CN112368051A - 用于治疗骨病的基因治疗剂 - Google Patents
用于治疗骨病的基因治疗剂 Download PDFInfo
- Publication number
- CN112368051A CN112368051A CN201980031173.0A CN201980031173A CN112368051A CN 112368051 A CN112368051 A CN 112368051A CN 201980031173 A CN201980031173 A CN 201980031173A CN 112368051 A CN112368051 A CN 112368051A
- Authority
- CN
- China
- Prior art keywords
- bone
- gly
- nucleic acid
- pro
- raav
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 108090000623 proteins and genes Proteins 0.000 title claims description 114
- 239000003814 drug Substances 0.000 title description 13
- 208000020084 Bone disease Diseases 0.000 title description 6
- 229940124597 therapeutic agent Drugs 0.000 title description 6
- 210000000988 bone and bone Anatomy 0.000 claims abstract description 228
- 210000000963 osteoblast Anatomy 0.000 claims abstract description 168
- 150000007523 nucleic acids Chemical class 0.000 claims abstract description 164
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 146
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 146
- 210000002997 osteoclast Anatomy 0.000 claims abstract description 146
- 108700019146 Transgenes Proteins 0.000 claims abstract description 84
- 230000000694 effects Effects 0.000 claims abstract description 81
- 239000013598 vector Substances 0.000 claims abstract description 79
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims abstract description 76
- 238000000034 method Methods 0.000 claims abstract description 69
- 230000006870 function Effects 0.000 claims abstract description 49
- 210000004409 osteocyte Anatomy 0.000 claims abstract description 44
- 230000001965 increasing effect Effects 0.000 claims abstract description 40
- 208000001132 Osteoporosis Diseases 0.000 claims abstract description 35
- 208000035475 disorder Diseases 0.000 claims abstract description 29
- 230000003247 decreasing effect Effects 0.000 claims abstract description 19
- 208000002865 osteopetrosis Diseases 0.000 claims abstract description 8
- 230000014509 gene expression Effects 0.000 claims description 176
- 210000004027 cell Anatomy 0.000 claims description 158
- 230000008685 targeting Effects 0.000 claims description 93
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 89
- 108090000565 Capsid Proteins Proteins 0.000 claims description 72
- 102100023321 Ceruloplasmin Human genes 0.000 claims description 72
- 230000002401 inhibitory effect Effects 0.000 claims description 72
- 230000011164 ossification Effects 0.000 claims description 70
- 102100028336 Transcription factor HIVEP3 Human genes 0.000 claims description 63
- 102000004169 proteins and genes Human genes 0.000 claims description 63
- 101000723938 Homo sapiens Transcription factor HIVEP3 Proteins 0.000 claims description 52
- 210000001519 tissue Anatomy 0.000 claims description 49
- 201000010099 disease Diseases 0.000 claims description 47
- 238000002347 injection Methods 0.000 claims description 44
- 239000007924 injection Substances 0.000 claims description 44
- 108090000445 Parathyroid hormone Proteins 0.000 claims description 38
- 102000019307 Sclerostin Human genes 0.000 claims description 38
- 108050006698 Sclerostin Proteins 0.000 claims description 38
- 102000003982 Parathyroid hormone Human genes 0.000 claims description 37
- 229960001319 parathyroid hormone Drugs 0.000 claims description 37
- 239000000199 parathyroid hormone Substances 0.000 claims description 37
- 238000010361 transduction Methods 0.000 claims description 37
- 230000026683 transduction Effects 0.000 claims description 37
- 108090000625 Cathepsin K Proteins 0.000 claims description 34
- 102000004171 Cathepsin K Human genes 0.000 claims description 34
- 230000037182 bone density Effects 0.000 claims description 34
- 230000002829 reductive effect Effects 0.000 claims description 33
- 230000004097 bone metabolism Effects 0.000 claims description 29
- 241000702423 Adeno-associated virus - 2 Species 0.000 claims description 27
- 239000003112 inhibitor Substances 0.000 claims description 26
- 108091032973 (ribonucleotides)n+m Proteins 0.000 claims description 25
- 210000001612 chondrocyte Anatomy 0.000 claims description 25
- 150000001413 amino acids Chemical class 0.000 claims description 22
- 108020004705 Codon Proteins 0.000 claims description 20
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 20
- 108091027967 Small hairpin RNA Proteins 0.000 claims description 20
- 239000004055 small Interfering RNA Substances 0.000 claims description 18
- IVRMZWNICZWHMI-UHFFFAOYSA-N azide group Chemical group [N-]=[N+]=[N-] IVRMZWNICZWHMI-UHFFFAOYSA-N 0.000 claims description 15
- 239000013612 plasmid Substances 0.000 claims description 14
- 101710177551 Transcription factor HIVEP3 Proteins 0.000 claims description 13
- 241000972680 Adeno-associated virus - 6 Species 0.000 claims description 12
- 241000702421 Dependoparvovirus Species 0.000 claims description 12
- 241001655883 Adeno-associated virus - 1 Species 0.000 claims description 11
- 108091070501 miRNA Proteins 0.000 claims description 11
- 239000002679 microRNA Substances 0.000 claims description 11
- 241000580270 Adeno-associated virus - 4 Species 0.000 claims description 10
- 241001634120 Adeno-associated virus - 5 Species 0.000 claims description 10
- 241001164823 Adeno-associated virus - 7 Species 0.000 claims description 10
- 241001164825 Adeno-associated virus - 8 Species 0.000 claims description 10
- 230000006378 damage Effects 0.000 claims description 9
- 238000007918 intramuscular administration Methods 0.000 claims description 9
- 101150011252 CTSK gene Proteins 0.000 claims description 8
- 241000202702 Adeno-associated virus - 3 Species 0.000 claims description 7
- 108700026244 Open Reading Frames Proteins 0.000 claims description 7
- 230000009885 systemic effect Effects 0.000 claims description 7
- OGSPWJRAVKPPFI-UHFFFAOYSA-N Alendronic Acid Chemical compound NCCCC(O)(P(O)(O)=O)P(O)(O)=O OGSPWJRAVKPPFI-UHFFFAOYSA-N 0.000 claims description 6
- 102000005600 Cathepsins Human genes 0.000 claims description 6
- 108010084457 Cathepsins Proteins 0.000 claims description 6
- 108020004459 Small interfering RNA Proteins 0.000 claims description 6
- 229940062527 alendronate Drugs 0.000 claims description 6
- 230000007547 defect Effects 0.000 claims description 6
- 102000040650 (ribonucleotides)n+m Human genes 0.000 claims description 5
- 208000018084 Bone neoplasm Diseases 0.000 claims description 5
- 208000027418 Wounds and injury Diseases 0.000 claims description 5
- 208000014674 injury Diseases 0.000 claims description 5
- 238000001990 intravenous administration Methods 0.000 claims description 5
- 241000649045 Adeno-associated virus 10 Species 0.000 claims description 4
- 206010005949 Bone cancer Diseases 0.000 claims description 4
- 101000711796 Homo sapiens Sclerostin Proteins 0.000 claims description 4
- 102100034201 Sclerostin Human genes 0.000 claims description 4
- 201000008968 osteosarcoma Diseases 0.000 claims description 4
- 208000009912 sclerosteosis Diseases 0.000 claims description 4
- 206010000599 Acromegaly Diseases 0.000 claims description 3
- 206010006187 Breast cancer Diseases 0.000 claims description 3
- 208000026310 Breast neoplasm Diseases 0.000 claims description 3
- 206010027476 Metastases Diseases 0.000 claims description 3
- 206010031243 Osteogenesis imperfecta Diseases 0.000 claims description 3
- 206010060862 Prostate cancer Diseases 0.000 claims description 3
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 3
- 210000000481 breast Anatomy 0.000 claims description 3
- 208000006454 hepatitis Diseases 0.000 claims description 3
- 231100000283 hepatitis Toxicity 0.000 claims description 3
- 210000003127 knee Anatomy 0.000 claims description 3
- 230000009401 metastasis Effects 0.000 claims description 3
- 206010028537 myelofibrosis Diseases 0.000 claims description 3
- 208000015943 Coeliac disease Diseases 0.000 claims description 2
- 206010016818 Fluorosis Diseases 0.000 claims description 2
- 206010020850 Hyperthyroidism Diseases 0.000 claims description 2
- 208000022559 Inflammatory bowel disease Diseases 0.000 claims description 2
- 206010067584 Type 1 diabetes mellitus Diseases 0.000 claims description 2
- 208000006673 asthma Diseases 0.000 claims description 2
- 208000004042 dental fluorosis Diseases 0.000 claims description 2
- 206010025135 lupus erythematosus Diseases 0.000 claims description 2
- 230000001394 metastastic effect Effects 0.000 claims description 2
- 206010061289 metastatic neoplasm Diseases 0.000 claims description 2
- 201000006417 multiple sclerosis Diseases 0.000 claims description 2
- 201000001245 periodontitis Diseases 0.000 claims description 2
- 206010039073 rheumatoid arthritis Diseases 0.000 claims description 2
- 208000037921 secondary disease Diseases 0.000 claims description 2
- 125000003275 alpha amino acid group Chemical group 0.000 claims 3
- 108091006084 receptor activators Proteins 0.000 claims 3
- 230000036244 malformation Effects 0.000 claims 2
- 239000002924 silencing RNA Substances 0.000 claims 1
- 239000000203 mixture Substances 0.000 abstract description 54
- 230000004069 differentiation Effects 0.000 abstract description 47
- 210000002449 bone cell Anatomy 0.000 abstract description 29
- -1 e.g. Substances 0.000 abstract description 11
- 239000013608 rAAV vector Substances 0.000 abstract description 11
- 230000007423 decrease Effects 0.000 abstract description 9
- 241000699670 Mus sp. Species 0.000 description 132
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 89
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 89
- 239000005090 green fluorescent protein Substances 0.000 description 89
- 210000000689 upper leg Anatomy 0.000 description 73
- 108091026821 Artificial microRNA Proteins 0.000 description 64
- 235000018102 proteins Nutrition 0.000 description 49
- 210000000234 capsid Anatomy 0.000 description 47
- 102000004196 processed proteins & peptides Human genes 0.000 description 40
- 241000699666 Mus <mouse, genus> Species 0.000 description 38
- 210000001185 bone marrow Anatomy 0.000 description 37
- 210000000629 knee joint Anatomy 0.000 description 33
- 239000002773 nucleotide Substances 0.000 description 33
- 125000003729 nucleotide group Chemical group 0.000 description 33
- 238000011282 treatment Methods 0.000 description 30
- 208000006386 Bone Resorption Diseases 0.000 description 29
- 230000024279 bone resorption Effects 0.000 description 29
- 238000001727 in vivo Methods 0.000 description 28
- 229920001184 polypeptide Polymers 0.000 description 28
- 238000004458 analytical method Methods 0.000 description 25
- 238000000338 in vitro Methods 0.000 description 25
- 238000001356 surgical procedure Methods 0.000 description 24
- 108020004414 DNA Proteins 0.000 description 23
- 241000282414 Homo sapiens Species 0.000 description 23
- 210000004349 growth plate Anatomy 0.000 description 23
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 22
- 239000002953 phosphate buffered saline Substances 0.000 description 22
- 206010065687 Bone loss Diseases 0.000 description 21
- 239000002243 precursor Substances 0.000 description 21
- 230000001054 cortical effect Effects 0.000 description 20
- 238000012634 optical imaging Methods 0.000 description 20
- 230000002188 osteogenic effect Effects 0.000 description 20
- 210000004417 patella Anatomy 0.000 description 20
- 238000012384 transportation and delivery Methods 0.000 description 20
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 19
- 239000000243 solution Substances 0.000 description 19
- 238000012360 testing method Methods 0.000 description 19
- 239000002502 liposome Substances 0.000 description 18
- 239000013607 AAV vector Substances 0.000 description 17
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 17
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 16
- 230000001939 inductive effect Effects 0.000 description 16
- 230000001404 mediated effect Effects 0.000 description 16
- 238000011144 upstream manufacturing Methods 0.000 description 16
- 102000007591 Tartrate-Resistant Acid Phosphatase Human genes 0.000 description 15
- 108010032050 Tartrate-Resistant Acid Phosphatase Proteins 0.000 description 15
- 210000001188 articular cartilage Anatomy 0.000 description 15
- 238000000799 fluorescence microscopy Methods 0.000 description 15
- 238000003197 gene knockdown Methods 0.000 description 15
- 108010050848 glycylleucine Proteins 0.000 description 15
- 238000003119 immunoblot Methods 0.000 description 15
- 230000001105 regulatory effect Effects 0.000 description 15
- 238000003757 reverse transcription PCR Methods 0.000 description 15
- 235000001014 amino acid Nutrition 0.000 description 14
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 14
- 230000001225 therapeutic effect Effects 0.000 description 14
- 108010061238 threonyl-glycine Proteins 0.000 description 14
- 108010079364 N-glycylalanine Proteins 0.000 description 13
- RGCKGOZRHPZPFP-UHFFFAOYSA-N alizarin Chemical compound C1=CC=C2C(=O)C3=C(O)C(O)=CC=C3C(=O)C2=C1 RGCKGOZRHPZPFP-UHFFFAOYSA-N 0.000 description 13
- 229940024606 amino acid Drugs 0.000 description 13
- 230000030279 gene silencing Effects 0.000 description 13
- 239000003446 ligand Substances 0.000 description 13
- 238000011002 quantification Methods 0.000 description 13
- TVZRAEYQIKYCPH-UHFFFAOYSA-N 3-(trimethylsilyl)propane-1-sulfonic acid Chemical compound C[Si](C)(C)CCCS(O)(=O)=O TVZRAEYQIKYCPH-UHFFFAOYSA-N 0.000 description 12
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 12
- 101150111543 SHN3 gene Proteins 0.000 description 12
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 description 12
- 108010057821 leucylproline Proteins 0.000 description 12
- 238000004519 manufacturing process Methods 0.000 description 12
- 108020004999 messenger RNA Proteins 0.000 description 12
- 210000003205 muscle Anatomy 0.000 description 12
- 238000010186 staining Methods 0.000 description 12
- 108091026890 Coding region Proteins 0.000 description 11
- 241001465754 Metazoa Species 0.000 description 11
- 101710081079 Minor spike protein H Proteins 0.000 description 11
- DEGAKNSWVGKMLS-UHFFFAOYSA-N calcein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC(CN(CC(O)=O)CC(O)=O)=C(O)C=C1OC1=C2C=C(CN(CC(O)=O)CC(=O)O)C(O)=C1 DEGAKNSWVGKMLS-UHFFFAOYSA-N 0.000 description 11
- 238000012512 characterization method Methods 0.000 description 11
- 229960002378 oftasceine Drugs 0.000 description 11
- 102000040430 polynucleotide Human genes 0.000 description 11
- 108091033319 polynucleotide Proteins 0.000 description 11
- 239000002157 polynucleotide Substances 0.000 description 11
- 208000001685 postmenopausal osteoporosis Diseases 0.000 description 11
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 10
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 10
- 108010077245 asparaginyl-proline Proteins 0.000 description 10
- 230000010256 bone deposition Effects 0.000 description 10
- 238000009472 formulation Methods 0.000 description 10
- 238000001415 gene therapy Methods 0.000 description 10
- 230000005764 inhibitory process Effects 0.000 description 10
- 230000001737 promoting effect Effects 0.000 description 10
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 9
- 108010046938 Macrophage Colony-Stimulating Factor Proteins 0.000 description 9
- 102100028123 Macrophage colony-stimulating factor 1 Human genes 0.000 description 9
- 102100039019 Nuclear receptor subfamily 0 group B member 1 Human genes 0.000 description 9
- 108010032428 Protein Deglycase DJ-1 Proteins 0.000 description 9
- 102000007659 Protein Deglycase DJ-1 Human genes 0.000 description 9
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 9
- 230000015572 biosynthetic process Effects 0.000 description 9
- 108010087823 glycyltyrosine Proteins 0.000 description 9
- 108010016686 methionyl-alanyl-serine Proteins 0.000 description 9
- UHFUZWSZQKMDSX-DCAQKATOSA-N Arg-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UHFUZWSZQKMDSX-DCAQKATOSA-N 0.000 description 8
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 8
- 238000000692 Student's t-test Methods 0.000 description 8
- ZHQWPWQNVRCXAX-XQQFMLRXSA-N Val-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZHQWPWQNVRCXAX-XQQFMLRXSA-N 0.000 description 8
- 230000033558 biomineral tissue development Effects 0.000 description 8
- 239000003795 chemical substances by application Substances 0.000 description 8
- 238000012217 deletion Methods 0.000 description 8
- 230000037430 deletion Effects 0.000 description 8
- 238000001317 epifluorescence microscopy Methods 0.000 description 8
- 239000012634 fragment Substances 0.000 description 8
- 235000013922 glutamic acid Nutrition 0.000 description 8
- 239000004220 glutamic acid Substances 0.000 description 8
- 108010089804 glycyl-threonine Proteins 0.000 description 8
- 210000004185 liver Anatomy 0.000 description 8
- 210000003141 lower extremity Anatomy 0.000 description 8
- 238000010172 mouse model Methods 0.000 description 8
- 239000000047 product Substances 0.000 description 8
- 230000002463 transducing effect Effects 0.000 description 8
- CCDFBRZVTDDJNM-GUBZILKMSA-N Ala-Leu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CCDFBRZVTDDJNM-GUBZILKMSA-N 0.000 description 7
- 241000701022 Cytomegalovirus Species 0.000 description 7
- 101150003028 Hprt1 gene Proteins 0.000 description 7
- 101100181592 Mus musculus Lep gene Proteins 0.000 description 7
- 101100046557 Mus musculus Tnfrsf11a gene Proteins 0.000 description 7
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 7
- 108091034117 Oligonucleotide Proteins 0.000 description 7
- JAIZPWVHPQRYOU-ZJDVBMNYSA-N Val-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O JAIZPWVHPQRYOU-ZJDVBMNYSA-N 0.000 description 7
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 7
- 230000000295 complement effect Effects 0.000 description 7
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 7
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Chemical compound NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 7
- 210000003041 ligament Anatomy 0.000 description 7
- 230000004048 modification Effects 0.000 description 7
- 238000012986 modification Methods 0.000 description 7
- 239000013642 negative control Substances 0.000 description 7
- 230000004072 osteoblast differentiation Effects 0.000 description 7
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 7
- 108010051242 phenylalanylserine Proteins 0.000 description 7
- 108010077112 prolyl-proline Proteins 0.000 description 7
- 230000009467 reduction Effects 0.000 description 7
- 239000013609 scAAV vector Substances 0.000 description 7
- 210000002966 serum Anatomy 0.000 description 7
- 108010015666 tryptophyl-leucyl-glutamic acid Proteins 0.000 description 7
- 210000002845 virion Anatomy 0.000 description 7
- GSCLWXDNIMNIJE-ZLUOBGJFSA-N Ala-Asp-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GSCLWXDNIMNIJE-ZLUOBGJFSA-N 0.000 description 6
- KIUYPHAMDKDICO-WHFBIAKZSA-N Ala-Asp-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KIUYPHAMDKDICO-WHFBIAKZSA-N 0.000 description 6
- VCSABYLVNWQYQE-UHFFFAOYSA-N Ala-Lys-Lys Natural products NCCCCC(NC(=O)C(N)C)C(=O)NC(CCCCN)C(O)=O VCSABYLVNWQYQE-UHFFFAOYSA-N 0.000 description 6
- YCTIYBUTCKNOTI-UWJYBYFXSA-N Ala-Tyr-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCTIYBUTCKNOTI-UWJYBYFXSA-N 0.000 description 6
- AYZAWXAPBAYCHO-CIUDSAMLSA-N Asn-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N AYZAWXAPBAYCHO-CIUDSAMLSA-N 0.000 description 6
- XEDQMTWEYFBOIK-ACZMJKKPSA-N Asp-Ala-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O XEDQMTWEYFBOIK-ACZMJKKPSA-N 0.000 description 6
- UFAQGGZUXVLONR-AVGNSLFASA-N Asp-Gln-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N)O UFAQGGZUXVLONR-AVGNSLFASA-N 0.000 description 6
- YIDFBWRHIYOYAA-LKXGYXEUSA-N Asp-Ser-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YIDFBWRHIYOYAA-LKXGYXEUSA-N 0.000 description 6
- 238000002965 ELISA Methods 0.000 description 6
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 6
- BEQGFMIBZFNROK-JGVFFNPUSA-N Gly-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)CN)C(=O)O BEQGFMIBZFNROK-JGVFFNPUSA-N 0.000 description 6
- BDHUXUFYNUOUIT-SRVKXCTJSA-N His-Asp-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BDHUXUFYNUOUIT-SRVKXCTJSA-N 0.000 description 6
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 6
- BRJGUPWVFXKBQI-XUXIUFHCSA-N Pro-Leu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRJGUPWVFXKBQI-XUXIUFHCSA-N 0.000 description 6
- VVAWNPIOYXAMAL-KJEVXHAQSA-N Pro-Thr-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VVAWNPIOYXAMAL-KJEVXHAQSA-N 0.000 description 6
- LVHHEVGYAZGXDE-KDXUFGMBSA-N Thr-Ala-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(=O)O)N)O LVHHEVGYAZGXDE-KDXUFGMBSA-N 0.000 description 6
- WFUAUEQXPVNAEF-ZJDVBMNYSA-N Thr-Arg-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CCCN=C(N)N WFUAUEQXPVNAEF-ZJDVBMNYSA-N 0.000 description 6
- NMCBVGFGWSIGSB-NUTKFTJISA-N Trp-Ala-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N NMCBVGFGWSIGSB-NUTKFTJISA-N 0.000 description 6
- YRSOERSDNRSCBC-XIRDDKMYSA-N Trp-His-Cys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CN=CN3)C(=O)N[C@@H](CS)C(=O)O)N YRSOERSDNRSCBC-XIRDDKMYSA-N 0.000 description 6
- VPRHDRKAPYZMHL-SZMVWBNQSA-N Trp-Leu-Glu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 VPRHDRKAPYZMHL-SZMVWBNQSA-N 0.000 description 6
- NXRAUQGGHPCJIB-RCOVLWMOSA-N Val-Gly-Asn Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O NXRAUQGGHPCJIB-RCOVLWMOSA-N 0.000 description 6
- 241000700605 Viruses Species 0.000 description 6
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 6
- 238000010171 animal model Methods 0.000 description 6
- 238000005452 bending Methods 0.000 description 6
- 238000004624 confocal microscopy Methods 0.000 description 6
- 238000011161 development Methods 0.000 description 6
- 230000018109 developmental process Effects 0.000 description 6
- 230000008482 dysregulation Effects 0.000 description 6
- 108010048367 enhanced green fluorescent protein Proteins 0.000 description 6
- 108010025306 histidylleucine Proteins 0.000 description 6
- 108010092114 histidylphenylalanine Proteins 0.000 description 6
- 108010034529 leucyl-lysine Proteins 0.000 description 6
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 6
- 239000002609 medium Substances 0.000 description 6
- 230000035772 mutation Effects 0.000 description 6
- 238000001543 one-way ANOVA Methods 0.000 description 6
- 108010031719 prolyl-serine Proteins 0.000 description 6
- 108010015796 prolylisoleucine Proteins 0.000 description 6
- 230000010076 replication Effects 0.000 description 6
- 239000000523 sample Substances 0.000 description 6
- 239000011780 sodium chloride Substances 0.000 description 6
- 229960001603 tamoxifen Drugs 0.000 description 6
- NHCPCLJZRSIDHS-ZLUOBGJFSA-N Ala-Asp-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O NHCPCLJZRSIDHS-ZLUOBGJFSA-N 0.000 description 5
- VCSABYLVNWQYQE-SRVKXCTJSA-N Ala-Lys-Lys Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O VCSABYLVNWQYQE-SRVKXCTJSA-N 0.000 description 5
- BHTBAVZSZCQZPT-GUBZILKMSA-N Ala-Pro-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N BHTBAVZSZCQZPT-GUBZILKMSA-N 0.000 description 5
- ASQYTJJWAMDISW-BPUTZDHNSA-N Arg-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N ASQYTJJWAMDISW-BPUTZDHNSA-N 0.000 description 5
- GNKVBRYFXYWXAB-WDSKDSINSA-N Asn-Glu-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O GNKVBRYFXYWXAB-WDSKDSINSA-N 0.000 description 5
- GKKUBLFXKRDMFC-BQBZGAKWSA-N Asn-Pro-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O GKKUBLFXKRDMFC-BQBZGAKWSA-N 0.000 description 5
- RDLYUKRPEJERMM-XIRDDKMYSA-N Asn-Trp-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(C)C)C(O)=O RDLYUKRPEJERMM-XIRDDKMYSA-N 0.000 description 5
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 5
- PGUYEUCYVNZGGV-QWRGUYRKSA-N Asp-Gly-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PGUYEUCYVNZGGV-QWRGUYRKSA-N 0.000 description 5
- 108010051219 Cre recombinase Proteins 0.000 description 5
- XQDGOJPVMSWZSO-SRVKXCTJSA-N Gln-Pro-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N XQDGOJPVMSWZSO-SRVKXCTJSA-N 0.000 description 5
- OSCLNNWLKKIQJM-WDSKDSINSA-N Gln-Ser-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O OSCLNNWLKKIQJM-WDSKDSINSA-N 0.000 description 5
- SGVGIVDZLSHSEN-RYUDHWBXSA-N Gln-Tyr-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O SGVGIVDZLSHSEN-RYUDHWBXSA-N 0.000 description 5
- SBCYJMOOHUDWDA-NUMRIWBASA-N Glu-Asp-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SBCYJMOOHUDWDA-NUMRIWBASA-N 0.000 description 5
- CUXJIASLBRJOFV-LAEOZQHASA-N Glu-Gly-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O CUXJIASLBRJOFV-LAEOZQHASA-N 0.000 description 5
- YTSVAIMKVLZUDU-YUMQZZPRSA-N Gly-Leu-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YTSVAIMKVLZUDU-YUMQZZPRSA-N 0.000 description 5
- VEPBEGNDJYANCF-QWRGUYRKSA-N Gly-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN VEPBEGNDJYANCF-QWRGUYRKSA-N 0.000 description 5
- PNUFMLXHOLFRLD-KBPBESRZSA-N Gly-Tyr-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 PNUFMLXHOLFRLD-KBPBESRZSA-N 0.000 description 5
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 5
- ARRIJPQRBWRNLT-DCAQKATOSA-N Leu-Met-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ARRIJPQRBWRNLT-DCAQKATOSA-N 0.000 description 5
- BMVFXOQHDQZAQU-DCAQKATOSA-N Leu-Pro-Asp Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N BMVFXOQHDQZAQU-DCAQKATOSA-N 0.000 description 5
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 5
- YIRIDPUGZKHMHT-ACRUOGEOSA-N Leu-Tyr-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YIRIDPUGZKHMHT-ACRUOGEOSA-N 0.000 description 5
- XFIHDSBIPWEYJJ-YUMQZZPRSA-N Lys-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN XFIHDSBIPWEYJJ-YUMQZZPRSA-N 0.000 description 5
- LCMWVZLBCUVDAZ-IUCAKERBSA-N Lys-Gly-Glu Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CCC([O-])=O LCMWVZLBCUVDAZ-IUCAKERBSA-N 0.000 description 5
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 5
- YRAWWKUTNBILNT-FXQIFTODSA-N Met-Ala-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YRAWWKUTNBILNT-FXQIFTODSA-N 0.000 description 5
- 101100107119 Mus musculus Hivep3 gene Proteins 0.000 description 5
- UNLYPPYNDXHGDG-IHRRRGAJSA-N Phe-Gln-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 UNLYPPYNDXHGDG-IHRRRGAJSA-N 0.000 description 5
- YYKZDTVQHTUKDW-RYUDHWBXSA-N Phe-Gly-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N YYKZDTVQHTUKDW-RYUDHWBXSA-N 0.000 description 5
- APJPXSFJBMMOLW-KBPBESRZSA-N Phe-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 APJPXSFJBMMOLW-KBPBESRZSA-N 0.000 description 5
- YFNOUBWUIIJQHF-LPEHRKFASA-N Pro-Asp-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O YFNOUBWUIIJQHF-LPEHRKFASA-N 0.000 description 5
- DMNANGOFEUVBRV-GJZGRUSLSA-N Pro-Trp-Gly Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(=O)O)C(=O)[C@@H]1CCCN1 DMNANGOFEUVBRV-GJZGRUSLSA-N 0.000 description 5
- 108010079005 RDV peptide Proteins 0.000 description 5
- 108700008625 Reporter Genes Proteins 0.000 description 5
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 5
- LRZLZIUXQBIWTB-KATARQTJSA-N Ser-Lys-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LRZLZIUXQBIWTB-KATARQTJSA-N 0.000 description 5
- XKFJENWJGHMDLI-QWRGUYRKSA-N Ser-Phe-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O XKFJENWJGHMDLI-QWRGUYRKSA-N 0.000 description 5
- GCXFWAZRHBRYEM-NUMRIWBASA-N Thr-Gln-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O GCXFWAZRHBRYEM-NUMRIWBASA-N 0.000 description 5
- ZMYCLHFLHRVOEA-HEIBUPTGSA-N Thr-Thr-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ZMYCLHFLHRVOEA-HEIBUPTGSA-N 0.000 description 5
- QGVBFDIREUUSHX-IFFSRLJSSA-N Thr-Val-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O QGVBFDIREUUSHX-IFFSRLJSSA-N 0.000 description 5
- 108091023040 Transcription factor Proteins 0.000 description 5
- 102000040945 Transcription factor Human genes 0.000 description 5
- CYDVHRFXDMDMGX-KKUMJFAQSA-N Tyr-Asn-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O CYDVHRFXDMDMGX-KKUMJFAQSA-N 0.000 description 5
- DWAMXBFJNZIHMC-KBPBESRZSA-N Tyr-Leu-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O DWAMXBFJNZIHMC-KBPBESRZSA-N 0.000 description 5
- BYAKMYBZADCNMN-JYJNAYRXSA-N Tyr-Lys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O BYAKMYBZADCNMN-JYJNAYRXSA-N 0.000 description 5
- LUMQYLVYUIRHHU-YJRXYDGGSA-N Tyr-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUMQYLVYUIRHHU-YJRXYDGGSA-N 0.000 description 5
- SZTTYWIUCGSURQ-AUTRQRHGSA-N Val-Glu-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SZTTYWIUCGSURQ-AUTRQRHGSA-N 0.000 description 5
- IJGPOONOTBNTFS-GVXVVHGQSA-N Val-Lys-Glu Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O IJGPOONOTBNTFS-GVXVVHGQSA-N 0.000 description 5
- 108010070944 alanylhistidine Proteins 0.000 description 5
- 108010092854 aspartyllysine Proteins 0.000 description 5
- 239000006185 dispersion Substances 0.000 description 5
- 238000006073 displacement reaction Methods 0.000 description 5
- 238000009826 distribution Methods 0.000 description 5
- 239000003623 enhancer Substances 0.000 description 5
- 210000003414 extremity Anatomy 0.000 description 5
- HPAIKDPJURGQLN-UHFFFAOYSA-N glycyl-L-histidyl-L-phenylalanine Natural products C=1C=CC=CC=1CC(C(O)=O)NC(=O)C(NC(=O)CN)CC1=CN=CN1 HPAIKDPJURGQLN-UHFFFAOYSA-N 0.000 description 5
- 108010059898 glycyl-tyrosyl-lysine Proteins 0.000 description 5
- 108010077515 glycylproline Proteins 0.000 description 5
- 210000002216 heart Anatomy 0.000 description 5
- 108010040030 histidinoalanine Proteins 0.000 description 5
- 108010085325 histidylproline Proteins 0.000 description 5
- 238000003384 imaging method Methods 0.000 description 5
- 238000011534 incubation Methods 0.000 description 5
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 5
- 208000030159 metabolic disease Diseases 0.000 description 5
- 230000007935 neutral effect Effects 0.000 description 5
- 239000002245 particle Substances 0.000 description 5
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 5
- 229920000642 polymer Polymers 0.000 description 5
- 238000002360 preparation method Methods 0.000 description 5
- 108091007428 primary miRNA Proteins 0.000 description 5
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 5
- 150000003839 salts Chemical class 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- 238000012385 systemic delivery Methods 0.000 description 5
- 210000002303 tibia Anatomy 0.000 description 5
- 238000013518 transcription Methods 0.000 description 5
- 230000035897 transcription Effects 0.000 description 5
- 230000010415 tropism Effects 0.000 description 5
- 108010045269 tryptophyltryptophan Proteins 0.000 description 5
- 230000003612 virological effect Effects 0.000 description 5
- LBJYAILUMSUTAM-ZLUOBGJFSA-N Ala-Asn-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O LBJYAILUMSUTAM-ZLUOBGJFSA-N 0.000 description 4
- FBHOPGDGELNWRH-DRZSPHRISA-N Ala-Glu-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O FBHOPGDGELNWRH-DRZSPHRISA-N 0.000 description 4
- ZVFVBBGVOILKPO-WHFBIAKZSA-N Ala-Gly-Ala Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O ZVFVBBGVOILKPO-WHFBIAKZSA-N 0.000 description 4
- MQIGTEQXYCRLGK-BQBZGAKWSA-N Ala-Gly-Pro Chemical compound C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O MQIGTEQXYCRLGK-BQBZGAKWSA-N 0.000 description 4
- NHWYNIZWLJYZAG-XVYDVKMFSA-N Ala-Ser-His Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N NHWYNIZWLJYZAG-XVYDVKMFSA-N 0.000 description 4
- MMLHRUJLOUSRJX-CIUDSAMLSA-N Ala-Ser-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN MMLHRUJLOUSRJX-CIUDSAMLSA-N 0.000 description 4
- JQFJNGVSGOUQDH-XIRDDKMYSA-N Arg-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCN=C(N)N)N)C(O)=O)=CNC2=C1 JQFJNGVSGOUQDH-XIRDDKMYSA-N 0.000 description 4
- GMFAGHNRXPSSJS-SRVKXCTJSA-N Arg-Leu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GMFAGHNRXPSSJS-SRVKXCTJSA-N 0.000 description 4
- IGFJVXOATGZTHD-UHFFFAOYSA-N Arg-Phe-His Natural products NC(CCNC(=N)N)C(=O)NC(Cc1ccccc1)C(=O)NC(Cc2c[nH]cn2)C(=O)O IGFJVXOATGZTHD-UHFFFAOYSA-N 0.000 description 4
- HUZGPXBILPMCHM-IHRRRGAJSA-N Asn-Arg-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HUZGPXBILPMCHM-IHRRRGAJSA-N 0.000 description 4
- PCKRJVZAQZWNKM-WHFBIAKZSA-N Asn-Asn-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O PCKRJVZAQZWNKM-WHFBIAKZSA-N 0.000 description 4
- KXFCBAHYSLJCCY-ZLUOBGJFSA-N Asn-Asn-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O KXFCBAHYSLJCCY-ZLUOBGJFSA-N 0.000 description 4
- PHJPKNUWWHRAOC-PEFMBERDSA-N Asn-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N PHJPKNUWWHRAOC-PEFMBERDSA-N 0.000 description 4
- UGKZHCBLMLSANF-CIUDSAMLSA-N Asp-Asn-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O UGKZHCBLMLSANF-CIUDSAMLSA-N 0.000 description 4
- UGIBTKGQVWFTGX-BIIVOSGPSA-N Asp-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N)C(=O)O UGIBTKGQVWFTGX-BIIVOSGPSA-N 0.000 description 4
- SFJUYBCDQBAYAJ-YDHLFZDLSA-N Asp-Val-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SFJUYBCDQBAYAJ-YDHLFZDLSA-N 0.000 description 4
- 101150044789 Cap gene Proteins 0.000 description 4
- 102000012422 Collagen Type I Human genes 0.000 description 4
- 108010022452 Collagen Type I Proteins 0.000 description 4
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 4
- PRBLYKYHAJEABA-SRVKXCTJSA-N Gln-Arg-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O PRBLYKYHAJEABA-SRVKXCTJSA-N 0.000 description 4
- KVXVVDFOZNYYKZ-DCAQKATOSA-N Gln-Gln-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O KVXVVDFOZNYYKZ-DCAQKATOSA-N 0.000 description 4
- IVCOYUURLWQDJQ-LPEHRKFASA-N Gln-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O IVCOYUURLWQDJQ-LPEHRKFASA-N 0.000 description 4
- VOLVNCMGXWDDQY-LPEHRKFASA-N Gln-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O VOLVNCMGXWDDQY-LPEHRKFASA-N 0.000 description 4
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 4
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 4
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 4
- QSQXZZCGPXQBPP-BQBZGAKWSA-N Gly-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)CN)C(=O)N[C@@H](CS)C(=O)O QSQXZZCGPXQBPP-BQBZGAKWSA-N 0.000 description 4
- AASLOGQZZKZWKH-SRVKXCTJSA-N His-Cys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N AASLOGQZZKZWKH-SRVKXCTJSA-N 0.000 description 4
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 4
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 4
- STAVRDQLZOTNKJ-RHYQMDGZSA-N Leu-Arg-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O STAVRDQLZOTNKJ-RHYQMDGZSA-N 0.000 description 4
- IGUOAYLTQJLPPD-DCAQKATOSA-N Leu-Asn-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IGUOAYLTQJLPPD-DCAQKATOSA-N 0.000 description 4
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 4
- PTRKPHUGYULXPU-KKUMJFAQSA-N Leu-Phe-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O PTRKPHUGYULXPU-KKUMJFAQSA-N 0.000 description 4
- UCBPDSYUVAAHCD-UWVGGRQHSA-N Leu-Pro-Gly Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UCBPDSYUVAAHCD-UWVGGRQHSA-N 0.000 description 4
- MPOHDJKRBLVGCT-CIUDSAMLSA-N Lys-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N MPOHDJKRBLVGCT-CIUDSAMLSA-N 0.000 description 4
- DJPXNKUDJKGQEE-BZSNNMDCSA-N Phe-Asp-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O DJPXNKUDJKGQEE-BZSNNMDCSA-N 0.000 description 4
- QSWKNJAPHQDAAS-MELADBBJSA-N Phe-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O QSWKNJAPHQDAAS-MELADBBJSA-N 0.000 description 4
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 4
- VGVCNKSUVSZEIE-IHRRRGAJSA-N Pro-Phe-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O VGVCNKSUVSZEIE-IHRRRGAJSA-N 0.000 description 4
- GNADVDLLGVSXLS-ULQDDVLXSA-N Pro-Phe-His Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC=N1)C(O)=O GNADVDLLGVSXLS-ULQDDVLXSA-N 0.000 description 4
- IMNVAOPEMFDAQD-NHCYSSNCSA-N Pro-Val-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IMNVAOPEMFDAQD-NHCYSSNCSA-N 0.000 description 4
- 241000714474 Rous sarcoma virus Species 0.000 description 4
- UGJRQLURDVGULT-LKXGYXEUSA-N Ser-Asn-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UGJRQLURDVGULT-LKXGYXEUSA-N 0.000 description 4
- YMAWDPHQVABADW-CIUDSAMLSA-N Ser-Gln-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O YMAWDPHQVABADW-CIUDSAMLSA-N 0.000 description 4
- KZPRPBLHYMZIMH-MXAVVETBSA-N Ser-Phe-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KZPRPBLHYMZIMH-MXAVVETBSA-N 0.000 description 4
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 4
- 208000006011 Stroke Diseases 0.000 description 4
- YBXMGKCLOPDEKA-NUMRIWBASA-N Thr-Asp-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O YBXMGKCLOPDEKA-NUMRIWBASA-N 0.000 description 4
- YXONONCLMLHWJX-SZMVWBNQSA-N Trp-Glu-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O)=CNC2=C1 YXONONCLMLHWJX-SZMVWBNQSA-N 0.000 description 4
- UJRIVCPPPMYCNA-HOCLYGCPSA-N Trp-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N UJRIVCPPPMYCNA-HOCLYGCPSA-N 0.000 description 4
- HKIUVWMZYFBIHG-KKUMJFAQSA-N Tyr-Arg-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O HKIUVWMZYFBIHG-KKUMJFAQSA-N 0.000 description 4
- DMWNPLOERDAHSY-MEYUZBJRSA-N Tyr-Leu-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DMWNPLOERDAHSY-MEYUZBJRSA-N 0.000 description 4
- OKDNSNWJEXAMSU-IRXDYDNUSA-N Tyr-Phe-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)NCC(O)=O)C1=CC=C(O)C=C1 OKDNSNWJEXAMSU-IRXDYDNUSA-N 0.000 description 4
- MGVYZTPLGXPVQB-CYDGBPFRSA-N Val-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C(C)C)N MGVYZTPLGXPVQB-CYDGBPFRSA-N 0.000 description 4
- 239000004480 active ingredient Substances 0.000 description 4
- 230000002411 adverse Effects 0.000 description 4
- 239000007864 aqueous solution Substances 0.000 description 4
- 108010060035 arginylproline Proteins 0.000 description 4
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 4
- OSASVXMJTNOKOY-UHFFFAOYSA-N chlorobutanol Chemical compound CC(C)(O)C(Cl)(Cl)Cl OSASVXMJTNOKOY-UHFFFAOYSA-N 0.000 description 4
- 238000003776 cleavage reaction Methods 0.000 description 4
- 150000001875 compounds Chemical class 0.000 description 4
- 108010069495 cysteinyltyrosine Proteins 0.000 description 4
- 238000012246 gene addition Methods 0.000 description 4
- 238000012226 gene silencing method Methods 0.000 description 4
- 108010078144 glutaminyl-glycine Proteins 0.000 description 4
- 108010049041 glutamylalanine Proteins 0.000 description 4
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 4
- 108010077435 glycyl-phenylalanyl-glycine Proteins 0.000 description 4
- 238000010562 histological examination Methods 0.000 description 4
- 239000004615 ingredient Substances 0.000 description 4
- 229910052500 inorganic mineral Inorganic materials 0.000 description 4
- 108010047926 leucyl-lysyl-tyrosine Proteins 0.000 description 4
- 230000000670 limiting effect Effects 0.000 description 4
- 239000007788 liquid Substances 0.000 description 4
- 239000003550 marker Substances 0.000 description 4
- 235000010755 mineral Nutrition 0.000 description 4
- 239000011707 mineral Substances 0.000 description 4
- 238000010369 molecular cloning Methods 0.000 description 4
- 210000001616 monocyte Anatomy 0.000 description 4
- 238000001422 normality test Methods 0.000 description 4
- 238000004806 packaging method and process Methods 0.000 description 4
- 108010012581 phenylalanylglutamate Proteins 0.000 description 4
- 108010029020 prolylglycine Proteins 0.000 description 4
- 108010053725 prolylvaline Proteins 0.000 description 4
- 238000003753 real-time PCR Methods 0.000 description 4
- 230000007017 scission Effects 0.000 description 4
- 150000003384 small molecules Chemical class 0.000 description 4
- 210000000130 stem cell Anatomy 0.000 description 4
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 4
- 238000007920 subcutaneous administration Methods 0.000 description 4
- 239000003981 vehicle Substances 0.000 description 4
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 4
- 238000001262 western blot Methods 0.000 description 4
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 3
- CBCCCLMNOBLBSC-XVYDVKMFSA-N Ala-His-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O CBCCCLMNOBLBSC-XVYDVKMFSA-N 0.000 description 3
- BTRULDJUUVGRNE-DCAQKATOSA-N Ala-Pro-Lys Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O BTRULDJUUVGRNE-DCAQKATOSA-N 0.000 description 3
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 3
- LSMDIAAALJJLRO-XQXXSGGOSA-N Ala-Thr-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O LSMDIAAALJJLRO-XQXXSGGOSA-N 0.000 description 3
- QOIGKCBMXUCDQU-KDXUFGMBSA-N Ala-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C)N)O QOIGKCBMXUCDQU-KDXUFGMBSA-N 0.000 description 3
- VHAQSYHSDKERBS-XPUUQOCRSA-N Ala-Val-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O VHAQSYHSDKERBS-XPUUQOCRSA-N 0.000 description 3
- WVNFNPGXYADPPO-BQBZGAKWSA-N Arg-Gly-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O WVNFNPGXYADPPO-BQBZGAKWSA-N 0.000 description 3
- FVBZXNSRIDVYJS-AVGNSLFASA-N Arg-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N FVBZXNSRIDVYJS-AVGNSLFASA-N 0.000 description 3
- UZSQXCMNUPKLCC-FJXKBIBVSA-N Arg-Thr-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UZSQXCMNUPKLCC-FJXKBIBVSA-N 0.000 description 3
- CGWVCWFQGXOUSJ-ULQDDVLXSA-N Arg-Tyr-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O CGWVCWFQGXOUSJ-ULQDDVLXSA-N 0.000 description 3
- NVGWESORMHFISY-SRVKXCTJSA-N Asn-Asn-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O NVGWESORMHFISY-SRVKXCTJSA-N 0.000 description 3
- PIWWUBYJNONVTJ-ZLUOBGJFSA-N Asn-Asp-Asn Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)C(=O)N PIWWUBYJNONVTJ-ZLUOBGJFSA-N 0.000 description 3
- XSGBIBGAMKTHMY-WHFBIAKZSA-N Asn-Asp-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O XSGBIBGAMKTHMY-WHFBIAKZSA-N 0.000 description 3
- FTSAJSADJCMDHH-CIUDSAMLSA-N Asn-Lys-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N FTSAJSADJCMDHH-CIUDSAMLSA-N 0.000 description 3
- BKFXFUPYETWGGA-XVSYOHENSA-N Asn-Phe-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BKFXFUPYETWGGA-XVSYOHENSA-N 0.000 description 3
- VCJCPARXDBEGNE-GUBZILKMSA-N Asn-Pro-Pro Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 VCJCPARXDBEGNE-GUBZILKMSA-N 0.000 description 3
- VHQSGALUSWIYOD-QXEWZRGKSA-N Asn-Pro-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O VHQSGALUSWIYOD-QXEWZRGKSA-N 0.000 description 3
- ZLGKHJHFYSRUBH-FXQIFTODSA-N Asp-Arg-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLGKHJHFYSRUBH-FXQIFTODSA-N 0.000 description 3
- BRRPVTUFESPTCP-ACZMJKKPSA-N Asp-Ser-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O BRRPVTUFESPTCP-ACZMJKKPSA-N 0.000 description 3
- XLLSMEFANRROJE-GUBZILKMSA-N Cys-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CS)N XLLSMEFANRROJE-GUBZILKMSA-N 0.000 description 3
- HBHMVBGGHDMPBF-GARJFASQSA-N Cys-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CS)N HBHMVBGGHDMPBF-GARJFASQSA-N 0.000 description 3
- 108091029865 Exogenous DNA Proteins 0.000 description 3
- 206010017076 Fracture Diseases 0.000 description 3
- 101000834253 Gallus gallus Actin, cytoplasmic 1 Proteins 0.000 description 3
- 108010010803 Gelatin Proteins 0.000 description 3
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 3
- LJEPDHWNQXPXMM-NHCYSSNCSA-N Gln-Arg-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O LJEPDHWNQXPXMM-NHCYSSNCSA-N 0.000 description 3
- ULXXDWZMMSQBDC-ACZMJKKPSA-N Gln-Asp-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N ULXXDWZMMSQBDC-ACZMJKKPSA-N 0.000 description 3
- MADFVRSKEIEZHZ-DCAQKATOSA-N Gln-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N MADFVRSKEIEZHZ-DCAQKATOSA-N 0.000 description 3
- NSORZJXKUQFEKL-JGVFFNPUSA-N Gln-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCC(=O)N)N)C(=O)O NSORZJXKUQFEKL-JGVFFNPUSA-N 0.000 description 3
- ZBKUIQNCRIYVGH-SDDRHHMPSA-N Gln-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N ZBKUIQNCRIYVGH-SDDRHHMPSA-N 0.000 description 3
- FNAJNWPDTIXYJN-CIUDSAMLSA-N Gln-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O FNAJNWPDTIXYJN-CIUDSAMLSA-N 0.000 description 3
- MFORDNZDKAVNSR-SRVKXCTJSA-N Gln-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O MFORDNZDKAVNSR-SRVKXCTJSA-N 0.000 description 3
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 3
- UBRQJXFDVZNYJP-AVGNSLFASA-N Gln-Tyr-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O UBRQJXFDVZNYJP-AVGNSLFASA-N 0.000 description 3
- AUTNXSQEVVHSJK-YVNDNENWSA-N Glu-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O AUTNXSQEVVHSJK-YVNDNENWSA-N 0.000 description 3
- VGUYMZGLJUJRBV-YVNDNENWSA-N Glu-Ile-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O VGUYMZGLJUJRBV-YVNDNENWSA-N 0.000 description 3
- PMSDOVISAARGAV-FHWLQOOXSA-N Glu-Tyr-Phe Chemical compound C([C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 PMSDOVISAARGAV-FHWLQOOXSA-N 0.000 description 3
- JBRBACJPBZNFMF-YUMQZZPRSA-N Gly-Ala-Lys Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN JBRBACJPBZNFMF-YUMQZZPRSA-N 0.000 description 3
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 3
- OGCIHJPYKVSMTE-YUMQZZPRSA-N Gly-Arg-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O OGCIHJPYKVSMTE-YUMQZZPRSA-N 0.000 description 3
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 3
- CIMULJZTTOBOPN-WHFBIAKZSA-N Gly-Asn-Asn Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CIMULJZTTOBOPN-WHFBIAKZSA-N 0.000 description 3
- GGEJHJIXRBTJPD-BYPYZUCNSA-N Gly-Asn-Gly Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GGEJHJIXRBTJPD-BYPYZUCNSA-N 0.000 description 3
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 3
- ZLCLYFGMKFCDCN-XPUUQOCRSA-N Gly-Ser-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CO)NC(=O)CN)C(O)=O ZLCLYFGMKFCDCN-XPUUQOCRSA-N 0.000 description 3
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Natural products NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 3
- 241000238631 Hexapoda Species 0.000 description 3
- HVCRQRQPIIRNLY-IUCAKERBSA-N His-Gln-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)NCC(=O)O)N HVCRQRQPIIRNLY-IUCAKERBSA-N 0.000 description 3
- VUUFXXGKMPLKNH-BZSNNMDCSA-N His-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CC3=CN=CN3)N VUUFXXGKMPLKNH-BZSNNMDCSA-N 0.000 description 3
- 101001035951 Homo sapiens Hyaluronan-binding protein 2 Proteins 0.000 description 3
- 101001135770 Homo sapiens Parathyroid hormone Proteins 0.000 description 3
- 101001135738 Homo sapiens Parathyroid hormone-related protein Proteins 0.000 description 3
- 101001135995 Homo sapiens Probable peptidyl-tRNA hydrolase Proteins 0.000 description 3
- 102100039238 Hyaluronan-binding protein 2 Human genes 0.000 description 3
- LQSBBHNVAVNZSX-GHCJXIJMSA-N Ile-Ala-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N LQSBBHNVAVNZSX-GHCJXIJMSA-N 0.000 description 3
- QYZYJFXHXYUZMZ-UGYAYLCHSA-N Ile-Asn-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N QYZYJFXHXYUZMZ-UGYAYLCHSA-N 0.000 description 3
- DFFTXLCCDFYRKD-MBLNEYKQSA-N Ile-Gly-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N DFFTXLCCDFYRKD-MBLNEYKQSA-N 0.000 description 3
- JTBFQNHKNRZJDS-SYWGBEHUSA-N Ile-Trp-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](C)C(=O)O)N JTBFQNHKNRZJDS-SYWGBEHUSA-N 0.000 description 3
- 108010065920 Insulin Lispro Proteins 0.000 description 3
- 108010028750 Integrin-Binding Sialoprotein Proteins 0.000 description 3
- 102000016921 Integrin-Binding Sialoprotein Human genes 0.000 description 3
- DBVWMYGBVFCRBE-CIUDSAMLSA-N Leu-Asn-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O DBVWMYGBVFCRBE-CIUDSAMLSA-N 0.000 description 3
- ZURHXHNAEJJRNU-CIUDSAMLSA-N Leu-Asp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZURHXHNAEJJRNU-CIUDSAMLSA-N 0.000 description 3
- FLNPJLDPGMLWAU-UWVGGRQHSA-N Leu-Met-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC(C)C FLNPJLDPGMLWAU-UWVGGRQHSA-N 0.000 description 3
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 3
- QUCDKEKDPYISNX-HJGDQZAQSA-N Lys-Asn-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QUCDKEKDPYISNX-HJGDQZAQSA-N 0.000 description 3
- ZXEUFAVXODIPHC-GUBZILKMSA-N Lys-Glu-Asn Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZXEUFAVXODIPHC-GUBZILKMSA-N 0.000 description 3
- VEGLGAOVLFODGC-GUBZILKMSA-N Lys-Glu-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VEGLGAOVLFODGC-GUBZILKMSA-N 0.000 description 3
- IZJGPPIGYTVXLB-FQUUOJAGSA-N Lys-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IZJGPPIGYTVXLB-FQUUOJAGSA-N 0.000 description 3
- ALEVUGKHINJNIF-QEJZJMRPSA-N Lys-Phe-Ala Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 ALEVUGKHINJNIF-QEJZJMRPSA-N 0.000 description 3
- GIKFNMZSGYAPEJ-HJGDQZAQSA-N Lys-Thr-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O GIKFNMZSGYAPEJ-HJGDQZAQSA-N 0.000 description 3
- JHNOXVASMSXSNB-WEDXCCLWSA-N Lys-Thr-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O JHNOXVASMSXSNB-WEDXCCLWSA-N 0.000 description 3
- WXHHTBVYQOSYSL-FXQIFTODSA-N Met-Ala-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O WXHHTBVYQOSYSL-FXQIFTODSA-N 0.000 description 3
- HZLSUXCMSIBCRV-RVMXOQNASA-N Met-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCSC)N HZLSUXCMSIBCRV-RVMXOQNASA-N 0.000 description 3
- GGXZOTSDJJTDGB-GUBZILKMSA-N Met-Ser-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O GGXZOTSDJJTDGB-GUBZILKMSA-N 0.000 description 3
- OTKQHDPECKUDSB-SZMVWBNQSA-N Met-Val-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCSC)C(O)=O)=CNC2=C1 OTKQHDPECKUDSB-SZMVWBNQSA-N 0.000 description 3
- 101000723939 Mus musculus Transcription factor HIVEP3 Proteins 0.000 description 3
- 102000004067 Osteocalcin Human genes 0.000 description 3
- 108090000573 Osteocalcin Proteins 0.000 description 3
- HXSUFWQYLPKEHF-IHRRRGAJSA-N Phe-Asn-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HXSUFWQYLPKEHF-IHRRRGAJSA-N 0.000 description 3
- KIEPQOIQHFKQLK-PCBIJLKTSA-N Phe-Asn-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KIEPQOIQHFKQLK-PCBIJLKTSA-N 0.000 description 3
- MYQCCQSMKNCNKY-KKUMJFAQSA-N Phe-His-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CO)C(=O)O)N MYQCCQSMKNCNKY-KKUMJFAQSA-N 0.000 description 3
- DOXQMJCSSYZSNM-BZSNNMDCSA-N Phe-Lys-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O DOXQMJCSSYZSNM-BZSNNMDCSA-N 0.000 description 3
- FKFCKDROTNIVSO-JYJNAYRXSA-N Phe-Pro-Met Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(O)=O FKFCKDROTNIVSO-JYJNAYRXSA-N 0.000 description 3
- BPIMVBKDLSBKIJ-FCLVOEFKSA-N Phe-Thr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BPIMVBKDLSBKIJ-FCLVOEFKSA-N 0.000 description 3
- KIZQGKLMXKGDIV-BQBZGAKWSA-N Pro-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 KIZQGKLMXKGDIV-BQBZGAKWSA-N 0.000 description 3
- ICTZKEXYDDZZFP-SRVKXCTJSA-N Pro-Arg-Pro Chemical compound N([C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(O)=O)C(=O)[C@@H]1CCCN1 ICTZKEXYDDZZFP-SRVKXCTJSA-N 0.000 description 3
- ZVEQWRWMRFIVSD-HRCADAONSA-N Pro-Phe-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N3CCC[C@@H]3C(=O)O ZVEQWRWMRFIVSD-HRCADAONSA-N 0.000 description 3
- FYKUEXMZYFIZKA-DCAQKATOSA-N Pro-Pro-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O FYKUEXMZYFIZKA-DCAQKATOSA-N 0.000 description 3
- SBVPYBFMIGDIDX-SRVKXCTJSA-N Pro-Pro-Pro Chemical compound OC(=O)[C@@H]1CCCN1C(=O)[C@H]1N(C(=O)[C@H]2NCCC2)CCC1 SBVPYBFMIGDIDX-SRVKXCTJSA-N 0.000 description 3
- SNGZLPOXVRTNMB-LPEHRKFASA-N Pro-Ser-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N2CCC[C@@H]2C(=O)O SNGZLPOXVRTNMB-LPEHRKFASA-N 0.000 description 3
- GZNYIXWOIUFLGO-ZJDVBMNYSA-N Pro-Thr-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZNYIXWOIUFLGO-ZJDVBMNYSA-N 0.000 description 3
- ZMLRZBWCXPQADC-TUAOUCFPSA-N Pro-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 ZMLRZBWCXPQADC-TUAOUCFPSA-N 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- MMGJPDWSIOAGTH-ACZMJKKPSA-N Ser-Ala-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MMGJPDWSIOAGTH-ACZMJKKPSA-N 0.000 description 3
- CRZRTKAVUUGKEQ-ACZMJKKPSA-N Ser-Gln-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O CRZRTKAVUUGKEQ-ACZMJKKPSA-N 0.000 description 3
- IOVHBRCQOGWAQH-ZKWXMUAHSA-N Ser-Gly-Ile Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOVHBRCQOGWAQH-ZKWXMUAHSA-N 0.000 description 3
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 3
- HBTCFCHYALPXME-HTFCKZLJSA-N Ser-Ile-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HBTCFCHYALPXME-HTFCKZLJSA-N 0.000 description 3
- NNFMANHDYSVNIO-DCAQKATOSA-N Ser-Lys-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NNFMANHDYSVNIO-DCAQKATOSA-N 0.000 description 3
- ILZAUMFXKSIUEF-SRVKXCTJSA-N Ser-Ser-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ILZAUMFXKSIUEF-SRVKXCTJSA-N 0.000 description 3
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 3
- PURRNJBBXDDWLX-ZDLURKLDSA-N Ser-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CO)N)O PURRNJBBXDDWLX-ZDLURKLDSA-N 0.000 description 3
- OQSQCUWQOIHECT-YJRXYDGGSA-N Ser-Tyr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OQSQCUWQOIHECT-YJRXYDGGSA-N 0.000 description 3
- 108020005038 Terminator Codon Proteins 0.000 description 3
- GFDUZZACIWNMPE-KZVJFYERSA-N Thr-Ala-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O GFDUZZACIWNMPE-KZVJFYERSA-N 0.000 description 3
- GZYNMZQXFRWDFH-YTWAJWBKSA-N Thr-Arg-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O GZYNMZQXFRWDFH-YTWAJWBKSA-N 0.000 description 3
- JEDIEMIJYSRUBB-FOHZUACHSA-N Thr-Asp-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O JEDIEMIJYSRUBB-FOHZUACHSA-N 0.000 description 3
- VYEHBMMAJFVTOI-JHEQGTHGSA-N Thr-Gly-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O VYEHBMMAJFVTOI-JHEQGTHGSA-N 0.000 description 3
- YGCDFAJJCRVQKU-RCWTZXSCSA-N Thr-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O YGCDFAJJCRVQKU-RCWTZXSCSA-N 0.000 description 3
- NDZYTIMDOZMECO-SHGPDSBTSA-N Thr-Thr-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O NDZYTIMDOZMECO-SHGPDSBTSA-N 0.000 description 3
- NHQVWACSJZJCGJ-FLBSBUHZSA-N Thr-Thr-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O NHQVWACSJZJCGJ-FLBSBUHZSA-N 0.000 description 3
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 3
- QNTBGBCOEYNAPV-CWRNSKLLSA-N Trp-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)O QNTBGBCOEYNAPV-CWRNSKLLSA-N 0.000 description 3
- GTNCSPKYWCJZAC-XIRDDKMYSA-N Trp-Asp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N GTNCSPKYWCJZAC-XIRDDKMYSA-N 0.000 description 3
- NOFFAYIYPAUNRM-HKUYNNGSSA-N Trp-Gly-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC2=CNC3=CC=CC=C32)N NOFFAYIYPAUNRM-HKUYNNGSSA-N 0.000 description 3
- SEXRBCGSZRCIPE-LYSGOOTNSA-N Trp-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O SEXRBCGSZRCIPE-LYSGOOTNSA-N 0.000 description 3
- AYHSJESDFKREAR-KKUMJFAQSA-N Tyr-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AYHSJESDFKREAR-KKUMJFAQSA-N 0.000 description 3
- YLRLHDFMMWDYTK-KKUMJFAQSA-N Tyr-Cys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 YLRLHDFMMWDYTK-KKUMJFAQSA-N 0.000 description 3
- TWAVEIJGFCBWCG-JYJNAYRXSA-N Tyr-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N TWAVEIJGFCBWCG-JYJNAYRXSA-N 0.000 description 3
- QSFJHIRIHOJRKS-ULQDDVLXSA-N Tyr-Leu-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QSFJHIRIHOJRKS-ULQDDVLXSA-N 0.000 description 3
- LMKKMCGTDANZTR-BZSNNMDCSA-N Tyr-Phe-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 LMKKMCGTDANZTR-BZSNNMDCSA-N 0.000 description 3
- WURLIFOWSMBUAR-SLFFLAALSA-N Tyr-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)C(=O)O WURLIFOWSMBUAR-SLFFLAALSA-N 0.000 description 3
- WQOHKVRQDLNDIL-YJRXYDGGSA-N Tyr-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O WQOHKVRQDLNDIL-YJRXYDGGSA-N 0.000 description 3
- HZWPGKAKGYJWCI-ULQDDVLXSA-N Tyr-Val-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)Cc1ccc(O)cc1)C(C)C)C(O)=O HZWPGKAKGYJWCI-ULQDDVLXSA-N 0.000 description 3
- QPZMOUMNTGTEFR-ZKWXMUAHSA-N Val-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N QPZMOUMNTGTEFR-ZKWXMUAHSA-N 0.000 description 3
- HHSILIQTHXABKM-YDHLFZDLSA-N Val-Asp-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](Cc1ccccc1)C(O)=O HHSILIQTHXABKM-YDHLFZDLSA-N 0.000 description 3
- JTWIMNMUYLQNPI-WPRPVWTQSA-N Val-Gly-Arg Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N JTWIMNMUYLQNPI-WPRPVWTQSA-N 0.000 description 3
- KISFXYYRKKNLOP-IHRRRGAJSA-N Val-Phe-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N KISFXYYRKKNLOP-IHRRRGAJSA-N 0.000 description 3
- GQMNEJMFMCJJTD-NHCYSSNCSA-N Val-Pro-Gln Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O GQMNEJMFMCJJTD-NHCYSSNCSA-N 0.000 description 3
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 3
- JXWGBRRVTRAZQA-ULQDDVLXSA-N Val-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N JXWGBRRVTRAZQA-ULQDDVLXSA-N 0.000 description 3
- 102000013814 Wnt Human genes 0.000 description 3
- 108050003627 Wnt Proteins 0.000 description 3
- 108010047495 alanylglycine Proteins 0.000 description 3
- PWIGYBONXWGOQE-UHFFFAOYSA-N alizarin complexone Chemical compound O=C1C2=CC=CC=C2C(=O)C2=C1C=C(CN(CC(O)=O)CC(=O)O)C(O)=C2O PWIGYBONXWGOQE-UHFFFAOYSA-N 0.000 description 3
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 3
- 239000003263 anabolic agent Substances 0.000 description 3
- 230000001195 anabolic effect Effects 0.000 description 3
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 3
- 230000003915 cell function Effects 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 3
- 230000001419 dependent effect Effects 0.000 description 3
- 230000008021 deposition Effects 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 238000010586 diagram Methods 0.000 description 3
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 3
- 239000002612 dispersion medium Substances 0.000 description 3
- 229940079593 drug Drugs 0.000 description 3
- 239000003937 drug carrier Substances 0.000 description 3
- 108020001507 fusion proteins Proteins 0.000 description 3
- 102000037865 fusion proteins Human genes 0.000 description 3
- 239000008273 gelatin Substances 0.000 description 3
- 229920000159 gelatin Polymers 0.000 description 3
- 235000019322 gelatine Nutrition 0.000 description 3
- 235000011852 gelatine desserts Nutrition 0.000 description 3
- 230000009368 gene silencing by RNA Effects 0.000 description 3
- 230000002068 genetic effect Effects 0.000 description 3
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 3
- 108010015792 glycyllysine Proteins 0.000 description 3
- 230000036541 health Effects 0.000 description 3
- 102000058004 human PTH Human genes 0.000 description 3
- 238000003364 immunohistochemistry Methods 0.000 description 3
- 239000000411 inducer Substances 0.000 description 3
- 230000006698 induction Effects 0.000 description 3
- 208000015181 infectious disease Diseases 0.000 description 3
- 230000002452 interceptive effect Effects 0.000 description 3
- 239000007927 intramuscular injection Substances 0.000 description 3
- 238000010253 intravenous injection Methods 0.000 description 3
- 150000002632 lipids Chemical class 0.000 description 3
- 238000011068 loading method Methods 0.000 description 3
- 239000006166 lysate Substances 0.000 description 3
- 239000012139 lysis buffer Substances 0.000 description 3
- 108010003700 lysyl aspartic acid Proteins 0.000 description 3
- 244000005700 microbiome Species 0.000 description 3
- 238000012544 monitoring process Methods 0.000 description 3
- 239000002088 nanocapsule Substances 0.000 description 3
- 101150070206 oc gene Proteins 0.000 description 3
- 230000010412 perfusion Effects 0.000 description 3
- 230000008488 polyadenylation Effects 0.000 description 3
- 229920001223 polyethylene glycol Polymers 0.000 description 3
- 239000000843 powder Substances 0.000 description 3
- 239000003755 preservative agent Substances 0.000 description 3
- 108010014614 prolyl-glycyl-proline Proteins 0.000 description 3
- 108010004914 prolylarginine Proteins 0.000 description 3
- 102000005962 receptors Human genes 0.000 description 3
- 108020003175 receptors Proteins 0.000 description 3
- 239000013644 scAAV2 vector Substances 0.000 description 3
- 230000028327 secretion Effects 0.000 description 3
- 230000011664 signaling Effects 0.000 description 3
- 210000003625 skull Anatomy 0.000 description 3
- 239000002904 solvent Substances 0.000 description 3
- 238000003860 storage Methods 0.000 description 3
- 238000001890 transfection Methods 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 238000013519 translation Methods 0.000 description 3
- 238000011269 treatment regimen Methods 0.000 description 3
- 238000010200 validation analysis Methods 0.000 description 3
- DIGQNXIGRZPYDK-WKSCXVIASA-N (2R)-6-amino-2-[[2-[[(2S)-2-[[2-[[(2R)-2-[[(2S)-2-[[(2R,3S)-2-[[2-[[(2S)-2-[[2-[[(2S)-2-[[(2S)-2-[[(2R)-2-[[(2S,3S)-2-[[(2R)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[2-[[(2S)-2-[[(2R)-2-[[2-[[2-[[2-[(2-amino-1-hydroxyethylidene)amino]-3-carboxy-1-hydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1,5-dihydroxy-5-iminopentylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]hexanoic acid Chemical compound C[C@@H]([C@@H](C(=N[C@@H](CS)C(=N[C@@H](C)C(=N[C@@H](CO)C(=NCC(=N[C@@H](CCC(=N)O)C(=NC(CS)C(=N[C@H]([C@H](C)O)C(=N[C@H](CS)C(=N[C@H](CO)C(=NCC(=N[C@H](CS)C(=NCC(=N[C@H](CCCCN)C(=O)O)O)O)O)O)O)O)O)O)O)O)O)O)O)N=C([C@H](CS)N=C([C@H](CO)N=C([C@H](CO)N=C([C@H](C)N=C(CN=C([C@H](CO)N=C([C@H](CS)N=C(CN=C(C(CS)N=C(C(CC(=O)O)N=C(CN)O)O)O)O)O)O)O)O)O)O)O)O DIGQNXIGRZPYDK-WKSCXVIASA-N 0.000 description 2
- BRPMXFSTKXXNHF-IUCAKERBSA-N (2s)-1-[2-[[(2s)-pyrrolidine-2-carbonyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound OC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H]1NCCC1 BRPMXFSTKXXNHF-IUCAKERBSA-N 0.000 description 2
- SGKRLCUYIXIAHR-AKNGSSGZSA-N (4s,4ar,5s,5ar,6r,12ar)-4-(dimethylamino)-1,5,10,11,12a-pentahydroxy-6-methyl-3,12-dioxo-4a,5,5a,6-tetrahydro-4h-tetracene-2-carboxamide Chemical compound C1=CC=C2[C@H](C)[C@@H]([C@H](O)[C@@H]3[C@](C(O)=C(C(N)=O)C(=O)[C@H]3N(C)C)(O)C3=O)C3=C(O)C2=C1O SGKRLCUYIXIAHR-AKNGSSGZSA-N 0.000 description 2
- NHBKXEKEPDILRR-UHFFFAOYSA-N 2,3-bis(butanoylsulfanyl)propyl butanoate Chemical compound CCCC(=O)OCC(SC(=O)CCC)CSC(=O)CCC NHBKXEKEPDILRR-UHFFFAOYSA-N 0.000 description 2
- HXUVTXPOZRFMOY-NSHDSACASA-N 2-[[(2s)-2-[[2-[(2-aminoacetyl)amino]acetyl]amino]-3-phenylpropanoyl]amino]acetic acid Chemical compound NCC(=O)NCC(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 HXUVTXPOZRFMOY-NSHDSACASA-N 0.000 description 2
- LHYQAEFVHIZFLR-UHFFFAOYSA-L 4-(4-diazonio-3-methoxyphenyl)-2-methoxybenzenediazonium;dichloride Chemical compound [Cl-].[Cl-].C1=C([N+]#N)C(OC)=CC(C=2C=C(OC)C([N+]#N)=CC=2)=C1 LHYQAEFVHIZFLR-UHFFFAOYSA-L 0.000 description 2
- HFDKKNHCYWNNNQ-YOGANYHLSA-N 75976-10-2 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(N)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@@H](NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](C)N)C(C)C)[C@@H](C)O)C1=CC=C(O)C=C1 HFDKKNHCYWNNNQ-YOGANYHLSA-N 0.000 description 2
- 102100022900 Actin, cytoplasmic 1 Human genes 0.000 description 2
- 108010085238 Actins Proteins 0.000 description 2
- FJVAQLJNTSUQPY-CIUDSAMLSA-N Ala-Ala-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN FJVAQLJNTSUQPY-CIUDSAMLSA-N 0.000 description 2
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 2
- LWUWMHIOBPTZBA-DCAQKATOSA-N Ala-Arg-Lys Chemical compound NC(=N)NCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O LWUWMHIOBPTZBA-DCAQKATOSA-N 0.000 description 2
- ZEXDYVGDZJBRMO-ACZMJKKPSA-N Ala-Asn-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N ZEXDYVGDZJBRMO-ACZMJKKPSA-N 0.000 description 2
- MPLOSMWGDNJSEV-WHFBIAKZSA-N Ala-Gly-Asp Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MPLOSMWGDNJSEV-WHFBIAKZSA-N 0.000 description 2
- XHNLCGXYBXNRIS-BJDJZHNGSA-N Ala-Lys-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O XHNLCGXYBXNRIS-BJDJZHNGSA-N 0.000 description 2
- KLALXKYLOMZDQT-ZLUOBGJFSA-N Ala-Ser-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(N)=O KLALXKYLOMZDQT-ZLUOBGJFSA-N 0.000 description 2
- KUFVXLQLDHJVOG-SHGPDSBTSA-N Ala-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C)N)O KUFVXLQLDHJVOG-SHGPDSBTSA-N 0.000 description 2
- XSLGWYYNOSUMRM-ZKWXMUAHSA-N Ala-Val-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O XSLGWYYNOSUMRM-ZKWXMUAHSA-N 0.000 description 2
- UXJCMQFPDWCHKX-DCAQKATOSA-N Arg-Arg-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O UXJCMQFPDWCHKX-DCAQKATOSA-N 0.000 description 2
- VXXHDZKEQNGXNU-QXEWZRGKSA-N Arg-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N VXXHDZKEQNGXNU-QXEWZRGKSA-N 0.000 description 2
- OQCWXQJLCDPRHV-UWVGGRQHSA-N Arg-Gly-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O OQCWXQJLCDPRHV-UWVGGRQHSA-N 0.000 description 2
- FSPQNLYOFCXUCE-BPUTZDHNSA-N Arg-Trp-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N FSPQNLYOFCXUCE-BPUTZDHNSA-N 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 2
- JRVABKHPWDRUJF-UBHSHLNASA-N Asn-Asn-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N JRVABKHPWDRUJF-UBHSHLNASA-N 0.000 description 2
- RAKKBBHMTJSXOY-XVYDVKMFSA-N Asn-His-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(O)=O RAKKBBHMTJSXOY-XVYDVKMFSA-N 0.000 description 2
- HFPXZWPUVFVNLL-GUBZILKMSA-N Asn-Leu-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HFPXZWPUVFVNLL-GUBZILKMSA-N 0.000 description 2
- RAUPFUCUDBQYHE-AVGNSLFASA-N Asn-Phe-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O RAUPFUCUDBQYHE-AVGNSLFASA-N 0.000 description 2
- SUIJFTJDTJKSRK-IHRRRGAJSA-N Asn-Pro-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 SUIJFTJDTJKSRK-IHRRRGAJSA-N 0.000 description 2
- WUQXMTITJLFXAU-JIOCBJNQSA-N Asn-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N)O WUQXMTITJLFXAU-JIOCBJNQSA-N 0.000 description 2
- KRXIWXCXOARFNT-ZLUOBGJFSA-N Asp-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O KRXIWXCXOARFNT-ZLUOBGJFSA-N 0.000 description 2
- VBVKSAFJPVXMFJ-CIUDSAMLSA-N Asp-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N VBVKSAFJPVXMFJ-CIUDSAMLSA-N 0.000 description 2
- CELPEWWLSXMVPH-CIUDSAMLSA-N Asp-Asp-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O CELPEWWLSXMVPH-CIUDSAMLSA-N 0.000 description 2
- GHODABZPVZMWCE-FXQIFTODSA-N Asp-Glu-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O GHODABZPVZMWCE-FXQIFTODSA-N 0.000 description 2
- SVABRQFIHCSNCI-FOHZUACHSA-N Asp-Gly-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O SVABRQFIHCSNCI-FOHZUACHSA-N 0.000 description 2
- YWLDTBBUHZJQHW-KKUMJFAQSA-N Asp-Lys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N YWLDTBBUHZJQHW-KKUMJFAQSA-N 0.000 description 2
- KPSHWSWFPUDEGF-FXQIFTODSA-N Asp-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(O)=O KPSHWSWFPUDEGF-FXQIFTODSA-N 0.000 description 2
- GCACQYDBDHRVGE-LKXGYXEUSA-N Asp-Thr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC(O)=O GCACQYDBDHRVGE-LKXGYXEUSA-N 0.000 description 2
- LLRJPYJQNBMOOO-QEJZJMRPSA-N Asp-Trp-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N LLRJPYJQNBMOOO-QEJZJMRPSA-N 0.000 description 2
- QPDUWAUSSWGJSB-NGZCFLSTSA-N Asp-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N QPDUWAUSSWGJSB-NGZCFLSTSA-N 0.000 description 2
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 2
- 101000577180 Aspergillus oryzae (strain ATCC 42149 / RIB 40) Neutral protease 2 Proteins 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 2
- 102000029816 Collagenase Human genes 0.000 description 2
- 108060005980 Collagenase Proteins 0.000 description 2
- 108091035707 Consensus sequence Proteins 0.000 description 2
- 102000015775 Core Binding Factor Alpha 1 Subunit Human genes 0.000 description 2
- 108010024682 Core Binding Factor Alpha 1 Subunit Proteins 0.000 description 2
- XIZWKXATMJODQW-KKUMJFAQSA-N Cys-His-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CS)N XIZWKXATMJODQW-KKUMJFAQSA-N 0.000 description 2
- 102100024230 Dendritic cell-specific transmembrane protein Human genes 0.000 description 2
- 101710190014 Dendritic cell-specific transmembrane protein Proteins 0.000 description 2
- 102100036912 Desmin Human genes 0.000 description 2
- 108010044052 Desmin Proteins 0.000 description 2
- 241000196324 Embryophyta Species 0.000 description 2
- 241000283074 Equus asinus Species 0.000 description 2
- 241000282326 Felis catus Species 0.000 description 2
- 108010046649 GDNP peptide Proteins 0.000 description 2
- 241000287828 Gallus gallus Species 0.000 description 2
- JSYULGSPLTZDHM-NRPADANISA-N Gln-Ala-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O JSYULGSPLTZDHM-NRPADANISA-N 0.000 description 2
- VSXBYIJUAXPAAL-WDSKDSINSA-N Gln-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O VSXBYIJUAXPAAL-WDSKDSINSA-N 0.000 description 2
- HVQCEQTUSWWFOS-WDSKDSINSA-N Gln-Gly-Cys Chemical compound C(CC(=O)N)[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N HVQCEQTUSWWFOS-WDSKDSINSA-N 0.000 description 2
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 2
- PODFFOWWLUPNMN-DCAQKATOSA-N Gln-His-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PODFFOWWLUPNMN-DCAQKATOSA-N 0.000 description 2
- FALJZCPMTGJOHX-SRVKXCTJSA-N Gln-Met-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O FALJZCPMTGJOHX-SRVKXCTJSA-N 0.000 description 2
- UESYBOXFJWJVSB-AVGNSLFASA-N Gln-Phe-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O UESYBOXFJWJVSB-AVGNSLFASA-N 0.000 description 2
- WATXSTJXNBOHKD-LAEOZQHASA-N Glu-Asp-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O WATXSTJXNBOHKD-LAEOZQHASA-N 0.000 description 2
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 2
- GWCRIHNSVMOBEQ-BQBZGAKWSA-N Gly-Arg-Ser Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O GWCRIHNSVMOBEQ-BQBZGAKWSA-N 0.000 description 2
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 2
- FXLVSYVJDPCIHH-STQMWFEESA-N Gly-Phe-Arg Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FXLVSYVJDPCIHH-STQMWFEESA-N 0.000 description 2
- SSFWXSNOKDZNHY-QXEWZRGKSA-N Gly-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN SSFWXSNOKDZNHY-QXEWZRGKSA-N 0.000 description 2
- IALQAMYQJBZNSK-WHFBIAKZSA-N Gly-Ser-Asn Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O IALQAMYQJBZNSK-WHFBIAKZSA-N 0.000 description 2
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 2
- DHCLVCXQIBBOPH-UHFFFAOYSA-N Glycerol 2-phosphate Chemical compound OCC(CO)OP(O)(O)=O DHCLVCXQIBBOPH-UHFFFAOYSA-N 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- WZUVPPKBWHMQCE-UHFFFAOYSA-N Haematoxylin Chemical compound C12=CC(O)=C(O)C=C2CC2(O)C1C1=CC=C(O)C(O)=C1OC2 WZUVPPKBWHMQCE-UHFFFAOYSA-N 0.000 description 2
- 102100034051 Heat shock protein HSP 90-alpha Human genes 0.000 description 2
- 102100021519 Hemoglobin subunit beta Human genes 0.000 description 2
- 108091005904 Hemoglobin subunit beta Proteins 0.000 description 2
- PLCAEMGSYOYIPP-GUBZILKMSA-N His-Ser-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 PLCAEMGSYOYIPP-GUBZILKMSA-N 0.000 description 2
- 101001016865 Homo sapiens Heat shock protein HSP 90-alpha Proteins 0.000 description 2
- 101000869796 Homo sapiens Microprocessor complex subunit DGCR8 Proteins 0.000 description 2
- 101000837639 Homo sapiens Thyroxine-binding globulin Proteins 0.000 description 2
- GAZGFPOZOLEYAJ-YTFOTSKYSA-N Ile-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N GAZGFPOZOLEYAJ-YTFOTSKYSA-N 0.000 description 2
- OVDKXUDMKXAZIV-ZPFDUUQYSA-N Ile-Lys-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OVDKXUDMKXAZIV-ZPFDUUQYSA-N 0.000 description 2
- UAELWXJFLZBKQS-WHOFXGATSA-N Ile-Phe-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](Cc1ccccc1)C(=O)NCC(O)=O UAELWXJFLZBKQS-WHOFXGATSA-N 0.000 description 2
- IITVUURPOYGCTD-NAKRPEOUSA-N Ile-Pro-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IITVUURPOYGCTD-NAKRPEOUSA-N 0.000 description 2
- 206010061218 Inflammation Diseases 0.000 description 2
- 108091092195 Intron Proteins 0.000 description 2
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 2
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 2
- 229930182816 L-glutamine Natural products 0.000 description 2
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 2
- 241000880493 Leptailurus serval Species 0.000 description 2
- 108010092277 Leptin Proteins 0.000 description 2
- 102000016267 Leptin Human genes 0.000 description 2
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 2
- YFBBUHJJUXXZOF-UWVGGRQHSA-N Leu-Gly-Pro Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O YFBBUHJJUXXZOF-UWVGGRQHSA-N 0.000 description 2
- USLNHQZCDQJBOV-ZPFDUUQYSA-N Leu-Ile-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O USLNHQZCDQJBOV-ZPFDUUQYSA-N 0.000 description 2
- QLDHBYRUNQZIJQ-DKIMLUQUSA-N Leu-Ile-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QLDHBYRUNQZIJQ-DKIMLUQUSA-N 0.000 description 2
- REPBGZHJKYWFMJ-KKUMJFAQSA-N Leu-Lys-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N REPBGZHJKYWFMJ-KKUMJFAQSA-N 0.000 description 2
- ONPJGOIVICHWBW-BZSNNMDCSA-N Leu-Lys-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 ONPJGOIVICHWBW-BZSNNMDCSA-N 0.000 description 2
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 2
- KNKHAVVBVXKOGX-JXUBOQSCSA-N Lys-Ala-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KNKHAVVBVXKOGX-JXUBOQSCSA-N 0.000 description 2
- ULUQBUKAPDUKOC-GVXVVHGQSA-N Lys-Glu-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O ULUQBUKAPDUKOC-GVXVVHGQSA-N 0.000 description 2
- GNLJXWBNLAIPEP-MELADBBJSA-N Lys-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCCCN)N)C(=O)O GNLJXWBNLAIPEP-MELADBBJSA-N 0.000 description 2
- KEPWSUPUFAPBRF-DKIMLUQUSA-N Lys-Ile-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O KEPWSUPUFAPBRF-DKIMLUQUSA-N 0.000 description 2
- XIZQPFCRXLUNMK-BZSNNMDCSA-N Lys-Leu-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCCCN)N XIZQPFCRXLUNMK-BZSNNMDCSA-N 0.000 description 2
- IPTUBUUIFRZMJK-ACRUOGEOSA-N Lys-Phe-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)CCCCN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 IPTUBUUIFRZMJK-ACRUOGEOSA-N 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- IUYCGMNKIZDRQI-BQBZGAKWSA-N Met-Gly-Ala Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O IUYCGMNKIZDRQI-BQBZGAKWSA-N 0.000 description 2
- ORRNBLTZBBESPN-HJWJTTGWSA-N Met-Ile-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ORRNBLTZBBESPN-HJWJTTGWSA-N 0.000 description 2
- 102000003792 Metallothionein Human genes 0.000 description 2
- 108090000157 Metallothionein Proteins 0.000 description 2
- 108091033773 MiR-155 Proteins 0.000 description 2
- 102100032459 Microprocessor complex subunit DGCR8 Human genes 0.000 description 2
- 241000699660 Mus musculus Species 0.000 description 2
- 101100025201 Mus musculus Msc gene Proteins 0.000 description 2
- 101000981469 Mus musculus Parkinson disease protein 7 homolog Proteins 0.000 description 2
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 2
- 108010066427 N-valyltryptophan Proteins 0.000 description 2
- 102000018886 Pancreatic Polypeptide Human genes 0.000 description 2
- 241001494479 Pecora Species 0.000 description 2
- 229930182555 Penicillin Natural products 0.000 description 2
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 2
- 241000009328 Perro Species 0.000 description 2
- NAXPHWZXEXNDIW-JTQLQIEISA-N Phe-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 NAXPHWZXEXNDIW-JTQLQIEISA-N 0.000 description 2
- QPVFUAUFEBPIPT-CDMKHQONSA-N Phe-Gly-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O QPVFUAUFEBPIPT-CDMKHQONSA-N 0.000 description 2
- WFHRXJOZEXUKLV-IRXDYDNUSA-N Phe-Gly-Tyr Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 WFHRXJOZEXUKLV-IRXDYDNUSA-N 0.000 description 2
- BEEVXUYVEHXWRQ-YESZJQIVSA-N Phe-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O BEEVXUYVEHXWRQ-YESZJQIVSA-N 0.000 description 2
- JLLJTMHNXQTMCK-UBHSHLNASA-N Phe-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 JLLJTMHNXQTMCK-UBHSHLNASA-N 0.000 description 2
- RAGOJJCBGXARPO-XVSYOHENSA-N Phe-Thr-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RAGOJJCBGXARPO-XVSYOHENSA-N 0.000 description 2
- 102000011755 Phosphoglycerate Kinase Human genes 0.000 description 2
- 102000012288 Phosphopyruvate Hydratase Human genes 0.000 description 2
- 108010022181 Phosphopyruvate Hydratase Proteins 0.000 description 2
- 108010076039 Polyproteins Proteins 0.000 description 2
- DIFXZGPHVCIVSQ-CIUDSAMLSA-N Pro-Gln-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O DIFXZGPHVCIVSQ-CIUDSAMLSA-N 0.000 description 2
- UUHXBJHVTVGSKM-BQBZGAKWSA-N Pro-Gly-Asn Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O UUHXBJHVTVGSKM-BQBZGAKWSA-N 0.000 description 2
- ULWBBFKQBDNGOY-RWMBFGLXSA-N Pro-Lys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@@H]2C(=O)O ULWBBFKQBDNGOY-RWMBFGLXSA-N 0.000 description 2
- ZTHYODDOHIVTJV-UHFFFAOYSA-N Propyl gallate Chemical compound CCCOC(=O)C1=CC(O)=C(O)C(O)=C1 ZTHYODDOHIVTJV-UHFFFAOYSA-N 0.000 description 2
- 102000014128 RANK Ligand Human genes 0.000 description 2
- 108010025832 RANK Ligand Proteins 0.000 description 2
- 102000000574 RNA-Induced Silencing Complex Human genes 0.000 description 2
- 108010016790 RNA-Induced Silencing Complex Proteins 0.000 description 2
- 108091030071 RNAI Proteins 0.000 description 2
- 238000010240 RT-PCR analysis Methods 0.000 description 2
- 241000700159 Rattus Species 0.000 description 2
- MWMKFWJYRRGXOR-ZLUOBGJFSA-N Ser-Ala-Asn Chemical compound N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)O)CC(N)=O)C)CO MWMKFWJYRRGXOR-ZLUOBGJFSA-N 0.000 description 2
- DWUIECHTAMYEFL-XVYDVKMFSA-N Ser-Ala-His Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 DWUIECHTAMYEFL-XVYDVKMFSA-N 0.000 description 2
- JPIDMRXXNMIVKY-VZFHVOOUSA-N Ser-Ala-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPIDMRXXNMIVKY-VZFHVOOUSA-N 0.000 description 2
- WBINSDOPZHQPPM-AVGNSLFASA-N Ser-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N)O WBINSDOPZHQPPM-AVGNSLFASA-N 0.000 description 2
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 2
- NLOAIFSWUUFQFR-CIUDSAMLSA-N Ser-Leu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O NLOAIFSWUUFQFR-CIUDSAMLSA-N 0.000 description 2
- ZKBKUWQVDWWSRI-BZSNNMDCSA-N Ser-Phe-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKBKUWQVDWWSRI-BZSNNMDCSA-N 0.000 description 2
- ADJDNJCSPNFFPI-FXQIFTODSA-N Ser-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO ADJDNJCSPNFFPI-FXQIFTODSA-N 0.000 description 2
- NUEHQDHDLDXCRU-GUBZILKMSA-N Ser-Pro-Arg Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NUEHQDHDLDXCRU-GUBZILKMSA-N 0.000 description 2
- ZSDXEKUKQAKZFE-XAVMHZPKSA-N Ser-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N)O ZSDXEKUKQAKZFE-XAVMHZPKSA-N 0.000 description 2
- PIQRHJQWEPWFJG-UWJYBYFXSA-N Ser-Tyr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O PIQRHJQWEPWFJG-UWJYBYFXSA-N 0.000 description 2
- PQEQXWRVHQAAKS-SRVKXCTJSA-N Ser-Tyr-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CO)N)CC1=CC=C(O)C=C1 PQEQXWRVHQAAKS-SRVKXCTJSA-N 0.000 description 2
- UIIMBOGNXHQVGW-UHFFFAOYSA-M Sodium bicarbonate Chemical compound [Na+].OC([O-])=O UIIMBOGNXHQVGW-UHFFFAOYSA-M 0.000 description 2
- 108091081024 Start codon Proteins 0.000 description 2
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 2
- 229930006000 Sucrose Natural products 0.000 description 2
- RAHZWNYVWXNFOC-UHFFFAOYSA-N Sulphur dioxide Chemical compound O=S=O RAHZWNYVWXNFOC-UHFFFAOYSA-N 0.000 description 2
- 241000282898 Sus scrofa Species 0.000 description 2
- 101000983124 Sus scrofa Pancreatic prohormone precursor Proteins 0.000 description 2
- 239000004098 Tetracycline Substances 0.000 description 2
- 101001099217 Thermotoga maritima (strain ATCC 43589 / DSM 3109 / JCM 10099 / NBRC 100826 / MSB8) Triosephosphate isomerase Proteins 0.000 description 2
- UNURFMVMXLENAZ-KJEVXHAQSA-N Thr-Arg-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O UNURFMVMXLENAZ-KJEVXHAQSA-N 0.000 description 2
- NIEWSKWFURSECR-FOHZUACHSA-N Thr-Gly-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NIEWSKWFURSECR-FOHZUACHSA-N 0.000 description 2
- UJQVSMNQMQHVRY-KZVJFYERSA-N Thr-Met-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O UJQVSMNQMQHVRY-KZVJFYERSA-N 0.000 description 2
- ABWNZPOIUJMNKT-IXOXFDKPSA-N Thr-Phe-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O ABWNZPOIUJMNKT-IXOXFDKPSA-N 0.000 description 2
- RVMNUBQWPVOUKH-HEIBUPTGSA-N Thr-Ser-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMNUBQWPVOUKH-HEIBUPTGSA-N 0.000 description 2
- AAZOYLQUEQRUMZ-GSSVUCPTSA-N Thr-Thr-Asn Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O AAZOYLQUEQRUMZ-GSSVUCPTSA-N 0.000 description 2
- COYHRQWNJDJCNA-NUJDXYNKSA-N Thr-Thr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O COYHRQWNJDJCNA-NUJDXYNKSA-N 0.000 description 2
- 102100028709 Thyroxine-binding globulin Human genes 0.000 description 2
- 102100032317 Transcription factor Sp7 Human genes 0.000 description 2
- 239000013504 Triton X-100 Substances 0.000 description 2
- 229920004890 Triton X-100 Polymers 0.000 description 2
- WVHUFSCKCBQKJW-HKUYNNGSSA-N Trp-Gly-Tyr Chemical compound C([C@H](NC(=O)CNC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(O)=O)C1=CC=C(O)C=C1 WVHUFSCKCBQKJW-HKUYNNGSSA-N 0.000 description 2
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 2
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 2
- ZWZOCUWOXSDYFZ-CQDKDKBSSA-N Tyr-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 ZWZOCUWOXSDYFZ-CQDKDKBSSA-N 0.000 description 2
- NMKJPMCEKQHRPD-IRXDYDNUSA-N Tyr-Gly-Tyr Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 NMKJPMCEKQHRPD-IRXDYDNUSA-N 0.000 description 2
- NKUGCYDFQKFVOJ-JYJNAYRXSA-N Tyr-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NKUGCYDFQKFVOJ-JYJNAYRXSA-N 0.000 description 2
- PRONOHBTMLNXCZ-BZSNNMDCSA-N Tyr-Leu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 PRONOHBTMLNXCZ-BZSNNMDCSA-N 0.000 description 2
- LVFZXRQQQDTBQH-IRIUXVKKSA-N Tyr-Thr-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O LVFZXRQQQDTBQH-IRIUXVKKSA-N 0.000 description 2
- LDKDSFQSEUOCOO-RPTUDFQQSA-N Tyr-Thr-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LDKDSFQSEUOCOO-RPTUDFQQSA-N 0.000 description 2
- ZMDCGGKHRKNWKD-LAEOZQHASA-N Val-Asn-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZMDCGGKHRKNWKD-LAEOZQHASA-N 0.000 description 2
- UZDHNIJRRTUKKC-DLOVCJGASA-N Val-Gln-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N UZDHNIJRRTUKKC-DLOVCJGASA-N 0.000 description 2
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 2
- UZFNHAXYMICTBU-DZKIICNBSA-N Val-Phe-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N UZFNHAXYMICTBU-DZKIICNBSA-N 0.000 description 2
- ZEBRMWPTJNHXAJ-JYJNAYRXSA-N Val-Phe-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)O)N ZEBRMWPTJNHXAJ-JYJNAYRXSA-N 0.000 description 2
- 229930003448 Vitamin K Natural products 0.000 description 2
- DVKFVGVMPLXLKC-PUGXJXRHSA-N [(2s,3r,4s,5s,6r)-2-[(2s,3s,4s,5r)-3,4-dihydroxy-2,5-bis(hydroxymethyl)oxolan-2-yl]-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl] dihydrogen phosphate Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@]1(CO)[C@@]1(OP(O)(O)=O)[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 DVKFVGVMPLXLKC-PUGXJXRHSA-N 0.000 description 2
- 238000010521 absorption reaction Methods 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- 230000001154 acute effect Effects 0.000 description 2
- 230000002776 aggregation Effects 0.000 description 2
- 238000004220 aggregation Methods 0.000 description 2
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 2
- 108010005233 alanylglutamic acid Proteins 0.000 description 2
- 108010087924 alanylproline Proteins 0.000 description 2
- 239000012637 allosteric effector Substances 0.000 description 2
- 102000013529 alpha-Fetoproteins Human genes 0.000 description 2
- 108010026331 alpha-Fetoproteins Proteins 0.000 description 2
- 229940124325 anabolic agent Drugs 0.000 description 2
- 239000003242 anti bacterial agent Substances 0.000 description 2
- 230000000844 anti-bacterial effect Effects 0.000 description 2
- 239000003429 antifungal agent Substances 0.000 description 2
- 229940121375 antifungal agent Drugs 0.000 description 2
- 239000000074 antisense oligonucleotide Substances 0.000 description 2
- 238000012230 antisense oligonucleotides Methods 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 239000012736 aqueous medium Substances 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 108010013835 arginine glutamate Proteins 0.000 description 2
- 235000009582 asparagine Nutrition 0.000 description 2
- 229960001230 asparagine Drugs 0.000 description 2
- 108010047857 aspartylglycine Proteins 0.000 description 2
- 230000001580 bacterial effect Effects 0.000 description 2
- 210000004271 bone marrow stromal cell Anatomy 0.000 description 2
- 239000000872 buffer Substances 0.000 description 2
- 210000004899 c-terminal region Anatomy 0.000 description 2
- AIYUHDOJVYHVIT-UHFFFAOYSA-M caesium chloride Chemical compound [Cl-].[Cs+] AIYUHDOJVYHVIT-UHFFFAOYSA-M 0.000 description 2
- 239000011575 calcium Substances 0.000 description 2
- 229910052791 calcium Inorganic materials 0.000 description 2
- 210000000845 cartilage Anatomy 0.000 description 2
- 229960004926 chlorobutanol Drugs 0.000 description 2
- 238000000576 coating method Methods 0.000 description 2
- 229960002424 collagenase Drugs 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 238000012258 culturing Methods 0.000 description 2
- 210000005045 desmin Anatomy 0.000 description 2
- UREBDLICKHMUKA-CXSFZGCWSA-N dexamethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O UREBDLICKHMUKA-CXSFZGCWSA-N 0.000 description 2
- 239000003085 diluting agent Substances 0.000 description 2
- 238000010494 dissociation reaction Methods 0.000 description 2
- 230000005593 dissociations Effects 0.000 description 2
- 239000012153 distilled water Substances 0.000 description 2
- 239000002552 dosage form Substances 0.000 description 2
- 229960003722 doxycycline Drugs 0.000 description 2
- 238000012377 drug delivery Methods 0.000 description 2
- 210000002889 endothelial cell Anatomy 0.000 description 2
- BEFDCLMNVWHSGT-UHFFFAOYSA-N ethenylcyclopentane Chemical compound C=CC1CCCC1 BEFDCLMNVWHSGT-UHFFFAOYSA-N 0.000 description 2
- CBOQJANXLMLOSS-UHFFFAOYSA-N ethyl vanillin Chemical compound CCOC1=CC(C=O)=CC=C1O CBOQJANXLMLOSS-UHFFFAOYSA-N 0.000 description 2
- 230000005714 functional activity Effects 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 230000006251 gamma-carboxylation Effects 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 2
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 2
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 2
- 108010037850 glycylvaline Proteins 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- 102000048079 human HIVEP3 Human genes 0.000 description 2
- 238000010166 immunofluorescence Methods 0.000 description 2
- 230000001976 improved effect Effects 0.000 description 2
- 230000004054 inflammatory process Effects 0.000 description 2
- 230000000977 initiatory effect Effects 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 238000010255 intramuscular injection Methods 0.000 description 2
- 239000007951 isotonicity adjuster Substances 0.000 description 2
- 210000004962 mammalian cell Anatomy 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 210000002901 mesenchymal stem cell Anatomy 0.000 description 2
- 230000003278 mimic effect Effects 0.000 description 2
- 238000002156 mixing Methods 0.000 description 2
- 238000009126 molecular therapy Methods 0.000 description 2
- 210000005087 mononuclear cell Anatomy 0.000 description 2
- 239000002105 nanoparticle Substances 0.000 description 2
- 210000002569 neuron Anatomy 0.000 description 2
- 238000010606 normalization Methods 0.000 description 2
- 238000009806 oophorectomy Methods 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 230000001582 osteoblastic effect Effects 0.000 description 2
- 230000001575 pathological effect Effects 0.000 description 2
- 229940049954 penicillin Drugs 0.000 description 2
- 239000008194 pharmaceutical composition Substances 0.000 description 2
- YBYRMVIVWMBXKQ-UHFFFAOYSA-N phenylmethanesulfonyl fluoride Chemical compound FS(=O)(=O)CC1=CC=CC=C1 YBYRMVIVWMBXKQ-UHFFFAOYSA-N 0.000 description 2
- 239000008363 phosphate buffer Substances 0.000 description 2
- SHUZOJHMOBOZST-UHFFFAOYSA-N phylloquinone Natural products CC(C)CCCCC(C)CCC(C)CCCC(=CCC1=C(C)C(=O)c2ccccc2C1=O)C SHUZOJHMOBOZST-UHFFFAOYSA-N 0.000 description 2
- 230000035790 physiological processes and functions Effects 0.000 description 2
- 230000006798 recombination Effects 0.000 description 2
- 238000005215 recombination Methods 0.000 description 2
- 230000003362 replicative effect Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 108091008146 restriction endonucleases Proteins 0.000 description 2
- 239000011734 sodium Substances 0.000 description 2
- 235000010199 sorbic acid Nutrition 0.000 description 2
- 239000004334 sorbic acid Substances 0.000 description 2
- 229940075582 sorbic acid Drugs 0.000 description 2
- 241000894007 species Species 0.000 description 2
- 239000003381 stabilizer Substances 0.000 description 2
- 238000007619 statistical method Methods 0.000 description 2
- 229960005322 streptomycin Drugs 0.000 description 2
- 230000035882 stress Effects 0.000 description 2
- 239000005720 sucrose Substances 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 229960002180 tetracycline Drugs 0.000 description 2
- 229930101283 tetracycline Natural products 0.000 description 2
- 235000019364 tetracycline Nutrition 0.000 description 2
- 150000003522 tetracyclines Chemical class 0.000 description 2
- 230000002103 transcriptional effect Effects 0.000 description 2
- 239000012096 transfection reagent Substances 0.000 description 2
- 230000001052 transient effect Effects 0.000 description 2
- GETQZCLCWQTVFV-UHFFFAOYSA-N trimethylamine Chemical compound CN(C)C GETQZCLCWQTVFV-UHFFFAOYSA-N 0.000 description 2
- 210000003462 vein Anatomy 0.000 description 2
- 239000000277 virosome Substances 0.000 description 2
- 235000019168 vitamin K Nutrition 0.000 description 2
- 239000011712 vitamin K Substances 0.000 description 2
- 150000003721 vitamin K derivatives Chemical class 0.000 description 2
- 229940046010 vitamin k Drugs 0.000 description 2
- 210000005253 yeast cell Anatomy 0.000 description 2
- JARGNLJYKBUKSJ-KGZKBUQUSA-N (2r)-2-amino-5-[[(2r)-1-(carboxymethylamino)-3-hydroxy-1-oxopropan-2-yl]amino]-5-oxopentanoic acid;hydrobromide Chemical compound Br.OC(=O)[C@H](N)CCC(=O)N[C@H](CO)C(=O)NCC(O)=O JARGNLJYKBUKSJ-KGZKBUQUSA-N 0.000 description 1
- PQFMROVJTOPVDF-JBDRJPRFSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-amino-3-carboxypropanoyl]amino]-3-carboxypropanoyl]amino]-4-carboxybutanoyl]amino]butanedioic acid Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O PQFMROVJTOPVDF-JBDRJPRFSA-N 0.000 description 1
- 230000006269 (delayed) early viral mRNA transcription Effects 0.000 description 1
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 1
- CHHHXKFHOYLYRE-UHFFFAOYSA-M 2,4-Hexadienoic acid, potassium salt (1:1), (2E,4E)- Chemical compound [K+].CC=CC=CC([O-])=O CHHHXKFHOYLYRE-UHFFFAOYSA-M 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- QMOQBVOBWVNSNO-UHFFFAOYSA-N 2-[[2-[[2-[(2-azaniumylacetyl)amino]acetyl]amino]acetyl]amino]acetate Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(O)=O QMOQBVOBWVNSNO-UHFFFAOYSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- PUMGFEMNXBLDKD-UHFFFAOYSA-N 3,6-diaminoacridine-9-carbonitrile Chemical compound C1=CC(N)=CC2=NC3=CC(N)=CC=C3C(C#N)=C21 PUMGFEMNXBLDKD-UHFFFAOYSA-N 0.000 description 1
- WXNZTHHGJRFXKQ-UHFFFAOYSA-N 4-chlorophenol Chemical compound OC1=CC=C(Cl)C=C1 WXNZTHHGJRFXKQ-UHFFFAOYSA-N 0.000 description 1
- 102000013563 Acid Phosphatase Human genes 0.000 description 1
- 108010051457 Acid Phosphatase Proteins 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 1
- SVBXIUDNTRTKHE-CIUDSAMLSA-N Ala-Arg-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O SVBXIUDNTRTKHE-CIUDSAMLSA-N 0.000 description 1
- JAMAWBXXKFGFGX-KZVJFYERSA-N Ala-Arg-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JAMAWBXXKFGFGX-KZVJFYERSA-N 0.000 description 1
- YAXNATKKPOWVCP-ZLUOBGJFSA-N Ala-Asn-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O YAXNATKKPOWVCP-ZLUOBGJFSA-N 0.000 description 1
- GFBLJMHGHAXGNY-ZLUOBGJFSA-N Ala-Asn-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O GFBLJMHGHAXGNY-ZLUOBGJFSA-N 0.000 description 1
- GORKKVHIBWAQHM-GCJQMDKQSA-N Ala-Asn-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GORKKVHIBWAQHM-GCJQMDKQSA-N 0.000 description 1
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 1
- IKKVASZHTMKJIR-ZKWXMUAHSA-N Ala-Asp-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O IKKVASZHTMKJIR-ZKWXMUAHSA-N 0.000 description 1
- HXNNRBHASOSVPG-GUBZILKMSA-N Ala-Glu-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O HXNNRBHASOSVPG-GUBZILKMSA-N 0.000 description 1
- DVJSJDDYCYSMFR-ZKWXMUAHSA-N Ala-Ile-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O DVJSJDDYCYSMFR-ZKWXMUAHSA-N 0.000 description 1
- SUMYEVXWCAYLLJ-GUBZILKMSA-N Ala-Leu-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O SUMYEVXWCAYLLJ-GUBZILKMSA-N 0.000 description 1
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 1
- FCXAUASCMJOFEY-NDKCEZKHSA-N Ala-Leu-Thr-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(O)=O FCXAUASCMJOFEY-NDKCEZKHSA-N 0.000 description 1
- OINVDEKBKBCPLX-JXUBOQSCSA-N Ala-Lys-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OINVDEKBKBCPLX-JXUBOQSCSA-N 0.000 description 1
- XUCHENWTTBFODJ-FXQIFTODSA-N Ala-Met-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O XUCHENWTTBFODJ-FXQIFTODSA-N 0.000 description 1
- 108010011667 Ala-Phe-Ala Proteins 0.000 description 1
- DXTYEWAQOXYRHZ-KKXDTOCCSA-N Ala-Phe-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N DXTYEWAQOXYRHZ-KKXDTOCCSA-N 0.000 description 1
- FFZJHQODAYHGPO-KZVJFYERSA-N Ala-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N FFZJHQODAYHGPO-KZVJFYERSA-N 0.000 description 1
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 1
- SYIFFFHSXBNPMC-UWJYBYFXSA-N Ala-Ser-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N SYIFFFHSXBNPMC-UWJYBYFXSA-N 0.000 description 1
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 1
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 1
- AOAKQKVICDWCLB-UWJYBYFXSA-N Ala-Tyr-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N AOAKQKVICDWCLB-UWJYBYFXSA-N 0.000 description 1
- NLYYHIKRBRMAJV-AEJSXWLSSA-N Ala-Val-Pro Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N NLYYHIKRBRMAJV-AEJSXWLSSA-N 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- 102000052866 Amino Acyl-tRNA Synthetases Human genes 0.000 description 1
- 108700028939 Amino Acyl-tRNA Synthetases Proteins 0.000 description 1
- QGZKDVFQNNGYKY-UHFFFAOYSA-O Ammonium Chemical compound [NH4+] QGZKDVFQNNGYKY-UHFFFAOYSA-O 0.000 description 1
- 206010002091 Anaesthesia Diseases 0.000 description 1
- 108091023037 Aptamer Proteins 0.000 description 1
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 1
- BVBKBQRPOJFCQM-DCAQKATOSA-N Arg-Asn-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BVBKBQRPOJFCQM-DCAQKATOSA-N 0.000 description 1
- OCOZPTHLDVSFCZ-BPUTZDHNSA-N Arg-Asn-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N OCOZPTHLDVSFCZ-BPUTZDHNSA-N 0.000 description 1
- ALOVURZCXKYKJC-NAKRPEOUSA-N Arg-Asp-Gln-Ser Chemical compound N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O ALOVURZCXKYKJC-NAKRPEOUSA-N 0.000 description 1
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 description 1
- KBBKCNHWCDJPGN-GUBZILKMSA-N Arg-Gln-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KBBKCNHWCDJPGN-GUBZILKMSA-N 0.000 description 1
- VNFWDYWTSHFRRG-SRVKXCTJSA-N Arg-Gln-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O VNFWDYWTSHFRRG-SRVKXCTJSA-N 0.000 description 1
- BQBPFMNVOWDLHO-XIRDDKMYSA-N Arg-Gln-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N BQBPFMNVOWDLHO-XIRDDKMYSA-N 0.000 description 1
- OOIMKQRCPJBGPD-XUXIUFHCSA-N Arg-Ile-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O OOIMKQRCPJBGPD-XUXIUFHCSA-N 0.000 description 1
- YBZMTKUDWXZLIX-UWVGGRQHSA-N Arg-Leu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YBZMTKUDWXZLIX-UWVGGRQHSA-N 0.000 description 1
- UZGFHWIJWPUPOH-IHRRRGAJSA-N Arg-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UZGFHWIJWPUPOH-IHRRRGAJSA-N 0.000 description 1
- JEOCWTUOMKEEMF-RHYQMDGZSA-N Arg-Leu-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEOCWTUOMKEEMF-RHYQMDGZSA-N 0.000 description 1
- BTJVOUQWFXABOI-IHRRRGAJSA-N Arg-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCNC(N)=N BTJVOUQWFXABOI-IHRRRGAJSA-N 0.000 description 1
- UULLJGQFCDXVTQ-CYDGBPFRSA-N Arg-Pro-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O UULLJGQFCDXVTQ-CYDGBPFRSA-N 0.000 description 1
- AWMAZIIEFPFHCP-RCWTZXSCSA-N Arg-Pro-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O AWMAZIIEFPFHCP-RCWTZXSCSA-N 0.000 description 1
- JOTRDIXZHNQYGP-DCAQKATOSA-N Arg-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N JOTRDIXZHNQYGP-DCAQKATOSA-N 0.000 description 1
- LYJXHXGPWDTLKW-HJGDQZAQSA-N Arg-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O LYJXHXGPWDTLKW-HJGDQZAQSA-N 0.000 description 1
- ZPWMEWYQBWSGAO-ZJDVBMNYSA-N Arg-Thr-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZPWMEWYQBWSGAO-ZJDVBMNYSA-N 0.000 description 1
- WTFIFQWLQXZLIZ-UMPQAUOISA-N Arg-Thr-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O WTFIFQWLQXZLIZ-UMPQAUOISA-N 0.000 description 1
- XMGVWQWEWWULNS-BPUTZDHNSA-N Arg-Trp-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N XMGVWQWEWWULNS-BPUTZDHNSA-N 0.000 description 1
- UVTGNSWSRSCPLP-UHFFFAOYSA-N Arg-Tyr Natural products NC(CCNC(=N)N)C(=O)NC(Cc1ccc(O)cc1)C(=O)O UVTGNSWSRSCPLP-UHFFFAOYSA-N 0.000 description 1
- CPTXATAOUQJQRO-GUBZILKMSA-N Arg-Val-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O CPTXATAOUQJQRO-GUBZILKMSA-N 0.000 description 1
- YNDLOUMBVDVALC-ZLUOBGJFSA-N Asn-Ala-Ala Chemical compound C[C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CC(=O)N)N YNDLOUMBVDVALC-ZLUOBGJFSA-N 0.000 description 1
- HZPSDHRYYIORKR-WHFBIAKZSA-N Asn-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CC(N)=O HZPSDHRYYIORKR-WHFBIAKZSA-N 0.000 description 1
- IARGXWMWRFOQPG-GCJQMDKQSA-N Asn-Ala-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IARGXWMWRFOQPG-GCJQMDKQSA-N 0.000 description 1
- VDCIPFYVCICPEC-FXQIFTODSA-N Asn-Arg-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O VDCIPFYVCICPEC-FXQIFTODSA-N 0.000 description 1
- HOIFSHOLNKQCSA-FXQIFTODSA-N Asn-Arg-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O HOIFSHOLNKQCSA-FXQIFTODSA-N 0.000 description 1
- PTNFNTOBUDWHNZ-GUBZILKMSA-N Asn-Arg-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(O)=O PTNFNTOBUDWHNZ-GUBZILKMSA-N 0.000 description 1
- DAPLJWATMAXPPZ-CIUDSAMLSA-N Asn-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(N)=O DAPLJWATMAXPPZ-CIUDSAMLSA-N 0.000 description 1
- VKCOHFFSTKCXEQ-OLHMAJIHSA-N Asn-Asn-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VKCOHFFSTKCXEQ-OLHMAJIHSA-N 0.000 description 1
- OWUCNXMFJRFOFI-BQBZGAKWSA-N Asn-Gly-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O OWUCNXMFJRFOFI-BQBZGAKWSA-N 0.000 description 1
- OOWSBIOUKIUWLO-RCOVLWMOSA-N Asn-Gly-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O OOWSBIOUKIUWLO-RCOVLWMOSA-N 0.000 description 1
- MOHUTCNYQLMARY-GUBZILKMSA-N Asn-His-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N MOHUTCNYQLMARY-GUBZILKMSA-N 0.000 description 1
- PNHQRQTVBRDIEF-CIUDSAMLSA-N Asn-Leu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(=O)N)N PNHQRQTVBRDIEF-CIUDSAMLSA-N 0.000 description 1
- WIDVAWAQBRAKTI-YUMQZZPRSA-N Asn-Leu-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O WIDVAWAQBRAKTI-YUMQZZPRSA-N 0.000 description 1
- JLNFZLNDHONLND-GARJFASQSA-N Asn-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N JLNFZLNDHONLND-GARJFASQSA-N 0.000 description 1
- DJIMLSXHXKWADV-CIUDSAMLSA-N Asn-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(N)=O DJIMLSXHXKWADV-CIUDSAMLSA-N 0.000 description 1
- COWITDLVHMZSIW-CIUDSAMLSA-N Asn-Lys-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O COWITDLVHMZSIW-CIUDSAMLSA-N 0.000 description 1
- ZJIFRAPZHAGLGR-MELADBBJSA-N Asn-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC(=O)N)N)C(=O)O ZJIFRAPZHAGLGR-MELADBBJSA-N 0.000 description 1
- YUOXLJYVSZYPBJ-CIUDSAMLSA-N Asn-Pro-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O YUOXLJYVSZYPBJ-CIUDSAMLSA-N 0.000 description 1
- IDUUACUJKUXKKD-VEVYYDQMSA-N Asn-Pro-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O IDUUACUJKUXKKD-VEVYYDQMSA-N 0.000 description 1
- JWQWPRCDYWNVNM-ACZMJKKPSA-N Asn-Ser-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N JWQWPRCDYWNVNM-ACZMJKKPSA-N 0.000 description 1
- GZXOUBTUAUAVHD-ACZMJKKPSA-N Asn-Ser-Glu Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O GZXOUBTUAUAVHD-ACZMJKKPSA-N 0.000 description 1
- UGXYFDQFLVCDFC-CIUDSAMLSA-N Asn-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O UGXYFDQFLVCDFC-CIUDSAMLSA-N 0.000 description 1
- VLDRQOHCMKCXLY-SRVKXCTJSA-N Asn-Ser-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O VLDRQOHCMKCXLY-SRVKXCTJSA-N 0.000 description 1
- WLVLIYYBPPONRJ-GCJQMDKQSA-N Asn-Thr-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O WLVLIYYBPPONRJ-GCJQMDKQSA-N 0.000 description 1
- QUMKPKWYDVMGNT-NUMRIWBASA-N Asn-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QUMKPKWYDVMGNT-NUMRIWBASA-N 0.000 description 1
- ZUFPUBYQYWCMDB-NUMRIWBASA-N Asn-Thr-Glu Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZUFPUBYQYWCMDB-NUMRIWBASA-N 0.000 description 1
- XIDSGDJNUJRUHE-VEVYYDQMSA-N Asn-Thr-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(O)=O XIDSGDJNUJRUHE-VEVYYDQMSA-N 0.000 description 1
- AMGQTNHANMRPOE-LKXGYXEUSA-N Asn-Thr-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O AMGQTNHANMRPOE-LKXGYXEUSA-N 0.000 description 1
- KZYSHAMXEBPJBD-JRQIVUDYSA-N Asn-Thr-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KZYSHAMXEBPJBD-JRQIVUDYSA-N 0.000 description 1
- RTFXPCYMDYBZNQ-SRVKXCTJSA-N Asn-Tyr-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O RTFXPCYMDYBZNQ-SRVKXCTJSA-N 0.000 description 1
- QNNBHTFDFFFHGC-KKUMJFAQSA-N Asn-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QNNBHTFDFFFHGC-KKUMJFAQSA-N 0.000 description 1
- JZLFYAAGGYMRIK-BYULHYEWSA-N Asn-Val-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O JZLFYAAGGYMRIK-BYULHYEWSA-N 0.000 description 1
- SYZWMVSXBZCOBZ-QXEWZRGKSA-N Asn-Val-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(=O)N)N SYZWMVSXBZCOBZ-QXEWZRGKSA-N 0.000 description 1
- HPNDBHLITCHRSO-WHFBIAKZSA-N Asp-Ala-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)NCC(O)=O HPNDBHLITCHRSO-WHFBIAKZSA-N 0.000 description 1
- YNQIDCRRTWGHJD-ZLUOBGJFSA-N Asp-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(O)=O YNQIDCRRTWGHJD-ZLUOBGJFSA-N 0.000 description 1
- UQBGYPFHWFZMCD-ZLUOBGJFSA-N Asp-Asn-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O UQBGYPFHWFZMCD-ZLUOBGJFSA-N 0.000 description 1
- FRYULLIZUDQONW-IMJSIDKUSA-N Asp-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(O)=O FRYULLIZUDQONW-IMJSIDKUSA-N 0.000 description 1
- WCFCYFDBMNFSPA-ACZMJKKPSA-N Asp-Asp-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(O)=O WCFCYFDBMNFSPA-ACZMJKKPSA-N 0.000 description 1
- ZCKYZTGLXIEOKS-CIUDSAMLSA-N Asp-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)O)N ZCKYZTGLXIEOKS-CIUDSAMLSA-N 0.000 description 1
- VZNOVQKGJQJOCS-SRVKXCTJSA-N Asp-Asp-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VZNOVQKGJQJOCS-SRVKXCTJSA-N 0.000 description 1
- NYQHSUGFEWDWPD-ACZMJKKPSA-N Asp-Gln-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N NYQHSUGFEWDWPD-ACZMJKKPSA-N 0.000 description 1
- XDGBFDYXZCMYEX-NUMRIWBASA-N Asp-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)O)N)O XDGBFDYXZCMYEX-NUMRIWBASA-N 0.000 description 1
- YDJVIBMKAMQPPP-LAEOZQHASA-N Asp-Glu-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O YDJVIBMKAMQPPP-LAEOZQHASA-N 0.000 description 1
- ZSVJVIOVABDTTL-YUMQZZPRSA-N Asp-Gly-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)O)N ZSVJVIOVABDTTL-YUMQZZPRSA-N 0.000 description 1
- POTCZYQVVNXUIG-BQBZGAKWSA-N Asp-Gly-Pro Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O POTCZYQVVNXUIG-BQBZGAKWSA-N 0.000 description 1
- WSGVTKZFVJSJOG-RCOVLWMOSA-N Asp-Gly-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O WSGVTKZFVJSJOG-RCOVLWMOSA-N 0.000 description 1
- RTXQQDVBACBSCW-CFMVVWHZSA-N Asp-Ile-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RTXQQDVBACBSCW-CFMVVWHZSA-N 0.000 description 1
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 1
- HJZLUGQGJWXJCJ-CIUDSAMLSA-N Asp-Pro-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O HJZLUGQGJWXJCJ-CIUDSAMLSA-N 0.000 description 1
- DWBZEJHQQIURML-IMJSIDKUSA-N Asp-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(O)=O DWBZEJHQQIURML-IMJSIDKUSA-N 0.000 description 1
- ZVGRHIRJLWBWGJ-ACZMJKKPSA-N Asp-Ser-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZVGRHIRJLWBWGJ-ACZMJKKPSA-N 0.000 description 1
- KGHLGJAXYSVNJP-WHFBIAKZSA-N Asp-Ser-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O KGHLGJAXYSVNJP-WHFBIAKZSA-N 0.000 description 1
- JSHWXQIZOCVWIA-ZKWXMUAHSA-N Asp-Ser-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JSHWXQIZOCVWIA-ZKWXMUAHSA-N 0.000 description 1
- IWLZBRTUIVXZJD-OLHMAJIHSA-N Asp-Thr-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O IWLZBRTUIVXZJD-OLHMAJIHSA-N 0.000 description 1
- JSNWZMFSLIWAHS-HJGDQZAQSA-N Asp-Thr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O JSNWZMFSLIWAHS-HJGDQZAQSA-N 0.000 description 1
- MRYDJCIIVRXVGG-QEJZJMRPSA-N Asp-Trp-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(O)=O MRYDJCIIVRXVGG-QEJZJMRPSA-N 0.000 description 1
- IHZFGJLKDYINPV-XIRDDKMYSA-N Asp-Trp-His Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC(O)=O)N)C(O)=O)C1=CN=CN1 IHZFGJLKDYINPV-XIRDDKMYSA-N 0.000 description 1
- 206010072395 Atypical fracture Diseases 0.000 description 1
- 108090000145 Bacillolysin Proteins 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 208000004434 Calcinosis Diseases 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 101710197665 Capsid protein VP2 Proteins 0.000 description 1
- 241000700199 Cavia porcellus Species 0.000 description 1
- 101710094648 Coat protein Proteins 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 102000004420 Creatine Kinase Human genes 0.000 description 1
- 108010042126 Creatine kinase Proteins 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- SBORMUFGKSCGEN-XHNCKOQMSA-N Cys-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N)C(=O)O SBORMUFGKSCGEN-XHNCKOQMSA-N 0.000 description 1
- LBOLGUYQEPZSKM-YUMQZZPRSA-N Cys-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CS)N LBOLGUYQEPZSKM-YUMQZZPRSA-N 0.000 description 1
- 102000005927 Cysteine Proteases Human genes 0.000 description 1
- 108010005843 Cysteine Proteases Proteins 0.000 description 1
- 102000004127 Cytokines Human genes 0.000 description 1
- 108090000695 Cytokines Proteins 0.000 description 1
- 101710190440 Cytotoxin 1 Proteins 0.000 description 1
- 101710177611 DNA polymerase II large subunit Proteins 0.000 description 1
- 101710184669 DNA polymerase II small subunit Proteins 0.000 description 1
- 230000004543 DNA replication Effects 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- 102100022375 Dentin matrix acidic phosphoprotein 1 Human genes 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- 238000012286 ELISA Assay Methods 0.000 description 1
- UPEZCKBFRMILAV-JNEQICEOSA-N Ecdysone Natural products O=C1[C@H]2[C@@](C)([C@@H]3C([C@@]4(O)[C@@](C)([C@H]([C@H]([C@@H](O)CCC(O)(C)C)C)CC4)CC3)=C1)C[C@H](O)[C@H](O)C2 UPEZCKBFRMILAV-JNEQICEOSA-N 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 241000283073 Equus caballus Species 0.000 description 1
- 102000010834 Extracellular Matrix Proteins Human genes 0.000 description 1
- 108010037362 Extracellular Matrix Proteins Proteins 0.000 description 1
- 206010049811 Extraskeletal ossification Diseases 0.000 description 1
- 208000036119 Frailty Diseases 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- YJIUYQKQBBQYHZ-ACZMJKKPSA-N Gln-Ala-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YJIUYQKQBBQYHZ-ACZMJKKPSA-N 0.000 description 1
- INKFLNZBTSNFON-CIUDSAMLSA-N Gln-Ala-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O INKFLNZBTSNFON-CIUDSAMLSA-N 0.000 description 1
- HHWQMFIGMMOVFK-WDSKDSINSA-N Gln-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O HHWQMFIGMMOVFK-WDSKDSINSA-N 0.000 description 1
- ZPDVKYLJTOFQJV-WDSKDSINSA-N Gln-Asn-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O ZPDVKYLJTOFQJV-WDSKDSINSA-N 0.000 description 1
- QYTKAVBFRUGYAU-ACZMJKKPSA-N Gln-Asp-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QYTKAVBFRUGYAU-ACZMJKKPSA-N 0.000 description 1
- WLODHVXYKYHLJD-ACZMJKKPSA-N Gln-Asp-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N WLODHVXYKYHLJD-ACZMJKKPSA-N 0.000 description 1
- NKCZYEDZTKOFBG-GUBZILKMSA-N Gln-Gln-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NKCZYEDZTKOFBG-GUBZILKMSA-N 0.000 description 1
- CITDWMLWXNUQKD-FXQIFTODSA-N Gln-Gln-Asn Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CITDWMLWXNUQKD-FXQIFTODSA-N 0.000 description 1
- PKVWNYGXMNWJSI-CIUDSAMLSA-N Gln-Gln-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKVWNYGXMNWJSI-CIUDSAMLSA-N 0.000 description 1
- GPISLLFQNHELLK-DCAQKATOSA-N Gln-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N GPISLLFQNHELLK-DCAQKATOSA-N 0.000 description 1
- KCJJFESQRXGTGC-BQBZGAKWSA-N Gln-Glu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O KCJJFESQRXGTGC-BQBZGAKWSA-N 0.000 description 1
- MAGNEQBFSBREJL-DCAQKATOSA-N Gln-Glu-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N MAGNEQBFSBREJL-DCAQKATOSA-N 0.000 description 1
- VGTDBGYFVWOQTI-RYUDHWBXSA-N Gln-Gly-Phe Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 VGTDBGYFVWOQTI-RYUDHWBXSA-N 0.000 description 1
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 1
- MWERYIXRDZDXOA-QEWYBTABSA-N Gln-Ile-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MWERYIXRDZDXOA-QEWYBTABSA-N 0.000 description 1
- LGIKBBLQVSWUGK-DCAQKATOSA-N Gln-Leu-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LGIKBBLQVSWUGK-DCAQKATOSA-N 0.000 description 1
- QKCZZAZNMMVICF-DCAQKATOSA-N Gln-Leu-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O QKCZZAZNMMVICF-DCAQKATOSA-N 0.000 description 1
- IULKWYSYZSURJK-AVGNSLFASA-N Gln-Leu-Lys Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O IULKWYSYZSURJK-AVGNSLFASA-N 0.000 description 1
- KLKYKPXITJBSNI-CIUDSAMLSA-N Gln-Met-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O KLKYKPXITJBSNI-CIUDSAMLSA-N 0.000 description 1
- DRNMNLKUUKKPIA-HTUGSXCWSA-N Gln-Phe-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@@H](N)CCC(N)=O)C(O)=O DRNMNLKUUKKPIA-HTUGSXCWSA-N 0.000 description 1
- DOQUICBEISTQHE-CIUDSAMLSA-N Gln-Pro-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O DOQUICBEISTQHE-CIUDSAMLSA-N 0.000 description 1
- NYCVMJGIJYQWDO-CIUDSAMLSA-N Gln-Ser-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NYCVMJGIJYQWDO-CIUDSAMLSA-N 0.000 description 1
- OKARHJKJTKFQBM-ACZMJKKPSA-N Gln-Ser-Asn Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OKARHJKJTKFQBM-ACZMJKKPSA-N 0.000 description 1
- JILRMFFFCHUUTJ-ACZMJKKPSA-N Gln-Ser-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O JILRMFFFCHUUTJ-ACZMJKKPSA-N 0.000 description 1
- JKDBRTNMYXYLHO-JYJNAYRXSA-N Gln-Tyr-Leu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 JKDBRTNMYXYLHO-JYJNAYRXSA-N 0.000 description 1
- ZMXZGYLINVNTKH-DZKIICNBSA-N Gln-Val-Phe Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ZMXZGYLINVNTKH-DZKIICNBSA-N 0.000 description 1
- VYOILACOFPPNQH-UMNHJUIQSA-N Gln-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N VYOILACOFPPNQH-UMNHJUIQSA-N 0.000 description 1
- FITIQFSXXBKFFM-NRPADANISA-N Gln-Val-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FITIQFSXXBKFFM-NRPADANISA-N 0.000 description 1
- HNAUFGBKJLTWQE-IFFSRLJSSA-N Gln-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCC(=O)N)N)O HNAUFGBKJLTWQE-IFFSRLJSSA-N 0.000 description 1
- PBEQPAZRHDVJQI-SRVKXCTJSA-N Glu-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)O)N PBEQPAZRHDVJQI-SRVKXCTJSA-N 0.000 description 1
- WOSRKEJQESVHGA-CIUDSAMLSA-N Glu-Arg-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O WOSRKEJQESVHGA-CIUDSAMLSA-N 0.000 description 1
- RDDSZZJOKDVPAE-ACZMJKKPSA-N Glu-Asn-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RDDSZZJOKDVPAE-ACZMJKKPSA-N 0.000 description 1
- OXEMJGCAJFFREE-FXQIFTODSA-N Glu-Gln-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O OXEMJGCAJFFREE-FXQIFTODSA-N 0.000 description 1
- NKLRYVLERDYDBI-FXQIFTODSA-N Glu-Glu-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKLRYVLERDYDBI-FXQIFTODSA-N 0.000 description 1
- BUZMZDDKFCSKOT-CIUDSAMLSA-N Glu-Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BUZMZDDKFCSKOT-CIUDSAMLSA-N 0.000 description 1
- SJPMNHCEWPTRBR-BQBZGAKWSA-N Glu-Glu-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O SJPMNHCEWPTRBR-BQBZGAKWSA-N 0.000 description 1
- QJCKNLPMTPXXEM-AUTRQRHGSA-N Glu-Glu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O QJCKNLPMTPXXEM-AUTRQRHGSA-N 0.000 description 1
- QIQABBIDHGQXGA-ZPFDUUQYSA-N Glu-Ile-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O QIQABBIDHGQXGA-ZPFDUUQYSA-N 0.000 description 1
- WVYJNPCWJYBHJG-YVNDNENWSA-N Glu-Ile-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O WVYJNPCWJYBHJG-YVNDNENWSA-N 0.000 description 1
- ZSWGJYOZWBHROQ-RWRJDSDZSA-N Glu-Ile-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZSWGJYOZWBHROQ-RWRJDSDZSA-N 0.000 description 1
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 1
- PJBVXVBTTFZPHJ-GUBZILKMSA-N Glu-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N PJBVXVBTTFZPHJ-GUBZILKMSA-N 0.000 description 1
- DNPCBMNFQVTHMA-DCAQKATOSA-N Glu-Leu-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DNPCBMNFQVTHMA-DCAQKATOSA-N 0.000 description 1
- UGSVSNXPJJDJKL-SDDRHHMPSA-N Glu-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N UGSVSNXPJJDJKL-SDDRHHMPSA-N 0.000 description 1
- MFNUFCFRAZPJFW-JYJNAYRXSA-N Glu-Lys-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFNUFCFRAZPJFW-JYJNAYRXSA-N 0.000 description 1
- QDMVXRNLOPTPIE-WDCWCFNPSA-N Glu-Lys-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QDMVXRNLOPTPIE-WDCWCFNPSA-N 0.000 description 1
- SUIAHERNFYRBDZ-GVXVVHGQSA-N Glu-Lys-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O SUIAHERNFYRBDZ-GVXVVHGQSA-N 0.000 description 1
- QNJNPKSWAHPYGI-JYJNAYRXSA-N Glu-Phe-Leu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=CC=C1 QNJNPKSWAHPYGI-JYJNAYRXSA-N 0.000 description 1
- TWYFJOHWGCCRIR-DCAQKATOSA-N Glu-Pro-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O TWYFJOHWGCCRIR-DCAQKATOSA-N 0.000 description 1
- MWTGQXBHVRTCOR-GLLZPBPUSA-N Glu-Thr-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MWTGQXBHVRTCOR-GLLZPBPUSA-N 0.000 description 1
- XAXJIUAWAFVADB-VJBMBRPKSA-N Glu-Trp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XAXJIUAWAFVADB-VJBMBRPKSA-N 0.000 description 1
- NTHIHAUEXVTXQG-KKUMJFAQSA-N Glu-Tyr-Arg Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O NTHIHAUEXVTXQG-KKUMJFAQSA-N 0.000 description 1
- HQTDNEZTGZUWSY-XVKPBYJWSA-N Glu-Val-Gly Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(O)=O)C(=O)NCC(O)=O HQTDNEZTGZUWSY-XVKPBYJWSA-N 0.000 description 1
- RMWAOBGCZZSJHE-UMNHJUIQSA-N Glu-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N RMWAOBGCZZSJHE-UMNHJUIQSA-N 0.000 description 1
- 102400000321 Glucagon Human genes 0.000 description 1
- 108060003199 Glucagon Proteins 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- RLFSBAPJTYKSLG-WHFBIAKZSA-N Gly-Ala-Asp Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O RLFSBAPJTYKSLG-WHFBIAKZSA-N 0.000 description 1
- UGVQELHRNUDMAA-BYPYZUCNSA-N Gly-Ala-Gly Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)NCC([O-])=O UGVQELHRNUDMAA-BYPYZUCNSA-N 0.000 description 1
- FKJQNJCQTKUBCD-XPUUQOCRSA-N Gly-Ala-His Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O FKJQNJCQTKUBCD-XPUUQOCRSA-N 0.000 description 1
- PHONXOACARQMPM-BQBZGAKWSA-N Gly-Ala-Met Chemical compound [H]NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O PHONXOACARQMPM-BQBZGAKWSA-N 0.000 description 1
- CLODWIOAKCSBAN-BQBZGAKWSA-N Gly-Arg-Asp Chemical compound NC(N)=NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(O)=O)C(O)=O CLODWIOAKCSBAN-BQBZGAKWSA-N 0.000 description 1
- XUORRGAFUQIMLC-STQMWFEESA-N Gly-Arg-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CN)O XUORRGAFUQIMLC-STQMWFEESA-N 0.000 description 1
- UXJHNZODTMHWRD-WHFBIAKZSA-N Gly-Asn-Ala Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O UXJHNZODTMHWRD-WHFBIAKZSA-N 0.000 description 1
- DWUKOTKSTDWGAE-BQBZGAKWSA-N Gly-Asn-Arg Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DWUKOTKSTDWGAE-BQBZGAKWSA-N 0.000 description 1
- FMVLWTYYODVFRG-BQBZGAKWSA-N Gly-Asn-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)CN FMVLWTYYODVFRG-BQBZGAKWSA-N 0.000 description 1
- KQDMENMTYNBWMR-WHFBIAKZSA-N Gly-Asp-Ala Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O KQDMENMTYNBWMR-WHFBIAKZSA-N 0.000 description 1
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 1
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 1
- QPDUVFSVVAOUHE-XVKPBYJWSA-N Gly-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)CN)C(O)=O QPDUVFSVVAOUHE-XVKPBYJWSA-N 0.000 description 1
- MBOAPAXLTUSMQI-JHEQGTHGSA-N Gly-Glu-Thr Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MBOAPAXLTUSMQI-JHEQGTHGSA-N 0.000 description 1
- UFPXDFOYHVEIPI-BYPYZUCNSA-N Gly-Gly-Asp Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O UFPXDFOYHVEIPI-BYPYZUCNSA-N 0.000 description 1
- OLPPXYMMIARYAL-QMMMGPOBSA-N Gly-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)CN OLPPXYMMIARYAL-QMMMGPOBSA-N 0.000 description 1
- HPAIKDPJURGQLN-KBPBESRZSA-N Gly-His-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CNC=N1 HPAIKDPJURGQLN-KBPBESRZSA-N 0.000 description 1
- ALOBJFDJTMQQPW-ONGXEEELSA-N Gly-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)CN ALOBJFDJTMQQPW-ONGXEEELSA-N 0.000 description 1
- HMHRTKOWRUPPNU-RCOVLWMOSA-N Gly-Ile-Gly Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O HMHRTKOWRUPPNU-RCOVLWMOSA-N 0.000 description 1
- NSTUFLGQJCOCDL-UWVGGRQHSA-N Gly-Leu-Arg Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NSTUFLGQJCOCDL-UWVGGRQHSA-N 0.000 description 1
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 1
- CLNSYANKYVMZNM-UWVGGRQHSA-N Gly-Lys-Arg Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N CLNSYANKYVMZNM-UWVGGRQHSA-N 0.000 description 1
- CVFOYJJOZYYEPE-KBPBESRZSA-N Gly-Lys-Tyr Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CVFOYJJOZYYEPE-KBPBESRZSA-N 0.000 description 1
- FJWSJWACLMTDMI-WPRPVWTQSA-N Gly-Met-Val Chemical compound [H]NCC(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O FJWSJWACLMTDMI-WPRPVWTQSA-N 0.000 description 1
- OOCFXNOVSLSHAB-IUCAKERBSA-N Gly-Pro-Pro Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OOCFXNOVSLSHAB-IUCAKERBSA-N 0.000 description 1
- OHUKZZYSJBKFRR-WHFBIAKZSA-N Gly-Ser-Asp Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O OHUKZZYSJBKFRR-WHFBIAKZSA-N 0.000 description 1
- YXTFLTJYLIAZQG-FJXKBIBVSA-N Gly-Thr-Arg Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YXTFLTJYLIAZQG-FJXKBIBVSA-N 0.000 description 1
- FKESCSGWBPUTPN-FOHZUACHSA-N Gly-Thr-Asn Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O FKESCSGWBPUTPN-FOHZUACHSA-N 0.000 description 1
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 1
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 1
- FOKISINOENBSDM-WLTAIBSBSA-N Gly-Thr-Tyr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O FOKISINOENBSDM-WLTAIBSBSA-N 0.000 description 1
- JKSMZVCGQWVTBW-STQMWFEESA-N Gly-Trp-Asn Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O JKSMZVCGQWVTBW-STQMWFEESA-N 0.000 description 1
- RIYIFUFFFBIOEU-KBPBESRZSA-N Gly-Tyr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 RIYIFUFFFBIOEU-KBPBESRZSA-N 0.000 description 1
- GJHWILMUOANXTG-WPRPVWTQSA-N Gly-Val-Arg Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GJHWILMUOANXTG-WPRPVWTQSA-N 0.000 description 1
- MUGLKCQHTUFLGF-WPRPVWTQSA-N Gly-Val-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)CN MUGLKCQHTUFLGF-WPRPVWTQSA-N 0.000 description 1
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 1
- 239000007995 HEPES buffer Substances 0.000 description 1
- 101710088172 HTH-type transcriptional regulator RipA Proteins 0.000 description 1
- 208000020061 Hand, Foot and Mouth Disease Diseases 0.000 description 1
- 208000025713 Hand-foot-and-mouth disease Diseases 0.000 description 1
- 239000012981 Hank's balanced salt solution Substances 0.000 description 1
- 241000700721 Hepatitis B virus Species 0.000 description 1
- 208000028782 Hereditary disease Diseases 0.000 description 1
- 208000034970 Heterotopic Ossification Diseases 0.000 description 1
- ZJSMFRTVYSLKQU-DJFWLOJKSA-N His-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC1=CN=CN1)N ZJSMFRTVYSLKQU-DJFWLOJKSA-N 0.000 description 1
- VBOFRJNDIOPNDO-YUMQZZPRSA-N His-Gly-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N VBOFRJNDIOPNDO-YUMQZZPRSA-N 0.000 description 1
- JENKOCSDMSVWPY-SRVKXCTJSA-N His-Leu-Asn Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O JENKOCSDMSVWPY-SRVKXCTJSA-N 0.000 description 1
- LNDVNHOSZQPJGI-AVGNSLFASA-N His-Pro-Pro Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CN=CN1 LNDVNHOSZQPJGI-AVGNSLFASA-N 0.000 description 1
- YEKYGQZUBCRNGH-DCAQKATOSA-N His-Pro-Ser Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CN=CN2)N)C(=O)N[C@@H](CO)C(=O)O YEKYGQZUBCRNGH-DCAQKATOSA-N 0.000 description 1
- DGLAHESNTJWGDO-SRVKXCTJSA-N His-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N DGLAHESNTJWGDO-SRVKXCTJSA-N 0.000 description 1
- GIRSNERMXCMDBO-GARJFASQSA-N His-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O GIRSNERMXCMDBO-GARJFASQSA-N 0.000 description 1
- 101000804518 Homo sapiens Cyclin-D-binding Myb-like transcription factor 1 Proteins 0.000 description 1
- 101000901629 Homo sapiens Dentin matrix acidic phosphoprotein 1 Proteins 0.000 description 1
- 101000907904 Homo sapiens Endoribonuclease Dicer Proteins 0.000 description 1
- 101000958041 Homo sapiens Musculin Proteins 0.000 description 1
- 101000979333 Homo sapiens Neurofilament light polypeptide Proteins 0.000 description 1
- 101000601727 Homo sapiens Parkinson disease protein 7 Proteins 0.000 description 1
- 241000700588 Human alphaherpesvirus 1 Species 0.000 description 1
- 101150079986 Ibsp gene Proteins 0.000 description 1
- LKACSKJPTFSBHR-MNXVOIDGSA-N Ile-Gln-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N LKACSKJPTFSBHR-MNXVOIDGSA-N 0.000 description 1
- HTDRTKMNJRRYOJ-SIUGBPQLSA-N Ile-Gln-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HTDRTKMNJRRYOJ-SIUGBPQLSA-N 0.000 description 1
- DFJJAVZIHDFOGQ-MNXVOIDGSA-N Ile-Glu-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N DFJJAVZIHDFOGQ-MNXVOIDGSA-N 0.000 description 1
- LEHPJMKVGFPSSP-ZQINRCPSSA-N Ile-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 LEHPJMKVGFPSSP-ZQINRCPSSA-N 0.000 description 1
- AKOYRLRUFBZOSP-BJDJZHNGSA-N Ile-Lys-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N AKOYRLRUFBZOSP-BJDJZHNGSA-N 0.000 description 1
- MSASLZGZQAXVFP-PEDHHIEDSA-N Ile-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N MSASLZGZQAXVFP-PEDHHIEDSA-N 0.000 description 1
- HQEPKOFULQTSFV-JURCDPSOSA-N Ile-Phe-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)O)N HQEPKOFULQTSFV-JURCDPSOSA-N 0.000 description 1
- VEPIBPGLTLPBDW-URLPEUOOSA-N Ile-Phe-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N VEPIBPGLTLPBDW-URLPEUOOSA-N 0.000 description 1
- BJECXJHLUJXPJQ-PYJNHQTQSA-N Ile-Pro-His Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N BJECXJHLUJXPJQ-PYJNHQTQSA-N 0.000 description 1
- NAFIFZNBSPWYOO-RWRJDSDZSA-N Ile-Thr-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N NAFIFZNBSPWYOO-RWRJDSDZSA-N 0.000 description 1
- WCNWGAUZWWSYDG-SVSWQMSJSA-N Ile-Thr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)O)N WCNWGAUZWWSYDG-SVSWQMSJSA-N 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 1
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 1
- 238000012404 In vitro experiment Methods 0.000 description 1
- 208000026350 Inborn Genetic disease Diseases 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 238000012313 Kruskal-Wallis test Methods 0.000 description 1
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 1
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 108091026898 Leader sequence (mRNA) Proteins 0.000 description 1
- ZRLUISBDKUWAIZ-CIUDSAMLSA-N Leu-Ala-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O ZRLUISBDKUWAIZ-CIUDSAMLSA-N 0.000 description 1
- MDVZJYGNAGLPGJ-KKUMJFAQSA-N Leu-Asn-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MDVZJYGNAGLPGJ-KKUMJFAQSA-N 0.000 description 1
- YKNBJXOJTURHCU-DCAQKATOSA-N Leu-Asp-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YKNBJXOJTURHCU-DCAQKATOSA-N 0.000 description 1
- MYGQXVYRZMKRDB-SRVKXCTJSA-N Leu-Asp-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN MYGQXVYRZMKRDB-SRVKXCTJSA-N 0.000 description 1
- VPKIQULSKFVCSM-SRVKXCTJSA-N Leu-Gln-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VPKIQULSKFVCSM-SRVKXCTJSA-N 0.000 description 1
- DPWGZWUMUUJQDT-IUCAKERBSA-N Leu-Gln-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O DPWGZWUMUUJQDT-IUCAKERBSA-N 0.000 description 1
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 1
- HFBCHNRFRYLZNV-GUBZILKMSA-N Leu-Glu-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HFBCHNRFRYLZNV-GUBZILKMSA-N 0.000 description 1
- NEEOBPIXKWSBRF-IUCAKERBSA-N Leu-Glu-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O NEEOBPIXKWSBRF-IUCAKERBSA-N 0.000 description 1
- OGUUKPXUTHOIAV-SDDRHHMPSA-N Leu-Glu-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N OGUUKPXUTHOIAV-SDDRHHMPSA-N 0.000 description 1
- LLBQJYDYOLIQAI-JYJNAYRXSA-N Leu-Glu-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LLBQJYDYOLIQAI-JYJNAYRXSA-N 0.000 description 1
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 1
- VGPCJSXPPOQPBK-YUMQZZPRSA-N Leu-Gly-Ser Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O VGPCJSXPPOQPBK-YUMQZZPRSA-N 0.000 description 1
- HGFGEMSVBMCFKK-MNXVOIDGSA-N Leu-Ile-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O HGFGEMSVBMCFKK-MNXVOIDGSA-N 0.000 description 1
- HNDWYLYAYNBWMP-AJNGGQMLSA-N Leu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N HNDWYLYAYNBWMP-AJNGGQMLSA-N 0.000 description 1
- LIINDKYIGYTDLG-PPCPHDFISA-N Leu-Ile-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LIINDKYIGYTDLG-PPCPHDFISA-N 0.000 description 1
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 1
- IDGZVZJLYFTXSL-DCAQKATOSA-N Leu-Ser-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IDGZVZJLYFTXSL-DCAQKATOSA-N 0.000 description 1
- IWMJFLJQHIDZQW-KKUMJFAQSA-N Leu-Ser-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IWMJFLJQHIDZQW-KKUMJFAQSA-N 0.000 description 1
- FGZVGOAAROXFAB-IXOXFDKPSA-N Leu-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(C)C)N)O FGZVGOAAROXFAB-IXOXFDKPSA-N 0.000 description 1
- HOMFINRJHIIZNJ-HOCLYGCPSA-N Leu-Trp-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(O)=O HOMFINRJHIIZNJ-HOCLYGCPSA-N 0.000 description 1
- BTEMNFBEAAOGBR-BZSNNMDCSA-N Leu-Tyr-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BTEMNFBEAAOGBR-BZSNNMDCSA-N 0.000 description 1
- XZNJZXJZBMBGGS-NHCYSSNCSA-N Leu-Val-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O XZNJZXJZBMBGGS-NHCYSSNCSA-N 0.000 description 1
- NLOZZWJNIKKYSC-WDSOQIARSA-N Lys-Arg-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CCCCN)C(O)=O)=CNC2=C1 NLOZZWJNIKKYSC-WDSOQIARSA-N 0.000 description 1
- NCTDKZKNBDZDOL-GARJFASQSA-N Lys-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N)C(=O)O NCTDKZKNBDZDOL-GARJFASQSA-N 0.000 description 1
- QUYCUALODHJQLK-CIUDSAMLSA-N Lys-Asp-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O QUYCUALODHJQLK-CIUDSAMLSA-N 0.000 description 1
- MQMIRLVJXQNTRJ-SDDRHHMPSA-N Lys-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCCN)N)C(=O)O MQMIRLVJXQNTRJ-SDDRHHMPSA-N 0.000 description 1
- GCMWRRQAKQXDED-IUCAKERBSA-N Lys-Glu-Gly Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)N[C@@H](CCC([O-])=O)C(=O)NCC([O-])=O GCMWRRQAKQXDED-IUCAKERBSA-N 0.000 description 1
- NKKFVJRLCCUJNA-QWRGUYRKSA-N Lys-Gly-Lys Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN NKKFVJRLCCUJNA-QWRGUYRKSA-N 0.000 description 1
- ZJWIXBZTAAJERF-IHRRRGAJSA-N Lys-Lys-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N ZJWIXBZTAAJERF-IHRRRGAJSA-N 0.000 description 1
- UQRZFMQQXXJTTF-AVGNSLFASA-N Lys-Lys-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O UQRZFMQQXXJTTF-AVGNSLFASA-N 0.000 description 1
- WBSCNDJQPKSPII-KKUMJFAQSA-N Lys-Lys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O WBSCNDJQPKSPII-KKUMJFAQSA-N 0.000 description 1
- VSTNAUBHKQPVJX-IHRRRGAJSA-N Lys-Met-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O VSTNAUBHKQPVJX-IHRRRGAJSA-N 0.000 description 1
- LUAJJLPHUXPQLH-KKUMJFAQSA-N Lys-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCCN)N LUAJJLPHUXPQLH-KKUMJFAQSA-N 0.000 description 1
- BOJYMMBYBNOOGG-DCAQKATOSA-N Lys-Pro-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O BOJYMMBYBNOOGG-DCAQKATOSA-N 0.000 description 1
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 1
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 1
- MIFFFXHMAHFACR-KATARQTJSA-N Lys-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN MIFFFXHMAHFACR-KATARQTJSA-N 0.000 description 1
- RMOKGALPSPOYKE-KATARQTJSA-N Lys-Thr-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O RMOKGALPSPOYKE-KATARQTJSA-N 0.000 description 1
- XYLSGAWRCZECIQ-JYJNAYRXSA-N Lys-Tyr-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCC(O)=O)C(O)=O)CC1=CC=C(O)C=C1 XYLSGAWRCZECIQ-JYJNAYRXSA-N 0.000 description 1
- 102000043136 MAP kinase family Human genes 0.000 description 1
- 108091054455 MAP kinase family Proteins 0.000 description 1
- 241000282553 Macaca Species 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 208000030136 Marchiafava-Bignami Disease Diseases 0.000 description 1
- 102000003939 Membrane transport proteins Human genes 0.000 description 1
- 108090000301 Membrane transport proteins Proteins 0.000 description 1
- 208000024556 Mendelian disease Diseases 0.000 description 1
- HUKLXYYPZWPXCC-KZVJFYERSA-N Met-Ala-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HUKLXYYPZWPXCC-KZVJFYERSA-N 0.000 description 1
- DGNZGCQSVGGYJS-BQBZGAKWSA-N Met-Gly-Asp Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O DGNZGCQSVGGYJS-BQBZGAKWSA-N 0.000 description 1
- UZWMJZSOXGOVIN-LURJTMIESA-N Met-Gly-Gly Chemical compound CSCC[C@H](N)C(=O)NCC(=O)NCC(O)=O UZWMJZSOXGOVIN-LURJTMIESA-N 0.000 description 1
- WUYLWZRHRLLEGB-AVGNSLFASA-N Met-Met-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O WUYLWZRHRLLEGB-AVGNSLFASA-N 0.000 description 1
- CIDICGYKRUTYLE-FXQIFTODSA-N Met-Ser-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O CIDICGYKRUTYLE-FXQIFTODSA-N 0.000 description 1
- HLZORBMOISUNIV-DCAQKATOSA-N Met-Ser-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C HLZORBMOISUNIV-DCAQKATOSA-N 0.000 description 1
- FIZZULTXMVEIAA-IHRRRGAJSA-N Met-Ser-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FIZZULTXMVEIAA-IHRRRGAJSA-N 0.000 description 1
- KYXDADPHSNFWQX-VEVYYDQMSA-N Met-Thr-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(O)=O KYXDADPHSNFWQX-VEVYYDQMSA-N 0.000 description 1
- KLGIQJRMFHIGCQ-ZFWWWQNUSA-N Met-Trp-Gly Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)CCSC)C(=O)NCC(O)=O)=CNC2=C1 KLGIQJRMFHIGCQ-ZFWWWQNUSA-N 0.000 description 1
- VYDLZDRMOFYOGV-TUAOUCFPSA-N Met-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCSC)N VYDLZDRMOFYOGV-TUAOUCFPSA-N 0.000 description 1
- VVQNEPGJFQJSBK-UHFFFAOYSA-N Methyl methacrylate Chemical compound COC(=O)C(C)=C VVQNEPGJFQJSBK-UHFFFAOYSA-N 0.000 description 1
- 108091007780 MiR-122 Proteins 0.000 description 1
- 241000713333 Mouse mammary tumor virus Species 0.000 description 1
- 101000761505 Mus musculus Cathepsin K Proteins 0.000 description 1
- 101100144701 Mus musculus Drosha gene Proteins 0.000 description 1
- 101100500493 Mus musculus Eapp gene Proteins 0.000 description 1
- 101000702766 Mus musculus Sclerostin Proteins 0.000 description 1
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 1
- 229910020700 Na3VO4 Inorganic materials 0.000 description 1
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 1
- 206010028851 Necrosis Diseases 0.000 description 1
- 102000035092 Neutral proteases Human genes 0.000 description 1
- 108091005507 Neutral proteases Proteins 0.000 description 1
- 108091005461 Nucleic proteins Proteins 0.000 description 1
- CTQNGGLPUBDAKN-UHFFFAOYSA-N O-Xylene Chemical compound CC1=CC=CC=C1C CTQNGGLPUBDAKN-UHFFFAOYSA-N 0.000 description 1
- 206010030247 Oestrogen deficiency Diseases 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 102100031475 Osteocalcin Human genes 0.000 description 1
- 229930040373 Paraformaldehyde Natural products 0.000 description 1
- 235000019483 Peanut oil Nutrition 0.000 description 1
- QMMRHASQEVCJGR-UBHSHLNASA-N Phe-Ala-Pro Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=CC=C1 QMMRHASQEVCJGR-UBHSHLNASA-N 0.000 description 1
- UHRNIXJAGGLKHP-DLOVCJGASA-N Phe-Ala-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O UHRNIXJAGGLKHP-DLOVCJGASA-N 0.000 description 1
- KAHUBGWSIQNZQQ-KKUMJFAQSA-N Phe-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 KAHUBGWSIQNZQQ-KKUMJFAQSA-N 0.000 description 1
- CDNPIRSCAFMMBE-SRVKXCTJSA-N Phe-Asn-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CDNPIRSCAFMMBE-SRVKXCTJSA-N 0.000 description 1
- OPEVYHFJXLCCRT-AVGNSLFASA-N Phe-Gln-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O OPEVYHFJXLCCRT-AVGNSLFASA-N 0.000 description 1
- BYAIIACBWBOJCU-URLPEUOOSA-N Phe-Ile-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BYAIIACBWBOJCU-URLPEUOOSA-N 0.000 description 1
- PEFJUUYFEGBXFA-BZSNNMDCSA-N Phe-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=CC=C1 PEFJUUYFEGBXFA-BZSNNMDCSA-N 0.000 description 1
- PBWNICYZGJQKJV-BZSNNMDCSA-N Phe-Phe-Cys Chemical compound N[C@@H](Cc1ccccc1)C(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CS)C(O)=O PBWNICYZGJQKJV-BZSNNMDCSA-N 0.000 description 1
- RVEVENLSADZUMS-IHRRRGAJSA-N Phe-Pro-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O RVEVENLSADZUMS-IHRRRGAJSA-N 0.000 description 1
- MMJJFXWMCMJMQA-STQMWFEESA-N Phe-Pro-Gly Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)NCC(O)=O)C1=CC=CC=C1 MMJJFXWMCMJMQA-STQMWFEESA-N 0.000 description 1
- ZVRJWDUPIDMHDN-ULQDDVLXSA-N Phe-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 ZVRJWDUPIDMHDN-ULQDDVLXSA-N 0.000 description 1
- ZJPGOXWRFNKIQL-JYJNAYRXSA-N Phe-Pro-Pro Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=CC=C1 ZJPGOXWRFNKIQL-JYJNAYRXSA-N 0.000 description 1
- NJJBATPLUQHRBM-IHRRRGAJSA-N Phe-Pro-Ser Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)N)C(=O)N[C@@H](CO)C(=O)O NJJBATPLUQHRBM-IHRRRGAJSA-N 0.000 description 1
- YMIZSYUAZJSOFL-SRVKXCTJSA-N Phe-Ser-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O YMIZSYUAZJSOFL-SRVKXCTJSA-N 0.000 description 1
- XDMMOISUAHXXFD-SRVKXCTJSA-N Phe-Ser-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O XDMMOISUAHXXFD-SRVKXCTJSA-N 0.000 description 1
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 1
- IAOZOFPONWDXNT-IXOXFDKPSA-N Phe-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IAOZOFPONWDXNT-IXOXFDKPSA-N 0.000 description 1
- VGTJSEYTVMAASM-RPTUDFQQSA-N Phe-Thr-Tyr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VGTJSEYTVMAASM-RPTUDFQQSA-N 0.000 description 1
- JSGWNFKWZNPDAV-YDHLFZDLSA-N Phe-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 JSGWNFKWZNPDAV-YDHLFZDLSA-N 0.000 description 1
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- DBALDZKOTNSBFM-FXQIFTODSA-N Pro-Ala-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DBALDZKOTNSBFM-FXQIFTODSA-N 0.000 description 1
- DRVIASBABBMZTF-GUBZILKMSA-N Pro-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@@H]1CCCN1 DRVIASBABBMZTF-GUBZILKMSA-N 0.000 description 1
- HFZNNDWPHBRNPV-KZVJFYERSA-N Pro-Ala-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HFZNNDWPHBRNPV-KZVJFYERSA-N 0.000 description 1
- INXAPZFIOVGHSV-CIUDSAMLSA-N Pro-Asn-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1 INXAPZFIOVGHSV-CIUDSAMLSA-N 0.000 description 1
- ZYBUKTMPPFQSHL-JYJNAYRXSA-N Pro-Asp-Trp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O ZYBUKTMPPFQSHL-JYJNAYRXSA-N 0.000 description 1
- YKQNVTOIYFQMLW-IHRRRGAJSA-N Pro-Cys-Tyr Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H]1NCCC1)C1=CC=C(O)C=C1 YKQNVTOIYFQMLW-IHRRRGAJSA-N 0.000 description 1
- WGAQWMRJUFQXMF-ZPFDUUQYSA-N Pro-Gln-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WGAQWMRJUFQXMF-ZPFDUUQYSA-N 0.000 description 1
- SKICPQLTOXGWGO-GARJFASQSA-N Pro-Gln-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O SKICPQLTOXGWGO-GARJFASQSA-N 0.000 description 1
- NMELOOXSGDRBRU-YUMQZZPRSA-N Pro-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 NMELOOXSGDRBRU-YUMQZZPRSA-N 0.000 description 1
- WVOXLKUUVCCCSU-ZPFDUUQYSA-N Pro-Glu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WVOXLKUUVCCCSU-ZPFDUUQYSA-N 0.000 description 1
- UEHYFUCOGHWASA-HJGDQZAQSA-N Pro-Glu-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 UEHYFUCOGHWASA-HJGDQZAQSA-N 0.000 description 1
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 1
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 1
- FEVDNIBDCRKMER-IUCAKERBSA-N Pro-Gly-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)CNC(=O)[C@@H]1CCCN1 FEVDNIBDCRKMER-IUCAKERBSA-N 0.000 description 1
- BODDREDDDRZUCF-QTKMDUPCSA-N Pro-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@@H]2CCCN2)O BODDREDDDRZUCF-QTKMDUPCSA-N 0.000 description 1
- XYHMFGGWNOFUOU-QXEWZRGKSA-N Pro-Ile-Gly Chemical compound OC(=O)CNC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 XYHMFGGWNOFUOU-QXEWZRGKSA-N 0.000 description 1
- ZTMLZUNPFDGPKY-VKOGCVSHSA-N Pro-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@@H]3CCCN3 ZTMLZUNPFDGPKY-VKOGCVSHSA-N 0.000 description 1
- FXGIMYRVJJEIIM-UWVGGRQHSA-N Pro-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FXGIMYRVJJEIIM-UWVGGRQHSA-N 0.000 description 1
- JUJCUYWRJMFJJF-AVGNSLFASA-N Pro-Lys-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]1CCCN1 JUJCUYWRJMFJJF-AVGNSLFASA-N 0.000 description 1
- DWGFLKQSGRUQTI-IHRRRGAJSA-N Pro-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]1CCCN1 DWGFLKQSGRUQTI-IHRRRGAJSA-N 0.000 description 1
- WIPAMEKBSHNFQE-IUCAKERBSA-N Pro-Met-Gly Chemical compound CSCC[C@@H](C(=O)NCC(=O)O)NC(=O)[C@@H]1CCCN1 WIPAMEKBSHNFQE-IUCAKERBSA-N 0.000 description 1
- WLJYLAQSUSIQNH-GUBZILKMSA-N Pro-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@@H]1CCCN1 WLJYLAQSUSIQNH-GUBZILKMSA-N 0.000 description 1
- FHZJRBVMLGOHBX-GUBZILKMSA-N Pro-Pro-Asp Chemical compound OC(=O)C[C@H](NC(=O)[C@@H]1CCCN1C(=O)[C@@H]1CCCN1)C(O)=O FHZJRBVMLGOHBX-GUBZILKMSA-N 0.000 description 1
- KWMZPPWYBVZIER-XGEHTFHBSA-N Pro-Ser-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWMZPPWYBVZIER-XGEHTFHBSA-N 0.000 description 1
- CXGLFEOYCJFKPR-RCWTZXSCSA-N Pro-Thr-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O CXGLFEOYCJFKPR-RCWTZXSCSA-N 0.000 description 1
- XDKKMRPRRCOELJ-GUBZILKMSA-N Pro-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 XDKKMRPRRCOELJ-GUBZILKMSA-N 0.000 description 1
- ZAUHSLVPDLNTRZ-QXEWZRGKSA-N Pro-Val-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O ZAUHSLVPDLNTRZ-QXEWZRGKSA-N 0.000 description 1
- OOZJHTXCLJUODH-QXEWZRGKSA-N Pro-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 OOZJHTXCLJUODH-QXEWZRGKSA-N 0.000 description 1
- IIRBTQHFVNGPMQ-AVGNSLFASA-N Pro-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 IIRBTQHFVNGPMQ-AVGNSLFASA-N 0.000 description 1
- 108010050808 Procollagen Proteins 0.000 description 1
- 241000169446 Promethis Species 0.000 description 1
- 229940124158 Protease/peptidase inhibitor Drugs 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 102000009572 RNA Polymerase II Human genes 0.000 description 1
- 108010009460 RNA Polymerase II Proteins 0.000 description 1
- 102000014450 RNA Polymerase III Human genes 0.000 description 1
- 108010078067 RNA Polymerase III Proteins 0.000 description 1
- 238000011529 RT qPCR Methods 0.000 description 1
- 208000037340 Rare genetic disease Diseases 0.000 description 1
- 108010038036 Receptor Activator of Nuclear Factor-kappa B Proteins 0.000 description 1
- 108010091086 Recombinases Proteins 0.000 description 1
- 102000018120 Recombinases Human genes 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 101150098533 SOST gene Proteins 0.000 description 1
- 208000034189 Sclerosis Diseases 0.000 description 1
- IDQFQFVEWMWRQQ-DLOVCJGASA-N Ser-Ala-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O IDQFQFVEWMWRQQ-DLOVCJGASA-N 0.000 description 1
- HQTKVSCNCDLXSX-BQBZGAKWSA-N Ser-Arg-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O HQTKVSCNCDLXSX-BQBZGAKWSA-N 0.000 description 1
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 1
- XVAUJOAYHWWNQF-ZLUOBGJFSA-N Ser-Asn-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O XVAUJOAYHWWNQF-ZLUOBGJFSA-N 0.000 description 1
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 1
- FIDMVVBUOCMMJG-CIUDSAMLSA-N Ser-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO FIDMVVBUOCMMJG-CIUDSAMLSA-N 0.000 description 1
- ICHZYBVODUVUKN-SRVKXCTJSA-N Ser-Asn-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ICHZYBVODUVUKN-SRVKXCTJSA-N 0.000 description 1
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 1
- UFKPDBLKLOBMRH-XHNCKOQMSA-N Ser-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N)C(=O)O UFKPDBLKLOBMRH-XHNCKOQMSA-N 0.000 description 1
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 1
- MUARUIBTKQJKFY-WHFBIAKZSA-N Ser-Gly-Asp Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MUARUIBTKQJKFY-WHFBIAKZSA-N 0.000 description 1
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 1
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 1
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 1
- CLKKNZQUQMZDGD-SRVKXCTJSA-N Ser-His-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CC1=CN=CN1 CLKKNZQUQMZDGD-SRVKXCTJSA-N 0.000 description 1
- JIPVNVNKXJLFJF-BJDJZHNGSA-N Ser-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N JIPVNVNKXJLFJF-BJDJZHNGSA-N 0.000 description 1
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 1
- HEUVHBXOVZONPU-BJDJZHNGSA-N Ser-Leu-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HEUVHBXOVZONPU-BJDJZHNGSA-N 0.000 description 1
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 1
- IXZHZUGGKLRHJD-DCAQKATOSA-N Ser-Leu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IXZHZUGGKLRHJD-DCAQKATOSA-N 0.000 description 1
- WNDUPCKKKGSKIQ-CIUDSAMLSA-N Ser-Pro-Gln Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O WNDUPCKKKGSKIQ-CIUDSAMLSA-N 0.000 description 1
- FKYWFUYPVKLJLP-DCAQKATOSA-N Ser-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FKYWFUYPVKLJLP-DCAQKATOSA-N 0.000 description 1
- XZKQVQKUZMAADP-IMJSIDKUSA-N Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(O)=O XZKQVQKUZMAADP-IMJSIDKUSA-N 0.000 description 1
- WLJPJRGQRNCIQS-ZLUOBGJFSA-N Ser-Ser-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O WLJPJRGQRNCIQS-ZLUOBGJFSA-N 0.000 description 1
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 1
- RXUOAOOZIWABBW-XGEHTFHBSA-N Ser-Thr-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RXUOAOOZIWABBW-XGEHTFHBSA-N 0.000 description 1
- SQHKXWODKJDZRC-LKXGYXEUSA-N Ser-Thr-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O SQHKXWODKJDZRC-LKXGYXEUSA-N 0.000 description 1
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 1
- PCMZJFMUYWIERL-ZKWXMUAHSA-N Ser-Val-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O PCMZJFMUYWIERL-ZKWXMUAHSA-N 0.000 description 1
- BEBVVQPDSHHWQL-NRPADANISA-N Ser-Val-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O BEBVVQPDSHHWQL-NRPADANISA-N 0.000 description 1
- 238000012311 Shapiro-Wilk normality test Methods 0.000 description 1
- 102000005157 Somatostatin Human genes 0.000 description 1
- 108010056088 Somatostatin Proteins 0.000 description 1
- 108010043267 Sp7 Transcription Factor Proteins 0.000 description 1
- 101100404994 Streptomyces niveus novP gene Proteins 0.000 description 1
- 101710172711 Structural protein Proteins 0.000 description 1
- 102000017299 Synapsin-1 Human genes 0.000 description 1
- 108050005241 Synapsin-1 Proteins 0.000 description 1
- 108091008874 T cell receptors Proteins 0.000 description 1
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 1
- 108010049264 Teriparatide Proteins 0.000 description 1
- CAJFZCICSVBOJK-SHGPDSBTSA-N Thr-Ala-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAJFZCICSVBOJK-SHGPDSBTSA-N 0.000 description 1
- JMZKMSTYXHFYAK-VEVYYDQMSA-N Thr-Arg-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O JMZKMSTYXHFYAK-VEVYYDQMSA-N 0.000 description 1
- VIBXMCZWVUOZLA-OLHMAJIHSA-N Thr-Asn-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O VIBXMCZWVUOZLA-OLHMAJIHSA-N 0.000 description 1
- TZKPNGDGUVREEB-FOHZUACHSA-N Thr-Asn-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O TZKPNGDGUVREEB-FOHZUACHSA-N 0.000 description 1
- JBHMLZSKIXMVFS-XVSYOHENSA-N Thr-Asn-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JBHMLZSKIXMVFS-XVSYOHENSA-N 0.000 description 1
- VXMHQKHDKCATDV-VEVYYDQMSA-N Thr-Asp-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VXMHQKHDKCATDV-VEVYYDQMSA-N 0.000 description 1
- RCEHMXVEMNXRIW-IRIUXVKKSA-N Thr-Gln-Tyr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N)O RCEHMXVEMNXRIW-IRIUXVKKSA-N 0.000 description 1
- GKWNLDNXMMLRMC-GLLZPBPUSA-N Thr-Glu-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O GKWNLDNXMMLRMC-GLLZPBPUSA-N 0.000 description 1
- SHOMROOOQBDGRL-JHEQGTHGSA-N Thr-Glu-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O SHOMROOOQBDGRL-JHEQGTHGSA-N 0.000 description 1
- SLUWOCTZVGMURC-BFHQHQDPSA-N Thr-Gly-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O SLUWOCTZVGMURC-BFHQHQDPSA-N 0.000 description 1
- DJDSEDOKJTZBAR-ZDLURKLDSA-N Thr-Gly-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O DJDSEDOKJTZBAR-ZDLURKLDSA-N 0.000 description 1
- KRGDDWVBBDLPSJ-CUJWVEQBSA-N Thr-His-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O KRGDDWVBBDLPSJ-CUJWVEQBSA-N 0.000 description 1
- RRRRCRYTLZVCEN-HJGDQZAQSA-N Thr-Leu-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O RRRRCRYTLZVCEN-HJGDQZAQSA-N 0.000 description 1
- NCXVJIQMWSGRHY-KXNHARMFSA-N Thr-Leu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O NCXVJIQMWSGRHY-KXNHARMFSA-N 0.000 description 1
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 1
- KKPOGALELPLJTL-MEYUZBJRSA-N Thr-Lys-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KKPOGALELPLJTL-MEYUZBJRSA-N 0.000 description 1
- STUAPCLEDMKXKL-LKXGYXEUSA-N Thr-Ser-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O STUAPCLEDMKXKL-LKXGYXEUSA-N 0.000 description 1
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 1
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 1
- WPSKTVVMQCXPRO-BWBBJGPYSA-N Thr-Ser-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WPSKTVVMQCXPRO-BWBBJGPYSA-N 0.000 description 1
- QYDKSNXSBXZPFK-ZJDVBMNYSA-N Thr-Thr-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYDKSNXSBXZPFK-ZJDVBMNYSA-N 0.000 description 1
- MFMGPEKYBXFIRF-SUSMZKCASA-N Thr-Thr-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MFMGPEKYBXFIRF-SUSMZKCASA-N 0.000 description 1
- QJIODPFLAASXJC-JHYOHUSXSA-N Thr-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O QJIODPFLAASXJC-JHYOHUSXSA-N 0.000 description 1
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 1
- JAWUQFCGNVEDRN-MEYUZBJRSA-N Thr-Tyr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O JAWUQFCGNVEDRN-MEYUZBJRSA-N 0.000 description 1
- QNXZCKMXHPULME-ZNSHCXBVSA-N Thr-Val-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O QNXZCKMXHPULME-ZNSHCXBVSA-N 0.000 description 1
- 108091036066 Three prime untranslated region Proteins 0.000 description 1
- 108010022394 Threonine synthase Proteins 0.000 description 1
- HYVLNORXQGKONN-NUTKFTJISA-N Trp-Ala-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 HYVLNORXQGKONN-NUTKFTJISA-N 0.000 description 1
- VZBWRZGNEPBRDE-HZUKXOBISA-N Trp-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N VZBWRZGNEPBRDE-HZUKXOBISA-N 0.000 description 1
- SSNGFWKILJLTQM-QEJZJMRPSA-N Trp-Gln-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SSNGFWKILJLTQM-QEJZJMRPSA-N 0.000 description 1
- NWQCKAPDGQMZQN-IHPCNDPISA-N Trp-Lys-Leu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O NWQCKAPDGQMZQN-IHPCNDPISA-N 0.000 description 1
- TUUXFNQXSFNFLX-XIRDDKMYSA-N Trp-Met-Glu Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N TUUXFNQXSFNFLX-XIRDDKMYSA-N 0.000 description 1
- RERRMBXDSFMBQE-ZFWWWQNUSA-N Trp-Met-Gly Chemical compound CSCC[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N RERRMBXDSFMBQE-ZFWWWQNUSA-N 0.000 description 1
- UIRPULWLRODAEQ-QEJZJMRPSA-N Trp-Ser-Glu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 UIRPULWLRODAEQ-QEJZJMRPSA-N 0.000 description 1
- GEGYPBOPIGNZIF-CWRNSKLLSA-N Trp-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)O GEGYPBOPIGNZIF-CWRNSKLLSA-N 0.000 description 1
- YCQXZDHDSUHUSG-FJHTZYQYSA-N Trp-Thr-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 YCQXZDHDSUHUSG-FJHTZYQYSA-N 0.000 description 1
- NMOIRIIIUVELLY-WDSOQIARSA-N Trp-Val-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)C(C)C)=CNC2=C1 NMOIRIIIUVELLY-WDSOQIARSA-N 0.000 description 1
- 238000010162 Tukey test Methods 0.000 description 1
- 102100040247 Tumor necrosis factor Human genes 0.000 description 1
- 102100028787 Tumor necrosis factor receptor superfamily member 11A Human genes 0.000 description 1
- HTHCZRWCFXMENJ-KKUMJFAQSA-N Tyr-Arg-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O HTHCZRWCFXMENJ-KKUMJFAQSA-N 0.000 description 1
- XHALUUQSNXSPLP-UFYCRDLUSA-N Tyr-Arg-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 XHALUUQSNXSPLP-UFYCRDLUSA-N 0.000 description 1
- GFHYISDTIWZUSU-QWRGUYRKSA-N Tyr-Asn-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GFHYISDTIWZUSU-QWRGUYRKSA-N 0.000 description 1
- AYPAIRCDLARHLM-KKUMJFAQSA-N Tyr-Asn-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O AYPAIRCDLARHLM-KKUMJFAQSA-N 0.000 description 1
- NSTPFWRAIDTNGH-BZSNNMDCSA-N Tyr-Asn-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O NSTPFWRAIDTNGH-BZSNNMDCSA-N 0.000 description 1
- RYSNTWVRSLCAJZ-RYUDHWBXSA-N Tyr-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 RYSNTWVRSLCAJZ-RYUDHWBXSA-N 0.000 description 1
- QAYSODICXVZUIA-WLTAIBSBSA-N Tyr-Gly-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O QAYSODICXVZUIA-WLTAIBSBSA-N 0.000 description 1
- FBHBVXUBTYVCRU-BZSNNMDCSA-N Tyr-His-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CN=CN1 FBHBVXUBTYVCRU-BZSNNMDCSA-N 0.000 description 1
- GITNQBVCEQBDQC-KKUMJFAQSA-N Tyr-Lys-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O GITNQBVCEQBDQC-KKUMJFAQSA-N 0.000 description 1
- CNNVVEPJTFOGHI-ACRUOGEOSA-N Tyr-Lys-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CNNVVEPJTFOGHI-ACRUOGEOSA-N 0.000 description 1
- QFXVAFIHVWXXBJ-AVGNSLFASA-N Tyr-Ser-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O QFXVAFIHVWXXBJ-AVGNSLFASA-N 0.000 description 1
- HRHYJNLMIJWGLF-BZSNNMDCSA-N Tyr-Ser-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 HRHYJNLMIJWGLF-BZSNNMDCSA-N 0.000 description 1
- PLVVHGFEMSDRET-IHPCNDPISA-N Tyr-Ser-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC3=CC=C(C=C3)O)N PLVVHGFEMSDRET-IHPCNDPISA-N 0.000 description 1
- BIVIUZRBCAUNPW-JRQIVUDYSA-N Tyr-Thr-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O BIVIUZRBCAUNPW-JRQIVUDYSA-N 0.000 description 1
- SMUWZUSWMWVOSL-JYJNAYRXSA-N Tyr-Val-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N SMUWZUSWMWVOSL-JYJNAYRXSA-N 0.000 description 1
- DJIJBQYBDKGDIS-JYJNAYRXSA-N Tyr-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)Cc1ccc(O)cc1)C(C)C)C(O)=O DJIJBQYBDKGDIS-JYJNAYRXSA-N 0.000 description 1
- 108091023045 Untranslated Region Proteins 0.000 description 1
- 101150004676 VGF gene Proteins 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- UEOOXDLMQZBPFR-ZKWXMUAHSA-N Val-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N UEOOXDLMQZBPFR-ZKWXMUAHSA-N 0.000 description 1
- YFOCMOVJBQDBCE-NRPADANISA-N Val-Ala-Glu Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N YFOCMOVJBQDBCE-NRPADANISA-N 0.000 description 1
- UDLYXGYWTVOIKU-QXEWZRGKSA-N Val-Asn-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N UDLYXGYWTVOIKU-QXEWZRGKSA-N 0.000 description 1
- AUMNPAUHKUNHHN-BYULHYEWSA-N Val-Asn-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N AUMNPAUHKUNHHN-BYULHYEWSA-N 0.000 description 1
- DBOXBUDEAJVKRE-LSJOCFKGSA-N Val-Asn-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N DBOXBUDEAJVKRE-LSJOCFKGSA-N 0.000 description 1
- ZQGPWORGSNRQLN-NHCYSSNCSA-N Val-Asp-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N ZQGPWORGSNRQLN-NHCYSSNCSA-N 0.000 description 1
- OVLIFGQSBSNGHY-KKHAAJSZSA-N Val-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N)O OVLIFGQSBSNGHY-KKHAAJSZSA-N 0.000 description 1
- CPTQYHDSVGVGDZ-UKJIMTQDSA-N Val-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N CPTQYHDSVGVGDZ-UKJIMTQDSA-N 0.000 description 1
- MHAHQDBEIDPFQS-NHCYSSNCSA-N Val-Glu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C MHAHQDBEIDPFQS-NHCYSSNCSA-N 0.000 description 1
- WDIGUPHXPBMODF-UMNHJUIQSA-N Val-Glu-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N WDIGUPHXPBMODF-UMNHJUIQSA-N 0.000 description 1
- PIFJAFRUVWZRKR-QMMMGPOBSA-N Val-Gly-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O PIFJAFRUVWZRKR-QMMMGPOBSA-N 0.000 description 1
- FEFZWCSXEMVSPO-LSJOCFKGSA-N Val-His-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](C)C(O)=O FEFZWCSXEMVSPO-LSJOCFKGSA-N 0.000 description 1
- XBRMBDFYOFARST-AVGNSLFASA-N Val-His-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](C(C)C)C(=O)O)N XBRMBDFYOFARST-AVGNSLFASA-N 0.000 description 1
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 1
- YLRAFVVWZRSZQC-DZKIICNBSA-N Val-Phe-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N YLRAFVVWZRSZQC-DZKIICNBSA-N 0.000 description 1
- YKNOJPJWNVHORX-UNQGMJICSA-N Val-Phe-Thr Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CC1=CC=CC=C1 YKNOJPJWNVHORX-UNQGMJICSA-N 0.000 description 1
- XBJKAZATRJBDCU-GUBZILKMSA-N Val-Pro-Ala Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O XBJKAZATRJBDCU-GUBZILKMSA-N 0.000 description 1
- QSPOLEBZTMESFY-SRVKXCTJSA-N Val-Pro-Val Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O QSPOLEBZTMESFY-SRVKXCTJSA-N 0.000 description 1
- UJMCYJKPDFQLHX-XGEHTFHBSA-N Val-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N)O UJMCYJKPDFQLHX-XGEHTFHBSA-N 0.000 description 1
- YQYFYUSYEDNLSD-YEPSODPASA-N Val-Thr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O YQYFYUSYEDNLSD-YEPSODPASA-N 0.000 description 1
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 1
- NGXQOQNXSGOYOI-BQFCYCMXSA-N Val-Trp-Gln Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 NGXQOQNXSGOYOI-BQFCYCMXSA-N 0.000 description 1
- JVGDAEKKZKKZFO-RCWTZXSCSA-N Val-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N)O JVGDAEKKZKKZFO-RCWTZXSCSA-N 0.000 description 1
- 108010051583 Ventricular Myosins Proteins 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- 108020005202 Viral DNA Proteins 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- 239000003070 absorption delaying agent Substances 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 108091005764 adaptor proteins Proteins 0.000 description 1
- 102000035181 adaptor proteins Human genes 0.000 description 1
- 230000001464 adherent effect Effects 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- 235000010419 agar Nutrition 0.000 description 1
- 230000032683 aging Effects 0.000 description 1
- 238000013019 agitation Methods 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 1
- 108010041407 alanylaspartic acid Proteins 0.000 description 1
- 108010044940 alanylglutamine Proteins 0.000 description 1
- 108010070783 alanyltyrosine Proteins 0.000 description 1
- 230000000172 allergic effect Effects 0.000 description 1
- UPEZCKBFRMILAV-UHFFFAOYSA-N alpha-Ecdysone Natural products C1C(O)C(O)CC2(C)C(CCC3(C(C(C(O)CCC(C)(C)O)C)CCC33O)C)C3=CC(=O)C21 UPEZCKBFRMILAV-UHFFFAOYSA-N 0.000 description 1
- 102000006707 alpha-beta T-Cell Antigen Receptors Human genes 0.000 description 1
- 108010087408 alpha-beta T-Cell Antigen Receptors Proteins 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 125000003277 amino group Chemical group 0.000 description 1
- 235000011114 ammonium hydroxide Nutrition 0.000 description 1
- 230000037005 anaesthesia Effects 0.000 description 1
- 230000033115 angiogenesis Effects 0.000 description 1
- 239000005557 antagonist Substances 0.000 description 1
- 108010008355 arginyl-glutamine Proteins 0.000 description 1
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 1
- 108010043240 arginyl-leucyl-glycine Proteins 0.000 description 1
- 210000001367 artery Anatomy 0.000 description 1
- 206010003246 arthritis Diseases 0.000 description 1
- 235000010323 ascorbic acid Nutrition 0.000 description 1
- 229960005070 ascorbic acid Drugs 0.000 description 1
- 239000011668 ascorbic acid Substances 0.000 description 1
- CKLJMWTZIZZHCS-REOHCLBHSA-N aspartic acid group Chemical group N[C@@H](CC(=O)O)C(=O)O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 1
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 1
- 108010021908 aspartyl-aspartyl-glutamyl-aspartic acid Proteins 0.000 description 1
- 238000003556 assay Methods 0.000 description 1
- 206010003549 asthenia Diseases 0.000 description 1
- 208000010668 atopic eczema Diseases 0.000 description 1
- 150000001540 azides Chemical class 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 230000002146 bilateral effect Effects 0.000 description 1
- 239000012620 biological material Substances 0.000 description 1
- 230000031018 biological processes and functions Effects 0.000 description 1
- 230000003592 biomimetic effect Effects 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 230000017531 blood circulation Effects 0.000 description 1
- 210000004204 blood vessel Anatomy 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- 230000008468 bone growth Effects 0.000 description 1
- 210000002798 bone marrow cell Anatomy 0.000 description 1
- 230000018678 bone mineralization Effects 0.000 description 1
- 230000037186 bone physiology Effects 0.000 description 1
- 230000010478 bone regeneration Effects 0.000 description 1
- 230000010072 bone remodeling Effects 0.000 description 1
- 230000008416 bone turnover Effects 0.000 description 1
- 239000007853 buffer solution Substances 0.000 description 1
- 235000011116 calcium hydroxide Nutrition 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 1
- 230000000747 cardiac effect Effects 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 239000006285 cell suspension Substances 0.000 description 1
- YRQNKMKHABXEJZ-UVQQGXFZSA-N chembl176323 Chemical compound C1C[C@]2(C)[C@@]3(C)CC(N=C4C[C@]5(C)CCC6[C@]7(C)CC[C@@H]([C@]7(CC[C@]6(C)[C@@]5(C)CC4=N4)C)CCCCCCCC)=C4C[C@]3(C)CCC2[C@]2(C)CC[C@H](CCCCCCCC)[C@]21C YRQNKMKHABXEJZ-UVQQGXFZSA-N 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 230000002648 chondrogenic effect Effects 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 229940096422 collagen type i Drugs 0.000 description 1
- 239000000084 colloidal system Substances 0.000 description 1
- 239000002131 composite material Substances 0.000 description 1
- 239000002285 corn oil Substances 0.000 description 1
- 235000005687 corn oil Nutrition 0.000 description 1
- 238000004132 cross linking Methods 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- WZHCOOQXZCIUNC-UHFFFAOYSA-N cyclandelate Chemical compound C1C(C)(C)CC(C)CC1OC(=O)C(O)C1=CC=CC=C1 WZHCOOQXZCIUNC-UHFFFAOYSA-N 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 238000002716 delivery method Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 229960003957 dexamethasone Drugs 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- 210000003275 diaphysis Anatomy 0.000 description 1
- 102000004419 dihydrofolate reductase Human genes 0.000 description 1
- UGMCXQCYOVCMTB-UHFFFAOYSA-K dihydroxy(stearato)aluminium Chemical compound CCCCCCCCCCCCCCCCCC(=O)O[Al](O)O UGMCXQCYOVCMTB-UHFFFAOYSA-K 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- 208000037765 diseases and disorders Diseases 0.000 description 1
- KAKKHKRHCKCAGH-UHFFFAOYSA-L disodium;(4-nitrophenyl) phosphate;hexahydrate Chemical compound O.O.O.O.O.O.[Na+].[Na+].[O-][N+](=O)C1=CC=C(OP([O-])([O-])=O)C=C1 KAKKHKRHCKCAGH-UHFFFAOYSA-L 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 230000003828 downregulation Effects 0.000 description 1
- 238000011304 droplet digital PCR Methods 0.000 description 1
- UPEZCKBFRMILAV-JMZLNJERSA-N ecdysone Chemical compound C1[C@@H](O)[C@@H](O)C[C@]2(C)[C@@H](CC[C@@]3([C@@H]([C@@H]([C@H](O)CCC(C)(C)O)C)CC[C@]33O)C)C3=CC(=O)[C@@H]21 UPEZCKBFRMILAV-JMZLNJERSA-N 0.000 description 1
- 230000004821 effect on bone Effects 0.000 description 1
- 238000005538 encapsulation Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 230000006862 enzymatic digestion Effects 0.000 description 1
- 229940088598 enzyme Drugs 0.000 description 1
- YQGOJNYOYNNSMM-UHFFFAOYSA-N eosin Chemical compound [Na+].OC(=O)C1=CC=CC=C1C1=C2C=C(Br)C(=O)C(Br)=C2OC2=C(Br)C(O)=C(Br)C=C21 YQGOJNYOYNNSMM-UHFFFAOYSA-N 0.000 description 1
- 230000003628 erosive effect Effects 0.000 description 1
- 239000003797 essential amino acid Substances 0.000 description 1
- 235000020776 essential amino acid Nutrition 0.000 description 1
- 229940073505 ethyl vanillin Drugs 0.000 description 1
- DEFVIWRASFVYLL-UHFFFAOYSA-N ethylene glycol bis(2-aminoethyl)tetraacetic acid Chemical compound OC(=O)CN(CC(O)=O)CCOCCOCCN(CC(O)=O)CC(O)=O DEFVIWRASFVYLL-UHFFFAOYSA-N 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 210000002744 extracellular matrix Anatomy 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 239000012530 fluid Substances 0.000 description 1
- 238000004108 freeze drying Methods 0.000 description 1
- 239000012737 fresh medium Substances 0.000 description 1
- 108010044804 gamma-glutamyl-seryl-glycine Proteins 0.000 description 1
- 238000012239 gene modification Methods 0.000 description 1
- MASNOZXLGMXCHN-ZLPAWPGGSA-N glucagon Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O)C(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C1=CC=CC=C1 MASNOZXLGMXCHN-ZLPAWPGGSA-N 0.000 description 1
- 229960004666 glucagon Drugs 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 108010008237 glutamyl-valyl-glycine Proteins 0.000 description 1
- 108010019832 glycyl-asparaginyl-glycine Proteins 0.000 description 1
- 108010072405 glycyl-aspartyl-glycine Proteins 0.000 description 1
- 108010051307 glycyl-glycyl-proline Proteins 0.000 description 1
- 108010010147 glycylglutamine Proteins 0.000 description 1
- 108010081551 glycylphenylalanine Proteins 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 229940093915 gynecological organic acid Drugs 0.000 description 1
- 238000010842 high-capacity cDNA reverse transcription kit Methods 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 108010028295 histidylhistidine Proteins 0.000 description 1
- 102000046949 human MSC Human genes 0.000 description 1
- 102000054831 human PARK7 Human genes 0.000 description 1
- 235000011167 hydrochloric acid Nutrition 0.000 description 1
- 229910052588 hydroxylapatite Inorganic materials 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 238000010185 immunofluorescence analysis Methods 0.000 description 1
- 238000003125 immunofluorescent labeling Methods 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 238000012750 in vivo screening Methods 0.000 description 1
- 230000000415 inactivating effect Effects 0.000 description 1
- 230000002757 inflammatory effect Effects 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 239000003978 infusion fluid Substances 0.000 description 1
- 239000007972 injectable composition Substances 0.000 description 1
- 150000007529 inorganic bases Chemical class 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 239000007928 intraperitoneal injection Substances 0.000 description 1
- 238000007919 intrasynovial administration Methods 0.000 description 1
- 230000002601 intratumoral effect Effects 0.000 description 1
- 235000014413 iron hydroxide Nutrition 0.000 description 1
- NCNCGGDMXMBVIA-UHFFFAOYSA-L iron(ii) hydroxide Chemical class [OH-].[OH-].[Fe+2] NCNCGGDMXMBVIA-UHFFFAOYSA-L 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- JJWLVOIRVHMVIS-UHFFFAOYSA-N isopropylamine Chemical compound CC(C)N JJWLVOIRVHMVIS-UHFFFAOYSA-N 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 238000011813 knockout mouse model Methods 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 239000000787 lecithin Substances 0.000 description 1
- 229940067606 lecithin Drugs 0.000 description 1
- 235000010445 lecithin Nutrition 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 230000004777 loss-of-function mutation Effects 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 230000002132 lysosomal effect Effects 0.000 description 1
- 108010009298 lysylglutamic acid Proteins 0.000 description 1
- 108010038320 lysylphenylalanine Proteins 0.000 description 1
- 108010017391 lysylvaline Proteins 0.000 description 1
- TWRXJAOTZQYOKJ-UHFFFAOYSA-L magnesium chloride Substances [Mg+2].[Cl-].[Cl-] TWRXJAOTZQYOKJ-UHFFFAOYSA-L 0.000 description 1
- 229910001629 magnesium chloride Inorganic materials 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 239000008155 medical solution Substances 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 108010056582 methionylglutamic acid Proteins 0.000 description 1
- 108091051828 miR-122 stem-loop Proteins 0.000 description 1
- 108091056862 miR-64 stem-loop Proteins 0.000 description 1
- 238000010603 microCT Methods 0.000 description 1
- 239000011859 microparticle Substances 0.000 description 1
- 239000004005 microsphere Substances 0.000 description 1
- 230000004079 mineral homeostasis Effects 0.000 description 1
- 150000007522 mineralic acids Chemical class 0.000 description 1
- 239000003068 molecular probe Substances 0.000 description 1
- 210000000663 muscle cell Anatomy 0.000 description 1
- 210000003098 myoblast Anatomy 0.000 description 1
- VTPSNRIENVXKCI-UHFFFAOYSA-N n-(2,4-dimethylphenyl)-3-hydroxynaphthalene-2-carboxamide Chemical compound CC1=CC(C)=CC=C1NC(=O)C1=CC2=CC=CC=C2C=C1O VTPSNRIENVXKCI-UHFFFAOYSA-N 0.000 description 1
- 239000002077 nanosphere Substances 0.000 description 1
- 230000017074 necrotic cell death Effects 0.000 description 1
- 230000001537 neural effect Effects 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 108091027963 non-coding RNA Proteins 0.000 description 1
- 102000042567 non-coding RNA Human genes 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 150000007530 organic bases Chemical class 0.000 description 1
- 210000004663 osteoprogenitor cell Anatomy 0.000 description 1
- 230000036407 pain Effects 0.000 description 1
- 239000012188 paraffin wax Substances 0.000 description 1
- 229920002866 paraformaldehyde Polymers 0.000 description 1
- 230000007918 pathogenicity Effects 0.000 description 1
- 239000000312 peanut oil Substances 0.000 description 1
- 239000001814 pectin Substances 0.000 description 1
- 235000010987 pectin Nutrition 0.000 description 1
- 229920001277 pectin Polymers 0.000 description 1
- XYJRXVWERLGGKC-UHFFFAOYSA-D pentacalcium;hydroxide;triphosphate Chemical compound [OH-].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O XYJRXVWERLGGKC-UHFFFAOYSA-D 0.000 description 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- 238000002135 phase contrast microscopy Methods 0.000 description 1
- 229960003742 phenol Drugs 0.000 description 1
- 108010084572 phenylalanyl-valine Proteins 0.000 description 1
- 150000003904 phospholipids Chemical class 0.000 description 1
- 235000011007 phosphoric acid Nutrition 0.000 description 1
- 150000003016 phosphoric acids Chemical class 0.000 description 1
- 239000011574 phosphorus Substances 0.000 description 1
- 229910052698 phosphorus Inorganic materials 0.000 description 1
- 229920000771 poly (alkylcyanoacrylate) Polymers 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 210000003240 portal vein Anatomy 0.000 description 1
- 230000001323 posttranslational effect Effects 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- 235000011118 potassium hydroxide Nutrition 0.000 description 1
- 235000010241 potassium sorbate Nutrition 0.000 description 1
- 239000004302 potassium sorbate Substances 0.000 description 1
- 229940069338 potassium sorbate Drugs 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 230000002335 preservative effect Effects 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- MFDFERRIHVXMIY-UHFFFAOYSA-N procaine Chemical compound CCN(CC)CCOC(=O)C1=CC=C(N)C=C1 MFDFERRIHVXMIY-UHFFFAOYSA-N 0.000 description 1
- 229960004919 procaine Drugs 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 230000000770 proinflammatory effect Effects 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 239000000473 propyl gallate Substances 0.000 description 1
- 235000010388 propyl gallate Nutrition 0.000 description 1
- 229940075579 propyl gallate Drugs 0.000 description 1
- 238000002731 protein assay Methods 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 201000010108 pycnodysostosis Diseases 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 239000013645 rAAV1 vector Substances 0.000 description 1
- 239000013646 rAAV2 vector Substances 0.000 description 1
- 239000013647 rAAV8 vector Substances 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 238000010814 radioimmunoprecipitation assay Methods 0.000 description 1
- 230000003439 radiotherapeutic effect Effects 0.000 description 1
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 1
- 230000001172 regenerating effect Effects 0.000 description 1
- 230000014493 regulation of gene expression Effects 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 101150066583 rep gene Proteins 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 108010071207 serylmethionine Proteins 0.000 description 1
- 239000008159 sesame oil Substances 0.000 description 1
- 235000011803 sesame oil Nutrition 0.000 description 1
- 229960002930 sirolimus Drugs 0.000 description 1
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- 235000017557 sodium bicarbonate Nutrition 0.000 description 1
- 229910000030 sodium bicarbonate Inorganic materials 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- 235000011121 sodium hydroxide Nutrition 0.000 description 1
- 210000004872 soft tissue Anatomy 0.000 description 1
- NHXLMOGPVYXJNR-ATOGVRKGSA-N somatostatin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CO)C(=O)N[C@@H](CSSC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(=O)N1)[C@@H](C)O)NC(=O)CNC(=O)[C@H](C)N)C(O)=O)=O)[C@H](O)C)C1=CC=CC=C1 NHXLMOGPVYXJNR-ATOGVRKGSA-N 0.000 description 1
- 229960000553 somatostatin Drugs 0.000 description 1
- 238000000527 sonication Methods 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
- 230000001954 sterilising effect Effects 0.000 description 1
- 238000004659 sterilization and disinfection Methods 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- 229940044609 sulfur dioxide Drugs 0.000 description 1
- 235000010269 sulphur dioxide Nutrition 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 238000007910 systemic administration Methods 0.000 description 1
- 230000001839 systemic circulation Effects 0.000 description 1
- 239000011975 tartaric acid Substances 0.000 description 1
- OGBMKVWORPGQRR-UMXFMPSGSA-N teriparatide Chemical compound C([C@H](NC(=O)[C@H](CCSC)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)[C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CNC=N1 OGBMKVWORPGQRR-UMXFMPSGSA-N 0.000 description 1
- 229960005460 teriparatide Drugs 0.000 description 1
- UEUXEKPTXMALOB-UHFFFAOYSA-J tetrasodium;2-[2-[bis(carboxylatomethyl)amino]ethyl-(carboxylatomethyl)amino]acetate Chemical compound [Na+].[Na+].[Na+].[Na+].[O-]C(=O)CN(CC([O-])=O)CCN(CC([O-])=O)CC([O-])=O UEUXEKPTXMALOB-UHFFFAOYSA-J 0.000 description 1
- 238000002560 therapeutic procedure Methods 0.000 description 1
- RTKIYNMVFMVABJ-UHFFFAOYSA-L thimerosal Chemical compound [Na+].CC[Hg]SC1=CC=CC=C1C([O-])=O RTKIYNMVFMVABJ-UHFFFAOYSA-L 0.000 description 1
- 229940033663 thimerosal Drugs 0.000 description 1
- 238000004448 titration Methods 0.000 description 1
- 229950003937 tolonium Drugs 0.000 description 1
- HNONEKILPDHFOL-UHFFFAOYSA-M tolonium chloride Chemical compound [Cl-].C1=C(C)C(N)=CC2=[S+]C3=CC(N(C)C)=CC=C3N=C21 HNONEKILPDHFOL-UHFFFAOYSA-M 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 230000005026 transcription initiation Effects 0.000 description 1
- 238000003151 transfection method Methods 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 238000011830 transgenic mouse model Methods 0.000 description 1
- 238000003146 transient transfection Methods 0.000 description 1
- 238000004929 transmission Raman spectroscopy Methods 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 108010080629 tryptophan-leucine Proteins 0.000 description 1
- 239000011882 ultra-fine particle Substances 0.000 description 1
- 238000002604 ultrasonography Methods 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 239000002691 unilamellar liposome Substances 0.000 description 1
- 238000012762 unpaired Student’s t-test Methods 0.000 description 1
- 238000001291 vacuum drying Methods 0.000 description 1
- 108010015385 valyl-prolyl-proline Proteins 0.000 description 1
- 210000005166 vasculature Anatomy 0.000 description 1
- 235000015112 vegetable and seed oil Nutrition 0.000 description 1
- 239000008158 vegetable oil Substances 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
- 239000008096 xylene Substances 0.000 description 1
Images















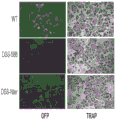









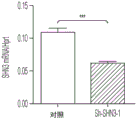


































































































Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/005—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'active' part of the composition delivered, i.e. the nucleic acid delivered
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/08—Drugs for skeletal disorders for bone diseases, e.g. rachitism, Paget's disease
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/08—Drugs for skeletal disorders for bone diseases, e.g. rachitism, Paget's disease
- A61P19/10—Drugs for skeletal disorders for bone diseases, e.g. rachitism, Paget's disease for osteoporosis
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/005—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from viruses
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/575—Hormones
- C07K14/635—Parathyroid hormone, i.e. parathormone; Parathyroid hormone-related peptides
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/111—General methods applicable to biologically active non-coding nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
- C12N15/1137—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing against enzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/07—Animals genetically altered by homologous recombination
- A01K2217/075—Animals genetically altered by homologous recombination inducing loss of function, i.e. knock out
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
- A01K2227/105—Murine
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2267/00—Animals characterised by purpose
- A01K2267/03—Animal model, e.g. for test or diseases
- A01K2267/035—Animal model for multifactorial diseases
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/14—Type of nucleic acid interfering N.A.
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/14—Type of nucleic acid interfering N.A.
- C12N2310/141—MicroRNAs, miRNAs
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/50—Physical structure
- C12N2310/53—Physical structure partially self-complementary or closed
- C12N2310/531—Stem-loop; Hairpin
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2320/00—Applications; Uses
- C12N2320/30—Special therapeutic applications
- C12N2320/32—Special delivery means, e.g. tissue-specific
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2330/00—Production
- C12N2330/50—Biochemical production, i.e. in a transformed host cell
- C12N2330/51—Specially adapted vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14122—New viral proteins or individual genes, new structural or functional aspects of known viral proteins or genes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14141—Use of virus, viral particle or viral elements as a vector
- C12N2750/14143—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14141—Use of virus, viral particle or viral elements as a vector
- C12N2750/14145—Special targeting system for viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14171—Demonstrated in vivo effect
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Biomedical Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biotechnology (AREA)
- Molecular Biology (AREA)
- Zoology (AREA)
- General Health & Medical Sciences (AREA)
- Wood Science & Technology (AREA)
- General Engineering & Computer Science (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Physical Education & Sports Medicine (AREA)
- Medicinal Chemistry (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- Pharmacology & Pharmacy (AREA)
- Virology (AREA)
- Orthopedic Medicine & Surgery (AREA)
- Rheumatology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Epidemiology (AREA)
- Gastroenterology & Hepatology (AREA)
- Endocrinology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Toxicology (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Materials For Medical Uses (AREA)
Abstract
在一些方面,本公开涉及用于调节(例如,增加和/或减少)受试者中骨量的组合物和方法。在一些方面,本公开提供了分离的核酸,和例如rAAV载体的载体,其被配置以表达促进(例如,增加)或抑制(例如,减少)某些类型的骨细胞的活性、分化或功能的转基因,这些骨细胞例如成骨细胞、破骨细胞、骨细胞等。在一些实施方案中,本公开描述的分离的核酸和载体可用于治疗与骨量增加(例如骨硬化症)或骨量减少(例如骨质疏松症)有关的病症和病况。
Description
相关申请
根据35U.S.C.§119(e),本申请要求2018年3月23日提交的标题为“用于治疗骨病的基因治疗剂”的美国临时申请号62/647,595,以及2019年2月1日提交的标题为“用于治疗骨病的基因治疗剂”的美国临时申请号62/799,843的优先权。
背景技术
骨代谢的缺陷引起各种不同的骨病,包括与病理学损耗或骨量有关的病症以及与骨量的病理学增加有关的病症。对骨量的影响可能是全身性或局部的。例如,骨质疏松症是以骨量减少为特征的疾病,并且是与衰老有关的脆弱和痛苦的主要来源。估计1000万50岁以上的美国人患有骨质疏松症,并且每年约有150万个体发生与骨质疏松症有关的骨折,具有严重的健康后果。用于骨质疏松症的大多数现有治疗剂抑制破骨细胞(OC)的骨吸收,并且这种抑制伴随着许多副作用,包括非典型性骨折和颌骨坏死。间断应用的甲状旁腺激素(PTH)是合成代谢药剂,其促进成骨细胞(OB)功能并可用于治疗骨质疏松症患者。然而,由于对PTH诱导的骨肿瘤的担心,这种药剂的使用受到限制。此外,一种新开发的合成代谢药物抗骨硬化蛋白抗体通过增强的Wnt信号传递促进OB分化。然而,在炎性关节炎的情况下,已观察到抗骨硬化蛋白抗体在TNF依赖性炎症的情况下增加骨组织破坏并提高中风风险。同样地,归因于升高的中风发病率,组织蛋白酶K的小分子抑制剂(例如奥当卡替)从FDA考量中被撤消。
发明内容
本公开的一些方面涉及用于调节(例如,增加或减少)骨形成和/或新陈代谢的组合物和方法。本公开部分基于编码一种或多种调节骨代谢的转基因的重组腺相关病毒(rAAV)。因此,在一些实施方案中,本公开描述的rAAV可用于治疗与骨代谢失调(例如骨密度降低、骨密度增加等)有关的疾病或病症。
因此,在一些方面,本公开提供了一种分离的核酸,其编码:第一区域,其包含第一腺相关病毒(AAV)反向末端重复(ITR)或其变体;和第二区域,其包含编码至少一种骨代谢调节剂的转基因。
在一些实施方案中,骨代谢调节剂是骨形成促进剂。在一些实施方案中,骨形成促进剂选自由以下组成的组:促进OB和/或骨细胞(OCY)分化或活性的蛋白、抑制OC分化或活性的蛋白以及抑制OC分化或活性的抑制性核酸。
在一些实施方案中,骨代谢调节剂是骨形成抑制剂。在一些实施方案中,骨形成抑制剂选自由以下组成的组:抑制OB和/或OCY分化或活性的蛋白、促进OC分化或活性的蛋白以及抑制OB表达或活性的抑制性核酸。
在一些实施方案中,转基因编码选自由以下组成的组的骨形成促进剂:甲状旁腺激素(PTH)、PTH相关蛋白(PTHrP)、去糖化酶(deglycase)DJ1、靶向骨硬化蛋白(SOST)的抑制性核酸、靶向schnurri-3(SHN3)的抑制性核酸和靶向组织蛋白酶K(CTSK)的抑制性核酸。
在一些实施方案中,转基因编码选自由以下组成的组的骨形成抑制剂:骨硬化蛋白(SOST)、schnurri-3(SHN3)、组织蛋白酶K(CTSK)、靶向甲状旁腺激素(PTH)的抑制性核酸、靶向PTH相关蛋白(PTHrP)的抑制性核酸和靶向去糖化酶DJ1的抑制性核酸。
在一些实施方案中,转基因编码选自由dsRNA、siRNA、shRNA、miRNA和人造miRNA(amiRNA)组成的组的至少一种抑制性核酸。
在一些实施方案中,抑制性核酸起到突变末端重复(mTR)的功能。
在一些实施方案中,转基因包含SEQ ID NO:1-15中任何一个所示的序列。在一些实施方案中,转基因靶向(例如,与之杂交或与之结合)SEQ ID NO:1-15中任何一个所示的序列或其互补序列。
在一些实施方案中,本公开描述的分离的核酸进一步包含与转基因有效连接的至少一个启动子。
在一些实施方案中,本公开描述的分离的核酸进一步包含含有第二AAV ITR或其变体的第三区域。
在一些方面,本公开提供了包含如本公开所述的分离的核酸的载体。在一些实施方案中,载体是质粒。
在一些方面,本公开提供了包含如本公开所述的分离的核酸或载体的宿主细胞。在一些实施方案中,宿主细胞是细菌细胞、酵母细胞、昆虫(例如,Sf9)细胞或哺乳动物细胞。
本公开部分基于以骨细胞如OB、OCY、OC等的向性增加为特征的rAAV。在一些实施方案中,本公开描述的rAAV包含异源骨靶向肽或结合至骨靶向部分。
因此,在一些方面,本公开提供了分离的核酸,其编码包含异源骨靶向肽的重组腺相关病毒(rAAV)衣壳蛋白。在一些实施方案中,异源骨靶向肽靶向OC(例如,相对于OB,尤其或优先靶向OC)。在一些实施方案中,异源骨靶向肽靶向OB(例如,相对于OC,尤其或优先靶向OB)。在一些实施方案中,异源骨靶向肽包含SEQ ID NO:16、17、57、58、59、60、61、62和63中所示的氨基酸序列。
在一些方面,本公开提供了包含一个或多个携带叠氮化物的非天然氨基酸的rAAV衣壳蛋白。在一些实施方案中,衣壳蛋白经由一个或多个携带叠氮化物的非天然氨基酸结合至一个或多个阿仑膦酸盐(Ale)部分。
在一些方面,本公开提供了重组腺相关病毒(rAAV),其包含:衣壳蛋白;和如本公开所述的分离的核酸。
在一些实施方案中,衣壳蛋白的血清型选自AAV1、AAV2、AAV3、AAV4、AAV5、AAV6、AAV6.2、AAV7、AAV8、AAV9、AAV.rh8、AAV.rh10、AAV.rh39、AAV.43、AAV2/2-66、AAV2/2-84和AAV2/2-125,或前述SEQ ID NO:18-34中任何一个的变体。
在一些实施方案中,衣壳蛋白转导OB和/或OCY。在一些实施方案中,衣壳蛋白(例如,转导OB和/或OCY的衣壳蛋白)的血清型选自AAV4、AAV1、AAV6、AAV6.2和AAV9,或前述任何一种的变体。
在一些实施方案中,衣壳蛋白转导OC。在一些实施方案中,衣壳蛋白(例如,转导OC的衣壳蛋白)的血清型选自AAV1、AAV5、AAV6、AAV6.2、AAV7、AAV8、AAV9、AAV10、AAV.rh39和AAV.rh43,或前述任何一种的变体。
在一些实施方案中,衣壳蛋白包含异源骨靶向肽,例如包含SEQ ID NO:16、17、57、58、59、60、61、62和63所示的氨基酸序列的异源骨靶向肽。在一些实施方案中,异源骨靶向肽靶向OC(例如,相对于OB,尤其或优先靶向OC)。在一些实施方案中,异源骨靶向肽靶向OB(例如,相对于OC,尤其或优先靶向OB)。
在一些实施方案中,将编码异源骨靶向肽的核酸序列插入衣壳蛋白的VP2开放阅读框中。在一些实施方案中,将核酸序列插入对应于编码AAV2衣壳蛋白的核酸序列的N587和R588的密码子之间或N末端。在一些实施方案中,将核酸序列插入对应于编码AAV9衣壳蛋白的核酸序列的Q588和A589的密码子之间或N-末端。
在一些实施方案中,衣壳蛋白由具有一个或多个携带叠氮化物的非天然氨基酸的氨基酸序列编码。在一些实施方案中,衣壳蛋白经由一个或多个携带叠氮化物的非天然氨基酸结合至一个或多个阿仑膦酸盐(Ale)部分。
在一些实施方案中,rAAV是自互补AAV(scAAV)。
在一些方面,本公开提供了用于将转基因递送至骨组织的方法,该方法包括施用如本公开所述的分离的核酸、组合物或rAAV给受试者。
在一些方面,本公开提供了用于治疗与骨密度降低有关的疾病或病症的方法,该方法包括施用给患有或怀疑患有如本文所述的与骨密度降低有关的疾病或病症的受试者,其中rAAV的转基因编码骨形成促进剂。在一些实施方案中,骨形成促进剂选自由以下组成的组:促进OB和/或OCY分化或活性的蛋白、抑制OC分化或活性的蛋白和抑制OC分化或活性的抑制性核酸。
在一些实施方案中,骨形成促进剂选自由以下组成的组:甲状旁腺激素(PTH)、PTH相关蛋白(PTHrP)、去糖化酶DJ1、靶向骨硬化蛋白(SOST)的抑制性核酸、靶向schnurri-3(SHN3)的抑制性核酸和靶向组织蛋白酶K(CTSK)的抑制性核酸。
在一些实施方案中,与骨密度降低有关的疾病或病症选自由以下组成的组:骨质疏松症、临界大小骨缺损(critical sized-bone defect)、由废用或受伤引起的机械性病症以及例如乳腺癌或前列腺癌转移的继发性病症、1型糖尿病、狼疮、类风湿性关节炎、炎性肠疾病、甲状腺功能亢进、乳糜泻、哮喘、牙周炎和多发性硬化。
在一些方面,本公开提供了用于治疗与骨密度增加有关的疾病或病症的方法,例如选自由骨硬化症、骨肉瘤和异位骨化组成的组的疾病,该方法包括施用如本文所述的rAAV给患有或怀疑患有与骨密度增加有关的疾病或病症的受试者,其中rAAV的转基因编码骨形成抑制剂。在一些实施方案中,骨形成抑制剂选自由以下组成的组:抑制OB和/或OCY分化或活性的蛋白、促进OC分化或活性的蛋白和抑制OC分化或活性的抑制性核酸。
在一些实施方案中,骨形成抑制剂选自由以下组成的组:骨硬化蛋白(SOST)、schnurri-3(SHN3)、组织蛋白酶K(CTSK)、靶向甲状旁腺激素(PTH)的抑制性核酸、靶向PTH相关蛋白(PTHrP)的抑制性核酸和靶向去糖化酶DJ1的抑制性核酸。
在一些实施方案中,与骨密度降低有关的疾病或病症选自由以下组成的组:骨质疏松症、致密性成骨不全症(pycnodysostosis)、骨硬化症(sclerosteosis)、肢端肥大症、氟蚀病、骨髓纤维化、丙型肝炎相关性骨硬化和骨癌,例如骨肉瘤和转移性骨癌。
在本公开描述的方法的一些实施方案中,施用通过注射而发生。在一些实施方案中,注射是全身注射(例如,尾静脉注射)、局部注射(例如,肌肉内(IM)注射、膝注射或股骨髓内注射)。
在一些实施方案中,施用通过将包含如本公开描述的rAAV的组织或移植物植入受试者而发生。
在一些实施方案中,施用导致选自由OB、OCY、OC和软骨细胞组成的组的细胞类型的转导。
附图简要说明
图1显示了体外转导小鼠原代OB前体的scAAV血清型的鉴定。在出生后第3-5天从新生鼠颅盖分离出小鼠OB前体,并将其培养于生长培养基中以扩增。将细胞与编码GFP蛋白的14种不同scAAV血清型温育2天,并使用表面荧光显微镜术通过GFP表达分析它们的转导效率。
图2显示了体外转导小鼠ATDC5软骨细胞系的scAAV血清型的鉴定。将小鼠软骨细胞祖细胞系ATDC5与编码GFP蛋白的14种不同scAAV血清型温育2天,并使用表面荧光显微镜术通过GFP表达分析它们的转导效率。
图3显示了可体外转导小鼠原代OC的scAAV血清型的鉴定。从2月龄小鼠(C57BL/6J)的长骨分离衍生自骨髓的单核细胞(BM-MO),并通过添加小鼠m M-CSF(40ng/ml)将其扩增。在小鼠M-CSF(40ng/ml)和小鼠Rank配体(10ng/ml)的存在下,将BM-MO与编码GFP蛋白的15种不同scAAV血清型温育6天,并使用表面荧光显微镜术通过GFP表达分析它们的转导效率。
图4显示了可体外转导小鼠Raw264.7 OC系的scAAV血清型的鉴定。在用小鼠Rank配体(5ng/ml)处理后2天,在小鼠Rank配体(5ng/ml)存在下,将Raw264.7细胞与编码GFP蛋白的17种不同scAAV血清型温育6天。使用表面荧光显微镜术通过GFP表达分析它们的转导效率。
图5显示了小鼠中表达GFP的AAV转导的组织的光学图像。将单剂量的PBS或1012~1013/ml个基因组拷贝的编码GFP的scAAV血清型(scAAV4、5、6.2和9)注射到2月龄小鼠(C57BL/6J)的两个膝关节中,并在4周后处死小鼠,并通过IVIS-100光学成像系统(全身,顶部)监测膝关节中的GFP表达。解剖右后肢,并在去除肌肉后通过IVIS-100光学成像系统(后肢,底部)监测GFP表达。
图6A-6B显示了可转导关节软骨中的软骨细胞和/或骨表面的OB和/或OC的scAAV血清型的鉴定。将单剂量的1012-1013/ml个基因组拷贝的编码GFP的scAAV血清型(scAAV4、5、6.2和9)注射到2月龄小鼠(C57BL/6J)的两个膝关节中,并在4周后将膝关节(图6A)和股骨(图6B)冰冻切片以用于组织学。AC:关节软骨,CB:皮质骨,BM:骨髓,比例尺:50μm。
图7显示了脂质体可以通过降低小鼠中scAAV9转导对肌肉的感染力来增强scAAV9转导对骨细胞的选择性。将编码GFP的scAAV9血清型的1012~1013/ml基因组拷贝与PBS或X-tremeGENE(脂质体,Roche)以1:1的比例混合。温育1小时后,将单剂量的混合物注射到2月龄的小鼠(C57BL/6J)的膝关节中。1周后,安乐死小鼠,并通过IVIS-100光学成像系统监测膝关节(左)中的GFP表达。将股骨冰冻切片以用于组织学(右)。CB:皮质骨,M:肌肉。
图8显示了编码GFP的scAAV9血清型可以转导小鼠中骨表面的OB、OC和OCY。将编码GFP的scAAV9血清型的1012~1013/ml个基因组拷贝与PBS或X-tremeGENE(脂质体)以1:1的比例混合。温育1小时后,将单剂量的混合物注射到2月龄小鼠(C57BL/6J)的膝关节中。将单剂量的1012~1013/ml个基因组拷贝的编码GFP的scAAV9血清型注射到2月龄小鼠(C57BL/6J)的膝关节中,并在4周后将股骨冰冻切片以用于组织学,并且通过共聚焦显微镜观察GFP表达。高倍(high-powered)照片显示了用编码GFP的scAAV9血清型与X-tremeGENE的混合物处理的股骨中scAAV9转导的OB、OC和OCY(底部)。通过相差显微镜观察到皮质骨中的GFP表达(左)。GP:生长板(growth plate),TB:小梁骨,CB:皮质骨,BM:骨髓;比例尺:50μm。
图9显示了骨探查AAV载体的开发。(A)通过遗传操作将骨靶向肽DSS((AspSerSer)6或HABP)或(CγEPRRγEVAγELγEPRRγEVAγEL)插入VP2衣壳蛋白中。(B)将WT AAV载体用携带叠氮化物的氨基酸以位点特异的方式标记,然后附着上骨探查分子(ADIBO-Ale)。
图10的图描绘了具有骨靶向肽的VP2衣壳蛋白(方框;(AspSerSer)6,DSS)。通过遗传操作将DSS插入VP2衣壳蛋白的Q588和A589之间或N端。
图11A-11C显示了OB中DSS-scAAV9的体外特征化。将小鼠OB前体与scAAV9-WT(WT)或两种DSS-scAAV9(DSS-588、DSS-Nter)温育2天。使用抗GFP的western印迹(图11A)和表面荧光(图11B,左)通过GFP表达分析它们的转导效率。使用Hsp90作为上样对照。或者,将转导的OB在OB分化条件下培养6天,并通过碱性磷酸酶(ALK)染色评估OB分化(图11B,右),并通过RT-PCR评估OB基因表达(标准化为Hprt,图11C)。N.S.:不显著。
图12A-12C显示了OC中DSS-scAAV9的体外特征化。用小鼠Rank配体(5ng/ml)处理后2天,用scAAV9-WT(WT)或两种DSS-scAAV9(DSS-588、DSS-Nter)处理Raw264.7。转导后2天,使用抗GFP抗体的western印迹(图12A)和表面荧光(图12B,左)通过GFP表达来分析它们的转导效率。在Rank配体存在下培养转导的OC,并在3天后通过TRAP染色评估OC分化(图12B,右),并通过RT-PCR评估OC基因表达(标准化为Hprt,图12C)。N.S:不显著。
图13显示了DSS-scAAV9(Nter)可以转导小鼠中骨表面的OB、OC和OCY。将编码GFP的scAAV9-WT(WT)或两种DSS-scAAV9(DSS-588、DSS-Nter)的1011~1012/ml个基因组拷贝与X-tremeGENE(脂质体)以1:1的比例混合。温育1小时后,将单剂量的混合物注射到2月龄小鼠(C57BL/6J)的膝关节中。1周后,将股骨冰冻切片以用于组织学,并通过共聚焦显微镜观察GFP表达。高倍照片显示了用编码GFP的scAAV9血清型与X-tremeGENE的混合物处理的股骨中scAAV9转导的OB、OC和OCY(底部)。GP:生长板,CB:皮质骨,BM:骨髓;GFP:绿色,DAPI:蓝色。
图14显示了成熟OB中SHN3的瞬时缺失增加了成年小鼠的骨量。将1月龄雌性Shn3-fl/fl(WT)或Shn3-fl/fl;OCN/ERT-cre(CKO)小鼠用他莫昔芬(50mg/kg)处理5天,并在6周后通过microCT分析测量骨量。显示的是小梁骨的3D重建(左),且定量参数显示在右图中:骨体积/总体积(BV/TV)。**:P,0.005。
图15显示了SHN3缺失防止了小鼠中雌激素缺乏诱导的骨质流失。3月龄雌性小鼠经历了卵巢切除(OVX)手术或经历了假的手术(假手术),并在手术后2个月通过microCT分析测量骨量。显示的是小梁骨(左上)和干体中间皮质骨(左下)的3D重建。定量参数显示在右图中:骨体积/总体积(BV/TV)。**:P,0.005,N.S:不显著。
图16A-16D显示了OB中scAAV9-mSHN3i的体外特征化。用编码scAAV9的对照载体(对照)或两种小鼠-SHN3 shRNAsi(Sh-SHN3-1、-2)处理小鼠原代颅盖OB。转导后3天,分别通过使用表面荧光的GFP表达和使用RT-PCR的SHN3 mRNA水平分析它们的转导效率(图13A)和敲低效率(图13B)。(图13C和13D)在OB分化条件下培养转导的OB,并在培养的第6天和第15天进行RT-PCR和茜素红染色。*:P,0.05,**:P,0.005。
图17A-17B显示了scAAV9-mSHN3i的体内特征化。将编码GFP的scAAV9(对照,Sh-SHN3-1)的1012~1013/ml基因组拷贝与X-tremeGENE(脂质体)以1:1的比例混合。温育1小时后,将单剂量的混合物注射到2月龄小鼠(C57BL/6J)的膝关节中。1周后,将股骨冰冻切片以用于组织学,并通过共聚焦显微镜观察GFP表达。高倍照片显示了股骨中表达GFP的OB和OCY,表明了:与对照-scAAV9载体相似,Sh-SHN3-1scAAV9载体可以转导骨中的OB和OCY(图17A)。用机械和酶消解(2型胶原酶和中性蛋白酶)处理股骨,以分离BMSC。使用FACS分选从BMSC中进一步分离出表达GFP的细胞,并将其用于RT-PCR分析以测量SHN3 mRNA水平(图17B)。CB:皮质骨,BM:骨髓,TB:小梁骨。
图18A-18D显示了OC中scAAV9-mCTSKi的体外特征化。用小鼠Rank配体(5ng/ml)处理后2天,用scAAV9-对照(对照)或两种scAAV9-mCTSKi(Sh-CTSK-1、-2)处理Raw264.7。转导后2天,通过使用表面荧光的GFP表达和使用RT-PCR的CTSK mRNA水平分别分析它们的转导效率(图18A)和敲低效率(图18B)。图18C-18D显示了在Rank配体存在下培养转导的OB,并在3天后通过TRAP活性(图18C,顶部)和染色(图18C,底部)评估OC分化,并通过RT-PCR评估OC基因表达(标准化为Hprt,图18D)。*:P,0.05,**:P,0.005。
图19A-19B显示了scAAV9-mCTSKi的体内表征。将编码GFP的scAAV9(对照,Sh-CTSK-1)的1012~1013/ml基因组拷贝与X-tremeGENE(脂质体)以1:1的比例混合。温育1小时后,将单剂量的混合物注射到2月龄小鼠(C57BL/6J)的膝关节中。1周后,将股骨冰冻切片以用于组织学,并通过共聚焦显微镜观察GFP表达。高倍图片显示了股骨中scAAV9转导的OB和OC(图19A)。将冰冻切片的股骨用抗CTSK抗体染色以评估表达GFP的OC中的CTSK表达。使用IgG抗体作为阴性对照。高倍照片显示了在用scAAV9-mCTSKi转导的表达GFP的OC中CTSK表达的降低(图19B)。GP:生长板,CB:皮质骨,BM:骨髓,TB:小梁骨;GFP:绿色,DAPI:蓝色,CTSK:红色。
图20显示了骨靶向scAAV9介导的基因沉默的策略。将对OB基因(SHN3i、SOSTi)或对OC基因(CTSKi)特异的ShRNA克隆到BT-scAAV9血清型(DSS或HABP-scAAV9、Ale-scAAV9)中。将这些scAAV9血清型注射到小鼠的髓内股骨中以进行局部递送。对于全身递送,将它们IP或IV注射到小鼠中以沉默OB或骨细胞中的SHN3或SOST表达,或以沉默骨表面OC中的CTSK表达。
图21显示了用于全身生产的AAV介导的基因添加。将人PTH(1-84aa)、人PTHrP(1-140aa)或小鼠DJ-1cDNA克隆到scAAV9载体中,并将它们肌肉内注射到小鼠中以进行全身表达。
图22A-22G显示了体外和体内转导骨细胞的scAAV载体。图22A和22B显示了用PBS或用相同CB-Egfp转基因包装的14种不同的AAV衣壳处理颅骨成骨细胞(COB)、衍生自骨髓的破骨细胞前体(BM-OCP)或软骨细胞(ATDC5)。两天后,通过抗GFP抗体的免疫印迹评估EGFP表达。使用抗Hsp90抗体作为上样对照。通过Image J软件以内源性Hsp90蛋白水平百分比测量EGFP蛋白的免疫印迹定量。图22C显示了将单剂量的1x1011个基因组拷贝的scAAV关节内(i.a.)注射到两月龄雄性小鼠的膝关节中,并且通过IVIS-100光学成像监测后肢中的EGFP表达。图22D显示了将股骨冰冻切片并通过荧光显微镜术评估EGFP表达。图22E和22F显示了表达EGFP的成骨细胞(OB)、骨细胞(OCY)和成熟破骨细胞(OC)的高倍图像。图22G还用抗BgIap抗体对冰冻切片的股骨免疫染色,以鉴定成熟破骨细胞。TB,小梁骨;BM,骨髓;GP,生长板;CB,皮质骨。比例尺:500μm(图22D);100μm(图22E);75μm(左)和25μm(中,右)(图22F);和25μm(图22G)。
图23A-23K显示了成骨细胞中Shn3的诱导性缺失增加成年小鼠的骨增长(boneaccrual)。在图23A-23D中,将单剂量的4×1011个基因组拷贝的scAAV9-Egfp静脉内(i.v.)注射到两月龄雄性小鼠中。图23A显示了在注射后两周通过IVIS-100光学成像监测的个体组织中的EGFP表达。y轴,辐射效率(p/sec/cm2/sr/μW/cm2)。图23B和23C显示了在冰冻切片的心脏和肝脏(23B)和股骨(23C,右为高倍)中的EGFP表达。图23D是用抗EGFP抗体进行的组织裂解物的免疫印迹。在图23E-23G中,用100mg/kg他莫昔芬处理两月龄雌性Ocn-Ert;RosamT/mG和Shn3Ocn-Ert;RosamT/mG小鼠连续5天。在图23E中,两个月后将股骨横切以鉴定表达EGFP的成骨细胞。图23F和23G显示了通过microCT(图23F)和相对定量(图23G)评估的股骨小梁骨量的代表性3D构建。小梁骨体积/总体积(Tb.BV/TV)、小梁厚度(Tb.Th)、每立方毫米的小梁数(Tb.N)和小梁间隔(Tb.Sp)(n=6/组)。在图23H-23K中,将单剂量的4×1011个基因组拷贝的scAAV9-Egfp或scAAV9-Cre i.v.注射到三月龄雄性Shn3fl/fl;RosamTmG小鼠中。图23H显示了治疗后两个月的胫骨骨RNA中的Cre和Shn3 mRNA水平并标准化为Hprt表达。图23I显示了冰冻切片的股骨上的荧光显微镜术以鉴定表达EGFP的细胞(图23I),并且通过microCT评估股骨小梁骨量。图23J表示了代表性3D重构,且图23K显示了相对定量。小梁骨体积/总体积(Tb.BV/TV)、小梁厚度(Tb.Th)、每立方毫米的小梁数(Tb.N)和连续密度(Conn.Dn)(n=6/组)。比例尺:50μm(23B);500μm(左),75μm(右)(23C);25μm(23E);1mm(23F和23J);250μm(23I)。数值代表平均值±标准偏差:*,P<0.05;**,P<0.01;和***,P<0.001,通过未配对两尾学生t检验(23G、23H和23K)。
图24A-24K显示了通过全身递送的AAV9进行的SHN3沉默促进骨形成。图24A的图显示了含有CMV增强子/鸡β-肌动蛋白启动子(CB)、amiR-ctrl或amiR-shn3、Egfp报告基因(EGFP)、β-珠蛋白polyA序列(PA)和反向末端重复(ITR)的scAAV9构建体。在图24B-24D中,在将编码amiR-ctrl或amiR-shn3的scAAV9关节内(i.a.)注射到两月龄雄性小鼠的膝关节两周后,通过IVIS 100光学成像(图24B)和冰冻切片的股骨的荧光显微镜术(图24C)评估EGFP表达。在图24D中,在来自股骨的以荧光激活细胞分选术(FACS)分选的表达EGFP的细胞中评估标准化为hprt的EGFP蛋白水平(顶部)和shn3 mRNA水平(底部)。在图24E-24F中,在将携带amiR-ctrl或amiR-shn3的scAAV9 i.a.注射到两月龄雌性小鼠的膝关节中两个月后,通过microCT评估股骨小梁骨量。显示了代表性3D重建(图24E)和相对定量(图24F)(n=6/组)。在图24G-24K中,将单剂量的4×1011个基因组拷贝的编码amiR-ctrl或amiR-shn3的AAV9i.v.注射到三月龄雌性小鼠中。两个月后,测量胫骨RNA中的shn3 mRNA水平并标准化为hprt(图24G,n=8/组)。通过microCT测量股骨小梁骨量。显示了代表性3D重建(图24H)和相对定量(图24I)(n=8/组)。显示了代表性的钙黄绿素/茜素红标记(图24J)和BFR/BS、MAR和Ob.S/BS的相对组织形态定量(图24K)。箭头表明钙黄绿素和茜素红标记之间的距离。BFR/BS,骨形成率/骨表面;MAR,矿物质沉积率;Ob.S/BS,成骨细胞表面/骨表面。GP,生长板;BM,骨髓;TB,小梁骨。比例尺:250μm(图24C);1mm(图24E和24H);50μm(图24J)。数值代表平均值±SD:**,P<0.01;***,P<0.001;和****,P<0.0001,通过未配对两尾学生t检验(图24F、24G、24I和24K)。
图25A-25J显示了通过全身递送的AAV9的Shn3沉默防止绝经后骨质疏松症的小鼠模型中的骨质流失。图25A-25B显示了在三月龄雌性Shn3+/+和Shn3-/-小鼠上实施假手术或OVX手术,并在两个月后通过microCT评估股骨小梁骨量。显示了股骨(图25A)和相对BV/TV(图25B)的代表性图像(n=6/组)。图25C的图显示了研究和处理方法。在三月龄雌性小鼠上实施假手术或OVX手术,并在六周后i.v.注射单剂量的4×1011个基因组拷贝的携带amiR-ctrl或amiR-shn3的scAAV9。注射后七周,将股骨冰冻切片以鉴定表达EGFP的细胞(图25D)。在标准化为hprt后,显示胫骨中的shn3 mRNA水平(n=8-12/组)(图25E)。通过microCT评估股骨小梁骨量。显示了代表性3D重建(图25F)和相对定量(图25G)(n=7-8/组)。钙黄绿素/茜素红标记(图25H)和BFR/BS和MAR的相对组织形态定量(图25I)的代表性图片。箭头表明钙黄绿素和茜素红标记之间的距离。对包括弯曲刚度、弯曲力矩、表观弯曲模量和表观弯曲应力在内的股骨生物力学性质进行定量(n=5-9/组)(图25J)。比例尺:1mm(25A和25F);250μm(图25D);和50μm(图25H)。数值代表平均值±SD:N.S.,不显著;*,P<0.05;**,P<0.01;***,P<0.001;和****,P<0.0001,通过未配对两尾学生t检验(图25B)和单向ANOVA检验(图25E、25G、25I和25J)。
图26A-26M:骨归巢(bone-homing)AAV9。DSS-Nter衣壳介导Shn3沉默,以防止绝经后骨质疏松症的小鼠模型的骨质流失。图26A的图是合理设计的骨特异的AAV衣壳的构建体。将骨靶向肽基序(DSS,红色)插入AAV9衣壳的Q588和A589之间(DSS-588)或AAV9-VP2的N端(DSS-Nter)。cap:衣壳蛋白。图26B和26C显示了在感染不同浓度的scAAV9、scAAV9.DSS-587或scAAV9.DSS-Nter后两天,在成骨条件下培养COB六天。通过用抗EGFP抗体进行的免疫印迹(图26B)或荧光显微镜术(图26C)评估EGFP表达。通过快蓝染色评估ALP活性(图26C)。图26D-26H显示了将单剂量的4×1011个基因组拷贝的scAAV9或scAAV9.DSS-Nteri.v.注射到两月龄雄性小鼠中。在注射后两周通过IVIS-100光学成像监测个体组织中的EGFP表达(图26D)。免疫印迹显示了组织裂解物中的EGFP表达(图26E)和通过Image J软件进行的相对定量(图26F,n=3/组)。在冰冻切片的股骨上进行荧光显微镜术以鉴定表达EGFP的细胞(图26G),并通过Image J软件定量股骨中每个骨表面的表达EGFP的细胞数量(图26H,n=5/组)。(图26I-26M)显示了在三月龄雌性小鼠上实施假手术或OVX手术。六周后,i.v.注射单剂量的4×1011个基因组拷贝的携带amiR-ctrl或amiR-shn3的scAAV9.DSS-Nter。注射后7周,评估胫骨中的shn3 mRNA水平(图26I,n=10/组)。通过microCT评估股骨和腰椎中的小梁骨量。显示了定量(图26J和26M)和代表性3D重建(图26K和26L)(n=6-8/组)。GP,生长板;BM,骨髓;TB,小梁骨。比例尺:100μm,(图26C和26G);1mm(图26K和26L)。数值代表平均值±SD:N.S.,不显著;*,P<0.05;**,P<0.01;***,P<0.001;和****,p<0.0001,通过未配对双尾学生t检验(图26F和26H)和单向ANOVA检验(图26I、26J和26M)。
图27A-27C显示了体外转导成骨细胞、破骨细胞和软骨细胞的scAAV血清型的鉴定。用PBS或14种不同的AAV血清型处理颅骨成骨细胞(COB,图27A)、衍生自骨髓的破骨细胞前体(BM-OCP,图27B)或软骨细胞系(ATDC5,图27C)。两天后,通过荧光显微镜术监测EGFP表达。比例尺:100μm。
图28A-28B显示了转导骨和软骨的scAAV血清型的鉴定。将单剂量的PBS或1x1011个基因组拷贝的scAAV9-EGFP关节内(i.a.)注射到两月龄雄性小鼠的膝关节中。将膝关节(图28A)和股骨(图28B)冰冻切片以鉴定表达EGFP的细胞。使用DAPI染色细胞核。AC,关节软骨;M,肌肉;CB,皮质骨;BM,骨髓。比例尺:100μm,图(图28A;250μm,图28B)。
图29A-29D显示了小鼠中全身递送的scAAV9的组织分布。图29A和29B显示了将单剂量的PBS或4×1011个基因组拷贝的scAAV9-EGFP静脉内(iv)注射到两月龄雄性小鼠中,并且在注射后两周通过IVIS-100光学成像监测EGFP表达。显示了全身中的EGFP表达(图29A)和在图28A中显示的解剖组织中的EGFP表达的定量(图29B)。使用PBS注射作为阴性对照。图29C和29D显示了将解剖自注射了PBS或rAAV9-EGFP的小鼠的组织冰冻切片以定位表达EGFP的细胞。比例尺:100μm,图29C;500μm,图29D。
图30显示了股骨中全身递送的scAAV9的分布。将单剂量的4×1011个基因组拷贝的scAAV-EGFP i.v.注射到两月龄雄性小鼠中,并在注射后两周在冰冻切片的股骨中评估EGFP表达。L,韧带;GP,生长板;AC,关节软骨;BM,骨髓;CB,皮质骨;P,髌骨;M,肌肉。比例尺:100μm。
图31A-31E显示了Shn3fl/fl成骨细胞中scAAV9-Cre的体外特征化。图31A的图显示了含有CMV增强子/鸡β-肌动蛋白启动子(CB)、EGFP报告基因(EGFP)或Cre重组酶(Cre)、β-珠蛋白polyA序列(PA)和反向末端重复(ITR)的rAAV9构建体。图31B显示了用scAAV9-EGFP或scAAV9-Cre感染COB两天,且裂解细胞并用指定抗体进行免疫印迹。图31C-31E显示了在用scAAV9-EGFP或scAAV9-Cre处理后两天,在成骨条件下培养COB六天,并通过RT-PCR测量Shn3(图31C)和成骨基因(图31D)的mRNA水平。培养21天后,通过茜素红染色评估矿化作用(图31E)。数值代表平均值±SD:***,P<0.001,通过未配对两尾学生t检验(图31C和31D)。
图32A-32C显示了成骨细胞中携带amiR-shn3的scAAV9的体外特征化。用携带amiR-ctrl或amiR-shn3的scAAV9处理后两天,在成骨条件下培养COB。分别通过荧光显微镜术、RT-PCR和茜素红染色评估EGFP表达(图32A)、Shn3和成骨基因的mRNA水平(图32B)和矿化作用(图32C)。比例尺:100mm(图32A)。数值代表平均值±SD:*,P<0.05;***,P<0.001;和****,P<0.0001,通过未配对两尾学生t检验(图32B和32C)。
图33A-33F显示了用全身递送的携带amiR-shn3的scAAV9处理的小鼠的特征化。将单剂量的4×1011个基因组拷贝的携带amiR-ctrl或amiR-shn3的scAAV9 i.v.注射到三月龄雌性小鼠中。治疗后两个月,用钙黄绿素和茜素红标记小鼠以用于动态组织形态测定。使用未标记的小鼠以使用IVIS-100光学成像监测EGFP表达。显示了全身(图33A)和解剖组织(图33B)中的EGFP表达。将股骨冰冻切片以鉴定表达EGFP的成骨细胞谱系细胞(图33C)。来自用携带amiR-ctrl或amiR-shn3的scAAV9处理的五月龄雌性小鼠的股骨(n=6-7)的TRAP染色的纵剖面(图33D)和组织形态测定分析(图33E)。每骨周的破骨细胞数(N.Oc/B.Pm)。通过EFISA评估血清CTX水平(n=6)(图33F)。比例尺:100μm,图33C;50mm,图33D。数值代表平均值±SD;N.S.,不显著,通过未配对两尾学生t检验(图33E和33F)。
图34A-34C显示了绝经后骨质疏松症的小鼠模型中全身递送的scAAV9-amiR-shn3的治疗效果。在三月龄雌性小鼠上实施假手术或OVX手术,并在六周后i.v.注射单剂量的4×1011个基因组拷贝的携带amiR-ctrl或amiR-shn3的scAAV9。注射后七周,用钙黄绿素和茜素红标记小鼠以用于动态组织形态测定。在来自用携带amiR-ctrl或amiR-shn3的scAAV9处理的五月龄雌性OVX小鼠的股骨的纵剖面上实施Von Kossa(图34A)或TRAP(图34B)染色。通过ELISA评估血清CTX水平(n=7)(图34C)。比例尺:1mm(图34A);50mm(图34B)。数值代表平均值±SD;NS,不显著,***,P<0.001和****,P<0.0001,通过未配对两尾学生t检验(图34C)。
图35A-35C显示了在体外或体内的scAAV9.DSS载体的特征化。(图35A)将单剂量的1×1011个基因组拷贝的scAAV9-Egfp、scAAV9.DSS-588-Egfp或rAAV9.DSS-Nter-Egfp i.a.注射到两月龄雄性小鼠的膝关节中,并在注射后两周将股骨冰冻切片以鉴定表达EGFP的细胞。GP,生长板;CB,皮质骨;BM,骨髓。比例尺:500μm,图35A。图35B和35C显示了用scAAV9-Egfp、scAAV9.DSS-588-Egfp或scAAV9.DSS-Nter-Egfp感染后两天,在成骨条件下培养COB六天。通过ALP活性(图35B)和成骨基因表达(图35C)评估成骨细胞的分化。数值代表平均值±SD:N.S,不显著,通过单向ANOVA检验(图35B和35C)。
图36A-36E显示了小鼠中全身递送的scAAV9.DSS-Nter的组织分布。将单剂量的PBS或4×1011个基因组拷贝的scAAV9、scAAV9.DSS-588或scAAV9.DSS-Nter i.v.注射到两月龄雄性小鼠中,并在注射后两周使用IVIS-100光学成像监测EGFP表达。显示了在全身中的EGFP表达(图36A)和在解剖组织中的EGFP表达的定量(图36B)。将心脏(图36C)、肝(图36D)和腰椎(图36E)冰冻切片以鉴定表达EGFP的细胞。GP,生长板;BM,骨髓。比例尺:100μm(图36C、36D和36E)。数值代表平均值±SD:*,P<0.05;**,P<0.01和***,P<0.001,通过单向ANOVA检验(图36B)。
图37A-37C显示了在绝经后骨质疏松症的小鼠模型中全身递送的携带amiR-shn3的scAAV9.DSS-Nter的治疗效果。在三月龄雌性小鼠上实施假手术或OVX手术,并在六周后i.v.注射单剂量的PBS或4×1011个基因组拷贝的携带amiR-ctrl或amiR-shn3的scAAV9.DSS-Nter。注射后七周,通过IVIS-100光学成像监测EGFP表达(图37A)。通过荧光显微镜术鉴定冰冻切片的股骨中的表达EGFP的细胞(图37B)。通过microCT评估腰椎中的小梁骨量,并显示定量(n=7-8/组)(图37C)。每立方毫米的小梁数(Tb.N)、小梁厚度(Tb.Th)和小梁间距(Tb.Sp)。TB,小梁骨;BM,骨髓。比例尺:100mm,图b。数值代表平均值±SD:N.S,不显著;*,P<0.05;**,P<0.01;***,P<0.001,通过单向ANOVA检验(图37C)。
具体实施方式
本公开的一些方面涉及组合物(例如,分离的核酸,rAAV等),该组合物在被递送至受试者时有效地调节骨代谢,例如通过促进或抑制骨形成和/或促进或抑制骨吸收。因此,本公开描述的方法和组合物在一些实施方案中可用于治疗与骨代谢失调有关的疾病和病症,例如骨质疏松症、炎症引起的骨质流失、乳腺癌或前列腺癌转移引起的骨质流失、骨硬化症、骨肉瘤和异养性骨化。
分离的核酸
本公开中提供了用于将转基因(例如抑制性RNA,如shRNA、miRNA等)递送至受试者的组合物和方法。组合物通常包含编码能够调节骨代谢的转基因(例如蛋白、抑制性核酸等)的分离的核酸。例如,在一些实施方案中,转基因降低靶蛋白的表达,例如与促进或抑制骨形成有关的靶蛋白。
“骨代谢”通常指涉及骨形成和/或骨吸收的生物过程。在一些实施方案中,骨代谢涉及产生自成骨细胞(OB)和分化的骨细胞的新骨的形成,和/或被破骨细胞(OC)吸收的成熟骨组织。OB源自衍生自骨髓的间充质细胞,这些间充质细胞最终末期分化为骨细胞。OB(和骨细胞)的功能或活性包括但不限于骨形成、骨矿化作用和OC活性的调控。已经观察到骨量减少由OB和/或骨细胞功能或活性的抑制导致。已经观察到骨量增加由OB和/或骨细胞功能或活性的增加导致。OC源自衍生自骨髓的单核细胞,并且在一些实施方案中已经观察到OC由来自OB的信号控制。OC的功能包括骨吸收。在一些实施方案中,已经观察到骨量减少由OC活性的增加导致。在一些实施方案中,已经观察到骨量增加由OC活性的抑制导致。
在一些实施方案中,本公开描述的分离的核酸或rAAV包含编码至少一种骨代谢调节剂(例如,1种、2种、3种、4种、5种、6种、7种、8种、9种、10种或更多种骨代谢调节剂)的转基因。如本文所用,“骨代谢调节剂”指诱导或抑制骨形成或沉积的分子(由核酸如转基因编码的核酸或蛋白),例如通过增加或减少涉及骨形成或骨吸收的蛋白、细胞等的表达、活性和/或功能。通常,骨代谢调节剂可以是肽、蛋白或干扰核酸(例如,dsRNA、siRNA、shRNA、miRNA、人工miRNA等)。在一些实施方案中,骨代谢调节剂是骨形成诱导剂。在一些实施方案中,骨代谢调节剂是骨形成抑制剂。
“骨形成诱导剂”指通过促进OB和/或骨细胞(OCY)分化或活性和/或通过抑制OC活性来促进骨合成的分子。在一些实施方案中,骨形成诱导剂是核酸(例如,RNAi寡核苷酸或miRNA寡核苷酸或反义寡核苷酸)或由核酸(例如转基因)编码的蛋白,其促进OB和/或骨细胞的功能或活性(例如,骨形成、矿化作用、破骨细胞活性或功能的调控等)。在一些实施方案中,促进OB和/或骨细胞的活性或功能的骨形成诱导剂的示例包括但不限于甲状旁腺激素(PTH)、PTH相关蛋白(PTHrP)、去糖化酶DJ1。在一些实施方案中,骨形成诱导剂是抑制OC分化或活性的抑制性核酸,如靶向骨硬化蛋白(SOST)、schnurri-3(SHN3)、组织蛋白酶K(CTSK)等的抑制性核酸。
“骨形成抑制剂”指抑制OB和/或骨细胞分化或活性和/或增加OC分化、活性或功能的分子。在一些实施方案中,骨形成抑制剂是核酸(例如RNAi寡核苷酸或miRNA寡核苷酸或反义寡核苷酸)或由核酸(例如转基因)编码的蛋白,其抑制OB和/或骨细胞分化或活性。在一些实施方案中,抑制OB和/或骨细胞活性或功能的骨形成抑制剂的示例包括但不限于MAPK抑制剂和促炎细胞因子(例如,肿瘤坏死因子α(TNF-α)等)。在一些实施方案中,骨形成抑制剂是抑制OB和/或骨细胞分化或活性的抑制性核酸。
在一些实施方案中,分离的核酸编码一种或多种(例如1种、2种、3种、4种、5种、6种、7种、8种、9种、10种或更多种)抑制性核酸,例如dsRNA、siRNA、shRNA、miRNA、人工microRNA(ami-RNA)等。通常,抑制性核酸特异性结合(例如,与之杂交)编码与骨代谢有关的基因产物(例如蛋白)的基因(例如PTH、PTHrP、DJ1、SOST、SHN3、CTSK等)的至少两个(例如2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个、18个、19个、20个、21个、22个、23个、24个、25个或更多个)连续碱基。如本文所用,“连续碱基”指相互共价结合(例如,通过一个或多个磷酸二酯键等)的两个或更多个核苷酸碱基(例如作为核酸分子的一部分)。在一些实施方案中,该至少一种抑制性核酸与编码与骨代谢有关的基因产物(例如蛋白)的基因(例如PTH、PTHrP、DJ1、SOST、SHN3、CTSK等)的两个或更多个(例如2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个、18个、19个、20个、21个、22个、23个、24个、25个或更多个)连续碱基的同一性为约50%、约60%、约70%、约80%、约90%、约95%、约99%或约100%。
“microRNA”或“miRNA”是能够介导转录或翻译后基因沉默的小的非编码RNA分子。通常,miRNA被转录为发夹或茎环(例如,具有自互补性,单链主链)双链体结构,被称为初级miRNA(pri-miRNA),其被酶加工(例如,通过Drosha、DGCR8、Pasha等)成pre-miRNA。pri-miRNA的长度可以变化。在一些实施方案中,pri-miRNA的长度范围从约100个至约5000个碱基对(例如,约100个、约200个、约500个、约1000个、约1200个、约1500个、约1800个或约2000个碱基对)。在一些实施方案中,pri-miRNA的长度大于200个碱基对(例如,长度为2500个、5000个、7000个、9000个或更多个碱基对)。
也以发夹或茎环双链体结构为特征的pre-miRNA的长度也可以变化。在一些实施方案中,pre-miRNA长度的大小范围从约40个碱基对至约500个碱基对。在一些实施方案中,pre-miRNA长度的大小范围从约50个至100个碱基对。在一些实施方案中,pre-miRNA长度的大小范围从约50个至约90个碱基对(例如,长度为约50个、约52个、约54个、约56个、约58个、约60个、约62个、约64个、约66个、约68个、约70个、约72个、约74个、约76个、约78个、约80个、约82个、约84个、约86个、约88个或约90个碱基对)。
通常,pre-miRNA被输出到细胞质中,并经Dicer酶加工以首先产生不完美的miRNA/miRNA*双链体,并随后产生单链成熟miRNA分子,随后将其装载到RNA诱导的沉默复合体(RISC)中。通常,成熟miRNA分子长度的大小范围从约19个至约30个碱基对。在一些实施方案中,成熟miRNA分子的长度是约19个、约20个、约21个、约22个、约23个、约24个、约25个、约26个、约27个、约28个、约29个或30个碱基对。
在一些方面,本公开提供了编码一种或多种人工miRNA的分离的核酸和载体(例如,rAAV载体)。如本文所用,“人工miRNA”或“amiRNA”指内源pri-miRNA或pre-miRNA(例如,miRNA主链,其是能够产生功能性成熟miRNA的前体miRNA),其中miRNA和miRNA*(例如,miRNA双链体的过客链)序列已被指导靶基因的高效RNA沉默的相应amiRNA/amiRNA*序列所替代,例如Eamens等人(2014),Methods Mol.Biol.1062:211-224中所描述的。例如,在一些实施方案中,人工miRNA包含miR-155pri-miRNA主链,其中编码骨代谢调节(例如,骨形成抑制剂)miRNA的序列已被插入以替代内源miR-155成熟miRNA编码序列。在一些实施方案中,本公开所述的miRNA(例如人工miRNA)包含miR-155主链序列、miR-30主链序列、mir-64主链序列或miR-122主链序列。
在一些实施方案中,本公开提供了分离的核酸,其包含编码靶向SHN3基因(GeneID:59269)的人工microRNA的转基因,该SHN3基因编码Schnurri-3蛋白。Schnurri-3(SHN3)蛋白是调控NK-κβ蛋白表达以及免疫球蛋白和T细胞受体抗体重组的转录因子。在一些实施方案中,SHN3基因由NCBI登录号NM_001127714.2或NM_024503.5代表。在一些实施方案中,SHN3蛋白由NCBI登录号NP_001121186.1或NP_078779.2代表。
在一些方面,本公开涉及包含编码人工microRNA的转基因的分离的核酸,其用于减少SHN3表达(例如,来自SHN3基因的一种或多种基因产物的表达,例如由SEQ ID NO:69中核苷酸序列编码的mRNA或编码具有SEQ ID NO:70所示氨基酸序列的蛋白的那个)。
在一些实施方案中,人工microRNA靶向(例如,与之结合或包含与之互补的区域)SHN3基因的至少6个连续核苷酸。在一些实施方案中,人工microRNA靶向(例如,与之结合或包含与之互补的区域)SHN3基因的6个至30个连续核苷酸。在一些实施方案中,人工microRNA靶向SHN3基因的12个至24个连续核苷酸。在一些实施方案中,人工microRNA靶向SHN3基因的9个至27个连续核苷酸。在一些实施方案中,人工microRNA靶向SHN3基因的至少6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个、18个、19个、20个、21个、22个、23个、24个、25个、26个、27个、28个、29个或30个连续核苷酸。
在一些实施方案中,人工microRNA的长度在6个至50个核苷酸之间。在一些实施方案中,人工microRNA的长度在8个至24个核苷酸之间。在一些实施方案中,人工microRNA的长度在12个至36个核苷酸之间。在一些实施方案中,人工microRNA的长度是6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个、18个、19个、20个、21个、22个、23个、24个、25个、26个、27个、28个、29个、30个、31个、32个、33个、34个、35个、36个、37个、38个、39个、40个、41个、42个、43个、44个、45个、46个、47个、48个、49个或50个核苷酸。
在一些实施方案中,分离的抑制性核酸使靶基因的表达降低50%至99%(例如,50%至99%之间的任何整数,包含端值)。在一些方面,分离的抑制性核酸使靶基因的表达降低75%至90%。在一些方面,分离的抑制性核酸使靶基因的表达降低80%至99%。在一些实施方案中,分离的抑制性核酸使SHN3基因的表达降低50%至99%(例如,50%至99%之间的任何整数,包含端值)。在一些实施方案中,分离的抑制性核酸使SHN3基因的表达降低75%至90%。在一些方面,分离的抑制性核酸使SHN3基因的表达降低80%至99%。
包含转基因的区域(例如,第二区域、第三区域、第四区域等)可以被置于分离的核酸的任何合适的位置。该区域可以被置于核酸的任何非翻译部分,包括例如内含子、5’或3’非翻译区域等。
在一些情况下,将该区域(例如,第二区域、第三区域、第四区域等)置于编码蛋白的核酸序列(例如蛋白编码序列)的第一密码子的上游可以是合意的。例如,该区域可以被置于蛋白编码序列的第一密码子和第一密码子上游2000个核苷酸之间。该区域可以被置于蛋白编码序列的第一密码子和第一密码子上游1000个核苷酸之间。该区域可以被置于蛋白编码序列的第一密码子和第一密码子上游500个核苷酸之间。该区域可以被置于蛋白编码序列的第一密码子和第一密码子上游250个核苷酸之间。该区域可以被置于蛋白编码序列的第一密码子和第一密码子上游150个核苷酸之间。
在一些情况下(例如当转基因缺乏蛋白编码序列时),将该区域(例如,第二区域、第三区域、第四区域等)置于转基因的poly-A尾的上游可以是合意的。例如,该区域可以被置于poly-A尾的第一碱基和第一碱基上游2000个核苷酸之间。该区域可以被置于poly-A尾的第一碱基和第一碱基上游1000个核苷酸之间。该区域可以被置于poly-A尾的第一碱基和第一碱基上游500个核苷酸之间。该区域可以被置于poly-A尾的第一碱基和第一碱基上游250个核苷酸之间。该区域可以被置于poly-A尾的第一碱基和第一碱基上游150个核苷酸之间。该区域可以被置于poly-A尾的第一碱基和第一碱基上游100个核苷酸之间。该区域可以被置于poly-A尾的第一碱基和第一碱基上游50个核苷酸之间。该区域可以被置于poly-A尾的第一碱基和第一碱基上游20个核苷酸之间。在一些实施方案中,该区域被置于启动子序列的最后一个核苷酸碱基和poly-A尾序列的第一个核苷酸碱基之间。
在某些情况下,该区域可以被置于转基因poly-A尾的最后一个碱基的下游。该区域可以在poly-A尾的最后一个碱基和最后一个碱基的下游2000个核苷酸的位置之间。该区域可以在poly-A尾的最后一个碱基和最后一个碱基的下游1000个核苷酸的位置之间。该区域可以在poly-A尾的最后一个碱基和最后一个碱基的下游500个核苷酸的位置之间。该区域可以在poly-A尾的最后一个碱基和最后一个碱基的下游250个核苷酸的位置之间。该区域可以在poly-A尾的最后一个碱基和最后一个碱基的下游150个核苷酸的位置之间。
应当理解,在转基因编码多于一个miRNA的情况下,每个miRNA均可以被置于转基因内的任何合适的位置。例如,编码第一miRNA的核酸可以被置于转基因的内含子中,并且编码第二miRNA的核酸序列可以被置于另一个非翻译区域中(例如,蛋白编码序列的最后一个密码子和转基因的poly-A尾的第一个碱基之间)。
在一些实施方案中,转基因进一步包含编码一个或多个表达控制序列(例如启动子等)的核酸序列。表达控制序列包括合适的转录起始、终止、启动子和增强子序列;有效的RNA加工信号,例如剪接和多聚腺苷酸化(polyA)信号;稳定细胞质mRNA的序列;增强翻译效率的序列(即Kozak共有序列);增强蛋白稳定性的序列;和当需要时增强编码产物分泌的序列。大量表达控制序列,包括天然的、组成型、诱导型和/或组织特异性启动子,在本领域中已知且可以被利用。
“启动子”指由细胞的合成机制或引入的合成机制识别并被启动基因的特异性转录所需要的DNA序列。短语“有效放置”、“在控制下”或“在转录控制下”意指:启动子相对于核酸而言处于正确的位置和方向,以控制基因的RNA聚合酶起始和表达。
对于编码蛋白的核酸,通常将多聚腺苷酸化序列插入转基因序列之后和3’AAVITR序列之前。可用于本公开的rAAV构建体还可以含有内含子,理想地位于启动子/增强子序列和转基因之间。一个可能的内含子序列衍生自SV-40,并被称为SV-40T内含子序列。可以使用的另一个载体元件是内部核糖体进入位点(IRES)。IRES序列用于从单个基因转录物中生产多于一种多肽。IRES序列将用于生产含有多于一条多肽链的蛋白。这些和其他常见载体元件的选择是常规的,并且许多这样的序列是可获得的[参见,例如,Sambrook等人,和其中引用的参考文献,例如第3.18 3.26和16.17 16.27页,以及Ausubel等人,CurrentProtocols in Molecular Biology,John Wiley&Sons,New York,1989]。在一些实施方案中,手足口病病毒2A序列包含在多蛋白中;这是小肽(长度约18个氨基酸),其已显示出介导多蛋白的切割(Ryan,M D等人,EMBO,1994;4:928-933;Mattion,N M等人,J Virology,1996年11月;p.8124-8127;Furler,S等人,Gene Therapy,2001;8:864-873;和Halpin,C等人,The Plant Journal,1999;4:453-459)。2A序列的切割活性先前已在包括质粒和基因治疗载体(AAV和逆转录病毒)的人工系统中被证实(Ryan,M D等人,EMBO,1994;4:928-933;Mattion,N M等人,J Virology,1996年11月;p.8124-8127;Furler,S等人,Gene Therapy,2001;8:864-873;和Halpin,C等人,The Plant Journal,1999;4:453-459;de Felipe,P等人,Gene Therapy,1999;6:198-208;de Felipe,P等人,Human Gene Therapy,2000;11:1921-1931.;和Klump,H等人,Gene Therapy,2001;8:811-817)。
组成型启动子的示例包括但不限于:逆转录病毒劳斯肉瘤病毒(RSV)LTR启动子(任选地具有RSV增强子)、巨细胞病毒(CMV)启动子(任选地具有CMV增强子)[参见,例如,Boshart等人,Cell,41:521-530(1985)]、SV40启动子、二氢叶酸还原酶启动子、β-肌动蛋白启动子、磷酸甘油激酶(PGK)启动子和EF1α启动子[Invitrogen]。在一些实施方案中,启动子是增强的鸡β-肌动蛋白启动子。在一些实施方案中,启动子是U6启动子。
诱导型启动子允许基因表达的调控,并且可以被以下调控:外源提供的化合物,环境因素例如温度,或特定生理状态(例如急性期)、特定细胞分化状态的存在或仅在复制细胞中。诱导型启动子和诱导型系统可从各种商业来源获得,包括但不限于Invitrogen、Clontech和Ariad。许多其他系统已经被描述,并且可由本领域技术人员容易地选择。由外源提供的启动子调控的诱导型启动子的示例包括锌诱导型绵羊金属硫蛋白(MT)启动子、地塞米松(Dex)诱导型小鼠乳腺肿瘤病毒(MMTV)启动子、T7聚合酶启动子系统(WO 98/10088);蜕皮激素昆虫启动子(No等人,Proc.Natl.Acad.Sci.USA,93:3346-3351(1996))、四环素抑制系统(Gossen等人,Proc.Natl.Acad.Sci.USA,89:5547-5551(1992))、四环素诱导系统(Gossen等人,Science,268:1766-1769(1995),另参见Harvey等人,Curr.Opin.Chem.Biol.,2:512-518(1998))、RU486诱导系统(Wang等人,Nat.Biotech.,15:239-243(1997)和Wang等人,Gene Ther.,4:432-441(1997))和雷帕霉素诱导系统(Magari等人,J.Clin.Invest.,100:2865-2872(1997))。也可用于这种情况的其他类型的诱导型启动子是那些被以下调控的:特定生理状态(例如温度、急性期)、细胞特定分化状态或仅在复制细胞中。
在另一个实施方案中,将使用转基因的天然启动子。当期望转基因的表达应模仿天然表达时,天然启动子可以是优选的。当转基因的表达必须被暂时地或发育地调控,或以组织特异性方式调控,或应答于特定转录刺激而调控时,可以使用天然启动子。在进一步的实施方案中,还可以使用其他天然表达控制元件,例如增强子元件、多聚腺苷酸化位点或Kozak共有序列,以模拟天然表达。
在一些实施方案中,调控序列赋予组织特异性基因表达能力。在一些情况下,组织特异性调控序列结合以组织特异性方式诱导转录的组织特异性转录因子。这样的组织特异性调控序列(例如启动子、增强子等)是本领域公知的。示例性组织特异性调控序列包括但不限于以下组织特异性启动子:肝特异性甲状腺素结合球蛋白(TBG)启动子、胰岛素启动子、胰高血糖素启动子、生长抑素启动子、胰多肽(PPY)启动子、突触蛋白-1(Syn)启动子、肌酸激酶(MCK)启动子、哺乳动物结蛋白(DES)启动子、α-肌球蛋白重链(a-MHC)启动子或心肌肌钙蛋白T(cTnT)启动子。其他示例性启动子包括β-肌动蛋白启动子、乙型肝炎病毒核心启动子,Sandig等人,Gene Ther.,3:1002-9(1996);α-甲胎蛋白(AFP)启动子,Arbuthnot等人,Hum.Gene Ther.,7:1503-14(1996))、骨骨钙素启动子(Stein等人,Mol.Biol.Rep.,24:185-96(1997));骨唾液蛋白启动子(Chen等人,J.Bone Miner.Res.,11:654-64(1996))、CD2启动子(Hansal等人,J.Immunol.,161:1063-8(1998);免疫球蛋白重链启动子;T细胞受体α-链启动子、神经元的如神经元特异性烯醇化酶(NSE)启动子(Andersen等人,Cell.Mol.Neurobiol.,13:503-15(1993))、神经丝轻链基因启动子(Piccioli等人,Proc.Natl.Acad.Sci.USA,88:5611-5(1991))和神经元特异性vgf基因启动子(Piccioli等人,Neuron,15:373-84(1995)),以及其他对技术人员而言显而易见的启动子。
在一些实施方案中,组织特异性启动子是骨组织特异性启动子。骨组织特异性启动子的示例包括但不限于成骨相关转录因子(osterix)、骨钙素、1型胶原蛋白α1、DMP1、组织蛋白酶K、Rank等的启动子。
本公开的一些方面涉及包含多于一个启动子(例如2个、3个、4个、5个或更多个启动子)的分离的核酸。例如,在具有包含编码蛋白的第一区域和编码抑制性RNA(例如,miRNA)的第二区域的转基因的构建体的情况下,使用第一启动子序列(例如,有效连接至蛋白编码区域的第一启动子序列)驱动蛋白编码区域的表达,并用第二启动子序列驱动抑制性RNA编码区域的表达(例如,有效连接至抑制性RNA编码区域的第二启动子序列)可以是合意的。通常,第一启动子序列和第二启动子序列可以是相同的启动子序列或不同的启动子序列。在一些实施方案中,第一启动子序列(例如,驱动蛋白编码区域表达的启动子)是RNA聚合酶III(polIII)启动子序列。polIII启动子序列的非限制性示例包括U6和H1启动子序列。在一些实施方案中,第二启动子序列(例如,驱动抑制性RNA表达的启动子序列)是RNA聚合酶II(polII)启动子序列。PolII启动子序列的非限制性示例包括T7、T3、SP6、RSV和巨细胞病毒启动子序列。在一些实施方案中,polIII启动子序列驱动抑制性RNA(例如,miRNA)编码区域的表达。在一些实施方案中,polII启动子序列驱动蛋白编码区域的表达。
重组AAV(rAAV)
本公开的分离的核酸可以是重组腺相关病毒(AAV)载体(rAAV载体)。在一些实施方案中,如本公开所述的分离的核酸包含含有第一腺相关病毒(AAV)反向末端重复(ITR)或其变体的区域(例如,第一区域)。可以将分离的核酸(例如,重组AAV载体)包装到衣壳蛋白中并施用给受试者和/或递送至选择的靶细胞。“重组AAV(rAAV)载体”通常至少由转基因及其调控序列,以及5’和3’AAV反向末端重复(ITR)组成。如本公开别处所述的,转基因可以包含编码一种或多种蛋白和/或包含靶向受试者的内源mRNA的核酸的抑制性核酸(例如shRNA、miRNA等)的一个或多个区域。如本公开别处所述的,转基因还可以包含编码例如蛋白和/或表达控制序列(例如,poly-A尾)的区域。
通常,ITR序列的长度为约145bp。优选地,分子中使用编码ITR的实质上整个的序列,尽管对这些序列的一定程度的微小修饰是允许的。修饰这些ITR序列的能力在本领域能力范围内。(参见,例如,如Sambrook等人,"Molecular Cloning.A Laboratory Manual",2ded.,Cold Spring Harbor Laboratory,New York(1989);和K.Fisher等人,J Virol.,70:520 532(1996)的教材)。本发明中采用的这种分子的一个示例是含有转基因的“顺式作用”质粒,其中选择的转基因序列和相关调控元件的侧翼是5’和3’AAV ITR序列。AAV ITR序列可以获自任何已知的AAV,包括目前已鉴定的哺乳动物AAV类型。在一些实施方案中,分离的核酸(例如,rAAV载体)包含具有选自以下血清型的至少一个ITR:AAV1、AAV2、AAV3、AAV4、AAV5、AAV6、AAV6.2、AAV7、AAV8、AAVrh8、AAV9、AAVrh10、AAVrh39、AAVrh43、AAV2/2-66、AAV2/2-84、AAV2/2-125及其变体。在一些实施方案中,分离的核酸包含编码AAV2 ITR的区域(例如,第一区域)。
在一些实施方案中,分离的核酸进一步包含含有第二AAV ITR的区域(例如,第二区域、第三区域、第四区域等)。在一些实施方案中,第二AAV ITR具有选自以下的血清型:AAV1、AAV2、AAV3、AAV4、AAV5、AAV6、AAV6.2、AAV7、AAV8、AAVrh8、AAV9、AAVrh10、AAVrh39、AAVrh43、AAV2/2-66、AAV2/2-84、AAV2/2-125及其变体。在一些实施方案中,第二ITR是缺乏功能性末端解离位点(TRS,terminal resolution site)的突变体ITR。术语“缺乏末端解离位点”可以指包含消除ITR的末端解离位点(TRS)的功能的突变(例如,有义突变,如非同义突变或错义突变)的AAV ITR,或指缺乏编码功能性TRS的核酸序列(例如ΔTRS ITR)的截短的AAV ITR。不希望受到任何特定理论的束缚,包含缺乏功能性TRS的ITR的rAAV载体产生自互补的rAAV载体,例如如McCarthy(2008)Molecular Therapy 16(10):1648-1656所述的。
如本文所用,术语“自互补的AAV载体”(scAAV)指含有双链载体基因组的载体,该双链载体基因组由AAV的一个ITR中的末端解离位点(TR)的缺乏产生。TR的缺乏阻止在TR不存在之处的载体末端的复制起始。通常,scAAV载体产生单链、反向重复基因组,其在每个末端具有野生型(wt)AAV TR且在中间具有突变的TR(mTR)。本发明部分基于以下认识:编码RNA发夹结构(例如shRNA、miRNA和AmiRNA)的DNA片段在病毒基因组复制过程中可以起到类似于突变的反向末端重复(mTR)的功能,产生自互补的AAV载体基因组。例如,在一些实施方案中,本公开提供了包含在两个末端的每个末端均具有反向末端重复(ITR)的单链自互补核酸和包含有效连接有编码发夹形成RNA(例如,shRNA、miRNA、ami-RNA等)的序列的启动子的中心部分的rAAV(例如,自互补的AAV;scAAV)载体。在一些实施方案中,编码发夹形成RNA(例如,shRNA、miRNA、ami-RNA等)的序列在通常被突变ITR占据的自互补核酸的位置被取代。
“重组AAV(rAAV)载体”通常至少由转基因及其调控序列,以及5’和3’AAV反向末端重复(ITR)组成。这种重组AAV载体被包装到衣壳蛋白中并被递送至选择的靶细胞。在一些实施方案中,转基因是与载体序列异源的核酸序列,其编码目标多肽、蛋白、功能性RNA分子(例如,miRNA、miRNA抑制剂)或其他基因产物。核酸编码序列以允许转基因在靶组织的细胞中转录、翻译和/或表达的方式有效连接至调控组分。
本公开提供了包含单个顺式作用的野生型ITR的载体。在一些实施方案中,ITR是5’ITR。在一些实施方案中,ITR是3’ITR。通常,ITR序列的长度为约145bp。优选地,分子中使用编码ITR的实质上整个的序列,尽管对这些序列的一定程度的微小修饰是可允许的。修饰这些ITR序列的能力在本领域能力范围内。(参见,例如,如Sambrook等人,"MolecularCloning.A Laboratory Manual",2d ed.,Cold Spring Harbor Laboratory,New York(1989);和K.Fisher等人,J Virol.,70:520 532(1996)的教材)。例如,ITR可以在其末端解离位点(TR)被突变,其抑制在TR已经被突变的载体末端的复制,并导致自互补AAV的形成。本公开中采用的这种分子的一个示例是含有转基因的“顺式作用”质粒,其中选择的转基因序列和相关调控元件的侧翼是5’AAV ITR序列和3’发夹形成RNA序列。AAV ITR序列可以获自任何已知的AAV,包括目前已鉴定的哺乳动物AAV类型。在一些实施方案中,ITR序列是AAV2、AAV3、AAV4、AAV5、AAV6、AAV7、AAV8、AAVrh8、AAV9、AAV10和/或AAVrh10 ITR序列。
在一些实施方案中,本公开的rAAV是假型rAAV。例如,含有被Y的蛋白衣壳化的血清型X的ITR的假型AAV载体将被命名为AAVX/Y(例如,AAV2/1具有AAV2的ITR和AAV1的衣壳)。在一些实施方案中,假型rAAV可用于组合来自一种AAV血清型的衣壳蛋白的组织特异性靶向能力与来自另一种AAV血清型的病毒DNA,从而允许转基因靶向递送至靶组织。
用于获得具有所需衣壳蛋白的重组AAV的方法是本领域中公知的。(参见,例如,US2003/0138772),其内容通过引用以其整体并入本文)。通常,该方法涉及培养含有编码AAV衣壳蛋白的核酸序列;功能性rep基因;由AAV反向末端重复(ITR)和转基因组成的重组AAV载体;和允许重组AAV载体包装到AAV衣壳蛋白中的足够辅助功能的宿主细胞。在一些实施方案中,衣壳蛋白是由AAV的cap基因编码的结构蛋白。AAV包含三种衣壳蛋白,即病毒体蛋白1至3(命名为VP1、VP2和VP3),所有这些蛋白均经由选择性剪接转录自单个cap基因。在一些实施方案中,VP1、VP2和VP3的分子量分别为约87kDa、约72kDa和约62kDa。在一些实施方案中,经由翻译,衣壳蛋白在病毒基因组周围形成球状的60-mer蛋白壳。在一些实施方案中,衣壳蛋白的功能是保护病毒基因组,递送基因组并与宿主相互作用。在一些方面,衣壳蛋白以组织特异性的方式将病毒基因组递送至宿主。
在一些实施方案中,AAV衣壳蛋白具有的AAV血清型选自由以下组成的组:AAV1、AAV2、AAV3、AAV4、AAV5、AAV6、AAV6.2、AAV7、AAV8、AAVrh8、AAV9、AAVrh10、AAVrh39、AAVrh43、AAV2/2-66、AAV2/2-84、AAV2/2-125。在一些实施方案中,AAV衣壳蛋白具有的血清型衍生自非人灵长类动物,例如scAAV.rh8、AAV.rh39或AAV.rh43血清型。在一些实施方案中,AAV衣壳蛋白具有AAV9血清型。
本公开部分基于包含对骨组织具有增加的向性的衣壳蛋白的rAAV。在一些实施方案中,将衣壳蛋白接枝到骨靶向肽。异源骨靶向肽可以靶向OC(例如,相对于OB,尤其或优先靶向OC)或OB(例如,相对于OC,尤其或优先靶向OB)。在一些实施方案中,骨靶向肽是(AspSerSer)6肽,其也可以被称为DSS6肽(例如SEQ ID NO:16)。其他的骨靶向肽是HABP-19肽(CγEPRRγEVAγELγEPRRγEVAγEL;SEQ ID NO:17),其也可以被称为HABP肽。在一些实施方案中,骨靶向肽是包含8-14个天冬氨酸残基的(Asp)8-14肽(例如,如SEQ ID NO:57-63所示)。骨靶向肽的进一步示例包括但不限于Ouyang等人(2009)Lett.Organic Chem 6(4):272-277描述的那些。在一些实施方案中,骨靶向肽包含SEQ ID NO:16、17、57、58、59、60、61、62和63所示的序列。
如本文所用,“接枝(grafting)”指将一个分子与另一个分子结合或联合。在一些实施方案中,术语接枝指至少两个分子的结合或联合,使得至少两个分子中的一个被插入到至少两个分子中的另一个中。在一些实施方案中,术语接枝指至少两个聚合物分子的结合或联合,使得至少两个分子中的一个附接到至少两个分子中的另一个。在一些实施方案中,术语接枝指一个聚合物分子(例如,核酸、多肽)与另一个聚合物分子(例如,核酸、多肽)的结合或联合。在一些实施方案中,术语接枝指至少两个核酸分子的结合或联合,使得至少两个分子中的一个附接到至少两个核酸分子中的另一个。
在一些实施方案中,术语接枝指至少两个核酸分子的结合或联合,使得至少两个核酸分子中的一个被插入到至少两个核酸分子中的另一个中。例如,已经观察到靶向肽可以被接枝到编码VP2 AAV衣壳蛋白的核酸的某些基因座上。在一些实施方案中,将靶向肽(例如骨靶向肽)插入到对应于编码AAV2或AAV9 VP2衣壳蛋白的Q588和A589和/或N587和R588的密码子之间的位置的位置。在一些实施方案中,将靶向肽插入到编码VP3衣壳蛋白的N587和R588的密码子之间的位置(或对应于AAV2或AAV9中的这些氨基酸位置的位置)。在一些实施方案中,将靶向肽插入到编码VP1衣壳蛋白的S452和G453的密码子之间的位置。其他可能的位置可以是N587和R588。
在一些实施方案中,通过接枝形成的核酸(接枝的核酸)编码嵌合蛋白。在一些实施方案中,接枝的核酸编码嵌合蛋白,使得一个多肽被有效地插入到另一个多肽中(例如,在N末端之前或C末端之后不直接结合),从而产生两个多肽的连续融合。在一些实施方案中,接枝的核酸编码嵌合蛋白,使得一个多肽被有效地附接到另一多肽上(例如,在N末端之前或C末端之后直接结合),从而产生两个多肽的连续融合。在一些实施方案中,术语接枝指至少两个多肽或其片段的结合或联合,使得至少两个多肽或其片段中的一个被插入到至少两个多肽或其片段中的另一个中。在一些实施方案中,术语接枝指至少两个多肽或其片段的结合或联合,使得至少两个多肽或其片段中的一个被附接到至少两个多肽或其片段中的另一个。
在一些实施方案中,本公开涉及结合至一个或多个骨靶向部分的腺相关病毒(AAV)衣壳蛋白。“骨靶向部分”通常指促进rAAV转运到骨或骨组织的小分子、肽、核酸等。例如,在一些实施方案中,骨靶向部分是与骨细胞(例如,OB、OC、骨细胞等)上的受体结合的肽或小分子。骨靶向部分的示例包括但不限于阿仑膦酸盐(ALE)、多肽例如环状精氨酸-甘氨酸-天冬氨酸-酪氨酸-赖氨酸(cRGCyk)、Asp-Asp-Asp-Asp-Asp-Asp-Asp-Asp(D-Asp8)和适体例如CH6。骨靶向部分可以直接结合至衣壳蛋白或经由接头分子(例如氨基酸接头、PEG接头等)结合至衣壳蛋白。
在一些实施方案中,接头是富含甘氨酸的接头。在一些实施方案中,接头包含至少两个甘氨酸残基。在一些实施方案中,接头包含GGGGS(SEQ ID NO:64)。在一些实施方案中,接头包含选自由以下组成的组的式:[G]n(SEQ ID NO:65)、[G]nS(SEQ ID NO:66)、[GS]n(SEQ ID NO:67)和[GGSG]n(SEQ ID NO:68),其中G是甘氨酸,且其中n是大于1的整数(例如,2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25或更大)。在一些实施方案中,n是在2至10、2至20、5至10、5至15或5至25的范围内的整数。因此,在一些实施方案中,异源靶向肽结合至接头。
在一些实施方案中,衣壳蛋白包含一个或多个携带叠氮化物的非天然氨基酸,其能够与标记有ADIBO的骨靶向部分反应(例如,经由“点击化学”以形成衣壳蛋白-骨靶向部分结合物)。包含携带叠氮化物的非天然氨基酸的衣壳蛋白由例如Zhang等人(2016)Biomaterials 80:134-145描述,并且用于肽结合的基于ADIBO的点击化学由例如Prim等人(2013)Molecules 18(8):9833-49描述。
可以将待培养于宿主细胞中以将rAAV载体包装在AAV衣壳中的组分反式提供给宿主细胞。可选择地,可以由稳定的宿主细胞提供所需组分(例如,重组AAV载体、rep序列、cap序列和/或辅助功能)的任何一种或多种,该稳定的宿主细胞已经使用本领域技术人员已知的方法被工程化以含有所需组分的一种或多种。最合适地,这种稳定的宿主细胞将含有在诱导型启动子控制下的所需组分。然而,所需组分可以在组成型启动子的控制下。在适合与转基因一起使用的调控元件的讨论中,本文提供了合适的诱导型和组成型启动子的示例。在另一个替代中,选择的稳定的宿主细胞可以含有在组成型启动子控制下的选择的组分和在一个或多个诱导型启动子控制下的其他选择的组分。例如,可以产生稳定的宿主细胞,其衍生自293细胞(其含有在组成型启动子控制下的E1辅助功能),但是其含有在诱导型启动子控制下的rep和/或cap蛋白。本领域技术人员还可以产生其他稳定的宿主细胞。
生产本公开的rAAV所需的重组AAV载体、rep序列、cap序列和辅助功能可以使用任何合适的遗传元件(载体)递送至包装宿主细胞。选择的遗传元件可以通过任何合适的方法递送,包括本文所描述的那些。用于构建本公开的任何实施方案的方法是核酸操作领域的技术人员已知的,并且包括基因工程、重组工程和合成技术。参见,例如,Sambrook等人,Molecular Cloning:A Laboratory Manual,Cold Spring Harbor Press,Cold SpringHarbor,N.Y。类似地,产生rAAV病毒体的方法是公知的,并且合适方法的选择不是本公开的限制。参见,例如,K.Fisher等人,J.Virol.,70:520-532(1993)和美国专利号5,478,745。
在一些实施方案中,可以使用三重转染方法(在美国专利号6,001,650中详细描述)生产重组AAV。通常,通过用待包装进AAV颗粒的重组AAV载体(包含转基因)、AAV辅助功能载体和附属功能载体转染宿主细胞来生产重组AAV。AAV辅助功能载体编码“AAV辅助功能”序列(即,rep和cap),其以反式发挥作用,用于生产性的AAV复制和衣壳化。优选地,AAV辅助功能载体支持有效的AAV载体生产而不产生任何可检测的野生型AAV病毒体(即,含有功能性rep和cap基因的AAV病毒体)。适用于本公开的载体的非限制性示例包括描述于美国专利号6,001,650的pHLP19和描述于美国专利号6,156,303的pRep6cap6载体,这两篇文献以其全文通过引用并入本文。附属功能载体编码用于非AAV衍生的病毒功能和/或细胞功能的核苷酸序列,AAV依赖这些核苷酸序列进行复制(即“附属功能”)。附属功能包括AAV复制所需的那些功能,包括但不限于,涉及AAV基因转录的激活、阶段特异的AAV mRNA剪接、AAVDNA复制、cap表达产物的合成和AAV衣壳装配的那些部分。基于病毒的附属功能可以源自任何已知的辅助病毒,例如腺病毒、疱疹病毒(除了单纯疱疹病毒1型)和牛痘病毒。
在一些方面,本公开提供了转染的宿主细胞。术语“转染”用于指细胞摄取外源DNA,并且当外源DNA已被引入细胞膜内侧时,细胞已经被“转染”。若干转染技术是本领域公知的。参见,例如,Graham等人(1973)Virology,52:456,Sambrook等人(1989)MolecularCloning,a laboratory manual,Cold Spring Harbor Laboratories,New York,Davis等人(1986)Basic Methods in Molecular Biology,Elsevier和Chu等人(1981)Gene 13:197。这些技术可用于将一种或多种外源核酸,例如核苷酸整合载体和其他核酸分子引入合适的宿主细胞中。
“宿主细胞”指包含或能够包含目的物质的任何细胞。通常,宿主细胞是哺乳动物细胞。在一些实施方案中,宿主细胞是细菌细胞、酵母细胞、昆虫细胞(Sf9)或哺乳动物(例如人、啮齿动物、非人灵长类动物等)细胞。宿主细胞可用作AAV辅助构建体、AAV小基因质粒、附属功能载体或与重组AAV生产相关的其他转移DNA的受体。该术语包括已经被转染的原始细胞的后代。因此,本文所用的“宿主细胞”可以指已用外源DNA序列转染的细胞。应当理解,归因于天然的、偶然的或蓄意的突变,单个亲本细胞的后代与原始亲本在形态或基因组或总DNA互补上不一定完全相同。
如本文所用,术语“细胞系”指能够在体外连续或长期生长和分裂的细胞群。通常,细胞系是源自单个祖细胞的克隆群体。本领域中进一步已知的是,在这些克隆群体的储存或转移期间,核型可能发生自发或诱导的变化。因此,源自所指细胞系的细胞可以不与祖细胞或培养物精确相同,并且所指细胞系包括这类变体。
如本文所用,术语“重组细胞”指其中已引入外源DNA片段的细胞,如导致生物活性多肽的转录或生物活性核酸(例如RNA)的产生的DNA片段。
在一些方面,本公开提供了包含衣壳蛋白和分离的核酸的重组AAV,该分离的核酸包含编码AAV ITR的第一区域和包含转基因的第二区域,其中该转基因编码人工microRNA。人工microRNA可降低细胞(例如成骨细胞、破骨细胞、骨细胞、软骨细胞)或受试者中靶基因的表达。在一些实施方案中,rAAV包含降低细胞或受试者中SHN3表达的人工microRNA。
rAAV可包含至少一个修饰,其增加rAAV对骨细胞(例如成骨细胞、破骨细胞、骨细胞、软骨细胞)的靶向。增加rAAV对骨细胞靶向的修饰的非限制性示例包括异源骨靶向肽(例如,如SEQ ID NO:16、17、57、58、59、60、61、62或63中任何一个所示的)、AAV衣壳血清型(例如AAV1、AAV4、AAV5、AAV6、AAV6.2、AAV7、AAV8、AAV9、AAV10、AAVrh39、AAVrh43)。
使用本公开的rAAV可以使细胞或受试者中SHN3的表达降低50%至99%(例如,50%至99%之间的任何整数,包含端值)。使用本公开的rAAV可以使细胞或受试者中SHN3的表达降低75%至90%。使用本公开的rAAV可以使细胞或受试者中SHN3的表达降低80%至99%。
用于将重组载体包装在所需AAV衣壳中以生产本公开的rAAV的前述方法并不意指是限制性的,并且其他合适的方法对技术人员而言是显而易见的。
施用方式和组合物
根据本领域中已知的任何合适方法可以将本公开的rAAV以组合物的形式递送至受试者。例如,可以将优选地悬浮在生理学相容的载体(例如在组合物中)中的rAAV施用给受试者,例如宿主动物,例如人、小鼠、大鼠、猫、狗、绵羊、兔子、马、奶牛、山羊、猪、豚鼠、仓鼠、鸡、火鸡或非人类灵长类动物(例如猕猴)。在一些实施方案中,宿主动物不包括人。
rAAV到哺乳动物受试者的递送可以通过例如肌肉内注射或通过施用至哺乳动物受试者的血流中。施用至血流中可以通过注射进静脉、动脉或任何其他血管。在一些实施方案中,通过隔离肢体灌注(isolated limb perfusion)的方式施用rAAV至血流中,这是外科领域中公知的技术,该方法基本上使技术人员能够在rAAV病毒体的施用之前将肢体与全身循环隔离。技术人员还可以采用隔离肢体灌注技术的变体(描述于美国专利号6,177,403中)来施用病毒体至隔离肢体的脉管系统中,以潜在增强向肌细胞或组织的转导。此外,在某些情况下,将病毒体递送至受试者的骨(例如骨组织)中可以是合意的。“骨组织”意指脊椎动物的骨和/或关节(例如,软骨、轴骨(axial bone)和附肢骨(appendicular bone)等)的所有细胞和组织。因此,该术语包括但不限于成骨细胞、骨细胞、破骨细胞、软骨细胞等。经由使用针、导管或相关装置的滑膜内注射、膝注射、股骨髓内注射等,通过使用本领域中已知的外科技术,可以将重组AAV直接递送至骨。在一些实施方案中,通过静脉内注射施用如本公开所述的rAAV。在一些实施方案中,通过肌肉内注射施用rAAV。
本公开的一些方面涉及包含含有衣壳蛋白和编码转基因的核酸的重组AAV的组合物,其中转基因包含编码一种或多种骨代谢调节剂的核酸序列。在一些实施方案中,核酸进一步包含一个或多个AAV ITR。在一些实施方案中,rAAV包含含有SEQ ID NO:1-15中任何一个所示的序列(或其互补序列)或其部分的rAAV载体。在一些实施方案中,组合物进一步包含药学上可接受的载体。
在一些实施方案中,组合物包含含有衣壳蛋白和核酸的重组AAV,该核酸包含编码AAV ITR的第一区域和包含转基因的第二区域,其中该转基因编码靶向SHN3的人工microRNA。在一些实施方案中,重组AAV包含SEQ ID NO:3所示的序列。在一些实施方案中,衣壳蛋白进一步包含SEQ ID NO:16-17或57-63所示的异源骨靶向肽。
本公开的一些方面提供了降低细胞中SHN3表达的方法。细胞可以是单个细胞或细胞群(例如培养物)。细胞可以是体内的(例如在受试者中)或体外的(例如在培养物中)。受试者可以是哺乳动物,任选地是人、小鼠、大鼠、非人灵长类动物、猪、狗、猫、鸡或奶牛。
通过使用本公开的分离的核酸、rAAV或组合物,可以使细胞或受试者中SHN3的表达降低50%至99%(例如,50%至99%之间的任何整数,包含端值)。通过使用本公开的分离的核酸、rAAV或组合物,可以使细胞或受试者中SHN3的表达降低75%至99%。通过使用本公开的分离的核酸、rAAV或组合物,可以使细胞或受试者中SHN3的表达降低80%至99%。
本公开的组合物可以仅包含rAAV,或与一种或多种其他病毒(例如,编码一种或多种不同转基因的第二rAAV)组合。在一些实施方案中,组合物包含1种、2种、3种、4种、5种、6种、7种、8种、9种、10种或更多种不同的rAAV,每一种rAAV均具有一个或多个不同的转基因。
考虑到rAAV被指示的适应症,本领域技术人员可以容易地选择合适的载体。例如,一种合适的载体包括盐水,其可以与多种缓冲溶液(例如磷酸盐缓冲盐水)一起配制。其他示例性载体包括无菌盐水、乳糖、蔗糖、磷酸钙、明胶、葡聚糖、琼脂、果胶、花生油、芝麻油和水。载体的选择不是本公开的限制。
任选地,除rAAV和载体之外,本发明的组合物还可以含有其他常规的药物成分,例如防腐剂或化学稳定剂。合适的示例性防腐剂包括氯丁醇、山梨酸钾、山梨酸、二氧化硫、没食子酸丙酯、对羟基苯甲酸类、乙基香草醛、甘油、苯酚和对氯酚。合适的化学稳定剂包括明胶和白蛋白。
以足够的量施用rAAV以转染目标组织的细胞并提供足够水平的基因转移和表达而没有过度的不利影响。常规的和药学上可接受的施用途径包括但不限于,直接递送至选择的器官(例如,门静脉内递送至肝脏)、口服、吸入(包括鼻内和气管内递送)、眼内、静脉内、肌肉内、皮下、皮内、瘤内和其他胃肠外(parental)施用途径。如需要可以组合施用途径。
获得特定“治疗效果”所需的rAAV病毒体的剂量,例如,基因组拷贝/每千克体重(GC/kg)的剂量单位,将基于多种因素而变化,这些因素包括但不限于:rAAV病毒体的施用途径、获得治疗效果所需的基因或RNA表达水平、所治疗的特定疾病或病症以及基因或RNA产物的稳定性。基于上述因素以及本领域公知的其他因素,本领域技术人员可以容易地确定用于治疗患有特定疾病或病症的患者的rAAV病毒体的剂量范围。
rAAV的“有效量”是足以靶向感染动物、靶向所需组织(例如骨组织)的量。有效量将主要取决于诸如物种、年龄、体重、受试者的健康状况以及要靶向的组织的因素,并且因此可以在动物和组织之间变化。例如,rAAV的有效量的范围通常在约1ml至约100ml的溶液中含有约109至1016个基因组拷贝。在一些情况下,在约1011至1013个rAAV基因组拷贝之间的剂量是合适的。在某些实施方案中,1012或1013个rAAV基因组拷贝有效地靶向骨组织。
在一些实施方案中,以每个日历日(例如24小时期间)不多于一次施用一个剂量的rAAV给受试者。在一些实施方案中,以每2个、3个、4个、5个、6个、7个日历日不多于一次施用一个剂量的rAAV给受试者。在一些实施方案中,以每个日历周(例如7个日历日)不多于一次施用一个剂量的rAAV给受试者。在一些实施方案中,以不多于每两周一次(例如在两个日历周期间一次)施用一个剂量的rAAV给受试者。在一些实施方案中,以每个日历月不多于一次(例如,在30个日历日中一次)施用一个剂量的rAAV给受试者。在一些实施方案中,以每六个日历月不多于一次施用一个剂量的rAAV给受试者。在一些实施方案中,以每个日历年(例如,365天或闰年的366天)不多于一次施用一个剂量的rAAV给受试者。
在一些实施方案中,配制rAAV组合物以减少组合物中AAV颗粒的聚集,特别是在高rAAV浓度存在处(例如~1013GC/ml或更高)。用于减少rAAV聚集的方法是本领域公知的,并且包括例如添加表面活性剂、调节pH、调节盐浓度等。(参见,例如,Wright FR等人,Molecular Therapy(2005)12,171-178,其内容通过引用并入本文。)
药学上可接受的赋形剂和载体溶液的配制是本领域技术人员公知的,用于在多种治疗方案中使用本文所述的特定组合物的合适的剂量和治疗方案的开发也是公知的。
通常,这些制剂可以含有至少约0.1%或更多的活性化合物,尽管活性成分的百分比当然可以变化并且可以方便地介于总配方重量或体积的约1%或2%至约70%或80%之间或更多。自然地,可以以在化合物的任何给定单位剂量中获得合适剂量的方式制备每种治疗上有用的组合物中的活性化合物的量。制备这些药物制剂的领域的技术人员将考虑如溶解度、生物利用度、生物学半衰期、施用途径、产品保存期限以及其他药理学考虑的因素,并且因此,多种剂量和治疗方案可以是合意的。
在某些情况下,以皮下、胰内、鼻内、胃肠道外、静脉内、肌肉内、鞘内、股骨髓内或口服、腹膜内或通过吸入的方式递送本文中公开的合适配制的药物组合物中的基于rAAV的治疗构建体将是合意的。在一些实施方案中,可以使用如美国专利号5,543,158;5,641,515和5,399,363(各自通过引用整体并入本文)中描述的施用形式递送rAAV。在一些实施方案中,施用的优选模式是通过门静脉注射。
适用于注射用途的药物形式包括无菌水溶液或分散液和用于临时制备无菌注射溶液或分散液的无菌粉末。分散液也可以在甘油、液体聚乙二醇及其混合物中和油中制备。在储存和使用的常规情况下,这些制剂含有防腐剂以防止微生物的生长。在许多情况下,该形式是无菌的且流动性达到容易注射的程度。它在生产和储存条件下必须是稳定的,并且必须防腐以免于微生物如细菌和真菌的污染作用。载体可以是含有例如水、乙醇、多元醇(例如甘油、丙二醇和液体聚乙二醇等)、其合适的混合物和/或植物油的溶剂或分散介质。例如通过使用如卵磷脂的包衣、通过在分散液的情况下维持所需的粒径以及通过使用表面活性剂可以维持适当的流动性。通过各种抗细菌剂和抗真菌剂例如对羟苯甲酸类、氯丁醇、苯酚、山梨酸、硫柳汞等可以实现对微生物作用的阻止。在许多情况下,优选包括例如糖或氯化钠的等渗剂。通过在组合物中使用延迟吸收的试剂,例如单硬脂酸铝和明胶,可以实现注射组合物的延长吸收。
例如,对于施用注射水溶液,如需要可以合适地将溶液进行缓冲,并且首先用足够的盐水或葡萄糖使液体稀释剂等渗。这些特定的水溶液特别适合于静脉内、肌肉内、皮下和腹膜内施用。在这一点上,本领域技术人员将知道可以采用的无菌水性介质。例如,可以将一个剂量溶于1ml等渗的NaCl溶液中,然后添加到1000ml皮下输液液体中,或在建议的输注部位注射(参见例如,"Remington's Pharmaceutical Sciences"15th Edition,1035-1038页和1570-1580页)。取决于宿主的状况,剂量必然会发生一些变化。在任何情况下,负责施用的人员将确定对于个体宿主的合适剂量。
通过将所需量的活性rAAV并入具有本文列举的多种其他成分的合适溶剂中然后过滤灭菌(需要时)来制备无菌注射溶液。通常,通过将各种灭菌的活性成分并入含有基础分散介质和来自以上列举的那些所需的其他成分的无菌媒介物中来制备分散体。就用于制备无菌注射溶液的无菌粉末而言,优选的制备方法是真空干燥和冰冻干燥技术,其从其先前无菌过滤的溶液中产生活性成分和任何其他所需成分的粉末。
本文公开的rAAV组合物也可以以中性或盐形式配制。药学上可接受的盐包括酸加成盐(与蛋白的游离氨基形成),并且其与例如盐酸或磷酸的无机酸或如乙酸、草酸、酒石酸、苦杏仁酸等的有机酸形成。与游离羧基形成的盐也可以源自例如钠、钾、铵、钙或铁的氢氧化物的无机碱,以及如异丙胺、三甲胺、组氨酸、普鲁卡因等的有机碱。经由制剂,将以与剂型相容的方式和以治疗有效的量来施用溶液。以各种剂型如可注射溶液、药物释放胶囊等容易地施用制剂。
如本文所用,“载体”包括任何和所有的溶剂、分散介质、媒介物、包衣、稀释剂、抗细菌和抗真菌剂、等渗和吸收延迟剂、缓冲剂、载体溶液、悬浮液、胶体等。用于药物活性物质的这些介质和试剂的使用是本领域公知的。补充的活性成分也可以并入组合物中。短语“药学上可接受的”指当施用给宿主时不产生过敏或相似的不良反应的分子实体和组合物。
递送载体如脂质体、纳米胶囊、微粒、微球、脂质颗粒、囊泡等可用于将本公开的组合物引入合适的宿主细胞中。特别地,rAAV载体递送的转基因可以被配制以包裹在脂质颗粒、脂质体、囊泡、纳米球或纳米颗粒等中的形式进行递送。
这些制剂可以优选用于本文公开的核酸或rAAV构建体的药学上可接受的制剂的引入。脂质体的形成和使用是本领域技术人员通常已知的。最近,开发了具有改进的血清稳定性和循环半衰期的脂质体(美国专利号5,741,516)。此外,已经描述了脂质体和脂质体样制备物作为潜在药物载体的各种方法(美国专利号5,567,434;5,552,157;5,565,213;5,738,868和5,795,587)。
脂质体已成功用于对其他程序的转染通常有抵抗的多种细胞类型。此外,脂质体不存在基于病毒的递送系统典型的DNA长度的限制。脂质体已被有效地用于将基因、药物、放射治疗剂、病毒、转录因子和变构效应物(allosteric effector)引入各种培养的细胞系和动物中。此外,已经完成了多种成功的检查脂质体介导的药物递送的有效性的临床试验。
脂质体由分散在水性介质中并自发形成多层同心双层囊泡(也被称为多层囊泡(MLV))的磷脂形成。MLV的直径通常为25nm至4μm。MLV的超声处理导致直径范围在200至 内的其核心中含有水溶液的小单层囊泡(SUV)的形成。
内的其核心中含有水溶液的小单层囊泡(SUV)的形成。
或者,可以使用rAAV的纳米胶囊制剂。纳米胶囊通常可以以稳定且可再现的方式截留物质。为了避免归因于细胞内聚合体超载引起的副作用,应使用能够在体内降解的聚合物来设计这些超细颗粒(尺寸约0.1μm)。考虑使用满足这些要求的可生物降解的聚氰基-丙烯酸烷酯纳米颗粒。
除上述递送方法外,还考虑将以下技术作为将rAAV组合物递送至宿主的替代方法。超声促渗(sonophoresis)(即超声)已被使用并描述于美国专利号5,656,016,其作为用于增加药物渗透进和通过循环系统的速率和功效的装置。考虑的其他药物递送替代方式是骨内注射(美国专利号5,779,708)、微芯片装置(美国专利号5,797,898)、托吡卡胺制剂(ophthalmic formulation)(Bourlais等人,1998)、透皮基质(美国专利号5,770,219和5,783,208)和反馈控制的递送(美国专利号5,697,899)。
治疗方法
本公开提供了用于递送有效量的转基因(例如,编码一种或多种骨代谢调节剂的分离的核酸或rAAV)至受试者的方法。在一些实施方案中,该方法包括施用有效量的编码能够促进或抑制骨形成的干扰RNA的分离的核酸给受试者的步骤。在一些实施方案中,该方法包括施用有效量的编码能够促进或抑制骨吸收的干扰RNA的分离的核酸给受试者的步骤。因此,在一些实施方案中,本文所述的分离的核酸、rAAV和组合物用于治疗患有或怀疑患有与骨代谢失调有关的疾病或病症的受试者。
如本文所用,“与骨代谢失调有关的疾病或病症”指以骨沉积和骨吸收之间的失衡为特征的病症,其导致以下之一:1)相对于健康个体(例如,未患有以骨沉积和骨吸收之间的失衡为特征的疾病的受试者)的异常增加的骨沉积(例如,形成),或2)相对于健康个体(例如,未患有以骨沉积和骨吸收之间的失衡为特征的疾病的受试者)的异常减少的骨沉积(例如,形成),或3)相对于健康个体(例如,未患有以骨沉积和骨吸收之间的失衡为特征的疾病的受试者)的异常增加的骨吸收(例如,破坏),或4)相对于健康个体(例如,未患有以骨沉积和骨吸收之间的失衡为特征的疾病的受试者)的异常减少的骨吸收(例如,破坏)。
“与骨密度降低有关的疾病”指由以下原因导致的以增加的骨孔隙度(boneporosity)为特征的病况:1)相对于健康个体(例如,未患有以骨密度降低为特征的疾病的受试者)的异常减少的骨沉积(例如,形成),或2)相对于健康个体(例如,未患有以骨密度降低为特征的疾病的受试者)的异常增加的骨吸收(例如,破坏)。与增加的骨孔隙度有关的疾病可以由以下两种原因之一引起:1)相对于健康个体(例如,未患有以骨密度降低为特征的疾病的受试者)的异常减少的OB和/或骨细胞的分化、功能或活性,和/或2)相对于健康个体(例如,未患有以骨密度降低为特征的疾病的受试者)的异常增加的OC分化、功能或活性。“孔隙度”通常指未被骨组织占据的骨部分的体积。
“与骨密度增加有关的疾病”指以由以下原因之一导致的降低的骨孔隙度(boneporosity)为特征的病况:1)相对于健康个体(例如,未患有以骨密度增加为特征的疾病的受试者)的异常增加的骨沉积(例如,形成),或2)相对于健康个体(例如,未患有以骨密度增加为特征的疾病的受试者)的异常减少的骨吸收(例如,破坏)。与降低的骨孔隙度有关的疾病可以由以下两种原因之一引起:1)相对于健康个体(例如,未患有以骨密度增加为特征的疾病的受试者)的异常增加的OB和/或骨细胞的分化、功能或活性,和或2)相对于健康个体(例如,未患有以骨密度增加为特征的疾病的受试者)的异常减少的OC分化、功能或活性。
本公开的一些方面提供了治疗与骨代谢失调有关的疾病或病症的方法。骨代谢失调可以是与骨密度降低有关的疾病(例如,骨质疏松症、临界大小骨缺损、由废用或受伤引起的机械性病症)。骨代谢失调可以是与骨密度增加有关的疾病(例如,骨硬化症、致密性成骨不全症、硬化性狭窄病、肢端肥大症、氟蚀病、骨髓纤维化、丙型肝炎相关性骨硬化症、异养性骨化)。
在一些实施方案中,治疗与骨代谢失调有关的疾病或病症的方法包括施用包含转基因的重组AAV(rAAV)给有此需要的受试者。rAAV可以包含促进其靶向骨细胞(例如破骨细胞和成骨细胞)的修饰。促进其靶向骨细胞的rAAV的非限制性修饰包括SEQ ID NO:16-17或57-63中的异源骨靶向肽、骨特异性启动子和具有相对于其他组织增加的骨靶向的AAV血清型。在一些实施方案中,治疗骨代谢失调的方法包括施用包含如SEQ ID NO:16-17或57-63中的异源骨靶向肽的rAAV给有此需要的受试者。
在一些实施方案中,包含异源骨靶向肽的rAAV包含上调或下调与骨代谢失调有关的靶基因的转基因。在一些实施方案中,该转基因上调靶基因的表达,该靶基因的表达在与骨密度降低有关的病症(例如,骨质疏松症、临界大小骨缺损、由废用或受伤引起的机械性病症)中降低。在一些实施方案中,转基因下调在与骨密度降低有关的疾病中增加的靶基因的表达。在一些实施方案中,转基因上调靶基因的表达,该靶基因的表达在与骨密度降低有关的病症(例如,骨质疏松症、临界大小骨缺损、由废用或受伤引起的机械性病症)中降低。在一些实施方案中,转基因下调在与骨密度降低有关的疾病中增加的靶基因的表达。
本公开的一些方面提供了用于治疗与以骨代谢失调为特征的疾病或病症有关的疾病或病症的方法,该方法包括施用包含衣壳蛋白和编码抑制性核酸的分离的核酸的rAAV给受试者。rAAV可以包含抑制性核酸(例如,siRNA、shRNA、miRNA或amiRNA)。抑制性核酸可以减少或增加与以骨代谢失调为特征的疾病或病症有关的靶基因的表达。
在一些实施方案中,本公开提供了治疗与骨密度降低相关的疾病或病症的方法。该方法包括施用包含靶向与骨密度降低有关的基因的转基因的rAAV或分离的核酸给有此需要的受试者。在一些实施方案中,rAAV或分离的核酸包含编码靶向与骨密度降低有关的基因的人工microRNA的转基因。在一些实施方案中,靶基因是SHN3、PTH、PTHrP、DJ1、SOST、CTSK或RANK。
本公开的一些方面提供了治疗与骨密度降低有关的疾病或病症的方法,包括施用rAAV或分离的核酸。在一些实施方案中,rAAV或分离的核酸包含SEQ ID NO:3所示的序列或其互补序列。在一些实施方案中,rAAV包含含有SEQ ID NO:18-34中任何一个所示的序列的衣壳蛋白。在一些实施方案中,rAAV包含含有SEQ ID NO:16-17和57-63中任何一个所示的序列的异源骨靶向肽。
通过使用本公开的方法,可以将细胞或受试者中SHN3的表达降低50%至99%(例如,50%至99%之间的任何整数,包含端值)。通过使用本公开的方法,可以将细胞或受试者中SHN3的表达降低75%至90%。通过使用本公开的方法,可以将细胞或受试者中SHN3的表达降低80%至99%。
在一些实施方案中,物质的“有效量”是足以产生所需效果(例如,转导骨细胞或骨组织)的量。在一些实施方案中,分离的核酸的有效量是足以转染(或在rAAV介导的递送的情况下感染)足够数量的受试者靶组织的靶细胞的量。在一些实施方案中,靶组织是骨组织(例如,骨和骨组织细胞,例如OB、OC、骨细胞、软骨细胞等)。在一些实施方案中,分离的核酸(例如,其可以经由rAAV递送)的有效量可以是足以在受试者中具有治疗益处(例如,增加OB和/或骨细胞的活性或功能、抑制OB和/或骨细胞的活性、增加OC的活性或功能、抑制OC的活性或功能等)的量。有效量将取决于多种因素,例如受试者的物种、年龄、体重、健康状况以及所靶向的组织,并且因此可以如本公开中别处所述在受试者和组织间变化。
通过以下实施例将更详细地描述本发明的示例性实施方案。这些实施方案是本发明的示例,本领域技术人员将认识到本发明不限于示例性实施方案。
实施例
实施例1
已经鉴定了几种骨形成的关键调节子作为骨质疏松症的治疗靶标。例如,归因于增加的OB活性,天然产生的骨形成抑制剂骨硬化蛋白(SOST)或衔接蛋白schnurri-3(SHN3,也称为HIVEP3)的抑制导致骨量的逐渐增加。不同于主要在OB中起作用的SHN3和SOST,组织蛋白酶K(CTSK)在OC中高度表达,并且其抑制通过阻断OC活性增加了骨量。最后,用包括PTH、PTH相关蛋白(PTHrP)或DJ-1的骨合成代谢因子处理促进了骨形成。在这个实施例中,描述了可以通过使用骨靶向腺相关病毒(AAV)介导的基因沉默或添加来操纵这些候选基因表达的基因治疗剂。在一些实施方案中,治疗剂(例如,本公开描述的组合物)通过促进OB功能和骨形成或通过抑制OC活性和骨破坏阻止骨质流失,而仅具有有限的对骨重塑和再生活性的不良作用。
使用骨靶向腺相关病毒(BT-AAV)开发基因治疗剂
高转导效率、持续的转基因表达以及缺乏感染后的免疫原性和致病性,这些使得AAV成为用于基因治疗中的非常有吸引力的病毒载体。迄今为止,已经在全球超过130个临床试验和2,000例患者中评估了AAV载体。然而,非特异的细胞靶向、可能的预先存在的免疫和其他限速事件使得鉴定更多天然AAV血清型和通过载体工程化改进AAV血清型的性质和功能成为必要。在此,鉴定了可以在体外和体内转导OB和/或OC的AAV血清型。
转导OB、OC和软骨细胞的AAV血清型的鉴定
为此,将增强的绿色荧光蛋白(GFP)报告基因包装到17种AAV衣壳(scAAV1、scAAV2、scAAV3、scAAV4、scAAV5、scAAV6、scAAV6.2、scAAV7、scAAV8、scAAV9、scAAVrh8、scAAVrh10、scAAVrh39、scAAVrh43、scAAV2/2-66、scAAV2/2-84、scAAV2/2-125)中。通过使用表面荧光显微术监测GFP表达评估了这些纯化的AAV血清型载体转导源自间充质干细胞(MSC)的小鼠OB谱系细胞或软骨细胞谱系细胞或源自骨髓单核细胞(BM-MO)的小鼠OC的能力。首先,为了测试它们对OB谱系细胞或软骨细胞谱系细胞的转导能力,分别从Cyagen和ATCC购买了小鼠MSC和软骨细胞祖细胞系(ATDC5)。此外,小鼠OB前体细胞(pre-OB)分离自三种不同的同基因背景(C57BL/6J、BALB/cJ、129S1/SvlmJ)的出生后第3-5天的小鼠新生鼠的颅盖,并在成骨培养基中培养6天以分化成成熟OB(mOB)。将单剂量的17种纯化的AAV血清型的1012~1013/ml个基因组拷贝与这些细胞一起温育2天,并通过表面荧光显微术(表1)和针对EGFP的免疫印迹(图22)来分析GFP表达。
表1:可在体外转导小鼠MSC谱系细胞的scAAV血清型的鉴定。



在17种AAV血清型中,scAAV4在三种不同的小鼠背景scAAV1、scAAV5、scAAV6上转导小鼠OB谱系细胞是最有效的,且scAAV6.2(scAAV6的工程化版本)在三种不同的小鼠背景上转导小鼠OB谱系细胞和软骨细胞谱系细胞是最有效的,且scAAV9在C57B6/J背景上仅转导pre-OB是最有效的(图1和图2中的代表性图像)。
接下来,研究了纯化的AAV血清型转导小鼠OC前体细胞的能力。小鼠原代OC前体细胞(BM-MO,源自骨髓的单核细胞)分离自两月龄小鼠(C57BL/6J)的长骨,并通过添加小鼠M-CSF(40ng/ml,R&D Systems)进行扩增。在小鼠M-CSF(40ng/ml)和小鼠Rank配体(10ng/ml,R&D Systems)的存在下培养BM-MO 6天,以分化成成熟OC(图3)。此外,在用小鼠Rank配体(10ng/ml)培养4天后,将小鼠OC前体细胞系(Raw264.7)分化成成熟OC(图4)。将单剂量的17种纯化的AAV血清型的1012~1013/ml个基因组拷贝与这些细胞一起温育2天,并通过表面荧光显微镜术分析GFP表达(表2)。
表2:在体外转导小鼠OC的scAAV血清型的鉴定。


在17种AAV血清型中,scAAV1、5、6、6.2、7和9有效地转导小鼠原代OC和Raw264.7OC系,而scAAV8和10、scAAVrh39和43仅转导Raw264.7OC系。(图3和图4中的代表性图像)。
为了检查AAV衣壳对关节软骨和骨的向性,从体外筛选中选出八种scAAV-Egfp载体(scAAV1、scAAV4、scAAV5、scAAV6、scAAV7、scAAV9、scAAVrh.10和scAAVrh.39)。为了测试它们转导关节软骨上的软骨细胞和/或骨表面的OB和/或OC的能力,将单剂量的八种选择的编码GFP的AAV血清型的1012~1013/ml个基因组拷贝注射到2月龄小鼠(C57BL/6J)的两个膝关节中,并在4周后安乐死小鼠,并通过位于UMMS光学成像设施的IVIS-100光学成像系统监测AAV到关节软骨和/或骨的转导(图5)。作为阴性对照,给小鼠注射PBS。对于大多数衣壳而言,EGFP在关节软骨(图28)或生长板(图22)中从几乎没有表达至无表达。这种不一致可归因于scAAV载体对嵌入这些结构的无血管微环境中的软骨细胞的差的可及性。或者,载体可简单地在成年小鼠中表现较低的原代软骨细胞感染力。GFP蛋白在膝关节和后肢中高表达,且它们的表达限于局部注射区域(图5,顶部,图28)。特别地,即使在去除肌肉后,仍在骨和膝关节中检测到GFP表达(图5,底部)。为了确认GFP在关节软骨的软骨细胞中和/或在骨表面的OB和/或OC中的表达,进行了膝关节和股骨的冰冻切片上的组织学检查。如图6A所示,在注射了scAAV1、scAAV4、scAAV5、scAAV6、scAAV7、scAAV9、scAAVrh.10和scAAVrh.39的膝关节中检测到关节软骨中无或几乎没有GFP蛋白表达。在注射了scAAV9的膝关节中,在少数软骨细胞群中检测到GFP表达。与使用软骨细胞前体细胞系ATDC5的体外数据相反,这些结果表明某些scAAV血清型在体内不能有效地转导关节软骨中的软骨细胞。
相比之下,当将scAAV9注射入膝关节时,GFP蛋白在位于皮质骨中的OB和骨细胞中高表达。经处理的小鼠的全身和单个器官成像显示,EGFP表达在肝脏和后肢中最高(图23和29)。心脏和股骨中的表达是中等的,而未检测到肺、肾和脾中的表达。通过荧光显微镜术和免疫印迹分析进一步证实了心脏、肝和股骨中的EGFP表达(图23)。如观察到的,EGFP蛋白主要在皮质骨和小梁骨的骨内成骨细胞和骨细胞中表达,而不在韧带、关节软骨、生长板、骨膜成骨细胞、骨髓和髌骨(patellta)中表达(图23和30)。这些结果证明,全身递送的scAAV9载体靶向位于骨内的成骨细胞谱系细胞。
除scAAV9外,还在scAAV5处理中观察到皮质骨骨膜细胞中GFP的高表达和骨细胞中GFP的低表达。当注射scAAV4时,小群的骨膜细胞表达GFP蛋白,而在scAAV6.2处理中未检测到GFP表达(图6B)。因此,这些结果表明,scAAV9血清型在转导小鼠骨表面上的OB和OC是最有效的。为了提高scAAV9对骨组织的转导效率,将scAAV9与PBS或X-tremeGene 9DNA转染试剂(Roche,一种具有极低细胞毒性的脂质混合物)一起配制,并注射到小鼠的膝关节中(图7和8)。当与X-tremeGene 9(脂质体)一起配制时,GFP蛋白在生长板下和小梁骨表面(桡骨)上有活性的OB和OC中以及在皮质骨(骨干)中终末分化的OB、骨细胞中高表达。但是,GFP表达在肌肉中显著减少,表明X-tremeGene 9制剂改变了scAAV9的体内向性。
经由衣壳蛋白的遗传或化学修饰的骨靶向-scAAV9(BT-scAA9)血清型的开发
为了最佳化骨质疏松症中AAV介导的基因治疗,scAAV9血清型归巢并累积在OB和OC位于其中的骨表面上是合意的。已经观察到骨靶向肽((AspSerSer)6,DSS)有效地引导成骨的包裹siRNA的脂质体至骨形成表面。已经报道了其他的骨靶向肽HABP-19(CγEPRRγEVAγELγEPRRγEVAγEL;SEQ ID NO:17)选择性结合培养物中和小鼠中的骨羟磷灰石。HABP-19是骨钙素的仿生物,是分泌自OB的最丰富的非胶原蛋白。γ(Gla残基)-羧化谷氨酸(Glu)通过维生素K依赖的γ-羧化衍生自Glu。
该实施例描述了将骨靶向肽插入AAV衣壳中以引导工程化的scAAV9血清型至骨(图9A,DSS-scAAV9、HABP-scAAV9)。通过使用标准克隆方法,将编码(AspSerSer)6(SEQ IDNO:16)的DNA序列插入衣壳蛋白VP2开放阅读框(ORF)的谷氨酰胺587和丙氨酸588(DSS-587)之间、谷氨酰胺588和精氨酸589(DSS-588)之间或VP2-ORF的N端(DSS-Nter)(图10和26)。此外,产生了经由化学反应结合趋骨性(bone-seeking)分子的AAV衣壳(图9B)。已经观察到,亲骨分子(ADIBO-Ale)附着于细胞表面上的叠氮化物部分显著增强了非骨细胞(例如,Jurkat T白血病细胞系)结合骨片段的能力。
为了检查DSS插入是否影响scAAV9的感染力,将包装进原型AAV9、AAV9.DSS-587或AAV9,DSS-Nter衣壳的载体感染到COB中,并通过免疫印迹或荧光显微镜术评估EGFP表达(图29)。与scAAV9相比,scAAV9.-DSS-Nter在较低MOI(109GC/mL)下显示感染力的中度降低,而在经scAAV9.DSS-587处理的COB中几乎未检测到EGFP表达(图29)。相似地,当经由i.a.注射处理小鼠时,scAAV9和scAAV9.DSS-Nter如之前一样强烈地转导股骨(图35)。与之相反,scAAV9.DSS-587几乎不产生或不产生转基因表达。此外,碱性磷酸酶(ALP)活性和成骨基因的表达在经scAAV9和scAAV9.DSS载体处理的COB中是相当的,表明scAAV对成骨细胞分化没有不利影响(图29和35)。
测试了用衣壳蛋白上的骨靶向分子修饰的工程化的scAAV9血清型(Ale-scAAV9)。为了在AAV衣壳蛋白上创造含叠氮化物的氨基酸,将VP3衣壳蛋白中的天冬酰胺587改变为琥珀密码子(TAG)或将此琥珀密码子插入天冬酰胺587和精氨酸588之间。与这些突变VP3质粒一起,使用DNA转染试剂将pHelper、pAAV-GFP和pPyIRS/tRNACUA以1:1:1:2的摩尔比瞬时转染到AAV-293包装细胞中。6小时后,用含有1mM N-2-叠氮基O乙基氧羰基-L-赖氨酸(N-2-azideoethyloxycarbonyl-L-lysine,NAEK)的新鲜培养基替换培养基,并且72小时后从转染的细胞收获具有携带叠氮化物的氨基酸的scAAV9血清型(叠氮化物-scAAV9)。表达自pPyIRS/tRNACUA质粒的正交琥珀抑制剂氨酰基-tRNA合成酶/tRNA-CUA对在NAEK存在下于琥珀密码子位点处合成携带叠氮化物的非天然氨基酸。
通过用抗VP3抗体的免疫印迹确认了含有叠氮化物部分的VP3突变体的表达。一旦确认,通过监测GFP表达来评估叠氮化物-scAAV9血清型转导OB或OC的能力。用编码GFP的叠氮化物-scAAV9血清型处理原代小鼠OB,并通过表面荧光显微镜术评估GFP的表达。此外,这些scAAV9血清型用于在M-CSF和Rank配体存在下感染小鼠BM-MO(OC前体细胞)。将它们的转导效率与编码GFP的WT-scAAV9血清型进行比较。
接下来,经由点击化学,通过交联亲骨分子(ADIBO-Ale)和叠氮化物-scAAV9血清型的VP3衣壳蛋白中携带叠氮化物的氨基酸,生产骨靶向scAAV9血清型(Ale-scAAV9)。将叠氮化物-scAAV9血清型在室温下与不同浓度的ADIBO-Ale(FutureChem)温育,并在2小时后使用透析去除未结合的ADIBO-Ale。通过监测GFP表达来检查Ale-scAAV9血清型转导原代OB或OC的能力。
DSS-scAAV9转导至骨细胞和组织的验证
之前已报道,当将肽无效地或不合适地融合到AAV衣壳中时,AAV的转导效率会显著降低。为了测试DSS肽插入对scAAV9转导至OB和OC的能力的影响,用不同剂量的编码GFP的scAAV9(WT-、DSS-588、DSS-Nter)处理小鼠OB和OC前体细胞。2天后,通过使用抗GFP抗体的western印迹和通过表面荧光显微镜术来分析GFP的表达。如图11和12中所见(A和B-左),当经DSS-588处理时,在OB和OC中均几乎未检测到或未检测到GFP蛋白表达。相比之下,与WT-scAAV9相比,DSS-Nter scAAV9的处理显示了OB和OC中GFP表达的减少,并且其表达以剂量依赖的方式增加。在这些scAAV9的处理中,OB(图11B-右和11C)和OC(图12B-右和12C)的分化是正常的,表明scAAV9转导不影响OB和OC功能。
接下来,研究了DSS-scAAV9载体在体内转导至骨细胞的能力。用X-tremeGene 9配制编码GFP的scAAV9载体(WT-、DSS-588、DSS-Nter),并将单剂量的1012~1013/ml个基因组拷贝的这些scAAV9载体注射到2月龄小鼠(C57BL/6J)的膝关节中,1周后,对股骨的冰冻切片进行组织学检查,并使用共聚焦显微术评估OB、OC和/或骨细胞中的GFP表达(图13)。PBS注射充当非GFP表达的对照。与体外实验相似(图11和12),在用DSS-588scAAV9处理的股骨中几乎未观察到或未观察到GFP表达。尽管与WT-scAAV9相比,表达GFP的细胞群减少,但DSS-Nter scAAV成功转导了所有的骨细胞(bone cells),包括OB、OC和骨细胞(osteocytes)。
测试了AAV衣壳在体内的骨靶向活性。如之前所述,将scAAV9或scAAV9-DSS-Nteri.v.注射到两月龄小鼠中,并在注射后两周通过EGFP表达评估组织分布。尽管在经scAAV9或scAAV9-DSS-Nter全身处理的小鼠的全身中观察到相等水平的EGFP蛋白(图36),但经scAAV9.DSS-Nter注射的小鼠产生了分别在心脏和肝中经scAAV9实现的那些的~55%和~75%的EGFP表达水平(图26和图36)。重要地,股骨和腰椎中的表达在处理组之间是相对来说相当的(图26和36)。值得注意的是,与经scAAV9处理的股骨相比,经scAAV9.DSS-Nter处理的股骨显示了增加数量的表达EGFP的细胞(图26)。这些结果表明,与骨靶向肽基序(DSS)融合的工程化的VP2衣壳蛋白通过去靶向至非骨骼组织的递送来提高scAAV9的骨归巢特异性,并转而增加了其对骨的向性。
用于体内特异性骨转导的BT-scAAV9血清型的全身递送的验证
为了检查BT-scAAV9血清型在体内归巢于骨的能力,局部或全身施用单剂量的1×1010个基因组拷贝的编码GFP的scAAV9载体(WT-、DSS-或HABP、Ale)给小鼠。对于局部施用,将这些scAAV9血清型注射到2月龄小鼠(C57BL/6J)的膝关节中,并在1周或4周后通过IVIS-100光学成像系统监测AAV至骨上的OB、OC和/或骨细胞的递送。此外,在股骨的冰冻切片上进行组织学检查以检测通过这些scAAV9血清型转导的表达GFP的OB、OC和/或骨细胞。PBS注射充当非GFP表达的对照。对于全身施用,经由静脉内(IV)或腹膜内(IP)注射施用编码GFP的WT-、DSS-、HABP-或Ale-scAAV9血清型给小鼠。1周或4周后,通过IVIS-100光学成像系统监控AAV至骨的递送,并且GFP阳性的骨将被进一步冰冻切片以进行组织学检查。
编码特异于小鼠Schnurri-3(SHN3)、骨硬化蛋白(SOST)或组织蛋白酶K(CTSK)的shRNA的scAAV9载体的生成
硬化性狭窄病是一种具有高骨量的罕见遗传性疾病,并且已被观察到与编码骨硬化蛋白的SOST基因中的丧失功能型突变有关。骨硬化蛋白分泌自骨细胞、终末分化的成骨细胞,并且抑制骨形成和增强骨吸收。经单克隆人抗骨硬化蛋白抗体的处理通过促进骨形成和抑制骨吸收来恢复患有骨质疏松症的人患者和动物模型的骨质流失。然而,归因于增加的中风风险,FDA的批准目前是不太可能的。不同于抑制成骨细胞分化的骨硬化蛋白,组织蛋白酶K(CTSK,一种溶酶体半胱氨酸蛋白酶)在对骨吸收重要的成熟破骨细胞中高表达。致密性成骨不全症(Pycnodysostosis,一种具有高骨量的罕见遗传性疾病)由人体内CTSK基因的失活性突变导致。经CTSK的小分子抑制剂的处理通过抑制骨吸收同时限制对骨再生活性的不利影响来阻止患有骨质疏松症的人患者和动物模型的骨质流失。然而,归因于升高的中风发生率,其最近已从FDA的考虑中撤消。
Schnurri-3(SHN3)作为成骨细胞分化的新型抑制剂。使用可诱导的loxP:Cre系统瞬时缺失OB中的SHN3导致小鼠中骨量的显著增加,表明SHN3表达的下调提供了一种有吸引力的治疗方法以恢复骨质疏松症中的低骨量(图14)。同样地,SHN3的抑制通过促进骨形成阻止了骨质疏松症小鼠模型中的骨质流失(图15)。然而,不同于骨硬化蛋白和CTSK,SHN3缺乏对骨特异,并与非骨组织的表型无关。因此,将实施例1中所述的骨靶向scAAV9载体随后用于载体,以在体外和体内沉默OB和/或OC中的小鼠SHN3、SOST或CTSK。
改造靶向上述基因(例如SHN3、CTSK)的两个shRNA发夹以替代功能性自互补AAV载体(例如mTR)所需的突变的反向末端重复(mTR),并且修饰的shRNA-mTR序列描述于序列一节中。将这些修饰的shRNA-mTR在限制性酶位点PstI和Bgl2处克隆到pAAVscCB6-EGFP载体中,并包装到scAAV9衣壳中。
生产表达特异于小鼠schnurri-3(SHN3)和小鼠组织蛋白酶K(CTSK)的两个shRNA发夹的纯化的scAAV9载体(scAAV9-mSHN3i和scAAV9-mCTSKi)。对于体外特征化,分别在OB和OC中测试scAAV9-mSHN3i和scAAV9-mCTSKi的感染力、敲低效率和功能活性。首先,用小鼠原代OB前体细胞处理单剂量的1012~1013/ml个基因组拷贝的两种scAAV9-mSHN3i(Sh-SHN3-1、-2)或scAAV-载体对照(对照)。转导后2天,通过表面荧光显微镜术监测GFP表达,并通过使用RT-PCR测量SHN3mRNA水平来评估敲低效率。分别在OB培养的第6天和第15天通过测量OB分化基因(例如,骨唾液蛋白(BSP)和成骨相关转录因子(OSX))的表达来评估OB分化和通过茜素红染色来评估矿化作用活性(图16A-16D)。scAAV9-mSHN3i至OB的转导与scAAV9-对照的一样有效。scAAV9-mSHN3i(Sh-SHN3-1)能够使SHN3 mRNA水平降低50%(图16A-16B)。SHN3敲低增加了OB分化基因的矿化作用活性和表达(图16C-16D)。
接下来,检查了体内scAAV9-mSHN3i载体的转导和敲低效率(图17)。用X-tremeGene 9配制编码GFP的scAAV9载体(Sh-SHN3-1),并将单剂量的1012~1013/ml个基因组拷贝的此scAAV9载体注射到2月龄小鼠(C57BL/6J)的膝关节中。1周后,对股骨的冰冻切片进行组织学检查,并使用共聚焦显微镜评估OB和骨细胞中的GFP表达。PBS注射充当非GFP表达对照。与对照scAAV9相似,在用scAAV9-mSHN3i载体处理的股骨中观察到OB和骨细胞中的GFP表达(图17A)。或者,使用FACS分选从股骨分离表达GFP的细胞,并通过RT-PCR评估SHN3 mRNA水平,表明通过转导scAAV9-Sh-SHN3-1载体,SHN3 mRNA水平降低50%(图17B)。
此外,还在小鼠OC中研究了scAAV9-mCTSKi的感染力、敲低效率和功能活性。为获得OC前体细胞,将小鼠单核细胞系Raw264.7用Rank配体(5ng/ml)处理2天。随后,将这些OC前体细胞用单剂量的1012~1013/ml个基因组拷贝的两种scAAV9-mCTSKi(Sh-CTSK-1、-2)或scAAV-载体对照(对照)处理2天。使用表面荧光显微镜术通过GFP表达来评估转导效率(图18A-18D),并通过使用RT-PCR测量CTSK mRNA水平来评估敲低效率(图18B)。此外,通过测量TRAP酶活性、TRAP染色的OC的多核化和OC分化基因(例如,树突细胞特异的跨膜蛋白(DC-STAMP)和TRAP)的表达来评估OC分化(图18C和18D)。scAAV9-mCTSKi至OC前体细胞的转导与scAAV9-对照的一样有效。scAAV9-mCTSKi(Sh-CTSK-1)能够将CTSK mRNA水平降低70%(图18A-18B)。CTSK敲低导致OC分化的轻度降低(图18C-18D)。为了检查scAAV9-mCTSKi载体在体内转导至OC的能力,将单剂量的1012~1013/ml个基因组拷贝的编码GFP的scAAV9载体(Sh-CTSK-1)与X-tremeGene 9的制剂注射到2月龄小鼠(C57BL/6J)的膝关节中。对GFP和CTSK表达的免疫荧光分析确认,对照-scAAV9和scAAV9-mCTSKi载体均能体内转导骨表面上的OC(图19A)。仅当用scAAV9-mCTSKi载体转导时,表达GFP的OC中的CTSK表达显著降低(图19B)。
编码特异于小鼠骨硬化蛋白(SOST)shRNA的两种shRNA发夹(scAAV9-mSOSTi)的pAAVscCB6载体的敲低效率在具有骨硬化蛋白高表达的表达GFP-DMP1的骨细胞系中得到验证。一旦生成,将单剂量的1012~1013/ml个基因组拷贝的两种scAAV9-mCTSKi或scAAV9-载体对照(对照)注射到具有骨硬化蛋白高表达的小鼠骨细胞系中。转导后2天,通过Western印迹评估GFP表达,并使用RT-PCR通过测量SOST mRNA水平评估敲低效率。
使用BT-AAV介导的基因沉默开发用于骨质疏松症的基因治疗剂
此实施例描述了编码特异于小鼠SHN3、SOST、CTSK的shRNA发夹(SHN3i、SOSTi、CTSKi)的scAAV9血清型的功能性功效的测试。将shRNA发夹克隆到编码GFP的AAV载体中,并包装到BT-AAV衣壳(DSS-scAAV9、Ale-scAAV9)中(图20)。作为阴性对照,将对照ShRNA(cont-i)克隆到AAV载体中。将编码cont-i、SHN3i或SOSTi的BT-AAV血清型转导至原代小鼠OB中,并在三天后通过定量PCR评估SOST或SHN3的敲低效率。通过编码cont-i或CTSKi的BT-AAV血清型转导小鼠原代OC前体细胞,并在M-CSF和RANK配体存在下培养。转导后三天,通过定量PCR分析CTSK的敲低效率,并在六天后评估CSTK沉默抑制OC分化的能力。
为了检查这些基因治疗剂在骨质疏松症小鼠模型中阻止骨质流失的能力,在假手术或OVX手术后4周,对4月龄雌性小鼠(C57BL/6J,n=12只小鼠/组)IV或IP注射单剂量的1×1012个基因组拷贝的这些BT-scAAV9血清型。或者,IV或IP注射22月龄雌性小鼠(C57BL/6J,n=12只小鼠/组)。作为阴性对照,施用具有对照shRNA(cont-i)的编码GFP的scAAV9载体到这些小鼠中。处理后两个月,用钙黄绿素和茜素红标记小鼠,并进行动态组织形态测定以评估体内OB和OC的数量、骨形成速率和OC吸收活性。为了定位表达GFP的scAAV9转导的细胞,在全身进行IVIS-100光学成像。表达GFP的组织在冰冻切片上被进一步处理以用于组织学检查。此外,使用FACS分选从长骨分离表达GFP蛋白的scAAV9转导的OB和/或OC,并通过定量PCR评估SOST、SHN3或CTSK的mRNA水平。对于骨骼分析,进行长骨和椎骨的microCT以分析骨量和结构。
此外,用耐酒石酸的酸性磷酸酶(TRAP)染色组织切片作为OC分化的标记,并且对I型胶原α1(Coll)和Runx2的免疫组织化学(IHC)作为OB分化的标记。此分析伴有测量OB分化基因表达的骨RNA的定量PCR分析。最后,如在患有骨质疏松症的人患者中一样,使用ELISA通过测量血清骨更新标记(包括I型胶原C端端肽(CTX)、1型前胶原的N端前肽(P1NP)和骨特异的碱性磷酸酶(BSAP))的水平来分析全身OB和OC活性。
实施例2:使用AAV介导的基因添加的用于骨质疏松症的新型基因治疗剂的开发
在一些实施方案中,经由皮下注射的重组PTH肽(1-34aa)或重组PTHrP肽(1-36aa)的间断性治疗在患有骨质疏松症的人患者和动物模型中增加OB活性并促进骨形成。这些肽(特立帕肽(teriparatide)、阿巴帕肽(abaloparatide))被FDA批准,并且目前用于患有骨质疏松症的人患者。在一些实施方案中,分泌性因子DJ-1充当OB与内皮细胞间交叉感知的介导物的作用。在一些实施方案中,DJ-1的治疗促进人MSC中的OB分化和人内皮细胞中的血管生成,同时其抑制OC分化。
该实施例描述了经由肌肉内(IM)注射的编码分泌性成骨因子的scAAV9血清型至动物的递送,经由之,被注射的肌肉充当生物泵,提供了血液循环中这些因子的稳定的高表达,以促进骨质疏松症环境中的骨形成(图21)。为此,将编码人PTH(1-84aa)、人PTHrP(1-140aa)或小鼠DJ-1(1-190aa)的cDNA克隆到pAAVscCB6-EGFP载体中,其在限制性酶位点Agel和Hind3间含有用于蛋白分泌的常规信号肽,并包装到肌肉向性的AAV衣壳(PTH-scAAV9、PTHrP-scAAV9、DJ-1-scAAV9)中。这些cDNA序列在序列一节中描述。
为了在体外验证AAV转导的细胞中这些分泌性成骨因子的产生,使用scAAV9血清型转导小鼠成肌细胞系(C2C12),并在培养后三天收获上清液和通过ELISA测定分泌因子的水平。或者,裂解细胞并通过免疫印迹评估细胞内蛋白。一旦确认它们的分泌,在成骨培养条件下将这些成骨因子与小鼠原代OB一同温育,且将评估它们的成骨潜力。作为阴性对照,使用编码GFP的scAAV9血清型。
接下来,研究分泌性成骨因子的AAV介导的基因添加在骨质疏松症环境中是否阻止骨质流失。在4月龄雌性小鼠(C57BL/6J,n=12只小鼠/组)中进行假手术或OVX手术,并在手术后4周经由IM注射施用单剂量的1x1010个基因组拷贝的表达PTH、PTHrP或DJ-1(PTH-scAAV9、PTHrP-scAAV9、DJ-1-scAAV9)的编码GFP的scAAV9血清型到后肢的四头肌中。作为阴性对照,施用编码GFP的scAAV9载体对照(cont-scAAV9)到这些小鼠中。或者,将这些AAV血清型IM注射到22月龄雌性小鼠(C57BL/6J,n=12只小鼠/组)中。处理后两个月,用钙黄绿素和茜素红标记小鼠,并进行动态组织形态测定以体内评估OB和OC活性。对于骨骼分析,在长骨和椎骨中进行microCT、TRAP染色(OC分化)和针对Coll和Runx2的IHC(OB分化)。最后,通过ELISA或比色分析测量CTX(骨吸收)、P1NP和BSAP(骨形成)以及钙和磷(矿物质稳态)的血清水平。此分析伴有测量OB分化基因表达的骨RNA的qPCR分析。最后,通过ELISA测量转基因(PTH、PTHrP或DJ-1)的血清水平。
实施例3:成骨细胞中Shn3的诱导性缺失促进成年小鼠中的骨形成
为了检查SHN3的短期抑制对骨形成的影响,通过将Shn3fl/fl小鼠与在成熟成骨细胞(Shn3Ocn-Ert)中表达他莫昔芬诱导的Cre重组酶的骨钙素-CreERT小鼠杂交以产生可诱导的、成骨细胞特异性Shn3-敲除小鼠。将这些小鼠进一步与Cre报告基因RosamT/mG小鼠杂交以可视化表达Cre的细胞(Shn3Ocn-Ert;RosamT/mG)。用他莫昔芬处理Shn3Ocn-Ert;RosamT/mG小鼠导致位于小梁和皮质骨表面的成熟成骨细胞中的GFP表达,表明了Shn3的成骨细胞特异性缺失(图23)。因此,与他莫昔芬处理的对照小鼠相比,这些小鼠显示了小梁骨量的显著增加(图23)。这些结果表明,成熟成骨细胞中Shn3的诱导性缺失足以增加成年小鼠的骨量。
生成编码Cre的scAAV9载体(scAAV9-Cre,图30)以充当用于Shn3fl/fl小鼠中Cre重组的促进剂。首先,在分离自Shn3fl/fl小鼠的培养的COB中用scAAV9-Cre处理Shn3fl/fl小鼠(图30),并且如预期的,Shn3fl/fl COB中scAAV9介导的Cre表达导致Shn3的缺失和增强的成骨细胞分化(图31)。接下来,经由i.v.施用将scAAV9-Cre注射到两月龄Shn3Ocn-Ert;RosamT/mG小鼠中。注射后两个月,分别通过RT-PCR和荧光显微镜术验证股骨中Cre mRNA的表达(图31)和位于骨表面的成骨细胞谱系细胞中的EGFP蛋白的Cre介导的表达(图30)。与scAAV9-EGFP处理的股骨相比,scAAV 9-Cre处理的股骨显示了shn3 mRNA水平的显著降低(图31)和相对小梁骨量的增加(图31)。这些结果表明,在Shn3fl/fl小鼠中全身递送的scAAV9-Cre靶向成骨细胞谱系细胞并介导Shn3缺失以增加骨量。重要的是,这些结果证明了scAAV9介导的至成骨细胞谱系细胞的转基因递送显著改变骨生理的潜能。
实施例4:通过携带amiR-shn3转基因的scAAV9沉默Shn3促进体内骨形成
已显示人造microRNA(amiR设计进入miRNA支架中的siRNA盒)有效促进体内靶标信息降解。此外,这些设计允许表达盒由pol II启动子驱动,扩展了用scAAV载体控制基因敲低的能力。工程化人工microRNA盒以靶向shn3(amiR-shn3)或对照(amiR-ctrl)。在此设计中,amiR被内含子地(intronically)插入CB启动子和Egfp报告基因之间(图24),其允许阳性转导(positively transduced)的细胞或组织的视觉追踪。然后,将测试盒包装到AAV9衣壳中。scANV9-amiR-shn3或scAAV9-amiR-ctrl的处理导致体外阳性转导的COB(图32)。与用amiR-ctrl处理的COB相比,scAAV9-amiR-shn3的处理导致shn3 mRNA水平降低~50%,和ibsp表达和矿化作用的相对增加(图32)。
为了检查amiR在体内增强骨合成代谢活性的能力,经由i.a.施用将scAAV9-amiR-shn3载体注射到两月龄小鼠的膝关节中。处理后两个月,分别通过IVIS光学成像(图24)和荧光显微镜术(图24)检查后肢和股骨中的EGFP表达。重要的是,分离自股骨的FACS分选的表达EGFP的细胞显示了shn3 mRNA水平降低~50%(图24)。与经amiR-ctrl处理的股骨相比,经amiR-shn3处理的股骨显示了相对小梁骨量的显著增加(图24)。这些结果表明,scAAV9-amiR-shn3的局部递送在敲低成骨细胞谱系细胞中的SHN3表达中有效,并进而增加体内骨量。
然后检查了scAAV9-amiR-shn3在全身递送后能促进体内骨合成代谢活性的能力。i.v.施用到三月龄小鼠中后两个月,如预期的,主要在后肢、肝和股骨中检测到EGFP表达(图33)。通过scAAV9-amiR-shn3转导的股骨显示了shn3 mRNA水平降低~50%(图24),和小梁骨量和皮质骨矿物质密度的显著增加(图24)。同样地,体内成骨细胞活性在这些小鼠中增加,如更高的骨形成速率(BFR)、矿物质沉积速率(MAR)和每骨表面的成骨细胞表面(Ob.S/BS)所显示的(图24)。然而,在这些小鼠中,抗酒石酸的酸性磷酸酶(TRAP)阳性的破骨细胞的数量和骨吸收标记C末端端肽I型胶原(CTX)的血清水平没有改变(图33)。这些结果表明,全身递送的AAV9-amiR-shn3减少成骨细胞谱系细胞中shn3的表达,增强成骨细胞活性,并增加了骨量,而没有破骨细胞数量和功能的任何体内改变。因此,scAAV9-amiR-shn3载体可作为有力的骨合成代谢剂用于治疗骨质疏松症。
实施例4:scAAV9介导的Shn3沉默抵消绝经后骨质疏松症中的骨质流失
Wnt拮抗剂的抑制已被识别为用于骨质疏松症患者中的治疗性干预的一种新方法。先前的研究鉴定了SHN3经由干扰Wnt信号传导而作为成骨细胞分化的抑制剂。卵巢切除(OVX)小鼠是绝经后骨质疏松症的已建立模型。为了进一步证实Shn3的抑制可以是一个有吸引力的促进骨形成而作为骨质疏松症疗法的靶标,将缺少SHN3(Shn3-/-)的三月龄雌性小鼠进行卵巢切除术,并在手术后两个月通过microCT评估骨量。尽管OVX手术诱导WT小鼠中小梁骨量的显著减少,但通过Shn3缺失完全阻止了OVX诱导的骨质流失,因为小梁骨量在假手术-Shn3-/-小鼠和OVX-Shn3-/-小鼠之间相当(图25)。因此,靶向Shn3具有阻止绝经后骨质疏松症中骨质流失的治疗潜力。
为了测试scAAV9-amiR-shn3在绝经后骨质疏松症中的治疗效果,对三月龄野生型雌性小鼠进行假手术或OVX手术,且在手术后六周以i.v.注射载体(图25)。七周后,经处理的股骨显示了有效的转导,导致~50%的shn3敲低(图25)。如预期的,表达amiR-ctrl的OVX小鼠相对于假手术小鼠显示了小梁骨量的显著降低。然而,当用scAAV9-amiR-shn3处理时,骨质流失在OVX小鼠的股骨中完全逆转,如通过更高的小梁BV/TV、厚度和连接密度所显示的(图25和图34)。同样地,相对于表达amiR-ctrl的OVX小鼠,这些小鼠中的股骨BFR和MAR增加,表明增强的体内成骨细胞活性(图25)。值得注意的是,通过scAAV9-amiR-shn3实现的shn3沉默不改变体内破骨细胞功能,因为TRAP阳性破骨细胞的数量和骨吸收活性在表达amiR-ctrl和amiR-shn3的OVX小鼠之间相当(图34)。最后,生物力学测试显示,经scAAV9-amiR-shn3处理的小鼠的股骨的强度和刚度受到相当的保护以免受OVX诱导的骨质流失(图25),表明scAAV9介导的shn3沉默改善骨质疏松症小鼠的临床上有意义的终点。综上所述,这些结果证明,在OVX诱导的骨质疏松症发作后,全身递送的scAAV9-amiR-shn3促进骨形成并增强骨的临床相关的机械性能。
实施例5:骨靶向肽基序到AAV9衣壳上的接枝改善骨特异性转导
检查了新AAV9.DSS-Nter亲骨(bone-tropic)衣壳递送治疗性amiR-shn3转基因(scAAV9.DSS-Nter-amiR-shn3)至OVX小鼠的能力。对三月龄雌性小鼠进行假手术或OVX手术,并在手术后六周i.v.注射scAAV9.DSS-Nter-amiR-shn3。注射后七周,动物在动物的整个后部(图37)和股骨的成骨细胞谱系细胞(图37)中表现了强的EGFP表达,表明强烈的转导。相对于表达amiR-ctrl的假手术或OVX股骨,shn3 mRNA水平在表达amiR-shn3的OVX股骨中显著降低(图27)。尽管表达amiR-ctrl的OVX小鼠相对于假手术小鼠显示了小梁骨量的显著减少,但骨质流失在经scAAV9.DSS-Nter-amiR-shn3处理的OVX小鼠的股骨(图27)和腰椎骨(图27,图37)中完全逆转,如通过更高的小梁BV/TV、厚度、数量和连接密度所显示的。综上所述,这些结果证明,通过亲骨AAV9.DSS-Nter衣壳的amiR-shn3的递送能抵消绝经后骨质疏松症中的骨质流失。
实施例6:骨质疏松症的人患者和动物模型中骨质流失的抑制
针对NF-κβ(RANK、TNFRSF11A)配体的受体激活的人源化生物抗体干扰RANK配体(RANKL)和RANK之间的相互作用,其抑制破骨细胞分化所需的RANK信号传导。因此,它的治疗通过抑制破骨细胞介导的骨吸收防止患有骨质疏松症的人患者和动物模型中的骨质流失。
为了通过沉默破骨细胞前体细胞中的RANK而抑制破骨细胞分化,从而抑制骨质疏松症的人患者和动物模型中的骨质流失,检查了新AAV9.DSS-Nter亲骨衣壳递送治疗性amiR-33-mRANKi转基因(scAAV9.DSS-Nter-amiR-mRANKi 1/2)的能力。
方法
scAAV载体设计与生产
以gBlock形式合成amiR-33-ctrl和amiR-33-shn3的DNA序列,并将其在限制性酶切位点(Pstl和Bg1II)克隆到pAAVsc-CB6-Egfp质粒的内含子区域中。pAAVsc-CB6-Cre载体通过用Cre重组酶替换Egfp报告基因产生。通过测序验证构建体。先前的研究表明,转基因小鼠中靶向小鼠Shn3的shRNA的多西环素(doxycycline)诱导的表达导致了shn3 mRNA水平的降低和骨量的相对增加。相同的靶向序列用于产生amiR-33-shn3盒。将pAAV-amiR-ctrl和pAAV-amiR-shn3构建体包装到AAV9衣壳中。此外,将pAAVsc-CB6-Egfp构建体包装到AAV1、AAV2、AAV3、AAV4、AAV5、AAV6、AAV6.2、AAV7、AAV8、AAV9、AAV9-HR、AAVrh8、AAVrh10、AAVrh39和AAVrh43衣壳中。如先前所述,通过HEK293细胞的瞬时转染进行scAAV的生产,通过CsCl沉淀进行纯化,通过使用Egfp引物/探针组在QX200 ddPCR系统(Bio-Rad)上的微滴式数字PCR(ddPCR)进行滴定。表3列出了gBlock和用于ddPCR的寡核苷酸的序列。
表3:引物、探针和gblock的序列


骨靶向scAAV9载体的产生
对编码骨靶向肽基序DSS(AspSerSer)6(SEQ ID NO:16)的DNA序列进行密码子优化。为了产生Q588-DSS-A589衣壳(DSS-588),对表达AAV2rep基因和AAV9 cap基因的质粒(pAAV2/9)进行修饰以将DSS序列在Q588和A589密码子之间插入AAV9 cap基因中(pAAV2/9.Q588-DSS-A589)。此质粒可用于scAAV生产。为了产生DSS-Nter衣壳,使用了一对质粒。首先,突变pAAV2/9中VP2的起始密码子(ACG→ACC),因此仅VP1和VP3被表达(pAAV2/9.noVP2)。在另一个质粒中,将DSS序列融合到AAV9 VP2 ORF的N端。将Kozak序列和ATG起始密码子直接置于DSS序列的上游,以允许由CMV启动子驱动的最佳表达[pcDNA.DSS-VP2(AAV9)]。质粒pAAV2/9.noVP2和pcDNA.DSS-VP2(AAV9)用于scAAV生产。
细胞
从Sigma购入软骨形成的ATDC5细胞,并培养在添加有2%FBS、2mM L-谷氨酰胺和1%青霉素/链霉素的DMEM/Ham’s F12培养基中。此外,通过使用II型胶原酶(50mg/ml,Worthington,LS004176)和中性蛋白酶II(100mg/ml,Roche,10165859001),从五日龄野生型新生鼠(C57BL/6J)的颅盖中分离出原代骨原细胞(COB),并保持在含有10%FBS(Gibco)、2mM L-谷氨酰胺(Corning)、1%青霉素/链霉素(Corning)和1%非必需氨基酸(Corning)的α-MEM培养基(Gibco)中。用抗坏血酸(200μM,Sigma,A8960)和β-甘油磷酸酯(10mM,Sigma,G9422)分化COB。最后,从两月龄小鼠(C57BL/6J)的股骨和胫骨中冲洗出骨髓细胞,并培养在含有10%FBS和20ng/ml M-CSF(R&D系统)的α-MEM培养基中的培养皿中,以获得源自骨髓的破骨细胞前体细胞(BM-OCP)。12小时后,将非贴壁细胞重新铺板到组织培养皿中,并在相同的培养基中培养三天。BM-OCP随后在RAMKL(20ng/ml;R&D系统)和M-CSF(20ng/ml;R&D系统)存在下持续六天分化为破骨细胞。
小鼠
如先前所述产生Shn3-/-小鼠和Shn3fl/fl小鼠,并分别保持在BALB/cJ和C57BL/6J背景上。将具有成熟成骨细胞中他莫昔芬诱导的Cre重组酶表达的骨钙素-ERT/Cre小鼠与Shn3fl/fl小鼠杂交,以获得Shn3fl/fl;Ocn-ERT/Cre小鼠。为了标记表达Cre的细胞,将Shn3fl /fl;Ocn-ERT/Cre小鼠进一步与RosamT/mG cre报告基因小鼠杂交。为了ERT/Cre的出生后激活,每天一次连续5天将玉米油(Sigma)中的100mg/kg他莫昔芬(Sigma)腹膜内注射到2月龄雌性小鼠中。
通过尾基因组DNA上的PCR确定小鼠基因型。引物序列应要求提供。在所有实验中均使用和分析同窝对照。
MicroCT分析
MicroCT用于对小梁和皮质骨微结构的定性和定量评估,并由不知道所分析的动物的基因型的研究人员进行。用10%中性缓冲的福尔马林固定切除自指定小鼠的股骨,并使用microCT 35(Scanco Medical)以7μm的空间分辨率对其进行扫描。对于股骨远端的小梁骨分析,对始自生长板近侧280μm的上部2.1mm区域进行轮廓化(contoured)。对于股骨的皮质骨分析,使用了长度为0.6mm的干体中段区域。使用12μm的等向性体素尺寸进行L4脊髓节段的MicroCT扫描。通过基于二值化图像的距离转换的方法从轮廓化的2D图像获得3D重建图像。或者,使用Inveon多模态3D可视化程序(Siemens Medical Solutions USA,Inc)来生成microCT模态的多个静态或动态体积的融合3D视图。展示的所有图像是各自基因型的代表(n>5)。
组织学、组织形态测定和免疫荧光
对于组织学分析,从经rAAV载体处理的小鼠解剖出股骨和椎骨,在10%中性缓冲的福尔马林中固定2天,并用5%四钠EDTA脱钙2至4周。通过乙醇系列使组织脱水,在二甲苯中清洗两次,包埋在石蜡中,并沿冠状板从前向后以6μm的厚度进行切片。用苏木精和曙红(H&E)或抗酒石酸的酸性磷酸酶(TRAP)对脱钙的股骨切片进行染色。
对于动态组织形态测定分析,以六天间隔将溶解于2%碳酸氢钠溶液中的25mg/kg钙黄绿素(Sigma,C0875)和50mg/kg茜素-3-甲基亚氨基二乙酸(Sigma,A3882)皮下注射到小鼠中。在10%中性缓冲的福尔马林中固定两天后,将未脱钙的股骨样品包埋在甲基丙烯酸甲酯中,并将近端干骺端纵向切片(5μm),并以McNeal氏三色染色用于类骨质评估,甲苯胺蓝用于成骨细胞,和TRAP用于破骨细胞。明确目标区域,并使用接口到半自动分析系统(Osteometrics)的Nikon Optiphot 2显微镜来测量骨形成率/骨表面(BFR/BS)、矿物质沉积率(MAR)、骨表面(BS)、成骨细胞表面(Ob.S/BS)和破骨细胞表面(Oc.S/BS)。测量在两个切片/样品(相隔~25μm)上进行并在归一化前求和,以获得根据ASBMR标准的单个测量/样品。此方法已经经过广泛的质量控制和验证,并且结果由两位不同的研究人员以盲目方式进行评估。
对于免疫荧光,收集解剖自经rAAV处理的小鼠的新鲜股骨和椎骨,并立即固定于冰冷的4%多聚甲醛溶液中两天。在0.5M EDTA pH 7.4于4℃以持续摇动(年龄≥1周)进行半脱钙五天,并随后用一天的20%蔗糖磷酸盐缓冲液和第二天的25%蔗糖磷酸盐缓冲液的混合物进行浸润。将所有样品包埋在25%蔗糖溶液和OCT化合物(Sakura)的50/50混合物中,并使用低温恒温器(Leica)切成12μm厚的径向切片。如先前所述进行免疫荧光染色和分析。简言之,在用0.2%Triton X-100处理10分钟后,在室温下用5%驴血清将切片封闭30分钟,并在4℃下用抗BGLAP抗体(sc-365797,Santa Cruz,1:150)温育过夜。用驴抗大鼠IgGAlexa-594(1:500,Molecular Probes)使一抗可视化。用DAPI复染细胞核。使用OlympusIX81共聚焦显微镜或Leica TCS SP5 II Zeiss LSM-880共聚焦显微镜成像样品。
生物力学分析
使用位于骨骼研究成像和生物力学测试中心(Center for Skeletal ResearchImaging and Biomechanical Testing Core)的电力机械测试仪(Electroforce 3230,Bose Corporation,Eden Prairie,MN)在三点弯曲中机械性测试股骨。弯曲夹具的底部跨度长度为8mm。通过在位移控制中以0.05mm/sec的速度用力移动的负载点来进行测试,并以60Hz收集位移数据。在测试过程中,所有骨都以相同的方向放置,且颅骨表面置于支撑物上并承受张力。基于来自测试的力和位移数据和用microCT测量的干体中段几何形状来计算弯曲刚度(El,N-mm2)、表观弹性模量(Eapp,MPa)、极限力矩(Mult,N-mm)、表观极限应力(σapp,MPa)、断裂功(Wfrac,mJ)和表观韧度(Uapp,mJ/mm3)。断裂功是导致股骨断裂所需的能量,且它是通过使用黎曼求和法(Riemann Sum method)求出力-位移曲线下的面积来计算的。使用力-位移曲线的线性部分计算弯曲刚度。在计算表观弹性模量时,使用最小惯性力矩(Imin)。
ELISA分析
根据制造商说明通过使用试剂盒进行CTX1 ELISA(Abclonal MC0850)分析。
成骨细胞分化分析
对于碱性磷酸酶(ALP)染色,用10%中性福尔马林缓冲液固定成骨细胞,并用含有Fast Blue(Sigma,FBS25)和萘酚AS-MX(Sigma,855)的溶液染色。或者,将成骨细胞与10倍稀释的Alamar Blue溶液(Invitrogen,DAL1100)一起温育以进行细胞增殖。随后,洗涤细胞并将其与含有6.5mM Na2CO3、18.5mM NaHCO3、2mM MgCl2和磷酸酶底物(Sigma,S0942)的溶液一起温育,并通过光度计(Biorad)测量ALP活性。
为了评估成熟成骨细胞中细胞外基质矿化作用,将细胞用磷酸盐缓冲盐水(PBS)洗涤两次,并在室温下在70%EtOH中固定15分钟。将固定的细胞用蒸馏水洗涤两次,并随后用2%茜素红溶液(Sigma,A5533)染色5分钟。然后将细胞用蒸馏水洗涤三遍,并检查钙沉积物的存在。通过乙酸提取法定量矿化作用。
定量RT-PCR分析
使用QIAzol(QIAGEN)从细胞纯化总RNA,并使用来自Applied Biosystems的High-Capacity cDNA Reverse Transcription Kit合成cDNA。使用 Green PCR MasterMix(Bio-Rad)和CFX连接RT-PCR检测系统(Bio-Rad)进行定量RT-PCR。为了测量骨组织中的Shn3 mRNA水平,在去除骨髓后,将胫骨在液氮中速冻30秒,并随后在1ml QIAzol中均质化1分钟。
Green PCR MasterMix(Bio-Rad)和CFX连接RT-PCR检测系统(Bio-Rad)进行定量RT-PCR。为了测量骨组织中的Shn3 mRNA水平,在去除骨髓后,将胫骨在液氮中速冻30秒,并随后在1ml QIAzol中均质化1分钟。
或者,将解剖自经rAAV9处理的小鼠的股骨和胫骨在含有10mM HEPES(pH 7.2)(CellGro)的汉克斯平衡盐溶液(Life Technologies)中压碎,然后用2.5mg/mL胶原酶A(Roche)和1单位/mL中性蛋白酶II(Roche)于37℃在温和搅拌下酶消化15分钟。将所得细胞悬浮液过滤(40μm),使用含有0.5%BSA(组分V)和2mM EDTA的PBS(pH 7.2)洗涤。洗涤后,将细胞重悬于含2mM EDTA和1μg/mL 4-6,联脒-2-苯基吲哚(DAPI)的PBS(pH 7.2)中(活/死排除),并使用FACS Aria II SORP细胞分选仪(Becton Dickinson)在排除DAPI+细胞和双联体(doublet)下分选表达EGFP的细胞。使用QIAzol从细胞中纯化总RNA。表3中描述了用于PCR的引物。
免疫印迹分析
在TNT裂解缓冲液(50mM Tris-HCl(pH 7.4)、150mM NaCl、1%Triton X-100、1mMEDTA、1mM EGTA、50mM NaF、1mM Na3VO4、1mM PMSF和蛋白酶抑制剂混合物(Sigma))中裂解细胞,并使用DC蛋白测定法(Bio-Rad)测量蛋白量。将等量的蛋白进行SDS-PAGE,转膜至Immunobilon-P膜(Millipore),用抗GFP抗体(JL-8,632381,Takara,1:1000)、抗Cre重组酶抗体(ab24607,Abcam,1:1000)、抗Hsp90抗体(675402,Biolegend,1:1000)进行免疫印迹,并用ECL(Thermo fisher scientific)进行显色。用抗Hsp90抗体的免疫印迹作为上样对照。或者,将解剖的股骨和软组织在RIPA裂解缓冲液(89900,Thermo fisher scientific)中均质化,并将组织裂解物进行免疫印迹分析。
体外转导成骨细胞、破骨细胞或软骨细胞的rAAV血清型的筛选
将ATDC5细胞或原代COB以1×104个细胞/孔的密度铺板在24孔板中,并在24小时后将它们与包装有CB-Egfp报告基因转基因的rAAV1、rAAV2、rAAV3、rAAV4、rAAV5、rAAV6、rAAV6.2、rAAV7、rAAV8、rAAV9、rAAVrh8、rAAVrh10、rAAVrh39或rAAVrh43载体以三种不同的滴度(109-1011/mL个基因组拷贝)一起温育。48小时后,用PBS洗涤细胞,并通过EVOS FL成像系统(Thermo fisher scientific)监测EGFP的表达。或者,在TNT裂解缓冲液中裂解细胞,并通过用抗EGFP抗体的免疫印迹来评估EGFP表达和使用Image J软件来定量。最后,将原代骨髓单核细胞以5×105个细胞/孔的密度铺板在24孔板中,并在10ng/ml RAMKL和20ng/mlM-CSF的存在下培养两天,以分化成破骨细胞前体细胞。用rAAV-Egfp载体处理后三天,通过EVOS FL成像系统和通过用抗EGFP抗体的免疫印迹来评估EGFP的表达。
对于体内筛选rAAV载体,将10μL的rAAV-Egfp载体(1×1011GC;5×1012GC/kg)关节内(i.a.)注射到两月龄雄性小鼠(Jackson Laboratory)的膝关节中。注射后两周,解剖股骨和膝关节用于IVIS-100光学成像或冰冻切片。
rAAV9介导的Cre重组酶或amiR-shn3递送对骨形成的影响
对于局部递送,将10μL的携带amiR-ctrl或amiR-shn3的rAAV9(1×1011GC;5×1012GC/kg)i.a.注射到两月龄雄性小鼠的膝关节中。注射后两个月,解剖股骨用于microCT分析。
对于全身递送,将200μL的携带Egfp、Cre、amiR-ctrl或amiR-shn3的rAAV9(4×1011GC;2×1013GC/kg)静脉内(i.v.)注射到小鼠中,并在两个月后,以六天的间隔对小鼠皮下注射钙黄绿素和茜素-3-甲基亚氨基二乙酸以用于动态组织形态测定分析。使用未标记的小鼠以使用IVIS-100光学成像或冰冻切片监测EGFP表达。
全身递送的rAAV9-amiR-shn3在绝经后骨质疏松症小鼠模型中的治疗效果
通过麻醉和双侧卵巢切除(OVX)三月龄雌性小鼠(Jackson Laboratory)产生绝经后骨质疏松症的小鼠模型。手术后六周,对假手术或OVX小鼠i.v.注射200μL的携带amiR-ctrl或amiR-shn3的rAAV9或rAAV9.DSS-Nter(4×1011GC;2×1013GC/kg)。将小鼠随机分成具有rAAV9或rAAV9.DSS-Nter的六组:假手术+rAAV9-amiR-ctrl、OVX+rAAV9-amiR-ctrl、OVX+rAAV9-amiR-shn3、假手术+rAAV9.DSS-Nter-amiR-ctrl、OVX+rAAV9.DSS-Nter-amiR-ctrl、OVX+rAAV9.DSS-Nter-amiR-shn3。注射后七周,以六天的间隔对小鼠皮下注射钙黄绿素和茜素-3-甲基亚氨基二乙酸以用于动态组织形态测定分析。使用未标记的小鼠以使用IVIS-100光学成像或冰冻切片监测EGFP表达。
统计方法
所有数据均以平均值±s.e.m表示。在以下假设上计算样本量:所测参数的30%差异被认为与预期平均值的10-20%的σ估计是生物学上显著的。α和β分别设置为.05和0.8的标准值。没有动物或样品被排除在分析之外,并且在适用的情况下将动物随机化到处理组和对照组。对于相关的数据分析,在相关的情况下,首先进行Shapiro-Wilk正态性检验以用于检查组的正态分布。若通过了正态性检验,则两尾、未配对学生t检验,并且若正态性检验失败,则使用Mann-Whitney检验用于两组之间的比较。对于三组或四组的比较,若通过了正态性检验,则使用单向ANOVA,随之对所有成对的组进行Tukey氏多重比较检验。若正态性检验失败,则进行Kruskal-Wallis检验,并随之进行Dunn氏多重比较检验。使用GraphPadPRISM软件(v6.0a,La Jolla,CA)进行统计分析。P<0.05被认为是统计学上显著的。*,P<0.05;**,P<0.01;***,P<0.001;和****,P<0.0001。
序列
>SEQ ID NO:1;amiR-33-mSHN3i-1:
tttgtcttttatttcaggtcccAGATCTAGGGCTCTGCGTTTGCTCCAGGTAGTCCGCTGCTCCCTTGGGCCTGGGCCCACTGACAGCCCTGGTGCCTCTGGCCGGCTGCACACCTCCTGGCGGGCAGCTGTGTACAAACTACTTGAGAGCAGGTGTTCTGGCAATACCTGCCTGCTCTGTAATAGTTTGTACACGGAGGCCTGCCCTGACTGCCCACGGTGCCGTGGCCAAAGAGGATCTAAGGGCACCGCTGAGGGCCTACCTAACCATCGTGGGGAATAAGGACAGTGTCACCCCTGCAGgggatccggtggtggtgcaaatca
>SEQ ID NO:2;amiR-33-mSHN3i-2:
tttgtcttttatttcaggtcccAGATCTAGGGCTCTGCGTTTGCTCCAGGTAGTCCGCTGCTCCCTTGGGCCTGGGCCCACTGACAGCCCTGGTGCCTCTGGCCGGCTGCACACCTCCTGGCGGGCAGCTGTGACTACAGGTACTCACAAGCTCTGTTCTGGCAATACCTGGAGCTTGTCTGCACCTGTAGTCACGGAGGCCTGCCCTGACTGCCCACGGTGCCGTGGCCAAAGAGGATCTAAGGGCACCGCTGAGGGCCTACCTAACCATCGTGGGGAATAAGGACAGTGTCACCCCTGCAGgggatccggtggtggtgcaaatca
>SEQ ID NO:3;amiR-33-hSHN3i-1:
GtcttttatttcaggtcccagatcttAGGGCTCTGCGTTTGCTCCAGGTAGTCCGCTGCTCCCTTGGGCCTGGGCCCACTGACAGCCCTGGTGCCTCTGGCCGGCTGCACACCTCCTGGCGGGCAGCTGTGtttccatggtaagttcaaggcTGTTCTGGCAATACCTGGCCTTGAAGATGCCATGGAAACACGGAGGCCTGCCCTGACTGCCCACGGTGCCGTGGCCAAAGAGGATCTAAGGGCACCGCTGAGGGCCTACCTAACCATCGTGGGGAATAAGGACAGTGTCACCCccctgcaggggatccggtggtggtgcaaat
>SEQ ID NO:4;amiR-33-mCTSKi-1:
tttgtcttttatttcaggtcccAGATCTAGGGCTCTGCGTTTGCTCCAGGTAGTCCGCTGCTCCCTTGGGCCTGGGCCCACTGACAGCCCTGGTGCCTCTGGCCGGCTGCACACCTCCTGGCGGGCAGCTGTGTTTCATCATAGTACACACCTCTGTTCTGGCAATACCTGGAGGTGTGATCCATGATGAAACACGGAGGCCTGCCCTGACTGCCCACGGTGCCGTGGCCAAAGAGGATCTAAGGGCACCGCTGAGGGCCTACCTAACCATCGTGGGGAATAAGGACAGTGTCACCCCTGCAGgggatccggtggtggtgcaaatca
>SEQ ID NO:5;amiR-33-mCTSKi-2:
tttgtcttttatttcaggtcccAGATCTAGGGCTCTGCGTTTGCTCCAGGTAGTCCGCTGCTCCCTTGGGCCTGGGCCCACTGACAGCCCTGGTGCCTCTGGCCGGCTGCACACCTCCTGGCGGGCAGCTGTGTTACTGTAGGATCGAGAGGGATGTTCTGGCAATACCTGTCCCTCTCCTTACTACAGTAACACGGAGGCCTGCCCTGACTGCCCACGGTGCCGTGGCCAAAGAGGATCTAAGGGCACCGCTGAGGGCCTACCTAACCATCGTGGGGAATAAGG
>SEQ ID NO:6;amiR-33-hCTSK-1:
GtcttttatttcaggtcccagatcttAGGGCTCTGCGTTTGCTCCAGGTAGTCCGCTGCTCCCTTGGGCCTGGGCCCACTGACAGCCCTGGTGCCTCTGGCCGGCTGCACACCTCCTGGCGGGCAGCTGTGattatcgctattgcagctttcTGTTCTGGCAATACCTGGAAAGCTGGTACAGCGATAATCACGGAGGCCTGCCCTGACTGCCCACGGTGCCGTGGCCAAAGAGGATCTAAGGGCACCGCTGAGGGCCTACCTAACCATCGTGGGGAATAAGGACAGTGTCACCCccctgcaggggatccggtggtggtgcaaat
>SEQ ID NO:7;amiR-33-hCTSK-2:
GtcttttatttcaggtcccagatcttAGGGCTCTGCGTTTGCTCCAGGTAGTCCGCTGCTCCCTTGGGCCTGGGCCCACTGACAGCCCTGGTGCCTCTGGCCGGCTGCACACCTCCTGGCGGGCAGCTGTGtcagattatcgctattgcagcTGTTCTGGCAATACCTGGCTGCAATTCCAATAATCTGACACGGAGGCCTGCCCTGACTGCCCACGGTGCCGTGGCCAAAGAGGATCTAAGGGCACCGCTGAGGGCCTACCTAACCATCGTGGGGAATAAGGACAGTGTCACCCccctgcaggggatccggtggtggtgcaaat
>SEQ ID NO:8;amiR-33-mSOSTi-1:
tttgtcttttatttcaggtcccAGATCTAGGGCTCTGCGTTTGCTCCAGGTAGTCCGCTGCTCCCTTGGGCCTGGGCCCACTGACAGCCCTGGTGCCTCTGGCCGGCTGCACACCTCCTGGCGGGCAGCTGTGAcaagtaggcagatgaggcacTGTTCTGGCAATACCTGGTGCCTCAAGTACCTACTTGTCACGGAGGCCTGCCCTGACTGCCCACGGTGCCGTGGCCAAAGAGGATCTAAGGGCACCGCTGAGGGCCTACCTAACCATCGTGGGGAATAAGGACAGTGTCACCCCTGCAGgggatccggtggtggtgcaaatca
>SEQ ID NO:9;amiR-33-mSOSTi-2:
tttgtcttttatttcaggtcccAGATCTAGGGCTCTGCGTTTGCTCCAGGTAGTCCGCTGCTCCCTTGGGCCTGGGCCCACTGACAGCCCTGGTGCCTCTGGCCGGCTGCACACCTCCTGGCGGGCAGCTGTGtgacctctgtggcatcattccTGTTCTGGCAATACCTGGGAATGATCGCGCAGAGGTCACACGGAGGCCTGCCCTGACTGCCCACGGTGCCGTGGCCAAAGAGGATCTAAGGGCACCGCTGAGGGCCTACCTAACCATCGTGGGGAATAAGGACAGTGTCACCCCTGCAGgggatccggtggtggtgcaaatca
>SEQ ID NO:10;amiR-33-hSosT-1:
GtcttttatttcaggtcccagatcttAGGGCTCTGCGTTTGCTCCAGGTAGTCCGCTGCTCCCTTGGGCCTGGGCCCACTGACAGCCCTGGTGCCTCTGGCCGGCTGCACACCTCCTGGCGGGCAGCTGTGatggtcttgttgttctccagcTGTTCTGGCAATACCTGGCTGGAGATGAGCAAGACCATCACGGAGGCCTGCCCTGACTGCCCACGGTGCCGTGGCCAAAGAGGATCTAAGGGCACCGCTGAGGGCCTACCTAACCATCGTGGGGAATAAGGACAGTGTCACCCccctgcaggggatccggtggtggtgcaaat
>SEQ ID NO:11;amiR-33-hSosT-2:
GtcttttatttcaggtcccagatcttAGGGCTCTGCGTTTGCTCCAGGTAGTCCGCTGCTCCCTTGGGCCTGGGCCCACTGACAGCCCTGGTGCCTCTGGCCGGCTGCACACCTCCTGGCGGGCAGCTGTGACGtCtttGGtCtCAAAGGGGTGTTCTGGCAATACCTGCCCCTTTGTCATCAAAGACGTCACGGAGGCCTGCCCTGACTGCCCACGGTGCCGTGGCCAAAGAGGATCTAAGGGCACCGCTGAGGGCCTACCTAACCATCGTGGGGAATAAGGACAGTGTCACCCccctgcaggggatccggtggtggtgcaaat
>SEQ ID NO:12;人PTH(1-84aa):
ggaattgtacccgcggccgatccAccggtGCCACCATGATACCTGCAAAAGACATGGCTAAAGTTATGATTGTCATGTTGGCAATTTGTTTTCTTACAAAATCGGATGGGAAATCTGTTAAGAAGAGATCTGTGAGTGAAATACAGCTTATGCATAACCTGGGAAAACATCTGAACTCGATGGAGAGAGTAGAATGGCTGCGTAAGAAGCTGCAGGATGTGCACAATTTTGTTGCCCTTGGAGCTCCTCTAGCTCCCAGAGATGCTGGTTCCCAGAGGCCCCGAAAAAAGGAAGACAATGTCTTGGTTGAGAGCCATGAAAAAAGTCTTGGAGAGGCAGACAAAGCTGATGTGAATGTATTAACTAAAGCTAAATCCCAGTGAagcttatcgataccgtcgactagagctc
>SEQ ID NO:13;人PTHrP(1-140aa):
ggaattgtacccgcggccgatccAccggtGCCACCATGCAGCGGAGACTGGTTCAGCAGTGGAGCGTCGCGGTGTTCCTGCTGAGCTACGCGGTGCCCTCCTGCGGGCGCTCGGTGGAGGGTCTCAGCCGCCGCCTCAAAAGAGCTGTGTCTGAACATCAGCTCCTCCATGACAAGGGGAAGTCCATCCAAGATTTACGGCGACGATTCTTCCTTCACCATCTGATCGCAGAAATCCACACAGCTGAAATCAGAGCTACCTCGGAGGTGTCCCCTAACTCCAAGCCCTCTCCCAACACAAAGAACCACCCCGTCCGATTTGGGTCTGATGATGAGGGCAGATACCTAACTCAGGAAACTAACAAGGTGGAGACGTACAAAGAGCAGCCGCTCAAGACACCTGGGAAGAAAAAGAAAGGCAAGCCCGGGAAACGCAAGGAGCAGGAAAAGAAAAAACGGCGAACTCGCTCTGCCTGGTTAGACTCTGGAGTGACTGGGAGTGGGCTAGAAGGGGACCACCTGTCTGACACCTCCACAACGTCGCTGGAGCTCGATTCACGGTAAagcttatcgataccgtcgactagagctc
>SEQ ID NO:14;小鼠DJ-1(1-190aa):
ggaattgtacccgcggccgatccaccggtcGCCACCATGGGATGGAGCTGTATTATCCTGTTTCTCGTCGCTACTGCCACCGGAGCTCATTCCGCTTCCAAAAGAGCTCTGGTCATCCTGGCCAAAGGAGCAGAGGAGATGGAGACAGTGATTCCTGTGGATGTCATGCGGCGAGCCGGGATCAAAGTCACTGTTGCAGGCTTGGCTGGGAAGGACCCCGTGCAGTGTAGCCGTGATGTAATGATTTGTCCAGATACCAGTCTGGAAGATGCAAAAACGCAGGGACCATACGATGTGGTGGTTCTTCCAGGAGGAAATCTGGGTGCACAGAATTTATCTGAGTCGCCTATGGTGAAGGAGATCCTCAAGGAGCAGGAGAGCAGGAAGGGCCTCATAGCTGCCATCTGTGCAGGTCCTACGGCTCTGTTGGCTCACGAAGTAGGTTTTGGATGCAAGGTCACAACACACCCACTGGCTAAGGACAAAATGATGAATGGCAGTCACTACAGC TACTCAGAGAGCCGCGTGGAGAAGGACGGCCTGATCCTCACCAGCCGCGGGCCGGGGACCAGCTTTGAGTTTGCACTAGCCATTGTGGAGGCACTCGTGGGGAAAGACATGGCCAACCAAGTGAAGGCACCGCTTGTTCTCAAAGACTAGTAAaagcttatcgataccgtcgactagagctcgctg
>SEQ ID NO:15;人DJ-1(1-190aa):
ggaattgtacccgcggccgatccaccggtc GCCACC ATG GGA TGG AGC TGT ATT ATC CTGTTTCTC GTC GCT ACT GCC ACC GGA GCT CAT TCCGCTTCCAAAAGAGCTCTGGTCATCCTGGCTAAAGGAGCAGAGGAAATGGAGACGGTCATCCCTGTAGATGTCATGAGGCGAGCTGGGATTAAGGTCACCGTTGCAGGCCTGGCTGGAAAAGACCCAGTACAGTGTAGCCGTGATGTGGTCATTTGTCCTGATGCCAGCCTTGAAGATGCAAAAAAAGAGGGACCATATGATGTGGTGGTTCTACCAGGAGGTAATCTGGGCGCACAGAATTTATCTGAGTCTGCTGCTGTGAAGGAGATACTGAAGGAGCAGGAAAACCGGAAGGGCCTGATAGCCGCCATCTGTGCAGGTCCTACTGCTCTGTTGGCTCATGAAATAGGTTTTGGAAGTAAAGTTACAACACACCCTCTTGCTAAAGACAAAATGATGAATGGAGGTCATTACACCTACTCTGAGAATCGTGTGGAAAAAGACGGCCTGATTCTTACAAGCCGGGGGCCTGGGACCAGCTTCGAGTTTGCGCTTGCAATTGTTGAAGCCCTGAATGGCAAGGAGGTGGCGGCTCAAGTGAAGGCTCCACTTGTTCTTAAAGACTAGTAAaagcttatcgataccgtcgactagagctcgctg
>SEQ ID NO:16;(AspSerSer)6骨靶向肽
DSSDSSDSSDSSDSSDSS
>SEQ ID NO:17;HABP-19,骨靶向肽
CγEPRRγEVAγELγEPRRγEVAγEL,
γ(Gla残基):γ-羧化谷氨酸(Glu)通过维生素K依赖的γ-羧化衍生自Glu。
>SEQ ID NO 18:AAV衣壳1;
MAADGYLPDWLEDNLSEGIREWWDLKPGAPKPKANQQKQDDGRGLVLPGYKYLGPFNGLDKGEPVNAADAAALEHDKAYDQQLKAGDNPYLRYNHADAEFQERLQEDTSFGGNLGRAVFQAKKRVLEPLGLVEEGAKTAPGKKRPVEQSPQEPDSSSGIGKTGQQPAKKRLNFGQTGDSESVPDPQPLGEPPATPAAVGPTTMASGGGAPMADNNEGADGVGNASGNWHCDSTWLGDRVITTSTRTWALPTYNNHLYKQISSASTGASNDNHYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKRLNFKLFNIQVKEVTTNDGVTTIANNLTSTVQVFSDSEYQLPYVLGSAHQGCLPPFPADVFMIPQYGYLTLNNGSQAVGRSSFYCLEYFPSQMLRTGNNFTFSYTFEEVPFHSSYAHSQSLDRLMNPLIDQYLYYLNRTQNQSGSAQNKDLLFSRGSPAGMSVQPKNWLPGPCYRQQRVSKTKTDNNNSNFTWTGASKYNLNGRESIINPGTAMASHKDDEDKFFPMSGVMIFGKESAGASNTALDNVMITDEEEIKATNPVATERFGTVAVNFQSSSTDPATGDVHAMGALPGMVWQDRDVYLQGPIWAKIPHTDGHFHPSPLMGGFGLKNPPPQILIKNTPVPANPPAEFSATKFASFITQYSTGQVSVEIEWELQKENSKRWNPEVQYTSNYAKSANVDFTVDNNGLYTEPRPIGTRYLTRPL
>SEQ ID NO 19:AAV衣壳2;
MAADGYLPDWLEDTLSEGIRQWWKLKPGPPPPKPAERHKDDSRGLVLPGYKYLGPFNGLDKGEPVNEADAAALEHDKAYDRQLDSGDNPYLKYNHADAEFQERLKEDTSFGGNLGRAVFQAKKRVLEPLGLVEEPVKTAPGKKRPVEHSPVEPDSSSGTGKAGQQPARKRLNFGQTGDADSVPDPQPLGQPPAAPSGLGTNTMATGSGAPMADNNEGADGVGNSSGNWHCDSTWMGDRVITTSTRTWALPTYNNHLYKQISSQSGASNDNHYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKRLNFKLFNIQVKEVTQNDGTTTIANNLTSTVQVFTDSEYQLPYVLGSAHQGCLPPFPADVFMVPQYGYLTLNNGSQAVGRSSFYCLEYFPSQMLRTGNNFTFSYTFEDVPFHSSYAHSQSLDRLMNPLIDQYLYYLSRTNTPSGTTTQSRLQFSQAGASDIRDQSRNWLPGPCYRQQRVSKTSADNNNSEYSWTGATKYHLNGRDSLVNPGPAMASHKDDEEKFFPQSGVLIFGKQGSEKTNVDIEKVMITDEEEIRTTNPVATEQYGSVSTNLQRGNRQAATADVNTQGVLPGMVWQDRDVYLQGPIWAKIPHTDGHFHPSPLMGGFGLKHPPPQILIKNTPVPANPSTTFSAAKFASFITQYSTGQVSVEIEWELQKENSKRWNPEIQYTSNYNKSVNVDFTVDTNGVYSEPRPIGTRYLTRNL
>SEQ ID NO 20:AAV衣壳3B;
MAADGYLPDWLEDNLSEGIREWWALKPGVPQPKANQQHQDNRRGLVLPGYKYLGPGNGLDKGEPVNEADAAALEHDKAYDQQLKAGDNPYLKYNHADAEFQERLQEDTSFGGNLGRAVFQAKKRILEPLGLVEEAAKTAPGKKRPVDQSPQEPDSSSGVGKSGKQPARKRLNFGQTGDSESVPDPQPLGEPPAAPTSLGSNTMASGGGAPMADNNEGADGVGNSSGNWHCDSQWLGDRVITTSTRTWALPTYNNHLYKQISSQSGASNDNHYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKKLSFKLFNIQVKEVTQNDGTTTIANNLTSTVQVFTDSEYQLPYVLGSAHQGCLPPFPADVFMVPQYGYLTLNNGSQAVGRSSFYCLEYFPSQMLRTGNNFQFSYTFEDVPFHSSYAHSQSLDRLMNPLIDQYLYYLNRTQGTTSGTTNQSRLLFSQAGPQSMSLQARNWLPGPCYRQQRLSKTANDNNNSNFPWTAASKYHLNGRDSLVNPGPAMASHKDDEEKFFPMHGNLIFGKEGTTASNAELDNVMITDEEEIRTTNPVATEQYGTVANNLQSSNTAPTTRTVNDQGALPGMVWQDRDVYLQGPIWAKIPHTDGHFHPSPLMGGFGLKHPPPQIMIKNTPVPANPPTTFSPAKFASFITQYSTGQVSVEIEWELQKENSKRWNPEIQYTSNYNKSVNVDFTVDTNGVYSEPRPIGTRYLTRNL
>SEQ ID NO 21:AAV衣壳4:
MTDGYLPDWLEDNLSEGVREWWALQPGAPKPKANQQHQDNARGLVLPGYKYLGPGNGLDKGEPVNAADAAALEHDKAYDQQLKAGDNPYLKYNHADAEFQQRLQGDTSFGGNLGRAVFQAKKRVLEPLGLVEQAGETAPGKKRPLIESPQQPDSSTGIGKKGKQPAKKKLVFEDETGAGDGPPEGSTSGAMSDDSEMRAAAGGAAVEGGQGADGVGNASGDWHCDSTWSEGHVTTTSTRTWVLPTYNNHLYKRLGESLQSNTYNGFSTPWGYFDFNRFHCHFSPRDWQRLINNNWGMRPKAMRVKIFNIQVKEVTTSNGETTVANNLTSTVQIFADSSYELPYVMDAGQEGSLPPFPNDVFMVPQYGYCGLVTGNTSQQQTDRNAFYCLEYFPSQMLRTGNNFEITYSFEKVPFHSMYAHSQSLDRLMNPLIDQYLWGLQSTTTGTTLNAGTATTNFTKLRPTNFSNFKKNWLPGPSIKQQGFSKTANQNYKIPATGSDSLIKYETHSTLDGRWSALTPGPPMATAGPADSKFSNSQLIFAGPKQNGNTATVPGTLIFTSEEELAATNATDTDMWGNLPGGDQSNSNLPTVDRLTALGAVPGMVWQNRDIYYQGPIWAKIPHTDGHFHPSPLIGGFGLKHPPPQIFIKNTPVPANPATTFSSTPVNSFITQYSTGQVSVQIDWEIQKERSKRWNPEVQFTSNYGQQNSLLWAPDAAGKYTEPRAIGTRYLTHHL
>SEQ ID NO 22:AAV衣壳5:
MSFVDHPPDWLEEVGEGLREFLGLEAGPPKPKPNQQHQDQARGLVLPGYNYLGPGNGLDRGEPVNRADEVAREHDISYNEQLEAGDNPYLKYNHADAEFQEKLADDTSFGGNLGKAVFQAKKRVLEPFGLVEEGAKTAPTGKRIDDHFPKRKKARTEEDSKPSTSSDAEAGPSGSQQLQIPAQPASSLGADTMSAGGGGPLGDNNQGADGVGNASGDWHCDSTWMGDRVVTKSTRTWVLPSYNNHQYREIKSGSVDGSNANAYFGYSTPWGYFDFNRFHSHWSPRDWQRLINNYWGFRPRSLRVKIFNIQVKEVTVQDSTTTIANNLTSTVQVFTDDDYQLPYVVGNGTEGCLPAFPPQVFTLPQYGYATLNRDNTENPTERSSFFCLEYFPSKMLRTGNNFEFTYNFEEVPFHSSFAPSQNLFKLANPLVDQYLYRFVSTNNTGGVQFNKNLAGRYANTYKNWFPGPMGRTQGWNLGSGVNRASVSAFATTNRMELEGASYQVPPQPNGMTNNLQGSNTYALENTMIFNSQPANPGTTATYLEGNMLITSESETQPVNRVAYNVGGQMATNNQSSTTAPATGTYNLQEIVPGSVWMERDVYLQGPIWAKIPETGAHFHPSPAMGGFGLKHPPPMMLIKNTPVPGNITSFSDVPVSSFITQYSTGQVTVEMEWELKKENSKRWNPEIQYTNNYNDPQFVDFAPDSTGEYRTTRPIGTRYLTRPL
>SEQ ID NO 23:AAV衣壳6:
MAADGYLPDWLEDNLSEGIREWWDLKPGAPKPKANQQKQDDGRGLVLPGYKYLGPFNGLDKGEPVNAADAAALEHDKAYDQQLKAGDNPYLRYNHADAEFQERLQEDTSFGGNLGRAVFQAKKRVLEPFGLVEEGAKTAPGKKRPVEQSPQEPDSSSGIGKTGQQPAKKRLNFGQTGDSESVPDPQPLGEPPATPAAVGPTTMASGGGAPMADNNEGADGVGNASGNWHCDSTWLGDRVITTSTRTWALPTYNNHLYKQISSASTGASNDNHYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKRLNFKLFNIQVKEVTTNDGVTTIANNLTSTVQVFSDSEYQLPYVLGSAHQGCLPPFPADVFMIPQYGYLTLNNGSQAVGRSSFYCLEYFPSQMLRTGNNFTFSYTFEDVPFHSSYAHSQSLDRLMNPLIDQYLYYLNRTQNQSGSAQNKDLLFSRGSPAGMSVQPKNWLPGPCYRQQRVSKTKTDNNNSNFTWTGASKYNLNGRESIINPGTAMASHKDDKDKFFPMSGVMIFGKESAGASNTALDNVMITDEEEIKATNPVATERFGTVAVNLQSSSTDPATGDVHVMGALPGMVWQDRDVYLQGPIWAKIPHTDGHFHPSPLMGGFGLKHPPPQILIKNTPVPANPPAEFSATKFASFITQYSTGQVSVEIEWELQKENSKRWNPEVQYTSNYAKSANVDFTVDNNGLYTEPRPIGTRYLTRPL
>SEQ ID NO 24:AAV衣壳6.2;
MAADGYLPDWLEDNLSEGIREWWDLKPGAPKPKANQQKQDDGRGLVLPGYKYLGPFNGLDKGEPVNAADAAALEHDKAYDQQLKAGDNPYLRYNHADAEFQERLQEDTSFGGNLGRAVFQAKKRVLEPLGLVEEGAKTAPGKKRPVEQSPQEPDSSSGIGKTGQQPAKKRLNFGQTGDSESVPDPQPLGEPPATPAAVGPTTMASGGGAPMADNNEGADGVGNASGNWHCDSTWLGDRVITTSTRTWALPTYNNHLYKQISSASTGASNDNHYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKRLNFKLFNIQVKEVTTNDGVTTIANNLTSTVQVFSDSEYQLPYVLGSAHQGCLPPFPADVFMIPQYGYLTLNNGSQAVGRSSFYCLEYFPSQMLRTGNNFTFSYTFEDVPFHSSYAHSQSLDRLMNPLIDQYLYYLNRTQNQSGSAQNKDLLFSRGSPAGMSVQPKNWLPGPCYRQQRVSKTKTDNNNSNFTWTGASKYNLNGRESIINPGTAMASHKDDKDKFFPMSGVMIFGKESAGASNTALDNVMITDEEEIKATNPVATERFGTVAVNLQSSSTDPATGDVHVMGALPGMVWQDRDVYLQGPIWAKIPHTDGHFHPSPLMGGFGLKHPPPQILIKNTPVPANPPAEFSATKFASFITQYSTGQVSVEIEWELQKENSKRWNPEVQYTSNYAKSANVDFTVDNNGLYTEPRPIGTRYLTRPL
>SEQ ID NO 25:AAV衣壳7:
MAADGYLPDWLEDNLSEGIREWWDLKPGAPKPKANQQKQDNGRGLVLPGYKYLGPFNGLDKGEPVNAADAAALEHDKAYDQQLKAGDNPYLRYNHADAEFQERLQEDTSFGGNLGRAVFQAKKRVLEPLGLVEEGAKTAPAKKRPVEPSPQRSPDSSTGIGKKGQQPARKRLNFGQTGDSESVPDPQPLGEPPAAPSSVGSGTVAAGGGAPMADNNEGADGVGNASGNWHCDSTWLGDRVITTSTRTWALPTYNNHLYKQISSETAGSTNDNTYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKKLRFKLFNIQVKEVTTNDGVTTIANNLTSTIQVFSDSEYQLPYVLGSAHQGCLPPFPADVFMIPQYGYLTLNNGSQSVGRSSFYCLEYFPSQMLRTGNNFEFSYSFEDVPFHSSYAHSQSLDRLMNPLIDQYLYYLARTQSNPGGTAGNRELQFYQGGPSTMAEQAKNWLPGPCFRQQRVSKTLDQNNNSNFAWTGATKYHLNGRNSLVNPGVAMATHKDDEDRFFPSSGVLIFGKTGATNKTTLENVLMTNEEEIRPTNPVATEEYGIVSSNLQAANTAAQTQVVNNQGALPGMVWQNRDVYLQGPIWAKIPHTDGNFHPSPLMGGFGLKHPPPQILIKNTPVPANPPEVFTPAKFASFITQYSTGQVSVEIEWELQKENSKRWNPEIQYTSNFEKQTGVDFAVDSQGVYSEPRPIGTRYLTRNL
>SEQ ID NO 26:AAV衣壳8:
MAADGYLPDWLEDNLSEGIREWWALKPGAPKPKANQQKQDDGRGLVLPGYKYLGPFNGLDKGEPVNAADAAALEHDKAYDQQLQAGDNPYLRYNHADAEFQERLQEDTSFGGNLGRAVFQAKKRVLEPLGLVEEGAKTAPGKKRPVEPSPQRSPDSSTGIGKKGQQPARKRLNFGQTGDSESVPDPQPLGEPPAAPSGVGPNTMAAGGGAPMADNNEGADGVGSSSGNWHCDSTWLGDRVITTSTRTWALPTYNNHLYKQISNGTSGGATNDNTYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKRLSFKLFNIQVKEVTQNEGTKTIANNLTSTIQVFTDSEYQLPYVLGSAHQGCLPPFPADVFMIPQYGYLTLNNGSQAVGRSSFYCLEYFPSQMLRTGNNFQFTYTFEDVPFHSSYAHSQSLDRLMNPLIDQYLYYLSRTQTTGGTANTQTLGFSQGGPNTMANQAKNWLPGPCYRQQRVSTTTGQNNNSNFAWTAGTKYHLNGRNSLANPGIAMATHKDDEERFFPSNGILIFGKQNAARDNADYSDVMLTSEEEIKTTNPVATEEYGIVADNLQQQNTAPQIGTVNSQGALPGMVWQNRDVYLQGPIWAKIPHTDGNFHPSPLMGGFGLKHPPPQILIKNTPVPADPPTTFNQSKLNSFITQYSTGQVSVEIEWELQKENSKRWNPEIQYTSNYYKSTSVDFAVNTEGVYSEPRPIGTRYLTRNL
>SEQ ID NO 27:AAV衣壳9:
MAADGYLPDWLEDNLSEGIREWWALKPGAPQPKANQQHQDNARGLVLPGYKYLGPGNGLDKGEPVNAADAAALEHDKAYDQQLKAGDNPYLKYNHADAEFQERLKEDTSFGGNLGRAVFQAKKRLLEPLGLVEEAAKTAPGKKRPVEQSPQEPDSSAGIGKSGAQPAKKRLNFGQTGDTESVPDPQPIGEPPAAPSGVGSLTMASGGGAPVADNNEGADGVGSSSGNWHCDSQWLGDRVITTSTRTWALPTYNNHLYKQISNSTSGGSSNDNAYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKRLNFKLFNIQVKEVTDNNGVKTIANNLTSTVQVFTDSDYQLPYVLGSAHEGCLPPFPADVFMIPQYGYLTLNDGSQAVGRSSFYCLEYFPSQMLRTGNNFQFSYEFENVPFHSSYAHSQSLDRLMNPLIDQYLYYLSKTINGSGQNQQTLKFSVAGPSNMAVQGRNYIPGPSYRQQRVSTTVTQNNNSEFAWPGASSWALNGRNSLMNPGPAMASHKEGEDRFFPLSGSLIFGKQGTGRDNVDADKVMITNEEEIKTTNPVATESYGQVATNHQSAQAQAQTGWVQNQGILPGMVWQDRDVYLQGPIWAKIPHTDGNFHPSPLMGGFGMKHPPPQILIKNTPVPADPPTAFNKDKLNSFITQYSTGQVSVEIEWELQKENSKRWNPEIQYTSNYYKSNNVEFAVNTEGVYSEPRPIGTRYLTRNL
>SEQ ID NO 28:AAV衣壳rh8:
MAADGYLPDWLEDNLSEGIREWWDLKPGAPKPKANQQKQDDGRGLVLPGYKYLGPFNGLDKGEPVNAADAAALEHDKAYDQQLKAGDNPYLRYNHADAEFQERLQEDTSFGGNLGRAVFQAKKRVLEPLGLVEEGAKTAPGKKRPVEQSPQEPDSSSGIGKTGQQPAKKRLNFGQTGDSESVPDPQPLGEPPAAPSGLGPNTMASGGGAPMADNNEGADGVGNSSGNWHCDSTWLGDRVITTSTRTWALPTYNNHLYKQISNGTSGGSTNDNTYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKRLNFKLFNIQVKEVTTNEGTKTIANNLTSTVQVFTDSEYQLPYVLGSAHQGCLPPFPADVFMVPQYGYLTLNNGSQALGRSSFYCLEYFPSQMLRTGNNFQFSYTFEDVPFHSSYAHSQSLDRLMNPLIDQYLYYLVRTQTTGTGGTQTLAFSQAGPSSMANQARNWVPGPCYRQQRVSTTTNQNNNSNFAWTGAAKFKLNGRDSLMNPGVAMASHKDDDDRFFPSSGVLIFGKQGAGNDGVDYSQVLITDEEEIKATNPVATEEYGAVAINNQAANTQAQTGLVHNQGVIPGMVWQNRDVYLQGPIWAKIPHTDGNFHPSPLMGGFGLKHPPPQILIKNTPVPADPPLTFNQAKLNSFITQYSTGQVSVEIEWELQKENSKRWNPEIQYTSNYYKSTNVDFAVNTEGVYSEPRPIGTRYLTRNL
>SEQ ID NO 29:AAV衣壳rh10:
MAADGYLPDWLEDNLSEGIREWWDLKPGAPKPKANQQKQDDGRGLVLPGYKYLGPFNGLDKGEPVNAADAAALEHDKAYDQQLKAGDNPYLRYNHADAEFQERLQEDTSFGGNLGRAVFQAKKRVLEPLGLVEEGAKTAPGKKRPVEPSPQRSPDSSTGIGKKGQQPAKKRLNFGQTGDSESVPDPQPIGEPPAGPSGLGSGTMAAGGGAPMADNNEGADGVGSSSGNWHCDSTWLGDRVITTSTRTWALPTYNNHLYKQISNGTSGGSTNDNTYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKRLNFKLFNIQVKEVTQNEGTKTIANNLTSTIQVFTDSEYQLPYVLGSAHQGCLPPFPADVFMIPQYGYLTLNNGSQAVGRSSFYCLEYFPSQMLRTGNNFEFSYQFEDVPFHSSYAHSQSLDRLMNPLIDQYLYYLSRTQSTGGTAGTQQLLFSQAGPNNMSAQAKNWLPGPCYRQQRVSTTLSQNNNSNFAWTGATKYHLNGRDSLVNPGVAMATHKDDEERFFPSSGVLMFGKQGAGKDNVDYSSVMLTSEEEIKTTNPVATEQYGVVADNLQQQNAAPIVGAVNSQGALPGMVWQNRDVYLQGPIWAKIPHTDGNFHPSPLMGGFGLKHPPPQILIKNTPVPADPPTTFSQAKLASFITQYSTGQVSVEIEWELQKENSKRWNPEIQYTSNYYKSTNVDFAVNTDGTYSEPRPIGTRYLTRNL
>SEQ ID NO 30:AAV衣壳rh39:
MAADGYLPDWLEDNLSEGIREWWALKPGAPKPKANQQKQDDGRGLVLPGYKYLGPFNGLDKGEPVNAADAAALEHDKAYDQQLKAGDNPYLRYNHADAEFQERLQEDTSFGGNLGRAVFQAKKRVLEPLGLVEEAAKTAPGKKRPVEPSPQRSPDSSTGIGKKGQQPAKKRLNFGQTGDSESVPDPQPIGEPPAGPSGLGSGTMAAGGGAPMADNNEGADGVGSSSGNWHCDSTWLGDRVITTSTRTWALPTYNNHLYKQISNGTSGGSTNDNTYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKRLSFKLFNIQVKEVTQNEGTKTIANNLTSTIQVFTDSEYQLPYVLGSAHQGCLPPFPADVFMIPQYGYLTLNNGSQAVGRSSFYCLEYFPSQMLRTGNNFEFSYTFEDVPFHSSYAHSQSLDRLMNPLIDQYLYYLSRTQSTGGTQGTQQLLFSQAGPANMSAQAKNWLPGPCYRQQRVSTTLSQNNNSNFAWTGATKYHLNGRDSLVNPGVAMATHKDDEERFFPSSGVLMFGKQGAGRDNVDYSSVMLTSEEEIKTTNPVATEQYGVVADNLQQTNTGPIVGNVNSQGALPGMVWQNRDVYLQGPIWAKIPHTDGNFHPSPLMGGFGLKHPPPQILIKNTPVPADPPTTFSQAKLASFITQYSTGQVSVEIEWELQKENSKRWNPEIQYTSNYYKSTNVDFAVNTEGTYSEPRPIGTRYLTRNL
>SEQ ID NO 31:AAV衣壳rh43:
MAADGYLPDWLEDNLSEGIREWWDLKPGAPKPKANQQKQDDGRGLVLPGYKYLGPFNGLDKGEPVNAADAAALEHDKAYDQQLEAGDNPYLRYNHADAEFQERLQEDTSFGGNLGRAVFQAKKRVLEPLGLVEEGAKTAPGKKRPVEQSPQEPDSSSGIGKKGQQPARKRLNFGQTGDSESVPDPQPLGEPPAAPSGVGPNTMAAGGGAPMADNNEGADGVGSSSGNWHCDSTWLGDRVITTSTRTWALPTYNNHLYKQISNGTSGGATNDNTYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKRLSFKLFNIQVKEVTQNEGTKTIANNLTSTIQVFTDSEYQLPYVLGSAHQGCLPPFPADVFMIPQYGYLTLNNGSQAVGRSSFYCLEYFPSQMLRTGNNFQFTYTFEDVPFHSSYAHSQSLDRLMNPLIDQYLYYLSRTQTTGGTANTQTLGFSQGGPNTMANQAKNWLPGPCYRQQRVSTTTGQNNNSNFAWTAGTKYHLNGRNSLANPGIAMATHKDDEERFFPSNGILIFGKQNAARDNADYSDVMLTSEEEIKTTNPVATEEYGIVADNLQQQNTAPQIGTVNSQGALPGMVWQNRDVYLQGPIWAKIPHTDGNFHPSPLMGGFGLKHPPPQILIKNTPVPADPPTTFNQSKLNSFITQYSTGQVSVEIEWELQKENSKRWNPEIQYTSNYYKSTSVDFAVNTEGVYSEPRPIGTRYLTRNL
>SEQ ID NO 32:AAV衣壳2/2-66:
MAADGYLPDWLEDTLSEGIRQWWKLKPGPPPPKPAERHQDDSRGLVLPGYKYLGPFNGLDKGEPVNEADAAALEHDKAYDRQLDSGDNPYLKYNHADAEFQERLKEDTSFGGNLGRAVFQAKKRVLEPLGLVEEPVKTAPGKKRPVEHSPAEPDSSSGTGKAGQQPARKRLNFGQTGDADSVPDPQPLGQPPAAPSGLGTNTMATGSGAPMADNNEGADGVGNSSGNWHCDSTWMGDRVITTSTRTWALPTYNNHLYKQISSQSGASNDNHYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKRLNFKLFNIQVKEVTQNDGTTTIANNLTSTVQVFTDSEYQLPYVLGSAHQGCLPPFPADVFMVPQYGYLTLNNGSQAVGRSSFYCLEYFPSQMLRTGNNFTFSYTFEDVPFHSSYAHSQSLDRLMNPLIDQYLYYLSKTNAPSGTTTMSRLQFSQAGASDIRDQSRNWLPGPCYRQQRVSKTAADNNNSDYSWTGATKYHLNGRDSLVNPGPAMASHKDDEEKYFPQSGVLIFGKQDSGKTNVDIEKVMITDEEEIRTTNPVATEQYGSVSTNLQSGNTQAATTDVNTQGVLPGMVWQDRDVYLQGPIWAKIPHTDGHFHPSPLMGGFGLKHPPPQILIKNTPVPANPSTTFSAAKFASFITQYSTGQVSVEIEWELQKENSKRWNPEIQYTSNYNKSVNVDFTVDTNGVYSEPRPIGTRYLTRNL
>SEQ ID NO 33:AAV衣壳2/2-84:
MAADGYLPDWLEDTLSEGIRQWWKLKPGPPPPKPAERHQDDSRGLVLPGYKYLGPFNGLDKGEPVNEADAAALEHDKAYDRQLDSGDNPYLKYNHADAEFQERLKEDTSFGGNLGRAVFQAKKRVLEPLGLVEEPVKTAPGKKRPVEHSPAEPDSSSGTGKAGQQPARKRLNFGQTGDADSVPDPQPLGQPPAAPSGLGTNTMATGSGAPMADNNEGADGVGNSSGNWHCDSTWMGDRVITTSTRTWALPTYNNHLYKQISSQSGASNDNHYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKRLNFKLFNIQVKEVTQNDGTTTIANNLTSTVQVFTDSEYQLPYVLGSAHQGCLPPFPADVFMVPQYGYLTLNNGSQAVGRSSFYCLEYFPSQMLRTGNNFTFSYTFEDVPFHSSYAHSQSLDRLMNPLIDQYLYYLSKTNAPSGTTTMSRLQFSQAGASDIRDQSRNWLPGPCYRQQRVSKTAADNNNSDYSWTGATKYHLNGRDSLVNPGPAMASHKDDEEKYFPQSGVLIFGKQDSGKTNVDIEKVMITDEEEIRTTNPVATEQYGSVSTNLQSGNTQAATTDVNTQGVLPGMVWQDRDVYLQGPIWAKIPHTDGHFHPSPLMGGFGLKHPPPQILIKNTPVPANPSTTFSAAKLASFITQYSTGQVSVEIEWELQKENSKRWNPEIQYTSNYNKSVNVDFTVDTNGVYSEPRPIGTRYLTRNL
>SEQ ID NO 34:AAV衣壳2/2-125:
MAADGYLPDWLEDTLSEGIRQWWKLKPGPPPPKPAERHKDDSRGLVLPGYKYLGPFNGLDKGEPVNEADAAALEHDKAYDRQLDSGDNPYLKYNHADAEFQERLKEDTSFGGNLARAVFQAKKRVLEPLGLVEEPVKTAPGKKRPVEHSPAEPDSSSGTGKSGQQPARKRLNFGQTGDADSVPDPQPLGQPPAAPSGLGTNTMASGSGAPMADNNEGADGVGNSSGNWHCDSTWMGDRVITTSTRTWALPTYNNHLYKQISSQSGASNDNHYFGYSTPWGYFDFNRFHCHFSPRDWQRLINNNWGFRPKRLNFKLFNIQVKEVTQNDGTTTIANNLTSTVQVFTDSEYQLPYVLGSAHQGCLPPFPADVFMVPQYGYLTLNNGSQTVGRSSFYCLEYFPSQMLRTGNNFTFSYTFEDVPFHSSYAHSQSLDRLMNPLIDQYLYYLSRTNTPSGTTTQSRLRFSQAGASDIRDQSRNWLPGPCYRQQRVSKTAADNNNSDYSWTGATKYHLNGRDSLVNPGTAMASHKDDEEKYFPQSGVLIFGKQDSGKTNVDIERVMITDEEEIRTTNPVATEQYGSVSTNLQSGNTQAATSDVNTQGVLPGMVWQDRDVYLQGPIWAKIPHTDGHFHPSPLMGGFGLKHPPPQILIKNTPVPANPSTTFSAAKFASFITQYSTGQVSVEIEWELQKENSKRWNPEIQYTSNYNKSVNVDFTVDTNGVYSEPRPIGTRYLTRNL
>SEQ ID NO:69人Schnurri-3核苷酸序列
CTCACAACCAGCCGACTCTCCCATTATCCAGCTGCCTAGTTTGGTGCTTCAATGTACATGGCTATTCCGTGTGCATATGTGTGTATACAAACACGCATGCATGCCTGGATGGACATACGTATGCACAGGTTATTTTTTAAGGACAATTCTTTCAATAAGGTCTTTACCCCTTACTTGAAACAGGTGTTCATGAAAAAAATGCACAAAATCCTGCCTGGCCGGAATAATTCATGAAGAAGGGGCTGGATCCGTGGGTCAGAGAACACAGGACCAGTTTGCCATCCCAAGGCCGAAGGATTCGAGGCACAAACCCAGCAGCCTCAACCTAGTTCATGGAGGAGCCTCGCGGGGTCCTGGCCAAGCAAGCCCGCCCCTCTGGTGGGAAGAGCGGCGCCTAGGTGGAGGGTGGCTGCCGTAGGAGTGGACATGAATGCTGGCTTTCAGAGAGAACAGCGTTTCAGTTTTGGTCATCGGAAGTGGTGCCTTCAGCACAGAAGAAGAGCGTGATTTCTCCTCCAAGGCCGTTGATCTCCAACCCAGAACTAAAGGGGAGAAGAGCCACCCCCAGCATCCAGCGTGGCATCTCTTGTGCCAGGACCAGGGATGACTGGGCCATGGACACAGATGTCTCCAACCTTCAACCGTTTGCATAGCACACGGGGGACTCGTGGGGGCCACCTGCCACTGCCAGCTGAAACAATACAATGGCAATACTGACATCCTTCATGACGTTTTCCCGACAGACATTCAGGCAGAAAGTGCTGGTGCGTTTTCTGTCTGCAAAGTAGAGGGCCATGCCTCACCAATAGAATAGCGTGGGCCCTGATGACCTGCTCCGAGTCCACTCACAGCCAGTGACACTTGCAAAAAACTCCCAAAGCCGTCTTGGGTTTGGCTCCCACAGCTCTTGACCAATGTGGCCAAAGCTGGACACCTCCTTGGGACACTGGGATTATTCATAAATGCAGCCCGCCCTGACTCTCCCTGAATAGCATCTGAAGTCTTTGTGAAGGTCATGGATCCTGAACAAAGTGTCAAGGGCACCAAGAAGGCTGAGGGAAGTCCCCGGAAGCGGCTGACCAAAGGAGAGGCCATTCAGACCAGTGTTTCTTCCAGCGTCCCATACCCAGGCAGCGGCACAGCTGCCACCCAAGAGAGCCCCGCCCAAGAGCTCTTAGCCCCGCAGCCCTTCCCGGGCCCCTCATCAGTTCTTAGGGAAGGCTCTCAGGAGAAAACGGGCCAGCAGCAGAAGCCCCCCAAAAGGCCCCCCATCGAAGCATCCGTCCACATCTCACAGCTTCCGCAGCACCCTCTGACACCAGCATTCATGTCGCCTGGCAAACCTGAGCATCTCCTGGAGGGGTCCACATGGCAACTGGTTGACCCCATGAGACCTGGACCCTCTGGCTCCTTCGTGGCCCCTGGGCTCCATCCTCAGAGCCAGCTCCTTCCTTCCCACGCTTCCATCATTCCCCCCGAGGACCTTCCTGGAGTCCCCAAAGTCTTCGTGCCTCGTCCTTCCCAGGTCTCCTTGAAGCCCACAGAAGAGGCACACAAGAAGGAGAGGAAGCCCCAGAAGCCAGGCAAGTACATCTGCCAGTACTGCAGCCGGCCCTGTGCCAAGCCCAGCGTGCTCCAGAAGCACATTCGCTCACACACAGGTGAGAGGCCCTACCCCTGCGGCCCCTGTGGCTTCTCCTTCAAGACCAAGAGTAATCTCTACAAGCACAGGAAGTCCCATGCCCACCGCATCAAAGCAGGCCTGGCCTCAGGCATGGGTGGCGAGATGTACCCACATGGGCTGGAGATGGAGCGGATCCCTGGGGAAGAGTTTGAGGAGCCCACTGAGGGAGAAAGCACAGATTCTGAAGAGGAGACTAGTGCCACCTCTGGTCACCCTGCAGAGCTCTCCCCAAGACCCAAGCAGCCCCTTCTCTCCAGCGGGCTATACAGCTCTGGGAGCCACAGTTCCAGCCACGAACGCTGTTCCCTGTCCCAGTCCAGCACAGCCCAGTCACTCGAAGACCCCCCTCCATTTGTGGAACCCTCATCTGAGCACCCCCTGAGCCATAAACCTGAAGACACCCACACGATTAAGCAGAAGCTGGCCCTCCGCTTAAGCGAGAGGAAGAAGGTGATCGATGAGCAGGCGTTTCTGAGCCCAGGCAGCAAAGGGAGTACTGAGTCTGGGTATTTCTCTCGCTCCGAGAGTGCAGAGCAGCAGGTCAGCCCCCCAAACACCAACGCCAAGTCCTACGCTGAGATCATCTTTGGCAAGTGTGGGCGAATAGGACAGCGGACCGCCATGCTGACAGCCACCTCCACCCAGCCCCTCCTGCCCCTGTCCACCGAAGACAAGCCCAGCCTGGTGCCTTTGTCTGTACCCCGGACGCAGGTGATCGAGCACATCACGAAGCTCATCACCATCAACGAGGCCGTGGTGGACACCAGCGAGATCGACAGCGTGAAGCCAAGGCGGAGCTCACTGTCCAGGCGCAGCAGCATGGAGTCCCCAAAATCCAGCCTCTACCGGGAGCCCCTGTCATCCCACAGTGAGAAAACCAAGCCTGAACAATCACTGCTGAGCCTCCAGCACCCGCCCAGTACCGCCCCCCCTGTGCCTCTCCTGAGAAGCCACTCAATGCCTTCTGCCGCCTGCACTATCAGCACCCCCCACCACCCCTTCCGAGGTAGCTACTCCTTCGATGACCATATCACCGACTCCGAAGCCCTGAGCCACAGCAGTCACGTGTTTACCTCCCACCCCCGGATGCTGAAGCGCCAGCCGGCAATCGAATTACCTTTGGGAGGGGAATACAGTTCTGAGGAGCCTGGCCCAAGCAGCAAAGACACAGCCTCCAAGCCCTCGGACGAAGTGGAACCCAAGGAAAGCGAGCTTACCAAAAAGACCAAGAAGGGTTTGAAAACAAAAGGGGTGATCTACGAATGTAACATATGTGGTGCTCGGTACAAGAAAAGGGATAACTACGAAGCCCACAAAAAATACTACTGCTCAGAGCTTCAGATCGCAAAGCCCATCTCTGCAGGCACCCACACATCTCCAGAAGCTGAAAAGAGTCAGATTGAGCATGAGCCGTGGTCCCAAATGATGCATTACAAACTGGGAACCACCCTGGAACTCACTCCACTGAGGAAGAGGAGGAAAGAGAAGAGCCTTGGGGACGAGGAAGAGCCACCTGCCTTTGAGTCCACAAAAAGTCAGTTTGGCAGCCCCGGGCCATCTGATGCTGCTCGGAACCTTCCCCTGGAGTCCACCAAGTCACCAGCAGAACCAAGTAAATCAGTGCCCTCCTTGGAGGGACCCACGGGCTTCCAGCCAAGGACTCCCAAGCCAGGGTCCGGTTCAGAATCAGGGAAGGAGAGGAGAACAACGTCCAAAGAAATTTCTGTCATCCAGCACACCAGCTCCTTTGAGAAATCTGATTCTCTCGAGCAGCCGAGTGGCTTGGAAGGGGAAGACAAACCTCTGGCCCAGTTCCCATCACCCCCACCTGCCCCACACGGACGCTCTGCTCACTCCCTGCAGCCTAAGTTGGTCCGCCAGCCCAACATTCAGGTTCCTGAGATCCTAGTAACTGAGGAGCCTGACCGGCCGGACACAGAGCCAGAGCCGCCCCCTAAGGAACCTGAGAAGACTGAGGAGTTCCAATGGCCCCAGCGCAGCCAGACACTTGCCCAGCTCCCAGCTGAGAAGCTGCCACCCAAAAAGAAGAGGTTGCGCCTGGCAGAGATGGCCCAATCATCAGGGGAGTCCAGCTTCGAGTCCTCTGTGCCTCTGTCTCGCAGCCCGAGCCAGGAAAGCAATGTCTCTTTGAGTGGGTCCAGCCGCTCAGCCTCGTTTGAGAGGGATGACCATGGGAAAGCCGAGGCCCCCAGTCCCTCATCTGACATGCGCCCCAAACCCCTGGGCACCCACATGTTGACTGTCCCCAGCCACCACCCACATGCCCGAGAGATGCGGAGGTCAGCCTCAGAGCAGAGCCCCAACGTTTCCCATTCTGCCCACATGACCGAGACACGCAGCAAATCCTTTGACTATGGCAGCTTGTCCTTGACAGGCCCTTCTGCTCCAGCCCCAGTGGCTCCACCAGCGCGGGTGGCCCCGCCAGAGAGAAGAAAATGCTTCTTGGTGAGACAGGCCTCTCTGAGCAGGCCTCCAGAATCTGAGTTGGAGGTTGCCCCCAAGGGAAGACAGGAGAGCGAAGAACCACAGCCCTCATCCAGTAAACCCTCTGCCAAAAGCTCATTGTCCCAGATTTCCTCTGCGGCCACCTCACATGGTGGACCCCCGGGAGGCAAGGGCCCAGGGCAGGACAGGCCCCCATTGGGGCCCACTGTGCCCTACACAGAAGCACTGCAAGTGTTCCACCACCCCGTTGCCCAGACACCCCTGCATGAGAAGCCATACCTGCCCCCACCAGTCTCCCTTTTCTCCTTCCAGCATCTCGTGCAGCATGAGCCAGGACAGTCTCCAGAATTCTTCTCCACCCAGGCCATGTCCAGCCTCCTGTCCTCACCATACTCCATGCCCCCACTTCCTCCCTCCTTATTTCAAGCCCCACCGCTTCCTCTCCAGCCTACTGTTCTGCACCCAGGCCAACTCCATCTCCCCCAGCTCATGCCTCACCCAGCCAACATCCCCTTCAGGCAGCCCCCTTCCTTCCTCCCCATGCCATACCCGACCTCCTCAGCACTGTCTTCTGGGTTTTTCCTGCCTCTGCAATCCCAGTTTGCACTTCAGCTCCCTGGTGATGTGGAAAGCCATCTGCCCCAGATCAAAACCAGCCTGGCCCCACTGGCAACAGGAAGTGCTGGCCTCTCCCCCAGCACAGAGTACAGCAGTGACATCCGGCTACCCCCTGTGGCTCCCCCAGCCAGCTCCTCAGCACCTACATCAGCTCCTCCACTGGCCCTGCCTGCCTGTCCAGACACCATGGTGTCCCTGGTTGTGCCTGTCCGTGTTCAGACCAATATGCCGTCCTATGGGAGCGCAATGTACACCACCCTTTCCCAGATCTTGGTCACCCAGTCCCAAGGCAGCTCAGCAACTGTGGCACTTCCCAAGTTTGAGGAACCCCCATCAAAGGGGACGACTGTATGTGGTGCAGATGTGCATGAGGTTGGGCCCGGCCCTTCTGGGTTAAGTGAAGAGCAAAGCAGAGCTTTCCCAACTCCATACCTGAGAGTGCCTGTGACATTACCTGAAAGAAAAGGCACTTCCCTGTCATCAGAGAGTATCTTGAGCCTGGAGGGGAGTTCATCAACAGCAGGGGGAAGCAAACGTGTCCTTTCACCAGCTGGCAGCCTTGAACTTACCATGGAAACCCAGCAGCAAAAAAGAGTGAAGGAGGAGGAGGCTTCCAAGGCAGATGAAAAACTTGAGCTGGTAAAACCATGCAGTGTGGTCCTACCAGCACCGAGGATGGGAAGAGGCCAGAGAAATCCCACTTAGGCAACCAGGGCCAAGGCAGGAGGGAGCTAGAAATGCTGTCCAGCCTGTCCTCAGATCCATCTGACACAAAGGAAATTCCTCCCCTCCCTCACCCTGCATTGTCCCATGGGACAGCCCCAGGCTCAGAAGCTTTGAAGGAATATCCCCAGCCATCTGGCAAACCTCACCGAAGAGGGTTGACCCCACTGAGCGTGAAGAAAGAAGATTCCAAGGAACAACCTGATCTCCCCTCCTTGGCACCTCCGAGCTCTCTGCCTCTGTCAGAAACGTCCTCCAGACCAGCCAAGTCACAAGAAGGTACGGACTCAAAGAAGGTACTGCAGTTCCCCAGCCTCCACACAACCACTAATGTCAGTTGGTGCTATTTAAACTACATTAAGCCAAATCACATCCAGCATGCAGATAGGAGGTCCTCTGTTTACGCTGGTTGGTGCATAAGTTTGTACAACCCCAACCTTCCGGGGGTTTCCACTAAAGCTGCTTTGTCCCTCCTGAGGTCTAAGCAGAAAGTGAGCAAAGAGACATACACCATGGCCACAGCTCCGCATCCTGAGGCAGGAAGGCTTGTGCCATCCAGCTCCCGCAAGCCCCGCATGACAGAGGTTCACCTCCCTTCACTGGTTTCCCCGGAAGGCCAGAAAGATCTAGCTAGAGTGGAGAAGGAAGAAGAGAGGAGAGGGGAGCCGGAGGAGGATGCTCCTGCCTCCCAGAGAGGGGAGCCGGCGAGGATCAAAATCTTCGAAGGAGGGTACAAATCAAACGAAGAGTATGTATATGTGCGAGGCCGCGGCCGAGGGAAATATGTTTGTGAGGAGTGTGGAATTCGCTGCAAGAAGCCCAGCATGCTGAAGAAACACATCCGCACCCACACTGACGTCCGGCCCTATGTGTGCAAGCACTGTCACTTTGCTTTTAAAACCAAAGGGAATCTGACTAAGCACATGAAGTCGAAGGCCCACAGCAAAAAGTGCCAAGAGACAGGGGTGCTGGAGGAGCTGGAAGCCGAAGAAGGAACCAGTGACGACCTGTTCCAGGACTCGGAAGGACGAGAGGGTTCAGAGGCTGTGGAGGAGCACCAGTTTTCGGACCTGGAGGACTCGGACTCAGACTCAGACCTGGACGAAGACGAGGATGAGGATGAGGAGGAGAGCCAGGATGAGCTGTCCAGACCATCCTCAGAGGCGCCCCCGCCTGGCCCACCACATGCACTGCGGGCAGACTCCTCACCCATCCTGGGCCCTCAGCCCCCAGATGCCCCCGCCTCTGGCACGGAGGCTACACGAGGCAGCTCGGTCTCGGAAGCTGAGCGCCTGACAGCCAGCAGCTGCTCCATGTCCAGCCAGAGCATGCCGGGCCTCCCCTGGCTGGGACCGGCCCCTCTGGGCTCTGTGGAGAAAGACACAGGCTCAGCCTTGAGCTACAAGCCTGTGTCCCCAAGAAGACCGTGGTCCCCAAGCAAAGAAGCAGGCAGCCGTCCACCACTAGCCCGCAAACACTCGCTAACCAAAAACGACTCATCTCCCCAGCGATGCTCCCCGGCCCGAGAACCACAGGCCTCAGCCCCAAGCCCACCTGGCCTGCACGTGGACCCAGGAAGGGGCATGGGCGCTCTCCCTTGTGGGTCTCCAAGACTTCAGCTGTCTCCTCTCACCCTCTGCCCCCTGGGAAGAGAACTGGCCCCTCGAGCACATGTGCTCTCCAAACTCGAGGGTACCACCGACCCAGGCCTCCCCAGATACTCGCCCACCAGGAGATGGTCTCCAGGTCAGGCCGAGTCACCACCACGGTCAGCGCCGCCAGGGAAGTGGGCCTTGGCTGGGCCGGGCAGCCCCTCAGCGGGGGAGCATGGCCCAGGCTTGGGGCTGGACCCACGGGTTCTCTTCCCGCCCGCGCCTCTACCTCACAAGCTCCTCAGCAGAAGCCCAGAGACCTGCGCCTCCCCGTGGAAGGCCGAGTCCCGAAGTCCCTCCTGCTCACCCGGCCCTGCTCATCCTCTCTCCTCCCGACCCTTCTCCGCCCTCCATGACTTCCACGGCCACATCCTGGCCCGGACAGAGGAGAACATCTTCAGCCACCTGCCTCTGCACTCCCAGCACTTGACCCGTGCCCCATGTCCCTTGATTCCCATCGGTGGGATCCAGATGGTGCAGGCCCGGCCAGGAGCCCACCCCACCCTGCTGCCAGGGCCCACCGCAGCCTGGGTCAGTGGCTTCTCCGGGGGTGGCAGCGACCTGACAGGGGCCCGGGAGGCCCAGGAGCGAGGCCGCTGGAGTCCCACTGAGAGCTCGTCAGCCTCCGTGTCGCCTGTGGCTAAGGTCTCCAAATTCACACTCTCCTCAGAGCTGGAGGGCGGGGACTACCCCAAGGAGAGGGAGAGGACCGGCGGAGGCCCGGGCAGGCCTCCTGACTGGACACCCCATGGGACCGGGGCACCTGCAGAGCCCACACCCACGCACAGCCCCTGCACCCCACCCGACACCTTGCCCCGGCCGCCCCAGGGACGCCGGGCAGCGCAGTCCTGGAGCCCCCGCTTGGGTCCCCGCGTGCACCGACCAACCCCGAGCCTTCTGCCACCCCGCCGCTGGACCGCAGCAGCTCTGTGGGCTGCCTGGCAGAGGCCTCTGCCCGCTTCCCAGCCCGGACGAGGAACCTCTCCGGGGAACCCAGGACCAGGCAGGACTCCCCCAAGCCCTCAGGAAGTGGGGAGCCCAGGGCACATCCACATCAGCCTGAGGACAGGGTTCCCCCCAACGCTTAGCCTCTCTCCAACTGCTTCAGCATCTGGCTTCCAGTGTCCAGCAACAGACGTTTCCAGCCACTTTCCTCGAATCATCCCACTTCCTCAGCCCCATCTGTCCCTCCGTCCAGGAGCTCTCACGGCCCCATCTGTTGTACCTTCCCATGTATGCAGTTACCTGTGCCTTTTTCTACACCTTTTGTTGCTTAAAAAGAAACAAAACAAATCACATACATACATTTAAAAAAAAAACAACAACCCACGAGGAGTCTGAGGCTGTGAATAGTTTATGGTTTTGGGGAAAGGCTGATGGTGAAGCCTCCTGACCCTCCCCGCTGTGGTTGGCAGCCACCCACCCCAGAGGCTGGCAGAGGGAAAGGGGTACACTGAGGGAGAAAGGAAAAGGAAACTTCAAACAATATAGAATTAAATGTAAAAGGAAGCACTCCTGTGTACAGATGCGATCAAGGTTCCTGTTTATTGCCACTTCACCCCCCTGCCCAGCTCGTAGCCACCCCTCTCTGCCAGCAGAAAGGCCAGTGTCCCCAGGCAGAGGGGCACAAACACAGGCAGGTGACCCCCACCCAGGCCCCAGCAGGCAGGCCCAGAAAAACTAATCTTTTCCTTTTTTTTTTTTTTTTTTTTTTTTGCAAGAAAATAAAATGATACTTTTCCTAGGATTTCAACACAAAATAATAGGTGCAGGTAGAAGGAGGAGGGCTGGCTCCCCAAGGGCTCCTGGATACTCTGGTAGTCTGAGTCATGGGCCCATCCTGGCACTCCACAGGTGGGCAGGCCACCCCACCCACGCACCCCCACTCCAGACACCTCCCTTCTGCACCCCACCCTGGCCCCCTGGGCTGGGGAAGGAGCCCTGACTGTCCGTCCCTGGCTCCCAAGCCCCTGACCGAGGCCTCACTCTCCTGTTGCCTCCTCTGTTCTAAAACCACCAAACCACCCACAAAGGCAGAAGTGGCAGGGCCCGAGCCCTAGCGGCCGTTCCTGAGACTGGGTTTTGGGTTTTGTTTCATCTTGGTCCCTGGGGTACAAGGGAGCCTGTTCCCCTCATGGCTGGGTTTTTCCAGTTCTCCACAGCAGAGGTTTGCGGGGAACTGTTTCAGGACCACTTTGCCACAGGACCGTTTCCCCCCGTCCCTGCCCCTGTCTCCACTACCCCAAGGAAATACCCACAACTGTGGCTGGTGGATACGGCCTGGACCTGTTTGCTGTCTTACACCTCTTTTTTAAAAAGAGAGAGGATGGTGTTTGATACTTCACCCAGCCACCACAGATTCTTTTGACCTAGAGGATTTTTGAATTGTCCTAACTCGTTGGAATTCTCCAAAGCAATCAGTGTGAGCCAGTGCCTCTTCCTTACCCACATCTCTACTTTCAAGAAGCTGCCCTGCATTTCCTGGGGCAAAACTCTACTTTGTAAGAAAAATAATAGGACCAGAAATTTAAATCCCAAATTGAACTATGGAACTTGAACTCTAGCGTGTTCGCCCCAACTGGGAGAGGTGAGCTTTTTCCCAGTGTTTCAGAACTGATTTTCTTTACTTTCTACAAGGGAGGGCAGCACAGGGACTACGGTTGAGGCCCGTGAAGGCTGGGTTTGATGCCACCCTATACAGAGCAGGGACCTCTCTGGCTAATCCCCAGTCCTCAGCCAGGCTGTGTGAATCAAGTGCCTGCCCCAGGGCTCTTGAGCTATTGAAGCTGCTTGGGTACAGGACACAGTAGGTGGGGAGGGTTAAGACCCTTCTGTGAGTTCCCTGTGCGGGGCTGTACTTGCCTCTTCCAATTCGTGGCCTTTCCCTGCTTGGTCCCTACTAGACAGACAAACCAGCCACAGTCCAGCCTGCAGCCAGACCACCTTGTTCACTCATTCTCCTTTGCCTCAGAGCTAAGACAAAAATGAGACAGAAGGCAGGGCTCCCTGGGAGTCCACTGTGCTCCAGGGTTCTGGGGAATCAGGGTTAGCCAGCAGCTCCTGGCTGCTTCCCTCAGAGACTAGGGCTCTCATCCTCCCCAAGAGAAGCAGCAAGCCCAGCCTGGACCACACTGTCCATATTGCTGGACAGTGGCCTGACAGAAAGTGACTCCTCCAAGTCCCAGGAGGCCAGGGCTTTTCTCATCCTTGCCTTTCAGCCCTAACCCATGGGACTGCCCACGGATTGGAGACTTCAAGGGCTGAGGTCTGGGAGCTGCATAAAGGGCATTGCTTCAGCCCAGGTTAGAAATCTGCCTGGGCAAGCTCTTCCTGCCCCAGACCTACAAAGCAGCAGACCGGGGGCTCTGGTGGACTAGCCCCTGACATTGGTGGGGGGCCCCACACCACTCCACCCCACCCTGCCTTCCAGCTCTCCTGGGCATTTTTCTCCCTGTACTCAAACAGCCTACCCACCCAAGGTTTCCTCCCTGGGCAGCCTAGCAATGAACAGTGCAGCCGGCAGGGCAGAGGCCCGGCAGTCACCGGGCCCGTCAGGCTCAGGCAGAGAAGCCACAGGGGCCAGGAGTCACTGGAGACTATTTCTAAATGATGGGGGTAAATGCACAAATAGAATCTCACCAAAGGGCTGCCTCCACATTGATGCCGTGCCCAGAGGGACAGAACCAATGCCACCAGCCTGGGTATATGTCACTGGGCACAGCTCTAACCCCCTCCTCCGGACTCTAGTCCCGCTCCTCTGCGCACAGAGCCCCCAGCCCACAGGTACACCTTCATGATTTGGAGAAAGACGCTCGCCCCATGCACGCCCTCCTCTGGGCCTTCTGCCCTGCTCCCAGTCACTTCCAAGCTTCCTGTTTGCCTGTGATGTTATTGTGCCTGTTGAGGGAAGCAGCAGAGGAGGCAGTGGCTGACTTGGCACAGATGCCTGCTACGTGCTCTGTTGAAATGCGCGGGGTGGCCATTCCTCGGTACAGACTAGTCCTGGTCCTTGGGTGTGGGCAGTGGGGGAGGAACCAACTGGTCGAGGTTTCAGAGCCAAACCTTGCCTTTGGTTGGTGAGTCCTTGCCCCCCAGGCCTGCGCTCCACGATGCCTTTCACCCTTGGCAATCTCAGGGCCATCCTGGGTAGTAACCCCACTCCTCTCTGCTCCCGCCCGCACCTGTGGCTCTCACTCTGGGCTCAACCCCTGCAACCCTCCAGGAGCCCGACAGCAGCCAGCTGCCTGCACTGTCGCCTCCGTAAGCTCCAACTTCCAGACCCAGAAGTCCCTCTGCTTCCCTCTGTTGGAAAAAGCCTAAAAGAATTAGCTTCCAGATTCCTCTAGCCCCTGCTCCATTCCCACCCAGTCCTTCTGAAGAGGAATGAGCAATACATCTGAGCTGGATTTCTCTCTAGTCCTTTCTCCAGACAAATCCTTCTTAAAGCAAAAGTCCTGGCTGAGCACCTGTCCTTGGGGACCGATCTGCCGTGTGACCAGGGGAAGAAAGTTCCCGAAAGCCTGTTCCACCAATTCTGCTTCTGTGTTGTGAATCCAGTCTGCTTTCCATTAGAAAACCGCTTCGGCACTTATGGTCACTTTAATAAATCTAGTATGTAAAAAAAGAAAGAAAGAAAAGAAACAGAAAAAAGAAACGTGCAGGCAAATGTAAAATACAATGCTCTCTGTAAGATAAATATTTGCCTTTTTTTCTAAAAGGTGTACGTATTCTGTATGTGAAATTGTCTGTAGAAAGTTTCTATGTTCTTAAATGGCAATACATTCCAAAAATTGTACTGTAGATATGTACAGCAACCGCACTGGGATGGGGTAGTTTTGCCTGTAATTTTATTTAAACTCCAGTTTCCACACTTGCTCTTGCAATGTTGGTATGGTATATATCAGTGCAAAAGAAAAAACAAAACAGAAACAAACAAAAAAAAAAAACAAAAATCCACGCAGGTCTAAAGCACAGAGTCTGACGTACAAAAGGAAAAATGCTCAGTATTGATGTGTGTGACCTTTGTTGTAAATTACATCTGTACTGTGAATGAGAAGTTTTTACAAGTATAATAATTGCCTTTATTACAGCTCTGGCTGAGTGTTCAGCCTGAGGATATTTTTTAAAAAAAAAAGAATTAGCATGTTGGAATAAATTTGAAAATCCCAACATAAAAAAA
>SEQ ID NO:70人Schnurri-3氨基酸序列
MDPEQSVKGTKKAEGSPRKRLTKGEAIQTSVSSSVPYPGSGTAATQESPAQELLAPQPFPGPSSVLREGSQEKTGQQQKPPKRPPIEASVHISQLPQHPLTPAFMSPGKPEHLLEGSTWQLVDPMRPGPSGSFVAPGLHPQSQLLPSHASIIPPEDLPGVPKVFVPRPSQVSLKPTEEAHKKERKPQKPGKYICQYCSRPCAKPSVLQKHIRSHTGERPYPCGPCGFSFKTKSNLYKHRKSHAHRIKAGLASGMGGEMYPHGLEMERIPGEEFEEPTEGESTDSEEETSATSGHPAELSPRPKQPLLSSGLYSSGSHSSSHERCSLSQSSTAQSLEDPPPFVEPSSEHPLSHKPEDTHTIKQKLALRLSERKKVIDEQAFLSPGSKGSTESGYFSRSESAEQQVSPPNTNAKSYAEIIFGKCGRIGQRTAMLTATSTQPLLPLSTEDKPSLVPLSVPRTQVIEHITKLITINEAVVDTSEIDSVKPRRSSLSRRSSMESPKSSLYREPLSSHSEKTKPEQSLLSLQHPPSTAPPVPLLRSHSMPSAACTISTPHHPFRGSYSFDDHITDSEALSHSSHVFTSHPRMLKRQPAIELPLGGEYSSEEPGPSSKDTASKPSDEVEPKESELTKKTKKGLKTKGVIYECNICGARYKKRDNYEAHKKYYCSELQIAKPISAGTHTSPEAEKSQIEHEPWSQMMHYKLGTTLELTPLRKRRKEKSLGDEEEPPAFESTKSQFGSPGPSDAARNLPLESTKSPAEPSKSVPSLEGPTGFQPRTPKPGSGSESGKERRTTSKEISVIQHTSSFEKSDSLEQPSGLEGEDKPLAQFPSPPPAPHGRSAHSLQPKLVRQPNIQVPEILVTEEPDRPDTEPEPPPKEPEKTEEFQWPQRSQTLAQLPAEKLPPKKKRLRLAEMAQSSGESSFESSVPLSRSPSQESNVSLSGSSRSASFERDDHGKAEAPSPSSDMRPKPLGTHMLTVPSHHPHAREMRRSASEQSPNVSHSAHMTETRSKSFDYGSLSLTGPSAPAPVAPPARVAPPERRKCFLVRQASLSRPPESELEVAPKGRQESEEPQPSSSKPSAKSSLSQISSAATSHGGPPGGKGPGQDRPPLGPTVPYTEALQVFHHPVAQTPLHEKPYLPPPVSLFSFQHLVQHEPGQSPEFFSTQAMSSLLSSPYSMPPLPPSLFQAPPLPLQPTVLHPGQLHLPQLMPHPANIPFRQPPSFLPMPYPTSSALSSGFFLPLQSQFALQLPGDVESHLPQIKTSLAPLATGSAGLSPSTEYSSDIRLPPVAPPASSSAPTSAPPLALPACPDTMVSLVVPVRVQTNMPSYGSAMYTTLSQILVTQSQGSSATVALPKFEEPPSKGTTVCGADVHEVGPGPSGLSEEQSRAFPTPYLRVPVTLPERKGTSLSSESILSLEGSSSTAGGSKRVLSPAGSLELTMETQQQKRVKEEEASKADEKLELVKPCSVVLTSTEDGKRPEKSHLGNQGQGRRELEMLSSLSSDPSDTKEIPPLPHPALSHGTAPGSEALKEYPQPSGKPHRRGLTPLSVKKEDSKEQPDLPSLAPPSSLPLSETSSRPAKSQEGTDSKKVLQFPSLHTTTNVSWCYLNYIKPNHIQHADRRSSVYAGWCISLYNPNLPGVSTKAALSLLRSKQKVSKETYTMATAPHPEAGRLVPSSSRKPRMTEVHLPSLVSPEGQKDLARVEKEEERRGEPEEDAPASQRGEPARIKIFEGGYKSNEEYVYVRGRGRGKYVCEECGIRCKKPSMLKKHIRTHTDVRPYVCKHCHFAFKTKGNLTKHMKSKAHSKKCQETGVLEELEAEEGTSDDLFQDSEGREGSEAVEEHQFSDLEDSDSDSDLDEDEDEDEEESQDELSRPSSEAPPPGPPHALRADSSPILGPQPPDAPASGTEATRGSSVSEAERLTASSCSMSSQSMPGLPWLGPAPLGSVEKDTGSALSYKPVSPRRPWSPSKEAGSRPPLARKHSLTKNDSSPQRCSPAREPQASAPSPPGLHVDPGRGMGALPCGSPRLQLSPLTLCPLGRELAPRAHVLSKLEGTTDPGLPRYSPTRRWSPGQAESPPRSAPPGKWALAGPGSPSAGEHGPGLGLDPRVLFPPAPLPHKLLSRSPETCASPWKAESRSPSCSPGPAHPLSSRPFSALHDFHGHILARTEENIFSHLPLHSQHLTRAPCPLIPIGGIQMVQARPGAHPTLLPGPTAAWVSGFSGGGSDLTGAREAQERGRWSPTESSSASVSPVAKVSKFTLSSELEGGDYPKERERTGGGPGRPPDWTPHGTGAPAEPTPTHSPCTPPDTLPRPPQGRRAAQSWSPRLESPRAPTNPEPSATPPLDRSSSVGCLAEASARFPARTRNLSGEPRTRQDSPKPSGSGEPRAHPHQPEDRVPPNA
>SEQ ID NO:55;amiR-33-mRANKi-1:
AGGGCTCTGCGTTTGCTCCAGGTAGTCCGCTGCTCCCTTGGGCCTGGGCCCACTGACAGCCCTGGTGCCTCTGGCCGGCTGCACACCTCCTGGCGGGCAGCTGTGAATGGTCCACATTTCAGGGACTGTTCTGGCAATACCTGGTCCCTGATTTATGGACCATTCACGGAGGCCTGCCCTGACTGCCCACGGTGCCGTGGCCAAAGAGGATCTAAGGGCACCGCTGAGGGCCTACCTAACCATCGTGGGGAATAAGGACAGTGTCACCC
>SEQ ID NO:56;amiR-33-mRANKi-2:
AGGGCTCTGCGTTTGCTCCAGGTAGTCCGCTGCTCCCTTGGGCCTGGGCCCACTGACAGCCCTGGTGCCTCTGGCCGGCTGCACACCTCCTGGCGGGCAGCTGTGACAAATTAGCTGTCAGCGCTGTTCTGGCAATACCTGGCGCTGACTGCAAATTTGTCACGGAGGCCTGCCCTGACTGCCCACGGTGCCGTGGCCAAAGAGGATCTAAGGGCACCGCTGAGGGCCTACCTAACCATCGTGGGGAATAAGGACAGTGTCACCC
>SEQ ID NO:57;骨吸收肽(8-mer)
DDDDDDDD
>SEQ ID NO:58;骨吸收肽(9-mer)
DDDDDDDDD
>SEQ ID NO:59;骨吸收肽(10-mer)
DDDDDDDDDD
>SEQ ID NO:60;骨吸收肽(11-mer)
DDDDDDDDDDD
>SEQ ID NO:61;骨吸收肽(12-mer)
DDDDDDDDDDDD
>SEQ ID NO:62;骨吸收肽(13-mer)
DDDDDDDDDDDDD
>SEQ ID NO:63;骨吸收肽(14-mer)
DDDDDDDDDDDDDD
序列表
<110> 马萨诸塞大学(沃斯特)(University of Massachusetts at Worcester)
<120> 用于治疗骨病的基因治疗剂
<130> U0120.70099WO00
<140> 尚未指定
<141> 同上
<150> US 62/799,843
<151> 2019-02-01
<150> US 62/647,595
<151> 2018-03-23
<160> 70
<170> PatentIn version 3.5
<210> 1
<211> 327
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 1
tttgtctttt atttcaggtc ccagatctag ggctctgcgt ttgctccagg tagtccgctg 60
ctcccttggg cctgggccca ctgacagccc tggtgcctct ggccggctgc acacctcctg 120
gcgggcagct gtgtacaaac tacttgagag caggtgttct ggcaatacct gcctgctctg 180
taatagtttg tacacggagg cctgccctga ctgcccacgg tgccgtggcc aaagaggatc 240
taagggcacc gctgagggcc tacctaacca tcgtggggaa taaggacagt gtcacccctg 300
caggggatcc ggtggtggtg caaatca 327
<210> 2
<211> 327
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 2
tttgtctttt atttcaggtc ccagatctag ggctctgcgt ttgctccagg tagtccgctg 60
ctcccttggg cctgggccca ctgacagccc tggtgcctct ggccggctgc acacctcctg 120
gcgggcagct gtgactacag gtactcacaa gctctgttct ggcaatacct ggagcttgtc 180
tgcacctgta gtcacggagg cctgccctga ctgcccacgg tgccgtggcc aaagaggatc 240
taagggcacc gctgagggcc tacctaacca tcgtggggaa taaggacagt gtcacccctg 300
caggggatcc ggtggtggtg caaatca 327
<210> 3
<211> 325
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 3
gtcttttatt tcaggtccca gatcttaggg ctctgcgttt gctccaggta gtccgctgct 60
cccttgggcc tgggcccact gacagccctg gtgcctctgg ccggctgcac acctcctggc 120
gggcagctgt gtttccatgg taagttcaag gctgttctgg caatacctgg ccttgaagat 180
gccatggaaa cacggaggcc tgccctgact gcccacggtg ccgtggccaa agaggatcta 240
agggcaccgc tgagggccta cctaaccatc gtggggaata aggacagtgt cacccccctg 300
caggggatcc ggtggtggtg caaat 325
<210> 4
<211> 327
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 4
tttgtctttt atttcaggtc ccagatctag ggctctgcgt ttgctccagg tagtccgctg 60
ctcccttggg cctgggccca ctgacagccc tggtgcctct ggccggctgc acacctcctg 120
gcgggcagct gtgtttcatc atagtacaca cctctgttct ggcaatacct ggaggtgtga 180
tccatgatga aacacggagg cctgccctga ctgcccacgg tgccgtggcc aaagaggatc 240
taagggcacc gctgagggcc tacctaacca tcgtggggaa taaggacagt gtcacccctg 300
caggggatcc ggtggtggtg caaatca 327
<210> 5
<211> 285
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 5
tttgtctttt atttcaggtc ccagatctag ggctctgcgt ttgctccagg tagtccgctg 60
ctcccttggg cctgggccca ctgacagccc tggtgcctct ggccggctgc acacctcctg 120
gcgggcagct gtgttactgt aggatcgaga gggatgttct ggcaatacct gtccctctcc 180
ttactacagt aacacggagg cctgccctga ctgcccacgg tgccgtggcc aaagaggatc 240
taagggcacc gctgagggcc tacctaacca tcgtggggaa taagg 285
<210> 6
<211> 325
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 6
gtcttttatt tcaggtccca gatcttaggg ctctgcgttt gctccaggta gtccgctgct 60
cccttgggcc tgggcccact gacagccctg gtgcctctgg ccggctgcac acctcctggc 120
gggcagctgt gattatcgct attgcagctt tctgttctgg caatacctgg aaagctggta 180
cagcgataat cacggaggcc tgccctgact gcccacggtg ccgtggccaa agaggatcta 240
agggcaccgc tgagggccta cctaaccatc gtggggaata aggacagtgt cacccccctg 300
caggggatcc ggtggtggtg caaat 325
<210> 7
<211> 325
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 7
gtcttttatt tcaggtccca gatcttaggg ctctgcgttt gctccaggta gtccgctgct 60
cccttgggcc tgggcccact gacagccctg gtgcctctgg ccggctgcac acctcctggc 120
gggcagctgt gtcagattat cgctattgca gctgttctgg caatacctgg ctgcaattcc 180
aataatctga cacggaggcc tgccctgact gcccacggtg ccgtggccaa agaggatcta 240
agggcaccgc tgagggccta cctaaccatc gtggggaata aggacagtgt cacccccctg 300
caggggatcc ggtggtggtg caaat 325
<210> 8
<211> 327
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 8
tttgtctttt atttcaggtc ccagatctag ggctctgcgt ttgctccagg tagtccgctg 60
ctcccttggg cctgggccca ctgacagccc tggtgcctct ggccggctgc acacctcctg 120
gcgggcagct gtgacaagta ggcagatgag gcactgttct ggcaatacct ggtgcctcaa 180
gtacctactt gtcacggagg cctgccctga ctgcccacgg tgccgtggcc aaagaggatc 240
taagggcacc gctgagggcc tacctaacca tcgtggggaa taaggacagt gtcacccctg 300
caggggatcc ggtggtggtg caaatca 327
<210> 9
<211> 327
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 9
tttgtctttt atttcaggtc ccagatctag ggctctgcgt ttgctccagg tagtccgctg 60
ctcccttggg cctgggccca ctgacagccc tggtgcctct ggccggctgc acacctcctg 120
gcgggcagct gtgtgacctc tgtggcatca ttcctgttct ggcaatacct gggaatgatc 180
gcgcagaggt cacacggagg cctgccctga ctgcccacgg tgccgtggcc aaagaggatc 240
taagggcacc gctgagggcc tacctaacca tcgtggggaa taaggacagt gtcacccctg 300
caggggatcc ggtggtggtg caaatca 327
<210> 10
<211> 325
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 10
gtcttttatt tcaggtccca gatcttaggg ctctgcgttt gctccaggta gtccgctgct 60
cccttgggcc tgggcccact gacagccctg gtgcctctgg ccggctgcac acctcctggc 120
gggcagctgt gatggtcttg ttgttctcca gctgttctgg caatacctgg ctggagatga 180
gcaagaccat cacggaggcc tgccctgact gcccacggtg ccgtggccaa agaggatcta 240
agggcaccgc tgagggccta cctaaccatc gtggggaata aggacagtgt cacccccctg 300
caggggatcc ggtggtggtg caaat 325
<210> 11
<211> 325
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 11
gtcttttatt tcaggtccca gatcttaggg ctctgcgttt gctccaggta gtccgctgct 60
cccttgggcc tgggcccact gacagccctg gtgcctctgg ccggctgcac acctcctggc 120
gggcagctgt gacgtctttg gtctcaaagg ggtgttctgg caatacctgc ccctttgtca 180
tcaaagacgt cacggaggcc tgccctgact gcccacggtg ccgtggccaa agaggatcta 240
agggcaccgc tgagggccta cctaaccatc gtggggaata aggacagtgt cacccccctg 300
caggggatcc ggtggtggtg caaat 325
<210> 12
<211> 411
<212> DNA
<213> 智人(Homo sapiens)
<400> 12
ggaattgtac ccgcggccga tccaccggtg ccaccatgat acctgcaaaa gacatggcta 60
aagttatgat tgtcatgttg gcaatttgtt ttcttacaaa atcggatggg aaatctgtta 120
agaagagatc tgtgagtgaa atacagctta tgcataacct gggaaaacat ctgaactcga 180
tggagagagt agaatggctg cgtaagaagc tgcaggatgt gcacaatttt gttgcccttg 240
gagctcctct agctcccaga gatgctggtt cccagaggcc ccgaaaaaag gaagacaatg 300
tcttggttga gagccatgaa aaaagtcttg gagaggcaga caaagctgat gtgaatgtat 360
taactaaagc taaatcccag tgaagcttat cgataccgtc gactagagct c 411
<210> 13
<211> 591
<212> DNA
<213> 智人(Homo sapiens)
<400> 13
ggaattgtac ccgcggccga tccaccggtg ccaccatgca gcggagactg gttcagcagt 60
ggagcgtcgc ggtgttcctg ctgagctacg cggtgccctc ctgcgggcgc tcggtggagg 120
gtctcagccg ccgcctcaaa agagctgtgt ctgaacatca gctcctccat gacaagggga 180
agtccatcca agatttacgg cgacgattct tccttcacca tctgatcgca gaaatccaca 240
cagctgaaat cagagctacc tcggaggtgt cccctaactc caagccctct cccaacacaa 300
agaaccaccc cgtccgattt gggtctgatg atgagggcag atacctaact caggaaacta 360
acaaggtgga gacgtacaaa gagcagccgc tcaagacacc tgggaagaaa aagaaaggca 420
agcccgggaa acgcaaggag caggaaaaga aaaaacggcg aactcgctct gcctggttag 480
actctggagt gactgggagt gggctagaag gggaccacct gtctgacacc tccacaacgt 540
cgctggagct cgattcacgg taaagcttat cgataccgtc gactagagct c 591
<210> 14
<211> 696
<212> DNA
<213> 小家鼠(Mus musculus)
<400> 14
ggaattgtac ccgcggccga tccaccggtc gccaccatgg gatggagctg tattatcctg 60
tttctcgtcg ctactgccac cggagctcat tccgcttcca aaagagctct ggtcatcctg 120
gccaaaggag cagaggagat ggagacagtg attcctgtgg atgtcatgcg gcgagccggg 180
atcaaagtca ctgttgcagg cttggctggg aaggaccccg tgcagtgtag ccgtgatgta 240
atgatttgtc cagataccag tctggaagat gcaaaaacgc agggaccata cgatgtggtg 300
gttcttccag gaggaaatct gggtgcacag aatttatctg agtcgcctat ggtgaaggag 360
atcctcaagg agcaggagag caggaagggc ctcatagctg ccatctgtgc aggtcctacg 420
gctctgttgg ctcacgaagt aggttttgga tgcaaggtca caacacaccc actggctaag 480
gacaaaatga tgaatggcag tcactacagc tactcagaga gccgcgtgga gaaggacggc 540
ctgatcctca ccagccgcgg gccggggacc agctttgagt ttgcactagc cattgtggag 600
gcactcgtgg ggaaagacat ggccaaccaa gtgaaggcac cgcttgttct caaagactag 660
taaaagctta tcgataccgt cgactagagc tcgctg 696
<210> 15
<211> 696
<212> DNA
<213> 智人(Homo sapiens)
<400> 15
ggaattgtac ccgcggccga tccaccggtc gccaccatgg gatggagctg tattatcctg 60
tttctcgtcg ctactgccac cggagctcat tccgcttcca aaagagctct ggtcatcctg 120
gctaaaggag cagaggaaat ggagacggtc atccctgtag atgtcatgag gcgagctggg 180
attaaggtca ccgttgcagg cctggctgga aaagacccag tacagtgtag ccgtgatgtg 240
gtcatttgtc ctgatgccag ccttgaagat gcaaaaaaag agggaccata tgatgtggtg 300
gttctaccag gaggtaatct gggcgcacag aatttatctg agtctgctgc tgtgaaggag 360
atactgaagg agcaggaaaa ccggaagggc ctgatagccg ccatctgtgc aggtcctact 420
gctctgttgg ctcatgaaat aggttttgga agtaaagtta caacacaccc tcttgctaaa 480
gacaaaatga tgaatggagg tcattacacc tactctgaga atcgtgtgga aaaagacggc 540
ctgattctta caagccgggg gcctgggacc agcttcgagt ttgcgcttgc aattgttgaa 600
gccctgaatg gcaaggaggt ggcggctcaa gtgaaggctc cacttgttct taaagactag 660
taaaagctta tcgataccgt cgactagagc tcgctg 696
<210> 16
<211> 18
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 16
Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp
1 5 10 15
Ser Ser
<210> 17
<211> 19
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<220>
<221> MOD_RES
<222> (2)..(2)
<223> 是γ-羧化谷氨酸
<220>
<221> MOD_RES
<222> (6)..(6)
<223> 是γ-羧化谷氨酸
<220>
<221> MOD_RES
<222> (9)..(9)
<223> 是γ-羧化谷氨酸
<220>
<221> MOD_RES
<222> (11)..(11)
<223> 是γ-羧化谷氨酸
<220>
<221> MOD_RES
<222> (15)..(15)
<223> 是γ-羧化谷氨酸
<220>
<221> MOD_RES
<222> (18)..(18)
<223> 是γ-羧化谷氨酸
<400> 17
Cys Glu Pro Arg Arg Glu Val Ala Glu Leu Glu Pro Arg Arg Glu Val
1 5 10 15
Ala Glu Leu
<210> 18
<211> 736
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 18
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Asp Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Gly Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Ser Gly Ile Gly
145 150 155 160
Lys Thr Gly Gln Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro Pro
180 185 190
Ala Thr Pro Ala Ala Val Gly Pro Thr Thr Met Ala Ser Gly Gly Gly
195 200 205
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ala
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Ser Ala Ser Thr Gly Ala Ser Asn Asp Asn His
260 265 270
Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe
275 280 285
His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn
290 295 300
Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln
305 310 315 320
Val Lys Glu Val Thr Thr Asn Asp Gly Val Thr Thr Ile Ala Asn Asn
325 330 335
Leu Thr Ser Thr Val Gln Val Phe Ser Asp Ser Glu Tyr Gln Leu Pro
340 345 350
Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala
355 360 365
Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly
370 375 380
Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro
385 390 395 400
Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe
405 410 415
Glu Glu Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp
420 425 430
Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Asn Arg
435 440 445
Thr Gln Asn Gln Ser Gly Ser Ala Gln Asn Lys Asp Leu Leu Phe Ser
450 455 460
Arg Gly Ser Pro Ala Gly Met Ser Val Gln Pro Lys Asn Trp Leu Pro
465 470 475 480
Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Lys Thr Asp Asn
485 490 495
Asn Asn Ser Asn Phe Thr Trp Thr Gly Ala Ser Lys Tyr Asn Leu Asn
500 505 510
Gly Arg Glu Ser Ile Ile Asn Pro Gly Thr Ala Met Ala Ser His Lys
515 520 525
Asp Asp Glu Asp Lys Phe Phe Pro Met Ser Gly Val Met Ile Phe Gly
530 535 540
Lys Glu Ser Ala Gly Ala Ser Asn Thr Ala Leu Asp Asn Val Met Ile
545 550 555 560
Thr Asp Glu Glu Glu Ile Lys Ala Thr Asn Pro Val Ala Thr Glu Arg
565 570 575
Phe Gly Thr Val Ala Val Asn Phe Gln Ser Ser Ser Thr Asp Pro Ala
580 585 590
Thr Gly Asp Val His Ala Met Gly Ala Leu Pro Gly Met Val Trp Gln
595 600 605
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
Thr Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu
625 630 635 640
Lys Asn Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
Asn Pro Pro Ala Glu Phe Ser Ala Thr Lys Phe Ala Ser Phe Ile Thr
660 665 670
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Val Gln Tyr Thr Ser Asn
690 695 700
Tyr Ala Lys Ser Ala Asn Val Asp Phe Thr Val Asp Asn Asn Gly Leu
705 710 715 720
Tyr Thr Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Pro Leu
725 730 735
<210> 19
<211> 735
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 19
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Thr Leu Ser
1 5 10 15
Glu Gly Ile Arg Gln Trp Trp Lys Leu Lys Pro Gly Pro Pro Pro Pro
20 25 30
Lys Pro Ala Glu Arg His Lys Asp Asp Ser Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Glu Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Arg Gln Leu Asp Ser Gly Asp Asn Pro Tyr Leu Lys Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Lys Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Pro Val Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu His Ser Pro Val Glu Pro Asp Ser Ser Ser Gly Thr Gly
145 150 155 160
Lys Ala Gly Gln Gln Pro Ala Arg Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Ala Asp Ser Val Pro Asp Pro Gln Pro Leu Gly Gln Pro Pro
180 185 190
Ala Ala Pro Ser Gly Leu Gly Thr Asn Thr Met Ala Thr Gly Ser Gly
195 200 205
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ser
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Met Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Ser Gln Ser Gly Ala Ser Asn Asp Asn His Tyr
260 265 270
Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe His
275 280 285
Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn Trp
290 295 300
Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln Val
305 310 315 320
Lys Glu Val Thr Gln Asn Asp Gly Thr Thr Thr Ile Ala Asn Asn Leu
325 330 335
Thr Ser Thr Val Gln Val Phe Thr Asp Ser Glu Tyr Gln Leu Pro Tyr
340 345 350
Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala Asp
355 360 365
Val Phe Met Val Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly Ser
370 375 380
Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro Ser
385 390 395 400
Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe Glu
405 410 415
Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp Arg
420 425 430
Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Ser Arg Thr
435 440 445
Asn Thr Pro Ser Gly Thr Thr Thr Gln Ser Arg Leu Gln Phe Ser Gln
450 455 460
Ala Gly Ala Ser Asp Ile Arg Asp Gln Ser Arg Asn Trp Leu Pro Gly
465 470 475 480
Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Ser Ala Asp Asn Asn
485 490 495
Asn Ser Glu Tyr Ser Trp Thr Gly Ala Thr Lys Tyr His Leu Asn Gly
500 505 510
Arg Asp Ser Leu Val Asn Pro Gly Pro Ala Met Ala Ser His Lys Asp
515 520 525
Asp Glu Glu Lys Phe Phe Pro Gln Ser Gly Val Leu Ile Phe Gly Lys
530 535 540
Gln Gly Ser Glu Lys Thr Asn Val Asp Ile Glu Lys Val Met Ile Thr
545 550 555 560
Asp Glu Glu Glu Ile Arg Thr Thr Asn Pro Val Ala Thr Glu Gln Tyr
565 570 575
Gly Ser Val Ser Thr Asn Leu Gln Arg Gly Asn Arg Gln Ala Ala Thr
580 585 590
Ala Asp Val Asn Thr Gln Gly Val Leu Pro Gly Met Val Trp Gln Asp
595 600 605
Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His Thr
610 615 620
Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu Lys
625 630 635 640
His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala Asn
645 650 655
Pro Ser Thr Thr Phe Ser Ala Ala Lys Phe Ala Ser Phe Ile Thr Gln
660 665 670
Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln Lys
675 680 685
Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr Ser Asn Tyr
690 695 700
Asn Lys Ser Val Asn Val Asp Phe Thr Val Asp Thr Asn Gly Val Tyr
705 710 715 720
Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Asn Leu
725 730 735
<210> 20
<211> 736
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 20
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Ala Leu Lys Pro Gly Val Pro Gln Pro
20 25 30
Lys Ala Asn Gln Gln His Gln Asp Asn Arg Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Gly Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Glu Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Lys Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Ile Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Ala Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Asp Gln Ser Pro Gln Glu Pro Asp Ser Ser Ser Gly Val Gly
145 150 155 160
Lys Ser Gly Lys Gln Pro Ala Arg Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro Pro
180 185 190
Ala Ala Pro Thr Ser Leu Gly Ser Asn Thr Met Ala Ser Gly Gly Gly
195 200 205
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ser
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Gln Trp Leu Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Ser Gln Ser Gly Ala Ser Asn Asp Asn His Tyr
260 265 270
Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe His
275 280 285
Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn Trp
290 295 300
Gly Phe Arg Pro Lys Lys Leu Ser Phe Lys Leu Phe Asn Ile Gln Val
305 310 315 320
Lys Glu Val Thr Gln Asn Asp Gly Thr Thr Thr Ile Ala Asn Asn Leu
325 330 335
Thr Ser Thr Val Gln Val Phe Thr Asp Ser Glu Tyr Gln Leu Pro Tyr
340 345 350
Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala Asp
355 360 365
Val Phe Met Val Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly Ser
370 375 380
Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro Ser
385 390 395 400
Gln Met Leu Arg Thr Gly Asn Asn Phe Gln Phe Ser Tyr Thr Phe Glu
405 410 415
Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp Arg
420 425 430
Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Asn Arg Thr
435 440 445
Gln Gly Thr Thr Ser Gly Thr Thr Asn Gln Ser Arg Leu Leu Phe Ser
450 455 460
Gln Ala Gly Pro Gln Ser Met Ser Leu Gln Ala Arg Asn Trp Leu Pro
465 470 475 480
Gly Pro Cys Tyr Arg Gln Gln Arg Leu Ser Lys Thr Ala Asn Asp Asn
485 490 495
Asn Asn Ser Asn Phe Pro Trp Thr Ala Ala Ser Lys Tyr His Leu Asn
500 505 510
Gly Arg Asp Ser Leu Val Asn Pro Gly Pro Ala Met Ala Ser His Lys
515 520 525
Asp Asp Glu Glu Lys Phe Phe Pro Met His Gly Asn Leu Ile Phe Gly
530 535 540
Lys Glu Gly Thr Thr Ala Ser Asn Ala Glu Leu Asp Asn Val Met Ile
545 550 555 560
Thr Asp Glu Glu Glu Ile Arg Thr Thr Asn Pro Val Ala Thr Glu Gln
565 570 575
Tyr Gly Thr Val Ala Asn Asn Leu Gln Ser Ser Asn Thr Ala Pro Thr
580 585 590
Thr Arg Thr Val Asn Asp Gln Gly Ala Leu Pro Gly Met Val Trp Gln
595 600 605
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
Thr Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu
625 630 635 640
Lys His Pro Pro Pro Gln Ile Met Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
Asn Pro Pro Thr Thr Phe Ser Pro Ala Lys Phe Ala Ser Phe Ile Thr
660 665 670
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr Ser Asn
690 695 700
Tyr Asn Lys Ser Val Asn Val Asp Phe Thr Val Asp Thr Asn Gly Val
705 710 715 720
Tyr Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Asn Leu
725 730 735
<210> 21
<211> 734
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 21
Met Thr Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser Glu
1 5 10 15
Gly Val Arg Glu Trp Trp Ala Leu Gln Pro Gly Ala Pro Lys Pro Lys
20 25 30
Ala Asn Gln Gln His Gln Asp Asn Ala Arg Gly Leu Val Leu Pro Gly
35 40 45
Tyr Lys Tyr Leu Gly Pro Gly Asn Gly Leu Asp Lys Gly Glu Pro Val
50 55 60
Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp Gln
65 70 75 80
Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Lys Tyr Asn His Ala Asp
85 90 95
Ala Glu Phe Gln Gln Arg Leu Gln Gly Asp Thr Ser Phe Gly Gly Asn
100 105 110
Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro Leu
115 120 125
Gly Leu Val Glu Gln Ala Gly Glu Thr Ala Pro Gly Lys Lys Arg Pro
130 135 140
Leu Ile Glu Ser Pro Gln Gln Pro Asp Ser Ser Thr Gly Ile Gly Lys
145 150 155 160
Lys Gly Lys Gln Pro Ala Lys Lys Lys Leu Val Phe Glu Asp Glu Thr
165 170 175
Gly Ala Gly Asp Gly Pro Pro Glu Gly Ser Thr Ser Gly Ala Met Ser
180 185 190
Asp Asp Ser Glu Met Arg Ala Ala Ala Gly Gly Ala Ala Val Glu Gly
195 200 205
Gly Gln Gly Ala Asp Gly Val Gly Asn Ala Ser Gly Asp Trp His Cys
210 215 220
Asp Ser Thr Trp Ser Glu Gly His Val Thr Thr Thr Ser Thr Arg Thr
225 230 235 240
Trp Val Leu Pro Thr Tyr Asn Asn His Leu Tyr Lys Arg Leu Gly Glu
245 250 255
Ser Leu Gln Ser Asn Thr Tyr Asn Gly Phe Ser Thr Pro Trp Gly Tyr
260 265 270
Phe Asp Phe Asn Arg Phe His Cys His Phe Ser Pro Arg Asp Trp Gln
275 280 285
Arg Leu Ile Asn Asn Asn Trp Gly Met Arg Pro Lys Ala Met Arg Val
290 295 300
Lys Ile Phe Asn Ile Gln Val Lys Glu Val Thr Thr Ser Asn Gly Glu
305 310 315 320
Thr Thr Val Ala Asn Asn Leu Thr Ser Thr Val Gln Ile Phe Ala Asp
325 330 335
Ser Ser Tyr Glu Leu Pro Tyr Val Met Asp Ala Gly Gln Glu Gly Ser
340 345 350
Leu Pro Pro Phe Pro Asn Asp Val Phe Met Val Pro Gln Tyr Gly Tyr
355 360 365
Cys Gly Leu Val Thr Gly Asn Thr Ser Gln Gln Gln Thr Asp Arg Asn
370 375 380
Ala Phe Tyr Cys Leu Glu Tyr Phe Pro Ser Gln Met Leu Arg Thr Gly
385 390 395 400
Asn Asn Phe Glu Ile Thr Tyr Ser Phe Glu Lys Val Pro Phe His Ser
405 410 415
Met Tyr Ala His Ser Gln Ser Leu Asp Arg Leu Met Asn Pro Leu Ile
420 425 430
Asp Gln Tyr Leu Trp Gly Leu Gln Ser Thr Thr Thr Gly Thr Thr Leu
435 440 445
Asn Ala Gly Thr Ala Thr Thr Asn Phe Thr Lys Leu Arg Pro Thr Asn
450 455 460
Phe Ser Asn Phe Lys Lys Asn Trp Leu Pro Gly Pro Ser Ile Lys Gln
465 470 475 480
Gln Gly Phe Ser Lys Thr Ala Asn Gln Asn Tyr Lys Ile Pro Ala Thr
485 490 495
Gly Ser Asp Ser Leu Ile Lys Tyr Glu Thr His Ser Thr Leu Asp Gly
500 505 510
Arg Trp Ser Ala Leu Thr Pro Gly Pro Pro Met Ala Thr Ala Gly Pro
515 520 525
Ala Asp Ser Lys Phe Ser Asn Ser Gln Leu Ile Phe Ala Gly Pro Lys
530 535 540
Gln Asn Gly Asn Thr Ala Thr Val Pro Gly Thr Leu Ile Phe Thr Ser
545 550 555 560
Glu Glu Glu Leu Ala Ala Thr Asn Ala Thr Asp Thr Asp Met Trp Gly
565 570 575
Asn Leu Pro Gly Gly Asp Gln Ser Asn Ser Asn Leu Pro Thr Val Asp
580 585 590
Arg Leu Thr Ala Leu Gly Ala Val Pro Gly Met Val Trp Gln Asn Arg
595 600 605
Asp Ile Tyr Tyr Gln Gly Pro Ile Trp Ala Lys Ile Pro His Thr Asp
610 615 620
Gly His Phe His Pro Ser Pro Leu Ile Gly Gly Phe Gly Leu Lys His
625 630 635 640
Pro Pro Pro Gln Ile Phe Ile Lys Asn Thr Pro Val Pro Ala Asn Pro
645 650 655
Ala Thr Thr Phe Ser Ser Thr Pro Val Asn Ser Phe Ile Thr Gln Tyr
660 665 670
Ser Thr Gly Gln Val Ser Val Gln Ile Asp Trp Glu Ile Gln Lys Glu
675 680 685
Arg Ser Lys Arg Trp Asn Pro Glu Val Gln Phe Thr Ser Asn Tyr Gly
690 695 700
Gln Gln Asn Ser Leu Leu Trp Ala Pro Asp Ala Ala Gly Lys Tyr Thr
705 710 715 720
Glu Pro Arg Ala Ile Gly Thr Arg Tyr Leu Thr His His Leu
725 730
<210> 22
<211> 724
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 22
Met Ser Phe Val Asp His Pro Pro Asp Trp Leu Glu Glu Val Gly Glu
1 5 10 15
Gly Leu Arg Glu Phe Leu Gly Leu Glu Ala Gly Pro Pro Lys Pro Lys
20 25 30
Pro Asn Gln Gln His Gln Asp Gln Ala Arg Gly Leu Val Leu Pro Gly
35 40 45
Tyr Asn Tyr Leu Gly Pro Gly Asn Gly Leu Asp Arg Gly Glu Pro Val
50 55 60
Asn Arg Ala Asp Glu Val Ala Arg Glu His Asp Ile Ser Tyr Asn Glu
65 70 75 80
Gln Leu Glu Ala Gly Asp Asn Pro Tyr Leu Lys Tyr Asn His Ala Asp
85 90 95
Ala Glu Phe Gln Glu Lys Leu Ala Asp Asp Thr Ser Phe Gly Gly Asn
100 105 110
Leu Gly Lys Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro Phe
115 120 125
Gly Leu Val Glu Glu Gly Ala Lys Thr Ala Pro Thr Gly Lys Arg Ile
130 135 140
Asp Asp His Phe Pro Lys Arg Lys Lys Ala Arg Thr Glu Glu Asp Ser
145 150 155 160
Lys Pro Ser Thr Ser Ser Asp Ala Glu Ala Gly Pro Ser Gly Ser Gln
165 170 175
Gln Leu Gln Ile Pro Ala Gln Pro Ala Ser Ser Leu Gly Ala Asp Thr
180 185 190
Met Ser Ala Gly Gly Gly Gly Pro Leu Gly Asp Asn Asn Gln Gly Ala
195 200 205
Asp Gly Val Gly Asn Ala Ser Gly Asp Trp His Cys Asp Ser Thr Trp
210 215 220
Met Gly Asp Arg Val Val Thr Lys Ser Thr Arg Thr Trp Val Leu Pro
225 230 235 240
Ser Tyr Asn Asn His Gln Tyr Arg Glu Ile Lys Ser Gly Ser Val Asp
245 250 255
Gly Ser Asn Ala Asn Ala Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr
260 265 270
Phe Asp Phe Asn Arg Phe His Ser His Trp Ser Pro Arg Asp Trp Gln
275 280 285
Arg Leu Ile Asn Asn Tyr Trp Gly Phe Arg Pro Arg Ser Leu Arg Val
290 295 300
Lys Ile Phe Asn Ile Gln Val Lys Glu Val Thr Val Gln Asp Ser Thr
305 310 315 320
Thr Thr Ile Ala Asn Asn Leu Thr Ser Thr Val Gln Val Phe Thr Asp
325 330 335
Asp Asp Tyr Gln Leu Pro Tyr Val Val Gly Asn Gly Thr Glu Gly Cys
340 345 350
Leu Pro Ala Phe Pro Pro Gln Val Phe Thr Leu Pro Gln Tyr Gly Tyr
355 360 365
Ala Thr Leu Asn Arg Asp Asn Thr Glu Asn Pro Thr Glu Arg Ser Ser
370 375 380
Phe Phe Cys Leu Glu Tyr Phe Pro Ser Lys Met Leu Arg Thr Gly Asn
385 390 395 400
Asn Phe Glu Phe Thr Tyr Asn Phe Glu Glu Val Pro Phe His Ser Ser
405 410 415
Phe Ala Pro Ser Gln Asn Leu Phe Lys Leu Ala Asn Pro Leu Val Asp
420 425 430
Gln Tyr Leu Tyr Arg Phe Val Ser Thr Asn Asn Thr Gly Gly Val Gln
435 440 445
Phe Asn Lys Asn Leu Ala Gly Arg Tyr Ala Asn Thr Tyr Lys Asn Trp
450 455 460
Phe Pro Gly Pro Met Gly Arg Thr Gln Gly Trp Asn Leu Gly Ser Gly
465 470 475 480
Val Asn Arg Ala Ser Val Ser Ala Phe Ala Thr Thr Asn Arg Met Glu
485 490 495
Leu Glu Gly Ala Ser Tyr Gln Val Pro Pro Gln Pro Asn Gly Met Thr
500 505 510
Asn Asn Leu Gln Gly Ser Asn Thr Tyr Ala Leu Glu Asn Thr Met Ile
515 520 525
Phe Asn Ser Gln Pro Ala Asn Pro Gly Thr Thr Ala Thr Tyr Leu Glu
530 535 540
Gly Asn Met Leu Ile Thr Ser Glu Ser Glu Thr Gln Pro Val Asn Arg
545 550 555 560
Val Ala Tyr Asn Val Gly Gly Gln Met Ala Thr Asn Asn Gln Ser Ser
565 570 575
Thr Thr Ala Pro Ala Thr Gly Thr Tyr Asn Leu Gln Glu Ile Val Pro
580 585 590
Gly Ser Val Trp Met Glu Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp
595 600 605
Ala Lys Ile Pro Glu Thr Gly Ala His Phe His Pro Ser Pro Ala Met
610 615 620
Gly Gly Phe Gly Leu Lys His Pro Pro Pro Met Met Leu Ile Lys Asn
625 630 635 640
Thr Pro Val Pro Gly Asn Ile Thr Ser Phe Ser Asp Val Pro Val Ser
645 650 655
Ser Phe Ile Thr Gln Tyr Ser Thr Gly Gln Val Thr Val Glu Met Glu
660 665 670
Trp Glu Leu Lys Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln
675 680 685
Tyr Thr Asn Asn Tyr Asn Asp Pro Gln Phe Val Asp Phe Ala Pro Asp
690 695 700
Ser Thr Gly Glu Tyr Arg Thr Thr Arg Pro Ile Gly Thr Arg Tyr Leu
705 710 715 720
Thr Arg Pro Leu
<210> 23
<211> 736
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 23
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Asp Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Phe Gly Leu Val Glu Glu Gly Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Ser Gly Ile Gly
145 150 155 160
Lys Thr Gly Gln Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro Pro
180 185 190
Ala Thr Pro Ala Ala Val Gly Pro Thr Thr Met Ala Ser Gly Gly Gly
195 200 205
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ala
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Ser Ala Ser Thr Gly Ala Ser Asn Asp Asn His
260 265 270
Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe
275 280 285
His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn
290 295 300
Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln
305 310 315 320
Val Lys Glu Val Thr Thr Asn Asp Gly Val Thr Thr Ile Ala Asn Asn
325 330 335
Leu Thr Ser Thr Val Gln Val Phe Ser Asp Ser Glu Tyr Gln Leu Pro
340 345 350
Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala
355 360 365
Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly
370 375 380
Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro
385 390 395 400
Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe
405 410 415
Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp
420 425 430
Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Asn Arg
435 440 445
Thr Gln Asn Gln Ser Gly Ser Ala Gln Asn Lys Asp Leu Leu Phe Ser
450 455 460
Arg Gly Ser Pro Ala Gly Met Ser Val Gln Pro Lys Asn Trp Leu Pro
465 470 475 480
Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Lys Thr Asp Asn
485 490 495
Asn Asn Ser Asn Phe Thr Trp Thr Gly Ala Ser Lys Tyr Asn Leu Asn
500 505 510
Gly Arg Glu Ser Ile Ile Asn Pro Gly Thr Ala Met Ala Ser His Lys
515 520 525
Asp Asp Lys Asp Lys Phe Phe Pro Met Ser Gly Val Met Ile Phe Gly
530 535 540
Lys Glu Ser Ala Gly Ala Ser Asn Thr Ala Leu Asp Asn Val Met Ile
545 550 555 560
Thr Asp Glu Glu Glu Ile Lys Ala Thr Asn Pro Val Ala Thr Glu Arg
565 570 575
Phe Gly Thr Val Ala Val Asn Leu Gln Ser Ser Ser Thr Asp Pro Ala
580 585 590
Thr Gly Asp Val His Val Met Gly Ala Leu Pro Gly Met Val Trp Gln
595 600 605
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
Thr Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu
625 630 635 640
Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
Asn Pro Pro Ala Glu Phe Ser Ala Thr Lys Phe Ala Ser Phe Ile Thr
660 665 670
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Val Gln Tyr Thr Ser Asn
690 695 700
Tyr Ala Lys Ser Ala Asn Val Asp Phe Thr Val Asp Asn Asn Gly Leu
705 710 715 720
Tyr Thr Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Pro Leu
725 730 735
<210> 24
<211> 736
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 24
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Asp Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Gly Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Ser Gly Ile Gly
145 150 155 160
Lys Thr Gly Gln Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro Pro
180 185 190
Ala Thr Pro Ala Ala Val Gly Pro Thr Thr Met Ala Ser Gly Gly Gly
195 200 205
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ala
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Ser Ala Ser Thr Gly Ala Ser Asn Asp Asn His
260 265 270
Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe
275 280 285
His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn
290 295 300
Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln
305 310 315 320
Val Lys Glu Val Thr Thr Asn Asp Gly Val Thr Thr Ile Ala Asn Asn
325 330 335
Leu Thr Ser Thr Val Gln Val Phe Ser Asp Ser Glu Tyr Gln Leu Pro
340 345 350
Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala
355 360 365
Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly
370 375 380
Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro
385 390 395 400
Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe
405 410 415
Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp
420 425 430
Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Asn Arg
435 440 445
Thr Gln Asn Gln Ser Gly Ser Ala Gln Asn Lys Asp Leu Leu Phe Ser
450 455 460
Arg Gly Ser Pro Ala Gly Met Ser Val Gln Pro Lys Asn Trp Leu Pro
465 470 475 480
Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Lys Thr Asp Asn
485 490 495
Asn Asn Ser Asn Phe Thr Trp Thr Gly Ala Ser Lys Tyr Asn Leu Asn
500 505 510
Gly Arg Glu Ser Ile Ile Asn Pro Gly Thr Ala Met Ala Ser His Lys
515 520 525
Asp Asp Lys Asp Lys Phe Phe Pro Met Ser Gly Val Met Ile Phe Gly
530 535 540
Lys Glu Ser Ala Gly Ala Ser Asn Thr Ala Leu Asp Asn Val Met Ile
545 550 555 560
Thr Asp Glu Glu Glu Ile Lys Ala Thr Asn Pro Val Ala Thr Glu Arg
565 570 575
Phe Gly Thr Val Ala Val Asn Leu Gln Ser Ser Ser Thr Asp Pro Ala
580 585 590
Thr Gly Asp Val His Val Met Gly Ala Leu Pro Gly Met Val Trp Gln
595 600 605
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
Thr Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu
625 630 635 640
Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
Asn Pro Pro Ala Glu Phe Ser Ala Thr Lys Phe Ala Ser Phe Ile Thr
660 665 670
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Val Gln Tyr Thr Ser Asn
690 695 700
Tyr Ala Lys Ser Ala Asn Val Asp Phe Thr Val Asp Asn Asn Gly Leu
705 710 715 720
Tyr Thr Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Pro Leu
725 730 735
<210> 25
<211> 737
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 25
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Asp Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
Lys Ala Asn Gln Gln Lys Gln Asp Asn Gly Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Gly Ala Lys Thr Ala Pro Ala Lys Lys Arg
130 135 140
Pro Val Glu Pro Ser Pro Gln Arg Ser Pro Asp Ser Ser Thr Gly Ile
145 150 155 160
Gly Lys Lys Gly Gln Gln Pro Ala Arg Lys Arg Leu Asn Phe Gly Gln
165 170 175
Thr Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro
180 185 190
Pro Ala Ala Pro Ser Ser Val Gly Ser Gly Thr Val Ala Ala Gly Gly
195 200 205
Gly Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn
210 215 220
Ala Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val
225 230 235 240
Ile Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His
245 250 255
Leu Tyr Lys Gln Ile Ser Ser Glu Thr Ala Gly Ser Thr Asn Asp Asn
260 265 270
Thr Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg
275 280 285
Phe His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn
290 295 300
Asn Trp Gly Phe Arg Pro Lys Lys Leu Arg Phe Lys Leu Phe Asn Ile
305 310 315 320
Gln Val Lys Glu Val Thr Thr Asn Asp Gly Val Thr Thr Ile Ala Asn
325 330 335
Asn Leu Thr Ser Thr Ile Gln Val Phe Ser Asp Ser Glu Tyr Gln Leu
340 345 350
Pro Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro
355 360 365
Ala Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn
370 375 380
Gly Ser Gln Ser Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe
385 390 395 400
Pro Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Glu Phe Ser Tyr Ser
405 410 415
Phe Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu
420 425 430
Asp Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Ala
435 440 445
Arg Thr Gln Ser Asn Pro Gly Gly Thr Ala Gly Asn Arg Glu Leu Gln
450 455 460
Phe Tyr Gln Gly Gly Pro Ser Thr Met Ala Glu Gln Ala Lys Asn Trp
465 470 475 480
Leu Pro Gly Pro Cys Phe Arg Gln Gln Arg Val Ser Lys Thr Leu Asp
485 490 495
Gln Asn Asn Asn Ser Asn Phe Ala Trp Thr Gly Ala Thr Lys Tyr His
500 505 510
Leu Asn Gly Arg Asn Ser Leu Val Asn Pro Gly Val Ala Met Ala Thr
515 520 525
His Lys Asp Asp Glu Asp Arg Phe Phe Pro Ser Ser Gly Val Leu Ile
530 535 540
Phe Gly Lys Thr Gly Ala Thr Asn Lys Thr Thr Leu Glu Asn Val Leu
545 550 555 560
Met Thr Asn Glu Glu Glu Ile Arg Pro Thr Asn Pro Val Ala Thr Glu
565 570 575
Glu Tyr Gly Ile Val Ser Ser Asn Leu Gln Ala Ala Asn Thr Ala Ala
580 585 590
Gln Thr Gln Val Val Asn Asn Gln Gly Ala Leu Pro Gly Met Val Trp
595 600 605
Gln Asn Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro
610 615 620
His Thr Asp Gly Asn Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly
625 630 635 640
Leu Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro
645 650 655
Ala Asn Pro Pro Glu Val Phe Thr Pro Ala Lys Phe Ala Ser Phe Ile
660 665 670
Thr Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu
675 680 685
Gln Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr Ser
690 695 700
Asn Phe Glu Lys Gln Thr Gly Val Asp Phe Ala Val Asp Ser Gln Gly
705 710 715 720
Val Tyr Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Asn
725 730 735
Leu
<210> 26
<211> 738
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 26
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Ala Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Gln Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Gly Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Pro Ser Pro Gln Arg Ser Pro Asp Ser Ser Thr Gly Ile
145 150 155 160
Gly Lys Lys Gly Gln Gln Pro Ala Arg Lys Arg Leu Asn Phe Gly Gln
165 170 175
Thr Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro
180 185 190
Pro Ala Ala Pro Ser Gly Val Gly Pro Asn Thr Met Ala Ala Gly Gly
195 200 205
Gly Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Ser
210 215 220
Ser Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val
225 230 235 240
Ile Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His
245 250 255
Leu Tyr Lys Gln Ile Ser Asn Gly Thr Ser Gly Gly Ala Thr Asn Asp
260 265 270
Asn Thr Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn
275 280 285
Arg Phe His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn
290 295 300
Asn Asn Trp Gly Phe Arg Pro Lys Arg Leu Ser Phe Lys Leu Phe Asn
305 310 315 320
Ile Gln Val Lys Glu Val Thr Gln Asn Glu Gly Thr Lys Thr Ile Ala
325 330 335
Asn Asn Leu Thr Ser Thr Ile Gln Val Phe Thr Asp Ser Glu Tyr Gln
340 345 350
Leu Pro Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe
355 360 365
Pro Ala Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn
370 375 380
Asn Gly Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr
385 390 395 400
Phe Pro Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Gln Phe Thr Tyr
405 410 415
Thr Phe Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser
420 425 430
Leu Asp Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu
435 440 445
Ser Arg Thr Gln Thr Thr Gly Gly Thr Ala Asn Thr Gln Thr Leu Gly
450 455 460
Phe Ser Gln Gly Gly Pro Asn Thr Met Ala Asn Gln Ala Lys Asn Trp
465 470 475 480
Leu Pro Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Thr Thr Thr Gly
485 490 495
Gln Asn Asn Asn Ser Asn Phe Ala Trp Thr Ala Gly Thr Lys Tyr His
500 505 510
Leu Asn Gly Arg Asn Ser Leu Ala Asn Pro Gly Ile Ala Met Ala Thr
515 520 525
His Lys Asp Asp Glu Glu Arg Phe Phe Pro Ser Asn Gly Ile Leu Ile
530 535 540
Phe Gly Lys Gln Asn Ala Ala Arg Asp Asn Ala Asp Tyr Ser Asp Val
545 550 555 560
Met Leu Thr Ser Glu Glu Glu Ile Lys Thr Thr Asn Pro Val Ala Thr
565 570 575
Glu Glu Tyr Gly Ile Val Ala Asp Asn Leu Gln Gln Gln Asn Thr Ala
580 585 590
Pro Gln Ile Gly Thr Val Asn Ser Gln Gly Ala Leu Pro Gly Met Val
595 600 605
Trp Gln Asn Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile
610 615 620
Pro His Thr Asp Gly Asn Phe His Pro Ser Pro Leu Met Gly Gly Phe
625 630 635 640
Gly Leu Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val
645 650 655
Pro Ala Asp Pro Pro Thr Thr Phe Asn Gln Ser Lys Leu Asn Ser Phe
660 665 670
Ile Thr Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu
675 680 685
Leu Gln Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr
690 695 700
Ser Asn Tyr Tyr Lys Ser Thr Ser Val Asp Phe Ala Val Asn Thr Glu
705 710 715 720
Gly Val Tyr Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg
725 730 735
Asn Leu
<210> 27
<211> 736
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 27
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Ala Leu Lys Pro Gly Ala Pro Gln Pro
20 25 30
Lys Ala Asn Gln Gln His Gln Asp Asn Ala Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Gly Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Lys Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Lys Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Leu Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Ala Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Ala Gly Ile Gly
145 150 155 160
Lys Ser Gly Ala Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Thr Glu Ser Val Pro Asp Pro Gln Pro Ile Gly Glu Pro Pro
180 185 190
Ala Ala Pro Ser Gly Val Gly Ser Leu Thr Met Ala Ser Gly Gly Gly
195 200 205
Ala Pro Val Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Ser Ser
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Gln Trp Leu Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Asn Ser Thr Ser Gly Gly Ser Ser Asn Asp Asn
260 265 270
Ala Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg
275 280 285
Phe His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn
290 295 300
Asn Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile
305 310 315 320
Gln Val Lys Glu Val Thr Asp Asn Asn Gly Val Lys Thr Ile Ala Asn
325 330 335
Asn Leu Thr Ser Thr Val Gln Val Phe Thr Asp Ser Asp Tyr Gln Leu
340 345 350
Pro Tyr Val Leu Gly Ser Ala His Glu Gly Cys Leu Pro Pro Phe Pro
355 360 365
Ala Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asp
370 375 380
Gly Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe
385 390 395 400
Pro Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Gln Phe Ser Tyr Glu
405 410 415
Phe Glu Asn Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu
420 425 430
Asp Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Ser
435 440 445
Lys Thr Ile Asn Gly Ser Gly Gln Asn Gln Gln Thr Leu Lys Phe Ser
450 455 460
Val Ala Gly Pro Ser Asn Met Ala Val Gln Gly Arg Asn Tyr Ile Pro
465 470 475 480
Gly Pro Ser Tyr Arg Gln Gln Arg Val Ser Thr Thr Val Thr Gln Asn
485 490 495
Asn Asn Ser Glu Phe Ala Trp Pro Gly Ala Ser Ser Trp Ala Leu Asn
500 505 510
Gly Arg Asn Ser Leu Met Asn Pro Gly Pro Ala Met Ala Ser His Lys
515 520 525
Glu Gly Glu Asp Arg Phe Phe Pro Leu Ser Gly Ser Leu Ile Phe Gly
530 535 540
Lys Gln Gly Thr Gly Arg Asp Asn Val Asp Ala Asp Lys Val Met Ile
545 550 555 560
Thr Asn Glu Glu Glu Ile Lys Thr Thr Asn Pro Val Ala Thr Glu Ser
565 570 575
Tyr Gly Gln Val Ala Thr Asn His Gln Ser Ala Gln Ala Gln Ala Gln
580 585 590
Thr Gly Trp Val Gln Asn Gln Gly Ile Leu Pro Gly Met Val Trp Gln
595 600 605
Asp Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
Thr Asp Gly Asn Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Met
625 630 635 640
Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
Asp Pro Pro Thr Ala Phe Asn Lys Asp Lys Leu Asn Ser Phe Ile Thr
660 665 670
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr Ser Asn
690 695 700
Tyr Tyr Lys Ser Asn Asn Val Glu Phe Ala Val Asn Thr Glu Gly Val
705 710 715 720
Tyr Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Asn Leu
725 730 735
<210> 28
<211> 736
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 28
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Asp Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Gly Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Ser Gly Ile Gly
145 150 155 160
Lys Thr Gly Gln Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro Pro
180 185 190
Ala Ala Pro Ser Gly Leu Gly Pro Asn Thr Met Ala Ser Gly Gly Gly
195 200 205
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ser
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Asn Gly Thr Ser Gly Gly Ser Thr Asn Asp Asn
260 265 270
Thr Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg
275 280 285
Phe His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn
290 295 300
Asn Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile
305 310 315 320
Gln Val Lys Glu Val Thr Thr Asn Glu Gly Thr Lys Thr Ile Ala Asn
325 330 335
Asn Leu Thr Ser Thr Val Gln Val Phe Thr Asp Ser Glu Tyr Gln Leu
340 345 350
Pro Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro
355 360 365
Ala Asp Val Phe Met Val Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn
370 375 380
Gly Ser Gln Ala Leu Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe
385 390 395 400
Pro Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Gln Phe Ser Tyr Thr
405 410 415
Phe Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu
420 425 430
Asp Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Val
435 440 445
Arg Thr Gln Thr Thr Gly Thr Gly Gly Thr Gln Thr Leu Ala Phe Ser
450 455 460
Gln Ala Gly Pro Ser Ser Met Ala Asn Gln Ala Arg Asn Trp Val Pro
465 470 475 480
Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Thr Thr Thr Asn Gln Asn
485 490 495
Asn Asn Ser Asn Phe Ala Trp Thr Gly Ala Ala Lys Phe Lys Leu Asn
500 505 510
Gly Arg Asp Ser Leu Met Asn Pro Gly Val Ala Met Ala Ser His Lys
515 520 525
Asp Asp Asp Asp Arg Phe Phe Pro Ser Ser Gly Val Leu Ile Phe Gly
530 535 540
Lys Gln Gly Ala Gly Asn Asp Gly Val Asp Tyr Ser Gln Val Leu Ile
545 550 555 560
Thr Asp Glu Glu Glu Ile Lys Ala Thr Asn Pro Val Ala Thr Glu Glu
565 570 575
Tyr Gly Ala Val Ala Ile Asn Asn Gln Ala Ala Asn Thr Gln Ala Gln
580 585 590
Thr Gly Leu Val His Asn Gln Gly Val Ile Pro Gly Met Val Trp Gln
595 600 605
Asn Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His
610 615 620
Thr Asp Gly Asn Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu
625 630 635 640
Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala
645 650 655
Asp Pro Pro Leu Thr Phe Asn Gln Ala Lys Leu Asn Ser Phe Ile Thr
660 665 670
Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln
675 680 685
Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr Ser Asn
690 695 700
Tyr Tyr Lys Ser Thr Asn Val Asp Phe Ala Val Asn Thr Glu Gly Val
705 710 715 720
Tyr Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Asn Leu
725 730 735
<210> 29
<211> 738
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 29
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Asp Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Gly Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Pro Ser Pro Gln Arg Ser Pro Asp Ser Ser Thr Gly Ile
145 150 155 160
Gly Lys Lys Gly Gln Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln
165 170 175
Thr Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Ile Gly Glu Pro
180 185 190
Pro Ala Gly Pro Ser Gly Leu Gly Ser Gly Thr Met Ala Ala Gly Gly
195 200 205
Gly Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Ser
210 215 220
Ser Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val
225 230 235 240
Ile Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His
245 250 255
Leu Tyr Lys Gln Ile Ser Asn Gly Thr Ser Gly Gly Ser Thr Asn Asp
260 265 270
Asn Thr Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn
275 280 285
Arg Phe His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn
290 295 300
Asn Asn Trp Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn
305 310 315 320
Ile Gln Val Lys Glu Val Thr Gln Asn Glu Gly Thr Lys Thr Ile Ala
325 330 335
Asn Asn Leu Thr Ser Thr Ile Gln Val Phe Thr Asp Ser Glu Tyr Gln
340 345 350
Leu Pro Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe
355 360 365
Pro Ala Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn
370 375 380
Asn Gly Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr
385 390 395 400
Phe Pro Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Glu Phe Ser Tyr
405 410 415
Gln Phe Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser
420 425 430
Leu Asp Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu
435 440 445
Ser Arg Thr Gln Ser Thr Gly Gly Thr Ala Gly Thr Gln Gln Leu Leu
450 455 460
Phe Ser Gln Ala Gly Pro Asn Asn Met Ser Ala Gln Ala Lys Asn Trp
465 470 475 480
Leu Pro Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Thr Thr Leu Ser
485 490 495
Gln Asn Asn Asn Ser Asn Phe Ala Trp Thr Gly Ala Thr Lys Tyr His
500 505 510
Leu Asn Gly Arg Asp Ser Leu Val Asn Pro Gly Val Ala Met Ala Thr
515 520 525
His Lys Asp Asp Glu Glu Arg Phe Phe Pro Ser Ser Gly Val Leu Met
530 535 540
Phe Gly Lys Gln Gly Ala Gly Lys Asp Asn Val Asp Tyr Ser Ser Val
545 550 555 560
Met Leu Thr Ser Glu Glu Glu Ile Lys Thr Thr Asn Pro Val Ala Thr
565 570 575
Glu Gln Tyr Gly Val Val Ala Asp Asn Leu Gln Gln Gln Asn Ala Ala
580 585 590
Pro Ile Val Gly Ala Val Asn Ser Gln Gly Ala Leu Pro Gly Met Val
595 600 605
Trp Gln Asn Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile
610 615 620
Pro His Thr Asp Gly Asn Phe His Pro Ser Pro Leu Met Gly Gly Phe
625 630 635 640
Gly Leu Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val
645 650 655
Pro Ala Asp Pro Pro Thr Thr Phe Ser Gln Ala Lys Leu Ala Ser Phe
660 665 670
Ile Thr Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu
675 680 685
Leu Gln Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr
690 695 700
Ser Asn Tyr Tyr Lys Ser Thr Asn Val Asp Phe Ala Val Asn Thr Asp
705 710 715 720
Gly Thr Tyr Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg
725 730 735
Asn Leu
<210> 30
<211> 738
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 30
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Ala Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Lys Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Ala Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Pro Ser Pro Gln Arg Ser Pro Asp Ser Ser Thr Gly Ile
145 150 155 160
Gly Lys Lys Gly Gln Gln Pro Ala Lys Lys Arg Leu Asn Phe Gly Gln
165 170 175
Thr Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Ile Gly Glu Pro
180 185 190
Pro Ala Gly Pro Ser Gly Leu Gly Ser Gly Thr Met Ala Ala Gly Gly
195 200 205
Gly Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Ser
210 215 220
Ser Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val
225 230 235 240
Ile Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His
245 250 255
Leu Tyr Lys Gln Ile Ser Asn Gly Thr Ser Gly Gly Ser Thr Asn Asp
260 265 270
Asn Thr Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn
275 280 285
Arg Phe His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn
290 295 300
Asn Asn Trp Gly Phe Arg Pro Lys Arg Leu Ser Phe Lys Leu Phe Asn
305 310 315 320
Ile Gln Val Lys Glu Val Thr Gln Asn Glu Gly Thr Lys Thr Ile Ala
325 330 335
Asn Asn Leu Thr Ser Thr Ile Gln Val Phe Thr Asp Ser Glu Tyr Gln
340 345 350
Leu Pro Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe
355 360 365
Pro Ala Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn
370 375 380
Asn Gly Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr
385 390 395 400
Phe Pro Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Glu Phe Ser Tyr
405 410 415
Thr Phe Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser
420 425 430
Leu Asp Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu
435 440 445
Ser Arg Thr Gln Ser Thr Gly Gly Thr Gln Gly Thr Gln Gln Leu Leu
450 455 460
Phe Ser Gln Ala Gly Pro Ala Asn Met Ser Ala Gln Ala Lys Asn Trp
465 470 475 480
Leu Pro Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Thr Thr Leu Ser
485 490 495
Gln Asn Asn Asn Ser Asn Phe Ala Trp Thr Gly Ala Thr Lys Tyr His
500 505 510
Leu Asn Gly Arg Asp Ser Leu Val Asn Pro Gly Val Ala Met Ala Thr
515 520 525
His Lys Asp Asp Glu Glu Arg Phe Phe Pro Ser Ser Gly Val Leu Met
530 535 540
Phe Gly Lys Gln Gly Ala Gly Arg Asp Asn Val Asp Tyr Ser Ser Val
545 550 555 560
Met Leu Thr Ser Glu Glu Glu Ile Lys Thr Thr Asn Pro Val Ala Thr
565 570 575
Glu Gln Tyr Gly Val Val Ala Asp Asn Leu Gln Gln Thr Asn Thr Gly
580 585 590
Pro Ile Val Gly Asn Val Asn Ser Gln Gly Ala Leu Pro Gly Met Val
595 600 605
Trp Gln Asn Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile
610 615 620
Pro His Thr Asp Gly Asn Phe His Pro Ser Pro Leu Met Gly Gly Phe
625 630 635 640
Gly Leu Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val
645 650 655
Pro Ala Asp Pro Pro Thr Thr Phe Ser Gln Ala Lys Leu Ala Ser Phe
660 665 670
Ile Thr Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu
675 680 685
Leu Gln Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr
690 695 700
Ser Asn Tyr Tyr Lys Ser Thr Asn Val Asp Phe Ala Val Asn Thr Glu
705 710 715 720
Gly Thr Tyr Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg
725 730 735
Asn Leu
<210> 31
<211> 737
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 31
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Asp Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Glu Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Gly Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Gln Ser Pro Gln Glu Pro Asp Ser Ser Ser Gly Ile Gly
145 150 155 160
Lys Lys Gly Gln Gln Pro Ala Arg Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro Pro
180 185 190
Ala Ala Pro Ser Gly Val Gly Pro Asn Thr Met Ala Ala Gly Gly Gly
195 200 205
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Ser Ser
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Asn Gly Thr Ser Gly Gly Ala Thr Asn Asp Asn
260 265 270
Thr Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg
275 280 285
Phe His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn
290 295 300
Asn Trp Gly Phe Arg Pro Lys Arg Leu Ser Phe Lys Leu Phe Asn Ile
305 310 315 320
Gln Val Lys Glu Val Thr Gln Asn Glu Gly Thr Lys Thr Ile Ala Asn
325 330 335
Asn Leu Thr Ser Thr Ile Gln Val Phe Thr Asp Ser Glu Tyr Gln Leu
340 345 350
Pro Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro
355 360 365
Ala Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn
370 375 380
Gly Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe
385 390 395 400
Pro Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Gln Phe Thr Tyr Thr
405 410 415
Phe Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu
420 425 430
Asp Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Ser
435 440 445
Arg Thr Gln Thr Thr Gly Gly Thr Ala Asn Thr Gln Thr Leu Gly Phe
450 455 460
Ser Gln Gly Gly Pro Asn Thr Met Ala Asn Gln Ala Lys Asn Trp Leu
465 470 475 480
Pro Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Thr Thr Thr Gly Gln
485 490 495
Asn Asn Asn Ser Asn Phe Ala Trp Thr Ala Gly Thr Lys Tyr His Leu
500 505 510
Asn Gly Arg Asn Ser Leu Ala Asn Pro Gly Ile Ala Met Ala Thr His
515 520 525
Lys Asp Asp Glu Glu Arg Phe Phe Pro Ser Asn Gly Ile Leu Ile Phe
530 535 540
Gly Lys Gln Asn Ala Ala Arg Asp Asn Ala Asp Tyr Ser Asp Val Met
545 550 555 560
Leu Thr Ser Glu Glu Glu Ile Lys Thr Thr Asn Pro Val Ala Thr Glu
565 570 575
Glu Tyr Gly Ile Val Ala Asp Asn Leu Gln Gln Gln Asn Thr Ala Pro
580 585 590
Gln Ile Gly Thr Val Asn Ser Gln Gly Ala Leu Pro Gly Met Val Trp
595 600 605
Gln Asn Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro
610 615 620
His Thr Asp Gly Asn Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly
625 630 635 640
Leu Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro
645 650 655
Ala Asp Pro Pro Thr Thr Phe Asn Gln Ser Lys Leu Asn Ser Phe Ile
660 665 670
Thr Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu
675 680 685
Gln Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr Ser
690 695 700
Asn Tyr Tyr Lys Ser Thr Ser Val Asp Phe Ala Val Asn Thr Glu Gly
705 710 715 720
Val Tyr Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Asn
725 730 735
Leu
<210> 32
<211> 735
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 32
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Thr Leu Ser
1 5 10 15
Glu Gly Ile Arg Gln Trp Trp Lys Leu Lys Pro Gly Pro Pro Pro Pro
20 25 30
Lys Pro Ala Glu Arg His Gln Asp Asp Ser Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Glu Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Arg Gln Leu Asp Ser Gly Asp Asn Pro Tyr Leu Lys Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Lys Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Pro Val Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu His Ser Pro Ala Glu Pro Asp Ser Ser Ser Gly Thr Gly
145 150 155 160
Lys Ala Gly Gln Gln Pro Ala Arg Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Ala Asp Ser Val Pro Asp Pro Gln Pro Leu Gly Gln Pro Pro
180 185 190
Ala Ala Pro Ser Gly Leu Gly Thr Asn Thr Met Ala Thr Gly Ser Gly
195 200 205
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ser
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Met Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Ser Gln Ser Gly Ala Ser Asn Asp Asn His Tyr
260 265 270
Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe His
275 280 285
Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn Trp
290 295 300
Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln Val
305 310 315 320
Lys Glu Val Thr Gln Asn Asp Gly Thr Thr Thr Ile Ala Asn Asn Leu
325 330 335
Thr Ser Thr Val Gln Val Phe Thr Asp Ser Glu Tyr Gln Leu Pro Tyr
340 345 350
Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala Asp
355 360 365
Val Phe Met Val Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly Ser
370 375 380
Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro Ser
385 390 395 400
Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe Glu
405 410 415
Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp Arg
420 425 430
Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Ser Lys Thr
435 440 445
Asn Ala Pro Ser Gly Thr Thr Thr Met Ser Arg Leu Gln Phe Ser Gln
450 455 460
Ala Gly Ala Ser Asp Ile Arg Asp Gln Ser Arg Asn Trp Leu Pro Gly
465 470 475 480
Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Ala Ala Asp Asn Asn
485 490 495
Asn Ser Asp Tyr Ser Trp Thr Gly Ala Thr Lys Tyr His Leu Asn Gly
500 505 510
Arg Asp Ser Leu Val Asn Pro Gly Pro Ala Met Ala Ser His Lys Asp
515 520 525
Asp Glu Glu Lys Tyr Phe Pro Gln Ser Gly Val Leu Ile Phe Gly Lys
530 535 540
Gln Asp Ser Gly Lys Thr Asn Val Asp Ile Glu Lys Val Met Ile Thr
545 550 555 560
Asp Glu Glu Glu Ile Arg Thr Thr Asn Pro Val Ala Thr Glu Gln Tyr
565 570 575
Gly Ser Val Ser Thr Asn Leu Gln Ser Gly Asn Thr Gln Ala Ala Thr
580 585 590
Thr Asp Val Asn Thr Gln Gly Val Leu Pro Gly Met Val Trp Gln Asp
595 600 605
Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His Thr
610 615 620
Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu Lys
625 630 635 640
His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala Asn
645 650 655
Pro Ser Thr Thr Phe Ser Ala Ala Lys Phe Ala Ser Phe Ile Thr Gln
660 665 670
Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln Lys
675 680 685
Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr Ser Asn Tyr
690 695 700
Asn Lys Ser Val Asn Val Asp Phe Thr Val Asp Thr Asn Gly Val Tyr
705 710 715 720
Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Asn Leu
725 730 735
<210> 33
<211> 735
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 33
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Thr Leu Ser
1 5 10 15
Glu Gly Ile Arg Gln Trp Trp Lys Leu Lys Pro Gly Pro Pro Pro Pro
20 25 30
Lys Pro Ala Glu Arg His Gln Asp Asp Ser Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Glu Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Arg Gln Leu Asp Ser Gly Asp Asn Pro Tyr Leu Lys Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Lys Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Pro Val Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu His Ser Pro Ala Glu Pro Asp Ser Ser Ser Gly Thr Gly
145 150 155 160
Lys Ala Gly Gln Gln Pro Ala Arg Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Ala Asp Ser Val Pro Asp Pro Gln Pro Leu Gly Gln Pro Pro
180 185 190
Ala Ala Pro Ser Gly Leu Gly Thr Asn Thr Met Ala Thr Gly Ser Gly
195 200 205
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ser
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Met Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Ser Gln Ser Gly Ala Ser Asn Asp Asn His Tyr
260 265 270
Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe His
275 280 285
Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn Trp
290 295 300
Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln Val
305 310 315 320
Lys Glu Val Thr Gln Asn Asp Gly Thr Thr Thr Ile Ala Asn Asn Leu
325 330 335
Thr Ser Thr Val Gln Val Phe Thr Asp Ser Glu Tyr Gln Leu Pro Tyr
340 345 350
Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala Asp
355 360 365
Val Phe Met Val Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly Ser
370 375 380
Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro Ser
385 390 395 400
Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe Glu
405 410 415
Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp Arg
420 425 430
Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Ser Lys Thr
435 440 445
Asn Ala Pro Ser Gly Thr Thr Thr Met Ser Arg Leu Gln Phe Ser Gln
450 455 460
Ala Gly Ala Ser Asp Ile Arg Asp Gln Ser Arg Asn Trp Leu Pro Gly
465 470 475 480
Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Ala Ala Asp Asn Asn
485 490 495
Asn Ser Asp Tyr Ser Trp Thr Gly Ala Thr Lys Tyr His Leu Asn Gly
500 505 510
Arg Asp Ser Leu Val Asn Pro Gly Pro Ala Met Ala Ser His Lys Asp
515 520 525
Asp Glu Glu Lys Tyr Phe Pro Gln Ser Gly Val Leu Ile Phe Gly Lys
530 535 540
Gln Asp Ser Gly Lys Thr Asn Val Asp Ile Glu Lys Val Met Ile Thr
545 550 555 560
Asp Glu Glu Glu Ile Arg Thr Thr Asn Pro Val Ala Thr Glu Gln Tyr
565 570 575
Gly Ser Val Ser Thr Asn Leu Gln Ser Gly Asn Thr Gln Ala Ala Thr
580 585 590
Thr Asp Val Asn Thr Gln Gly Val Leu Pro Gly Met Val Trp Gln Asp
595 600 605
Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His Thr
610 615 620
Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu Lys
625 630 635 640
His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala Asn
645 650 655
Pro Ser Thr Thr Phe Ser Ala Ala Lys Leu Ala Ser Phe Ile Thr Gln
660 665 670
Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln Lys
675 680 685
Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr Ser Asn Tyr
690 695 700
Asn Lys Ser Val Asn Val Asp Phe Thr Val Asp Thr Asn Gly Val Tyr
705 710 715 720
Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Asn Leu
725 730 735
<210> 34
<211> 735
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 34
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Thr Leu Ser
1 5 10 15
Glu Gly Ile Arg Gln Trp Trp Lys Leu Lys Pro Gly Pro Pro Pro Pro
20 25 30
Lys Pro Ala Glu Arg His Lys Asp Asp Ser Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Glu Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Arg Gln Leu Asp Ser Gly Asp Asn Pro Tyr Leu Lys Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Lys Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Ala Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Pro Val Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu His Ser Pro Ala Glu Pro Asp Ser Ser Ser Gly Thr Gly
145 150 155 160
Lys Ser Gly Gln Gln Pro Ala Arg Lys Arg Leu Asn Phe Gly Gln Thr
165 170 175
Gly Asp Ala Asp Ser Val Pro Asp Pro Gln Pro Leu Gly Gln Pro Pro
180 185 190
Ala Ala Pro Ser Gly Leu Gly Thr Asn Thr Met Ala Ser Gly Ser Gly
195 200 205
Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Asn Ser
210 215 220
Ser Gly Asn Trp His Cys Asp Ser Thr Trp Met Gly Asp Arg Val Ile
225 230 235 240
Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His Leu
245 250 255
Tyr Lys Gln Ile Ser Ser Gln Ser Gly Ala Ser Asn Asp Asn His Tyr
260 265 270
Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn Arg Phe His
275 280 285
Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn Asn Asn Trp
290 295 300
Gly Phe Arg Pro Lys Arg Leu Asn Phe Lys Leu Phe Asn Ile Gln Val
305 310 315 320
Lys Glu Val Thr Gln Asn Asp Gly Thr Thr Thr Ile Ala Asn Asn Leu
325 330 335
Thr Ser Thr Val Gln Val Phe Thr Asp Ser Glu Tyr Gln Leu Pro Tyr
340 345 350
Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe Pro Ala Asp
355 360 365
Val Phe Met Val Pro Gln Tyr Gly Tyr Leu Thr Leu Asn Asn Gly Ser
370 375 380
Gln Thr Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr Phe Pro Ser
385 390 395 400
Gln Met Leu Arg Thr Gly Asn Asn Phe Thr Phe Ser Tyr Thr Phe Glu
405 410 415
Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser Leu Asp Arg
420 425 430
Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu Ser Arg Thr
435 440 445
Asn Thr Pro Ser Gly Thr Thr Thr Gln Ser Arg Leu Arg Phe Ser Gln
450 455 460
Ala Gly Ala Ser Asp Ile Arg Asp Gln Ser Arg Asn Trp Leu Pro Gly
465 470 475 480
Pro Cys Tyr Arg Gln Gln Arg Val Ser Lys Thr Ala Ala Asp Asn Asn
485 490 495
Asn Ser Asp Tyr Ser Trp Thr Gly Ala Thr Lys Tyr His Leu Asn Gly
500 505 510
Arg Asp Ser Leu Val Asn Pro Gly Thr Ala Met Ala Ser His Lys Asp
515 520 525
Asp Glu Glu Lys Tyr Phe Pro Gln Ser Gly Val Leu Ile Phe Gly Lys
530 535 540
Gln Asp Ser Gly Lys Thr Asn Val Asp Ile Glu Arg Val Met Ile Thr
545 550 555 560
Asp Glu Glu Glu Ile Arg Thr Thr Asn Pro Val Ala Thr Glu Gln Tyr
565 570 575
Gly Ser Val Ser Thr Asn Leu Gln Ser Gly Asn Thr Gln Ala Ala Thr
580 585 590
Ser Asp Val Asn Thr Gln Gly Val Leu Pro Gly Met Val Trp Gln Asp
595 600 605
Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile Pro His Thr
610 615 620
Asp Gly His Phe His Pro Ser Pro Leu Met Gly Gly Phe Gly Leu Lys
625 630 635 640
His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val Pro Ala Asn
645 650 655
Pro Ser Thr Thr Phe Ser Ala Ala Lys Phe Ala Ser Phe Ile Thr Gln
660 665 670
Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu Leu Gln Lys
675 680 685
Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr Ser Asn Tyr
690 695 700
Asn Lys Ser Val Asn Val Asp Phe Thr Val Asp Thr Asn Gly Val Tyr
705 710 715 720
Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg Asn Leu
725 730 735
<210> 35
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 35
agaggccatt cagacgagtg t 21
<210> 36
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 36
ctgcggaagc tgagagatgt 20
<210> 37
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 37
cacaatatca aggatatcga cgtga 25
<210> 38
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 38
acatcagttc tgttcttcgg gtaca 25
<210> 39
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 39
tacaaaccat acccagtccc tgttt 25
<210> 40
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 40
agtgctctaa ccacagtcca tgca 24
<210> 41
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 41
cagggaggca gtgactcttc 20
<210> 42
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 42
agtgtggaaa gtgtggcgtt 20
<210> 43
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 43
atggcgtcct ctctgcttga 20
<210> 44
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 44
gaagggtggg tagtcatttg 20
<210> 45
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 45
gcagcacagg tcctaaatag 20
<210> 46
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 46
gggcaataag gtagtgaaca g 21
<210> 47
<211> 18
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 47
ctgtcccaac ccccaaag 18
<210> 48
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 48
acgtattctt ccgggcagaa 20
<210> 49
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 49
ctggtgaaaa ggacctctcg aag 23
<210> 50
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 50
ccagtttcac taatgacaca aacg 24
<210> 51
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 51
agcaaagacc ccaacgagaa 20
<210> 52
<211> 15
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 52
ggcggcggtc acgaa 15
<210> 53
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<220>
<221> misc_feature
<222> (1)..(1)
<223> 被6FAM修饰
<220>
<221> misc_feature
<222> (22)..(22)
<223> 被TAMRA修饰
<400> 53
cgcgatcaca tggtcctgct gg 22
<210> 54
<211> 327
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 54
tttgtctttt atttcaggtc ccagatctag ggctctgcgt ttgctccagg tagtccgctg 60
ctcccttggg cctgggccca ctgacagccc tggtgcctct ggccggctgc acacctcctg 120
gcgggcagct gtgtacaaac tacttgagag caggtgttct ggcaatacct gcctgctctg 180
taatagtttg tacacggagg cctgccctga ctgcccacgg tgccgtggcc aaagaggatc 240
taagggcacc gctgagggcc tacctaacca tcgtggggaa taaggacagt gtcacccctg 300
caggggatcc ggtggtggtg caaatca 327
<210> 55
<211> 269
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 55
agggctctgc gtttgctcca ggtagtccgc tgctcccttg ggcctgggcc cactgacagc 60
cctggtgcct ctggccggct gcacacctcc tggcgggcag ctgtgaatgg tccacatttc 120
agggactgtt ctggcaatac ctggtccctg atttatggac cattcacgga ggcctgccct 180
gactgcccac ggtgccgtgg ccaaagagga tctaagggca ccgctgaggg cctacctaac 240
catcgtgggg aataaggaca gtgtcaccc 269
<210> 56
<211> 265
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多核苷酸
<400> 56
agggctctgc gtttgctcca ggtagtccgc tgctcccttg ggcctgggcc cactgacagc 60
cctggtgcct ctggccggct gcacacctcc tggcgggcag ctgtgacaaa ttagctgtca 120
gcgctgttct ggcaatacct ggcgctgact gcaaatttgt cacggaggcc tgccctgact 180
gcccacggtg ccgtggccaa agaggatcta agggcaccgc tgagggccta cctaaccatc 240
gtggggaata aggacagtgt caccc 265
<210> 57
<211> 8
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 57
Asp Asp Asp Asp Asp Asp Asp Asp
1 5
<210> 58
<211> 9
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 58
Asp Asp Asp Asp Asp Asp Asp Asp Asp
1 5
<210> 59
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 59
Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp
1 5 10
<210> 60
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 60
Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp
1 5 10
<210> 61
<211> 12
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 61
Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp
1 5 10
<210> 62
<211> 13
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 62
Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp
1 5 10
<210> 63
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 63
Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp Asp
1 5 10
<210> 64
<211> 5
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<400> 64
Gly Gly Gly Gly Ser
1 5
<210> 65
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<220>
<221> MISC_FEATURE
<222> (3)..(25)
<223> 可不存在
<400> 65
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly Gly Gly Gly Gly Gly
20 25
<210> 66
<211> 26
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<220>
<221> MISC_FEATURE
<222> (3)..(25)
<223> 可不存在
<400> 66
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly Gly Gly Gly Gly Gly Ser
20 25
<210> 67
<211> 50
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<220>
<221> MISC_FEATURE
<222> (5)..(50)
<223> 可不存在
<400> 67
Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser
1 5 10 15
Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser
20 25 30
Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser
35 40 45
Gly Ser
50
<210> 68
<211> 100
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成的多肽
<220>
<221> MISC_FEATURE
<222> (9)..(100)
<223> 可不存在
<400> 68
Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly
20 25 30
Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly
35 40 45
Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly
50 55 60
Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly
65 70 75 80
Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly
85 90 95
Gly Gly Ser Gly
100
<210> 69
<211> 12322
<212> DNA
<213> 智人(Homo sapiens)
<400> 69
ctcacaacca gccgactctc ccattatcca gctgcctagt ttggtgcttc aatgtacatg 60
gctattccgt gtgcatatgt gtgtatacaa acacgcatgc atgcctggat ggacatacgt 120
atgcacaggt tattttttaa ggacaattct ttcaataagg tctttacccc ttacttgaaa 180
caggtgttca tgaaaaaaat gcacaaaatc ctgcctggcc ggaataattc atgaagaagg 240
ggctggatcc gtgggtcaga gaacacagga ccagtttgcc atcccaaggc cgaaggattc 300
gaggcacaaa cccagcagcc tcaacctagt tcatggagga gcctcgcggg gtcctggcca 360
agcaagcccg cccctctggt gggaagagcg gcgcctaggt ggagggtggc tgccgtagga 420
gtggacatga atgctggctt tcagagagaa cagcgtttca gttttggtca tcggaagtgg 480
tgccttcagc acagaagaag agcgtgattt ctcctccaag gccgttgatc tccaacccag 540
aactaaaggg gagaagagcc acccccagca tccagcgtgg catctcttgt gccaggacca 600
gggatgactg ggccatggac acagatgtct ccaaccttca accgtttgca tagcacacgg 660
gggactcgtg ggggccacct gccactgcca gctgaaacaa tacaatggca atactgacat 720
ccttcatgac gttttcccga cagacattca ggcagaaagt gctggtgcgt tttctgtctg 780
caaagtagag ggccatgcct caccaataga atagcgtggg ccctgatgac ctgctccgag 840
tccactcaca gccagtgaca cttgcaaaaa actcccaaag ccgtcttggg tttggctccc 900
acagctcttg accaatgtgg ccaaagctgg acacctcctt gggacactgg gattattcat 960
aaatgcagcc cgccctgact ctccctgaat agcatctgaa gtctttgtga aggtcatgga 1020
tcctgaacaa agtgtcaagg gcaccaagaa ggctgaggga agtccccgga agcggctgac 1080
caaaggagag gccattcaga ccagtgtttc ttccagcgtc ccatacccag gcagcggcac 1140
agctgccacc caagagagcc ccgcccaaga gctcttagcc ccgcagccct tcccgggccc 1200
ctcatcagtt cttagggaag gctctcagga gaaaacgggc cagcagcaga agccccccaa 1260
aaggcccccc atcgaagcat ccgtccacat ctcacagctt ccgcagcacc ctctgacacc 1320
agcattcatg tcgcctggca aacctgagca tctcctggag gggtccacat ggcaactggt 1380
tgaccccatg agacctggac cctctggctc cttcgtggcc cctgggctcc atcctcagag 1440
ccagctcctt ccttcccacg cttccatcat tccccccgag gaccttcctg gagtccccaa 1500
agtcttcgtg cctcgtcctt cccaggtctc cttgaagccc acagaagagg cacacaagaa 1560
ggagaggaag ccccagaagc caggcaagta catctgccag tactgcagcc ggccctgtgc 1620
caagcccagc gtgctccaga agcacattcg ctcacacaca ggtgagaggc cctacccctg 1680
cggcccctgt ggcttctcct tcaagaccaa gagtaatctc tacaagcaca ggaagtccca 1740
tgcccaccgc atcaaagcag gcctggcctc aggcatgggt ggcgagatgt acccacatgg 1800
gctggagatg gagcggatcc ctggggaaga gtttgaggag cccactgagg gagaaagcac 1860
agattctgaa gaggagacta gtgccacctc tggtcaccct gcagagctct ccccaagacc 1920
caagcagccc cttctctcca gcgggctata cagctctggg agccacagtt ccagccacga 1980
acgctgttcc ctgtcccagt ccagcacagc ccagtcactc gaagaccccc ctccatttgt 2040
ggaaccctca tctgagcacc ccctgagcca taaacctgaa gacacccaca cgattaagca 2100
gaagctggcc ctccgcttaa gcgagaggaa gaaggtgatc gatgagcagg cgtttctgag 2160
cccaggcagc aaagggagta ctgagtctgg gtatttctct cgctccgaga gtgcagagca 2220
gcaggtcagc cccccaaaca ccaacgccaa gtcctacgct gagatcatct ttggcaagtg 2280
tgggcgaata ggacagcgga ccgccatgct gacagccacc tccacccagc ccctcctgcc 2340
cctgtccacc gaagacaagc ccagcctggt gcctttgtct gtaccccgga cgcaggtgat 2400
cgagcacatc acgaagctca tcaccatcaa cgaggccgtg gtggacacca gcgagatcga 2460
cagcgtgaag ccaaggcgga gctcactgtc caggcgcagc agcatggagt ccccaaaatc 2520
cagcctctac cgggagcccc tgtcatccca cagtgagaaa accaagcctg aacaatcact 2580
gctgagcctc cagcacccgc ccagtaccgc cccccctgtg cctctcctga gaagccactc 2640
aatgccttct gccgcctgca ctatcagcac cccccaccac cccttccgag gtagctactc 2700
cttcgatgac catatcaccg actccgaagc cctgagccac agcagtcacg tgtttacctc 2760
ccacccccgg atgctgaagc gccagccggc aatcgaatta cctttgggag gggaatacag 2820
ttctgaggag cctggcccaa gcagcaaaga cacagcctcc aagccctcgg acgaagtgga 2880
acccaaggaa agcgagctta ccaaaaagac caagaagggt ttgaaaacaa aaggggtgat 2940
ctacgaatgt aacatatgtg gtgctcggta caagaaaagg gataactacg aagcccacaa 3000
aaaatactac tgctcagagc ttcagatcgc aaagcccatc tctgcaggca cccacacatc 3060
tccagaagct gaaaagagtc agattgagca tgagccgtgg tcccaaatga tgcattacaa 3120
actgggaacc accctggaac tcactccact gaggaagagg aggaaagaga agagccttgg 3180
ggacgaggaa gagccacctg cctttgagtc cacaaaaagt cagtttggca gccccgggcc 3240
atctgatgct gctcggaacc ttcccctgga gtccaccaag tcaccagcag aaccaagtaa 3300
atcagtgccc tccttggagg gacccacggg cttccagcca aggactccca agccagggtc 3360
cggttcagaa tcagggaagg agaggagaac aacgtccaaa gaaatttctg tcatccagca 3420
caccagctcc tttgagaaat ctgattctct cgagcagccg agtggcttgg aaggggaaga 3480
caaacctctg gcccagttcc catcaccccc acctgcccca cacggacgct ctgctcactc 3540
cctgcagcct aagttggtcc gccagcccaa cattcaggtt cctgagatcc tagtaactga 3600
ggagcctgac cggccggaca cagagccaga gccgccccct aaggaacctg agaagactga 3660
ggagttccaa tggccccagc gcagccagac acttgcccag ctcccagctg agaagctgcc 3720
acccaaaaag aagaggttgc gcctggcaga gatggcccaa tcatcagggg agtccagctt 3780
cgagtcctct gtgcctctgt ctcgcagccc gagccaggaa agcaatgtct ctttgagtgg 3840
gtccagccgc tcagcctcgt ttgagaggga tgaccatggg aaagccgagg cccccagtcc 3900
ctcatctgac atgcgcccca aacccctggg cacccacatg ttgactgtcc ccagccacca 3960
cccacatgcc cgagagatgc ggaggtcagc ctcagagcag agccccaacg tttcccattc 4020
tgcccacatg accgagacac gcagcaaatc ctttgactat ggcagcttgt ccttgacagg 4080
cccttctgct ccagccccag tggctccacc agcgcgggtg gccccgccag agagaagaaa 4140
atgcttcttg gtgagacagg cctctctgag caggcctcca gaatctgagt tggaggttgc 4200
ccccaaggga agacaggaga gcgaagaacc acagccctca tccagtaaac cctctgccaa 4260
aagctcattg tcccagattt cctctgcggc cacctcacat ggtggacccc cgggaggcaa 4320
gggcccaggg caggacaggc ccccattggg gcccactgtg ccctacacag aagcactgca 4380
agtgttccac caccccgttg cccagacacc cctgcatgag aagccatacc tgcccccacc 4440
agtctccctt ttctccttcc agcatctcgt gcagcatgag ccaggacagt ctccagaatt 4500
cttctccacc caggccatgt ccagcctcct gtcctcacca tactccatgc ccccacttcc 4560
tccctcctta tttcaagccc caccgcttcc tctccagcct actgttctgc acccaggcca 4620
actccatctc ccccagctca tgcctcaccc agccaacatc cccttcaggc agcccccttc 4680
cttcctcccc atgccatacc cgacctcctc agcactgtct tctgggtttt tcctgcctct 4740
gcaatcccag tttgcacttc agctccctgg tgatgtggaa agccatctgc cccagatcaa 4800
aaccagcctg gccccactgg caacaggaag tgctggcctc tcccccagca cagagtacag 4860
cagtgacatc cggctacccc ctgtggctcc cccagccagc tcctcagcac ctacatcagc 4920
tcctccactg gccctgcctg cctgtccaga caccatggtg tccctggttg tgcctgtccg 4980
tgttcagacc aatatgccgt cctatgggag cgcaatgtac accacccttt cccagatctt 5040
ggtcacccag tcccaaggca gctcagcaac tgtggcactt cccaagtttg aggaaccccc 5100
atcaaagggg acgactgtat gtggtgcaga tgtgcatgag gttgggcccg gcccttctgg 5160
gttaagtgaa gagcaaagca gagctttccc aactccatac ctgagagtgc ctgtgacatt 5220
acctgaaaga aaaggcactt ccctgtcatc agagagtatc ttgagcctgg aggggagttc 5280
atcaacagca gggggaagca aacgtgtcct ttcaccagct ggcagccttg aacttaccat 5340
ggaaacccag cagcaaaaaa gagtgaagga ggaggaggct tccaaggcag atgaaaaact 5400
tgagctggta aaaccatgca gtgtggtcct accagcaccg aggatgggaa gaggccagag 5460
aaatcccact taggcaacca gggccaaggc aggagggagc tagaaatgct gtccagcctg 5520
tcctcagatc catctgacac aaaggaaatt cctcccctcc ctcaccctgc attgtcccat 5580
gggacagccc caggctcaga agctttgaag gaatatcccc agccatctgg caaacctcac 5640
cgaagagggt tgaccccact gagcgtgaag aaagaagatt ccaaggaaca acctgatctc 5700
ccctccttgg cacctccgag ctctctgcct ctgtcagaaa cgtcctccag accagccaag 5760
tcacaagaag gtacggactc aaagaaggta ctgcagttcc ccagcctcca cacaaccact 5820
aatgtcagtt ggtgctattt aaactacatt aagccaaatc acatccagca tgcagatagg 5880
aggtcctctg tttacgctgg ttggtgcata agtttgtaca accccaacct tccgggggtt 5940
tccactaaag ctgctttgtc cctcctgagg tctaagcaga aagtgagcaa agagacatac 6000
accatggcca cagctccgca tcctgaggca ggaaggcttg tgccatccag ctcccgcaag 6060
ccccgcatga cagaggttca cctcccttca ctggtttccc cggaaggcca gaaagatcta 6120
gctagagtgg agaaggaaga agagaggaga ggggagccgg aggaggatgc tcctgcctcc 6180
cagagagggg agccggcgag gatcaaaatc ttcgaaggag ggtacaaatc aaacgaagag 6240
tatgtatatg tgcgaggccg cggccgaggg aaatatgttt gtgaggagtg tggaattcgc 6300
tgcaagaagc ccagcatgct gaagaaacac atccgcaccc acactgacgt ccggccctat 6360
gtgtgcaagc actgtcactt tgcttttaaa accaaaggga atctgactaa gcacatgaag 6420
tcgaaggccc acagcaaaaa gtgccaagag acaggggtgc tggaggagct ggaagccgaa 6480
gaaggaacca gtgacgacct gttccaggac tcggaaggac gagagggttc agaggctgtg 6540
gaggagcacc agttttcgga cctggaggac tcggactcag actcagacct ggacgaagac 6600
gaggatgagg atgaggagga gagccaggat gagctgtcca gaccatcctc agaggcgccc 6660
ccgcctggcc caccacatgc actgcgggca gactcctcac ccatcctggg ccctcagccc 6720
ccagatgccc ccgcctctgg cacggaggct acacgaggca gctcggtctc ggaagctgag 6780
cgcctgacag ccagcagctg ctccatgtcc agccagagca tgccgggcct cccctggctg 6840
ggaccggccc ctctgggctc tgtggagaaa gacacaggct cagccttgag ctacaagcct 6900
gtgtccccaa gaagaccgtg gtccccaagc aaagaagcag gcagccgtcc accactagcc 6960
cgcaaacact cgctaaccaa aaacgactca tctccccagc gatgctcccc ggcccgagaa 7020
ccacaggcct cagccccaag cccacctggc ctgcacgtgg acccaggaag gggcatgggc 7080
gctctccctt gtgggtctcc aagacttcag ctgtctcctc tcaccctctg ccccctggga 7140
agagaactgg cccctcgagc acatgtgctc tccaaactcg agggtaccac cgacccaggc 7200
ctccccagat actcgcccac caggagatgg tctccaggtc aggccgagtc accaccacgg 7260
tcagcgccgc cagggaagtg ggccttggct gggccgggca gcccctcagc gggggagcat 7320
ggcccaggct tggggctgga cccacgggtt ctcttcccgc ccgcgcctct acctcacaag 7380
ctcctcagca gaagcccaga gacctgcgcc tccccgtgga aggccgagtc ccgaagtccc 7440
tcctgctcac ccggccctgc tcatcctctc tcctcccgac ccttctccgc cctccatgac 7500
ttccacggcc acatcctggc ccggacagag gagaacatct tcagccacct gcctctgcac 7560
tcccagcact tgacccgtgc cccatgtccc ttgattccca tcggtgggat ccagatggtg 7620
caggcccggc caggagccca ccccaccctg ctgccagggc ccaccgcagc ctgggtcagt 7680
ggcttctccg ggggtggcag cgacctgaca ggggcccggg aggcccagga gcgaggccgc 7740
tggagtccca ctgagagctc gtcagcctcc gtgtcgcctg tggctaaggt ctccaaattc 7800
acactctcct cagagctgga gggcggggac taccccaagg agagggagag gaccggcgga 7860
ggcccgggca ggcctcctga ctggacaccc catgggaccg gggcacctgc agagcccaca 7920
cccacgcaca gcccctgcac cccacccgac accttgcccc ggccgcccca gggacgccgg 7980
gcagcgcagt cctggagccc ccgcttgggt ccccgcgtgc accgaccaac cccgagcctt 8040
ctgccacccc gccgctggac cgcagcagct ctgtgggctg cctggcagag gcctctgccc 8100
gcttcccagc ccggacgagg aacctctccg gggaacccag gaccaggcag gactccccca 8160
agccctcagg aagtggggag cccagggcac atccacatca gcctgaggac agggttcccc 8220
ccaacgctta gcctctctcc aactgcttca gcatctggct tccagtgtcc agcaacagac 8280
gtttccagcc actttcctcg aatcatccca cttcctcagc cccatctgtc cctccgtcca 8340
ggagctctca cggccccatc tgttgtacct tcccatgtat gcagttacct gtgccttttt 8400
ctacaccttt tgttgcttaa aaagaaacaa aacaaatcac atacatacat ttaaaaaaaa 8460
aacaacaacc cacgaggagt ctgaggctgt gaatagttta tggttttggg gaaaggctga 8520
tggtgaagcc tcctgaccct ccccgctgtg gttggcagcc acccacccca gaggctggca 8580
gagggaaagg ggtacactga gggagaaagg aaaaggaaac ttcaaacaat atagaattaa 8640
atgtaaaagg aagcactcct gtgtacagat gcgatcaagg ttcctgttta ttgccacttc 8700
acccccctgc ccagctcgta gccacccctc tctgccagca gaaaggccag tgtccccagg 8760
cagaggggca caaacacagg caggtgaccc ccacccaggc cccagcaggc aggcccagaa 8820
aaactaatct tttccttttt tttttttttt tttttttttg caagaaaata aaatgatact 8880
tttcctagga tttcaacaca aaataatagg tgcaggtaga aggaggaggg ctggctcccc 8940
aagggctcct ggatactctg gtagtctgag tcatgggccc atcctggcac tccacaggtg 9000
ggcaggccac cccacccacg cacccccact ccagacacct cccttctgca ccccaccctg 9060
gccccctggg ctggggaagg agccctgact gtccgtccct ggctcccaag cccctgaccg 9120
aggcctcact ctcctgttgc ctcctctgtt ctaaaaccac caaaccaccc acaaaggcag 9180
aagtggcagg gcccgagccc tagcggccgt tcctgagact gggttttggg ttttgtttca 9240
tcttggtccc tggggtacaa gggagcctgt tcccctcatg gctgggtttt tccagttctc 9300
cacagcagag gtttgcgggg aactgtttca ggaccacttt gccacaggac cgtttccccc 9360
cgtccctgcc cctgtctcca ctaccccaag gaaataccca caactgtggc tggtggatac 9420
ggcctggacc tgtttgctgt cttacacctc ttttttaaaa agagagagga tggtgtttga 9480
tacttcaccc agccaccaca gattcttttg acctagagga tttttgaatt gtcctaactc 9540
gttggaattc tccaaagcaa tcagtgtgag ccagtgcctc ttccttaccc acatctctac 9600
tttcaagaag ctgccctgca tttcctgggg caaaactcta ctttgtaaga aaaataatag 9660
gaccagaaat ttaaatccca aattgaacta tggaacttga actctagcgt gttcgcccca 9720
actgggagag gtgagctttt tcccagtgtt tcagaactga ttttctttac tttctacaag 9780
ggagggcagc acagggacta cggttgaggc ccgtgaaggc tgggtttgat gccaccctat 9840
acagagcagg gacctctctg gctaatcccc agtcctcagc caggctgtgt gaatcaagtg 9900
cctgccccag ggctcttgag ctattgaagc tgcttgggta caggacacag taggtgggga 9960
gggttaagac ccttctgtga gttccctgtg cggggctgta cttgcctctt ccaattcgtg 10020
gcctttccct gcttggtccc tactagacag acaaaccagc cacagtccag cctgcagcca 10080
gaccaccttg ttcactcatt ctcctttgcc tcagagctaa gacaaaaatg agacagaagg 10140
cagggctccc tgggagtcca ctgtgctcca gggttctggg gaatcagggt tagccagcag 10200
ctcctggctg cttccctcag agactagggc tctcatcctc cccaagagaa gcagcaagcc 10260
cagcctggac cacactgtcc atattgctgg acagtggcct gacagaaagt gactcctcca 10320
agtcccagga ggccagggct tttctcatcc ttgcctttca gccctaaccc atgggactgc 10380
ccacggattg gagacttcaa gggctgaggt ctgggagctg cataaagggc attgcttcag 10440
cccaggttag aaatctgcct gggcaagctc ttcctgcccc agacctacaa agcagcagac 10500
cgggggctct ggtggactag cccctgacat tggtgggggg ccccacacca ctccacccca 10560
ccctgccttc cagctctcct gggcattttt ctccctgtac tcaaacagcc tacccaccca 10620
aggtttcctc cctgggcagc ctagcaatga acagtgcagc cggcagggca gaggcccggc 10680
agtcaccggg cccgtcaggc tcaggcagag aagccacagg ggccaggagt cactggagac 10740
tatttctaaa tgatgggggt aaatgcacaa atagaatctc accaaagggc tgcctccaca 10800
ttgatgccgt gcccagaggg acagaaccaa tgccaccagc ctgggtatat gtcactgggc 10860
acagctctaa ccccctcctc cggactctag tcccgctcct ctgcgcacag agcccccagc 10920
ccacaggtac accttcatga tttggagaaa gacgctcgcc ccatgcacgc cctcctctgg 10980
gccttctgcc ctgctcccag tcacttccaa gcttcctgtt tgcctgtgat gttattgtgc 11040
ctgttgaggg aagcagcaga ggaggcagtg gctgacttgg cacagatgcc tgctacgtgc 11100
tctgttgaaa tgcgcggggt ggccattcct cggtacagac tagtcctggt ccttgggtgt 11160
gggcagtggg ggaggaacca actggtcgag gtttcagagc caaaccttgc ctttggttgg 11220
tgagtccttg ccccccaggc ctgcgctcca cgatgccttt cacccttggc aatctcaggg 11280
ccatcctggg tagtaacccc actcctctct gctcccgccc gcacctgtgg ctctcactct 11340
gggctcaacc cctgcaaccc tccaggagcc cgacagcagc cagctgcctg cactgtcgcc 11400
tccgtaagct ccaacttcca gacccagaag tccctctgct tccctctgtt ggaaaaagcc 11460
taaaagaatt agcttccaga ttcctctagc ccctgctcca ttcccaccca gtccttctga 11520
agaggaatga gcaatacatc tgagctggat ttctctctag tcctttctcc agacaaatcc 11580
ttcttaaagc aaaagtcctg gctgagcacc tgtccttggg gaccgatctg ccgtgtgacc 11640
aggggaagaa agttcccgaa agcctgttcc accaattctg cttctgtgtt gtgaatccag 11700
tctgctttcc attagaaaac cgcttcggca cttatggtca ctttaataaa tctagtatgt 11760
aaaaaaagaa agaaagaaaa gaaacagaaa aaagaaacgt gcaggcaaat gtaaaataca 11820
atgctctctg taagataaat atttgccttt ttttctaaaa ggtgtacgta ttctgtatgt 11880
gaaattgtct gtagaaagtt tctatgttct taaatggcaa tacattccaa aaattgtact 11940
gtagatatgt acagcaaccg cactgggatg gggtagtttt gcctgtaatt ttatttaaac 12000
tccagtttcc acacttgctc ttgcaatgtt ggtatggtat atatcagtgc aaaagaaaaa 12060
acaaaacaga aacaaacaaa aaaaaaaaac aaaaatccac gcaggtctaa agcacagagt 12120
ctgacgtaca aaaggaaaaa tgctcagtat tgatgtgtgt gacctttgtt gtaaattaca 12180
tctgtactgt gaatgagaag tttttacaag tataataatt gcctttatta cagctctggc 12240
tgagtgttca gcctgaggat attttttaaa aaaaaaagaa ttagcatgtt ggaataaatt 12300
tgaaaatccc aacataaaaa aa 12322
<210> 70
<211> 2405
<212> PRT
<213> 智人(Homo sapiens)
<400> 70
Met Asp Pro Glu Gln Ser Val Lys Gly Thr Lys Lys Ala Glu Gly Ser
1 5 10 15
Pro Arg Lys Arg Leu Thr Lys Gly Glu Ala Ile Gln Thr Ser Val Ser
20 25 30
Ser Ser Val Pro Tyr Pro Gly Ser Gly Thr Ala Ala Thr Gln Glu Ser
35 40 45
Pro Ala Gln Glu Leu Leu Ala Pro Gln Pro Phe Pro Gly Pro Ser Ser
50 55 60
Val Leu Arg Glu Gly Ser Gln Glu Lys Thr Gly Gln Gln Gln Lys Pro
65 70 75 80
Pro Lys Arg Pro Pro Ile Glu Ala Ser Val His Ile Ser Gln Leu Pro
85 90 95
Gln His Pro Leu Thr Pro Ala Phe Met Ser Pro Gly Lys Pro Glu His
100 105 110
Leu Leu Glu Gly Ser Thr Trp Gln Leu Val Asp Pro Met Arg Pro Gly
115 120 125
Pro Ser Gly Ser Phe Val Ala Pro Gly Leu His Pro Gln Ser Gln Leu
130 135 140
Leu Pro Ser His Ala Ser Ile Ile Pro Pro Glu Asp Leu Pro Gly Val
145 150 155 160
Pro Lys Val Phe Val Pro Arg Pro Ser Gln Val Ser Leu Lys Pro Thr
165 170 175
Glu Glu Ala His Lys Lys Glu Arg Lys Pro Gln Lys Pro Gly Lys Tyr
180 185 190
Ile Cys Gln Tyr Cys Ser Arg Pro Cys Ala Lys Pro Ser Val Leu Gln
195 200 205
Lys His Ile Arg Ser His Thr Gly Glu Arg Pro Tyr Pro Cys Gly Pro
210 215 220
Cys Gly Phe Ser Phe Lys Thr Lys Ser Asn Leu Tyr Lys His Arg Lys
225 230 235 240
Ser His Ala His Arg Ile Lys Ala Gly Leu Ala Ser Gly Met Gly Gly
245 250 255
Glu Met Tyr Pro His Gly Leu Glu Met Glu Arg Ile Pro Gly Glu Glu
260 265 270
Phe Glu Glu Pro Thr Glu Gly Glu Ser Thr Asp Ser Glu Glu Glu Thr
275 280 285
Ser Ala Thr Ser Gly His Pro Ala Glu Leu Ser Pro Arg Pro Lys Gln
290 295 300
Pro Leu Leu Ser Ser Gly Leu Tyr Ser Ser Gly Ser His Ser Ser Ser
305 310 315 320
His Glu Arg Cys Ser Leu Ser Gln Ser Ser Thr Ala Gln Ser Leu Glu
325 330 335
Asp Pro Pro Pro Phe Val Glu Pro Ser Ser Glu His Pro Leu Ser His
340 345 350
Lys Pro Glu Asp Thr His Thr Ile Lys Gln Lys Leu Ala Leu Arg Leu
355 360 365
Ser Glu Arg Lys Lys Val Ile Asp Glu Gln Ala Phe Leu Ser Pro Gly
370 375 380
Ser Lys Gly Ser Thr Glu Ser Gly Tyr Phe Ser Arg Ser Glu Ser Ala
385 390 395 400
Glu Gln Gln Val Ser Pro Pro Asn Thr Asn Ala Lys Ser Tyr Ala Glu
405 410 415
Ile Ile Phe Gly Lys Cys Gly Arg Ile Gly Gln Arg Thr Ala Met Leu
420 425 430
Thr Ala Thr Ser Thr Gln Pro Leu Leu Pro Leu Ser Thr Glu Asp Lys
435 440 445
Pro Ser Leu Val Pro Leu Ser Val Pro Arg Thr Gln Val Ile Glu His
450 455 460
Ile Thr Lys Leu Ile Thr Ile Asn Glu Ala Val Val Asp Thr Ser Glu
465 470 475 480
Ile Asp Ser Val Lys Pro Arg Arg Ser Ser Leu Ser Arg Arg Ser Ser
485 490 495
Met Glu Ser Pro Lys Ser Ser Leu Tyr Arg Glu Pro Leu Ser Ser His
500 505 510
Ser Glu Lys Thr Lys Pro Glu Gln Ser Leu Leu Ser Leu Gln His Pro
515 520 525
Pro Ser Thr Ala Pro Pro Val Pro Leu Leu Arg Ser His Ser Met Pro
530 535 540
Ser Ala Ala Cys Thr Ile Ser Thr Pro His His Pro Phe Arg Gly Ser
545 550 555 560
Tyr Ser Phe Asp Asp His Ile Thr Asp Ser Glu Ala Leu Ser His Ser
565 570 575
Ser His Val Phe Thr Ser His Pro Arg Met Leu Lys Arg Gln Pro Ala
580 585 590
Ile Glu Leu Pro Leu Gly Gly Glu Tyr Ser Ser Glu Glu Pro Gly Pro
595 600 605
Ser Ser Lys Asp Thr Ala Ser Lys Pro Ser Asp Glu Val Glu Pro Lys
610 615 620
Glu Ser Glu Leu Thr Lys Lys Thr Lys Lys Gly Leu Lys Thr Lys Gly
625 630 635 640
Val Ile Tyr Glu Cys Asn Ile Cys Gly Ala Arg Tyr Lys Lys Arg Asp
645 650 655
Asn Tyr Glu Ala His Lys Lys Tyr Tyr Cys Ser Glu Leu Gln Ile Ala
660 665 670
Lys Pro Ile Ser Ala Gly Thr His Thr Ser Pro Glu Ala Glu Lys Ser
675 680 685
Gln Ile Glu His Glu Pro Trp Ser Gln Met Met His Tyr Lys Leu Gly
690 695 700
Thr Thr Leu Glu Leu Thr Pro Leu Arg Lys Arg Arg Lys Glu Lys Ser
705 710 715 720
Leu Gly Asp Glu Glu Glu Pro Pro Ala Phe Glu Ser Thr Lys Ser Gln
725 730 735
Phe Gly Ser Pro Gly Pro Ser Asp Ala Ala Arg Asn Leu Pro Leu Glu
740 745 750
Ser Thr Lys Ser Pro Ala Glu Pro Ser Lys Ser Val Pro Ser Leu Glu
755 760 765
Gly Pro Thr Gly Phe Gln Pro Arg Thr Pro Lys Pro Gly Ser Gly Ser
770 775 780
Glu Ser Gly Lys Glu Arg Arg Thr Thr Ser Lys Glu Ile Ser Val Ile
785 790 795 800
Gln His Thr Ser Ser Phe Glu Lys Ser Asp Ser Leu Glu Gln Pro Ser
805 810 815
Gly Leu Glu Gly Glu Asp Lys Pro Leu Ala Gln Phe Pro Ser Pro Pro
820 825 830
Pro Ala Pro His Gly Arg Ser Ala His Ser Leu Gln Pro Lys Leu Val
835 840 845
Arg Gln Pro Asn Ile Gln Val Pro Glu Ile Leu Val Thr Glu Glu Pro
850 855 860
Asp Arg Pro Asp Thr Glu Pro Glu Pro Pro Pro Lys Glu Pro Glu Lys
865 870 875 880
Thr Glu Glu Phe Gln Trp Pro Gln Arg Ser Gln Thr Leu Ala Gln Leu
885 890 895
Pro Ala Glu Lys Leu Pro Pro Lys Lys Lys Arg Leu Arg Leu Ala Glu
900 905 910
Met Ala Gln Ser Ser Gly Glu Ser Ser Phe Glu Ser Ser Val Pro Leu
915 920 925
Ser Arg Ser Pro Ser Gln Glu Ser Asn Val Ser Leu Ser Gly Ser Ser
930 935 940
Arg Ser Ala Ser Phe Glu Arg Asp Asp His Gly Lys Ala Glu Ala Pro
945 950 955 960
Ser Pro Ser Ser Asp Met Arg Pro Lys Pro Leu Gly Thr His Met Leu
965 970 975
Thr Val Pro Ser His His Pro His Ala Arg Glu Met Arg Arg Ser Ala
980 985 990
Ser Glu Gln Ser Pro Asn Val Ser His Ser Ala His Met Thr Glu Thr
995 1000 1005
Arg Ser Lys Ser Phe Asp Tyr Gly Ser Leu Ser Leu Thr Gly Pro
1010 1015 1020
Ser Ala Pro Ala Pro Val Ala Pro Pro Ala Arg Val Ala Pro Pro
1025 1030 1035
Glu Arg Arg Lys Cys Phe Leu Val Arg Gln Ala Ser Leu Ser Arg
1040 1045 1050
Pro Pro Glu Ser Glu Leu Glu Val Ala Pro Lys Gly Arg Gln Glu
1055 1060 1065
Ser Glu Glu Pro Gln Pro Ser Ser Ser Lys Pro Ser Ala Lys Ser
1070 1075 1080
Ser Leu Ser Gln Ile Ser Ser Ala Ala Thr Ser His Gly Gly Pro
1085 1090 1095
Pro Gly Gly Lys Gly Pro Gly Gln Asp Arg Pro Pro Leu Gly Pro
1100 1105 1110
Thr Val Pro Tyr Thr Glu Ala Leu Gln Val Phe His His Pro Val
1115 1120 1125
Ala Gln Thr Pro Leu His Glu Lys Pro Tyr Leu Pro Pro Pro Val
1130 1135 1140
Ser Leu Phe Ser Phe Gln His Leu Val Gln His Glu Pro Gly Gln
1145 1150 1155
Ser Pro Glu Phe Phe Ser Thr Gln Ala Met Ser Ser Leu Leu Ser
1160 1165 1170
Ser Pro Tyr Ser Met Pro Pro Leu Pro Pro Ser Leu Phe Gln Ala
1175 1180 1185
Pro Pro Leu Pro Leu Gln Pro Thr Val Leu His Pro Gly Gln Leu
1190 1195 1200
His Leu Pro Gln Leu Met Pro His Pro Ala Asn Ile Pro Phe Arg
1205 1210 1215
Gln Pro Pro Ser Phe Leu Pro Met Pro Tyr Pro Thr Ser Ser Ala
1220 1225 1230
Leu Ser Ser Gly Phe Phe Leu Pro Leu Gln Ser Gln Phe Ala Leu
1235 1240 1245
Gln Leu Pro Gly Asp Val Glu Ser His Leu Pro Gln Ile Lys Thr
1250 1255 1260
Ser Leu Ala Pro Leu Ala Thr Gly Ser Ala Gly Leu Ser Pro Ser
1265 1270 1275
Thr Glu Tyr Ser Ser Asp Ile Arg Leu Pro Pro Val Ala Pro Pro
1280 1285 1290
Ala Ser Ser Ser Ala Pro Thr Ser Ala Pro Pro Leu Ala Leu Pro
1295 1300 1305
Ala Cys Pro Asp Thr Met Val Ser Leu Val Val Pro Val Arg Val
1310 1315 1320
Gln Thr Asn Met Pro Ser Tyr Gly Ser Ala Met Tyr Thr Thr Leu
1325 1330 1335
Ser Gln Ile Leu Val Thr Gln Ser Gln Gly Ser Ser Ala Thr Val
1340 1345 1350
Ala Leu Pro Lys Phe Glu Glu Pro Pro Ser Lys Gly Thr Thr Val
1355 1360 1365
Cys Gly Ala Asp Val His Glu Val Gly Pro Gly Pro Ser Gly Leu
1370 1375 1380
Ser Glu Glu Gln Ser Arg Ala Phe Pro Thr Pro Tyr Leu Arg Val
1385 1390 1395
Pro Val Thr Leu Pro Glu Arg Lys Gly Thr Ser Leu Ser Ser Glu
1400 1405 1410
Ser Ile Leu Ser Leu Glu Gly Ser Ser Ser Thr Ala Gly Gly Ser
1415 1420 1425
Lys Arg Val Leu Ser Pro Ala Gly Ser Leu Glu Leu Thr Met Glu
1430 1435 1440
Thr Gln Gln Gln Lys Arg Val Lys Glu Glu Glu Ala Ser Lys Ala
1445 1450 1455
Asp Glu Lys Leu Glu Leu Val Lys Pro Cys Ser Val Val Leu Thr
1460 1465 1470
Ser Thr Glu Asp Gly Lys Arg Pro Glu Lys Ser His Leu Gly Asn
1475 1480 1485
Gln Gly Gln Gly Arg Arg Glu Leu Glu Met Leu Ser Ser Leu Ser
1490 1495 1500
Ser Asp Pro Ser Asp Thr Lys Glu Ile Pro Pro Leu Pro His Pro
1505 1510 1515
Ala Leu Ser His Gly Thr Ala Pro Gly Ser Glu Ala Leu Lys Glu
1520 1525 1530
Tyr Pro Gln Pro Ser Gly Lys Pro His Arg Arg Gly Leu Thr Pro
1535 1540 1545
Leu Ser Val Lys Lys Glu Asp Ser Lys Glu Gln Pro Asp Leu Pro
1550 1555 1560
Ser Leu Ala Pro Pro Ser Ser Leu Pro Leu Ser Glu Thr Ser Ser
1565 1570 1575
Arg Pro Ala Lys Ser Gln Glu Gly Thr Asp Ser Lys Lys Val Leu
1580 1585 1590
Gln Phe Pro Ser Leu His Thr Thr Thr Asn Val Ser Trp Cys Tyr
1595 1600 1605
Leu Asn Tyr Ile Lys Pro Asn His Ile Gln His Ala Asp Arg Arg
1610 1615 1620
Ser Ser Val Tyr Ala Gly Trp Cys Ile Ser Leu Tyr Asn Pro Asn
1625 1630 1635
Leu Pro Gly Val Ser Thr Lys Ala Ala Leu Ser Leu Leu Arg Ser
1640 1645 1650
Lys Gln Lys Val Ser Lys Glu Thr Tyr Thr Met Ala Thr Ala Pro
1655 1660 1665
His Pro Glu Ala Gly Arg Leu Val Pro Ser Ser Ser Arg Lys Pro
1670 1675 1680
Arg Met Thr Glu Val His Leu Pro Ser Leu Val Ser Pro Glu Gly
1685 1690 1695
Gln Lys Asp Leu Ala Arg Val Glu Lys Glu Glu Glu Arg Arg Gly
1700 1705 1710
Glu Pro Glu Glu Asp Ala Pro Ala Ser Gln Arg Gly Glu Pro Ala
1715 1720 1725
Arg Ile Lys Ile Phe Glu Gly Gly Tyr Lys Ser Asn Glu Glu Tyr
1730 1735 1740
Val Tyr Val Arg Gly Arg Gly Arg Gly Lys Tyr Val Cys Glu Glu
1745 1750 1755
Cys Gly Ile Arg Cys Lys Lys Pro Ser Met Leu Lys Lys His Ile
1760 1765 1770
Arg Thr His Thr Asp Val Arg Pro Tyr Val Cys Lys His Cys His
1775 1780 1785
Phe Ala Phe Lys Thr Lys Gly Asn Leu Thr Lys His Met Lys Ser
1790 1795 1800
Lys Ala His Ser Lys Lys Cys Gln Glu Thr Gly Val Leu Glu Glu
1805 1810 1815
Leu Glu Ala Glu Glu Gly Thr Ser Asp Asp Leu Phe Gln Asp Ser
1820 1825 1830
Glu Gly Arg Glu Gly Ser Glu Ala Val Glu Glu His Gln Phe Ser
1835 1840 1845
Asp Leu Glu Asp Ser Asp Ser Asp Ser Asp Leu Asp Glu Asp Glu
1850 1855 1860
Asp Glu Asp Glu Glu Glu Ser Gln Asp Glu Leu Ser Arg Pro Ser
1865 1870 1875
Ser Glu Ala Pro Pro Pro Gly Pro Pro His Ala Leu Arg Ala Asp
1880 1885 1890
Ser Ser Pro Ile Leu Gly Pro Gln Pro Pro Asp Ala Pro Ala Ser
1895 1900 1905
Gly Thr Glu Ala Thr Arg Gly Ser Ser Val Ser Glu Ala Glu Arg
1910 1915 1920
Leu Thr Ala Ser Ser Cys Ser Met Ser Ser Gln Ser Met Pro Gly
1925 1930 1935
Leu Pro Trp Leu Gly Pro Ala Pro Leu Gly Ser Val Glu Lys Asp
1940 1945 1950
Thr Gly Ser Ala Leu Ser Tyr Lys Pro Val Ser Pro Arg Arg Pro
1955 1960 1965
Trp Ser Pro Ser Lys Glu Ala Gly Ser Arg Pro Pro Leu Ala Arg
1970 1975 1980
Lys His Ser Leu Thr Lys Asn Asp Ser Ser Pro Gln Arg Cys Ser
1985 1990 1995
Pro Ala Arg Glu Pro Gln Ala Ser Ala Pro Ser Pro Pro Gly Leu
2000 2005 2010
His Val Asp Pro Gly Arg Gly Met Gly Ala Leu Pro Cys Gly Ser
2015 2020 2025
Pro Arg Leu Gln Leu Ser Pro Leu Thr Leu Cys Pro Leu Gly Arg
2030 2035 2040
Glu Leu Ala Pro Arg Ala His Val Leu Ser Lys Leu Glu Gly Thr
2045 2050 2055
Thr Asp Pro Gly Leu Pro Arg Tyr Ser Pro Thr Arg Arg Trp Ser
2060 2065 2070
Pro Gly Gln Ala Glu Ser Pro Pro Arg Ser Ala Pro Pro Gly Lys
2075 2080 2085
Trp Ala Leu Ala Gly Pro Gly Ser Pro Ser Ala Gly Glu His Gly
2090 2095 2100
Pro Gly Leu Gly Leu Asp Pro Arg Val Leu Phe Pro Pro Ala Pro
2105 2110 2115
Leu Pro His Lys Leu Leu Ser Arg Ser Pro Glu Thr Cys Ala Ser
2120 2125 2130
Pro Trp Lys Ala Glu Ser Arg Ser Pro Ser Cys Ser Pro Gly Pro
2135 2140 2145
Ala His Pro Leu Ser Ser Arg Pro Phe Ser Ala Leu His Asp Phe
2150 2155 2160
His Gly His Ile Leu Ala Arg Thr Glu Glu Asn Ile Phe Ser His
2165 2170 2175
Leu Pro Leu His Ser Gln His Leu Thr Arg Ala Pro Cys Pro Leu
2180 2185 2190
Ile Pro Ile Gly Gly Ile Gln Met Val Gln Ala Arg Pro Gly Ala
2195 2200 2205
His Pro Thr Leu Leu Pro Gly Pro Thr Ala Ala Trp Val Ser Gly
2210 2215 2220
Phe Ser Gly Gly Gly Ser Asp Leu Thr Gly Ala Arg Glu Ala Gln
2225 2230 2235
Glu Arg Gly Arg Trp Ser Pro Thr Glu Ser Ser Ser Ala Ser Val
2240 2245 2250
Ser Pro Val Ala Lys Val Ser Lys Phe Thr Leu Ser Ser Glu Leu
2255 2260 2265
Glu Gly Gly Asp Tyr Pro Lys Glu Arg Glu Arg Thr Gly Gly Gly
2270 2275 2280
Pro Gly Arg Pro Pro Asp Trp Thr Pro His Gly Thr Gly Ala Pro
2285 2290 2295
Ala Glu Pro Thr Pro Thr His Ser Pro Cys Thr Pro Pro Asp Thr
2300 2305 2310
Leu Pro Arg Pro Pro Gln Gly Arg Arg Ala Ala Gln Ser Trp Ser
2315 2320 2325
Pro Arg Leu Glu Ser Pro Arg Ala Pro Thr Asn Pro Glu Pro Ser
2330 2335 2340
Ala Thr Pro Pro Leu Asp Arg Ser Ser Ser Val Gly Cys Leu Ala
2345 2350 2355
Glu Ala Ser Ala Arg Phe Pro Ala Arg Thr Arg Asn Leu Ser Gly
2360 2365 2370
Glu Pro Arg Thr Arg Gln Asp Ser Pro Lys Pro Ser Gly Ser Gly
2375 2380 2385
Glu Pro Arg Ala His Pro His Gln Pro Glu Asp Arg Val Pro Pro
2390 2395 2400
Asn Ala
2405
Claims (34)
1.一种分离的核酸,其编码:
(i)包含第一腺相关病毒(AAV)反向末端重复(ITR)或其变体的第一区域;和,
(ii)包含编码至少一个骨代谢调节剂的转基因的第二区域。
2.如权利要求1所述的分离的核酸,其中所述骨代谢调节剂是骨形成促进剂,任选地,其中所述骨形成促进剂选自由以下组成的组:促进成骨细胞和/或骨细胞功能或活性的蛋白、抑制破骨细胞功能的蛋白和抑制破骨细胞表达或活性的抑制性核酸。
3.如权利要求1所述的分离的核酸,其中所述骨代谢调节剂是骨形成抑制剂,任选地,其中所述骨形成抑制剂选自由以下组成的组:抑制成骨细胞和/或骨细胞功能或活性的蛋白、促进破骨细胞功能或活性的蛋白和抑制成骨细胞表达或活性的抑制性核酸。
4.如权利要求2所述的分离的核酸,其中所述转基因编码选自由以下组成的组的骨形成促进剂:甲状旁腺激素(PTH)、PTH相关蛋白(PTHrP)、去糖化酶DJ1、靶向骨硬化蛋白(SOST)的抑制性核酸、靶向schnurri-3(SHN3)的抑制性核酸、靶向组织蛋白酶K(CTSK)的抑制性核酸和靶向NF-κβ的受体激活剂(RANK)的抑制性核酸。
5.如权利要求3所述的分离的核酸,其中所述转基因编码选自由以下组成的组的骨形成抑制剂:骨硬化蛋白(SOST)、schnurri-3(SHN3)、组织蛋白酶K(CTSK)、靶向甲状旁腺激素(PTH)的抑制性核酸、靶向PTH相关蛋白(PTHrP)的抑制性核酸和靶向去糖化酶DJ1的抑制性核酸。
6.如权利要求1至5任一项所述的分离的核酸,其中所述转基因编码至少一种选自由dsRNA、siRNA、shRNA、miRNA和人工miRNA(amiRNA)组成的组的抑制性核酸。
7.如权利要求6所述的分离的核酸,其中所述抑制性核酸的功能为突变的末端重复(mTR)。
8.如权利要求1至7任一项所述的分离的核酸,其中所述转基因包含SEQ ID NO:1-15或55-56中任何一个所示的序列。
9.如权利要求1至8任一项所述的分离的核酸,其进一步包含至少一个有效连接至所述转基因的启动子。
10.如权利要求1至9任一项所述的分离的核酸,其进一步包含含有第二AAV ITR或其变体的第三区域。
11.一种载体,其包含权利要求1至10任一项所述的分离的核酸,任选地,其中所述载体是质粒。
12.一种宿主细胞,其包含权利要求1至10任一项所述的分离的核酸或权利要求11所述的载体。
13.一种重组腺相关病毒(rAAV),其包含:
(i)衣壳蛋白;和,
(ii)权利要求1至10任一项所述的分离的核酸。
14.如权利要求13所述的rAAV,其中所述衣壳蛋白具有选自以下的血清型:AAV1、AAV2、AAV3、AAV4、AAV5、AAV6、AAV6.2、AAV7、AAV8、AAV9、AAV.rh8、AAV.rh10、AAV.rh39、AAV.43、AAV2/2-66、AAV2/2-84和AAV2/2-125或前述任一种的变体,任选地,其中所述衣壳蛋白包含SEQ ID NOs:18-34中任一个所示的序列。
15.如权利要求14所述的rAAV,其中所述衣壳蛋白转导成骨细胞(OB),任选地,其中所述衣壳蛋白具有选自AAV4、AAV1、AAV6、AAV6.2和AAV9或前述任一种的变体的血清型。
16.如权利要求14所述的rAAV,其中所述衣壳蛋白转导破骨细胞(OC),任选地,其中所述衣壳蛋白具有选自AAV1、AAV5、AAV6、AAV6.2、AAV7、AAV8、AAV9、AAV10、AAV.rh39、AAV.rh43或前述任一种的变体的血清型。
17.如权利要求13至16任一项所述的rAAV,其中所述衣壳蛋白包含异源骨靶向肽。
18.如权利要求17所述的rAAV,其中所述异源骨靶向肽包含SEQ ID NO:16、17、57、58、59、60、61、62或63所示的氨基酸序列。
19.如权利要求17或18所述的rAAV,其中将编码所述异源骨靶向肽的核酸序列插入衣壳蛋白的VP2开放阅读框中,任选地,其中将所述核酸序列插入对应于编码所述AAV9衣壳蛋白的核酸序列的N587和R588的密码子之间。
20.如权利要求13至16任一项所述的rAAV,其中所述衣壳蛋白由具有一个或多个携带叠氮化物的非天然氨基酸的氨基酸序列编码。
21.如权利要求20所述的rAAV,其中所述衣壳蛋白经由一个或多个携带叠氮化物的非天然氨基酸结合至一个或多个阿仑膦酸盐(Ale)部分。
22.如权利要求13至21任一项所述的rAAV,其中所述rAAV是自互补AAV(scAAV)。
23.一种编码包含异源骨靶向肽的重组腺相关病毒(rAAV)衣壳蛋白的分离的核酸,任选地,其中所述异源骨靶向肽包含SEQ ID NO:16、17、57、58、59、60、61、62或63所示的氨基酸序列。
24.一种包含一个或多个携带叠氮化物的非天然氨基酸的重组AAV衣壳蛋白,任选地,其中所述衣壳蛋白经由一个或多个携带叠氮化物的非天然氨基酸结合至一个或多个阿仑膦酸盐(Ale)部分。
25.一种将转基因递送至骨组织的方法,该方法包括施用权利要求1至10任一项所述的分离的核酸或权利要求13至22任一项所述的rAAV给受试者。
26.一种治疗与骨密度降低有关的疾病或病症的方法,该方法包括施用权利要求13至22任一项所述的rAAV给患有或怀疑患有与骨密度降低有关的疾病或病症的受试者,其中转基因编码骨形成促进剂,任选地,其中所述骨形成促进剂选自由以下组成的组:促进成骨细胞和/或破骨细胞功能或活性的蛋白、抑制破骨细胞功能或活性的蛋白和抑制破骨细胞表达或活性的抑制性核酸。
27.如权利要求26所述的方法,其中所述骨形成促进剂选自由以下组成的组:甲状旁腺激素(PTH)、PTH相关蛋白(PTHrP)、去糖化酶DJ1、靶向骨硬化蛋白(SOST)的抑制性核酸、靶向schnurri-3(SHN3)的抑制性核酸、靶向组织蛋白酶K(CTSK)的抑制性核酸和靶向NF-κβ的受体激活剂(RANK)的抑制性核酸。
28.如权利要求26或27所述的方法,其中所述与骨密度降低有关的疾病或病症是骨质疏松症、临界大小骨缺损、由废用或受伤引起的机械性病症以及例如乳腺癌或前列腺癌转移的继发性病症、1型糖尿病、狼疮、类风湿性关节炎、炎性肠疾病、甲状腺功能亢进、乳糜泻、哮喘、多发性硬化和牙周炎。
29.一种治疗与骨密度畸形和夸张(例如,增加)有关的疾病或病症的方法,该方法包括施用权利要求13至22任一项所述的rAAV给患有或怀疑患有与骨密度增加有关的疾病或病症的受试者,其中转基因编码骨形成抑制剂,任选地,其中所述骨形成抑制剂选自由以下组成的组:抑制成骨细胞和/或骨细胞功能或活性的蛋白、促进破骨细胞功能或活性的蛋白和抑制成骨细胞表达或活性的抑制性核酸。
30.如权利要求29所述的方法,其中所述骨形成抑制剂选自由以下组成的组:骨硬化蛋白(SOST)、schnurri-3(SHN3)、组织蛋白酶K(CTSK)、靶向甲状旁腺激素(PTH)的抑制性核酸、靶向PTH相关蛋白(PTHrP)的抑制性核酸、靶向去糖化酶DJ1的抑制性核酸和靶向NF-κβ的受体激活剂(RANK)的抑制性核酸。
31.如权利要求29或30所述的方法,其中所述与骨密度畸形和夸张(例如,增加)有关的疾病或病症是骨硬化症、致密性成骨不全症、硬化性狭窄病、肢端肥大症、氟蚀病、骨髓纤维化、丙型肝炎相关性骨硬化症、异养性骨化和骨癌,例如骨肉瘤和转移性骨癌。
32.如权利要求25至31任一项所述的方法,其中所述施用通过注射进行,任选地,其中所述注射是全身注射(例如,静脉内注射),和局部注射(例如,肌肉内(IM)注射、膝注射和股骨骨髓内注射)。
33.如权利要求26至31任一项所述的方法,其中所述施用通过将包含权利要求13至22任一项所述的rAAV的组织或移植物植入所述受试者进行。
34.如权利要求25至33任一项所述的方法,其中所述施用导致选自由成骨细胞、骨细胞、破骨细胞和软骨细胞组成的组的细胞类型的转导。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862647595P | 2018-03-23 | 2018-03-23 | |
| US62/647,595 | 2018-03-23 | ||
| US201962799843P | 2019-02-01 | 2019-02-01 | |
| US62/799,843 | 2019-02-01 | ||
| PCT/US2019/023759 WO2019183605A1 (en) | 2018-03-23 | 2019-03-22 | Gene therapeutics for treating bone disorders |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN112368051A true CN112368051A (zh) | 2021-02-12 |
Family
ID=67986628
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201980031173.0A Pending CN112368051A (zh) | 2018-03-23 | 2019-03-22 | 用于治疗骨病的基因治疗剂 |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US20210023241A1 (zh) |
| EP (2) | EP3768386A4 (zh) |
| JP (1) | JP2021519065A (zh) |
| KR (1) | KR20200135433A (zh) |
| CN (1) | CN112368051A (zh) |
| AU (1) | AU2019237514A1 (zh) |
| CA (1) | CA3094217A1 (zh) |
| WO (1) | WO2019183605A1 (zh) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113913463A (zh) * | 2021-09-19 | 2022-01-11 | 郭保生 | 抑制sost基因表达的重组质粒及其骨靶向重组腺相关病毒与应用 |
| CN118453845A (zh) * | 2024-05-30 | 2024-08-09 | 山东第一医科大学附属省立医院(山东省立医院) | 提高dj-1基因表达量的试剂在制备抗血管钙化药物中的应用 |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20240002844A1 (en) * | 2020-08-19 | 2024-01-04 | University Of Massachusetts | Development of novel gene therapeutics for inflammation-induced bone loss |
| WO2023081771A1 (en) * | 2021-11-04 | 2023-05-11 | University Of Massachusetts | Wnt-modulating gene silencers as bone anabolic therapy for osteoporosis and critical-sized bone defect |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20100008979A1 (en) * | 2004-06-10 | 2010-01-14 | Saint Louis University | Delivery of therapeutic agents to the bone |
| US20100239503A1 (en) * | 2009-02-06 | 2010-09-23 | The Regents Of The University Of California | Calcium-binding agents induce hair growth and/or nail growth |
| US20130136729A1 (en) * | 2011-11-11 | 2013-05-30 | University of Virginia Patent Foundation, d/b/a University of Virginia Licensing & Ventures Group | Compositions and methods for targeting and treating diseases and injuries using adeno-associated virus vectors |
| US20130202533A1 (en) * | 2010-01-14 | 2013-08-08 | President And Fellows Of Harvard College | Methods for modulating skeletal remodeling and patterning by modulating shn2 activity, shn3 activity, or shn2 and shn3 activity in combination |
| US20140256917A1 (en) * | 2005-06-14 | 2014-09-11 | The United States Government As Represented By The Department Of Veterans Affairs | Compositions and methods for osteogenic gene therapy |
| CN107073051A (zh) * | 2014-10-21 | 2017-08-18 | 马萨诸塞大学 | 重组aav变体及其用途 |
| WO2018027329A1 (en) * | 2016-08-11 | 2018-02-15 | Precithera, Inc. | TGF-β ANTAGONIST CONJUGATES |
| WO2018035503A1 (en) * | 2016-08-18 | 2018-02-22 | The Regents Of The University Of California | Crispr-cas genome engineering via a modular aav delivery system |
Family Cites Families (31)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5549910A (en) | 1989-03-31 | 1996-08-27 | The Regents Of The University Of California | Preparation of liposome and lipid complex compositions |
| US5252334A (en) | 1989-09-08 | 1993-10-12 | Cygnus Therapeutic Systems | Solid matrix system for transdermal drug delivery |
| JP3218637B2 (ja) | 1990-07-26 | 2001-10-15 | 大正製薬株式会社 | 安定なリポソーム水懸濁液 |
| JP2958076B2 (ja) | 1990-08-27 | 1999-10-06 | 株式会社ビタミン研究所 | 遺伝子導入用多重膜リポソーム及び遺伝子捕捉多重膜リポソーム製剤並びにその製法 |
| US5399363A (en) | 1991-01-25 | 1995-03-21 | Eastman Kodak Company | Surface modified anticancer nanoparticles |
| US5478745A (en) | 1992-12-04 | 1995-12-26 | University Of Pittsburgh | Recombinant viral vector system |
| US5543158A (en) | 1993-07-23 | 1996-08-06 | Massachusetts Institute Of Technology | Biodegradable injectable nanoparticles |
| US5942496A (en) * | 1994-02-18 | 1999-08-24 | The Regent Of The University Of Michigan | Methods and compositions for multiple gene transfer into bone cells |
| US5741516A (en) | 1994-06-20 | 1998-04-21 | Inex Pharmaceuticals Corporation | Sphingosomes for enhanced drug delivery |
| US5795587A (en) | 1995-01-23 | 1998-08-18 | University Of Pittsburgh | Stable lipid-comprising drug delivery complexes and methods for their production |
| US5697899A (en) | 1995-02-07 | 1997-12-16 | Gensia | Feedback controlled drug delivery system |
| IE80468B1 (en) | 1995-04-04 | 1998-07-29 | Elan Corp Plc | Controlled release biodegradable nanoparticles containing insulin |
| US5738868A (en) | 1995-07-18 | 1998-04-14 | Lipogenics Ltd. | Liposome compositions and kits therefor |
| US6001650A (en) | 1995-08-03 | 1999-12-14 | Avigen, Inc. | High-efficiency wild-type-free AAV helper functions |
| US5656016A (en) | 1996-03-18 | 1997-08-12 | Abbott Laboratories | Sonophoretic drug delivery system |
| US5797898A (en) | 1996-07-02 | 1998-08-25 | Massachusetts Institute Of Technology | Microchip drug delivery devices |
| US5783208A (en) | 1996-07-19 | 1998-07-21 | Theratech, Inc. | Transdermal drug delivery matrix for coadministering estradiol and another steroid |
| US5779708A (en) | 1996-08-15 | 1998-07-14 | Cyberdent, Inc. | Intraosseous drug delivery device and method |
| CA2264482A1 (en) | 1996-09-06 | 1998-03-12 | The Trustees Of The University Of Pennsylvania | An inducible method for production of recombinant adeno-associated viruses utilizing t7 polymerase |
| US6177403B1 (en) | 1996-10-21 | 2001-01-23 | The Trustees Of The University Of Pennsylvania | Compositions, methods, and apparatus for delivery of a macromolecular assembly to an extravascular tissue of an animal |
| US6156303A (en) | 1997-06-11 | 2000-12-05 | University Of Washington | Adeno-associated virus (AAV) isolates and AAV vectors derived therefrom |
| NZ578982A (en) | 2001-11-13 | 2011-03-31 | Univ Pennsylvania | A method of detecting and/or identifying adeno-associated virus (AAV) sequences and isolating novel sequences identified thereby |
| ES2975413T3 (es) * | 2001-12-17 | 2024-07-05 | Univ Pennsylvania | Secuencias de serotipo 8 de virus adenoasociado (AAV), vectores que las contienen y usos de las mismas |
| EP2561073B1 (en) * | 2010-04-23 | 2016-08-24 | University of Massachusetts | Cns targeting aav vectors and methods of use thereof |
| TWI636993B (zh) * | 2010-10-27 | 2018-10-01 | 安美基公司 | Dkk1抗體及使用方法 |
| WO2014005314A1 (zh) * | 2012-07-05 | 2014-01-09 | 香港中文大学 | 基于小核酸药物成骨治疗的骨靶向递送系统及其制备方法 |
| RU2749882C2 (ru) * | 2014-11-14 | 2021-06-18 | Вояджер Терапьютикс, Инк. | Модулирующие полинуклеотиды |
| RU2696378C2 (ru) * | 2015-01-16 | 2019-08-01 | Академиа Синика | Молекулярные конструкции с нацеливающими и эффекторными элементами |
| IL310375A (en) * | 2015-01-20 | 2024-03-01 | Genzyme Corp | Analytical ultracentrifugation for characterization of recombinant viral particles |
| CA2976075A1 (en) * | 2015-02-10 | 2016-08-18 | Genzyme Corporation | Variant rnai |
| EP3294894B8 (en) * | 2015-05-12 | 2019-09-25 | The U.S.A. as represented by the Secretary, Department of Health and Human Services | Aav isolate and fusion protein comprising nerve growth factor signal peptide and parathyroid hormone |
-
2019
- 2019-03-22 EP EP19771342.3A patent/EP3768386A4/en not_active Withdrawn
- 2019-03-22 EP EP22199907.1A patent/EP4169576A1/en active Pending
- 2019-03-22 JP JP2020551357A patent/JP2021519065A/ja active Pending
- 2019-03-22 KR KR1020207030053A patent/KR20200135433A/ko active Search and Examination
- 2019-03-22 CA CA3094217A patent/CA3094217A1/en active Pending
- 2019-03-22 AU AU2019237514A patent/AU2019237514A1/en not_active Abandoned
- 2019-03-22 CN CN201980031173.0A patent/CN112368051A/zh active Pending
- 2019-03-22 WO PCT/US2019/023759 patent/WO2019183605A1/en active Application Filing
- 2019-03-22 US US16/982,640 patent/US20210023241A1/en active Pending
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20100008979A1 (en) * | 2004-06-10 | 2010-01-14 | Saint Louis University | Delivery of therapeutic agents to the bone |
| US20140256917A1 (en) * | 2005-06-14 | 2014-09-11 | The United States Government As Represented By The Department Of Veterans Affairs | Compositions and methods for osteogenic gene therapy |
| US20100239503A1 (en) * | 2009-02-06 | 2010-09-23 | The Regents Of The University Of California | Calcium-binding agents induce hair growth and/or nail growth |
| US20130202533A1 (en) * | 2010-01-14 | 2013-08-08 | President And Fellows Of Harvard College | Methods for modulating skeletal remodeling and patterning by modulating shn2 activity, shn3 activity, or shn2 and shn3 activity in combination |
| US20130136729A1 (en) * | 2011-11-11 | 2013-05-30 | University of Virginia Patent Foundation, d/b/a University of Virginia Licensing & Ventures Group | Compositions and methods for targeting and treating diseases and injuries using adeno-associated virus vectors |
| CN107073051A (zh) * | 2014-10-21 | 2017-08-18 | 马萨诸塞大学 | 重组aav变体及其用途 |
| WO2018027329A1 (en) * | 2016-08-11 | 2018-02-15 | Precithera, Inc. | TGF-β ANTAGONIST CONJUGATES |
| WO2018035503A1 (en) * | 2016-08-18 | 2018-02-22 | The Regents Of The University Of California | Crispr-cas genome engineering via a modular aav delivery system |
Non-Patent Citations (1)
| Title |
|---|
| TAE-KYUNG RYU 等: "Bone-targeted delivery of nanodiamond-based drug carriers conjugated with alendronate for potential osteoporosis treatment", JOURNAL OF CONTROLLED RELEASE, vol. 232, pages 152 - 160, XP029565150, DOI: 10.1016/j.jconrel.2016.04.025 * |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113913463A (zh) * | 2021-09-19 | 2022-01-11 | 郭保生 | 抑制sost基因表达的重组质粒及其骨靶向重组腺相关病毒与应用 |
| CN113913463B (zh) * | 2021-09-19 | 2023-08-18 | 郭保生 | 抑制sost基因表达的重组质粒及其骨靶向重组腺相关病毒与应用 |
| CN118453845A (zh) * | 2024-05-30 | 2024-08-09 | 山东第一医科大学附属省立医院(山东省立医院) | 提高dj-1基因表达量的试剂在制备抗血管钙化药物中的应用 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3768386A1 (en) | 2021-01-27 |
| WO2019183605A1 (en) | 2019-09-26 |
| EP4169576A1 (en) | 2023-04-26 |
| CA3094217A1 (en) | 2019-09-26 |
| EP3768386A4 (en) | 2022-04-13 |
| KR20200135433A (ko) | 2020-12-02 |
| JP2021519065A (ja) | 2021-08-10 |
| US20210023241A1 (en) | 2021-01-28 |
| AU2019237514A1 (en) | 2020-10-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20230073187A1 (en) | Prostate targeting adeno-associated virus serotype vectors | |
| CN112368051A (zh) | 用于治疗骨病的基因治疗剂 | |
| RU2727015C2 (ru) | Векторы aav, нацеленные на центральную нервную систему | |
| JP2024045321A (ja) | 合成肝臓指向性アデノ随伴ウイルスカプシドおよびその使用 | |
| JP7303816B2 (ja) | Aavベクター | |
| KR20230043869A (ko) | Aav 벡터를 사용한 플라코필린-2(pkp2) 유전자 요법 | |
| KR20210090619A (ko) | 대칭인 변형된 역말단반복을 포함하는 변형된 폐쇄형 DNA(ceDNA) | |
| EP4213891A2 (en) | Methods for treating neurological disease | |
| KR20170098931A (ko) | 뇌 질환을 치료하기 위한 방법 및 조성물 | |
| JP2023510784A (ja) | 脳腫瘍を処置するための血液脳関門を横断する免疫療法剤を送達するための方法および組成物 | |
| JP2023099082A (ja) | 筋強直性ジストロフィーの処置 | |
| US20240002844A1 (en) | Development of novel gene therapeutics for inflammation-induced bone loss | |
| US10519445B2 (en) | Intrathecal delivery of nucleic acid sequences encoding ABCD1 for treatment of adrenomyeloneuropathy | |
| WO2020176732A1 (en) | TREATMENT OF PULMONARY FIBROSIS WITH SERCA2a GENE THERAPY | |
| JP2022022698A (ja) | Aav9を含む骨疾患の予防または治療用の薬学的組成物およびその利用 | |
| EP1358208A2 (en) | Sequences upstream of the carp gene, vectors containing them and uses thereof | |
| WO2023081771A1 (en) | Wnt-modulating gene silencers as bone anabolic therapy for osteoporosis and critical-sized bone defect | |
| WO2024020376A1 (en) | Aav-mediated delivery of osteoblast/osteoclast-regulating mirnas for osteoporosis therapy | |
| WO2024097521A2 (en) | Compositions for treatment of osteogenesis imperfecta | |
| WO2024220758A1 (en) | Rnas targeting activin a subunits | |
| KR20210131236A (ko) | Aav9을 포함하는 골 질환 예방 또는 치료용 약학적 조성물 및 그의 이용 | |
| KR20230127269A (ko) | 센스, 억제자 트랜스퍼 rna 조성물 및 관련된 용도와기능 | |
| JP2023513211A (ja) | タンパク質合成を増強するためのCRISPR-Cas13による標的RNA翻訳 | |
| CN116723868A (zh) | 治疗神经系统疾病的方法 | |
| Morine et al. | Systemic Myostatin Inhibition via Liver-Targeted Gene Transfer in Normal and |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| WD01 | Invention patent application deemed withdrawn after publication | ||
| WD01 | Invention patent application deemed withdrawn after publication |
Application publication date: 20210212 |