JP2006127460A - 半導体装置、半導体信号処理装置、およびクロスバースイッチ - Google Patents
半導体装置、半導体信号処理装置、およびクロスバースイッチ Download PDFInfo
- Publication number
- JP2006127460A JP2006127460A JP2005143109A JP2005143109A JP2006127460A JP 2006127460 A JP2006127460 A JP 2006127460A JP 2005143109 A JP2005143109 A JP 2005143109A JP 2005143109 A JP2005143109 A JP 2005143109A JP 2006127460 A JP2006127460 A JP 2006127460A
- Authority
- JP
- Japan
- Prior art keywords
- data
- register
- bit
- arithmetic
- circuit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images







































































































































Classifications
-
- G—PHYSICS
- G11—INFORMATION STORAGE
- G11C—STATIC STORES
- G11C7/00—Arrangements for writing information into, or reading information out from, a digital store
- G11C7/10—Input/output [I/O] data interface arrangements, e.g. I/O data control circuits, I/O data buffers
- G11C7/1006—Data managing, e.g. manipulating data before writing or reading out, data bus switches or control circuits therefor
Abstract
【課題】 大量のデータを、その演算内容およびデータビット幅にかかわらず高速で演算処理する。
【解決手段】 メモリセルマット(30)を複数のエントリ(ERY)に分割し、各エントリ(ERY)に対応して、演算処理ユニット(ALU)を配置し、これらのエントリと対応の演算処理ユニットとの間で、ビットシリアルかつエントリパラレル態様で演算処理を実行する。並列演算性が低い場合には、このメモリセルマット(30)下部に設けられた演算器群(82)に対して、エントリシリアルかつビットパラレル態様でデータを転送して演算処理を実行する。
【選択図】 図30
【解決手段】 メモリセルマット(30)を複数のエントリ(ERY)に分割し、各エントリ(ERY)に対応して、演算処理ユニット(ALU)を配置し、これらのエントリと対応の演算処理ユニットとの間で、ビットシリアルかつエントリパラレル態様で演算処理を実行する。並列演算性が低い場合には、このメモリセルマット(30)下部に設けられた演算器群(82)に対して、エントリシリアルかつビットパラレル態様でデータを転送して演算処理を実行する。
【選択図】 図30
Description
この発明は、半導体装置に関し、特に、高速に大量のデータの演算処理を行なう半導体メモリを用いた演算回路の構成に関する。
近年、携帯端末機器の普及に伴い、音声および画像のような大量のデータを高速に処理するデジタル信号処理の重要性が高くなってきている。このデジタル信号処理には、一般に、専用の半導体装置として、DSP(デジタル・シグナル・プロセサ)が用いられる。音声および画像に対するデジタル信号処理においては、フィルタ処理などのデータ処理が行なわれ、このような処理においては、積和演算を繰返す演算処理が多い。したがって、一般に、DSPの構成においては、乗算回路、加算回路および累算用のレジスタが設けられる。このような専用のDSPを用いると、積和演算を1マシンサイクルで実行することが可能となり、高速演算処理が可能となる。
このような積和演算を行なう際に、レジスタファイルを利用する構成が、特許文献1(特開平6−324862号公報)に示されている。この特許文献1においては、レジスタファイルに格納された2項のオペランドデータを読出して、演算器で加算した後、再び書込データレジスタを介してレジスタファイルに書込む。この特許文献1に示される構成では、レジスタファイルに対して、書込アドレスおよび読出アドレスを同時に与えて、データの書込およびデータの読出を同時に行なうことにより、データの書込サイクルおよびデータの読出サイクルを別々に設けて演算処理する構成に比べて、処理時間を短縮することを図る。
また、大量のデータを、高速で処理することを意図する構成が、特許文献2(特開平5−197550号公報)に示されている。この特許文献2に示される構成においては、複数の演算装置を並列に配置し、それぞれの演算装置にメモリを内蔵する。各演算装置において個々にメモリアドレスを生成することにより、並列演算を高速で行なうことを図る。
また、画像データのDCT変換(離散コサイン変換)などの処理を高速に行なうことを目的とする信号処理装置が、特許文献3(特開平10−74141号公報)に示されている。この特許文献3に示される構成においては、画像データがビットパラレルかつワードシリアルなシーケンスで、すなわちワード(画素データ)単位で入力されるため、直列/並列変換回路を用いてワードパラレルかつビットシリアルなデータに変換してメモリアレイに書込む。メモリアレイに対応して配置される演算器(ALU)へデータを転送して並列処理を実行する。メモリアレイは、画像データブロックに応じてブロックに分割されており、各ブロックにおいては、対応の画像ブロックを構成する画素データが、行ごとにワード単位で格納される。
この特許文献3に示される構成においては、メモリブロックと対応の演算器との間でワード(1つの画素に対応するデータ)単位でデータを転送する。各ブロック個々に、対応の演算器において同一処理を転送されたワードに対して実行することにより、DCT変換などのフィルタ処理を高速で実行することを図る。演算処理結果は、再びメモリアレイに書込み、再度並列/直列変換を行なってビットシリアルかつワードパラレルデータをビットパラレルかつワードシリアルなデータに変換して1ラインごとのデータを順次出力する。通常の処理においては、データのビット位置の変換は行なわず、演算器において通常の演算処理を、複数のデータに対して並列に実行する。
また、複数の異なる演算処理を並行して実行することを目的とするデータ処理装置が特許文献4(特開2003−114797号公報)に示されている。この特許文献4においては、各々その機能が限定された複数の論理モジュールを、マルチポート構成のデータメモリに接続する。これらの論理モジュールとマルチポートデータメモリとの接続においては、論理モジュールが接続されるマルチポートメモリのポートおよびメモリが制限されており、従って、各論理モジュールが、マルチポートデータメモリへアクセスしてデータの読出および書込を行なうことのできるアドレス領域は制限される。各論理モジュールで演算を行なった結果を、アクセスが許可されたデータメモリに書き込み、これらのマルチポートデータメモリを介してデータを順次論理モジュールを介して転送することにより、パイプライン的に、データを処理することを図る。
また、複数の演算回路の接続を切り換える構成として、特許文献5(特開平10−254843号公報)にクロスバースイッチが示されている。
特開平6−324862号公報
特開平5−197550号公報
特開平10−74141号公報
特開2003−114797号公報
特開平10−254843号公報
処理対象のデータ量が非常に多い場合には、専用のDSPを用いても、性能を飛躍的に向上させることは困難である。たとえば、演算対象のデータが1万組ある場合、1つ1つのデータに対する演算を1マシンサイクルで実行することができたとしても、最低でも1万サイクルが演算に必要となる。したがって、特許文献1に示されるような、レジスタファイルを用いて積和演算を行なうような構成の場合、1つ1つの処理は高速であるものの、データ処理が直列に行なわれるため、データ量が多くなるとそれに比例して処理時間が長くなり、高速処理を実現することができない。
また、このような専用のDSPを利用する場合、処理性能は動作周波数に大きく依存することになるため、高速処理を優先した場合、消費電力が増大することになる。
また、この特許文献1に示されるようなレジスタファイルおよび演算器を利用する場合、ある用途に特化して設計されることが多く、演算ビット幅および演算回路の構成等が固定されることになり、他の用途に転用する場合には、そのビット幅および演算回路の構成等を設計し直す必要があり、複数の演算処理用途に、柔軟に対応することができなくなるという問題が生じる。
また、特許文献2に示される構成においては、演算装置個々にメモリが内蔵されており、各演算装置において異なるメモリアドレス領域をアクセスして処理を行なう。しかしながら、データメモリと演算装置とは、別々の領域に配置されており、論理モジュール内において演算装置とメモリとの間でアドレスを転送およびデータアクセスを行なう必要があり、データ転送に時間を要し、このため、マシンサイクルを短縮することができなくなり、高速処理を行なうことができなくなるという問題が生じる。
また、特許文献3に示される構成においては、画像データのDCT変換などの処理を高速化することを図っており、画面1ラインの画素データを1行のメモリセルに格納して、行方向に整列する画像ブロックに対して並列に処理を実行している。したがって、画像の高精細化のために1ラインの画素数が増大した場合、メモリアレイの構成が膨大なものとなる。たとえば、1画素のデータが8ビットで、1ラインの画素数が512個の場合、メモリアレイの1行においては、メモリセルの数が、8・512=4Kビットとなり、1行のメモリセルが接続される行選択線(ワード線)の負荷が大きくなり、高速でメモリセルを選択して、データを演算部とメモリセルの間に転送することができなくなり、応じて高速処理を実現することができなくなるという問題が生じる。
また、この特許文献3においては、メモリセルアレイを、演算回路群両側に配置する構成は示されているものの、具体的なメモリセルアレイ構造は示されておらず、また、演算器において演算器をアレイ状に配置することは示されているものの、どのように演算器群を配置するかの詳細については何ら示されていない。
また、特許文献4に示される構成においては、複数のマルチポートデータメモリと、これらのマルチポートデータメモリに対してアクセス領域が制限される複数の低機能の演算器(ALU)とが設けられている。しかしながら、この演算器(ALU)とメモリとは別の領域に配置されており、配線容量などにより、高速でデータを転送することができず、パイプライン処理を実行しても、このパイプラインのマシンサイクルを短縮することができなくなるという問題が生じる。
また、これらの特許文献1から4においては、演算処理対象のデータの語構成が異なる場合、どのように対応するかについては何ら検討していない。
また、演算器が多数配置され、これらの演算器群においてデータの転送を行って並列演算処理を行う構成においては、データの転送経路を切り替えることにおり処理内容の変更に柔軟に対処することができる。このようなデータ転送経路の切り替えとしては、通信分野の回線切り替えおよび並列計算機において特許文献5に示されるようにクロスバースイッチが用いられる。
この特許文献5に示されるクロスバースイッチの構成においては、機能ブロックの接続可能な経路にスイッチを配置し、経路指定情報に従ってスイッチを選択的に導通状態としてデータ転送経路を設定する。しかしながら、この様なスイッチマトリクスを利用する場合、接続対象の演算器(機能ブロック)の数が増大すると応じて接続可能経路も増大し、スイッチ回路のレイアウト面積が増大し、また、スイッチ制御信号線の配置が錯綜する。
それゆえに、この発明の目的は、高速で大量のデータを処理することのできる半導体装置を提供することである。
この発明の他の目的は、データの語構成および演算内容にかかわらず、高速で演算処理を実行することのできる半導体装置を提供することである。
この発明のさらに他の目的は、柔軟に処理内容を変更することのできる演算機能内蔵半導体装置を提供することである。
それゆえに、この発明さらに他の目的は、小占有積で演算器群間の接続経路を設定することのできるクロスバースイッチ回路を提供することである。
この発明に係る半導体装置は、行列状に配列されかつ複数のエントリに分割される複数のメモリセルを有するメモリセルアレイと、各エントリに対応して配置され、各々が指定された演算を対応のエントリのデータに対して行なう複数の第1の演算回路と、各エントリと対応の第1の演算回路との間でデータを転送する複数のデータ転送線と、これらのデータ転送線それぞれに対応して配置され、対応のデータ転送線との間でビット単位でかつエントリパラレルの態様でデータを転送する複数のデータ転送回路とを含む。
各エントリにおいては多ビットデータが格納され、各第1の演算回路は、対応のエントリの多ビットデータに対して、ビットシリアル態様で演算を実行する。
この発明に係る半導体信号処理装置は、複数のエントリに分割されるメモリセルアレイと、各エントリに対応して配置される複数の演算回路と、演算回路の演算を制御する制御回路とを備える。演算回路は、演算器と、第1および第2のレジスタと、マスクレジスタとを含む。制御回路は、第1のレジスタに対応のエントリからの演算ビットを格納し、こ
の第1のレジスタの演算ビットとメモリセルアレイからの第2の演算ビットとの演算を実
行し、該演算結果を第1のレジスタに格納して、この第1のレジスタの格納値をメモリセルアレイの対応の位置に格納するように制御する。
の第1のレジスタの演算ビットとメモリセルアレイからの第2の演算ビットとの演算を実
行し、該演算結果を第1のレジスタに格納して、この第1のレジスタの格納値をメモリセルアレイの対応の位置に格納するように制御する。
この発明の第2の観点に係る半導体信号処理装置は、複数のエントリに分割されるメモリセルマットと、エントリに対応して配置される複数の演算回路とを備える。この演算回路は、対応のエントリの第1の領域からのデータビットの組について2次のブースアルゴリズムに従ってデコードした結果を格納するブースレジスタ回路と、対応のエントリの第2および第3の領域の対応の位置からのデータビットを受け、ブースレジスタ回路の格納データに従って受けたデータに対して演算処理を行う演算器と、この演算器の出力データを格納する結果レジスタとを備える。
この第2の観点に係る半導体信号処理装置は、さらに、メモリセルマットの各エントリから第1、第2および第3の領域からのデータを対応の演算回路に転送しかつ演算器の出力データを対応のエントリの第3の領域に転送して書込み、かつ演算器の演算処理を制御する制御回路を備える。
この発明の第3の観点に係る半導体信号処理装置は、複数のエントリに分割されるメモリセルマットと、エントリに対応して配置される複数の演算回路と、これらの複数の演算回路の所定数の演算回路に対応して設けられ、対応の演算回路に動作制御信号を伝達する演算制御信号線を備える。
この発明の第4の観点に係る半導体信号処理装置は、各々が、複数のエントリに分解されるメモリセルマットと、エントリに対応して配置される複数の演算回路とを含み、個々に演算処理を実行することが可能な複数の基本演算ブロックと、これらの複数の基本演算ブロックに共通に配置される内部データバスと、この内部データバスに結合される大容量のメモリと、大容量メモリと、選択された基本演算ブロックとの間で大容量メモリの1行のデータ単位でデータ転送を行う制御回路とを備える。
この発明の第5の観点に係る半導体信号処理装置は、各々が、複数のエントリに分割されるメモリセルマットと、各エントリに対応して配置される演算回路とを備える複数の演算ブロックと、隣接演算ブロックの対応のエントリを相互接続する隣接ブロック接続バスと、演算ブロック内の演算器を相互接続するビット転送回路とを備える。
この発明の第6の観点に係る半導体信号処理装置は、各々が、複数のエントリに分割されるメモリセルマットと、エントリに対応して配置される演算器とを含む複数の演算回路ブロックと、これらの複数の演算回路ブロックに共通に配置されるグローバルデータバスと、外部処理装置に接続されるシステムバスと、このシステムバスと第1の内部伝送バスとの間に配置され、これらのバスに転送されるデータの構成を変更する直交変換回路と、第1の内部転送バスと第2の内部転送バスとの間に配置され、これらの第1および第2の内部転送バスの接続経路を変更するクロスバースイッチと、第2の内部転送バスとグローバルデータバスとの間に接続され、これらのバス線を選択的に接続する選択回路とを備える。
この発明に係るクロスバースイッチは、一列に配列される複数の第1機能ブロックと、複数の第1機能ブロックに対向して配置される複数の第2機能ブロックとの間に設けられ、第1および第2の機能ブロックを1対1で任意の組合せで接続するクロスバースイッチであって、各第1機能ブロックに対応して設けられ手対応の第1機能ブロックのデータ信号端子に接続され、複数の第1機能ブロックの配列方向と同じ方向に延在する第1データ信号線と、各第1データ信号線に対応して設けられ、対応の第1機能ブロックからのセレクト信号に従って複数の第2機能ブロックのうちのいずれかの第1機能ブロックを選択し、選択した第2機能ブロックのデータ信号端子と対応の第1データ信号線とを接続する選択回路とを備える。
メモリセルアレイを複数のエントリに分割し、各エントリに対して第1の演算回路を配置しており、複数のエントリのデータに対する演算を並列に行なうことができ、高速処理が実現される。
また、第1の演算回路とデータ転送線との間のデータ転送をビット単位で実行し、第1の演算回路においてビットシリアル態様で演算を実行することにより、演算対象のデータの語構成にかかわらず、対応のエントリの多ビットデータに対して指定された演算処理を実行することができる。すなわち、各エントリに有意データワードを格納し、ビットシリアル態様で各第1の演算回路で演算処理を行なう構成とすれば、データの語構成(ビット幅)の変更に対しても、大幅なハードウェアの変更を行なうことなく対応して演算処理を行なうことができ、種々のアプリケーションに対して柔軟に対応することができる。
演算回路内に演算器とレジスタとを配置することにより、演算対象データをレジスタに格納してビットシリアル態様で種々の演算処理を実行することができる。
また、演算回路内に複数のレジスタ回路を配置することにより、ビットシリアル態様で乗算を行う場合においても2次のブースアルゴリズムに従って乗算を行うことが可能となる。
また、演算ブロックに対して所定数ごとの演算ブロックに共通に制御信号を伝達することにより、所定数の演算ブロック単位で必要とされる演算を実行することができ、個々の演算ブロックを個別に制御する構成に比べて演算制御が容易となり、容易に単一命令で複数のデータの処理を実行することができる。
また、複数の演算ブロックに共通に大容量メモリを設けることにより、大容量メモリと演算ブロックとの間のデータ転送のバンド幅を大きくすることができ、個々の演算ブロックにおける演算処理に対してデータ転送がボトルネックとなるのを防止することができる。
また、演算ブロック間でおよび演算器間でデータを転送することができるように配置することにより、隣接画素間の演算処理などを容易に実行することができる。
また、入出力インターフェイス部分にデータ変換回路を配置することにより、容易にワードシリアルかつビットパラレルのデータ列とビットシリアルかつワードパラレルのデータ列の変換を行うことができ、演算器内においてビットシリアルにデータ処理を行い外部ではワード単位で処理を行うことができる。
この発明に係るクロスバースイッチでは、各第1機能ブロックに対応して第1データ信号線を設け、その第1データ信号線をセレクト信号によって指定された第2機能ブロックに接続する。したがって、構成の簡単化を図ることができ、レイアウト面積が小さくて済む。
[実施の形態1]
図1は、この発明の実施の形態1に従う半導体演算装置を利用する処理システムの構成を概略的に示す図である。図1において、処理システムは、並列演算を実行する半導体演算装置1と、この半導体演算装置1における処理の制御、システム全体の制御およびデータ処理を行なうホストCPU2と、このシステムの主記憶として利用されて必要な種々のデータを格納するメモリ3と、メモリ3に対し、直接ホストCPU2を介することなくアクセスするDMA(ダイレクト・メモリ・アクセス)回路4とを含む。このDMA回路4の制御により、メモリ3と半導体演算装置1の間でデータ転送を行なうことができ、また、半導体演算装置1へ直接アクセスすることとができる。
図1は、この発明の実施の形態1に従う半導体演算装置を利用する処理システムの構成を概略的に示す図である。図1において、処理システムは、並列演算を実行する半導体演算装置1と、この半導体演算装置1における処理の制御、システム全体の制御およびデータ処理を行なうホストCPU2と、このシステムの主記憶として利用されて必要な種々のデータを格納するメモリ3と、メモリ3に対し、直接ホストCPU2を介することなくアクセスするDMA(ダイレクト・メモリ・アクセス)回路4とを含む。このDMA回路4の制御により、メモリ3と半導体演算装置1の間でデータ転送を行なうことができ、また、半導体演算装置1へ直接アクセスすることとができる。
ホストCPU2、メモリ3、DMA回路4、および半導体演算装置1は、システムバス5を介して相互接続される。半導体演算装置1は、複数の並列に設けられる基本演算ブロックFB1−FBnと、システムバス5とデータ/命令を転送する入出力回路10と、この半導体演算装置1内部での動作処理を制御する集中制御ユニット15を含む。
基本演算ブロックFB1−FBnおよび入出力回路10は、内部データバス12に結合され、また集中制御ユニット15、入出力回路10および基本演算ブロックFB1−FBnは、内部バス14に結合される。基本演算ブロックFB(FB1−FBnを総称的に示す)の間には、ブロック間データバス16が設けられる(図1においては、基本演算ブロックFB1およびFB2の間に配置される隣接ブロック間データバス16を代表的に示す。
基本演算ブロックFB1−FBnを並列に設けて、半導体演算装置1内部で並列に同一または異なる演算処理を実行する。これらの基本演算ブロックFB1−FBnは、同一構成を有するため、図1においては基本演算ブロックFB1の構成を代表的に示す。
基本演算ブロックFB1は、メモリセルアレイおよび演算器を含む主演算回路20と、マイクロコード化された実行プログラムを格納するマイクロプログラム格納メモリ23と、基本演算ブロックFB1の内部動作を制御するコントローラ21と、アドレスポインタ等として用いられるレジスタ群22と、主演算回路20における不良の救済を行なうためのヒューズプログラムを実行するためのヒューズ回路24を含む。
コントローラ21は、ホストCPU2から、システムバス5および入出力回路10を介して与えられる制御命令により、制御が手渡されて、基本演算ブロックFB1−FBnの動作を制御する。これらの基本演算ブロックFB1−FBnにマイクロプログラム格納メモリ23を設け、コントローラ21が、このメモリ23内に実行プログラムを格納することにより、基本演算ブロックFB1−FBnそれぞれにおいて実行する処理内容を変更することができ、基本演算ブロックFB1−FBnにおいて、それぞれ演算実行される処理内容を変更することができる。
隣接ブロック間データバス16が、基本演算ブロックFB1−FBnの間のデータ転送を行うために設けられる。この隣接ブロック間データバス16は、内部データバス12を占有することなく、基本演算ブロック間の高速データ転送を可能とし、たとえば、ある基本演算ブロックに内部データバス12を介してデータ転送中に、別の基本演算ブロック間でデータ転送を行なうことができる。
集中制御ユニット15は、制御用CPU25と、この制御用CPUが実行する命令を格納する命令メモリ26と、制御用CPU25のワーキングレジスタまたはポインタ格納用のレジスタを含むレジスタ群27と、マイクロプログラムのライブラリを格納するマイクロプログラムライブラリ格納メモリ23を含む。集中制御ユニット15は、内部バス14を介してホストCPU2から制御権を手渡され、内部バス14を介して基本演算ブロックFB1−FBnの処理動作を制御する。
マイクロプログラムライブラリ格納メモリ23に、各種シーケンス処理がコード化されたマイクロプログラムをライブラリとして格納することにより、集中制御ユニット15から必要なマイクロプログラムを選択して、基本演算ブロックFB1−FBnのマイクロプログラム格納メモリ23に格納されるマイクロプログラムを変更することができ、処理内容の変更に柔軟に対応することができる。
また、ヒューズ回路24を利用することにより、この基本演算ブロックFB1−FBnそれぞれにおいて不良発生時、冗長置換を用いて不良救済を行なうことにより、歩留まりを改善する。
図2は、図1に示す基本演算ブロックFB1−FBnそれぞれに含まれる主演算回路20の要部の構成を概略的に示す図である。図2において、主演算回路20は、メモリセルMCが行列状に配列されるメモリマット30と、このメモリマット30の一方端に配列される演算処理ユニット(ALU)群32を含む。
メモリマット30においては、行列状に配列されるメモリセルMCが、m個のエントリERYに分割される。エントリERYは、nビットのビット幅を有する。本実施の形態1においては、1つのエントリERYは、一列のメモリセルで構成される。
演算処理ユニット群32は、このエントリERYそれぞれに対して設けられる演算処理ユニット(ALU)34を含む。演算処理ユニット34は、加算、論理積、一致検出(EXOR)、および反転(NOT)などの演算を実行することができる。
このエントリERYと対応の演算処理ユニット34の間で、データのロードおよびストアを行なって演算処理を行なう。このエントリERYは、メモリマット30の列方向に整列して配置されるメモリセルMCで構成され、演算処理ユニットALU34は、ビットシリアルな(データワードをビット単位で処理する)態様で演算処理を実行し、従って演算処理ユニット群32において、ビットシリアルかつ複数のエントリが並行して処理されるエントリパラレルな態様でデータの演算処理が実行される。
演算処理ユニット(ALU)34において、ビットシリアル態様で演算処理を実行することにより、演算対象のデータのビット幅が異なる場合においても、単に演算サイクル数がデータワードのビット幅に応じて変更されるだけであり、その処理内容は変更されず、容易に語構成の異なるデータを処理することができる。
また、複数のエントリERYのデータを、演算処理ユニット群32において同時に処理することができ、エントリ数mを多くすることにより、大量のデータを一括して演算処理することができる。
ここで、一例として、エントリ数mは、1024であり、1エントリのビット幅nは、512ビットである。
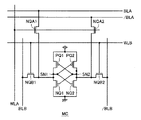
図3は、図2に示すメモリセルMCの構成の一例を示す図である。図3において、メモリセルMCは、電源ノードとストレージノードSN1の間に接続されかつそのゲートがストレージノードSN2に接続されるPチャネルMOSトランジスタPQ1と、電源ノードとストレージノードSN2の間に接続されかつそのゲートがストレージノードSN1に接続されるPチャネルMOSトランジスタPQ2と、ストレージノードSN1と接地ノードの間に接続されかつそのゲートがストレージノードSN2に接続されるNチャネルMOSトランジスタNQ1と、ストレージノードSN2と接地ノードの間に接続されかつそのゲートがストレージノードSN1に接続されるNチャネルMOSトランジスタNQ2と、ワード線WL上の電位に応答してストレージノードSN1およびSN2を、それぞれ、ビット線BLおよび/BLに接続するNチャネルMOSトランジスタNQ3およびNQ4を含む。
この図3に示すメモリセルMCは、フルCMOS(相補MOS)構成のSRAM(スタティック・ランダム・アクセス・メモリ)セルであり、高速で、データの書込/読出を行なう。
メモリセルMCとしては、2つのDRAMセルがビット線BLおよび/BLの間に直列に接続されかつ共通のワード線WLで選択状態とされる「ツインセル構造」のDRAMセルユニットが用いられてもよい。
主演算回路20において演算を行なう場合には、まず各エントリERYに、演算対象データの格納を行なう。次いで、格納されたデータのある桁のビットを、すべてのエントリERYについて並列に読出して、対応の演算処理ユニット34へ転送(ロード)する。2項演算の場合には、各エントリにおいて別のデータワードのビットに対しても同様の転送動作を行なった後、各演算処理ユニット34で、2入力演算を行なう。この演算処理結果は、演算処理ユニット34から対応のエントリ内の所定領域に再書込(ストア)される。
図4は、図2に示す主演算回路20における演算操作を例示的に示す図である。この図4においては、2ビット幅のデータワードaおよびbの加算を行なって、データワードcを生成する。エントリERYには、演算対象の組をなすデータワードaおよびbがともに格納される。
図4においては、第1行目のエントリERYに対する演算処理ユニットにおいては、10B+01Bの加算が行なわれ、2行目のエントリに対する演算処理ユニットにおいては、00B+11Bの演算が行なわれる。ここで、“B”は、2進数を示す。3行目のエントリに対する演算処理ユニットにおいては11B+10Bの演算が行なわれる。以下、同様に、各エントリに格納されたデータワードaおよびbの加算演算が行なわれる。
演算は、下位側ビットから順にビットシリアル態様で行なわれる。まず、エントリERYにおいてデータワードaの下位ビットa[0]を対応の演算処理ユニット(以下、ALUと称す)34へ転送する。次にデータワードbの下位ビットb[0]を対応のALU34へ転送する。ALU34においては、これらの与えられた2ビットデータを用いて加算演算を行なう。この加算演算結果a[0]+b[0]は、データワードcの下位ビットc[0]の位置に書込まれる(ストアされる)。すなわち、1行目のエントリERYにおいては、“1”が、c[0]の位置に書込まれる。
この加算処理を、次いで、上位ビットa[1]およびb[1]に対しても行ない、その演算結果a[1]+b[1]が、ビットc[1]の位置に書込まれる。
加算演算においては、桁上がりが生じる可能性があり、この桁上がり(キャリ)値が、ビットc[2]の位置に書込まれる。これにより、データワードaおよびbの加算が、すべてのエントリERYにおいて完了し、その結果がデータcとして各エントリERYにおいて格納される。エントリ数mとして、たとえば1024を準備した場合、1024組のデータの加算を並列に実行することができる。
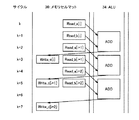
図5は、この加算演算処理時の内部タイミングを模式的に示す図である。以下、この図5を参照して、加算演算の内部タイミングについて説明する。ALU34において、2ビット加算器(ADD)が利用される。
図5において、“Read”は、メモリマットから演算対象のデータビットを読出して対応のALU34に転送する動作(ロード)を示し、“Write”は、ALU34の演算結果データを対応のエントリの対応のビット位置に書き込む動作(ストア)または動作を命令示す。
マシンサイクルkにおいて、データビットa[i]がメモリマット30から読出され、次のマシンサイクル(k+1)で、次の演算対象のデータビットb[i]が読出され(Read)、ALU34の加算器(ADD)にそれぞれ与えられる。
マシンサイクル(k+2)においては、ALU34の加算器(ADD)において、与えられたデータビットa[i]およびb[i]の加算処理が行なわれ、マシンサイクル(k+3)で、加算結果c[i]が対応のエントリの対応の位置に書込まれる。
次のマシンサイクル(k+4)および(k+5)において、次の演算対象のデータビットa[i+1]およびb[i+1]が読出されて、ALU34の加算器(ADD)へ転送され、マシンサイクル(k+5)において、ALU34により加算処理が行なわれ、マシンサイクル(k+6)において加算結果がビット位置c[i+1]へ格納される。
メモリマット30とALU34の間でのデータビット転送に、それぞれ1サイクル必要とされ、ALU34において1マシンサイクルの演算サイクルが必要とされる。したがって、2ビットデータの加算および加算結果の格納を行なうために、4マシンサイクルが必要とされる。メモリマットを複数のエントリに分割し、各エントリに演算対象データの組をそれぞれ格納して、対応のALU34においてビットシリアル態様で演算処理を行なう方式の特徴は、1つ1つのデータの演算には、比較的多くのマシンサイクルが必要とされるものの、処理すべきデータ量が非常に多い場合には、演算の並列度を高くすることで、高速データ処理を実現することができる。また、ビットシリアル態様で演算処理を行なっており、処理されるデータのビット幅は固定されないため、種々のデータ構成を有する種々のアプリケーションに適用することができる。
演算対象のデータワードのビット幅がNの場合、各エントリの演算には、4・Nマシンサイクルが必要となる。演算対象のデータワードのビット幅は、8ビットから64ビット程度であり、エントリ数mをたとえば1024と大きくすることにより、並列演算処理時に、たとえば8ビットデータの場合、32マシンサイクルで、1024個の演算結果を得ることができ、1024組のデータをシーケンシャルに処理する場合に比べて、大幅に処理時間を短縮することができる。
図6は、主演算回路20の構成をより具体的に示す図である。メモリマット30においては、メモリセルMCが行列状に配列され、各メモリセル行に対応してワード線WLが配置され、メモリセル列それぞれに対応してビット線対BLPが配置される。メモリセルMCは、これらのビット線対BLPとワード線WLの交差部に対応して配置される。ワード線WLには、対応の行のメモリセルが接続され、また、ビット線対BLPには、対応の列のメモリセルが接続される。
エントリERYは、各ビット線対BLPに対応して設けられ、メモリマット30においては、ビット線対BLP0からBLP(m−1)それぞれに対応して、エントリERY0−ERY(m−1)が配置される。ビット線対BLPが対応のエントリERYと対応のALU34との間のデータ転送線として利用される。エントリERYを1列のメモリセルで構成することにより、1エントリに格納されるデータのビット幅が用途に応じてまたは処理内容に応じて変更される場合においても、ビットシリアル態様で対応のALUで演算処理を行うことができ、データビット幅の変更に容易に対応することができる。
メモリマット30のワード線WLに対して、コントローラ21(図1参照)からのアドレス信号に従って、演算対象のデータビットが接続されるワード線WLを選択状態へ駆動するロウデコーダ46が設けられる。ワード線WLには、エントリERY0−ERY(m−1)の同一位置のメモリセルが接続されており、このロウデコーダ46により、各エントリERYにおいて同一位置のデータビットを選択する。
演算処理ユニット群(ALU群)32においては、各ALU34がビット線対BLP0−BLP(m−1)に対応して配置されるが、図6においては、明確には示していない。このALU群32とメモリマット30との間に、データのロード/ストア(転送)を行なうためのセンスアンプ群40およびライトドライバ群42が設けられる。
センスアンプ群40は、各ビット線対BLPに対応して設けられるセンスアンプを含み、対応のビット線対BLP(BLP0−BLP(m−1))に読出されるデータを増幅して、演算処理ユニット群32の対応のALU34に伝達する。
ライトドライバ群42も同様、ビット線対BLP(BLP0−BLP(m−1))それぞれに対応して配置されるライトドライバを含み、演算処理ユニット群32の対応のALU34からのデータを増幅して対応のビット線対BLPへデータを転送する。
これらのセンスアンプ群40およびライトドライバ群42がビット線(データ転送線)とALU34との間の転送回路を構成し、メモリマットとALUとの間で双方向にデータを転送することができる。
これらのセンスアンプ群40およびライトドライバ群42に対し、入出力回路48が設けられ、図1に示す内部データバス12との間でデータの転送が行なわれる。この入出力回路48のデータの入出力態様は、エントリ数およびデータビット幅に応じて適当に定められる。
演算処理ユニット群32に対してさらに、スイッチ回路44が設けられる。このスイッチ回路44は、ALU34間の相互接続経路を、図1に示すコントローラ21からの制御信号に基づいて設定する。これにより、バレルシフタ等と同様に、隣接ALU間でのデータ転送のみならず、遠く物理的に離れたALU間でのデータ転送を行なうことができる。このALU間相互接続用スイッチ回路44は、たとえば、FPGA(フィールド・プログラム・ゲート・アレイ)などを用いたクロスバースイッチで実現される。
また、このスイッチ回路44としては、バレルシフタなどのように、1マシンサイクル内で複数ビット間のシフト動作を行なう構成が用いられてもよい。
なお、図6においては、図1に示す隣接ブロック間データバス16は明確には示していない。この隣接ブロック間データバス16は、ALU間相互接続用スイッチ回路44に接続されてもよく、また入出力回路48とセンスアンプ群40およびライトドライバ群42との間の内部データ転送バスに接続されてもよい。
なお、演算処理ユニット群32のALU34は、コントローラ21からの制御信号に従ってその演算処理動作タイミングおよび演算操作内容が決定される。
図7は、1つのALUの構成の一例を示す図である。図7において、ALU34は、指定された演算処理を行なう算術演算論理回路50と、対応のエントリから読出されたデータを一時的に格納するAレジスタ52と、対応のエントリから読出されたデータまたは算術演算論理回路50の演算処理結果データまたはライトドライバへ転送するデータを一時的に格納するXレジスタ54と、加減算処理時のキャリまたはボローを格納するCレジスタ56と、この算術演算論理回路50を演算処理の禁止を指定するマスクデータを格納するMレジスタ58を含む。
図6に示すセンスアンプ群40およびライトドライバ群42は、単位構成の基本回路ととして、対応のビット線対BLPに対応して設けられるセンスアンプ62およびライトドライバ60を含む。センスアンプ62は、対応のエントリのメモリセルから読出されたデータを増幅して、Aレジスタ52またはXレジスタ54へその増幅データを内部データ転送線63を介して転送する。ライトドライバ60は、Xレジスタ54に格納されたデータをバッファ処理して、対応のエントリのメモリセルへ対応のビット線対BLPを介して書込む。
算術演算論理回路50は、加算(ADD)、論理積(AND)、論理和(OR)、排他的論理和(EXOR)、反転(NOT)等の演算を実行することができ、その演算内容が、コントローラからの制御信号(図7には示さず)により設定される。Mレジスタ58に格納されるマスクデータは、“0”のときに、このALU34の演算処理動作を停止させ、“1”のときに、このALU34の演算処理動作をイネーブルする。この演算マスク機能を利用することにより、仮に全エントリが利用されない場合においても有効エントリに対してのみ演算を実行することができ、正確な処理を行うことができ、また、不必要な演算を停止させることにより消費電流を低減することができる。
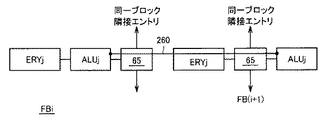
Xレジスタ54は、また、スイッチ回路44に含まれるALU間接続回路65を介して他のALUに接続される。このALU間接続回路65は、FPGAセルなどのスイッチ回路で構成され、演算処理ユニット群32に含まれる任意のALU34に対してデータを転送する際に用いられる。このALU間接続回路65の転送機能により、メモリマット内のさまざまな物理位置に格納されているデータとの演算を実現することができ、演算の自由度を高くすることができる。
ALU間接続回路65は、例えば、スイッチマトリクスで構成されればよく、また、その占有面積が問題となる場合には、転送可能なALUの経路が制限されてもよい。たとえば、m個のエントリを複数のブロックにグループ化し、このグループ間でのデータ転送のみが行なわれるように、ALU間接続回路65の転送経路が制限されてもよい。
図8は、この図7に示すALU34の動作シーケンスを示す図である。図8においては、1ビット加算器を利用して、2項加算演算a+bを実行する。
まず、マシンサイクル(k−1)において、Mレジスタ58に、ビット“1”をセットして演算処理実行を指定し、また、Cレジスタ56を“0”にクリアして初期化する。
マシンサイクルkにおいて、メモリマットから、データビットa[i]が読出され、センスアンプ62を介してXレジスタ54に転送されて格納される。このXレジスタ54の格納値は、次のマシンサイクル(k+1)において確定する。
マシンサイクル(k+1)において、メモリマット30から、データビットb[i]が読出されてAレジスタ52に転送されて格納される。
マシンサイクル(k+2)においては、データビットa[i]およびb[i]が確定状態にあるため、ALU34において演算が実行され、マシンサイクル(k+3)において、その演算結果(加算結果)c[i]の書込が、ライトドライバ60を介して行なわれる。ALU34においては、マシンサイクル(k+2)において、加算結果a[i]+b[i]が確定しており、また、キャリC[i]の有無も確定している。従って、マシンサイクル(k+3)において、ALU34のXレジスタ54からライトドライバ60を介して、メモリマットのビットc[i]に加算結果を書込むことができる。キャリC[i]はCレジスタ56に格納され、その書込は行われない。
次のマシンサイクル(k+4)において、次の上位データビットa[i+1]が読出され、ALU34に転送され、次のマシンサイクル(k+5)において、Xレジスタ54の格納データビットが、ビットa[i+1]に確定する。このマシンサイクル(k+5)において、メモリマット30においてビットb[i+1]が読出される。このとき、メモリマットからALU34のAレジスタ52に対してビットの転送が行なわれており、Aレジスタ52(図7)においては、先のマシンサイクル(k+1)において読出されたデータビットb[i]が格納されている(マシンサイクル(k+5)においてAレジスタ52の書き換えが行われ、その格納データが、マシンサイクル(k+6)においては確定状態にある。
マシンサイクル(k+6)において、Aレジスタ52およびXレジスタ54の格納データビットが確定状態にあり、これらのビットに対して演算(加算演算)が実行され、次のマシンサイクル(k+7)において、加算結果a[i+1]+b[i+1]が、ビットc[i+1]の位置に書込まれる。また、キャリC[i+1]が、Cレジスタに格納される。これらの一連の動作を、対応のエントリのデータワードaおよびbの全ビットに対して繰返し実行することにより、データワードaおよびbの加算演算が実現される。最終ビットの加算演算結果の書込後、Cレジスタの格納するキャリCの書込が、データワードcの格納領域の最上ビット位置に対して行なわれる。
メモリマット30のワード線WLの選択時、図6に示すロウデコーダ46は、これらのデータワードa、bおよびcの各ビットの記憶領域の開始時点をレジスタ群のポインタ値として格納し、各マシンサイクルごとに、そのポインタ値を増分することにより、下位ビットから上位ビットへの加算および加算結果の格納を実現することができる。
図9に示すように、メモリマット30において、データワードaを格納する領域♯A、データワードbを格納する領域♯Bおよび演算結果ワードcを格納する領域♯Cにおいてそれぞれ、最下位ビット[0]の位置をポインタPA、PBおよびPCでそれぞれ指定し、各マシンサイクルごとに、これらのポインタを順次活性化するとともに、1ビットデータについての演算完了後、ポインタ値を増分する。この場合、メモリマット30において、領域♯Aおよび♯Bのビット幅が予め決定される場合、ポインタPBおよびPCとしては、ポインタPAに基づいてこのデータ領域♯A、♯Bのビット幅に応じた加算値が用いられてもよい。これらのポインタPA−PCは、図1に示すレジスタ群22に格納され、図6に示すロウデコーダ46へ与えられる。
このレジスタ群にポインタPA−PCを設定して、順次マシンサイクルごとにロウデコーダへ与えることにより、演算対象のデータワードのビット幅に応じて、メモリマット30におけるデータワードの格納領域を設定することができる。
ポインタPA−PCを発生する構成としては、カウント回路が用いられてもよく、また、コントローラ21(図1参照)によりレジスタの格納値が更新されてもよい。
以上のように、この発明の実施の形態1に従えば、メモリマットを複数のエントリに分割し、各エントリに対応して演算処理ユニットを設け、ビットシリアル態様で、各演算処理ユニットが並列に演算処理を行なっており、大量のデータを並列演算処理することができ、データビット幅に係らず高速演算処理を行なうことのできる演算装置を実現することができる。
[実施の形態2]
図10は、この発明の実施の形態2に従うメモリマットのメモリセルMCの構成を示す図である。この図10において、メモリセルMCは、書込ポートと読出ポートが別々に設けられたデュアルポートメモリセルである。このメモリセルMCに対しては、読出ワード線RWLおよび書込ワード線WWLが設けられ、また読出ビット線RBLおよび/RBLと書込ビット線WBLおよび/WBLが設けられる。読出ポートは、この読出ワード線RWLの信号電位に応答して記憶ノードSN1およびSN2をそれぞれ読出ビット線RBLおよび/RBLに接続するNチャネルMOSトランジスタNQ5およびNQ6を含む。書込ポートは、書込ワード線WWL上の信号電位に応答してストレージノードSN1およびSN2を、それぞれ書込ビット線WBLおよび/WBLに接続するNチャネルMOSトランジスタNQ7およびNQ8を含む。
図10は、この発明の実施の形態2に従うメモリマットのメモリセルMCの構成を示す図である。この図10において、メモリセルMCは、書込ポートと読出ポートが別々に設けられたデュアルポートメモリセルである。このメモリセルMCに対しては、読出ワード線RWLおよび書込ワード線WWLが設けられ、また読出ビット線RBLおよび/RBLと書込ビット線WBLおよび/WBLが設けられる。読出ポートは、この読出ワード線RWLの信号電位に応答して記憶ノードSN1およびSN2をそれぞれ読出ビット線RBLおよび/RBLに接続するNチャネルMOSトランジスタNQ5およびNQ6を含む。書込ポートは、書込ワード線WWL上の信号電位に応答してストレージノードSN1およびSN2を、それぞれ書込ビット線WBLおよび/WBLに接続するNチャネルMOSトランジスタNQ7およびNQ8を含む。
このメモリセルMCのデータ記憶部は、負荷PチャネルMOSトランジスタPQ1およびPQ2と、ドライブ用のNチャネルMOSトランジスタNQ1およびNQ2を含む。
この図10に示すデュアルポートメモリセル構造を利用することにより、ビットシリアル態様でデータの演算処理を行なう場合、書込および読出を同時に行なうことができる。この場合、演算結果が書込まれる領域は、演算対象のデータが格納される領域とは別に設けられており、これらのメモリセルにおいて、書込データおよび読出データの衝突は生じず、通常のマルチポートメモリにおけるアービトレーションの問題は生じない。
図11は、この発明の実施の形態2における演算処理動作時の内部タイミングを例示的に示す図である。以下、図11を参照して、先の実施の形態1と同様、1ビット加算器を利用する演算処理操作について説明する。ALUの構成およびメモリマットのエントリの構成は、先の実施の形態1と同様である。従って、この実施の形態2においても、メモリマットは、各列に対応してエントリに分割されており、各エントリに対応して、ALU(34)が配置される。
マシンサイクルkにおいて、データビットa[i]が読出される(Read)。この読出動作時においては、データビットa[i]に対応する読出ワード線RWLが選択状態へ駆動され、メモリセルのストレージノードSN1およびSN2が、読出ビット線RBLおよび/RBLに結合されて、データビットa[i]の読出が行なわれる。
次のマシンサイクル(k+1)において、次のデータビットb[i]が読出され、対応のALU34の加算器(ADD)へ与えられる。このALU34においては、マシンサイクル(k+2)において演算処理が行なわれ、その演算結果データc[i]が、結果レジスタ、すなわちXレジスタ54に格納される。
マシンサイクル(k+2)において、次のデータビットa[i+1]がメモリマットから読出されて、ALUへ読出ビット線RBLおよび/RBLを介して転送される。
マシンサイクル(k+3)において、マシンサイクル(k+2)で生成された演算処理結果(a[i]+b[i])が、メモリマットのビットc[i]の位置に書込まれる(Write)。この書込動作時においては、ビットc[i]に対応する書込ワード線WWLが選択状態へ駆動され、書込ポートのMOSトランジスタNQ7およびNQ8が導通し、ストレージノードSN1およびSN2が、書込ビット線WBLおよび/WBLに接続され、対応のライトドライバからのデータビットが格納される。
このマシンサイクル(k+3)において、並行して、データビットb[i+1]の読出が行なわれ、ALU34へ読出ビット線RBLおよび/RBLを介してこの読出されたデータビットb[i+1]が転送される。
マシンサイクル(k+4)において、ALUにおいてビットa[i+1]およびb[i+1]の加算が行なわれる。このマシンサイクル(k+4)において、加算(演算)操作と並行して、メモリマットにおいてビットa[i+2]が読出されて、ALUへ転送される。
マシンサイクル(k+5)において、マシンサイクル(k+4)において確定した演算結果a[i+1]+b[i+1]が、ビットc[i+1]に書込ビット線を介して、対応のライトドライバから転送され、対応のメモリセルへ書込ポートを介して書込まれる。
このマシンサイクル(k+5)において、また、書込と並行して、次の演算対象のビットb[i+2]が読出され、ALU34に転送される。マシンサイクル(k+5)において、ALUにおいて加算操作が行なわれ、その演算結果が、マシンサイクル(k+6)においてメモリマットのビットc[i+2]の位置に書込まれる。
上述のように、デュアルポートメモリセルを利用する場合、書込動作および読出動作時においては、データビットは、それぞれ読出ビット線および書込ビット線と別々の経路を介して転送されるため、並行して書込データおよび読出データの転送を行なうことができる。データの書込は、2サイクルに1回であり、また、各データマシンサイクルにおいて演算対象のビットを読出すことができる。1ビット加算操作に必要なサイクルは、書込および読出が並行して行なわれるため、2サイクルに低減され、Nビットのデータ幅を有するデータワードの演算(加算)操作においては、2・Nサイクルで、加算処理を行なうことができ、4・Nサイクルが必要となる先の実施の形態1の処理性能と比べると、2倍の演算性能(処理速度)を実現することができる。従って、ビットシリアル態様で加算演算操作を行なっても、高速の演算処理を実現することができる。
なお、加算演算実行と並行して、次の演算対象のデータビットが転送される。したがって、演算結果を格納するレジスタと、最初に転送される演算対象のデータビット(a[i])が格納するレジスタは、別々のレジスタ回路とするのがデータの衝突を避ける上で好ましい。例えば、先の図7に示すALU34の構成において、Aレジスタ52に最初に転送される演算対象のビットa[i]を格納し、Xレジスタ54に加算演算結果を格納してライトドライバを介して転送する構成とすることにより、次の演算対象のデータビットa[i+1]と演算結果a[i]+b[i]との衝突を防止することができる。
図12は、この発明の実施の形態2に従う主演算回路20の構成を概略的に示す図である。この図12に示す主演算回路20の構成においても、メモリマット30において、メモリセルMCは、デュアルポートSRAMセルで構成され、行列状に配列される。メモリセルMCの各行に対応して、書込ワード線WWLおよび読出ワード線RWLが配置される。メモリセルMCの各列に対応して、書込ビット線対WBLPおよび読出ビット線対RBLPが配置される。メモリセルMCの各列が、エントリERYとして利用される。ここで、書込ビット線対WBLPは、書込ビット線WBLおよび/WBLで構成され、読出ビット線対RBLPは、読出ビット線RBLおよび/RBLで構成される。
周辺部のセンスアンプ群40およびライトドライバ群42、演算処理ユニット群32およびALU間相互接続用スイッチ回路44および入出力回路48は、先の実施の形態1と同様である。
センスアンプ群40は、各エントリERY0−ERY(m−1)それぞれに対応して設けられるセンスアンプSAを含む。センスアンプSAは、対応のエントリの読出ビット線対RBLPに接続され、かつ演算処理ユニット群32の対応のALUに結合される。
ライトドライバ群42は、エントリERY0−ERY(m−1)それぞれに対応して配置されるライトドライバWDを含む。このライトドライバWDは、対応のエントリの書込ビット線対WBLPに接続される。ライトドライバWDは、対応のALUに結合され、演算処理結果データを対応の書込ビット線対WBLPに転送する。
読出ワード線RWLおよび書込ワード線WWLがそれぞれ別々に設けられており、従って、ロウデコーダとして、書込ワード線WWLを選択するライト用ロウデコーダ36wと、読出ワード線RWLを選択するリード用ロウデコーダ36rが別々に設けられる。これらのロウデコーダ36wおよび36rは、図1に示すコントローラ21から与えられたアドレス信号に従って、また制御信号に従って選択的に活性化され、指定されたワード線RWLおよびWWLを選択状態へ駆動する。これらのロウデコーダ36wおよび36rに対するアドレスは、図12においては明確には示していないが、先の実施の形態1と同様に、ポインタを利用して生成される。
この実施の形態2における図12に示す主演算回路20の構成において、メモリマット30において、メモリセルMCがデュアルポートメモリセルで構成され、かつ書込用および読出用にそれぞれ内部のデータ転送線としての読出ビット線対および書込ビット線対が設けられ、また読出用および書込用のワード線選択用のロウデコーダが別々に設けられる構成を除いては、実施の形態1と同じであり、ライト用ロウデコーダ36wは、1ビット加算器を利用する加算演算操作の場合には2マシンサイクルに1回活性化され、また、リード用ロウデコーダ36rは、各サイクルごとに活性化される。
以上のように、この発明の実施の形態2に従えば、メモリセルをデュアルポートメモリセルで構成し、演算処理ユニットとメモリマットとの間で書込および読出データを並行して同時に転送するように構成しており、演算処理時間を短縮することができる。
[実施の形態3]
図13は、この発明の実施の形態3に従う主演算回路20の要部の構成を概略的に示す図である。この図13に示す主演算回路20においては、演算処理ユニット群32の両側に、メモリマット30Aおよび30Bが配置される。これらのメモリマット30Aおよび30Bは、同一構成を有し、データビット幅がnビットのエントリERYが、それぞれm個配置される。このメモリマット30Aおよび30Bの各エントリの間に、演算処理ユニット群32のALU34が配置される。このALU34は、メモリマット30Aおよび30Bの対応のエントリをデータについて、指定された演算処理を行なう。2項演算を各ALU34が行なう場合、メモリマット30Aおよび30Bに、各項の演算対象データを格納し、その演算処理結果は、メモリマット30Aおよび30Bの一方に格納する。従って、メモリマット30Aおよび30Bにおいては、格納されるデータ量が1つのメモリマットを利用する構成に比べて少なくすることができる。メモリマット30Aおよび30Bのエントリの合計サイズ(ビット幅)が、実施の形態1または2のメモリマット30のエントリのサイズ(ビット幅)と同程度にされてもよい。メモリセルとしては、先の実施の形態2と同様、デュアルポートメモリセルが利用される。
図13は、この発明の実施の形態3に従う主演算回路20の要部の構成を概略的に示す図である。この図13に示す主演算回路20においては、演算処理ユニット群32の両側に、メモリマット30Aおよび30Bが配置される。これらのメモリマット30Aおよび30Bは、同一構成を有し、データビット幅がnビットのエントリERYが、それぞれm個配置される。このメモリマット30Aおよび30Bの各エントリの間に、演算処理ユニット群32のALU34が配置される。このALU34は、メモリマット30Aおよび30Bの対応のエントリをデータについて、指定された演算処理を行なう。2項演算を各ALU34が行なう場合、メモリマット30Aおよび30Bに、各項の演算対象データを格納し、その演算処理結果は、メモリマット30Aおよび30Bの一方に格納する。従って、メモリマット30Aおよび30Bにおいては、格納されるデータ量が1つのメモリマットを利用する構成に比べて少なくすることができる。メモリマット30Aおよび30Bのエントリの合計サイズ(ビット幅)が、実施の形態1または2のメモリマット30のエントリのサイズ(ビット幅)と同程度にされてもよい。メモリセルとしては、先の実施の形態2と同様、デュアルポートメモリセルが利用される。
図14は、この発明の実施の形態3における主演算回路20の演算シーケンスの内部タイミングを示す図である。以下、図14を参照して、この図13に示す主演算回路20の演算操作について説明する。
メモリマット30Aおよび30Bには、演算対象のデータワードaおよびbの組が、それぞれ対応のエントリに格納される。マシンサイクルkにおいて、メモリマット30Aおよび30Bから、対応のデータビットa[i]およびb[i]が読出される。
マシンサイクル(k+1)において、ALUにおいて、ADD演算処理(加算処理)がこれらのデータビットa[i]およびb[i]に対して行なわれる。メモリマット30Aおよび30Bは、メモリセルがデュアルポートメモリセルで構成されており、演算結果が、マシンサイクル(k+2)においてメモリマット30Aのビットc[i]に書込まれる。一方、マシンサイクル(k+1)においては、次のデータビットa[i+1]およびb[i+1]が読出され、対応のALUへ与えられ、マシンサイクル(k+2)において、書込データ(加算演算結果データ)のビットc[i]への転送と並行して次の演算対象のデータビットの組に対して加算演算操作が行なわれる。
このマシンサイクル(k+2)においては、再び次の演算対象のデータビットa[i+2]およびb[i+2]が読出され、ALU34に転送される。
マシンサイクル(k+3)においては、マシンサイクル(k+2)においてALU34で行なった演算操作結果が確定するため、対応のメモリセルビットc[i+1]への演算結果データの書込が行なわれる。このマシンサイクル(k+3)においては、さらに、次のデータビットa[i+3]およびb[i+3]の読出が行なわれ、ALU34への転送が行なわれる。
したがって、このメモリマット30Aおよび30Bに2項演算の各項のデータワードをそれぞれ対応するエントリに格納し、同一マシンサイクルで、これらのメモリマット30Aおよび30Bから対応のデータビットを読出してALUへ転送することにより、各マシンサイクルにおいてデータの書込を行なうことができる。したがって、Nビットのデータ幅を有するデータワードの加算の場合、Nマシンサイクルで、演算操作を完了することができ、さらに、動作速度(処理速度)を高速化することができる。
図15は、この発明の実施の形態3に従う主演算回路20の構成をより具体的に示す図である。メモリマット30Aおよび30Bにおいては、メモリセルMCが、先の実施の形態2に示すメモリセルの構成と同様、デュアルポートメモリセルであり、書込ワード線WWLおよび読出ワード線RWLが、行方向に配列されるメモリセルに対応して設けられ、また列方向に整列するメモリセルに対して、書込ビット線対WBLPおよび読出ビット線対RBLPがそれぞれ配置される。これらのメモリマット30Aおよび30Bは、それぞれエントリERY0−ERY(m−1)のm個のエントリをそれぞれ有し、これらのエントリが対応して配置される。
図15においては明確に示していないが、メモリマット30Aおよび30Bの間に、演算処理ユニット群32が設けられる。この演算処理ユニット群32に対しては、先の実施の形態1と同様、ALU間相互接続用スイッチ回路が同様配置され、物理的に離れた位置のALU間のデータ転送を可能にする。
この演算処理ユニット群32とメモリマット30Aの間に、センスアンプ群40Aおよびライトドライバ群42Aが配置され、演算処理ユニット群32とメモリマット30Bの間に、センスアンプ群40Bおよびライトドラバ群42Bが配置される。
センスアンプ群40Aは、メモリマット30Aの読出ビット線対RBL(RBLP0−RBLP(m−1))それぞれに対応して配置されるセンスアンプSAを含み、ライトドライバ群42Aはメモリマット30Aの書込ビット線対WELP(WELP0−WELP(m−1))それぞれに対応して配置されるライトドライバWDを含む。
センスアンプ群40Bも、同様、メモリマット30Bの読出ビット線対RBLP(RBLP0−RBLP(m−1))それぞれに対応して設けられるセンスアンプSAを含み、ライトドライバ群42Bは、このメモリマット30Bの書込ビット線対WBLP(WBLP0−WBLP(m−1))それぞれに対応して配置されるライトドライバWDを含む。
メモリマット30Aに対しては、読出ワード線RWLを選択するリード用ロウデコーダ36rAおよび書込ワード線WWLを選択するライト用ロウデコーダ36wAが設けられ、メモリマット30Bに対しても、同様、読出ワード線RWLを選択するためのリード用ロウデコーダ36rBおよび書込ワード線WWLを選択するライト用ロウデコーダ36wBが設けられる。
このセンスアンプ群40Aおよびライトドライバ群42Aとライトドライバ群42Bおよびセンスアンプ群40Bに対して、内部データバス(図1のバス12)とデータの転送を行なう入出力回路49が設けられる。
この入出力回路49は、実施の形態1と異なり、メモリマット30Aおよび30Bそれぞれに転送されるデータを並列に受けて転送する。これらのメモリマット30Aおよび30Bそれぞれに格納されるデータそれぞれがメモリマット単位で、ビット位置の並べ替えが行なわれてもよく、またメモリマット30Aおよび30Bそれぞれに、直並列変換および並直列変換用のレジスタ回路が配置され、ワード線単位でのデータの書込および読出がこのレジスタ回路とメモリマットの間で行なわれて、外部とのデータの入出力が行なわれてもよい。また、他の構成が利用されてもよい。
ライト用ロウデコーダ36wAおよび36wBおよびリード用ロウデコーダ36rAおよび36rBは、先の実施の形態2の構成と同様である。リード用ロウデコーダ36rAおよび36rBが、同一マシンサイクルで、同一ビット位置の読出ワード線を選択状態へ駆動する。演算操作結果が、メモリマット30Aに格納される場合には、ライト用ロウデコーダ36wAが活性化されて、対応の書込ワード線が選択状態へ駆動される。この場合、メモリマット30Bにおけるライト用ロウデコーダ36wBは、非活性状態に維持される。
以上のように、この発明の実施の形態3に従えば、メモリマットを2つ配置し、これらの間にALU群を配置しており、各メモリマットに演算対象のデータの組をそれぞれ格納することにより、各マシンサイクルごとに演算、データの書込およびデータの読出を行なうことができ、高速演算処理が実現される。
[実施の形態4]
図16は、この発明の実施の形態4に従う主演算回路20の構成を概略的に示す図である。この図16において、メモリマット30においてデュアルポートメモリセルMCが行列状に配列される。メモリマット30においては、ワード線WLAおよびWLBが互いに直交する方向に配列され、またビット線対BLPAおよびBLPBが互いに直交する方向に配置される。すなわち、ワード線WLAおよびビット線対BLPBが平行して配置され、ワード線WLBおよびビット線対BLPAが平行に配置される。このメモリマット30に対して、演算処理を行なうための、演算処理ユニット群32、メモリマット30と演算処理ユニット群32の間でデータの転送を行なうためのセンスアンプ群A71およびライトドライバ群A73と、演算処理ユニット(ALU)群32のALU間のデータ転送経路を切換えるALU間相互接続用スイッチ回路44が設けられる。
図16は、この発明の実施の形態4に従う主演算回路20の構成を概略的に示す図である。この図16において、メモリマット30においてデュアルポートメモリセルMCが行列状に配列される。メモリマット30においては、ワード線WLAおよびWLBが互いに直交する方向に配列され、またビット線対BLPAおよびBLPBが互いに直交する方向に配置される。すなわち、ワード線WLAおよびビット線対BLPBが平行して配置され、ワード線WLBおよびビット線対BLPAが平行に配置される。このメモリマット30に対して、演算処理を行なうための、演算処理ユニット群32、メモリマット30と演算処理ユニット群32の間でデータの転送を行なうためのセンスアンプ群A71およびライトドライバ群A73と、演算処理ユニット(ALU)群32のALU間のデータ転送経路を切換えるALU間相互接続用スイッチ回路44が設けられる。
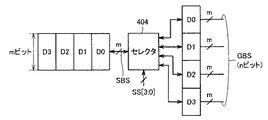
センスアンプ群A71おいては、ビット線対BLPAに対してセンスアンプSAが設けられ、ライトドライバ群A73においては、ビット線対BLPAに対してワードドライバWDが設けられる。演算処理ユニット(ALU)群32においては、したがって、このビット線対BLPAが1つのエントリを構成し、1つのビット線対BLPAに対して1つのALUが配置される。
一方、ビット線対BLPBに対して、センスアンプ群B70とライトドライバ群B72と内部データバス12(図1参照)との間でデータ転送を行なう入出力回路74が設けられる。これらのセンスアンプ群70、ライトドライバ群72および入出力回路74は、内部データバス12とメモリマット30の間のビット線対BLPBの間でデータ転送を行なう。したがって、このセンスアンプ群B70、ライトドライバ群72および入出力回路74は、そのビット幅が、メモリマット30の1つのエントリのビット幅と等しくされる(コラムデコーダは設けられていない)。
ワード線WLAに対してはロウデコーダA66が設けられ、ワード線WLBに対してはロウデコーダB76が設けられる。これらのロウデコーダA66およびロウデコーダB76は、図1のコントローラ21から与えられるアドレスに従ってワード線の選択を行なう。
図16に示す主演算回路20の構成において、メモリマット30の列を選択することは要求されないため、コラムデコーダは設けられない。エントリ単位で内部データバス12とめモリマット30との間でデータの転送が行なわれ(エントリシリアルビットパラレルにデータの転送が行われ)、また、演算実行時には、各エントリに対して並行にビットシリアルにデータ転送が演算処理ユニット群32との間で実行されて、演算処理が行なわれる。
すなわち、データの内部データバス12との転送時においては、ロウデコーダB76によりワード線WLBを選択して、1つのエントリを選択状態へ駆動して、エントリシリアルかつビットパラレルで内部データバス12との間でデータ転送を行なう。演算実行時においては、演算処理ユニット群32に対しては、各エントリ内のデータをビットシリアル態様で転送してビットシリアルかつエントリパラレルの態様で、演算操作を実行する。
したがって、内部データバスとのデータ転送時においては、エントリの数に等しいサイクルだけ時間がデータ転送に必要とされる。2項演算を行なう場合、演算結果を格納する領域には、データを格納する必要はない。この場合、単に、結果データ書込領域には、データ“0”が格納されればよい。
また、入出力回路74において、内部データバス12からの演算対象のデータをワードシリアル態様で受ける場合、この入出力回路74において、データ入力部に、ワードシリアルに入力されるデータワード(演算対象データ)を並列データに変換して、センスアンプ群70を介して対応のエントリに書込む構成が利用されてもよい。また、演算結果データのみの内部データバス12への転送が必要とされる場合、入出力回路74においては、ライトドライバ群B72の出力のうち、コントローラ21の出力する制御信号の制御の下に、演算結果データ領域のデータのみを選択的に内部データバス12に出力するように構成されてもよい。従って、内部データバス12のバス幅は、エントリのビット幅に等しくする必要はない。
図17は、図16に示すメモリセルMCの構成の一例を示す図である。この図17において、メモリセルMCは、交差結合される負荷PチャネルMOSトランジスタPQ1およびPQ2と、交差結合されるドライブNチャネルMOSトランジスタNQ1およびNQ2を記憶部として含む。このメモリセルMCは、さらに、ワード線WLA上の信号に応答してストレージノードSN1およびSN2をビット線BLAおよび/BLAに接続するNチャネルMOSトランジスタNQA1およびNQA2と、ワード線WLB上の信号電位に従ってストレージノードSN1およびSN2をビット線BLBおよび/BLBに接続するNチャネルMOSトランジスタNQB1およびNQB2を含む。
ビット線BLAおよび/BLAがビット線対BLPAを構成し、ビット線BLBおよび/BLBが、ビット線対BLPBを構成する。ワード線WLBは、ビット線BLAおよび/BLAと平行に配設され、ワード線WLAが、ビット線BLBおよび/BLBと平行に配設される。これにより、メモリマット30において、データ書込時と演算操作時に行列方向を90°回転させて、データの外部との転送および演算処理時のデータ転送を実現することができ、内部データバス12との間のデータ転送に要する時間を短縮することができる。
なお、ビット線対BLAおよび/BLAとビット線BLBおよび/BLBが直交し、またワード線WLAおよびWLBが直交する。この場合、ワード線WLAおよびWLBを異なる配線層で構成し、またビット線BLBおよび/BLBとビット線BLAおよび/BLAを異なる配線層で形成することにより、このビット線の直交配置およびワード線の直交配置を実現することができる。
以上のように、この発明の実施の形態4に従えば、メモリマット30において、ビット線を互いに直交する方向に配置するとともに、ワード線も互いに直交する方向に2組配置しており、データ転送を外部の内部データバスと行なう場合には、エントリシリアルビットパラレル態様で行なうことができ、内部データバスとメモリマットとの間のデータ転送に要する時間を短縮することができ、この結果、高速演算処理を実現することができる。
[実施の形態5]
図18は、この発明に従う演算装置における演算対象データの分布の一例を概略的に示す図である。この図18においては、メモリマット30においてエントリERYがm個配置され、また各エントリERYは、そのデータビット幅がnビットである。エントリERYそれぞれに対応して、ALU34が配置される。
図18は、この発明に従う演算装置における演算対象データの分布の一例を概略的に示す図である。この図18においては、メモリマット30においてエントリERYがm個配置され、また各エントリERYは、そのデータビット幅がnビットである。エントリERYそれぞれに対応して、ALU34が配置される。
演算対象データ領域OPRに格納される演算対象データが、エントリのデータビット幅方向において一部分であるものの、メモリマット30のエントリERY全体にわたって分布している場合、ビットシリアルでかつエントリパラレルの態様で、演算処理を実行することにより、高い演算性能を実現することができる。
しかしながら、演算処理内容によっては、図19に示すように、演算対象データが、少数のエントリにわたる領域OPBにしか存在しない場合もある。図19においては、演算対象データ領域OPBが、3つのエントリERYに分布するだけであり、残りのエントリには、演算対象データが存在しない。このような場合、ビットシリアルかつエントリパラレルで演算処理を行なっても、データビット幅nが、演算対象データを格納する有効エントリ数mよりも大きいため、演算処理性能がかえって低下する。このようなエントリ間での並列度が低いデータに対しても、効率的に高速で演算処理を行なうのが、汎用性の高い演算装置を実現する上で重要である。
図20は、この発明の実施の形態5に従う演算装置の構成を概略的に示す図である。図20において、メモリマット30においては、先の実施の形態1から4と同様、メモリセルMCが行列状に配列される。図20の水平方向に並列されるメモリセルMCにより、1つのエントリERYが形成され、各エントリERYに対して、演算処理ユニット群32においてALU34が配置される。
一方、この図の垂直方向のメモリセルに対して、スイッチ回路80を介して、演算器群82が配置される。この演算器群82においては、複数のALU84が配置される。これらのALU84は、その演算内容は、個々に設定可能であり、いわゆるMIMD(マルチ・インストラクション・データ・ストリーム)演算を実現することができる。
スイッチ回路80は、このメモリマット30の列方向に整列されるメモリセル列を接続経路を切換えて、演算器群82のALU84に接続する。このスイッチ回路80は、たとえば、FPGAなどのクロスバースイッチで構成される。また、これに代えて、スイッチマトリクスで、このスイッチ回路80が構成されてもよい。スイッチ回路80としては、メモリマット30の列と演算器群82のALU84との接続経路を選択的に切換えて確立する構成が利用されればよい。
この図20に示す構成の場合、エントリ間並列度の高いデータの演算処理を行なう場合には、メモリマット30の右側に配置された演算処理ユニット群32のALU34を用いてビットシリアルかつエントリパラレルで演算を行ない、並列演算処理による処理性能を発揮する。
一方、図19に示すように、エントリ間並列度が低く、演算対象データが少数のエントリ間に分布する場合、スイッチ回路80を介して、メモリマット30を演算を実行するALU84に接続する。この場合、エントリシリアルかつビットパラレルで、各エントリごとに、演算処理が実行される。したがって、エントリERYにおいて演算対象データaおよびbが存在する場合、この演算処理対象データaおよびbが並列に読出されて、スイッチ回路80を介して対応のALU84に結合されて演算処理が行なわれまたその演算結果が、対応のエントリERYの演算結果格納領域(c:図示せず)に格納される。
このスイッチ回路80を利用することにより、各エントリERYにおいて、演算対象データ格納領域および演算結果書込領域を自由に設定することができ、またエントリ数が少数であるため、エントリシリアルに演算処理を行なっても、その処理時間の増大は抑制される。特に、メモリマット30と演算器群82とが同一チップ上に形成される場合、これらの間の内部配線がチップ上配線であり、高速でデータの転送を行なうことができ、メモリマットと演算器ALU(84)とが別々のチップに設けられている構成に比べて、高速でデータを転送して処理を実行することができる。
また、スイッチ回路80により、メモリマット30の列と演算器群82のALU84との接続を設定することにより、演算処理対象のデータのビット幅が変更される場合においても、容易に対応することができる。たとえば、演算器群82において、ALU84が8ビットの演算処理を行なう構成の場合、16ビットデータの処理の場合には、隣接する2つのALU84を利用して、上位バイトおよび下位バイトをビットALUに与えて演算処理を行なうことにより、データビット幅が異なる場合にも容易に対応することができる。ただし、この場合、加算処理を行なう場合キャリー伝搬があるため、隣接ALU間でキャリーの伝搬を行なう必要がある。この場合、図7に示すCレジスタ56において、シフト機能を持たせることにより、このような上位バイトおよび下位バイト並列演算処理時においてもキャリー伝搬を行なって加算を行なうことができる。
実際の信号処理においては、アプリケーションによって演算対象データの形態が大きく異なる。また、ある1つのアプリケーションにおいても、処理のプロセスごとにデータの形態が異なる場合がある。したがって、この演算対象データの形態に応じて、メモリマット30の右側に配置される演算処理ユニット32のALU34を利用するかまたは、このメモリマット30の下側に配置される演算器群82のALU84を用いて処理を行なうかを、図1に示すコントローラ21の制御の下にダイナミックに切換える。これにより、演算対象データの形態にかかわらず、高い演算処理能力を有する演算装置を実現することができる。
特に、この演算処理ユニット群32のALU34を利用してデータ処理を行なう状態と、このメモリマット30の下辺に配置される演算器群82のALU84を用いてデータ処理を行なう状態の切換は、図1に示すコントローラ21からの演算内容に応じたリアルタイムで生成される制御信号によって行なわれる。この場合、メモリマット30の右辺および下側に配置されるロウデコーダ、センスアンプ、ライトドライバおよびALU群を動作させるかが制御信号によって切換えられる(活性/非活性化される)だけであり、この演算形態切換に伴う時間的なオーバーヘッドは全くなく、時間的に連続的に、演算処理形態を切換えて、演算処理を実行することができる。
図21は、この発明の実施の形態5に従う主演算回路20の構成をより具体的に示す図である。図21において、メモリマット30の右側に、エントリパラレルで演算処理を行なうための演算処理ユニット群32が配置され、メモリマット30の下側に、エントリシリアルかつビットパラレルで演算処理を行なう演算器群(ALU群B)82が配置される。演算処理ユニット群32とメモリマット30の間に、センスアンプ群A71とライトドライバ群A73が配置され、演算器群82とメモリマット30の間に、センスアンプ群B70とライトドライバ群B72が配置される。
演算処理ユニット群32に対しては、またALU間の転送を行なうためのALU間相互接続用スイッチ回路44が設けられる。演算器群82とライトドライバ群B72およびセンスアンプ群B70の間に、スイッチ回路80が設けられる。このセンスアンプ群B70およびライトドライバ群B72は、入出力回路87に結合され、内部データバス12とデータ転送を行なう。したがって、この入出力回路87は、先に実施の形態3における図16に示す入出力回路74と同様の構成であってもよい。
メモリマット30の右側および下側に、演算対象データを転送するために、メモリマット30においては、図の水平方向に沿ってビット線対BLPAが配置され、このビット線対BLPAと直交する方向にビット線対BLPBが配置される。ビット線対BLPAと平行に、ワード線WLBが配置され、ビット線対BLPBと平行に、ワード線WLAが配置される。ビット線対BLPAは、センスアンプ群A71およびライトドライバ群A73に結合され、それぞれセンスアンプSAおよびライトドライバWDにビット線対BLPAが結合される。
ビット線対BLPBは、センスアンプ群B70のセンスアンプおよびライトドライバ群72のライトドライバに結合される。これらのセンスアンプ群B70およびライトドライバ群72と演算器群82のALUとの接続は、スイッチ回路80によりその経路が決定される。スイッチ回路80の接続経路は、図1に示すコントローラ21からのスイッチング情報により設定され、また、演算器群82のALUの実行する演算内容は、コントローラ21からの再構成情報に基づいてその演算処理内容が決定される、または活性化されるALUが指定される。
ワード線WLAに対してロウデコーダA66が設けられ、ワード線WLBに対してロウデコーダB76が設けられる。これらのロウデコーダA66およびロウデコーダB76に対しては、コントローラ21からアドレス信号またはレジスタに格納されたポインタが与えられ、これらのロウデコーダA66およびロウデコーダB76の一方が、演算内容に応じて、コントローラ21により選択的に活性化される。
このコントローラ21により、メモリマット30の右側の演算処理ユニット群32および下側の演算器群82の一方を選択的に活性化することにより、演算処理内容をダイナミックに変更することができる。
メモリセルMCが、このワード線WLAおよびWLBとビット線対BLPAおよびBLPBの交差部に対応して配置される。メモリセルMCの構成は、先の実施の形態4において図17を参照して説明したメモリセルMCのデュアルポートメモリセル構造を利用することができる。これにより、データバス12とメモリマット30の間での効率的なデータ転送を実現するとともに、演算処理、処理プログラムにおいて更新することができる。
以上のように、この発明の実施の形態5に従えば、メモリマットの直交する2辺にそれぞれALU群を配置しており、演算対象データの形態に応じてビットパラレルかつエントリシリアルまたはエントリシリアルかつビットパラレルの演算処理を実現することができ、演算処理データの形態にかかわらず高速演算を実現することができる。
また、このメモリマットの各列と演算器群との接続経路を切換えるスイッチ回路80を設けることにより、1つのエントリ内に、演算対象の組のデータが配置される場合においても、確実に、演算対象のデータの組を対応のALUに転送することができる。また、このスイッチ回路を利用することにより、ALUの演算ビット幅をも変更することができ、また各ALUの演算内容を変更することにより、複数命令を並列に実行するMIMD演算を実現することができる。
[実施の形態6]
図22は、この発明の実施の形態6に従う主演算回路の構成を概略的に示す図である。この図22に示す主演算回路20の構成においても、メモリマット30が、複数のエントリERY(m個)に分割され、このメモリマット30の図の右側に、演算処理ユニット群32の各ALU34が各エントリERYに対応して配置される。一方、メモリマット30の下側に、スイッチ回路90を介して演算器群82のALU84が配置される。この演算器群82のALU84は、図22に示すように、コントローラ21からの再構成情報に従って、この演算ビット幅を変更することができる。たとえば、このALUが、加算器の場合、8ビット演算から16ビット演算に変更される場合には、キャリーの伝搬経路を延長するために8ビット加算演算を行なう2つのALUにおいてキャリーの伝搬経路が接続される。これは、単にセレクタまたはスイッチ回路を選択的に導通状態とすることにより、8ビット加算器または16ビット加算器を択一的に設定することができる。
図22は、この発明の実施の形態6に従う主演算回路の構成を概略的に示す図である。この図22に示す主演算回路20の構成においても、メモリマット30が、複数のエントリERY(m個)に分割され、このメモリマット30の図の右側に、演算処理ユニット群32の各ALU34が各エントリERYに対応して配置される。一方、メモリマット30の下側に、スイッチ回路90を介して演算器群82のALU84が配置される。この演算器群82のALU84は、図22に示すように、コントローラ21からの再構成情報に従って、この演算ビット幅を変更することができる。たとえば、このALUが、加算器の場合、8ビット演算から16ビット演算に変更される場合には、キャリーの伝搬経路を延長するために8ビット加算演算を行なう2つのALUにおいてキャリーの伝搬経路が接続される。これは、単にセレクタまたはスイッチ回路を選択的に導通状態とすることにより、8ビット加算器または16ビット加算器を択一的に設定することができる。
減算を行なう場合、例えば、2の補数表示のデータを用いて8ビット減算から16ビット減算を行なう場合、上位バイトの最下位ビットでの“1”加算に代えて、下位バイトの最上位ビットからのキャリーが与えられる。この構成も、コントローラからの再構成情報に従ってセレクタを用いることにより、容易に実現することができる。
したがって、たとえば図22に示すように、演算器群82の2つのALU84aおよび84bを用いて演算を行なう場合、これらのALU84aおよび84bのビット幅の合計のビット幅のALU88を等価的に実現して演算を実行することができる。
スイッチ回路90は、先の実施の形態5と同様、コントローラからの接続経路情報に従ってその接続経路が設定される。このデータビットの変更時、コントローラ21からの演算器再構成情報に基づいて、演算器群82のALU84の構成が再構成される。この再構成情報は、コントローラ21から演算対象データのビット幅に応じてダイナミックに与えられるため、この演算器群82の再構成に伴う時間的オーバーヘッドは存在しない。したがって、高速で、種々のデータビット幅のデータに対して演算処理を実行することができる。
なお、スイッチ回路90は、先の実施の形態5のスイッチ回路80と同様の、FPGAなどのクロスバースイッチ回路を利用することができ、また、単に、データ転送経路を切換えるスイッチマトリクスで構成されてもよい。
以上のように、この発明の実施の形態6に従えば、エントリシリアルかつビットパラレルの演算処理時、演算器の処理演算ビット幅を変更可能に設定しており、種々のデータのビット幅に対応して高速で演算処理を実行することができる。
[実施の形態7]
図23は、この発明の実施の形態7に従う主演算回路の要部の構成を概略的に示す図である。この図23においては、メモリマット30の下部に配置される演算器群82に対応する部分の構成を示す。この図23に示す構成においては、演算器群として、複数段の演算器群OG1−OGkが配置される。メモリマット30と各演算器群OG1−OGkの間に、スイッチ回路SK0,SK1,SK2…が配置される。演算器群OG1−OGkそれぞれにおいては、ALU(演算器)100が配置される。これらのALU100は、コントローラからの再構成情報に従ってその内部構成およびビット幅を変更することができるようにされてもよい。ALU100は全てその構成が同一とされてもよい。
図23は、この発明の実施の形態7に従う主演算回路の要部の構成を概略的に示す図である。この図23においては、メモリマット30の下部に配置される演算器群82に対応する部分の構成を示す。この図23に示す構成においては、演算器群として、複数段の演算器群OG1−OGkが配置される。メモリマット30と各演算器群OG1−OGkの間に、スイッチ回路SK0,SK1,SK2…が配置される。演算器群OG1−OGkそれぞれにおいては、ALU(演算器)100が配置される。これらのALU100は、コントローラからの再構成情報に従ってその内部構成およびビット幅を変更することができるようにされてもよい。ALU100は全てその構成が同一とされてもよい。
信号処理演算においては、積和演算を繰返すなど非常に複雑な演算処理が多い。したがって、1段のALU群を用いた場合、十分な処理速度を得ることができない場合が考えられる。この図23に示すように複数段の演算器群OG1−OGkを利用し、これらの間のスイッチ間SK0,SK1,SK2…で接続経路を設定する。これに、複数段の演算器群OG1−OGk、たとえば乗算および加算などの異なる演算を順次実行することにより、パイプライン的に処理を実行することにより、高速処理が実現される。また、1つの乗算処理において、中間の部分積を生成する加算部、中間部分積を加算して最終積を生成する最終積回路を、各段のALUでそれぞれ実現することにより、高速の乗算装置を実現することができる。
また、スイッチ回路SK0−SK2,…を用いて、各演算器群OG1−OGkのALU100の接続経路を設定しており、物理的に位置の離れたALUの演算結果同士で新たな演算を実行することができ、非常に複雑な演算も実現することができる。
以上のように、この発明の実施の形態7に従えば、エントリシリアルに演算を行なう演算器群において複数段の演算器群を配置しており、高速に、複雑な演算処理を実現することができる。
なお、このスイッチ回路SK0−SK2,…の接続経路は、先の実施の形態6と同様、コントローラ21からの経路設定情報に続いてその経路が指定されて設定される。これらのスイッチ回路SK0−SK2,…は、FPGAを利用するクロスバースイッチ回路またはスイッチマトリクスで構成されてもよい。
[実施の形態8]
図24は、この発明の実施の形態8に従う主演算回路20の要部の構成を概略的に示す図である。この図24に示す構成においても、メモリマット30の下部に配置されるエントリシリアルかつビットパラレルで演算を行なう演算器群の構成を概略的に示す。この図24に示す構成においては、複数段の演算器群OG1−OGkが配置され、これらのメモリマット30および演算器群OG1−OGkの間に、スイッチ回路SK0−SK2,…が配置されて、データ転送経路が選択的に確立される。
図24は、この発明の実施の形態8に従う主演算回路20の要部の構成を概略的に示す図である。この図24に示す構成においても、メモリマット30の下部に配置されるエントリシリアルかつビットパラレルで演算を行なう演算器群の構成を概略的に示す。この図24に示す構成においては、複数段の演算器群OG1−OGkが配置され、これらのメモリマット30および演算器群OG1−OGkの間に、スイッチ回路SK0−SK2,…が配置されて、データ転送経路が選択的に確立される。
演算器群OG1−OGkにおいて、演算処理ユニットの処理データビット幅を再構成可能に設定する。図24において、演算器群OG1において、ALU110が配置され、演算器群OG2は、演算器群OG1のALU110のビット幅の4倍のビット幅を有するALU112が構成され、演算器群OGkにおいては、演算器群OG1のALU110のビット幅の2倍のビット幅を有するALU114が構成される。
演算器群OG1−OGkそれぞれにおいて、ALUの処理ビット幅を変更可能に設定することにより、演算処理などを実行して、データの有効ビット幅が変化した場合においても、容易に対応することができる。これらの演算器群OG1−OGkの各ALUのビット幅は、図1に示すコントローラ21からの構成情報に基づいて設定され、またスイッチ回路SK0−SK2,…も、その接続経路が、コントローラからの接続情報に基づいて経路が設定される。
図25は、ビット幅が再構成可能なALUの構成の一例を概略的に示す図である。この図25に示す構成においては、演算器としては、8ビットデータの処理、16ビットデータの処理、および32ビットのデータの加算を行なう2項加算回路の構成が一例として示される。
図25において、4つの8ビット加算器120a−120dが配置される。これらの8ビット加算器120a−120dは、それぞれ、キャリー入力Ci、および2項入力IN1およびIN2と、サム出力Sおよびキャリー出力Cを含む。8ビット加算器120aには、キャリー入力Ciにビット“0”が与えられ、また入力IN1およびIN2に、8ビットオペランドデータOP1およびOP2が与えられる。加算器120bへは、8ビットオペランドデータOP3およびOP4が与えられ、加算器120cには、8ビットオペランドデータOP5およびOP6が与えられ、加算器120dには、オペランドデータOP7およびOP8が入力IN1およびIN2にそれぞれ与えられる。
加算器120bのキャリー入力Ciに対しては、加算器120aのキャリー出力Cとビット“0”の一方を選択するセレクタ122aが設けられ、加算器120cのキャリー入力Ciに対しては、加算器120bのキャリー出力Cとビット“0”の一方を選択するセレクタ122bが設けられ、加算器120dのキャリー入力Ciに対しては、加算器120cのキャリー出力とビット“0”の一方を選択するセレクタ122cが設けられる。
セレクタ122aは、x8ビット構成指示信号X8の活性化時、固定ビット“0”を選択し、それ以外では、加算器120aのキャリー出力Cを選択する。セレクタ122bは、32ビットワード構成を指定する×32ビット指示信号X32の活性化時、加算器120bのキャリー出力を選択し、それ以外では、固定ビット“0”を選択する。セレクタ122cは、8ビットワード構成が指定されたとき、×8ビット指示信号X8に従って固定ビット“0”を選択し、それ以外では、加算器120cの出力信号を選択する。
これらの加算器120a−120dに対し、信号X8、X16およびX32をそれぞれビット幅選択信号として受けるビット幅選択スイッチ回路124が設けられる。
データ処理が、×8ビット構成で行なわれる場合には、セレクタ122a−122cは、それぞれ、固定ビット“0”を選択し、ビット幅選択スイッチ回路124は、それぞれ加算器120a−120dから出力される8ビットのサム出力Sおよび1ビットのキャリー出C力を選択して並列に出力する。加算器120a−120dは、したがって、キャリー入力Ciには固定ビット“0”が与えられるため、それぞれ対応のオペランドデータに基づいて、2項加算処理を実行する。
×16ビット構成の場合、セレクタ122aが、加算器120aのキャリー出力Cを選択し、またセレクタ122cが、加算器120cのキャリー出力Cを選択する。セレクタ122bは、この状態においても、固定ビット“0”を選択する。したがって、加算器120aおよび120bが、16ビット加算器として動作し、また加算器120cおよび120dが、16ビット加算回路として動作する。ビット幅選択スイッチ回路124は、この場合、16ビットデータワード構成を指定する信号X16に従って、加算器120bおよび120dのキャリー出力を選択し、かつサム出力Sとして、各加算器120a−120dのサム出力を選択する。この場合、ビット幅選択スイッチ回路124が以下のように構成されてもよい。加算器120aおよび120cのキャリー出力が、次段の演算器群のALUで利用されないため、そのスイッチ回路124の出力経路を、1ビット下位ビット方向にシフトして、加算器120bおよび120dの出力信号を生成し、それぞれ、加算器120aおよび120bに対して、入力ビットデータと1ビットのキャリーの17ビットデータを出力し、また加算器120cおよび120dに対しても、同様、16ビットのサム出力および1ビットのキャリー出力とで構成される17ビットデータを出力する。
×32ビット構成のデータの処理を行なう場合には、セレクタ122aおよび122cが、それぞれ加算器120aおよび120cのキャリー出力を選択する。セレクタ122bが、また、加算器120bのキャリー出力を選択する。したがって、これらの加算器120a−120dが接続されて、32ビット加算回路が実現される。ビット幅選択スイッチ回路124は、×32ビットデータ構造を指示する信号×32に従って、加算器120a−120dのそれぞれの8ビットサム出力と、加算器120dのキャリー出力を選択し、32ビットデータで構成されるサム出力Sおよび1ビットのキャリー出力Cを生成する。
図25に示すようなビット幅選択スイッチ回路124を利用することにより、基本単位として8ビットデータを演算する加算回路120a−120dを利用して、×16ビットデータおよび32ビットデータの加算を実行することができる。64ビットデータの場合、この図25に示す構成をさらに縦続接続する。
なお、この図25に示す加算器の構成においては、セレクタ122a−122cにより、キャリー出力が選択的に伝搬されており、リップルキャリー加算器が実現され、キャリー伝搬により加算時間が長くなることが考えられる。この場合、キャリールックアヘッド方式またはキャリーセーブ加算方式が利用されてもよい。
以上のように、この発明の実施の形態8に従えば、エントリシリアルで演算を行なう場合、演算器を複数段配置し、かつ各段の演算器の処理データビット幅をリコンフィギアラブルに構成しており、データビット幅および演算処理内容にかかわらず、高速で、必要な演算処理を実現することができる。
[実施の形態9]
図26は、この発明に従う半導体装置を利用する処理システムの構成の一例を示す図である。図26において、図1に示す構成と同様、システムバス5に、ホストCPU(中央演算処理装置)2、DMA回路4およびメモリ3が接続される。このシステムバス5に対し、さらに、この発明に従う半導体演算装置1が接続される。この半導体演算装置1内において、図1に示すように、制御CPU(25)を主要構成要素とする集中制御ユニット15が設けられる。この半導体演算装置1は、システムバス5に対し並列に複数個設けられてもよい。この図26に示す処理システムの構成の場合、ホストCPU2が、メモリ3に格納されるデータを利用して必要な処理を実行する。画像データ処理などの大量のデータに対する処理が必要な場合には、この発明に従う半導体演算装置1が、データの処理を担当する。すなわち、システム構成を、ホストCPU2および半導体演算装置1内の集中制御ユニット15の階層CPU構成とすることにより、高速に処理を実行することができる。
図26は、この発明に従う半導体装置を利用する処理システムの構成の一例を示す図である。図26において、図1に示す構成と同様、システムバス5に、ホストCPU(中央演算処理装置)2、DMA回路4およびメモリ3が接続される。このシステムバス5に対し、さらに、この発明に従う半導体演算装置1が接続される。この半導体演算装置1内において、図1に示すように、制御CPU(25)を主要構成要素とする集中制御ユニット15が設けられる。この半導体演算装置1は、システムバス5に対し並列に複数個設けられてもよい。この図26に示す処理システムの構成の場合、ホストCPU2が、メモリ3に格納されるデータを利用して必要な処理を実行する。画像データ処理などの大量のデータに対する処理が必要な場合には、この発明に従う半導体演算装置1が、データの処理を担当する。すなわち、システム構成を、ホストCPU2および半導体演算装置1内の集中制御ユニット15の階層CPU構成とすることにより、高速に処理を実行することができる。
[変更例1]
図27は、この発明に従う半導体装置1を利用する処理システムの変更例1のシステム構築例を示す図である。この図27に示す処理システムにおいては、図26に示す処理システムと同様、システムバス5を介して、半導体演算装置1、ホストCPU2、メモリ3、およびDMA回路4が接続される。この半導体演算装置1内においては、図1に示すように基本演算ブロック(FB1−FBn)が並列に配設され、各基本演算ブロックの主演算回路(20)内においては、メモリマット30が配置される。したがって、これらの基本演算ブロック内のメモリマット30を、画像データを格納するフレームメモリとして利用させることにより、この半導体演算装置1を、メモリマクロとして動作させることができる。したがって、画像データ処理のワーキングメモリとしてこの半導体演算装置1を利用することができ、またフレームバッファとして、この半導体演算装置1を利用することができる。
図27は、この発明に従う半導体装置1を利用する処理システムの変更例1のシステム構築例を示す図である。この図27に示す処理システムにおいては、図26に示す処理システムと同様、システムバス5を介して、半導体演算装置1、ホストCPU2、メモリ3、およびDMA回路4が接続される。この半導体演算装置1内においては、図1に示すように基本演算ブロック(FB1−FBn)が並列に配設され、各基本演算ブロックの主演算回路(20)内においては、メモリマット30が配置される。したがって、これらの基本演算ブロック内のメモリマット30を、画像データを格納するフレームメモリとして利用させることにより、この半導体演算装置1を、メモリマクロとして動作させることができる。したがって、画像データ処理のワーキングメモリとしてこの半導体演算装置1を利用することができ、またフレームバッファとして、この半導体演算装置1を利用することができる。
また、この半導体演算装置1内においては、このメモリマット30がSRAMセルで構成されており、高速のメモリが実現される場合、メモリマット30をキャッシュメモリとして利用し、メモリ3を主記憶として利用することにより、高速のデータ処理システムを構築することができる。
[変更例2]
図28は、主演算回路20に含まれるビットシリアルかつエントリパラレルの演算を行なう演算器(ALU)34の構成の一例を概略的に示す図である。図28において、ALU34は、ANDゲート132と、NOTゲート134と、およびEXORゲート136と、演算処理内容を設定するデータを格納するレジスタ回路130と、レジスタ回路130の出力信号に従ってAレジスタおよびXレジスタとこれらのゲート132、134、…136との間の接続経路を設定する選択回路138と、レジスタ回路130の格納データに従ってこれらのゲート回路132−136の出力を、CレジスタおよびXレジスタへ選択的に結合する選択回路139を含む。
図28は、主演算回路20に含まれるビットシリアルかつエントリパラレルの演算を行なう演算器(ALU)34の構成の一例を概略的に示す図である。図28において、ALU34は、ANDゲート132と、NOTゲート134と、およびEXORゲート136と、演算処理内容を設定するデータを格納するレジスタ回路130と、レジスタ回路130の出力信号に従ってAレジスタおよびXレジスタとこれらのゲート132、134、…136との間の接続経路を設定する選択回路138と、レジスタ回路130の格納データに従ってこれらのゲート回路132−136の出力を、CレジスタおよびXレジスタへ選択的に結合する選択回路139を含む。
1ビット乗算を行なう場合には、ANDゲート132が利用され、加算動作を行なう場合には、ANDゲート132およびEXORゲート136を利用する。比較演算操作を行なう場合には、EXORゲート136を利用する。減算を実行する場合、NOTゲート134を利用し、その後、2の補数表示の加算を実行する。
このALU34の演算処理内容を、レジスタ回路130の格納データにより設定する。レジスタ回路130の格納データは、図1に示すマイクロプログラム格納メモリ23に格納されるプログラム命令に従ってコントローラ21が設定する。したがって、ALU34の個々の演算処理内容は、プログラマブルである。したがって、図1に示すように、基本演算ブロックFB1−FBnが複数個設けられている場合、この半導体演算装置1を、種々の論理回路を実現するプログラマブルロジック回路として利用することができる。この場合、プログラムデータを、システム起動時または半導体演算装置1の動作時にロードすることにより、その演算処理内容を設定することができる。
この演算器(ALU34)の演算処理内容が、レジスタ回路130に格納されるデータに応じて変更される構成は、エントリシリアルかつビットパラレルで演算処理を行なうALU84等においても同様、適用することができる。その場合には、加算回路、乗算回路、および比較回路等の演算回路が選択される。
[変更例3]
図29は、この発明の実施の形態9の変更例3に従う処理システムの構成を概略的に示す図である。この図29に示す処理システムにおいても、システムバス5に、CPU2、メモリ3、DMA回路4および半導体演算装置1が接続される。この半導体演算装置1内においては、図1に示すように複数の基本演算ブロックFB1−FBnが並列に設けられ、各基本演算ブロックFB1−FBn内に、メモリマットおよびALU群が配置される主演算回路が設けられる。このALU群の演算処理内容は、先の図28に示すように、プログラマブルである。したがって、これらの基本演算ブロックFB1−FBnにおいては、互いに独立に、その内部に含まれるコントローラによりマイクロプログラム格納メモリ(23)に格納されたマイクロプログラムに従って処理が実行され、それらの処理内容は互いに独立に設定することができる。したがって、これらの基本演算ブロックFB1−FBnを、完全に同一機能を有する演算ブロックとして取扱うことができ、また、一部をメモリ、一部をプログラマブルロジック回路および一部を高速演算処理回路(並列演算処理実行による高速演算処理装置)として利用することができる。これにより、処理システムにおける演算処理内容に応じて、種々の演算処理を並列に実行する並列演算装置を実現することができ、高速かつ高性能の処理システムを構築することができる。
図29は、この発明の実施の形態9の変更例3に従う処理システムの構成を概略的に示す図である。この図29に示す処理システムにおいても、システムバス5に、CPU2、メモリ3、DMA回路4および半導体演算装置1が接続される。この半導体演算装置1内においては、図1に示すように複数の基本演算ブロックFB1−FBnが並列に設けられ、各基本演算ブロックFB1−FBn内に、メモリマットおよびALU群が配置される主演算回路が設けられる。このALU群の演算処理内容は、先の図28に示すように、プログラマブルである。したがって、これらの基本演算ブロックFB1−FBnにおいては、互いに独立に、その内部に含まれるコントローラによりマイクロプログラム格納メモリ(23)に格納されたマイクロプログラムに従って処理が実行され、それらの処理内容は互いに独立に設定することができる。したがって、これらの基本演算ブロックFB1−FBnを、完全に同一機能を有する演算ブロックとして取扱うことができ、また、一部をメモリ、一部をプログラマブルロジック回路および一部を高速演算処理回路(並列演算処理実行による高速演算処理装置)として利用することができる。これにより、処理システムにおける演算処理内容に応じて、種々の演算処理を並列に実行する並列演算装置を実現することができ、高速かつ高性能の処理システムを構築することができる。
以上のように、この発明の実施の形態9に従えば、この発明に従う半導体装置を用いて処理システムを構築することにより、演算データのビット幅の制限もなく、非常に柔軟に、データ処理形態をダイナミックに変化させて演算処理を行なうことができるとともに、種々の階層CPUシステム、階層メモリシステムおよびコプロセッサシステムを柔軟に構築することができる。
[実施の形態10]
一般に、RAM(ランダム・アクセス・メモリ)においては、ウェハプロセスでメモリマット内に不良が発生した場合には、予め準備された冗長ビットと不良ビットとを置換することにより、不良ビットを等価的に救済して良品RAMとして用いる不良救済回路技術が一般的に用いられる。本発明においても、主演算回路は、大部分がメモリセルで構成されるため、この不良救済技術を用いて、製品歩留りを向上させることが可能となる。以下、この構成について説明する。
一般に、RAM(ランダム・アクセス・メモリ)においては、ウェハプロセスでメモリマット内に不良が発生した場合には、予め準備された冗長ビットと不良ビットとを置換することにより、不良ビットを等価的に救済して良品RAMとして用いる不良救済回路技術が一般的に用いられる。本発明においても、主演算回路は、大部分がメモリセルで構成されるため、この不良救済技術を用いて、製品歩留りを向上させることが可能となる。以下、この構成について説明する。
図30は、この発明の実施の形態10に従う主演算回路20の要部の構成を概略的に示す図である。この図30に示す主演算回路20は、図21に示す主演算回路20と同様の構成を備える。しかしながら、本実施の形態10における主演算回路20の構成としては、他の実施の形態における主演算回路の構成であっても同様適用することができる。
図30に示す主演算回路20は、以下の点で、図21に示す主演算回路20とその構成が異なる。すなわち、ロウデコーダB76とメモリマット30のワード線WLBとの間に左側冗長救済回路142が設けられ、ロウデコーダA66とワード線WLAとの間に上側冗長救済回路144が設けられる。ビット線対BLPAと演算処理ユニット(ALU)群32の間に、右側冗長救済回路146が設けられ、ビット線対BLPBと演算器群(ALU群B)82の間に、下側冗長救済回路が設けられる。
これらの冗長救済回路142、144、146および148の救済態様を設定するために、図1に示すヒューズ24からのヒューズ情報をデコードして、ヒューズデコード情報X,Yを生成するヒューズデコード回路140が設けられる。冗長救済回路142および146に対し同じヒューズデコード情報Xが与えられ、冗長救済回路144および148に対し共通のヒューズデコード情報Yが与えられる。ワード線WLAの不良救済時においては、このワード線WLAに接続されるメモリセルが接続するビット線対BLPBについても、不良救済を行なう必要があるためであり、同様、ワード線WLBが不良救済を行なう必要がある場合、ビット線対BLPAの不良救済を行なう必要があるためである。
ワード線に対する冗長救済回路142および144は、テスト時において、各種のヒューズ素子を用いて予めプログラムされた不良アドレスを回避して、メモリマット30にアクセスするように動作する。すなわち、これらの冗長救済回路142および144は、いわゆる「シフトリダンダンシ」方式に従って不良救済を行なう。
ALU群32および82に対しても、冗長救済回路146および148がそれぞれ配置されるのは以下の理由による。ロウデコーダ76および/または66においてワード線の不良救済が行なわれる場合、同様、これらのビット線対BLPAおよびBLPBにおいても連動して、不良救済を行なう必要がある。このビット線対に対する冗長救済回路146および148を配置することにより、演算処理ユニット群(ALU群)32および演算器群(ALU群B)82それぞれにおいて、メモリマット30における不良置換の有無にかかわりなく、正常に、正常メモリセルに格納されたデータを用いて演算処理を実行することができる。
不良アドレスのプログラムは、ウェハテスト時に、メモリマット30に対するデータの読出および書込動作の試験を行なった後、ヒューズ用の溶断可能なメタル線を、レーザ等のエネルギー線を用いて切断することにより行なわれる。これらの不良アドレスプログラム用のヒューズは、図1に示す基本演算ブロックFB1−FBn内にそれぞれヒューズ24として配置されている。このヒューズ情報は、図30に示すヒューズデコード回路140を用いて、ヒューズデコード情報X,Yに変換される。このヒューズデコード情報X,Yが、たとえばチップ起動時などに各冗長救済回路へ転送され、不良救済処理を実現する。
図31は、ロウデコーダに対して設けられる冗長救済回路の構成の一例を示す図である。図31においては、メモリマット30におけるワード線WLn−WL(n+3)を代表的に示す。この図31に示すワード線WLは、ワード線WLAまたはWLBである。これらのワード線WLn−WL(n+3)をアドレス入力に従って選択状態へ駆動するために、ワード線デコード回路150が設けられる。このワード線デコード回路150は、図30に示すロウデコーダA66またはロウデコーダB76に対応する。
ワード線デコード回路150の出力WOn−WO(n+2)に対して、それぞれ、ヒューズデコード情報レジスタ155n−155(n+2)が設けられる。これらのヒューズデコード情報レジスタ155n−155(n+2)は、シフトレジスタ回路またスキャンパスを構成し、ヒューズデコード回路140(図30参照)により生成されたヒューズデコード情報を、順次シフトして対応のワード線に対するヒューズデコード情報を格納する。
また、ワード線デコード回路150の出力WOn−WO(n+2)それぞれに対応して、ヒューズデコード情報レジスタ155n−155(n+2)の格納データに従ってワード線デコード回路150の出力WOn−WO(n+2)の転送経路を切換えるシフト切換用マルチプレクサ160n−160(n+2)が配置される。これらのシフト切換用マルチプレクサ160n−160(n+2)は、対応のヒューズデコード情報レジスタの格納データが“0”のときには、ワード線デコード回路の対応の出力信号を対応のワード線に伝達し、一方、対応のヒューズデコード情報レジスタの格納データが“1”のときには、図の上側方向(ワード線番号の大きい方)にシフトして、ワード線デコード回路の出力信号を伝達する。
今、図31に示すように、ヒューズデコード情報レジスタ155nに、ビット“0”が格納され、ヒューズデコード情報レジスタ155(n+1)および155(n+2)にビット“1”が格納されている状態を考える。この場合、シフト切換用マルチプレクサ160nは、ヒューズデコード情報レジスタ155nの格納ビット“0”に従って、ワード線デコード回路150の出力信号WOnを、対応のワード線WLnへ伝達する。このワード線WLnよりも番号の少ないワード線には、したがって、ワード線デコード回路150の出力信号がシフトされることなく転送される。
一方、ヒューズデコード情報レジスタ155(n+1)および155(n+2)にはビット“1”が選択格納されているため、シフト切換用マルチプレクサ160(n+1)および160(n+2)は、それぞれワード線デコード回路150の出力信号WO(n+1)およびWO(n+2)をワード線WL(n+2)およびWL(n+3)へ伝達する。したがって、ワード線WL(n+1)は、ワード線デコード回路150の出力から分離されており、このワード線WL(n+1)は、常時非活性状態に維持される。これにより、不良ワード線WL(n+1)を、常時非選択状態に維持することができ、不良アドレスを回避する不良救済を実現することができる。
なお、いうまでもなく、メモリマット30においては、シフトリダンダンシ方式に従って不良救済が行なわれるため、このメモリマット30のアドレス空間(エントリ数)よりも多い数のワード線を設けることが要求される。
上述のように、ワード線WLnまでは、順次ワード線デコード回路150の出力信号に従って選択状態へ駆動される。不良ワード線に対するレジスタ回路およびそれより上位のレジスタ回路の格納データを“1”に設定して転送経路をシフトさせることにより、ワード線デコード回路150の出力信号WO(n+1)に従って、ワード線WL(n+2)が選択される。以降、ワード線とワード線デコード回路150の出力WOの対応関係が1つシフトされて、順次メモリマット30の正常ワード線が選択状態へ駆動される。
すなわち、不良ワード線およびそれ以降に対応するヒューズデコード情報レジスタにビット“1”を格納することにより、不良ワード線とワード線デコード回路150とを分離することができ、不良アドレスが選択されるのを防止することができる。
図32は、センスアンプ群およびライトドライバ群に対して設けられる冗長救済回路(146,148)の構成を概略的に示す図である。図32において、メモリマット30のビット線対BLPn−BLP(n+3)に対して設けられる冗長救済回路の構成を代表的に示す。これらのビット線対BLPn−BLP(n+3)は、ビット線対BLPAn−BLPA(n+3)またはBLPBn−BLPB(n+3)のいずれかである。
ビット線対BLPn−BLP(n+3)それぞれに対応して、センスアンプ・ライトドライバ172n−172(n+3)が配置される。これらのセンスアンプ・ライトドライバ172n−172(n+3)の各々は、対応のセンスアンプ群およびライトドライバ群に含まれるセンスアンプおよびライトドライバで構成される。
ビット線対BLPn−BLP(n+2)それぞれに対応して、単位ALU回路ブロック170n−170(n+2)が設けられる。単位ALU回路ブロック170n−170(n+2)の各々は、ALU34または、演算器群(ALU群B)82に含まれる単位ALU(1ビット演算を行なう回路)に対応する。
BLP冗長救済回路(146,148)においては、ビット線対BLPn−BLP(n+2)に対応して、ヒューズデコード情報を格納するヒューズデコード情報レジスタ180n−180(n+2)が設けられる。これらのヒューズデコード情報レジスタ180n−180(n+2)は、先の図30に示すヒューズデコード回路140から生成される。これらのヒューズデコード情報レジスタ180n−180(n+2)は、シフトレジスタ回路を構成し、順次ヒューズデコード情報をシフト動作により転送して、対応のビット線対に対するヒューズデコード情報を格納する。
これらのヒューズデコード情報レジスタ180n−180(n+2)それぞれに対応して、シフト切換用マルチプレクサ182n−182(n+2)が設けられる。これらのシフト切換用マルチプレクサ182n−182(n+2)は、それぞれ、対応のビット線対に配置されるセンスアンプ・ライトドライバ172n−172(n+2)と、1列上側方向にシフトしたセンスアンプ・ライトドライバ172(n+1)−172(n+3)とに結合される。
これらのシフト切換用マルチプレクサ182n−182(n+2)は、それぞれ、対応のヒューズデコード情報レジスタ180n−180(n+2)の格納データがビット“0”のときには、対応のビット線BLPを対応の単位ALU回路ブロック170に接続し、ビット“1”が格納されている場合には、対応のビット線BLPを1列上位側にシフトした単位ALU回路ブロック170に接続する。
今、図32に示すように、ヒューズデコード情報レジスタ180nにビット“0”が格納され、ヒューズデコード情報レジスタ180(n+1)および180(n+2)にビット“1”が格納されている状態を考える。この状態においては、シフト切換用マルチプレクサ182nは、ビット線対BLPnに対して設けられたセンスアンプ・ライトドライバ172nを対応の単位ALU回路ブロック170nに結合する。一方、シフト切換用マルチプレクサ180(n+1)は、ビット線対BLP(n+2)に対して設けられたセンスアンプ・ライトドライバ172(n+2)を単位ALU回路ブロック170(n+1)に結合し、同様、シフト切換用マルチプレクサ172(n+2)は、ビット線対BLP(n+3)に対して設けられたセンスアンプ・ライトドライバ172(n+3)を単位ALU回路ブロック170(n+2)に結合する。
したがって、ビット線対BLP(n+2)に対して設けられたセンスアンプ・ライトドライバ172(n+1)は、対応の単位ALU回路ブロック170(n+1)から分離され、いずれの単位ALU回路ブロックにも結合されない。このビット線対BLP(n+1)は、不良ワード線WL(n+1)に対応する。したがって、この不良ワード線の冗長置換に連動して、ビット線対の置換を行なうことにより、正確に、正常なメモリセルのみを利用して、単位ALU回路ブロック170において演算処理を行なうことができる。
以上のように、この発明の実施の形態10に従えば、不良冗長置換を行なうことにより、不良セルの救済を行なうことができ、正確な、演算処理を行なう装置が実現され、歩留りが改善される。
また、メモリマットにおいて、ワード線が直交方向に配列され、またビット線対も直交して配置される構成の場合、不良ワード線の冗長置換に連動して、不良ワード線に対応するビット線対も冗長置換を同様にして行なうことにより、確実に、正常にデータを記憶するメモリセルを用いて演算処理を行なうことができ、装置の信頼性を確保することができる。
[実施の形態11]
図33は、この発明の実施の形態11に従う基本演算ブロックFBiの要部の構成を概略的に示す図である。図33において、メモリセルマット30はエントリERYとして、番号0からMAX_ENTRYが付されたエントリを含む。各エントリは、ビット位置として0からBIT_MAXを有し、そのビット幅が、BIT_MAX+1である。
図33は、この発明の実施の形態11に従う基本演算ブロックFBiの要部の構成を概略的に示す図である。図33において、メモリセルマット30はエントリERYとして、番号0からMAX_ENTRYが付されたエントリを含む。各エントリは、ビット位置として0からBIT_MAXを有し、そのビット幅が、BIT_MAX+1である。
演算処理ユニット群(ALU群)32においては、各エントリに対応して演算処理ユニット(以下、適宜ALUユニットと称す)34が配置される。この演算処理ユニット群32に対して、ALU間相互接続用スイッチ回路44が設けられる。
この主演算回路20の動作は、プログラム格納メモリ23に格納されるプログラム(マイクロプログラム)により設定される。コントローラ21が、このプログラム格納メモリ23に格納されたプログラムに従って処理を実行する。
先の実施の形態1においては、プログラム格納メモリ23において、マイクロプログラムが格納される。本実施の形態11においては、このプログラム格納メモリ23に格納されるプログラム命令は、マイクロ命令でなくてもよく、マクロ命令であってもよい。コントローラ21が、プログラム命令をデコードし、この命令により指定された動作に必要な処理を実行する。
レジスタ群22においては、ポインタレジスタr0−r3が設けられ、演算対象のデータのメモリセルマット30のアドレスが、これらのポインタレジスタr0−r3に格納される。コントローラ21は、このポインタレジスタr0−r3に格納されるポインタに従って主演算回路20におけるエントリまたはエントリ内位置を指定するアドレスを生成して、メモリセルマット30と演算処理ユニット群32との間のデータの転送(ロード/ストア)を制御し、また、ALUユニット34間の接続指定情報を設定する。
図34は、図33に示す演算処理ユニット34の構成を概略的に示す図である。図34において、ALU34においては、内部データ線200を介してXレジスタ54が、ライトドライバ60およびセンスアンプ62に結合される。この内部データ線200は算術演算論理回路50に結合される。
この図34に示す単位ALU回路ブロック(ALUユニット34)においては、先の図7に示す構成と異なり、Aレジスタは設けられない。Xレジスタ54が、対応のエントリのメモリセルからのロードデータの一時保存を行ない、かつ算術演算論理回路50の演算途中の結果の一時保存を行なう。2項演算処理時において、Xレジスタ54に第1の演算データが格納されたとき、次の(別の)演算データは算術演算論理回路50に直接与えられて演算処理が実行される。
Xレジスタ54が、ALU間接続回路65を介して他の単位ALU回路ブロック(ALUユニット)に結合され、異なるALUユニット間でデータ転送を行なうことができる。
図34に示すALUユニット34の他の構成は、図7に示す単位ALU回路ブロック34の構成と同じであり、対応する部分には同一の参照番号を付し、その詳細説明は省略する。
図35は、図33に示すポインタレジスタr0−r3に対する操作命令(レジスタ命令)を一覧にして示す図である。レジスタ命令として、5種類の命令が準備される。
命令“reg.set n,rx”は、レジスタrxに、定数nをセットする命令である。定数nは、1つのエントリにおけるビット位置を示すものであり、1エントリのビット0からMAX_BITのいずれかの値を規定する。
命令“reg.cpy rx,ry”は、ポインタレジスタrxの内容を、ポインタレジスタryにコピーする命令である。
命令“reg.inc rx”は、ポインタレジスタrxの格納値を1増分する命令である。
命令“reg.dec rx”は、ポインタレジスタrxの格納値を1減分する命令である。
命令“reg.sft rx”は、ポインタレジスタrxの格納値を1ビット左シフトする命令である。
これらの5種類のレジスタ命令により、ポインタレジスタr0−r3の格納値(ポインタ)を操作して、メモリセルマットの演算対象データのアドレスを指定する。
図36は、図34に示すALU34に対する操作命令を一覧にして示す図である。以下、図36を参照して、各ALU命令の操作内容について簡単に説明する。
命令“alu.set.♯”は、レジスタ♯(X、CまたはM)に“1”をセットする命令である。このALUセット命令は、エントリ単位でレジスタのセットを指定する。
命令“alu.clr.♯”は、レジスタ♯の格納値を“0”にクリアする命令である。
命令“alu.cpy.♯1♯2”は、レジスタ♯1の格納値をレジスタ♯2へコピーする命令である。
このaluコピー命令が実行されると、各エントリに対して設けられたALU内でレジスタ間データ転送が実行される。
図37は、メモリセルマットとALUとの間のデータ転送を規定するALU命令のロード/ストア命令を示す図である。
命令“mem.ld@rx”は、ポインタレジスタrxの示すメモリセル位置からXレジスタへデータをロードする命令である。
命令“mem.st@rx”は、Mレジスタ(マスクレジスタ58)にビット“1”が設定されている場合には、Xレジスタに格納されたデータを、ポインタレジスタrxが指定するアドレス位置へ格納する命令である。
このメモリロード/ストア命令を利用することにより、ポインタレジスタrxの格納値をアドレスとして、メモリセルとALUユニットとの間でデータ転送を行なうことができる。
図38は、ALU命令のうち、エントリ間のデータ移動(Move)を行なう命令を一覧にして示す図である。
命令“ecm.mv.n♯n”は、データ移動命令(move)における移動量を数値♯nで規定する。したがって、この命令では、Xレジスタ3のデータ転送において、エントリj+nのXレジスタの格納値が、エントリjのXレジスタに移動される。エントリ移動量nは、0から128の範囲の整数値を取り、最大128ビット離れた位置のエントリ間でデータ移動(Move)を行うことができる。ただし、ENTRY_MAXは、128以上である。
命令“ecm.mv.r rx”は、ポインタレジスタrxに格納された値だけエントリ間をデータ移動させる命令であり、この命令が実行されると、エントリj+rxのXレジスタの格納値を、エントリjのXレジスタに転送する。
図35から図38に一覧して示す命令を利用することにより、ALUユニットに、所望のエントリのデータを設定することができる。
図39は、各単位ALU回路ブロック(ALUユニット)で行なわれる演算を指定する命令を示す図である。
命令“alu.op.adc@rx”は、ポインタレジスタrxが指定するメモリセルアドレスのデータとXレジスタに格納されたデータとを加算し、その加算結果をXレジスタに格納することを指定する命令である。加算演算時、全加算演算が行なわれるため、キャリ発生時、Cレジスタにキャリが格納される。Xレジスタ(Xj)には、ポインタレジスタrxが指定するアドレスのメモリセルデータAj[rx]とXレジスタに格納されたビット値XjとCレジスタに格納されたキャリCjの排他的論理和(“^”)演算によりサムSumが生成されて、Xレジスタに格納される。
キャリCjは、メモリセルデータAj[rx]とXレジスタの格納ビットXjとCレジスタの格納値Cjのビットの各ビットの組のAND演算(&)の論理和(+)により求められる。
この加算命令は、マスクレジスタ(MレジスタMj)に“1”が設定されたときに実行され、マスクレジスタに“0”が設定されている場合には、このエントリにおいて加算命令は実行されない。
命令“alu.op.sbb@rx”は、減算命令であり、この減算命令実行時、ポインタレジスタrxが指定するメモリアドレスのデータAj[rx]からXレジスタに格納されたビット値を減算する。減算結果がXレジスタに格納され、Cレジスタにはボローが格納される。
この減算時においては、Xレジスタに格納されたビットXjの反転値!Xjが用いられ、加算時と同様の処理が行なわれる。したがって、この減算命令が与えられた場合には、Xレジスタに格納された値が反転されて加算器へ与えられる(最下位ビットのキャリが1にセットされる)。
図40は、ALU内で行なわれる論理演算を指定する命令を一覧にして示す図である。
命令“alu.op.and@rx”は、AND命令であり、この命令実行時、ポインタレジスタrxのポインタが指定するメモリアドレスのデータAj[rx]とXレジスタに格納されたビット値Xjの論理積(AND)をとり、その論理積結果がXレジスタに格納される。但し、マスクレジスタMjの格納値(Mjで示す)が“0”の場合には、このAND命令は実行されない。以下の論理演算命令についても同様に、マスクレジスタの格納値により。指定された演算の実行/禁止が指定される。
命令“alu.op.and@rx”は、AND命令であり、この命令実行時、ポインタレジスタrxのポインタが指定するメモリアドレスのデータAj[rx]とXレジスタに格納されたビット値Xjの論理積(AND)をとり、その論理積結果がXレジスタに格納される。但し、マスクレジスタMjの格納値(Mjで示す)が“0”の場合には、このAND命令は実行されない。以下の論理演算命令についても同様に、マスクレジスタの格納値により。指定された演算の実行/禁止が指定される。
命令“alu.op.or@rx”は、ポインタレジスタrxのポインタが指定するメモリアドレスのデータAj[rx]とXレジスタの格納ビットXjの論理和(OR演算)を行ない、その結果を、Xレジスタに格納する。
命令“alu.op.eq@rx”は、EXOR命令であり、ポインタレジスタrxのポインタが指定するアドレスのメモリセルデータAj[rx]とXレジスタの格納ビットXjの値の排他的論理和演算(EXOR演算)が行なわれ、その演算結果が、Xレジスタに格納される。
命令“alu.op.not”は、NOT命令(反転命令)であり、Xレジスタのビット値Xjを反転し、その反転結果!XjをXレジスタに格納する。
ALU34を、マスクレジスタ(Mレジスタ)58、Cレジスタ56、Xレジスタ54、および算術演算論理回路50で構成し、図35から図40に示す命令を組合せて演算処理を記述することにより、種々の演算処理を、ワードパラレルかつビットシリアル態様で実行することができる。
図41は、この発明の実施の形態11に従う基本演算ブロックにおける加算演算を実行するプログラムの一例を示す図である。図41において、行番号によりプログラム内の各演算命令の行が指定され、その行において、実行される命令が指定され、“//”の後に、実行される演算命令の内容が説明される。この“//”後の内容は、演算内容の説明であり、何ら実行命令ではない。以下、図41に示す加算プログラムは、2項加算処理であり、(a+b)=cの処理が実行される。以下、図41に示す加算プログラムの処理動作について説明する。
行番号0において、マスクレジスタ(Mレジスタ)に“1”が設定され、キャリレジスタ(Cレジスタ)の格納値が“0”にクリアされる。
行番号1において、ポインタレジスタr0に定数asが格納され、ポインタレジスタr1に定数bsが格納され、ポインタレジスタr2に定数csが格納される。これらの定数as、bs、およびcsは、それぞれ2項加算演算(a+b=c)の各演算数a、bおよびcの最下位ビットの対応のエントリ内の位置を示す。
行番号2および行番号3において、加算命令が指定される。iが0から演算データのビット幅(bit_count)−1の間、繰返し加算が実行され、各加算命令実行毎に、iが増分される(i++)。for文の後の中括弧で囲まれる関数の内容が、“forループ命令”の条件が満たされるまで、すなわちiが演算対象数のビット幅に到達するまで、繰返し実行される。
このfor文で規定されるループ命令においては、ポインタレジスタr0の内容が対応のALUユニットに転送され(ロードされ)てXレジスタに格納され、次いで、ポインタレジスタr1に格納されるポインタ値が示すメモリセルのデータが対応のALUユニットへ転送されてXレジスタの格納値と加算される(Cレジスタの格納値と合わせて)。加算結果が、ポインタレジスタr2のポインタが示すアドレス位置に格納される。この命令列において“r0+”、“r1+”および“r2+”は、この命令実行後、ポインタレジスタr0、r1およびr2のポインタが1増分されることを示す。
行番号3において、このループ命令時に実行される命令列の末尾が示される。
このfor{}のループ命令が完了し、データビット列について加算処理が完了すると、行番号4において、Cレジスタの格納値が、Xレジスタに転送され、次いで、このXレジスタの格納値が、ポインタレジスタr2が指定するアドレス位置に格納される。この処理により、加算結果のキャリが格納される。
このfor{}のループ命令が完了し、データビット列について加算処理が完了すると、行番号4において、Cレジスタの格納値が、Xレジスタに転送され、次いで、このXレジスタの格納値が、ポインタレジスタr2が指定するアドレス位置に格納される。この処理により、加算結果のキャリが格納される。
図42は、図41に示す加算操作を概略的に示す図である。まず演算数a、bおよびcのエントリERYの格納領域の最下位ビット位置as、bsおよびcsが、それぞれポインタレジスタr0、r1およびr2のポインタにより指定される。次いで、このポインタレジスタr0、r1およびr2のポインタが示すメモリセルのデータaiおよびbiが読出されて加算され、その加算結果が、ポインタレジスタr2が示すメモリセル位置に格納される。演算数aおよびbが3ビットデータの場合、i=0〜2において、加算、およびストアが実行され、最終的に、Cレジスタの格納値がXレジスタを介してポインタレジスタr2の指定するビット位置(cs+3)に格納される。
この演算命令“alu.op.adc@r1+”により、このALUユニットにおいてALU回路(算術論理演算回路)の実行内容を加算に設定することができる。
図43は、演算数aおよびbの減算(a−b)を行ない、減算結果cを生成する減算プログラムの一例を示す図である。以下、図43を参照して、2項減算処理について説明する。
まず、行番号0において、MレジスタおよびCレジスタの初期設定が、加算演算処理時と同様に行なわれる。
行番号1において、加算演算時と同様に、演算数のエントリ内のアドレスの初期設定が行なわれ、ポインタレジスタr0、r1およびr2に、各対象演算数a、bおよびcの最下位ビット位置が設定される。
行番号2および行番号3において、ループ演算命令が、加算演算実行プログラムと同様に指定される。命令“alu.op.sbb@r1+”により、演算数aから演算数bを減算する処理が実行される。ロード命令“mem.ld”およびストア命令“mem.st”は、加算時と同様であり、演算データのALUユニットへの転送および減算結果のメモリセルマットのc[i]への格納が実行される。
行番号3においてループ演算命令の内容の末尾が指定される。
行番号4において、行番号2および3の指定するループ命令の完了後(演算数aおよびbの全ビットについての減算が完了後)、Cレジスタの内容がXレジスタに転送され、次いで、Xレジスタの内容がポインタレジスタr2が指定するメモリ位置に格納されて、ボローが格納される。
行番号4において、行番号2および3の指定するループ命令の完了後(演算数aおよびbの全ビットについての減算が完了後)、Cレジスタの内容がXレジスタに転送され、次いで、Xレジスタの内容がポインタレジスタr2が指定するメモリ位置に格納されて、ボローが格納される。
減算処理の場合の各ビットの流れとしては、図42に示す加算演算において“加算”に代えて、“減算”が行なわれればよく、ビットの流れは同じである。
図44は、乗算a・b=cを行なう乗算プログラムの一例を示す図である。以下、図44を参照して、2項乗算演算処理について説明する。
まず、行番号0において、ポインタレジスタr2およびr3に、定数asおよびcsが設定される。この行番号0に挙げる初期設定時においては、被乗数aおよび乗算結果cの領域の初期設定が行なわれ、乗数bの領域の設定はまだ行なわれない。
行番号1において、for文において、被乗数aの格納領域範囲のビット幅だけ乗算を繰返すことが指定される。“a_bit_count”は、被乗数aのビット幅を示す。
行番号2の関数文において、ポインタレジスタr2の指定する被乗数ビットa[j]が転送されてXレジスタに格納される。次いで、このXレジスタに格納された被乗数ビットa[j]が、マスクレジスタ(Mレジスタ)に格納される(被乗数ビットa[j]が“0”のときに乗算を行なう必要がないため、乗算を停止するためである。)
行番号3の命令により、ポインタレジスタr3のポインタがポインタレジスタr0にコピーされ、次いで、ポインタレジスタr1に、定数bsが設定され、乗数bの初期アドレスが設定される。
行番号3の命令により、ポインタレジスタr3のポインタがポインタレジスタr0にコピーされ、次いで、ポインタレジスタr1に、定数bsが設定され、乗数bの初期アドレスが設定される。
行番号4において、Cレジスタのクリアが行なわれる。
行番号5において、for文により、乗数bに対する繰返し処理が指定される。“b_bit_count”は、乗数bのビット幅を示す。
行番号5において、for文により、乗数bに対する繰返し処理が指定される。“b_bit_count”は、乗数bのビット幅を示す。
行番号6における関数文においては、ポインタレジスタr0のポインタが指定するメモリセルデータ、すなわち乗算結果がXレジスタへ転送される(ロードされる)。次に、ポインタレジスタr1が指定する乗数ビットb[i]のALUユニットへの転送が行われ、、Mレジスタの格納値が1のときに、Xレジスタの乗算結果cと乗数bの対応のビットb[i]との加算が行なわれる。この加算演算命令は、Mレジスタ(マスクレジスタ)の格納値が“0”のときには行なわれない。この処理により、乗算a[j]xb[i]が実現され、この乗算結果がそれまでの部分積と加算される。
この加算結果が、ポインタレジスタr0が示す位置に転送されて格納され、ポインタレジスタr0のカウンタが1増分される。行番号6の関数文の命令が、行番号5のfor文の条件が満たされるまで、すなわち、乗数bの全ビットについて、繰返し実行される。この加算処理により、1つのビットa[j]についての部分積生成とそれまでに生成された部分積との加算が実行される。
1つの乗数bの全ビットについての処理が完了すると、行番号8において、Cレジスタの格納値がXレジスタに格納され、ポインタレジスタr0が指定するアドレス位置に、このXレジスタに転送されたキャリが格納される。これにより、部分積の加算演算処理が完了する。
次いで、行番号9において、ポインタレジスタr3のポインタが1増分され、次の桁の乗数が指定される。行番号2から行番号9の演算処理が、被乗数aの各ビットについて繰返し実行される。これらの一連の処理により、ビットシリアルに乗算を行なうことができる。
図45は、図44に示す乗算プログラム実行時のビットの流れを模式的に示す図である。図45において、被乗数aのビットajがマスクレジスタ(M)に格納される。次いで、乗算結果ビットcjが読出されてXレジスタに格納され、また乗数ビットbiが読出されて、加算が選択的に行なわれる。この加算時において、マスクレジスタ(Mレジスタ)に格納された被乗数ビットajが“1”のときに、乗算結果ビットcjと乗数ビットbiとの加算が行なわれる。被乗数ビットajが“0”のときには、この加算は行なわれず、Xレジスタには乗算結果ビットcjが維持される。したがって、この加算結果は、cj+aj・biを示しており、この加算結果が元のビット位置cjに格納される。この処理が、乗数bの全ビットについて繰返し実行される。したがって、乗数bと被乗数ビットajの部分積が求められて、その部分積結果が対応の桁の部分積ビットに加算される。したがって、被乗数aの各ビット毎に部分積生成して、それまでの部分積とを加算する処理が繰返される。
図46は、除算a/b=c...dを行なう際のエントリのアドレスの割当を概略的に示
す図である。被除数aの開始アドレスasがポインタレジスタr0により指定され、余りdの格納領域の開始アドレスdsが、ポインタレジスタr1に格納される。除数bおよび商sは開始アドレスが、それぞれ、bsおよびcsである。
す図である。被除数aの開始アドレスasがポインタレジスタr0により指定され、余りdの格納領域の開始アドレスdsが、ポインタレジスタr1に格納される。除数bおよび商sは開始アドレスが、それぞれ、bsおよびcsである。
図47は、この除算を行なうプログラムの一例を示す図である。以下、図47を参照しして、除算プログラムの演算内容について説明する。
図47において、行番号0の命令により、単位ALU回路におけるマスクレジスタ(Mレジスタ)がセットされ、対応のALU回路が演算可能状態に設定される。また、ポインタレジスタr0およびr1に、それぞれ、演算数aおよびbの開始アドレスasおよびbsが設定される。
行番号1において、繰返し文(for文)が記述され指定され、余りの初期設定が行なわれる。すなわち、ポインタレジスタr0に従って、被除数aがポインタレジスタr1の指定する余り格納領域にXレジスタを介して転送されて格納される。被除数aの全ビットについて、この動作が繰返され、初期状態において、余りdとして、被除数aが設定される。この余り格納領域は、被除数aの上位ビット領域にビット幅拡張されて、そのビット幅が十分に大きくされており、このビット幅拡張された領域に、ビット幅調整された被除数が格納される。
行番号2の命令において、ポインタレジスタr2に、商cの開始アドレスcsと商cのビット幅より1小さい数(bit_count−1)との和が設定される。これにより、ポインタレジスタr3には、商cの格納領域の最上位アドレスが設定される。この行番号2の命令において、同様、ポインタレジスタr2に、余りdの開始アドレスdsと余りdのビット幅より1小さい値(bit_count−1)との和が設定される。これにより、ポインタレジスタr2に、初期値として、最初の被除算対象ビットを格納する領域の最下位アドレスが設定される。
行番号3において、繰返し文(for文)が記述される。この行番号3の繰返し文に続いて、行番号4から行番号7までの命令が、繰返し関数として規定される。
まず、行番号4において、マスクレジスタ(Mレジスタ)がセットされ、また、Xレジスタがクリアされる。このXレジスタのクリア値が、ポインタレジスタr3の規定するアドレス領域、すなわち商cの最上位ビット位置に格納される。これにより、商の初期化(クリア)が実行される。
行番号5の命令により、ポインタレジスタr2の内容が、ポインタレジスタr0に格納される。次いで、ポインタレジスタr1に、除数の開始アドレスbsが設定され、また、Cレジスタがクリアされる。
行番号6において、再び、繰返し文が記述され、繰返し関数として、行番号7の命令が規定される。すなわち、ポインタレジスタr0が指定するアドレスのメモリセルのデータがXレジスタに格納され、このポインタレジスタr0のポインタが1増分される。次いで、ポインタレジスタr1が指定するアドレスのメモリセルデータが、Xレジスタに格納されたデータから減算される。この処理が繰返し実行される。
この減算が完了すると、次いで、行番号9の命令により、Cレジスタの内容が、Xレジスタに転送される。このXレジスタの格納値が反転され、Mレジスタにその反転値が格納される。この演算により、除数bと最初の被除数との大小が判定される。
行番号10において、ポインタレジスタr2の内容が、再び、ポインタレジスタr0にコピーされ、またポインタレジスタr1に、再び、乗数bの開始アドレスbsが初期設定されて、Cレジスタがクリアされる。次の処理の準備が行われる。
行番号11において再び繰返し文が指定され、ポインタレジスタr0の指定するアドレスのメモリセルデータから、ポインタレジスタr1が規定するメモリセルのデータが減算される。このとき、ポインタレジスタr1のポインタが1増分される。この演算結果がXレジスタに格納され、この減算結果が、ポインタレジスタr0が規定するメモリセルアドレスの位置、すなわち元の読出位置に格納され、ポインタレジスタr0のポインタが1増分される。この動作が、繰返し実行される。
行番号14において、ポインタレジスタr2の値を1減分し、行番号15の命令により、Xレジスタに1を格納し、このXレジスタに格納された値をポインタレジスタr3が指定するメモリセル位置に格納し、このポインタレジスタr3の値が1減分される。
行番号16において行番号1の指定する繰返し文の関数の完了が規定されており、したがってこの行番号2から15に示す処理が、繰返し実行される。
したがって、この図47に示す除算プログラムにおいても、ビットシリアル態様で被除数から除数を順次減算し、その減算を、選択的に、除数と被除数の大小関係に応じて実行することにより、除数ビットを生成することができる。また、余りdの領域に、被除数を格納し、この余りの領域の演算開始位置を順次減分して下位ビット方向へシフトさせることにより、除算時の被除数の桁下げを行って、順次被除数から除数を減算して、商として1が立つかを決定する。この操作を繰返すことにより、除算完了時に、余りを確実に求めることができる。
図48は、図47に示す除算プログラム実行時のデータの流れを示す図である。以下、図48を参照して、具体的に除算処理について説明する。
図48(A)に示すように、行番号0の命令文により、マスクレジスタ(Mレジスタ)に“1”が設定され、ポインタレジスタr0が、被除数aの最下位ビットアドレスasを指定する。また、ポインタレジスタr1は、余りdの格納領域の最下位ビットアドレス位置dsを指定する。
行番号1の命令により、ポインタレジスタr0およびr1を順次増分してメモリロード/ストア動作を実行することにより、被除数aが、剰余格納領域にコピーされる。この剰余格納領域のビット幅は、被除数aのビット幅よりも大きい(被除数aおよび除数bのビット幅の和以上のビット幅が準備される)。
この剰余領域に被除数aを下位ビット領域にコピーすることにより、被除数aの上位ビットが拡張され、ビット幅調整された被除数から除数を順次減算して、商を求める準備が行なわれる。
次いで、行番号2の命令群により、ポインタレジスタr3に商格納領域の最上位ビット位置アドレスが設定され、またポインタレジスタr2が、剰余格納領域における被乗数aの最上位ビット位置を指定する状態に設定される。
次いで、図48(B)に示すように、行番号4の命令群により、マスクレジスタ(Mレジスタ)が再び、“1”に設定され、Xレジスタがクリアされ、“0”を格納する状態に設定され、このXレジスタの格納値が、商格納領域の最上位ビット位置に格納され、前の演算サイクル時における商のクリアが行なわれる。
次いで、このポインタレジスタr0およびポインタレジスタr2のポインタを転送し、剰余格納領域における被除数aの最上位ビット位置を指定する。この状態で、ポインタレジスタr0およびr1のポインタを順次増分して、減算動作を実行し、その減算結果が、XレジスタおよびCレジスタに格納される。この操作は、被除数aの最上位ビットamから除数bのビット幅分上位のビットで構成される値から除数bを減算する操作に対応する。すなわち、桁合わせされた被除数の上位ビット側から除数bを減分する操作が実行される。
次いで図48(C)に示すように、商cの最初のビットについての比較ループが実行された後に、行番号9の命令群により、Cレジスタの内容がXレジスタに転送され、このXレジスタの格納値が反転(NOT)され、反転値がMレジスタに転送される。Cレジスタの格納値が“1”の場合には、ボローが発生しており、除数bの方が、大きく、商cの最上位ビットに1を立てることができない状態を示す。Cレジスタの格納値が0の場合には、差分値が正であることを示しており、この場合、Mレジスタ(マスクレジスタ)に1が格納される。マスクレジスタ(MレジスタMレジスタ)が“0”を格納しているときには、指定された命令は実行されない。マスクレジスタ(Mレジスタ)の格納値が“1”のときに、指定された命令に従った演算処理が実行される。すなわち、商として0が立つか1が立つかを、マスクレジスタ(Mレジスタ)の格納値により決定する。
次いで、図48(D)に示すように、行番号10および11の命令群により、再び被除数aの最上位ビットamを最下位ビットとする数から除数bの減算処理が行なわれ、この減算結果が、Xレジスタに格納されかつ上位領域の元の領域に格納される。この減算処理は、ポインタr1およびr0(ポインタr2のポインタ値が転送されている)を順次増分することにより行なわれる。この減算処理は、マスクレジスタ(Mレジスタ)の格納値が“1”のときに行なわれ、マスクレジスタ(Mレジスタ)の格納値が“0”のときには、この減算処理は実行されない。商として0が立つ場合には、この減算処理を行う必要がなく、商cの対応のビットに0を格納することが要求される。この不必要な処理についても、分岐を行わずに命令が仮想的に実行されるのは、他のエントリでの除算において1が立つ可能性があり、全エントリにおいて並行して除算処理を実行する必要があるためである(コントローラから共通の制御信号が各エントリに対して生成される)。
次いで、図48(E)に示すように、減算処理が完了すると、行番号14の命令に従ってポインタレジスタr2のポインタが1減分され、次いで、Xレジスタに1が設定され、ポインタレジスタr3のポインタが示す位置に“1”が格納される。この処理は、Mレジスタが1の場合に実行され、Mレジスタ(マスクレジスタ)の格納値が0の場合には格納されず、商cの格納領域のポインタレジスタr3の指定する位置には“0”が維持される。
これにより、ポインタレジスタr3のポインタが1減分され、次の商のビット位置が指定される。
以降、上述の処理を繰返すことにより、最終的に、図48(F)において、ポインタレジスタr3が商cの最下位ビットcsを指定し、またはポインタレジスタr0が、剰余格納領域における最下位ビットdsを指定する状態に設定される。これにより、減算処理を繰り返し実行することにより、商cの最下位ビットについての減算結果が求められる。剰余格納領域においては、被除数aと除数bの減算結果に基づいた減分値が格納される(Mレジスタの格納値が1の場合)。
剰余領域の被除数aが除数bよりも小さい場合には、Mレジスタの格納値は“0”となるため、最終的に商c=0、剰余d=aなる演算結果が求められる。
このALUユニットにおいて、レジスタを複数個設け、これらのレジスタを用いることにより、除算処理を、ビットシリアル態様で実現することができる。これにより、複数のデータに対する除算処理を並列に実行することができ、各エントリにおける除算内容が、商に1が立つ場合および0が立つ場合においても、その動作演算サイクル数は同じであり、並列除算処理が実現することができる。
以上のように、この発明の実施の形態11に従えば、演算処理ユニット群において各単位ALU回路ブロック(演算処理ユニット)にマスクレジスタ、キャリレジスタ、およびXレジスタを設け、演算回路の演算処理については、プログラム命令に従ってコントローラによりその処理を設定することにより、ビットシリアル態様で大量のワードに対して並列処理を行なうことができる。
なお、コントローラの構成としては、プログラム命令をデコードし、そのデコード結果に従ってメモリセルマット(主演算回路)のメモリセル選択および書込/読出の制御信号を生成し、またALUユニットの論理演算処理回路の論理演算内容を、指定された演算状態を実現するようにレジスタ制御信号および演算器選択信号を生成すればよく、また、アドレス算出は、汎用レジスタおよびポインタレジスタを用いて実行することができる。
[実施の形態12]
図49は、この発明の実施の形態12に従う単位ALU回路ブロック(ALUユニット)34の構成を概略的に示す図である。図49においては、ALUユニット34は、算術演算論理回路(ALU)50、Xレジスタ54およびCレジスタ56に加えて、Yレジスタ200と、Yaレジスタ201と、Dレジスタ202と、Dレジスタ202の格納値に従ってYレジスタ200およびYaレジスタ201の格納値の一方を選択して算術演算論理回路50へ転送するセレクタ(SEL)203と、Zレジスタ204とを含む。
図49は、この発明の実施の形態12に従う単位ALU回路ブロック(ALUユニット)34の構成を概略的に示す図である。図49においては、ALUユニット34は、算術演算論理回路(ALU)50、Xレジスタ54およびCレジスタ56に加えて、Yレジスタ200と、Yaレジスタ201と、Dレジスタ202と、Dレジスタ202の格納値に従ってYレジスタ200およびYaレジスタ201の格納値の一方を選択して算術演算論理回路50へ転送するセレクタ(SEL)203と、Zレジスタ204とを含む。
このZレジスタ204は、算術演算論理回路(ALU)、Xレジスタ54およびCレジスタ56からのデータを受けて、別エントリのXレジスタまたはメモリセルマット30の対応のエントリへデータを転送する。また、Xレジスタ54は、他エントリのレジスタとデータを転送することができる。
ALUユニット34は、さらに、Fレジスタ205と、Fレジスタ205の格納値に従ってXレジスタ54の格納値を選択的に算術演算論理回路50へ転送するゲート回路206と、定数値を格納するNレジスタ207と、算術演算論理回路50およびZレジスタ204の活性/非活性を制御するマスクビットを格納するVレジスタ208を含む。Vレジスタ208は、先の実施の形態11のマスクレジスタ(Mレジスタ)と同様の機能を実現する。
この図49に示すALUユニット34の構成においては、レジスタ回路の数が、実施の形態11に比べて増加される。これらの増加したレジスタ回路を効果的に利用して、乗算処理を、2次のブースアルゴリズムに従って実行する。2次のブースアルゴリズムは、生成される部分積の個数を半減する。被乗数をX、乗数をY、積をZとすると、積Zは、次式(1)で表わされる。

上式(1)から、乗数Yの隣り合う3ビットを同時に見ることにより、被乗数Xとの乗算により生成される部分積の個数を半減することができる。また、上式(1)の括弧の中の値は、0、±1、±2の間で変化するため、加算されるべき部分積は、±2・X・2j、±X・22j、0のいずれかとなる。2倍演算は、1ビット左シフトにより実現することができる。負の演算は、2の補数値を加算することにより実現される。
図50は、2次のブースアルゴリズムに従う部分積生成の手順を示す図である。X2jについては、対応の3ビットy(2j+1)、y(2j)、およびy(2j−1)がすべて0であるかすべて1の場合には、上式(1)から0であるため、シフトアップは不要であり、0が格納される(演算は行なわない)。ここで、乗数ビットの下付の添え字を括弧内の数字で示す。
乗数ビットy(2j+1)が0のときに、乗数ビットy(2j)またはy(2j−1)の一方が1の場合には、被乗数ビットX・2jが1倍されるため、元のビット位置に格納する(2jビットシフトアップ)。
乗数ビットy(2j+1)が0であり、乗数ビットy(2j)およびy(2j−1)が共に1の場合には、この被乗数ビットX・2jが2倍され、1ビットさらにシフトアップされるため、(2j+1)ビット分、そのビット位置がシフトアップされる。
乗数ビットy(2j+1)が1であり、乗数ビットy(2j)およびy(2j−1)が共に0の場合には、−2倍となるため、(2j+1)ビットシフトアップし、かつその2の補数値を求めるかまたは2の補数値を先に求めてから(2j+1)ビットシフトする。
乗数ビットy(2j+1)が1であり、乗数ビットy(2j)またはy(2j−1)のいずれかが1の場合には、被乗数Xが−1倍されるため、2jビットだけ乗算結果をシフトアップしかつその2の補数を求める(または、乗算結果の2の補数値を2jビットシフトアップする)。
図51は、図50に示す部分積生成手順を模式的に示す図である。被乗数Xに対し、乗数ビットy(2j−1)、y(2j)およびy(2j+1)のデコード結果を乗算して部分積を生成する。この場合、3ビットの乗数の値に応じて、被乗数Xに対する係数は、0、±1、±2のいずれかとなる。
乗数ビットy(2j)桁に対応する部分積を生成するため、この被乗数Xは、係数±1の場合には、2j桁シフトし、係数±2の場合には、さらに、1桁上位ビット方向にシフトする。2次のブースアルゴリズムに従って、被乗数Xをシフトすることにより、部分積Pを生成することができる。
図52は、この2次のブースアルゴリズムに従う部分積生成の具体例を示す図である。図52においては、被乗数aが(0111)であり、乗数bが(0110)である。2次のブースアルゴリズムに従って、乗数ビットの組においては、偶数ビット(y(2j))
)が、その中心ビットとして利用される。したがって、乗数bの第0ビットb[0]を乗数ビットy(2j)と置く。このとき、乗数ビットy(2j−1)は0に設定される。この場合には、図50に示す表から、−2倍の演算処理を行なうため、被乗数aを1ビットシフトし、その2の補数を求める。これにより、(10010)が、部分積として算出される。乗算結果のビット位置の調整のために、常時ビット方向に符号拡張が行われ、上位ビットに“1”が設定される。
)が、その中心ビットとして利用される。したがって、乗数bの第0ビットb[0]を乗数ビットy(2j)と置く。このとき、乗数ビットy(2j−1)は0に設定される。この場合には、図50に示す表から、−2倍の演算処理を行なうため、被乗数aを1ビットシフトし、その2の補数を求める。これにより、(10010)が、部分積として算出される。乗算結果のビット位置の調整のために、常時ビット方向に符号拡張が行われ、上位ビットに“1”が設定される。
次の部分積生成においては、乗数ビットb[2]が、乗数ビットy(2j)として用いられる。したがって、この場合では、乗数aを2倍することにより、部分積が求められ、jが1であるため、3ビット左シフトさせることにより、部分積が得られる。これらの部分積を加算することにより、乗算結果Z=(00101010)が求められる。これにより、axb=7x6=42が求められる。
この2次のブースアルゴリズムの場合、4ビットの乗算を行なう場合には、部分積計算が2回であり、各ビットについて部分積を算出する場合に比べて、大幅に部分積算出回数を低減することができる。この2次のブースアルゴリズムに従う乗算を、図49に示すALUユニット34を用いて実現する。以下、この2次のブースアルゴリズムを実行するための演算命令を定義する。
図53は、この発明の実施の形態12におけるレジスタに対する操作を表わすレジスタ命令を一覧にして示す図である。この図53においては、実施の形態11のレジスタ命令に加えて、さらに、1命令で2増分する操作を示す命令“reg.inc2 rx”が準備される。この命令“reg.inc2 rx”は、ポインタレジスタrxのポインタを2増分する命令である。他のレジスタ命令は、先の実施の形態11において図35を参照して説明したレジスタ命令と同じである。
図54は、ALUユニットに含まれるXレジスタ、Vレジスタ、Nレジスタ、CレジスタおよびFレジスタに対する操作命令を一覧して示す図である。
命令“alu.set.♯R”は、レジスタ♯R(Xレジスタ、Vレジスタ、およびNレジスタ)に“1”をセットする命令である。
命令“alu.clr.♯RR”は、レジスタ♯RR(Xレジスタ、Cレジスタ、およびFレジスタ)をクリアする(0をセットする)命令である。
これらのセット/クリア命令は、先の実施の形態11のALU命令のセット/クリア命令と同様である。しかしながら、本実施の形態12においては、Xレジスタ、Vレジスタ、Nレジスタがセット可能であり、またXレジスタ、CレジスタおよびFレジスタがクリア可能である。
図55は、ALUユニットに含まれるレジスタに対するレジスタ間転送命令を一覧にして示す図である。
この命令“alu.cpy.♯R♯U”は、レジスタ♯Rの内容を、レジスタ♯Uへコピーする操作を指令する。この図55に示すコピー命令も、先の実施の形態11のレジスタ間転送命令と、単に利用されるレジスタの命名が異なるだけであり、操作内容は同様である。
図56は、この発明の実施の形態12におけるALU命令のうちロード/ストア命令を一覧にして示す図である。
命令“mem.ld.♯R@rx”は、ポインタレジスタrxの指定するアドレスのメモリセルデータAj[rx]をレジスタ♯R(Xレジスタ、Yレジスタ)へ格納する命令である。
命令“mem.st@rx”は、Zレジスタの格納値を、ポインタレジスタrxが指定するメモリセルアドレスAj[rx]へ格納する命令である。このストア命令は、Vレジスタの格納値が“1”であり、対応のALUユニットがイネーブル状態に設定されるときに実行される。マスクレジスタ(Vレジスタ)Vがクリア状態のときには、このストア動作は実行されない。
図57は、エントリ間のデータ移動を行なう命令を一覧にして示す図である。
命令“ecm.mov.n♯n”は、定数n離れたエントリj+nのZレジスタの格納値がエントリjのXレジスタに移動される。このエントリ間データ転送時においては、サイクリックに転送先が決定される(最大エントリ番号を超えると最小エントリ番号のエントリに戻る)。
命令“ecm.mov.n♯n”は、定数n離れたエントリj+nのZレジスタの格納値がエントリjのXレジスタに移動される。このエントリ間データ転送時においては、サイクリックに転送先が決定される(最大エントリ番号を超えると最小エントリ番号のエントリに戻る)。
命令“ecm.mov.r rn”は、レジスタrxの格納値rn離れたエントリj+rnのZレジスタの格納値がエントリjのXレジスタに移動される。この移動時においても、転送先は、サイクリックに決定される。
このレジスタ設定値rnに従うエントリ間データ転送時、用いられるポインタレジスタは、r0からr3の4つのポインタレジスタの格納値のいずれかにより設定される。
このエントリ間データ転送時においては、ZレジスタからXレジスタへのデータ転送が行なわれる。
図58は、演算処理ユニット(ALUユニット)における算術演算を規定する命令を一覧にして示す図である。
命令“alu.op.adc”は、ポインタレジスタrxが指定するメモリアドレスのデータをYレジスタに格納し、このYレジスタの格納値とXレジスタに格納された値との全加算を行なう命令である。加算結果(Sum)は、Zレジスタに格納され、キャリは、Cレジスタに格納される。この加算演算は、NレジスタおよびVレジスタが共にセットされているときに実行される。
命令“alu.op.sbb”は、ポインタレジスタrxに指定されているメモリアドレスのデータをYレジスタに格納し、このYレジスタに格納された値とXレジスタに格納された値との減算を行なう命令である(Y−X)。減算結果がZレジスタに格納され、ボローがCレジスタに格納される。この減算命令も、Nレジスタ207およびVレジスタ208が共にセットされているときに実行される。
図59は、ALU命令のうちの2次のブースアルゴリズム実行に関連する算術演算命令を一覧にして示す図である。
命令“alu.op.booth”は、2次のブースアルゴリズムにおける条件分岐に必要な値(y(2j+1)、y(2j)、y(2j−1))=(Y,X,F)の格納値を用いて2次のブースアルゴリズム実行に必要な条件分岐レジスタNレジスタおよびVレジスタの値を決定する。このブース命令“alu.op.booth”の実行前に、ロード命令を用いて2ビットの乗数がXレジスタ54およびYレジスタ200にそれぞれ格納される。これらの処理は、マスクレジスタ(Vレジスタ)208がセットされているときに実行される。
Nレジスタには、乗算によりシフトアップを行なうか否かを示す情報が設定される。Dレジスタ202には、(2j+1)ビットシフトするかの情報が格納される。Yレジスタの値が、Fレジスタ205に格納される。すなわち、Nレジスタにおいては、Yレジスタの格納値y(2j+1)が“1”のときには、XレジスタおよびFレジスタの格納値(y(2j)およびy(2j−1)の少なくとも一方が0のときに“1”がセットされ、また、Yレジスタ200の格納ビットy(2j+1)が0のときには、XレジスタおよびFレジスタに格納されたビット値y(2j)およびy(2j−1)の一方が“1”のときに、このNレジスタに“1”がセットされ、シフトアップが指定される。
Dレジスタは、Yレジスタの格納値y(2j+1)が0でありかつXレジスタおよびFレジスタの格納値y(2j)およびy(2j−1)が共に0であるか、またはYレジスタの格納値が1のときにXレジスタおよびFレジスタの格納値が共に0のときに、“1”に設定される。このDレジスタの格納値は、(2j+1)ビットのシフトアップを指定する。このYレジスタの内容をFレジスタへ転送することにより、乗数ビットy(2j+1)を、jが1増分されたときの次の演算時に、乗数ビットy(2j−1)として利用することができる。
命令“alu.op.exe”は、この2次のブースアルゴリズムの実行命令であり、DレジスタおよびFレジスタに格納値に従って条件分岐を行なう。
Dレジスタの格納値が1の場合には、Yaレジスタの値をセレクタ203により選択する。Dレジスタ202の格納値が0のときには、Yレジスタの格納値が選択される。この実行命令(EXE命令)において、Fレジスタの格納値が0の場合には加算命令となり、Fレジスタの格納値が1の場合には減算命令となる。
この実行命令“alu.op.exe”の有効時、Fレジスタ205の格納値に従って図49に示すゲート回路206が、Xレジスタ54の格納値の反転または非反転を行なう。ブース命令実行時においては、このゲート回路206は、Xレジスタ54およびFレジスタ205の格納値の相補値X,!XおよびF,!Fを生成する。
ゲート回路206の演算処理内容は、コントローラ含まれる命令デコーダからの制御信号(ALU制御)に基づいて決定される。
図60は、この図58に示すブース命令実行時の各レジスタ、すなわちYレジスタ200、Xレジスタ54、Fレジスタ205、Dレジスタ202およびNレジスタ207の格納値およびその対応の制御内容(部分積生成手順)を一覧にして示す図である。
上述のように、Yレジスタ200、Xレジスタ54およびFレジスタ205に、それぞれ乗数ビットy(2j+1)、y(2j)、y(2j−1)がセットされる。これらのYレジスタ、XレジスタおよびFレジスタの格納値に従ってブース命令“alu.op.booth”を実行することにより、Dレジスタ202およびNレジスタ207に、0または1がセットされる。このブース命令により、被乗数Xに対する部分積を算出する準備が完了する。
Fレジスタの値は、DレジスタおよびNレジスタの格納値との組合せで、部分積生成時に乗数を補数にするか否かの判定に用いられる。また、ブースアルゴリズム実行時に、Fレジスタの格納値に従って、加算および減算を切換えることにより、部分積の選択的な補数生成を行なうことができる(減算操作は、補数の加算と同じである)。
また命令“alu.op.exe”は、ブースアルゴリズム乗算以外においても適用用途が存在し、Dレジスタ202の格納値に従って加算および減算のいずれかを選択的に実行することができ、この実行命令“alu.op.exe”は、加算命令および減算命令を包含した命令である。
また、Yaレジスタ201を用いることにより、乗数のシフト動作が実現される。Yaレジスタ201には、ブース命令の実行時、前回ロードされたYレジスタ200の格納値がコピーされている(EXE命令におけるYa=Yj)。したがって、このYaレジスタ201の初期値を0から開始すれば、Yレジスタ、Xレジスタ、およびYaレジスタの格納する3ビットにより、2ビット乗数をロードして1ビット乗数をシフトした状態を作ることができる。すなわち、(y1、y0,0)から、ビットy1をYaレジスタに格納することにより、次のブース命令の実行によるロード時に(y3、y2、y1)の3ビットの組を生成することができる。
図61は、ALU命令のうちの論理演算を行なう命令を一覧にして示す図である。
命令“alu.op.and”は、ポインタレジスタrxのポインタが指定するアドレスのメモリセルデータをYレジスタに格納し、このYレジスタの格納値とXレジスタの格納値に対し論理積演算を行ない、その論理積演算結果をZレジスタに格納する操作を指定する。Vレジスタ(マスクレジスタ)がセットされていないときには、この論理積演算(AND演算)は実行されない。
命令“alu.op.and”は、ポインタレジスタrxのポインタが指定するアドレスのメモリセルデータをYレジスタに格納し、このYレジスタの格納値とXレジスタの格納値に対し論理積演算を行ない、その論理積演算結果をZレジスタに格納する操作を指定する。Vレジスタ(マスクレジスタ)がセットされていないときには、この論理積演算(AND演算)は実行されない。
命令“alu.op.or”は、ポインタレジスタrxのポインタが指定するアドレスのメモリセルデータをYレジスタに格納し、このYレジスタの格納値とXレジスタに格納されている値との論理和演算を行なって、論理和演算結果をZレジスタに格納する命令である。この論理和演算命令は、マスクレジスタ(Vレジスタ)がセットされているときに実行される。
命令“alu.op.exor”は、ポインタレジスタrxのポインタが指定するメモリアドレスのデータをYレジスタに格納し、このYレジスタに格納されたデータビットとXレジスタのビットとの排他的論理和演算を行ない、その演算結果をZレジスタに格納する操作を指定する。この排他的論理和演算(EXOR演算)も、Vレジスタがセットされたときに行なわれ、Vレジスタがクリア状態のときには実行されない。
命令“alu.op.not”は、Xレジスタの格納値を反転し、その反転結果をZレジスタに格納する操作を指定する。この反転命令も、Vレジスタがクリア状態のときには実行されない。
命令“alu.op.LT”は、Cレジスタの格納値に従ってNレジスタを1にセットまたは0にクリアする命令である。Cレジスタの格納値が1のときにNレジスタが0にクリアされる。
2次のブースアルゴリズムに従って乗算を行なう操作を、これらの命令を用いて記述したプログラムを図62に示す。以下、図62を参照して、2次のブースアルゴリズムに従う乗算操作について説明する。
まず、行番号0の命令により、マスクレジスタ(Vレジスタ)がセットされ、演算の実行を指定される。
行番号1の命令文により、ポインタレジスタr2およびr3に、それぞれ、乗数bの開始アドレスおよび乗算結果cを格納する領域の開始アドレスcsがセットされる。また、Fレジスタがクリアされ、“0”が格納される。
行番号2において、繰り返し文が記述され、被乗数aのビット幅が決定され、この繰り返し文の実行時に、jが2倍される。
行番号3において、ポインタレジスタr2に設定されたデータビットがXレジスタに格納され、またポインタレジスタr2が指定するメモリセルのデータが、Yレジスタに格納される。このとき、ポインタレジスタr2は、命令実行時1増分されており、したがってこの行番号3の命令により、2ビットの乗数が、y(2j+1)およびy(2j)が、それぞれYレジスタおよびXレジスタに格納される。
行番号4において、ブース命令が実行され、図59の操作内容に示すように、NレジスタおよびDレジスタの記憶値が設定され、またYレジスタの格納ビットがFレジスタにコピーされる。これにより、部分積生成手順が設定される。
行番号5の命令文により、レジスタr3に格納された乗算結果cの最初のビット位置を示すアドレスがポインタレジスタr0にコピーされ、またポインタレジスタr1に被乗数aの初期アドレス(最下位ビットアドレス)asがセットされる。
行番号6において繰返し文が記述され、乗数bについて繰返し操作が、iについてのfor文の条件が満たされるまで実行される。この乗数bについては、繰返し回数を示す定数iは、1ずつ増分する。
行番号7の命令文により、ポインタレジスタr0に格納されたデータ(乗算結果値)がXレジスタに格納され、次いで、ポインタレジスタr1のポインタが指定するデータすなわち被乗数aの対応のビットがYレジスタに格納される。この状態で、ブースアルゴリズム実行命令(EXE命令)を実行し、被乗数ビットajと乗算結果ビットの加算または減算が実行され、部分積の加算が実行され、加算結果がZレジスタに格納される。この後、ポインタレジスタr0が指定するメモリセル位置に、このZレジスタに格納された加算または減算結果が格納される。
行番号8において、この行番号6で規定される繰返し文の終了が示される。したがって、この関数文においては、乗数bの3ビットの組を固定して、被乗数aの部分積生成およびそれまでの部分積との加算が実行される。
行番号9において再び繰返し文が、乗数bのビット幅について規定される。部分積の符号拡張による桁合わせの処理が行う。
行番号10の命令文により、ポインタレジスタr0が指定するアドレス位置のデータがXレジスタに格納され、先の行番号7の命令により生成された部分積が読出される。次いで再び、2次のブースアルゴリズムに従って演算が行なわれ、部分積生成が行なわれ、再びポインタレジスタr0が指定するメモリセル位置にこの部分積生成結果が格納される。ポインタレジスタr0は、乗算結果cの格納位置を指定しており、ポインタレジスタr0のポインタを増分することにより、先の処理により生成された部分積の上位ビット位置に、符号ビットを記述する。生成される部分積のビット幅を最終的な乗算結果cのビット幅に一致させる。
乗算結果cの符号拡張処理が完了すると、行番号12において、ポインタレジスタr3のポインタを2増分する。
行番号13の関数文の末尾の記述により、被乗数aの1つのビットajについての一連の処理が完了し、次の被乗数aの1ビット上位のデータについて処理が実行される。
図63は、この図62に示す符号付きブースアルゴリズム乗算プログラムが初期値の1つのエントリのアドレスを示す図である。乗算結果cを格納する領域の先頭位置(最下位ビット位置)は、アドレスcsで設定される。被乗数aは、ビット幅a_bit_countを有し、その最下位ビット位置はアドレスasで指定される。乗数bは、ビット幅b_bit_countを有し、その最下位ビット位置が、アドレスbsに設定される。
図64に示すように、まず、図62の行番号1の命令文によりポインタレジスタr3にアドレスcsが設定され、またポインタレジスタr2にアドレスbsが設定される。
行番号3の命令により、ポインタレジスタr2の指定する乗数ビットy(2j)およびy(2j+1)がそれぞれXレジスタおよびYレジスタに格納される。これにより、Fレジスタ、DレジスタおよびNレジスタの初期値が、行番号4のブース命令により設定される。これにより、部分積について、デコード結果が指定され、0、±1、±2のいずれの演算を行なうかが設定される。
次いで、行番号5の命令文により、ポインタレジスタr3の内容がポインタレジスタr0に転送されて、乗算結果を格納する領域のアドレスがポインタレジスタr0に指定される。また、被乗数aの最下位ビットアドレスasが、ポインタレジスタr1に設定される。行番号7の命令文により、ポインタレジスタr0のポインタにより、Xレジスタに先のサイクルの乗算結果ビットciが格納され、またポインタレジスタr1のポインタに従って乗数aのビットaiがYレジスタに格納される。Yaレジスタには、前のサイクルの被乗数ビットa(i−1)が格納される。Dレジスタの格納内容に従って、YレジスタおよびYaレジスタの一方が選択され、Nレジスタが“1”のとき、Fレジスタの格納値に従って加算または減算が行なわれる。この演算結果は、この結果ビットciが読出されたビット位置に格納される。
このYaレジスタおよびYレジスタの選択により、2jビットシフトまたは2j+1ビットシフト操作が実現される。
次に、再び、ポインタレジスタr0およびr1のポインタを増分して、Fレジスタ、DレジスタおよびNレジスタの内容を固定して、同様の演算処理が実行され、それまでに求められた部分積に対し、新たな被乗数の加算/減算が、ビットシリアル態様で行なわれる。
これらの部分積生成動作が完了すると、次いで行番号9からの命令に従って、乗算結果格納領域の上位ビット位置において、ポインタレジスタr0が指定する位置に対し同様のブース実行命令演算が行なわれる。このときYレジスタには、被乗数aの最上位ビットamが格納され、Yaレジスタには、次の上位ビットa(m−1)が格納される。従って、先の部分積最上位ビット生成と同様の操作を行って、操作結果をポインタレジスタr0が指定する位置へ再度書込む。これにより、符号拡張処理が行なわれ、上位ビット位置に0または1が順次格納される。
これらの処理の完了後、図65に示すように、ポインタレジスタr3のポインタが2増分され、またポインタレジスタr2の値が増分され、次の2次のブースデコード動作が行なえる準備が完了する。乗数bについて、偶数ビットとその隣接奇数ビットとの組について、上述の一連の処理を実行することにより、ビットシリアル態様で、順次部分積の生成および前の部分積への加算を行って最終積を求めることができる。
図62の行番号2の繰返し文に見られるように、部分積の加算処理は、乗数bのビット幅の1/2回で完了し、乗算処理を高速で行なうことができる。
上述の命令群は、2次のブースアルゴリズムによる乗算のみならず、通常の加減算および除算演算に対しても適用することができる。以下、各演算について説明する。
図66は、この発明の実施の形態12に従う演算命令を用いた加算プログラムを示す図である。図66(A)において、2項加算(a+b)=cを行う。演算数aおよびbおよびcのそれぞれの最下位ビットアドレスが、as、bsおよびcsに設定される。
図66(B)に、この2項加算を行なうプログラムを示す。この加算プログラムにおいては、用いられるレジスタの名称が異なるだけであり、先の実施の形態11と同様の演算処理が実行される。
図67は、この発明の実施の形態12における2項減算を行なうプログラムを示す図である。図67(A)に示すように、(a−b)=cの演算を行なう。演算数a、bおよびcの最下位ビットアドレスはas、bsおよびcsである。
図67(B)に、この減算プログラムを示す。この図67(B)に示す減算プログラムは、先の実施の形態11と同様であり、演算命令の名称が異なるだけであり、同様の減算処理を、減算命令“alu.op.sbb”に従って実行することができる。
図68は、この発明の実施の形態12に従う演算命令を用いる符号なし2項乗算のプログラムを示す図である。この図68に示すプログラムにおいては、a・b=cの2項乗算が行なわれる。演算数a、bおよびcのそれぞれの最下位ビットのアドレスはas、bsおよびcsである。
この図68に示す乗算プログラムにおいても、用いられる命令の名称が異なるものの、実施の形態11と同様の処理が行なわれており、部分積の同一桁のビットを順次加算して、最終積を求めることができる。
図69は、この発明の実施の形態12に従う演算命令を用いる除算プログラムの一例を示す図である。この図69に示す除算プログラムにおいては、a/b=c…dの演算が行なわれる。被除数a、除数b、商cおよび余りdのそれぞれの最下位ビットのアドレスは、as、bs、csおよびdsに設定される。
この図69に示す除算プログラムにおいても、実施の形態11と同様の処理が、異なる名称のレジスタを用いて実行されており、順次被除数aから除数bを減算する処理を行なって、商および余りを求めることができる。
以上のように、この発明の実施の形態12に従えば、単位ALU回路ブロック(演算処理ユニット)内に、複数のレジスタおよびゲート回路を設け、演算命令としてブース命令“alu.op.booth”およびブースアルゴリズム実行命令“alu.op.exe”を設けており、2次のブースアルゴリズムに従って乗算を行なうことができ、高速乗算を実現することができる。
[実施の形態13]
図70は、この発明の実施の形態13に従う単位ALU回路ブロック(演算処理ユニット;ALUユニット)34の構成を概略的に示す図である。この実施の形態13においては、メモリセルマットにおいては、1つのエントリERYが、偶数アドレスのデータビットA[2i]を格納する偶数エントリERYeと、奇数アドレスのデータビットA[2i+1]を格納する奇数エントリERYoに分割される。偶数エントリERYeおよび奇数エントリERYoの同じアドレスのデータビットに対し並列に演算処理を行なうことにより、処理の高速化を図る。
図70は、この発明の実施の形態13に従う単位ALU回路ブロック(演算処理ユニット;ALUユニット)34の構成を概略的に示す図である。この実施の形態13においては、メモリセルマットにおいては、1つのエントリERYが、偶数アドレスのデータビットA[2i]を格納する偶数エントリERYeと、奇数アドレスのデータビットA[2i+1]を格納する奇数エントリERYoに分割される。偶数エントリERYeおよび奇数エントリERYoの同じアドレスのデータビットに対し並列に演算処理を行なうことにより、処理の高速化を図る。
ALUユニット34においては、演算処理を行なうための縦続接続される全加算器210および211が演算処理装置として設けられる。このALUユニット34における処理データおよび演算内容を設定するレジスタ、すなわちXレジスタ54、Cレジスタ56、Fレジスタ205、Vレジスタ208、Nレジスタ207は、先の実施の形態12と同様の機能を実現する。
この実施の形態13においては、ALUユニット34内において、さらに、2ビットデータを並列に格納するためのXHレジスタ220およびXLレジスタ221と、レジスタ54、220および221からのデータの組の一方の2ビットを、Dレジスタ222の格納値に従って選択するセレクタ(SEL)227と、Fレジスタ205の格納ビットに従ってセレクタ227の選択した2ビットに対する反転/非反転(正転)操作を行なう選択反転回路217と、レジスタ207および208の格納データに従って全加算器210および211の3出力Sを選択的に出力するゲート223および224が設けられる。
選択反転回路217の2ビット出力は、全加算器210および211のA入力へそれぞれ与えられる。XHレジスタ220およびXLレジスタ221は、それぞれ内部データ線226および228を介して奇数エントリERYoの奇数アドレスビットおよび偶数エントリERYeと偶数アドレスビットの転送を行なう。Xレジスタ54は、スイッチ回路SWaおよびSWbにより、内部データ線226および228の一方に選択的に接続される。
全加算器210のB入力は、内部データ線226に結合され、全加算器210のS出力を受けるゲート223の出力が、また、内部データ線226に接続される。全加算器211のB入力は、スイッチ回路SWcおよびSWdにより、内部データ線226および228の一方に選択的に接続される。全加算器211のS出力を受けるゲート224の出力は、また、スイッチ回路SWeおよびSWfに従って内部データ線226および228の一方に選択的に接続される。これらのスイッチ回路SWa−SWfにより、2ビット並列除算処理を行なう場合の、1ビット単位のビットシリアル処理を実行する。
ゲート223および224は、Vレジスタ208およびNレジスタ207の格納値がともに“1”のときに、指定された演算処理を実行し、それ以外においてはハイインピーダンスを出力する(出力ハイインピーダンス状態となる)。
また、Cレジスタ56の格納値が、全加算器211のキャリ入力Cinに接続される。全加算器210のキャリ出力Coは、全加算器211のキャリ入力Cinに接続され、また、スイッチ225を介して、全加算器210のキャリ入力Cinに接続される。このスイッチ225は、1ビット単位での演算処理を行なう場合に、全加算器210のキャリ出力Coを切り離して、全加算器211のキャリ入力CinをCレジスタ56に接続する。
この図70に示すALUユニット34においては、Zレジスタは用いられておらず、Xレジスタ54、XHレジスタ220およびXLレジスタ221が、他のエントリの対応のレジスタとデータ転送を行なうことができる。
この実施の形態13においては、メモリセルマットのアドレスを指定するポインタレジスタとして、ポインタレジスタp0−p3が用いられる。別に、汎用レジスタ内のポインタレジスタr0−r3も利用される。
図71は、ポインタレジスタp0−p3の操作を行なうポインタレジスタ命令を一覧にして示す図である。
命令“ptr.set n,px”は、任意の値nを、ポインタレジスタpxにセットする命令である。この任意の値nは、1つのエントリのビット幅(0‐BIT_MAX)の範囲で任意の値を取ることができる。
命令“ptr.cpy px,py”は、ポインタレジスタpxの内容を、ポインタレジスタpyに転送して格納するコピー命令である。
命令“ptr.inc px”は、ポインタレジスタpxのポインタを1増分する命令である。
命令“ptr.inc2 px”は、ポインタレジスタpxのポインタを2増分する命令である。
命令“ptr.dec px”は、ポインタレジスタpxのポインタを1減分する命令である。
命令“ptr.dec2 px”は、ポインタレジスタpxのポインタを2減分する命令である。
命令“ptr.sft px”は、ポインタレジスタpxのポインタを、1ビット左シフトする命令である。
命令“ptr.inc2 px”および命令“ptr.dec2 px”を利用することにより、2ビット並列に処理を行なうことができる(奇数および偶数アドレスを同時に更新する)。
図72は、1ビット動作時のロードストア命令を一覧にして示す図である。
図72において、命令“mem.ld.♯R@px”は、ポインタレジスタpxのポインタが示す位置Aj[px]のデータを、レジスタ♯Rに格納する(ロードする)命令である。
図72において、命令“mem.ld.♯R@px”は、ポインタレジスタpxのポインタが示す位置Aj[px]のデータを、レジスタ♯Rに格納する(ロードする)命令である。
命令“mem.st.♯R@px”は、レジスタ♯Rの格納値を、ポインタレジスタpxの指定するメモリセル位置Aj[px]へ書込む(ストアする)命令である。このストア命令は、マスクレジスタ(Vレジスタ208)がクリアされているときには、実行されない。
命令“mem.swp.X@px”は、Xレジスタの格納値とポインタレジスタpxの指定するメモリセル位置Aj[px]のデータとを交換する命令である。このスワップ命令は、マスクレジスタ(Vレジスタ)208およびNレジスタ207にともに“1”がセットされているときに実行される。Xレジスタのクリア/セットを、メモリセルの格納データで実行することにより、回路構成を簡略化する。
図73は、2ビット動作時のALUユニットに対するロード/ストア命令を一覧にして示す図である。
図73において、命令“mem2.ld.X@px”は、ポインタレジスタpxの指定するメモリセル位置Aj[px]およびAj[px+1]のメモリセルのデータを、XLレジスタ221およびXHレジスタ220に格納する命令である。すなわち、連続アドレス位置のデータの下位ビットが、XLレジスタに格納され、上位ビットがXHレジスタに格納される。
命令“mem2.st.X@px”は、ポインタレジスタpxの指定するアドレスの連続アドレスAj[px]およびAj[px+1]のメモリセルへ、それぞれ、XLレジスタおよびXHレジスタの格納値を格納する命令である。ただし、この動作は、マスクレジスタ(Vレジスタ)がクリア状態のときには実行されない。
命令“mem2.swp.X@px”は、ポインタレジスタpxの指定するアドレスおよび上位アドレスAj[px]およびAj[px+1]のデータが、それぞれ、XLレジスタおよびXHレジスタの格納値と交換される命令である。ただし、このスワップ命令は、VレジスタおよびNレジスタがともにクリアされているときには、実行されない。
この2ビット動作時においては、ポインタレジスタpxのポインタを用いて連続アドレスAj[px]およびAj[px+1]へ同時にアクセスすることにより、2ビット並列処理を実現する。
図74は、1ビット動作時のエントリ間データ移動(move)を行なう命令を一覧にして示す図である。このエントリ間データ移動時には、ポインタレジスタrnが用いられる。エントリ間データ移動用ポインタレジスタrnの候補レジスタとしては、4つのポインタレジスタr0−r3が設けられる。
命令“ecm.mv.n ♯n”は、定数n離れたエントリj+nのXレジスタの格納値を、エントリjのXレジスタに転送することを示す命令である。
命令“ecm.mv.r rn”は、レジスタrnの格納値離れたエントリj+rnのXレジスタの値が、エントリjのXレジスタに転送される操作を示す命令である。
命令“ecm.swp”は、隣接エントリj+1およびjのXレジスタの格納値を交換する操作を指令する命令である。
図75は、2ビット動作時のALUにおけるエントリ間データ移動(move)の操作を指令する命令を一覧にして示す図である。この2ビット操作時においては、命令記述子“ecm2”が命令記述子“ecm”に代えて用いられる。この命令記述子“ecm2”が指定されると、2ビット単位での演算処理が指定され、XHレジスタおよびXLレジスタ間での並列のデータ転送が行なわれ、各レジスタ間の転送内容の指定には、先の1ビット動作時と同じ命令記述子“mv.n#n”、“mv.r rn”および“swp”が用いられる。
図76は、1ビット動作時のALUユニットにおける算術演算命令を一覧にして示す図である。
命令“alu.adc@px”は、加算命令である。ポインタレジスタpxのポインタが示すメモリアドレスのAj[px]のデータとXレジスタの格納値Xjとを加算し、その結果zを元のメモリセルに格納する。すなわち、アドレスAj[px]のメモリセルには、加算後の値Sum(サム)が格納され、Cレジスタには、キャリが格納される。
命令“alu.sbc@px”は、減算命令である。ポインタレジスタpxのポインタが示すメモリアドレスのAj[px]のデータからXレジスタの格納値Xjを減算し、その減算結果を元のメモリ位置Aj[px]に格納する。減算操作後には、元のメモリセルに減算後の値が格納され、Cレジスタにボローが格納される。
命令“alu.inv@px”は、反転演算命令である。ポインタレジスタpxのポインタが指定するメモリアドレスAj[px]のデータを反転して元のメモリセル位置に格納する。
これらの加算命令、減算命令および反転命令は、NレジスタおよびVレジスタがともにセットされているときに実行され、NレジスタおよびVレジスタの一方がクリア状態のときには実行されない。
命令“alu.let f”は、レジスタ設定命令である。Fレジスタ、Dレジスタ、NレジスタおよびCレジスタに、関数値f(4ビット)で指定される値が、それぞれ対応のレジスタに設定される(f=F・8+D・4+N・2+C)。
図77は、2ビット演算操作時のALUユニットにおける算術演算命令を一覧にして示す図である。図77においては、2次のブースアルゴリズムに従って乗算を2ビット単位で行なう命令が示される。
命令“alu2.booth”は、ブース命令である。このブース命令実行時、XHレジスタ、XLレジスタおよびFレジスタの格納値から、次の演算用に、Nレジスタ、DレジスタおよびFレジスタの格納値を求める。このブース命令は、Vレジスタがセットされたときに実行される。このブース命令の実行内容は、以下に説明するブース命令実行時のブースデコード結果に基づいて設定される。
命令“alu2.exe@px”は、ブース演算の実行命令(EXE命令)であり、DレジスタおよびFレジスタの格納値に従って、シフト動作、および正転(非反転)/反転操作が行なわれる。
このブースアルゴリズムに従う乗算の操作内容については、以下に具体的に説明する。
図78は、図77に示すブース命令実行時のレジスタDおよびNの格納値を一覧にして示す図である。
図78は、図77に示すブース命令実行時のレジスタDおよびNの格納値を一覧にして示す図である。
ブース命令実行時においては、XHレジスタ、XLレジスタおよびFレジスタには、乗数ビットy(2j+1)、y(2j)、およびy(2j−1)が格納される。したがって、DレジスタおよびNレジスタのビット値が、先の実施の形態12の場合と同じであり、Nレジスタがビット“1”を格納する場合には、シフト動作を行なうことが指定され、Dレジスタの格納値がビット“1”の場合には、(2j+1)ビットシフトアップすることが指定される。XHレジスタの格納値がビット“1”のときに、シフトアップ時に補数が生成される。
このブース命令実行時においては、XHレジスタの格納値が、Fレジスタへ転送され、またCレジスタへ転送される。これにより、次の演算時において、Fレジスタに乗数ビットy(2j−1)が格納される。
Xレジスタには、初期値“0”が格納される。このXレジスタの初期格納値を用いることにより、乗数ビットを1ビットシフトした値を生成することができる。
ブース実行命令(EXE命令)の実行時においては、まずポインタレジスタpxの指定するメモリセルデータAj[px]とXHレジスタまたはXLレジスタの格納値またはその反転値との加算が行なわれ、加算結果が元のメモリセル位置Aj[px]に格納される。キャリは、次のメモリセルアドレスAj[px+1]の演算時のキャリとして利用される。このとき、キャリccを用いて、アドレスAj[px+1]のメモリセルデータと、XLレジスタまたはXHレジスタの格納値またはその反転値との加算が行なわれ、加算結果が元のメモリセル位置Aj[px+1]に格納される。また、Xレジスタの値が、XLレジスタの格納値にDレジスタの格納値が1のときに変更される。これにより、(2j+1)ビットシフトする際に、Xレジスタに、yi(=2j)を乗数ビットとして格納することができる。
図79は、この発明の実施の形態13におけるブースアルゴリズム乗算処理を示すプログラムを示す図である。被乗数a、乗数bおよび乗算結果cの最下位ビットアドレスは、それぞれ、as、bsおよびcsである。ここでは、簡単化のために、乗数bおよび被乗数aはともに同一のビット幅bit_countを有するとする。
まず、行番号0の命令群により、ポインタレジスタp2に、乗数bの最下位ビットアドレスbsがセットされ、またポインタレジスタp3に、乗算結果cの最下位ビットアドレスcsが設定される。
行番号1において、for文により、ブースアルゴリズムの乗数ビットの組の範囲が指定される(2iずつiが増分する)。
行番号2の命令により、まずポインタレジスタp2の指定するアドレスAj[p2]およびAj[p2+1]のデータが、XHレジスタおよびXLレジスタにそれぞれ格納されて、次いで、ブース命令が実行され、Nレジスタ、DレジスタおよびFレジスタの値が設定される。
行番号3の命令により、ポインタレジスタp3のポインタ値csが、ポインタレジスタp0にコピーされ、また、ポインタレジスタp1に被乗数aの最下位ビットアドレスasがセットされる。
行番号4において、2ビット単位の処理が実行するため、被乗数のアドレスjの変化範囲および増分量が設定される。
行番号5の命令により、まずポインタレジスタp1の指定する被乗数ビットが、XHレジスタおよびXLレジスタにそれぞれ格納される。次いで、ポインタレジスタp0の指定するメモリセルのデータ、すなわち先のサイクルにおける部分積とポインタレジスタp1により指定された被乗数ビットとを用いて、ブース実行命令が行なわれる。この行番号5の命令実行時においては、ポインタレジスタp1およびp0は、2ビット処理が行なわれるため、そのポインタ値が2増分される(2アドレス増分される)。
この処理が、jが指定する回数繰返し実行され、したがって被乗数aの全ビットについて、2ビット単位で2次のブースアルゴリズムに従って部分積の生成およびその前のサイクルにおいて生成された部分積との加算が行なわれ、その加算結果が部分積格納領域に格納される。
行番号6において、この行番号4で示すfor文が規定する関数の終了が指定される。1つの乗数ビットの組が完了すると、行番号7において、また、for文が記述され、2ビット単位での符号拡張処理が指定される。すなわちこの場合、行番号8に示す実行命令に従って、ポインタレジスタp0が指定する領域、すなわち、部分積格納領域の上位ビット領域に、符号拡張処理が行なわれ、最上位ビット位置まで符号拡張が行なわれる。
行番号9において、この行番号7のfor文の関数の完了が指定される。符号拡張処理が完了すると、行番号10の命令に従って、ポインタレジスタp3のポインタ2増分される。
行番号12において、行番号1のfor文の末尾が指定され、したがって、乗数bの次の乗数ビットの組を用いて、再び2ビット単位で部分積の生成および前のサイクルの部分積との加算が実行される。
この図79に示すプログラムにおいては、ポインタレジスタp1、p2およびp3は、それぞれ、2づつ増分される。しかしながら、主演算回路のメモリセルマットにおいては、先に示すように、偶数エントリおよび奇数エントリの同一ビット位置に偶数アドレスおよび奇数アドレスのビットが格納されており、メモリセルマットに対するアドレス制御においては、1ずつエントリ内のビット位置が更新される。
図80は、2ビット演算時における単位ALU回路ブロック34の接続を概略的に示す図である。この2ビット演算時、特にブースアルゴリズムに従って乗算を行なう場合、Xレジスタ54は、スイッチ回路SWaを介して内部データ線226に結合される。スイッチ回路SWbは、XLレジスタ54と内部データ線228を切離す状態に設定される。
スイッチ回路SWdが、全加算器211のB入力を内部データ線228に結合し、スイッチ回路SWcは、全加算器211のB入力と内部データ線226とを切離す。スイッチ回路225は、全加算器210のキャリ出力Coと全加算器210のキャリ入力Cinとを分離する。Cレジスタ56は、スイッチ回路225を介して全加算器210のキャリ入力Cinに結合される。ゲート回路224の出力は、スイッチ回路SWfにより内部データ線228に結合される。
この2ビット演算においては、全加算器210および211が並列に動作し、図77に示す実行命令(EXE命令)の実行時に、加算結果zzを、ビットAj[px]およびAj[px+1]について並列に算出する。
メモリセルマットにおいては、偶数エントリERYeおよび奇数エントリERYoにそれぞれ、偶数アドレスA[2i]および奇数アドレスA[2i+1]のデータビットが格納される。ポインタレジスタpxにより、これらの偶数エントリERYaおよび奇数エントリERYoの同一ビット位置メモリセルが指定される。したがって、プログラム実行時において、ポインタレジスタをpxカウント値が2増分されることにより、奇数エントリERYoおよび偶数エントリERYeにおいて、1ビットそのビット位置が上位方向にシフトされる。この操作は、単にポインタレジスタpxのポインタに基づいて、メモリセルマットのワード線を選択するアドレスが生成されれば、ワード線切換により、ポインタレジスタpxのポインタの2増分を実現することができる。
図81は、2次のブースアルゴリズムに従う乗算を行なう際のデータの流れを概略的に示す図である。図81においては、まずブース命令実行時のデータの流れを示す。エントリは偶数エントリERYeおよび奇数エントリERYoに分割される。乗数bの最下位ビットアドレスbsがポインタレジスタp2に設定され、また乗算結果cの最下位ビットアドレスcsがポインタレジスタp3に設定される。図79に示す行番号2の命令群を実行することにより、ポインタレジスタp2が指定する乗数bの2ビット(図81においてはビットb1およびb0を示す)が、XHレジスタおよびXLレジスタに格納される。初期状態においては、XレジスタおよびFレジスタは“0”に初期設定されている。
この状態で図77に示す操作内容に従ってDレジスタ、Nレジスタの格納値が決定され、これらのDレジスタおよびNレジスタの値の設定後、Fレジスタに、XHレジスタの格納ビット(b1)が格納される。これにより、乗数ビットy(2j+1)が、次の部分積生成時、y(2j−1)ビットとして用いられる状態が準備される。
図82は、ブース実行命令(EXE命令)実行時のデータビットの流れを概略的に示す図である。ポインタレジスタp3の格納値がポインタレジスタp0に転送され、また被乗数aの最下位ビットアドレスasがポインタレジスタp1に設定される。次いで、被乗数aの2ビット(a1およびa0)が、それぞれXHレジスタおよびXLレジスタに格納される。セレクタ(SEL;227)が、Dレジスタの格納内容に従って、XHレジスタおよびXLレジスタの一方およびXレジスタおよびXHレジスタの一方を選択する。
選択反転器(217)は、Fレジスタの格納値に従ってセレクタ(SEL)の出力ビットを選択的に反転して被加算ビットx1およびx2を生成する。これらは、全加算器210および225において、ポインタレジスタp0のポインタ値に従って読出された部分積からの2ビット(c0,C1)と加算(2ビット加算)される。この加算結果は、Nレジスタの格納ビットに従って選択的に元の位置へ格納される。
このセレクタ(SEL)による選択動作により、2jビットシフト時に、レジスタXHおよびXLレジスタの格納値に従って±1乗算を行なって、対応の部分積と加算して加算結果を元の部分積ビット位置に格納する。2j+1ビット加算シフト時には、XレジスタおよびXHレジスタの格納値を用いずに、前のサイクルで読出された被乗数ビットと対応の部分積との加算が行なわれ、結果として2j+1ビットシフトが実現される。この場合、Dレジスタ、FレジスタおよびNレジスタは、1つの部分積全体の生成時において、その値は固定であるため、セレクタ(SEL)および選択反転器の選択内容が固定されるため、2jビットシフトおよび2j+1ビットシフトによる部分積の生成とそれまでの部分積との加算を正確に行なうことができる。
ポインタレジスタp1およびp0のポインタは、2ずつ増分され、エントリERYeおよびERYoにおいては、等価的に1ビットずつその位置がシフトされ2ビット単位での部分積生成および前の部分積との加算が実行される。
この演算の後、図79に示す行番号8および9の命令により、この生成された部分積の符号拡張が行なわれ、上位ビット位置に、符号ビットが順次格納される。
この図70に示すように、ALUユニット34において、2つの全加算器210および211を設けて2ビット加算を行なうことにより、2ビット単位での部分積生成および前の部分積との加算を行なうことができる。
なお、図77に示すように、ブース実行命令(EXE命令)は、Fレジスタの格納値に従って加算または減算を実行することができ、したがって、この実行命令は、加算および減算を包含する命令である。
加算および減算も2ビット単位で実行することができ、また、1ビット単位で演算することもできる。しかしながら、除算は、被除数のビット位置をづつ右シフトして減算を行う必要があり、1ビット単位で演算を実行する。この1ビット演算を実現するために図80においてスイッチ回路225が設けられている。
図83は、1ビット加減算時におけるALUユニット34の接続の一例を概略的に示す図である。1ビット演算の接続時においては、Xレジスタ54が、内部データ線226および228にスイッチ回路SWaおよびSWbを介してそれぞれ接続され、このXレジスタ54出力がセレクタ227により選択される。スイッチ回路SWaおよびSWbの接続はポインタpxにより決定される。
Fレジスタ205の格納ビットに従って、選択反転器217により加算/減算が実行される。この反転選択器217の出力は、全加算器211のA入力に与えられる。全加算器210のB入力は、内部データ線226に接続される。この全加算器210のキャリ出力Coが、スイッチ回路225により、全加算器210のキャリ入力Cinと分離され、この全加算器210のサム出力Sがゲート223を介して内部データ線226に結合される。全加算器210は加算演算には用いられない。全加算器211のキャリ入力CinがCレジスタ56にスイッチ回路225を介して結合される。全加算器のB入力は、ポインタpxによりスイッチ回路SWcおよびSWdを介して内部データ線226または228に選択的に結合される。また、全加算器211のサム出力Sがゲート224およびスイッチSWeおよびSWfを介して選択的に内部データ線226および228に接続される。
減算演算を2の補数の加算演算により行なう場合には、Cレジスタ56に、初期値として“1”が格納され、Xレジスタ54からのビット値が、選択反転器217により反転される。加算演算を行う場合には、Cレジスタ56は、初期状態として、“0”にクリアされる。
エントリにおいて内部データ線226および228に接続される領域には連続アドレスのデータビットA(2i)およびA(2i+1)が格納されて、内部データ線226および228を介してXレジスタ54にデータを転送する。
図84は、1ビット構成のALUユニット34を用いて2項加算を行なうプログラムの一例を示す図である。図84に示す2項加算プログラムにおいて、命令“mem.ld.C 0”は、メモリセルマットの特定の領域に格納されるデータビット“0”を、Cレジスタに格納する命令である。Cレジスタに、セット/リセット機能を持たせる場合、回路構成が複雑となる。メモリセルマットにおいて、リセット用のクリアビットを特定領域に格納し、このクリアビットを用いてCレジスタをクリア状態に設定する。
この2項加算演算処理は、演算a+b=aが行われる。Fレジスタ205により、選択反転器217が、非反転状態に設定され、ポインタレジスタp1が指定する加算数bからのビットと、ポインタレジスタp0が指定する被加算数aの対応のビットの加算が行なわれる。加算命令においては、図76に示すように、このサムが、元の被加算数aのビット位置へ格納され、加算(a+b)=aが実現される。ポインタレジスタpxのポインタにしたがってXレジスタ54および全加算器の接続を切り換えることにより、偶数エントリおよび奇数エントリのデータビットについて逐次加算を行うことができる。
図85は、2項減算のプログラムの一例を示す図である。この2項減算においては、a=(a−b)が実行される。図85に示すプログラムにおいて、命令“men.ld.C
1”は、Cレジスタに1をセットする命令であり、減算数bの2の補数を生成して補数と被減算数aとの加算を実行する。
1”は、Cレジスタに1をセットする命令であり、減算数bの2の補数を生成して補数と被減算数aとの加算を実行する。
選択反転器217は、Fレジスタの格納値に従って反転器として設定される。加算結果が、被減算数aの元の位置に格納される。スイッチ回路SWa−SWfの切換は加算演算時と同様ポインタレジスタpxのポインタに従って行われる。
図86は、1ビット単位での符号なし乗算を行なう際の乗算プログラムの一例を示す図である。被乗数a、乗数bおよび乗算結果cは、それぞれ最下位ビットアドレスは、as、bsおよびcsである。
ポインタレジスタp2およびp3それぞれに最下位ビットアドレスbsおよびcsがセットされる。ついで、Nレジスタ207に、ポインタレジスタp2が指定する乗数bの対応のビットを格納し、全加算器211のサムSum出力を受けるゲート224の処理を設定する。ポインタレジスタp0にポインタレジスタp3の乗算結果格納位置をコピーする。Cレジスタがクリアされて、初期状態が設定される。ポインタレジスタp1に被乗数aの先頭アドレスをセットして、被乗数aのビットをXレジスタ54にロードする。全加算器211を用いて、乗算結果cの対応のビットと被乗数aのビットの加算を行なう。
この加算結果は、Nレジスタ207の格納値が“1”のときにのみ、ポインタレジスタp0が指定するアドレス位置に格納される。これにより、ビットbiとビットaiとの乗算および部分積との加算を行なうことができる。部分積生成後、Cレジスタに格納されたキャリをこの部分積の最上位ビット位置に格納する。
この乗算時においては、乗数bのビットbiを固定して、1つの全体の部分積を生成する。1つの全体部分積生成後、この部分積の最下位ビット位置を指定するポインタp3を1つ増分して、新たな部分積を指定する。ついで、乗数bのビット位置を増分して次の乗算を行なう。これにより1ビットづつ逐次乗算を行うことができる。この乗算時においてもスイッチ回路SWa−SWfの接続が、各ポインタの偶数/奇数に従って制御される。
図87は、除算を行なうプログラムを示す図である。この除算時においては、a/b=c...dが実行される。この図87に示す除算プログラムにおいて、for文が規定する関数文の演算命令“alu.let(0b0011)”により、Fレジスタ、Dレジスタ、NレジスタおよびCレジスタの初期設定が行なわれる(これらのレジスタに(0011)が設定される。
命令“mem.st.C tp”は、Cレジスタの格納値tpを、メモリの特定の領域に格納する操作を指定する命令である。
演算命令“alu.inv tp”は、この特定のビット値tpを反転して再び元のメモリ位置に書込む操作を指定する命令である。
命令“mem.ld.N tp”は、この反転された特定ビット値tpを、Nレジスタに格納する操作を指定する命令である。
これらの一連の命令の実行により、セレクタSELが、Xレジスタの出力を選択する状態に設定され、選択反転器217が、反転を行なう状態に設定され、減算操作“alu.sbc@p0”が実現される。
この除算操作時においては、2ビットのデータがXHレジスタおよびXLレジスタに格納されてついでエントリの剰余格納領域に格納される。この被除数のコピー動作時に2ビット単位でコピーを実行することにより、剰余生成処理を高速化する。ALUの回路接続は、先の加減演算および乗算演算時と同様、1つの全加算器211を用いる状態に設定される。
次いで、1ビットごとに、Xレジスタに除数bを格納し、剰余領域の桁合わせされた被除数aから減算し、減算結果を、Nレジスタの格納値に従って選択的に元の剰余格納領域に格納する。この処理が繰返し実行される。
これにより、除数bと被除数aの大小関係が決定され(Cレジスタのキャリtpの値が決定され)、この大小関係に基づいて、Nレジスタの格納値が設定される。次の減算処理が、Nレジスタの格納値に従って選択的に加算操作を用いて実行される。この加算操作により、剰余領域の元の値を選択的に復元する(商ビットが0のときには、ビット位置をずらせて減算処理を行う必要がある)。商のビットとしてNレジスタの格納値の反転値を設定する。ついで、商および剰余領域のビット位置を1ビット右シフトして、同様の動作を繰返す。
このビットシリアルに除算を行なう場合においても、全加算器211のB入力を、スイッチ回路SWcおよびSWdを用いて選択的に、内部データ線226および228に接続し、Xレジスタ54をスイッチ回路SWaおよびSWbにより、交互に内部データ線226および228に接続する。
したがって、先の加減算操作および乗算操作と同様にして、偶数エントリおよび奇数エントリの格納領域のデータについて、ビットシリアル態様に除算を行なうことができる。
なお、加算および減算は、全加算器210および211をともに用いて2ビット加算処理を行うことにより、2ビット単位で加算および減算を行うことができる。
図88は、1エントリERYの偶数エントリERYeおよび奇数エントリERYoにデータを分散して書込む経路の構成の一例を概略的に示す図である。図88において、転置メモリ230は、外部からワードシリアルかつビットパラレル態様で与えられる外部データEWを、ビットシリアルかつワードパラレルなメモリデータMWに変換してメモリデータバスMDBに転送する。このメモリデータバスMDBには、列選択ゲートCSGoおよびCSGeを介して奇数エントリERYoおよび偶数エントリERYeを構成するビット線対が結合される。列選択ゲートCSGoおびCSGeは、列選択信号CLoおよびCLeに応答して選択的に導通する。
これらの列選択信号CLoおよびCLeを、ポインタレジスタpx(x=0−3)の最下位ビットpx[0]の偶数/奇数に従って選択状態へ駆動する。これにより、転置メモリ230から読出されたワードパラレルかつビットシリアルなメモリデータMWの偶数ビットおよび奇数ビットを、それぞれ、偶数エントリERYeおよび奇数エントリERYoに分散させることができる。
この図88に示す構成において、偶数エントリERYeおよび奇数エントリERYoを、それぞれ別々のエントリとして利用する場合には、ポインタレジスタpxの最下位ビットpx[0]を、全エントリに対するデータ書込まで、0または1に固定し、全エントリ書込後、このポインタレジスタpxの最下位ビットpx[0]を変更する。これにより、偶数エントリ領域にデータワードが書込まれた後、奇数エントリ領域に別のデータワードを書込むことができ、エントリ単位でデータを格納することができる。
以上のように、この発明の実施の形態13に従えば、偶数エントリおよび奇数エントリを設け、また演算処理ユニット内に並列動作する全加算器を配置し、2ビット単位で、ALU処理を行なっており、高速の演算処理を実現することができる。
[実施の形態14]
図89は、この発明の実施の形態14に従う半導体信号処理装置の要部の構成を概略的に示す図である。この図89に示す構成においては、演算処理ユニット群32に含まれるALUユニット34に対し、コントローラ21からのALU制御信号が共通にALU制御線を介して与えられる。このALUユニット(演算処理ユニット)34は、メモリセルマット30のエントリERYそれぞれに対応して配置される。
図89は、この発明の実施の形態14に従う半導体信号処理装置の要部の構成を概略的に示す図である。この図89に示す構成においては、演算処理ユニット群32に含まれるALUユニット34に対し、コントローラ21からのALU制御信号が共通にALU制御線を介して与えられる。このALUユニット(演算処理ユニット)34は、メモリセルマット30のエントリERYそれぞれに対応して配置される。
この図89に示す構成においては、メモリセルマット30に含まれるエントリERYに対し、同一の演算処理を並行して実行することができる。これにより、シングル・インストラクション・マルチ・データ(SIMD)構成を容易に実現することができる。
なお、コントローラ21からのALU制御信号は、図1等において示すマイクロ命令メモリに格納されるプログラムのデコード結果に基づいて生成される。
以上のように、この発明の実施の形態14に従えば、演算処理ユニット群の単位ALUユニットに共通にALU制御線を配設して共通の制御信号を伝達しており、容易に各エントリに対して同一のALU演算を実行することができる。
[実施の形態15]
図90は、この実施の形態15に従う主演算回路の要部の構成を概略的に示す図である。図90に示す構成においては、メモリセルマット30が、エントリ方向に沿って2つのサブマット30aおよび30bに分割される。演算処理ユニット群32も、メモリサブマット30aおよび30bに対応して、ALU群32aおよび32bに分割される。ALU群32aには、コントローラ21に含まれるALU制御回路240aからのALU制御信号が、ALU制御線232aを介して与えられる。ALU群32bのALUユニット34に対しては、コントローラ21に含まれるALU制御回路240bからのALU制御信号が、ALU制御線232bを介して与えられる。
図90は、この実施の形態15に従う主演算回路の要部の構成を概略的に示す図である。図90に示す構成においては、メモリセルマット30が、エントリ方向に沿って2つのサブマット30aおよび30bに分割される。演算処理ユニット群32も、メモリサブマット30aおよび30bに対応して、ALU群32aおよび32bに分割される。ALU群32aには、コントローラ21に含まれるALU制御回路240aからのALU制御信号が、ALU制御線232aを介して与えられる。ALU群32bのALUユニット34に対しては、コントローラ21に含まれるALU制御回路240bからのALU制御信号が、ALU制御線232bを介して与えられる。
ALU制御回路240aおよび240bは、このコントローラ21において命令をデコードする命令デコーダの出力信号に従って選択的に活性化され、それぞれ個々に制御信号を生成する。
この図90に示す構成においては、演算処理ユニット群32において、ALU群32aおよび32bの演算内容を個々に設定することができ、より複雑な演算処理を実現することができる。
この場合、メモリセルマット30において、特に同一アドレスのデータビットを、ALU群32aおよび32bにおいて演算処理することは要求されない。たとえば、サブメモリセルマット30aとALU群32aの間のデータの転送および演算と、サブメモリセルマット30bとALU群32bのデータの転送と演算処理を、交互に実行する。たとえば、ALU群32aにおけるデータ転送時、ALU群32bで演算処理を実行する。ALU群32aの演算処理時、ALU群32bでデータ転送を行なう。演算処理サイクル数などの問題により、このサブメモリセルマット30aおよび30bにおけるデータビットのアクセス競合が生じた場合、コントローラ21において、アクセスの仲裁回路を設け、一方のサブメモリセルマットのデータアクセスを先に完了し、次のサイクルで、他方のメモリセルマットに対してデータのアクセスを行なう。これにより、異なるアドレスのデータビットを用いて演算処理を各ALU群32aおよび32bにおいて実行することができる。
また、これに代えて、サブメモリマット30aおよび30bの一方にアクセスの優先権を与え、プログラム時に、この優先権の与えられるサブメモリマットのアクセスの有無をフラグでモニタするとともに、このモニタ結果に従って他方のサブメモリマットへアクセスを行なう処理を記述することにより、異なるメモリセルサブマット間での同一アドレス位置へのデータアクセスの競合の問題は、回避することができる。
以上のように、この発明の実施の形態15に従えば、ALU回路、複数のグループに分割し、各ALU群個々に、ALU制御信号線を配設しており、各ALU群で異なる演算処理を実行することができ、複雑な演算処理を高速に行なうことができる。
[実施の形態16]
図91は、この発明の実施の形態16に従う半導体装置の要部の構成を概略的に示す図である。図91において、内部データバス12(グローバルデータバスGBS)に基本演算ブロックFB1−FBnが並列に結合される。このグローバルデータバスGBSに対し、大容量メモリ250が接続される。グローバルデータバスGBSは、入出力回路10を介して外部に設けられたシステムバス5に結合される。
図91は、この発明の実施の形態16に従う半導体装置の要部の構成を概略的に示す図である。図91において、内部データバス12(グローバルデータバスGBS)に基本演算ブロックFB1−FBnが並列に結合される。このグローバルデータバスGBSに対し、大容量メモリ250が接続される。グローバルデータバスGBSは、入出力回路10を介して外部に設けられたシステムバス5に結合される。
大容量メモリ250は、たとえば、ダイナミック・ランダム・アクセス・メモリ(DRAM)であり、たとえば1枚の画像のデータを格納することのできる記憶容量を有し、数Mビットから数十Mビットの記憶容量を有する。
この大容量メモリ250へは、入出力回路10を介して外部に設けられたホストCPUから演算処理データが格納される。この大容量メモリ250におけるデータの格納態様については後に詳細に説明する。基本演算ブロックFB1−FBnが、グローバルデータバスGBSを介して大容量メモリ250とデータを転送する。グローバルデータバスGBSのデータ線は、チップ上配線であり、多くのビット幅を有することができる。したがって、この大容量メモリ250と基本演算ブロックFB1−FBnのいずれかとの間でのデータ転送のバンド幅を大きくすることができ、このデータ転送に要する時間が演算処理に対するボトルネックとなるのを防止することができる。
図92は、大容量メモリ250と1つの基本演算ブロックFBiとの間のデータ転送経路を概略的に示す図である。主演算回路20において、メモリセルマット30Aおよび30Bの間に、演算処理ユニット群(ALUユニット群)32が設けられる。これらのメモリセルマット30Aおよび30Bが、グローバルデータバスGBSを介して大容量メモリ250とデータ転送を行なうことができる。主演算回路20においては、メモリセルマット30Aおよび30BとグローバルデータバスGBSとのインタフェースとなる入出力回路は設けられているが、この入出力回路は図92においては示していない。
グローバルデータバスGBSのバス幅が、メモリセルマット30Aおよび30Bのエントリ数に等しい場合、たとえば、これらのメモリセルマット30Aおよび30Bの1行のデータビットを大容量メモリ250との間で転送することができる。この場合、大容量メモリ250の入出力データビットが、メモリセルマット30Aおよび30Bの1つのエントリのビット幅と同じであってもよい。1つのエントリの内容を1回のデータ転送サイクルで転送することができる(この場合には、メモリセルマットにおいてデュアルポートメモリセルを利用する)。
図93は、大容量メモリ250と1つのメモリセルマット30の間のデータ転送を行なう部分の構成の一例を示す図である。大容量メモリ250のデータアクセスの制御は、図1に示す集中制御ユニット内の制御CPU25により行なわれる。メモリセルマット30のデータの入出力は、対応の基本演算ブロック内に含まれるコントローラ21により行なわれる。制御CPU25およびコントローラ21の間で、データ転送要求REQおよびデータ転送了解ACKを転送して、データ転送が行なわれる。
大容量メモリ250が、一例として2ポート構成であり、入出力回路10とポートEXPを介してデータ転送を行ない、また、大容量メモリ250が、内部ポートINPを介してメモリセルマット30とデータ転送を行なう。したがって、入出力回路10から外部ポートEXPを介してデータEDTが格納され、ポートINPを介してそれと直交する方向に整列するデータブロックTRDがメモリセルマット30に対して転送される。メモリセルマット30においては、エントリERY0−ERYmが設けられ、これらのエントリERY0−ERYmの同一ビット位置のデータのブロックXRDが大容量メモリ250との間で転送される。
したがって、大容量メモリ250とメモリセルマット30の間でのデータ転送時、データブロックTRDおよびXRDがそれぞれ1つのワード線に接続するメモリセルデータの場合、1つのワード線選択を行うだけで、データブロックTRDまたはXRDを転送することができる。
大容量メモリ250は、外部からは、ポートEXPを介してワード単位でデータの格納が行なわれてもよい。データブロックEDTが、このポートEXPのワード線方向に対応する。従って、大容量メモリ250が、データの転置機能を備える。外部バスのインターフェイスの入出力回路が、転置機能を備えている場合には、この大容量メモリ250は、データの転置機能を持つ必要はない。デュアルポート構成で、入出力回路10と大容量メモリ250との間のデータ転送バスと大容量メモリと基本演算ブロックとの間のデータ転送バスとが別々のバスであれば、大容量メモリと外部とのデータ転送と機能ブロックとの間のデータ転送を並行して実行することができる。このデュアルポート構成の場合、ポートINPのビット幅は、メモリセルマット30のエントリ数(m+1)またはグローバルデータバスのビット幅となる。
しかしながら、大容量メモリ250は、シングルポートメモリであっても良く、この場合には、大容量メモリ250への外部からのデータ転送完了後に、大容量メモリ250と基本演算ブロックとの間のデータ転送が行われる。また、大容量メモリ250と基本演算ブロックFB1‐FBnとの間のデータ転送において、1つの基本演算ブロックの演算処理実行時に大容量メモリと別の基本演算ブロックとの間でデータ転送が行われ、データ転送と演算とがインターリーブ態様またはパイプライン的に実行されても良い。
図94は、この大容量メモリ250とメモリセルマット30の間のデータ転送の別の態様を概略的に示す図である。図94において、大容量メモリ250は、シングルポートメモリであり、グローバルデータバスGBSに結合される。主演算回路20のメモリセルマット30は、デュアルポートメモリであり、ポートAを介してグローバルデータバスGBSに結合され、またポートBを介してグローバルデータバスGBSに結合される。ポートAを介して大容量メモリ250とエントリERY単位でのデータ転送を行なう。ポートBは、グローバルデータバスGBSの特定のバスを利用して、外部のホストCPUと入出力回路10を介してデータ転送を行なう。
この図94に示す構成において、大容量メモリ250は、外部からのデータEDTを各ワード線ごとに格納する場合、このワード線上の複数ワードのデータEDTをグローバルデータバスGBSを介し、メモリセルネット30へポートAから転送することにより、エントリERYのデータを、一括してメモリセルマット30に転送することができる。
ポートBは、入出力回路10と直接データの転送を行う場合に利用される。入出力回路10は、この場合、グローバルデータバスGBSと同一のビット幅を有することは特に要求されない。ポートBが、入出力回路10とメモリセルマットの入出力ビット幅の調整を行う。ポートBを利用する入出力回路とのデータ転送時には、入出力回路10においてはデータの位置を交換する転置回路が必要とされる。
この図94に示す構成の場合には、主演算回路のメモリセルマットが2ポート構成であるものの、ポートAが大容量メモリ250および入出力回路10とのデータ転送に用いられ、メモリセルのポートBがALU群32とのデータ転送にのみ利用される場合には、特に、主演算回路20外部にデータの転置を行なうための構成を設ける必要がない。外部のCPUに対するデータは、ポートAを介して格納することができる。
また、この図94に示す構成における大容量メモリ250と主演算回路20のメモリセルマット30の間のデータ転送は、図93に示す構成と同様、制御CPU25とコントローラ21とを用いて内部のアドレスポインタ(ポインタレジスタ)を参照して行なわれる。
以上のように、この発明の実施の形態16に従えば、複数の基本演算ブロックに対し共通に大容量メモリを設け、大きなビット幅の内部データバスを介して、選択された基本演算ブロックと大容量メモリの間でデータ転送を行なっており、データ転送に要する時間を短縮することができ、高速演算処理を実現することができる。
[実施の形態17]
図95は、この発明の実施の形態17に従う半導体演算装置の要部の構成を概略的に示す図である。この図95に示す半導体演算装置においては、内部データバス(グローバルデータバス)GBSに結合される大容量メモリ250が、複数のバンクBK0−BKkに分割される。これらのバンクBK0−BKkの各々は、基本演算ブロックFB1−FBnに含まれるメモリセルマットと同程度の記憶容量を有する。したがって、大容量メモリ250の記憶容量は、(バンク数)・(メモリマットの容量)となる。
図95は、この発明の実施の形態17に従う半導体演算装置の要部の構成を概略的に示す図である。この図95に示す半導体演算装置においては、内部データバス(グローバルデータバス)GBSに結合される大容量メモリ250が、複数のバンクBK0−BKkに分割される。これらのバンクBK0−BKkの各々は、基本演算ブロックFB1−FBnに含まれるメモリセルマットと同程度の記憶容量を有する。したがって、大容量メモリ250の記憶容量は、(バンク数)・(メモリマットの容量)となる。
図96は、大容量メモリ250と1つの基本演算ブロックFBiの主演算回路20との接続関係を概略的に示す図である。主演算回路20において、メモリセルマット30に係数データを格納する。大容量メモリ250において、バンクBK0−BKk各々に、画像データが格納され、グローバルデータバスGBSを介してALUユニット32とデータ転送を行なう。この場合には、グローバルデータバスGBSのビット幅は、メモリセルマット内のエントリ数に等しくなる。
画像処理においては、フィルタ処理などを行なう場合、係数と演算処理データとの乗算が実行される。この場合、処理対象のデータと演算処理に必要とされる係数データとでは、係数データよりも処理データの方が圧倒的に数が多い。このため、比較的小容量のメモリセルマット30に係数データを格納し、処理対象の画像データを、大容量メモリ250のバンクBK0−BKkにそれぞれ分散して格納する。
演算処理時においては、バンクBK0−BKkをバンクセレクト信号(図示せず)に従って選択して、選択バンクのデータを演算処理群32のALU群にデータを伝達する。処理完了後の画像データは、外部へ転送し、また新たなデータが対応のバンクに格納される。この外部との間のデータ転送時、別のバンクが選択され、基本演算ブロックFBiにおいて並列演算処理が実行される。
図97は、この発明の実施の形態17に従う半導体演算装置の要部の構成を概略的に示す図である。図97に示す構成においては、大容量メモリ250が、ポートA回路252aおよびポートB回路252bと、複数のバンクBK0−BKkを含む。内部データバス(グローバルデータバス)は、入出力回路10に結合される内部データバスGBSaと、大容量メモリ250のポートB回路252bと主演算回路20の演算処理ユニット群32とに結合されるグローバルデータバスGBSbを含む。グローバルデータバスGBSbは、演算処理ユニット群32の各ALUユニットそれぞれに対して並列にデータビットを転送することのできるビット幅を有する。主演算回路の入出力回路(図示せず)は、内部データバスGBSaに結合される。この内部データバスGBSaは、基本演算ブロックのマイクロ命令メモリへのプログラムデータおよび他のコントローラ21に対する制御情報等を転送する。
大容量メモリ250のアクセス制御が、メモリコントローラ255により行なわれ、主演算回路20の操作制御は、基本演算ブロック内のコントローラ21により行なわれる。コントローラ21は、メモリコントローラ255に対してロード/ストアの命令を転送する。メモリコントローラ255およびコントローラ21は、個々に、アドレスポインタを生成する。
図98は、図97に示すメモリ構成の動作を示すタイミング図である。この図98に示すように、まず外部のホストCPUからの指令が与えられ、コントローラ21の制御のもとに、メモリセルマット30に対し、データが格納される。次いで、外部のホストCPUの指示によりメモリコントローラ255が起動され、ホストCPUの制御の下に外部のメモリから入出力回路10を介してバンクBK0−BKkに対し処理データのロードが行われる。この大容量メモリ250へのデータのロードは、DMAモードで図1に示すDMA4の制御のもとに実行されてもよい。
メモリセルマット30およびバンクBK0−BKkへのデータのロードが完了すると、コントローラ21が、演算処理を開始する。メモリセルマット30およびバンク♯0(BK0)のデータについて演算処理が行なわれ、演算結果がバンクBK0に格納される。1つのバンクの処理が完了すると、バンクを切換えて次のバンク♯1、♯2、…のデータの処理が実行される。バンク♯0(BK0)の処理後のデータは、ポートA回路252aを介してメモリコントローラ255からの起動を受けたDMA回路4により、DMAモードで外部メモリに対して転送され、また、新たな画像データが、このバンク♯0(BK0)へ格納される。
したがって、1つのバンクに対し、ポートA回路252aを介してデータをストアする処理に時間を要しても、他バンクの演算処理が終了し、次にこのバンクの処理が開始されるまでに、このバンク♯0への新たなデータのロードが完了していることが要求されるだけである。ポートA回路252aのビット幅が、内部データバスGBSaのビット幅により制限されるものの、内部データバスGBSaおよびGBSbは別々に設けられており、外部メモリと大容量メモリ250との間でのデータ転送は、何ら主演算回路におけるデータの演算処理に悪影響を及ぼさない。
また、大容量メモリ250の各バンクBK0−BKkは、グローバルデータバスGBSbを介して演算処理ユニット群32とデータを転送しており、各演算サイクルごとに、必要とされるデータを転送でき、高速演算処理を実現することができる。
以上のように、この発明の実施の形態17に従えば、大容量メモリをマルチバンク構成とし、1つのバンクを主演算回路のメモリセルマットとみなして演算処理を実行しており、画像データの処理後の画像データおよび新たな画像データの転送をパイプライン的に実行でき、高速演算処理が実現される。
なお、主演算回路20において、メモリセルマット30は、デュアルポート構成であってもよく、また、シングルポート構成であってもよい(ただしシングルポート構成の場合には、メモリセルマット30への書込データは、ビット位置変更処理を受ける)。
[実施の形態18]
図99は、この発明の実施の形態18に従う半導体演算装置の要部の構成を概略的に示す図である。この図99においては、内部データバス(グローバルデータバス)GBSに複数の基本演算ブロックが並列に結合される。図99において、これらの基本演算ブロックに含まれる主演算回路(20)MPA0−MPA3を代表的に示す。これらの主演算回路(20)MPA0−MPA3の各々は、メモリセルマット30Aおよび30Bとこれらのメモリセルマット30Aおよび30Bの間に配設されるALU群を含む。このALU群は、図99においては示していない。ALU群に対しては、ALUユニットを相互接続するためのALU間相互接続用スイッチ回路(44)ECMが設けられる。
図99は、この発明の実施の形態18に従う半導体演算装置の要部の構成を概略的に示す図である。この図99においては、内部データバス(グローバルデータバス)GBSに複数の基本演算ブロックが並列に結合される。図99において、これらの基本演算ブロックに含まれる主演算回路(20)MPA0−MPA3を代表的に示す。これらの主演算回路(20)MPA0−MPA3の各々は、メモリセルマット30Aおよび30Bとこれらのメモリセルマット30Aおよび30Bの間に配設されるALU群を含む。このALU群は、図99においては示していない。ALU群に対しては、ALUユニットを相互接続するためのALU間相互接続用スイッチ回路(44)ECMが設けられる。
これらのALU間相互接続用スイッチ回路(44)は、以下の説明においては、符号“ECM”を用いて参照する。
メモリセルマット30Aおよび30Bは、各々、複数のエントリERYに分割されており、これらのエントリERYそれぞれに対して、ALU間接続回路(65)が設けられる。
図1において示すように、基本演算ブロック間においては、隣接ブロック間データバス16が設けられる。この隣接ブロック間データバス16は、隣接基本演算ブロックのALU間接続回路(図7の回路65)を相互接続する隣接ブロックエントリ相互接続線260を含む。この隣接ブロックエントリ相互接続線260は、隣接する基本演算ブロックの主演算回路MPAの同一位置のエントリを相互接続する。
グローバルデータバスGBSは、入出力回路10を介して外部のシステムバス5に結合される。
図100は、この隣接ブロックエントリ相互接続線260の具体的接続態様を示す図である。図100において、基本演算ブロックFBiおよびFB(i+1)において、ビット線方向(エントリの延びる方向)に平行に隣接ブロックエントリ接続線260が延在して配置され、同一列のエントリERYjに対して設けられるALUユニットALUjを相互接続する。この隣接ブロックエントリ相互接続線260は、このエントリの延在方向、すなわちビット線と同一方向にメモリセルマット上を延在して配置され、最短距離で、隣接基本演算ブロックFBiおよびFB(i+1)の同一列のエントリの単位ALU回路ブロック(ALUユニット)ALUjを相互接続する。
図99に示すグローバルデータバスGBSは、各基本演算ブロックの入出力回路(図15参照)を介して対応のセンスアンプ群およびライトドライバ群に結合される。主演算回路MPA0−MPA3それぞれにおいて、センスアンプ群およびライトドライバ群と入出力回路を接続する相互配線(メモリ内部配線)は、これらのセンスアンプ群およびライトドライバ群の上層配線またはメモリセルマット上層配線により形成され、複数ビットのデータを並列に転送する。
隣接ブロックエントリ相互接続線260は、図100においては、ALU間を接続している。しかしながら、この隣接ブロックエントリ間相互接続線260は対応のALUユニットALUjを介して対応のALU間接続回路65に結合される。したがって、この隣接ブロックエントリ接続線260は、またALU間接続回路65に直接結合されてもよい。このALU間接続回路65は、ALUユニット内のXレジスタまたはZレジスタに結合される。
[変更例1]
図101は、この発明の実施の形態18の変更例1の隣接ブロック間データバスの配置を概略的に示す図である。図101において、グローバルデータバスGBSに並列に、基本演算ブロックに含まれる主演算回路MPA0−MPAkが結合される。これらの主演算回路MPA0−MPAk各々において、メモリセルマット30Aおよび30Bの間にALU間接続用スイッチ回路ECMが配置される。隣接ブロックエントリ接続線260により、ALU間接続用スイッチ回路ECM内の隣接する主演算回路の同一位置のエントリに対するALU間接続回路(65)が接続される。
図101は、この発明の実施の形態18の変更例1の隣接ブロック間データバスの配置を概略的に示す図である。図101において、グローバルデータバスGBSに並列に、基本演算ブロックに含まれる主演算回路MPA0−MPAkが結合される。これらの主演算回路MPA0−MPAk各々において、メモリセルマット30Aおよび30Bの間にALU間接続用スイッチ回路ECMが配置される。隣接ブロックエントリ接続線260により、ALU間接続用スイッチ回路ECM内の隣接する主演算回路の同一位置のエントリに対するALU間接続回路(65)が接続される。
この図101に示す構成において、さらに、最も遠く離れた基本演算ブロックの主演算回路MPA0およびMPAkの同一位置のエントリに対して設けられるALUユニットおよびALU間接続回路が、フィードバック配線262により相互接続される。これにより、主演算回路MPA0−MPAkの同一位置のエントリのALUユニットが、リング状に相互接続される。
このリング状に、各基本演算ブロックの同一位置のエントリに対するALUユニットおよびALU間接続回路を相互接続することにより、任意の位置の主演算回路間でデータ転送を行なうことができる。
なお、図101においては、このフィードバック配線262は、主演算回路MPA0−MPAkのメモリセルマット上部を直線的に延在するように示される。しかしながら、このフィードバック配線262は、主演算回路(メモリセルマット)外部を迂回してフィードバックループを形成するように配置されてもよい。
図102は、このリング状隣接ブロック間データバスの構成の他の例を概略的に示す図である。図102において、グローバルデータバスGBSの一方側に主演算回路MPA0およびMPA1が配置され、このグローバルデータバスGBSの他方側に、主演算回路MPA2およびMPA3が配置される。グローバルデータバスGBSに関して同一側に配置される隣接主演算回路MPA0およびMPA1は、同一位置のエントリのALUユニットが隣接ブロックエントリ相互接続バスNBAaを介して相互接続される。この隣接ブロックエントリ相互接続バスNBAaは、隣接する主演算回路MPA0およびMPA1の同一位置のエントリERYに対し設けられるALUユニットおよびALU間接続回路(65)を相互接続する隣接ブロックエントリ接続線260を含む。
また、グローバルデータバスGBSの他方側において配置される隣接主演算回路MPA2およびMPA3においても、隣接ブロックエントリ接続バスNBAbが配置される。この隣接ブロックエントリ相互接続バスNBAbは、主演算回路MPA2およびMPA3の同一位置のエントリERYに対して設けられるALUユニットおよびALU間相互接続回路を接続する隣接ブロックエントリ相互接続線260を含む。
この隣接ブロック間相互接続バス(隣接ブロック間データバス16)は、さらに、グローバルデータバスGBSに対して対向する位置の主演算回路MPA0およびMPA2の対応するエントリERYに対して設けられるALUおよびALU間相互接続回路を接続する隣接ブロックエントリ相互接続バスNBBaにより相互接続される。この隣接ブロックエントリ相互接続バスNBBaは、主演算回路MPA0およびMPA2の対応の位置のエントリERYに対して設けられるALUユニットおよびALU間接続回路を相互接続する配線262aを含む。
同様に、主演算回路MPA1およびMPA3の対応の位置のエントリERYに対して設けられるALUユニットおよびALU間接続回路が、隣接ブロック相互接続バスNBBbにより相互接続される。この隣接ブロックエントリ相互接続バスNBBbは、各ALUユニットおよびALU間接続回路に対して配設される配線262bを含む。
したがってこの図102に示すように、行列状に整列して基本演算ブロック(主演算回路MPA0−MPA3)が配設される場合においても、グローバルデータバスの一方側の両端の主演算回路およびグローバルデータバスの他方側の両端の基本演算ブロック(主演算回路)のALUユニットおよびALU間接続回路を相互接続することにより、これらの主演算回路MPA0−MPA3のALUユニットをリング状に相互接続することができ、任意の主演算回路間でデータの転送を行なうことができる。
特に、この図102に示すように、各隣接ブロック相互接続バスNBBaおよびNBBbにおいて、対向して配置される主演算回路の同一位置のエントリERYに対して設けられるALUユニットおよびALU間相互接続回路を配線262aおよび262bにより相互接続することにより、相互接続配線262aおよび262bは、それぞれのバスNBBaおよびNBBbにおいて同じ長さとなり、信号伝搬遅延を同一とすることができ、信号のスキューを低減でき、高速転送を実現することができる。
また、この隣接ブロックエントリ相互接続バスNBBaおよびNBBbは、それぞれメモリセルマット30Aおよび30B上に延在される第1の配線部分と、グローバルデータバスGBSに関して対向する主演算回路のメモリセルマット上を第1の配線部分と直交する方向に延在する第2の配線部分とで構成し、これらの第1の配線部分および第2の配線部分をメモリセルマット上で相互接続することにより、グローバルデータバスに関して対向するメモリマット間の相互接続配線をコンパクトに配置することができ、配線面積増大によるメモリアレイ面積の増大を抑制することができる。
以上のように、この発明の実施の形態18に従えば、隣接する基本演算ブロックの主演算回路の各対応のエントリを内部配線で相互接続しており、特にリング状に相互接続することにより、グローバルデータバスGBSを介することなく、主演算回路間で高速でデータ転送を行なうことができる。
なお、図102においては、ALU間相互接続用スイッチ回路ECMの内部構成を示していない。このALU間相互接続用スイッチ回路ECMにおいては、ALUユニットおよびALU間接続回路が含まれており、各ALUユニットおよびALU間接続回路が、対応の配線260または262a,262bにより接続される。
[実施の形態19]
図103は、この発明の実施の形態19に従うALU間相互接続用スイッチ回路(44)ECMの接続の態様を概略的に示す図である。図103においては、一例として、1つの主演算回路において、8個の単位ALU回路ブロック(34)ALU0−ALU7が設けられる。この単位ALU回路ブロックは、演算回路および各レジスタ回路を含み、内部構成は、実現する演算内容に応じて適宜決定される。この単位ALU回路ブロックは、先の実施の形態におけるALUユニット(演算処理ユニット)に対応する。以下では、説明の煩雑を避けるために、単に「ALU」で、この演算処理ユニット(ALUユニット)を参照する。
図103は、この発明の実施の形態19に従うALU間相互接続用スイッチ回路(44)ECMの接続の態様を概略的に示す図である。図103においては、一例として、1つの主演算回路において、8個の単位ALU回路ブロック(34)ALU0−ALU7が設けられる。この単位ALU回路ブロックは、演算回路および各レジスタ回路を含み、内部構成は、実現する演算内容に応じて適宜決定される。この単位ALU回路ブロックは、先の実施の形態におけるALUユニット(演算処理ユニット)に対応する。以下では、説明の煩雑を避けるために、単に「ALU」で、この演算処理ユニット(ALUユニット)を参照する。
これらの8個のALUに対して、ALU間相互接続用スイッチ回路ECMにおいては、ALU間を1ビットシフト(move)するスイッチ回路および配線を配置する1ビットシフト領域AR0と、2ビットシフトするスイッチ回路および配線を配置する2ビットシフト領域AR1と、4ビットシフトするスイッチ回路および配線を配置する4ビットシフト領域AR2とが設けられる。これらのシフト領域AR0、AR1、およびAR2においては、1つの基本演算ブロック内において、図の縦方向に1ビット、2ビットまたは4ビットシフトする位置のALU間でデータを転送する。2の乗数ビット、ALU間のデータ転送(シフト)を実現することにより、任意のALU間のデータ転送を2サイクルで行なうことができる。
ただし、各データシフトのために配線領域が必要となる。最大2のn乗のALU間のデータシフトを行なう場合、1ビットシフト領域から2のn乗ビットシフト領域まで、合計(n+1)の配線領域が必要となる。
図104は、このシフト領域AR0−AR2において設けられるALU間接続回路の構成の一例を示す図である。この図104に示すALU間接続回路が、各ALUに対応して設けられる。この図104に示すALU間接続回路は、図7に示すALU間接続回路65に対応する。
図104において、ALU間接続回路(65)は、上方シフト指示信号UPおよび下方向シフト指示信号DWに従って選択的に活性化される送受信レジスタ270と、kビットシフト指示信号ENkに従って選択的に導通し、送受信レジスタ270をkビット先のALU間接続回路に接続するトランスファーゲート272および273を含む。kビット転送指示信号ENkの活性化により、2のk乗ビットのデータシフトが実現される(k=0、1、…)。
送受信レジスタ270は、シフト指示信号UPおよびDWによりデータの送信および受信方向が決定される(送信レジスタおよび受信レジスタの接続が決定される)。この送受信レジスタ270は、対応のALU間接続回路内の全kビットシフトスイッチ(トランスファーゲート)272および273に共通に配置される。
この図104に示すように、送受信レジスタ270を配置することにより、双方向に、ALU間でデータビットを転送することができる。この送受信レジスタ270が、対応のALUのXレジスタに接続される(図7に示す構成の場合)。ALU内にXレジスタおよびZレジスタが存在し、Xレジスタが受信レジスタとして用いられ、かつZレジスタが送信レジスタとして用いられる場合には(図49参照)、この送受信レジスタ270は、特に設けられなくても良い。
また、図103に示す構成において、1ビットシフト領域AR0においては、ALU0およびALU7が相互接続される(スイッチ回路を介して)。これにより、リング状に、双方向に、データビットを同一主演算回路ブロック内において転送することができる。
[変更例1]
図105は、この発明の実施の形態19の変更例1の構成を概略的に示す図である。図105において、ALU間相互接続用スイッチ回路ECMにおいて、ALU間を1ビットシフトする1ビットシフト領域AR0と、2ビットまたは4ビットシフトする配線/スイッチが配置される2/4ビットシフト領域AR3が設けられる。1ビットシフト領域AR0においては、先の図103に示すように、隣接ALU間でデータ転送を行なうことができる。
図105は、この発明の実施の形態19の変更例1の構成を概略的に示す図である。図105において、ALU間相互接続用スイッチ回路ECMにおいて、ALU間を1ビットシフトする1ビットシフト領域AR0と、2ビットまたは4ビットシフトする配線/スイッチが配置される2/4ビットシフト領域AR3が設けられる。1ビットシフト領域AR0においては、先の図103に示すように、隣接ALU間でデータ転送を行なうことができる。
一方、2/4ビットシフト領域AR3においては、プログラマブルスイッチ回路PSWにおいて、2ビットシフトまたは4ビットシフトが択一的に実現される。この図105に示す構成の場合、2ビットシフトおよび4ビットシフトを切換えるために、プログラマブルスイッチ回路PSWが必要となるものの、転送(move)バス配線数を低減でき、バスの占有面積を低減できる。
この図105に示すプログラマブルスイッチ回路PSWは、図103に示す2ビットシフト領域AR1における各配線間に配置される。
図106は、このプログラマブルスイッチ回路PSWの構成の一例を概略的に示す図である。図106において、プログラマブルスイッチ回路PSWは、イネーブル信号ENaに従って配線275aおよび275bを選択的に分離する転送ゲート280と、イネーブル信号ENbに従って選択的に配線275aを送受信レジスタ270の一方のノードに接続するトランスファーゲート281と、イネーブル信号ENcに従って配線275bを送受信レジスタ270の他方ノードに接続する転送ゲート282を含む。送受信レジスタおおよびプログラマブルスイッチ回路PSWによりALU間接続回路(65)が構成される。
送受信レジスタ270は、送信レジスタおよび受信レジスタを含み、上向き矢印に従って上方向シフト、下向き矢印に従って下方向にデータを転送する。この送受信レジスタ270は、対応のALUに含まれるたとえばXレジスタに結合される。
この図106に示すプログラマブルスイッチ回路PSWにおいて転送ゲート280−282を選択的に導通/非導通状態に設定することにより、2ビットシフトおよび4ビットシフトを選択的に実現することができ、また上方向および下方向の双方向にデータビットの転送を行なうことができる。
切換制御信号ENa−ENcは、コントローラ(21)からのプログラムのデコード結果に基づいて生成されるALU制御信号に含まれる。
図107は、このプログラマブルスイッチ回路PSWの接続状態の1つである分断状態の接続を概略的に示す図である。図107において、プログラマブルスイッチ回路PSWの分断状態ITPにおいては、転送ゲート281および282が導通状態となり、転送ゲート280が非導通状態となる。この場合、接続配線275aおよび275bは、転送ゲート280により分断され、対応のALU間接続回路(65)を介してデータの転送が行なわれる。データの転送方向は、送信および受信レジスタの接続状態により決定される。
図108は、プログラマブルスイッチ回路PSWの接続状態のうちのスルー状態の接続を概略的に示す図である。このスルー状態THRにおいては、転送ゲート270が導通状態に設定され。転送ゲート281および282が非導通状態に設定される。したがって、接続配線275aおよび275bが相互接続され、対応のALUユニットから分離される。従って、このスルー状態THRにおいては、接続配線275aおよび275b上のデータビットは、対応のALUを通過して別のALUへ転送される。このスルー配線により、4ビット転送時、2ビット先のALUユニットを通過して、4ビット先のALUユニットへのデータ転送を実現する。
図109は、プログラマブルスイッチ回路PSWの接続状態のうちの分断/ダミー状態IRDの接続を概略的に示す図である。この分断/ダミー状態IRDにおいては、転送ゲート280および282が非導通状態に設定され、転送ゲート282が導通状態に設定される。したがって、接続配線275bが対応のALUに接続され、接続配線275aは対応のALUから分離される。接続配線275aが、対応のALUとデータのビットの転送を行ない、接続配線275bは、データ転送に寄与せず、ダミー配線として配置される。
図110は、2ビット/4ビットシフト領域AR3のプログラマブルスイッチ回路PSWの接続の一例を示す図である。図110において、スイッチ回路PSWaが分断状態ITPに設定され、スイッチ回路PSWbがスルー状態THRに設定される。したがって、ALU(ALUユニット)0、ALU2、ALU4、およびALU6の間でプログラマブルスイッチ回路PSWaおよびPSWcによりデータ転送が行なわれ、またALU1、ALU3、ALU5およびALU7の間でも、分断状態の。プログラマブルスイッチ回路PSWaによりデータ転送が行なわれる。同様、スルー状態のプログラマブルスイッチ回路PSWbにより、ALU6とALU0の間およびALU1とALU7の間でデータ転送が行なわれる。このスイッチの接続により、ALU0−ALU7において2ビットシフト動作が実現される。
ALU6において、スイッチ回路PSWcが、分断・ダミー状態に設定されている。ALU6は、ALU0とプログラマブルスイッチ回路PSWbを介して接続される。従って、このALU6に対して配置されるプログラマブルスイッチ回路PSWcは、さらに下方向に向けてデータを転送することは要求されず、片側の接続配線が、常時ダミー配線状態である。従って、このALU6に対して配置されるプログラマブルスイッチ回路PSWcは、図109に示す転送ゲート280および282が常時非導通状態に設定されても良い。また、これに代えて、ALU6に対するスイッチ回路PSWcが、図109に示す転送ゲート281のみで構成されても良い。
図111は、4ビットシフト(move)動作時のプログラマブルスイッチ回路の接続の一例を示す図である。図111において、プログラマブルスイッチ回路PSWaが分断状態ITPに設定され、プログラマブルスイッチ回路PSWbがスルー状態THRに設定され、プログラマブルスイッチ回路PSWcが分断/ダミー状態IRDに設定される。
この図111に示す接続状態においては、ALU0がALU4と結合され、ALU4がALU6と分離されてスルー状態THRのプログラマブルスイッチ回路PSWcによりALU2に接続される。ALU2は、分断/ダミー状態のプログラマブルスイッチ回路PSWcによりALU0と分離される。
ALU6が、分断/ダミー状態のスイッチ回路PSWcを介してALU1に結合され、ALU7がALU3に結合される。ALU3は、ALU1とプログラマブルスイッチ回路PSWcにより分離される。
したがって、このシフト領域AR3においてプログラマブルスイッチ回路PSWを、状態ITP、THRおよびIRDのいずれかに設定することにより、2ビットシフト(move)動作および4ビットシフト動作を実現することができる。これにより、2ビットシフト用の配線および4ビットシフト用の配線を別々に設ける必要がなく、配線占有面積を低減することができる。
[変更例2]
シフト領域AR0−AR2またはAR0およびAR3の配線のピッチ条件(スイッチ回路PSWの配置に対する制約条件)を緩和するために、ALUの配置を、図112に示すように設定する。
シフト領域AR0−AR2またはAR0およびAR3の配線のピッチ条件(スイッチ回路PSWの配置に対する制約条件)を緩和するために、ALUの配置を、図112に示すように設定する。
図112において、4つの単位ALU回路ブロック(ALU)がエントリ延在方向に整列して配置される。一方側のメモリセルマットのセンスアンプ/ライトドライバ(データレジスタ)DRG0a−DRG7aと、他方側のメモリセルマットのセンスアンプ/ライトドライバDRG0b−DRG7bがそれぞれ各エントリ(図示せず)に対応して配置される。
この図112に示すように、1つのメモリセルマットについて4つのエントリ(センスアンプ/ライトドライバDRG)の配置ピッチに対し、単位ALU回路ブロック(以下、単にALUと称す)ALUのピッチを決定する。これにより、ALUに対するALU間シフト用の配線のピッチを緩和することができ、数多くのシフト用配線を余裕を持って各ALUに対して配置して接続することができる。
図113は、図112に示すALUの配置に対するALU間接続用スイッチ回路の配線レイアウトを概略的に示す図である。図113においては、4行5列に配置されるALUを符号“X[0]−X[19]”で示す。通常、ALU間データビット転送時においては、Xレジスタを用いてデータビットの転送が行なわれるため、このALU間接続において各ALUに含まれるXレジスタに対する接続が行なわれる状態を一例として示す。
図のY方向(エントリ延在方向)に隣接するALUの接続は、X[i]およびX[i+1]を接続する接続配線290aにより実現される。このY方向に整列するALUの最も右に位置するALU、すなわちX[i+3]は、次の隣接行の左側に位置するALUユニット、すなわちX[4i+1]に接続される。これらの配線290aおよび290bにより、4行5列に整列されるALUユニットを逐次接続して、1ビットシフト動作を実現することができる。
X方向において隣接するALUが配線292により相互接続される(スイッチ回路は示さず)。この配線292により、ALU(X[i])が、4ビット離れたALU([Xi+4])に結合され、4ビットシフト動作を、この配線292により実現することができる。
配線296は、さらに離れたALU間のシフトを行なう配線であり、この配線926二より、たとえば32ビットシフトおよび64ビットシフトを実現することができる。
1つの主演算回路において、256エントリが設けられている場合、隣接ブロック間データバスNBS(図1のバス16)を介して隣接する主演算回路の対応のALUに接続され、256ビットシフトが実現される。
図114は、隣接ブロック間データバスNBS(図1のバス16)の配置の一例を概略的に示す図である。メモリセルマット30におていは、一例として、256エントリが配設される。この基本演算ブロック(主演算回路)FBiのALUユニット群32Lにおいては、4つのALUが各行に整列して配置される。したがって、このALUユニット群32Lにおいて、ALU0−ALU255(X[0]−X[255])が配置される。
基本演算ブロックFB(i+1)においては、同様、256エントリに対応して、4つのALUが行方向に整列して配置される。基本演算ブロックFBiおよびFBi+1は、アドレス領域(外部CPUのアドレス領域)について連続しており、このALUユニット群32Rにおける256個のALUに対して連続番号が付され、ALU(X[256]−X[511])が配設される。
隣接ブロック間データバスNBSにおいて、このALUユニット郡32Lおよび32Rの同一位置に配設されるALUが隣接ブロック間データ線290により相互接続される。たとえば、ALU(X[3])は、ALUユニット群32RのALU(X[259])に接続される。同様、ALUユニット群32LのALU(X[255])は、ALUユニット群32RのALU(X[511])に接続される。これにより、データビットを、この隣接ブロック間データバスNBSを介して転送することにより、256ビットシフト動作を実現することができる。
この基本演算ブロックFBiのALUユニット群32Lの各ALUは、また隣接ブロック間データバスNBSを介して別の隣接する基本演算ブロックの主演算回路内のALUに接続される。
図113に示すALUの配置における8個のALUを単位として階層的に配置し、かつ各配線の接続に対し、スイッチ回路またはプログラマブルスイッチ回路(図105参照)を適用することにより、1ビットシフト動作から2のn乗のビットのシフト動作を実現することができる。
[変更例3]
図115は、この発明の実施の形態19の変更例3の構成を概略的に示す図である。この図115に示す構成において、ALU間接続用スイッチ回路ECMの接続を制御するためにALUシフト制御回路300が設けられる。このALUシフト制御回路300は、主演算回路MPA0−MPA3に含まれるALU間接続用スイッチ回路ECM0−ECM3それぞれの接続を個々に設定する。これにより、主演算回路MPA0−MPA3それぞれにおいてALU間シフト量を互いに異ならせて演算処理を行なうことができる。
図115は、この発明の実施の形態19の変更例3の構成を概略的に示す図である。この図115に示す構成において、ALU間接続用スイッチ回路ECMの接続を制御するためにALUシフト制御回路300が設けられる。このALUシフト制御回路300は、主演算回路MPA0−MPA3に含まれるALU間接続用スイッチ回路ECM0−ECM3それぞれの接続を個々に設定する。これにより、主演算回路MPA0−MPA3それぞれにおいてALU間シフト量を互いに異ならせて演算処理を行なうことができる。
なお、このALUシフト制御回路300におけるシフト制御は、図1に示す基本演算ブロックFB内に含まれるコントローラ21の制御のもとに実行されてもよい。また、ALUシフト制御回路300が、各基本演算ブロック内のコントローラに分散して配置され、対応のALU巻相互接続スイッチ回路の接続を制御しても良い。また、これに代えて、ALUシフト制御回路300は、システムバス5を介して外部のホストCPUの制御のもとに各ALU間相互接続スイッチ回路ECM0‐ECM3のシフト量を設定してもよい。
[変更例4]
図116は、この発明の実施の形態19の変更例4の構成を概略的に示す図である。この図116に示す構成においては、主演算回路MPA0−MPA3それぞれにおいて、ALU間接続用スイッチ回路ECMが、上側スイッチ回路ECMUおよび下側スイッチ回路ECMDに分割される。これらの上側スイッチ回路ECMUおよび下側スイッチ回路ECMDを、主演算回路MPA0−MPA3それぞれで個々に制御するため、ALUシフト制御回路310が、主演算回路MPA0‐MPA3の上側スイッチ回路および下側スイッチ回路に対して個々に制御信号(符号UおよびD)に与える。符号Uで示す制御信号がう上側スイッチ回路ECMの接続を制御し、符号Dで示される制御信号が、下側スイッチ回路ECMDの接続を制御する。
図116は、この発明の実施の形態19の変更例4の構成を概略的に示す図である。この図116に示す構成においては、主演算回路MPA0−MPA3それぞれにおいて、ALU間接続用スイッチ回路ECMが、上側スイッチ回路ECMUおよび下側スイッチ回路ECMDに分割される。これらの上側スイッチ回路ECMUおよび下側スイッチ回路ECMDを、主演算回路MPA0−MPA3それぞれで個々に制御するため、ALUシフト制御回路310が、主演算回路MPA0‐MPA3の上側スイッチ回路および下側スイッチ回路に対して個々に制御信号(符号UおよびD)に与える。符号Uで示す制御信号がう上側スイッチ回路ECMの接続を制御し、符号Dで示される制御信号が、下側スイッチ回路ECMDの接続を制御する。
この図116に示す他の構成は、図115に示す構成と同じであり、対応する部分には同一参照番号を付し、その詳細説明は省略する。
この図116に示す構成の場合、主演算回路MPA0−MPA3各々において、ALU間シフトビット量を上側スイッチ回路ECMUおよび下側スイッチ回路ECMDそれぞれ個々に設定することができる。したがって、たとえば上側スイッチ回路ECMUに対応するALUにおいて、8ビットシフト動作を行ない、下側スイッチ回路ECMDに対応するALUにおいて2ビットシフト動作を行なうことができ、異なる演算を並列に実行することができる。
なお、このALUシフト制御回路310は、先の変更例3の構成と同様、主演算回路MPA0−MPA3に含まれるコントローラ(21)がそのALUシフト制御動作を行なうように構成されてもよい。また、ALU間シフト動作を制御するために専用に、このALUシフト制御回路310が設けられてもよい。
また、図116に示す構成においては、主演算回路MPA0−MPA3それぞれにおいて、ALU間接続用スイッチ回路が2つのスイッチ回路に分割されている。しかしながら、このALU間接続用スイッチ回路の分割数は2に限定されず、さらに多くのブロックに分割されてもよい。各ブロックごとに、ALUシフト制御回路310により、そのシフト量を制御する。
この図116に示す構成の場合、主演算回路それぞれにおいて、個々に複数のALU間シフト量を設定することができ、主演算回路それぞれにおいて異なる演算処理を行なうことができ、より複雑な演算処理を実現することができる。
[変更例5]
図117は、このALU間接続回路の構成の変更例を示す図である。図117において、図107に示す配線275aおよび275bそれぞれとして、+1ビットシフト線320au、+4ビットシフト線320bu、+16ビットシフト線320cu、およびNバスシフト線320du、−1ビットシフト線320ad、−4ビットシフト線320bd、−16ビットシフト線320cd、−Nバスシフト線320ddが設けられる。Nバスシフト線320duおよび320ddは、隣接ブロック間データバスNBSの配線である。
図117は、このALU間接続回路の構成の変更例を示す図である。図117において、図107に示す配線275aおよび275bそれぞれとして、+1ビットシフト線320au、+4ビットシフト線320bu、+16ビットシフト線320cu、およびNバスシフト線320du、−1ビットシフト線320ad、−4ビットシフト線320bd、−16ビットシフト線320cd、−Nバスシフト線320ddが設けられる。Nバスシフト線320duおよび320ddは、隣接ブロック間データバスNBSの配線である。
このAUL間接続回路は、さらに、シフトコマンド信号に従って信号線320au−320duの一方を選択するマルチプレクサ(MUX)315uと、同様、シフトコマンド信号に従って信号線320ad−320ddのいずれかを選択するマルチプレクサ(MUX)315dと、これらのマルチプレクサ315uおよび315dを介して選択された信号線と対応のALUユニット319との間でデータを双方向に送信および受信する送受信データレジスタ317を含む。
送受信データレジスタ317へは、+シフト/−シフトを指定する転送方向指示信号U/Dが与えられる。
これらの転送方向指示信号を含むシフトコマンド信号は、対応の基本演算ブロックのコントローラからのALU制御信号として生成されても良く、また、先の変更例3または4のシフト制御回路300または310から生成されても良い。
また、送受信データレジスタ317は、図104および106に示す送受信レジスタ270に対応する。
これらのマルチプレクサ315uおよび315dが、先の図105に示すプログラマブルスイッチ回路PSWとして利用されてもよい。マルチプレクサ315uおよび315dの接続を制御することにより、先の図105から図111に示すプログラマブルスイッチ回路PSWのスルー状態、分断状態およびダミー状態を実現することができる。
図118は、図117に示す送受信データレジスタ317の構成の一例を示す図である。対応のALUユニット319においては、このALU間データ転送を行なうレジスタ回路として、Xレジスタ320を代表的に示す。このALUユニット319において、XHレジスタ、XLレジスタ、またはZレジスタなどの別のレジスタが、ALU間データ転送に用いられてもよい。
送受信データレジスタ317は、Xレジスタ320の出力OUTからのデータビットを受ける送信レジスタ325と、与えられたデータを取込んで、Xレジスタ320の入力INへ伝達する受信レジスタ326と、転送方向指示信号U/Dに従って送信レジスタ325および受信レジスタ326を選択的にプラス(+)方向シフト配線320uおよびマイナス(−)方向シフト配線320dに接続する経路設定回路330を含む。
プラス方向320uシフト配線は、図117に示すシフト配線320au−320duを含み、マイナス方向シフト配線320dは、図117に示すシフト配線320ad−320ddを含む。この図118に示す構成において、図117に示すマルチプレクサ315uおよび315dは示していない。
この図118に示す構成において、プラス(+)方向にデータビットを転送する場合、経路設定回路330は、送信レジスタ325をプラス方向シフト配線320uに結合し、受信レジスタ326をマイナス方向シフト配線320dに結合する。送信レジスタ325のデータが上方向のALUに転送されて対応の接続先の受信レジスタに格納される。受信レジスタ326が、下側からのALUの送信レジスタから転送されたデータを格納する。
マイナス方向にデータ転送を行なう場合には、この経路設定回路330は、送信レジスタ325を、マイナス方向シフト配線320dに接続し、受信レジスタ326をプラス方向シフト配線320uに接続する。送信レジスタ325が、下側の接続先のALUの受信レジスタにデータを転送し、受信レジスタ326が、上側のソースALUから送信されたデータを受信する。
これにより、マイナス方向およびプラス方向いずれの方向においてもデータビットのシフト(転送)が行なわれる場合においても、データの送受信を行なうことができる。この図118に示す送信レジスタ325および受信レジスタ326は、図104に示すALU間接続回路の構成において、送受信レジスタ270として用いられる。
また、経路設定回路330は、スイッチ回路で接続を切り換えるスイッチマトリクスで構成されても良い。また、また、経路設定回路330において、送信用トライステートバッファおよび受信用トライステートバッファの組をデータ転送方向に応じて2組設け、トライステートバッファの組を選択的に活性化してデータ転送方向が設定されても良い。
[変更例6]
図119は、この発明の実施の形態19の変更例6の構成を概略的に示す図である。この図119に示す構成においては、ALU間の接続配線が、メモリセルマット30をY方向(エントリ延在方向)に延在する配線340と、X方向にメモリセルマット30を延在してそれぞれ所定ビット離れた配線340を相互接続する配線342とにより形成される。
図119は、この発明の実施の形態19の変更例6の構成を概略的に示す図である。この図119に示す構成においては、ALU間の接続配線が、メモリセルマット30をY方向(エントリ延在方向)に延在する配線340と、X方向にメモリセルマット30を延在してそれぞれ所定ビット離れた配線340を相互接続する配線342とにより形成される。
ALUユニット群32において、たとえば先の図112に示すように4つのALUが1列に整列して配置される場合(ALUのピッチがビット線ピッチの4倍の場合)、4ビット離れた配線340を相互接続することにより、64ビット転送の経路を形成することができる。ALUユニット群32内に長距離にわたる配線を配置する構成に代えて、メモリセルマット30上に長距離間データ転送配線を配置することにより、配線レイアウトが容易となる。
なお、このメモリセルマット30上を延在して配置される配線340および342は、たとえば128ビット離れたALUを相互接続する配線であってもよい。
また、このALU間相互接続用スイッチ回路の構成において、ビットシフト量は、2n
(n=0…8)の構成が一例として示されている。しかしながら、実行される演算内容に応じて、シフトされるビット量およびそのシフトに必要とされるクロックサイクル数に応じてまたメモリセルマット30に含まれるエントリの数に応じて、適当なシフト量を実現するシフト配線接続が用いられればよい。
(n=0…8)の構成が一例として示されている。しかしながら、実行される演算内容に応じて、シフトされるビット量およびそのシフトに必要とされるクロックサイクル数に応じてまたメモリセルマット30に含まれるエントリの数に応じて、適当なシフト量を実現するシフト配線接続が用いられればよい。
以上のように、この発明の実施の形態19に従えば、主演算回路におけるALU間の接続経路を各主演算回路個々に設定し、また接続経路をプログラマブルに設定することにより、ALU間相互接続用配線面積を増大させることなく、効率的に、ALU間接続を実現することができ、並列演算性能を、配線レイアウト面積と増大させることなく向上させることができる。
[実施の形態20]
図120は、この発明の実施の形態20に従う入出力回路10の構成を概略的に示す図である。この入出力回路10は、図1に示すように、システムバス5を介してホストCPUに結合される。内部データバス16(グローバルデータバスGBS)は、内部の複数の基本演算ブロックに共通に結合される。
図120は、この発明の実施の形態20に従う入出力回路10の構成を概略的に示す図である。この入出力回路10は、図1に示すように、システムバス5を介してホストCPUに結合される。内部データバス16(グローバルデータバスGBS)は、内部の複数の基本演算ブロックに共通に結合される。
入出力回路10は、jビットのホストシステムバス5(バス線HBS[(j−1):0])と内部のkビットの第1の内部転送バスCBS[(k−1):0]との間でデータ転送を行ないかつデータビット配列の直交変換を行なう直交変換回路400と、kビットの第1の内部転送バスCBS[(k−1):0]とmビットの第2の内部転送バスSBS[(m−1):0]の間で選択的にデータ転送経路を設定してデータビットの転送を行なうクロスバースイッチ402と、第2の内部転送バスSBS[(m−1):0]とnビットの内部データバス16(グローバルデータバスGBS[(n−1):0]の間でデータの転送を行なうセレクタ404を含む。
ホストシステムバス5は、シングルエンドのバス線で構成され、第1および第2の転送バスCBSおよびSBS並びにグローバルデータバスGBS(内部データバス16)は、各々、ダブルエンドのバス線で構成され、相補信号を伝達する。以下の説明において、これらのバスについて各ビットを特に参照しない場合には、符号CBS、SBS、GBSおよびHBSを用いて、バスを参照する。
入出力回路10において、jビットのワードシリアルかつビットパラレル態様で転送されるデータとnビットのグローバルデータバスGBS上に伝達されるワードパラレルかつビットシリアルのデータの間のデータ配列の変換および転送データビット幅の変換が行なわれる。
図121は、図120に示す直交変換回路400の第1の転送バスCBSからホストシステムバスHBS(バス5)にデータを転送する出力部分の構成を概略的に示す図である。図121において、直交変換回路400のデータ出力部は、k行j列に配列される変換素子TXF00−TXF(k−1)(j−1)を含む。変換素子TXF00−TXF(k−1)(j−1)は同一構成を有するため、図121においては、変換素子TXF00の構成を代表的に示す。変換素子TXF00は、クロック入力に与えられる制御信号SDoi[0]に従って相補内部データバス線CBS[0]および/CBS[0]上の信号を取込みラッチするフリップフロップFFaと、出力制御信号SToo[0]に従ってフリップフロップFFaの出力信号をシングルエンドのシステムバス線HBS[0]へ伝達するトライステートバッファBFを含む。
変換素子TXF(変換素子を総称的に示す)の各行に対応して第1の内部転送バス線CBS[u],/CBS[u]が配設され、変換素子各列に対応してホストシステムバス線HBS[v]が配設される。ここで、u=0〜(k−1)であり、v=0〜(j−1)である。
行方向に整列する変換素子TXFに対して共通に出力制御信号SToo[u]がそれぞれの出力バッファBFに与えられる。列方向に整列する変換素子のフリップフロップFFaのクロック入力に対し共通に、入力制御信号SDoi[v]が与えられる。
これらの制御信号SDo[(j−1):0]およびSToo[(k−1):0]は、ホストCPUからの制御の下に、図1に示す制御用CPU(25)が生成してもよく、また各基本演算ブロック内に設けられるコントローラからのDMA転送要求に従って、CPU25が同様に生成してもよい。また、ホストCPUが直接生成しても良く、DMAモード転送のときには外部のDMAコントローラの制御の下に生成されても良い。
図122は、この図121に示す直交変換回路400の出力部の動作を模式的に示す図である。第1の内部転送バスCBSから、ビットシリアルかつワードパラレルの態様でデータが転送される。今、データビットA[a]、B[a]・・・G[a]が並列に与えられる。この場合、入力制御信号SDoi(a)に従って、第a列の変換素子TXFが、与えられたデータビットを取込みラッチする。したがって、この直交変換回路400において、第1の内部転送バスCBSからのデータによりフル状態となった場合には、列方向において、ワードA、B、…Gの同一ビット位置のデータが配列され、行方向には、各ワードのビットが整列して配置される。
データ出力時においては、出力制御信号SDoo[b]に従って行方向に整列する変換素子TXFが同時に出力状態に設定される。したがって、ホストシステムバスHBSには、1つのデータワードDの各ビット[0]−[j−1]が並列に出力される。これにより、第1の内部転送バスCBSからエントリの同一位置のビットが並列に転送されてきた場合、ホストシステムバスHBSに、各データワードがシリアルに出力される。
図123は、変換素子TXFの構成の一例を示す図である。図123において、フリップフロップFFaは、入力制御信号SDoi[u]に従って転送バス線CBS[s]および/CBS[s]上の信号を伝達するトランスファーゲート421aおよび421bと、活性化時、トランスファーゲート421aおよび421bから転送されたデータを差動的に増幅する交差結合型差動増幅回路422と、入力制御信号SDoi[u]に従って交差結合型差動増幅回路422のPチャネルMOSトランジスタへ電源電圧を供給するPチャネルMOSトランジスタ423pと、この入力制御信号SDoi[u]の反転信号ZSDoi[u]に従って交差結合型差動増幅回路422のNチャネルMOSトランジスタを接地ノードに結合するNチャネルMOSトランジスタ423nを含む。
このフリップフロップFFaは、入力制御信号SDoi[u]がHレベルのときに、対応の転送バス線CBS[s]および/CBS[s]上の信号を、交差結合型差動増幅器422に伝達する。入力制御信号SDoi[u]が非活性状態となると、交差結合型差動増幅回路422が、MOSトランジスタ423pおよび423nにより活性化され、トランスファーゲート421aおよび421bにより転送されたデータを差動的に増幅してラッチする。
トライステートバッファBFは、電源ノードに結合されかつフリップフロップFFaの出力Qをインバータを介してゲートに受けるPチャネルMOSトランジスタPX1と、接地ノードに結合されかつフリップフロップFFaの出力/Qをゲートに受けるNチャネルMOSトランジスタNX1と、出力制御信号SDoo[v]に従ってMOSトランジスタNX1を対応のホストシステムバス線HBS[t]に結合するNチャネルMOSトランジスタNX2と、出力制御信号SDoo[v]のインバータを通した信号に応答してMOSトランジスタPX1を対応のホストシステムバス線HBS[t]に結合するPチャネルMOSトランジスタPX2を含む。
この図123に示すトライステートバッファBFは、出力制御信号SDoo[v]がLレベルのときには、MOSトランジスタPX2およびNX2がともにオフ状態であり、出力ハイインピーダンス状態である。
出力制御信号SDoo[v]がHレベルとなると、MOSトランジスタPX2およびNX2がオン状態となり、MOSトランジスタPX1およびNX1が、対応のホストシステムバス線HBS[t]に結合され、フリップフロップFFの出力Q、/Qの信号に従ってホストシステムバス線HBS[t]を駆動する。
この図123に示す変換回路TXFの構成は単なる一例であり、別の構成が用いられてもよく、入力制御信号SDoi[u]に従って相補信号を取込みラッチし、出力制御信号SDoo[v]の活性化時、この取込んだ相補信号に従ってシングルエンドのシステムバス線を駆動する構成であれば任意の回路構成を利用することができる。
図124は、図120に示す直交変換回路400のデータ入力部の構成を概略的に示す図である。図124においては、ホストシステムバスHBSを介して伝達される1ワードのデータに対する入力部の構成を示す。ホストシステムバスHBSのビット幅(jビット)に応じて、この図124に示す入力部の構成が拡張され、また第1の内部転送バスCBSのビット幅(kビット)に従って、この図124に示す構成が列方向に繰返し配置される。
図124において、直交変換回路400の入力部は、ホストシステムバスHBSのバス線HBS[0]−HBS[7]それぞれに対して設けられる入力変換素子TXFI0−TXFI7と、ワード単位でデータのマスクを指示するマスク信号線HBSm[0]に従って、これらの入力変換素子TXFI0−TXFI7の出力にマスクをかけるワードマスク制御回路430を含む。
入力変換素子TXFI0−TXFI7は、各々、入力制御信号SDii[x]に従って対応のホストシステムバス線HBS[0]−HBS[7]上の信号を取込むフリップフロップFFbと、活性化時、対応のフリップフロップFFbのラッチ信号に従って転送バス線CBS[x]および/CBS[x]に相補信号を伝達するトライステートバッファ432と、ワードマスク制御回路430からのマスク制御信号と対応の出力制御信号SDio[a]とを受けて対応のトライステートバッファ432を活性化するAND回路431を含む。ここで、出力制御信号SDio[a]において、a=0−7である。
ワードマスク制御回路430は、リセット信号SDir[x]に応答してリセットされ、対応の1ワード(8ビット)の入力変換素子TXFI0−TXFI7の出力にマスクをかけるフリップフロップFFcと、フリップフロップFFcの出力信号とマスク信号線HBSm[0]上の信号とを受けるNORゲート433を含む。フリップフロップFFcは、NORゲート433の出力信号を入力制御信号SDii[x]に従って取込みラッチする。次に、この図124に示す直交変換回路400の入力部の動作について説明する。
ホストシステムバスHBSからデータが転送されるとき、まず、リセット信号SDir[x]が活性化され、ワードマスク制御回路430のフリップフロップFFcがリセットされる。これにより、入力変換素子TXFI0−TXFI7それぞれにおいて、ANDゲート431がディスエーブルされ、入力変換素子が、出力ハイインピーダンス状態に設定される。
入力制御信号SDii[x]とホストシステムバスのマスク信号線HBSm[0]とに従って、ホストシステムバス線HBS[0]−HBS[7]上のデータビットが、入力変換素子TXFI0−TXFI7のそれぞれのフリップフロップFFb内に選択的に取込まれる。マスク信号線HBSm[0]上の信号がHレベルのときには、ワードマスク制御回路430のNORゲート433の出力信号が、Hレベルとなり、フリップフロップFFcが、入力制御信号SDii[x]に従ってこのHレベルの信号を取込みラッチする。フリップフロップFFcのHレベルの出力信号に従って、入力変換素子TXFI0−TXFI7それぞれのANDゲート431がイネーブルされる。このとき、また、入力制御信号SDii[x]に従って入力変換素子TXFI0−TXFI7それぞれにおいてフリップフロップFFbが、ホストシステムバス線HBS[0]−HBS[7]上の信号を取込みラッチする。
マスク信号HBSm[0]がLレベルのときには、ワードマスク制御回路430のフリップフロップFFcの出力信号はLレベルであり、入力変換素子TXFI0−TXFI7それぞれにおいて、ANDゲート431はディスエーブル状態に維持される。このときにも、対応のホストシステムバス線上のデータ信号の取込はフリップフロップFFbにおいて実行される。ラッチデータビットの出力時においては、出力制御信号SDio[0]−SDio[7]が順次活性化される。ワードマスク制御回路430の出力信号がLレベルのときには、これらのANDゲート431の出力信号がLレベルであるため、対応の出力制御信号SDio[0]−SDio[7]がHレベルに活性化されても、トライステートバッファ432は出力ハイインピーダンス状態である。したがって、この場合には、入力変換素子TXFI0−TXFI7からデータビットの転送は行なわれず、CPUからのワードに対してマスクがかけられる。
ワードマスク制御回路430の出力信号がHレベルのときには、ANDゲート431が、出力制御信号SDio[0]−SDio[7]に従ってそれぞれ活性化され、トライステートバッファ432が対応のフリップフロップFFbのラッチ信号に従って相補転送バス線/CBS[x]およびCBS[x]を駆動する。
図125は、この図124に示す直交変換回路400の入力部のデータ転送動作を模式的に示す図である。直交変換回路400においては、データ入力時、入力制御信号SDii[x]に従って、ホストシステムバスHBS上のデータが取込まれてラッチされる。このホストシステムバスHBS上のデータはワード単位でマスクデータm[0]−m[(j−8)/8]に従って選択的にマスクがかけられる。最終的に入力制御信号SDii[j−1]が活性化されると、この直交変換回路400の入力部において格納領域が一杯となる。
データ出力時においては、出力制御信号SDio[v]に従って、図の斜線で示す縦方向に1列に整列するデータが第1の内部転送バスCBS上に並列に転送される。今、マスク信号HSBMに従ってマスクが指定されたマスクデータMSDTが存在する場合、対応の転送バス線CBS[k−1]上には、データは転送されず、このマスクデータMSDTにマスクがかけられる。
この入力部の構成を用いることにより、ホストCPUからのデータをワード単位でマスクをかけて、内部の基本演算ブロックの主演算回路のメモリセルマットへ格納することができる。
なお、制御信号SDii[x]、リセット信号SDir[x]および出力制御信号SDio[v]は、外部のホストCPUまたは図1に示す集中制御ユニット15から、データ入力時に生成されてもよく、また、専用のカウンタ回路(シフトレジスタ)により、これらの制御信号が順次活性化されてもよい。
この図121に示す出力部および図124に示す入力部を2セット設け、これらの入力/出力部を、インタリーブ態様で動作させることにより、外部のホストCPUおよび内部データバスの間のデータ転送速度の差を吸収して、連続的に(ギャップレスで)データ転送を行なうことができる。
なお、この直交変換回路400においては、変換素子を構成するためにフリップフロップとトライステートバッファ回路が用いられている。しかしながら、先の実施の形態において示したように、デュアルポートメモリを用いて、一方のポートをホストシステムバスに結合し、他方のポートを第1の内部転送バスに結合する構成を利用してもよい。このようなデュアルポートメモリを利用する場合、面積利用効率を改善することができ、チップ面積を低減することができる。
図126は、図120に示されるクロスバースイッチの構成を概略的に示す図である。図126においては、第2の内部転送バスSBS[(m−1):0]のうち1ビットの転送バスSBS[y]および/SBS[y]に対するクロスバースイッチの構成を示す。この図126に示す構成が、第2の内部転送バスSBSの各バス線に対して設けられる。
図126において、クロスバースイッチ402は、第1の内部転送バス線CBS[0],CBS[0]−CBS[m−1],/CBS[m−1]のそれぞれに対して設けられるデコーダDDD0−DDD(m−1)と、デコーダDDD0−DDD(m−1)の出力信号に従って、第1の内部転送バス線CBS[0],/CBS[0]−CBS[m−1],/CBS[m−1]を第2の内部転送バス線SBS[y]/SBS[y]に接続する選択スイッチ回路DSW0−DSW(m−1)を含む。
デコーダDDD0−DDD(m−1)は、接続制御信号DEC[0]−DEC[4]をデコードするデコード回路440と、デコード回路440の出力するプリデコード信号に従ってスイッチ制御信号を対応のスイッチ回路DSW0−DSW(m−1)に出力するAND回路441を含む。
接続制御信号DEC[0]−DEC[4]は、5ビットの接続制御信号であり、第1の内部転送バスCBSが32ビットの場合を想定する。この接続制御信号DECのビット幅は、第1の内部転送バスCBSのバス幅に応じて定められる。デコーダDDD0−DDD(m−1)の1つの出力信号が選択状態となり、対応の選択スイッチ回路DSW(DSW0−DSW(m−1)のいずれか)が導通状態となり、選択された第1の内部転送バス線CBS[z],/CBS[z]が、第2の内部転送バス線SBS[y],/SBS[y]に接続される。
第2の内部転送バス線SBSのバス線それぞれにおいて、このデコード動作に基づいて接続を設定することにより、第1の内部転送バスCBSと第2の内部転送バスSBSとのバス幅を整合させて選択的な接続を形成することができる。
図127は、図126に示す接続制御信号DEC[0]−DEC[4]を発生する部分の構成を概略的に示す図である。図127において、接続制御信号発生回路は、行列状に配列されるレジスタ回路XG00−XG34と、第2の内部転送バス線SBS[y]および/SBS[y]上の信号を増幅してシングルエンドの信号を生成するセンスアンプ回路SACと、レジスタ回路XG00−XG34のY方向に整列するレジスタ回路それぞれに対応して設けられ、それぞれ選択信号SCb[0]−SCb[4]に従って選択的に導通し、導通時、センスアンプ回路SACの出力信号を伝達する選択ゲートSSG0−SSG4と、レジスタ回路XG00−XG34の各列に対応して設けられ、対応のレジスタ回路の出力信号を増幅して接続制御信号DEC[0]−DEC[4]をそれぞれ生成するドライバDRV0−DRV4を含む。
レジスタ回路XG00−XG34においては、X方向に整列するレジスタ回路に共通に入力制御信号SCi[0]−SCi[3]および出力制御信号SCc[0]−SCc[3]がそれぞれ与えられる。
レジスタ回路XG00−XG34の各々は、対応の入力制御信号SCi[z]に従って対応の選択ゲートSSG(SSG0−SSG4のいずれか)からのデータを転送するトランスファーゲート452と、トランスファーゲート452を介して与えられたデータをラッチするラッチ回路453と、出力制御信号SCc[z]に従って対応のラッチ回路453にラッチされたデータを対応のドライバDRV(DRV0−DRV4)へ転送する転送ゲート454を含む。ラッチ回路453は、インバータで構成されるラッチを備え、与えられた信号をラッチする。
センスアンプ回路SACは、センスアンプ活性化信号SCsに従って活性化され、基本演算ブロックから第2の内部転送バス線SBS[y]および/SBS[y]上に転送されたデータビットを増幅する。
この図127に示す接続制御信号発生部の構成においては、センスアンプ回路SACが生成した1ビットコンテキスト情報が、選択ゲートSSG0−SSG4と入力制御信号SCi[0]−SCi[3]より選択されたレジスタ回路へ転送されてラッチされる。X方向に整列するレジスタ回路XGa0−XGa4に、クロスバースイッチの接続態様を決定する1つのコンテキスト情報が格納される。したがって、基本演算ブロックから内部転送バス線SBS[y],/SBS[y]へ5ビットシリアルに情報を転送し、このデータ転送と同期して選択信号SCb[0]−SCb[4]を活性状態とすることにより、選択ゲートSSG0−SSG4を介してコンテキスト情報ビットが転送される。このときに、1つの入力制御信号SCiを選択状態に維持することにより、X方向に整列するレジスタ回路に転送されたコンテキスト情報ビットが順次ラッチされる。これにより、X方向に整列するレジスタ回路により、1つのクロスバースイッチの接続態様を決定するコンテキスト情報が格納される。
したがって、入力制御信号SCi[0]−SCi[3]それぞれがコンテキスト情報を選択することができるため、4ウェイのコンテキスト情報(4面のコンテキスト情報)を格納することができる。必要な接続態様を決定するコンテキスト情報は、出力制御信号SCc[0]−SCc[3]のいずれかを活性状態にすることにより読出されて、ドライバDRV0−DRV4を介して伝達される。これにより、図126に示すデコーダDDD0−DDD(a−1)により、32対の内部転送バス線CBS[0],/CBS[0]−CBS[m−1],/CBS[m−1]の1つが選択される。
このクロスバースイッチの接続態様を決定するために4種類の情報を格納することにより、クロスバースイッチの接続態様をリアルタイムで切換えることができ、データ配列順序を、転送時に容易に変換して演算を行なうことができる。例えば、第1の内部転送バスCBSが8ビットであり、第2の内部転送バスSBSが32ビットの場合、この4面のコンテキスト情報により、クロスバースイッチ402において、8ビットデータの転送を行う経路を順次切り換えることにより、バス幅の調整を行ってデータの転送を行うことができる。
図128は、クロスバースイッチ402の全体構成を概略的に示す図である。図128において、クロスバースイッチ402は、第2の内部転送バス線SBS[0]−SBS[k−1]それぞれに対応して配置されるスイッチ列460aを含むスイッチマトリクス464と、スイッチ列464aそれぞれに対応して配置されるデコーダ群462aを含み、スイッチマトリクス464の接続経路を設定するルート決定回路462と、デコーダ群462aそれぞれに対応して配置されるコンテキスト情報格納部460aを含み、ルート決定回路462の接続ルートを決定する情報を格納するルート情報格納回路460を含む。
スイッチ列464aは、図126に示す選択スイッチ回路DSW0−DSW(m−1)を含み、第1の内部転送バス線CBS[0]−CBS[m−1]のいずれかを対応の第2の内部転送バス線SBS[0]−SBS[k−1]に接続する。
デコーダ群462aは、図126に示すデコーダDDD0−DDD(j−1)を含み、対応のスイッチ列464aの選択スイッチ回路の導通/非導通を設定する。
コンテキスト情報格納回路460aは、図127に示す構成を備え、対応のデコーダ群462aに対し、4種類のコンテキスト情報を格納し、出力制御信号SCcに従って、格納したコンテキスト情報のいずれかを対応のデコーダ群462aに出力する。
このルート情報格納回路460へは、センスアンプ回路群466からのkビットの経路指定情報が与えられる。センスアンプ回路群466は、図127に示すセンスアンプ回路SACを第2の内部転送バス線SBS[0]−SBS[k−1]それぞれに対応して含み、活性化時、基本演算ブロックから与えられたkビットのデータを増幅して、それぞれ対応のコンテキスト情報格納回路460aに転送する。
内第2の内部転送バス線SBS[0]−SBS[k−1]へは、基本演算ブロックFBiの経路情報格納メモリ460からの情報が、内部のコントローラ21の制御の下に読出されて転送される。このコントローラ21は、集中制御ユニット15に含まれる制御用CPU25の制御の下に動作し、メモリ460に格納された接続情報を順次出力する。この制御用CPU25は、また経路情報格納回路460に対する制御信号SCb、SCc、およびSCiをそれぞれ出力する。選択制御信号SCbが5回トグルされることにより、信号SCb[4:0]が1回全て選択され、1つのコンテキスト情報の格納が完了する。
経路情報格納メモリ460については、主演算回路内のメモリセルマットの特定の領域が用いられてもよく、またメモリセルマットと別に専用に設けられても良い。
制御用CPU25はまた、センスアンプ回路群466に含まれるセンスアンプ回路(SAC)に対するセンス活性化信号(SCc)を生成する(この経路は示さず)。
図129は、図128に示すデコーダ群462aのデコーダ/スイッチ回路(単位接続回路と以下称す)とデコード信号の対応関係を概略的に示す図である。図129において、単位接続回路UCBSW0は、接続制御信号DECが0(十進)のときに、第1の転送バス線CBS[i]を第2の転送バス線SBS[i]に接続する。単位接続回路UCBSWxは、接続制御信号DECが(0+x)(十進)のとき、第1の内部転送バス線CBS[(i+x)mod.m]を第2の内部転送バス線SBS[i]に接続する。
第1の内部転送バスCBSはmビット幅であり、接続制御信号DECが“0”のときには、常に、第1の内部転送バス線CBS[i]が第2の内部転送バス線SBS[i]に接続される。従って、この接続経路がサイクリックに切換える場合においても、接続制御信号DECのモジューロmの演算値により、この第1の内部転送バスCBSの接続を容易に決定することができ、各デコーダ群462aにおいて、デコード信号DECが“0”のときには、それぞれ同一番号の転送バス線CBS[j]およびSBS[j]の接続を行なうことができ、接続情報のためのプログラムが容易となる。
図130は、図120に示すセレクタ404の構成を概略的に示す図である。図130においては、1つの第2の内部転送バス線SBS[z],/SBS[z]に対するセレクタの構成を示す。この図130に示す構成においては、グローバルデータバスGBSは、第2の内部転送バスSBSの4倍のビット幅を有する(n=4・m)。
セレクタ404は、選択信号SS[0]に従ってグローバルデータバス線GBS[4z],/GBS[4z]を転送バス線SBS[z],/SBS[z]に接続する接続ゲートTGW0と、選択信号SS[1]に従ってグローバルデータバス線GBS[4z+1],/GBS[4z+1]を転送バス線SBS[z],/SBS[z]に接続する接続ゲートTGW1と、選択信号SS[2]に従ってグローバルデータバス線GBS[4z+2],/GBS[4z+2]を転送バス線SBS[z],/SBS[z]に接続する接続ゲートTGW2と、グローバルデータバス線GBS[4z+3],/GBS[4z+3]を選択信号SS[3]に従って転送バス線SBS[z],/SBS[z]に接続する接続ゲートTGW3を含む。
これらのグローバルデータバス線GBS[4z],/GBS[4z]−GBS[4z+3],/GBS[4z+3]は、互いに隣接するデータバス線であることは特に要求されない。mビット離れたバス線であってもよい。
選択信号SS[0]−SS[3]は、図1に示す集中制御ユニット15に含まれる制御用CPU25から生成され、データ転送時、順次活性化される。
図131は、この図130に示すセレクタ404の選択動作を模式的に示す図である。第2の内部転送バスSBS上では、mビットのデータD0−D3が順次転送される。セレクタ404は、1/4選択を行っており、本実施の形態においては、選択信号SS[3:0]に従ってグローバルデータバスGBSのmビットのバス線を順次選択する。これにより、セレクタ404からのデータD0、D1、D2およびD3が、グローバルデータバスGBSのそれぞれmビットのデータバス線に分配される。
このグローバルデータバスGBSにおいて、この図131に示す選択方式の場合、データD0−D3は、各々、互いに異なるデータワードのビットで構成され、データD0−D3は、各々異なるエントリに格納される。
データD0−D3が、それぞれデータワードAD−DDの組の異なるビットで構成されるように、同一ワードの組の異なるデータビットで構成され、これらのデータD0−D3を、順次主演算回路内のメモリセルマットの共通のエントリに書込む必要がある場合には、セレクタ404の接続経路が固定され、たとえばグローバルデータバスGBSの特定のmビットのデータ線に連続的にデータD0−D3が出力される。この状態を図132に示す。
図132において、グローバルデータバス線GBS[4z]にデータD0−D3が順次転送される場合を示す。ただし、4zは0から(m−1)であり、隣接データバス線で構成される。これにより、同一ワードのデータビットを順次同一のグローバルデータバス線を介して転送することができ、応じて、主演算回路内のメモリセルマットの共通のエントリに順次格納することができる。セレクタ404は双方向スイッチ回路であり、グローバルデータバスGBSから第2の内部転送バスSBSのデータ転送時にも、この図131または図132に示すデータの転送シーケンスに従ってデータ転送が行なわれる。
なお、この図132に示すデータの分配においても、グローバルデータバスGBSにおいてデータD0−D3は、グローバルデータバスGBSのmビットの隣接バス線GBS[(j−1):0]に配置されている。しかしながら、隣接バス線ではなく、たとえばGBS[4z|z=0〜(m−1)]のように、すなわち、GBS[0]、GBS[4]・・・のように互いにmビット離れたバス線に分散して配置されても良い。
このデータバスの接続制御においては、主演算回路のメモリセルマットのエントリにワードの各ビットが格納されるという条件が満たされ、入出力回路でデータ配列の変換が行われるという条件が満たされる限り、このデータの分配経路の設定は任意に定めることができる。
以上のように、この発明の実施の形態20に従えば、外部CPUに接続されるシステムバスと内部の基本演算ブロックが接続されるグローバルデータバスの間に、データの並べ替えおよびビット幅を調整する入出力回路を設けており、確実に、ホストCPUの処理するデータワードのビット幅にかかわらず、各基本演算ブロックの主演算回路内のエントリに、各ワードをビットシリアル態様で転送することができる。
[実施の形態21]
図133は、この発明の実施の形態21に従う半導体集積回路装置の構成を示す回路ブロック図である。図133において、この半導体集積回路装置は、複数(ここでは4つとする)の機能ブロックFBA1〜FBA4と、4つの機能ブロックFBB1〜FBB4と、クロスバースイッチとを備える。機能ブロックFBA1〜FBA4は図中X方向に配列され、機能ブロックFBB1〜FBB4は図中X方向に配列され、機能ブロックFBB1〜FBB4はそれぞれ機能ブロックFBA1〜FBA4に対向して配置される。
図133は、この発明の実施の形態21に従う半導体集積回路装置の構成を示す回路ブロック図である。図133において、この半導体集積回路装置は、複数(ここでは4つとする)の機能ブロックFBA1〜FBA4と、4つの機能ブロックFBB1〜FBB4と、クロスバースイッチとを備える。機能ブロックFBA1〜FBA4は図中X方向に配列され、機能ブロックFBB1〜FBB4は図中X方向に配列され、機能ブロックFBB1〜FBB4はそれぞれ機能ブロックFBA1〜FBA4に対向して配置される。
これらの機能ブロックFBA1〜FBA4およびFBB1〜FBB4は、これまでの実施の形態において説明した主演算回路に対応する回路ブロックであってもよく、また、別の各々所定の演算処理が割当てられる回路ブロックであってもよい。以下の実施の形態においては、機能ブロックは単に演算処理を行うことのできる構成であればよい。
クロスバースイッチは、機能ブロックFBA1〜FBA4と機能ブロックBB1〜BB4との間に配置され、機能ブロックFBA1〜FBA4と機能ブロックBB1〜BB4とを1対1で任意の組合せで接続する。接続の組合せは、4!通りある。
すなわち、クロスバースイッチは、セレクト信号線対LLP1〜LLP8、データ信号線LL1〜LL8、デコード回路501〜516、およびワイヤードORスイッチ521〜536を含む。データ信号線LL5〜LL8の各々は、図中機能ブロックFBB1から機能ブロックFBB4にわたって、X方向に延在するように設けられる。データ信号線LL1〜LL4の各々は図中X方向と直交する図中Y方向に延在し、データ信号線LL1〜LL4の一方端はそれぞれ機能ブロックFBA1〜FBA4のデータ信号端子に接続され、データ信号線LL1〜LL4の他方端はビアホールを介してそれぞれデータ信号線LL5〜LL8に接続される。
ワイヤードORスイッチ521〜524;525〜528;529〜532;533〜536は、それぞれデータ信号線LL5〜LL8に対応して配置される。ワイヤードORスイッチ521〜524は、それぞれ対応のデータ信号線LL5と機能ブロックFBB1〜FBB4のデータ信号端子との間に接続され、それぞれデコード回路501〜504の出力信号によって制御される。ワイヤードORスイッチ525〜528は、それぞれ対応のデータ信号線LL6と機能ブロックFBB1〜FBB4のデータ信号端子との間に接続され、それぞれデコード回路505〜508の出力信号によって制御される。
ワイヤードORスイッチ529〜532は、それぞれ対応のデータ信号線LL7と機能ブロックFBB1〜FBB4のデータ信号端子との間に接続され、それぞれデコード回路509〜512の出力信号によって制御される。ワイヤードORスイッチ533〜536は、それぞれ対応のデータ信号線LL8と機能ブロックFBB1〜FBB4のデータ信号端子との間に接続され、それぞれデコード回路513〜516の出力信号によって制御される。
セレクト信号線対LLP1〜LLP4の各々は図中Y方向に延在し、セレクト信号線対LLP1〜LLP4の一方端はそれぞれ機能ブロックFBA1〜FBA4のセレクト信号端子対に接続され、セレクト信号線対LLP1〜LLP4の他方端はそれぞれデコード回路501,506,511,516に接続される。
セレクト信号線対LLP5〜LLP8の各々は、図中X方向に延在し、機能ブロックFBB1から機能ブロックFBB4にわたって設けられる。セレクト信号対LLP5は、ビアホールを介してセレクト信号対LLP1に接続され、機能ブロックFBA1からのセレクト信号をデコード回路502,503,504の各々に伝達させる。セレクト信号対LLP6は、ビアホールを介してセレクト信号対LLP2に接続され、機能ブロックFBA2からのセレクト信号をデコード回路505,507,508の各々に伝達する。セレクト信号対LLP7は、ビアホールを介してセレクト信号対LLP3に接続され、機能ブロックFBA3からのセレクト信号をデコード回路509,510,512の各々に伝達させる。セレクト信号対LLP8は、ビアホールを介してセレクト信号対LLP4に接続され、機能ブロックFBA4からのセレクト信号をデコード回路513,514,515の各々に伝達させる。
機能ブロックFBA1〜FBA4の各々からセレクト信号が出力されると、デコード回路501〜504の出力信号のうちのいずれか1つの出力信号と、デコード回路505〜508の出力信号のうちのいずれか1つの出力信号と、デコード回路509〜512の出力信号のうちのいずれか1つの出力信号と、デコード回路513〜516の出力信号のうちのいずれか1つの出力信号とが、活性化レベルの「H」レベルにされる。
これにより、ワイヤードORスイッチ521〜524のうちのいずれか1つ(たとえばスイッチ522)と、ワイヤードORスイッチ525〜528のうちのいずれか1つ(たとえばスイッチ528)と、ワイヤードORスイッチ529〜532のうちのいずれか1つ(たとえばスイッチ529)と、ワイヤードORスイッチ533〜536のうちのいずれか1つ(たとえばスイッチ535)とが導通する。このようにして、機能ブロックFBA1〜FBA4と機能ブロックFBB1〜FBB4とが1対1で任意の組合せで接続される。
図134は、クロスバースイッチの構成をより詳細に示す回路ブロック図である。図134において、ワイヤードORスイッチ521〜524は、それぞれNチャネルMOSトランジスタ(スイッチング素子)521a〜524aを含む。NチャネルMOSトランジスタ521a〜524aの第1の電極(ソースまたはドレイン)はともに対応のデータ信号線LL5に接続され、それらの第2の電極(ドレインまたはソース)はそれぞれ機能ブロックFBB1〜FBB4のデータ信号端子に接続され、それらのゲートはそれぞれデコード回路501〜504の出力信号を受ける。NチャネルMOSトランジスタ521a〜524aは、それぞれデコード回路501〜504の出力信号が「H」レベルにされた場合に導通する。他のワイヤードORスイッチ525〜528;529〜532;533〜536もワイヤードORスイッチ521〜524と同様である。
セレクト信号線対LLP1〜LLP8の各々は、2本の信号線を含む。セレクト信号は、2ビットのデータ信号を含む。デコード回路501〜504の各々には、予め固有のセレクト信号が割り当てられている。たとえばデコード回路501〜504には、それぞれ00,01,10,11のセレクト信号が割り当てられている。デコード回路501は、セレクト信号が00の場合、すなわちセレクト信号に含まれる2ビットの信号がともに「L」レベルになった場合に「H」レベルを出力し、他の場合は「L」レベルを出力する。
デコード回路502は、セレクト信号が01の場合、すなわちセレクト信号に含まれる2ビットの信号がそれぞれ「L」レベルおよび「H」レベルになった場合に「H」レベルを出力し、他の場合は「L」レベルを出力する。デコード回路503は、セレクト信号が10の場合、すなわちセレクト信号に含まれる2ビットの信号がそれぞれ「H」レベルおよび「L」レベルになった場合に「H」レベルを出力し、他の場合は「L」レベルを出力する。デコード回路504は、セレクト信号が11の場合、すなわちセレクト信号に含まれる2ビットの信号がともに「H」レベルになった場合に「H」レベルを出力し、他の場合は「L」レベルを出力する。他のデコード回路505〜508;509〜512;513〜516も、デコード回路501〜504と同様である。
機能ブロックFBA1からセレクト信号が出力されると、デコード回路501〜504のうちのいずれか1つ(たとえばデコード回路1)の出力信号が「H」レベルになり、そのデコード回路501に対応するNチャネルMOSトランジスタ521aが導通し、機能ブロックFBA1のデータ信号端子と機能ブロックFBB1のデータ信号端子とが接続される。
次に、この実施の形態21の効果について説明する。このクロスバースイッチでは、Y方向の配線はデータ信号線LL1〜LL4とセレクト信号線対LLP1〜LLP4の合計12本であり、X方向の配線はデータ信号線LL5〜LL8とセレクト信号線対LLP5〜LLP8の合計12本である。スイッチ521〜536は16個であり、デコード回路501〜516は16個である。
図133のクロスバースイッチと同じ構成で、N=2^m個の機能ブロックFBA1〜FBANとN個の機能ブロックFBB1〜FBBNとを接続するクロスバースイッチを構成することを考える。記号^は、べき乗を示し、Nは2のm乗に等しい。この場合、Y方向の配線は(m+1)N本となり、X方向の配線は(m+1)N本となり、スイッチはN×N個となり、m入力のデコード回路はN×N個となる。
ここで、従来のスイッチマトリクスのように信号線の交差部に対応してスイッチを配置する場合、たとえばN=128(m=7)の場合、一方側の機能ブロックに対して128×128、他方側の機能ブロックに対して128×128および制御信号線が、128×128のY方向の信号線がX方向に延在する128本の信号線を介して結合され、合計Y方向の配線が3×128×128=49152本となり、X方向の配線が128本となり、スイッチが32768個となる(=2×128×128;一方および他方側の機能ブロックに対してスイッチが配置される)。一方、本発明では、Y方向の配線が8×128=1024本となり、X方向の配線が8×128=1024本となり、スイッチが16384となり、デコーダ回路が16384個となる。したがって、本発明は、配線数が少なくなる。また、上述のような単純なスイッチマトリクス構成では、Y方向の配線が密集するとともに、Y方向の配線と機能ブロックとの間のスイッチが密集するのに対し、本発明では配線およびスイッチがX方向とY方向に均等に配分される。よって、本発明は、従来例よりもレイアウト面積が小さくなる。
また、本発明では、機能ブロックFBA1〜FBA4と機能ブロックFBB1〜FBB4との間で双方向のデータ転送を行う場合でも、基本的には図133と同じ構成で実現できる。つまり、接続先情報を含むセレクト信号を機能ブロックFBB1〜FBB4から発信すればよい。したがって、双方向のデータ転送を行う場合は、本発明と単純スイッチマトリクス構成とのレイアウト面積の差は一層大きくなる。
次に、本発明の用途について説明する。図133で示した機能ブロックFBA1〜FBA4,FBB1〜FBB4の各々をALU(Arithmetic and Logic Unit)のユニットセルで構成する。ALUユニットセルは、各種演算ユニットセルで構成されている。複数の基本演算ユニットセル(Add,Mul,Div,Sub,Shift等)を有機的に結合することにより、機能エレメントを構成できる。図133に示したように、複数のALUユニットセルを上下に配置し、クロスバースイッチの動作をプログラミングすることにより、機能エレメントを構成することができる。この場合、結合の方向を双方向にすることにより、大きな機能エレメントを構成できる。また、クロスバースイッチのプログラミングすなわちP&R(Place and router)を再構築することにより、リコンフィギュラブルなロジックを構成することができる。
[実施の形態22]
図135は、この発明の実施の形態22に従う半導体集積回路装置の要部を示す回路ブロック図であって、図134と対比される図である。図135を参照して、この半導体集積回路装置が実施の形態21の半導体集積回路装置と異なる点は、デコード回路501〜516の各々の出力ノードにラッチ回路537が追加されている点である。たとえばデコード回路501に対応するラッチ回路537は、ラッチ信号φLに応答して対応のデコード回路1の出力信号をラッチして対応のワイヤードORスイッチ521に含まれるNチャネルMOSトランジスタ521aのゲートに与える。
図135は、この発明の実施の形態22に従う半導体集積回路装置の要部を示す回路ブロック図であって、図134と対比される図である。図135を参照して、この半導体集積回路装置が実施の形態21の半導体集積回路装置と異なる点は、デコード回路501〜516の各々の出力ノードにラッチ回路537が追加されている点である。たとえばデコード回路501に対応するラッチ回路537は、ラッチ信号φLに応答して対応のデコード回路1の出力信号をラッチして対応のワイヤードORスイッチ521に含まれるNチャネルMOSトランジスタ521aのゲートに与える。
この実施の形態22では、ラッチ回路537群によってデコード回路501〜516の出力信号をラッチした後は、セレクト信号線対LLP1〜LLP8を開放して他の用途に用いることができる。
[実施の形態23]
図136は、この発明の実施の形態23に従う半導体集積回路装置の構成を示すブロック図である。図136を参照して、この半導体集積回路装置が図133に示す半導体集積回路装置と異なる点は、デコード回路501〜516がデコード回路部DDで置換され、冗長機能ブロックFRBA,冗長デコード回路部RDD、冗長ワイヤードORスイッチ部RSS、および冗長機能ブロックFRBBが追加されている点である。ワイヤードORスイッチ部SSは、図133のワイヤードORスイッチ521〜536を含む。
図136は、この発明の実施の形態23に従う半導体集積回路装置の構成を示すブロック図である。図136を参照して、この半導体集積回路装置が図133に示す半導体集積回路装置と異なる点は、デコード回路501〜516がデコード回路部DDで置換され、冗長機能ブロックFRBA,冗長デコード回路部RDD、冗長ワイヤードORスイッチ部RSS、および冗長機能ブロックFRBBが追加されている点である。ワイヤードORスイッチ部SSは、図133のワイヤードORスイッチ521〜536を含む。
デコード回路部DDは、図133のデコード回路501〜516に加えて、機能ブロックFBB1のうちの不良な機能ブロックを指定するセレクト信号を記憶するためのプログラム回路を含む。たとえば機能ブロックFBB4が不良な場合は、機能ブロックFBB4を指定するセレクト信号がデコード回路DDのプログラム回路に格納される。
たとえば機能ブロックFBA1から正常な機能ブロックFBB2を指定するセレクト信号が与えられた場合は、デコード回路部DDおよびワイヤードORスイッチ部SSは、図133のデコード回路501〜516およびワイヤードORスイッチ521〜536と同様に動作し、機能ブロックFBA1と機能ブロックFBB2を接続する。
たとえば機能ブロックFBA1から不良な機能ブロックFBB4を指定するセレクト信号が与えられた場合は、デコード回路部DDおよびワイヤードORスイッチ部SSのうちの不良な機能ブロックFBB4に対応する部分が非活性化されるとともに、冗長デコード回路部RDDおよび冗長ワイヤードORスイッチ部RSSが活性化される。冗長デコード回路部RDDおよび冗長ワイヤードORスイッチ部RSSは、機能ブロックFBA1と冗長機能ブロックFRBBを接続する。このようにして、不良な機能ブロックFBB4が冗長機能ブロックRFBBで置換される。なお、双方向のデータ転送を行う場合は、同様にして、機能ブロックFBA1〜FBA4のうちの不良な機能ブロックが冗長機能ブロックFRBAで置換される。
この実施の形態3では、機能ブロックおよびクロスバースイッチに冗長機能を設けたので、通常は冗長機能を持たすことができないランダムロジックにも冗長機能を持たすことができ、歩留の向上を図ることができる。
[実施の形態24]
図137は、この発明の実施の形態24に従う半導体集積回路装置の構成を示すブロック図である。図137において、この半導体集積回路装置は、多数の機能ブロックFBA1〜FBAn(ただし、nは2以上の整数である)と、多数の機能ブロックFBB1〜FBBnと、クロスバースイッチとを備え、クロスバースイッチは、グローバルデコード回路部GDD、ローカルデコード回路部LDDおよびワイヤードORスイッチ部SSを含む。
図137は、この発明の実施の形態24に従う半導体集積回路装置の構成を示すブロック図である。図137において、この半導体集積回路装置は、多数の機能ブロックFBA1〜FBAn(ただし、nは2以上の整数である)と、多数の機能ブロックFBB1〜FBBnと、クロスバースイッチとを備え、クロスバースイッチは、グローバルデコード回路部GDD、ローカルデコード回路部LDDおよびワイヤードORスイッチ部SSを含む。
ワイヤードORスイッチ部SSは、図133で説明したように、機能ブロックFBA1〜FBAnの各々に対応してn個のワイヤードORスイッチを含む。n個のワイヤードORスイッチは、それぞれ機能ブロックFBB1〜FBBnに対応している。
n個のワイヤードORスイッチは、各々がA個のワイアードORスイッチを含むB個のスイッチグループに分割されている。グローバルデコード回路部GDDは、各機能ブロックFBAからのグローバルセレクト信号に従ってその機能ブロックFBAに対応するB個のスイッチグループのうちのいずれかのスイッチグループを選択する。ローカルデコード回路部LDDは、各機能ブロックFBAからのローカルセレクト信号に従って、その機能ブロックFBAに対応し、かつグローバルデコード回路部GDDによって選択されたスイッチグループに属するA個のワイヤードORスイッチのうちのいずれかのワイヤードORスイッチを選択し、そのワイヤードORスイッチを導通させる。
たとえばn=16の場合は、ワイヤードORスイッチ部SSは、機能ブロックFBA1〜FBA16の各々に対応して16個のワイヤードORスイッチを含む。16個のワイヤードORスイッチは、それぞれ機能ブロックFBB1〜FBB16に対応している。
16個のワイヤードORスイッチは、4個ずつ4個のスイッチグループに分割されている。グローバルデコード回路部GDDは、図138に示すように、それぞれ4個のスイッチグループに対応する4個のグローバルデコード回路540を含む。ローカルデコード回路LDDは、それぞれ16個のワイヤードORスイッチに対応する16個のローカルデコード回路541を含む。
対応の機能ブロックFBAからグローバルセレクト信号GGS1,GGS2が出力されると、4個のグローバルデコード回路540のうちのいずれか1つのグローバルデコード回路540の出力信号が「H」レベルになり、そのグローバルデコード回路540に対応する4個のローカルデコード回路541が活性化される。対応の機能ブロックFBAからローカルセレクト信号LLS1〜LLS4が出力されると、活性化された4個のローカルデコード回路541のうちのいずれか1つのローカルデコード回路541の出力信号が「H」レベルになり、そのローカルデコード回路541に対応するワイヤードORスイッチが導通する。このようにして、機能ブロックFBA1〜FBA16と機能ブロックFBB1〜FBB16が1対1で所望の組合せで接続される。
この実施の形態24では、デコード回路部を階層化したので、セレクト信号用の配線数を低減化することができ、デコード回路部のコンパクト化を図ることができる。
[実施の形態25]
図139は、この発明の実施の形態25に従う半導体集積回路装置の構成を示すブロック図である。図139において、この半導体集積回路は、複数(図139では5つ)の機能ブロックFBA1〜FBA5と、5つの機能ブロックFBB1〜FBB5と、クロスバースイッチとを備える。機能ブロックFBA1〜FBA5は、複数のグループに分割されており、図139では、機能ブロックFBA1〜FBA3が属する第1のグループと、機能ブロックFBA4,FBA5が属する第2のグループに分割される。
図139は、この発明の実施の形態25に従う半導体集積回路装置の構成を示すブロック図である。図139において、この半導体集積回路は、複数(図139では5つ)の機能ブロックFBA1〜FBA5と、5つの機能ブロックFBB1〜FBB5と、クロスバースイッチとを備える。機能ブロックFBA1〜FBA5は、複数のグループに分割されており、図139では、機能ブロックFBA1〜FBA3が属する第1のグループと、機能ブロックFBA4,FBA5が属する第2のグループに分割される。
クロスバースイッチのデコード回路部は、第1のグループに対応するデコード回路部DD1と、第2のグループに対応するデコード回路部DD2に分割される。クロスバースイッチのワイヤードORスイッチ部は、第1のグループに対応するワイヤードORスイッチ部SS1と、第2のグループに対応するワイヤードORスイッチ部SS2に分割される。機能ブロックFBB1〜FBB5は、第1のグループに対応する機能ブロックFBB1〜FBB3と、第2のグループに対応する機能ブロックFBB4,FBB5に分割される。
この半導体集積回路装置では、機能ブロックFBA1〜FBA3、デコード回路部DD1、ワイヤードORスイッチ部SS1および機能ブロックFBB1〜FBB3に電源電圧VCC1を供給する電源供給線PPL1と、機能ブロックFBA4、FBA5、デコード回路部DD2、ワイヤードORスイッチ部SS2および機能ブロックFBB4、FBB5に電源電圧VCC2を供給する電源供給線PPL2とが別々に設けられている。したがって、たとえば機能ブロックFBA1〜FBA3およびそれに関連する部分のみを活性化させる場合は、電源供給線PPL1に電源電圧VCC1を供給し、電源供給線PPL2への電源電圧VCC2の供給を停止することにより、不要な電力消費を削減することができ、消費電力の低減化を図ることができる。
また、この半導体集積回路装置では、2つの機能エレメントを同時に構成できるので、2つの同じ機能のエレメントを構成することにより、演算のパラレル処理を行うことができ、高性能なプロセッシング機能を実現することができる。
この発明は、一般に、データ処理システムに対して適用可能である。特に、画像または音声データなどの大量のデータを処理することが要求される処理システムに対して適用することにより、高速演算処理システムを実現することができる。
なお、チップ構成としては、1つの主演算回路部分が1チップ(半導体チップ)で構成されてもよく、また1つの基本演算ブロックが1チップ(半導体チップ)で構成されてもよい。また、1つの半導体演算装置が、システムLSIのように、1チップ(半導体チップ)で構成されてもよい。
1 半導体演算装置、FB1−FBm 基本演算ブロック、2 ホストCPU、3 メモリ、5 システムバス、10 入出力回路、12 内部データバス、14 内部バス、15 集中制御ユニット、6 隣接ブロック間データバス、20 主演算回路、21 コントローラ、22 レジスタ群、23 マイクロプログラム格納メモリ、24 ヒューズ、30 メモリマット、40 センスアンプ群、42 ライトドライバ群、44 ALU相互接続用スイッチ回路、46 ロウデコーダ、48 入出力回路、32 演算処理ユニット群(ALU群)、50 算術演算論理回路、52 Aレジスタ、54 Xレジスタ、56 Cレジスタ、58 Mレジスタ、60 ライトドライバ、62 センスアンプ、65 ALU間接続回路、NQ1−NQ8 NチャネルMOSトランジスタ、PQ1,PQ2 PチャネルMOSトランジスタ、36r リード用ロウデコーダ、36w ライト用ロウデコーダ、40A,40B センスアンプ群、42A,42B ライトドライバ群、200 ALU内内部データ線、210,211 全加算器、220 XHレジスタ、221 XLレジスタ、222 セレクタ、217 選択反転回路、208 Vレジスタ、207 Nレジスタ、205 Fレジスタ、222 Dレジスタ、SWa−SWf スイッチ回路、225 スイッチ回路、250 大容量メモリ、GBS グローバルデータバス、BK0−BKq バンク、260 隣接ブロックエントリ間接続配線、262 隣接ブロックエントリフィードバック接続配線、262a,262b 隣接ブロックエントリ間接続配線、PSW プログラマブルスイッチ回路、NBAa,NBAb 隣接ブロック間データバス、PSW プログラマブルスイッチ回路、315u,315d マルチプレクサ(MUX)、320au,320du,320ad−320dd シフト信号線、317 送受信データレジスタ、319 ALUユニット、320 Xレジスタ、325 送信レジスタ、326 受信レジスタ、340,342 メモリセルマット上配線、400 直交変換回路、402 クロスバースイッチ、404 セレクタ、TXF00−TXF(k−1),(j−1) 変換素子、TXFI0−TXFI7 入力変換素子、430 ワードマスク制御回路、DDD−DDD(a−1) デコーダ、DSW0−DSW(m−1) 選択スイッチ回路、SAC センスアンプ回路、XG00−XG34 レジスタ回路、SSG0−SSG4 選択ゲート、DRV0−DRV4 ドライバ、460 接続情報保持回路、460a コンテキスト情報格納回路、462 接続ルート決定回路、464 スイッチマトリクス回路、464a スイッチ列、462a デコーダ群、TGW0−TGW3 選択ゲート、 FBA,FBB 機能ブロック、FRBA,FRBB 冗長機能ブロック、LL,LLX,LLY データ信号線、LLP セレクト信号線対、501〜516 デコード回路、521〜536,551,552,553 スイッチ、521a〜524a,551a,552a NチャネルMOSトランジスタ、537 ラッチ回路、DD デコード回路部、GDD グローバルデコード回路部、LDD ローカルデコード回路部、SS ワイヤードORスイッチ部。
Claims (40)
- 行列状に配列されかつ複数のエントリに分割される複数のメモリセルを有するメモリセルアレイ、
各前記エントリに対応して配置され、各々が指定された演算を対応のエントリのデータに対して行なう複数の第1の演算回路、
各前記エントリと対応の第1の演算回路との間でデータを転送する複数のデータ転送線、および
前記複数のデータ転送線それぞれに対応して配置され、対応のデータ転送線と対応の第1の演算回路との間でビット単位でかつエントリパラレル態様でデータを転送する複数のデータ転送回路を備え、
各前記エントリには多ビットデータが格納され、各前記第1の演算回路は対応のエントリの多ビットデータに対してビットシリアルな態様で演算を実行する、半導体装置。 - 前記複数の第1の演算回路の間でデータを転送する接続切換転送回路をさらに備える、請求項1記載の半導体装置。
- 前記複数のエントリは、前記メモリセルアレイの各列に対応して配置されるエントリを備え、
前記データ転送線は、各列に対応して配置される、請求項1記載の半導体装置。 - 各前記メモリセルは、書込ポートと読出ポートとを有するマルチポートメモリセルであり、
前記複数のデータ転送線は、対応のエントリのメモリセルの書込ポートに接続される書込データ線と、対応のエントリのメモリセルの読出ポートに接続される読出データ線とを備える、請求項1記載の半導体装置。 - 前記メモリセルアレイの各エントリにおいて同一位置のメモリセルの読出ポートを選択状態へ駆動する読出セル選択回路と、
前記読出セル選択回路と別に設けられかつ並行して動作可能であり、前記メモリセルアレイの各エントリの同一位置のメモリセルの書込ポートを選択状態へ駆動する書込セル選択回路とをさらに備える、請求項4記載の半導体装置。 - 前記メモリセルアレイは、各前記エントリを分割するように第1のメモリアレイと第2のメモリアレイとに分割され、
前記複数の第1の演算回路は、前記第1および第2のメモリアレイの間に配置され、前記第1および第2のメモリアレイの対応するエントリからデータを並行して受けて該受けたデータに対して演算を実行する、請求項1記載の半導体装置。 - 各前記第1の演算回路は、演算を実行する演算部と、対応のエントリから与えられたデータを格納するレジスタ回路と、前記演算部の演算結果を格納する結果レジスタと、前記演算部の演算処理を禁止するマスクデータを格納するマスクレジスタ回路を備える、請求項1記載の半導体装置。
- 各前記メモリセルは、互いに独立に選択可能な第1および第2のポートを有するマルチポートメモリセルであり、かつ
前記複数のメモリセルは、前記行および列の一方に対応する第1の方向および前記行および列の他方に対応する第2の方向に整列して配置され、
前記半導体装置は、さらに、
各々が前記第1の方向に沿って整列して配置されるメモリセルに対応して配置され、各々に対応のメモリセルの第1のポートが接続される複数の第1のワード線と、
各々が前記第2の方向に沿って整列して配置されるメモリセルに対応して配置され、かつ各々が対応のメモリセルの第1のポートに結合されて、かつさらに、前記データ転送線を構成する複数の第1のビット線と、
各々が前記第2の方向に沿って整列して配置されるメモリセルに対応して配置され、かつ各々が対応のメモリセルの第2のポートに接続する複数の第2のワード線と、
各々が前記第1の方向に沿って整列して配置されるメモリセルに対応して配置され、かつ各々が対応のメモリセルの第2のポートに接続する複数の第2のビット線と、
前記複数の第2のビット線と対向してかつデータを転送可能に配置される複数の第2の演算回路とをさらに備える、請求項1記載の半導体装置。 - 前記複数の第2のビット線と前記複数の第2の演算回路とのデータ転送経路を変更する経路変更回路をさらに備える、請求項8記載の半導体装置。
- 各前記エントリには、多ビットデータワードが格納され、前記複数の第2の演算回路は、与えられた多ビットデータワードをワード単位で演算する、請求項8記載の半導体装置。
- 前記第2の演算回路は、複数段にわたって配置される演算器を備える、請求項8記載の半導体装置。
- 前記複数の第2のビット線と装置外部との間でデータをエントリ単位で転送する入出力回路をさらに備える、請求項8記載の半導体装置。
- 前記第1のワード線に対応して配置され、第1の不良アドレス情報に従って前記複数の第1のワード線とアドレスとの対応をシフトして切り替えて不良アドレスを救済する第1のシフト冗長救済回路、
前記第2のワード線に対応して配置され、第2の不良アドレス情報に従って前記複数の第2のワード線とアドレスとの対応をシフトして切り換えて不良アドレスを救済する第2のシフト冗長救済回路、
前記複数の第2のビット線に対して設けられ、前記第1の不良アドレス情報に従って、前記複数の第2のビット線と前記複数の第2の演算回路との対応をシフトして切り替える第3のシフト冗長救済回路、および
前記複数の第1のビット線に対して設けられ、前記第2の不良アドレス情報に従って前記複数の第1のビット線と前記複数の第1の演算回路との対応をシフトして切り替える第4のシフト冗長救済回路をさらに備える、請求項8記載の半導体装置。 - 前記複数の第2の演算回路に対応して配置され、前記複数の第2の演算回路間でデータを転送する、転送経路が変更可能なデータ転送回路をさらに備える、請求項8記載の半導体装置。
- 前記メモリセルアレイのメモリセル列それぞれに対応して配置され、各々に対応の列のメモリセルが接続し、かつ前記複数のデータ転送線を構成する複数のビット線、および
前記複数の第1の演算回路に対応して配置され、前記データ転送線と前記第1の演算回路との対応をシフトして変更して不良演算回路を救済する冗長回路をさらに備える、請求項1記載の半導体装置。 - 前記メモリセルアレイの各エントリに対して共通に配置され、各エントリにおいて有意のデータが格納される領域を指定するポインタ回路をさらに備え、前記ポインタ回路は、各前記エントリに複数の多ビットデータが格納されるとき、各多ビットデータの格納領域を指定する、請求項1記載の半導体装置。
- 行列状に配列されるメモリセルを有し、各々が複数ビットを有する複数のエントリに分割されるメモリセルアレイ、および
各行に対応して配置される複数の演算回路を備え、前記演算回路は、演算器と、少なくとも第1および第2のレジスタと、1つのマスクレジスタとを含み、さらに、
前記第1のレジスタに第1の演算ビットを格納し、前記演算器に前記メモリアレイからのデータビットと前記第1の演算ビットの演算を行わせ、該演算結果を前記第1のレジスタに格納して、該第1のレジスタの格納値を前記メモリセルアレイの対応の位置に書き込む制御回路を備え
、前記制御回路は前記演算器の演算内容を設定する、半導体信号処理装置。 - 前記第2のレジスタは、加減算演算時のキャリを格納し、
前記制御回路は、演算最終時に前記第2のレジスタの格納データを対応のエントリの対応のビット位置に格納する、請求項17記載の半導体信号処理装置。 - 乗算時には、前記マスクレジスタに被乗数ビットを格納し、
前記マスクレジスタの格納値にしたがって、前記対応のエントリの乗数ビットと乗算結果ビットとの加算を選択的に行い、該演算結果を前記第1のレジスタに格納して対応の乗算結果格納領域の元の位置に書込み、前記乗数のビット全てについて選択的加算を行った後、前記被乗数ビットの対応のエントリのビット位置を指定するビット位置アドレスを増分してかつ前記乗算結果ビットの位置のアドレスを1増分して、乗数について同様の動作を繰り返すように前記制御回路が動作する、請求項17記載の半導体信号処理装置。 - 行列状に配列される複数のメモリセルを有し、かつ複数のエントリに分割されるメモリセルマット、および
各エントリに対応して配置される複数の演算回路を備え、
各前記演算回路は、
対応のエントリの第1の領域からのデータビットの組について2次のブースアルゴリズムに従ってデコードした結果を格納するブースレジスタ回路と、
前記対応のエントリの第2および第3の領域の対応にビット位置からのデータビットを受け、前記ブースレジスタ回路の格納データにしたがって受けたデータに対して演算処理を行う演算器と、
前記演算器の出力データを格納する結果レジスタとを備え、さらに、
前記メモリセルマットの各エントリから前記第1、第2および第3の領域のデータを対応
の演算回路に転送し、かつ前記演算器の出力データを対応のエントリの第3の領域に転送
して書き込み、かつさらに、前記演算回路の演算動作を制御する制御回路を備える、半導体信号処理装置。 - 前記演算器は、前記ブースレジスタ回路の格納値に従って、前記第2および第3の領域からのデータの組について、前記第2の領域からのデータの1ビットまたは2ビットシフトおよび反転または正転および無演算を選択的に行い、該演算結果と前記第3の領域からのデータとの加算を行う、請求項20記載の半導体信号処理装置。
- 各前記エントリは、偶数ビットを格納する偶数エントリと奇数ビットを格納する奇数エントリとを含み、
各前記演算器は、対応のエントリの偶数エントリおよび奇数エントリの対応のビット位置のデータを並列に受けて処理を実行する、請求項20記載の半導体信号処理装置。 - 行列状に配列される複数のメモリセルを有し、各々が同一ビット幅を有する複数のエントリに分割されるメモリセルマット、
各エントリに対応して配置され、各々が対応のエントリのデータに対して指定された処理を実行する複数の演算回路を含む演算ブロック、
前記演算ブロックの所定数の演算回路に対応して設けられ、対応の演算回路に対して演算内容を指定する制御信号を伝達する演算制御信号線を備える、半導体信号処理装置。 - 行列状に配列される複数のメモリセルを有し、かつ各々がワード単位のデータを格納するメモリセルを含む複数のエントリに分割されるメモリセルマットと、各エントリに対応して配置される演算器を含み、互いに演算処理を個々に実行することのできる複数の基本演算ブロック、
各基本演算ブロックに共通に配置される内部データバス、
前記内部データバスに結合され、行列状に配列されるメモリセル含みかつ各基本演算ブロックとデータ転送を行うことのできる大容量メモリ、および
前記大容量メモリと選択された基本演算ブロックとの間で、前記大容量メモリの1行のデータ単位でデータ転送を行う制御回路とを備える、半導体信号処理装置。 - 前記大容量メモリは、互いに独立にアクセスすることのできる複数のバンクを備え、各前記バンクは、前記メモリセルマットと同一構成を有する、請求項24記載の半導体信号処理装置。
- 各々が、行列状に配列される複数のメモリセルを有し、かつ複数のエントリに分割されるメモリセルマットと、各エントリに対応して配置される演算回路とを備える複数の演算ブロック、
隣接演算ブロック間の対応の位置の演算回路を選択的に結合する隣接ブロック接続バス、および
各演算ブロックにおいて、演算回路を選択的に結合するビット転送回路を備える、半導 体信号処理装置。 - 前記ビット転送回路は、
隣接演算回路に対応して配置される第1のバス線と、
所定数はなれた位置の演算回路に対して配置される第2のバス線と、
前記第1および第2のバス線に対して配置され、導通時対応のバス線と演算回路とを接続するスイッチ回路を備える、請求項26記載の半導体信号処理装置。 - 前記スイッチ回路は、接続態様がスルー状態、対応のバス線と対応の演算回路とのデータ転送可能状態、および対応のバス線のデータ転送を禁止するダミー状態のいずれかに切り換えられるプログラマブルスイッチ回路を備える、請求項27記載の半導体信号処理装置。
- 前記複数のスイッチ回路の接続態様を各前記演算ブロック個々に設定する接続制御回路をさらに備える、請求項27記載の半導体信号処理装置。
- 各々が、行列状に配列される複数のメモリセルを有しかつ複数のエントリに分割されるメモリセルマットと、各メモリセルマットのエントリに対応して配置される複数の演算回路とを含む複数の演算回路ブロックと、
前記複数の演算回路ブロックに共通に配置されるグローバルデータバス、
外部処理装置に結合されるシステムデータバス、
前記システムデータバスと第1の内部転送バスとの間に接続され、前記システムバスと前記第1の内部転送バスそれぞれに転送されるデータの構成を変更する直交変換回路、
前記第1の内部転送バスと第2の内部転送バスとの間に接続され、前記第1および第2の内部転送バスの接続経路を変更するクロスバースイッチ、および
前記第2の内部転送バスと前記グローバルデータバスとの間に接続され、前記第2の内部転送バスと前記グローバルデータバスのバス線を選択的に接続する選択回路を備える、半導体信号処理装置。 - 前記クロスバースイッチは、
演算回路ブロックからの接続情報をデコードするデコード回路と、
前記デコード回路の出力信号に従って前記第1および第2の内部転送バスの接続経路を確立するスイッチマトリクスを備える、請求項30記載の半導体信号処理装置。 - 1列に配置された複数の第1機能ブロックと、それぞれ前記複数の第1機能ブロックに対向して設けられた複数の第2機能ブロックとの間に設けられ、前記複数の第1機能ブロックと前記複数の第2機能ブロックとを1対1で任意の組合せで接続するクロスバースイッチであって、
各第1機能ブロックに対応して設けられて対応の第1機能ブロックのデータ信号端子に接続され、前記複数の第1機能ブロックの配列方向と同じ方向に延在する第1データ信号線、および
各第1データ信号線に対応して設けられ、対応の第1機能ブロックからのセレクト信号に従って前記複数の第2機能ブロックのうちのいずれかの第2機能ブロックを選択し、選択した第2機能ブロックのデータ信号端子と対応の第1データ信号線とを接続する選択回路を備える、クロスバースイッチ。 - 各第1機能ブロックに対応して設けられ、前記複数の第1機能ブロックの配列方向と直交する方向に延在する第2データ信号線を備え、
前記第1データ信号線は、対応の第2データ信号線を介して対応の第1機能ブロックのデータ信号端子に接続されている、請求項32に記載のクロスバースイッチ。 - 前記選択回路は、
それぞれ前記複数の第2機能ブロックに対応して設けられ、各々が対応の第2機能ブロックのデータ信号端子と対応の第1データ信号線との間に接続された複数のスイッチング素子、および
それぞれ前記複数のスイッチング素子に対応して設けられ、各々が予め割り当てられたセレクト信号が与えられたことに応じて対応のスイッチング素子を導通させる複数のデコード回路を含む、請求項32に記載のクロスバースイッチ。 - 前記選択回路は、
対応の第1機能ブロックのセレクト信号端子と前記複数のデコード回路のうちのあるデコード回路との間に接続され、前記複数の第1機能ブロックの配列方向と直交する方向に延在する第1セレクト信号線、および
前記第1セレクト信号線に接続されて前記複数の第1機能ブロックの配列方向と同じ方向に延在し、前記セレクト信号を他のデコード回路に与える第2セレクト信号線を含む、請求項34に記載のクロスバースイッチ。 - 前記選択回路は、各デコード回路に対応して設けられ、対応のデコード回路の出力信号をラッチするラッチ回路を含む、請求34に記載のクロスバースイッチ。
- 前記セレクト信号は、グローバルセレクト信号とローカルセレクト信号を含み、
前記選択回路は、
それぞれ前記複数の第2機能ブロックに対応して設けられて予め複数のグループに分割され、各々が対応の第2機能ブロックのデータ信号端子と対応の第1データ信号線との間に接続された複数のスイッチング素子、
それぞれ前記複数のグループに対応して設けられ、各々が予め割り当てられたグローバルセレクト信号が与えられたことに応じて活性化信号を出力する複数のグローバルデコード回路、および
各グループに対応して設けられて対応のグループの複数のスイッチング素子にそれぞれ対応して設けられ、各々が、対応のグローバルデコード回路から活性化信号が出力され、かつ予め割り当てられたローカルセレクト信号が与えられたことに応じて対応のスイッチング素子を導通させる複数のローカルデコード回路を含む、請求項32に記載のクロスバースイッチ。 - 前記選択回路は、さらに、対応の第1機能ブロックに対向する第2機能ブロックからのセレクト信号に従って前記複数の第2機能ブロックのうちのいずれかの第2機能ブロックを選択し、選択した第2機能ブロックのデータ信号端子と対応の第1データ信号線とを接続する、請求項32に記載のクロスバースイッチ。
- 前記複数の第2機能ブロックのうちの不良な第2機能ブロックと置換するための冗長第2機能ブロックが設けられ、
前記選択回路は、対応の第1機能ブロックからのセレクト信号によって前記不良な第2機能ブロックが指定された場合は、前記不良な第2機能ブロックの代わりに前記冗長第2機能ブロックを選択し、選択した冗長第2機能ブロックのデータ信号端子と対応の第1データ信号線とを接続する、請求項32に記載のクロスバースイッチ。 - 前記複数の第1機能ブロックおよび前記複数の第2機能ブロックは複数組設けられ、
前記クロスバースイッチは、各組毎に前記複数の第1機能ブロックと前記複数の第2機能ブロックとを1対1で任意の組合せで接続し、
前記第1データ信号線および前記選択回路は各組毎に設けられ、
電源電圧は、各組毎に供給/遮断することが可能になっている、請求項32に記載のクロスバースイッチ。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005143109A JP2006127460A (ja) | 2004-06-09 | 2005-05-16 | 半導体装置、半導体信号処理装置、およびクロスバースイッチ |
| US11/148,369 US7562198B2 (en) | 2004-06-09 | 2005-06-09 | Semiconductor device and semiconductor signal processing apparatus |
| US12/213,131 US7791962B2 (en) | 2004-06-09 | 2008-06-16 | Semiconductor device and semiconductor signal processing apparatus |
| US12/857,063 US8089819B2 (en) | 2004-06-09 | 2010-08-16 | Semiconductor device and semiconductor signal processing apparatus |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004171658 | 2004-06-09 | ||
| JP2004175193 | 2004-06-14 | ||
| JP2004282449 | 2004-09-28 | ||
| JP2005143109A JP2006127460A (ja) | 2004-06-09 | 2005-05-16 | 半導体装置、半導体信号処理装置、およびクロスバースイッチ |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2006127460A true JP2006127460A (ja) | 2006-05-18 |
Family
ID=35505177
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005143109A Pending JP2006127460A (ja) | 2004-06-09 | 2005-05-16 | 半導体装置、半導体信号処理装置、およびクロスバースイッチ |
Country Status (2)
| Country | Link |
|---|---|
| US (3) | US7562198B2 (ja) |
| JP (1) | JP2006127460A (ja) |
Cited By (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008047031A (ja) * | 2006-08-21 | 2008-02-28 | Kumamoto Univ | 並列演算装置 |
| JP2009098861A (ja) * | 2007-10-16 | 2009-05-07 | Renesas Technology Corp | 並列演算処理装置 |
| JP2009104521A (ja) * | 2007-10-25 | 2009-05-14 | Mitsubishi Electric Corp | 並列処理装置 |
| JP2010003151A (ja) * | 2008-06-20 | 2010-01-07 | Renesas Technology Corp | データ処理装置 |
| JP2010244095A (ja) * | 2009-04-01 | 2010-10-28 | Seiko Epson Corp | データ処理装置、印刷システムおよびプログラム |
| JP2011134304A (ja) * | 2009-12-22 | 2011-07-07 | Intel Corp | ビット範囲分離命令、方法、および装置 |
| JP2014182800A (ja) * | 2013-03-15 | 2014-09-29 | Intel Corp | データ要素内のビットをゼロ化するためのシステム、装置、および方法 |
| JP2016042223A (ja) * | 2014-08-14 | 2016-03-31 | 富士ゼロックス株式会社 | データ処理装置およびプログラム |
| US9472265B2 (en) | 2013-03-04 | 2016-10-18 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| JP2016532919A (ja) * | 2013-08-08 | 2016-10-20 | マイクロン テクノロジー, インク. | 論理演算を、センス回路を使用して実行する装置及び方法 |
| WO2016199808A1 (ja) * | 2015-06-08 | 2016-12-15 | 井上 克己 | メモリ型プロセッサ、メモリ型プロセッサを含んだ装置、その使用方法。 |
| JP2017016668A (ja) * | 2013-12-23 | 2017-01-19 | 井上 克己 | 情報検索機能を備えたメモリ、その利用方法、装置、情報処理方法。 |
| JP2017503229A (ja) * | 2013-11-08 | 2017-01-26 | マイクロン テクノロジー, インク. | メモリ用の除算演算 |
| JP2020512653A (ja) * | 2017-03-22 | 2020-04-23 | マイクロン テクノロジー,インク. | インデータパス計算動作のための装置及び方法 |
| JP2021114353A (ja) * | 2017-06-02 | 2021-08-05 | ウルトラメモリ株式会社 | 半導体モジュール |
Families Citing this family (229)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006127460A (ja) * | 2004-06-09 | 2006-05-18 | Renesas Technology Corp | 半導体装置、半導体信号処理装置、およびクロスバースイッチ |
| JP4010335B2 (ja) | 2005-06-30 | 2007-11-21 | セイコーエプソン株式会社 | 集積回路装置及び電子機器 |
| JP4010333B2 (ja) * | 2005-06-30 | 2007-11-21 | セイコーエプソン株式会社 | 集積回路装置及び電子機器 |
| US7567479B2 (en) | 2005-06-30 | 2009-07-28 | Seiko Epson Corporation | Integrated circuit device and electronic instrument |
| US7561478B2 (en) | 2005-06-30 | 2009-07-14 | Seiko Epson Corporation | Integrated circuit device and electronic instrument |
| US7564734B2 (en) | 2005-06-30 | 2009-07-21 | Seiko Epson Corporation | Integrated circuit device and electronic instrument |
| KR100828792B1 (ko) | 2005-06-30 | 2008-05-09 | 세이코 엡슨 가부시키가이샤 | 집적 회로 장치 및 전자 기기 |
| JP4661400B2 (ja) | 2005-06-30 | 2011-03-30 | セイコーエプソン株式会社 | 集積回路装置及び電子機器 |
| JP4186970B2 (ja) | 2005-06-30 | 2008-11-26 | セイコーエプソン株式会社 | 集積回路装置及び電子機器 |
| JP4151688B2 (ja) | 2005-06-30 | 2008-09-17 | セイコーエプソン株式会社 | 集積回路装置及び電子機器 |
| US7764278B2 (en) | 2005-06-30 | 2010-07-27 | Seiko Epson Corporation | Integrated circuit device and electronic instrument |
| JP4661401B2 (ja) | 2005-06-30 | 2011-03-30 | セイコーエプソン株式会社 | 集積回路装置及び電子機器 |
| US20070001974A1 (en) * | 2005-06-30 | 2007-01-04 | Seiko Epson Corporation | Integrated circuit device and electronic instrument |
| KR100826695B1 (ko) * | 2005-06-30 | 2008-04-30 | 세이코 엡슨 가부시키가이샤 | 집적 회로 장치 및 전자 기기 |
| US7593270B2 (en) | 2005-06-30 | 2009-09-22 | Seiko Epson Corporation | Integrated circuit device and electronic instrument |
| JP4830371B2 (ja) | 2005-06-30 | 2011-12-07 | セイコーエプソン株式会社 | 集積回路装置及び電子機器 |
| JP4010336B2 (ja) | 2005-06-30 | 2007-11-21 | セイコーエプソン株式会社 | 集積回路装置及び電子機器 |
| JP4010332B2 (ja) * | 2005-06-30 | 2007-11-21 | セイコーエプソン株式会社 | 集積回路装置及び電子機器 |
| US7755587B2 (en) | 2005-06-30 | 2010-07-13 | Seiko Epson Corporation | Integrated circuit device and electronic instrument |
| JP4665677B2 (ja) | 2005-09-09 | 2011-04-06 | セイコーエプソン株式会社 | 集積回路装置及び電子機器 |
| JP4738112B2 (ja) * | 2005-09-12 | 2011-08-03 | ルネサスエレクトロニクス株式会社 | 半導体記憶装置 |
| JP4586739B2 (ja) | 2006-02-10 | 2010-11-24 | セイコーエプソン株式会社 | 半導体集積回路及び電子機器 |
| JP2007264909A (ja) * | 2006-03-28 | 2007-10-11 | Toshiba Corp | 演算処理装置 |
| US7292485B1 (en) * | 2006-07-31 | 2007-11-06 | Freescale Semiconductor, Inc. | SRAM having variable power supply and method therefor |
| JP5194302B2 (ja) * | 2008-02-20 | 2013-05-08 | ルネサスエレクトロニクス株式会社 | 半導体信号処理装置 |
| US7788528B2 (en) * | 2008-05-23 | 2010-08-31 | Himax Technologies Limited | Repair module for memory, repair device using the same and method thereof |
| US7956639B2 (en) * | 2008-07-23 | 2011-06-07 | Ndsu Research Foundation | Intelligent cellular electronic structures |
| JP2010039625A (ja) * | 2008-08-01 | 2010-02-18 | Renesas Technology Corp | 並列演算装置 |
| US8755515B1 (en) | 2008-09-29 | 2014-06-17 | Wai Wu | Parallel signal processing system and method |
| JP5261738B2 (ja) * | 2009-01-15 | 2013-08-14 | 国立大学法人広島大学 | 半導体装置 |
| US8194478B2 (en) * | 2010-02-04 | 2012-06-05 | Qualcomm Incorporated | Systems and methods for writing to multiple port memory circuits |
| US20130027416A1 (en) * | 2011-07-25 | 2013-01-31 | Karthikeyan Vaithianathan | Gather method and apparatus for media processing accelerators |
| TWI607454B (zh) | 2012-02-13 | 2017-12-01 | 中村維男 | 無記憶體瓶頸的行進記憶體,雙向行進記憶體,複雜行進記憶體,及計算機系統 |
| US8885425B2 (en) | 2012-05-28 | 2014-11-11 | Kabushiki Kaisha Toshiba | Semiconductor memory and method of controlling the same |
| US8964496B2 (en) | 2013-07-26 | 2015-02-24 | Micron Technology, Inc. | Apparatuses and methods for performing compare operations using sensing circuitry |
| US9153305B2 (en) | 2013-08-30 | 2015-10-06 | Micron Technology, Inc. | Independently addressable memory array address spaces |
| US9330040B2 (en) * | 2013-09-12 | 2016-05-03 | Qualcomm Incorporated | Serial configuration of a reconfigurable instruction cell array |
| US9019785B2 (en) | 2013-09-19 | 2015-04-28 | Micron Technology, Inc. | Data shifting via a number of isolation devices |
| US9449675B2 (en) | 2013-10-31 | 2016-09-20 | Micron Technology, Inc. | Apparatuses and methods for identifying an extremum value stored in an array of memory cells |
| US10459674B2 (en) | 2013-12-10 | 2019-10-29 | Apple Inc. | Apparatus and methods for packing and transporting raw data |
| US9892084B2 (en) | 2013-12-10 | 2018-02-13 | Apple Inc. | Methods and apparatus for virtual channel allocation via a high speed bus interface |
| US9934856B2 (en) | 2014-03-31 | 2018-04-03 | Micron Technology, Inc. | Apparatuses and methods for comparing data patterns in memory |
| JP2015207334A (ja) * | 2014-04-23 | 2015-11-19 | マイクロン テクノロジー, インク. | 半導体装置 |
| US9711207B2 (en) | 2014-06-05 | 2017-07-18 | Micron Technology, Inc. | Performing logical operations using sensing circuitry |
| US9496023B2 (en) | 2014-06-05 | 2016-11-15 | Micron Technology, Inc. | Comparison operations on logical representations of values in memory |
| US10074407B2 (en) | 2014-06-05 | 2018-09-11 | Micron Technology, Inc. | Apparatuses and methods for performing invert operations using sensing circuitry |
| US9449674B2 (en) | 2014-06-05 | 2016-09-20 | Micron Technology, Inc. | Performing logical operations using sensing circuitry |
| US9910787B2 (en) | 2014-06-05 | 2018-03-06 | Micron Technology, Inc. | Virtual address table |
| US9711206B2 (en) | 2014-06-05 | 2017-07-18 | Micron Technology, Inc. | Performing logical operations using sensing circuitry |
| US9786335B2 (en) | 2014-06-05 | 2017-10-10 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US9704540B2 (en) | 2014-06-05 | 2017-07-11 | Micron Technology, Inc. | Apparatuses and methods for parity determination using sensing circuitry |
| US9830999B2 (en) | 2014-06-05 | 2017-11-28 | Micron Technology, Inc. | Comparison operations in memory |
| US9779019B2 (en) | 2014-06-05 | 2017-10-03 | Micron Technology, Inc. | Data storage layout |
| US9455020B2 (en) | 2014-06-05 | 2016-09-27 | Micron Technology, Inc. | Apparatuses and methods for performing an exclusive or operation using sensing circuitry |
| US9904515B2 (en) | 2014-09-03 | 2018-02-27 | Micron Technology, Inc. | Multiplication operations in memory |
| US9589602B2 (en) | 2014-09-03 | 2017-03-07 | Micron Technology, Inc. | Comparison operations in memory |
| US10068652B2 (en) | 2014-09-03 | 2018-09-04 | Micron Technology, Inc. | Apparatuses and methods for determining population count |
| US9740607B2 (en) | 2014-09-03 | 2017-08-22 | Micron Technology, Inc. | Swap operations in memory |
| US9847110B2 (en) * | 2014-09-03 | 2017-12-19 | Micron Technology, Inc. | Apparatuses and methods for storing a data value in multiple columns of an array corresponding to digits of a vector |
| US9898252B2 (en) | 2014-09-03 | 2018-02-20 | Micron Technology, Inc. | Multiplication operations in memory |
| US9747961B2 (en) | 2014-09-03 | 2017-08-29 | Micron Technology, Inc. | Division operations in memory |
| US9830289B2 (en) | 2014-09-16 | 2017-11-28 | Apple Inc. | Methods and apparatus for aggregating packet transfer over a virtual bus interface |
| US10176039B2 (en) | 2014-09-19 | 2019-01-08 | Micron Technology, Inc. | Self-accumulating exclusive OR program |
| US9836218B2 (en) * | 2014-10-03 | 2017-12-05 | Micron Technology, Inc. | Computing reduction and prefix sum operations in memory |
| US9940026B2 (en) | 2014-10-03 | 2018-04-10 | Micron Technology, Inc. | Multidimensional contiguous memory allocation |
| US10078361B2 (en) | 2014-10-08 | 2018-09-18 | Apple Inc. | Methods and apparatus for running and booting an inter-processor communication link between independently operable processors |
| US10163467B2 (en) | 2014-10-16 | 2018-12-25 | Micron Technology, Inc. | Multiple endianness compatibility |
| US10147480B2 (en) | 2014-10-24 | 2018-12-04 | Micron Technology, Inc. | Sort operation in memory |
| US9779784B2 (en) | 2014-10-29 | 2017-10-03 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US9747960B2 (en) * | 2014-12-01 | 2017-08-29 | Micron Technology, Inc. | Apparatuses and methods for converting a mask to an index |
| US10073635B2 (en) | 2014-12-01 | 2018-09-11 | Micron Technology, Inc. | Multiple endianness compatibility |
| US10061590B2 (en) | 2015-01-07 | 2018-08-28 | Micron Technology, Inc. | Generating and executing a control flow |
| US10032493B2 (en) | 2015-01-07 | 2018-07-24 | Micron Technology, Inc. | Longest element length determination in memory |
| US9583163B2 (en) | 2015-02-03 | 2017-02-28 | Micron Technology, Inc. | Loop structure for operations in memory |
| US9842036B2 (en) | 2015-02-04 | 2017-12-12 | Apple Inc. | Methods and apparatus for controlled recovery of error information between independently operable processors |
| EP3254286B1 (en) | 2015-02-06 | 2019-09-11 | Micron Technology, INC. | Apparatuses and methods for parallel writing to multiple memory device locations |
| EP3254287A4 (en) * | 2015-02-06 | 2018-08-08 | Micron Technology, INC. | Apparatuses and methods for memory device as a store for program instructions |
| WO2016126472A1 (en) | 2015-02-06 | 2016-08-11 | Micron Technology, Inc. | Apparatuses and methods for scatter and gather |
| US10522212B2 (en) | 2015-03-10 | 2019-12-31 | Micron Technology, Inc. | Apparatuses and methods for shift decisions |
| US9741399B2 (en) | 2015-03-11 | 2017-08-22 | Micron Technology, Inc. | Data shift by elements of a vector in memory |
| US9898253B2 (en) | 2015-03-11 | 2018-02-20 | Micron Technology, Inc. | Division operations on variable length elements in memory |
| EP3268965A4 (en) * | 2015-03-12 | 2018-10-03 | Micron Technology, INC. | Apparatuses and methods for data movement |
| US10146537B2 (en) | 2015-03-13 | 2018-12-04 | Micron Technology, Inc. | Vector population count determination in memory |
| US10049054B2 (en) | 2015-04-01 | 2018-08-14 | Micron Technology, Inc. | Virtual register file |
| US10140104B2 (en) | 2015-04-14 | 2018-11-27 | Micron Technology, Inc. | Target architecture determination |
| US9959923B2 (en) | 2015-04-16 | 2018-05-01 | Micron Technology, Inc. | Apparatuses and methods to reverse data stored in memory |
| US10073786B2 (en) | 2015-05-28 | 2018-09-11 | Micron Technology, Inc. | Apparatuses and methods for compute enabled cache |
| US9704541B2 (en) | 2015-06-12 | 2017-07-11 | Micron Technology, Inc. | Simulating access lines |
| US10042794B2 (en) | 2015-06-12 | 2018-08-07 | Apple Inc. | Methods and apparatus for synchronizing uplink and downlink transactions on an inter-device communication link |
| US9921777B2 (en) | 2015-06-22 | 2018-03-20 | Micron Technology, Inc. | Apparatuses and methods for data transfer from sensing circuitry to a controller |
| US9996479B2 (en) | 2015-08-17 | 2018-06-12 | Micron Technology, Inc. | Encryption of executables in computational memory |
| US9905276B2 (en) | 2015-12-21 | 2018-02-27 | Micron Technology, Inc. | Control of sensing components in association with performing operations |
| US9952925B2 (en) | 2016-01-06 | 2018-04-24 | Micron Technology, Inc. | Error code calculation on sensing circuitry |
| US10085214B2 (en) | 2016-01-27 | 2018-09-25 | Apple Inc. | Apparatus and methods for wake-limiting with an inter-device communication link |
| US10048888B2 (en) | 2016-02-10 | 2018-08-14 | Micron Technology, Inc. | Apparatuses and methods for partitioned parallel data movement |
| US9892767B2 (en) | 2016-02-12 | 2018-02-13 | Micron Technology, Inc. | Data gathering in memory |
| US9971541B2 (en) | 2016-02-17 | 2018-05-15 | Micron Technology, Inc. | Apparatuses and methods for data movement |
| US9899070B2 (en) | 2016-02-19 | 2018-02-20 | Micron Technology, Inc. | Modified decode for corner turn |
| US10956439B2 (en) | 2016-02-19 | 2021-03-23 | Micron Technology, Inc. | Data transfer with a bit vector operation device |
| US10191852B2 (en) | 2016-02-29 | 2019-01-29 | Apple Inc. | Methods and apparatus for locking at least a portion of a shared memory resource |
| US9697876B1 (en) | 2016-03-01 | 2017-07-04 | Micron Technology, Inc. | Vertical bit vector shift in memory |
| US9997232B2 (en) | 2016-03-10 | 2018-06-12 | Micron Technology, Inc. | Processing in memory (PIM) capable memory device having sensing circuitry performing logic operations |
| US10262721B2 (en) | 2016-03-10 | 2019-04-16 | Micron Technology, Inc. | Apparatuses and methods for cache invalidate |
| US10379772B2 (en) | 2016-03-16 | 2019-08-13 | Micron Technology, Inc. | Apparatuses and methods for operations using compressed and decompressed data |
| US9910637B2 (en) | 2016-03-17 | 2018-03-06 | Micron Technology, Inc. | Signed division in memory |
| US11074988B2 (en) | 2016-03-22 | 2021-07-27 | Micron Technology, Inc. | Apparatus and methods for debugging on a host and memory device |
| US10388393B2 (en) | 2016-03-22 | 2019-08-20 | Micron Technology, Inc. | Apparatus and methods for debugging on a host and memory device |
| US10120740B2 (en) | 2016-03-22 | 2018-11-06 | Micron Technology, Inc. | Apparatus and methods for debugging on a memory device |
| US10977033B2 (en) | 2016-03-25 | 2021-04-13 | Micron Technology, Inc. | Mask patterns generated in memory from seed vectors |
| US10474581B2 (en) | 2016-03-25 | 2019-11-12 | Micron Technology, Inc. | Apparatuses and methods for cache operations |
| US10430244B2 (en) | 2016-03-28 | 2019-10-01 | Micron Technology, Inc. | Apparatuses and methods to determine timing of operations |
| US10074416B2 (en) | 2016-03-28 | 2018-09-11 | Micron Technology, Inc. | Apparatuses and methods for data movement |
| US10191859B2 (en) | 2016-03-31 | 2019-01-29 | Apple Inc. | Memory access protection apparatus and methods for memory mapped access between independently operable processors |
| US10453502B2 (en) | 2016-04-04 | 2019-10-22 | Micron Technology, Inc. | Memory bank power coordination including concurrently performing a memory operation in a selected number of memory regions |
| US10607665B2 (en) | 2016-04-07 | 2020-03-31 | Micron Technology, Inc. | Span mask generation |
| US9818459B2 (en) | 2016-04-19 | 2017-11-14 | Micron Technology, Inc. | Invert operations using sensing circuitry |
| US10153008B2 (en) | 2016-04-20 | 2018-12-11 | Micron Technology, Inc. | Apparatuses and methods for performing corner turn operations using sensing circuitry |
| US9659605B1 (en) | 2016-04-20 | 2017-05-23 | Micron Technology, Inc. | Apparatuses and methods for performing corner turn operations using sensing circuitry |
| US10042608B2 (en) | 2016-05-11 | 2018-08-07 | Micron Technology, Inc. | Signed division in memory |
| US9659610B1 (en) | 2016-05-18 | 2017-05-23 | Micron Technology, Inc. | Apparatuses and methods for shifting data |
| US10049707B2 (en) | 2016-06-03 | 2018-08-14 | Micron Technology, Inc. | Shifting data |
| US10523867B2 (en) | 2016-06-10 | 2019-12-31 | Apple Inc. | Methods and apparatus for multi-lane mapping, link training and lower power modes for a high speed bus interface |
| US10387046B2 (en) | 2016-06-22 | 2019-08-20 | Micron Technology, Inc. | Bank to bank data transfer |
| US10037785B2 (en) | 2016-07-08 | 2018-07-31 | Micron Technology, Inc. | Scan chain operation in sensing circuitry |
| US10388360B2 (en) | 2016-07-19 | 2019-08-20 | Micron Technology, Inc. | Utilization of data stored in an edge section of an array |
| US10387299B2 (en) | 2016-07-20 | 2019-08-20 | Micron Technology, Inc. | Apparatuses and methods for transferring data |
| US10733089B2 (en) | 2016-07-20 | 2020-08-04 | Micron Technology, Inc. | Apparatuses and methods for write address tracking |
| US9767864B1 (en) | 2016-07-21 | 2017-09-19 | Micron Technology, Inc. | Apparatuses and methods for storing a data value in a sensing circuitry element |
| US9972367B2 (en) | 2016-07-21 | 2018-05-15 | Micron Technology, Inc. | Shifting data in sensing circuitry |
| US10303632B2 (en) | 2016-07-26 | 2019-05-28 | Micron Technology, Inc. | Accessing status information |
| US10468087B2 (en) | 2016-07-28 | 2019-11-05 | Micron Technology, Inc. | Apparatuses and methods for operations in a self-refresh state |
| US9990181B2 (en) | 2016-08-03 | 2018-06-05 | Micron Technology, Inc. | Apparatuses and methods for random number generation |
| KR102620562B1 (ko) * | 2016-08-04 | 2024-01-03 | 삼성전자주식회사 | 비휘발성 메모리 장치 |
| US11017838B2 (en) | 2016-08-04 | 2021-05-25 | Samsung Electronics Co., Ltd. | Nonvolatile memory devices |
| US11029951B2 (en) | 2016-08-15 | 2021-06-08 | Micron Technology, Inc. | Smallest or largest value element determination |
| US10606587B2 (en) | 2016-08-24 | 2020-03-31 | Micron Technology, Inc. | Apparatus and methods related to microcode instructions indicating instruction types |
| US10466928B2 (en) | 2016-09-15 | 2019-11-05 | Micron Technology, Inc. | Updating a register in memory |
| US10387058B2 (en) | 2016-09-29 | 2019-08-20 | Micron Technology, Inc. | Apparatuses and methods to change data category values |
| US10014034B2 (en) | 2016-10-06 | 2018-07-03 | Micron Technology, Inc. | Shifting data in sensing circuitry |
| US10529409B2 (en) | 2016-10-13 | 2020-01-07 | Micron Technology, Inc. | Apparatuses and methods to perform logical operations using sensing circuitry |
| US9805772B1 (en) | 2016-10-20 | 2017-10-31 | Micron Technology, Inc. | Apparatuses and methods to selectively perform logical operations |
| US9922696B1 (en) * | 2016-10-28 | 2018-03-20 | Samsung Electronics Co., Ltd. | Circuits and micro-architecture for a DRAM-based processing unit |
| CN207637499U (zh) | 2016-11-08 | 2018-07-20 | 美光科技公司 | 用于形成在存储器单元阵列上方的计算组件的设备 |
| US10551902B2 (en) | 2016-11-10 | 2020-02-04 | Apple Inc. | Methods and apparatus for providing access to peripheral sub-system registers |
| US10775871B2 (en) | 2016-11-10 | 2020-09-15 | Apple Inc. | Methods and apparatus for providing individualized power control for peripheral sub-systems |
| US10423353B2 (en) | 2016-11-11 | 2019-09-24 | Micron Technology, Inc. | Apparatuses and methods for memory alignment |
| US9761300B1 (en) * | 2016-11-22 | 2017-09-12 | Micron Technology, Inc. | Data shift apparatuses and methods |
| US11227653B1 (en) | 2016-12-06 | 2022-01-18 | Gsi Technology, Inc. | Storage array circuits and methods for computational memory cells |
| US10847213B1 (en) | 2016-12-06 | 2020-11-24 | Gsi Technology, Inc. | Write data processing circuits and methods associated with computational memory cells |
| US10854284B1 (en) | 2016-12-06 | 2020-12-01 | Gsi Technology, Inc. | Computational memory cell and processing array device with ratioless write port |
| US10249362B2 (en) | 2016-12-06 | 2019-04-02 | Gsi Technology, Inc. | Computational memory cell and processing array device using the memory cells for XOR and XNOR computations |
| US10847212B1 (en) | 2016-12-06 | 2020-11-24 | Gsi Technology, Inc. | Read and write data processing circuits and methods associated with computational memory cells using two read multiplexers |
| US10943648B1 (en) | 2016-12-06 | 2021-03-09 | Gsi Technology, Inc. | Ultra low VDD memory cell with ratioless write port |
| US10521229B2 (en) * | 2016-12-06 | 2019-12-31 | Gsi Technology, Inc. | Computational memory cell and processing array device using memory cells |
| US10891076B1 (en) | 2016-12-06 | 2021-01-12 | Gsi Technology, Inc. | Results processing circuits and methods associated with computational memory cells |
| US10860320B1 (en) | 2016-12-06 | 2020-12-08 | Gsi Technology, Inc. | Orthogonal data transposition system and method during data transfers to/from a processing array |
| US10770133B1 (en) | 2016-12-06 | 2020-09-08 | Gsi Technology, Inc. | Read and write data processing circuits and methods associated with computational memory cells that provides write inhibits and read bit line pre-charge inhibits |
| US10777262B1 (en) | 2016-12-06 | 2020-09-15 | Gsi Technology, Inc. | Read data processing circuits and methods associated memory cells |
| US10402340B2 (en) | 2017-02-21 | 2019-09-03 | Micron Technology, Inc. | Memory array page table walk |
| US10403352B2 (en) * | 2017-02-22 | 2019-09-03 | Micron Technology, Inc. | Apparatuses and methods for compute in data path |
| US10268389B2 (en) * | 2017-02-22 | 2019-04-23 | Micron Technology, Inc. | Apparatuses and methods for in-memory operations |
| US10838899B2 (en) * | 2017-03-21 | 2020-11-17 | Micron Technology, Inc. | Apparatuses and methods for in-memory data switching networks |
| US11222260B2 (en) | 2017-03-22 | 2022-01-11 | Micron Technology, Inc. | Apparatuses and methods for operating neural networks |
| US10049721B1 (en) | 2017-03-27 | 2018-08-14 | Micron Technology, Inc. | Apparatuses and methods for in-memory operations |
| US10043570B1 (en) | 2017-04-17 | 2018-08-07 | Micron Technology, Inc. | Signed element compare in memory |
| US10147467B2 (en) | 2017-04-17 | 2018-12-04 | Micron Technology, Inc. | Element value comparison in memory |
| US10761589B2 (en) * | 2017-04-21 | 2020-09-01 | Intel Corporation | Interconnect fabric link width reduction to reduce instantaneous power consumption |
| US9997212B1 (en) | 2017-04-24 | 2018-06-12 | Micron Technology, Inc. | Accessing data in memory |
| US10942843B2 (en) | 2017-04-25 | 2021-03-09 | Micron Technology, Inc. | Storing data elements of different lengths in respective adjacent rows or columns according to memory shapes |
| US10236038B2 (en) | 2017-05-15 | 2019-03-19 | Micron Technology, Inc. | Bank to bank data transfer |
| US10068664B1 (en) | 2017-05-19 | 2018-09-04 | Micron Technology, Inc. | Column repair in memory |
| US10013197B1 (en) | 2017-06-01 | 2018-07-03 | Micron Technology, Inc. | Shift skip |
| US10152271B1 (en) | 2017-06-07 | 2018-12-11 | Micron Technology, Inc. | Data replication |
| US10262701B2 (en) | 2017-06-07 | 2019-04-16 | Micron Technology, Inc. | Data transfer between subarrays in memory |
| US10318168B2 (en) | 2017-06-19 | 2019-06-11 | Micron Technology, Inc. | Apparatuses and methods for simultaneous in data path compute operations |
| US10346226B2 (en) | 2017-08-07 | 2019-07-09 | Time Warner Cable Enterprises Llc | Methods and apparatus for transmitting time sensitive data over a tunneled bus interface |
| US10162005B1 (en) | 2017-08-09 | 2018-12-25 | Micron Technology, Inc. | Scan chain operations |
| US10534553B2 (en) | 2017-08-30 | 2020-01-14 | Micron Technology, Inc. | Memory array accessibility |
| US10346092B2 (en) | 2017-08-31 | 2019-07-09 | Micron Technology, Inc. | Apparatuses and methods for in-memory operations using timing circuitry |
| US10741239B2 (en) | 2017-08-31 | 2020-08-11 | Micron Technology, Inc. | Processing in memory device including a row address strobe manager |
| US10416927B2 (en) | 2017-08-31 | 2019-09-17 | Micron Technology, Inc. | Processing in memory |
| US10409739B2 (en) | 2017-10-24 | 2019-09-10 | Micron Technology, Inc. | Command selection policy |
| CN111527485B (zh) * | 2017-11-03 | 2023-09-12 | 相干逻辑公司 | 存储器网络处理器 |
| US10522210B2 (en) | 2017-12-14 | 2019-12-31 | Micron Technology, Inc. | Apparatuses and methods for subarray addressing |
| US10332586B1 (en) | 2017-12-19 | 2019-06-25 | Micron Technology, Inc. | Apparatuses and methods for subrow addressing |
| US10331612B1 (en) | 2018-01-09 | 2019-06-25 | Apple Inc. | Methods and apparatus for reduced-latency data transmission with an inter-processor communication link between independently operable processors |
| US10614875B2 (en) | 2018-01-30 | 2020-04-07 | Micron Technology, Inc. | Logical operations using memory cells |
| US11194477B2 (en) | 2018-01-31 | 2021-12-07 | Micron Technology, Inc. | Determination of a match between data values stored by three or more arrays |
| US10437557B2 (en) | 2018-01-31 | 2019-10-08 | Micron Technology, Inc. | Determination of a match between data values stored by several arrays |
| US11792307B2 (en) | 2018-03-28 | 2023-10-17 | Apple Inc. | Methods and apparatus for single entity buffer pool management |
| US10725696B2 (en) | 2018-04-12 | 2020-07-28 | Micron Technology, Inc. | Command selection policy with read priority |
| US11381514B2 (en) | 2018-05-07 | 2022-07-05 | Apple Inc. | Methods and apparatus for early delivery of data link layer packets |
| US10430352B1 (en) | 2018-05-18 | 2019-10-01 | Apple Inc. | Methods and apparatus for reduced overhead data transfer with a shared ring buffer |
| US10636459B2 (en) * | 2018-05-30 | 2020-04-28 | Micron Technology, Inc. | Wear leveling |
| US10440341B1 (en) | 2018-06-07 | 2019-10-08 | Micron Technology, Inc. | Image processor formed in an array of memory cells |
| US10585699B2 (en) | 2018-07-30 | 2020-03-10 | Apple Inc. | Methods and apparatus for verifying completion of groups of data transactions between processors |
| US10534840B1 (en) * | 2018-08-08 | 2020-01-14 | Sandisk Technologies Llc | Multiplication using non-volatile memory cells |
| US10719376B2 (en) | 2018-08-24 | 2020-07-21 | Apple Inc. | Methods and apparatus for multiplexing data flows via a single data structure |
| US10846224B2 (en) | 2018-08-24 | 2020-11-24 | Apple Inc. | Methods and apparatus for control of a jointly shared memory-mapped region |
| US10789110B2 (en) | 2018-09-28 | 2020-09-29 | Apple Inc. | Methods and apparatus for correcting out-of-order data transactions between processors |
| US10838450B2 (en) | 2018-09-28 | 2020-11-17 | Apple Inc. | Methods and apparatus for synchronization of time between independently operable processors |
| US11175915B2 (en) | 2018-10-10 | 2021-11-16 | Micron Technology, Inc. | Vector registers implemented in memory |
| US10769071B2 (en) | 2018-10-10 | 2020-09-08 | Micron Technology, Inc. | Coherent memory access |
| US10483978B1 (en) | 2018-10-16 | 2019-11-19 | Micron Technology, Inc. | Memory device processing |
| KR20200057475A (ko) * | 2018-11-16 | 2020-05-26 | 삼성전자주식회사 | 연산 회로를 포함하는 메모리 장치 및 그것을 포함하는 뉴럴 네트워크 시스템 |
| US11184446B2 (en) | 2018-12-05 | 2021-11-23 | Micron Technology, Inc. | Methods and apparatus for incentivizing participation in fog networks |
| US10853066B1 (en) | 2019-05-07 | 2020-12-01 | Memryx Incorporated | Memory processing units and methods of computing DOT products including zero bit skipping |
| US10998037B2 (en) | 2019-05-07 | 2021-05-04 | Memryx Incorporated | Memory processing units and methods of computing dot products |
| US11488650B2 (en) | 2020-04-06 | 2022-11-01 | Memryx Incorporated | Memory processing unit architecture |
| US10930341B1 (en) | 2019-06-18 | 2021-02-23 | Gsi Technology, Inc. | Processing array device that performs one cycle full adder operation and bit line read/write logic features |
| US10958272B2 (en) * | 2019-06-18 | 2021-03-23 | Gsi Technology, Inc. | Computational memory cell and processing array device using complementary exclusive or memory cells |
| US10877731B1 (en) | 2019-06-18 | 2020-12-29 | Gsi Technology, Inc. | Processing array device that performs one cycle full adder operation and bit line read/write logic features |
| US10867655B1 (en) | 2019-07-08 | 2020-12-15 | Micron Technology, Inc. | Methods and apparatus for dynamically adjusting performance of partitioned memory |
| US11860782B2 (en) * | 2019-08-13 | 2024-01-02 | Neuroblade Ltd. | Compensating for DRAM activation penalties |
| US11360768B2 (en) | 2019-08-14 | 2022-06-14 | Micron Technolgy, Inc. | Bit string operations in memory |
| US11558348B2 (en) | 2019-09-26 | 2023-01-17 | Apple Inc. | Methods and apparatus for emerging use case support in user space networking |
| US11829303B2 (en) | 2019-09-26 | 2023-11-28 | Apple Inc. | Methods and apparatus for device driver operation in non-kernel space |
| US20210103533A1 (en) * | 2019-10-04 | 2021-04-08 | Etron Technology, Inc. | Memory system and memory chip |
| US11449577B2 (en) | 2019-11-20 | 2022-09-20 | Micron Technology, Inc. | Methods and apparatus for performing video processing matrix operations within a memory array |
| US11853385B2 (en) | 2019-12-05 | 2023-12-26 | Micron Technology, Inc. | Methods and apparatus for performing diversity matrix operations within a memory array |
| US11169876B2 (en) * | 2019-12-31 | 2021-11-09 | Micron Technology, Inc. | Apparatuses, systems, and methods for error correction |
| US11606302B2 (en) | 2020-06-12 | 2023-03-14 | Apple Inc. | Methods and apparatus for flow-based batching and processing |
| US11227641B1 (en) | 2020-07-21 | 2022-01-18 | Micron Technology, Inc. | Arithmetic operations in memory |
| US11775359B2 (en) | 2020-09-11 | 2023-10-03 | Apple Inc. | Methods and apparatuses for cross-layer processing |
| US11954540B2 (en) | 2020-09-14 | 2024-04-09 | Apple Inc. | Methods and apparatus for thread-level execution in non-kernel space |
| US11799986B2 (en) | 2020-09-22 | 2023-10-24 | Apple Inc. | Methods and apparatus for thread level execution in non-kernel space |
| US11537462B2 (en) * | 2020-09-29 | 2022-12-27 | Micron Technology, Inc. | Apparatuses and methods for cyclic redundancy calculation for semiconductor device |
| US11882051B2 (en) | 2021-07-26 | 2024-01-23 | Apple Inc. | Systems and methods for managing transmission control protocol (TCP) acknowledgements |
| US11876719B2 (en) | 2021-07-26 | 2024-01-16 | Apple Inc. | Systems and methods for managing transmission control protocol (TCP) acknowledgements |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH09106389A (ja) * | 1995-10-12 | 1997-04-22 | Sony Corp | 信号処理装置 |
| JPH1026966A (ja) * | 1994-06-02 | 1998-01-27 | Accelerix Ltd | シングルチップフレームバッファおよびグラフィックアクセラレータ |
| JPH1074141A (ja) * | 1996-08-30 | 1998-03-17 | Matsushita Electric Ind Co Ltd | 信号処理装置 |
| JPH10134176A (ja) * | 1996-10-29 | 1998-05-22 | Sony Corp | 画像信号処理方法及び装置 |
| JP2001216275A (ja) * | 2000-02-01 | 2001-08-10 | Sony Corp | 画像処理装置および画像処理方法 |
| JP2004021645A (ja) * | 2002-06-17 | 2004-01-22 | Canon Inc | 画像処理装置およびその制御方法 |
| JP2006099232A (ja) * | 2004-09-28 | 2006-04-13 | Renesas Technology Corp | 半導体信号処理装置 |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4811297A (en) * | 1986-12-16 | 1989-03-07 | Fujitsu Limited | Boundary-free semiconductor memory device |
| JPH05197550A (ja) | 1992-01-21 | 1993-08-06 | Fujitsu Ltd | 超並列計算機のalu構成方式 |
| JPH06324862A (ja) | 1993-05-11 | 1994-11-25 | Nippon Telegr & Teleph Corp <Ntt> | 演算用記憶装置 |
| JPH10254843A (ja) | 1997-03-06 | 1998-09-25 | Hitachi Ltd | クロスバスイッチ、該クロスバスイッチを備えた並列計算機及びブロードキャスト通信方法 |
| KR100275745B1 (ko) * | 1998-10-19 | 2000-12-15 | 윤종용 | 가변적인 페이지 수 및 가변적인 페이지 길이를 갖는 반도체 메모리장치 |
| KR100387719B1 (ko) * | 2000-12-29 | 2003-06-18 | 주식회사 하이닉스반도체 | 반도체 메모리 장치 및 그의 메모리 셀 블록 활성화 제어방법 |
| US6614695B2 (en) * | 2001-08-24 | 2003-09-02 | Micron Technology, Inc. | Non-volatile memory with block erase |
| JP2003114797A (ja) | 2001-10-04 | 2003-04-18 | Matsushita Electric Ind Co Ltd | データ処理装置 |
| US6775184B1 (en) * | 2003-01-21 | 2004-08-10 | Nexflash Technologies, Inc. | Nonvolatile memory integrated circuit having volatile utility and buffer memories, and method of operation thereof |
| JP2006127460A (ja) * | 2004-06-09 | 2006-05-18 | Renesas Technology Corp | 半導体装置、半導体信号処理装置、およびクロスバースイッチ |
-
2005
- 2005-05-16 JP JP2005143109A patent/JP2006127460A/ja active Pending
- 2005-06-09 US US11/148,369 patent/US7562198B2/en not_active Expired - Fee Related
-
2008
- 2008-06-16 US US12/213,131 patent/US7791962B2/en not_active Expired - Fee Related
-
2010
- 2010-08-16 US US12/857,063 patent/US8089819B2/en not_active Expired - Fee Related
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1026966A (ja) * | 1994-06-02 | 1998-01-27 | Accelerix Ltd | シングルチップフレームバッファおよびグラフィックアクセラレータ |
| JPH09106389A (ja) * | 1995-10-12 | 1997-04-22 | Sony Corp | 信号処理装置 |
| JPH1074141A (ja) * | 1996-08-30 | 1998-03-17 | Matsushita Electric Ind Co Ltd | 信号処理装置 |
| JPH10134176A (ja) * | 1996-10-29 | 1998-05-22 | Sony Corp | 画像信号処理方法及び装置 |
| JP2001216275A (ja) * | 2000-02-01 | 2001-08-10 | Sony Corp | 画像処理装置および画像処理方法 |
| JP2004021645A (ja) * | 2002-06-17 | 2004-01-22 | Canon Inc | 画像処理装置およびその制御方法 |
| JP2006099232A (ja) * | 2004-09-28 | 2006-04-13 | Renesas Technology Corp | 半導体信号処理装置 |
Cited By (43)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7769980B2 (en) | 2006-08-21 | 2010-08-03 | Renesas Technology Corp. | Parallel operation device allowing efficient parallel operational processing |
| JP2008047031A (ja) * | 2006-08-21 | 2008-02-28 | Kumamoto Univ | 並列演算装置 |
| JP2009098861A (ja) * | 2007-10-16 | 2009-05-07 | Renesas Technology Corp | 並列演算処理装置 |
| JP2009104521A (ja) * | 2007-10-25 | 2009-05-14 | Mitsubishi Electric Corp | 並列処理装置 |
| US8402260B2 (en) | 2008-06-20 | 2013-03-19 | Renesas Electronics Corporation | Data processing apparatus having address conversion circuit |
| JP2010003151A (ja) * | 2008-06-20 | 2010-01-07 | Renesas Technology Corp | データ処理装置 |
| JP2010244095A (ja) * | 2009-04-01 | 2010-10-28 | Seiko Epson Corp | データ処理装置、印刷システムおよびプログラム |
| US10579379B2 (en) | 2009-12-22 | 2020-03-03 | Intel Corporation | Processor to perform a bit range isolation instruction |
| JP2011134304A (ja) * | 2009-12-22 | 2011-07-07 | Intel Corp | ビット範囲分離命令、方法、および装置 |
| JP2018160288A (ja) * | 2009-12-22 | 2018-10-11 | インテル・コーポレーション | プロセッサ、方法、プログラム、および機械可読記録媒体 |
| US9003170B2 (en) | 2009-12-22 | 2015-04-07 | Intel Corporation | Bit range isolation instructions, methods, and apparatus |
| JP2016026365A (ja) * | 2009-12-22 | 2016-02-12 | インテル・コーポレーション | プロセッサ、システムオンチップ(SoC)、ハンドヘルドデバイス、および装置 |
| US10372455B2 (en) | 2009-12-22 | 2019-08-06 | Intel Corporation | Hand held device to perform a bit range isolation instruction |
| US10579380B2 (en) | 2009-12-22 | 2020-03-03 | Intel Corporation | System-on-chip (SoC) to perform a bit range isolation instruction |
| JP2014081953A (ja) * | 2009-12-22 | 2014-05-08 | Intel Corp | ビット範囲分離命令、方法、および装置 |
| US10656947B2 (en) | 2009-12-22 | 2020-05-19 | Intel Corporation | Processor to perform a bit range isolation instruction |
| US10796733B2 (en) | 2013-03-04 | 2020-10-06 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US11276439B2 (en) | 2013-03-04 | 2022-03-15 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US9472265B2 (en) | 2013-03-04 | 2016-10-18 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US9892766B2 (en) | 2013-03-04 | 2018-02-13 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US11727963B2 (en) | 2013-03-04 | 2023-08-15 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US9959913B2 (en) | 2013-03-04 | 2018-05-01 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US10431264B2 (en) | 2013-03-04 | 2019-10-01 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US10153009B2 (en) | 2013-03-04 | 2018-12-11 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| JP2014182800A (ja) * | 2013-03-15 | 2014-09-29 | Intel Corp | データ要素内のビットをゼロ化するためのシステム、装置、および方法 |
| JP2016532919A (ja) * | 2013-08-08 | 2016-10-20 | マイクロン テクノロジー, インク. | 論理演算を、センス回路を使用して実行する装置及び方法 |
| US10186303B2 (en) | 2013-08-08 | 2019-01-22 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US10535384B2 (en) | 2013-08-08 | 2020-01-14 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US9899068B2 (en) | 2013-08-08 | 2018-02-20 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US9589607B2 (en) | 2013-08-08 | 2017-03-07 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US11495274B2 (en) | 2013-08-08 | 2022-11-08 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US10878863B2 (en) | 2013-08-08 | 2020-12-29 | Micron Technology, Inc. | Apparatuses and methods for performing logical operations using sensing circuitry |
| US10055196B2 (en) | 2013-11-08 | 2018-08-21 | Micron Technology, Inc. | Division operations for memory |
| US10579336B2 (en) | 2013-11-08 | 2020-03-03 | Micron Technology, Inc. | Division operations for memory |
| JP2017503229A (ja) * | 2013-11-08 | 2017-01-26 | マイクロン テクノロジー, インク. | メモリ用の除算演算 |
| JP2017016668A (ja) * | 2013-12-23 | 2017-01-19 | 井上 克己 | 情報検索機能を備えたメモリ、その利用方法、装置、情報処理方法。 |
| JP2016042223A (ja) * | 2014-08-14 | 2016-03-31 | 富士ゼロックス株式会社 | データ処理装置およびプログラム |
| WO2016199808A1 (ja) * | 2015-06-08 | 2016-12-15 | 井上 克己 | メモリ型プロセッサ、メモリ型プロセッサを含んだ装置、その使用方法。 |
| US10817442B2 (en) | 2017-03-22 | 2020-10-27 | Micron Technology, Inc. | Apparatus and methods for in data path compute operations |
| US11048652B2 (en) | 2017-03-22 | 2021-06-29 | Micron Technology, Inc. | Apparatus and methods for in data path compute operations |
| JP2020512653A (ja) * | 2017-03-22 | 2020-04-23 | マイクロン テクノロジー,インク. | インデータパス計算動作のための装置及び方法 |
| US11550742B2 (en) | 2017-03-22 | 2023-01-10 | Micron Technology, Inc. | Apparatus and methods for in data path compute operations |
| JP2021114353A (ja) * | 2017-06-02 | 2021-08-05 | ウルトラメモリ株式会社 | 半導体モジュール |
Also Published As
| Publication number | Publication date |
|---|---|
| US7562198B2 (en) | 2009-07-14 |
| US20050285862A1 (en) | 2005-12-29 |
| US20090027978A1 (en) | 2009-01-29 |
| US8089819B2 (en) | 2012-01-03 |
| US20100308858A1 (en) | 2010-12-09 |
| US7791962B2 (en) | 2010-09-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2006127460A (ja) | 半導体装置、半導体信号処理装置、およびクロスバースイッチ | |
| Wang et al. | 14.2 A compute SRAM with bit-serial integer/floating-point operations for programmable in-memory vector acceleration | |
| CN108701476B (zh) | 用于针对拐角转变的经修改解码的设备和方法 | |
| JP4989900B2 (ja) | 並列演算処理装置 | |
| JP6799520B2 (ja) | Dram基盤プロセシングユニット | |
| TWI656533B (zh) | 用於在資料路徑中計算之裝置及方法 | |
| US4580215A (en) | Associative array with five arithmetic paths | |
| CN101782893B (zh) | 可重构数据处理平台 | |
| CN109147842B (zh) | 同时进行数据路径中计算操作的设备及方法 | |
| JP4738112B2 (ja) | 半導体記憶装置 | |
| JP2006164183A (ja) | 半導体信号処理装置 | |
| US4546428A (en) | Associative array with transversal horizontal multiplexers | |
| Akyel et al. | DRC 2: Dynamically Reconfigurable Computing Circuit based on memory architecture | |
| JPS62139066A (ja) | オンバンドramおよびアドレス発生装置を有する単一命令多重デ−タセルアレイ処理装置 | |
| JP7264897B2 (ja) | メモリ装置及びそれを制御するための方法 | |
| TWI671744B (zh) | 用於在記憶體中資料切換網路的裝置及方法 | |
| CN114341981B (zh) | 具有人工智能模式的存储器 | |
| Sutradhar et al. | Look-up-table based processing-in-memory architecture with programmable precision-scaling for deep learning applications | |
| JP2008047031A (ja) | 並列演算装置 | |
| CN114341983A (zh) | 用于人工智能操作的激活函数 | |
| Hanindhito et al. | Wave-pim: Accelerating wave simulation using processing-in-memory | |
| JP2007004542A (ja) | 半導体信号処理装置 | |
| JPS62138936A (ja) | セルアレイプロセツサチツプの試験方法と装置 | |
| Chen et al. | BRAMAC: Compute-in-BRAM Architectures for Multiply-Accumulate on FPGAs | |
| Myjak et al. | A two-level reconfigurable architecture for digital signal processing |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20080401 |
|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A712 Effective date: 20100609 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110920 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20120131 |