WO2021132546A1 - 翻訳用組成物及びペプチドの製造方法 - Google Patents
翻訳用組成物及びペプチドの製造方法 Download PDFInfo
- Publication number
- WO2021132546A1 WO2021132546A1 PCT/JP2020/048652 JP2020048652W WO2021132546A1 WO 2021132546 A1 WO2021132546 A1 WO 2021132546A1 JP 2020048652 W JP2020048652 W JP 2020048652W WO 2021132546 A1 WO2021132546 A1 WO 2021132546A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- trna
- anticodon
- base
- seq
- letter
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
- 0 C*([C@@](CCc1ccccc1)C(OCC#*)=O)C(OCc1ccc(*(C)(C)C(CC2C=CC(C)=CC2C)=O)cc1)=O Chemical compound C*([C@@](CCc1ccccc1)C(OCC#*)=O)C(OCc1ccc(*(C)(C)C(CC2C=CC(C)=CC2C)=O)cc1)=O 0.000 description 2
- LYHODIYZIBIHOA-BVHINDKJSA-N C/[O]=C(\[C@H](C=CCC1)N1C(OCC(CC#C1)=CC=C1NC(CC1C#CC(F)=CC1)=O)=O)/[O]=C/C#N Chemical compound C/[O]=C(\[C@H](C=CCC1)N1C(OCC(CC#C1)=CC=C1NC(CC1C#CC(F)=CC1)=O)=O)/[O]=C/C#N LYHODIYZIBIHOA-BVHINDKJSA-N 0.000 description 1
- XTDKZSUYCXHXJM-UHFFFAOYSA-N COC1OCCCC1 Chemical compound COC1OCCCC1 XTDKZSUYCXHXJM-UHFFFAOYSA-N 0.000 description 1
- UHXSJCVBSLSFME-LURJTMIESA-N C[C@@H]1OC2(CC2)CC1 Chemical compound C[C@@H]1OC2(CC2)CC1 UHXSJCVBSLSFME-LURJTMIESA-N 0.000 description 1
Images












Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K1/00—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/67—General methods for enhancing the expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P21/00—Preparation of peptides or proteins
- C12P21/02—Preparation of peptides or proteins having a known sequence of two or more amino acids, e.g. glutathione
Definitions
- the present disclosure relates to a composition for translation and a method for producing a peptide.
- Non-Patent Document 1 artificially reconstructed by mixing only factors related to protein translation is used in a wide range of fields from elucidation of biological phenomena to new drug development. Since the cell-free translation system does not use microorganisms or cells, it can be used for the synthesis of highly toxic proteins. Further, since constituent components such as amino acids, tRNAs, and aminoacyl-tRNA synthetases can be removed or added according to the purpose, it is possible to change the correspondence between codons and amino acids (reprogramming of the genetic code). Due to these characteristics, the cell-free translation system is also applied to the synthesis of unnatural amino acid-containing proteins and the construction of display libraries incorporating various building blocks.
- Non-Patent Document 3 An attempt is made to assign one unnatural amino acid and one natural amino acid to CGC / G, GUC / G and GGC / G. According to the same document, as a measure to reduce misreading of GGC codons by Gly- bound tRNA Gly CCC , the translation reaction is stopped before the amino acid precharged tRNA having anticodon GCC complementary to GGC is depleted. However, it is not described what kind of translation composition can reduce the misreading of codons. Further, in Non-Patent Documents 4 to 7 and Patent Documents 1 and 2, attempts are made to artificially divide the codon box, but there is no description of a method for reducing codon misreading.
- the present invention has been made in view of such a situation, and a translation composition and a translation composition capable of reducing the rate of erroneous translation of unintended amino acids due to misreading of codons by tRNA.
- One of the objects is to provide a method for producing a peptide using the translation composition.
- the combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) of the first tRNA is (1) 32U, 33U, 37G, 38A, (2) 32A, 33U, 37G, 38U, (3) 32A, 33U, 37A, 38U, (4) 32U, 33U, 37G, 38U, (5) 32U, 33U, 37A, 38U, or (6) 32C, 33U, 37G, 38A, And
- the bases of the first letter of the anticodon of the first tRNA and the second tRNA are different from each other.
- the base of the second character of the anticodon of the first tRNA and the second tRNA is the same,
- the base of the third character of the anticodon of the first tRNA and the second tRNA is the same, At least one of the first amino acid and the second amino acid is an unnatural amino acid.
- A is adenine
- C is cytosine
- G is guanine
- U is uracil.
- the anticodon of the first tRNA is N 11 N 12 N 13 (where N 11 , N 12 , and N 13 are A, C, G, or U independently of each other), [ 1]
- the anticodon of the second tRNA is N 21 N 22 N 23 (where N 21 , N 22 and N 23 are A, C, G or U independently of each other), [ The composition according to 1] or [2]. [4] The composition according to any one of [1] to [3], wherein the tRNA body of the first tRNA is a chimeric tRNA body. [5] Whether the base of the first letter of the anticodon of the first tRNA is A or G and the base of the first letter of the anticodon of the second tRNA is C or U. The first letter base of the anticodon of the first tRNA is C or U, and the first letter base of the anticodon of the second tRNA is A or G.
- the first letter base of the anticodon of the first tRNA is A or G
- the first letter base of the anticodon of the second tRNA is C or U, [1] to [5].
- first letter base of the anticodon of the first tRNA is G and the first letter base of the anticodon of the second tRNA is C.
- first letter base of the anticodon of the first tRNA is C and the first letter base of the anticodon of the second tRNA is G.
- first letter base of the anticodon of the first tRNA is A and the first letter base of the anticodon of the second tRNA is U.
- first letter base of the anticodon of the first tRNA is U and the first letter base of the anticodon of the second tRNA is A.
- the first letter base of the anticodon of the first tRNA is G and the first letter base of the anticodon of the second tRNA is U, or the first letter of the anticodon of the first tRNA.
- the base of the second tRNA is U, and the base of the first letter of the anticodon of the second tRNA is G.
- first letter base of the anticodon of the first tRNA is A and the first letter base of the anticodon of the second tRNA is U.
- first letter base of the anticodon of the first tRNA is U and the first letter base of the anticodon of the second tRNA is A.
- the first letter base of the anticodon of the first tRNA is G and the first letter base of the anticodon of the second tRNA is U, or the first letter of the anticodon of the first tRNA.
- the base of the second tRNA is U, and the base of the first letter of the anticodon of the second tRNA is G.
- the base of the second tRNA is G, and the base of the first letter of the anticodon of the second tRNA is C.
- the first letter base of the anticodon of the first tRNA is G, and the first letter base of the anticodon of the second tRNA is C, or The first letter base of the anticodon of the first tRNA is C, and the first letter base of the anticodon of the second tRNA is G.
- the first letter base of the anticodon of the first tRNA is A and the first letter base of the anticodon of the second tRNA is C, or the anticodon of the first tRNA
- the base of the first letter is C, and the base of the first letter of the anticodon of the second tRNA is A.
- the base of the first character of the anticodon of the first tRNA is G, and the base of the first character of the anticodon of the second tRNA is C, or The first letter base of the anticodon of the first tRNA is C, and the first letter base of the anticodon of the second tRNA is G.
- the first letter base of the anticodon of the first tRNA is A and the first letter base of the anticodon of the second tRNA is U, or the anticodon of the first tRNA The base of the first letter is U, and the base of the first letter of the anticodon of the second tRNA is A.
- the first letter base of the anticodon of the first tRNA is G
- the first letter base of the anticodon of the second tRNA is U
- the anticodon of the first tRNA is U
- the base of the first letter of the anticodon of the second tRNA is G.
- the base sequences of positions 1 to 31 and 39 to 74 (tRNA numbering rule) of the first tRNA are selected from the group consisting of SEQ ID NOs: 275, 294, 295, 296, 302, 303, and 304.
- the base sequences at positions 1 to 31 and 39 to 74 (tRNA numbering rule) of the first tRNA are (a) SEQ ID NO: 253, (b) SEQ ID NO: 255, and (c) SEQ ID NO: : Any of [1] to [22] derived from the base sequences of positions 1 to 31 and 39 to 74 (tRNA numbering rule) in a tRNA having at least one base sequence selected from the group consisting of 254.
- the base sequences at positions 1 to 31 and 39 to 74 (tRNA numbering rule) of the first tRNA are (a) SEQ ID NO: 253, (b) SEQ ID NO: 255, and (c) SEQ ID NO: : Any of [1] to [23], which is the base sequence of positions 1 to 31 and 39 to 74 (tRNA numbering rule) in the tRNA having the base sequence according to at least one selected from the group consisting of 254. The composition described in Crab.
- the base sequence of the first tRNA at positions 1 to 31 and 39 to 74 (tRNA numbering rule) has the base sequence according to any one of (a) to (c) of [24].
- the base sequence at positions 1 to 31 and 39 to 74 (tRNA numbering rule) of the second tRNA is selected from the group consisting of SEQ ID NOs: 275, 294, 295, 296, 302, 303, and 304.
- the base sequences at positions 1 to 31 and 39 to 74 (tRNA numbering rule) of the second tRNA are (a) SEQ ID NO: 253, (b) SEQ ID NO: 255, and (c) SEQ ID NO: : Any of [1] to [26] derived from the base sequences of positions 1 to 31 and 39 to 74 (tRNA numbering rule) in a tRNA having at least one base sequence selected from the group consisting of 254.
- the base sequences at positions 1 to 31 and 39 to 74 (tRNA numbering rule) of the second tRNA are (a) SEQ ID NO: 253, (b) SEQ ID NO: 255, and (c) SEQ ID NO: : Described in any one of [1] to [27], which is a base sequence at positions 1 to 31 and 39 to 74 (tRNA numbering rule) in a tRNA having at least one base sequence selected from the group consisting of 254. Composition.
- the tRNA having the base sequence at positions 1 to 31 and 39 to 74 (tRNA numbering rule) of the second tRNA has the base sequence according to any one of (a) to (c) of [28].
- the base sequences of the 1st to 31st positions and the 39th to 74th positions (tRNA numbering rule) of the first tRNA and the second tRNA are the same, or 80% or more, preferably 90% or more. , More preferably the composition according to any one of [1] to [29], which has 95% or more sequence identity.
- the chimeric tRNA body is a chimeric tRNA body in which the combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) and the origin of the base sequence of other sites are different.
- the base sequence of the first tRNA at positions 32 to 38 is different from the base sequence of Escherichia coli wild-type tRNA at positions 32 to 38 (tRNA numbering rule), [1] to [ 32]
- the composition according to any one of. [34] The composition according to any one of [1] to [33], wherein the first tRNA is a tRNA having a chimeric anticodon loop. [35] The composition according to any one of [1] to [34], wherein the second amino acid is an unnatural amino acid. [36] The composition according to any one of [1] to [35], wherein the first amino acid is an unnatural amino acid.
- the composition according to any one of [1] to [39], wherein the base sequence at positions 75 and 76 (tRNA numbering rule) of the first tRNA is CA.
- composition according to any one of [1] to [40], wherein the base sequence at positions 75 and 76 (tRNA numbering rule) of the second tRNA is CA.
- the composition according to any one of [1] to [43] wherein the first amino acid is bound to the 3'end of the first tRNA.
- the second tRNA is a tRNA to which an amino acid is bound outside the translation system.
- the combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) of the first tRNA is (1) 32U, 33U, 37G, 38A, (2) 32A, 33U, 37G, 38U, (3) 32A, 33U, 37A, 38U, or (4) 32U, 33U, 37G, 38U, The composition according to any one of [1] to [50].
- the combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) of the first tRNA is (1) 32U, 33U, 37G, 38A, (2) 32A, 33U, 37G, 38U, or (3) 32A, 33U, 37A, 38U, The composition according to any one of [1] to [51].
- the combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) of the first tRNA is (1) 32U, 33U, 37G, 38A, (3) 32A, 33U, 37A, 38U, or (4) 32U, 33U, 37G, 38U, The composition according to any one of [1] to [52].
- the combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) of the first tRNA is 32U, 33U, 37G, 38A, or 32U, 33U, 37G, 38U, [1].
- the combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) of the first tRNA is 32U, 33U, 37G, 38A, according to any one of [1] to [54].
- Composition. The combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) of the first tRNA is 32A, 33U, 37G, 38U, according to any one of [1] to [52].
- the combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) of the first tRNA is 32A, 33U, 37A, 38U, according to any one of [1] to [53].
- Composition. [58] The combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) of the first tRNA is 32U, 33U, 37G, 38U, according to any one of [1] to [51].
- Composition. [59] The combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) of the first tRNA is 32U, 33U, 37A, 38U, according to any one of [1] to [50].
- the combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) of the first tRNA is 32C, 33U, 37G, 38A, according to any one of [1] to [50].
- the combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) of the second tRNA is (1) 32U, 33U, 37G, 38A, (2) 32A, 33U, 37G, 38U, (3) 32A, 33U, 37A, 38U, (4) 32U, 33U, 37G, 38U, (5) 32U, 33U, 37A, 38U, or (6) 32C, 33U, 37G, 38A, The composition according to any one of [1] to [60].
- the combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) of the second tRNA is (1) 32U, 33U, 37G, 38A, (2) 32A, 33U, 37G, 38U, (3) 32A, 33U, 37A, 38U, or (4) 32U, 33U, 37G, 38U, The composition according to any one of [1] to [61].
- the composition according to any one of [1] to [63] which is a composition for cell-free translation.
- the composition according to any one of [1] to [65] which is a cell-free translation composition reconstituted with a factor derived from Escherichia coli.
- the composition according to any one of [1] to [67] which comprises mRNA having a codon complementary to the anticodon of the second tRNA.
- composition according to any one of [1] to [68], wherein the codon complementary to the anticodon of the second tRNA may be contained in the same mRNA or in different mRNAs.
- composition according to any one of [1] to [70] (provided that the first tRNA and the second tRNA are located at positions 32, 33, 37 and 38 (tRNA numbering rule) of the above [1]. ] (4), and has the base sequence specified in (4), and has the base sequence shown in SEQ ID NO: 255 at positions 1 to 31 and 39 to 74 (tRNA numbering rule).
- the composition in which the combination of the anticodons of the first tRNA and the second tRNA is GCG and CCG, and CCG and GCG. Except for compositions that are).
- composition according to any one of [1] to [71] (provided that the first tRNA and the second tRNA are located at positions 32, 33, 37 and 38 (tRNA numbering rule) of the above [1].
- composition in which the combination of the first tRNA and the anticodon of the second tRNA is GCG and CCG, and CCG and Excluding compositions that are GCG).
- composition according to any one of [1] to [72] (provided that the first tRNA and the second tRNA are located at positions 32, 33, 37 and 38 (tRNA numbering rule) of the above [1].
- the combination of the anticodon of the first tRNA and the second tRNA is AAG and UAG, AAG and CAG. Except for certain compositions, as well as compositions that are UAGs and CAGs).
- the composition according to any one of [1] to [73] (provided that the first tRNA and the second tRNA are located at positions 32, 33, 37 and 38 (tRNA numbering rule) of the above [1].
- the second letter base of the anticodon of the first tRNA and the second tRNA is both C, and the third letter.
- compositions in which the bases of are all G are all G.
- composition according to any one of [1] to [76] (provided that the first tRNA is specified at positions 32, 33, 37 and 38 (tRNA numbering rule) in the above [1] and (4). Except for compositions in which the second-letter base of the first tRNA anticodon is A and the third-letter base is G).
- composition according to any one of [1] to [77] (provided that the first tRNA is specified at positions 32, 33, 37 and 38 (tRNA numbering rule) in the above [1] and (1). Except for compositions in which the anticodons of the first tRNA are UGG and CGG, where the combination of bases is.
- composition according to any one of [1] to [78] (provided that the first tRNA is specified at positions 32, 33, 37 and 38 (tRNA numbering rule) in the above [1] and (2). Except for compositions in which the anticodons of the first tRNA are AGG and GGG, where the combination of bases is.
- composition according to any one of [1] to [79] (provided that the first tRNA is specified at positions 32, 33, 37 and 38 (tRNA numbering rule) in the above [1] and (6). Except for compositions in which the anticodons of the first tRNA are GCG and CCG, in the case of having a chimeric tRNA body having a combination of bases to be used).
- composition according to any one of [1] to [80] (provided that the first tRNA is specified at positions 32, 33, 37 and 38 (tRNA numbering rule) in the above [1] and (3). Except for compositions in which the anticodons of the first tRNA are AGC and GGC in the case of having a chimeric tRNA body having a combination of bases to be used).
- compositions in which the anticodons of the first tRNA are AGC and GGC in the case of having a chimeric tRNA body having a combination of bases to be used.
- the composition according to any one of [1] to [81] wherein the first tRNA and the second tRNA are extended tRNAs.
- At least the step of preparing the first tRNA and / or the second tRNA is selected from the group consisting of the pCpA method, the pdCpA method, the method using flexizyme, and the method using aaRS.
- the method according to [86] which is carried out by one method.
- the method according to [86] or [87] which comprises the step of preparing the first tRNA by in vitro transcription.
- Nucleic acid is translated using the translation composition according to any one of [1] to [85] or the translation composition produced by the method according to any one of [86] to [89].
- a method for producing a peptide including the above.
- [A2] Translate the nucleic acid using the translation composition according to any one of [1] to [85] or the translation composition produced by the method according to any one of [86] to [89].
- [A3] The method according to [A1] or [A2], wherein the nucleic acid is an mRNA having a codon complementary to the anticodon of the second tRNA.
- the nucleic acid is an mRNA having a codon complementary to the anticodon of the first tRNA, and optionally complements the codon complementary to the anticodon of the first tRNA and the anticodon of the second tRNA. Codons may be contained in the same mRNA or in different mRNAs, according to the method according to [A3].
- [A6] The codon according to any one of [A1] to [A5], wherein the codon complementary to the anticodon of the first tRNA is a codon that forms a Watson-click base pair at all three bases with the anticodon.
- Method. [A7] The codon according to any one of [A1] to [A6], wherein the codon complementary to the anticodon of the second tRNA is a codon that forms a Watson-click base pair at all three bases with the anticodon.
- Method. [A8] The method according to any one of [A1] to [A5], wherein the third character of the codon complementary to the anticodon of the first tRNA forms a wobble base pair with the first character of the anticodon.
- the method described. [A10] The method according to any one of [A1] to [A9], wherein the nucleic acid is mRNA.
- [A13] A peptide produced using the translation composition according to any one of [1] to [85] or the translation composition produced by the method according to any one of [86] to [89].
- Library. [A14] Binding to the target molecule, which comprises the step of producing a peptide library using the method according to any one of [A1] to [A10], and the step of contacting the target molecule with the peptide library. Peptide identification method.
- tRNA which comprises substituting at least one base selected from the group consisting of positions 32, 33, 37 and 38 (tRNA numbering rule) of the tRNA having an anticodon complementary to the first codon.
- tRNA numbering rule tRNA numbering rule
- the first letter of the first codon and the second codon are the same base
- the first codon and the second letter of the second codon are the same base
- the method, wherein the first codon and the third letter of the second codon are bases that are different from each other.
- [B3] Substituting at least one base selected from the group consisting of positions 32, 37 and 38 (tRNA numbering rule) of tRNA having an anticodon complementary to the first codon, [B1] or The method according to [B2].
- the first codon is M 1 M 2 X
- the second codon is M 1 M 2 Y.
- the M 1 and the M 2 are independently A, C, G or U, respectively.
- [B5] The method according to [B4], wherein the combination of the X and Y bases is one selected from the following groups: (a1) U and G; (a2) G and U; (a3) U and A; (a4) A and U; (a5) C and A; (a6) A and C; (a7) C and G; and (a8) G and C.
- [B6] The method according to [B4] or [B5], wherein the combination of the bases of X and Y is selected from the following groups: (a1) U and G; (a2) G and U; (a3) U and A; (a5) C and A; and (a7) C and G.
- [B7] The method according to [B5], wherein the combination of the bases of X and Y is (a1) U and G, or (a2) G and U.
- [B8] The method according to any one of [B5] to [B7], wherein the combination of the bases of X and Y is (a1) U and G.
- [B9] The method according to any one of [B5] to [B7], wherein the combination of the bases of X and Y is (a2) G and U.
- [B10] The method according to [B5] or [B6], wherein the combination of the bases of X and Y is (a3) U and A.
- [B14] The method according to [B13], wherein M 1 M 2 is any base sequence selected from the following groups: (b1) CC; (b2) CU; and (b3) GG.
- [B15] The method according to [B13] or [B14], wherein the base sequence of M 1 M 2 is (b 1) CC.
- [B16] The method according to [B13] or [B14], wherein the base sequence of M 1 M 2 is (b 2) CU.
- [B17] The method according to [B13] or [B14], wherein the base sequence of M 1 M 2 is (b3) GG.
- [B18] The method according to any one of [B1] to [B17], wherein the first codon and the anticodon of the tRNA form a Watson-click base pair at all three bases.
- [B19] The method according to any one of [B1] to [B17], wherein the base of the third character of the first codon and the base of the first character of the anticodon of the tRNA form a wobble base pair.
- the base sequences of positions 1 to 31 and 39 to 74 (tRNA numbering rule) of the tRNA are (a) SEQ ID NO: 253, (b) SEQ ID NO: 255, and (c) SEQ ID NO: 254.
- the base sequences of positions 1 to 31 and 39 to 74 (tRNA numbering rule) of the tRNA are (a) SEQ ID NO: 253, (b) SEQ ID NO: 255, and (c) SEQ ID NO: 254. Described in any one of [B1] to [B20], which is the base sequence of positions 1 to 31 and 39 to 74 (tRNA numbering rule) in the tRNA having the base sequence according to at least one selected from the group. the method of.
- [B22] The base sequences of positions 1 to 31 and 39 to 74 (tRNA numbering rule) of the tRNA are 1 to 1 in the tRNA having the base sequence described in any of (a) to (c) of [B20]. Any of [B1] to [B21] having a sequence identity of 80% or more, preferably 90% or more, more preferably 95% or more with the base sequence of the 31st position and the 39th to 74th position (tRNA numbering rule). The method described. [B23] The method according to any one of [B1] to [B22], which comprises binding an amino acid to the tRNA outside the translation system.
- Binding of the amino acid to tRNA outside the translation system is carried out by at least one method selected from the group consisting of the pCpA method, the pdCpA method, the method using flexizyme, and the method using aaRS.
- [B27] The method according to any of [B1] to [B26], further comprising synthesizing the tRNA from a template nucleic acid by transcription in vitro.
- [B28] The method according to any one of [B1] to [B27], wherein the base at position 37 (tRNA numbering rule) before modification of the tRNA is A.
- [B29] The method according to any one of [B1] to [B28], wherein the base at position 33 (tRNA numbering rule) before modification of the tRNA is U.
- [B30] The method according to any one of [B1] to [B29], wherein the base at position 32 (tRNA numbering rule) before modification of the tRNA is C or U.
- [B31] The method according to any one of [B1] to [B30], wherein the base at position 32 (tRNA numbering rule) before modification of the tRNA is C.
- [B32] The method according to any one of [B1] to [B30], wherein the base at the 32-position (tRNA numbering rule) before modification of the tRNA is U.
- [B33] The method according to any one of [B1] to [B32], wherein the base at position 38 (tRNA numbering rule) before modification of the tRNA is A or C.
- [B34] The method according to any one of [B1] to [B33], wherein the base at position 38 (tRNA numbering rule) before modification of the tRNA is A.
- [B35] The method according to any one of [B1] to [B33], wherein the base at position 38 (tRNA numbering rule) before modification of the tRNA is C.
- [B36] The combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) after the substitution is (1) 32U, 33U, 37G, 38A, (2) 32A, 33U, 37G, 38U, (3) 32A, 33U, 37A, 38U, or (4) 32U, 33U, 37G, 38U, The method according to any one of [B1] to [B35].
- [B37] The combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) after the substitution is (1) 32U, 33U, 37G, 38A, (2) 32A, 33U, 37G, 38U, or (3) 32A, 33U, 37A, 38U, The method according to any one of [B1] to [B36].
- [B38] The method according to any one of [B1] to [B37] (however, the combination of bases at positions 32, 33, 37 and 38 (tRNA numbering rule) after the substitution is specified in [B2] (4).
- the base sequences of the 1st to 31st positions and 39th to 74th positions (tRNA numbering rule) of the tRNA are the 1st to 31st positions and the 39th to 74th positions of the tRNA having the base sequence shown in SEQ ID NO: 255 (tRNA numbering rule).
- the method in which the combination of the first codon and the second codon is CGC and CGG, and the method in which CGG and CGC are used).
- [B39] The method according to any of [B1] to [B38], further comprising translating the nucleic acid in a translation system comprising a base-substituted tRNA.
- [B40] The method according to any one of [B26] to [B39], wherein the N-substituted amino acid is an N-methyl amino acid.
- [B41] The method according to any one of [B23] to [B40], wherein the amino acid is a translatable amino acid.
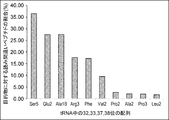
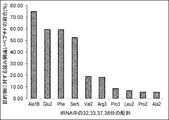
- the values in the figure are based on the results of translating mRNA having a CUG codon in the coexistence of tRNA having cag and aag as anticodons (see Table 10 for the specific amount of translation), and for the object on the vertical axis.
- the percentage of misread peptides is calculated from the formula shown below.
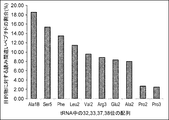
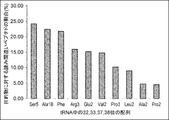
- the values in the figure are based on the results of translating mRNA having a CUU codon in the coexistence of tRNA having aag and cag as anticodons (see Table 11 for the specific amount of translation), and for the object on the vertical axis.
- the percentage of misread peptides is calculated from the formula shown below.
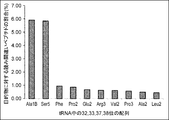
- the values in the figure are based on the results of translating mRNA having a CUG codon in the coexistence of tRNA having cag and aag as anticodons (see Table 12 for the specific amount of translation), and for the object on the vertical axis.
- the percentage of misread peptides is calculated from the formula shown below.
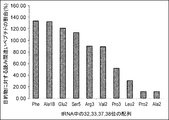
- the values in the figure are based on the results of translating mRNA having a CUU codon in the coexistence of tRNA having aag and cag as anticodons (see Table 13 for the specific amount of translation), and for the object on the vertical axis.
- the percentage of misread peptides is calculated from the formula shown below.
- the values in the figure are based on the results of translating mRNA having a CUG codon in the coexistence of tRNA having cag and aag as anticodons (see Table 14 for the specific amount of translation), and for the object on the vertical axis.
- the percentage of misread peptides is calculated from the formula shown below.
- the values in the figure are based on the results of translating mRNA having a CUU codon in the coexistence of tRNA having aag and cag as anticodons (see Table 15 for the specific translation amount), and for the object on the vertical axis.
- the percentage of misread peptides is calculated from the formula shown below.
- the values in the figure are based on the results of translating mRNA having a GGA codon in the coexistence of tRNA having ucc and acc as anticodons (see Table 16 for the specific amount of translation).
- the misread peptide ratio (%) is calculated from the formula shown below.
- the values in the figure are based on the results of translating mRNA having a GGA codon in the coexistence of tRNA having ucc and gcc as anticodons (see Table 17 for the specific amount of translation).
- the misread peptide ratio (%) is calculated from the formula shown below.
- the values in the figure are based on the results of translating mRNA having a GGG codon in the coexistence of tRNA having ccc and gcc as anticodons (see Table 18 for the specific amount of translation), and for the object on the vertical axis.
- the percentage of misread peptides is calculated from the formula shown below.
- a "codon” is a combination of three bases (triplet) corresponding to each amino acid when the genetic information in the living body is translated into a protein.
- DNA four types of bases, adenine (A), guanine (G), cytosine (C), and thymine (T), are used, and in the case of mRNA, adenine (A), guanine (G), and cytosine are used.
- C uracil
- the table showing the correspondence between each codon and the amino acid is called the genetic code table or codon table, and 20 types of amino acids are assigned to 61 types of codons excluding the stop codon (Table 1).
- the genetic code table shown in Table 1 is also called a standard genetic code table or a universal genetic code table because it is commonly used by almost all organisms in eukaryotes and protozoa (eubacteria and archaea). ..
- the genetic code table used in a naturally occurring organism is referred to as a natural genetic code table, and is referred to as an artificially reprogrammed genetic code table (the correspondence between codons and amino acids is modified). Distinguish.
- four codons in which the first and second characters are common and only the third character is different are usually grouped in one box, and these are called codon boxes.
- a specific codon box is represented by arranging "M” meaning any base selected from A, C, G and U after the bases of the first and second letters of the codon.
- M any base selected from A, C, G and U after the bases of the first and second letters of the codon.
- codons in mRNA may be represented by "M 1 M 2 M 3".
- M 1 , M 2 , and M 3 represent the bases of the first, second, and third letters of the codon, respectively.
- Anticodon is three consecutive bases on tRNA that correspond to codons on mRNA. Similar to mRNA, four types of bases, adenine (A), guanine (G), cytosine (C), and uracil (U), are used as anticodons. Further, a modified base obtained by modifying them may be used. When a codon is specifically recognized by an anticodon, the genetic information on the mRNA is read and translated into a protein. Since the codon sequence in the 5'to 3'direction on the mRNA and the anticodon sequence in the 5'to 3'direction on the tRNA are complementary to each other, the bases of the first, second, and third characters of the codon are combined.
- Complementary base pairs are formed with the bases of the third, second, and first letters of the anticodon, respectively.
- the "modified base” means a base having a structure in which a part of the base structure is different from that of A, C, G and U.
- the anticodon in the first tRNA may be represented by "N 11 N 12 N 13 " and the anticodon in the second tRNA may be represented by "N 21 N 22 N 23 ".
- N 11 , N 12 , and N 13 and N 21 , N 22 , and N 23 represent the bases of the first, second, and third letters of the anticodon, respectively.
- N 11 , N 12 , and N 13 and N 21 , N 22 , and N 23 are numbered at positions 34, 35, and 36 of the tRNA, respectively.
- bases A, C, G, U, and T may be written in lowercase, but uppercase and lowercase are used interchangeably.
- GGG and ggg are used interchangeably.
- thermodynamically stable base pairs are said to be “complementary” to each other.
- Watson-click base pairs such as adenine and uracil (AU) and guanine and cytosine (GC)
- non-Watson-click wobble base pairs of guanine and uracil (GU) are also “complementary” in the present disclosure. Included in base pairs.
- a certain relationship between a codon and an anticodon may be expressed as "complementary".
- a Watson-click base pair is formed between the first letter of the codon and the third letter of the anticodon, the second letter of the codon and the second letter of the anticodon, and between the third letter of the codon and the first letter of the anticodon.
- the relationship between codons and anticodons that forms Watson-click or wobble base pairs is referred to as "complementary".
- the anticodons complementary to the codon UCU are AGA and GGA
- the codons complementary to the anticodon GCG are CGC and CGU.
- RNA essential RNA
- the genetic information is encoded on mRNA as codons, which correspond to all 20 types of amino acids.
- Protein translation begins at the start codon and ends at the stop codon.
- the start codon in eukaryotes is AUG, but in prokaryotes (eubacteria and archaea), GUG and UUG may be used as start codons in addition to AUG.
- AUG is a codon that encodes methionine (Met), and in eukaryotes and archaea, translation is started from methionine as it is.
- start codon AUG corresponds to N-formylmethionine (fMet), so translation is started from formylmethionine.
- stop codons There are three types of stop codons: UAA (ocher), UAG (amber), and UGA (opal).
- RF release factor
- Transfer RNA is a short RNA of 100 bases or less that mediates peptide synthesis using mRNA as a template. On the secondary structure, it has a clover leaf-like structure consisting of three stem loops (D arm, anticodon arm, T arm) and one stem (acceptor stem). Depending on the tRNA, one additional variable loop may be included.
- the anticodon arm has a region consisting of three consecutive bases called an anticodon, and the codon is recognized by forming a base pair with the codon on the mRNA.
- a nucleic acid sequence consisting of cytidine-cytidine-adenosine exists at the 3'end of tRNA, and an amino acid is added to the adenosine residue at the end (specifically, ribose of the adenosine residue).
- the hydroxyl group at the 2- or 3-position of the amino acid and the carboxyl group of the amino acid are ester-bonded).
- Amino acid-bound tRNAs are called "aminoacyl-tRNAs".
- aminoacyl-tRNA is also included in the definition of tRNA.
- a method is known in which two terminal residues (C and A) are removed from the CCA sequence of tRNA and used for the synthesis of aminoacyl-tRNA.
- a tRNA from which such a 3'-terminal CA sequence has been removed is also included in the definition of tRNA in the present disclosure.
- aminoacyl-tRNA synthetase aaRS or ARS.
- aaRS aminoacyl-tRNA synthetase
- Each base in tRNA is numbered according to the tRNA numbering rule (SRocl et al., Nucleic Acids Res (1998) 26: 148-153).
- the numbering of bases in tRNA follows the same numbering rule. For example, anticodons are numbered at positions 34-36 and the CCA sequence at the 3'end is numbered at positions 74-76.
- the tRNA numbering rule (SRocl et al., Nucleic Acids Res (1998) 26: 148-153) and abbreviations for bases (A, C, G or U) Is used.
- “32U” means that the base at position 32 according to the tRNA numbering rule is U (uracil). They are also used to represent base substitutions at specific positions in tRNAs.
- “C32U” means the substitution of the base at position 32 according to the tRNA numbering rule from C (cytosine) to U (uracil).
- An "anticodon loop” is a base at positions 32 to 38 in a tRNA, that is, seven consecutive bases containing three consecutive bases of an anticodon and two bases on the 5'side and 2 bases on the 3'side of the anticodon. Is. Four types of bases, adenine (A), guanine (G), cytosine (C), and uracil (U), are used in the anticodon loop. Further, a modified base obtained by modifying them may be used.
- tRNA body in the present disclosure refers to the main body part (main structural part composed of nucleic acid) of tRNA excluding anticodon (positions 34 to 36).
- the tRNA bodies of the present disclosure refer to positions 1-33 and 37-76 of the tRNA.
- the tRNA body of the present disclosure refers to positions 1-33 and 37-74 of the tRNA.
- a "chimeric tRNA body” is a tRNA body in which a portion of the tRNA body is derived from a particular source or type of tRNA, while the rest is derived from a different source or type of tRNA. The chimeric tRNA body does not contain a tRNA body derived from only one type of tRNA.
- the chimeric tRNA body may be any tRNA body derived from two or more types of tRNA, and may be derived from three or more types of tRNA.
- the chimeric tRNA body of the present disclosure may be a chimeric tRNA body in which the combination of bases at positions 32, 33, 37 and 38 and the origin of the base sequence of other sites are different.
- Examples of the chimeric tRNA body include a tRNA body in which the combination of bases at positions 32, 33, 37 and 38 of the tRNA body is derived from tRNAPro2, and the remaining base sequence is derived from tRNAGlu2.
- the combination of bases at positions 32, 33, 37 and 38 of a tRNA 32, 33, 37 and 32, 33, 37 of the base sequence of tRNA derived from Escherichia coli (SEQ ID NO: 274 to 319) and With reference to the base combination at position 38, it can be determined that it is derived from a tRNA having the same base combination at positions 32, 33, 37 and 38.
- the combination of bases at positions 32, 33, 37 and 38, CUxxxAC can be determined to be derived from tRNAGlu2 or tRNAAsp1 by referring to SEQ ID NOs: 274 to 319.
- the tRNA body whose base sequence other than the positions 32, 33, 37 and 38 is derived from tRNAGlu2 or tRNAAsp1 is a tRNA body derived from only one type of tRNA. Not included.
- a base, a combination of bases, or a base sequence "derived" from a certain origin is highly similar to that base, a combination of bases, or a base sequence, or a base, a combination of bases, or a base sequence. It means that the sequence to be used is isolated from a certain origin. For example, when a base constituting a tRNA, a combination of a certain base, or a base sequence is isolated from a certain type of tRNA, the base, a combination of a certain base, or a base sequence is the said specific type. Expressed as "derived" from tRNA.
- tRNA may be described as follows.
- -"TRNA Xxx" or "tRNA (Xxx)” Represents a tRNA body having a specific base sequence identified by Xxx.
- tRNA Glu2 or tRNA (Glu2), tRNA Ser5 or tRNA (Ser5), tRNA AsnE2 or tRNA (AsnE2), tRNA Asp1 or tRNA (Asp1) can be mentioned.
- -"TRNA (Xxx) nnn A tRNA having a specific tRNA body identified by Xxx and representing a full-length tRNA having an anticodon sequence of nnn.
- tRNA Glu2 uga and tRNA (AsnE2) uga can be mentioned.
- -"TRNA (Xxx + Yyy)" Has a specific base sequence identified by Xxx other than positions 32, 33, 37 and 38, and a combination of specific bases identified by Yyy at positions 32, 33, 37 and 38. Represents a chimeric tRNA body that has.
- tRNA Glu2 + Ser5
- tRNA AsnE2 + Phe
- -"TRNA (Xxx + Yyy) nnn" A combination of specific base sequences identified by Xxx other than positions 32, 33, 37 and 38, and specific bases identified by Yyy at positions 32, 33, 37 and 38.
- tRNA (Glu2 + Ser5) uga and tRNA (AsnE2 + Phe) uga can be mentioned.
- -Adding "-CA" to the end of the above tRNA name may indicate that the CA sequence at the 3'end of the tRNA has been removed.
- tRNA (Glu2) -CA, tRNA (Glu2) uga-CA, tRNA (Glu2 + Ser5) -CA, and tRNA (Glu2 + Ser5) uga-CA can be mentioned.
- a specific combination of bases at positions 32, 33, 37 and 38 in a tRNA may be referred to by the name of the tRNA from which it is derived.
- “Initiator tRNA” is a specific tRNA used at the beginning of translation of mRNA. Translation is initiated by the initiation factor (IF) -catalyzed introduction into the ribosome of the initiation tRNA bound to the initiation amino acid and binding to the initiation codon on the mRNA. Since AUG, which is a methionine codon, is generally used as the start codon, the start tRNA has an anticodon corresponding to AUG, and methionine (formylmethionine in prokaryotes) is bound as the start amino acid. There is. As an example of the starting tRNA, tRNAfMet (SEQ ID NO: 283, 284) can be mentioned.
- Elongator tRNA is a tRNA used in the peptide chain extension reaction in the translation process. In peptide synthesis, the elongation reaction of the peptide chain proceeds by sequentially transporting the amino acid-bound elongated tRNA to the ribosome by the GTP-ized translation factor (EF) EF-Tu / eEF-1. .. Examples of elongated tRNAs include tRNAs corresponding to various amino acids (SEQ ID NOs: 274 to 282, 285 to 319).
- the “translation system” in the present disclosure is defined as a composition for translating a peptide (sometimes referred to as a "translation composition” in the present disclosure).
- Typical translation systems are composed of ribosomes, translation factors, tRNAs, amino acids, aminoacyl-tRNA synthetase (aaRS), and factors required for the translation reaction of peptides such as ATP and GTP. Included as.
- the main types of translation systems are translation systems that use living cells and translation systems that use cell extracts (cell-free translation systems (used synonymously with "cell-free translation compositions" in the present disclosure). )).
- a translation system using living cells for example, a system in which desired aminoacyl tRNA and mRNA are introduced into living cells such as African turkey oocytes and mammalian cells by a microinjection method or a lipofection method to perform peptide translation.
- living cells such as African turkey oocytes and mammalian cells by a microinjection method or a lipofection method to perform peptide translation.
- cell-free translation systems include Escherichia coli (Chen et al., Methods Enzymol (1983) 101: 674-690), yeast (Gasior et al., J Biol Chem (1979) 254: 3965-3969), and wheat germ.
- the cell-free translation system also includes a translation system (reconstituted cell-free translation system) constructed by isolating and purifying the factors required for peptide translation and reconstructing them (Shimizu et al). ., Nat Biotech (2001) 19: 751-755).
- Reconstituted cell-free translation systems usually include ribosomes, amino acids, tRNAs, aminoacyl-tRNA synthetase (aaRS), translation initiation factors (eg, IF1, IF2, IF3), translation elongation.
- RNA polymerase and the like may be further included.
- Various factors contained in the cell-free translation system can be isolated and purified by a method well known to those skilled in the art, and a reconstituted cell-free translation system can be appropriately constructed using them. Alternatively, commercially available reconstituted cell-free translation systems such as Genefrontier's PUREfrex® and New England Biolabs' PURExpress® can be used. In the case of a reconstituted cell-free translation system, a desired translation system can be constructed by reconstructing only the necessary components among the components of the translation system.
- aminoacyl-tRNA is synthesized in the translation system and used for peptide translation.
- aminoacyl-tRNA prepared outside the translation system can be used as it is as a component of the translation system (in the present disclosure, it may be referred to as "precharge method").
- the precharge method include a method of binding an amino acid to tRNA by aaRS outside the translation system, a pdCpA method, a pCpA method, and a method using an artificial RNA catalyst (flexizyme).
- aminoacylation with unnatural amino acids is performed in advance by the pdCpA method, pCpA method, or a method using flexizyme.
- a precharge method using the prepared tRNA as a constituent is desirable.
- the translation is started by adding mRNA to the translation system.
- the mRNA usually contains a sequence encoding the peptide of interest, and further, a sequence for increasing the efficiency of the translation reaction (eg, Shine-Dalgarno (SD) sequence in prokaryotes, true (Kozac sequence in prokaryotes, etc.) may be included.
- Pre-transcribed mRNA may be added directly to the system, or by adding template DNA containing a promoter and suitable RNA polymerase (for example, T7 promoter and T7 RNA polymerase) to the system instead of mRNA, the mRNA can be added. It may be transcribed from the template DNA.
- Codon misreading means that an aminoacyl-tRNA having a specific anticodon recognizes a codon that is not complementary to the anticodon, so that an unintended amino acid is translated and introduced.
- an aminoacyl-tRNA having an anticodon AGG complementary to the codon CCU may unintentionally translate and introduce an amino acid acylated into the tRNA by erroneously recognizing the codon CCG.
- Pro is assigned to both codons CCG and CCU, so there is no difference in the amino acids translated and introduced depending on the presence or absence of such misreading.
- misreading of this codon can be a problem when reprogramming the genetic code table and assigning different amino acids to the codons CCG and CCU.
- alkyl is a monovalent group derived by removing one arbitrary hydrogen atom from an aliphatic hydrocarbon, and does not contain a heteroatom or an unsaturated carbon-carbon bond in the skeleton. It has a subset of hydrocarbyl or hydrocarbon group structures containing hydrogen and carbon atoms.
- cycloalkyl means a saturated or partially saturated cyclic monovalent aliphatic hydrocarbon group, and includes a monocyclic ring, a bicyclo ring, and a spiro ring.
- examples of the cycloalkyl include C 3- C 10 cycloalkyl, and specific examples thereof include cyclopropyl, cyclobutyl, cyclopentyl, cyclohexyl, cycloheptyl, cyclooctyl, and bicyclo [2.2.1] heptyl. ..
- alkenyl is a monovalent group having at least one double bond (two adjacent SP2 carbon atoms). Depending on the arrangement of the double bond and the substitution (if any), the geometry of the double bond can be in the Chrysler (E) or tuzanmen (Z), cis or trans arrangement. Examples thereof include straight-chain or branched-chain alkenyl, including straight-chain containing internal olefins.
- Alkenyl for example, C 2 -C 10 alkenyl, C 2 -C 6 such as alkenyl can be mentioned, specifically, vinyl, allyl, 1-propenyl, 2-propenyl, 1-butenyl, 2-butenyl (cis, (Including trans), 3-butenyl, pentenyl, hexenyl and the like.
- alkynyl is a monovalent group having at least one triple bond (two adjacent SP carbon atoms).
- Linear or branched alkynyls include internal alkylenes.
- the alkynyl for example C 2 -C 10 alkynyl, C 2 -C 6 alkynyl and the like, specifically, ethynyl, 1-propynyl, propargyl, 3-butynyl, pentynyl, hexynyl, 3-phenyl-2- Propinyl, 3- (2'-fluorophenyl) -2-propynyl, 2-hydroxy-2-propynyl, 3- (3-fluorophenyl) -2-propynyl, 3-methyl- (5-phenyl) -4-pentynyl And so on.
- aryl means a monovalent aromatic hydrocarbon ring.
- the aryl for example C 6 -C 10 aryl and the like, specifically, phenyl, naphthyl (e.g., 1-naphthyl, 2-naphthyl).
- heteroaryl means a monovalent group of an aromatic ring containing a hetero atom in the atoms constituting the ring, and may be partially saturated.
- the ring may be a monocycle or two fused rings (eg, a bicyclic heteroaryl fused with benzene or monocyclic heteroaryl).
- the number of atoms constituting the ring is, for example, 5-10 (5-membered-10-membered heteroaryl).
- the number of heteroatoms contained in the atoms constituting the ring is, for example, 1-5.
- heteroaryl examples include frill, thienyl, pyrrolyl, imidazolyl, pyrazolyl, thiazolyl, isothiazolyl, oxazolyl, isooxazolyl, oxadiazolyl, thiadiazolyl, triazolyl, tetrazolyl, pyridyl, pyrimidyl, pyridadinyl, pyrazinyl, triazinyl, benzofuranyl and benzothienyl.
- arylalkyl means a group containing both aryl and alkyl, for example, a group in which at least one hydrogen atom of the alkyl is substituted with aryl.
- aralkyl examples include C 5- C 10 aryl C 1- C 6 alkyl, and specific examples thereof include benzyl.
- alkylene means a divalent group derived by further removing one arbitrary hydrogen atom from the "alkyl”, and may be linear or branched.
- the linear alkylene, C 2 -C 6 linear alkylene, such as C 4 -C 5 straight-chain alkylene can be mentioned, specifically, -CH 2 -, - (CH 2) 2 -, - (CH 2 ) 3 -,-(CH 2 ) 4 -,-(CH 2 ) 5 -,-(CH 2 ) 6 -etc.
- alkenylene means a divalent group derived by further removing one arbitrary hydrogen atom from the “alkenyl”, and may be linear or branched. Depending on the double bond and the configuration of the substituents (if present), an entogen (E) or tuzanmen (Z), cis or trans configuration can be taken.
- arylene means a divalent group derived by further removing one arbitrary hydrogen atom from the aryl.
- the ring may be a monocyclic ring or a condensed ring.
- the number of atoms constituting the ring is not particularly limited, for example, 6-10 (C 6 -C 10 arylene).
- Specific examples of the arylene include phenylene and naphthalene.
- heteroarylene means a divalent group derived by further removing one arbitrary hydrogen atom from the heteroaryl.
- the ring may be a monocyclic ring or a condensed ring.
- the number of atoms constituting the ring is not particularly limited, but is, for example, 5-10 (5-membered to 10-membered heteroarylene).
- heteroarylene examples include pyrrol diyl, imidazole diyl, pyrazole diyl, pyridine diyl, pyridazine diyl, pyrimidine diyl, pyrazine diyl, triazole diyl, triazine diyl, isooxazole diyl, oxazole diyl, oxadiazole diyl, and isothiazole diyl. , Thiadiazole diyl, thiadiazole diyl, frangyl, thiophendiyl and the like.
- the present disclosure relates to a translation composition and a translation kit comprising a first tRNA with a first amino acid attached and a second tRNA with a second amino acid attached. Also in one aspect, the present disclosure relates to a method of translating a nucleic acid using a first tRNA to which a first amino acid is bound and a second tRNA to which a second amino acid is bound.
- the present disclosure relates to a method for producing a peptide while reducing or suppressing codon misreading by tRNA, as well as compositions and kits for use in that method.
- composition in the present disclosure may contain, in addition to the tRNA in the present disclosure, a buffer or a substance usually used for translation of nucleic acid.
- the tRNA in the present disclosure can be pre-packaged together with various substances usually used for peptide translation and supplied as a kit.
- the various substances contained in the kits of the present disclosure may be in powder form or liquid form depending on the mode of use thereof. In addition, these can be stored in a suitable container and used in a timely manner.
- the base combinations at positions 32, 33, 37, and 38 of the tRNAs of the present disclosure are: (1) 32U, 33U, 37G, 38A, (2) 32A, 33U, 37G, 38U, (3) 32A, 33U, 37A, 38U, (4) 32U, 33U, 37G, 38U, It may be (5) 32U, 33U, 37A, 38U, or (6) 32C, 33U, 37G, 38A.
- the tRNAs of the present disclosure have positions 32, 33, 37, and 38 as described above (1) to (4); said (1) to (3); or said (1), (3).
- tRNA that is a combination of bases selected from the group consisting of and (4), or the above (1); the above (2); the above (3); the above (4); the above (5); or , TRNA which is a combination of the bases of the above (6) may be used.
- the bases at positions 32, 33, 37 and 38 of the tRNAs of the present disclosure are not modified bases.
- the anticodon of the first tRNA of the present disclosure may be represented by N 11 N 12 N 13
- the anticodon of the second tRNA of the present disclosure may be represented by N 21 N 22 N 23
- the N 11 , N 12 , and N 13 and N 21 N 22 N 23 may be independently A, C, G, or U, respectively.
- the first, second, and third letters of the anticodon of the tRNA of the present disclosure may be A, C, G, or U, respectively.
- the second and third character sequences of the anticodon of the tRNA of the present disclosure may be CC, GC, AC, GU, CG, GG, AG, or GA, or GG, AG, or CC. You can.
- the second and third character sequences of the anticodon are not CG.
- the tRNAs of the present disclosure do not have a modified base on the anticodon, or the first letter of the anticodon is a modified base, or the nucleoside of the first letter has a modification described below. Good.
- the tRNAs of the present disclosure are prokaryotic-derived tRNAs or eukaryotic-derived tRNAs.
- a tRNA may be prepared by modifying a prokaryotic-derived tRNA or a eukaryotic-derived tRNA, or the modified tRNA is the highest base of a prokaryotic-derived tRNA or a eukaryotic-derived tRNA. It may have sequence identity.
- Eukaryotes are further classified into animals, plants, fungi and protists.
- the tRNA of the present disclosure may be, for example, a human-derived tRNA. Prokaryotes are further classified into eubacteria and archaea.
- eubacteria examples include Escherichia coli, Bacillus subtilis, lactic acid bacteria, and Desulfitobacterium hafniense.
- archaea examples include highly halophilic bacteria, thermophiles, and methanogens (for example, Methanosarcina mazei, Methanosarcina barkeri, Methanocaldococcus jannaschii).
- the tRNA of the present disclosure may be, for example, a tRNA derived from Escherichia coli, Desulfitobacterium hafniense, or Methanosarcina mazei.
- the tRNAs of the present disclosure may differ by one or more bases from the base sequence of the reference tRNA, such as 2 or more, 3 or more, 4 or more, 5 or more, 6 or more, 7 or more. 8 or more, 9 or more, 10 or more, 11 or more or 12 or more bases may be different, and 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 or 12 bases may be different. It may be different, 15 or less, 14 or less, 13 or less, 12 or less, 11 or less, 10 or less, 9 or less, 8 or less, 7 or less, 6 or less, 5 or less, 4 or less, 3 or less, or 2 or less bases. May be different.
- the tRNAs of the present disclosure are 80% or more, 85% or more, 90% or more, 91% or more, 92% or more, 93% or more, 94% or more, 95, as compared to the nucleotide sequence of the reference tRNA. It may have a sequence identity of% or more, 96% or more, 97% or more, or 98% or more.
- percentage (%) sequence identity for a base sequence is any conservative substitution after aligning the sequences for maximum percent sequence identity and, if necessary, introducing gaps. Is also defined as the percentage ratio of the bases in the candidate sequence that are the same as the bases in the reference base sequence when not considered to be part of the sequence identity.
- Alignment for the purpose of determining the percent sequence identity of a base sequence can be performed by various methods within the scope of the technology in the art, such as BLAST, BLAST-2, ALIGN, Megalign (DNASTAR) software, or GENETYX®. This can be achieved by using publicly available computer software such as (Genetics Co., Ltd.).
- One of skill in the art can determine the appropriate parameters for sequence alignment, including any algorithm required to achieve maximum alignment over the overall length of the sequence being compared.
- the tRNA of the present disclosure may differ from the base sequence of the reference tRNA in the base sequence of the anticodon loop (positions 32 to 38).
- the tRNAs of the present disclosure may have a chimeric anticodon loop.
- the "chimeric anticodon loop" in the present disclosure means an anticodon loop in which the tRNA from which the bases at positions 32, 33, 37 and 38 are derived from the base sequence of the anticodon is different. For example, it can be determined as follows whether or not the anticodon loop containing the anticodon UGA corresponds to the chimeric anticodon loop.
- tRNA Ser1 (SEQ ID NO: 306) derived from Escherichia coli is identified as a tRNA having an anticodon UGA
- the SEQ ID NO: refers to the base sequence of tRNA described in 274 to 319.
- the base sequence of the anticodon loop of the tRNA Ser1 is CUugaAA. Therefore, if the bases at positions 32, 33, 37 and 38 contained in the anticodon loop are a combination of bases other than the Ser5 sequence (32C, 33U, 37A, and 38A), the anticodon loop is determined to be a chimeric anticodon loop.
- the anticodon loop of a tRNA of the present disclosure is an anticodon loop contained in a tRNA having the nucleotide sequence set forth in any of SEQ ID NOs: 274 to 282, 285 to 304, and 306 to 319 (32 of the tRNA numbering rule). ⁇ 38th place) may be different.
- the body of the tRNA of the present disclosure may differ by one or more bases from the base sequence of the body of the reference tRNA, which may be 2 or more, 3 or more, 4 or more, 5 or more, 6 or more.
- the tRNA body of the present disclosure is 80% or more, 85% or more, 90% or more, 91% or more, 92% or more, 93% or more, 94% or more compared to the base sequence of the reference tRNA body.
- the tRNA of the present disclosure may differ from the base of the reference tRNA in at least one selected from the group consisting of positions 32, 33, 37 and 38 thereof.
- the tRNA body of the present disclosure may differ from the base of the reference tRNA body in at least one selected from the group consisting of positions 32, 33, 37 and 38.
- the tRNAs of the present disclosure are characterized by being non-naturally occurring tRNAs.
- the tRNA body of the present disclosure may be a tRNA body not derived from a tRNA having the nucleotide sequence set forth in SEQ ID NO: 275 and / or set forth in SEQ ID NOs: 294, 295, and 296. It may be a tRNA body that is not derived from any of the tRNAs having a base sequence, and / or a tRNA body that is not derived from any of the tRNAs having a base sequence set forth in SEQ ID NOs: 302, 303, and 304. May be good.
- the tRNA body is any of the tRNAs having the base sequences set forth in SEQ ID NOs: 294, 295, and 296. It does not have to be derived, in the case of the Ala2 sequence, the tRNA body does not have to be derived from the tRNA having the base sequence set forth in SEQ ID NO: 275, and in the case of the Pro2 or Pro3 sequence, the tRNA body is the SEQ ID NO: : It does not have to be derived from any of the tRNAs having the base sequences described in 302, 303, and 304.
- the reference tRNA and the reference tRNA body in the present disclosure may be a natural tRNA derived from an arbitrary organism (for example, Escherichia coli) or a body thereof, respectively, or an unnatural tRNA obtained by artificially synthesizing a sequence different from the natural tRNA.
- it may be a tRNA (artificial tRNA) obtained by artificially synthesizing a sequence such as natural tRNA, or a body thereof, or a tRNA chimera in which tRNAs of different origins are artificially combined.
- it may be the body thereof.
- the reference tRNA or reference tRNA body in the present disclosure can be appropriately selected from tRNA or tRNA bodies having arbitrary base sequences, respectively.
- the reference tRNA or reference tRNA body is tRNA Ala, tRNA Arg, tRNA Asn, tRNA Asp, tRNA Cys, tRNA Gln, tRNA Glu, tRNA Gly, tRNA His, tRNA Ile, tRNA Leu, tRNA Lys, tRNAMet, tRNAPhe, tRNAPro, tRNASer, tRNAThr, tRNATrp, tRNATyr, tRNAVal, and tRNASec (selenocysteine) (SEQ ID NOs: 274-282, 285-319), as well as tRNAGlu2, tRNA.
- tRNAfMet SEQ ID NO: 283,284
- tRNAPyl pyrolysine
- tRNAAsnE2 Ohta, A .; Murakami, H .; Higashimura, E .; Suga, H. Chem. Biol. 2007, 14, 1315-1322 (See.)
- tRNAfMet SEQ ID NO: 283,284
- tRNAPyl pyrolysine
- tRNAAsnE2 Ohta, A .; Murakami, H .; Higashimura, E .; Suga, H. Chem. Biol. 2007, 14, 1315-1322 (See.)
- tRNAAsnE2 Ohta, A .; Murakami, H .; Higashimura, E .; Suga, H. Chem. Biol. 2007, 14, 1315-1322 (See.
- tRNAPro1E2 which is a tRNA chimera obtained by transplanting the T-stem of tRNAGlu2 into tRNAPro1 and further mutating it, and its body can also be used as a reference.
- the tRNA or tRNA body of the present disclosure may be at least one tRNA or body thereof selected from the group consisting of tRNAGlu2, tRNAAsp1 and tRNAAsnE2.
- exemplary nucleotide sequences at positions 1-74 are shown in SEQ ID NOs: 253-255, 320, 321.
- the reference tRNA body exemplified here may be used as the origin sequence of the portion other than the anticodon loop in the chimeric tRNA body in the present disclosure.
- the difference between the tRNA or tRNA body of the present disclosure from the reference tRNA or the reference tRNA body is a part of the sequence based on the sequence information (eg, base sequence information) of the reference tRNA or the reference tRNA body. May be caused by modifying.
- sequence information eg, base sequence information
- the sequence information of the tRNA or tRNA body of the present disclosure is obtained, it is possible to prepare the tRNA or tRNA body of the present disclosure without the need for the reference sequence information.
- modification means at least one modification of an existing tRNA or a base sequence (existing sequence) of a tRNA body, or at least one modification selected from the following group, or 2, 3, 4 Means introducing 5, 6, 7, 8, 9, 10, 11 or 12 or more: (i) Addition (adding any new base to an existing sequence), (ii) Deletion (existing) (Remove any nucleotide from the sequence), (iii) Substitution (replace any base in the existing sequence with another arbitrary base), (iv) Insert (new between any two nucleotides in the existing sequence) (Adding any nucleotide), (v) Modification (changing a part of the structure of any nucleoside in an existing sequence (for example, a base part or a sugar part) to another structure).
- Modifications may be made to any structure of the tRNA or tRNA body (eg, D-arm, anticodon arm, T-arm, acceptor stem, variable loop, etc.).
- the tRNA or tRNA body modification of the present disclosure is at least one selected from the group consisting of positions 32, 33, 37, and 38 of the tRNA, or the group consisting of positions 32, 37, and 38, 2 It is performed on one or more, three or more, or four bases.
- the tRNA and tRNA bodies of the present disclosure do not have to be in fact modified based on the reference tRNA or reference tRNA body.
- the tRNA and the tRNA body of the present disclosure also include a tRNA or a tRNA body having a base sequence obtained when the reference tRNA or the reference tRNA body is modified as described above.
- Modifications in the present disclosure include, for example, substituting bases so that the combination of bases at positions 32, 33, 37 and 38 of the tRNA is the same as the combination of bases at the relevant site of the tRNA of the present disclosure. Be done.
- the base before substitution is not particularly limited, but for example, the base at position 32 before substitution may be C or U, the base at position 37 before substitution may be A, and the base at position 38 before substitution may be. It may be A or C, and / or the base at position 33 before substitution may be U.
- the base at position 32, 33, 37 or 38 is already the desired base, no substitution is required.
- substitution of the base at position 33 is not required.
- the tRNAs of the present disclosure may have a chimeric tRNA body.
- the chimeric tRNA body include a chimeric tRNA body derived from a tRNA body in which the anticodon loop portion (that is, positions 32, 33, 37 and 38) of the tRNA body and the other portion are different from each other.
- the following are examples of base sequences at positions 1 to 74 of the chimeric tRNA body.
- the base sequence at positions 32 to 38 of the tRNA of the present disclosure may differ from the base sequence at positions 32 to 38 of the wild-type tRNA of Escherichia coli or a naturally occurring tRNA.
- the tRNAs of the present disclosure have a chimeric tRNA body having a combination of 32U, 33U, 37G, 38A bases, the tRNAs whose anticodons are UGG and / or CGG are disclosed herein. May be excluded from the tRNA of.
- the tRNA of the present disclosure has a chimeric tRNA body having a combination of 32A, 33U, 37G, 38U bases, the tRNA whose anticodon is AGG and / or GGG is excluded from the tRNA of the present disclosure. You may. In some embodiments, if the tRNA of the present disclosure has a chimeric tRNA body having a combination of 32A, 33U, 37A, 38U bases, the tRNA whose anticodon is AGC and / or GGC is excluded from the tRNA of the present disclosure. You may.
- the tRNA of the present disclosure has a chimeric tRNA body having a combination of 32C, 33U, 37G, 38A bases, the tRNA whose anticodon is UCG and / or CCG is excluded from the tRNA of the present disclosure. You may.
- the tRNA of the present disclosure has a chimeric tRNA body having a combination of 32U, 33U, 37G, 38U bases, the second letter base of the anticodon is A and the third letter base is.
- a tRNA that is G may be excluded from the tRNAs of the present disclosure.
- the tRNA of the present disclosure is not particularly limited in its base sequence other than its anticodon loop, but may be selected from other than tRNAAla, tRNAPro and tRNALeu.
- the base sequence other than the anticodon loop may be the base sequence at positions 1 to 31 and 39 to 76 of tRNA.
- the nucleotide sequences at positions 1 to 31 and 39 to 74 of the tRNA of the present disclosure are not particularly limited, but (a) SEQ ID NO: 253, (b) SEQ ID NO: 255, and (c). It may be derived from the base sequences of positions 1 to 31 and 39 to 74 in the tRNA having the base sequence described in at least one selected from the group consisting of SEQ ID NO: 254.
- the base sequences at positions 1 to 31 and 39 to 74 of the tRNAs of the present disclosure are tRNAs having the base sequence according to at least one selected from the group consisting of (a) to (c) above. It may be the base sequence of positions 1 to 31 and 39 to 74 in.
- nucleotide sequences of positions 1 to 31 and 39 to 74 of the tRNA of the present disclosure are the nucleotide sequences of positions 1 to 31 and the tRNA having the nucleotide sequence according to any one of (a) to (c) above.
- Nucleotide sequence and sequence identity at positions 39 to 74 are 80% or more, 85% or more, 90% or more, 91% or more, 92% or more, 93% or more, 94% or more, 95% or more, 96% or more, 97%. It may be more than or equal to 98% or more.
- the base at position 75 of the tRNA of the present disclosure may be C and the base at position 76 may be A.
- Positions 75 and 76 of the tRNAs disclosed in the present disclosure may be pCpA (dinucleotide containing cytidine and adenosine) or pdCpA (dinucleotide containing deoxycytidine and adenosine).
- the tRNAs of the present disclosure are at its 3'end, more specifically at the 3'end adenosine residue, and more specifically at the 3'end adenosine residue at position 76. It may be a tRNA to which an amino acid is bound.
- the modifications in the present disclosure include modifications made to the first-letter base of the anticodon of tRNA or nucleosides (for example, substitution with lysidine, lysidine derivative, agmatidine, or agmatidine derivative).
- the lysidin derivative is a molecule prepared by modifying a part of the structure of lysidin (for example, a base part), and when used as a part of an anticodon, a codon identification equivalent to that of lysidin. It means a molecule having the ability (the ability to form complementary base pairs).
- An agmatidine derivative is a molecule prepared by modifying a part of the structure of agmatidine (for example, a base portion), and when used as a part of an anticodon, has a codon discrimination ability equivalent to that of agmatidine. It means a molecule having (ability to form complementary base pairs).
- a base that has been modified or otherwise modified as exemplified here may be referred to as a "modified base”.
- "L" in the base sequence or nucleic acid sequence means lysidine.
- Lysidine in natural tRNA is synthesized by the action of an enzyme called tRNA Ile-lysidine synthesize; TilS.
- TilS has the activity of specifically recognizing tRNA (tRNAIle2) corresponding to isoleucine as a substrate and modifying (converting) cytidine (C) in the first letter (N1) of its anticodon to lysidine (k2C). ing.
- tRNAIle2 tRNA Ile-2
- C cytidine
- N1 first letter
- lysidine in the tRNA of the present disclosure may be synthesized via TilS or may not be synthesized via TilS.
- the tRNA of the present disclosure may be a tRNA that does not contain a modified base.
- tRNA prepared by in vitro transcription may be referred to as "transcriptional tRNA".
- the tRNA of the present disclosure may be a transcribed tRNA or a transcribed tRNA containing no modified base.
- the term "artificial tRNA” may be used to distinguish it from naturally occurring natural tRNAs.
- the tRNA of the present disclosure may be an artificial tRNA, or may be an artificial tRNA that does not contain a modified base or a modified nucleoside.
- the method for preparing tRNA that does not contain a modified base, tRNA that does not contain a modified nucleoside, transcribed tRNA, and artificial tRNA is not particularly limited, but for example, tRNA is obtained from a template DNA by an in vitro transcription reaction using an RNA polymerase such as T7 RNA polymerase. It may be prepared by synthesizing and purifying the RNA as needed. RNeasy kit (Qiagen) or the like can be used for RNA purification.
- the base of the tRNA of the present disclosure may be composed of A, C, G and U.
- the tRNAs of the present disclosure may have a base consisting of A, C, G, and U.
- the tRNA of the present disclosure may be bound to an amino acid.
- the amino acid is usually attached to the 3'end of the tRNA, more specifically to the adenosine residue of the CCA sequence at the 3'end.
- the adenosine residue at the 3'end may be at position 76 of the tRNA numbering rule.
- the specific type of amino acid bound to tRNA can be appropriately selected from the amino acids described below, and examples thereof include unnatural amino acids.
- the amino acids in the present disclosure include ⁇ -amino acids, ⁇ -amino acids, ⁇ -amino acids and the like.
- the three-dimensional structure includes both L-type amino acids and D-type amino acids.
- the amino acids in the present disclosure include natural amino acids and unnatural amino acids.
- ⁇ -amino acids are natural amino acids: glycine (Gly), alanine (Ala), serine (Ser), threonine (Thr), valine (Val), leucine (Leu), isoleucine (Ile), phenylalanine ( Phe), tyrosine (Tyr), tryptophan (Trp), histidine (His), glutamic acid (Glu), aspartic acid (Asp), glutamine (Gln), aspartic acid (Asn), cysteine (Cys), methionine (Met), lysine Consists of (Lys), arginine (Arg), and proline (Pro). Natural amino acids are usually L-type amino acids.
- the unnatural amino acid refers to all amino acids except the natural amino acid consisting of the above 20 kinds of ⁇ -amino acids.
- unnatural amino acids are ⁇ -amino acids, ⁇ -amino acids, D-type amino acids, ⁇ -amino acids having different side chains from natural amino acids, ⁇ , ⁇ -disubstituted amino acids, and amino acids in which the amino group in the main chain has a substituent. (In the present disclosure, it may be referred to as "N-substituted amino acid"), hydroxycarboxylic acid (hydroxy acid), and the like.
- N-substituted amino acid examples include, but are not limited to, N-methyl amino acid, N-ethyl amino acid, N-propyl amino acid, and N-butyl amino acid.
- the side chain of the unnatural amino acid is not particularly limited, but may have, for example, alkyl, alkenyl, alkynyl, aryl, heteroaryl, aralkyl, cycloalkyl and the like in addition to the hydrogen atom.
- ⁇ , ⁇ -disubstituted amino acids two side chains may form a ring. In addition, these side chains may have one or more substituents.
- the substituent can be selected from any functional group, including a halogen atom, an O atom, an S atom, an N atom, a B atom, a Si atom, or a P atom.
- C 1 -C 6 alkyl having substituent halogen in the present disclosure, it means a "C 1 -C 6 alkyl" in which at least one hydrogen atom is substituted with a halogen atom in an alkyl, specifically For example, trifluoromethyl, difluoromethyl, fluoromethyl, pentafluoroethyl, tetrafluoroethyl, trifluoroethyl, difluoroethyl, fluoroethyl, trichloromethyl, dichloromethyl, chloromethyl, pentachloroethyl, tetrachloroethyl, trichloro.
- C 5- C 10 aryl C 1- C 6 alkyl having a substituent means “C 5- C 10 aryl C in which at least one hydrogen atom in aryl and / or alkyl is substituted with a substituent". It means “1- C 6 alkyl”.
- “having two or more substituents” means that a certain functional group (for example, a functional group containing an S atom) is used as a substituent, and the functional group is another substituent (for example, amino or halogen). It also includes having a substituent (such as).
- WO2013 / 100132 and WO2018 / 143145 can also be referred to.
- the amino group of the main chain of the unnatural amino acid may be an unsubstituted amino group (-NH 2 group) or a substituted amino group (-NHR group).
- R represents alkyl, alkenyl, alkynyl, aryl, heteroaryl, aralkyl, cycloalkyl which may have a substituent.
- a carbon chain bonded to the N atom of the amino group of the main chain and a carbon atom at the ⁇ -position, such as proline may form a ring.
- the substituent can be selected from any functional group including a halogen atom, an O atom, an S atom, an N atom, a B atom, a Si atom, or a P atom.
- alkyl substitutions of amino groups include N-methylation, N-ethylation, N-propylation, N-butylation and the like, and examples of aralkyl substitutions include N-benzylation and the like.
- N-methyl amino acids include N-methylalanine, N-methylglycine, N-methylphenylalanine, N-methyltyrosine, N-methyl-3-chlorophenylalanine, N-methyl-4-chlorophenylalanine, Examples thereof include N-methyl-4-methoxyphenylalanine, N-methyl-4-thiazolealanine, N-methylhistidine, N-methylserine, and N-methylaspartic acid.
- substituents containing a halogen atom include fluoro (-F), chloro (-Cl), bromo (-Br), iodine (-I) and the like.
- oxy examples include alkoxy, cycloalkoxy, alkenyloxy, alkynyloxy, aryloxy, heteroaryloxy, aralkyloxy and the like.
- Examples of carbonyloxy include alkylcarbonyloxy, cycloalkylcarbonyloxy, alkenylcarbonyloxy, alkynylcarbonyloxy, arylcarbonyloxy, heteroarylcarbonyloxy, aralkylcarbonyloxy and the like. ..
- carbonylthio examples include alkylcarbonylthio, cycloalkylcarbonylthio, alkenylcarbonylthio, alkynylcarbonylthio, arylcarbonylthio, heteroarylcarbonylthio, aralkylcarbonylthio and the like. ..
- Examples of oxycarbonylamino include alkoxycarbonylamino, cycloalkoxycarbonylamino, alkenyloxycarbonylamino, alkynyloxycarbonylamino, aryloxycarbonylamino, heteroaryloxycarbonylamino, aralkyloxy. Examples include carbonylamino.
- sulfonylamino examples include alkylsulfonylamino, cycloalkylsulfonylamino, alkenylsulfonylamino, alkynylsulfonylamino, arylsulfonylamino, heteroarylsulfonylamino, aralkylsulfonylamino and the like.
- the H atom bonded to the N atom in -NH-SO 2- R is substituted with a substituent selected from the group consisting of alkyl, cycloalkyl, alkenyl, alkynyl, aryl, heteroaryl, and aralkyl. May be good.
- aminosulfonyl (-SO 2 -NHR), alkylaminosulfonyl, cycloalkyl aminosulfonyl, alkenyl aminosulfonyl, alkynyl aminosulfonyl, arylaminosulfonyl, heteroaryl, aminosulfonyl, and the like aralkylaminosulfonlyaryl is.
- H atom bonded to the N atom in the -SO 2 -NHR is alkyl, cycloalkyl, alkenyl, alkynyl, aryl, heteroaryl, and optionally substituted with a substituent selected from the group consisting of aralkyl .
- sulfamoylamino examples include alkylsulfamoylamino, cycloalkylsulfamoylamino, alkenyl sulfamoylamino, alkynylsulfamoylamino, arylsulfamoylamino, hetero.
- Aryl sulfamoyl amino, alkyne sulfamoyl amino and the like can be mentioned.
- At least one of the two H atoms bonded to the N atom in -NH-SO 2- NHR is selected from the group consisting of alkyl, cycloalkyl, alkenyl, alkynyl, aryl, heteroaryl, and aralkyl. It may be substituted with a substituent. When the two H atoms are substituted together, the substituents may be selected independently of each other, or these two substituents may form a ring.
- thio examples include alkylthio, cycloalkylthio, alkenylthio, alkynylthio, arylthio, heteroarylthio, aralkylthio and the like.
- sulfinyl examples include alkylsulfinyl, cycloalkylsulfinyl, alkenylsulfinyl, alkynylsulfinyl, arylsulfinyl, heteroarylsulfinyl, aralkylsulfinyl and the like.
- Examples of the sulfonyl (-S (O) 2- R) include alkylsulfonyl, cycloalkylsulfonyl, alkenylsulfonyl, alkynylsulfonyl, arylsulfonyl, heteroarylsulfonyl, aralkylsulfonyl and the like.
- substituents containing N atoms include azide (-N 3 ), cyano (-CN), primary amino (-NH 2 ), secondary amino (-NH-R), tertiary amino (-NR (-NR)).
- Examples of the secondary amino (-NH-R) include alkylamino, cycloalkylamino, alkenylamino, alkynylamino, arylamino, heteroarylamino, aralkylamino and the like.
- the two substituents R and R'on the N atom at the tertiary amino are independently selected from the group consisting of alkyl, cycloalkyl, alkenyl, alkynyl, aryl, heteroaryl, and aralkyl. can do.
- Examples of tertiary aminos include alkyl (aralkyl) aminos and the like. These two substituents may form a ring.
- substituted amidinos include, for example, alkyl (aralkyl) (aryl) amidinos. These substituents may form a ring with each other.
- the three substituents R, R', and R'' on the N atom in aminocarbonylamino are hydrogen atom, alkyl, cycloalkyl, alkenyl, alkynyl, aryl, hetero. It can be independently selected from the group consisting of aryl and alkyne. These substituents may form a ring with each other.
- substituents containing a B atom include boron (-BR (R')) and dioxyboryl (-B (OR) (OR')).
- the two substituents R and R'on the B atom can be independently selected from the group consisting of hydrogen atom, alkyl, cycloalkyl, alkenyl, alkynyl, aryl, heteroaryl, and aralkyl. These substituents may form a ring with each other.
- the hydroxycarboxylic acid in the present disclosure includes ⁇ -hydroxycarboxylic acid, ⁇ -hydroxycarboxylic acid, ⁇ -hydroxycarboxylic acid and the like. Similar to amino acids, side chains other than hydrogen atoms may be bonded to the carbon at the ⁇ -position of the hydroxycarboxylic acid.
- the three-dimensional structure may include both L-type and D-type.
- the structure of the side chain can be defined in the same manner as the side chain of a natural amino acid or an unnatural amino acid described above. Examples of hydroxycarboxylic acids include hydroxyacetic acid, lactic acid, phenyllactic acid and the like.
- the amino acid in the present disclosure may be a translatable amino acid.
- translatable amino acid means an amino acid that can be incorporated into a peptide by translational synthesis (eg, using the translation system described in the present disclosure). Whether or not a certain amino acid is translatable can be confirmed by a translation synthesis experiment using tRNA to which the amino acid is bound. A reconstituted cell-free translation system may be used for translational synthesis experiments (see, eg, WO2013100132).
- the amino acids in the present disclosure include Pic2 ((2S) -piperidine-2-carboxylic acid), dA ((2R) -2-aminopropanoic acid), MeHph ((2S) -2- (methylamino)- 4-phenyl-butanoic acid), SPh2Cl ((2S) -2-amino-3- (2-chlorophenoxy) propanoic acid), MeG (2- (methylamino) acetic acid), nBuG (2- (butylamino) acetic acid) Etc. can be exemplified.
- the unnatural amino acid in the present disclosure can be prepared by a conventionally known chemical synthesis method, a synthesis method described in Examples described later, or a synthesis method similar thereto.
- tRNA for example, prepare a DNA encoding a desired tRNA gene, place an appropriate promoter such as T7, T3, or SP6 upstream of the DNA, and use RNA polymerase adapted to each promoter using the DNA as a template. It can be synthesized by carrying out a transcription reaction. TRNA can also be prepared by purification from biological material. For example, tRNA can be recovered by preparing an extract from a material containing tRNA such as cells and adding a probe containing a sequence complementary to the base sequence of tRNA to the extract. At this time, an expression vector capable of expressing a desired tRNA can be prepared, and cells transformed with the expression vector can be used as a material for preparation.
- TRNA can also be prepared by purification from biological material. For example, tRNA can be recovered by preparing an extract from a material containing tRNA such as cells and adding a probe containing a sequence complementary to the base sequence of tRNA to the extract.
- TRNAs synthesized by in vitro transcription usually contain only four typical bases: adenine, guanine, cytosine, and uracil.
- the tRNA synthesized in the cell may also contain modified bases obtained by modifying them. It is considered that a modified base in a natural tRNA (for example, lysidin) is specifically introduced into the tRNA by the action of an enzyme (for example, TilS) for modifying the tRNA after it is synthesized by transcription. There is.
- Aminoacyl-tRNA can also be prepared by chemical and / or biological synthetic methods.
- aminoacyl-tRNA synthetase ARS
- ARS aminoacyl-tRNA synthetase
- the amino acid may be a natural amino acid or an unnatural amino acid as long as it can be a substrate for ARS.
- the amino acid may be chemically modified after binding the natural amino acid to the tRNA.
- Aminoacyl-tRNA can be synthesized by (pdCpA method; Hecht et al., J Biol Chem (1978) 253: 4517-4520).
- a method using pCpA (dinucleotide containing cytidine and adenosine as a nucleoside) instead of pdCpA is also known (pCpA method; Wang et al., ACS Chem Biol (2015) 10: 2187-2192).
- Aminoacyl-tRNA can also be synthesized by binding an unnatural amino acid previously activated by esterification to tRNA using a flexizyme which is an artificial RNA catalyst (WO2007 / 066627, WO2012 / 026566, H.I.
- Flexizyme is an artificial RNA catalyst capable of linking an amino acid or a hydroxy acid to tRNA.
- the flexizyme in the present disclosure includes a prototype flexizyme (Fx), a modified dinitrobenzyl flexizyme (dFx), an enhanced flexizyme (eFx), an aminoflexizyme (aFx), and the like.
- the present disclosure provides a set of tRNAs suitable for peptide translation.
- a set of tRNAs contains a plurality of different types of tRNAs, and a plurality of different types of amino acids can be translated from these tRNAs.
- the present disclosure provides a translational composition comprising a plurality of different types of tRNAs suitable for peptide translation.
- the present disclosure provides a method for producing the translation composition.
- the present disclosure provides a method for producing a peptide, which comprises providing a plurality of different types of tRNAs suitable for peptide translation.
- the tRNAs of the present disclosure are included. The following description relates to a set of tRNAs suitable for peptide translation, a composition for translation, a method for producing a composition for translation, a method for reducing codon misreading, and a method for producing a peptide.
- the set of tRNAs in the present disclosure may include the tRNAs of the present disclosure described above (sometimes referred to as "first tRNAs" in the present disclosure) and a second tRNA. Any tRNA may be used as the second tRNA, but it may be the tRNA of the present disclosure described above independently of the first tRNA.
- the first letter base of the anticodon of the first tRNA and the second tRNA contained in the set of tRNAs in the present disclosure may be different from each other.
- the second-letter base of the anticodon of the first tRNA and the second tRNA is the same, and the third-letter base of the anticodon of the first tRNA and the second tRNA are the same.
- the codon complementary to the anticodon of the first tRNA and the codon complementary to the anticodon of the second tRNA may be present in the same codon box.
- the first tRNA of the present disclosure and the second tRNA of the present disclosure can be used to translate at least two amino acids from a single codon box.
- the first letter base of the anticodon of the first tRNA may be A or G
- the first letter base of the anticodon of the second tRNA may be C or U. ..
- the first letter base of each anticodon of the first tRNA and the second tRNA is exemplified by the following combinations: (A, C); (C, A); (G). , C); (C, G); (A, U); (U, A); (G, U); (U, G).
- (A, C) indicates that the first-letter base of the anticodon of the first tRNA is A and the first-letter base of the anticodon of the second tRNA is C.
- the tRNA bodies of the first tRNA and the second tRNA contained in the set of tRNAs in the present disclosure may be different from each other or may be the same.
- the base sequences at positions 1-31 and 39-74 of the first tRNA and the second tRNA are the same, or 80% or more, 85% or more, 90% or more, 91% or more, It may have 92% or more, 93% or more, 94% or more, 95% or more, 96% or more, 97% or more, or 98% or more sequence identity.
- different amino acids may be bound to the first tRNA and the second tRNA contained in the set of tRNAs in the present disclosure.
- the amino acid bound to the first tRNA may be referred to as the first amino acid
- the amino acid bound to the second tRNA may be referred to as the second amino acid.
- at least one selected from the first and second amino acids in the present disclosure may be an unnatural amino acid. That is, at least one or both of the set of tRNAs in the present disclosure may be bound to unnatural amino acids.
- one or both of the first tRNA and the second tRNA may be tRNAs in which unnatural amino acids are bound to the tRNA outside the translation system.
- first tRNA and the second tRNA have a chimeric tRNA body having a combination of 32U, 33U, 37G, and 38U bases:
- the set of tRNAs including the first tRNA and the second tRNA having at least one anticodon combination selected from the group consisting of (L1) to (L4) is from the set of tRNAs of the present disclosure.
- the second letter base of (L3) anticodon is C and the third letter base is G; and the second letter base of (L4) anticodon is A and the third letter.
- the bases of are all G.
- the composition for translation in the present disclosure is not limited as long as it contains the tRNA of the present disclosure, but may contain components necessary for translation, and may contain the same components as the translation system in the present disclosure.
- the translation composition in the present disclosure may be a cell-free translation system or a reconstituted cell-free translation system.
- the translational composition in the present disclosure may be a cell-free translation system reconstituted with E. coli-derived factors, including ribosomes, translation initiation factors, translation termination factors, translations. It may contain elongation factors, amino acids, aminoacyl-tRNA synthetase (aaRS), and the like.
- the translational compositions of the present disclosure may comprise E. coli-derived ribosomes.
- the tRNAs of the present disclosure may be E. coli-derived tRNAs.
- the translational composition of the present disclosure may include a set of tRNAs of the present disclosure.
- the composition for translation in the present disclosure may include 1 set, 2 sets, 3 sets, 4 sets, 5 sets, 6 sets, 7 sets or 8 sets of the set of tRNAs in the present disclosure, or 1 set.
- Set or more, 2 sets or more, 3 sets or more, 4 sets or more, 5 sets or more, or 6 sets or more may be included, or 8 sets or less, 7 sets or less, 6 sets or less, 5 sets or less, 4 sets or less. 3, 3 sets or less, or 2 sets or less may be included.
- the translational compositions of the present disclosure may contain tRNAs other than those described above.
- the set of tRNAs in the present disclosure included in the translational composition of the present disclosure is a tRNA that, if the translational composition contains aaRS, has an orthogonal relationship with the aaRS. It's okay.
- a tRNA having an orthogonal relationship with aaRS means a tRNA that is not aminoacylated by aaRS present in the translation composition, but can be incorporated into the ribosome to translate and introduce amino acids. Examples of such tRNA include tRNA such as tRNAGlu2, tRNAAsnE2, tRNAAsp1 and tRNAPro1E2, or tRNA derived from these. If necessary, aaRS that recognizes these tRNAs is removed from the translation composition.
- the translational compositions of the present disclosure need not include aaRS, which is capable of binding an amino acid to any of the tRNAs.
- the translation compositions and translation kits of the present disclosure can reduce codon misreading.
- the translation compositions and translation kits of the present disclosure can reduce the rate at which unintended amino acids are translated and introduced due to codon misreading.
- the translation compositions and translation kits of the present disclosure can reduce the rate at which codons contained in template mRNA are translated by tRNAs that have anticodons that are not complementary to the codons.
- the translation compositions and kits of the present disclosure have anticodons in the second and third letters complementary to the second and first letters of the codon, respectively, and Watson- It is possible to form a click-type base pair, and further, it is possible to reduce misreading of the codon due to tRNA in which the first character of the anticodon is not complementary to the third character of the codon. In some embodiments, this reduction in misreading allows the use of the translation compositions and translation kits of the present disclosure to assign two or more amino acids within the same codon box. In certain embodiments, it is possible to assign two or more unnatural amino acids within the same codon box.
- the properties of the tRNA itself can be altered according to the present disclosure, so that the amount of aminoacyl-tRNA contained in the translation composition or constituting the translation kit is adjusted or the translation reaction is stopped prematurely. It is more convenient than the method of doing.
- the reverse misreading will occur. It is possible that it will occur.
- the translation composition and translation kit in the present disclosure are also useful in that accurate peptide translation can be realized without increasing the amount of aminoacyl-tRNA in the translation system.
- the translation compositions and translation kits of the present disclosure can be used in conjunction with techniques such as adjusting the amount of aminoacyl-tRNA and stopping the translation reaction prematurely to achieve higher codon readings. An error reduction effect can be obtained.
- multiple tRNAs that bind different amino acids assigned to different codons in the same codon box are independent relationships that do not misread each other. It can be said that there is an orthogonal (orthogonal) relationship.
- orthogonal (orthogonal) relationship In the translation system of naturally occurring organisms, a strict correspondence between codons and amino acids is originally established, and when non-orthogonal tRNA is added to it, the correspondence is broken and translation is performed. It may have a fatal effect on the function of the system. Therefore, in one aspect of the present disclosure, the establishment of orthogonality between the plurality of types of tRNAs can be one of the important features.
- the translation compositions and kits of the present disclosure are naturally inherited, such as UCM, CUM, CCM, CGM, ACM, GUM, GCM, GGM, while reducing codon misreading. It is possible to assign a plurality of amino acids, particularly a plurality of amino acids including an unnatural amino acid, to a codon box to which only one amino acid is assigned in the code table.
- the method of assigning amino acids is not particularly limited, but for example, the first type of amino acid is assigned to the codon of M 1 M 2 U or M 1 M 2 C, and the second type of amino acid is assigned to M 1 M 2 A or M 1 M 2 C.
- the first type of amino acid may be assigned to the codon of M 1 M 2 U, or the second type of amino acid may be assigned to the codon of M 1 M 2 G.
- the translation compositions and translation kits of the present disclosure complement at least one mRNA having a codon complementary to the anticodon of the second tRNA and / or the anticodon of the first tRNA. It may contain at least one type of mRNA having a specific codon. In some embodiments, the two codons may be on the same mRNA or on different mRNAs. In some embodiments, the translational compositions of the present disclosure may comprise multiple types of mRNA that are different in sequence from each other and may include an mRNA library.
- the method of making the translation composition and translation kit of the present disclosure may include the step of preparing the first and / or second tRNA by in vitro transcription.
- the method of making a translation composition and a translation kit of the present disclosure may comprise preparing the tRNA of the present disclosure by binding an amino acid to the tRNA outside the translation system. It may include preparing a first tRNA and a second tRNA by binding an amino acid to the tRNA outside the translation system.
- the methods of making the translation compositions and translation kits of the present disclosure may include the methods of preparing the tRNAs of the present disclosure described above.
- the amino acid may be an unnatural amino acid.
- the method for producing a peptide of the present disclosure may comprise translating a template nucleic acid using the translation composition or translation kit of the present disclosure.
- the translation method is not limited, but examples thereof include in vitro translation, for example, translation using a reconstituted cell-free translation system, and more specifically, a reconstituted cell-free translation system derived from Escherichia coli was used. Translation is illustrated.
- the method for producing a peptide of the present disclosure is an mRNA having a codon complementary to the anticodon of the second tRNA, and / or the first, using the translation composition or translation kit of the present disclosure. It may include translating an mRNA having a codon complementary to the anticodon of one tRNA. In some embodiments, the two codons may be contained in the same mRNA or in different mRNAs. In some embodiments, the method for producing a peptide of the present disclosure may comprise translating a plurality of types of nucleic acids with different sequences from each other using the translational compositions of the present disclosure, translating a nucleic acid library. May include translating the mRNA library.
- the mRNA may encode a peptide having the desired or random amino acid sequence.
- translation of the mRNA into a peptide can be performed.
- RNA polymerase for transcribing DNA into mRNA is included in the translation system, by adding the DNA to the translation system of the present disclosure, the transcription of the DNA into the mRNA and the transcription of the mRNA into the peptide are performed. Translation can also be performed.
- the codon complementary to the anticodon may be a codon that forms a Watson-click base pair at all three bases of the anticodon, or the third letter of the codon is one of the anticodons. It may be a codon that forms a wobble base pair with the letter.
- the methods for producing the peptides of the present disclosure are at least one, two or more, three or more selected from the group consisting of UCM, CUM, CCM, CGM, ACM, GUM, GCM, and GGM. It may include assigning a plurality of types of amino acids to four or more, five or more, or six or more codon boxes. Even in such a case, accurate peptide translation may be possible.
- Codon misreading can be reduced by assigning different types of amino acids to codons that are: (i) U and G, (ii) C and G, (iii) U and A, and (iv) C and A.
- reduction of codon misreading by tRNA may be evaluated by translating one type of template mRNA using a plurality of tRNAs having different anticodons to which different amino acids are bound.
- the plurality of tRNAs include tRNA having an anticodon complementary to a specific codon to be translated, and tRNA having an anticodon complementary to a codon existing in the same codon box as the codon and having an anticodon different from the anticodon. You may choose.
- a translation system containing a tRNA having anticodon AGG and binding to amino acid AA 1 and a tRNA having anticodon CGG and binding to amino acid AA 2 to evaluate misreading of codon CCG by a tRNA having anticodon AGG.
- AA 2 translated and introduced by a tRNA having a CGG complementary to the codon CCG in the anticodon is the target translated amino acid
- AA 1 translated and introduced by a tRNA having an AGG not complementary to the codon CCG in the anticodon Is a translated amino acid caused by misreading.
- the reduction of misreading may be evaluated using the ratio of such translation products as an index.
- MR-1 to MR-7 described in Examples may be selected and used, or another mRNA may be used according to the codon to be evaluated.
- the translation system for translating the template mRNA a reconstituted cell-free protein synthesis system derived from prokaryotes (for example, PURE system) may be used. Further, as the translation condition, "translation condition 1" in the present disclosure may be used. More detailed translation methods and evaluation methods are described in Examples.
- the reduction of codon misreading by tRNA can be evaluated by the ratio (%) of misread peptides to the target molecule.
- the ratio is calculated using the following formula. When the ratio is lower than that of the control tRNA in which the combination of the bases at positions 32, 33, 37 and 38 is not modified, it is judged that the tRNA to be evaluated has the effect of reducing codon misreading.
- the reduction rate of the above-mentioned ratio is not particularly limited, but the tRNA of the present disclosure has the above-mentioned ratio of 5% or more, 10% or more, 20% or more, 30% or more, 40% or more, or 50% or more as compared with the control. May show a decrease in.
- a peptide obtained when read correctly may be referred to as a translation product or a target product when read correctly.
- the translation amount of the peptide may be determined by the following method. That is, the translation product solution obtained after the completion of the translation reaction is diluted and analyzed using the LC-FLR-MS device. An example of the dilution ratio is 10 times. The retention time of the target translated peptide is identified from the obtained MS data, and the amount of peptide translation is evaluated by quantifying the fluorescence peak of the corresponding retention time. The quantification is performed by creating a calibration curve using the standard and calculating the content by relative quantification. As the standard, LCT-67 or LCT-12 may be used.
- LCT-67 The sequence of LCT-67 is BdpF: Thr: Phe: Ile: Ile: Gly: Phe: Ile: Ile: Ile: Pro: Ile: Gly (SEQ ID NO: 237), and the sequence of LCT-12 is BdpF: Thr: It is represented by Ile: Phe: Pro: Gly: Phe: Ile: Ile: Thr: Thr: Gly: Thr: Gly: Thr: Gly: Ala (SEQ ID NO: 238).
- the present disclosure provides peptides and peptide libraries produced using the translational compositions of the present disclosure.
- the peptides in the present disclosure include peptides obtained by chemical modification after translation, and also include peptide-nucleic acid complexes to which nucleic acids are linked.
- An example of post-translational chemical modification is cyclization of linear peptides.
- a peptide bond formed from an amino group and a carboxyl group can be used.
- Carbon-carbon bonds can be formed by transition metal-catalyzed reactions such as the Suzuki reaction, the Heck reaction, and the Sonogashira reaction.
- the peptides of the present disclosure contain at least one set of functional groups capable of forming the above bonds in the molecule.
- the formation of the cyclic portion may be carried out by separately carrying out a reaction for binding the above-mentioned functional groups after the linear peptide is produced using the translation system of the present disclosure.
- a method for identifying a peptide that can bind to a target molecule from a peptide library (display library) using a peptide-nucleic acid complex is known.
- a display library is a library characterized in that a phenotype and a genotype are associated with each other by binding a peptide and a nucleic acid encoding the peptide to form one complex.
- major display libraries are the mRNA display method (Roberts and Szostak, Proc Natl Acad Sci USA (1997) 94: 12297-12302), in vitro virus method (Nemoto et al., FEBS Lett (1997) 414: 405).
- cDNA display method (Yamaguchi et al., Nucleic Acids Res (2009) 37: e108), Ribosome display method (Mattheakis et al, Proc Natl Acad Sci USA (1994) 91: 9022-9026), covalent display method (Reiersen et al., Nucleic Acids Res (2005) 33: e10), CIS display method (Odegrip et al., Proc Natl Acad Sci USA (2004) 101: 2806-2810), etc. Can be done.
- a library created by using the in vitro compartmentalization method (Tawfik and Griffiths, Nat Biotechnol (1998) 16: 652-656) can also be mentioned as one aspect of the display library.
- the present disclosure provides a method for identifying a peptide having binding activity to a target molecule, which comprises contacting the target molecule with the peptide library described in the present disclosure.
- the target molecule is not particularly limited, and can be appropriately selected from, for example, low molecular weight compounds, high molecular weight compounds, nucleic acids, peptides, proteins, sugars, lipids and the like.
- the target molecule may be a molecule existing outside the cell or a molecule existing inside the cell. Alternatively, it may be a molecule present in the cell membrane, in which case any of the extracellular domain, transmembrane domain, and intracellular domain may be targeted.
- the target molecule In the step of contacting the peptide library with the target molecule, the target molecule is usually immobilized on some solid phase carrier (eg, microtiter plate, microbead, etc.). Then, by removing the peptide that is not bound to the target molecule and recovering only the peptide that is bound to the target molecule, the peptide having the binding activity to the target molecule can be selectively concentrated (). Panning method).
- the peptide library used is a nucleic acid display library
- the nucleic acid encoding the genetic information is bound to the recovered peptide. Therefore, by isolating and analyzing them, the nucleic acid encoding the recovered peptide is used.
- the sequence and amino acid sequence can be easily identified. Furthermore, based on the obtained nucleic acid sequence or amino acid sequence, the identified peptides can be individually produced by chemical synthesis or gene recombination method.
- the present disclosure provides a method for reducing codon misreading by tRNA, compositions and kits for reducing codon misreading by tRNA.
- Such compositions and kits may include the tRNAs in the present disclosure.
- the method may also include obtaining the tRNAs of the present disclosure by modifying the tRNAs. Specifically, the second with the tRNA comprising substituting at least one base selected from the group consisting of positions 32, 33, 37 and 38 of the tRNA having an anti-codon complementary to the first codon.
- a method for reducing codon misreading wherein the substituted tRNA is the tRNA of the present disclosure, and the first letter of the first codon and the first character of the second codon are the same base.
- the second letter of the first codon and the second codon may be the same base, and the third letter of the first codon and the second codon may be different bases.
- the first codon is M 1 M 2 X and the second codon is M 1 M 2 Y, said M. 1 and M 2 are independently A, C, G or U, respectively, and X and Y may be different bases selected from A, C, G and U, respectively.
- the combination of the bases of X and Y may be selected from the group consisting of the following (a1) to (a8): (a1) U and G; (a2) G and U; (a3). ) U and A; (a4) A and U; (a5) C and A; (a6) A and C; (a7) C and G; and (a8) G and C.
- the combination of the bases X and Y is M 31 and M 32 means that X is base M 31 and Y is base M 32 .
- the combination of the X and Y bases is selected from the group consisting of (a1)-(a3), (a5) and (a7), or the group consisting of (a1) and (a2). It may be any of the above.
- the M 1 M 2 may be any of the nucleotide sequences selected from the group consisting of (b1)-(b8) below: (b1) CC; (b2) CU; (b3) GG; (b4) GU; (b5) GC; (b6) UC; (b7) CG; and (b8) AC.
- the M 1 M 2 may be any base sequence selected from the group consisting of (b1) to (b3).
- the first codon and the anticodon of the tRNA may form Watson-click base pairs at all three bases, or
- the third-letter base of the first codon and the first-letter base of the anticodon of the tRNA may form wobble base pairs.
- a method of reducing codon misreading of the present disclosure is a method of reducing codon misreading that is complementary to the anticodon of the second tRNA of the present disclosure by the first tRNA of the present disclosure. It may be there. In some embodiments, the method of reducing codon misreading of the present disclosure may include the method of preparing the tRNA of the present disclosure described above.
- BdpFL-Phe may be referred to as "BdpF".
- the buffer solution A was prepared as follows. Acetic acid was added to an aqueous solution of N, N, N-trimethylhexadecane-1-aminium chloride (6.40 g, 20 mmol) and imidazole (6.81 g, 100 mmol), and pH 8, 20 mM N, N, N-trimethylhexadecane- A buffer solution A (1 L) of 1-aminium and 100 mM imidazole was obtained.
- Dihydrogen phosphate ((2R, 3R, 4R, 5R) -5- (4-amino-2-oxopyrimidine-1 (2H) -yl) -3-((((((((()) 2R, 3S, 4R, 5R) -5- (6-amino-9H-purine-9-yl) -3,4-dihydroxytetra-2-yl) methoxy) (hydroxy) phosphoryl) oxy) -4-(( Methyl (compound pc01) (127 mg, 0.176 mmol) (tetra-2-yl) oxy) tetrahydrofuran-2-yl) is dissolved to dissolve (S) -2-((((4- (2- (4-fluorophenyl)).
- Trifluoroacetic acid (2.3 mL) was added to the reaction solution, the reaction solution was freeze-dried, and then subjected to reverse phase silica gel column chromatography (0.05% trifluoroacetic acid aqueous solution / 0.05% trifluoroacetic acid acetonitrile). Purification gave the title compound (Compound SS45, F-Pnaz-MeG-pCpA) (76.7 mg, 26%).
- LCMS (ESI) m / z 1007.5 (MH)- Retention time: 0.48 minutes (analysis condition SQDFA05_02)
- Lysidine-diphosphate for introducing Lysidine unit into the 3'end of the tRNA fragment by the ligation method
- the method for synthesizing Lyphosphate diphosphate used to introduce the Lysidine unit into the 3'end of the tRNA fragment by the ligation method was improved. That is, Lysidine-diphosphate (SS04, pLp) was synthesized according to the following scheme.
- the mixture was stirred at room temperature for 18 hours under a hydrogen atmosphere.
- the reaction mixture was filtered through Celite and washed several times with ultrapure water.
- 1 mol / L hydrochloric acid (2.74 mL, 2.74 mmol) was added to the obtained filtrate (24.66 mL), and the mixture was allowed to stand at room temperature for 1 hour.
- the reaction mixture was filtered through Celite and washed several times with ultrapure water. After lyophilizing the filtrate, the obtained powder was dissolved again in ultrapure water (1.52 mL), centrifuged, and the supernatant was recovered.
- Example 3 Synthesis of peptide (LCT-67) having BdpFL at N-terminus
- Fmoc-Gly-OH as an Fmoc amino acid, Fmoc-Thr (THP) -OH synthesized by the method described in Patent Document (WO20182255864) using 2-kuguchi lithyl resin (100 mg) carrying Fmoc-Gly-OH. (Aa01), Fmoc-Ile-OH, Fmoc-Leu-OH, Fmoc-Phe-OH, Fmoc-MePhe-OH, and Fmoc-Pro-OH were used to extend the peptide in a peptide synthesizer (amino acid). Abbreviations are described separately in this specification).
- the peptide was elongated according to the peptide synthesis method by the Fmoc method (WO2013100132B2). After elongation of the peptide, the N-terminal Fmoc group was removed on a peptide synthesizer, and then the resin was washed with DCM. TFE / DCM (1: 1, v / v, 2 mL) was added to the resin and shaken for 1 hour to cut out the peptide from the resin. After completion of the reaction, the resin was removed by filtering the solution in the tube with a synthetic column, and the resin was washed twice with TFE / DCM (1: 1, v / v, 1 mL).
- the N-terminal Fmoc group was removed on a peptide synthesizer, and then the resin was washed with DCM.
- TFE / DCM (1: 1, v / v, 2 mL) was added to the resin and shaken for 1 hour to cut out the peptide from the resin.
- the resin was removed by filtering the solution in the tube with a synthetic column, and the resin was washed twice with TFE / DCM (1: 1, v / v, 1 mL). All the extracts were mixed, DMF (2 mL) was added, and the mixture was concentrated under reduced pressure.
- Example 4 Synthesis of aminoacyl-tRNA
- TR-1 to TR-107 was synthesized from template DNA (TD-1 to TD-107) by in vitro transcription reaction using T7 RNA polymerase, and RNeasy kit (Qiagen). Purified by the company).
- Template DNA SEQ ID NO: 1 (TD-1) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCCTaagAAGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 2 (TD-2) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTaagACGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 3 (TD-3) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTaagAAGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 4 (TD-4) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCCTaagACGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 5 (TD-5) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCCTaagGAGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 6 (TD-6) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTaagATGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 7 DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTaagGTGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 8 (TD-8) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTaagGAGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 10 DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCATaagATGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 28 (TD-28) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTaggGAGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 31 (TD-31) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCCTcggAAGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 32 (TD-32) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTcggACGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 33 (TD-33) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTcggAAGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 34 (TD-34) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCCTcggACGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 35 (TD-35) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCCTcggGAGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 36 (TD-36) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTcggATGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 37 (TD-37) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTcggGTGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 38 (TD-38) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTcggGAGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 40 DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCATcggATGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 41 (TD-41) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCCTaccAAGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 42 (TD-42) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTaccACGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 44 (TD-44) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCCTaccACGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 45 (TD-45) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCCTaccGAGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 46 (TD-46) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTaccATGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 48 DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTaccGAGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 51 (TD-51) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCCTcccAAGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 52 (TD-52) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTcccACGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 61 (TD-61) DNA sequence: GGCGTAATACGACTCACTATAGGAGCGGTAGTTCAGTCGGTTAGAATACCTGCCTaagAAGCAGGGGGTCGCGGGTTCGAGTCCCGTCCGTTCCGC
- Template DNA SEQ ID NO: 62 (TD-62) DNA sequence: GGCGTAATACGACTCACTATAGGAGCGGTAGTTCAGTCGGTTAGAATACCTGCTTaagACGCAGGGGGTCGCGGGTTCGAGTCCCGTCCGTTCCGC
- Template DNA SEQ ID NO: 64 (TD-64) DNA sequence: GGCGTAATACGACTCACTATAGGAGCGGTAGTTCAGTCGGTTAGAATACCTGCCTaagACGCAGGGGGTCGCGGGTTCGAGTCCCGTCCGTTCCGC
- Template DNA SEQ ID NO: 65 (TD-65) DNA sequence: GGCGTAATACGACTCACTATAGGAGCGGTAGTTCAGTCGGTTAGAATACCTGCCTaagGAGCAGGGGGTCGCGGGTTCGAGTCCCGTCCGTTCCGC
- Template DNA SEQ ID NO: 66 (TD-66) DNA sequence: GGCGTAATACGACTCACTATAGGAGCGGTAGTTCAGTCGGTTAGAATACCTGCTTaagATGCAGGGGGTCGCGGGTTCGAGTCCCGTCCGTTCCGC
- Template DNA SEQ ID NO: 68 (TD-68) DNA sequence: GGCGTAATACGACTCACTATAGGAGCGGTAGTTCAGTCGGTTAGAATACCTGCTTaagGAGCAGGGGGTCGCGGGTTCGAGTCCCGTCCGTTCCGC
- Template DNA SEQ ID NO: 70 (TD-70) DNA sequence: GGCGTAATACGACTCACTATAGGAGCGGTAGTTCAGTCGGTTAGAATACCTGCATaagATGCAGGGGGTCGCGGGTTCGAGTCCCGTCCGTTCCGC
- Template DNA SEQ ID NO: 71 (TD-71) DNA sequence: GGCGTAATACGACTCACTATAGGAGCGGTAGTTCAGTCGGTTAGAATACCTGCCTcagAAGCAGGGGGTCGCGGGTTCGAGTCCCGTCCGTTCCGC
- Template DNA SEQ ID NO: 72 (TD-72) DNA sequence: GGCGTAATACGACTCACTATAGGAGCGGTAGTTCAGTCGGTTAGAATACCTGCTTcagACGCAGGGGGTCGCGGGTTCGAGTCCCGTCCGTTCCGC
- Template DNA SEQ ID NO: 74 (TD-74) DNA sequence: GGCGTAATACGACTCACTATAGGAGCGGTAGTTCAGTCGGTTAGAATACCTGCCTcagACGCAGGGGGTCGCGGGTTCGAGTCCCGTCCGTTCCGC
- Template DNA SEQ ID NO: 75 (TD-75) DNA sequence: GGCGTAATACGACTCACTATAGGAGCGGTAGTTCAGTCGGTTAGAATACCTGCCTcagGAGCAGGGGGTCGCGGGTTCGAGTCCCGTCCGTTCCGC
- Template DNA SEQ ID NO: 80 (TD-80) DNA sequence: GGCGTAATACGACTCACTATAGGAGCGGTAGTTCAGTCGGTTAGAATACCTGCATcagATGCAGGGGGTCGCGGGTTCGAGTCCCGTCCGTTCCGC
- Template DNA SEQ ID NO: 81 (TD-81) DNA sequence: GGCGTAATACGACTCACTATAGGCTCTGTAGTTCAGTCGGTAGAACGGCGGACTaagAATCCGTATGTCACTGGTTCGAGTCCAGTCAGAGCCGC
- Template DNA SEQ ID NO: 82 (TD-82) DNA sequence: GGCGTAATACGACTCACTATAGGCTCTGTAGTTCAGTCGGTAGAACGGCGGATTaagACTCCGTATGTCACTGGTTCGAGTCCAGTCAGAGCCGC
- Template DNA SEQ ID NO: 83 (TD-83) DNA sequence: GGCGTAATACGACTCACTATAGGCTCTGTAGTTCAGTCGGTAGAACGGCGGATTaagAATCCGTATGTCACTGGTTCGAGTCCAGTCAGAGCCGC
- Template DNA SEQ ID NO: 84 (TD-84) DNA sequence: GGCGTAATACGACTCACTATAGGCTCTGTAGTTCAGTCGGTAGAACGGCGGACTaagACTCCGTATGTCACTGGTTCGAGTCCAGTCAGAGCCGC
- Template DNA SEQ ID NO: 85 (TD-85) DNA sequence: GGCGTAATACGACTCACTATAGGCTCTGTAGTTCAGTCGGTAGAACGGCGGACTaagGATCCGTATGTCACTGGTTCGAGTCCAGTCAGAGCCGC
- Template DNA SEQ ID NO: 86 (TD-86) DNA sequence: GGCGTAATACGACTCACTATAGGCTCTGTAGTTCAGTCGGTAGAACGGCGGATTaagATTCCGTATGTCACTGGTTCGAGTCCAGTCAGAGCCGC
- Template DNA SEQ ID NO: 88 (TD-88) DNA sequence: GGCGTAATACGACTCACTATAGGCTCTGTAGTTCAGTCGGTAGAACGGCGGATTaagGATCCGTATGTCACTGGTTCGAGTCCAGTCAGAGCCGC
- Template DNA SEQ ID NO: 90 (TD-90) DNA sequence: GGCGTAATACGACTCACTATAGGCTCTGTAGTTCAGTCGGTAGAACGGCGGAATaagATTCCGTATGTCACTGGTTCGAGTCCAGTCAGAGCCGC
- Template DNA SEQ ID NO: 91 (TD-91) DNA sequence: GGCGTAATACGACTCACTATAGGCTCTGTAGTTCAGTCGGTAGAACGGCGGACTcagAATCCGTATGTCACTGGTTCGAGTCCAGTCAGAGCCGC
- Template DNA SEQ ID NO: 92 (TD-92) DNA sequence: GGCGTAATACGACTCACTATAGGCTCTGTAGTTCAGTCGGTAGAACGGCGGATTcagACTCCGTATGTCACTGGTTCGAGTCCAGTCAGAGCCGC
- Template DNA SEQ ID NO: 94 (TD-94) DNA sequence: GGCGTAATACGACTCACTATAGGCTCTGTAGTTCAGTCGGTAGAACGGCGGACTcagACTCCGTATGTCACTGGTTCGAGTCCAGTCAGAGCCGC
- Template DNA SEQ ID NO: 97 (TD-97) DNA sequence: GGCGTAATACGACTCACTATAGGCTCTGTAGTTCAGTCGGTAGAACGGCGGATTcagGTTCCGTATGTCACTGGTTCGAGTCCAGTCAGAGCCGC
- Template DNA SEQ ID NO: 100 (TD-100) DNA sequence: GGCGTAATACGACTCACTATAGGCTCTGTAGTTCAGTCGGTAGAACGGCGGAATcagATTCCGTATGTCACTGGTTCGAGTCCAGTCAGAGCCGC
- Template DNA SEQ ID NO: 101 DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCCTgccACGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 102 (TD-102) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCTTgccGTGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- Template DNA SEQ ID NO: 104 (TD-104) DNA sequence: GGCGTAATACGACTCACTATAGTCCCCTTCGTCTAGAGGCCCAGGACACCGCCCTtccACGGCGGTAACAGGGGTTCGAATCCCCTAGGGGACGC
- tRNA SEQ ID NO: 108 (TR-1) tRNA (Glu2 + Ser5) aag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUaagAAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 109 (TR-2) tRNA (Glu2 + Ala1B) aag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaagACGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 110 TR-3 tRNA (Glu2 + Phe) aag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaagAAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 111 TR-4) tRNA (Glu2) aag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUaagACGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 112 TR-5 tRNA (Glu2 + Arg3) aag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUaagGAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 113 TR-6 tRNA (Glu2 + Val2) aag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaagAUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 114 (TR-7) tRNA (Glu2 + Leu2) aag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaagGUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 115 TR-8 tRNA (Glu2 + Pro3) aag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaagGAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 116 TR-9) tRNA (Glu2 + Pro2) aag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCAUaagGUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 117 TR-10 tRNA (Glu2 + Ala2) aag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCAUaagAUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 118 (TR-11) tRNA (Glu2 + Ser5) cag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUcagAAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 119 (TR-12) tRNA (Glu2 + Ala1B) cag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcagACGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 120 (TR-13) tRNA (Glu2 + Phe) cag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcagAAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 121 TR-14 tRNA (Glu2) cag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUcagACGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 122 TR-15 tRNA (Glu2 + Arg3) cag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUcagGAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 123 (TR-16) tRNA (Glu2 + Val2) cag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcagAUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 124 (TR-17) tRNA (Glu2 + Leu2) cag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcagGUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 125 (TR-18) tRNA (Glu2 + Pro3) cag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcagGAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 126 TR-19 tRNA (Glu2 + Pro2) cag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCAUcagGUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 127 TR-20 tRNA (Glu2 + Ala2) cag-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCAUcagAUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 128 (TR-21) tRNA (Glu2 + Ser5) agg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUaggAAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 129 TR-22
- tRNA (Glu2 + Ala1B) agg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaggACGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 130 (TR-23) tRNA (Glu2 + Phe) agg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaggAAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 131 TR-24 tRNA (Glu2) agg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUaggACGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 132 TR-25 tRNA (Glu2 + Arg3) agg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUaggGAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 133 TR-26 tRNA (Glu2 + Val2) agg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaggAUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 134 TR-27 tRNA (Glu2 + Leu2) agg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaggGUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 135 TR-28 tRNA (Glu2 + Pro3) agg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaggGAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 136 TR-29 tRNA (Glu2 + Pro2) agg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCAUaggGUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 137 TR-30 tRNA (Glu2 + Ala2) agg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCAUaggAUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 138 (TR-31) tRNA (Glu2 + Ser5) cgg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUcggAAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 139 TR-32
- tRNA (Glu2 + Ala1B) cgg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcggACGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 140 (TR-33) tRNA (Glu2 + Phe) cgg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcggAAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 141 TR-34) tRNA (Glu2) cgg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUcggACGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 142 TR-35 tRNA (Glu2 + Arg3) cgg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUcggGAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 143 (TR-36) tRNA (Glu2 + Val2) cgg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcggAUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 144 TR-37 tRNA (Glu2 + Leu2) cgg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcggGUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 145 (TR-38) tRNA (Glu2 + Pro3) cgg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcggGAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 146 TR-39 tRNA (Glu2 + Pro2) cgg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCAUcggGUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 147 (TR-40) tRNA (Glu2 + Ala2) cgg-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCAUcggAUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 148 (TR-41) tRNA (Glu2 + Ser5) acc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUaccAAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 149 (TR-42) tRNA (Glu2 + Ala1B) acc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaccACGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 150 TR-43 tRNA (Glu2 + Phe) acc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaccAAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 151 TR-44) tRNA (Glu2) acc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUaccACGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 152 TR-45 tRNA (Glu2 + Arg3) acc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUaccGAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 153 TR-46) tRNA (Glu2 + Val2) acc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaccAUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 154 TR-47 tRNA (Glu2 + Leu2) acc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaccGUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 155 TR-48 tRNA (Glu2 + Pro3) acc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUaccGAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 156 TR-49 tRNA (Glu2 + Pro2) acc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCAUaccGUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 157 TR-50 tRNA (Glu2 + Ala2) acc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCAUaccAUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 158 TR-51) tRNA (Glu2 + Ser5) ccc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUcccAAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 159 TR-52 tRNA (Glu2 + Ala1B) ccc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcccACGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 160 TR-53 tRNA (Glu2 + Phe) ccc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcccAAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 161 TR-54
- tRNA SEQ ID NO: 162 TR-55 tRNA (Glu2 + Arg3) ccc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUcccGAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 163 TR-56
- tRNA (Glu2 + Val2) ccc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcccAUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 164 TR-57 tRNA (Glu2 + Leu2)
- ccc-CA RNA sequence GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcccGUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 165 TR-58 tRNA (Glu2 + Pro3) ccc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUcccGAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 166 TR-59 tRNA (Glu2 + Pro2) ccc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCAUcccGUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 167 TR-60 tRNA (Glu2 + Ala2) ccc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCAUcccAUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 168 (TR-61) tRNA (Asp1 + Ser5) aag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCCUaagAAGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 169 (TR-62) tRNA (Asp1 + Ala1B) aag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCUUaagACGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 170 TR-63 tRNA (Asp1 + Phe) aag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCUUaagAAGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 171 TR-64) tRNA (Asp1) aag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCCUaagACGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 172 (TR-65) tRNA (Asp1 + Arg3) aag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCCUaagGAGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 173 (TR-66) tRNA (Asp1 + Val2) aag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCUUaagAUGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 174 (TR-67) tRNA (Asp1 + Leu2) aag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCUUaagGUGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 175 (TR-68) tRNA (Asp1 + Pro3) aag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCUUaagGAGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 176 TR-69 tRNA (Asp1 + Pro2) aag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCAUaagGUGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 177 (TR-70) tRNA (Asp1 + Ala2) aag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCAUaagAUGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 178 (TR-71) tRNA (Asp1 + Ser5) cag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCCUcagAAGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 179 (TR-72) tRNA (Asp1 + Ala1B) cag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCUUcagACGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 180 (TR-73) tRNA (Asp1 + Ph2) cag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCUUcagAAGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 181 (TR-74) tRNA (Asp1) cag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCCUcagACGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 182 (TR-75) tRNA (Asp1 + Arg3) cag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCCUcagGAGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 183 (TR-76) tRNA (Asp1 + Val2) cag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCUUcagAUGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 184 (TR-77) tRNA (Asp1 + Leu2) cag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCUUcagGUGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 185 (TR-78) tRNA (Asp1 + Pro3) cag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCUUcagGAGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 186 (TR-79) tRNA (Asp1 + Pro2) cag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCAUcagGUGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 187 (TR-80) tRNA (Asp1 + Ala2) cag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCAUcagAUGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 188 (TR-81) tRNA (AsnE2) aag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGACUaagAAUCCGUAUGUCUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 189 (TR-82) tRNA (AsnE2 + Ala1B) aag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAUUaagACUCCGUAUGUCACUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 190 (TR-83) tRNA (AsnE2 + Phe) aag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAUUaagAAUCCGUAUGUCACUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 191 TR-84 tRNA (AsnE2 + Glu2) aag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGACUaagACUCCGUAUGUCUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 192 (TR-85) tRNA (AsnE2 + Arg3) aag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGACUaagGAUCCGUAUGUCUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 193 (TR-86) tRNA (AsnE2 + Val2) aag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAUUaagAUUCCGUAUGUCACUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 194 (TR-87) tRNA (AsnE2 + Leu2) aag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAUUaagGUUCCGUAUGUCACUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 195 (TR-88) tRNA (AsnE2 + Pro3) aag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAUUaagGAUCCGUAUGUCACUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 196 TR-89 tRNA (AsnE2 + Pro2) aag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAAUaagGUUCCGUAUGUCUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 197 (TR-90) tRNA (AsnE2 + Ala2) aag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAAUaagAUUCCGUAUGUCUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 198 (TR-91) tRNA (AsnE2) cag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGACUcagAAUCCGUAUGUCUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 199 (TR-92) tRNA (AsnE2 + Ala1B) cag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAUUcagACUCCGUAUGUCACUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 200 (TR-93) tRNA (AsnE2 + Phe) cag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAUUcagAAUCCGUAUGUCACUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 201 (TR-94) tRNA (AsnE2 + Glu2) cag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGACUcagACUCCGUAUGUCUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 202 (TR-95) tRNA (AsnE2 + Arg3) cag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGACUcagGAUCCGUAUGUCUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 203 (TR-96) tRNA (AsnE2 + Val2) cag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAUUcagAUUCCGUAUGUCACUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 204 (TR-97) tRNA (AsnE2 + Leu2) cag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAUUcagGUUCCGUAUGUCACUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 205 (TR-98) tRNA (AsnE2 + Pro3) cag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAUUcagGAUCCGUAUGUCACUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 206 (TR-99) tRNA (AsnE2 + Pro2) cag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAAUcagGUUCCGUAUGUCACUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 207 (TR-100) tRNA (AsnE2 + Ala2) cag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAAUcagAUUCCGUAUGUCUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 208 TR-101 tRNA (Glu2) gcc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUgccACGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 209 TR-102 tRNA (Glu2 + Leu2) gcc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUgccGUGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 210 TR-103 tRNA (Glu2 + Pro3) gcc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCUUgccGAGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 211 TR-104 tRNA (Glu2) ucc-CA RNA sequence: GUCCCCUUCGUCUAGAGGCCCAGGACACCGCCCUuccACGGCGGUAACAGGGGUUCGAAUCCCCUAGGGGACGC
- tRNA SEQ ID NO: 212 (TR-105) tRNA (fMet) cau-CA RNA sequence: GGCGGGGUGGAGCAGCCUGGUAGCUCGUCGGGCUcauAACCCGAAGAUCGUCGGUUCAAAUCCGGCCCCCGCAAC
- tRNA SEQ ID NO: 213 TR-106
- tRNA (Asp1 + Leu2) _uag-CA RNA sequence GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCUUuagGUGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- tRNA SEQ ID NO: 214 (TR-107) tRNA (AsnE2 + Leu2) _uag-CA RNA sequence: GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAUUuagGUUCCGUAUGUCACUGGUUCGAGUCCAGUCAGAGCCGC
- Example 4-2 Preparation of tRNA-CA by ligation reaction
- Various tRNA-CAs were prepared by ligating the tRNA5'fragment, pLp, and tRNA3' fragments using the ligation reaction according to the procedure described below.
- a chemically synthesized product (GeneDesign, Inc.) was used for the tRNA5'fragment and the tRNA3' fragment.
- the sequence of each tRNA fragment and the full length is shown below.
- FR-1 and FR-2 were used for the preparation of TR-108
- FR-3 and FR-4 were used for the preparation of TR-109 as tRNA5'fragments and tRNA3' fragments, respectively.
- SEQ ID NO: 217 FR-1 tRNA (Asp1) 5'RNA sequence GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCUU
- tRNA (Asp1) 3'ag RNA sequence AGGUGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC tRNA SEQ ID NO: 215 (TR-108) tRNA (Asp1 + Leu2) Lag-CA RNA sequence: GGAGCGGUAGUUCAGUCGGUUAGAAUACCUGCUULagGUGCAGGGGGUCGCGGGUUCGAGUCCCGUCCGUUCCGC
- SEQ ID NO: 219 (FR-3) tRNA (AsnE2) 5'RNA sequence GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAUU
- SEQ ID NO: 220 FR-4 tRNA (AsnE2) 3'ag RNA sequence AGGUUCCGUAUGUCACUGGUUCGAGUCCAGUCAGAGCCGC
- tRNA SEQ ID NO: 216 (TR-109) tRNA (AsnE2 + Leu2) Lag-CA RNA sequence GGCUCUGUAGUUCAGUCGGUAGAACGGCGGAUULagGUUCCGUAUGUCUGGUUCGAGUCCAGUCAGAGCCGC
- Sodium periodate (NaIO 4 ) cleaved the ribose at the 3'end of the tRNA5'fragment to prevent the unreacted tRNA5'fragment from being carried over to the next ligation reaction.
- the cleavage reaction was carried out by allowing the mixture to stand on ice and in the dark for 30 minutes in the presence of a 10 ⁇ M ligation product and 10 mM sodium periodate. After the reaction, 1/10 volume of 100 mM glucose was added, and the mixture was allowed to stand on ice in the dark for 30 minutes to decompose excess sodium periodate. The reaction product was recovered by ethanol precipitation.
- the 5'end of the ligation product after the periodic acid treatment was phosphorylated, and the 3'end was dephosphorylated by T4 PNK (T4 polynucleotide kinase) treatment.
- Ligation product after 10 ⁇ M periodic acid treatment reaction solution with composition of 50 mM Tris-HCl (pH 8.0), 10 mM MgCl 2 , 5 mM DTT, 300 ⁇ M ATP, 0.5 U / ⁇ L T4 PNK (TaKaRa) The reaction was carried out by allowing the mixture to stand at 37 ° C. for 30 to 60 minutes. The reaction product was extracted with phenol / chloroform and recovered by ethanol precipitation.
- a ligation reaction was carried out between the reaction product after PNK treatment and the tRNA3'fragment.
- a solution having a composition of 10 ⁇ M PNK-treated reaction product, 10 ⁇ M tRNA3'fragment, 50 mM HEPES-KOH (pH 7.5), and 15 mM MgCl 2 is heated at 65 ° C. for 7 minutes and then at room temperature for 30 minutes.
- the reaction product after PNK treatment was annealed with the tRNA3'fragment by allowing it to stand for 1 hour.
- T4 PNK treatment was performed to phosphorylate the 5'end of the tRNA3'fragment.
- T4 PNK treatment For T4 PNK treatment, add DTT (final concentration 3.5 mM), ATP (final concentration 300 ⁇ M), and T4 PNK (final concentration 0.5 U / ⁇ L) to the annealed solution, and let stand at 37 ° C for 30 minutes. I went by thing. Subsequently, T4 RNA ligase (New England Biolabs) was added to this solution to a final concentration of 0.9 U / ⁇ L, and the mixture was allowed to stand at 37 ° C. for 30 to 40 minutes to carry out a ligation reaction. The ligation product was subjected to phenol-chloroform extraction and recovered by ethanol precipitation.
- DTT final concentration 3.5 mM
- ATP final concentration 300 ⁇ M
- T4 PNK final concentration 0.5 U / ⁇ L
- TRNA-CA prepared by the ligation method is subjected to preparative purification by high performance reverse phase chromatography (HPLC) (15 mM TEA and 400 mM HFIP aqueous solution / 15 mM TEA and 400 mM HFIP methanol solution), and then 10% modified urea. It was confirmed by polyacrylamide gel electrophoresis that it had the desired length.
- HPLC high performance reverse phase chromatography
- RNA was converted to 3'of G base by allowing a reaction solution containing 10 ⁇ M tRNA-CA, 5 U / ⁇ L RNaseT 1 (Epicentre or ThermoFisher Scientific), and 10 mM ammonium acetate (pH 5.3) to stand at 37 ° C. for 1 hour. RNA fragments containing lysidine (L) specifically cleaved on the side and introduced at pHp were analyzed.
- CUU L AGp LCMS (ESI) m / z 1020 ((M-2H) / 2)- Retention time: 3.84 minutes (analytical conditions LTQTEA / HFIP05_03) Since the molecular weights of the fragment (CUUAGp) assumed when pLp is not ligated and the fragment derived from other parts of RNA (UUCAGp) are equal, the analysis of RNA (TR-108) in the unfragmented state is also performed. went.
- AAtR-1 extended aminoacyl-tRNA
- aminoacyl-pCpA (SS15) is subjected to a ligation reaction, phenol-chloroform extraction, and ethanol precipitation by the method described above, and then extended.
- Aminoacyl-tRNAs (AAtR-2 to AAtR-103, AAtR-132, AAtR-133, AAtR-136, AAtR-137) were prepared. These aminoacyl-tRNAs were dissolved in 1 mM aqueous sodium acetate solution prior to addition to the translation mixture.
- transcribed tRNAs (TR-4, TR-14, TR-24, TR-34, TR-44, TR-54, TR-64, TR-74, TR-81, TR-91, TR-104).
- Aminoacyl-pCpA (SS16) was subjected to ligation reaction, phenol-chloroform extraction, and ethanol precipitation by the above-mentioned method to prepare extended aminoacyl-tRNA (AAtR-104 to AAtR-114).
- aminoacyl-tRNAs were dissolved in 1 mM aqueous sodium acetate solution prior to addition to the translation mixture.
- aminoacyl-pCpA (SS14) is subjected to ligation reaction, phenol-chloroform extraction, and ethanol precipitation by the method described above, and then extended.
- Aminoacyl-tRNAs (AAtR-115 to AAtR-118) were prepared. These aminoacyl-tRNAs were dissolved in 1 mM aqueous sodium acetate solution prior to addition to the translation mixture.
- aminoacyl-pCpA (SS45) was ligated to the transcribed tRNA (TR-44, TR-47, TR-48, TR-50, TR-24, TR-34) by the method described above, and phenol-chloroform was subjected to the above-mentioned method. Extraction and ethanol precipitation were performed to prepare extended aminoacyl-tRNA (AAtR-119 to AAtR-122, AAtR-129, AAtR-130). These aminoacyl-tRNAs were dissolved in 1 mM aqueous sodium acetate solution prior to addition to the translation mixture.
- aminoacyl pCpA compound ts14 synthesized by the method described in Patent Document (WO2018143145A1)
- a ligation reaction by the method described above, and phenol / chloroform.
- Extraction and ethanol precipitation were performed to prepare extended aminoacyl-tRNA (AAtR-127, AAtR-131, AAtR-135).
- This aminoacyl-tRNA was dissolved in 1 mM aqueous sodium acetate solution before being added to the translation mixture.
- AAtR-128 was recovered by ethanol precipitation and dissolved in 1 mM aqueous sodium acetate solution before being added to the translation mixture.
- Template DNA SEQ ID NO: 221 (MD-1) DNA sequence: GGCGTAATACGACTCACTATAGGGTTAACTTTAAGAAGGAGATATACATATGACTTTTATTATTGGTTTTcttATTATTCCGATTGGTTAAGCTTCG
- Template DNA SEQ ID NO: 222 (MD-2) DNA sequence: GGCGTAATACGACTCACTATAGGGTTAACTTTAAGAAGGAGATATACATATGACTTTTATTATTGGTTTTctgATTATTCCGATTGGTTAAGCTTCG
- Template DNA SEQ ID NO: 224 (MD-4) DNA sequence: GGCGTAATACGACTCACTATAGGGTTAACTTTAAGAAGGAGATATACATATGACTTTTATTATTGGTTTTccgATTATTGCTATTGGTTAAGCTTCG
- Template DNA SEQ ID NO: 225 (MD-5) DNA sequence: GGCGTAATACGACTCACTATAGGGTTAACTTTAAGAAGGAGATATACATATGACTTTTATTATTCTATTTggtATTATTCCGATTCTATAAGCTTCG
- RNA sequence GGGUUAACUUUAAGAAGGAGAUAUACAUAUGACUUUUAUUAUUGGUUUcuuAUUAUUCCGAUUGGUUAAGCUUCG
- RNA sequence GGGUUAACUUUAAGAAGGAGAUAUACAUAUGACUUUUAUUAUUGGUUUUcugAUUAUUCCGAUUGGUUAAGCUUCG
- RNA sequence GGGUUAACUUUAAGAAGGAGAUAUACAUAUGACUUUUAUUAUUGGUUUUccuAUUAUUGCUAUUGGUUAAGCUUCG
- RNA sequence GGGUUAACUUUAAGAAGGAGAUAUACAUAUGACUUUUAUUAUUGGUUUUccgAUUAUUGCUAUUGGUUAAGCUUCG
- RNA sequence GGGUUAACUUUAAGAAGGAGAUAUACAUAUGACUUUUAUUAUUCUAUUUgguAUUAUUCCGAUUCUAUAAGCUUCG
- RNA sequence GGGUUAACUUUAAGAAGGAGAUAUACAUAUGACUUUUAUUAUUCUAUUUgggAUUAUUCCGAUUCUAUAAGCUUCG
- RNA sequence GGGUUAACUUUAAGAAGGAGAUAUACAUAUGACUUUUAUUAUUGGUUUUcuaAUUAUUCCGAUUGGUUAAGCUUCG
- Example 6 Translational synthesis of peptides
- Example 6-1 The presence of two extended aminoacyl tRNAs with anticodons corresponding to different codons within the same codon box to assess the effect of the combination of bases at positions 32, 33, 37, and 38 of the tRNA on translation accuracy.
- a translation experiment was conducted below. Specifically, aminoacyl-tRNA (AatR-1 to AAtR-10 and AAtR-105) is used as the template mRNA (MR-2), and aminoacyl-tRNA (AAtR-11 to AAtR-) is used as the template mRNA (MR-1).
- Translation condition 1 A translation experiment was conducted to evaluate the amount of misreading of codon CCG by tRNA having anticodon agg.
- the translation system used was the PURE system, which is a reconstituted cell-free protein synthesis system derived from prokaryotes.
- translation solutions (1 mM GTP, 1 mM ATP, 20 mM creatine phosphate, 50 mM HEPES-KOH pH7.6, 100 mM potassium acetate, 10 mM magnesium acetate, 2 mM spermidin, 1 mM dithiothreitol, 1.5 mg / mL E.coli MRE600 (RNase negative) -derived tRNA (Roche), 0.24 ⁇ M or 0.26 ⁇ M EF-G, 0.24 ⁇ M RF2, 0.17 ⁇ M RF3, 0.5 ⁇ M RRF, 3.7 ⁇ M or 4 ⁇ g / mL creatine kinase, 2.8 ⁇ M or 3 ⁇ g / mL myokinase, 1.9 unit / mL or 2 unit / mL inorganic pyrophosphatase, 1.0 ⁇ g / mL or 1.1 ⁇ g / mL nucleoside diphosphate kinas
- translation condition 1 As a translation product, BdpF: Thr: Phe: Ile: Ile: Gly: Phe: MeHph: Ile: Ile: Ala: Ile: Gly (SEQ ID NO: 241 (Pep-3).
- the template mRNA was designed so that the amino acid sequence (which may be separated by) is translated.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: SPh2Cl: Ile: Ile: Ala: Ile: Gly (SEQ ID NO: 242 (Pep-4)) is translated when an aminoacyl-tRNA misreads a codon. ..
- a translation experiment was conducted to evaluate the amount of misreading of codon CCU by tRNA having anticodon cgg. Translation was performed according to the above translation condition 1 except that the template mRNA (MR-3) and the extended aminoacyl-tRNA (any one of AAtR-31 to AAtR-40 and AAtR-106) were used.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: MeHph: Ile: Ile: Ala: Ile: Gly (SEQ ID NO: 241 (Pep-3)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: SPh2Cl: Ile: Ile: Ala: Ile: Gly (SEQ ID NO: 242 (Pep-4)) is translated when a misreading occurs due to aminoacyl-tRNA.
- a translation experiment was conducted to evaluate the amount of misreading of codon GGG by tRNA with anticodon acc.
- Translation was performed according to the above translation condition 1 except that the template mRNA (MR-6) and the extended aminoacyl-tRNA (any one of AAtR-41 to AAtR-50 and AAtR-109) were used.
- BdpF Thr: Phe: Ile: Ile: Leu: Phe: MeHph: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 243 (Pep-5)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Leu: Phe: SPh2Cl: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 244 (Pep-6)) is translated when a misreading occurs due to aminoacyl-tRNA.
- a translation experiment was conducted to evaluate the amount of misreading of codon GGU by tRNA having anticodon ccc. Translation was performed according to the above translation condition 1 except that the template mRNA (MR-5) and the extended aminoacyl-tRNA (any one of AAtR-51 to AAtR-60 and AAtR-108) were used.
- BdpF Thr: Phe: Ile: Ile: Leu: Phe: MeHph: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 243 (Pep-5)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Leu: Phe: SPh2Cl: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 244 (Pep-6)) is translated when a misreading occurs due to aminoacyl-tRNA.
- a translation experiment was conducted to evaluate the amount of misreading of codon CUG by tRNA with anticodon aag. Translation was performed according to the above translation condition 1 except that the template mRNA (MR-2) and the extended aminoacyl-tRNA (any one of AAtR-1 to AAtR-10 and AAtR-105) were used.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: MeHph: Ile: Ile: Ile: Pro: Ile: Gly (SEQ ID NO: 239 (Pep-1)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: SPh2Cl: Ile: Ile: Pro: Ile: Gly (SEQ ID NO: 240 (Pep-2)) is translated when a misreading occurs due to aminoacyl-tRNA.
- a translation experiment was conducted to evaluate the amount of misreading of codon CUU by tRNA with anticodon cag.
- Translation was performed according to the above translation condition 1 except that the template mRNA (MR-1) and the extended aminoacyl-tRNA (any one of AAtR-11 to AAtR-20, and AAtR-104) were used.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: MeHph: Ile: Ile: Ile: Pro: Ile: Gly (SEQ ID NO: 239 (Pep-1)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: SPh2Cl: Ile: Ile: Pro: Ile: Gly (SEQ ID NO: 240 (Pep-2)) is translated when a misreading occurs due to aminoacyl-tRNA.
- Example 6-2 The tRNA body was changed and the same experiment as in Example 6-1 was performed.
- the template mRNA (MR-2) is aminoacyl-tRNA (AatR-61 to AAtR-70 and AAtR111), and the template mRNA (MR-1) is aminoacyl-tRNA (AAtR-71 to AAtR-80).
- AAtR-110) is used with either, the template mRNA (MR-2) is aminoacyl-tRNA (AAtR-81 to AAtR-90 and AAtR-113), and the template mRNA (MR-1) is aminoacyl-tRNA (AAtR-).
- Translation was performed using any of 91 to AAtR-100 and AAtR-112), and the peptide was translated and synthesized.
- Translation conditions A translation experiment was conducted to evaluate the amount of misreading of codon CUG by tRNA with anticodon aag. Translation was performed according to the above translation condition 1 except that the template mRNA (MR-2) and the extended aminoacyl-tRNA (any one of AAtR-81 to AAtR-90 and AAtR-113) were used.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: MeHph: Ile: Ile: Ile: Pro: Ile: Gly (SEQ ID NO: 239 (Pep-1)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: SPh2Cl: Ile: Ile: Pro: Ile: Gly (SEQ ID NO: 240 (Pep-2)) is translated when a misreading occurs due to aminoacyl-tRNA.
- a translation experiment was conducted to evaluate the amount of misreading of codon CUU by tRNA with anticodon cag.
- Translation was performed according to the above translation condition 1 except that the template mRNA (MR-1) and the extended aminoacyl-tRNA (any one of AAtR-91 to AAtR-100 and AAtR-112) were used.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: MeHph: Ile: Ile: Ile: Pro: Ile: Gly (SEQ ID NO: 239 (Pep-1)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: SPh2Cl: Ile: Ile: Pro: Ile: Gly (SEQ ID NO: 240 (Pep-2)) is translated when a misreading occurs due to aminoacyl-tRNA.
- a translation experiment was conducted to evaluate the amount of misreading of codon CUG by tRNA with anticodon aag. Translation was performed according to the above translation condition 1 except that the template mRNA (MR-2) and the extended aminoacyl-tRNA (any one of AAtR-61 to AAtR-70 and AAtR-111) were used.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: MeHph: Ile: Ile: Ile: Pro: Ile: Gly (SEQ ID NO: 239 (Pep-1)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: SPh2Cl: Ile: Ile: Pro: Ile: Gly (SEQ ID NO: 240 (Pep-2)) is translated when a misreading occurs due to aminoacyl-tRNA.
- a translation experiment was conducted to evaluate the amount of misreading of codon CUU by tRNA with anticodon cag.
- Translation was performed according to the above translation condition 1 except that the template mRNA (MR-1) and the extended aminoacyl-tRNA (any one of AAtR-71 to AAtR-80 and AAtR-110) were used.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: MeHph: Ile: Ile: Ile: Pro: Ile: Gly (SEQ ID NO: 239 (Pep-1)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: SPh2Cl: Ile: Ile: Pro: Ile: Gly (SEQ ID NO: 240 (Pep-2)) is translated when a misreading occurs due to aminoacyl-tRNA.
- Example 6-3 The same experiments as in Examples 6-1 and 6-2 were performed by changing the codons used. Specifically, aminoacyl-tRNA (AAtR-44, AAtR-47 or AAtR-48 and AAtR-114) is used as the template mRNA (MR-7), and aminoacyl-tRNA (AAtR-) is used as the template mRNA (MR-7). Using any of 101 to AAtR-103 and AAtR-114), the template mRNA (MR-6) is translated using aminoacyl-tRNA (AatR-101 to AAtR-103 and AAtR-109), and the peptide is translated and synthesized. did.
- Translation conditions A translation experiment was conducted to evaluate the amount of misreading of codon GGA by tRNA with anticodon acc. Translation is performed according to the above translation condition 1 except that the template mRNA (MR-7) and the extended aminoacyl-tRNA (AAtR-44, AAtR-47 and AAtR-48, and AAtR-114) are used. went. BdpF: Thr: Phe: Ile: Ile: Leu: Phe: MeHph: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 243 (Pep-5)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Leu: Phe: SPh2Cl: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 244 (Pep-6)) is translated when a misreading occurs due to aminoacyl-tRNA.
- a translation experiment was conducted to evaluate the amount of misreading of codon GGA by tRNA with anticodon gcc. Translation was performed according to the above translation condition 1 except that the template mRNA (MR-7) and the extended aminoacyl-tRNA (any one of AAtR-101 to AAtR-103 and AAtR-114) were used.
- BdpF Thr: Phe: Ile: Ile: Leu: Phe: MeHph: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 243 (Pep-5)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Leu: Phe: SPh2Cl: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 244 (Pep-6)) is translated when a misreading occurs due to aminoacyl-tRNA.
- a translation experiment was conducted to evaluate the amount of misreading of codon GGG by tRNA with anticodon gcc. Translation was performed according to the above translation condition 1 except that the template mRNA (MR-6) and the extended aminoacyl-tRNA (any one of AAtR-101 to AAtR-103 and AAtR-109) were used.
- BdpF Thr: Phe: Ile: Ile: Leu: Phe: MeHph: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 243 (Pep-5)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Leu: Phe: SPh2Cl: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 244 (Pep-6)) is translated when a misreading occurs due to aminoacyl-tRNA.
- Example 6-4 The same experiment as in Examples 6-1 to 6-3 was performed using a tRNA in which the first letter of the anticodon was modified (tRNA in which the nucleoside of the first letter of the anticodon is lysidine).
- the template mRNA MR-1, MR-8, or MR-2
- MR-1, MR-8, or MR-2 is used as an aminoacyl-tRNA (AAtR-132 or AAtR-133, AAtR-131 and AAtR-134), or an aminoacyl-tRNA (AAtR).
- -136 or AAtR-137 and AAtR-135 and AAtR-138 translation was performed according to the above translation condition 1 to translate and synthesize peptides.
- Example 6-5 The amino acids were changed and the same experiments as in Examples 6-1 to 6-4 were carried out.
- the template mRNA is aminoacyl-tRNA (AAtR-115 to AAtR-118 and AAtR-109, or AAtR-119 to AAtR-122 and AAtR-109, or AAtR-123 to.
- Use one of AAtR-126 and AAtR-127 use aminoacyl-tRNA (AAtR-21 to AAtR-30 and AAtR-130) as template mRNA (MR-4), and use aminoacyl-tRNA (MR-3) as template mRNA (MR-3).
- Translation was performed using tRNA (any of AAtR-31 to AAtR-40 and AAtR-129), and the peptide was translated and synthesized.
- Translation conditions A translation experiment was conducted to evaluate the amount of misreading of codon GGG by tRNA with anticodon acc. Translation was performed according to the above translation condition 1 except that the template mRNA (MR-6) and the extended aminoacyl-tRNA (any one of AAtR-115 to AAtR-118 and AAtR-109) were used. BdpF: Thr: Phe: Ile: Ile: Leu: Phe: MeHph: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 243 (Pep-5)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Leu: Phe: Pic2: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 245 (Pep-7)) is translated when a misreading occurs due to aminoacyl-tRNA.
- a translation experiment was conducted to evaluate the amount of misreading of codon GGG by tRNA with anticodon acc.
- Translation was performed according to the above translation condition 1 except that the template mRNA (MR-6) and the extended aminoacyl-tRNA (any one of AAtR-119 to AAtR-122 and AAtR-109) were used.
- BdpF Thr: Phe: Ile: Ile: Leu: Phe: MeHph: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 243 (Pep-5)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Leu: Phe: MeG: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 246 (Pep-8)) is translated when a misreading occurs due to aminoacyl-tRNA.
- a translation experiment was conducted to evaluate the amount of misreading of codon GGG by tRNA with anticodon acc.
- Translation was performed according to the above translation condition 1 except that the template mRNA (MR-6) and the extended aminoacyl-tRNA (any one of AAtR-123 to AAtR-126 and AAtR-127) were used.
- BdpF Thr: Phe: Ile: Ile: Leu: Phe: nBuG: Ile: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 247 (Pep-9)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Leu: Phe: dA: Ile: Ile: Pro: Ile: Leu (SEQ ID NO: 248 (Pep-10)) is translated when a misreading occurs due to aminoacyl-tRNA.
- a translation experiment was conducted to evaluate the amount of misreading of codon CCG by tRNA having anticodon agg. Translation was performed according to the above translation condition 1 except that the template mRNA (MR-4) and the extended aminoacyl-tRNA (any one of AAtR-21 to AAtR-30 and AAtR-130) were used.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: MeG: Ile: Ile: Ala: Ile: Gly (SEQ ID NO: 249 (Pep-11)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: SPh2Cl: Ile: Ile: Ala: Ile: Gly (SEQ ID NO: 242 (Pep-4)) is translated when a misreading occurs due to aminoacyl-tRNA.
- a translation experiment was conducted to evaluate the amount of misreading of codon CCU by tRNA having anticodon cgg. Translation was performed according to the above translation condition 1 except that the template mRNA (MR-3) and the extended aminoacyl-tRNA (any one of AAtR-31 to AAtR-40 and AAtR-129) were used.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: MeG: Ile: Ile: Ala: Ile: Gly (SEQ ID NO: 249 (Pep-11)) is translated as a translation product when read correctly.
- the template mRNA was designed as described above.
- BdpF Thr: Phe: Ile: Ile: Gly: Phe: SPh2Cl: Ile: Ile: Ala: Ile: Gly (SEQ ID NO: 242 (Pep-4)) is translated when a misreading occurs due to aminoacyl-tRNA.
- Example 7 Analysis of Translated Peptide
- the translation product solution obtained by the translation reaction of Examples 6-1 to 6-5 was diluted 10-fold and analyzed using an LC-FLR-MS device.
- the retention time of the target translated peptide was identified from the obtained MS data, and the amount of peptide translation was evaluated by quantifying the fluorescence peak of the corresponding retention time.
- a calibration curve was prepared using LCT-67 synthesized in Example 3 as a standard, and the content was calculated by relative quantification.
- LC-MS was analyzed according to the conditions of Method 1 in Table 5 below. Further, based on the obtained peptide translation amount, the ratio (%) of the misread peptide to the target substance was calculated using the following formula.
- a peptide obtained when read correctly may be referred to as a translation product or a target product when read correctly.
- the rate of codon misreading by tRNA modified with the combination of bases at positions 32, 33, 37, and 38 was as follows: Ser5 sequence and Ala1B sequence for the combination of bases at positions 32, 33, 37, and 38. , And Phe sequence increased, and Pro3 sequence, Pro2 sequence, Ala2 sequence, Leu2 sequence, Arg3 sequence and Val2 sequence tended to decrease (Figs. 1 to 6 and Tables 6 to 11). .. Among them, the Pro3 sequence, Pro2 sequence, Ala2 sequence and Leu2 sequence tended to decrease. Even when the tRNA body was changed, the ranking of misreading was not affected (Figs. 7 to 10 and Tables 12 to 15).
- the table below shows the translation results of CCG codon reading by tRNA with ag or cgg in the anticodon, with the combination of bases at positions 32, 33, 37, and 38 modified.
- tRNA Glu2 (AAtR-24) in which the base combination at positions 32, 33, 37 and 38 is not modified
- (AAtR-27-30) reduction of codon misreading was observed (Fig. 1).
- the table below shows the translation results of the CCU codon reading by tRNA with the combination of bases at positions 32, 33, 37, and 38 modified and cgg or agg in the anticodon.
- tRNAGlu2 AAA-444
- the combination of the bases was changed to Phe sequence, Arg3 sequence, Val2 sequence, Pro2 sequence, Leu2 sequence, Ala2. Codon misreading was reduced in sequences or tRNAs modified to Pro3 sequences (AAtR33 and AAtR35-40), especially in tRNAs modified to Pro2, Leu2, Ala2, or Pro3 sequences.
- the effect of reducing mistakes was high (Fig. 2).
- the table below shows the translation results of GGG codon reading by tRNA with acc or ccc in the anticodon, with the combination of bases at positions 32, 33, 37, and 38 modified.
- tRNAGlu2 AAA-414
- the combination of the bases was changed to Arg3 sequence, Phe sequence, Val2 sequence, Pro2 sequence, Leu2 sequence, Ala2.
- Codon misreading was reduced in sequences or tRNAs modified to Pro3 sequences (AAtR-43 and AAtR45-50), especially in tRNAs modified to Pro2, Leu2, Ala2, or Pro3 sequences.
- the effect of reducing misreading was high (Fig. 3).
- the table below shows the translation results of GGU codon reading by tRNA with ccc or acc in the anticodon, with the combination of bases at positions 32, 33, 37, and 38 modified.
- tRNAGlu2 AtR-54 in which the combination of bases at positions 32, 33, 37 and 38 was not modified, the amount of peptide translation due to misreading of codons was low, but the combination of bases was changed to Phe sequence, Ala1B sequence, and so on.
- the table below shows the translation results of CUG codons by tRNAs with modified base combinations at positions 32, 33, 37, and 38 and having cag or aag as anticodons.
- tRNA Glu2 (AAtR-4) in which the combination of bases at positions 32, 33, 37 and 38 is not modified, the combination derived from the base is modified to Pro2 sequence or Pro3 sequence (AAtR-8 and In 9), reduction of codon misreading was observed, and the amount of peptide translation due to codon misreading was kept low even in the Ala2 sequence (Fig. 5).
- the table below shows the translation results of CUU codon reading by tRNA with modified base combinations at positions 32, 33, 37, and 38 and having aag or cag in the anticodon.
- tRNAGlu2 (AAtR-14) in which the combination of bases at positions 32, 33, 37 and 38 was not modified, the amount of peptide translation due to codon misreading was low, but the combination derived from the base was used as the Phe sequence and Pro2 sequence.
- Leu2 sequence, Ala2 sequence, Pro3 sequence, Arg3 sequence, or Val2 sequence-modified tRNA (AAtR-13 and AAtR-15 to 20) also kept low peptide translation amount due to codon misreading. A tendency similar to that of the above embodiment was observed (Fig. 6).
- TRNA AsnE2 was selected as the tRNA in which the combination of bases at positions 32, 33, 37 and 38 is the Ser5 sequence.
- the table below shows the translation results of CUG codon reading by tRNA having a tRNA (AsnE2) body, modified base combinations at positions 32, 33, 37, and 38, and having aag or cag as anticodon.
- tRNA AsnE2
- AAAtR-81 tRNA
- the combination derived from the base was compared with Arg3 sequence, Val2 sequence, Pro2 sequence, Leu2 sequence, Ala2.
- Codon misreading was reduced in the tRNA modified to the sequence or Pro3 sequence (AAtR-85 to 90), and the codon reading was particularly found in the tRNA modified to the Pro2 sequence, Leu2 sequence, Ala2 sequence, or Pro3 sequence. The effect of reducing mistakes was high (Fig. 7).
- the table below shows the translation results of CUU codon reading by tRNA having a tRNA (AsnE2) body, modified base combinations at positions 32, 33, 37, and 38, and having cag or aag as anticodon.
- tRNA AsnE2
- AsnR-91 tRNA in which the combination of bases at positions 32, 33, 37 and 38 was not modified
- the combination derived from the base was compared with Arg3 sequence, Val2 sequence, Pro2 sequence, Leu2 sequence, Ala2. Codon reading errors were reduced in the tRNA modified to the sequence or Pro3 sequence (AAtR-95-100), especially in the tRNA modified to the Pro2 sequence, Leu2 sequence, Ala2 sequence, or Pro3 sequence.
- the effect of reducing mistakes was high (Fig. 8).
- the table below shows the translation results of CUU codon reading by tRNA having a tRNA (Asp1) body, modified base combinations at positions 32, 33, 37, and 38, and having cag or aag as anticodon.
- tRNA Asp1
- AtR-74 tRNA in which the combination of bases at positions 32, 33, 37 and 38 was not modified, the amount of peptide translation due to codon misreading was low, but the combination derived from the base was used as the Phe sequence.
- Codon misreading was also reduced in tRNAs (AAtR-76-80) modified to Val2 sequence, Pro2 sequence, Leu2 sequence, Ala2 sequence, or Pro3 sequence, and the same tendency as in the above example was observed (the same tendency as in the above example).
- FIG. 10 The same tendency as in the above example was observed (the same tendency as in the above example).
- the effect of reducing misreading was verified when a codon whose base in the third character was different from the codon used in the above example was used.
- the table below shows the translation results of the reading of GGA codons by tRNAs with modified base combinations at positions 32, 33, 37, and 38 and having ucc or acc in the anticodon.
- the combination of bases at positions 32, 33, 37 and 38 of the tRNA having the anticodon acc was modified to the Leu2 sequence or the Pro3 sequence, the misreading of the codon GGA was reduced (Fig. 11).
- the table below shows the translation results of GGA codon reading by tRNA with a modified combination of bases at positions 32, 33, 37, and 38 and having ucc or gcc in the anticodon.
- the combination of bases at positions 32, 33, 37 and 38 of the tRNA having the anticodon gcc was modified to the Leu2 sequence or the Pro3 sequence, the misreading of the codon GGA was reduced (Fig. 12).
- the table below shows the translation results of GGG codon reading by tRNA with ccc or gcc in the anticodon, with the combination of bases at positions 32, 33, 37, and 38 modified.
- the combination of bases at positions 32, 33, 37 and 38 of the tRNA having the anticodon gcc was modified to the Leu2 sequence or the Pro3 sequence, the misreading of the codon GGG was reduced (Fig. 13).
- codon misreading was verified by changing the type of amino acid.
- the table below shows the translation results of GGG codon reading by tRNA with modified base combinations at positions 32, 33, 37, and 38 and having acc or ccc in the anticodon. Codon misreading was reduced in tRNAs in which the combination of bases at positions 32, 33, 37 and 38 was modified to the Leu2 sequence, Ala2 sequence, or Pro3 sequence (Fig. 14).
- the table below shows the translation results of GGG codon reading by tRNA with acc or ccc in the anticodon, with the combination of bases at positions 32, 33, 37, and 38 modified. Codon misreading was reduced in tRNAs in which the combination of bases at positions 32, 33, 37 and 38 was modified to the Leu2 sequence, Ala2 sequence, or Pro3 sequence (Fig. 15).
- the table below shows the translation results of GGG codon reading by tRNA with acc or ccc in the anticodon, with the combination of bases at positions 32, 33, 37, and 38 modified. Codon misreading was reduced in tRNAs in which the combination of bases at positions 32, 33, 37 and 38 was modified to the Leu2 sequence, Ala2 sequence, or Pro3 sequence (Fig. 16).
- the table below shows the translation results of the CCG codon reading by tRNA with the combination of bases at positions 32, 33, 37, and 38 modified and cgg or agg in the anticodon. Codon misreading was reduced in tRNAs in which the combination of bases at positions 32, 33, 37 and 38 was modified to the Pro2 sequence, Leu2 sequence, Ala2 sequence, or Pro3 sequence (Fig. 17).
- the table below shows the translation results of the CCU codon reading by tRNA with the combination of bases at positions 32, 33, 37, and 38 modified and the anticodon having agg or cgg. Codon misreading was reduced in tRNA in which the combination of bases at positions 32, 33, 37 and 38 was modified to Phe sequence, Pro2 sequence, Leu2 sequence, Ala2 sequence, Pro3 sequence, Arg3 sequence or Val2 sequence. The effect was remarkable in the Pro2 sequence, the Leu2 sequence, the Ala2 sequence, and the Pro3 sequence (Fig. 18).
- compositions, methods and the like in the present disclosure are particularly useful in the field of translational synthesis of peptides.
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Plant Pathology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Medicinal Chemistry (AREA)
- Analytical Chemistry (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Organic Low-Molecular-Weight Compounds And Preparation Thereof (AREA)
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP20906472.4A EP4026906A4 (en) | 2019-12-26 | 2020-12-25 | TRANSLATION COMPOSITION AND METHOD FOR PRODUCING PEPTIDE |
| US17/787,809 US20230108274A1 (en) | 2019-12-26 | 2020-12-25 | Composition for translation, and method for producing peptide |
| JP2021567657A JP7744244B2 (ja) | 2019-12-26 | 2020-12-25 | 翻訳用組成物及びペプチドの製造方法 |
| KR1020227023690A KR20220121831A (ko) | 2019-12-26 | 2020-12-25 | 번역용 조성물 및 펩타이드의 제조 방법 |
| CN202080076538.4A CN114641569A (zh) | 2019-12-26 | 2020-12-25 | 翻译用组合物及肽的制备方法 |
| JP2025151312A JP2025172162A (ja) | 2019-12-26 | 2025-09-11 | 翻訳用組成物及びペプチドの製造方法 |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JPPCT/JP2019/051241 | 2019-12-26 | ||
| PCT/JP2019/051241 WO2020138336A1 (ja) | 2018-12-26 | 2019-12-26 | コドン拡張のための変異tRNA |
| JP2020109292 | 2020-06-25 | ||
| JP2020-109292 | 2020-06-25 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021132546A1 true WO2021132546A1 (ja) | 2021-07-01 |
Family
ID=76573318
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/048652 Ceased WO2021132546A1 (ja) | 2019-12-26 | 2020-12-25 | 翻訳用組成物及びペプチドの製造方法 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20230108274A1 (https=) |
| EP (1) | EP4026906A4 (https=) |
| JP (2) | JP7744244B2 (https=) |
| KR (1) | KR20220121831A (https=) |
| CN (1) | CN114641569A (https=) |
| WO (1) | WO2021132546A1 (https=) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12281141B2 (en) | 2017-06-09 | 2025-04-22 | Chugai Seiyaku Kabushiki Kaisha | Method for synthesizing peptide containing N-substituted amino acid |
| US12312297B2 (en) | 2018-11-07 | 2025-05-27 | Chugai Seiyaku Kabushiki Kaisha | O-substituted serine derivative production method |
| US12371454B2 (en) | 2019-11-07 | 2025-07-29 | Chugai Seiyaku Kabushiki Kaisha | Cyclic peptide compound having Kras inhibitory action |
| US12391971B2 (en) | 2017-01-31 | 2025-08-19 | Chugai Seiyaku Kabushiki Kaisha | Method for synthesizing peptides in cell-free translation system |
| US12410212B2 (en) | 2022-05-06 | 2025-09-09 | Chugai Seiyaku Kabushiki Kaisha | Cyclic compound having selective KRAS inhibitory effect on HRAS and NRAS |
| US12415835B2 (en) | 2011-12-28 | 2025-09-16 | Chugai Seiyaku Kabushiki Kaisha | Peptide-compound cyclization method |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP4166664A1 (en) | 2015-03-13 | 2023-04-19 | Chugai Seiyaku Kabushiki Kaisha | Modified aminoacyl-trna synthetase and use thereof |
| EP3939962A4 (en) | 2019-03-15 | 2022-12-28 | Chugai Seiyaku Kabushiki Kaisha | PROCESS FOR PREPARING AN AROMATIC AMINO ACID DERIVATIVE |
Citations (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2006135096A1 (ja) | 2005-06-14 | 2006-12-21 | Gifu University | 部位特異的にタンパク質にチロシンアナログを導入する方法 |
| WO2007061136A1 (ja) | 2005-11-24 | 2007-05-31 | Riken | 非天然型アミノ酸を組み込んだタンパク質の製造方法 |
| WO2007066627A1 (ja) | 2005-12-06 | 2007-06-14 | The University Of Tokyo | 多目的アシル化触媒とその用途 |
| WO2007103307A2 (en) | 2006-03-03 | 2007-09-13 | California Institute Of Technology | Site-specific incorporation of amino acids into molecules |
| WO2008001947A1 (en) | 2006-06-28 | 2008-01-03 | Riken | MUTANT SepRS, AND METHOD FOR SITE-SPECIFIC INTRODUCTION OF PHOSPHOSERINE INTO PROTEIN BY USING THE SAME |
| WO2010141851A1 (en) | 2009-06-05 | 2010-12-09 | Salk Institute For Biological Studies | Improving unnatural amino acid incorporation in eukaryotic cells |
| WO2012026566A1 (ja) | 2010-08-27 | 2012-03-01 | 国立大学法人 東京大学 | 新規人工翻訳合成系 |
| WO2012033154A1 (ja) | 2010-09-09 | 2012-03-15 | 国立大学法人 東京大学 | N-メチルアミノ酸およびその他の特殊アミノ酸を含む特殊ペプチド化合物ライブラリーの翻訳構築と活性種探索法 |
| WO2012074130A1 (ja) | 2010-12-03 | 2012-06-07 | 国立大学法人東京大学 | ペプチドライブラリーの製造方法、ペプチドライブラリー、及びスクリーニング方法 |
| WO2013100132A1 (ja) | 2011-12-28 | 2013-07-04 | 中外製薬株式会社 | ペプチド化合物の環化方法 |
| WO2015030014A1 (ja) | 2013-08-26 | 2015-03-05 | 国立大学法人東京大学 | 大環状ペプチド、その製造方法、及び大環状ペプチドライブラリを用いるスクリーニング方法 |
| WO2015120287A2 (en) | 2014-02-06 | 2015-08-13 | Yale University | Compositions and methods of use thereof for making polypeptides with many instances of nonstandard amino acids |
| JP2017063672A (ja) * | 2015-09-29 | 2017-04-06 | 国立大学法人 東京大学 | タンパク質を製造するための翻訳系、及びタンパク質の製造方法 |
| WO2018052002A1 (ja) | 2016-09-13 | 2018-03-22 | 第一三共株式会社 | Thrombospondin 1結合ペプチド |
| WO2018143145A1 (ja) | 2017-01-31 | 2018-08-09 | 中外製薬株式会社 | 無細胞翻訳系におけるペプチドの合成方法 |
| WO2018225864A1 (ja) | 2017-06-09 | 2018-12-13 | 中外製薬株式会社 | 膜透過性の高い環状ペプチド化合物、及びこれを含むライブラリ |
| WO2019077887A1 (ja) | 2017-10-16 | 2019-04-25 | 国立大学法人東京大学 | D-アミノ酸及びβ-アミノ酸の取り込みを増強するtRNAのD及びTアームの改変 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006500927A (ja) * | 2002-09-13 | 2006-01-12 | ザ・ユニバーシティ・オブ・クイーンズランド | コドン翻訳効率に基づく遺伝子発現系 |
| JP6440055B2 (ja) * | 2013-05-10 | 2018-12-19 | 国立大学法人 東京大学 | ペプチドライブラリの製造方法、ペプチドライブラリ、及びスクリーニング方法 |
| JPWO2019139126A1 (ja) | 2018-01-11 | 2021-04-08 | 国立大学法人 東京大学 | Ntcp阻害剤 |
| EP3904568A4 (en) * | 2018-12-26 | 2024-03-20 | Chugai Seiyaku Kabushiki Kaisha | Mutated trna for codon expansion |
| WO2022104001A1 (en) * | 2020-11-13 | 2022-05-19 | Bristol-Myers Squibb Company | Expanded protein libraries and uses thereof |
-
2020
- 2020-12-25 CN CN202080076538.4A patent/CN114641569A/zh active Pending
- 2020-12-25 WO PCT/JP2020/048652 patent/WO2021132546A1/ja not_active Ceased
- 2020-12-25 JP JP2021567657A patent/JP7744244B2/ja active Active
- 2020-12-25 US US17/787,809 patent/US20230108274A1/en active Pending
- 2020-12-25 KR KR1020227023690A patent/KR20220121831A/ko active Pending
- 2020-12-25 EP EP20906472.4A patent/EP4026906A4/en active Pending
-
2025
- 2025-09-11 JP JP2025151312A patent/JP2025172162A/ja active Pending
Patent Citations (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2006135096A1 (ja) | 2005-06-14 | 2006-12-21 | Gifu University | 部位特異的にタンパク質にチロシンアナログを導入する方法 |
| WO2007061136A1 (ja) | 2005-11-24 | 2007-05-31 | Riken | 非天然型アミノ酸を組み込んだタンパク質の製造方法 |
| WO2007066627A1 (ja) | 2005-12-06 | 2007-06-14 | The University Of Tokyo | 多目的アシル化触媒とその用途 |
| WO2007103307A2 (en) | 2006-03-03 | 2007-09-13 | California Institute Of Technology | Site-specific incorporation of amino acids into molecules |
| WO2008001947A1 (en) | 2006-06-28 | 2008-01-03 | Riken | MUTANT SepRS, AND METHOD FOR SITE-SPECIFIC INTRODUCTION OF PHOSPHOSERINE INTO PROTEIN BY USING THE SAME |
| WO2010141851A1 (en) | 2009-06-05 | 2010-12-09 | Salk Institute For Biological Studies | Improving unnatural amino acid incorporation in eukaryotic cells |
| WO2012026566A1 (ja) | 2010-08-27 | 2012-03-01 | 国立大学法人 東京大学 | 新規人工翻訳合成系 |
| WO2012033154A1 (ja) | 2010-09-09 | 2012-03-15 | 国立大学法人 東京大学 | N-メチルアミノ酸およびその他の特殊アミノ酸を含む特殊ペプチド化合物ライブラリーの翻訳構築と活性種探索法 |
| WO2012074130A1 (ja) | 2010-12-03 | 2012-06-07 | 国立大学法人東京大学 | ペプチドライブラリーの製造方法、ペプチドライブラリー、及びスクリーニング方法 |
| WO2013100132A1 (ja) | 2011-12-28 | 2013-07-04 | 中外製薬株式会社 | ペプチド化合物の環化方法 |
| WO2015030014A1 (ja) | 2013-08-26 | 2015-03-05 | 国立大学法人東京大学 | 大環状ペプチド、その製造方法、及び大環状ペプチドライブラリを用いるスクリーニング方法 |
| WO2015120287A2 (en) | 2014-02-06 | 2015-08-13 | Yale University | Compositions and methods of use thereof for making polypeptides with many instances of nonstandard amino acids |
| JP2017063672A (ja) * | 2015-09-29 | 2017-04-06 | 国立大学法人 東京大学 | タンパク質を製造するための翻訳系、及びタンパク質の製造方法 |
| WO2018052002A1 (ja) | 2016-09-13 | 2018-03-22 | 第一三共株式会社 | Thrombospondin 1結合ペプチド |
| WO2018143145A1 (ja) | 2017-01-31 | 2018-08-09 | 中外製薬株式会社 | 無細胞翻訳系におけるペプチドの合成方法 |
| WO2018225864A1 (ja) | 2017-06-09 | 2018-12-13 | 中外製薬株式会社 | 膜透過性の高い環状ペプチド化合物、及びこれを含むライブラリ |
| WO2019077887A1 (ja) | 2017-10-16 | 2019-04-25 | 国立大学法人東京大学 | D-アミノ酸及びβ-アミノ酸の取り込みを増強するtRNAのD及びTアームの改変 |
Non-Patent Citations (35)
| Title |
|---|
| ANTIVIRAL CHEMISTRY & CHEMOTHERAPY, vol. 14, no. 4, 2003, pages 183 - 194 |
| AZUSA ET AL., PEPTIDE SCIENCE, 2009, pages 17 - 18 |
| BARTON ET AL., METHODS ENZYMOL, vol. 275, 1996, pages 35 - 57 |
| BIOCONJUG. CHEM., vol. 18, 2007, pages 469 - 476 |
| CHEM. COMMUN. (CAMB, vol. 47, 2011, pages 9946 - 9958 |
| CHEMBIOCHEM, vol. 10, 2009, pages 787 - 798 |
| COMB. CHEM. HIGH THROUGHPUT SCREEN, vol. 13, 2010, pages 75 - 87 |
| ERICKSON ET AL., METHODS ENZYMOL, vol. 101, 1983, pages 674 - 690 |
| GAN ET AL., BIOCHEM. BIOPHYS. ACTA, vol. 1861, December 2017 (2017-12-01), pages 3047 - 3052 |
| GASIOR ET AL., J BIOL CHEM, vol. 254, 1979, pages 3965 - 3969 |
| H. MURAKAMI ET AL., CHEMISTRY & BIOLOGY, vol. 10, 2003, pages 1077 - 1084 |
| H. MURAKAMI ET AL., NATURE METHODS, vol. 3, 2006, pages 357 - 359 |
| HECHT ET AL., J BIOL CHEM, vol. 253, 1978, pages 4517 - 4520 |
| HELV. CHIM. ACTA, vol. 90, pages 297 - 310 |
| IWANE ET AL., METHOD MOL. BIOL., vol. 1728, 2018, pages 17 - 47 |
| IWANE ET AL., NAT. CHEM., vol. 8, 2016, pages 317 - 325 |
| KANDA, T. ET AL.: "Sense Codon-Dependent Introduction of Unnatural Amino Acids into Multiple Sites of a Protein", BIOCHEMICAL AND BIOPHYSICAL RESEARCH COMMUNICATIONS, vol. 270, 2000, pages 1136 - 1139, XP055029960, DOI: 10.1006/bbrc.2000.2556 * |
| MATTHEAKIS ET AL., PROC. NATL. ACAD. SCI. USA, vol. 91, 1994, pages 9022 - 9026 |
| N. NIWA ET AL., BIOORGANIC & MEDICINAL CHEMISTRY LETTERS, vol. 19, 2009, pages 3892 - 3894 |
| NAT. CHEM. BIOL., vol. 5, 2009, pages 888 - 507 |
| NEMOTO ET AL., FEBS LETT, vol. 414, 1997, pages 405 - 408 |
| NOWAK ET AL., SCIENCE, vol. 268, 1995, pages 439 - 442 |
| ODEGRIP, PROC. NATL. ACAD. SCI. USA, vol. 101, 2004, pages 2806 - 2810 |
| OHTA, A.MURAKAMI, H.HIGASHIMURA, E.SUGA, H, CHEM. BIOL, vol. 14, 2007, pages 1315 - 1322 |
| PASSIOURA ET AL., CELL CHEM. BIOL., vol. 25, 2018, pages 906 - 915 |
| PASSIOURA ET AL., JAM. CHEM. SOC., vol. 140, 2018, pages 11551 - 11555 |
| REIERSEN, NUCLEIC ACIDS RES., vol. 33, 2005 |
| ROBERTSSZOSTAK, PROC. NATL. ACAD. SCI. USA, vol. 94, 1997, pages 12297 - 12302 |
| SHIMIZU ET AL., NAT BIOTECH, vol. 19, 2001, pages 751 - 755 |
| SHIMIZU ET AL., NAT. BIOTECHNOL., vol. 19, no. 8, August 2001 (2001-08-01), pages 751 - 755 |
| SWERDEL ET AL., COMP BIOCHEM PHYSIOL B, vol. 93, 1989, pages 803 - 806 |
| TAWFIKGRIFFITHS, NAT. BIOTECHNOL., vol. 16, 1998, pages 652 - 656 |
| URAKAMI ET AL., NAT. STRUCT. MOL. BIOL., vol. 16, March 2009 (2009-03-01), pages 353 - 358 |
| WANG ET AL., ACS CHEM BIOL, vol. 10, 2015, pages 2187 - 2192 |
| YAMAGUCHI ET AL., NUCLEIC ACIDS RES., vol. 37, 2009, pages el08 |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12415835B2 (en) | 2011-12-28 | 2025-09-16 | Chugai Seiyaku Kabushiki Kaisha | Peptide-compound cyclization method |
| US12391971B2 (en) | 2017-01-31 | 2025-08-19 | Chugai Seiyaku Kabushiki Kaisha | Method for synthesizing peptides in cell-free translation system |
| US12281141B2 (en) | 2017-06-09 | 2025-04-22 | Chugai Seiyaku Kabushiki Kaisha | Method for synthesizing peptide containing N-substituted amino acid |
| US12312297B2 (en) | 2018-11-07 | 2025-05-27 | Chugai Seiyaku Kabushiki Kaisha | O-substituted serine derivative production method |
| US12371454B2 (en) | 2019-11-07 | 2025-07-29 | Chugai Seiyaku Kabushiki Kaisha | Cyclic peptide compound having Kras inhibitory action |
| US12410212B2 (en) | 2022-05-06 | 2025-09-09 | Chugai Seiyaku Kabushiki Kaisha | Cyclic compound having selective KRAS inhibitory effect on HRAS and NRAS |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4026906A4 (en) | 2023-12-27 |
| CN114641569A (zh) | 2022-06-17 |
| JPWO2021132546A1 (https=) | 2021-07-01 |
| EP4026906A1 (en) | 2022-07-13 |
| JP7744244B2 (ja) | 2025-09-25 |
| KR20220121831A (ko) | 2022-09-01 |
| JP2025172162A (ja) | 2025-11-20 |
| US20230108274A1 (en) | 2023-04-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7744244B2 (ja) | 翻訳用組成物及びペプチドの製造方法 | |
| JP7357642B2 (ja) | コドン拡張のための変異tRNA | |
| Wang et al. | Expanding the genetic code | |
| JP4972191B2 (ja) | ペプチド、蛋白質及びペプチドミメティック合成のための方法及び組成物 | |
| EP3591048A1 (en) | Method for synthesizing peptides in cell-free translation system | |
| WO2021261577A1 (ja) | 改変された遺伝暗号表を有する翻訳系 | |
| KR20150064209A (ko) | 개선된 발현을 위해 박테리아 추출물 중 선택 단백질의 단백질분해 불활성화 | |
| WO2012033154A1 (ja) | N-メチルアミノ酸およびその他の特殊アミノ酸を含む特殊ペプチド化合物ライブラリーの翻訳構築と活性種探索法 | |
| US8642291B2 (en) | Method for producing proteins comprising non-natural amino acids incorporated therein | |
| JP7267458B2 (ja) | 非天然アミノ酸を含むペプチドの製造方法 | |
| EP2221370A1 (en) | Process for production of non-natural protein having ester bond therein | |
| Katoh et al. | Ribosomal incorporation of negatively charged d-α-and N-methyl-l-α-amino acids enhanced by EF-Sep | |
| JP2004531225A5 (https=) | ||
| Daskalova et al. | Elongation factor P modulates the incorporation of structurally diverse noncanonical amino acids into Escherichia coli dihydrofolate reductase | |
| US20240384267A1 (en) | Compositions and methods for multiplex decoding of quadruplet codons | |
| WO2022173627A2 (en) | Ribosome-mediated polymerization of novel chemistries | |
| HK40068807A (en) | Composition for translation, and method for producing peptide | |
| HK1167003A (en) | Mono charging system for selectively introducing non-native amino acids into proteins using an in vitro protein synthesis system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20906472 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021567657 Country of ref document: JP Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2020906472 Country of ref document: EP Effective date: 20220404 |
|
| ENP | Entry into the national phase |
Ref document number: 20227023690 Country of ref document: KR Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |