KR20220053587A - 이형접합성 소실에 반응성인 세포 표면 수용체 - Google Patents
이형접합성 소실에 반응성인 세포 표면 수용체 Download PDFInfo
- Publication number
- KR20220053587A KR20220053587A KR1020227007569A KR20227007569A KR20220053587A KR 20220053587 A KR20220053587 A KR 20220053587A KR 1020227007569 A KR1020227007569 A KR 1020227007569A KR 20227007569 A KR20227007569 A KR 20227007569A KR 20220053587 A KR20220053587 A KR 20220053587A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- ligand
- domain
- receptor
- cell
- Prior art date
Links
- 108010001857 Cell Surface Receptors Proteins 0.000 title description 2
- 102000006240 membrane receptors Human genes 0.000 title 1
- 210000004027 cell Anatomy 0.000 claims abstract description 440
- 108020001756 ligand binding domains Proteins 0.000 claims abstract description 271
- 210000002865 immune cell Anatomy 0.000 claims abstract description 190
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 138
- 238000000034 method Methods 0.000 claims abstract description 79
- 201000011510 cancer Diseases 0.000 claims abstract description 68
- 239000013598 vector Substances 0.000 claims abstract description 43
- 102000005962 receptors Human genes 0.000 claims description 331
- 108020003175 receptors Proteins 0.000 claims description 331
- 239000003446 ligand Substances 0.000 claims description 329
- 108091008874 T cell receptors Proteins 0.000 claims description 283
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 claims description 281
- 230000003834 intracellular effect Effects 0.000 claims description 203
- 102100025584 Leukocyte immunoglobulin-like receptor subfamily B member 1 Human genes 0.000 claims description 170
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 140
- 230000027455 binding Effects 0.000 claims description 125
- 239000000427 antigen Substances 0.000 claims description 119
- 108091007433 antigens Proteins 0.000 claims description 119
- 102000036639 antigens Human genes 0.000 claims description 119
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 claims description 110
- 102100028972 HLA class I histocompatibility antigen, A alpha chain Human genes 0.000 claims description 102
- 108010075704 HLA-A Antigens Proteins 0.000 claims description 100
- 230000002401 inhibitory effect Effects 0.000 claims description 97
- 230000004913 activation Effects 0.000 claims description 91
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 89
- 108090000623 proteins and genes Proteins 0.000 claims description 87
- 108010017736 Leukocyte Immunoglobulin-like Receptor B1 Proteins 0.000 claims description 80
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 80
- 108091008042 inhibitory receptors Proteins 0.000 claims description 79
- 229920001184 polypeptide Polymers 0.000 claims description 70
- 108700028369 Alleles Proteins 0.000 claims description 62
- 102000001301 EGF receptor Human genes 0.000 claims description 62
- 108060006698 EGF receptor Proteins 0.000 claims description 62
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 claims description 31
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 claims description 31
- 239000012634 fragment Substances 0.000 claims description 28
- 102000003735 Mesothelin Human genes 0.000 claims description 26
- 108090000015 Mesothelin Proteins 0.000 claims description 26
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 claims description 24
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 claims description 24
- 210000002593 Y chromosome Anatomy 0.000 claims description 20
- 108010033576 Transferrin Receptors Proteins 0.000 claims description 19
- 239000008194 pharmaceutical composition Substances 0.000 claims description 18
- 102100028971 HLA class I histocompatibility antigen, C alpha chain Human genes 0.000 claims description 16
- 108010052199 HLA-C Antigens Proteins 0.000 claims description 16
- 238000011467 adoptive cell therapy Methods 0.000 claims description 16
- 102100028976 HLA class I histocompatibility antigen, B alpha chain Human genes 0.000 claims description 15
- 108010058607 HLA-B Antigens Proteins 0.000 claims description 15
- 108700029634 Y-Linked Genes Proteins 0.000 claims description 10
- 101100264174 Mus musculus Xiap gene Proteins 0.000 claims description 8
- 210000003719 b-lymphocyte Anatomy 0.000 claims description 8
- 239000003814 drug Substances 0.000 claims description 8
- 210000000987 immune system Anatomy 0.000 claims description 8
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 claims description 7
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 claims description 7
- 102100028970 HLA class I histocompatibility antigen, alpha chain E Human genes 0.000 claims description 6
- 102100028966 HLA class I histocompatibility antigen, alpha chain F Human genes 0.000 claims description 6
- 102100028967 HLA class I histocompatibility antigen, alpha chain G Human genes 0.000 claims description 6
- 108010024164 HLA-G Antigens Proteins 0.000 claims description 6
- 101000986085 Homo sapiens HLA class I histocompatibility antigen, alpha chain E Proteins 0.000 claims description 6
- 101000986080 Homo sapiens HLA class I histocompatibility antigen, alpha chain F Proteins 0.000 claims description 6
- 102100025475 Carcinoembryonic antigen-related cell adhesion molecule 5 Human genes 0.000 claims description 5
- 108010091373 HA-1 antigen Proteins 0.000 claims description 5
- 230000035605 chemotaxis Effects 0.000 claims description 5
- 102000035160 transmembrane proteins Human genes 0.000 claims description 5
- 108091005703 transmembrane proteins Proteins 0.000 claims description 5
- 108010067225 Cell Adhesion Molecules Proteins 0.000 claims description 4
- 102000016289 Cell Adhesion Molecules Human genes 0.000 claims description 4
- 102000003688 G-Protein-Coupled Receptors Human genes 0.000 claims description 4
- 108090000045 G-Protein-Coupled Receptors Proteins 0.000 claims description 4
- 102000003886 Glycoproteins Human genes 0.000 claims description 4
- 108090000288 Glycoproteins Proteins 0.000 claims description 4
- 101000914324 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 5 Proteins 0.000 claims description 4
- 102000004310 Ion Channels Human genes 0.000 claims description 4
- 230000023549 cell-cell signaling Effects 0.000 claims description 4
- 238000004519 manufacturing process Methods 0.000 claims description 4
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 claims description 3
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 claims description 3
- 239000003085 diluting agent Substances 0.000 claims description 3
- 230000001965 increasing effect Effects 0.000 claims description 3
- 239000002858 neurotransmitter agent Substances 0.000 claims description 3
- 239000000546 pharmaceutical excipient Substances 0.000 claims description 3
- 239000003937 drug carrier Substances 0.000 claims description 2
- 102000007238 Transferrin Receptors Human genes 0.000 claims 2
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 abstract description 24
- 108091033319 polynucleotide Proteins 0.000 abstract description 23
- 239000002157 polynucleotide Substances 0.000 abstract description 23
- 102000040430 polynucleotide Human genes 0.000 abstract description 23
- 201000010099 disease Diseases 0.000 abstract description 18
- 208000035475 disorder Diseases 0.000 abstract description 6
- 239000012190 activator Substances 0.000 description 204
- 239000003112 inhibitor Substances 0.000 description 120
- 101710145789 Leukocyte immunoglobulin-like receptor subfamily B member 1 Proteins 0.000 description 85
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 81
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 description 80
- 230000014509 gene expression Effects 0.000 description 61
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 48
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 48
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 48
- 102000004169 proteins and genes Human genes 0.000 description 48
- 230000002829 reductive effect Effects 0.000 description 46
- 108020001507 fusion proteins Proteins 0.000 description 43
- 102000037865 fusion proteins Human genes 0.000 description 43
- 230000001086 cytosolic effect Effects 0.000 description 38
- 238000010586 diagram Methods 0.000 description 38
- 239000012636 effector Substances 0.000 description 38
- 125000003275 alpha amino acid group Chemical group 0.000 description 34
- 230000000139 costimulatory effect Effects 0.000 description 33
- 229940024606 amino acid Drugs 0.000 description 31
- 239000011324 bead Substances 0.000 description 31
- 102100025570 Cancer/testis antigen 1 Human genes 0.000 description 30
- 101000856237 Homo sapiens Cancer/testis antigen 1 Proteins 0.000 description 30
- 230000000694 effects Effects 0.000 description 30
- 230000004068 intracellular signaling Effects 0.000 description 29
- 150000001413 amino acids Chemical class 0.000 description 28
- 230000006870 function Effects 0.000 description 28
- 230000011664 signaling Effects 0.000 description 26
- 102100027748 Rho GTPase-activating protein 45 Human genes 0.000 description 24
- 101001081189 Homo sapiens Rho GTPase-activating protein 45 Proteins 0.000 description 23
- 238000012217 deletion Methods 0.000 description 22
- 230000037430 deletion Effects 0.000 description 22
- 230000004083 survival effect Effects 0.000 description 21
- 241000282414 Homo sapiens Species 0.000 description 20
- 230000005764 inhibitory process Effects 0.000 description 20
- 239000002773 nucleotide Substances 0.000 description 20
- 230000004936 stimulating effect Effects 0.000 description 20
- 125000003729 nucleotide group Chemical group 0.000 description 19
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 description 18
- 102100026144 Transferrin receptor protein 1 Human genes 0.000 description 18
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 description 18
- -1 for example Proteins 0.000 description 18
- 108700018351 Major Histocompatibility Complex Proteins 0.000 description 17
- 102100040678 Programmed cell death protein 1 Human genes 0.000 description 17
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 17
- 230000020382 suppression by virus of host antigen processing and presentation of peptide antigen via MHC class I Effects 0.000 description 17
- 210000004881 tumor cell Anatomy 0.000 description 17
- SSOORFWOBGFTHL-OTEJMHTDSA-N (4S)-5-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[2-[(2S)-2-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S,3S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-5-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-5-amino-1-[[(2S)-5-carbamimidamido-1-[[(2S)-5-carbamimidamido-1-[[(1S)-4-carbamimidamido-1-carboxybutyl]amino]-1-oxopentan-2-yl]amino]-1-oxopentan-2-yl]amino]-1,5-dioxopentan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-1-oxohexan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1,5-dioxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-1-oxopropan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-3-methyl-1-oxopentan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxopropan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]carbamoyl]pyrrolidin-1-yl]-2-oxoethyl]amino]-3-(1H-indol-3-yl)-1-oxopropan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-3-(1H-imidazol-4-yl)-1-oxopropan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-4-[[(2S)-2-[[(2S)-2-[[(2S)-2,6-diaminohexanoyl]amino]-3-methylbutanoyl]amino]propanoyl]amino]-5-oxopentanoic acid Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H](Cc1c[nH]c2ccccc12)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@H](Cc1c[nH]cn1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)CCCCN)C(C)C)C(C)C)C(C)C)C(C)C)C(C)C)C(C)C)C(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SSOORFWOBGFTHL-OTEJMHTDSA-N 0.000 description 15
- 108010041397 CD4 Antigens Proteins 0.000 description 14
- 102100036011 T-cell surface glycoprotein CD4 Human genes 0.000 description 14
- 238000003556 assay Methods 0.000 description 14
- 210000001519 tissue Anatomy 0.000 description 14
- 238000000338 in vitro Methods 0.000 description 13
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 12
- 229940045513 CTLA4 antagonist Drugs 0.000 description 12
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 12
- 108700012411 TNFSF10 Proteins 0.000 description 12
- 150000001875 compounds Chemical class 0.000 description 12
- 238000003780 insertion Methods 0.000 description 12
- 230000037431 insertion Effects 0.000 description 12
- 239000002245 particle Substances 0.000 description 12
- 101100112922 Candida albicans CDR3 gene Proteins 0.000 description 11
- 108020004414 DNA Proteins 0.000 description 11
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 11
- 230000003213 activating effect Effects 0.000 description 11
- 238000005259 measurement Methods 0.000 description 11
- 230000008685 targeting Effects 0.000 description 11
- 101000946843 Homo sapiens T-cell surface glycoprotein CD8 alpha chain Proteins 0.000 description 10
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 10
- 102100034922 T-cell surface glycoprotein CD8 alpha chain Human genes 0.000 description 10
- 239000000463 material Substances 0.000 description 10
- 150000007523 nucleic acids Chemical group 0.000 description 10
- 230000002062 proliferating effect Effects 0.000 description 10
- 230000004044 response Effects 0.000 description 10
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 9
- 241000700605 Viruses Species 0.000 description 9
- 230000004663 cell proliferation Effects 0.000 description 9
- 230000001419 dependent effect Effects 0.000 description 9
- 230000001939 inductive effect Effects 0.000 description 9
- 239000005089 Luciferase Substances 0.000 description 8
- 108700008625 Reporter Genes Proteins 0.000 description 8
- 230000020411 cell activation Effects 0.000 description 8
- 239000003795 chemical substances by application Substances 0.000 description 8
- 230000007423 decrease Effects 0.000 description 8
- 239000000203 mixture Substances 0.000 description 8
- 210000004986 primary T-cell Anatomy 0.000 description 8
- 239000000243 solution Substances 0.000 description 8
- 239000000126 substance Substances 0.000 description 8
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 7
- 101000818543 Homo sapiens Tyrosine-protein kinase ZAP-70 Proteins 0.000 description 7
- 108060003951 Immunoglobulin Proteins 0.000 description 7
- 108060001084 Luciferase Proteins 0.000 description 7
- 102000043129 MHC class I family Human genes 0.000 description 7
- 108091054437 MHC class I family Proteins 0.000 description 7
- 102000018697 Membrane Proteins Human genes 0.000 description 7
- 108010052285 Membrane Proteins Proteins 0.000 description 7
- 102100021125 Tyrosine-protein kinase ZAP-70 Human genes 0.000 description 7
- 239000013604 expression vector Substances 0.000 description 7
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 7
- 102000018358 immunoglobulin Human genes 0.000 description 7
- 230000003902 lesion Effects 0.000 description 7
- 239000012528 membrane Substances 0.000 description 7
- 230000000638 stimulation Effects 0.000 description 7
- 102100021396 Cell surface glycoprotein CD200 receptor 1 Human genes 0.000 description 6
- 102000003839 Human Proteins Human genes 0.000 description 6
- 108090000144 Human Proteins Proteins 0.000 description 6
- 108010043610 KIR Receptors Proteins 0.000 description 6
- 102000002698 KIR Receptors Human genes 0.000 description 6
- 241000699666 Mus <mouse, genus> Species 0.000 description 6
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 description 6
- 230000002159 abnormal effect Effects 0.000 description 6
- 230000006907 apoptotic process Effects 0.000 description 6
- 230000003915 cell function Effects 0.000 description 6
- 238000001727 in vivo Methods 0.000 description 6
- 230000000977 initiatory effect Effects 0.000 description 6
- 210000000265 leukocyte Anatomy 0.000 description 6
- 239000002609 medium Substances 0.000 description 6
- 230000001394 metastastic effect Effects 0.000 description 6
- 206010061289 metastatic neoplasm Diseases 0.000 description 6
- 210000001616 monocyte Anatomy 0.000 description 6
- 230000035772 mutation Effects 0.000 description 6
- 102000039446 nucleic acids Human genes 0.000 description 6
- 108020004707 nucleic acids Proteins 0.000 description 6
- 108020001580 protein domains Proteins 0.000 description 6
- 230000006798 recombination Effects 0.000 description 6
- 238000005215 recombination Methods 0.000 description 6
- 239000000523 sample Substances 0.000 description 6
- 230000004614 tumor growth Effects 0.000 description 6
- 239000013603 viral vector Substances 0.000 description 6
- 102100038080 B-cell receptor CD22 Human genes 0.000 description 5
- 102000004127 Cytokines Human genes 0.000 description 5
- 108090000695 Cytokines Proteins 0.000 description 5
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 5
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 description 5
- 101000934341 Homo sapiens T-cell surface glycoprotein CD5 Proteins 0.000 description 5
- 108010002350 Interleukin-2 Proteins 0.000 description 5
- 102000000588 Interleukin-2 Human genes 0.000 description 5
- 108010064548 Lymphocyte Function-Associated Antigen-1 Proteins 0.000 description 5
- 241001465754 Metazoa Species 0.000 description 5
- 102100025244 T-cell surface glycoprotein CD5 Human genes 0.000 description 5
- 238000013459 approach Methods 0.000 description 5
- 230000008901 benefit Effects 0.000 description 5
- 230000015572 biosynthetic process Effects 0.000 description 5
- 210000004369 blood Anatomy 0.000 description 5
- 239000008280 blood Substances 0.000 description 5
- 239000000872 buffer Substances 0.000 description 5
- 238000002659 cell therapy Methods 0.000 description 5
- 230000008859 change Effects 0.000 description 5
- 210000005220 cytoplasmic tail Anatomy 0.000 description 5
- 231100000433 cytotoxic Toxicity 0.000 description 5
- 230000001472 cytotoxic effect Effects 0.000 description 5
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 5
- 230000009977 dual effect Effects 0.000 description 5
- 230000008014 freezing Effects 0.000 description 5
- 238000007710 freezing Methods 0.000 description 5
- 239000000833 heterodimer Substances 0.000 description 5
- 208000032839 leukemia Diseases 0.000 description 5
- 239000007788 liquid Substances 0.000 description 5
- 230000001404 mediated effect Effects 0.000 description 5
- 239000002953 phosphate buffered saline Substances 0.000 description 5
- 102200006531 rs121913529 Human genes 0.000 description 5
- 102200006539 rs121913529 Human genes 0.000 description 5
- 210000002966 serum Anatomy 0.000 description 5
- 238000004448 titration Methods 0.000 description 5
- 238000005406 washing Methods 0.000 description 5
- 102000006306 Antigen Receptors Human genes 0.000 description 4
- 108010083359 Antigen Receptors Proteins 0.000 description 4
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 4
- 102100027314 Beta-2-microglobulin Human genes 0.000 description 4
- 102100027207 CD27 antigen Human genes 0.000 description 4
- 108010021472 Fc gamma receptor IIB Proteins 0.000 description 4
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 4
- BCCRXDTUTZHDEU-VKHMYHEASA-N Gly-Ser Chemical compound NCC(=O)N[C@@H](CO)C(O)=O BCCRXDTUTZHDEU-VKHMYHEASA-N 0.000 description 4
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 description 4
- 101000969553 Homo sapiens Cell surface glycoprotein CD200 receptor 1 Proteins 0.000 description 4
- 101000584612 Homo sapiens GTPase KRas Proteins 0.000 description 4
- 101001109501 Homo sapiens NKG2-D type II integral membrane protein Proteins 0.000 description 4
- 101000934346 Homo sapiens T-cell surface antigen CD2 Proteins 0.000 description 4
- 101000611183 Homo sapiens Tumor necrosis factor Proteins 0.000 description 4
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 description 4
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 description 4
- 108091008026 Inhibitory immune checkpoint proteins Proteins 0.000 description 4
- 102000037984 Inhibitory immune checkpoint proteins Human genes 0.000 description 4
- 208000008839 Kidney Neoplasms Diseases 0.000 description 4
- 102100029205 Low affinity immunoglobulin gamma Fc region receptor II-b Human genes 0.000 description 4
- 241000699670 Mus sp. Species 0.000 description 4
- 102100022680 NKG2-D type II integral membrane protein Human genes 0.000 description 4
- 102000011779 Nitric Oxide Synthase Type II Human genes 0.000 description 4
- 108010076864 Nitric Oxide Synthase Type II Proteins 0.000 description 4
- 206010038389 Renal cancer Diseases 0.000 description 4
- 208000005718 Stomach Neoplasms Diseases 0.000 description 4
- 102100025237 T-cell surface antigen CD2 Human genes 0.000 description 4
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 description 4
- 239000000654 additive Substances 0.000 description 4
- 125000000539 amino acid group Chemical group 0.000 description 4
- 238000002617 apheresis Methods 0.000 description 4
- 108010081355 beta 2-Microglobulin Proteins 0.000 description 4
- 210000001185 bone marrow Anatomy 0.000 description 4
- 210000004899 c-terminal region Anatomy 0.000 description 4
- 230000010261 cell growth Effects 0.000 description 4
- 230000001413 cellular effect Effects 0.000 description 4
- 238000012258 culturing Methods 0.000 description 4
- 231100000673 dose–response relationship Toxicity 0.000 description 4
- 229940079593 drug Drugs 0.000 description 4
- 206010017758 gastric cancer Diseases 0.000 description 4
- 230000012010 growth Effects 0.000 description 4
- 208000014829 head and neck neoplasm Diseases 0.000 description 4
- 210000002443 helper t lymphocyte Anatomy 0.000 description 4
- 102000057041 human TNF Human genes 0.000 description 4
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 description 4
- 208000015181 infectious disease Diseases 0.000 description 4
- 201000010982 kidney cancer Diseases 0.000 description 4
- 150000002632 lipids Chemical class 0.000 description 4
- 210000004698 lymphocyte Anatomy 0.000 description 4
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 4
- 230000035755 proliferation Effects 0.000 description 4
- 230000009467 reduction Effects 0.000 description 4
- 230000001105 regulatory effect Effects 0.000 description 4
- 230000010076 replication Effects 0.000 description 4
- 230000000717 retained effect Effects 0.000 description 4
- 230000002441 reversible effect Effects 0.000 description 4
- 201000011549 stomach cancer Diseases 0.000 description 4
- 208000024891 symptom Diseases 0.000 description 4
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 3
- 102100027205 B-cell antigen receptor complex-associated protein alpha chain Human genes 0.000 description 3
- 102100027203 B-cell antigen receptor complex-associated protein beta chain Human genes 0.000 description 3
- 102100038078 CD276 antigen Human genes 0.000 description 3
- 108091026890 Coding region Proteins 0.000 description 3
- 206010009944 Colon cancer Diseases 0.000 description 3
- 108010076525 DNA Repair Enzymes Proteins 0.000 description 3
- 102000011724 DNA Repair Enzymes Human genes 0.000 description 3
- 208000000461 Esophageal Neoplasms Diseases 0.000 description 3
- 108010087819 Fc receptors Proteins 0.000 description 3
- 102000009109 Fc receptors Human genes 0.000 description 3
- 101150000578 HLA-B gene Proteins 0.000 description 3
- 101000914489 Homo sapiens B-cell antigen receptor complex-associated protein alpha chain Proteins 0.000 description 3
- 101000914491 Homo sapiens B-cell antigen receptor complex-associated protein beta chain Proteins 0.000 description 3
- 101000984190 Homo sapiens Leukocyte immunoglobulin-like receptor subfamily B member 1 Proteins 0.000 description 3
- 101001109503 Homo sapiens NKG2-C type II integral membrane protein Proteins 0.000 description 3
- 101000914496 Homo sapiens T-cell antigen CD7 Proteins 0.000 description 3
- 101000801234 Homo sapiens Tumor necrosis factor receptor superfamily member 18 Proteins 0.000 description 3
- 101000679851 Homo sapiens Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 description 3
- 108091006905 Human Serum Albumin Proteins 0.000 description 3
- 102000008100 Human Serum Albumin Human genes 0.000 description 3
- 108090000862 Ion Channels Proteins 0.000 description 3
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 3
- 241000713666 Lentivirus Species 0.000 description 3
- 102100022683 NKG2-C type II integral membrane protein Human genes 0.000 description 3
- 108091028043 Nucleic acid sequence Proteins 0.000 description 3
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 3
- 108010038807 Oligopeptides Proteins 0.000 description 3
- 102000015636 Oligopeptides Human genes 0.000 description 3
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 3
- 108091000080 Phosphotransferase Proteins 0.000 description 3
- 102000001253 Protein Kinase Human genes 0.000 description 3
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 3
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 3
- 230000005867 T cell response Effects 0.000 description 3
- 102100027208 T-cell antigen CD7 Human genes 0.000 description 3
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 3
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 3
- 102100033728 Tumor necrosis factor receptor superfamily member 18 Human genes 0.000 description 3
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 description 3
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 3
- 230000000996 additive effect Effects 0.000 description 3
- 230000009286 beneficial effect Effects 0.000 description 3
- 231100000135 cytotoxicity Toxicity 0.000 description 3
- 230000003013 cytotoxicity Effects 0.000 description 3
- 238000002784 cytotoxicity assay Methods 0.000 description 3
- 231100000263 cytotoxicity test Toxicity 0.000 description 3
- 230000034994 death Effects 0.000 description 3
- 231100000517 death Toxicity 0.000 description 3
- 239000008121 dextrose Substances 0.000 description 3
- 210000003162 effector t lymphocyte Anatomy 0.000 description 3
- 201000004101 esophageal cancer Diseases 0.000 description 3
- 230000001747 exhibiting effect Effects 0.000 description 3
- 238000000684 flow cytometry Methods 0.000 description 3
- 230000004927 fusion Effects 0.000 description 3
- 230000002068 genetic effect Effects 0.000 description 3
- 201000010536 head and neck cancer Diseases 0.000 description 3
- 230000028993 immune response Effects 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- 238000002955 isolation Methods 0.000 description 3
- FZWBNHMXJMCXLU-BLAUPYHCSA-N isomaltotriose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1OC[C@@H]1[C@@H](O)[C@H](O)[C@@H](O)[C@@H](OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C=O)O1 FZWBNHMXJMCXLU-BLAUPYHCSA-N 0.000 description 3
- 230000002147 killing effect Effects 0.000 description 3
- 230000000670 limiting effect Effects 0.000 description 3
- 238000011068 loading method Methods 0.000 description 3
- FVVLHONNBARESJ-NTOWJWGLSA-H magnesium;potassium;trisodium;(2r,3s,4r,5r)-2,3,4,5,6-pentahydroxyhexanoate;acetate;tetrachloride;nonahydrate Chemical compound O.O.O.O.O.O.O.O.O.[Na+].[Na+].[Na+].[Mg+2].[Cl-].[Cl-].[Cl-].[Cl-].[K+].CC([O-])=O.OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C([O-])=O FVVLHONNBARESJ-NTOWJWGLSA-H 0.000 description 3
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 3
- 239000003550 marker Substances 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 3
- 238000000386 microscopy Methods 0.000 description 3
- 230000005012 migration Effects 0.000 description 3
- 238000013508 migration Methods 0.000 description 3
- 201000002528 pancreatic cancer Diseases 0.000 description 3
- 208000008443 pancreatic carcinoma Diseases 0.000 description 3
- 102000020233 phosphotransferase Human genes 0.000 description 3
- 230000006461 physiological response Effects 0.000 description 3
- 230000000069 prophylactic effect Effects 0.000 description 3
- 108060006633 protein kinase Proteins 0.000 description 3
- 210000003289 regulatory T cell Anatomy 0.000 description 3
- 230000001177 retroviral effect Effects 0.000 description 3
- 230000019491 signal transduction Effects 0.000 description 3
- 238000006467 substitution reaction Methods 0.000 description 3
- 239000000758 substrate Substances 0.000 description 3
- 210000001541 thymus gland Anatomy 0.000 description 3
- 238000013518 transcription Methods 0.000 description 3
- 230000035897 transcription Effects 0.000 description 3
- 241001430294 unidentified retrovirus Species 0.000 description 3
- 208000031261 Acute myeloid leukaemia Diseases 0.000 description 2
- 206010005003 Bladder cancer Diseases 0.000 description 2
- 208000003174 Brain Neoplasms Diseases 0.000 description 2
- 206010006187 Breast cancer Diseases 0.000 description 2
- 208000026310 Breast neoplasm Diseases 0.000 description 2
- 101710185679 CD276 antigen Proteins 0.000 description 2
- 210000001266 CD8-positive T-lymphocyte Anatomy 0.000 description 2
- 102100037904 CD9 antigen Human genes 0.000 description 2
- 102100029382 CMRF35-like molecule 6 Human genes 0.000 description 2
- 208000005623 Carcinogenesis Diseases 0.000 description 2
- 101710176977 Cell surface glycoprotein CD200 receptor 1 Proteins 0.000 description 2
- 206010008342 Cervix carcinoma Diseases 0.000 description 2
- 241000701022 Cytomegalovirus Species 0.000 description 2
- 102000053602 DNA Human genes 0.000 description 2
- 102100027828 DNA repair protein XRCC4 Human genes 0.000 description 2
- 101710147736 DNA repair protein XRCC4 Proteins 0.000 description 2
- 102100033553 Delta-like protein 4 Human genes 0.000 description 2
- 241000702421 Dependoparvovirus Species 0.000 description 2
- 206010014733 Endometrial cancer Diseases 0.000 description 2
- 206010014759 Endometrial neoplasm Diseases 0.000 description 2
- 102000004190 Enzymes Human genes 0.000 description 2
- 108090000790 Enzymes Proteins 0.000 description 2
- 108700039887 Essential Genes Proteins 0.000 description 2
- 102100027286 Fanconi anemia group C protein Human genes 0.000 description 2
- 102100030708 GTPase KRas Human genes 0.000 description 2
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 2
- 102100026122 High affinity immunoglobulin gamma Fc receptor I Human genes 0.000 description 2
- 101000738354 Homo sapiens CD9 antigen Proteins 0.000 description 2
- 101000990034 Homo sapiens CMRF35-like molecule 6 Proteins 0.000 description 2
- 101000872077 Homo sapiens Delta-like protein 4 Proteins 0.000 description 2
- 101000914680 Homo sapiens Fanconi anemia group C protein Proteins 0.000 description 2
- 101000986086 Homo sapiens HLA class I histocompatibility antigen, A alpha chain Proteins 0.000 description 2
- 101000913074 Homo sapiens High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 description 2
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 description 2
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 description 2
- 101000945490 Homo sapiens Killer cell immunoglobulin-like receptor 3DL2 Proteins 0.000 description 2
- 101000945493 Homo sapiens Killer cell immunoglobulin-like receptor 3DL3 Proteins 0.000 description 2
- 101000777628 Homo sapiens Leukocyte antigen CD37 Proteins 0.000 description 2
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 2
- 101000917839 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-B Proteins 0.000 description 2
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 description 2
- 101000578059 Homo sapiens Non-homologous end-joining factor 1 Proteins 0.000 description 2
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 description 2
- 101000946860 Homo sapiens T-cell surface glycoprotein CD3 epsilon chain Proteins 0.000 description 2
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 description 2
- 101000830565 Homo sapiens Tumor necrosis factor ligand superfamily member 10 Proteins 0.000 description 2
- 241000725303 Human immunodeficiency virus Species 0.000 description 2
- 206010061218 Inflammation Diseases 0.000 description 2
- 102100027268 Interferon-stimulated gene 20 kDa protein Human genes 0.000 description 2
- 108010050904 Interferons Proteins 0.000 description 2
- 102000014150 Interferons Human genes 0.000 description 2
- 108010002586 Interleukin-7 Proteins 0.000 description 2
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 2
- 208000007766 Kaposi sarcoma Diseases 0.000 description 2
- 102100034840 Killer cell immunoglobulin-like receptor 3DL2 Human genes 0.000 description 2
- 102100034834 Killer cell immunoglobulin-like receptor 3DL3 Human genes 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- 102100031586 Leukocyte antigen CD37 Human genes 0.000 description 2
- 102100029185 Low affinity immunoglobulin gamma Fc region receptor III-B Human genes 0.000 description 2
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 2
- 102100034709 Lymphocyte cytosolic protein 2 Human genes 0.000 description 2
- 101710195102 Lymphocyte cytosolic protein 2 Proteins 0.000 description 2
- 206010025323 Lymphomas Diseases 0.000 description 2
- 241000829100 Macaca mulatta polyomavirus 1 Species 0.000 description 2
- 102000012750 Membrane Glycoproteins Human genes 0.000 description 2
- 108010090054 Membrane Glycoproteins Proteins 0.000 description 2
- 102100023123 Mucin-16 Human genes 0.000 description 2
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 description 2
- 102100028156 Non-homologous end-joining factor 1 Human genes 0.000 description 2
- 206010033128 Ovarian cancer Diseases 0.000 description 2
- 206010061535 Ovarian neoplasm Diseases 0.000 description 2
- 108091008606 PDGF receptors Proteins 0.000 description 2
- 102100032543 Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase and dual-specificity protein phosphatase PTEN Human genes 0.000 description 2
- 101710132081 Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase and dual-specificity protein phosphatase PTEN Proteins 0.000 description 2
- 102000011653 Platelet-Derived Growth Factor Receptors Human genes 0.000 description 2
- RJKFOVLPORLFTN-LEKSSAKUSA-N Progesterone Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H](C(=O)C)[C@@]1(C)CC2 RJKFOVLPORLFTN-LEKSSAKUSA-N 0.000 description 2
- 206010060862 Prostate cancer Diseases 0.000 description 2
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 2
- 102000001183 RAG-1 Human genes 0.000 description 2
- 108060006897 RAG1 Proteins 0.000 description 2
- 238000003559 RNA-seq method Methods 0.000 description 2
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 102000014400 SH2 domains Human genes 0.000 description 2
- 108050003452 SH2 domains Proteins 0.000 description 2
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 2
- 208000000453 Skin Neoplasms Diseases 0.000 description 2
- 230000006044 T cell activation Effects 0.000 description 2
- 102100035794 T-cell surface glycoprotein CD3 epsilon chain Human genes 0.000 description 2
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 description 2
- 102000002259 TNF-Related Apoptosis-Inducing Ligand Receptors Human genes 0.000 description 2
- 108010000449 TNF-Related Apoptosis-Inducing Ligand Receptors Proteins 0.000 description 2
- 208000024313 Testicular Neoplasms Diseases 0.000 description 2
- 206010057644 Testis cancer Diseases 0.000 description 2
- 208000024770 Thyroid neoplasm Diseases 0.000 description 2
- 108091005956 Type II transmembrane proteins Proteins 0.000 description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 2
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 2
- 108010032099 V(D)J recombination activating protein 2 Proteins 0.000 description 2
- 102100029591 V(D)J recombination-activating protein 2 Human genes 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 231100001075 aneuploidy Toxicity 0.000 description 2
- 208000036878 aneuploidy Diseases 0.000 description 2
- 230000000259 anti-tumor effect Effects 0.000 description 2
- 210000000612 antigen-presenting cell Anatomy 0.000 description 2
- 230000000890 antigenic effect Effects 0.000 description 2
- 230000033228 biological regulation Effects 0.000 description 2
- 210000001772 blood platelet Anatomy 0.000 description 2
- 239000001506 calcium phosphate Substances 0.000 description 2
- 229910000389 calcium phosphate Inorganic materials 0.000 description 2
- 235000011010 calcium phosphates Nutrition 0.000 description 2
- 230000036952 cancer formation Effects 0.000 description 2
- 231100000504 carcinogenesis Toxicity 0.000 description 2
- 230000030833 cell death Effects 0.000 description 2
- 210000000170 cell membrane Anatomy 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- 201000010881 cervical cancer Diseases 0.000 description 2
- 238000003501 co-culture Methods 0.000 description 2
- 208000029742 colonic neoplasm Diseases 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 230000036461 convulsion Effects 0.000 description 2
- 230000002596 correlated effect Effects 0.000 description 2
- 230000000875 corresponding effect Effects 0.000 description 2
- 230000004940 costimulation Effects 0.000 description 2
- DDRJAANPRJIHGJ-UHFFFAOYSA-N creatinine Chemical compound CN1CC(=O)NC1=N DDRJAANPRJIHGJ-UHFFFAOYSA-N 0.000 description 2
- 230000001461 cytolytic effect Effects 0.000 description 2
- 229940119744 dextran 40 Drugs 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 210000003743 erythrocyte Anatomy 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 238000001476 gene delivery Methods 0.000 description 2
- 150000004676 glycans Chemical class 0.000 description 2
- 229930004094 glycosylphosphatidylinositol Natural products 0.000 description 2
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Chemical compound NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 2
- 239000001963 growth medium Substances 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 102000044949 human TNFSF10 Human genes 0.000 description 2
- 230000001900 immune effect Effects 0.000 description 2
- 230000037451 immune surveillance Effects 0.000 description 2
- 238000003364 immunohistochemistry Methods 0.000 description 2
- 230000001506 immunosuppresive effect Effects 0.000 description 2
- 238000010348 incorporation Methods 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 230000006698 induction Effects 0.000 description 2
- 230000004054 inflammatory process Effects 0.000 description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 2
- 229940079322 interferon Drugs 0.000 description 2
- 231100000518 lethal Toxicity 0.000 description 2
- 230000001665 lethal effect Effects 0.000 description 2
- 239000002502 liposome Substances 0.000 description 2
- 201000007270 liver cancer Diseases 0.000 description 2
- 208000014018 liver neoplasm Diseases 0.000 description 2
- 230000007774 longterm Effects 0.000 description 2
- 238000004020 luminiscence type Methods 0.000 description 2
- 201000005202 lung cancer Diseases 0.000 description 2
- 208000020816 lung neoplasm Diseases 0.000 description 2
- 210000001165 lymph node Anatomy 0.000 description 2
- 229920002521 macromolecule Polymers 0.000 description 2
- 210000002540 macrophage Anatomy 0.000 description 2
- 230000005291 magnetic effect Effects 0.000 description 2
- 201000001441 melanoma Diseases 0.000 description 2
- 210000003071 memory t lymphocyte Anatomy 0.000 description 2
- 239000002207 metabolite Substances 0.000 description 2
- 239000000693 micelle Substances 0.000 description 2
- 238000010369 molecular cloning Methods 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 210000000822 natural killer cell Anatomy 0.000 description 2
- 210000000440 neutrophil Anatomy 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 201000008968 osteosarcoma Diseases 0.000 description 2
- 230000005298 paramagnetic effect Effects 0.000 description 2
- 229920001282 polysaccharide Polymers 0.000 description 2
- 239000005017 polysaccharide Substances 0.000 description 2
- 229940002612 prodrug Drugs 0.000 description 2
- 239000000651 prodrug Substances 0.000 description 2
- 230000000770 proinflammatory effect Effects 0.000 description 2
- 150000003839 salts Chemical class 0.000 description 2
- 238000007493 shaping process Methods 0.000 description 2
- 238000009097 single-agent therapy Methods 0.000 description 2
- 201000000849 skin cancer Diseases 0.000 description 2
- 150000003384 small molecules Chemical class 0.000 description 2
- DAEPDZWVDSPTHF-UHFFFAOYSA-M sodium pyruvate Chemical compound [Na+].CC(=O)C([O-])=O DAEPDZWVDSPTHF-UHFFFAOYSA-M 0.000 description 2
- 230000002269 spontaneous effect Effects 0.000 description 2
- 206010041823 squamous cell carcinoma Diseases 0.000 description 2
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 201000003120 testicular cancer Diseases 0.000 description 2
- 230000001225 therapeutic effect Effects 0.000 description 2
- 201000002510 thyroid cancer Diseases 0.000 description 2
- 230000002103 transcriptional effect Effects 0.000 description 2
- 238000010361 transduction Methods 0.000 description 2
- 230000026683 transduction Effects 0.000 description 2
- 230000001131 transforming effect Effects 0.000 description 2
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 2
- 241000701161 unidentified adenovirus Species 0.000 description 2
- 201000005112 urinary bladder cancer Diseases 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- 239000003981 vehicle Substances 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 2
- HKZAAJSTFUZYTO-LURJTMIESA-N (2s)-2-[[2-[[2-[[2-[(2-aminoacetyl)amino]acetyl]amino]acetyl]amino]acetyl]amino]-3-hydroxypropanoic acid Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O HKZAAJSTFUZYTO-LURJTMIESA-N 0.000 description 1
- 108020005029 5' Flanking Region Proteins 0.000 description 1
- 108010085238 Actins Proteins 0.000 description 1
- 102000007469 Actins Human genes 0.000 description 1
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 1
- 208000010507 Adenocarcinoma of Lung Diseases 0.000 description 1
- 239000012114 Alexa Fluor 647 Substances 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 206010003445 Ascites Diseases 0.000 description 1
- 241000714230 Avian leukemia virus Species 0.000 description 1
- 102100029822 B- and T-lymphocyte attenuator Human genes 0.000 description 1
- 208000004736 B-Cell Leukemia Diseases 0.000 description 1
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 description 1
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 1
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 125000001433 C-terminal amino-acid group Chemical group 0.000 description 1
- 108010008629 CA-125 Antigen Proteins 0.000 description 1
- 102100024263 CD160 antigen Human genes 0.000 description 1
- 102100035793 CD83 antigen Human genes 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 241000282836 Camelus dromedarius Species 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 108010022366 Carcinoembryonic Antigen Proteins 0.000 description 1
- 201000009030 Carcinoma Diseases 0.000 description 1
- 241000700198 Cavia Species 0.000 description 1
- 102000000844 Cell Surface Receptors Human genes 0.000 description 1
- 102100024046 Cell adhesion molecule 3 Human genes 0.000 description 1
- 101710197433 Cell adhesion molecule 3 Proteins 0.000 description 1
- 208000030808 Clear cell renal carcinoma Diseases 0.000 description 1
- 108010060434 Co-Repressor Proteins Proteins 0.000 description 1
- 102000008169 Co-Repressor Proteins Human genes 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- 108010009392 Cyclin-Dependent Kinase Inhibitor p16 Proteins 0.000 description 1
- 102100024458 Cyclin-dependent kinase inhibitor 2A Human genes 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 102100039410 Eukaryotic translation initiation factor 1A, Y-chromosomal Human genes 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 102100027581 Forkhead box protein P3 Human genes 0.000 description 1
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 208000009329 Graft vs Host Disease Diseases 0.000 description 1
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 1
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 1
- 102100029966 HLA class II histocompatibility antigen, DP alpha 1 chain Human genes 0.000 description 1
- 101150118346 HLA-A gene Proteins 0.000 description 1
- 108010074032 HLA-A2 Antigen Proteins 0.000 description 1
- 102000025850 HLA-A2 Antigen Human genes 0.000 description 1
- 102000012153 HLA-B27 Antigen Human genes 0.000 description 1
- 108010061486 HLA-B27 Antigen Proteins 0.000 description 1
- 102000006354 HLA-DR Antigens Human genes 0.000 description 1
- 108010058597 HLA-DR Antigens Proteins 0.000 description 1
- 102100029360 Hematopoietic cell signal transducer Human genes 0.000 description 1
- 102000001554 Hemoglobins Human genes 0.000 description 1
- 108010054147 Hemoglobins Proteins 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- 208000017604 Hodgkin disease Diseases 0.000 description 1
- 208000021519 Hodgkin lymphoma Diseases 0.000 description 1
- 208000010747 Hodgkins lymphoma Diseases 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000777636 Homo sapiens ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Proteins 0.000 description 1
- 101000864344 Homo sapiens B- and T-lymphocyte attenuator Proteins 0.000 description 1
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 1
- 101000761938 Homo sapiens CD160 antigen Proteins 0.000 description 1
- 101000884279 Homo sapiens CD276 antigen Proteins 0.000 description 1
- 101000946856 Homo sapiens CD83 antigen Proteins 0.000 description 1
- 101001036335 Homo sapiens Eukaryotic translation initiation factor 1A, Y-chromosomal Proteins 0.000 description 1
- 101000861452 Homo sapiens Forkhead box protein P3 Proteins 0.000 description 1
- 101000864089 Homo sapiens HLA class II histocompatibility antigen, DP alpha 1 chain Proteins 0.000 description 1
- 101000930802 Homo sapiens HLA class II histocompatibility antigen, DQ alpha 1 chain Proteins 0.000 description 1
- 101000968032 Homo sapiens HLA class II histocompatibility antigen, DR beta 3 chain Proteins 0.000 description 1
- 101000990188 Homo sapiens Hematopoietic cell signal transducer Proteins 0.000 description 1
- 101000935040 Homo sapiens Integrin beta-2 Proteins 0.000 description 1
- 101000945339 Homo sapiens Killer cell immunoglobulin-like receptor 2DS2 Proteins 0.000 description 1
- 101000971538 Homo sapiens Killer cell lectin-like receptor subfamily F member 1 Proteins 0.000 description 1
- 101100128412 Homo sapiens LILRB1 gene Proteins 0.000 description 1
- 101000984192 Homo sapiens Leukocyte immunoglobulin-like receptor subfamily B member 3 Proteins 0.000 description 1
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 description 1
- 101000996109 Homo sapiens Neuroligin-4, Y-linked Proteins 0.000 description 1
- 101001072579 Homo sapiens Protein PAXX Proteins 0.000 description 1
- 101000633784 Homo sapiens SLAM family member 7 Proteins 0.000 description 1
- 101000766306 Homo sapiens Serotransferrin Proteins 0.000 description 1
- 101000738413 Homo sapiens T-cell surface glycoprotein CD3 gamma chain Proteins 0.000 description 1
- 101000738335 Homo sapiens T-cell surface glycoprotein CD3 zeta chain Proteins 0.000 description 1
- 101000658151 Homo sapiens Thymosin beta-4, Y-chromosomal Proteins 0.000 description 1
- 101000830594 Homo sapiens Tumor necrosis factor ligand superfamily member 14 Proteins 0.000 description 1
- 101000795169 Homo sapiens Tumor necrosis factor receptor superfamily member 13C Proteins 0.000 description 1
- 101001022129 Homo sapiens Tyrosine-protein kinase Fyn Proteins 0.000 description 1
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 1
- 229920001612 Hydroxyethyl starch Polymers 0.000 description 1
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 1
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 1
- 102100039615 Inactive tyrosine-protein kinase transmembrane receptor ROR1 Human genes 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 102100025390 Integrin beta-2 Human genes 0.000 description 1
- 108010064593 Intercellular Adhesion Molecule-1 Proteins 0.000 description 1
- 102100037877 Intercellular adhesion molecule 1 Human genes 0.000 description 1
- 102100037850 Interferon gamma Human genes 0.000 description 1
- 108010074328 Interferon-gamma Proteins 0.000 description 1
- 102000003814 Interleukin-10 Human genes 0.000 description 1
- 108090000174 Interleukin-10 Proteins 0.000 description 1
- 102000013462 Interleukin-12 Human genes 0.000 description 1
- 108010065805 Interleukin-12 Proteins 0.000 description 1
- 102000003812 Interleukin-15 Human genes 0.000 description 1
- 108090000172 Interleukin-15 Proteins 0.000 description 1
- 102000008193 Interleukin-2 Receptor beta Subunit Human genes 0.000 description 1
- 108010060632 Interleukin-2 Receptor beta Subunit Proteins 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 102000004388 Interleukin-4 Human genes 0.000 description 1
- 102000000704 Interleukin-7 Human genes 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 230000035986 JAK-STAT signaling Effects 0.000 description 1
- 102100033630 Killer cell immunoglobulin-like receptor 2DS2 Human genes 0.000 description 1
- 102100021458 Killer cell lectin-like receptor subfamily F member 1 Human genes 0.000 description 1
- PWKSKIMOESPYIA-BYPYZUCNSA-N L-N-acetyl-Cysteine Chemical compound CC(=O)N[C@@H](CS)C(O)=O PWKSKIMOESPYIA-BYPYZUCNSA-N 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- 101710145805 Leukocyte immunoglobulin-like receptor subfamily B member 3 Proteins 0.000 description 1
- 239000000232 Lipid Bilayer Substances 0.000 description 1
- 208000028018 Lymphocytic leukaemia Diseases 0.000 description 1
- FYYHWMGAXLPEAU-UHFFFAOYSA-N Magnesium Chemical compound [Mg] FYYHWMGAXLPEAU-UHFFFAOYSA-N 0.000 description 1
- 208000004059 Male Breast Neoplasms Diseases 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 102000000440 Melanoma-associated antigen Human genes 0.000 description 1
- 108050008953 Melanoma-associated antigen Proteins 0.000 description 1
- 108010061593 Member 14 Tumor Necrosis Factor Receptors Proteins 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 description 1
- 101600097262 Monodelphis domestica Cyclin-dependent kinase inhibitor 2A (isoform 1) Proteins 0.000 description 1
- 241000713333 Mouse mammary tumor virus Species 0.000 description 1
- 208000034578 Multiple myelomas Diseases 0.000 description 1
- 108010085220 Multiprotein Complexes Proteins 0.000 description 1
- 102000007474 Multiprotein Complexes Human genes 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- 241000714177 Murine leukemia virus Species 0.000 description 1
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 description 1
- 108060008487 Myosin Proteins 0.000 description 1
- 102000003505 Myosin Human genes 0.000 description 1
- 125000001429 N-terminal alpha-amino-acid group Chemical group 0.000 description 1
- 108091008877 NK cell receptors Proteins 0.000 description 1
- 102000010648 Natural Killer Cell Receptors Human genes 0.000 description 1
- 102100034448 Neuroligin-4, Y-linked Human genes 0.000 description 1
- 102000007607 Non-Receptor Type 11 Protein Tyrosine Phosphatase Human genes 0.000 description 1
- 108010032107 Non-Receptor Type 11 Protein Tyrosine Phosphatase Proteins 0.000 description 1
- 238000000636 Northern blotting Methods 0.000 description 1
- 208000010505 Nose Neoplasms Diseases 0.000 description 1
- 101710163270 Nuclease Proteins 0.000 description 1
- 108091005461 Nucleic proteins Proteins 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 229930182555 Penicillin Natural products 0.000 description 1
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 1
- 102000010292 Peptide Elongation Factor 1 Human genes 0.000 description 1
- 108010077524 Peptide Elongation Factor 1 Proteins 0.000 description 1
- 206010035226 Plasma cell myeloma Diseases 0.000 description 1
- 208000002151 Pleural effusion Diseases 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 102100036663 Protein PAXX Human genes 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 239000012979 RPMI medium Substances 0.000 description 1
- 239000012980 RPMI-1640 medium Substances 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 108010006700 Receptor Tyrosine Kinase-like Orphan Receptors Proteins 0.000 description 1
- 101710110428 Rho GTPase-activating protein 45 Proteins 0.000 description 1
- 241000714474 Rous sarcoma virus Species 0.000 description 1
- 102100029198 SLAM family member 7 Human genes 0.000 description 1
- 108010029477 STAT5 Transcription Factor Proteins 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- XZKQVQKUZMAADP-IMJSIDKUSA-N Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(O)=O XZKQVQKUZMAADP-IMJSIDKUSA-N 0.000 description 1
- 102100024481 Signal transducer and activator of transcription 5A Human genes 0.000 description 1
- 108010074687 Signaling Lymphocytic Activation Molecule Family Member 1 Proteins 0.000 description 1
- 102000008115 Signaling Lymphocytic Activation Molecule Family Member 1 Human genes 0.000 description 1
- 241000700584 Simplexvirus Species 0.000 description 1
- 238000002105 Southern blotting Methods 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 230000020385 T cell costimulation Effects 0.000 description 1
- 108700042075 T-Cell Receptor Genes Proteins 0.000 description 1
- 102100037911 T-cell surface glycoprotein CD3 gamma chain Human genes 0.000 description 1
- 102100037906 T-cell surface glycoprotein CD3 zeta chain Human genes 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- 102000006601 Thymidine Kinase Human genes 0.000 description 1
- 108020004440 Thymidine kinase Proteins 0.000 description 1
- 102100034999 Thymosin beta-4, Y-chromosomal Human genes 0.000 description 1
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 1
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 1
- 108700019146 Transgenes Proteins 0.000 description 1
- 206010052779 Transplant rejections Diseases 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 description 1
- 102100024586 Tumor necrosis factor ligand superfamily member 14 Human genes 0.000 description 1
- 102100029690 Tumor necrosis factor receptor superfamily member 13C Human genes 0.000 description 1
- 102100028785 Tumor necrosis factor receptor superfamily member 14 Human genes 0.000 description 1
- 102100035221 Tyrosine-protein kinase Fyn Human genes 0.000 description 1
- 102100021657 Tyrosine-protein phosphatase non-receptor type 6 Human genes 0.000 description 1
- 101710128901 Tyrosine-protein phosphatase non-receptor type 6 Proteins 0.000 description 1
- 210000001766 X chromosome Anatomy 0.000 description 1
- 241001193851 Zeta Species 0.000 description 1
- UGXQOOQUZRUVSS-ZZXKWVIFSA-N [5-[3,5-dihydroxy-2-(1,3,4-trihydroxy-5-oxopentan-2-yl)oxyoxan-4-yl]oxy-3,4-dihydroxyoxolan-2-yl]methyl (e)-3-(4-hydroxyphenyl)prop-2-enoate Chemical compound OC1C(OC(CO)C(O)C(O)C=O)OCC(O)C1OC1C(O)C(O)C(COC(=O)\C=C\C=2C=CC(O)=CC=2)O1 UGXQOOQUZRUVSS-ZZXKWVIFSA-N 0.000 description 1
- 229960004308 acetylcysteine Drugs 0.000 description 1
- 230000003044 adaptive effect Effects 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 239000000823 artificial membrane Substances 0.000 description 1
- 239000012298 atmosphere Substances 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 210000003651 basophil Anatomy 0.000 description 1
- CXQCLLQQYTUUKJ-ALWAHNIESA-N beta-D-GalpNAc-(1->4)-[alpha-Neup5Ac-(2->8)-alpha-Neup5Ac-(2->3)]-beta-D-Galp-(1->4)-beta-D-Glcp-(1<->1')-Cer(d18:1/18:0) Chemical compound O[C@@H]1[C@@H](O)[C@H](OC[C@H](NC(=O)CCCCCCCCCCCCCCCCC)[C@H](O)\C=C\CCCCCCCCCCCCC)O[C@H](CO)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@]2(O[C@H]([C@H](NC(C)=O)[C@@H](O)C2)[C@H](O)[C@@H](CO)O[C@]2(O[C@H]([C@H](NC(C)=O)[C@@H](O)C2)[C@H](O)[C@H](O)CO)C(O)=O)C(O)=O)[C@@H](O[C@H]2[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O2)NC(C)=O)[C@@H](CO)O1 CXQCLLQQYTUUKJ-ALWAHNIESA-N 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 238000010170 biological method Methods 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 210000000988 bone and bone Anatomy 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 239000007975 buffered saline Substances 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000032823 cell division Effects 0.000 description 1
- 230000022534 cell killing Effects 0.000 description 1
- 210000003169 central nervous system Anatomy 0.000 description 1
- 239000002738 chelating agent Substances 0.000 description 1
- 239000003638 chemical reducing agent Substances 0.000 description 1
- 229960005091 chloramphenicol Drugs 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 206010073251 clear cell renal cell carcinoma Diseases 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 230000004186 co-expression Effects 0.000 description 1
- 238000001246 colloidal dispersion Methods 0.000 description 1
- 239000000084 colloidal system Substances 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 108091036078 conserved sequence Proteins 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 229940109239 creatinine Drugs 0.000 description 1
- 230000016396 cytokine production Effects 0.000 description 1
- 102000003675 cytokine receptors Human genes 0.000 description 1
- 108010057085 cytokine receptors Proteins 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- 230000002939 deleterious effect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 239000000539 dimer Substances 0.000 description 1
- 230000005782 double-strand break Effects 0.000 description 1
- 230000003828 downregulation Effects 0.000 description 1
- 230000004064 dysfunction Effects 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 239000000839 emulsion Substances 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 210000003979 eosinophil Anatomy 0.000 description 1
- 238000010195 expression analysis Methods 0.000 description 1
- 210000004700 fetal blood Anatomy 0.000 description 1
- 230000001605 fetal effect Effects 0.000 description 1
- 231100000221 frame shift mutation induction Toxicity 0.000 description 1
- 230000037433 frameshift Effects 0.000 description 1
- 239000012595 freezing medium Substances 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 238000012239 gene modification Methods 0.000 description 1
- 102000054767 gene variant Human genes 0.000 description 1
- 231100000118 genetic alteration Toxicity 0.000 description 1
- 230000004077 genetic alteration Effects 0.000 description 1
- 238000012252 genetic analysis Methods 0.000 description 1
- 230000005017 genetic modification Effects 0.000 description 1
- 230000001295 genetical effect Effects 0.000 description 1
- 235000013617 genetically modified food Nutrition 0.000 description 1
- 238000010362 genome editing Methods 0.000 description 1
- 238000003205 genotyping method Methods 0.000 description 1
- 239000003862 glucocorticoid Substances 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- RWSXRVCMGQZWBV-WDSKDSINSA-N glutathione Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@@H](CS)C(=O)NCC(O)=O RWSXRVCMGQZWBV-WDSKDSINSA-N 0.000 description 1
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 1
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 1
- 208000024908 graft versus host disease Diseases 0.000 description 1
- 210000000224 granular leucocyte Anatomy 0.000 description 1
- 239000008187 granular material Substances 0.000 description 1
- 210000003714 granulocyte Anatomy 0.000 description 1
- 210000002768 hair cell Anatomy 0.000 description 1
- 210000003494 hepatocyte Anatomy 0.000 description 1
- 229940064366 hespan Drugs 0.000 description 1
- 210000003630 histaminocyte Anatomy 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 125000001165 hydrophobic group Chemical group 0.000 description 1
- 239000012642 immune effector Substances 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 229940121354 immunomodulator Drugs 0.000 description 1
- 230000028709 inflammatory response Effects 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 102000006029 inositol monophosphatase Human genes 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 108010044426 integrins Proteins 0.000 description 1
- 102000006495 integrins Human genes 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 230000037427 ion transport Effects 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 230000033001 locomotion Effects 0.000 description 1
- 238000003670 luciferase enzyme activity assay Methods 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 201000005249 lung adenocarcinoma Diseases 0.000 description 1
- 208000003747 lymphoid leukemia Diseases 0.000 description 1
- 230000001048 lympholytic effect Effects 0.000 description 1
- 239000011777 magnesium Substances 0.000 description 1
- 229910052749 magnesium Inorganic materials 0.000 description 1
- 201000003175 male breast cancer Diseases 0.000 description 1
- 208000010907 male breast carcinoma Diseases 0.000 description 1
- 208000026037 malignant tumor of neck Diseases 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- 238000012737 microarray-based gene expression Methods 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 239000004005 microsphere Substances 0.000 description 1
- 230000000394 mitotic effect Effects 0.000 description 1
- 238000012243 multiplex automated genomic engineering Methods 0.000 description 1
- 208000025113 myeloid leukemia Diseases 0.000 description 1
- 108700003805 myo-inositol-1 (or 4)-monophosphatase Proteins 0.000 description 1
- 239000002088 nanocapsule Substances 0.000 description 1
- 210000004882 non-tumor cell Anatomy 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 238000012856 packing Methods 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 229940049954 penicillin Drugs 0.000 description 1
- 102000014187 peptide receptors Human genes 0.000 description 1
- 108010011903 peptide receptors Proteins 0.000 description 1
- 210000005105 peripheral blood lymphocyte Anatomy 0.000 description 1
- 230000002688 persistence Effects 0.000 description 1
- 210000001539 phagocyte Anatomy 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 238000000053 physical method Methods 0.000 description 1
- 229940081858 plasmalyte a Drugs 0.000 description 1
- 239000013612 plasmid Substances 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 239000000186 progesterone Substances 0.000 description 1
- 229960003387 progesterone Drugs 0.000 description 1
- 210000002307 prostate Anatomy 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- XNSAINXGIQZQOO-SRVKXCTJSA-N protirelin Chemical compound NC(=O)[C@@H]1CCCN1C(=O)[C@@H](NC(=O)[C@H]1NC(=O)CC1)CC1=CN=CN1 XNSAINXGIQZQOO-SRVKXCTJSA-N 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 230000001373 regressive effect Effects 0.000 description 1
- 230000029058 respiratory gaseous exchange Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 1
- 230000008054 signal transmission Effects 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 229940054269 sodium pyruvate Drugs 0.000 description 1
- 230000000392 somatic effect Effects 0.000 description 1
- 125000006850 spacer group Chemical group 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 102000009076 src-Family Kinases Human genes 0.000 description 1
- 108010087686 src-Family Kinases Proteins 0.000 description 1
- 238000010186 staining Methods 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 229960005322 streptomycin Drugs 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 239000004094 surface-active agent Substances 0.000 description 1
- 230000005062 synaptic transmission Effects 0.000 description 1
- 238000002626 targeted therapy Methods 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- 238000010257 thawing Methods 0.000 description 1
- 208000013077 thyroid gland carcinoma Diseases 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 230000005026 transcription initiation Effects 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000005748 tumor development Effects 0.000 description 1
- 102000003298 tumor necrosis factor receptor Human genes 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 210000003462 vein Anatomy 0.000 description 1
- 230000035899 viability Effects 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
Images













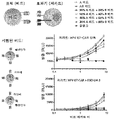


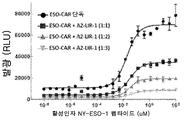











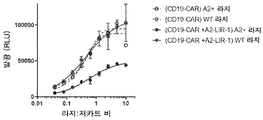




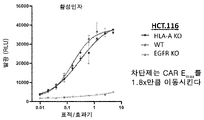






































Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/461—Cellular immunotherapy characterised by the cell type used
- A61K39/4611—T-cells, e.g. tumor infiltrating lymphocytes [TIL], lymphokine-activated killer cells [LAK] or regulatory T cells [Treg]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/463—Cellular immunotherapy characterised by recombinant expression
- A61K39/4631—Chimeric Antigen Receptors [CAR]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/463—Cellular immunotherapy characterised by recombinant expression
- A61K39/4632—T-cell receptors [TCR]; antibody T-cell receptor constructs
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464402—Receptors, cell surface antigens or cell surface determinants
- A61K39/464403—Receptors for growth factors
- A61K39/464404—Epidermal growth factor receptors [EGFR]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464402—Receptors, cell surface antigens or cell surface determinants
- A61K39/464411—Immunoglobulin superfamily
- A61K39/464412—CD19 or B4
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464466—Adhesion molecules, e.g. NRCAM, EpCAM or cadherins
- A61K39/464468—Mesothelin [MSLN]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464484—Cancer testis antigens, e.g. SSX, BAGE, GAGE or SAGE
- A61K39/464486—MAGE
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464484—Cancer testis antigens, e.g. SSX, BAGE, GAGE or SAGE
- A61K39/464488—NY-ESO
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/7051—T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2833—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against MHC-molecules, e.g. HLA-molecules
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3069—Reproductive system, e.g. ovaria, uterus, testes, prostate
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/40—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against enzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
- C12N15/625—DNA sequences coding for fusion proteins containing a sequence coding for a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0635—B lymphocytes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0646—Natural killers cells [NK], NKT cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
- A61K2039/507—Comprising a combination of two or more separate antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/10—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterized by the structure of the chimeric antigen receptor [CAR]
- A61K2239/22—Intracellular domain
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/31—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterized by the route of administration
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/38—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterised by the dose, timing or administration schedule
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/46—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterised by the cancer treated
- A61K2239/48—Blood cells, e.g. leukemia or lymphoma
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/46—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterised by the cancer treated
- A61K2239/57—Skin; melanoma
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/32—Immunoglobulins specific features characterized by aspects of specificity or valency specific for a neo-epitope on a complex, e.g. antibody-antigen or ligand-receptor
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/03—Fusion polypeptide containing a localisation/targetting motif containing a transmembrane segment
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
Abstract
본 개시내용은 이형접합성 소실에 의해 확인된 표적 세포에 전체적으로 설계되고 질환 또는 장애, 예를 들어 암을 치료하기 위해 사용되는 리간드 결합 도메인을 각각 갖는 2개의 조작된 수용체의 시스템에 관한 것이다. 본 개시내용은 2개의 조작된 수용체를 발현하는 면역 세포, 이를 제조하는 방법, 및 이를 암호화하는 폴리뉴클레오타이드 및 벡터를 제공한다.
Description
관련 출원의 상호 참조
본 출원은 2019년 8월 9일에 출원된 미국 가출원 제62/885,093호 및 2020년 4월 6일에 출원된 미국 가출원 제63/005,670호의 우선권의 이익을 주장하고, 이들의 각각의 내용은 본원에 그 전체가 참고로 포함된다.
서열 목록의 참고에 의한 포함
본 출원은 전자 형식으로 서열 목록과 함께 제출된다. 서열 목록은 크기가 404 킬로바이트이고 2020년 8월 5일에 생성된 명칭이 A2BI-00903WO_SeqList.txt인 파일로서 제공된다. 서열 목록의 전자 형식의 정보는 그 전체가 참고로 포함된다.
세포 치료는 다양한 질환, 특히 암의 치료에 강력한 도구이다. 종래의 입양 세포 치료에서, 면역 세포는 수용체와 표적 세포에 의해 발현된 리간드의 상호작용을 통해 세포 표적에 면역 세포의 활성을 지시하는 특이적 수용체, 예를 들어 키메라 항원 수용체(CAR: chimeric antigen receptor) 또는 T 세포 수용체(TCR: T Cell Receptor)를 발현하도록 조작된다. 적합한 표적 분자의 확인은 도전으로 남아 있다. 세포 치료에 의해 질환, 특히 암의 치료에서 유용한 조성물 및 방법에 대한 수요가 당해 분야에 있다.
본 개시내용은 일반적으로 이형접합성 소실을 나타내는 종양 세포에 조작된 면역 세포, 예를 들어 입양 세포 치료에 사용된 면역 세포를 표적화하도록 사용될 수 있는 이들 면역 세포에서 발현된 2개-수용체 시스템에 관한 것이다. 이 2개 수용체 시스템에서, 제1 수용체는 면역 세포를 활성화하거나 이의 활성화를 촉진하도록 작용하지만, 제2 수용체는 제1 수용체에 의한 활성화를 억제하도록 작용한다. 예를 들어, 억제 리간드를 암호화하는 유전자좌의 이형접합성 소실을 통한 제1 수용체 및 제2 수용체에 대한 리간드의 차등 발현은 제2 억제 리간드가 아니라 제1 활성인자 리간드를 발현하는 표적 세포에 의한 면역 세포의 활성화를 매개한다.
본 개시내용은 (a) 제1 조작된 수용체이되, 제1 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 제1 리간드에 특이적으로 결합할 수 있는 제1 리간드 결합 도메인을 포함하는, 제1 조작된 수용체; 및 (b) 제2 조작된 수용체이되, 제2 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 제2 리간드에 특이적으로 결합할 수 있는 제2 리간드 결합 도메인을 포함하는, 제2 조작된 수용체를 포함하는 면역 세포를 제공하고, 제1 리간드에 대한 제1 리간드 결합 도메인의 결합은 수용체에 의해 면역 세포를 활성화하거나 이의 활성화를 촉진하고, 제2 리간드에 대한 제2 리간드 결합 도메인의 결합은 제1 수용체에 의한 면역 세포의 활성화를 억제한다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제2 리간드는 제2 리간드를 암호화하는 유전자의 이형접합성 소실로 인해 표적 세포에서 발현되지 않는다. 일부 실시형태에서, 제2 리간드는 HLA 클래스 I 대립유전자 또는 부 조직접합 항원(MiHA: minor histocompatibility antigen)이다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제2 리간드는 MiHA이다. 일부 실시형태에서, MiHA는 표 8 및 표 9에서의 MiHA의 군으로부터 선택된다. 일부 실시형태에서, MiHA는 HA-1이다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제2 리간드는 HLA 클래스 I 대립유전자이다. 일부 실시형태에서, HLA 클래스 I 대립유전자는 HLA-A, HLA-B 또는 HLA-C를 포함한다. 일부 실시형태에서, HLA 클래스 I 대립유전자는 HLA-A*02 대립유전자이다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제2 리간드는 Y 염색체 소실로 인해 표적 세포에서 발현되지 않는다. 일부 실시형태에서, 제2 리간드는 Y 염색체 유전자에 의해 암호화된다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제1 리간드 및 제2 리간드는 동일하지 않다. 일부 실시형태에서, 제1 리간드는 표적 세포에 의해 발현된다. 일부 실시형태에서, 제1 리간드는 표적 세포 및 비표적 세포에 의해 발현된다. 일부 실시형태에서, 제2 리간드는 표적 세포에 의해 발현되지 않고, 복수의 비표적 세포에 의해 발현된다. 일부 실시형태에서, 복수의 비표적 세포는 제1 리간드 및 제2 리간드 둘 다를 발현한다.
일부 실시형태에서, 표적 세포는 암 세포이고, 비표적 세포는 비암성 세포이다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제1 리간드는 세포 부착 분자, 세포-세포 신호전달 분자, 세포외 도메인, 화학주성에 관여된 분자, 당단백질, G 단백질 커플링된 수용체, 막관통 단백질, 신경전달인자를 위한 수용체 및 전압 게이팅된 이온 채널로 이루어진 군으로부터 선택된다. 일부 실시형태에서, 제1 리간드는 표 5에서의 항원의 군으로부터 선택된다. 일부 실시형태에서, 제1 리간드는 트랜스페린 수용체(TFRC: transferrin receptor), 표피 성장 인자 수용체(EGFR: epidermal growth factor receptor), CEA 세포 부착 분자 5(CEA: CEA cell adhesion molecule 5), CD19 분자(CD19: CD19 molecule), erb-b2 수용체 티로신 키나제 2(HER2: erb-b2 receptor tyrosine kinase 2) 및 메소텔린(MSLN: mesothelin), 또는 이의 펩타이드 항원으로 이루어진 군으로부터 선택된다. 일부 실시형태에서, 제1 리간드는 HLA-A, HLA-B, HLA-C, HLA-E, HLA-F 또는 HLA-G를 포함한다. 일부 실시형태에서, 제1 리간드는 pan-HLA 리간드이다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제2 리간드는 HLA 클래스 I 대립유전자, 부 조직접합 항원(MiHA) 및 Y 염색체 유전자로 이루어진 군으로부터 선택된다. 일부 실시형태에서, 제2 리간드의 발현은 이형접합성 소실로부터 표적 세포에서 소실된다. 일부 실시형태에서, MiHA는 HA-1이다. 일부 실시형태에서, HLA 클래스 I 대립유전자는 HLA-A*02 대립유전자이다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제1 조작된 수용체는 T 세포 수용체(TCR) 또는 키메라 항원 수용체(CAR)이다. 일부 실시형태에서, 제2 조작된 수용체는 T 세포 수용체(TCR) 또는 키메라 항원 수용체(CAR)이다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제1 리간드 결합 도메인은 단일 사슬 Fv 항체 단편(ScFv), β 사슬 가변 도메인(Vβ), TCR α 사슬 가변 도메인 및 TCR β 사슬 가변 도메인, 또는 가변 중쇄(VH) 도메인 및 가변 경쇄(VL) 도메인을 포함한다. 일부 실시형태에서, 제2 리간드 결합 도메인은 ScFv, Vβ 도메인, TCR α 사슬 가변 도메인 및 TCR β 사슬 가변 도메인, 또는 가변 중쇄(VH) 도메인 및 가변 경쇄(VL) 도메인을 포함한다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제1 리간드는 EGFR 또는 이의 펩타이드 항원이다. 일부 실시형태에서, 제1 리간드 결합 도메인은 서열 번호 102, 서열 번호 104, 서열 번호 106, 서열 번호 108, 서열 번호 110, 서열 번호 112, 서열 번호 114, 서열 번호 116, 서열 번호 118 또는 서열 번호 391의 서열, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함한다. 일부 실시형태에서, 제1 리간드 결합 도메인은 서열 번호 131 내지 서열 번호 166으로부터 선택된 CDR을 포함한다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제1 리간드는 MSLN 또는 이의 펩타이드 항원이다. 일부 실시형태에서, 제1 리간드 결합 도메인은 서열 번호 86, 서열 번호 88, 서열 번호 90 또는 서열 번호 92의 서열, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함한다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제1 리간드는 CEA 또는 이의 펩타이드 항원이다. 일부 실시형태에서, 제1 리간드 결합 도메인은 서열 번호 94, 서열 번호 96, 서열 번호 98, 서열 번호 100, 서열 번호 282, 서열 번호 284 또는 서열 번호 286, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함한다. 일부 실시형태에서, 제1 리간드 결합 도메인은 서열 번호 294 내지 서열 번호 302로부터 선택된 CDR을 포함한다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제1 리간드는 CD19 또는 이의 펩타이드 항원이고, 제1 리간드 결합 도메인은 서열 번호 275 또는 서열 번호 277, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함한다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제1 리간드는 pan-HLA 리간드이다. 일부 실시형태에서, 제1 리간드 결합 도메인은 서열 번호 167, 서열 번호 169, 서열 번호 171, 서열 번호 173, 서열 번호 175 또는 서열 번호 177의 서열, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함한다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제2 리간드는 HA-1을 포함한다. 일부 실시형태에서, 제2 리간드 결합 도메인은 서열 번호 199를 포함하는 TCR 알파 가변 도메인, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열, 및 서열 번호 200을 포함하는 TCR 베타 가변 도메인, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함한다. 일부 실시형태에서, 제2 리간드 결합 도메인은 서열 번호 199를 포함하는 TCR 알파 가변 도메인 및 서열 번호 200을 포함하는 TCR 베타 가변 도메인을 포함한다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제2 리간드는 HLA-A*02 대립유전자를 포함한다. 일부 실시형태에서, 제2 리간드 결합 도메인은 서열 번호 53 내지 64 중 어느 하나, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함한다. 일부 실시형태에서, 제2 리간드 결합 도메인은 서열 번호 41 내지 서열 번호 52로부터 선택된 CDR을 포함한다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제2 조작된 수용체는 면역수용체 티로신계 억제 모티프(ITIM: immunoreceptor tyrosine-based inhibitory motif)를 포함한다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제2 조작된 수용체는 LILRB1 세포내 도메인 또는 이의 기능적 변이체를 포함한다. 일부 실시형태에서, LILRB1 세포내 도메인은 서열 번호 76과 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 제2 조작된 수용체는 LILRB1 막관통 도메인 또는 이의 기능적 변이체를 포함한다. 일부 실시형태에서, LILRB1 막관통 도메인 또는 이의 기능적 변이체는 서열 번호 85와 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 제2 조작된 수용체는 LILRB1 힌지 도메인 또는 이의 기능적 단편 또는 변이체를 포함한다. 일부 실시형태에서, LILRB1 힌지 도메인은 서열 번호 84, 서열 번호 77 또는 서열 번호 78과 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 제2 조작된 수용체는 LILRB1 세포내 도메인 및 LILRB1 막관통 도메인, 또는 이들의 기능적 변이체를 포함한다. 일부 실시형태에서, LILRB1 세포내 도메인 및 LILRB1 막관통 도메인은 서열 번호 80 또는 서열 번호 80과 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 제2 조작된 수용체는 서열 번호 80을 포함하는 제1 폴리펩타이드 또는 TCR 알파 가변 도메인에 융합된 이것과 적어도 95%의 동일성을 갖는 서열, 및 서열 번호 80을 포함하는 제2 폴리펩타이드 또는 TCR 베타 가변 도메인에 융합된 이것과 적어도 95%의 동일성을 갖는 서열을 포함한다.
본 개시내용의 면역 세포의 일부 실시형태에서, 제1 수용체 및 제2 수용체는 약 1:10 내지 10:1의 제1 수용체 대 제2 수용체의 비로 면역 세포의 표면에서 발현된다. 일부 실시형태에서, 제1 수용체 및 제2 수용체는 약 1:3 내지 3:1의 제1 수용체 대 제2 수용체의 비로 면역 세포의 표면에서 발현된다. 일부 실시형태에서, 제1 수용체 및 제2 수용체는 약 1:1의 비로 면역 세포의 표면에서 발현된다.
본 개시내용의 면역 세포의 일부 실시형태에서, 면역 세포는 T 세포, B 세포 및 자연 살해(NK: Natural Killer) 세포로 이루어진 군으로부터 선택된다. 일부 실시형태에서, 면역 세포는 비자연이다. 일부 실시형태에서, 면역 세포는 단리된다.
본 개시내용은 약제로서 사용하기 위한 본 개시내용의 2개의 수용체 시스템을 발현하는 면역 세포를 제공한다. 일부 실시형태에서, 약제는 암의 치료에 사용하기 위한 것이다.
본 개시내용은 본 개시내용의 면역 세포를 포함하는 약제학적 조성물을 제공한다. 일부 실시형태에서, 약제학적 조성물은 약제학적으로 허용 가능한 담체, 희석제 또는 부형제를 포함한다. 일부 실시형태에서, 약제학적 조성물은 치료학적 유효량의 면역 세포를 포함한다.
본 개시내용은 본 개시내용의 복수의 면역 세포 또는 약제학적 조성물을 대상체에게 투여하는 단계를 포함하는, 대상체에서 입양 세포 치료의 특이성을 증가시키는 방법을 제공한다.
본 개시내용은 치료학적 유효량의 본 개시내용의 면역 세포 또는 약제학적 조성물을 대상체에게 투여하는 단계를 포함하는 암의 치료를 필요로 하는 대상체에서 암을 치료하는 방법을 제공한다.
본 개시내용의 방법의 일부 실시형태에서, 대상체는 암을 갖는다. 일부 실시형태에서, 암의 세포는 제1 리간드를 발현한다. 일부 실시형태에서, 암의 세포는 이형접합성 소실 또는 Y 염색체 소실로 인해 제2 리간드를 발현하지 않는다.
본 개시내용은 (a) 복수의 면역 세포를 제공하는 단계; 및 (b) 면역 세포를 막관통 영역 및 세포외 영역을 포함하는 제1 조작된 수용체를 암호화하는 벡터이되, 세포외 영역은 제1 리간드에 특이적으로 결합할 수 있는 제1 리간드 결합 도메인을 포함하는 벡터, 및 막관통 영역 및 세포외 영역을 포함하는 제2 조작된 수용체를 암호화하는 벡터이되, 세포외 영역은 제2 리간드에 특이적으로 결합할 수 있는 제2 리간드 결합 도메인을 포함하는 벡터에 의해 형질전환하는 단계를 포함하는 본 개시내용의 면역 세포를 제조하는 방법을 제공하고; 제1 리간드에 대한 제1 리간드 결합 도메인의 결합은 면역 세포를 활성화하거나 이의 활성화를 촉진하고, 제2 리간드에 대한 제2 리간드 결합 도메인의 결합은 제1 리간드에 의해 면역 세포의 활성화를 억제한다.
본 개시내용은 본 개시내용의 면역 세포 또는 약제학적 조성물을 포함하는 키트를 제공한다.
본 개시내용은 HA-1 부 조직접합 항원(MiHA)에 특이적으로 결합을 할 수 있는 세포외 리간드 결합 도메인 및 적어도 하나의 면역수용체 티로신계 억제 모티프(ITIM)를 포함하는 세포내 도메인을 포함하는 억제 수용체를 제공한다.
본 개시내용의 억제 수용체의 일부 실시형태에서, 세포외 리간드 결합 도메인은 VLRDDLLEA(서열 번호 266)의 HA-1(R) 펩타이드에 대한 것보다 VLHDDLLEA(서열 번호 191)의 HA-1(H) 펩타이드에 대한 더 높은 친화성을 갖는다. 일부 실시형태에서, 억제 수용체는 VLHDDLLEA(서열 번호 191)의 HA-1(H) 펩타이드에 의해 활성화되고, 활성화되지 않거나, 더 적은 정도로 VLRDDLLEA(서열 번호 266)의 HA-1(R) 펩타이드에 의해 활성화된다. 일부 실시형태에서, 세포외 리간드 결합 도메인은 서열 번호 199를 포함하는 TCR 알파 가변 도메인, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열, 및 서열 번호 200을 포함하는 TCR 베타 가변 도메인, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함한다. 일부 실시형태에서, 세포외 리간드 결합 도메인은 서열 번호 199를 포함하는 TCR 알파 가변 도메인 및 서열 번호 200을 포함하는 TCR 베타 가변 도메인을 포함한다.
본 개시내용의 억제 수용체의 일부 실시형태에서, 세포내 도메인은 LILRB1 세포내 도메인 또는 이의 기능적 변이체를 포함한다. 일부 실시형태에서, LILRB1 세포내 도메인 또는 이의 기능적 변이체는 서열 번호 76과 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 억제 수용체는 LILRB1 막관통 도메인 또는 이의 기능적 변이체를 포함한다. 일부 실시형태에서, LILRB1 막관통 도메인 또는 이의 기능적 변이체는 서열 번호 85와 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 억제 수용체는 LILRB1 세포내 도메인 및 LILRB1 막관통 도메인, 또는 이들의 기능적 변이체를 포함한다. 일부 실시형태에서, LILRB1 세포내 도메인 및 LILRB1 막관통 도메인은 서열 번호 80, 또는 서열 번호 80과 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 억제 수용체는 서열 번호 80을 포함하는 제1 폴리펩타이드 또는 TCR 알파 가변 도메인에 융합된 이것과 적어도 95% 동일한 서열, 및 서열 번호 80을 포함하는 제2 폴리펩타이드 또는 TCR 베타 가변 도메인에 융합된 이것과 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 억제 수용체는 서열 번호 195 또는 이것과 적어도 95%의 동일성에서의 폴리펩타이드 및 서열 번호 197 또는 이것과 적어도 95%의 동일성에서의 폴리펩타이드를 포함한다.
본 개시내용은 (a) 제1 조작된 수용체이되, 제1 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 CD19 리간드에 특이적으로 결합할 수 있는 제1 리간드 결합 도메인을 포함하는, 제1 조작된 수용체; 및 (b) 제2 조작된 수용체이되, 제2 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 HLA-A*02 대립유전자에 특이적으로 결합할 수 있는 제2 리간드 결합 도메인을 포함하는, 제2 조작된 수용체를 포함하는 면역 세포를 제공하고, CD19 리간드에 대한 제1 리간드 결합 도메인의 결합은 제1 수용체에 의해 면역 세포를 활성화하거나 이의 활성화를 촉진하고, HLA-A*02 대립유전자에 대한 제2 리간드 결합 도메인의 결합은 제1 수용체에 의한 면역 세포의 활성화를 억제한다.
본 개시내용은 (a) 제1 조작된 수용체이되, 제1 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 EGFR 리간드에 특이적으로 결합할 수 있는 제1 리간드 결합 도메인을 포함하는, 제1 조작된 수용체; 및 (b) 제2 조작된 수용체이되, 제2 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 HLA-A*02 대립유전자에 특이적으로 결합할 수 있는 제2 리간드 결합 도메인을 포함하는, 제2 조작된 수용체를 포함하는 면역 세포를 제공하고, EGFR 리간드에 대한 제1 리간드 결합 도메인의 결합은 제1 수용체에 의해 면역 세포를 활성화하거나 이의 활성화를 촉진하고, HLA-A*02 대립유전자에 대한 제2 리간드 결합 도메인의 결합은 제1 수용체에 의한 면역 세포의 활성화를 억제한다.
본 개시내용은 (a) 제1 조작된 수용체이되, 제1 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 메소텔린(MSLN) 리간드에 특이적으로 결합할 수 있는 제1 리간드 결합 도메인을 포함하는, 제1 조작된 수용체; 및 (b) 제2 조작된 수용체이되, 제2 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 HLA-A*02 대립유전자에 특이적으로 결합할 수 있는 제2 리간드 결합 도메인을 포함하는, 제2 조작된 수용체를 포함하는 면역 세포를 제공하고, MSLN 리간드에 대한 제1 리간드 결합 도메인의 결합은 제1 수용체에 의해 면역 세포를 활성화하거나 이의 활성화를 촉진하고, HLA-A*02 대립유전자에 대한 제2 리간드 결합 도메인의 결합은 제1 수용체에 의한 면역 세포의 활성화를 억제한다.
본 발명의 특징 및 이점의 더 양호한 이해는 본 발명의 원칙이 사용된 예시적인 실시형태를 기재한 하기 상세한 설명 및 하기의 첨부된 도면을 참조하여 얻어질 것이다:
도 1은 정상 조직을 구성하는 이형접합성 세포의 배경에 대한 종양을 형성하는 반접합성 종양 세포를 예시하는 다이어그램이다. 반접합성 종양 세포는 오직 표적 A를 발현하고, 이형접합성 소실(LOH)로 인해 표적 B를 소실하지만, 정상 세포는 표적 A와 표적 B 둘 다를 발현한다. 표적 B에 의해 차단되고 표적 A에 의해 활성화된 종양 선택적 세포독성 치료제를 생성하기 위해 이 유전적 차이가 이용될 수 있는데, 이로써 종양을 선택적으로 사멸한다.
도 2a는 종양에서 LOH에 기초한 이중 표적화된 치료의 예시적인 구성을 보여주는 다이어그램이다. 이 예에서, 활성인자 및 차단제 신호의 세포 기반 통합이 있다.
도 2b는 다양한 활성인자 및 수용체 형식 및 조합을 보여주는 일련의 다이어그램이다.
도 3a는 TCR 형식의 본 개시내용의 예시적인 이중 수용체 작제물을 보여주는 한 쌍의 다이어그램이다. 이 예에서, 활성인자 및 억제제(차단제) LBD는 각각 TCR의 CD3 감마 아단위에 별개로 융합된다.
도 3b는 CAR 형식의 본 개시내용의 예시적인 이중 수용체 작제물을 보여주는 다이어그램 및 표이다. 억제제 CAR의 예시적인 ITIM 및 억제제 도메인은 표에서 오른쪽에 기재되어 있다.
도 4a는 GTEx 데이터베이스로부터 인간 조직에서의 트랜스페린 수용체(TFRC)의 RNA-Seq 발현 프로파일을 보여주는 선도이다. 트랜스페린 수용체(TFRC)는 표적 A(활성인자)에 대한 후보이다. RNA 수준에서의 TFRC의 발현은 편재하고 비교적 고르다. TRFC는 필수 유전자이다: 기능 소실 동형접합성 돌연변이는 마우스에서 배아 치사이다.
도 4b는 HLA-A 및 HLA-B의 RNA-Seq 발현 프로파일을 보여주는 선도이다.
도 5a 내지 도 5h는 LIR-1 차단제가 모듈식이고 큰 EC50 이동을 매개한다는 것을 보여준다.
도 5a는 차단제 작제물을 평가하기 위한 T2-저카트 실험의 도식을 보여준디.
도 5b는 NY-ESO-1 차단제 펩타이드가 로딩될 때 MAGE-A3 CAR 활성인자(MP1-CAR)의 EC50에 대한 다양한 NY-ESO-1 scFv LBD 차단제 모듈(PD-1, CTLA-4, LIR-1)의 효과를 보여준다. 오차 막대는 ± SD(n=2)를 나타낸다.
도 5c는 상응하는 펩타이드가 로딩될 때 MAGE-A3 CAR 활성인자 (MP1-CAR)의 EC50에 대한 다양한 scFv LBD(ESO, MP1 LBD 1, MP1 LBD 2, HPV E6 LBD 1, HPV E6 LBD 2, HPV E7)를 갖는 LIR-1 차단제 모듈의 효과를 보여준다. 오차 막대는 ± SD(n=2)를 나타낸다.
도 5d는 NY-ESO-1 차단제 펩타이드가 로딩될 때 상이한 MAGE-A3 CAR 활성인자(MP1-CAR 또는 MP2-CAR)의 EC50에 대한 NY-ESO-1 scFv LBD를 갖는 LIR-1 차단제 모듈의 효과를 보여준다. 오차 막대는 ± SD(n=2)를 나타낸다.
도 5e는 NY-ESO-1 차단제 펩타이드가 로딩될 때 상이한 TCR 활성인자(MP1-TCR, MP2-TCR, HPV E6-TCR)의 EC50에 대한 NY-ESO-1 scFv LBD를 갖는 LIR-1 차단제 모듈의 효과를 보여준다. 오차 막대는 ± SD (n=2)를 나타낸다. 3개의 상이한 TCR 활성인자는 ESO scFv, LIR-1 힌지, LIR-1 TM 및 LIR-1 ICD를 갖는 NY-ESO-LIR-1에 의해 차단된다.
도 5f는 MAGE-A3 CAR 및 TCR 활성인자(MP1-CAR, MP1-TCR)의 EC50에 대한 NY-ESO-1 Ftcr LBD를 갖는 LIR-1 차단제 모듈의 효과를 보여준다. 오차 막대는 ± SD (n=2)를 나타낸다. 제3 세대 CAR 활성인자 또는 정기적 TCR 활성인자 둘 다는 TCRa ECD, LIR-1 TM, LIR-1 ICD 및 TCRb ECD, LIR-1 TM 및 LIR-1 ICD를 갖는 NY-ESO-1 Ftcr-LIR-1에 의해 차단될 수 있다.
도 5g는 활성인자(HPV E7) 및 차단제(NY-ESO-1) 항원의 다양한 비를 나타내는 비드와 동시배양된 HPV E7-CAR 또는 HPV E7-CAR 및 A2-LIR-1에 의해 형질주입된 저카트 세포가 트랜스가 아니라 시스에서의 차단을 나타낸다는 것을 보여준다.
도 5h는 A2-LIR-1 차단제 모듈이 다양한 활성인자 대 차단제 비에서 CD19-CAR 활성인자를 차단한다는 것을 보여준다. E:T 비: 효과기: 표적 비.
도 6a, 도 6c 내지 도 6e는 LIR-1 차단제를 발현하는 1차 T 세포가 pMHC 및 비-pMHC 개념 증명 표적에 의해 종양 세포를 선택적으로 사멸한다는 것을 보여준다.
도 6a는 HPV E7-TCR 활성인자 및 ESO-LIR-1 차단제에 의해 형질도입된 1차 T 세포가 1차 T 세포 사멸 검정에서 EC50을 약 100배 이동시킨다는 것을 보여준다. 오차 막대는 +/- SD(n=2)를 나타낸다.
도 6b는 HLA-A*02-LIR-1이 저카트 세포에서 다양한 활성인자:차단제 DNA 비로 NY-ESO-1 CAR 활성인자를 차단한다는 것을 보여준다.
도 6c는 CD19 CAR 활성인자 및 HLA-A*02 차단제에 의해 형질도입된 1차 T 세포가 시험관내 세포독성 검정에서 "종양" 세포를 "정상" 세포와 구별하고, 3:1의 E:T에서 혼합 표적 세포 검정에서 "종양" 세포의 선택적 사멸을 나타낸다는 것을 보여준다. A2-LIR-1 : HLA-A2*02 LBD를 갖는 LIR-1 기반 수용체
도 6d 내지 도 6e는 CD19 CAR 활성인자 및 HLA-A*02 차단제에 의해 형질도입된 1차 T 세포가 3:1의 E:T에서 시험관내 세포독성 검정에서 3 회차의 항원 노출(AB-A-AB 및 A-AB-A) 후 가역적 봉쇄(도 6d) 및 활성화(도 6e)를 나타낸다는 것을 보여준다. 1차 T 세포 세포독성 검정은 3개의 HLA-A*02-음성 공여자에 의해 재현되었다.
도 7a 내지 도 7e는 변형된 CAR-T 세포(즉, 활성인자 및 차단제 수용체 둘 다를 발현하는 CAR-T 세포)가 이종이식 모델에서 종양을 선택적으로 사멸한다는 것을 보여준다.
도 7a는 CD19 CAR 활성인자 및 HLA-A*02 차단제에 의해 형질도입된 1차 T 세포가 10일에 걸쳐 CD3/28 자극에 의해 약 20배 확장을 나타낸다는 것을 보여준다.
도 7b는 생체내 연구 설계의 도식을 보여준다: HLA-A*02 NSG 마우스는 "종양 세포"(A2-음성 라지 세포(Raji cell)) 또는 "정상 세포"(A2-양성 라지 세포)가 동시에 투여되고, 라지 이종이식편이 평균 약 70 mm3일 때 1차 T 세포(인간, HLA-A*02-음성 공여자)가 꼬리 정맥으로 주사된다.
도 7c 내지 도 7e는 캘리퍼 측정에 의한 종양 크기의 판독정보(도 7c), 유세포분석법에 의한 인간 혈액 T 세포 수(도 7d) 및 생존율(도 7e)을 보여준다. 오차 막대는 평균의 표준 오치(s.e.m.)이다. UTD: 비형질도입됨.
도 8은 활성화 EC50의 펩타이드-로딩 이동이 통상적으로 약 10x 미만이라는 것을 보여준다. 활성화 MAGE-A3 CAR(MP2 CAR)에 대한 차단제 펩타이드 로딩(NY-ESO-1, MAGE-A3, HPV E6 및 HPV E7의 50 uM 각각)의 효과가 도시되어 있다.
도 9는 LIR-1 차단제 모듈이 리간드 의존적이라는 것을 보여준다. 다양한 농도의 NY-ESO-1 차단제 펩타이드가 로딩될 때 활성화 MAGE-A3 CAR(MP1-CAR)의 EC50에 대한 NY-ESO-1-LIR-1 차단제의 효과가 도시되어 있다.
도 10은 ICD가 없는 또는 돌연변이된 비기능적 ICD를 갖는 차단제가 활성화를 차단하지 않는다는 것을 보여준다. 10 uM의 NY-ESO-1 차단제 펩타이드가 로딩될 때 MAGE-A3 CAR 활성인자(MP2-CAR)의 EC50에 대한 ICD를 함유하지 않는 변형된 LIR-1 차단제 모듈(청색) 또는 NY-ESO-1 scFv LBD를 갖는 돌연변이된 ICD(자주색)의 효과가 도시되어 있다.
도 11은 HLA-A*02+ (A2+) 라지 세포에서 CD19가 저카트 활성화를 활성화하고 A2-LIR-1이 이를 차단한다는 것을 보여준다. CD19 또는 CD19와 A2-LIR-1에 의해 형질주입된 저카트 세포를 다양한 세포 비율에서 WT (A2-) 라지 세포 또는 A2+ 라지 세포와 동시배양하였다.
도 12는 종양 성장에 대한 마우스 혈액에서의 hCD3+ T 세포의 상관관계를 보여주는 4개의 패널이다. A2- 및 A2+ 라지 세포에 의한 T 세포 주사 후 10일 및 17일에 종양 용적과 비교된 hCD3+ T 세포의 그래프가 도시되어 있다.
도 13은 EGFR CAR 활성인자 및 HLA-A*02 LIR-1 차단제를 발현하는 저카트 세포가 EGFR+/HLA-A*02+ HeLa 표적 세포가 아니라 EGFR+/HLA-A*02- HeLa 표적 세포에 의해 활성화된다는 것을 보여준다.
도 14a는 HLA-A*02에 의해 형질도입된 HeLa 세포 및 HCT116 세포에 대한 HLA-A*02의 발현을 보여준다. HeLa 및 HCT1116 세포를 항-HLA-A2 항체 BB7.2로 표지하고, FAC를 분류하였다. 녹색: 비표지된 HeLa; 오렌지색: 비표지된 HCT116; 청색: BB7.2로 표지된 야생형 HCT116; 적색: HLA-A*02에 의해 형질도입되고 BB7.2에 의해 표지된 HeLa 세포.
도 14b는 HeLa 세포 및 HCT116 세포에 대한 EGFR의 발현을 보여준다. HeLa 및 HCT1116 세포를 항-EGFR 항체로 표지하고, FAC를 분류하였다. 녹색: 비표지된 HeLa; 오렌지색: 비표지된 HCT1116; 청색: 항-EGFR로 표지된 야생형 HCT116; 적색: HLA-A*02에 의해 형질도입되고 항-EGFR에 의해 표지된 HeLa 세포.
도 15a는 EGFR CAR을 발현하는 저카트 세포 및 HCT116 표적 세포의 EGFR CAR 활성화를 보여준다.
도 15b는 저카트 세포의 EGFR CAR 활성화가 HLA-A*02 LIR-1 억제 수용체에 의해 차단될 수 있다는 것을 보여준다. 저카트 세포가 EGFR 및 HLA-A*02를 발현하는 HCT116 표적 세포에 의해 제시될 때 저카트 세포에 의한 EGFR CAR 및 HLA-A*02 LIR-1 억제 수용체의 동시발현은 대략 1.8x의 CAR EMAX의 이동으로 이어진다.
도 16a는 활성인자 대 차단제 항원의 최적 비를 결정하기 위한 비드 기반 검정에서의 활성인자 항원의 적정을 보여준다.
도 16b는 활성인자 대 차단제 항원의 최적 비를 결정하기 위한 비드 기반 검정에서의 활성인자 항원의 일정한 양의 존재 하에서의 차단제 (억제) 항원의 적정을 보여준다.
도 17은 NY-ESO-1 ScFv LIR-1 기반 억제 수용체가 표적 세포로서의 고형 종양 세포주 A375를 사용하여 MP1 MAGE-A3 TCR에 의한 저카트 세포 활성화의 활성화를 억제할 수 있다는 것을 보여주는 다이어그램(왼쪽) 및 선도(오른쪽)이다.
도 18은 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체가 표적 세포로서의 B 세포 백혈병 계통 NALM6을 사용하여 CD19 ScFv CAR에 의한 저카트 세포 활성화의 활성화를 억제할 수 있다는 것을 보여주는 다이어그램(왼쪽) 및 선도(오른쪽)이다.
도 19는 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체가 용량 의존적 방식으로 NY-ESO-1 ScFv CAR 활성인자에 의해 저카트 세포의 활성화를 억제할 수 있다는 것을 보여주는 다이어그램(왼쪽) 및 선도(오른쪽)이다.
도 20은 pan HLA(pan 클래스 I) ScFv CAR이 T2 표적 세포 및 루시퍼라제 검정을 사용하여 저카트 세포에서 분석될 때 조정 가능항 강도로 HAL-A*02 LIR-1 차단제의 발현에 의해 차단된다는 것을 보여준다.
도 21a는 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체가 무세포 비드 기반 검정에서 시스로 저카트 세포의 활성화를 억제할 수 있다는 것을 보여준다.
도 21b는 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체가 표적 세포로서의 백혈병 세포주 K562를 사용하여 MSLN ScFv CAR에 의해 저카트 세포의 활성화를 억제할 수 있다는 것을 보여준다.
도 22는 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체가 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체 및 표적 세포로서의 HLA-A*02+ HeLa 및 SiHa 세포를 사용하여 MSLN ScFv CAR에 의해 IFNγ의 배수 유도에 의해 측정된 것처럼 저카트 세포의 활성화를 억제할 수 있다는 것을 보여주는 다이어그램(왼쪽) 및 챠트(오른쪽)이다.
도 23은 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체가 HLA-A*02- SiHa 세포가 아니라 HLA-A*02+ SiHa 세포를 사용하여 MSLN CAR 활성인자에 의한 사멸을 억제한다는 것을 보여준다.
도 24는 비드 기반 검정을 사용한 EGFR ScFv CAR을 발현하는 저카트 세포의 활성화가 활성인자 및 억제제 항원이 트랜스로 비드에 존재할 때가 아니라 활성인자 및 억제제 항원이 시스로 비드에 존재할 때 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체에 의해 차단될 수 있다는 것을 보여준다.
도 25a는 EGFR ScFv CAR에 의한 저카트 세포의 활성화가 HLA-A*02(SiHa WT)를 발현하지 않는 SiHa 세포에 의해서가 아니라 HLA-A*02(SiHa A02)를 발현하는 SiHa 표적 세포를 사용하여 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체에 의해 차단될 수 있다는 것을 보여준다.
도 25b는 EGFR ScFv CAR에 의한 저카트 세포의 활성화가 HLA-A*02(HeLa WT)를 발현하지 않는 HeLa 세포에 의해서가 아니라 HLA-A*02(HeLa A02)를 발현하는 HeLa 표적 세포를 사용하여 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체에 의해 차단될 수 있다는 것을 보여준다.
도 26은 LIR-1 억제 도메인에 융합된 추가 ScFv가 용량 의존적 방식으로 항시적 CAR 활성인자를 억제한다는 것을 보여준다. 저카트-NFAT 루시퍼라제 리포터 세포는 높은 긴장성 신호전달을 나타내는 활성화 CAR 작제물 및 다양한 pMHC를 인식하는 억제 작제물에 의해 형질주입되었다. NFAT-루시퍼라제의 활성화에 대한 효과는 형질주입된 저카트 세포를 다양한 양의 억제 펩타이드가 로딩된 T2 세포와 동시배양하여 측정되었다.
도 27은 MiHA-b 대리자 ScFv 리간드 결합 도메인(KRAS G12V ScFv-차단제)을 포함하는 억제 수용체가 T2 표적 세포를 사용하여 MiHA-a 대리자(KRAS G12D TCR, C-891)를 표적화하는 활성인자 TCR에 의해 저카트 효과기 세포 활성화를 억제한다는 것을 보여주는 다이어그램(왼쪽) 및 선도(오른쪽)이다.
도 28은 LIR-1 힌지, TM 및 ICD에 융합된 MiHA-b 대리자 ScFv 리간드 결합 도메인(KRAS G12D ScFv-차단제)을 포함하는 억제 수용체가 T2 표적 세포를 사용하여 MiHA-a 대리자(KRAS G12V TCR, C-913)를 표적화하는 TCR에 의해 저카트 효과기 세포 활성화를 억제한다는 것을 보여주는 다이어그램(왼쪽) 및 선도(오른쪽)이다.
도 29는 LIR1 TM 및 ICD에 융합된 MiHA-b 대리자 Ftcr 결합 도메인(KRAS G12V Ftcr-차단제)을 포함하는 억제 수용체가 T2 표적 세포를 사용하여 MiHA-a 대리자(KRAS G12D TCR)를 표적화하는 TCR에 의해 저카트 효과기 세포 활성화를 억제한다는 것을 보여주는 다이어그램(왼쪽) 및 선도(오른쪽)이다.
도 30은 LIR-1 TM 및 ICD에 융합된 MiHA-b 대리자 Ftcr 결합 도메인(KRAS G12D Ftcr-차단제)을 포함하는 억제 수용체가 T2 표적 세포를 사용하여 MiHA-a 대리자(KRAS G12V TCR)를 표적화하는 TCR에 의해 저카트 효과기 세포 활성화를 억제한다는 것을 보여주는 다이어그램(왼쪽) 및 선도(오른쪽)이다.
도 31a는 하나의 돌연변이체 KRAS 펩타이드[KRAS G12D] 및 LIR-1 힌지에 결합하는 MiHA-b ScFv 리간드 결합 도메인, 막관통 도메인 및 다른 돌연변이체 KRAS 펩타이드(KRAS G12V)에 결합하는 세포내 도메인(ICD)을 포함하는 억제 수용체를 사용한 MiHA-a TCR에 의한 저카트 세포 활성화의 억제를 보여주는 선도이다. 흑색: C-891 활성인자; 청색: C-891 활성인자, C-1761 억제제; 적색: C-891 활성인자, C-2371 및 C2369 억제제.
도 31b는 MiHA-b Ftcr 리간드 결합 도메인 및 LIR-1 막관통 도메인 및 세포내 도메인(ICD)을 함유하는 억제 수용체를 사용한 MiHA-a TCR에 의한 저카트 세포 활성화의 억제를 보여주는 선도이다. 흑색: C-913 활성인자; 청색: C-913 활성인자, C-1761 억제제; 적색: C-913 활성인자, C2365 및 C2367 억제제.
도 32는 마우스 MiHA-Y TCR이 저카트 효과기 세포를 활성화할 수 있다는 것을 보여주는 선도이다.
도 33a는 HA-1 Ftcr이 HA-1(H) 펩타이드의 존재 하에 NY-ESO-1 TCR을 특이적으로 차단할 수 있다는 것을 보여주는 선도 및 표이다.
도 33b는 비특이적인 대립유전자 변이체 HA-1(R) 펩타이드의 존재 하에 HA-1 Ftcr에 의한 NY-ESO-1 TCR의 차단이 본질적으로 없다는 것을 보여주는 선도 및 표이다.
도 34a는 HA-1 Ftcr이 HA-1(H) 차단제 펩타이드의 존재 하에 KRAS TCR을 특이적으로 차단할 수 있다는 것을 보여주는 선도 및 표이다.
도 34b는 비특이적인 대립유전자 변이체 HA-1(R) 펩타이드의 존재 하에 HA-1 Ftcr에 의한 KRAS TCR의 차단이 본질적으로 없다는 것을 보여주는 선도 및 표이다.
도 35는 유세포분석법에 의해 T2 세포에서 HA-1(R), HA-1(H) 및 NY-ESO-1 펩타이드의 펩타이드 로딩을 비교하는 선도이다.
도 36a는 MAGE-A3 MP1 ScFv CAR 및 NY-ESO-1 ScFv LIR1 차단제를 사용한 활성화 용량 반응을 보여주는 선도 및 표이다.
도 36b는 MAGE-A3 MP1 ScFv CAR 및 NY-ESO-1 ScFv LIR1 차단제를 사용한 억제 용량 반응을 보여주는 선도 및 표이다.
도 36c는 각각의 곡선에 사용된 일정한 활성인자 MAGE 펩타이드 농도로 정규화되고 x축에 작도된 도 36b로부터의 x-값 차단제 NY-ESO-1 펩타이드 농도를 보여주는 선도이다. B: NY-ESO-1 LIR1 차단제, A: MAGE-A3 펩타이드 2 ScFv CAR.
도 37은 HLA-A*02 ScFv LIR1 억제제가 상이한 EGFR ScFv CAR 활성인자와 사용될 때 상이한 정도의 차단이 관찰된다는 것을 보여주는 일련의 선도 및 표이다.
도 38a는 상이한 EGFR ScFv CAR 및 HLA-A*02 ScFv LIR1 억제제를 발현하는 T 세포와 EGFR 활성인자 단독(표적 A), 억제제 표적 단독(표적 B) 또는 활성인자와 억제제 표적(표적 AB)을 발현하는 HeLa 세포의 항온처리 후 T 세포에 의한 EGFR ScFv CAR 활성인자 수용체의 발현을 보여주는 일련의 형광 활성 세포 분류(FACS) 선도이다.
도 38b는 표적 세포에 대한 노출 전 및 활성인자 리간드 단독(표적 A)을 발현하는 표적 세포 또는 활성인자와 차단제 리간드 둘 다(표적 AB)를 발현하는 표적 세포와의 120시간 동시배양 후 활성인자 수용체 발현의 정량화를 보여주는 선도이다.
도 39a는 동일한 세포에 EGFR(표적 A), HLA-A*02(표적 B), EGFR과 HLA-A*02의 조합(표적 AB)을 발현하는 HeLa 세포의 집단, 상이한 세포에 표적 A와 표적 AB를 발현하는 HeLa 세포의 혼합 집단, 또는 상이한 세포에 표적 B와 표적 AB를 발현하는 HeLa 세포의 혼합 집단과의 동시배양 후 EGFR ScFv CAR(CT-482) 활성인자 및 HLA-A*02 ScFv LIR1 억제제(C1765)를 발현하는 T 세포에 대한 활성인자 수용체의 세포 표면 발현을 보여주는 선도이다.
도 39b는 동일한 세포에 EGFR(표적 A), HLA-A*02(표적 B), EGFR과 HLA-A*02의 조합(표적 AB)을 발현하는 HeLa 세포의 집단, 상이한 세포에 표적 A와 표적 AB를 발현하는 HeLa 세포의 혼합 집단, 또는 상이한 세포에 표적 B와 표적 AB를 발현하는 HeLa 세포의 혼합 집단과의 동시배양 후 EGFR ScFv CAR(CT-482) 활성인자 및 HLA-A*02 ScFv LIR1 억제제(C1765)를 발현하는 T 세포에 대한 억제제 수용체의 세포 표면 발현을 보여주는 선도이다.
도 40은 T 세포에 의한 활성인자 수용체의 발현 소실이 가역적인지를 결정하기 위한 실험의 다이어그램이다.
도 41a는 활성인자 표면 발현 소실이 가역적이고 T 세포 세포독성에 상응한다는 것을 보여주는 일련의 선도이다. 상부에서: T 세포에 의한 표적 HeLa 세포의 퍼센트 사멸이 도시되어 있다. 하부에서: FACS에 의해 분석된 것과 같은 활성인자 및 억제제 수용체 발현.
도 41b는 활성인자 표면 발현 소실이 가역적이고 T 세포 세포독성에 상응한다는 것을 보여주는 일련의 선도이다. 상부에서: T 세포에 의한 표적 HeLa 세포의 퍼센트 사멸이 도시되어 있다. 하부에서: FACS에 의해 분석된 것과 같은 활성인자 및 억제제 수용체 발현.
도 1은 정상 조직을 구성하는 이형접합성 세포의 배경에 대한 종양을 형성하는 반접합성 종양 세포를 예시하는 다이어그램이다. 반접합성 종양 세포는 오직 표적 A를 발현하고, 이형접합성 소실(LOH)로 인해 표적 B를 소실하지만, 정상 세포는 표적 A와 표적 B 둘 다를 발현한다. 표적 B에 의해 차단되고 표적 A에 의해 활성화된 종양 선택적 세포독성 치료제를 생성하기 위해 이 유전적 차이가 이용될 수 있는데, 이로써 종양을 선택적으로 사멸한다.
도 2a는 종양에서 LOH에 기초한 이중 표적화된 치료의 예시적인 구성을 보여주는 다이어그램이다. 이 예에서, 활성인자 및 차단제 신호의 세포 기반 통합이 있다.
도 2b는 다양한 활성인자 및 수용체 형식 및 조합을 보여주는 일련의 다이어그램이다.
도 3a는 TCR 형식의 본 개시내용의 예시적인 이중 수용체 작제물을 보여주는 한 쌍의 다이어그램이다. 이 예에서, 활성인자 및 억제제(차단제) LBD는 각각 TCR의 CD3 감마 아단위에 별개로 융합된다.
도 3b는 CAR 형식의 본 개시내용의 예시적인 이중 수용체 작제물을 보여주는 다이어그램 및 표이다. 억제제 CAR의 예시적인 ITIM 및 억제제 도메인은 표에서 오른쪽에 기재되어 있다.
도 4a는 GTEx 데이터베이스로부터 인간 조직에서의 트랜스페린 수용체(TFRC)의 RNA-Seq 발현 프로파일을 보여주는 선도이다. 트랜스페린 수용체(TFRC)는 표적 A(활성인자)에 대한 후보이다. RNA 수준에서의 TFRC의 발현은 편재하고 비교적 고르다. TRFC는 필수 유전자이다: 기능 소실 동형접합성 돌연변이는 마우스에서 배아 치사이다.
도 4b는 HLA-A 및 HLA-B의 RNA-Seq 발현 프로파일을 보여주는 선도이다.
도 5a 내지 도 5h는 LIR-1 차단제가 모듈식이고 큰 EC50 이동을 매개한다는 것을 보여준다.
도 5a는 차단제 작제물을 평가하기 위한 T2-저카트 실험의 도식을 보여준디.
도 5b는 NY-ESO-1 차단제 펩타이드가 로딩될 때 MAGE-A3 CAR 활성인자(MP1-CAR)의 EC50에 대한 다양한 NY-ESO-1 scFv LBD 차단제 모듈(PD-1, CTLA-4, LIR-1)의 효과를 보여준다. 오차 막대는 ± SD(n=2)를 나타낸다.
도 5c는 상응하는 펩타이드가 로딩될 때 MAGE-A3 CAR 활성인자 (MP1-CAR)의 EC50에 대한 다양한 scFv LBD(ESO, MP1 LBD 1, MP1 LBD 2, HPV E6 LBD 1, HPV E6 LBD 2, HPV E7)를 갖는 LIR-1 차단제 모듈의 효과를 보여준다. 오차 막대는 ± SD(n=2)를 나타낸다.
도 5d는 NY-ESO-1 차단제 펩타이드가 로딩될 때 상이한 MAGE-A3 CAR 활성인자(MP1-CAR 또는 MP2-CAR)의 EC50에 대한 NY-ESO-1 scFv LBD를 갖는 LIR-1 차단제 모듈의 효과를 보여준다. 오차 막대는 ± SD(n=2)를 나타낸다.
도 5e는 NY-ESO-1 차단제 펩타이드가 로딩될 때 상이한 TCR 활성인자(MP1-TCR, MP2-TCR, HPV E6-TCR)의 EC50에 대한 NY-ESO-1 scFv LBD를 갖는 LIR-1 차단제 모듈의 효과를 보여준다. 오차 막대는 ± SD (n=2)를 나타낸다. 3개의 상이한 TCR 활성인자는 ESO scFv, LIR-1 힌지, LIR-1 TM 및 LIR-1 ICD를 갖는 NY-ESO-LIR-1에 의해 차단된다.
도 5f는 MAGE-A3 CAR 및 TCR 활성인자(MP1-CAR, MP1-TCR)의 EC50에 대한 NY-ESO-1 Ftcr LBD를 갖는 LIR-1 차단제 모듈의 효과를 보여준다. 오차 막대는 ± SD (n=2)를 나타낸다. 제3 세대 CAR 활성인자 또는 정기적 TCR 활성인자 둘 다는 TCRa ECD, LIR-1 TM, LIR-1 ICD 및 TCRb ECD, LIR-1 TM 및 LIR-1 ICD를 갖는 NY-ESO-1 Ftcr-LIR-1에 의해 차단될 수 있다.
도 5g는 활성인자(HPV E7) 및 차단제(NY-ESO-1) 항원의 다양한 비를 나타내는 비드와 동시배양된 HPV E7-CAR 또는 HPV E7-CAR 및 A2-LIR-1에 의해 형질주입된 저카트 세포가 트랜스가 아니라 시스에서의 차단을 나타낸다는 것을 보여준다.
도 5h는 A2-LIR-1 차단제 모듈이 다양한 활성인자 대 차단제 비에서 CD19-CAR 활성인자를 차단한다는 것을 보여준다. E:T 비: 효과기: 표적 비.
도 6a, 도 6c 내지 도 6e는 LIR-1 차단제를 발현하는 1차 T 세포가 pMHC 및 비-pMHC 개념 증명 표적에 의해 종양 세포를 선택적으로 사멸한다는 것을 보여준다.
도 6a는 HPV E7-TCR 활성인자 및 ESO-LIR-1 차단제에 의해 형질도입된 1차 T 세포가 1차 T 세포 사멸 검정에서 EC50을 약 100배 이동시킨다는 것을 보여준다. 오차 막대는 +/- SD(n=2)를 나타낸다.
도 6b는 HLA-A*02-LIR-1이 저카트 세포에서 다양한 활성인자:차단제 DNA 비로 NY-ESO-1 CAR 활성인자를 차단한다는 것을 보여준다.
도 6c는 CD19 CAR 활성인자 및 HLA-A*02 차단제에 의해 형질도입된 1차 T 세포가 시험관내 세포독성 검정에서 "종양" 세포를 "정상" 세포와 구별하고, 3:1의 E:T에서 혼합 표적 세포 검정에서 "종양" 세포의 선택적 사멸을 나타낸다는 것을 보여준다. A2-LIR-1 : HLA-A2*02 LBD를 갖는 LIR-1 기반 수용체
도 6d 내지 도 6e는 CD19 CAR 활성인자 및 HLA-A*02 차단제에 의해 형질도입된 1차 T 세포가 3:1의 E:T에서 시험관내 세포독성 검정에서 3 회차의 항원 노출(AB-A-AB 및 A-AB-A) 후 가역적 봉쇄(도 6d) 및 활성화(도 6e)를 나타낸다는 것을 보여준다. 1차 T 세포 세포독성 검정은 3개의 HLA-A*02-음성 공여자에 의해 재현되었다.
도 7a 내지 도 7e는 변형된 CAR-T 세포(즉, 활성인자 및 차단제 수용체 둘 다를 발현하는 CAR-T 세포)가 이종이식 모델에서 종양을 선택적으로 사멸한다는 것을 보여준다.
도 7a는 CD19 CAR 활성인자 및 HLA-A*02 차단제에 의해 형질도입된 1차 T 세포가 10일에 걸쳐 CD3/28 자극에 의해 약 20배 확장을 나타낸다는 것을 보여준다.
도 7b는 생체내 연구 설계의 도식을 보여준다: HLA-A*02 NSG 마우스는 "종양 세포"(A2-음성 라지 세포(Raji cell)) 또는 "정상 세포"(A2-양성 라지 세포)가 동시에 투여되고, 라지 이종이식편이 평균 약 70 mm3일 때 1차 T 세포(인간, HLA-A*02-음성 공여자)가 꼬리 정맥으로 주사된다.
도 7c 내지 도 7e는 캘리퍼 측정에 의한 종양 크기의 판독정보(도 7c), 유세포분석법에 의한 인간 혈액 T 세포 수(도 7d) 및 생존율(도 7e)을 보여준다. 오차 막대는 평균의 표준 오치(s.e.m.)이다. UTD: 비형질도입됨.
도 8은 활성화 EC50의 펩타이드-로딩 이동이 통상적으로 약 10x 미만이라는 것을 보여준다. 활성화 MAGE-A3 CAR(MP2 CAR)에 대한 차단제 펩타이드 로딩(NY-ESO-1, MAGE-A3, HPV E6 및 HPV E7의 50 uM 각각)의 효과가 도시되어 있다.
도 9는 LIR-1 차단제 모듈이 리간드 의존적이라는 것을 보여준다. 다양한 농도의 NY-ESO-1 차단제 펩타이드가 로딩될 때 활성화 MAGE-A3 CAR(MP1-CAR)의 EC50에 대한 NY-ESO-1-LIR-1 차단제의 효과가 도시되어 있다.
도 10은 ICD가 없는 또는 돌연변이된 비기능적 ICD를 갖는 차단제가 활성화를 차단하지 않는다는 것을 보여준다. 10 uM의 NY-ESO-1 차단제 펩타이드가 로딩될 때 MAGE-A3 CAR 활성인자(MP2-CAR)의 EC50에 대한 ICD를 함유하지 않는 변형된 LIR-1 차단제 모듈(청색) 또는 NY-ESO-1 scFv LBD를 갖는 돌연변이된 ICD(자주색)의 효과가 도시되어 있다.
도 11은 HLA-A*02+ (A2+) 라지 세포에서 CD19가 저카트 활성화를 활성화하고 A2-LIR-1이 이를 차단한다는 것을 보여준다. CD19 또는 CD19와 A2-LIR-1에 의해 형질주입된 저카트 세포를 다양한 세포 비율에서 WT (A2-) 라지 세포 또는 A2+ 라지 세포와 동시배양하였다.
도 12는 종양 성장에 대한 마우스 혈액에서의 hCD3+ T 세포의 상관관계를 보여주는 4개의 패널이다. A2- 및 A2+ 라지 세포에 의한 T 세포 주사 후 10일 및 17일에 종양 용적과 비교된 hCD3+ T 세포의 그래프가 도시되어 있다.
도 13은 EGFR CAR 활성인자 및 HLA-A*02 LIR-1 차단제를 발현하는 저카트 세포가 EGFR+/HLA-A*02+ HeLa 표적 세포가 아니라 EGFR+/HLA-A*02- HeLa 표적 세포에 의해 활성화된다는 것을 보여준다.
도 14a는 HLA-A*02에 의해 형질도입된 HeLa 세포 및 HCT116 세포에 대한 HLA-A*02의 발현을 보여준다. HeLa 및 HCT1116 세포를 항-HLA-A2 항체 BB7.2로 표지하고, FAC를 분류하였다. 녹색: 비표지된 HeLa; 오렌지색: 비표지된 HCT116; 청색: BB7.2로 표지된 야생형 HCT116; 적색: HLA-A*02에 의해 형질도입되고 BB7.2에 의해 표지된 HeLa 세포.
도 14b는 HeLa 세포 및 HCT116 세포에 대한 EGFR의 발현을 보여준다. HeLa 및 HCT1116 세포를 항-EGFR 항체로 표지하고, FAC를 분류하였다. 녹색: 비표지된 HeLa; 오렌지색: 비표지된 HCT1116; 청색: 항-EGFR로 표지된 야생형 HCT116; 적색: HLA-A*02에 의해 형질도입되고 항-EGFR에 의해 표지된 HeLa 세포.
도 15a는 EGFR CAR을 발현하는 저카트 세포 및 HCT116 표적 세포의 EGFR CAR 활성화를 보여준다.
도 15b는 저카트 세포의 EGFR CAR 활성화가 HLA-A*02 LIR-1 억제 수용체에 의해 차단될 수 있다는 것을 보여준다. 저카트 세포가 EGFR 및 HLA-A*02를 발현하는 HCT116 표적 세포에 의해 제시될 때 저카트 세포에 의한 EGFR CAR 및 HLA-A*02 LIR-1 억제 수용체의 동시발현은 대략 1.8x의 CAR EMAX의 이동으로 이어진다.
도 16a는 활성인자 대 차단제 항원의 최적 비를 결정하기 위한 비드 기반 검정에서의 활성인자 항원의 적정을 보여준다.
도 16b는 활성인자 대 차단제 항원의 최적 비를 결정하기 위한 비드 기반 검정에서의 활성인자 항원의 일정한 양의 존재 하에서의 차단제 (억제) 항원의 적정을 보여준다.
도 17은 NY-ESO-1 ScFv LIR-1 기반 억제 수용체가 표적 세포로서의 고형 종양 세포주 A375를 사용하여 MP1 MAGE-A3 TCR에 의한 저카트 세포 활성화의 활성화를 억제할 수 있다는 것을 보여주는 다이어그램(왼쪽) 및 선도(오른쪽)이다.
도 18은 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체가 표적 세포로서의 B 세포 백혈병 계통 NALM6을 사용하여 CD19 ScFv CAR에 의한 저카트 세포 활성화의 활성화를 억제할 수 있다는 것을 보여주는 다이어그램(왼쪽) 및 선도(오른쪽)이다.
도 19는 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체가 용량 의존적 방식으로 NY-ESO-1 ScFv CAR 활성인자에 의해 저카트 세포의 활성화를 억제할 수 있다는 것을 보여주는 다이어그램(왼쪽) 및 선도(오른쪽)이다.
도 20은 pan HLA(pan 클래스 I) ScFv CAR이 T2 표적 세포 및 루시퍼라제 검정을 사용하여 저카트 세포에서 분석될 때 조정 가능항 강도로 HAL-A*02 LIR-1 차단제의 발현에 의해 차단된다는 것을 보여준다.
도 21a는 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체가 무세포 비드 기반 검정에서 시스로 저카트 세포의 활성화를 억제할 수 있다는 것을 보여준다.
도 21b는 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체가 표적 세포로서의 백혈병 세포주 K562를 사용하여 MSLN ScFv CAR에 의해 저카트 세포의 활성화를 억제할 수 있다는 것을 보여준다.
도 22는 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체가 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체 및 표적 세포로서의 HLA-A*02+ HeLa 및 SiHa 세포를 사용하여 MSLN ScFv CAR에 의해 IFNγ의 배수 유도에 의해 측정된 것처럼 저카트 세포의 활성화를 억제할 수 있다는 것을 보여주는 다이어그램(왼쪽) 및 챠트(오른쪽)이다.
도 23은 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체가 HLA-A*02- SiHa 세포가 아니라 HLA-A*02+ SiHa 세포를 사용하여 MSLN CAR 활성인자에 의한 사멸을 억제한다는 것을 보여준다.
도 24는 비드 기반 검정을 사용한 EGFR ScFv CAR을 발현하는 저카트 세포의 활성화가 활성인자 및 억제제 항원이 트랜스로 비드에 존재할 때가 아니라 활성인자 및 억제제 항원이 시스로 비드에 존재할 때 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체에 의해 차단될 수 있다는 것을 보여준다.
도 25a는 EGFR ScFv CAR에 의한 저카트 세포의 활성화가 HLA-A*02(SiHa WT)를 발현하지 않는 SiHa 세포에 의해서가 아니라 HLA-A*02(SiHa A02)를 발현하는 SiHa 표적 세포를 사용하여 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체에 의해 차단될 수 있다는 것을 보여준다.
도 25b는 EGFR ScFv CAR에 의한 저카트 세포의 활성화가 HLA-A*02(HeLa WT)를 발현하지 않는 HeLa 세포에 의해서가 아니라 HLA-A*02(HeLa A02)를 발현하는 HeLa 표적 세포를 사용하여 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체에 의해 차단될 수 있다는 것을 보여준다.
도 26은 LIR-1 억제 도메인에 융합된 추가 ScFv가 용량 의존적 방식으로 항시적 CAR 활성인자를 억제한다는 것을 보여준다. 저카트-NFAT 루시퍼라제 리포터 세포는 높은 긴장성 신호전달을 나타내는 활성화 CAR 작제물 및 다양한 pMHC를 인식하는 억제 작제물에 의해 형질주입되었다. NFAT-루시퍼라제의 활성화에 대한 효과는 형질주입된 저카트 세포를 다양한 양의 억제 펩타이드가 로딩된 T2 세포와 동시배양하여 측정되었다.
도 27은 MiHA-b 대리자 ScFv 리간드 결합 도메인(KRAS G12V ScFv-차단제)을 포함하는 억제 수용체가 T2 표적 세포를 사용하여 MiHA-a 대리자(KRAS G12D TCR, C-891)를 표적화하는 활성인자 TCR에 의해 저카트 효과기 세포 활성화를 억제한다는 것을 보여주는 다이어그램(왼쪽) 및 선도(오른쪽)이다.
도 28은 LIR-1 힌지, TM 및 ICD에 융합된 MiHA-b 대리자 ScFv 리간드 결합 도메인(KRAS G12D ScFv-차단제)을 포함하는 억제 수용체가 T2 표적 세포를 사용하여 MiHA-a 대리자(KRAS G12V TCR, C-913)를 표적화하는 TCR에 의해 저카트 효과기 세포 활성화를 억제한다는 것을 보여주는 다이어그램(왼쪽) 및 선도(오른쪽)이다.
도 29는 LIR1 TM 및 ICD에 융합된 MiHA-b 대리자 Ftcr 결합 도메인(KRAS G12V Ftcr-차단제)을 포함하는 억제 수용체가 T2 표적 세포를 사용하여 MiHA-a 대리자(KRAS G12D TCR)를 표적화하는 TCR에 의해 저카트 효과기 세포 활성화를 억제한다는 것을 보여주는 다이어그램(왼쪽) 및 선도(오른쪽)이다.
도 30은 LIR-1 TM 및 ICD에 융합된 MiHA-b 대리자 Ftcr 결합 도메인(KRAS G12D Ftcr-차단제)을 포함하는 억제 수용체가 T2 표적 세포를 사용하여 MiHA-a 대리자(KRAS G12V TCR)를 표적화하는 TCR에 의해 저카트 효과기 세포 활성화를 억제한다는 것을 보여주는 다이어그램(왼쪽) 및 선도(오른쪽)이다.
도 31a는 하나의 돌연변이체 KRAS 펩타이드[KRAS G12D] 및 LIR-1 힌지에 결합하는 MiHA-b ScFv 리간드 결합 도메인, 막관통 도메인 및 다른 돌연변이체 KRAS 펩타이드(KRAS G12V)에 결합하는 세포내 도메인(ICD)을 포함하는 억제 수용체를 사용한 MiHA-a TCR에 의한 저카트 세포 활성화의 억제를 보여주는 선도이다. 흑색: C-891 활성인자; 청색: C-891 활성인자, C-1761 억제제; 적색: C-891 활성인자, C-2371 및 C2369 억제제.
도 31b는 MiHA-b Ftcr 리간드 결합 도메인 및 LIR-1 막관통 도메인 및 세포내 도메인(ICD)을 함유하는 억제 수용체를 사용한 MiHA-a TCR에 의한 저카트 세포 활성화의 억제를 보여주는 선도이다. 흑색: C-913 활성인자; 청색: C-913 활성인자, C-1761 억제제; 적색: C-913 활성인자, C2365 및 C2367 억제제.
도 32는 마우스 MiHA-Y TCR이 저카트 효과기 세포를 활성화할 수 있다는 것을 보여주는 선도이다.
도 33a는 HA-1 Ftcr이 HA-1(H) 펩타이드의 존재 하에 NY-ESO-1 TCR을 특이적으로 차단할 수 있다는 것을 보여주는 선도 및 표이다.
도 33b는 비특이적인 대립유전자 변이체 HA-1(R) 펩타이드의 존재 하에 HA-1 Ftcr에 의한 NY-ESO-1 TCR의 차단이 본질적으로 없다는 것을 보여주는 선도 및 표이다.
도 34a는 HA-1 Ftcr이 HA-1(H) 차단제 펩타이드의 존재 하에 KRAS TCR을 특이적으로 차단할 수 있다는 것을 보여주는 선도 및 표이다.
도 34b는 비특이적인 대립유전자 변이체 HA-1(R) 펩타이드의 존재 하에 HA-1 Ftcr에 의한 KRAS TCR의 차단이 본질적으로 없다는 것을 보여주는 선도 및 표이다.
도 35는 유세포분석법에 의해 T2 세포에서 HA-1(R), HA-1(H) 및 NY-ESO-1 펩타이드의 펩타이드 로딩을 비교하는 선도이다.
도 36a는 MAGE-A3 MP1 ScFv CAR 및 NY-ESO-1 ScFv LIR1 차단제를 사용한 활성화 용량 반응을 보여주는 선도 및 표이다.
도 36b는 MAGE-A3 MP1 ScFv CAR 및 NY-ESO-1 ScFv LIR1 차단제를 사용한 억제 용량 반응을 보여주는 선도 및 표이다.
도 36c는 각각의 곡선에 사용된 일정한 활성인자 MAGE 펩타이드 농도로 정규화되고 x축에 작도된 도 36b로부터의 x-값 차단제 NY-ESO-1 펩타이드 농도를 보여주는 선도이다. B: NY-ESO-1 LIR1 차단제, A: MAGE-A3 펩타이드 2 ScFv CAR.
도 37은 HLA-A*02 ScFv LIR1 억제제가 상이한 EGFR ScFv CAR 활성인자와 사용될 때 상이한 정도의 차단이 관찰된다는 것을 보여주는 일련의 선도 및 표이다.
도 38a는 상이한 EGFR ScFv CAR 및 HLA-A*02 ScFv LIR1 억제제를 발현하는 T 세포와 EGFR 활성인자 단독(표적 A), 억제제 표적 단독(표적 B) 또는 활성인자와 억제제 표적(표적 AB)을 발현하는 HeLa 세포의 항온처리 후 T 세포에 의한 EGFR ScFv CAR 활성인자 수용체의 발현을 보여주는 일련의 형광 활성 세포 분류(FACS) 선도이다.
도 38b는 표적 세포에 대한 노출 전 및 활성인자 리간드 단독(표적 A)을 발현하는 표적 세포 또는 활성인자와 차단제 리간드 둘 다(표적 AB)를 발현하는 표적 세포와의 120시간 동시배양 후 활성인자 수용체 발현의 정량화를 보여주는 선도이다.
도 39a는 동일한 세포에 EGFR(표적 A), HLA-A*02(표적 B), EGFR과 HLA-A*02의 조합(표적 AB)을 발현하는 HeLa 세포의 집단, 상이한 세포에 표적 A와 표적 AB를 발현하는 HeLa 세포의 혼합 집단, 또는 상이한 세포에 표적 B와 표적 AB를 발현하는 HeLa 세포의 혼합 집단과의 동시배양 후 EGFR ScFv CAR(CT-482) 활성인자 및 HLA-A*02 ScFv LIR1 억제제(C1765)를 발현하는 T 세포에 대한 활성인자 수용체의 세포 표면 발현을 보여주는 선도이다.
도 39b는 동일한 세포에 EGFR(표적 A), HLA-A*02(표적 B), EGFR과 HLA-A*02의 조합(표적 AB)을 발현하는 HeLa 세포의 집단, 상이한 세포에 표적 A와 표적 AB를 발현하는 HeLa 세포의 혼합 집단, 또는 상이한 세포에 표적 B와 표적 AB를 발현하는 HeLa 세포의 혼합 집단과의 동시배양 후 EGFR ScFv CAR(CT-482) 활성인자 및 HLA-A*02 ScFv LIR1 억제제(C1765)를 발현하는 T 세포에 대한 억제제 수용체의 세포 표면 발현을 보여주는 선도이다.
도 40은 T 세포에 의한 활성인자 수용체의 발현 소실이 가역적인지를 결정하기 위한 실험의 다이어그램이다.
도 41a는 활성인자 표면 발현 소실이 가역적이고 T 세포 세포독성에 상응한다는 것을 보여주는 일련의 선도이다. 상부에서: T 세포에 의한 표적 HeLa 세포의 퍼센트 사멸이 도시되어 있다. 하부에서: FACS에 의해 분석된 것과 같은 활성인자 및 억제제 수용체 발현.
도 41b는 활성인자 표면 발현 소실이 가역적이고 T 세포 세포독성에 상응한다는 것을 보여주는 일련의 선도이다. 상부에서: T 세포에 의한 표적 HeLa 세포의 퍼센트 사멸이 도시되어 있다. 하부에서: FACS에 의해 분석된 것과 같은 활성인자 및 억제제 수용체 발현.
본 발명자들은 적합한 마커를 확인하고 세포 치료에 의한 질환, 특히 암의 치료에서 세포 선택도를 달성하는 문제에 대한 해결책을 개발하였다. 본 발명의 일차 목적은 이형접합성 소실에 기초하여 세포를 표적화하는 것이다(도 1). 활성 신호 및 억제 신호가 세포 수준에서 통합된 2개의 수용체 시스템을 사용하여(도 2a, 도 2b, 도 3a 및 도 3b), 비종양 세포가 아니라 종양 세포의 선택적 표적화가 달성된다. 표적 세포에서 부재하거나 소실되지만 정상 세포에 존재하는 표면 단백질의 발현의 차이는 이로써 표적화된 항-종양 세포 치료로 전환된다. 이 차이는 세포 치료에 의해 표적화를 개선하고, 입양 세포 치료에 사용된 효과기 세포의 세포독성 효과로부터 정상 세포를 보호한다.
본원에 개시된 이 접근법은 일부 실시형태에서 활성인자 리간드에 대한 리간드 결합 도메인을 포함하는 제1의 것 및 억제제 리간드에 대한 리간드 결합 도메인을 포함하는 제2의 것인 2개의 조작된 수용체를 사용하고, 이는 "AND NOT" Boolean 로직을 사용하여 표적 세포에서 선택적으로 활성화된다(도 2a, 도 2b, 도 3a 및 도 3b). 정상 세포는 활성인자 리간드 및 억제제 리간드 둘 다를 발현하지만, 제1 수용체를 통한 효과기 세포의 활성화는 억제제 리간드에 대한 억제제 LBD를 포함하는 제2 수용체의 결합에 의해 차단되고, 이것은 보호 효과를 발휘하고, 제1의, 활성인자 수용체의 활성을 지배한다. 이와 반대로, 활성인자 리간드를 발현하지만 억제제 리간드를 발현하지 않는 표적 세포에서, 활성인자 LBD에 의한 활성인자 리간드의 결합은 세포를 활성화한다. 본 개시내용의 이중 활성인자/억제제 수용체 전략의 이점은 강력하지만 특이적 종양-표적화된 입양 세포 치료를 생성하는 활성인자 및 억제제 조합을 조정하는 능력을 포함한다. 추가로, 이 접근법은 신체에서 가변 효과기 대 표적 세포 비(E:T 비), 및 입양 세포 치료에 의해 종양 세포를 표적화할 때 보인 잠재적으로 매우 과량의 정상 세포 대 종양 세포(예를 들어, 1013개의 정상 세포 대 109개의 종양 세포)의 도전을 극복할 수 있다. 훨씬 추가로, 본 발명자들은 큰 가능한 환자 조합을 다루는 활성인자 및 억제제를 확인하였고, 이는 이것이 상업적으로 실행 가능한 접근법이 되게 한다.
특이적 세포 유형에 대한 입양 세포 치료의 특이성은 제1 수용체 및 제2 수용체의 상이한 활성, 및 제1 리간드 및 제2 리간드의 차등 발현을 통해 달성될 수 있다. 제1 수용체에 대한 제1 리간드의 결합은 활성화 신호를 제공하지만, 제2 수용체에 대한 제2 리간드의 결합은 제1 리간드의 존재 하에서도 효과기 세포의 활성화를 방지하거나 감소시킨다. 제1 리간드는 예를 들어 입양 세포 치료에 의해 표적화된 세포, 및 입양 세포 치료에 대한 표적 세포가 아닌 건강한 세포(비표적 세포) 둘 다에서 제2 리간드보다 더 광범위하게 발현될 수 있다. 이와 반대로, 제2 리간드는 비표적 세포에서 발현되고, 표적 세포에서 발현되지 않는다. 비표적 세포가 아니고 오직 표적 세포는 제2 리간드가 아니라 제1 리간드를 발현하고, 이로써 이들 세포의 존재 하에 본 개시내용의 이중 수용체를 포함하는 효과기 세포를 활성화한다.
본 개시내용은 2개의 조작된 수용체의 사용을 통해 이형접합성 소실에 기초한 표적화 세포(예를 들어, 종양 세포)로부터의 조성물 및 방법을 제공한다. 1개의 억제제 및 1개의 활성인자인 2개의 조작된 수용체는 상이한 리간드를 인식하는 상이한 리간드 결합 도메인을 각각 포함한다. 제1 리간드 및 제2 리간드의 발현의 차이는 제1의, 활성인자 리간드가 오직 존재할 때 2개의 수용체를 발현하는 효과기 세포를 선택적으로 활성화하도록 사용된다. 따라서, 일부 실시형태에서, 제1 리간드 결합 도메인 및 제2 리간드 결합 도메인은 상이한 수용체 분자; 즉 단일 유전 작제물, 융합 단백질 또는 단백질 복합체의 일부가 아닌 별개의 수용체에 있다. 일부 실시형태에서, 각각 이의 동족 리간드에 결합할 때 수용체 중 하나는 세포를 활성화하고, 다른 수용체는 세포를 억제한다. 일부 실시형태에서, 제2의, 억제제 리간드 결합 도메인을 포함하는 수용체는 신호전달을 지배하여서, 표적 세포가 표적 둘 다를 발현하면, 그 결과는 효과기 세포의 억제이다. 억제 표적이 세포로부터 부재할 때에만, 제1의, 활성인자 리간드가 제1의, 활성인자 리간드 결합 도메인을 포함하는 수용체를 통해 효과기 세포의 활성화를 유도한다.
임의의 광범위하게 발현된 세포 표면 분자, 예를 들어 세포 부착 분자, 세포-세포 신호전달 분자, 세포외 도메인, 화학주성에 관여된 분자, 당단백질, G 단백질 커플링된 수용체, 막관통, 신경전달인자를 위한 수용체 또는 전압 게이팅된 이온 채널, 또는 임의의 이들의 펩타이드 항원은 제1 리간드로서 사용될 수 있다. 추가의 예로서, 제1 리간드는 트랜스페린 수용체(TFRC)일 수 있다. 표적 세포의 표면에서 발현되지 않은 임의의 세포 표면 분자는 제2 리간드로서 사용될 수 있다. 암을 치료하기 위해 조작된 수용체가 입양 세포 치료에서 사용되고 표적 세포가 암 세포인 이들 실시형태에서, 제2 리간드는 암 세포에서 제2 리간드의 이형접합성 소실에 기초하여 선택될 수 있다. 예를 들어, 이형접합성 소실로 이어지는 돌연변이로 인해 암 세포에서 발현이 흔히 소실되는 예시적인 유전자는 HLA 클래스 I 대립유전자, 부 조직접합 항원(MiHA) 및 Y 염색체 유전자를 포함한다.
본 개시내용은 추가로 본원에 기재된 조작된 수용체를 암호화하는 벡터 및 폴리뉴클레오타이드를 제공한다.
본 개시내용은 추가로 본원에 기재된 조작된 수용체를 포함하는 면역 세포 집단을 제조하는 방법, 및 이를 사용하여 질환을 치료하는 방법을 제공한다.
정의
본 개시내용을 더 자세히 기술하기 전에, 이는 본원에 사용되는 소정의 용어의 정의를 제공하도록 이의 이해에 도움일 수 있다.
달리 정의되지 않는 한, 본원에 사용된 모든 기술 용어 및 과학 용어는 본 발명이 속하는 분야의 당업자에 의해 흔히 이해되는 것과 동일한 의미를 갖는다. 본원에 기재된 것과 유사하거나 동등한 임의의 방법 및 재료가 특정 실시형태의 실행 또는 교시에서 사용될 수 있지만, 조성물, 방법 및 재료의 바람직한 실시형태가 본원에 기재된다. 본 개시내용의 목적을 위해, 하기 용어가 하기 정의되어 있다. 추가 정의는 본 개시내용에 걸쳐 기재되어 있다.
관사 "a", "an" 및 "the"는 관사의 문법적 목적어의 하나 또는 하나 초과(즉, 적어도 하나 또는 하나 이상)를 지칭하도록 본원에 사용된다. 예에 의해, "요소"는 하나의 요소 또는 하나 이상의 요소를 의미한다.
대안(예를 들어, "또는")의 사용은 대안의 하나, 둘 다, 또는 임의의 이들의 조합을 의미하도록 이해되어야 한다.
"및/또는"이라는 용어는 대안의 하나 또는 둘 다를 의미하도록 이해되어야 한다.
본 명세서에 걸쳐, 문맥이 달리 요하지 않는 한, "포함한다", "포함한" 및 "포함하는"의 단어는 임의의 다른 단계 또는 요소 또는 단계 또는 요소의 그룹의 배타가 아니라 기술된 단계 또는 요소 또는 단계 또는 요소의 그룹의 포함을 암시한다고 이해될 것이다. "이루어지는"에 의해 "이루어지는"의 구절에 어떤 것이 뒤따르든지 간에 이에 제한 없이 포함하는 것이 의도된다. 이와 같이, "이루어지는"의 구절은 열거된 요소가 필요하거나 의무적이고, 다른 요소가 존재하지 않을 수 있다는 것을 나타낸다. "본질적으로 이루어지는"에 의해 열거된 요소에 대해 본 개시내용에 기재된 활성 또는 작용을 방해하지 않고 이에 기여하는 다른 요소에 제한 없이 그 구절 후에 열거된 임의의 요소를 포함하는 것이 의도된다. 이와 같이, "본질적으로 이루어지는"의 구절은 열거된 요소가 필요하거나 의무적이지만, 열거된 요소의 활성 또는 작용에 중요하게 영향을 미치는 다른 요소가 존재하지 않을 수 있다는 것을 나타낸다.
"일 실시형태", "하나의 실시형태," "특정 실시형태", "관련 실시형태", "소정의 실시형태", "추가 실시형태" 또는 "추가의 실시형태" 또는 이들의 조합에 대해 본 명세서에 걸친 언급은 그 실시형태와 연결되어 기재된 특정한 특징, 구조 또는 특성이 적어도 하나의 실시형태에 포함된다는 것을 의미한다. 이와 같이, 본 명세서에 걸쳐 다양한 위치에서 상기 구절의 출현은 반드시 모두 동일한 실시형태를 지칭하지는 않는다. 더욱이, 하나 이상의 실시형태에서 특정한 특징, 구조 또는 특성은 임의의 적합한 방식으로 조합될 수 있다. 일 실시형태에서 특징의 긍정 인용이 특정 실시형태에서 특징을 배제하기 위한 기준으로서 작용한다고 또한 이해된다.
본원에 사용된 것과 같이, "약" 또는 "대략"이라는 용어는 기준 분량, 수준, 값, 수, 빈도, 백분율, 치수, 크기, 양, 중량 또는 길이와 15%, 10%, 9%, 8%, 7%, 6%, 5%, 4%, 3%, 2% 또는 1%만큼 많이 변하는 분량, 수준, 값, 수, 빈도, 백분율, 치수, 크기, 양, 중량 또는 길이를 지칭한다. 일 실시형태에서, "약" 또는 "대략"이라는 용어는 기준 분량, 수준, 값, 수, 빈도, 백분율, 치수, 크기, 양, 중량 또는 길이 주위의 분량, 수준, 값, 수, 빈도, 백분율, 치수, 크기, 양, 중량 또는 길이 ± 15%, ± 10%, ± 9%, ± 8%, ± 7%, ± 6%, ± 5%, ± 4%, ± 3%, ± 2% 또는 ± 1%의 범위를 지칭한다.
본원에 사용된 것과 같이, "단리된"이라는 용어는 자연적 상태에서 재료가 보통 수반하는 성분이 실질적으로 또는 본질적으로 없는 재료를 의미한다. 특정 실시형태에서, "얻은" 또는 "유래된"이라는 용어는 단리된과 동의어로 사용된다.
"대상체", "환자" 및 "개체"라는 용어는 척추동물, 바람직하게는 포유류, 더 바람직하게는 인간을 지칭하도록 본원에 상호교환 가능하게 사용된다. 생체내 얻거나 시험관내 배양된 생물학적 집합체의 조직, 세포 및 이의 자손이 또한 포함된다. 본원에 사용된 것과 같이 "대상체", "환자" 또는 "개체"는 본원에 고려된 벡터, 조성물 및 방법에 의해 치료될 수 있는 통증을 나타내는 임의의 동물을 포함한다. 적합한 대상체(예를 들어, 환자)는 실험실 동물(예컨대, 마우스, 래트, 토끼 또는 기니아 피그), 농장 동물 및 가축 동물 또는 애완동물(예컨대, 고양이 또는 개)을 포함한다. 비인간 영장류 및 바람직하게는 인간 환자가 포함된다.
본원에 사용된 것과 같이 "치료" 또는 "치료하는"은 임의의 유리하거나 바람직한 효과를 포함하고, 심지어 최소 증상 개선을 포함할 수 있다. "치료"는 반드시 질환 또는 병태, 또는 이의 연관된 증상의 완전한 소거 또는 치유를 나타내지는 않는다.
본원에 사용된 것과 같이, "예방한다" 및 "예방된", "예방하는" 등과 같은 유사한 단어는 질환의 증상의 가능성을 예방하거나 억제하거나 감소시키기 위한 접근법을 나타낸다. 이것은 또한 질환 또는 병태의 발병 또는 재발을 지연시키는 것 또는 질환의 증상의 발생 또는 재발을 지연시키는 것을 지칭한다. 본원에 사용된 것과 같이, "예방" 및 유사한 단어는 또한 발병 또는 재발 전에 질환의 강도, 효과, 증상 및/또는 부담을 감소시키는 것을 포함한다.
본원에 사용된 것과 같이, "양"이라는 용어는 임상 결과를 포함하는 유리하거나 원하는 예방 효과 또는 치료 효과를 달성하기 위한 바이러스의 "효과적인 양" 또는 "유효량"을 지칭한다.
"예방학적 유효량"은 원하는 예방 결과를 달성하기에 효과적인 바이러스의 양을 지칭한다. 반드시는 아니지만 통상적으로, 질환의 단계 전에 또는 이의 더 이른 단계에서 예방 용량이 대상체에 사용되므로, 예방학적 유효량은 치료학적 유효량보다 적다.
바이러스 또는 세포의 "치료학적 유효량"은 개체의 질환 상태, 연령, 성별 및 체중 및 개체에서 원하는 반응을 일으키는 바이러스 또는 세포의 능력과 같은 인자에 따라 변할 수 있다. 치료학적 유효량은 또한 치료학적으로 유리한 효과가 바이러스 또는 세포의 임의의 독성 또는 해로운 효과를 능가하는 것이다. "치료학적 유효량"이라는 용어는 대상체(예를 들어, 환자)를 "치료"하기에 효과적인 양을 포함한다.
생리학적 반응, 예를 들어 전기생리학적 활성 또는 세포 활성의 "증가된" 또는 "향상된" 양은 통상적으로 "통게학적으로 유의미한" 양이고, 비치료된 세포에서 활성의 수준의 1.1배, 1.2배, 1.5배, 2배, 3배, 4배, 5배, 6배, 7배, 8배, 9배, 10배, 15배, 20배, 30배 또는 이것 초과(예를 들어, 500배, 1000배)(1 초과, 예를 들어 1.5, 1.6, 1.7. 1.8 등 및 이들 사이의 모든 정수 및 소수점을 포함)인 증가를 포함할 수 있다.
생리학적 반응, 예를 들어 전기생리학적 활성 또는 세포 활성의 "감소" 또는 "감소된" 양은 통상적으로 "통게학적으로 유의미한" 양이고, 비치료된 세포에서 활성의 수준의 1.1배, 1.2배, 1.5배, 2배, 3배, 4배, 5배, 6배, 7배, 8배, 9배, 10배, 15배, 20배, 30배 또는 이것 초과(예를 들어, 500배, 1000배)(1 초과, 예를 들어 1.5, 1.6, 1.7. 1.8 등 및 이들 사이의 모든 정수 및 소수점을 포함)인 감소를 포함할 수 있다.
"유지한다" 또는 "보존한다" 또는 "유지" 또는 "무변화" 또는 "실질적인 무변화" 또는 "실질적인 무감소"에 의해 일반적으로 비히클, 또는 대조군 분자/조성물 중 어느 하나에 의해 야기된 반응에 필적하는 생리학적 반응을 지칭한다. 필적하는 반응은 기준 반응과 유의미하게 상이하지 않거나 측정 가능하게 상이하지 않은 것이다.
일반적으로, "서열 동일성" 또는 "서열 상동성"은 각각 2개의 폴리뉴클레오타이드 또는 폴리펩타이드 서열의 정확한 뉴클레오타이드-대-뉴클레오타이드 또는 아미노산-대-아미노산 관련성을 지칭한다. 통상적으로, 서열 동일성을 결정하기 위한 기법은 폴리뉴클레오타이드의 뉴클레오타이드 서열을 결정하는 것 및/또는 이로써 암호화된 아미노산 서열을 결정하는 것, 및 이 서열을 제2 뉴클레오타이드 또는 아미노산 서열과 비교하는 것을 포함한다. 2개 이상의 서열(폴리뉴클레오타이드 또는 아미노산)은 이의 "퍼센트 동일성"을 결정함으로써 비교될 수 있다. 2개의 서열의 퍼센트 동일성은, 핵산 서열 또는 아미노산 서열이든, 2개의 정렬된 서열 사이의 정확한 일치의 수를 더 짧은 서열의 길이에 의해 나누고 100을 곱한 것이다. 예를 들어, National Institutes of Health로부터 입수 가능한 버전 2.2.9를 포함하는 어드밴스드 BLAST 컴퓨터 프로그램을 사용하여 서열 정보를 비교함으로써 퍼센트 동일성이 또한 결정될 수 있다. BLAST 프로그램은 Altschul, 등, J. Mol. Biol. 215:403-410 (1990); Karlin And Altschul, Proc. Natl. Acad. Sci. USA 90:5873-5877 (1993); 및 Altschul 등, Nucleic Acids Res. 25:3389-3402 (1997)에 기재된 것처럼 Karlin and Altschul, Proc. Natl. Acad. Sci. USA 87:2264-2268 (1990)의 정렬 방법에 기초한다. 간단히, BLAST 프로그램은 2개의 서열 중 더 짧은 것에서의 기호의 총 수에 의해 나눈 동일한 정렬된 기호(일반적으로 뉴클레오타이드 또는 아미노산)의 수로서 동일성을 정의한다. 프로그램은 비교되는 단백질의 전체 길이에 걸쳐 퍼센트 동일성을 결정하도록 사용될 수 있다. 디폴트 매개변수는 blastp 프로그램에서, 예를 들어 이에 의해 짧은 쿼리 서열과의 검색을 최적화하도록 제공된다. 프로그램은 또한 Wootton and Federhen, Computers and Chemistry 17:149-163 (1993)의 SEG 프로그램에 의해 결정된 것과 같이 쿼리 서열의 분절을 밝히기 위해 SEG 필터의 사용을 허용한다. 원하는 정도의 서열 동일성이 범위는 대략 80% 내지 100% 및 이들 사이의 정수 값이다. 통상적으로, 개시된 서열과 청구된 서열 사이의 퍼센트 동일성은 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95% 또는 적어도 98%이다.
"외인성"이라는 용어는 유기체의 밖으로부터 기원한 핵산, 단백질 또는 펩타이드, 소분자 화합물 및 기타를 포함하는 임의의 분자를 지칭하도록 본원에 사용된다. 이와 반대로, "내인성"이라는 용어는 유기체 안에서 기원한 임의의 분자(즉, 유기체에 의해 자연적으로 생성됨)를 지칭한다.
"MOI"라는 용어는 물질(예를 들어, 바이러스 입자) 대 감염 표적(예를 들어, 세포)의 비인 감염 다중도를 지칭하도록 본원에 사용된다.
본원에 언급된 모든 공보 및 특허는, 각각의 개별 공보 또는 특허 출원이 참조로 포함된 것으로 구체적으로 및 개별적으로 표시되는 것처럼 본원에 그 전체가 참조로 포함된다. 상충의 경우에, 임의의 정의를 포함하는 본 출원이 규제할 것이다. 그러나, 본원에 인용된 임의의 참고문헌, 논문, 공보, 특허, 특허 공보 및 특허 출원의 언급은 이들이 세계에서 어떠한 나라에서 유효한 선행 기술을 구성하거나 흔한 일반 지식의 일부를 형성한다는 것인 승인, 또는 제시의 임의의 형태로 취해지지 않고 취해지지 않아야 한다.
본 설명에서, 임의의 농도 범위, 백분율 범위, 비율 범위 또는 정수 범위는, 달리 표시되지 않는 한, 인용된 범위 내의 임의의 정수의 값 및 적절할 때 이의 분수(예컨대, 정수의 10/1 및 100/1)를 포함한다고 이해되어야 한다. "약"이라는 용어는, 수 또는 숫자에 바로 선행할 때, 수 또는 숫자 범위의 플러스 또는 마이너스 10%라는 것을 의미한다.
본원에 사용된 것과 같이, "표적 세포"는 입양 세포 치료에 의해 표적화된 세포를 지칭한다. 예를 들어, 표적 세포는 입양 세포 치료의 이식된 T 세포에 의해 사멸될 수 있는 암 세포일 수 있다. 본 개시내용의 표적 세포는 본원에 기재된 것과 같은 활성인자 리간드를 발현하고, 억제제 리간드를 발현하지 않는다.
활성인자
본 개시내용은 제1 리간드, 활성인자, 및 제1 활성인자 리간드에 결합하는 제1 리간드 결합 도메인을 포함하는 제1 조작된 수용체를 제공한다.
본 개시내용은 세포외 영역을 포함하는 제1 조작된 수용체를 포함하고, 세포외 영역은, 수용체를 발현하는 효과기 세포의 활성화를 촉진하는, 수용체를 활성화하거나 이의 활성화를 촉진하는 제1 리간드에 특이적으로 결합할 수 있는 제1 리간드 결합 도메인을 포함한다. 본 개시내용은 제2 리간드에 결합할 수 있는 제2 리간드 결합 도메인을 포함하는 제2 조작된 수용체를 추가로 제공하고, 제2 리간드 결합 도메인에 의한 제2 리간드의 결합은 제1 리간드에 결합된 제1 수용체의 존재 하에서도 효과기 세포의 활성화를 억제하거나 감소시킨다.
본원에 사용된 것과 같이, "활성인자" 또는 "활성인자 리간드"는 CAR 또는 TCR과 같은 본 개시내용의 조작된 수용체의 제1의, 활성인자 리간드 결합 도메인(LBD)에 결합하여서, 조작된 수용체를 발현하는 T 세포의 활성화를 매개하는 제1 리간드를 지칭한다. 활성인자는 표적 세포, 예를 들어 암 세포에 의해 발현되고, 또한 바로 표적 세포보다 더 광범위하게 발현될 수 있다. 예를 들어, 활성인자는 정상인 비표적 세포의 일부 유형 또는 모든 유형에서 발현될 수 있다.
일부 실시형태에서, 제1 리간드는 본원에 개시된 임의의 활성인자 표적으로부터의 펩타이드 리간드이다. 일부 실시형태에서, 제1 리간드는 주요 조직적합성(MHC) 클래스 I 복합체(펩타이드 MHC 또는 pMHC), 예를 들어 인간 백혈구 항원 A*02 대립유전자(HLA-A*02)를 포함하는 MHC 복합체와 복합체화된 펩타이드 항원이다.
임의의 인간 백혈구 항원(HLA) HLA-A, HLA-B, HLA-C, HLA-E, HLA-F 및 HLA-G를 포함하는 pMHC와 복합체화된 펩타이드 항원을 포함하는 표적 세포-특이적 제1 활성인자 리간드는 본 개시내용의 범위 내에서 고안된다. 일부 실시형태에서, 제1 리간드는 HLA-A를 포함하는 pMHC를 포함한다. HLA-A 수용체는 중 α 사슬 및 더 작은 β 사슬을 포함하는 이종이합체이다. α 사슬은 HLA-A의 변이체에 의해 암호화되지만, β 사슬(β2-마이크로글로불린)은 비변이체이다. 수천개의 HLA-A 유전자 변이체가 있고, 이들 모두는 본 개시내용의 범위 내에 해당한다. 일부 실시형태에서, MHC-I은 인간 백혈구 항원 A*02 대립유전자(HLA-A*02)를 포함한다.
일부 실시형태에서, 제1 활성인자 리간드는 HLA-B를 포함하는 pMHC를 포함한다. HLA-B 유전자의 수백개의 버전(대립유전자)이 공지되어 있고, 이들의 각각은 특정 수(예컨대, HLA-B*27)가 주어진다.
일부 실시형태에서, 제1 활성인자 리간드는 HLA-C를 포함하는 pMHC를 포함한다. HLA-C는 HLA 클래스 I 중쇄 파랄로그에 속한다. 이 클래스 I 분자는 중쇄 및 경쇄(베타-2 마이크로글로불린)로 이루어진 이종이합체이다. 백개 초과의 HLA-C 대립유전자가 당해 분야에 공지되어 있다.
일부 실시형태에서, 제1 활성인자 리간드는 HLA-A를 포함하는 pMHC를 포함한다. 일부 실시형태에서, 제1 활성인자 리간드는 HLA-B를 포함하는 pMHC를 포함한다. 일부 실시형태에서, 제1 활성인자 리간드는 HLA-C를 포함하는 pMHC를 포함한다. 일부 실시형태에서, 제1 활성인자 리간드는 HLA-E를 포함하는 pMHC를 포함한다. 일부 실시형태에서, 제1 활성인자 리간드는 HLA-F를 포함하는 pMHC를 포함한다. 일부 실시형태에서, 제1 활성인자 리간드는 HLA-G를 포함하는 pMHC를 포함한다.
일부 실시형태에서, 제1 활성인자 리간드는 HLA-A를 포함한다. 일부 실시형태에서, 제1 활성인자 리간드는 HLA-B를 포함한다. 일부 실시형태에서, 제1 활성인자 리간드는 HLA-C를 포함한다. 일부 실시형태에서, 제1 활성인자 리간드는 HLA-E를 포함한다. 일부 실시형태에서, 제1 활성인자 리간드는 HLA-F를 포함한다. 일부 실시형태에서, 제1 활성인자 리간드는 HLA-G를 포함한다. 일부 실시형태에서, 제1 활성인자 리간드는 HLA-A, HLA-B, HLA-C, HLA-E, HLA-F 또는 HLA-G를 포함한다.
일부 실시형태에서, 제1의, 활성인자 리간드 결합 도메인은 ScFv 도메인을 포함한다.
일부 실시형태에서, 제1의, 활성인자 리간드 결합 도메인은 Vβ 단독 리간드 결합 도메인을 포함한다.
일부 실시형태에서, 제1의, 활성인자 리간드 결합 도메인은 T 세포 수용체(TCR)로부터 단리되거나 유래된 항원 결합 도메인을 포함한다. 예를 들어, 제1의, 활성인자 리간드 결합 도메인은 TCR α 및 β 사슬 가변 도메인을 포함한다.
일부 실시형태에서, 제1의, 활성인자 리간드 및 제2의, 억제제 리간드는 동일하지 않다.
일부 실시형태에서, 제1의, 활성인자 리간드는 표적 세포에 의해 발현되고, 비표적 세포(즉, 입양 세포 치료에 의해 표적화되지 않은 정상 세포)에 의해 발현되지 않는다. 일부 실시형태에서, 표적 세포는 암 세포이고, 비표적 세포는 비암성 세포이다.
일부 실시형태에서, 활성인자 리간드는 표적 세포에서 높은 세포 표면 발현을 갖는다. 이 높은 세포 표면 발현은 큰 활성화 신호를 전달하는 능력을 부여한다. 세포 표면 발현을 측정하는 방법은 당업자에게 공지될 것이고, 활성인자 리간드에 대한 적절한 항체를 사용한 면역조직화학, 이어서 현미경검사 또는 형광 활성 세포 분류(FACS: fluorescence activated cell sorting)를 포함하지만, 이들로 제한되지는 않는다.
일부 실시형태에서, 활성인자 리간드는 필수 세포 기능을 갖는 유전자에 의해 암호화된다. 필수 세포 기능은 세포가 살게 하는 데 필요한 기능이고, 단백질 및 지질 합성, 세포 분열, 복제, 호흡, 대사, 이온 수송 및 조직에 대한 구조 지지체의 제공을 포함한다. 필수 세포 기능을 갖는 유전자에 의해 암호화된 활성인자 리간드의 선택은 암 세포에서의 이수성으로 인한 활성인자 리간드의 소실을 방지하고, 활성인자 리간드를 암호화하는 유전자가 암의 진화 동안 돌연변이유발을 덜 겪게 한다. 일부 실시형태에서, 활성인자 리간드는 반수체기능부전인 유전자에 의해 암호화되고, 즉 활성인자 리간드를 암호화하는 유전자의 카피의 소실은 세포에 의해 관용되지 않고, 세포사 또는 불리한 돌연변이체 표현형으로 이어진다.
일부 실시형태에서, 활성인자 리간드는 모든 표적 세포에 존재한다. 일부 실시형태에서, 표적 세포는 암 세포이다.
일부 실시형태에서, 활성인자 리간드는 복수의 표적 세포에 존재한다. 일부 실시형태에서, 표적 세포는 암 세포이다. 일부 실시형태에서, 활성인자 리간드는 적어도 50%, 적어도 60%, 적어도 70%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 적어도 99.9%의 표적 세포에 존재한다. 일부 실시형태에서, 활성인자 리간드는 적어도 95%의 표적 세포에 존재한다. 일부 실시형태에서, 활성인자 리간드는 적어도 99%의 표적 세포에 존재한다.
일부 실시형태에서, 활성인자 리간드는 모든 세포에 존재한다(유비쿼터스 활성인자 리간드). 예를 들어, 제2 억제제 리간드가 또한 표적 세포를 제외한 모든 세포에서 발현되면 활성인자 리간드는 모든 세포에서 발현될 수 있다.
일부 실시형태에서, 제1의, 활성인자 리간드는 복수의 표적 세포 및 복수의 비표적 세포에 의해 발현된다. 일부 실시형태에서, 복수의 비표적 세포는 제1의, 활성인자 리간드 및 제2의 억제제 리간드 둘 다를 발현한다.
일부 실시형태에서, 제1의, 활성인자 리간드 및 제2의, 억제제 리간드는 제1 리간드 대 제2 리간드의 약 1:100 내지 약 100:1의 비로 복수의 비표적 표적 세포에 존재한다. 일부 실시형태에서, 제1의, 활성인자 리간드 및 제2의, 억제제 리간드는 제1 리간드 대 제2 리간드의 약 1:50 대 약 50:1의 비로 복수의 비표적 표적 세포에 존재한다. 일부 실시형태에서, 제1의, 활성인자 리간드 및 제2의, 억제제 리간드는 제1 리간드 대 제2 리간드의 약 1:25 대 약 25:1의 비로 복수의 비표적 표적 세포에 존재한다. 일부 실시형태에서, 제1의, 활성인자 리간드 및 제2의, 억제제 리간드는 제1 리간드 대 제2 리간드의 약 1:10 내지 약 10:1의 비로 복수의 비표적 표적 세포에 존재한다. 일부 실시형태에서, 제1의, 활성인자 리간드 및 제2의, 억제제 리간드는 제1 리간드 대 제2 리간드의 약 1:5 대 약 5:1의 비로 복수의 비표적 표적 세포에 존재한다. 일부 실시형태에서, 제1의, 활성인자 리간드 및 제2의, 억제제 리간드는 제1 리간드 대 제2 리간드의 약 1:3 대 약 3:1의 비로 복수의 비표적 표적 세포에 존재한다. 일부 실시형태에서, 제1의, 활성인자 리간드 및 제2의, 억제제 리간드는 제1 리간드 대 제2 리간드의 약 1:2 대 약 2:1의 비로 복수의 비표적 표적 세포에 존재한다. 일부 실시형태에서, 제1의, 활성인자 리간드 및 제2의, 억제제 리간드는 약 1:1의 비로 복수의 비표적 표적 세포에 존재한다.
제1의, 활성인자 리간드는 제1 리간드 결합 도메인(때때로 본원에서 활성인자 LBD라 칭함)에 의해 인식된다.
예시적인 활성인자 리간드는 세포 부착 분자, 세포-세포 신호전달 분자, 세포외 도메인, 화학주성에 관여된 분자, 당단백질, G 단백질 커플링된 수용체, 막관통 단백질, 신경전달인자에 대한 수용체 및 전압 게이팅된 이온 채널로 이루어진 군으로부터 선택된 리간드를 포함한다. 일부 실시형태에서, 제1의, 활성인자 리간드는 트랜스페린 수용체(TFRC) 또는 이의 펩타이드 항원이다. 인간 트랜스페린 수용체는 NCBI 기록 AAA61153.1호에 기재되어 있고, 이의 내용은 본원에 참고로 포함된다. 일부 실시형태에서, TFRC는

의 서열에 의해 암호화된다.
일부 실시형태에서, 활성인자 리간드는 종양 특이적 항원(TSA)이다. 일부 실시형태에서, 종양 특이적 항원은 메소텔린(MSLN: mesothelin), CEA 세포 부착 분자 5(CEACAM5 또는 CEA), 표피 성장 인자 수용체(EGFR: epidermal growth factor receptor) 또는 이의 펩타이드 항원이다. 일부 실시형태에서, TSA는 MSLN, CEA, EGFR, 델타 유사 정규 노치 리간드 4(DLL4: delta like canonical Notch ligand 4), 뮤신 16, 세포 표면 연관(CA125로도 공지된 MUC 16), 강글리오사이드 GD2(GD2), 수용체 티로신 키나제 유사 고아 수용체 1(ROR1: receptor tyrosine kinase like orphan receptor 1), erb-b2 수용체 티로신 키나제 2(HER2/NEU) 또는 이의 펩타이드 항원이다. TSA를 표적화하는 예시적인 마우스 및 인간화된 ScFv 항원 결합 도메인은 하기 표 1에 기재되어 있다:




일부 실시형태에서, 활성인자 리간드는 MSLN 또는 이의 펩타이드 항원이고, 활성인자 리간드 결합 도메인은 MSLN 결합 도메인을 포함한다. 일부 실시형태에서, MSLN 리간드 결합 도메인은 ScFv 도메인을 포함한다. 일부 실시형태에서, MSLN 리간드 결합 도메인은 서열 번호 86, 서열 번호 88, 서열 번호 90 또는 서열 번호 92의 서열을 포함한다. 일부 실시형태에서, MSLN 리간드 결합 도메인은 서열 번호 86, 서열 번호 88, 서열 번호 90 또는 서열 번호 92와 적어도 90%, 적어도 95% 또는 적어도 99% 동일한 서열을 포함한다. 일부 실시형태에서, MSLN 리간드 결합 도메인은 서열 번호 87, 서열 번호 89, 서열 번호 91 또는 서열 번호 93을 포함하는 서열에 의해 암호화된다. 일부 실시형태에서, MSLN 리간드 결합 도메인은 서열 번호 87, 서열 번호 89, 서열 번호 91 또는 서열 번호 93의 서열과 적어도 80%의 동일성, 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성 또는 적어도 99%의 동일성을 갖는 서열에 의해 암호화된다.
일부 실시형태에서, 활성인자 리간드는 CEA 또는 이의 펩타이드 항원이고, 활성인자 리간드 결합 도메인은 CEA 결합 도메인을 포함한다. 일부 실시형태에서, CEA 리간드 결합 도메인은 ScFv 도메인을 포함한다. 일부 실시형태에서, CEA 리간드 결합 도메인은 서열 번호 94, 서열 번호 96, 서열 번호 98, 서열 번호 100, 서열 번호 282, 서열 번호 284 또는 서열 번호 286의 서열을 포함한다. 일부 실시형태에서, CEA 리간드 결합 도메인은 서열 번호 94, 서열 번호 96, 서열 번호 98, 서열 번호 100, 서열 번호 282, 서열 번호 284 또는 서열 번호 286과 적어도 90%, 적어도 95% 또는 적어도 99% 동일한 서열을 포함한다. 일부 실시형태에서, CEA 리간드 결합 도메인은 서열 번호 95, 서열 번호 97, 서열 번호 99, 서열 번호 101, 서열 번호 283, 서열 번호 285 또는 서열 번호 287을 포함하는 서열에 의해 암호화된다. 일부 실시형태에서, CEA 리간드 결합 도메인은 서열 번호 95, 서열 번호 97, 서열 번호 99, 서열 번호 101, 서열 번호 283, 서열 번호 285 또는 서열 번호 287의 서열과 적어도 80%의 동일성, 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성 또는 적어도 99%의 동일성을 갖는 서열에 의해 암호화된다.
일부 실시형태에서, 활성인자 리간드는 CEA 또는 이의 펩타이드 항원이고, 활성인자 리간드 결합 도메인은 CEA 결합 도메인을 포함한다. 일부 실시형태에서, CEA 리간드 결합 도메인은 EFGMN(서열 번호 294)의 CDR-H1, WINTKTGEATYVEEFKG(서열 번호 295)의 CDR-H2, WDFAYYVEAMDY(서열 번호 296) 또는 WDFAHYFQTMDY(서열 번호 297)의 CDR-H3, KASQNVGTNVA(서열 번호 298) 또는 KASAAVGTYVA(서열 번호 299)의 CDR-L1, SASYRYS(서열 번호 300) 또는 SASYRKR(서열 번호 301)의 CDR-L2 및 HQYYTYPLFT(서열 번호 302)의 CDR-L3 또는 이것과 적어도 85% 또는 적어도 95%의 동일성을 갖는 서열을 포함한다. 일부 실시형태에서, CEA ScFv는 EFGMN(서열 번호 294)의 CDR-H1, WINTKTGEATYVEEFKG(서열 번호 295)의 CDR-H2, WDFAYYVEAMDY(서열 번호 296) 또는 WDFAHYFQTMDY(서열 번호 297)의 CDR-H3, KASQNVGTNVA(서열 번호 298) 또는 KASAAVGTYVA(서열 번호 299)의 CDR-L1, SASYRYS(서열 번호 300) 또는 SASYRKR(서열 번호 301)의 CDR-L2 및 HQYYTYPLFT(서열 번호 302)의 CDR-L3을 포함한다. 일부 실시형태에서, CEA 결합 도메인은 EFGMN(서열 번호 294)의 CDR-H1, WINTKTGEATYVEEFKG(서열 번호 295)의 CDR-H2, WDFAYYVEAMDY(서열 번호 296)의 CDR-H3, KASQNVGTNVA(서열 번호 298)의 CDR-L1, SASYRYS(서열 번호 300)의 CDR-L2 및 HQYYTYPLFT(서열 번호 302)의 CDR-L3을 포함한다. 일부 실시형태에서, CEA ScFv는 EFGMN(서열 번호 294)의 CDR-H1, WINTKTGEATYVEEFKG(서열 번호 295)의 CDR-H2, WDFAYYVEAMDY(서열 번호 296)의 CDR-H3, KASAAVGTYVA(서열 번호 299)의 CDR-L1, SASYRKR의 CDR-L2 및 HQYYTYPLFT(서열 번호 302)의 CDR-L3을 포함한다. 일부 실시형태에서, CEA 결합 도메인은 EFGMN(서열 번호 294)의 CDR-H1, WINTKTGEATYVEEFKG(서열 번호 295)의 CDR-H2, WDFAHYFQTMDY(서열 번호 297)의 CDR-H3, KASAAVGTYVA(서열 번호 299)의 CDR-L1, SASYRKR의 CDR-L2 및 HQYYTYPLFT(서열 번호 302)의 CDR-L3을 포함한다.
일부 실시형태에서, 활성인자 리간드는 CEA 또는 이의 펩타이드 항원이고, 활성인자 수용체는 CEA CAR이다. 일부 실시형태에서, CEA CAR은 서열 번호 288, 서열 번호 290 또는 서열 번호 292와 적어도 90%, 적어도 95% 또는 적어도 99% 동일한 서열을 포함한다. 일부 실시형태에서, CEA CAR은 서열 번호 288, 서열 번호 290 또는 서열 번호 292를 포함하거나 이들로 본질적으로 이루어진다. 일부 실시형태에서, CEA CAR은 서열 번호 289, 서열 번호 291 또는 서열 번호 293을 포함하거나 이들로 본질적으로 이루어진 서열에 의해 암호화된다. 일부 실시형태에서, CEA CAR은 서열 번호 289, 서열 번호 291 또는 서열 번호 293과 적어도 80%의 동일성, 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성 또는 적어도 99%의 동일성을 갖는 서열에 의해 암호화된다.
일부 실시형태에서, 활성인자 리간드는 EGFR 또는 이의 펩타이드 항원이고, 활성인자 리간드 결합 도메인은 EGFR 결합 도메인을 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 ScFv 도메인을 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 102, 서열 번호 104, 서열 번호 106, 서열 번호 108, 서열 번호 110, 서열 번호 112, 서열 번호 114, 서열 번호 116, 서열 번호 118 또는 서열 번호 391의 서열을 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 102, 서열 번호 104, 서열 번호 106, 서열 번호 108, 서열 번호 110, 서열 번호 112, 서열 번호 114, 서열 번호 116, 서열 번호 118 또는 서열 번호 391과 적어도 90%, 적어도 95% 또는 적어도 99% 동일한 서열을 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 103, 서열 번호 104, 서열 번호 107, 서열 번호 109, 서열 번호 111, 서열 번호 113, 서열 번호 115, 서열 번호 117 또는 서열 번호 119를 포함하는 서열에 의해 암호화된다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 103, 서열 번호 104, 서열 번호 107, 서열 번호 109, 서열 번호 111, 서열 번호 113, 서열 번호 115, 서열 번호 117 또는 서열 번호 119의 서열과 적어도 80%의 동일성, 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성 또는 적어도 99%의 동일성을 갖는 서열에 의해 암호화된다.
일부 실시형태에서, 활성인자 리간드는 EGFR 또는 이의 펩타이드 항원이고, 활성인자 리간드 결합 도메인은 EGFR 리간드 결합 도메인을 포함한다. 일부 실시형태에서, EGFR 결합 도메인은 표 2에 개시된 군으로부터 선택된 VH 및/또는 VL 도메인, 또는 이것과 적어도 90%의 동일성을 갖는 서열을 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 120, 서열 번호 122, 서열 번호 124, 서열 번호 126, 서열 번호 128 및 서열 번호 130으로 이루어진 군으로부터 선택된 VH 도메인을 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 120, 서열 번호 122, 서열 번호 124, 서열 번호 126, 서열 번호 128 및 서열 번호 130 또는 이들과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열로 이루어진 군으로부터 선택된 VH를 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 121, 서열 번호 123, 서열 번호 125, 서열 번호 127, 서열 번호 129 및 서열 번호 131로 이루어진 군으로부터 선택된 VL 도메인을 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 121, 서열 번호 123, 서열 번호 125, 서열 번호 127, 서열 번호 129 및 서열 번호 131 또는 이들과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열로 이루어진 군으로부터 선택된 VH를 포함한다.

일부 실시형태에서, 활성인자 리간드는 EGFR 또는 이의 펩타이드 항원이고, 활성인자 리간드 결합 도메인은 EGFR 리간드 결합 도메인이다. 일부 실시형태에서, EGFR 결합 도메인은 표 3에 개시된 CDR의 군으로부터 선택된 상보성 결정 영역(CDR)을 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 표 3에 개시된 CDR과 적어도 95%의 서열 동일성을 갖는 CDR을 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 131 내지 서열 번호 166으로부터 선택된 CDR을 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 132 내지 서열 번호 137로 이루어진 군으로부터 선택된 중쇄 CDR 1(CDR H1)을 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 138 내지 서열 번호 143으로 이루어진 군으로부터 선택된 중쇄 CDR 2(CDR H2)를 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 144 내지 서열 번호 149로 이루어진 군으로부터 선택된 중쇄 CDR 3(CDR H3)을 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 150 내지 서열 번호 155로 이루어진 군으로부터 선택된 경쇄 CDR 1(CDR L1)을 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 156 내지 서열 번호 160으로 이루어진 군으로부터 선택된 경쇄 CDR 2(CDR L2)를 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 161 내지 서열 번호 166으로 이루어진 군으로부터 선택된 경쇄 CDR 3(CDR L3)을 포함한다. 일부 실시형태에서, EGFR 리간드 결합 도메인은 서열 번호 132 내지 서열 번호 137로부터 선택된 CDR H1, 서열 번호 138 내지 서열 번호 143으로부터 선택된 CDR H2, 서열 번호 144 내지 서열 번호 149로부터 선택된 CDR H3, 서열 번호 150 내지 서열 번호 155로부터 선택된 CDR L1, 서열 번호 156 내지 서열 번호 160으로부터 선택된 CDR L2 및 서열 번호 156 내지 서열 번호 160으로부터 선택된 CDR L3을 포함한다.

일부 실시형태에서, 활성인자 리간드는 pan-HLA 리간드이고, 활성인자 결합 도메인은 pan-HLA 결합 도메인, 즉 HLA A, HLA B 및 HLA C 유전자좌의 산물 중에서 공유된 항원 결정인자에 결합하고 이를 인식하는 결합 도메인이다. 당해 분야에 공지되거나 본원에 개시된 다양한 단일 가변 도메인은 실시형태에 사용하기에 적합하다. 이러한 scFv는 예를 들어 제한 없이 하기 마우스 및 인간화된 pan-HLA scFv 항체를 포함한다. 예시적인 pan-HLA 리간드는 HLA 클래스 I 알파3 및 알파2 도메인과 반응하는 구성적 에피토프를 인식하는 W6/32이다.

일부 실시형태에서, 활성인자 리간드는 pan-HLA 리간드이고, 활성인자 리간드 결합 도메인은 pan-HLA 리간드 결합 도메인을 포함한다. 일부 실시형태에서, pan-HLA 리간드 결합 도메인은 ScFv 도메인을 포함한다. 일부 실시형태에서, pan-HLA 리간드 결합 도메인은 서열 번호 167, 서열 번호 169, 서열 번호 171, 서열 번호 173, 서열 번호 175 또는 서열 번호 177의 서열을 포함한다. 일부 실시형태에서, pan-HLA 리간드 결합 도메인은 서열 번호 167, 서열 번호 169, 서열 번호 171, 서열 번호 173, 서열 번호 175 또는 서열 번호 177과 적어도 90%, 적어도 95% 또는 적어도 99% 동일한 서열을 포함한다. 일부 실시형태에서, pan-HLA 리간드 결합 도메인은 서열 번호 168, 서열 번호 170, 서열 번호 172, 서열 번호 174, 서열 번호 176 또는 서열 번호 178을 포함하는 서열에 의해 암호화된다. 일부 실시형태에서, pan-HLA 리간드 결합 도메인은 서열 번호 168, 서열 번호 170, 서열 번호 172, 서열 번호 174, 서열 번호 176 또는 서열 번호 178의 서열과 적어도 80%의 동일성, 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성 또는 적어도 99%의 동일성을 갖는 서열에 의해 암호화된다.
일부 실시형태에서, 활성인자 리간드는 CD19 분자(CD19) 또는 이의 펩타이드 항원이고, 활성인자 리간드 결합 도메인은 CD19 리간드 결합 도메인을 포함한다. 일부 실시형태에서, CD19 리간드 결합 도메인은 ScFv 도메인을 포함한다. 일부 실시형태에서, CD19 리간드 결합 도메인은 서열 번호 275 또는 서열 번호 277과 적어도 90%, 적어도 95% 또는 적어도 99% 동일한 서열을 포함한다. 일부 실시형태에서, CD-19 리간드 결합 도메인은 서열 번호 275 또는 서열 번호 277의 서열을 포함한다. 일부 실시형태에서, CD19 리간드 결합 도메인은 서열 번호 276 또는 서열 번호 278을 포함하는 서열에 의해 암호화된다. 일부 실시형태에서, CD19 리간드 결합 도메인은 서열 번호 276 또는 서열 번호 278의 서열과 적어도 80%의 동일성, 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성 또는 적어도 99%의 동일성을 갖는 서열에 의해 암호화된다.
일부 실시형태에서, 활성인자 리간드는 CD19 분자(CD19) 또는 이의 펩타이드 항원이고, 활성인자 수용체는 CAR이다. 일부 실시형태에서, CD19 CAR은 서열 번호 279 또는 서열 번호 281과 적어도 90%, 적어도 95% 또는 적어도 99% 동일한 서열을 포함한다. 일부 실시형태에서, CD19 CAR은 서열 번호 279 또는 서열 번호 281을 포함하거나 이들로 본질적으로 이루어진다. 일부 실시형태에서, CD19 CAR은 서열 번호 280 또는 서열 번호 390의 서열과 적어도 80%의 동일성, 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성 또는 적어도 99%의 동일성을 갖는 서열에 의해 암호화된다. 일부 실시형태에서, CD19 CAR은 서열 번호 280 또는 서열 번호 390을 포함하거나 이들로 본질적으로 이루어진 서열에 의해 암호화된다. 제1 수용체에 대한 제1의, 활성인자 리간드 결합 도메인이 비제한적인 예로서 분야 인정된 T 세포 수용체, 키메라 항원 수용체 및 항체 결합 도메인을 포함하는 당해 분야에 공지된 임의의 원천으로부터 단리되거나 유래될 수 있다는 것이 당업자에 의해 이해될 것이다. 예를 들어, 제1 리간드 결합 도메인은 표 5에 개시된 임의의 항체로부터 유래되고, 표 5에 기재된 항원으로부터 선택된 제1 리간드에 결합할 수 있다. 따라서, 기재된 2개의 수용체 시스템을 포함하는 면역 세포는 표 5에 기재된 임의의 질환 또는 장애를 치료하기 위해 사용될 수 있다. 본원에 기재된 임의의 암을 치료하기 위한 적절한 제1의, 활성인자 수용체 리간드 결합 도메인의 선택은 당업자에게 자명할 것이다.





억제제
본 개시내용은 제2 리간드, 억제제, 및 억제제 리간드에 결합하는 제2 리간드 결합 도메인을 포함하는 제2 조작된 수용체를 제공한다.
본 개시내용은 세포외 영역을 포함하는 제2 조작된 수용체를 제공하고, 세포외 영역은 제1 수용체 및 제2 수용체를 발현하는 효과기 세포의 활성화를 억제하는 제2 리간드에 특이적으로 결합할 수 있는 제2 리간드 결합 도메인을 포함하고, 효과기 세포는 제1 조작된 수용체에 대한 제1 리간드의 결합에 의해 활성화된다.
본원에 사용된 것과 같이 "차단제"라고 때때로 칭하는 "억제제" 또는 "억제제 리간드"는 본 개시내용의 조작된 수용체의 제2의, 리간드 결합 도메인(억제제 LBD)에 결합하지만, 조작된 수용체를 발현하는 면역 세포의 활성화를 억제하는 제2 리간드를 지칭한다. 억제제는 표적 세포에 의해 발현되지 않는다. 억제제 리간드는 활성인자 리간드를 발현하는 정상인 비표적 세포를 포함하는 복수의 정상인 비표적 세포에서 또한 발현되어서 입양 세포 치료의 세포독성 효과로부터 이 세포를 보호한다. 이론에 의해 구속되고자 바라지 않으면서, 억제제 리간드는 다양한 기전을 통해 효과기 세포의 활성화를 차단할 수 있다. 예를 들어, 억제제 LBD에 대한 억제제 리간드의 결합은 억제제의 부재 하에 본원에 기재된 조작된 수용체를 발현하는 면역 세포의 활성화로 어이지는 활성인자 LBD에 대한 활성인자 리간드의 결합 시 발생하는 신호의 전송을 차단할 수 있다.
대안적으로 또는 게다가, 제2 조작된 수용체에 대한 억제제 리간드의 결합은 본원에 기재된 2개의 수용체 시스템을 포함하는 면역 세포의 표면으로부터 제1의, 활성인자 수용체의 세포 표면 발현의 소실을 야기할 수 있다. 이론에 의해 구속되고자 바라지 않으면서, 정상 세포에 대한 활성인자 및 억제제 리간드의 면역 세포 관여가 억제제 수용체가 면역 세포 표면으로부터 근처의 활성인자 수용체 분자를 제거하게 하도록 야기한다고 생각된다. 이 과정은 면역 세포를 국소로 탈감작시켜서, 이의 활성화 한계치를 가역적으로 상승시킨다. 표적 세포에서 오직 활성인자 리간드를 관여시키는 면역 세포는 제2의, 억제 수용체로부터의 신호에 의해 방해받지 않는 국소 활성화 신호를 야기한다. 이 국소 활성화는 세포독성 과립의 방출이 표적 세포 선택적 세포사로 이어질 때까지 증가한다. 그러나, 표면 수용체 발현 수준의 조절은 차단제 수용체가 제1 활성인자 수용체에 의해 면역 세포의 활성화를 억제하는 유일한 기전이 아닐 수 있다. 이론에 의해 구속되고자 바라지 않으면서, 비제한적인 예로서 활성인자와 차단제 수용체 신호전달 경로 사이의 혼선을 포함하는 다른 기전이 작동할 수 있다.
일부 실시형태에서, 제2 리간드는 표적 세포에 의해 발현되지 않고, 비표적 세포에 의해 발현된다. 일부 실시형태에서, 표적 세포는 암 세포이고, 비표적 세포는 비암성 세포이다.
일부 실시형태에서, 제2의, 억제제 리간드 결합 도메인은 ScFv 도메인을 포함한다.
일부 실시형태에서, 제2의, 억제제 리간드 결합 도메인은 Vβ 단독 리간드 결합 도메인을 포함한다.
일부 실시형태에서, 제2의, 억제제 리간드 결합 도메인은 T 세포 수용체(TCR)로부터 단리되거나 유래된 항원 결합 도메인을 포함한다. 예를 들어, 제2의, 억제제 리간드 결합 도메인은 TCR α 및 β 사슬 가변 도메인을 포함한다.
억제제 표적
일부 실시형태에서, 억제제 리간드는 조직에 걸친 높은 균질한 표면 발현을 갖는 유전자 또는 이의 펩타이드 항원을 포함한다. 이론에 의해 구속되고자 바라지 않으면서, 조직에 걸친 높은 균질한 표면 발현은 억제제 리간드가 큰 고른 억제 신호를 전달하게 한다. 대안적으로 또는 게다가, 활성인자 및 억제제 표적의 발현은 상관될 수 있고, 즉 2개는 비표적 세포에서 유사한 수준으로 발현된다.
일부 실시형태에서, 제2의, 억제제 리간드는 펩타이드 리간드이다. 일부 실시형태에서, 제2의, 억제제 리간드는 주요 조직적합성(MHC) 클래스 I 복합체(펩타이드 MHC 또는 pMHC)와 복합체화된 펩타이드 항원이다. 임의의 HLA-A, HLA-B 또는 HLA-C를 포함하는 pMHC와 복합체화된 펩타이드 항원을 포함하는 억제제 리간드는 본 개시내용의 범위 내로서 고안된다.
일부 실시형태에서, 억제제 리간드는 항원에서 부재하거나 다형성인 유전자에 의해 암호화된다.
표적 세포와 비표적 세포 사이의 억제제 리간드의 차등 발현을 구별하는 방법은 당업자에게 용이하게 자명할 것이다. 예를 들어, 비표적 세포 및 표적 세포에서의 억제제 리간드의 존재 또는 부재는 억제제 리간드에 결합하는 항체에 의한 면역조직화학에 의해 분석될 수 있고, 이후에 억제제 리간드의 게놈 유전자좌가 표적 세포 또는 비표적 세포에서 돌연변이를 포함하는지를 결정하기 위해 현미경검사 또는 FACS, 표적 세포 및 비표적 세포의 RNA 발현 프로파일링, 또는 비표적 세포 및 표적 세포의 DNA 시퀀싱이 이어진다.
이형접합성 소실(LOH)로 인해 소실된 대립유전자
1차 종양에서의 동형접합성 결실은 희귀하고 작고, 따라서 표적 B 후보를 생성하지 않을 것이다. 예를 들어, 21개의 인간 암 유형에 걸친 2218개의 1차 종양의 분석에서, 상위 4개의 후보는 사이클린 의존적 키나제 억제제 2A(CDKN2A), RB 전사 동시억제인자 1(RB1), 포스파타제 및 텐신 동족체(PTEN) 및 N3PB2였다. 그러나, CDKN2A(P16)는 모든 암에 걸쳐 불과 5% 동형접합성 결실로 결실되었다. 동형접합성 HLA-A 결실은 암의 0.2% 미만에서 발견되었다(Cheng 등, Nature Comm. 8:1221 (2017)). 이와 반대로, 반접합성 소실로 인한 암 세포에서의 유전자의 단일 카피의 결실은 훨씬 더 흔히 발생한다.
일부 실시형태에서, 제2의, 억제제 리간드는 이형접합성 소실로 인해 표적 세포에서 소실된 유전자의 대립유전자를 포함한다. 일부 실시형태에서, 표적 세포는 암 세포를 포함한다. 암 세포는 중복 및 결실을 포함하는 빈번한 게놈 재배열을 겼는다. 이 결실은 암 세포에서의 하나 이상의 유전자의 하나의 카피의 결실로 이어질 수 있다.
본원에 사용된 것과 같이, "이형접합성 소실(LOH)"은 암에서 높은 빈도로 발생하는 유전 변화를 지칭하고, 이에 의해 2개의 대립유전자 중 하나가 결실되어서, 단일의 모노-대립유전자(반접합성) 유전자좌를 남긴다.
HLA 클래스 I 대립유전자
일부 실시형태에서, 제2의, 억제제 리간드는 HLA 클래스 I 대립유전자를 포함한다. 주요 조직적합 복합체(MHC) 클래스 I은 면역계의 세포에 항원을 디스플레이하여 면역 반응을 촉발하는 단백질 복합체이다. MHC 클래스 I에 상응하는 인간 백혈구 항원(HLA)은 HLA-A, HLA-B 및 HLA-C이다.
일부 실시형태에서, 제2의, 억제제 리간드는 HLA 클래스 I 대립유전자를 포함한다. 일부 실시형태에서, 제2의, 억제제 리간드는 LOH를 통해 표적 세포에서 소실된 HLA 클래스 I의 대립유전자를 포함한다. HLA-A는 HLA-A 유전자좌에 의해 암호화된 주요 조직적합 복합체(MHC)의 인간 백혈구 항원(HLA)의 그룹이다. HLA-A는 인간 MHC 클래스 I 세포 표면 수용체의 3개의 주요 유형 중 하나이다. 수용체는 중 α 사슬 및 더 작은 β 사슬을 포함하는 이종이합체이다. α 사슬은 HLA-A의 변이체에 의해 암호화되지만, β 사슬(β2-마이크로글로불린)은 비변이체이다. 수천개의 HLA-A 변이체가 있고, 이들 모두는 본 개시내용의 범위 내에 해당한다.
일부 실시형태에서, 제2의, 억제제 리간드는 HLA-B 대립유전자를 포함한다. HLA-B 유전자는 많은 가능한 변이(대립유전자)를 갖는다. HLA-B 유전자의 백개의 버전(대립유전자)이 공지되어 있고, 이들의 각각은 특정 숫자(예컨대, HLA-B27)가 주어진다.
일부 실시형태에서, 제2의, 억제제 리간드는 HLA-C 대립유전자를 포함한다. HLA-C는 HLA 클래스 I 중쇄 파랄로그에 속한다. 이 클래스 I 분자는 중쇄 및 경쇄(베타-2 마이크로글로불린)로 이루어진 이종이합체이다. 100개 초과의 HLA-C 대립유전자가 기재되어 있다.
일부 실시형태에서, HLA 클래스 I 대립유전자는 넓은 또는 편재한 RNA 발현을 갖는다.
일부 실시형태에서, HLA 클래스 I 대립유전자는 공지된 또는 일반적으로 높은 소수의 대립유전자 빈도를 갖는다.
일부 실시형태에서, 예를 들어 HLA 클래스 I 대립유전자가 pan-HLA 리간드 결합 도메인에 의해 인식될 때 HLA 클래스 I 대립유전자는 펩타이드-MHC 항원을 요하지 않는다.
일부 실시형태에서, 제2 억제제 리간드는 HLA-A 대립유전자를 포함한다. 일부 실시형태에서, HLA-A 대립유전자는 HLA-A*02를 포함한다. HLA-A*02에 결합하고 이를 인식하는 당해 분야에 공지되거나 본원에 개시된 다양한 단일 가변 도메인은 실시형태에 사용하기에 적합하다. 이러한 scFv는 예를 들어 및 제한 없이 하기 표 6에 도시된 펩타이드 독립적 방식으로 HLA-A*02에 결합하는 하기 마우스 및 인간화된 scFv 항체를 포함한다(상보성 결정 영역 밑줄 표시):


HLA-A*02 리간드 결합 도메인에 대한 예시적인 중쇄 및 경쇄 CDR(각각 CDR-H1, CDR-H2 및 CDR-H3, 또는 CDR-L1, CDR-L2 및 CDR-L3)은 하기 표 7에 기재되어 있다.

일부 실시형태에서, scFv는 서열 번호 41 내지 서열 번호 52 중 어느 하나의 상보성 결정 영역(CDR)을 포함한다. 일부 실시형태에서, scFv는 서열 번호 41 내지 서열 번호 52 중 어느 하나와 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, scFv는 서열 번호 41 내지 서열 번호 52 중 어느 하나와 동일한 서열을 포함한다. 일부 실시형태에서, 항체의 중쇄는 서열 번호 53 내지 서열 번호 64 중 어느 하나의 중쇄 CDR을 포함하고, 항체의 경쇄는 서열 번호 53 내지 서열 번호 64 중 어느 하나의 경쇄 CDR을 포함한다. 일부 실시형태에서, 항체의 중쇄는 서열 번호 53 내지 서열 번호 64 중 어느 하나의 중쇄 부분과 적어도 95% 동일한 서열을 포함하고, 항체의 경쇄는 서열 번호 53 내지 서열 번호 64 중 어느 하나의 경쇄 부분과 적어도 95% 동일한 서열을 포함한다.
일부 실시형태에서, 항체의 중쇄는 서열 번호 53 내지 서열 번호 64 중 어느 하나의 중쇄 부분과 동일한 서열을 포함하고, 항체의 경쇄는 서열 번호 53 내지 서열 번호 64 중 어느 하나의 경쇄 부분과 동일한 서열을 포함한다.
일부 실시형태에서, ScFv는 서열 번호 53 내지 서열 번호 64 중 어느 하나와 적어도 95% 동일한, 적어도 96% 동일한, 적어도 97% 동일한, 적어도 98% 동일한, 적어도 99% 동일한 또는 동일한 서열을 포함한다.
일부 실시형태에서, 제2의, 억제 리간드는 HLA-A*02이고, 억제 리간드 결합 도메인은 HLA-A*02 리간드 결합 도메인을 포함한다. 일부 실시형태에서, 제2 리간드 결합 도메인은 HLA-A*02를 포함하는 pMHC 복합체에서 펩타이드와 독립적인 HLA-A*02에 결합한다. 일부 실시형태에서, HLA-A*02 리간드 결합 도메인은 ScFv 도메인을 포함한다. 일부 실시형태에서, HLA-A*02 리간드 결합 도메인은 서열 번호 53 내지 서열 번호 64 중 어느 하나의 서열을 포함한다. 일부 실시형태에서, HLA-A*02 리간드 결합 도메인은 서열 번호 53 내지 서열 번호 64 중 어느 하나의 서열과 적어도 90%, 적어도 95% 또는 적어도 99% 동일한 서열을 포함한다. 일부 실시형태에서, HLA-A*02 리간드 결합 도메인은 서열 번호 179 내지 서열 번호 190 중 어느 하나를 포함하는 서열에 의해 암호화된다. 일부 실시형태에서, HLA-A*02 리간드 결합 도메인은 서열 번호 179 내지 서열 번호 190 중 어느 하나의 서열과 적어도 80%의 동일성, 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성 또는 적어도 99%의 동일성을 갖는 서열에 의해 암호화된다.
부 조직접합 항원
일부 실시형태에서, 제2의, 억제제 리간드는 부 조직접합 항원(MiHA)을 포함한다. 일부 실시형태에서, 제2의, 억제제 리간드는 LOH를 통해 표적 세포에서 소실된 MiHA의 대립유전자를 포함한다.
MiHA는 대립유전자 사이의 비동의 차이를 함유하는 단백질로부터 유래된 펩타이드이고, 흔한 HLA 대립유전자에 의해 디스플레이된다. 비동의 차이는 MiHA를 암호화하는 유전자의 코딩 서열에서 SNP, 결실, 프레임쉬프트 돌연변이 또는 삽입으로부터 생길 수 있다. 예시적인 MiHA는 약 9개 내지 12개의 아미노산 길이일 수 있고, MHC 클래스 I 및 MHC 클래스 II 단백질에 결합할 수 있다. MiHA를 디스플레이하는 MHC 복합체에 대한 TCR의 결합은 T 세포를 활성화할 수 있다. MiHA의 유전적 특성 및 면역학적 특성은 당업자에게 잘 공지될 것이다. 후보 MiHA는 공지된 HLA 클래스 I 대립유전자에 의해 제시된 공지된 펩타이드이고, 임상에서(예를 들어, 이식편 대 숙주 질환 또는 이식물 거부에서) T 세포 반응을 이끌어내는 것으로 공지되어 있고, 단순한 SNP 유전자형분석에 의해 환자 선택이 가능하게 한다.
일부 실시형태에서, MiHA는 넓은 또는 편재한 RNA 발현을 갖는다.
일부 실시형태에서, MiHA는 높은 소수 대립유전자 빈도를 갖는다.
일부 실시형태에서, MiHA는 Y 염색체 유전자로부터 유래된 펩타이드를 포함한다.
일부 실시형태에서, 제2 억제제 리간드는 표 8 및 표 9에 개시된 MiHA의 군으로부터 선택된 MiHA를 포함한다.
본 발명의 범위 내로서 고려되는 MiHA의 예시적이지만 비제한적인 예는 하기 표 8에 개시되어 있다. 표 8에서의 칼럼은 왼쪽에서 오른쪽으로 MiHA의 명칭, 이것이 유래된 유전자, MiHA를 디스플레이할 수 있는 MHC 클래스 I 변이체 및 펩타이드 변이체의 서열[괄호에 표시된 A/B 변이체)을 나타낸다.





본 발명의 범위 내로서 고려되는 MiHA의 예시적이지만 비제한적인 예는 하기 표 9에 개시되어 있다. 표 9에서의 칼럼은 왼쪽에서 오른쪽으로 MiHA의 명칭, 이것이 유래된 유전자, MiHA를 디스플레이할 수 있는 MHC 클래스 I 변이체 및 펩타이드 변이체의 서열[괄호에 표시된 A/B 변이체)을 나타낸다.

일부 실시형태에서, MiHA는 HA-1을 포함한다. HA-1은 VL[H/R]DDLLEA(서열 번호 273)의 서열을 갖는 펩타이드 항원이고, Rho GTPase 활성화 단백질 45 (HA-1) 유전자로부터 유래된다.
HA-1 변이체 H 펩타이드(VLHDDLLEA(서열 번호 191))에 선택적으로 결합하는 예시적인 리간드 결합 도메인은 하기 표 10에 기재되어 있다. 서열 번호 193에서의 TCR 알파 및 TCR 베타 서열은 N 말단 GSG 링커를 갖는 서열 ATNFSLLKQAGDVEENPGP(서열 번호 192)의 P2A 자가 절단 폴리펩타이드에 의해 분리된다.

일부 실시형태에서, 제2의, 억제 리간드는 HA-1(H)을 포함한다. 일부 실시형태에서, 제2의, 억제 리간드 결합은 TCR로부터 단리되거나 유래된다. 일부 실시형태에서, 제2의, 억제 리간드 결합 도메인은 TCR 알파 및 TCR 베타 가변 도메인을 포함한다. 일부 실시형태에서, TCR 알파 및 TCR 베타 가변 도메인은 자가 절단 폴리펩타이드 서열에 의해 분리된다. 일부 실시형태에서, 자가 절단 폴리펩타이드 서열에 의해 분리된 TCR 알파 및 TCR 베타 가변 도메인은 서열 번호 193을 포함한다. 일부 실시형태에서, 자가 절단 폴리펩타이드 서열에 의해 분리된 TCR 알파 및 TCR 베타 가변 도메인은 서열 번호 193, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함한다. 일부 실시형태에서, TCR 알파 및 TCR 베타 가변 도메인은 서열 번호 194의 서열, 또는 이것과 적어도 80%의 동일성, 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열에 의해 암호화된다. 일부 실시형태에서, TCR 알파 가변 도메인은 서열 번호 199 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함한다. 일부 실시형태에서, TCR 베타 가변 도메인은 서열 번호 200 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함한다.
Y 염색체 항원의 소실
일부 실시형태에서, 제2의, 억제제 리간드는 Y 염색체 유전자, 즉 Y 염색체에서의 유전자에 의해 암호화된 펩타이드를 포함한다. 일부 실시형태에서, 제2의, 억제제 리간드는 Y 염색체 소실(LoY)을 통해 표적 세포에서 소실된 Y 염색체 유전자에 의해 암호화된 펩타이드를 포함한다. 예를 들어, 규명된 MiHA의 약 1/3은 Y 염색체로부터 생긴다. Y 염색체는 200개가 넘는 단백질 코딩 유전자를 함유하고, 이들의 모두는 본 개시내용의 범위 내로서 고안된다.
본원에 사용된 것과 같이, "Y 소실" 또는 "LoY"는 종양에서 높은 빈도로 발생하여서 Y 염색체의 일부 또는 전부의 하나의 카피가 결실되어서 Y 염색체 암호화된 유전자(들)를 소실시키는 유전 변경을 지칭한다.
염색체 소실은 소정의 암에서 생기는 것으로 공지되어 있다. 예를 들어, 신장 투명 세포 암에서 Y 염색체의 40% 체세포 소실이 보고되었다(Arseneault 등, Sci. Rep. 7: 44876 (2017)). 유사하게, 남성 유방암 대상체에서 Y 염색체의 클론 소실은 31명 중 5명에서 보고되었다(Wong 등, Oncotarget 6(42):44927-40 (2015)). 남성 환자로부터의 종양에서의 Y 염색체 소실은 두경부암 환자의 "일관된 특징"으로 기재된다(el-Naggar 등, Am J Clin Pathol 105(1):102-8 (1996)). 추가로, Y 염색체 소실은 위암을 갖는 7명의 남성 환자 중 4명에서 X 염색체 이염색체성과 연관된다(Saal 등, Virchows Arch B Cell Pathol (1993)). 이와 같이, Y 염색체 유전자는 다양한 암에서 소실될 수 있고, 암 세포를 표적화하는 본 개시내용의 조작된 수용체를 갖는 억제제 리간드로서 사용될 수 있다.
항원 결합 도메인
본 개시내용은 제1 조작된 수용체를 활성화하여서 제1 조작된 수용체를 발현하는 면역 세포를 활성화하는 제1 리간드 결합 도메인, 및 제1 리간드에 결합된 제1 조작된 수용체의 존재 하에서도 제2 조작된 수용체를 발현하는 면역 세포의 활성화를 억제하는 제2 조작된 수용체를 활성화하는 제2 리간드 결합 도메인을 제공한다.
리간드 의존적 방식으로 수용체의 활성을 조절할 수 있는 리간드 결합 도메인의 임의의 유형은 본 개시내용의 범위 내로서 고안된다. 일부 실시형태에서, 리간드 결합 도메인은 항원 결합 도메인이다. 예시적인 항원 결합 도메인은 특히 ScFv, SdAb, Vβ 단독 도메인, 및 TCR α 및 β 사슬 가변 도메인으로부터 유래된 TCR 항원 결합 도메인을 포함한다.
일부 실시형태에서, 제1의, 활성인자 LBD는 항원 결합 도메인을 포함한다. 일부 실시형태에서, 제2의, 억제제 LBD는 항원 결합 도메인을 포함한다. 항원 결합 도메인의 임의의 유형은 본 개시내용의 범위 내로서 고안된다.
예를 들어, 제1의, 활성인자 LBD 및/또는 제2의, 억제제 LBD는 쥣과 항체, 인간화된 항체 또는 인간 항체로부터 유래된 예를 들어 단일 도메인 항체 단편(sdAb) 또는 중쇄 항체 HCAb, 단일 사슬 항체(scFv)를 포함하는 인접한 폴리펩타이드 사슬의 일부로서 발현될 수 있는 항원 결합 도메인을 포함할 수 있다(Harlow 등, 1999, In: Using Antibodies: A Laboratory Manual, Cold Spring Harbor Laboratory Press, N.Y.; Harlow 등, 1989, In: Antibodies: A Laboratory Manual, Cold Spring Harbor, N.Y.; Houston 등, 1988, Proc. Natl. Acad. Sci. USA 85:5879-5883; Bird 등, 1988, Science 242:423-426). 일부 양태에서, 제1의, 활성인자 LBD 및/또는 제2의, 억제제 LBD는 항체 단편을 포함하는 항원 결합 도메인을 포함한다. 추가의 양태에서, 활성인자 LBD는 scFv 또는 sdAb를 포함하는 항체 단편을 포함한다. 추가의 양태에서, 억제제 LBD는 scFv 또는 sdAb를 포함하는 항체 단편을 포함한다.
본원에 사용된 것과 같이, "항체"라는 용어는 항원에 특이적으로 결합하는 면역글로불린 분자로부터 유래된 단백질 또는 폴리펩타이드 서열을 지칭한다. 항체는 다중클론 또는 단일클론 기원의 온전한 면역글로불린, 또는 이의 단편일 수 있고, 자연으로부터 또는 재조합 원천으로부터 유래될 수 있다.
"항체 단편" 또는 "항체 결합 도메인"이라는 용어는 항원 결합 도메인을 함유하는 항체 또는 이의 재조합 변이체의 적어도 하나의 부분, 즉 항원 및 이의 한정된 에피토프와 같은 표적에 대한 항체 단편의 인식 및 특이적 결합을 부여하기에 충분한 온전한 항체의 항원 결정 가변 영역을 지칭한다. 항체 단편의 예는 Fab, Fab', F(ab')2, 및 Fv 단편, 단일-사슬 (sc)Fv("scFv") 항체 단편, 선형 항체, 단일 도메인 항체("sdAb"로 축약됨)(VL 또는 VH 중 어느 하나), 낙타 VHH 도메인, 및 항체 단편으로부터 형성된 다중-특이적 항체를 포함하지만, 이들로 제한되지는 않는다.
"scFv"라는 용어는 경쇄의 가변 영역을 포함하는 적어도 하나의 항체 단편 및 중쇄의 가변 영역을 포함하는 적어도 하나의 항체 단편을 포함하는 융합 단백질을 지칭하고, 경쇄 및 중쇄 가변 영역은 짧은 가요성 폴리펩타이드 링커를 통해 인접하여 연결되고, 단일 폴리펩타이드 사슬로서 발현될 수 있고, scFv는 이것이 유래된 온전한 항체의 특이성을 보유한다.
항체와 관련하여 "중쇄 가변 영역" 또는 "VH"(또는 단일 도메인 항체, 예를 들어 나노바디의 경우에는, "VHH")는 프레임워크 영역으로 공지된 플랭킹 스트레치 사이에 끼워진 3개의 CDR을 함유하는 중쇄의 단편을 지칭하고, 이 프레임워크 영역은 CDR보다 일반적으로 더 고도로 보존되고, CDR을 지지하도록 스캐폴드를 형성한다.
달리 기술되지 않는 한, 본원에 사용된 것과 같이 scFv는 어느 한 순서로, 예를 들어 폴리펩타이드의 N-말단 및 C-말단 끝과 관련하여 VL 가변 영역 및 VH 가변 영역을 가질 수 있고, scFv는 VL-링커-VH를 포함할 수 있거나 VH-링커-VL을 포함할 수 있다.
"항체 경쇄"라는 용어는 이의 자연 발생 구성에서 항체 분자로 존재하는 폴리펩타이드 사슬의 2개의 유형 중 더 적은 것을 지칭한다. 카파("K") 및 람다("λ") 경쇄는 2개의 주요 항체 경쇄 이소형을 지칭한다.
"재조합 항체"라는 용어는 예를 들어 박테리오파지 또는 효모 발현 시스템에 의해 발현된 항체와 같은 재조합 DNA 기술을 사용하여 생성된 항체를 지칭한다. 상기 용어는 또한 항체를 암호화하는 DNA 분자의 합성에 의해 생성되고 DNA 분자가 항체 단백질, 또는 항체를 명시하는 아미노산 서열을 발현하는 항체를 의미하도록 해석되어야 하고, 당해 분야에서 이용 가능하고 잘 공지된 재조합 DNA 또는 아미노산 서열 기술을 사용하여 DNA 또는 아미노산 서열이 얻어졌다.
"Vβ 도메인", "Vβ 단독 도메인", "β 사슬 가변 도메인" 또는 "단일 가변 도메인 TCR(svd-TCR)"이라는 용어는 제2 TCR 가변 도메인의 부재 하에 항원에 특이적으로 결합하는 단일 T 세포 수용체(TCR) 베타 가변 도메인으로 본질적으로 이루어진 항원 결합 도메인을 지칭한다. 일부 실시형태에서, 제1의, 활성인자 LBD는 Vβ 단독 도메인을 포함하거나 본질적으로 이것으로 이루어진다. 일부 실시형태에서, 제2의, 억제제 LBD는 Vβ 단독 도메인을 포함하거나 본질적으로 이것으로 이루어진다.
일부 실시형태에서, Vβ 단독 도메인은 추가 아미노산 서열, 추가 단백질 도메인(TCR 가변 도메인과 공유 회합된, 비공유 회합된 또는 공유로 회합되고 비공유로 회합된), TCR 가변 도메인과 다른 유형의 거대분자(예를 들어, 폴리뉴클레오타이드, 폴리사카라이드, 지질, 또는 이들의 조합)의 융합 또는 비공유 회합, TCR 가변 도메인과 하나 이상의 소분자, 화합물 또는 리간드의 융합 또는 비공유 회합, 또는 이들의 조합을 포함하는 TCR 가변 도메인 이외의 추가 요소를 포함할 수 있다. 기재된 것과 같은 임의의 추가 요소는 조합될 수 있고, 단 TCR 가변 도메인은 제2 TCR 가변 도메인의 부재 하에 에피토프에 특이적으로 결합하도록 구성될 수 있다.
다른 실시형태에서, 본원에 기재된 것과 같은 Vβ 단독 도메인은 Vα 분절이 결여된 사슬과 독립적으로 기능한다. 예를 들어, 일부 실시형태에서 하나 이상의 Vβ 단독 도메인은 항원에 반응하여 T 세포를 활성화할 수 있는 막관통(예를 들어, CD3ζ 및 CD28) 및 세포내 도메인 단백질(예를 들어, CD3ζ, CD28, 및/또는 4-1BB)에 융합된다.
일부 실시형태에서, Vβ 단독 도메인은 상보성 결정 영역(CDR)을 사용하여 항원을 관여시킨다. 각각의 Vβ 단독 도메인은 3개의 보체 결정 영역(CDR1, CDR2 및 CDR3)을 함유한다.
일부 실시형태에서, 제1 Vβ 단독 도메인은 TCR Vβ 도메인 또는 이의 항원 결합 단편을 포함한다.
인간에서, α 사슬 및 γ 사슬의 TCR 가변 영역은 각각 V 분절 및 J 분절에 의해 암호화되는 반면, β 사슬 및 δ 사슬의 가변 영역은 각각 추가로 D 분절에 의해 암호화된다. 다수의 가변(V) 유전자 분절, 다양성(D) 유전자 분절 및 연결(J) 유전자 분절(예를 들어, 52개의 Vβ 유전자 분절, 2개의 Dβ 유전자 분절 및 13개의 Jβ 유전자 분절)(Janeway 등 (eds.), 2001, Immunobiology: The Immune System in Health and Disease. 5th Edition, New York, Figure 4.13)이 있고, 이는 V, D 및 J 유전자 분절의 코딩 서열에 인접한 재조합 신호 서열(RSS)을 인식하는 효소 RAG-1 및 RAG-2를 사용하여 상이한 V(D)J 배열에서 재조합될 수 있다. RSS는 12 또는 23 bp의 스페이서에 의해 분리된 보존된 7합체 및 9합체로 이루어진다. RSS은 각각의 V 분절의 3' 측면에서, 각각의 D 분절의 5' 측면과 3' 측면 둘 다에서 그리고 각각의 J 분절의 5'에서 발견된다. 재조합 동안, RAG-1 및 RAG-2는 조인트(코딩 조인트)의 코딩 말단에서의 DNA 헤어핀의 형성 및 RSS 및 이들 사이의 중재 서열(신호 조인트)의 제거를 야기한다. 가변 영역은 코딩 말단 뉴클레오타이드의 가변 수에 의한 결실, 말단 데옥시뉴클레오티딜 전환효소(TdT)에 의한 뉴클레오타이드의 랜덤 첨가, 및 비대칭적으로 절단된 코딩 헤어핀의 주형 매개 충전으로 인해 생긴 회귀성 뉴클레오타이드에 의해 연접부에서 추가로 다양화된다.
특허 출원 WO 2009/129247호(본원에서 그 전체가 참고로 포함됨)는 시험관내 신생 항체를 생성하기 위해 V(D)J 재조합을 사용하는 HuTarg 시스템이라 칭하는 시험관내 시스템을 개시한다. TCR-특이적 V 요소, D 요소 및 J 요소를 사용함으로써 이 동일한 시스템은 특허 출원 WO 2017/091905호(본원에 그 전체가 참고로 포함됨)에서처럼 Vβ 단독 도메인의 가변 영역을 생성하도록 사용되었다. 자연 생체내 시스템에서, CDR1 및 CDR2를 암호화하는 핵산 서열은 V(α, β, γ 또는 δ) 유전자 분절 내에 함유되고, CDR3을 암호화하는 서열은, TdT 및 다른 재조합 및 DNA 보수 효소의 작용으로 인해 V-J 및 V-D-J 재조합 연접부에서 뉴클레오타이드의 랜덤 삽입 및 결실을 갖긴 하지만, (Vα 또는 V γ에 대해서는) V 분절 및 J 분절의 일부 또는 V 분절의 일부, 전체 D 분절 및 (Vβ 또는 Vδ에 대해서는) J 분절의 일부로부터 제조된다. 이로부터 발현된 생성된 T 세포 수용체가 하는 것처럼(즉, FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4), 재조합된 T- 세포 수용체 유전자는 교대 프레임워크(FR) 및 CDR 서열을 포함한다. 시험관내 V(D)J 재조합(즉, V-J 또는 V-D-J 재조합)을 사용하여, 무작위화된 삽입 및 결실은 CDR1, CDR2 및/또는 CDR3(즉, 바로 CDR3이 아님)에서 또는 이에 인접하게 첨가될 수 있고, 추가 삽입은 CDR1, CDR2 및/또는 CDR3 전에 및/또는 후에 재조합 기질에서 플랭킹 서열을 사용하여 첨가될 수 있고, 추가 결실은 CDR1, CDR2 및/또는 CDR3에서 또는 이에 인접하게 재조합 기질에서 서열을 결실시킴으로써 이루어질 수 있다.
일부 실시형태에서, TCR Vβ 사슬의 부재에서 에피토프에 특이적으로 결합하는 TCR Vα 사슬이 확인되었다. TCR Vα 사슬의 부재 하에 에피토프에 결합하는 예시적인 CDR3 아미노산 서열은 하기 표 11에 열거되어 있다.

일부 실시형태에서, Vβ 단독 도메인은 제2 TCR 가변 도메인의 부재 하에 에피토프에 특이적으로 결합하고, FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4 영역에 의해 한정된 가변 도메인을 플랭킹하는 (임의의 길이 또는 서열의) 선택적인 N 말단 및/또는 C 말단 아미노산 서열로 이루어진다. FR1, FR2, FR3 및 FR4는 자연 Vα, Vβ, Vγ 또는 Vδ 도메인으로부터 얻어지거나, 자연 Vα, Vβ, Vγ 또는 Vδ 유전자 분절에 의해 암호화될 수 있지만, 선택적으로 독립적으로 FR1의 C 말단, FR2의 N 말단, FR2의 C 말단, FR3의 N 말단, FR3의 C 말단 및 FR4의 N 말단 중 하나 이상에서 (예를 들어, 0개, 1개, 2개, 3개, 4개, 5개 또는 5개 초과의 아미노산) 아미노산의 결실 또는 삽입을 포함한다. CDR1, CDR2 및 CDR3은 자연 Vα, Vβ, Vγ 또는 Vδ 도메인으로부터 얻어지거나, 자연 Vα, Vβ, Vγ 또는 Vδ 유전자 분절에 의해 암호화될 수 있지만, CDR1, CDR2 및 CDR3 중 하나 이상은 독립적으로 C 말단, N 말단 또는 CDR 서열 내의 어느 곳에서 삽입(예를 들어, 0개, 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 10개 또는 10개 초과의 아미노산) 및/또는 결실(예를 들어, 0개, 1개, 2개, 3개, 4개, 5개 또는 5개 초과의 아미노산)을 함유한다. 일부 실시형태에서, CDR1은 N 말단으로, C 말단으로 또는 내부로 아미노산의 삽입 또는 결실을 함유하고, 자연 CDR 아미노산 잔기의 적어도 50%(또는 선택적으로 60%, 70% 또는 80%)가 보유된다. 일부 실시형태에서, CDR2는 N 말단으로, C 말단으로 또는 내부로 아미노산의 삽입 또는 결실을 함유하고, 자연 CDR 아미노산 잔기의 적어도 50%(또는 선택적으로 60%, 70% 또는 80%)가 보유된다. 일부 실시형태에서, CDR3은 N 말단으로, C 말단으로 또는 내부로 아미노산의 삽입 또는 결실을 함유하고, 자연 CDR 아미노산 잔기의 적어도 50%(또는 선택적으로 60%, 70% 또는 80%)가 보유된다. 삽입 및/또는 결실은 시험관내 V(D)J 재조합 방법의 결과로서 또는 TdT 및 재조합 및 DNA 보수 효소(예를 들어, 아르테미스 뉴클레아제(Artemis nuclease), NDA 의존적 단백질 키나제(DNA-PK: NDA-dependent protein kinase), X선 보수 교차-보완 단백질 4(XRCC4: X-ray repair cross-complementing protein 4), DNA 분해효소 IV, 비상동성 말단 연결 인자 1(NHEJ1: non-homologous end-joining factor 1), PAXX, 및 DNA 중합효소 λ 및 μ 중 하나 이상)의 시험관내 작용으로부터 제조될 수 있다. (치환을 포함하는) 삽입 및/또는 결실은 추가로 시험관내 V(D)J 재조합 기질의 CDR 핵산 서열에 대한 삽입 및/또는 결실로부터 생길 수 있다. Vβ 단독 도메인은 TCR 불변 영역 또는 이의 부분을 추가로 포함할 수 있다. Vβ 단독 도메인은 추가의 단백질 도메인에 융합되고/되거나 이와 복합체화될 수 있다. DNA에서의 이중 가닥 파괴는 상기 재조합 및 DNA 보수 효소의 시험관내 사용 전에 도입될 수 있다. Vβ 단독 도메인은 융합 단백질일 수 있다(또는 이것에 혼입될 수 있다). 본원에 사용된 것과 같이, "융합 단백질"이라는 용어는 이 유전자의 유기체 원천이 동일하거나 상이한지와 무관하게 별개의 유전자로부터의 2개 이상의 코딩 서열의 융합체로 이루어진 적어도 하나의 핵산 코딩 서열에 의해 암호화된 단백질을 의미한다.
일부 실시형태에서, 제1의, 활성인자 LBD는 ScFv 도메인을 포함하고, 제2의, 억제제 LBD는 Vβ 단독 도메인을 포함한다. 일부 실시형태에서, 제1의, 활성인자 LBD는 Vβ 단독 도메인을 포함하고, 제2의, 억제제 LBD는 ScFv 도메인을 포함한다. 일부 실시형태에서, 제1의, 활성인자 LBD 및 제2의, 억제제 LBD 둘 다는 ScFv 도메인이다. 일부 실시형태에서, 제1의, 활성인자 LBD 및 제2의, 억제제 LBD 둘 다는 Vβ 단독 도메인이다.
본 개시내용의 활성인자 및/또는 억제제 수용체와 사용되는 추가 항원 결합 도메인은 하기 표 12에 기재되어 있다. 표 12에서, 작제물의 명칭은 ScFv 억제제 명칭[B]/ScFv 활성인자 명칭[A]으로 기재되어 있다. 일부 실시형태에서, 제1 리간드 결합 도메인 또는 제2 리간드 결합 도메인은 서열 번호 210, 서열 번호212, 서열 번호 214, 서열 번호216, 서열 번호 218, 서열 번호220, 서열 번호 222 또는 서열 번호224 중 어느 하나의 서열, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함한다.


조작된 수용체
본 개시내용은 본원에 기재된 제1 활성인자 리간드 결합 도메인을 포함하는 제1 조작된 수용체 및 제2 억제제 리간드 결합 도메인을 포함하는 제2 조작된 수용체를 제공한다.
키메라 항원 수용체(CAR)
일부 실시형태에서, 제1 조작된 수용체 또는 제2 조작된 수용체 중 어느 하나는 키메라 항원 수용체(CAR)이다. 일부 실시형태에서, 제1 조작된 수용체 및 제2 조작된 수용체는 키메라 항원 수용체이다. 모든 CAR 구성은 본 개시내용의 범위 내로서 고안된다.
세포외 도메인
일부 실시형태에서, 제1 리간드 결합 도메인 또는 제2 리간드 결합 도메인은 CAR의 세포외 도메인에 융합된다.
힌지 영역
일부 실시형태에서, 본 개시내용의 CAR은 세포외 힌지 영역을 포함한다. 힌지 영역의 혼입은 CAR-T 세포로부터의 사이토카인 생성에 영향을 미치고, 생체내 CAR-T 세포의 확장을 개선할 수 있다. 예시적인 힌지는 IgD 및 CD8 도메인, 예를 들어 IgG1로부터 단리되거나 유래될 수 있다.
일부 실시형태에서, 힌지는 CD8α 또는 CD28로부터 단리되거나 유래된다. 일부 실시형태에서, CD8α 힌지는 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나, TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACD(서열 번호 1)의 서열과 동일하다. 일부 실시형태에서, CD8α 힌지는 서열 번호 1을 포함한다. 일부 실시형태에서, CD8α 힌지는 본질적으로 서열 번호 1로 이루어진다. 일부 실시형태에서, CD8α 힌지는 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 뉴클레오타이드 서열에 의해 암호화되거나,
의 서열과 동일하다.
일부 실시형태에서, CD8α 힌지는 서열 번호 2에 의해 암호화된다.
일부 실시형태에서, CD28 힌지는 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나, CTIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKP(서열 번호 3)의 서열과 동일하다. 일부 실시형태에서, CD28 힌지는 서열 번호 3을 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, CD28 힌지는 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 뉴클레오타이드 서열에 의해 암호화되거나,

의 서열과 동일하다.
일부 실시형태에서, CD28 힌지는 서열 번호 4에 의해 암호화된다.
막관통 도메인
본 개시내용의 CAR은 CAR의 세포외 도메인에 융합된 막관통 도메인을 포함하도록 설계될 수 있다. 일부 실시형태에서, CAR에서 도메인 중 하나와 자연적으로 연관된 막관통 도메인이 사용된다. 예를 들어, CD28 공자극 도메인을 포함하는 CAR은 또한 CD28 막관통 도메인을 사용할 수 있다. 일부 경우에, 막관통 도메인은 수용체 복합체의 다른 구성원과의 상호작용을 최소화하도록 동일한 또는 상이한 표면 막 단백질의 막관통 도메인에 대한 이러한 도메인의 결합을 피하도록 아미노산 치환에 의해 선택되거나 변형될 수 있다.
막관통 도메인은 자연 원천 또는 합성 원천 중 어느 하나로부터 유래될 수 있다. 원천이 자연이면, 도메인은 임의의 막 결합된 단백질 또는 막관통 단백질로부터 유래될 수 있다. 막관통 영역은 T 세포 수용체의 알파, 베타 또는 제타 사슬, CD28, CD3 엡실론, CD45, CD4, CD5, CD8, CD9, CD16, CD22, CD33, CD37, CD64, CD80, CD86, CD134, CD137, CD154, 또는 면역글로불린, 예컨대 IgG4로부터 단리되거나 유래될 수 있다(즉, 적어도 이들의 막관통 영역(들)을 포함함). 대안적으로 막관통 도메인은 합성일 수 있고, 이 경우에 이것은 주로 류신 및 발린과 같은 소수성 잔기를 함유할 것이다. 일부 실시형태에서, 페닐알라닌, 트립토판 및 발린의 트리플렛은 합성 막관통 도메인의 각각의 말단에서 발견될 것이다. 선택적으로, 바람직하게는 2개 내지 10개의 아미노산 길이의 짧은 올리고펩타이드 또는 폴리펩타이드 링커는 CAR의 막관통 도메인과 세포질 신호전달 도메인 사이에 연결을 형성할 수 있다. 글리신-세린 더블렛은 특히 적합한 링커를 제공한다.
본 개시내용의 CAR의 일부 실시형태에서, CAR은 CD28 막관통 도메인을 포함한다. 일부 실시형태에서, CD28 막관통 도메인은 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나, FWVLVVVGGVLACYSLLVTVAFIIFWV(서열 번호 5)의 서열과 동일하다. 일부 실시형태에서, CD28 막관통 도메인은 서열 번호 5를 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, CD28 막관통 도메인은 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 뉴클레오타이드 서열에 의해 암호화되거나,
의 서열과 동일하다.
일부 실시형태에서, CD28 막관통 도메인은 서열 번호 6에 의해 암호화된다.
본 개시내용의 CAR의 일부 실시형태에서, CAR은 IL-2R베타 막관통 도메인을 포함한다. 일부 실시형태에서, IL-2R베타 막관통 도메인은 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나, IPWLGHLLVGLSGAFGFIILVYLLI(서열 번호 7)의 서열과 동일하다. 일부 실시형태에서, IL-2R베타 막관통 도메인은 서열 번호 7을 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, IL-2R베타 막관통 도메인은 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 뉴클레오타이드 서열에 의해 암호화되거나,

의 서열과 동일하다.
일부 실시형태에서, IL-2R베타 막관통 도메인은 서열 번호 8에 의해 암호화된다.
세포질 도메인
본 발명의 CAR의 세포질 도메인 또는 달리 세포내 신호전달 도메인은 CAR이 위치한 면역 세포의 정상 효과기 기능 중 적어도 하나의 활성화를 책임진다. "효과기 기능"이라는 용어는 특수 세포 기능을 지칭한다. 조절 T 세포의 효과기 기능은 예를 들어 효과기 T 세포의 유도 또는 증식의 억제 또는 하항조절을 포함한다. 이와 같이, "세포내 신호전달 도메인"이라는 용어는 효과기 기능 신호를 형질도입하고 세포가 특수 기능을 수행하도록 지시하는 단백질의 부분을 지칭한다. 보통 전체 세포내 신호전달 도메인이 사용될 수 있지만, 많은 경우에 전체 도메인을 사용는 것이 필요하지 않다. 세포내 신호전달 도메인의 절두된 부분이 사용되는 정도로, 이러한 절두된 부분은 이것이 효과기 기능 신호를 형질도입하는 한 온전한 사슬 대신에 사용될 수 있다. 일부 경우에, 다수의 세포내 도메인은 본 개시내용의 CAR-T 세포의 원하는 기능을 달성하도록 조합될 수 있다. 세포내 신호전달 도메인이란 용어는 이와 같이 효과기 기능 신호를 형질도입하기에 충분한 하나 이상의 세포내 신호전달 도메인의 임의의 절두된 부분을 포함하도록 의도된다.
본 개시내용의 CAR에 사용하기 위한 세포내 신호전달 도메인의 예는 항원 수용체 관여 후 신호 형질도입을 개시시키도록 협동으로 작용하는 T 세포 수용체(TCR) 및 동시수용체의 세포질 서열뿐만 아니라, 이들 서열의 임의의 유도체 또는 변이체 및 동일한 기능 능력을 갖는 임의의 합성 서열을 포함한다. 따라서, 본 개시내용의 CAR의 세포내 도메인은 적어도 하나의 세포질 활성화 도메인을 포함한다. 일부 실시형태에서, 세포내 활성화 도메인은 CAR T 세포의 효과기 기능을 활성화하는 데 필요한 T 세포 수용체(TCR) 신호전달이 있다는 것을 보장한다. 일부 실시형태에서, 적어도 하나의 세포질 활성화는 CD247 분자(CD3ζ) 활성화 도메인, 자극 살해 면역글로불린-유사 수용체(KIR) KIR2DS2 활성화 도메인, 또는 12 kDa의 DNAX-활성화 단백질(DAP12) 활성화 도메인이다. 일부 실시형태에서, CD3ζ 활성화 도메인은 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나,

의 서열과 동일하다.
일부 실시형태에서, CD3ζ 활성화 도메인은 서열 번호 9를 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, CD3ζ 활성화 도메인은 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 뉴클레오타이드 서열에 의해 암호화되거나,

의 서열과 동일하다.
일부 실시형태에서, CD3ζ 활성화 도메인은 서열 번호 10에 의해 암호화된다.
TCR 단독을 통해 생성된 신호가 대개 T 세포의 완전 활성화에 불충분하고 2차 신호 또는 공자극 신호가 또한 필요하다고 공지되어 있다. 이와 같이, T 세포 활성화는 TCR을 통해 항원 의존적 1차 활성화를 개시시키는 것(1차 세포질 신호전달 서열) 및 2차 신호 또는 공자극 신호를 제공하는 항원 독립적 방식으로 작용하는 것(2차 세포질 신호전달 서열)의 세포질 신호전달 서열의 2개의 구별되는 종류에 의해 매개된다고 말해질 수 있다.
1차 세포질 신호전달 서열은 자극 방식 또는 억제 방식 중 어느 하나로 TCR 복합체의 1차 활성화를 조절한다. 자극 방식으로 작용하는 1차 세포질 신호전달 서열은 면역수용체 티로신계 활성화 모티프 또는 ITAM으로 공지된 신호전달 모티프를 함유할 수 있다. 일부 실시형태에서, ITAM은 임의의 2개의 다른 아미노산 (YxxL)(서열 번호 21)에 의해 류신 또는 이소류신으로부터 분리된 티로신을 함유한다.
일부 실시형태에서, 세포질 도메인은 1개, 2개 또는 3개의 ITAM을 함유한다. 일부 실시형태에서, 세포질 도메인은 1개의 ITAM을 함유한다. 일부 실시형태에서, 세포질 도메인은 2개의 ITAM을 함유한다. 일부 실시형태에서, 세포질 도메인은 3개의 ITAM을 함유한다. 일부 실시형태에서, 세포질 도메인은 4개의 ITAM을 함유한다. 일부 실시형태에서, 세포질 도메인은 5개의 ITAM을 함유한다.
일부 실시형태에서, 세포질 도메인은 CD3ζ 활성화 도메인이다. 일부 실시형태에서, CD3ζ 활성화 도메인은 단일 ITAM을 포함한다. 일부 실시형태에서, CD3ζ 활성화 도메인은 2개의 ITAM을 포함한다. 일부 실시형태에서, CD3ζ 활성화 도메인은 3개의 ITAM을 포함한다.
일부 실시형태에서, 단일 ITAM을 포함하는 CD3ζ 활성화 도메인은 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나, RVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLHMQALPPR(서열 번호 11)의 서열과 동일하다. 일부 실시형태에서, CD3ζ 활성화 도메인은 서열 번호 11을 포함한다. 일부 실시형태에서, 단일 ITAM을 포함하는 CD3ζ 활성화 도메인은 RVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLHMQALPPR(서열 번호 11)의 아미노산 서열을 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, 단일 ITAM을 포함하는 CD3ζ 활성화 도메인은 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 뉴클레오타이드 서열에 의해 암호화되거나,

의 서열과 동일하다.
일부 실시형태에서, CD3ζ 활성화 도메인은 서열 번호 12에 의해 암호화된다.
본 개시내용의 CAR에 사용될 수 있는 1차 세포질 신호전달 서열을 함유하는 ITAM의 추가의 예는 TCRζ, FcRγ, FcRβ, CD3γ, CD3δ, CD3ε, CD3ζ, CD5, CD22, CD79a, CD79b 및 CD66d로부터 유래된 것을 포함한다. 본 발명의 CAR에서의 세포질 신호전달 분자가 CD3ζ로부터 유래된 세포질 신호전달 서열을 포함하는 것이 특히 바람직하다.
공자극 도메인
일부 실시형태에서, CAR의 세포질 도메인은 CD3ζ 신호전달 도메인을 홀로 함유하도록 설계되거나 본 개시내용의 CAR의 맥락에서 유용한 임의의 다른 원하는 세포질 도메인(들)과 조합될 수 있다. 예를 들어, CAR의 세포질 도메인은 CD3ζ 사슬 부분 및 공자극 도메인을 포함할 수 있다. 공자극 도메인은 공자극 분자의 세포내 도메인을 포함하는 CAR의 부분을 지칭한다. 공자극 분자는 항원에 대한 림프구의 효과적인 반응에 필요한 항원 수용체 또는 이의 리간드 이외의 세포 표면 분자이다. 이러한 분자의 예는 IL-2Rβ, Fc 수용체 감마(FcRγ), Fc 수용체 베타(FcRβ), CD3g 분자 감마(CD3γ), CD3δ, CD3ε, CD5 분자(CD5), CD22 분자(CD22), CD79a 분자(CD79a), CD79b 분자(CD79b), 암배아 항원 관련 세포 부착 분자 3(CD66d), CD27 분자(CD27), CD28 분자(CD28), TNF 수용체 슈퍼패밀리 구성원 9(4-1BB), TNF 수용체 슈퍼패밀리 구성원 4(OX40), TNF 수용체 슈퍼패밀리 구성원 8(CD30), CD40 분자(CD40), 예정 세포사1(PD-1), 유도성 T 세포 공자극(ICOS), 림프구 기능 연관 항원-1(LFA-1), CD2 분자(CD2), CD7 분자(CD7), TNF 슈퍼패밀리 구성원 14(LIGHT), 살해 세포 렉틴 유사 수용체 C2(NKG2C) 및 CD276 분자(B7-H3) c-자극 도메인, 또는 이들의 기능적 단편으로 이루어진 군으로부터 선택된 공자극 도메인을 포함한다.
본 개시내용의 CAR의 세포질 신호전달 부분 내의 세포질 도메인은 랜덤 순서로 또는 규정된 순서로 서로에 연결될 수 있다. 선택적으로, 예를 들어 2개 내지 10개의 아미노산 길이의 짧은 올리고펩타이드 또는 폴리펩타이드 링커는 연결을 형성할 수 있다. 글리신-세린 더블렛은 적합한 링커의 예를 제공한다.
일부 실시형태에서, 본 개시내용의 CAR의 세포내 도메인은 적어도 하나의 공자극 도메인을 포함한다. 일부 실시형태에서, 공자극 도메인은 CD28로부터 단리되거나 유래된다. 일부 실시형태에서, CD28 공자극 도메인은 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나,
의 서열과 동일하다.
일부 실시형태에서, CD28 공자극 도메인은 서열 번호 13을 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, CD28 공자극 도메인은 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 뉴클레오타이드 서열에 의해 암호화되거나,
의 서열과 동일하다.
일부 실시형태에서, CD28 공자극 도메인은 서열 번호 14에 의해 암호화된다.
일부 실시형태에서, 본 개시내용의 CAR의 세포내 도메인은 인터류킨-2 수용체 베타-사슬(IL-2R베타 또는 IL-2R-베타) 세포질 도메인을 포함한다. 일부 실시형태에서, IL-2R베타 도메인은 절두된다. 일부 실시형태에서, IL-2R베타 세포질 도메인은 하나 이상의 STAT5-동원 모티프를 포함한다. 일부 실시형태에서, CAR은 IL-2R베타 세포질 도메인 밖의 하나 이상의 STAT5-동원 모티프를 포함한다.
일부 실시형태에서, IL-2-R베타 세포내 도메인은 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나,
의 서열과 동일하다.
일부 실시형태에서, IL2R-베타 세포내 도메인은 서열 번호 15를 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, IL-2R-베타 세포내 도메인은 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 뉴클레오타이드 서열에 의해 암호화되거나,

의 서열과 동일하다.
일부 실시형태에서, IL-2R-베타 세포내 도메인은 서열 번호 16에 의해 암호화된다.
일 실시형태에서, IL-2R-베타 세포질 도메인은 하나 이상의 STAT5-동원 모티프를 포함한다. 예시적인 STAT5-동원 모티프는 Passerini 등의 문헌(2008) STAT5-signaling cytokines regulate the expression of FOXP3 in CD4+CD25+ regulatory T cells and CD4+CD25+ effector T cells. International Immunology, Vol. 20, No. 3, pp. 421-431, 및 Kagoya 등의 문헌(2018) A novel chimeric antigen receptor containing a JAK-STAT signaling domain mediates superior antitumor effects. Nature Medicine doi:10.1038/nm.4478에 의해 제공된다.
일부 실시형태에서, STAT5-동원 모티프(들)는 서열 Tyr-Leu-Ser-Leu(서열 번호 17)로 이루어진다.
억제 도메인
일부 실시형태에서, 예를 들어 억제 신호를 제공하는 본 개시내용의 제2 조작된 수용체에서, 억제 신호는 수용체의 세포내 도메인을 통해 전단된다. 일부 실시형태에서, 조작된 수용체는 억제 세포내 도메인을 포함한다. 일부 실시형태에서, 제2 조작된 수용체는 억제 세포내 도메인을 포함하는 CAR(억제 CAR)이다.
일부 실시형태에서, 억제 세포내 도메인은 면역수용체 티로신계 억제 모티프(ITIM)를 포함한다. 일부 실시형태에서, ITIM을 포함하는 억제 세포내 도메인은 CTLA-4 및 PD-1과 같은 면역 관문 억제제로부터 단리되거나 유래될 수 있다. CTLA-4 및 PD-1은 T 세포의 표면에서 발현된 면역 억제 수용체이고, T 세포 반응을 약화시키거나 종료시키는 데 중추적 역할을 한다.
억제 도메인은 인간 종양 괴사 인자 관련 아폽토시스 유도 리간드(TRAIL: human tumor necrosis factor related apoptosis inducing ligand) 수용체 및 CD200 수용체 1로부터 단리될 수 있다.
일부 실시형태에서, 억제 도메인은 세포내 도메인, 막관통 또는 이들의 조합을 포함한다. 일부 실시형태에서, 억제 도메인은 세포내 도메인, 막관통 도메인, 힌지 영역 또는 이들의 조합을 포함한다. 일부 실시형태에서, 억제 도메인은 면역수용체 티로신계 억제 모티프(ITIM)를 포함한다. 일부 실시형태에서, ITIM을 포함하는 억제 도메인은 CTLA-4 및 PD-1과 같은 면역 관문 억제제로부터 단리되거나 유래될 수 있다.
억제 도메인은 인간 종양 괴사 인자 관련 아폽토시스 유도 리간드(TRAIL) 수용체 및 CD200 수용체 1로부터 단리될 수 있다. 일부 실시형태에서, 억제 도메인은 인간 단백질, 예를 들어 인간 TRAIL 수용체, CTLA-4 또는 PD-1 단백질로부터 단리되거나 유래된다. 일부 실시형태에서, TRAIL 수용체는 TR10A, TR10B 또는 TR10D를 포함한다.
내인성 TRAIL은 혈장 막에 앵커링되고 세포 표면에 제시된 281-아미노산 II형 막관통 단백질로서 발현된다. TRAIL은 자연 살해 세포에 의해 발현되고, 이는 세포-세포 접촉의 확립 후, 표적 세포에서 TRAIL 의존적 아폽토시스를 유도할 수 있다. 생리학적으로, TRAIL 신호전달 시스템은 면역 감시에, T-헬퍼 세포 2에 대한 T-헬퍼 세포 1의 조절뿐만 아니라 "무헬프" CD8+ T 세포 수를 통해 면역계를 형성하기 위해 그리고 자발적인 종양 형성의 억제에 필수적인 것으로 나타났다.
일부 실시형태에서, 억제 도메인은 CD200 수용체로부터 단리되거나 유래된 세포내 도메인을 포함한다. 세포 표면 당단백질 CD200 수용체 1(Uniprot 참조번호: Q8TD46)은 본 발명의 억제 세포내 도메인의 다른 예를 나타낸다. CD200/OX2 세포 표면 당단백질에 대한 이 억제 수용체는 선택된 자극에 반응하여 TNF-알파, 인터페론 및 유도성 산화질소 합성효소(iNOS: inducible nitric oxide synthase)를 포함하는 전염증성 분자의 발현을 억제함으로써 염증을 제한한다.
일부 실시형태에서, 조작된 수용체는 살해 세포 면역글로불린 유사 수용체, 3개의 Ig 도메인 및 긴 세포질 꼬리 2(KIR3DL2), 살해 세포 면역글로불린 유사 수용체, 3개의 Ig 도메인 및 긴 세포질 꼬리 3(KIR3DL3), 백혈구 면역글로불린 유사 수용체 B1(LIR1, LIR-1 및 LILRB1이라고도 칭함), 예정 세포사 1(PD-1), Fc 감마 수용체 IIB(FcgRIIB), 살해 세포 렉틴 유사 수용체 K1(NKG2D), 합성 일치 ITIM을 함유하는 CTLA-4, 도메인, ZAP70 SH2 도메인(예를 들어, N 말단 및 C 말단 SH2 도메인의 하나 또는 둘 다) 또는 ZAP70 KI_K369A(키나제 불활성 ZAP70)로부터 단리되거나 유래된 억제 도메인을 포함한다.
일부 실시형태에서, 억제 도메인은 인간 단백질로부터 단리되거나 유래된다.
일부 실시형태에서, 제2의, 억제 수용체는 동일한 단백질, 예를 들어 ITIM 함유 단백질로부터 단리되거나 유래된 세포질 도메인 및 막관통 도메인을 포함한다. 일부 실시형태에서, 제2의, 억제 수용체는 동일한 단백질, 예를 들어 ITIM 함유 단백질로부터 단리되거나 유래된 단리되거나 유래된 세포질 도메인, 막관통 도메인 및 세포외 도메인 또는 이의 일부를 포함한다. 일부 실시형태에서, 제2의, 억제 수용체는 세포내 도메인 및/또는 막관통 도메인과 동일한 단백질, 예를 들어 ITIM 함유 단백질로부터 단리되거나 유래된 단리되거나 유래된 힌지 영역을 포함한다.
일부 실시형태에서, 제2의, 억제 조작된 수용체는 억제 도메인을 포함한다. 일부 실시형태에서, 제2의, 억제 조작된 수용체는 억제 세포내 도메인 및/또는 억제 막관통 도메인을 포함한다. 일부 실시형태에서, 제2 조작된 수용체는 억제 도메인을 포함하는 CAR(억제 CAR)이다. 일부 실시형태에서, 억제 세포내 도메인은 CAR의 세포내 도메인에 융합된다. 일부 실시형태에서, 억제 세포내 도메인은 CAR의 막관통 도메인에 융합된다.
T 세포 수용체(TCR)
일부 실시형태에서, 제1 조작된 수용체 또는 제2 조작된 수용체는 T 세포 수용체(TCR)이다. 일부 실시형태에서, 제1 조작된 수용체 및 제2 조작된 수용체는 T 세포 수용체(TCR)이다.
본원에 사용된 것과 같이, 때때로 "TCR 복합체" 또는 "TCR/CD3 복합체"라고도 칭하는 "TCR"은 때때로 아단위라 칭하는 TCR 알파 사슬, TCR 베타 사슬 및 비변이체 CD3 사슬(제타, 감마, 델타 및 엡실론)의 하나 이상을 포함하는 단백질 복합체라 칭한다. TCR 알파 및 베타 사슬은 펩타이드-MHC 복합체에 결합하는 이종이합체로서 작용하도록 디설파이드 연결될 수 있다. TCR 알파/베타 이종이합체가 펩타이드-MHC를 관여시키면, 연관된 비변이체 CD3 아단위에서의 TCR 복합체의 구성적 변화가 유도되는데, 이는 이의 인산화 및 하류 단백질과의 연관으로 이어져서 1차 자극 신호를 전달한다. 예시적인 TCR 복합체에서, TCR 알파 및 TCR 베타 폴리펩타이드는 이종이합체를 형성하고, CD3 엡실론 및 CD3 델타는 이종이합체를 형성하고, CD3 엡실론 및 CD3 감마는 이종이합체를 형성하고, 2개의 CD3 제타는 동종이합체를 형성한다.
세포외 도메인
본 개시내용은 제1 세포외 리간드 결합 도메인을 포함하는 제1 조작된 수용체 및 제2 세포외 리간드 결합 도메인을 포함하는 제2 조작된 수용체를 제공한다. 제1 조작된 수용체, 제2 조작된 수용체 중 어느 하나, 또는 둘 다는 TCR일 수 있다. 임의의 적합한 리간드 결합 도메인은 본원에 기재된 조작된 TCR의 세포외 도메인, 힌지 도메인 또는 막관통에 융합될 수 있다.
일부 실시형태에서, 제1 리간드 결합 도메인 및/또는 제2 리간드 결합 도메인은 TCR 아단위의 세포외 도메인에 융합된다. TCR 아단위는 TCR 알파, TCR 베타, CD3 델타, CD3 엡실론 또는 CD3 감마일 수 있다. 일부 실시형태에서, 제1 리간드 결합 도메인 및 제2 리간드 결합 도메인 둘 다는 상이한 TCR 수용체에서 동일한 TCR 아단위에 융합된다. 일부 실시형태에서, 제1 리간드 결합 도메인 및 제2 리간드 결합 도메인은 상이한 TCR 수용체에서 상이한 TCR 아단위에 융합된다. 일부 실시형태에서, 제1의, 활성인자 리간드 결합 도메인은 제1 조작된 수용체에서 제1 TCR 아단위에 융합되고, 제2의, 억제제 리간드 결합 도메인은 제2 조작된 수용체에서 제2 TCR 아단위에 융합된다. 일부 실시형태에서, 제1 TCR 아단위 및 제2 TCR 아단위는 동일한 아단위가 아니다. 일부 실시형태에서, 제1 TCR 아단위 및 제2 TCR 아단위는 동일한 아단위이다. 예를 들어, 제1 리간드 결합 도메인은 TCR 알파에 융합될 수 있고, 제2 리간드 결합 도메인은 TCR 베타에 융합될 수 있다. 추가의 예로서, 제1 리간드 결합은 TCR 베타에 융합되고, 제2 리간드 결합 도메인은 TCR 알파에 융합되도록 사용된다.
일부 실시형태에서, 제1의, 활성인자 LBD는 ScFv 도메인을 포함하고, 제2의, 억제제 LBD는 Vβ 단독 도메인을 포함한다. 일부 실시형태에서, 제1의, 활성인자 LBD는 Vβ 단독 도메인을 포함하고, 제2의, 억제제 LBD는 ScFv 도메인을 포함한다. 일부 실시형태에서, 제1의, 활성인자 LBD 및 제2의, 억제제 LBD 둘 다는 ScFv 도메인이다. 일부 실시형태에서, 제1의, 활성인자 LBD 및 제2의, 억제제 LBD 둘 다는 Vβ 단독 도메인이다.
일부 실시형태에서, 본 개시내용의 제1 조작된 TCR은 Vβ 단독 도메인을 포함하는 세포외 도메인, 막관통 도메인 및 세포내 도메인을 포함하다. 일부 실시형태에서, 세포내 도메인은 하나 이상의 외인성 도메인을 포함한다.
일부 실시형태에서, 본 개시내용의 제1 조작된 TCR은 ScFv 도메인을 포함하는 세포외 도메인, 막관통 도메인 및 세포내 도메인을 포함하다. 일부 실시형태에서, 세포내 도메인은 하나 이상의 외인성 도메인을 포함한다.
일부 실시형태에서, 본 개시내용의 제2 조작된 TCR은 Vβ 단독 도메인을 포함하는 세포외 도메인, 막관통 도메인 및 억제 세포내 도메인을 포함하다.
일부 실시형태에서, 본 개시내용의 제2 조작된 TCR은 ScFv 도메인을 포함하는 세포외 도메인, 막관통 도메인 및 억제 세포내 도메인을 포함하다.
TCR 아단위는 TCR 알파, TCR 베타, CD3 제타, CD3 델타, CD3 감마 및 CD3 엡실론을 포함한다. TCR 알파, TCR 베타 사슬, CD3 감마, CD3 델타 또는 CD3 엡실론, 또는 이들의 단편 또는 유도체의 임의의 하나 이상은 본 개시내용의 자극 신호를 제공하여서 TCR 기능 및 활성을 향상시킬 수 있는 하나 이상의 도메인에 융합될 수 있다. TCR 알파, TCR 베타 사슬, CD3 감마, CD3 델타 또는 CD3 엡실론, 또는 이들의 단편 또는 유도체의 임의의 하나 이상은 본 개시내용의 억제 세포내 도메인에 융합될 수 있다.
일부 실시형태에서, 예를 들어 제1 조작된 수용체 또는 제2 조작된 수용체가 제1 폴리펩타이드 및 제2 폴리펩타이드를 포함하는 실시형태에서, 항원 결합 도메인은 T 세포 수용체(TCR) 세포외 도메인 또는 항체로부터 단리되거나 유래된다.
일부 실시형태에서, 제1 조작된 수용체 및 제2 조작된 수용체는 제1 항원 결합 도메인 및 제2 항원 결합 도메인을 포함한다. 항원 결합 도메인 또는 조작된 수용체의 도메인은 세포내 도메인과 동일한 또는 상이한 폴리펩타이드에 제공될 수 있다.
일부 실시형태에서, 제1 조작된 수용체 및/또는 제2 조작된 수용체의 항원 결합 도메인은 단일 사슬 가변 단편(scFv)을 포함한다.
일부 실시형태에서, 제1 조작된 수용체 및/또는 제2 조작된 수용체는 제2 폴리펩타이드를 포함한다. 본 개시내용은 각각 리간드 결합 도메인의 일부(예를 들어, 이종이합체성 LDB의 동족, 예컨대 TCRα/β 기반 LBD 또는 Fab 기반 LBD)를 갖는 2개의 폴리펩타이드를 갖는 수용체를 제공한다. 본 개시내용은 각각 리간드 결합 도메인의 일부(예를 들어, 이종이합체성 LDB의 동족, 예컨대 TCRα/β 기반 LBD 또는 Fab 기반 LBD)를 갖는 2개의 폴리펩타이드를 갖는 수용체를 추가로 제공하고, 리간드 결합 도메인의 하나의 일부는 힌지 또는 막관통 도메인에 융합되지만, 리간드 결합 도메인의 다른 일부는 세포내 도메인을 갖지 않는다. 추가의 변이는 각각의 폴리펩타이드가 힌지 도메인을 갖는 수용체, 그리고 각각의 폴리펩타이드가 힌지 및 막관통 도메인을 갖는 수용체를 포함한다. 일부 실시형태에서, 힌지 도메인은 부재한다. 다른 실시형태에서, 힌지 도메인은 막 근위 세포외 영역(MPER: membrane proximal extracellular region), 예컨대 LILRB1 D3D4 도메인이다.
일부 실시형태에서, 예를 들어 제1 조작된 수용체 및/또는 제2 조작된 수용체가 적어도 2개의 폴리펩타이드를 포함하는 실시형태에서, 제1 폴리펩타이드는 항체의 제1 사슬을 포함하고, 제2 폴리펩타이드는 상기 항체의 제2 사슬을 포함한다.
일부 실시형태에서, 수용체는 항체의 Fab 단편을 포함한다. 실시형태에서, 제1 폴리펩타이드는 항체의 중쇄의 항원 결합 단편 및 세포내 도메인을 포함하고, 제2 폴리펩타이드는 항체의 경쇄의 항원 결합 단편을 포함한다. 일부 실시형태에서, 제1 폴리펩타이드는 항체의 경쇄의 항원 결합 단편 및 세포내 도메인을 포함하고, 제2 폴리펩타이드는 항체의 중쇄의 항원 결합 단편을 포함한다.
일부 실시형태에서, 제1 조작된 수용체 및/또는 제2 조작된 수용체는 T 세포 수용체(TCR)의 세포외 단편을 포함한다. 일부 실시형태에서, 제1 폴리펩타이드는 TCR의 알파 사슬의 항원 결합 단편 및 세포내 도메인을 포함하고, 제2 폴리펩타이드는 TCR의 베타 사슬의 항원 결합 단편을 포함한다. 일부 실시형태에서, 제1 폴리펩타이드는 TCR의 베타 사슬의 항원 결합 단편 및 세포내 도메인을 포함하고, 제2 폴리펩타이드는 TCR의 알파 사슬의 항원 결합 단편을 포함한다.
Vβ 단독 도메인을 포함하는 TCR
본 개시내용의 소정의 실시형태는 TCR 가변 도메인을 포함하는 조작된 TCR에 관한 것이고, TCR 가변 도메인은 제2 TCR 가변 도메인(Vβ 단독 도메인)의 부재 하에 항원에 특이적으로 결합한다.
일부 실시형태에서, 조작된 TCR은 추가 아미노산 서열, 추가 단백질 도메인(TCR 가변 도메인과 공유 회합된, 비공유 회합된 또는 공유로 회합되고 비공유로 회합된), TCR 가변 도메인과 다른 유형의 거대분자(예를 들어, 폴리뉴클레오타이드, 폴리사카라이드, 지질, 또는 이들의 조합)의 융합 또는 비공유 회합, TCR 가변 도메인과 하나 이상의 소분자, 화합물 또는 리간드의 융합 또는 비공유 회합, 또는 이들의 조합을 포함하는 TCR 가변 도메인 이외의 추가 요소를 포함할 수 있다. 기재된 것과 같은 임의의 추가 요소는 조합될 수 있고, 단 TCR 가변 도메인은 제2 TCR 가변 도메인의 부재 하에 에피토프에 특이적으로 결합하도록 구성될 수 있다.
본원에 기재된 것과 같은 Vβ 단독 도메인을 포함하는 조작된 TCR은 단일 TCR 사슬(예를 들어, α, β, γ 또는 δ 사슬)을 포함할 수 있거나, 이것은 (예를 들어, α, β, γ 또는 δ 사슬의) 단일 TCR 가변 도메인을 포함할 수 있다. 조작된 TCR이 단일 TCR 사슬이면, TCR 사슬은 막관통 도메인, 불변(또는 C 도메인) 및 가변(또는 V 도메인)을 포함하고, 제2 TCR 가변 도메인을 포함하지 않는다. 조작된 TCR은 따라서 TCR α 사슬, TCR β 사슬, TCR γ 사슬 또는 TCR δ 사슬을 포함하거나 이들로 이루어질 수 있다. 조작된 TCR은 막 결합된 단백질일 수 있다. 조작된 TCR은 대안적으로 막 회합된 단백질일 수 있다.
일부 실시형태에서, 본원에 기재된 것과 같은 조작된 TCR은 6개의 CD3 아단위와 복합체화된 활성화-유능 TCR을 형성하는 Vα 분절이 결여된 대리 α 사슬을 사용한다.
다른 실시형태에서, 본원에 기재된 것과 같은 조작된 TCR은 Vα 분절이 결여된 대리 α 사슬과 독립적으로 기능한다. 예를 들어, 일부 실시형태에서 하나 이상의 조작된 TCR은 항원에 반응하여 T 세포를 활성화할 수 있는 막관통(예를 들어, CD3ζ 및 CD28) 및 세포내 도메인 단백질(예를 들어, CD3ζ, CD28, 및/또는 4-1BB)에 융합된다.
일부 실시형태에서, 조작된 TCR은 본원에 기재된 Vβ 단독 도메인에 융합된 하나 이상의 단일 TCR 사슬을 포함한다. 예를 들어, 조작된 TCR은 하나 이상의 Vβ 단독 도메인에 융합된 단일 α TCR 사슬, 단일 β TCR 사슬, 단일 γ TCR 사슬 또는 단일 δ TCR 사슬을 포함하거나 본질적으로 이들로 이루어질 수 있다.
일부 실시형태에서, 조작된 TCR은 상보성 결정 영역(CDR)을 사용하여 항원을 관여시킨다. 각각의 조작된 TCR은 3개의 보체 결정 영역(CDR1, CDR2 및 CDR3)을 함유한다.
제1 및/또는 제2 리간드 결합 Vβ 단독 도메인은 인간 TCR 가변 도메인일 수 있다. 대안적으로, 제1 및/또는 제2 Vβ 단독 도메인은 비인간 TCR 가변 도메인일 수 있다. 제1 및/또는 제2 Vβ 단독 도메인은 포유류 TCR 가변 도메인일 수 있다. 제1 및/또는 제2 Vβ 단독 도메인은 척추동물 TCR 가변 도메인일 수 있다.
실시형태에서, Vβ 단독 도메인은 융합 단백질, 예를 들어 TCR 아단위, 및 선택적으로, 추가 자극 세포내 도메인을 포함하는 융합 단백질로 혼입된다. 융합 단백질은 Vβ 단독 도메인 및 임의의 다른 단백질 도메인 또는 도메인들을 포함할 수 있다.
막관통 도메인
본 개시내용은 제1의, 활성인자 LBD를 포함하는 제1 융합 단백질 및 제2의, 억제제 LBD 및 억제제 세포내 도메인을 포함하는 제2 융합 단백질을 제공한다. 일부 실시형태에서, 제1 융합 단백질 및 제2 융합 단백질은 막관통 도메인을 포함한다.
본 개시내용은 막관통 도메인, 및 자극 신호 또는 억제 신호를 제공할 수 있는 세포내 도메인을 포함하는 폴리펩타이드를 제공한다. 일부 실시형태에서, 조작된 TCR은 자극 신호를 제공할 수 있는 다수의 세포내 도메인을 포함한다.
본원에 사용된 것과 같이, "막관통 도메인"은 세포의 막에 걸친 단백질의 도메인을 지칭한다. 막관통 도메인은 통상적으로 주로 비극성 아미노산으로 이루어지고, 1회 또는 수회 지질 이중층을 횡단할 수 있다. 막관통 도메인은 보통 내부 수소 결합을 최대화하는 구성인 알파 나선을 포함한다.
임의의 원천으로부터 단리되거나 유래된 막관통 도메인은 본 개시내용의 융합 단백질의 범위 내로서 고안된다.
일부 실시형태에서, 막관통 도메인은 융합 단백질의 다른 도메인의 하나와 연관되거나, 융합 단백질의 다른 도메인 중 하나와 동일한 단백질로부터 단리되거나 유래된 것이다. 일부 실시형태에서, 막관통 도메인 및 제2 세포내 도메인은 동일한 단백질, 예를 들어 TCR 복합체 아단위, 예컨대 TCR 알파, TCR 베타, CD3 델타, CD3 엡실론 또는 CD3 감마 유래이다. 일부 실시형태에서, 세포외 도메인(svd-TCR), 막관통 도메인 및 제2 세포내 도메인은 동일한 단백질, 예를 들어 TCR 복합체 아단위, 예컨대 TCR 알파, TCR 베타, CD3 델타, CD3 엡실론 또는 CD3 감마 유래이다. 다른 실시형태에서, 세포외 도메인(하나 이상의 리간드 결합 도메인, 예컨대 Vβ 단독 도메인 및 ScFv 도메인을 포함), 막관통 도메인 및 세포내 도메인(들)은 상이한 단백질 유래이다. 예를 들어, 일부 실시형태에서 조작된 svd-TCR은 CD28 막관통 도메인을 CD28, 4-1BB 및 CD3ζ 세포내 도메인과 함께 포함한다.
막관통 도메인은 자연 또는 재조합 원천 중 어느 하나로부터 유래될 수 있다. 원천이 자연이면, 도메인은 임의의 막 결합된 단백질 또는 막관통 단백질로부터 유래될 수 있다.
일부 실시형태에서, 막관통 도메인은 TCR 복합체가 표적에 결합될 때마다 세포내 도메인(들)에 신호전달을 할 수 있다. 본 발명에서 특별히 사용되는 막관통 도메인은 예를 들어 TCR의 알파, 베타 또는 제타 사슬, CD3 델타, CD3 엡실론 또는 CD3 감마, CD28, CD3 엡실론, CD45, CD4, CD5, CD8, CD9, CD16, CD22, CD33, CD37, CD64, CD80, CD86, CD134, CD137, CD154의 막관통 영역(들)을 적어도 포함할 수 있다.
일부 실시형태에서, 막관통 도메인은 힌지, 예를 들어 인간 단백질로부터의 힌지를 통해 융합 단백질의 세포외 영역, 예를 들어 TCR 알파 또는 베타 사슬의 항원 결합 도메인에 부착될 수 있다. 예를 들어, 일 실시형태에서, 힌지는 인간 면역글로불린 (Ig) 힌지, 예를 들어 IgG4 힌지 또는 CD8a 힌지일 수 있다.
일부 실시형태에서, 힌지는 CD8α 또는 CD28로부터 단리되거나 유래된다. 일부 실시형태에서, CD8α 힌지는 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나, TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACD(서열 번호 1)의 서열과 동일하다. 일부 실시형태에서, CD8α 힌지는 서열 번호 1을 포함한다. 일부 실시형태에서, CD8α 힌지는 본질적으로 서열 번호 1로 이루어진다. 일부 실시형태에서, CD8α 힌지는 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 뉴클레오타이드 서열에 의해 암호화되거나,
일부 실시형태에서, CD8α 힌지는 서열 번호 2에 의해 암호화된다.
일부 실시형태에서, CD28 힌지는 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나, CTIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKP(서열 번호 3)의 서열과 동일하다. 일부 실시형태에서, CD28 힌지는 서열 번호 3을 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, CD28 힌지는 적어도 80%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 99%의 동일성을 갖는 뉴클레오타이드 서열에 의해 암호화되거나,
의 서열과 동일하다.
일부 실시형태에서, CD28 힌지는 서열 번호 4에 의해 암호화된다.
일부 실시형태에서, 막관통 도메인은 TCR 알파 막관통 도메인을 포함한다. 일부 실시형태에서, TCR 알파 막관통 도메인은 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 96%의 동일성, 적어도 97%의 동일성, 적어도 98%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나, VIGFRILLLKVAGFNLLMTLRLW(서열 번호 26)의 서열과 동일하다. 일부 실시형태에서, TCR 알파 막관통 도메인은 서열 번호 26을 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, TCR 알파 막관통 도메인은
의 서열에 의해 암호화된다.
일부 실시형태에서, 막관통 도메인은 TCR 베타 막관통 도메인을 포함한다. 일부 실시형태에서, TCR 베타 막관통 도메인은 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 96%의 동일성, 적어도 97%의 동일성, 적어도 98%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나, TILYEILLGKATLYAVLVSALVL(서열 번호 28)의 서열과 동일하다. 일부 실시형태에서, TCR 베타 막관통 도메인은 서열 번호 28을 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, TCR 베타 막관통 도메인은
의 서열에 의해 암호화된다.
일부 실시형태에서, 막관통은 CD3 제타 막관통 도메인을 포함한다. 일부 실시형태에서, CD3 제타 막관통 도메인은 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 96%의 동일성, 적어도 97%의 동일성, 적어도 98%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나, LCYLLDGILFIYGVILTALFL(서열 번호 29)의 서열과 동일하다. 일부 실시형태에서, CD3 제타 막관통 도메인은 서열 번호 29를 포함하거나 이것으로 본질적으로 이루어진다.
막관통 도메인은 막관통 영역에 인접한 하나 이상의 추가 아미노산, 예를 들어 막관통이 유래된 단백질의 세포외 영역과 연관된 하나 이상의 아미노산(예를 들어, 세포외 영역의 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 10개 또는 15개 이하의 아미노산) 및/또는 막관통 단백질이 유래된 단백질의 세포내 영역과 연관된 하나 이상의 추가 아미노산(예를 들어, 세포내 영역의 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 10개 또는 15개 이하의 아미노산)을 포함할 수 있다.
일부 실시형태에서, 막관통 도메인은 예를 들어 수용체 복합체의 다른 구성원과의 상호작용을 최소화하도록 동일한 또는 상이한 표면 막 단백질의 막관통 도메인에 대한 이러한 도메인의 결합을 피하도록 아미노산 치환에 의해 선택되거나 변형될 수 있다.
막관통 도메인은 존재할 때 자연 TCR 막관통 도메인, 이종성 막 단백질로부터의 자연 막관통 도메인, 또는 인공 막관통 도메인일 수 있다. 막관통 도메인은 막 앵커 도메인일 수 있다. 제한 없이, 자연 또는 인공 막관통 도메인은 대개 막관통 분절을 플랭킹하는 양전하를 갖는 약 20개의 아미노산의 소수성 a-나선을 포함할 수 있다. 막관통 도메인은 1개의 막관통 분절 또는 1개 초과의 막관통 분절을 가질 수 있다. 공공으로 이용 가능한 예측 도구를 사용하여 막관통 도메인/분절의 예측이 이루어질 수 있다(예를 들어, TMHMM, Krogh 등 Journal of Molecular Biology 2001 ; 305(3):567-580; 또는 TMpred, Hofmann & Stoffel Biol. Chem. Hoppe-Seyler 1993; 347: 166). 막 앵커 시스템의 비제한적인 예는 혈소판 유래 성장 인자 수용체(PDGFR) 막관통 도메인, 글리코실포스파티딜이노시톨(GPI) 앵커(신호 서열에 번역후 첨가됨) 및 기타를 포함한다.
세포내 도메인
본 개시내용은 세포내 도메인을 포함하는 융합 단백질을 제공한다. "세포내 도메인"은, 그 용어가 본원에 사용되면서, 단백질의 세포내 부분을 지칭한다.
일부 실시형태에서, 세포내 도메인은 막관통 도메인에 자극 신호를 제공할 수 있는 하나 이상의 도메인을 포함한다. 일부 실시형태에서, 세포내 도메인은 자극 신호를 제공할 수 있는 제1 세포내 도메인 및 자극 신호를 제공할 수 있는 제2 세포내 도메인을 포함한다. 다른 실시형태에서, 세포내 도메인은 자극 신호를 제공할 수 있는 제1 세포내 도메인, 제2 세포내 도메인 및 제3 세포내 도메인을 포함한다. 자극 신호를 제공할 수 있는 세포내 도메인은 CD28 분자(CD28) 도메인, LCK 프로토-종양유전자, Src 패밀리 티로신 키나제(Lck) 도메인, TNF 수용체 슈퍼패밀리 구성원 9(4-1BB) 도메인, TNF 수용체 슈퍼패밀리 구성원 18(GITR) 도메인, CD4 분자 (CD4) 도메인, CD8a 분자(CD8a) 도메인, FYN 프로토-종양유전자, Src 패밀리 티로신 키나제(Fyn) 도메인, T 세포 수용체 연관된 단백질 키나제 70의 제타 사슬(ZAP70) 도메인, T 세포의 활성화를 위한 링커(LAT) 도메인, 림프구 시토졸 단백질 2(SLP76) 도메인, (TCR) 알파, TCR 베타, CD3 델타, CD3 감마 및 CD3 엡실론 세포내 도메인으로 이루어진 군으로부터 선택된다.
일부 실시형태에서, 세포내 도메인은 적어도 하나의 세포내 신호전달 도메인을 포함한다. 세포내 신호전달 도메인은 세포의 기능, 예를 들어 TCR 함유 세포, 예를 들어 TCR 발현 T 세포의 면역 효과기 기능을 촉진하는 신호를 생성한다. 일부 실시형태에서, 본 개시내용의 융합 단백질의 세포내 도메인은 적어도 하나의 세포내 신호전달 도메인을 포함한다. 예를 들어, CD3 감마, 델타 또는 엡실론의 세포내 도메인은 신호전달 도메인을 포함한다.
일부 실시형태에서, 세포외 도메인, 막관통 도메인 및 세포내 도메인은 동일한 단백질, 예를 들어 T 세포 수용체(TCR) 알파, TCR 베타, CD3 델타, CD3 감마 또는 CD3 엡실론으로부터 단리되거나 유래된다.
본 개시내용의 융합 단백질에 사용하기 위한 세포내 도메인의 예는 TCR 알파, TCR 베타, CD3 제타 및 4-1BB, 및 항원 수용체 관여 후 신호 형질도입을 개시시키도록 협동으로 작용하는 세포내 신호전달 동시수용체의 세포질 서열뿐만 아니라, 이들 서열의 임의의 유도체 또는 변이체 및 동일한 기능적 능력을 갖는 임의의 재조합 서열을 포함한다.
일부 실시형태에서, 세포내 신호전달 도메인은 1차 세포내 신호전달 도메인을 포함한다. 예시적인 1차 세포내 신호전달 도메인은 1차 자극 또는 항원 의존적 자극을 담당하는 단백질로부터 유래된 것을 포함한다.
세포내 신호전달 도메인은 일반적으로 융합 단백질이 도입된 면역 세포의 정상 효과기 기능 중 적어도 하나의 활성화를 담당한다. "효과기 기능"이라는 용어는 특수 세포 기능을 지칭한다. T 세포의 효과기 기능은 예를 들어 사이토카인의 분비를 포함하는 세포용해 활성 또는 헬퍼 활성일 수 있다. 이와 같이, "세포내 신호전달 도메인"이라는 용어는 효과기 기능 신호를 전달하고 세포가 특수 기능을 수행하도록 지시하는 단백질의 부분을 지칭한다.
일부 경우에 전체 세포내 신호전달 도메인이 사용될 수 있지만, 많은 경우에 전체 세포내 신호전달 도메인을 사용는 것이 필요하지 않다. 세포내 신호전달 도메인의 절두된 부분이 사용되는 정도로, 이러한 절두된 부분은 이것이 효과기 기능 신호를 전달하는 한 온전한 사슬 대신에 사용될 수 있다. 세포내 신호전달 도메인이란 용어는 이와 같이 효과기 기능 신호를 전달하기에 충분한 세포내 신호전달 도메인의 임의의 절두된 부분을 포함하도록 의도된다.
일부 실시형태에서, 세포내 도메인은 CD3 델타 세포내 도메인을 포함한다. 일부 실시형태에서, CD3 델타 세포내 도메인은 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 96%의 동일성, 적어도 97%의 동일성, 적어도 98%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나,
의 서열과 동일하다.
일부 실시형태에서, CD3 델타 세포내 도메인은 서열 번호 30을 포함하거나 이것로 본질적으로 이루어진다. 일부 실시형태에서, CD3 델타 세포내 도메인은

의 서열에 의해 암호화된다.
일부 실시형태에서, 세포내 도메인은 CD3 엡실론 세포내 도메인을 포함한다. 일부 실시형태에서, CD3 엡실론 세포내 도메인은 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 96%의 동일성, 적어도 97%의 동일성, 적어도 98%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나, KNRKAKAKPVTRGAGAGGRQRGQNKERPPPVPNPDYEPIRKGQRDLYSGLNQRRIGGSRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS(서열 번호 32)의 서열과 동일하다. 일부 실시형태에서, CD3 엡실론 세포내 도메인은 서열 번호 32를 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, CD3 엡실론 세포내 도메인은

의 서열에 의해 암호화된다.
일부 실시형태에서, 세포내 도메인은 CD3 감마 세포내 도메인을 포함한다. 일부 실시형태에서, CD3 감마 세포내 도메인은 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 96%의 동일성, 적어도 97%의 동일성, 적어도 98%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나,
의 서열과 동일하다.
일부 실시형태에서, CD3 감마 세포내 도메인은 서열 번호 33을 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, CD3 감마 세포내 도메인은

의 서열에 의해 암호화된다.
일부 실시형태에서, 세포내 도메인은 CD3 제타 세포내 도메인을 포함한다. 일부 실시형태에서, CD3 제타 세포내 도메인은 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 96%의 동일성, 적어도 97%의 동일성, 적어도 98%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나, RVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR(서열 번호 9)의 서열 또는 이의 하위서열과 동일하다.
일부 실시형태에서, CD3 제타 세포내 도메인은 서열 번호 9를 포함하거나 이것으로 본질적으로 이루어진다.
일부 실시형태에서, 세포내 도메인은 TCR 알파 세포내 도메인을 포함한다. 일부 실시형태에서, TCR 알파 세포내 도메인은 Ser-Ser을 포함한다. 일부 실시형태에서, TCR 알파 세포내 도메인은 TCCAGC의 서열에 의해 암호화된다.
일부 실시형태에서, 세포내 도메인은 TCR 베타 세포내 도메인을 포함한다. 일부 실시형태에서, TCR 베타 세포내 도메인은 적어도 80%의 동일성, 적어도 90%의 동일성을 갖는 아미노산 서열을 포함하거나, MAMVKRKDSR(서열 번호 35)의 서열과 동일하다. 일부 실시형태에서, TCR 베타 세포내 도메인은 서열 번호 35를 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, TCR 베타 세포내 도메인은
의 서열에 의해 암호화된다.
일부 실시형태에서, 세포내 신호전달 도메인은 적어도 하나의 자극 세포내 도메인을 포함한다. 일부 실시형태에서, 세포내 신호전달 도메인은 1차 세포내 신호전달 도메인, 예컨대 CD3 델타, CD3 감마 및 CD3 엡실론 세포내 도메인, 및 1개의 추가 자극 세포내 도메인, 예를 들어 공자극 도메인을 포함한다. 일부 실시형태에서, 세포내 신호전달 도메인은 1차 세포내 신호전달 도메인, 예컨대 CD3 델타, CD3 감마 및 CD3 엡실론 세포내 도메인, 및 2개의 추가 자극 세포내 도메인을 포함한다.
예시적인 공자극 세포내 신호전달 도메인은 공자극 신호 또는 항원 독립적 자극을 담당하는 단백질로부터 유래된 것을 포함한다.
"공자극 분자"라는 용어는 공자극 리간드와 특이적으로 결합하여서 비제한적인 예로서 증식과 같은 T 세포에 의한 공자극 반응을 매개하는 T 세포 상에서의 동족 결합 파트너를 지칭한다. 공자극 분자는 항원 수용체 이외의 세포 표면 분자이다. 공자극 분자 및 이의 리간드는 효과적인 면역 반응에 필요하다. 공자극 분자는 MHC 클래스 I 분자, BTLA, 톨 리간드 수용체(Toll ligand receptor)뿐만 아니라 DAP10, DAP12, CD30, LIGHT, OX40, CD2, CD27, CDS, ICAM-1, LFA-1(CD11a/CD18) 4-1BB(CD137, TNF 수용체 슈퍼패밀리 구성원 9) 및 CD28 분자(CD28)를 포함하지만, 이들로 제한되지는 않는다.
"공자극 세포내 신호전달 도메인"이라 때때로 칭하는 "공자극 도메인"은 공자극 단백질의 세포내 부분일 수 있다. 공자극 도메인은 공자극 신호를 전달하는 공자극 단백질의 도메인일 수 있다. 공자극 단백질은 TNF 수용체 단백질, 면역글로불린 유사 단백질, 사이토카인 수용체, 인테그린, 신호전달 림프구용해 활성화 분자(SLAM 단백질) 및 활성화 NK 세포 수용체의 단백질 패밀리에서 표시될 수 있다. 이러한 분자의 예는 CD27, CD28, 4-1BB(CD137), OX40, GITR, CD30, CD40, ICOS, BAFFR, HVEM, 림프구 기능 연관 항원-1(LFA-1), CD2, CD7, LIGHT, NKG2C, SLAMF7, NKp80, CD160, B7-H3, CD83, CD4 및 기타와 특이적으로 결합하는 리간드를 포함한다. 공자극 도메인은 이것이 유래된 분자의 전체 세포내 부분 또는 전체 자연적 세포내 신호전달 도메인, 또는 이의 기능적 단편을 포함할 수 있다.
일부 실시형태에서, 자극 도메인은 공자극 도메인을 포함한다. 일부 실시형태에서, 공자극 도메인은 CD28 또는 4-1BB 공자극 도메인을 포함한다. CD28 및 4-1BB는 전체 T 세포 활성화에 필요하고 T 세포 효과기 기능을 향상시키는 것으로 공지된 잘 규명된 공자극 분자이다. 예를 들어, CD28 및 4-1BB는 오직 CD3 제타 신호전달 도메인을 함유하는 제1 세대 CAR에 비해 사이토카인 방출, 세포용해 기능 및 지속성을 부스팅하기 위해 키메라 항원 수용체(CAR)에 사용되었다. 마찬가지로, 조작된 TCR에서의 공자극 도메인, 예를 들어 CD28 및 4-1BB 도메인의 포함은 T 세포 효과기 기능을 증가시키고 특이적으로 공자극 리간드의 부재 하에 동시자극이 가능하게 할 수 있고, 이는 통상적으로 종양 세포의 표면에서 하향조절된다.
일부 실시형태에서, 자극 도메인은 CD28 세포내 도메인을 포함한다. 일부 실시형태에서, CD28 세포내 도메인은 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 96%의 동일성, 적어도 97%의 동일성, 적어도 98%의 동일성, 적어도 99%의 동일성의 동일성을 갖는 아미노산 서열을 포함하거나, RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS(서열 번호 37)의 서열과 동일하다. 일부 실시형태에서, CD28 세포내 도메인은 RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS(서열 번호 37)를 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, CD28 세포내 도메인은
를 포함하는 뉴클레오타이드 서열에 의해 암호화된다.
일부 실시형태에서, 자극 도메인은 4-1BB 세포내 도메인을 포함한다. 일부 실시형태에서, 4-1BB 세포내 도메인은 적어도 85%의 동일성, 적어도 90%의 동일성, 적어도 95%의 동일성, 적어도 96%의 동일성, 적어도 97%의 동일성, 적어도 98%의 동일성, 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하거나, KRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL(서열 번호 39)의 서열과 동일하다. 일부 실시형태에서, 4-1BB 세포내 도메인은 KRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL(서열 번호 39)을 포함하거나 이것으로 본질적으로 이루어진다. 일부 실시형태에서, 4-1BB 세포내 도메인은 AAACGGGGCAGAAAGAAACTCCTGTATATATTCAAACAACCATTTATGAGGCCAGTACAAACTACTCAAGAGGAAGATGGCTGTAGCTGCCGATTTCCAGAAGAAGAAGAAGGAGGATGTGAACTG(서열 번호 40)를 포함하는 뉴클레오타이드 서열에 의해 암호화된다.
억제 도메인
본 개시내용은 억제 TCR을 생성하기 위해 임의의 TCR 아단위의 막관통 도메인 또는 세포내 도메인에 융합될 수 있는 억제 세포내 도메인을 제공한다.
일부 실시형태에서, 억제 세포내 도메인은 면역수용체 티로신계 억제 모티프(ITIM)를 포함한다. 일부 실시형태에서, ITIM을 포함하는 억제 세포내 도메인은 CTLA-4 및 PD-1과 같은 면역 관문 억제제로부터 단리되거나 유래될 수 있다. CTLA-4 및 PD-1은 T 세포의 표면에서 발현된 면역 억제 수용체이고, T 세포 반응을 약화시키거나 종료시키는 데 중추적 역할을 한다.
억제 도메인은 인간 종양 괴사 인자 관련 아폽토시스 유도 리간드(TRAIL) 수용체 및 CD200 수용체 1로부터 단리될 수 있다.
일부 실시형태에서, 억제 도메인은 세포내 도메인, 막관통 또는 이들의 조합을 포함한다. 일부 실시형태에서, 억제 도메인은 세포내 도메인, 막관통 도메인, 힌지 영역 또는 이들의 조합을 포함한다. 일부 실시형태에서, 억제 도메인은 면역수용체 티로신계 억제 모티프(ITIM)를 포함한다. 일부 실시형태에서, ITIM을 포함하는 억제 도메인은 CTLA-4 및 PD-1과 같은 면역 관문 억제제로부터 단리되거나 유래될 수 있다.
억제 도메인은 인간 종양 괴사 인자 관련 아폽토시스 유도 리간드(TRAIL) 수용체 및 CD200 수용체 1로부터 단리될 수 있다. 일부 실시형태에서, 억제 도메인은 인간 단백질, 예를 들어 인간 TRAIL 수용체, CTLA-4 또는 PD-1 단백질로부터 단리되거나 유래된다. 일부 실시형태에서, TRAIL 수용체는 TR10A, TR10B 또는 TR10D를 포함한다.
내인성 TRAIL은 혈장 막에 앵커링되고 세포 표면에 제시된 281-아미노산 II형 막관통 단백질로서 발현된다. TRAIL은 자연 살해 세포에 의해 발현되고, 이는 세포-세포 접촉의 확립 후, 표적 세포에서 TRAIL 의존적 아폽토시스를 유도할 수 있다. 생리학적으로, TRAIL 신호전달 시스템은 면역 감시에, T-헬퍼 세포 2에 대한 T-헬퍼 세포 1의 조절뿐만 아니라 "무헬프" CD8+ T 세포 수를 통해 면역계를 형성하기 위해 그리고 자발적인 종양 형성의 억제에 필수적인 것으로 나타났다.
일부 실시형태에서, 억제 도메인은 CD200 수용체로부터 단리되거나 유래된 세포내 도메인을 포함한다. 세포 표면 당단백질 CD200 수용체 1(Uniprot 참조번호: Q8TD46)은 본 발명의 억제 세포내 도메인의 다른 예를 나타낸다. CD200/OX2 세포 표면 당단백질에 대한 이 억제 수용체는 선택된 자극에 반응하여 TNF-알파, 인터페론 및 유도성 산화질소 합성효소(iNOS)를 포함하는 전염증성 분자의 발현을 억제함으로써 염증을 제한한다.
일부 실시형태에서, 조작된 수용체는 살해 세포 면역글로불린 유사 수용체, 3개의 Ig 도메인 및 긴 세포질 꼬리 2(KIR3DL2), 살해 세포 면역글로불린 유사 수용체, 3개의 Ig 도메인 및 긴 세포질 꼬리 3(KIR3DL3), 백혈구 면역글로불린 유사 수용체 B1(LIR1), 예정 세포사 1(PD-1), Fc 감마 수용체 IIB(FcgRIIB), 살해 세포 렉틴 유사 수용체 K1(NKG2D), 합성 일치 ITIM을 함유하는 CTLA-4, 도메인, ZAP70 SH2 도메인(예를 들어, N 말단 및 C 말단 SH2 도메인의 하나 또는 둘 다) 또는 ZAP70 KI_K369A(키나제 불활성 ZAP70)로부터 단리되거나 유래된 억제 도메인을 포함한다.
일부 실시형태에서, 억제 도메인은 인간 단백질로부터 단리되거나 유래된다.
일부 실시형태에서, 제2의, 억제 수용체는 동일한 단백질, 예를 들어 ITIM 함유 단백질로부터 단리되거나 유래된 세포질 도메인 및 막관통 도메인을 포함한다. 일부 실시형태에서, 제2의, 억제 수용체는 동일한 단백질, 예를 들어 ITIM 함유 단백질로부터 단리되거나 유래된 단리되거나 유래된 세포질 도메인, 막관통 도메인 및 세포외 도메인 또는 이의 일부를 포함한다. 일부 실시형태에서, 제2의, 억제 수용체는 세포내 도메인 및/또는 막관통 도메인과 동일한 단백질, 예를 들어 ITIM 함유 단백질로부터 단리되거나 유래된 단리되거나 유래된 힌지 영역을 포함한다.
일부 실시형태에서, 제2 조작된 수용체는 억제 도메인을 포함하는 TCR(억제 TCR)이다. 일부 실시형태에서, 억제 TCR은 억제 세포내 도메인 및/또는 억제 막관통 도메인을 포함한다. 일부 실시형태에서, 억제 세포내 도메인은 TCR 알파, TCR 베타, CD3 델타, CD3 감마 또는 CD3 엡실론의 세포내 도메인 또는 TCR의 이의 일부에 융합된다. 일부 실시형태에서, 억제 세포내 도메인은 TCR 알파, TCR 베타, CD3 델타, CD3 감마 또는 CD3 엡실론의 막관통 도메인에 융합된다.
일부 실시형태에서, 제2 조작된 수용체는 억제 도메인을 포함하는 TCR(억제 TCR)이다. 일부 실시형태에서, 억제 도메인은 LILRB1로부터 단리되거나 유래된다.
LILRB1 억제 수용체
본 개시내용은 LILRB1 억제 도메인, 및 선택적으로, LILRB1 막관통 및/또는 힌지 도메인, 또는 이의 기능적 변이체를 포함하는 제2의, 억제 수용체를 제공한다. 억제 수용체에서의 LILRB1 막관통 도메인 및/또는 LILRB1 힌지 도메인의 포함은 다른 막관통 도메인 또는 다른 힌지 도메인을 갖는 기준 억제 수용체와 비교하여 억제 수용체에 의해 생성된 억제 신호를 증가시킬 수 있다. LILRB1 억제 도메인을 포함하는 제2의, 억제 수용체는 본원에 기재된 것과 같은 CAR 또는 TCR일 수 있다. 본원에 기재된 것과 같은 임의의 적합한 리간드 결합 도메인은 LILRB1 기반 제2의, 억제 수용체에 융합될 수 있다.
백혈구 면역글로불린 유사 수용체 B1뿐만 아니라 ILT2, LIR1, MIR7, PIRB, CD85J, ILT-2 LIR-1, MIR-7 및 PIR-B로도 공지된 백혈구 면역글로불린 유사 수용체 하위패밀리 B 구성원 1(LILRB1)은 백혈구 면역글로불린 유사 수용체(LIR) 패밀리의 구성원이다. LILRB1 단백질은 LIR 수용체의 하위패밀리 B 클래스에 속한다. 이들 수용체는 2개 내지 4개의 세포외 면역글로불린 도메인, 막관통 도메인, 및 2개 내지 4개의 세포질 면역수용체 티로신계 억제 모티프(ITIM)를 함유한다. LILRB1 수용체는 면역 세포에서 발현되고, 여기서 이것은 항원 제시 세포에서 MHC 클래스 I 분자에 결합하고 면역 반응의 자극을 억제하는 음성 신호를 전달한다. LILRB1은 염증 반응뿐만 아니라 세포독성을 조절하고, 제한하는 자가-반응성에서 역할을 하는 것으로 생각된다. LILRB1의 상이한 이소형을 암호화하는 다수의 전사체 변이체가 존재하고, 이들의 모두는 본 개시내용의 범위 내로서 고려된다.
본원에 기재된 억제 수용체의 일부 실시형태에서, 억제 수용체는 LILRB1로부터 단리되거나 유래된 하나 이상의 도메인을 포함한다. LILRB1로부터 단리되거나 유래된 하나 이상의 도메인을 갖는 수용체의 일부 실시형태에서, LILRB1의 하나 이상의 도메인은 서열 번호 65의 서열 또는 하위서열과 적어도 80%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%이거나 동일한 아미노산 서열을 포함한다. 일부 실시형태에서, LILRB1의 하나 이상의 도메인은 서열 번호 65의 서열 또는 하위서열과 동일한 아미노산 서열을 포함한다. 일부 실시형태에서, LILRB1의 하나 이상의 도메인은 서열 번호 65의 서열 또는 하위서열과 적어도 80%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99% 또는 동일한 아미노산 서열로 이루어진다. 일부 실시형태에서, LILRB1의 하나 이상의 도메인은 서열 번호 65의 서열 또는 하위서열과 동일한 아미노산 서열로 이루어진다.
LILRB1로부터 단리되거나 유래된 하나 이상의 도메인을 갖는 수용체의 일부 실시형태에서, LILRB1의 하나 이상의 도메인은 서열 번호 66의 서열 또는 하위서열과 적어도 80%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%이거나 동일한 폴리뉴클레오타이드 서열에 의해 암호화된다.
LILRB1의 하나 이상의 도메인을 갖는 수용체의 일부 실시형태에서, LILRB1의 하나 이상의 도메인은 서열 번호 66의 서열 또는 하위서열과 동일한 폴리뉴클레오타이드 서열에 의해 암호화된다.
다양한 실시형태에서, 폴리펩타이드를 포함하는 억제 수용체가 제공되고, 폴리펩타이드는 하기 중 하나 이상을 포함한다: LILRB1 힌지 도메인 또는 이의 기능적 단편 또는 변이체; LILRB1 막관통 도메인 또는 이의 기능적 변이체; 및 LILRB1 세포내 도메인 또는 적어도 1개 또는 적어도 2개의 면역수용체 티로신계 억제 모티프(ITIM)를 포함하는 세포내 도메인, 여기서 각각의 ITIM은 NLYAAV(서열 번호 67), VTYAEV(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70)로부터 독립적으로 선택된다.
본원에 사용된 것과 같이 "면역수용체 티로신계 억제 모티프" 또는 "ITIM"은 면역계의 많은 억제 수용체의 세포질 꼬리에서 발견되는 S/I/V/LxYxxI/V/L의 일치 서열을 갖는 아미노산의 보존된 서열(서열 번호 274) 또는 기타를 지칭한다. ITIM 보유 억제 수용체가 이의 리간드와 상호작용한 후, ITIM 모티프는 인산화되어서, 억제 수용체가 다른 효소, 예컨대 포스포티로신 포스파타제 SHP-1 및 SHP-2, 또는 SHIP라 불리는 이노시톨-포스파타제를 동원하게 한다.
일부 실시형태에서, 폴리펩타이드는 적어도 1개의 면역수용체 티로신계 억제 모티프(ITIM), 적어도 2개의 ITIM, 적어도 3개의 ITIM, 적어도 4개의 ITIM, 적어도 5개의 ITIM 또는 적어도 6개의 ITIM을 포함하는 세포내 도메인을 포함한다. 일부 실시형태에서, 세포내 도메인은 1개, 2개, 3개, 4개, 5개 또는 6개의 ITIM을 갖는다.
일부 실시형태에서, 폴리펩타이드는 NLYAAV(서열 번호 67), VTYAEV(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70)로 이루어진 ITIM의 군으로부터 선택된 적어도 하나의 ITIM을 포함하는 세포내 도메인을 포함한다.
추가의 특정 실시형태에서, 폴리펩타이드는 적어도 2개의 면역수용체 티로신계 억제 모티프(ITIM)를 포함하는 세포내 도메인을 포함하고, 각각의 ITIM은 NLYAAV(서열 번호 67), VTYAEV(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70)로부터 독립적으로 선택된다.
일부 실시형태에서, 세포내 도메인은 ITIM NLYAAV(서열 번호 67) 및 VTYAEV(서열 번호 68) 둘 다를 포함한다. 일부 실시형태에서, 세포내 도메인은 서열 번호 71과 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 세포내 도메인은 서열 번호 71과 동일한 서열을 포함하거나 이것으로 본질적으로 이루어진다.
일부 실시형태에서, 세포내 도메인은 ITIM VTYAEV(서열 번호 68) 및 VTYAQL(서열 번호 69) 둘 다를 포함한다. 일부 실시형태에서, 세포내 도메인은 서열 번호 72와 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 세포내 도메인은 서열 번호 72와 동일한 서열을 포함하거나 이것으로 본질적으로 이루어진다.
일부 실시형태에서, 세포내 도메인은 ITIM VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70) 둘 다를 포함한다. 일부 실시형태에서, 세포내 도메인은 서열 번호 73과 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 세포내 도메인은 서열 번호 73과 동일한 서열을 포함하거나 이것으로 본질적으로 이루어진다.
일부 실시형태에서, 세포내 도메인은 ITIM NLYAAV(서열 번호 67), VTYAEV (서열 번호 68) 및 VTYAQL(서열 번호 69)을 포함한다. 일부 실시형태에서, 세포내 도메인은 서열 번호 74와 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 세포내 도메인은 서열 번호 74와 동일한 서열을 포함하거나 이것으로 본질적으로 이루어진다.
일부 실시형태에서, 세포내 도메인은 ITIM VTYAEV(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70)을 포함한다. 일부 실시형태에서, 세포내 도메인은 서열 번호 75와 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 세포내 도메인은 서열 번호 75와 동일한 서열을 포함하거나 이것으로 본질적으로 이루어진다.
일부 실시형태에서, 세포내 도메인은 ITIM NLYAAV(서열 번호 67), VTYAEV(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70)을 포함한다. 실시형태에서, 세포내 도메인은 서열 번호 76과 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 세포내 도메인은 서열 번호 76과 동일한 서열을 포함하거나 이것으로 본질적으로 이루어진다.
일부 실시형태에서, 세포내 도메인은 LILRB1 세포내 도메인과 적어도 95% 동일한 서열(서열 번호 81)을 포함한다. 일부 실시형태에서, 세포내 도메인은 LILRB1 세포내 도메인(서열 번호 81)과 동일한 서열을 포함하거나 이것으로 본질적으로 이루어진다.
본 개시내용의 LILRB1 세포내 도메인 또는 이의 기능적 변이체는 적어도 1개, 적어도 2개, 적어도 4개, 적어도 4개, 적어도 5개, 적어도 6개, 적어도 7개 또는 적어도 8개의 ITIM을 가질 수 있다. 일부 실시형태에서, LILRB1 세포내 도메인 또는 이의 기능적 변이체는 2개, 3개, 4개, 5개 또는 6개의 ITIM을 갖는다.
특정 실시형태에서, 세포내 도메인은 2개, 3개, 4개, 5개 또는 6개의 면역수용체 티로신계 억제 모티프(ITIM)를 포함하고, 각각의 ITIM은 NLYAAV(서열 번호 67), VTYAEV(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70)로부터 독립적으로 선택된다.
특정 실시형태에서, 세포내 도메인은 적어도 3개의 면역수용체 티로신계 억제 모티프(ITIM)를 포함하고, 각각의 ITIM은 NLYAAV(서열 번호 67), VTYAEV(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70)로부터 독립적으로 선택된다.
특정 실시형태에서, 세포내 도메인은 3개의 면역수용체 티로신계 억제 모티프(ITIM)를 포함하고, 각각의 ITIM은 NLYAAV(서열 번호 67), VTYAEV(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70)로부터 독립적으로 선택된다.
특정 실시형태에서, 세포내 도메인은 4개의 면역수용체 티로신계 억제 모티프(ITIM)를 포함하고, 각각의 ITIM은 NLYAAV(서열 번호 67), VTYAEV(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70)로부터 독립적으로 선택된다.
특정 실시형태에서, 세포내 도메인은 5개의 면역수용체 티로신계 억제 모티프(ITIM)를 포함하고, 각각의 ITIM은 NLYAAV(서열 번호 67), VTYAEV(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70)로부터 독립적으로 선택된다.
특정 실시형태에서, 세포내 도메인은 6개의 면역수용체 티로신계 억제 모티프(ITIM)를 포함하고, 각각의 ITIM은 NLYAAV(서열 번호 67), VTYAEV(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70)로부터 독립적으로 선택된다.
특정 실시형태에서, 세포내 도메인은 적어도 7개의 면역수용체 티로신계 억제 모티프(ITIM)를 포함하고, 각각의 ITIM은 NLYAAV(서열 번호 67), VTYAEV(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70)로부터 독립적으로 선택된다.
LILRB1 단백질은 D1, D2, D3 및 D4라 칭하는 4개의 면역글로불린(Ig) 유사 도메인을 갖는다. 일부 실시형태에서, LILRB1 힌지 도메인은 LILRB1 D3D4 도메인 또는 이의 기능적 변이체를 포함한다. 일부 실시형태에서, LILRB1 D3D4 도메인은 서열 번호 77과 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99% 또는 동일한 서열을 포함한다. 일부 실시형태에서, LILRB1 D3D4 도메인은 서열 번호 77을 포함하거나 이것으로 본질적으로 이루어진다.
일부 실시형태에서, 폴리펩타이드는 LILRB1 힌지 도메인 또는 이의 기능적 단편 또는 변이체를 포함한다. 실시형태에서, LILRB1 힌지 도메인 또는 이의 기능적 단편 또는 변이체는 서열 번호 84, 서열 번호 77 또는 서열 번호 78과 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99% 동일한 또는 동일한 서열을 포함한다. 실시형태에서, LILRB1 힌지 도메인 또는 이의 기능적 단편 또는 변이체는 서열 번호 84, 서열 번호 77 또는 서열 번호 78과 적어도 95% 동일한 서열을 포함한다.
일부 실시형태에서, LILRB1 힌지 도메인은 서열 번호 84, 서열 번호 77 또는 서열 번호 78과 동일한 서열을 포함한다.
일부 실시형태에서, LILRB1 힌지 도메인은 본질적으로 서열 번호 84, 서열 번호 77 또는 서열 번호 78과 동일한 서열로 이루어진다.
일부 실시형태에서, 막관통 도메인은 LILRB1 막관통 도메인 또는 이의 기능적 변이체이다. 일부 실시형태에서, LILRB1 막관통 도메인 또는 이의 기능적 변이체는 서열 번호 85와 적어도 95% 동일한, 적어도 96% 동일한, 적어도 97% 동일한, 적어도 98% 동일한 또는 적어도 99% 동일한 서열을 포함한다. 일부 실시형태에서, LILRB1 막관통 도메인 또는 이의 기능적 변이체는 서열 번호 85와 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, LILRB1 막관통 도메인은 서열 번호 85와 동일한 서열을 포함한다. 실시형태에서, LILRB1 막관통 도메인은 본질적으로 서열 번호 85와 동일한 서열로 이루어진다.
일부 실시형태에서, 막관통 도메인은 힌지, 예를 들어 인간 단백질로부터의 힌지를 통해 제2의, 억제 수용체의 세포외 영역, 예를 들어 항원 결합 도메인 또는 리간드 결합 도메인에 부착될 수 있다. 예를 들어, 일부 실시형태에서, 힌지는 인간 면역글로불린(Ig) 힌지, 예를 들어 IgG4 힌지, CD8a 힌지 또는 LILRB1 힌지일 수 있다.
일부 실시형태에서, 제2의, 억제 수용체는 억제 도메인을 포함한다. 일부 실시형태에서, 제2의, 억제 수용체는 억제 세포내 도메인 및/또는 억제 막관통 도메인을 포함한다. 일부 실시형태에서, 억제 도메인은 LILR1B로부터 단리되거나 유래된다.
LILRB1 도메인의 조합을 포함하는 억제 수용체
일부 실시형태에서, 본 개시내용의 LILRB1 기반 억제 수용체는 하나 초과의 LILRB1 도메인 또는 이의 기능적 균등물을 포함한다. 예를 들어, 일부 실시형태에서, 억제 수용체는 LILRB1 막관통 도메인 및 세포내 도메인, 또는 LILRB1 힌지 도메인, 막관통 도메인 및 세포내 도메인을 포함한다.
특정 실시형태에서, 억제 수용체는 LILRB1 힌지 도메인 또는 이의 기능적 단편 또는 변이체, 및 LILRB1 막관통 도메인 또는 이의 기능적 변이체를 포함한다. 일부 실시형태에서, 폴리펩타이드는 서열 번호 79와 적어도 95% 동일한, 적어도 96% 동일한, 적어도 97% 동일한, 적어도 98% 동일한, 적어도 99% 동일한 또는 동일한 서열을 포함한다. 일부 실시형태에서, 폴리펩타이드는 서열 번호 79와 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 폴리펩타이드는 서열 번호 79와 동일한 서열을 포함한다.
추가의 실시형태에서, 억제 수용체는 LILRB1 막관통 도메인 또는 이의 기능적 변이체, 및 LILRB1 세포내 도메인 및/또는 적어도 하나의 면역수용체 티로신계 억제 모티프(ITIM)를 포함하는 세포내 도메인을 포함하고, ITIM은 NLYAAV(서열 번호 67), VTYAEV(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70)로부터 선택된다. 일부 실시형태에서, 폴리펩타이드는 LILRB1 막관통 도메인 또는 이의 기능적 변이체, 및 LILRB1 세포내 도메인 및/또는 적어도 2개의 ITIM을 포함하는 세포내 도메인을 포함하고, 각각의 ITIM은 NLYAAV(서열 번호 67), VTYAEV(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 70)로부터 독립적으로 선택된다.
일부 실시형태에서, 억제 수용체는 LILRB1 막관통 도메인 및 세포내 도메인을 포함한다. 일부 실시형태에서, 폴리펩타이드는 서열 번호 80과 적어도 95% 동일한, 적어도 96% 동일한, 적어도 97% 동일한, 적어도 98% 동일한, 적어도 99% 동일한 또는 동일한 서열을 포함한다. 일부 실시형태에서, 폴리펩타이드는 서열 번호 80과 적어도 95% 동일한 서열을 포함한다. 일부 실시형태에서, 폴리펩타이드는 서열 번호 80과 동일한 서열을 포함한다. 일부 실시형태에서, 억제 수용체는 LILRB1 막관통 도메인 및 세포외 리간드 결합 도메인에 융합된 서열 번호 80의 세포내 도메인을 포함한다. 일부 실시형태에서, 억제 수용체는 TCR 알파 가변 도메인에 융합된 서열 번호 80을 포함하는 제1 폴리펩타이드, 및 TCR 베타 가변 도메인에 융합된 서열 번호 80을 포함하는 제2 폴리펩타이드를 포함한다.
바람직한 실시형태에서, 억제 수용체는 LILRB1 힌지 도메인 또는 이의 기능적 단편 또는 변이체; LILRB1 막관통 도메인 또는 이의 기능적 변이체; 및 LILRB1 세포내 도메인 및/또는 적어도 2개의 면역수용체 티로신계 억제 모티프(ITIM)를 포함하는 세포내 도메인을 포함하고, 각각의 ITIM은 LYAAV(서열 번호 67), VTYAE(서열 번호 68), VTYAQL(서열 번호 69) 및 SIYATL(서열 번호 11)로부터 독립적으로 선택된다.
일부 실시형태에서, 억제 수용체는 서열 번호 82 또는 서열 번호 83과 적어도 95% 동일한, 또는 서열 번호 82 또는 서열 번호 83과 적어도 99% 동일한, 또는 서열 번호 82 또는 서열 번호 83과 동일한 서열을 포함한다.
일부 실시형태에서, 폴리펩타이드는 서열 번호 79와 적어도 99% 동일한, 또는 서열 번호 79와 적어도 99% 동일한, 또는 서열 번호 79와 동일한 서열을 포함한다.
일부 실시형태에서, 폴리펩타이드는 서열 번호 80과 적어도 99% 동일한, 또는 서열 번호 80과 적어도 99% 동일한, 또는 서열 번호 80과 동일한 서열을 포함한다.



링커
일부 실시형태에서, 조작된 수용체는 조작된 수용체의 2개의 도메인을 연결하는 링커를 포함한다. 본원에는 일부 실시형태에서 본원에 기재된 조작된 수용체의 도메인을 연결하도록 사용될 수 있는 링커가 제공된다.
단백질 도메인, 예를 들어 세포내 도메인 또는 scFv 내의 도메인을 연결하는 것의 맥락에서 사용된 것과 같은 "링커" 및 "가요성 폴리펩타이드 링커"라는 용어는 2개의 도메인을 함께 연결하기 위해 단독으로 또는 조합으로 사용된 글리신 및/또는 세린 잔기와 같은 아미노산으로 이루어진 펩타이드 링커를 지칭한다.
임의의 링커가 사용될 수 있고, 많은 융합 단백질 링커 형식이 공지되어 있다. 예를 들어, 링커는 가요성 또는 경질일 수 있다. 경질 및 가요성 링커의 비제한적인 예는 Chen 등 (Adv Drug Deliv Rev. 2013; 65(10):1357-1369)에 제공된다.
본원에 기재된 항원 결합 도메인은 랜덤 순서로 또는 규정된 순서로 서로에 연결될 수 있다.
본원에 기재된 항원 결합 도메인은 N 말단에서 C 말단으로의 임의의 배향으로 서로에 연결될 수 있다.
선택적으로, 예를 들어 2개 내지 40개의 아미노산(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개 또는 10개의 아미노산) 길이의 짧은 올리고펩타이드 또는 폴리펩타이드 링커는 도메인 사이에 연결을 형성할 수 있다.
일부 실시형태에서, 링커는 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 10개, 11개, 12개, 13개, 14개, 15개, 16개, 17개, 18개, 19개, 20개, 21개, 22개, 23개, 24개, 25개, 26개, 27개, 28개, 29개, 30개 또는 30개 초과의 아미노산 잔기의 펩타이드이다. 링커에서 발견된 아미노산의 비제한적인 예는 Gly, Ser, Glu, Gin, Ala, Leu, 이소, Lys, Arg, Pro 등을 포함한다. 일부 실시형태에서, 링커는 [(Gly)n1Ser]n2이고, 여기서 n1 및 n2는 임의의 수일 수 있다(예를 들어, n1 및 n2은 독립적으로 1, 2, 4, 5, 6, 7, 8, 9, l0 또는 10 초과일 수 있음). 일부 실시형태에서, n1은 4이다.
일부 실시형태에서, 가요성 폴리펩타이드 링커는 Gly/Ser 링커이고, n회 반복될 수 있는 아미노산 서열(Gly-Gly-Ser), (Gly-Gly-Gly-Ser, 서열 번호 231) 또는 (Gly-Gly-Gly-Gly-Ser, 서열 번호 226)을 포함하고, 여기서 n은 1 이상의 양의 정수이다. 예를 들어, n=1, n=2, n=3, n=4, n=5, n=6, n=7, n=8, n=9 및 n=10. 일부 실시형태에서, 가요성 폴리펩타이드 링커는 GGS, GGGGS(서열 번호 226), GGGGS GGGGS(서열 번호 227), GGGGS GGGGS GGGGS(서열 번호 228), GGGGS GGGGS GGGGS GG(서열 번호 229) 또는 GGGGS GGGGS GGGGS GGGGS(서열 번호 230)를 포함하지만, 이들로 제한되지는 않는다.
일부 실시형태에서, 링커는 (Gly Gly Ser), (Gly Ser) 또는 (Gly Gly Gly Ser(서열 번호 231))의 다수의 반복부를 포함한다. WO2012/138475(본원에 참고로 포함됨)에 기재된 링커가 본 발명의 범위 내에 또한 포함된다.
일부 실시형태에서, 링커 서열은 긴 링커(LL) 서열을 포함한다. 일부 실시형태에서, 긴 링커 서열은 4회 반복된 GGGGS(서열 번호 226)를 포함한다. 일부 실시형태에서, GGGGS GGGGS GGGGS GGGGS(서열 번호 230)는 본 개시내용의 TCR 알파 융합 단백질에서 세포내 도메인을 연결하도록 사용된다.
일부 실시형태에서, 긴 링커 서열은 3회 반복된 GGGGS(서열 번호 226)를 포함한다. 일부 실시형태에서, GGGGS GGGGS GGGGS(서열 번호 228)는 본 개시내용의 TCR 베타 융합 단백질에서 세포내 도메인을 연결하도록 사용된다.
일부 실시형태에서, 링커 서열은 짧은 링커(SL) 서열을 포함한다. 일부 실시형태에서, 짧은 링커 서열은 GGGGS(서열 번호 226)를 포함한다.
일부 실시형태에서, 글리신-세린 더블렛은 적합한 링커로서 사용될 수 있다.
일부 실시형태에서, 도메인은 링커의 사용 없이 펩타이드 결합을 통해 서로 직접 융합된다.
검정
본원에는 본 개시내용의 조작된 수용체의 활성을 측정하기 위해 사용될 수 있는 검정이 제공된다.
루시퍼라제 리포터와 같은 수용체 활성의 리포터를 발현하도록 조작된 세포주를 사용하여 조작된 수용체의 활성을 분석할 수 있다. 당해 분야에 공지된 임의의 적합한 세포주가 사용될 수 있지만, 예시적인 세포주는 저카트 T 세포를 포함한다. 예를 들어, NFAT 프로모터의 제어 하에 루시퍼라제 리포터를 발현하는 저카트 세포는 효과기 세포로서 사용될 수 있다. 이 세포주에 의한 루시퍼라제의 발현은 TCR 매개된 신호전달을 반영한다.
리포터 세포는 본원에 기재된 각각의 다양한 융합 단백질 작제물, 융합 단백질 작제물의 조합 또는 대조군으로 형질주입될 수 있다.
리포터 세포에서의 융합 단백질의 발현은 융합 단백질의 발현을 검출하기 위해 형광으로 표지된 MHC 사합체, 예를 들어 Alexa Fluor 647 표지된 NY-ESO-1-MHC 사합체를 사용함으로써 확인될 수 있다.
조작된 수용체의 활성을 분석하기 위해, 표적 세포는 리포터 및 조작된 수용체를 포함하는 효과기 세포에 대한 노출 전에 항원이 로딩된다. 예를 들어, 표적 세포는 효과기 세포에 대한 노출 전에 적어도 12시간, 14시간, 16시간, 18시간, 20시간, 22시간 또는 24시간 항원이 로딩될 수 있다. 당해 분야에 공지된 임의의 적합한 세포가 사용될 수 있지만, 예시적인 표적 세포는 A375 세포를 포함한다. 일부 경우에, 표적 세포는 NY-ESO-1 펩타이드와 같은 항원의 연속 희석된 농도로 로딩될 수 있다. 효과기 세포는 이후 적합한 시간 기간, 예를 들어 6시간 동안 표적 세포와 동시배양될 수 있다. 이후, 루시퍼라제는 동시배양 후 발광 판독에 의해 측정된다. 루시퍼라제 발광은 각각의 조작된 수용체 작제물에 대해 활성화 펩타이드 농도의 비교가 가능하게 하도록 최대 강도 및 최소 강도로 정규화될 수 있다.
본원에는 본 개시내용의 조작된 수용체의 상대 EC50을 결정하는 방법이 제공된다. 본원에 사용된 것과 같이, "EC50"은 반응(또는 결합)이 반만큼 감소되는 억제제 또는 물질의 농도를 지칭한다. 본 개시내용의 조작된 수용체의 EC50은 항원에 대한 조작된 수용체의 결합이 반만큼 감소되는 항원의 농도를 지칭한다. 표지된 펩타이드 또는 표지된 펩타이드-MHC 복합체, 예를 들어 형광단과 접합된 MHC:NY-ESO-1 pMHC 복합체에 의한 염색에 의해 조작된 수용체에 대한 항원 또는 프로브의 결합이 측정될 수 있다. 펩타이드 적정에 의해 리포터 신호의 비선형 회귀 곡선 적합화에 의해 EC50을 얻을 수 있다. 프로브 결합 및 EC50은 융합 단백질, 예를 들어 NY-ESO-1(클론 1G4) 없이 벤치마크 TCR의 수준으로 정규화될 수 있다.
폴리뉴클레오타이드
본 개시내용은 본원에 기재된 조작된 수용체의 서열(들)을 암호화하는 폴리뉴클레오타이드를 제공한다.
일부 실시형태에서, 제1 융합 단백질 및/또는 제2 융합 단백질의 서열은 프로모터에 작동 가능하게 연결된다. 일부 실시형태에서, 제1 융합 단백질을 암호화하는 서열은 제1 프로모터에 작동 가능하게 연결되고, 제2 융합 단백질을 암호화하는 서열은 제2 프로모터에 작동 가능하게 연결된다.
본 개시내용은 본원에 기재된 폴리뉴클레오타이드를 포함하는 벡터를 제공한다.
본 개시내용은 본원에 기재된 임의의 조작된 수용체의 서열 또는 서열들을 암호화하는 벡터를 제공한다. 일부 실시형태에서, 제1 융합 단백질 및/또는 제2 융합 단백질의 서열은 프로모터에 작동 가능하게 연결된다. 일부 실시형태에서, 제1 융합 단백질을 암호화하는 서열은 제1 프로모터에 작동 가능하게 연결되고, 제2 융합 단백질을 암호화하는 서열은 제2 프로모터에 작동 가능하게 연결된다.
일부 실시형태에서, 제1 조작된 수용체는 제1 벡터에 의해 암호화되고, 제2 조작된 수용체는 제2 벡터에 의해 암호화된다. 일부 실시형태에서, 조작된 수용체 둘 다는 단일 벡터에 의해 암호화된다.
일부 실시형태에서, 제1 수용체 및 제2 수용체는 단일 벡터에 의해 암호화된다. 단일 벡터를 사용하여 다수의 폴리펩타이드를 암호화하는 방법은 당업자에게 공지될 것이고, 특히 상이한 프로모터의 제어 하에 다수의 폴리펩타이드를 암호화하는 것, 또는 단일 프로모터가 다수의 폴리펩타이드의 전사를 제어하도록 사용되면, 내부 리보솜 진입 부위(IRES: internal ribosome entry site) 및/또는 자가 절단 펩타이드를 암호화하는 서열의 사용을 포함한다. 예시적인 자가절단 펩타이드는 T2A, P2A, E2A 및 F2A 자가절단 펩타이드를 포함한다. 일부 실시형태에서, T2A 자가 절단 펩타이드는 EGRGSLLTCGDVEENPGP(서열 번호 271)의 서열을 포함한다. 일부 실시형태에서, P2A 자가 절단 펩타이드는 ATNFSLLKQAGDVEENPGP(서열 번호 192)의 서열을 포함한다. 일부 실시형태에서, E2A 자가 절단 펩타이드는 QCTNYALLKLAGDVESNPGP(서열 번호 272)의 서열을 포함한다. 일부 실시형태에서, F2A 자가절단 펩타이드는 VKQTLNFDLLKLAGDVESNPGP(서열 번호 273)의 서열을 포함한다.
일부 실시형태에서, 벡터는 적합한 세포에서 발현 벡터, 즉 융합 단백질의 발현을 위한 것이다.
렌티바이러스와 같은 레트로바이러스로부터 유래된 벡터는 전이유전자의 장기간의 안정한 내재화 및 딸 세포에서의 이의 증식이 가능하게 하므로 장기간 유전자 전달을 달성하기 위한 적합한 도구이다. 렌티바이러스 벡터는 간세포와 같은 비증식 세포를 형질도입할 수 있다는 점에서 쥣과 백혈병 바이러스와 같은 종양-레트로바이러스(onco-retroviruse)로부터 유래된 벡터에 비해 상가 이점을 갖는다. 이들은 또한 낮은 면역원성의 상가 이점을 갖는다.
융합 단백질을 암호화하는 자연 핵산 또는 합성 핵산의 발현은 통상적으로 융합 단백질 또는 이의 일부를 암호화하는 핵산을 프로모터에 작동 가능하게 연결하는 것, 및 작제물을 발현 벡터로 혼입하는 것에 의해 달성된다. 벡터는 복제 및 내재성 진핵생물에 적합할 수 있다. 통상적인 클로닝 벡터는 전사 및 번역 종결자, 개시 서열, 및 원하는 핵산 서열의 발현의 조절에 유용한 프로모터를 함유한다.
융합 단백질을 암호화하는 폴리뉴클레오타이드는 다수의 벡터 유형으로 클로닝될 수 있다. 예를 들어, 폴리뉴클레오타이드는 비제한적인 예로서 플라스미드, 파지미드, 파지 유도체, 동물 바이러스 및 코스미드를 포함하는 벡터로 클로닝될 수 있다. 특히 관심 있는 벡터는 발현 벡터, 복제 벡터, 프로브 생성 벡터 및 시퀀싱 벡터를 포함한다.
추가로, 발현 벡터는 바이러스 벡터의 형태로 면역 세포와 같은 세포에 제공될 수 있다. 바이러스 벡터 기술은 당해 분야에 잘 공지되어 있고, 예를 들어 Sambrook 등 (2001, Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory, New York) 및 다른 바이러스학 및 분자 생물학 매뉴얼에 기재되어 있다. 벡터로서 유용한 바이러스는 레트로바이러스, 아데노바이러스, 아데노 연관 바이러스, 헤르페스 바이러스 및 렌티바이러스를 포함하지만, 이들로 제한되지는 않는다. 일반적으로, 적합한 벡터는 적어도 하나의 유기체에서 기능적인 복제 기원, 프로모터 서열, 편리한 제한 엔도뉴클레아제 부위 및 하나 이상의 선택 가능한 마커를 함유한다(예를 들어, WO 01/96584호; WO 01/29058호; 및 미국 특허 제6,326,193호).
다수의 바이러스 기반 시스템은 포유류 세포로의 유전자 전달을 위해 개발되었다. 예를 들어, 레트로바이러스는 유전자 전달 시스템에 대한 편리한 플랫폼을 제공한다. 선택된 유전자는 벡터로 삽입되고, 당해 분야에 공지된 기법을 사용하여 레트로바이러스 입자에 패키징될 수 있다. 이후, 재조합 바이러스는 생체내 또는 생체외 단리되고 대상체의 세포로 전달될 수 있다. 다수의 레트로바이러스 시스템이 당해 분야에 공지되어 있다. 일부 실시형태에서, 아데노바이러스 벡터가 사용된다. 다수의 아데노바이러스 벡터가 당해 분야에 공지되어 있다. 일 실시형태에서, 렌티바이러스 벡터가 사용된다.
추가 프로모터 요소, 예를 들어 인핸서는 전사 개시의 빈도를 조절한다. 통상적으로, 다수의 프로모터가 또한 출발 부위의 하류에 기능적 요소를 함유하는 것으로 최근에 밝혀졌지만, 이들이 출발 부위의 상류에 영역 30개 내지 110개 염기쌍(bp)에 위치한다. 요소들이 서로에 대해 도립되거나 이동할 때 프로모터 기능이 보존되도록 프로모터 요소 사이의 간격은 흔히 융통성이 있다. 티미딘 키나제(tk) 프로모터에서, 프로모터 요소 사이의 간격은 활성이 감소하기 시작하기 전에 떨어져 50 bp로 증가할 수 있다. 프로모터에 따라, 개별 요소가 전사를 활성화하도록 협동적으로 또는 독립적으로 작용할 수 있는 것으로 보인다.
적합한 프로모터의 하나의 예는 즉시 초기 사이토메갈로바이러스(CMV) 프로모터 서열이다. 이 프로모터 서열은 이에 작동 가능하게 연결된 임의의 폴리뉴클레오타이드 서열의 높은 발현 수준을 유도할 수 있는 강한 항시적 프로모터 서열이다. 적합한 프로모터의 다른 예는 연장 성장 인자-1α(EF-1α: Elongation Growth Factor-1α)이다. 그러나, 비제한적인 예로서 유인원 바이러스 40(SV40: simian virus 40) 초기 프로모터, 마우스 유방 종양 바이러스(MMTV: mouse mammary tumor virus), 인간 면역결핍 바이러스(HIV: human immunodeficiency virus) 긴 말단 반복부(LTR: long terminal repeat) 프로모터, MoMuLV 프로모터, 조류 백혈병 바이러스 프로모터, 엡스타인 바 바이러스(Epstein-Barr virus) 즉시 초기 프로모터, 라우스 육종 바이러스 프로모터를 포함하는 다른 항시적 프로모터 서열뿐만 아니라 비제한적인 예로서 액틴 프로모터, 미오신 프로모터, 헤모글로빈 프로모터 및 크레아티닌 키나제 프로모터와 같은 인간 유전자 프로모터를 또한 사용할 수 있다. 추가로, 본 발명은 항시적 프로모터의 사용으로 제한되지 않아야 한다. 본 발명의 일부로서 유도성 프로모터가 또한 고려된다. 유도성 프로모터의 사용은 이것이 이러한 발현이 원해질 때 작동 가능하게 연결된 폴리뉴클레오타이드 서열의 발현을 키거나, 발현이 원해지지 않을 때 발현을 끌 수 있는 분자 스위치를 제공한다. 유도성 프로모터의 예는 메탈로티오닌 프로모터, 글루코코르티코이드 프로모터, 프로게스테론 프로모터 및 테트라사이클린 프로모터를 포함하지만, 이들로 제한되지는 않는다.
융합 단백질의 발현을 평가하기 위해, 세포로 도입되는 발현 벡터는 또한 바이러스 벡터를 통해 형질주입되거나 감염되도록 추구되는 세포의 집단으로부터 발현 세포의 확인 및 선택이 용이하게 하도록 선택 가능한 마커 유전자 또는 리포터 유전자 또는 둘 다를 함유할 수 있다. 다른 양태에서, 선택 가능한 마커는 DNA의 별개의 조각에서 수행되고 동시형질주입 절차에서 사용될 수 있다. 선택 가능한 마커 및 리포터 유전자 둘 다는 숙주 세포에서 발현이 가능하게 하는 적절한 조절 서열에 의해 플랭킹될 수 있다. 유용한 선택 가능한 마커는 예를 들어 항생제 내성 유전자, 예컨대 네오 등을 포함한다.
리포터 유전자는 잠재적으로 형질주입된 또는 형질도입된 세포를 확인하고 조절 서열의 기능을 평가하기 위해 사용된다. 일반적으로, 리포터 유전자는 수혜자 유기체 또는 조직에 존재하거나 이에 의해 발현되고, 일부 용이하게 검출 가능한 특성, 예를 들어 효소 활성에 의해 발현이 나타나는 폴리펩타이드를 암호화하는 유전자이다. DNA가 수혜자 세포로 도입된 후 적합한 시간에 리포터 유전자의 발현이 분석된다. 적합한 리포터 유전자는 루시퍼라제, 베타-갈락토시다제, 클로르암페니콜 아세틸 전환효소, 분비된 알칼리 포스파타제를 암호화하는 유전자, 또는 녹색 형광 단백질 유전자를 포함할 수 있다(예를 들어, Ui-Tei 등, 2000 FEBS Letters 479: 79-82). 적합한 발현 시스템은 잘 공지되어 있고, 공지된 기법을 사용하여 제조되거나 상업적으로 얻어질 수 있다. 일반적으로, 리포터 유전자의 가장 높은 발현 수준을 보여주는 최소 5' 플랭킹 영역을 갖는 작제물이 프로모터로서 확인된다. 이러한 프로모터 영역은 리포터 유전자에 연결되고 프로모터 유발 전사를 조절하는 능력에 대해 물질을 평가하도록 사용될 수 있다.
유전자를 세포로 도입하고 이를 발현하는 방법이 당해 분야에 공지되어 있다. 발현 벡터의 맥락에서, 벡터는 당해 분야에서의 임의의 방법에 의해 숙주 세포, 예를 들어 포유류, 박테리아, 효모 또는 곤충 세포로 용이하게 도입될 수 있다. 예를 들어, 발현 벡터는 물리적 수단, 화학적 수단 또는 생물학적 수단에 의해 숙주 세포로 전달될 수 있다.
폴리뉴클레오타이드를 숙주 세포로 도입하기 위한 물리적 방법은 인산칼슘 침전, 리포펙션, 입자 포격, 미량주사, 전기천공 등을 포함한다. 벡터 및/또는 외인성 핵산을 포함하는 세포를 제조하는 방법은 당해 분야에 잘 공지되어 있다. 예를 들어, Sambrook 등 (2001, Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory, New York)을 참조한다. 폴리뉴클레오타이드를 숙주 세포로 도입하기 위한 하나의 방법은 인산칼슘 형질주입이다.
숙주 세포로 관심 폴리뉴클레오타이드를 도입하기 위한 생물학적 방법은 DNA 및 RNA 벡터의 사용을 포함한다. 바이러스 벡터, 및 특히 레트로바이러스 벡터는 포유류, 예를 들어 인간 세포로 유전자를 삽입하기 위한 가장 널리 사용되는 방법이 되었다. 다른 바이러스 벡터는 렌티바이러스, 폭스바이러스, 단순 포진 바이러스 I, 아데노바이러스 및 아데노 연관 바이러스 등으로부터 유래될 수 있다. 예를 들어, 미국 특허 제5,350,674호 및 제5,585,362호를 참조한다.
폴리뉴클레오타이드를 숙주 세포로 도입하기 위한 화학적 수단은 콜로이드 분산 시스템, 예컨대 거대분자 복합체, 나노캡슐, 마이크로구, 비드, 및 수중유 에멀션, 미셀, 혼합 미셀 및 리포솜을 포함하는 지질 기반 시스템을 포함한다. 시험관내 및 생체내 전달 비히클로서 사용하기 위한 예시적인 콜로이드 시스템은 리포솜(예를 들어, 인공 막 베시클)이다.
외인성 핵산을 숙주 세포로 도입하거나 그렇지 않으면 세포를 본 발명의 억제제에 노출시키기 위해 사용된 방법과 관련하여, 숙주 세포에서 재조합 DNA 서열의 존재를 확인하기 위해, 다양한 검정을 수행할 수 있다. 이러한 검정은 본 발명의 범위 내에 해당하는 물질을 확인하기 위해 예를 들어 당업자에게 잘 공지된 "분자 생물학적" 검정, 예컨대 사우던 블로팅 및 노던 블로팅, RT-PCR 및 PCR; 예를 들어 면역학적 수단(ELISA 및 웨스턴 블롯)에 의한 또는 본원에 기재된 검정에 의한 특정 펩타이드의 존재 또는 부재의 검출과 같은 "생화학적" 검정을 포함한다.
면역 세포
본원에는 본원에 기재된 폴리뉴클레오타이드, 벡터, 융합 단백질 및 조작된 수용체를 포함하는 면역 세포가 제공된다.
본원에 사용된 것과 같이, "면역 세포"라는 용어는 선천성 또는 적응(획득) 면역계에 관여된 세포를 지칭한다. 예시적인 선천성 면역 세포는 식세포 세포, 예컨대 중성구, 단핵구 및 대식세포, 자연 살해(NK) 세포, 다형핵 백혈구, 예컨대 호중구, 호산구 및 호염기구 및 단핵 세포, 예컨대 단핵구, 대식세포 및 비만 세포를 포함한다. 획득 면역에서 역할을 갖는 면역 세포는 T 세포 및 B 세포와 같은 림프구를 포함한다.
본원에 사용된 것과 같이, "T 세포"는 흉선에서 발생하는 골수 전구체로부터 기원하는 림프구의 유형을 지칭한다. 헬퍼 CD4+ T 세포, 세포독성 CD8+ T 세포, 기억 T 세포, 조절 CD4+ T 세포 및 줄기 기억 T 세포를 포함하는 흉선으로 이동 시 발생하는 몇몇 구별되는 유형의 T 세포가 있다. 상이한 유형의 T 세포는 이의 마커 발현에 기초하여 당업자에 의해 구별될 수 있다. T 세포 유형 사이를 구별하는 방법은 당업자에게 용이하게 자명할 것이다.
일부 실시형태에서, 조작된 면역 세포는 제1 수용체 대 제2 수용체의 약 100:1 내지 1:100의 비로 제1 수용체 및 제2 수용체를 발현한다. 일부 실시형태에서, 조작된 면역 세포는 제1 수용체 대 제2 수용체의 약 50:1 내지 1:50의 비로 제1 수용체 및 제2 수용체를 발현한다. 일부 실시형태에서, 조작된 면역 세포는 제1 수용체 대 제2 수용체의 약 10:1 내지 1:10의 비로 제1 수용체 및 제2 수용체를 발현한다. 일부 실시형태에서, 조작된 면역 세포는 제1 수용체 대 제2 수용체의 약 5:1 내지 1:5의 비로 제1 수용체 및 제2 수용체를 발현한다. 일부 실시형태에서, 조작된 면역 세포는 제1 수용체 대 제2 수용체의 약 3:1 내지 1:3의 비로 제1 수용체 및 제2 수용체를 발현한다. 일부 실시형태에서, 조작된 면역 세포는 제1 수용체 대 제2 수용체의 약 2:1 내지 1:2의 비로 제1 수용체 및 제2 수용체를 발현한다. 일부 실시형태에서, 조작된 면역 세포는 약 1:1의 비로 제1 수용체 및 제2 수용체를 발현한다.
일부 실시형태에서, 본 개시내용의 조작된 수용체를 포함하는 조작된 면역 세포는 T 세포이다. 일부 실시형태에서, T 세포는 효과기 T 세포 또는 조절 T 세포이다.
본 개시내용의 벡터에 의해 T 세포와 같은 면역 세포의 집단을 형질전환하는 방법은 당업자에게 용이하게 자명할 것이다. 예를 들어, 제조사의 지시에 따라 CD3+ T 세포 음성 단리 키트(Miltenyi)를 사용하여 PBMC로부터 CD3+ T 세포를 단리할 수 있다. CD3/28 Dynabead(1:1의 세포 대 비드 비) 및 300 단위/mL의 IL-2(Miltenyi)의 존재 하에 5% 인간 A/B 혈청 및 1% Pen/strep가 보충된 X-Vivo 15 배지에서 1 x 10^6개의 세포/mL의 밀도로 T 세포를 배양할 수 있다. 2일 후, 당해 분야에 공지된 방법을 사용하여 렌티바이러스 벡터와 같은 바이러스 벡터에 의해 T 세포를 형질도입할 수 있다. 일부 실시형태에서, 바이러스 벡터는 5의 다중 감염도(MOI: multiplicity of infection)로 형질도입된다. 이후, 농후화 전 추가 5일 동안 IL-2 또는 다른 사이토카인, 예컨대 IL-7/15/21의 조합에서 세포를 배양할 수 있다. 면역 세포의 다른 집단, 예컨대 B 세포, 또는 다른 T 세포 집단을 단리하고 배양하는 방법은 당업자에게 용이하게 자명할 것이다. 이 방법이 가능한 접근법을 개략화하지만, 이 방법론이 신속히 발전한다는 것이 주목되어야 한다. 예를 들어, 99% 초과의 CD3+ 고도로 형질도입된 세포 집단을 생성시키도록 성장 5일 후 말초혈 단핵 세포의 훌륭한 바이러스 형질도입을 달성할 수 있다.
조작된 TCR, CAR, 융합 단백질 또는 본 개시내용의 융합 단백질을 암호화하는 벡터를 포함하는 T 세포의 집단을 활성화하고 배양하는 방법은 당업자에게 용이하게 자명할 것이다.
조작된 TCR을 발현하기 위한 T 세포의 유전 변형 전이든 또는 후이든, T 세포는 일반적으로 예를 들어 미국 특허 제6,352,694호; 제6,534,055호; 제6,905,680호; 제6,692,964호; 제5,858,358호; 제6,887,466호; 제6,905,681호; 제7,144,575호; 제7,067,318호; 제7,172,869호; 제7,232,566호; 제7,175,843호; 제5,883,223호; 제6,905,874호; 제6,797,514호; 제6,867,041호, 제10040846호; 및 미국 특허 출원 공보 제2006/0121005호에 기재된 것과 같은 방법을 사용하여 활성화되거나 확장될 수 있다.
일부 실시형태에서, 본 개시내용의 T 세포는 시험관내 확장되고 활성화된다. 일반적으로, 본 개시내용의 T 세포는 CD3/TCR 복합체 연관 신호를 자극하는 물질 및 T 세포의 표면에 공자극 분자를 자극하는 리간드가 부착된 표면과의 접촉에 의해 시험관내 확장된다. 특히, T 세포 집단은 예컨대 항-CD3 항체와의 접촉에 의해 본원에 기재된 것처럼 자극될 수 있다. T 세포의 표면에 보조 분자의 공자극을 위해, 보조 분자에 결합하는 리간드가 사용된다. 예를 들어, T 세포의 집단은 T 세포의 증식을 자극하기 위한 적절한 조건 하에 항-CD3 항체 및 항-CD28 항체와 접촉할 수 있다. CD4+ T 세포 또는 CD8+ T 세포의 증식을 자극하기 위해, 항-CD3 항체 및 항-CD28 항체가 사용될 수 있다. 항-CD28 항체의 예는 9.3, B-T3을 포함하고, XR-CD28(Diaclone, 프랑스 브장송)은 당해 분야에 흔히 공지된 다른 방법이 사용될 수 있는 것처럼 사용될 수 있다(Berg 등, Transplant Proc. 30(8):3975-3977, 1998; Haanen 등, J. Exp. Med. 190(9):13191328, 1999; Garland 등, J. Immunol Meth. 227(1-2):53-63, 1999).
일부 실시형태에서, T 세포에 대한 1차 자극 신호 및 공자극 신호는 상이한 프로토콜에 의해 제공될 수 있다. 예를 들어, 각각의 신호를 제공하는 물질은 용액 중에 있거나 표면에 커플링될 수 있다. 물질은 표면에 커플링될 때 동일한 표면에(즉, "시스" 형성으로) 커플링되거나 별개의 표면에(즉, "트랜스" 형성으로) 커플링될 수 있다. 대안적으로, 하나의 물질은 표면 및 용액 중의 다른 물질에 커플링될 수 있다. 일부 실시형태에서, 공자극 신호를 제공하는 물질은 세포 표면에 결합되고, 1차 활성화 신호를 제공하는 물질은 용액 중에 있거나 표면에 커플링된다. 소정의 실시형태에서, 물질 둘 다는 용액에 있을 수 있다. 다른 실시형태에서, 그 물질은 가용성 형태일 수 있고, 이후 표면, 예컨대 Fc 수용체를 발현하는 세포 또는 항체 또는 그 물질에 결합하는 다른 결합제에 가교결합된다. 이와 관련하여, 본 발멸에서 T 세포를 활성화하고 확장시키는 데 사용하기 위해 고려되는 인공 항원 제시 세포(aAPC: artificial antigen presenting cell)에 대해 예를 들어 미국 특허 출원 공보 제20040101519호 및 제20060034810호를 참조한다.
일부 실시형태에서, 2종의 물질은 동일한 비드에, 즉 "시스"로 또는 별개의 비드에, 즉 "트랜스"로 비드에 부동화된다. 예에 의해, 1차 활성화 신호를 제공하는 물질은 항-CD3 항체 또는 이의 항원 결합 단편이고, 공자극 신호를 제공하는 물질은 항-CD28 항체 또는 이의 항원 결합 단편이고, 물질 둘 다는 동등한 분자 양으로 동일한 비드에 동시부동화된다. 일 실시형태에서, CD4+ T 세포 확장 및 T 세포 성장을 위해 비드에 결합된 각각의 항체의 1:1 비를 사용한다. 일부 실시형태에서, 비드에 결합된 CD3 : CD28 항체의 비는 100:1 내지 1:100 및 이들 사이의 모든 정수 값의 범위이다. 본 발명의 일 양태에서, 항-CD3 항체보다 더 많은 항-CD28 항체가 입자에 결합되고, 즉 CD3 : CD28의 비는 1보다 작다. 본 발명의 소정의 실시형태에서, 비드에 결합된 항 CD28 항체 대 항 CD3 항체의 비는 2:1 초과이다.
1:500 대 500:1 및 이들 사이의 임의의 정수 값의 입자 대 세포의 비는 T 세포 또는 다른 표적 세포를 자극하기 위해 사용될 수 있다. 당업자가 용이하게 이해할 수 있는 것처럼, 입자 대 세포의 비는 표적 세포에 대한 입자 크기에 따라 달라질 수 있다. 예를 들어, 작은 크기의 비드는 오직 약간의 세포에 결합할 수 있지만, 더 큰 비드가 많이 결합할 수 있었다. 소정의 실시형태에서, 세포 대 입자의 비는 1:100 내지 100:1 및 이들 사이의 임의의 정수 값의 범위이고, 추가의 실시형태에서 그 비는 1:9 내지 9:1을 포함하고, 이들 사이의 임의의 정수 값은 또한 T 세포를 자극하도록 사용될 수 있다. 일부 실시형태에서, 1:1의 세포 대 비드의 비가 사용된다. 당업자는 다양한 다른 비가 본 발명에 사용하기에 적합할 수 있다는 것을 이해할 것이다. 특히, 비는 입자 크기 및 세포 크기 및 유형에 따라 변할 것이다.
본 발명의 추가의 실시형태에서, T 세포와 같은 세포는 물질 코팅된 비드와 조합되고, 비드 및 세포는 후속하여 분리되고, 이후 세포가 배양된다. 대안적인 실시형태에서, 배양 전에, 물질 코팅된 비드 및 세포는 분리되지 않고 함께 배양된다. 추가의 실시형태에서, 비드 및 세포는 처음에 자기 힘과 같은 힘의 적용에 의해 농축되어서, 세포 표면 마커의 결찰을 증가시키고, 이로써 세포 자극을 유도한다.
예에 의해, 항-CD3 및 항-CD28이 부착된 상자성 비드가 T 세포를 접촉시키게 하여서 세포 표면 단백질이 결찰될 수 있다. 일 실시형태에서, 세포(예를 들어, CD4+ T 세포) 및 비드(예를 들어, 1:1의 비의 DYNABEAD CD3/CD28 T 상자성 비드)는 완충액 중에 조합된다. 다시, 당업자는 임의의 세포 농도가 사용될 수 있다는 것을 용이하게 인식할 수 있다. 소정의 실시형태에서, 세포 및 입자의 최대 접촉을 보장하도록 입자 및 세포가 함께 혼합되는 부피를 유의미하게 감소시키는 것(즉, 세포의 농도를 증가시키는 것)이 바람직할 수 있다. 예를 들어, 일 실시형태에서, 약 20억개의 세포/ml의 농도가 사용된다. 다른 실시형태에서, 10000만개의 세포/ml 초과가 사용된다. 추가의 실시형태에서, 1000만개, 1500만개, 2000만개, 2500만개, 3000만개, 3500만개, 4000만개, 4500만개 또는 5000만개의 세포/ml의 세포의 농도가 사용된다. 또 다른 실시형태에서, 750억, 800억, 850억, 900억, 950억 또는 1000억개의 세포/ml의 세포의 농도가 사용된다. 추가의 실시형태에서, 12500만개 또는 15000만개의 세포/ml의 농도가 사용될 수 있다. 일부 실시형태에서, 1x106개의 세포/mL의 밀도로 배양된 세포가 사용된다.
일부 실시형태에서, 혼합물은 몇 시간(약 3시간) 내지 약 14일 또는 이들 사이의 임의의 시간당 정수 값 동안 배양될 수 있다. 다른 실시형태에서, 비드 및 T 세포는 2일 내지 3일 동안 함께 배양된다. T 세포 배양에 적절한 조건은 혈청(예를 들어, 소 태아 또는 인간 혈청), 인터류킨-2(IL-2), 인슐린, IFN-γ, IL-4, IL-7, GM-CSF, IL-10, IL-12, IL-15, TGFβ 및 TNF-α, 또는 당업자에게 공지된 세포의 성장을 위한 임의의 다른 첨가제를 포함하는 증식 및 생존능력에 필요한 인자를 함유할 수 있는 적절한 배지(예를 들어, 최소 필수 배지(Minimal Essential Media) 또는 RPMI 배지 1640 또는 X-vivo 15(Lonza))를 포함한다. 세포의 성장을 위한 다른 첨가제는 계면활성제, 플라스마네이트 및 환원제, 예컨대 N-아세틸-시스테인 및 2-머캅토에탄올을 포함하지만, 이들로 제한되지는 않는다. 배지는, 무혈청인 또는 혈청(또는 혈장) 또는 한정된 호르몬 세트의 적절한 양, 및/또는 T 세포의 성장 및 확장에 충분한 사이토카인(들)의 양이 보충된, 아미노산, 피루브산나트륨 및 비타민이 첨가된, RPMI 1640, AIM-V, DMEM, MEM, α-MEM, F-12, X-Vivo 15 및 X-Vivo 20, Optimizer를 포함할 수 있다. 일부 실시형태에서, 배지는 5% 인간 A/B 혈청, 1% 페니실린/스트렙토마이신(pen/strep) 및 300 단위/ml의 IL-2(Miltenyi)가 보충된 X-VIVO-15 배지를 포함한다.
T 세포는 성장을 지지하는 데 필요한 조건, 예를 들어 적절한 온도(예를 들어, 37℃) 및 분위기(예를 들어, 공기와 5% CO2) 하에 유지된다.
일부 실시형태에서, 본 개시내용의 조작된 TCR을 포함하는 T 세포는 자가유래이다. 확장 및 게놈 변형 전에, 대상체로부터 T 세포의 원천을 얻는다. 말초혈 단핵 세포, 골수, 림프절 조직, 제대혈, 흉선 조직, 감염 부위로부터의 조직, 복수, 흉막 삼출, 비장 조직 및 종양을 포함하는 많은 원천으로부터 T 세포와 같은 면역 세포를 얻을 수 있다. 본 발명의 소정의 실시형태에서, 당해 분야에서 이용 가능한 임의의 수의 T 세포주가 사용될 수 있다. 본 발명의 소정의 실시형태에서, Ficoll™ 분리와 같은 당업자에게 공지된 임의의 수의 기법을 사용하여 대상체로부터 수집된 혈액의 단위로부터 T 세포를 얻을 수 있다.
일부 실시형태에서, 성분채집술에 의해 개체의 순환 혈액으로부터의 세포를 얻는다. 성분채집술 생성물은 통상적으로 T 세포, 단핵구, 괴립구, B 세포, 다른 제핵된 백혈구, 적혈구 및 혈소판을 포함하는 림프구를 함유한다. 일부 실시형태에서, 혈장 분획을 제거하고 세포를 후속 가공 단계를 위한 적절한 완충액 또는 배지에 두도록 성분채집술에 의해 수집된 세포를 세척할 수 있다. 일부 실시형태에서, 세포를 인산염 완충 식염수(PBS)로 세척한다. 대안적인 실시형태에서, 세척 용액은 칼슘이 결여되고, 마그네슘이 결여되거나, 모두는 아니지만 많은 2가 양이온이 결여될 수 있다. 당업자가 용이하게 이해하는 것처럼, 세척 단계는 제조사의 지시에 따라 당업자에게 공지된 방법에 의해, 예컨대 반자동 "통과 흐름" 원심분리(예를 들어, Cobe 2991 세포 가공자, Baxter CytoMate, 또는 Haemonetics Cell Saver 5)를 사용하여 달성될 수 있다. 세척 후, 세포는 예를 들어 완충액과 함께 또는 이것 없이 Ca2+ 비함유, Mg2+ 비함유 PBS, PlasmaLyte A, 또는 다른 식염수 용액과 같은 다양한 생체적합성 완충액에 재현탁될 수 있다. 대안적으로, 성분채집술 샘플의 바람직하지 않은 성분은 제거되고, 세포는 배양 배지에 바로 재현탁될 수 있다.
일부 실시형태에서, T 세포와 같은 면역 세포는 적혈구의 용해 및 단핵구의 고갈에 의해, 예를 들어 PERCOLL™ 구배를 통한 원심분리에 의해 또는 향류 원심 세정에 의해 말초혈 림프구로부터 단리된다. T 세포, B 세포, 또는 CD4+ T 세포와 같은 면역 세포의 특정 하위집단은 양성 선택 기법 또는 음성 선택 기법에 의해 추가로 단리될 수 있다. 예를 들어, 일 실시형태에서, T 세포는 원하는 T 세포의 양성 선택에 충분한 시간 기간 동안 항-CD4 접합된 비드와의 항온처리에 의해 단리된다.
음성 선택에 의한 면역 세포 집단, 예컨대 T 세포 집단의 농후화는 음성으로 선택된 세포에 고유한 표면 마커에 지향된 항체의 조합에 의해 달성될 수 있다. 하나의 방법은 음성으로 선택된 세포에 존재하는 세포 표면 마커에 지향된 단일클론 항체의 칵테일을 사용하는 음성 자기 면역부착 또는 유세포분석법을 통한 세포 분류 및/또는 선택이다. 예를 들어, 음성 선택에 의해 CD4+ 세포를 농후화하기 위해, 단일클론 항체 칵테일은 통상적으로 CD14, CD20, CD 11b, CD 16, HLA-DR 및 CD8에 대한 항체를 포함한다.
양성 선택 또는 음성 선택에 의한 원하는 면역 세포 집단의 단리를 위해, 세포 및 표면(예를 들어, 입자, 예컨대 비드)의 농도가 변할 수 있다. 소정의 실시형태에서, 세포 및 비드의 최대 접촉을 보장하도록 비드 및 세포가 함께 혼합되는 부피를 유의미하게 감소시키는 것(즉, 세포의 농도를 증가시키는 것)이 바람직할 수 있다.
일부 실시형태에서, 2℃ 내지 10℃에서 또는 실온에서 변하는 속도로 변하는 시간 길이 동안 회전자에서 세포를 항온처리할 수 있다.
자극을 위한 T 세포 또는 T 세포와 같은 면역 세포가 단리된 PBMC는 또한 세척 단계 후 동결될 수 있다. 이론에 의해 구속되지 않고자 바라면서, 동결 및 후속 해동 단계는 세포 집단에서 과립구를 제거하고 어느 정도로 단핵구를 제거함으로써 더 균일한 생성물을 제공한다. 혈장 및 혈소판을 제거하는 세척 단계 후, 세포는 동결 용액에서 현탁될 수 있다. 많은 동결 용액 및 매개변수가 당해 분야에 공지되어 있고 이 문맥에서 유용할 것이지만, 하나의 방법은 20%의 DMSO 및 8%의 인간 혈청 알부민을 함유하는 PBS, 또는 10%의 덱스트란 40 및 5%의 덱스트로스, 20%의 인간 혈청 알부민 및 7.5%의 DMSO, 또는 31.25%의 Plasmalyte-A, 31.25%의 덱스트로스 5%, 0.45%의 NaCl, 10%의 덱스트란 40 및 5%의 덱스트로스, 20%의 인간 혈청 알부민 및 7.5%의 DMSO를 함유하는 배양 배지 또는 예를 들어 Hespan 및 PlasmaLyte A를 함유하는 다른 적합한 세포 동결 배지를 사용하는 것을 수반하고, 이후 세포는 분당 1°의 속도로 -80℃로 동결되고, 액체 질소 저장 탱크의 기상에서 저장된다. 제어 동결의 다른 방법뿐만 아니라 즉시 -20℃에서 또는 액체 질소에서 비제어 동결을 사용할 수 있다.
약제학적 조성물
본 개시내용은 본 개시내용의 조작된 수용체를 포함하는 면역 세포 및 약제학적으로 허용 가능한 희석제, 담체 또는 부형제를 포함하는 약제학적 조성물을 제공한다.
이러한 조성물은 완충액, 예컨대 천연 완충 식염수, 인산염 완충 식염수 등; 탄수화물, 예컨대 글루코스, 만노스, 수크로스 또는 덱스트란, 만니톨; 단백질; 폴리펩타이드 또는 아미노산, 예컨대 글리신; 항산화제; 킬레이트화제, 예컨대 EDTA 또는 글루타티온; 및 보존제를 포함할 수 있다.
질환을 치료하는 방법
본원에는 본 개시내용의 조작된 수용체를 포함하는 면역 세포를 포함하는 조성물의 치료학적 유효량을 대상체에게 투여하는 단계를 포함하는 치료를 필요로 하는 대상체를 치료하는 방법이 제공된다. 면역 세포는 동일한 세포에서 조작된 수용체 둘 다를 발현한다.
일부 실시형태에서, 치료를 필요로 하는 대상체는 암을 갖는다. 암은 제어 없이 비정상 세포가 분열하고 근처의 조직에 분산하는 질환이다. 일부 실시형태에서, 암은 액체 종양 또는 고형 종양을 포함한다. 예시적인 액체 종양은 백혈병 및 림프종을 포함한다. 액체 종양인 추가의 암은 예를 들어 혈액, 골수 및 림프절에서 발생하는 것일 수 있고, 예를 들어 백혈병, 골수성 백혈병, 림프구성 백혈병, 림프종, 호지킨 림프종, 흑색종 및 다발성 골수종을 포함할 수 있다. 백혈병은 예를 들어 급성 림프아구성 백혈병(ALL: acute lymphoblastic leukemia), 급성 골수성 백혈병(AML: acute myeloid leukemia), 만성 림프구성 백혈병(CLL: chronic lymphocytic leukemia), 만성 골수성 백혈병(CML: chronic myelogenous leukemia) 및 모발 세포 백혈병을 포함한다. 예시적인 고형 종양은 육종 및 암종을 포함한다. 암은 사살상 혈액, 골수, 폐, 유방, 결장, 골, 중추 신경계, 췌장, 전립선 및 난소를 포함하는 신체에서의 장기에서 생길 수 있다. 고형 종양인 추가의 암은 예를 들어 전립선암, 고환암, 유방암, 뇌암, 췌장암, 결장암, 갑상선암, 위암, 폐암, 난소암, 카포시 육종, 피부암, 편평 세포 피부암, 신장암, 두경부암, 갑상선암, 코, 입, 목의 촉촉한 점막 내벽에 형성하는 편평 암종, 방광암, 골육종, 자궁경부암, 자궁내막암, 식도암, 간암 및 신장암을 포함한다. 일부 실시형태에서, 본원에 기재된 방법에 의해 치료되는 병태는 흑색종 세포, 전립선암 세포, 고환암 세포, 유방암 세포, 뇌암 세포, 췌장암 세포, 결장암 세포, 갑상선암 세포, 위암 세포, 폐암 세포, 난소암 세포, 카포시 육종 세포, 피부암 세포, 신장암 세포, 두경부암 세포, 목암 세포, 편평 암종 세포, 방광암 세포, 골육종 세포, 자궁경부암 세포, 자궁내막암 세포, 식도암 세포, 간암 세포 또는 신장암 세포의 전이이다.
복수의 암 세포가 제1의, 활성인자 리간드를 발현하고 제2의, 억제제 리간드를 발현하지 않는 임의의 암은 본 개시내용의 범위 내로서 고안된다. 예를 들어, 본원에 기재된 방법을 사용하여 치료될 수 있는 CEA 양성 암은 결장직장암, 췌장암, 식도암, 위암, 폐 선암, 두경부암, 미만성 대형 B 세포 암 또는 급성 골수성 백혈병 암을 포함한다.
암을 치료하는 것은 종양의 크기를 감소시킬 수 있다. 종양의 크기의 감소는 "종양 회귀"라고도 칭해질 수 있다. 바람직하게는, 치료 후, 종양 크기는 치료 전의 이의 크기에 비해 5% 이상만큼 감소하고; 더 바람직하게는, 종양 크기는 10% 이상만큼 감소하고; 더 바람직하게는, 20% 이상만큼 감소하고; 더 바람직하게는, 30% 이상만큼 감소하고; 더 바람직하게는, 40% 이상만큼 감소하고; 훨씬 더 바람직하게는, 50% 이상만큼 감소하고; 가장 바람직하게는, 75% 이상 초과만큼 감소한다. 종양의 크기는 임의의 재현가능한 측정 수단에 의해 측정될 수 있다. 종양의 크기는 종양의 직경으로서 측정될 수 있다.
암을 치료하는 것은 종양 용적을 감소시킬 수 있다. 바람직하게는, 치료 후, 종양 용적은 치료 전의 이의 용적에 비해 5% 이상만큼 감소하고; 더 바람직하게는, 종양 용적은 10% 이상만큼 감소하고; 더 바람직하게는, 20% 이상만큼 감소하고; 더 바람직하게는, 30% 이상만큼 감소하고; 더 바람직하게는, 40% 이상만큼 감소하고; 훨씬 더 바람직하게는, 50% 이상만큼 감소하고; 가장 바람직하게는, 75% 이상 초과만큼 감소한다. 종양 용적은 임의의 재현가능한 측정 수단에 의해 측정될 수 있다.
암을 치료하는 것은 종양의 수를 감소시킨다. 바람직하게는, 치료 후, 종양 수는 치료 전의 수에 비해 5% 이상만큼 감소하고; 더 바람직하게는, 종양 수는 10% 이상만큼 감소하고; 더 바람직하게는, 20% 이상만큼 감소하고; 더 바람직하게는, 30% 이상만큼 감소하고; 더 바람직하게는, 40% 이상만큼 감소하고; 훨씬 더 바람직하게는, 50% 이상만큼 감소하고; 가장 바람직하게는, 75% 초과만큼 감소한다. 종양의 수는 임의의 재현가능한 측정 수단에 의해 측정될 수 있다. 종양의 수는 나안에 가시적인 종양을 계수함으로써 또는 규정된 배율에서 측정될 수 있다. 바람직하게는, 규정된 배열은 2x, 3x, 4x, 5x, 10x 또는 50x이다.
암을 치료하는 것은 1차 종양 부위로부터 먼 다른 조직 또는 장기에서의 전이성 병변의 수를 감소시킬 수 있다. 바람직하게는, 치료 후, 전이성 병변의 수는 치료 전의 수에 비해 5% 이상만큼 감소하고; 더 바람직하게는, 전이성 병변의 수는 10% 이상만큼 감소하고; 더 바람직하게는, 20% 이상만큼 감소하고; 더 바람직하게는, 30% 이상만큼 감소하고; 더 바람직하게는, 40% 이상만큼 감소하고; 훨씬 더 바람직하게는, 50% 이상만큼 감소하고; 가장 바람직하게는, 75% 초과만큼 감소한다. 전이성 병변의 수는 임의의 재현가능한 측정 수단에 의해 측정될 수 있다. 전이성 병변의 수는 나안에 가시적인 전이성 병변을 계수함으로써 또는 규정된 배율에서 측정될 수 있다. 바람직하게는, 규정된 배열은 2x, 3x, 4x, 5x, 10x 또는 50x이다.
암을 치료하는 것은 담체 단독을 받는 집단과 비교하여 치료된 대상체의 집단의 평균 생존 시간을 증가시킬 수 있다. 바람직하게는, 평균 생존 시간은 30일 초과만큼 증가하고; 더 바람직하게는, 60일 초과만큼; 더 바람직하게는, 90일 초과만큼; 가장 바람직하게는, 120일 초과만큼 증가한다. 집단의 평균 생존 시간의 증가는 임의의 재현가능한 수단에 의해 측정될 수 있다. 집단의 평균 생존 시간의 증가는 예를 들어 활성 화합물에 의한 치료의 개시 후 집단에 대해 생존기간의 평균 길이를 계산함으로써 측정될 수 있다. 집단의 평균 생존 시간의 증가는 또한 예를 들어 활성 화합물에 의한 1회차의 치료의 완료 후 집단에 대해 생존기간의 평균 길이를 계산함으로써 측정될 수 있다.
암을 치료하는 것은 비치료된 대상체의 집단과 비교하여 치료된 대상체의 집단의 평균 생존 시간을 증가시킬 수 있다. 바람직하게는, 평균 생존 시간은 30일 초과만큼 증가하고; 더 바람직하게는, 60일 초과만큼; 더 바람직하게는, 90일 초과만큼; 가장 바람직하게는, 120일 초과만큼 증가한다. 집단의 평균 생존 시간의 증가는 임의의 재현가능한 수단에 의해 측정될 수 있다. 집단의 평균 생존 시간의 증가는 예를 들어 활성 화합물에 의한 치료의 개시 후 집단에 대해 생존기간의 평균 길이를 계산함으로써 측정될 수 있다. 집단의 평균 생존 시간의 증가는 또한 예를 들어 활성 화합물에 의한 1회차의 치료의 완료 후 집단에 대해 생존기간의 평균 길이를 계산함으로써 측정될 수 있다.
암을 치료하는 것은 본 발명의 화합물, 또는 이의 약제학적으로 허용 가능한 염, 프로드럭, 대사물질, 유사체 또는 유도체가 아닌 약물에 의한 단일치료를 받는 집단과 비교하여 치료된 대상체의 집단의 평균 생존 시간을 증가시킬 수 있다. 바람직하게는, 평균 생존 시간은 30일 초과만큼 증가하고; 더 바람직하게는, 60일 초과만큼; 더 바람직하게는, 90일 초과만큼; 가장 바람직하게는, 120일 초과만큼 증가한다. 집단의 평균 생존 시간의 증가는 임의의 재현가능한 수단에 의해 측정될 수 있다. 집단의 평균 생존 시간의 증가는 예를 들어 활성 화합물에 의한 치료의 개시 후 집단에 대해 생존기간의 평균 길이를 계산함으로써 측정될 수 있다. 집단의 평균 생존 시간의 증가는 또한 예를 들어 활성 화합물에 의한 1회차의 치료의 완료 후 집단에 대해 생존기간의 평균 길이를 계산함으로써 측정될 수 있다.
암을 치료하는 것은 담체 단독을 받는 집단과 비교하여 치료된 대상체의 집단의 사망률을 감소시킬 수 있다. 암을 치료하는 것은 비치료된 집단과 비교하여 치료된 대상체의 집단의 사망률을 감소시킬 수 있다. 암을 치료하는 것은 본 발명의 화합물, 또는 이의 약제학적으로 허용 가능한 염, 프로드럭, 대사물질, 유사체 또는 유도체가 아닌 약물에 의한 단일치료를 받는 집단과 비교하여 치료된 대상체의 집단의 사망률을 감소시킬 수 있다. 바람직하게는, 사망률은 2% 초과만큼; 더 바람직하게는, 5% 초과만큼; 더 바람직하게는, 10% 초과만큼; 가장 바람직하게는, 25% 초과만큼 감소한다. 치료된 대상체의 집단의 사망률의 감소는 임의의 재현가능한 수단에 의해 측정될 수 있다. 집단의 사망률의 감소는 예를 들어 활성 화합물에 의한 치료의 개시 후 집단에 대해 단위 시간당 질환 관련 사망의 평균 수를 계산함으로써 측정될 수 있다. 집단의 사망률의 감소는 또한 예를 들어 활성 화합물에 의한 1회차의 치료의 완료 후 집단에 대해 단위 시간당 질환 관련 사망의 평균 수를 계산함으로써 측정될 수 있다.
암을 치료하는 것은 종양 성장 속도를 감소시킬 수 있다. 바람직하게는, 치료 후, 종양 성장 속도는 치료 전의 수에 비해 적어도 5%만큼 감소하고; 더 바람직하게는, 종양 성장 속도는 적어도 10%만큼 감소하고; 더 바람직하게는, 적어도 20%만큼 감소하고; 더 바람직하게는, 적어도 30%만큼 감소하고; 더 바람직하게는, 적어도 40%만큼 감소하고; 더 바람직하게는, 적어도 50%만큼 감소하고; 훨씬 더 바람직하게는, 적어도 50%만큼 감소하고; 가장 바람직하게는, 적어도 75%만큼 감소한다. 종양 성장 속도는 임의의 재현가능한 측정 수단에 의해 측정될 수 있다. 종양 성장 속도는 단위 시간당 종양 직경의 변화에 따라 측정될 수 있다.
암을 치료하는 것은 종양 재성장을 감소시킬 수 있다. 바람직하게는, 치료 후, 종양 재성장은 5% 미만이고; 더 바람직하게는, 종양 재성장은 10% 미만이고; 더 바람직하게는, 20% 미만; 더 바람직하게는, 30% 미만; 더 바람직하게는, 40% 미만; 더 바람직하게는, 50% 미만; 훨씬 더 바람직하게는, 50% 미만; 및 가장 바람직하게는, 75% 미만이다. 종양 재성장은 임의의 재현가능한 측정 수단에 의해 측정될 수 있다. 종양 재성장은 예를 들어 치료 뒤에 이어지는 과거의 종양 수축 후에 종양의 직경의 증가를 측정함으로써 측정된다. 종양 재성장의 감소는 치료가 중단된 후 재발생하는 종양의 실패에 의해 표시된다.
세포 증식성 장애를 치료하거나 예방하는 것은 세포 증식의 속도를 감소시킬 수 있다. 바람직하게는, 치료 후, 세포 증식의 속도는 적어도 5%; 더 바람직하게는, 적어도 10%; 더 바람직하게는, 적어도 20%; 더 바람직하게는, 적어도 30%; 더 바람직하게는, 적어도 40%; 더 바람직하게는, 적어도 50%; 훨씬 더 바람직하게는, 적어도 50%; 가장 바람직하게는, 적어도 75%만큼 감소한다. 세포 증식의 속도는 임의의 재현가능한 측정 수단에 의해 측정될 수 있다. 세포 증식의 속도는 예를 들어 단위 시간당 조직 샘플에서의 분열 세포의 수를 측정하여 측정된다.
세포 증식성 장애를 치료하거나 예방하는 것은 증식 세포의 비율을 감소시킬 수 있다. 바람직하게는, 치료 후, 증식 세포의 비율은 적어도 5%; 더 바람직하게는, 적어도 10%; 더 바람직하게는, 적어도 20%; 더 바람직하게는, 적어도 30%; 더 바람직하게는, 적어도 40%; 더 바람직하게는, 적어도 50%; 훨씬 더 바람직하게는, 적어도 50%; 가장 바람직하게는, 적어도 75%만큼 감소한다. 증식 세포의 비율은 임의의 재현가능한 측정 수단에 의해 측정될 수 있다. 바람직하게는, 증식 세포의 비율은 예를 들어 조직 샘플에서의 비분열 세포의 수에 대해 분열 세포의 수를 정량화함으로써 측정된다. 증식 세포의 비율은 유사분열 지수와 동등할 수 있다.
세포 증식성 장애를 치료하거나 예방하는 것은 세포 증식의 부위 또는 구역의 크기를 감소시킬 수 있다. 바람직하게는, 치료 후, 세포 증식의 부위 또는 구역의 크기는 치료 전의 이의 크기에 비해 적어도 5%만큼 감소하고; 더 바람직하게는, 적어도 10%만큼 감소하고; 더 바람직하게는, 적어도 20%만큼 감소하고; 더 바람직하게는, 적어도 30%만큼 감소하고; 더 바람직하게는, 적어도 40%만큼 감소하고; 더 바람직하게는, 적어도 50%만큼 감소하고; 훨씬 더 바람직하게는, 적어도 50%만큼 감소하고; 가장 바람직하게는, 적어도 75%만큼 감소한다. 세포 증식의 부위 또는 구역의 크기는 임의의 재현가능한 측정 수단에 의해 측정될 수 있다. 세포 증식의 부위 또는 구역의 크기는 세포 증식의 부위 또는 구역의 직경 또는 폭으로서 측정될 수 있다.
세포 증식성 장애를 치료하거나 예방하는 것은 비정상 외관 또는 형태를 갖는 세포의 수 또는 비율을 감소시킬 수 있다. 바람직하게는, 치료 후, 비정상 형태를 갖는 세포의 수는 치료 전의 이의 크기에 비해 적어도 5%만큼 감소하고; 더 바람직하게는, 적어도 10%만큼 감소하고; 더 바람직하게는, 적어도 20%만큼 감소하고; 더 바람직하게는, 적어도 30%만큼 감소하고; 더 바람직하게는, 적어도 40%만큼 감소하고; 더 바람직하게는, 적어도 50%만큼 감소하고; 훨씬 더 바람직하게는, 적어도 50%만큼 감소하고; 가장 바람직하게는, 적어도 75%만큼 감소한다. 비정상 세포 외관 또는 형태는 임의의 재현가능한 측정 수단에 의해 측정될 수 있다. 비정상 세포 형태는 예를 들어 도립 조직 배양 현미경을 사용하여 현미경검사에 의해 측정될 수 있다. 비정상 세포 형태는 핵 다형태성의 형태를 취할 수 있다.
키트 및 제조 물품
본 개시내용은 본원에 기재된 조작된 수용체를 암호화하는 폴리뉴클레오타이드 및 벡터, 및 본원에 기재된 조작된 수용체를 포함하는 면역 세포를 포함하는 키트 및 제조 물품을 제공한다. 일부 실시형태에서, 키트는 물품, 예컨대 바이알, 주사기 및 사용 설명서를 포함한다.
일부 실시형태에서, 키트는 본 개시내용의 하나 이상의 조작된 수용체를 암호화하는 서열을 포함하는 폴리뉴클레오타이드 또는 벡터를 포함한다.
일부 실시형태에서, 키트는 본원에 기재된 것과 같은 조작된 수용체를 포함하는 복수의 면역 세포를 포함한다. 일부 실시형태에서, 복수의 면역 세포는 복수의 T 세포를 포함한다.
실시예
실시예 1: 활성인자 표적 리간드의 선택
본 발명자들은 활성인자 리간드에 대한 GTex 유전자 발현 데이터베이스(gtexportal.org/home/)를 살펴보았다. 활성인자 리간드는 하기 특징을 가져야 한다: 처음에, 하나의 유형의 활성인자 리간드는 큰 활성화 신호를 전달하는 가능성을 부여하는 높은 표면 발현을 가져야 한다. 대안적으로, MiHA와 같은 활성인자는 세포 표면에서 낮은 밀도를 가질 수 있다. 둘째로, 활성인자 리간드는 필수 세포 기능을 가져야 하고, 이는 활성인자 리간드의 대립유전자가 종양 세포에서의 이수성으로 인해 소실되는 방지하고, 이들이 종양의 전개 동안 돌연변이유발을 덜 겪게 한다. 마지막으로, 활성인자 리간드는 모든 종양 세포에 존재해야 한다. 억제제 리간드가 또한 표적 세포를 제외한 모든 세포에서 발현되면 활성인자 리간드는 모든 세포에서 발현될 수 있다. 활성인자는 또한 암 세포에서 발현되어야 한다. 활성인자는 억제제와 조합되어 사용될 때 예를 들어 모든 세포에서 널리 발현될 수 있다.
도 4a는 트랜스페린 수용체(TFRC)인 예시적인 활성인자 리간드의 RNA 발현 프로파일을 보여준다. 도 4a에서 볼 수 있는 것처럼, RNA 수준에서의 TFRC의 발현은 편재하고 비교적 고르다. 추가로, TFRC는 필수 유전자이다: 기능 동형접합성 TFRC 돌연변이의 소실은 마우스에서 배아 치사이다.
도 4b는 후보 차단제, HLA-A 및 후보 활성인자, HLA-B의 발현 프로파일을 보여준다. 도 4b에서 볼 수 있는 것처럼, 후보 활성인자 및 차단제 HLA 클래스 I 발현은 함께 추적하여 활성인자와 차단제 쌍의 최적화의 도전을 쉽게 한다.
실시예 2: 암 세포에서 소실된 억제제 표적 리간드의 선택
이형접합성 소실
억제제 리간드의 하나의 가능한 풀은 이형접합성 소실로 인해 종양 세포에서 소실된 리간드이다. 26개의 조직학적 유형에 걸친 3131개의 종양 샘플의 분석에서, Beroukhim 등은 통상적인 종양에서, 게놈의 25%가 아암 수 단일 카피 수 변경(중복 및 결실)에 의해 영향을 받고, 게놈의 10%가 2% 오버랩으로 병소 단일 카피 수 변경에 의해 영향을 받는다는 것을 발견하였다. (Beroukhim et al, Nature 463:899-905 (2010)). 추가로, 많은 LOH 영역은 종양 유형들 사이에 중첩하고, 영역의 불과 22%는 하나의 종양 유형에 고유하다. 예를 들어, Beroukhim 등은 증폭 피크의 80% 및 결실 피크의 78%가 17개의 가장 대표적인 종양 유형에 흔하다는 것을 발견하였다. 이와 같이, 억제제 LBD에 의해 선택적으로 결합될 수 있는 LOH로 소실된 대립유전자는 표적 세포에 의해 발현되지 않은 잠재적인 억제제 표적이다.
본 발명자들은 이형접합성 소실을 통해 암에서 소실된 잠재적인 억제제 리간드에 대해 Cancer Genome Atlas Program (http://portals.broadinstitute.org/tcga/home)을 조사하였다. 데이터세트인 all_cancers dataset(모든_암)는 33개의 암 유형으로부터의 10,844개의 암으로 이루어졌다. 하나의 유형의 억제제 리간드는 하기 특징을 가져야 한다: 처음에, 억제제 리간드는 조직에 걸쳐 높은 균질한 표면 발현을 가져야 한다. 이는 큰 공평한 억제 신호를 전달하는 능력을 부여한다. 억제제 리간드는 많은 종양에서 부재하거나 다형성이어야 한다. 추가로, 항체 균주 또는 유전 분석과 같은 종래의 방법을 통해 종양 세포에서 억제제 리간드의 소실을 구별하는 것이 쉬워야 한다. MiHA와 같은 다른 유형의 억제제 리간드는 낮은 표면 발현을 가질 수 있다.
억제제 리간드의 하나의 풀은 암 세포에서 LOH를 통해 소실된 주요 조직적합 복합체(MHC) 대립유전자이다. 억제제 리간드로서의 이 대립유전자의 사용은 펩타이드 MHC 표적(pMHC)을 요하지 않고, 예를 들어 pan HLA-A*02 대립유전자가 사용될 수 있다.
Y 염색체의 소실
성인 남성 발현된 Y 염색체 유전자는 Y 염색체의 소실을 통한 잠재적인 억제제 리간드이다. Y 염색체에서 적어도 60개의 단백질 코딩 유전자가 있다. 몇몇 Y 염색체 유전자는 성인 남성에서 광범위하게 발현되고, Y 염색체 소실로 인해 암에서 소실될 수 있다. 몇몇 다른 광범위하게 발현된 세포질 단백질은 pMHC 억제제 후보(예를 들어, TMSB4Y, EIF1AY)이다. NLGN4Y는 광범위하게 남성에서 그리고 또한 후보에서 발현된 I형 내재성 막 단백질이다.
실시예 3: 쌍을 지은 A 수용체 및 B 수용체를 갖는 표면 항원이 결여된 세포의 표적화
본 발명자들은 이형접합성 소실에 대한 표적화 시스템이 시험관내 및 마우스 암 모델에서 작동한다는 것을 보여준다.
정상 세포와 종양 세포 사이의 구별은 2개의 기능에 따라 달라진다: (i) 종양에서 또한 보유된 정상 세포의 표면 상의 에피토프를 인식하는 활성인자("A") 수용체; 및 (ii) 종양 세포로부터 소실된 대립유전자 생성물에서의 제2 표면 에피토프를 인식하는 차단제("B") 수용체. 이 실시예에서, 본 발명자들은 A 및 B 둘 다에 대해 펩타이드-MHC(pMHC) 표적을 사용하였다(도 5a 참조):
PD-1 ICD 또는 CTLA-4-ICD를 갖는 각각의 차단제(B) 수용체는 자극으로서 T2 세포에 로딩된 펩타이드의 적정에 의해 측정된 것처럼 10x 미만의 저카트 세포에서의 활성화의 EC50의 이동을 매개하였다(도 5b). 놀랍게도, NY-ESO-1 LBD 및 LIR-1의 세포내 도메인, 막관통 도메인 및 힌지 도메인(LILRB1) 수용체를 포함하는 B 수용체는 5,000x 초과의 EC50 이동을 매개하였다(또한 도 5b). SLLMWITQC/V 이외의 비관련된 대조군 HLA-A*02-결합 펩타이드의 적정은 통상적으로 10x 미만의 총 이동에 대한 기여인 이용 가능한 HLA 분자에 대해 T2 세포에 대한 로딩된 펩타이드의 경쟁에 의해 야기된 이동의 추정치를 제공하였다(도 8). 본원에 보고된 EC50 이동 값에 대해, 본 발명자들은 통상적으로 활성인자 단독 작제물의 EC50을 비교한다.
4개의 상이한 pMHC 표적에 대해, 총 6개의 상이한 scFv는 10 내지 1,000x의 범위의 EC50으로 LIR-1 매개된 급격한 이동에 일을 하였다(도 5c). EC50 이동의 정도(즉, 차단 강도)는 표준 CAR에 융합될 때 scFv의 EC50과 상관되었다(데이터 비도시). LIR-1 B 신호전달은 다수의 A 표적 및 scFv로부터의 A 신호전달을 차단하였다(도 5d, 도 26). 봉쇄는 리간드 의존적이었다(도 9). LBD를 갖지만, ICD가 결여되거나 ICD의 중요한 요소에서 돌연변이를 함유하는 대조군 B 수용체는 A 수용체 신호에 의해 활성화를 차단하지 않는다. (도 10). A 수용체 및 B 수용체를 갖는 조작된 T 세포는 다수의 표적 항원 및 항원 결합 도메인(즉, LBD 서열)에 걸쳐 작용한다.
LIR-1 ICD는 또한 3개의 상이한 pMHC 표적에 의해 T 세포 수용체(TCR) 세포외 도메인에 융합될 때 작용한다(방법 참조). MAGE-A3으로부터 2개 및 HPV로부터의 1개인 3개의 상이한 pMHC 표적에 대한 TCR을 분석하였다. 모든 경우에, LIR-1 기반 B 수용체는 활성화 EC50을 1,000 내지 10,000x의 범위로 다량 이동시켰다. NY-ESO-1 TCR 가변 도메인 LBD "ESO(Ftcr)"가 이것에 융합된 LIR-1 기반 B 수용체는 또한 CAR 또는 TCR에 의한 활성화를 차단할 수 있었다. 이는 하기 수용체 쌍을 포함하였다.
1.
MAGE-A3FLWGPRALV 펩타이드:MHC 복합체에 결합하는 TCR LBD를 포함하는 활성인자(A) TCR("MP1-TCR")은 scFv NY-ESO-1 scFv LBD("ESO") 및 LIR-1 ICD를 포함하는 B 수용체에 의해 차단되었고, 이는 활성화 EC50을 다량 이동시켰다(도 5e);
2.
MAGE-A3 MPKVAELVHFL 펩타이드:MHC 복합체에 결합하는 제2 TCR LBD를 포함하는 A TCR("MP2-TCR")은 scFv NY-ESO-1 scFv LBD("ESO") 및 LIR-1 ICD를 포함하는 B 수용체에 의해 차단되었고, 이는 활성화 EC50을 다량 이동시켰다(도 5e);
3.
HPVTIHDIILECV 펩타이드:MHC 복합체에 결합하는 TCR LBD를 포함하는 A TCR("HPV E6-TCR")은 scFv NY-ESO-1 scFv LBD("ESO") 및 LIR-1 ICD를 포함하는 B 수용체에 의해 차단되었고, 이는 활성화 EC50을 다량 이동시켰다(도 5e);
4.
MAGE-A3FLWGPRALV 펩타이드:MHC 복합체에 결합하는 TCR LBD를 포함하는 A TCR("MP1-TCR")은 NY-ESO-1 TCR LBD("ESO(Ftcr)") 및 LIR-1 ICD를 포함하는 B 수용체에 의해 차단되었다, 이 차단제는 활성화 EC50을 다량 이동시켰다(도 5f);
5.
MAGE-A3 FLWGPRALV 펩타이드:MHC 복합체에 결합하는 scFv LBD를 포함하는 A CAR("MP1-CAR")은 TCR NY-ESO-1 TCR 가변 도메인 LBD("ESO(Ftcr)") 및 LIR-1 ICD를 포함하는 B 수용체에 의해 차단되었다. 이 차단제는 활성화 EC50을 다량 이동시켰다(도 5f).
시스 효과의 확인
조작된 효과기 세포는 오직 A+인 잠재적인 표적 세포를 구별해야 하고, 즉 이중 A+ 및 B+인 것으로부터 활성인자를 오직 디스플레이해야 한다. 의도된 것처럼 본 발명자들의 수용체 시스템 작업을 단언하기 위해, 대략 세포 크기(d 약 2.8 μm)의 표적 로딩된 비드가 A 수용체 및 B 수용체를 갖는 조작된 효과기 세포(저카트 세포)에 의해 시험되었다(도 5g). A+ 비드가 총 비드의 불과 20%를 포함할 때에도 효과기 세포는 확실히 A+ 비드와 B+ 비드의 혼합물에 의해 활성화되었다. 이는 효과기 세포가 (B+ 비드에 의해 표시된) 정상 세포를 포함하는 혼합 집단에서 (A+ 비드에 의해 표시된) 이형접합성 소실을 갖는 표적을 인식할 수 있다는 것을 확인시켜준다.
표적 농도 독립성의 확인
환자에서, 표적 밀도는 A 표적 및 B 표적의 발현 수준에 따라 변할 것이다. 본 발명자들은 상기 시스템이 A 표적 밀도가 변할 때(데이터 비기재) 및 B 표적 밀도가 변할 때(도 5h)인 둘 다에 고밀도 표적 및 저밀도 표적 둘 다로 작동한다는 것을 확인하였다. 도 5h에서, 펩타이드 독립적 방식으로 B 세포 마커 CD19 또는 HLA-A*02에 결합된 scFv가 시험되었다. 이 비-pMHC 표적은 100,000개의 에피토프/세포의 범위로 연장될 수 있는 표면 항원을 나타낸다. 이 경우에, A 대 B 모듈 발현의 비는 일시적 형질주입 검정에서 상이한 DNA 농도를 사용하여 변했다. 10x 초과의 Emax 이동이 관찰되었다. 이 실험은 pMHC 표적에 관찰된 이중 수용체 시스템의 특성이 고밀도 표적에 대해 일반적으로 동일하다는 것을 보여주었다.
1차 T 세포에서의 B 수용체 기능
세포 생존능력에 대한 판독정보로서 루시퍼라제에 의해 표적 펩타이드의 적정이 로딩된 레닐라 루시퍼라제(Biosettia)를 발현하는 MCF7 종양 세포는 표적 세포로서 사용되었다. 1차 T 세포는 A 수용체로서의 HPV TCR("HPV E7 TCR") 및 LIR-1 힌지, 막관통 도메인 및 ICD에 융합된 항-NY-ESO-1 scFv을 포함하는 B 수용체("ESO-LIR-1")에 의해 형질도입되거나, 형질도입되지 않는다("비형질도입됨"). 형질도입된 T 세포는 B 수용체 LBD에 결합하는 HLA-A*02 사합체에 커플링된 비드를 사용하여 물리적 선택을 통해 농후화된다. 표적 농도를 변화시키기 위해, 표적 세포는 다양한 양의 HPV 펩타이드가 로딩되었다. 1차 T 세포는 용량 의존적 방식으로 활성화되었다. B 수용체의 발현은 EC50 곡선을 약 100x만큼 이동시켰다(도 6a). 저카트 세포에서 (다양한 활성인자 : 차단제 DNA 비를 형질주입하여 달성된) A 수용체 대 B 수용체의 다양한 비에서 항-HLA-A*02 LBD 및 LIR-1 힌지, 막관통 도메인 및 ICD를 포함하는 B 수용체와 쌍을 이룬 항-NY-ESO-1 CAR A 수용체에 대해 유사한 결과를 얻었다(도 6b). 이 결과는 T 세포에서 HLA-A*02 차단제와 쌍을 이룬 CD19 CAR 활성인자에 의해 확인되었다(도 6c). 이와 같이, 활성인자 및 차단제 수용체 쌍의 기본 기능은 이의 복합함, 이질성 및 공여자-대-공여자 가변성에도 불구하고 1차 T 세포에서 재현되었다.
실시예 4: 쌍을 이룬 A 및 B 수용체에 의한 이형접합성 소실의 표적화
HLA 유전자좌는 오직 HLA-A*02 대립유전자를 갖는 집단의 하위집단으로 다형이다. 로딩된 펩타이드에 독립적인 HLA*A02 대립유전자의 MHC에 결합하는 리간드 결합 도메인("pan HLA-A*02" LBD)은 종양 세포에서 HLA에 이형접합성이고 HLA-A*02 대립유전자의 LOH를 갖는 대상체에서 종양을 표적화하도록 사용될 수 있다.
HLA-A*02-특이적 scFv는 LIR-1 모듈에 융합되고, 저카트 세포에서 pMHC 의존적 활성인자(ESO-CAR, 도 6b)의 존재 하에 차단제로서 기능하는 것으로 나타났다. 게다가, 항-CD19 scFv를 포함하는 A 수용체 및 HLA-A*02-특이적 scFv 및 LIR-1 LBD를 포함하는 B 수용체 둘 다를 발현하는 1차 T 세포에서, B 수용체는 A 수용체를 원하는 대로 차단하였다(도 6c).
CD19+이고 HLA-A*02에 음성인 라지 표적 세포는 LOH를 통해 소실된 HLA-A*02를 갖는 종양 세포를 모델링하도록 사용될 수 있다. HLA-A*02를 안정하게 발현하는 동일한 세포주는 정상 세포의 모델로서 사용될 수 있다. 라지 표적 세포가 오직 CD19를 발현하면 라지 세포주는 CD19 CAR 및 HLA-A*02 LIR-1 차단제를 발현하는 저카트 효과기 세포를 활성화하였다. 라지 표적 세포가 HLA-A*02를 발현하는 폴리뉴클레오타이드에 의해 형질주입될 때, 저카트 효과기 세포의 활성화가 차단되었다(도 11).
상기 기재된 것처럼, A 수용체 결합 CD19 및 B 수용체 결합 HLA-A*02는 1차 T 세포뿐만 아니라 저카트 세포에서 작동하였다. 조작된 T 세포는 HLA-A*02 발현의 부재 하에 CD19 발현 라지 세포를 사멸하였다(도 6c, 상부 패널). CD19 및 HLA-A*02 둘 다를 발현한 라지 세포는 오직 활성화 모듈을 발현하는 T 세포에 의해 사멸되었지만, 활성인자 및 차단제 모듈 둘 다를 발현하는 T 세포에 의해 동시배양될 때 감마-인터페론(IFNg) 분비(데이터 비도시) 및 세포독성 둘 다로부터 차단되었다(도 6c, 중간 패널). 활성인자 및 차단제 모듈을 보유하는 1차 T 세포는 혼합된 배양에서 CD19+/HLA-A*02+ "정상" 세포(도 6c, 오른쪽 패널)로부터 CD19+ "종양"(도 6c, 하부 패널)을 구별하였다.
활성인자 및 차단제 기전에 기초한 T 세포 치료제는 가역적으로 작용할 수 있어야 하고, 즉 봉쇄의 상태로부터 활성화로 그리고 다시 봉쇄로 사이클링할 수 있어야 한다. 효과기 세포를 CD19+ 또는 D19+/HLA-A2*02+ 중 어느 하나인 여러 회차의 라지 세포와 동시배양하였고, 이들은 회차들 사이의 배양으로부터 제거되었다. 원하는 것처럼, 표적 세포 노출의 차단-사멸-차단 프로그램(도 6d) 및 사멸-차단-사멸 프로그램(도 6e) 둘 다에 대해 정상 세포에 노출된 효과기 세포는 라지 표적 세포에 노출될 때 활성화되지 않았다. 효과기 T 세포는 이들이 노출된 표적 세포에 따라 차단의 상태로부터 세포독성으로 그리고 다시 사이클링할 수 있었다.
실시예 5: 쌍을 지은 A 및 B 수용체에 의한 이형접합성 소실의 생체내 표적화
본 발명자들은 생체내 실험에 대해 준비하기 위해 1차 T 세포에서 조작된 CD19/HLA-A*02 활성인자/차단제 쌍이 표준 CD3/CD28 자극을 사용하여 많은 수로 시험관내 확장이 가능하게 되었다는 것을 보여주었다(도 7a). 이와 같이, 세포 산물은 치료제로서 환자에서 사용하기 위한 충분한 분량으로 제조될 수 있다.
면역손상된 (NGS-HLA-A2.1) 마우스의 옆구리로 라지 표적 세포를 주사함으로써 CD19+/HLA-A*02+ 또는 CD19+/ HLA-A*02- 종양 세포 마우스 이종이식편이 생성되었다(도 7b). 라지 세포를 2e6개 또는 1e7개의 T 세포인 2의 용량에서 주사하고, 시간에 걸쳐 종양 성장 및 이식된 T 세포의 지속성을 분석하였다. 오직 CD19+/HLA-A*02- 종양 세포는 전달된 T 세포 수에 의해 추적된 마우스 및 종양 대조군에서 사멸되어서 숙주 마우스의 생존을 촉진한다(도 7c 내지 도 7e 및 도 12). 정상 세포를 모델링하도록 설계된 정상 CD19+/HLA-A*02+ 세포는 치료에 의해 영향을 받지 않는다.
요약
본 발명자들은 LOH로부터 유래된 암 표적의 광범위한 새로운 종류의 이점을 취할 수 있는 합성 신호 통합 시스템을 개발하였다. 상기 시스템은 부당한 실험 없이 LOH를 갖는 환자에 대한 세포 치료의 요건을 충족한다. 상기 시스템은 저카트 세포, 1차 T 세포 및 생체내에서 튼튼히 작동한다. 이 시스템은 또한 (i) 모듈식 및 가요성이고, 상이한 표적 밀도로 CAR 및 TCR 양상에 걸쳐 작동하고; (ii) 차단제 및 활성인자 표적에 의해 침묵화될 때 소수의 세포가 오직 활성인자를 발현할 때가 아니라 시스에서 하나의 표면에 존재하고; (iii) 신체에 걸쳐 종양 세포를 사냥할 필요성과 일치하여 가역적으로 상태를 스위칭한다.
실시예 6: 실시예 3 내지 실시예 5를 위한 방법
세포 배양
BPS Bioscience로부터 NFAT 루시퍼라제 리포터를 암호화하는 저카트 세포를 얻었다. ATCC로부터 이 연구에서 사용된 모든 다른 세포주를 얻었다. 배양에서, 저카트 세포를 10% FBS, 1% Pen/Strep 및 0.4mg/mL G418/제네티신이 보충된 RPMI 배지에서 유지켰다. ATCC에 의해 제시된 것처럼 T2, MCF7 및 라지 세포를 유지시켰다. 5의 MOI에서 라지 세포를 HLA-A*02 렌티바이러스(커스텀 렌티바이러스, Alstem)로 형질도입함으로써 "정상" 라지 세포를 제조하였다. FACSMelody Cell Sorter(BD)를 사용하여 HLA-A*02-양성 라지 세포를 분류하였다.
플라스미드 작제
힌지, 막관통 영역, 및/또는 백혈구 면역글로불린 유사 수용체 하위패밀리 B 구성원 1, LILRB1(LIR-1), 예정 세포사 단백질 1, PDCD1(PD-1) 또는 세포독성 T 림프구 단백질 4, CTLA4(CTLA-4)의 세포내 도메인을 포함하는 수용체의 도메인에 NY-ESO-1 scFv LBD를 융합함으로써 NY-ESO-1-반응성 억제 작제물이 생성되었다. 유전자 분절은 Golden Gate 클로닝을 사용하여 조합되고, 렌티바이러스 발현 플라스미드에 함유된 인간 EF1α 프로모터의 하류에 삽입되었다.
저카트 세포 형질주입
3 펄스, 1500 V, 10 msec의 설정을 사용하여 제조사의 프로토콜에 따라 100 uL 형식 Neon 전기천공 시스템(Thermo Fisher Scientific)을 통해 저카트 세포를 일시적으로 형질주입하였다. 동시형질주입을 1e6개의 세포당 1 내지 3 ug의 활성인자 CAR 또는 TCR 작제물 및 1 내지 3 ug의 scFv 또는 Ftcr 차단제 작제물 또는 빈 벡터로 수행하고, 20% 열 불활성화된 FBS 및 0.1% Pen/Strep가 보충된 RPMI 배지에서 회수하였다.
저카트-NFAT-루시퍼라제 활성화 연구
Genscript에 의해 펩타이드, MAGE-A3(MP1; FLWGPRALV), MAGE-A3(MP2; MPKVAELVHFL), HPV E6(TIHDIILECV), HPV E7(YMLDLQPET) 및 변형된 NY-ESO-1 ESO(ESO; SLLMWITQV)를 합성하였다. 활성화 펩타이드는 50 uM에서 시작하여 연속 희석되었다. 차단제 펩타이드인 NY-ESO-1은 (달리 표시되지 않는 한) 50 uM으로 희석되었고, 이것은 활성화 펩타이드 연속 희석액에 첨가되고 후속하여 1% BSA 및 0.1 % Pen/Strep가 보충된 15 uL의 RPMI 중에 1e4 T2 세포에 로딩되고, Corning® 384웰 Low Flange White Flat Bottom Polystyrene TC-treated Microplates에서 항온처리되었다. 다음날, 1e4 저카트 세포를 10% 열 불활화된 FBS 및 0.1% Pen/Strep가 보충된 15 uL의 RPMI에 재현탁시키고, 펩타이드 로딩된 T2 세포에 첨가하고, 6시간 동안 동시배양하였다. 저카트 발광을 평가하도록 ONE-Step Luciferase Assay System(BPS Bioscience)이 사용되었다. 기술적 중복으로 검정이 수행되었다.
1차 T 세포 형질도입, 확장 및 농후화
동결된 PBMC를 37℃ 수욕에서 해동하고, 1% 인간 혈청을 갖는 LymphoONE(Takara)에서 1e6개의 세포/mL로 배양하고, IL-15(10ng/mL) 및 IL-21(10ng/mL)이 보충된 1:100의 T 세포 TransAct(Miltenyi)를 사용하여 활성화하였다. 24시간 후, 렌티바이러스를 5의 MOI에서 PBMC에 첨가하였다. 세포가 TransAct 자극 하에 확장하게 하도록 PBMC를 추가 2일 내지 3일 동안 배양하였다. 확장 후, 제조사의 지시에 따라 항-PE 마이크로비드(Miltenyi)를 사용하여 활성인자 및 차단제 형질도입된 1차 T 세포는 농후화되었다. 간단히, 1차 T 세포를 MACS 완충액(PBS 중의 0.5% BSA + 2 mM EDTA)에서 4℃에서 30분 동안 1:100 희석으로 CD19-Fc(R&D Systems)와 항온처리하였다. 세포를 MACS 완충액 중에 3회 세척하고, MACS 완충액 중에 4℃에서 30분 동안 2차 항체(1:200) 중에 항온처리하였다. 이후, 세포를 항-PE 마이크로비드에서 항온처리하고, LS 칼럼(Miltenyi)을 통해 통과시켰다.
1차 T 세포 시험관내 세포독성 연구
pMHC 표적에 의한 세포독성 연구를 위해, 농후화된 1차 T 세포를 48시간 동안 3:1의 효과기:표적 비로 상기 기재된 것처럼 표적 펩타이드의 적정으로 로딩된 레닐라 루시퍼라제(Biosettia)를 발현하는 2e3개의 MCF7 세포와 항온처리하였다. Renilla Luciferase Reporter Assay System(Promega)을 사용하여 살아 있는 루시퍼라제 발현 MCF7 세포를 정량화하였다. 비-pMHC 표적에 의한 세포독성 연구를 위해, 농후화된 1차 T 세포를 6일 이하 동안 3:1의 효과기:표적 비로 2e3개의 WT 라지 세포("종양" 세포) 또는 HLA-A*02 형질도입된 라지 세포("정상" 세포)와 항온처리하였다. GFP 및 레닐라 루시퍼라제(Biosettia)를 안정하게 발현하는 WT "종양" 라지 세포 또는 HLA-A*02 "정상 " 라지 세포는 안정하게 발현하는 RFP이고, 반딧불이 루시퍼라제(Biosettia)는 IncuCyte 생 세포 영상화기를 사용하여 비표지된 1차 T 세포와 함께 영상화하였다. IncuCyte 영상화 소프트웨어를 사용하여 시간에 걸쳐 생 라지 세포의 형광 강도를 정량화하였다. 가역성 연구를 위해, 농후화된 1차 T 세포를 3일 동안 "정상" 또는 "종양" 라지 세포와 유사하게 동시배양하고 영상화하였다. 3일 후, T 세포를 CD19 음성 선택을 사용하여 남은 라지 세포로부터 분리하고, 기재된 것처럼 새로운 "정상" 또는 "종양" 라지 세포로 재시딩하였다. 별개의 웰에서, Dual-Luciferase Reporter Assay System(Promega)을 사용하여 생 루시퍼라제 발현 라지 세포를 정량화하였다.
마우스 이종이식 연구
동결된 PBMC를 37℃ 수욕에서 해동하고, 활성화 전에 무혈청 TexMACS 배지(Miltenyi)에서 밤새 휴지시켰다. IL-15(20ng/mL) 및 IL-21(20ng/mL)이 보충된 T 세포 TransAct (Miltenyi) 및 TexMACS 배지를 사용하여 PBMC를 1.5e6개의 세포/mL에서 활성화하였다. 24시간 후, 렌티바이러스를 5의 MOI에서 PBMC에 첨가하였다. 세포가 TransAct 자극 하에 확장하게 하도록 PBMC를 추가 8일 내지 9일 동안 배양하였다. 확장 후, 생체내 주사 전에 스트렙타비딘-PE-HLA-A*02-pMHC에 대해 항-PE 마이크로비드(Miltenyi)를 사용하여 T 세포는 A2-LIR-1(LIR-1 힌지, TM 및 ICD에 융합된 pMHC HLA-A*02 ScFv)에서 농후화되었다.
The Jackson Labs로부터 5주령 내지 6주령 암컷 NOD.Cg-Prkdcscid Il2rgtm1Wjl Tg(HLA-A/H2-D/B2M)1Dvs/SzJ (NSG-HLA-A2/HHD) 마우스를 구입하였다. 동물을 연구의 개시 전 적어도 3일 동안 수용 환경에 순응시켰다. 동물을 오른쪽 옆구리에서 피하로 100 uL의 부피로 2e6개의 WT 라지 세포 또는 HLA-A*02 형질도입된 라지 세포로 주사하였다. 종양이 70 mm3의 평균에 도달할 때(V = L x W x W/2), 동물을 5개의 그룹으로 무작위화하고(n=7), 2e6개(데이터 비기재) 또는 1e7개의 T 세포를 꼬리 정맥을 통해 투여하였다. T 세포 주사 후, 종양 측정을 매주 3회 수행하고, 유동 분석 후 10일 및 17일에 혈액을 수집하였다. RBC 용해 후, 세포를 항-hCD3 항체, 항-hCD4 항체, 항-hCD8 항체, 항-msCD45 항체(Biolegend)에 의해 염색하였다.
실시예 7:
이전에 기재된 것처럼 NFAT-루시퍼라제 리포터 시스템을 사용하여 EGFR 항원 결합 도메인(CT479)과 함께 활성인자 CAR을 발현하는 저카트 세포의 활성화를 차단하는 HLA-A-A*02 항원 결합 도메인 및 LIR-1 ICD(C1765)를 갖는 차단제 수용체의 능력을 분석하였다. EGFR+ 및 HLA-A*02-인 야생형 HeLa 종양 세포를 표적 세포로서 사용하였다. 활성인자 및 차단제 항원 둘 다를 발현하는 표적 세포로서 사용하기 위해 EGFR+ /HLA-A*02+ HeLa 세포를 생성하기 위해 HLA-A*02+를 암호화하는 폴리뉴클레오타이드에 의해 EGFR+/ HLA-A*02- HeLa 세포를 또한 형질도입하였다.
도 13에 도시된 것처럼, EGFR CAR을 발현하는 저카트 세포에서의 HLA-A*02 LIR-1 차단제의 발현은 차단제를 발현하지 않는 저카트 세포의 CAR Emax와 비교하여 5배 초과만큼 CAR EMAX를 이동시킨다.
게다가, 표적 세포에서 더 낮은 HLA-A2 발현 수준에 의해 더 낮은 차단이 관찰되었다. 야생형 HCT116 세포는 EGFR+ 및 HLA-A*02이다. EGFR 및 HLA-A*02의 수준은 항-EGFR 항체 및 항-HLA-A*02 항체(BB7.2)를 사용하여 HLA-A*02 폴리뉴클레오타이드를 암호화하는 폴리뉴클레오타이드에 의해 형질도입된 HCT116 세포 및 HeLa 세포에서 분석된 후 FACs 분류가 되었다. 도 14a 및 도 14b에 도시된 것처럼, HCT116 세포는 형질도입된 HeLa 세포보다 차단제 HLA-A*02 항원의 더 낮은 수준을 갖는다. EGFR CAR 및 HLA-A*02 LIR-1 차단제를 발현하는 저카트 세포가 EGFR 및 HLA-A*02 항원을 발현하는 HCT116 표적 세포에 의해 제시될 때, HLA-A*02 LIR-1 차단제의 존재는 EGFR CAR의 EMAX를 1.8배 이동시켰다(도 15b). 이와 반대로, 더 높은 수준의 HLA-A*02 항원을 발현한 형질도입된 HeLa 세포는 5배 초과의 EGFR CAR EMAX 이동을 매개할 수 있었다(도 13). 대조군으로서, EGFR 넉아웃 HCT116 세포에 의한 최소 활성화가 있었다(도 15a).
EGFR CAR 및 HLA-A*02 LIR-1 차단제를 사용하여 50% 차단을 달성하는 데 필요한 차단제 대 활성인자의 비는 비드 기반 시스템을 사용하여 분석되었고, 이는 도 16a 및 도 16b에 도시되어 있다.
활성인자 항원의 EC50을 결정하기 위해, 활성인자 비드를 상이한 농도에서 활성인자 항원으로 코팅하였다. 비관련 단백질은 총 단백질 농도가 동일하도록 각각의 농도로 첨가되었고, 일정한 양의 비드는 EGFR CAR을 발현하는 저카트 효과기 세포에 첨가되었다(도 16a).
차단제 항원 IC50을 결정하기 위해, 비드를 (도 16a에서 결정된) EC50 농도에서 활성인자 항원으로 코팅하고, 상이한 농도에서 차단제 항원으로 코팅하였다. 비관련 단백질은 총 단백질 농도가 동일하게 있도록 각각의 농도에서 첨가되었고, 일정한 양의 비드는 EGFR CAR 또는 EGFR CAR 및 HLA-A*02 LIR-1 차단제를 발현하는 저카트 효과기 세포에 첨가되었다(도 16b).
실시예 8: LIR-1 기반 차단제는 고형 종양 세포주를 사용하여 TCR 신호전달을 억제할 수 있다
상이한 농도의 활성인자 및 차단제 펩타이드가 로딩된 A375 표적 세포를 사용하여 MAGE-A3 활성인자 TCR 및 NY-ESO-1 scFv LIR-1 기반 억제 수용체(LIR-1 힌지, TM 및 ICD를 포함)를 발현하는 저카트 효과기 세포를 분석하였다. 저카트 세포 활성화는 NFAT 루시퍼라제 검정을 사용하여 분석되었다(실시예 6 참조). 도 17에 도시된 것처럼, 50 μM NY-ESO-1 펩타이드에 의한 A375 세포의 로딩은 활성인자 TCR EMAX를 10배 초과로 이동시켰다. A375 세포 대 T2 표적 세포에서 펩타이드 로딩 효율의 약 100x 차이가 추정되었다. 펩타이드 로딩은 명확한 치료학적 지수에 원인일 수 있다.
실시예 9: HLA-A*02 LIR-1 기반 차단제는 B 세포 백혈병 세포주를 사용하여 CAR 신호전달을 억제할 수 있다
NALM6 표적 세포를 사용하여 pMHC HLA-A*02 scFv LIR-1 기반 억제 수용체(LIR 힌지, TIM 및 ICD를 포함)의 동시발현이 있거나 없는 비-pMHC, 고밀도 CD19 특이적 활성인자(CD19 scFv CAR 활성인자)를 발현하는 저카트 효과기 세포를 분석하였다. 저카트 세포 활성화는 NFAT 루시퍼라제 검정(실시예 6 참조)을 사용하여 분석되었고, 효과기 대 표적 세포(E:T) 비가 변했다.
도 18에 도시된 것처럼, 저카트 세포에 의한 차단제의 발현은 CAR의 EMAX를 5배 초과만큼 이동시킬 수 있었다.
실시예 10: HLA-A*02 LIR-1 기반 차단제는 용량 의존적 방식으로 CAR 신호전달을 억제할 수 있다
변하는 양의 펩타이드가 로딩된 T2 표적 세포를 사용하여 NY-ESO-1 scFv CAR 및 pMHC HLA-A*02 scFv LIR-1 기반 억제 수용체를 발현하는 저카트 효과기 세포를 분석하였다(주목, 이 경우에 활성인자 및 차단제 ScFv 둘 다에 의해 동일한 펩타이드가 인식된다). 저카트 세포 활성화는 NFAT 루시퍼라제 검정을 사용하여 분석되었다(실시예 6 참조). 저카트 세포에 의해 발현된 수용체의 비를 변화시키도록 활성인자 대 차단제 DNA의 다양한 비, 즉 1:1, 1:2 및 1:3의 활성인자 대 차단제에 의해 저카트 세포를 형질주입하였다.
도 19에서 볼 수 있는 것처럼, 1:1의 비로 활성인자 및 차단제 수용체 DNA에 의해 형질주입된 저카트 세포에 의해서도, MHC HLA-A*02 scFv LIR-1 기반 억제 수용체(차단제)는 활성인자 CAR에 의해 저카트 세포의 활성화를 억제할 수 있었다. 게다가, 억제 수용체가 활성화를 차단하는 정도는 저카트 세포 형질주입에서 사용된 활성인자 수용체 DNA와 비교하여 억제 수용체 DNA의 증가된 양에 의해 증가하였다.
실시예 11: HLA-A*02 LIR-1 기반 차단제는 조정 가능한 강도로 보편적 (pan HLA 클래스 I) 활성인자를 억제할 수 있다
HLA-A*02 양성 T2 세포를 사용하여 pan HLA 항체 W6/32에 기초한 3개의 상이한 scFv 결합 도메인을 갖는 pan HLA scFv CAR, 및 pMHC HLA-A*02 scFv LIR-1 기반 억제 수용체를 발현하는 저카트 효과기 세포의 활성화를 분석하였다. 도 20으로부터 볼 수 있는 것처럼, 각각의 활성인자 scFv는 HLA-A*02-음성 저카트 세포에서 상이한 기능적 신호를 지지하였다. 저카트 세포가 1:2의 E:T 비에서 HLA-A*02-양성 T2 표적 세포와 접촉될 때 pMHC HLA-A*02 scFv LIR-1 기반 억제 수용체는 모든 3개의 pan HLA scFv CAR로부터 기능적 신호를 차단할 수 있었다. 게다가, pMHC HLA-A*02 scFv LIR-1 기반 억제 수용체는 25배까지 활성인자를 억제할 수 있었다.
실시예 12: HLA-A*02 LIR-1 기반 억제 수용체는 MSLN CAR 활성인자에 의해 활성화를 차단할 수 있다
실시예 6에 기재된 것과 같은 NFAT 루시퍼라제 검정을 사용하여 MSLN CAR 활성인자 및 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체를 발현하는 저카트 효과기 세포의 활성화를 분석하였다.
저카트 세포를 1:4의 비의 활성인자:차단제 DNA에 의해 형질주입하고, 무세포 비드 기반 검정에서 활성화를 분석하였다(도 21a). 비드를 활성인자 항원, 또는 활성인자 및 차단제 항원으로 로딩하고, 비드 대 저카트 세포의 비가 변했다. 무세포 비드 기반 검정에서, pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체는 세포가 시스로 pMHC HLA-A*02 차단제 및 MSLN 활성인자를 보유하는 비드와 접촉할 때 저카트 세포의 활성화를 차단할 수 있었다. 비드에서의 pMHC HLA-A*02 차단제의 존재는 12X 이상만큼 MSLN CAR의 EMAX를 이동시킬 수 있었다(도 21a).
만성 골수성 백혈병 세포주 K562를 사용하여 활성화에 대해 1:4 DNA 비의 동일한 활성인자 및 차단제에 의해 형질주입된 활성화 저카트 세포를 분석하였다. K562는 MLSN인 활성인자 항원을 발현한다. 활성인자 및 차단제 항원(MSLN+ HLA-A*02+) 둘 다를 발현하도록 HLA-A*02에 의해 형질도입된 K562 세포 및 차단제 항원이 아니라 활성인자를 발현한 비형질도입된 K562 (MSLN+ HLA-A*02-)에 대한 저카트 효과기 세포의 반응을 분석하였다. 도 21b로부터 볼 수 있는 것처럼, K562 세포에 의한 HLA-A*02+의 발현은 MSLN CAR EMAX를 5X 초과만큼 이동시킬 수 있었다.
실시예 6에서 라지에 기재된 것처럼 효과기 1차 T 세포 및 SiHa 또는 HeLa 표적 세포를 사용하여 MSNL ScFv CAR을 통해 활성화를 차단하는 pMHC HLA-A*02 억제 수용체의 능력을 또한 분석하였다. SiHa 및 HeLa 세포는 MSLN을 내인성으로 발현하고, HLA-A*02 억제 수용체 표적을 발현하도록 형질도입되었다. IFNγ의 배수 유도를 살펴보아 1차 효과기 T 세포의 활성화를 분석하였다. 도 22에 도시된 것처럼, pMHC HLA-A*02 LIR-1 억제 수용체는 1차 T 세포가 HLA-A*02를 발현하는 SiHa 또는 HeLa 표적 세포에 의해 제시될 때 1차 T 세포의 활성화를 차단할 수 있었다(각각 10X 및 5X 억제를 초과).
T 세포가 HLA-A*02가 아니라 MSLN을 발현한 SiHa 세포에 의해 제시될 때, pMHC HLA-A*02 억제 수용체는 또한 MSLN ScFv CAR 및 pMHC HLA-A*02 LIR-1 억제 수용체 둘 다를 발현하는 T 세포에 의한 사멸을 억제할 수 있었다(도 23).
실시예 13: HLA-A*02 LIR-1 기반 억제 수용체는 EGFR CAR 활성인자에 의해 활성화를 차단할 수 있다
실시예 6에 기재된 것과 같은 NFAT 루시퍼라제 검정을 사용하여 EGFR CAR 활성인자 및 pMHC HLA-A*02 ScFv LIR-1 기반 억제 수용체(LIR-1 힌지, 막관통 및 ICD를 포함)를 발현하는 저카트 효과기 세포의 활성화를 분석하였다.
저카트 세포를 활성인자 및 차단제 수용체 DNA에 의해 형질주입하고, 무세포 비드 기반 검정에서 활성화를 분석하였다(도 24). 비드는 활성인자 항원, 차단제 항원, 또는 활성인자 및 억제제 항원이 로딩되고, 비드 대 저카트 세포의 비가 변했다. 무세포 비드 기반 검정에서, HLA-A*02 ScFv LIR-1 기반 억제 수용체는 HLA-A*02 차단제 및 EGFR 활성인자가 (상이한 비드에서) 트랜스일 때가 아니라 세포가 시스로 HLA-A*02 차단제 및 EGFR 활성인자를 보유하는 비드와 접촉할 때 저카트 세포의 활성화를 차단할 수 있었다. 비드에서의 HLA-A*02 차단제의 존재는 9X 이상만큼 EGFR CAR의 EMAX를 이동시킬 수 있었다(도 24).
표적 세포로서 HeLa 및 SiHa 세포를 사용하여 EGFR CAR 활성인자 및 HLA-A*02 ScFv LIR-1 기반 억제 수용체를 발현하는 저카트 세포의 활성화를 또한 분석하였다. 야생형 HeLa 및 SiHa 세포주는 HLA-A*02(SiHa WT 및 HeLa WT)가 아니라 EGFR을 발현하지만, HLA-A*02 억제 수용체 표적(SiHa A02 및 HeLa A02)을 발현하도록 형질도입되었다. 도 25a 내지 도 25b로부터 볼 수 있는 것처럼, HLA-A*02 ScFv LIR-1 기반 억제 수용체는 SiHa 표적 세포를 사용하여 4X 초과(도 25a) 및 HeLa 표적 세포를 사용하여 5X 초과(도 25b)만큼 EGFR EMAX를 이동시킬 수 있었다.
실시예 14: 활성인자 및 차단제 쌍은 KRAS 대립유전자 사이를 구별할 수 있다
MiHA는 대립유전자 사이의 비동의 차이를 함유하는 단백질로부터 유래된 펩타이드이다. MiHA에 대한 모델로서 KRAS를 사용하여, 활성인자 및 차단제 쌍은 KRAS G12V 및 KRAS G12D 돌연변이에 특이적인 항원 결합 도메인을 사용하여 상이한 KRAS 변이체를 구별하고 이에 반응할 수 있었다.
실시예 6에 기재된 저카트-NFAT-루시퍼라제 활성화 연구 및 T2 표적 세포를 사용하여, 활성인자 KRAS CAR 또는 TCR에 의해 매개된 활성화를 억제하는 KRAS ScFv 또는 Ftcr 억제 LIR-1 기반 수용체의 능력이 분석되었다.
도 27은 KRAS G12V ScFV 차단제가 KRAS G12D TCR(C-891)에 의해 저카트 세포의 활성화를 억제하고 KRAS G12D EMax를 14X만큼 이동시킬 수 있다는 것을 보여준다. 도 28은 KRAS G12D ScFv 차단제 및 KRAS G12V TCR 활성인자(C-913)인 상호적 쌍에 의한 유사한 결과를 보여주고, 여기서 억제제는 KRAS G12V EMax를 8X만큼 이동시킬 수 있었다.
도 29는 KRAS G12V Ftcr 차단제가 KRAS G12D TCR을 억제할 수 있었다는 것을 보여준다. 억제제는 50X 초과만큼 KRAS G12D EMax를 이동시킬 수 있었다. 이 경우에, LIR-1 막관통 도메인 및 세포내 도메인을 갖는 작제물은 억제 TCR의 알파 및 베타 사슬 둘 다(알파 및 베타에서 LIR-1), 오직 TCR 알파 사슬(오직 알파에서 LIR-1), 오직 TCR 베타 사슬(오직 베타에서 LIR-1)에 포함되었고, LIR-1 ICD가 없는 버전은 대조군으로서 포함되었다(LIR-1 무). 상호적 실험에서, KRAS G12D Ftcr 차단제는 KRAS G12V 활성인자 TCR를 억제할 수 있어서, KRAS G12V EMax를 500X 초과만큼 이동시켰다.
마지막으로, 비관련 ScFv 도메인을 갖는 억제 수용체와의 쌍이 활성인자 EMAX에 대한 적은 효과를 가지면서 이 효과는 특이적 리간드 결합 도메인에 의존적이었다(도 31a 내지 도 31b).
표 14는 KRAS ScFv 및 Ftcr 서열을 열거한다. 모든 ScFv는 LIR-1 힌지, TM 및 ICD에 융합되었다. 모든 Ftcr은 LIR-1 TM 및 ICD에 융합되었다.



실시예 15: MiHA-Y를 인식하는 TCR의 규명
Jb2.3 및 P2A 마우스 TCR로부터의 TCR 알파 및 베타 세포외 도메인을 활성인자 TCR 작제물로 클로닝하였다. 자연적 마우스 또는 인간 불변 영역을 사용하였다. mH-Y H-2Db 펩타이드 KCSRNRQYL(서열 번호 256)이 로딩된 EL5 세포는 MiHA-Y TCR이 형질주입된 저카트 세포의 활성화를 분석하도록 표적 세포로서 사용되었다(도 32). 도 32로부터 볼 수 있는 것처럼, C-003121은 튼튼한 저카트 세포 활성화를 지지한다.

실시예 16: 부 조직접합 항원 HA-1 억제 수용체
HLA-A*02 및 A*11 클래스 I 대립유전자를 보유하는 T2 세포를 50 uM A*02-특이적 HA-1 차단제 펩타이드의 부재 또는 존재 하에 A*02-특이적 NY-ESO-1 펩타이드의 적정으로 로딩하였다. 상기 기재된 것처럼 NY-ESO-1 TCR 또는 NY-ESO-1 TCR 및 HA-1 Ftcr을 발현하는 저카트 효과기 세포의 활성화를 분석하였다(실시예 6 참조). 도 33a는 차단제 펩타이드의 부재 하에 NY-ESO-1 TCR의 민감성이 HA-1 Ftcr의 존재에 의해 영향을 받지 않는다는 것을 보여준다. HA-1(H) 차단제 펩타이드의 존재 하에, NY-ESO-1 및 HA-1(H) 펩타이드는 동일한 HLA-A*02 대립유전자에 대해 경쟁하여 약 30x의 EC50 오른쪽 이동을 야기한다(실선 정사각형 대 파선 정사각형). 그렇지만, 약 10x의 활성의 추가 오른쪽 이동이 HA-1 Ftcr 차단제의 존재 하에 관찰된다(파선 정사각형 대 파선 원). 게다가, Emax는 1.5x 하향 이동하였다(고체 원대 파선 원). 도 33b는 비특이적인 대립유전자 변이체 HA-1(R) 차단제 펩타이드의 존재 하에, 본질적으로 차단이 관찰되지 않는다는 것을 보여주고, 이는 차단이 단일 아미노산에 특이적이라는 것을 제시한다. 일반적으로, NY-ESO-1이 HA-1(R)보다 더 효과적으로 HLA-A*02로 로딩하므로(도 35 참조), HA-1(R) 차단제 펩타이드의 존재 하에 관찰된 3-5x 오른쪽 이동이 또한 있다(실선에서 파선).
펩타이드 서열은 하기와 같았다:
NY-ESO-1 = SLLMWITQV (서열 번호 265),
HA-1(H) = VLHDDLLEA (서열 번호 191),
HA-1(R) = VLRDDLLEA (서열 번호 266).
HA-1 Ftcr은 또한 HA-1(H) 펩타이드의 존재 하에 KRAS TCR을 특이적으로 차단할 수 있다. HLA-A*02 및 A*11 클래스 I 대립유전자를 보유하는 T2 세포를 50 uM A*02-특이적 HA-1 차단제 펩타이드의 부재 또는 존재 하에 A*11-특이적 KRAS 펩타이드의 적정으로 로딩하였다. 상기 기재된 것처럼 NY-ESO-1 TCR 또는 NY-ESO-1 TCR 및 HA-1 Ftcr을 발현하는 저카트 효과기 세포의 활성화를 분석하였다(실시예 6 참조). 도 34a는 차단제 펩타이드의 부재 하에 KRAS TCR의 민감성이 HA-1 Ftcr의 존재에 의해 영향을 받지 않는다는 것을 보여준다. HA-1(H) 차단제 펩타이드의 존재 하에, HA-1 Ftcr은 활성에서 KRAS TCR을 약 5x만큼 차단한다(고체 원 대 파선 원). 게다가, Emax는 2.7x 하향 이동하였다(고체 원대 파선 원). 도 34b는 비특이적인 대립유전자 변이체 HA-1(R) 차단제 펩타이드의 존재 하에 본질적으로 차단이 관찰되지 않는다는 것을 보여주고, 이는 차단이 단일 아미노산에 특이적이라는 것을 제시한다. 일반적으로, KRAS 및 HA-1(H) 또는 HA-1(R)이 동일한 대립유전자로 로딩하지 않으므로, 차단제 펩타이드의 존재 하에 관찰된 유의미한 오른쪽 이동이 없다(실선 대 파선).
펩타이드 로딩된 HLA-A*02 클래스 I 대립유전자 생성물을 특이적으로 인식하는 BB7.2 염색을 사용하여 T2 세포에 의한 NY-ESO, HA-1(H) 및 HA-1(R) 펩타이드의 로딩이 비교되고, 유세포분석법을 사용하여 정량화되었다. 도 35는 HLA-A*02-특이적 NY-ESO-1 및 HA-1(H) 펩타이드의 로딩이 T2 세포에서 매우 유사하다는 것을 보여준다. 대립유전자 변이체인 HA-1(R)은 HA-1(H) 및 NY-ESO-1 펩타이드보다 약간 덜 효율적으로 로딩한다.
HA-1(H) Ftcr 서열은 표 10에 기재되어 있고, NY-ESO-1 및 KRAS TCR은 하기 표 17에 기재되어 있다.

실시예 17: 활성인자 및 억제제 펩타이드의 비
활성인자 및 차단제 펩타이드 로딩된 T2 세포에 의한 동시배양의 6시간 후 단독으로 또는 NY-ESO-1 ScFv LIR1 차단제와 조합되어 활성인자 MAGE-A3 CAR에 의해 형질도입된 저카트 세포의 NFAT-루시퍼라제 신호를 측정하였다. 도 36a는 적정된 양의 활성인자 MAGE-A3 펩타이드 및 고정된 농도의 차단제 NY-ESO-1 펩타이드가 로딩된 T2 세포와 동시배양된 저카트 세포의 반응을 보여준다. 도 36b는 적정된 양의 차단제 NY-ESO-1 펩타이드 및 Emax 농도(약 0.1 μM)보다 높은 고정된 농도의 활성인자 MAGE-A3 펩타이드가 로딩된 T2 세포에 대한 저카트의 반응을 보여준다. 도 36c는 각각의 곡선에 사용된 일정한 활성인자 MAGE 펩타이드 농도로 정규화되고 x축에 작도된 도 36b로부터의 x-값 차단제 NY-ESO-1 펩타이드 농도를 보여준다. 각각의 곡선에 대해 50% 차단(IC50)에 필요한 차단제 펩타이드 대 활성인자 펩타이드의 비가 표시된다. 필요한 B:A 펩타이드 비는 1 미만이어서, 활성인자 pMHC 항원을 차단하기 위해 표적 세포에서 활성인자 CAR 및 차단제의 이 쌍에 대해 유사한(또는 더 적은) 차단제 pMHC 항원이 필요하다는 것을 나타낸다. 활성화 pMHC CAR에서 반응을 생성하는 것과 유사한 pMHC 항원 밀도에서 차단이 가능하다.
실시예 18: 특이적 수용체 쌍의 최적화
EGFR ScFv CAR 활성인자(도 37에 표시된 것처럼 CT-479, CT-482, CT-486, CT-487 또는 CT-488), 또는 EGFR ScFv CAR 활성인자 중 어느 하나 및 HLA-A*02 PA2.1 ScFv LIR1 억제제(C1765)에 의해 형질주입된 T 세포를 HeLa 표적 세포와 동시배양하였다. 야생형 HeLa 세포주는 HLA-A*02가 아니라 EGFR을 발현하지만, HLA-A*02 억제 수용체 표적을 발현하도록 형질도입되었다. 세포를 효과기 대 표적(E:T)의 1:1 비로 동시배양하였다. 도 37의 하부 오른쪽에서, 효과기 세포 수용체 발현이 처음에 표시되지만, HeLa 세포 발현은 괄호 안에 있다. 도 37로부터 볼 수 있는 것처럼, 동일한 HLA-A*02 PA2.1 ScFv LIR1 억제제가 상이한 EGFR 활성인자 수용체와 사용될 때 상이한 정도의 차단이 관찰된다.
실시예 19: 억제 수용체는 T 세포에서 활성인자 수용체의 표면 수준을 가역적으로 감소시킨다
EGFR ScFv CAR 활성인자(CT-479, CT-482, CT-486, CT-487 또는 CT-488) 및 HLA-A*02 PA2.1 ScFv LIR1 억제제(C1765)에 의해 2개의 HLA-A*02 음성 공여자로부터의 1차 T 세포를 형질도입하였다. 형질도입된 세포는 차단제 및 활성인자 수용체에 대한 FACS 분류, 또는 차단제 및 활성인자 수용체에 대한 이중 칼럼 정제에 의해 농후화된다. 형질도입된 T 세포를 HeLa 표적 세포와 동시배양하였다. 야생형 HeLa 세포주는 HLA-A*02가 아니라 EGFR을 발현하지만, HLA-A*02 억제 수용체 표적을 발현하도록 형질도입되었다. 세포를 효과기 대 표적(E:T)의 1:1 비로 동시배양하였다. 활성인자 및 차단제 수용체를 결합시킨 표지된 펩타이드, 및 형광 활성 세포 분류를 사용하여 120시간 후 EGFR CAR 활성인자의 표면 발현을 분석하였다. 활성인자 및 차단제 리간드 둘 다를 발현하는 HeLa 세포에 의한 동시배양 후 활성인자 표면 수준의 변화는 표적 세포를 사멸하는 T 세포의 능력에 상응하였다(도 37 및 도 38을 비교).
CT-482 EGFR ScFv CAR 활성인자 및 HLA-A*02 PA2.1 ScFv LIR1 억제제(C1765) 조합을 발현하는 T 세포를 EGFR(표적 A), HLA-A*02(표적 B), 동일한 세포에서 EGFR 및 HLA-A*02의 조합(표적 AB), 상이한 세포에서 표적 A 및 표적 AB를 발현하는 HeLa 세포의 혼합 집단, 또는 상이한 세포에서 표적 B 및 표적 AB를 발현하는 HeLa 세포의 혼합 집단을 발현하는 HeLa 세포와 동시배양하였다(도 39a 내지 도 39b). T 세포를 1:1의 효과기 세포 대 표적 세포의 비로 HeLa 표적 세포와 배양하였다. T 세포를 HeLa 세포의 표적 A와 표적 AB 집단과 동시배양할 때, 활성인자의 수준은 감소되고, 이후 회수되었다(도 39a). 게다가, 활성인자 및 차단제 항원은 효과기 T 세포에서 활성인자 표면 발현 소실을 촉발하도록 동일한 세포에 함께 존재해야 한다. 활성인자와 반대로, 차단제 발현은 크게 변하지 않았다(도 39b).
도 40은 T 세포에 의한 활성인자 수용체의 발현 소실이 가역적인지를 결정하기 위한 실험에 대한 도식을 보여준다. EGFR ScFv CAR 활성인자 수용체(CT-487) 및 HLA-A*02 PA2.1 ScFv LIR1(C1765) 억제제 수용체를 발현하는 T 세포를 활성인자 및 차단제 수용체 표적(AB) 둘 다를 발현하는 HeLa 표적 세포와 동시배양하였다. 3일 동시배양 후, HeLa 세포를 항-EGFR 칼럼을 사용하여 제거하고, T 세포를 활성인자 및 억제제 수용체에 대해 염색하거나, 추가 3일 동안 오직 EGFR 활성인자 표적을 발현하는 HeLa 세포와 동시배양하였다. 추가 3일 동시배양 후, HeLa 세포를 항-EGFR 칼럼을 사용하여 다시 제거하고, T 세포를 활성인자 및 억제제 수용체에 대해 염색하거나, 염색 전에 오직 EGFR 활성인자 표적 또는 활성인자 및 차단제 표적(AB) 둘 다를 발현하는 HeLa 세포와 추가 3일 동안 동시배양하였다. T 세포를 표지된 EGFR 및 A2 프로브를 사용하여 활성인자 및 억제제 수용체(염색된)의 존재에 대해 분석하고, 형광 활성화 세포 분류를 사용하여 수용체 발현의 수준을 정량화하였다. 실험의 결과는 도 41a 내지 도 41b에 도시되어 있다. 도 41a 내지 도 41b에 도시된 것처럼, T 세포와 활성인자 및 억제제 표적 둘 다를 발현하는 HeLa 세포와의 동시배양은 EGFR 활성인자 염색을 감소시킨다(도 41a 내지 도 41b, 왼쪽 패널). T 세포가 2회차에서 활성인자(오직 표적 A)를 발현하는 HeLa 세포와 동시배양될 때, EGFR 활성인자의 발현은 증가한다. 이와 같이, 활성인자 표면 소실은 가역적이고, T 세포 세포독성에 의해 추적한다.
SEQUENCE LISTING
<110> A2 Biotherapeutics, Inc.
<120> Cell Surface Receptors Responsive to Loss of Heterozygosity
<130> A2BI-009/03WO331656-2034
<150> 62/885,093
<151> 2019-08-09
<150> 63/005,670
<151> 2020-04-06
<160> 391
<170> PatentIn version 3.5
<210> 1
<211> 45
<212> PRT
<213> Artificial Sequence
<220>
<223> CD8alpha hinge
<400> 1
Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala
1 5 10 15
Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly
20 25 30
Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp
35 40 45
<210> 2
<211> 135
<212> DNA
<213> Artificial Sequence
<220>
<223> CD8alpha hinge
<400> 2
accacgacgc cagcgccgcg accaccaaca ccggcgccca ccatcgcgtc gcagcccctg 60
tccctgcgcc cagaggcgtg ccggccagcg gcggggggcg cagtgcacac gagggggctg 120
gacttcgcct gtgat 135
<210> 3
<211> 41
<212> PRT
<213> Artificial Sequence
<220>
<223> CD28 hinge
<400> 3
Cys Thr Ile Glu Val Met Tyr Pro Pro Pro Tyr Leu Asp Asn Glu Lys
1 5 10 15
Ser Asn Gly Thr Ile Ile His Val Lys Gly Lys His Leu Cys Pro Ser
20 25 30
Pro Leu Phe Pro Gly Pro Ser Lys Pro
35 40
<210> 4
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<223> CD28 hinge
<400> 4
tgtaccattg aagttatgta tcctcctcct tacctagaca atgagaagag caatggaacc 60
attatccatg tgaaagggaa acacctttgt ccaagtcccc tatttcccgg accttctaag 120
ccc 123
<210> 5
<211> 27
<212> PRT
<213> Artificial Sequence
<220>
<223> CD28 transmembrane domain
<400> 5
Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu
1 5 10 15
Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val
20 25
<210> 6
<211> 81
<212> DNA
<213> Artificial Sequence
<220>
<223> CD28 transmembrane domain
<400> 6
ttctgggtgc tggtcgttgt gggcggcgtg ctggcctgct acagcctgct ggtgacagtg 60
gccttcatca tcttttgggt g 81
<210> 7
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> IL-2R beta transmembrane domain
<400> 7
Ile Pro Trp Leu Gly His Leu Leu Val Gly Leu Ser Gly Ala Phe Gly
1 5 10 15
Phe Ile Ile Leu Val Tyr Leu Leu Ile
20 25
<210> 8
<211> 75
<212> DNA
<213> Artificial Sequence
<220>
<223> IL-2R beta transmembrane domain
<400> 8
attccgtggc tcggccacct cctcgtgggc ctcagcgggg cttttggctt catcatctta 60
gtgtacttgc tgatc 75
<210> 9
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> CD3 zeta activation domain
<400> 9
Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Lys Gln Gly
1 5 10 15
Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr
20 25 30
Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys
35 40 45
Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys
50 55 60
Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg
65 70 75 80
Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala
85 90 95
Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
100 105 110
<210> 10
<211> 336
<212> DNA
<213> Artificial Sequence
<220>
<223> CD3 zeta activation domain
<400> 10
agagtgaagt tcagcaggag cgcagacgcc cccgcgtaca agcagggcca gaaccagctc 60
tataacgagc tcaatctagg acgaagagag gagtacgatg ttttggacaa gcgtagaggc 120
cgggaccctg agatgggggg aaagccgaga aggaagaacc ctcaggaagg cctgtacaat 180
gaactgcaga aagataagat ggcggaggcc tacagtgaga ttgggatgaa aggcgagcgc 240
cggaggggca aggggcacga tggcctttac cagggactca gtacagccac caaggacacc 300
tacgacgccc ttcacatgca ggccctgccc cctcgc 336
<210> 11
<211> 43
<212> PRT
<213> Artificial Sequence
<220>
<223> CD3 zeta activation domain
<400> 11
Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly
1 5 10 15
Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr
20 25 30
Asp Val Leu His Met Gln Ala Leu Pro Pro Arg
35 40
<210> 12
<211> 129
<212> DNA
<213> Artificial Sequence
<220>
<223> CD3 zeta activation domain
<400> 12
agagtgaagt tcagcaggag cgcagacgcc cccgcgtacc agcagggcca gaaccagctc 60
tataacgagc tcaatctagg acgaagagag gagtacgatg ttttgcacat gcaggccctg 120
ccccctcgc 129
<210> 13
<211> 41
<212> PRT
<213> Artificial Sequence
<220>
<223> CD28 co-stimulatory domain
<400> 13
Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr
1 5 10 15
Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro
20 25 30
Pro Arg Asp Phe Ala Ala Tyr Arg Ser
35 40
<210> 14
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<223> CD28 co-stimulatory domain
<400> 14
aggagcaagc ggagcagact gctgcacagc gactacatga acatgacccc ccggaggcct 60
ggccccaccc ggaagcacta ccagccctac gcccctccca gggatttcgc cgcctaccgg 120
agc 123
<210> 15
<211> 94
<212> PRT
<213> Artificial Sequence
<220>
<223> IL-2-Rbeta intracellular domain
<400> 15
Asn Cys Arg Asn Thr Gly Pro Trp Leu Lys Lys Val Leu Lys Cys Asn
1 5 10 15
Thr Pro Asp Pro Ser Lys Phe Phe Ser Gln Leu Ser Ser Glu His Gly
20 25 30
Gly Asp Val Gln Lys Trp Leu Ser Ser Pro Phe Pro Ser Ser Ser Phe
35 40 45
Ser Pro Gly Gly Leu Ala Pro Glu Ile Ser Pro Leu Glu Val Leu Glu
50 55 60
Arg Asp Lys Val Thr Gln Leu Leu Pro Leu Asn Thr Asp Ala Tyr Leu
65 70 75 80
Ser Leu Gln Glu Leu Gln Gly Gln Asp Pro Thr His Leu Val
85 90
<210> 16
<211> 282
<212> DNA
<213> Artificial Sequence
<220>
<223> IL-2-Rbeta intracellular domain
<400> 16
aactgcagga acaccgggcc atggctgaag aaggtcctga agtgtaacac cccagacccc 60
tcgaagttct tttcccagct gagctcagag catggaggcg acgtccagaa gtggctctct 120
tcgcccttcc cctcatcgtc cttcagccct ggcggcctgg cacctgagat ctcgccacta 180
gaagtgctgg agagggacaa ggtgacgcag ctgctccccc tgaacactga tgcctacttg 240
tctctccaag aactccaggg tcaggaccca actcacttgg tg 282
<210> 17
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> STAT5 recruitment motif
<400> 17
Tyr Leu Ser Leu
1
<210> 18
<211> 760
<212> PRT
<213> Homo sapiens
<400> 18
Met Met Asp Gln Ala Arg Ser Ala Phe Ser Asn Leu Phe Gly Gly Glu
1 5 10 15
Pro Leu Ser Tyr Thr Arg Phe Ser Leu Ala Arg Gln Val Asp Gly Asp
20 25 30
Asn Ser His Val Glu Met Lys Leu Ala Val Asp Glu Glu Glu Asn Ala
35 40 45
Asp Asn Asn Thr Lys Ala Asn Val Thr Lys Pro Lys Arg Cys Ser Gly
50 55 60
Ser Ile Cys Tyr Gly Thr Ile Ala Val Ile Val Phe Phe Leu Ile Gly
65 70 75 80
Phe Met Ile Gly Tyr Leu Gly Tyr Cys Lys Gly Val Glu Pro Lys Thr
85 90 95
Glu Cys Glu Arg Leu Ala Gly Thr Glu Ser Pro Val Arg Glu Glu Pro
100 105 110
Gly Glu Asp Phe Pro Ala Ala Arg Arg Leu Tyr Trp Asp Asp Leu Lys
115 120 125
Arg Lys Leu Ser Glu Lys Leu Asp Ser Thr Asp Phe Thr Ser Thr Ile
130 135 140
Lys Leu Leu Asn Glu Asn Ser Tyr Val Pro Arg Glu Ala Gly Ser Gln
145 150 155 160
Lys Asp Glu Asn Leu Ala Leu Tyr Val Glu Asn Gln Phe Arg Glu Phe
165 170 175
Lys Leu Ser Lys Val Trp Arg Asp Gln His Phe Val Lys Ile Gln Val
180 185 190
Lys Asp Ser Ala Gln Asn Ser Val Ile Ile Val Asp Lys Asn Gly Arg
195 200 205
Leu Val Tyr Leu Val Glu Asn Pro Gly Gly Tyr Val Ala Tyr Ser Lys
210 215 220
Ala Ala Thr Val Thr Gly Lys Leu Val His Ala Asn Phe Gly Thr Lys
225 230 235 240
Lys Asp Phe Glu Asp Leu Tyr Thr Pro Val Asn Gly Ser Ile Val Ile
245 250 255
Val Arg Ala Gly Lys Ile Thr Phe Ala Glu Lys Val Ala Asn Ala Glu
260 265 270
Ser Leu Asn Ala Ile Gly Val Leu Ile Tyr Met Asp Gln Thr Lys Phe
275 280 285
Pro Ile Val Asn Ala Glu Leu Ser Phe Phe Gly His Ala His Leu Gly
290 295 300
Thr Gly Asp Pro Tyr Thr Pro Gly Phe Pro Ser Phe Asn His Thr Gln
305 310 315 320
Phe Pro Pro Ser Arg Ser Ser Gly Leu Pro Asn Ile Pro Val Gln Thr
325 330 335
Ile Ser Arg Ala Ala Ala Glu Lys Leu Phe Gly Asn Met Glu Gly Asp
340 345 350
Cys Pro Ser Asp Trp Lys Thr Asp Ser Thr Cys Arg Met Val Thr Ser
355 360 365
Glu Ser Lys Asn Val Lys Leu Thr Val Ser Asn Val Leu Lys Glu Ile
370 375 380
Lys Ile Leu Asn Ile Phe Gly Val Ile Lys Gly Phe Val Glu Pro Asp
385 390 395 400
His Tyr Val Val Val Gly Ala Gln Arg Asp Ala Trp Gly Pro Gly Ala
405 410 415
Ala Lys Ser Gly Val Gly Thr Ala Leu Leu Leu Lys Leu Ala Gln Met
420 425 430
Phe Ser Asp Met Val Leu Lys Asp Gly Phe Gln Pro Ser Arg Ser Ile
435 440 445
Ile Phe Ala Ser Trp Ser Ala Gly Asp Phe Gly Ser Val Gly Ala Thr
450 455 460
Glu Trp Leu Glu Gly Tyr Leu Ser Ser Leu His Leu Lys Ala Phe Thr
465 470 475 480
Tyr Ile Asn Leu Asp Lys Ala Val Leu Gly Thr Ser Asn Phe Lys Val
485 490 495
Ser Ala Ser Pro Leu Leu Tyr Thr Leu Ile Glu Lys Thr Met Gln Asn
500 505 510
Val Lys His Pro Val Thr Gly Gln Phe Leu Tyr Gln Asp Ser Asn Trp
515 520 525
Ala Ser Lys Val Glu Lys Leu Thr Leu Asp Asn Ala Ala Phe Pro Phe
530 535 540
Leu Ala Tyr Ser Gly Ile Pro Ala Val Ser Phe Cys Phe Cys Glu Asp
545 550 555 560
Thr Asp Tyr Pro Tyr Leu Gly Thr Thr Met Asp Thr Tyr Lys Glu Leu
565 570 575
Ile Glu Arg Ile Pro Glu Leu Asn Lys Val Ala Arg Ala Ala Ala Glu
580 585 590
Val Ala Gly Gln Phe Val Ile Lys Leu Thr His Asp Val Glu Leu Asn
595 600 605
Leu Asp Tyr Glu Arg Tyr Asn Ser Gln Leu Leu Ser Phe Val Arg Asp
610 615 620
Leu Asn Gln Tyr Arg Ala Asp Ile Lys Glu Met Gly Leu Ser Leu Gln
625 630 635 640
Trp Leu Tyr Ser Ala Arg Gly Asp Phe Phe Arg Ala Thr Ser Arg Leu
645 650 655
Thr Thr Asp Phe Gly Asn Ala Glu Lys Thr Asp Arg Phe Val Met Lys
660 665 670
Lys Leu Asn Asp Arg Val Met Arg Val Glu Tyr His Phe Leu Ser Pro
675 680 685
Tyr Val Ser Pro Lys Glu Ser Pro Phe Arg His Val Phe Trp Gly Ser
690 695 700
Gly Ser His Thr Leu Pro Ala Leu Leu Glu Asn Leu Lys Leu Arg Lys
705 710 715 720
Gln Asn Asn Gly Ala Phe Asn Glu Thr Leu Phe Arg Asn Gln Leu Ala
725 730 735
Leu Ala Thr Trp Thr Ile Gln Gly Ala Ala Asn Ala Leu Ser Gly Asp
740 745 750
Val Trp Asp Ile Asp Asn Glu Phe
755 760
<210> 19
<211> 300
<212> DNA
<213> CD3 epsilon intracellular domain
<400> 19
aagaatagaa aggccaaggc caagcctgtg acacgaggag cgggtgctgg cggcaggcaa 60
aggggacaaa acaaggagag gccaccacct gttcccaacc cagactatga gcccatccgg 120
aaaggccagc gggacctgta ttctggcctg aatcagcgca gaatcggcgg aagcaggagc 180
aagcggagca gactgctgca cagcgactac atgaacatga ccccccggag gcctggcccc 240
acccggaagc actaccagcc ctacgcccct cccagggatt tcgccgccta ccggagctag 300
<210> 20
<211> 69
<212> DNA
<213> Artificial SEquence
<220>
<223> TCR beta transmembrane domain
<400> 20
accatcctct atgagatctt gctagggaag gccaccttgt atgccgtgct ggtcagtgcc 60
ctcgtgctg 69
<210> 21
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> ITAM motif
<220>
<221> X
<222> (2)..(3)
<223> X can be any amino acid
<400> 21
Tyr Xaa Xaa Leu
1
<210> 22
<211> 270
<212> DNA
<213> Artificial Sequence
<220>
<223> CD3 gamma intracellular domain
<400> 22
ggacaggatg gagttcgcca gtcgagagct tcagacaagc agactctgtt gcccaatgac 60
cagctctacc agcccctcaa ggatcgagaa gatgaccagt acagccacct tcaaggaaac 120
cagttgagga ggaatggcgg aagcaggagc aagcggagca gactgctgca cagcgactac 180
atgaacatga ccccccggag gcctggcccc acccggaagc actaccagcc ctacgcccct 240
cccagggatt tcgccgccta ccggagctag 270
<210> 23
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> UTY peptide
<220>
<221> X
<222> (1)..(1)
<223> X is R or G
<220>
<221> X
<222> (6)..(6)
<223> X is E or A
<220>
<221> X
<222> (8)..(8)
<223> X is V or P
<400> 23
Xaa Glu Ser Glu Glu Xaa Ser Xaa Ser Leu
1 5 10
<210> 24
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> RPSY peptide
<220>
<221> X
<222> (8)..(8)
<223> X is V or L
<400> 24
Thr Ile Arg Tyr Pro Asp Pro Xaa Ile
1 5
<210> 25
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> UTY peptide
<220>
<221> X
<222> (5)..(5)
<223> X is H or R
<220>
<221> X
<222> (7)..(7)
<223> X is D or N
<400> 25
Leu Pro His Asn Xaa Thr Xaa Leu
1 5
<210> 26
<211> 23
<212> PRT
<213> Artificial Sequence
<220>
<223> TCR alpha transmembrane domain
<400> 26
Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala Gly Phe Asn Leu
1 5 10 15
Leu Met Thr Leu Arg Leu Trp
20
<210> 27
<211> 69
<212> DNA
<213> Artificial Sequence
<220>
<223> TCR alpha transmembrane domain
<400> 27
gtgattgggt tccgaatcct cctcctgaaa gtggccgggt ttaatctgct catgacgctg 60
cggctgtgg 69
<210> 28
<211> 23
<212> PRT
<213> Artificial Sequence
<220>
<223> TCR beta transmembrane domain
<400> 28
Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala Val
1 5 10 15
Leu Val Ser Ala Leu Val Leu
20
<210> 29
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> CD3 zeta transmembrane domain
<400> 29
Leu Cys Tyr Leu Leu Asp Gly Ile Leu Phe Ile Tyr Gly Val Ile Leu
1 5 10 15
Thr Ala Leu Phe Leu
20
<210> 30
<211> 89
<212> PRT
<213> Artificial Sequence
<220>
<223> CD3 delta intracellular domain
<400> 30
Gly His Glu Thr Gly Arg Leu Ser Gly Ala Ala Asp Thr Gln Ala Leu
1 5 10 15
Leu Arg Asn Asp Gln Val Tyr Gln Pro Leu Arg Asp Arg Asp Asp Ala
20 25 30
Gln Tyr Ser His Leu Gly Gly Asn Trp Ala Arg Asn Lys Gly Gly Ser
35 40 45
Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr
50 55 60
Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro
65 70 75 80
Pro Arg Asp Phe Ala Ala Tyr Arg Ser
85
<210> 31
<211> 269
<212> DNA
<213> Artificial Sequence
<220>
<223> CD3 delta intracellular domain
<400> 31
ggacatgaga ctggaaggct gtctggggct gccgacacac aagctctgtt gaggaatgac 60
caggtctatc agcccctccg agatcgagat gatgctcagt acagccacct tggaggaaac 120
tgggctcgga acaagggcgg aagcaggagc aagcggagca gactgctgca cagcgactac 180
atgaacatga ccccccggag gcctggcccc acccggaagc actaccagcc ctacgcccct 240
cccagggatt tcgccgccta ccggagcta 269
<210> 32
<211> 99
<212> PRT
<213> Artificial Sequence
<220>
<223> CD3 epsilon intracellular domain
<400> 32
Lys Asn Arg Lys Ala Lys Ala Lys Pro Val Thr Arg Gly Ala Gly Ala
1 5 10 15
Gly Gly Arg Gln Arg Gly Gln Asn Lys Glu Arg Pro Pro Pro Val Pro
20 25 30
Asn Pro Asp Tyr Glu Pro Ile Arg Lys Gly Gln Arg Asp Leu Tyr Ser
35 40 45
Gly Leu Asn Gln Arg Arg Ile Gly Gly Ser Arg Ser Lys Arg Ser Arg
50 55 60
Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro
65 70 75 80
Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala
85 90 95
Tyr Arg Ser
<210> 33
<211> 89
<212> PRT
<213> Artificial Sequence
<220>
<223> CD3 gamma intracellular domain
<400> 33
Gly Gln Asp Gly Val Arg Gln Ser Arg Ala Ser Asp Lys Gln Thr Leu
1 5 10 15
Leu Pro Asn Asp Gln Leu Tyr Gln Pro Leu Lys Asp Arg Glu Asp Asp
20 25 30
Gln Tyr Ser His Leu Gln Gly Asn Gln Leu Arg Arg Asn Gly Gly Ser
35 40 45
Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr
50 55 60
Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro
65 70 75 80
Pro Arg Asp Phe Ala Ala Tyr Arg Ser
85
<210> 34
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> SMCY peptide
<220>
<221> X
<222> (3)..(3)
<223> X is S or A
<220>
<221> X
<222> (8)..(8)
<223> X is R or Q
<400> 34
Ser Pro Xaa Val Asp Lys Ala Xaa Ala Glu Leu
1 5 10
<210> 35
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> TCR beta intracellular domain
<400> 35
Met Ala Met Val Lys Arg Lys Asp Ser Arg
1 5 10
<210> 36
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> TCR beta intracellular domain
<400> 36
atggccatgg tcaagagaaa ggattccaga 30
<210> 37
<211> 41
<212> PRT
<213> Artificial Sequence
<220>
<223> CD28 intracellular domain
<400> 37
Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr
1 5 10 15
Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro
20 25 30
Pro Arg Asp Phe Ala Ala Tyr Arg Ser
35 40
<210> 38
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<223> CD28 intracellular domain
<400> 38
aggagcaagc ggagcagact gctgcacagc gactacatga acatgacccc ccggaggcct 60
ggccccaccc ggaagcacta ccagccctac gcccctccca gggatttcgc cgcctaccgg 120
agc 123
<210> 39
<211> 42
<212> PRT
<213> Artificial Sequence
<220>
<223> 4-1BB intracellular domain
<400> 39
Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met
1 5 10 15
Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe
20 25 30
Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu
35 40
<210> 40
<211> 126
<212> DNA
<213> Artificial Sequence
<220>
<223> 4-1BB intracellular domain
<400> 40
aaacggggca gaaagaaact cctgtatata ttcaaacaac catttatgag gccagtacaa 60
actactcaag aggaagatgg ctgtagctgc cgatttccag aagaagaaga aggaggatgt 120
gaactg 126
<210> 41
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 CDR-L1
<400> 41
Arg Ser Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu
1 5 10 15
<210> 42
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 CDR-L2
<400> 42
Lys Val Ser Asn Arg Phe Ser Gly Val Pro Asp Arg
1 5 10
<210> 43
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 CDR-L3
<400> 43
Phe Gln Gly Ser His Val Pro Arg Thr
1 5
<210> 44
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 CDR-H1
<400> 44
Ala Ser Gly Tyr Thr Phe Thr Ser Tyr His Ile His
1 5 10
<210> 45
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 CDR-H2
<400> 45
Trp Ile Tyr Pro Gly Asn Val Asn Thr Glu Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly Lys
<210> 46
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 CDR-H3
<400> 46
Glu Glu Ile Thr Tyr Ala Met Asp Tyr
1 5
<210> 47
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 CDR-L1
<400> 47
Arg Ser Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Asp
1 5 10 15
<210> 48
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 CDR-L2
<400> 48
Lys Val Ser Asn Arg Phe Ser Gly Val Pro Asp Arg
1 5 10
<210> 49
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 CDR-L3
<400> 49
Met Gln Gly Ser His Val Pro Arg Thr
1 5
<210> 50
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 CDR-H1
<400> 50
Ser Gly Tyr Thr Phe Thr Ser Tyr His Met His
1 5 10
<210> 51
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 CDR-H2
<400> 51
Trp Ile Tyr Pro Gly Asp Gly Ser Thr Gln Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 52
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 CDR-H3
<400> 52
Glu Gly Thr Tyr Tyr Ala Met Asp Tyr
1 5
<210> 53
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 ScFv
<400> 53
Asp Val Leu Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Ile Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr Cys Phe Gln Gly
85 90 95
Ser His Val Pro Arg Thr Ser Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gln Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly
130 135 140
Ala Ser Val Arg Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser
145 150 155 160
Tyr His Ile His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp
165 170 175
Ile Gly Trp Ile Tyr Pro Gly Asn Val Asn Thr Glu Tyr Asn Glu Lys
180 185 190
Phe Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala
195 200 205
Tyr Met His Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe
210 215 220
Cys Ala Arg Glu Glu Ile Thr Tyr Ala Met Asp Tyr Trp Gly Gln Gly
225 230 235 240
Thr Ser Val Thr Val Ser Ser
245
<210> 54
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 ScFv
<400> 54
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
His Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Asn Thr Glu Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Glu Ile Thr Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Glu Ile Val Leu Thr Gln Ser Pro Gly
130 135 140
Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ser
145 150 155 160
Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr
165 170 175
Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Lys Val Ser
180 185 190
Asn Arg Phe Ser Gly Ile Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu Pro Glu Asp Phe Ala
210 215 220
Val Tyr Tyr Cys Phe Gln Gly Ser His Val Pro Arg Thr Phe Gly Gly
225 230 235 240
Gly Thr Lys Val Glu Ile Lys
245
<210> 55
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 ScFv
<400> 55
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
His Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Asn Thr Glu Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Glu Ile Thr Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Asp Ile Val Met Thr Gln Thr Pro Leu
130 135 140
Ser Leu Pro Val Thr Pro Gly Glu Pro Ala Ser Ile Ser Cys Arg Ser
145 150 155 160
Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr
165 170 175
Leu Gln Lys Pro Gly Gln Ser Pro Gln Leu Leu Ile Tyr Lys Val Ser
180 185 190
Asn Arg Phe Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Asp Phe Thr Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly
210 215 220
Val Tyr Tyr Cys Phe Gln Gly Ser His Val Pro Arg Thr Phe Gly Gly
225 230 235 240
Gly Thr Lys Val Glu Ile Lys
245
<210> 56
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 ScFv
<400> 56
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
His Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Asn Thr Glu Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Thr Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Glu Ile Thr Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln Ser Pro Ser
130 135 140
Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ser
145 150 155 160
Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr
165 170 175
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Lys Val Ser
180 185 190
Asn Arg Phe Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala
210 215 220
Thr Tyr Tyr Cys Phe Gln Gly Ser His Val Pro Arg Thr Phe Gly Gly
225 230 235 240
Gly Thr Lys Val Glu Ile Lys
245
<210> 57
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 ScFv
<400> 57
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
His Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asn Val Asn Thr Glu Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Ile Thr Ala Asp Glu Ser Thr Asn Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Glu Ile Thr Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln Ser Pro Ser
130 135 140
Thr Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ser
145 150 155 160
Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr
165 170 175
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Lys Val Ser
180 185 190
Asn Arg Phe Ser Gly Val Pro Ala Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Asp Asp Phe Ala
210 215 220
Thr Tyr Tyr Cys Phe Gln Gly Ser His Val Pro Arg Thr Phe Gly Gln
225 230 235 240
Gly Thr Lys Val Glu Val Lys
245
<210> 58
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 ScFv
<400> 58
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Tyr Pro Gly Asn Val Asn Thr Glu Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Thr Asn Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Phe Cys
85 90 95
Ala Arg Glu Glu Ile Thr Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Asp Val Gln Met Thr Gln Ser Pro Ser
130 135 140
Thr Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Ser Ser
145 150 155 160
Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Met Glu Trp Tyr
165 170 175
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Lys Val Ser
180 185 190
Asn Arg Phe Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Asp Asp Phe Ala
210 215 220
Thr Tyr Tyr Cys His Gln Gly Ser His Val Pro Arg Thr Phe Gly Gln
225 230 235 240
Gly Thr Lys Val Glu Val Lys
245
<210> 59
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 ScFv
<400> 59
Gln Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
His Ile Gln Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asp Gly Ser Thr Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Thr Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Leu Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Ile Tyr Phe Cys
85 90 95
Ala Arg Glu Gly Thr Tyr Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Ser Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Asp Val Leu Met Thr Gln Thr Pro Leu
130 135 140
Ser Leu Pro Val Ser Leu Gly Asp Gln Val Ser Ile Ser Cys Arg Ser
145 150 155 160
Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr
165 170 175
Leu Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile Tyr Lys Val Ser
180 185 190
Asn Arg Phe Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Asp Phe Thr Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Leu Gly
210 215 220
Val Tyr Tyr Cys Phe Gln Gly Ser His Val Pro Arg Thr Phe Gly Gly
225 230 235 240
Gly Thr Lys Leu Glu Ile Lys
245
<210> 60
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 ScFv
<400> 60
Gln Leu Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
His Ile Gln Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asp Gly Ser Thr Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Asn Leu Asp Ser Val Ser Ala Ala Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Arg Glu Gly Thr Tyr Tyr Ala Met Asp Tyr Trp Gly Lys Gly Ser
100 105 110
Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln Ser Pro Ser
130 135 140
Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ser
145 150 155 160
Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr
165 170 175
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Lys Val Ser
180 185 190
Asn Arg Phe Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Asp Phe Thr Phe Thr Ile Ser Ser Leu Gln Pro Glu Asp Ile Ala
210 215 220
Thr Tyr Tyr Cys Phe Gln Gly Ser His Val Pro Arg Thr Phe Gly Pro
225 230 235 240
Gly Thr Lys Val Asp Ile Lys
245
<210> 61
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 ScFv
<400> 61
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Leu Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
His Ile Gln Trp Val Lys Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Trp Ile Tyr Pro Gly Asp Gly Ser Thr Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Thr Asn Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Gly Thr Tyr Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln Ser Pro Ser
130 135 140
Thr Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ser
145 150 155 160
Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr
165 170 175
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Lys Val Ser
180 185 190
Asn Arg Phe Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Asp Asp Phe Ala
210 215 220
Thr Tyr Tyr Cys Phe Gln Gly Ser His Val Pro Arg Thr Phe Gly Gln
225 230 235 240
Gly Thr Lys Val Glu Val Lys
245
<210> 62
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 ScFv
<400> 62
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
His Ile Gln Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Tyr Pro Gly Asp Gly Ser Thr Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Gly Thr Tyr Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Glu Ile Val Leu Thr Gln Ser Pro Gly
130 135 140
Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ser
145 150 155 160
Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr
165 170 175
Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Lys Val Ser
180 185 190
Asn Arg Phe Ser Gly Ile Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu Pro Glu Asp Phe Ala
210 215 220
Val Tyr Tyr Cys Phe Gln Gly Ser His Val Pro Arg Thr Phe Gly Gly
225 230 235 240
Gly Thr Lys Val Glu Ile Lys
245
<210> 63
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 ScFv
<400> 63
Gln Val Thr Leu Lys Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Thr Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
His Val Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Leu
35 40 45
Gly Arg Ile Tyr Pro Gly Asp Gly Ser Thr Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Val Thr Ile Thr Ala Asp Lys Ser Met Asp Thr Ser Phe
65 70 75 80
Met Glu Leu Thr Ser Leu Thr Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Gly Thr Tyr Tyr Ala Met Asp Leu Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Glu Ile Val Leu Thr Gln Ser Pro Gly
130 135 140
Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ser
145 150 155 160
Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Ala Trp Tyr
165 170 175
Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Ser Lys Val Ser
180 185 190
Asn Arg Phe Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu Pro Glu Asp Phe Ala
210 215 220
Val Tyr Tyr Cys Gln Gln Gly Ser His Val Pro Arg Thr Phe Gly Gly
225 230 235 240
Gly Thr Lys Val Glu Ile Lys
245
<210> 64
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> HLA-A*02 ScFv
<400> 64
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Trp Met
35 40 45
Gly Trp Ile Tyr Pro Gly Asp Gly Ser Thr Gln Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Val Thr Ile Thr Arg Asp Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Gly Thr Tyr Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Asp Ile Val Met Thr Gln Thr Pro Leu
130 135 140
Ser Leu Pro Val Thr Pro Gly Glu Pro Ala Ser Ile Ser Cys Arg Ser
145 150 155 160
Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Asp Trp Tyr
165 170 175
Leu Gln Lys Pro Gly Gln Ser Pro Gln Leu Leu Ile Tyr Lys Val Ser
180 185 190
Asn Arg Phe Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Asp Phe Thr Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly
210 215 220
Val Tyr Tyr Cys Met Gln Gly Ser His Val Pro Arg Thr Phe Gly Gly
225 230 235 240
Gly Thr Lys Val Glu Ile Lys
245
<210> 65
<211> 670
<212> PRT
<213> Homo sapiens
<400> 65
Met Thr Pro Ile Leu Thr Val Leu Ile Cys Leu Gly Leu Ser Leu Gly
1 5 10 15
Pro Arg Thr His Val Gln Ala Gly His Leu Pro Lys Pro Thr Leu Trp
20 25 30
Ala Glu Pro Gly Ser Val Ile Thr Gln Gly Ser Pro Val Thr Leu Arg
35 40 45
Cys Gln Gly Gly Gln Glu Thr Gln Glu Tyr Arg Leu Tyr Arg Glu Lys
50 55 60
Lys Thr Ala Leu Trp Ile Thr Arg Ile Pro Gln Glu Leu Val Lys Lys
65 70 75 80
Gly Gln Phe Pro Ile Pro Ser Ile Thr Trp Glu His Ala Gly Arg Tyr
85 90 95
Arg Cys Tyr Tyr Gly Ser Asp Thr Ala Gly Arg Ser Glu Ser Ser Asp
100 105 110
Pro Leu Glu Leu Val Val Thr Gly Ala Tyr Ile Lys Pro Thr Leu Ser
115 120 125
Ala Gln Pro Ser Pro Val Val Asn Ser Gly Gly Asn Val Ile Leu Gln
130 135 140
Cys Asp Ser Gln Val Ala Phe Asp Gly Phe Ser Leu Cys Lys Glu Gly
145 150 155 160
Glu Asp Glu His Pro Gln Cys Leu Asn Ser Gln Pro His Ala Arg Gly
165 170 175
Ser Ser Arg Ala Ile Phe Ser Val Gly Pro Val Ser Pro Ser Arg Arg
180 185 190
Trp Trp Tyr Arg Cys Tyr Ala Tyr Asp Ser Asn Ser Pro Tyr Glu Trp
195 200 205
Ser Leu Pro Ser Asp Leu Leu Glu Leu Leu Val Leu Gly Val Ser Lys
210 215 220
Lys Pro Ser Leu Ser Val Gln Pro Gly Pro Ile Val Ala Pro Glu Glu
225 230 235 240
Thr Leu Thr Leu Gln Cys Gly Ser Asp Ala Gly Tyr Asn Arg Phe Val
245 250 255
Leu Tyr Lys Asp Gly Glu Arg Asp Phe Leu Gln Leu Ala Gly Ala Gln
260 265 270
Pro Gln Ala Gly Leu Ser Gln Ala Asn Phe Thr Leu Gly Pro Val Ser
275 280 285
Arg Ser Tyr Gly Gly Gln Tyr Arg Cys Tyr Gly Ala His Asn Leu Ser
290 295 300
Ser Glu Trp Ser Ala Pro Ser Asp Pro Leu Asp Ile Leu Ile Ala Gly
305 310 315 320
Gln Phe Tyr Asp Arg Val Ser Leu Ser Val Gln Pro Gly Pro Thr Val
325 330 335
Ala Ser Gly Glu Asn Val Thr Leu Leu Cys Gln Ser Gln Gly Trp Met
340 345 350
Gln Thr Phe Leu Leu Thr Lys Glu Gly Ala Ala Asp Asp Pro Trp Arg
355 360 365
Leu Arg Ser Thr Tyr Gln Ser Gln Lys Tyr Gln Ala Glu Phe Pro Met
370 375 380
Gly Pro Val Thr Ser Ala His Ala Gly Thr Tyr Arg Cys Tyr Gly Ser
385 390 395 400
Gln Ser Ser Lys Pro Tyr Leu Leu Thr His Pro Ser Asp Pro Leu Glu
405 410 415
Leu Val Val Ser Gly Pro Ser Gly Gly Pro Ser Ser Pro Thr Thr Gly
420 425 430
Pro Thr Ser Thr Ser Gly Pro Glu Asp Gln Pro Leu Thr Pro Thr Gly
435 440 445
Ser Asp Pro Gln Ser Gly Leu Gly Arg His Leu Gly Val Val Ile Gly
450 455 460
Ile Leu Val Ala Val Ile Leu Leu Leu Leu Leu Leu Leu Leu Leu Phe
465 470 475 480
Leu Ile Leu Arg His Arg Arg Gln Gly Lys His Trp Thr Ser Thr Gln
485 490 495
Arg Lys Ala Asp Phe Gln His Pro Ala Gly Ala Val Gly Pro Glu Pro
500 505 510
Thr Asp Arg Gly Leu Gln Trp Arg Ser Ser Pro Ala Ala Asp Ala Gln
515 520 525
Glu Glu Asn Leu Tyr Ala Ala Val Lys His Thr Gln Pro Glu Asp Gly
530 535 540
Val Glu Met Asp Thr Arg Ser Pro His Asp Glu Asp Pro Gln Ala Val
545 550 555 560
Thr Tyr Ala Glu Val Lys His Ser Arg Pro Arg Arg Glu Met Ala Ser
565 570 575
Pro Pro Ser Pro Leu Ser Gly Glu Phe Leu Asp Thr Lys Asp Arg Gln
580 585 590
Ala Glu Glu Asp Arg Gln Met Asp Thr Glu Ala Ala Ala Ser Glu Ala
595 600 605
Pro Gln Asp Val Thr Tyr Ala Gln Leu His Ser Leu Thr Leu Arg Arg
610 615 620
Glu Ala Thr Glu Pro Pro Pro Ser Gln Glu Gly Pro Ser Pro Ala Val
625 630 635 640
Pro Ser Ile Tyr Ala Thr Leu Ala Ile His Pro Ser Gln Glu Gly Pro
645 650 655
Ser Pro Ala Val Pro Ser Ile Tyr Ala Thr Leu Ala Ile His
660 665 670
<210> 66
<211> 3229
<212> DNA
<213> Homo sapiens
<400> 66
aaatgagttt taaaaaggct tgtccaggaa gcacatatgg gagctggtca ctctgcattt 60
tgggccctcc tggaggtgtt tagaccttcc gagagagaaa ctgagacaca tgagagggaa 120
gaaatgactc agtggtgaga ccctgtggag tcccacccac aaccagcaca ctgtgaccca 180
ctgcacaaac ctctagccca cagctcactt cctcctttaa gaagagaaga gaaaagagga 240
gaggagagga ggaacagaaa agaaaagaaa agaaaaagtg ggaaacaaat aatctaagaa 300
tgaggagaaa gcaagaagag tgaccccctt gtgggcactc cattggtttt atggcgcctc 360
tactttctgg agtttgtgta aaacaaaaat attatggtct ttgtgcacat ttacatcaag 420
ctcagcctgg gcggcacagc cagatgcgag atgcgtctct gctgatctga gtctgcctgc 480
agcatggacc tgggtcttcc ctgaagcatc tccagggctg gagggacgac tgccatgcac 540
cgagggctca tccatccaca gagcagggca gtgggaggag acgccatgac ccccatcctc 600
acggtcctga tctgtctcgg gctgagtctg ggcccccgga cccacgtgca ggcagggcac 660
ctccccaagc ccaccctctg ggctgaacca ggctctgtga tcacccaggg gagtcctgtg 720
accctcaggt gtcagggggg ccaggagacc caggagtacc gtctatatag agaaaagaaa 780
acagcaccct ggattacacg gatcccacag gagcttgtga agaagggcca gttccccatc 840
ccatccatca cctgggaaca cacagggcgg tatcgctgtt actatggtag cgacactgca 900
ggccgctcag agagcagtga ccccctggag ctggtggtga caggagccta catcaaaccc 960
accctctcag cccagcccag ccccgtggtg aactcaggag ggaatgtaac cctccagtgt 1020
gactcacagg tggcatttga tggcttcatt ctgtgtaagg aaggagaaga tgaacaccca 1080
caatgcctga actcccagcc ccatgcccgt gggtcgtccc gcgccatctt ctccgtgggc 1140
cccgtgagcc cgagtcgcag gtggtggtac aggtgctatg cttatgactc gaactctccc 1200
tatgagtggt ctctacccag tgatctcctg gagctcctgg tcctaggtgt ttctaagaag 1260
ccatcactct cagtgcagcc aggtcctatc gtggcccctg aggagaccct gactctgcag 1320
tgtggctctg atgctggcta caacagattt gttctgtata aggacgggga acgtgacttc 1380
cttcagctcg ctggcgcaca gccccaggct gggctctccc aggccaactt caccctgggc 1440
cctgtgagcc gctcctacgg gggccagtac agatgctacg gtgcacacaa cctctcctcc 1500
gagtggtcgg cccccagcga ccccctggac atcctgatcg caggacagtt ctatgacaga 1560
gtctccctct cggtgcagcc gggccccacg gtggcctcag gagagaacgt gaccctgctg 1620
tgtcagtcac agggatggat gcaaactttc cttctgacca aggagggggc agctgatgac 1680
ccatggcgtc taagatcaac gtaccaatct caaaaatacc aggctgaatt ccccatgggt 1740
cctgtgacct cagcccatgc ggggacctac aggtgctacg gctcacagag ctccaaaccc 1800
tacctgctga ctcaccccag tgaccccctg gagctcgtgg tctcaggacc gtctgggggc 1860
cccagctccc cgacaacagg ccccacctcc acatctggcc ctgaggacca gcccctcacc 1920
cccaccgggt cggatcccca gagtggtctg ggaaggcacc tgggggttgt gatcggcatc 1980
ttggtggccg tcatcctact gctcctcctc ctcctcctcc tcttcctcat cctccgacat 2040
cgacgtcagg gcaaacactg gacatcgacc cagagaaagg ctgatttcca acatcctgca 2100
ggggctgtgg ggccagagcc cacagacaga ggcctgcagt ggaggtccag cccagctgcc 2160
gatgcccagg aagaaaacct ctatgctgcc gtgaagcaca cacagcctga ggatggggtg 2220
gagatggaca ctcggagccc acacgatgaa gacccccagg cagtgacgta tgccgaggtg 2280
aaacactcca gacctaggag agaaatggcc tctcctcctt ccccactgtc tggggaattc 2340
ctggacacaa aggacagaca ggcggaagag gacaggcaga tggacactga ggctgctgca 2400
tctgaagccc cccaggatgt gacctacgcc cagctgcaca gcttgaccct cagacgggag 2460
gcaactgagc ctcctccatc ccaggaaggg ccctctccag ctgtgcccag catctacgcc 2520
actctggcca tccactagcc caggggggga cgcagacccc acactccatg gagtctggaa 2580
tgcatgggag ctgccccccc agtggacacc attggacccc acccagcctg gatctacccc 2640
aggagactct gggaactttt aggggtcact caattctgca gtataaataa ctaatgtctc 2700
tacaattttg aaataaagca acagacttct caataatcaa tgaagtagct gagaaaacta 2760
agtcagaaag tgcattaaac tgaatcacaa tgtaaatatt acacatcaag cgatgaaact 2820
ggaaaactac aagccacgaa tgaatgaatt aggaaagaaa aaaagtagga aatgaatgat 2880
cttggctttc ctataagaaa tttagggcag ggcacggtgg ctcacgcctg taattccagc 2940
actttgggag gccgaggcgg gcagatcacg agttcaggag atcgagacca tcttggccaa 3000
catggtgaaa ccctgtctct cctaaaaata caaaaattag ctggatgtgg tggcagtgcc 3060
tgtaatccca gctatttggg aggctgaggc aggagaatcg cttgaaccag ggagtcagag 3120
gtttcagtga gccaagatcg caccactgct ctccagcctg gcgacagagg gagactccat 3180
ctcaaattaa aaaaaaaaaa aaaaaagaaa gaaaaaaaaa aaaaaaaaa 3229
<210> 67
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> ITIM
<400> 67
Asn Leu Tyr Ala Ala Val
1 5
<210> 68
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> ITIM
<400> 68
Val Thr Tyr Ala Glu Val
1 5
<210> 69
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> ITIM
<400> 69
Val Thr Tyr Ala Gln Leu
1 5
<210> 70
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> ITIM
<400> 70
Ser Ile Tyr Ala Thr Leu
1 5
<210> 71
<211> 35
<212> PRT
<213> Artificial Sequence
<220>
<223> ITIM 1-2
<400> 71
Asn Leu Tyr Ala Ala Val Lys His Thr Gln Pro Glu Asp Gly Val Glu
1 5 10 15
Met Asp Thr Arg Ser Pro His Asp Glu Asp Pro Gln Ala Val Thr Tyr
20 25 30
Ala Glu Val
35
<210> 72
<211> 58
<212> PRT
<213> Artificial Sequence
<220>
<223> ITIM 2-3
<400> 72
Val Thr Tyr Ala Glu Val Lys His Ser Arg Pro Arg Arg Glu Met Ala
1 5 10 15
Ser Pro Pro Ser Pro Leu Ser Gly Glu Phe Leu Asp Thr Lys Asp Arg
20 25 30
Gln Ala Glu Glu Asp Arg Gln Met Asp Thr Glu Ala Ala Ala Ser Glu
35 40 45
Ala Pro Gln Asp Val Thr Tyr Ala Gln Leu
50 55
<210> 73
<211> 36
<212> PRT
<213> Artificial Sequence
<220>
<223> ITIM 3-4
<400> 73
Val Thr Tyr Ala Gln Leu His Ser Leu Thr Leu Arg Arg Glu Ala Thr
1 5 10 15
Glu Pro Pro Pro Ser Gln Glu Gly Pro Ser Pro Ala Val Pro Ser Ile
20 25 30
Tyr Ala Thr Leu
35
<210> 74
<211> 87
<212> PRT
<213> Artificial Sequence
<220>
<223> ITIM 1-3
<400> 74
Asn Leu Tyr Ala Ala Val Lys His Thr Gln Pro Glu Asp Gly Val Glu
1 5 10 15
Met Asp Thr Arg Ser Pro His Asp Glu Asp Pro Gln Ala Val Thr Tyr
20 25 30
Ala Glu Val Lys His Ser Arg Pro Arg Arg Glu Met Ala Ser Pro Pro
35 40 45
Ser Pro Leu Ser Gly Glu Phe Leu Asp Thr Lys Asp Arg Gln Ala Glu
50 55 60
Glu Asp Arg Gln Met Asp Thr Glu Ala Ala Ala Ser Glu Ala Pro Gln
65 70 75 80
Asp Val Thr Tyr Ala Gln Leu
85
<210> 75
<211> 88
<212> PRT
<213> Artificial Sequence
<220>
<223> ITIM 2-4
<400> 75
Val Thr Tyr Ala Glu Val Lys His Ser Arg Pro Arg Arg Glu Met Ala
1 5 10 15
Ser Pro Pro Ser Pro Leu Ser Gly Glu Phe Leu Asp Thr Lys Asp Arg
20 25 30
Gln Ala Glu Glu Asp Arg Gln Met Asp Thr Glu Ala Ala Ala Ser Glu
35 40 45
Ala Pro Gln Asp Val Thr Tyr Ala Gln Leu His Ser Leu Thr Leu Arg
50 55 60
Arg Glu Ala Thr Glu Pro Pro Pro Ser Gln Glu Gly Pro Ser Pro Ala
65 70 75 80
Val Pro Ser Ile Tyr Ala Thr Leu
85
<210> 76
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> ITIM 1-4
<400> 76
Asn Leu Tyr Ala Ala Val Lys His Thr Gln Pro Glu Asp Gly Val Glu
1 5 10 15
Met Asp Thr Arg Ser Pro His Asp Glu Asp Pro Gln Ala Val Thr Tyr
20 25 30
Ala Glu Val Lys His Ser Arg Pro Arg Arg Glu Met Ala Ser Pro Pro
35 40 45
Ser Pro Leu Ser Gly Glu Phe Leu Asp Thr Lys Asp Arg Gln Ala Glu
50 55 60
Glu Asp Arg Gln Met Asp Thr Glu Ala Ala Ala Ser Glu Ala Pro Gln
65 70 75 80
Asp Val Thr Tyr Ala Gln Leu His Ser Leu Thr Leu Arg Arg Glu Ala
85 90 95
Thr Glu Pro Pro Pro Ser Gln Glu Gly Pro Ser Pro Ala Val Pro Ser
100 105 110
Ile Tyr Ala Thr Leu
115
<210> 77
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> D3D4 domain
<400> 77
Tyr Gly Ser Gln Ser Ser Lys Pro Tyr Leu Leu Thr His Pro Ser Asp
1 5 10 15
Pro Leu Glu Leu
20
<210> 78
<211> 43
<212> PRT
<213> Artificial Sequence
<220>
<223> short hinge
<400> 78
Val Val Ser Gly Pro Ser Gly Gly Pro Ser Ser Pro Thr Thr Gly Pro
1 5 10 15
Thr Ser Thr Ser Gly Pro Glu Asp Gln Pro Leu Thr Pro Thr Gly Ser
20 25 30
Asp Pro Gln Ser Gly Leu Gly Arg His Leu Gly
35 40
<210> 79
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> hinge- transmembrane
<400> 79
Tyr Gly Ser Gln Ser Ser Lys Pro Tyr Leu Leu Thr His Pro Ser Asp
1 5 10 15
Pro Leu Glu Leu Val Val Ser Gly Pro Ser Gly Gly Pro Ser Ser Pro
20 25 30
Thr Thr Gly Pro Thr Ser Thr Ser Gly Pro Glu Asp Gln Pro Leu Thr
35 40 45
Pro Thr Gly Ser Asp Pro Gln Ser Gly Leu Gly Arg His Leu Gly Val
50 55 60
Val Ile Gly Ile Leu Val Ala Val Ile Leu Leu Leu Leu Leu Leu Leu
65 70 75 80
Leu Leu Phe Leu Ile Leu
85
<210> 80
<211> 190
<212> PRT
<213> Artificial Sequence
<220>
<223> hinge-transmembrane-intracellular domain
<400> 80
Val Val Ile Gly Ile Leu Val Ala Val Ile Leu Leu Leu Leu Leu Leu
1 5 10 15
Leu Leu Leu Phe Leu Ile Leu Arg His Arg Arg Gln Gly Lys His Trp
20 25 30
Thr Ser Thr Gln Arg Lys Ala Asp Phe Gln His Pro Ala Gly Ala Val
35 40 45
Gly Pro Glu Pro Thr Asp Arg Gly Leu Gln Trp Arg Ser Ser Pro Ala
50 55 60
Ala Asp Ala Gln Glu Glu Asn Leu Tyr Ala Ala Val Lys His Thr Gln
65 70 75 80
Pro Glu Asp Gly Val Glu Met Asp Thr Arg Ser Pro His Asp Glu Asp
85 90 95
Pro Gln Ala Val Thr Tyr Ala Glu Val Lys His Ser Arg Pro Arg Arg
100 105 110
Glu Met Ala Ser Pro Pro Ser Pro Leu Ser Gly Glu Phe Leu Asp Thr
115 120 125
Lys Asp Arg Gln Ala Glu Glu Asp Arg Gln Met Asp Thr Glu Ala Ala
130 135 140
Ala Ser Glu Ala Pro Gln Asp Val Thr Tyr Ala Gln Leu His Ser Leu
145 150 155 160
Thr Leu Arg Arg Glu Ala Thr Glu Pro Pro Pro Ser Gln Glu Gly Pro
165 170 175
Ser Pro Ala Val Pro Ser Ile Tyr Ala Thr Leu Ala Ile His
180 185 190
<210> 81
<211> 167
<212> PRT
<213> Artificial Sequence
<220>
<223> LILRB1 intracellular domain
<400> 81
Arg His Arg Arg Gln Gly Lys His Trp Thr Ser Thr Gln Arg Lys Ala
1 5 10 15
Asp Phe Gln His Pro Ala Gly Ala Val Gly Pro Glu Pro Thr Asp Arg
20 25 30
Gly Leu Gln Trp Arg Ser Ser Pro Ala Ala Asp Ala Gln Glu Glu Asn
35 40 45
Leu Tyr Ala Ala Val Lys His Thr Gln Pro Glu Asp Gly Val Glu Met
50 55 60
Asp Thr Arg Ser Pro His Asp Glu Asp Pro Gln Ala Val Thr Tyr Ala
65 70 75 80
Glu Val Lys His Ser Arg Pro Arg Arg Glu Met Ala Ser Pro Pro Ser
85 90 95
Pro Leu Ser Gly Glu Phe Leu Asp Thr Lys Asp Arg Gln Ala Glu Glu
100 105 110
Asp Arg Gln Met Asp Thr Glu Ala Ala Ala Ser Glu Ala Pro Gln Asp
115 120 125
Val Thr Tyr Ala Gln Leu His Ser Leu Thr Leu Arg Arg Glu Ala Thr
130 135 140
Glu Pro Pro Pro Ser Gln Glu Gly Pro Ser Pro Ala Val Pro Ser Ile
145 150 155 160
Tyr Ala Thr Leu Ala Ile His
165
<210> 82
<211> 253
<212> PRT
<213> Artificial Sequence
<220>
<223> LILRB1 hinge-transmemebrane-intracellular domain
<400> 82
Tyr Gly Ser Gln Ser Ser Lys Pro Tyr Leu Leu Thr His Pro Ser Asp
1 5 10 15
Pro Leu Glu Leu Val Val Ser Gly Pro Ser Gly Gly Pro Ser Ser Pro
20 25 30
Thr Thr Gly Pro Thr Ser Thr Ser Gly Pro Glu Asp Gln Pro Leu Thr
35 40 45
Pro Thr Gly Ser Asp Pro Gln Ser Gly Leu Gly Arg His Leu Gly Val
50 55 60
Val Ile Gly Ile Leu Val Ala Val Ile Leu Leu Leu Leu Leu Leu Leu
65 70 75 80
Leu Leu Phe Leu Ile Leu Arg His Arg Arg Gln Gly Lys His Trp Thr
85 90 95
Ser Thr Gln Arg Lys Ala Asp Phe Gln His Pro Ala Gly Ala Val Gly
100 105 110
Pro Glu Pro Thr Asp Arg Gly Leu Gln Trp Arg Ser Ser Pro Ala Ala
115 120 125
Asp Ala Gln Glu Glu Asn Leu Tyr Ala Ala Val Lys His Thr Gln Pro
130 135 140
Glu Asp Gly Val Glu Met Asp Thr Arg Ser Pro His Asp Glu Asp Pro
145 150 155 160
Gln Ala Val Thr Tyr Ala Glu Val Lys His Ser Arg Pro Arg Arg Glu
165 170 175
Met Ala Ser Pro Pro Ser Pro Leu Ser Gly Glu Phe Leu Asp Thr Lys
180 185 190
Asp Arg Gln Ala Glu Glu Asp Arg Gln Met Asp Thr Glu Ala Ala Ala
195 200 205
Ser Glu Ala Pro Gln Asp Val Thr Tyr Ala Gln Leu His Ser Leu Thr
210 215 220
Leu Arg Arg Glu Ala Thr Glu Pro Pro Pro Ser Gln Glu Gly Pro Ser
225 230 235 240
Pro Ala Val Pro Ser Ile Tyr Ala Thr Leu Ala Ile His
245 250
<210> 83
<211> 233
<212> PRT
<213> Artificial Sequence
<220>
<223> LILRB1 hinge-TM-intracellular domain
<400> 83
Val Val Ser Gly Pro Ser Gly Gly Pro Ser Ser Pro Thr Thr Gly Pro
1 5 10 15
Thr Ser Thr Ser Gly Pro Glu Asp Gln Pro Leu Thr Pro Thr Gly Ser
20 25 30
Asp Pro Gln Ser Gly Leu Gly Arg His Leu Gly Val Val Ile Gly Ile
35 40 45
Leu Val Ala Val Ile Leu Leu Leu Leu Leu Leu Leu Leu Leu Phe Leu
50 55 60
Ile Leu Arg His Arg Arg Gln Gly Lys His Trp Thr Ser Thr Gln Arg
65 70 75 80
Lys Ala Asp Phe Gln His Pro Ala Gly Ala Val Gly Pro Glu Pro Thr
85 90 95
Asp Arg Gly Leu Gln Trp Arg Ser Ser Pro Ala Ala Asp Ala Gln Glu
100 105 110
Glu Asn Leu Tyr Ala Ala Val Lys His Thr Gln Pro Glu Asp Gly Val
115 120 125
Glu Met Asp Thr Arg Ser Pro His Asp Glu Asp Pro Gln Ala Val Thr
130 135 140
Tyr Ala Glu Val Lys His Ser Arg Pro Arg Arg Glu Met Ala Ser Pro
145 150 155 160
Pro Ser Pro Leu Ser Gly Glu Phe Leu Asp Thr Lys Asp Arg Gln Ala
165 170 175
Glu Glu Asp Arg Gln Met Asp Thr Glu Ala Ala Ala Ser Glu Ala Pro
180 185 190
Gln Asp Val Thr Tyr Ala Gln Leu His Ser Leu Thr Leu Arg Arg Glu
195 200 205
Ala Thr Glu Pro Pro Pro Ser Gln Glu Gly Pro Ser Pro Ala Val Pro
210 215 220
Ser Ile Tyr Ala Thr Leu Ala Ile His
225 230
<210> 84
<211> 63
<212> PRT
<213> Artificial Sequence
<220>
<223> LILRB1 hinge domain
<400> 84
Tyr Gly Ser Gln Ser Ser Lys Pro Tyr Leu Leu Thr His Pro Ser Asp
1 5 10 15
Pro Leu Glu Leu Val Val Ser Gly Pro Ser Gly Gly Pro Ser Ser Pro
20 25 30
Thr Thr Gly Pro Thr Ser Thr Ser Gly Pro Glu Asp Gln Pro Leu Thr
35 40 45
Pro Thr Gly Ser Asp Pro Gln Ser Gly Leu Gly Arg His Leu Gly
50 55 60
<210> 85
<211> 23
<212> PRT
<213> Artificial Sequence
<220>
<223> LILRB1 transmembrane domain
<400> 85
Val Val Ile Gly Ile Leu Val Ala Val Ile Leu Leu Leu Leu Leu Leu
1 5 10 15
Leu Leu Leu Phe Leu Ile Leu
20
<210> 86
<211> 237
<212> PRT
<213> Artificial Sequence
<220>
<223> MSLN binding domain
<400> 86
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Glu Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Pro Asn Ser Gly Gly Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ser Gly Trp Asp Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Asp Ile Val Met Thr Gln Ser Ser Ser Leu Ser Ala
130 135 140
Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile
145 150 155 160
Arg Tyr Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys
165 170 175
Leu Leu Ile Tyr Thr Ala Ser Ile Leu Gln Asn Gly Val Pro Ser Arg
180 185 190
Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser
195 200 205
Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Thr Tyr Thr
210 215 220
Thr Pro Asp Phe Gly Pro Gly Thr Lys Val Glu Ile Lys
225 230 235
<210> 87
<211> 711
<212> DNA
<213> Artificial Sequence
<220>
<223> MSLN binding domain
<400> 87
caggtgcagc tggtgcagtc tggggctgag gtggagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggata caccttcacc gactactata tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggatgg atcaacccta acagtggtgg cacaaactat 180
gcacagaagt ttcagggcag ggtcaccatg accagggaca cgtccatcag cacagcctac 240
atggagctga gcaggctgag atctgacgac acggccgtgt attactgtgc gtctggctgg 300
gactttgact actggggcca gggaaccctg gtcaccgtgt cctcaggcgg aggtggaagc 360
ggagggggag gatctggcgg cggaggaagc ggaggcgaca tcgtgatgac ccagtcttcc 420
tccctgtctg catctgtcgg agacagagtc accatcactt gccgggccag tcagagcatt 480
aggtactatt taagttggta tcagcagaaa ccaggaaaag cccctaagct cctgatctat 540
actgcatcca ttttacaaaa tggggtccca tcaaggttca gtggcagtgg atctgggaca 600
gatttcactc tcaccatcag cagcctgcaa cctgaggatt ttgcaactta ttactgcctc 660
cagacttaca ctactccgga ctttggccca gggaccaagg tggaaatcaa a 711
<210> 88
<211> 246
<212> PRT
<213> Artificial Sequence
<220>
<223> MSLN binding domain
<400> 88
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Arg Ala Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Phe Thr Phe Arg Gly Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Asn Pro Ser Gly Gly Ser Arg Ala Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Asp Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Thr Ala Ser Cys Gly Gly Asp Cys Tyr Tyr Leu Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr
130 135 140
Gln Ser Pro Pro Thr Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile
145 150 155 160
Thr Cys Arg Ala Ser Glu Asn Val Asn Ile Trp Leu Ala Trp Tyr Gln
165 170 175
Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Lys Ser Ser Ser
180 185 190
Leu Ala Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Ala
195 200 205
Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Asp Asp Phe Ala Thr
210 215 220
Tyr Tyr Cys Gln Gln Tyr Gln Ser Tyr Pro Leu Thr Phe Gly Gly Gly
225 230 235 240
Thr Lys Val Glu Ile Lys
245
<210> 89
<211> 738
<212> DNA
<213> Artificial Sequence
<220>
<223> MSLN binding domain
<400> 89
caggtgcagc tggtgcagtc tggggctgag gtgagggcac ctggggcctc agtgaagatt 60
tcctgcaagg cttctggatt caccttcaga ggctactata tccactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaatc atcaacccta gtggtggtag cagagcctac 180
gcacagaagt tccagggcag ggtcaccatg accagggaca cttccacgag cacagtctac 240
atggagctga gcagcctgag atctgacgac acggccatgt attactgtgc gagaaccgca 300
agttgtggtg gtgactgcta ctaccttgac tactggggcc agggaaccct ggtcaccgtg 360
tcctcaggcg gaggtggaag cggaggggga ggatctggcg gcggaggaag cggaggcgac 420
atccagatga cccagtctcc tcccaccctg tctgcatctg taggagacag agtcaccatc 480
acttgccggg ccagtgagaa tgttaatatc tggttggcct ggtatcagca gaaaccaggg 540
aaagccccta agctcctgat ctataagtca tccagtttag caagtggggt cccatcaagg 600
ttcagtggca gtggatctgg ggcagaattc actctcacca tcagcagcct gcagcctgat 660
gattttgcaa cttattactg ccaacagtat caaagttacc ccctcacttt cggcggaggg 720
accaaggtgg aaatcaaa 738
<210> 90
<211> 242
<212> PRT
<213> Artificial Sequence
<220>
<223> MSLN binding domain
<400> 90
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Thr Met Asn Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Trp Met
35 40 45
Gly Leu Ile Thr Pro Tyr Asn Gly Ala Ser Ser Tyr Asn Gln Lys Phe
50 55 60
Arg Gly Arg Val Thr Ile Thr Arg Asp Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Asp Gly Arg Gly Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln Ser Pro
130 135 140
Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Ser
145 150 155 160
Ala Ser Ser Ser Val Ser Tyr Met His Trp Tyr Gln Gln Lys Pro Gly
165 170 175
Lys Ala Pro Lys Arg Leu Ile Tyr Asp Thr Ser Lys Leu Ala Ser Gly
180 185 190
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu
195 200 205
Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln
210 215 220
Gln Trp Ser Gly Tyr Pro Leu Thr Phe Gly Gln Gly Thr Lys Leu Glu
225 230 235 240
Ile Lys
<210> 91
<211> 726
<212> DNA
<213> Artificial Sequence
<220>
<223> MSLN binding domain
<400> 91
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg cttctggata ctcattcacc ggctacacca tgaactgggt gaggcaggcc 120
cctggacaaa gacttgagtg gatgggactt atcacccctt acaatggtgc ttctagctac 180
aaccagaagt tcaggggcag ggtcacaatc actagagaca cgtcagccag cacagcctac 240
atggagctct ccagcctgag atctgaagac actgcagtct attactgtgc aagggggggt 300
tacgacggga ggggttttga ctactggggc cagggaacca cggtcaccgt gtcctcaggc 360
ggaggtggaa gcggaggggg aggatctggc ggcggaggaa gcggaggcga catccagatg 420
acccagtctc cttcaagctt gtctgcatct gtaggagaca gggtcaccat cacttgcagt 480
gccagctcaa gtgtaagtta catgcactgg tatcagcaga aaccaggcaa ggcccctaag 540
agattgatct atgacacatc caaattagca agtggggtcc caagtcgctt cagtggcagt 600
ggatctggga ccgaattcac tctcaccatc agcagcttgc agcctgagga ttttgcaact 660
tattactgcc agcagtggag tggttaccct ctcacgttcg gtcaggggac aaagttggaa 720
atcaaa 726
<210> 92
<211> 242
<212> PRT
<213> Artificial Sequence
<220>
<223> MSLN binding domain
<400> 92
Gln Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Glu Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Thr Met Asn Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Leu Ile Thr Pro Tyr Asn Gly Ala Ser Ser Tyr Asn Gln Lys Phe
50 55 60
Arg Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Asp Leu Leu Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala Arg Gly Gly Tyr Asp Gly Arg Gly Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Glu Leu Thr Gln Ser Pro
130 135 140
Ala Ile Met Ser Ala Ser Pro Gly Glu Lys Val Thr Met Thr Cys Ser
145 150 155 160
Ala Ser Ser Ser Val Ser Tyr Met His Trp Tyr Gln Gln Lys Ser Gly
165 170 175
Thr Ser Pro Lys Arg Trp Ile Tyr Asp Thr Ser Lys Leu Ala Ser Gly
180 185 190
Val Pro Gly Arg Phe Ser Gly Ser Gly Ser Gly Asn Ser Tyr Ser Leu
195 200 205
Thr Ile Ser Ser Val Glu Ala Glu Asp Asp Ala Thr Tyr Tyr Cys Gln
210 215 220
Gln Trp Ser Gly Tyr Pro Leu Thr Phe Gly Ala Gly Thr Lys Leu Glu
225 230 235 240
Ile Lys
<210> 93
<211> 726
<212> DNA
<213> Artificial Sequence
<220>
<223> MSLN binding domain
<400> 93
caggtgcagc tgcagcagtc tgggcctgag ctggagaagc ctggggcctc agtgaagatt 60
tcctgcaagg cttctggata ctcattcacc ggctacacca tgaactgggt gaagcagagc 120
catggaaaaa gccttgagtg gattggactt atcacccctt acaatggtgc ttctagctac 180
aaccagaagt tcaggggcaa ggccacatta actgtagaca agtcatccag cacagcctac 240
atggacctcc tcagcctgac atctgaagac tctgcagtct atttctgtgc aagggggggt 300
tacgacggga ggggttttga ctactggggc cagggaacca cggtcaccgt gtcctcaggc 360
ggaggtggaa gcggaggggg aggatctggc ggcggaggaa gcggaggcga catcgagctc 420
acccagtctc ctgcaatcat gtctgcatct ccaggagaga aggtcaccat gacttgcagt 480
gccagctcaa gtgtaagtta catgcactgg tatcagcaga aatcaggcac ctcccctaag 540
agatggatct atgacacatc caaattggca agtggggtcc caggtcgctt cagtggcagt 600
ggatctggga actcttactc tctcaccatc agcagcgtgg aggctgagga tgatgcaact 660
tattactgcc agcagtggag tggttaccct ctcacgttcg gtgctgggac aaagttggaa 720
atcaaa 726
<210> 94
<211> 243
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA binding domain
<400> 94
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Val Arg Ser Gly Thr
1 5 10 15
Ser Val Lys Leu Ser Cys Thr Ala Ser Gly Phe Asn Ile Lys Asp Ser
20 25 30
Tyr Met His Trp Leu Arg Gln Gly Pro Glu Gln Gly Leu Glu Trp Ile
35 40 45
Gly Trp Ile Asp Pro Glu Asn Gly Asp Thr Glu Tyr Ala Pro Lys Phe
50 55 60
Gln Gly Lys Ala Thr Phe Thr Thr Asp Thr Ser Ser Asn Thr Ala Tyr
65 70 75 80
Leu Gln Leu Ser Ser Leu Thr Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Asn Glu Gly Thr Pro Thr Gly Pro Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Glu Asn Val Leu Thr Gln Ser
130 135 140
Pro Ala Ile Met Ser Ala Ser Pro Gly Glu Lys Val Thr Ile Thr Cys
145 150 155 160
Ser Ala Ser Ser Ser Val Ser Tyr Met His Trp Phe Gln Gln Lys Pro
165 170 175
Gly Thr Ser Pro Lys Leu Trp Ile Tyr Ser Thr Ser Asn Leu Ala Ser
180 185 190
Gly Val Pro Ala Arg Phe Ser Gly Ser Gly Ser Gly Thr Ser Tyr Ser
195 200 205
Leu Thr Ile Ser Arg Met Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys
210 215 220
Gln Gln Arg Ser Ser Tyr Pro Leu Thr Phe Gly Ala Gly Thr Lys Leu
225 230 235 240
Glu Leu Lys
<210> 95
<211> 729
<212> DNA
<213> Artificial Sequence
<220>
<223> CEA binding domain
<400> 95
caggtccagc tgcagcagtc tggggcagag cttgtgaggt cagggacctc agtcaagttg 60
tcctgcacag cttctggctt caacattaaa gactcctata tgcactggtt gaggcagggg 120
cctgaacagg gcctggagtg gattggatgg attgatcctg agaatggtga tactgaatat 180
gccccgaagt tccagggcaa ggccactttt actacagaca catcctccaa cacagcctac 240
ctgcagctca gcagcctgac atctgaggac actgccgtct attactgtaa tgaagggaca 300
ccgacagggc catactattt tgactactgg ggtcaaggaa ccacagtcac cgtgtcctca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cgagaacgtt 420
ctcacccagt ctccagcaat catgtctgca tctccagggg agaaggtcac cataacctgc 480
agtgccagct caagtgtaag ttacatgcac tggttccagc agaagccagg cacttctccc 540
aaactctgga tttatagcac atccaacctg gcttctggag tccctgctcg cttcagtggc 600
agtggatctg ggacctctta ctctctcaca atcagccgaa tggaggctga agatgctgcc 660
acttattact gccagcaaag gagtagttac ccgctcacgt tcggtgctgg gaccaagctg 720
gagctgaaa 729
<210> 96
<211> 243
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA binding domain
<400> 96
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Lys Asp Ser
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asp Pro Glu Asn Gly Asp Thr Glu Tyr Ala Pro Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Asn Glu Gly Thr Pro Thr Gly Pro Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Glu Ile Val Leu Thr Gln Ser
130 135 140
Pro Ala Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys
145 150 155 160
Ser Ala Ser Ser Ser Val Ser Tyr Met His Trp Tyr Gln Gln Lys Pro
165 170 175
Gly Leu Ala Pro Arg Leu Leu Ile Tyr Ser Thr Ser Asn Leu Ala Ser
180 185 190
Gly Ile Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
195 200 205
Leu Thr Ile Ser Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys
210 215 220
Gln Gln Arg Ser Ser Tyr Pro Leu Thr Phe Gly Gln Gly Thr Lys Leu
225 230 235 240
Glu Ile Lys
<210> 97
<211> 729
<212> DNA
<213> Artificial Sequence
<220>
<223> CEA binding domain
<400> 97
caggtccagc tggtgcagtc tggggcagag gtgaagaaac caggggcctc agtcaaggtg 60
tcctgcaaag cttctggctt caacattaaa gactcctata tgcactgggt gaggcaggcg 120
cctggacagg gcctggagtg gatgggatgg attgatcctg agaatggtga tactgaatat 180
gccccgaagt tccagggcag ggtcactatg actacagaca catccacctc cacagcctac 240
atggagctca ggagcctgag atctgacgac actgccgtct attactgtaa tgaagggaca 300
ccgacagggc catactattt tgactactgg ggtcaaggaa ccacagtcac cgtgtcctca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cgagatcgtt 420
ctcacccagt ctccagcaac cttgtctctg tctccagggg agagggccac cctaagctgc 480
agtgccagct caagtgtaag ttacatgcac tggtaccagc agaagccagg ccttgctccc 540
agactcctga tttatagcac atccaacctg gcttctggaa tccctgatcg cttcagtggc 600
agtggatctg ggaccgattt cactctcaca atcagccgac tggagcctga agatttcgcc 660
gtttattact gccagcaaag gagtagttac ccgctcacgt tcggtcaggg gaccaagctg 720
gagatcaaa 729
<210> 98
<211> 243
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA binding domain
<400> 98
Glu Val Gln Leu Ala Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Asp
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ser Asn Glu Phe Leu Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Ser Ser Glu Leu Thr Gln Asp Pro Ala Val
130 135 140
Ser Val Ala Leu Gly Gln Thr Val Arg Ile Thr Cys Gln Gly Asp Ser
145 150 155 160
Leu Arg Ser Ser Tyr Ala Ser Trp Tyr Arg Gln Arg Pro Gly Gln Ala
165 170 175
Pro Val Leu Val Ile Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro
180 185 190
Asp Arg Phe Ser Gly Ser Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile
195 200 205
Thr Gly Ala Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Trp Asn Ser Ser
210 215 220
Tyr Ala Trp Leu Pro Tyr Val Val Phe Gly Gly Gly Thr Lys Leu Thr
225 230 235 240
Val Leu Gly
<210> 99
<211> 729
<212> DNA
<213> Artificial Sequence
<220>
<223> CEA binding domain
<400> 99
gaggtgcagc tggcggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc agcgatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtgt attactgtgc aaagtctaat 300
gagtttcttt ttgactactg gggccaaggt accctggtca ccgtgtcgag tggcggaggt 360
ggaagcggag ggggaggatc tggcggcgga ggaagcggag gctcttctga gctgactcag 420
gaccctgctg tgtctgtggc cttgggacag acagtcagga tcacatgcca aggagacagc 480
ctcagaagct cttatgcaag ctggtaccgg cagaggccag gacaggcccc tgtacttgtc 540
atctatggta aaaacaaccg gccctcaggg atcccagacc gattctctgg ctccagctca 600
ggaaacacag cttccttgac catcactggg gctcaggcgg aagatgaggc tgactattac 660
tggaactcca gctacgcttg gctgccctac gtggtattcg gcggagggac caagctgacc 720
gtcctaggt 729
<210> 100
<211> 243
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA binding domain
<400> 100
Gln Val Gln Leu Glu Gln Ser Gly Ala Gly Val Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Phe Asn Ile Lys Asp Ser
20 25 30
Tyr Met His Trp Leu Arg Gln Gly Pro Gly Gln Arg Leu Glu Trp Ile
35 40 45
Gly Trp Ile Asp Pro Glu Asn Gly Asp Thr Glu Tyr Ala Pro Lys Phe
50 55 60
Gln Gly Lys Ala Thr Phe Thr Thr Asp Thr Ser Ala Asn Thr Ala Tyr
65 70 75 80
Leu Gly Leu Ser Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Asn Glu Gly Thr Pro Thr Gly Pro Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Glu Asn Val Leu Thr Gln Ser
130 135 140
Pro Ser Ser Met Ser Val Ser Val Gly Asp Arg Val Asn Ile Ala Cys
145 150 155 160
Ser Ala Ser Ser Ser Val Pro Tyr Met His Trp Leu Gln Gln Lys Pro
165 170 175
Gly Lys Ser Pro Lys Leu Leu Ile Tyr Leu Thr Ser Asn Leu Ala Ser
180 185 190
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Tyr Ser
195 200 205
Leu Thr Ile Ser Ser Val Gln Pro Glu Asp Ala Ala Thr Tyr Tyr Cys
210 215 220
Gln Gln Arg Ser Ser Tyr Pro Leu Thr Phe Gly Gly Gly Thr Lys Leu
225 230 235 240
Glu Ile Lys
<210> 101
<211> 729
<212> DNA
<213> Artificial Sequence
<220>
<223> CEA binding domain
<400> 101
caggtccagc tggagcagtc tggggcaggg gttgtgaagc caggggcctc agtcaagttg 60
tcctgcaaag cttctggctt caacattaaa gactcctata tgcactggtt gaggcagggg 120
cctggacagc gcctggagtg gattggatgg attgatcctg agaatggtga tactgaatat 180
gccccgaagt tccagggcaa ggccactttt actacagaca catccgccaa cacagcctac 240
ctggggctca gcagcctgag acctgaggac actgccgtct attactgtaa tgaagggaca 300
ccgacagggc catactattt tgactactgg ggtcaaggaa ccctagtcac cgtgtcctca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cgagaacgtt 420
ctcacccagt ctccaagctc tatgtctgta tctgtcgggg acagggtcaa catcgcctgc 480
agtgccagct caagtgtacc ttacatgcac tggctccagc agaagccagg caaatctccc 540
aaactcctga tttatctcac atccaacctg gcttctggag tccctagccg cttcagtggc 600
agtggatctg ggaccgatta ctctctcaca atcagctcag tgcagcctga agatgctgcc 660
acttattact gccagcaaag gagtagttac ccgctcacgt tcggtggtgg gaccaagctg 720
gagatcaaa 729
<210> 102
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 102
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Thr Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Trp Asp Asp Gly Ser Tyr Lys Tyr Tyr Gly Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Ile Thr Met Val Arg Gly Val Met Lys Asp Tyr Phe
100 105 110
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Ala Ile
130 135 140
Gln Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg
145 150 155 160
Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser Ser Ala Leu Val
165 170 175
Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Asp
180 185 190
Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Glu
195 200 205
Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp
210 215 220
Phe Ala Thr Tyr Tyr Cys Gln Gln Phe Asn Ser Tyr Pro Leu Thr Phe
225 230 235 240
Gly Gly Gly Thr Lys Val Glu Ile Lys
245
<210> 103
<211> 747
<212> DNA
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 103
caggtgcagc tggtggagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcag cgtctggatt caccttcagt acctatggca tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtggcagtt atatgggatg atggaagtta taaatactat 180
ggagactccg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggctgtgt attactgtgc gagagatggt 300
attactatgg ttcggggagt tatgaaggac tactttgact actggggcca gggaaccctg 360
gtcaccgtct cctcaggcgg aggtggaagc ggagggggag gatctggcgg cggaggaagc 420
ggaggcgcca tccagttgac ccagtctcca tcctccctgt ctgcatctgt aggagacaga 480
gtcaccatca cttgccgggc aagtcaggac attagcagtg ctttagtctg gtatcagcag 540
aaaccaggga aagctcctaa gctcctgatc tatgatgcct ccagtttgga aagtggggtc 600
ccatcaaggt tcagcggcag tgaatctggg acagatttca ctctcaccat cagcagcctg 660
cagcctgaag attttgcaac ttattactgt caacagttta atagttaccc gctcactttc 720
ggcggaggga ccaaggtgga gatcaaa 747
<210> 104
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 104
Ala Ile Gln Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser Ser Ala
20 25 30
Leu Val Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Glu Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Phe Asn Ser Tyr Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Gly Gly Gly Gly Ser
100 105 110
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gln Val Gln Leu
115 120 125
Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg Ser Leu Arg Leu
130 135 140
Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Thr Tyr Gly Met His Trp
145 150 155 160
Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ala Val Ile Trp
165 170 175
Asp Asp Gly Ser Tyr Lys Tyr Tyr Gly Asp Ser Val Lys Gly Arg Phe
180 185 190
Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn
195 200 205
Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Asp Gly
210 215 220
Ile Thr Met Val Arg Gly Val Met Lys Asp Tyr Phe Asp Tyr Trp Gly
225 230 235 240
Gln Gly Thr Leu Val Thr Val Ser Ser
245
<210> 105
<211> 747
<212> DNA
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 105
gccatccagt tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca ggacattagc agtgctttag tctggtatca gcagaaacca 120
gggaaagctc ctaagctcct gatctatgat gcctccagtt tggaaagtgg ggtcccatca 180
aggttcagcg gcagtgaatc tgggacagat ttcactctca ccatcagcag cctgcagcct 240
gaagattttg caacttatta ctgtcaacag tttaatagtt acccgctcac tttcggcgga 300
gggaccaagg tggagatcaa aggcggaggt ggaagcggag ggggaggatc tggcggcgga 360
ggaagcggag gccaggtgca gctggtggag tctgggggag gcgtggtcca gcctgggagg 420
tccctgagac tctcctgtgc agcgtctgga ttcaccttca gtacctatgg catgcactgg 480
gtccgccagg ctccaggcaa ggggctggag tgggtggcag ttatatggga tgatggaagt 540
tataaatact atggagactc cgtgaagggc cgattcacca tctccagaga caattccaag 600
aacacgctgt atctgcaaat gaacagcctg agagccgagg acacggctgt gtattactgt 660
gcgagagatg gtattactat ggttcgggga gttatgaagg actactttga ctactggggc 720
cagggaaccc tggtcaccgt ctcctca 747
<210> 106
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 106
Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Lys Lys Pro Gly Glu
1 5 10 15
Thr Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Glu Tyr
20 25 30
Pro Ile His Trp Val Lys Gln Ala Pro Gly Lys Gly Phe Lys Trp Met
35 40 45
Gly Met Ile Tyr Thr Asp Ile Gly Lys Pro Thr Tyr Ala Glu Glu Phe
50 55 60
Lys Gly Arg Phe Ala Phe Ser Leu Glu Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Asn Asn Leu Lys Asn Glu Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Val Arg Asp Arg Tyr Asp Ser Leu Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Asp Val Val Met Thr Gln Thr Pro Leu
130 135 140
Ser Leu Pro Val Ser Leu Gly Asp Gln Ala Ser Ile Ser Cys Arg Ser
145 150 155 160
Ser Gln Ser Leu Val His Ser Asn Gly Asn Thr Tyr Leu His Trp Tyr
165 170 175
Leu Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile Tyr Lys Val Ser
180 185 190
Asn Arg Phe Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Asp Phe Thr Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Leu Gly
210 215 220
Val Tyr Phe Cys Ser Gln Ser Thr His Val Pro Trp Thr Phe Gly Gly
225 230 235 240
Gly Thr Lys Leu Glu Ile Lys
245
<210> 107
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 107
cagatccagt tggtgcagtc tggacctgag ctgaagaagc ctggagagac agtcaagatc 60
tcctgcaagg cctctgggta taccttcaca gaatatccaa tacactgggt gaagcaggct 120
ccaggaaagg gtttcaagtg gatgggcatg atatacaccg acattggaaa gccaacatat 180
gctgaagagt tcaagggacg gtttgccttc tctttggaga cctctgccag cactgcctat 240
ttgcagatca acaacctcaa gaatgaggac acggctacat atttctgtgt aagagatcga 300
tatgattccc tctttgacta ctggggccaa ggcaccactc tcacagtctc ctcaggcgga 360
ggtggaagcg gagggggagg atctggcggc ggaggaagcg gaggcgatgt tgtgatgacc 420
caaactccac tctccctgcc tgtcagtctt ggagatcaag cctccatctc ttgcagatct 480
agtcagagcc ttgtacacag taatggaaac acctatttac attggtacct gcagaagcca 540
ggccagtctc caaagctcct gatctacaaa gtttccaacc gattttctgg ggtcccagac 600
aggttcagtg gcagtggatc agggacagat ttcacactca agatcagcag agtggaggct 660
gaggatctgg gagtttattt ctgctctcaa agtacacatg ttccgtggac gttcggtgga 720
ggcaccaagc tggaaatcaa a 741
<210> 108
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 108
Asp Val Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys Ser Gln Ser
85 90 95
Thr His Val Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Lys Lys Pro Gly
130 135 140
Glu Thr Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Glu
145 150 155 160
Tyr Pro Ile His Trp Val Lys Gln Ala Pro Gly Lys Gly Phe Lys Trp
165 170 175
Met Gly Met Ile Tyr Thr Asp Ile Gly Lys Pro Thr Tyr Ala Glu Glu
180 185 190
Phe Lys Gly Arg Phe Ala Phe Ser Leu Glu Thr Ser Ala Ser Thr Ala
195 200 205
Tyr Leu Gln Ile Asn Asn Leu Lys Asn Glu Asp Thr Ala Thr Tyr Phe
210 215 220
Cys Val Arg Asp Arg Tyr Asp Ser Leu Phe Asp Tyr Trp Gly Gln Gly
225 230 235 240
Thr Thr Leu Thr Val Ser Ser
245
<210> 109
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 109
gatgttgtga tgacccaaac tccactctcc ctgcctgtca gtcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagccttgta cacagtaatg gaaacaccta tttacattgg 120
tacctgcaga agccaggcca gtctccaaag ctcctgatct acaaagtttc caaccgattt 180
tctggggtcc cagacaggtt cagtggcagt ggatcaggga cagatttcac actcaagatc 240
agcagagtgg aggctgagga tctgggagtt tatttctgct ctcaaagtac acatgttccg 300
tggacgttcg gtggaggcac caagctggaa atcaaaggcg gaggtggaag cggaggggga 360
ggatctggcg gcggaggaag cggaggccag atccagttgg tgcagtctgg acctgagctg 420
aagaagcctg gagagacagt caagatctcc tgcaaggcct ctgggtatac cttcacagaa 480
tatccaatac actgggtgaa gcaggctcca ggaaagggtt tcaagtggat gggcatgata 540
tacaccgaca ttggaaagcc aacatatgct gaagagttca agggacggtt tgccttctct 600
ttggagacct ctgccagcac tgcctatttg cagatcaaca acctcaagaa tgaggacacg 660
gctacatatt tctgtgtaag agatcgatat gattccctct ttgactactg gggccaaggc 720
accactctca cagtctcctc a 741
<210> 110
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 110
Glu Met Gln Leu Val Glu Ser Gly Gly Gly Phe Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser His Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Thr Pro Lys Gln Arg Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ala Ser Gly Gly Asp Ile Thr Tyr Tyr Ala Asp Thr Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Gln Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Phe Tyr Cys
85 90 95
Ser Arg Ser Ser Tyr Gly Asn Asn Gly Asp Ala Leu Asp Phe Trp Gly
100 105 110
Gln Gly Thr Ser Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Val Val Met Thr Gln
130 135 140
Thr Pro Leu Ser Leu Pro Val Ser Leu Gly Asp Gln Ala Ser Ile Ser
145 150 155 160
Cys Arg Ser Ser Gln Ser Leu Val His Ser Asn Gly Asn Thr Tyr Leu
165 170 175
His Trp Tyr Leu Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile Tyr
180 185 190
Lys Val Ser Asn Arg Phe Ser Gly Val Pro Asp Arg Phe Ser Gly Ser
195 200 205
Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Arg Val Glu Ala Glu
210 215 220
Asp Leu Gly Val Tyr Phe Cys Ser Gln Ser Thr His Val Leu Thr Phe
225 230 235 240
Gly Ser Gly Thr Lys Leu Glu Ile Lys
245
<210> 111
<211> 747
<212> DNA
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 111
gaaatgcagc tggtggagtc tgggggaggc ttcgtgaagc ctggagggtc cctgaaactc 60
tcatgtgcag cctctggatt cgctttcagt cactatgaca tgtcttgggt tcgccagact 120
ccgaagcaga ggctggagtg ggtcgcatac attgctagtg gtggtgatat cacctactat 180
gcagacactg tgaagggccg attcaccatc tccagagaca atgcccagaa caccctgtac 240
ctgcaaatga gcagtctgaa gtctgaggac acagccatgt tttactgttc acgatcctcc 300
tatggtaaca acggagatgc cctggacttc tggggtcaag gtacctcagt caccgtctcc 360
tcaggcggag gtggaagcgg agggggagga tctggcggcg gaggaagcgg aggcgatgtt 420
gtgatgaccc aaactccact ctccctgcct gtcagtcttg gagatcaagc ctccatctct 480
tgcagatcta gtcagagcct tgttcacagt aatggaaaca cctatttaca ttggtacctg 540
cagaagccag gccagtctcc aaagctcctg atctacaaag tttccaaccg attttctggg 600
gtcccagaca ggttcagtgg cagtggatca gggacagatt tcacactcaa gatcagcaga 660
gtggaggctg aggatctggg agtttatttc tgctctcaaa gtacacatgt tctcacgttc 720
ggctcgggga caaagttgga aataaaa 747
<210> 112
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 112
Asp Val Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys Ser Gln Ser
85 90 95
Thr His Val Leu Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Gly
100 105 110
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Glu Met Gln Leu Val Glu Ser Gly Gly Gly Phe Val Lys Pro Gly Gly
130 135 140
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser His Tyr
145 150 155 160
Asp Met Ser Trp Val Arg Gln Thr Pro Lys Gln Arg Leu Glu Trp Val
165 170 175
Ala Tyr Ile Ala Ser Gly Gly Asp Ile Thr Tyr Tyr Ala Asp Thr Val
180 185 190
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Gln Asn Thr Leu Tyr
195 200 205
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Phe Tyr Cys
210 215 220
Ser Arg Ser Ser Tyr Gly Asn Asn Gly Asp Ala Leu Asp Phe Trp Gly
225 230 235 240
Gln Gly Thr Ser Val Thr Val Ser Ser
245
<210> 113
<211> 747
<212> DNA
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 113
gatgttgtga tgacccaaac tccactctcc ctgcctgtca gtcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagccttgtt cacagtaatg gaaacaccta tttacattgg 120
tacctgcaga agccaggcca gtctccaaag ctcctgatct acaaagtttc caaccgattt 180
tctggggtcc cagacaggtt cagtggcagt ggatcaggga cagatttcac actcaagatc 240
agcagagtgg aggctgagga tctgggagtt tatttctgct ctcaaagtac acatgttctc 300
acgttcggct cggggacaaa gttggaaata aaaggcggag gtggaagcgg agggggagga 360
tctggcggcg gaggaagcgg aggcgaaatg cagctggtgg agtctggggg aggcttcgtg 420
aagcctggag ggtccctgaa actctcatgt gcagcctctg gattcgcttt cagtcactat 480
gacatgtctt gggttcgcca gactccgaag cagaggctgg agtgggtcgc atacattgct 540
agtggtggtg atatcaccta ctatgcagac actgtgaagg gccgattcac catctccaga 600
gacaatgccc agaacaccct gtacctgcaa atgagcagtc tgaagtctga ggacacagcc 660
atgttttact gttcacgatc ctcctatggt aacaacggag atgccctgga cttctggggt 720
caaggtacct cagtcaccgt ctcctca 747
<210> 114
<211> 243
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 114
Gln Val Gln Leu Lys Gln Ser Gly Pro Gly Leu Val Gln Pro Ser Gln
1 5 10 15
Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro Phe Thr
50 55 60
Ser Arg Leu Ser Ile Asn Lys Asp Asn Ser Lys Ser Gln Val Phe Phe
65 70 75 80
Lys Met Asn Ser Leu Gln Ser Asn Asp Thr Ala Ile Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ala Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Leu Leu Thr Gln Ser Pro
130 135 140
Val Ile Leu Ser Val Ser Pro Gly Glu Arg Val Ser Phe Ser Cys Arg
145 150 155 160
Ala Ser Gln Ser Ile Gly Thr Asn Ile His Trp Tyr Gln Gln Arg Thr
165 170 175
Asn Gly Ser Pro Arg Leu Leu Ile Lys Tyr Ala Ser Glu Ser Ile Ser
180 185 190
Gly Ile Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
195 200 205
Leu Ser Ile Asn Ser Val Glu Ser Glu Asp Ile Ala Asp Tyr Tyr Cys
210 215 220
Gln Gln Asn Asn Asn Trp Pro Thr Thr Phe Gly Ala Gly Thr Lys Leu
225 230 235 240
Glu Leu Lys
<210> 115
<211> 729
<212> DNA
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 115
caggtgcagc tgaagcagtc cggccccggc ctggtgcagc cctcccagtc cctgtccatc 60
acctgcaccg tgtccggctt ctccctgacc aactacggcg tgcactgggt gcggcagtcc 120
cccggcaagg gcctggagtg gctgggcgtg atctggtccg gcggcaacac cgactacaac 180
acccccttca cctcccggct gtccatcaac aaggacaact ccaagtccca ggtgttcttc 240
aagatgaact ccctgcagtc caacgacacc gccatctact actgcgcccg ggccctgacc 300
tactacgact acgagttcgc ctactggggc cagggcaccc tggtgaccgt gtccgccggc 360
ggaggtggaa gcggaggggg aggatctggc ggcggaggaa gcggaggcga catcctgctg 420
acccagtccc ccgtgatcct gtccgtgtcc cccggcgagc gggtgtcctt ctcctgccgg 480
gcctcccagt ccatcggcac caacatccac tggtaccagc agcggaccaa cggctccccc 540
cggctgctga tcaagtacgc ctccgagtcc atctccggca tcccctcccg gttctccggc 600
tccggctccg gcaccgactt caccctgtcc atcaactccg tggagtccga ggacatcgcc 660
gactactact gccagcagaa caacaactgg cccaccacct tcggcgccgg caccaagctg 720
gagctgaag 729
<210> 116
<211> 244
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 116
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser His
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Glu Phe Asn Pro Ser Asn Gly Arg Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Lys Ala Thr Met Thr Val Asp Thr Ser Thr Asn Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ser Arg Asp Tyr Asp Tyr Asp Gly Arg Tyr Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln
130 135 140
Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr
145 150 155 160
Cys Ser Ala Ser Ser Ser Val Thr Tyr Met Tyr Trp Tyr Gln Gln Lys
165 170 175
Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Asp Thr Ser Asn Leu Ala
180 185 190
Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Tyr
195 200 205
Thr Phe Thr Ile Ser Ser Leu Gln Pro Glu Asp Ile Ala Thr Tyr Tyr
210 215 220
Cys Gln Gln Trp Ser Ser His Ile Phe Thr Phe Gly Gln Gly Thr Lys
225 230 235 240
Val Glu Ile Lys
<210> 117
<211> 731
<212> DNA
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 117
aggtgcagct ggtgcagtcc ggcgccgagg tgaagaagcc cggcgcctcc gtgaaggtgt 60
cctgcaaggc ctccggctac accttcacct cccactggat gcactgggtg cggcaggccc 120
ccggccaggg cctggagtgg atcggcgagt tcaacccctc caacggccgg accaactaca 180
acgagaagtt caagtccaag gccaccatga ccgtggacac ctccaccaac accgcctaca 240
tggagctgtc ctccctgcgg tccgaggaca ccgccgtgta ctactgcgcc tcccgggact 300
acgactacga cggccggtac ttcgactact ggggccaggg caccctggtg accgtgtcct 360
ccggcggagg tggaagcgga gggggaggat ctggcggcgg aggaagcgga ggcgacatcc 420
agatgaccca gtccccctcc tccctgtccg cctccgtggg cgaccgggtg accatcacct 480
gctccgcctc ctcctccgtg acctacatgt actggtacca gcagaagccc ggcaaggccc 540
ccaagctgct gatctacgac acctccaacc tggcctccgg cgtgccctcc cggttctccg 600
gctccggctc cggcaccgac tacaccttca ccatctcctc cctgcagccc gaggacatcg 660
ccacctacta ctgccagcag tggtcctccc acatcttcac cttcggccag ggcaccaagg 720
tggagatcaa g 731
<210> 118
<211> 243
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 118
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Gly Ser Val Ser Ser Gly
20 25 30
Asp Tyr Tyr Trp Thr Trp Ile Arg Gln Ser Pro Gly Lys Gly Leu Glu
35 40 45
Trp Ile Gly His Ile Tyr Tyr Ser Gly Asn Thr Asn Tyr Asn Pro Ser
50 55 60
Leu Lys Ser Arg Leu Thr Ile Ser Ile Asp Thr Ser Lys Thr Gln Phe
65 70 75 80
Ser Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Ile Tyr Tyr
85 90 95
Cys Val Arg Asp Arg Val Thr Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln Ser Pro
130 135 140
Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Gln
145 150 155 160
Ala Ser Gln Asp Ile Ser Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro
165 170 175
Gly Lys Ala Pro Lys Leu Leu Ile Tyr Asp Ala Ser Asn Leu Glu Thr
180 185 190
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
195 200 205
Phe Thr Ile Ser Ser Leu Gln Pro Glu Asp Ile Ala Thr Tyr Phe Cys
210 215 220
Gln His Phe Asp His Leu Pro Leu Ala Phe Gly Gly Gly Thr Lys Val
225 230 235 240
Glu Ile Lys
<210> 119
<211> 729
<212> DNA
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 119
caggtgcagc tgcaggagtc cggccccggc ctggtgaagc cctccgagac cctgtccctg 60
acctgcaccg tgtccggcgg ctccgtgtcc tccggcgact actactggac ctggatccgg 120
cagtcccccg gcaagggcct ggagtggatc ggccacatct actactccgg caacaccaac 180
tacaacccct ccctgaagtc ccggctgacc atctccatcg acacctccaa gacccagttc 240
tccctgaagc tgtcctccgt gaccgccgcc gacaccgcca tctactactg cgtgcgggac 300
cgggtgaccg gcgccttcga catctggggc cagggcacca tggtgaccgt gtcctccggc 360
ggaggtggaa gcggaggggg aggatctggc ggcggaggaa gcggaggcga catccagatg 420
acccagtccc cctcctccct gtccgcctcc gtgggcgacc gggtgaccat cacctgccag 480
gcctcccagg acatctccaa ctacctgaac tggtaccagc agaagcccgg caaggccccc 540
aagctgctga tctacgacgc ctccaacctg gagaccggcg tgccctcccg gttctccggc 600
tccggctccg gcaccgactt caccttcacc atctcctccc tgcagcccga ggacatcgcc 660
acctacttct gccagcactt cgaccacctg cccctggcct tcggcggcgg caccaaggtg 720
gagatcaag 729
<210> 120
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR VH
<400> 120
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Thr Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Trp Asp Asp Gly Ser Tyr Lys Tyr Tyr Gly Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Ile Thr Met Val Arg Gly Val Met Lys Asp Tyr Phe
100 105 110
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 121
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR VL
<400> 121
Ala Ile Gln Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser Ser Ala
20 25 30
Leu Val Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Glu Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Phe Asn Ser Tyr Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 122
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR VH
<400> 122
Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Lys Lys Pro Gly Glu
1 5 10 15
Thr Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Glu Tyr
20 25 30
Pro Ile His Trp Val Lys Gln Ala Pro Gly Lys Gly Phe Lys Trp Met
35 40 45
Gly Met Ile Tyr Thr Asp Ile Gly Lys Pro Thr Tyr Ala Glu Glu Phe
50 55 60
Lys Gly Arg Phe Ala Phe Ser Leu Glu Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Asn Asn Leu Lys Asn Glu Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Val Arg Asp Arg Tyr Asp Ser Leu Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Leu Thr Val Ser Ser
115
<210> 123
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR VL
<400> 123
Asp Val Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys Ser Gln Ser
85 90 95
Thr His Val Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 124
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR VH
<400> 124
Glu Met Gln Leu Val Glu Ser Gly Gly Gly Phe Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser His Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Thr Pro Lys Gln Arg Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ala Ser Gly Gly Asp Ile Thr Tyr Tyr Ala Asp Thr Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Gln Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Phe Tyr Cys
85 90 95
Ser Arg Ser Ser Tyr Gly Asn Asn Gly Asp Ala Leu Asp Phe Trp Gly
100 105 110
Gln Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 125
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR VL
<400> 125
Asp Val Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys Ser Gln Ser
85 90 95
Thr His Val Leu Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 126
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> EGR VH
<400> 126
Gln Val Gln Leu Lys Gln Ser Gly Pro Gly Leu Val Gln Pro Ser Gln
1 5 10 15
Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro Phe Thr
50 55 60
Ser Arg Leu Ser Ile Asn Lys Asp Asn Ser Lys Ser Gln Val Phe Phe
65 70 75 80
Lys Met Asn Ser Leu Gln Ser Asn Asp Thr Ala Ile Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ala
115
<210> 127
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR VL
<400> 127
Asp Ile Leu Leu Thr Gln Ser Pro Val Ile Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Val Ser Phe Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr Asn
20 25 30
Ile His Trp Tyr Gln Gln Arg Thr Asn Gly Ser Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Glu Ser Ile Ser Gly Ile Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Ser Ile Asn Ser Val Glu Ser
65 70 75 80
Glu Asp Ile Ala Asp Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 128
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR VH
<400> 128
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser His
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Glu Phe Asn Pro Ser Asn Gly Arg Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Lys Ala Thr Met Thr Val Asp Thr Ser Thr Asn Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ser Arg Asp Tyr Asp Tyr Asp Gly Arg Tyr Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 129
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR VL
<400> 129
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Ser Ala Ser Ser Ser Val Thr Tyr Met
20 25 30
Tyr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr
35 40 45
Asp Thr Ser Asn Leu Ala Ser Gly Val Pro Ser Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Asp Tyr Thr Phe Thr Ile Ser Ser Leu Gln Pro Glu
65 70 75 80
Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser His Ile Phe Thr
85 90 95
Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 130
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR VH
<400> 130
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Gly Ser Val Ser Ser Gly
20 25 30
Asp Tyr Tyr Trp Thr Trp Ile Arg Gln Ser Pro Gly Lys Gly Leu Glu
35 40 45
Trp Ile Gly His Ile Tyr Tyr Ser Gly Asn Thr Asn Tyr Asn Pro Ser
50 55 60
Leu Lys Ser Arg Leu Thr Ile Ser Ile Asp Thr Ser Lys Thr Gln Phe
65 70 75 80
Ser Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Ile Tyr Tyr
85 90 95
Cys Val Arg Asp Arg Val Thr Gly Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 131
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR VL
<400> 131
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Phe Cys Gln His Phe Asp His Leu Pro Leu
85 90 95
Ala Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 132
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H1
<400> 132
Thr Tyr Gly Met His
1 5
<210> 133
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H1
<400> 133
Glu Tyr Pro Ile His
1 5
<210> 134
<211> 5
<212> PRT
<213> Artificial SEquence
<220>
<223> EGFR CDR-H1
<400> 134
His Tyr Asp Met Ser
1 5
<210> 135
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H1
<400> 135
Asn Tyr Gly Val His
1 5
<210> 136
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H1
<400> 136
Ser His Trp Met His
1 5
<210> 137
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H1
<400> 137
Ser Gly Asp Tyr Tyr Trp Thr
1 5
<210> 138
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H2
<400> 138
Val Ile Trp Asp Asp Gly Ser Tyr Lys Tyr Tyr Gly Asp Ser Val Lys
1 5 10 15
Gly
<210> 139
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H2
<400> 139
Met Ile Tyr Thr Asp Ile Gly Lys Pro Thr Tyr Ala Glu Glu Phe Lys
1 5 10 15
Gly
<210> 140
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H2
<400> 140
Tyr Ile Ala Ser Gly Gly Asp Ile Thr Tyr Tyr Ala Asp Thr Val Lys
1 5 10 15
Gly
<210> 141
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H2
<400> 141
Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro Phe Thr Ser
1 5 10 15
<210> 142
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H2
<400> 142
Glu Phe Asn Pro Ser Asn Gly Arg Thr Asn Tyr Asn Glu Lys Phe Lys
1 5 10 15
Ser
<210> 143
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H2
<400> 143
His Ile Tyr Tyr Ser Gly Asn Thr Asn Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 144
<211> 16
<212> PRT
<213> Artificial Sequnece
<220>
<223> EGFR CDR-H3
<400> 144
Asp Gly Ile Thr Met Val Arg Gly Val Met Lys Asp Tyr Phe Asp Tyr
1 5 10 15
<210> 145
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H3
<400> 145
Asp Arg Tyr Asp Ser Leu Phe Asp Tyr
1 5
<210> 146
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H3
<400> 146
Ser Ser Tyr Gly Asn Asn Gly Asp Ala Leu Asp Phe
1 5 10
<210> 147
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H3
<400> 147
Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr
1 5 10
<210> 148
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H3
<400> 148
Arg Asp Tyr Asp Tyr Asp Gly Arg Tyr Phe Asp Tyr
1 5 10
<210> 149
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-H3
<400> 149
Asp Arg Val Thr Gly Ala Phe Asp Ile
1 5
<210> 150
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L1
<400> 150
Arg Ala Ser Gln Asp Ile Ser Ser Ala Leu Val
1 5 10
<210> 151
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L1
<400> 151
Arg Ser Ser Gln Ser Leu Val His Ser Asn Gly Asn Thr Tyr Leu His
1 5 10 15
<210> 152
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFRR CDR-L1
<400> 152
Arg Ser Ser Gln Ser Leu Val His Ser Asn Gly Asn Thr Tyr Leu His
1 5 10 15
<210> 153
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L1
<400> 153
Arg Ala Ser Gln Ser Ile Gly Thr Asn Ile His
1 5 10
<210> 154
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L1
<400> 154
Ser Ala Ser Ser Ser Val Thr Tyr Met Tyr
1 5 10
<210> 155
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L1
<400> 155
Gln Ala Ser Gln Asp Ile Ser Asn Tyr Leu Asn
1 5 10
<210> 156
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L2
<400> 156
Asp Ala Ser Ser Leu Glu Ser
1 5
<210> 157
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L2
<400> 157
Lys Val Ser Asn Arg Phe Ser
1 5
<210> 158
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L2
<400> 158
Tyr Ala Ser Glu Ser Ile Ser
1 5
<210> 159
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L2
<400> 159
Asp Thr Ser Asn Leu Ala Ser
1 5
<210> 160
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L2
<400> 160
Asp Ala Ser Asn Leu Glu Thr
1 5
<210> 161
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L3
<400> 161
Gln Gln Phe Asn Ser Tyr Pro Leu Thr
1 5
<210> 162
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L3
<400> 162
Ser Gln Ser Thr His Val Pro Trp Thr
1 5
<210> 163
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L3
<400> 163
Ser Gln Ser Thr His Val Leu Thr
1 5
<210> 164
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L3
<400> 164
Gln Gln Asn Asn Asn Trp Pro Thr Thr
1 5
<210> 165
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L3
<400> 165
Gln Gln Trp Ser Ser His Ile Phe Thr
1 5
<210> 166
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR CDR-L3
<400> 166
Gln His Phe Asp His Leu Pro Leu Ala
1 5
<210> 167
<211> 246
<212> PRT
<213> Artificial Sequence
<220>
<223> pan-HLA ScFv
<400> 167
Gln Val Gln Leu Lys Gln Ser Gly Pro Gly Leu Val Gln Pro Ser Gln
1 5 10 15
Ser Leu Ser Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Ser Tyr
20 25 30
Gly Val His Trp Val Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Ser Thr Asp Tyr Asn Ala Ala Phe Ile
50 55 60
Ser Arg Leu Ser Ile Arg Lys Asp Asn Ser Lys Ser Gln Val Phe Phe
65 70 75 80
Lys Met Asn Ser Leu Gln Ala Asp Asp Thr Ala Ile Tyr Tyr Cys Ala
85 90 95
Arg Thr Phe Thr Thr Ser Thr Ser Ala Trp Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ala Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Ser Ile Val Met Thr Gln Thr
130 135 140
Pro Lys Phe Leu Leu Val Ser Ala Gly Asp Arg Val Thr Ile Thr Cys
145 150 155 160
Lys Ala Ser Gln Ser Val Ser Asn Asp Val Ala Trp Tyr Gln Gln Lys
165 170 175
Pro Gly Gln Ser Pro Ile Cys Leu Leu Ile Tyr Tyr Ala Ser Asn Arg
180 185 190
Tyr Thr Gly Val Pro Asp Arg Phe Thr Gly Ser Gly Tyr Gly Thr Asp
195 200 205
Phe Thr Phe Thr Ile Ser Thr Val Gln Ala Glu Asp Leu Ala Val Tyr
210 215 220
Phe Cys Gln Gln Asp Tyr Ser Ser Pro Pro Trp Thr Phe Gly Gly Gly
225 230 235 240
Thr Lys Leu Glu Ile Arg
245
<210> 168
<211> 738
<212> DNA
<213> Artificial Sequence
<220>
<223> pan-HLA ScFv
<400> 168
caggtgcagc tgaagcagtc aggacctggc ctagtgcagc cctcacagag cctgtccctg 60
acctgcacag tctctggttt ctcattaact agttatggcg tacactgggt tcgccagcct 120
ccaggaaagg gtctggagtg gctgggagtg atctggagtg gtggaagcac agactataat 180
gctgctttca tatccagact gagcatcagg aaggacaact ccaagagcca agtcttcttt 240
aaaatgaaca gtctgcaagc tgatgacaca gccatatact actgtgccag aacctttact 300
acgtctacct cggcctggtt tgcttactgg ggccaaggga ctctggtcac tgtctctgca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cagcatcgtg 420
atgacccaga ctccaaaatt cctgcttgtg tctgcgggag acagagtcac catcacttgc 480
aaggcgagtc agtctgtgag caacgacgta gcttggtatc agcagaaacc agggcaatct 540
cctatctgtc tcctgatcta ctatgcatct aatcggtata caggggtccc tgataggttc 600
accggaagtg gatatgggac agatttcact ttcaccatca gcaccgtgca ggctgaagat 660
cttgcagtat atttctgtca acaggattat agtagtcctc cgtggacttt cggcggaggg 720
accaagttgg agatcaga 738
<210> 169
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> pan-HLA ScFv
<400> 169
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Ser Tyr
20 25 30
Gly Val His Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Val Ile Trp Ser Gly Gly Ser Thr Asp Tyr Asn Ala Ala Phe Ile
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Thr Phe Thr Thr Ser Thr Ser Ala Trp Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Val Met Thr Gln Ser
130 135 140
Pro Asp Ser Leu Ala Val Ser Leu Gly Glu Arg Ala Thr Ile Asn Cys
145 150 155 160
Lys Ala Ser Gln Ser Val Ser Asn Asp Val Ala Trp Tyr Gln Gln Lys
165 170 175
Pro Gly Gln Pro Pro Lys Leu Leu Ile Tyr Tyr Ala Ser Asn Arg Tyr
180 185 190
Thr Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe
195 200 205
Thr Leu Thr Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr
210 215 220
Cys Gln Gln Asp Tyr Ser Ser Pro Pro Trp Thr Phe Gly Gly Gly Thr
225 230 235 240
Lys Val Glu Ile Lys
245
<210> 170
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> pan-HLA ScFv
<400> 170
caggtgcagc tgcaggagtc cggacctggc ctagtgaagc cctcacagac cctgtccctg 60
acctgcacag tctctggttt ctcattaact agctatggtg tacactggat tagacagcct 120
ccaggaaagg gtctggagtg gattggagtg atctggagtg gtggaagcac agactataat 180
gctgctttca tatccagagt gaccatcagc gtggacacct ccaagaacca attctccctt 240
aaactgagca gtgtgacagc tgccgacaca gccgtatact actgtgccag aacctttact 300
acgtctacct cggcctggtt tgcttactgg ggccaaggga ctctggtcac tgtctcttca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cgacatcgtg 420
atgacccaga gtccagattc cctggctgtg tctctgggag agagagccac catcaattgc 480
aaggcgagtc agtctgtgag caacgacgta gcttggtatc agcagaaacc agggcaacct 540
cctaaactcc tgatctacta tgcatctaat cggtatacag gggtccctga taggttcagc 600
ggaagtggat ctgggacaga tttcactctc accatcagca gcctgcaggc tgaagatgtt 660
gcagtatatt actgtcaaca ggattatagt agtcctccgt ggactttcgg cggagggacc 720
aaggtggaga tcaaa 735
<210> 171
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> pan-HLA ScFv
<400> 171
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Ser Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Trp Ser Gly Gly Ser Thr Asp Tyr Asn Ala Ala Phe Ile
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Thr Phe Thr Thr Ser Thr Ser Ala Trp Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln Ser
130 135 140
Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys
145 150 155 160
Lys Ala Ser Gln Ser Val Ser Asn Asp Val Ala Trp Tyr Gln Gln Lys
165 170 175
Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Tyr Ala Ser Asn Arg Tyr
180 185 190
Thr Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe
195 200 205
Thr Phe Thr Ile Ser Ser Leu Gln Pro Glu Asp Ile Ala Thr Tyr Tyr
210 215 220
Cys Gln Gln Asp Tyr Ser Ser Pro Pro Trp Thr Phe Gly Gly Gly Thr
225 230 235 240
Lys Val Glu Ile Lys
245
<210> 172
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> pan-HLA ScFv
<400> 172
gaggtgcagc tgctggagtc cggaggtggc ctagtgcagc ccggagggag cctgcgcctg 60
agctgcgcag cctctggttt ctcattaact agctatggtg tacactgggt tagacaggct 120
ccaggaaagg gtctggagtg ggttagcgtg atctggagtg gtggaagcac agactataat 180
gctgctttca tatccagatt taccatcagc cgggacaact ccaagaacac actctacctt 240
caaatgaaca gtttgagagc tgaagacaca gccgtatact actgtgccag aacctttact 300
acgtctacct cggcctggtt tgcttactgg ggccaaggga ctctggtcac tgtctcttca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cgacatccag 420
atgacccaga gtccaagctc cctgtctgcg tctgtgggag acagagtcac catcacttgc 480
aaggcgagtc agtctgtgag caacgacgta gcttggtatc agcagaaacc agggaaagct 540
cctaaactcc tgatctacta tgcatctaat cggtatacag gggtccctag taggttcagc 600
ggaagtggat ctgggacaga tttcactttc accatcagca gcctgcagcc tgaagatatt 660
gcaacatatt actgtcaaca ggattatagt agtcctccgt ggactttcgg cggagggacc 720
aaggtggaga tcaaa 735
<210> 173
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> pan-HLA ScFv
<400> 173
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Ser Tyr
20 25 30
Gly Val His Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Val Ile Trp Ser Gly Gly Ser Thr Asp Tyr Asn Ala Ala Phe Ile
50 55 60
Ser Arg Val Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Thr Phe Thr Thr Ser Thr Ser Ala Trp Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Val Met Thr Gln Thr
130 135 140
Pro Leu Ser Leu Ser Val Thr Pro Gly Gln Pro Ala Ser Ile Ser Cys
145 150 155 160
Lys Ala Ser Gln Ser Val Ser Asn Asp Val Ala Trp Tyr Leu Gln Lys
165 170 175
Pro Gly Gln Ser Pro Gln Leu Leu Ile Tyr Tyr Ala Ser Asn Arg Tyr
180 185 190
Thr Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe
195 200 205
Thr Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr
210 215 220
Cys Gln Gln Asp Tyr Ser Ser Pro Pro Trp Thr Phe Gly Gly Gly Thr
225 230 235 240
Lys Val Glu Ile Lys
245
<210> 174
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> pan-HLA ScFv
<400> 174
caggtgcagc tgcaggagtc cggacctggc ctagtgaagc cctcagaaac cctgtccctg 60
acctgcacag tctctggttt ctcattaact agctatggtg tacactggat tagacagcct 120
ccaggaaagg gtctggagtg gattggagtg atctggagtg gtggaagcac agactataat 180
gctgctttca tatccagagt gaccatcagc agggacacct ccaagaacca attctccctt 240
aaactgagca gtgtgacagc tgccgacaca gccgtatact actgtgccag aacctttact 300
acgtctacct cggcctggtt tgcttactgg ggccaaggga ctctggtcac tgtctcttca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cgacatcgtg 420
atgacccaga ctccactttc cctgtctgtg actccgggac agccagccag catcagttgc 480
aaggcgagtc agtctgtgag caacgacgta gcttggtatc tgcagaaacc agggcaatct 540
cctcaactcc tgatctacta tgcatctaat cggtatacag gggtccctga taggttcagc 600
ggaagtggat ctgggacaga tttcactttg aagatcagca gggtggaggc tgaagatgtt 660
ggagtatatt actgtcaaca ggattatagt agtcctccgt ggactttcgg cggagggacc 720
aaggtggaga tcaaa 735
<210> 175
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> pan-HLA ScFv
<400> 175
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Phe Ser Leu Thr Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Trp Ser Gly Gly Ser Thr Asp Tyr Asn Ala Ala Phe Ile
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Lys Thr Phe Thr Thr Ser Thr Ser Ala Trp Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Glu Ile Val Leu Thr Gln Ser
130 135 140
Pro Ala Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys
145 150 155 160
Arg Ala Ser Gln Ser Val Ser Asn Asp Leu Ala Trp Tyr Gln Gln Lys
165 170 175
Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Tyr Ala Ser Asn Arg Tyr
180 185 190
Thr Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe
195 200 205
Thr Leu Thr Ile Ser Ser Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr
210 215 220
Cys Gln Gln Asp Tyr Ser Ser Pro Pro Trp Thr Phe Gly Gln Gly Thr
225 230 235 240
Lys Val Glu Ile Lys
245
<210> 176
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> pan-HLA ScFv
<400> 176
caggtgcagc tggtggagtc cggaggtggc gtagtgcagc ccggaaggag cctgcgcctg 60
agctgcgcag tctctggttt ctcattaact agctatggta tgcactgggt tagacaggct 120
ccaggaaagg gtctggagtg ggttgcagtg atctggagtg gtggaagcac agactataat 180
gctgctttca tatccagatt taccatcagc cgggacaact ccaagaacac actctacctt 240
caaatgaaca gtttgagagc tgaagacaca gccgtatact actgtgccaa aacctttact 300
acgtctacct cggcctggtt tgcttactgg ggccaaggga ctctggtcac tgtctcttca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cgagatcgtg 420
ctgacccaga gtccagctac cctgtctctg tctccgggag agagagccac cctcagttgc 480
agggcgagtc agtctgtgag caacgaccta gcttggtatc agcagaaacc agggcaagct 540
cctagactcc tgatctacta tgcatctaat cggtatacag gggtccctga taggttcagc 600
ggaagtggat ctgggacaga tttcactctc accatcagca gcctggagcc tgaagatttt 660
gcagtatatt actgtcaaca ggattatagt agtcctccgt ggactttcgg ccaagggacc 720
aaggtggaga tcaaa 735
<210> 177
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> pan-HLA ScFv
<400> 177
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Phe Ser Leu Thr Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Trp Ser Gly Gly Ser Thr Asp Tyr Asn Ala Ala Phe Ile
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Thr Phe Thr Thr Ser Thr Ser Ala Trp Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln Ser
130 135 140
Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys
145 150 155 160
Gln Ala Ser Gln Ser Val Ser Asn Asp Leu Asn Trp Tyr Gln Gln Lys
165 170 175
Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Tyr Ala Ser Asn Arg Tyr
180 185 190
Thr Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe
195 200 205
Thr Phe Thr Ile Ser Ser Leu Gln Pro Glu Asp Ile Ala Thr Tyr Tyr
210 215 220
Cys Gln Gln Asp Tyr Ser Ser Pro Pro Trp Thr Phe Gly Gly Gly Thr
225 230 235 240
Lys Val Glu Ile Lys
245
<210> 178
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> pan-HLA ScFv
<400> 178
caggtgcagc tggtggagtc cggaggtggc gtagtgcagc ccggaaggag cctgcgcctg 60
agctgcgcag tctctggttt ctcattaact agctatggta tgcactgggt tagacaggct 120
ccaggaaagg gtctggagtg ggttgcagtg atctggagtg gtggaagcac agactataat 180
gctgctttca tatccagatt taccatcagc cgggacaact ccaagaacac actctacctt 240
caaatgaaca gtttgagagc tgaagacaca gccgtatact actgtgccag aacctttact 300
acgtctacct cggcctggtt tgcttactgg ggccaaggga ctctggtcac tgtctcttca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cgacatccag 420
atgacccaga gtccaagctc cctgtctgcg tctgtgggag acagagtcac catcacttgc 480
caggcgagtc agtctgtgag caacgaccta aattggtatc agcagaaacc agggaaagct 540
cctaaactcc tgatctacta tgcatctaat cggtatacag gggtccctga taggttcagc 600
ggaagtggat ctgggacaga tttcactttc accatcagca gcctgcagcc tgaagatatt 660
gcaacatatt actgtcaaca ggattatagt agtcctccgt ggactttcgg cggagggacc 720
aaggtggaga tcaaa 735
<210> 179
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> HLA-A*02 antigen binding domain
<400> 179
gatgttttga tgacccaaac tccactctcc ctgcctgtca gtcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagcattgta catagtaatg gaaacaccta tttagaatgg 120
tacctgcaga aaccaggcca gtctccaaag ctcctgatct acaaagtttc caaccgattt 180
tctggggtcc cagacaggtt cagtggcagt ggatcaggga cagatttcac actcaagatc 240
agtagagtgg aggctgagga tctgggagtt tattactgct ttcaaggttc acatgttcct 300
cggacgtccg gtggaggcac caagctggaa atcaaaggcg gaggtggaag cggaggggga 360
ggatctggcg gcggaggaag cggaggccag gtccagctgc agcagtctgg acctgagctg 420
gtgaagcctg gggcttcagt gaggatatcc tgcaaggctt ctggctacac cttcacaagt 480
taccatatac attgggtgaa gcagaggcct ggacagggac ttgagtggat tggatggatt 540
tatcctggaa atgttaatac tgagtacaat gagaagttca agggcaaggc cacactgact 600
gcagacaaat cgtccagcac agcctacatg cacctcagca gcctgacctc tgaggactct 660
gcggtctatt tctgtgccag agaggagatt acctatgcta tggactactg gggtcaagga 720
acctcagtca ccgtgtcctc a 741
<210> 180
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> HLA-A*02 antigen binding domain
<400> 180
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc agtgaaggtt 60
tcctgcaagg cttctggata caccttcact agctatcata tacattgggt gcgccaggcc 120
cccggacaag ggcttgagtg gatgggatgg atctaccctg gcaatgttaa cacagaatat 180
aatgagaagt tcaagggcaa agccaccatt accgcggaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaagac acggctgtgt attactgtgc gagggaggaa 300
attacctacg ctatggacta ctggggccag ggaaccacag tcaccgtgtc ctcaggcgga 360
ggtggaagcg gagggggagg atctggcggc ggaggaagcg gaggcgagat tgtattgacc 420
cagagcccag gcaccctgag cctctctcca ggagagcggg ccaccctcag ttgtagatcc 480
agtcagagta ttgtacacag taatgggaac acctatttgg aatggtatca gcagaaacca 540
ggtcaagccc caagattgct catctacaaa gtctctaaca gatttagtgg tattccagac 600
aggttcagcg gttccggaag tggtactgat ttcaccctca cgatctccag gctcgagcca 660
gaagatttcg ccgtttatta ctgttttcaa ggttcacatg tgccgcgcac attcggtggg 720
ggtactaaag tagaaatcaa a 741
<210> 181
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> HLA-A*02 antigen binding domain
<400> 181
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc agtgaaggtt 60
tcctgcaagg cttctggata caccttcact agctatcata tacattgggt gcgccaggcc 120
cccggacaag ggcttgagtg gatgggatgg atctaccctg gcaatgttaa cacagaatat 180
aatgagaagt tcaagggcaa agccaccatt accgcggaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaagac acggctgtgt attactgtgc gagggaggaa 300
attacctacg ctatggacta ctggggccag ggaaccacag tcaccgtgtc ctcaggcgga 360
ggtggaagcg gagggggagg atctggcggc ggaggaagcg gaggcgacat tgtaatgacc 420
cagaccccac tcagcctgcc cgtcactcca ggagagccgg ccagcatcag ttgtagatcc 480
agtcagagta ttgtacacag taatgggaac acctatttgg aatggtatct gcagaaacca 540
ggtcaatccc cacaattgct catctacaaa gtctctaaca gatttagtgg tgtaccagac 600
aggttcagcg gttccggaag tggtactgat ttcaccctca agatctccag ggtcgaggca 660
gaagatgtcg gcgtttatta ctgttttcaa ggttcacatg tgccgcgcac attcggtggg 720
ggtactaaag tagaaatcaa a 741
<210> 182
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> HLA-A*02 antigen binding domain
<400> 182
gaggtgcagc tggtggagtc tgggggtggg ctggtgaagc ctgggggctc actgaggctt 60
tcctgcgcgg cttctggata caccttcact agctatcata tacattgggt gcgccaggcc 120
cccggaaaag ggcttgagtg ggtgggatgg atctaccctg gcaatgttaa cacagaatat 180
aatgagaagt tcaagggcag attcaccatt agcagggacg attccaagaa cacactctac 240
ctgcagatga acagcctgaa aactgaagac acggctgtgt attactgtgc gagggaggaa 300
attacctacg ctatggacta ctggggccag ggaaccacag tcaccgtgtc ctcaggcgga 360
ggtggaagcg gagggggagg atctggcggc ggaggaagcg gaggcgacat tcaaatgacc 420
cagagcccat ccagcctgag cgcatctgta ggtgaccggg tcaccatcac ttgtagatcc 480
agtcagagta ttgtacacag taatgggaac acctatttgg aatggtatca gcagaaacca 540
ggtaaagccc caaaattgct catctacaaa gtctctaaca gatttagtgg tgtaccaagc 600
aggttcagcg gttccggaag tggtactgat ttcaccctca cgatctcctc tctccagcca 660
gaagatttcg ccacttatta ctgttttcaa ggttcacatg tgccgcgcac attcggtggg 720
ggtactaaag tagaaatcaa a 741
<210> 183
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> HLA-A*02 antigen binding domain
<400> 183
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc agtgaaggtt 60
tcctgcaagg cttctggata caccttcact agctatcata tacattgggt gcgccaggcc 120
cccggacaag ggcttgagtg gatcggatgg atctaccctg gcaatgttaa cacagaatat 180
aatgagaagt tcaagggcaa agccaccatt accgcggacg aatccacgaa cacagcctac 240
atggagctga gcagcctgag atctgaagac acggctgtgt attactgtgc gagggaggaa 300
attacctacg ctatggacta ctggggccag ggaaccctgg tcaccgtgtc ctcaggcgga 360
ggtggaagcg gagggggagg atctggcggc ggaggaagcg gaggcgacat tcaaatgacc 420
cagagcccat ccaccctgag cgcatctgta ggtgaccggg tcaccatcac ttgtagatcc 480
agtcagagta ttgtacacag taatgggaac acctatttgg aatggtatca gcagaaacca 540
ggtaaagccc caaaattgct catctacaaa gtctctaaca gatttagtgg tgtaccagcc 600
aggttcagcg gttccggaag tggtactgaa ttcaccctca cgatctcctc tctccagcca 660
gatgatttcg ccacttatta ctgttttcaa ggttcacatg tgccgcgcac attcggtcag 720
ggtactaaag tagaagtcaa a 741
<210> 184
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> HLA-A*02 antigen binding domain
<400> 184
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc agtgaaggtt 60
tcctgcaagg cttctggata caccttcact agctatcata tgcattgggt gcgccaggcc 120
cccggacaag ggcttgagtg gatcggatac atctaccctg gcaatgttaa cacagaatat 180
aatgagaagt tcaagggcaa agccaccctt accgcggaca aatccacgaa cacagcctac 240
atggagctga gcagcctgag atctgaagac acggctgtgt atttctgtgc gagggaggaa 300
attacctacg ctatggacta ctggggccag ggaaccctgg tcaccgtgtc ctcaggcgga 360
ggtggaagcg gagggggagg atctggcggc ggaggaagcg gaggcgacgt tcaaatgacc 420
cagagcccat ccaccctgag cgcatctgta ggtgaccggg tcaccatcac ttgtagctcc 480
agtcagagta ttgtacacag taatgggaac acctatatgg aatggtatca gcagaaacca 540
ggtaaagccc caaaattgct catctacaaa gtctctaaca gatttagtgg tgtaccagac 600
aggttcagcg gttccggaag tggtactgaa ttcaccctca cgatctcctc tctccagcca 660
gatgatttcg ccacttatta ctgtcatcaa ggttcacatg tgccgcgcac attcggtcag 720
ggtactaaag tagaagtcaa a 741
<210> 185
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> HLA-A*02 antigen binding domain
<400> 185
caggtgcagc tgcagcagtc tgggcctgag ctggtgaagc ctggggcctc agtgaagatg 60
tcctgcaagg cttctggata caccttcact agctatcata tccagtgggt gaagcagagg 120
cctggacaag ggcttgagtg gatcggatgg atctaccctg gcgatggtag tacacagtat 180
aatgagaagt tcaagggcaa aaccaccctt accgcggaca aatcctccag cacagcctac 240
atgttgctga gcagcctgac ctctgaagac tctgctatct atttctgtgc gagggagggg 300
acctactacg ctatggacta ctggggccag ggaacctcag tcaccgtgtc ctcaggcgga 360
ggtggaagcg gagggggagg atctggcggc ggaggaagcg gaggcgatgt tttgatgacc 420
cagactccac tctccctgcc tgtctctctt ggagaccaag tctccatctc ttgtagatcc 480
agtcagagta ttgtacacag taatgggaac acctatttag aatggtatct gcagaaacca 540
ggtcagtctc caaagttgct catctacaaa gtctctaaca gatttagtgg tgtaccagac 600
aggttcagcg gttccggaag tggtactgat ttcaccctca agatctcgag agtggaggct 660
gaggatctgg gagtttatta ctgttttcaa ggttcacatg tgccgcgcac attcggtgga 720
ggtactaaac tggaaatcaa a 741
<210> 186
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> HLA-A*02 antigen binding domain
<400> 186
cagctgcagc tgcaggagtc tgggcccggg ctggtgaagc cttcggaaac gctgagcctc 60
acctgcacgg tttctggata caccttcacc agctatcata tccagtggat ccgacagccc 120
cctggaaaag ggcttgagtg gatcggatgg atctaccctg gcgatggttc aacacagtac 180
aatgagaagt tcaagggcag agccacgatt agcgtggaca catccaagaa ccaattctcc 240
ctgaacctgg acagcgtgag tgctgcggac acggccattt attactgtgc gagagaggga 300
acttactacg ctatggacta ctggggcaaa gggagcacgg tcaccgtgtc ctcaggcgga 360
ggtggaagcg gagggggagg atctggcggc ggaggaagcg gaggcgacat ccagatgacc 420
cagagcccaa gctccctgag tgcgtccgtg ggcgaccgcg tgaccatcac ttgcagatcc 480
tctcagtcca tcgtgcactc caacggcaac acgtacctcg agtggtacca gcagaagccc 540
gggaaggccc cgaaactgct catctacaag gtgagcaacc ggttctccgg cgtccccagc 600
cgcttctcag ggtccggctc ggggacggat ttcaccttca cgattagcag cttgcagccc 660
gaagacatcg ccacgtacta ctgctttcag ggaagtcacg tgccgcgtac cttcgggccg 720
ggcacgaaag tggatattaa g 741
<210> 187
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> HLA-A*02 antigen binding domain
<400> 187
gaggtgcagc tggtgcagtc tggggccgag ctgaagaagc ctgggtcctc ggtgaaggtg 60
tcctgcaagg cttctggata caccttcacc agctatcata tccagtgggt aaaacaggcc 120
cctggacaag ggcttgagtg gatcggatgg atctaccctg gcgatggttc aacacagtac 180
aatgagaagt tcaagggcaa agccacgctt accgtggaca aatccacgaa cacagcctac 240
atggagctga gcagcctgag atctgaggac acggccgtat attactgtgc gagagaggga 300
acttactacg ctatggacta ctggggccaa gggaccctgg tcaccgtgtc ctcaggcgga 360
ggtggaagcg gagggggagg atctggcggc ggaggaagcg gaggcgacat ccagatgacc 420
cagagcccat ccaccctgag tgcgtccgtg ggcgaccgcg tgaccatcac ttgcagatcc 480
tctcagtcca tcgtgcactc caacggcaac acgtacctcg agtggtacca gcagaagccc 540
gggaaggccc cgaaactgct catctacaag gtgagcaacc ggttctccgg cgtccccagc 600
cgcttctcag ggtccggctc ggggacggat ttcaccctca cgattagcag cttgcagccc 660
gatgacttcg ccacgtacta ctgctttcag ggaagtcacg tgccgcgtac cttcgggcag 720
ggcacgaaag tggaagttaa g 741
<210> 188
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> HLA-A*02 antigen binding domain
<400> 188
caggtgcagc tggtgcagtc tggggccgag gtgaagaagc ctgggtcctc ggtgaaggtg 60
tcctgcaagg cttctggata caccttcacc agctatcata tccagtgggt acgacaggcc 120
cctggacaag ggcttgagtg gatgggatgg atctaccctg gcgatggttc aacacagtac 180
aatgagaagt tcaagggcag agtcacgatt accgcggaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac acggccgtat attactgtgc gagagaggga 300
acttactacg ctatggacta ctggggccaa gggaccacgg tcaccgtgtc ctcaggcgga 360
ggtggaagcg gagggggagg atctggcggc ggaggaagcg gaggcgagat cgtcctgacc 420
cagagcccag ggaccctgag tttgtccccg ggcgagcgcg cgaccctcag ttgcagatcc 480
tctcagtcca tcgtgcactc caacggcaac acgtacctcg agtggtacca gcagaagccc 540
gggcaggccc cgcgactgct catctacaag gtgagcaacc ggttctccgg catccccgac 600
cgcttctcag ggtccggctc ggggacggat ttcaccctca cgattagccg cttggagccc 660
gaagacttcg ccgtgtacta ctgctttcag ggaagtcacg tgccgcgtac cttcgggggg 720
ggcacgaaag tggaaattaa g 741
<210> 189
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> HLA-A*02 antigen binding domain
<400> 189
caggtgaccc tgaagcagtc tggggccgag gtgaagaagc ctgggtcctc ggtgaaggtg 60
tcctgcacgg cttctggata caccttcacc agctatcatg tcagctgggt acgacaggcc 120
cctggacaag ggcttgagtg gttgggaagg atctaccctg gcgatggttc aacacagtac 180
aatgagaagt tcaagggcaa agtcacgatt accgcggaca aatccatgga cacatccttc 240
atggagctga ccagcctgac atctgaggac acggccgtat attactgtgc gagagaggga 300
acttactacg ctatggacct ctggggccaa gggaccctgg tcaccgtgtc ctcaggcgga 360
ggtggaagcg gagggggagg atctggcggc ggaggaagcg gaggcgagat cgtcctgacc 420
cagagcccag ggaccctgag tttgtccccg ggcgagcgcg cgaccctcag ttgcagatcc 480
tctcagtcca tcgtgcactc caacggcaac acgtacctcg cgtggtacca gcagaagccc 540
gggcaggccc cgcgactgct catctccaag gtgagcaacc ggttctccgg cgtccccgac 600
cgcttctcag ggtccggctc ggggacggat ttcaccctca cgattagccg cttggagccc 660
gaagacttcg ccgtgtacta ctgccaacag ggaagtcacg tgccgcgtac cttcgggggg 720
ggcacgaaag tggaaattaa g 741
<210> 190
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> HLA-A*02 antigen binding domain
<400> 190
caggtgcagc tggtgcagtc tggggccgag gtgaagaagc ctggggcctc ggtgaaggtg 60
tcctgcaagg cttctggata caccttcacc agctatcata tgcactgggt acgacaggcc 120
cctggacaaa ggcttgagtg gatgggatgg atctaccctg gcgatggttc aacacagtac 180
aatgagaagt tcaagggcaa agtcacgatt acccgggaca catccgcgag cacagcctac 240
atggagctga gcagcctgag atctgaggac acggccgtat attactgtgc gagagaggga 300
acttactacg ctatggacta ctggggccaa gggaccctgg tcaccgtgtc ctcaggcgga 360
ggtggaagcg gagggggagg atctggcggc ggaggaagcg gaggcgacat cgtcatgacc 420
cagaccccac tgtccctgcc tgtgaccccg ggcgagcccg cgagcatcag ttgcagatcc 480
tctcagtcca tcgtgcactc caacggcaac acgtacctcg actggtacct gcagaagccc 540
gggcagtccc cgcaactgct catctacaag gtgagcaacc ggttctccgg cgtccccgac 600
cgcttctcag ggtccggctc ggggacggat ttcaccctca agattagccg cgtggaggcc 660
gaagacgtcg gcgtgtacta ctgcatgcag ggaagtcacg tgccgcgtac cttcgggggg 720
ggcacgaaag tggaaattaa g 741
<210> 191
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> HA-1 variant H peptide
<400> 191
Val Leu His Asp Asp Leu Leu Glu Ala
1 5
<210> 192
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> P2A self cleaving peptide
<400> 192
Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val Glu Glu Asn
1 5 10 15
Pro Gly Pro
<210> 193
<211> 608
<212> PRT
<213> Artificial Sequence
<220>
<223> HA-1H TCR alpha and beta
<400> 193
Met Val Lys Ile Arg Gln Phe Leu Leu Ala Ile Leu Trp Leu Gln Leu
1 5 10 15
Ser Cys Val Ser Ala Ala Lys Asn Glu Val Glu Gln Ser Pro Gln Asn
20 25 30
Leu Thr Ala Gln Glu Gly Glu Phe Ile Thr Ile Asn Cys Ser Tyr Ser
35 40 45
Val Gly Ile Ser Ala Leu His Trp Leu Gln Gln His Pro Gly Gly Gly
50 55 60
Ile Val Ser Leu Phe Met Leu Ser Ser Gly Lys Lys Lys His Gly Arg
65 70 75 80
Leu Ile Ala Thr Ile Asn Ile Gln Glu Lys His Ser Ser Leu His Ile
85 90 95
Thr Ala Ser His Pro Arg Asp Ser Ala Val Tyr Ile Cys Ala Val Arg
100 105 110
Ser Val Ser Gly Ala Gly Ser Tyr Gln Leu Thr Phe Gly Lys Gly Thr
115 120 125
Lys Leu Ser Val Ile Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr
130 135 140
Gln Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr
145 150 155 160
Asp Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val
165 170 175
Tyr Ile Thr Asp Lys Cys Val Leu Asp Met Arg Ser Met Asp Phe Lys
180 185 190
Ser Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala
195 200 205
Asn Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser
210 215 220
Pro Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr
225 230 235 240
Asp Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile
245 250 255
Leu Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu
260 265 270
Trp Ser Ser Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala
275 280 285
Gly Asp Val Glu Glu Asn Pro Gly Pro Met Gly Thr Ser Leu Leu Cys
290 295 300
Trp Met Ala Leu Cys Leu Leu Gly Ala Asp His Ala Asp Thr Gly Val
305 310 315 320
Ser Gln Asn Pro Arg His Lys Ile Thr Lys Arg Gly Gln Asn Val Thr
325 330 335
Phe Arg Cys Asp Pro Ile Ser Glu His Asn Arg Leu Tyr Trp Tyr Arg
340 345 350
Gln Thr Leu Gly Gln Gly Pro Glu Phe Leu Thr Tyr Phe Gln Asn Glu
355 360 365
Ala Gln Leu Glu Lys Ser Arg Leu Leu Ser Asp Arg Phe Ser Ala Glu
370 375 380
Arg Pro Lys Gly Ser Phe Ser Thr Leu Glu Ile Gln Arg Thr Glu Gln
385 390 395 400
Gly Asp Ser Ala Met Tyr Leu Cys Ala Ser Ser Ile Asp Ser Phe Asn
405 410 415
Glu Gln Phe Phe Gly Pro Gly Thr Arg Leu Thr Val Leu Glu Asp Leu
420 425 430
Lys Asn Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro Ser Glu Ala
435 440 445
Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu Ala Thr Gly
450 455 460
Phe Tyr Pro Asp His Val Glu Leu Ser Trp Trp Val Asn Gly Lys Glu
465 470 475 480
Val His Ser Gly Val Cys Thr Asp Pro Gln Pro Leu Lys Glu Gln Pro
485 490 495
Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu Arg Val Ser
500 505 510
Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys Gln Val Gln
515 520 525
Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp Arg Ala Lys
530 535 540
Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg Ala Asp Cys
545 550 555 560
Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu Ser Ala Thr Ile
565 570 575
Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala Val Leu Val
580 585 590
Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp Ser Arg Gly
595 600 605
<210> 194
<211> 1827
<212> DNA
<213> Artificial Sequence
<220>
<223> HA-1(H) TCR alpha and beta
<400> 194
atggtgaaga tccggcaatt tttgttggct attttgtggc ttcagctaag ctgtgtaagt 60
gccgccaaaa atgaagtgga gcagagtcct cagaacctga ctgcccagga aggagaattt 120
atcacaatca actgcagtta ctcggtagga ataagtgcct tacactggct gcaacagcat 180
ccaggaggag gcattgtttc cttgtttatg ctgagctcag ggaagaagaa gcatggaaga 240
ttaattgcca caataaacat acaggaaaag cacagctccc tgcacatcac agcctcccat 300
cccagagact ctgccgtcta catctgtgct gtcagaagcg tgtccggggc cggctcctac 360
cagctcacct ttgggaaggg gaccaaatta tcagtcattc caaatatcca gaaccctgac 420
cctgccgtgt accagctgag agactctaaa tccagtgaca agtctgtctg cctattcacc 480
gattttgatt ctcaaacaaa tgtgtcacaa agtaaggatt ctgatgtgta tatcacagac 540
aaatgtgtgc tagacatgag gtctatggac ttcaagagca acagtgctgt ggcctggagc 600
aacaaatctg actttgcatg tgcaaacgcc ttcaacaaca gcattattcc agaagacacc 660
ttcttcccca gcccagaaag ttcctgtgat gtcaagctgg tcgagaaaag ctttgaaaca 720
gatacgaacc taaactttca aaacctgtca gtgattgggt tccgaatcct cctcctgaaa 780
gtggccgggt ttaatctgct catgacgctg cggctgtggt ccagcggatc cggagccacc 840
aacttcagcc tgctgaagca ggccggcgac gtggaggaga accccggccc catgggcacc 900
agcctcctct gctggatggc cctgtgtctc ctgggggcag atcacgcaga tactggagtc 960
tcccagaacc ccagacacaa gatcacaaag aggggacaga atgtaacttt caggtgtgat 1020
ccaatttctg aacacaaccg cctttattgg taccgacaga ccctggggca gggcccagag 1080
tttctgactt acttccagaa tgaagctcaa ctagaaaaat caaggctgct cagtgatcgg 1140
ttctctgcag agaggcctaa gggatctttc tccaccttgg agatccagcg cacagagcag 1200
ggggactcgg ccatgtatct ctgtgccagc agcatcgact ccttcaacga gcagttcttc 1260
gggccgggca ccaggctcac ggtcctcgag gacctgaaaa acgtgttccc acccgaggtc 1320
gctgtgtttg agccatcaga agcagagatc tcccacaccc aaaaggccac actggtgtgc 1380
ctggccacag gcttctaccc cgaccacgtg gagctgagct ggtgggtgaa tgggaaggag 1440
gtgcacagtg gggtctgcac agacccgcag cccctcaagg agcagcccgc cctcaatgac 1500
tccagatact gcctgagcag ccgcctgagg gtgtcggcca ccttctggca gaacccccgc 1560
aaccacttcc gctgtcaagt ccagttctac gggctctcgg agaatgacga gtggacccag 1620
gatagggcca aacctgtcac ccagatcgtc agcgccgagg cctggggtag agcagactgt 1680
ggcttcacct ccgagtctta ccagcaaggg gtcctgtctg ccaccatcct ctatgagatc 1740
ttgctaggga aggccacctt gtatgccgtg ctggtcagtg ccctcgtgct gatggccatg 1800
gtcaagagaa aggattccag aggctag 1827
<210> 195
<211> 440
<212> PRT
<213> Artificial Sequence
<220>
<223> Ftcr alpha LIR1 HA-1H
<400> 195
Met Val Lys Ile Arg Gln Phe Leu Leu Ala Ile Leu Trp Leu Gln Leu
1 5 10 15
Ser Cys Val Ser Ala Ala Lys Asn Glu Val Glu Gln Ser Pro Gln Asn
20 25 30
Leu Thr Ala Gln Glu Gly Glu Phe Ile Thr Ile Asn Cys Ser Tyr Ser
35 40 45
Val Gly Ile Ser Ala Leu His Trp Leu Gln Gln His Pro Gly Gly Gly
50 55 60
Ile Val Ser Leu Phe Met Leu Ser Ser Gly Lys Lys Lys His Gly Arg
65 70 75 80
Leu Ile Ala Thr Ile Asn Ile Gln Glu Lys His Ser Ser Leu His Ile
85 90 95
Thr Ala Ser His Pro Arg Asp Ser Ala Val Tyr Ile Cys Ala Val Arg
100 105 110
Ser Val Ser Gly Ala Gly Ser Tyr Gln Leu Thr Phe Gly Lys Gly Thr
115 120 125
Lys Leu Ser Val Ile Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr
130 135 140
Gln Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr
145 150 155 160
Asp Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val
165 170 175
Tyr Ile Thr Asp Lys Cys Val Leu Asp Met Arg Ser Met Asp Phe Lys
180 185 190
Ser Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala
195 200 205
Asn Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser
210 215 220
Pro Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr
225 230 235 240
Asp Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Val Ile Gly Ile Leu
245 250 255
Val Ala Val Ile Leu Leu Leu Leu Leu Leu Leu Leu Leu Phe Leu Ile
260 265 270
Leu Arg His Arg Arg Gln Gly Lys His Trp Thr Ser Thr Gln Arg Lys
275 280 285
Ala Asp Phe Gln His Pro Ala Gly Ala Val Gly Pro Glu Pro Thr Asp
290 295 300
Arg Gly Leu Gln Trp Arg Ser Ser Pro Ala Ala Asp Ala Gln Glu Glu
305 310 315 320
Asn Leu Tyr Ala Ala Val Lys His Thr Gln Pro Glu Asp Gly Val Glu
325 330 335
Met Asp Thr Arg Ser Pro His Asp Glu Asp Pro Gln Ala Val Thr Tyr
340 345 350
Ala Glu Val Lys His Ser Arg Pro Arg Arg Glu Met Ala Ser Pro Pro
355 360 365
Ser Pro Leu Ser Gly Glu Phe Leu Asp Thr Lys Asp Arg Gln Ala Glu
370 375 380
Glu Asp Arg Gln Met Asp Thr Glu Ala Ala Ala Ser Glu Ala Pro Gln
385 390 395 400
Asp Val Thr Tyr Ala Gln Leu His Ser Leu Thr Leu Arg Arg Glu Ala
405 410 415
Thr Glu Pro Pro Pro Ser Gln Glu Gly Pro Ser Pro Ala Val Pro Ser
420 425 430
Ile Tyr Ala Thr Leu Ala Ile His
435 440
<210> 196
<211> 1279
<212> DNA
<213> Artificial Sequence
<220>
<223> Ftcr alpha LIR1 HA-1H
<400> 196
atggtgaaga tccggcaatt tttgttggct attttgtggc ttcagctaag ctgtgtaagt 60
gccgccaaaa atgaagtgga gcagagtcct cagaacctga ctgcccagga aggagaattt 120
atcacaatca actgcagtta ctcggtagga ataagtgcct tacactggct gcaacagcat 180
ccaggaggag gcattgtttc cttgtttatg ctgagctcag ggaagaagaa gcatggaaga 240
ttaattgcca caataaacat acaggaaaag cacagctccc tgcacatcac agcctcccat 300
cccagagact ctgccgtcta catctgtgct gtcagaagcg tgtccggggc cggctcctac 360
cagctcacct ttgggaaggg gaccaaatta tcagtcattc caaatatcca gaaccctgac 420
cctgccgtgt accagctgag agactctaaa tccagtgaca agtctgtctg cctattcacc 480
gattttgatt ctcaaacaaa tgtgtcacaa agtaaggatt ctgatgtgta tatcacagac 540
aaatgtgtgc tagacatgag gtctatggac ttcaagagca acagtgctgt ggcctggagc 600
aacaaatctg actttgcatg tgcaaacgcc ttcaacaaca gcattattcc agaagacacc 660
ttcttcccca gcccagaaag ttcctgtgat gtcaagctgg tcgagaaaag ctttgaaaca 720
gatacgaacc taaactttca aaacctgtca gttgtgatcg gcatcttggt ggccgtcatc 780
ctactgctcc tcctcctcct cctcctcttc ctcatcctcc gacatcgacg tcagggcaaa 840
cactggacat cgacccagag aaaggctgat ttccaacatc ctgcaggggc tgtggggcca 900
gagcccacag acagaggcct gcagtggagg tccagcccag ctgccgatgc ccaggaagaa 960
aacctctatg ctgccgtgaa gcacacacag cctgaggatg gggtggagat ggacactcgg 1020
agcccacacg atgaagaccc ccaggcagtg acgtatgccg aggtgaaaca ctccagacct 1080
aggagagaaa tggcctctcc tccttcccca ctgtctgggg aattcctgga cacaaaggac 1140
agacaggcgg aagaggacag gcagatggac actgaggctg ctgcatctga agccccccag 1200
gatgtgacct acgcccagct gcacagcttg accctcagac gggaggcaac tgagcctcct 1260
ccatcccagg aagggccct 1279
<210> 197
<211> 466
<212> PRT
<213> Artificial Sequence
<220>
<223> Ftcr beta LIR1 HA-1H
<400> 197
Met Gly Thr Ser Leu Leu Cys Trp Met Ala Leu Cys Leu Leu Gly Ala
1 5 10 15
Asp His Ala Asp Thr Gly Val Ser Gln Asn Pro Arg His Lys Ile Thr
20 25 30
Lys Arg Gly Gln Asn Val Thr Phe Arg Cys Asp Pro Ile Ser Glu His
35 40 45
Asn Arg Leu Tyr Trp Tyr Arg Gln Thr Leu Gly Gln Gly Pro Glu Phe
50 55 60
Leu Thr Tyr Phe Gln Asn Glu Ala Gln Leu Glu Lys Ser Arg Leu Leu
65 70 75 80
Ser Asp Arg Phe Ser Ala Glu Arg Pro Lys Gly Ser Phe Ser Thr Leu
85 90 95
Glu Ile Gln Arg Thr Glu Gln Gly Asp Ser Ala Met Tyr Leu Cys Ala
100 105 110
Ser Ser Ile Asp Ser Phe Asn Glu Gln Phe Phe Gly Pro Gly Thr Arg
115 120 125
Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala
130 135 140
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro
180 185 190
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
195 200 205
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
225 230 235 240
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
245 250 255
Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln
260 265 270
Gly Val Leu Ser Val Val Ile Gly Ile Leu Val Ala Val Ile Leu Leu
275 280 285
Leu Leu Leu Leu Leu Leu Leu Phe Leu Ile Leu Arg His Arg Arg Gln
290 295 300
Gly Lys His Trp Thr Ser Thr Gln Arg Lys Ala Asp Phe Gln His Pro
305 310 315 320
Ala Gly Ala Val Gly Pro Glu Pro Thr Asp Arg Gly Leu Gln Trp Arg
325 330 335
Ser Ser Pro Ala Ala Asp Ala Gln Glu Glu Asn Leu Tyr Ala Ala Val
340 345 350
Lys His Thr Gln Pro Glu Asp Gly Val Glu Met Asp Thr Arg Ser Pro
355 360 365
His Asp Glu Asp Pro Gln Ala Val Thr Tyr Ala Glu Val Lys His Ser
370 375 380
Arg Pro Arg Arg Glu Met Ala Ser Pro Pro Ser Pro Leu Ser Gly Glu
385 390 395 400
Phe Leu Asp Thr Lys Asp Arg Gln Ala Glu Glu Asp Arg Gln Met Asp
405 410 415
Thr Glu Ala Ala Ala Ser Glu Ala Pro Gln Asp Val Thr Tyr Ala Gln
420 425 430
Leu His Ser Leu Thr Leu Arg Arg Glu Ala Thr Glu Pro Pro Pro Ser
435 440 445
Gln Glu Gly Pro Ser Pro Ala Val Pro Ser Ile Tyr Ala Thr Leu Ala
450 455 460
Ile His
465
<210> 198
<211> 1401
<212> DNA
<213> Artificial Sequence
<220>
<223> Ftcr beta LIR1 HA-1H
<400> 198
atgggcacca gcctcctctg ctggatggcc ctgtgtctcc tgggggcaga tcacgcagat 60
actggagtct cccagaaccc cagacacaag atcacaaaga ggggacagaa tgtaactttc 120
aggtgtgatc caatttctga acacaaccgc ctttattggt accgacagac cctggggcag 180
ggcccagagt ttctgactta cttccagaat gaagctcaac tagaaaaatc aaggctgctc 240
agtgatcggt tctctgcaga gaggcctaag ggatctttct ccaccttgga gatccagcgc 300
acagagcagg gggactcggc catgtatctc tgtgccagca gcatcgactc cttcaacgag 360
cagttcttcg ggccgggcac caggctcacg gtcctcgagg acctgaaaaa cgtgttccca 420
cccgaggtcg ctgtgtttga gccatcagaa gcagagatct cccacaccca aaaggccaca 480
ctggtgtgcc tggccacagg cttctacccc gaccacgtgg agctgagctg gtgggtgaat 540
gggaaggagg tgcacagtgg ggtctgcaca gacccgcagc ccctcaagga gcagcccgcc 600
ctcaatgact ccagatactg cctgagcagc cgcctgaggg tgtcggccac cttctggcag 660
aacccccgca accacttccg ctgtcaagtc cagttctacg ggctctcgga gaatgacgag 720
tggacccagg atagggccaa acctgtcacc cagatcgtca gcgccgaggc ctggggtaga 780
gcagactgtg gcttcacctc cgagtcttac cagcaagggg tcctgtctgt tgtgatcggc 840
atcttggtgg ccgtcatcct actgctcctc ctcctcctcc tcctcttcct catcctccga 900
catcgacgtc agggcaaaca ctggacatcg acccagagaa aggctgattt ccaacatcct 960
gcaggggctg tggggccaga gcccacagac agaggcctgc agtggaggtc cagcccagct 1020
gccgatgccc aggaagaaaa cctctatgct gccgtgaagc acacacagcc tgaggatggg 1080
gtggagatgg acactcggag cccacacgat gaagaccccc aggcagtgac gtatgccgag 1140
gtgaaacact ccagacctag gagagaaatg gcctctcctc cttccccact gtctggggaa 1200
ttcctggaca caaaggacag acaggcggaa gaggacaggc agatggacac tgaggctgct 1260
gcatctgaag ccccccagga tgtgacctac gcccagctgc acagcttgac cctcagacgg 1320
gaggcaactg agcctcctcc atcccaggaa gggccctctc cagctgtgcc cagcatctac 1380
gccactctgg ccatccacta g 1401
<210> 199
<211> 250
<212> PRT
<213> Artificial Sequence
<220>
<223> HA-1H TCR alpha
<400> 199
Met Val Lys Ile Arg Gln Phe Leu Leu Ala Ile Leu Trp Leu Gln Leu
1 5 10 15
Ser Cys Val Ser Ala Ala Lys Asn Glu Val Glu Gln Ser Pro Gln Asn
20 25 30
Leu Thr Ala Gln Glu Gly Glu Phe Ile Thr Ile Asn Cys Ser Tyr Ser
35 40 45
Val Gly Ile Ser Ala Leu His Trp Leu Gln Gln His Pro Gly Gly Gly
50 55 60
Ile Val Ser Leu Phe Met Leu Ser Ser Gly Lys Lys Lys His Gly Arg
65 70 75 80
Leu Ile Ala Thr Ile Asn Ile Gln Glu Lys His Ser Ser Leu His Ile
85 90 95
Thr Ala Ser His Pro Arg Asp Ser Ala Val Tyr Ile Cys Ala Val Arg
100 105 110
Ser Val Ser Gly Ala Gly Ser Tyr Gln Leu Thr Phe Gly Lys Gly Thr
115 120 125
Lys Leu Ser Val Ile Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr
130 135 140
Gln Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr
145 150 155 160
Asp Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val
165 170 175
Tyr Ile Thr Asp Lys Cys Val Leu Asp Met Arg Ser Met Asp Phe Lys
180 185 190
Ser Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala
195 200 205
Asn Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser
210 215 220
Pro Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr
225 230 235 240
Asp Thr Asn Leu Asn Phe Gln Asn Leu Ser
245 250
<210> 200
<211> 276
<212> PRT
<213> Artificial Sequence
<220>
<223> HA-1H TCR beta
<400> 200
Met Gly Thr Ser Leu Leu Cys Trp Met Ala Leu Cys Leu Leu Gly Ala
1 5 10 15
Asp His Ala Asp Thr Gly Val Ser Gln Asn Pro Arg His Lys Ile Thr
20 25 30
Lys Arg Gly Gln Asn Val Thr Phe Arg Cys Asp Pro Ile Ser Glu His
35 40 45
Asn Arg Leu Tyr Trp Tyr Arg Gln Thr Leu Gly Gln Gly Pro Glu Phe
50 55 60
Leu Thr Tyr Phe Gln Asn Glu Ala Gln Leu Glu Lys Ser Arg Leu Leu
65 70 75 80
Ser Asp Arg Phe Ser Ala Glu Arg Pro Lys Gly Ser Phe Ser Thr Leu
85 90 95
Glu Ile Gln Arg Thr Glu Gln Gly Asp Ser Ala Met Tyr Leu Cys Ala
100 105 110
Ser Ser Ile Asp Ser Phe Asn Glu Gln Phe Phe Gly Pro Gly Thr Arg
115 120 125
Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala
130 135 140
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro
180 185 190
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
195 200 205
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
225 230 235 240
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
245 250 255
Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln
260 265 270
Gly Val Leu Ser
275
<210> 201
<211> 750
<212> DNA
<213> Artificial Sequence
<220>
<223> HA-1H TCR alpha
<400> 201
atggtgaaga tccggcaatt tttgttggct attttgtggc ttcagctaag ctgtgtaagt 60
gccgccaaaa atgaagtgga gcagagtcct cagaacctga ctgcccagga aggagaattt 120
atcacaatca actgcagtta ctcggtagga ataagtgcct tacactggct gcaacagcat 180
ccaggaggag gcattgtttc cttgtttatg ctgagctcag ggaagaagaa gcatggaaga 240
ttaattgcca caataaacat acaggaaaag cacagctccc tgcacatcac agcctcccat 300
cccagagact ctgccgtcta catctgtgct gtcagaagcg tgtccggggc cggctcctac 360
cagctcacct ttgggaaggg gaccaaatta tcagtcattc caaatatcca gaaccctgac 420
cctgccgtgt accagctgag agactctaaa tccagtgaca agtctgtctg cctattcacc 480
gattttgatt ctcaaacaaa tgtgtcacaa agtaaggatt ctgatgtgta tatcacagac 540
aaatgtgtgc tagacatgag gtctatggac ttcaagagca acagtgctgt ggcctggagc 600
aacaaatctg actttgcatg tgcaaacgcc ttcaacaaca gcattattcc agaagacacc 660
ttcttcccca gcccagaaag ttcctgtgat gtcaagctgg tcgagaaaag ctttgaaaca 720
gatacgaacc taaactttca aaacctgtca 750
<210> 202
<211> 828
<212> DNA
<213> Artificial Sequence
<220>
<223> HA-1H TCR beta
<400> 202
atgggcacca gcctcctctg ctggatggcc ctgtgtctcc tgggggcaga tcacgcagat 60
actggagtct cccagaaccc cagacacaag atcacaaaga ggggacagaa tgtaactttc 120
aggtgtgatc caatttctga acacaaccgc ctttattggt accgacagac cctggggcag 180
ggcccagagt ttctgactta cttccagaat gaagctcaac tagaaaaatc aaggctgctc 240
agtgatcggt tctctgcaga gaggcctaag ggatctttct ccaccttgga gatccagcgc 300
acagagcagg gggactcggc catgtatctc tgtgccagca gcatcgactc cttcaacgag 360
cagttcttcg ggccgggcac caggctcacg gtcctcgagg acctgaaaaa cgtgttccca 420
cccgaggtcg ctgtgtttga gccatcagaa gcagagatct cccacaccca aaaggccaca 480
ctggtgtgcc tggccacagg cttctacccc gaccacgtgg agctgagctg gtgggtgaat 540
gggaaggagg tgcacagtgg ggtctgcaca gacccgcagc ccctcaagga gcagcccgcc 600
ctcaatgact ccagatactg cctgagcagc cgcctgaggg tgtcggccac cttctggcag 660
aacccccgca accacttccg ctgtcaagtc cagttctacg ggctctcgga gaatgacgag 720
tggacccagg atagggccaa acctgtcacc cagatcgtca gcgccgaggc ctggggtaga 780
gcagactgtg gcttcacctc cgagtcttac cagcaagggg tcctgtct 828
<210> 203
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> NY-ESO CDR
<400> 203
Cys Ala Ser Ser Leu Gly Leu Gly Tyr Glu Gln Tyr Phe
1 5 10
<210> 204
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> NY-ESO CDR
<400> 204
Cys Ala Ser Ser Leu Gly Gly Pro Arg Gly Leu Ala Gly Leu Arg Gly
1 5 10 15
Asp Glu Gln Phe
20
<210> 205
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> NY-ESO CDR
<400> 205
Cys Ala Ser Ser Leu Arg Arg Asp Asn Glu Gln Phe
1 5 10
<210> 206
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> MAGE-A3 CDR
<400> 206
Cys Ala Ser Ser Leu Glu Val Leu Leu Gly Ala Asp Phe Pro Asp Thr
1 5 10 15
Gln Tyr Phe
<210> 207
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> MAGE-A3 CDR
<400> 207
Cys Ala Ser Ser Phe Pro Ala Gly His Gly Ala Asp Leu Asp Asn Glu
1 5 10 15
Gln Phe
<210> 208
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> MAGE-A3 CDR
<400> 208
Cys Ala Ser Ser Glu Ile Thr Gly Arg Ile Gly Glu Gln Phe
1 5 10
<210> 209
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> MAGE-A3 CDR
<400> 209
Cys Ala Ser Ser Leu Gly Gly Asp Glu Leu Gly Ala Asp Gly Asn Glu
1 5 10 15
Gln Phe
<210> 210
<211> 241
<212> PRT
<213> Artificial Sequence
<220>
<223> NY-ESO-1 ScFv
<400> 210
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Gly Gly Gly Gly Ser
100 105 110
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Glu Val Gln Leu
115 120 125
Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu
130 135 140
Ser Cys Ala Ala Ser Gly Phe Thr Val Tyr Asp Tyr Met Ser Trp Val
145 150 155 160
Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Val Ile Tyr Ser
165 170 175
Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
180 185 190
Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu
195 200 205
Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Tyr Ser Tyr Tyr
210 215 220
Tyr Tyr Tyr Met Asp Val Trp Gly Lys Gly Thr Thr Val Thr Val Ser
225 230 235 240
Ser
<210> 211
<211> 723
<212> DNA
<213> Artificial Sequence
<220>
<223> NY-ESO-1 ScFv
<400> 211
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gagcattagc agctatttaa attggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatccagtt tgcaaagtgg ggtcccatca 180
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg caacttacta ctgtcaacag agttacagta cccctctcac tttcggcggc 300
ggaacaaagg tggagatcaa gggcggaggt ggaagcggag ggggaggatc tggcggcgga 360
ggaagcggag gcgaagtgca gctggtggaa agcggcggag gcctggtgca gcctggcggc 420
agcctgagac tgtcttgcgc cgccagcggc ttcaccgtgt acgactacat gagctgggtc 480
cgccaggccc ctggcaaggg actggaatgg gtgtccgtga tctacagcgg cggcagcacc 540
tactacgccg acagcgtgaa gggtcgattc accatcagcc gggacaacag caagaacacc 600
ctgtacctgc agatgaacag cctgcgggcc gaggacaccg ccgtgtatta ctgtgcgagg 660
tactcctact actactacta catggacgtc tggggcaaag ggaccacggt caccgtgtcc 720
tca 723
<210> 212
<211> 244
<212> PRT
<213> Artificial Sequence
<220>
<223> MAGE-A3 antigen binding domain
<400> 212
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Asp
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Ser Gly Tyr Ser Ile Ser Ser Ser
20 25 30
Asn Trp Trp Gly Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
35 40 45
Ile Gly Tyr Ile Tyr Tyr Ser Gly Ser Thr Tyr Tyr Asn Pro Ser Leu
50 55 60
Lys Ser Arg Val Thr Met Ser Val Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Ser Ser Val Thr Ala Val Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ile Pro Phe Gly Asp Trp Trp Tyr Phe Asp Leu Trp Gly Arg
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln Ser
130 135 140
Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys
145 150 155 160
Arg Ala Ser Gln Ser Ile Ser Ser Tyr Leu Asn Trp Tyr Gln Gln Lys
165 170 175
Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln
180 185 190
Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe
195 200 205
Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr
210 215 220
Cys Gln Gln Ser Tyr Ser Phe Val Leu Thr Phe Gly Gly Gly Thr Lys
225 230 235 240
Val Glu Ile Lys
<210> 213
<211> 732
<212> DNA
<213> Artificial Sequence
<220>
<223> MAGE-A3 antigen binding domain
<400> 213
caggtgcagc tgcaggaaag cggccctggc ctggtgaaac ccagcgacac cctgagcctg 60
acctgcgccg tgtccggcta cagcatcagc agcagcaatt ggtggggctg gatcagacag 120
ccccctggca agggcctgga atggatcggc tacatctact acagcggcag cacctactac 180
aaccccagcc tgaagtccag agtgaccatg agcgtggaca ccagcaagaa ccagttcagc 240
ctgaagctga gcagcgtgac cgccgtcgat accgctgtgt attactgtgc gagaataccc 300
tttggggatt ggtggtactt cgatctctgg ggccgtggca ccctggtcac tgtgtcctca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cgacatccag 420
atgacccaga gccccagcag cctgagcgcc agcgtgggcg acagagtgac catcacctgt 480
cgggccagcc agtcgatcag cagctacctg aactggtatc agcagaagcc cggcaaggcc 540
cccaagctgc tgatctacgc cgccagctcc ctgcagagcg gcgtgccaag cagattcagc 600
ggcagcggct ccggcaccga cttcaccctg accatcagca gcctgcagcc cgaggacttc 660
gccacctact actgccagca gagttacagt ttcgttctca ctttcggcgg agggaccaag 720
gtggagatca aa 732
<210> 214
<211> 248
<212> PRT
<213> Artificial Sequence
<220>
<223> MAGE-A3 antigen binding domain
<400> 214
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Val Ser Gly Tyr Thr Leu Thr Glu Leu
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Gly Phe Asp Pro Glu Asp Gly Glu Thr Ile Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Glu Asp Thr Ser Thr Asp Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr Asp Leu Tyr Ser Ser Ser Trp Tyr Cys Asp Ala Phe Asp Ile
100 105 110
Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met
130 135 140
Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr
145 150 155 160
Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr Leu Asn Trp Tyr
165 170 175
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala Ser
180 185 190
Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala
210 215 220
Thr Tyr Tyr Cys Gln Gln Ser Trp Ala Ser Thr Pro Leu Thr Phe Gly
225 230 235 240
Gly Gly Thr Lys Val Glu Ile Lys
245
<210> 215
<211> 744
<212> DNA
<213> Artificial Sequence
<220>
<223> MAGE-A3 antigen binding domain
<400> 215
caggtgcagc tggtgcagtc tggcgccgaa gtgaagaaac ctggcgcctc cgtgaaggtg 60
tcctgcaagg tgtccggcta caccctgacc gagctgtcga tgcactgggt ccgccaggca 120
cctggcaagg gactggaatg gatgggcggc tttgaccccg aggacggcga gacaatctac 180
gcccagaaat tccagggcag agtgaccatg accgaggaca ccagcaccga caccgcctac 240
atggaactga gcagcctgcg gagcgaggac accgctgtgt attactgtgc aacagatctg 300
tatagcagca gctggtactg tgatgctttt gatatctggg gccaagggac aatggtcacc 360
gtgtcctcag gcggaggtgg aagcggaggg ggaggatctg gcggcggagg aagcggaggc 420
gacatccaga tgacccagag ccccagcagc ctgagcgcca gcgtgggcga cagagtgacc 480
atcacctgtc gggccagcca gtcgatcagc agctacctga actggtatca gcagaagccc 540
ggcaaggccc ccaagctgct gatctacgcc gccagctccc tgcagagcgg cgtgccaagc 600
agattcagcg gcagcggctc cggcaccgac ttcaccctga ccatcagcag cctgcagccc 660
gaggacttcg ccacctacta ctgccagcag agttgggcca gcacccctct cactttcggc 720
ggagggacca aggtggagat caaa 744
<210> 216
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> HPV E6 antigen binding domain
<400> 216
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Val Trp Val
35 40 45
Ser Arg Ile Asn Ser Asp Gly Ser Ser Thr Ser Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Asn Gly Val Val Lys Trp Tyr Phe Asp Leu Trp Gly Arg
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln Ser
130 135 140
Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys
145 150 155 160
Arg Ala Ser Gln Ser Ile Ser Ser Tyr Leu Asn Trp Tyr Gln Gln Lys
165 170 175
Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln
180 185 190
Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe
195 200 205
Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr
210 215 220
Cys Gln Gln Ser Tyr Ser Thr Pro Leu Phe Pro Phe Gly Gly Gly Thr
225 230 235 240
Lys Val Glu Ile Lys
245
<210> 217
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> HPV E6 antigen binding domain
<400> 217
gaagtgcagc tggtggaaag cggcggaggc ctggtgcagc ctggcggcag cctgagactg 60
tcttgcgccg ccagcggctt caccttcagc agctactgga tgcactgggt ccgccaggcc 120
cctggcaagg gactggtctg ggtgtctcga atcaacagcg acggcagcag caccagctac 180
gccgacagcg tgaagggccg gttcaccatc agccgggaca acgccaagaa caccctgtac 240
ctgcagatga acagcctgcg ggccgaggac accgccgtgt attactgtgc cagggagaac 300
ggcgtggtga agtggtactt cgacctgtgg ggccgtggca ccctggtcac tgtgtcctca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cgacatccag 420
atgacccaga gccccagcag cctgagcgcc agcgtgggcg acagagtgac catcacctgt 480
cgggccagcc agtcgatcag cagctacctg aactggtatc agcagaagcc cggcaaggcc 540
cccaagctgc tgatctacgc cgccagctcc ctgcagagcg gcgtgccaag cagattcagc 600
ggcagcggct ccggcaccga cttcaccctg accatcagca gcctgcagcc cgaggacttc 660
gccacctact actgccagca gagttacagt acccctctct ttcccttcgg cggagggacc 720
aaggtggaga tcaaa 735
<210> 218
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> HPV E6 antigen binding domain
<400> 218
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Ser Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Lys Asp Gly Arg Gly Ser Pro Phe Tyr Gly Gly Ala Phe Asp Ile
100 105 110
Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met
130 135 140
Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr
145 150 155 160
Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr Leu Asn Trp Tyr
165 170 175
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala Ser
180 185 190
Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala
210 215 220
Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Leu Thr Phe Gly Gly
225 230 235 240
Gly Thr Lys Val Glu Ile Lys
245
<210> 219
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> HPV E6 antigen binding domain
<400> 219
gaagtgcagc tggtggaaag cggcggaggc ctggtgcagc ccggtcgaag cctgagactg 60
agctgcgccg ccagcggctt cacctttgac gactacgcca tgcactgggt ccgccaggcc 120
cctggcaagg gactggaatg ggtgtccggc atcagctgga acagcggcag catcggctac 180
gccgacagcg tgaagggccg gttcaccatc agccgggaca acgccaagaa cagcctgtac 240
ctgcagatga acagcctgcg ggccgaggac accgccttgt attactgtgc caaggacggc 300
aggggctccc ccttctacgg cggcgccttc gacatctggg gccaagggac aatggtcacc 360
gtgtcctcag gcggaggtgg aagcggaggg ggaggatctg gcggcggagg aagcggaggc 420
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 480
atcacttgcc gggcaagtca gagcattagc agctatttaa attggtatca gcagaaacca 540
gggaaagccc ctaagctcct gatctatgct gcatccagtt tgcaaagtgg ggtcccatca 600
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 660
gaagattttg caacttacta ctgtcaacag agttacagta cccctctcac tttcggcggc 720
ggaacaaagg tggagatcaa g 741
<210> 220
<211> 251
<212> PRT
<213> Artificial Sequence
<220>
<223> HPV E7 antigen binding domain
<400> 220
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Ala
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Arg Ile Lys Ser Lys Thr Asp Gly Gly Thr Thr Asp Tyr Ala Ala
50 55 60
Pro Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Thr Thr Ser Tyr Asp Tyr Leu Leu Asn Pro Tyr Arg Trp Asn
100 105 110
Trp Phe Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
145 150 155 160
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
165 170 175
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
180 185 190
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
195 200 205
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
210 215 220
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Leu
225 230 235 240
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
245 250
<210> 221
<211> 753
<212> DNA
<213> Artificial Sequence
<220>
<223> HPV E7 antigen binding domain
<400> 221
gaagtgcagc tggtggaaag cggcggaggc ctggtgaaac ctggcggcag cctgagactg 60
agctgcgccg ccagcggctt caccttctcg aacgcctgga tgagctgggt ccgccaggcc 120
cctggcaagg gactggaatg ggtcggacgg atcaagagca agaccgacgg cggcaccacc 180
gactacgctg cccccgtgaa gggccggttc accatcagcc gggacgacag caagaacacc 240
ctgtacctgc agatgaacag cctgaaaacc gaggacaccg ccgtgtatta ctgtaccacc 300
tcctacgatt accttctcaa tccttatcgt tggaactggt tcgacccctg gggccaggga 360
accctggtca ccgtgtcctc aggcggaggt ggaagcggag ggggaggatc tggcggcgga 420
ggaagcggcg gagacatcca gatgacccag tctccatcct ccctgtctgc atctgtagga 480
gacagagtca ccatcacttg ccgggcaagt cagagcatta gcagctattt aaattggtat 540
cagcagaaac cagggaaagc ccctaagctc ctgatctatg ctgcatccag tttgcaaagt 600
ggggtcccat caaggttcag tggcagtgga tctgggacag atttcactct caccatcagc 660
agtctgcaac ctgaagattt tgcaacttac tactgtcaac agagttacag tacccctctc 720
actttcggcg gcggaacaaa ggtggagatc aag 753
<210> 222
<211> 246
<212> PRT
<213> Artificial Sequence
<220>
<223> MAGE-A3 antigen binding domain
<400> 222
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Met Asp Thr Phe Ser Met Val Thr Leu Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr
130 135 140
Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile
145 150 155 160
Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr Leu Asn Trp Tyr Gln
165 170 175
Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala Ser Ser
180 185 190
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr
195 200 205
Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr
210 215 220
Tyr Tyr Cys Gln Gln Ser Tyr Ser Trp Pro Leu Thr Phe Gly Gly Gly
225 230 235 240
Thr Lys Val Glu Ile Lys
245
<210> 223
<211> 738
<212> DNA
<213> Artificial Sequence
<220>
<223> MAGE-A3 antigen binding domain
<400> 223
caggtgcagc tggtgcagtc tggcgccgaa gtgaagaaac ccggcagcag cgtgaaggtg 60
tcctgcaagg ccagcggcgg caccttcagc agctacgcca tcagctgggt ccgccaggct 120
cctggacagg gactggaatg gatgggcggc atcatcccca tcttcggcac cgccaactac 180
gcccagaaat tccagggcag agtgaccatc accgccgacg agagcaccag caccgcctac 240
atggaactga gcagccttcg aagcgaggac accgctgtgt attactgtgc cagggacatg 300
gacaccttct ccatggtgac cctgttcgac tactggggcc agggcaccct ggtcaccgtg 360
tcctcaggcg gaggtggaag cggaggggga ggatctggcg gcggaggaag cggaggcgac 420
atccagatga cccagagccc cagcagcctg agcgccagcg tgggcgacag agtgaccatc 480
acctgtcggg ccagccagtc gatcagcagc tacctgaact ggtatcagca gaagcccggc 540
aaggccccca agctgctgat ctacgccgcc agctccctgc agagcggcgt gccaagcaga 600
ttcagcggca gcggctccgg caccgacttc accctgacca tcagcagcct gcagcccgag 660
gacttcgcca cctactactg ccagcagagt tacagttggc ctctcacttt cggcggaggg 720
accaaggtgg agatcaaa 738
<210> 224
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> KRAS G12V antigen binding domain
<400> 224
Gln Val Thr Leu Arg Glu Ser Gly Pro Ala Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Thr Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Gly Met Cys Val Ser Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala Leu Ile Asp Trp Asp Asp Asp Lys Tyr Tyr Ser Thr Ser
50 55 60
Leu Lys Thr Arg Leu Thr Ile Ser Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Tyr
85 90 95
Cys Ala Arg Ser Tyr Asp Glu Leu Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln Ser
130 135 140
Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys
145 150 155 160
Arg Ala Ser Gln Ser Ile Trp Thr Ser Tyr Leu Asn Trp Tyr Gln Gln
165 170 175
Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala Ser Ser Leu
180 185 190
Gln Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
195 200 205
Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr
210 215 220
Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Leu Thr Phe Gly Gly Gly Thr
225 230 235 240
Lys Val Glu Ile Lys
245
<210> 225
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> KRAS G12V antigen binding domain
<400> 225
caggtcacac tgagagagtc cggccctgcc ctggtgaaac ccacccagac cctgaccctg 60
acatgcacct tcagcggctt cagcctgagc accagcggga tgtgcgtgtc ctggattcga 120
cagccccctg gcaaggccct ggaatggctg gccctgattg actgggacga cgacaagtac 180
tacagcacca gcctgaaaac ccggctgacc atcagcaagg acaccagcaa gaaccaggtg 240
gtgctgacca tgaccaacat ggaccccgtg gacaccgcca cgtattactg tgcacggagt 300
tacgacgagc tctactactt tgactactgg ggccagggaa ccctggtcac cgtgtcctca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cgacatccag 420
atgacccaga gccccagctc cctctctgca tctgtgggcg acagagtgac catcacctgt 480
cgggccagcc agtcgatctg gaccagctac ctgaactggt atcagcagaa gcccggcaag 540
gcccccaagc tgctgatcta cgccgccagc tccctgcaga gcggcgtgcc aagcagattc 600
agcggcagcg gctccggcac cgacttcacc ctgaccatca gcagcctgca gcccgaggac 660
ttcgccacct actactgcca gcagagttac agtacccctc tcactttcgg cggagggacc 720
aaggtggaga tcaaa 735
<210> 226
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> linker
<400> 226
Gly Gly Gly Gly Ser
1 5
<210> 227
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> linker
<400> 227
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10
<210> 228
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> linker
<400> 228
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 229
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> linker
<400> 229
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 230
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> linker
<400> 230
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser
20
<210> 231
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> linker
<400> 231
Gly Gly Gly Ser
1
<210> 232
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> KRAS ScFv
<400> 232
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Phe Thr Arg Asp Tyr Tyr Tyr Tyr Tyr Tyr Met Asp Val
100 105 110
Trp Gly Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met
130 135 140
Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr
145 150 155 160
Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr Leu Asn Trp Tyr
165 170 175
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala Ser
180 185 190
Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala
210 215 220
Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Leu Thr Phe Gly Gly
225 230 235 240
Gly Thr Lys Val Glu Ile Lys
245
<210> 233
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> KRAS ScFv
<400> 233
caggtgcagc tggtggaaag cggcggaggc ctggtgaaac ctggcggcag cctgagactg 60
agctgcgccg ccagcggctt caccttcagc gactactaca tgagctggat cagacaggcc 120
cctggcaagg gactggaatg ggtgtcctac atcagcagca gcggctcgac catctactac 180
gccgacagcg tgaagggccg gttcaccatc agccgggaca acgccaagaa cagcctgtac 240
ctgcagatga acagcctgcg ggccgaggac accgccgtgt attactgtgc cagggacttc 300
accagggact actactacta ctactacatg gacgtgtggg gcaaagggac cacggtcacc 360
gtgtcctcag gcggaggtgg aagcggaggg ggaggatctg gcggcggagg aagcggaggc 420
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 480
atcacttgcc gggcaagtca gagcattagc agctatttaa attggtatca gcagaaacca 540
gggaaagccc ctaagctcct gatctatgct gcatccagtt tgcaaagtgg ggtcccatca 600
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 660
gaagattttg caacttacta ctgtcaacag agttacagta cccctctcac tttcggcggc 720
ggaacaaagg tggagatcaa g 741
<210> 234
<211> 244
<212> PRT
<213> Artificial Sequence
<220>
<223> KRAS ScFv
<400> 234
Gln Val Thr Leu Arg Glu Ser Gly Pro Ala Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Thr Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Gly Met Cys Val Ser Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala Leu Ile Asp Trp Asp Asp Asp Lys Tyr Tyr Ser Thr Ser
50 55 60
Leu Lys Thr Arg Leu Thr Ile Ser Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Tyr
85 90 95
Cys Ala Arg Ser Tyr Asp Glu Leu Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln Ser
130 135 140
Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys
145 150 155 160
Arg Ala Ser Gln Ser Ile Ser Ser Tyr Leu Asn Trp Tyr Gln Gln Lys
165 170 175
Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln
180 185 190
Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe
195 200 205
Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr
210 215 220
Cys Gln Gln Ser Tyr Ser Thr Pro Leu Thr Phe Gly Gly Gly Thr Lys
225 230 235 240
Val Glu Ile Lys
<210> 235
<211> 732
<212> DNA
<213> Artificial Sequence
<220>
<223> KRAS ScFv
<400> 235
caggtcacac tgagagagtc cggccctgcc ctggtgaaac ccacccagac cctgaccctg 60
acatgcacct tcagcggctt cagcctgagc accagcggga tgtgcgtgtc ctggattcga 120
cagccccctg gcaaggccct ggaatggctg gccctgattg actgggacga cgacaagtac 180
tacagcacca gcctgaaaac ccggctgacc atcagcaagg acaccagcaa gaaccaggtg 240
gtgctgacca tgaccaacat ggaccccgtg gacaccgcca cgtattactg tgcacggagt 300
tacgacgagc tctactactt tgactactgg ggccagggaa ccctggtcac cgtgtcctca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cgacatccag 420
atgacccagt ctccatcctc cctgtctgca tctgtaggag acagagtcac catcacttgc 480
cgggcaagtc agagcattag cagctattta aattggtatc agcagaaacc agggaaagcc 540
cctaagctcc tgatctatgc tgcatccagt ttgcaaagtg gggtcccatc aaggttcagt 600
ggcagtggat ctgggacaga tttcactctc accatcagca gtctgcaacc tgaagatttt 660
gcaacttact actgtcaaca gagttacagt acccctctca ctttcggcgg cggaacaaag 720
gtggagatca ag 732
<210> 236
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> KRAS ScFv
<400> 236
Gln Val Thr Leu Arg Glu Ser Gly Pro Ala Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Thr Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Gly Met Cys Val Ser Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala Leu Ile Asp Trp Asp Asp Asp Lys Tyr Tyr Ser Thr Ser
50 55 60
Leu Lys Thr Arg Leu Thr Ile Ser Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Tyr
85 90 95
Cys Ala Arg Ser Tyr Asp Glu Leu Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln Ser
130 135 140
Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys
145 150 155 160
Arg Ala Ser Gln Ser Ile Trp Thr Ser Tyr Leu Asn Trp Tyr Gln Gln
165 170 175
Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala Ser Ser Leu
180 185 190
Gln Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
195 200 205
Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr
210 215 220
Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Leu Thr Phe Gly Gly Gly Thr
225 230 235 240
Lys Val Glu Ile Lys
245
<210> 237
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> KRAS ScFv
<400> 237
caggtcacac tgagagagtc cggccctgcc ctggtgaaac ccacccagac cctgaccctg 60
acatgcacct tcagcggctt cagcctgagc accagcggga tgtgcgtgtc ctggattcga 120
cagccccctg gcaaggccct ggaatggctg gccctgattg actgggacga cgacaagtac 180
tacagcacca gcctgaaaac ccggctgacc atcagcaagg acaccagcaa gaaccaggtg 240
gtgctgacca tgaccaacat ggaccccgtg gacaccgcca cgtattactg tgcacggagt 300
tacgacgagc tctactactt tgactactgg ggccagggaa ccctggtcac cgtgtcctca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cgacatccag 420
atgacccaga gccccagctc cctctctgca tctgtgggcg acagagtgac catcacctgt 480
cgggccagcc agtcgatctg gaccagctac ctgaactggt atcagcagaa gcccggcaag 540
gcccccaagc tgctgatcta cgccgccagc tccctgcaga gcggcgtgcc aagcagattc 600
agcggcagcg gctccggcac cgacttcacc ctgaccatca gcagcctgca gcccgaggac 660
ttcgccacct actactgcca gcagagttac agtacccctc tcactttcgg cggagggacc 720
aaggtggaga tcaaa 735
<210> 238
<211> 244
<212> PRT
<213> Artificial Sequence
<220>
<223> KRAS ScFv
<400> 238
Gln Val Thr Leu Arg Glu Ser Gly Pro Ala Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Thr Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Gly Met Cys Val Ser Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala Leu Ile Asp Trp Asp Asp Asp Lys Tyr Tyr Ser Thr Ser
50 55 60
Leu Lys Thr Arg Leu Thr Ile Ser Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Tyr
85 90 95
Cys Ala Arg Ser Tyr Asp Glu Leu Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln Ser
130 135 140
Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys
145 150 155 160
Arg Ala Ser Gln Ser Ile Ser Ser Tyr Leu Asn Trp Tyr Gln Gln Lys
165 170 175
Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln
180 185 190
Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe
195 200 205
Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr
210 215 220
Cys Gln Gln Ser Tyr Ser Thr Arg Leu Thr Phe Gly Gly Gly Thr Lys
225 230 235 240
Val Glu Ile Lys
<210> 239
<211> 732
<212> DNA
<213> Artificial Sequence
<220>
<223> KRAS ScFv
<400> 239
caggtcacac tgagagagtc cggccctgcc ctggtgaaac ccacccagac cctgaccctg 60
acatgcacct tcagcggctt cagcctgagc accagcggga tgtgcgtgtc ctggattcga 120
cagccccctg gcaaggccct ggaatggctg gccctgattg actgggacga cgacaagtac 180
tacagcacca gcctgaaaac ccggctgacc atcagcaagg acaccagcaa gaaccaggtg 240
gtgctgacca tgaccaacat ggaccccgtg gacaccgcca cgtattactg tgcacggagt 300
tacgacgagc tctactactt tgactactgg ggccagggaa ccctggtcac cgtgtcctca 360
ggcggaggtg gaagcggagg gggaggatct ggcggcggag gaagcggagg cgacatccag 420
atgacccaga gccccagctc cctctctgca tctgtgggcg acagagtgac catcacctgt 480
cgggccagcc agtcgatcag cagctacctg aactggtatc agcagaagcc cggcaaggcc 540
cccaagctgc tgatctacgc cgccagctcc ctgcagagcg gcgtgccaag cagattcagc 600
ggcagcggct ccggcaccga cttcaccctg accatcagca gcctgcagcc cgaggacttc 660
gccacctact actgccagca gagttacagt acccggctca ctttcggcgg agggaccaag 720
gtggagatca aa 732
<210> 240
<211> 244
<212> PRT
<213> Artificial Sequence
<220>
<223> KRAS TCR alpha
<400> 240
Met Gln Arg Asn Leu Gly Ala Val Leu Gly Ile Leu Trp Val Gln Ile
1 5 10 15
Cys Trp Val Arg Gly Asp Gln Val Glu Gln Ser Pro Ser Ala Leu Ser
20 25 30
Leu His Glu Gly Thr Asp Ser Ala Leu Arg Cys Asn Phe Thr Thr Thr
35 40 45
Met Arg Ser Val Gln Trp Phe Arg Gln Asn Ser Arg Gly Ser Leu Ile
50 55 60
Ser Leu Phe Tyr Leu Ala Ser Gly Thr Lys Glu Asn Gly Arg Leu Lys
65 70 75 80
Ser Ala Phe Asp Ser Lys Glu Arg Arg Tyr Ser Thr Leu His Ile Arg
85 90 95
Asp Ala Gln Leu Glu Asp Ser Gly Thr Tyr Phe Cys Ala Ala Asp Ser
100 105 110
Ser Asn Thr Gly Tyr Gln Asn Phe Tyr Phe Gly Lys Gly Thr Ser Leu
115 120 125
Thr Val Ile Pro Asn Ile Gln Asn Pro Glu Pro Ala Val Tyr Gln Leu
130 135 140
Lys Asp Pro Arg Ser Gln Asp Ser Thr Leu Cys Leu Phe Thr Asp Phe
145 150 155 160
Asp Ser Gln Ile Asn Val Pro Lys Thr Met Glu Ser Gly Thr Phe Ile
165 170 175
Thr Asp Lys Cys Val Leu Asp Met Lys Ala Met Asp Ser Lys Ser Asn
180 185 190
Gly Ala Ile Ala Trp Ser Asn Gln Thr Ser Phe Thr Cys Gln Asp Ile
195 200 205
Phe Lys Glu Thr Asn Ala Thr Tyr Pro Ser Ser Asp Val Pro Cys Asp
210 215 220
Ala Thr Leu Thr Glu Lys Ser Phe Glu Thr Asp Met Asn Leu Asn Phe
225 230 235 240
Gln Asn Leu Ser
<210> 241
<211> 732
<212> DNA
<213> Artificial Sequence
<220>
<223> KRAS TCR alpha
<400> 241
atgcagagga acctgggagc tgtgctgggg attctgtggg tgcagatttg ctgggtgaga 60
ggggatcagg tggagcagag tccttcagcc ctgagcctcc acgagggaac cgattctgct 120
ctgagatgca attttacgac caccatgagg agtgtgcagt ggttccgaca gaattccagg 180
ggcagcctca tcagtttgtt ctacttggct tcaggaacaa aggagaatgg gaggctaaag 240
tcagcatttg attctaagga gcggcgctac agcaccctgc acatcaggga tgcccagctg 300
gaggactcag gcacttactt ctgtgctgct gactcttcga acacgggtta ccagaacttc 360
tattttggga aaggaacaag tttgactgtc attccaaaca tccagaaccc agaacctgct 420
gtgtaccagt taaaagatcc tcggtctcag gacagcaccc tctgcctgtt caccgacttt 480
gactcccaaa tcaatgtgcc gaaaaccatg gaatctggaa cgttcatcac tgacaaatgt 540
gtgctggaca tgaaagctat ggattccaag agcaatgggg ccattgcctg gagcaaccag 600
acaagcttca cctgccaaga tatcttcaaa gagaccaacg ccacctaccc cagttcagac 660
gttccctgtg atgccacgtt gaccgagaaa agctttgaaa cagatatgaa cctgaacttt 720
caaaacctgt ct 732
<210> 242
<211> 283
<212> PRT
<213> Artificial Sequence
<220>
<223> KRAS TCR beta
<400> 242
Met Ser Asn Thr Ala Phe Pro Asp Pro Ala Trp Asn Thr Thr Leu Leu
1 5 10 15
Ser Trp Val Ala Leu Phe Leu Leu Gly Thr Ser Ser Ala Asn Ser Gly
20 25 30
Val Val Gln Ser Pro Arg Tyr Ile Ile Lys Gly Lys Gly Glu Arg Ser
35 40 45
Ile Leu Lys Cys Ile Pro Ile Ser Gly His Leu Ser Val Ala Trp Tyr
50 55 60
Gln Gln Thr Gln Gly Gln Glu Leu Lys Phe Phe Ile Gln His Tyr Asp
65 70 75 80
Lys Met Glu Arg Asp Lys Gly Asn Leu Pro Ser Arg Phe Ser Val Gln
85 90 95
Gln Phe Asp Asp Tyr His Ser Glu Met Asn Met Ser Ala Leu Glu Leu
100 105 110
Glu Asp Ser Ala Val Tyr Phe Cys Ala Ser Ser Leu Thr Asp Pro Leu
115 120 125
Asp Ser Asp Tyr Thr Phe Gly Ser Gly Thr Arg Leu Leu Val Ile Glu
130 135 140
Asp Leu Arg Asn Val Thr Pro Pro Lys Val Ser Leu Phe Glu Pro Ser
145 150 155 160
Lys Ala Glu Ile Ala Asn Lys Gln Lys Ala Thr Leu Val Cys Leu Ala
165 170 175
Arg Gly Phe Phe Pro Asp His Val Glu Leu Ser Trp Trp Val Asn Gly
180 185 190
Lys Glu Val His Ser Gly Val Cys Thr Asp Pro Gln Ala Tyr Lys Glu
195 200 205
Ser Asn Tyr Ser Tyr Cys Leu Ser Ser Arg Leu Arg Val Ser Ala Thr
210 215 220
Phe Trp His Asn Pro Arg Asn His Phe Arg Cys Gln Val Gln Phe His
225 230 235 240
Gly Leu Ser Glu Glu Asp Lys Trp Pro Glu Gly Ser Pro Lys Pro Val
245 250 255
Thr Gln Asn Ile Ser Ala Glu Ala Trp Gly Arg Ala Asp Cys Gly Ile
260 265 270
Thr Ser Ala Ser Tyr Gln Gln Gly Val Leu Ser
275 280
<210> 243
<211> 849
<212> DNA
<213> Artificial Sequence
<220>
<223> KRAS TCR beta
<400> 243
atgtctaaca ctgccttccc tgaccccgcc tggaacacca ccctgctatc ttgggttgct 60
ctctttctcc tgggaacaag ttcagcaaat tctggggttg tccagtctcc aagatacata 120
atcaaaggaa agggagaaag gtccattcta aaatgtattc ccatctctgg acatctctct 180
gtggcctggt atcaacagac tcaggggcag gaactaaagt tcttcattca gcattatgat 240
aaaatggaga gagataaagg aaacctgccc agcagattct cagtccaaca gtttgatgac 300
tatcactctg agatgaacat gagtgccttg gagctagagg actctgccgt gtacttctgt 360
gccagctctc tcacagatcc gctagactcc gactacacct tcggctcagg gaccaggctt 420
ttggtaatag aggatctgag aaatgtgact ccacccaagg tctccttgtt tgagccatca 480
aaagcagaga ttgcaaacaa acaaaaggct accctcgtgt gcttggccag gggcttcttc 540
cctgaccacg tggagctgag ctggtgggtg aatggcaagg aggtccacag tggggtctgc 600
acggaccctc aggcctacaa ggagagcaat tatagctact gcctgagcag ccgcctgagg 660
gtctctgcta ccttctggca caatcctcgc aaccacttcc gctgccaagt gcagttccat 720
gggctttcag aggaggacaa gtggccagag ggctcaccca aacctgtcac acagaacatc 780
agtgcagagg cctggggccg agcagactgt gggattacct cagcatccta tcaacaaggg 840
gtcttgtct 849
<210> 244
<211> 283
<212> PRT
<213> Artificial Sequence
<220>
<223> KRAS TCR beta
<400> 244
Met Ser Asn Thr Ala Phe Pro Asp Pro Ala Trp Asn Thr Thr Leu Leu
1 5 10 15
Ser Trp Val Ala Leu Phe Leu Leu Gly Thr Ser Ser Ala Asn Ser Gly
20 25 30
Val Val Gln Ser Pro Arg Tyr Ile Ile Lys Gly Lys Gly Glu Arg Ser
35 40 45
Ile Leu Lys Cys Ile Pro Ile Ser Gly His Leu Ser Val Ala Trp Tyr
50 55 60
Gln Gln Thr Gln Gly Gln Glu Leu Lys Phe Phe Ile Gln His Tyr Asp
65 70 75 80
Lys Met Glu Arg Asp Lys Gly Asn Leu Pro Ser Arg Phe Ser Val Gln
85 90 95
Gln Phe Asp Asp Tyr His Ser Glu Met Asn Met Ser Ala Leu Glu Leu
100 105 110
Glu Asp Ser Ala Val Tyr Phe Cys Ala Ser Ser Leu Thr Asp Pro Leu
115 120 125
Asp Ser Asp Tyr Thr Phe Gly Ser Gly Thr Arg Leu Leu Val Ile Glu
130 135 140
Asp Leu Arg Asn Val Thr Pro Pro Lys Val Ser Leu Phe Glu Pro Ser
145 150 155 160
Lys Ala Glu Ile Ala Asn Lys Gln Lys Ala Thr Leu Val Cys Leu Ala
165 170 175
Arg Gly Phe Phe Pro Asp His Val Glu Leu Ser Trp Trp Val Asn Gly
180 185 190
Lys Glu Val His Ser Gly Val Cys Thr Asp Pro Gln Ala Tyr Lys Glu
195 200 205
Ser Asn Tyr Ser Tyr Cys Leu Ser Ser Arg Leu Arg Val Ser Ala Thr
210 215 220
Phe Trp His Asn Pro Arg Asn His Phe Arg Cys Gln Val Gln Phe His
225 230 235 240
Gly Leu Ser Glu Glu Asp Lys Trp Pro Glu Gly Ser Pro Lys Pro Val
245 250 255
Thr Gln Asn Ile Ser Ala Glu Ala Trp Gly Arg Ala Asp Cys Gly Ile
260 265 270
Thr Ser Ala Ser Tyr Gln Gln Gly Val Leu Ser
275 280
<210> 245
<211> 849
<212> DNA
<213> KRAS TCR beta
<400> 245
atgtctaaca ctgccttccc tgaccccgcc tggaacacca ccctgctatc ttgggttgct 60
ctctttctcc tgggaacaag ttcagcaaat tctggggttg tccagtctcc aagatacata 120
atcaaaggaa agggagaaag gtccattcta aaatgtattc ccatctctgg acatctctct 180
gtggcctggt atcaacagac tcaggggcag gaactaaagt tcttcattca gcattatgat 240
aaaatggaga gagataaagg aaacctgccc agcagattct cagtccaaca gtttgatgac 300
tatcactctg agatgaacat gagtgccttg gagctagagg actctgccgt gtacttctgt 360
gccagctctc tcacagatcc gctagactcc gactacacct tcggctcagg gaccaggctt 420
ttggtaatag aggatctgag aaatgtgact ccacccaagg tctccttgtt tgagccatca 480
aaagcagaga ttgcaaacaa acaaaaggct accctcgtgt gcttggccag gggcttcttc 540
cctgaccacg tggagctgag ctggtgggtg aatggcaagg aggtccacag tggggtctgc 600
acggaccctc aggcctacaa ggagagcaat tatagctact gcctgagcag ccgcctgagg 660
gtctctgcta ccttctggca caatcctcgc aaccacttcc gctgccaagt gcagttccat 720
gggctttcag aggaggacaa gtggccagag ggctcaccca aacctgtcac acagaacatc 780
agtgcagagg cctggggccg agcagactgt gggattacct cagcatccta tcaacaaggg 840
gtcttgtct 849
<210> 246
<211> 248
<212> PRT
<213> Artificial Sequence
<220>
<223> KRAS TCRa
<400> 246
Met Lys Thr Val Thr Gly Pro Leu Phe Leu Cys Phe Trp Leu Gln Leu
1 5 10 15
Asn Cys Val Ser Arg Gly Glu Gln Val Glu Gln Arg Pro Pro His Leu
20 25 30
Ser Val Arg Glu Gly Asp Ser Ala Val Ile Thr Cys Thr Tyr Thr Asp
35 40 45
Pro Asn Ser Tyr Tyr Phe Phe Trp Tyr Lys Gln Glu Pro Gly Ala Ser
50 55 60
Leu Gln Leu Leu Met Lys Val Phe Ser Ser Thr Glu Ile Asn Glu Gly
65 70 75 80
Gln Gly Phe Thr Val Leu Leu Asn Lys Lys Asp Lys Arg Leu Ser Leu
85 90 95
Asn Leu Thr Ala Ala His Pro Gly Asp Ser Ala Ala Tyr Phe Cys Ala
100 105 110
Val Ser Gly Gly Thr Asn Ser Ala Gly Asn Lys Leu Thr Phe Gly Ile
115 120 125
Gly Thr Arg Val Leu Val Arg Pro Asp Ile Gln Asn Pro Glu Pro Ala
130 135 140
Val Tyr Gln Leu Lys Asp Pro Arg Ser Gln Asp Ser Thr Leu Cys Leu
145 150 155 160
Phe Thr Asp Phe Asp Ser Gln Ile Asn Val Pro Lys Thr Met Glu Ser
165 170 175
Gly Thr Phe Ile Thr Asp Lys Cys Val Leu Asp Met Lys Ala Met Asp
180 185 190
Ser Lys Ser Asn Gly Ala Ile Ala Trp Ser Asn Gln Thr Ser Phe Thr
195 200 205
Cys Gln Asp Ile Phe Lys Glu Thr Asn Ala Thr Tyr Pro Ser Ser Asp
210 215 220
Val Pro Cys Asp Ala Thr Leu Thr Glu Lys Ser Phe Glu Thr Asp Met
225 230 235 240
Asn Leu Asn Phe Gln Asn Leu Ser
245
<210> 247
<211> 744
<212> DNA
<213> Artificial Sequence
<220>
<223> KRAS TCRa
<400> 247
atgaagacgg tgactggacc tttgttcctg tgcttctggc tgcagctgaa ctgtgtgagc 60
agaggcgagc aggtggagca gcgccctcct cacctgagtg tccgggaggg agacagtgcc 120
gttatcacct gcacctacac agaccctaac agttattact tcttctggta caagcaagag 180
ccgggggcaa gtcttcagtt gcttatgaag gttttctcaa gtacggaaat aaacgaagga 240
caaggattca ctgtcctact gaacaagaaa gacaaacgac tctctctgaa cctcacagct 300
gcccatcctg gggactcagc cgcgtacttc tgcgcagtca gtggagggac taacagtgca 360
gggaacaagc taacttttgg aattggaacc agggtgctgg tcaggccaga catccagaac 420
ccagaacctg ctgtgtacca gttaaaagat cctcggtctc aggacagcac cctctgcctg 480
ttcaccgact ttgactccca aatcaatgtg ccgaaaacca tggaatctgg aacgttcatc 540
actgacaaat gtgtgctgga catgaaagct atggattcca agagcaatgg ggccattgcc 600
tggagcaacc agacaagctt cacctgccaa gatatcttca aagagaccaa cgccacctac 660
cccagttcag acgttccctg tgatgccacg ttgaccgaga aaagctttga aacagatatg 720
aacctgaact ttcaaaacct gtct 744
<210> 248
<211> 272
<212> PRT
<213> Artificial Sequence
<220>
<223> KRAS TCRb
<400> 248
Met Gly Cys Arg Leu Leu Ser Cys Val Ala Phe Cys Leu Leu Gly Ile
1 5 10 15
Gly Pro Leu Glu Thr Ala Val Phe Gln Thr Pro Asn Tyr His Val Thr
20 25 30
Gln Val Gly Asn Glu Val Ser Phe Asn Cys Lys Gln Thr Leu Gly His
35 40 45
Asp Thr Met Tyr Trp Tyr Lys Gln Asp Ser Lys Lys Leu Leu Lys Ile
50 55 60
Met Phe Ser Tyr Asn Asn Lys Gln Leu Ile Val Asn Glu Thr Val Pro
65 70 75 80
Arg Arg Phe Ser Pro Gln Ser Ser Asp Lys Ala His Leu Asn Leu Arg
85 90 95
Ile Lys Ser Val Glu Pro Glu Asp Ser Ala Val Tyr Leu Cys Ala Ser
100 105 110
Ser Arg Asp Trp Gly Pro Ala Glu Gln Phe Phe Gly Pro Gly Thr Arg
115 120 125
Leu Thr Val Leu Glu Asp Leu Arg Asn Val Thr Pro Pro Lys Val Ser
130 135 140
Leu Phe Glu Pro Ser Lys Ala Glu Ile Ala Asn Lys Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Arg Gly Phe Phe Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro
180 185 190
Gln Ala Tyr Lys Glu Ser Asn Tyr Ser Tyr Cys Leu Ser Ser Arg Leu
195 200 205
Arg Val Ser Ala Thr Phe Trp His Asn Pro Arg Asn His Phe Arg Cys
210 215 220
Gln Val Gln Phe His Gly Leu Ser Glu Glu Asp Lys Trp Pro Glu Gly
225 230 235 240
Ser Pro Lys Pro Val Thr Gln Asn Ile Ser Ala Glu Ala Trp Gly Arg
245 250 255
Ala Asp Cys Gly Ile Thr Ser Ala Ser Tyr His Gln Gly Val Leu Ser
260 265 270
<210> 249
<211> 816
<212> DNA
<213> Artificial Sequence
<220>
<223> KRAS TCRb
<400> 249
atgggctgta ggctcctaag ctgtgtggcc ttctgcctct tgggaatagg ccctttggag 60
acagctgttt tccagactcc aaactatcat gtcacacagg tgggaaatga agtgtctttc 120
aattgtaagc aaactctggg ccacgatact atgtattggt acaagcaaga ctctaagaaa 180
ttgctgaaga ttatgtttag ctacaataat aagcaactca ttgtaaacga aacagttcca 240
aggcgcttct cacctcagtc ttcagataaa gctcatttga atcttcgaat caagtctgta 300
gagccggagg actctgctgt gtatctctgt gccagcagtc gggactgggg gcctgctgag 360
cagttcttcg gaccagggac acgactcacc gtcctagagg atctgagaaa tgtgactcca 420
cccaaggtct ccttgtttga gccatcaaaa gcagagattg caaacaaaca aaaggctacc 480
ctcgtgtgct tggccagggg cttcttccct gaccacgtgg agctgagctg gtgggtgaat 540
ggcaaggagg tccacagtgg ggtctgcacg gaccctcagg cctacaagga gagcaattat 600
agctactgcc tgagcagccg cctgagggtc tctgctacct tctggcacaa tcctcgaaac 660
cacttccgct gccaagtgca gttccatggg ctttcagagg aggacaagtg gccagagggc 720
tcacccaaac ctgtcacaca gaacatcagt gcagaggcct ggggccgagc agactgtgga 780
atcacttcag catcctatca tcagggggtt ctgtct 816
<210> 250
<211> 272
<212> PRT
<213> Artificial Sequence
<220>
<223> KRAS TCRb
<400> 250
Met Gly Cys Arg Leu Leu Ser Cys Val Ala Phe Cys Leu Leu Gly Ile
1 5 10 15
Gly Pro Leu Glu Thr Ala Val Phe Gln Thr Pro Asn Tyr His Val Thr
20 25 30
Gln Val Gly Asn Glu Val Ser Phe Asn Cys Lys Gln Thr Leu Gly His
35 40 45
Asp Thr Met Tyr Trp Tyr Lys Gln Asp Ser Lys Lys Leu Leu Lys Ile
50 55 60
Met Phe Ser Tyr Asn Asn Lys Gln Leu Ile Val Asn Glu Thr Val Pro
65 70 75 80
Arg Arg Phe Ser Pro Gln Ser Ser Asp Lys Ala His Leu Asn Leu Arg
85 90 95
Ile Lys Ser Val Glu Pro Glu Asp Ser Ala Val Tyr Leu Cys Ala Ser
100 105 110
Ser Arg Asp Trp Gly Pro Ala Glu Gln Phe Phe Gly Pro Gly Thr Arg
115 120 125
Leu Thr Val Leu Glu Asp Leu Arg Asn Val Thr Pro Pro Lys Val Ser
130 135 140
Leu Phe Glu Pro Ser Lys Ala Glu Ile Ala Asn Lys Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Arg Gly Phe Phe Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro
180 185 190
Gln Ala Tyr Lys Glu Ser Asn Tyr Ser Tyr Cys Leu Ser Ser Arg Leu
195 200 205
Arg Val Ser Ala Thr Phe Trp His Asn Pro Arg Asn His Phe Arg Cys
210 215 220
Gln Val Gln Phe His Gly Leu Ser Glu Glu Asp Lys Trp Pro Glu Gly
225 230 235 240
Ser Pro Lys Pro Val Thr Gln Asn Ile Ser Ala Glu Ala Trp Gly Arg
245 250 255
Ala Asp Cys Gly Ile Thr Ser Ala Ser Tyr His Gln Gly Val Leu Ser
260 265 270
<210> 251
<211> 816
<212> DNA
<213> Artificial Sequence
<220>
<223> KRAS TCRb
<400> 251
atgggctgta ggctcctaag ctgtgtggcc ttctgcctct tgggaatagg ccctttggag 60
acagctgttt tccagactcc aaactatcat gtcacacagg tgggaaatga agtgtctttc 120
aattgtaagc aaactctggg ccacgatact atgtattggt acaagcaaga ctctaagaaa 180
ttgctgaaga ttatgtttag ctacaataat aagcaactca ttgtaaacga aacagttcca 240
aggcgcttct cacctcagtc ttcagataaa gctcatttga atcttcgaat caagtctgta 300
gagccggagg actctgctgt gtatctctgt gccagcagtc gggactgggg gcctgctgag 360
cagttcttcg gaccagggac acgactcacc gtcctagagg atctgagaaa tgtgactcca 420
cccaaggtct ccttgtttga gccatcaaaa gcagagattg caaacaaaca aaaggctacc 480
ctcgtgtgct tggccagggg cttcttccct gaccacgtgg agctgagctg gtgggtgaat 540
ggcaaggagg tccacagtgg ggtctgcacg gaccctcagg cctacaagga gagcaattat 600
agctactgcc tgagcagccg cctgagggtc tctgctacct tctggcacaa tcctcgaaac 660
cacttccgct gccaagtgca gttccatggg ctttcagagg aggacaagtg gccagagggc 720
tcacccaaac ctgtcacaca gaacatcagt gcagaggcct ggggccgagc agactgtgga 780
atcacttcag catcctatca tcagggggtt ctgtct 816
<210> 252
<211> 244
<212> PRT
<213> Artificial Sequence
<220>
<223> TCRa control
<400> 252
Met Gln Arg Asn Leu Gly Ala Val Leu Gly Ile Leu Trp Val Gln Ile
1 5 10 15
Cys Trp Val Arg Gly Asp Gln Val Glu Gln Ser Pro Ser Ala Leu Ser
20 25 30
Leu His Glu Gly Thr Asp Ser Ala Leu Arg Cys Asn Phe Thr Thr Thr
35 40 45
Met Arg Ser Val Gln Trp Phe Arg Gln Asn Ser Arg Gly Ser Leu Ile
50 55 60
Ser Leu Phe Tyr Leu Ala Ser Gly Thr Lys Glu Asn Gly Arg Leu Lys
65 70 75 80
Ser Ala Phe Asp Ser Lys Glu Arg Arg Tyr Ser Thr Leu His Ile Arg
85 90 95
Asp Ala Gln Leu Glu Asp Ser Gly Thr Tyr Phe Cys Ala Ala Asp Ser
100 105 110
Ser Asn Thr Gly Tyr Gln Asn Phe Tyr Phe Gly Lys Gly Thr Ser Leu
115 120 125
Thr Val Ile Pro Asn Ile Gln Asn Pro Glu Pro Ala Val Tyr Gln Leu
130 135 140
Lys Asp Pro Arg Ser Gln Asp Ser Thr Leu Cys Leu Phe Thr Asp Phe
145 150 155 160
Asp Ser Gln Ile Asn Val Pro Lys Thr Met Glu Ser Gly Thr Phe Ile
165 170 175
Thr Asp Lys Cys Val Leu Asp Met Lys Ala Met Asp Ser Lys Ser Asn
180 185 190
Gly Ala Ile Ala Trp Ser Asn Gln Thr Ser Phe Thr Cys Gln Asp Ile
195 200 205
Phe Lys Glu Thr Asn Ala Thr Tyr Pro Ser Ser Asp Val Pro Cys Asp
210 215 220
Ala Thr Leu Thr Glu Lys Ser Phe Glu Thr Asp Met Asn Leu Asn Phe
225 230 235 240
Gln Asn Leu Ser
<210> 253
<211> 732
<212> DNA
<213> Artificial Sequence
<220>
<223> TCRa control
<400> 253
atgcagagga acctgggagc tgtgctgggg attctgtggg tgcagatttg ctgggtgaga 60
ggggatcagg tggagcagag tccttcagcc ctgagcctcc acgagggaac cgattctgct 120
ctgagatgca attttacgac caccatgagg agtgtgcagt ggttccgaca gaattccagg 180
ggcagcctca tcagtttgtt ctacttggct tcaggaacaa aggagaatgg gaggctaaag 240
tcagcatttg attctaagga gcggcgctac agcaccctgc acatcaggga tgcccagctg 300
gaggactcag gcacttactt ctgtgctgct gactcttcga acacgggtta ccagaacttc 360
tattttggga aaggaacaag tttgactgtc attccaaaca tccagaaccc agaacctgct 420
gtgtaccagt taaaagatcc tcggtctcag gacagcaccc tctgcctgtt caccgacttt 480
gactcccaaa tcaatgtgcc gaaaaccatg gaatctggaa cgttcatcac tgacaaatgt 540
gtgctggaca tgaaagctat ggattccaag agcaatgggg ccattgcctg gagcaaccag 600
acaagcttca cctgccaaga tatcttcaaa gagaccaacg ccacctaccc cagttcagac 660
gttccctgtg atgccacgtt gaccgagaaa agctttgaaa cagatatgaa cctgaacttt 720
caaaacctgt ct 732
<210> 254
<211> 248
<212> PRT
<213> Artificial Sequence
<220>
<223> TCRa control
<400> 254
Met Lys Thr Val Thr Gly Pro Leu Phe Leu Cys Phe Trp Leu Gln Leu
1 5 10 15
Asn Cys Val Ser Arg Gly Glu Gln Val Glu Gln Arg Pro Pro His Leu
20 25 30
Ser Val Arg Glu Gly Asp Ser Ala Val Ile Thr Cys Thr Tyr Thr Asp
35 40 45
Pro Asn Ser Tyr Tyr Phe Phe Trp Tyr Lys Gln Glu Pro Gly Ala Ser
50 55 60
Leu Gln Leu Leu Met Lys Val Phe Ser Ser Thr Glu Ile Asn Glu Gly
65 70 75 80
Gln Gly Phe Thr Val Leu Leu Asn Lys Lys Asp Lys Arg Leu Ser Leu
85 90 95
Asn Leu Thr Ala Ala His Pro Gly Asp Ser Ala Ala Tyr Phe Cys Ala
100 105 110
Val Ser Gly Gly Thr Asn Ser Ala Gly Asn Lys Leu Thr Phe Gly Ile
115 120 125
Gly Thr Arg Val Leu Val Arg Pro Asp Ile Gln Asn Pro Glu Pro Ala
130 135 140
Val Tyr Gln Leu Lys Asp Pro Arg Ser Gln Asp Ser Thr Leu Cys Leu
145 150 155 160
Phe Thr Asp Phe Asp Ser Gln Ile Asn Val Pro Lys Thr Met Glu Ser
165 170 175
Gly Thr Phe Ile Thr Asp Lys Cys Val Leu Asp Met Lys Ala Met Asp
180 185 190
Ser Lys Ser Asn Gly Ala Ile Ala Trp Ser Asn Gln Thr Ser Phe Thr
195 200 205
Cys Gln Asp Ile Phe Lys Glu Thr Asn Ala Thr Tyr Pro Ser Ser Asp
210 215 220
Val Pro Cys Asp Ala Thr Leu Thr Glu Lys Ser Phe Glu Thr Asp Met
225 230 235 240
Asn Leu Asn Phe Gln Asn Leu Ser
245
<210> 255
<211> 744
<212> DNA
<213> Artificial Sequence
<220>
<223> TCRa control
<400> 255
atgaagacgg tgactggacc tttgttcctg tgcttctggc tgcagctgaa ctgtgtgagc 60
agaggcgagc aggtggagca gcgccctcct cacctgagtg tccgggaggg agacagtgcc 120
gttatcacct gcacctacac agaccctaac agttattact tcttctggta caagcaagag 180
ccgggggcaa gtcttcagtt gcttatgaag gttttctcaa gtacggaaat aaacgaagga 240
caaggattca ctgtcctact gaacaagaaa gacaaacgac tctctctgaa cctcacagct 300
gcccatcctg gggactcagc cgcgtacttc tgcgcagtca gtggagggac taacagtgca 360
gggaacaagc taacttttgg aattggaacc agggtgctgg tcaggccaga catccagaac 420
ccagaacctg ctgtgtacca gttaaaagat cctcggtctc aggacagcac cctctgcctg 480
ttcaccgact ttgactccca aatcaatgtg ccgaaaacca tggaatctgg aacgttcatc 540
actgacaaat gtgtgctgga catgaaagct atggattcca agagcaatgg ggccattgcc 600
tggagcaacc agacaagctt cacctgccaa gatatcttca aagagaccaa cgccacctac 660
cccagttcag acgttccctg tgatgccacg ttgaccgaga aaagctttga aacagatatg 720
aacctgaact ttcaaaacct gtct 744
<210> 256
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> mH-Y-2Db peptide
<400> 256
Lys Cys Ser Arg Asn Arg Gln Tyr Leu
1 5
<210> 257
<211> 614
<212> PRT
<213> Artificial Sequence
<220>
<223> H-Y TCR alpha and beta
<400> 257
Met Phe Pro Val Thr Ile Leu Leu Leu Ser Ala Phe Phe Ser Leu Arg
1 5 10 15
Gly Asn Ser Ala Gln Ser Val Asp Gln Pro Asp Ala His Val Thr Leu
20 25 30
Ser Glu Gly Ala Ser Leu Glu Leu Arg Cys Ser Tyr Ser Tyr Ser Ala
35 40 45
Ala Pro Tyr Leu Phe Trp Tyr Val Gln Tyr Pro Gly Gln Ser Leu Gln
50 55 60
Phe Leu Leu Lys Tyr Ile Thr Gly Asp Thr Val Val Lys Gly Thr Lys
65 70 75 80
Gly Phe Glu Ala Glu Phe Arg Lys Ser Asn Ser Ser Phe Asn Leu Lys
85 90 95
Lys Ser Pro Ala His Trp Ser Asp Ser Ala Lys Tyr Phe Cys Ala Leu
100 105 110
Glu Gly Gln Asp Gln Gly Gly Ser Ala Lys Leu Ile Phe Gly Glu Gly
115 120 125
Thr Lys Leu Thr Val Ser Ser Pro Asp Ile Gln Asn Pro Glu Pro Ala
130 135 140
Val Tyr Gln Leu Lys Asp Pro Arg Ser Gln Asp Ser Thr Leu Cys Leu
145 150 155 160
Phe Thr Asp Phe Asp Ser Gln Ile Asn Val Pro Lys Thr Met Glu Ser
165 170 175
Gly Thr Phe Ile Thr Asp Lys Thr Val Leu Asp Met Lys Ala Met Asp
180 185 190
Ser Lys Ser Asn Gly Ala Ile Ala Trp Ser Asn Gln Thr Ser Phe Thr
195 200 205
Cys Gln Asp Ile Phe Lys Glu Thr Asn Ala Thr Tyr Pro Ser Ser Asp
210 215 220
Val Pro Cys Asp Ala Thr Leu Thr Glu Lys Ser Phe Glu Thr Asp Met
225 230 235 240
Asn Leu Asn Phe Gln Asn Leu Ser Val Met Gly Leu Arg Ile Leu Leu
245 250 255
Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser
260 265 270
Ser Arg Ala Lys Arg Ser Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu
275 280 285
Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Ser Asn Thr
290 295 300
Ala Phe Pro Asp Pro Ala Trp Asn Thr Thr Leu Leu Ser Trp Val Ala
305 310 315 320
Leu Phe Leu Leu Gly Thr Lys His Met Glu Ala Ala Val Thr Gln Ser
325 330 335
Pro Arg Asn Lys Val Ala Val Thr Gly Gly Lys Val Thr Leu Ser Cys
340 345 350
Asn Gln Thr Asn Asn His Asn Asn Met Tyr Trp Tyr Arg Gln Asp Thr
355 360 365
Gly His Gly Leu Arg Leu Ile His Tyr Ser Tyr Gly Ala Gly Ser Thr
370 375 380
Glu Lys Gly Asp Ile Pro Asp Gly Tyr Lys Ala Ser Arg Pro Ser Gln
385 390 395 400
Glu Asn Phe Ser Leu Ile Leu Glu Leu Ala Thr Pro Ser Gln Thr Ser
405 410 415
Val Tyr Phe Cys Ala Ser Gly Asp Asn Ser Ala Glu Thr Leu Tyr Phe
420 425 430
Gly Pro Gly Thr Arg Leu Thr Val Leu Glu Asp Leu Arg Asn Val Thr
435 440 445
Pro Pro Lys Val Ser Leu Phe Glu Pro Ser Lys Ala Glu Ile Ala Asn
450 455 460
Lys Gln Lys Ala Thr Leu Val Cys Leu Ala Arg Gly Phe Phe Pro Asp
465 470 475 480
His Val Glu Leu Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly
485 490 495
Val Ser Thr Asp Pro Gln Ala Tyr Lys Glu Ser Asn Tyr Ser Tyr Cys
500 505 510
Leu Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp His Asn Pro Arg
515 520 525
Asn His Phe Arg Cys Gln Val Gln Phe His Gly Leu Ser Glu Glu Asp
530 535 540
Lys Trp Pro Glu Gly Ser Pro Lys Pro Val Thr Gln Asn Ile Ser Ala
545 550 555 560
Glu Ala Trp Gly Arg Ala Asp Cys Gly Ile Thr Ser Ala Ser Tyr His
565 570 575
Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys
580 585 590
Ala Thr Leu Tyr Ala Val Leu Val Ser Gly Leu Val Leu Met Ala Met
595 600 605
Val Lys Lys Lys Asn Ser
610
<210> 258
<211> 1845
<212> DNA
<213> Artificial Sequence
<220>
<223> H-Y TCR alpha and beta
<400> 258
atgttccccg ttaccatatt gctcctgagt gctttcttca gtttgcgagg gaactctgcc 60
caatctgtcg atcagccaga tgcacacgtt accctttccg agggtgcgtc acttgaactg 120
aggtgttcct atagctactc agcagcccct tatctgtttt ggtacgtaca atacccaggg 180
cagagtctcc aatttctcct taaatatata accggggaca ctgtagtgaa ggggactaaa 240
ggttttgaag cagagtttag gaagagcaac agctccttca accttaagaa gtcacccgca 300
cactggtcag actccgcgaa atacttctgt gctctggaag ggcaagacca gggtggaagt 360
gccaaattga tatttggtga gggtactaaa ttgactgtta gctcaccaga catccagaac 420
ccagaacctg ctgtgtacca gttaaaagat cctcggtctc aggacagcac cctctgcctg 480
ttcaccgact ttgactccca aatcaatgtg ccgaaaacca tggaatctgg aacgttcatc 540
actgacaaaa ctgtgctgga catgaaagct atggattcca agagcaatgg ggccattgcc 600
tggagcaacc agacaagctt cacctgccaa gatatcttca aagagaccaa cgccacctac 660
cccagttcag acgttccctg tgatgccacg ttgaccgaga aaagctttga aacagatatg 720
aacctaaact ttcaaaacct gtcagttatg ggactccgaa tcctcctgct gaaagtagcg 780
ggatttaacc tgctcatgac gctgaggctg tggtccagtc gggccaagcg gtccggatcc 840
ggagccacca acttcagcct gctgaagcag gccggcgacg tggaggagaa ccccggcccc 900
atgtctaata ctgcatttcc agatccggcc tggaatacta cactccttag ttgggttgcc 960
ctcttcctcc ttggcacgaa gcacatggaa gccgccgtca cccagagtcc gagaaacaaa 1020
gtagcggtca ccggcggtaa ggtaacattg agttgtaacc aaacgaacaa ccataacaat 1080
atgtactggt atagacaaga cacaggccat ggcttgcgcc tgattcacta cagctatgga 1140
gcggggagta cggagaaggg tgatattccc gatggctata aagcctctcg gcctagccag 1200
gagaatttta gtttgatcct ggagctcgca acccccagtc agactagcgt ctacttttgt 1260
gcctcaggcg acaatagtgc ggaaaccctt tacttcggcc ctgggacaag acttacagtt 1320
ctagaggatc tgagaaatgt gactccaccc aaggtctcct tgtttgagcc atcaaaagca 1380
gagattgcaa acaaacaaaa ggctaccctc gtgtgcttgg ccaggggctt cttccctgac 1440
cacgtggagc tgagctggtg ggtgaatggc aaggaggtcc acagtggggt cagcacggac 1500
cctcaggcct acaaggagag caattatagc tactgcctga gcagccgcct gagggtctct 1560
gctaccttct ggcacaatcc tcgaaaccac ttccgctgcc aagtgcagtt ccatgggctt 1620
tcagaggagg acaagtggcc agagggctca cccaaacctg tcacacagaa catcagtgca 1680
gaggcctggg gccgagcaga ctgtggaatc acttcagcat cctatcatca gggggttctg 1740
tctgcaacca tcctctatga gatcctactg gggaaggcca ccctatatgc tgtgctggtc 1800
agtggcctgg tgctgatggc catggtcaag aaaaaaaatt cctag 1845
<210> 259
<211> 619
<212> PRT
<213> Artificial Sequence
<220>
<223> H-Y TCR alpha and beta
<400> 259
Met Phe Pro Val Thr Ile Leu Leu Leu Ser Ala Phe Phe Ser Leu Arg
1 5 10 15
Gly Asn Ser Ala Gln Ser Val Asp Gln Pro Asp Ala His Val Thr Leu
20 25 30
Ser Glu Gly Ala Ser Leu Glu Leu Arg Cys Ser Tyr Ser Tyr Ser Ala
35 40 45
Ala Pro Tyr Leu Phe Trp Tyr Val Gln Tyr Pro Gly Gln Ser Leu Gln
50 55 60
Phe Leu Leu Lys Tyr Ile Thr Gly Asp Thr Val Val Lys Gly Thr Lys
65 70 75 80
Gly Phe Glu Ala Glu Phe Arg Lys Ser Asn Ser Ser Phe Asn Leu Lys
85 90 95
Lys Ser Pro Ala His Trp Ser Asp Ser Ala Lys Tyr Phe Cys Ala Leu
100 105 110
Glu Gly Gln Asp Gln Gly Gly Ser Ala Lys Leu Ile Phe Gly Glu Gly
115 120 125
Thr Lys Leu Thr Val Ser Ser Pro Tyr Ile Gln Asn Pro Asp Pro Ala
130 135 140
Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu
145 150 155 160
Phe Thr Asp Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser
165 170 175
Asp Val Tyr Ile Thr Asp Lys Cys Val Leu Asp Met Arg Ser Met Asp
180 185 190
Phe Lys Ser Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala
195 200 205
Cys Ala Asn Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe
210 215 220
Pro Ser Pro Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe
225 230 235 240
Glu Thr Asp Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe
245 250 255
Arg Ile Leu Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu
260 265 270
Arg Leu Trp Ser Ser Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys
275 280 285
Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Ser Asn Thr Ala
290 295 300
Phe Pro Asp Pro Ala Trp Asn Thr Thr Leu Leu Ser Trp Val Ala Leu
305 310 315 320
Phe Leu Leu Gly Thr Lys His Met Glu Ala Ala Val Thr Gln Ser Pro
325 330 335
Arg Asn Lys Val Ala Val Thr Gly Gly Lys Val Thr Leu Ser Cys Asn
340 345 350
Gln Thr Asn Asn His Asn Asn Met Tyr Trp Tyr Arg Gln Asp Thr Gly
355 360 365
His Gly Leu Arg Leu Ile His Tyr Ser Tyr Gly Ala Gly Ser Thr Glu
370 375 380
Lys Gly Asp Ile Pro Asp Gly Tyr Lys Ala Ser Arg Pro Ser Gln Glu
385 390 395 400
Asn Phe Ser Leu Ile Leu Glu Leu Ala Thr Pro Ser Gln Thr Ser Val
405 410 415
Tyr Phe Cys Ala Ser Gly Asp Asn Ser Ala Glu Thr Leu Tyr Phe Gly
420 425 430
Pro Gly Thr Arg Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro
435 440 445
Pro Glu Val Ala Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr
450 455 460
Gln Lys Ala Thr Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His
465 470 475 480
Val Glu Leu Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val
485 490 495
Cys Thr Asp Pro Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser
500 505 510
Arg Tyr Cys Leu Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln
515 520 525
Asn Pro Arg Asn His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser
530 535 540
Glu Asn Asp Glu Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile
545 550 555 560
Val Ser Ala Glu Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu
565 570 575
Ser Tyr Gln Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu
580 585 590
Leu Gly Lys Ala Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu
595 600 605
Met Ala Met Val Lys Arg Lys Asp Ser Arg Gly
610 615
<210> 260
<211> 1860
<212> DNA
<213> Artificial Sequence
<220>
<223> H-Y TCR alpha and beta
<400> 260
atgttccccg ttaccatatt gctcctgagt gctttcttca gtttgcgagg gaactctgcc 60
caatctgtcg atcagccaga tgcacacgtt accctttccg agggtgcgtc acttgaactg 120
aggtgttcct atagctactc agcagcccct tatctgtttt ggtacgtaca atacccaggg 180
cagagtctcc aatttctcct taaatatata accggggaca ctgtagtgaa ggggactaaa 240
ggttttgaag cagagtttag gaagagcaac agctccttca accttaagaa gtcacccgca 300
cactggtcag actccgcgaa atacttctgt gctctggaag ggcaagacca gggtggaagt 360
gccaaattga tatttggtga gggtactaaa ttgactgtta gctcaccgta tatccagaac 420
cctgaccctg ccgtgtacca gctgagagac tctaaatcca gtgacaagtc tgtctgccta 480
ttcaccgatt ttgattctca aacaaatgtg tcacaaagta aggattctga tgtgtatatc 540
acagacaaat gtgtgctaga catgaggtct atggacttca agagcaacag tgctgtggcc 600
tggagcaaca aatctgactt tgcatgtgca aacgccttca acaacagcat tattccagaa 660
gacaccttct tccccagccc agaaagttcc tgtgatgtca agctggtcga gaaaagcttt 720
gaaacagata cgaacctaaa ctttcaaaac ctgtcagtga ttgggttccg aatcctcctc 780
ctgaaagtgg ccgggtttaa tctgctcatg acgctgcggc tgtggtccag cggatccgga 840
gccaccaact tcagcctgct gaagcaggcc ggcgacgtgg aggagaaccc cggccccatg 900
tctaatactg catttccaga tccggcctgg aatactacac tccttagttg ggttgccctc 960
ttcctccttg gcacgaagca catggaagcc gccgtcaccc agagtccgag aaacaaagta 1020
gcggtcaccg gcggtaaggt aacattgagt tgtaaccaaa cgaacaacca taacaatatg 1080
tactggtata gacaagacac aggccatggc ttgcgcctga ttcactacag ctatggagcg 1140
gggagtacgg agaagggtga tattcccgat ggctataaag cctctcggcc tagccaggag 1200
aattttagtt tgatcctgga gctcgcaacc cccagtcaga ctagcgtcta cttttgtgcc 1260
tcaggcgaca atagtgcgga aaccctttac ttcggccctg ggacaagact tacagttctg 1320
gaggacctga aaaacgtgtt cccacccgag gtcgctgtgt ttgagccatc agaagcagag 1380
atctcccaca cccaaaaggc cacactggtg tgcctggcca caggcttcta ccccgaccac 1440
gtggagctga gctggtgggt gaatgggaag gaggtgcaca gtggggtctg cacagacccg 1500
cagcccctca aggagcagcc cgccctcaat gactccagat actgcctgag cagccgcctg 1560
agggtgtcgg ccaccttctg gcagaacccc cgcaaccact tccgctgtca agtccagttc 1620
tacgggctct cggagaatga cgagtggacc caggataggg ccaaacctgt cacccagatc 1680
gtcagcgccg aggcctgggg tagagcagac tgtggcttca cctccgagtc ttaccagcaa 1740
ggggtcctgt ctgccaccat cctctatgag atcttgctag ggaaggccac cttgtatgcc 1800
gtgctggtca gtgccctcgt gctgatggcc atggtcaaga gaaaggattc cagaggctag 1860
<210> 261
<211> 614
<212> PRT
<213> Artificial Sequence
<220>
<223> H-Y TCR alpha and beta
<400> 261
Met Phe Pro Val Thr Ile Leu Leu Leu Ser Ala Phe Phe Ser Leu Arg
1 5 10 15
Gly Asn Ser Ala Gln Ser Val Asp Gln Pro Asp Ala His Val Thr Leu
20 25 30
Ser Glu Gly Ala Ser Leu Glu Leu Arg Cys Ser Tyr Ser Tyr Ser Ala
35 40 45
Ala Pro Tyr Leu Phe Trp Tyr Val Gln Tyr Pro Gly Gln Ser Leu Gln
50 55 60
Phe Leu Leu Lys Tyr Ile Thr Gly Asp Thr Val Val Lys Gly Thr Lys
65 70 75 80
Gly Phe Glu Ala Glu Phe Arg Lys Ser Asn Ser Ser Phe Asn Leu Lys
85 90 95
Lys Ser Pro Ala His Trp Ser Asp Ser Ala Lys Tyr Phe Cys Ala Leu
100 105 110
Glu Gly Gln Asp Gln Gly Gly Ser Ala Lys Leu Ile Phe Gly Glu Gly
115 120 125
Thr Lys Leu Thr Val Ser Ser Pro Asp Ile Gln Asn Pro Glu Pro Ala
130 135 140
Val Tyr Gln Leu Lys Asp Pro Arg Ser Gln Asp Ser Thr Leu Cys Leu
145 150 155 160
Phe Thr Asp Phe Asp Ser Gln Ile Asn Val Pro Lys Thr Met Glu Ser
165 170 175
Gly Thr Phe Ile Thr Asp Lys Thr Val Leu Asp Met Lys Ala Met Asp
180 185 190
Ser Lys Ser Asn Gly Ala Ile Ala Trp Ser Asn Gln Thr Ser Phe Thr
195 200 205
Cys Gln Asp Ile Phe Lys Glu Thr Asn Ala Thr Tyr Pro Ser Ser Asp
210 215 220
Val Pro Cys Asp Ala Thr Leu Thr Glu Lys Ser Phe Glu Thr Asp Met
225 230 235 240
Asn Leu Asn Phe Gln Asn Leu Ser Val Met Gly Leu Arg Ile Leu Leu
245 250 255
Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser
260 265 270
Ser Arg Ala Lys Arg Ser Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu
275 280 285
Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Ser Asn Thr
290 295 300
Ala Phe Pro Asp Pro Ala Trp Asn Thr Thr Leu Leu Ser Trp Val Ala
305 310 315 320
Leu Phe Leu Leu Gly Thr Lys His Met Glu Ala Ala Val Thr Gln Ser
325 330 335
Pro Arg Asn Lys Val Ala Val Thr Gly Gly Lys Val Thr Leu Ser Cys
340 345 350
Asn Gln Thr Asn Asn His Asn Asn Met Tyr Trp Tyr Arg Gln Asp Thr
355 360 365
Gly His Gly Leu Arg Leu Ile His Tyr Ser Tyr Gly Ala Gly Ser Thr
370 375 380
Glu Lys Gly Asp Ile Pro Asp Gly Tyr Lys Ala Ser Arg Pro Ser Gln
385 390 395 400
Glu Asn Phe Ser Leu Ile Leu Glu Leu Ala Thr Pro Ser Gln Thr Ser
405 410 415
Val Tyr Phe Cys Ala Ser Gly Asp Asn Ser Ala Glu Thr Leu Tyr Phe
420 425 430
Gly Pro Gly Thr Arg Leu Leu Val Leu Glu Asp Leu Arg Asn Val Thr
435 440 445
Pro Pro Lys Val Ser Leu Phe Glu Pro Ser Lys Ala Glu Ile Ala Asn
450 455 460
Lys Gln Lys Ala Thr Leu Val Cys Leu Ala Arg Gly Phe Phe Pro Asp
465 470 475 480
His Val Glu Leu Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly
485 490 495
Val Ser Thr Asp Pro Gln Ala Tyr Lys Glu Ser Asn Tyr Ser Tyr Cys
500 505 510
Leu Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp His Asn Pro Arg
515 520 525
Asn His Phe Arg Cys Gln Val Gln Phe His Gly Leu Ser Glu Glu Asp
530 535 540
Lys Trp Pro Glu Gly Ser Pro Lys Pro Val Thr Gln Asn Ile Ser Ala
545 550 555 560
Glu Ala Trp Gly Arg Ala Asp Cys Gly Ile Thr Ser Ala Ser Tyr His
565 570 575
Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys
580 585 590
Ala Thr Leu Tyr Ala Val Leu Val Ser Gly Leu Val Leu Met Ala Met
595 600 605
Val Lys Lys Lys Asn Ser
610
<210> 262
<211> 1845
<212> DNA
<213> Artificial Sequence
<220>
<223> H-Y TCR alpha and beta
<400> 262
atgttccccg ttaccatatt gctcctgagt gctttcttca gtttgcgagg gaactctgcc 60
caatctgtcg atcagccaga tgcacacgtt accctttccg agggtgcgtc acttgaactg 120
aggtgttcct atagctactc agcagcccct tatctgtttt ggtacgtaca atacccaggg 180
cagagtctcc aatttctcct taaatatata accggggaca ctgtagtgaa ggggactaaa 240
ggttttgaag cagagtttag gaagagcaac agctccttca accttaagaa gtcacccgca 300
cactggtcag actccgcgaa atacttctgt gctctggaag ggcaagacca gggtggaagt 360
gccaaattga tatttggtga gggtactaaa ttgactgtta gctcaccaga catccagaac 420
ccagaacctg ctgtgtacca gttaaaagat cctcggtctc aggacagcac cctctgcctg 480
ttcaccgact ttgactccca aatcaatgtg ccgaaaacca tggaatctgg aacgttcatc 540
actgacaaaa ctgtgctgga catgaaagct atggattcca agagcaatgg ggccattgcc 600
tggagcaacc agacaagctt cacctgccaa gatatcttca aagagaccaa cgccacctac 660
cccagttcag acgttccctg tgatgccacg ttgaccgaga aaagctttga aacagatatg 720
aacctaaact ttcaaaacct gtcagttatg ggactccgaa tcctcctgct gaaagtagcg 780
ggatttaacc tgctcatgac gctgaggctg tggtccagtc gggccaagcg gtccggatcc 840
ggagccacca acttcagcct gctgaagcag gccggcgacg tggaggagaa ccccggcccc 900
atgtctaata ctgcatttcc agatccggcc tggaatacta cactccttag ttgggttgcc 960
ctcttcctcc ttggcacgaa gcacatggaa gccgccgtca cccagagtcc gagaaacaaa 1020
gtagcggtca ccggcggtaa ggtaacattg agttgtaacc aaacgaacaa ccataacaat 1080
atgtactggt atagacaaga cacaggccat ggcttgcgcc tgattcacta cagctatgga 1140
gcggggagta cggagaaggg tgatattccc gatggctata aagcctctcg gcctagccag 1200
gagaatttta gtttgatcct ggagctcgca acccccagtc agactagcgt ctacttttgt 1260
gcctcaggcg acaatagtgc ggaaaccctt tacttcggcc ctgggacaag acttttggtt 1320
ctagaggatc tgagaaatgt gactccaccc aaggtctcct tgtttgagcc atcaaaagca 1380
gagattgcaa acaaacaaaa ggctaccctc gtgtgcttgg ccaggggctt cttccctgac 1440
cacgtggagc tgagctggtg ggtgaatggc aaggaggtcc acagtggggt cagcacggac 1500
cctcaggcct acaaggagag caattatagc tactgcctga gcagccgcct gagggtctct 1560
gctaccttct ggcacaatcc tcgaaaccac ttccgctgcc aagtgcagtt ccatgggctt 1620
tcagaggagg acaagtggcc agagggctca cccaaacctg tcacacagaa catcagtgca 1680
gaggcctggg gccgagcaga ctgtggaatc acttcagcat cctatcatca gggggttctg 1740
tctgcaacca tcctctatga gatcctactg gggaaggcca ccctatatgc tgtgctggtc 1800
agtggcctgg tgctgatggc catggtcaag aaaaaaaatt cctag 1845
<210> 263
<211> 619
<212> PRT
<213> Artificial Sequence
<220>
<223> H-Y TCR alpha and beta
<400> 263
Met Phe Pro Val Thr Ile Leu Leu Leu Ser Ala Phe Phe Ser Leu Arg
1 5 10 15
Gly Asn Ser Ala Gln Ser Val Asp Gln Pro Asp Ala His Val Thr Leu
20 25 30
Ser Glu Gly Ala Ser Leu Glu Leu Arg Cys Ser Tyr Ser Tyr Ser Ala
35 40 45
Ala Pro Tyr Leu Phe Trp Tyr Val Gln Tyr Pro Gly Gln Ser Leu Gln
50 55 60
Phe Leu Leu Lys Tyr Ile Thr Gly Asp Thr Val Val Lys Gly Thr Lys
65 70 75 80
Gly Phe Glu Ala Glu Phe Arg Lys Ser Asn Ser Ser Phe Asn Leu Lys
85 90 95
Lys Ser Pro Ala His Trp Ser Asp Ser Ala Lys Tyr Phe Cys Ala Leu
100 105 110
Glu Gly Gln Asp Gln Gly Gly Ser Ala Lys Leu Ile Phe Gly Glu Gly
115 120 125
Thr Lys Leu Thr Val Ser Ser Pro Tyr Ile Gln Asn Pro Asp Pro Ala
130 135 140
Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu
145 150 155 160
Phe Thr Asp Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser
165 170 175
Asp Val Tyr Ile Thr Asp Lys Cys Val Leu Asp Met Arg Ser Met Asp
180 185 190
Phe Lys Ser Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala
195 200 205
Cys Ala Asn Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe
210 215 220
Pro Ser Pro Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe
225 230 235 240
Glu Thr Asp Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe
245 250 255
Arg Ile Leu Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu
260 265 270
Arg Leu Trp Ser Ser Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys
275 280 285
Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Ser Asn Thr Ala
290 295 300
Phe Pro Asp Pro Ala Trp Asn Thr Thr Leu Leu Ser Trp Val Ala Leu
305 310 315 320
Phe Leu Leu Gly Thr Lys His Met Glu Ala Ala Val Thr Gln Ser Pro
325 330 335
Arg Asn Lys Val Ala Val Thr Gly Gly Lys Val Thr Leu Ser Cys Asn
340 345 350
Gln Thr Asn Asn His Asn Asn Met Tyr Trp Tyr Arg Gln Asp Thr Gly
355 360 365
His Gly Leu Arg Leu Ile His Tyr Ser Tyr Gly Ala Gly Ser Thr Glu
370 375 380
Lys Gly Asp Ile Pro Asp Gly Tyr Lys Ala Ser Arg Pro Ser Gln Glu
385 390 395 400
Asn Phe Ser Leu Ile Leu Glu Leu Ala Thr Pro Ser Gln Thr Ser Val
405 410 415
Tyr Phe Cys Ala Ser Gly Asp Asn Ser Ala Glu Thr Leu Tyr Phe Gly
420 425 430
Pro Gly Thr Arg Leu Leu Val Leu Glu Asp Leu Lys Asn Val Phe Pro
435 440 445
Pro Glu Val Ala Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr
450 455 460
Gln Lys Ala Thr Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His
465 470 475 480
Val Glu Leu Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val
485 490 495
Cys Thr Asp Pro Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser
500 505 510
Arg Tyr Cys Leu Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln
515 520 525
Asn Pro Arg Asn His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser
530 535 540
Glu Asn Asp Glu Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile
545 550 555 560
Val Ser Ala Glu Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu
565 570 575
Ser Tyr Gln Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu
580 585 590
Leu Gly Lys Ala Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu
595 600 605
Met Ala Met Val Lys Arg Lys Asp Ser Arg Gly
610 615
<210> 264
<211> 1860
<212> DNA
<213> Artificial Sequence
<220>
<223> H-Y TCR alpha and beta
<400> 264
atgttccccg ttaccatatt gctcctgagt gctttcttca gtttgcgagg gaactctgcc 60
caatctgtcg atcagccaga tgcacacgtt accctttccg agggtgcgtc acttgaactg 120
aggtgttcct atagctactc agcagcccct tatctgtttt ggtacgtaca atacccaggg 180
cagagtctcc aatttctcct taaatatata accggggaca ctgtagtgaa ggggactaaa 240
ggttttgaag cagagtttag gaagagcaac agctccttca accttaagaa gtcacccgca 300
cactggtcag actccgcgaa atacttctgt gctctggaag ggcaagacca gggtggaagt 360
gccaaattga tatttggtga gggtactaaa ttgactgtta gctcaccgta tatccagaac 420
cctgaccctg ccgtgtacca gctgagagac tctaaatcca gtgacaagtc tgtctgccta 480
ttcaccgatt ttgattctca aacaaatgtg tcacaaagta aggattctga tgtgtatatc 540
acagacaaat gtgtgctaga catgaggtct atggacttca agagcaacag tgctgtggcc 600
tggagcaaca aatctgactt tgcatgtgca aacgccttca acaacagcat tattccagaa 660
gacaccttct tccccagccc agaaagttcc tgtgatgtca agctggtcga gaaaagcttt 720
gaaacagata cgaacctaaa ctttcaaaac ctgtcagtga ttgggttccg aatcctcctc 780
ctgaaagtgg ccgggtttaa tctgctcatg acgctgcggc tgtggtccag cggatccgga 840
gccaccaact tcagcctgct gaagcaggcc ggcgacgtgg aggagaaccc cggccccatg 900
tctaatactg catttccaga tccggcctgg aatactacac tccttagttg ggttgccctc 960
ttcctccttg gcacgaagca catggaagcc gccgtcaccc agagtccgag aaacaaagta 1020
gcggtcaccg gcggtaaggt aacattgagt tgtaaccaaa cgaacaacca taacaatatg 1080
tactggtata gacaagacac aggccatggc ttgcgcctga ttcactacag ctatggagcg 1140
gggagtacgg agaagggtga tattcccgat ggctataaag cctctcggcc tagccaggag 1200
aattttagtt tgatcctgga gctcgcaacc cccagtcaga ctagcgtcta cttttgtgcc 1260
tcaggcgaca atagtgcgga aaccctttac ttcggccctg ggacaagact tttggttctg 1320
gaggacctga aaaacgtgtt cccacccgag gtcgctgtgt ttgagccatc agaagcagag 1380
atctcccaca cccaaaaggc cacactggtg tgcctggcca caggcttcta ccccgaccac 1440
gtggagctga gctggtgggt gaatgggaag gaggtgcaca gtggggtctg cacagacccg 1500
cagcccctca aggagcagcc cgccctcaat gactccagat actgcctgag cagccgcctg 1560
agggtgtcgg ccaccttctg gcagaacccc cgcaaccact tccgctgtca agtccagttc 1620
tacgggctct cggagaatga cgagtggacc caggataggg ccaaacctgt cacccagatc 1680
gtcagcgccg aggcctgggg tagagcagac tgtggcttca cctccgagtc ttaccagcaa 1740
ggggtcctgt ctgccaccat cctctatgag atcttgctag ggaaggccac cttgtatgcc 1800
gtgctggtca gtgccctcgt gctgatggcc atggtcaaga gaaaggattc cagaggctag 1860
<210> 265
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> NY-ESO-1
<400> 265
Ser Leu Leu Met Trp Ile Thr Gln Val
1 5
<210> 266
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> HA-1(R) peptide
<400> 266
Val Leu Arg Asp Asp Leu Leu Glu Ala
1 5
<210> 267
<211> 607
<212> PRT
<213> Artificial Sequence
<220>
<223> NY-ESO-1 TCR alpha and beta
<400> 267
Met Glu Thr Leu Leu Gly Leu Leu Ile Leu Trp Leu Gln Leu Gln Trp
1 5 10 15
Val Ser Ser Lys Gln Glu Val Thr Gln Ile Pro Ala Ala Leu Ser Val
20 25 30
Pro Glu Gly Glu Asn Leu Val Leu Asn Cys Ser Phe Thr Asp Ser Ala
35 40 45
Ile Tyr Asn Leu Gln Trp Phe Arg Gln Asp Pro Gly Lys Gly Leu Thr
50 55 60
Ser Leu Leu Leu Ile Gln Ser Ser Gln Arg Glu Gln Thr Ser Gly Arg
65 70 75 80
Leu Asn Ala Ser Leu Asp Lys Ser Ser Gly Arg Ser Thr Leu Tyr Ile
85 90 95
Ala Ala Ser Gln Pro Gly Asp Ser Ala Thr Tyr Leu Cys Ala Val Arg
100 105 110
Pro Leu Tyr Gly Gly Ser Tyr Ile Pro Thr Phe Gly Arg Gly Thr Ser
115 120 125
Leu Ile Val His Pro Tyr Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln
130 135 140
Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp
145 150 155 160
Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr
165 170 175
Ile Thr Asp Lys Cys Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser
180 185 190
Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn
195 200 205
Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro
210 215 220
Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp
225 230 235 240
Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu
245 250 255
Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp
260 265 270
Ser Ser Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly
275 280 285
Asp Val Glu Glu Asn Pro Gly Pro Met Ser Ile Gly Leu Leu Cys Cys
290 295 300
Ala Ala Leu Ser Leu Leu Trp Ala Gly Pro Val Asn Ala Gly Val Thr
305 310 315 320
Gln Thr Pro Lys Phe Gln Val Leu Lys Thr Gly Gln Ser Met Thr Leu
325 330 335
Gln Cys Ala Gln Asp Met Asn His Glu Tyr Met Ser Trp Tyr Arg Gln
340 345 350
Asp Pro Gly Met Gly Leu Arg Leu Ile His Tyr Ser Val Gly Ala Gly
355 360 365
Ile Thr Asp Gln Gly Glu Val Pro Asn Gly Tyr Asn Val Ser Arg Ser
370 375 380
Thr Thr Glu Asp Phe Pro Leu Arg Leu Leu Ser Ala Ala Pro Ser Gln
385 390 395 400
Thr Ser Val Tyr Phe Cys Ala Ser Ser Tyr Val Gly Asn Thr Gly Glu
405 410 415
Leu Phe Phe Gly Glu Gly Ser Arg Leu Thr Val Leu Glu Asp Leu Lys
420 425 430
Asn Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro Ser Glu Ala Glu
435 440 445
Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu Ala Thr Gly Phe
450 455 460
Tyr Pro Asp His Val Glu Leu Ser Trp Trp Val Asn Gly Lys Glu Val
465 470 475 480
His Ser Gly Val Cys Thr Asp Pro Gln Pro Leu Lys Glu Gln Pro Ala
485 490 495
Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu Arg Val Ser Ala
500 505 510
Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys Gln Val Gln Phe
515 520 525
Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp Arg Ala Lys Pro
530 535 540
Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg Ala Asp Cys Gly
545 550 555 560
Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu Ser Ala Thr Ile Leu
565 570 575
Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala Val Leu Val Ser
580 585 590
Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp Ser Arg Gly
595 600 605
<210> 268
<211> 1824
<212> DNA
<213> Artificial Sequence
<220>
<223> NY-ESO-1 TCR alpha and beta
<400> 268
atggagacac tcttgggcct gcttatcctt tggctgcagc tgcaatgggt gagcagcaaa 60
caggaggtga cgcagattcc tgcagctctg agtgtcccag aaggagaaaa cttggttctg 120
aactgcagtt tcactgatag cgctatttac aacctccagt ggtttaggca ggaccctggg 180
aaaggactca catctctgtt gcttattcag tcaagtcaga gagagcaaac aagtggaaga 240
cttaatgcct cgctggataa atcatcagga cgtagtactt tatacattgc agcttctcag 300
cctggtgact cagccaccta cctctgtgct gtgaggcccc tctacggagg aagctacata 360
cctacatttg gaagaggaac cagccttatt gttcatccgt atatccagaa ccctgaccct 420
gccgtgtacc agctgagaga ctctaaatcc agtgacaagt ctgtctgcct attcaccgat 480
tttgattctc aaacaaatgt gtcacaaagt aaggattctg atgtgtatat cacagacaaa 540
tgtgtgctag acatgaggtc tatggacttc aagagcaaca gtgctgtggc ctggagcaac 600
aaatctgact ttgcatgtgc aaacgccttc aacaacagca ttattccaga agacaccttc 660
ttccccagcc cagaaagttc ctgtgatgtc aagctggtcg agaaaagctt tgaaacagat 720
acgaacctaa actttcaaaa cctgtcagtg attgggttcc gaatcctcct cctgaaagtg 780
gccgggttta atctgctcat gacgctgcgg ctgtggtcca gcggatccgg agccaccaac 840
ttcagcctgc tgaagcaggc cggcgacgtg gaggagaacc ccggccccat gagcatcggc 900
ctcctgtgct gtgcagcctt gtctctcctg tgggcaggtc cagtgaatgc tggtgtcact 960
cagaccccaa aattccaggt cctgaagaca ggacagagca tgacactgca gtgtgcccag 1020
gatatgaacc atgaatacat gtcctggtat cgacaagacc caggcatggg gctgaggctg 1080
attcattact cagttggtgc tggtatcact gaccaaggag aagtccccaa tggctacaat 1140
gtctccagat caaccacaga ggatttcccg ctcaggctgc tgtcggctgc tccctcccag 1200
acatctgtgt acttctgtgc cagcagttac gtcgggaaca ccggggagct gttttttgga 1260
gaaggctcta ggctgaccgt actggaggac ctgaaaaacg tgttcccacc cgaggtcgct 1320
gtgtttgagc catcagaagc agagatctcc cacacccaaa aggccacact ggtgtgcctg 1380
gccacaggct tctaccccga ccacgtggag ctgagctggt gggtgaatgg gaaggaggtg 1440
cacagtgggg tctgcacaga cccgcagccc ctcaaggagc agcccgccct caatgactcc 1500
agatactgcc tgagcagccg cctgagggtg tcggccacct tctggcagaa cccccgcaac 1560
cacttccgct gtcaagtcca gttctacggg ctctcggaga atgacgagtg gacccaggat 1620
agggccaaac ctgtcaccca gatcgtcagc gccgaggcct ggggtagagc agactgtggc 1680
ttcacctccg agtcttacca gcaaggggtc ctgtctgcca ccatcctcta tgagatcttg 1740
ctagggaagg ccaccttgta tgccgtgctg gtcagtgccc tcgtgctgat ggccatggtc 1800
aagagaaagg attccagagg ctag 1824
<210> 269
<211> 612
<212> PRT
<213> Artificial Sequence
<220>
<223> KRAS TCR
<400> 269
Met Gln Arg Asn Leu Gly Ala Val Leu Gly Ile Leu Trp Val Gln Ile
1 5 10 15
Cys Trp Val Arg Gly Asp Gln Val Glu Gln Ser Pro Ser Ala Leu Ser
20 25 30
Leu His Glu Gly Thr Asp Ser Ala Leu Arg Cys Asn Phe Thr Thr Thr
35 40 45
Met Arg Ser Val Gln Trp Phe Arg Gln Asn Ser Arg Gly Ser Leu Ile
50 55 60
Ser Leu Phe Tyr Leu Ala Ser Gly Thr Lys Glu Asn Gly Arg Leu Lys
65 70 75 80
Ser Ala Phe Asp Ser Lys Glu Arg Arg Tyr Ser Thr Leu His Ile Arg
85 90 95
Asp Ala Gln Leu Glu Asp Ser Gly Thr Tyr Phe Cys Ala Ala Asp Ser
100 105 110
Ser Asn Thr Gly Tyr Gln Asn Phe Tyr Phe Gly Lys Gly Thr Ser Leu
115 120 125
Thr Val Ile Pro Asn Ile Gln Asn Pro Glu Pro Ala Val Tyr Gln Leu
130 135 140
Lys Asp Pro Arg Ser Gln Asp Ser Thr Leu Cys Leu Phe Thr Asp Phe
145 150 155 160
Asp Ser Gln Ile Asn Val Pro Lys Thr Met Glu Ser Gly Thr Phe Ile
165 170 175
Thr Asp Lys Thr Val Leu Asp Met Lys Ala Met Asp Ser Lys Ser Asn
180 185 190
Gly Ala Ile Ala Trp Ser Asn Gln Thr Ser Phe Thr Cys Gln Asp Ile
195 200 205
Phe Lys Glu Thr Asn Ala Thr Tyr Pro Ser Ser Asp Val Pro Cys Asp
210 215 220
Ala Thr Leu Thr Glu Lys Ser Phe Glu Thr Asp Met Asn Leu Asn Phe
225 230 235 240
Gln Asn Leu Ser Val Met Gly Leu Arg Ile Leu Leu Leu Lys Val Ala
245 250 255
Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser Arg Ala Lys
260 265 270
Arg Ser Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly
275 280 285
Asp Val Glu Glu Asn Pro Gly Pro Met Ser Asn Thr Ala Phe Pro Asp
290 295 300
Pro Ala Trp Asn Thr Thr Leu Leu Ser Trp Val Ala Leu Phe Leu Leu
305 310 315 320
Gly Thr Ser Ser Ala Asn Ser Gly Val Val Gln Ser Pro Arg Tyr Ile
325 330 335
Ile Lys Gly Lys Gly Glu Arg Ser Ile Leu Lys Cys Ile Pro Ile Ser
340 345 350
Gly His Leu Ser Val Ala Trp Tyr Gln Gln Thr Gln Gly Gln Glu Leu
355 360 365
Lys Phe Phe Ile Gln His Tyr Asp Lys Met Glu Arg Asp Lys Gly Asn
370 375 380
Leu Pro Ser Arg Phe Ser Val Gln Gln Phe Asp Asp Tyr His Ser Glu
385 390 395 400
Met Asn Met Ser Ala Leu Glu Leu Glu Asp Ser Ala Val Tyr Phe Cys
405 410 415
Ala Ser Ser Leu Thr Asp Pro Leu Asp Ser Asp Tyr Thr Phe Gly Ser
420 425 430
Gly Thr Arg Leu Leu Val Ile Glu Asp Leu Arg Asn Val Thr Pro Pro
435 440 445
Lys Val Ser Leu Phe Glu Pro Ser Lys Ala Glu Ile Ala Asn Lys Gln
450 455 460
Lys Ala Thr Leu Val Cys Leu Ala Arg Gly Phe Phe Pro Asp His Val
465 470 475 480
Glu Leu Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser
485 490 495
Thr Asp Pro Gln Ala Tyr Lys Glu Ser Asn Tyr Ser Tyr Cys Leu Ser
500 505 510
Ser Arg Leu Arg Val Ser Ala Thr Phe Trp His Asn Pro Arg Asn His
515 520 525
Phe Arg Cys Gln Val Gln Phe His Gly Leu Ser Glu Glu Asp Lys Trp
530 535 540
Pro Glu Gly Ser Pro Lys Pro Val Thr Gln Asn Ile Ser Ala Glu Ala
545 550 555 560
Trp Gly Arg Ala Asp Cys Gly Ile Thr Ser Ala Ser Tyr Gln Gln Gly
565 570 575
Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr
580 585 590
Leu Tyr Ala Val Leu Val Ser Thr Leu Val Val Met Ala Met Val Lys
595 600 605
Arg Lys Asn Ser
610
<210> 270
<211> 1839
<212> DNA
<213> Artificial Sequence
<220>
<223> KRAS TCR
<400> 270
atgcagagga acctgggagc tgtgctgggg attctgtggg tgcagatttg ctgggtgaga 60
ggggatcagg tggagcagag tccttcagcc ctgagcctcc acgagggaac cgattctgct 120
ctgagatgca attttacgac caccatgagg agtgtgcagt ggttccgaca gaattccagg 180
ggcagcctca tcagtttgtt ctacttggct tcaggaacaa aggagaatgg gaggctaaag 240
tcagcatttg attctaagga gcggcgctac agcaccctgc acatcaggga tgcccagctg 300
gaggactcag gcacttactt ctgtgctgct gactcttcga acacgggtta ccagaacttc 360
tattttggga aaggaacaag tttgactgtc attccaaaca tccagaaccc agaacctgct 420
gtgtaccagt taaaagatcc tcggtctcag gacagcaccc tctgcctgtt caccgacttt 480
gactcccaaa tcaatgtgcc gaaaaccatg gaatctggaa cgttcatcac tgacaaaact 540
gtgctggaca tgaaagctat ggattccaag agcaatgggg ccattgcctg gagcaaccag 600
acaagcttca cctgccaaga tatcttcaaa gagaccaacg ccacctaccc cagttcagac 660
gttccctgtg atgccacgtt gaccgagaaa agctttgaaa cagatatgaa cctgaacttt 720
caaaacctgt cagttatggg actccgaatc ctcctgctga aagtagcggg atttaacctg 780
ctcatgacgc tgaggctgtg gtccagtcgg gccaagcggt ccggatccgg agccaccaac 840
ttcagcctgc tgaagcaggc cggcgacgtg gaggagaacc ccggccccat gtctaacact 900
gccttccctg accccgcctg gaacaccacc ctgctatctt gggttgctct ctttctcctg 960
ggaacaagtt cagcaaattc tggggttgtc cagtctccaa gatacataat caaaggaaag 1020
ggagaaaggt ccattctaaa atgtattccc atctctggac atctctctgt ggcctggtat 1080
caacagactc aggggcagga actaaagttc ttcattcagc attatgataa aatggagaga 1140
gataaaggaa acctgcccag cagattctca gtccaacagt ttgatgacta tcactctgag 1200
atgaacatga gtgccttgga gctagaggac tctgccgtgt acttctgtgc cagctctctc 1260
acagatccgc tagactccga ctacaccttc ggctcaggga ccaggctttt ggtaatagag 1320
gatctgagaa atgtgactcc acccaaggtc tccttgtttg agccatcaaa agcagagatt 1380
gcaaacaaac aaaaggctac cctcgtgtgc ttggccaggg gcttcttccc tgaccacgtg 1440
gagctgagct ggtgggtgaa tggcaaggag gtccacagtg gggtcagcac ggaccctcag 1500
gcctacaagg agagcaatta tagctactgc ctgagcagcc gcctgagggt ctctgctacc 1560
ttctggcaca atcctcgcaa ccacttccgc tgccaagtgc agttccatgg gctttcagag 1620
gaggacaagt ggccagaggg ctcacccaaa cctgtcacac agaacatcag tgcagaggcc 1680
tggggccgag cagactgtgg gattacctca gcatcctatc aacaaggggt cttgtctgcc 1740
accatcctct atgagatcct gctagggaaa gccaccctgt atgctgtgct tgtcagtaca 1800
ctggtggtga tggctatggt caaaagaaag aattcatag 1839
<210> 271
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> T2A self cleaving peptide
<400> 271
Glu Gly Arg Gly Ser Leu Leu Thr Cys Gly Asp Val Glu Glu Asn Pro
1 5 10 15
Gly Pro
<210> 272
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> E2A self cleaving peptide
<400> 272
Gln Cys Thr Asn Tyr Ala Leu Leu Lys Leu Ala Gly Asp Val Glu Ser
1 5 10 15
Asn Pro Gly Pro
20
<210> 273
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> F2A self cleaving peptide
<400> 273
Val Lys Gln Thr Leu Asn Phe Asp Leu Leu Lys Leu Ala Gly Asp Val
1 5 10 15
Glu Ser Asn Pro Gly Pro
20
<210> 274
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> ITIM
<220>
<221> Z
<222> (1)..(1)
<223> Z is S, I V or L
<220>
<221> X
<222> (2)..(2)
<223> X is any amino acid
<220>
<221> X
<222> (4)..(5)
<223> X is any amino acid
<220>
<221> Z
<222> (6)..(6)
<223> Z is I, V or L
<400> 274
Glx Xaa Tyr Xaa Xaa Glx
1 5
<210> 275
<211> 242
<212> PRT
<213> Artificial Sequence
<220>
<223> CD19 ScFv
<400> 275
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Arg Ala Ser Gln Asp Ile Ser Lys Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Asp Gly Thr Val Lys Leu Leu Ile
35 40 45
Tyr His Thr Ser Arg Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Leu Glu Gln
65 70 75 80
Glu Asp Ile Ala Thr Tyr Phe Cys Gln Gln Gly Asn Thr Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Thr Gly Gly Gly Gly Ser
100 105 110
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Lys Leu Gln Glu
115 120 125
Ser Gly Pro Gly Leu Val Ala Pro Ser Gln Ser Leu Ser Val Thr Cys
130 135 140
Thr Val Ser Gly Val Ser Leu Pro Asp Tyr Gly Val Ser Trp Ile Arg
145 150 155 160
Gln Pro Pro Arg Lys Gly Leu Glu Trp Leu Gly Val Ile Trp Gly Ser
165 170 175
Glu Thr Thr Tyr Tyr Asn Ser Ala Leu Lys Ser Arg Leu Thr Ile Ile
180 185 190
Lys Asp Asn Ser Lys Ser Gln Val Phe Leu Lys Met Asn Ser Leu Gln
195 200 205
Thr Asp Asp Thr Ala Ile Tyr Tyr Cys Ala Lys His Tyr Tyr Tyr Gly
210 215 220
Gly Ser Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr Ser Val Thr Val
225 230 235 240
Ser Ser
<210> 276
<211> 726
<212> DNA
<213> Artificial Sequence
<220>
<223> CD19 ScFv
<400> 276
gacatccaga tgacacagac tacatcctcc ctgtctgcct ctctgggaga cagagtcacc 60
atcagttgca gggcaagtca ggacattagt aaatatttaa attggtatca gcagaaacca 120
gatggaactg ttaaactcct gatctaccat acatcaagat tacactcagg agtcccatca 180
aggttcagtg gcagtgggtc tggaacagat tattctctca ccattagcaa cctggagcaa 240
gaagatattg ccacttactt ttgccaacag ggtaatacgc ttccgtacac gttcggaggg 300
gggaccaagc tggagatcac aggtggcggt ggctcgggcg gtggtgggtc gggtggcggc 360
ggatctgagg tgaaactgca ggagtcagga cctggcctgg tggcgccctc acagagcctg 420
tccgtcacat gcactgtctc aggggtctca ttacccgact atggtgtaag ctggattcgc 480
cagcctccac gaaagggtct ggagtggctg ggagtaatat ggggtagtga aaccacatac 540
tataattcag ctctcaaatc cagactgacc atcatcaagg acaactccaa gagccaagtt 600
ttcttaaaaa tgaacagtct gcaaactgat gacacagcca tttactactg tgccaaacat 660
tattactacg gtggtagcta tgctatggac tactggggcc aaggaacctc agtcaccgtg 720
tcctca 726
<210> 277
<211> 244
<212> PRT
<213> Artificial Sequence
<220>
<223> CD19 ScFv
<400> 277
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Arg Ala Ser Gln Asp Ile Ser Lys Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Asp Gly Thr Val Lys Leu Leu Ile
35 40 45
Tyr His Thr Ser Arg Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Leu Glu Gln
65 70 75 80
Glu Asp Ile Ala Thr Tyr Phe Cys Gln Gln Gly Asn Thr Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Thr Gly Gly Gly Gly Ser
100 105 110
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Glu Val Lys Leu
115 120 125
Gln Glu Ser Gly Pro Gly Leu Val Ala Pro Ser Gln Ser Leu Ser Val
130 135 140
Thr Cys Thr Val Ser Gly Val Ser Leu Pro Asp Tyr Gly Val Ser Trp
145 150 155 160
Ile Arg Gln Pro Pro Arg Lys Gly Leu Glu Trp Leu Gly Val Ile Trp
165 170 175
Gly Ser Glu Thr Thr Tyr Tyr Asn Ser Ala Leu Lys Ser Arg Leu Thr
180 185 190
Ile Ile Lys Asp Asn Ser Lys Ser Gln Val Phe Leu Lys Met Asn Ser
195 200 205
Leu Gln Thr Asp Asp Thr Ala Ile Tyr Tyr Cys Ala Lys His Tyr Tyr
210 215 220
Tyr Gly Gly Ser Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr Ser Val
225 230 235 240
Thr Val Ser Ser
<210> 278
<211> 732
<212> DNA
<213> Artificial Sequence
<220>
<223> CD19 ScFv
<400> 278
gacatccaga tgacacagac tacatcctcc ctgtctgcct ctctgggaga cagagtcacc 60
atcagttgca gggcaagtca ggacattagt aaatatttaa attggtatca gcagaaacca 120
gatggaactg ttaaactcct gatctaccat acatcaagat tacactcagg agtcccatca 180
aggttcagtg gcagtgggtc tggaacagat tattctctca ccattagcaa cctggagcaa 240
gaagatattg ccacttactt ttgccaacag ggtaatacgc ttccgtacac gttcggaggg 300
gggaccaagc tggagatcac aggcggaggt ggaagcggag ggggaggatc tggcggcgga 360
ggaagcggag gcgaggtgaa actgcaggag tcaggacctg gcctggtggc gccctcacag 420
agcctgtccg tcacatgcac tgtctcaggg gtctcattac ccgactatgg tgtaagctgg 480
attcgccagc ctccacgaaa gggtctggag tggctgggag taatatgggg tagtgaaacc 540
acatactata attcagctct caaatccaga ctgaccatca tcaaggacaa ctccaagagc 600
caagttttct taaaaatgaa cagtctgcaa actgatgaca cagccattta ctactgtgcc 660
aaacattatt actacggtgg tagctatgct atggactact ggggccaagg aacctcagtc 720
accgtgtcct ca 732
<210> 279
<211> 509
<212> PRT
<213> Artificial Sequence
<220>
<223> CD19 CAR
<400> 279
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Arg Ala Ser Gln Asp Ile Ser Lys Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Asp Gly Thr Val Lys Leu Leu Ile
35 40 45
Tyr His Thr Ser Arg Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Leu Glu Gln
65 70 75 80
Glu Asp Ile Ala Thr Tyr Phe Cys Gln Gln Gly Asn Thr Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Thr Gly Gly Gly Gly Ser
100 105 110
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Lys Leu Gln Glu
115 120 125
Ser Gly Pro Gly Leu Val Ala Pro Ser Gln Ser Leu Ser Val Thr Cys
130 135 140
Thr Val Ser Gly Val Ser Leu Pro Asp Tyr Gly Val Ser Trp Ile Arg
145 150 155 160
Gln Pro Pro Arg Lys Gly Leu Glu Trp Leu Gly Val Ile Trp Gly Ser
165 170 175
Glu Thr Thr Tyr Tyr Asn Ser Ala Leu Lys Ser Arg Leu Thr Ile Ile
180 185 190
Lys Asp Asn Ser Lys Ser Gln Val Phe Leu Lys Met Asn Ser Leu Gln
195 200 205
Thr Asp Asp Thr Ala Ile Tyr Tyr Cys Ala Lys His Tyr Tyr Tyr Gly
210 215 220
Gly Ser Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr Ser Val Thr Val
225 230 235 240
Ser Ser Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr
245 250 255
Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala
260 265 270
Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp Phe
275 280 285
Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu
290 295 300
Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser Arg
305 310 315 320
Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro
325 330 335
Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala
340 345 350
Tyr Arg Ser Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln
355 360 365
Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser
370 375 380
Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys
385 390 395 400
Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Lys Gln Gly Gln Asn Gln
405 410 415
Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu
420 425 430
Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg
435 440 445
Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met
450 455 460
Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly
465 470 475 480
Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp
485 490 495
Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
500 505
<210> 280
<211> 1527
<212> DNA
<213> Artificial Sequence
<220>
<223> CD19 CAR
<400> 280
gacatccaga tgacacagac tacatcctcc ctgtctgcct ctctgggaga cagagtcacc 60
atcagttgca gggcaagtca ggacattagt aaatatttaa attggtatca gcagaaacca 120
gatggaactg ttaaactcct gatctaccat acatcaagat tacactcagg agtcccatca 180
aggttcagtg gcagtgggtc tggaacagat tattctctca ccattagcaa cctggagcaa 240
gaagatattg ccacttactt ttgccaacag ggtaatacgc ttccgtacac gttcggaggg 300
gggaccaagc tggagatcac aggtggcggt ggctcgggcg gtggtgggtc gggtggcggc 360
ggatctgagg tgaaactgca ggagtcagga cctggcctgg tggcgccctc acagagcctg 420
tccgtcacat gcactgtctc aggggtctca ttacccgact atggtgtaag ctggattcgc 480
cagcctccac gaaagggtct ggagtggctg ggagtaatat ggggtagtga aaccacatac 540
tataattcag ctctcaaatc cagactgacc atcatcaagg acaactccaa gagccaagtt 600
ttcttaaaaa tgaacagtct gcaaactgat gacacagcca tttactactg tgccaaacat 660
tattactacg gtggtagcta tgctatggac tactggggcc aaggaacctc agtcaccgtg 720
tcctcaacca cgacgccagc gccgcgacca ccaacaccgg cgcccaccat cgcgtcgcag 780
cccctgtccc tgcgcccaga ggcgtgccgg ccagcggcgg ggggcgcagt gcacacgagg 840
gggctggact tcgcctgtga tttctgggtg ctggtcgttg tgggcggcgt gctggcctgc 900
tacagcctgc tggtgacagt ggccttcatc atcttttggg tgaggagcaa gcggagcaga 960
ctgctgcaca gcgactacat gaacatgacc ccccggaggc ctggccccac ccggaagcac 1020
taccagccct acgcccctcc cagggatttc gccgcctacc ggagcaaacg gggcagaaag 1080
aaactcctgt atatattcaa acaaccattt atgaggccag tacaaactac tcaagaggaa 1140
gatggctgta gctgccgatt tccagaagaa gaagaaggag gatgtgaact gagagtgaag 1200
ttcagcagga gcgcagacgc ccccgcgtac aagcagggcc agaaccagct ctataacgag 1260
ctcaatctag gacgaagaga ggagtacgat gttttggaca agcgtagagg ccgggaccct 1320
gagatggggg gaaagccgag aaggaagaac cctcaggaag gcctgtacaa tgaactgcag 1380
aaagataaga tggcggaggc ctacagtgag attgggatga aaggcgagcg ccggaggggc 1440
aaggggcacg atggccttta ccagggactc agtacagcca ccaaggacac ctacgacgcc 1500
cttcacatgc aggccctgcc ccctcgc 1527
<210> 281
<211> 509
<212> PRT
<213> Artificial Sequence
<220>
<223> CD19 CAR
<400> 281
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Arg Ala Ser Gln Asp Ile Ser Lys Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Asp Gly Thr Val Lys Leu Leu Ile
35 40 45
Tyr His Thr Ser Arg Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Leu Glu Gln
65 70 75 80
Glu Asp Ile Ala Thr Tyr Phe Cys Gln Gln Gly Asn Thr Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Thr Gly Gly Gly Gly Ser
100 105 110
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Lys Leu Gln Glu
115 120 125
Ser Gly Pro Gly Leu Val Ala Pro Ser Gln Ser Leu Ser Val Thr Cys
130 135 140
Thr Val Ser Gly Val Ser Leu Pro Asp Tyr Gly Val Ser Trp Ile Arg
145 150 155 160
Gln Pro Pro Arg Lys Gly Leu Glu Trp Leu Gly Val Ile Trp Gly Ser
165 170 175
Glu Thr Thr Tyr Tyr Asn Ser Ala Leu Lys Ser Arg Leu Thr Ile Ile
180 185 190
Lys Asp Asn Ser Lys Ser Gln Val Phe Leu Lys Met Asn Ser Leu Gln
195 200 205
Thr Asp Asp Thr Ala Ile Tyr Tyr Cys Ala Lys His Tyr Tyr Tyr Gly
210 215 220
Gly Ser Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr Ser Val Thr Val
225 230 235 240
Ser Ser Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr
245 250 255
Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala
260 265 270
Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp Phe
275 280 285
Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu
290 295 300
Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser Arg
305 310 315 320
Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro
325 330 335
Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala
340 345 350
Tyr Arg Ser Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln
355 360 365
Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser
370 375 380
Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys
385 390 395 400
Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Lys Gln Gly Gln Asn Gln
405 410 415
Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu
420 425 430
Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg
435 440 445
Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met
450 455 460
Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly
465 470 475 480
Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp
485 490 495
Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
500 505
<210> 282
<211> 246
<212> PRT
<213> CEA ScFv
<400> 282
Gln Val Gln Leu Val Gln Ser Gly Ser Glu Leu Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Glu Phe
20 25 30
Gly Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Thr Lys Thr Gly Glu Ala Thr Tyr Val Glu Glu Phe
50 55 60
Lys Gly Arg Phe Val Phe Ser Leu Asp Thr Ser Val Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Ser Ser Leu Lys Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Asp Phe Ala Tyr Tyr Val Glu Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln
130 135 140
Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr
145 150 155 160
Cys Lys Ala Ser Gln Asn Val Gly Thr Asn Val Ala Trp Tyr Gln Gln
165 170 175
Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ser Ala Ser Tyr Arg
180 185 190
Tyr Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
195 200 205
Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr
210 215 220
Tyr Cys His Gln Tyr Tyr Thr Tyr Pro Leu Phe Thr Phe Gly Gln Gly
225 230 235 240
Thr Lys Leu Glu Ile Lys
245
<210> 283
<211> 1542
<212> DNA
<213> Artificial Sequence
<220>
<223> CEA ScFv
<400> 283
caggtgcagc tggtgcaatc tgggtctgag ttgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg cttctggata caccttcact gagtttggaa tgaactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggatgg ataaacacca aaactggaga ggcaacatat 180
gttgaagagt ttaagggacg gtttgtcttc tccttggaca cctctgtcag cacggcatat 240
ctgcagatca gcagcctaaa ggctgaagac actgccgtgt attactgtgc gagatgggac 300
ttcgcttatt acgtggaggc tatggactac tggggccaag ggaccacggt caccgtctcc 360
tcaggcggag gtggaagcgg agggggagga tctggcggcg gaggaagcgg aggcgatatc 420
cagatgaccc agtctccatc ctccctgtct gcatctgtgg gagacagagt caccatcact 480
tgcaaggcca gtcagaatgt gggtactaat gttgcctggt atcagcagaa accagggaaa 540
gcacctaagc tcctgatcta ttcggcatcc taccgctaca gtggagtccc atcaaggttc 600
agtggcagtg gatctgggac agatttcact ctcaccatca gcagtctgca acctgaagat 660
ttcgcaactt actactgtca ccaatattac acctatcctc tattcacgtt tggccagggc 720
accaagctcg agatcaagat ggacatgagg gtccccgctc agctcctggg gctcctgcta 780
ctctggctcc gaggtgccag atgtcaggtg cagctggtgc aatctgggtc tgagttgaag 840
aagcctgggg cctcagtgaa ggtttcctgc aaggcttctg gatacacctt cactgagttt 900
ggaatgaact gggtgcgaca ggcccctgga caagggcttg agtggatggg atggataaac 960
accaaaactg gagaggcaac atatgttgaa gagtttaagg gacggtttgt cttctccttg 1020
gacacctctg tcagcacggc atatctgcag atcagcagcc taaaggctga agacactgcc 1080
gtgtattact gtgcgagatg ggacttcgct tattacgtgg aggctatgga ctactggggc 1140
caagggacca cggtcaccgt ctcctcaggc ggaggtggaa gcggaggggg aggatctggc 1200
ggcggaggaa gcggaggcga tatccagatg acccagtctc catcctccct gtctgcatct 1260
gtgggagaca gagtcaccat cacttgcaag gccagtcaga atgtgggtac taatgttgcc 1320
tggtatcagc agaaaccagg gaaagcacct aagctcctga tctattcggc atcctaccgc 1380
tacagtggag tcccatcaag gttcagtggc agtggatctg ggacagattt cactctcacc 1440
atcagcagtc tgcaacctga agatttcgca acttactact gtcaccaata ttacacctat 1500
cctctattca cgtttggcca gggcaccaag ctcgagatca ag 1542
<210> 284
<211> 246
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA ScFv
<400> 284
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Glu Phe
20 25 30
Gly Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Thr Lys Thr Gly Glu Ala Thr Tyr Val Glu Glu Phe
50 55 60
Lys Gly Arg Val Thr Phe Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Asp Phe Ala Tyr Tyr Val Glu Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln
130 135 140
Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr
145 150 155 160
Cys Lys Ala Ser Ala Ala Val Gly Thr Tyr Val Ala Trp Tyr Gln Gln
165 170 175
Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ser Ala Ser Tyr Arg
180 185 190
Lys Arg Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
195 200 205
Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr
210 215 220
Tyr Cys His Gln Tyr Tyr Thr Tyr Pro Leu Phe Thr Phe Gly Gln Gly
225 230 235 240
Thr Lys Leu Glu Ile Lys
245
<210> 285
<211> 738
<212> DNA
<213> Artificial Sequence
<220>
<223> CEA ScFv
<400> 285
caggtgcagc tggtgcagtc tggcgccgaa gtgaagaaac ctggagctag tgtgaaggtg 60
tcctgcaagg ccagcggcta caccttcacc gagttcggca tgaactgggt ccgacaggct 120
ccaggccagg gcctcgaatg gatgggctgg atcaacacca agaccggcga ggccacctac 180
gtggaagagt tcaagggcag agtgaccttc accacggaca ccagcaccag caccgcctac 240
atggaactgc ggagcctgag aagcgacgac accgccgtgt actactgcgc cagatgggac 300
ttcgcttatt acgtggaagc catggactac tggggccagg gcaccaccgt gaccgtgtct 360
agcggcggag gtggaagcgg agggggagga tctggcggcg gaggaagcgg aggcgatatc 420
cagatgaccc agtctccatc ctccctgtct gcatctgtgg gagacagagt caccatcact 480
tgcaaggcca gtgcggctgt gggtacgtat gttgcgtggt atcagcagaa accagggaaa 540
gcacctaagc tcctgatcta ttcggcatcc taccgcaaaa ggggagtccc atcaaggttc 600
agtggcagtg gatctgggac agatttcact ctcaccatca gcagtctgca acctgaagat 660
ttcgcaactt actactgtca ccaatattac acctatcctc tattcacgtt tggccagggc 720
accaagctcg agatcaag 738
<210> 286
<211> 246
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA ScFv
<400> 286
Gln Val Gln Leu Val Gln Ser Gly Ser Glu Leu Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Glu Phe
20 25 30
Gly Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Thr Lys Thr Gly Glu Ala Thr Tyr Val Glu Glu Phe
50 55 60
Lys Gly Arg Phe Val Phe Ser Leu Asp Thr Ser Val Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Ser Ser Leu Lys Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Asp Phe Ala His Tyr Phe Gln Thr Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Asp Ile Gln Met Thr Gln
130 135 140
Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr
145 150 155 160
Cys Lys Ala Ser Ala Ala Val Gly Thr Tyr Val Ala Trp Tyr Gln Gln
165 170 175
Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ser Ala Ser Tyr Arg
180 185 190
Lys Arg Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
195 200 205
Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr
210 215 220
Tyr Cys His Gln Tyr Tyr Thr Tyr Pro Leu Phe Thr Phe Gly Gln Gly
225 230 235 240
Thr Lys Leu Glu Ile Lys
245
<210> 287
<211> 738
<212> DNA
<213> Artificial Sequence
<220>
<223> CEA ScFv
<400> 287
caggtgcagc tggtgcaatc tgggtctgag ttgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg cttctggata caccttcact gagtttggaa tgaactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggatgg ataaacacca aaactggaga ggcaacatat 180
gttgaagagt ttaagggacg gtttgtcttc tccttggaca cctctgtcag cacggcatat 240
ctgcagatca gcagcctaaa ggctgaagac actgccgtgt attactgtgc gagatgggac 300
tttgctcatt actttcagac tatggactac tggggccaag ggaccacggt caccgtctcc 360
tcaggcggag gtggaagcgg agggggagga tctggcggcg gaggaagcgg aggcgatatc 420
cagatgaccc agtctccatc ctccctgtct gcatctgtgg gagacagagt caccatcact 480
tgcaaggcca gtgcggctgt gggtacgtat gttgcgtggt atcagcagaa accagggaaa 540
gcacctaagc tcctgatcta ttcggcatcc taccgcaaaa ggggagtccc atcaaggttc 600
agtggcagtg gatctgggac agatttcact ctcaccatca gcagtctgca acctgaagat 660
ttcgcaactt actactgtca ccaatattac acctatcctc tattcacgtt tggccagggc 720
accaagctcg agatcaag 738
<210> 288
<211> 535
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA CAR
<400> 288
Met Asp Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp
1 5 10 15
Leu Arg Gly Ala Arg Cys Gln Val Gln Leu Val Gln Ser Gly Ser Glu
20 25 30
Leu Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly
35 40 45
Tyr Thr Phe Thr Glu Phe Gly Met Asn Trp Val Arg Gln Ala Pro Gly
50 55 60
Gln Gly Leu Glu Trp Met Gly Trp Ile Asn Thr Lys Thr Gly Glu Ala
65 70 75 80
Thr Tyr Val Glu Glu Phe Lys Gly Arg Phe Val Phe Ser Leu Asp Thr
85 90 95
Ser Val Ser Thr Ala Tyr Leu Gln Ile Ser Ser Leu Lys Ala Glu Asp
100 105 110
Thr Ala Val Tyr Tyr Cys Ala Arg Trp Asp Phe Ala Tyr Tyr Val Glu
115 120 125
Ala Met Asp Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
145 150 155 160
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
165 170 175
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asn Val Gly Thr Asn
180 185 190
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
195 200 205
Tyr Ser Ala Ser Tyr Arg Tyr Ser Gly Val Pro Ser Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
225 230 235 240
Glu Asp Phe Ala Thr Tyr Tyr Cys His Gln Tyr Tyr Thr Tyr Pro Leu
245 250 255
Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Thr Thr Thr Pro
260 265 270
Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu
275 280 285
Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His
290 295 300
Thr Arg Gly Leu Asp Phe Ala Cys Asp Phe Trp Val Leu Val Val Val
305 310 315 320
Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile
325 330 335
Ile Phe Trp Val Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr
340 345 350
Met Asn Met Thr Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln
355 360 365
Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg Ser Lys Arg Gly
370 375 380
Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val
385 390 395 400
Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu
405 410 415
Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp
420 425 430
Ala Pro Ala Tyr Lys Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn
435 440 445
Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg
450 455 460
Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly
465 470 475 480
Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu
485 490 495
Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu
500 505 510
Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His
515 520 525
Met Gln Ala Leu Pro Pro Arg
530 535
<210> 289
<211> 1608
<212> DNA
<213> Artificial Sequence
<220>
<223> CEA CAR
<400> 289
atggacatga gggtccccgc tcagctcctg gggctcctgc tactctggct ccgaggtgcc 60
agatgtcagg tgcagctggt gcaatctggg tctgagttga agaagcctgg ggcctcagtg 120
aaggtttcct gcaaggcttc tggatacacc ttcactgagt ttggaatgaa ctgggtgcga 180
caggcccctg gacaagggct tgagtggatg ggatggataa acaccaaaac tggagaggca 240
acatatgttg aagagtttaa gggacggttt gtcttctcct tggacacctc tgtcagcacg 300
gcatatctgc agatcagcag cctaaaggct gaagacactg ccgtgtatta ctgtgcgaga 360
tgggacttcg cttattacgt ggaggctatg gactactggg gccaagggac cacggtcacc 420
gtctcctcag gcggaggtgg aagcggaggg ggaggatctg gcggcggagg aagcggaggc 480
gatatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtgggaga cagagtcacc 540
atcacttgca aggccagtca gaatgtgggt actaatgttg cctggtatca gcagaaacca 600
gggaaagcac ctaagctcct gatctattcg gcatcctacc gctacagtgg agtcccatca 660
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 720
gaagatttcg caacttacta ctgtcaccaa tattacacct atcctctatt cacgtttggc 780
cagggcacca agctcgagat caagacaacg acgccagctc cccgcccgcc aacccctgca 840
cctacgattg catcacaacc gctgtccctg cggcctgaag cttgtcgccc agccgcaggt 900
ggcgccgtac atacacgggg gctggatttt gcctgtgatt tctgggtgct ggtcgttgtg 960
ggcggcgtgc tggcctgcta cagcctgctg gtgacagtgg ccttcatcat cttttgggtg 1020
aggagcaagc ggagtcgact gctgcacagc gactacatga acatgacccc ccggaggcct 1080
ggccccaccc ggaagcacta ccagccctac gcccctccca gggatttcgc cgcctaccgg 1140
agcaaacggg gcagaaagaa actcctgtat atattcaaac aaccatttat gaggccagta 1200
caaactactc aagaggaaga tggctgtagc tgccgatttc cagaagaaga agaaggagga 1260
tgtgaactga gagtgaagtt cagcaggagc gcagacgccc ccgcgtacaa gcagggccag 1320
aaccagctct ataacgagct caatctagga cgaagagagg agtacgatgt tttggacaag 1380
cgtagaggcc gggaccctga gatgggggga aagccgagaa ggaagaaccc tcaggaaggc 1440
ctgtacaatg aactgcagaa agataagatg gcggaggcct acagtgagat tgggatgaaa 1500
ggcgagcgcc ggaggggcaa ggggcacgat ggcctttacc agggactcag tacagccacc 1560
aaggacacct acgacgccct tcacatgcag gccctgcccc ctcgctag 1608
<210> 290
<211> 537
<212> PRT
<213> CEA CAR
<400> 290
Met Asp Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp
1 5 10 15
Leu Arg Gly Ala Arg Cys Gln Val Gln Leu Val Gln Ser Gly Ala Glu
20 25 30
Val Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly
35 40 45
Tyr Thr Phe Thr Glu Phe Gly Met Asn Trp Val Arg Gln Ala Pro Gly
50 55 60
Gln Gly Leu Glu Trp Met Gly Trp Ile Asn Thr Lys Thr Gly Glu Ala
65 70 75 80
Thr Tyr Val Glu Glu Phe Lys Gly Arg Val Thr Phe Thr Thr Asp Thr
85 90 95
Ser Thr Ser Thr Ala Tyr Met Glu Leu Arg Ser Leu Arg Ser Asp Asp
100 105 110
Thr Ala Val Tyr Tyr Cys Ala Arg Trp Asp Phe Ala Tyr Tyr Val Glu
115 120 125
Ala Met Asp Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
145 150 155 160
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
165 170 175
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Ala Ala Val Gly Thr Tyr
180 185 190
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
195 200 205
Tyr Ser Ala Ser Tyr Arg Lys Arg Gly Val Pro Ser Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
225 230 235 240
Glu Asp Phe Ala Thr Tyr Tyr Cys His Gln Tyr Tyr Thr Tyr Pro Leu
245 250 255
Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Thr Thr
260 265 270
Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln
275 280 285
Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala
290 295 300
Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp Phe Trp Val Leu Val
305 310 315 320
Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu Val Thr Val Ala
325 330 335
Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser Arg Leu Leu His Ser
340 345 350
Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro Thr Arg Lys His
355 360 365
Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg Ser Lys
370 375 380
Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg
385 390 395 400
Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro
405 410 415
Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser
420 425 430
Ala Asp Ala Pro Ala Tyr Lys Gln Gly Gln Asn Gln Leu Tyr Asn Glu
435 440 445
Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg
450 455 460
Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln
465 470 475 480
Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr
485 490 495
Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp
500 505 510
Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala
515 520 525
Leu His Met Gln Ala Leu Pro Pro Arg
530 535
<210> 291
<211> 1614
<212> DNA
<213> Artificial Sequence
<220>
<223> CEA CAR
<400> 291
atggacatga gggtccccgc tcagctcctg gggctcctgc tactctggct ccgaggtgcc 60
agatgtcagg tgcagctggt gcagtctggc gccgaagtga agaaacctgg agctagtgtg 120
aaggtgtcct gcaaggccag cggctacacc ttcaccgagt tcggcatgaa ctgggtccga 180
caggctccag gccagggcct cgaatggatg ggctggatca acaccaagac cggcgaggcc 240
acctacgtgg aagagttcaa gggcagagtg accttcacca cggacaccag caccagcacc 300
gcctacatgg aactgcggag cctgagaagc gacgacaccg ccgtgtacta ctgcgccaga 360
tgggacttcg cttattacgt ggaagccatg gactactggg gccagggcac caccgtgacc 420
gtgtctagcg gcggaggtgg aagcggaggg ggaggatctg gcggcggagg aagcggaggc 480
gatatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtgggaga cagagtcacc 540
atcacttgca aggccagtgc ggctgtgggt acgtatgttg cgtggtatca gcagaaacca 600
gggaaagcac ctaagctcct gatctattcg gcatcctacc gcaaaagggg agtcccatca 660
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 720
gaagatttcg caacttacta ctgtcaccaa tattacacct atcctctatt cacgtttggc 780
cagggcacca agctcgagat caagcgtacg acaacgacgc cagctccccg cccgccaacc 840
cctgcaccta cgattgcatc acaaccgctg tccctgcggc ctgaagcttg tcgcccagcc 900
gcaggtggcg ccgtacatac acgggggctg gattttgcct gtgatttctg ggtgctggtc 960
gttgtgggcg gcgtgctggc ctgctacagc ctgctggtga cagtggcctt catcatcttt 1020
tgggtgagga gcaagcggag tcgactgctg cacagcgact acatgaacat gaccccccgg 1080
aggcctggcc ccacccggaa gcactaccag ccctacgccc ctcccaggga tttcgccgcc 1140
taccggagca aacggggcag aaagaaactc ctgtatatat tcaaacaacc atttatgagg 1200
ccagtacaaa ctactcaaga ggaagatggc tgtagctgcc gatttccaga agaagaagaa 1260
ggaggatgtg aactgagagt gaagttcagc aggagcgcag acgcccccgc gtacaagcag 1320
ggccagaacc agctctataa cgagctcaat ctaggacgaa gagaggagta cgatgttttg 1380
gacaagcgta gaggccggga ccctgagatg gggggaaagc cgagaaggaa gaaccctcag 1440
gaaggcctgt acaatgaact gcagaaagat aagatggcgg aggcctacag tgagattggg 1500
atgaaaggcg agcgccggag gggcaagggg cacgatggcc tttaccaggg actcagtaca 1560
gccaccaagg acacctacga cgcccttcac atgcaggccc tgccccctcg ctag 1614
<210> 292
<211> 536
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA CAR
<400> 292
Met Asp Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp
1 5 10 15
Leu Arg Gly Ala Arg Cys Gln Val Gln Leu Val Gln Ser Gly Ser Glu
20 25 30
Leu Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly
35 40 45
Tyr Thr Phe Thr Glu Phe Gly Met Asn Trp Val Arg Gln Ala Pro Gly
50 55 60
Gln Gly Leu Glu Trp Met Gly Trp Ile Asn Thr Lys Thr Gly Glu Ala
65 70 75 80
Thr Tyr Val Glu Glu Phe Lys Gly Arg Phe Val Phe Ser Leu Asp Thr
85 90 95
Ser Val Ser Thr Ala Tyr Leu Gln Ile Ser Ser Leu Lys Ala Glu Asp
100 105 110
Thr Ala Val Tyr Tyr Cys Ala Arg Trp Asp Phe Ala His Tyr Phe Gln
115 120 125
Thr Met Asp Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
145 150 155 160
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
165 170 175
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Ala Ala Val Gly Thr Tyr
180 185 190
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
195 200 205
Tyr Ser Ala Ser Tyr Arg Lys Arg Gly Val Pro Ser Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
225 230 235 240
Glu Asp Phe Ala Thr Tyr Tyr Cys His Gln Tyr Tyr Thr Tyr Pro Leu
245 250 255
Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Thr Thr
260 265 270
Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro
275 280 285
Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val
290 295 300
His Thr Arg Gly Leu Asp Phe Ala Cys Asp Phe Trp Val Leu Val Val
305 310 315 320
Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu Val Thr Val Ala Phe
325 330 335
Ile Ile Phe Trp Val Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp
340 345 350
Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr
355 360 365
Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg Ser Lys Arg
370 375 380
Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro
385 390 395 400
Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu
405 410 415
Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala
420 425 430
Asp Ala Pro Ala Tyr Lys Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu
435 440 445
Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly
450 455 460
Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu
465 470 475 480
Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser
485 490 495
Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly
500 505 510
Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu
515 520 525
His Met Gln Ala Leu Pro Pro Arg
530 535
<210> 293
<211> 1611
<212> DNA
<213> Artificial Sequence
<220>
<223> CEA CAR
<400> 293
atggacatga gggtccccgc tcagctcctg gggctcctgc tactctggct ccgaggtgcc 60
agatgtcagg tgcagctggt gcaatctggg tctgagttga agaagcctgg ggcctcagtg 120
aaggtttcct gcaaggcttc tggatacacc ttcactgagt ttggaatgaa ctgggtgcga 180
caggcccctg gacaagggct tgagtggatg ggatggataa acaccaaaac tggagaggca 240
acatatgttg aagagtttaa gggacggttt gtcttctcct tggacacctc tgtcagcacg 300
gcatatctgc agatcagcag cctaaaggct gaagacactg ccgtgtatta ctgtgcgaga 360
tgggactttg ctcattactt tcagactatg gactactggg gccaagggac cacggtcacc 420
gtctcctcag gcggaggtgg aagcggaggg ggaggatctg gcggcggagg aagcggaggc 480
gatatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtgggaga cagagtcacc 540
atcacttgca aggccagtgc ggctgtgggt acgtatgttg cgtggtatca gcagaaacca 600
gggaaagcac ctaagctcct gatctattcg gcatcctacc gcaaaagggg agtcccatca 660
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 720
gaagatttcg caacttacta ctgtcaccaa tattacacct atcctctatt cacgtttggc 780
cagggcacca agctcgagat caagcgtaca acgacgccag ctccccgccc gccaacccct 840
gcacctacga ttgcatcaca accgctgtcc ctgcggcctg aagcttgtcg cccagccgca 900
ggtggcgccg tacatacacg ggggctggat tttgcctgtg atttctgggt gctggtcgtt 960
gtgggcggcg tgctggcctg ctacagcctg ctggtgacag tggccttcat catcttttgg 1020
gtgaggagca agcggagtcg actgctgcac agcgactaca tgaacatgac cccccggagg 1080
cctggcccca cccggaagca ctaccagccc tacgcccctc ccagggattt cgccgcctac 1140
cggagcaaac ggggcagaaa gaaactcctg tatatattca aacaaccatt tatgaggcca 1200
gtacaaacta ctcaagagga agatggctgt agctgccgat ttccagaaga agaagaagga 1260
ggatgtgaac tgagagtgaa gttcagcagg agcgcagacg cccccgcgta caagcagggc 1320
cagaaccagc tctataacga gctcaatcta ggacgaagag aggagtacga tgttttggac 1380
aagcgtagag gccgggaccc tgagatgggg ggaaagccga gaaggaagaa ccctcaggaa 1440
ggcctgtaca atgaactgca gaaagataag atggcggagg cctacagtga gattgggatg 1500
aaaggcgagc gccggagggg caaggggcac gatggccttt accagggact cagtacagcc 1560
accaaggaca cctacgacgc ccttcacatg caggccctgc cccctcgcta g 1611
<210> 294
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA CDR-H1
<400> 294
Glu Phe Gly Met Asn
1 5
<210> 295
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA CDR-H2
<400> 295
Trp Ile Asn Thr Lys Thr Gly Glu Ala Thr Tyr Val Glu Glu Phe Lys
1 5 10 15
Gly
<210> 296
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA CDR-H3
<400> 296
Trp Asp Phe Ala Tyr Tyr Val Glu Ala Met Asp Tyr
1 5 10
<210> 297
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA CDR-H3
<400> 297
Trp Asp Phe Ala His Tyr Phe Gln Thr Met Asp Tyr
1 5 10
<210> 298
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA CDR-L1
<400> 298
Lys Ala Ser Gln Asn Val Gly Thr Asn Val Ala
1 5 10
<210> 299
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA CDR-L1
<400> 299
Lys Ala Ser Ala Ala Val Gly Thr Tyr Val Ala
1 5 10
<210> 300
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA CDR-L2
<400> 300
Ser Ala Ser Tyr Arg Tyr Ser
1 5
<210> 301
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA CDR-L2
<400> 301
Ser Ala Ser Tyr Arg Lys Arg
1 5
<210> 302
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CEA CDR-L3
<400> 302
His Gln Tyr Tyr Thr Tyr Pro Leu Phe Thr
1 5 10
<210> 303
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-CYBA-1Y peptide
<220>
<221> X
<222> (10)..(10)
<223> X is Y or H
<400> 303
Ser Thr Met Glu Arg Trp Gly Gln Lys Xaa
1 5 10
<210> 304
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-OAS1-1R
<220>
<221> X
<222> (7)..(7)
<223> X is R or T
<400> 304
Glu Thr Asp Asp Pro Arg Xaa Tyr Gln Lys Tyr
1 5 10
<210> 305
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> HA-2 peptide
<220>
<221> X
<222> (9)..(9)
<223> X is V or M
<400> 305
Tyr Ile Gly Glu Val Leu Val Ser Xaa
1 5
<210> 306
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> HA-8 peptide
<220>
<221> X
<222> (1)..(1)
<223> X is R or P
<400> 306
Xaa Thr Leu Asp Lys Val Leu Glu Val
1 5
<210> 307
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> HA-3 peptide
<220>
<221> X
<222> (2)..(2)
<223> X is T or M
<400> 307
Val Xaa Glu Pro Gly Thr Ala Gln Tyr
1 5
<210> 308
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> HwA11-S peptide
<220>
<221> X
<222> (6)..(6)
<223> X is S or T
<400> 308
Cys Ile Pro Pro Asp Xaa Leu Leu Phe Pro Ala
1 5 10
<210> 309
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-ADIR-1F peptide
<220>
<221> X
<222> (9)..(9)
<223> X is F or S
<400> 309
Ser Val Ala Pro Ala Leu Ala Leu Xaa Pro Ala
1 5 10
<210> 310
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-HIVEP1-1S peptide
<220>
<221> X
<222> (6)..(6)
<223> X is S or N
<400> 310
Ser Leu Pro Lys His Xaa Val Thr Ile
1 5
<210> 311
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-NISCH-1A peptide
<220>
<221> X
<222> (7)..(7)
<223> X is A or V
<400> 311
Ala Leu Ala Pro Ala Pro Xaa Glu Val
1 5
<210> 312
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-SSR1-1S peptide
<220>
<221> X
<222> (1)..(1)
<223> X is S or L
<400> 312
Xaa Leu Ala Val Ala Gln Asp Leu Thr
1 5
<210> 313
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-WNK1-1I peptide
<220>
<221> X
<222> (7)..(7)
<223> X is I or M
<400> 313
Arg Thr Leu Ser Pro Glu Xaa Ile Thr Val
1 5 10
<210> 314
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> T4A peptide
<220>
<221> X
<222> (10)..(10)
<223> X is A or E
<400> 314
Gly Leu Tyr Thr Tyr Trp Ser Ala Gly Xaa
1 5 10
<210> 315
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> UTA2-1 peptide
<220>
<221> X
<222> (3)..(3)
<223> X is L or P
<400> 315
Gln Leu Xaa Asn Ser Val Leu Thr Leu
1 5
<210> 316
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-CLYBL-1Y peptide
<220>
<221> X
<222> (5)..(5)
<223> X is Y or D
<400> 316
Ser Leu Ala Ala Xaa Ile Pro Arg Leu
1 5
<210> 317
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> TRIM22 peptide
<220>
<221> X
<222> (7)..(7)
<223> X is C or R
<400> 317
Met Ala Val Pro Pro Cys Xaa Ile Gly Val
1 5 10
<210> 318
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> PARP10-1L peptide
<220>
<221> X
<222> (3)..(3)
<223> X is L or P
<400> 318
Gly Leu Xaa Gly Gln Glu Gly Leu Val Glu Ile
1 5 10
<210> 319
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> FAM119A-1T peptide
<220>
<221> X
<222> (8)..(8)
<223> X is T or I
<400> 319
Ala Met Leu Glu Arg Gln Phe Xaa Val
1 5
<210> 320
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> GLRX3-1S peptide
<220>
<221> X
<222> (3)..(3)
<223> X is S or P
<400> 320
Phe Leu Xaa Ser Ala Asn Glu His Leu
1 5
<210> 321
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> HNF4G-1M peptide
<220>
<221> X
<222> (2)..(2)
<223> X is M or I
<400> 321
Met Xaa Tyr Lys Asp Ile Leu Leu Leu
1 5
<210> 322
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> HMMR-1V peptide
<220>
<221> X
<222> (6)..(6)
<223> X is V or A
<400> 322
Ser Leu Gln Glu Lys Xaa Ala Lys Ala
1 5
<210> 323
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> BCL2A1 peptide
<220>
<221> X
<222> (4)..(4)
<223> X is N or K
<400> 323
Val Leu Gln Xaa Val Ala Phe Ser Val
1 5
<210> 324
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDC26-1F peptide
<220>
<221> X
<222> (1)..(1)
<223> X is F or S
<400> 324
Xaa Val Ala Gly Thr Gln Glu Val Phe Val
1 5 10
<210> 325
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> APOBEC3F-1S/A peptide
<220>
<221> X
<222> (3)..(3)
<223> X is S or A
<400> 325
Phe Leu Xaa Glu His Pro Asn Val Thr Leu
1 5 10
<210> 326
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-PRCP-1D peptide
<220>
<221> X
<222> (8)..(8)
<223> X is D or E
<400> 326
Phe Met Trp Asp Val Ala Glu Xaa Leu
1 5
<210> 327
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-PRCP-1D peptide
<220>
<221> X
<222> (8)..(8)
<223> X is D or E
<400> 327
Phe Met Trp Asp Val Ala Glu Xaa Leu Lys Ala
1 5 10
<210> 328
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-CCL4-1T peptide
<220>
<221> X
<222> (7)..(7)
<223> X is T or S
<400> 328
Cys Ala Asp Pro Ser Glu Xaa Trp Val
1 5
<210> 329
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-NCAPD3-1Q peptide
<220>
<221> X
<222> (3)..(3)
<223> X is Q or R
<400> 329
Trp Leu Xaa Gly Val Val Pro Val Val
1 5
<210> 330
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-NDC80-1P peptide
<220>
<221> X
<222> (7)..(7)
<223> X is P or A
<400> 330
His Leu Glu Glu Gln Ile Xaa Lys Val
1 5
<210> 331
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-TTK-1D peptide
<220>
<221> X
<222> (4)..(4)
<223> X is D or E
<400> 331
Arg Leu His Xaa Gly Arg Val Phe Val
1 5
<210> 332
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> WDR27-1L peptide
<220>
<221> X
<222> (2)..(2)
<223> X is L or P
<400> 332
Ser Xaa Asp Asp His Val Val Ala Val
1 5
<210> 333
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> MIIP peptide
<220>
<221> X
<222> (8)..(8)
<223> X is K or E
<400> 333
Ser Glu Glu Ser Ala Val Pro Xaa Arg Ser Trp
1 5 10
<210> 334
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> MIIP peptide
<220>
<221> X
<222> (7)..(7)
<223> X is K or E
<400> 334
Glu Glu Ser Ala Val Pro Xaa Arg Ser Trp
1 5 10
<210> 335
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-DHX33-1C peptide
<220>
<221> X
<222> (9)..(9)
<223> X is C or R
<400> 335
Tyr Leu Tyr Glu Gly Gly Ile Ser Xaa
1 5
<210> 336
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> PANE1 peptide
<400> 336
Arg Val Trp Asp Leu Pro Gly Val Leu Lys
1 5 10
<210> 337
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> SP110 peptide
<220>
<221> X
<222> (4)..(4)
<223> X is R or G
<400> 337
Ser Leu Pro Xaa Gly Thr Ser Thr Pro Lys
1 5 10
<210> 338
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> ACC-1C/Y
<220>
<221> X
<222> (5)..(5)
<223> X is Y or C
<400> 338
Asp Tyr Leu Gln Xaa Val Leu Gln Ile
1 5
<210> 339
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> P2RX7 peptide
<220>
<221> X
<222> (6)..(6)
<223> X is H or R
<400> 339
Trp Phe His His Cys Xaa Pro Lys Tyr
1 5
<210> 340
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> ACC-4 peptide
<220>
<221> X
<222> (9)..(9)
<223> X is R or G
<400> 340
Ala Thr Leu Pro Leu Leu Cys Ala Xaa
1 5
<210> 341
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> ACC-5
<220>
<221> X
<222> (10)..(10)
<223> X is R or G
<400> 341
Trp Ala Thr Leu Pro Leu Leu Cys Ala Xaa
1 5 10
<210> 342
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> AKAP13 peptide
<220>
<221> X
<222> (9)..(9)
<223> X is M or T
<400> 342
Ala Pro Ala Gly Val Arg Glu Val Xaa
1 5
<210> 343
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-APOBEC3B-1K peptide
<220>
<221> X
<222> (1)..(1)
<223> X is K or E
<400> 343
Xaa Pro Gln Tyr His Ala Glu Met Cys Phe
1 5 10
<210> 344
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> APOBEC3H peptide
<220>
<221> X
<222> (5)..(5)
<223> X is K or E
<400> 344
Lys Pro Gln Gln Xaa Gly Leu Arg Leu
1 5
<210> 345
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-ARHGDIB-1R peptide
<220>
<221> X
<222> (6)..(6)
<223> X is R or P
<400> 345
Pro Arg Ala Cys Trp Xaa Glu Ala
1 5
<210> 346
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-BCAT2-1R peptide
<220>
<221> X
<222> (3)..(3)
<223> X is R or T
<400> 346
Gln Pro Xaa Arg Ala Leu Leu Phe Val Ile
1 5 10
<210> 347
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> BFAR peptide
<220>
<221> X
<222> (11)..(11)
<223> X is M or R
<400> 347
Ala Pro Asn Thr Gly Arg Ala Asn Gln Gln Xaa
1 5 10
<210> 348
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> C14orf169 peptide
<220>
<221> X
<222> (4)..(4)
<223> X is A or V
<400> 348
Arg Pro Arg Xaa Pro Thr Glu Glu Leu Ala Leu
1 5 10
<210> 349
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-C16ORF-1R peptide
<220>
<221> X
<222> (1)..(1)
<223> X is R or W
<400> 349
Xaa Pro Cys Pro Ser Val Gly Leu Ser Phe Leu
1 5 10
<210> 350
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> C18orf21 peptide
<220>
<221> X
<222> (6)..(6)
<223> X is A or T
<400> 350
Asn Pro Ala Thr Pro Xaa Ser Lys Leu
1 5
<210> 351
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-EBI3-1I peptide
<220>
<221> X
<222> (8)..(8)
<223> X is I or V
<400> 351
Arg Pro Arg Ala Arg Tyr Tyr Xaa Gln Val
1 5 10
<210> 352
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> POP1 peptide
<220>
<221> X
<222> (7)..(7)
<223> X is N or K
<400> 352
Leu Pro Gln Lys Lys Ser Xaa Ala Leu
1 5
<210> 353
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> SCRIB peptide
<220>
<221> X
<222> (7)..(7)
<223> X is L or P
<400> 353
Leu Pro Gln Gln Pro Pro Xaa Ser Leu
1 5
<210> 354
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> MTRR peptide
<220>
<221> X
<222> (5)..(5)
<223> X is S or L
<400> 354
Ser Pro Ala Ser Xaa Arg Thr Asp Leu
1 5
<210> 355
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LLGL2
<220>
<221> X
<222> (5)..(5)
<223> X is R or H
<400> 355
Ser Pro Ser Leu Xaa Ile Leu Ala Ile
1 5
<210> 356
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-ECGF-1H peptide
<220>
<221> X
<222> (3)..(3)
<223> X is H or R
<400> 356
Arg Pro Xaa Ala Ile Arg Arg Pro Leu Ala Leu
1 5 10
<210> 357
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-ERAP1-1R peptide
<220>
<221> X
<222> (3)..(3)
<223> X is R or P
<400> 357
His Pro Xaa Gln Glu Gln Ile Ala Leu Leu Ala
1 5 10
<210> 358
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-ERAP1-1R peptide
<220>
<221> X
<222> (3)..(3)
<223> X is R or P
<400> 358
His Pro Xaa Gln Glu Gln Ile Ala Leu
1 5
<210> 359
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-FUCA2-1V peptide
<220>
<221> X
<222> (5)..(5)
<223> X is V or M
<400> 359
Arg Leu Arg Gln Xaa Gly Ser Trp Leu
1 5
<210> 360
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-GEMIN4-1V peptide
<220>
<221> X
<222> (9)..(9)
<223> X is V or E
<400> 360
Phe Pro Ala Leu Arg Phe Val Glu Xaa
1 5
<210> 361
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> HDGF peptide
<220>
<221> X
<222> (11)..(11)
<223> X is L or P
<400> 361
Leu Pro Met Glu Val Glu Lys Asn Ser Thr Xaa
1 5 10
<210> 362
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-PDCD11-1F peptide
<220>
<221> X
<222> (8)..(8)
<223> X is F or L
<400> 362
Gly Pro Asp Ser Ser Lys Thr Xaa Leu Cys Leu
1 5 10
<210> 363
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-PFAS-1P peptide
<220>
<221> X
<222> (2)..(2)
<223> X is P or S
<400> 363
Ala Xaa Gly His Thr Arg Arg Lys Leu
1 5
<210> 364
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-TEP1-1S peptide
<220>
<221> X
<222> (9)..(9)
<223> X is S or P
<400> 364
Ala Pro Asp Gly Ala Lys Val Ala Xaa Leu
1 5 10
<210> 365
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-TMEM8A-1I peptide
<220>
<221> X
<222> (7)..(7)
<223> X is I or V
<400> 365
Arg Pro Arg Ser Val Thr Xaa Gln Pro Leu Leu
1 5 10
<210> 366
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-USP15-1I peptide
<220>
<221> X
<222> (8)..(8)
<223> X is I or T
<400> 366
Met Pro Ser His Leu Arg Asn Xaa Leu Leu
1 5 10
<210> 367
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LRH-1 peptide
<400> 367
Thr Pro Asn Gln Arg Gln Asn Val Cys
1 5
<210> 368
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-MOB3A-1C peptide
<220>
<221> X
<222> (1)..(1)
<223> X is C or S
<400> 368
Xaa Pro Arg Pro Gly Thr Trp Thr Cys
1 5
<210> 369
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-ZDHHC6-1Y peptide
<220>
<221> X
<222> (4)..(4)
<223> X is Y or H
<400> 369
Arg Pro Arg Xaa Trp Ile Leu Leu Val Lys Ile
1 5 10
<210> 370
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> ZAPHIR peptide
<400> 370
Ile Pro Arg Asp Ser Trp Trp Val Glu Leu
1 5 10
<210> 371
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> HEATR1 peptide
<220>
<221> X
<222> (7)..(7)
<223> X is E or G
<400> 371
Ile Ser Lys Glu Arg Ala Xaa Ala Leu
1 5
<210> 372
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-GSTP1-1V peptide
<220>
<221> X
<222> (7)..(7)
<223> X is V or I
<400> 372
Asp Leu Arg Cys Lys Tyr Xaa Ser Leu
1 5
<210> 373
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> HA-1/B60 peptide
<220>
<221> X
<222> (6)..(6)
<223> X is H or R
<400> 373
Lys Glu Cys Val Leu Xaa Asp Asp Leu
1 5
<210> 374
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-SON-1R peptide
<220>
<221> X
<222> (6)..(6)
<223> X is R or C
<400> 374
Ser Glu Thr Lys Gln Xaa Thr Val Leu
1 5
<210> 375
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-SWAP70-1Q peptide
<220>
<221> X
<222> (6)..(6)
<223> X is Q or E
<400> 375
Met Glu Gln Leu Glu Xaa Leu Glu Leu
1 5
<210> 376
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-TRIP10-1EPC peptide
<220>
<221> X
<222> (2)..(2)
<223> X is E or G
<220>
<221> X
<222> (3)..(3)
<223> X is P or S
<220>
<221> X
<222> (7)..(7)
<223> X is C or G
<400> 376
Gly Xaa Xaa Gln Asp Leu Xaa Thr Leu
1 5
<210> 377
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-NUP133-1R peptide
<220>
<221> X
<222> (8)..(8)
<223> X is R or Q
<400> 377
Ser Glu Asp Leu Ile Leu Cys Xaa Leu
1 5
<210> 378
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> LB-ZNFX1-1Q peptide
<220>
<221> X
<222> (8)..(8)
<223> X is Q or H
<400> 378
Asn Glu Ile Glu Asp Val Trp Xaa Leu Asp Leu
1 5 10
<210> 379
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> SLC1A5 peptide
<220>
<221> X
<222> (3)..(3)
<223> X is A or P
<400> 379
Ala Glu Xaa Thr Ala Asn Gly Gly Leu Ala Leu
1 5 10
<210> 380
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> ACC-2 peptide
<220>
<221> X
<222> (6)..(6)
<223> X is D or G
<400> 380
Lys Glu Phe Glu Asp Xaa Ile Ile Asn Trp
1 5 10
<210> 381
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> ACC-6 peptide
<400> 381
Met Glu Ile Phe Ile Glu Val Phe Ser His Phe
1 5 10
<210> 382
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> HB-1H/Y peptide
<220>
<221> X
<222> (8)..(8)
<223> X is H or Y
<400> 382
Glu Glu Lys Arg Gly Ser Leu Xaa Val Trp
1 5 10
<210> 383
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> DPH1 peptide
<220>
<221> X
<222> (2)..(2)
<223> X is V or L
<400> 383
Ser Xaa Leu Pro Glu Val Asp Val Trp
1 5
<210> 384
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> UGT2B17/A02 peptide
<400> 384
Cys Val Ala Thr Met Ile Phe Met Ile
1 5
<210> 385
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> UGT2B17/A29
<400> 385
Ala Glu Leu Leu Asn Ile Pro Phe Leu Tyr
1 5 10
<210> 386
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> UGT2B17/B44 peptide
<400> 386
Ala Glu Leu Leu Asn Ile Pro Phe Leu Tyr
1 5 10
<210> 387
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> DFFRY peptide
<220>
<221> X
<222> (4)..(4)
<223> X is C or S
<400> 387
Ile Val Asp Xaa Leu Thr Glu Met Tyr
1 5
<210> 388
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> SMCY peptide
<400> 388
Phe Ile Asp Ser Tyr Ile Cys Gln Val
1 5
<210> 389
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> TMSB4Y peptide
<400> 389
Glu Val Leu Leu Arg Pro Gly Leu His Phe Arg
1 5 10
<210> 390
<211> 1533
<212> DNA
<213> Artificial Sequence
<220>
<223> CD19 CAR
<400> 390
gacatccaga tgacacagac tacatcctcc ctgtctgcct ctctgggaga cagagtcacc 60
atcagttgca gggcaagtca ggacattagt aaatatttaa attggtatca gcagaaacca 120
gatggaactg ttaaactcct gatctaccat acatcaagat tacactcagg agtcccatca 180
aggttcagtg gcagtgggtc tggaacagat tattctctca ccattagcaa cctggagcaa 240
gaagatattg ccacttactt ttgccaacag ggtaatacgc ttccgtacac gttcggaggg 300
gggaccaagc tggagatcac aggcggaggt ggaagcggag ggggaggatc tggcggcgga 360
ggaagcggag gcgaggtgaa actgcaggag tcaggacctg gcctggtggc gccctcacag 420
agcctgtccg tcacatgcac tgtctcaggg gtctcattac ccgactatgg tgtaagctgg 480
attcgccagc ctccacgaaa gggtctggag tggctgggag taatatgggg tagtgaaacc 540
acatactata attcagctct caaatccaga ctgaccatca tcaaggacaa ctccaagagc 600
caagttttct taaaaatgaa cagtctgcaa actgatgaca cagccattta ctactgtgcc 660
aaacattatt actacggtgg tagctatgct atggactact ggggccaagg aacctcagtc 720
accgtgtcct caaccacgac gccagcgccg cgaccaccaa caccggcgcc caccatcgcg 780
tcgcagcccc tgtccctgcg cccagaggcg tgccggccag cggcgggggg cgcagtgcac 840
acgagggggc tggacttcgc ctgtgatttc tgggtgctgg tcgttgtggg cggcgtgctg 900
gcctgctaca gcctgctggt gacagtggcc ttcatcatct tttgggtgag gagcaagcgg 960
agcagactgc tgcacagcga ctacatgaac atgacccccc ggaggcctgg ccccacccgg 1020
aagcactacc agccctacgc ccctcccagg gatttcgccg cctaccggag caaacggggc 1080
agaaagaaac tcctgtatat attcaaacaa ccatttatga ggccagtaca aactactcaa 1140
gaggaagatg gctgtagctg ccgatttcca gaagaagaag aaggaggatg tgaactgaga 1200
gtgaagttca gcaggagcgc agacgccccc gcgtacaagc agggccagaa ccagctctat 1260
aacgagctca atctaggacg aagagaggag tacgatgttt tggacaagcg tagaggccgg 1320
gaccctgaga tggggggaaa gccgagaagg aagaaccctc aggaaggcct gtacaatgaa 1380
ctgcagaaag ataagatggc ggaggcctac agtgagattg ggatgaaagg cgagcgccgg 1440
aggggcaagg ggcacgatgg cctttaccag ggactcagta cagccaccaa ggacacctac 1500
gacgcccttc acatgcaggc cctgccccct cgc 1533
<210> 391
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR ScFv
<400> 391
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Gly Ser Ile Ser Ser Gly
20 25 30
Asp Tyr Tyr Trp Ser Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
35 40 45
Trp Ile Gly Tyr Ile Tyr Tyr Ser Gly Ser Thr Asp Tyr Asn Pro Ser
50 55 60
Leu Lys Ser Arg Val Thr Met Ser Val Asp Thr Ser Lys Asn Gln Phe
65 70 75 80
Ser Leu Lys Val Asn Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Arg Val Ser Ile Phe Gly Val Gly Thr Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Glu Ile Val Met Thr Gln
130 135 140
Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser
145 150 155 160
Cys Arg Ala Ser Gln Ser Val Ser Ser Tyr Leu Ala Trp Tyr Gln Gln
165 170 175
Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Asp Ala Ser Asn Arg
180 185 190
Ala Thr Gly Ile Pro Ala Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
195 200 205
Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro Glu Asp Phe Ala Val Tyr
210 215 220
Tyr Cys His Gln Tyr Gly Ser Thr Pro Leu Thr Phe Gly Gly Gly Thr
225 230 235 240
Lys Ala Glu Ile Lys
245
Claims (102)
- 면역 세포로서,
a. 제1 조작된 수용체이되, 제1 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 상기 세포외 영역은 제1 리간드에 특이적으로 결합할 수 있는 제1 리간드 결합 도메인을 포함하는, 제1 조작된 수용체; 및
b. 제2 조작된 수용체이되, 제2 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 제2 리간드에 특이적으로 결합할 수 있는 제2 리간드 결합 도메인을 포함하는, 제2 조작된 수용체를 포함하고,
상기 제1 리간드에 대한 제1 리간드 결합 도메인의 결합은 제1 수용체에 의해 면역 세포를 활성화하거나 이의 활성화를 촉진하고,
상기 제2 리간드에 대한 제2 리간드 결합 도메인의 결합은 제1 수용체에 의한 면역 세포의 활성화를 억제하는, 면역 세포. - 제1항에 있어서, 상기 제2 리간드는 제2 리간드를 암호화하는 유전자의 이형접합성 소실로 인해 표적 세포에서 발현되지 않는, 면역 세포.
- 제1항 또는 제2항에 있어서, 상기 제2 리간드는 HLA 클래스 I 대립유전자 또는 부 조직접합 항원(MiHA: minor histocompatibility antigen)인, 면역 세포.
- 제1항에 있어서, 상기 제2 리간드는 Y 염색체 소실로 인해 표적 세포에서 발현되지 않는, 면역 세포.
- 제3항에 있어서, 상기 MiHA는 표 8 및 표 9에서의 MiHA의 군으로부터 선택되는, 면역 세포.
- 제3항에 있어서, 상기 MiHA는 HA-1인, 면역 세포.
- 제3항에 있어서, 상기 HLA 클래스 I 대립유전자는 HLA-A, HLA-B 또는 HLA-C를 포함하는, 면역 세포.
- 제7항에 있어서, 상기 HLA 클래스 I 대립유전자는 HLA-A*02 대립유전자인, 면역 세포.
- 제4항에 있어서, 상기 제2 리간드는 Y 염색체 유전자에 의해 암호화되는, 면역 세포.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 상기 제1 리간드 및 제2 리간드는 동일하지 않는, 면역 세포.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 상기 제1 리간드는 표적 세포에 의해 발현되는, 면역 세포.
- 제1항 내지 제11항 중 어느 한 항에 있어서, 상기 제1 리간드는 표적 세포 및 복수의 비표적 세포에 의해 발현되는, 면역 세포.
- 제12항에 있어서, 상기 복수의 비표적 세포는 제1 리간드 및 제2 리간드 둘 다를 발현하는, 면역 세포.
- 제1항 내지 제13항 중 어느 한 항에 있어서, 상기 제2 리간드는 표적 세포에 의해 발현되지 않고, 복수의 비표적 세포에 의해 발현되는, 면역 세포.
- 제12항 내지 제14항 중 어느 한 항에 있어서, 상기 표적 세포는 암 세포이고, 상기 비표적 세포는 비암성 세포인, 면역 세포.
- 제1항 내지 제15항 중 어느 한 항에 있어서, 상기 제1 리간드는 세포 부착 분자, 세포-세포 신호전달 분자, 세포외 도메인, 화학주성에 관여된 분자, 당단백질, G 단백질 커플링된 수용체, 막관통 단백질, 신경전달인자를 위한 수용체 및 전압 게이팅된 이온 채널, 또는 이의 펩타이드 항원으로 이루어진 군으로부터 선택되는, 면역 세포.
- 제1항 내지 제15항 중 어느 한 항에 있어서, 상기 제1 리간드는 암 항원인, 면역 세포.
- 제1항 내지 제15항 중 어느 한 항에 있어서, 상기 제1 리간드는 표 5에서의 항원의 군으로부터 선택되는, 면역 세포.
- 제18항에 있어서, 상기 제1 리간드 결합 도메인은 표 5에서의 항체의 항원 결합 도메인으로부터 단리되거나 유래되는, 면역 세포.
- 제1항 내지 제15항 중 어느 한 항에 있어서, 상기 제1 리간드는 트랜스페린 수용체(TFRC: transferrin receptor), 표피 성장 인자 수용체(EGFR: epidermal growth factor receptor), CEA 세포 부착 분자 5(CEA), CD19 분자(CD19: CD19 molecule), erb-b2 수용체 티로신 키나제 2(HER2) 및 메소텔린(MSLN), 또는 이의 펩타이드 항원으로 이루어진 군으로부터 선택되는, 면역 세포.
- 제1항 내지 제15항 중 어느 한 항에 있어서, 상기 제1 리간드는 pan-HLA 리간드인, 면역 세포.
- 제1항 내지 제15항 중 어느 한 항에 있어서, 상기 제1 리간드는 HLA-G의 HLA-A, HLA-B, HLA-C, HLA-E, HLA-F를 포함하는, 면역 세포.
- 제1항 내지 제22항 중 어느 한 항에 있어서, 상기 제1 조작된 수용체는 T 세포 수용체(TCR: T cell receptor) 또는 키메라 항원 수용체(CAR: chimeric antigen receptor)인, 면역 세포.
- 제1항 내지 제23항 중 어느 한 항에 있어서, 상기 제2 조작된 수용체는 T 세포 수용체(TCR) 또는 키메라 항원 수용체(CAR)인, 면역 세포.
- 제1항 내지 제24항 중 어느 한 항에 있어서, 상기 제1 리간드 결합 도메인은 단일 사슬 Fv 항체 단편(ScFv: single chain Fv antibody fragment) 또는 β 사슬 가변 도메인(Vβ: β chain variable domain)을 포함하는, 면역 세포.
- 제1항 내지 제24항 중 어느 한 항에 있어서, 상기 제1 리간드 결합 도메인은 TCR α 사슬 가변 도메인 및 TCR β 사슬 가변 도메인을 포함하는, 면역 세포.
- 제1항 내지 제24항 중 어느 한 항에 있어서, 상기 제1 리간드 결합 도메인은 가변 중쇄(VH: variable heavy chain) 도메인 및 가변 경쇄(VL: variable light chain) 도메인을 포함하는, 면역 세포.
- 제25항에 있어서, 상기 제1 리간드는 EGFR 또는 이의 펩타이드 항원이고, 상기 제1 리간드 결합 도메인은 서열 번호 102, 서열 번호 104, 서열 번호 106, 서열 번호 108, 서열 번호 110, 서열 번호 112, 서열 번호 114, 서열 번호 116, 서열 번호 118 또는 서열 번호 391의 서열, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함하는, 면역 세포.
- 제25항에 있어서, 상기 제1 리간드는 MSLN 또는 이의 펩타이드 항원이고, 제1 리간드 결합 도메인은 서열 번호 86, 서열 번호 88, 서열 번호 90 또는 서열 번호 92의 서열, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함하는, 면역 세포.
- 제25항에 있어서, 상기 제1 리간드는 CEA 또는 이의 펩타이드 항원이고, 제1 리간드 결합 도메인은 서열 번호 94, 서열 번호 96, 서열 번호 98, 서열 번호 100, 서열 번호 282, 서열 번호 284 또는 서열 번호 286, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함하는, 면역 세포.
- 제25항에 있어서, 상기 제1 리간드는 CD19 또는 이의 펩타이드 항원이고, 제1 리간드 결합 도메인은 서열 번호 275 또는 서열 번호 277, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함하는, 면역 세포.
- 제25항에 있어서, 상기 제1 리간드는 pan-HLA 리간드를 포함하고, 제1 리간드 결합 도메인은 서열 번호 167, 서열 번호 169, 서열 번호 171, 서열 번호 173, 서열 번호 175 또는 서열 번호 177의 서열, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함하는, 면역 세포.
- 제25항 내지 제27항 중 어느 한 항에 있어서, 상기 제1 리간드는 EGFR 또는 이의 펩타이드 항원을 포함하고, 제1 리간드 결합 도메인은 서열 번호 131 내지 서열 번호 166으로부터 선택된 CDR을 포함하는, 면역 세포.
- 제25항 내지 제27항 중 어느 한 항에 있어서, 상기 제1 리간드는 CEA 리간드 또는 이의 펩타이드 항원을 포함하고, 제1 리간드 결합 도메인은 서열 번호 294 내지 서열 번호 302로부터 선택된 CDR을 포함하는, 면역 세포.
- 제1항 내지 제34항 중 어느 한 항에 있어서, 상기 제2 리간드 결합 도메인은 ScFv 또는 Vβ 도메인을 포함하는, 면역 세포.
- 제1항 내지 제34항 중 어느 한 항에 있어서, 상기 제2 리간드 결합 도메인은 TCR α 사슬 가변 도메인 및 TCR β 사슬 가변 도메인을 포함하는, 면역 세포.
- 제1항 내지 제34항 중 어느 한 항에 있어서, 상기 제1 리간드 결합 도메인은 가변 중쇄(VH) 도메인 및 가변 경쇄(VL) 도메인을 포함하는, 면역 세포.
- 제36항에 있어서, 상기 제2 리간드는 HA-1을 포함하고, 제2 리간드 결합 도메인은 서열 번호 199를 포함하는 TCR 알파 가변 도메인, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열, 및 서열 번호 200을 포함하는 TCR 베타 가변 도메인, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함하는, 면역 세포.
- 제35항에 있어서, 상기 제2 리간드는 HLA-A*02 대립유전자를 포함하고, 제2 리간드 결합 도메인은 서열 번호 53 내지 64 중 어느 하나, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함하는, 면역 세포.
- 제35항 내지 제37항 중 어느 한 항에 있어서, 상기 제2 리간드는 HLA-A*02 대립유전자를 포함하고, 제2 리간드 결합 도메인은 서열 번호 41 내지 서열 번호 52로부터 선택된 CDR을 포함하는, 면역 세포.
- 제1항 내지 제40항 중 어느 한 항에 있어서, 상기 제2 조작된 수용체는 적어도 하나의 면역수용체 티로신계 억제 모티프(ITIM: immunoreceptor tyrosine-based inhibitory motif)를 포함하는, 면역 세포.
- 제1항 내지 제41항 중 어느 한 항에 있어서, 상기 제2 조작된 수용체는 LILRB1 세포내 도메인 또는 이의 기능적 변이체를 포함하는, 면역 세포.
- 제42항에 있어서, 상기 LILRB1 세포내 도메인은 서열 번호 76과 적어도 95% 동일한 서열을 포함하는, 면역 세포.
- 제1항 내지 제43항 중 어느 한 항에 있어서, 상기 제2 조작된 수용체는 LILRB1 막관통 도메인 또는 이의 기능적 변이체를 포함하는, 면역 세포.
- 제44항에 있어서, 상기 LILRB1 막관통 도메인 또는 이의 기능적 변이체는 서열 번호 85와 적어도 95% 동일한 서열을 포함하는, 면역 세포.
- 제1항 내지 제45항 중 어느 한 항에 있어서, 상기 제2 조작된 수용체는 LILRB1 힌지 도메인 또는 이의 기능적 단편 또는 변이체를 포함하는, 면역 세포.
- 제46항에 있어서, 상기 LILRB1 힌지 도메인은 서열 번호 84, 서열 번호 77 또는 서열 번호 78과 적어도 95% 동일한 서열을 포함하는, 면역 세포.
- 제1항 내지 제45항 중 어느 한 항에 있어서, 상기 제2 조작된 수용체는 LILRB1 세포내 도메인 및 LILRB1 막관통 도메인, 또는 이들의 기능적 변이체를 포함하는, 면역 세포.
- 제48항에 있어서, 상기 LILRB1 세포내 도메인 및 LILRB1 막관통 도메인은 서열 번호 80 또는 서열 번호 80과 적어도 95% 동일한 서열을 포함하는, 면역 세포.
- 제1항 내지 제45항 중 어느 한 항에 있어서, 상기 제2 조작된 수용체는 서열 번호 80을 포함하는 제1 폴리펩타이드 또는 TCR 알파 가변 도메인에 융합된 이것과 적어도 95%의 동일성을 갖는 서열, 및 서열 번호 80을 포함하는 제2 폴리펩타이드 또는 TCR 베타 가변 도메인에 융합된 이것과 적어도 95%의 동일성을 갖는 서열을 포함하는, 면역 세포.
- 제1항 내지 제50항 중 어느 한 항에 있어서, 상기 제1 수용체 및 제2 수용체는 약 1:10 내지 10:1의 제1 수용체 대 제2 수용체의 비로 면역 세포의 표면에서 발현되는, 면역 세포.
- 제1항 내지 제50항 중 어느 한 항에 있어서, 상기 제1 수용체 및 제2 수용체는 약 1:3 내지 3:1의 제1 수용체 대 제2 수용체의 비로 면역 세포의 표면에서 발현되는, 면역 세포.
- 제1항 내지 제52항 중 어느 한 항에 있어서, 상기 면역 세포는 T 세포, B 세포 및 자연 살해(NK) 세포로 이루어진 군으로부터 선택되는, 면역 세포.
- 제1항 내지 제53항 중 어느 한 항에 있어서, 상기 면역 세포는 비자연인, 면역 세포.
- 제1항 내지 제54항 중 어느 한 항에 있어서, 상기 면역 세포는 단리된, 면역 세포.
- 제1항 내지 제55항 중 어느 한 항에 있어서, 약제로서 사용하기 위한, 면역 세포.
- 제56항에 있어서, 상기 약제는 대상체에서의 암의 치료를 위한 것인, 면역 세포.
- 약제학적 조성물로서,
제1항 내지 제57항 중 어느 한 항의 복수의 면역 세포를 포함하는 약제학적 조성물. - 제58항에 있어서, 약제학적으로 허용 가능한 담체, 희석제 또는 부형제를 포함하는, 약제학적 조성물.
- 제58항 또는 제59항에 있어서, 치료학적 유효량의 면역 세포를 포함하는, 약제학적 조성물.
- 대상체에서 입양 세포 치료의 특이성을 증가시키는 방법으로서,
제1항 내지 제57항 중 어느 한 항의 복수의 면역 세포 또는 제58항 내지 제60항 중 어느 한 항의 약제학적 조성물을 대상체에게 투여하는 단계를 포함하는 방법. - 입양 세포 치료에 의해 암을 치료하는 방법으로서,
제1항 내지 제57항 중 어느 한 항의 복수의 면역 세포 또는 제58항 내지 제60항 중 어느 한 항의 약제학적 조성물을 대상체에게 투여하는 단계를 포함하는 방법. - 제62항에 있어서, 상기 암의 세포는 제1 리간드를 발현하는, 방법.
- 제62항 또는 제63항에 있어서, 상기 암의 세포는 이형접합성 소실 또는 Y 염색체 소실로 인해 제2 리간드를 발현하지 않는, 방법.
- 제62항 내지 제64항 중 어느 한 항에 있어서, 비표적 세포는 제1 리간드 및 제2 리간드 둘 다를 발현하는, 방법.
- 제1항 내지 제57항 중 어느 한 항의 면역 세포를 제조하는 방법으로서,
a. 복수의 면역 세포를 제공하는 단계; 및
b. 상기 면역 세포를 막관통 영역 및 세포외 영역을 포함하는 제1 조작된 수용체를 암호화하는 벡터이되, 세포외 영역은 제1 리간드에 특이적으로 결합할 수 있는 제1 리간드 결합 도메인을 포함하는 벡터 및 막관통 영역 및 세포외 영역을 포함하는 제2 조작된 수용체를 암호화하는 벡터이되, 세포외 영역은 제2 리간드에 특이적으로 결합할 수 있는 제2 리간드 결합 도메인을 포함하는 벡터에 의해 형질전환하는 단계를 포함하고;
상기 제1 리간드에 대한 제1 리간드 결합 도메인의 결합은 면역 세포를 활성화하거나 이의 활성화를 촉진하고,
상기 제2 리간드에 대한 제2 리간드 결합 도메인의 결합은 제1 리간드에 의한 면역 세포의 활성화를 억제하는, 방법. - 키트로서,
제1항 내지 제57항 중 어느 한 항의 면역 세포 또는 제58항 내지 제60항 중 어느 한 항의 약제학적 조성물을 포함하는 키트. - 제67항에 있어서, 사용 설명서를 추가로 포함하는, 키트.
- 억제 수용체로서,
HA-1 부 조직접합 항원(MiHA)에 특이적으로 결합을 할 수 있는 세포외 리간드 결합 도메인 및 적어도 하나의 면역수용체 티로신계 억제 모티프(ITIM)를 포함하는 세포내 도메인을 포함하는 억제 수용체. - 제69항에 있어서, 상기 세포외 리간드 결합 도메인은 VLRDDLLEA(서열 번호 266)의 HA-1(R) 펩타이드에 대한 것보다 VLHDDLLEA(서열 번호 191)의 HA-1(H) 펩타이드에 대한 더 높은 친화성을 갖는, 억제 수용체.
- 제69항에 있어서, 상기 억제 수용체는 VLHDDLLEA(서열 번호 191)의 HA-1(H) 펩타이드에 의해 활성화되고, VLRDDLLEA(서열 번호 266)의 HA-1(R) 펩타이드에 의해 활성화되지 않거나 더 적은 정도로 활성화되는, 억제 수용체.
- 제69항 내지 제71항 중 어느 한 항에 있어서, 상기 세포외 리간드 결합 도메인은 서열 번호 199를 포함하는 TCR 알파 가변 도메인, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열, 및 서열 번호 200을 포함하는 TCR 베타 가변 도메인, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함하는, 억제 수용체.
- 제69항 내지 제71항 중 어느 한 항에 있어서, 상기 세포외 리간드 결합 도메인은 서열 번호 199를 포함하는 TCR 알파 가변 도메인 및 서열 번호 200을 포함하는 TCR 베타 가변 도메인을 포함하는, 억제 수용체.
- 제69항 내지 제71항 중 어느 한 항에 있어서, 상기 세포내 도메인은 LILRB1 세포내 도메인 또는 이의 기능적 변이체를 포함하는, 억제 수용체.
- 제74항에 있어서, 상기 LILRB1 세포내 도메인 또는 이의 기능적 변이체는 서열 번호 76과 적어도 95% 동일한 서열을 포함하는, 억제 수용체.
- 제69항 내지 제75항 중 어느 한 항에 있어서, 상기 억제 수용체는 LILRB1 막관통 도메인 또는 이의 기능적 변이체를 포함하는, 억제 수용체.
- 제76항에 있어서, 상기 LILRB1 막관통 도메인 또는 이의 기능적 변이체는 서열 번호 85와 적어도 95% 동일한 서열을 포함하는, 억제 수용체.
- 제69항 내지 제77항 중 어느 한 항에 있어서, 상기 억제 수용체는 LILRB1 세포내 도메인 및 LILRB1 막관통 도메인, 또는 이들의 기능적 변이체를 포함하는, 억제 수용체.
- 제78항에 있어서, 상기 LILRB1 세포내 도메인 및 LILRB1 막관통 도메인은 서열 번호 80 또는 서열 번호 80과 적어도 95% 동일한 서열을 포함하는, 억제 수용체.
- 제79항에 있어서, 상기 억제 수용체는 서열 번호 80을 포함하는 제1 폴리펩타이드 또는 TCR 알파 가변 도메인에 융합된 이것과 적어도 95% 동일한 서열, 및 서열 번호 80을 포함하는 제2 폴리펩타이드 또는 TCR 베타 가변 도메인에 융합된 이것과 적어도 95% 동일한 서열을 포함하는, 억제 수용체.
- 제69항 내지 제80항 중 어느 한 항에 있어서, 서열 번호 195 또는 이것과 적어도 95%의 동일성의 폴리펩타이드 및 서열 번호 197 또는 이것과 적어도 95%의 동일성의 폴리펩타이드를 포함하는, 억제 수용체.
- 면역 세포로서,
a. 제1 조작된 수용체이되, 제1 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 CD19 리간드에 특이적으로 결합할 수 있는 제1 리간드 결합 도메인을 포함하는, 제1 조작된 수용체; 및
b. 제2 조작된 수용체이되, 제2 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 HLA-A*02 대립유전자에 특이적으로 결합할 수 있는 제2 리간드 결합 도메인을 포함하는, 제2 조작된 수용체를 포함하고,
상기 CD19 리간드에 대한 제1 리간드 결합 도메인의 결합은 제1 수용체에 의해 면역 세포를 활성화하거나 이의 활성화를 촉진하고,
상기 HLA-A*02 대립유전자에 대한 제2 리간드 결합 도메인의 결합은 제1 수용체에 의한 면역 세포의 활성화를 억제하는, 면역 세포. - 제82항에 있어서, 상기 제2 리간드 결합 도메인은 서열 번호 53 내지 64 중 어느 하나, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함하는, 면역 세포.
- 제82항에 있어서, 상기 제2 리간드 결합 도메인은 서열 번호 41 내지 서열 번호 52로부터 선택된 CDR을 포함하는, 면역 세포.
- 제82항 내지 제84항 중 어느 한 항에 있어서, 상기 제1 리간드 결합 도메인은 서열 번호 275 또는 서열 번호 277, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함하는, 면역 세포.
- 제82항 내지 제85항 중 어느 한 항에 있어서, 상기 제2 조작된 수용체는 LILRB1로부터 단리되거나 유래된 세포내 도메인을 포함하는, 면역 세포.
- 면역 세포로서,
a. 제1 조작된 수용체이되, 제1 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 EGFR 리간드에 특이적으로 결합할 수 있는 제1 리간드 결합 도메인을 포함하는, 제1 조작된 수용체; 및
b. 제2 조작된 수용체이되, 제2 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 HLA-A*02 대립유전자에 특이적으로 결합할 수 있는 제2 리간드 결합 도메인을 포함하는, 제2 조작된 수용체를 포함하고,
상기 EGFR 리간드에 대한 제1 리간드 결합 도메인의 결합은 제1 수용체에 의해 면역 세포를 활성화하거나 이의 활성화를 촉진하고,
상기 HLA-A*02 대립유전자에 대한 제2 리간드 결합 도메인의 결합은 제1 수용체에 의한 면역 세포의 활성화를 억제하는, 면역 세포. - 제87항에 있어서, 상기 제1 리간드 결합 도메인은 서열 번호 102, 서열 번호 104, 서열 번호 106, 서열 번호 108, 서열 번호 110, 서열 번호 112, 서열 번호 114, 서열 번호 116, 서열 번호 118 또는 서열 번호 391의 서열, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함하는, 면역 세포.
- 제87항에 있어서, 상기 제1 리간드 결합 도메인은 서열 번호 131 내지 서열 번호 166으로부터 선택된 CDR을 포함하는, 면역 세포.
- 제87항 내지 제89항 중 어느 한 항에 있어서, 상기 제2 리간드 결합 도메인은 서열 번호 53 내지 64 중 어느 하나, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함하는, 면역 세포.
- 제87항 내지 제89항 중 어느 한 항에 있어서, 상기 제2 리간드 결합 도메인은 서열 번호 41 내지 서열 번호 52로부터 선택된 CDR을 포함하는, 면역 세포.
- 제87항 내지 제91항 중 어느 한 항에 있어서, 상기 제2 조작된 수용체는 LILRB1로부터 단리되거나 유래된 세포내 도메인을 포함하는, 면역 세포.
- 면역 세포로서,
a. 제1 조작된 수용체이되, 제1 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 메소텔린(MSLN) 리간드에 특이적으로 결합할 수 있는 제1 리간드 결합 도메인을 포함하는, 제1 조작된 수용체; 및
b. 제2 조작된 수용체이되, 제2 조작된 수용체는 막관통 영역 및 세포외 영역을 포함하고, 세포외 영역은 HLA-A*02 대립유전자에 특이적으로 결합할 수 있는 제2 리간드 결합 도메인을 포함하는, 제2 조작된 수용체를 포함하고,
상기 MSLN 리간드에 대한 제1 리간드 결합 도메인의 결합은 제1 수용체에 의해 면역 세포를 활성화하거나 이의 활성화를 촉진하고,
상기 HLA-A*02 대립유전자에 대한 제2 리간드 결합 도메인의 결합은 제1 수용체에 의한 면역 세포의 활성화를 억제하는, 면역 세포. - 제93항에 있어서, 상기 제1 리간드 결합 도메인은 서열 번호 86, 서열 번호 88, 서열 번호 90 또는 서열 번호 92의 서열, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함하는, 면역 세포.
- 제93항 또는 제94항에 있어서, 상기 제2 리간드 결합 도메인은 서열 번호 53 내지 64 중 어느 하나, 또는 이것과 적어도 90%, 적어도 95% 또는 적어도 99%의 동일성을 갖는 서열을 포함하는, 면역 세포.
- 제93항 또는 제94항에 있어서, 상기 제2 리간드 결합 도메인은 서열 번호 41 내지 서열 번호 52로부터 선택된 CDR을 포함하는, 면역 세포.
- 제93항 내지 제96항 중 어느 한 항에 있어서, 상기 제2 조작된 수용체는 LILRB1로부터 단리되거나 유래된 세포내 도메인을 포함하는, 면역 세포.
- 약제학적 조성물로서,
제82항 내지 제97항 중 어느 한 항의 복수의 면역 세포를 포함하는 약제학적 조성물. - 입양 세포 치료에 의해 암을 치료하는 방법으로서,
제82항 내지 제97항 중 어느 한 항의 복수의 면역 세포 또는 제98항의 약제학적 조성물을 대상체에게 투여하는 단계를 포함하는 방법. - 제99항에 있어서, 상기 암의 세포는 제1 리간드를 발현하는, 방법.
- 제99항 또는 제100항에 있어서, 상기 암의 세포는 이형접합성 소실 또는 Y 염색체 소실로 인해 제2 리간드를 발현하지 않는, 방법.
- 제99항 내지 제101항 중 어느 한 항에 있어서, 비표적 세포는 제1 리간드 및 제2 리간드 둘 다를 발현하는, 방법.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201962885093P | 2019-08-09 | 2019-08-09 | |
| US62/885,093 | 2019-08-09 | ||
| US202063005670P | 2020-04-06 | 2020-04-06 | |
| US63/005,670 | 2020-04-06 | ||
| PCT/US2020/045228 WO2021030149A1 (en) | 2019-08-09 | 2020-08-06 | Cell-surface receptors responsive to loss of heterozygosity |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220053587A true KR20220053587A (ko) | 2022-04-29 |
Family
ID=74571174
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020227007569A KR20220053587A (ko) | 2019-08-09 | 2020-08-06 | 이형접합성 소실에 반응성인 세포 표면 수용체 |
Country Status (10)
| Country | Link |
|---|---|
| EP (1) | EP4010377A4 (ko) |
| JP (1) | JP2022543702A (ko) |
| KR (1) | KR20220053587A (ko) |
| CN (1) | CN114585645A (ko) |
| AU (1) | AU2020329881A1 (ko) |
| BR (1) | BR112022002465A2 (ko) |
| CA (1) | CA3150071A1 (ko) |
| IL (1) | IL290413A (ko) |
| MX (1) | MX2022001711A (ko) |
| WO (1) | WO2021030149A1 (ko) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2020401315B2 (en) | 2019-12-11 | 2023-11-09 | A2 Biotherapeutics, Inc. | LILRB1-based chimeric antigen receptor |
| JP2023515055A (ja) * | 2020-02-20 | 2023-04-12 | センティ バイオサイエンシズ インコーポレイテッド | 阻害性キメラ受容体アーキテクチャ |
| US20230330227A1 (en) | 2020-08-13 | 2023-10-19 | A2 Biotherapeutics, Inc. | Gene fusions for control of genetically modified cells |
| WO2022040470A1 (en) * | 2020-08-20 | 2022-02-24 | A2 Biotherapeutics, Inc. | Compositions and methods for treating ceacam positive cancers |
| MX2023002017A (es) | 2020-08-20 | 2023-04-28 | A2 Biotherapeutics Inc | Composiciones y métodos para tratar cánceres positivos para ceacam. |
| CA3188862A1 (en) | 2020-08-20 | 2022-02-24 | Carl Alexander Kamb | Compositions and methods for treating mesothelin positive cancers |
| WO2022040444A1 (en) * | 2020-08-20 | 2022-02-24 | A2 Biotherapeutics, Inc. | Compositions and methods for treating egfr positive cancers |
| IL304857A (en) | 2021-02-16 | 2023-10-01 | A2 Biotherapeutics Inc | Preparations and methods for treating HER2 POSITIVE cancer |
| WO2023014633A2 (en) * | 2021-08-03 | 2023-02-09 | A2 Biotherapeutics, Inc. | Vector systems for delivery of two polynucleotides and methods of making and using same |
| WO2023147019A2 (en) * | 2022-01-28 | 2023-08-03 | A2 Biotherapeutics, Inc. | Compositions and methods for treating mesothelin positive cancers |
| US20230348560A1 (en) * | 2022-02-04 | 2023-11-02 | Nkilt Therapeutics, Inc. | Chimeric ilt receptor compositions and methods |
| WO2023172954A2 (en) * | 2022-03-08 | 2023-09-14 | A2 Biotherapeutics, Inc. | Engineered receptors specific to hla-e and methods of use |
| WO2023215183A1 (en) * | 2022-05-02 | 2023-11-09 | Tscan Therapeutics, Inc. | Multiplexed t cell receptor compositions, combination therapies, and uses thereof |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| IL159225A0 (en) * | 2001-06-13 | 2004-06-01 | Genmab As | Human monoclonal antibodies to epidermal growth factor receptor (egfr) |
| US7915036B2 (en) * | 2004-09-13 | 2011-03-29 | The United States Of America As Represented By The Secretary, Department Of Health And Human Services | Compositions comprising T cell receptors and methods of use thereof |
| DK3214091T3 (en) * | 2010-12-09 | 2019-01-07 | Univ Pennsylvania | USE OF CHEMICAL ANTIGEN RECEPTOR MODIFIED T CELLS FOR TREATMENT OF CANCER |
| CA2868121C (en) * | 2012-03-23 | 2021-06-01 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Anti-mesothelin chimeric antigen receptors |
| EP2990416B1 (en) * | 2014-08-29 | 2018-06-20 | GEMoaB Monoclonals GmbH | Universal chimeric antigen receptor expressing immune cells for targeting of diverse multiple antigens and method of manufacturing the same and use of the same for treatment of cancer, infections and autoimmune disorders |
| JP7023708B2 (ja) * | 2014-11-12 | 2022-03-03 | アロジーン セラピューティクス,インコーポレイテッド | 阻害性キメラ抗原受容体 |
| SG10201913583QA (en) * | 2016-08-23 | 2020-02-27 | Univ California | Proteolytically cleavable chimeric polypeptides and methods of use thereof |
| MX2019003176A (es) * | 2016-09-23 | 2019-07-04 | Hutchinson Fred Cancer Res | Receptores de linfocitos t (tcr) especificos del antigeno menor de histocompatibilidad (h) ah-1 y sus usos. |
| EP3609914A4 (en) * | 2017-04-14 | 2021-04-14 | The General Hospital Corporation | LYMPHOCYTES T RECEPTOR OF CHEMERICAL ANTIGENS TARGETING THE TUMOR MICRO-ENVIRONMENT |
| AU2018338418A1 (en) * | 2017-09-19 | 2020-04-09 | Cdrd Ventures Inc. | Anti-HLA-A2 antibodies and methods of using the same |
| EP3688155B1 (en) * | 2017-09-28 | 2023-01-04 | Immpact-Bio Ltd. | A universal platform for preparing an inhibitory chimeric antigen receptor (icar) |
| US11732257B2 (en) * | 2017-10-23 | 2023-08-22 | Massachusetts Institute Of Technology | Single cell sequencing libraries of genomic transcript regions of interest in proximity to barcodes, and genotyping of said libraries |
| WO2021222576A1 (en) * | 2020-05-01 | 2021-11-04 | A2 Biotherapeutics, Inc. | Pag1 fusion proteins and methods of making and using same |
-
2020
- 2020-08-06 JP JP2022508455A patent/JP2022543702A/ja active Pending
- 2020-08-06 CN CN202080068565.7A patent/CN114585645A/zh active Pending
- 2020-08-06 CA CA3150071A patent/CA3150071A1/en active Pending
- 2020-08-06 BR BR112022002465A patent/BR112022002465A2/pt unknown
- 2020-08-06 MX MX2022001711A patent/MX2022001711A/es unknown
- 2020-08-06 EP EP20853234.1A patent/EP4010377A4/en active Pending
- 2020-08-06 AU AU2020329881A patent/AU2020329881A1/en active Pending
- 2020-08-06 KR KR1020227007569A patent/KR20220053587A/ko unknown
- 2020-08-06 WO PCT/US2020/045228 patent/WO2021030149A1/en active Application Filing
-
2022
- 2022-02-07 IL IL290413A patent/IL290413A/en unknown
Also Published As
| Publication number | Publication date |
|---|---|
| WO2021030149A1 (en) | 2021-02-18 |
| EP4010377A1 (en) | 2022-06-15 |
| AU2020329881A1 (en) | 2022-03-24 |
| CA3150071A1 (en) | 2021-02-18 |
| AU2020329881A8 (en) | 2022-06-02 |
| BR112022002465A2 (pt) | 2022-05-03 |
| JP2022543702A (ja) | 2022-10-13 |
| MX2022001711A (es) | 2022-05-10 |
| IL290413A (en) | 2022-04-01 |
| EP4010377A4 (en) | 2023-09-06 |
| CN114585645A (zh) | 2022-06-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20220053587A (ko) | 이형접합성 소실에 반응성인 세포 표면 수용체 | |
| KR102632082B1 (ko) | 혈액 악성종양을 표적으로 하는 키메라 항원 수용체(car), 조성물 및 이의 용도 | |
| CN110494451B (zh) | 靶向tim-1的嵌合抗原受体 | |
| CN112639102B (zh) | 抗间皮素嵌合抗原受体(car)构建体及其用途 | |
| KR20220133318A (ko) | 선택적 단백질 발현을 위한 조성물 및 방법 | |
| KR20230100748A (ko) | 키메라 항원 수용체 및 pd-1 억제제의 조합 요법 | |
| CA3057306A1 (en) | Biomarkers and car t cell therapies with enhanced efficacy | |
| KR20190036551A (ko) | Pro-m2 대식세포 분자의 억제제를 병용하는, 키메라 항원 수용체를 이용한 암의 치료 | |
| KR20180118175A (ko) | 다중 키메라 항원 수용체 (car) 분자를 발현하는 세포 및 그에 따른 용도 | |
| CA2999070A1 (en) | Car t cell therapies with enhanced efficacy | |
| AU2016297014A1 (en) | Methods for improving the efficacy and expansion of immune cells | |
| KR20220016083A (ko) | 키메라 수용체 및 이의 사용 방법 | |
| US20210187022A1 (en) | Engineered t cells for the treatment of cancer | |
| AU2024200719A1 (en) | LILRB1-based chimeric antigen receptor | |
| CN112638947A (zh) | 用于治疗实体瘤的嵌合抗原受体细胞 | |
| KR20230052291A (ko) | Ceacam 양성 암을 치료하기 위한 조성물 및 방법 | |
| CN113039209A (zh) | 用于使用融合蛋白进行tcr重编程的组合物和方法 | |
| KR102588292B1 (ko) | 항-bcma 키메라 항원 수용체 | |
| KR20230051677A (ko) | 메소텔린 양성 암을 치료하기 위한 조성물 및 방법 | |
| TW202214846A (zh) | 用於治療egfr陽性癌症之組合物及方法 | |
| JP2023524811A (ja) | Cd70特異的融合タンパク質を使用したtcrリプログラミングのための組成物及び方法 | |
| CN113423720A (zh) | CAR文库和scFv的制造方法 | |
| US11802159B2 (en) | Humanized anti-GDNF family alpha-receptor 4 (GRF-alpha-4) antibodies and chimeric antigen receptors (CARs) | |
| RU2809160C2 (ru) | Виды комбинированной терапии с использованием химерных антигенных рецепторов и ингибиторов pd-1 | |
| CN116249559A (zh) | 抗独特型组合物及其使用方法 |