JP2011521663A - 高容量アデノウイルスをパッケージングするための系 - Google Patents
高容量アデノウイルスをパッケージングするための系 Download PDFInfo
- Publication number
- JP2011521663A JP2011521663A JP2011512159A JP2011512159A JP2011521663A JP 2011521663 A JP2011521663 A JP 2011521663A JP 2011512159 A JP2011512159 A JP 2011512159A JP 2011512159 A JP2011512159 A JP 2011512159A JP 2011521663 A JP2011521663 A JP 2011521663A
- Authority
- JP
- Japan
- Prior art keywords
- polynucleotide
- adenovirus
- cell
- sequence
- protein
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000004806 packaging method and process Methods 0.000 title claims abstract description 71
- 241000701161 unidentified adenovirus Species 0.000 title claims description 110
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 184
- 239000013598 vector Substances 0.000 claims abstract description 119
- 238000004519 manufacturing process Methods 0.000 claims abstract description 74
- 241000700605 Viruses Species 0.000 claims abstract description 52
- 230000010076 replication Effects 0.000 claims abstract description 33
- 230000003612 virological effect Effects 0.000 claims abstract description 33
- 239000002245 particle Substances 0.000 claims abstract description 28
- 102000040430 polynucleotide Human genes 0.000 claims description 232
- 108091033319 polynucleotide Proteins 0.000 claims description 232
- 239000002157 polynucleotide Substances 0.000 claims description 232
- 230000014509 gene expression Effects 0.000 claims description 87
- 230000002103 transcriptional effect Effects 0.000 claims description 67
- 108091008146 restriction endonucleases Proteins 0.000 claims description 54
- 239000013604 expression vector Substances 0.000 claims description 53
- 238000000034 method Methods 0.000 claims description 51
- 238000013518 transcription Methods 0.000 claims description 41
- 230000035897 transcription Effects 0.000 claims description 41
- 238000001890 transfection Methods 0.000 claims description 40
- 108010061833 Integrases Proteins 0.000 claims description 37
- 102100034343 Integrase Human genes 0.000 claims description 35
- 239000002773 nucleotide Substances 0.000 claims description 32
- 125000003729 nucleotide group Chemical group 0.000 claims description 32
- 230000001105 regulatory effect Effects 0.000 claims description 32
- 102000004169 proteins and genes Human genes 0.000 claims description 29
- 230000027455 binding Effects 0.000 claims description 28
- 230000010354 integration Effects 0.000 claims description 28
- 239000000411 inducer Substances 0.000 claims description 27
- 108010024878 Adenovirus E1A Proteins Proteins 0.000 claims description 26
- 230000004568 DNA-binding Effects 0.000 claims description 26
- 102100039556 Galectin-4 Human genes 0.000 claims description 25
- 101000608765 Homo sapiens Galectin-4 Proteins 0.000 claims description 25
- 108010087905 Adenovirus E1B Proteins Proteins 0.000 claims description 24
- VKHAHZOOUSRJNA-GCNJZUOMSA-N mifepristone Chemical compound C1([C@@H]2C3=C4CCC(=O)C=C4CC[C@H]3[C@@H]3CC[C@@]([C@]3(C2)C)(O)C#CC)=CC=C(N(C)C)C=C1 VKHAHZOOUSRJNA-GCNJZUOMSA-N 0.000 claims description 23
- 208000015181 infectious disease Diseases 0.000 claims description 22
- 108010042407 Endonucleases Proteins 0.000 claims description 21
- 230000004913 activation Effects 0.000 claims description 21
- 101150075174 E1B gene Proteins 0.000 claims description 20
- 102100031780 Endonuclease Human genes 0.000 claims description 20
- 230000002458 infectious effect Effects 0.000 claims description 14
- 108020001756 ligand binding domains Proteins 0.000 claims description 8
- 239000003550 marker Substances 0.000 claims description 8
- 101000574060 Homo sapiens Progesterone receptor Proteins 0.000 claims description 7
- 229960003248 mifepristone Drugs 0.000 claims description 7
- 101710199711 Early E1A protein Proteins 0.000 claims description 6
- 230000000708 anti-progestin effect Effects 0.000 claims description 5
- 239000003418 antiprogestin Substances 0.000 claims description 5
- 108091026890 Coding region Proteins 0.000 claims description 4
- 238000012258 culturing Methods 0.000 claims description 4
- 241001446247 uncultured actinomycete Species 0.000 claims description 2
- 102000005747 Transcription Factor RelA Human genes 0.000 claims 3
- 108010031154 Transcription Factor RelA Proteins 0.000 claims 3
- 210000000234 capsid Anatomy 0.000 abstract description 7
- 238000005538 encapsulation Methods 0.000 abstract description 3
- 230000007774 longterm Effects 0.000 abstract 1
- 210000004027 cell Anatomy 0.000 description 228
- 239000013612 plasmid Substances 0.000 description 87
- 108020004414 DNA Proteins 0.000 description 54
- 238000006243 chemical reaction Methods 0.000 description 30
- 230000003321 amplification Effects 0.000 description 27
- 230000001939 inductive effect Effects 0.000 description 27
- 238000003199 nucleic acid amplification method Methods 0.000 description 27
- 235000018102 proteins Nutrition 0.000 description 24
- 108091023040 Transcription factor Proteins 0.000 description 23
- 239000012634 fragment Substances 0.000 description 22
- 102000040945 Transcription factor Human genes 0.000 description 19
- 230000006798 recombination Effects 0.000 description 19
- 238000005215 recombination Methods 0.000 description 19
- 230000008569 process Effects 0.000 description 17
- 230000008488 polyadenylation Effects 0.000 description 16
- 238000010276 construction Methods 0.000 description 15
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 15
- 210000003527 eukaryotic cell Anatomy 0.000 description 15
- 239000002953 phosphate buffered saline Substances 0.000 description 15
- 238000011534 incubation Methods 0.000 description 14
- 102000018120 Recombinases Human genes 0.000 description 13
- 108010091086 Recombinases Proteins 0.000 description 13
- 230000001404 mediated effect Effects 0.000 description 13
- 239000002609 medium Substances 0.000 description 13
- 239000000047 product Substances 0.000 description 13
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 13
- 241000829100 Macaca mulatta polyomavirus 1 Species 0.000 description 12
- 239000000872 buffer Substances 0.000 description 12
- 108091006106 transcriptional activators Proteins 0.000 description 12
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 11
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 11
- 238000010367 cloning Methods 0.000 description 11
- 239000000284 extract Substances 0.000 description 11
- 239000000243 solution Substances 0.000 description 11
- 102000004190 Enzymes Human genes 0.000 description 10
- 108090000790 Enzymes Proteins 0.000 description 10
- 101000607560 Homo sapiens Ubiquitin-conjugating enzyme E2 variant 3 Proteins 0.000 description 10
- 102100039936 Ubiquitin-conjugating enzyme E2 variant 3 Human genes 0.000 description 10
- 230000029087 digestion Effects 0.000 description 10
- 229940088598 enzyme Drugs 0.000 description 10
- 238000009396 hybridization Methods 0.000 description 10
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 9
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 9
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 9
- 108010067390 Viral Proteins Proteins 0.000 description 9
- 238000004925 denaturation Methods 0.000 description 9
- 230000036425 denaturation Effects 0.000 description 9
- 238000001962 electrophoresis Methods 0.000 description 9
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 9
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 8
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 8
- 101100121050 Caenorhabditis elegans gad-1 gene Proteins 0.000 description 8
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 8
- 108020004440 Thymidine kinase Proteins 0.000 description 8
- 229960000723 ampicillin Drugs 0.000 description 8
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 8
- 230000003115 biocidal effect Effects 0.000 description 8
- 230000015572 biosynthetic process Effects 0.000 description 8
- 239000003795 chemical substances by application Substances 0.000 description 8
- 210000004962 mammalian cell Anatomy 0.000 description 8
- 210000004940 nucleus Anatomy 0.000 description 8
- 241000588724 Escherichia coli Species 0.000 description 7
- 102100022898 Galactoside-binding soluble lectin 13 Human genes 0.000 description 7
- 101001011003 Gallus gallus Gallinacin-13 Proteins 0.000 description 7
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 7
- 101000620927 Homo sapiens Galactoside-binding soluble lectin 13 Proteins 0.000 description 7
- 238000003556 assay Methods 0.000 description 7
- 229910002091 carbon monoxide Inorganic materials 0.000 description 7
- 239000003153 chemical reaction reagent Substances 0.000 description 7
- 238000011109 contamination Methods 0.000 description 7
- 230000001419 dependent effect Effects 0.000 description 7
- 238000001514 detection method Methods 0.000 description 7
- 239000000499 gel Substances 0.000 description 7
- 239000001963 growth medium Substances 0.000 description 7
- 238000003780 insertion Methods 0.000 description 7
- 230000037431 insertion Effects 0.000 description 7
- 239000000203 mixture Substances 0.000 description 7
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 6
- 239000006391 Luria-Bertani Medium Substances 0.000 description 6
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 6
- 229930193140 Neomycin Natural products 0.000 description 6
- 239000004365 Protease Substances 0.000 description 6
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 6
- 108010084455 Zeocin Proteins 0.000 description 6
- -1 Zif268 Proteins 0.000 description 6
- 239000011543 agarose gel Substances 0.000 description 6
- 238000004458 analytical method Methods 0.000 description 6
- 230000012010 growth Effects 0.000 description 6
- 210000005260 human cell Anatomy 0.000 description 6
- 239000003446 ligand Substances 0.000 description 6
- 229960004927 neomycin Drugs 0.000 description 6
- 238000007857 nested PCR Methods 0.000 description 6
- CWCMIVBLVUHDHK-ZSNHEYEWSA-N phleomycin D1 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC[C@@H](N=1)C=1SC=C(N=1)C(=O)NCCCCNC(N)=N)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C CWCMIVBLVUHDHK-ZSNHEYEWSA-N 0.000 description 6
- 239000013641 positive control Substances 0.000 description 6
- 238000000746 purification Methods 0.000 description 6
- 108091005804 Peptidases Proteins 0.000 description 5
- 102000035195 Peptidases Human genes 0.000 description 5
- 108700026226 TATA Box Proteins 0.000 description 5
- 108010006785 Taq Polymerase Proteins 0.000 description 5
- 102000006601 Thymidine Kinase Human genes 0.000 description 5
- 239000007983 Tris buffer Substances 0.000 description 5
- 230000001580 bacterial effect Effects 0.000 description 5
- 230000008859 change Effects 0.000 description 5
- 239000008367 deionised water Substances 0.000 description 5
- 229910021641 deionized water Inorganic materials 0.000 description 5
- 238000012217 deletion Methods 0.000 description 5
- 230000037430 deletion Effects 0.000 description 5
- 238000004520 electroporation Methods 0.000 description 5
- 230000004927 fusion Effects 0.000 description 5
- 108020001507 fusion proteins Proteins 0.000 description 5
- 102000037865 fusion proteins Human genes 0.000 description 5
- 229940088597 hormone Drugs 0.000 description 5
- 239000005556 hormone Substances 0.000 description 5
- 230000000977 initiatory effect Effects 0.000 description 5
- 229920000136 polysorbate Polymers 0.000 description 5
- 235000019419 proteases Nutrition 0.000 description 5
- 238000003786 synthesis reaction Methods 0.000 description 5
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 5
- 210000002845 virion Anatomy 0.000 description 5
- 241000894006 Bacteria Species 0.000 description 4
- 241000282412 Homo Species 0.000 description 4
- 101000979342 Homo sapiens Nuclear factor NF-kappa-B p105 subunit Proteins 0.000 description 4
- 206010028980 Neoplasm Diseases 0.000 description 4
- 108020005497 Nuclear hormone receptor Proteins 0.000 description 4
- 108091028043 Nucleic acid sequence Proteins 0.000 description 4
- 108700008625 Reporter Genes Proteins 0.000 description 4
- 229960000583 acetic acid Drugs 0.000 description 4
- AIYUHDOJVYHVIT-UHFFFAOYSA-M caesium chloride Chemical compound [Cl-].[Cs+] AIYUHDOJVYHVIT-UHFFFAOYSA-M 0.000 description 4
- 201000011510 cancer Diseases 0.000 description 4
- 238000004587 chromatography analysis Methods 0.000 description 4
- 210000000349 chromosome Anatomy 0.000 description 4
- 230000002950 deficient Effects 0.000 description 4
- ZMMJGEGLRURXTF-UHFFFAOYSA-N ethidium bromide Chemical compound [Br-].C12=CC(N)=CC=C2C2=CC=C(N)C=C2[N+](CC)=C1C1=CC=CC=C1 ZMMJGEGLRURXTF-UHFFFAOYSA-N 0.000 description 4
- 229960005542 ethidium bromide Drugs 0.000 description 4
- 239000012894 fetal calf serum Substances 0.000 description 4
- 238000001415 gene therapy Methods 0.000 description 4
- 239000012362 glacial acetic acid Substances 0.000 description 4
- 102000047410 human NFKB1 Human genes 0.000 description 4
- 239000013642 negative control Substances 0.000 description 4
- 102000006255 nuclear receptors Human genes 0.000 description 4
- 108020004017 nuclear receptors Proteins 0.000 description 4
- 239000011535 reaction buffer Substances 0.000 description 4
- 238000010186 staining Methods 0.000 description 4
- 238000012546 transfer Methods 0.000 description 4
- 230000014616 translation Effects 0.000 description 4
- 238000011144 upstream manufacturing Methods 0.000 description 4
- VOXZDWNPVJITMN-ZBRFXRBCSA-N 17β-estradiol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 VOXZDWNPVJITMN-ZBRFXRBCSA-N 0.000 description 3
- CSCPPACGZOOCGX-UHFFFAOYSA-N Acetone Chemical compound CC(C)=O CSCPPACGZOOCGX-UHFFFAOYSA-N 0.000 description 3
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 3
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 3
- 102100026189 Beta-galactosidase Human genes 0.000 description 3
- 241000283707 Capra Species 0.000 description 3
- 239000000055 Corticotropin-Releasing Hormone Substances 0.000 description 3
- 108010051219 Cre recombinase Proteins 0.000 description 3
- 102000016911 Deoxyribonucleases Human genes 0.000 description 3
- 108010053770 Deoxyribonucleases Proteins 0.000 description 3
- 108010046276 FLP recombinase Proteins 0.000 description 3
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 description 3
- 102000004269 Granulocyte Colony-Stimulating Factor Human genes 0.000 description 3
- 108010051696 Growth Hormone Proteins 0.000 description 3
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 3
- 108060003951 Immunoglobulin Proteins 0.000 description 3
- 108090000723 Insulin-Like Growth Factor I Proteins 0.000 description 3
- 102000012330 Integrases Human genes 0.000 description 3
- 108010057464 Prolactin Proteins 0.000 description 3
- 102000003946 Prolactin Human genes 0.000 description 3
- 102100038803 Somatotropin Human genes 0.000 description 3
- 102000011923 Thyrotropin Human genes 0.000 description 3
- 108010061174 Thyrotropin Proteins 0.000 description 3
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 3
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 3
- 108090000631 Trypsin Proteins 0.000 description 3
- 102000004142 Trypsin Human genes 0.000 description 3
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 3
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 3
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 3
- 239000003242 anti bacterial agent Substances 0.000 description 3
- 230000003263 anti-adenoviral effect Effects 0.000 description 3
- KBZOIRJILGZLEJ-LGYYRGKSSA-N argipressin Chemical compound C([C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CSSC[C@@H](C(N[C@@H](CC=2C=CC(O)=CC=2)C(=O)N1)=O)N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(N)=O)C1=CC=CC=C1 KBZOIRJILGZLEJ-LGYYRGKSSA-N 0.000 description 3
- 108010005774 beta-Galactosidase Proteins 0.000 description 3
- UDSAIICHUKSCKT-UHFFFAOYSA-N bromophenol blue Chemical compound C1=C(Br)C(O)=C(Br)C=C1C1(C=2C=C(Br)C(O)=C(Br)C=2)C2=CC=CC=C2S(=O)(=O)O1 UDSAIICHUKSCKT-UHFFFAOYSA-N 0.000 description 3
- 238000004113 cell culture Methods 0.000 description 3
- 239000002299 complementary DNA Substances 0.000 description 3
- 230000001276 controlling effect Effects 0.000 description 3
- 231100000433 cytotoxic Toxicity 0.000 description 3
- 230000001472 cytotoxic effect Effects 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 239000012153 distilled water Substances 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 239000012091 fetal bovine serum Substances 0.000 description 3
- 239000012737 fresh medium Substances 0.000 description 3
- 102000018358 immunoglobulin Human genes 0.000 description 3
- 230000006698 induction Effects 0.000 description 3
- 238000011068 loading method Methods 0.000 description 3
- 239000011159 matrix material Substances 0.000 description 3
- 239000012528 membrane Substances 0.000 description 3
- 235000013336 milk Nutrition 0.000 description 3
- 239000008267 milk Substances 0.000 description 3
- 210000004080 milk Anatomy 0.000 description 3
- 238000012858 packaging process Methods 0.000 description 3
- 108090000765 processed proteins & peptides Proteins 0.000 description 3
- 229940097325 prolactin Drugs 0.000 description 3
- 238000001243 protein synthesis Methods 0.000 description 3
- 102000005962 receptors Human genes 0.000 description 3
- 108020003175 receptors Proteins 0.000 description 3
- 238000010839 reverse transcription Methods 0.000 description 3
- 239000006152 selective media Substances 0.000 description 3
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 3
- 239000011780 sodium chloride Substances 0.000 description 3
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 description 3
- 108091008023 transcriptional regulators Proteins 0.000 description 3
- 239000012588 trypsin Substances 0.000 description 3
- 239000013603 viral vector Substances 0.000 description 3
- 238000005406 washing Methods 0.000 description 3
- 238000001262 western blot Methods 0.000 description 3
- 229910052725 zinc Inorganic materials 0.000 description 3
- 239000011701 zinc Substances 0.000 description 3
- 101710169336 5'-deoxyadenosine deaminase Proteins 0.000 description 2
- OPIFSICVWOWJMJ-AEOCFKNESA-N 5-bromo-4-chloro-3-indolyl beta-D-galactoside Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1OC1=CNC2=CC=C(Br)C(Cl)=C12 OPIFSICVWOWJMJ-AEOCFKNESA-N 0.000 description 2
- LRFVTYWOQMYALW-UHFFFAOYSA-N 9H-xanthine Chemical compound O=C1NC(=O)NC2=C1NC=N2 LRFVTYWOQMYALW-UHFFFAOYSA-N 0.000 description 2
- 241000186361 Actinobacteria <class> Species 0.000 description 2
- 208000010370 Adenoviridae Infections Diseases 0.000 description 2
- 206010060931 Adenovirus infection Diseases 0.000 description 2
- 102100038778 Amphiregulin Human genes 0.000 description 2
- 108010033760 Amphiregulin Proteins 0.000 description 2
- 101800001288 Atrial natriuretic factor Proteins 0.000 description 2
- 102400001282 Atrial natriuretic peptide Human genes 0.000 description 2
- 101800001890 Atrial natriuretic peptide Proteins 0.000 description 2
- 102000007350 Bone Morphogenetic Proteins Human genes 0.000 description 2
- 108010007726 Bone Morphogenetic Proteins Proteins 0.000 description 2
- 102100028892 Cardiotrophin-1 Human genes 0.000 description 2
- 102000019034 Chemokines Human genes 0.000 description 2
- 108010012236 Chemokines Proteins 0.000 description 2
- 102100025841 Cholecystokinin Human genes 0.000 description 2
- 101800001982 Cholecystokinin Proteins 0.000 description 2
- 108010062540 Chorionic Gonadotropin Proteins 0.000 description 2
- 102000011022 Chorionic Gonadotropin Human genes 0.000 description 2
- 102400000739 Corticotropin Human genes 0.000 description 2
- 101800000414 Corticotropin Proteins 0.000 description 2
- 102000012289 Corticotropin-Releasing Hormone Human genes 0.000 description 2
- 108010022152 Corticotropin-Releasing Hormone Proteins 0.000 description 2
- 102000012410 DNA Ligases Human genes 0.000 description 2
- 108010061982 DNA Ligases Proteins 0.000 description 2
- 108010017826 DNA Polymerase I Proteins 0.000 description 2
- 102000004594 DNA Polymerase I Human genes 0.000 description 2
- 229920002307 Dextran Polymers 0.000 description 2
- 101150059079 EBNA1 gene Proteins 0.000 description 2
- 102000003951 Erythropoietin Human genes 0.000 description 2
- 108090000394 Erythropoietin Proteins 0.000 description 2
- 241000620209 Escherichia coli DH5[alpha] Species 0.000 description 2
- 241000701959 Escherichia virus Lambda Species 0.000 description 2
- 108091029865 Exogenous DNA Proteins 0.000 description 2
- 108090000385 Fibroblast growth factor 7 Proteins 0.000 description 2
- 102000012673 Follicle Stimulating Hormone Human genes 0.000 description 2
- 108010079345 Follicle Stimulating Hormone Proteins 0.000 description 2
- 102000034615 Glial cell line-derived neurotrophic factor Human genes 0.000 description 2
- 108091010837 Glial cell line-derived neurotrophic factor Proteins 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 239000000579 Gonadotropin-Releasing Hormone Substances 0.000 description 2
- 239000000095 Growth Hormone-Releasing Hormone Substances 0.000 description 2
- WZUVPPKBWHMQCE-UHFFFAOYSA-N Haematoxylin Chemical compound C12=CC(O)=C(O)C=C2CC2(O)C1C1=CC=C(O)C(O)=C1OC2 WZUVPPKBWHMQCE-UHFFFAOYSA-N 0.000 description 2
- 229920000209 Hexadimethrine bromide Polymers 0.000 description 2
- 241000598171 Human adenovirus sp. Species 0.000 description 2
- SIKJAQJRHWYJAI-UHFFFAOYSA-N Indole Chemical compound C1=CC=C2NC=CC2=C1 SIKJAQJRHWYJAI-UHFFFAOYSA-N 0.000 description 2
- 102000014429 Insulin-like growth factor Human genes 0.000 description 2
- 102000000589 Interleukin-1 Human genes 0.000 description 2
- 108010002352 Interleukin-1 Proteins 0.000 description 2
- 102000013462 Interleukin-12 Human genes 0.000 description 2
- 108010065805 Interleukin-12 Proteins 0.000 description 2
- 102000003812 Interleukin-15 Human genes 0.000 description 2
- 108090000172 Interleukin-15 Proteins 0.000 description 2
- 102400000531 Interleukin-16 Human genes 0.000 description 2
- 101800003050 Interleukin-16 Proteins 0.000 description 2
- 102000000588 Interleukin-2 Human genes 0.000 description 2
- 108010002350 Interleukin-2 Proteins 0.000 description 2
- 102000004889 Interleukin-6 Human genes 0.000 description 2
- 108090001005 Interleukin-6 Proteins 0.000 description 2
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 2
- 241000713666 Lentivirus Species 0.000 description 2
- 102000016267 Leptin Human genes 0.000 description 2
- 108010092277 Leptin Proteins 0.000 description 2
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 2
- 102000009151 Luteinizing Hormone Human genes 0.000 description 2
- 108010073521 Luteinizing Hormone Proteins 0.000 description 2
- 102100033342 Lysosomal acid glucosylceramidase Human genes 0.000 description 2
- YJPIGAIKUZMOQA-UHFFFAOYSA-N Melatonin Natural products COC1=CC=C2N(C(C)=O)C=C(CCN)C2=C1 YJPIGAIKUZMOQA-UHFFFAOYSA-N 0.000 description 2
- KWYHDKDOAIKMQN-UHFFFAOYSA-N N,N,N',N'-tetramethylethylenediamine Chemical compound CN(C)CCN(C)C KWYHDKDOAIKMQN-UHFFFAOYSA-N 0.000 description 2
- 102000004140 Oncostatin M Human genes 0.000 description 2
- 108090000630 Oncostatin M Proteins 0.000 description 2
- 101710084414 POU domain, class 2, transcription factor 1 Proteins 0.000 description 2
- 102100035593 POU domain, class 2, transcription factor 1 Human genes 0.000 description 2
- 102000003728 Peroxisome Proliferator-Activated Receptors Human genes 0.000 description 2
- 108090000029 Peroxisome Proliferator-Activated Receptors Proteins 0.000 description 2
- 108091000080 Phosphotransferase Proteins 0.000 description 2
- 108010038512 Platelet-Derived Growth Factor Proteins 0.000 description 2
- 102000010780 Platelet-Derived Growth Factor Human genes 0.000 description 2
- 101150096292 Ppme1 gene Proteins 0.000 description 2
- 241000288906 Primates Species 0.000 description 2
- LCTONWCANYUPML-UHFFFAOYSA-M Pyruvate Chemical compound CC(=O)C([O-])=O LCTONWCANYUPML-UHFFFAOYSA-M 0.000 description 2
- 108091027981 Response element Proteins 0.000 description 2
- 206010038997 Retroviral infections Diseases 0.000 description 2
- 241000700584 Simplexvirus Species 0.000 description 2
- 102100022831 Somatoliberin Human genes 0.000 description 2
- 101710142969 Somatoliberin Proteins 0.000 description 2
- 102000005157 Somatostatin Human genes 0.000 description 2
- 108010056088 Somatostatin Proteins 0.000 description 2
- 101000857870 Squalus acanthias Gonadoliberin Proteins 0.000 description 2
- 239000004098 Tetracycline Substances 0.000 description 2
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 description 2
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 description 2
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 2
- 108010004977 Vasopressins Proteins 0.000 description 2
- 102000002852 Vasopressins Human genes 0.000 description 2
- 108020005202 Viral DNA Proteins 0.000 description 2
- 108700005077 Viral Genes Proteins 0.000 description 2
- MZVQCMJNVPIDEA-UHFFFAOYSA-N [CH2]CN(CC)CC Chemical group [CH2]CN(CC)CC MZVQCMJNVPIDEA-UHFFFAOYSA-N 0.000 description 2
- 230000003213 activating effect Effects 0.000 description 2
- 208000011589 adenoviridae infectious disease Diseases 0.000 description 2
- WPYMKLBDIGXBTP-UHFFFAOYSA-N benzoic acid Chemical compound OC(=O)C1=CC=CC=C1 WPYMKLBDIGXBTP-UHFFFAOYSA-N 0.000 description 2
- 230000033228 biological regulation Effects 0.000 description 2
- 229940112869 bone morphogenetic protein Drugs 0.000 description 2
- 239000001506 calcium phosphate Substances 0.000 description 2
- 229910000389 calcium phosphate Inorganic materials 0.000 description 2
- 235000011010 calcium phosphates Nutrition 0.000 description 2
- 108010041776 cardiotrophin 1 Proteins 0.000 description 2
- NSQLIUXCMFBZME-MPVJKSABSA-N carperitide Chemical compound C([C@H]1C(=O)NCC(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@H](C(NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CSSC[C@@H](C(=O)N1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)=O)[C@@H](C)CC)C1=CC=CC=C1 NSQLIUXCMFBZME-MPVJKSABSA-N 0.000 description 2
- 239000006143 cell culture medium Substances 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- 210000002230 centromere Anatomy 0.000 description 2
- 229940107137 cholecystokinin Drugs 0.000 description 2
- 238000000975 co-precipitation Methods 0.000 description 2
- 238000012761 co-transfection Methods 0.000 description 2
- IDLFZVILOHSSID-OVLDLUHVSA-N corticotropin Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)NC(=O)[C@@H](N)CO)C1=CC=C(O)C=C1 IDLFZVILOHSSID-OVLDLUHVSA-N 0.000 description 2
- 229960000258 corticotropin Drugs 0.000 description 2
- 229940041967 corticotropin-releasing hormone Drugs 0.000 description 2
- KLVRDXBAMSPYKH-RKYZNNDCSA-N corticotropin-releasing hormone (human) Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(N)=O)[C@@H](C)CC)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](C)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H]1N(CCC1)C(=O)[C@H]1N(CCC1)C(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CO)[C@@H](C)CC)C(C)C)C(C)C)C1=CNC=N1 KLVRDXBAMSPYKH-RKYZNNDCSA-N 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- 238000006471 dimerization reaction Methods 0.000 description 2
- VLCYCQAOQCDTCN-UHFFFAOYSA-N eflornithine Chemical compound NCCCC(N)(C(F)F)C(O)=O VLCYCQAOQCDTCN-UHFFFAOYSA-N 0.000 description 2
- 230000008030 elimination Effects 0.000 description 2
- 238000003379 elimination reaction Methods 0.000 description 2
- 229940105423 erythropoietin Drugs 0.000 description 2
- 229960005309 estradiol Drugs 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 229940028334 follicle stimulating hormone Drugs 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- XLXSAKCOAKORKW-AQJXLSMYSA-N gonadorelin Chemical compound C([C@@H](C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)NCC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 XLXSAKCOAKORKW-AQJXLSMYSA-N 0.000 description 2
- 229940035638 gonadotropin-releasing hormone Drugs 0.000 description 2
- 239000000122 growth hormone Substances 0.000 description 2
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 229940084986 human chorionic gonadotropin Drugs 0.000 description 2
- 230000002055 immunohistochemical effect Effects 0.000 description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 2
- 229940117681 interleukin-12 Drugs 0.000 description 2
- 102000003898 interleukin-24 Human genes 0.000 description 2
- 108090000237 interleukin-24 Proteins 0.000 description 2
- 229940100601 interleukin-6 Drugs 0.000 description 2
- 238000004255 ion exchange chromatography Methods 0.000 description 2
- 101150066555 lacZ gene Proteins 0.000 description 2
- 238000011031 large-scale manufacturing process Methods 0.000 description 2
- 229940039781 leptin Drugs 0.000 description 2
- NRYBAZVQPHGZNS-ZSOCWYAHSA-N leptin Chemical compound O=C([C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC(C)C)CCSC)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CS)C(O)=O NRYBAZVQPHGZNS-ZSOCWYAHSA-N 0.000 description 2
- 239000002502 liposome Substances 0.000 description 2
- 201000005296 lung carcinoma Diseases 0.000 description 2
- 229940040129 luteinizing hormone Drugs 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 229960003987 melatonin Drugs 0.000 description 2
- DRLFMBDRBRZALE-UHFFFAOYSA-N melatonin Chemical compound COC1=CC=C2NC=C(CCNC(C)=O)C2=C1 DRLFMBDRBRZALE-UHFFFAOYSA-N 0.000 description 2
- 238000000520 microinjection Methods 0.000 description 2
- 102000039446 nucleic acids Human genes 0.000 description 2
- 108020004707 nucleic acids Proteins 0.000 description 2
- 150000007523 nucleic acids Chemical class 0.000 description 2
- 102000020233 phosphotransferase Human genes 0.000 description 2
- 229920002401 polyacrylamide Polymers 0.000 description 2
- 229920001184 polypeptide Polymers 0.000 description 2
- OXCMYAYHXIHQOA-UHFFFAOYSA-N potassium;[2-butyl-5-chloro-3-[[4-[2-(1,2,4-triaza-3-azanidacyclopenta-1,4-dien-5-yl)phenyl]phenyl]methyl]imidazol-4-yl]methanol Chemical compound [K+].CCCCC1=NC(Cl)=C(CO)N1CC1=CC=C(C=2C(=CC=CC=2)C2=N[N-]N=N2)C=C1 OXCMYAYHXIHQOA-UHFFFAOYSA-N 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 102000004196 processed proteins & peptides Human genes 0.000 description 2
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 2
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 2
- 238000013207 serial dilution Methods 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- IZTQOLKUZKXIRV-YRVFCXMDSA-N sincalide Chemical compound C([C@@H](C(=O)N[C@@H](CCSC)C(=O)NCC(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(N)=O)NC(=O)[C@@H](N)CC(O)=O)C1=CC=C(OS(O)(=O)=O)C=C1 IZTQOLKUZKXIRV-YRVFCXMDSA-N 0.000 description 2
- 229960002930 sirolimus Drugs 0.000 description 2
- NHXLMOGPVYXJNR-ATOGVRKGSA-N somatostatin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CO)C(=O)N[C@@H](CSSC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(=O)N1)[C@@H](C)O)NC(=O)CNC(=O)[C@H](C)N)C(O)=O)=O)[C@H](O)C)C1=CC=CC=C1 NHXLMOGPVYXJNR-ATOGVRKGSA-N 0.000 description 2
- 229960000553 somatostatin Drugs 0.000 description 2
- 230000010473 stable expression Effects 0.000 description 2
- 239000003270 steroid hormone Substances 0.000 description 2
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 2
- 239000006228 supernatant Substances 0.000 description 2
- 239000013589 supplement Substances 0.000 description 2
- 229960002180 tetracycline Drugs 0.000 description 2
- 229930101283 tetracycline Natural products 0.000 description 2
- 235000019364 tetracycline Nutrition 0.000 description 2
- 150000003522 tetracyclines Chemical class 0.000 description 2
- 239000005495 thyroid hormone Substances 0.000 description 2
- 229960000874 thyrotropin Drugs 0.000 description 2
- 230000001748 thyrotropin Effects 0.000 description 2
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 2
- 241001430294 unidentified retrovirus Species 0.000 description 2
- 229960003726 vasopressin Drugs 0.000 description 2
- 230000035899 viability Effects 0.000 description 2
- 230000029812 viral genome replication Effects 0.000 description 2
- IOWMKBFJCNLRTC-XWXSNNQWSA-N (24S)-24-hydroxycholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CC[C@H](O)C(C)C)[C@@]1(C)CC2 IOWMKBFJCNLRTC-XWXSNNQWSA-N 0.000 description 1
- DIGQNXIGRZPYDK-WKSCXVIASA-N (2R)-6-amino-2-[[2-[[(2S)-2-[[2-[[(2R)-2-[[(2S)-2-[[(2R,3S)-2-[[2-[[(2S)-2-[[2-[[(2S)-2-[[(2S)-2-[[(2R)-2-[[(2S,3S)-2-[[(2R)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[2-[[(2S)-2-[[(2R)-2-[[2-[[2-[[2-[(2-amino-1-hydroxyethylidene)amino]-3-carboxy-1-hydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1,5-dihydroxy-5-iminopentylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]hexanoic acid Chemical compound C[C@@H]([C@@H](C(=N[C@@H](CS)C(=N[C@@H](C)C(=N[C@@H](CO)C(=NCC(=N[C@@H](CCC(=N)O)C(=NC(CS)C(=N[C@H]([C@H](C)O)C(=N[C@H](CS)C(=N[C@H](CO)C(=NCC(=N[C@H](CS)C(=NCC(=N[C@H](CCCCN)C(=O)O)O)O)O)O)O)O)O)O)O)O)O)O)O)N=C([C@H](CS)N=C([C@H](CO)N=C([C@H](CO)N=C([C@H](C)N=C(CN=C([C@H](CO)N=C([C@H](CS)N=C(CN=C(C(CS)N=C(C(CC(=O)O)N=C(CN)O)O)O)O)O)O)O)O)O)O)O)O DIGQNXIGRZPYDK-WKSCXVIASA-N 0.000 description 1
- BRZYSWJRSDMWLG-DJWUNRQOSA-N (2r,3r,4r,5r)-2-[(1s,2s,3r,4s,6r)-4,6-diamino-3-[(2s,3r,4r,5s,6r)-3-amino-4,5-dihydroxy-6-[(1r)-1-hydroxyethyl]oxan-2-yl]oxy-2-hydroxycyclohexyl]oxy-5-methyl-4-(methylamino)oxane-3,5-diol Chemical compound O1C[C@@](O)(C)[C@H](NC)[C@@H](O)[C@H]1O[C@@H]1[C@@H](O)[C@H](O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H]([C@@H](C)O)O2)N)[C@@H](N)C[C@H]1N BRZYSWJRSDMWLG-DJWUNRQOSA-N 0.000 description 1
- CUKWUWBLQQDQAC-VEQWQPCFSA-N (3s)-3-amino-4-[[(2s)-1-[[(2s)-1-[[(2s)-1-[[(2s,3s)-1-[[(2s)-1-[(2s)-2-[[(1s)-1-carboxyethyl]carbamoyl]pyrrolidin-1-yl]-3-(1h-imidazol-5-yl)-1-oxopropan-2-yl]amino]-3-methyl-1-oxopentan-2-yl]amino]-3-(4-hydroxyphenyl)-1-oxopropan-2-yl]amino]-3-methyl-1-ox Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(O)=O)C(C)C)C1=CC=C(O)C=C1 CUKWUWBLQQDQAC-VEQWQPCFSA-N 0.000 description 1
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 1
- SGKRLCUYIXIAHR-AKNGSSGZSA-N (4s,4ar,5s,5ar,6r,12ar)-4-(dimethylamino)-1,5,10,11,12a-pentahydroxy-6-methyl-3,12-dioxo-4a,5,5a,6-tetrahydro-4h-tetracene-2-carboxamide Chemical compound C1=CC=C2[C@H](C)[C@@H]([C@H](O)[C@@H]3[C@](C(O)=C(C(N)=O)C(=O)[C@H]3N(C)C)(O)C3=O)C3=C(O)C2=C1O SGKRLCUYIXIAHR-AKNGSSGZSA-N 0.000 description 1
- ULAADVBNYHGIBP-GFEQUFNTSA-N (8r,9s,13s,14s,17s)-3-methoxy-13-methyl-6,7,8,9,11,12,14,15,16,17-decahydrocyclopenta[a]phenanthren-17-ol Chemical compound C1C[C@]2(C)[C@@H](O)CC[C@H]2[C@@H]2CCC3=CC(OC)=CC=C3[C@H]21 ULAADVBNYHGIBP-GFEQUFNTSA-N 0.000 description 1
- 102100025573 1-alkyl-2-acetylglycerophosphocholine esterase Human genes 0.000 description 1
- LQGNCUXDDPRDJH-UHFFFAOYSA-N 3'-GMP Natural products C1C(O)C(O)CC2(C)C(C(O)CC3(C(C(C)(O)C(O)CCC(C)C)CCC33O)C)C3=CC(=O)C21 LQGNCUXDDPRDJH-UHFFFAOYSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical group C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- ALVRMEAFUDMCLE-UHFFFAOYSA-N 4-aminobutyl benzoate Chemical compound NCCCCOC(=O)C1=CC=CC=C1 ALVRMEAFUDMCLE-UHFFFAOYSA-N 0.000 description 1
- TVZGACDUOSZQKY-LBPRGKRZSA-N 4-aminofolic acid Chemical compound C1=NC2=NC(N)=NC(N)=C2N=C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 TVZGACDUOSZQKY-LBPRGKRZSA-N 0.000 description 1
- JWMFYGXQPXQEEM-NUNROCCHSA-N 5β-pregnane Chemical compound C([C@H]1CC2)CCC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H](CC)[C@@]2(C)CC1 JWMFYGXQPXQEEM-NUNROCCHSA-N 0.000 description 1
- SHGAZHPCJJPHSC-ZVCIMWCZSA-N 9-cis-retinoic acid Chemical class OC(=O)/C=C(\C)/C=C/C=C(/C)\C=C\C1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-ZVCIMWCZSA-N 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 102000055025 Adenosine deaminases Human genes 0.000 description 1
- 206010001258 Adenoviral infections Diseases 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- 102100027211 Albumin Human genes 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 241000710929 Alphavirus Species 0.000 description 1
- 239000004382 Amylase Substances 0.000 description 1
- 102000013142 Amylases Human genes 0.000 description 1
- 108010065511 Amylases Proteins 0.000 description 1
- 102400000344 Angiotensin-1 Human genes 0.000 description 1
- 101800000734 Angiotensin-1 Proteins 0.000 description 1
- 102400000345 Angiotensin-2 Human genes 0.000 description 1
- 101800000733 Angiotensin-2 Proteins 0.000 description 1
- 108700031308 Antennapedia Homeodomain Proteins 0.000 description 1
- 101100107610 Arabidopsis thaliana ABCF4 gene Proteins 0.000 description 1
- 108010024976 Asparaginase Proteins 0.000 description 1
- 108020000946 Bacterial DNA Proteins 0.000 description 1
- 239000005711 Benzoic acid Substances 0.000 description 1
- 108010087504 Beta-Globulins Proteins 0.000 description 1
- 102100038495 Bile acid receptor Human genes 0.000 description 1
- 238000009010 Bradford assay Methods 0.000 description 1
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 1
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 description 1
- 108010084313 CD58 Antigens Proteins 0.000 description 1
- 101100539485 Caenorhabditis elegans unc-86 gene Proteins 0.000 description 1
- 108060001064 Calcitonin Proteins 0.000 description 1
- 102400000113 Calcitonin Human genes 0.000 description 1
- 108090000565 Capsid Proteins Proteins 0.000 description 1
- 241000486661 Ceramica Species 0.000 description 1
- 102100023321 Ceruloplasmin Human genes 0.000 description 1
- 102000001326 Chemokine CCL4 Human genes 0.000 description 1
- 108010055165 Chemokine CCL4 Proteins 0.000 description 1
- 102100040428 Chitobiosyldiphosphodolichol beta-mannosyltransferase Human genes 0.000 description 1
- 101100124635 Chondrus crispus HOX gene Proteins 0.000 description 1
- 108090000317 Chymotrypsin Proteins 0.000 description 1
- 241000581364 Clinitrachus argentatus Species 0.000 description 1
- 102100022641 Coagulation factor IX Human genes 0.000 description 1
- 102100023804 Coagulation factor VII Human genes 0.000 description 1
- 102000029816 Collagenase Human genes 0.000 description 1
- 108060005980 Collagenase Proteins 0.000 description 1
- 108010029704 Constitutive Androstane Receptor Proteins 0.000 description 1
- PMATZTZNYRCHOR-CGLBZJNRSA-N Cyclosporin A Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O PMATZTZNYRCHOR-CGLBZJNRSA-N 0.000 description 1
- 108010036949 Cyclosporine Proteins 0.000 description 1
- 108010080611 Cytosine Deaminase Proteins 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 230000004544 DNA amplification Effects 0.000 description 1
- 231100001074 DNA strand break Toxicity 0.000 description 1
- 241000702421 Dependoparvovirus Species 0.000 description 1
- 101150029662 E1 gene Proteins 0.000 description 1
- UPEZCKBFRMILAV-JNEQICEOSA-N Ecdysone Natural products O=C1[C@H]2[C@@](C)([C@@H]3C([C@@]4(O)[C@@](C)([C@H]([C@H]([C@@H](O)CCC(O)(C)C)C)CC4)CC3)=C1)C[C@H](O)[C@H](O)C2 UPEZCKBFRMILAV-JNEQICEOSA-N 0.000 description 1
- 108010041308 Endothelial Growth Factors Proteins 0.000 description 1
- 102400001368 Epidermal growth factor Human genes 0.000 description 1
- 101800003838 Epidermal growth factor Proteins 0.000 description 1
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 1
- 102100038595 Estrogen receptor Human genes 0.000 description 1
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 1
- 108010076282 Factor IX Proteins 0.000 description 1
- 108010014172 Factor V Proteins 0.000 description 1
- 108010023321 Factor VII Proteins 0.000 description 1
- 108010054218 Factor VIII Proteins 0.000 description 1
- 102000001690 Factor VIII Human genes 0.000 description 1
- 108010014173 Factor X Proteins 0.000 description 1
- 108010074864 Factor XI Proteins 0.000 description 1
- 108010071289 Factor XIII Proteins 0.000 description 1
- 101710145505 Fiber protein Proteins 0.000 description 1
- 108010049003 Fibrinogen Proteins 0.000 description 1
- 102000008946 Fibrinogen Human genes 0.000 description 1
- 102000018233 Fibroblast Growth Factor Human genes 0.000 description 1
- 108050007372 Fibroblast Growth Factor Proteins 0.000 description 1
- 102000003972 Fibroblast growth factor 7 Human genes 0.000 description 1
- 108010011145 Fushi Tarazu Transcription Factors Proteins 0.000 description 1
- 101150101889 GAS4 gene Proteins 0.000 description 1
- 108010093031 Galactosidases Proteins 0.000 description 1
- 102000002464 Galactosidases Human genes 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 102400000921 Gastrin Human genes 0.000 description 1
- 108010052343 Gastrins Proteins 0.000 description 1
- 102400000321 Glucagon Human genes 0.000 description 1
- 108060003199 Glucagon Proteins 0.000 description 1
- 108090000079 Glucocorticoid Receptors Proteins 0.000 description 1
- 102100033417 Glucocorticoid receptor Human genes 0.000 description 1
- 108010017544 Glucosylceramidase Proteins 0.000 description 1
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 1
- 108010068250 Herpes Simplex Virus Protein Vmw65 Proteins 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- 102000007625 Hirudins Human genes 0.000 description 1
- 108010007267 Hirudins Proteins 0.000 description 1
- 108700005087 Homeobox Genes Proteins 0.000 description 1
- 102000009331 Homeodomain Proteins Human genes 0.000 description 1
- 108010048671 Homeodomain Proteins Proteins 0.000 description 1
- 101000603876 Homo sapiens Bile acid receptor Proteins 0.000 description 1
- 101000891557 Homo sapiens Chitobiosyldiphosphodolichol beta-mannosyltransferase Proteins 0.000 description 1
- 101000863721 Homo sapiens Deoxyribonuclease-1 Proteins 0.000 description 1
- 101001067140 Homo sapiens Porphobilinogen deaminase Proteins 0.000 description 1
- 101001050288 Homo sapiens Transcription factor Jun Proteins 0.000 description 1
- 101000785559 Homo sapiens Zinc finger and SCAN domain-containing protein 26 Proteins 0.000 description 1
- 108010003272 Hyaluronate lyase Proteins 0.000 description 1
- 102000001974 Hyaluronidases Human genes 0.000 description 1
- LELOWRISYMNNSU-UHFFFAOYSA-N Hydrocyanic acid Natural products N#C LELOWRISYMNNSU-UHFFFAOYSA-N 0.000 description 1
- 101150032643 IVa2 gene Proteins 0.000 description 1
- 102100029199 Iduronate 2-sulfatase Human genes 0.000 description 1
- 101710096421 Iduronate 2-sulfatase Proteins 0.000 description 1
- 102000004627 Iduronidase Human genes 0.000 description 1
- 108010003381 Iduronidase Proteins 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 102000004218 Insulin-Like Growth Factor I Human genes 0.000 description 1
- 102000048143 Insulin-Like Growth Factor II Human genes 0.000 description 1
- 108090001117 Insulin-Like Growth Factor II Proteins 0.000 description 1
- 102100021244 Integral membrane protein GPR180 Human genes 0.000 description 1
- 102100025390 Integrin beta-2 Human genes 0.000 description 1
- 108010064593 Intercellular Adhesion Molecule-1 Proteins 0.000 description 1
- 102100037877 Intercellular adhesion molecule 1 Human genes 0.000 description 1
- 102000003996 Interferon-beta Human genes 0.000 description 1
- 108090000467 Interferon-beta Proteins 0.000 description 1
- 102000008070 Interferon-gamma Human genes 0.000 description 1
- 108010074328 Interferon-gamma Proteins 0.000 description 1
- 102400001355 Interleukin-8 Human genes 0.000 description 1
- 108090001007 Interleukin-8 Proteins 0.000 description 1
- 101150026829 JUNB gene Proteins 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- 229930182816 L-glutamine Natural products 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- 108010059881 Lactase Proteins 0.000 description 1
- 108010063045 Lactoferrin Proteins 0.000 description 1
- 102100032241 Lactotransferrin Human genes 0.000 description 1
- 101100237293 Leishmania infantum METK gene Proteins 0.000 description 1
- 102000004882 Lipase Human genes 0.000 description 1
- 108090001060 Lipase Proteins 0.000 description 1
- 239000004367 Lipase Substances 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 108010064548 Lymphocyte Function-Associated Antigen-1 Proteins 0.000 description 1
- 101150108651 MAT2 gene Proteins 0.000 description 1
- 102000007651 Macrophage Colony-Stimulating Factor Human genes 0.000 description 1
- 108010046938 Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 101710151321 Melanostatin Proteins 0.000 description 1
- 102000003792 Metallothionein Human genes 0.000 description 1
- 108090000157 Metallothionein Proteins 0.000 description 1
- 102000016943 Muramidase Human genes 0.000 description 1
- 108010014251 Muramidase Proteins 0.000 description 1
- LRJUYAVTHIEHAI-UHFFFAOYSA-N Muristeron A Natural products C1C(O)C(O)CC2(C)C(C(O)CC3(C(C(C)(O)C(O)CCC(C)C)CCC33O)C)C3=CC(=O)C21O LRJUYAVTHIEHAI-UHFFFAOYSA-N 0.000 description 1
- LRJUYAVTHIEHAI-LHBNDURVSA-N Muristerone Chemical compound C1[C@@H](O)[C@@H](O)C[C@]2(C)[C@@H]([C@H](O)C[C@@]3([C@@H]([C@@](C)(O)[C@H](O)CCC(C)C)CC[C@]33O)C)C3=CC(=O)[C@@]21O LRJUYAVTHIEHAI-LHBNDURVSA-N 0.000 description 1
- 108010062010 N-Acetylmuramoyl-L-alanine Amidase Proteins 0.000 description 1
- 102000003945 NF-kappa B Human genes 0.000 description 1
- 108010057466 NF-kappa B Proteins 0.000 description 1
- 102400000064 Neuropeptide Y Human genes 0.000 description 1
- 108091092724 Noncoding DNA Proteins 0.000 description 1
- YJQPYGGHQPGBLI-UHFFFAOYSA-N Novobiocin Natural products O1C(C)(C)C(OC)C(OC(N)=O)C(O)C1OC1=CC=C(C(O)=C(NC(=O)C=2C=C(CC=C(C)C)C(O)=CC=2)C(=O)O2)C2=C1C YJQPYGGHQPGBLI-UHFFFAOYSA-N 0.000 description 1
- 102000019040 Nuclear Antigens Human genes 0.000 description 1
- 108010051791 Nuclear Antigens Proteins 0.000 description 1
- 102100038494 Nuclear receptor subfamily 1 group I member 2 Human genes 0.000 description 1
- 102100038512 Nuclear receptor subfamily 1 group I member 3 Human genes 0.000 description 1
- CTQNGGLPUBDAKN-UHFFFAOYSA-N O-Xylene Chemical compound CC1=CC=CC=C1C CTQNGGLPUBDAKN-UHFFFAOYSA-N 0.000 description 1
- 101150100692 ODC gene Proteins 0.000 description 1
- 101150007210 ORF6 gene Proteins 0.000 description 1
- 108700026244 Open Reading Frames Proteins 0.000 description 1
- 229940122060 Ornithine decarboxylase inhibitor Drugs 0.000 description 1
- 102400000050 Oxytocin Human genes 0.000 description 1
- 101800000989 Oxytocin Proteins 0.000 description 1
- XNOPRXBHLZRZKH-UHFFFAOYSA-N Oxytocin Natural products N1C(=O)C(N)CSSCC(C(=O)N2C(CCC2)C(=O)NC(CC(C)C)C(=O)NCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(CCC(N)=O)NC(=O)C(C(C)CC)NC(=O)C1CC1=CC=C(O)C=C1 XNOPRXBHLZRZKH-UHFFFAOYSA-N 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 238000002944 PCR assay Methods 0.000 description 1
- 101150054854 POU1F1 gene Proteins 0.000 description 1
- 102000018886 Pancreatic Polypeptide Human genes 0.000 description 1
- 108700020479 Pancreatic hormone Proteins 0.000 description 1
- 108090000526 Papain Proteins 0.000 description 1
- 108090000445 Parathyroid hormone Proteins 0.000 description 1
- 102000003982 Parathyroid hormone Human genes 0.000 description 1
- 229930182555 Penicillin Natural products 0.000 description 1
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 1
- 102000003992 Peroxidases Human genes 0.000 description 1
- 102000011755 Phosphoglycerate Kinase Human genes 0.000 description 1
- 229920001030 Polyethylene Glycol 4000 Polymers 0.000 description 1
- 102100034391 Porphobilinogen deaminase Human genes 0.000 description 1
- 108010001511 Pregnane X Receptor Proteins 0.000 description 1
- 101710164463 Preterminal protein Proteins 0.000 description 1
- 102100033237 Pro-epidermal growth factor Human genes 0.000 description 1
- 102000007568 Proto-Oncogene Proteins c-fos Human genes 0.000 description 1
- 108010071563 Proto-Oncogene Proteins c-fos Proteins 0.000 description 1
- 101710185720 Putative ethidium bromide resistance protein Proteins 0.000 description 1
- 238000012181 QIAquick gel extraction kit Methods 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- 101150002757 RSL1 gene Proteins 0.000 description 1
- 108090000783 Renin Proteins 0.000 description 1
- 102100028255 Renin Human genes 0.000 description 1
- 108020005091 Replication Origin Proteins 0.000 description 1
- 102000004389 Ribonucleoproteins Human genes 0.000 description 1
- 108010081734 Ribonucleoproteins Proteins 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 101100068078 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) GCN4 gene Proteins 0.000 description 1
- 108010086019 Secretin Proteins 0.000 description 1
- 102100037505 Secretin Human genes 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 108091027967 Small hairpin RNA Proteins 0.000 description 1
- 108020004459 Small interfering RNA Proteins 0.000 description 1
- 108010023197 Streptokinase Proteins 0.000 description 1
- 241000187747 Streptomyces Species 0.000 description 1
- 101710172711 Structural protein Proteins 0.000 description 1
- 102000019197 Superoxide Dismutase Human genes 0.000 description 1
- 108010012715 Superoxide dismutase Proteins 0.000 description 1
- 101001099217 Thermotoga maritima (strain ATCC 43589 / DSM 3109 / JCM 10099 / NBRC 100826 / MSB8) Triosephosphate isomerase Proteins 0.000 description 1
- 108010022394 Threonine synthase Proteins 0.000 description 1
- 108090000190 Thrombin Proteins 0.000 description 1
- 108010000499 Thromboplastin Proteins 0.000 description 1
- 102000002262 Thromboplastin Human genes 0.000 description 1
- AUYYCJSJGJYCDS-LBPRGKRZSA-N Thyrolar Chemical class IC1=CC(C[C@H](N)C(O)=O)=CC(I)=C1OC1=CC=C(O)C(I)=C1 AUYYCJSJGJYCDS-LBPRGKRZSA-N 0.000 description 1
- 108090000373 Tissue Plasminogen Activator Proteins 0.000 description 1
- 102100033571 Tissue-type plasminogen activator Human genes 0.000 description 1
- 108010068068 Transcription Factor TFIIIA Proteins 0.000 description 1
- 108700009124 Transcription Initiation Site Proteins 0.000 description 1
- 102100028509 Transcription factor IIIA Human genes 0.000 description 1
- 102100023132 Transcription factor Jun Human genes 0.000 description 1
- 102100035100 Transcription factor p65 Human genes 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- GXBMIBRIOWHPDT-UHFFFAOYSA-N Vasopressin Natural products N1C(=O)C(CC=2C=C(O)C=CC=2)NC(=O)C(N)CSSCC(C(=O)N2C(CCC2)C(=O)NC(CCCN=C(N)N)C(=O)NCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(CCC(N)=O)NC(=O)C1CC1=CC=CC=C1 GXBMIBRIOWHPDT-UHFFFAOYSA-N 0.000 description 1
- 102100026383 Vasopressin-neurophysin 2-copeptin Human genes 0.000 description 1
- 102100025342 Voltage-dependent N-type calcium channel subunit alpha-1B Human genes 0.000 description 1
- 101710088658 Voltage-dependent N-type calcium channel subunit alpha-1B Proteins 0.000 description 1
- 108010027570 Xanthine phosphoribosyltransferase Proteins 0.000 description 1
- 102100026583 Zinc finger and SCAN domain-containing protein 26 Human genes 0.000 description 1
- WTIJXIZOODAMJT-WBACWINTSA-N [(3r,4s,5r,6s)-5-hydroxy-6-[4-hydroxy-3-[[5-[[4-hydroxy-7-[(2s,3r,4s,5r)-3-hydroxy-5-methoxy-6,6-dimethyl-4-(5-methyl-1h-pyrrole-2-carbonyl)oxyoxan-2-yl]oxy-8-methyl-2-oxochromen-3-yl]carbamoyl]-4-methyl-1h-pyrrole-3-carbonyl]amino]-8-methyl-2-oxochromen- Chemical compound O([C@@H]1[C@H](C(O[C@H](OC=2C(=C3OC(=O)C(NC(=O)C=4C(=C(C(=O)NC=5C(OC6=C(C)C(O[C@@H]7[C@@H]([C@H](OC(=O)C=8NC(C)=CC=8)[C@@H](OC)C(C)(C)O7)O)=CC=C6C=5O)=O)NC=4)C)=C(O)C3=CC=2)C)[C@@H]1O)(C)C)OC)C(=O)C1=CC=C(C)N1 WTIJXIZOODAMJT-WBACWINTSA-N 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 229960001445 alitretinoin Drugs 0.000 description 1
- SHGAZHPCJJPHSC-YCNIQYBTSA-N all-trans-retinoic acid Chemical compound OC(=O)\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-YCNIQYBTSA-N 0.000 description 1
- 108010050122 alpha 1-Antitrypsin Proteins 0.000 description 1
- 102000015395 alpha 1-Antitrypsin Human genes 0.000 description 1
- 229940024142 alpha 1-antitrypsin Drugs 0.000 description 1
- UPEZCKBFRMILAV-UHFFFAOYSA-N alpha-Ecdysone Natural products C1C(O)C(O)CC2(C)C(CCC3(C(C(C(O)CCC(C)(C)O)C)CCC33O)C)C3=CC(=O)C21 UPEZCKBFRMILAV-UHFFFAOYSA-N 0.000 description 1
- 229940024606 amino acid Drugs 0.000 description 1
- 150000001413 amino acids Chemical class 0.000 description 1
- 229960003896 aminopterin Drugs 0.000 description 1
- 235000019418 amylase Nutrition 0.000 description 1
- ORWYRWWVDCYOMK-HBZPZAIKSA-N angiotensin I Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(O)=O)C(C)C)C1=CC=C(O)C=C1 ORWYRWWVDCYOMK-HBZPZAIKSA-N 0.000 description 1
- 229950006323 angiotensin ii Drugs 0.000 description 1
- 238000000137 annealing Methods 0.000 description 1
- 239000005557 antagonist Substances 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- FOIVPCKZDPCJJY-JQIJEIRASA-N arotinoid acid Chemical compound C=1C=C(C(CCC2(C)C)(C)C)C2=CC=1C(/C)=C/C1=CC=C(C(O)=O)C=C1 FOIVPCKZDPCJJY-JQIJEIRASA-N 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 235000010233 benzoic acid Nutrition 0.000 description 1
- 101150038738 ble gene Proteins 0.000 description 1
- 108010006025 bovine growth hormone Proteins 0.000 description 1
- 239000007853 buffer solution Substances 0.000 description 1
- 238000010804 cDNA synthesis Methods 0.000 description 1
- 229960004015 calcitonin Drugs 0.000 description 1
- BBBFJLBPOGFECG-VJVYQDLKSA-N calcitonin Chemical compound N([C@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(N)=O)C(C)C)C(=O)[C@@H]1CSSC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1 BBBFJLBPOGFECG-VJVYQDLKSA-N 0.000 description 1
- 244000309466 calf Species 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 239000003054 catalyst Substances 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 239000013522 chelant Substances 0.000 description 1
- AOXOCDRNSPFDPE-UKEONUMOSA-N chembl413654 Chemical compound C([C@H](C(=O)NCC(=O)N[C@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@H](CCSC)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CC=1C=CC=CC=1)C(N)=O)NC(=O)[C@@H](C)NC(=O)[C@@H](CCC(O)=O)NC(=O)[C@@H](CCC(O)=O)NC(=O)[C@@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H]1N(CCC1)C(=O)CNC(=O)[C@@H](N)CCC(O)=O)C1=CC=C(O)C=C1 AOXOCDRNSPFDPE-UKEONUMOSA-N 0.000 description 1
- 229960002376 chymotrypsin Drugs 0.000 description 1
- 229960001265 ciclosporin Drugs 0.000 description 1
- 229960002424 collagenase Drugs 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 229950001513 coumamycin Drugs 0.000 description 1
- 125000004093 cyano group Chemical group *C#N 0.000 description 1
- 229930182912 cyclosporin Natural products 0.000 description 1
- 230000000120 cytopathologic effect Effects 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 239000003599 detergent Substances 0.000 description 1
- MTHSVFCYNBDYFN-UHFFFAOYSA-N diethylene glycol Chemical compound OCCOCCO MTHSVFCYNBDYFN-UHFFFAOYSA-N 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- 229960003722 doxycycline Drugs 0.000 description 1
- UPEZCKBFRMILAV-JMZLNJERSA-N ecdysone Chemical compound C1[C@@H](O)[C@@H](O)C[C@]2(C)[C@@H](CC[C@@]3([C@@H]([C@@H]([C@H](O)CCC(C)(C)O)C)CC[C@]33O)C)C3=CC(=O)[C@@H]21 UPEZCKBFRMILAV-JMZLNJERSA-N 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 229940116977 epidermal growth factor Drugs 0.000 description 1
- 229930182833 estradiol Natural products 0.000 description 1
- 229940011871 estrogen Drugs 0.000 description 1
- 239000000262 estrogen Substances 0.000 description 1
- 108010038795 estrogen receptors Proteins 0.000 description 1
- 229960004222 factor ix Drugs 0.000 description 1
- 229940012413 factor vii Drugs 0.000 description 1
- 229960000301 factor viii Drugs 0.000 description 1
- 229940012426 factor x Drugs 0.000 description 1
- 229940012444 factor xiii Drugs 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 229940012952 fibrinogen Drugs 0.000 description 1
- 229940126864 fibroblast growth factor Drugs 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 239000000834 fixative Substances 0.000 description 1
- 230000008014 freezing Effects 0.000 description 1
- 238000007710 freezing Methods 0.000 description 1
- 229960005390 galsulfase Drugs 0.000 description 1
- 108010089296 galsulfase Proteins 0.000 description 1
- 229940044627 gamma-interferon Drugs 0.000 description 1
- 102000034356 gene-regulatory proteins Human genes 0.000 description 1
- 108091006104 gene-regulatory proteins Proteins 0.000 description 1
- 238000007429 general method Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- MASNOZXLGMXCHN-ZLPAWPGGSA-N glucagon Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O)C(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C1=CC=CC=C1 MASNOZXLGMXCHN-ZLPAWPGGSA-N 0.000 description 1
- 229960004666 glucagon Drugs 0.000 description 1
- 239000003862 glucocorticoid Substances 0.000 description 1
- 210000003714 granulocyte Anatomy 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 239000007902 hard capsule Substances 0.000 description 1
- 210000003494 hepatocyte Anatomy 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 229940006607 hirudin Drugs 0.000 description 1
- WQPDUTSPKFMPDP-OUMQNGNKSA-N hirudin Chemical compound C([C@@H](C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC(OS(O)(=O)=O)=CC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCCCN)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@H]1NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]2CSSC[C@@H](C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(=O)N[C@H](C(NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N2)=O)CSSC1)C(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]1NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=2C=CC(O)=CC=2)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)C(C)C)[C@@H](C)O)CSSC1)C(C)C)[C@@H](C)O)[C@@H](C)O)C1=CC=CC=C1 WQPDUTSPKFMPDP-OUMQNGNKSA-N 0.000 description 1
- 101150113423 hisD gene Proteins 0.000 description 1
- 238000000265 homogenisation Methods 0.000 description 1
- 230000006801 homologous recombination Effects 0.000 description 1
- 238000002744 homologous recombination Methods 0.000 description 1
- 102000055805 human DNASE1 Human genes 0.000 description 1
- 229960002773 hyaluronidase Drugs 0.000 description 1
- 229910052588 hydroxylapatite Inorganic materials 0.000 description 1
- 108010002685 hygromycin-B kinase Proteins 0.000 description 1
- 229960002127 imiglucerase Drugs 0.000 description 1
- 108010039650 imiglucerase Proteins 0.000 description 1
- 230000028993 immune response Effects 0.000 description 1
- 238000003365 immunocytochemistry Methods 0.000 description 1
- 230000002163 immunogen Effects 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- PZOUSPYUWWUPPK-UHFFFAOYSA-N indole Natural products CC1=CC=CC2=C1C=CN2 PZOUSPYUWWUPPK-UHFFFAOYSA-N 0.000 description 1
- RKJUIXBNRJVNHR-UHFFFAOYSA-N indolenine Natural products C1=CC=C2CC=NC2=C1 RKJUIXBNRJVNHR-UHFFFAOYSA-N 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 229960001388 interferon-beta Drugs 0.000 description 1
- 229940096397 interleukin-8 Drugs 0.000 description 1
- XKTZWUACRZHVAN-VADRZIEHSA-N interleukin-8 Chemical compound C([C@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@@H](NC(C)=O)CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCSC)C(=O)N1[C@H](CCC1)C(=O)N1[C@H](CCC1)C(=O)N[C@@H](C)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CCC(O)=O)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CC=1C=CC(O)=CC=1)C(=O)N[C@H](CO)C(=O)N1[C@H](CCC1)C(N)=O)C1=CC=CC=C1 XKTZWUACRZHVAN-VADRZIEHSA-N 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000011835 investigation Methods 0.000 description 1
- CSSYQJWUGATIHM-IKGCZBKSSA-N l-phenylalanyl-l-lysyl-l-cysteinyl-l-arginyl-l-arginyl-l-tryptophyl-l-glutaminyl-l-tryptophyl-l-arginyl-l-methionyl-l-lysyl-l-lysyl-l-leucylglycyl-l-alanyl-l-prolyl-l-seryl-l-isoleucyl-l-threonyl-l-cysteinyl-l-valyl-l-arginyl-l-arginyl-l-alanyl-l-phenylal Chemical compound C([C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 CSSYQJWUGATIHM-IKGCZBKSSA-N 0.000 description 1
- 229940116108 lactase Drugs 0.000 description 1
- 229940078795 lactoferrin Drugs 0.000 description 1
- 235000021242 lactoferrin Nutrition 0.000 description 1
- OTQCKZUSUGYWBD-BRHMIFOHSA-N lepirudin Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCCN)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)C(C)C)[C@@H](C)O)[C@@H](C)O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)[C@@H](C)O)C1=CC=C(O)C=C1 OTQCKZUSUGYWBD-BRHMIFOHSA-N 0.000 description 1
- 229960004408 lepirudin Drugs 0.000 description 1
- 235000019421 lipase Nutrition 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 102000004311 liver X receptors Human genes 0.000 description 1
- 108090000865 liver X receptors Proteins 0.000 description 1
- 239000012139 lysis buffer Substances 0.000 description 1
- 229960000274 lysozyme Drugs 0.000 description 1
- 239000004325 lysozyme Substances 0.000 description 1
- 235000010335 lysozyme Nutrition 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- FRQMUZJSZHZSGN-HBNHAYAOSA-N medroxyprogesterone Chemical compound C([C@@]12C)CC(=O)C=C1[C@@H](C)C[C@@H]1[C@@H]2CC[C@]2(C)[C@@](O)(C(C)=O)CC[C@H]21 FRQMUZJSZHZSGN-HBNHAYAOSA-N 0.000 description 1
- 229960004616 medroxyprogesterone Drugs 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 108091070501 miRNA Proteins 0.000 description 1
- 239000002679 microRNA Substances 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 238000009126 molecular therapy Methods 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 230000004660 morphological change Effects 0.000 description 1
- 230000035772 mutation Effects 0.000 description 1
- QYYXITIZXRMPSZ-UHFFFAOYSA-N n'-tert-butyl-n'-(3,5-dimethylbenzoyl)-2-ethyl-3-methoxybenzohydrazide Chemical compound CCC1=C(OC)C=CC=C1C(=O)NN(C(C)(C)C)C(=O)C1=CC(C)=CC(C)=C1 QYYXITIZXRMPSZ-UHFFFAOYSA-N 0.000 description 1
- 230000007514 neuronal growth Effects 0.000 description 1
- VIKNJXKGJWUCNN-XGXHKTLJSA-N norethisterone Chemical class O=C1CC[C@@H]2[C@H]3CC[C@](C)([C@](CC4)(O)C#C)[C@@H]4[C@@H]3CCC2=C1 VIKNJXKGJWUCNN-XGXHKTLJSA-N 0.000 description 1
- 229960002950 novobiocin Drugs 0.000 description 1
- YJQPYGGHQPGBLI-KGSXXDOSSA-N novobiocin Chemical compound O1C(C)(C)[C@H](OC)[C@@H](OC(N)=O)[C@@H](O)[C@@H]1OC1=CC=C(C(O)=C(NC(=O)C=2C=C(CC=C(C)C)C(O)=CC=2)C(=O)O2)C2=C1C YJQPYGGHQPGBLI-KGSXXDOSSA-N 0.000 description 1
- URPYMXQQVHTUDU-OFGSCBOVSA-N nucleopeptide y Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(N)=O)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 URPYMXQQVHTUDU-OFGSCBOVSA-N 0.000 description 1
- 230000030648 nucleus localization Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 239000002818 ornithine decarboxylase inhibitor Substances 0.000 description 1
- 229960001723 oxytocin Drugs 0.000 description 1
- XNOPRXBHLZRZKH-DSZYJQQASA-N oxytocin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CSSC[C@H](N)C(=O)N1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(N)=O)=O)[C@@H](C)CC)C1=CC=C(O)C=C1 XNOPRXBHLZRZKH-DSZYJQQASA-N 0.000 description 1
- 229940055729 papain Drugs 0.000 description 1
- 235000019834 papain Nutrition 0.000 description 1
- 229960001319 parathyroid hormone Drugs 0.000 description 1
- 239000000199 parathyroid hormone Substances 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- 229940049954 penicillin Drugs 0.000 description 1
- XYJRXVWERLGGKC-UHFFFAOYSA-D pentacalcium;hydroxide;triphosphate Chemical compound [OH-].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O XYJRXVWERLGGKC-UHFFFAOYSA-D 0.000 description 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 239000013600 plasmid vector Substances 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 239000002244 precipitate Substances 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 102000003998 progesterone receptors Human genes 0.000 description 1
- 108090000468 progesterone receptors Proteins 0.000 description 1
- 150000003146 progesterones Chemical class 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 238000002331 protein detection Methods 0.000 description 1
- 239000013636 protein dimer Substances 0.000 description 1
- 101150068068 ptp gene Proteins 0.000 description 1
- 229950010131 puromycin Drugs 0.000 description 1
- 108010045647 puromycin N-acetyltransferase Proteins 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 238000004064 recycling Methods 0.000 description 1
- 230000031267 regulation of DNA replication Effects 0.000 description 1
- 230000008844 regulatory mechanism Effects 0.000 description 1
- 230000003252 repetitive effect Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 229930002330 retinoic acid Natural products 0.000 description 1
- 108090000064 retinoic acid receptors Proteins 0.000 description 1
- 102000003702 retinoic acid receptors Human genes 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 108010074523 rimabotulinumtoxinB Proteins 0.000 description 1
- 230000009291 secondary effect Effects 0.000 description 1
- 229960002101 secretin Drugs 0.000 description 1
- OWMZNFCDEHGFEP-NFBCVYDUSA-N secretin human Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(N)=O)[C@@H](C)O)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)C1=CC=CC=C1 OWMZNFCDEHGFEP-NFBCVYDUSA-N 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 1
- 239000002924 silencing RNA Substances 0.000 description 1
- 239000004055 small Interfering RNA Substances 0.000 description 1
- 238000002791 soaking Methods 0.000 description 1
- 238000000527 sonication Methods 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 239000007858 starting material Substances 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 238000003756 stirring Methods 0.000 description 1
- 229960005202 streptokinase Drugs 0.000 description 1
- 229960005322 streptomycin Drugs 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 230000000153 supplemental effect Effects 0.000 description 1
- 230000001502 supplementing effect Effects 0.000 description 1
- 230000008093 supporting effect Effects 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 229920001059 synthetic polymer Polymers 0.000 description 1
- 102000055501 telomere Human genes 0.000 description 1
- 108091035539 telomere Proteins 0.000 description 1
- 210000003411 telomere Anatomy 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 238000010257 thawing Methods 0.000 description 1
- 229960004072 thrombin Drugs 0.000 description 1
- 210000001685 thyroid gland Anatomy 0.000 description 1
- 229940036555 thyroid hormone Drugs 0.000 description 1
- 102000004217 thyroid hormone receptors Human genes 0.000 description 1
- 108090000721 thyroid hormone receptors Proteins 0.000 description 1
- 238000004448 titration Methods 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000003151 transfection method Methods 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- 229960001727 tretinoin Drugs 0.000 description 1
- 230000010415 tropism Effects 0.000 description 1
- 101150081616 trpB gene Proteins 0.000 description 1
- 238000005199 ultracentrifugation Methods 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- VBEQCZHXXJYVRD-GACYYNSASA-N uroanthelone Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(C)C)[C@@H](C)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C1=CC=C(O)C=C1 VBEQCZHXXJYVRD-GACYYNSASA-N 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 238000011179 visual inspection Methods 0.000 description 1
- 229940075420 xanthine Drugs 0.000 description 1
- 239000008096 xylene Substances 0.000 description 1
- 230000004572 zinc-binding Effects 0.000 description 1
Images














Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
- C12N15/861—Adenoviral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N7/00—Viruses; Bacteriophages; Compositions thereof; Preparation or purification thereof
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/09—Fusion polypeptide containing a localisation/targetting motif containing a nuclear localisation signal
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/70—Fusion polypeptide containing domain for protein-protein interaction
- C07K2319/71—Fusion polypeptide containing domain for protein-protein interaction containing domain for transcriptional activaation, e.g. VP16
- C07K2319/715—Fusion polypeptide containing domain for protein-protein interaction containing domain for transcriptional activaation, e.g. VP16 containing a domain for ligand dependent transcriptional activation, e.g. containing a steroid receptor domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/80—Fusion polypeptide containing a DNA binding domain, e.g. Lacl or Tet-repressor
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2710/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA dsDNA viruses
- C12N2710/00011—Details
- C12N2710/10011—Adenoviridae
- C12N2710/10311—Mastadenovirus, e.g. human or simian adenoviruses
- C12N2710/10341—Use of virus, viral particle or viral elements as a vector
- C12N2710/10343—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2710/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA dsDNA viruses
- C12N2710/00011—Details
- C12N2710/10011—Adenoviridae
- C12N2710/10311—Mastadenovirus, e.g. human or simian adenoviruses
- C12N2710/10351—Methods of production or purification of viral material
- C12N2710/10352—Methods of production or purification of viral material relating to complementing cells and packaging systems for producing virus or viral particles
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/30—Vector systems comprising sequences for excision in presence of a recombinase, e.g. loxP or FRT
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/40—Systems of functionally co-operating vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/80—Vectors containing sites for inducing double-stranded breaks, e.g. meganuclease restriction sites
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2830/00—Vector systems having a special element relevant for transcription
- C12N2830/001—Vector systems having a special element relevant for transcription controllable enhancer/promoter combination
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2840/00—Vectors comprising a special translation-regulating system
- C12N2840/20—Vectors comprising a special translation-regulating system translation of more than one cistron
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Organic Chemistry (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Biotechnology (AREA)
- Biomedical Technology (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Virology (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Medicinal Chemistry (AREA)
- Immunology (AREA)
- Pharmacology & Pharmacy (AREA)
- Epidemiology (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
本発明は、ヘルパーウイルスの使用を必要とせず、宿主細胞のゲノム内に、ウイルス粒子の制御、複製およびパッケージングに必要なアデノウイルス遺伝子を組み込むことを特徴とする高容量アデノウイルスベクターの新規な生産およびパッケージング(キャプシド封入)系に関し、これにより長期間生産系の安定性が改良される。
Description
発明の属する技術分野
本発明は、バイオテクノロジーの分野、より具体的には、標的細胞における異種遺伝子の発現のためのベクターの分野に関する。特に、本発明は、遺伝子導入に有用な高容量アデノウイルスベクターの生産およびパッケージングのための系に関する。
本発明は、バイオテクノロジーの分野、より具体的には、標的細胞における異種遺伝子の発現のためのベクターの分野に関する。特に、本発明は、遺伝子導入に有用な高容量アデノウイルスベクターの生産およびパッケージングのための系に関する。
背景
高容量アデノウイルス(HC)は、ガットレスアデノウイルスまたはヘルパー依存性アデノウイルスとしても知られ、齧歯類および霊長類の双方において、極めて低い関連免疫原性を示し、高い形質導入効率と広い向性を有することから、in vivoにおける遺伝子療法のためのベクターとして非常に魅力的である。これらのベクターは、それらの複製およびパッケージングのために必要なDNA配列のみを含んでおり、他のアデノウイルスの遺伝子を欠いているため、結果として最大36kbまでの配列を収容することができるという特徴を持つ。ウイルスDNAの複製およびウイルス粒子内へのそのパッケージングのために、これらのベクターにシスで必要なアデノウイルス配列は、線状DNAの両端に位置するITR配列(逆方向末端反復配列)、およびパッケージングシグナル(Ψ)のみである(Grable and Hearing, 1992, J. Virol, 66: 723-731; Hearing and Shenk, 1983, Cell, 33: 695-703)。
高容量アデノウイルス(HC)は、ガットレスアデノウイルスまたはヘルパー依存性アデノウイルスとしても知られ、齧歯類および霊長類の双方において、極めて低い関連免疫原性を示し、高い形質導入効率と広い向性を有することから、in vivoにおける遺伝子療法のためのベクターとして非常に魅力的である。これらのベクターは、それらの複製およびパッケージングのために必要なDNA配列のみを含んでおり、他のアデノウイルスの遺伝子を欠いているため、結果として最大36kbまでの配列を収容することができるという特徴を持つ。ウイルスDNAの複製およびウイルス粒子内へのそのパッケージングのために、これらのベクターにシスで必要なアデノウイルス配列は、線状DNAの両端に位置するITR配列(逆方向末端反復配列)、およびパッケージングシグナル(Ψ)のみである(Grable and Hearing, 1992, J. Virol, 66: 723-731; Hearing and Shenk, 1983, Cell, 33: 695-703)。
高容量アデノウイルスは総てのウイルスコード領域を欠いているため、ヘルパーまたは補助ウイルスと呼ばれる第2のウイルス、すなわち、欠陥ウイルスの複製および感染力を有するウイルス粒子へのその封入に必要な総てのタンパク質をコードし得るウイルスとともに細胞を重感染させた場合にのみ、それらの増殖が可能である。高容量アデノウイルスベクターを生産する場合、ヘルパーウイルスはE1アデノウイルス領域において欠失があり、また、ガットレスウイルスの後代の複製およびアセンブリに必要なウイルスタンパク質の全レパートリーをトランスで提供することを特徴とする。後者の増殖には、ヘルパーウイルスの前記E1領域の欠失を補足し得る細胞系統、例えば293系統(Graham, et al., 1977, J. Gene. Virol, 36: 59-74)、またはPerC6系統(Fallaux et al., 1998, Hum. Gene Ther., 9: 1909-1917)の使用が必要である。
しかしながら、この増殖系もまた、ヘルパーウイルスのゲノムをキャプシド封入し、高容量アデノウイルスの最終調製物を汚染する、望ましくないウイルス粒子の生成につながる。これまで、ヘルパーウイルスのパッケージングプロセスを阻止している前記の混入を排除しようとする様々な系が開発および記載されてきた。一般に、これらの系は、ヘルパーウイルスのパッケージングシグナル、そのゲノムサイズの増加、および、より詳しくは、ウイルス生産プロセス中のパッケージングシグナルの特異的排除における突然変異の組み込みに基づいている。
しかしながら、この増殖系もまた、ヘルパーウイルスのゲノムをキャプシド封入し、高容量アデノウイルスの最終調製物を汚染する、望ましくないウイルス粒子の生成につながる。これまで、ヘルパーウイルスのパッケージングプロセスを阻止している前記の混入を排除しようとする様々な系が開発および記載されてきた。一般に、これらの系は、ヘルパーウイルスのパッケージングシグナル、そのゲノムサイズの増加、および、より詳しくは、ウイルス生産プロセス中のパッケージングシグナルの特異的排除における突然変異の組み込みに基づいている。
Parksら(1996, Proc. Natl. Acad. Sci. USA, 93: 13565-13570)は、Cre−loxP組換え系によるヘルパーウイルスのΨパッケージングシグナルの排除を記載している。この系では、ΨシグナルはloxP部位により隣接され、ウイルスの増殖は、Creレコンビナーゼを発現する293細胞(293Cre細胞)内で行われる。ヘルパーウイルスが細胞に入ると、レコンビナーゼはΨシグナルを切り出し、パッケージングできないようにするが、その複製能は維持し、その結果、高容量アデノウイルスのパッケージングに必要なコード配列の発現が維持される。
Grothら(Proc. Natl. Acad. Sci. USA, 2000, 97: 5995-6000)は、特異的に認識されるattB/attP部位がΨシグナルを隣接して配置されている、一方向性レコンビナーゼ、特に、ΦC31レコンビナーゼの使用を提案している。PhiC31レコンビナーゼが、attB/attP部位に隣接された配列を切り出すと、それは認識配列を改変し、それらをattR/attL配列へ変換して、認識が再度起こるのを防ぎ、その結果、Ψシグナルの再導入を防ぐ。
Ngら(2001, Mol. Ther., 3: 809-815)は、高容量アデノウイルスの増殖が酵母FLPレコンビナーゼ(293FLPおよび293CreFLP系統)を発現し得る293細胞中で行われ、ヘルパーウイルスのΨシグナルが、該FLPレコンビナーゼにより特異的に認識されるfrt部位により隣接されている、別の組換え系FLP/frtを提案している。ガットレスウイルスの増幅効率(実行3回で108bfu/ml)、ならびにヘルパーウイルスの混入レベル(CsCl勾配で精製後0.5%)は、従前のCre−loxP系を用いて生産されたものと極めて類似していた。
これらの系の改良を試みるために、PalmerおよびNg (2003, Mol. Ther., 8: 846 852)は、ヘルパーウイルスのパッケージングシグナルの反転を包含した、Cre−loxP系に由来する系を開発した。
一方、Sargentら(2004, Gene Ther., 11: 504-511)は、35kbより大きく、IXタンパク質の遺伝子が欠失しているヘルパーウイルス、ならびに前記欠失を補足し得る293細胞系統が用いられる、サイズに基づく制限系を提案している。
しかしながら、これらの改良にもかかわらず、これまで、これらの系に、生産工程に含まれる2つのウイルスの配列間の組換えを回避し、その結果、サンプルへの複製能を有するアデノウイルスの混入を回避できるようになったものはない。Albaらは最近の総説(2005, Gene Ther, 12 Suppl 1: S18-27)で、混入レベルは、使用する系に応じて、生産された高容量アデノウイルスのウイルス粒子の数に対して0.02%〜1%の間で変動し得ると述べている。これらの混入レベルは、遺伝子療法の臨床診断法に用いるには高すぎると考えられる。
さらに、高容量アデノウイルスを使用するためのもう1つの重要な限定要因は、それらの大規模生産が困難であることに関連している。現在、このタイプの生産法は複雑であり、効率が低く、ウイルスヘルパーを用いる重感染を何回も繰り返す必要がある。
これを行うためには、手順を改良すると同時に、臨床使用に必要とされる量とともに質(ウイルス粒子の混入のない)で高容量アデノウイルスベクターを生産するための代替系の開発が必要である。
この問題の理想的な解決方法は、高容量アデノウイルスベクターの大規模生産のための特定の細胞系統の開発であろう。しかしながら、ヘルパーウイルスの関与に依存しない生産系には、アデノウイルス遺伝子の高い発現レベルから生じる細胞傷害性の問題があり、このことは、今まで、このタイプの生産系の開発を大いに制限してきた。これに対し、本発明者らは、感染の後期においてウイルス粒子の大量生産を可能にする構造タンパク質の発現を伴うDNAの複製の調整に必要な一連の事象を正確に再現することは、極めて難しいという事実を付け加えなければならない(Farley, et al., 2004, J. Virol, 78: 1782-1791)。
WO0072887では、(i)E1、E3、E4領域ならびにpTPおよびDBP遺伝子を欠失させたアデノウイルスゲノムとともに、エプスタイン−バーウイルス(EBV)の複製エレメントに基づく、安定型の環状エピソームを少ないコピー数で含む、パッケージング細胞系統、および(ii)アデノウイルスゲノムの複製およびパッケージングに必要なエレメントを含み、エピソーム(E4領域、pTP遺伝子およびDBP)ならびに異種遺伝子が存在しないベクター、から形成される2成分系に基づく、ヘルパーアデノウイルスには依存しない高容量アデノウイルスの生産系を開示している。この系においては、(i)パッケージングシグナルを欠いており、かつ(ii)そのサイズがアデノウイルスのパッケージング容量を超えているために、エピソームはビリオン中にパッケージングされない。
他方、WO0042208では、(i)E1、E3領域、およびビリオンのアセンブリ工程に関与する繊維タンパク質をコードする遺伝子(L5)を欠失させたアデノウイルスベクター、ならびに(ii)前記ベクターの複製およびパッケージングを補足し得る特定の細胞系統を含んでなる、ヘルパーウイルスに依存しないアデノウイルス生産系が開示されている。ウイルス粒子の複製およびパッケージングの工程に必要な総ての遺伝子は、アデノウイルスベクターの配列の中に含められている。
最後に、Catalucci et al. (2005, J. Virol, 79: 6400-6409)により最近記載された系は、エプスタイン−バーウイルスの複製起点からなるエピソームプラスミドの使用が、核抗原EBNA1(293EBNA)を安定して発現するよう改変された293細胞系統の核内におけるその維持を可能にすることを示唆している。このエピソームは、血清型5アデノウイルスのITR配列、アデノウイルスゲノムの、初期領域(E2)およびE4領域に含まれるORF6の遺伝子を含む。これらのアデノウイルス遺伝子の転写は、誘導プロモーターの制御下にあるが、キャプシドの形成に必要な他の遺伝子は、高容量アデノウイルスの配列の中に含まれている。
一般に、これらのヘルパー非依存性アデノウイルスベクター生産系は総て、これらのアデノウイルスベクター総てがベクターの複製またはパッケージングの工程に必要な1以上のアデノウイルスの遺伝子を含むので、ベクターに挿入することができるDNA配列のサイズにより制限される。さらに、これらのアデノウイルス遺伝子の存在は、臨床応用する場合に、免疫原性作用があり得るというリスクを伴う。
従って、このことは、補助アデノウイルスベクターの使用を必要とせず、またこれまでに知られている補助ベクターの欠点を克服する、高容量アデノウイルス生産系を得る技術の必要性を証明する。
発明の概要
第1の態様において、本発明は、
(a)転写レギュレーターをコードするヌクレオチド配列を含んでなる第1の発現カセット;
(b)制限エンドヌクレアーゼをコードするヌクレオチド配列を含んでなり、(a)で定義されたポリヌクレオチドによりコードされる転写レギュレーターにより活性化可能な転写調節配列の機能的制御下にある、第2の発現カセット
を含んでなる、ポリヌクレオチド(本発明の第1のポリヌクレオチド)または発現ベクターに関する。
第1の態様において、本発明は、
(a)転写レギュレーターをコードするヌクレオチド配列を含んでなる第1の発現カセット;
(b)制限エンドヌクレアーゼをコードするヌクレオチド配列を含んでなり、(a)で定義されたポリヌクレオチドによりコードされる転写レギュレーターにより活性化可能な転写調節配列の機能的制御下にある、第2の発現カセット
を含んでなる、ポリヌクレオチド(本発明の第1のポリヌクレオチド)または発現ベクターに関する。
第2の態様において、本発明は、
(a)転写レギュレーターをコードするヌクレオチド配列を含んでなる第1の発現カセット;
(b)制限エンドヌクレアーゼをコードするヌクレオチド配列を含んでなり、転写レギュレーター(a)により活性化可能な転写調節配列の機能的制御下にある、第2の発現カセット、および
(c)選択されたアデノウイルスE1Aタンパク質、またはアデノウイルスE1AおよびE1Bタンパク質をコードするヌクレオチド配列を含んでなり、転写レギュレーター(a)により活性化可能な転写調節配列の機能的制御下にある、第3の発現カセット
を含んでなる、ポリヌクレオチド(本発明の第2のポリヌクレオチド)または発現ベクターに関する。
(a)転写レギュレーターをコードするヌクレオチド配列を含んでなる第1の発現カセット;
(b)制限エンドヌクレアーゼをコードするヌクレオチド配列を含んでなり、転写レギュレーター(a)により活性化可能な転写調節配列の機能的制御下にある、第2の発現カセット、および
(c)選択されたアデノウイルスE1Aタンパク質、またはアデノウイルスE1AおよびE1Bタンパク質をコードするヌクレオチド配列を含んでなり、転写レギュレーター(a)により活性化可能な転写調節配列の機能的制御下にある、第3の発現カセット
を含んでなる、ポリヌクレオチド(本発明の第2のポリヌクレオチド)または発現ベクターに関する。
別の態様において、本発明は、少なくとも、Ψパッケージング配列とE1AまたはE1A/E1Bタンパク質をコードする配列を欠いている組換えアデノウイルスのゲノムを含んでなるヌクレオチド配列を含んでなり、組換えアデノウイルスゲノムを含んでなる該配列が、制限エンドヌクレアーゼに対する特異的認識配列により隣接されている、ポリヌクレオチド(本発明の第3のポリヌクレオチド)または発現ベクターに関する。
別の態様において、本発明は、本発明の1つまたはいくつかのポリヌクレオチドまたは発現ベクターを含んでなる宿主細胞に関する。
別の態様において、本発明は、
(i)細胞を、本発明の第1のポリヌクレオチドもしくは該ポリヌクレオチドを含んでなるベクターで、または本発明の第2のポリヌクレオチドもしくは該ポリヌクレオチドを含んでなるベクターでトランスフェクトすること、および
(ii)該細胞を、本発明の第3のポリヌクレオチドまたは該ポリヌクレオチドを含んでなるベクターでトランスフェクトすること
を含んでなり、工程(i)および(ii)は任意の順序でまたは同時に行うことができ、かつ、工程(i)において細胞が本発明の第1のポリヌクレオチドでトランスフェクトされる場合には、アデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列を含んでなる細胞が用いられる、高容量アデノウイルスの感染性粒子の生産およびパッケージングに好適な細胞の生産方法に関する。
(i)細胞を、本発明の第1のポリヌクレオチドもしくは該ポリヌクレオチドを含んでなるベクターで、または本発明の第2のポリヌクレオチドもしくは該ポリヌクレオチドを含んでなるベクターでトランスフェクトすること、および
(ii)該細胞を、本発明の第3のポリヌクレオチドまたは該ポリヌクレオチドを含んでなるベクターでトランスフェクトすること
を含んでなり、工程(i)および(ii)は任意の順序でまたは同時に行うことができ、かつ、工程(i)において細胞が本発明の第1のポリヌクレオチドでトランスフェクトされる場合には、アデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列を含んでなる細胞が用いられる、高容量アデノウイルスの感染性粒子の生産およびパッケージングに好適な細胞の生産方法に関する。
別の態様において、本発明は、本発明による方法によって生産することができる細胞に関する。
別の態様において、本発明は、
(a)本発明による細胞、および
(b)高容量アデノウイルス
を含んでなる高容量アデノウイルスの生産のための系に関する。
(a)本発明による細胞、および
(b)高容量アデノウイルス
を含んでなる高容量アデノウイルスの生産のための系に関する。
別の態様において、本発明は、
(a)宿主細胞を、生産したい高容量アデノウイルスのゲノムを含んでなるポリヌクレオチド、または該ポリヌクレオチドを含んでなる発現ベクターでトランスフェクトするか、または感染させる工程、
(b)該トランスフェクト/感染細胞を高容量アデノウイルスの複製およびパッケージングを可能とする条件下で培養する工程、
(c)高容量アデノウイルスのウイルス粒子を回収する工程、および場合により、
(d)工程(a)〜(c)を繰り返す工程(工程(c)で生産された高容量ウイルス粒子を次のサイクルの工程(a)で用いる)
を含んでなり、
工程(a)で用いられる宿主細胞が、
(i)本発明の第1のポリヌクレオチドと、アデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列とを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、第3のポリヌクレオチドおよび/または該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(ii)本発明の第2のポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、本発明の第3のポリヌクレオチドおよび/または該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(iii)本発明の第3のポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、第1のポリヌクレオチドでのトランスフェクション工程が行われ、該細胞はアデノウイルスE1Aタンパク質および場合によりアデノウイルスのE1Bタンパク質をコードする配列を含んでなる)、
(iv)本発明の第3のポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、本発明の第2のポリヌクレオチドおよび/または該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(v)本発明の第1のポリヌクレオチド、本発明の第3のポリヌクレオチド、ならびにアデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列を含んでなる細胞、および
(vi)本発明の第2のポリヌクレオチドおよび本発明の第3のポリヌクレオチドを含んでなる細胞
からなる群から選択される、高容量アデノウイルスベクターの生産方法に関する。
(a)宿主細胞を、生産したい高容量アデノウイルスのゲノムを含んでなるポリヌクレオチド、または該ポリヌクレオチドを含んでなる発現ベクターでトランスフェクトするか、または感染させる工程、
(b)該トランスフェクト/感染細胞を高容量アデノウイルスの複製およびパッケージングを可能とする条件下で培養する工程、
(c)高容量アデノウイルスのウイルス粒子を回収する工程、および場合により、
(d)工程(a)〜(c)を繰り返す工程(工程(c)で生産された高容量ウイルス粒子を次のサイクルの工程(a)で用いる)
を含んでなり、
工程(a)で用いられる宿主細胞が、
(i)本発明の第1のポリヌクレオチドと、アデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列とを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、第3のポリヌクレオチドおよび/または該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(ii)本発明の第2のポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、本発明の第3のポリヌクレオチドおよび/または該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(iii)本発明の第3のポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、第1のポリヌクレオチドでのトランスフェクション工程が行われ、該細胞はアデノウイルスE1Aタンパク質および場合によりアデノウイルスのE1Bタンパク質をコードする配列を含んでなる)、
(iv)本発明の第3のポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、本発明の第2のポリヌクレオチドおよび/または該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(v)本発明の第1のポリヌクレオチド、本発明の第3のポリヌクレオチド、ならびにアデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列を含んでなる細胞、および
(vi)本発明の第2のポリヌクレオチドおよび本発明の第3のポリヌクレオチドを含んでなる細胞
からなる群から選択される、高容量アデノウイルスベクターの生産方法に関する。
発明の詳細な説明
本発明者らは、ヘルパーウイルスの使用を必要とせず、また宿主細胞のゲノム内にウイルス粒子の制御、複製およびパッケージングに必要なアデノウイルス遺伝子を組み込むことを特徴とし、この生産系の安定性を長期にわたって向上させる、高容量アデノウイルスベクターのための、新規の生産およびパッケージング系(キャプシド封入)を設計した。同様に、用いられる高容量アデノウイルスベクターは、該ベクターのクローニング能力が他のヘルパー非依存系または他の補助ベクターにおいて示されている能力を上回るように、ビリオンの複製およびパッケージングに必要な配列(ITR配列およびΨシグナル)のみを含む。最後に、高容量ベクターにこれらのアデノウイルス遺伝子が存在しないことで、その臨床適用の際にベクターに対する免疫応答のリスクが排除される。
本発明者らは、ヘルパーウイルスの使用を必要とせず、また宿主細胞のゲノム内にウイルス粒子の制御、複製およびパッケージングに必要なアデノウイルス遺伝子を組み込むことを特徴とし、この生産系の安定性を長期にわたって向上させる、高容量アデノウイルスベクターのための、新規の生産およびパッケージング系(キャプシド封入)を設計した。同様に、用いられる高容量アデノウイルスベクターは、該ベクターのクローニング能力が他のヘルパー非依存系または他の補助ベクターにおいて示されている能力を上回るように、ビリオンの複製およびパッケージングに必要な配列(ITR配列およびΨシグナル)のみを含む。最後に、高容量ベクターにこれらのアデノウイルス遺伝子が存在しないことで、その臨床適用の際にベクターに対する免疫応答のリスクが排除される。
本発明の第1のポリヌクレオチド(A1ポリヌクレオチド)
第1の態様において、本発明は、
(a)転写レギュレーターをコードするヌクレオチド配列を含んでなる第1の発現カセット;
(b)制限エンドヌクレアーゼをコードするヌクレオチド配列を含んでなり、(a)で定義されるポリヌクレオチドによりコードされる転写レギュレーターにより活性化可能な転写調節配列の機能的制御下にある、第2の発現カセット
を含んでなる、ポリヌクレオチド(以下、本発明のA1ポリヌクレオチド)または発現ベクターに関する。
第1の態様において、本発明は、
(a)転写レギュレーターをコードするヌクレオチド配列を含んでなる第1の発現カセット;
(b)制限エンドヌクレアーゼをコードするヌクレオチド配列を含んでなり、(a)で定義されるポリヌクレオチドによりコードされる転写レギュレーターにより活性化可能な転写調節配列の機能的制御下にある、第2の発現カセット
を含んでなる、ポリヌクレオチド(以下、本発明のA1ポリヌクレオチド)または発現ベクターに関する。
本発明において「転写レギュレーター」または「トランスアクチベーター」は、該遺伝子の非コード領域内の該タンパク質に特異的な認識領域へのその結合により、決定された遺伝子の転写を活性化し得るタンパク質として等しく理解される。特定の実施形態では、該トランスアクチベーターまたは転写レギュレーターは、調節可能な転写レギュレーターである。本発明において「調節可能な転写レギュレーター」とは、該レギュレーターに特異的な結合部位を含んでなる遺伝子に応じて供給または除去することができる付加的因子によりその活性が調整され得る転写レギュレーターとして理解される。当業者ならば、調節された基底転写を最小限にして、調節された発現を可能にする限り、本発明が転写レギュレーターの発現を調節するためのいずれの方法をも含むことが分かるであろう。従って、誘導剤に応答し、誘導剤の不在下では基底発現を全く示さないか、または示してもごくわずかであり、かつ、3’位にある遺伝子の活性化を促進することができる誘導プロモーターにより転写アクチベーターを調節することができる。誘導剤の種類によって、誘導プロモーターはTetオン/オフプロモーター(Gossen and Bujard (1992) Proc. Natl. Acad. Sci. USA, 89:5547-5551; Gossen et al., 1995, Science 268:1766-1769; Rossi and Blau, 1998, Curr. Opin. Biotechnol. 9:451-456);Pipオン/オフプロモーター(米国特許第6,287,813号);抗プロゲスチン依存性プロモーター(US2004132086)、エクジソン依存性プロモーター(Christopherson et al., 1992, Proc. Natl. Acad. Sci. USA, 89:6314-6318; No et al., 1996, Proc. Natl. Acad. Sci. USA, 93:3346-3351, Suhr et al., 1998, Proc. Natl. Acad. Sci. USA, 95:7999-8004およびWO9738117)、メタロチオネイン依存性プロモーター(WO8604920)およびラパマイシン依存性プロモーター(Riv
era et al., 1996, Nat. Med. 2:1028-32)に分類される。
era et al., 1996, Nat. Med. 2:1028-32)に分類される。
あるいは、本発明は、発現レベルの増大によってではなく、通常、レギュレーターの細胞質から核への移行により始められる転写活性の増大を引き起こす誘導剤によってその誘導が起こる転写レギュレーターの使用を包含する。この種の転写レギュレーターは通常、DNA結合ドメインすなわちDBD、リガンド結合ドメインすなわちLBD、および活性化ドメインすなわちADにより形成される。
DNA結合ドメインは、合成、キメラまたは類似体DNA結合ドメインを含む、既知の特異的結合エレメントが存在するいずれのドメインでもよい。本発明に好適なDNA結合ドメインとしては、(i)一般に、3本のαヘリックスからなる二次構造を有するおよそ61個のアミノ酸の鎖により形成されるホメオドメイン(Scott et al., 1989, Biochim. Biophys. Acta 989:25-48; Rosenfeld et al., 1991, Genes Dev. 5:897-907)、(ii)直列に組織された、一般式Cys2His2のDNAの2〜3ダースのジンクフィンガーにより形成されるジンクフィンガー(例えば、TFIIIA、Zif268、GliおよびSRE−ZBP)(ここで、各モジュールは3〜5塩基対のDNA領域と接触できるαヘリックス、高親和性DNA結合部位を生じるのに必要な少なくとも3つのジンクフィンガー、および低親和性DNA結合部位を生じるための少なくとも2つのジンクフィンガーを含んでなる)、(iii)ヘリックス−ターン−ヘリックスすなわちHLHと呼ばれるDNA結合ドメイン、例えば、MAT1、MAT2、MATa1、Antennapedia、Ultrabithorax、Engrailed、Paired、Fushi tarazu、HOX、Unc86、Oct1、Oct2およびPit−1、(iv)ロイシンジッパー型のDNA結合ドメイン、例えば、GCN4、C/EBP、c−Fos/c−JunおよびJunBが挙げられる。本発明において好適なDNA結合ドメインの例としては、DNA結合ドメインGAL4、LexA、転写因子、グループH核受容体、ステロイド/甲状腺ホルモンスーパーファミリーの核受容体が挙げられる。当業者ならば、いくつかのDNA結合モチーフにより形成されたハイブリッドDNA結合ドメインを用いれば、それらを含んでなるエレメントのもの以外のDNA結合部位を認識し得ることが分かるであろう。従って、ジンクフィンガーおよびホメオボックスの結合により形成されたDNA結合ドメインを使用することが可能である。好ましい実施形態では、DNA結合ドメインは、サッカロミセス・セレビシエのGAL4タンパク質のものである。
本発明で用いるのに好適な、それらを含む転写アクチベーターの核局在を促進し得るリガンド結合配列としては、15−デスオキシ−[デルタ]−プロスタグランジンJ2の存在下で核に移行するPPAR(ペルオキシソーム増殖因子活性化受容体)、9−シス−レチノイン酸のα、βまたはγ異性体の存在下で核へ移行するレチノイン酸受容体、レチノイン酸およびTTNPBにより活性化可能なファルネソイドX受容体、24−ヒドロキシコレステロールにより活性化可能な肝臓X受容体、安息香酸4−アミノブチルにより活性化可能な安息好酸X受容体、構成的アンドロスタン受容体、プレグノロン−16カルボニトリルにより誘導可能なプレグナン受容体、リファンピシンにより誘導可能なステロイドおよび生体異物受容体、メドロキシプロゲステロンならびにミフェリプリストンアゴニストおよびアンタゴニストおよび19−ノルエチステロン誘導体により誘導可能なプロゲステロン受容体、グルココルチコイドにより活性化可能なグルココルチコイド受容体、T3および/またはT4により活性化可能な甲状腺ホルモン受容体、エストロゲンおよびそれらの誘導体(17β−エストラジオールおよびエストラジオールなど)により活性化可能なエストロゲン受容体、「tet−off」テトラサイクリン/ドキシサイクリンにより誘導可能なtTAトランスアクチベーター(Gossen and Bujard, 1992, Proc. Natl. Acad. Sci. USA, 89: 5547-5551)、「tet−on」テトラサイクリンにより誘導可能なrtTAトランスアクチベーター(Gossen et al., 1995, Science, 268: 1766-1769)、ムリステロンAまたはエクジソン受容体の類似体リガンドにより誘導可能なトランスアクチベーター(No et al., 1996, Proc. Natl. Acad. Sci. USA, 93: 3346-3351)、RSL1リガンドにより誘導可能なトランスアクチベーター、例えば、Palli et al. (2003, Eur. J. Biochem., 270: 1308-1315)により最初に記載されたRheoSwitch系、ラパマイシンまたはラパマイシン類似体により誘導可能なトランスアクチベーター(Ho et al., 1996, Nature, 382: 822-826; Amara et al., 1997, Proc. Natl. Acad. Sci. USA, 94: 10618-10623)、ならびにそれぞれインデューサーおよびレプレッサーとして競合的に働くクーママイシン/ノボビオシンにより誘導可能なトランスアクチベーター(Zhao et al., 2003, Hum. Gene Ther., 14: 1619-1629)由来の局在配列が挙げられる。好ましい実施形態では、該LBDは、RU486またはミフェプリストンなどのプロゲステロンの誘導体を含む合成抗プロゲスチンで活性化され得るが、Wang et al. (Proc. Natl. Acad. Sci. USA. 1994, 91: 8180-4)により記載されているように患者においては効果を示さない、ヒトプロゲステロン受容体のリガンド結合ドメインである。
最後に、該活性化ドメインは、グループH核受容体、甲状腺またはステロイドホルモンの核受容体の活性化ドメイン、VP16、GAL4、NF−kB、B42、BP64またはp65の活性化ドメインであり得る。好ましい実施形態では、該活性化ドメインはヒトNF−κBタンパク質由来である。
好ましい実施形態では、該転写アクチベーターは、サッカロミセス・セレビシエのGAL4のDNA結合ドメイン(Laughon and Gesteland, 1984, Mol. Cell Biol, 4: 260-267; Marmorstein et al., 1992, Nature, 356: 408-414)、ヒトプロゲステロン受容体のリガンド結合ドメイン(Kastner et al., 1990, Embo J., 9: 1603-1614; Wang et al., 1994, Proc. Natl. Acad. Sci. USA, 91: 8180-8184)およびヒトNF−κBタンパク質の活性化ドメイン(Burcin et al., 1999, Proc. Natl. Acad. Sci. USA, 96: 355-360; Deloukas and van Loon, 1993, Hum. Mol. Genet, 2: 1895-1900)を含んでなる、GAL4−hPR−p65と呼ばれる融合タンパク質である。この転写レギュレーターは、ミフェプリストンまたはその類似体RU487により誘導可能である。ミフェプリストンの不在下で、該レギュレーター融合タンパク質はチミジンキナーゼの最小プロモーターから構成的に発現される。このタンパク質は主として核内に局在し、不活性である。インデューサーであるミフェプリストン、またはその類似体RU486を加えると、これはGAL4−hPR−p65のhPR−LBD領域に高い親和性で結合し、コンフォメーション変化を引き起こし、結果としてタンパク質の二量体化およびその活性型への変換が起こる。これらのホモ二量体は、特異的部位(UAS:上流活性化配列)に結合することができ、該活性化配列に対して3’の配向に局在する遺伝子の転写を引き起こし、従って、目的遺伝子および実際の転写因子をコードする遺伝子の転写を活性化する(図2C)。
当業者ならば、レギュレーターの核への移行またはそれらの活性型へのコンフォメーション変化を促進する外因性化合物の添加により活性が調節される、この種の転写レギュレーターは、それらの転写が特に微細な転写制御を受けることを必要としないことが分かるであろう。一般論として、トランスアクチベーターまたは転写レギュレーターをコードする配列は、その転写および発現を命令する好適なプロモーターに、また、ポリアデニル化シグナルにも関連している。この種のレギュレーターの転写は厳密に制御する必要がないために、それらは構成プロモーターの制御下に見られる。限定されないが、該最小プロモーターは、とりわけ、CMVもしくはRSVなどの構成的ウイルスプロモーター、またはPGKもしくはEF1などの真核細胞構成プロモーターであり得る。あるいは、転写レギュレーターをコードする遺伝子のプロモーター領域に、その発現が正のフィードバックサイクルによりその発現の増大を引き起こすように、転写レギュレーターに対する応答エレメントを含めることが可能である。一実施形態において、該転写レギュレーターは、単純ヘルペスウイルスのチミジンキナーゼ遺伝子(Ptk)の最小プロモーターと結合している、GAL4 DNA結合ドメインに対する1つまたはいくつかの結合エレメント、好ましくは、GAL4 DNA結合ドメインに対する4つの結合エレメントにより形成される領域により調節される。
A1ポリヌクレオチドの第2のエレメントは、本発明の第1のポリヌクレオチド内に存在する第1の発現カセットにコードされている転写レギュレーターの機能的制御下にある制限エンドヌクレアーゼをコードする発現カセットを含んでなる。該制限エンドヌクレアーゼは、特定のDNA部位の認識および断裂により2本鎖DNAを切断する酵素である。本発明においてエンドヌクレアーゼとは、ヒト細胞のDNAゲノムの特異的部位を認識せず、従って、該細胞の天然ゲノムにおいて断裂を引き起こすことはないエンドヌクレアーゼである。限定されないが、該制限エンドヌクレアーゼは、とりわけ、I−SceI、PI−SceI、I−PpoI、I−DmoIまたはPI−TliIであり得る。特定の実施形態では、A1ポリヌクレオチドによりコードされる制限エンドヌクレアーゼは、サッカロミセス・セレビシエのI−SceIである。制限エンドヌクレアーゼのコード配列を含むポリヌクレオチドは、本発明のポリヌクレオチドの第1のエレメントによりコードされる転写レギュレーターに対する結合配列の機能的制御下にある。このようにして、プロモーターはエンドヌクレアーゼの転写および発現を活性化または抑制するトランスアクチベーターの結合に応答する。しかしながら、トランスアクチベーターのプロモーターと結合して相互作用する能力は、調節因子がリガンドまたは誘導剤に結合するかどうかによって変動する。結果として、誘導剤の利用可能性を制御することで、目的遺伝子の転写を調節することができる。誘導剤は遺伝子の転写および発現を活性化および促進することにより作用する場合もあれば、誘導剤の存在はその発現を抑制する場合もある。好ましい実施形態では、転写レギュレーターはGAL4−hPR−p65であり、制限エンドヌクレアーゼをコードするこのポリヌクレオチドは、GAL4 DNA結合ドメインに対する種々の数の結合配列に対して3’位にある。さらにより好ましい実施形態では、制限エンドヌクレアーゼをコードする遺伝子は、GAL4転写因子の6つの結合配列およびE1b(PE1b)アデノウイルス遺伝子のTATAボックスの配列(Lillie and Green, 1989, Nature, 338: 39-44)からなるレギュレーターエレメントに対して3’位にある。
A1ポリヌクレオチドの特定の実施形態では、転写レギュレーターはGAL4−hPR−p65であり、制限エンドヌクレアーゼはI−SceIである。
本発明の第2のポリヌクレオチド(A2ポリヌクレオチド)
第2の態様において、本発明は、
(a)転写レギュレーターをコードするヌクレオチド配列を含んでなる第1の発現カセット;
(b)制限エンドヌクレアーゼをコードするヌクレオチド配列を含んでなり、転写レギュレーター(a)により活性化可能な転写調節配列の機能的制御下にある、第2の発現カセット、および
(c)選択されたアデノウイルスE1Aタンパク質またはアデノウイルスE1AおよびE1Bタンパク質をコードするヌクレオチド配列を含んでなり、転写レギュレーター(a)により活性化可能な転写調節配列の機能的制御下にある、第3の発現カセット
を含んでなる、ポリヌクレオチド(以下、A2ポリヌクレオチド)または発現ベクターに関する。
第2の態様において、本発明は、
(a)転写レギュレーターをコードするヌクレオチド配列を含んでなる第1の発現カセット;
(b)制限エンドヌクレアーゼをコードするヌクレオチド配列を含んでなり、転写レギュレーター(a)により活性化可能な転写調節配列の機能的制御下にある、第2の発現カセット、および
(c)選択されたアデノウイルスE1Aタンパク質またはアデノウイルスE1AおよびE1Bタンパク質をコードするヌクレオチド配列を含んでなり、転写レギュレーター(a)により活性化可能な転写調節配列の機能的制御下にある、第3の発現カセット
を含んでなる、ポリヌクレオチド(以下、A2ポリヌクレオチド)または発現ベクターに関する。
A2ポリヌクレオチドのエレメント(a)および(b)は、本発明の第1のポリヌクレオチドの一部を形成し、従前に記載されているものに本質的に相当する。
A2ポリヌクレオチドの成分(c)は、選択されたアデノウイルスE1Aタンパク質またはアデノウイルスE1AおよびE1Bタンパク質をコードするヌクレオチド配列を含んでなる発現カセットを含んでなる。遺伝子E1Aおよび場合によりE1Bは、任意の種類のアデノウイルスまたはヒトアデノウイルス血清型(ヒトにおいて単離された)、例えば血清型2(Ad2)、5(Ad5)、11(Ad11)または3(Ad3)のゲノムに由来するものであり得る。特定の実施形態では、該成分はアデノウイルス血清型5のゲノム(GenBank:AC000008)の505番〜3511番の範囲の配列を含む。この配列は、転写レギュレーター(a)により活性化可能な転写レギュレーター配列の機能的制御下にある。このようにして、プロモーターは、転写の活性化または抑制、および構造遺伝子E1AおよびE1Bの発現を行うトランスアクチベーターの結合に応答する。しかしながら、トランスアクチベーターのプロモーターと結合して相互作用する能力は、調節因子がリガンドまたは誘導剤に結合するかどうかによって変動する。結果として、誘導剤の利用可能性を制御することで、E1Aおよび場合によりE1B遺伝子の転写を調節することができる。好ましい実施形態では、本発明のA2ポリヌクレオチドの成分(c)は、GAL4転写因子の6つの結合配列およびE1b(PE1b)アデノウイルス遺伝子のTATAボックス配列(Lillie and Green, 1989, Nature, 338: 39-44)からなるハイブリッドプロモーターの制御下にある。
当業者ならば、転写アクチベーターに応答するA2ポリヌクレオチドでの遺伝子の配向はその機能のために重要ではないことが分かるであろう。従って、好ましい実施形態では、第2および第3のカセットは、反対方向に転写される。別の好ましい実施形態では、第2および第3のカセットを制御する転写調節配列は転写レギュレーター(a)と同じ結合部位を共有している。好ましい実施形態では、制限エンドヌクレアーゼおよびアデノウイルスタンパク質をコードする遺伝子は、GAL4転写因子に対する6つの結合配列およびE1b(PE1b)アデノウイルス遺伝子のTATAボックス配列(Lillie and Green, 1989, Nature, 338: 39-44)からなる、同じハイブリッドプロモーターの制御下にある。さらにより好ましい実施形態では、本発明のA2ポリヌクレオチドの第2および第3のカセットは反対方向に転写され、GAL4転写因子のDNA結合ドメインに対する結合配列を共有する。
A2ポリヌクレオチドの特定の実施形態では、第1の発現カセット(a)は転写レギュレーターGAL4−hPR−p65をコードする配列を含んでなり、第2の発現カセット(b)はGAL4タンパク質の1つまたはいくつかの結合部位の制御下にI−SceI制限エンドヌクレアーゼをコードする配列を含んでなり、第3の発現カセット(c)はGAL4タンパク質の1つまたはいくつかの結合部位の制御下にE1AおよびE1B遺伝子の配列を含んでなる。さらにより好ましい実施形態では、I−SceI制限エンドヌクレアーゼをコードする配列ならびにE1AおよびE1B遺伝子の配列の発現を命令する調節可能なプロモーターは、GAL4−hPR−p65と同じ応答エレメントを共有する。
本発明の第3のポリヌクレオチド(Bポリヌクレオチド)
別の態様において、本発明は、組換えアデノウイルスのゲノムを含んでなり、少なくともΨパッケージング配列およびE1Aタンパク質またはE1A/E1Bタンパク質をコードする配列を欠いているヌクレオチド配列を含んでなり、組換えアデノウイルスのゲノムを含んでなる該配列が、制限エンドヌクレアーゼに特異的な認識配列により隣接されている、ポリヌクレオチド(以下、Bポリヌクレオチド)または発現ベクターに関する。アデノウイルスゲノムの配列は、任意の種類のアデノウイルスまたはヒトアデノウイルス血清型(ヒトにおいて単離された)、例えば、血清型2(Ad2)、5(Ad5)、11(Ad11)または3(Ad3)のゲノムから作製することができる。
別の態様において、本発明は、組換えアデノウイルスのゲノムを含んでなり、少なくともΨパッケージング配列およびE1Aタンパク質またはE1A/E1Bタンパク質をコードする配列を欠いているヌクレオチド配列を含んでなり、組換えアデノウイルスのゲノムを含んでなる該配列が、制限エンドヌクレアーゼに特異的な認識配列により隣接されている、ポリヌクレオチド(以下、Bポリヌクレオチド)または発現ベクターに関する。アデノウイルスゲノムの配列は、任意の種類のアデノウイルスまたはヒトアデノウイルス血清型(ヒトにおいて単離された)、例えば、血清型2(Ad2)、5(Ad5)、11(Ad11)または3(Ad3)のゲノムから作製することができる。
好ましくは、制限エンドヌクレアーゼの認識配列は、両末端のITR配列(ゲノムの複製および転写に好適な領域が見られる)に対して5’および3’の位置でアデノウイルスゲノムにより隣接されている。当業者ならば、このBポリヌクレオチドに用いる制限標的は本発明のA1およびA2ポリヌクレオチドにコードされている制限エンドヌクレアーゼに依存することが分かるであろう。よって、アデノウイルスを隣接する標的配列は、A1およびA2ポリヌクレオチドによりコードされているエンドヌクレアーゼを表す際に従前に示したものと同じ特徴および要件を有する制限エンドヌクレアーゼに対する特異的認識配列である。限定されないが、これらの配列は、とりわけ、I−SceI、PI−SceI、I−PpoI、I−DmoIまたはPI−TliIエンドヌクレアーゼによるそれらの認識に特異的なものであり得る。特定の実施形態では、それらはI−SceIエンドヌクレアーゼによる認識に特異的なものである。
さらに、別の好ましい実施形態では、本発明によるBポリヌクレオチドは、パッケージング細胞のゲノムへの該ポリヌクレオチドの挿入を助ける配列を含んでなる。さらにより好ましい実施形態では、ゲノムへの組込みに好都合な配列は、インテグラーゼに対する特異的認識配列である。好ましくは、インテグラーゼの標的配列は、エンドヌクレアーゼに対する第1の認識配列に対して5’位にある。
本発明の実施形態に好適なインテグラーゼの標的配列としては、限定されるものではないが、P1ファージのCreレコンビナーゼの標的配列(LoxP)、S.セレビシエのFLPレコンビナーゼ(Frt)の標的配列、放線菌ΦC31ファージのインテグラーゼの標的配列(attB、attP)、TP901−1レコンビナーゼの標的配列およびR4レコンビナーゼの標的配列またはλインテグラーゼの標的配列を含む。好ましい実施形態では、本発明の標的配列としては、2つの特異的部位またはDNA配列間の一方向組換えを媒介するファージのインテグラーゼに対する特異的配列を含む。より詳しくは、インテグラーゼはセリンインテグラーゼファミリーに属し、それらがDNA鎖の断裂に触媒的セリン残基を用いることを特徴とする(Thorpe and Smith, 1998, Proc. Natl. Acad. Sci. USA, 95: 5505-5510)。これらのインテグラーゼにより認識される組換え部位(attBおよびattP)は他のレコンビナーゼにより認識される組換え配列とは配列が異なり、それよりも短い。この種のインテグラーゼにより媒介される組込みは、組換え配列により厳格に制御される一方向プロセスである(Thorpe et al., 2000, Mol. Microbiol., 38: 232-241)。もう1つの重要な特徴は、宿主におけるattPおよびattB間の組換えには補因子が働く必要がないということである。これらのインテグラーゼは現在、哺乳類細胞における遺伝子操作法に用いられており、外から導入されたattP部位または該attP部位と部分的な同一性を有する天然配列(pseudo−attP)への遺伝物質の効率的な組込みを媒介することが示されている。限定されないが、インテグラーゼの標的配列は、とりわけ、PhiC31、TP901−1またはR4インテグラーゼに対する特異的認識配列であり得る。特定の実施形態では、インテグラーゼの標的配列は、PhiC31ファージのインテグラーゼに特異的な細菌DNAのアンカー部位に相当するattBである。このインテグラーゼは、このattB配列とヒト細胞のゲノムに存在するpseudo−attP配列の間の一方向組換えを媒介し得る。
よって、別の好ましい実施形態では、Bポリヌクレオチドは、5’から3’方向に、場合により、インテグラーゼ認識配列、第1のエンドヌクレアーゼ認識、アデノウイルスゲノム(その限界はアデノウイルスのITRにより定義される)および第2の制限エンドヌクレアーゼ配列を含む。
本発明のベクターおよび宿主細胞ならびにそれらを得るための方法
本発明のポリヌクレオチドは単離してもよいし、好適な宿主細胞において該ポリヌクレオチドの増幅を可能とするベクターの一部をなしてもよい。よって、別の態様において、本発明は、本発明のA1、A2またはBポリヌクレオチドを含んでなる、発現ベクターなどのベクターに関する。
本発明のポリヌクレオチドは単離してもよいし、好適な宿主細胞において該ポリヌクレオチドの増幅を可能とするベクターの一部をなしてもよい。よって、別の態様において、本発明は、本発明のA1、A2またはBポリヌクレオチドを含んでなる、発現ベクターなどのベクターに関する。
本発明のポリヌクレオチドの挿入に好適なベクターとしては、pUC18、pUC19、Bluescriptおよびそれらの誘導体、mp18、mp19、pBR322、pMB9、CoIE1、pCR1、RP4などの原核生物における発現ベクター;pSA3およびpAT28などのファージおよび「シャトル」ベクター;2ミクロン、組込みプラスミド、YEPベクター、セントロメアプラスミドなどのプラスミド種ベクターなどの酵母における発現ベクター;ならびに同様にpAC系およびpVL系ベクターなどの昆虫細胞における発現ベクター;pIBI、pEarleyGate、pAVA、pCAMBIA、pGSA、pGWB、pMDC、pMY、pORE系ベクターなどの植物における発現ベクター;ならびにウイルスベクター(アデノウイルス、アデノウイルス随伴ウイルスならびにレトロウイルス、特に、レンチウイルス)ならびに非ウイルスベクター(pSilencer 4.1−CMV(Ambion)、pcDNA3、pcDNA3.1/hyg pHCMV/Zeo、pCR3.1、pEFl/His、pIND/GS、pRc/HCMV2、pSV40/Zeo2、pTRACER−HCMV、pUB6/V5−His、pVAX1、pZeoSV2、pCI、pSVLおよびpKSV−10、pBPV−1、pML2dおよびpTDT1ベクターなどの)に基づく真核細胞における同様の発現ベクターが挙げられる。該ポリヌクレオチドの挿入に特に適当なベクターは、宿主細胞で維持および/または複製および/または発現させることができる、ウイルスベクター(アデノ随伴ウイルス、レトロウイルス、レンチウイルス、ヘルペスウイルス、SV40およびαウイルスなど)に基づくか、または非ウイルスベクター(プラスミドなど)に基づく高等真核細胞における発現ベクターである。さらに詳しい実施形態では、該発現ベクターは、ex vivoで哺乳類細胞、特に、ヒト細胞をトランスフェクトまたは感染させるのに好適である。
一般に、真核生物発現ベクターは、例えば、5’および3’に位置する配列の転写制御下に1以上のクローニングされた遺伝子と選択マーカーを含む。限定されないが、これらの制御配列は、真核細胞で発現させることができるプロモーター(転写開始部位を含む)、リボソーム結合部位、RNAプロセシングシグナル、転写終結部位および/またはポリアデニル化シグナルを含む。
好ましくは、これらのベクターは、それを発現する細胞に表現型を与え、ベクターと接触された後にそのベクターを組み込んだ細胞の識別および/または選択を助けるリポーターまたは選択遺伝子を含んでなる。選択の表現型はトランスフェクションまたは感染前にはその真核細胞で発現されないことが好ましい。本発明において有用なリポーター遺伝子としては、lacZ、ルシフェラーゼ、チミジンキナーゼ、GFPおよび同様のものが挙げられる。本発明において有用な選択遺伝子としては、例えば、G418アミノグルコシド耐性を与えるネオマイシン耐性遺伝子、ハイグロマイシン耐性を与えるハイグロマイシンホスホトランスフェラーゼ遺伝子、オルニチンデカルボキシラーゼ阻害剤(2−(ジフルオロメチル)−DL−オルニチン:DFMO)耐性を与えるODC遺伝子、メトトレキサート耐性を与えるジヒドロ葉酸レダクターゼ(dihiyrofolate reductase)遺伝子、ピューロマイシン耐性を与えるピューロマイシンN−アセチルトランスフェラーゼ遺伝子、ゼオシン耐性を与えるble遺伝子、9−β−D−キシロフラノースアデニン耐性を与えるアデノシンデアミナーゼ遺伝子、N−(ホスホノアセチル)−L−アスパルテートの存在下で細胞を増殖可能とするシトシンデアミナーゼ遺伝子、アミノプテリンの存在下で細胞を増殖可能とするチミジンキナーゼ遺伝子、キサンチンの存在下、かつ、グアニンの不在下で細胞を増殖可能とするキサンチン−グアニンホスホリボシルトランスフェラーゼ遺伝子、トリプトファンの代わりにインドールの存在下で細胞を増殖可能とする大腸菌(E. coli)のtrpB遺伝子、ヒスチジンの代わりに細胞のヒスチジノール使用を可能とする大腸菌のhisD遺伝子が挙げられる。選択遺伝子は、真核細胞での該遺伝子の発現に好適なプロモーター(例えば、プロモーターCMVまたはSV40)、翻訳の開始の最適化部位(例えば、いわゆるKozak則またはIRES則に従う部位)、ポリアデニル化部位(例えば、SV40またはホスホグリセリン酸キナーゼのポリアデニル化部位など)、またはイントロン(例えば、β−グロブリン遺伝子のイントロンなど)をさらに含み得るプラスミドに組み込まれる。あるいは、同じベクター中で同時にリポーター遺伝子と選択遺伝子の組合せを使用することもできる。
本発明のポリヌクレオチドおよびそれらを含む発現ベクターは、当業者に公知であり、"Molecular Cloning: a Laboratory manual", J. Sambrook and D.W. Russel編, 発行者: Cold Spring Harbor Laboratory Press,第3版, 2001 (ISBN 978-0879695774)などの概論および手引き書で認知される分子生物学および遺伝子工学の従来技術により作製することができる。また、本発明のポリヌクレオチドのための発現ベクターの構築を助けることができる市販の系も存在する。よって、例えば、Aポリヌクレオチドを含む哺乳類細胞のための発現ベクターの構築は、ミフェリプリストンによる目的遺伝子の誘導発現のためのベクターの構築を可能とするGeneSwitch(商標)誘導発現系(Invitrogen, Carlsbad CA92008 USA, カタログ番号K1060-01およびK1060-2)、リガンドRLS1による目的遺伝子の誘導発現を可能とするRheoSwitch(商標)誘導発現系(New England Biolabs, Beverly, MAO1915-5599 USA)、または他の等価な市販の系などの系を用いれば容易となる。
本発明のポリヌクレオチドおよびベクターは、組換えアデノウイルスを生産するためにベクターの増殖ビヒクルおよびパッケージング細胞の双方として働く宿主細胞の一部を形成していると見られる場合がある。よって、別の態様では、本発明は、本発明のA1、A2もしくはBポリヌクレオチド、または前述のポリヌクレオチドのいずれかを含んでなる発現ベクターを含んでなる宿主細胞に関する。これらの細胞をアデノウイルスの生産のためのパッケージング細胞として用いる場合には、それらはアデノウイルスの生産および感染を支えることができる必要がある。この実施形態によれば、好適な真核細胞はアデノウイルスの感染および複製を許容するいずれの細胞であってもよい。
好ましい実施形態では、この細胞系統は安定な細胞系統である。限定されないが、宿主細胞はHeLa、A549、KB、HuH7細胞、またはアデノウイルスの生活環を支援することができる他の任意の真核細胞であり得る。E1AまたはE1A/E1Bポリペプチドがこの細胞により支援される場合(本発明のA1ポリヌクレオチドが用いられる場合)、その発現は、Bポリヌクレオチドに含まれるアデノウイルス遺伝子の発現の開始をより良く制御するために誘導剤を介して調節可能なプロモーターの制御下にあってもよく、従って、過剰な発現タンパク質に由来する細胞傷害作用のリスクを最大限制限することができる。この場合、該タンパク質を構成的に発現する細胞、例えば、293またはPerC6細胞が好適であろう。
特定の実施形態では、該宿主細胞は哺乳類、好ましくは霊長類、特にはヒトに由来する。好ましい実施形態では、該細胞系統は肺癌腫系統である。いっそうより好ましい実施形態では、該宿主細胞はA549系統の細胞である。Giard et al. (1973, J. Natl. Cancer Inst, 51: 1417-1423)により誘導され、その後、Lieber et al. (1976, Int. J. Cancer., 17: 62-70)により深く特性決定されたこの細胞系統は、アデノウイルス感染に対して感受性が高く、ウイルス生産系統として高い能力を与える(Smith et al., 1986, J. Clin. Microbiol, 24: 265-268)。
好ましい実施形態では、本発明は、本発明のA1ポリヌクレオチドまたは該ポリヌクレオチドを含んでなるベクターを含んでなる宿主細胞に関する。いっそうより好ましい実施形態では、該細胞は、アデノウイルスE1Aタンパク質をコードする配列および場合によりアデノウイルスE1Bタンパク質をコードする配列をさらに含んでなる。
別の好ましい実施形態では、本発明は、本発明のA2ポリヌクレオチドまたは該ポリヌクレオチドを含んでなるベクターを含んでなる宿主細胞に関する。
別の実施形態では、本発明は、本発明のBポリヌクレオチドまたは該ポリヌクレオチドを含んでなるベクターを含んでなる宿主細胞に関する。
別の実施形態では、本発明は、本発明のA1ポリヌクレオチドとBポリヌクレオチドを含んでなる宿主細胞に関する。いっそうより好ましい実施形態では、該細胞は、アデノウイルスE1Aタンパク質をコードする配列および場合によりアデノウイルスE1Bタンパク質をコードする配列をさらに含んでなる。
別の実施形態では、本発明は、本発明のA2ポリヌクレオチドとBポリヌクレオチドを含んでなる宿主細胞に関する。
本発明のA1およびBポリヌクレオチドを含んでなる細胞とA2およびBポリヌクレオチドを含んでなる細胞は双方とも、高容量アデノウイルスベクターの生産およびパッケージングに特に好適であり、このため、本発明のA1およびBポリヌクレオチドを含んでなる細胞とA2およびBポリヌクレオチドを含んでなる細胞は該ベクターの生産およびパッケージングのための手順および系に使用することができる。しかしながら、アデノウイルスの生産に特に有用なのは、Bポリヌクレオチド中で欠陥のあるアデノウイルスゲノムを隣接している標的部位がA1およびA2ポリヌクレオチドによりコードされている制限エンドヌクレアーゼに相当しているものであり、そうでなければ、A1またはA2ポリヌクレオチドによりコードされている制限エンドヌクレアーゼは、ゲノムの複製および転写に不可欠なアデノウイルスゲノムを放出するBポリヌクレオチドに作用することができないからである。
本発明の宿主細胞は、本発明のポリヌクレオチドまたはベクターを一時的に導入するか、または好ましくはベクターのポリヌクレオチドを安定に導入することにより得ることができる。これを行うためには、本発明のベクターと宿主細胞とを、細胞へのDNAの取り込みに好適な条件で接触させる必要がある。本発明のベクターを、当業者に公知のトランスフェクション法(Ausubel, F.M. et al, "Current Protocols in Molecular Biology", John Wiley & Sons Inc; 2003の第9.1節〜第9.5節を参照)のいずれかを用いて検討対象の細胞に導入する。特に、これらの細胞は、DNAのリン酸カルシウム、DEAE−デキストラン、ポリブレンとの共沈殿、エレクトロポレーション、マイクロインジェクション、リポソームにより媒介される融合、リポフェクション、レトロウイルスによる感染およびバイオリスティックトランスフェクションによりトランスフェクトすることができる。
よって、別の態様では、本発明は、
(i)細胞を本発明のA1ポリヌクレオチドでトランスフェクトすること、および
(ii)該細胞を本発明のBポリヌクレオチドでトランスフェクトすること
を含んでなり、
工程(i)および(ii)は任意の順序でまたは同時に行うことができ、かつ、アデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列を含んでなる細胞が用いられる、高容量アデノウイルスの感染性粒子の生産およびパッケージングに好適な細胞の生産方法に関する。
(i)細胞を本発明のA1ポリヌクレオチドでトランスフェクトすること、および
(ii)該細胞を本発明のBポリヌクレオチドでトランスフェクトすること
を含んでなり、
工程(i)および(ii)は任意の順序でまたは同時に行うことができ、かつ、アデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列を含んでなる細胞が用いられる、高容量アデノウイルスの感染性粒子の生産およびパッケージングに好適な細胞の生産方法に関する。
よって、別の態様では、本発明は、
(i)細胞を本発明のA2ポリヌクレオチドでトランスフェクトすること、および
(ii)該細胞を本発明のBポリヌクレオチドでトランスフェクトすること
を含んでなり、
工程(i)および(ii)は任意の順序でまたは同時に行うことができる、高容量アデノウイルスの感染性粒子の生産およびパッケージングに好適な細胞の生産方法に関する。
(i)細胞を本発明のA2ポリヌクレオチドでトランスフェクトすること、および
(ii)該細胞を本発明のBポリヌクレオチドでトランスフェクトすること
を含んでなり、
工程(i)および(ii)は任意の順序でまたは同時に行うことができる、高容量アデノウイルスの感染性粒子の生産およびパッケージングに好適な細胞の生産方法に関する。
当業者ならば、上記の方法の工程(i)および(ii)は、細胞内に該ポリヌクレオチドまたはベクターが一時的に存在するように行うこともできるし、あるいは、A1/A2および/またはBポリヌクレオチドの安定発現が得られるように行うこともできることが分かるであろう。宿主細胞において本発明のベクターの安定発現を得たい場合には、そのDNAが染色体外の位置にある細胞系統のゲノムにそのDNAを組み込んだ細胞を選択することができるように、所定の抗生物質に対する耐性をコードする遺伝子を、トランスフェクションまたは感染工程中に含める必要がある。これらの細胞の選択を可能とする遺伝子は、本発明の目的構築物を含む同じベクターの一部として提供することもできるし、あるいは、該耐性遺伝子を含む第2のプラスミドと同時トランスフェクションを行うことにより別に提供することもできる。この後者の場合では、トランスフェクション混合物に、DNA構築物を含むプラスミドを、耐性遺伝子の組込みの度に検討対象のプロモーターを含む遺伝子の高い組み込み率が得られるように、耐性遺伝子に対してモル過剰量で提供する。好ましくは、DNA構築物を含むプラスミドは、リポーター耐性遺伝子を含むベクターに対して少なくとも5倍過剰量で提供する。好ましくは、耐性遺伝子は本発明のベクター内に含められる。トランスフェクションに好適な耐性遺伝子は従前に記載されている。よって、好ましい実施形態では、本発明によるA1およびBまたはA2およびBポリヌクレオチドを含んでなる細胞の生産方法は、工程(i)および(ii)で用いられたポリヌクレオチドに存在する選択マーカーに基づき、第1および/または第2のポリヌクレオチドを安定に組み込んだ細胞が選択される付加的な選択工程を含む。
一方、A2ポリヌクレオチドを含んでなる発現ベクターでトランスフェクションを行うと、該ポリヌクレオチドを安定に(細胞は培養で最大4か月維持された)組み込む細胞クローンを選択することが可能であった。有利にも、E1A/E1Bタンパク質と制限エンドヌクレアーゼの発現は抑制され、細胞に害の無い基底発現レベルを維持すること、およびこの発現が用いる特定の構築物に好適な誘導剤の好適な量を培養物に添加することにより誘導および活性化され得ることが確認された。
さらに、インテグラーゼ認識部位を含んでなるBポリヌクレオチドの変異体が用いられる特定の場合では、Bポリヌクレオチドの細胞ゲノムへの組込みを可能とするために、Bポリヌクレオチドを含んでなる発現ベクターを、インテグラーゼをコードし発現し、かつ、インテグラーゼの認識配列を認識するプラスミドとともに同時にトランスフェクトすることにより工程(ii)を行う必要がある。好ましくは、インテグラーゼの認識部位がattB部位である場合には、工程(ii)は、PhiC31ファージのインテグラーゼをコードするプラスミドとの同時トランスフェクションを含み、これにより、このattB配列とヒト細胞の染色体に存在するpseudo−attP配列の間の組換えによる、細胞ゲノムへのBポリヌクレオチドまたは該ポリヌクレオチドを含むベクターの組込みが可能となる。この一方向組換えおよび組込みはPhiC31インテグラーゼにより媒介される。種々のウイルス領域の発現とそれに続くBポリヌクレオチドに存在するウイルスゲノムの複製には、このウイルスのITR末端がフリーである必要があり、加えて、ウイルスE1A/E1Bタンパク質が存在することも必要である。結果として、生じた細胞は欠陥アデノウイルスのゲノムを持つが、これは発現または複製することができない。組込みは無作為にBポリヌクレオチドを生じることもできるが、pseudo−attP配列への組込みが主要であり、遺伝物質の損失も伴わない。
前述の方法は高容量アデノウイルスベクターのパッケージングに好適な細胞系統の生産を可能とする。よって、別の態様では、本発明は、前述の方法のいずれかによって得られる細胞に関する。特に、本発明は、A1およびBポリヌクレオチドまたはA2およびBポリヌクレオチドを含んでなる(該ポリヌクレオチドが細胞ゲノムに安定に組み込まれ得るか、または一時的に見られる)細胞を含む。
本発明のアデノウイルスベクターの生産およびパッケージングのための系および方法
本発明ポリヌクレオチドまたはそれらを含んでなるベクターを細胞系統に導入することにより生産されたパッケージング細胞は、そのアデノウイルスゲノムを含んでなるポリヌクレオチドによるトランスフェクションか、その遺伝子を含んでなる組換えアデノウイルスによる感染のいずれかにより、目的遺伝子を含んでなるアデノウイルスゲノムを細胞へ導入することによる高容量アデノウイルスベクターの作製に使用することができる。アデノウイルス/目的遺伝子を含んでなるアデノウイルスゲノムを含んでなるポリヌクレオチドによる感染/トランスフェクションを行い、それらの細胞とA1またはA2ポリヌクレオチドに含まれる遺伝子の発現を促進する薬剤とを接触させた後、細胞内で転写レギュレーターが生産され始め、そしてそれらは制限エンドヌクレアーゼをコードする遺伝子の転写を活性化する。これは次に、Bポリヌクレオチドに含まれる欠陥アデノウイルスゲノムを隣接している標的部位において働き、細胞ゲノムからのその切り出しが起こるが、これは該ゲノムの一部をなすアデノウイルス遺伝子が次に転写されるために必要な条件である。Bポリヌクレオチドからのアデノウイルス遺伝子の転写にはまた、A2ポリヌクレオチドにより(この場合には、それらは転写レギュレーターの活性化に応答する)、または実際のパッケージング細胞に(これもまた転写レギュレーターの制御下にコードされている)初期E1AおよびE1B遺伝子の発現も必要とされる。
本発明ポリヌクレオチドまたはそれらを含んでなるベクターを細胞系統に導入することにより生産されたパッケージング細胞は、そのアデノウイルスゲノムを含んでなるポリヌクレオチドによるトランスフェクションか、その遺伝子を含んでなる組換えアデノウイルスによる感染のいずれかにより、目的遺伝子を含んでなるアデノウイルスゲノムを細胞へ導入することによる高容量アデノウイルスベクターの作製に使用することができる。アデノウイルス/目的遺伝子を含んでなるアデノウイルスゲノムを含んでなるポリヌクレオチドによる感染/トランスフェクションを行い、それらの細胞とA1またはA2ポリヌクレオチドに含まれる遺伝子の発現を促進する薬剤とを接触させた後、細胞内で転写レギュレーターが生産され始め、そしてそれらは制限エンドヌクレアーゼをコードする遺伝子の転写を活性化する。これは次に、Bポリヌクレオチドに含まれる欠陥アデノウイルスゲノムを隣接している標的部位において働き、細胞ゲノムからのその切り出しが起こるが、これは該ゲノムの一部をなすアデノウイルス遺伝子が次に転写されるために必要な条件である。Bポリヌクレオチドからのアデノウイルス遺伝子の転写にはまた、A2ポリヌクレオチドにより(この場合には、それらは転写レギュレーターの活性化に応答する)、または実際のパッケージング細胞に(これもまた転写レギュレーターの制御下にコードされている)初期E1AおよびE1B遺伝子の発現も必要とされる。
よって、別の態様では、本発明は、
(a)本発明による細胞と、
(b)高容量アデノウイルス
を含んでなる、高容量アデノウイルスの生産のための系に関する。
(a)本発明による細胞と、
(b)高容量アデノウイルス
を含んでなる、高容量アデノウイルスの生産のための系に関する。
別の態様では、本発明は、
(a)宿主細胞を、生産を意図する高容量アデノウイルスのゲノムを含んでなるポリヌクレオチド、または該ポリヌクレオチドを含んでなる発現ベクターでトランスフェクトするか、または感染させる工程、
(b)該トランスフェクト/感染細胞を高容量アデノウイルスの複製およびパッケージングを可能とするのに十分な条件下で培養する工程、
(c)高容量アデノウイルスのウイルス粒子を回収する工程および場合により、
(d)工程(a)〜(c)を繰り返す工程(工程(c)で生産された高容量ウイルス粒子を次のサイクルの工程(a)で用いる)
を含んでなり、
工程(a)で用いられる宿主細胞が、
(i)本発明のA1ポリヌクレオチドと、アデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列とを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、本発明のBポリヌクレオチドまたは該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(ii)本発明のA2ポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、本発明のBポリヌクレオチドまたは該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(iii)本発明のBポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、本発明のA1ポリヌクレオチドでのトランスフェクション工程が行われ、該細胞はアデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列を含んでなる)、
(iv)本発明のBポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、本発明のA2ポリヌクレオチドまたは該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(v)本発明のA1ポリヌクレオチド、本発明のBポリヌクレオチド、ならびにアデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列を含んでなる細胞、および
(vi)本発明のA2およびBポリヌクレオチドを含んでなる細胞
からなる群から選択される、高容量アデノウイルスベクターの生産およびパッケージングのための方法に関する。
(a)宿主細胞を、生産を意図する高容量アデノウイルスのゲノムを含んでなるポリヌクレオチド、または該ポリヌクレオチドを含んでなる発現ベクターでトランスフェクトするか、または感染させる工程、
(b)該トランスフェクト/感染細胞を高容量アデノウイルスの複製およびパッケージングを可能とするのに十分な条件下で培養する工程、
(c)高容量アデノウイルスのウイルス粒子を回収する工程および場合により、
(d)工程(a)〜(c)を繰り返す工程(工程(c)で生産された高容量ウイルス粒子を次のサイクルの工程(a)で用いる)
を含んでなり、
工程(a)で用いられる宿主細胞が、
(i)本発明のA1ポリヌクレオチドと、アデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列とを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、本発明のBポリヌクレオチドまたは該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(ii)本発明のA2ポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、本発明のBポリヌクレオチドまたは該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(iii)本発明のBポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、本発明のA1ポリヌクレオチドでのトランスフェクション工程が行われ、該細胞はアデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列を含んでなる)、
(iv)本発明のBポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、本発明のA2ポリヌクレオチドまたは該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(v)本発明のA1ポリヌクレオチド、本発明のBポリヌクレオチド、ならびにアデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列を含んでなる細胞、および
(vi)本発明のA2およびBポリヌクレオチドを含んでなる細胞
からなる群から選択される、高容量アデノウイルスベクターの生産およびパッケージングのための方法に関する。
高容量アデノウイルスベクターの生産およびパッケージングのための方法の工程(a)は、パッケージング細胞と高容量アデノウイルスまたは該アデノウイルスのゲノムを含んでなるポリヌクレオチドもしくはベクターとを接触させることを含んでなる。
本発明による「高容量アデノウイルス」は、例えばAlba et al. (2005, Gene Therapy, 12:S18-S27)により記載されているように、アデノウイルスゲノムの、ITR 5’および3’領域とΨパッケージング領域を除く総ての遺伝子を欠いていることを特徴とする、補助依存性またはガットレスと呼ばれる組換えアデノウイルスとして理解される。これらのアデノウイルスは、それらの固有のアデノウイルスゲノム配列を欠いているので、36kDaまでの異種配列を許容する。本発明の方法に従ってこのガットレスベクターに組み込むことができる異種遺伝子はとしては、エリスロポエチン(EPO)、レプチン、コルチコトロピン放出ホルモン(CRH)、成長ホルモン放出ホルモン(GHRH)、ゴナドトロピン放出ホルモン(GnRH)、チロトロピン放出ホルモン(TRH)、プロラクチン放出ホルモン(PRH)、メラトニン放出ホルモン(MRH)、プロラクチン放出ホルモン(PIH)、ソマトスタチン、副腎皮質刺激ホルモン(ACTH)、ソマトトロピンまたは成長ホルモン(GH)、黄体形成ホルモン(LH)、卵胞刺激ホルモン(FSH)、チロトロピン(TSHまたは甲状腺刺激ホルモン)、プロラクチン、オキシトシン、抗利尿ホルモン(ADHまたはバソプレシン)、メラトニン、ミュラー管阻害因子、カルシトニン、副甲状腺ホルモン、ガストリン、コレシストキニン(CCK)、セクレチン、PBGD、I型インスリン様成長因子(IGF−I)、II型インスリン様成長因子(IGF−II)、心房性ナトリウム利尿ペプチド(ANP)、ヒト絨毛性性腺刺激ホルモン(hCG)、インスリン、グルカゴン、ソマトスタチン、膵臓ポリペプチド(PP)、レプチン、ニューロペプチドY、レニン、アンギオテンシンI、アンギオテンシンII、VIII因子、IX因子、組織因子、VII因子、X因子、トロンビン、V因子、XI因子、XIII因子、インターロイキン1(IL−1)、インターロイキン2(IL−2)、腫瘍壊死因子−α(TNF−α)、インターロイキン6(IL−6)、インターロイキン8(IL−8およびケモカイン)、インターロイキン12(IL−12)、インターロイキン16(IL−16)、インターロイキン15(IL−15)、インターロイキン24(IL−24)、α、β、γインターフェロン、CD3、ICAM−1、LFA−1、LFA−3、ケモカイン(RANTES1α、MIP−Iα、MIP−1βを含む)、ニューロン成長因子(NGF)、血小板由来成長因子(PDGF)、トランスフォーミング成長因子−β(TGF−β)、骨形成タンパク質(BMP)、繊維芽細胞成長因子(FGFおよびKGF)、上皮成長因子(EGFおよび関連のもの)、血管内皮成長因子(VEGF)、顆粒球コロニー刺激因子(G−CSF)、グリア細胞由来神経栄養因子(GDNF)、ケラチノサイト成長因子、内皮成長因子、α−1抗トリプシン、腫瘍壊死因子、顆粒球およびマクロファージコロニー刺激因子(GM−CSF)、カルジオトロフィン1(CT−1)、オンコスタチンM(OSM)、アンフィレギュリン(AR)、シクロスポリン、フィブリノゲン、ラクトフェリン、組織型プラスミノーゲンアクチベーター(tPA)、キモトリプシン、免疫グロブリン、ヒルディン、スーパーオキシドジスムターゼ、イミグルセラーゼ、β−グルコセレブロシダーゼ、グルコシダーゼ−α、α−L−イズロニダーゼ、イズロネート−2−スルファターゼ、ガルスルファーゼ、α−ヒトガラクトシダーゼA、プロテイナーゼ阻害剤α−1、ラクターゼ、膵臓酵素(リパーゼ、アミラーゼ、プロテアーゼ)、アデノシンデアミナーゼ、免疫グロブリン、アルブミン、A型およびB型ボツリヌス菌毒素、コラゲナーゼ、ヒトデオキシリボヌクレアーゼI、ヒアルロニダーゼ、パパイン、L−アスパラギナーゼ、レピルジン、ストレプトキナーゼ、WO0331155、WO200519244およびWO0393293(その内容は引用することにより本明細書の一部とされる)に記載されているものなどのトランスフォーミング成長βペプチド(TGF−β)、干渉RNA分子(shRNA、siRNA、miRNA、リボヌクレオプロテインU1の改変RNA)の転写に好適な発現カセットをコードする遺伝子が挙げられる。該異種遺伝子の他、本発明で用いるガットレスアデノウイルスは、Parks et al. (1999, J. Virol., 73:8027-8034)により記載されているλファージゲノムに由来するstuffer配列またはSandig et al. (2000, Proc. Natl. Acad. Sci. USA, 97:1002-7)により記載されているようなpSTK120に見られるstuffer DNAなどのstuffer領域を含み得る。これらの領域は通常、ヒトゲノムに存在し、かつ、該ヒトstuffer DNAの代わりにParks et al. (1999, J. Virol., 73:8027-8034)に記載されているλファージの22kbフラグメントを含んでなる対照アデノウイルスに対して異種の遺伝子の発現を増強することができる配列を含む。ヒトstuffer DNAの全長は様々であるが、20〜30kb、好ましくは20〜25kb、またはいっそうより好ましくは21〜23kbの範囲であり、例えば22kbである。該stuffer DNAにおいてシスで働く配列の数は、2、3、4またはそれ以上の中で様々であり、限定されるものではないが、16.2kbの反復alphoidドメイン(Smith et al., 1995, Mol. Cell. Biol., 15:5165-72に記載);例えば6型アデノウイルスの左端を含む4.2kbのフラグメントまたは免疫グロブリンκの2コピーのマトリックス付着領域などのマトリックス付着領域(MAR)(Betz et al., 1994, Cell, 77:239-248に記載);肝細胞制御領域(HCR)、例えば、該HCRを含んでなる1.2kbのフラグメント(Miao et al., 2000, Molecular Therapy, 1:522-32に記載);またはニワトリリゾチームの2.8kb領域(Phi-Van et al., 1990, Mol. Cell. Biol. 10:2302-2307により記載)、インターフェロンβの5’領域のマトリックス付着領域(Bode et al. 1992, Science, 10:195-197により記載)などの別のマトリックス付着領域またはテロメアもしくはセントロメア配列などの他の非コードヒト配列が挙げられる。
宿主細胞と、アデノウイルスゲノムを含んでなるポリヌクレオチドとの接触は、リン酸カルシウム、DEAE−デキストラン、ポリブレンによるDNAの共沈殿、エレクトロポレーション、マイクロインジェクション、リポソームにより媒介される融合、レトロウイルスによる感染およびバイオリスティックトランスフェクションによる該ポリヌクレオチドまたはそれを含んでなるベクターのトランスフェクションなど、当業者に公知の技術を用いて行う。あるいは、細胞と、増幅させたいアデノウイルスとを接触させることもでき、この場合には細胞を感染させるアデノウイルスの実際の能力により該ゲノムを細胞に導入することができる。
「パッケージング細胞」は、本発明で記載され、少なくとも本発明のA1/A2ポリヌクレオチドまたはBポリヌクレオチドを含む任意の細胞と理解される。当業者ならば、種々のパッケージング細胞を使用できることが分かるであろう。しかしながら、本発明の1以上のポリヌクレオチド中にパッケージング細胞が存在するかしないかによって、工程(a)に先立ち、または同時に、これらの細胞と、パッケージング細胞には見られず、アデノウイルスゲノムの複製のため、ならびにアデノウイルス細胞のアセンブリに必要なポリペプチドを細胞で生産するために不可欠なエレメントを提供するために必要とされる本発明のポリヌクレオチドとを接触させるトランスフェクション工程を行わなければならない。よって、本発明のA1ポリヌクレオチドとアデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列を含んでなる細胞をパッケージング細胞として使用することができる。しかしながら、このパッケージング細胞の使用には、工程(a)に先立ち、または同時に、該細胞を本発明のBポリヌクレオチドまたは該ポリヌクレオチドを含んでなる発現ベクターでトランスフェクトすることからなる工程が必要である。
本発明のA2ポリヌクレオチドを含んでなる細胞を用いる場合には、工程(a)に先立ち、または同時に、本発明のBポリヌクレオチドまたは該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程を行うことができる。
本発明のBポリヌクレオチドを含んでなる細胞をパッケージング細胞として用いる場合には、工程(a)に先立ち、または同時に、本発明のA1ポリヌクレオチドでのトランスフェクション工程を行うことができ、この場合、細胞は、アデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列をさらに含むことができる。
本発明のBポリヌクレオチドを含んでなる細胞を用いる場合には、工程(a)に先立ち、または同時に、本発明のA2ポリヌクレオチドまたは該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程を行うことができる。
また、本発明のA1ポリヌクレオチド、本発明のBポリヌクレオチドならびにアデノウイルスE1Aタンパク質および場合によりアデノウイルスE1Bタンパク質をコードする配列を含んでなる細胞、あるいは、本発明のA2およびBポリヌクレオチドを含んでなる細胞を使用することもできる。
本発明の方法の工程(b)は、工程(a)で得られたトランスフェクト/感染細胞を高容量アデノウイルスの複製およびパッケージングを可能とする条件で維持することを含んでなる。このためには、該条件がA1またはA2ポリヌクレオチドによりコードされている転写レギュレーターの発現を可能とし、これがA1およびA2ポリヌクレオチドに存在するエンドヌクレアーゼの遺伝子のレギュレーター領域内のそれらの結合部位に、また、A2ポリヌクレオチドに存在するアデノウイルスE1AおよびE1B遺伝子のレギュレーター領域内のその結合部位に作用するようにする必要がある。これを行うため、A1およびA2ポリヌクレオチドによりコードされている転写レギュレーターが活性化可能なレギュレーターである場合には、工程(b)は細胞と転写レギュレーター活性化することができる薬剤とを接触させることを含む。好ましい実施形態では、A1およびA2ポリヌクレオチドによりコードされている転写レギュレーターは、従前に記載されているようなGAL4−hPR−p65であり、この場合には、誘導剤はミフェプリストンである。
工程(b)は、Shabram et al., (1997, Hum. Gene Ther., 8:453-465)により記載されているようなHPLCに基づくResource Q法などの標準的手段によって、または間接的に細胞内の細胞傷害作用の視覚的検査によって決定されるような、ウイルス粒子の濃度が十分高くなるのに必要な時間行う。場合により、細胞培養は新鮮培地の添加を含んでもよい。
工程(c)では、工程(b)で生じたアデノウイルスを細胞培養から回収する。これを行うため、当業者に公知のいずれかの方法(トリプシン処理および遠心分離または濾過)によって培養培地の細胞を分離し、これらの細胞を不活性な溶液中で溶解させ(冷凍/解凍サイクル、ホモジナイゼーション、音波処理、キャビテーション、洗剤および類似品の使用)、アデノウイルス粒子を、CsCl勾配での超遠心分離などの既知の方法により、またはイオンクロマトグラフィーと金属キレートアフィニティークロマトグラフィーの組合せ(Huyghe et al., 1996, Hum. Gene Ther., 6:1403-1416)、イオン交換クロマトグラフィーとゲル分画クロマトグラフィーの組合せ(WO07059473)、ジエチルアミノエチル(DEAE)セルロースでのクロマトグラフィー(Haruna et al., 1961, Virology 13, 264-267)、ヒドロキシルアパタイトでのクロマトグラフィー(US2002/0064860)ならびにソフトゲル(アガロース)、透過クロマトグラフィーを含む合成ポリマーに基づく多孔質ポリマー(フラクトゲル)および硬質カプセル中のソフトゲルに基づく材料(例えば、Ceramica HyperD(登録商標)F)(Rodrigues, 1997, J. Chromatogr. B Biomed. Sci. Appl 699:47-61)などの種々のタイプのクロマトグラフィーにより精製することが必要である。
任意の工程(d)は、工程(a)〜(c)を1回または数回繰り返すことからなる。これを行うため、サイクルの各工程(a)では、前のサイクルの工程(c)で得られたアデノウイルス粒子を出発材料として用いる。このようにして、本発明のプロセスを数回繰り返して、各サイクルでより多数のアデノウイルス粒子を得ることができる。
以下、本発明を、本発明の範囲の非限定的な例示として示される下記実施例に基づいて説明する。
実施例1:E1aおよびE1bアデノウイルス遺伝子の、また、I−SceI制限酵素の誘導発現のためのpGal4−2RU−E1−SceIプラスミドの構築
本実施形態では、本発明で定義されるようなA2ポリヌクレオチドを含むpGal4−2RU−E1−SceIプラスミド(図1A)を、アデノウイルス遺伝子E1aおよびE1bの発現の、転写レベルでの制御のために具体的に設計した。この構築物内の、同じタイプの転写制御下に、I−SceI制限エンドヌクレアーゼをコードする遺伝子が含まれていた。このA2ポリヌクレオチド内に含まれるヌクレオチド配列から、E1a、E1bおよびI−SceI遺伝子の発現を制御する転写レギュレーターが構成的に発現される。
本実施形態では、本発明で定義されるようなA2ポリヌクレオチドを含むpGal4−2RU−E1−SceIプラスミド(図1A)を、アデノウイルス遺伝子E1aおよびE1bの発現の、転写レベルでの制御のために具体的に設計した。この構築物内の、同じタイプの転写制御下に、I−SceI制限エンドヌクレアーゼをコードする遺伝子が含まれていた。このA2ポリヌクレオチド内に含まれるヌクレオチド配列から、E1a、E1bおよびI−SceI遺伝子の発現を制御する転写レギュレーターが構成的に発現される。
本発明に含まれる転写調節のメカニズムは抗プロゲスチン系ミフェリプリストンにより媒介される(Burcin et al., 1999, Proc. Natl. Acad. Sci. USA, 96: 355-360)。この調節は内因性ヒトホルモンに対して感受性がないが、ヒトにおいて二次的作用を避けるのに十分な低用量の合成抗プロゲスチン(RU486)の存在下で活性な、融合タンパク質を介して起こる。
pGal4−2RU−E1−SceIプラスミドの構築に基づき、市販の系GeneSwitch(商標)(Invitrogen, Carlsbad CA92008 USA, カタログ番号K1060-01およびK1060-2)が用いられている。この系は、A2ポリヌクレオチドを含むプラスミドの設計に必要な総ての遺伝成分を提供する。
GeneSwitch(商標)系の第1の成分は、転写アクチベーターとして働く融合GAL4−hPR−p65タンパク質をコードするpSwitchベクターである(図2A)。このタンパク質はサッカロミセス・セレビシエのGAL4タンパク質のDNA結合ドメイン(DBD)(Laughon and Gesteland, 1984, Mol. Cell Biol., 4: 260-267; Marmorstein, et al., 1992, Nature, 356: 408-414)、ヒトプロゲステロン受容体の末端切断型リガンド結合ドメイン(hPR−LBD)(Kastner, et al., 1990, Embo J., 9: 1603-1614; Wang, et al., 1994, Proc. Natl. Acad. Sci. USA, 91: 8180-8184)およびヒトNF−κBタンパク質の活性化ドメイン(AD)(Burcin, et al., 1999, Proc. Natl. Acad. Sci. USA, 96: 355-360; Deloukas and van Loon, 1993, Hum. Mol. Genet., 2: 1895-1900)に分けられる。レギュレータータンパク質の発現は、サッカロミセス・セレビシエのGAL4の活性化配列(UAS:上流活性化配列)(Giniger et al., 1985, Cell, 40: 767-774; Wang et al., 1994, Proc. Natl. Acad. Sci. USA, 91: 8180-8184)と単純ヘルペスウイルスのチミジンキナーゼ遺伝子(Ptk)の最小プロモーターの結合に由来するハイブリッドプロモーターの制御下にある。このプロモーターの活性化領域は、4コピーの配列5’−(T/C GGAGTACTGTCCTCCG−3’(配列番号1)を含む。それらはそれぞれ、GAL4転写因子のDNA結合ドメイン2分子に対して結合部位として働く(Marmorstein, et al., 1992, Nature, 356: 408-414)。
GeneSwitch(商標)の第2の成分は、目的遺伝子の発現を制御するpGene/V5−HisAプラスミドである(図2B)。この場合、転写を制御するハイブリッドプロモーターは、GAL4転写因子の6つの結合配列およびE1b(PE1b)アデノウイルス遺伝子のTATAボックス配列(Lillie and Green, 1989, Nature, 338: 39-44)からなる。
ミフェリプリストンの不在下では、この系はチミジンキナーゼ最小プロモーターからレギュレーター融合GAL4−hPR−p65タンパク質を構成的に発現する。このタンパク質は主として核に局在し、不活性である。インデューサーミフェリプリストンまたはその類似体RU486を添加した際、これはGAL4−hPR−p65のhPR−LBD領域と高い親和性で結合し、タンパク質の二量体化およびその活性型への変換をもたらすコンフォメーション変化が起こる。これらのホモ二量体は、pGene/V5−HisAおよびpSwitchプラスミドに存在するGAL4の結合配列(UAS)と相互作用し、目的遺伝子と実際の転写因子をコードする遺伝子の転写を活性化する(図2C)。
本発明で示唆される、Ad5のE1領域とI−SceIエンドヌクレアーゼの遺伝子を誘導系GeneSwitch(商標)の制御下に置くというアイデアに基づき、まず、調節系と505番〜3511番の間のアデノウイルスゲノムの配列(Ad5(505〜3511))(GenBank:AC000008)とおよびI−SceIのコード遺伝子の種々の組合せを設計した。これらの組合せにおいて、調節のメカニズムは1つまたは2つのプラスミドの使用に基づき、ここで、遺伝子E1および遺伝子I−SceIはなお、単一のプロモーターの制御下にあるか、または同じもしくは異なる配向で配置された異なるプロモーターの制御下にある(図3A)。これらの組合せをそれぞれ、それらのE1領域および遺伝子I−SceIの発現調節能およびその細胞ゲノム内への安定な組込み能を決定するために試験する。これらの総てから、pGal4−2RU−E1−SceI構築物は、ヘルパーの非依存的高容量アデノウイルス生産系の設計におけるその適用に最も好適であると考えられた。
下記の構築物の増幅に用いた細菌株は大腸菌(Escherichia coli)DH5αおよび大腸菌STBL2である。増殖は、選択培地としての、アンピシリン(100μg/ml)(Sigma-Aldrich)を添加したLuria Bertani培地(LB)(Sigma-Aldrich, 28760 Madrid, Spain)で、DH5α株の場合は37℃、STBL2株の場合は30℃で行った。これらの細菌を、最初にHanahan (1983, J. Mol. Biol, 166: 557-580)により記載されたCaCl2プロトコールに従って形質転換させた。これを行うため、10〜20ngのプラスミドDNAを100μlのコンピテント細胞と混合し、これを氷中で30分間維持した。その後、プロセスの効率を高めるために、この混合物を42℃で1分間インキュベートし、すぐに氷に移し、これをさらに2分間インキュベートした。最後に、1mlのLB培地を加え、攪拌下、37℃で1時間インキュベートした。
プラスミドの精製、およびアガロースゲルで分離した後の制限酵素による消化から生じたDNAフラグメントの精製は、それぞれFX microplasmid prepキット系(GE Healthcare Europe, 8290 Barcelona, Spain)およびQIAquick Gel抽出キット(Qiagen, Valencia CA91355, USA)を用い、製造業者の推奨に従って行った。
DNAフラグメントのクローニングでは、連結反応を、1UのT4−DNAリガーゼ(New Englamd Biolabs, Beverly MA01915-5599, USA)および2μlの10倍反応バッファー(New England Biolabs)を含む最終量20μlとして設計した。平滑末端を有するフラグメントの場合には、反応は、1UのT4−DNAリガーゼ(New England Biolabs)、2μlの10倍反応バッファー(New England Biolabs)および2μlの50% PEG4000を含む最終量20μlとして設計した。総ての場合で、これらの反応は総て、周囲温度で2時間インキュベートし、対応する大腸菌株に導入する前に65℃で10分間不活性化した。組換えクローンはベクターによりコードされている耐性マーカーに基づいて選択し、制限エンドヌクレアーゼによる消化および1%アガロースゲルでの電気泳動によって確認した。
pGal4−2RU−E1−SceIプラスミドの合成プロセスにおいて設計されたPCR反応は総て、1UのTaqポリメラーゼ酵素(BioTaq, Bioline, London NW2 6EW, UK)、PCRバッファー(Bioline)、MgCl2 4mM、0.4mMの各dNTP、10pmolの各プライマー、DNAおよび最終量50μlまでの無菌脱イオン水の存在下で行った。増幅条件は次の通りとした:95℃で4分の変性1回;94℃で50秒の変性、50℃で40秒のプライマーハイブリダイゼーションおよび72℃で40秒の伸長を29回;72℃で5分の最終伸長1回。増幅産物の分析のため、サンプルを1.5μlのローディング溶液(蒸留水中0.25%のブロモフェノールブルー;40%グリセロール;100mM EDTA)と混合し、それらをTAE 1倍バッファー(40mM Tris Base;20mM氷酢酸;1mM EDTA、pH8.0)を用いたアガロースゲル(1%)での電気泳動により分析し、臭化エチジウム(0.5μg/ml)染色によりDNAを表した。
pGal4−2RU−E1−SceI調節プラスミドは下記のような5工程で設計した。
1)pGene−リンカーRU2ベクターの構築:
リンカーRU2を含めるために、pSwitchプラスミドをSbfI(38番)およびBamHI(2484番)制限酵素で線状化した。これは下記のプライマーから予め合成したものである。
リンカーRU−1:
5’-GGACCACCAAGGATCCTCTAGAACCGTTTAAACACCACTAGTCCAACGCGTGATATCACCGCGGCCGCA-3’(配列番号2)
リンカーRU−2:
5’-GATCTGCGGCCGCGGTGATATCACGCGTTGGACTAGTGGTGTTTAAACGGTTCTAGAGGATCCTTGGTGGTCCTGCA-3’(配列番号3)
リンカーRU2を含めるために、pSwitchプラスミドをSbfI(38番)およびBamHI(2484番)制限酵素で線状化した。これは下記のプライマーから予め合成したものである。
リンカーRU−1:
5’-GGACCACCAAGGATCCTCTAGAACCGTTTAAACACCACTAGTCCAACGCGTGATATCACCGCGGCCGCA-3’(配列番号2)
リンカーRU−2:
5’-GATCTGCGGCCGCGGTGATATCACGCGTTGGACTAGTGGTGTTTAAACGGTTCTAGAGGATCCTTGGTGGTCCTGCA-3’(配列番号3)
アニーリング反応では、10μlの各プライマーを50mM濃度でバッファー溶液(50mM Tris−HCl pH8.0;100mM NaCl;1mM EDTA)に混合した。反応条件は次の通りとした:95℃で2分および52℃10分。次に、リンカーRU2プライマーを、T4酵素キナーゼポリヌクレオチドを用い、製造業者(New England Biolabs)の推奨に従ってリン酸化した。この反応物を37℃で30分インキュベートし、65℃で15分間不活性化した。その後、リンカーRU2とpSwitchベクターとの連結を行い、これを大腸菌DH5αに形質転換させた。得られた構築物をpSwitch−リンカーRU2と呼んだ。
次に、pSwitch−リンカーRU2ベクターをFspI酵素(pSwitchの6623番)およびApaI(pSwitchの2721番)で消化し、pSwitchベクターの隣接配列のリンカーRU2ドラッギング部分を遊離させた。このフラグメントを、予めこれらの同じ酵素で消化したpGeneV5−HisAベクターにサブクローニングした。得られたベクターはpGene−リンカーRU2と呼ばれ、pGal4−2RU−E1−SceIベクターの構築の基礎となる。
2)アデノウイルスのE1領域のクローニング:
pGL3−Basicベクター(Groskreutz and Schenborn, 1997, Methods Mol. Biol, 63: 11-30)から、BamHIおよびXbaIで消化することにより、262pbのフラグメントが遊離し、これはSV40のポリアデニル化シグナル(SV40pA)を含んでいた。この配列を、予めこれらの同じ酵素で消化したpBluescript II KS(+)プラスミド(Stratagene, La Jolla CA92037, USA)にクローニングし、PBS−SV40pAプラスミドを得た。
pGL3−Basicベクター(Groskreutz and Schenborn, 1997, Methods Mol. Biol, 63: 11-30)から、BamHIおよびXbaIで消化することにより、262pbのフラグメントが遊離し、これはSV40のポリアデニル化シグナル(SV40pA)を含んでいた。この配列を、予めこれらの同じ酵素で消化したpBluescript II KS(+)プラスミド(Stratagene, La Jolla CA92037, USA)にクローニングし、PBS−SV40pAプラスミドを得た。
並行して、pGeneV5−HisAプラスミドをSalI(151番)およびPvuII(895番)酵素で順次消化したところ、ウシ成長ホルモン(BGHpA)のポリアデニル化シグナルを単離することができた。この744pbのフラグメントを、予めSalIおよびBamHIで線状化し、そして、そのBamHI末端を予めクレノウを用い、製造業者(DNAポリメラーゼI、ラージ(クレノウ)フラグメント;New England Biolabs)の推奨に従って平滑化したpBS−SV40pAプラスミドにクローニングした。このようにして、BamHI制限酵素の標的配列により連結されたポリアデニル化シグナルBGHおよびSV40を含んでなる挿入部が作出された。
次に、pGeneLinkerRU2−2pAプラスミドを合成した。これを行うため、pBS−BGHpA−SV40pAベクターをXbaIで消化したところ、2つのポリアデニル化配列を含む623pbのフラグメントが遊離し、これをpGene−リンカーRU2プラスミドのリンカーRU2に存在するユニークなXbaI部位内にクローニングした。挿入部が正しい向き(5’−SV40pA−BGHpA−3’)であることを、PmeIで制限することにより確認した。
Ad5のE1領域をプライマー:
ad19 5’-GAGTGCCAGCGAGTAGAGTT-3’(配列番号4)および
ad22 5’-GAATTCTCAATCTGTATCTTCATC-3’(配列番号5)
を用いたPCRにより増幅した。
ad19 5’-GAGTGCCAGCGAGTAGAGTT-3’(配列番号4)および
ad22 5’-GAATTCTCAATCTGTATCTTCATC-3’(配列番号5)
を用いたPCRにより増幅した。
得られた3kbの産物をPCR pGemT−Easy産物(Promega Biotech Iberica, 28108 Madrid, Spain)用の特異的ベクターにクローニングした。EcdRIで消化することにより該E1領域を精製し、pGeneLinkerRU2−2pAベクターのEcoRI標的内にサブクローニングし、BGHpAポリアデニル化シグナルから「下流に」配置した。得られたプラスミドをpGeneLinkerRU2−2pA−E1と呼んだ。
3)GAL4−DBD/hPR−LBD/p65−AD遺伝子(転写レギュレーター)およびその自己調節プロモーター領域のクローニング
pSwitchベクターをSbfI(38番)およびBamHI(2485番)制限酵素で消化し、転写レギュレーターに対する結合配列(UAS領域)、キナーゼタンパク質の最小プロモーター(Ptk)および転写アクチベーターGAL4−DBD/hPR−LBD/p65−ADをコードする遺伝子を単離した。この2.4kbのSbfI−BamHIフラグメントを、予め同じ酵素で消化したpGeneLinkerRU2−2pAプラスミドにクローニングしたところ、ポリアデニル化配列SV40pAの欠失が起こった。得られた構築物をpGeneLinkerRU2−Gal4−BGHpA−E1の名称とした。
pSwitchベクターをSbfI(38番)およびBamHI(2485番)制限酵素で消化し、転写レギュレーターに対する結合配列(UAS領域)、キナーゼタンパク質の最小プロモーター(Ptk)および転写アクチベーターGAL4−DBD/hPR−LBD/p65−ADをコードする遺伝子を単離した。この2.4kbのSbfI−BamHIフラグメントを、予め同じ酵素で消化したpGeneLinkerRU2−2pAプラスミドにクローニングしたところ、ポリアデニル化配列SV40pAの欠失が起こった。得られた構築物をpGeneLinkerRU2−Gal4−BGHpA−E1の名称とした。
この第2のポリアデニル化シグナルを回収するため、SV40pA配列を、BamHIで消化することにより、最初のpGeneLinkerRU2−2pA構築物から精製した。0.2kbのフラグメントをpGeneLinkerRU2−Gal4−BGHpA−E1プラスミドの単一の標的BamHI内にクローニングした。
4)I−SceI遺伝子のクローニング
I−SceIエンドヌクレアーゼをコードする遺伝子をpI−SceIプラスミド(Choulika, et al., 1994, C. R Acad. Sci, III, 317: 1013-1019)からプライマー:
SceI−b1 5’-AAACCATGGGATCAAGATCGC-3’(配列番号6)および
SceI−b2 5’-CCCTCTAGATTATTTCAGGAAAGTTTCGGAGGA-3’(配列番号7)
を用いたPCRにより得た。それをpGemT−Easyにクローニングした後、それをNotI制限酵素で消化することにより遊離させた。精製したフラグメントの末端を、クレノウ断片を用い、製造業者(New England Biolabs)の推奨に従って平滑末端化した後、SpeI制限酵素により2回目の消化を行った。最後に、精製した0.8kbのフラグメントをpGeneV5−HisAベクターのSpeI(478番)標的とNotI(522番、クレノウで処理)標的の間にクローニングした。クレノウによる処置はNotI標的の欠失を必然的に伴った。得られたプラスミドをpGene−ISceIと呼んだ。
I−SceIエンドヌクレアーゼをコードする遺伝子をpI−SceIプラスミド(Choulika, et al., 1994, C. R Acad. Sci, III, 317: 1013-1019)からプライマー:
SceI−b1 5’-AAACCATGGGATCAAGATCGC-3’(配列番号6)および
SceI−b2 5’-CCCTCTAGATTATTTCAGGAAAGTTTCGGAGGA-3’(配列番号7)
を用いたPCRにより得た。それをpGemT−Easyにクローニングした後、それをNotI制限酵素で消化することにより遊離させた。精製したフラグメントの末端を、クレノウ断片を用い、製造業者(New England Biolabs)の推奨に従って平滑末端化した後、SpeI制限酵素により2回目の消化を行った。最後に、精製した0.8kbのフラグメントをpGeneV5−HisAベクターのSpeI(478番)標的とNotI(522番、クレノウで処理)標的の間にクローニングした。クレノウによる処置はNotI標的の欠失を必然的に伴った。得られたプラスミドをpGene−ISceIと呼んだ。
pGene−ISceIプラスミドをXbaIで消化し、E1bアデノウイルス遺伝子(PE1B)の最小プロモーターの転写制御下にエンドヌクレアーゼI−SceIの遺伝子を含む1.2kbのフラグメントを遊離させた。このフラグメントをpGeneLinkerRU2−Gal4−2pA−E1プラスミド内のポリアデニル化配列BGHとE1領域の間に局在するSpeI適合標的内にサブクローニングした。得られた構築物をpGeneLinkerRU2−Gal4−2pA−ISceI−E1と呼んだ。
5)I−SceIおよびアデノウイルスE1領域の転写の制御のための二重誘導プロモーターのクローニング
転写アクチベーターと結合するレギュレーター配列(UAS)と最小プロモーターPE1Bを含むpGeneV5−HisAベクターの領域は、プライマー:
PRU−1 5’-AATACTAGTCCGAGCTCTTACGCGGGTC-3’(配列番号8)、および
PRU−2 5’-AATACGCGTGGTGGCCTGTGAAGAGAAAAAA-3’(配列番号9)
を用いたPCRによる増幅によって得、それをpGemT−Easyベクターにサブクローニングした。その後、NotIで消化することにより挿入部を遊離させ、それをGeneLinkerRU2−Gal4−2pA−ISceI−E1構築物の、I−SceIの最小プロモーターPE1BとアデノウイルスE1領域の間にあるNotI標的内にサブクローニングした。得られた構築物をpGal4 2RU−SceI−E1と呼んだ(図3B)。
転写アクチベーターと結合するレギュレーター配列(UAS)と最小プロモーターPE1Bを含むpGeneV5−HisAベクターの領域は、プライマー:
PRU−1 5’-AATACTAGTCCGAGCTCTTACGCGGGTC-3’(配列番号8)、および
PRU−2 5’-AATACGCGTGGTGGCCTGTGAAGAGAAAAAA-3’(配列番号9)
を用いたPCRによる増幅によって得、それをpGemT−Easyベクターにサブクローニングした。その後、NotIで消化することにより挿入部を遊離させ、それをGeneLinkerRU2−Gal4−2pA−ISceI−E1構築物の、I−SceIの最小プロモーターPE1BとアデノウイルスE1領域の間にあるNotI標的内にサブクローニングした。得られた構築物をpGal4 2RU−SceI−E1と呼んだ(図3B)。
実施例2:パッケージングシグナルと遺伝子E1aおよびE1bが欠失した、I−SceIエンドヌクレアーゼをコードするアデノウイルスゲノムを哺乳類細胞に組み込むためのpRCAd2プラスミドの構築
アデノウイルスゲノムを含む配列内で、他のウイルス遺伝子の発現をより強く制御するために、パッケージング配列と初期遺伝子E1aおよびE1bに相当する領域を欠失させた。同様に、このアデノウイルス配列は、両末端とも、それらの標的配列(TAGGGATAACAGGGTAA−配列番号8)の大きさおよびそれらの高い特異性のために、その細胞ゲノム内の配列をトランスフェクトのために認識しないサッカロミセス・セレビシエのI−SceI制限エンドヌクレアーゼの認識配列(Anglana and Bacchetti, 1999, Nucleic Acids Res., 27: 4276-4281)を境界とする。これらの配列を挿入することで、I−SceIタンパク質の存在下でのみウイルスゲノムの放出が助長される。このような消化により、ウイルスDNAの適切な転写および複製に必要なアデノウイルスのITR末端が遊離状態で残る。
アデノウイルスゲノムを含む配列内で、他のウイルス遺伝子の発現をより強く制御するために、パッケージング配列と初期遺伝子E1aおよびE1bに相当する領域を欠失させた。同様に、このアデノウイルス配列は、両末端とも、それらの標的配列(TAGGGATAACAGGGTAA−配列番号8)の大きさおよびそれらの高い特異性のために、その細胞ゲノム内の配列をトランスフェクトのために認識しないサッカロミセス・セレビシエのI−SceI制限エンドヌクレアーゼの認識配列(Anglana and Bacchetti, 1999, Nucleic Acids Res., 27: 4276-4281)を境界とする。これらの配列を挿入することで、I−SceIタンパク質の存在下でのみウイルスゲノムの放出が助長される。このような消化により、ウイルスDNAの適切な転写および複製に必要なアデノウイルスのITR末端が遊離状態で残る。
最後に、この構築物の5’末端は放線菌ファージのPhiC31レコンビナーゼにより媒介されるプロセスである細胞ゲノム内へのプラスミドの組込みを促進するattB配列を含んでいた。この酵素は特異的な一方向を生じ、他のレコンビナーゼで見られるものよりも高い正味の組込み頻度を有するので、哺乳類細胞における外因性DNAの組込み系として大きな可能性持つ(Thyagarajan et al., 2001, Mol. Cell. Biol., 21: 3926-3934)。PhiC31インテグラーゼの認識配列はattBおよびattPと呼ばれ、配列が異なる。組込み反応の後、生じたatt配列は元のattBおよびattP配列と異なり、二次的な組換え反応が阻止される。ヒト細胞において、PhiC31は、attPと部分的同一性を有する配列(pseudo−attPと呼ばれる)が存在するゲノム点で組換え事象を媒介することができる(図4)。Thyagarajan et al. (2001, 前掲)によれば、pseudo−attP配列の総数は102〜103の間であり、これにより組込み頻度は相同組換えにより媒介される組込みの場合よりも2〜3倍高くなり、さらにはCreレコンビナーゼなどの他の特異的レコンビナーゼにより媒介されるものよりも10〜100倍高くなる。
下記の構築物の増幅のために用いた大腸菌株はDH5α、STBL2およびBJ5183であった。これらの細菌を、実施例1に記載のCaCl2プロトコールに従って形質転換した。増殖は、選択培地としてアンピシリン(100μg/ml)(Sigma-Aldrich)を添加したLuria Bertani培地(LB)にて、DH5αおよびBJ5183株の場合には37℃、大腸菌STBL2の場合には30℃で行った。
pRcAd2プラスミドの合成プロセスにおいて設計されたPCR反応は総て、実施例1に記載のものと同じ条件で行った。核酸の精製および操作に適用した一般法も実施例1に記載されている。
pRcAd2ベクターは下記の4工程で設計した。
1)attB−ISceI−Ad(1〜190)配列のクローニング
pRcAd2ベクター構築の第一工程は、pTA−attBプラスミド(Groth, et al., 2000, Proc. Natl. Acad. Sci. USA, 97: 5995-6000)を鋳型として用い、プライマー:
attB−P1 5’-AGATCTGTCGACGATGTAGGTCACGGTCTCCGAAGC-3’(配列番号11)および
attB−P2 5’-TTAATTAATTACCCTGTTATCCCTAGTCGACATGCCCGCCGTGA-3’(配列番号12)
を用いたPCRによる増幅であった。この増幅フラグメントを、PCR pGemT−Easy産物(Promega)に対する特異的ベクターに、製造業者の推奨に従ってサブクローニングした。このattB−P2プライマーはサッカロミセス・セレビシエのI−SceI制限酵素の認識配列を有するリンカーを含む。
pRcAd2ベクター構築の第一工程は、pTA−attBプラスミド(Groth, et al., 2000, Proc. Natl. Acad. Sci. USA, 97: 5995-6000)を鋳型として用い、プライマー:
attB−P1 5’-AGATCTGTCGACGATGTAGGTCACGGTCTCCGAAGC-3’(配列番号11)および
attB−P2 5’-TTAATTAATTACCCTGTTATCCCTAGTCGACATGCCCGCCGTGA-3’(配列番号12)
を用いたPCRによる増幅であった。この増幅フラグメントを、PCR pGemT−Easy産物(Promega)に対する特異的ベクターに、製造業者の推奨に従ってサブクローニングした。このattB−P2プライマーはサッカロミセス・セレビシエのI−SceI制限酵素の認識配列を有するリンカーを含む。
attB−I−SceIフラグメント(316pb)をpGemT−Easyベクターから、制限酵素NcoIおよびPacIで消化することにより遊離させ、それを予めこれらの同じ酵素で消化したpGemT/A6プラスミドにサブクローニングした。pGemT/A6は、プライマー:
ad63: 5’-AGATCTAGGGATAACAGGGTAATCATCATCAATAATATACCTT-3’(配列番号13)および
ad64: 5’-AGATCTCGGCGCACACCAAAAACGTC-3’(配列番号14)
を用いた、1番〜190番の間に含まれるアデノウイルスゲノム血清型5の領域のPCRにより増幅し、それをpGemT−Easyベクターにクローニングすることに由来する。
ad63: 5’-AGATCTAGGGATAACAGGGTAATCATCATCAATAATATACCTT-3’(配列番号13)および
ad64: 5’-AGATCTCGGCGCACACCAAAAACGTC-3’(配列番号14)
を用いた、1番〜190番の間に含まれるアデノウイルスゲノム血清型5の領域のPCRにより増幅し、それをpGemT−Easyベクターにクローニングすることに由来する。
得られた構築物pGemT/attB−A6において、I−SceIの制限標的はattB領域とアデノウイルスゲノムの1番の間に挿入されていた。
2)Ad(3528〜4459)領域のクローニング
512pbの挿入部attB−ISceI−Ad(1〜190)をBglII消化により切り出し、それをpRC/A4−A5ベクターにサブクローニングした。このベクターはプライマー:
ad57 5’-AGATCTCGTGGCTTAAGGGTGGGAAA-3’(配列番号15)および
ad58: 5’-TCTAGATTATATGGCTGGGAACATAGCC-3’(配列番号16)を用いた、3528番〜4459番の間に含まれるアデノウイルス配列を増幅し、それを、哺乳類細胞での選択のためのアンピシリン耐性遺伝子、ネオマイシン耐性遺伝子をさらに含む真核生物発現pRC/RSV(Invitrogen)を用いてクローニングした産物である。pRC/RSVにAd(3528〜4459)配列を挿入するために、プライマーad57およびad58の5’末端にそれぞれBglIIおよびXbaI標的配列に含めた。この挿入部をベクターの13番〜701番の間に組み込まれていた。
512pbの挿入部attB−ISceI−Ad(1〜190)をBglII消化により切り出し、それをpRC/A4−A5ベクターにサブクローニングした。このベクターはプライマー:
ad57 5’-AGATCTCGTGGCTTAAGGGTGGGAAA-3’(配列番号15)および
ad58: 5’-TCTAGATTATATGGCTGGGAACATAGCC-3’(配列番号16)を用いた、3528番〜4459番の間に含まれるアデノウイルス配列を増幅し、それを、哺乳類細胞での選択のためのアンピシリン耐性遺伝子、ネオマイシン耐性遺伝子をさらに含む真核生物発現pRC/RSV(Invitrogen)を用いてクローニングした産物である。pRC/RSVにAd(3528〜4459)配列を挿入するために、プライマーad57およびad58の5’末端にそれぞれBglIIおよびXbaI標的配列に含めた。この挿入部をベクターの13番〜701番の間に組み込まれていた。
ベクターpRC/A4−A5にattB−SceI−Ad(1〜190)フラグメントを連結することから得られた構築物をpRC/A6−A5と呼んだ。このようにして、アデノウイルスのE1領域は欠失され、190番〜3528番の間に存在すると思われた。
3)Ad(34901〜35938)領域のクローニング
アデノウイルスゲノムの3’末端(34901番〜35938番)をプライマー:
ad59: 5’−TCTAGATTAGCTATGCTAACCAGCGTAG−3’(配列番号17)および
ad65:5’-GGTACCTAGGGATAACAGGGTAATCATCATCAATAATATACCTT-3’(配列番号18)
を用いて増幅した。
アデノウイルスゲノムの3’末端(34901番〜35938番)をプライマー:
ad59: 5’−TCTAGATTAGCTATGCTAACCAGCGTAG−3’(配列番号17)および
ad65:5’-GGTACCTAGGGATAACAGGGTAATCATCATCAATAATATACCTT-3’(配列番号18)
を用いて増幅した。
I−SceI制限酵素の標的配列(下線)をad65プライマーの5’末端に含めた。両プライマーはそれらの5’にXbaI(ad59)およびKpnI(ad65)の制限標的を含む。この増幅産物である1060pbのフラグメントを、pRC/A6−A5ベクターに挿入されたAd(3528〜4459)領域の「下流」サブクローニングを容易にするためにこれらの酵素で切断した。得られた構築物をpRC/A6−A7と呼んだ。
4)pRcAd2プラスミドの取得
pRC/A6−A7プラスミドをXbaIで線状化し、製造業者の推奨に従い、アルカリ性ホスファターゼ(アルカリ性ホスファターゼ、ウシ腸管(CIP);New England Biolabs)で脱リン酸化した。
pRC/A6−A7プラスミドをXbaIで線状化し、製造業者の推奨に従い、アルカリ性ホスファターゼ(アルカリ性ホスファターゼ、ウシ腸管(CIP);New England Biolabs)で脱リン酸化した。
同様に、pTG3602プラスミド(Chartier, et al., 1996, J. Virol, 70: 4805-4810)をPacIで消化し、アデノウイルス血清型5ゲノムの完全コピーを遊離させた。その末端をアルカリ性ホスファターゼで脱リン酸化することにより、その再循環を回避した。
線状化ベクターpRC/A6−A7とpTG3602プラスミドの遊離した挿入部の双方を同時に用い、大腸菌BJ5183(BJ5183エレクトロポレーションコンピテント細胞;Stratagene)のエレクトロコンピテント細菌株に導入を行った。これらの細胞は特に、目的遺伝子を含む導入ベクター(このベクターはアデノウイルスゲノムを含む)の相同配列間の組換えプロセスを促進するように設計される。この場合、両DNAフラグメント(Ad(3528〜4459)およびAd(34901〜35938領域)に含まれる相同領域が、その分析にpRC/A6−A7ベクター内およびウイルスの4459番の後へのアデノウイルスゲノムの挿入を必要とする該組換えプロセスに好都合である(図5)。
エレクトロポレーションプロセスは製造業者の推奨に従い、Gene Pulser(Biorad)エレクトロポレーション系にて、以下のパラメーター:電圧2.5kV、抵抗200Ω、容量25μF、パルス持続時間5分に設定して行った。最後に、1mlのLB培地を加え、この懸濁液を37℃で1時間インキュベートした。次に、形質転換細胞の連続希釈液を作製した。それらをpRC/A6−A7プラスミドの選択抗生物質としてアンピシリン(100μg/ml)を添加した培養培地のプレートに播種した。インキュベーションを37℃で耐性クローンが現れるまで継続した。
HindIIIを用いた制限分析により、得られたクローンの1つだけでアデノウイルスゲノムの適切な挿入部が確認され、これをpRcAd2と呼んだ。
このpRcAd2プラスミドは、E1領域に相当する190番〜3528番の間に位置する領域を除き、完全なアデノウイルスゲノムを含む。この配列はI−SceIの制限標的を境界とし、その5’末端にattB配列を有する(図5)。
実施例3:高容量アデノウイルスベクターの生産およびパッケージングのための安定な細胞系統の構築および特性決定
本発明は、高容量アデノウイルスベクターの生産およびパッケージングのために設計された安定な細胞系統の生産を提案する。これらの細胞はウイルスの複製、アセンブリおよび機能に必要な成分の総てを産生することができるであろう。
本発明は、高容量アデノウイルスベクターの生産およびパッケージングのために設計された安定な細胞系統の生産を提案する。これらの細胞はウイルスの複製、アセンブリおよび機能に必要な成分の総てを産生することができるであろう。
高レベルのウイルスタンパク質により行う細胞傷害性のため、ミフェリプリストンのより誘導可能な転写調節系は遺伝子E1aおよびE1bの発現を制御し、また、残りのアデノウイルスゲノムの発現および複製の命令も行う。この同じ系が、真核細胞のゲノムに組み込まれたアデノウイルスゲノムの遊離に必要なI−SceI制限エンドヌクレアーゼの生産も制御し、これは第2のレベルの転写制御を提供する。この誘導(従って、ウイルス粒子の生産)は、培養培地にミフェリプリストンまたはその類似体RU486を添加した際に始まる。
生産プロセス中にヘルパーウイルスを使用する必要がないので、本発明者らにより開発された系によれば、ヘルパーウイルスのゲノムコピーを含むウイルス粒子の望ましくない残留混入のないウイルス抽出液を生産することができる。
本実施形態では、肺癌腫A549のヒト細胞系統を、非依存性高容量ヘルパーベクターの生産系の設計に用いた。Giard et al (1973, J. Natl. Cancer Inst., 51: 1417-1423)により誘導され、その後、Lieber et al. (1976, Int. J. Cancer, 17: 62-70)により深く特性決定されたこの細胞系統は、アデノウイルス感染に対して感受性が高く、ウイルス生産系統として高い能力を与える(Smith et al., 1986, J. Clin. Microbiol, 24: 265-268)。これらの細胞はそれらの形態に変動なく容易に培養することができ、重要な分化シグナルを示さずに10〜14日の間生存を維持する。
実施例3.1:アデノウイルスゲノム(Bポリヌクレオチド)の安定な組込みのための、pRcAd2プラスミドのトランスフェクションによる細胞系統の作出
高容量アデノウイルスの複製、キャプシド形成およびパッケージングに含まれるウイルスタンパク質の合成を実施可能なパッケージング細胞系統を生産するため、A549細胞を10cm2プレートにて37℃、5%CO2で、集密度80%に達するまでインキュベートした。これらの細胞をリポフェクタミンにより、3μgのpRcAd2構築物(ネオマイシン耐性を与える(neor))と、放線菌PhiC31ファージのインテグラーゼをコードし、細胞ゲノムへのプラスミドの安定な組込みを促進する1μgのpCMV−Intプラスミド(Groth et al., 2000, Proc. Natl. Acad. Sci. USA, 97: 5995-6000)とで同時にトランスフェクトした(図6A)。
高容量アデノウイルスの複製、キャプシド形成およびパッケージングに含まれるウイルスタンパク質の合成を実施可能なパッケージング細胞系統を生産するため、A549細胞を10cm2プレートにて37℃、5%CO2で、集密度80%に達するまでインキュベートした。これらの細胞をリポフェクタミンにより、3μgのpRcAd2構築物(ネオマイシン耐性を与える(neor))と、放線菌PhiC31ファージのインテグラーゼをコードし、細胞ゲノムへのプラスミドの安定な組込みを促進する1μgのpCMV−Intプラスミド(Groth et al., 2000, Proc. Natl. Acad. Sci. USA, 97: 5995-6000)とで同時にトランスフェクトした(図6A)。
両プラスミドのDNAを予めOPTI−MEM血清を含まない培地(Gibco(登録商標): Invitrogen, Carlsbad CA92008, USA)500μlで希釈した。DNAと陽イオン脂質の間の複合体の形成を促進するために、試薬Plus Reagent(Invitrogen)を1:0.75比(DNA: Plus Reagent)で加えた。周囲温度で5分インキュベートした後、6μlのリポフェクタミンLTX(Invitrogen)を加え、この混合物を再び周囲温度で25分インキュベートした。次に、この希釈液を細胞培養培地:ウシ胎児血清(Gibco(登録商標));1%L−グルタミン(0.85%NaCl中200mM;Lonza Iberica, 08006 Barcelona, Spain);および1%ペニシリン/ストレプトマイシン(0.85%NaCl中10mg/ml;Gibco(登録商標))を添加したDMEMに滴下した。37℃、5%CO2で4時間インキュベートした後、培地を新鮮なDMEM培地に置き換え、インキュベーションをさらに24時間継続した。最後に、培地を除去し、1倍リン酸緩衝生理食塩水(PBS)(Gibco(登録商標))で洗浄した後に、トランスフェクト細胞をトリプシン(トリプシン−EDTA;Gibco(登録商標))ですすぎ、それらを周囲温度にて1250rpmで5分遠心分離した。細胞沈殿を6mlの培養培地に再懸濁させ、それらを3枚の60cm2プレートに分注した。新鮮培地(この場合、ネオマイシンの類似体である選択抗生物質G418を600μg/mlで添加)を加えた。抗生物質耐性の単離クローンが現れるまで(2〜3週間)、2日おきに培養培地を交換した。クローンを、トリプシンを用いて浮上させ、それらを選択培地の入った0.3cm2ウェルに移した。80%の集密度に達するまでインキュベーションを続けた後、それらをより表面積の大きなウェルに移した。一連の工程の後、G418耐性クローンが単離され、これをpRc−1と呼んだ。クローンの安定性を証明するため、これらの細胞を4か月培養下で維持したところ、それらの形態または生存率に変化は見られなかった。
単離されたクローンにおけるpRcAd2プラスミドの組込みを確認するために、pRc−1クローンのゲノムDNAをQIAmp DNAミニキット(Qiagen)系で製造業者の推奨に従って抽出した。このDNAをネステッドPCRアッセイで用い、アデノウイルス遺伝子IIIa、IV、プロテアーゼをコードする遺伝子およびウイルスポリメラーゼをコードする遺伝子の存在を検出した。この検出に用いたプライマーは次のものであった。
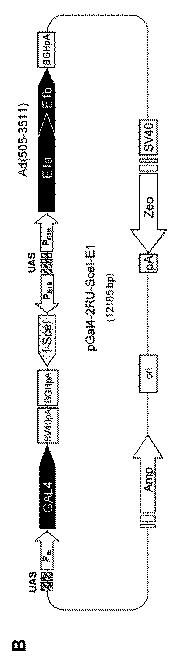
ネステッドPCRの外部プライマー(プライマー1および2)を用いたPCR反応は、1Uの酵素Taqポリメラーゼ(BioTaq, Bioline)、PCRバッファー(Bioline)、1.5mM MgCl2、0.4mMの各dNTP、10pmolの各プライマー、DNAおよび最終量50μlまでの無菌脱イオン水の存在下で行った。増幅条件は次の通りとした:94℃dで2分、94℃で50秒の変性、50秒のプライマーとのハイブリダイゼーション(Tmは増幅する遺伝子に応じる、表参照)および72℃で50秒の伸長を1回;94℃で50秒の変性、50秒のプライマーとのハイブリダイゼーション(Tmは増幅する遺伝子に応じる、表参照)および72℃で50秒の伸長を35回;72℃で7分の最終伸長1回。ネステッドPCRの内部プライマー(プライマー3および4)を用いた増幅反応は、2μ前PCR反応物から、1Uの酵素Taqポリメラーゼ(BioTaq, Bioline)、PCRバッファー(Bioline)、MgCl2 2.5mM、0.4mMの各dNTP、10pmolの各プライマー、DNAおよび最終量50μlまでの無菌脱イオン水の存在下で行った。この場合の増幅条件は、94℃で50秒の変性、50秒のプライマーとのハイブリダイゼーション(Tmは増幅する遺伝子に応じる、表参照)および72℃で50秒の伸長を35回;72℃で7分の最終伸長1回。
また、attB領域の欠損も、プライマーattB−P1、attB−P2を用いたPCR反応により確認した(実施例2)。PCR反応は、1Uの酵素Taqポリメラーゼ(BioTaq, Bioline)、PCRバッファー(Bioline)、4mM MgCl2、0.4mMの各dNTP、10pmolの各プライマー、DNAおよび最終量50μlまでの無菌脱イオン水の存在下で行った。増幅条件は次の通りとした:95℃で4分の変性1回;94℃で50秒の変性、50℃で40秒の第一鎖とのハイブリダイゼーションおよび72℃で40秒の伸長を29回;72℃で5分の最終伸長1回。
増幅産物を分析するために、これらのサンプルを1.5μlのローディング溶液(蒸留水中0.25%のブロモフェノールブルー;40%グリセロール;100mM EDTA)と混合し、それらを、TAE 1倍バッファー(40mM Tris Base;20mM氷酢酸;EDTA 1mM、pH8.0)を用いたアガロースゲル(1%)での電気泳動により分析し、臭化エチジウム(0.5μg/ml)染色によりDNAを表した。
得られた結果(図6B)により、真核細胞A549のゲノムにBポリヌクレオチドが適切に組み込まれていることが確認される。さらに、attB領域の欠損から、この組込みがPhiC31インテグラーゼにより特異的かつ一方向で媒介されたことが確認される。
次に、アデノウイルス遺伝子の発現を調べるために、pRc−1クローンを20cm2プレートにて37℃、5%CO2で80%の集密度に達するまでインキュベートした。この時、これらの細胞を、前述の手順に従い、構築物pGal4−2RU−SceI−E1の希釈液5μg、Plus Reagent(1:0.75)および12μlのリポフェクタミンLTXでトランスフェクトした。トランスフェクションは、10−8M濃度のRU486インデューサーの存在下でプレートの1つを2回インキュベートすることにより行った。インキュベーション48時間、1mlのTRIZOL(Invitrogen)を用い、総て製造業者の推奨に従って細胞を溶解させ、全RNAの抽出を行った。このRNAをアデノウイルス遺伝子に対して特異的なプライマーを用いた逆転写アッセイ(RT)−PCRに用いた。
これらのアッセイでは、1μgのRNAを予め、反応バッファー(20mM Tris−HCl、pH8.4;2mM MgCl2;50mM KCl)中、最終量10μlで、1ユニットのDNアーゼ(DNasaI amplification grade; Invitrogen)で処理した。この反応物を周囲温度で15分インキュベートし、1μlの25mM EDTA溶液を加え、65℃で10分インキュベートすることによりDNアーゼを不活性化した。cDNA合成反応では、このDNA不含RNA625ngを用いた。逆転写反応は、サンプルを10pmolの特異的プライマー、1μlのdNTP(10mM)および最終量13μlまでの水と混合して開始した。65℃で5分インキュベートした後、この混合物を氷中で冷却し、2μlの0.1M DTTおよび4μlの反応バッファー(250mM Tris−HCl、pH8.3;375mM KCl;15mM MgCl2)を用いた。最後に、37℃で2分新たにインキュベートした後、200UのM−MLV逆転写酵素(Invitrogen)を加え、インキュベーションを37℃で50分続けた。次に、得られたcDNAをPCR反応の鋳型として用いて検討下の遺伝子の転写産物を増幅した。陰性対照として、また、ゲノムDNAの混入が無いことを確認するために、いずれの場合にも、DNアーゼで処理したRNAを鋳型として用いる増幅反応を含めた。得られた逆転写反応のcDNAを用いたPCR反応に用いた増幅条件は、ゲノムDNAの増幅反応で用いたものと同じであった。
図7に示すこれらのアッセイの結果から、真核細胞の染色体に安定に組み込まれたアデノウイルス遺伝子の転写能力が確認される。
最後に、ウイルスmRNAからウイルスタンパク質を産生する細胞の能力を確認するために、ウイルスキャプシドのタンパク質検出を免疫組織化学アッセイによりアッセイした。タンパク質合成を誘導するために、pRc−1クローンを予め構築物pGal4−2RU−SceI−E1でトランスフェクトした。トランスフェクションは2回行った。これらの細胞をRU486インデューサーの存在下および不在下でインキュベートした。インキュベーション24時間後、細胞をトリプシンで剥離し、8×104細胞を4セルカルチャースライド(four-cell cultureslide)(BD Falcon Cultureslide; BD Biosciences, Erembodegem 9320, Belgium)に移し、インデューサーRU486を含む、および含まない培養培地を加えた。翌日、培地を除去し、細胞をPBSで洗浄した。次に、それらを予め−20℃に冷却したアセトン:メタノール(1:1)溶液で固定した。固定液を周囲温度で蒸発させ(30分)、これらのスライドを1倍PBSに浸漬した。3分間PBSで3回洗浄した後、予めPBSで希釈した(1:75)一次抗体(マウス抗アデノウイルスモノクローナル抗体ブレンド;Millipore Iberica, 28050 Madrid, Spain)とハイブリダイズさせた。このハイブリダイゼーションは、暗所、加湿チャンバーにて、4℃で一晩行った。
翌日、余分な抗体をPBSで洗浄し(3分で3回洗浄)、これを、この場合にもPBSで希釈した(1:400)二次抗体(イムノピュアヤギ抗マウスIgG−ペルオキシダーゼ;Pierce Biotechnology, Rockford IL61105, USA)とハイブリダイズさせた。このハイブリダイゼーションを周囲温度、暗所で45分インキュベートした。これらのサンプルを再び1倍PBSで3回洗浄し、それらを、DAB色素原(DakoCytomation Liquid DAB Substrate Chromogen System; Dako Diagnosticos, Sant Just Desvern E-08960, Barcelona, Spain)を用い、製造業者の推奨に従って現像した。核を特異的に染色するためにこれらのサンプルをマイヤーのヘマトキシリンで対比染色し(5秒)、15分後に水洗し、サンプルを70%、96%および100%アルコールに1分、そしてキシレンに10分浸漬することで脱水した。
サンプルにおいて検出された茶色により、ウイルスキャプシドのタンパク質合成が確認される。インデューサー無しではこれらのタンパク質のわずかな基底生産が検出されるに過ぎないが、免疫細胞化学の結果はRU486インデューサーの存在下でのウイルスタンパク質の発現レベルに対して明瞭な差を明らかにし、クローンpRc−1のゲノムに組み込まれたウイルス遺伝子発現の制御においてミフェリプリストン調節系が機能していることが確認される。
実施例3.2:E1領域とI−SceI遺伝子を双方ともミフェリプリストンにより誘導可能な転写調節の制御下で組み込んだ安定な細胞系統を作出するための、pGal4−2RUSceI−E1プラスミド(ポリヌクレオチドA)によるA549細胞のトランスフェクション
第2の実施形態では、本発明で定義されるようにA2ポリヌクレオチドが組み込まれた安定な細胞系統を設計した(図1A)。よって、このようにして得られた細胞系統は、Bポリヌクレオチドに含まれるアデノウイルス遺伝子の発現の開始および制御に必要な遺伝子を有する。従って、これらの遺伝子、例えば、I−SceI制限エンドヌクレアーゼをコードする遺伝子とE1AおよびE1Bタンパク質をコードするE1アデノウイルス領域は、ミフェリプリストンにより調節されるプロモーターの制御下にある。調節因子GAL4−hPR−p65はA2ポリヌクレオチドに含まれ、従って、それは細胞ゲノムに同時に組み込まれる。該トランスアクチベーターは改変された細胞により構成的に発現されることになる。
第2の実施形態では、本発明で定義されるようにA2ポリヌクレオチドが組み込まれた安定な細胞系統を設計した(図1A)。よって、このようにして得られた細胞系統は、Bポリヌクレオチドに含まれるアデノウイルス遺伝子の発現の開始および制御に必要な遺伝子を有する。従って、これらの遺伝子、例えば、I−SceI制限エンドヌクレアーゼをコードする遺伝子とE1AおよびE1Bタンパク質をコードするE1アデノウイルス領域は、ミフェリプリストンにより調節されるプロモーターの制御下にある。調節因子GAL4−hPR−p65はA2ポリヌクレオチドに含まれ、従って、それは細胞ゲノムに同時に組み込まれる。該トランスアクチベーターは改変された細胞により構成的に発現されることになる。
この細胞系統を得るために、A549細胞を10cm2プレートにて、37℃、5%CO2で80%の集密度に達するまでインキュベートした。これらの細胞を、リポフェクタミン法により、第3.1節に記載されている手順に従い、pGal4−2RUSceI−E1構築物(ゼオマイシン耐性遺伝子(zeor))でトランスフェクトし、pRc−1クローンを得た。これらの細胞を、10%ウシ胎児血清、1%L−Gluおよび1%P/Sおよび400μg/ml濃度の抗生物質ゼオマイシンを添加したDMEM培地でインキュベートした。一連の増幅を行った後、抗生物質耐性クローンが単離され、これをGal−13と呼んだ。pRc−1クローンの場合と同様に、Gal−13クローンの安定性を、4か月を超える期間、連続35回を超えて培養維持できるかどうかを試験した。
細胞のゲノムDNAからのPCRアッセイにより、アデノウイルス遺伝子E1aおよびE1bの存在、I−SceIエンドヌクレアーゼをコードする遺伝子の存在および転写を調節し、ミフェリプリストンにより誘導可能なGAL4タンパク質−hPR−p65融合物をコードする遺伝子の存在が確認された。用いたプライマーは、
細胞のゲノムDNAを、QIAmp DNAミニキット系(Qiagen)を用い、製造業者の推奨に従って抽出し、PCR反応は、1Uの酵素Taqポリメラーゼ(BioTaq, Bioline)、PCRバッファー(Bioline)、4mM MgCl2、0.4mMの各dNTP、10pmolの各プライマー、DNAおよび最終量50μlまでの無菌脱イオン水の存在下で行った。増幅は次の通りとした:95℃で4分の変性1回;94℃で50秒の変性、50℃で40秒の第一鎖とのハイブリダイゼーションおよび72℃で40秒の伸長を29回;72℃で5分の最終伸長1回。増幅産物の分析のため、これらのサンプルを1.5μlのローディング溶液(蒸留水中0.25%ブロモフェノールブルー;40%グリセロール;100mM EDTA)と混合し、それらをTAE 1倍バッファー(40mM Tris Base;20mM氷酢酸;1mM EDTA、pH8.0)を用い、アガロースゲル(1%)での電気泳動により分析し、臭化エチジウム(0.5μg/ml)染色によりDNAを表した。増幅結果により、A549系統のゲノム内にA2ポリヌクレオチドに含まれる遺伝子が適切に組込まれていることが確認された(図8)。
次に、ミフェリプリストンにより誘導可能な系の遺伝子発現の調節能を確認するために、ウエスタンブロットを行い、10−8M濃度のRU486インデューサーの存在下および不在下でインキュベートした培養物から得られたタンパク質サンプルに由来するE1AおよびI−SceIタンパク質の合成を分析した。これらのタンパク質抽出液を500μlのPassive Lysisバッファー1倍(Promega)で精製し、総タンパク質レベルをタンパク質定量のためのブラッドフォード法(Bradford, 1976, Anal. Biochem., 72: 248-254)を用いて測定した。これらのサンプルを不連続ポリアクリルアミド−SDSゲルおよびLaemli電気泳動バッファー(25mM Tris HCl;192mMグリシン;0.1%w/v SDS)での電気泳動により分析した。分解ゲルは0.1%SDSとともに、0.39M Tris−HClバッファー(pH8.8)中12%のポリアクリルアミドからなった。触媒として0.1%PSAおよび0.94%TEMEDを用いた。その一部として、スタッキングゲルは0.1%SDS、0.1%PSAおよび0.01%TEMEDとともに、0.125M Tris−HCl(pH6.8)中5%のポリアクリルアミドからなった。これらのサンプルを4℃で2時間、トランスファーバッファー(0.3%Tris−Base;186mMグリシン;20%メタノール)中のHybond−Fメンブラン(GE Healthcare Europe)に移した。次に、このメンブランを4℃で一晩、PBS+Tween(0.05%)中、5%ミルク溶液でブロッキングした。一次抗体とのハイブリダイゼーションは、周囲温度で1.5時間、1%ミルク+PBS−Tween溶液中で行った。PBS−Tweenで10分間3回洗浄して余分な抗体を除去した。二次抗体とのハイブリダイゼーションは、周囲温度で30分、1%ミルク+PBS−Tween中で行った。E1Aタンパク質の検出において、抗アデノウイルス2 E1A抗体(マウス)(1:500)(Calbiochem(登録商標): EMD, La Jolla CA92039-2087, USA)を、そして、二次抗体としてイムノピュアヤギ抗マウスIgGペルオキシダーゼ(1:5000)(Pierce Biotechnology)を用いた。I−SceIタンパク質の場合には、ただ1つの抗体、抗HA−ペルオキシダーゼ高親和性(1:500)(Roche Diagnostics, 08174 Barcelona, Spain)を用いた。このメンブランをPBS−Tweenで10分間3回洗浄した後、それを現像した。これを行うため、Western lightning化学発光試薬系(Perkin-Elmer, 28760 Madrid, Spain)を製造業者の推奨に従って用いた。得られた結果を図9に示し、これらは分析したタンパク質の適正な生産ならびにインデューサーの存在下でのこれらのタンパク質の発現レベルの増大を実証する。しかしながら、インデューサーの不在下でも、調節を受けたタンパク質の基底発現が存在することを考慮する必要がある。
実施例3.3:Gal4−2RUSceI−E1(ポリヌクレオチドA)およびpRcAd2(Bポリヌクレオチド)プラスミドでのA549細胞の二重トランスフェクションによる安定な細胞系統の作出
ウイルス粒子の生産に必要な遺伝子を総て備えたユニークな細胞系統を得るために、ゼオマイシン耐性クローンGal−13(実施例3.2)を、残りのアデノウイルス遺伝子を含んだpRcAd2(neor)構築物およびPhiC31インテグラーゼをコードするpCMV−Intプラスミドでトランスフェクトした。トランスフェクション条件はGal−13クローンを得るのに用いたものと同じであり、選択は抗生物質G418(600μg/ml)およびゼオマイシン(400μg/ml)の存在下で行った。この選択により、2つの二重耐性クローン(zeor+neor)が得られ、これらをそれぞれGAd−1およびGAd−6と呼んだ。両クローンの形態的特徴は親系統(parenteral line)A549およびその誘導体Gal−13と大きく異なる。これらの新規なトランスフェクトクローンは球形で、小さい傾向がある。この形態変化はおそらくGal−13クローンで事前に検出されたE1遺伝子の基底転写のためであり、pRcAd2プラスミドにクローニングされ、細胞ゲノムに挿入されたアデノウイルス遺伝子の残りの部分の転写を必然的に伴う。しかしながら、ウイルスタンパク質レベルは、それらを4か月を超える期間培養維持した後に確認されたように、細胞の安定性および生存力に有意な影響を及ぼさない。
ウイルス粒子の生産に必要な遺伝子を総て備えたユニークな細胞系統を得るために、ゼオマイシン耐性クローンGal−13(実施例3.2)を、残りのアデノウイルス遺伝子を含んだpRcAd2(neor)構築物およびPhiC31インテグラーゼをコードするpCMV−Intプラスミドでトランスフェクトした。トランスフェクション条件はGal−13クローンを得るのに用いたものと同じであり、選択は抗生物質G418(600μg/ml)およびゼオマイシン(400μg/ml)の存在下で行った。この選択により、2つの二重耐性クローン(zeor+neor)が得られ、これらをそれぞれGAd−1およびGAd−6と呼んだ。両クローンの形態的特徴は親系統(parenteral line)A549およびその誘導体Gal−13と大きく異なる。これらの新規なトランスフェクトクローンは球形で、小さい傾向がある。この形態変化はおそらくGal−13クローンで事前に検出されたE1遺伝子の基底転写のためであり、pRcAd2プラスミドにクローニングされ、細胞ゲノムに挿入されたアデノウイルス遺伝子の残りの部分の転写を必然的に伴う。しかしながら、ウイルスタンパク質レベルは、それらを4か月を超える期間培養維持した後に確認されたように、細胞の安定性および生存力に有意な影響を及ぼさない。
GAd−1およびGAd−6クローンにpRcAd2プラスミドが組み込まれていることを確認するため、QIAmp DNAミニキット系(Qiagen)を用い、製造業者の推奨に従ってゲノムDNAを抽出した。このDNAをネステッドPCRアッセイに用い、アデノウイルス遺伝子IIIa、IV、プロテアーゼをコードする遺伝子およびウイルスポリメラーゼをコードする遺伝子の存在を検出した。この検出の用いたプライマーは第3.1節で用いたものと同じであった。同様に、増幅反応も第3.1節の記載と同様に行った。
増幅産物は、TAE1倍バッファー(40mM Tris Base;20mM氷酢酸;1mM EDTA、pH8.0)用いたアガロースゲル(1%)での電気泳動により分析し、臭化エチジウム(0.5μg/ml)染色によりDNAを可視化した(図10)。
ウイルスタンパク質の合成を確認するために、ウイルスキャプシドに対する免疫組織化学アッセイを設計した。この場合、GAd1およびGAd6クローンを10−8M濃度のRU486インデューサーの存在下および不在下の双方で48時間インキュベートした。次に、6×104細胞を4ウェル培養プレート(BD Falcon Cultureslide; BD)に移し、pRC−1クローン(pRc-1 cline)の場合(実施例3.1)と同様に行った。一次抗体として、PBSで希釈した(1:75)マウス抗アデノウイルスモノクローナル抗体ブレンド(Millipore)抗体を用い、二次抗体として、これもまたPBSで希釈した(1:400)抗体イムノピュアヤギ抗マウスIgG−ペルオキシダーゼ(Pierce Biotechnology)を用いた。
このサンプルにおいて検出される茶色によりウイルスキャプシドのタンパク質合成が確認される。しかしながら、RU486インデューサーの存在下でインキュベートしたサンプルとその不在下でインキュベートしたサンプルの間に明らかな違いは検出されなかった。よって、細胞ゲノムに組み込まれたアデノウイルス遺伝子の残りの部分の発現を開始させるには、転写レギュレーターGAL4−hPR−p65の制御を逃れたE1タンパク質の基本発現で十分である。
実施例4:KCZガットレスウイルスの感染性粒子の生産およびパッケージング
実施例4.1:2つのプラスミドでのコトランスフェクション系によるpRc−1パッケージン系統におけるKCZウイルスの生産およびパッケージング
本実施例では、実施例3.1で作出された細胞系統から選択されたクローンを、高容量アデノウイルスまたはガットレスアデノウイルスの生産およびパッケージングに用いた。この生産系により、pRcAd2プラスミドに欠失している遺伝子の補足としてのヘルパーウイルスを使用する必要なく、真核細胞の染色体に安定に組み込まれる高容量アデノウイルスの抽出液を得ることができる。
実施例4.1:2つのプラスミドでのコトランスフェクション系によるpRc−1パッケージン系統におけるKCZウイルスの生産およびパッケージング
本実施例では、実施例3.1で作出された細胞系統から選択されたクローンを、高容量アデノウイルスまたはガットレスアデノウイルスの生産およびパッケージングに用いた。この生産系により、pRcAd2プラスミドに欠失している遺伝子の補足としてのヘルパーウイルスを使用する必要なく、真核細胞の染色体に安定に組み込まれる高容量アデノウイルスの抽出液を得ることができる。
E1領域の欠損を補うために、この系は、生産工程のそれぞれで細胞系統をpGal4−2RU−SceI−E1プラスミドでトランスフェクトすることを必要とする。この補足プラスミドは、ミフェリプリストンにより調節される誘導プロモーターから遺伝子E1aおよびE1bを発現し(図1A)、これにより残りのアデノウイルス遺伝子の発現が始まる。さらに、組み込まれたウイルスゲノムの複製は、pGal4−2RU−SceI−E1プラスミドに含まれ、また、GAL4−hPR−p65レギュレーターにより転写レベルで制御されるI−SceIエンドヌクレアーゼの発現時にのみ可能である。ウイルスゲノムの放出およびその複製の開始によってその複数のコピー、従って、高容量アデノウイルスのキャプシド封入およびその高力価での精製に十分なレベルのウイルスタンパク質が取得可能となる。
この系が感染性粒子を生産することができるかどうかを調べるために、8×105細胞のpRc−1クローンを20cm2のディッシュにて37℃、5%CO2で、80%の集密度に達するまでインキュベートした。次に。これらの細胞を、5μgのpGal4−2RU−SceI−E1プラスミド、および制限酵素Pme1で消化して複製開始点、アンピシリン耐性遺伝子を除去し、ベクターのITR末端をフリーとした12μgのKCZガットレスベクターでコトランスフェクトした。リポーター遺伝子として、KCZベクターは細菌β−ガラクトシダーゼ遺伝子(lacZ)を有する。
このコトランスフェクションでは、真核細胞でのDNAインターナリゼーションのための系としてリポフェクタミンを用いた。よって、両プラスミドのDNAを予め、OPTI−MEM(Gibco(登録商標))血清を含まない1mlの培地で希釈した。DNAと陽イオン脂質の間の複合体の形成を促進するために、Plus Reagent(Invitrogen)試薬を1:0.75比で加えた。周囲温度で5分インキュベートした後、12μlのリポフェクタミンLTX(Invitrogen)を加え、この混合物を再び周囲温度で25分インキュベートした。次に、この希釈液を細胞培養培地(10%ウシ胎児血清を添加したDMEM)に滴下した。
37℃、5%CO2で4時間インキュベートした後、培地を2%ウシ胎児血清および10−8M濃度のRU486インデューサーを添加した新鮮なDMEM培地に置き換えた。
37℃、5%CO2で4時間インキュベートした後、培地を2%ウシ胎児血清および10−8M濃度のRU486インデューサーを添加した新鮮なDMEM培地に置き換えた。
明瞭な細胞変性作用が見られなかったので、これらの細胞を48〜120時間の間でインキュベートし、その後、種々の時点でそれらの固有の培地に採取した。1250rpmで5分遠心分離を行った後、沈殿を200μlの0.1M Tris−HCl(pH8.0)に再懸濁させ、これらの細胞を冷凍/解凍を3回繰り返すことにより溶解させた。
細胞残渣を遠心分離し、上清の力価を、KCZベクターの調製物に感染させた293S細胞のX−gal染色により測定した。これを行うため、293S細胞を2cmウェルにて2%ウシ胎児血清および1%ピルビン酸Naを添加したDMEM培地で80%の集密度に達するまで増殖させた。次に、培養培地を除去し、細胞を2%DMEM+FBS+1%ピルビン酸Na中、ウイルス抽出液の連続希釈液で感染させた。37℃、5%CO2で4時間インキュベートした後、新鮮培地を加え、さらに48時間インキュベーションを続けた。最後に、細胞をPBS中0.5%のグルタルアルデヒド溶液中、周囲温度で10分固定し、PBSで3回洗浄し、37℃にて4時間、20mM MgCl2、5mM K3Fe(CN6)および5mM K4Fe(CN6)を添加したPBS中、1mg/mlのX−gal(5−ブロモ−4−クロロ−3−インドリル−β−ガラクトピラノシド)で染色した。
得られた結果によれば、pRc−1クローンを生産およびパッケージング系統として用いた場合、継代0代までの生産は48〜72時間後にその最大レベルに達し、7×105感染単位(ui)/ml前後である(図11)。連続的増幅の実施では、これらの抽出液を、予めpGal4−2RU−SceI−E1プラスミドでトランスフェクトした新たなpRc−1細胞の感染に用いた。従って、記載の系は、ヘルパーウイルスに由来する感染性粒子を含まない高容量アデノウイルスの抽出液の回収ならびに高い生産レベルでのそれらの取得を可能とする。
実施例4.2:GAd−1およびGAd−6クローンの細胞におけるKCZウイルスの生産およびパッケージング。高容量ベクターを用いたユニークなトランスフェクション系
下記の生産系は、本発明で記載したA2およびBポリヌクレオチドが安定に組み込まれている改良系統をパッケージング細胞として用いる(図1A、1B)。高容量アデノウイルスベクターに相当するポリヌクレオチドを除き、この細胞系統は感染力を有するウイルス粒子の生産のために付加的な要素(プラスミドまたはウイルスヘルパー)を何も必要としない。
下記の生産系は、本発明で記載したA2およびBポリヌクレオチドが安定に組み込まれている改良系統をパッケージング細胞として用いる(図1A、1B)。高容量アデノウイルスベクターに相当するポリヌクレオチドを除き、この細胞系統は感染力を有するウイルス粒子の生産のために付加的な要素(プラスミドまたはウイルスヘルパー)を何も必要としない。
この系は、キャプシド封入および高容量アデノウイルスの複製に必要なアデノウイルス遺伝子(Bポリヌクレオチド)ならびに従来のウイルスタンパク質の高レベルでの制御発現に必要なE1領域およびI−SceI制限エンドヌクレアーゼの遺伝子(A2ポリヌクレオチド)を単一の細胞に組み込む。最後に、この生産プロセスの開始は、その対応する誘導プロモーターおよび転写アクチベーターGAL4−hPR−p65からのE1領域および制限エンドヌクレアーゼの遺伝子の発現により調節される。
この感染性粒子生産の例では、GAd−6およびGAd−1パッケージング系統を、実施例4.1に示されるように、β−ガラクトシダーゼのリポーター遺伝子をコードし、予めPme1制限酵素で線状化した12μgのKCZガットレスベクターでトランスフェクトした。高容量ベクターでのトランスフェクションは、pRc−1パッケージング系統を用いた生産系に記載されている手順(実施例4.1)に従って行った。
これらの細胞を、2%ウシ胎児血清を添加したDMEM培地中、10−8M濃度のRU486インデューサーの存在下で48〜120時間の間インキュベートした。種々の時点で細胞を採取し、1250rpmで5分遠心分離し、最後に、200μlの0.1M Tris−HClに再懸濁させた。冷凍/解凍を3回繰り返すことでそれを溶解させた後、細胞残渣を遠心分離し、上清を293S細胞系統にて、従前の実施例に記載されているプロトコールに従って滴定した。
GAd−1クローンを生産およびパッケージング系統として用いた場合、継代0代の生産レベルは最大1.7×106感染単位(ui/ml)であったが、GAd−6クローンでは滴定値3×106ui/ml(図12)が得られた。
GAd−1クローンを生産およびパッケージング系統として用いた場合、継代0代の生産レベルは最大1.7×106感染単位(ui/ml)であったが、GAd−6クローンでは滴定値3×106ui/ml(図12)が得られた。
従前の実施例と同様に、これらの抽出液を、連続増幅実施中の新たなパッケージング細胞の感染に用いた。本実施形態に記載されている系は、2つのプラスミドでコトランスフェクトするこれまでの系(実施例4.1)またはウイルス増幅実施中の各段階でパッケージング細胞のトランスフェクション/感染プロセスを排除することによる他のヘルパー依存系とは異なる。この特徴は生産時間を十分短縮し、その収量を増大する。他の大きな利点は、ヘルパーウイルスの混入が無いことであり、これにより、ウイルス精製プロセスが簡単になり、ヒトにおける遺伝子療法手順に用いるのに十分な量の生産が可能となる。
Claims (28)
- (a)転写レギュレーターをコードするヌクレオチド配列を含んでなる第1の発現カセット;
(b)制限エンドヌクレアーゼをコードするヌクレオチド配列を含んでなり、(a)で定義されたポリヌクレオチドによりコードされる転写レギュレーターにより活性化可能な転写調節配列の機能的制御下にある、第2の発現カセット
を含んでなる、ポリヌクレオチドまたは発現ベクター。 - カセット(a)によりコードされている転写レギュレーターが、活性化可能な転写レギュレーターである、請求項1に記載のポリヌクレオチドまたは発現ベクター。
- 活性化可能な転写レギュレーター(a)が、GAL4のDNA結合ドメイン、ヒトプロゲステロン受容体のリガンド結合ドメインおよびNF−κB p65の活性化ドメインにより形成される、請求項2に記載のポリヌクレオチドまたは発現ベクター。
- カセット(b)によりコードされている制限エンドヌクレアーゼが、I−SceIである、請求項1〜3のいずれか一項に記載のポリヌクレオチドまたは発現ベクター。
- (a)転写レギュレーターをコードするヌクレオチド配列を含んでなる第1の発現カセット;
(b)制限エンドヌクレアーゼをコードするヌクレオチド配列を含んでなり、転写レギュレーター(a)により活性化可能な転写調節配列の機能的制御下にある、第2の発現カセット、および
(c)選択されたアデノウイルスE1Aタンパク質、またはアデノウイルスE1AおよびE1Bタンパク質をコードするヌクレオチド配列を含んでなり、転写レギュレーター(a)により活性化可能な転写調節配列の機能的制御下にある、第3の発現カセット
を含んでなる、ポリヌクレオチドまたは発現ベクター。 - 第2および第3のカセットが反対方向に転写される、請求項5に記載のポリヌクレオチドまたは発現ベクター。
- 第2および第3のカセットを制御する転写のレギュレーター配列が、転写レギュレーター(a)と同じ結合部位を共有する、請求項6に記載のポリヌクレオチドまたは発現ベクター。
- カセット(a)によりコードされている転写レギュレーターが、活性化可能な転写レギュレーターである、請求項5〜7のいずれか一項に記載のポリヌクレオチドまたは発現ベクター。
- 活性化可能な転写レギュレーター(a)が、GAL4のDNA結合ドメイン、ヒトプロゲステロン受容体のリガンド結合ドメインおよびNF−κB p65の活性化ドメインにより形成される、請求項8に記載のポリヌクレオチドまたは発現ベクター。
- 第2カセット(b)によりコードされている制限エンドヌクレアーゼがI−SceIである、請求項5〜9のいずれか一項に記載のポリヌクレオチドまたは発現ベクター。
- 少なくとも、Ψパッケージング配列とE1Aタンパク質またはE1A/E1Bタンパク質をコードする配列を欠いている組換えアデノウイルスのゲノムを含んでなるヌクレオチド配列を含んでなり、組換えアデノウイルスゲノムを含んでなる該配列が、制限エンドヌクレアーゼに対する特異的認識配列により隣接されている、ポリヌクレオチドまたは発現ベクター。
- インテグラーゼによる特異的認識のためのヌクレオチド配列をさらに含んでなり、該インテグラーゼ認識配列が、制限エンドヌクレアーゼの第1の認識配列に対して5’位にある、請求項11に記載のポリヌクレオチドまたは発現ベクター。
- インテグラーゼによる認識のためのヌクレオチド配列が、PhiC31インテグラーゼに特異的なattBである、請求項12に記載のポリヌクレオチドまたは発現ベクター。
- エンドヌクレアーゼの認識配列が、I−SceIエンドヌクレアーゼに特異的である、請求項11〜13のいずれか一項に記載のポリヌクレオチドまたは発現ベクター。
- 請求項1〜4のいずれか一項に記載のポリヌクレオチドまたは発現ベクターを含んでなる、宿主細胞。
- アデノウイルスE1Aタンパク質をコードする配列および、場合により、アデノウイルスE1Bタンパク質をコードする配列をさらに含んでなる、宿主細胞。
- 請求項5〜10のいずれか一項に記載のポリヌクレオチドまたは発現ベクターを含んでなる、宿主細胞。
- 請求項11〜14のいずれか一項に記載の、または請求項15〜17のいずれか一項に記載の宿主細胞への請求項11〜14のいずれか一項に記載のポリヌクレオチドの組込みにより得ることができるポリヌクレオチドまたは発現ベクターをさらに含んでなる、請求項15〜17のいずれか一項に記載の宿主細胞。
- 請求項11〜14のいずれか一項に記載のポリヌクレオチドまたは発現ベクターに由来するウイルスゲノムを隣接する制限標的が、請求項1〜10のいずれか一項に記載のポリヌクレオチドに由来する転写レギュレーター(a)により活性化可能な転写レギュレーター配列の機能的制御下にあるエンドヌクレアーゼ制限により特異的に認識される、請求項18に記載の細胞。
- 高容量アデノウイルスの感染性粒子の生産およびパッケージングに好適な細胞の生産方法であって、
(i)細胞を、請求項1〜4のいずれか一項に記載の第1のポリヌクレオチドもしくは該ポリヌクレオチドを含んでなるベクターで、または請求項5〜10のいずれか一項に記載のポリヌクレオチドもしくは該ポリヌクレオチドを含んでなるベクターでトランスフェクトすること、および
(ii)該細胞を、請求項11〜14のいずれか一項に記載のポリヌクレオチドまたは該ポリヌクレオチドを含んでなるベクターでトランスフェクトすること
を含んでなり、工程(i)および(ii)は任意の順序でまたは同時に行うことができ、かつ、工程(i)において細胞が請求項1〜4のいずれか一項に記載のポリヌクレオチドでトランスフェクトされる場合には、アデノウイルスE1Aタンパク質および、場合により、アデノウイルスE1Bタンパク質をコードする配列を含んでなる細胞が用いられる、方法。 - 工程(i)および/または(ii)が、工程(i)および(ii)で用いられたポリヌクレオチドに存在する選択マーカーに基づいて、第1および/または第2のポリヌクレオチドを安定に組み込んだ細胞が選択される付加的な選択工程を含む、請求項20に記載の方法。
- 請求項11〜14のいずれか一項に記載のポリヌクレオチドが、インテグラーゼによる特異的認識のためのヌクレオチド配列をさらに含んでなり、工程(ii)で実施されるトランスフェクションが、該認識配列に特異的なインテグラーゼをコードするポリヌクレオチドをさらに含む、請求項20または21に記載の方法。
- 特異的インテグラーゼが放線菌PhiC31ファージのインテグラーゼであり、特異的認識部位がattB部位である、請求項22に記載の方法。
- 請求項20〜23のいずれか一項に記載の方法によって生産することができる、細胞。
- (a)請求項15〜19および24のいずれか一項に記載の細胞、および
(b)高容量アデノウイルス
を含んでなる、高容量アデノウイルスの生産のための系。 - 高容量アデノウイルスベクターの生産方法であって、
(a)宿主細胞を、生産を意図する高容量アデノウイルスのゲノムを含んでなるポリヌクレオチド、または該ポリヌクレオチドを含んでなる発現ベクターでトランスフェクトするか、または感染させる工程、
(b)該トランスフェクト/感染細胞を高容量アデノウイルスの複製およびパッケージングを可能とするのに十分な条件下で培養する工程、
(c)高容量アデノウイルスのウイルス粒子を回収する工程、および、場合により、
(d)工程(a)〜(c)を繰り返す工程(工程(c)で生産された高容量ウイルス粒子を次のサイクルの工程(a)で用いる)
を含んでなり、
工程(a)で用いられる宿主細胞が、
(i)請求項1〜4のいずれか一項に記載のポリヌクレオチドと、アデノウイルスE1Aタンパク質および、場合により、アデノウイルスE1Bタンパク質をコードする配列とを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、請求項11〜14のいずれか一項に記載のポリヌクレオチドおよび/または該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(ii)請求項5〜10のいずれか一項に記載のポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、請求項11〜14のいずれか一項に記載のポリヌクレオチドおよび/または該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(iii)請求項11〜14のいずれか一項に記載のポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、請求項1〜4のいずれか一項に記載のポリヌクレオチドでのトランスフェクション工程が行われ、該細胞はアデノウイルスE1Aタンパク質および、場合により、アデノウイルスE1Bタンパク質をコードする配列を含んでなる)、
(iv)請求項11〜14のいずれか一項に記載のポリヌクレオチドを含んでなる細胞(この場合には、工程(a)に先立ち、または同時に、請求項5〜10のいずれか一項に記載のポリヌクレオチドおよび/または該ポリヌクレオチドを含んでなる発現ベクターでのトランスフェクション工程が行われる)、
(v)請求項1〜4のいずれか一項に記載のポリヌクレオチド、請求項11〜14のいずれか一項に記載のポリヌクレオチド、ならびにアデノウイルスE1Aタンパク質および、場合により、アデノウイルスE1Bタンパク質をコードする配列を含んでなる細胞、および
(vi)請求項5〜10のいずれか一項に記載のポリヌクレオチドおよび請求項11〜14のいずれか一項に記載のポリヌクレオチドを含んでなる細胞
からなる群から選択される、方法。 - 工程(b)の培養が、請求項1〜4および5〜10のいずれか一項に記載のポリヌクレオチドに含まれるヌクレオチド配列によりコードされる転写レギュレーターの特異的誘導剤の存在下で行われる、請求項26に記載の方法。
- 転写レギュレーターが、GAL4のDNA結合ドメイン、ヒトプロゲステロン受容体のリガンド結合ドメインおよびNF−κB p65の活性化ドメインにより形成され、誘導剤が、合成抗プロゲスチン、好ましくは、ミフェプリストンである、請求項27に記載の方法。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| ES200801682A ES2330826B1 (es) | 2008-06-04 | 2008-06-04 | Sistema para empaquetamiento de adenovirus de alta capacidad. |
| ESP200801682 | 2008-06-04 | ||
| PCT/ES2009/070194 WO2009147271A2 (es) | 2008-06-04 | 2009-06-01 | Sistema para empaquetamiento de adenovirus de alta capacidad |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2011521663A true JP2011521663A (ja) | 2011-07-28 |
| JP2011521663A5 JP2011521663A5 (ja) | 2012-01-05 |
Family
ID=41259582
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011512159A Pending JP2011521663A (ja) | 2008-06-04 | 2009-06-01 | 高容量アデノウイルスをパッケージングするための系 |
Country Status (11)
| Country | Link |
|---|---|
| US (1) | US20110081718A1 (ja) |
| EP (1) | EP2298925B1 (ja) |
| JP (1) | JP2011521663A (ja) |
| CN (1) | CN102112616A (ja) |
| AU (1) | AU2009254522A1 (ja) |
| BR (1) | BRPI0913383A2 (ja) |
| CA (1) | CA2727104A1 (ja) |
| ES (1) | ES2330826B1 (ja) |
| MX (1) | MX2010013365A (ja) |
| RU (1) | RU2010154410A (ja) |
| WO (1) | WO2009147271A2 (ja) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| TWI702955B (zh) | 2012-05-15 | 2020-09-01 | 澳大利亞商艾佛蘭屈澳洲私營有限公司 | 使用腺相關病毒(aav)sflt-1治療老年性黃斑部退化(amd) |
| EP2878674A1 (en) * | 2013-11-28 | 2015-06-03 | Fundación Centro Nacional de Investigaciones Cardiovasculares Carlos III (CNIC) | Stable episomes based on non-integrative lentiviral vectors |
| KR102537394B1 (ko) | 2014-03-17 | 2023-05-30 | 애드베룸 바이오테크놀로지스, 인코포레이티드 | 원추세포에서 증강된 유전자 발현을 위한 조성물 및 방법 |
| MY187898A (en) | 2015-03-02 | 2021-10-27 | Adverum Biotechnologies Inc | Compositions and methods for intravitreal delivery of polynucleotides to retinal cones |
| GB2545763A (en) | 2015-12-23 | 2017-06-28 | Adverum Biotechnologies Inc | Mutant viral capsid libraries and related systems and methods |
| CA3136545A1 (en) * | 2019-04-12 | 2020-10-15 | Freeline Therapeutics Limited | Plasmid system |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2002092786A2 (en) * | 2001-03-26 | 2002-11-21 | The Board Of Trustees Of The Leland Stanford Junior University | A helper dependent adenoviral vector system and methods for using the same |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA92008A (en) | 1904-04-28 | 1905-03-07 | Josiah Byram Millet | Submarine signalling |
| CA91355A (en) | 1904-11-22 | 1905-02-07 | John Jay Tonkin | Steam boiler |
| CA92037A (en) | 1904-11-25 | 1905-03-07 | The Hooven, Owens, Rentchler Company | Turbine bearings |
| WO1979000514A1 (en) | 1978-01-18 | 1979-08-09 | Chubb Electronics Ltd | Cash registers |
| DE3688418T2 (de) | 1985-02-13 | 1993-08-26 | Scios Nova Inc | Menschlicher metallothionein ii-promotor in saeugetierexpressionssystemen. |
| EP0910652B1 (en) | 1996-04-05 | 2014-10-08 | The Salk Institute For Biological Studies | Hormone-mediated methods for modulating expression of exogenous genes in mammalian systems, and products related thereto |
| AU772630B2 (en) * | 1999-01-14 | 2004-05-06 | Novartis Ag | Adenovirus vectors, packaging cell lines, compositions, and methods for preparation and use |
| WO2000049166A2 (en) * | 1999-02-18 | 2000-08-24 | Merck & Co., Inc. | Production of helper dependent adenovirus vectors based on use of endonucleases |
| US6287813B1 (en) | 1999-04-23 | 2001-09-11 | Cistronics Cell Technology Gmbh | Antibiotic-based gene regulation system |
| AU5451300A (en) * | 1999-05-28 | 2000-12-18 | Mount Sinai School Of Medicine, The | A novel packaging cell line for the rescue, production and titration of high-capacity adenovirus amplicon vectors |
| US6750015B2 (en) | 2000-06-28 | 2004-06-15 | Kathryn B. Horwitz | Progesterone receptor-regulated gene expression and methods related thereto |
| US20020064860A1 (en) | 2000-11-29 | 2002-05-30 | Schering Corporation | Method for purifying adenoviruses |
| DE10148294C1 (de) | 2001-09-29 | 2003-01-16 | Unicor Rohrsysteme Gmbh | Formbackenhälfte für einen Corrugator zum Herstellen von Querrippenrohren |
| WO2003093293A2 (en) | 2002-04-29 | 2003-11-13 | Saint Louis University | Peptide antagonists of tgf-beta family members and therapeutic uses thereof |
| ES2304069B1 (es) | 2003-08-22 | 2009-08-12 | Proyecto De Biomedicina Cima, S.L. | Peptidos con capacidad de unirse al factor transformante de crecimiento beta 1 (tgf-b1). |
| WO2007059473A2 (en) | 2005-11-12 | 2007-05-24 | Introgen Therapeutics, Inc. | Methods for the production and purification of adenoviral vectors |
-
2008
- 2008-06-04 ES ES200801682A patent/ES2330826B1/es not_active Expired - Fee Related
-
2009
- 2009-06-01 AU AU2009254522A patent/AU2009254522A1/en not_active Abandoned
- 2009-06-01 US US12/996,346 patent/US20110081718A1/en not_active Abandoned
- 2009-06-01 RU RU2010154410/10A patent/RU2010154410A/ru not_active Application Discontinuation
- 2009-06-01 BR BRPI0913383A patent/BRPI0913383A2/pt not_active IP Right Cessation
- 2009-06-01 CA CA2727104A patent/CA2727104A1/en not_active Abandoned
- 2009-06-01 CN CN2009801300439A patent/CN102112616A/zh active Pending
- 2009-06-01 EP EP09757650A patent/EP2298925B1/en active Active
- 2009-06-01 MX MX2010013365A patent/MX2010013365A/es active IP Right Grant
- 2009-06-01 WO PCT/ES2009/070194 patent/WO2009147271A2/es not_active Ceased
- 2009-06-01 JP JP2011512159A patent/JP2011521663A/ja active Pending
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2002092786A2 (en) * | 2001-03-26 | 2002-11-21 | The Board Of Trustees Of The Leland Stanford Junior University | A helper dependent adenoviral vector system and methods for using the same |
Non-Patent Citations (5)
| Title |
|---|
| JPN5011004450; NICOLAS A L: 'CREATION AND REPAIR OF SPECIFIC DNA DOUBLE-STRAND BREAKS IN VIVO FOLLOWING 以下備考' VIROLOGY V266 N1, 20000105, P211-224, ACADEMIC PRESS * |
| JPN5011004452; BURCIN: 'ADENOVIRUS-MEDIATED REGULABLE TARGET GENE EXPRESSION IN VIVO' PROCEEDINGS OF THE NATIONAL ACADEMY OF SCIENCES OF USA V96, 19990101, P355-360, NATIONAL ACADEMY OF SCIENCE * |
| JPN5011004459; HILLGENBERG M: 'SYSTEM FOR EFFICIENT HELPER-DEPENDENT MINIMAL ADENOVIRUS CONSTRUCTION AND RESCUE' HUMAN GENE THERAPY V12 N6, 20010410, P643-657, MARY ANN LIEBERT * |
| JPN5011004462; GAO G: 'HIGH THROUGHPUT CREATION OF RECOMBINANT ADENOVIRUS VECTORS BY DIRECT CLONING, 以下備考' GENE THERAPY V10 N22, 20031001, P1926-1930, MACMILLAN PRESS LTD. * |
| JPN6013064167; ウイルス Vol.57, No.1, 2007, p.37-46 * |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2298925A2 (en) | 2011-03-23 |
| BRPI0913383A2 (pt) | 2016-07-05 |
| MX2010013365A (es) | 2011-01-25 |
| WO2009147271A3 (es) | 2010-04-22 |
| AU2009254522A1 (en) | 2009-12-10 |
| WO2009147271A2 (es) | 2009-12-10 |
| RU2010154410A (ru) | 2012-07-20 |
| ES2330826B1 (es) | 2010-07-26 |
| ES2330826A1 (es) | 2009-12-15 |
| EP2298925B1 (en) | 2013-02-20 |
| CA2727104A1 (en) | 2009-12-10 |
| CN102112616A (zh) | 2011-06-29 |
| US20110081718A1 (en) | 2011-04-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3672494B2 (ja) | 機能的ゲノム適用にライブラリーを使用される遺伝子機能に関する高度処理能力スクリーニング法 | |
| CN100374574C (zh) | 稳定的腺病毒载体及其增殖方法 | |
| JP3565859B2 (ja) | 改良されたアデノウイルスおよびその使用法 | |
| EP1015620B1 (en) | Dual selection cassette and plasmids containing same | |
| EP0973866A1 (en) | Adenovirus e1-complementing cell lines | |
| WO2002067861A2 (en) | Oncolytic adenoviral vectors | |
| RU2520809C2 (ru) | Самоинактивирующиеся аденовирусы-помощники для получения рекомбинантных аденовирусов с высокой емкостью | |
| EP2298925B1 (en) | System for packaging of high-capacity adenoviruses | |
| US20200157567A1 (en) | Viral Vector | |
| Ross et al. | Assembly of helper-dependent adenovirus DNA into chromatin promotes efficient gene expression | |
| US9404090B2 (en) | Adenovirus producing novel cell line and the use thereof | |
| Catalucci et al. | An adenovirus type 5 (Ad5) amplicon-based packaging cell line for production of high-capacity helper-independent ΔE1-E2-E3-E4 Ad5 vectors | |
| AU5426299A (en) | Inducible expression system | |
| AU781775B2 (en) | Adenoviral vectors for treating disease | |
| Kang et al. | Establishment of a mouse melanoma model system for the efficient infection and replication of human adenovirus type 5-based oncolytic virus | |
| JP2004517610A (ja) | 自己再編成性dnaベクター | |
| Chaurasiya et al. | Adenoviral vector construction I: mammalian systems | |
| US20070014769A1 (en) | Adenovirus vectors comprising meganuclease-type endonucleases, and related systems | |
| US7135187B2 (en) | System for production of helper dependent adenovirus vectors based on use of endonucleases | |
| US20010046965A1 (en) | Adenovirus E1-complementing cell lines | |
| Kolibius et al. | Genome-replicating HC-AdV: A novel high-capacity adenoviral vector class featuring enhanced in situ payload expression | |
| AU2002247188A1 (en) | Novel oncolytic adenoviral vectors |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20111110 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20120522 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20140107 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20140808 |