBBMTOGSOSAKJ-HJXMPXNTSA-N Trp-Ala-Ile Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MJBBMTOGSOSAKJ-HJXMPXNTSA-N 0.000 description 1
- ADBFWLXCCKIXBQ-XIRDDKMYSA-N Trp-Asn-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N ADBFWLXCCKIXBQ-XIRDDKMYSA-N 0.000 description 1
- OFTGYORHQMSPAI-PJODQICGSA-N Trp-Met-Ala Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O OFTGYORHQMSPAI-PJODQICGSA-N 0.000 description 1
- ZJPSMXCFEKMZFE-IHPCNDPISA-N Trp-Tyr-Ser Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O ZJPSMXCFEKMZFE-IHPCNDPISA-N 0.000 description 1
- 108010040002 Tumor Suppressor Proteins Proteins 0.000 description 1
- 102000001742 Tumor Suppressor Proteins Human genes 0.000 description 1
- AYPAIRCDLARHLM-KKUMJFAQSA-N Tyr-Asn-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O AYPAIRCDLARHLM-KKUMJFAQSA-N 0.000 description 1
- IUQDEKCCHWRHRW-IHPCNDPISA-N Tyr-Asn-Trp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O IUQDEKCCHWRHRW-IHPCNDPISA-N 0.000 description 1
- DANHCMVVXDXOHN-SRVKXCTJSA-N Tyr-Asp-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 DANHCMVVXDXOHN-SRVKXCTJSA-N 0.000 description 1
- BEIGSKUPTIFYRZ-SRVKXCTJSA-N Tyr-Asp-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O BEIGSKUPTIFYRZ-SRVKXCTJSA-N 0.000 description 1
- NRFTYDWKWGJLAR-MELADBBJSA-N Tyr-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O NRFTYDWKWGJLAR-MELADBBJSA-N 0.000 description 1
- SMLCYZYQFRTLCO-UWJYBYFXSA-N Tyr-Cys-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O SMLCYZYQFRTLCO-UWJYBYFXSA-N 0.000 description 1
- GHUNBABNQPIETG-MELADBBJSA-N Tyr-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O GHUNBABNQPIETG-MELADBBJSA-N 0.000 description 1
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 1
- RIJPHPUJRLEOAK-JYJNAYRXSA-N Tyr-Gln-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O RIJPHPUJRLEOAK-JYJNAYRXSA-N 0.000 description 1
- FNWGDMZVYBVAGJ-XEGUGMAKSA-N Tyr-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC1=CC=C(C=C1)O)N FNWGDMZVYBVAGJ-XEGUGMAKSA-N 0.000 description 1
- VXFXIBCCVLJCJT-JYJNAYRXSA-N Tyr-Pro-Pro Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N1CCC[C@H]1C(O)=O VXFXIBCCVLJCJT-JYJNAYRXSA-N 0.000 description 1
- QPOUERMDWKKZEG-HJPIBITLSA-N Tyr-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 QPOUERMDWKKZEG-HJPIBITLSA-N 0.000 description 1
- WQOHKVRQDLNDIL-YJRXYDGGSA-N Tyr-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O WQOHKVRQDLNDIL-YJRXYDGGSA-N 0.000 description 1
- ZYVAAYAOTVJBSS-GMVOTWDCSA-N Tyr-Trp-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O ZYVAAYAOTVJBSS-GMVOTWDCSA-N 0.000 description 1
- UUJHRSTVQCFDPA-UFYCRDLUSA-N Tyr-Tyr-Val Chemical compound C([C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 UUJHRSTVQCFDPA-UFYCRDLUSA-N 0.000 description 1
- MJUTYRIMFIICKL-JYJNAYRXSA-N Tyr-Val-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MJUTYRIMFIICKL-JYJNAYRXSA-N 0.000 description 1
- KTVKGXZZBQCBGD-UHFFFAOYSA-M Tyropanoate sodium Chemical compound [Na+].CCCC(=O)NC1=C(I)C=C(I)C(CC(CC)C([O-])=O)=C1I KTVKGXZZBQCBGD-UHFFFAOYSA-M 0.000 description 1
- 208000002495 Uterine Neoplasms Diseases 0.000 description 1
- NMANTMWGQZASQN-QXEWZRGKSA-N Val-Arg-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N NMANTMWGQZASQN-QXEWZRGKSA-N 0.000 description 1
- ZMDCGGKHRKNWKD-LAEOZQHASA-N Val-Asn-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZMDCGGKHRKNWKD-LAEOZQHASA-N 0.000 description 1
- XTAUQCGQFJQGEJ-NHCYSSNCSA-N Val-Gln-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N XTAUQCGQFJQGEJ-NHCYSSNCSA-N 0.000 description 1
- QHFQQRKNGCXTHL-AUTRQRHGSA-N Val-Gln-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QHFQQRKNGCXTHL-AUTRQRHGSA-N 0.000 description 1
- JXGWQYWDUOWQHA-DZKIICNBSA-N Val-Gln-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N JXGWQYWDUOWQHA-DZKIICNBSA-N 0.000 description 1
- NYTKXWLZSNRILS-IFFSRLJSSA-N Val-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N)O NYTKXWLZSNRILS-IFFSRLJSSA-N 0.000 description 1
- UZDHNIJRRTUKKC-DLOVCJGASA-N Val-Gln-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N UZDHNIJRRTUKKC-DLOVCJGASA-N 0.000 description 1
- SZTTYWIUCGSURQ-AUTRQRHGSA-N Val-Glu-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SZTTYWIUCGSURQ-AUTRQRHGSA-N 0.000 description 1
- OXGVAUFVTOPFFA-XPUUQOCRSA-N Val-Gly-Cys Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N OXGVAUFVTOPFFA-XPUUQOCRSA-N 0.000 description 1
- YTPLVNUZZOBFFC-SCZZXKLOSA-N Val-Gly-Pro Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N1CCC[C@@H]1C(O)=O YTPLVNUZZOBFFC-SCZZXKLOSA-N 0.000 description 1
- JZWZACGUZVCQPS-RNJOBUHISA-N Val-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N JZWZACGUZVCQPS-RNJOBUHISA-N 0.000 description 1
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 1
- BTWMICVCQLKKNR-DCAQKATOSA-N Val-Leu-Ser Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C([O-])=O BTWMICVCQLKKNR-DCAQKATOSA-N 0.000 description 1
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 1
- MLADEWAIYAPAAU-IHRRRGAJSA-N Val-Lys-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N MLADEWAIYAPAAU-IHRRRGAJSA-N 0.000 description 1
- SVFRYKBZHUGKLP-QXEWZRGKSA-N Val-Met-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SVFRYKBZHUGKLP-QXEWZRGKSA-N 0.000 description 1
- ILMVQSHENUZYIZ-JYJNAYRXSA-N Val-Met-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N ILMVQSHENUZYIZ-JYJNAYRXSA-N 0.000 description 1
- RYQUMYBMOJYYDK-NHCYSSNCSA-N Val-Pro-Glu Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)O)C(=O)O)N RYQUMYBMOJYYDK-NHCYSSNCSA-N 0.000 description 1
- MIKHIIQMRFYVOR-RCWTZXSCSA-N Val-Pro-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C(C)C)N)O MIKHIIQMRFYVOR-RCWTZXSCSA-N 0.000 description 1
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 1
- GVNLOVJNNDZUHS-RHYQMDGZSA-N Val-Thr-Lys Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O GVNLOVJNNDZUHS-RHYQMDGZSA-N 0.000 description 1
- DVLWZWNAQUBZBC-ZNSHCXBVSA-N Val-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N)O DVLWZWNAQUBZBC-ZNSHCXBVSA-N 0.000 description 1
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 1
- VBTFUDNTMCHPII-UHFFFAOYSA-N Val-Trp-Tyr Natural products C=1NC2=CC=CC=C2C=1CC(NC(=O)C(N)C(C)C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 VBTFUDNTMCHPII-UHFFFAOYSA-N 0.000 description 1
- GUIYPEKUEMQBIK-JSGCOSHPSA-N Val-Tyr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)NCC(O)=O GUIYPEKUEMQBIK-JSGCOSHPSA-N 0.000 description 1
- AEFJNECXZCODJM-UWVGGRQHSA-N Val-Val-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)NCC([O-])=O AEFJNECXZCODJM-UWVGGRQHSA-N 0.000 description 1
- 229930003427 Vitamin E Natural products 0.000 description 1
- 210000002593 Y chromosome Anatomy 0.000 description 1
- 150000001242 acetic acid derivatives Chemical class 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 239000011543 agarose gel Substances 0.000 description 1
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 1
- 108010070944 alanylhistidine Proteins 0.000 description 1
- 108010070783 alanyltyrosine Proteins 0.000 description 1
- 229910052783 alkali metal Inorganic materials 0.000 description 1
- 229910052784 alkaline earth metal Inorganic materials 0.000 description 1
- 125000005600 alkyl phosphonate group Chemical group 0.000 description 1
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 1
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 229940037003 alum Drugs 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- YVPYQUNUQOZFHG-UHFFFAOYSA-N amidotrizoic acid Chemical compound CC(=O)NC1=C(I)C(NC(C)=O)=C(I)C(C(O)=O)=C1I YVPYQUNUQOZFHG-UHFFFAOYSA-N 0.000 description 1
- ROBVIMPUHSLWNV-UHFFFAOYSA-N aminoglutethimide Chemical compound C=1C=C(N)C=CC=1C1(CC)CCC(=O)NC1=O ROBVIMPUHSLWNV-UHFFFAOYSA-N 0.000 description 1
- 229960003437 aminoglutethimide Drugs 0.000 description 1
- 230000006538 anaerobic glycolysis Effects 0.000 description 1
- 230000019552 anatomical structure morphogenesis Effects 0.000 description 1
- 210000003484 anatomy Anatomy 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 239000005557 antagonist Substances 0.000 description 1
- 238000009175 antibody therapy Methods 0.000 description 1
- 230000005904 anticancer immunity Effects 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 229940034982 antineoplastic agent Drugs 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- PYMYPHUHKUWMLA-WDCZJNDASA-N arabinose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)C=O PYMYPHUHKUWMLA-WDCZJNDASA-N 0.000 description 1
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 1
- 108010062796 arginyllysine Proteins 0.000 description 1
- 210000001367 artery Anatomy 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- LMEKQMALGUDUQG-UHFFFAOYSA-N azathioprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC=NC2=C1NC=N2 LMEKQMALGUDUQG-UHFFFAOYSA-N 0.000 description 1
- 229960002170 azathioprine Drugs 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 229960000686 benzalkonium chloride Drugs 0.000 description 1
- CADWTSSKOVRVJC-UHFFFAOYSA-N benzyl(dimethyl)azanium;chloride Chemical compound [Cl-].C[NH+](C)CC1=CC=CC=C1 CADWTSSKOVRVJC-UHFFFAOYSA-N 0.000 description 1
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 229960004395 bleomycin sulfate Drugs 0.000 description 1
- 210000000601 blood cell Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- KGBXLFKZBHKPEV-UHFFFAOYSA-N boric acid Chemical compound OB(O)O KGBXLFKZBHKPEV-UHFFFAOYSA-N 0.000 description 1
- 239000004327 boric acid Substances 0.000 description 1
- 229940098773 bovine serum albumin Drugs 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 229960002092 busulfan Drugs 0.000 description 1
- KDYFGRWQOYBRFD-NUQCWPJISA-N butanedioic acid Chemical compound O[14C](=O)CC[14C](O)=O KDYFGRWQOYBRFD-NUQCWPJISA-N 0.000 description 1
- 238000010804 cDNA synthesis Methods 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229940095658 calcium ipodate Drugs 0.000 description 1
- 159000000007 calcium salts Chemical class 0.000 description 1
- 238000004422 calculation algorithm Methods 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 150000004657 carbamic acid derivatives Chemical class 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- OKTJSMMVPCPJKN-BJUDXGSMSA-N carbon-11 Chemical compound [11C] OKTJSMMVPCPJKN-BJUDXGSMSA-N 0.000 description 1
- 150000004649 carbonic acid derivatives Chemical class 0.000 description 1
- 229960005243 carmustine Drugs 0.000 description 1
- 239000003054 catalyst Substances 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 230000001364 causal effect Effects 0.000 description 1
- 230000005779 cell damage Effects 0.000 description 1
- 208000037887 cell injury Diseases 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 230000030570 cellular localization Effects 0.000 description 1
- 210000003793 centrosome Anatomy 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 230000003196 chaotropic effect Effects 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- HVZGHKKROPCBDE-HZIJXFFPSA-L chembl2068725 Chemical compound [Ca+2].CN(C)\C=N\C1=C(I)C=C(I)C(CCC([O-])=O)=C1I.CN(C)\C=N\C1=C(I)C=C(I)C(CCC([O-])=O)=C1I HVZGHKKROPCBDE-HZIJXFFPSA-L 0.000 description 1
- 239000013000 chemical inhibitor Substances 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 1
- 229960004630 chlorambucil Drugs 0.000 description 1
- 229960004926 chlorobutanol Drugs 0.000 description 1
- 229960001265 ciclosporin Drugs 0.000 description 1
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 1
- 229960004316 cisplatin Drugs 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 238000012411 cloning technique Methods 0.000 description 1
- 201000010989 colorectal carcinoma Diseases 0.000 description 1
- 230000024203 complement activation Effects 0.000 description 1
- 239000003184 complementary RNA Substances 0.000 description 1
- 238000011109 contamination Methods 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 229960004397 cyclophosphamide Drugs 0.000 description 1
- 229930182912 cyclosporin Natural products 0.000 description 1
- 230000016396 cytokine production Effects 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 229940127089 cytotoxic agent Drugs 0.000 description 1
- 239000002254 cytotoxic agent Substances 0.000 description 1
- 231100000599 cytotoxic agent Toxicity 0.000 description 1
- 229960003901 dacarbazine Drugs 0.000 description 1
- 229960000640 dactinomycin Drugs 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 238000004925 denaturation Methods 0.000 description 1
- 230000036425 denaturation Effects 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 238000001212 derivatisation Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 229960005423 diatrizoate Drugs 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- 239000000539 dimer Substances 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical compound [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 1
- 206010013023 diphtheria Diseases 0.000 description 1
- 230000005750 disease progression Effects 0.000 description 1
- PRAKJMSDJKAYCZ-UHFFFAOYSA-N dodecahydrosqualene Natural products CC(C)CCCC(C)CCCC(C)CCCCC(C)CCCC(C)CCCC(C)C PRAKJMSDJKAYCZ-UHFFFAOYSA-N 0.000 description 1
- 229960004679 doxorubicin Drugs 0.000 description 1
- 241001493065 dsRNA viruses Species 0.000 description 1
- 239000012636 effector Substances 0.000 description 1
- 230000013020 embryo development Effects 0.000 description 1
- 210000001671 embryonic stem cell Anatomy 0.000 description 1
- 230000012202 endocytosis Effects 0.000 description 1
- 210000002889 endothelial cell Anatomy 0.000 description 1
- 230000003511 endothelial effect Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 230000009088 enzymatic function Effects 0.000 description 1
- 210000000918 epididymis Anatomy 0.000 description 1
- 201000010063 epididymitis Diseases 0.000 description 1
- ZMMJGEGLRURXTF-UHFFFAOYSA-N ethidium bromide Chemical compound [Br-].C12=CC(N)=CC=C2C2=CC=C(N)C=C2[N+](CC)=C1C1=CC=CC=C1 ZMMJGEGLRURXTF-UHFFFAOYSA-N 0.000 description 1
- 229960005542 ethidium bromide Drugs 0.000 description 1
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 1
- 229960005420 etoposide Drugs 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 210000003608 fece Anatomy 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 229910052731 fluorine Inorganic materials 0.000 description 1
- 239000011737 fluorine Substances 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- 235000019253 formic acid Nutrition 0.000 description 1
- 125000000524 functional group Chemical group 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- UIWYJDYFSGRHKR-UHFFFAOYSA-N gadolinium atom Chemical compound [Gd] UIWYJDYFSGRHKR-UHFFFAOYSA-N 0.000 description 1
- WIGCFUFOHFEKBI-UHFFFAOYSA-N gamma-tocopherol Natural products CC(C)CCCC(C)CCCC(C)CCCC1CCC2C(C)C(O)C(C)C(C)C2O1 WIGCFUFOHFEKBI-UHFFFAOYSA-N 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 238000012239 gene modification Methods 0.000 description 1
- 230000005017 genetic modification Effects 0.000 description 1
- 235000013617 genetically modified food Nutrition 0.000 description 1
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 1
- 108010010096 glycyl-glycyl-tyrosine Proteins 0.000 description 1
- 108010077435 glycyl-phenylalanyl-glycine Proteins 0.000 description 1
- 108010020688 glycylhistidine Proteins 0.000 description 1
- 108010077515 glycylproline Proteins 0.000 description 1
- 108010087823 glycyltyrosine Proteins 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 108010009253 histidyl-asparaginyl-glutamyl-leucine Proteins 0.000 description 1
- 102000054751 human RUNX1T1 Human genes 0.000 description 1
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 210000003297 immature b lymphocyte Anatomy 0.000 description 1
- 210000002861 immature t-cell Anatomy 0.000 description 1
- 229940044680 immune agonist Drugs 0.000 description 1
- 239000012651 immune agonist Substances 0.000 description 1
- 210000002865 immune cell Anatomy 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 239000012642 immune effector Substances 0.000 description 1
- 230000008073 immune recognition Effects 0.000 description 1
- 238000010166 immunofluorescence Methods 0.000 description 1
- 238000010820 immunofluorescence microscopy Methods 0.000 description 1
- 229940121354 immunomodulator Drugs 0.000 description 1
- 229940055742 indium-111 Drugs 0.000 description 1
- APFVFJFRJDLVQX-AHCXROLUSA-N indium-111 Chemical compound [111In] APFVFJFRJDLVQX-AHCXROLUSA-N 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 230000002458 infectious effect Effects 0.000 description 1
- 230000028709 inflammatory response Effects 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 230000019734 interleukin-12 production Effects 0.000 description 1
- 230000017306 interleukin-6 production Effects 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 229910052740 iodine Inorganic materials 0.000 description 1
- 239000011630 iodine Substances 0.000 description 1
- 229960002979 iopanoic acid Drugs 0.000 description 1
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 1
- 150000002540 isothiocyanates Chemical class 0.000 description 1
- 210000002510 keratinocyte Anatomy 0.000 description 1
- 210000003292 kidney cell Anatomy 0.000 description 1
- 210000002429 large intestine Anatomy 0.000 description 1
- 108010076756 leucyl-alanyl-phenylalanine Proteins 0.000 description 1
- 108010051673 leucyl-glycyl-phenylalanine Proteins 0.000 description 1
- 108010047926 leucyl-lysyl-tyrosine Proteins 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 238000013332 literature search Methods 0.000 description 1
- 210000005228 liver tissue Anatomy 0.000 description 1
- 229960002247 lomustine Drugs 0.000 description 1
- 239000007937 lozenge Substances 0.000 description 1
- 201000005202 lung cancer Diseases 0.000 description 1
- VZCYOOQTPOCHFL-UPHRSURJSA-N maleic acid Chemical compound OC(=O)\C=C/C(O)=O VZCYOOQTPOCHFL-UPHRSURJSA-N 0.000 description 1
- 239000011976 maleic acid Substances 0.000 description 1
- 230000003211 malignant effect Effects 0.000 description 1
- 210000003519 mature b lymphocyte Anatomy 0.000 description 1
- 230000010534 mechanism of action Effects 0.000 description 1
- MIKKOBKEXMRYFQ-WZTVWXICSA-N meglumine amidotrizoate Chemical compound C[NH2+]C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO.CC(=O)NC1=C(I)C(NC(C)=O)=C(I)C(C([O-])=O)=C1I MIKKOBKEXMRYFQ-WZTVWXICSA-N 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 229960000554 metrizamide Drugs 0.000 description 1
- 238000002493 microarray Methods 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 210000003470 mitochondria Anatomy 0.000 description 1
- 230000008811 mitochondrial respiratory chain Effects 0.000 description 1
- 230000025608 mitochondrion localization Effects 0.000 description 1
- 241000264288 mixed libraries Species 0.000 description 1
- 102000035118 modified proteins Human genes 0.000 description 1
- 108091005573 modified proteins Proteins 0.000 description 1
- 229940035032 monophosphoryl lipid a Drugs 0.000 description 1
- 210000004897 n-terminal region Anatomy 0.000 description 1
- 210000005170 neoplastic cell Anatomy 0.000 description 1
- 230000009826 neoplastic cell growth Effects 0.000 description 1
- 230000001613 neoplastic effect Effects 0.000 description 1
- BOPGDPNILDQYTO-NNYOXOHSSA-N nicotinamide-adenine dinucleotide Chemical compound C1=CCC(C(=O)N)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OC[C@@H]2[C@H]([C@@H](O)[C@@H](O2)N2C3=NC=NC(N)=C3N=C2)O)O1 BOPGDPNILDQYTO-NNYOXOHSSA-N 0.000 description 1
- 229930027945 nicotinamide-adenine dinucleotide Natural products 0.000 description 1
- 229910017604 nitric acid Inorganic materials 0.000 description 1
- 108091027963 non-coding RNA Proteins 0.000 description 1
- 102000042567 non-coding RNA Human genes 0.000 description 1
- 231100000252 nontoxic Toxicity 0.000 description 1
- 230000003000 nontoxic effect Effects 0.000 description 1
- 239000000346 nonvolatile oil Substances 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 229940127084 other anti-cancer agent Drugs 0.000 description 1
- 230000002611 ovarian Effects 0.000 description 1
- 229960001592 paclitaxel Drugs 0.000 description 1
- FJKROLUGYXJWQN-UHFFFAOYSA-N papa-hydroxy-benzoic acid Natural products OC(=O)C1=CC=C(O)C=C1 FJKROLUGYXJWQN-UHFFFAOYSA-N 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 238000005192 partition Methods 0.000 description 1
- 230000007918 pathogenicity Effects 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 230000035515 penetration Effects 0.000 description 1
- 238000010647 peptide synthesis reaction Methods 0.000 description 1
- 230000004526 pharmaceutical effect Effects 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- 108010012581 phenylalanylglutamate Proteins 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 150000008298 phosphoramidates Chemical class 0.000 description 1
- 150000003013 phosphoric acid derivatives Chemical class 0.000 description 1
- 150000003014 phosphoric acid esters Chemical class 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 102000020233 phosphotransferase Human genes 0.000 description 1
- 108010025488 pinealon Proteins 0.000 description 1
- 210000005059 placental tissue Anatomy 0.000 description 1
- 108700028325 pokeweed antiviral Proteins 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 1
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 1
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 1
- 159000000001 potassium salts Chemical class 0.000 description 1
- 239000002244 precipitate Substances 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 230000037452 priming Effects 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 1
- 230000002685 pulmonary effect Effects 0.000 description 1
- 238000007388 punch biopsy Methods 0.000 description 1
- 238000004445 quantitative analysis Methods 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 239000011535 reaction buffer Substances 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000002829 reductive effect Effects 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 230000035806 respiratory chain Effects 0.000 description 1
- 230000004043 responsiveness Effects 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 125000000548 ribosyl group Chemical group C1([C@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 1
- 108091092562 ribozyme Proteins 0.000 description 1
- 229960004889 salicylic acid Drugs 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 238000013515 script Methods 0.000 description 1
- 210000000717 sertoli cell Anatomy 0.000 description 1
- 108010048818 seryl-histidine Proteins 0.000 description 1
- 210000002027 skeletal muscle Anatomy 0.000 description 1
- 210000000813 small intestine Anatomy 0.000 description 1
- ZEYOIOAKZLALAP-UHFFFAOYSA-M sodium amidotrizoate Chemical compound [Na+].CC(=O)NC1=C(I)C(NC(C)=O)=C(I)C(C([O-])=O)=C1I ZEYOIOAKZLALAP-UHFFFAOYSA-M 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 159000000000 sodium salts Chemical class 0.000 description 1
- 229960003037 sodium tyropanoate Drugs 0.000 description 1
- PUZPDOWCWNUUKD-ULWFUOSBSA-M sodium;fluorine-18(1-) Chemical compound [18F-].[Na+] PUZPDOWCWNUUKD-ULWFUOSBSA-M 0.000 description 1
- 238000010532 solid phase synthesis reaction Methods 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 210000001082 somatic cell Anatomy 0.000 description 1
- 230000021595 spermatogenesis Effects 0.000 description 1
- 229940031439 squalene Drugs 0.000 description 1
- TUHBEKDERLKLEC-UHFFFAOYSA-N squalene Natural products CC(=CCCC(=CCCC(=CCCC=C(/C)CCC=C(/C)CC=C(C)C)C)C)C TUHBEKDERLKLEC-UHFFFAOYSA-N 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 210000000130 stem cell Anatomy 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 230000004960 subcellular localization Effects 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 230000000153 supplemental effect Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 239000006188 syrup Substances 0.000 description 1
- 235000020357 syrup Nutrition 0.000 description 1
- 239000003826 tablet Substances 0.000 description 1
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 1
- 229940056501 technetium 99m Drugs 0.000 description 1
- ABZLKHKQJHEPAX-UHFFFAOYSA-N tetramethylrhodamine Chemical compound C=12C=CC(N(C)C)=CC2=[O+]C2=CC(N(C)C)=CC=C2C=1C1=CC=CC=C1C([O-])=O ABZLKHKQJHEPAX-UHFFFAOYSA-N 0.000 description 1
- 229940126622 therapeutic monoclonal antibody Drugs 0.000 description 1
- 230000004797 therapeutic response Effects 0.000 description 1
- RTKIYNMVFMVABJ-UHFFFAOYSA-L thimerosal Chemical compound [Na+].CC[Hg]SC1=CC=CC=C1C([O-])=O RTKIYNMVFMVABJ-UHFFFAOYSA-L 0.000 description 1
- 229940033663 thimerosal Drugs 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 1
- 229930003799 tocopherol Natural products 0.000 description 1
- 229960001295 tocopherol Drugs 0.000 description 1
- 239000011732 tocopherol Substances 0.000 description 1
- 235000010384 tocopherol Nutrition 0.000 description 1
- 239000003440 toxic substance Substances 0.000 description 1
- VZCYOOQTPOCHFL-UHFFFAOYSA-N trans-butenedioic acid Natural products OC(=O)C=CC(O)=O VZCYOOQTPOCHFL-UHFFFAOYSA-N 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000003151 transfection method Methods 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 239000000439 tumor marker Substances 0.000 description 1
- 231100000588 tumorigenic Toxicity 0.000 description 1
- 230000000381 tumorigenic effect Effects 0.000 description 1
- 238000010396 two-hybrid screening Methods 0.000 description 1
- 108010077037 tyrosyl-tyrosyl-phenylalanine Proteins 0.000 description 1
- 108010003137 tyrosyltyrosine Proteins 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 206010046766 uterine cancer Diseases 0.000 description 1
- 230000002792 vascular Effects 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 235000019165 vitamin E Nutrition 0.000 description 1
- 239000011709 vitamin E Substances 0.000 description 1
- 229940046009 vitamin E Drugs 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- GVJHHUAWPYXKBD-IEOSBIPESA-N α-tocopherol Chemical compound OC1=C(C)C(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-IEOSBIPESA-N 0.000 description 1
Images









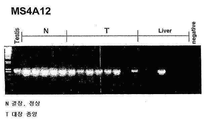
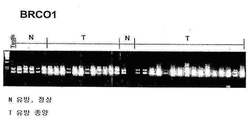



Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/39558—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against tumor tissues, cells, antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- A61P35/04—Antineoplastic agents specific for metastasis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/04—Immunostimulants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4748—Tumour specific antigens; Tumour rejection antigen precursors [TRAP], e.g. MAGE
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3015—Breast
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3023—Lung
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3053—Skin, nerves, brain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3069—Reproductive system, e.g. ovaria, uterus, testes, prostate
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
- C12Q1/6886—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material for cancer
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/112—Disease subtyping, staging or classification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/158—Expression markers
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Immunology (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Genetics & Genomics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Wood Science & Technology (AREA)
- Cell Biology (AREA)
- Microbiology (AREA)
- Oncology (AREA)
- Biotechnology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Pathology (AREA)
- Analytical Chemistry (AREA)
- General Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Physics & Mathematics (AREA)
- Epidemiology (AREA)
- Hospice & Palliative Care (AREA)
- Mycology (AREA)
- Toxicology (AREA)
- Gastroenterology & Hepatology (AREA)
- Neurology (AREA)
- Gynecology & Obstetrics (AREA)
- Pregnancy & Childbirth (AREA)
Abstract
본 발명은 종양과 관련하여 발현되는 유전자 산물 및 이를 코딩하는 핵산의 동정에 관한 것이다. 본 발명은 상기 종양과 관련하여 발현하는 유전자 산물이 이상 발현하는 질병의 치료 및 진단에 관한 것이다. 본 발명은 또한 종양과 관련하여 발현되는 단백질, 폴리펩타이드 및 펩타이드, 및 이들을 코딩하는 핵산에 관한 것이다.
Description
본 발명은 종양과 관련하여 발현되는 유전자 산물 및 이를 코딩하는 핵산의 동정, 상기 종양과 관련하여 발현하는 유전자 산물이 이상 발현하는 질병의 치료 및 진단, 및 종양과 관련하여 발현되는 단백질, 폴리펩타이드 및 펩타이드, 및 이들을 코딩하는 핵산에 관한 것이다.
통상적인 치료 방법의 완벽한 이용 및 학제적(interdisciplinary) 접근에도불구하고, 암은 여전히 주요한 사인 중 하나이다. 보다 최근 치료 개념은 재조합 종양 백신 및 항체 요법과 같은 다른 특수한 방법을 사용하여 환자의 면역계를 전체적인 치료 개념에 통합시키는 것을 목적으로 한다. 이러한 방법의 성공을 위한 필수 조건은 그 작용 인자(effector)의 기능이 간섭적으로 증진되는 환자의 면역계에 의하여 종양 특이적 또는 종양 관련 항원 또는 에피토프를 인식하는 것이다. 종양 세포는 이들의 기원인 비악성 세포와 생물학적으로 실질적으로 다르다. 이러한 차이점은 종양 발생 동안의 유전적 변형에 기인하며, 특히, 암 세포 내에서의 질적 또는 양적으로 변형된 분자 구조체의 형성을 또한 야기한다. 종양 잠복(harboring) 숙주의 특정 면역계에 의하여 인식되는 이러한 종류의 종양 관련 구조체를 종양 관련 항원(tumor-associated antigen)이라 칭한다. 종양 관련 항원의 특이적 인식은 두 개의 기능적으로 상호 연결된 단위인 세포성 및 체액성 메카니즘을 수반한다: CD4+ 및 CD8+ T 림프구가 MHC (major histocompatibility complex) 클래스 II 및 I 각각의 분자 상에 노출된 프로세싱된 항원을 인식하는 한편, B 림프구는 프로세싱되지 않은 항원에 직접 결합하는 순환 항체를 생산한다. 잠재적인 종양 관련 항원의 임상 치료적 중요성은 면역계에 의한 종양(neoplastic) 세포 상의 항원 인식이 세포 독성(cytotoxic) 작용 인자 메카니즘을 개시시키고, T 헬퍼 세포의 존재 하에서, 암 세포를 제거할 수 있다는 데 있다 (Pardoll, Nat . Med . 4:525-31, 1998). 따라서, 종양 면역학의 주요한 목적은 이들 구조체를 분자적으로 정의하는 것이다. 이들 항원의 분자적 특성은 오랜 기간동안 알려지지 않았었다. 적절한 클로닝 기술이 개발된 후에야, 세포독성 T 림프구 (CTL) (van der Bruggen 등, Science 254:1643-7, 1991)의 표적 구조체를 분석하거나 프로브로서 순환 자기 항체 (Sahin 등, Curr . Opin . Immunol . 9:709-16, 1997)를 사용함에 의하여 종양 관련 항원에 대하여 계통적으로 종양 cDNA 발현 라이브러리를 스크리닝하는 것이 가능해졌다. 이 때문에, cDNA 발현 라이브러리를 신선한 종양 조직으로부터 제작하고 적절한 시스템에서 단백질로서 재조합적으로 발현시켰다. 환자로부터 분리한 면역 작용 인자(immunoeffectors), 즉 종양 특이적 세포 용해(lysis) 패턴을 갖는 CTL 클론, 또는 순환 자기 항체를 사용하여 각각의 항체를 클로닝하였다.
최근, 이러한 접근에 의하여 다수의 항원이 다양한 종양(neoplasias) 내에서 정의되었다. 여기에서, 암/정소 항원(cancer/testis antigens, CTA) 종류가 매우 중요하다. CTA 및 이를 코딩하는 유전자 (cancer/testis genes 또는 CTG)가 이들의 특징적인 발현 패턴에 의하여 정의되어 있다 [Tureci et al, Mol Med Today . 3:342-9, 1997]. 이들은 정소와 생식 세포를 제외하고는 정상 조직에서 발견되지 않지만, 많은 인간 악성 종양(malignoma)에서 종양형 특이적이지 않지만 매우 상이한 기원의 종양 실체에서 상이한 빈도로 발현된다 (Chen & Old, Cancer J. Sci . Am. 5:16-7, 1999). CTA에 대한 혈청 반응성 또한 건강한 대조군에서는 발견되지 않으며 종양 환자에서만 발견된다. 이러한 종류의 항원은, 특히 그 조직 분포 때문에, 면역 치료 계획에 특히 유용하며 통상적인 임상적 환자 연구에서 시험된다 (Marchand 등, Int . J. Cancer 80:219-30, 1999; Knuth 등, Cancer Chemother . Pharmacol. 46:p46-51, 2000).
그러나, 전술한 통상적인 방법으로 항원을 동정하는데 사용되는 프로브는 일반적으로 이미 암이 진행된 환자로부터 얻은 면역 작용 인자 (순환 자기항체 또는 CTL 클론)이다. 많은 데이터가 종양이, 예컨대, T 세포의 무감작화(anergization) 및 내성화(tolerization)를 야기할 수 있고, 질병의 진행 중에, 특히 효과적인 면역 인식을 일으킬 수 있는 이러한 특이성을 면역 작용 인자 레퍼토리로부터 상실시킨다는 것을 보여준다. 통상적인 환자 연구는 아직까지 상기 이미 발견되고 사용되는 종양 관련 항원의 실제 작용에 대한 어떠한 믿을 수 있는 증거도 얻지 못했다. 따라서, 자발적 면역 반응을 일으키는 단백질은 부적절한 표적 구조체라는 사실을 배제할 수 없다.
발명의 요약
본 발명은 암의 진단 및 치료를 위한 표적 구조체를 제공하는 것을 목적으로 한다.
*본 발명에 있어서, 이러한 목적은 청구의 범위의 주된 내용에 의하여 달성된다.
본 발명에 있어서, 종양과 관련하여 발현되는 항원 및 이를 코딩하는 핵산을 동정하고 제공하기 위한 계획을 추구한다. 이러한 계획은 일반적으로 성인 조직에서는 발현하지 않는(silent) 실질적으로 정소 특이적이고, 따라서 생식 세포 특이적인, 유전자가 종양 세포에서 이소적(ectopic)이고 금지된 방법으로 재활성화된다는 사실에 기초한다. 우선, 데이터 마이닝(data mining)에 의하여 모든 알려진 정소 특이적 유전자의 가능한 한 완벽한 목록을 얻은 후, 특이적 RT-PCR에 의한 발현 분석에 의하여 종양에서의 상기 유전자의 이상 활성화를 평가한다. 데이터 마이닝은 공지된 종양 관련 유전자 동정법 중 하나이다. 그러나, 통상적인 치료 계획에 있어서, 잔존 유전자가 종양 특이적이라는 전제하에서, 일반적으로 종양 조직 라이브러리로부터 정상 조직 라이브러리의 전사체(transcriptom)를 공제한다 (Schmitt 등, Nucleic Acids Res . 27:4251-60, 1999; Vasmatzis 등, Proc . Natl . Acad . Sci. USA . 95:300-4, 1998. Scheurle 등, Cancer Res . 60:4037-43, 2000).
그러나, 보다 성공적인 것으로 판명된 본 발명의 개념은 모든 정소 특이적 유전자를 전자적으로 추출하고, 종양에서의 상기 유전자의 이소적 발현을 평가하기 위하여 데이터 마이닝을 이용하는 것에 기초한다.
따라서, 하나의 측면에 있어서, 본 발명은 종양에서 특이적으로 발현하는 유전자를 동정하기 위한 방법에 관한 것이다. 상기 방법은 공지의 서열 라이브러리("in silico")의 데이터 마이닝과 이어지는 실험실 시험("wet bench") 연구의 평가를 결합한 것이다.
본 발명에 있어서, 두 가지의 상이한 바이오인포매틱 스크립트에 기초하는 결합된 방법은 암/정소 (CT) 유전자 종류의 새로운 구성원을 동정 가능하게 하였다. 이들은 단순히 정소 특이적, 생식 세포 특이적 또는 정자 특이적으로 이미 분류되어 있다. 이러한 유전자가 종양 세포에서 이상 활성화된다는 발견에 의하여 이들에 기능적 관련을 갖는 실질적으로 신규한 특질이 부여될 수 있다. 본 발명에 있어서, 이들 종양 관련 유전자와 이에 의하여 코딩되는 유전자 산물을 면역원성 작용과 독립적으로 동정하고 제공하였다.
본 발명에 따라서 동정된 상기 종양 관련 항원은 (a) SEQ ID NOs: 1-5, 19-21, 29, 31-33, 37, 39, 40, 54-57, 62, 63, 70, 74 및 85-88로 이루어진 군 중에서 선택된 핵산 서열 또는 그 일부 또는 그 유도체를 포함하는 핵산, (b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산, (c) 핵산 (a) 또는 (b)에 대하여 축퇴(degenerate)된 핵산 및 (d) 핵산 (a), (b) 또는 (c)에 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩되는 아미노산 서열을 갖는다. 바람직한 구체예에 있어서, 본 발명에 따라서 동정된 종양 관련 항원은 SEQ ID NOs: 1-5, 19-21, 29, 31-33, 37, 39, 40, 54-57, 62, 63, 70, 74 및 85-88로 이루어진 군 중에서 선택된 핵산에 의하여 코딩되는 아미노산을 갖는다. 보다 바람직한 구체예에 있어서, 본 발명에 따라서 동정된 종양 관련 항원은 SEQ ID NOs: 6-13, 14-18, 22-24, 30, 34-36, 38, 41, 58-61, 64, 65, 71, 75, 80-84 및 89-100으로 이루어진 군 중에서 선택된 아미노산 서열 또는 그 일부 또는 그 유도체를 포함한다.
본 발명은 개괄적으로 본 발명에 따라 동정된 종양 관련 항원 또는 그 일부, 이를 코딩하는 핵산 또는 상기 코딩 핵산에 대하여 유도된 핵산 또는 본 발명에 따라 동정된 종양 관련 항원 또는 그 일부에 대하여 유도된 항체의 치료 및 진단에 있어서의 용도에 관한 것이다. 이러한 이용은 이들 항원, 기능적 단편, 핵산, 항체 등의 단독 뿐 아니라 이들 중 두 가지 이상의 조합과 관련있으며, 한 구체예는 또한 진단, 치료 및 처치 대조군용의 다른 종양 관련 유전자와의 결합과 관련있다.
치료 및/또는 진단을 위한 적합한 질병은 본 발명에 따라서 동정된 상기 종양 관련 항원 중 하나 이상이 선택적으로 발현되거나 비정상적으로 발현되는 질병이다.
본 발명은 또한 종양 세포와 관련하여 발현되고 공지된 유전자의 변형된 스플라이싱 (스플라이스 변이체)에 의하여 생산되거나 대체적인(alternative) 오픈 리딩 프레임을 사용하는 변형된 번역(translation)에 의하여 생산되는 유전자 산물 및 핵산과 관련된 것이다. 상기 핵산은 서열 목록의 SEQ ID NO: 2-5, 20, 21, 31-33, 54-57 및 85-88에 따른 서열을 포함한다. 게다가, 상기 유전자 산물은 서열 목록의 SEQ ID NO: 7-13, 23, 24, 34-36, 58-61 및 89-100에 따른 서열을 포함한다. 본 발명의 스플라이스 변이체는 종양(neoplastic) 질병의 진단 및 치료를 위한 표적으로서 본 발명에 따라서 사용될 수 있다.
예컨대,
- 다양한 전사 개시 부위의 사용,
- 추가적인 엑손의 사용,
- 단독 또는 두 개 이상의 엑손의 완전 또는 불완전한 스플라이싱,
- 돌연변이(새로운 공여체/수용체 서열의 생성 및 결실)에 의하여 변형된 스플라이스 조절 서열,
- 인트론 서열의 불완전한 제거와 같은 매우 다양한 메카니즘에 의하여 스플라이스 변이체가 생산된다.
유전자의 변형된 스플라이싱에 의하여 변형된 전사체 서열(스플라이스 변이체)이 생긴다. 스플라이스 변이체의 변형된 서열 부위에서의 번역에 의하여 구조와 기능에 있어서 원래 단백질과 뚜렷하게 구별되는 변형된 단백질이 생성된다. 종양 관련 스플라이스 변이체는 종양 관련 전사체 및 종양 관련 단백질/항원을 생산할 수 있다. 이들은 종양 세포의 검출 및 종양의 치료 표적 모두를 위한 분자 표지로서 이용할 수 있다. 예컨대, 혈액, 혈청, 골수, 타액, 기관지 세척, 신체 분비 및 조직 생체 검사와 같은 종양 세포 검출을, 예컨대, 스플라이스 특이적 올리고뉴클레오타이드를 사용하는 PCR 증폭에 의한 핵산 추출 후에, 본 발명에 따라서 수행할 수 있다. 본 발명에 있어서, 모든 서열 의존적 검출 시스템이 검출에 적합하다. 이들은, PCR과 별도로, 예컨대, 유전자 칩/마이크로어레이 시스템, 노던 블라트, RNAse 보호 분석법 (RNAse protection assays, RDA) 등이다. 모든 검출 시스템은 공통적으로 하나 이상의 스플라이스 변이체 특이적 핵산 서열과의 특이적 혼성화에 기초하여 검출한다는 특성을 갖는다. 그러나, 종양 세포는 또한 상기 스플라이스 변이체에 의하여 코딩되는 특정 에피토프를 인식하는 항체에 의하여 본 발명에 따라서 검출될 수 있다. 상기 항체는 상기 스플라이스 변이체에 특이적인 면역화 펩타이드를 사용하여 제조할 수 있다. 건강한 세포에서 우선적으로 생산되는 유전적 산물의 변이체와 뚜렷하게 구별되는 에피토프를 갖는 아미노산이 면역화에 특히 적합하다. 항체를 사용하는 종양 세포의 검출을 환자로부터 분리된 샘플 상에서 또는 정맥내 투여된 항체에 의한 화상 진단(imaging)으로서 수행할 수 있다. 진단 유용성 외에도, 새로운 또는 변형된 에피토프를 갖는 스플라이스 변이체는 면역 치료에 있어서 흥미있는 표적이다. 본 발명의 에피토프를 치료적 활성을 갖는 모노클로날 항체 또는 T 림프구의 표적화를 위하여 사용할 수 있다. 수동 면역치료에 있어서, 스플라이스 변이체 특이적 에피토프를 인식하는 항체 또는 T 림프구를 여기에 선택적으로 전달시킬 수 있다. 다른 항원의 경우에서와 같이, 이들 에피토프를 포함하는 폴리펩타이드와 함께 표준 기술 (동물의 면역화, 재조합 항체의 분리를 위한 엄격한 방법)을 사용하여 항체를 또한 생성할 수 있다. 또는, 면역화를 위하여 상기 에피토프를 포함하는 올리고펩타이드 또는 폴리펩타이드를 코딩하는 핵산을 사용하는 것이 가능하다. 에피토프 특이적 T 림프구의 생체외(in vitro) 또는 생체내(in vivo) 생성을 위한 다양한 기술이 공지되어 있고, 예컨대, Kessler JH, 등, 2001, Sahin 등, 1997에 상세하게 기재되어 있으며, 또한 스플라이스 변이체 특이적 에피토프를 포함하는 올리고펩타이드 또는 폴리펩타이드 또는 상기 올리고펩타이드 또는 폴리펩타이드를 코딩하는 핵산을 사용하는 것에 기초한다. 스플라이스 변이체 특이적 에피토프를 포함하는 올리고펩타이드 또는 폴리펩타이드 또는 상기 폴리펩타이드를 코딩하는 핵산은 또한 능동 면역 치료 (백신화, 백신 요법)에 있어서 약학적 활성 물질로서 사용될 수 있다.
한 측면에 있어서, 본 발명은 본 발명에 따라서 동정된 종양 관련 항원을 인식하고 본 발명에 따라서 동정된 종양 관련 항원 발현되거나 또는 비정상적으로 발현되는 세포에 대하여 우선적으로 선택적인 작용제(agent)를 함유하는 약학 조성물에 관한 것이다. 구체예에 있어서, 상기 작용제는 세포 사멸의 유도, 세포 성장의 감소, 사이토카인의 분비 또는 세포막의 손상을 야기하며, 바람직하게는 종양 억제 활성을 갖는다. 다른 구체예에 있어서, 상기 작용제는 상기 종양 관련 항원을 코딩하는 핵산과 선택적으로 혼성화하는 안티센스 핵산이다. 또 다른 구체예에 있어서, 상기 작용제는 종양 관련 항원에 선택적으로 결합하는 항체, 특히, 상기 종양 관련 항원에 선택적으로 결합하는 보체 활성화된(complement-activated) 항체이다. 또 다른 구체예에 있어서, 상기 작용제는 두 가지 이상의 작용제를 포함하며, 각각의 작용제는 상이한 종양 관련 항원을 인식하고, 상기 항원 중 적어도 하나는 본 발명에 따라서 동정된 종양 관련 항원이다. 인식이 반드시 상기 항원의 발현 또는 활성의 억제를 직접적으로 수반할 필요는 없다. 본 발명의 이러한 측면에 있어서, 선택적으로 종양에 한정된 상기 항원은 이러한 특정 위치에 대한 보충 작용 인자 메카니즘의 표지로서의 역할을 한다. 바람직한 예에 있어서, 상기 작용제는 HLA 분자 상의 항원을 인식하고 이러한 방법으로 표지된 세포를 용해시키는 세포독성 T 림프구이다. 또 다른 구체예에 있어서, 상기 작용제는 종양 관련 항원에 선택적으로 결합하여 상기 세포에 천연 또는 인공 작용 인자 메카니즘을 보충시키는 항체이다. 또 다른 구체예에 있어서, 상기 작용제는 상기 항원을 특이적으로 인식하는 다른 세포의 작용 인자 기능을 증진시키는 T 헬퍼 림프구이다.
한 측면에 있어서, 본 발명은 본 발명에 따라서 동정된 종양 관련 항원의 활성 또는 발현을 억제하는 작용제를 포함하는 약학 조성물에 관한 것이다. 바람직한 예에 있어서, 상기 작용제는 종양 관련 항원을 코딩하는 핵산과 선택적으로 혼성화하는 안티센스 핵산이다. 또 다른 구체예에 있어서, 상기 작용제는 종양 관련 항원에 선택적으로 결합하는 항체이다. 또 다른 구체예에 있어서, 상기 작용제는 두 가지 이상의 작용제를 포함하며, 상기 각각의 작용제는 상이한 종양 관련 항원의 활성 또는 발현을 선택적으로 억제하는 것이고, 상기 항원 중 적어도 하나 이상은 본 발명에 따라서 동정된 종양 관련 항원이다.
또한, 본 발명은 투여시 본 발명에 따라서 동정된 종양 관련 항원 유래의 펩타이드 에피토프와 HLA 분자 간의 복합체의 양을 선택적으로 증가시키는 작용제를 함유하는 약학 조성물에 관한 것이다. 한 구체예에 있어서, 상기 작용제는 (i) 종양 관련 항원 또는 그 일부, (ii) 상기 종양 관련 항원 또는 그 일부를 코딩하는 핵산, (iii) 상기 종양 관련 항원 또는 그 일부를 발현시키는 숙주 세포, 및 (iv) 상기 종양 관련 항원 유래의 펩타이드 에피토프와 MHC 분자 간의 분리된 복합체로 이루어진 군 중에서 선택된 한 가지 이상의 성분을 함유한다. 한 구체예에 있어서, 상기 작용제는 두 가지 이상의 작용제를 포함하며, 상기 각각의 작용제는 MHC 분자와 상이한 종양 관련 항원의 펩타이드 에피토프 간의 복합체의 양을 선택적으로 증가시키는 것이고, 상기 항원 중 적어도 하나는 본 발명에 따라서 동정된 종양 관련 항원이다.
또한, 본 발명은 (i) 본 발명에 따라서 동정되는 종양 관련 항원 및 그 일부, (ii) 본 발명에 따라서 동정되는 종양 관련 항원 또는 그 일부를 코딩하는 핵산, (iii) 본 발명에 따라 동정된 종양 관련 항원 또는 그 일부에 결합하는 항체, (iv) 본 발명에 따라서 동정되는 종양 관련 항원을 코딩하는 핵산과 특이적으로 혼성화하는 안티센스 핵산, (v) 본 발명에 따라서 동정되는 종양 관련 항원 또는 그 일부를 발현시키는 숙주 세포, 및 (vi) 본 발명에 따라서 동정되는 종양 관련 항원 또는 그 일부와 HLA 분자 간의 분리된 복합체로 이루어진 군 중에서 선택된 한 가지 이상의 성분을 함유하는 약학 조성물에 관한 것이다.
본 발명에 따라서 동정되는 종양 관련 항원 또는 그 일부를 코딩하는 핵산이 발현 백터 내에 프로모터와 기능적으로 연결되어 상기 약학 조성물 내에 포함될 수 있다.
본 발명의 약학 조성물에 존재하는 숙주 세포는 종양 관련 항원 또는 그 일부를 분비하고 이를 표면 상에 발현시키거나, 상기 종양 관련 항원 또는 상기 그 일부에 결합하는 HLA 분자를 추가적으로 발현시킬 수 있다. 한 구체예에 있어서, 상기 숙주 세포는 HLA 분자를 내생적으로 발현시킨다. 또 다른 구체예에 있어서, 상기 숙수 세포는 HLA 분자 및/또는 종양 관련 항원 또는 그 일부를 재조합적 방법으로 발현시킨다. 상기 숙수 세포는 비증식적인 것이 바람직하다. 바람직한 예에 있어서, 상기 숙주 세포는 항원 제시(antigen-presenting) 세포, 특히 수지상 세포(dendritic cell), 단핵 세포 또는 대식 세포(macrophage)이다.
본 발명의 약학 조성물에 존재하는 항체는 모노클로날 항체일 수 있다. 또 다른 구체예에 있어서, 상기 항체는 키메라 항체 또는 인간화된 항체, 천연 항체 또는 합성 항체의 단편이며, 이들 모두는 조합적 기술에 의하여 생산할 수 있다. 상기 항체는 치료 또는 진단에 유용한 작용제와 결합될 수 있다.
본 발명의 약학 조성물에 존재하는 안티센스 핵산은, 본 발명에 따라서 동정되는 종양 관련 항원을 코딩하는 핵산에 인접한 뉴클레오타이드 6 내지 50 개의 서열, 특히, 10 내지 30 개, 15 내지 30 개 및 20 내지 30 개의 서열을 포함할 수 있다.
또 다른 구체예에 있어서, 본 발명의 약학 조성물에 의하여 직접 또는 핵산 발현현을 통하여 제공되는 종양 관련 항원, 또는 그 일부가 세포 표면의 MHC 분자와 결합하고, 상기 결합은 세포 독성 반응을 유발시키거나 및/또는 사이토카인 방출을 유도하는 것이 바람직하다.
본 발명의 약학 조성물은 약학적으로 양립 가능한 담체 및/또는 아쥬반트를 함유할 수 있다. 상기 아쥬반트는 사포닌, GM-CSF, CpG 뉴클레오타이드, RNA, 사이토카인 또는 케모카인 중에서 선택될 수 있다. 본 발명의 약학 조성물은 종양 관련 항원의 선택적 발현 또는 비정상적 발현 특징을 갖는 질병의 치료에 사용되는 것이 바람직하다. 바람직한 예에 있어서, 상기 질병은 암이다.
또한, 본 발명은 한 가지 이상의 종양 관련 항원의 발현 또는 비정상적 발현 특징을 갖는 질병의 진단 방법 또는 치료 방법과 관련된 것이다. 한 구체예에 있어서, 상기 치료는 본 발명의 약학 조성물을 투여하는 것을 포함한다.
한 측면에 있어서, 상기 발명은 본 발명에 의하여 동정되는 종양 관련 항원의 발현 또는 비정상적 발현 특징을 갖는 질병의 진단 방법에 관한 것이다. 상기 방법은 환자로부터 분리된 생물학적 시료 내에서 (i) 상기 종양 관련 항원을 코딩하는 핵산 또는 그 일부의 검출 및/또는 (ii) 상기 종양 관련 항원 또는 그 일부의 검출 및/또는 (iii) 상기 종양 관련 항원 또는 그 일부에 대한 항체의 검출 및/또는 (iv) 상기 종양 관련 항원 또는 그 일부에 특이적인 세포 독성 또는 T 헬퍼 림프구의 검출을 포함한다. 구체예에 있어서, 검출은 (i) 상기 생물학적 시료를 상기 종양 관련 항원 또는 그 일부를 코딩하는 핵산, 상기 종양 관련 항원 또는 그 일부, 상기 항체 또는 상기 종양 관련 항원 또는 그 일부에 특이적인 세포 독성 또는 T 헬퍼 림프구에 특이적으로 결합하는 작용제와 접촉시키고 (ii) 상기 작용제와 상기 핵산 또는 그 일부, 상기 종양 관련 항원 또는 그 일부, 상기 항체 또는 상기 세포독성 또는 T 헬퍼 림프구 간의 복합체 형성을 검출하는 것을 포함한다. 구체예에 있어서, 상기 질병은 두 가지 이상의 서로 다른 종양 관련 항원의 발현 또는 비정상적 발현 특성을 가지며, 그 검출은 상기 두 가지 이상의 서로 다른 종양 관련 항원 또는 그 일부를 코딩하는 두 가지 이상의 핵산의 검출, 상기 두 가지 이상의 서로 다른 종양 관련 항원 또는 그 일부의 검출, 상기 두 가지 이상의 종양 관련 항원 또는 그 일부에 결합하는 두 가지 이상의 항체의 검출 또는 상기 두 가지 이상의 서로 다른 종양 관련 항원에 특이적인 두 가지 이상의 세포 독성 또는 T 헬퍼 림프구의 검출을 포함한다. 또 다른 구체예에 있어서, 상기 환자로부터 분리한 생물학적 시료를 유사한 정상 생물학적 시료와 비교한다.
또 다른 측면에 있어서, 본 발명은 본 발명에 따라서 동정되는 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖는 질병의 퇴축(regression), 경과 또는 발병의 결정 방법에 관한 것으로, 상기 방법은 (i) 종양 관련 항원 또는 그 일부를 코딩하는 핵산의 양, (ii) 종양 관련 항원 또는 그 일부의 양, (iii) 종양 관련 항원 또는 그 일부에 결합하는 항체의 양, 및 (iv) 종양 관련 항원 또는 그 일부와 MHC 분자 간의 복합체에 특이적인 세포 용해 T 세포 또는 T 헬퍼 세포의 양으로 이루어진 군 중에서 선택된 한 가지 이상의 파라미터에 대하여, 상기 질병을 앓고 있거나 상기 질병에 걸릴 가능성이 높은 환자로부터 얻은 시료를 모니터링하는 것을 포함한다. 상기 방법은 상기 파라미터를 첫 번째 시점의 첫 번째 시료에서 측정하고, 두 번째 시점의 또 다른 시료에서 측정하는 것을 포함하며, 상기 두 시료를 비교함으로써 병의 경과를 결정한다. 구체예에 있어서, 상기 질병은 두 가지 이상의 종양 관련 항원의 발현 또는 비정상적 발현의 특성을 갖는 것이며, 모니터링은 (i) 상기 두 가지 이상의 서로 다른 종양 관련 항원을 코딩하는 두 가지 이상의 핵산 또는 그 일부의 양, 및/또는 (ii) 상기 두 가지 이상의 서로 다른 종양 관련 항원 또는 그 일부의 양, 및/또는 (iii) 상기 두 가지 이상의 서로 다른 종양 관련 항원 또는 그 일부에 결합하는 두 가지 이상의 항체의 양, 및/또는 (iv) 상기 두 가지 이상의 서로 다른 종양 관련 항원 또는 그 일부와 MHC 분자 간의 복합체에 특이적인 두 가지 이상의 세포 용해성 T 세포 또는 T 헬퍼 세포의 양을 모니터링하는 것을 포함한다.
본 발명에 있어서, 핵산 또는 그 일부의 검출 또는 핵산 또는 그 일부의 모니터링은 상기 핵산 또는 그 일부와 특이적으로 혼성화하는 폴리뉴클레오타이드 프로브를 사용하여 수행하거나, 상기 핵산 또는 상기 그 일부를 선택적으로 증폭시킴으로써 수행할 수 있다. 구체예에 있어서, 상기 폴리뉴클레오타이드 프로브는 상기 핵산의 인접 뉴클레오타이드 6 내지 50 개의 서열, 특히 10 내지 30 개, 15 내지 30 개 및 20 내지 30 개의 서열을 포함한다.
구체예에 있어서, 검출하고자 하는 종양 관련 항원 또는 그 일부는 세포내 또는 세포 표면에 존재한다. 본 발명에 있어서, 종양 관련 항원 또는 그 일부의 검출 또는 종양 관련 항원 또는 그 일부의 양의 모니터링은 상기 종양 관련 항원 또는 상기 그 일부에 특이적으로 결합하는 항체를 사용하여 수행할 수 있다.
또 다른 구체예에 있어서, 검출하고자 하는 상기 종양 관련 항원 또는 그 일부는 MHC 분자, 특히 HLA 분자와의 복합체 형태로 존재한다.
본 발명에 있어서, 항체의 검출 또는 항체의 양의 모니터링은 상기 항체에 특이적으로 결합하는 펩타이드 또는 단백질을 사용하여 수행할 수 있다.
본 발명에 있어서, 항원 또는 그 일부와 MHC 분자 간의 복합체에 특이적인 세포 용해성 T 세포 또는 T 헬퍼 세포의 검출 또는 세포 용해성 T 세포 또는 T 헬퍼 세포의 양의 모니터링은 상기 항원 또는 그 일부와 MHC 분자 간의 복합체를 제시하는 세포를 사용하여 수행할 수 있다.
검출 및 모니터링에 사용되는 상기 폴리뉴클레오타이드 프로브, 항체, 단백질 또는 펩타이드 또는 세포는 탐지 가능한 방법으로 표지되는 것이 바람직하다. 구체예에 있어서, 상기 탐지 가능한 표지로는 방사성 표지 또는 효소 표지가 있다. MHC와 종양 관련 항원 또는 그 일부와의 복합체를 사용하는 특이적 자극에 의하여 유발되는 T 림프구의 세포 독성 활성, 사이토카인 생산 및 증식을 탐지함으로써 의하여 T 림프구를 추가적으로 검출할 수 있다. T 림프구는 또한 재조합 MHC 분자 또는 한 가지 이상의 종양 관련 항원의 특정 면역원성 단편이 로딩되어 있고 특이적 T 세포 수용체를 접촉시킴으로써 특이적 T 림프구를 동정할 수 있는 두 가지 이상의 MHC 분자의 복합체를 통하여 검출할 수 있다.
또 다른 측면에 있어서, 본 발명은 본 발명에 따라서 동정되는 종양 관련 항원의 발현 또는 비정상적인 발현 특성을 갖는 질병의 치료, 진단 또는 모니터링 방법에 관한 것으로, 상기 방법은 상기 종양 관련 항원 또는 그 일부에 결합하는 항체를 치료제 또는 진단제와 함께 투여하는 것을 포함한다. 상기 항체는 모노클로날 항체일 수 있다. 또 다른 구체예에 있어서, 상기 항체는 키메라 항체 또는 인간화된 항체 또는 천연 항체의 단편이다.
본 발명은 또한 본 발명에 따라 동정되는 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖는 질병을 앓는 환자의 치료 방법에 관한 것으로, 상기 방법은 (i) 상기 환자로부터 면역 반응성 세포를 포함하는 시료를 추출하고, (ii) 상기 종양 관련 항원 또는 그 일부에 대항하는 세포 용해성 T 세포의 생산에 유리한 조건 하에서, 상기 시료를 상기 종양 관련 항원 또는 그 일부를 발현하는 숙주 세포와 접촉시키고 (iii) 세포 용해성 T 세포를 상기 종양 관련 항원 또는 그 일부를 발현하는 세포를 용해시키기에 적절한 양으로 환자에 도입시키는 것을 포함한다. 또한, 본 발명은 상기 종양 관련 항원에 대항하는 세포 용해성 T 세포의 T 세포 수용체를 클로닝하는 것과 관련된 것이다. 상기 수용체는 다른 T 세포로 전달될 수 있고, 이에 따라서 상기 T 세포는 원하는 특이성을 수여받게 되고, (iii) 단계에 의하여 환자내로 도입될 수 있다.
한 구체예에 있어서, 상기 숙주 세포는 HLA 분자를 내생적으로 발현한다. 또 다른 구체예에 있어서, 상기 숙주 세포는 HLA 분자 및/또는 상기 종양 관련 항원 또는 그 일부를 재조합적으로 발현한다. 상기 숙주 세포는 비증식적인 것이 바람직하다. 바람직한 구체예에 있어서, 상기 숙수 세포는 항원 제시 세포, 특히 수지상 세포, 단핵 세포 또는 대식 세포이다.
또 다른 측면에 있어서, 본 발명은 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖는 질병을 앓는 환자의 치료 방법에 관한 것으로, 상기 방법은 (i) 본 발명에 따라서 동정되는 종양 관련 항원을 코딩하고 상기 질병과 관련된 세포에 의하여 발현되는 핵산을 동정하고, (ii) 상기 핵산 또는 그 일부로 숙주 세포를 형질 감염(transfection)시키고, (iii) 상기 형질 감염된 숙주 세포를 배양하여 상기 핵산을 발현시키고 (형질 감염률이 높은 경우, 이 단계는 필수적이지 않다), (iv) 상기 숙주 세포 또는 이의 추출물을 상기 질병과 관련된 환자의 세포와의 면역 응답을 증가시키기에 적절한 양으로 상기 환자에게 도입시키는 것을 포함한다. 상기 방법은 상기 동정된 MHC 분자를 발현하고 상기 종양 관련 항원 또는 그 일부를 제시하는 숙주 세포를 사용하여 상기 종양 관련 항원 또는 그 일부를 제시하는 MHC 분자를 동정하는 것을 포함한다. 상기 면역 응답은 B 세포 응답 또는 T 세포 응답을 포함할 수 있다. 또한, T 세포 응답은 종양 관련 항원 또는 그 일부를 제시하는 숙주 세포에 특이적이거나 상기 종양 관련 항원 또는 그 일부를 발현하는 환자의 세포에 특이적인 세포 용해성 T 세포 또는 T 헬퍼 세포의 생산을 포함한다.
본 발명은 또한 본 발명에 따라서 동정되는 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖는 질병의 치료 방법에 관한 것으로, 상기 방법은 (i) 상기 종양 관련 항원을 비정상적 양으로 발현하는 환자로부터 얻은 세포를 동정하고, (ii) 상기 세포 시료를 분리하고, (iii) 상기 세포를 배양하고, (iv) 상기 세포를 상기 세포에 대한 면역 응답을 유발하기에 적절한 양으로 환자에게 도입시키는 것을 포함한다.
본 발명에서 사용되는 숙주 세포는 비증식적이거나 비증식적으로 되는 것이 바람직하다. 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖는 질병은 특히 암이다.
본 발명은 또한 (a) SEQ ID NOs: 2-5, 20-21, 31-33, 39, 54-57, 62, 63 및 85-88으로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산, (b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산, (c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, (d) 핵산 (a), (b) 또는 (c)에 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 관한 것이다. 본 발명은 또한 SEQ ID NOs: 7-13, 14-18, 23-24, 34-36, 58-61, 64, 65 및 89-100로 이루어진 군 중에서 선택된 아미노산 서열, 그 일부 또는 그 유도체를 포함하는 폴리펩타이드 또는 단백질을 코딩하는 핵산에 관한 것이다.
또 다른 측면에 있어서, 본 발명은 본 발명이 핵산의 프로모터 서열에 관한 것이다. 이들 서열은 바람직하게는 발현 벡터 내에서 다른 유전자와 기능적으로 연결되어 있어서 적절한 세포 내에서 상기 유전자의 선택적인 발현을 보장할 수 있다.
또 다른 측면에 있어서, 본 발명은 재조합 핵산 분자, 특히 DNA 또는 RNA 분자에 관한 것으로, 상기 핵산 분자는 본 발명의 핵산을 포함한다.
본 발명은 또한 본 발명의 핵산 또는 본 발명의 핵산을 포함하는 재조합 핵산 분자를 포함하는 숙주 세포에 관한 것이다.
상기 숙주 세포는 또한 HLA 분자를 코딩하는 핵산을 포함할 수 있다. 일례에 있어서, 숙주 세포는 HLA 분자를 내생적으로 발현한다. 또 다른 구체예에 있어서, 숙주 세포는 HLA 분자 및/또는 본 발명의 핵산 또는 그 일부를 재조합적으로 발현시킨다. 상기 숙주 세포는 비증식적인 것이 바람직하다. 바람직한 예에 있어서, 상기 숙주 세포는 항원 제시 세포, 특히 수지상 세포, 단핵 세포 또는 대식 세포이다.
또 다른 구체예에 있어서, 본 발명은 본 발명에 따라서 동정된 핵산과 혼성화하고 유전자 프로브 또는 "안티센스" 분자로서 사용될 수 있는 올리고뉴클레오타이드에 관한 것이다. 본 발명에 따라서 동정된 핵산 또는 그 일부와 혼성화하는 올리고뉴클레오타이드 프라이머 또는 응답력 있는 (competent) 시료의 형태로 핵산 분자를 사용하여 본 발명에 따라서 동정된 상기 핵산과 상동인 핵산을 찾을 수 있다. PCR 증폭, 서던 및 노던 혼성화를 이용하여 상동인 핵산을 찾을 수 있다. 혼성화는 낮은 수준의 엄격한 조건하에서 수행될 수 있으며, 중간 수준의 엄격한 수준에서 수행되는 것이 보다 바람직하고, 매우 엄격한 조건에서 수행되는 것이 가장 바람직하다. 본 발명에서 "엄격한 조건 (stringent conditions)"이라 함은 폴리뉴클레오타이드 간의 특이적 혼성화를 가능하게 하는 조건을 의미하는 것이다.
또 다른 측면에 있어서, 본 발명은 (a) SEQ ID NOs: 2-5, 20-21, 31-33, 39, 54-57, 62, 63 및 85-88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산, (b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산, (c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, (d) 핵산 (a), (b) 또는 (c)과 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩되는 폴리펩타이드 또는 단백질에 관한 것이다. 바람직한 예에 있어서, 본 발명은 SEQ ID NOs: 7-13, 14-18, 23-24, 34-36, 58-61, 64, 65 및 89-100로 이루어진 군 중에서 선택된 아미노산 서열, 그 일부 또는 그 유도체를 포함하는 폴리펩타이드 또는 단백질에 관한 것이다.
또 다른 측면에 있어서, 본 발명은 본 발명에 따라서 동정된 종양 관련 항원의 면역원성 단편에 관한 것이다. 상기 단편은 인간 HLA 수용체 또는 인간 항체에 결합하는 것이 바람직하다. 본 발명의 단편은 6 개 이상, 특히 8 개 이상, 10 개 이상, 12 개 이상, 15 개 이상, 20 개 이상, 30 개 이상 또는 50 개 이상의 아미노산을 포함하는 것이 바람직하다.
또 다른 측면에 있어서, 본 발명은 본 발명에 따라서 동정된 종양 관련 항원 또는 그 일부에 결합하는 작용제에 관한 것이다. 바람직한 예에 있어서, 상기 작용제는 항체이다. 또 다른 구체예에 있어서, 상기 항체는 키메라 항체, 인간화 항체 또는 조합적 기술에 의하여 생산된 항체이거나 항체의 단편이다. 또한, 본 발명은 (i) 본 발명에 따라서 동정된 종양 관련 항원 또는 그 일부와 (ii) 상기 본 발명에 따라서 동정된 종양 관련 항원 또는 그 일부가 결합하는 MHC 분자의 복합체에 선택적으로 결합하는 항체에 관한 것이며, 상기 항체는 단독으로 존재하는 (i) 또는 (ii)에는 결합하지 않는다. 본 발명의 항체는 모노클로날 항체일 수 있다. 또 다른 구체예에 있어서, 상기 항체는 키메라 항체 또는 인간화된 항체 또는 천연 항체의 단편이다.
본 발명은 본 발명의 항체 또는 본 발명에 따라서 동정된 종양 관련 항원 또는 그 일부에 결합하는 본 발명의 작용제와 치료제 또는 진단제와의 콘쥬게이트에 관한 것이다. 한 구체예에 있어서, 상기 치료제 또는 진단제는 독소이다.
또 다른 측면에 있어서, 본 발명은 본 발명에 따라서 동정된 종양 관련 항원의 발현 또는 비정상적인 발현을 탐지하기 위한 키트에 관한 것으로, 상기 키트는 (i) 상기 종양 관련 항원 또는 그 일부를 코딩하는 핵산, (ii) 상기 종양 관련 항원 또는 그 일부, (iii) 상기 종양 관련 항원 또는 그 일부에 결합하는 항체, 및/또는 (iv) 상기 종양 관련 항원 또는 그 일부와 MHC 분자와의 복합체에 특이적인 T 세포의 검출을 위한 작용제를 포함한다. 일례에 있어서, 상기 핵산 또는 그 일부의 검출을 위한 작용제는 상기 핵산을 선택적으로 증폭시키기 위한 핵산 분자이며, 상기 핵산의 인접 뉴클레오타이드 6 내지 50 개, 특히, 10 내지 30 개, 15 내지 30 개 및 20 내지 30 개의 서열을 포함하는 것이다.
도 1: eCT 의 클로닝을 개략적으로 나타낸 것. 상기 방법은 데이타베이스에서 후보자 유전자 (GOI="Genes of interest")를 동정하고, RT-PCR에 의하여 상기 유전자를 테스트하는 것을 포함한다.
도 2: LDH C의 스플라이싱 . 대체적인(alternative) 스플라이싱에 의하여, 엑손 3 (SEQ ID NO:2), 두 개의 엑손 3 및 4 (SEQ ID NO:3), 엑손 3, 6 및 7 (SEQ ID NO:4) 및 엑손 7 (SEQ ID NO:5)이 결실된다. ORF = 개방 해독틀(open reading frame), aa = 아미노산.
도 3: 가능한 LDH -C 단백질의 정렬. SEQ ID NO:8 및 SEQ ID NO:10은 원형 단백질 (SEQ ID NO:6)의 절단된 부분이다. 단백질 서열 SEQ ID NO:7, SEQ ID NO:9, SEQ ID NO:11, SEQ ID NO:12 및 SEQ ID NO:13는 추가적으로 변형되고 종양 특이적 에피토프만을 함유한다 (굵은체로 표시). 촉매 중심을 네모틀 안에 표시하였다.
도 4: 실시간 PCT 에 의한 다양한 조직에서의 LDH C의 정량 분석. 전사체가 정소를 제외한 정상 조직에서는 탐지되지 않았지만, 종양에서는 상당한 수준의 발현이 탐지되었다.
도 5: TPTE 변이체의 엑손 조성. 본 발명에 있어서, 정소 조직 및 종양에서 발현하고 프레임 쉬프트가 일어나 서열 부위가 변형된 스플라이스 변이체 (SEQ ID NO:20, SEQ ID NO:21, SEQ ID NO:54, SEQ ID NO:55, SEQ ID NO:56, SEQ ID NO:57)를 동정하였다.
도 6: 가능한 TPTE 단백질의 정렬. 대체적인 스플라이싱은 해독틀은 원칙적으로 보존하면서 코딩되는 단백질의 변경을 초래한다. 추정되는 막통과 도메인을 굵은체로 표시하고, 촉매 도매인을 네모칸으로 표시하였다.
도 7: 핵산 수준에서의 TSBP 변이체의 정렬. 공지된 서열 (NM 006781, SEQ ID NO: 29)에 대한 본 발명에 있어서 발견되는 TSBP 변이체의 핵산 서열(SEQ ID NO:31, SEQ ID NO:32, SEQ ID NO:33)의 차이점을 굵은체로 표시하였다.
도 8: 단백질 수준에서의 TSBP 변이체의 정렬. 본 발명에서 발견되는 TSBP 변이체에 의하여 코딩되는 단백질 (SEQ ID NO:34, SEQ ID NO:35, SEQ ID NO:36)에 있어서, 프레임 쉬프트가 이전에 개시된 단백질 (SEQ ID NO:30, NM 006781)과의 실질적인 차이를 야기시키며 이를 굵은체로 나타내었다.
도 9: MS4A12 에 대한 RT - PCR . 테스트된 조직 중에서 정소, 결장 및 결장 암종 (colon ca's)에서만 발현이 검출되었다. 나타낸 6 개의 간 조직 시료 중 하나에서, 상기 샘플이 결장 암종 전이의 침투를 받았기 때문에, MS4A12에 대하여 양성 검출(positive detection)을 수행하였다. 이후의 연구 역시 결장 암종 전이에서의 구별되는 발현을 보여주었다.
도 10: BRCO1 에 대한 RT - PCR . BRCO1은 포유류의 정상 유선 조직에서의 발현과 비교하여 유방 종양에서 뚜렷하게 과발현한다.
도 11: MORC , TPX1 , LDHC , SGY -1에 대한 RT - PCR . 다양한 정상 조직의 연구에 의하여 정소에서만 발현함이 밝혀졌다(1 피부, 2 소장, 3 결장, 4 간, 5 폐, 6 위, 7 유방, 8 신장, 9 난소, 10 전립선, 11 갑상선, 12 백혈구, 13 흉선, 14 음성 대조군, 15 정소). 종양 시험 (1-17 폐 종양, 18-29 흑색종, 30 음성 대조군, 31 정소)에 의하여 각각의 eCT에 대하여 상이한 빈도로 상기 종양에서 이소적으로 발현함을 밝혔다.
도 12: MCF -7 유방암 세포계에서의 LDHC 의 미토콘드리아 위치화 . MCF-7 세포를 LDHC 발현 플라스미드로 일시적으로 형질 감염시켰다. LDHC 특이적 항체를 사용하여 항원을 검출하였고, 미토콘드리아 호흡쇄 효소(mitochondrial respiratory chain enzyme) 사이토크롬 C-산화 효소와의 독특한 공동 위치화(colocalization)를 나타내었다.
도 13: TPTE 의 예상 위상 기하학 및 MCF -7 세포의 세포 표면 상의 세포 하부(subcellular ) 위치화 . 왼편의 다이어그램은 4 개의 추정 TPTE 막통과 도메인 (화살표)을 나타낸 것이다. MCF-7 세포를 TPTE 발현 플라스미드를 사용하여 일시적으로 형질 감염시켰다. TPTE 특이적 항체를 사용하여 항원을 검출하였고, 세포 표면 상에 위치하는 MHC I 분자와의 독특한 공동 위치화를 나타내었다.
도 14: 세포막 상의 MS4A12 위치화 . 종양 세포를 GFP-표지된 MS4A12 구조체를 사용하여 일시적으로 형질 감염시키고, 공초점 면역형광 현미경으로 플라즈마 멤브레인 표지와의 완벽한 공동 위치화를 나타내었다.
도 2: LDH C의 스플라이싱 . 대체적인(alternative) 스플라이싱에 의하여, 엑손 3 (SEQ ID NO:2), 두 개의 엑손 3 및 4 (SEQ ID NO:3), 엑손 3, 6 및 7 (SEQ ID NO:4) 및 엑손 7 (SEQ ID NO:5)이 결실된다. ORF = 개방 해독틀(open reading frame), aa = 아미노산.
도 3: 가능한 LDH -C 단백질의 정렬. SEQ ID NO:8 및 SEQ ID NO:10은 원형 단백질 (SEQ ID NO:6)의 절단된 부분이다. 단백질 서열 SEQ ID NO:7, SEQ ID NO:9, SEQ ID NO:11, SEQ ID NO:12 및 SEQ ID NO:13는 추가적으로 변형되고 종양 특이적 에피토프만을 함유한다 (굵은체로 표시). 촉매 중심을 네모틀 안에 표시하였다.
도 4: 실시간 PCT 에 의한 다양한 조직에서의 LDH C의 정량 분석. 전사체가 정소를 제외한 정상 조직에서는 탐지되지 않았지만, 종양에서는 상당한 수준의 발현이 탐지되었다.
도 5: TPTE 변이체의 엑손 조성. 본 발명에 있어서, 정소 조직 및 종양에서 발현하고 프레임 쉬프트가 일어나 서열 부위가 변형된 스플라이스 변이체 (SEQ ID NO:20, SEQ ID NO:21, SEQ ID NO:54, SEQ ID NO:55, SEQ ID NO:56, SEQ ID NO:57)를 동정하였다.
도 6: 가능한 TPTE 단백질의 정렬. 대체적인 스플라이싱은 해독틀은 원칙적으로 보존하면서 코딩되는 단백질의 변경을 초래한다. 추정되는 막통과 도메인을 굵은체로 표시하고, 촉매 도매인을 네모칸으로 표시하였다.
도 7: 핵산 수준에서의 TSBP 변이체의 정렬. 공지된 서열 (NM 006781, SEQ ID NO: 29)에 대한 본 발명에 있어서 발견되는 TSBP 변이체의 핵산 서열(SEQ ID NO:31, SEQ ID NO:32, SEQ ID NO:33)의 차이점을 굵은체로 표시하였다.
도 8: 단백질 수준에서의 TSBP 변이체의 정렬. 본 발명에서 발견되는 TSBP 변이체에 의하여 코딩되는 단백질 (SEQ ID NO:34, SEQ ID NO:35, SEQ ID NO:36)에 있어서, 프레임 쉬프트가 이전에 개시된 단백질 (SEQ ID NO:30, NM 006781)과의 실질적인 차이를 야기시키며 이를 굵은체로 나타내었다.
도 9: MS4A12 에 대한 RT - PCR . 테스트된 조직 중에서 정소, 결장 및 결장 암종 (colon ca's)에서만 발현이 검출되었다. 나타낸 6 개의 간 조직 시료 중 하나에서, 상기 샘플이 결장 암종 전이의 침투를 받았기 때문에, MS4A12에 대하여 양성 검출(positive detection)을 수행하였다. 이후의 연구 역시 결장 암종 전이에서의 구별되는 발현을 보여주었다.
도 10: BRCO1 에 대한 RT - PCR . BRCO1은 포유류의 정상 유선 조직에서의 발현과 비교하여 유방 종양에서 뚜렷하게 과발현한다.
도 11: MORC , TPX1 , LDHC , SGY -1에 대한 RT - PCR . 다양한 정상 조직의 연구에 의하여 정소에서만 발현함이 밝혀졌다(1 피부, 2 소장, 3 결장, 4 간, 5 폐, 6 위, 7 유방, 8 신장, 9 난소, 10 전립선, 11 갑상선, 12 백혈구, 13 흉선, 14 음성 대조군, 15 정소). 종양 시험 (1-17 폐 종양, 18-29 흑색종, 30 음성 대조군, 31 정소)에 의하여 각각의 eCT에 대하여 상이한 빈도로 상기 종양에서 이소적으로 발현함을 밝혔다.
도 12: MCF -7 유방암 세포계에서의 LDHC 의 미토콘드리아 위치화 . MCF-7 세포를 LDHC 발현 플라스미드로 일시적으로 형질 감염시켰다. LDHC 특이적 항체를 사용하여 항원을 검출하였고, 미토콘드리아 호흡쇄 효소(mitochondrial respiratory chain enzyme) 사이토크롬 C-산화 효소와의 독특한 공동 위치화(colocalization)를 나타내었다.
도 13: TPTE 의 예상 위상 기하학 및 MCF -7 세포의 세포 표면 상의 세포 하부(subcellular ) 위치화 . 왼편의 다이어그램은 4 개의 추정 TPTE 막통과 도메인 (화살표)을 나타낸 것이다. MCF-7 세포를 TPTE 발현 플라스미드를 사용하여 일시적으로 형질 감염시켰다. TPTE 특이적 항체를 사용하여 항원을 검출하였고, 세포 표면 상에 위치하는 MHC I 분자와의 독특한 공동 위치화를 나타내었다.
도 14: 세포막 상의 MS4A12 위치화 . 종양 세포를 GFP-표지된 MS4A12 구조체를 사용하여 일시적으로 형질 감염시키고, 공초점 면역형광 현미경으로 플라즈마 멤브레인 표지와의 완벽한 공동 위치화를 나타내었다.
본 발명은 종양 세포에서 선택적으로 발현되거나 이상 발현되고, 종양 관련 항원인 유전자를 기재한다.
본 발명에 있어서, 이들 유전자 또는 그 유도체는 치료적 접근을 위한 우선적 표적 구조체이다. 개념적으로, 상기 치료적 접근은 선택적으로 발현된 종양 관련 유전자 산물의 활성을 억제하는 것을 목적으로 한다. 이는, 상기 각각의 선택적 이상 발현이 종양 병원성에 기능적으로 중요하고 그 연결이 해당 세포의 선택적 손상에 의하여 이루어지는 경우에 있어서, 유용하다. 다른 치료 개념은 종양 세포에 대하여 선택적으로 세포 손상 잠재성을 갖는 작용 인자 메카니즘을 보충하는 표지로서의 종양 관련 항원을 계획한다. 이 때, 상기 표적 분자 자체의 기능 및 종양 발달에 있어서의 그의 역할은 전적으로 관계가 없다.
본 발명에 있어서, 핵산의 "유도체 (derivative)"는 상기 핵산 내에 단일 또는 다수의 뉴클레오타이드 치환, 결실 및/또는 부가가 존재하는 것을 의미한다. 또한, 상기 유도체라 함은 또한 뉴클레오타이드 염기, 당 또는 포스페이트 상에서의 핵산의 화학적 유도체화를 포함한다. 상기 유도체라 함은 또한 자연 발생적이지 않은 뉴클레오타이드 및 뉴클레오타이드 유사체를 포함하는 핵산을 포함한다.
본 발명에 있어서, 핵산은 디옥시리보핵산(DNA) 또는 리보핵산(RNA)인 것이 바람직하다. 본 발명에 있어서, 핵산은 게놈 DNA, cDNA, mRNA, 재조합적으로 생산되고 화학적으로 합성된 분자들을 포함한다. 본 발명에 있어서, 핵산은 단일 가닥 또는 이중 가닥 및 선형 또는 공유적으로 형성된 환상의 닫힌 분자의 형태로서 존재할 수 있다.
본 발명에 기재된 상기 핵산은 분리된 것이 바람직하다. 본 발명에 있어서, 상기 "분리된 핵산(isolated nucleic acid)"이라 함은 핵산이 (i) 예컨대, 중합효소 연쇄 반응(PCR)에 의하여, 생체외(in vitro) 증폭되거나, (ii) 클로닝에 의하여 재조합적으로 생산되거나, (iii) 예컨대, 절단 및 겔-전기영동 분획에 의하여, 정제되거나, (iv) 예컨대 화학 합성에 의하여 합성된 것임을 의미한다. 분리된 핵산은 재조합 DNA 기술에 의한 조작에 사용 가능한 것이다.
두 핵산 서열이 서로 혼성화 가능하고 다른 하나와 안정된 이중 나선 구조를 형성할 수 있는 경우, 하나의 핵산이 다른 하나의 핵산에 대하여 상보적이라고 하며, 이 때, 상기 혼성화는 폴리뉴클레오타이드 간의 특이적 혼성화를 가능하게 하는 조건 (엄격한 조건) 하에서 수행되는 것이 바람직하다. 엄격한 조건은, 예컨대, Molecular Cloning (A Laboratory Manual, J. Sambrook 등, Editors, 2nd Edition, Cold Spring Harbor Laboratory press, Cold Spring Harbor, New York, 1989) 또는 Current Protocols in Molecular Biology (F.M. Ausubel 등, Editors, John Wiley & Sons, Inc., New York)에 기재되어 있으며, 예컨대, 65 ℃의 혼성화 완충액 (3.5 x SSC, 0.02 % Ficoll, 0.02 % 폴리비닐피롤리돈, 0.02 % 소 혈청 알부민, 2.5 mM NaH2PO4 (pH 7), 0.5 % SDS, 2 mM EDTA)에서의 혼성화를 기재하고 있다. SSC는 pH 7의 0.15 M 염화나트륨/0.15 M 시트르산나트륨이다. 혼성화 후, DNA가 전달되어 있는 멤브레인을, 예컨대, 실온에서 2 x SSC로 세척하고 나서, 68 ℃까지의 온도에서 0.1 내지 0.5 x SSC/0.1 x SDS로 세척한다.
본 발명에 있어서, 상보적 핵산은 적어도 40 %, 특히 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 90 % 및 바람직하게는 적어도 95 %, 적어도 98 % 또는 적어도 99% 이상의 뉴클레오타이드 상동성을 갖는다.
본 발명에 있어서, 종양 관련 항원을 코딩하는 핵산은 단독 또는 다른 핵산, 특히 이형(heterologous) 핵산과 함께 존재할 수 있다. 바람직한 예에 있어서, 핵산은 상기 핵산에 대하여 상동 또는 이형일 수 있는 발현 제어 서열 또는 조절 서열과 기능적으로 연결되어 있다. 코딩 서열 및 조절 서열은, 이들이 상기 코딩 서열의 발현이 상기 조절 서열의 제어 또는 영향을 받도록 하는 방법으로 서로 공유적으로 연결되어 있는 경우, 서로 "기능적으로(functionally)" 연결되어 있다고 한다. 그리고 나서, 상기 코딩 서열에 기능적으로 연결된 조절 서열과 함께, 상기 코딩 서열이 기능적 단백질로 번역되는 경우, 상기 조절 서열은, 코딩 서열 내에서의 프래임 쉬프트(frame shift) 또는 상기 코딩 서열이 원하는 단백질 또는 펩타이드로 번역되지 못하게 되는 일 없이, 상기 코딩 서열의 전사를 일으킨다.
본 발명에 있어서, "발현 제어 서열(expression control sequence)" 또는 "조절 서열(regulatory sequence)"이라 함은 프로모터, 인핸서 및 유전자의 발현을 조절하는 다른 조절 인자를 포함한다. 본 발명의 구체예에 있어서, 발현 제어 서열은 조절 가능하다. 조절 서열의 정확한 구조는 종 또는 세포 유형에 따라서 다양할 것이나, 일반적으로, TATA 박스, 캡형성(capping) 서열, CAAT 서열 등과 같이, 각각 전사 및 번역의 개시에 수반되는 5' 미전사(untranscribed) 서열 및 5' 미번역(untranslated) 서열을 포함한다. 보다 구체적으로, 5' 미전사 조절 서열은 기능적으로 연결된 유전자의 전사 제어를 위한 프로모터 서열을 포함하는 프로모터 부위를 포함한다. 조절 서열은 또한 인핸서 서열 또는 상류 활성화 인자 서열을 포함한다.
따라서, 한편으로는, 본 명세서에 설명된 상기 종양 관련 항원은 모든 발현 제어 서열 및 프로모터와 결합될 수 있다. 그러나, 또 다른 한편으로는, 본 발명에 있어서, 본 명세서에 설명된 종양 관련 유전자 산물의 프로모터는 모든 다른 유전자와 결합될 수 있다. 이는 이들 프로모터의 선택적 활성을 이용할 수 있도록 한다.
본 발명에 있어서, 핵산은 또한 숙주 세포로부터의 상기 핵산에 의하여 코딩되는 단백질 또는 폴리펩타이드의 분비를 제어하는 폴리펩타이드를 코딩하는 다른 핵산과 함께 존재할 수 있다. 본 발명에 있어서, 핵산은 또한 코딩되는 단백질 또는 폴리펩타이드를 숙주 세포의 세포막 상에 고정시키거나(anchored), 상기 세포의 특정 세포 기관 내로 구획화시키는 폴리펩타이드를 코딩하는 다른 핵산과 함께 존재할 수 있다.
바람직한 예에 있어서, 본 발명에 있어서, 재조합 DNA 분자는 벡터이며, 적합하게는, 예컨대, 본 발명의 종양 관련 항원을 코딩하는 핵산과 같은, 핵산의 발혀을 조절하는 프로모터를 갖는다. "벡터(vector)"라 함은 본 명세서에서 그의 가장 일반적인 의미로 사용되며, 상기 핵산을, 예컨대, 원핵 세포 또는 진핵 세포 내로 도입시키거나, 적절한 경우, 게놈 내로 통합시킬 수 있는 핵산을 위한 모든 중간 운반체(intermediary vehicle)를 포함한다. 이러한 종유의 벡터는 세포 내에서 복제 및/또는 발현되는 것이 바람직하다. 중간 운반체를, 예컨대, 전기영동, 미세 발사물(microprojectiles)에 의한 충격, 리포좀 투여, 아그로박테리아에 의한 전달 또는 DNA 바이러스 또는 RNA 바이러스를 통한 삽입에 사용하기 위하여 적응시킬 수 있다. 벡터는 플라스미드, 파지미드 또는 바이러스 게놈을 포함한다.
본 발명에 따라서 동정된 종양 관련 항원을 코딩하는 핵산을 사용하여 숙주 세포를 형질 감염시킬 수 있다. 본 명세서에서 핵산은 재조합 DNA와 RNA를 모두 의미한다. 재조합 RNA는 DNA 주형의 생체외 전사에 의하여 제조할 수 있다. 또한, 이를 적용 전에 서열 안정화, 캡형성 및 폴리아데닐화에 의하여 변형시킬 수 있다. 본 발명에 있어서, "숙주 세포(host cell)"라 함은 외래 핵산으로 형질 감염되거나 형질 전환될 수 있는 모든 세포를 의미한다. 본 발명에 있어서, 숙주세포라 함은 원핵 세포 (예컨대, E. coli) 또는 진핵 세포 (예컨대, 수지상 세포, B 세포, CHO 세포, COS 세포, K562 세포, 효모 세포 및 곤충 세포)를 포함한다. 인간, 마우스, 햄스터, 돼지, 염소, 영장류로부터 유래하는 세포와 같은 포유류 세포가 특히 바람직하다. 상기 세포는 다수의 조직형으로부터 유래하고 1차 세포 및 세포계를 포함할 수 있다. 구체예에 있어서, 케라틴 세포(keratinocytes), 말초혈 백혈구, 골수의 줄기 세포 및 배아 줄기 세포가 포함된다. 또 다른 구체예에 있어서, 상기 숙수 세포는 항원 제시 세포, 특히, 수지상 세포, 단핵 세포 또는 대식 세포이다. 핵산은 숙수 세포내에 단일 복제물 또는 둘 이상의 복제물의 형태로 존재할 수 있으며, 일례에 있어서, 숙주 세포에서 발현된다.
본 발명에 있어서, "발현(expression)"이라 함은 그의 가장 일반적인 의미로 사용되며, RNA 또는 RNA 및 단백질의 생산을 포함한다. 이는 또한 핵산의 부분적 발현도 포함한다. 또한, 발현은 일시적 또는 지속적으로 수행될 수 있다. 포유류 세포에서의 바람직한 발현 시스템으로서 pcDNA3.1 및 pRc/CMV (Invitrogen, Carlsbad, CA) 등이 있으며, 이들은 사이토메갈로바이러스(CMV)의 인핸서-프로모터 서열 및 G418에 대하여 저항성을 부여하는 유전자 (이로 인하여 안정적으로 형질 감염된 세포주를 선별할 수 있음)와 같은 선별 표지를 포함한다.
본 발명에서 HLA 분자가 종양 관련 항원 또는 그 일부를 제시하는 이들 경우에 있어서, 발현 벡터는 또한 상기 HLA 분자를 코딩하는 핵산 서열을 포함할 수 있다. HLA 분자를 코딩하는 핵산 서열이 종양 관련 항원 또는 그 일부를 코딩하는 핵산과 동일한 발현 벡터상에 존재하거나, 두 핵산이 서로 다른 발현 벡터 상에 존재할 수 있다. 후자의 경우, 두 발현 벡터를 세포내로 동시 형질 감염시킬 수 있다. 숙주 세포가 종양 관련 항원 또는 그 일부 및 HLA 분자 모두를 발현하지 않는 경우, 이들을 코딩하는 두 핵산을 동일 발현 벡터 또는 서로 다른 발현 벡터 상에서 세포 내로 형질 감염시킨다. 세포가 이미 HLA 분자를 발현하는 경우, 종양 관련 항원 또는 그 일부를 코딩하는 핵산 서열만을 세포 내로 형질 감염시킬 수 있다.
본 발명은 또한 종양 관련 항원을 코딩하는 핵산을 증폭시키기 위한 키트를 포함한다. 이러한 키트는, 예컨대, 종양 관련 항원을 코딩하는 핵산과 혼성화하는 한 쌍의 증폭 프라이머를 포함한다. 상기 프라이머는 상기 핵산의 인접 뉴클레오타이드 6 내지 50 개, 특히, 10 내지 30 개, 15 내지 30 개 및 20 내지 30 개의 서열을 포함하고, 프라이머 다이머의 형성을 피하기 위하여, 중복되지 않는 것이 바람직하다. 프라이머 중 하나는 종양 관련 항원을 코딩하는 핵산의 한 가닥과 혼성화하고, 다른 프라이머는 종양 관련 항원을 코딩하는 핵산의 증폭을 가능하게 하는 배열로 상보적 가닥과 혼성화 할 것이다.
"안티센스" 분자 또는 "안티센스" 핵산을 사용하여 핵산 발현을 조절, 특히, 감소시킬 수 있다. 본 발명에 있어서, "안티센스 분자" 또는 "안티센스 핵산"이라 함은 생리적 조건 하에서 특정 유전자를 포함하는 DNA 또는 상기 유전자의 mRNA와 혼성화하여 상기 유전자의 전사 및/또는 상기 mRNA의 번역을 억제하는, 올리고리보뉴클레오타이드 또는 올리고디옥시리보뉴클레오타이드, 변형된 올리고리보뉴클레오타이드 또는 변형된 올리고디옥시리보뉴클레오타이드 등의 올리고뉴클레오타이드를 의미한다. 본 발명에 있어서, 상기 "안티센스 분자"는 또한 핵산 또는 그 일부를 그의 천연 프로모터에 대하여 역방향으로 포함하는 구조체를 포함한다. 핵산 또는 그 일부의 안티센스 전사체는 효소를 특정화하는 자연 발생적 mRNA와 이중 나선을 형성하여 mRNA의 축적 또는 mRNA의 활성 효소로의 번역을 방지할 수 있다. 핵산을 불활성화시키기 위하여 리보자임을 사용하는 것 또한 가능하다. 본 발명에 있어서, 안티센스 올리고뉴클레오타이드는 표적 핵산의 인접 뉴클레오타이드 6 내지 50 개, 특히, 10 내지 30 개, 15 내지 30 개 및 20 내지 30 개의 서열을 갖고 표적 핵산 또는 그 일부와 완전히 상보적인 것이 바람직하다.
바람직한 예에 있어서, 안티센스 올리고뉴클레오타이드는 번역 개시 부위, 전사 개시 부위 또는 프로모터 부위와 같은 5' 상류 부위 및 N-말단과 혼성화한다. 다른 구체예에 있어서, 상기 안티센스 올리고뉴클레오타이드는 3' 미번역 부위 또는 mRNA 스플라이싱 부위와 혼성화한다.
일례에 있어서, 본 발명이 올리고뉴클레오타이드는 리보뉴클레오타이드, 디옥시리보뉴클레오타이드 또는 이들의 조합으로 이루어지며, 이들의 5' 말단의 하나의 뉴클레오타이드와 3' 말단의 다른 하나의 뉴클레오타이드는 포스포디에스테르 결합에 의하여 서로 연결되어 있다. 이들 올리고뉴클레오타이드는 통상적인 방법으로 합성되거나 재조합적으로 생산될 수 있다.
바람직한 예에 있어서, 본 발명의 올리고뉴클레오타이드는 "변형된(modified)" 올리고뉴클레오타이드이다. 여기서, 상기 올리고뉴클레오타이드는, 예컨대, 안정성 또는 치료 효율 등을 증가시키기 위하여, 그의 표적에 결합하는 능력을 손상시키지 않고, 매우 다양한 방법으로 변형시킬 수 있다. 본 발명에 있어서, "변형된 올리고뉴클레오타이드"라 함은 (i) 이들의 뉴클레오타이드 중 2 개 이상이 합성 뉴클레오사이드 간 결합 (즉, 포스포디에스테르 결합이 아닌 뉴클레오사이드 간 결합)에 의하여 서로 결합되어 있고, 및/또는 (ii) 핵산에서는 일반적으로 발견되지 않는 화학기가 상기 올리고뉴클레오타이드에 공유적으로 결합되어 있는 올리고뉴클레오타이드를 의미한다. 상기 합성 뉴클레오사이드 결합은 포스포로티오에이트, 알킬 포스포네이트, 포스포로디티오에이트, 인산에스테르, 알킬 포스포노티오에이트, 포스포아미데이트(phosphoramidates), 카바메이트, 카보네이트, 인산트리에스테르, 아세타미데이트(acetamidates), 카복시메틸에스테르 및 펩타이드인 것이 바람직하다.
"변형된 올리고뉴클레오타이드"라 함은 또한 공유적으로 변형된 염기 및/또는 당을 갖는 올리고뉴클레오타이드를 포함한다. "변형된 올리고뉴클레오타이드"는, 예컨대, 3' 위치의 수산화기 및 5' 위치의 인산기를 제외한 저분자량 유기 작용기와 공유적으로 결합하는 당 잔기를 갖는 올리고뉴클레오타이드를 포함한다. 변형된 올리고뉴클레오타이드는, 예컨대, 2'-O-알킬화 리보오스 잔기 또는 리보오스 대신에 아라비노오스와 같은 다른 당을 포함할 수 있다.
본 발명에 개시된 단백질 및 폴리펩타이드는 분리된 것이 바람직하다. "분리된(isolated) 단백질" 또는 "분리된 폴리펩타이드"라 함은 단백질 또는 폴리펩타이드가 그의 본래 환경으로부터 분리된 것을 의미한다. 분리된 단백질 또는 폴리 펩타이드는 본질적으로 정제된 상태일 수 있다. "본질적으로 정제된(essentially purified)"이라 함은 단백질 또는 폴리펩타이드가 자연 상태 또는 생체내에서 이들과 결합된 다른 물질을 본질적으로 갖지 않는 것을 의미한다.
이러한 단백질 및 폴리펩타이드는, 예컨대, 항체의 생산 및 면역학적 또는 진단 분석법에 사용되거나 치료제로서 사용될 수 있다. 본 발명에 개시된 단백질 및 폴리펩타이드는 조직 또는 세포 균질 파쇄액(homogenate)과 같은 생물학적 시료로부터 분리될 수 있으며, 또한, 다수의 원핵 또는 진핵 발현 시스템에서 재조합적으로 발현될 수 있다.
본 발명에 있어서, 단백질 또는 폴리펩타이드 또는 아미노산 서열의 "유도체(derivatives)"는 아미노산 삽입 변이체, 아미노산 결실 변이체 및/또는 아미노산 치환 변이체를 포함한다.
아미노산 삽입 변이체는 아미노 말단 및/또는 카복시 말단 융합 및 특정 아미노산 서열 내 하나 또는 두 개 이상의 아미노산의 삽입을 포함한다. 삽입을 갖는 아미노산 서열 변이체의 경우에 있어서, 하나 이상의 아미노산 잔기가 아미노산 서열의 특정 자리에 삽입되며, 결과 생성물의 적절한 스크리닝이 가능한 무작위 삽입 또한 가능하다. 아미노산 결실 변이체는 서열로부터 하나 이상의 아미노산이 제거된 특성을 갖는다. 아미노산 치환 변이체는 서열 내 하나 이상의 잔기가 제거되고 그 자리에 다른 잔기가 삽입된 특성을 갖는다. 상동 단백질 또는 펩타이드 간의 비보존적인 아미노산 서열 내 위치에 존재하는 변형이 바람직하다. 아미노산을 소수성, 친수성, 전기 음성도, 측쇄의 부피 등과 같은 유사한 성질을 갖는 다른 아미노산으로 치환하는 것이 바람직하다 (보존적 치환). 보존적 치환은, 예컨대, 아미노산을 아래에 열거된 아미노산 군 중에서 상기 치환될 아미노산과 동일한 군의 아미노산으로 교체할 수 있다:
1. 작은 지방족, 비극성 또는 약간 극성인 잔기: Ala, Ser, Thr (Pro, Gly)
2. 음성 하전된 잔기 및 그의 아마이드: Asn, Asp, Glu, Gln
3. 양성 하전된 잔기: His, Arg, Lys
4. 큰 지방족, 비극성 잔기: Met, Leu, Ile, Val (Cys)
5. 큰 방향족 잔기: Phe, Tyr, Trp.
세 개의 잔기는, 단백질 구조에 있어서의 이들의 특수한 역할 때문에, 괄호 안에 나타내었다. Gly는 측쇄가 없는 유일한 잔기이기 때문에 사슬에 유연성을 부여한다. Pro는 사슬을 매우 제한하는 특수한 기하학적 구조를 갖는다. Cys는 디설파이드 가교를 형성할 수 있다.
상기 아미노산 변이체는, 예컨대, 고상 합성(solid phase synthesis, Merrifield, 1964) 및 유사한 방법과 같은 공지된 펩타이드 합성 기술에 의하여, 또는 재조합 DNA 조작에 의하여 용이하게 제작할 수 있다. 치환 돌연변이를 그 서열이 알려지거나 부분적으로 알려진 DNA 내의 미리 정해진 위치에 삽입하기 위한 기술은 공지되어 있으며, 예컨대, M13 변이 유발(M13 mutagenesis)을 포함한다. 치환, 삽입 또는 결실을 갖는 단백질 제조를 위한 DNA 서열의 조작은, 예컨대, Sambrook 등, (1989)에 상세하기 개시되어 있다.
본 발명에 있어서, 단백질 또는 폴리펩타이드의 "유도체"는 또한, 탄수화물, 지질 및/또는 단백질 또는 폴리펩타이드와 같이, 효소와 관련된 모든 분자의 단일 또는 다중 치환, 결실 및/또는 부가를 포함한다. 또한, "유도체"라 함은 상기 단백질 또는 폴리펩타이드의 모든 기능적 화학 등가물로 확장될 수 있다.
*본 발명에 있어서, 종양 관련 항원의 일부 또는 단편 이들이 유도된 폴리펩타이드의 기능적 특성을 갖는다. 이러한 기능적 특성에는 항체와의 상호 작용, 다른 펩타이드 또는 단백질과의 상호 작용, 핵산의 선택적 결합 및 효소 활성 등이 있다. 특수한 성질은 HLA와 복합체를 형성하고, 적절한 경우, 면역 응답을 생성시키는 능력이다. 이러하 면역 응답은 세포 독성 또는 T 헬퍼 세포를 자극하는 것에 기초할 수 있다. 본 발명의 종양 관련 항원의 일부 또는 단편은 종양 관련 항원의 연속적인 아미노산이 6 개 이상, 특히 8 개 이상, 10 개 이상, 12 개 이상, 15 개 이상, 20 개 이상, 30 개 이상 또는 50 개 이상인 서열을 포함하는 것이 바람직하다.
본 발명에 있어서, 종양 관련 항원을 코딩하는 핵산의 일부 또는 단편은 적어도 종양 관련 항원 및/또는, 상기 정의된 바와 같은, 상기 종양 관련 항원의 일부 또는 단편을 코딩하는 핵산의 일부와 관련된 것이다.
종양 관련 항원을 코딩하는 유전자의 분리 및 동정은 또한 한 가지 이상의 종양 관련 항원의 발현 특성을 갖는 질병의 진단을 가능하게 한다. 이러한 방법은 종양 관련 항원을 코딩하는 하나 이상의 핵산을 결정하거나 및/또는 코딩된 종양 관련 항원 및/또는 이로부터 유도된 펩타이드를 결정하는 것을 포함한다. 핵산은 표지된 프로브를 사용하는 혼성화 또는 중합효소 연쇄 반응을 포함하는 통상적인 방법으로 결정할 수 있다. 종양 관련 항원 또는 이로부터 유도된 펩타이드는 상기 항원 및/또는 펩타이드를 인식하는 것에 대하여 환자의 항혈청을 스크리닝함으로써 결정할 수 있다. 이들은 또한 상응하는 종양 관련 항원에 대한 특이성에 대하여 환자의 T 세포를 스크리닝함으로써 결정할 수도 있다.
본 발명은 또한, 상기 종양 관련 항원의 세포 결합 파트너 및 항체를 포함하여, 본 명세서에 개시된 종양 관련 항원에 결합하는 단백질을 분리 가능하도록 한다.드
본 발명에 있어서, 특정 구체예는 종양 관련 항원으로부터 유도된 "우성 음성(dominant negative)" 폴리펩타이드를 제공하는 것을 반드시 수반한다. 우성 음성 폴리펩타이드는, 세포 기관과 상호 작용함으로써, 활성 단백질이 세포 기관과 상호 작용하는 것을 방해하거나, 활성 단백질과 경쟁하여, 상기 활성 단백질의 효율을 감소시키는, 불활성 단백질이다. 예컨대, 리간드와 결합하지만 상기 리간드와 의 결합에 대한 응답으로서 어떠한 신호도 발생시키지 않는 우성 음성 수용체는 상기 리간드의 생물학적 효율을 감소시킬 수 있다. 유사하게, 일반적으로 표적 단백질과 상호 작용하지만 상기 표적 단백질을 인산화시키지 않는 우성 음성 촉매적 불활성 키나아제는 세포 신호에 대한 응답으로서의 상기 표적 단백질의 인산화를 감소시킬 수 있다. 유사하게, 유전자 조절 부위 내의 프로모터에 결합하지만 상기 유저자의 전사를 증가시키지 않는 우성 음성 전사 인자는 전사를 증가시키지 않고 프로모터 결합 부위를 차지함으로써 정상 전사 인자의 효율을 감소시킬 수 있다.
우성 음성 폴리펩타이드의 세포내 발현 결과, 활성 단백질의 기능이 감소된다. 이 발명이 속하는 기술 분야의 통상의 지식을 가진 자는, 예켠대, 통상적인 변이 유발 방법 및 폴리펩타이드 변이체의 우성 음성 효율을 평가함으로써, 단백질의 우성 음성 변이체를 제조할 수 있을 것이다.
본 발명은 또한 종양 관련 항원에 결합하는 폴리펩타이드와 같은 물질을 포함한다. 이러한 결합 물질은, 예컨대, 종양 관련 항원 및 종양 관련 항원과 이들의 결합 파트너와의 복합체를 검출하는 스크리닝 분석법 및 상기 종양 관련 항원 및 상기 종양 관련 항원과 이들의 결합 파트너와의 복합체의 정제에 사용될 수 있다. 이러한 물질은 또한 종양 관련 항원의 활성을, 예컨대, 이러한 항원에 결합함으로써, 억제하기 위하여 사용할 수 있다.
따라서, 본 발명은, 예컨대, 종양 관련 항원에 선택적으로 결합할 수 있는, 항체 또는 항체 단편과 같은 결합 물질을 포함한다. 항체에는 통상적인 방법으로 생산되는 폴리클로날 항체 및 모노클로날 항체 등이 있다.
항체의 작은 부분인 파라토프 만이 항체가 자신의 에피토프에 결합하는 데 수반된다는 것이 알려져 있다 (cf. Clark, W.R. (1986), The Experimental Foundations of Modern Immunology, Wiley & Sons, Inc., New York; Roitt, I. (1991), Essential Immunology, 7th Edition, Blackwell Scientific Publications, Oxford). 예컨대, pFc' 및 Fc 부위는 보체 캐스케이드(cascade)의 작용 인자이지만 항원 결합에는 수반되지 않는다. pFc' 부위가 효소적으로 제거되어 있거나 pFc' 부위 없이 생산된, F(ab')2 단편이라고 불리는 항체는 완전한 항체의 두 항원 결합 부위를 모두 운반한다. 유사하게, Fc 부위가 효소적으로 제거되어 있거나 상기 Fc 부위 없이 생산된, Fab 단편이라고 불리는 항체는 본래 항체 분자의 한 항원 결합 부위를 운반한다. 또한, Fab 단편은 공유적으로 결합된 항체 경쇄 및, Fd라고 불리는, 상기 항체의 중쇄 부분으로 구성된다. Fd 단편은 항체 특이성의 주요한 결정 인자이며 (단일 Fd 단편은, 항체의 특이성을 변화시키지 않고, 10 개까지의 서로 다른 경쇄와 결합할 수 있음), Fd 단편은, 분리시, 에피토프에 결합하는 활성을 보유한다.
항원 에피토프와 직접적으로 상호 작용하는 상보적 결정 부위(complementary-determining regions, CDRs)와 파라토프의 3차 구조를 유지하는 프레임워크 부위(framework regions, FRs)가 항체의 항원 결합 부분 내에 위치한다. IgG 면역글로불린의 경쇄 및 중쇄의 Fd 단편은 모두 4 개의 프레임워크 부위(FR1 내지 FR4)를 포함하며, 이들은 각각 3 개의 상보적 결정 부위(CDR1 내지 CDR3)에 의하여 분리된다. CDRs, 구체적으로, CDR3 부위, 보다 구체적으로 중쇄의 CDR3이 항체 특이성에 큰 비중으로 관여한다.
포유류 항체의 CDR 이외의 부위는, 원 항체의 에피토프에 대한 특이성을 보유하면서, 동일하거나 상이한 특이성을 갖는 항체의 유사 부위로 대체될 수 있다는 것이 알려져 있다. 이는 인간 이외의 CDRs가 인간 FR 및 Fc/pFc' 부위에 결합하여 기능적 항체를 생산하는 "인간화된(humanized)" 항체의 개발을 가능하게 한다.
예컨대, 국제공개공보 제92/04381호는 적어도 쥐 FR 부위의 일부가 인간 기원의 FR 부위로 대체되어 있는 인간화된 쥐의 RSV 항체의 생산 및 용도를 개시하고 있다. 항원 결합 능력을 갖는 본래 항체의 단편을 포함하는, 이러한 종류의 항체를 보통 "키메라(chimeric)" 항체라고 부른다.
본 발명은 또한 항체의 F(ab')2, Fab, Fv 및 Fd 단편, Fc 및/또는 FR 및/또는 CDR1 및/또는 CDR2 및/또는 경쇄-CDR3 부위가 인간 또는 인간 이외의 상동 서열로 대체되어 있는 키메라 항체, FR 및/또는 CDR1 및/또는 CDR2 및/또는 경쇄-CDR3 부위가 인간 또는 인간 이외의 상동 서열로 대체되어 있는 키메라 F(ab')2-단편 항체, FR 및/또는 CDR1 및/또는 CDR2 및/또는 경쇄-CDR3 부위가 인간 또는 인간 이외의 상동 서열로 대체되어 있는 키메라 Fab-단편 항체, 및 FR 및/또는 CDR1 및/또는 CDR2 부위가 인간 또는 인간 이외의 상동 서열로 대체되어 있는 키메라 Fd-단편 항체를 제공한다. 본 발명은 또한 "단쇄(single-chain)" 항체를 포함한다.
본 발명은 또한 종양 관련 항원에 특이적으로 결합하는 폴리펩타이드를 포함한다. 이러한 종류의 폴리펩타이드 결합 물질은, 예컨대, 파지 디스플레이 라이브러리로서 또는 고정화된 형태로 용액내에서 간단히 제작될 수 있는 축퇴 (degenerate) 펩타이드 라이브러리에 의하여 제공될 수 있다. 마찬가지로, 하나 이상의 아미노산을 갖는 펩타이드의 조합 라이브러리를 제작하는 것이 가능하다. 비펩타이드 합성 잔기(nonpeptidic synthetic residues) 및 펩타이드의 라이브러리 또한 제작할 수 있다.
파지 디스플레이는 본 발명의 결합 펩타이드를 동정하는데 특히 효과적이다. 이와 관련하여, 예컨대, 4 내지 약 80 개의 아미노산 잔기 길이의 삽입물을 제공하는 파지 라이브러리를 (예컨대, M13, fd 또는 람다 파지를 사용하여) 제작한다. 그리고 나서, 종양 관련 항원에 결합하는 삼입물을 운반할 파지를 선별한다. 이러한 공정은 2 회 이상의 종양 관련 항원에 결합하는 파지의 재선별을 통하여 반복할 수 있다. 반복 수행에 의하여 특정 서열을 운반하는 파지가 농축된다. 발현된 폴리펩타이드 서열을 동정하기 위해서 DNA 서열 분석을 수행할 수 있다. 종양 관련 항원에 결합하는 서열의 최소 선형 부분을 결정할 수 있다. 효모의 "2종 하이브리드 시스템(two-hybrid system)"을 또한 종양 관련 항원에 결합하는 폴리펩타이드를 동정하는데 사용할 수 있다. 본 발명에 기재된 종양 관련 항원 또는 그의 단편은, 상기 종양 관련 항원의 펩타이드 결합 파트너를 동정하고 선별하기 위하여, 파지 디스플레이 라이브러리를 포함하는 펩타이드 라이브러리를 스크리닝하는데 사용할 수 있다. 이러한 분자는, 예컨대, 스크리닝 분석법, 정제 프로토콜, 종양 관련 항원 기능 방해 및 이 발명이 속하는 기술 분야의 통상의 지식을 가진 자에게 공지된 다른 목적에 사용될 수 있다.
상기 항체 및 다른 결합 분자는, 예컨대, 종양 관련 항원을 발현하는 조직을 동정하는데 사용될 수 있다. 항체는 또한 종양 관련 항원을 발현하는 조직 및 세포를 보여주기 위한 특정 진단 물질과 결합될 수 있다. 이들은 또한 치료적 유용 물질과 결합될 수도 있다. 상기 진단 물질에는 황산바륨, 이오세탐산(iocetamic acid), 이오파노산(iopanoic acid), 칼슘 이포데이트(calcium ipodate), 소듐 디아트리조에이트(sodium diatrizoate), 메글루민 디아트리조에이트(meglumine diatrizoate), 메트리즈아미드(metrizamide), 소듐 티로파노에이트(sodium tyropanoate) 및 불소-18 및 탄소-11과 같은 양전자 방출체, 요오드-123, 테크네튬-99m, 요오드-131 및 인듐 111과 같은 감마 방출체, 불소 및 가돌리늄과 같은 핵 자기 공명용 핵종(nuclides)을 포함하는 방사성 진단제 등이 있으며, 이에 한정되는 것은 아니다. 본 발명에 있어서, "치료적 유용 물질(therapeutically useful substance)"이라 함은, 원하는 바에 따라, 하나 이상의 종양 관련 항원을 발현하는 세포에 선택적으로 도입되는 모든 치료적 분자를 의미하는 것으로, 항암제, 방사성 요오드 표지된 화합물, 독소, 세포 증식 억제제 또는 세포 용해제, 등을 포함하며, 상기 항암제에는, 예컨대, 아미노글루테티미드(aminoglutethimide), 아자티오프린(azathioprine), 벨로마이신 설페이드(bleomycin sulfate), 부설판(busulfan), 카무스틴(carmustine), 클로람부실(chlorambucil), 시스플라틴(cisplatin), 시클로포스파미드(cyclophosphamide), 시클로스포린(cyclosporine), 시타라비딘(cytarabidine), 다카바진(dacarbazine), 닥티노마이신(dactinomycin), 다우노루빈(daunorubin), 독소루비신(doxorubicin), 택솔(taxol), 에토포시드(etoposide), 플루오로우라실(fluorouracil), 인터페론-α, 로무스틴(lomustine), 머캅토퓨린(mercaptopurine), 메토트렉세이트(methotrexate), 미토탄(mitotane), 프로카바진 HCl(procarbazine HCl), 티오구아닌(thioguanine), 빈블라스틴 설페이트(vinblastine sulfate) 및 빈크리스틴 설페이트(vincristine sulfate) 등이 있다. 다른 항암제가, 예컨대, Goodman과 Gilman의 "The Pharmacological Basis of Therapeutics" (8th Edition, 1990, McGraw-Hill, Inc.), 특히 52장 [Antineoplastic Agents (Paul Calabresi and Bruce A. Chabner]에 개시되어 있다. 독소는 포크위드 항바이러스 단백질(pokeweed antiviral protein), 콜레라 독소, 백일해 독소(pertussis toxin), 리신(ricin), 겔로닌(gelonin), 아브린(abrin), 디프테리아 외독소(diphtheria exotoxin) 또는 수도모나스(Pseudomonas) 외독소와 같은 단백질일 수 있다. 독소 잔기는 또한 코발트-60 등의 고에너지 방출 방사성 핵종(radionuclide)일 수 있다.
본 발명에 있어서, "환자(patient)"라 함은 인간, 인간 이외의 영장류 또는 다른 동물, 특히, 소, 말, 돼지, 양, 염소, 개, 고양이 또는 마우스와 래트 같은 설치류 등의 포유류를 의미한다. 특히 바람직한 구체예에 있어서, 상기 환자는 인간이다.
*본 발명에 있어서, "질병(disease)"이라 함은 종양 관련 항원이 발현되거나 비정상적으로 발현되는 모든 병적 상태를 의미하는 것이다. 본 발명에 있어서, "비정상적 발현(Abnormal expression)"은 발현이 건강한 개체의 상태와 비교하여 변형된, 특히 증가된 것을 의미한다. 발현의 증가는 10 % 이상, 특히 20 % 이상, 50 % 이상 또는 100 % 이상 증가하는 것을 의미한다. 일례에 있어서, 상기 종양 관련 항원은 질병을 앓는 개체의 조직에서만 발현하는 반면, 건강한 개체에서는 발현이 억제된다. 이러한 질병의 한 예가 암이며, 특히, 정상피종(seminomas), 흑색종(melanomas), 기형종(teratomas), 신경교종(gliomas), 결장암, 유방암, 전립선암, 자궁암, 난소암 및 폐암이다.
본 발명에 있어서, 생물학적 시료는 조직 시료 및/또는 세포 시료일 수 있고, 본 명세서에 기재된 다양한 방법에 사용하기 위하여, 세절채취 생검(punch biopsy)을 포함하는 조직 생검 및 혈액, 기관지 흡인물, 소변, 대변, 또는 다른 체액을 채취하는 통상적인 방법으로 얻을 수 있다.
본 발명에 있어서, "면역 활성 세포(immunoreactive cell)"라 함은 적절한 자극에 의하여 면역 세포(B 세포, T 헬퍼 세포 또는 세포 용해 T 세포 등)로 성숙할 수 있는 세포를 의미한다. 면역 활성 세포는 CD34+ 조혈 모세포(hematopoietic stem cells), 미숙 및 성숙 T 세포 및 미숙 및 성숙 B 세포를 포함한다. 종양 관련 항원을 인식하는 세포 용해성 또는 T 헬퍼 세포의 생산이 소망되는 경우, 상기 면역 활성 세포를 세포 용해성 T 세포 및 T 헬퍼 세포의 생산, 분화 및/또는 선별에 유리한 조건하에서 종양 관련 항원을 발현하는 세포와 접촉시킨다. 항원에 노출시 T 세포 전구체의 세포 용해성 T 세포로의 분화는 면역계의 클론 선택(clonal selection)과 유사하다.
몇 가지 치료 방법, 하나 이상의 종양 관련 항원을 제시하는 암세포와 같은 항원 제시 세포의 세포 용해를 일으키는, 환자의 면역계 반응에 기초한다. 이와 관련하여, 예컨대, 종양 관련 항원과 MHC 분자의 복합체에 특이적인 자기 유래(autologous) 세포독성 T 림프구를 세포 이상을 갖는 환자에게 투여한다. 이러한 세포독성 T 림프구의 생체외(in vitro) 생산이 공지되어 있다. T 세포를 분화시키는 방법의 일례를 WO-A-9633265에서 찾을 수 있다. 일반적으로, 혈액 세포와 같은 세포를 함유하는 시료를 환자로부터 채취하고, 상기 세포를 복합체를 제시하고 세포 독성 T 림프구(예컨대, 수지상 세포)의 증식을 유발시킬수 있는 세포와 접촉시킨다. 표적 세포는 COS 세포와 같이 형질 감염된 세포일 수 있다. 이러한 형질 감염된 세포는 자신의 표면에 원하는 복합체를 제시하고, 세포 독성 T 림프구와 접촉시, 후자의 증식을 촉진시킨다. 그리고 나서, 상기 클론 확장된 (clonally expanded) 자기 유래 세포 독성 T 림프구를 환자에 투여한다.
항원 특이적 세포독성 T 림프구를 선별하는 다른 방법에 있어서, MHC 클래스 I 분자/펩타이드 복합체의 형광(fluorogenic) 테트라머를 세포 독성 T 림프구의 특정 클론을 검출하는데 사용한다 (Altman 등, Science 274:94-96, 1996; Dunbar 등, Curr. Biol . 8:413-416, 1998). 용해성 MHC 클래스 I 분자는 β2 마이크로글로불린과 상기 클래스 I 분자에 결합하는 펩타이드 항원의 존재하의 생체외(in vitro)에서 접힌다. MHC/펩타이드 복합체를 정제한 후 바이오틴으로 표지하였다. 바이오틴 부착된 펩타이드-MHC 복합체을 표지된 아비딘(예컨대, 피코에리트린)와 4:1의 몰비로 혼합하여 테트라머를 형성한다. 그리고 나서, 테트라머를 말초혈 또는 림프절과 같은 세포독성 T 림프구와 접촉시킨다. 상기 테트라머는 펩타이드 항원/MHC 클래스 I 복합체를 인식하는 세포 독성 T 림프구에 결합한다. 상기 테트라머에 결합하는 세포를 형광 제어(fluorescence-controlled) 세포 분류에 의하여 분류하여 반응성 세포 독성 T 림프구를 분리할 수 있다. 그리고 나서, 상기 분리된 세포 독성 T 림프구를 생체외(in vitro) 증식시킬 수 있다.
입양 전이(adoptive transfer)(Greenberg, J. Immunol . 136(5):1917, 1986; Riddel 등, Science 257:238, 1992; Lynch 등, Eur . J. Immunol . 21:1403-1410, 1991; Kast 등, Cell 59:603-614, 1989)라 불리는 치료 방법에 있어서, 소망하는 복합체(예컨대, 수지상 세포)를 제시하는 세포를 치료하고자 하는 환자의 세포 독성 T 림프구와 결합시켜, 특정 세포 독성 T 림프구를 증식시킨다. 그리고 나서, 상기 증식된 세포 독성 T 림프구를 특정 복합체를 제시하는 특이한 비정상 세포 특성을 갖는 세포 이형(anomaly)을 갖는 환자에게 투여한다. 그리고 나면, 상기 세포 독성 T 림프구는 상기 비정상 세포를 용해시키고, 이에 의하여 소망하는 치료 효과가 달성된다.
종종, 환자의 T 세포 레퍼토리 중에서, 이러한 종류의 특정 복합체에 대하여 높은 친화성을 갖는 T 세포들은 내성 발달에 의하여 소멸되기 때문에, 낮은 친화성을 갖는 T 세포만이 증식될 수 있다. 이 때, 대안으로서 T 세포 수용체 자체를 전달시킬 수 있다. 이를 위해서, 또한, 소망하는 복합체 (예컨대, 수지상 세포)를 제시하는 세포를 건강한 개체의 세포 독성 T 림프구와 결합시킨다. 그 결과, 공여체가 상기 특정 복합체와 미리 접촉하지 않았다면, 높은 친화성을 갖는 특이적 세포 독성 T 림프구를 증식시킬 수 있다. 이들 증식된 특이적 T 림프구의 높은 친화성의 T 세포 수용체를 클로닝하고, 예컨대 레트로바이러스 벡터를 사용하여, 유전자 전이를 통하여, 원하는 바와 같은 다른 환자의 T 세포내로 형질 도입시킬 수 있다. 그리고 나서, 이들 유전자 변형된 T 림프구를 사용하여 입양 전이를 수행한다 (Stanislawski 등, Nat Immunol. 2:962-70, 2001; Kessels 등, Nat Immunol. 2:957-61, 2001).
상기 치료 측면은 환자의 비정상 세포 중 적어도 일부가 종양 관련 항원과 HLA 분자와의 복합체를 제시한다는 사실로부터 출발한다. 이러한 세포는 공지의 방법 자체로 동정할 수 있다. 복합체를 제시하는 세포가 동정되자, 이들을 세포 독성 T 림프구를 포함하는 환자로부터 추출한 시료와 조합하여 사용할 수 있었다. 상기 세포 독성 T 림프구가 상기 복합체를 제시하는 세포를 용해한다면, 종양 관련 항원이 제시되었다고 추측할 수 있다.
입양 전이는 본 발명에 따라 적용될 수 있는 치료의 형태인 것만은 아니다. 세포 독성 T 림프구는 또한 공지된 방법 자체로 생체내(in vivo) 생성 가능하다. 한 가지 방법은 상기 복합체를 발현하는 비증식성 세포를 이용한다. 본 발명에서 사용되는 세포는 복합체의 제시에 필요한 하나 또는 양쪽 유전자로 형질 감염된 세포 또는 방사선 조사된 종양 세포와 같이, 복합체 (즉, 항원 펩타이드 및 제시 HLA 분자)를 일반적으로 발현하는 세포일 수 있다. 다양한 세포형을 사용할 수 있다. 또한, 원하는 하나 또는 양쪽 유전자를 운반하는 벡터를 사용하는 것이 가능하다. 바이러스 벡터 또는 박테리아 벡터가 특히 바람직하다. 예컨대, 종양 관련 항원 또는 그 일부를 코딩하는 핵산을 특정 조직 또는 세포 유형에서의 상기 종양 관련 항원 또는 그의 단편의 발현을 제어하는 프로모터 및 인핸서 서열과 기능적으로 연결시킬 수 있다. 상기 핵산을 발현 벡터에 통합시킬 수 있다. 상기 발현 벡터는 외래 핵산을 삽입할 수 있는 비변형 염색체외 핵산, 플라스미드 또는 바이러스 게놈일 수 있다. 종양 관련 항원을 코딩하는 핵산을 또한 레트로바이러스 게놈 내로 삽입하여, 핵산이 표적 조직 또는 표적 세포내로 통합시킬 수 있다. 이러한 시스템에 있어서, 백시니아 바이러스, 폭스 바이러스, 헤르페스 심플렉스 바이러스, 레트로바이러스 또는 아데노바이러스와 같은 미생물이 원하는 유전자를 운반하고, 사실상 숙주 세포를 "감염(infect)"시킨다. 또 다른 바람직한 형태는, 예컨대, 리포좀 전달(liposomal transfer) 또는 전기 영동에 의하여 세포 내로 도입될 수 있는 재조합 RNA 형태로 종양 관련 항원을 도입하는 것이다. 얻어진 세포는 원하는 복합체를 제시하고, 나중에 증식되는 자기 유래 세포 독성 T 림프구에 의하여 인식된다.
항원 제시 세포내로의 생체내 통합을 가능하게 하기 위하여 종양 관련 항원 또는 그 단편을 아쥬반트와 조합함으로써 유사한 효과를 얻을 수 있다. 상기 종양 관련 항원 또는 그 단편은 단백질, DNA (예컨대, 벡터 내에 포함되어), 또는 RNA로서 표현될 수 있다. 상기 종양 관련 항원은 HLA 분자에 대한 펩타이드 파트너를 생산하도록 가공되는 한편, 그의 단편은 추가적인 가공이 필요없이 제시될 수 있다. 후자는 특히, 이들이 HLA 분자에 결합할 수 있는 경우이다. 완전한 항원이 수지상 세포에 의하여 생체내에서 가공되는 투여 형태가, 효과적인 면역 응답에 요구되는 T 헬퍼 세포 응답을 생성할 수 있기 때문에, 바람직하다 (Ossendorp 등, Immunol Lett. 74:75-9, 2000; Ossendorp 등, J. Exp . Med . 187:693-702, 1998). 일반적으로, 종양 관련 항원의 유효량을, 예컨대, 피내(intradermal) 주입을 통하여, 환자에게 투여하는 것이 가능하다. 그러나, 림프절 내로 주입하는 것도 가능하다 (Maloy 등, Proc Natl Acad Sci USA 98:3299-303, 2001). 또한, 수지상 세포내로의 흡수를 촉진시키는 시약과 조합하여 주입하는 것도 가능하다. 종양 관련 항원은 많은 암환자의 T 세포 또는 동종이계 암 항혈청(allogenic cancer antisera)과 반응하는 것이 생체내 바람직하다. 그러나, 이에 대한 자발적인 면역 응답이 미리 존재하지 않는 것들이 특히 중요하다. 명백히, 종양을 용해할 수 있는 이들 면역 응답에 대하여 유도하는 것이 가능하다 (Keogh 등, J. Immunol . 167:787-96, 2001; Appella 등, Biomed Pept Proteins Nucleic Acids 1:177-84, 1995; Wentworth 등, Mol Immunol . 32:603-12, 1995).
본 발명에 개시된 약학 조성물은 또한 면역화를 위한 백신으로서 사용 가능하다. 본 발명에 있어서, "면역화(immunization)" 또는 "백신화(vaccination)"라 함은 항원에 대한 면역 응답을 증가시키거나 활성화시키는 것을 의미한다. 종양 관련 항원 또는 이를 코딩하는 핵산의 사용에 의한 암에 대한 면역화 효과를 테스트하기 위하여 동물 모델을 사용하는 것이 가능하다. 예컨대, 인간 암세포를 마우스에 도입시켜, 암을 유발하고, 종양 관련 항원을 코딩하는 핵산을 하나 이상 투여할 수 있다. 암세포에 대한 효과 (예컨대, 종양 크기의 감소)를 핵산에 의한 면역화의 유효성을 측정함으로서 측정할 수 있다.
면역화를 위한 조성물의 일부로서, 한 가지 이상의 종양 관련 항원 또는 그의 자극 단편을 면역 응답을 유도하거나 면역 응답을 증가시키기 위한 한 가지 이상의 아쥬반트와 함께 투여한다. 아쥬반트는 항원에 통합되거나 또는 후자와 함께 투여되어 면역 응답을 강화시키는 물질이다. 아쥬반트는 항원 보유체(reservoir) (세포외적으로 또는 대식세포 내)를 제공하고, 대식세포를 활성화시키고, 특정 림프구를 자극함으로써 면역 응답을 강화시킨다. 아쥬반트는 알려져 있고, 모노포스포릴 리피드 A (MPL, SmithKline Beecham), QS21 (SmithKline Beecham), DQS21 (SmithKline Beecham; WO 96/33739), QS7, QS17, QS18 및 QS-L1 (So 등, Mol. Cells 7:178-186, 1997)과 같은 사포닌, 불완전 프로인드 아쥬반트(incomplete Freund's adjuvant), 완전 프로인드 아쥬반트(complete Freund's adjuvant), 비타민 E, 몬타나이드(montanide), 알룸(alum), CpG 올리고뉴클레오타이드 (cf. Kreig 등, Nature 374:546-9, 1995) 및 스쿠알렌 및/또는 토코페롤과 같은 생분해성 오일로부터 제조되는 다양한 유중수 (water-in-oil) 에멀젼을 포함하지만, 이에 한정되는 것은 아니다. 펩타이드를 DQS21/MPL와 혼합하여 투여하는 것이 바람직하다. MPL에 대한 DQS21의 비율은 통상적으로 약 1:10 내지 10:1이고, 약 1:5 내지 5:1이 바람직하고, 약 1:1이 특히 바람직하다. 인간에 투여하기 위하여, 백신 제제는 통상적으로 DQS21 및 MPL를 약 1 ㎍ 내지 약 100 ㎍ 범위로 함유한다.
환자의 면역 응답을 자극하는 다른 물질을 또한 투여할 수 있다. 예컨대, 사이토카인을, 그의 림프구에 대한 조절 특성으로 인하여, 백신화에 사용하는 것이 가능하다. 이러한 사이토카인에는, 예컨대, 백신에 대한 보호 작용을 증가시키는 것으로 나타난 인터루킨-12 (IL-12) (cf. Science 268:1432-1434, 1995), GM-CSF 및 IL-18 등이 있다.
면역 응답을 강화시켜 백신화에 사용될 수 있는 화합물이 많이 있다. 상기 화합물은 단백질 또는 핵산의 형태로 제공되는 공동 자극 분자를 포함한다. 이러한 공동 자극 분자의 예로서 수지상 세포 (DC) 상에서 발현되며 T 세포 상에 발현되는 CD28 분자와 상호 작용하는 B7-1 및 B7-2 (각각, CD80 및 CD86) 등이 있다. 이러한 상호 작용은 항원/MHC/TCR 자극된 (신호 1) T 세포에 대한 공동 자극 (신호 2)을 제공하여 상기 T 세포의 증식 및 작용 인자 기능을 증진시킨다. B7도 또한 T 세포 상에서 CTLA4 (CD152)와 반응하며, CTLA4와 B7 리간드를 수반하는 연구에 의하여 B7-CTLA4 상호 작용이 항암 면역성과 CTL 증식을 증진시키는 것으로 나타났다(Zheng, P. 등, Proc . Natl . Acad . Sci . USA 95(11): 6284-6289 (1998)).
B7은 통상적으로 종양 세포에서 발현되지 않으며, 이들은 T 세포에 대하여 유효한 항원 제시 세포 (APCs)가 아니다. B7 발현의 유도에 의하여 종양 세포가 세포 독성 T 림프구의 증식 및 작용 인자의 기능을 보다 효과적으로 자극할 수 있게 된다. B7/IL-6/IL-12의 조합에 의한 공동 자극이 T 세포 집단 내의 IFN-감마 및 Th1-사이토카인 양상의 유도를 나타내며, T 세포 활성을 보다 증진기키는 결과를 가져온다 (Gajewski 등, J. Immunol . 154: 5637-5648 (1995)).
세포 독성 T 림프구의 완전한 활성화 및 완전한 작용 인자 기능은 T 헬퍼 세포 상의 CD40 리간드와 수지상 세포에 의하여 발현되는 CD40 분자 간의 상호 작용을 통한 T 헬퍼 세포의 수반을 필요로 한다 (Ridge 등, Nature 393:474 (1998), Bennett 등, Nature 393:478 (1998), Schoberger 등, Nature 393:480 (1998)). 이러한 공동 자극 신호의 메카니즘은 아마도 B7 생산 및 상기 수지상 세포 (항원 제시 세포)에 의한 관련된 IL-6/IL-12 생산의 증가와 관련있다. 따라서, CD40-CD40L 상호 작용은 신호 1 (항원/MHC-TCR)과 신호 2 (B7-CD28)와의 상호 작용을 보완한다.
수지상 세포를 자극시키기 위하여 항CD40 항체를 사용함으로써, 일반적으로 염증 반응 범위 밖이거나 비전문적 항원 제시 세포 (종양 세포)에 의하여 제시되는 종양 항원에 대한 반응이 직접적으로 증진될 것으로 기대된다. 이러한 상황에서, T 헬퍼 및 B7 공동 자극 신호는 제공되지 않는다. 이러한 메카니즘은 항원 펄스된(antigen-pulsed) 수지상 세포에 기초하는 치료법과 관련하여 또는 T 헬퍼 에피토프가 공지된 TRA 전구체에 정의되어 있지 않은 경우 사용할 수 있었다.
본 발명은 또한 핵산, 폴리펩타이드 또는 펩타이드를 투여하는 것을 제공한다. 폴리펩타이드와 펩타이드는 공지된 방법 자체로 투여할 수 있다. 일례에 있어서, 생체외적(ex vivo) 방법, 즉, 세포를 환자로부터 추출하고 종양 관련 항원을 통합시키기 위하여 상기 세포를 유전자 변형시키고 상기 변형된 세포를 환자 내로 다시 도입시킴으로써, 핵산을 투여한다. 이는 일반적으로 유전자의 기능적 복제를 환자의 세포 내로 생체외적으로(in vitro) 도입시키고, 상기 유전자 변형된 세포를 다시 환자 내로 도입시키는 것을 포함한다. 상기 유전자의 기능적 복제는 상기 유전자가 유전자 변형된 세포에서 발현될 수 있도록 하는 조절 인자의 기능적 조절하에 있다. 형질 감염법 및 형질 도입법은 이 발명이 속하는 기술 분야의 통상의 지식을 가진 자에게 잘 알려져 있다. 본 발명은 또한 표적 제어 리포좀 및 바이러스와 같은 벡터를 사용하여 생체내적으로 핵산을 투여하는 것을 제공한다.
바람직한 예에 있어서, 종양 관련 항원을 코딩하는 핵산을 투여하기 위한 바이러스 벡터는 아데노바이러스, 아데노 관련 바이러스, 백시니아 바이러스 및 약독화 폭스 바이러스 등의 폭스 바이러스, 셈리키 삼림 바이러스 (Semliki Forest virus), 레트로바이러스, 신드비스 바이러스(Sindbis virus) 및 Ty 바이러스 유사 입자로 이루어진 군 중에서 선택된다. 아데노바이러스 및 레트로바이러스가 특히 바람직하다. 레트로바이러스는 통상적으로 복제 결함이 있다 (즉, 이들은 감염성 입자를 생성할 수 없다).
본 발명에 있어서 핵산을 생체외 또는 생체내적으로 세포 내로 도입시키기 위하여 다양한 방법을 사용할 수 있다. 이러한 종류의 방법은 핵산 CaPO4 침전물의 형질 감염, DEAE와 관련된 핵산의 형질 감염, 원하는 핵산을 운반하는 상기 바이러스를 사용하는 형질 감염 또는 감염, 리포좀 매개 형질 감염 등을 포함한다. 구체예에 있어서, 핵산을 특정 세포로 도입시키는 것이 바람직하다. 이러한 예에 있어서, 핵산을 세포에 투여하기 위하여 사용되는 담체 (예컨대, 레트로바이러스 또는 리포좀)는 결합된 표적 제어 분자를 가질 수 있다. 예컨대, 표적 세포 상의 표면 막 단백질에 특이적인 항체 또는 표적 세포 상의 수용체에 대한 리간드와 같은 분자를 상기 핵산 담체 내로 통합시키거나 여기에 부착시킬 수 있다. 바람직한 항체는 종양 관련 항원에 선택적으로 결합하는 항체를 포함한다. 핵산이 리포좀을 통하여 투여되는 것이 소망되는 경우, 표적 제어 및/또는 흡수를 가능하게 하기 위하여, 엔도사이토시스(endocytosis)와 관련된 표면 막 단백질에 결합하는 단백질을 리포좀 제제에 포함시킬 수 있다. 이러한 단백질로는 특정 세포 유형에 특이적인 캡시드 단백질 또는 그 단편, 흡수되는(internalized) 단백질에 대한 항체, 세포내 자리를 어드레싱(addressing)하는 단백질 등이 있다.
본 발명의 치료 조성물은 약학적으로 양립 가능한 제제 형태로 투여될 수 있다. 이러한 제제는 일반적으로 약학적으로 양립 가능한 농도의 염, 완충 물질, 보존제, 담체, 아쥬반트, CpG 및 사이토카인과 같은 면역 강화 물질, 및, 적절한 경우, 다른 치료 활성 화합물을 함유할 수 있다.
본 발명의 상기 치료 활성 화합물은 주사 또는 주입(infusion)과 같은 통상적인 경로를 통하여 투여할 수 있다. 상기 투여는, 예컨대, 경구 투여, 정맥내 투여, 복막내 투여, 근육내 투여, 피하 투여 또는 경피적 투여일 수 있다. 항체는 폐 에어로졸에 의하여 치료적으로 투여하는 것이 바람직하다. 안티센스 핵산은 느린 정맥내 투여에 의하여 투여하는 것이 바람직하다.
본 발명의 조성물은 유효량으로 투여된다. "유효량(effective amount)"이라 함은 단독 또는 추가적인 용량과 함께 소망하는 반응 또는 소망하는 효과를 달성하는 양을 의미한다. 하나 이상의 종양 관련 항원 발현 특성을 갖는 특정 질병 또는 특정 증상의 치료의 경우, 상기 소망하는 반응은 상기 질병의 경과를 억제하는 것과 관계된 것이다. 이는 질병의 진행 속도를 늦추고, 특히, 질병의 진행을 중단시키는 것을 포함한다. 이러한 질병 또는 증상의 치료에 있어서의 소망하는 반응은 또한 상기 질병 또는 상기 증상의 발병을 예방하거나 발병을 지연시키는 것일 수 있다.
본 발명의 조성물의 유효량은 치료하고자 하는 증상, 질병의 증세, 연령, 생리적 조건, 크기 및 체중 등의 환자의 개인적 파라미터, 치료 기간, 동반되는 치료법이 있는 경우 그 유형, 투여의 특정 경로 및 유사 인자에 따라 달라질 것이다.
본 발명의 약학 조성물은 살균 처리되고 치료적 활성 물질을 유효량으로 함유하여 소망하는 반응 또는 소망하는 효과를 발생시키는 것이 바람직하다.
본 발명의 조성물의 투여되는 분량은 투여 유형, 환자의 상태, 소망하는 투여 기간 등과 같은 다양한 파라미터에 따라서 달라질 수 있다. 환자에서의 반응이 초기 분량으로 불충분한 경우, 보다 많은 분량 (또는 다른 보다 국부화된 투여 경로에 의하여 달성되는 효과적으로 증가된 분량)을 사용할 수 있다.
일반적으로, 1 ng 내지 1 mg, 바람직하게는 10 ng 내지 100 ㎍ 분량의 종양 관련 항원을 제제화하고, 치료 또는 면역 응답을 발생시키거나 증가시키기 위하여 투여한다. 종양 관련 항원을 코딩하는 핵산 (DNA 및 RNA)의 투여가 소망되는 경우, 1 ng 내지 0.1 mg 분량을 제제화하고 투여한다.
본 발명의 약학 조성물을 일반적으로 약학적으로 양립 가능한 양 및 약학적으로 양립 가능한 조성으로 투여한다. "약학적으로 양립 가능한(pharmaceutically compatible)"이라 함은 약학 조성물의 활성 성분의 작용과 상호 작용하지 않는 비독성 물질을 의미한다. 이러한 종류의 제제는 일반적으로 염, 완충 물질, 보존제, 담체 및, 적절한 경우, 다른 치료적 활성 화합물을 함유할 수 있다. 의약품에 사용되는 경우, 상기 염은 약학적으로 양립 가능하여야 한다. 그러나, 약학적으로 양립 가능하지 않은 염은 약락적으로 양립 가능한 염을 제조하는데 사용할 수 있으며, 본 발명에 포함된다. 이러한 종류의 약리적 또는 약학적으로 양립 가능한 염은 염산, 브롬화수소산, 황산, 질산, 인산, 말레산, 아세트산, 살리실산, 시트르산, 포름산, 말론산, 숙신산 등의 산으로부터 제조된 것을 포함하지만, 이에 한정되지는 않는다. 약학적으로 양립 가능한 염은 또한 나트륨염, 칼륨염 또는 칼슘염과 같은 알칼리 금속염 또는 알칼리 토금속염으로서 제조될 수 있다.
본 발명의 약학 조성물은 약학적으로 양립 가능한 담체를 함유한다. 본 발명에 있어서, "약학적으로 양립 가능한 담체(pharmaceutically compatible carrier)"라 함은 인간에게 투여하기에 적합한 하나 이상의 양립 가능한 고체 또는 액체 충전제, 희석제 또는 인캡슐레이팅 물질을 의미하는 것이다. "담체(carrier)"라 함은 천연 또는 합성의 유기 또는 무기 성분으로서, 적용을 용이하게 하기 위하여 활성 성분이 결합되어 있는 것을 의미한다. 본 발명의 약학 조성물의 성분은 일반적으로 소망하는 약학적 효과를 실질적으로 손상시키는 상호 작용이 일어나지 않는 것들이다.
본 발명의 약학 조성물은 아세트산 염(acetic acid in a salt), 시트르산염(citric acid in a salt), 붕산염(boric acid in a salt) 및 인산염(phosphoric acid in a salt)과 같은 적절한 완충 물질을 함유할 수 있다.
상기 약학 조성물은 또한, 적절한 경우, 염화벤즈알코늄(benzalkonium chloride), 클로로부탄올, 파라벤 및 티메로살(thimerosal)과 같은 적절한 보존제를 함유할 수 있다.
상기 약학 조성물은 일반적으로 일정한 복용 형태로 제공되며, 알려진 방법 자체로 제조될 수 있다. 본 발명의 약학 조성물은, 예컨대, 캡슐, 타블렛, 로젠지(lozenges), 현탁액, 시럽, 엘릭서(elixir) 또는 에멀젼 형태일 수 있다.
비경구 투여에 적합한 조성물은 일반적으로, 수용자의 혈액과 등장인 것이 바람직한, 활성 화합물의 살균 수성 또는 비수성 제제를 포함한다. 양립 가능한 담체 및 용매의 예로서, 링거액 또는 염화나트륨 등장액이 있다. 또한, 일반적으로 살균된 고정유(fixed oil)를 용액 또는 현탁액 매질로서 사용할 수 있다.
이하, 본 발명은 후술하는 도면 및 실시예에 의하여 보다 상세히 설명할 것이나, 이들 도면 및 실시예는 단지 예시적인 목적으로 사용될 뿐이며 본 발명을 한정하는 것은 아니다. 발명의 상세한 설명 및 실시예에 의하여, 본 발명에 포함되는 유사한 다른 구체예들도 이 발명이 속하는 기술 분야의 통상의 지식을 가진 자가 용이하게 이해할 수 있을 것이다.
[
실시예
]
재료 및 방법
"인 실리코 클로닝(in silico cloning)", "전자적 클로닝(electronic cloning)" 및 "가상 클로닝(virtual cloning)"이라 함은, 단독적으로, 모의 실험실 시험 과정에서도 또한 사용되는, 데이터베이스에 기초한 방법의 사용을 의미한다.
다른 의미로 명시적으로 정의되지 않는 한, 모든 다른 단어 또는 표현은 이 발명이 속하는 기술 분야의 통상의 지식을 가진 자에 의하여 이해되는 바와 같이 사용된다. 기재된 기술 및 방법은 알려진 방법 자체에 의하여 수행되며, 예컨대, Molecular Cloning [Sambrook 등, Laboratory Manual, 2nd Edition (1989) Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y.]등에 기재되어 있다. 키트 및 시약의 사용을 포함하는 모든 방법은 제조자의 사용 설명서에 따라서 수행할 수 있다.
eCT (전자적으로 클로닝된 암/정소 유전자)의 결정을 위한 데이터 마이닝 기초 방법
두 가지의 in silico 방법, 즉, GenBank 키워드 검색 및 cDNAx프로파일러(cDNAxProfiler)을 조합하였다 (도 1). NCBI ENTREZ 검색과 복구 시스템(Retrieval System) (http://www.ncbi.nlm.nih.gov/Entrez)을 사용하여, 정소 조직에서 특이적으로 발현하는 것으로 주석이 달린 후보 유전자에 대한 GenBank 검색을 수행하였다 (Wheeler 등, Nucleic Acids Research 28:10-14, 2000).
키워드로 "정소 특이적 유전자(testis-specific gene)", "정자 특이적 유전자(sperm-specific gene)" "정원세포 특이적 유전자(spermatogonia-specific gene"를 사용하는 질문을 수행하여, 후보자 유전자 (GOI, genes of interest)를 데이터베이스로부터 추출하였다. 상기 검색은, 생물체에 관해서는 "호모 사피언스(homo sapience)", 분자 유형에 관해서는 "mRNA"라는 한정을 사용하여, 이들 데이터베이스의 총정보 중 일부로 한정하여 수행하였다.
발견된 GOI 목록을 동일한 서열에 대해서 상이한 이름을 결정하고 이러한 잉여성(redundancy)을 소거하여 큐레이팅하였다(curated).
키워드 검색으로 얻은 모든 후보자 유전자를 "전자 노던(electronic Northern, eNorthen)" 방법에 의하여 그들의 조직 분포에 대하여 차례로 연구를 수행하였다. 상기 eNorthern은 EST (발현된 서열 택, expressed sequence tag) 데이터베이스 (Adams 등, Science 252:1651, 1991) (http://www.ncbi.nlm.nih.gov/BLAST)에 의한 GOI 서열의 정렬에 기초한다. 상기 GOI와 상동인 것으로 나타난 각각의 EST의 조직 기원을 결정할 수 있고, 이러한 방법으로 모든 EST의 합계에 의하여 GOI의 조직 분포를 예비적으로 평가한다. 태반 및 태아 조직을 제외하고 정소 이외의 정상 세포로부터 유래하는 EST에 대하아ㅕ 상동성을 갖지 않는 GOI 만을 사용하여 추가적인 연구를 수행하였다. 이러한 평가는 또한 공지된 도메인이 잘못 주석이 달린 cDNA 라이브러리를 포함하고 있다는 것을 고려한 것이다 (Scheurle 등, Cancer Res . 60:4037-4043, 2000) (www.fau.edu/cmbb/publications/cancergenes6.htm).
사용된 두 번째 데이터마이닝법은 NCBI Cancer Genome Anatomy Project (http://cgap.nci.nih.gov/Tissues/xProfiler)의 cDNAxProfiler이다 (Hillier 등, Genome Research 6:807-828, 1996; Pennisi, Science 276:1023-1024, 1997). 이는 데이터베이스에 축적된 전사체(transcriptomes) 풀(pool)이 논리 연산자에 의하여 서로 연관되도록 할 수 있다. 혼합 라이브러리를 제외하고, 정소로부터 제조된 모든 발현 라이브러리가 할당된 풀 A를 정의하였다. 정소, 난소 또는 태아 조직을 제외한 정상 조직으로부터 제조된 모든 cDNA 라이브러리를 풀 B에 할당하였다. 일반적으로, 모든 cDNA 라이브러리를 기본적인 제작 방법에 관계없이 사용하였으며, 단, 1000보다 큰 사이즈를 갖는 것들만 허용하였다. BUT NOT 연산자에 의하여 풀 B를 풀 A로부터 디지탈 방식으로 공제하였다. 이러한 방식으로 발견된 GOI 세트에 대하여 또한 eNorthern 연구를 수행하였으며, 문헌적 검색에 의하여 확인하였다.
이러한 조합된 데이터마이닝은 공지된 도메인 내의 모든 약 13,000 전장 유전자를 포함하고, 이들 유전자들 중에서 잠재적 정소 특이적 발현을 갖는 총 140 유전자를 예측한다. 후자 중에서 25 유전자는 CT 유전자 클래스 중에서 이미 알려진 유전자이며, 이는 본 방법의 효율을 강조하는 것이다.
모든 다른 유전자를 특이적 RT-PCR에 의하여 정상 조직에서 일차적으로 평가하였다. 정소 이외의 정상 조직에서 발현하는 것으로 증명된 모든 GOI는 오류-포지티브(false-positive)로서 간주되어야 하였으며, 추가적 연구로부터 제외시켰다. 잔존하는 것들을 광범위하게 다양한 종양 조직의 커다란 패널에서 연구하였다. 여기서 하기에 설명되는 항원이 종양 세포에서 이소적으로 활성화된다는 것을 증명하였다.
RNA
추출,
폴리
-d(T)
프라이밍된
(
primed
)
cDNA
의 제작 및
RT
-
PCR
분석
카오트로픽제(chaotropic agent)로서 구아니듐 이소티오시아네이트를 사용하여 천연 조직 물질로부터 전체 RNA를 추출하였다 (Chomczynski & Sacchi, Anal . Biochem. 162:156-9, 1987). 산성 페놀로 추출하고 이소프로판올로 침전시킨 후, 상기 RNA를 DEPC 처리된 물에 용해시켰다.
제조자의 사용 설명서를 따라서, Superscript II (Invitrogen)을 사용하여, 20 ml의 반응 혼합물에서, 전체 RNA 2 내지 4 ㎍으로부터 첫 번째 가닥 cDNA 합성을 수행하였다. 프라이머로서 dT(18) 올리고뉴클레오타이드를 사용하였다. cDNA의 보존 및 특질을 PCR 30 회에 의한 p53의 증폭에 의하여 조사하였다 (센스 CGTGAGCGCTTCGAGATGTTCCG, 안티센스 CCTAACCAGCTGCCCAACTGTAG, 혼성화 온도 67℃).
첫 번째 가닥 cDNA의 집적소(archive)를 많은 정상 조직 및 종양 본체(entities)로부터 제작하였다. 발현 연구를 위하여, 이들 cDNA 0.5 ml를, GOI 특이적 프라이머(아래 참조) 및 HotStarTaq DNA 중합효소 (Qiagen) 1 U를 사용하여, 30 ml의 반응 혼합물에서 증폭시켰다. 각각의 반응 혼합물은 dNTPs 0.3 mM, 각각의 프라이머 0.3 mM 및 10 x 반응 완충물 3 ml을 함유하였다.
상기 프라이머는 서로 다른 두 개의 엑손에 위치하도록 선택하였으며, 오류-포지티브 결과에 대한 원인인 게놈 DNA의 오염에 의한 간섭의 배제를 주형인 비가역적(nonreverse) 전사된 DNA를 테스트하여 확인하였다. 95 ℃에서 15 분 후, HotStarTaq DNA 중합효소를 활성화시키기 위하여, PCR 35 회를 수행하였다 (94 ℃에서 1 분, 특정 혼성 온도에서 1 분, 72 ℃에서 2 분 및 72 ℃에서 6 분동안 최종적으로 신장시킴).
이러한 반응물 20 ㎕을 분류하고 브롬화에티듐 염색된 아가로오스 겔 상에서 분석하였다.
아래의 프라이머를 사용하여 표시된 혼성화 온도에서의 해당 항원의 발현을 분석하였다.
LDH-C (67 ℃)
센스 TGCCGTAGGCATGGCTTGTGC, 안티센스 CAACATCTGAGACACCATTCC
TPTE (64 ℃)
센스 TGGATGTCACTCTCATCCTTG, 안티센스 CCATAGTTCCTGTTCTATCTG
TSBP (63 ℃)
센스 TCTAGCACTGTCTCGATCAAG, 안티센스 TGTCCTCTTGGTACATCTGAC
MS4A12 (66 ℃)
센스 CTGTGTCAGCATCCAAGGAGC, 안티센스 TTCACCTTTGCCAGCATGTAG
BRCO1 (60 ℃)
센스 CTTGCTCTGAGTCATCAGATG, 안티센스 CACAGAATATGAGCCATACAG
TPX1 (65 ℃)
센스 TTTTGTCTATGGTGTAGGACC, 안티센스 GGAATGGCAATGATGTTACAG
무작위 헥사머 프라이밍된 ( hexamer - primed ) cDNA 의 제작 및 정량적 실시간(quantitative real time) PCR
LDHC 발현을 실시간 PCR에 의하여 정량 분석하였다.
ABI PRISM Sequence Detection System (PE Biosystems, USA)을 사용하는 정량적 실시간 PCR의 원리는 형광 리포터 염료의 방출을 통하여 PCR 산물을 직접적이고 특이적으로 검출하기 위하여 Taq DNA 중합효소의 5'-3' 엑소뉴클레아제(exonuclease) 활성을 이용한다. 센스 프라이머 및 안티센스 프라이머 외에도, 상기 PCR은 PCR 산물의 서열과 혼성화하는 이중 형광 표지된 프로브(TaqMan probe)를 사용한다. 상기 프로브는 리포터 염료 (예컨대, FAM)가 결합된 표지된 5'와 소광(quencher) 염료 (예컨대, TAMRA)와 결합된 3'이다. 상기 프로브가 본래 상태라면, 소광제에 대한 리포터의 공간적 접근성이 리포터 형광의 방출을 억제한다. 상기 프로브가 PCR 동안에 PCR 산물과 혼성화한다면, 상기 프로브는 Taq DNA 중합효소의 5'-3' 엑소뉴클레아제 활성에 의하여 절단되고 리포터 형광의 억제가 제거된다. 표적 증폭의 결과로서의 리포터 형광의 증가는 각각의 PCR 순환 후에 측정하며 정량화에 사용한다. 표적 유전자의 발현은 연구하고자 하는 조직에서 지속적으로 발현하는 대조군 유전자의 발현에 대하여 상대적으로 또는 절대적으로 정량화한다. LDHC 발현을, 상기 시료를 "하우스키핑(housekeeping)" 유전자인 18s RNA에 대하여 표준화시킨 후, ΔΔ-Ct법 (PE Biosystems, USA)을 사용하여 계산하였다. 상기 반응은 이중 혼합물에서 수행하였고 두 번 측정하였다. High Capacity cDNA Archive Kit (PE Biosystems, USA)를 사용하여 cDNA를 합성하고, 제조자의 사용 설명서에 따라서 헥사머 프라이머를 합성하였다. 각각의 경우에 있어서, 희석된 cDNA 5 ㎕를 총부피 25 ㎕로 PCR에 사용하였다: 센스 프라이머 (GGTGTCACTTCTGTGCCTTCCT) 300 nM; 안티센스 프라이머 (CGGCACCAGTTCCAACAATAG) 300 nM; TaqMan 프로브 (CAAAGGTTCTCCAAATGT) 250 nM; 센스 프라이머 18s RNA 50 nM; 안티센스 프라이머 18s RNA 50 nM; 18s RNA 시료 250 nM; 12.5 ㎕ TaqMan Universal PCR Master Mix; 최초 변성 95 ℃ (10 분); 95 ℃ (15 초); 60 ℃ (1 분); 40 회. 엑손 1과 엑손 2의 경계를 넘는 128 bp 산물의 증폭에 의하여, 본 명세서에 개시된 모든 LDHC 스플라이스 변이체를 상기 정량화에 포함시켰다.
클로닝
및 서열 분석
통상적인 방법에 의하여 전장 유전자와 유전자 단편을 클로닝하였다. pfu 프루프리딩 중합효소(Stratagene)을 사용하여 대응 항원을 증폭시켜서 상기 서열을 결정하였다. PCR 완료 후, 제조자의 사용 설명서에 따라서 상기 단편을 TOPO-TA 벡터내로 클로닝하기 위하여, 상기 증폭체(amplicon) 끝을 HotStarTaq DNA 중합효소를 사용하여 연결하였다. 상업적 시설에서 서열 분석을 수행하였다. 상기 서열은 통상적인 예측 프로그램 및 알고리즘에 의하여 분석하였다.
실시예
1:
신규한
종양 항원인
LDH
C의 동정
LDH C (SEQ ID NO:1) 및 그의 번역 산물 (SEQ ID NO:6)은 락테이트 탈수소 효소 계통의 정소 특이적 동질 효소(isoenzyme)로서 설명되어 있다. 상기 서열은 GenBank에 공지되어 있다 (accession number: NM_017448). 상기 효소는 140 kDa 분자량을 갖는 호모테트라머를 형성한다 (Goldberg, E. 등, Contraception 64(2):93-8, 2001; Cooker 등, Biol . Reprod . 48(6):1309-19, 1993; Gupta, G.S., Crit . Rev. Biochem . Mol . Biol . 34(6):361-85, 1999).
어디에서나 보편적으로 발현되는 관련 동질 효소 LDH A 및 LDH B를 교차 증폭시키지 않으며, 정소 특이적인 것으로 전술된 LDH C 원형 서열 NM_017448에 기초한 프라이머 쌍 (5'-TGCCGTAGGCATGGCTTGTGC-3' 5'-CAACATCTGAGACACCATTCC-3')을 이용하는 발현 분석을 위한 RT-PCR 연구는, 본 발명에 있어서, 테스트된 모든 정상 조직에서 발현이 일어나지 않음을 확인하였으며, 체세포에서의 상기 항원의 엄격산 전사 억제가 종양에의 경우에는 제거되었음을 보여주었다 (표 1 참조). CT 유전자에 전형적으로 전술된 바와 같이, LDH C는 많은 종양 본체(entities)로 발현되었다.
| 조직 | 테스트된 총 수 | 양성 | % |
| 흑색종 (Melanoma) | 16 | 7 | 44 |
| 유방 암종 (Mammary carcinomas) | 20 | 7 | 35 |
| 대장 종양 (Colorectal tumors) | 20 | 3 | 15 |
| 전립선 암종 (Prostate carcinomas) | 8 | 3 | 38 |
| 기관지 암종 (Bronchial carcinomas) | 17 | 8 | 47 |
| 신장 세포 암종 (Kidney cell carcinomas) | 7 | 4 | 57 |
| 난소 안종 (Ovarian carcinomas) | 7 | 3 | 43 |
| 갑상선 암종 (Thyroid carcinomas) | 4 | 1 | 25 |
| 자궁 경부 암종 (Cervical carcinomas) | 6 | 5 | 83 |
| 흑색종 세포계 (Melanoma cell lines) | 8 | 5 | 63 |
| 기관지 암종 세포계 (Bronchial carcinoma cell lines) |
6 | 2 | 33 |
상기의 PCR 프라이머를 사용하여 얻어진 증폭 산물의 예상 크기는 824 bp이다. 그러나, 본 발명에 있어서, 다수의 추가적인 밴드의 증폭이 종양에서 관찰되었으며, 정소에서는 관찰되지 않았다. 이는 대체적(alternative) 스플라이스 변이체의 존재를 나타내는 것이기 때문에, 완전한 개방 해독틀(complete open reading frame)을 LDH-C 특이적 프라이머 (5'-TAGCGCCTCAACTGTCGTTGG-3', 5'-CAACATCTGAGACACCATTCC-3')를 사용하여 증폭시키고, 독립적인 전장 클론을 서열 분석하였다. SEQ ID NO:1에 기재된 LDH C 서열의 원형 ORF 및 염색체 11 상의 게놈 서열과의 정렬에 의하여 추가적 스플라이스 변이체 (SEQ ID NO:2 내지 5)를 확인하였다. 상기 대체적 스플라이스는 엑손 3 (SEQ ID NO:2), 두 개의 엑손 3 및 4 (SEQ ID NO:3), 엑손 3, 6 및 7 (SEQ ID NO:4) 또는 엑손 7 (SEQ ID NO:5)의 결여를 초래한다 (도 2 참조).
이들 신규한 스플라이스 변이체는 오직 종양에서만 생성되었고, 정소에서는 생성되지 않았다. 대체적 스플라이싱은 해독틀의 변화를 가져오고, SEQ ID NO:7 내지 13 (SEQ ID NO:7에 대한 ORF: SEQ ID NO:2의 뉴클레오타이드 위치 59-214 및, 각각, SEQ ID NO:4; SEQ ID NO:8에 대한 ORF: SEQ ID NO:2의 뉴클레오타이드 위치 289-939; SEQ ID NO:9에 대한 ORF: SEQ ID NO:3의 뉴클레오타이드 위치 59-196; SEQ ID NO:10에 대한 ORF: SEQ ID NO:3의 뉴클레오타이드 위치 535-765; SEQ ID NO:11에 대한 ORF: SEQ ID NO:4의 뉴클레오타이드 위치 289-618; SEQ ID NO:12의 ORF: SEQ ID NO:4의 뉴클레오타이드 위치 497-697; SEQ ID NO:13에 대한 ORF: SEQ ID NO:5의 뉴클레오타이드 위치 59-784)에 나타낸 아미노산 서열을 코딩하는 새로운 가능한 ORFs를 발생시킨다 (도 2 및 3 참조). 미숙한 종결은 별도로 하고, 코딩되는 단백질을 N-말단 및 C-말단 모두에서 절단되도록 하기 위하여 대체적 개시 코돈을 이용하는 것 또한 가능하다.
SEQ ID NO:8 및 SEQ ID NO:10은 원형 단백질의 절단된 부분을 나타내며, SEQ ID NO:7, SEQ ID NO:9, SEQ ID NO:11, SEQ ID NO:12 및 SEQ ID NO:13의 단백질 서열은 추가적으로 변형되고 종양 특이적 에피토프(도 3에 굵은체로 표시)만을 포함한다. 종양 특이적 에피토프를 유발시킬 수 있는 펩타이드 부위는 다음과 같다 (프레임 쉬프트에 의하여 생성된 정확히 종양 특이적인 부위를 밑줄 그어 표시하였다):
SEQ ID NO:14: GAVGMACAISILLK ITVYLQTPE (SEQ ID NO:7 중 일부)
SEQ ID NO:15: GAVGMACAISILLK WIF (SEQ ID NO:9 중 일부)
SEQ ID NO:16: GWIIGEHGDSS GIIWNKRRTLSQYPLCLGAEWCLRCCEN (SEQ ID NO:11 중 일부)
SEQ ID NO:17: MVGLLENMVILV GLYGIKEELFL (SEQ ID NO:12 중 일부)
SEQ ID NO:18: EHWKNIHKQVIQ RDYME (SEQ ID NO:13 중 일부)
이들 부위는 MHC I 또는 MHC II 분자 상에서 T 림프구에 의하여 인식되며 정확한 종양 특이적 응답을 유발할 수 있는 에피토프를 잠재적으로 포함할 수 있다.
예측된 단백질이 모두, 혐기성 해당(glycolysis)의 마지막 단계를 의미하는, 피루베이트의 락테이트로의 NADH 의존적 대사를 위한 촉매적 락테이트 탈수소 효소 도메인을 갖는 것은 아니다. 이러한 도메인은 락테이트 탈수소 효소로서의 효소적 기능에 요구되는 것이다 (도 3에 네모틀로 표시). 예컨대, TMpred 및 pSORT (Nakai & Kanehisa, 1992)를 이용하는, 다른 분석에 의하여, 추정 단백질의 서로 다른 세포 하부 위치화를 예측한다.
본 발명에 있어서, 발현 정도를 특이적 프라이머-시료 세트를 사용하는 실시간 PCR에 의하여 정량화하였다. 증폭체(amplicon)가 엑손 1과 엑손 2 간의 접합점에 존재하여 모든 변이체 (SEQ ID NO:1 내지 5)를 검출한다. 또한, 이러한 연구에 의하여 정소를 제외한 모든 정상 조직에서 어떠한 전사체도 검출되지 않는다. 이들에 의하여, 종양에서 상당한 수준의 발현이 있음을 확인한다 (도 4 참조).
LDHC 특이적 폴리클로날 항체를 가장 N-말단 부위 MSTVKEQLIEKLIEDDENSQ (SEQ ID NO:80)로부터 펩타이드를 선택하여 본 발명에 따라서 생산하였다. LDHC 특이적 항체를 상기 펨타이드를 이용하여 래빗에서 생산하였다. 이어지는 단백질 발현에 대한 연구에 의하여, 정소 및 다양한 종양에서의 선택적 LDHC 발현을 확인하였다. 또한, 본 발명에 따른 면역 조직학적 연구에 의하여, 미토콘드리아에서의 LDHC의 사이토크롬 C와의 독특한 공동 위치화를 밝혔다. 이는 LDHC가 종양의 호흡쇄에 있어서 중요한 역학을 한다는 것을 보여주는 것이다.
실시예
2:
신규한
종양 항원인
TPTE
의 동정
TPTE 전사체 (SEQ ID NO:19) 및 이의 번역 산물 (SEQ ID NO:22)의 서열은 GenBank에 공지되어 있다 (accession number NM_013315) [Walker, S.M. 등, Biochem. J. 360(Pt 2):277-83, 2001; Guipponi M. 등, Hum . Genet . 107(2):127-31, 2000; Chen H. 등, Hum . Genet . 105(5):399-409, 1999]. TPTE는 가능한 막통과 티로신포스파타아제를 코딩하는 유전자로 기재되어 있으며, 21번, 13번, 15번, 22번 및 Y 염색체의 동원체 주변 부의에 위치하는 정소 특이적 발현 특성을 갖는다 (Chen, H. 등, Hum . Genet . 105:399-409, 1999). 본 발명에 따른 정렬 연구에 의하여, 3번 및 7번 염색체 상의 상동 게놈 서열을 추가적으로 밝혔다.
본 발명에 있어서, PCR 프라이머 (5'-TGGATGTCACTCTCATCCTTG-3' 및 5'-CCATAGTTCCTGTTCTATCTG-3')를 TPTE (SEQ ID NO:19) 서열에 기초하여 생성하고, 많은 인간 조직에서 RT-PCR 분석에 사용하였다 (95 ℃ 15 분; 94 ℃ 1 분; 63 ℃ 1 분; 72 ℃ 1 분; 35 회). 정상 조직에서의 발현은 정소에 국한된 것으로 나타났다. 다른 eCT에 대하여 설명한 바와 같이, TPTE 변이체는 본 발명에 있어서 많은 조직에서 이소적으로 활성화되는 것으로 나타났다 (표 2 참조). 본 발명에 있어서, 정소 조직 및 종양 조직에서 발현하고 프레임 쉬프트가 일어나 서열 부위가 변경된, 추가적인 TPTE 스플라이스 변이체를 동정하였다 (SEQ ID NO:20, SEQ ID NO:21, SEQ ID NO:54, SEQ ID NO:55, SEQ ID NO:56 및 SEQ ID NO:57) (도 5).
| 조직 | 테트트된 총 수 | 양성 | % |
| 흑색종 | 18 | 9 | 50 |
| 유방 암종 | 20 | 4 | 20 |
| 대장 종양 | 20 | 0 | 0 |
| 전립선 암종 | 8 | 3 | 38 |
| 기관지 암종 | 23 | 9 | 39 |
| 신장 세포 암종 | 7 | 0 | 0 |
| 난소 암종 | 7 | 2 | 29 |
| 갑상선 암종 | 4 | 0 | 0 |
| 자궁 경부 암종 | 6 | 1 | 17 |
| 흑색종 세포계 | 8 | 4 | 50 |
| 기관지 암종 세포계 | 6 | 2 | 33 |
| 포유류 암종 세포계 | 5 | 4 | 80 |
상기 TPTE 게놈 서열은 24 엑손 (accession number NT_029430)을 포함한다. SEQ ID NO:19의 전사체는 이들 엑손 모두를 포함한다. SEQ ID NO:20의 스플라이스 변이체는 엑손 7을 편집(splicing out)하여 제작된다. SEQ ID NO:21의 스플라이스 변이체는 엑손 15 하류 쪽 인트론의 부분적 결합을 나타낸다. SEQ ID NO:54, SEQ ID NO:55, SEQ ID NO:56 및 SEQ ID NO:57의 변이체들이 나타내는 바와 같이, 엑손 18, 19, 20 및 21을 편집(splicing out)하는 것 또한 대체적(alternative)으로 가능하다.
이러한 대체적 스플라이싱은, 원칙적으로 해독틀을 유지하면서, 코딩되는 단백질의 변형을 유발한다 (도 6). 예컨대, SEQ ID NO:20 (SEQ ID NO:23)의 서열에 의하여 코딩되는 번역 산물은 SEQ ID NO:22의 서열과 비교하여 13 아미노산 결실을 갖는다. SEQ ID NO:21 (SEQ ID NO:24)의 서열에 의하여 코딩되는 번역 산물은 분자의 중앙 부위에 추가적인 삽입을 운반하여 다른 변이체와 14 아미노산이 상이하다.
변이체 SEQ ID NO:54, SEQ ID NO:55, SEQ ID NO:56 및 SEQ ID NO:57의 번역 산물, 즉, 단백질 SEQ ID NO:58, SEQ ID NO:59, SEQ ID NO:60 및 SEQ ID NO:61을 유사하게 변형시킨다.
기능적 도메인을 예측하기 위한 분석에 의하여, SEQ ID NO:22, SEQ ID NO:23, SEQ ID NO:24, SEQ ID NO:58 및 SED ID NO:60에 대한 티로신포스파타아제 도메인이 존재함을 밝혔지만, SEQ ID NO:59 및 SEQ ID NO:61에 대한 것은 존재하지 않는 것으로 나타났다. 모든 변이체에 대하여, 3 내지 4 막통과 도메인을 예측하였다 (도 6).
특이적 항체를 사용하는 TPTE 항원 발현 분석에 의하여, 정소 및 다수의 상이한 종양에서의 선택적 발현을 확인하였다. 공동 위치화 연구는 또한 본 발명에 있어서 TPTE가 종양 세포의 세포 표면에 클래스 I 면역 글로불린과 함께 위치하고 있음을 밝혔다. 이미, TPTE은 골지(Golgi) 관련 단백질로서 설명되어 있다. TPTE이 종양 세포의 세포 표면에서 발현하기 때문에, 이러한 종양 항원은 본 발명에 있어서 진단적 또는 치료적 모노클로날 항체의 개발을 위한 우수한 표적으로서 적합하다. 예측되는 TPTE의 막 위상(topology)에 의하여, 세포외 노출되는 부위가 본 발명의 목적에 특히 적합하다. 본 발명에 있어서, 이는 펩타이드 FTDSKLYIPLEYRS (SEQ ID NO:81)와 FDIKLLRNIPRWT (SEQ ID NO: 82)를 포함한다. 또한, TPTE는 종양 세포의 이동(migration)을 촉진시키는 것으로 나타났다. 이를 위하여, 진핵 세포의 프로모터의 조절 및 조절 세포 하에서 TPTE로 형질 감염된 종양 세포를 "보이덴 챔버(Boyden chamber)" 이동 실험에서, 이들이 유도된 이동성을 보이는지 여부에 대하여 시험하였다. 본 발명에 있어서, TPTE 형질 감염된 세포는, 4 개의 독립적인 시험에서, 현저하게 (3 배) 증가된 이동성을 보여주었다. 이러한 기능적 데이터는 TPTE가 종양의 전이에 중요한 역할을 한다는 것을 나타낸다. 따라서, 본 발명에 따라서, 예컨대, 발현 벡터 또는 레트로바이러스에 의한 서로 다른 RNA 간섭 (RNAi) 방법, 안티센스 RNA를 사용하거나 소분자를 사용하여, 종양 세포 내에서 내생 TPTE 활성을 억제하는 처리에 의하여, 전이를 감소시켜 매우 중요한 치료적 효과를 거둘 수 있었다. 종양에서의 포스파타아제의 활성, 증가된 이동성 및 증가된 전이 형성 간의 인과 관계가 최근 PTEN 티로신포스파타아제에 대하여 확립되었다 (Iijima and Devreotes Cell 109:599-610, 2002).
실시예
3: 새로운 종양 항원인
TSBP
의 동정
본 발명에서 사용된 전자 클로닝 방법에 의하여 TSBP (SEQ ID NO:29)와 이로부터 유도된 단백질 (SEQ ID NO:30)을 생산하였다. 상기 유전자는 이미 정소 특이적으로 조절되는 것으로 설명되어 있다 (accession number NM_006781). 상기 유전자는 염기성 단백질을 코딩하고 MHC 복합체 (C6orf10)을 코딩하는 서열과 인접하여 6번 염색체 상에 위치할 것으로 예상된다 (Stammers M. 등, Immunogenetics 51(4-5):373-82, 2000). 본 발명에 있어서, 이미 설명된 서열은 맞지 않는 것으로 나타났다. 본 발명의 서열은 공지된 서열과 실질적으로 다르다. 본 발명에 있어서, 3 개의 상이한 스플라이싱 변이체를 클로닝하였다. 본 발명에서 발견된 TSBP 변이체의 뉴클레오타이드 서열 (SEQ ID NO:31, SEQ ID NO: 32 및 SEQ ID NO:33)에 있어서의 차이점을 도 7에 나타내었다 (다른 부분을 굵은체로 표시). 이들은 프레임 쉬프트를 유발하여 본 발명에서 발견되는 TSBP 변이체에 의하여 코딩되는 단백질 (SEQ ID NO:34, SEQ ID NO:35 및 SEQ ID NO:36)이 이전에 기술된 단백질 (SEQ ID NO:30)과 실질적으로 달라지게 된다 (SEQ ID NO:30) (도 8).
본 발명에 있어서, 이 항원이 정상 조직에서 엄격하게 전사 억제된다는 것을 확인하였다 (PCR 프라이머 5'-TCTAGCACTGTCTCGATCAAG-3' 및 5'-TGTCCTCTTGGTACATCTGAC-3'). 그러나, 연구된 25 정상 조직에 있어서, TSBP는, 정소는 별론으로 하고, 정상 림프절 조직에서 발현하였다. 본 발명에 있어서, 종양에서의 TSBP의 이소적 활성화 또한 탐지되었으며, 따라서, 이는 종양 표지 또는 종양 관련 항원으로 자격이 있다 (표 3).
TSBP 발현은 초기 종양 조직에서 발견되지만, 해당 종양 본체의 영구적 세포계에서는 발견되지 않는다. 또한, 상기 유전자는 동맥에서 특이적으로 발현하고 혈관 형태 형성(morphogenesis)에 수반되는 Notch 4에 바로 인접하여 있다. 이들은 상기 유전자가 특이적 내피 세포에 대한 표지라는 표시이다. 따라서, TSBP는 종양 내피 및 신혈관(neovascular) 표적화에 대한 잠재적 표지로서의 역할을 할 수 있다.
결론적으로, TSBP 프로모터를 림프절에서의 선택적인 발현이 소망되는 다른 유전자 산물로 클로닝할 수 있다.
특이적 항원을 사용하여 SBP 항원 발현을 분석하여, 정소 및 림프절 뿐 아니라 흑색종 및 기관지 암종에서의 선택적인 위치화를 확인하였다. 또한, GFP 표지된 TSBP를 사용하는 면역 조직학적 연구에 의하여 독특한 핵주위 축적을 밝혔다.
| 조직 | 테스트된 총 수 | 양성 | % |
| 흑색종 | 12 | 2 | 16 |
| 유방 암종 | 15 | 0 | - |
| 대장 종양 | 15 | 0 | - |
| 전립선 암종 | 8 | 0 | - |
| 기관지 암종 | 7 | 17 | 41 |
| 신장 세포 암종 | 7 | 0 | - |
| 난소 암종 | 7 | 0 | - |
| 갑상선 암종 | 4 | 0 | - |
| 자궁 경부 암종 | 6 | 0 | - |
| 흑색종 세포계 | 8 | 0 | - |
| 기관지 암종 세포계 | 6 | 0 | - |
실시예
4:
신규한
종양 항원인
MS4A12
의 동정
MS4A12 (SEQ ID NO:37, accession number NM_017716)와 이의 번역 산물 (SEQ ID NO:38)이 B 세포 특이적 항원 CD20, 조혈 세포 특이적 단백질 HTm4 및 고친화성 IgE 수용체의 β 사슬과 관련된 다중 유전자족(multigene family)의 구성원으로서 기술되어 있다. 모든 유전자족 구성원은 적어도 4 개의 잠재적 막통과 도메인을 갖고 C-말단 및 N-말단이 모두 세포질 내에 있다는 특성을 갖는다 (Liang Y. 등, Immunogenetics 53(5):357-68, 2001; Liang Y. & Tedder, Genomics 72(2):119-27, 2001). 본 발명에 있어서, MS4A12에 대하여 RT-PCR 연구를 수행하였다. 공지된 MS4A12 서열 (NM_017716)에 기초하여 프라이머를 선택하였다 (센스: CTGTGTCAGCATCCAAGGAGC, 안티센스: TTCACCTTTGCCAGCATGTAG). 시험된 조직에 있어서, 정소, 결장 (6/8) 및 대장 암종 (colon-Ca's) (16/20) 및 결장 전이 (12/15)에서만 발현이 검출되었다 (도 9).
결장 전이에 있어서의 높은 발생률에 의하여 TSBP은 흥미있는 진단 및 치료 표적이 된다. 본 발명에 있어서, 단백질 서열 GVAGQDYWAVLSGKG (SEQ ID NO:83)를 포함하는 예측된 세포외 부위는 모노클로날 항체와 작은 화학적 억제제를 생산하는데 특히 적합하다. 본 발명에 있어서, 세포막에서의 MS4A12 단백질의 세포내 위치화 공초점 면역 형광에서의 플라즈마 멤브레인 표지를 사용하는 형광 중첩(superposition)에 의하여 확인하였다.
| 회장 | + |
| 결장 | + |
| 간 | - |
| 폐 | - |
| 림프절 | - |
| 위 | - |
| 비장 | - |
| 부신 | - |
| 신장 | - |
| 식도 | - |
| 난소 | - |
| 직장 | + |
| 정소 | + |
| 흉선 | - |
| 피부 | - |
| 유방 | - |
| 췌장 | - |
| PBMC | - |
| PBMC act. | - |
| 전립선 | - |
| 갑상선 | - |
| 난관(Tube) | - |
| 자궁 | - |
| 대뇌 | - |
| 소뇌 | - |
| 대장 종양 | 16/20 |
| 대장 종양 전이 | 12/15 |
따라서, MS4A12는 정상 결장 내피에 대하여 세포막 위치 분화 항원이며, 또한 대장 종양 및 전이에서도 발현한다.
실시예
5:
신규한
항원인
BRCO1
의 동정
BRCO1 및 이의 번역 산물은 이전에 기술되어 있지 않다. 본 발명의 데이터 마이닝법에 의하여 EST (expressed sequence tag) AI668620이 제작되었다. 발현 분석을 위하여 특정 프라이머 (센스: CTTGCTCTGAGTCATCAGATG, 안티센스: CACAGAATATGAGCCATACAG)를 사용하는 RT-PCR 연구를 수행하였다. 본 발명에 있어서, 정소 조직에서 뿐 아니라 정상 유선에서의 특이적으로 발현이 발견되었다 (Table 5). 다른 모든 조직에 있어서, 이 항원은 전사 억제된다. 이것은 유선 종양에서도 마찬가지로 검출된다 (20 중에서 20). BRCO1는 정상 유선 조직에서의 발현과 비교하여 유방 종양에서 뚜렷하게 과발현한다 (도 10).
EST 콘틱(contigs) (다음의 EST들이 포함됨: AW137203, BF327792, BF327797, BE069044 및 BF330665), 1500 bp 이상의 이 전사체를 본 발명에 따라서 전자적 전장 클로닝 (SEQ ID NO:39)에 의하여 클로닝하였다. 염색체 10p11-12에 대하여 서열을 지도화하였다. 동일한 부위에서, 바로 인접하여, 유방 분화 항원에 대한 유전자, NY-BR-1이 이미 기술되어 있다 (NM 052997; Jager, D. 등, Cancer Res . 61(5):2055-61, 2001).
| 회장 | - |
| 결장 | - |
| 간 | - |
| 폐 | - |
| 림프절 | - |
| 위 | - |
| 비장 | - |
| 부신 | - |
| 신장 | - |
| 식도 | - |
| 난소 | - |
| 직장 | - |
| 정소 | + |
| 흉선 | - |
| 피부 | - |
| 유방 | + |
| 췌장 | - |
| PBMC | - |
| PBMC act. | - |
| 전립선 | - |
| 갑상선 | - |
| 난관 | - |
| 자궁 | - |
| 대뇌 | - |
| 소뇌 | - |
| 유방 암종 | ++ (20/20) |
맞춤 쌍 (matched pair, 유방 암종 및 인접 정상 조직) 연구에 의하여 정상 조직과 비교하여 유방 암종의 70%에서 BRCO1이 과발현함을 밝혔다.
따라서, BRCO1은 유방 종양에서 과발현하는 정상 유선 내피에 대한 새로운 분화 항원이다.
실시예
6:
신규한
종양 항원인
TPX1
의 동정
TPX1 (Acc. No. NM 003296; SEQ ID NO: 40) 및 이의 번역 산물 (SEQ ID NO:41)의 서열이 알려져 있다. 상기 항원은 이미 정소 특이적인 것으로, 즉, 정자의 아크로솜(acrosome) 및 외부 섬유 요소로서 기재되어 있다. 이미, 정자가 세르톨리 세포(Sertoli cell)에 부착시에 접착 분자로서 수반되는 것이 상기 항원 덕분이라고 알려져 있다 (O'Bryan, M.K. 등, Mol . Reprod . Dev . 58(1):116-25, 2001; Maeda, T. 등, Dev . Growth Differ . 41(6):715-22, 1999). 본 발명은 최초로 고형암에서의 TPX1의 이상 발현을 밝혔다 (표 6). TPX1와 호중구(neutrophile) 특이적 매트릭스 당단백질 SGP 28 (Kjeldsen 등, FEBS Lett 380:246-259, 1996) 간의 현저한 아미노산 상동성 때문에, 펩타이드 SREVTTNAQR (SEQ ID NO:84)를 포함하는 TPX1 특이적 단백질 서열이 본 발명에 있어서 진단 및 치료 분자를 제조하는데 적합하다.
| 조직 | 테트트된 총 수 | 양성 | % |
| 흑색종 | 16 | 1 | 6 |
| 유방 암종 | 20 | 3 | 15 |
| 대장 종양 | 20 | 0 | 0 |
| 전립선 암종 | 8 | 3 | 37 |
| 기관지 암종 | 17 | 2 | 11 |
| 신장 세포 암종 | 7 | 1 | 14 |
| 난소 암종 | 7 | 1 | 14 |
| 갑상선 암종 | 4 | 0 | 0 |
| 자궁 경부 암종 | 6 | 1 | 16 |
| 흑색종 세포계 | 8 | 2 | 25 |
| 기관지 암종 세포계 | 6 | 1 | 16 |
실시예
7:
신규한
종양 유전자 산물인
BRCO2
의 동정
BROC2 및 그의 번역 산물은 이전에 공지되어 있지 않다. 본 발명의 방법에 의하여 ESTs (expressed sequence tag) BE069341, BF330573 및 AA601511를 제작하였다. 특정 프라이머 (센스: AGACATGGCTCAGATGTGCAG, 안티센스: GGAAATTAGCAAGGCTCTCGC)를 사용하는 RT-PCR에 연구를 수행하여 발현 분석을 하였다. 본 발명에 있어서, 정소 조직 뿐 아니라 정상 유선에서도 특이적 발현이 관찰되었다 (표 7). 모든 다른 조직에 있어서, 이 유전자 산물은 전사 억제된다. 이는 유선 종양에서도 유사하게 검출된다. EST 콘틱 (다음의 ESTs이 포함됨: BF330573, AL044891 및 AA601511)을 사용하여, 전자적 전장 클로닝에 의하여 본 발명에 따라서 1300 bp의 상기 전사체를 클로닝하였다 (SEQ ID 62). 염색체 10p11-12에 대하여 서열을 지도화하였다. 동일한 부위에서, 바로 인접하여, 유방 분화 유전자 산물을 코딩하는 유전자, NY-BR-1이 이미 개시되어 있으며 (NM 052997; Jager, D. 등, Cancer Res . 61(5):2055-61, 2001), 여기에, 상기 실시예 6에 기재된 BRCO1이 위치한다. 본 발명에 있어서, 다른 유전자 분석에 의하여 SEQ ID NO:62 하에 열거된 서열이, 이전에 기재된 바 없는, NY-BR-1 유전자의 3' 미번역 부위를 나타낸다는 것을 확인하였다.
| 조직 | 발현 |
| 정소 | + |
| 유방 | + |
| 피부 | - |
| 간 | - |
| 전립선 | - |
| 흉선 | - |
| 뇌 | - |
| 폐 | - |
| 림프절 | - |
| 비장 | - |
| 부신 | - |
| 난소 | - |
| 백혈구 | - |
| 결장 | - |
| 식도 | - |
| 자궁 | - |
| 골격근 | - |
| 부고환 | - |
| 방광 | - |
| 신장 | - |
| 유방 암종 | + |
BRCO2은 정상 유선 내피에 대한 신규한 분화 유전자 산물이며, 또한 유방 종양에서도 발현된다.
실시예
8:
신규한
종양 유전자 산물인
PCSC
의 동정
PCSC (SEQ ID NO:63) 및 이의 번역 산물은 이전에 기재되어 있는 바가 없다. 본 발명의 데이터마이닝법에 의하여 EST (expressed sequence tag) BF064073를 제조하였다. 특이적 프라이머 (센스: TCAGGTATTCCCTGCTCTTAC, 안티센스: TGGGCAATTCTCTCAGGCTTG)를 사용하여 RT-PCR 연구를 수행하여 발현을 분석하였다. 본 발명에 있어서, 정상 결장 뿐 아니라 결장 암종에서도 특이적 발현이 관찰되었다 (표 5). 다른 모든 조직에서, 이 유전자 산물은 전사 억제된다. PCSC는 두 개의 추정 ORFs (SEQ ID 64 및 SEQ ID 65)를 코딩한다. SEQ ID 64의 서열 분석 결과, CXC 사이토카인과 구조적 상동성을 갖는 것으로 나타났다. 또한, 4 개의 대체적 PCSC cDNA 단편을 클로닝하였다 (SEQ ID NO:85 내지 88). 본 발명에 있어서, 각각의 경우에서, 각 cDNA는 SEQ ID NO:89 내지 100의 서열을 갖는 폴리펩타이드를 코딩하는 3 개의 추정 ORFs를 포함한다.
| 회장 | + |
| 결장 | + |
| 간 | - |
| 폐 | - |
| 림프절 | - |
| 위 | - |
| 비장 | - |
| 부신 | - |
| 신장 | - |
| 식도 | - |
| 난소 | - |
| 직장 | + |
| 정소 | - |
| 흉선 | - |
| 피부 | - |
| 유방 | - |
| 췌장 | - |
| PBMC | - |
| PBMC act. | - |
| 전립선 | - |
| 갑상선 | - |
| 난관 | - |
| 자궁 | - |
| 대뇌 | - |
| 소뇌 | - |
| 대장 종양 | 19/20 |
| 대장 종양 전이 | 15/15 |
따라서, PCSC는 정상 결정 내피에 대한 분화 항원이며, 또한, 대장 종양 및 모든 결장 전이 연구에서도 발현된담. 본 발명에 있어서, 모든 대장 전이에서 검출되는 PCSC 발현으로 인하여 상기 종양 항원은 전이 결장 종양의 예방 및 치료를 위한 매우 중요한 표적이 된다.
실시예
9:
신규한
종양 항원인
SGY
-1의 동정
SGY-1 전사체의 서열 (SEQ ID NO:70) 및 이의 번역 산물의 서열 (SEQ ID NO:71)은 GenBank에 공지되어 있다 (accession number AF177398) (Krupnik 등, Gene 238, 301-313, 1999). Soggy-1은 Wnt 단백질족의 길항제 및 억제제로서 작용하는 딕코프(Dickkopf) 단백질족의 구성원으로 이미 기재되어 있다. 상기 Wnt 단백질은 배 발생 중에 차례로 중요한 기능을 갖는다. 본 발명에 있어서, SGY-1의 서열 (SEQ ID NO:70)에 기초하여, PCR 프라이머 (5'-CTCCTATCCATGATGCTGACG-3' 및 5'-CCTGAGGATGTACAGTAAGTG-3')를 제작하고, 많은 인간 조직에서 RT-PCR 분석 (95 ℃ 15 분; 94 ℃ 1 분; 63 ℃ 1 분; 72 ℃ 1 분; 35 회)하는데 사용하였다. 정상 조직에서의 발현은 정소에 국한되지 않는것으로 나타났다. 다른 eCT에 대하여 기재된 바와 같이, 본 발명에 있어서, SGY-1는 많은 인간 조직에서 이소적으로 활성화되는 것으로 나타났다 (표 9).
| 조직 | 테스트된 총 수 | 양성 | % |
| 흑색종 | 16 | 4 | 25 |
| 유방 암종 | 20 | 4 | 20 |
| 대장 종양 | 20 | 0 | 0 |
| 전립선 암종 | 8 | 1 | 13 |
| 기관지 암종 | 32 | 3 | 18 |
| 신장 세포 암종 | 7 | 0 | 0 |
| 난소 암종 | 7 | 4 | 57 |
| 갑상선 암종 | 4 | 0 | 0 |
| 자궁 경부 암종 | 6 | 2 | 33 |
| 흑색종 세포계 | 8 | 2 | 25 |
| 기관지 암종 세포계 | 6 | 2 | 33 |
| 포유류 암종 세포계 |
실시예
10:
신규한
종양 항원인
MORC
의 동정
MORC 전사체 서열 (SEQ ID NO:74) 및 이의 번역 산물 서열 (SEQ ID NO:75)은 GenBank에 공개되어 있다 (accession number XM 037008) (Inoue 등, Hum Mol Genet. Jul :8(7):1201-7, 1999).
MORC는 본래 정자 형성(spermatogenesis)에 수반되는 것으로 기재되어 있었다. 마우스에서 이 단백질을 변이시킨 결과 생식선이 발달하지 않았다.
본 발명에 있어서, MORC 서열 (SEQ ID NO:74)에 기초하여, PCR 프라이머 (5'-CTGAGTATCAGCTACCATCAG-3' 및 5'-TCTGTAGTCCTTCACATATCG-3')를 제조하고, 다수의 인간 조직에서의 RT-PCR 분석 (95 ℃ 15 분; 94 ℃ 1 분; 63 ℃ 1 분; 72 ℃ 1 분; 35 회)에 사용하였다. 정상 조직에서의 발현은 정소에 국한되지 않는 것으로 나타났다. 다른 eCT에 대하여 기재된 바와 같이, 본 발명에 있어서, MORC는 다수의 종양 조직에서 이소적으로 활성화하는 것으로 나타났다 (표 10).
| 조직 | 테스트된 총 수 | 양성 | % |
| 흑색종 | 16 | 3 | 18 |
| 유방 암종 | 20 | 0 | 0 |
| 대장 종양 | 20 | 0 | 0 |
| 전립선 암종 | 8 | 0 | 0 |
| 기관지 암종 | 17 | 3 | 18 |
| 신장 세포 암종 | 7 | 0 | 0 |
| 난소 암종 | 7 | 1 | 14 |
| 갑상선 암종 | 4 | 0 | 0 |
| 자궁 경부 암종 | 6 | 0 | 0 |
| 흑색종 세포계 | 8 | 1 | 12 |
| 기관지 암종 세포계 | 6 | 1 | 17 |
<110> Sahin Dr., Ugur
Tureci Dr., Ozlem
Koslowski Dr., Michael
<120> Differentiell in Tumoren exprimierte Genprodukte und deren
Verwendung
<130> 342-3PCT
<160> 100
<170> PatentIn version 3.1
<210> 1
<211> 1171
<212> DNA
<213> Homo sapiens
<400> 1
ctgtcgttgg tgtatttttc tggtgtcact tctgtgcctt ccttcaaagg ttctccaaat 60
gtcaactgtc aaggagcagc taattgagaa gctaattgag gatgatgaaa actcccagtg 120
taaaattact attgttggaa ctggtgccgt aggcatggct tgtgctatta gtatcttact 180
gaaggatttg gctgatgaac ttgcccttgt tgatgttgca ttggacaaac tgaagggaga 240
aatgatggat cttcagcatg gcagtctttt ctttagtact tcaaagatta cttctggaaa 300
agattacagt gtatctgcaa actccagaat agttattgtc acagcaggtg caaggcagca 360
ggagggagaa actcgccttg ccctggtcca acgtaatgtg gctataatga aatcaatcat 420
tcctgccata gtccattata gtcctgattg taaaattctt gttgtttcaa atccagtgga 480
tattttgaca tatatagtct ggaagataag tggcttacct gtaactcgtg taattggaag 540
tggttgtaat ctagactctg cccgtttccg ttacctaatt ggagaaaagt tgggtgtcca 600
ccccacaagc tgccatggtt ggattattgg agaacatggt gattctagtg tgcccttatg 660
gagtggggtg aatgttgctg gtgttgctct gaagactctg gaccctaaat taggaacgga 720
ttcagataag gaacactgga aaaatatcca taaacaagtt attcaaagtg cctatgaaat 780
tatcaagctg aaggggtata cctcttgggc tattggactg tctgtgatgg atctggtagg 840
atccattttg aaaaatctta ggagagtgca cccagtttcc accatggtta agggattata 900
tggaataaaa gaagaactct ttctcagtat cccttgtgtc ttggggcgga atggtgtctc 960
agatgttgtg aaaattaact tgaattctga ggaggaggcc cttttcaaga agagtgcaga 1020
aacactttgg aatattcaaa aggatctaat attttaaatt aaagccttct aatgttccac 1080
tgtttggaga acagaagata gcaggctgtg tattttaaat tttgaaagta ttttcattga 1140
tcttaaaaaa taaaaacaaa ttggagacct g 1171
<210> 2
<211> 1053
<212> DNA
<213> Homo sapiens
<400> 2
ctgtcgttgg tgtatttttc tggtgtcact tctgtgcctt ccttcaaagg ttctccaaat 60
gtcaactgtc aaggagcagc taattgagaa gctaattgag gatgatgaaa actcccagtg 120
taaaattact attgttggaa ctggtgccgt aggcatggct tgtgctatta gtatcttact 180
gaagattaca gtgtatctgc aaactccaga atagttattg tcacagcagg tgcaaggcag 240
caggagggag aaactcgcct tgccctggtc caacgtaatg tggctataat gaaatcaatc 300
attcctgcca tagtccatta tagtcctgat tgtaaaattc ttgttgtttc aaatccagtg 360
gatattttga catatatagt ctggaagata agtggcttac ctgtaactcg tgtaattgga 420
agtggttgta atctagactc tgcccgtttc cgttacctaa ttggagaaaa gttgggtgtc 480
caccccacaa gctgccatgg ttggattatt ggagaacatg gtgattctag tgtgccctta 540
tggagtgggg tgaatgttgc tggtgttgct ctgaagactc tggaccctaa attaggaacg 600
gattcagata aggaacactg gaaaaatatc cataaacaag ttattcaaag tgcctatgaa 660
attatcaagc tgaaggggta tacctcttgg gctattggac tgtctgtgat ggatctggta 720
ggatccattt tgaaaaatct taggagagtg cacccagttt ccaccatggt taagggatta 780
tatggaataa aagaagaact ctttctcagt atcccttgtg tcttggggcg gaatggtgtc 840
tcagatgttg tgaaaattaa cttgaattct gaggaggagg cccttttcaa gaagagtgca 900
gaaacacttt ggaatattca aaaggatcta atattttaaa ttaaagcctt ctaatgttcc 960
actgtttgga gaacagaaga tagcaggctg tgtattttaa attttgaaag tattttcatt 1020
gatcttaaaa aataaaaaca aattggagac ctg 1053
<210> 3
<211> 879
<212> DNA
<213> Homo sapiens
<400> 3
ctgtcgttgg tgtatttttc tggtgtcact tctgtgcctt ccttcaaagg ttctccaaat 60
gtcaactgtc aaggagcagc taattgagaa gctaattgag gatgatgaaa actcccagtg 120
taaaattact attgttggaa ctggtgccgt aggcatggct tgtgctatta gtatcttact 180
gaagtggata ttttgacata tatagtctgg aagataagtg gcttacctgt aactcgtgta 240
attggaagtg gttgtaatct agactctgcc cgtttccgtt acctaattgg agaaaagttg 300
ggtgtccacc ccacaagctg ccatggttgg attattggag aacatggtga ttctagtgtg 360
cccttatgga gtggggtgaa tgttgctggt gttgctctga agactctgga ccctaaatta 420
ggaacggatt cagataagga acactggaaa aatatccata aacaagttat tcaaagtgcc 480
tatgaaatta tcaagctgaa ggggtatacc tcttgggcta ttggactgtc tgtgatggat 540
ctggtaggat ccattttgaa aaatcttagg agagtgcacc cagtttccac catggttaag 600
ggattatatg gaataaaaga agaactcttt ctcagtatcc cttgtgtctt ggggcggaat 660
ggtgtctcag atgttgtgaa aattaacttg aattctgagg aggaggccct tttcaagaag 720
agtgcagaaa cactttggaa tattcaaaag gatctaatat tttaaattaa agccttctaa 780
tgttccactg tttggagaac agaagatagc aggctgtgta ttttaaattt tgaaagtatt 840
ttcattgatc ttaaaaaata aaaacaaatt ggagacctg 879
<210> 4
<211> 811
<212> DNA
<213> Homo sapiens
<400> 4
ctgtcgttgg tgtatttttc tggtgtcact tctgtgcctt ccttcaaagg ttctccaaat 60
gtcaactgtc aaggagcagc taattgagaa gctaattgag gatgatgaaa actcccagtg 120
taaaattact attgttggaa ctggtgccgt aggcatggct tgtgctatta gtatcttact 180
gaagattaca gtgtatctgc aaactccaga atagttattg tcacagcagg tgcaaggcag 240
caggagggag aaactcgcct tgccctggtc caacgtaatg tggctataat gaaatcaatc 300
attcctgcca tagtccatta tagtcctgat tgtaaaattc ttgttgtttc aaatccagtg 360
gatattttga catatatagt ctggaagata agtggcttac ctgtaactcg tgtaattgga 420
agtggttgta atctagactc tgcccgtttc cgttacctaa ttggagaaaa gttgggtgtc 480
caccccacaa gctgccatgg ttggattatt ggagaacatg gtgattctag tgggattata 540
tggaataaaa gaagaactct ttctcagtat cccttgtgtc ttggggcgga atggtgtctc 600
agatgttgtg aaaattaact tgaattctga ggaggaggcc cttttcaaga agagtgcaga 660
aacactttgg aatattcaaa aggatctaat attttaaatt aaagccttct aatgttccac 720
tgtttggaga acagaagata gcaggctgtg tattttaaat tttgaaagta ttttcattga 780
tcttaaaaaa taaaaacaaa ttggagacct g 811
<210> 5
<211> 1047
<212> DNA
<213> Homo sapiens
<400> 5
ctgtcgttgg tgtatttttc tggtgtcact tctgtgcctt ccttcaaagg ttctccaaat 60
gtcaactgtc aaggagcagc taattgagaa gctaattgag gatgatgaaa actcccagtg 120
taaaattact attgttggaa ctggtgccgt aggcatggct tgtgctatta gtatcttact 180
gaaggatttg gctgatgaac ttgcccttgt tgatgttgca ttggacaaac tgaagggaga 240
aatgatggat cttcagcatg gcagtctttt ctttagtact tcaaagatta cttctggaaa 300
agattacagt gtatctgcaa actccagaat agttattgtc acagcaggtg caaggcagca 360
ggagggagaa actcgccttg ccctggtcca acgtaatgtg gctataatga aatcaatcat 420
tcctgccata gtccattata gtcctgattg taaaattctt gttgtttcaa atccagtgga 480
tattttgaca tatatagtct ggaagataag tggcttacct gtaactcgtg taattggaag 540
tggttgtaat ctagactctg cccgtttccg ttacctaatt ggagaaaagt tgggtgtcca 600
ccccacaagc tgccatggtt ggattattgg agaacatggt gattctagtg tgcccttatg 660
gagtggggtg aatgttgctg gtgttgctct gaagactctg gaccctaaat taggaacgga 720
ttcagataag gaacactgga aaaatatcca taaacaagtt attcaaaggg attatatgga 780
ataaaagaag aactctttct cagtatccct tgtgtcttgg ggcggaatgg tgtctcagat 840
gttgtgaaaa ttaacttgaa ttctgaggag gaggcccttt tcaagaagag tgcagaaaca 900
ctttggaata ttcaaaagga tctaatattt taaattaaag ccttctaatg ttccactgtt 960
tggagaacag aagatagcag gctgtgtatt ttaaattttg aaagtatttt cattgatctt 1020
aaaaaataaa aacaaattgg agacctg 1047
<210> 6
<211> 332
<212> PRT
<213> Homo sapiens
<400> 6
Met Ser Thr Val Lys Glu Gln Leu Ile Glu Lys Leu Ile Glu Asp Asp
1 5 10 15
Glu Asn Ser Gln Cys Lys Ile Thr Ile Val Gly Thr Gly Ala Val Gly
20 25 30
Met Ala Cys Ala Ile Ser Ile Leu Leu Lys Asp Leu Ala Asp Glu Leu
35 40 45
Ala Leu Val Asp Val Ala Leu Asp Lys Leu Lys Gly Glu Met Met Asp
50 55 60
Leu Gln His Gly Ser Leu Phe Phe Ser Thr Ser Lys Ile Thr Ser Gly
65 70 75 80
Lys Asp Tyr Ser Val Ser Ala Asn Ser Arg Ile Val Ile Val Thr Ala
85 90 95
Gly Ala Arg Gln Gln Glu Gly Glu Thr Arg Leu Ala Leu Val Gln Arg
100 105 110
Asn Val Ala Ile Met Lys Ser Ile Ile Pro Ala Ile Val His Tyr Ser
115 120 125
Pro Asp Cys Lys Ile Leu Val Val Ser Asn Pro Val Asp Ile Leu Thr
130 135 140
Tyr Ile Val Trp Lys Ile Ser Gly Leu Pro Val Thr Arg Val Ile Gly
145 150 155 160
Ser Gly Cys Asn Leu Asp Ser Ala Arg Phe Arg Tyr Leu Ile Gly Glu
165 170 175
Lys Leu Gly Val His Pro Thr Ser Cys His Gly Trp Ile Ile Gly Glu
180 185 190
His Gly Asp Ser Ser Val Pro Leu Trp Ser Gly Val Asn Val Ala Gly
195 200 205
Val Ala Leu Lys Thr Leu Asp Pro Lys Leu Gly Thr Asp Ser Asp Lys
210 215 220
Glu His Trp Lys Asn Ile His Lys Gln Val Ile Gln Ser Ala Tyr Glu
225 230 235 240
Ile Ile Lys Leu Lys Gly Tyr Thr Ser Trp Ala Ile Gly Leu Ser Val
245 250 255
Met Asp Leu Val Gly Ser Ile Leu Lys Asn Leu Arg Arg Val His Pro
260 265 270
Val Ser Thr Met Val Lys Gly Leu Tyr Gly Ile Lys Glu Glu Leu Phe
275 280 285
Leu Ser Ile Pro Cys Val Leu Gly Arg Asn Gly Val Ser Asp Val Val
290 295 300
Lys Ile Asn Leu Asn Ser Glu Glu Glu Ala Leu Phe Lys Lys Ser Ala
305 310 315 320
Glu Thr Leu Trp Asn Ile Gln Lys Asp Leu Ile Phe
325 330
<210> 7
<211> 51
<212> PRT
<213> Homo sapiens
<400> 7
Met Ser Thr Val Lys Glu Gln Leu Ile Glu Lys Leu Ile Glu Asp Asp
1 5 10 15
Glu Asn Ser Gln Cys Lys Ile Thr Ile Val Gly Thr Gly Ala Val Gly
20 25 30
Met Ala Cys Ala Ile Ser Ile Leu Leu Lys Ile Thr Val Tyr Leu Gln
35 40 45
Thr Pro Glu
50
<210> 8
<211> 216
<212> PRT
<213> Homo sapiens
<400> 8
Met Lys Ser Ile Ile Pro Ala Ile Val His Tyr Ser Pro Asp Cys Lys
1 5 10 15
Ile Leu Val Val Ser Asn Pro Val Asp Ile Leu Thr Tyr Ile Val Trp
20 25 30
Lys Ile Ser Gly Leu Pro Val Thr Arg Val Ile Gly Ser Gly Cys Asn
35 40 45
Leu Asp Ser Ala Arg Phe Arg Tyr Leu Ile Gly Glu Lys Leu Gly Val
50 55 60
His Pro Thr Ser Cys His Gly Trp Ile Ile Gly Glu His Gly Asp Ser
65 70 75 80
Ser Val Pro Leu Trp Ser Gly Val Asn Val Ala Gly Val Ala Leu Lys
85 90 95
Thr Leu Asp Pro Lys Leu Gly Thr Asp Ser Asp Lys Glu His Trp Lys
100 105 110
Asn Ile His Lys Gln Val Ile Gln Ser Ala Tyr Glu Ile Ile Lys Leu
115 120 125
Lys Gly Tyr Thr Ser Trp Ala Ile Gly Leu Ser Val Met Asp Leu Val
130 135 140
Gly Ser Ile Leu Lys Asn Leu Arg Arg Val His Pro Val Ser Thr Met
145 150 155 160
Val Lys Gly Leu Tyr Gly Ile Lys Glu Glu Leu Phe Leu Ser Ile Pro
165 170 175
Cys Val Leu Gly Arg Asn Gly Val Ser Asp Val Val Lys Ile Asn Leu
180 185 190
Asn Ser Glu Glu Glu Ala Leu Phe Lys Lys Ser Ala Glu Thr Leu Trp
195 200 205
Asn Ile Gln Lys Asp Leu Ile Phe
210 215
<210> 9
<211> 45
<212> PRT
<213> Homo sapiens
<400> 9
Met Ser Thr Val Lys Glu Gln Leu Ile Glu Lys Leu Ile Glu Asp Asp
1 5 10 15
Glu Asn Ser Gln Cys Lys Ile Thr Ile Val Gly Thr Gly Ala Val Gly
20 25 30
Met Ala Cys Ala Ile Ser Ile Leu Leu Lys Trp Ile Phe
35 40 45
<210> 10
<211> 76
<212> PRT
<213> Homo sapiens
<400> 10
Met Asp Leu Val Gly Ser Ile Leu Lys Asn Leu Arg Arg Val His Pro
1 5 10 15
Val Ser Thr Met Val Lys Gly Leu Tyr Gly Ile Lys Glu Glu Leu Phe
20 25 30
Leu Ser Ile Pro Cys Val Leu Gly Arg Asn Gly Val Ser Asp Val Val
35 40 45
Lys Ile Asn Leu Asn Ser Glu Glu Glu Ala Leu Phe Lys Lys Ser Ala
50 55 60
Glu Thr Leu Trp Asn Ile Gln Lys Asp Leu Ile Phe
65 70 75
<210> 11
<211> 109
<212> PRT
<213> Homo sapiens
<400> 11
Met Lys Ser Ile Ile Pro Ala Ile Val His Tyr Ser Pro Asp Cys Lys
1 5 10 15
Ile Leu Val Val Ser Asn Pro Val Asp Ile Leu Thr Tyr Ile Val Trp
20 25 30
Lys Ile Ser Gly Leu Pro Val Thr Arg Val Ile Gly Ser Gly Cys Asn
35 40 45
Leu Asp Ser Ala Arg Phe Arg Tyr Leu Ile Gly Glu Lys Leu Gly Val
50 55 60
His Pro Thr Ser Cys His Gly Trp Ile Ile Gly Glu His Gly Asp Ser
65 70 75 80
Ser Gly Ile Ile Trp Asn Lys Arg Arg Thr Leu Ser Gln Tyr Pro Leu
85 90 95
Cys Leu Gly Ala Glu Trp Cys Leu Arg Cys Cys Glu Asn
100 105
<210> 12
<211> 66
<212> PRT
<213> Homo sapiens
<400> 12
Met Val Gly Leu Leu Glu Asn Met Val Ile Leu Val Gly Leu Tyr Gly
1 5 10 15
Ile Lys Glu Glu Leu Phe Leu Ser Ile Pro Cys Val Leu Gly Arg Asn
20 25 30
Gly Val Ser Asp Val Val Lys Ile Asn Leu Asn Ser Glu Glu Glu Ala
35 40 45
Leu Phe Lys Lys Ser Ala Glu Thr Leu Trp Asn Ile Gln Lys Asp Leu
50 55 60
Ile Phe
65
<210> 13
<211> 241
<212> PRT
<213> Homo sapiens
<400> 13
Met Ser Thr Val Lys Glu Gln Leu Ile Glu Lys Leu Ile Glu Asp Asp
1 5 10 15
Glu Asn Ser Gln Cys Lys Ile Thr Ile Val Gly Thr Gly Ala Val Gly
20 25 30
Met Ala Cys Ala Ile Ser Ile Leu Leu Lys Asp Leu Ala Asp Glu Leu
35 40 45
Ala Leu Val Asp Val Ala Leu Asp Lys Leu Lys Gly Glu Met Met Asp
50 55 60
Leu Gln His Gly Ser Leu Phe Phe Ser Thr Ser Lys Ile Thr Ser Gly
65 70 75 80
Lys Asp Tyr Ser Val Ser Ala Asn Ser Arg Ile Val Ile Val Thr Ala
85 90 95
Gly Ala Arg Gln Gln Glu Gly Glu Thr Arg Leu Ala Leu Val Gln Arg
100 105 110
Asn Val Ala Ile Met Lys Ser Ile Ile Pro Ala Ile Val His Tyr Ser
115 120 125
Pro Asp Cys Lys Ile Leu Val Val Ser Asn Pro Val Asp Ile Leu Thr
130 135 140
Tyr Ile Val Trp Lys Ile Ser Gly Leu Pro Val Thr Arg Val Ile Gly
145 150 155 160
Ser Gly Cys Asn Leu Asp Ser Ala Arg Phe Arg Tyr Leu Ile Gly Glu
165 170 175
Lys Leu Gly Val His Pro Thr Ser Cys His Gly Trp Ile Ile Gly Glu
180 185 190
His Gly Asp Ser Ser Val Pro Leu Trp Ser Gly Val Asn Val Ala Gly
195 200 205
Val Ala Leu Lys Thr Leu Asp Pro Lys Leu Gly Thr Asp Ser Asp Lys
210 215 220
Glu His Trp Lys Asn Ile His Lys Gln Val Ile Gln Arg Asp Tyr Met
225 230 235 240
Glu
<210> 14
<211> 23
<212> PRT
<213> Homo sapiens
<400> 14
Gly Ala Val Gly Met Ala Cys Ala Ile Ser Ile Leu Leu Lys Ile Thr
1 5 10 15
Val Tyr Leu Gln Thr Pro Glu
20
<210> 15
<211> 17
<212> PRT
<213> Homo sapiens
<400> 15
Gly Ala Val Gly Met Ala Cys Ala Ile Ser Ile Leu Leu Lys Trp Ile
1 5 10 15
Phe
<210> 16
<211> 39
<212> PRT
<213> Homo sapiens
<400> 16
Gly Trp Ile Ile Gly Glu His Gly Asp Ser Ser Gly Ile Ile Trp Asn
1 5 10 15
Lys Arg Arg Thr Leu Ser Gln Tyr Pro Leu Cys Leu Gly Ala Glu Trp
20 25 30
Cys Leu Arg Cys Cys Glu Asn
35
<210> 17
<211> 23
<212> PRT
<213> Homo sapiens
<400> 17
Met Val Gly Leu Leu Glu Asn Met Val Ile Leu Val Gly Leu Tyr Gly
1 5 10 15
Ile Lys Glu Glu Leu Phe Leu
20
<210> 18
<211> 17
<212> PRT
<213> Homo sapiens
<400> 18
Glu His Trp Lys Asn Ile His Lys Gln Val Ile Gln Arg Asp Tyr Met
1 5 10 15
Glu
<210> 19
<211> 2168
<212> DNA
<213> Homo sapiens
<400> 19
gaatccgcgg ggagggcaca acagctgcta cctgaacagt ttctgaccca acagttaccc 60
agcgccggac tcgctgcgcc ccggcggctc tagggacccc cggcgcctac acttagctcc 120
gcgcccgaga gaatgttgga ccgacgacac aagacctcag acttgtgtta ttctagcagc 180
tgaacacacc ccaggctctt ctgaccggca gtggctctgg aagcagtctg gtgtatagag 240
ttatggattc actaccagat tctactgtat gctcttgaca actatgacca caatggtcca 300
cccacaaatg aattatcagg agtgaaccca gaggcacgta tgaatgaaag tcctgatccg 360
actgacctgg cgggagtcat cattgagctc ggccccaatg acagtccaca gacaagtgaa 420
tttaaaggag caaccgagga ggcacctgcg aaagaaagcc cacacacaag tgaatttaaa 480
ggagcagccc gggtgtcacc tatcagtgaa agtgtgttag cacgactttc caagtttgaa 540
gttgaagatg ctgaaaatgt tgcttcatat gacagcaaga ttaagaaaat tgtgcattca 600
attgtatcat cctttgcatt tggactattt ggagttttcc tggtcttact ggatgtcact 660
ctcatccttg ccgacctaat tttcactgac agcaaacttt atattccttt ggagtatcgt 720
tctatttctc tagctattgc cttatttttt ctcatggatg ttcttcttcg agtatttgta 780
gaaaggagac agcagtattt ttctgactta tttaacattt tagatactgc cattattgtg 840
attcttctgc tggttgatgt cgtttacatt ttttttgaca ttaagttgct taggaatatt 900
cccagatgga cacatttact tcgacttcta cgacttatta ttctgttaag aatttttcat 960
ctgtttcatc aaaaaagaca acttgaaaag ctgataagaa ggcgggtttc agaaaacaaa 1020
aggcgataca caagggatgg atttgaccta gacctcactt acgttacaga acgtattatt 1080
gctatgtcat ttccatcttc tggaaggcag tctttctata gaaatccaat caaggaagtt 1140
gtgcggtttc tagataagaa acaccgaaac cactatcgag tctacaatct atgcagtgaa 1200
agagcttacg atcctaagca cttccataat agggtcgtta gaatcatgat tgatgatcat 1260
aatgtcccca ctctacatca gatggtggtt ttcaccaagg aagtaaatga gtggatggct 1320
caagatcttg aaaacatcgt agcgattcac tgtaaaggag gcacagatag aacaggaact 1380
atggtttgtg ccttccttat tgcctctgaa atatgttcaa ctgcaaagga aagcctgtat 1440
tattttggag aaaggcgaac agataaaacc cacagcgaaa aatttcaggg agtagaaact 1500
ccttctcaga agagatatgt tgcatatttt gcacaagtga aacatctcta caactggaat 1560
ctccctccaa gacggatact ctttataaaa cacttcatta tttattcgat tcctcgttat 1620
gtacgtgatc taaaaatcca aatagaaatg gagaaaaagg ttgtcttttc cactatttca 1680
ttaggaaaat gttcggtact tgataacatt acaacagaca aaatattaat tgatgtattc 1740
gacggtccac ctctgtatga tgatgtgaaa gtgcagtttt tctattcgaa tcttcctaca 1800
tactatgaca attgctcatt ttacttctgg ttgcacacat cttttattga aaataacagg 1860
ctttatctac caaaaaatga attggataat ctacataaac aaaaagcacg gagaatttat 1920
ccatcagatt ttgccgtgga gatacttttt ggcgagaaaa tgacttccag tgatgttgta 1980
gctggatccg attaagtata gctccccctt ccccttctgg gaaagaatta tgttctttcc 2040
aaccctgcca catgttcata tatcctaaat ctatcctaaa tgttcccttg aagtatttat 2100
ttatgtttat atatgtttat acatgttctt caataaatct attacatata tataaaaaaa 2160
aaaaaaaa 2168
<210> 20
<211> 2114
<212> DNA
<213> Homo sapiens
<400> 20
gaatccgcgg ggagggcaca acagctgcta cctgaacagt ttctgaccca acagttaccc 60
agcgccggac tcgctgcgcc ccggcggctc tagggacccc cggcgcctac acttagctcc 120
gcgcccgaga gaatgttgga ccgacgacac aagacctcag acttgtgtta ttctagcagc 180
tgaacacacc ccaggctctt ctgaccggca gtggctctgg aagcagtctg gtgtatagag 240
ttatggattc actaccagat tctactgtat gctcttgaca actatgacca caatggtcca 300
cccacaaatg aattatcagg agtgaaccca gaggcacgta tgaatgaaag tcctgatccg 360
actgacctgg cgggagtcat cattgagctc ggccccaatg acagtccaca gacaagtgaa 420
tttaaaggag caaccgagga ggcacctgcg aaagaaagtg tgttagcacg actttccaag 480
tttgaagttg aagatgctga aaatgttgct tcatatgaca gcaagattaa gaaaattgtg 540
cattcaattg tatcatcctt tgcatttgga ctatttggag ttttcctggt cttactggat 600
gtcactctca tccttgccga cctaattttc actgacagca aactttatat tcctttggag 660
tatcgttcta tttctctagc tattgcctta ttttttctca tggatgttct tcttcgagta 720
tttgtagaaa ggagacagca gtatttttct gacttattta acattttaga tactgccatt 780
attgtgattc ttctgctggt tgatgtcgtt tacatttttt ttgacattaa gttgcttagg 840
aatattccca gatggacaca tttacttcga cttctacgac ttattattct gttaagaatt 900
tttcatctgt ttcatcaaaa aagacaactt gaaaagctga taagaaggcg ggtttcagaa 960
aacaaaaggc gatacacaag ggatggattt gacctagacc tcacttacgt tacagaacgt 1020
attattgcta tgtcatttcc atcttctgga aggcagtctt tctatagaaa tccaatcaag 1080
gaagttgtgc ggtttctaga taagaaacac cgaaaccact atcgagtcta caatctatgc 1140
agtgaaagag cttacgatcc taagcacttc cataataggg tcgttagaat catgattgat 1200
gatcataatg tccccactct acatcagatg gtggttttca ccaaggaagt aaatgagtgg 1260
atggctcaag atcttgaaaa catcgtagcg attcactgta aaggaggcac agatagaaca 1320
ggaactatgg tttgtgcctt ccttattgcc tctgaaatat gttcaactgc aaaggaaagc 1380
ctgtattatt ttggagaaag gcgaacagat aaaacccaca gcgaaaaatt tcagggagta 1440
gaaactcctt ctcagaagag atatgttgca tattttgcac aagtgaaaca tctctacaac 1500
tggaatctcc ctccaagacg gatactcttt ataaaacact tcattattta ttcgattcct 1560
cgttatgtac gtgatctaaa aatccaaata gaaatggaga aaaaggttgt cttttccact 1620
atttcattag gaaaatgttc ggtacttgat aacattacaa cagacaaaat attaattgat 1680
gtattcgacg gtccacctct gtatgatgat gtgaaagtgc agtttttcta ttcgaatctt 1740
cctacatact atgacaattg ctcattttac ttctggttgc acacatcttt tattgaaaat 1800
aacaggcttt atctaccaaa aaatgaattg gataatctac ataaacaaaa agcacggaga 1860
atttatccat cagattttgc cgtggagata ctttttggcg agaaaatgac ttccagtgat 1920
gttgtagctg gatccgatta agtatagctc ccccttcccc ttctgggaaa gaattatgtt 1980
ctttccaacc ctgccacatg ttcatatatc ctaaatctat cctaaatgtt cccttgaagt 2040
atttatttat gtttatatat gtttatacat gttcttcaat aaatctatta catatatata 2100
aaaaaaaaaa aaaa 2114
<210> 21
<211> 2222
<212> DNA
<213> Homo sapiens
<400> 21
gaatccgcgg ggagggcaca acagctgcta cctgaacagt ttctgaccca acagttaccc 60
agcgccggac tcgctgcgcc ccggcggctc tagggacccc cggcgcctac acttagctcc 120
gcgcccgaga gaatgttgga ccgacgacac aagacctcag acttgtgtta ttctagcagc 180
tgaacacacc ccaggctctt ctgaccggca gtggctctgg aagcagtctg gtgtatagag 240
ttatggattc actaccagat tctactgtat gctcttgaca actatgacca caatggtcca 300
cccacaaatg aattatcagg agtgaaccca gaggcacgta tgaatgaaag tcctgatccg 360
actgacctgg cgggagtcat cattgagctc ggccccaatg acagtccaca gacaagtgaa 420
tttaaaggag caaccgagga ggcacctgcg aaagaaagcc cacacacaag tgaatttaaa 480
ggagcagccc gggtgtcacc tatcagtgaa agtgtgttag cacgactttc caagtttgaa 540
gttgaagatg ctgaaaatgt tgcttcatat gacagcaaga ttaagaaaat tgtgcattca 600
attgtatcat cctttgcatt tggactattt ggagttttcc tggtcttact ggatgtcact 660
ctcatccttg ccgacctaat tttcactgac agcaaacttt atattccttt ggagtatcgt 720
tctatttctc tagctattgc cttatttttt ctcatggatg ttcttcttcg agtatttgta 780
gaaaggagac agcagtattt ttctgactta tttaacattt tagatactgc cattattgtg 840
attcttctgc tggttgatgt cgtttacatt ttttttgaca ttaagttgct taggaatatt 900
cccagatgga cacatttact tcgacttcta cgacttatta ttctgttaag aatttttcat 960
ctgtttcatc aaaaaagaca acttgaaaag ctgataagaa ggcgggtttc agaaaacaaa 1020
aggcgataca caagggatgg atttgaccta gacctcactt acgttacaga acgtattatt 1080
gctatgtcat ttccatcttc tggaaggcag tctttctata gaaatccaat caaggaagtt 1140
gtgcggtttc tagataagaa acaccgaaac cactatcgag tctacaatct atgcagtatg 1200
tacattactc tatattgtgc tactgtagat agaaaacaga ttactgcacg tgaaagagct 1260
tacgatccta agcacttcca taatagggtc gttagaatca tgattgatga tcataatgtc 1320
cccactctac atcagatggt ggttttcacc aaggaagtaa atgagtggat ggctcaagat 1380
cttgaaaaca tcgtagcgat tcactgtaaa ggaggcacag atagaacagg aactatggtt 1440
tgtgccttcc ttattgcctc tgaaatatgt tcaactgcaa aggaaagcct gtattatttt 1500
ggagaaaggc gaacagataa aacccacagc gaaaaatttc agggagtaga aactccttct 1560
cagaagagat atgttgcata ttttgcacaa gtgaaacatc tctacaactg gaatctccct 1620
ccaagacgga tactctttat aaaacacttc attatttatt cgattcctcg ttatgtacgt 1680
gatctaaaaa tccaaataga aatggagaaa aaggttgtct tttccactat ttcattagga 1740
aaatgttcgg tacttgataa cattacaaca gacaaaatat taattgatgt attcgacggt 1800
ccacctctgt atgatgatgt gaaagtgcag tttttctatt cgaatcttcc tacatactat 1860
gacaattgct cattttactt ctggttgcac acatctttta ttgaaaataa caggctttat 1920
ctaccaaaaa atgaattgga taatctacat aaacaaaaag cacggagaat ttatccatca 1980
gattttgccg tggagatact ttttggcgag aaaatgactt ccagtgatgt tgtagctgga 2040
tccgattaag tatagctccc ccttcccctt ctgggaaaga attatgttct ttccaaccct 2100
gccacatgtt catatatcct aaatctatcc taaatgttcc cttgaagtat ttatttatgt 2160
ttatatatgt ttatacatgt tcttcaataa atctattaca tatatataaa aaaaaaaaaa 2220
aa 2222
<210> 22
<211> 551
<212> PRT
<213> Homo sapiens
<400> 22
Met Asn Glu Ser Pro Asp Pro Thr Asp Leu Ala Gly Val Ile Ile Glu
1 5 10 15
Leu Gly Pro Asn Asp Ser Pro Gln Thr Ser Glu Phe Lys Gly Ala Thr
20 25 30
Glu Glu Ala Pro Ala Lys Glu Ser Pro His Thr Ser Glu Phe Lys Gly
35 40 45
Ala Ala Arg Val Ser Pro Ile Ser Glu Ser Val Leu Ala Arg Leu Ser
50 55 60
Lys Phe Glu Val Glu Asp Ala Glu Asn Val Ala Ser Tyr Asp Ser Lys
65 70 75 80
Ile Lys Lys Ile Val His Ser Ile Val Ser Ser Phe Ala Phe Gly Leu
85 90 95
Phe Gly Val Phe Leu Val Leu Leu Asp Val Thr Leu Ile Leu Ala Asp
100 105 110
Leu Ile Phe Thr Asp Ser Lys Leu Tyr Ile Pro Leu Glu Tyr Arg Ser
115 120 125
Ile Ser Leu Ala Ile Ala Leu Phe Phe Leu Met Asp Val Leu Leu Arg
130 135 140
Val Phe Val Glu Arg Arg Gln Gln Tyr Phe Ser Asp Leu Phe Asn Ile
145 150 155 160
Leu Asp Thr Ala Ile Ile Val Ile Leu Leu Leu Val Asp Val Val Tyr
165 170 175
Ile Phe Phe Asp Ile Lys Leu Leu Arg Asn Ile Pro Arg Trp Thr His
180 185 190
Leu Leu Arg Leu Leu Arg Leu Ile Ile Leu Leu Arg Ile Phe His Leu
195 200 205
Phe His Gln Lys Arg Gln Leu Glu Lys Leu Ile Arg Arg Arg Val Ser
210 215 220
Glu Asn Lys Arg Arg Tyr Thr Arg Asp Gly Phe Asp Leu Asp Leu Thr
225 230 235 240
Tyr Val Thr Glu Arg Ile Ile Ala Met Ser Phe Pro Ser Ser Gly Arg
245 250 255
Gln Ser Phe Tyr Arg Asn Pro Ile Lys Glu Val Val Arg Phe Leu Asp
260 265 270
Lys Lys His Arg Asn His Tyr Arg Val Tyr Asn Leu Cys Ser Glu Arg
275 280 285
Ala Tyr Asp Pro Lys His Phe His Asn Arg Val Val Arg Ile Met Ile
290 295 300
Asp Asp His Asn Val Pro Thr Leu His Gln Met Val Val Phe Thr Lys
305 310 315 320
Glu Val Asn Glu Trp Met Ala Gln Asp Leu Glu Asn Ile Val Ala Ile
325 330 335
His Cys Lys Gly Gly Thr Asp Arg Thr Gly Thr Met Val Cys Ala Phe
340 345 350
Leu Ile Ala Ser Glu Ile Cys Ser Thr Ala Lys Glu Ser Leu Tyr Tyr
355 360 365
Phe Gly Glu Arg Arg Thr Asp Lys Thr His Ser Glu Lys Phe Gln Gly
370 375 380
Val Glu Thr Pro Ser Gln Lys Arg Tyr Val Ala Tyr Phe Ala Gln Val
385 390 395 400
Lys His Leu Tyr Asn Trp Asn Leu Pro Pro Arg Arg Ile Leu Phe Ile
405 410 415
Lys His Phe Ile Ile Tyr Ser Ile Pro Arg Tyr Val Arg Asp Leu Lys
420 425 430
Ile Gln Ile Glu Met Glu Lys Lys Val Val Phe Ser Thr Ile Ser Leu
435 440 445
Gly Lys Cys Ser Val Leu Asp Asn Ile Thr Thr Asp Lys Ile Leu Ile
450 455 460
Asp Val Phe Asp Gly Pro Pro Leu Tyr Asp Asp Val Lys Val Gln Phe
465 470 475 480
Phe Tyr Ser Asn Leu Pro Thr Tyr Tyr Asp Asn Cys Ser Phe Tyr Phe
485 490 495
Trp Leu His Thr Ser Phe Ile Glu Asn Asn Arg Leu Tyr Leu Pro Lys
500 505 510
Asn Glu Leu Asp Asn Leu His Lys Gln Lys Ala Arg Arg Ile Tyr Pro
515 520 525
Ser Asp Phe Ala Val Glu Ile Leu Phe Gly Glu Lys Met Thr Ser Ser
530 535 540
Asp Val Val Ala Gly Ser Asp
545 550
<210> 23
<211> 533
<212> PRT
<213> Homo sapiens
<400> 23
Met Asn Glu Ser Pro Asp Pro Thr Asp Leu Ala Gly Val Ile Ile Glu
1 5 10 15
Leu Gly Pro Asn Asp Ser Pro Gln Thr Ser Glu Phe Lys Gly Ala Thr
20 25 30
Glu Glu Ala Pro Ala Lys Glu Ser Val Leu Ala Arg Leu Ser Lys Phe
35 40 45
Glu Val Glu Asp Ala Glu Asn Val Ala Ser Tyr Asp Ser Lys Ile Lys
50 55 60
Lys Ile Val His Ser Ile Val Ser Ser Phe Ala Phe Gly Leu Phe Gly
65 70 75 80
Val Phe Leu Val Leu Leu Asp Val Thr Leu Ile Leu Ala Asp Leu Ile
85 90 95
Phe Thr Asp Ser Lys Leu Tyr Ile Pro Leu Glu Tyr Arg Ser Ile Ser
100 105 110
Leu Ala Ile Ala Leu Phe Phe Leu Met Asp Val Leu Leu Arg Val Phe
115 120 125
Val Glu Arg Arg Gln Gln Tyr Phe Ser Asp Leu Phe Asn Ile Leu Asp
130 135 140
Thr Ala Ile Ile Val Ile Leu Leu Leu Val Asp Val Val Tyr Ile Phe
145 150 155 160
Phe Asp Ile Lys Leu Leu Arg Asn Ile Pro Arg Trp Thr His Leu Leu
165 170 175
Arg Leu Leu Arg Leu Ile Ile Leu Leu Arg Ile Phe His Leu Phe His
180 185 190
Gln Lys Arg Gln Leu Glu Lys Leu Ile Arg Arg Arg Val Ser Glu Asn
195 200 205
Lys Arg Arg Tyr Thr Arg Asp Gly Phe Asp Leu Asp Leu Thr Tyr Val
210 215 220
Thr Glu Arg Ile Ile Ala Met Ser Phe Pro Ser Ser Gly Arg Gln Ser
225 230 235 240
Phe Tyr Arg Asn Pro Ile Lys Glu Val Val Arg Phe Leu Asp Lys Lys
245 250 255
His Arg Asn His Tyr Arg Val Tyr Asn Leu Cys Ser Glu Arg Ala Tyr
260 265 270
Asp Pro Lys His Phe His Asn Arg Val Val Arg Ile Met Ile Asp Asp
275 280 285
His Asn Val Pro Thr Leu His Gln Met Val Val Phe Thr Lys Glu Val
290 295 300
Asn Glu Trp Met Ala Gln Asp Leu Glu Asn Ile Val Ala Ile His Cys
305 310 315 320
Lys Gly Gly Thr Asp Arg Thr Gly Thr Met Val Cys Ala Phe Leu Ile
325 330 335
Ala Ser Glu Ile Cys Ser Thr Ala Lys Glu Ser Leu Tyr Tyr Phe Gly
340 345 350
Glu Arg Arg Thr Asp Lys Thr His Ser Glu Lys Phe Gln Gly Val Glu
355 360 365
Thr Pro Ser Gln Lys Arg Tyr Val Ala Tyr Phe Ala Gln Val Lys His
370 375 380
Leu Tyr Asn Trp Asn Leu Pro Pro Arg Arg Ile Leu Phe Ile Lys His
385 390 395 400
Phe Ile Ile Tyr Ser Ile Pro Arg Tyr Val Arg Asp Leu Lys Ile Gln
405 410 415
Ile Glu Met Glu Lys Lys Val Val Phe Ser Thr Ile Ser Leu Gly Lys
420 425 430
Cys Ser Val Leu Asp Asn Ile Thr Thr Asp Lys Ile Leu Ile Asp Val
435 440 445
Phe Asp Gly Pro Pro Leu Tyr Asp Asp Val Lys Val Gln Phe Phe Tyr
450 455 460
Ser Asn Leu Pro Thr Tyr Tyr Asp Asn Cys Ser Phe Tyr Phe Trp Leu
465 470 475 480
His Thr Ser Phe Ile Glu Asn Asn Arg Leu Tyr Leu Pro Lys Asn Glu
485 490 495
Leu Asp Asn Leu His Lys Gln Lys Ala Arg Arg Ile Tyr Pro Ser Asp
500 505 510
Phe Ala Val Glu Ile Leu Phe Gly Glu Lys Met Thr Ser Ser Asp Val
515 520 525
Val Ala Gly Ser Asp
530
<210> 24
<211> 569
<212> PRT
<213> Homo sapiens
<400> 24
Met Asn Glu Ser Pro Asp Pro Thr Asp Leu Ala Gly Val Ile Ile Glu
1 5 10 15
Leu Gly Pro Asn Asp Ser Pro Gln Thr Ser Glu Phe Lys Gly Ala Thr
20 25 30
Glu Glu Ala Pro Ala Lys Glu Ser Pro His Thr Ser Glu Phe Lys Gly
35 40 45
Ala Ala Arg Val Ser Pro Ile Ser Glu Ser Val Leu Ala Arg Leu Ser
50 55 60
Lys Phe Glu Val Glu Asp Ala Glu Asn Val Ala Ser Tyr Asp Ser Lys
65 70 75 80
Ile Lys Lys Ile Val His Ser Ile Val Ser Ser Phe Ala Phe Gly Leu
85 90 95
Phe Gly Val Phe Leu Val Leu Leu Asp Val Thr Leu Ile Leu Ala Asp
100 105 110
Leu Ile Phe Thr Asp Ser Lys Leu Tyr Ile Pro Leu Glu Tyr Arg Ser
115 120 125
Ile Ser Leu Ala Ile Ala Leu Phe Phe Leu Met Asp Val Leu Leu Arg
130 135 140
Val Phe Val Glu Arg Arg Gln Gln Tyr Phe Ser Asp Leu Phe Asn Ile
145 150 155 160
Leu Asp Thr Ala Ile Ile Val Ile Leu Leu Leu Val Asp Val Val Tyr
165 170 175
Ile Phe Phe Asp Ile Lys Leu Leu Arg Asn Ile Pro Arg Trp Thr His
180 185 190
Leu Leu Arg Leu Leu Arg Leu Ile Ile Leu Leu Arg Ile Phe His Leu
195 200 205
Phe His Gln Lys Arg Gln Leu Glu Lys Leu Ile Arg Arg Arg Val Ser
210 215 220
Glu Asn Lys Arg Arg Tyr Thr Arg Asp Gly Phe Asp Leu Asp Leu Thr
225 230 235 240
Tyr Val Thr Glu Arg Ile Ile Ala Met Ser Phe Pro Ser Ser Gly Arg
245 250 255
Gln Ser Phe Tyr Arg Asn Pro Ile Lys Glu Val Val Arg Phe Leu Asp
260 265 270
Lys Lys His Arg Asn His Tyr Arg Val Tyr Asn Leu Cys Ser Met Tyr
275 280 285
Ile Thr Leu Tyr Cys Ala Thr Val Asp Arg Lys Gln Ile Thr Ala Arg
290 295 300
Glu Arg Ala Tyr Asp Pro Lys His Phe His Asn Arg Val Val Arg Ile
305 310 315 320
Met Ile Asp Asp His Asn Val Pro Thr Leu His Gln Met Val Val Phe
325 330 335
Thr Lys Glu Val Asn Glu Trp Met Ala Gln Asp Leu Glu Asn Ile Val
340 345 350
Ala Ile His Cys Lys Gly Gly Thr Asp Arg Thr Gly Thr Met Val Cys
355 360 365
Ala Phe Leu Ile Ala Ser Glu Ile Cys Ser Thr Ala Lys Glu Ser Leu
370 375 380
Tyr Tyr Phe Gly Glu Arg Arg Thr Asp Lys Thr His Ser Glu Lys Phe
385 390 395 400
Gln Gly Val Glu Thr Pro Ser Gln Lys Arg Tyr Val Ala Tyr Phe Ala
405 410 415
Gln Val Lys His Leu Tyr Asn Trp Asn Leu Pro Pro Arg Arg Ile Leu
420 425 430
Phe Ile Lys His Phe Ile Ile Tyr Ser Ile Pro Arg Tyr Val Arg Asp
435 440 445
Leu Lys Ile Gln Ile Glu Met Glu Lys Lys Val Val Phe Ser Thr Ile
450 455 460
Ser Leu Gly Lys Cys Ser Val Leu Asp Asn Ile Thr Thr Asp Lys Ile
465 470 475 480
Leu Ile Asp Val Phe Asp Gly Pro Pro Leu Tyr Asp Asp Val Lys Val
485 490 495
Gln Phe Phe Tyr Ser Asn Leu Pro Thr Tyr Tyr Asp Asn Cys Ser Phe
500 505 510
Tyr Phe Trp Leu His Thr Ser Phe Ile Glu Asn Asn Arg Leu Tyr Leu
515 520 525
Pro Lys Asn Glu Leu Asp Asn Leu His Lys Gln Lys Ala Arg Arg Ile
530 535 540
Tyr Pro Ser Asp Phe Ala Val Glu Ile Leu Phe Gly Glu Lys Met Thr
545 550 555 560
Ser Ser Asp Val Val Ala Gly Ser Asp
565
<210> 25
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 25
tgccgtaggc atggcttgtg c 21
<210> 26
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 26
caacatctga gacaccattc c 21
<210> 27
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 27
tggatgtcac tctcatcctt g 21
<210> 28
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 28
ccatagttcc tgttctatct g 21
<210> 29
<211> 2192
<212> DNA
<213> Homo sapiens
<400> 29
agctcagctg ggagcgcaga ggctcacgcc tgtaatccca tcatttgctt aggtctgatc 60
aatctgctcc acacaatttc tcagtgatcc tctgcatctc tgcctacaag ggcctccctg 120
acacccaagt tcatattgct cagaaacagt gaacttgagt ttttcgtttt accttgatct 180
ctctctgaca aagaaatcca gatgatgcaa cacctgatga agacaataca tggaaaatga 240
cagtcttgga aataactttg gctgtcatcc tgactctact gggacttgcc atcctggcta 300
ttttgttaac aagatgggca cgacgtaagc aaagtgaaat gtatatctcc agatacagtt 360
cagaacaaag tgctagactt ctggactatg aggatggtag aggatcccga catgcatatc 420
aacacaaagt gacacttcat atgataaccg agagagatcc aaaaagagat tacacaccat 480
caaccaactc tctagcactg tctcgatcaa gtattgcttt acctcaagga tccatgagta 540
gtataaaatg tttacaaaca actgaagaac ctccttccag aactgcagga gccatgatgc 600
aattcacagc cctattcccg gagctacagg acctatcaag ctctctcaaa aaaccattgt 660
gcaaactcca ggacctattg tacaatatct ggatccaatg tcagatcgca tctcacacaa 720
tcactggtca ccttcagcac ccgcggtcac ccatggcacc cataataatt tcacagagaa 780
ccgcaagtca gctggcagca cctataagaa tacctcaagt tcacactatg gacagttctg 840
gaaaaatcac actgactcct gtggttatat taacaggtta catggacgaa gaacttcgaa 900
aaaaatcttg ttccaaaatc cagattctaa aatgtggagg cactgcaagg tctcagatag 960
ccgagaagaa aacaaggaag caactaaaga atgacatcat atttacgaat tctgtagaat 1020
ccttgaaatc agcacacata aaggagccag aaagagaagg aaaaggcact gatttagaga 1080
aagacaaaat aggaatggag gtcaaggtag acagtgacgc tggaatacca aaaagacagg 1140
aaacccaact aaaaatcagt gaagatgagt ataccacaag gacagggagc ccaaataaag 1200
aaaagtgtgt cagatgtacc aagaggacag gagtccaagt aaagaagagt gagtcaggtg 1260
tcccaaaagg acaagaagcc caagtaacga agagtgggtt ggttgtactg aaaggacagg 1320
aagcccaggt agagaagagt gagatgggtg tgccaagaag acaggaatcc caagtaaaga 1380
agagtcagtc tggtgtctca aagggacagg aagcccaggt aaagaagagg gagtcagttg 1440
tactgaaagg acaggaagcc caggtagaga agagtgagtt gaaggtacca aaaggacaag 1500
aaggccaagt agagaagact gaggcagatg tgccaaagga acaagaggtc caagaaaaga 1560
agagtgaggc aggtgtactg aaaggaccag aatcccaagt aaagaacact gaggtgagtg 1620
taccagaaac actggaatcc caagtaaaga agagtgagtc aggtgtacta aaaggacagg 1680
aagcccaaga aaagaaggag agttttgagg ataaaggaaa taatgataaa gaaaaggaga 1740
gagatgcaga gaaagatcca aataaaaaag aaaaaggtga caaaaacaca aaaggtgaca 1800
aaggaaagga caaagttaaa ggaaagagag aatcagaaat caatggtgaa aaatcaaaag 1860
gctcgaaaag gcgaaggcaa atacaggaag gaagtacaac aaaaaagtgg aagagtaagg 1920
ataaattttt taaaggccca taagacaagt gattattatg attcccatac tccagataca 1980
aaccatatcc cagccattgc ctaaacagat tacaattata aaatcccttt catcttcata 2040
tcacagtttc tgctcttcag aagtttcacc ctttttaatc tctcagccac aaacctcagt 2100
tccaatattg ttataagtta agacgtatat gattccgtca agaaagactg gatactttct 2160
gaagtaaaac attttaatta aagaaaaaaa aa 2192
<210> 30
<211> 568
<212> PRT
<213> Homo sapiens
<400> 30
Met Thr Val Leu Glu Ile Thr Leu Ala Val Ile Leu Thr Leu Leu Gly
1 5 10 15
Leu Ala Ile Leu Ala Ile Leu Leu Thr Arg Trp Ala Arg Arg Lys Gln
20 25 30
Ser Glu Met Tyr Ile Ser Arg Tyr Ser Ser Glu Gln Ser Ala Arg Leu
35 40 45
Leu Asp Tyr Glu Asp Gly Arg Gly Ser Arg His Ala Tyr Gln His Lys
50 55 60
Val Thr Leu His Met Ile Thr Glu Arg Asp Pro Lys Arg Asp Tyr Thr
65 70 75 80
Pro Ser Thr Asn Ser Leu Ala Leu Ser Arg Ser Ser Ile Ala Leu Pro
85 90 95
Gln Gly Ser Met Ser Ser Ile Lys Cys Leu Gln Thr Thr Glu Glu Pro
100 105 110
Pro Ser Arg Thr Ala Gly Ala Met Met Gln Phe Thr Ala Leu Phe Pro
115 120 125
Glu Leu Gln Asp Leu Ser Ser Ser Leu Lys Lys Pro Leu Cys Lys Leu
130 135 140
Gln Asp Leu Leu Tyr Asn Ile Trp Ile Gln Cys Gln Ile Ala Ser His
145 150 155 160
Thr Ile Thr Gly His Leu Gln His Pro Arg Ser Pro Met Ala Pro Ile
165 170 175
Ile Ile Ser Gln Arg Thr Ala Ser Gln Leu Ala Ala Pro Ile Arg Ile
180 185 190
Pro Gln Val His Thr Met Asp Ser Ser Gly Lys Ile Thr Leu Thr Pro
195 200 205
Val Val Ile Leu Thr Gly Tyr Met Asp Glu Glu Leu Arg Lys Lys Ser
210 215 220
Cys Ser Lys Ile Gln Ile Leu Lys Cys Gly Gly Thr Ala Arg Ser Gln
225 230 235 240
Ile Ala Glu Lys Lys Thr Arg Lys Gln Leu Lys Asn Asp Ile Ile Phe
245 250 255
Thr Asn Ser Val Glu Ser Leu Lys Ser Ala His Ile Lys Glu Pro Glu
260 265 270
Arg Glu Gly Lys Gly Thr Asp Leu Glu Lys Asp Lys Ile Gly Met Glu
275 280 285
Val Lys Val Asp Ser Asp Ala Gly Ile Pro Lys Arg Gln Glu Thr Gln
290 295 300
Leu Lys Ile Ser Glu Asp Glu Tyr Thr Thr Arg Thr Gly Ser Pro Asn
305 310 315 320
Lys Glu Lys Cys Val Arg Cys Thr Lys Arg Thr Gly Val Gln Val Lys
325 330 335
Lys Ser Glu Ser Gly Val Pro Lys Gly Gln Glu Ala Gln Val Thr Lys
340 345 350
Ser Gly Leu Val Val Leu Lys Gly Gln Glu Ala Gln Val Glu Lys Ser
355 360 365
Glu Met Gly Val Pro Arg Arg Gln Glu Ser Gln Val Lys Lys Ser Gln
370 375 380
Ser Gly Val Ser Lys Gly Gln Glu Ala Gln Val Lys Lys Arg Glu Ser
385 390 395 400
Val Val Leu Lys Gly Gln Glu Ala Gln Val Glu Lys Ser Glu Leu Lys
405 410 415
Val Pro Lys Gly Gln Glu Gly Gln Val Glu Lys Thr Glu Ala Asp Val
420 425 430
Pro Lys Glu Gln Glu Val Gln Glu Lys Lys Ser Glu Ala Gly Val Leu
435 440 445
Lys Gly Pro Glu Ser Gln Val Lys Asn Thr Glu Val Ser Val Pro Glu
450 455 460
Thr Leu Glu Ser Gln Val Lys Lys Ser Glu Ser Gly Val Leu Lys Gly
465 470 475 480
Gln Glu Ala Gln Glu Lys Lys Glu Ser Phe Glu Asp Lys Gly Asn Asn
485 490 495
Asp Lys Glu Lys Glu Arg Asp Ala Glu Lys Asp Pro Asn Lys Lys Glu
500 505 510
Lys Gly Asp Lys Asn Thr Lys Gly Asp Lys Gly Lys Asp Lys Val Lys
515 520 525
Gly Lys Arg Glu Ser Glu Ile Asn Gly Glu Lys Ser Lys Gly Ser Lys
530 535 540
Arg Arg Arg Gln Ile Gln Glu Gly Ser Thr Thr Lys Lys Trp Lys Ser
545 550 555 560
Lys Asp Lys Phe Phe Lys Gly Pro
565
<210> 31
<211> 1686
<212> DNA
<213> Homo sapiens
<400> 31
atgacagtct tggaaataac tttggctgtc atcctgactc tactgggact tgccatcctg 60
gctattttgt taacaagatg ggcacgatgt aagcaaagtg aaatgtatat ctccagatac 120
agttcagaac aaagtgctag acttctggac tatgaggatg gtagaggatc ccgacatgca 180
tattcaacac aaagtgacac ttcatatgat aaccgagaga gatccaaaag agattacaca 240
ccatcaacca actctctagc actgtctcga tcaagtattg ctttacctca aggatccatg 300
agtagtataa aatgtttaca aacaactgaa gaacctcctt ccagaactgc aggagccatg 360
atgcaattca cagcccctat tcccggagct acaggaccta tcaagctctc tcaaaaaacc 420
attgtgcaaa ctccaggacc tattgtacaa tatcctggat ccaatgctgg tccaccttca 480
gcaccccgcg gtccacccat ggcacccata ataatttcac agagaaccgc aagtcagctg 540
gcagcaccta taataatttc gcagagaact gcaagaatac ctcaagttca cactatggac 600
agttctggaa aaatcacact gactcctgtg gttatattaa caggttacat ggatgaagaa 660
cttgcaaaaa aatcttgttc caaaatccag attctaaaat gtggaggcac tgcaaggtct 720
cagaatagcc gagaagaaaa caaggaagca ctaaagaatg acatcatatt tacgaattct 780
gtagaatcct tgaaatcagc acacataaag gagccagaaa gagaaggaaa aggcactgat 840
ttagagaaag acaaaatagg aatggaggtc aaggtagaca gtgacgctgg aataccaaaa 900
agacaggaaa cccaactaaa aatcagtgag atgagtatac cacaaggaca gggagcccaa 960
ataaagaaaa gtgtgtcaga tgtaccaaga ggacaggagt cccaagtaaa gaagagtgag 1020
tcaggtgtcc caaaaggaca agaagcccaa gtaacgaaga gtgggttggt tgtactgaaa 1080
ggacaggaag cccaggtaga gaagagtgag atgggtgtgc caagaagaca ggaatcccaa 1140
gtaaagaaga gtcagtctgg tgtctcaaag ggacaggaag cccaggtaaa gaagagggag 1200
tcagttgtac tgaaaggaca ggaagcccag gtagagaaga gtgagttgaa ggtaccaaaa 1260
ggacaagaag gccaagtaga gaagactgag gcagatgtgc caaaggaaca agaggtccaa 1320
gaaaagaaga gtgaggcagg tgtactgaaa ggaccagaat cccaagtaaa gaacactgag 1380
gtgagtgtac cagaaacact ggaatcccaa gtaaagaaga gtgagtcagg tgtactaaaa 1440
ggacaggaag cccaagaaaa gaaggagagt tttgaggata aaggaaataa tgataaagaa 1500
aaggagagag atgcagagaa agatccaaat aaaaaagaaa aaggtgacaa aaacacaaaa 1560
ggtgacaaag gaaaggacaa agttaaagga aagagagaat cagaaatcaa tggtgaaaaa 1620
tcaaaaggct cgaaaagggc gaaggcaaat acaggaagga agtacaacaa aaaagtggaa 1680
gagtaa 1686
<210> 32
<211> 1710
<212> DNA
<213> Homo sapiens
<400> 32
atgacagtct tggaaataac tttggctgtc atcctgactc tactgggact tgccatcctg 60
gctattttgt taacaagatg ggcacgacgt aagcaaagtg aaatgcatat ctccagatac 120
agttcagaac aaagtgctag acttctggac tatgaggatg gtagaggatc ccgacatgca 180
tattcaacac aaagtgacac ttcatgtgat aaccgagaga gatccaaaag agattacaca 240
ccatcaacca actctctagc actgtctcga tcaagtattg ctttacctca aggatccatg 300
agtagtataa aatgtttaca aacaactgaa gaacttcctt ccagaactgc aggagccatg 360
atgcaattca cagcccctat tcccggagct acaggaccta tcaagctctc tcaaaaaacc 420
attgtgcaaa ctccaggacc tattgtacaa tatcctggac ccaatgtcag atcgcatcct 480
cacacaatca ctggtccacc ttcagcaccc cgcggtccac ccatggcacc cataataatt 540
tcacagagaa ccgcaagtca gctggcagca cctataataa tttcgcagag aactgcaaga 600
atacctcaag ttcacactat ggacagttct ggaaaaacca cactgactcc tgtggttata 660
ttaacaggtt acatggatga agaacttgca aaaaaatctt gttccaaaat ccagattcta 720
aaatgtggag gcactgcaag gtctcagaat agccgagaag aaaacaagga agcactaaag 780
aatgacatca tatttacgaa ttctgtagaa tccttgaaat cagcacacat aaaggagcca 840
gaaagagaag gaaaaggcac tgatttagag aaagacaaaa taggaatgga ggtcaaggta 900
gacagtgacg ctggaatacc aaaaagacag gaaacccaac taaaaatcag tgagatgagt 960
ataccacaag gacagggagc ccaaataaag aaaagtgtgt cagatgtacc aagaggacag 1020
gagtcccaag taaagaagag tgagtcaggt gtcccaaaag gacaagaagc ccaagtaacg 1080
aagagtgggt tggttgtact gaaaggacag gaagcccagg tagagaagag tgagatgggt 1140
gtgccaagaa gacaggaatc ccaagtaaag aagagtcagt ctggtgtctc aaagggacag 1200
gaagcccagg taaagaagag ggagtcagtt gtactgaaag gacaggaagc ccaggtagag 1260
aagagtgagt tgaaggtacc aaaaggacaa gaaggccaag tagagaagac tgaggcagat 1320
gtgccaaagg aacaagaggt ccaagaaaag aagagtgagg caggtgtact gaaaggacca 1380
gaatcccaag taaagaacac tgaggtgagt gtaccagaaa cactggaatc ccaagtaaag 1440
aagagtgagt caggtgtact aaaaggacag gaagcccaag aaaagaagga gagttttgag 1500
gataaaggaa ataatgataa agaaaaggag agagatgcag agaaagatcc aaataaaaaa 1560
gaaaaaggtg acaaaaacac aaaaggtgac aaaggaaagg acaaagttaa aggaaagaga 1620
gaatcagaaa tcaatggtga aaaatcaaaa ggctcgaaaa gggcgaaggc aaatacagga 1680
aggaagtaca acaaaaaagt ggaagagtaa 1710
<210> 33
<211> 1665
<212> DNA
<213> Homo sapiens
<400> 33
atgacagtct tggaaataac tttggctgtc atcctgactc tactgggact tgccatcctg 60
gctattttgt taacaagatg ggcacgatgt aagcaaagtg aaatgtatat ctccagatac 120
agttcagaac aaagtgctag acttctggac tatgaggatg gtagaggatc ccgacatgca 180
tattcaacac aaagtgagag atccaaaaga gattacacac catcaaccaa ctctctagca 240
ctgtctcgat caagtattgc tttacctcaa ggatccatga gtagtataaa atgtttacaa 300
acaactgaag aacctccttc cagaactgca ggagccatga tgcaattcac agcccctatt 360
cccggagcta caggacctat caagctctct caaaaaacca ttgtgcaaac tccaggacct 420
attgtacaat atcctggatc caatgctggt ccaccttcag caccccgcgg tccacccatg 480
gcacccataa taatttcaca gagaaccgca agtcagctgg cagcacctat aataatttcg 540
cagagaactg caagaatacc tcaagttcac actatggaca gttctggaaa aatcacactg 600
actcctgtgg ttatattaac aggttacatg gatgaagaac ttgcaaaaaa atcttgttcc 660
aaaatccaga ttctaaaatg tggaggcact gcaaggtctc agaatagccg agaagaaaac 720
aaggaagcac taaagaatga catcatattt acgaattctg tagaatcctt gaaatcagca 780
cacataaagg agccagaaag agaaggaaaa ggcactgatt tagagaaaga caaaatagga 840
atggaggtca aggtagacag tgacgctgga ataccaaaaa gacaggaaac ccaactaaaa 900
atcagtgaga tgagtatacc acaaggacag ggagcccaaa taaagaaaag tgtgtcagat 960
gtaccaagag gacaggagtc ccaagtaaag aagagtgagt caggtgtccc aaaaggacaa 1020
gaagcccaag taacgaagag tgggttggtt gtactgaaag gacaggaagc ccaggtagag 1080
aagagtgaga tgggtgtgcc aagaagacag gaatcccaag taaagaagag tcagtctggt 1140
gtctcaaagg gacaggaagc ccaggtaaag aagagggagt cagttgtact gaaaggacag 1200
gaagcccagg tagagaagag tgagttgaag gtaccaaaag gacaagaagg ccaagtagag 1260
aagactgagg cagatgtgcc aaaggaacaa gaggtccaag aaaagaagag tgaggcaggt 1320
gtactgaaag gaccagaatc ccaagtaaag aacactgagg tgagtgtacc agaaacactg 1380
gaatcccaag taaagaagag tgagtcaggt gtactaaaag gacaggaagc ccaagaaaag 1440
aaggagagtt ttgaggataa aggaaataat gataaagaaa aggagagaga tgcagagaaa 1500
gatccaaata aaaaagaaaa aggtgacaaa aacacaaaag gtgacaaagg aaaggacaaa 1560
gttaaaggaa agagagaatc agaaatcaat ggtgaaaaat caaaaggctc gaaaagggcg 1620
aaggcaaata caggaaggaa gtacaacaaa aaagtggaag agtaa 1665
<210> 34
<211> 561
<212> PRT
<213> Homo sapiens
<400> 34
Met Thr Val Leu Glu Ile Thr Leu Ala Val Ile Leu Thr Leu Leu Gly
1 5 10 15
Leu Ala Ile Leu Ala Ile Leu Leu Thr Arg Trp Ala Arg Cys Lys Gln
20 25 30
Ser Glu Met Tyr Ile Ser Arg Tyr Ser Ser Glu Gln Ser Ala Arg Leu
35 40 45
Leu Asp Tyr Glu Asp Gly Arg Gly Ser Arg His Ala Tyr Ser Thr Gln
50 55 60
Ser Asp Thr Ser Tyr Asp Asn Arg Glu Arg Ser Lys Arg Asp Tyr Thr
65 70 75 80
Pro Ser Thr Asn Ser Leu Ala Leu Ser Arg Ser Ser Ile Ala Leu Pro
85 90 95
Gln Gly Ser Met Ser Ser Ile Lys Cys Leu Gln Thr Thr Glu Glu Pro
100 105 110
Pro Ser Arg Thr Ala Gly Ala Met Met Gln Phe Thr Ala Pro Ile Pro
115 120 125
Gly Ala Thr Gly Pro Ile Lys Leu Ser Gln Lys Thr Ile Val Gln Thr
130 135 140
Pro Gly Pro Ile Val Gln Tyr Pro Gly Ser Asn Ala Gly Pro Pro Ser
145 150 155 160
Ala Pro Arg Gly Pro Pro Met Ala Pro Ile Ile Ile Ser Gln Arg Thr
165 170 175
Ala Ser Gln Leu Ala Ala Pro Ile Ile Ile Ser Gln Arg Thr Ala Arg
180 185 190
Ile Pro Gln Val His Thr Met Asp Ser Ser Gly Lys Ile Thr Leu Thr
195 200 205
Pro Val Val Ile Leu Thr Gly Tyr Met Asp Glu Glu Leu Ala Lys Lys
210 215 220
Ser Cys Ser Lys Ile Gln Ile Leu Lys Cys Gly Gly Thr Ala Arg Ser
225 230 235 240
Gln Asn Ser Arg Glu Glu Asn Lys Glu Ala Leu Lys Asn Asp Ile Ile
245 250 255
Phe Thr Asn Ser Val Glu Ser Leu Lys Ser Ala His Ile Lys Glu Pro
260 265 270
Glu Arg Glu Gly Lys Gly Thr Asp Leu Glu Lys Asp Lys Ile Gly Met
275 280 285
Glu Val Lys Val Asp Ser Asp Ala Gly Ile Pro Lys Arg Gln Glu Thr
290 295 300
Gln Leu Lys Ile Ser Glu Met Ser Ile Pro Gln Gly Gln Gly Ala Gln
305 310 315 320
Ile Lys Lys Ser Val Ser Asp Val Pro Arg Gly Gln Glu Ser Gln Val
325 330 335
Lys Lys Ser Glu Ser Gly Val Pro Lys Gly Gln Glu Ala Gln Val Thr
340 345 350
Lys Ser Gly Leu Val Val Leu Lys Gly Gln Glu Ala Gln Val Glu Lys
355 360 365
Ser Glu Met Gly Val Pro Arg Arg Gln Glu Ser Gln Val Lys Lys Ser
370 375 380
Gln Ser Gly Val Ser Lys Gly Gln Glu Ala Gln Val Lys Lys Arg Glu
385 390 395 400
Ser Val Val Leu Lys Gly Gln Glu Ala Gln Val Glu Lys Ser Glu Leu
405 410 415
Lys Val Pro Lys Gly Gln Glu Gly Gln Val Glu Lys Thr Glu Ala Asp
420 425 430
Val Pro Lys Glu Gln Glu Val Gln Glu Lys Lys Ser Glu Ala Gly Val
435 440 445
Leu Lys Gly Pro Glu Ser Gln Val Lys Asn Thr Glu Val Ser Val Pro
450 455 460
Glu Thr Leu Glu Ser Gln Val Lys Lys Ser Glu Ser Gly Val Leu Lys
465 470 475 480
Gly Gln Glu Ala Gln Glu Lys Lys Glu Ser Phe Glu Asp Lys Gly Asn
485 490 495
Asn Asp Lys Glu Lys Glu Arg Asp Ala Glu Lys Asp Pro Asn Lys Lys
500 505 510
Glu Lys Gly Asp Lys Asn Thr Lys Gly Asp Lys Gly Lys Asp Lys Val
515 520 525
Lys Gly Lys Arg Glu Ser Glu Ile Asn Gly Glu Lys Ser Lys Gly Ser
530 535 540
Lys Arg Ala Lys Ala Asn Thr Gly Arg Lys Tyr Asn Lys Lys Val Glu
545 550 555 560
Glu
<210> 35
<211> 569
<212> PRT
<213> Homo sapiens
<400> 35
Met Thr Val Leu Glu Ile Thr Leu Ala Val Ile Leu Thr Leu Leu Gly
1 5 10 15
Leu Ala Ile Leu Ala Ile Leu Leu Thr Arg Trp Ala Arg Arg Lys Gln
20 25 30
Ser Glu Met His Ile Ser Arg Tyr Ser Ser Glu Gln Ser Ala Arg Leu
35 40 45
Leu Asp Tyr Glu Asp Gly Arg Gly Ser Arg His Ala Tyr Ser Thr Gln
50 55 60
Ser Asp Thr Ser Cys Asp Asn Arg Glu Arg Ser Lys Arg Asp Tyr Thr
65 70 75 80
Pro Ser Thr Asn Ser Leu Ala Leu Ser Arg Ser Ser Ile Ala Leu Pro
85 90 95
Gln Gly Ser Met Ser Ser Ile Lys Cys Leu Gln Thr Thr Glu Glu Leu
100 105 110
Pro Ser Arg Thr Ala Gly Ala Met Met Gln Phe Thr Ala Pro Ile Pro
115 120 125
Gly Ala Thr Gly Pro Ile Lys Leu Ser Gln Lys Thr Ile Val Gln Thr
130 135 140
Pro Gly Pro Ile Val Gln Tyr Pro Gly Pro Asn Val Arg Ser His Pro
145 150 155 160
His Thr Ile Thr Gly Pro Pro Ser Ala Pro Arg Gly Pro Pro Met Ala
165 170 175
Pro Ile Ile Ile Ser Gln Arg Thr Ala Ser Gln Leu Ala Ala Pro Ile
180 185 190
Ile Ile Ser Gln Arg Thr Ala Arg Ile Pro Gln Val His Thr Met Asp
195 200 205
Ser Ser Gly Lys Thr Thr Leu Thr Pro Val Val Ile Leu Thr Gly Tyr
210 215 220
Met Asp Glu Glu Leu Ala Lys Lys Ser Cys Ser Lys Ile Gln Ile Leu
225 230 235 240
Lys Cys Gly Gly Thr Ala Arg Ser Gln Asn Ser Arg Glu Glu Asn Lys
245 250 255
Glu Ala Leu Lys Asn Asp Ile Ile Phe Thr Asn Ser Val Glu Ser Leu
260 265 270
Lys Ser Ala His Ile Lys Glu Pro Glu Arg Glu Gly Lys Gly Thr Asp
275 280 285
Leu Glu Lys Asp Lys Ile Gly Met Glu Val Lys Val Asp Ser Asp Ala
290 295 300
Gly Ile Pro Lys Arg Gln Glu Thr Gln Leu Lys Ile Ser Glu Met Ser
305 310 315 320
Ile Pro Gln Gly Gln Gly Ala Gln Ile Lys Lys Ser Val Ser Asp Val
325 330 335
Pro Arg Gly Gln Glu Ser Gln Val Lys Lys Ser Glu Ser Gly Val Pro
340 345 350
Lys Gly Gln Glu Ala Gln Val Thr Lys Ser Gly Leu Val Val Leu Lys
355 360 365
Gly Gln Glu Ala Gln Val Glu Lys Ser Glu Met Gly Val Pro Arg Arg
370 375 380
Gln Glu Ser Gln Val Lys Lys Ser Gln Ser Gly Val Ser Lys Gly Gln
385 390 395 400
Glu Ala Gln Val Lys Lys Arg Glu Ser Val Val Leu Lys Gly Gln Glu
405 410 415
Ala Gln Val Glu Lys Ser Glu Leu Lys Val Pro Lys Gly Gln Glu Gly
420 425 430
Gln Val Glu Lys Thr Glu Ala Asp Val Pro Lys Glu Gln Glu Val Gln
435 440 445
Glu Lys Lys Ser Glu Ala Gly Val Leu Lys Gly Pro Glu Ser Gln Val
450 455 460
Lys Asn Thr Glu Val Ser Val Pro Glu Thr Leu Glu Ser Gln Val Lys
465 470 475 480
Lys Ser Glu Ser Gly Val Leu Lys Gly Gln Glu Ala Gln Glu Lys Lys
485 490 495
Glu Ser Phe Glu Asp Lys Gly Asn Asn Asp Lys Glu Lys Glu Arg Asp
500 505 510
Ala Glu Lys Asp Pro Asn Lys Lys Glu Lys Gly Asp Lys Asn Thr Lys
515 520 525
Gly Asp Lys Gly Lys Asp Lys Val Lys Gly Lys Arg Glu Ser Glu Ile
530 535 540
Asn Gly Glu Lys Ser Lys Gly Ser Lys Arg Ala Lys Ala Asn Thr Gly
545 550 555 560
Arg Lys Tyr Asn Lys Lys Val Glu Glu
565
<210> 36
<211> 554
<212> PRT
<213> Homo sapiens
<400> 36
Met Thr Val Leu Glu Ile Thr Leu Ala Val Ile Leu Thr Leu Leu Gly
1 5 10 15
Leu Ala Ile Leu Ala Ile Leu Leu Thr Arg Trp Ala Arg Cys Lys Gln
20 25 30
Ser Glu Met Tyr Ile Ser Arg Tyr Ser Ser Glu Gln Ser Ala Arg Leu
35 40 45
Leu Asp Tyr Glu Asp Gly Arg Gly Ser Arg His Ala Tyr Ser Thr Gln
50 55 60
Ser Glu Arg Ser Lys Arg Asp Tyr Thr Pro Ser Thr Asn Ser Leu Ala
65 70 75 80
Leu Ser Arg Ser Ser Ile Ala Leu Pro Gln Gly Ser Met Ser Ser Ile
85 90 95
Lys Cys Leu Gln Thr Thr Glu Glu Pro Pro Ser Arg Thr Ala Gly Ala
100 105 110
Met Met Gln Phe Thr Ala Pro Ile Pro Gly Ala Thr Gly Pro Ile Lys
115 120 125
Leu Ser Gln Lys Thr Ile Val Gln Thr Pro Gly Pro Ile Val Gln Tyr
130 135 140
Pro Gly Ser Asn Ala Gly Pro Pro Ser Ala Pro Arg Gly Pro Pro Met
145 150 155 160
Ala Pro Ile Ile Ile Ser Gln Arg Thr Ala Ser Gln Leu Ala Ala Pro
165 170 175
Ile Ile Ile Ser Gln Arg Thr Ala Arg Ile Pro Gln Val His Thr Met
180 185 190
Asp Ser Ser Gly Lys Ile Thr Leu Thr Pro Val Val Ile Leu Thr Gly
195 200 205
Tyr Met Asp Glu Glu Leu Ala Lys Lys Ser Cys Ser Lys Ile Gln Ile
210 215 220
Leu Lys Cys Gly Gly Thr Ala Arg Ser Gln Asn Ser Arg Glu Glu Asn
225 230 235 240
Lys Glu Ala Leu Lys Asn Asp Ile Ile Phe Thr Asn Ser Val Glu Ser
245 250 255
Leu Lys Ser Ala His Ile Lys Glu Pro Glu Arg Glu Gly Lys Gly Thr
260 265 270
Asp Leu Glu Lys Asp Lys Ile Gly Met Glu Val Lys Val Asp Ser Asp
275 280 285
Ala Gly Ile Pro Lys Arg Gln Glu Thr Gln Leu Lys Ile Ser Glu Met
290 295 300
Ser Ile Pro Gln Gly Gln Gly Ala Gln Ile Lys Lys Ser Val Ser Asp
305 310 315 320
Val Pro Arg Gly Gln Glu Ser Gln Val Lys Lys Ser Glu Ser Gly Val
325 330 335
Pro Lys Gly Gln Glu Ala Gln Val Thr Lys Ser Gly Leu Val Val Leu
340 345 350
Lys Gly Gln Glu Ala Gln Val Glu Lys Ser Glu Met Gly Val Pro Arg
355 360 365
Arg Gln Glu Ser Gln Val Lys Lys Ser Gln Ser Gly Val Ser Lys Gly
370 375 380
Gln Glu Ala Gln Val Lys Lys Arg Glu Ser Val Val Leu Lys Gly Gln
385 390 395 400
Glu Ala Gln Val Glu Lys Ser Glu Leu Lys Val Pro Lys Gly Gln Glu
405 410 415
Gly Gln Val Glu Lys Thr Glu Ala Asp Val Pro Lys Glu Gln Glu Val
420 425 430
Gln Glu Lys Lys Ser Glu Ala Gly Val Leu Lys Gly Pro Glu Ser Gln
435 440 445
Val Lys Asn Thr Glu Val Ser Val Pro Glu Thr Leu Glu Ser Gln Val
450 455 460
Lys Lys Ser Glu Ser Gly Val Leu Lys Gly Gln Glu Ala Gln Glu Lys
465 470 475 480
Lys Glu Ser Phe Glu Asp Lys Gly Asn Asn Asp Lys Glu Lys Glu Arg
485 490 495
Asp Ala Glu Lys Asp Pro Asn Lys Lys Glu Lys Gly Asp Lys Asn Thr
500 505 510
Lys Gly Asp Lys Gly Lys Asp Lys Val Lys Gly Lys Arg Glu Ser Glu
515 520 525
Ile Asn Gly Glu Lys Ser Lys Gly Ser Lys Arg Ala Lys Ala Asn Thr
530 535 540
Gly Arg Lys Tyr Asn Lys Lys Val Glu Glu
545 550
<210> 37
<211> 1182
<212> DNA
<213> Homo sapiens
<400> 37
acacaggttg gagcagagaa agaggaaaca tagaggtgcc aaaggaacaa agacataatg 60
atgtcatcca agccaacaag ccatgctgaa gtaaatgaaa ccatacccaa cccttaccca 120
ccaggcagct ttatggctcc tggatttcaa cagcctctgg gttcaatcaa cttagaaaac 180
caagctcagg gtgctcagcg tgctcagccc tacggcatca catctccggg aatctttgct 240
agcagtcaac cgggtcaagg aaatatacaa atgataaatc caagtgtggg aacagcagta 300
atgaacttta aagaagaagc aaaggcacta ggggtgatcc agatcatggt tggattgatg 360
cacattggtt ttggaattgt tttgtgttta atatccttct cttttagaga agtattaggt 420
tttgcctcta ctgctgttat tggtggatac ccattctggg gtggcctttc ttttattatc 480
tctggctctc tctctgtgtc agcatccaag gagctttccc gttgtctggt gaaaggcagc 540
ctgggaatga acattgttag ttctatcttg gccttcattg gagtgattct gctgctggtg 600
gatatgtgca tcaatggggt agctggccaa gactactggg ccgtgctttc tggaaaaggc 660
atttcagcca cgctgatgat cttctccctc ttggagttct tcgtagcttg tgccacagcc 720
cattttgcca accaagcaaa caccacaacc aatatgtctg tcctggttat tccaaatatg 780
tatgaaagca accctgtgac accagcgtct tcttcagctc ctcccagatg caacaactac 840
tcagctaatg cccctaaata gtaaaagaaa aaggggtatc agtctaatct catggagaaa 900
aactacttgc aaaaacttct taagaagatg tcttttattg tctacaatga tttctagtct 960
ttaaaaactg tgtttgagat ttgtttttag gttggtcgct aatgatggct gtatctccct 1020
tcactgtctc ttcctacatt accactacta catgctggca aaggtgaagg atcagaggac 1080
tgaaaaatga ttctgcaact ctcttaaagt tagaaatgtt tctgttcata ttactttttc 1140
cttaataaaa tgtcattaga aacaaaaaaa aaaaaaaaaa aa 1182
<210> 38
<211> 267
<212> PRT
<213> Homo sapiens
<400> 38
Met Met Ser Ser Lys Pro Thr Ser His Ala Glu Val Asn Glu Thr Ile
1 5 10 15
Pro Asn Pro Tyr Pro Pro Gly Ser Phe Met Ala Pro Gly Phe Gln Gln
20 25 30
Pro Leu Gly Ser Ile Asn Leu Glu Asn Gln Ala Gln Gly Ala Gln Arg
35 40 45
Ala Gln Pro Tyr Gly Ile Thr Ser Pro Gly Ile Phe Ala Ser Ser Gln
50 55 60
Pro Gly Gln Gly Asn Ile Gln Met Ile Asn Pro Ser Val Gly Thr Ala
65 70 75 80
Val Met Asn Phe Lys Glu Glu Ala Lys Ala Leu Gly Val Ile Gln Ile
85 90 95
Met Val Gly Leu Met His Ile Gly Phe Gly Ile Val Leu Cys Leu Ile
100 105 110
Ser Phe Ser Phe Arg Glu Val Leu Gly Phe Ala Ser Thr Ala Val Ile
115 120 125
Gly Gly Tyr Pro Phe Trp Gly Gly Leu Ser Phe Ile Ile Ser Gly Ser
130 135 140
Leu Ser Val Ser Ala Ser Lys Glu Leu Ser Arg Cys Leu Val Lys Gly
145 150 155 160
Ser Leu Gly Met Asn Ile Val Ser Ser Ile Leu Ala Phe Ile Gly Val
165 170 175
Ile Leu Leu Leu Val Asp Met Cys Ile Asn Gly Val Ala Gly Gln Asp
180 185 190
Tyr Trp Ala Val Leu Ser Gly Lys Gly Ile Ser Ala Thr Leu Met Ile
195 200 205
Phe Ser Leu Leu Glu Phe Phe Val Ala Cys Ala Thr Ala His Phe Ala
210 215 220
Asn Gln Ala Asn Thr Thr Thr Asn Met Ser Val Leu Val Ile Pro Asn
225 230 235 240
Met Tyr Glu Ser Asn Pro Val Thr Pro Ala Ser Ser Ser Ala Pro Pro
245 250 255
Arg Cys Asn Asn Tyr Ser Ala Asn Ala Pro Lys
260 265
<210> 39
<211> 1948
<212> DNA
<213> Homo sapiens
<400> 39
gcacgaggtt ttgaggacca gcaacacagc aatacttcca gatctccata taacctctgt 60
tcatttggga ggggctttgt attttcaaca ggagagttca aagttcattt ttttttcagc 120
aactacagtt ctaagtgaaa tctattttta ttgatacatg gtattttaca tgtttatggg 180
atacatatga gtcataatct attttaaata ataccttagt gttgtaaaat caacagtgct 240
ttttaaaaga aatatacctt gttaattatc ccacatgtgt ctccagaagt acagcttgaa 300
caaatccacc ttctgtggac caagcaccac cctgggcatt tctagcatga gcaaaatcca 360
aggtcctggc tggactccag agatgctatt tacctcagaa gcatgacaat aggaggcaga 420
aggagcaggc aaatccaagt cctttcttgt agtttccttg tttggggagg aaaagttgag 480
ttttactatt atggaaaaga aacaggaaat agagacagac aaagagatat gacaatacag 540
tcctgccacc cagatactca tttccaccta ccattccatg catttgtttt gaatatataa 600
gtatgtacat aaaggtaggt actctcaagt ccatcagggc ttggctgtcc actgtttttg 660
aagttccaga atgtttttgc taagttgagg aaataccaaa tcaggactat gaaaattatg 720
gtatatattg atgtgtcaca gaacacagat gtgacataat aaagatgtgt aagattatat 780
atataacttg tgtgtacacc tacctcatct ggggataaca cctcaagttt aattttgagg 840
cttgggtcaa tcgtgcttcc cttccctttc ataggtcctc tatgagatat tgtcatagat 900
tccatgttat gcaatagcca tagaatatga catctctcta tgataattct atattacttt 960
aattgctgca cagaagttca ttgtatgtaa gtgccacagt atattataga tcttcttgtg 1020
ggacatctat ttctagttta tgtgatagta tagcactttc atgaatgttc ttgtacttga 1080
tctttacaca ttttcttttt tccttaggat gaattctgag agatgtaatt gatggggcaa 1140
aatgtactca ctgtttgagg tttgaaattt ttccatcaaa agctggtact cttggttttt 1200
taagacaaag agcaaatcct cccctgccag gattgacttt tggctctttt ttttcaaacc 1260
tcactgcttt ttggtttagt tgtcataaaa tgccaagcac catgaacagg gctccatgaa 1320
ggggctcaga ggtaggaggg ctgtgattag gagaaggctt ggactgatgg gcaatttgag 1380
tgctcagaat tagagtgagg gggtgggggt gctgcaggga cagatgctgg ggaaagacac 1440
cctgaagggc aaagggagca acaatggctg cagtacatgt ggcctttcag ctagcgcaga 1500
ggatggaaac cagagtgggc tgatgattgg atgccaggcc tgagccagca actgtgatcc 1560
tgagctgtgc acacttctgg ttgggattat ttctggtttc tacttcctgt ttgaagatgt 1620
ggcatggaga gtgctctgct ttgacctgaa gtattttatc tatcctcagt ctcaggacac 1680
tgttgatgga attaaggcca agcacatctg caaaaaagac attgctggag gaggtgcaaa 1740
gagctggaaa ccaagtctcc agtcctggga aaagcagtgg tatggaaaag caatggaaag 1800
agcattttga aaatgccatt ccactgtttt ctggccttta tgatttctgc tgagaaatcc 1860
actgttagtc tgatggggtc tccttcatag caccaatgac ctgaagagcc ttgttgaagg 1920
aagactccat ctgatgactc agagcaag 1948
<210> 40
<211> 1406
<212> DNA
<213> Homo sapiens
<400> 40
cggtgagagg ggcgcgcagc agcagctcct caacgccgca acgcgccggc ccaactgcag 60
gaaggtctgt gctctggagc cagggtaaat ggttataaaa ttatacacca tggccctcct 120
aaagacactc taggaaaacc atgtcatcct gatcttaaaa cacctgcaag aaagagcaca 180
gtacttcacc attaataaag tagatatttc atcctgctca gaaaaccaac atttccagca 240
atggctttac taccggtgtt gtttctggtt actgtgctgc ttccatcttt acctgcagaa 300
ggaaaggatc ccgcttttac tgctttgtta accacccagt tgcaagtgca aagggagatt 360
gtaaataaac acaatgaact aaggaaagca gtctctccac ctgccagtaa catgctaaag 420
atggaatgga gcagagaggt aacaacgaat gcccaaaggt gggcaaacaa gtgcacttta 480
caacatagtg atccagagga ccgcaaaacc agtacaagat gtggtgagaa tctctatatg 540
tcaagtgacc ctacttcctg gtcttctgca atccaaagct ggtatgacga gatcctagat 600
tttgtctatg gtgtaggacc aaagagtccc aatgcagttg ttggacatta tactcagctt 660
gtttggtact cgacttacca ggtaggctgt ggaattgcct actgtcccaa tcaagatagt 720
ctaaaatact actatgtttg ccaatattgt cctgctggta ataatatgaa tagaaagaat 780
accccgtacc aacaaggaac accttgtgcc ggttgccctg atgactgtga caaaggacta 840
tgcaccaata gttgccagta tcaagatctc ctaagtaact gtgattcctt gaagaataca 900
gctggctgtg aacatgagtt actcaaggaa aagtgcaagg ctacttgcct atgtgagaac 960
aaaatttact gatttaccta gtgagcattg tgcaagactg catggataag ggctgcatca 1020
tttaattgcg acataccagt ggaaattgta tgtatgttag tgacaaattt gatttcaaag 1080
agcaatgcat cttctccccc agatcatcac agaaatcact ttcaggcaat gatttacaaa 1140
agtagcatag tagatgatga caactgtgaa ctctgacata aatttagtgc tttataacga 1200
actgaatcag gttgaggatt ttgaaaactg tataaccata ggatttaggt cactaggact 1260
ttggatcaaa atggtgcatt acgtatttcc tgaaacatgc taaagaagaa gactgtaaca 1320
tcattgccat tcctactacc tgagttttta cttgcataaa caataaattc aaagctttac 1380
atctgcaaaa aaaaaaaaaa aaaaaa 1406
<210> 41
<211> 243
<212> PRT
<213> Homo sapiens
<400> 41
Met Ala Leu Leu Pro Val Leu Phe Leu Val Thr Val Leu Leu Pro Ser
1 5 10 15
Leu Pro Ala Glu Gly Lys Asp Pro Ala Phe Thr Ala Leu Leu Thr Thr
20 25 30
Gln Leu Gln Val Gln Arg Glu Ile Val Asn Lys His Asn Glu Leu Arg
35 40 45
Lys Ala Val Ser Pro Pro Ala Ser Asn Met Leu Lys Met Glu Trp Ser
50 55 60
Arg Glu Val Thr Thr Asn Ala Gln Arg Trp Ala Asn Lys Cys Thr Leu
65 70 75 80
Gln His Ser Asp Pro Glu Asp Arg Lys Thr Ser Thr Arg Cys Gly Glu
85 90 95
Asn Leu Tyr Met Ser Ser Asp Pro Thr Ser Trp Ser Ser Ala Ile Gln
100 105 110
Ser Trp Tyr Asp Glu Ile Leu Asp Phe Val Tyr Gly Val Gly Pro Lys
115 120 125
Ser Pro Asn Ala Val Val Gly His Tyr Thr Gln Leu Val Trp Tyr Ser
130 135 140
Thr Tyr Gln Val Gly Cys Gly Ile Ala Tyr Cys Pro Asn Gln Asp Ser
145 150 155 160
Leu Lys Tyr Tyr Tyr Val Cys Gln Tyr Cys Pro Ala Gly Asn Asn Met
165 170 175
Asn Arg Lys Asn Thr Pro Tyr Gln Gln Gly Thr Pro Cys Ala Gly Cys
180 185 190
Pro Asp Asp Cys Asp Lys Gly Leu Cys Thr Asn Ser Cys Gln Tyr Gln
195 200 205
Asp Leu Leu Ser Asn Cys Asp Ser Leu Lys Asn Thr Ala Gly Cys Glu
210 215 220
His Glu Leu Leu Lys Glu Lys Cys Lys Ala Thr Cys Leu Cys Glu Asn
225 230 235 240
Lys Ile Tyr
<210> 42
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 42
tctagcactg tctcgatcaa g 21
<210> 43
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 43
tgtcctcttg gtacatctga c 21
<210> 44
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 44
ctgtgtcagc atccaaggag c 21
<210> 45
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 45
ttcacctttg ccagcatgta g 21
<210> 46
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 46
cttgctctga gtcatcagat g 21
<210> 47
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 47
cacagaatat gagccataca g 21
<210> 48
<211> 22
<212> DNA
<213> Kunstliche Sequenz
<400> 48
ggtgtcactt ctgtgccttc ct 22
<210> 49
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 49
cggcaccagt tccaacaata g 21
<210> 50
<211> 18
<212> DNA
<213> Kunstliche Sequenz
<400> 50
caaaggttct ccaaatgt 18
<210> 51
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 51
tagcgcctca actgtcgttg g 21
<210> 52
<211> 23
<212> DNA
<213> Kunstliche Sequenz
<400> 52
cgtgagcgct tcgagatgtt ccg 23
<210> 53
<211> 23
<212> DNA
<213> Kunstliche Sequenz
<400> 53
cctaaccagc tgcccaactg tag 23
<210> 54
<211> 1550
<212> DNA
<213> Homo sapiens
<400> 54
atgaatgaaa gtcctgatcc gactgacctg gcgggagtca tcattgagct cggccccaat 60
gacagtccac agacaagtga atttaaagga gcaaccgagg aggcacctgc gaaagaaagc 120
ccacacacaa gtgaatttaa aggagcagcc cgggtgtcac ctatcagtga aagtgtgtta 180
gcacgacttt ccaagtttga agttgaagat gctgaaaatg ttgcttcata tgacagcaag 240
attaagaaaa ttgtgcattc aattgtatca tcctttgcat ttggactatt tggagttttc 300
ctggtcttac tggatgtcac tctcatcctt gccgacctaa ttttcactga cagcaaactt 360
tatattcctt tggagtatcg ttctatttct ctagctattg ccttattttt tctcatggat 420
gttcttcttc gagtatttgt agaaaggaga cagcagtatt tttctgactt atttaacatt 480
ttagatactg ccattattgt gattcttctg ctggttgatg tcgtttacat tttttttgac 540
attaagttgc ttaggaatat tcccagatgg acacatttac ttcgacttct acgacttatt 600
attctgttaa gaatttttca tctgtttcat caaaaaagac aacttgaaaa gctgataaga 660
aggcgggttt cagaaaacaa aaggcgatac acaagggatg gatttgacct agacctcact 720
tacgttacag aacgtattat tgctatgtca tttccatctt ctggaaggca gtctttctat 780
agaaatccaa tcaaggaagt tgtgcggttt ctagataaga aacaccgaaa ccactatcga 840
gtctacaatc tatgcagtga aagagcttac gatcctaagc acttccataa tagggtcgtt 900
agaatcatga ttgatgatca taatgtcccc actctacatc agatggtggt tttcaccaag 960
gaagtaaatg agtggatggc tcaagatctt gaaaacatcg tagcgattca ctgtaaagga 1020
ggcacagata gaacaggaac tatggtttgt gccttcctta ttgcctctga aatatgttca 1080
actgcaaagg aaagcctgta ttattttgga gaaaggcgaa cagataaaac ccacagcgaa 1140
aaatttcagg gagtagaaac tccttctcag gttatgtacg tgatctaaaa atccaaatag 1200
aaatggagaa aaaggttgtc ttttccacta tttcattagg aaaatgttcg gtacttgata 1260
acattacaac agacaaaata ttaattgatg tattcgacgg tccacctctg tatgatgatg 1320
tgaaagtgca gtttttctat tcgaatcttc ctacatacta tgacaattgc tcattttact 1380
tctggttgca cacatctttt attgaaaata acaggcttta tctaccaaaa aatgaattgg 1440
ataatctaca taaacaaaaa gcacggagaa tttatccatc agattttgcc gtggagatac 1500
tttttggcga gaaaatgact tccagtgatg ttgtagctgg atccgattaa 1550
<210> 55
<211> 1407
<212> DNA
<213> Homo sapiens
<400> 55
atgaatgaaa gtcctgatcc gactgacctg gcgggagtca tcattgagct cggccccaat 60
gacagtccac agacaagtga atttaaagga gcaaccgagg aggcacctgc gaaagaaagc 120
ccacacacaa gtgaatttaa aggagcagcc cgggtgtcac ctatcagtga aagtgtgtta 180
gcacgacttt ccaagtttga agttgaagat gctgaaaatg ttgcttcata tgacagcaag 240
attaagaaaa ttgtgcattc aattgtatca tcctttgcat ttggactatt tggagttttc 300
ctggtcttac tggatgtcac tctcatcctt gccgacctaa ttttcactga cagcaaactt 360
tatattcctt tggagtatcg ttctatttct ctagctattg ccttattttt tctcatggat 420
gttcttcttc gagtatttgt agaaaggaga cagcagtatt tttctgactt atttaacatt 480
ttagatactg ccattattgt gattcttctg ctggttgatg tcgtttacat tttttttgac 540
attaagttgc ttaggaatat tcccagatgg acacatttac ttcgacttct acgacttatt 600
attctgttaa gaatttttca tctgtttcat caaaaaagac aacttgaaaa gctgataaga 660
aggcgggttt cagaaaacaa aaggcgatac acaagggatg gatttgacct agacctcact 720
tacgttacag aacgtattat tgctatgtca tttccatctt ctggaaggca gtctttctat 780
agaaatccaa tcaaggaagt tgtgcggttt ctagataaga aacaccgaaa ccactatcga 840
gtctacaatc tatgcagtga aagagcttac gatcctaagc acttccataa tagggtcgtt 900
agaatcatga ttgatgatca taatgtcccc actctacatc agatggtggt tttcaccaag 960
gaagtaaatg agtggatggc tcaagatctt gaaaacatcg tagcgattca ctgtaaagga 1020
ggcacaggtt atgtacgtga tctaaaaatc caaatagaaa tggagaaaaa ggttgtcttt 1080
tccactattt cattaggaaa atgttcggta cttgataaca ttacaacaga caaaatatta 1140
attgatgtat tcgacggtcc acctctgtat gatgatgtga aagtgcagtt tttctattcg 1200
aatcttccta catactatga caattgctca ttttacttct ggttgcacac atcttttatt 1260
gaaaataaca ggctttatct accaaaaaat gaattggata atctacataa acaaaaagca 1320
cggagaattt atccatcaga ttttgccgtg gagatacttt ttggcgagaa aatgacttcc 1380
agtgatgttg tagctggatc cgattaa 1407
<210> 56
<211> 1413
<212> DNA
<213> Homo sapiens
<400> 56
atgaatgaaa gtcctgatcc gactgacctg gcgggagtca tcattgagct cggccccaat 60
gacagtccac agacaagtga atttaaagga gcaaccgagg aggcacctgc gaaagaaagt 120
gtgttagcac gactttccaa gtttgaagtt gaagatgctg aaaatgttgc ttcatatgac 180
agcaagatta agaaaattgt gcattcaatt gtatcatcct ttgcatttgg actatttgga 240
gttttcctgg tcttactgga tgtcactctc atccttgccg acctaatttt cactgacagc 300
aaactttata ttcctttgga gtatcgttct atttctctag ctattgcctt attttttctc 360
atggatgttc ttcttcgagt atttgtagaa aggagacagc agtatttttc tgacttattt 420
aacattttag atactgccat tattgtgatt cttctgctgg ttgatgtcgt ttacattttt 480
tttgacatta agttgcttag gaatattccc agatggacac atttacttcg acttctacga 540
cttattattc tgttaagaat ttttcatctg tttcatcaaa aaagacaact tgaaaagctg 600
ataagaaggc gggtttcaga aaacaaaagg cgatacacaa gggatggatt tgacctagac 660
ctcacttacg ttacagaacg tattattgct atgtcatttc catcttctgg aaggcagtct 720
ttctatagaa atccaatcaa ggaagttgtg cggtttctag ataagaaaca ccgaaaccac 780
tatcgagtct acaatctatg cagtgaaaga gcttacgatc ctaagcactt ccataatagg 840
gtcgttagaa tcatgattga tgatcataat gtccccactc tacatcagat ggtggttttc 900
accaaggaag taaatgagtg gatggctcaa gatcttgaaa acatcgtagc gattcactgt 960
aaaggaggca cagatagaac aggaactatg gtttgtgcct tccttattgc ctctgaaata 1020
tgttcaactg caaaggaaag cctgtattat tttggagaaa ggcgaacaga taaaacccac 1080
agcgaaaaat ttcagggagt agaaactcct tctgtacttg ataacattac aacagacaaa 1140
atattaattg atgtattcga cggtccacct ctgtatgatg atgtgaaagt gcagtttttc 1200
tattcgaatc ttcctacata ctatgacaat tgctcatttt acttctggtt gcacacatct 1260
tttattgaaa ataacaggct ttatctacca aaaaatgaat tggataatct acataaacaa 1320
aaagcacgga gaatttatcc atcagatttt gccgtggaga tactttttgg cgagaaaatg 1380
acttccagtg atgttgtagc tggatccgat taa 1413
<210> 57
<211> 1353
<212> DNA
<213> Homo sapiens
<400> 57
atgaatgaaa gtcctgatcc gactgacctg gcgggagtca tcattgagct cggccccaat 60
gacagtccac agacaagtga atttaaagga gcaaccgagg aggcacctgc gaaagaaagt 120
gtgttagcac gactttccaa gtttgaagtt gaagatgctg aaaatgttgc ttcatatgac 180
agcaagatta agaaaattgt gcattcaatt gtatcatcct ttgcatttgg actatttgga 240
gttttcctgg tcttactgga tgtcactctc atccttgccg acctaatttt cactgacagc 300
aaactttata ttcctttgga gtatcgttct atttctctag ctattgcctt attttttctc 360
atggatgttc ttcttcgagt atttgtagaa aggagacagc agtatttttc tgacttattt 420
aacattttag atactgccat tattgtgatt cttctgctgg ttgatgtcgt ttacattttt 480
tttgacatta agttgcttag gaatattccc agatggacac atttacttcg acttctacga 540
cttattattc tgttaagaat ttttcatctg tttcatcaaa aaagacaact tgaaaagctg 600
ataagaaggc gggtttcaga aaacaaaagg cgatacacaa gggatggatt tgacctagac 660
ctcacttacg ttacagaacg tattattgct atgtcatttc catcttctgg aaggcagtct 720
ttctatagaa atccaatcaa ggaagttgtg cggtttctag ataagaaaca ccgaaaccac 780
tatcgagtct acaatctatg cagtgaaaga gcttacgatc ctaagcactt ccataatagg 840
gtcgttagaa tcatgattga tgatcataat gtccccactc tacatcagat ggtggttttc 900
accaaggaag taaatgagtg gatggctcaa gatcttgaaa acatcgtagc gattcactgt 960
aaaggaggca caggttatgt acgtgatcta aaaatccaaa tagaaatgga gaaaaaggtt 1020
gtcttttcca ctatttcatt aggaaaatgt tcggtacttg ataacattac aacagacaaa 1080
atattaattg atgtattcga cggtccacct ctgtatgatg atgtgaaagt gcagtttttc 1140
tattcgaatc ttcctacata ctatgacaat tgctcatttt acttctggtt gcacacatct 1200
tttattgaaa ataacaggct ttatctacca aaaaatgaat tggataatct acataaacaa 1260
aaagcacgga gaatttatcc atcagatttt gccgtggaga tactttttgg cgagaaaatg 1320
acttccagtg atgttgtagc tggatccgat taa 1353
<210> 58
<211> 395
<212> PRT
<213> Homo sapiens
<400> 58
Met Asn Glu Ser Pro Asp Pro Thr Asp Leu Ala Gly Val Ile Ile Glu
1 5 10 15
Leu Gly Pro Asn Asp Ser Pro Gln Thr Ser Glu Phe Lys Gly Ala Thr
20 25 30
Glu Glu Ala Pro Ala Lys Glu Ser Pro His Thr Ser Glu Phe Lys Gly
35 40 45
Ala Ala Arg Val Ser Pro Ile Ser Glu Ser Val Leu Ala Arg Leu Ser
50 55 60
Lys Phe Glu Val Glu Asp Ala Glu Asn Val Ala Ser Tyr Asp Ser Lys
65 70 75 80
Ile Lys Lys Ile Val His Ser Ile Val Ser Ser Phe Ala Phe Gly Leu
85 90 95
Phe Gly Val Phe Leu Val Leu Leu Asp Val Thr Leu Ile Leu Ala Asp
100 105 110
Leu Ile Phe Thr Asp Ser Lys Leu Tyr Ile Pro Leu Glu Tyr Arg Ser
115 120 125
Ile Ser Leu Ala Ile Ala Leu Phe Phe Leu Met Asp Val Leu Leu Arg
130 135 140
Val Phe Val Glu Arg Arg Gln Gln Tyr Phe Ser Asp Leu Phe Asn Ile
145 150 155 160
Leu Asp Thr Ala Ile Ile Val Ile Leu Leu Leu Val Asp Val Val Tyr
165 170 175
Ile Phe Phe Asp Ile Lys Leu Leu Arg Asn Ile Pro Arg Trp Thr His
180 185 190
Leu Leu Arg Leu Leu Arg Leu Ile Ile Leu Leu Arg Ile Phe His Leu
195 200 205
Phe His Gln Lys Arg Gln Leu Glu Lys Leu Ile Arg Arg Arg Val Ser
210 215 220
Glu Asn Lys Arg Arg Tyr Thr Arg Asp Gly Phe Asp Leu Asp Leu Thr
225 230 235 240
Tyr Val Thr Glu Arg Ile Ile Ala Met Ser Phe Pro Ser Ser Gly Arg
245 250 255
Gln Ser Phe Tyr Arg Asn Pro Ile Lys Glu Val Val Arg Phe Leu Asp
260 265 270
Lys Lys His Arg Asn His Tyr Arg Val Tyr Asn Leu Cys Ser Glu Arg
275 280 285
Ala Tyr Asp Pro Lys His Phe His Asn Arg Val Val Arg Ile Met Ile
290 295 300
Asp Asp His Asn Val Pro Thr Leu His Gln Met Val Val Phe Thr Lys
305 310 315 320
Glu Val Asn Glu Trp Met Ala Gln Asp Leu Glu Asn Ile Val Ala Ile
325 330 335
His Cys Lys Gly Gly Thr Asp Arg Thr Gly Thr Met Val Cys Ala Phe
340 345 350
Leu Ile Ala Ser Glu Ile Cys Ser Thr Ala Lys Glu Ser Leu Tyr Tyr
355 360 365
Phe Gly Glu Arg Arg Thr Asp Lys Thr His Ser Glu Lys Phe Gln Gly
370 375 380
Val Glu Thr Pro Ser Gln Val Met Tyr Val Ile
385 390 395
<210> 59
<211> 468
<212> PRT
<213> Homo sapiens
<400> 59
Met Asn Glu Ser Pro Asp Pro Thr Asp Leu Ala Gly Val Ile Ile Glu
1 5 10 15
Leu Gly Pro Asn Asp Ser Pro Gln Thr Ser Glu Phe Lys Gly Ala Thr
20 25 30
Glu Glu Ala Pro Ala Lys Glu Ser Pro His Thr Ser Glu Phe Lys Gly
35 40 45
Ala Ala Arg Val Ser Pro Ile Ser Glu Ser Val Leu Ala Arg Leu Ser
50 55 60
Lys Phe Glu Val Glu Asp Ala Glu Asn Val Ala Ser Tyr Asp Ser Lys
65 70 75 80
Ile Lys Lys Ile Val His Ser Ile Val Ser Ser Phe Ala Phe Gly Leu
85 90 95
Phe Gly Val Phe Leu Val Leu Leu Asp Val Thr Leu Ile Leu Ala Asp
100 105 110
Leu Ile Phe Thr Asp Ser Lys Leu Tyr Ile Pro Leu Glu Tyr Arg Ser
115 120 125
Ile Ser Leu Ala Ile Ala Leu Phe Phe Leu Met Asp Val Leu Leu Arg
130 135 140
Val Phe Val Glu Arg Arg Gln Gln Tyr Phe Ser Asp Leu Phe Asn Ile
145 150 155 160
Leu Asp Thr Ala Ile Ile Val Ile Leu Leu Leu Val Asp Val Val Tyr
165 170 175
Ile Phe Phe Asp Ile Lys Leu Leu Arg Asn Ile Pro Arg Trp Thr His
180 185 190
Leu Leu Arg Leu Leu Arg Leu Ile Ile Leu Leu Arg Ile Phe His Leu
195 200 205
Phe His Gln Lys Arg Gln Leu Glu Lys Leu Ile Arg Arg Arg Val Ser
210 215 220
Glu Asn Lys Arg Arg Tyr Thr Arg Asp Gly Phe Asp Leu Asp Leu Thr
225 230 235 240
Tyr Val Thr Glu Arg Ile Ile Ala Met Ser Phe Pro Ser Ser Gly Arg
245 250 255
Gln Ser Phe Tyr Arg Asn Pro Ile Lys Glu Val Val Arg Phe Leu Asp
260 265 270
Lys Lys His Arg Asn His Tyr Arg Val Tyr Asn Leu Cys Ser Glu Arg
275 280 285
Ala Tyr Asp Pro Lys His Phe His Asn Arg Val Val Arg Ile Met Ile
290 295 300
Asp Asp His Asn Val Pro Thr Leu His Gln Met Val Val Phe Thr Lys
305 310 315 320
Glu Val Asn Glu Trp Met Ala Gln Asp Leu Glu Asn Ile Val Ala Ile
325 330 335
His Cys Lys Gly Gly Thr Gly Tyr Val Arg Asp Leu Lys Ile Gln Ile
340 345 350
Glu Met Glu Lys Lys Val Val Phe Ser Thr Ile Ser Leu Gly Lys Cys
355 360 365
Ser Val Leu Asp Asn Ile Thr Thr Asp Lys Ile Leu Ile Asp Val Phe
370 375 380
Asp Gly Pro Pro Leu Tyr Asp Asp Val Lys Val Gln Phe Phe Tyr Ser
385 390 395 400
Asn Leu Pro Thr Tyr Tyr Asp Asn Cys Ser Phe Tyr Phe Trp Leu His
405 410 415
Thr Ser Phe Ile Glu Asn Asn Arg Leu Tyr Leu Pro Lys Asn Glu Leu
420 425 430
Asp Asn Leu His Lys Gln Lys Ala Arg Arg Ile Tyr Pro Ser Asp Phe
435 440 445
Ala Val Glu Ile Leu Phe Gly Glu Lys Met Thr Ser Ser Asp Val Val
450 455 460
Ala Gly Ser Asp
465
<210> 60
<211> 470
<212> PRT
<213> Homo sapiens
<400> 60
Met Asn Glu Ser Pro Asp Pro Thr Asp Leu Ala Gly Val Ile Ile Glu
1 5 10 15
Leu Gly Pro Asn Asp Ser Pro Gln Thr Ser Glu Phe Lys Gly Ala Thr
20 25 30
Glu Glu Ala Pro Ala Lys Glu Ser Val Leu Ala Arg Leu Ser Lys Phe
35 40 45
Glu Val Glu Asp Ala Glu Asn Val Ala Ser Tyr Asp Ser Lys Ile Lys
50 55 60
Lys Ile Val His Ser Ile Val Ser Ser Phe Ala Phe Gly Leu Phe Gly
65 70 75 80
Val Phe Leu Val Leu Leu Asp Val Thr Leu Ile Leu Ala Asp Leu Ile
85 90 95
Phe Thr Asp Ser Lys Leu Tyr Ile Pro Leu Glu Tyr Arg Ser Ile Ser
100 105 110
Leu Ala Ile Ala Leu Phe Phe Leu Met Asp Val Leu Leu Arg Val Phe
115 120 125
Val Glu Arg Arg Gln Gln Tyr Phe Ser Asp Leu Phe Asn Ile Leu Asp
130 135 140
Thr Ala Ile Ile Val Ile Leu Leu Leu Val Asp Val Val Tyr Ile Phe
145 150 155 160
Phe Asp Ile Lys Leu Leu Arg Asn Ile Pro Arg Trp Thr His Leu Leu
165 170 175
Arg Leu Leu Arg Leu Ile Ile Leu Leu Arg Ile Phe His Leu Phe His
180 185 190
Gln Lys Arg Gln Leu Glu Lys Leu Ile Arg Arg Arg Val Ser Glu Asn
195 200 205
Lys Arg Arg Tyr Thr Arg Asp Gly Phe Asp Leu Asp Leu Thr Tyr Val
210 215 220
Thr Glu Arg Ile Ile Ala Met Ser Phe Pro Ser Ser Gly Arg Gln Ser
225 230 235 240
Phe Tyr Arg Asn Pro Ile Lys Glu Val Val Arg Phe Leu Asp Lys Lys
245 250 255
His Arg Asn His Tyr Arg Val Tyr Asn Leu Cys Ser Glu Arg Ala Tyr
260 265 270
Asp Pro Lys His Phe His Asn Arg Val Val Arg Ile Met Ile Asp Asp
275 280 285
His Asn Val Pro Thr Leu His Gln Met Val Val Phe Thr Lys Glu Val
290 295 300
Asn Glu Trp Met Ala Gln Asp Leu Glu Asn Ile Val Ala Ile His Cys
305 310 315 320
Lys Gly Gly Thr Asp Arg Thr Gly Thr Met Val Cys Ala Phe Leu Ile
325 330 335
Ala Ser Glu Ile Cys Ser Thr Ala Lys Glu Ser Leu Tyr Tyr Phe Gly
340 345 350
Glu Arg Arg Thr Asp Lys Thr His Ser Glu Lys Phe Gln Gly Val Glu
355 360 365
Thr Pro Ser Val Leu Asp Asn Ile Thr Thr Asp Lys Ile Leu Ile Asp
370 375 380
Val Phe Asp Gly Pro Pro Leu Tyr Asp Asp Val Lys Val Gln Phe Phe
385 390 395 400
Tyr Ser Asn Leu Pro Thr Tyr Tyr Asp Asn Cys Ser Phe Tyr Phe Trp
405 410 415
Leu His Thr Ser Phe Ile Glu Asn Asn Arg Leu Tyr Leu Pro Lys Asn
420 425 430
Glu Leu Asp Asn Leu His Lys Gln Lys Ala Arg Arg Ile Tyr Pro Ser
435 440 445
Asp Phe Ala Val Glu Ile Leu Phe Gly Glu Lys Met Thr Ser Ser Asp
450 455 460
Val Val Ala Gly Ser Asp
465 470
<210> 61
<211> 450
<212> PRT
<213> Homo sapiens
<400> 61
Met Asn Glu Ser Pro Asp Pro Thr Asp Leu Ala Gly Val Ile Ile Glu
1 5 10 15
Leu Gly Pro Asn Asp Ser Pro Gln Thr Ser Glu Phe Lys Gly Ala Thr
20 25 30
Glu Glu Ala Pro Ala Lys Glu Ser Val Leu Ala Arg Leu Ser Lys Phe
35 40 45
Glu Val Glu Asp Ala Glu Asn Val Ala Ser Tyr Asp Ser Lys Ile Lys
50 55 60
Lys Ile Val His Ser Ile Val Ser Ser Phe Ala Phe Gly Leu Phe Gly
65 70 75 80
Val Phe Leu Val Leu Leu Asp Val Thr Leu Ile Leu Ala Asp Leu Ile
85 90 95
Phe Thr Asp Ser Lys Leu Tyr Ile Pro Leu Glu Tyr Arg Ser Ile Ser
100 105 110
Leu Ala Ile Ala Leu Phe Phe Leu Met Asp Val Leu Leu Arg Val Phe
115 120 125
Val Glu Arg Arg Gln Gln Tyr Phe Ser Asp Leu Phe Asn Ile Leu Asp
130 135 140
Thr Ala Ile Ile Val Ile Leu Leu Leu Val Asp Val Val Tyr Ile Phe
145 150 155 160
Phe Asp Ile Lys Leu Leu Arg Asn Ile Pro Arg Trp Thr His Leu Leu
165 170 175
Arg Leu Leu Arg Leu Ile Ile Leu Leu Arg Ile Phe His Leu Phe His
180 185 190
Gln Lys Arg Gln Leu Glu Lys Leu Ile Arg Arg Arg Val Ser Glu Asn
195 200 205
Lys Arg Arg Tyr Thr Arg Asp Gly Phe Asp Leu Asp Leu Thr Tyr Val
210 215 220
Thr Glu Arg Ile Ile Ala Met Ser Phe Pro Ser Ser Gly Arg Gln Ser
225 230 235 240
Phe Tyr Arg Asn Pro Ile Lys Glu Val Val Arg Phe Leu Asp Lys Lys
245 250 255
His Arg Asn His Tyr Arg Val Tyr Asn Leu Cys Ser Glu Arg Ala Tyr
260 265 270
Asp Pro Lys His Phe His Asn Arg Val Val Arg Ile Met Ile Asp Asp
275 280 285
His Asn Val Pro Thr Leu His Gln Met Val Val Phe Thr Lys Glu Val
290 295 300
Asn Glu Trp Met Ala Gln Asp Leu Glu Asn Ile Val Ala Ile His Cys
305 310 315 320
Lys Gly Gly Thr Gly Tyr Val Arg Asp Leu Lys Ile Gln Ile Glu Met
325 330 335
Glu Lys Lys Val Val Phe Ser Thr Ile Ser Leu Gly Lys Cys Ser Val
340 345 350
Leu Asp Asn Ile Thr Thr Asp Lys Ile Leu Ile Asp Val Phe Asp Gly
355 360 365
Pro Pro Leu Tyr Asp Asp Val Lys Val Gln Phe Phe Tyr Ser Asn Leu
370 375 380
Pro Thr Tyr Tyr Asp Asn Cys Ser Phe Tyr Phe Trp Leu His Thr Ser
385 390 395 400
Phe Ile Glu Asn Asn Arg Leu Tyr Leu Pro Lys Asn Glu Leu Asp Asn
405 410 415
Leu His Lys Gln Lys Ala Arg Arg Ile Tyr Pro Ser Asp Phe Ala Val
420 425 430
Glu Ile Leu Phe Gly Glu Lys Met Thr Ser Ser Asp Val Val Ala Gly
435 440 445
Ser Asp
450
<210> 62
<211> 1299
<212> DNA
<213> Homo sapiens
<400> 62
cgcccttaga catggctcag atgtgcagcc acagtgagct tctgaacatt tcttctcaga 60
ctaagctctt acacacagtt gcagttgaaa gaaagaattg cttgacatgg ccacaggagc 120
aggcagcttc ctgcagacat gacagtcaac gcaaactcat gtcactgtgg gcagacacat 180
gtttgcaaag agactcagag ccaaacaagc acactcaatg tgctttgccc aaatttaccc 240
attaggtaaa tcttccctcc tcccaagaag aaagtggaga gagcatgagt cctcacatgg 300
gaacttgaag tcagggaaat gaaggctcac caattatttg tgcatgggtt taagttttcc 360
ttgaaattaa gttcaggttt gtctttgtgt gtaccaatta atgacaagag gttagataga 420
agtatgctag atggcaaaga gaaatatgtt ttgtgtcttc aattttgcta aaaataaccc 480
agaacatgga taattcattt attaattgat tttggtaagc caagtcctat ttggagaaaa 540
ttaatagttt ttctaaaaaa gaattttctc aatatcacct ggcttgataa catttttctc 600
cttcgagttc ctttttctgg agtttaacaa acttgttctt tacaaataga ttatattgac 660
tacctctcac tgatgttatg atattagttt ctattgctta ctttgtattt ctaattttag 720
gattcacaat ttagctggag aactattttt taacctgttg cacctaaaca tgattgagct 780
agaagacagt tttaccatat gcatgcattt tctctgagtt atattttaaa atctatacat 840
ttctcctaaa tatggaggaa atcactggca tcaaatgcca gtctcagacg gaagacctaa 900
agcccatttc tggcctggag ctacttggct ttgtgaccta tggtgaggca taagtgctct 960
gagtttgtgt tgcctctttt gtaaaatgag ggtttgactt aatcagtgat tttcatagct 1020
taaaattttt ttgaagaaca gaactttttt taaaaacagt tagatgcaac catattatat 1080
aaaacagaac agatacaagt agagctaact tgctaaagaa aggatggagg ctctgaagct 1140
gtgacttcat tatcccttaa tactgctatg tcctctgtag taccttagat ttctatggga 1200
catcgtttaa aaactattgt ttatgcgaga gccttgctaa tttcctaaaa attgtggata 1260
cattttttct cccatgtata attttctcac cttctattt 1299
<210> 63
<211> 405
<212> DNA
<213> Homo sapiens
<400> 63
gcacaaggcc tgctcttact ccaaaaagat ggacccaggt ccgaaggggc actgccactg 60
tggggggcat ggccatcctc caggtcactg cgggccaccc cctggccatg gcccagggcc 120
ctgcgggcca ccccccacca tggtccaggg ccctgcgggc caccccctgg ccatggccca 180
gggccctgcg ggccaccccc ccaccatggt ccagggccct gcgggcctcc ccctggccat 240
ggcccaggtc acccaccccc tggtccacat cactgaggaa gtagaagaaa acaggacaca 300
agatggcaag cctgagagaa ttgcccagct gacctggaat gaggcctaaa ccacaatctt 360
ctcttcctaa taaacagcct cctagaggcc acattctatt ctgta 405
<210> 64
<211> 106
<212> PRT
<213> Homo sapiens
<400> 64
Met Asp Pro Gly Pro Lys Gly His Cys His Cys Gly Gly His Gly His
1 5 10 15
Pro Pro Gly His Cys Gly Pro Pro Pro Gly His Gly Pro Gly Pro Cys
20 25 30
Gly Pro Pro Pro Thr Met Val Gln Gly Pro Ala Gly His Pro Leu Ala
35 40 45
Met Ala Gln Gly Pro Ala Gly His Pro Pro Thr Met Val Gln Gly Pro
50 55 60
Ala Gly Leu Pro Leu Ala Met Ala Gln Val Thr His Pro Leu Val His
65 70 75 80
Ile Thr Glu Glu Val Glu Glu Asn Arg Thr Gln Asp Gly Lys Pro Glu
85 90 95
Arg Ile Ala Gln Leu Thr Trp Asn Glu Ala
100 105
<210> 65
<211> 71
<212> PRT
<213> Homo sapiens
<400> 65
Met Ala Ile Leu Gln Val Thr Ala Gly His Pro Leu Ala Met Ala Gln
1 5 10 15
Gly Pro Ala Gly His Pro Pro Pro Trp Ser Arg Ala Leu Arg Ala Thr
20 25 30
Pro Trp Pro Trp Pro Arg Ala Leu Arg Ala Thr Pro Pro Pro Trp Ser
35 40 45
Arg Ala Leu Arg Ala Ser Pro Trp Pro Trp Pro Arg Ser Pro Thr Pro
50 55 60
Trp Ser Thr Ser Leu Arg Lys
65 70
<210> 66
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 66
agacatggct cagatgtgca g 21
<210> 67
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 67
ggaaattagc aaggctctcg c 21
<210> 68
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 68
tcaggtattc cctgctctta c 21
<210> 69
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 69
tgggcaattc tctcaggctt g 21
<210> 70
<211> 908
<212> DNA
<213> Homo sapiens
<400> 70
aaaattcggc acgaggccgg gctgtggtct agcataaagg cggagcccag aagaaggggc 60
ggggtatggg agaagcctcc ccacctgccc ccgcaaggcg gcatctgctg gtcctgctgc 120
tgctcctctc taccctggtg atcccctccg ctgcagctcc tatccatgat gctgacgccc 180
aagagagctc cttgggtctc acaggcctcc agagcctact ccaaggcttc agccgacttt 240
tcctgaaagg taacctgctt cggggcatag acagcttatt ctctgccccc atggacttcc 300
ggggcctccc tgggaactac cacaaagagg agaaccagga gcaccagctg gggaacaaca 360
ccctctccag ccacctccag atcgacaaga tgaccgacaa caagacagga gaggtgctga 420
tctccgagaa tgtggtggca tccattcaac cagcggaggg gagcttcgag ggtgatttga 480
aggtacccag gatggaggag aaggaggccc tggtacccat ccagaaggcc acggacagct 540
tccacacaga actccatccc cgggtggcct tctggatcat taagctgcca cggcggaggt 600
cccaccagga tgccctggag ggcggccact ggctcagcga gaagcgacac cgcctgcagg 660
ccatccggga tggactccgc aaggggaccc acaaggacgt cctagaagag gggaccgaga 720
gctcctccca ctccaggctg tccccccgaa agacccactt actgtacatc ctcaggccct 780
ctcggcagct gtaggggtgg ggaccgggga gcacctgcct gtagccccca tcagaccctg 840
ccccaagcac catatggaaa taaagttctt tcttacatct aaaaaaaaaa aaaaaaaaaa 900
aaaaaaaa 908
<210> 71
<211> 242
<212> PRT
<213> Homo sapiens
<400> 71
Met Gly Glu Ala Ser Pro Pro Ala Pro Ala Arg Arg His Leu Leu Val
1 5 10 15
Leu Leu Leu Leu Leu Ser Thr Leu Val Ile Pro Ser Ala Ala Ala Pro
20 25 30
Ile His Asp Ala Asp Ala Gln Glu Ser Ser Leu Gly Leu Thr Gly Leu
35 40 45
Gln Ser Leu Leu Gln Gly Phe Ser Arg Leu Phe Leu Lys Gly Asn Leu
50 55 60
Leu Arg Gly Ile Asp Ser Leu Phe Ser Ala Pro Met Asp Phe Arg Gly
65 70 75 80
Leu Pro Gly Asn Tyr His Lys Glu Glu Asn Gln Glu His Gln Leu Gly
85 90 95
Asn Asn Thr Leu Ser Ser His Leu Gln Ile Asp Lys Met Thr Asp Asn
100 105 110
Lys Thr Gly Glu Val Leu Ile Ser Glu Asn Val Val Ala Ser Ile Gln
115 120 125
Pro Ala Glu Gly Ser Phe Glu Gly Asp Leu Lys Val Pro Arg Met Glu
130 135 140
Glu Lys Glu Ala Leu Val Pro Ile Gln Lys Ala Thr Asp Ser Phe His
145 150 155 160
Thr Glu Leu His Pro Arg Val Ala Phe Trp Ile Ile Lys Leu Pro Arg
165 170 175
Arg Arg Ser His Gln Asp Ala Leu Glu Gly Gly His Trp Leu Ser Glu
180 185 190
Lys Arg His Arg Leu Gln Ala Ile Arg Asp Gly Leu Arg Lys Gly Thr
195 200 205
His Lys Asp Val Leu Glu Glu Gly Thr Glu Ser Ser Ser His Ser Arg
210 215 220
Leu Ser Pro Arg Lys Thr His Leu Leu Tyr Ile Leu Arg Pro Ser Arg
225 230 235 240
Gln Leu
<210> 72
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 72
ctcctatcca tgatgctgac g 21
<210> 73
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 73
cctgaggatg tacagtaagt g 21
<210> 74
<211> 2987
<212> DNA
<213> Homo sapiens
<400> 74
tttcccagcg aggtggtcat tcagagccta cacatctgtt ctgtatttta acccatggat 60
gagaatattc attcaagcca agagagttaa aactaaacat ctttgctatt gcctctacag 120
acccagaaag tatctttatg tcacatcttc ttttaaagga gcatttaaag atgaagttaa 180
aaaggcagaa gaagcagtaa agattgctga atccatattg aaagaagcac aaatcaaagt 240
aaaccagtgt gacagaacct ctttatcttc tgccaaggat gtattacaga gagctttgga 300
agatgtagaa gcaaagcaaa agaatcttaa agagaaacaa agagaattaa aaacagcaag 360
aacgctctcc ctgttctatg gagtgaacgt agaaaaccga agccaagctg gaatgttcat 420
ttacagtaat aaccgtttga tcaaaatgca tgaaaaagtg ggctcacagt tgaaactgaa 480
gtccttactt ggcgcaggcg tggttggaat tgttaatata cccttggagg tcatggaacc 540
atcccataat aaacaggaat ttctcaatgt ccaagagtat aatcatctac taaaagtcat 600
gggacagtac ttggtccagt actgtaagga caccggcatc aataatagaa atttaacatt 660
gttttgcaat gaatttggat accagaatga catcgatgtg gagaaacctt taaattcttt 720
tcaatatcaa agaagacaag ccatgggtat cccattcatc atacaatgtg atctttgtct 780
taaatggaga gtcttgcctt cctctactaa ttatcaggaa aaagaatttt ttgacatttg 840
gatttgtgct aataatccca accgcttgga aaacagttgt catcaggtag aatgtctacc 900
ttccatccca ctgggcacca tgagcacaat atcaccatca aaaaatgaga aagagaagca 960
acttagagag tcggtcataa agtatcaaaa tagactggca gaacagcagc cacagcctca 1020
atttatacca gtggacgaaa tcactgtcac ttccacctgc ctaacttcag cacataagga 1080
aaataccaaa acccagaaaa tcaggctttt gggcgatgac ttgaagcatg aatctctttc 1140
atcctttgag ctttcagcga gccgtagagg acagaaaaga aacatagaag agacagactc 1200
tgatgtagag tatatttcag aaacaaaaat tatgaaaaag tctatggagg agaaaatgaa 1260
ctctcaacag cagagaattc cagtagctct gccagaaaat gtcaaactag ctgagagatc 1320
ccagagaagt cagattgcta atattaccac tgtctggaga gctcaaccaa ctgaagggtg 1380
cctgaagaat gcccaggccg cttcttggga aatgaaaagg aagcagagtc tgaactttgt 1440
agaggaatgt aaggtattga ctgaagatga gaacacgagt gattcagata taatcctggt 1500
ttcagataaa agcaacactg atgtttcatt gaaacaagaa aaaaaggaaa ttcctctttt 1560
aaaccaagaa aaacaggagc tgtgcaatga tgttctagca atgaaaagaa gctcttcatt 1620
acctagctgg aaaagcttgc tcaatgtgcc gatggaagat gtgaatctaa gttctggaca 1680
catagccaga gtttctgtga gtggcagttg taaagttgct tcttcgccag cgtcttctca 1740
aagcacacct gtcaaggaaa cagtgagaaa actgaagtct aagttaaggg agattcttct 1800
gtattttttt cctgagcatc agctaccatc agaattggaa gaacctgcat taagttgtga 1860
gctggagcag tgcccagagc agatgaacaa aaagctgaaa atgtgtttca accagataca 1920
gaatacttac atggtccaat atgaaaaaaa aataaagagg aaattgcagt ccattatcta 1980
tgattcaaat acaagaggaa tacataatga aatctctctg gggcaatgtg aaaataaaag 2040
aaaaatctct gaggataagc tgaagaatct tcgtataaaa ctggcactat tgttgcagaa 2100
actccaactg ggtggtccag aaggtgacct ggagcagact gacacttatt tagaagcttt 2160
gcttaaagaa gataatcttc tcttccagaa caatttaaat aaagtaacta tagatgcaag 2220
acatagactc cctttagaaa aaaatgaaaa gacttcggaa aattaagtca gagatggtat 2280
taccttttaa aaaatgctaa taagaaaatt ggaagattct tttaaaaatt tttctttttt 2340
gttgttgtta ctgtaaagtc tattctgttt aacaataaga aataagaaat aatttttttc 2400
aaataagaaa attgtgtact ctagaaatgg agaccgattt acaatttatg tattccctaa 2460
tccaattatc taaatcttcc ttttctttca gaaatattaa taatatctag agttctctaa 2520
ttttcatgtg agctactgaa aaaaatgaaa atgtcactca agcttaactt ttgttattcc 2580
ttaaaagatt gttattgtaa ttttgttatt ccttaaaaac atttaaaagc agattttttc 2640
aaaatcgata tgtgaaggac tacagaatca cctcctcttg aagatattga aaaagaaaga 2700
cattatgccc tttctccact atagccaaca ctcagtcaag cagaaaatac aaatcccccc 2760
aaaactttga gacatagctt atataatttt attatttagt catagtaaaa gaataaatct 2820
cctaagcata atatgtatac atattacaca tatgtaaaaa ttgttgtttt acatttacat 2880
atacgtaaag aagtatgttt ttacactttt cttgataagt gttttttttt tgtttagaaa 2940
tgtctgaaac tttagacaaa aacagtaaaa catttaatat tcatttg 2987
<210> 75
<211> 735
<212> PRT
<213> Homo sapiens
<400> 75
Met Arg Ile Phe Ile Gln Ala Lys Arg Val Lys Thr Lys His Leu Cys
1 5 10 15
Tyr Cys Leu Tyr Arg Pro Arg Lys Tyr Leu Tyr Val Thr Ser Ser Phe
20 25 30
Lys Gly Ala Phe Lys Asp Glu Val Lys Lys Ala Glu Glu Ala Val Lys
35 40 45
Ile Ala Glu Ser Ile Leu Lys Glu Ala Gln Ile Lys Val Asn Gln Cys
50 55 60
Asp Arg Thr Ser Leu Ser Ser Ala Lys Asp Val Leu Gln Arg Ala Leu
65 70 75 80
Glu Asp Val Glu Ala Lys Gln Lys Asn Leu Lys Glu Lys Gln Arg Glu
85 90 95
Leu Lys Thr Ala Arg Thr Leu Ser Leu Phe Tyr Gly Val Asn Val Glu
100 105 110
Asn Arg Ser Gln Ala Gly Met Phe Ile Tyr Ser Asn Asn Arg Leu Ile
115 120 125
Lys Met His Glu Lys Val Gly Ser Gln Leu Lys Leu Lys Ser Leu Leu
130 135 140
Gly Ala Gly Val Val Gly Ile Val Asn Ile Pro Leu Glu Val Met Glu
145 150 155 160
Pro Ser His Asn Lys Gln Glu Phe Leu Asn Val Gln Glu Tyr Asn His
165 170 175
Leu Leu Lys Val Met Gly Gln Tyr Leu Val Gln Tyr Cys Lys Asp Thr
180 185 190
Gly Ile Asn Asn Arg Asn Leu Thr Leu Phe Cys Asn Glu Phe Gly Tyr
195 200 205
Gln Asn Asp Ile Asp Val Glu Lys Pro Leu Asn Ser Phe Gln Tyr Gln
210 215 220
Arg Arg Gln Ala Met Gly Ile Pro Phe Ile Ile Gln Cys Asp Leu Cys
225 230 235 240
Leu Lys Trp Arg Val Leu Pro Ser Ser Thr Asn Tyr Gln Glu Lys Glu
245 250 255
Phe Phe Asp Ile Trp Ile Cys Ala Asn Asn Pro Asn Arg Leu Glu Asn
260 265 270
Ser Cys His Gln Val Glu Cys Leu Pro Ser Ile Pro Leu Gly Thr Met
275 280 285
Ser Thr Ile Ser Pro Ser Lys Asn Glu Lys Glu Lys Gln Leu Arg Glu
290 295 300
Ser Val Ile Lys Tyr Gln Asn Arg Leu Ala Glu Gln Gln Pro Gln Pro
305 310 315 320
Gln Phe Ile Pro Val Asp Glu Ile Thr Val Thr Ser Thr Cys Leu Thr
325 330 335
Ser Ala His Lys Glu Asn Thr Lys Thr Gln Lys Ile Arg Leu Leu Gly
340 345 350
Asp Asp Leu Lys His Glu Ser Leu Ser Ser Phe Glu Leu Ser Ala Ser
355 360 365
Arg Arg Gly Gln Lys Arg Asn Ile Glu Glu Thr Asp Ser Asp Val Glu
370 375 380
Tyr Ile Ser Glu Thr Lys Ile Met Lys Lys Ser Met Glu Glu Lys Met
385 390 395 400
Asn Ser Gln Gln Gln Arg Ile Pro Val Ala Leu Pro Glu Asn Val Lys
405 410 415
Leu Ala Glu Arg Ser Gln Arg Ser Gln Ile Ala Asn Ile Thr Thr Val
420 425 430
Trp Arg Ala Gln Pro Thr Glu Gly Cys Leu Lys Asn Ala Gln Ala Ala
435 440 445
Ser Trp Glu Met Lys Arg Lys Gln Ser Leu Asn Phe Val Glu Glu Cys
450 455 460
Lys Val Leu Thr Glu Asp Glu Asn Thr Ser Asp Ser Asp Ile Ile Leu
465 470 475 480
Val Ser Asp Lys Ser Asn Thr Asp Val Ser Leu Lys Gln Glu Lys Lys
485 490 495
Glu Ile Pro Leu Leu Asn Gln Glu Lys Gln Glu Leu Cys Asn Asp Val
500 505 510
Leu Ala Met Lys Arg Ser Ser Ser Leu Pro Ser Trp Lys Ser Leu Leu
515 520 525
Asn Val Pro Met Glu Asp Val Asn Leu Ser Ser Gly His Ile Ala Arg
530 535 540
Val Ser Val Ser Gly Ser Cys Lys Val Ala Ser Ser Pro Ala Ser Ser
545 550 555 560
Gln Ser Thr Pro Val Lys Glu Thr Val Arg Lys Leu Lys Ser Lys Leu
565 570 575
Arg Glu Ile Leu Leu Tyr Phe Phe Pro Glu His Gln Leu Pro Ser Glu
580 585 590
Leu Glu Glu Pro Ala Leu Ser Cys Glu Leu Glu Gln Cys Pro Glu Gln
595 600 605
Met Asn Lys Lys Leu Lys Met Cys Phe Asn Gln Ile Gln Asn Thr Tyr
610 615 620
Met Val Gln Tyr Glu Lys Lys Ile Lys Arg Lys Leu Gln Ser Ile Ile
625 630 635 640
Tyr Asp Ser Asn Thr Arg Gly Ile His Asn Glu Ile Ser Leu Gly Gln
645 650 655
Cys Glu Asn Lys Arg Lys Ile Ser Glu Asp Lys Leu Lys Asn Leu Arg
660 665 670
Ile Lys Leu Ala Leu Leu Leu Gln Lys Leu Gln Leu Gly Gly Pro Glu
675 680 685
Gly Asp Leu Glu Gln Thr Asp Thr Tyr Leu Glu Ala Leu Leu Lys Glu
690 695 700
Asp Asn Leu Leu Phe Gln Asn Asn Leu Asn Lys Val Thr Ile Asp Ala
705 710 715 720
Arg His Arg Leu Pro Leu Glu Lys Asn Glu Lys Thr Ser Glu Asn
725 730 735
<210> 76
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 76
ctgagtatca gctaccatca g 21
<210> 77
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 77
tctgtagtcc ttcacatatc g 21
<210> 78
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 78
ttttgtctat ggtgtaggac c 21
<210> 79
<211> 21
<212> DNA
<213> Kunstliche Sequenz
<400> 79
ggaatggcaa tgatgttaca g 21
<210> 80
<211> 20
<212> PRT
<213> Homo sapiens
<400> 80
Met Ser Thr Val Lys Glu Gln Leu Ile Glu Lys Leu Ile Glu Asp Asp
1 5 10 15
Glu Asn Ser Gln
20
<210> 81
<211> 14
<212> PRT
<213> Homo sapiens
<400> 81
Phe Thr Asp Ser Lys Leu Tyr Ile Pro Leu Glu Tyr Arg Ser
1 5 10
<210> 82
<211> 13
<212> PRT
<213> Homo sapiens
<400> 82
Phe Asp Ile Lys Leu Leu Arg Asn Ile Pro Arg Trp Thr
1 5 10
<210> 83
<211> 15
<212> PRT
<213> Homo sapiens
<400> 83
Gly Val Ala Gly Gln Asp Tyr Trp Ala Val Leu Ser Gly Lys Gly
1 5 10 15
<210> 84
<211> 10
<212> PRT
<213> Homo sapiens
<400> 84
Ser Arg Glu Val Thr Thr Asn Ala Gln Arg
1 5 10
<210> 85
<211> 216
<212> DNA
<213> Homo sapiens
<400> 85
tgctcttact ccaaaaagat ggacccaggg ccctgcgggc ctccccctgg ccatggccca 60
ggtcacccac cccctggtcc acatcactga ggaagtagaa gaaaacagga cacaagatgg 120
caagcctgag agaattgccc agctgacctg gaaggaggcc taaaccgcaa tattctcttc 180
ctaataaaca gcctcctaga ggccacattc tattct 216
<210> 86
<211> 227
<212> DNA
<213> Homo sapiens
<400> 86
tgctcttact ccaaaaagat ggacccaggt ccgaaggggc actgccactg tggggggcat 60
ggccatcctc caggtcaccc accccctggt ccacatcact gaggaagtag aagaaaacag 120
gacacaagat ggcaagcctg agagaattgc ccagctgacc tggaatgagg cctaaaccac 180
aatcttctct tcctaataaa cagcctccta gaggccacat tctattc 227
<210> 87
<211> 261
<212> DNA
<213> Homo sapiens
<400> 87
tgctcttact ccaaaaagat ggacccaggt ccgaaggggc actgccactg tggggggcat 60
ggccatcctc caggtcactg cgggcctccc cctggccatg gcccaggtca cccaccccct 120
ggtccacatc actgaggaag tagaagaaaa caggacacaa gatggcaagc ctgagagaat 180
tgcccagctg acctggaatg aggcctaaac cacaatcttc tcttcctaat aaacagcctc 240
ctagaggcca cattctattc t 261
<210> 88
<211> 327
<212> DNA
<213> Homo sapiens
<400> 88
tgctcttact ccaaaaagat ggacccaggt ccgaaggggc actgccactg tggggggcat 60
ggccatcctc caggtcactg cgggccaccc ccccaccatg gtccagggcc ctgcgggcca 120
cccccccacc atggtccagg gccctgcggg cctccccctg gccatggccc aggtcaccca 180
ccccctggtc cacatcactg aggaagtaga agaaaacagg acacaagatg gcaagcctga 240
gagaattgcc cagctgacct ggaatgaggc ctaaaccaca atcttctctt cctaataaac 300
agcctcctag aggccacatt ctattct 327
<210> 89
<211> 31
<212> PRT
<213> Homo sapiens
<400> 89
Leu Leu Leu Gln Lys Asp Gly Pro Arg Ala Leu Arg Ala Ser Pro Trp
1 5 10 15
Pro Trp Pro Arg Ser Pro Thr Pro Trp Ser Thr Ser Leu Arg Lys
20 25 30
<210> 90
<211> 23
<212> PRT
<213> Homo sapiens
<400> 90
Met Asp Pro Gly Pro Cys Gly Pro Pro Pro Gly His Gly Pro Gly His
1 5 10 15
Pro Pro Pro Gly Pro His His
20
<210> 91
<211> 36
<212> PRT
<213> Homo sapiens
<400> 91
Met Ala Gln Val Thr His Pro Leu Val His Ile Thr Glu Glu Val Glu
1 5 10 15
Glu Asn Arg Thr Gln Asp Gly Lys Pro Glu Arg Ile Ala Gln Leu Thr
20 25 30
Trp Lys Glu Ala
35
<210> 92
<211> 34
<212> PRT
<213> Homo sapiens
<400> 92
Leu Leu Gln Lys Asp Gly Pro Arg Ser Glu Gly Ala Leu Pro Leu Trp
1 5 10 15
Gly Ala Trp Pro Ser Ser Arg Ser Pro Thr Pro Trp Ser Thr Ser Leu
20 25 30
Arg Lys
<210> 93
<211> 27
<212> PRT
<213> Homo sapiens
<400> 93
Met Asp Pro Gly Pro Lys Gly His Cys His Cys Gly Gly His Gly His
1 5 10 15
Pro Pro Gly His Pro Pro Pro Gly Pro His His
20 25
<210> 94
<211> 38
<212> PRT
<213> Homo sapiens
<400> 94
Met Ala Ile Leu Gln Val Thr His Pro Leu Val His Ile Thr Glu Glu
1 5 10 15
Val Glu Glu Asn Arg Thr Gln Asp Gly Lys Pro Glu Arg Ile Ala Gln
20 25 30
Leu Thr Trp Asn Glu Ala
35
<210> 95
<211> 46
<212> PRT
<213> Homo sapiens
<400> 95
Leu Leu Leu Gln Lys Asp Gly Pro Arg Ser Glu Gly Ala Leu Pro Leu
1 5 10 15
Trp Gly Ala Trp Pro Ser Ser Arg Ser Leu Arg Ala Ser Pro Trp Pro
20 25 30
Trp Pro Arg Ser Pro Thr Pro Trp Ser Thr Ser Leu Arg Lys
35 40 45
<210> 96
<211> 38
<212> PRT
<213> Homo sapiens
<400> 96
Met Asp Pro Gly Pro Lys Gly His Cys His Cys Gly Gly His Gly His
1 5 10 15
Pro Pro Gly His Cys Gly Pro Pro Pro Gly His Gly Pro Gly His Pro
20 25 30
Pro Pro Gly Pro His His
35
<210> 97
<211> 49
<212> PRT
<213> Homo sapiens
<400> 97
Met Ala Ile Leu Gln Val Thr Ala Gly Leu Pro Leu Ala Met Ala Gln
1 5 10 15
Val Thr His Pro Leu Val His Ile Thr Glu Glu Val Glu Glu Asn Arg
20 25 30
Thr Gln Asp Gly Lys Pro Glu Arg Ile Ala Gln Leu Thr Trp Asn Glu
35 40 45
Ala
<210> 98
<211> 68
<212> PRT
<213> Homo sapiens
<400> 98
Leu Leu Leu Gln Lys Asp Gly Pro Arg Ser Glu Gly Ala Leu Pro Leu
1 5 10 15
Trp Gly Ala Trp Pro Ser Ser Arg Ser Leu Arg Ala Thr Pro Pro Pro
20 25 30
Trp Ser Arg Ala Leu Arg Ala Thr Pro Pro Pro Trp Ser Arg Ala Leu
35 40 45
Arg Ala Ser Pro Trp Pro Trp Pro Arg Ser Pro Thr Pro Trp Ser Thr
50 55 60
Ser Leu Arg Lys
65
<210> 99
<211> 60
<212> PRT
<213> Homo sapiens
<400> 99
Met Asp Pro Gly Pro Lys Gly His Cys His Cys Gly Gly His Gly His
1 5 10 15
Pro Pro Gly His Cys Gly Pro Pro Pro His His Gly Pro Gly Pro Cys
20 25 30
Gly Pro Pro Pro His His Gly Pro Gly Pro Cys Gly Pro Pro Pro Gly
35 40 45
His Gly Pro Gly His Pro Pro Pro Gly Pro His His
50 55 60
<210> 100
<211> 71
<212> PRT
<213> Homo sapiens
<400> 100
Met Ala Ile Leu Gln Val Thr Ala Gly His Pro Pro Thr Met Val Gln
1 5 10 15
Gly Pro Ala Gly His Pro Pro Thr Met Val Gln Gly Pro Ala Gly Leu
20 25 30
Pro Leu Ala Met Ala Gln Val Thr His Pro Leu Val His Ile Thr Glu
35 40 45
Glu Val Glu Glu Asn Arg Thr Gln Asp Gly Lys Pro Glu Arg Ile Ala
50 55 60
Gln Leu Thr Trp Asn Glu Ala
65 70
Claims (117)
- 종양 관련 항원(tumor-associated antigen)의 발현 또는 활성을 억제하는 작용제를 포함하고,
상기 종양 관련 항원이
(a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된(degenerate) 핵산, 및
(d) 핵산 (a), (b) 또는 (c)와 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩된 서열을 갖는 것인 약학 조성물. - 종양 관련 항원을 발현하거나 비정상적으로 발현하는 세포에 대하여 선택적인 종양 억제 활성을 갖는 작용제를 포함하고,
상기 종양 관련 항원이
(a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)에 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩되는 서열을 갖는 것인 약학 조성물. - 제2항에 있어서, 상기 작용제가 세포 사멸 유도, 세포 성장 감소, 세포막 손상 또는 사이토카인 분비를 일으키는 것인 약학 조성물.
- 제1항 또는 제2항에 있어서, 상기 작용제가 상기 종양 관련 항원을 코딩하는 핵산과 선택적으로 혼성화하는 안티센스 핵산인 약학 조성물.
- 제1항 또는 제2항에 있어서, 상기 작용제가 상기 종양 관련 항원에 선택저으로 결합하는 항체인 약학 조성물.
- 제2항에 있어서, 상기 작용제가 상기 종양 관련 항원에 선택적으로 결합하는 보체 활성화 항체인 약학 조성물.
- 투여시, HLA 분자와 종양 관련 항원 또는 그 일부 간의 복합체의 양을 선택적으로 증가시키는 작용제를 포함하고,
상기 종양 관련 항원이
(a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)에 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩되는 서열을 갖는 것인 약학 조성물. - 제7항에 있어서, 상기 작용제가
(i) 상기 종양 관련 항원 또는 그 일부,
(ii) 상기 종양 관련 항원 또는 그 일부를 코딩하는 핵산,
(iii) 상기 종양 관련 항원 또는 그 일부를 발현하는 숙주 세포, 및
(iv) 상기 종양 관련 항원 또는 그 일부와 HLA 분자 간의 분리된 복합체로 이루어진 군 중에서 선택된 한 가지 이상의 성분을 포함하는 것인 약학 조성물. - 제1항, 제2항 또는 제7항 중 어느 하나의 항에 있어서, 상기 작용제가 각각의 경우에 있어서 서로 다른 종양 관련 항원의 발현 또는 활성을 선택적으로 억제하거나, 각각의 경우에 있어서 서로 다른 종양 관련 항원을 발현하는 세포에 대하여 선택적이거나, 또는 HLA 분자와 서로 다른 종양 관련 항원 또는 그 일부 간의 복합체의 양을 증가시키는 두 가지 이상의 작용제를 포함하고,
상기 종양 관련 항원 중 한 가지 이상은
(a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)에 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩되는 서열을 갖는 것인 약학 조성물. - (i) 종양 관련 항원 또는 그 일부,
(ii) 종양 관련 항원 또는 그 일부를 코딩하는 핵산,
(iii) 종양 관련 항원 또는 그 일부에 결합하는 항체,
(iv) 종양 관련 항원을 코딩하는 핵산과 특이적으로 혼성화하는 안티센스 핵산,
(v) 종양 관련 항원 또는 그 일부를 발현하는 숙주 세포, 및
(vi) 종양 관련 항원 또는 그 일부와 HLA 분자 간의 분리된 복합체로 이루어진 군 중에서 선택된 한 가지 이상의 성분을 포함하며,
상기 종양 관련 항원이
(a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)에 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩되는 서열을 갖는 것인 약학 조성물. - 제8항 또는 제10항에 있어서, 상기 (ii)의 핵산이 발현 벡터에 존재하는 것인 약학 조성물.
- 제8항 또는 제10항에 있어서, 상기 (ii)의 핵산이 프로모터와 기능적으로 연결되어 있는 것인 약학 조성물.
- 제8항 또는 제10항에 있어서, 상기 숙주 세포가 상기 종양 관련 항원 또는 그 일부를 분비하는 것인 약학 조성물.
- 제8항 또는 제10항에 있어서, 상기 숙주 세포가 상기 종양 관련 항원 또는 그 일부에 결합하는 HLA 분자를 추가적으로 발현하는 것인 약학 조성물.
- 제14항에 있어서, 상기 숙주 세포가 상기 HLA 분자 및/또는 상기 종양 관련 항원 또는 그 일부를 재조합적 방법으로 발현하는 것인 약학 조성물.
- 제14항에 있어서, 상기 숙주 세포가 상기 HLA 분자를 내생적으로 발현하는 것인 약학 조성물.
- 제8항, 제10항, 제14항 및 제16항 중 어느 하나의 항에 있어서, 상기 숙주 세포가 항원 제시 세포인 약학 조성물.
- 제17항에 있어서, 상기 항원 제시 세포가 수지상 세포 또는 대식 세포인 약학 조성물.
- 제8항, 제10항 및 제13 내지 제18항 중 어느 하나의 항에 있어서, 상기 숙주 세포가 비증식적인 것인 약학 조성물.
- 제5항 또는 제10항에 있어서, 상기 항체가 모노클로날 항체인 약학 조성물.
- 제5항 또는 제10항에 있어서, 상기 항체가 키메라 항체 또는 인간화된 항체 인 약학 조성물.
- 제5항 또는 제10항에 있어서, 상기 항체가 천연 항체의 단편인 약학 조성물.
- 제5항 또는 제10항에 있어서, 상기 항체가 치료제 또는 진단제와 결합되어 있는 것인 약학 조성물.
- 제4항 또는 제10항에 있어서, 상기 안티센스 핵산이 상기 종양 관련 항원을 코딩하는 핵산의 인접 뉴클레오타이드 6 내지 50 개의 서열을 포함하는 것인 약학 조성물.
- 제8항 및 제10항 내지 제13항 중 어느 하나의 항에 있어서, 상기 약학 조성물에 의하여 제공되는 상기 종양 관련 항원 또는 그 일부가 상기 종양 관련 항원 또는 그 일부를 비정상적 양으로 발현하는 세포 표면 상의 MHC 분자에 결합하는 것인 약학 조성물.
- 제25항에 있어서, 상기 결합으로 인하여 세포 독성 반응이 유발되거나 및/또는 사이토카인 방출이 유도되는 약학 조성물.
- 제1항 내지 제26항 중 어느 하나의 항에 있어서, 약학적으로 허용 가능한 담 체 및 또는 아쥬반트를 추가적으로 포함하는 약학 조성물.
- 제27항에 있어서, 상기 아쥬반트가 사포닌, GM-CSF, CpG, 사이토카인 또는 케모카인인 약학 조성물.
- 제1항 내지 제28항 중 어느 하나의 항에 있어서, 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖는 질병의 치료에 사용될 수 있는 약학 조성물.
- 제29항에 있어서, 상기 질병이 암인 약학 조성물.
- 제29항에 있어서, 상기 질병이 폐종양, 유방 종양, 전립선 종양, 흑색종, 결장 종양, 결장 종양의 전이, 신장 세포 암종 또는 자궁 경부 암종, 결장 암종 또는 유방 암종인 약학 조성물.
- 제1항 내지 제31항에 있어서, 상기 종양 관련 항원이 SEQ ID NOs: 6 내지 13, 14 내지 18, 22 내지 24, 30, 34 내지 36, 38, 41, 58 내지 61, 64, 65, 71, 75, 80 내지 84 및 89 내지 100으로 이루어진 군 중에서 선택된 아미노산 서열, 그 일부 또는 그 유도체를 포함하는 것인 약학 조성물.
- 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖는 질병의 진단 방법으 로서,
(i) 상기 종양 관련 항원 또는 그 일부를 코딩하는 핵산의 검출, 및/또는
(ii) 상기 종양 관련 항원 또는 그 일부의 검출, 및/또는
(iii) 상기 종양 관련 항원 또는 그 일부에 대한 항체의 검출, 및/또는
(iv) 환자로부터 분리한 생물학적 시료에서 상기 종양 관련 항원 또는 그 일부에 특이적인 세포 독성 또는 T 헬퍼 림프구의 검출하는 것을 포함하고,
상기 종양 관련 항원이
(a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)와 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩된 서열을 갖는 것인 진단 방법. - 제33항에 있어서, 상기 검출이
(i) 상기 생물학적 시료를 상기 종양 관련 항원을 코딩하는 핵산 또는 그 일부, 상기 종양 관련 항원 또는 그 일부, 상기 항체 또는 상기 세포 독성 또는 T 헬퍼 림프구와 특이적으로 결합하는 작용제와 접촉시키고,
(ii) 상기 작용제와 상기 핵산 또는 그 일부, 상기 종양 관련 항원 또는 그 일부, 상기 항체 또는 상기 세포 독성 또는 T헬퍼 림프구 간의 복합체 형성을 검출하는 것을 포함하는 것인 방법. - 제33항 또는 제34항에 있어서, 상기 검출을 비교 가능한 정상 생물학적 시료에서의 검출과 비교하는 것을 특징으로 하는 방법.
- 제33항 내지 제35항 중 어느 하나의 항에 있어서,
상기 질병이 두 가지 이상의 서로 다른 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖는 것이고,
상기 검출이 상기 두 가지 이상의 서로 다른 종양 관련 항원 또는 그 일부를 코딩하는 두 가지 이상의 핵산의 검출, 두 가지 이상의 서로 다른 종양 관련 항원 또는 그 일부의 검출, 상기 두 가지 이상의 서로 다른 종양 관련 항원 또는 그 일부에 결합하는 두 가지 이상의 항체의 검출 또는 상기 두 가지 이상의 서로 다른 종양 관련 항원에 특이적인 두 가지 이상의 세포 독성 또는 T 헬퍼 림프구의 검출을 포함하는 것인 방법. - 제33항 내지 제36항 중 어느 하나의 항에 있어서, 상기 핵산 또는 그 일부를 상기 핵산 또는 상기 그 일부에 특이적으로 혼성화하는 폴리뉴클레오타이드 프로브를 사용하여 검출하는 것을 특징으로 하는 방법.
- 제37항에 있어서, 상기 폴리뉴클레오타이드 프로브가 상기 종양 관련 항원을 코딩하는 핵산의 인접 뉴클레오타이드 6 내지 50 개의 서열을 포함하는 것인 방법.
- 제33항 내지 제36항 중 어느 하나의 항에 있어서, 상기 핵산 또는 그 일부를 상기 핵산 또는 상기 그 일부를 선택적으로 증폭시켜서 검출하는 것을 특징으로 하는 방법.
- 제33항 내지 제36항 중 어느 하나의 항에 있어서, 검출하고자 하는 상기 종양 관련 항원 또는 그 일부가 MHC 분자와 복합체 형태인 것인 방법.
- 제40항에 있어서, 상기 MHC 분자가 HLA 분자인 방법.
- 제33항 내지 제36항, 제40항 및 제41항 중 어느 하나의 항에 있어서, 상기 종양 관련 항원 또는 그 일부를 상기 종양 관련 항원 또는 상기 그 일부에 특이적으로 결합하는 항체를 사용하여 검출하는 것을 특징으로 하는 방법.
- 제33항 내지 제36항 중 어느 하나의 항에 있어서, 상기 항체를 상기 항체에 특이적으로 결합하는 단백질 또는 펩타이드를 사용하여 검출하는 것을 특징으로 하는 방법.
- 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖는 질병의 퇴축(regression), 경과 또는 발병의 측정 방법으로서, 상기 질병을 앓고 있거나 상기 질병에 걸린 것으로 의심되는 환자로부터 얻은 시료를
(i) 상기 종양 관련 항원을 코딩하는 핵산 또는 그 일부의 양,
(ii) 상기 종양 관련 항원 또는 그 일부의 양,
(iii) 상기 종양 관련 항원 또는 그 일부에 결합하는 항체의 양, 및
(iv) 상기 종양 관련 항원 또는 그 일부와 MHC 분자 간의 복합체에 대하여 특이적인 세포 용해성 또는 사이토카인 방출 T 세포의 양으로 이루어진 군 중에서 선택된 한 가지 이상의 파라미터에 대하여 모니터링하는 것을 포함하고,
상기 종양 관련 항원이
(a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)와 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩된 서열을 갖는 것인 방법. - 제44항에 있어서, 상기 파라미터를 첫 번째 시점에서 첫 번째 시료로부터 측정하고 두 번째 시점에서 다른 시료로부터 측정하여, 두 시료를 비교하여 질병의 경과를 측정하는 것을 특징으로 하는 방법.
- 제44항 또는 제45항에 있어서, 상기 질병이 두 가지 이상의 서로 다른 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖고,
(i) 상기 두 가지 이상의 서로 다른 종양 관련 항원을 코딩하는 두 가지 이상의 핵산 또는 그 일부의 양,
(ii) 상기 두 가지 이상의 서로 다른 종양 관련 항원 또는 그 일부의 양,
(iii) 상기 두 가지 이상의 서로 다른 종양 관련 항원 또는 그 일부에 결합하는 두 가지 이상의 항체의 양, 및/또는
(iv) 상기 두 가지 이상의 서로 다른 종양 관련 항원 또는 그 일부와 MHC 분자 간의 복합체에 특이적인 두 가지 이상의 세포 용해성 또는 사이토카인 방출 T 세포의 양을 모니터링하는 것을 포함하는 방법. - 제44항 내지 제46항 중 어느 하나의 항에 있어서, 상기 핵산 또는 그 일부의 양을 상기 핵산 또는 그 일부에 특이적으로 혼성화하는 폴리뉴클레오타이드 프로브를 사용하여 모니터링하는 것을 특징으로 하는 방법.
- 제47항에 있어서, 상기 폴리뉴클레오타이드 프로브가 상기 종양 관련 항원을 코딩하는 핵산의 인접 뉴클레오타이드 6 내지 50 개의 서열을 포함하는 것인 방법.
- 제44항 내지 제46항 중 어느 하나의 항에 있어서, 상기 핵산 또는 그 일부의 양을 상기 핵산 또는 상기 그 일부를 선택적으로 증폭시켜서 모니터링하는 것을 특징으로 하는 방법.
- 제44항 내지 제46항 중 어느 하나의 항에 있어서, 상기 종양 관련 항원 또는 그 일부의 양을 상기 종양 관련 항원 또는 그 일부에 특이적으로 결합하는 항체를 사용하여 모니터링하는 것을 특징으로 하는 방법.
- 제44항 내지 제46항 중 어느 하나의 항에 있어서, 상기 항체의 양을 상기 항체에 특이적으로 결합하는 단백질 또는 펩타이드를 사용하여 모니터링하는 것을 특징으로 하는 방법.
- 제44항 내지 제46항 중 어느 하나의 항에 있어서, 상기 세포 용해성 또는 사이토카인 방출 T 세포의 양을 상기 종양 관련 항원 또는 그 일부와 MHC 분자 간의 복합체를 제시하는 세포를 사용하여 모니터링하는 것을 특징으로 하는 방법.
- 제37항, 제38항, 제42항, 제43항, 47항, 제48항 및 제50항 내지 제52항에 있어서, 상기 폴리뉴클레오타이드 프로브, 항체, 단백질 또는 펩타이드, 또는 세포를 검출 가능한 방법으로 표지하는 것을 특징으로 하는 방법.
- 제53항에 있어서, 상기 검출 가능한 표지가 방사성 표지 또는 효소 표지인 방법.
- 제33항 내지 제54항 중 어느 하나의 항에 있어서, 상기 시료가 체액 및/또는 신체 조직을 포함하는 것인 방법.
- 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖는 질병의 치료 방법으로서, 제1항 내지 제32항 중 어느 한 항에 기재된 약학 조성물을 투여하는 것을 포함하고,
상기 종양 관련 항원이
(a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)와 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩된 서열을 갖는 것인 치료 방법. - 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖는 질병을 치료, 진단 또는 모니터링하는 방법으로서, 상기 종양 관련 항원 또는 그 일부에 결합하는 항체를 치료제 또는 진단제와 함께 투여하는 것을 포함하고,
상기 종양 관련 항원이
(a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)와 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩된 서열을 갖는 것인 방법. - 제42항, 제50항 또는 제57항에 있어서, 상기 항체가 모노클로날 항체인 방법.
- 제42항, 제50항 또는 제57항에 있어서, 상기 항체가 키메라 항체 또는 인간화된 항체인 방법.
- 제42항, 제50항 또는 제57항에 있어서, 상기 항체가 천연 항체의 단편인 방법.
- 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖는 질병을 앓는 환자의 치료 방법으로서,
(i) 상기 환자로부터 면역 반응성 세포를 추출하고,
(ii) 상기 종양 관련 항원 또는 그 일부에 대한 세포 용해성 또는 사이토카인 방출 T 세포의 생산에 유리한 조건 하에서, 상기 시료를 상기 종양 관련 항원 또는 그 일부를 발현하는 숙주 세포와 접촉시키고,
(iii) 상기 세포 용해성 또는 사이토카인 방출 T 세포를 종양 관련 항원 또는 그 일부를 발현하는 세포를 용해시키기에 적절한 양으로 환자 내로 도입시키는 것을 포함하고,
상기 종양 관련 항원이
(a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)와 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩된 서열을 갖는 것인 방법. - 제61항에 있어서, 상기 숙주 세포가 상기 종양 관련 항원 또는 그 일부에 결 합하는 HLA 분자를 재조합적으로 발현하는 것인 방법.
- 제62항에 있어서, 상기 숙주 세포가 상기 종양 관련 항원 또는 그 일부에 결합하는 HLA 분자를 내생적으로 발현하는 것인 방법.
- 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖는 질병을 앓는 환자의 치료 방법으로서,
(i) (a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)와 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩된 서열을 갖고, 상기 질병과 관련된 세포에서 발현되는 핵산을 동정하고,
(ii) 상기 핵산 또는 그 일부로 숙주 세포를 형질 감염시키고,
(iii) 상기 형질 감염된 세포를 배양하여 상기 핵산을 발현시키고,
(iv) 상기 숙주 세포 또는 그 추출물을 상기 질병과 관련된 환자의 세포에 대한 면역 응답을 증가시키기에 적합한 양으로 환자 내로 도입시키는 것을 포함하는 방법. - 제64항에 있어서, 상기 종양 관련 항원 또는 그 일부를 제시하는 MHC 분자를 동정하는 것을 추가적으로 포함하는 방법으로서, 상기 숙주 세포는 상기 동정된 MHC 분자를 발현하고 상기 종양 관련 항원 또는 그 일부를 제시하는 것인 방법.
- 제64항 또는 제65항에 있어서, 상기 면역 응답이 B 세포 응답 또는 T 세포 응답을 포함하는 것인 방법.
- 제66항에 있어서, 상기 면역 응답이 상기 종양 관련 항원 또는 그 일부를 제시하는 숙주 세포에 특이적이거나 또는 상기 종양 관련 항원 또는 그 일부를 발현하는 환자의 세포에 특이적인 세포 용해성 또는 사이토카인 방출 T 세포의 생산을 포함하는 T 세포 응답인 방법.
- 제61항 내지 제67항 중 어느 하나의 항에 있어서, 상기 숙주 세포가 비증식적인 것인 방법.
- 종양 관련 항원의 발현 또는 비정상적 발현 특성을 갖는 질병의 치료 방법으로서,
(i) 상기 종양 관련 항원을 비정상적 양으로 발현하는 환자로부터 얻은 세포를 동정하고,
(ii) 상기 세포 시료를 분리하고,
(iii) 상기 세포를 배양하고,
(iv) 상기 세포를 환자 내로 상기 세포에 대한 면역 응답을 유발하기에 적합한 양으로 도입시키는 것을 포함하고,
상기 종양 관련 항원이
(a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)와 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩된 서열을 갖는 것인 방법. - 제33항 내지 제69항 중 어느 하나의 항에 있어서, 상기 질병이 암인 방법.
- 제1항 내지 제32항 중 어느 하나의 항에 기재된 약학 조성물의 유효량을 투여하는 것을 포함하는, 환자에서의 암 발생(development) 억제 방법.
- 제33항 내지 제71항 중 어느 하나의 항에 있어서, 상기 종양 관련 항원이 SEQ ID NOs: 6 내지 13, 14 내지 18, 22 내지 24, 30, 34 내지 36, 38, 41, 58 내 지 61, 64, 65, 71, 75, 80 내지 84 및 89 내지 100으로 이루어진 군 중에서 선택된 아미노산 서열, 그 일부 또는 그 유도체를 포함하는 것인 방법.
- (a) SEQ ID NOs: 2 내지 5, 20, 21, 31 내지 33, 37, 39, 54 내지 57, 62, 63 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)와 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산. - SEQ ID NOs: 7 내지 13, 14 내지 18, 23, 24, 34 내지 36, 58 내지 61, 64, 65 및 89 내지 100으로 이루어진 군 중에서 선택된 아미노산 서열, 그 일부 또는 그 유도체를 포함하는 폴리펩타이드 또는 단백질을 코딩하는 핵산.
- 제73항 또는 제74항에 기재된 핵산을 포함하는 재조합 DNA 또는 RNA 분자.
- 제75항에 있어서, 벡터인 재조합 DNA 분자.
- 제76항에 있어서, 상기 벡터가 바이러스 벡터 또는 박테리오파아지인 재조합 DNA 분자.
- 제76항 내지 제77항 중 어느 하나의 항에 있어서, 상기 핵산의 발현을 조절하는 발현 조절 서열을 추가적으로 포함하는 재조합 DNA 분자.
- 제78항에 있어서, 상기 발현 조절 서열이 상기 핵산과 상동이거나 비상동인 재조합 DNA 분자.
- 제73항 또는 제74항에 기재된 핵산 또는 제75항 내지 제79항에 기재된 재조합 DNA 분자를 포함하는 숙주 세포.
- 제80항에 있어서, HLA 분자를 코딩하는 핵산을 추가적으로 포함하는 숙주 세포.
- 제73항에 기재된 핵산에 의하여 코딩되는 단백질 또는 폴리펩타이드.
- SEQ ID NOs: 7 내지 13, 14 내지 18, 23, 24, 34 내지 36, 58 내지 61, 64, 65 및 89 내지 100으로 이루어진 군 중에서 선택된 아미노산 서열, 그 일부 또는 그 유도체를 포함하는 단백질 또는 폴리펩타이드.
- 제82항 또는 제83항에 기재된 단백질 또는 폴리펩타이드의 면역원성 단편.
- 인간 HLA 수용체 또는 인간 항체에 결합하는, 제82항 또는 제83항에 기재된 단백질 또는 폴리펩타이드의 단편.
- (a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)와 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩되는 단백질 또는 폴리펩타이드 또는 그 일부에 특이적으로 결합하는 작용제. - 제86항에 있어서, 상기 단백질 또는 폴리펩타이드가 SEQ ID NOs: 6 내지 13, 14 내지 18, 22 내지 24, 30, 34 내지 36, 38, 41, 58 내지 61, 64, 65, 71, 75, 80 내지 84 및 89 내지 100으로 이루어진 군 중에서 선택된 아미노산 서열, 그 일부 또는 그 유도체를 포함하는 것인 작용제.
- 제86항 또는 제87항에 있어서, 항체인 작용제.
- 제88항에 있어서, 상기 항체가 모노클로날 항체, 키메라 항체 또는 인간화된 항체 또는 항체 단편인 작용제.
- (i) 단백질 또는 폴리펩타이드 또는 그 일부와
(ii) 상기 단백질 또는 폴리펩타이드 또는 그 일부가 결합하는 MHC 분자와의 복합체에 선택적으로 결합하고,
단독으로 존재하는 (i) 또는 (ii)에는 결합하지 않는 항체로서,
상기 단백질 또는 폴리펩타이드가
(a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)와 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산 서열에 의하여 코딩되는 것인 항체. - 제90항에 있어서, 상기 단백질 또는 폴리펩타이드가 SEQ ID NOs: 6 내지 13, 14 내지 18, 22 내지 24, 30, 34 내지 36, 38, 41, 58 내지 61, 64, 65, 71, 75, 80 내지 84 및 89 내지 100으로 이루어진 군 중에서 선택된 아미노산 서열, 그 일부 또는 그 유도체를 포함하는 것인 항체.
- 제90항 또는 제91항에 있어서, 모노클로날 항체, 키메라 항체 또는 인간화된 항체 또는 항체 단편인 항체.
- 제86항 내지 제89항 중 어느 하나의 항에 기재된 작용제 또는 제90항 내지 제92항 중 어느 하나의 항에 기재된 항체와 치료제 또는 진단제와의 콘쥬게이트.
- 제93항에 있어서, 상기 치료제 또는 진단제가 독소인 콘쥬게이트.
- 종양 관련 항원의 발현 또는 비정상적 발현 검출용 키트로서,
(i) 상기 종양 관련 항원 또는 그 일부를 코딩하는 핵산,
(ii) 상기 종양 관련 항원 또는 그 일부,
(iii) 상기 종양 관련 항원 또는 그 일부에 결합하는 항체, 및/또는
(iv) 상기 종양 관련 항원 또는 그 일부와 MHC 분자 간의 복합체에 특이적인 T 세포의 검출을 위한 작용제를 포함하고,
상기 종양 관련 항원이
(a) SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어진 군 중에서 선택된 핵산 서열, 그 일부 또는 그 유도체를 포함하는 핵산,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)와 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의해서 코딩되는 서열을 갖는 것인 키트. - 제95항에 있어서, 상기 종양 관련 항원 또는 그 일부를 코딩하는 핵산의 검출을 위한 작용제가 상기 핵산의 선택적인 증폭을 위한 핵산 분자인 키트.
- 제96항에 있어서, 상기 핵산의 선택적 증폭을 위한 핵산 분자가 상기 종양 관련 항원을 코딩하는 핵산의 인접 뉴클레오타이드 6 내지 50 개의 서열을 포함하는 것인 키트.
- SEQ ID NOs: 1 내지 5, 19 내지 21, 29, 31 내지 33, 37, 39, 40, 54 내지 57, 62, 63, 70, 74 및 85 내지 88로 이루어지는 군 중에서 선택된 핵산 서열로부터 유도된 프로모터 부위를 포함하는 재조합 DNA 분자.
- 종양 항원 TPTE, SEQ ID NOs: 19 및 22의 발현 또는 활성을 억제하는 작용제를 포함하는 약학 조성물.
- TPTE의 이동 활성 및 전이 활성을 억제하는 작용제를 포함하는 약학 조성물.
- 제99항 또는 제100항에 기재된 작용제로서 항체인 작용제.
- 제101항에 있어서, 상기 항체가 모노클로날 항체, 키메라 항체, 인간화된 항체 또는 항체 단편인 작용제.
- SEQ ID NOs: 81 및 82 서열을 포함하는 세포외 단백질 부위에 결합하는 항체.
- 제99항 또는 제100항에 기재된 작용제로서, TPTE를 코딩하는 핵산과 선택적으로 혼성화하는 안티센스 핵산인 작용제.
- 제104항에 있어서, 상기 안티센스 핵산이 TPTE를 코딩하는 핵산의 인접 뉴클레오타이드 6 내지 50 개의 서열을 포함하는 것인 작용제.
- 제99항 또는 제100항에 기재된 작용제로서, RNA 간섭체 (RNAi)인 작용제.
- 제106항에 있어서, 상기 RNAi이 '짧은 헤어핀(short hairpin)' 구조체 (shRNA)를 포함하는 것인 작용제.
- 제107항에 있어서, 상기 shRNA가 발현 벡터를 사용하여 감염된 후 전사되어 생성된 것인 작용제.
- 제107항에 있어서, 상기 shRNA가 레트로바이러스의 전사에 의하여 생산된 것인 작용제.
- 제107항에 있어서, 상기 shRNA가 렌티바이러스 시스템에 의하여 매개되는 것인 작용제.
- 제99항 또는 제100항에 기재된 작용제로서, 화학 소분자인 작용제.
- 제111항에 있어서, 상기 화학 소분자가 TPTE에 결합하는 것인 작용제.
- 제112항에 있어서, 상기 화학 소분자가 SEQ ID NO: 81 및 82을 포함하는 세포외 부위에 결합하는 것인 작용제.
- TPTE의 발현 또는 비정상적 발현 특성을 갖는 전이 종양의 치료, 진단 또는 모니터링 방법으로서, TPTE 또는 그 일부에 결합하는 항체를 치료제 또는 진단제와 함께 투여하는 것을 포함하고, 상기 TPTE가
(a) SEQ ID NO: 19을 포함하는 핵산, 그 일부 또는 그 유도체,
(b) 엄격한 조건 하에서 핵산 (a)와 혼성화하는 핵산,
(c) 핵산 (a) 또는 (b)에 대하여 축퇴된 핵산, 및
(d) 핵산 (a), (b) 또는 (c)와 상보적인 핵산으로 이루어진 군 중에서 선택된 핵산에 의하여 코딩되는 서열을 갖는 것인 방법. - 제114항에 있어서, 상기 항체가 모노클로날 항체인 방법.
- 제114항에 있어서, 상기 항체가 키메라 항체 또는 인간화된 항체인 방법.
- 제114항에 있어서, 상기 항체가 천연 항체의 단편인 항체.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DE10211088A DE10211088A1 (de) | 2002-03-13 | 2002-03-13 | Differentiell in Tumoren exprimierte Genprodukte und deren Verwendung |
| DE10211088.3 | 2002-03-13 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020047014321A Division KR101261887B1 (ko) | 2002-03-13 | 2003-03-12 | 종양에서 특이적으로 발현되는 유전자 산물 및 이의 용도 |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020127025908A Division KR20120127536A (ko) | 2002-03-13 | 2003-03-12 | 종양에서 특이적으로 발현되는 유전자 산물 및 이의 용도 |
| KR1020117024468A Division KR20110117735A (ko) | 2002-03-13 | 2003-03-12 | 종양에서 특이적으로 발현되는 유전자 산물 및 이의 용도 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20110026529A true KR20110026529A (ko) | 2011-03-15 |
Family
ID=27771250
Family Applications (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020127025908A KR20120127536A (ko) | 2002-03-13 | 2003-03-12 | 종양에서 특이적으로 발현되는 유전자 산물 및 이의 용도 |
| KR1020117004206A KR20110026529A (ko) | 2002-03-13 | 2003-03-12 | 종양에서 특이적으로 발현되는 유전자 산물 및 이의 용도 |
| KR1020047014321A KR101261887B1 (ko) | 2002-03-13 | 2003-03-12 | 종양에서 특이적으로 발현되는 유전자 산물 및 이의 용도 |
| KR1020117024468A KR20110117735A (ko) | 2002-03-13 | 2003-03-12 | 종양에서 특이적으로 발현되는 유전자 산물 및 이의 용도 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020127025908A KR20120127536A (ko) | 2002-03-13 | 2003-03-12 | 종양에서 특이적으로 발현되는 유전자 산물 및 이의 용도 |
Family Applications After (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020047014321A KR101261887B1 (ko) | 2002-03-13 | 2003-03-12 | 종양에서 특이적으로 발현되는 유전자 산물 및 이의 용도 |
| KR1020117024468A KR20110117735A (ko) | 2002-03-13 | 2003-03-12 | 종양에서 특이적으로 발현되는 유전자 산물 및 이의 용도 |
Country Status (14)
| Country | Link |
|---|---|
| US (8) | US7429461B2 (ko) |
| EP (18) | EP1483389B1 (ko) |
| JP (5) | JP4963778B2 (ko) |
| KR (4) | KR20120127536A (ko) |
| CN (4) | CN103251952B (ko) |
| AU (2) | AU2003219045B2 (ko) |
| CA (3) | CA3035543A1 (ko) |
| DE (1) | DE10211088A1 (ko) |
| ES (3) | ES2685053T3 (ko) |
| IL (4) | IL163900A0 (ko) |
| MX (1) | MXPA04008867A (ko) |
| NZ (1) | NZ535146A (ko) |
| PL (1) | PL215160B1 (ko) |
| WO (1) | WO2003076631A2 (ko) |
Families Citing this family (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE10211088A1 (de) * | 2002-03-13 | 2003-09-25 | Ugur Sahin | Differentiell in Tumoren exprimierte Genprodukte und deren Verwendung |
| CN102220423A (zh) * | 2002-08-20 | 2011-10-19 | 千年药品公司 | 用于鉴定,评估,预防和治疗子宫颈癌的组合物,试剂盒及方法 |
| DE10341812A1 (de) * | 2003-09-10 | 2005-04-07 | Ganymed Pharmaceuticals Ag | Differentiell in Tumoren exprimierte Genprodukte und deren Verwendung |
| DE10344799A1 (de) * | 2003-09-26 | 2005-04-14 | Ganymed Pharmaceuticals Ag | Identifizierung von Oberflächen-assoziierten Antigenen für die Tumordiagnose und -therapie |
| AU2015201737B2 (en) * | 2003-09-26 | 2016-09-15 | Biontech Ag | Identification of tumour-associated cell surface antigens for diagnosis and therapy |
| DE102004023187A1 (de) | 2004-05-11 | 2005-12-01 | Ganymed Pharmaceuticals Ag | Identifizierung von Oberflächen-assoziierten Antigenen für die Tumordiagnose und -therapie |
| WO2006073183A1 (ja) | 2005-01-07 | 2006-07-13 | Riken | 一塩基多型を用いた炎症性疾患の判定方法 |
| DE102005013846A1 (de) * | 2005-03-24 | 2006-10-05 | Ganymed Pharmaceuticals Ag | Identifizierung von Oberflächen-assoziierten Antigenen für die Tumordiagnose und -therapie |
| EP2083852B1 (en) * | 2006-10-04 | 2014-12-10 | Dana-Farber Cancer Institute, Inc. | Tumor immunity |
| EP2108701A1 (en) * | 2008-04-10 | 2009-10-14 | Ganymed Pharmaceuticals AG | Methods involving MS4A12 and agents targeting MS4A12 for therapy, diagnosis and testing |
| EP3572510B1 (en) | 2013-11-21 | 2022-09-21 | Repertoire Genesis Incorporation | T cell receptor and b cell receptor repertoire analysis system, and use of same in treatment and diagnosis |
| EA033478B1 (ru) | 2014-03-21 | 2019-10-31 | Haldor Topsoe As | Решетчатые модули без уплотнителей для подложки катализатора, а также модульная система подложки катализатора |
| US9913461B2 (en) | 2014-12-09 | 2018-03-13 | Regeneron Pharmaceuticals, Inc. | Genetically modified mouse whose genome comprises a humanized CD274 gene |
| IL305238A (en) | 2015-12-16 | 2023-10-01 | Gritstone Bio Inc | Identification of neoantigens, preparation, and use |
| WO2019075112A1 (en) | 2017-10-10 | 2019-04-18 | Gritstone Oncology, Inc. | IDENTIFICATION OF NEO-ANTIGENS USING HOT POINTS |
| US11885815B2 (en) | 2017-11-22 | 2024-01-30 | Gritstone Bio, Inc. | Reducing junction epitope presentation for neoantigens |
| CN110734925B (zh) * | 2018-07-20 | 2023-04-07 | 上海市免疫学研究所 | 一种粒细胞或单核细胞标记系统及其标记方法和应用 |
| WO2024002537A1 (en) | 2022-06-30 | 2024-01-04 | Kmc Kartoffelmelcentralen Amba | Starch based gelatine replacement products |
Family Cites Families (29)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0270056A1 (en) * | 1986-12-01 | 1988-06-08 | Northwestern University | Human LDH-C 4cDNA sequences encoding antigenic regions |
| US6020145A (en) * | 1989-06-30 | 2000-02-01 | Bristol-Myers Squibb Company | Methods for determining the presence of carcinoma using the antigen binding region of monoclonal antibody BR96 |
| GB9019812D0 (en) | 1990-09-11 | 1990-10-24 | Scotgen Ltd | Novel antibodies for treatment and prevention of infection in animals and man |
| US5677139A (en) | 1995-04-21 | 1997-10-14 | President And Fellows Of Harvard College | In vitro differentiation of CD34+ progenitor cells into T lymphocytes |
| UA56132C2 (uk) | 1995-04-25 | 2003-05-15 | Смітклайн Бічем Байолоджікалс С.А. | Композиція вакцини (варіанти), спосіб стабілізації qs21 відносно гідролізу (варіанти), спосіб приготування композиції вакцини |
| US5990299A (en) * | 1995-08-14 | 1999-11-23 | Icn Pharmaceuticals, Inc. | Control of CD44 gene expression for therapeutic use |
| AU1705397A (en) * | 1996-01-16 | 1997-08-11 | Northwestern University | Proteins and peptides for contraceptive vaccines and fertility diagnosis |
| US5840839A (en) * | 1996-02-09 | 1998-11-24 | The United States Of America As Represented By The Secretary Of The Department Of Health And Human Services | Alternative open reading frame DNA of a normal gene and a novel human cancer antigen encoded therein |
| WO1999041375A2 (en) * | 1998-02-12 | 1999-08-19 | Incyte Pharmaceuticals, Inc. | Human receptor proteins |
| EP1080227B1 (en) * | 1998-05-21 | 2006-02-08 | Diadexus, Inc. | Method of diagnosing, monitoring, and staging colon cancer |
| US6440663B1 (en) * | 1998-10-05 | 2002-08-27 | Ludwig Institute For Cancer Research | Renal cancer associated antigens and uses therefor |
| WO2001009345A1 (fr) * | 1999-07-29 | 2001-02-08 | Helix Research Institute | Nouveaux genes codant des proteines kinase et des proteines phosphatase |
| WO2001009316A1 (fr) * | 1999-07-29 | 2001-02-08 | Helix Research Institute | Nouveaux genes codant la proteine kinase / proteine phosphatase |
| DE19936563A1 (de) * | 1999-08-04 | 2001-02-08 | Boehringer Ingelheim Int | Tumorassoziiertes Antigen |
| AU7721500A (en) * | 1999-09-29 | 2001-04-30 | Human Genome Sciences, Inc. | Colon and colon cancer associated polynucleotides and polypeptides |
| US7442776B2 (en) * | 1999-10-08 | 2008-10-28 | Young David S F | Cancerous disease modifying antibodies |
| AU2001229340A1 (en) * | 2000-01-14 | 2001-07-24 | Millennium Pharmaceuticals, Inc. | Genes compositions, kits, and methods for identification, assessment, prevention, and therapy of breast cancer |
| AU2001233114A1 (en) * | 2000-02-04 | 2001-08-14 | Aeomica, Inc. | Methods and apparatus for predicting, confirming, and displaying functional information derived from genomic sequence |
| WO2001060860A2 (en) * | 2000-02-17 | 2001-08-23 | Millennium Predictive Medicine, Inc. | Genes differentially expressed in human prostate cancer and their use |
| AU6802801A (en) * | 2000-03-01 | 2001-09-24 | Genentech Inc | Secreted and transmembrane polypeptides and nucleic acids encoding the same |
| US6436703B1 (en) * | 2000-03-31 | 2002-08-20 | Hyseq, Inc. | Nucleic acids and polypeptides |
| CA2417359A1 (en) | 2000-07-28 | 2002-02-07 | Incyte Genomics, Inc. | Protein phosphatases |
| WO2002068579A2 (en) * | 2001-01-10 | 2002-09-06 | Pe Corporation (Ny) | Kits, such as nucleic acid arrays, comprising a majority of human exons or transcripts, for detecting expression and other uses thereof |
| AU2002253878A1 (en) * | 2001-01-25 | 2002-08-06 | Gene Logic, Inc. | Gene expression profiles in breast tissue |
| AU2002303219A1 (en) | 2001-03-30 | 2002-10-15 | Corixa Corporation | Compositions and methods for the therapy and diagnosis of cancer |
| US20040058341A1 (en) * | 2001-07-26 | 2004-03-25 | Y.Tom Tang | Protein phosphatases |
| EP2143438B1 (en) | 2001-09-18 | 2011-07-13 | Genentech, Inc. | Compositions and methods for the diagnosis and treatment of tumors |
| DE10211088A1 (de) * | 2002-03-13 | 2003-09-25 | Ugur Sahin | Differentiell in Tumoren exprimierte Genprodukte und deren Verwendung |
| JP5565375B2 (ja) | 2011-05-12 | 2014-08-06 | 三菱電機株式会社 | 入退室管理装置 |
-
2002
- 2002-03-13 DE DE10211088A patent/DE10211088A1/de not_active Withdrawn
-
2003
- 2003-03-12 EP EP03714811.1A patent/EP1483389B1/de not_active Expired - Lifetime
- 2003-03-12 EP EP10010636A patent/EP2311861A3/de not_active Withdrawn
- 2003-03-12 KR KR1020127025908A patent/KR20120127536A/ko not_active Application Discontinuation
- 2003-03-12 IL IL16390003A patent/IL163900A0/xx unknown
- 2003-03-12 EP EP10010627A patent/EP2287181A3/de not_active Ceased
- 2003-03-12 CN CN201310025680.8A patent/CN103251952B/zh not_active Expired - Lifetime
- 2003-03-12 WO PCT/EP2003/002556 patent/WO2003076631A2/de active Application Filing
- 2003-03-12 CN CNA038074931A patent/CN1646692A/zh active Granted
- 2003-03-12 EP EP10010629.3A patent/EP2289910B1/de not_active Expired - Lifetime
- 2003-03-12 CA CA3035543A patent/CA3035543A1/en not_active Expired - Lifetime
- 2003-03-12 EP EP10010630A patent/EP2277905A3/de not_active Withdrawn
- 2003-03-12 PL PL373384A patent/PL215160B1/pl unknown
- 2003-03-12 CN CN201510846314.8A patent/CN105396144B/zh not_active Expired - Lifetime
- 2003-03-12 EP EP10010632A patent/EP2277907A3/de not_active Withdrawn
- 2003-03-12 EP EP10010637A patent/EP2311862A3/de not_active Withdrawn
- 2003-03-12 EP EP10010633.5A patent/EP2311860B1/de not_active Expired - Lifetime
- 2003-03-12 CA CA2813780A patent/CA2813780C/en not_active Expired - Lifetime
- 2003-03-12 EP EP10010623A patent/EP2277901A3/de not_active Withdrawn
- 2003-03-12 KR KR1020117004206A patent/KR20110026529A/ko not_active Application Discontinuation
- 2003-03-12 ES ES10010629.3T patent/ES2685053T3/es not_active Expired - Lifetime
- 2003-03-12 US US10/506,443 patent/US7429461B2/en not_active Expired - Lifetime
- 2003-03-12 NZ NZ535146A patent/NZ535146A/en not_active IP Right Cessation
- 2003-03-12 EP EP10010638A patent/EP2314612A3/de not_active Withdrawn
- 2003-03-12 EP EP10010635A patent/EP2314611A3/de not_active Withdrawn
- 2003-03-12 MX MXPA04008867A patent/MXPA04008867A/es active IP Right Grant
- 2003-03-12 EP EP10010628.5A patent/EP2287182B1/de not_active Expired - Lifetime
- 2003-03-12 JP JP2003574831A patent/JP4963778B2/ja not_active Expired - Fee Related
- 2003-03-12 EP EP10010639A patent/EP2332973A3/de not_active Withdrawn
- 2003-03-12 CN CN03807493.1A patent/CN1646692B/zh not_active Expired - Lifetime
- 2003-03-12 AU AU2003219045A patent/AU2003219045B2/en not_active Expired
- 2003-03-12 KR KR1020047014321A patent/KR101261887B1/ko active IP Right Grant
- 2003-03-12 EP EP10010634.3A patent/EP2314610B1/de not_active Expired - Lifetime
- 2003-03-12 EP EP10010624A patent/EP2277902A3/de not_active Withdrawn
- 2003-03-12 KR KR1020117024468A patent/KR20110117735A/ko active IP Right Grant
- 2003-03-12 ES ES03714811.1T patent/ES2559079T3/es not_active Expired - Lifetime
- 2003-03-12 EP EP10010626A patent/EP2277904A3/de not_active Withdrawn
- 2003-03-12 EP EP10010625A patent/EP2277903A3/de not_active Withdrawn
- 2003-03-12 EP EP10010631A patent/EP2277906A3/de not_active Withdrawn
- 2003-03-12 ES ES10010628.5T patent/ES2688186T3/es not_active Expired - Lifetime
- 2003-03-12 CA CA2478413A patent/CA2478413C/en not_active Expired - Lifetime
-
2004
- 2004-09-02 IL IL163900A patent/IL163900A/en active IP Right Grant
-
2008
- 2008-08-25 US US12/197,960 patent/US8716455B2/en not_active Expired - Lifetime
- 2008-08-25 US US12/197,956 patent/US20090081214A1/en not_active Abandoned
- 2008-12-16 AU AU2008258158A patent/AU2008258158A1/en not_active Abandoned
-
2009
- 2009-10-21 JP JP2009242389A patent/JP2010047597A/ja active Pending
-
2011
- 2011-07-18 US US13/184,719 patent/US8551490B2/en not_active Expired - Lifetime
-
2012
- 2012-09-27 JP JP2012213517A patent/JP5711711B2/ja not_active Expired - Lifetime
- 2012-10-29 JP JP2012238202A patent/JP5756073B2/ja not_active Expired - Lifetime
-
2013
- 2013-03-04 JP JP2013041406A patent/JP5793158B2/ja not_active Expired - Lifetime
- 2013-03-12 US US13/796,094 patent/US9637794B2/en not_active Expired - Lifetime
-
2014
- 2014-05-02 US US14/268,160 patent/US9453260B2/en not_active Expired - Lifetime
- 2014-10-07 IL IL235085A patent/IL235085A/en active IP Right Grant
-
2015
- 2015-07-10 US US14/796,509 patent/US20160002738A1/en not_active Abandoned
-
2016
- 2016-03-14 IL IL244596A patent/IL244596A0/en unknown
- 2016-09-22 US US15/273,378 patent/US20170101479A1/en not_active Abandoned
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5793158B2 (ja) | 腫瘍において示差的に発現される遺伝子産物およびこの使用 | |
| JP5711698B2 (ja) | 腫瘍において示差的に発現される遺伝子産物およびこの使用 | |
| AU2012216265B2 (en) | Genetic products differentially expressed in tumors and use thereof | |
| AU2011218666A1 (en) | Genetic products which are differentially expressed in tumors and use thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A107 | Divisional application of patent | ||
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| A107 | Divisional application of patent | ||
| E90F | Notification of reason for final refusal | ||
| A107 | Divisional application of patent | ||
| E601 | Decision to refuse application |