CN114277447A - 靶序列随机sgRNA全覆盖组的制备方法 - Google Patents
靶序列随机sgRNA全覆盖组的制备方法 Download PDFInfo
- Publication number
- CN114277447A CN114277447A CN202111573668.1A CN202111573668A CN114277447A CN 114277447 A CN114277447 A CN 114277447A CN 202111573668 A CN202111573668 A CN 202111573668A CN 114277447 A CN114277447 A CN 114277447A
- Authority
- CN
- China
- Prior art keywords
- sgrna
- library
- dna
- full
- sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images












Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases RNAses, DNAses
-
- C—CHEMISTRY; METALLURGY
- C40—COMBINATORIAL TECHNOLOGY
- C40B—COMBINATORIAL CHEMISTRY; LIBRARIES, e.g. CHEMICAL LIBRARIES
- C40B40/00—Libraries per se, e.g. arrays, mixtures
- C40B40/04—Libraries containing only organic compounds
- C40B40/06—Libraries containing nucleotides or polynucleotides, or derivatives thereof
-
- C—CHEMISTRY; METALLURGY
- C40—COMBINATORIAL TECHNOLOGY
- C40B—COMBINATORIAL CHEMISTRY; LIBRARIES, e.g. CHEMICAL LIBRARIES
- C40B50/00—Methods of creating libraries, e.g. combinatorial synthesis
- C40B50/06—Biochemical methods, e.g. using enzymes or whole viable microorganisms
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- Biomedical Technology (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Microbiology (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Plant Pathology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Enzymes And Modification Thereof (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
本发明提供了一种靶序列随机sgRNA全覆盖组的制备方法,使用限制酶对目标序列的PAM区域进行切割;连接上sgRNA骨架;通过sgRNA骨架上的旁切活性限制酶位点进行靶向原间隔区域的序列获取;连接T7启动子;扩增获得带T7启动子的sgRNA文库;体外转录获得靶序列sgRNA文库。还公开了核糖体RNA的sgRNA文库制备方法以及去除RNA文库中核糖体RNA的方法,和在宿主基因组去除人全基因组的方法。本发明方法具有成本低、制作简单、覆盖均一、偏好性小、不受靶序列长度限制和无需大批量设计sgRNA等优点。
Description
技术领域
本发明专利涉及一种靶序列随机sgRNA全覆盖组的制备方法,属于生物技术领域。
背景技术
CRISPR基因编辑技术自从被开发出来就被广泛应用在基因治疗、体外诊断、基因捕获和靶基因去除等各个领域,并获得2020年诺贝尔生理医学奖,是一种高效且实用的技术。实用型CRISPR系统主要有两个部分组成,一个是具有两个核酸内切酶活性位点的Cas蛋白,负责切割靶位点DNA的两条链;另一个是具有与靶位点处DNA配对序列和Cas蛋白结合序列的引导RNA(sgRNA),负责募集Cas蛋白并引导Cas蛋白结合到互补配对的靶位点上。在CRISPR系统中,Cas蛋白先与sgRNA结合形成Cas-sgRNA复合物,并在DNA上进行检索。当检索到与sgRNA互补配对的区域(原间隔区域,ProtoSpacer),并且ProtoSpacer区域的3’端存在NGG序列(PAM序列)时,Cas蛋白将靶位点进行解旋,使得解开的双链DNA进入到Cas蛋白的DNA切割活性结构域,Cas蛋白对双链DNA进行切割,产生双链DNA断裂。断裂的DNA通过同源重组修复HR或者非同源末端连接NHEJ等DNA损伤修复方式完成靶基因的编辑。目前用于商业化应用的Cas蛋白主要有Cas9、Cas12、Cas13和Cas14及其变体,不同的Cas蛋白识别的PAM序列和要求,ProtoSpacer的长度也不同。因此,不同的CRISPR系统的具有不同的应用场景。
除Cas蛋白的纯化和制备外,sgRNA的体外构建和合成也是CRISPR商业化应用的重要环节。常规的方法需要利用引物合成的方式合成含T7启动子的靶标sgRNA引物,再利用重叠PCR获得全长sgRNA骨架模板,并利用体外转录的方法获得需要的sgRNA。这种方法耗时短、成本低、可控性高,已经大规模商业化,成为sgRNA体外制备的主要形式,但仍存在通量低的问题。基因捕获或者去除通常需要对大区域的基因组进行捕获或者去除,需要覆盖长度达1M bp甚至整个完整的基因组DNA。这需要设计和合成千万级别条数的sgRNA。在sgRNA的设计合成上,无论成本还是技术都是很大的挑战。
发明内容
本发明的目的是提供一种靶序列随机sgRNA全覆盖组的制备方法。
本发明采取的技术方案为:
一种靶序列随机sgRNA全覆盖组的制备方法,其特征在于其步骤包括:
(1)采用识别PAM序列的限制酶切割样本DNA,并将末端切平,切平是指去除双链DNA上的3'和5'单链悬垂,以产生钝端;
(2)步骤(1)获得的切平后的双链DNA3’端连接sgRNA骨架,其中sgRNA骨架带有旁切活性限制酶位点;
(3)采用旁切活性限制酶切割步骤(2)的连接产物,获取原间隔区域DNA,并将其5’端磷酸化;
(4)在原间隔区域DNA的5’端连接T7启动子序列;
(5)扩增获得含T7启动子的sgRNA文库模板;
(6)体外转录获得sgRNA文库。
优选的,步骤(1)中的限制酶为ScrFI、MspI、HpaII、BstNI、BfaI、DdeI中的一种或数种的混合物。
优选的,步骤(1)中采用Mung Bean Nuclease将末端切平。
优选的,步骤(2)的sgRNA骨架为两条单链DNA互补配对形成的双链DNA,其中正向序列为/rApp/-CGGTTGGAGCTAGAAATAGCAAGTCAACCTAACGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCGAGTCGGTGCTTTT-/NH2C6/,反向序列为/NH2C6/-AAAAGCACCGACTCGGTGCCACTTTTTCAAGTTGATAACGGACTAGCGTTAGGTTGACTTGCTATTTCTAGCTCCAACC-/ddG/,设有MmeI酶切位点;或者正向序列为/rApp/-CTGCTGGAGCTAGAAATAGCAAGTCAGCATAACGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCGAGTCGGTGCTTTT-/NH2C6/,反向序列为/NH2C6/-AAAAGCACCGACTCGGTGCCACTTTTTCAAGTTGATAACGGACTAGCGTTATGCTGACTTGCTATTTCTAGCTCCAGCA-/ddG/,设有EcoP15I酶切位点。
优选的,步骤(2)中使用T4 DNA连接酶突变体K159L连接sgRNA骨架与双链DNA。
优选的,步骤(3)的旁切活性限制酶为MmeI,步骤(4)中的T7启动子正向序列为/NH2C6/-TTCTAATACGACTCACTATAGGN N,反向序列为/ddC/-CTATAGTGAGTCGTATTAGAA-/NH2C6/。
优选的,步骤(3)的旁切活性限制酶为EcoP15I,步骤(4)中的T7启动子正向序列为/NH2C6/-TTCTAATACGACTCACTATAGG,反向序列为/ddN/-NCTATAGTGAGTCGTATTAGAA-/NH2C6/。
优选的,步骤(4)采用T4 DNA连接酶进行连接。
优选的,步骤(5)中使用正向序列为TTCTAATACGACTCACTATAGG,反向序列为AAAAGCACCGACTCGGTGCC的引物对进行文库扩增。
优选的,步骤(6)中采用T7 RNA聚合酶进行转录,使用RNA回收磁珠回收sgRNA文库。
本发明还公开了一种核糖体RNA的sgRNA文库制备方法,其特征在于其步骤包括:
A、逆转录制备18S和28S全长cDNA;
B、PCR扩增获得18S和28S全长双链DNA;
C、采用上述的方法,以18S和28S全长双链DNA为样本DNA,制得靶向覆盖18S和28S的sgRNA文库。
本发明还公开了一种去除RNA文库中核糖体RNA的方法,其特征在于其步骤包括:
A、将上面制得的sgRNA文库与Cas9蛋白预组装;
B、采用预组装的Cas9-sgRNA切割RNA文库;
C、RNA文库扩增并测序。
本发明还公开了一种在宿主基因组去除人全基因组的方法,其特征在于其步骤包括:
A、采用上述的方法,以人全基因组DNA为样本DNA,制得靶向覆盖人全基因组DNA的sgRNA文库;
B、制得的sgRNA文库与Cas9蛋白预组装;
C、采用预组装的Cas9-sgRNA切割宿主基因组DNA文库;
D、DNA文库扩增并测序。
本发明的有益效果为:
本发明公开了一种靶序列随机sgRNA制备方法RPTS(Random sgRNA Preparationof Target Sequence),可以一次性制备随机覆盖目标区域的所有sgRNA组。RPTS的原理和流程如下:使用限制酶对目标序列的PAM区域进行切割;连接上sgRNA骨架;通过sgRNA骨架上的旁切活性限制酶位点进行靶向原间隔区域的序列获取;连接T7启动子;扩增获得带T7启动子的sgRNA文库;体外转录获得靶序列sgRNA文库。RPTS具有成本低、制作简单、覆盖均一、偏好性小、不受靶序列长度限制和无需大批量设计sgRNA等优点。本发明还公开了RPTS在核糖体RNA去除和宿主基因组去除上的应用流程,打破了CRISPR技术在这些领域上的应用限制。
附图说明
图1正常sgRNA结合靶位点图。
图2包含MmeI酶切位点的sgRNA改造骨架。
图3包含EcoP15I酶切位点的sgRNA改造骨架。
图4 RPTS原理和流程示意图。
图5 RPTS技术中使用限制酶识别位点汇总。阴影表示该限制酶识别位点中包含PAM序列类型。
图6 18S rRNA的DNA上包含RPTS技术中使用限制酶的识别位点分布。
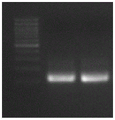
图7 18S和28S cDNA扩增结果,左侧条带为Marker,中间条带为28S,右边条带为18S。
图8 18S/28S DNA和人全基因组DNA(右)的RPTS文库扩增结果,左侧条带为Marker,中间条带为18S/28S DNA,右边条带为人全基因组DNA。
图9 18S/28S DNA(左)和人全基因组DNA(右)的体外转录结果,左侧条带为Marker,中间条带为18S/28S DNA,右边条带为人全基因组DNA。
图10 18S/28S RPTS库在CRISPR去除rRNA应用上的文库分布。浅色是未加RPTS库,深色是加入RPTS库。
图11 RNA-seq验证18S/28S RPTS库在CRISPR去除rRNA应用上去除效果。
图12人类全基因组RPTS库在CRISPR去除宿主基因组应用上的文库分布。浅色是未加RPTS库,深色是加入RPTS库。
图13 DNA-seq验证人全基因组RPTS库在CRISPR去除宿主基因组应用上去除效果。
具体实施方式
为了进一步描述使本发明的具体内容,以下结合实施例对本发明进行详细说明。实施例所涉及的操作方法及试剂为业内技术人员所熟知,应当理解,以下所描述的具体实施例仅仅用于对发明进行详细说明,但本发明的实施方式并不受下述实施例的限制。本实施例所使用的接头序列及修饰如表1所示,N为A、T、C、G中的任意碱基。
表1接头序列及修饰


实施例1:sgRNA骨架的设计和RPTS的流程
本实施例改造了传统sgRNA的骨架,融入了酶切位点MmeI或EcoP15I,但不改变sgRNA的结构和Cas9的结合。改造后的sgRNA序列和结构见图1-图3所示。
测试RPTS的流程,流程如图4所示:
(1)识别PAM序列的限制酶切割:
表2限制酶酶切体系
| 组分 | 用量 |
| PUC19 plasmid DNA | 1μg |
| 10×rCutSmart buffer | 8μL |
| ScrFI(NEB) | 5U |
| MspI(NEB) | 5U |
| HpaII(NEB) | 5U |
| BstNI(NEB) | 5U |
| BfaI(NEB) | 5U |
| DdeI(NEB) | 5U |
| 补水至 | 80μL |
37℃反应过夜。反应结束后,加入160μL Ampure DNA beads(Beckman)回收片段化的DNA。45μL水洗脱。
表3末端切平体系
| 组分 | 用量 |
| 上述回收的DNA | 43μL |
| 10×Mung Bean Nuclease Reaction Buffer | 5μL |
| Mung Bean Nuclease(NEB) | 20U |
| 补水至 | 50μL |
30℃反应2h。反应结束后,加入100μL Ampure DNA beads(Beckman)回收片段化的DNA。42μL水洗脱。
(2)含旁切活性限制酶酶切位点的sgRNA骨架连接。
骨架退火:sgM-F、sgM-R、sgE-F和sgE-R用100mM NaCl溶液溶解至100μM,取10μLsgM-F和10μL sgM-R于PCR管中,取10μL sgE-F和10μL sgE-R于另一PCR管中,在同一反应体系中,MmeI-sgRNA骨架和EcoP15I-sgRNA骨架二选一。95℃反应5min,每分钟降低1℃。反应结束后,用水将退火好的骨架稀释至10μM。
骨架连接:
表4骨架连接体系
| 组分 | 用量 |
| 上述回收的DNA | 40μL |
| 10μM sgRNA骨架接头 | 5μL |
| 10×T4 Ligase Reaction Buffer | 5μL |
| T4 DNA Ligase(K159L) | 2000U |
| 补水至 | 50μL |
20℃反应1h。反应结束后,加入22.5μL Ampure DNA beads回收DNA,去除掉未连接的接头。22μL水洗脱。
(3)MmeI或EcoP15I酶切
表5 MmeI酶切体系
| 组分 | 用量 |
| 上述回收的含MmeI-sgRNA骨架的DNA | 20μL |
| 10×rCutSmart buffer | 3μL |
| MmeI | 5U |
| 补水至 | 30μL |
表6 EcoP15I酶切体系


37℃反应2h。反应结束后,加入60μL Ampure DNA beads回收DNA。42μL水洗脱。
(4)T7启动子连接。
接头退火:T7M-F、T7M-R、T7E-F和T7E-R用100mM NaCl溶液溶解至100μM,取10μLT7M-F和10μL T7M-R于PCR管中,取10μL T7E-F和10μL T7E-R于另一PCR管中,根据上面的sgRNA骨架的类型选用合适的T7接头。95℃反应5min,每分钟降低1℃。反应结束后,用水将退火好的接头稀释至10μM。
接头连接:
表7接头连接体系
| 组分 | 用量 |
| 上述回收的DNA | 40μL |
| 10μM对应的T7接头 | 5μL |
| 10×T4 Ligase Reaction Buffer | 5μL |
| T4 DNA Ligase | 2000U |
| 补水至 | 50μL |
20℃反应1h。反应结束后,加入22.5μL Ampure DNA beads回收DNA,去除掉未连接的接头。22μL水洗脱。
(5)sgRNA库扩增
表8 sgRNA文库扩增体系
| 组分 | 用量 |
| 上述回收的DNA | 20μL |
| 10μM sgPCR-F/R | 5μL |
| Phusion High-Fidelity PCR Master Mix | 25μL |
| 补水至 | 50μL |
在98℃变性3min后,通过98℃10s变性、60℃20s退火和72℃10s延伸进行文库循环扩增。扩增产物使用70μL Ampure DNA beads进行回收,22μL DEPC水洗脱。
(6)sgRNA库体外转录
表9 sgRNA文库体外转录体系
| 组分 | 用量 |
| 上述回收的DNA | 1μg |
| 10×Transcription Buffer | 2μL |
| CTP/GTP/ATP/UTP(100mM each) | 2μL |
| T7 RNA Polymerase Mix(Yeasen) | 2μL |
| 补水至 | 20μL |
37℃反应4h后,加入10U DNase I(TAKARA),37℃反应1h。加入50μL Ampure RNAbeads(Beckman)回收RNA。琼脂糖凝胶电泳检测sgRNA大小。
如图5所述,我们设计的识别PAM序列(NRG)的限制酶组合包含6种限制性内切酶,这6种限制酶位点包括了Cas9蛋白的两个PAM序列。在DNA上,约每64bp就存在这样的限制酶位点,因此制备的sgRNA可以随机覆盖到整个基因组上。图6展示了18S rRNA上这6中限制酶位点的分布(阴影部分)。
实施例2:18S rRNA或28S rRNA的RPTS制备。
在本实施例中,我们利用RPTS制备了覆盖18S rRNA或28S rRNA的随机sgRNA库。具体实施方式如下:
(1)DNA片段的获取
表10逆转录体系
| 组分 | 用量 |
| 293细胞RNA | 1μg |
| 10μM逆转录引物18S-R或者28S-R | 1μL |
| 10mM dNTPs | 1 |
| 75℃反应5min | |
| 5×FS Buffer | 4μL |
| 0.1M DTT | 1μL |
| SuperScript IV(Thermo) | 2μL |
| 总体积 | 20μL |
42℃15min,50℃15min,55℃15min,50℃15min,55℃15min,70℃15min。
表11 PCR扩增体系
| 组分 | 用量 |
| 上述逆转录产物 | 1μL |
| 10μM 18S-F/R或者28S-F/R | 5μL |
| Phusion High-Fidelity PCR Master Mix | 25μL |
| 加水至 | 50μL |
在98℃变性3min后,通过98℃10s变性、60℃20s退火和72℃3min延伸进行文库循环扩增。扩增产物使用35μL Ampure DNA beads进行回收,22μL DEPC水洗脱。
RPTS制备sgRNA库:按照实施例1的方法制备18S sgRNA库或28S sgRNA库。
(3)RNA文库制备。使用翌圣生物的双模式RNA建库试剂盒(12252)进行RNA文库构建。连接DNA接头后,使用0.6×Ampure DNA beads回收文库。
(4)CRISPR去除18S和28S DNA。
表12 sgRNA库与Cas9蛋白预组装体系:
| 组分 | 用量 |
| 18SsgRNA库和28S sgRNA库 | 2-10μg |
| Cas9(NEB) | 0.2-0.5μg |
| 500mM氯化钠 | 1μL |
| 总体积 | 5μL |
37℃30min。
表13 CRISPR切割体系
| 组分 | 用量 |
| Cas9-sgRNA库 | 5μL |
| RNA文库 | 1-100ng |
| 10×NEB buffer 3.1 | 1μL |
| 总体积 | 10μL |
37℃30-90min,90℃10min。
(5)文库扩增
表14文库扩增体系
| 组分 | 用量 |
| 上述反应体系 | 10μL |
| Index Primer F/R(Yeasen,12610) | 5μL |
| 2×Canase PCR mix | 25μL |
| 补水至 | 50μL |
在98℃变性3min后,通过98℃10s变性、60℃30s退火和72℃30s延伸进行文库循环扩增。扩增产物使用45μL Ampure DNA beads进行回收,22μL DEPC水洗脱。
制备好的文库经过Qsep100质检后,在Illumina的NovaSeq 6000平台上进行测序并分析。
18S和28S RPTS结果如图7、图8和图9所示,RPTS技术能够成功构建18S或28S的sgRNA库。RNA建库结果和测序结果如图10和图11所示,RPTS方法制备的sgRNA文库能够有效去除18S和28S rRNA。
实施例3:人全基因组的RPTS制备。
在本实施例中,我们利用RPTS制备了覆盖人全基因组的随机sgRNA库。具体实施方式如下:
(1)RPTS制备sgRNA库:按照实施例1的方法制备sgRNA库,DNA使用人基因组DNA标准品NA12878(Coriell)。
(2)DNA文库制备。DNA使用人基因组DNA标准品NA12878(Coriell)和大肠杆菌基因组按照100:1比例混合的DNA标准品混合物。使用翌圣生物的一步法建库试剂盒(12204)进行DNA文库构建。连接DNA接头后,使用0.6×Ampure DNA beads回收文库。
(3)CRISPR去除人基因组DNA
表15 sgRNA库与Cas9蛋白预组装体系:
| 组分 | 用量 |
| 人基因组RPTS库 | 2-10μg |
| Cas9(NEB) | 0.2-0.5μg |
| 500mM氯化钠 | 1μL |
| 总体积 | 5μL |
37℃30min。
表16 CRISPR切割体系
| 组分 | 用量 |
| Cas9-sgRNA库 | 5μL |
| RNA文库 | 1-100ng |
| 10×NEB buffer 3.1 | 1μL |
| 总体积 | 10μL |
37℃30-90min,90℃10min。
(5)文库扩增
表17文库扩增体系
| 组分 | 用量 |
| 上述反应体系 | 10μL |
| Index Primer F/R(Yeasen,12610) | 5μL |
| 2×Canace pro PCR mix | 25μL |
| 补水至 | 50μL |
在98℃变性3min后,通过98℃10s变性、60℃30s退火和72℃30s延伸进行文库循环扩增。扩增产物使用45μL Ampure DNA beads进行回收,22μL DEPC水洗脱。
制备好的文库经过Qsep100质检后,在Illumina的NovaSeq 6000平台上进行测序并分析。
DNA建库结果和测序结果如图11和图12所示,RPTS方法制备的sgRNA文库能够有效去除DNA建库过程中的人类宿主基因组DNA。
综上,本发明公开了一种靶序列随机sgRNA制备方法RPTS(Random sgRNAPreparation of Target Sequence),可以一次性制备随机覆盖目标区域的所有sgRNA组。RPTS的原理和流程如下:使用限制酶对目标序列的PAM区域进行切割;连接上sgRNA骨架;通过sgRNA骨架上的旁切活性限制酶位点进行靶向原间隔区域的序列获取;连接T7启动子;扩增获得带T7启动子的sgRNA文库;体外转录获得靶序列sgRNA文库。RPTS具有成本低、制作简单、覆盖均一、偏好性小、不受靶序列长度限制和无需大批量设计sgRNA等优点。本发明还公开了RPTS在核糖体RNA去除和宿主基因组去除上的应用流程,打破了CRISPR技术在这些领域上的应用限制。
Claims (13)
1.一种靶序列随机sgRNA全覆盖组的制备方法,其特征在于其步骤包括:
(1)采用识别PAM序列的限制酶切割样本DNA,并将末端切平;
(2)步骤(1)获得的切平后的双链DNA3’端连接sgRNA骨架,其中sgRNA骨架带有旁切活性限制酶位点;
(3)采用旁切活性限制酶切割步骤(2)的连接产物,获取原间隔区域DNA,并将其5’端磷酸化;
(4)在原间隔区域DNA的5’端连接T7启动子序列;
(5)扩增获得含T7启动子的sgRNA文库模板;
(6)体外转录获得sgRNA文库。
2.根据权利要求1所述的靶序列随机sgRNA全覆盖组的制备方法,其特征在于:步骤(1)中的限制酶为ScrFI、MspI、HpaII、BstNI、BfaI、DdeI中的一种或数种的混合物。
3.根据权利要求1所述的靶序列随机sgRNA全覆盖组的制备方法,其特征为:步骤(1)中采用Mung Bean Nuclease将末端切平。
4.根据权利要求1所述的靶序列随机sgRNA全覆盖组的制备方法,其特征为:步骤(2)的sgRNA骨架为两条单链DNA互补配对形成的双链DNA,其中正向序列为/rApp/-CGGTTGGAGCTAGAAATAGCAAGTCAACCTAACGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCGAGTCGGTGCTTTT-/NH2C6/,反向序列为/NH2C6/-AAAAGCACCGACTCGGTGCCACTTTTTCAAGTTGATAACGGACTAGCGTTAGGTTGACTTGCTATTTCTAGCTCCAACC-/ddG/,设有MmeI酶切位点;或者正向序列为/rApp/-CTGCTGGAGCTAGAAATAGCAAGTCAGCATAACGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCGAGTCGGTGCTTTT-/NH2C6/,反向序列为/NH2C6/-AAAAGCACCGACTCGGTGCCACTTTTTCAAGTTGATAACGGACTAGCGTTATGCTGACTTGCTATTTCTAGCTCCAGCA-/ddG/,设有EcoP15I酶切位点。
5.根据权利要求6所述的靶序列随机sgRNA全覆盖组的制备方法,其特征为:步骤(2)中使用T4 DNA连接酶突变体K159L连接sgRNA骨架与双链DNA。
6.根据权利要求1所述的靶序列随机sgRNA全覆盖组的制备方法,其特征为:步骤(3)的旁切活性限制酶为MmeI,步骤(4)中的T7启动子正向序列为/NH2C6/-TTCTAATACGACTCACTATAGGNN,反向序列为/ddC/-CTATAGTGAGTCGTATTAGAA-/NH2C6/。
7.根据权利要求1所述的靶序列随机sgRNA全覆盖组的制备方法,其特征为:步骤(3)的旁切活性限制酶为EcoP15I,步骤(4)中的T7启动子正向序列为/NH2C6/-TTCTAATACGACTCACTATAGG,反向序列为/ddN/-NCTATAGTGAGTCGTATTAGAA-/NH2C6/。
8.根据权利要求1所述的靶序列随机sgRNA全覆盖组的制备方法,其特征为:步骤(4)采用T4 DNA连接酶进行连接。
9.根据权利要求1所述的靶序列随机sgRNA全覆盖组的制备方法,其特征为:步骤(5)中使用正向序列为TTCTAATACGACTCACTATAGG,反向序列为AAAAGCACCGACTCGGTGCC的引物对进行文库扩增。
10.根据权利要求1所述的靶序列随机sgRNA全覆盖组的制备方法,其特征为:步骤(6)中采用T7 RNA聚合酶进行转录,使用RNA回收磁珠回收sgRNA文库。
11.一种核糖体RNA的sgRNA文库制备方法,其特征在于其步骤包括:
A、逆转录制备18S和28S全长cDNA;
B、PCR扩增获得18S和28S全长双链DNA;
C、采用权利要求1-10中任一项所述的方法,以18S和28S全长双链DNA为样本DNA,制得靶向覆盖18S和28S的sgRNA文库。
12.一种去除RNA文库中核糖体RNA的方法,其特征在于其步骤包括:
A、将权利要求12制得的sgRNA文库与Cas9蛋白预组装;
B、采用预组装的Cas9-sgRNA切割RNA文库;
C、RNA文库扩增并测序。
13.一种在宿主基因组去除人全基因组的方法,其特征在于其步骤包括:
A、采用权利要求1-10中任一项所述的方法,以人全基因组DNA为样本DNA,制得靶向覆盖人全基因组DNA的sgRNA文库;
B、制得的sgRNA文库与Cas9蛋白预组装;
C、采用预组装的Cas9-sgRNA切割宿主基因组DNA文库;
D、DNA文库扩增并测序。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111573668.1A CN114277447A (zh) | 2021-12-21 | 2021-12-21 | 靶序列随机sgRNA全覆盖组的制备方法 |
| PCT/CN2022/140314 WO2023116681A1 (zh) | 2021-12-21 | 2022-12-20 | 靶序列随机sgRNA全覆盖组的制备方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111573668.1A CN114277447A (zh) | 2021-12-21 | 2021-12-21 | 靶序列随机sgRNA全覆盖组的制备方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114277447A true CN114277447A (zh) | 2022-04-05 |
Family
ID=80873594
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111573668.1A Pending CN114277447A (zh) | 2021-12-21 | 2021-12-21 | 靶序列随机sgRNA全覆盖组的制备方法 |
Country Status (2)
| Country | Link |
|---|---|
| CN (1) | CN114277447A (zh) |
| WO (1) | WO2023116681A1 (zh) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114293264A (zh) * | 2021-12-21 | 2022-04-08 | 翌圣生物科技(上海)股份有限公司 | 酶法靶序列随机sgRNA文库的制备方法 |
| WO2023116681A1 (zh) * | 2021-12-21 | 2023-06-29 | 翌圣生物科技(上海)股份有限公司 | 靶序列随机sgRNA全覆盖组的制备方法 |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20070048741A1 (en) * | 2005-08-24 | 2007-03-01 | Getts Robert C | Methods and kits for sense RNA synthesis |
| WO2013119827A1 (en) * | 2012-02-07 | 2013-08-15 | Pathogenica, Inc. | Direct rna capture with molecular inversion probes |
| CN106148322A (zh) * | 2015-04-22 | 2016-11-23 | 王金 | 一种合成dna的方法 |
| CN108221058A (zh) * | 2017-12-29 | 2018-06-29 | 苏州金唯智生物科技有限公司 | 一种猪全基因组sgRNA文库及其构建方法和应用 |
| US20190270984A1 (en) * | 2015-12-07 | 2019-09-05 | Arc Bio, Llc | Methods and compositions for the making and using of guide nucleic acids |
| CN110423785A (zh) * | 2019-05-29 | 2019-11-08 | 扬州大学 | 一种基于CRISPR-Cas9编辑技术的敲除鸡KPNA3基因的细胞系及其构建方法 |
| US20200255823A1 (en) * | 2016-10-06 | 2020-08-13 | Pioneer Biolabs, Llc | Guide strand library construction and methods of use thereof |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2017081097A1 (en) * | 2015-11-09 | 2017-05-18 | Ifom Fondazione Istituto Firc Di Oncologia Molecolare | Crispr-cas sgrna library |
| CN107488655B (zh) * | 2016-06-12 | 2021-07-09 | 中国科学院分子细胞科学卓越创新中心 | 测序文库构建中5’和3’接头连接副产物的去除方法 |
| CN108205614A (zh) * | 2017-12-29 | 2018-06-26 | 苏州金唯智生物科技有限公司 | 一种全基因组sgRNA文库的构建系统及其应用 |
| EP3927717A4 (en) * | 2019-02-19 | 2022-12-21 | Pioneer Biolabs, LLC | CONSTRUCTION OF GUIDED STRAND BANK AND RELATED METHODS OF USE |
| CN114277447A (zh) * | 2021-12-21 | 2022-04-05 | 翌圣生物科技(上海)股份有限公司 | 靶序列随机sgRNA全覆盖组的制备方法 |
-
2021
- 2021-12-21 CN CN202111573668.1A patent/CN114277447A/zh active Pending
-
2022
- 2022-12-20 WO PCT/CN2022/140314 patent/WO2023116681A1/zh unknown
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20070048741A1 (en) * | 2005-08-24 | 2007-03-01 | Getts Robert C | Methods and kits for sense RNA synthesis |
| WO2013119827A1 (en) * | 2012-02-07 | 2013-08-15 | Pathogenica, Inc. | Direct rna capture with molecular inversion probes |
| CN106148322A (zh) * | 2015-04-22 | 2016-11-23 | 王金 | 一种合成dna的方法 |
| US20190270984A1 (en) * | 2015-12-07 | 2019-09-05 | Arc Bio, Llc | Methods and compositions for the making and using of guide nucleic acids |
| US20200255823A1 (en) * | 2016-10-06 | 2020-08-13 | Pioneer Biolabs, Llc | Guide strand library construction and methods of use thereof |
| CN108221058A (zh) * | 2017-12-29 | 2018-06-29 | 苏州金唯智生物科技有限公司 | 一种猪全基因组sgRNA文库及其构建方法和应用 |
| CN110423785A (zh) * | 2019-05-29 | 2019-11-08 | 扬州大学 | 一种基于CRISPR-Cas9编辑技术的敲除鸡KPNA3基因的细胞系及其构建方法 |
Non-Patent Citations (1)
| Title |
|---|
| 贺添艳等: "T4 DNA连接酶性质及其平端连接功能", 河南科学, vol. 34, no. 07, pages 1058 - 1062 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114293264A (zh) * | 2021-12-21 | 2022-04-08 | 翌圣生物科技(上海)股份有限公司 | 酶法靶序列随机sgRNA文库的制备方法 |
| WO2023116681A1 (zh) * | 2021-12-21 | 2023-06-29 | 翌圣生物科技(上海)股份有限公司 | 靶序列随机sgRNA全覆盖组的制备方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2023116681A1 (zh) | 2023-06-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10669571B2 (en) | Compositions and methods for targeted depletion, enrichment, and partitioning of nucleic acids using CRISPR/Cas system proteins | |
| CN105986015B (zh) | 一种基于高通量测序的多样本的一个或多个靶序列的检测方法和试剂盒 | |
| CN110699426B (zh) | 基因目标区域富集方法及试剂盒 | |
| US20070172839A1 (en) | Asymmetrical adapters and methods of use thereof | |
| WO2023116681A1 (zh) | 靶序列随机sgRNA全覆盖组的制备方法 | |
| CN107058573B (zh) | 一种利用Cas9/gRNA系统构建扩增子文库的方法 | |
| CN109593757B (zh) | 一种探针及其适用于高通量测序的对目标区域进行富集的方法 | |
| US20210198660A1 (en) | Compositions and methods for making guide nucleic acids | |
| CN110607353B (zh) | 一种利用高效地连接技术快速制备dna测序文库的方法和试剂盒 | |
| CN111041026B (zh) | 一种高通量测序用核酸接头和文库构建方法 | |
| JP2023525880A (ja) | ライゲーションカップルドpcrの方法 | |
| CN111074353A (zh) | 全基因组甲基化文库单链建库方法和得到的全基因组甲基化文库 | |
| WO2023116718A1 (zh) | 酶法靶序列随机sgRNA文库的制备方法 | |
| CN110699425A (zh) | 基因目标区域的富集方法及体系 | |
| WO2023193748A1 (zh) | 基于crispr技术的靶基因捕获的方法 | |
| CN111989406A (zh) | 一种测序文库的构建方法 | |
| CN114808148A (zh) | 一种dna文库构建试剂盒、文库构建方法和应用 | |
| CN112176422B (zh) | Rna文库的构建方法 | |
| CN113136416B (zh) | 一种用于PacBio测序的文库构建方法 | |
| CN113817803B (zh) | 一种携带修饰的小rna的建库方法及其应用 | |
| CN112458085A (zh) | 一种新型分子捕获优化探针及其文库构建方法 | |
| CN116601310A (zh) | 连锁读段测序文库的制备 | |
| CA2962254C (en) | Composition and method for processing dna | |
| CN108265047B (zh) | 用于dna片段的非特异性复制的方法及试剂盒 | |
| CN113981043B (zh) | 一种制备二代测序接头的方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |