-
Die vorliegende Erfindung betrifft
ein Bilderzeugungssystem und ein Verfahren, die nichtperiodische Rauminformation
mit hoher Frequenz in Bildern feststellen und erhalten können. Insbesondere
betrifft die vorliegende Erfindung ein Bilderzeugungssystem und
ein Verfahren, die positionsempfindliche Detektoren verwenden, um
die Kantenfeststellungsreaktion in erfassten oder gescannten digitalen
Bildern zu erhöhen.
-
Die Reaktion des menschlichen Auges
auf Bildinhalte mit hoher Raumfrequenz ist stark von der Natur der
Merkmale abhängig.
Zum Beispiel integriert das Auge bestimmte Typen von Intensitätsvariationen
mit hoher Frequenz wie etwa eng benachbarte schwarze Punkte oder
Linien, indem sie diese glättet
und als solides Grau wahrnimmt. Im Gegensatz dazu werden andere
Typen von Intensitätsvariationen
mit hoher Frequenz wie etwa Kanten mit starkem Kontrast oder fehlausgerichtete
Linien nicht geglättet.
Fehlausrichtungen von Kanten oder Linien bleiben auch bei sehr hohen
Raumfrequenzen erkennbar. Die Erforschung der Sehfähigkeit
hat für ein
Muster mit benachbarten vertikalen Streifen mit Intensitäten von
jeweils 0% und 100% (Schwarz und Weiß) ergeben, dass die Fähigkeit
des menschlichen Sehsystems zur Unterscheidung des Musters von einem
gleichmäßigem Grau
bei im wesentlichen 150 Zyklen/Zoll (6 Zyklen/mm) und einem Standardsehabstand
von 12 Zoll (30 cm) stark abfällt.
Bei niedrigeren Kontraststufen zwischen den Intensitäten fällt die
Reaktion bei noch niedrigeren Raumfrequenzen ab. Dennoch bleibt
die menschliche Sehfähigkeit
extrem empfindlich gegenüber (nicht-periodischen)
Stufen mit hohem Kontrast in einem Bild wie etwa Schwarz-Weiß-Kanten.
Obwohl Kanten Information bei Frequenzen von weit mehr als 150 Zyklen/Zoll
(6 Zyklen/mm) enthalten, glättet
bzw. verwischt die Sehfähigkeit
die Kante nicht wesentlich und bleibt für deren genaue Position empfindlich.
Diese Eigenschaft der menschlichen Sehfähigkeit wurde als Hyperschärfe bezeichnet,
weil sie eine effektive Sehschärfe für bestimmte
Klassen von Objekten gestattet, die die normale Sehschärfe um das
bis zu Zehnfache übersteigt.
Der Hyperschärfeeffekt
kann einfach beobachtet werden, wenn eine Seite mit eng benachbarten
Zeilen betrachtet wird, wobei einige Zeilen unterbrochen und geringfügig verschoben
sind, um eine Zeilenfehlausrichtung vorzusehen. Wenn die Seite weit
genug entfernt gehalten wird, erscheint die Mehrzahl der Zeilen
zu kontinuierlichen Tönen
zu verschmelzen, wobei aber vergleichsweise kleine Details, wo die
Zeilen nicht miteinander ausgerichtet sind, weiterhin klar und deutlich
erkennbar bleiben.
-
Leider verursacht die Hyperschärfe der
menschlichen Sehkraft bestimmte Probleme für digitale Bilderzeugungseinrichtungen
wie etwa Scanner. Das Problem ist besonders groß bei Dokumenten oder Medien,
die sowohl Text als auch Fotos oder Halbtonbilder enthalten. Ein
Scanner ist erforderlich, um Fotos oder Halbtonbilder in einem Dokument
als kontinuierliche Grautöne
aufzubereiten, muss aber auch die Textkanten mit einer hohen Pixelgenauigkeit
platzieren können.
Es werden verschiedene Ansätze
verfolgt, um dieses Problem zu lösen.
Gewöhnlich
wird eine Vorverarbeitung des Bildes verwendet, um das Dokument
zu Text- und Bildteilen zu segmentieren. Text-ähnliche Elemente in einem Dokument
werden identifiziert und separat zu den Halbtonbildern oder kontinuierlichen
Bildern verarbeitet. Gewöhnlich
werden Verarbeitungsalgorithmen zur Verbesserung von Liniensegmenten
für den
Text verwendet, während
Glättungsalgorithmen
für die
Halbtonbilder oder kontinuierlichen Bilder verwendet werden. Dadurch
wird die Bildqualität
verbessert, wobei es jedoch schwierig ist, zuverlässige automatische
Segmentierungsalgorithmen zu entwickeln, und wobei die Segmentierung
häufig
fehlerhaft ist, wenn Text in einem Kontinuierlichtonbild eingebettet
ist.
-
Anstatt einer Segmentierung sieht
ein alternativer Ansatz eine Erhöhung
der Dichte der Abtastelemente (auch als „Pixelelemente" bezeichnet) vor,
um die Auflösung
zu verbessern. Dadurch wird zwar die Gesamtqualität verbessert,
doch stellt dies gewöhnlich
keine kostengünstige
Lösung
dar. Es soll zum Beispiel ein Bild betrachtet werden, das einen
soliden schwarzen Kreis im Zentrum vor einem weißen Hintergrund aufweist. Ein gewöhnliches
Abtastsystem nimmt die durchschnittliche Intensität, die auf
jedes Pixelelement einfällt.
Bei niedrigeren Abtastdichten und Auflösungen hat dieser Ansatz gezackte
Linien zur Folge, die im Originalbild nicht vorhanden sind. Eine
Abtastung mit höheren
Auflösungen
reduziert sicherlich die Sichtbarkeit dieser Merkmale an der Grenze
zwischen schwarzen und weißen
Bereichen, bringt jedoch ein Abtasten von durchgehend schwarzen
oder weißen
Intensitätsbereichen
mit einer unnötig
hohen Auflösung
mit sich. In der Praxis machen die hohen Kosten von sehr dichten
Abtastelementen in Verbindung mit den höheren Speicheranforderungen und
Bildverarbeitungszeiten die Entwicklung von Bilderzeugungssystemen
mit einer der menschlichen Hyperschärfe entsprechenden Reaktion
unmöglich.
-
Es ist dementsprechend eine Aufgabe
der vorliegenden Erfindung, ein Bilderzeugungssystem anzugeben,
das visuell wichtige Merkmale mit Subdetektorelement-Größe in gescannten
Bildern (bei einer Auflösung
mit Hyperschärfegrad)
unter Verwendung von Detektoren und Verarbeitungsverfahren mit einer
Subpixelreaktion rekonstruieren kann, wobei keine Abtastelemente
mit hoher Dichte und keine Segmentierung eines Bildes erforderlich
sind. Detektoren mit Subpixelauflösung umfassen Anordnungen von
positionsempfindlichen Detektoren („PSDs"), p-i-n-Übergangselemente mit Kontakten
an jeder Kante jedes PSD-Elements, die auf einer virtuellen Erde
gehalten werden. Wenn sichtbares Licht oder ein anderer Typ von
einfallender Strahlung (z. B. ultraviolettes Licht, infrarotes Licht
usw.) auf ein in geeigneter Weise vorgespanntes PSD-Element trifft, werden
Elektronen-Löcher-Ladungspaare
in einer intrinsischen Schicht (i-Schicht) erzeugt. Die Elektroden werden
von den Löchern
durch das elektrische Feld zwischen der p-Schicht und der n-Schicht
getrennt, wobei die Elektroden zu der n-Schciht und die Löcher zu
der p-Schicht fließen.
Die Elektroden in der n-Schicht fließen dann zu den Kantenkontakten
(die alle bei gleichem Potenzial gehalten werden) mit Strömen in jedem
Kontakt, die linear proportional zu dem Abstand zwischen dem Punkt
der Ladungserzeugung (entspricht dem Einfallspunkt des Lichts) und
dem Kontakt sind. Wenn der Strom an jeder Kante gemessen wird, kann
die Position des einfallenden Lichts bestimmt werden. Weil weiterhin
die allgemeine Verteilung der Intensität (mehrere Ereignisse einfallenden
Lichts) aus Überlagerungen
mehrerer Einzelpunkte abgeleitet werden können, ist eine Berechnung einer
zentralen Lichtintensität
innerhalb jedes PSD-Elements möglich.
In der Praxis sieht die Bilderkennung und -verarbeitung gemäß der vorliegenden
Erfindung unter Verwendung von Anordnungen von PSDs eine Bildinformation
mit einer viel effektiveren Auflösung
vor als bei herkömmlichen
p-i-n-Detektoren, die keine derartige Einfallslicht-Positionsinformation
vorsehen.
-
Es ist eine weitere Aufgabe der vorliegenden
Erfindung, eine getreue Aufbereitung und Wiedergabe von Dokumenten
mit visuell wichtigen Merkmalen sowohl in Text als auch in Kontinuierlichtönen ohne
vorausgehende Segmentierung zu gestatten. Die Aufbereitung muss
genau die Merkmale wiedergeben, die für ein hyperscharfes menschliches
Auge bei normalen Sichtdistanzen erkennbar sind. Die vorliegende
Erfindung ermöglicht
eine Subpixelauflösung
von kritischen Kanten- und Linienmerkmalen mit hohem Kontrast und
kann trotzdem periodische Merkmale mit hoher Frequenz zur Simulation
von kontinuierlichen Tönen
glatt integrieren.
-
Es ist eine weitere Aufgabe der vorliegenden
Endung, ein rechnerisch effizientes Verfahren in einem Durchlauf
zum Aufbereiten von visuell wichtigen Merkmalen in einem Bild anzugeben.
Im Gegensatz zu den Verfahren aus dem Stand der Technik, die eine
Segmentierung oder Isolation von sich über große Bereiche eines Bildes erstreckenden
Kantenmerkmalen erfordern, benötigt
das Verfahren der vorliegenden Erfindung nur einen einzigen Durchlauf über das
Bild. Dadurch kann der Zeitaufwand für die Verarbeitung und Aufbereitung
beträchtlich
reduziert werden.
-
Es ist eine weitere Aufgabe der vorliegenden
Erfindung, ein Verarbeitungsverfahren anzugeben, das lokal operiert
und keine weitreichende Abtastung von benachbarten Pixeln während der
Bildaufbereitung erfordert. Die Operation der Vorrichtung oder des
Verfahrens der vorliegenden Erfindung erfordert nicht viel Kontextinformation
in Bezug auf die Lichtintensität
in benachbarten Pixeln, sondern gewöhnlich nur Graustufeninformation
von höchstens
zwei benachbarten Pixeln und häufig
nur von einem einzigen benachbarten Pixel. Wiederum wird dadurch
die Verarbeitungszeit reduziert, wobei außerdem auch die Gesamtbildfehler
reduziert werden. Weil sich lokale Fehler bei der Aufbereitung nicht
aus dem Detektorbereich (einem einzelnen Pixel) heraus fortpflanzen,
wird die Möglichkeit
des Auftretens von visuell sichtbaren Artefakten während der
Aufbereitung im Vergleich zu den globalen Bildaufbereitungstechniken
aus dem Stand der Technik stark reduziert.
-
Es ist eine weitere Aufgabe der vorliegenden
Erfindung, eine Vorrichtung und ein Verfahren anzugeben, welche
die Intensität
erhalten. Mit anderen Worten soll die Gesamtintensität der aufbereiteten
Ausgabewiedergabe für
einen bestimmten PSD-Detektor immer gleich der in den PSD-Detektor
einfallenden Gesamtintensität
sein. Die Erhaltung der Intensität
ist von wesentlicher Bedeutung für
die Aufrechterhaltung des Erscheinungsbildes. Bei einem ausreichend
großen
Sichtabstand für
eine bestimmte Größe des Bildbereichs
erscheinen zwei Berieche in einem Bild mit gleicher Gesamtintensität für das Auge
im wesentlichen identisch. Die aufbereitete Ausgabe gemäß der vorliegenden
Erfindung erscheint dementsprechend bei einer der Fläche eines
Detektors entsprechenden Sichtdistanz dem Graumodell sehr ähnlich,
unabhängig
davon, wie schlecht Kanten oder kontinuierliche Merkmale modelliert
sind. Obwohl Details verloren gehen können und Moire-Muster auftreten
können,
verhindert die Grauumwandlung an dem PSD-Detektor das Auftreten
von Artefakten und groben Fehlern über einen großen Bereich
des Bildes.
-
Ein kleinerer Vorteil der vorliegenden
Erfindung liegt in der Möglichkeit,
Segmentierungsinformation aus einer während der Aufbereitung bestimmten
Kanteninformation zu extrahieren. Wie zuvor erläutert, ist unter Segmentierung
der Prozess der Unterteilung eines Bildes in mehrere Bereiche in Übereinstimmung
mit der Kategorie des Bildinhalts zu verstehen (d. h. Textbereiche,
Halbtonbildbereiche usw.). Weil die aufbereitete Ausgabe für Text und
Strichzeichnungen einen großen
Anteil von Detektoren mit Kanten enthält, während die Ausgabe für Kontinuierlichtonbilder
einen viel kleineren Anteil enthält,
kann der Anteil der Kanten enthaltenen Detektoren für einen
bestimmten Bildbereich als statistisches Maß verwendet werden, um zu bestimmen,
ob dieser Bereich des Bildes Text oder Abbildungen enthält. Die
aus der Operation der Vorrichtung oder des Verfahrens der vorliegenden
Erfindung erhaltene Segmentierungsinformation kann für Systeme
nützlich
sein, die eine Segmentierung erfordern, etwa für ein optisches Zeichenerkennungssystem
oder für
die Textanalyse.
-
In Übereinstimmung mit den zuvor
genannte Aufgaben und Vorteilen gibt die vorliegende Erfindung ein
Bildverarbeitungsverfahren sowie ein Bildertassungs- und Bildpunktverarbeitungssystem
mit den Merkmalen von jeweils Anspruch 1 und 8 an. Vorteilhafte
Ausführungsformen
sind in den Unteransprüchen
angegeben.
-
Bei einer Betrachtung der vorliegenden
Erfindung wird deutlich, dass die Ausgabe für jedes Pixel in Entsprechung
zu einem PSD-Detektorelement ein Satz von vier Parametern ist, die
entweder die Position, die Ausrichtung und die Intensitätsstufen
einer Kante oder die Koeffizienten für eine kontinuierliche Beschreibung (Ebenenmodell
oder bilineares Modell) angeben. Weil es sich dabei um eine analytische
Beschreibung des Subpixelbereichs handelt, sind Operationen wie
etwa eine Skalierung oder eine Drehung relativ einfach: die Wiedergabe
kann konstant gehalten werden, während
der Bereich des Ausgabebildes in Entsprechung zu jedem Detektor
skaliert oder gedreht werden kann.
-
Solange eine Transformation zwischen
einem Punkt an der ursprünglichen
Position des Detektors zu dem neuen Koordinatensystem des aufbereiteten
Pixels in einem Bild gefunden werden kann, kann die Aufbereitung
auf diesen transformierten Koordinaten durchgeführt werden. Im Gegensatz dazu
weisen herkömmliche
gescannte Bildwiedergaben, in denen nur die durchschnittliche Intensität für jeden
Detektor aus dem Scan (z. B. eine Graustufenwiedergabe) extrahiert
ist, keine so große
Flexibilität
in Bezug auf die Skalierung oder Drehung auf. Während Kanten in einem herkömmlichen
gescannten Bild glatt erscheinen können, wenn jeder Detektor einem
oder einigen wenigen Pixeln in dem Bild entspricht, wird die quadratische
Form der Fläche
jedes Detektors deutlich, wenn das Bild vergrößert wird (nach oben skaliert
wird). Die analytische Beschreibung ist auch von großem Nutzen
für die
Umwandlung der Auflösung.
Umwandlungen zu beliebigen Auflösungen
bei Erhaltung der Kanteninformation sind einfach umzusetzen.
-
Weitere Aufgaben, Vorteile und Merkmale
der vorliegenden Erfindung werden durch die folgende Beschreibung
und die Zeichnungen zu bevorzugten Ausführungsformen verdeutlicht.
-
1 ist
eine schematische Darstellung eines Dokumentverarbeitungssystems,
das einen Scanner, eine Bildverarbeitungsanordnung gemäß der Erfindung
und verschiedene Ausgabegeräte
umfasst.
-
2 zeigt
eine zweidimensionale Anordnung von positionsempfindlichen Detektoren
(PSDs), wobei die Eingabe und Ausgabe für einen einzelnen PSD gezeigt
sind.
-
3 ist
eine ausführlichere
Darstellung von vier Detektorelementen mit einem Koordinatensystem über einem
der Detektorelemente, um die Bestimmung eines Schwerpunkts (x, y)
und die Bestimmung von Kantenparametern zu erläutern.
-
4 ist
ein ursprüngliches
Kontinuierlichtonbild.
-
5 ist
ein aufbereitetes Bild eines Scans des Bilds von 4 unter Verwendung von Standarddetektoren
und einer Graumodellierung.
-
6 ist
ein aufbereitetes Bild eines Scans des Bilds von 4 unter Verwendung von positionsempfindlichen
Detektoren, die mit Subpixelgenauigkeit in Übereinstimmung mit dem Bildverarbeitungssystem
der vorliegenden Erfindung betrieben werden.
-
Ein Dokumentverarbeitungssystem 10,
das geeignet ist, um für
ein Dokument 11 mit einer 12 und einem
Text 14 ein digitales Scannen, eine Bildverarbeitung, eine
Aufbereitung und eine Anzeige vorzusehen, ist in 1 gezeigt. Das digitale Scannen wird
mit einem Scanner 20 einschließlich einer Detektoranordnung 22 bewerkstelligt.
In einer bevorzugten Ausführungsform
ist die Detektoranordnung 22 eine zweidimensionale Anordnung
mit einer Größe, die
einer gewöhnlichen
zu scannenden Seite entspricht, um die wesentlich gleichzeitige
Erfassung einer gesamten Bildseite zu ermöglichen. Alternativ hierzu
kann eine ausreichend lange lineare Anordnung verwendet werden,
um ein „Fenster" mit der Breite einer
Seite mit herkömmlicher
Größe zu scannen,
wobei die Position des Scanfensters in der Längsrichtung über die
Seite verschoben wird (durch die physikalische Bewegung der Detektoranordnung 22 oder
die optische Bewegung des Scanfensters unter Verwendung von sich
drehenden Spiegeln, Prismen usw.). Natürlich können auch alternative Scanschemata
einschließlich
der Verwendung von mehreren unabhängigen Anordnungen zum Scannen
von zusammenhängenden
Abschnitten eines Dokuments 11 verwendet werden.
-
Der Scanner 20 gibt Signale
in Entsprechung zu den durch die Detektoranordnung 22 festgestellten Lichtwerten
zu einer Bildverarbeitungsanordnung 30. Die Bildverarbeitungsanordnung 30 kann
ein serieller oder paralleler Universalcomputer mit einem Speicher 32 und
einem bzw. mehreren Prozessoren sein, der über ein Netzwerk (nicht gezeigt)
mit dem Scanner verbunden ist; sie kann aber auch dedizierte Hardware
umfassen, die direkt im Scanner integriert ist. Der Speicher 32 der
Bildverarbeitungsanordnung 30 wird verwendet, um die digitale
Wiedergabe einer von dem Scanner 20 erhaltenen Lichtintensitätsabbildung
in Entsprechung zu einem Dokument 11 zusammen mit anderen
zusätzlichen
Informationen zu speichern, die zu dem Licht bzw. Bild verfügbar sind.
Die empfangenen Informationen werden durch eine Lichtintensitätseinheit 33 verarbeitet,
um die Gesamtlichtintensität
in jedem Pixel zu bestimmen, sowie durch eine Momentberechnungseinheit 34,
um den Schwerpunkt der Lichtintensität in jedem Pixel zu bestimmen.
Die kombinierten Informationen werden dann durch eine Graustufenaufbereitungseinheit 36 verwendet,
um die entsprechende Graustufe für
jedes aufbereitete Pixel in einer konstruierten Bitmap (nicht gezeigt)
zu bestimmen. Die Bitmap wird zu einer gerätespezifischen Umwandlungseinheit 38 übertragen,
um die Bitmap zu einer Form umzuwandeln, die für das Drucken durch einen Drucker 40 geeignet
ist (dabei wird das wiedergegebene Dokument 16 mit der
wiedergegebenen 13 und dem wiedergegebenen
Text 15 ausgegeben). Alternativ hierzu kann die gerätespezifische
Umwandlungseinheit 38 Signale ausgeben, die für die vorübergehende
Anzeige des wiedergegebenen Dokuments auf einer Anzeige 42,
für das
langfristige Speichern in einer Speichereinheit 44 (die
eine Magnetplatte oder einen optischen Speicher umfassen kann) als
Bitmap oder als proprietäre
Bilddatei oder für die
Verwendung in Verbindung mit einem anderen herkömmlichen Ausgabegerät geeignet
sind.
-
Die Operation der Bildverarbeitungsanordnung 30 erfordert
Information zu der Lichtintensitätsverteilung
in jedem Pixelelement der Detektoranordnung 22 im Scanner 20.
In einer bevorzugten Ausführungsform der
vorliegenden Erfindung wird die Subpixel-Lichtintensitätsinformation
unter Verwendung einer zweidimensionalen positionsempfindlichen
Detektoranordnung 24 ausgegeben. Jeder positionsempfindliche
Detektor 26 in der zweidimensionalen Anordnung 24 umfasst
eine p-Schicht 52 (aus einem herkömmlichen dotierten Halbleitermaterial
des p-Typs), eine i-Schicht 54 (aus einem herkömmlichen
intrinsischen Halbleitermaterial) und eine n-Schicht 56 (aus
einem herkömmlichen
dotierten Halbleitermaterial des n-Typs), die zusammen ein Element
mit einem p-i-n-Übergang
bilden. Wenn sichtbares Licht oder ein anderer Typ von einfallender
Strahlung 50 (z. B. ultraviolettes Licht oder infrarotes
Licht) auf einen in geeigneter Weise vorgespannten positionsempfindlichen
Detektor 26 fällt,
werden Elektronen-Löcher-Ladungspaare
in der i-Schicht 54 erzeugt. Die Elektroden werden von den Löchern durch
das elektrische Feld zwischen der p-Schicht und der n-Schicht getrennt, wobei
die Elektronen zu der n-Schicht 56 fließen und die Löcher zu
der p-Schicht 52 fließen.
Die Elektroden in der n-Schicht fließen dann zu den Kantenkontakten 61, 63, 65 oder 67 (die
alle auf Erdpotential gehalten werden) mit den Strömen 60, 62, 64 und 66,
die an jedem Kantenkontakt linear proportional zu der Distanz zwischen
dem Punkt der Ladungserzeugung (d. h. dem Einfallspunkt des Lichts)
und dem jeweiligen Kantenkontakt sind. Dem Fachmann sollte deutlich
sein, dass verschiedene Verbesserungen, Modifikationen und Anpassungen
an den Materialien oder dem Aufbau der beschriebenen positionsempfindlichen
Detektoren vorgenommen werden können,
um beispielsweise die Lichterfassung zu verbessern, die Empfindlichkeit
für die
Lichtfrequenz zu vergrößern, die
Reaktionszeit zu optimieren oder die Linearität der Licht/Strom-Reaktion
zu verbessern.
-
Zum Beispiel können zusätzliche laterale Leitungsschichten
etwa aus Cermet oder Indiumzinnoxid vorgesehen werden, um die Ladungssammelzeiten
zu reduzieren.
-
Für
die Verwendung in Scannern, weist eine Ausführungsform der positionsempfindlichen
Detektoranordnung allgemein einzelne positionsempfindliche Detektoren
mit einer Größe von weniger
als 500 μm
auf, wobei gewöhnlich
Detektoren mit einer Größe zwischen
50 und 150 μm
verwendet werden. Positionsempfindliche Detektoren in den zuvor
genannten ungefähren
Größenbereichen
können
zu zweidimensionalen Anordnungen gruppiert werden, die eine Bilderfassung
mit 100 bis 600 Punkten pro Zoll (4 bis 24 Punkten/mm) über einen
Bereich mit der Größe einer
Druckseite gestatten, sie können
aber auch zu linearen Anordnungen gruppiert werden, die zum Scannen
einer Seite mit einer ähnlichen
Auflösung
verwendet werden. Jeder positionsempfindliche Detektor 26 in
der Anordnung 24 sendet digitalisierte Signale in Entsprechung
zu den vier empfangenen Strömen 60, 62, 64 und 66 für die vorübergehende
Speicherung im Speicher 32 der Bildverarbeitungsanordnung 30.
-
Die Operation der Lichtintensitätseinheit 33,
der Momentberechnungseinheit 34 und der Graustufenaufbereitungseinheit 36 schreitet
allgemein wie folgt fort:
- A. Verwendung von
im Speicher 32 gespeicherten digitalen Wiedergaben, um
die Gesamtintensität
I0 in der Lichtintensitätseinheit 33 zu bestimmen.
- B. Verwenden von digitalen Wiedergaben im Speicher 32,
um die x- und y-Momente (Schwerpunkt) der bei jedem Detektor einfallenden
Intensitätsverteilung
zu bestimmen.
- C. Wenn die Größe des Schwerpunkts
groß ist,
Verwenden der Graustufenaufbereitungseinheit 36, um den Bereich
unter Verwendung von kontextuellen Graustufen von benachbarten Detektoren
und ggf. einer Interpolation als eine Kante aufzubereiten. Diese
Information wird verwendet, um Kantenparameter zu finden, wobei
die tatsächliche
Kantenposition gegeben wird und eine Aufbereitung der Kante zwischen
zwei Graustufen G1 und G2 mit Subpixelpräzision gestattet wird.
- D. Wenn die Größe des Schwerpunkts
klein ist, Bestimmen der Pixelintensität und Aufbereiten der Fläche als
eine nicht-Kante, wobei gewöhnlich
ein bilineares Modell verwendet wird.
-
Wie aus 1 hervorgeht, können die Operationen A und
B gleichzeitig bestimmt werden, wobei die Ergebnisse beider Operationen
für die
Operation C oder D verfügbar
gemacht werden müssen.
Die gleichzeitige bzw. parallele Operation reduziert die Bildverarbeitungszeit
und damit den lokalen Umfang der Prozedur, sodass keine extensive
Abtastung von benachbarten Pixeln während der Bildaufbereitung
erforderlich ist. Außerdem
erfordert die Operation der vorliegenden Erfindung nicht viel kontextuelle
Information zu der Lichtintensität
in benachbarten Pixeln, sondern gewöhnlich nur Graustufeninformation
von höchstens
zwei benachbarten Pixeln und häufig
nur von einem benachbarten Pixel. Dadurch wird wiederum die Verarbeitungszeit
reduziert, wobei weiterhin der zusätzliche Vorteil einer Reduktion
von Gesamtbildfehlern vorgesehen wird. Weil sich lokale Fehler bei
der Aufbereitung nicht aus dem Detektorbereich (einem einzelnen
Pixel) heraus fortpflanzen, wird die Möglichkeit des Auftretens von
visuell sichtbaren Artefakten während
der Aufbereitung im Vergleich zu den globalen Bildaufbereitungstechniken
stark reduziert, die nicht so stark parallel arbeiten und viele entfernt
positionierte Pixel abtasten müssen.
-
Insbesondere basiert die Operation
der Lichtintensitätseinheit 33 zur
Bestimmung einer Gesamtlichtintensität in jedem Pixel und der Momentberechnungseinheit 34 zur
Bestimmung des Schwerpunkts der Lichtintensität in jedem Pixel auf der im
Speicher 32 gespeicherten empfangenen Information. Die
Lichtintensität
in jedem Pixel einer Bitmap, welche die durch jeden positionsempfindlichen
Detektor festgestellte Lichtintensität wiedergebt, ist einfach proportional
zu den addierten Werten der Stromeingaben 60 und 64 oder
alternativ der Stromeingaben 62 und 66. In einer
typischen Anwendung kann diese gesamte festgestellte Stromausgabe
digital zu einer 8-Bit-Lichtintensitätswiedergabe (Bereich 0-255)
gewandelt werden, die für
die Wiedergabe von schwarzweißen
Kontinuierlichton- und Halbtonanwendungen sowie für Text und
Strichzeichnungen geeignet ist. Farbbitmaps können erstellt werden, indem
mit einer 8-Bit-Präzision
in mehreren Frequenzbereichen gescannt wird, wobei dem Fachmann
natürlich
deutlich sein sollte, dass die Abtastungsauflösung variiert werden kann,
um eine effektive Auflösung
für Ausgabegeräte (Drucker,
CTR-Monitore, usw.) vorzusehen oder um die Geschwindigkeitskriterien
oder Speicherbeschränkungen
für gröbere Bildauflösungen oder
Schwarzweißbilder
zu erfüllen,
die wesentlich weniger Zeit und Speicher für das Scannen, Verarbeiten
und Aufbereiten benötigen.
-
Die Bestimmung eines Schwerpunkts
der Lichtintensität
für jedes
Pixel in einer Bitmap mittels der Momentberechnungseinheit 34 wird
am besten mit Bezug auf 3 erläutert, die
schematisch vier benachbarte positionsempfindliche Detektoren 71, 73, 75 und 77 zeigt.
Wie gezeigt, gibt es zwei distinkte Graustufen der Beleuchtung der
Detektoren, wobei eine gestrichelte Linie einen Bereich 81 markiert,
der mit einer ersten Graustufe 79 beleuchtet wird, während der
verbleibende Bereich 82 mit einer zweiten Graustufe 83 beleuchtet
wird. Eine Kante 80 demarkiert eine Grenze zwischen der
ersten Graustufe 79 und der zweiten Graustufe 83.
Der Detektor 75 wird vollständig mit einer bestimmten Intensität beleuchtet,
um eine vorbestimmte Graustufe 74 (in Entsprechung zu der
Graustufe 83) über
die gesamte Detektoroberfläche
vorzusehen. Der Detektor 73 wird beinahe vollständig beleuchtet,
wobei ein Großteil
seiner Fläche
bei einer zweiten Graustufe 83 bleibt, während ein
kleiner Teil auf der gegenüberliegenden
Seite der Kante 80 mit einer ersten Graustufe 84 (in
Entsprechung zu der Graustufe 79) beleuchtet wird. Weil
der Detektor 73 im Gegensatz zu dem Detektor 75 nicht
vollständig
mit einer konstanten Graustufe beleuchtet wird, weist er eine (integrierte)
Gesamtgraustufe 72 auf (die aus den entgegengesetzten Stromeingaben 60 und 64 oder 62 und 66 wie
mit Bezug auf 2 erläutert abgeleitet
wird), die sich geringfügig
von der Graustufe 83 unterscheidet. Weil entsprechend auch
ein Großteil der
Fläche
des Detektors 77 bei der zweiten Graustufe 79 bleibt,
während
ein kleiner Teil auf der gegenüberliegenden
Seite der Kante 80 mit einer ersten Graustufe 79 beleuchtet
wird, hat auch er eine (integrierte) Gesamtgraustufe 76,
die sich geringfügig
von der Graustufe 83 unterscheidet. Schließlich wird
der Detektor 71 vorwiegend mit der ersten Graustufe 79 beleuchtet
(es ist zu beachten, dass dies als Entsprechung zu G1 in der
folgenden Erläuterung
der Berechnung des Schwerpunkts für den allgemeinen Fall betrachtet
werden kann), während
ein kleiner Teil mit der Graustufe 86 beleuchtet wird (in
Entsprechung zu der zweiten Graustufe 83, die wiederum
G2 in der folgenden Erläuterung der Berechnung des
Schwerpunkts für
den allgemeinen Fall entspricht), um eine (integrierte) Gesamtgraustufe 70 (in
Entsprechung zu I0 in der folgenden Erläuterung
der Berechnung des Schwerpunkts für den allgemeinen Fall) für den Detektor 71 vorzusehen.
-
Um die Bestimmung eines Schwerpunkts
der Lichtintensität 90 und
die Kantenbestimmung mit Subpixelgenauigkeit besser verständlich zu
machen, wurde über
den Detektor 71 eine x-Achse 94 und eine y-Achse 92 gelegt,
deren Ursprung in dem Detektor 71 zentriert ist und die
parallel zu den Kanten des Detektors 71 verlaufen. Die
Größe der x-Achse 94 ist
zwischen –1
und 1 an gegenüberliegenden
Kanten der Detektorobertläche
zu nehmen, während
die y-Achse 92 entsprechend zu einer Größe zwischen –1 und 1
an gegebenüberliegenden
Kanten des Detektors skaliert ist. Die Parameter zur Positionsdefinition
der Kante 80 in Bezug auf die Koordinaten der x- und y-Achsen 92 und 94 umfassen
eine Radiuslinie 98, die von dem Ursprung senkrecht zu
der Kante 80 gezogen ist, und ein die Richtungsradiuslinie 98 definierender
Winkel 96 trifft die Kante 80. In einer bevorzugten
Ausführungsform
gemäß der vorliegenden
Erfindung werden die Kantenparameter (Radiuslinie 98 und
Winkel 96) von ersten Momenten der aktuellen Intensität in der
x- und y-Richtung (Schwerpunkt 90, x und y) zusammen mit
der integrierten Graustufe (in diesem Beispiel die Graustufe 70)
abgeleitet. Wenn die Größe des Schwerpunkts
(äquivalent
zu (x2 + y2)1/2, wobei der absolute Wert von x und y
zwischen 0 und 1 variiert), relativ groß und größer als ungefähr 1/3 ist,
wird die Kante 80 aufbereitet, während bei Größen des Schwerpunkts
von kleiner als 1/3 angenommen wird, dass der Detektor eine im wesentlichen
konstante Graustufe aufweist und dann keine Kanten aufzubereiten
sind. In diesem Fall kann ein Standardintensitätsmodell verwendet werden,
um die Intensitätsaufbereitung
des Pixels zu bestimmen. Ein praktisches Aufbereitungsmodell, das
für die
Verwendung in der vorliegenden Endung geeignet ist, ist ein herkömmliches
Ebenenmodell. Die Intensität
des Pixels wird der Form I(x,y) = Ax + By + I0 angepasst,
wobei die Konstanten A und B jeweils proportional zu dem x-Moment
und dem y-Moment sind. Natürlich
können
auch andere herkömmliche
Aufbereitungsmodelle zum Bestimmen der Intensität von Pixeln ohne Subpixelkanten
verwendet werden.
-
Wenn die Größe des Schwerpunkts groß ist, sodass
eine Aufbereitung einer Kante erforderlich ist, um eine Subpixelgenauigkeit
vorzusehen, müssen
zur Vereinfachung bestimmte Annahmen gemacht werden. Um eine eindeutige
Lösung
zu ermöglichen,
kann angenommen werden, dass nicht mehr als eine Kante zwischen den
auf den Detektor einfallenden Graustufen vorhanden sind, wobei wenigstens
eine Graustufe 0 (Schwarz, keine einfallende Beleuchtung) ist und
alle anderen Kanten linear sind. Unter diesen Annahmen und mit den vorstehenden
Informationen können
die Kantenparameter aus dem Schwerpunkt der Lichtintensität 90 mit Subpixelgenauigkeit
bestimmt werden. Um die rechnerische Effizienz sicherzustellen,
werden die Kantenparameter (Radiuslinie 98 und Winkel 96)
nicht analytisch de novo für
jeden Detektor berechnet, sondern werden durch Bezugnahme auf eine
vorberechnete Nachschlagetabelle bestimmt, die Kantenparameter in
Reaktion auf x- und y-Momenteingaben und Graustufeneingaben ausgibt.
Zum Beispiel kann eine Nachschlagetabelle mit vorberechneten Funktionen
verwendet werden, die den Schwerpunkt bei Eingaben für die Winkelradiuslinie 98,
den Winkel 96 und die Fläche des Detektors 71 mit
der Graustufe 86 ausgeben. Es können natürlich auch eine Interpolation
der Nachschlagetabelle, semi-analytische Techniken oder andere numerische
Annäherungstechniken
verwendet werden.
-
Für
den allgemeineren Fall, in dem nicht bekannt ist, dass eine Seite
einer Kante schwarz (nicht beleuchtet) ist, ist eine komplexere
Berechnung erforderlich, um den Schwerpunkt und die assoziierten
Kantenparameter in den Termen einer Grau-Graustufen-Verteilung zu
bestimmen.
-
Die Berechnung der x- und y-Momente
für diesen
allgemeineren Fall muss wie folgt fortschreiten:
wobei I'(x,y) die Schwarz-Grau-Intensitätsverteilung
ist, weil
-
-
Außerdem kann die folgende Beziehung
verwendet werden, um den
Ausdruck für
das Grau-Grau-Moment
x wie
folgt umzuschreiben:
der Gesamtintensität eines
vollständig
durch die Intensität
G
1 abgedeckten Detektors entspricht. Auf
diese Weise erhält
man schließlich
für
x' das Moment der Grau-Schwarz-Verteilung, die Beziehung
in Termen des Grau-Grau-Moments.
Das y-Moment kann in derselben Weise wie folgt transformiert werden:
-
-
Die Werte x', y' entsprechen den Momentwerten, wenn
G1 null war (d. h. wenn die Verteilung diejenige einer
schwarzen und grauen Kante war). Weil man die Position der Kante
in einem Bereich unter dem Pixel (Subpixelgenauigkeit) präzise finden
kann, wenn die Momente einer Schwarz/Grau-Kante gegeben sind, kann man
diese transformierten Momente verwenden, um die Position der Grau-Grau-Kante
präzise
zu bestimmen. Wenn IG1, nicht verfügbar ist,
kann die Transformation der x- und y-Momente unter Verwendung von
IG2 anstelle von IG1,
durchgeführt
werden. I'(x,y)
wird dann als (G1 – G2)
(negativ) für
Punkte (x,y) unterhalb und links von der Kante 80 und für Punkte
(x,y) oberhalb und rechts von der Kante 80 im Detektor 71 definiert.
-
Aus dem Vorstehenden wird deutlich,
dass in dem allgemeinen Fall von Grau-Grau-Kanten die x- und y-Momente
und entweder IG1, oder IG2 erforderlich
sind, um die oben für
die Bestimmung des Schwerpunkts beschriebenen Transformationen durchzuführen. Glücklicherweise
können
IG1, oder IG2 anhand
von „kontextuellem
Wissen" annähernd geschätzt werden,
d. h. anhand von Wissen zu den Graustufen oder Werten von benachbarten
Detektorelementen. In dem vorliegenden Beispiel von 3 ist dieser Graustufenkontext durch die
benachbarten Detektoren 73 und 77 gegeben, die
beide vorwiegend eine Graustufe 83 aufweisen. Idealerweise
weisen Detektoren auf beiden Seiten der Kante dieselbe Intensität auf wie
die entsprechende Seite der Kante. Zum Beispiel findet man gewöhnlich einen
benachbarten Detektor mit einer gleichmäßigen Intensitätsverteilung
I(x,y) = G1. Dann ist die Gesamtintensität dieses
Detektors I0 gleich IG1,
wobei die Graustufe benötigt wird,
um die Momente zu transformieren und die Kante präzise aufzubereiten.
Wenn die Merkmale in dem Bild weit voneinander beabstandet sind,
kann ein derartiger Detektor einfach gefunden werden, indem der
nächste Nachbar
in der Richtung normal zu der Kante gewählt wird. Weil eine der Intensitäten ausreicht,
kann man IG2 anstelle von IG1,
verwenden, wenn der Detektor auf der Seite mit niedriger Intensität der Kante
eine Kante enthält.
In einem typischeren Fall, in dem keine unzweideutige Graustufe
vorhanden ist, weil die benachbarten Detektoren unterschiedliche
Stufen aufweisen (z. B. sind die Graustufen 72 und 76 für den entsprechenden Detektor 73 und 75 nicht
identisch), kann ein durchschnittlicher oder interpolierter Wert
zwischen den zwei Graustufen verwendet werden.
-
Um die Kantenparameter nach der Berechnung
des Schwerpunkts
90 zu bestimmen, muss weiterhin der Wert
von G
2 verfügbar sein, wobei angenommen
wird, dass G
1 für den Kontext genommen wird.
Dieser Wert kann ohne zusätzliche
Informationen bestimmt werden. Es ist bekannt, dass die Gesamtintensität über den
Detektor wie folgt ist:
wobei A
G1 und
A
G2 die Bereiche auf den zwei Seiten der
Kante sind. Weil die Intensitäten über diesen
Bereich konstant sind und die Flächen
der zwei Bereiche zusammen die Gesamtfläche A
d des
Detektors ergeben, kann dies wie folgt vereinfacht werden:
A
G1 kann einfach berechnet werden, weil die
Position der Kante bereits bestimmt wurde. ES kann wie folgt zu G
2 aufgelöst
werden:
-
-
Dadurch wird die erforderliche Information
zur Bestimmung der Kantenparameter vorgesehen, die für die Subpixelaufbereitung
der Kanten erforderlich sind.
-
Um die vorliegende Erfindung zu verdeutlichen,
gibt der folgende Pseudocode eine Ausführungsform einer Simulation
einer Anordnung von positionsempfindlichen Detektoren an, die in Übereinstimmung
mit den zuvor beschriebenen Schritten betrieben wird, um Bilder
zu verarbeiten:
-
Ganzzahl N/*NXN ist die Anzahl der
Pixel in der Positionssensoranordnung*/
-
(1 : N, 1 : N, 1 : 4) Anordnungsströme/*die
Anordnung der Ströme
von der Anordnung positionsempfindlicher Sensoren – vier Ströme pro Sensor*/ (1
: M*N,1 : M*N) Anordnung Endbild/*Anordnung des Endbilds der Größe MNXMN*/
-
-
Es ist zu beachten, dass das Aufbereiten
eines Bildes gemäß der vorliegenden
Erfindung am nützlichsten
ist, wenn ein Bild für
ein bestimmtes Gerät
(durch die gerätespezifische
Umwandlungseinheit 38 von 1)
mit einer ausreichend hohen Auflösung
aufbereitet wird, um eine Anzeige der bestimmten Kantenparameterinformation
(Subpixelinformation) zu gestatten. Gewöhnlich stellt die Aufbereitung
mit der zwei- oder mehrfachen Auflösung des ursprünglichen
Scans (gemessen in Bezug auf die Detektorgröße) eine wesentliche Verbesserung
bei der Kantenaufbereitung des vorliegenden Systems und der entsprechenden
Technik im Vergleich zu herkömmlichen
Aufbereitungstechniken dar, die keine Subpixelinformation zur Erzeugung
eines aufbereiteten Bildes verwenden. Dies kann am besten durch
einen Vergleich von 4, 5 und 6 erkannt werden, wobei 6 durch die Anwendung einer Software
zur Implementierung des zuvor beschriebenen Pseudocodes für die Simulation
von positionsempfindlichen Detektoren mit einem Operationsmodus
gemäß der vorliegenden
Erfindung erzeugt wird. 4 zeigt
ein ursprüngliches
Kontinuierlichtonbild, und 5 zeigt
das Bild von 4, das
unter Verwendung eines Durchschnittsintensitäts-Aufbereitungsmodells (Graumodell) gescannt
und aufbereitet wurde (300 dpi, 12 Punkte /mm). Im Vergleich dazu
zeigt 6 das Bild, das
unter Verwendung von Techniken und Informationen gescannt und aufbereitet
wurde, die für
positionsempfindliche Detektoren zur Aufbereitung von Bildern gemäß der vorliegenden
Erfindung angewendet werden können.
Es ist deutlich, dass bei dem in 6 gezeigten
Bild im Vergleich zu der herkömmlichen
Aufbereitung von 5 die Kanten
im Textteil (Buchstabe „b") glätter aufbereitet
sind und weniger „würfelige" Graustufenübergänge im Kontinuierlichtonteil
vorhanden sind.
-
Wenn Information zu den Subpixel-Kantenmerkmalen
gespeichert und für
die Analyse verfügbar
gemacht werden, können
Autosegmentierungstechniken für
die Verwendung in Verbindung mit optischen Zeichenerkennungsgeräten verfügbar gemacht
werden. Zum Beispiel weisen Textteile allgemein eine häufigeres Auftreten
von Subpixel-Kantenmerkmalen auf als Kontinuierlichtonteile. Diese
statistische Differenz kann verwendet werden, um in gescannten Bildern
Text von Abbildungen zu trennen. Im Vergleich zu den Ansätzen aus dem
Stand der Technik, die nur deutlich voneinander getrennte Einheiten
von Text oder Abbildungen erkennen (Blocksegmentierung), gestattet
die vorliegende Erfindung eine Autosegmentierung auch dann, wenn
der Text in Kontinuierlichtonbildern eingebettet ist.





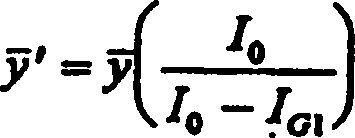
 AG1 kann einfach berechnet werden, weil die Position der Kante bereits bestimmt wurde. ES kann wie folgt zu G2 aufgelöst werden:
AG1 kann einfach berechnet werden, weil die Position der Kante bereits bestimmt wurde. ES kann wie folgt zu G2 aufgelöst werden:

