KR20210149734A - Rna-가이드된 엔도뉴클레아제를 사용한 dna 작제물의 통합을 위한 개선된 방법 - Google Patents
Rna-가이드된 엔도뉴클레아제를 사용한 dna 작제물의 통합을 위한 개선된 방법 Download PDFInfo
- Publication number
- KR20210149734A KR20210149734A KR1020217032629A KR20217032629A KR20210149734A KR 20210149734 A KR20210149734 A KR 20210149734A KR 1020217032629 A KR1020217032629 A KR 1020217032629A KR 20217032629 A KR20217032629 A KR 20217032629A KR 20210149734 A KR20210149734 A KR 20210149734A
- Authority
- KR
- South Korea
- Prior art keywords
- donor
- nucleotides
- seq
- donor dna
- cells
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 134
- 108010042407 Endonucleases Proteins 0.000 title claims description 63
- 102000004533 Endonucleases Human genes 0.000 title claims description 63
- 230000010354 integration Effects 0.000 title claims description 33
- 230000001976 improved effect Effects 0.000 title abstract description 4
- 210000004027 cell Anatomy 0.000 claims abstract description 294
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 claims abstract description 279
- 210000001744 T-lymphocyte Anatomy 0.000 claims abstract description 134
- 108020005004 Guide RNA Proteins 0.000 claims abstract description 94
- 101710163270 Nuclease Proteins 0.000 claims abstract description 43
- 108091032973 (ribonucleotides)n+m Proteins 0.000 claims abstract description 21
- 108020004414 DNA Proteins 0.000 claims description 551
- 102000053602 DNA Human genes 0.000 claims description 529
- 125000003729 nucleotide group Chemical group 0.000 claims description 263
- 239000002773 nucleotide Substances 0.000 claims description 244
- 230000004048 modification Effects 0.000 claims description 135
- 238000012986 modification Methods 0.000 claims description 135
- 108700004991 Cas12a Proteins 0.000 claims description 116
- 230000014509 gene expression Effects 0.000 claims description 112
- 108090000623 proteins and genes Proteins 0.000 claims description 108
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 claims description 100
- 108091033409 CRISPR Proteins 0.000 claims description 95
- 150000007523 nucleic acids Chemical class 0.000 claims description 76
- 102000039446 nucleic acids Human genes 0.000 claims description 61
- 108020004707 nucleic acids Proteins 0.000 claims description 61
- 229910019142 PO4 Inorganic materials 0.000 claims description 60
- 239000010452 phosphate Substances 0.000 claims description 60
- 230000002068 genetic effect Effects 0.000 claims description 51
- 101000914496 Homo sapiens T-cell antigen CD7 Proteins 0.000 claims description 45
- 241000282414 Homo sapiens Species 0.000 claims description 43
- 108091028113 Trans-activating crRNA Proteins 0.000 claims description 35
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 claims description 32
- 238000004520 electroporation Methods 0.000 claims description 23
- 235000000346 sugar Nutrition 0.000 claims description 19
- 102000004389 Ribonucleoproteins Human genes 0.000 claims description 18
- 108010081734 Ribonucleoproteins Proteins 0.000 claims description 18
- 230000035772 mutation Effects 0.000 claims description 16
- 230000002829 reductive effect Effects 0.000 claims description 13
- 102000005962 receptors Human genes 0.000 claims description 11
- 108020003175 receptors Proteins 0.000 claims description 11
- 108091034117 Oligonucleotide Proteins 0.000 claims description 10
- 238000006467 substitution reaction Methods 0.000 claims description 9
- 210000004986 primary T-cell Anatomy 0.000 claims description 7
- ASJSAQIRZKANQN-CRCLSJGQSA-N 2-deoxy-D-ribose Chemical compound OC[C@@H](O)[C@@H](O)CC=O ASJSAQIRZKANQN-CRCLSJGQSA-N 0.000 claims description 6
- 102000006306 Antigen Receptors Human genes 0.000 claims description 5
- 108010083359 Antigen Receptors Proteins 0.000 claims description 5
- 150000008163 sugars Chemical class 0.000 claims description 5
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical class OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 claims description 4
- 239000002502 liposome Substances 0.000 claims description 4
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 claims description 3
- 238000007069 methylation reaction Methods 0.000 claims description 3
- 150000008300 phosphoramidites Chemical class 0.000 claims description 3
- 230000011987 methylation Effects 0.000 claims description 2
- KZMAWJRXKGLWGS-UHFFFAOYSA-N 2-chloro-n-[4-(4-methoxyphenyl)-1,3-thiazol-2-yl]-n-(3-methoxypropyl)acetamide Chemical compound S1C(N(C(=O)CCl)CCCOC)=NC(C=2C=CC(OC)=CC=2)=C1 KZMAWJRXKGLWGS-UHFFFAOYSA-N 0.000 claims 1
- 239000013603 viral vector Substances 0.000 abstract description 10
- 230000008569 process Effects 0.000 abstract description 9
- 101000634853 Homo sapiens T cell receptor alpha chain constant Proteins 0.000 description 251
- 239000013615 primer Substances 0.000 description 220
- 102100029452 T cell receptor alpha chain constant Human genes 0.000 description 167
- 239000012634 fragment Substances 0.000 description 143
- 230000008685 targeting Effects 0.000 description 73
- 230000002441 reversible effect Effects 0.000 description 70
- 238000003780 insertion Methods 0.000 description 65
- 230000037431 insertion Effects 0.000 description 65
- 108091008874 T cell receptors Proteins 0.000 description 64
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 62
- 238000012163 sequencing technique Methods 0.000 description 53
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 48
- 229920002477 rna polymer Polymers 0.000 description 47
- 239000000047 product Substances 0.000 description 46
- 108090000765 processed proteins & peptides Proteins 0.000 description 45
- 238000001890 transfection Methods 0.000 description 42
- 102100040678 Programmed cell death protein 1 Human genes 0.000 description 39
- 229920001184 polypeptide Polymers 0.000 description 36
- 102000004196 processed proteins & peptides Human genes 0.000 description 36
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 35
- 102100027208 T-cell antigen CD7 Human genes 0.000 description 35
- 230000002494 anti-cea effect Effects 0.000 description 34
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 31
- 102000004169 proteins and genes Human genes 0.000 description 31
- 239000002777 nucleoside Substances 0.000 description 30
- 238000000684 flow cytometry Methods 0.000 description 29
- 101000777636 Homo sapiens ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Proteins 0.000 description 28
- 102000004457 Granulocyte-Macrophage Colony-Stimulating Factor Human genes 0.000 description 26
- 108091028043 Nucleic acid sequence Proteins 0.000 description 26
- 102100031585 ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Human genes 0.000 description 25
- 239000013598 vector Substances 0.000 description 23
- 238000010354 CRISPR gene editing Methods 0.000 description 22
- 230000034431 double-strand break repair via homologous recombination Effects 0.000 description 21
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 description 20
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 19
- 150000003833 nucleoside derivatives Chemical class 0.000 description 18
- 101001068133 Homo sapiens Hepatitis A virus cellular receptor 2 Proteins 0.000 description 17
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 17
- 238000002474 experimental method Methods 0.000 description 16
- 230000001404 mediated effect Effects 0.000 description 16
- 102000040430 polynucleotide Human genes 0.000 description 16
- 108091033319 polynucleotide Proteins 0.000 description 16
- 239000002157 polynucleotide Substances 0.000 description 16
- -1 OX-40 (CD134) Proteins 0.000 description 15
- 239000000203 mixture Substances 0.000 description 15
- 108091026890 Coding region Proteins 0.000 description 14
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 13
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 13
- 238000007385 chemical modification Methods 0.000 description 13
- 108020004682 Single-Stranded DNA Proteins 0.000 description 12
- 230000008901 benefit Effects 0.000 description 12
- 238000006243 chemical reaction Methods 0.000 description 12
- 239000012636 effector Substances 0.000 description 12
- 238000010362 genome editing Methods 0.000 description 12
- 125000003835 nucleoside group Chemical group 0.000 description 12
- 238000011144 upstream manufacturing Methods 0.000 description 12
- 230000003834 intracellular effect Effects 0.000 description 11
- 238000012360 testing method Methods 0.000 description 11
- 101150059443 cas12a gene Proteins 0.000 description 10
- 231100000135 cytotoxicity Toxicity 0.000 description 10
- 230000003013 cytotoxicity Effects 0.000 description 10
- 238000011534 incubation Methods 0.000 description 10
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 10
- 230000008439 repair process Effects 0.000 description 10
- 241001430294 unidentified retrovirus Species 0.000 description 10
- 238000013459 approach Methods 0.000 description 9
- 101150038500 cas9 gene Proteins 0.000 description 9
- 238000003776 cleavage reaction Methods 0.000 description 9
- 238000002784 cytotoxicity assay Methods 0.000 description 9
- 231100000263 cytotoxicity test Toxicity 0.000 description 9
- 230000000694 effects Effects 0.000 description 9
- 239000013604 expression vector Substances 0.000 description 9
- 239000013612 plasmid Substances 0.000 description 9
- 230000001177 retroviral effect Effects 0.000 description 9
- 230000007017 scission Effects 0.000 description 9
- 238000013518 transcription Methods 0.000 description 9
- 230000035897 transcription Effects 0.000 description 9
- 241001465754 Metazoa Species 0.000 description 8
- 230000027455 binding Effects 0.000 description 8
- 230000002147 killing effect Effects 0.000 description 8
- 238000010361 transduction Methods 0.000 description 8
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 7
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 7
- 108010002350 Interleukin-2 Proteins 0.000 description 7
- 241000700605 Viruses Species 0.000 description 7
- 230000000295 complement effect Effects 0.000 description 7
- 230000005782 double-strand break Effects 0.000 description 7
- 238000003209 gene knockout Methods 0.000 description 7
- 238000009396 hybridization Methods 0.000 description 7
- 230000006780 non-homologous end joining Effects 0.000 description 7
- 230000026683 transduction Effects 0.000 description 7
- 230000003612 virological effect Effects 0.000 description 7
- 101150046249 Havcr2 gene Proteins 0.000 description 6
- 102100037850 Interferon gamma Human genes 0.000 description 6
- 108010074328 Interferon-gamma Proteins 0.000 description 6
- 206010028980 Neoplasm Diseases 0.000 description 6
- 239000000427 antigen Substances 0.000 description 6
- 108091007433 antigens Proteins 0.000 description 6
- 102000036639 antigens Human genes 0.000 description 6
- 238000003556 assay Methods 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- 239000003795 chemical substances by application Substances 0.000 description 6
- 238000012761 co-transfection Methods 0.000 description 6
- 230000001086 cytosolic effect Effects 0.000 description 6
- 201000010099 disease Diseases 0.000 description 6
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 6
- 238000010363 gene targeting Methods 0.000 description 6
- 230000037361 pathway Effects 0.000 description 6
- 102220000529 rs118203992 Human genes 0.000 description 6
- 230000000638 stimulation Effects 0.000 description 6
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 5
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 5
- 238000004113 cell culture Methods 0.000 description 5
- 230000006870 function Effects 0.000 description 5
- 239000000499 gel Substances 0.000 description 5
- 239000005090 green fluorescent protein Substances 0.000 description 5
- 229910052739 hydrogen Inorganic materials 0.000 description 5
- 239000001257 hydrogen Substances 0.000 description 5
- 230000001965 increasing effect Effects 0.000 description 5
- 210000004962 mammalian cell Anatomy 0.000 description 5
- 229920000642 polymer Polymers 0.000 description 5
- 238000003259 recombinant expression Methods 0.000 description 5
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 4
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 description 4
- 238000010356 CRISPR-Cas9 genome editing Methods 0.000 description 4
- 238000010453 CRISPR/Cas method Methods 0.000 description 4
- 102000004127 Cytokines Human genes 0.000 description 4
- 108090000695 Cytokines Proteins 0.000 description 4
- 108060002716 Exonuclease Proteins 0.000 description 4
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 description 4
- 108091093037 Peptide nucleic acid Proteins 0.000 description 4
- 241000193996 Streptococcus pyogenes Species 0.000 description 4
- 108700019146 Transgenes Proteins 0.000 description 4
- 108010017070 Zinc Finger Nucleases Proteins 0.000 description 4
- 239000011543 agarose gel Substances 0.000 description 4
- 230000003321 amplification Effects 0.000 description 4
- 210000004369 blood Anatomy 0.000 description 4
- 239000008280 blood Substances 0.000 description 4
- 230000029087 digestion Effects 0.000 description 4
- 239000003814 drug Substances 0.000 description 4
- 239000003937 drug carrier Substances 0.000 description 4
- 102000013165 exonuclease Human genes 0.000 description 4
- 239000012091 fetal bovine serum Substances 0.000 description 4
- 238000003197 gene knockdown Methods 0.000 description 4
- 238000002744 homologous recombination Methods 0.000 description 4
- 230000006801 homologous recombination Effects 0.000 description 4
- 210000005260 human cell Anatomy 0.000 description 4
- 238000009169 immunotherapy Methods 0.000 description 4
- 229960003130 interferon gamma Drugs 0.000 description 4
- 230000000670 limiting effect Effects 0.000 description 4
- 239000002609 medium Substances 0.000 description 4
- 108020004999 messenger RNA Proteins 0.000 description 4
- 125000004573 morpholin-4-yl group Chemical group N1(CCOCC1)* 0.000 description 4
- 238000003199 nucleic acid amplification method Methods 0.000 description 4
- 150000004713 phosphodiesters Chemical group 0.000 description 4
- 125000004437 phosphorous atom Chemical group 0.000 description 4
- 210000000130 stem cell Anatomy 0.000 description 4
- 239000000126 substance Substances 0.000 description 4
- 239000006228 supernatant Substances 0.000 description 4
- 208000024891 symptom Diseases 0.000 description 4
- 238000012546 transfer Methods 0.000 description 4
- 230000009466 transformation Effects 0.000 description 4
- 210000004881 tumor cell Anatomy 0.000 description 4
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 3
- 241000282472 Canis lupus familiaris Species 0.000 description 3
- 102100025475 Carcinoembryonic antigen-related cell adhesion molecule 5 Human genes 0.000 description 3
- PHEDXBVPIONUQT-UHFFFAOYSA-N Cocarcinogen A1 Natural products CCCCCCCCCCCCCC(=O)OC1C(C)C2(O)C3C=C(C)C(=O)C3(O)CC(CO)=CC2C2C1(OC(C)=O)C2(C)C PHEDXBVPIONUQT-UHFFFAOYSA-N 0.000 description 3
- 108020004705 Codon Proteins 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 108700026244 Open Reading Frames Proteins 0.000 description 3
- 108010076504 Protein Sorting Signals Proteins 0.000 description 3
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 3
- 101000910035 Streptococcus pyogenes serotype M1 CRISPR-associated endonuclease Cas9/Csn1 Proteins 0.000 description 3
- 108700042075 T-Cell Receptor Genes Proteins 0.000 description 3
- 241001648840 Thosea asigna virus Species 0.000 description 3
- 108020004417 Untranslated RNA Proteins 0.000 description 3
- 102000039634 Untranslated RNA Human genes 0.000 description 3
- 230000004913 activation Effects 0.000 description 3
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical class C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 3
- 125000000217 alkyl group Chemical group 0.000 description 3
- 230000000735 allogeneic effect Effects 0.000 description 3
- 125000000539 amino acid group Chemical group 0.000 description 3
- 150000001413 amino acids Chemical class 0.000 description 3
- 238000004458 analytical method Methods 0.000 description 3
- 201000011510 cancer Diseases 0.000 description 3
- 101150058049 car gene Proteins 0.000 description 3
- 230000015556 catabolic process Effects 0.000 description 3
- 238000006731 degradation reaction Methods 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 238000010586 diagram Methods 0.000 description 3
- 239000000539 dimer Substances 0.000 description 3
- 210000003527 eukaryotic cell Anatomy 0.000 description 3
- 239000001963 growth medium Substances 0.000 description 3
- 210000003958 hematopoietic stem cell Anatomy 0.000 description 3
- 125000005842 heteroatom Chemical group 0.000 description 3
- 102000052645 human CD38 Human genes 0.000 description 3
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 3
- 238000001990 intravenous administration Methods 0.000 description 3
- 238000004519 manufacturing process Methods 0.000 description 3
- 125000000956 methoxy group Chemical group [H]C([H])([H])O* 0.000 description 3
- 229910052760 oxygen Inorganic materials 0.000 description 3
- PHEDXBVPIONUQT-RGYGYFBISA-N phorbol 13-acetate 12-myristate Chemical compound C([C@]1(O)C(=O)C(C)=C[C@H]1[C@@]1(O)[C@H](C)[C@H]2OC(=O)CCCCCCCCCCCCC)C(CO)=C[C@H]1[C@H]1[C@]2(OC(C)=O)C1(C)C PHEDXBVPIONUQT-RGYGYFBISA-N 0.000 description 3
- 229910052698 phosphorus Inorganic materials 0.000 description 3
- 210000002307 prostate Anatomy 0.000 description 3
- 238000007480 sanger sequencing Methods 0.000 description 3
- 230000028327 secretion Effects 0.000 description 3
- 230000011664 signaling Effects 0.000 description 3
- 239000000243 solution Substances 0.000 description 3
- 230000001225 therapeutic effect Effects 0.000 description 3
- 210000001519 tissue Anatomy 0.000 description 3
- 238000011282 treatment Methods 0.000 description 3
- BGFTWECWAICPDG-UHFFFAOYSA-N 2-[bis(4-chlorophenyl)methyl]-4-n-[3-[bis(4-chlorophenyl)methyl]-4-(dimethylamino)phenyl]-1-n,1-n-dimethylbenzene-1,4-diamine Chemical compound C1=C(C(C=2C=CC(Cl)=CC=2)C=2C=CC(Cl)=CC=2)C(N(C)C)=CC=C1NC(C=1)=CC=C(N(C)C)C=1C(C=1C=CC(Cl)=CC=1)C1=CC=C(Cl)C=C1 BGFTWECWAICPDG-UHFFFAOYSA-N 0.000 description 2
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 2
- 108700028369 Alleles Proteins 0.000 description 2
- 108010008014 B-Cell Maturation Antigen Proteins 0.000 description 2
- 102000006942 B-Cell Maturation Antigen Human genes 0.000 description 2
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 2
- 108010040467 CRISPR-Associated Proteins Proteins 0.000 description 2
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 2
- 239000003155 DNA primer Substances 0.000 description 2
- 102100038132 Endogenous retrovirus group K member 6 Pro protein Human genes 0.000 description 2
- 108091029865 Exogenous DNA Proteins 0.000 description 2
- 108700024394 Exon Proteins 0.000 description 2
- 101710083479 Hepatitis A virus cellular receptor 2 homolog Proteins 0.000 description 2
- 101000746373 Homo sapiens Granulocyte-macrophage colony-stimulating factor Proteins 0.000 description 2
- 101001008255 Homo sapiens Immunoglobulin kappa variable 1D-8 Proteins 0.000 description 2
- 101001047628 Homo sapiens Immunoglobulin kappa variable 2-29 Proteins 0.000 description 2
- 101001008321 Homo sapiens Immunoglobulin kappa variable 2D-26 Proteins 0.000 description 2
- 101001047619 Homo sapiens Immunoglobulin kappa variable 3-20 Proteins 0.000 description 2
- 101001008263 Homo sapiens Immunoglobulin kappa variable 3D-15 Proteins 0.000 description 2
- 101000998120 Homo sapiens Interleukin-3 receptor subunit alpha Proteins 0.000 description 2
- 101001137987 Homo sapiens Lymphocyte activation gene 3 protein Proteins 0.000 description 2
- 101000582254 Homo sapiens Nuclear receptor corepressor 2 Proteins 0.000 description 2
- 102100022949 Immunoglobulin kappa variable 2-29 Human genes 0.000 description 2
- 102100033493 Interleukin-3 receptor subunit alpha Human genes 0.000 description 2
- 108091092195 Intron Proteins 0.000 description 2
- 102000017578 LAG3 Human genes 0.000 description 2
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 2
- 101710160107 Outer membrane protein A Proteins 0.000 description 2
- 238000012408 PCR amplification Methods 0.000 description 2
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 2
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 2
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 2
- 229940126547 T-cell immunoglobulin mucin-3 Drugs 0.000 description 2
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 2
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 2
- 108700025316 aldesleukin Proteins 0.000 description 2
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 2
- 150000001408 amides Chemical class 0.000 description 2
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 2
- 210000004899 c-terminal region Anatomy 0.000 description 2
- 230000010261 cell growth Effects 0.000 description 2
- 239000013592 cell lysate Substances 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 238000012937 correction Methods 0.000 description 2
- 238000012258 culturing Methods 0.000 description 2
- 125000000753 cycloalkyl group Chemical group 0.000 description 2
- 238000003568 cytokine secretion assay Methods 0.000 description 2
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- NAGJZTKCGNOGPW-UHFFFAOYSA-N dithiophosphoric acid Chemical group OP(O)(S)=S NAGJZTKCGNOGPW-UHFFFAOYSA-N 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 239000003623 enhancer Substances 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 238000009472 formulation Methods 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- 238000011194 good manufacturing practice Methods 0.000 description 2
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 230000000977 initiatory effect Effects 0.000 description 2
- 238000007918 intramuscular administration Methods 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- PGHMRUGBZOYCAA-ADZNBVRBSA-N ionomycin Chemical compound O1[C@H](C[C@H](O)[C@H](C)[C@H](O)[C@H](C)/C=C/C[C@@H](C)C[C@@H](C)C(/O)=C/C(=O)[C@@H](C)C[C@@H](C)C[C@@H](CCC(O)=O)C)CC[C@@]1(C)[C@@H]1O[C@](C)([C@@H](C)O)CC1 PGHMRUGBZOYCAA-ADZNBVRBSA-N 0.000 description 2
- PGHMRUGBZOYCAA-UHFFFAOYSA-N ionomycin Natural products O1C(CC(O)C(C)C(O)C(C)C=CCC(C)CC(C)C(O)=CC(=O)C(C)CC(C)CC(CCC(O)=O)C)CCC1(C)C1OC(C)(C(C)O)CC1 PGHMRUGBZOYCAA-UHFFFAOYSA-N 0.000 description 2
- 210000004897 n-terminal region Anatomy 0.000 description 2
- 239000013642 negative control Substances 0.000 description 2
- 229910052754 neon Inorganic materials 0.000 description 2
- GKAOGPIIYCISHV-UHFFFAOYSA-N neon atom Chemical compound [Ne] GKAOGPIIYCISHV-UHFFFAOYSA-N 0.000 description 2
- 239000002853 nucleic acid probe Substances 0.000 description 2
- 230000009437 off-target effect Effects 0.000 description 2
- 239000001301 oxygen Substances 0.000 description 2
- 239000013600 plasmid vector Substances 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 229940087463 proleukin Drugs 0.000 description 2
- 230000000069 prophylactic effect Effects 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 239000002096 quantum dot Substances 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- 230000003007 single stranded DNA break Effects 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 229910052717 sulfur Inorganic materials 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 231100000331 toxic Toxicity 0.000 description 2
- 230000002588 toxic effect Effects 0.000 description 2
- 238000013519 translation Methods 0.000 description 2
- 241000701161 unidentified adenovirus Species 0.000 description 2
- 230000035899 viability Effects 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- OZFAFGSSMRRTDW-UHFFFAOYSA-N (2,4-dichlorophenyl) benzenesulfonate Chemical compound ClC1=CC(Cl)=CC=C1OS(=O)(=O)C1=CC=CC=C1 OZFAFGSSMRRTDW-UHFFFAOYSA-N 0.000 description 1
- WKKCYLSCLQVWFD-UHFFFAOYSA-N 1,2-dihydropyrimidin-4-amine Chemical class N=C1NCNC=C1 WKKCYLSCLQVWFD-UHFFFAOYSA-N 0.000 description 1
- YKBGVTZYEHREMT-KVQBGUIXSA-N 2'-deoxyguanosine Chemical class C1=NC=2C(=O)NC(N)=NC=2N1[C@H]1C[C@H](O)[C@@H](CO)O1 YKBGVTZYEHREMT-KVQBGUIXSA-N 0.000 description 1
- VGONTNSXDCQUGY-RRKCRQDMSA-N 2'-deoxyinosine Chemical group C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC2=O)=C2N=C1 VGONTNSXDCQUGY-RRKCRQDMSA-N 0.000 description 1
- MXHRCPNRJAMMIM-SHYZEUOFSA-N 2'-deoxyuridine Chemical group C1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 MXHRCPNRJAMMIM-SHYZEUOFSA-N 0.000 description 1
- CKTSBUTUHBMZGZ-SHYZEUOFSA-N 2'‐deoxycytidine Chemical compound O=C1N=C(N)C=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 CKTSBUTUHBMZGZ-SHYZEUOFSA-N 0.000 description 1
- 108020005065 3' Flanking Region Proteins 0.000 description 1
- ZOOGRGPOEVQQDX-UUOKFMHZSA-N 3',5'-cyclic GMP Chemical compound C([C@H]1O2)OP(O)(=O)O[C@H]1[C@@H](O)[C@@H]2N1C(N=C(NC2=O)N)=C2N=C1 ZOOGRGPOEVQQDX-UUOKFMHZSA-N 0.000 description 1
- KISUPFXQEHWGAR-RRKCRQDMSA-N 4-amino-5-bromo-1-[(2r,4s,5r)-4-hydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidin-2-one Chemical group C1=C(Br)C(N)=NC(=O)N1[C@@H]1O[C@H](CO)[C@@H](O)C1 KISUPFXQEHWGAR-RRKCRQDMSA-N 0.000 description 1
- LUCHPKXVUGJYGU-XLPZGREQSA-N 5-methyl-2'-deoxycytidine Chemical group O=C1N=C(N)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 LUCHPKXVUGJYGU-XLPZGREQSA-N 0.000 description 1
- 239000013607 AAV vector Substances 0.000 description 1
- 241000251468 Actinopterygii Species 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- 101100428022 Arabidopsis thaliana UTR3 gene Proteins 0.000 description 1
- 108010031480 Artificial Receptors Proteins 0.000 description 1
- 241000271566 Aves Species 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 108091032955 Bacterial small RNA Proteins 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 101150018129 CSF2 gene Proteins 0.000 description 1
- 101150069031 CSN2 gene Proteins 0.000 description 1
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 1
- 229940045513 CTLA4 antagonist Drugs 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 241000700199 Cavia porcellus Species 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 101150074775 Csf1 gene Proteins 0.000 description 1
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 1
- 238000010442 DNA editing Methods 0.000 description 1
- CKTSBUTUHBMZGZ-UHFFFAOYSA-N Deoxycytidine Natural products O=C1N=C(N)C=CN1C1OC(CO)C(O)C1 CKTSBUTUHBMZGZ-UHFFFAOYSA-N 0.000 description 1
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 1
- 102000007260 Deoxyribonuclease I Human genes 0.000 description 1
- RWSOTUBLDIXVET-UHFFFAOYSA-N Dihydrogen sulfide Chemical compound S RWSOTUBLDIXVET-UHFFFAOYSA-N 0.000 description 1
- 239000012591 Dulbecco’s Phosphate Buffered Saline Substances 0.000 description 1
- 101710091045 Envelope protein Proteins 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 241000283073 Equus caballus Species 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 101150106478 GPS1 gene Proteins 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 1
- 208000002250 Hematologic Neoplasms Diseases 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- 102100022132 High affinity immunoglobulin epsilon receptor subunit gamma Human genes 0.000 description 1
- 108091010847 High affinity immunoglobulin epsilon receptor subunit gamma Proteins 0.000 description 1
- 101000711567 Homo sapiens E3 ubiquitin-protein ligase RNF125 Proteins 0.000 description 1
- 101000611936 Homo sapiens Programmed cell death protein 1 Proteins 0.000 description 1
- 101000611183 Homo sapiens Tumor necrosis factor Proteins 0.000 description 1
- 108091006905 Human Serum Albumin Proteins 0.000 description 1
- 102000008100 Human Serum Albumin Human genes 0.000 description 1
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- 108091029795 Intergenic region Proteins 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 208000034578 Multiple myelomas Diseases 0.000 description 1
- 101100219625 Mus musculus Casd1 gene Proteins 0.000 description 1
- 101100385413 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) csm-3 gene Proteins 0.000 description 1
- 206010029350 Neurotoxicity Diseases 0.000 description 1
- 102100030569 Nuclear receptor corepressor 2 Human genes 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- 108010010677 Phosphodiesterase I Proteins 0.000 description 1
- ABLZXFCXXLZCGV-UHFFFAOYSA-N Phosphorous acid Chemical class OP(O)=O ABLZXFCXXLZCGV-UHFFFAOYSA-N 0.000 description 1
- 206010035226 Plasma cell myeloma Diseases 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 101710188315 Protein X Proteins 0.000 description 1
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 1
- 239000012980 RPMI-1640 medium Substances 0.000 description 1
- 101100047461 Rattus norvegicus Trpm8 gene Proteins 0.000 description 1
- 101100453133 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) ISY1 gene Proteins 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- UCKMPCXJQFINFW-UHFFFAOYSA-N Sulphide Chemical compound [S-2] UCKMPCXJQFINFW-UHFFFAOYSA-N 0.000 description 1
- 241000282898 Sus scrofa Species 0.000 description 1
- 230000006044 T cell activation Effects 0.000 description 1
- 206010044221 Toxic encephalopathy Diseases 0.000 description 1
- 108010073062 Transcription Activator-Like Effectors Proteins 0.000 description 1
- 108020004566 Transfer RNA Proteins 0.000 description 1
- 101150007199 UTR5 gene Proteins 0.000 description 1
- 108700005077 Viral Genes Proteins 0.000 description 1
- 208000036142 Viral infection Diseases 0.000 description 1
- SAZUGELZHZOXHB-UHFFFAOYSA-N acecarbromal Chemical compound CCC(Br)(CC)C(=O)NC(=O)NC(C)=O SAZUGELZHZOXHB-UHFFFAOYSA-N 0.000 description 1
- 210000005006 adaptive immune system Anatomy 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- 150000001336 alkenes Chemical class 0.000 description 1
- 125000005600 alkyl phosphonate group Chemical group 0.000 description 1
- 125000003275 alpha amino acid group Chemical group 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 229960000723 ampicillin Drugs 0.000 description 1
- 238000000137 annealing Methods 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 238000002617 apheresis Methods 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- 238000003149 assay kit Methods 0.000 description 1
- 238000007846 asymmetric PCR Methods 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 239000000090 biomarker Substances 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- KQNZDYYTLMIZCT-KQPMLPITSA-N brefeldin A Chemical compound O[C@@H]1\C=C\C(=O)O[C@@H](C)CCC\C=C\[C@@H]2C[C@H](O)C[C@H]21 KQNZDYYTLMIZCT-KQPMLPITSA-N 0.000 description 1
- JUMGSHROWPPKFX-UHFFFAOYSA-N brefeldin-A Natural products CC1CCCC=CC2(C)CC(O)CC2(C)C(O)C=CC(=O)O1 JUMGSHROWPPKFX-UHFFFAOYSA-N 0.000 description 1
- 210000001217 buttock Anatomy 0.000 description 1
- BPKIGYQJPYCAOW-FFJTTWKXSA-I calcium;potassium;disodium;(2s)-2-hydroxypropanoate;dichloride;dihydroxide;hydrate Chemical compound O.[OH-].[OH-].[Na+].[Na+].[Cl-].[Cl-].[K+].[Ca+2].C[C@H](O)C([O-])=O BPKIGYQJPYCAOW-FFJTTWKXSA-I 0.000 description 1
- 239000012830 cancer therapeutic Substances 0.000 description 1
- 125000001369 canonical nucleoside group Chemical group 0.000 description 1
- 101150055766 cat gene Proteins 0.000 description 1
- 230000020411 cell activation Effects 0.000 description 1
- 239000006143 cell culture medium Substances 0.000 description 1
- 230000022534 cell killing Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 238000000576 coating method Methods 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 101150055601 cops2 gene Proteins 0.000 description 1
- 230000000139 costimulatory effect Effects 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 206010052015 cytokine release syndrome Diseases 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 238000004925 denaturation Methods 0.000 description 1
- 230000036425 denaturation Effects 0.000 description 1
- 238000000432 density-gradient centrifugation Methods 0.000 description 1
- MXHRCPNRJAMMIM-UHFFFAOYSA-N desoxyuridine Natural products C1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 MXHRCPNRJAMMIM-UHFFFAOYSA-N 0.000 description 1
- ANCLJVISBRWUTR-UHFFFAOYSA-N diaminophosphinic acid Chemical compound NP(N)(O)=O ANCLJVISBRWUTR-UHFFFAOYSA-N 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- 239000007884 disintegrant Substances 0.000 description 1
- 230000008519 endogenous mechanism Effects 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 239000000796 flavoring agent Substances 0.000 description 1
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 1
- 125000001153 fluoro group Chemical group F* 0.000 description 1
- 235000003599 food sweetener Nutrition 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 238000003198 gene knock in Methods 0.000 description 1
- 231100000118 genetic alteration Toxicity 0.000 description 1
- 230000004077 genetic alteration Effects 0.000 description 1
- 231100000025 genetic toxicology Toxicity 0.000 description 1
- 230000001738 genotoxic effect Effects 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- 125000000623 heterocyclic group Chemical group 0.000 description 1
- 210000002865 immune cell Anatomy 0.000 description 1
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 230000008316 intracellular mechanism Effects 0.000 description 1
- 238000007917 intracranial administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 238000007914 intraventricular administration Methods 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- 238000011005 laboratory method Methods 0.000 description 1
- 210000000265 leukocyte Anatomy 0.000 description 1
- 239000003446 ligand Substances 0.000 description 1
- 125000005647 linker group Chemical group 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 239000000314 lubricant Substances 0.000 description 1
- 230000036210 malignancy Effects 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000008018 melting Effects 0.000 description 1
- 238000002844 melting Methods 0.000 description 1
- 125000000325 methylidene group Chemical group [H]C([H])=* 0.000 description 1
- 208000025113 myeloid leukemia Diseases 0.000 description 1
- 210000000107 myocyte Anatomy 0.000 description 1
- 210000000822 natural killer cell Anatomy 0.000 description 1
- 210000004498 neuroglial cell Anatomy 0.000 description 1
- 230000007135 neurotoxicity Effects 0.000 description 1
- 231100000228 neurotoxicity Toxicity 0.000 description 1
- QJGQUHMNIGDVPM-UHFFFAOYSA-N nitrogen group Chemical group [N] QJGQUHMNIGDVPM-UHFFFAOYSA-N 0.000 description 1
- 230000009871 nonspecific binding Effects 0.000 description 1
- 238000010899 nucleation Methods 0.000 description 1
- 230000006911 nucleation Effects 0.000 description 1
- 230000030648 nucleus localization Effects 0.000 description 1
- 229940046166 oligodeoxynucleotide Drugs 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 238000004806 packaging method and process Methods 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- SXADIBFZNXBEGI-UHFFFAOYSA-N phosphoramidous acid Chemical compound NP(O)O SXADIBFZNXBEGI-UHFFFAOYSA-N 0.000 description 1
- 150000008299 phosphorodiamidates Chemical class 0.000 description 1
- 230000008560 physiological behavior Effects 0.000 description 1
- 102000054765 polymorphisms of proteins Human genes 0.000 description 1
- 230000001124 posttranscriptional effect Effects 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 239000002987 primer (paints) Substances 0.000 description 1
- 230000000770 proinflammatory effect Effects 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000001603 reducing effect Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000037425 regulation of transcription Effects 0.000 description 1
- 230000009712 regulation of translation Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 108010056030 retronectin Proteins 0.000 description 1
- 238000010839 reverse transcription Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 150000003290 ribose derivatives Chemical class 0.000 description 1
- 229960004641 rituximab Drugs 0.000 description 1
- 239000000523 sample Substances 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- IIACRCGMVDHOTQ-UHFFFAOYSA-N sulfamic acid Chemical group NS(O)(=O)=O IIACRCGMVDHOTQ-UHFFFAOYSA-N 0.000 description 1
- 150000003456 sulfonamides Chemical group 0.000 description 1
- BDHFUVZGWQCTTF-UHFFFAOYSA-M sulfonate Chemical compound [O-]S(=O)=O BDHFUVZGWQCTTF-UHFFFAOYSA-M 0.000 description 1
- 150000003457 sulfones Chemical group 0.000 description 1
- 150000003462 sulfoxides Chemical class 0.000 description 1
- 125000004434 sulfur atom Chemical group 0.000 description 1
- 239000000829 suppository Substances 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 239000003765 sweetening agent Substances 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 230000002110 toxicologic effect Effects 0.000 description 1
- 231100000759 toxicological effect Toxicity 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 229940035893 uracil Drugs 0.000 description 1
- 108700026220 vif Genes Proteins 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 238000012070 whole genome sequencing analysis Methods 0.000 description 1
Images







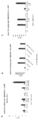















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
- C12N15/902—Stable introduction of foreign DNA into chromosome using homologous recombination
- C12N15/907—Stable introduction of foreign DNA into chromosome using homologous recombination in mammalian cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/461—Cellular immunotherapy characterised by the cell type used
- A61K39/4611—T-cells, e.g. tumor infiltrating lymphocytes [TIL], lymphokine-activated killer cells [LAK] or regulatory T cells [Treg]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/463—Cellular immunotherapy characterised by recombinant expression
- A61K39/4631—Chimeric Antigen Receptors [CAR]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464402—Receptors, cell surface antigens or cell surface determinants
- A61K39/464411—Immunoglobulin superfamily
- A61K39/464412—CD19 or B4
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464402—Receptors, cell surface antigens or cell surface determinants
- A61K39/464416—Receptors for cytokines
- A61K39/464417—Receptors for tumor necrosis factors [TNF], e.g. lymphotoxin receptor [LTR], CD30
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464402—Receptors, cell surface antigens or cell surface determinants
- A61K39/464424—CD20
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464402—Receptors, cell surface antigens or cell surface determinants
- A61K39/464426—CD38 not IgG
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/46448—Cancer antigens from embryonic or fetal origin
- A61K39/464482—Carcinoembryonic antigen [CEA]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/102—Mutagenizing nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
- C12N15/1138—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing against receptors or cell surface proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases RNAses, DNAses
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPRs]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/315—Phosphorothioates
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/321—2'-O-R Modification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/70—Enzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Microbiology (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Immunology (AREA)
- Cell Biology (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- Organic Chemistry (AREA)
- Mycology (AREA)
- Medicinal Chemistry (AREA)
- Biotechnology (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Epidemiology (AREA)
- Pharmacology & Pharmacy (AREA)
- General Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Oncology (AREA)
- Biochemistry (AREA)
- Physics & Mathematics (AREA)
- Biophysics (AREA)
- Plant Pathology (AREA)
- Hematology (AREA)
- Gynecology & Obstetrics (AREA)
- Pregnancy & Childbirth (AREA)
- Reproductive Health (AREA)
- Crystallography & Structural Chemistry (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
유전학적으로 가공된 세포를 개발하기 위해 개선되고, 보다 안전하고 효율적인 공정이 기재된다. 보다 구체적으로, 공여자 DNA 작제물, 가이드 RNA, 및 RNA 가이드된 뉴클레아제를 형질감염될 숙주 세포에 도입하는 단계; 및 상기 3개의 성분들을 숙주 세포에 도입하는 단계를 포함하는 방법이 기재된다. CAR (키메라 항원 수용체)를 숙주 세포의 한정된 게놈 부위로 삽입하기 위해 디자인된 공여자 DNA 작제물이 추가로 기재된다. 추가로, 본원의 개시내용은 안전성 문제가 존재할 수 있는 바이러스 벡터가 부재인 CAR로 형질감염된 숙주 세포를 제공한다. 본원의 개시내용은 CAR 작제물을 발현하도록 T 세포를 가공하기 위해 보다 효율적이고 보다 저렴한 방법을 제공한다.
Description
관련 출원
본 출원은 2019년 3월 11일에 출원된 미국 가특허 출원 번호 제62/816,836호 및 2019년 9월 17일에 출원된 미국 가특허 출원 번호 제62/901,735호에 대한 우선권을 주장하며, 이들 문헌 둘다는 그 내용 전체가 본원에 참고로 인용된다.
본원의 개시내용은 cas 단백질과 같은, RNA-가이드된 엔도뉴클레아제를 사용하여, 관심 대상의 DNA 서열을 표적 DNA 분자, 예를 들어, 숙주 게놈에 효율적으로 통합시키기 위한 방법 및 조성물을 제공한다.
외인성 DNA 서열의 게놈 유전자좌로의 표적화된 통합은 매우 요구되고 있다. CRISPR-Cas 게놈 가공은 유전자 기능을 녹아웃시키거나 유전자 보정 또는 유전자 태그 부착(tagging)을 위해 DNA 서열을 정확하게 녹인시키기 위한 신속하고 상대적으로 단순한 방법이다. 표적화된 유전자 녹아웃은 Cas9 뉴클레아제 및 가이드 RNA (gRNA)을 사용한, DNA 내 이중 가닥 절단 (DSB)의 생성을 통해 성취된다. DSB는 이어서 흔히 내인성 비-상동성 말단 연결 (NHEJ) 복구 경로를 통한 무작위 삽입 또는 결실 (삽입-결실)에 의해 불완전하게 복구된다. 녹인 실험을 위하여, Cas9 뉴클레아제 및 gRNA에 추가로, DNA 공여자 주형이 요구되고 DSB는 전형적으로 상동성-지시된 복구 (HDR) 경로를 통해 공여자 주형을 사용하여 복구된다.
단일 가닥 DNA (ssDNA) 공여자 올리고 또는 공여자 플라스미드 (dsDNA)인 공여자 주형을 사용한 녹인은 흔히 1 내지 10% 범위의 상대적으로 낮은 효율을 갖는다. 따라서, 성공적인 HDR-매개된 녹인 실험은 중요한 디자인 고려 및 실험 최적화를 필요로 한다. 짧은 상동성 아암을 갖는 단일 가닥 올리고데옥시뉴클레오타이드(ssODN)를 사용하여, 여러 그룹은 SNP 보정 또는 에피토프 태그 첨가와 같은 정확한 DNA 편집을 성취하였다. 공여자 플라스미드(dsDNA)는 보다 긴 외인성 DNA를 통합시킬 수 있지만 효율은 매우 낮다. 여러 그룹은 AAV (바이러스) 벡터를 사용하여 HDR 공여자 ssDNA를 제공하고 CRISPR/Cas9와 조합하여 40-60%의 유전자 녹인 효율을 성취하였다. 그러나, 이들 방법은 여전히 시간 소모적이고 임상적 적용을 위해 cGMP 생성과 양립할 필요가 있는 고역가의 AAV 벡터를 생성할 필요가 있다.
에스. 피오게네스(S. Pyogenes)와)와 같은 일부 세균의 II형 원핵 CRISPR ((클러스터링된 정기적 상호 공간 이격된 짧은 팔린드롬 반복체) 후천성 면역계의 성분을 기반으로 하는 게놈 가공 도구가 개발되었다. RNA-가이드된 Cas 뉴클레아제 시스템으로서 또는 보다 단순하게 CRISPR로서 언급되는 상기 다중-성분 시스템은 가이드 RNA에 의해 표적화된 특정 서열에서 게놈 DNA 내 이중 가닥 절단을 생성하는 능력을 갖는 가이드 RNA 분자와 커플링된 Cas 엔도뉴클레아제를 포함한다. RNA-가이드된 Cas 엔도뉴클레아제는 DNA를 절단하는 능력을 갖고, 여기서, 상기 RNA 가이드는 게놈 서열에 하이브리드화한다. 추가로, Cas9 뉴클레아제는 단지 프로토스페이서 인접 모티프(PAM)으로서 공지된 특정 서열이 게놈 내 표적 서열의 바로 다운스트림에 존재하는 경우 DNA를 절단한다. 에스. 피오게네스(S. Pyogenes)) 내 카노니칼 PAM 서열은 5′-NGG-3′이고, 여기서, N은 임의의 뉴클레오타이드를 언급한다.
본래의 II형 CRISPR 시스템에서 정상적으로 2개의 상이한 RNA로서 발현되는 단일 키메라 crRNA:tracrRNA 전사체의 발현이 Cas9 뉴클레아제가 표적 DNA 서열을 서열 특이적으로 절단하도록 지시하기에 충분한 것으로 입증되었다. 추가로, 여러 돌연변이체 형태의 Cas9 뉴클레아제가 개발되었다. 예를 들어, 하나의 돌연변이체 형태의 Cas9 뉴클레아제는 닉카제로서 기능하여 야생형 Cas9과 같이 2개의 가닥 보다는 DNA의 상보적 가닥에서 절단을 생성한다. 이것은 NHEJ 보다는 고충실도 경로를 사용한 DNA 주형의 복구를 가능하게 하여 표적화된 유전자좌에서 및 능히 게놈 내 다른 위치에서 삽입-결실의 형성을 차단하여 상동성 재조합을 진행하는 능력을 유지하면서 가능한 오프-표적/독성 효과를 감소시킨다. 쌍 형성 닉킹은 세포주에서 50- 내지 1,500-배까지 오프-표적 활성을 감소시킬 수 있고 온-표적 절단 효율을 상실시키는 것 없이 마우스 접합자에서 유전자 녹아웃을 촉진시킬 수 있다.
추가로, cas 단백질은 다양한 세균으로부터 단리되었고, 에스. 피오게네스(S. pyogenes) Cas9와는 상이한 PAM 서열을 사용하는 것으로 밝혀졌다. 추가로, Cas12a와 같은 일부 cas 단백질은 천연적으로 단일 RNA 가이드를 사용하고-, 즉, 이들은 표적 서열에 하이브리드화하는 crRNA를 사용하지만 tracrRNA를 사용하지 않는다.
입양 면역치료요법은 생체외 생성된 자가 항원-특이적 세포의 전달을 포함하고, 바이러스 감염 및 암을 치료하기 위해 전망있는 전략이다. 입양 면역치료요법을 위해 사용되는 세포는 항원-특이적 세포의 확장 또는 유전학적 가공을 통한 세포의 재지시에 의해 생성될 수 있다.
CAR은 단일 융합 분자 내 하나 이상의 신호전달 도메인과 연합된 표적화 모이어티로 이루어진 합성 수용체이다. 일반적으로, CAR의 결합 모이어티는 가요성 링커에 의해 연결된 모노클로날 항체의 경쇄 및 가변 단편을 포함하는, 단일쇄 항체 (scFv)의 항원-결합 도메인으로 이루어진다. 수용체 또는 리간드 도메인을 기반으로 하는 결합 모이어티는 또한 성공적으로 사용되어 왔다. 제1 세대 CAR을 위한 신호전달 도메인은 CD3제타 또는 Fc 수용체 감마쇄의 세포질 영역으로부터 유래한다. 제1 세대 CAR은 T 세포 세포독성을 성공적으로 재지시하는 것으로 나타났지만, 이들은 생체내 장기적 확장 및 항-종양 활성을 제공하지 못하였다. CD28, OX-40 (CD134), 및 4-1BB (CD137)을 포함하는 동시 자극 분자로부터의 신호전달 도메인은 단독으로 부가되거나 (제2 세대) 조합으로 부가되어 (제3 세대) CAR 변형된 T 세포의 생존율을 증진시키고 이의 증식을 증가시켰다. CAR은 성공적으로 T 세포가 림프종 및 고체 종양을 포함하는 다양한 악성종양으로부터의 종양 세포의 표면에서 발현되는 항원에 대해 재지시되도록 하였다.
CAR (키메라 항원 수용체) 세포 면역치료요법은 환자의 혈액으로부터 T-세포를 제거하는 단계, 유전자 전달을 통해 CAR을 첨가하는 단계 및 유전학적으로 가공된 세포를 다시 체내로 주입하는 단계를 포함하고 암을 치료하는데 가장 전망있는 방법 중 하나이다. 현재, 유전자 전달 기술은 감마-레트로바이러스 벡터 또는 렌티바이러스 벡터를 사용한 바이러스 기반 유전자 전달 방법을 포함한다. GMP(FDA 요구 우수 제조 관리 기준) 수준의 바이러스 벡터가 되기 위해서는 바이러스 벡터가 복제 불능, 낮은 유전자 독성, 및 낮은 면역원성과 같은 임상 안전 기준을 준수해야 한다. 이들 통상적인 접근법은 사용이 간편하고 합리적인 발현을 갖지만 T 세포로의 바이러스 게놈 통합으로 인한 원치 않는 혈액암 및 기타 사건과 같은 2차 형질전환 사건을 일으킬 수 있다.
검토 논문(Ren and Zhao, Protein Cell 8(9):634-643, 2017)은 CRISPR/Cas9의 임의의 사용이 여전히 CAR (키메라 항원 수용체) 작제물을 T 세포 게놈으로 삽입하기 위한 녹킹인 공정을 위한 바이러스 벡터의 용도를 포함함을 지적한다. “비-통합 바이러스, 예를 들어, 아데노바이러스 및 아데노바이러스-연합된 바이러스 (AAV)에 의해 암호화된 CRISPR을 사용한 유전자 편집이 또한 보고되었다.” 추가로, 2016년 11월 4일자로 온라인에 공개된 문헌(참조: Ren et al., Clin. Cancer Res. 16:1300)은 CD19 CAR 작제물을 사용하였고, T 세포에서 유전자 파괴가 렌티바이러스 및 아데노바이러스 CRISPR을 사용해서는 매우 효율적이지 않음을 밝혔다.
최근에 이량체 항원 수용체 또는 “DAR”은 기재되었다(WO 2019/173837). 이들 가공된 수용체는 2개의 폴리펩타이드 쇄를 포함하고, 상기 쇄 중 하나는 경쇄 항체 가변 및 불변 영역을 포함하고, 이의 다른 하나는 중쇄 항체 가변 및 불변 영역, 및 막관통 영역 및 세포내 영역을 포함한다. CAR과 같이, DAR은 암 세포 표면 항원에 결합하도록 가공될 수 있다. 작제물 암호화는 통상의 프로모터로부터 폴리펩타이드 둘다를 발현하도록 구성될 수 있다.
RNA-가이드된 엔도뉴클레아제, 예를 들어, Cas9/CRISPR 시스템은 일부 포유동물 세포를 유전학적으로 가공하기 위해 매력적인 접근법인 것으로 보이지만, 1차 세포에서, 특히 T 세포에서 Cas9/CRISPR은 하기 이유 때문에 유의적으로 보다 어렵다: (1) T-세포는 이들의 세포질 내 DNA의 도입에 의해 악영향을 미치고: 높은 비율의 아폽토시스는 세포를 DNA 벡터를 형질전환시키는 경우 관찰되고; (2) CRISPR 시스템은 세포에서 Cas9의 안정한 발현을 필요로 하지만 생세포에서 Cas9의 지속적인 발현은 염색체 결함을 유도할 수 있고; (3) 현재 RNA 가이드된 엔도뉴클레아제의 특이성은 단지 11개 뉴클레오타이드를 포함하는 서열 (N12-20NGG, 여기서, NGG는 PAM을 나타낸다)에 의해서만 결정되고, 이는 게놈 내 특유한 목적하는 유전자좌에서 표적 서열을 동정하기가 매우 어렵게 한다. Cas9에 추가로 다른 뉴클레아제는 Cas12a, 아연 핑거 뉴클레아제(ZFN) 또는 TAL 이펙터 뉴클레아제 (TALEN)이다.
본원의 개시내용은 숙주 세포, 예를 들어, T 세포에서 RNA-가이드된 엔도뉴클레아제를 효율적으로 수행하기 위해 이들 한계에 대한 해결책을 제공하는 것을 목적으로 한다. 당업계에서는 바이러스 벡터를 사용한 형질도입을 포함하지 않지만 대신 형질감염 기술을 사용할 수 있는 키메라 항원 수용체 작제물에 대해 보다 안전한 형질도입 기술이 요구된다. 이것은 환자에게 투여되는 형질도입된 세포에 의해 잠재적으로 표현되는 바이러스 유전자를 갖는 위험을 회피하면서, CAR 작제물 형질감염 효율을 증가시킴을 포함한다. 본원의 개시내용은 당업계에서 상기 필요성을 해결하기 위해 이루어졌다.
발명의 개요
본원의 개시내용은 면역치료요법을 위한 세포를 포함하는, 유전학적으로 가공되고 형질도입된 세포를 개발하기 위해 개선되고, 보다 안전하고 상업적으로 효율적인 방법을 제공한다. 보다 구체적으로, 본원에 기재된 방법은 RNA-가이드된 엔도뉴클레아제, 가이드 RNA, 및 공여자 DNA 작제물을 숙주 세포에 도입하는 단계를 포함하고, 여기서, 상기 가이드 RNA는 이것이 복합체화된 cas 단백질을 숙주 게놈의 표적화된 부위로 지시하도록 가공된다. RNA-가이드된 엔도뉴클레아제에 의한 표적 부위에서 게놈 DNA의 절단, 및 상동성-지시된 복구 (HDR)에 의해 상동성 아암을 포함하는 공여자 단편을 사용한 이중 가닥 절단의 후속적 복구는 상동성 아암 사이에 위치한 공여자 DNA 분자의 서열의 통합을 유도한다. 상기 방법을 사용하여 동시에, 표적 유전자좌에서 유전자를 녹아웃시키고 파괴된 유전자좌에서 공여자 DNA 분자에 제공된 전이유전자를 삽입하거나 “녹인”시킬 수 있다. 추가로, 제1 유전학적 유전자좌에서 유전학적 작제물을 삽입하기 위한 방법이 제공되고, 여기서, 유전하적 작제물의 삽입은 제1 유전자좌에서 유전자를 녹아웃시키고, 동시에 제2 유전자좌에서 유전자를 녹아웃시킨다. 녹인/이중 녹아웃은 2개의 RNP를 표적 세포에 도입함에 의해 성취되고, 제1 RNP는 제1 유전학적 유전자좌를 표적화하는 가이드를 갖고, 제2 RNP는 제2 유전학적 유전자좌를 표적화하는 가이드를 갖는다. 2개의 RNP는 동일하거나 (예를 들어, Cas12a) 상이한(예를 들어, Cas12a 및 Cas9) cas 단백질을 포함할 수 있다. 상기 방법은 원핵 및 진핵 세포를 포함하는 임의의 세포에 대해 사용될 수 있고, 사람 세포와 같은 포유동물 세포와 함께 사용될 수 있다. 상기 방법은 사용의 용이함, 효율 및 임상 적용을 포함하는 많은 적용에서 바람직하지 않을 수 있는 선택가능한 마커 또는 바이러스 벡터의 사용을 필요로 하지 않는 게놈 변형을 생성하는 능력에서의 이점을 갖는다. 일부 구현예에서, 숙주 세포는 예를 들어, T 세포와 같은 조혈 세포이다.
본원의 개시내용은 또한 공여자 DNA의 진핵 세포의 게놈의 유전자좌로의 표적화된 통합을 위한 시스템을 제공한다. 또한 공여자 DNA 조성물이 제공되고, 여기서, 상기 공여자 DNA 분자는 하나의 공여자 DNA 가닥의 뉴클레오타이드에 대해 하나 이상의 변형을 포함한다. 공여자 DNA는 숙주 게놈으로의 이의 통합이 요구되는 관심 대상의 서열을 플랭킹하는 상동성 아암을 포함할 수 있고, 여기서, 상기 상동성 아암은 표적 서열의 어느 측면 상에서 숙주 게놈내 존재하는 서열과 상동성인 서열을 갖는다. 일부 구현예에서 공여자 DNA는 이중 가닥 또는 실질적으로 이중 가닥이다. 다양한 구현예에서, 공여자 DNA는 공여자 DNA의 하나의 가닥의 5’ 말단에 인접한, 예를 들어, 공여자 DNA의 하나의 가닥의 5’ 말단의 10개 뉴클레오타이드 내 또는 5개 뉴클레오타이드 내에 존재하는 1 내지 10개의 변형된 뉴클레오타이드를 포함한다. 일부 구현예에서, 공여자 DNA는 공여자 DNA의 하나의 가닥의 5’ 말단에서 1 내지 10개 뉴클레오타이드의 적어도 2개 유형의 핵산 변형을 갖는다. 일부 구현예에서, 공여자 DNA는 공여자 DNA의 하나의 가닥의 5’ 말단에서 1 내지 10개 뉴클레오타이드의 2개 유형의 핵산 변형을 갖는다. 변형은 예를 들어, 뉴클레오타이드 사이에 포스포로티오에이트 (PS) 연결일 수 있거나, 공여자 DNA 분자의 하나 이상의 뉴클레오타이드의 데옥시리보스의 2’-O-메틸화일 수 있다. 예를 들어, 공여자 DNA 분자는 변형된 가닥의 5’ 말단으로부터 처음 5개, 처음 6개 또는 처음 7개 뉴클레오타이드 내에 1개, 2개, 3개 또는 4개의 PS 결합을 가질 수 있고 또한 변형된 가닥의 5’ 말단으로부터 처음 5개, 처음 6개 또는 처음 7개 뉴클레오타이드 내에 1개, 2개, 3개 또는 4개의 2’-O-메틸 변형된 뉴클레오타이드를 가질 수 있다. 일부 구현예에서, 공여자 DNA 분자는 이중 가닥이고 하나의 가닥은 5’ 말단에 변형을 포함한다. 일부 구현예에서, 공여자 DNA 분자는 이중 가닥이고 하나의 가닥은 5’ 말단으로부터 임의의 처음 10개 또는 처음 5개 뉴클레오타이드 상에 2개 이상의 변형을 갖고, 반대 가닥은 말단 5’ 포스페이트를 갖는다. 다양한 구현예에서, 공여자 DNA 분자는 이중 가닥이고, 공여자 DNA의 하나의 가닥 상에 적어도 2개의 PS 결합 및 적어도 2개의 2’O-메틸-변형된 뉴클레오타이드를 갖고, 여기서, 상기 PS 및 2’-O 메틸 변형은 변형된 가닥의 5’ 말단으로부터 처음 5개 뉴클레오타이드 내에 존재한다. 다양한 구현예에서, 공여자 DNA 분자는 이중 가닥 또는 실질적으로 이중 가닥이고, 공여자 DNA의 하나의 가닥 상에 3개의 PS 결합 및 3개의 2’O-메틸-변형된 뉴클레오타이드를 갖고, 여기서, 상기 PS 및 2’-O 메틸 변형은 변형된 가닥의 5’ 말단으로부터 처음 5개 뉴클레오타이드 내에 존재한다. 이들 구현예의 일부 예에서, 반대 가닥은 말단 5’ 포스페이트를 포함한다. 공여자 DNA는 이중 가닥 또는 실질적으로 이중 가닥 분자로서 세포에 도입될 수 있다.
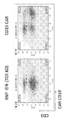
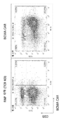
본원의 개시내용은 추가로 CAR (키메라 항원 수용체) 또는 DAR (이량체 항원 수용체)를 숙주 세포로 삽입하기 위해 디자인된 공여자 DNA 작제물을 제공한다. CAR 작제물은 당업계에 널리 공지되어 있고, 예를 들어, 문헌(참조: Zhang et al. (2017) Biomarker Res. 5:22)에서 검토되었다. 2개의 폴리펩타이드 수용체를 암호화하는 DAR 작제물은 예를 들어, WO 2019/173837에 기재되어 있다. 추가로, 본원 개시내용은 바이러스 벡터, 또는 레트로바이러스 또는 아데노-연관된 바이러스 (AAV) 벡터의 서열과 같은 이의 성분이 부재인 CAR이 형질도입된 숙주 세포를 제공한다. 본원의 개시내용은 CAR 또는 DAR 작제물을 발현하도록 T 세포를 가공하기 위해 보다 효율적이고 보다 저렴한 방법을 제공한다. CAR 또는 DAR 작제물은 상기 작제물을, 비제한적인 예로서 CAR 작제물의 녹인 및 TCR, PD-1, TIM3, GM-CSF, CD7 또는 기타 유전자의 녹아웃을 동시에 수행하기 위해 T 세포 수용체 유전자, PD-1 유전자, CD7 유전자, 또는 TIM3 유전자에 표적화하는 상동성 아암을 포함할 수 있다.
추가의 양상에서, 본원에서는 적어도 하나의 RNA-가이드된 엔도뉴클레아제 또는 RNA-가이드 엔도뉴클레아제를 암호화하는 적어도 하나의 핵산 분자; 적어도 하나의 가이드 RNA 또는 가이드 RNA를 암호화하는 적어도 하나의 핵산 분자; 및 공여자 DNA 분자를 포함하는, 게놈 변형을 위한 시스템이 제공되고, 여기서, 상기 공여자 DNA 분자는 5’ 말단의 20개 뉴클레오타이드 내, 10개 뉴클레오타이드 내 또는 5개 뉴클레오타이드 내에 적어도 하나의 뉴클레오타이드 변형을 포함한다. 일부 구현예에서, 공여자 DNA는 이중 가닥 또는 실질적으로 이중 가닥이고, 이중 가닥 공여자 분자의 하나 가닥의 10개 뉴클레오타이드 내 또는 5개 뉴클레오타이드 내 존재하는 적어도 1개, 적어도 2개 또는 적어도 3개의 뉴클레오타이드 상에 적어도 1개, 적어도 2개, 또는 적어도 3개의 변형을 포함한다. 상기 변형은 예를 들어, 뉴클레오타이드의 당의 포스포로티오에이트 결합 및/또는 2’-O 메틸화와 같은 골격 변형일 수 있다. 공여자 DNA는 적어도 250 nt 또는 bp의 길이일 수 있고, 적어도 300, 400, 500, 600, 700, 800, 900, 또는 1000 nt 또는 bp의 길이일 수 있고, 일부 구현예에서, 2000nt 또는 bp의 길이 초과일 수 있고, 예를 들어, 비제한적인 예로서, 약 0.5 및 4 kb 길이, 또는 약 1 kb 내지 3.5 kb 길이, 또는 약 1.5 kb 내지 약 2.8 kb 길이, 또는 약 1.8 kb 내지 약 3 kb길이일 수 있다. 공여자 DNA는 게놈으로 통합될 관심 대상의 서열을 플랭킹하는 상동성 아암(HA)을 가질 수 있다. 관심 대상의 서열은 예를 들어, 하나 이상의 항체 또는 수용체 도메인을 포함하는 작제물의 발현을 위한 발현 카세트일 수 있다. 상동성 아암은 약 50 내지 약 5000개 뉴클레오타이드 길이, 또는 약 100 내지 1000개 뉴클레오타이드 길이, 예를 들어, 약 120 내지 약 800개 뉴클레오타이드 길이, 또는 약 140개 및 약 600개 뉴클레오타이드 길이일 수 있다.
일부 구현예에서, 본원에 제공된 시스템 및 방법에 사용되는 RNA-가이드 뉴클레아제는 Cas9, Cas12a, CasX, 및 이의 조합으로 이루어진 그룹으로부터 선택된다. 가이드 RNA는 crRNA 및 tracrRNA 둘다의 서열을 갖는 키메라 가이드일 수 있거나 crRNA일 수 있고, 임의로 포스포로티오에이트 (PS) 올리고뉴클레오타이드를 포함하는, 하나 이상의 핵산 변형을 포함할 수 있다. 가이드가 crRNA이고, RNA-가이드된 엔도뉴클레아제가 tracrRNA를 사용하는 경우, 상기 시스템은 또한 tracrRNA를 포함할 수 있다. 예를 들어, Cas9은 crRNA 및 tracrRNA와 함께 사용될 수 있거나, crRNA와 tracrRNA의 구조적 특성을 조합한 키메라 가이드 RNA (때로는 단일 가이드 또는 “sgRNA”로 불리우는)와 함께 사용될 수 있다. 한편, Cas12a는 천연적으로 crRNA 만을 사용하고 연합된 tracrRNA를 갖지 않는다. 다양한 구현예에서, RNA-가이드 엔도뉴클레아제, 가이드 RNA (crRNA 또는 키메라 가이드 RNA일 수 있는) 및 포함되는 경우, tracr RNA는 세포에 도입된 리보뉴클레오단백질 복합체로서 복합체화될 수 있다. 공여자 DNA는 RNA와 함께, 또는 별도로, 예를 들어, 별도의 전기천공 또는 형질감염으로 표적 세포에 도입될 수 있다.
또한 본원에서는 공여자 DNA의 표적 DNA 분자로의 부위-특이적 통합을 위한 방법이 제공되고, 여기서, 상기 방법은 세포에 적어도 하나의 RNA-가이드된 엔도뉴클레아제 또는 RNA 가이드된 엔도뉴클레아제를 암호화하는 핵산 분자; 적어도 하나의 가공된 가이드 RNA 또는 가공된 가이드 RNA를 암호화하는 적어도 하나의 핵산 분자; 및 적어도 하나의 핵산 변형을 포함하는 공여자 DNA 분자를 도입함을 포함하고; 여기서, 상기 가이드 RNA는 표적 DNA에서 표적 부위 서열과 하이브리드화하도록 디자인된 표적 서열을 포함하고, 상기 공여자 DNA는 표적 부위에서 표적 DNA 분자로 삽입된다. 공여자 DNA는 예를 들어, 적어도 250개 뉴클레오타이드 또는 염기쌍 길이, 적어도 500개 뉴클레오타이드 또는 염기쌍, 적어도 1000개 뉴클레오타이드 또는 염기쌍, 적어도 1500개 뉴클레오타이드 또는 염기쌍, 적어도 2000개 뉴클레오타이드 또는 염기쌍, 적어도 2500개 뉴클레오타이드 또는 염기쌍, 또는 적어도 3000개 뉴클레오타이드 또는 염기쌍 (bp) 길이일 수 있고, 여기서, 상기 공여자 단편은 이중 가닥 또는 실질적으로 이중 가닥 분자로서 세포에 전달될 수 있다. 일부 구현예에서, RNA-가이드된 엔도뉴클레아제는 단백질로서 세포에 도입된다. 일부 구현예에서, 가이드 RNA는 RNA 분자로서 세포에 도입된다. 예시적인 구현예에서, RNA-가이드된 엔도뉴클레아제, 가이드 RNA, 및 경우에 따라, tracrRNA은 리보뉴클레오단백질 복합체 (RNP)로서 세포에 도입된다. 다양한 예에서, 상기 RNA-가이드된 엔도뉴클레아제는 Cas12a 엔도뉴클레아제이고, Cas12a의 경우에, crRNA인 가이드 RNA와 복합체화된 RNP로서 세포에 전달된다(예를 들어, 전기천공 또는 리포좀 전달에 의해).
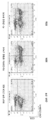
추가로, 제2 표적 유전자좌의 표적화된 녹아웃과 조합된 제1 표적 유전자좌로의 공여자 DNA의 부위-특이적 통합을 위한 방법이 제공된다. 제1 유전자좌에서 녹인/녹아웃 및 제2 유전자좌의 녹아웃은 하나의 형질전환에서 공여자 DNA, RNA-가이드된 엔도뉴클레아제 및 제1 유전자좌를 표적화하는 가이드, 및 RNA 가이드된 엔도뉴클레아제 및 제2 유전자좌를 표적화하는 가이드를 도입하는 단일 형질감염 이벤트에 의해 수행될 수 있다. 상기 방법은 세포에 제1 유전자좌를 표적화하는 제1 가공된 가이드 RNA와 복합체화된 제1 RNA-가이드된 엔도뉴클레아제; 제2 유전자좌를 표적화하는 제2 가공된 가이드 RNA와 복합체화된 제2 RNA-가이드된 엔도뉴클레아제; 및 공여자 DNA 분자를 동시에 도입하는 단계를 포함하고; 여기서, 상기 제1 가이드 RNA는 상기 표적 DNA에서 제1 표적 부위와 하이브리드화하도록 디자인된 표적 서열을 포함하고, 상기 공여자 DNA는 상기 제1 표적 부위에서 표적 DNA 분자에 삽입되고, 상기 제2 유전자좌는 상기 제2 RNA-가이드된 엔도뉴클레아제에 의한 변형에 의해 붕괴된다. 공여자 DNA는 적어도 1개, 적어도 2개, 적어도 3개의 핵산 변형을 가질 수 있고, 예를 들어, 적어도 250개 뉴클레오타이드 또는 염기쌍 길이, 적어도 500개 뉴클레오타이드 또는 염기쌍, 적어도 1000개 뉴클레오타이드 또는 염기쌍, 적어도 1500개 뉴클레오타이드 또는 염기쌍, 적어도 2000개 뉴클레오타이드 또는 염기쌍, 적어도 2500개 뉴클레오타이드 또는 염기쌍, 또는 적어도 3000개 뉴클레오타이드 또는 염기쌍 (bp) 길이일 수 있고, 여기서, 상기 공여자 단편은 이중 가닥 또는 실질적으로 이중 가닥 분자로서 세포에 전달될 수 있다. 상기 공여자 DNA는 유전자를 발현하기 위한 작제물과 같은 관심 대상의 서열을 플랭킹하는 상동성 아암을 갖고, 여기서, 상기 상동성 아암은 숙주 게놈에서 제1 표적 부위에 근접한 서열과 상동성을 갖는다. 제2 유전자좌는 바람직하게 이의 녹아웃이 요구되는 유전자 내 부위이다. 공여자 DNA의 제1 유전자좌로의 혼입 및 제2 유전자좌의 녹아웃은 형질감염된 세포 집단의 적어도 10%, 적어도 20%, 적어도 30%, 적어도 40%, 적어도 50%, 또는 적어도 60%로 존재할 수 있다.
본원에서는 세포에 2개의 RNP: 제1 유전학적 유전자좌를 표적화하기 위한 가이드 RNA를 포함하는 제1 RNP 및 제2 유전학적 유전자좌를 표적화하기 위한 가이드 RNA를 포함하는 제2 RNP를 전달함에 의해 2개의 상이한 유전학적 유전자좌에서 포유동물 세포, 예를 들어, 사람 세포, 예를 들어, 1차 사람 T 세포를 유전학적으로 변형시키기 위한 방법이 제공된다. 제1 및 제2 RNP는 동일하거나 상이한 cas 단백질을 포함할 수 있고, 상기 세포에 동시에 또는 순차적으로 전달될 수 있다. 예를 들어, 제1 RNP는 cas9 단백질을 포함할 수 있고, 제2 RNP는 cas12a 단백질을 포함할 수 있거나, 그 반대일 수 있다. 대안적으로, 제1 및 제2 RNA 둘다는 cas12a 단백질을 포함할 수 있다. 제1 유전학적 유전자좌에 대해 상동성 아암을 갖는 공여자 DNA는 또한 제1 RNP와 동시에 또는 후기 또는 조기 시점에 세포에 전달될 수 있다. 공여자 DNA가 전달되는 구현예에서, 상기 방법은 비-고유 유전학적 작제물의 세포의 제1 유전학적 유전자좌로의 삽입을 포함할 수 있고, 여기서, 상기 제1 유전학적 유전자좌는 비-고유 유전학적 작제물의 삽입에 의해 및 제2 RNA에 의해 표적화된 세포의 제2 유전학적 유전자좌의 cas-매개된 붕괴에 의해 붕괴될 수 있다. 이들 방법에 의해 변형된 세포는 비-고유 작제물, 예를 들어, 이에 제한되지 않지만, CAR 또는 DAR 작제물을 발현할 수 있고, 제1 및 제2 유전학적 유전자좌에서 내인성 유전자의 감소된 발현을 나타낼 수 있다. 예를 들어, 제1 및 제2 유전학적 유전자좌는 세포에 전달되는 cas 단백질 및 복합체화된 가이드 RNA에 의해 돌연변이될 수 있다. 제1 및 제2 유전자좌에서 유전자는 붕괴되어 유전자 발현을 크게 감소시키거나 제거(녹아웃)할 수 있다. 공여자 DNA는 적어도 하나의 가닥에 대한 적어도 2개의 핵산 변형을 갖는 이중 가닥 공여자 DNA와 같이, 본원에 제공된 바와 같은 임의의 공여자 DNA일 수 있다. 공여자 DNA는 바람직하게 유전학적 작제물 (예를 들어, CAR 또는 DAR 암호화 서열)을 플랭킹하는 제1 유전학적 유전자좌의 서열을 포함하는 상동성 아암을 갖는다.
본원에 제공된 상기 시스템, 조성물 및 방법의 다양한 구현예에서, 공여자 DNA는 적어도 2개의 변형된 뉴클레오타이드를 포함하고, 이는 동일하거나 상이한 변형을 가질 수 있고, 바람직하게 공여자 DNA의 하나의 가닥의 5’ 말단의 10개 뉴클레오타이드 또는 5개 뉴클레오타이드 내에 존재한다. 일부 구현예에서, 공여자 DNA는 이중 가닥이고, 하나 이상의 뉴클레오타이드 변형은 공여자 DNA 분자의 단일 가닥 상에 존재한다. 일부 구현예에서, 공여자 DNA는 이중 가닥이고, 하나 이상의 뉴클레오타이드 변형은 변형된 가닥의 5’ 말단의 20개 뉴클레오타이드, 10개 뉴클레오타이드 또는 5개 뉴클레오타이드 내의 공여자 DNA 분자의 단일 가닥 상에 존재한다. 일부 구현예에서, 공여자 DNA는 포스포르아미디트 또는 포스포로티오에이트 변형과 같은 골격 변형을 포함한다. 일부 구현예에서, 공여자 DNA는 뉴클레오타이드의 당 모이어티의 변형을 포함한다. 일부 구현예에서, 공여자 DNA는 이중 가닥이고, 공여자 DNA 준자의 단일 가닥의 5’ 말단의 5개 뉴클레오타이드 내 적어도 1개, 적어도 2개 또는 적어도 3개의 포스포로티오에이트 변형을 포함하고 추가로 공여자 DNA 분자의 단일 가닥의 5’ 말단의 5개 뉴클레오타이드 내 적어도 1개, 적어도 2개, 또는 적어도 3개의 2’-O-메틸화된 뉴클레오타이드를 포함한다. 다양한 구현예에서, 공여자 DNA는 예를 들어, 발현 카세트와 같은 관심 대상의 DNA 서열을 플랭킹하는 상동성 아암을 포함하고, 여기서, 상기 상동성 아암은 RNA-가이드 엔도뉴클레아제의 표적 부위의 어느 한 측면 상의 표적 게놈 내 부위와 상동성을 갖는다. 상동성 아암은 약 50 내지 약 2000 nt 길이일 수 있고, 예를 들어, 100 내지 1000개 nt 길이 또는 150 내지 650 nt 길이, 예를 들어, 150 내지 350 nt 길이 또는 150 내지 200 nt 길이일 수 있다. 다양한 구현예에서, 공여자 DNA 분자는 변형된 가닥 상에 2개 이상의 뉴클레오타이드 변형을 갖고 반대 가닥은 말단 포스페이트를 포함한다.
RNA-가이드된 엔도뉴클레아제는 cas 단백질일 수 있고, 비제한적인 예로서 Cas9, Cas12a, 또는 casX 단백질일 수 있다. 상기 방법의 다양한 구현예에서, 적어도 하나의 RNA-가이드된 엔도뉴클레아제 및 적어도 하나의 RNA 가이드는 하나 이상의 리보뉴클레오단백질 복합체 (RNP)로서 세포에 도입된다. 다양한 구현예에서, 제1 RNP는 cas 단백질 및 제1 가이드 RNA와 함께 형성되고, 제2 RNP는 cas 단백질 및 제2 가이드 RNA의 별도의 항온처리에서 형성된다. 각각의 RNP에 대한 cas 단백질은 동일하거나 상이할 수 있다. 예를 들어, 제1 RNP는 cas9와 함께 형성될 수 있고, 제2 RNP는 cas12와 함께 형성될 수 있다. cas9 단백질을 포함하는 하나 이상의 RNP는 일부 구현예에서 tracrRNA를 추가로 포함할 수 있다. 2개의 RNP, 및 임의로 공여자 DNA는 다중 부위 유전자 편집을 위해 세포에 첨가될 수 있고, 여기서, 상기 편집된 부위 중 적어도 하나는 임의로 DNA 공여자를 혼입한다. RNP는 예를 들어, 전기천공 또는 리포좀 전달을 포함하는 임의의 실행가능한 수단에 의해 표적 세포에 도입될 수 있다. 공여자 DNA는 하나 이상의 RNP와 동시에 또는 별도로 세포에 전달될 수 있다.
상기 방법을 사용하여 조류, 어류, 곤충 및 포유동물 세포를 포함하는 동물의 세포를 포함하는 진핵 세포의 게놈을 변형시킬 수 있다. 다양한 구현예에서, 이의 게놈이 본원에 제공된 방법 및 시스템을 사용하여 조작된 세포는 포유동물 세포이고, 사람 세포일 수 있다. 본원에 제공된 방법에 사용되는 세포는 세포주일 수 있거나, 예를 들어, T 세포 및 NK 세포를 포함하는 줄기 세포 또는 조혈 세포와 같은 1차 세포일 수 있다.
본원에서 추가로 사람 1차 T 세포일 수 있는 가공된 1차 T 세포가 포함되고, 여기서, 상기 세포는 RNA 가이드된 뉴클레아제의 제1 표적 부위를 포함하는 제1 유전학적 유전자좌에서 게놈으로 통합된 비-고유 유전학적 작제물 및 RNA-가이드된 뉴클레아제의 제2 표적 부위를 포함하는 제2 유전학적 유전자좌에서 돌연변이를 포함한다. 제2 게놈 유전자좌에서 돌연변이는 예를 들어, cas 뉴클레아제 활성의 결과로서 및 세포에 의한 잘못된 복구의 결과로서 제2 표적 부위에 삽입된 삽입 또는 결실에 의해 녹아웃 돌연변이일 수 있다. 제2 표적 부위는 이의 감소된 발현이 요구되는 유전자에 있을 수 있다. 비-고유 유전학적 작제물을 포함하는 공여자 단편이 삽입된 제1 표적 부위는 또한 이의 감소된 발현이 요구되는 유전자에 있을 수 있다. 본원에 사용된 바와 같은 “표적 부위”는 RNA-가이드된 뉴클레아제에 의해 인지되는 PAM 서열에 인접한 서열을 의미한다. 상기 PAM-인접한 서열(예를 들어 17-22개 뉴클레오타이드 길이의)은 가이드 RNA에서 표적 서열로서 사용되어 cas9 또는 cas12a와 같은 cas 뉴클레아제의 활성을 지시하여 게놈 DNA의 표적 부위를 절단할 수 있다.
비-고유 유전학적 작제물은 본원에 제공된 cas-매개된 방법을 사용한 통합을 위해 공여자 단편 상에 도입된 세포에 천연적으로 존재하지 않는 유전학적 작제물이다. 가공된 1차 T 세포는 비-고유 유전학적 작제물을 발현할 수 있고, 제2 유전학적 유전자좌에서 유전자의 감소된 발현을 가질 수 있고, 또한 제1 유전자학적 유전자좌에서 유전자의 감소된 발현을 가질 있고, 여기서, 제1 유전학적 유전자좌에서 유전자는 비-고유 유전학적 작제물의 삽입에 의해 붕괴될 수 있다.
비-고유 유전학적 작제물은 하나 이상의 면역글로불린 도메인을 갖는 하나 이상의 폴리펩타이드를 암호화하는 유전학적 작제물일 수 있다. 일부 구현예에서, 비-고유 유전학적 작제물은 CAR 또는 DAR을 암호화하는 작제물이다. 따라서, 일부 구현예에서, 1차 사람 T 세포가 제공되고 상기 세포는 게놈으로 통합된 CAR 또는 DAR-암호화 작제물과 같은 비-고유 유전학적 작제물을 포함하고, 여기서, 상기 세포는 작제물을 발현하고 (예를 들어, CAR 또는 DAR 분자를 발현한다), CAR 또는 DAR (또는 기타) 작제물의 삽입에 의해 붕괴된 유전자의 감소된 발현을 가질 수 있고, 세포가 제2 유전자의 감소된 발현을 유도하는 제2 부위 돌연변이를 가질 수 있다. 유전학적 작제물의 삽입에 의해 붕괴될 수 있는 유전자는 제한 없이, TCR, TRAC, PD-1, CTL4-A, TIM3, LAG3, GM-CSF, 및 CD7을 암호화하는 유전자를 포함한다. CAR 또는 DAR은 이에 제한되지 않지만 BCMA, CD19, CD20, CD38, CD123, 또는 임의의 다른 종양 세포 표면 항원과 같은 종양 세포 표면 항원에 결합하도록 디자인된 CAR 또는 DAR일 수 있다. 다양한 예에서, 본원에 제공된 세포 집단의 적어도 25%는 CAR, DAR, 또는 다른 도입된 작제물을 발현할 수 있고 제2 유전학적 유전자좌에서 유전자의 감소된 발현을 나타낼 수 있다. 다양한 예에서, 본원에 제공된 바와 같은 세포 집단의 적어도 25%는 CAR, DAR, 또는 다른 도입된 작제물을 발현할 수 있고, 비-고유 작제물이 도입된 제1 유전학적 유전자좌에서 유전자의 감소된 발현을 나타내고, 제2 유전학적 유전자좌에서 유전자의 감소된 발현을 나타낼 수 있다. 세포는 본원에 제공된 방법을 사용하여 제조될 수 있다.
여전히 또는 양상에서는 본원에 입증된 바와 같이 CD7 유전자에 삽입된 CAR 또는 DAR 작제물을 갖는 사람 1차 T 세포가 제공된다. CD7 유전자 내 CAR 또는 DAR 삽입을 갖는 T 세포 집단은 CAR 또는 DAR 발현, 및 CD7의 감소된 발현을 입증할 수 있다.
도 1 A)는 우측 구조에서 이들이 프라이머에 존재할 수 있는 바와 같이 뉴클레오타이드 간 결합의 포스포로티오에이트 (PS) 변형을 보여주는 화학적 도식을 제공한다. 좌측 상에 올리고뉴클레오타이드에서 보여주는 뉴클레오타이드는 (비변형된) 포스포디에스테르 결합을 통해 부착된다. B)는 2개의 PS 결합을 갖는 올리고뉴클레오타이드의 화학적 도식을 제공하고, 상기 결합은 5’-최외곽 뉴클레오타이드를 상기 올리고뉴클레오타이드 내 “다운스트림”의 다음 뉴클레오타이드에 연결시키고, 이는 이어서 PS 결합에 의해 상기 올리고뉴클레오타이드의 이어지는 다운스트림 뉴클레오타이드에 부착된다. 올리고뉴클레오타이드의 5’-최외곽 뉴클레오타이드는 2’ O-메틸 변형을 포함한다.
도 2 A)는 단일쇄 가변 단편 (scFv)에 이어서 CD8a 리더 펩타이드에 이어서 CD28 힌지-CD28 막관통-세포내 영역에 이어서 CD3 제타 세포내 도메인을 암호화하는 서열을 갖는 개방 판독 프레임을 포함하는 CAR 공여자 DNA 작제물의 다이아그램이다. 암호화 서열은 JeT 프로모터(서열번호 3)에 이어지고 작제물은 이 경우에 프로모터 및 암호화 서열을 플랭킹하는, 사람 TRAC 유전자좌의 서열과 매칭하는 상동성 아암(HA)을 포함한다. 이는 공여자 DNA 작제물의 구조 (상부) 및 올바른 녹인을 확인하기 위한 프라이머 디자인 (하부)을 보여준다. 이것은 공여자 DNA를 생성하기 위해 사용되는 주형 DNA의 다이아그램을 제공한다. 항-CD38A2는 CD38 CAR 전이유전자를 함유하고, 이의 발현은 JeT 프로모터에 의해 구동되고 5’ 및 3’ 측면 상에서 상동성 아암에 의해 플랭킹되어 있어 표적화된 통합을 가능하게 한다. B)는 CAR내 위치한 하나의 프라이머 및 5’ 및 3’ 말단 둘다에서 상동성 아암의 외부의 TRAC 내 하나의 프라이머를 사용한 증폭으로 각각의 통합이 표적화된 통합 부위에 있는 경우 1371-bp 및 1591-bp 생성물을 생성시키는 CAR 통합을 확인하기 위해 사용되는 PCR 프라이머의 위치를 지적하는 동일한 다이아그램을 보여준다.
도 3 A)는 항-CD38 CAR, 및 TRAC 유전자좌를 표적화하는 가이드 RNA를 포함하는 RNP를 발현하기 위한 작제물을 포함하는 공여자 DNA로 형질전환시킨 후 8일째 PBMC의 유동 세포측정 플롯을 제공한다. CAR 카세트는 TRAC 유전자의 엑손 1에서 통합 표적 부위를 플랭킹하는 TRAC 유전자좌 서열과 상동성을 갖는 상동성 아암에 의해 플랭킹되어 있다. Y 축은 세포 크기를 보여준다. 항-CD38 작제물 발현은 x 축에 따른다. 음성 대조군: 어떠한 공여자 DNA로 표적 세포가 형질전환되지 않음; 변형 부재- 공여자 DNA는 어떠한 화학적 변형을 갖지 않음; PS 변형: 3개의 포스포로티오에이트 결합이 5’ 최외곽 5개의 뉴클레오타이드 골격 위치 내에 존재함; PS + 2’-OMe: 포스포로티오에이트 결합에 추가로, 공여자의 5’ 최외곽 5개 뉴클레오타이드 내 3개의 뉴클레오타이드는 PS 변형 외에 2’-OMe를 포함함; TCR Ko/레트로바이러스 작제물: 세포는 공여자 DNA의 부재하에 RNP로 형질감염시켜 TCR 유전자를 녹아웃시키고 레트로바이러스를 형질도입하여 항-CD38 CAR을 발현함. B)는 형질감염 후 10일째에 A)에서와 동일한 배양물에 대해 수행된 유동 세포측정의 결과를 제공한다. C)는 형질감염 후 20일째에 이중으로 변형된 공여자 DNA 및 대조군 (단지 TRAC 녹아웃 및 레트로바이러스를 사용한 TRAC 녹아웃)을 제공받은 배양물에 대해 수행된 유동 세포측정의 결과를 제공한다.
도 4는 표적화된 TRAC (엑손1) 부위에서 공여자 DNA의 통합을 보여주는 PCR 생성물의 겔을 보여준다. 1차 사람 T 세포는 단독으로 또는 ssDNA와 함께 TRAC RNP를 사용하여 전기천공하였다. PCR을 사용하여 전기천공 2주 후에 TRAC 유전자좌에서 통합된 항-CD38A2 CAR 전이유전자의 존재를 확인하였다(5’ 및 3’ 통합 영역으로부터의 생성물을 도시하는, 레인 3 및 6). 어떠한 밴드도 형질전환되지 않은 ATC (레인 1 및 4) 또는 RNP를 표적화하는 TRAC 엑손 1으로 형질전환되었지만 공여자 DNA를 제공받지 않은 T 세포 (레인 2 및 5)에서 관찰되지 않았다.
도 5는 대조군으로서 활성화된 T 세포 (ATC, 별표), TCR 녹아웃 ATC, 항-CD38A2 레트로바이러스 형질도입된 CART 세포 RV CART(검정선), TRAC 녹아웃 레트로바이러스 형질도입된 CART 세포(점), 포스포로티오에이트 변형된 ss 공여자 DNA 녹인과 함께 TRAC 녹아웃(점선), 포스포로티오에이트 및 2’ O-메틸 변형된 ssDNA 녹인과 함께 TRAC 녹아웃 (점선 및 점)을 사용한 세포독성 검정 결과를 보여주는 그래프이다. 상기 플롯은 CD38을 발현하지 않는 RPE-표지된 K562 세포를 향하여 관찰된 세포독성을 보정한 후 GFP-표지된 RPMI8226 CD38-발현 세포를 향한 퍼센트 세포독성을 제공한다.
도 6은 K52 또는 RPMI18226 세포와 함께 동시 배양된 항-CD38 CART 세포 및 대조군을 사용한 사이토킨 분비 검정 결과의 그래프를 제공한다. 시험된 T 세포 배양물은 도 5에 제공된 바와 같다.
도 7은 상이한 길이의 상동성 아암 (HA)을 갖는 공여자 DNA를 시험한 결과를 제공한다. 배양물은 TCR (CD3) 발현 (Y 축) 및 항-CD38 발현 (X 축)의 상실에 대한 유동 세포측정에 의해 평가하였다.
도 8은 공여자 DNA 분자의 하나의 가닥의 5’ 말단에 근접하게 3개의 PS 결합 및 3개의 2’O 메틸 뉴클레오타이드의 첨가에 의해 변형된 이중 가닥 공여자 DNA를 시험한 결과를 제공한다. 배양물은 TCR 발현 (Y 축) 및 항-CD38 발현 (X 축)의 상실에 대한 유동 세포측정에 의해 평가하였다.
도 9는 항-CD19 CAR을 발현하기 위한 카세트를 포함하는, ds PS 및 2’-OMe-변형된 공여자 DNA로 형질감염된 세포에 대한 유동 세포측정의 결과를 제공한다. 공여자는 RNA로 동시 형질감염에 의해 TRAC 엑손 1 유전자좌로 지시되었다. TCR 발현은 Y 축 및 Y 축 상의 항-CD19 CAR 발현에 대해 결정되었다.
도 10은 항-BCMA CAR을 발현하기 위한 카세트를 포함하는, ds PS 및 2’-OMe-변형된 공여자 DNA로 형질감염된 세포에 대한 유동 세포측정의 결과를 제공한다. 공여자는 RNA로 동시 형질감염에 의해 TRAC 엑손 1 유전자좌로 지시되었다. TCR 발현은 Y 축 및 Y 축 상의 항-BCMA CAR 발현에 대해 결정되었다.
도 11은 항-CD38 CAR을 발현하기 위한 카세트를 포함하는, ds PS 및 2’-OMe-변형된 공여자 DNA로 형질감염된 세포에 대한 유동 세포측정의 결과를 제공한다. 공여자는 RNA로 동시 형질감염에 의해 TRAC 엑손 3 유전자좌로 지시되었다. TCR 발현은 Y 축 및 Y 축 상의 항-CD38 CAR 발현에 대해 결정되었다.
도 12는 항-CD19 CAR을 발현하기 위한 카세트를 포함하는, ds PS 및 2’-OMe-변형된 공여자 DNA로 형질감염된 세포에 대한 유동 세포측정의 결과를 제공한다. 하나의 배양물에서, TRAC 엑손 3으로부터 유래된 상동성 아암을 갖는 공여자는 엑손 3 가이드 RNA (2번째 패널)를 갖는 RNP로 동시형질감염시킴에 의해 TRAC 엑손 3 유전자좌로 지시되었다. 또 다른 배양물에서, TRAC 엑손 1로부터 유래된 상동성 아암을 갖는 공여자는 엑손 1 가이드 RNA (2번째 패널)를 갖는 RNP로 동시형질감염시킴에 의해 TRAC 엑손 1 유전자좌로 지시되었다. TCR 발현은 Y 축 및 Y 축 상의 항-CD19 CAR 발현에 대해 결정되었다.
도 13은 항-C38 CAR을 발현하기 위한 카세트 및 TRAC 유전자 또는 PD-1 유전자로부터 유래된 상동성 아암을 포함하는, ds PS 및 2’-OMe-변형된 공여자 DNA로 형질감염된 세포에 대한 유동 세포측정의 결과를 제공한다. 하나의 배양물에서, TRAC 엑손 1으로부터 유래된 상동성 아암을 갖는 공여자는 엑손 1 가이드 RNA (3번째 패널)를 갖는 RNP로 동시형질감염시킴에 의해 TRAC 엑손 1 유전자좌로 지시되었다. 또 다른 배양물에서, 공여자는 PD-1 유전자좌로부터 유래된 상동성 아암을 갖고 PD-I 유전자 가이드 RNA (4번째 패널)를 갖는 RNP로 동시형질감염시킴에 의해 PD-1 유전자로 지시되었다. TCR 발현은 Y 축 및 Y 축 상의 항-CD38 또는 PD-1 발현에 대해 결정되었다.
도 14는 항-CD38 CAR 작제물을 포함하는 이중으로 변형된 (PS 및 2’-OMe) 공여자 단편으로 형질감염된 T 세포 배양물을 사용한 세포독성 검정의 결과를 제공하고 PD-1 유전자-유래된 상동성 아암은 PD-1 유전자로부터 표적 서열을 갖는 가이드 RNA를 포함하는 RNP에 의해 PD-1 유저자에 표적화되었다.
도 15는 Cas9 단백질 (패널 4) 또는 Cas12a RNP (패널 5)를 포함하는 RNP와 함께, 항-CD38 DAR 작제물을 포함하는 공여자 DNA로 형질감염시킨 세포의 유동 세포측정의 결과를 제공한다. T 세포 수용체 발현은 Y 축 및 Y 축 상의 항-CD38 DAR 작제물의 발현에 대해 도시된다. 패널 2 및 3은 공여자 단편의 부재하에, Cas9 단백질 및 Cas12a 단백질 각각을 포함하는 RNP로 T 세포를 형질감염시킨 결과를 제공한다.
도 16은 항-CD38 DAR 작제물 및 Cas9 RNP 또는 Cas12a RNP로 형질감염된 T 세포를 사용하는 세포독성 검정 결과의 그래프를 제공한다.
도 17은 비변형된 활성화된 T 세포 (ATC) (좌측 패널), Tim3 유전자를 표적화하는 Cas12a RNP로 형질감염된 T 세포 (중앙 패널), 또는 항-CD38 DAR 작제물을 포함하는 공여자 DNA와 함께 Tim3 유전자를 표적화하는 Cas12a RNP로 형질감염된 T 세포(우측 패널)의 유동 세포측정의 결과를 제공한다.
도 18은 Cas9 RNP와 함께 항-CD38 CAR의 TRAC 유전자좌로의 삽입 동안에 생성된 오프-표적 돌연변이의 게놈 위치 및 비율을 제공하는 표이다.
도 19는 TRAC 유전자좌를 표적화하는 Cas9 RNP에 추가로 GM-CSF 유전자를 표적화하는 Cas9 RNP 및 TRAC 유전자좌로의 삽입을 위한 항-CD38 DAR 공여자 DNA로 형질감염된 T 세포 뿐만 아니라 TRAC 유전자좌를 표적화하는 Cas9 RNP 및 항-CD38 DAR 공여자 DNA로 형질감염된 T 세포의 유동 세포측정 데이터이다. 패널 E 및 H에서 또한 TRAC 유전자좌를 표적화하는 Cas12a RNP에 추가로 GM-CSF 유전자를 표적화하는 Cas12a RNP 및 TRAC 유전자좌로의 삽입을 위한 항-CD38 DAR 공여자 DNA로 형질감염된 T 세포의 유동 세포측정 데이터를 나타낸다.
도 20 A)는 공여자 DNA 없이, TRAC 유전자좌를 표적화하는 Cas12a RNP로 형질감염된 T 세포의 유동 세포측정 데이터를 제공하고, B) TRAC 유전자좌를 표적화하는 Cas12a RNP 및 항-CD20 DAR 작제물 공여자 DNA로 형질감염된 T 세포의 유동 세포측정 데이터를 제공한다.
도 21은 이펙터:표적 세포 비율의 함수로서, 항-CD20 DAR 작제물 및 항-CEA DAR 작제물로 형질감염된 T 세포의 퍼센트 세포독성의 그래프이다. 상기 검정에서 표적 세포는 Daudi 세포이다.
도 22는 A) 인터페론 감마 및 B) 항원 자극 후 항-CD20 DAR 작제물 및 항-CD19 CAR 작제물로 형질감염된 T 세포에 의해 분비된 GMCSF의 양을 보여주는 막대 챠트이다. T 세포는 K562 세포 또는 Daudi 세포로 자극하였다. Daudi 세포 자극만이 막대에 의해 지적된 바와 같이 유의적인 반응을 유도하였다. 어떠한 사이토킨 방출도 비자극된 세포로부터 검출되지 않았다.
도 23은 가공된 T 세포에 의한 T 세포 수용체 (CD3) 및 항-CEA CAR 작제물의 발현을 평가한 유동 세포측정의 결과를 제공한다: A) CD3 (TCR) 발현 및 항-CEA CAR 발현에 대해 평가된 공여자 단편 없이, TRAC 유전자좌를 표적화하는 RNP로 형질감염된 T 세포; B) TRAC 유전자좌를 표적화하는 RNP 및 CD3 (TCR) 발현 및 항-CEA CAR 발현에 대해 평가된 항-CEA CAR 작제물을 포함하는 공여자 단편으로 형질감염된 T 세포; C) CD7 발현 및 항-CEA CAR 발현에 대해 평가된 어떠한 공여자 단편 없이, TRAC 유전자좌를 표적화하는 RNP로 형질감염된 T 세포; 및 D) CD7 유전자좌를 표적화하는 RNP 및 CD7 발현 및 항-CEA CAR 발현에 대해 평가된 항-CEA CAR 작제물을 포함한 공여자 단편으로 형질감염된 T 세포.
도 24는 CD7 유전자좌에 표적화된 항-CEA CAR 작제물로 형질감염된 T 세포, TRAC 유전자좌에 표적화된 항-CEA CAR 작제물로 형질감염된 T 세포; 및 TRAC 유전자좌에서 녹아웃된 T 세포를 사용한 세포독성 검정의 결과를 제공한다. X 축은 상기 검정에서 이펙터 대 표적 세포 비율을 제공한다.
도 25는 TRAC 유전자좌에 표적화된 항-CEA CAR 작제물로 형질감염된 T 세포 및 CD7 유전자좌에 표적화된 항-CEA CAR로 형질감염된 T 세포에 의한 IFNγ 분비의 막대 그래프를 제공한다.
도 2 A)는 단일쇄 가변 단편 (scFv)에 이어서 CD8a 리더 펩타이드에 이어서 CD28 힌지-CD28 막관통-세포내 영역에 이어서 CD3 제타 세포내 도메인을 암호화하는 서열을 갖는 개방 판독 프레임을 포함하는 CAR 공여자 DNA 작제물의 다이아그램이다. 암호화 서열은 JeT 프로모터(서열번호 3)에 이어지고 작제물은 이 경우에 프로모터 및 암호화 서열을 플랭킹하는, 사람 TRAC 유전자좌의 서열과 매칭하는 상동성 아암(HA)을 포함한다. 이는 공여자 DNA 작제물의 구조 (상부) 및 올바른 녹인을 확인하기 위한 프라이머 디자인 (하부)을 보여준다. 이것은 공여자 DNA를 생성하기 위해 사용되는 주형 DNA의 다이아그램을 제공한다. 항-CD38A2는 CD38 CAR 전이유전자를 함유하고, 이의 발현은 JeT 프로모터에 의해 구동되고 5’ 및 3’ 측면 상에서 상동성 아암에 의해 플랭킹되어 있어 표적화된 통합을 가능하게 한다. B)는 CAR내 위치한 하나의 프라이머 및 5’ 및 3’ 말단 둘다에서 상동성 아암의 외부의 TRAC 내 하나의 프라이머를 사용한 증폭으로 각각의 통합이 표적화된 통합 부위에 있는 경우 1371-bp 및 1591-bp 생성물을 생성시키는 CAR 통합을 확인하기 위해 사용되는 PCR 프라이머의 위치를 지적하는 동일한 다이아그램을 보여준다.
도 3 A)는 항-CD38 CAR, 및 TRAC 유전자좌를 표적화하는 가이드 RNA를 포함하는 RNP를 발현하기 위한 작제물을 포함하는 공여자 DNA로 형질전환시킨 후 8일째 PBMC의 유동 세포측정 플롯을 제공한다. CAR 카세트는 TRAC 유전자의 엑손 1에서 통합 표적 부위를 플랭킹하는 TRAC 유전자좌 서열과 상동성을 갖는 상동성 아암에 의해 플랭킹되어 있다. Y 축은 세포 크기를 보여준다. 항-CD38 작제물 발현은 x 축에 따른다. 음성 대조군: 어떠한 공여자 DNA로 표적 세포가 형질전환되지 않음; 변형 부재- 공여자 DNA는 어떠한 화학적 변형을 갖지 않음; PS 변형: 3개의 포스포로티오에이트 결합이 5’ 최외곽 5개의 뉴클레오타이드 골격 위치 내에 존재함; PS + 2’-OMe: 포스포로티오에이트 결합에 추가로, 공여자의 5’ 최외곽 5개 뉴클레오타이드 내 3개의 뉴클레오타이드는 PS 변형 외에 2’-OMe를 포함함; TCR Ko/레트로바이러스 작제물: 세포는 공여자 DNA의 부재하에 RNP로 형질감염시켜 TCR 유전자를 녹아웃시키고 레트로바이러스를 형질도입하여 항-CD38 CAR을 발현함. B)는 형질감염 후 10일째에 A)에서와 동일한 배양물에 대해 수행된 유동 세포측정의 결과를 제공한다. C)는 형질감염 후 20일째에 이중으로 변형된 공여자 DNA 및 대조군 (단지 TRAC 녹아웃 및 레트로바이러스를 사용한 TRAC 녹아웃)을 제공받은 배양물에 대해 수행된 유동 세포측정의 결과를 제공한다.
도 4는 표적화된 TRAC (엑손1) 부위에서 공여자 DNA의 통합을 보여주는 PCR 생성물의 겔을 보여준다. 1차 사람 T 세포는 단독으로 또는 ssDNA와 함께 TRAC RNP를 사용하여 전기천공하였다. PCR을 사용하여 전기천공 2주 후에 TRAC 유전자좌에서 통합된 항-CD38A2 CAR 전이유전자의 존재를 확인하였다(5’ 및 3’ 통합 영역으로부터의 생성물을 도시하는, 레인 3 및 6). 어떠한 밴드도 형질전환되지 않은 ATC (레인 1 및 4) 또는 RNP를 표적화하는 TRAC 엑손 1으로 형질전환되었지만 공여자 DNA를 제공받지 않은 T 세포 (레인 2 및 5)에서 관찰되지 않았다.
도 5는 대조군으로서 활성화된 T 세포 (ATC, 별표), TCR 녹아웃 ATC, 항-CD38A2 레트로바이러스 형질도입된 CART 세포 RV CART(검정선), TRAC 녹아웃 레트로바이러스 형질도입된 CART 세포(점), 포스포로티오에이트 변형된 ss 공여자 DNA 녹인과 함께 TRAC 녹아웃(점선), 포스포로티오에이트 및 2’ O-메틸 변형된 ssDNA 녹인과 함께 TRAC 녹아웃 (점선 및 점)을 사용한 세포독성 검정 결과를 보여주는 그래프이다. 상기 플롯은 CD38을 발현하지 않는 RPE-표지된 K562 세포를 향하여 관찰된 세포독성을 보정한 후 GFP-표지된 RPMI8226 CD38-발현 세포를 향한 퍼센트 세포독성을 제공한다.
도 6은 K52 또는 RPMI18226 세포와 함께 동시 배양된 항-CD38 CART 세포 및 대조군을 사용한 사이토킨 분비 검정 결과의 그래프를 제공한다. 시험된 T 세포 배양물은 도 5에 제공된 바와 같다.
도 7은 상이한 길이의 상동성 아암 (HA)을 갖는 공여자 DNA를 시험한 결과를 제공한다. 배양물은 TCR (CD3) 발현 (Y 축) 및 항-CD38 발현 (X 축)의 상실에 대한 유동 세포측정에 의해 평가하였다.
도 8은 공여자 DNA 분자의 하나의 가닥의 5’ 말단에 근접하게 3개의 PS 결합 및 3개의 2’O 메틸 뉴클레오타이드의 첨가에 의해 변형된 이중 가닥 공여자 DNA를 시험한 결과를 제공한다. 배양물은 TCR 발현 (Y 축) 및 항-CD38 발현 (X 축)의 상실에 대한 유동 세포측정에 의해 평가하였다.
도 9는 항-CD19 CAR을 발현하기 위한 카세트를 포함하는, ds PS 및 2’-OMe-변형된 공여자 DNA로 형질감염된 세포에 대한 유동 세포측정의 결과를 제공한다. 공여자는 RNA로 동시 형질감염에 의해 TRAC 엑손 1 유전자좌로 지시되었다. TCR 발현은 Y 축 및 Y 축 상의 항-CD19 CAR 발현에 대해 결정되었다.
도 10은 항-BCMA CAR을 발현하기 위한 카세트를 포함하는, ds PS 및 2’-OMe-변형된 공여자 DNA로 형질감염된 세포에 대한 유동 세포측정의 결과를 제공한다. 공여자는 RNA로 동시 형질감염에 의해 TRAC 엑손 1 유전자좌로 지시되었다. TCR 발현은 Y 축 및 Y 축 상의 항-BCMA CAR 발현에 대해 결정되었다.
도 11은 항-CD38 CAR을 발현하기 위한 카세트를 포함하는, ds PS 및 2’-OMe-변형된 공여자 DNA로 형질감염된 세포에 대한 유동 세포측정의 결과를 제공한다. 공여자는 RNA로 동시 형질감염에 의해 TRAC 엑손 3 유전자좌로 지시되었다. TCR 발현은 Y 축 및 Y 축 상의 항-CD38 CAR 발현에 대해 결정되었다.
도 12는 항-CD19 CAR을 발현하기 위한 카세트를 포함하는, ds PS 및 2’-OMe-변형된 공여자 DNA로 형질감염된 세포에 대한 유동 세포측정의 결과를 제공한다. 하나의 배양물에서, TRAC 엑손 3으로부터 유래된 상동성 아암을 갖는 공여자는 엑손 3 가이드 RNA (2번째 패널)를 갖는 RNP로 동시형질감염시킴에 의해 TRAC 엑손 3 유전자좌로 지시되었다. 또 다른 배양물에서, TRAC 엑손 1로부터 유래된 상동성 아암을 갖는 공여자는 엑손 1 가이드 RNA (2번째 패널)를 갖는 RNP로 동시형질감염시킴에 의해 TRAC 엑손 1 유전자좌로 지시되었다. TCR 발현은 Y 축 및 Y 축 상의 항-CD19 CAR 발현에 대해 결정되었다.
도 13은 항-C38 CAR을 발현하기 위한 카세트 및 TRAC 유전자 또는 PD-1 유전자로부터 유래된 상동성 아암을 포함하는, ds PS 및 2’-OMe-변형된 공여자 DNA로 형질감염된 세포에 대한 유동 세포측정의 결과를 제공한다. 하나의 배양물에서, TRAC 엑손 1으로부터 유래된 상동성 아암을 갖는 공여자는 엑손 1 가이드 RNA (3번째 패널)를 갖는 RNP로 동시형질감염시킴에 의해 TRAC 엑손 1 유전자좌로 지시되었다. 또 다른 배양물에서, 공여자는 PD-1 유전자좌로부터 유래된 상동성 아암을 갖고 PD-I 유전자 가이드 RNA (4번째 패널)를 갖는 RNP로 동시형질감염시킴에 의해 PD-1 유전자로 지시되었다. TCR 발현은 Y 축 및 Y 축 상의 항-CD38 또는 PD-1 발현에 대해 결정되었다.
도 14는 항-CD38 CAR 작제물을 포함하는 이중으로 변형된 (PS 및 2’-OMe) 공여자 단편으로 형질감염된 T 세포 배양물을 사용한 세포독성 검정의 결과를 제공하고 PD-1 유전자-유래된 상동성 아암은 PD-1 유전자로부터 표적 서열을 갖는 가이드 RNA를 포함하는 RNP에 의해 PD-1 유저자에 표적화되었다.
도 15는 Cas9 단백질 (패널 4) 또는 Cas12a RNP (패널 5)를 포함하는 RNP와 함께, 항-CD38 DAR 작제물을 포함하는 공여자 DNA로 형질감염시킨 세포의 유동 세포측정의 결과를 제공한다. T 세포 수용체 발현은 Y 축 및 Y 축 상의 항-CD38 DAR 작제물의 발현에 대해 도시된다. 패널 2 및 3은 공여자 단편의 부재하에, Cas9 단백질 및 Cas12a 단백질 각각을 포함하는 RNP로 T 세포를 형질감염시킨 결과를 제공한다.
도 16은 항-CD38 DAR 작제물 및 Cas9 RNP 또는 Cas12a RNP로 형질감염된 T 세포를 사용하는 세포독성 검정 결과의 그래프를 제공한다.
도 17은 비변형된 활성화된 T 세포 (ATC) (좌측 패널), Tim3 유전자를 표적화하는 Cas12a RNP로 형질감염된 T 세포 (중앙 패널), 또는 항-CD38 DAR 작제물을 포함하는 공여자 DNA와 함께 Tim3 유전자를 표적화하는 Cas12a RNP로 형질감염된 T 세포(우측 패널)의 유동 세포측정의 결과를 제공한다.
도 18은 Cas9 RNP와 함께 항-CD38 CAR의 TRAC 유전자좌로의 삽입 동안에 생성된 오프-표적 돌연변이의 게놈 위치 및 비율을 제공하는 표이다.
도 19는 TRAC 유전자좌를 표적화하는 Cas9 RNP에 추가로 GM-CSF 유전자를 표적화하는 Cas9 RNP 및 TRAC 유전자좌로의 삽입을 위한 항-CD38 DAR 공여자 DNA로 형질감염된 T 세포 뿐만 아니라 TRAC 유전자좌를 표적화하는 Cas9 RNP 및 항-CD38 DAR 공여자 DNA로 형질감염된 T 세포의 유동 세포측정 데이터이다. 패널 E 및 H에서 또한 TRAC 유전자좌를 표적화하는 Cas12a RNP에 추가로 GM-CSF 유전자를 표적화하는 Cas12a RNP 및 TRAC 유전자좌로의 삽입을 위한 항-CD38 DAR 공여자 DNA로 형질감염된 T 세포의 유동 세포측정 데이터를 나타낸다.
도 20 A)는 공여자 DNA 없이, TRAC 유전자좌를 표적화하는 Cas12a RNP로 형질감염된 T 세포의 유동 세포측정 데이터를 제공하고, B) TRAC 유전자좌를 표적화하는 Cas12a RNP 및 항-CD20 DAR 작제물 공여자 DNA로 형질감염된 T 세포의 유동 세포측정 데이터를 제공한다.
도 21은 이펙터:표적 세포 비율의 함수로서, 항-CD20 DAR 작제물 및 항-CEA DAR 작제물로 형질감염된 T 세포의 퍼센트 세포독성의 그래프이다. 상기 검정에서 표적 세포는 Daudi 세포이다.
도 22는 A) 인터페론 감마 및 B) 항원 자극 후 항-CD20 DAR 작제물 및 항-CD19 CAR 작제물로 형질감염된 T 세포에 의해 분비된 GMCSF의 양을 보여주는 막대 챠트이다. T 세포는 K562 세포 또는 Daudi 세포로 자극하였다. Daudi 세포 자극만이 막대에 의해 지적된 바와 같이 유의적인 반응을 유도하였다. 어떠한 사이토킨 방출도 비자극된 세포로부터 검출되지 않았다.
도 23은 가공된 T 세포에 의한 T 세포 수용체 (CD3) 및 항-CEA CAR 작제물의 발현을 평가한 유동 세포측정의 결과를 제공한다: A) CD3 (TCR) 발현 및 항-CEA CAR 발현에 대해 평가된 공여자 단편 없이, TRAC 유전자좌를 표적화하는 RNP로 형질감염된 T 세포; B) TRAC 유전자좌를 표적화하는 RNP 및 CD3 (TCR) 발현 및 항-CEA CAR 발현에 대해 평가된 항-CEA CAR 작제물을 포함하는 공여자 단편으로 형질감염된 T 세포; C) CD7 발현 및 항-CEA CAR 발현에 대해 평가된 어떠한 공여자 단편 없이, TRAC 유전자좌를 표적화하는 RNP로 형질감염된 T 세포; 및 D) CD7 유전자좌를 표적화하는 RNP 및 CD7 발현 및 항-CEA CAR 발현에 대해 평가된 항-CEA CAR 작제물을 포함한 공여자 단편으로 형질감염된 T 세포.
도 24는 CD7 유전자좌에 표적화된 항-CEA CAR 작제물로 형질감염된 T 세포, TRAC 유전자좌에 표적화된 항-CEA CAR 작제물로 형질감염된 T 세포; 및 TRAC 유전자좌에서 녹아웃된 T 세포를 사용한 세포독성 검정의 결과를 제공한다. X 축은 상기 검정에서 이펙터 대 표적 세포 비율을 제공한다.
도 25는 TRAC 유전자좌에 표적화된 항-CEA CAR 작제물로 형질감염된 T 세포 및 CD7 유전자좌에 표적화된 항-CEA CAR로 형질감염된 T 세포에 의한 IFNγ 분비의 막대 그래프를 제공한다.
정의
달리 구체적으로 지적되지 않는 경우, 본원에 사용된 모든 기술적 및 과학적 용어는 당업자에 의해 통상적으로 이해되는 바와 동일한 의미를 갖는다. 추가로, 본원에 기재된 방법 또는 물질과 유사하거나 균등한 임의의 방법 또는 물질은 본원의 개시내용의 수행에 사용될 수 있다. 본원에 인용된 모든 공보는 이들의 전문이 참조로 인용된다.
본원에 사용된 바와 같은 용어 "a," "an," 또는 "the"는 하나의 구성원과의 양상 뿐만 아니라 하나 초과의 구성원과의 양상을 포함한다. 예를 들어, 단수형("a," "an" 및 "the")은, 문맥상 명백하게 달리 지시하지 않는 한, 복수형의 대상물을 포함한다. 따라서, 예를 들어, "세포 (a cell)"에 대한 언급은 복수의 상기 세포를 포함하고 "상기 제제(The agent)”에 대한 언급은 당업자에게 공지된 하나 이상의 제제 등에 대한 언급을 포함한다.
참조 수치와 관련하여 용어 "약"은 상기 값으로부터 + 또는 - 10%의 값의 범위를 포함할 수 있다. 예를 들어, "약 10"의 양은 9, 10 및 11의 참조 수치를 포함하는, 9 내지 11의 양을 포함한다. 참조 수치와 관련하여 용어 "약"은 또한 상기 값으로부터 + 또는 - 10%, 9%, 8%, 7%, 6%, 5%, 4%, 3%, 2%, 또는 1%의 값의 범위를 포함할 수 있다.
용어 "1차 세포"는 다중세포 유기체로부터 직접적으로 단리된 세포를 언급한다. 1차 세포는 전형적으로 집단 증가가 거의 일어나지 않고, 따라서 연속 (종양 또는 인공적으로 불멸화된) 세포주와 비교하여, 이들이 유래된 조직의 주요 기능성 성분을 보다 잘 나타낸다. 일부 경우에, 1차 세포는 단리되고 이어서 즉시 사용되는 세포이다. 다른 경우에, 1차 세포는 무한으로 분열할 수 없고 따라서 시험관내에서 장기간 동안 배양될 수 없다.
용어 "게놈 편집"은 하나 이상의 뉴클레아제를 사용하여, DNA가 삽입되거나, 대체되거나 표적 DNA, 예를 들어, 세포의 게놈으로부터 제거된 유전학적 가공의 하나의 유형을 언급한다. 뉴클레아제는 게놈 내 목적하는 위치에서 특이적 이중 가닥 절단(DSB)을 생성하고, 세포의 내인성 기전을 사용하여 상동성-지시된 복구 (DHR) (예를 들어, 상동성 재조합)에 의해 또는 비상동성 말단 연결 (NHEJ)에 의해 유도된 절단을 복구한다. 임의의 적합한 뉴클레아제는 세포에 도입되어 CRISPR-연합된 단백질 (Cas) 뉴클레아제, 아연 핑거 뉴클레아제 (ZFN), 전사 활성화인자 유사 이펙터 뉴클레아제 (TALEN), 메가뉴클레아제, 다른 엔도- 또는 엑소-뉴클레아제, 이의 변이체, 이의 단편 및 이의 조합을 포함하지만 이에 제한되지 않는 표적 DNA 서열의 게놈 편집을 유도할 수 있다. 표적 DNA 서열의 뉴클레아제-매개된 게놈 편집은 Cas 뉴클레아제 (예를 들어, Cas9 폴리펩타이드 또는 Cas9 mRNA)와 조합된 본원에 기재된 변형된 단일 가닥 RNA (sgRNA)를 사용하여 상동성-지시된 복구 (HDR)를 통한 정확한 게놈 편집의 효율을 개선시키기 위해 "유도된" 또는 "조절된"일 수 있다.
용어 "상동성-지시된 복구" 또는 "HDR"은 복구를 가이드하기 위한 상동성 주형을 사용하여 이중 가닥 DNA 절단을 정밀하게 및 정확하게 복구하기 하기 위한 세포 내 기전을 언급한다. 가장 통상적인 형태의 HDR은 뉴클레오타이드 서열이 2개의 유사하거나 동일한 DNA 분자 간에 교환되는 일종의 유전학적 재조합인 상동성 재조합(HR)이다.
용어 "비상동성 말단 연결" 또는 "NHEJ"는 절단된 말단이 상동성 주형에 대한 필요 없이 직접적으로 연결되는 이중 가닥 DNA 절단을 복구하는 경로를 언급한다.
용어 "핵산", "뉴클레오타이드" 또는 "폴리뉴클레오타이드"는 단일 가닥, 이중 가닥 또는 다중 가닥 형태의 데옥시리보핵산 (DNA), 리보핵산 (RNA) 및 이의 중합체를 언급한다. 상기 용어는 단일 가닥, 이중 가닥 또는 다중 가닥의 DNA 또는 RNA, 게놈 DNA, cDNA, DNA-DNA 하이브리드 또는 퓨린 및/또는 피리미딘 염기 또는 다른 천연, 화학적적으로 변형된, 생화학적으로 변형된, 비-천연, 합성 또는 유도체화된 뉴클레오타이드 염기를 포함하는 중합체를 포함하지만 이에 제한되지 않는다. 일부 구현예에서, 핵산은 DNA, RNA 및 이의 유사체의 혼합물을 포함할 수 있다. 상기 용어는 또한 참조 핵산과 유사한 결합 성질을 갖고 천연적으로 존재하는 뉴클레오타이드와 유사한 방식으로 대사되는 천연 뉴클레오타이드의 공지된 유사체를 함유하는 핵산을 포괄한다. 특정 핵산 서열은 또한 보존적으로 변형된 이의 변이체 (예를 들어, 축퇴성 코돈 치환), 대립유전자, 오톨로그, 단일 뉴클레오타이드 다형태 (SNP) 및 상보성 서열 및 명백하게 지적된 서열을 포괄한다. 구체적으로, 축퇴성 코돈 치환은 하나 이상의 선택된 (또는 모든) 코돈의 세번째 위치가 혼합-염기 및/또는 데옥시이노신 잔기로 대체된 서열을 생성함에 의해 성취될 수 있다(문헌참조: Batzer et al, Nucleic Acid Res. 19:5081 (1991); Ohtsuka et al, J. Biol. Chem. 260:2605-2608 (1985); and Rossolini et al, Mol. Cell. Probes 8:91-98 (1994)). 용어 핵산은 유전자, cDNA 및 유전자에 의해 암호화된 mRNA와 상호교환적으로 사용된다.
핵산 분자의 길이를 참조하는 경우, 용어 뉴클레오타이드 및 염기쌍은 상호교환적으로 사용될 수 있다.
용어 "뉴클레오타이드 유사체" 또는 "변형된 뉴클레오타이드"는 뉴클레오사이드의 질소성 염기(예를 들어, 시토신 (C), 티민 (T) 또는 우라실 (U), 아데닌 (A) 또는 구아닌 (G)) 내 또는 이의 상에, 뉴클레오사이드의 당 모이어티(예를 들어, 리보스, 데옥시리보스, 변형된 리보스, 변형된 데옥시리보스, 6원 당 유사체 또는 개방쇄 당 유사체), 또는 포스페이트 내 또는 이의 상에 하나 이상의 화학적 변형 (예를 들어, 치환)을 포함하는 뉴클레오타이드를 언급한다.
용어 “유전자” 또는 “폴리펩타이드를 암호화하는 뉴클레오타이드 서열"은 폴리펩타이드 쇄를 생성하는데 관여하는 DNA의 분절을 의미한다. DNA 분절은 유전자 생성물의 전사/해독 및 전사/해독의 조절에 관여하는 암호화 영역 (리더 및 트레일러), 및 개별 암호화 분절 (엑손) 사이의 개입 서열 (인트론)의 전방 및 후방 영역을 포함할 수 있다.
용어 “폴리펩타이드,” “펩타이드” 및 “단백질”은 아미노산 잔기들의 중합체를 언급하기 위해 상호교환적으로 사용된다. 상기 용어는 하나 이상의 아미노산 잔기가 비-천연적으로 존재하는 아미노산 중합체 뿐만 아니라 상응하는 천연적으로 존재하는 아미노산의 인공 화학적 모사체인 아미노산 중합체에 적용된다. 상기 용어는 전장 단백질을 포함하는 임의의 길이의 아미노산 쇄를 포함하고, 여기서, 상기 아미노산 잔기는 공유 펩타이드 결합에 의해 연결된다.
용어 "변이체"는 천연에 존재하는 것으로부터 이탈한 유기체, 균주, 유전자, 폴리뉴클레오타이드, 폴리펩타이드 또는 특징의 형태를 언급한다.
용어 "상보성"은 통상적인 왓슨-클릭 또는 다른 비-통상적인 유형에 의해 또 다른 핵산 서열과 수소 결합(들)을 형성하는 핵산의 능력을 언급한다. 퍼센트 상보성은 제2 핵산 서열과 수소 결합을 형성(예를 들어, 왓슨-클릭 염기쌍 형성)할 수 있는 핵산 분자 내 잔기의 퍼센트 (예를 들어, 10개중 5, 6, 7, 8, 9, 10개로서 50%, 60%, 70%, 80%, 90%, 및 100%의 상보성)를 지적한다. "완벽하게 상보성"은 핵산 서열의 모든 연속 잔기가 제2 핵산 서열 내 동일한 수의 연속 잔기와 수소 결합함을 의미한다. 본원에 사용된 바와 같은 "실질적으로 상보성"은 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%인 상보성 정도를 언급한다. 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 30, 35, 40, 45, 50개 이상의 뉴클레오타이드의 영역 상에 97%, 98%, 99%, 또는 100%는 엄중 조건하에서 하이브리드화하는 2개의 핵산을 언급한다.
하이브리드화에 대한 용어 "엄중 조건"은 표적 서열과 상보성을 갖는 핵산이 대부분 표적 서열과 하이브리드화하고 실질적으로 비-표적 서열과는 하이브리드화하지 않는 조건을 언급한다. 엄중 조건은 일반적으로 서열-의존성이고 다수의 인자에 의존하여 다양하다. 일반적으로, 서열이 길면 길수록 서열이 특이적으로 이의 표적 서열에 하이브리드화하는 온도는 보다 높아진다. 엄중 조건의 비제한적인 예는 문헌(참조: Tijssen (1993), Laboratory Techniques In Biochemistry And Molecular Biology -Hybridization With Nucleic Acid Probes Part 1, Second Chapter "Overview of principles of hybridization and the strategy of nucleic acid probe assay", Elsevier, N.Y.)에 상세히 기재되어 있다.
용어 "하이브리드화"는 하나 이상의 폴리뉴클레오타이드가 반응하여 뉴클레오타이드 잔기의 염기 간에 수소 결합을 통해 안정화된 복합체를 형성하는 반응을 언급한다. 수소 결합은 왓슨 클릭 염기쌍 형성에 의해, 후그슈타인 결합 (Hoogstein binding)에 의해 또는 임의의 다른 서열 특이적 방식으로 일어날 수 있다. 상기 복합체는 듀플렉스 구조를 형성하는 2개의 가닥, 다중 가닥의 복합체를 형성하는 3개 이상의 가닥, 단일 자가-하이브리드화 가닥 또는 이들의 임의의 조합을 포함할 수 있다.
"재조합 발현 벡터"는 숙주 세포에서 특정 폴리뉴클레오타이드 서열의 전사를 허용하는 일련의 특정 핵산 요소와 함께 재조합적으로 또는 합성적으로 생성된 핵산 작제물이다. 발현 벡터는 플라스미드, 바이러스 게놈 또는 핵산 단편의 일부일 수 있다. 전형적으로, 발현 벡터는 프로모터에 작동적으로 연결된, 전사될 폴리뉴클레오타이드를 포함한다.
"작동적으로 연결된"은 암호화 서열의 전사를 지시하는 프로모터와 같은 요소들의 적당한 생물학적 기능을 허용하는 상대적 위치에 위치하는 폴리뉴클레오타이드 암호화 서열 및 프로모터와 같은 2개 이상의 유전학적 요소를 의미한다.
용어 “비-고유”는 세포에 내인성이 아님을 의미하고, 즉, 작제물은 이것이 비-고유인 세포에 천연적으로 존재하지 않는다.
용어 "프로모터"는 핵산의 전사를 지시하는 핵산 제어 서열의 어레이를 언급한다. 본원에 사용된 바와 같은 프로모터는 폴리머라제 II형 프로모터의 경우에서와 같이 전사의 개시 부위 근처에 필요한 핵산 서열, TATA 요소를 포함한다. 프로모터는 또한 전사의 개시부위로부터 수천개의 염기쌍 정도의 원거리에 위치할 수 있는 원위 인핸서 또는 리프레서를 임의로 포함한다. 발현 벡터에 존재할 수 있는 다른 요소들은 발현 벡터로부터 생성된 재조합 단백질에 대한 특정 결합 친화성 또는 항원성을 부여하는 것들 뿐만 아니라 전사를 증진시키고 (예를 들어, 인핸서) 전사를 종결시키는 (예를 들어, 터미네이터) 것들을 포함한다.
“재조합체"는 유전학적으로 변형된 폴리뉴클레오타이드, 폴리펩타이드, 세포, 조직, 또는 유기체를 언급한다. 예를 들어, 재조합 폴리뉴클레오타이드(또는 재조합 폴리뉴클레오타이드의 카피 또는 상보체)는 널리 공지된 방법을 사용하여 조작된 것이다. 제2 폴리뉴클레오타이드 (예를 들어, 암호화 서열)에 작동적으로 연결된 프로모터를 포함하는 재조합 발현 카세트는 사람 조작 (예를 들어, 문헌(참조: Sambrook et al, Molecular Cloning - A Laboratory Manual, Cold Spring Harbor Laboratory, Cold Spring Harbor, New York, (1989) or Current Protocols in Molecular Biology Volumes 1-3, John Wiley & Sons, Inc. (1994-1998)에 기재된 방법에 의해)의 결과로서 제2 폴리뉴클레오타이드와 이종성인 프로모터를 포함할 수 있다. 재조합 발현 카세트 (또는 발현 벡터)는 전형적으로 천연에서 발견되지 않는 조합의 폴리뉴클레오타이드를 포함한다. 예를 들어, 사람 조작된 제한 부위 또는 플라스미드 벡터 서열은 다른 서열로부터 프로모터를 플랭킹하거나 분리할 수 있다. 재조합 단백질은 재조합 폴리뉴클레오타이드로부터 발현된 것이고, 재조합 세포, 조직 및 유기체는 재조합 서열 (폴리뉴클레오타이드 및/또는 폴리펩타이드)를 포함하는 것들이다.
용어 "단일 뉴클레오타이드 다형태" 또는 "SNP"는 대립유전자 내에 포함하는 폴리뉴클레오타이드에서 단일 뉴클레오타이드의 변화를 언급한다. 이것은 단일 뉴클레오타이드의 결실 또는 삽입 뿐만 아니라 하나의 뉴클레오타이드의 또 다른 뉴클레오타이드로의 대체를 포함할 수 있다. 대부분 전형적으로, SNP는 트리- 및 테트라-대립유전자 마커가 또한 존재할 수 있지만 바이대립유전자 마커이다. 비-제한적인 예로서, SNP A\C를 포함하는 핵산 분자는 다형태 위치에서 C 또는 A를 포함할 수 있다.
용어 “배양한다”, “배양하는”, “성장한다”, “성장하는”, “유지한다”, “유지하는”, “확장한다”, “확장하는” 등은 세포 배양 자체를 언급하거나 배양 공정을 언급하는 경우, 세포 (예를 들어, 1차 세포)가 제어된 조건하에서, 예를 들어, 생존을 위해 적합한 조건하에서 이의 정상 환경 외부에서 유지되는 것을 의미하기 위해 상호교환적으로 사용될 수 있다. 배양된 세포는 생존하도록 방치하고 배양은 세포 성장, 정지, 분화 또는 분열을 유도할 수 있다. 용어는 배양물 중에 모든 세포가 생존하거나, 성장하거나 분열함을 의미하지 않고 일부는 천연적으로 죽거나 뇌쇠할 수 있다. 세포는 전형적으로 배지에서 배양하고, 상기 배지는 배양 과정 동안에 갈아줄 수 있다.
용어 "대상체", "환자" 및 "개체"는 본원에서 사람 또는 동물을 포함하도록 상호교환적으로 사용된다. 예를 들어, 동물 대상체는 포유류, 영장류(예를 들어, 몽키), 가축 동물(예를 들어, 말, 소, 양, 돼지, 또는 염소), 반려 동물 (예를 들어, 개, 고양이), 연구 시험 동물(예를 들어, 마우스, 래트, 기니아 피그, 새), 수의학적으로 중요한 동물 또는 경제적으로 중요한 동물일 수 있다.
용어 "투여하는"은 경구 투여, 국소 접촉, 좌제로서의 투여, 대상체에게 정맥내, 복막내, 근육내, 병변내, 척수강내, 비강내 또는 피하 투여를 포함한다. 투여는 비경구 및 경점막 (예를 들어, 협측, 설하, 구개, 잇몸, 비강, 질, 직장 또는 경피)을 포함하는 임의의 경로에 의한 것이다. 비경구 투여는 예를 들어, 정맥내, 근육내, 동맥내, 피내, 피하, 복막내, 뇌실내, 및 두개내를 포함한다. 다른 전달 방식은 리포좀 제형의 사용, 정맥내 주입, 경피 패치 등을 포함하지만 이에 제한되지 않는다.
용어 "치료하는"은 치료학적 이득 및/또는 예방학적 이득을 포함하지만 이에 제한되지 않는 이로운 또는 목적하는 결과를 수득하기 위한 접근법을 언급한다. 치료학적 이득이란 치료 하의 하나 이상의 질환, 병태 또는 증상에서의 임의의 치료학적 관련 개선 또는 이에 대한 효과를 의미한다. 예방학적 이득을 위해, 조성물은 특정 질환, 병태 또는 증상을 발병할 위험에 처한 대상체에게 또는 질환, 병태 또는 증상이 아직 나타나지 않을 수 있지만 질환의 생리학적 증상 중 하나 이상을 보고하는 대상체에게 투여될 수 있다.
용어 “유효량” 또는 “충분한 양”은 이롭거나 목적하는 결과를 수행하기에 충분한 제제 (예를 들어, Cas 뉴클레아제, 변형된 단일 가이드 RNA 등)의 양을 언급한다. 치료학적 유효량은 치료 중인 대상체 및 질환 상태, 대상체의 체중 및 연령, 질환 상태의 중증도, 투여 방식 등에 의존하여 다양할 수 있고, 이는 당업자에 의해 용이하게 결정될 수 있다. 특정 양은 선택된 특정 제제, 표적 세포 유형, 대상체 내 표적 세포의 위치, 후속 투여 용법, 이것이 다른 제제와 조합하여 투여될 지의 여부, 투여 시기 및 이것이 운반되는 물리적 전달 시스템 중 하나 이상에 의존하여 다양할 수 있다.
용어 "약제학적으로 허용되는 담체"는 제제 (예를 들어, Cas 뉴클레아제, 변형된 단일 가이드 RNA 등)의 세포, 유기체 또는 대상체로의 투여를 보조하는 물질을 언급한다. "약제학적으로 허용되는 담체"는 조성물 또는 제형에 포함될 수 있고, 환자에 대해 어떠한 유의적인 독성학적 효과를 유발하지 않는 담체 또는 부형제를 언급한다. 약제학적으로 허용되는 담체의 비제한적인 예는 물, NaCl, 정규 식염수 용액, 락테이트화된 링거, 정규 슈크로스, 정규 글루코스, 결합제, 충전제, 붕해제, 윤활제, 코팅, 감미제, 향제 및 색제 등을 포함한다. 당업자는 다른 약제학적 담체가 본 발명에 유용함을 인지할 것이다.
CRISPR 시스템의 성분과 관련하여 용어 "증가하는 안정성"은 CRISPR 시스템의 임의의 분자 성분의 구조를 안정화시키는 변형을 언급한다. 상기 용어는 CRISPR 시스템의 임의의 분자 성분의 분해를 감소시키거나, 억제하거나, 약화시키거나 저하시키는 변형을 포함한다.
CRISPR 시스템과 관련된 용어 "증가하는 특이성"은 CRISPR 시스템의 임의의 분자 성분의 특이적 활성 (예를 들어, 온-표적 활성)을 증가시키는 변형을 언급한다. 상기 용어는 CRISPR 시스템의 임의의 분자 성분의 비-특이적 활성(예를 들어, 오프-표적 활성)을 감소시키거나, 억제하거나, 약화시키거나 저하시키는 변형을 포함한다.
CRISPR 시스템의 성분과 관련하여 용어 "감소하는 활성"은 세포, 유기체, 대상체 등에 대한 CRISPR 시스템의 임의의 분자 성분의 독성 효과를 감소시키거나, 억제하거나, 약화시키거나 저하시키는 변형을 언급한다.
CRISPR 시스템의 성분과 관련하여 및 유전자 조절 관점에서 용어 “증진된 활성”은 게놈 편집 및/또는 유전자 발현을 유도하거나, 조정하거나, 조절하거나 제어하는 효율 및/또는 빈도에서의 증가 또는 개선을 언급한다.
본원에서 방법 및 조성물은 이의 발현이 요구되는 유전자의 효율적인 녹아웃 및 동시 녹인을 위한 CRISPR/cas 시스템을 사용한다. CRISPR/Cas 시스템은 현재 표적화된 유전학적 변경 (게놈 변형)을 유도하기 위해 광범위하게 사용되고 있다. Cas9와 같은 cas 단백질에 의한 표적 인지는 가이드 RNA (gRNA) 내 “씨드” 서열, 및 표적 DNA, 예를 들어, 숙주 세포 게놈에서 gRNA-결합 영역의 업스트림에 프로토스페이서 인접 모티프(PAM) 서열을 함유하는 보존된 멀티뉴클레오타이드를 필요로 한다. 본원에 사용된 바와 같이, “표적 서열”은 게놈 내 PAM에 인접하고 (Cas9 CRISPR 시스템에서) 이의 업스트림에 바로 있는 서열이다. 표적 서열(또는 실질적으로 동일한 서열)은 가이드 RNA로 가공되고, 때로는 당업계에서 가이드 RNA의 “가이드 서열”로서 언급된다. 본원 개시내용의 목적을 위해, 문헌(Ran et al. (2013) Nature Protocols 8:2281-2308)에 따라, 가이드 RNA의 “표적 서열” (또는 가이드 서열)은 게놈 내 표적 서열의 반대 가닥과 하이브리드화한다.
Cas/CRISPR RNA-가이드된 엔도뉴클레아제 시스템은 RNA-가이드된 Cas9 엔도뉴클레아제를 사용하는 영구적 유전자 붕괴를 유도하여 오류 성향 복구 경로가 프레임 전환 돌연변이를 유도하도록 촉발시키는 DNA 이중 가닥 절단을 도입한다. 게놈을 변형시키기 위해 사용되는 CRISPR/Cas 시스템의 예는 예를 들어, 미국 특허 제8,697,359호, 제10,000,772호, 제9,790,490호, 및 미국 특허 출원 공개 번호 제US 2018/0346927홍 기재되어 있고 이 모두는 본원에 이들의 전문이 참조로 인용된다. Cas9, Cas12a, CasX, 또는 기타 Cas 엔도뉴클레아제가 또한 사용될 수 있고, 이는 Cas1, Cas1B, Cas2, Cas3, Cas4, Cas5, Cash, Cas7, Cas8, Cas9 (또한, Csn1 및 Csx12로서 공지된), Cas10, Cas12a (또한, Cpf1으로서 공지된), CasX, CasY, Csy1, Csy2, Csy3, Cse1, Cse2, Csc1, Csc2, Csa5, Csn2, Csm2, Csm3, Csm4, Csm5, Csm6, Cmr1, Cmr3, Cmr4, Cmr5, Cmr6, Csb1, Csb2, Csb3, Csx17, Csx14, Csx10, Csx16, CsaX, Csx3, Csx1, Csx15, Csf1, Csf2, Csf3, Csf4, T7, Fok1, 당업계에 공지된 다른 뉴클레아제, 이의 상동체, 또는 이의 변형된 버전을 포함하지만 이에 제한되지 않는다.
CRISPR/Cas 유전자 붕괴는 표적 유전자에 특이적인 gRNA 서열 및 Cas 엔도뉴클레아제가 복합체로서 또는 Cas 엔도뉴클레아제가 표적 유전자좌에 이중 가닥 절단을 도입할 수 있게 하는 복합체를 형성하도록 세포에 도입되는 경우 일어난다. 일부 경우에, CRISPR 시스템은 Cas 엔도뉴클레아제를 암호화하는 핵산 서열 및 표적 유전자에 특이적인 가이드 핵산 서열을 포함하는 하나 이상의 발현 벡터를 포함한다. 가이드 핵산 서열은 관심 대상의 유전자에 특이적이도록 디자인되고 (유전자 내 표적 서열과의 상동성에 의해) cas 엔도뉴클레아제-유도된 이중 가닥 절단을 위해 상기 유전자를 표적화한다. 따라서, 전형적으로 RNA 분자이고 변형된 RNA 분자일 수 있는 가이드 핵산 분자는 표적화된 유전자의 유전자좌 (표적 부위 또는 표적 서열)에서 발견되는 가이드 핵산 서열을 포함한다. 일부 구현예에서, 가이드 핵산 서열은 적어도 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 45, 50, 또는 50개 이상의 뉴클레오타이드 길이이다. 일부 경우에, 2개의 가이드 RNA는 cas 단백질, 상기 가이드 서열을 포함하는 cRNA 및 crRNA와 cas 단백질과 복합체를 형성하는 tracrRNA와 함께 사용된다. 일부 경우에, 예를 들어, Cas9의 경우에 키메라 가이드일 수 있는 단일 가이드 RNA가 사용될 수 있다. 일부 cas 엔도뉴클레아제, 예를 들어, Cas12a는 tracrRNA를 사용하지 않고, 즉, 이들은 천연적으로 단지 단일 가닥 RNA (crRNA)를 사용한다.
다양한 구현예에서, cas 단백질은 도입된 유전자 또는 RNA 분자로부터 세포에서 발현될 수 있다. cas 단백질은 또한 임의로 하나 이상의 가이드 RNA와 함께 도입될 수 있거나, cas 단백질은 단일 가이드 RNA 또는 2개의 복합체화된 가이드 RNA (예를 들어, crRNA 및 tracrRNA)와의 리보뉴클레오단백질 복합체로서 도입될 수 있다. 일부 구현예에서, 가이드 RNA는 표적 세포로 형질감염된 유전자로부터 발현되거나, 하나 이상의 가이드 RNA는 RNA 분자로서 세포에 도입될 수 있다. 2개 이상의 상이한 가이드 RNA에 대한 유전자는 동일하거나 상이한 벡터 상에서 표적 세포에 도입될 수 있다. 2개 이상의 가이드 RNA는 상이한 가이드 서열을 갖는 가이드 RNA (예를 들어, 상이한 유전자좌를 표적화하는)일 수 있다. 본원에 제공된 방법의 다양한 구현예에서, 가이드 RNA는 키메라 가이드(sgRNA)일 수 있거나, crRNA일 수 있다. 일부 구현예에서, crRNA 및 tracrRNA는 숙주 세포에 도입된다. 일부 구현예에서, RNA-가이드된 엔도뉴클레아제는 Cas9 엔도뉴클레아제 및 sgRNA (키메라 가이드 RNA), sgRNA를 포함하는 RNP이거나, sgRNA를 암호화하는 작제물은 세포에 도입된다. 대안적으로, crRNA 및 tracrRNA (또는 crRNA 및 tracrRNA를 암호화하는 작제물)는 Cas9 매개된 게놈 변형을 위해 세포 또는 RNP에 제공될 수 있다. 추가의 구현예, 예를 들어, tracrRNA를 요구하지 않는 엔도뉴클레아제로서 Cas12a를 사용한 구현예에서, crRNA, 또는 crRNA를 암호화하는 작제물은 tracrRNA 없이 도입될 수 있다. cas 엔도뉴클레아제를 위한 가이드 RNA는 이의 전문이 본원에 참조로 인용된 미국 특허 출원 공개 공보 US 2018/066242, 및 이의 모두의 전문이 본원에 참조로 인용된 미국 특허 제8,697,359호, 제10,000,772호, 제9,790,490호, 및 미국 특허 출원 공개 공보 제US 2018/0346927호에서 광범위하게 논의되었다.
오류-성향 복구 경로, 예를 들어, 비-상동성 말단-연결 (HHEJ)을 통해 발생하는 돌연변이를 생성시키는데 이들의 용도에 추가로, 예를 들어, Cas9, Cas12a, 또는 CasX와 같은 cas 단백질은 관심 대상의 DNA 서열을 표적화된 유전자좌로 삽입하기 위해 사용될 수 있고, 여기서, cas 단백질 및 하나 이상의 가이드 RNA, 또는 cas 단백질 및/또는 하나 이상의 가이드 RNA를 발현하기 위한 작제물에 추가로, 표적 세포는 또한 상동성-지시된 복구를 통해 cas 엔도뉴클레아제의 활성 후 유전자좌로의 삽입을 위해 공여자 DNA 분자로 형질감염시킨다. 다양한 구현예에서, 표적 부위로의 삽입을 위한 DNA 분자는 예를 들어, 발현 작제물과 같은 관심 대상의 DNA 서열을 포함하고, 예를 들어, DAR 작제물은 숙주 게놈 내 표적 부위의 어느 하나의 측면 상에서 게놈 서열에 상동성을 갖는 서열에 의해 플랭킹된다. 상기 상동성 아암은 (HA)은 예를 들어, 약 50 bp 길이 내지 약 2500 bp의 길이, 또는 약 100 bp 내지 약 2000 bp 길이, 또는 약 150 bp 내지 약 1500 bp 길이일 수 있다. 본 발명의 조성물, 방법 및 세포에 사용하기 위해 본원에 제공된 공여자 DNA 분자는 예를 들어, 약 250bp 미만의 길이, 약 200 bp 미만, 약 190 bp 미만, 약 180 bp 미만, 약 160 bp 미만, 또는 약 150 bp 미만의 길이, 예를 들어, 약 50 bp 내지 약 1500 bp 미만의 길이, 약 50 bp 내지 약 1000 bp의 길이, 약 50 bp 내지 약 800 bp의 길이, 약 50 bp 내지 약 600 bp의 길이, 약 50 bp 내지 약 350 bp의 길이, 약 50 bp 내지 약 180 bp의 길이, 또는 약 100 bp 내지 약 1000 bp의 길이, 약 140 bp 내지 약 800 bp의 길이, 약 140 bp 내지 약 600 bp의 길이, 약 100 bp 내지 약 350 bp의 길이, 약 100 bp 내지 약 200 bp의 길이, 약 140 bp 내지 약 800 bp의 길이, 약 140 bp 내지 약 600 bp의 길이, 약 140 bp 내지 약 350 bp의 길이, 또는 약 140 bp 내지 약 200 bp의 길이인 HA를 가질 수 있다.
공여자 DNA는 예를 들어, 적어도 50 뉴클레오타이드, 적어도 100 뉴클레오타이드, 적어도 200 뉴클레오타이드, 적어도 225 뉴클레오타이드, 적어도 250 뉴클레오타이드, 적어도 300 뉴클레오타이드, 적어도 400 뉴클레오타이드, 적어도 500 뉴클레오타이드, 적어도 600 뉴클레오타이드, 적어도 700 뉴클레오타이드, 적어도 800 뉴클레오타이드, 적어도 900 뉴클레오타이드, 적어도 1000 뉴클레오타이드, 적어도 1100 뉴클레오타이드, 적어도 1200 뉴클레오타이드, 적어도 1300 뉴클레오타이드, 적어도 1400 뉴클레오타이드, 적어도 1500 뉴클레오타이드, 적어도 1600 뉴클레오타이드, 적어도 1700 뉴클레오타이드, 적어도 1800 뉴클레오타이드, 적어도 1900 뉴클레오타이드, 적어도 2000 뉴클레오타이드, 적어도 2200 뉴클레오타이드, 적어도 2400 뉴클레오타이드, 적어도 2500 뉴클레오타이드, 적어도 2600 뉴클레오타이드, 적어도 2800 뉴클레오타이드, 적어도 3000 뉴클레오타이드, 적어도 3200 뉴클레오타이드, 적어도 3400 뉴클레오타이드, 적어도 3500 뉴클레오타이드, 적어도 3600 뉴클레오타이드, 적어도 3800 뉴클레오타이드, 적어도 4000 뉴클레오타이드, 적어도 4200 뉴클레오타이드, 적어도 4400 뉴클레오타이드, 적어도 4500 뉴클레오타이드, 적어도 4600 뉴클레오타이드, 적어도 4800 뉴클레오타이드, 적어도 5000 뉴클레오타이드, 적어도 5200 뉴클레오타이드, 적어도 5400 뉴클레오타이드, 적어도 5500 뉴클레오타이드, 적어도 5600 뉴클레오타이드, 적어도 5800 뉴클레오타이드, 적어도 6000 뉴클레오타이드, 적어도 6200 뉴클레오타이드, 적어도 6400 뉴클레오타이드, 적어도 6500 뉴클레오타이드, 적어도 6600 뉴클레오타이드, 적어도 6800 뉴클레오타이드, 적어도 7000 뉴클레오타이드, 적어도 7500 뉴클레오타이드, 적어도 8000 뉴클레오타이드, 적어도 8500 뉴클레오타이드, 적어도 9000 뉴클레오타이드, 적어도 9500 뉴클레오타이드, 또는 적어도 10,000 뉴클레오타이드, 또는 공여자 단편이 이중 가닥 또는 실질적으로 이중 가닥인 상응하는 수의 염기쌍 (bp)의 길이일 수 있다.
본원에 기재된 바와 같은 조성물, 방법 및 시스템에서 제공된 바와 같은 공여자 DNA는 단일 가닥, 이중 가닥 또는 실질적으로 이중 가닥일 수 있다. 공여자 DNA는 단일 가닥 또는 이중 가닥일 수 있고, 이는 실질적으로 이중 가닥 분자를 포함하고, 여기서, 상기 실질적으로 이중 가닥 공여자 DNA는 짧은 (예를 들어, 10개 이하, 8개 이하, 6개 이하 또는 3개 이하) 스트레치의 뉴클레오타이드가 단편의 말단에 또는 내부적으로 존재하는 반대 가닥과 염기쌍을 형성하지 않는 이중 가닥일 수 있고, 상기 짧은 스트레치는 단편의 뉴클레오타이드 길이의 50% 미만, 30% 미만 또는 5% 미만이다.
공여자 DNA 분자는 염기 모이어티, 당 모이어티 또는 포스포디에스테르 골격에서 변형될 수 있다. 변형은 전형적으로 상동성 아암에 의해 플랭킹된 게놈의 표적 유전자좌에 삽입될 작제물을 포함하는 주형의 PCR 증폭에 의해 간편하게 도입될 수 있다. 공여자 주형의 PCR 증폭은 공여자 DNA 분자를 생성하고, 여기서, 상기 증폭은 공여자 DNA 생성물에 혼입되는 목적하는 변형을 갖는 프라이머를 사용한다.
핵산 변형은 다음을 포함하지만 이에 제한되지 않는다: 2'O 메틸 변형된 뉴클레오타이드, 2' 플루오로 변형된 뉴클레오타이드, 잠금(locked) 핵산 (LNA) 변형된 뉴클레오타이드, 펩타이드 핵산 (PNA) 변형된 뉴클레오타이드, 포스포로티오에이트 연결을 갖는 뉴클레오타이드, 및 5' 캡(예를 들어, 7-메틸구아닐레이트 캡 (m7G)). 핵산 변형은 예를 들어, 데옥시티미딘에 대한 데옥시우리딘 치환, 데옥시시티딘에 대한 5-메틸-2'-데옥시시티딘 또는 5-브로모-2'-데옥시시티딘 치환을 포함할 수 있다. 당 모이어티의 변형은 리보스 당의 2’ 하이드록실의 변형으로 2'-O-메틸 또는 2'-O-알릴 당을 형성함을 포함할 수 있다. 펜토푸라노실 당을 포함하는 뉴클레오사이드에 대해, 포스페이트 그룹은 당의 2', 3', 또는 5’ 하이드록실 모이어티에 연결될 수 있다.
뉴클레오타이드는 뉴클레오사이드의 당 부분에 공유적으로 연결된 포스페이트 그룹을 포함하여 핵산 분자의 “뉴클레오사이드 상호 골격”을 형성하는 뉴클레오사이드이다. 천연적으로 존재하는 RNA 및 DNA 분자는 골격 전반에 걸쳐 3’에서 5’의 포스포디에스테르 연결을 갖는다. 데옥시리보스 포스페이트 골격은 모르폴리노 핵산을 생성하도록 변형될 수 있고, 여기서, 각각의 염기 모이어티는 6원 모르폴리노 환, 또는 데옥시포스페이트 골격이 슈도펩타이드 골격으로 대체되고, 4개의 염기가 보유된 펩타이드 핵산에 연결된다. 예를 들어, 문헌(Summerton and Weller (1997) Antisense Nucleic Acid Drug Dev. 7:187-195 and Hyrup et al. (1996) Bioorgan. Med. Chain. 4:5-23)을 참조한다. 추가로, 데옥시포스페이트 골격은 예를 들어, 포스포로티오에이트 또는 포스포로디티오에이트 골격, 포스포로아미디트 또는 알킬 포스포트리에스테르 골격으로 대체될 수 있다. 포스포로티오에이트 (PS) 결합(즉, 포스포로티오에이트 연결)은 핵산의 포스페이트 골격에서 비-브릿징 산소를 황 원자로 치환한다. 상기 변형은 뉴클레오타이드 간 연결이 뉴클레아제 분해에 내성이 되게 한다.
변형은 변형된 골격 또는 비-천연 뉴클레오타이드 간 연결을 함유하는 핵산을 포함한다. 변형된 골격을 갖는 핵산은 골격 내 인 원자를 보유하는 것들 및 골격 내 인 원자를 갖지 않는 것들을 포함한다. 인 원자를 함유하는 변형된 올리고뉴클레오타이드 골격은 예를 들어, 포스포로티오에이트, 키랄 포스포로티오에이트, 포스포로디티오에이트, 포스포로트리에스테르, 아미노알킬포스포트리에스테르, 3’-알킬렌 포스포네이트, 5’-알킬렌 포스포네이트 및 키랄 포스포네이트를 포함하는 메틸 및 다른 알킬 포스포네이트, 포스피네이트, 3’-아미노 포스포르아미데이트 및 아미노알킬포스포르아미데이트를 포함하는 포스포르아미데이트, 포스포로디아미데이트, 티오노포스포르아미데이트, 티오노알킬포스포네이트, 티오노알킬포스포트리에스테르, 셀레노포스페이트 및 정상 3’-5’ 연결을 갖는 보라노포스페이트, 이들의 2'-5’ 연결된 유사체, 및 하나 이상의 뉴클레오타이드 간 연결이 3'에서 3'로, 5'에서 5'로 또는 2'에서 2' 연결인 역위 극성을 갖는 것들을 포함한다. 역위 극성을 갖는 핵산은 3’ 최외곽 뉴클레오타이드 간 연결에서 단일 3’에서 3’ 연결, 즉, 염기성일 수 있는 단일 역위 뉴클레오사이드 잔기를 포함한다(핵염기는 상실되어 있거나 이 대신 하이드록실 그룹을 갖는다).
일부 구현예에서, 공여자 DNA는 하나 이상의 포스포로티오에이트 및/또는 헤테로원자 뉴클레오사이드 간 연결을 포함한다. MMI 유형의 뉴클레오사이드 간 연결은 미국 특허 제5,489,677호에 기재되어 있고, 상기 개시내용은 이의 전문이 참조로 인용된다. 적합한 아미드 뉴클레오타이드 간 연결은 미국 특허 제5,602,240호에 기재되어 있고, 상기 개시내용은 이의 전문이 참조로 인용된다.
여기서 인 원자를 포함하지 않는 추가의 변형된 폴리뉴클레오타이드 골격은 단쇄 알킬 또는 사이클로알킬 뉴클레오사이드 간 연결, 혼합 헤테로원자 및 알킬 또는 사이클로알킬 뉴클레오사이드 간 연결, 또는 하나 이상의 단쇄 헤테로원자 또는 헤테로사이클릭 뉴클레오사이드 간 연결에 의해 형성된 골격을 갖는다. 이들은 모르폴리노 연결 (부분적으로 뉴클레오사이드의 당 부분으로부터 형성된); 실록산 골격; 설파이드, 설폭사이드 및 설폰 골격; 포름아세틸 및 티오포름아세틸 골격; 메틸렌 포름아세틸 및 티오포름아세틸 골격; 리보아세틸 골격; 알켄 함유 골격; 설파메이트 골격; 메틸렌이미노 및 메틸렌하이드라지노 골격; 설포네이트 및 설폰아미드 골격; 아미드 골격; 및 혼합 N, O, S 및 CH2 성분 부분을 갖는 기타의 것들을 갖는 것들을 포함한다. 모르폴리노 골격 구조는 예를 들어, 미국 특허 제5,034,506호에 기재되어 있다. 예를 들어, 일부 구현예에서, 공여자 DNA는 데옥시리보스 환 대신 6원 모르폴리노 환을 갖는 하나 이상의 뉴클레오타이드를 포함할 수 있다. 이들 구현예의 일부에서, 포스포로디아미데이트 또는 기타 비-포스포디에스테르 뉴클레오타이드 간 연결은 포스포디에스테르 연결을 대체한다.
2'-O-메틸 변형된 뉴클레오타이드(도 1b 참조)는 전사 후 변형으로서 발생하는, tRNA 및 다른 소형 RNA에서 발견되는 RNA의 천연적으로 존재하는 변형이다. 2’-O-메틸 뉴클레오타이드를 함유하는 올리고뉴클레오타이드가 직접적으로 합성될 수 있다. 2' 플루오로 변형된 뉴클레오타이드(예를 들어, 2' 플루오로 염기)는 불소 변형된 당을 갖고 이는 결합 친화성(Tm)을 증가시키고 또한 일부 상대적 뉴클레아제 내성을 부여할 수 있다.
일부 구현예에서, 공여자 DNA 분자는 2'-O-메틸 변형된 뉴클레오타이드인 하나 이상의 뉴클레오타이드를 갖는다. 일부 구현예에서, 공여자 DNA 분자는 2’ 플루오로 변형된 뉴클레오타이드인 하나 이상의 뉴클레오타이드를 갖는다. 일부 구현예에서, 공여자 DNA 분자는 하나 이상의 LNA, PNA, pPNA, 또는 pHypPNA 뉴클레오타이드를 갖는다. 일부 구현예에서, 공여자 DNA는 포스포로티오에이트 결합에 의해 연결된 하나 이상의 뉴클레오타이드를 갖는다(즉, 공여자 DNA는 하나 이상의 포스포로티오에이트 연결을 갖는다). 일부 구현예에서, 공여자 DNA 분자는 변형된 뉴클레오타이드의 조합을 갖는다. 예를 들어, 공여자 DNA는 다른 변형 (예를 들어, 2'-O-메틸 뉴클레오타이드 및/또는 2' 플루오로 변형된 뉴클레오타이드 및/또는 LNA 염기)을 갖는 하나 이상의 뉴클레오타이드를 갖는 것에 추가로 1개, 2개, 3개 이상의 포스포로티오에이트 연결을 가질 수 있다. 이들 변형은 바람직하게 이중 가닥 DNA 분자의 단지 하나의 가닥 상에 존재하고 가장 유리하게는 이중 가닥 DNA 분자의 하나의 가닥의 5’ 말단에, 예를 들어, 이중 가닥 DNA 분자의 5’ 말단의 20개, 10개 또는 5개 뉴클레오타이드 내에 존재한다.
공여자 DNA의 도입은 예를 들어, 전기천공, 핵감염 또는 지질감염과 같은 숙주 세포로 DNA를 도입하는 임의의 수단에 의해 수행될 수 있다. 예시적인 구현예에서, 공여자 DNA는 바이러스 형질도입을 통해 도입되지 않는다. 예를 들어, 공여자는 전기천공되거나, cas 단백질, 및 선택된 삽입 유전자좌를 표적화하는 가이드 RNA를 포함하는 하나 이상의 RNP와 함께, 세포를 형질감염시키는 다른 수단에 의해 합성된 DNA 분자로서 제공될 수 있다. 표적화된 삽입 유전자좌는 임의로 발현 작제물의 삽입과 동시에 유전자의 발현을 제거하도록 이의 붕괴 (“녹아웃”)가 요구되는 유전자일 수 있다. 공여자 DNA는 표적 부위에서 숙주 게놈에 상동성인 서열을 포함하여 cas 뉴클레아제에 의한 표적 부위의 절단 후 HDR을 촉진시킬 수 있다. 대안적으로, 공여자 DNA는 cas 뉴클레아제 및/또는 가이드 RNA, 또는 cas 뉴클레아제, 및/또는 가이드 RNA를 발현하기 위한 작제물이 세포에 도입되기 전 또는 후에 세포에 도입될 수 있다.
본원에서는 고효율의 표적화된 유전자 통합 접근을 제공하는 방법이 제공된다. 상기 방법은 임의의 세포 유형의 게놈 가공을 위해 사용될 수 있고, 예를 들어, 가공된 세포가 환자에게 도입되는 적용에 사용될 수 있다.
본원에서는 제1 부위에서 고효율의 표적화된 유전자 통합을 제공하는 방법이 제공되고, 상기 제1 부위에서 내인성 유전자가 붕괴되어 있고 이와 함께 제2 부위에서 유전자가 동시 녹아웃되어 있다. 예를 들어, CAR 또는 DAR 작제물은 TRAC 또는 TRBC 유전자좌에 삽입함으로써 TRAC 또는 TRBC 유전자를 불활성화시킬 수 있고, 동시에 관문 억제제 또는 면역 조절인자 유전자, 예를 들어, 비제한적인 예로서, GM-CSF, PD-1, TIM3, CTLA-4, PDCD1, LAG3, 등을 암호화하는 유전자를 녹아웃시킬 수 있다. 제2 유전자좌의 동시 녹아웃과 함께 제1 유전자좌에서 녹아웃/녹인 방법은 세포에 제1 유전자좌를 표적화화는 제1 가이드 RNA와 복합체화된 제1 RNA 가이드된 뉴클레아제를 포함하는 제1 RNP, 제2 유전자좌를 표적화하는 제2 가이드 RNA와 복합체화된 제2 RNA 가이드된 뉴클레아제를 포함하는 제2 RNP, 및 본원에 기재된 바와 같이 변형되고 제1 유전자좌에서 게놈 서열과 상동성을 갖는 상동성 아암을 갖는 공여자 DNA를 도입하는 단계를 포함한다. 제1 및 제2 RNA 가이드된 엔도뉴클레아제는 동일하거나 상이할 수 있다. 예를 들어, 일부 구현예에서, 제1 및 제2 RNA-가이드된 엔도뉴클레아제는 둘다 cas9 뉴클레아제이다. 다른 예에서, 제1 및 제2 RNA 가이드된 엔도뉴클레아제는 둘다 cas12a 뉴클레아제이다. 추가의 예에서, 제1 RNA 가이드된 엔도뉴클레아제는 cas9이고, 제2 RNA 가이드된 엔도뉴클레아제는 cas12a이다. 추가의 예에서, 제1 RNA 가이드된 엔도뉴클레아제는 cas12a이고, 제2 RNA 가이드된 엔도뉴클레아제는 cas9이다. 상기 방법은 세포의 변형을 유도하고, 여기서, 공여자 DNA는 제1 유전자좌에 삽입되고, 제2 유전자좌에서 유전자는 붕괴된다.
일부 구현예에서, 본원에 제공된 방법은 예를 들어, 임의의 CD38, CD19, CD20, CD123, BCMA 등에 대한 암 치료 작제물, 예를 들어, CAR을 T 세포에 적용하기 위해 사용될 수 있다. 유전자 전달의 효율은 40-80%에 도달할 수 있다. 표적화된 유전자 통합을 사용한 상기 접근법은 자가 및 동종이계 접근법 둘다를 위해 사용될 수 있고, 중요하게는 가공된 세포가 환자에게 도입되는 경우 2차 및 원치 않는 세포 형질전환 위험을 갖지 않음에 따라서 현재의 통상적인 접근법 보다 안전하다. 추가의 이점은 변형된 가이드 가닥, 신뢰할 수 있는 유전자 통합, 대형 유전자의 통합, CAR의 유전자 통합, 및 높은 발현과 함께 CAR의 유전자 통합을 포함한다.
실시예는 포스포로티오에이트, 및 PCR에 의해 합성된 2’ O-메틸 변형된 단일-가닥 또는 이중-가닥 공여자 DNA를 사용하는 RNA 가이드된 엔도뉴클레아제-매개된 게놈 편집을 통해 CAR-T 세포를 제조하는 것을 기재한다. 바람직하게, 상기 변형된 단일-가닥 (ss) 또는 이중 가닥 (ds) DNA는 3개의 PS 결합을 하나의 프라이머의 5’ 말단의 10개 뉴클레오타이드 또는 5개 뉴클레오타이드 내의 뉴클레오타이드에 부가함에 의해 생성된다. 본 발명을 임의의 특정 기전으로 제한하는 것 없이, 상기 PS 변형은 공여자 DNA의 변형된 가닥의 엑소뉴클레아제 분해를 억제하는 것으로 사료된다. 프라이머의 5’ 말단의 10개 뉴클레오타이드 또는 5개 뉴클레오타이드 내의 뉴클레오타이드는 또한 2’ O-메틸로 변형시켜 포스포로티오에이트 결합에 의해 유발되는 비-특이적 결합을 회피한다. 포스포로티오에이트 및 2’ O-메틸 변형된 ds 공여자 DNA 및 ss 공여자 DNA는 PCR, 비대칭 PCR 또는 역 전사를 통해 제조될 수 있다. 대안적으로, 합성의 최종 ds DNA 생성물은 포스포로티오에이트 및 2’ O-메틸로 변형시킬 수 있고 dsDNA는 하나의 가닥 상에서만 변형을 갖도록 제조될 수 있다.
추가로, 즉, CAR (키메라 항원 수용체)를 숙주 세포의 한정된 게놈 부위로 삽입하기 위해 디자인된 CAR 작제물을 포함하는 포스포로티오에이트 및 2’O-메틸과 같은 화학적 변형을 갖는 공여자 DNA 작제물과 같은 공여자 DNA 작제물이 기재된다. 추가로, 본원의 개시내용은 안전성 문제가 존재할 수 있는 바이러스 벡터가 부재인 CAR로 형질감염된 숙주 세포를 제공한다.
하나의 가닥 상에 변형을 갖는 공여자 DNA를 사용한 상기 공정은 녹-인(knock-in) 효율을 적어도 2배 증가시킬 수 있고, 이는 바이러스 벡터 방법에 상응하고, 통합의 부위 특이성을 위해 이점을 갖고 통상적인 레트로바이러스 또는 렌티바이러스 접근법과 비교하여 T 세포에서 CAR 발현을 위해 매우 안정하다. 포스포로티오에이트 및/또는 2’O-메틸을 사용한 하나의 공여자 쇄의 적어도 이중 변형은 녹-인 효율을 증가시킬 수 있다. 상기 1단계 녹-아웃/녹-인 방법은 다중 암 치료요법을 위한 보다 신속하고 보다 저렴한 CAR-T 생성 공정을 제공한다. 이중 가닥 DNA를 사용하고 노동적이고 수율을 감소시키는, 공여자 작제물의 뉴클레아제 처리 및 단일 가닥의 회수를 회피하는 능력은 상기 방법의 또 다른 이득이다.
상기 적용에서, 본원 발명자들은 포스포로티오에이트 및 2’ O-메틸 변형을 갖는 변형된 dsDNA 또는 ssDNA 공여자에 의해 긴 dsDNA 또는 ssDNA (예를 들어, ~3kb 항-CD38 CAR 및 CD19 CAR)를 녹인시키기 위한 단순하고 강력한 방법을 제공한다. 본원 발명자는 변형된 긴 dsDNA 및 ssDNA 서열이 CAR의 1차 T 세포로의 통합을 위해 고도로 효율적인 HDR 주형임을 보여준다. 추가로, 본원 발명자는 상기 방법이 통합의 부위 특이성에 대한 이점을 갖고 통상적인 레트로바이러스 또는 렌티-바이러스 접근법과 비교하여 T 세포에서 CAR 발현을 위해 매우 안정함을 입증한다.
본원의 개시내용은 1차 세포에서 CAR 유전자를 발현시키기 위한 방법을 제공하고, 상기 방법은 상기 1차 세포에 (a) 선택된 녹아웃 핵산에 상보적인 제1 뉴클레오타이드 서열 및 CRISPR-연합된 단백질 (Cas) 폴리펩타이드와 상호작용하는 제2 뉴클레오타이드 서열을 포함하는 단일 가이드 RNA (sgRNA)로서, 상기 sgRNA 서열의 하나 이상의 뉴클레오타이드가 임의로 변형된 뉴클레오타이드인, 단일 가이드 RNA; 및 (b) Cas 폴리펩타이드, Cas 폴리펩타이드를 암호화하는 mRNA, 및/또는 Cas 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터 또는 Cas 폴리펩타이드(여기서, 상기 변형된 sgRNA는 Cas 폴리펩타이드를 녹아웃 핵산의 부위로 가이드한다), (c) 5’ HA 서열, 프로모터 서열, CAR 작제물, 및 3’HA 서열을 포함하는 공여자 표적 DNA로서, 상기 공여자 표적 DNA가 바람직하게 이중 가닥이고, 바람직하게 5’ 엑소뉴클레아제 절단을 감소시키기 위해 5’ 말단의 5개 뉴클레오타이드 내 적어도 하나의 포스포티오에이트 결합으로 변형된 2개의 가닥 또는 바람직하게 하나의 가닥을 갖고, 임의로 5’ 말단의 5개 뉴클레오타이드 내 1개, 2개, 3개 또는 4개의 2’-O-메틸-변형된 뉴클레오타이드를 포함하는 공여자 표적 DNA를 도입하는 단계를 포함한다. 바람직하게, 변형된 가닥에 대한 반대 가닥은 5’ 말단 포스페이트를 갖는다. 프로모터는 예를 들어, T 세포일 수 있는 1차 세포에서 작동가능하다.
본원의 개시내용은 1차 세포에서 CAR 유전자의 유전자 발현을 유도하기 위한 방법을 제공하고, 상기 방법은 상기 1차 세포에 (a) 선택된 표적 핵산에 상보적인 뉴클레오타이드 서열을 포함하는 crRNA로서, 상기 가이드 RNA 내 뉴클레오타이드의 하나 이상이 임의로 변형된 뉴클레오타이드인, crRNA; 및 (b) Cas 폴리펩타이드, Cas 폴리펩타이드를 암호화하는 mRNA, 및/또는 Cas 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 재조합 발현 벡터 (여기서, 상기 crRNA는 Cas 폴리펩타이드를 녹아웃 핵산의 부위로 가이드한다), 및 (c) 5’ HA 서열, 프로모터 서열, CAR 작제물, 및 3’ HA 서열을 포함하는 공여자 표적 DNA로서, 상기 공여자 표적 DNA가 바람직하게 이중 가닥이고, 5’ 엑소뉴클레아제 절단을 감소시키기 위해 공여자의 5’ 말단의 5개 뉴클레오타이드 내 적어도 하나의 포스포티오에이트 결합으로 변형된 2개의 가닥 또는 바람직하게 하나의 가닥을 갖고, 임의로 5’ 말단의 5개 뉴클레오타이드 내 1개, 2개, 3개 또는 4개의 2’-O-메틸-변형된 뉴클레오타이드를 포함하는, 공여자 표적 DNA를 도입하는 단계를 포함한다. 바람직하게, 변형된 가닥에 대한 반대 가닥은 5’ 말단 포스페이트를 갖는다. 프로모터는 임의로, T 세포일 수 있는 1차 세포에서 작동가능하다.
일부 구현예에서, 상기 세포는 세포 기반 치료요법을 위해 변형된다. 세포는 비제한적인 예로서 줄기 세포, 섬유아세포, 신경교 세포, 근세포, 또는 조혈 세포일 수 있고, 본원에 기재된 방법을 사용하여 변형되고, 환자에게 전달될 수 있다. 상기 세포는 환자와 관련하여 자가이거나 동종이계일 수 있다. 동종이계인 경우, 세포는 하나 또는 다수의 공여자로부터 기원할 수 있다.
실시예
실시예는 공여자 DNA를 녹킹인하고 T 세포 수용체 (TCR)와 같은 표적화된 내인성 유전자 또는 PD-1 유전자를 녹킹 아웃하기 위해 바이러스 벡터를 사용하지 않고 높은 형질감염 효율을 제공하는 기재된 공정의 이점을 보여준다. 또한 예시된 것은 제1 유전자좌에서 동시 유전자 녹아웃 및 유전자 녹인, 및 단일 형질감염으로부터 비롯된 제2 유전자좌에서 유전자 녹아웃이 예시된다.
건강한 자원 봉사자 공여자의 버피 코트는 샌디에고 혈액 은행으로부터 수득하였다. 일부 새로운 전혈 또는 백혈구성분채집 생성물은 제조원(StemCell Techologies (Vancouver, Canada))으로부터 수득하였다. 말초 혈액 단핵 세포 (PBMC)는 밀도 구배 원심분리에 의해 단리하였다. PBMC는 mL 당 106 세포의 밀도로, 300 U/mL의 IL-2 (Proleukin)와 함께 5% 태아 소 혈청 (Sigma, St. Louis, Mo)이 보충된 AIM-V 배지(ThermoFisher Scientific, Waltham, Ma)에서 2일 동안 CD3 항체(BioLegend, San Diego, CA) 100ng/mL로 활성화시켰다. 배지는 2 내지 3일마다 갈아주고 세포는 mL 당 106으로 재분주하였다. 상기 처리는 배양물 중에서 T 세포를 선택적으로 증폭시킨다. 일부 실험에서, 세포는 mL 당 106 세포의 밀도로, 300 U/mL의 IL-2 (Proleukin)와 함께 5% CTS™ 면역 세포 SR (Thermofisher scientific)이 보충된 CTS™ OpTmizer™ T 세포 확장 SFM (ThermoFisher Scientific)에서 배양하였다. 일부 실험에서, T 세포는 제조업자의 지침에 따라 EasySep™ 사람 T 세포 단리 키트 또는 CD3 양성 선택적 키트(Stemcell Technology Inc.) 또는 Dynabeads™ 사람 T-확장기 CD3/CD28 (ThermoFisher Scientific)를 사용한 자기 음성 선택을 사용하여 PBMC로부터 단리하였다.
세포독성 검정에 사용하기 위해, CD38을 발현하는 RPMI-8226 (다발성 골수종 세포주) 세포는 녹색 형광성 단백질 (GFP)을 발현하도록 형질도입하였고, CD38을 발현하지 않는 K562 (사람 불멸화된 골수성 백혈병) 세포는 R-피코에리트린(RPE)을 발현하도록 형질도입하였다. 세포주 둘다는 10% 태아 소 혈청(Sigma)이 보충된 RPMI1640 배지(ATCC)에서 배양하였다. CAR 플라스미드는 In-Fusion® HD 클로닝 키트(Takara Bio USA, Inc, Mountain View, CA)를 사용하여 생성하였다. 골격 플라스미드 pAAV-MCS (Cell Biolabs (San Diego, Ca))는 공여자 단편을 생성하기 위한 PCR 주형으로서 사용된 유전학적 작제물을 생성하기 위해 사용되었다.
일부 실험에서, 레트로바이러스-형질도입된 T 세포는 cas-매개된 녹-인 세포와 비교하였다. 레트로바이러스 작제물을 사용한 T 세포의 형질도입은 필수적으로 문헌(참조: Ma et al., (2004) The Prostate 61:12-25; and Ma et al., The Prostate 74(3):286-296, (2014), The Prostate 74(3):286-296, 이의 개시내용은 이들의 전문이 본원에 참조로 인용된다)에 기재된 바와 같이 수행하였다. 간략하게, 항-CD38 CAR (또는 다른 작제물) 플라스미드 DNA로 FuGene 시약(Promega, Madison, Wi)을 사용하여 Phoenix-Eco 세포주 (ATCC)를 형질감염시켜 에코트로픽 레트로바이러스를 생성시킴에 이어서 수거된 일과성 바이러스 상등액 (에코트로픽 바이러스)을 사용하여 GaLV 외피 단백질을 갖는 PG13 팩키징 세포를 형질도입하여 사람 세포를 감염시키기 위해 레트로바이러스를 생성하였다. PG13 세포로부터의 바이러스 상등액을 사용하여 CD3 또는 CD3/CD28 활성화 후 2 내지 3일에 활성화된 T 세포 (또는 PBMC)를 형질도입하였다. 활성화된 사람 T 세포는 2일 동안 제조업자의 매뉴얼에 따라 정상의 건강한 공여자 말초 혈액 단핵 세포 (PBMC)를 100 ng/ml의 마우스 항-사람 CD3 항체 OKT3 (Orth Biotech, Rartian, NJ) 또는 항-CD3, 항-CD28 T-세포 TransAct 시약 (Miltenly Biotech, San Diego, CA), 및 5% FBS가 보충된 AIM-V 성장 배지 (GIBCO-Thermo Fisher scientific, Waltham, MA) 중 300-1000 U/ml의 IL-2로 활성화시킴에 의해 생성하였다. 5×106 활성화된 사람 T 세포는 10 mg/ml의 레트로넥틴 (Takara Bio USA) 예비-코팅된 6-웰 플레이트에서 3ml의 바이러스 상등액으로 형질도입하였고, 32 ℃에서 1시간 동안 1000g에서 원심분리하였다. 형질도입 후, 형질도입된 T 세포는 5% FBS 및 300-1000 U/ml IL2가 보충된 AIM-V 성장 배지에서 확장시켰다.
[표 1]
공여자 DNA를 생성하기 위해 사용된 프라이머:
별표는 포스포로티오에이트 (PS) 연결; Am, 2’-O-메틸화된 데옥시아데노신;
Cm, 2’-O-메틸화된 데옥시시토신; Gm, 2’-O-메틸화된 데옥시구아노신을 지적한다.


실시예 1. 사람 T 세포에서 T-세포 수용체 유전자의 동시 녹아웃 및 항-CD38 CAR의 녹인.
상기 실시예에서, T 세포 수용체 알파 불변 (TRAC) 유전자 (Entrez Gene ID: 28755)는 공여자 DNA로서 항-CD38 CAR 직제물로 표적화하였다. pAAV-TRAC-항-CD38 작제물은 게놈에서 표적 서열(CAGGGTTCTGGATATCTGT (서열번호 1))을 플랭킹하는 T 세포 수용체 알파 불변 (TRAC)의 대략 1.3kb의 게놈 DNA 서열과 함께 디자인하였다. 표적 서열은 Cas9-매개된 유전자 붕괴 및 공여자 작제물의 삽입을 위한 TRAC 유전자의 엑손 1에서 Cas9 PAM (GGG)의 업스트림의 부위로서 동정되었다. 항-CD38 CAR 유전자 작제물 (서열번호 2)은 사람 CD38에 특이적인 단일쇄 가변 단편 (scFv)에 이어서 CD8 및 CD28 힌지 도메인-CD28 막관통 도메인-CD28 세포내 영역 및 CD3 제타 세포내 도메인을 암호화하는 서열을 포함하였다. 외인성 JeT 프로모터 (미국 특허 제6,555,674호; 서열번호 3)를 사용하여 항-CD38 CAR의 전사를 개시하였다.
공여자 DNA 단편 게놈 편집을 생성하기 위한 PCR 주형으로서 사용된 pAAV-항-CD38A2 공여자 플라스미드를 작제하기 위해, 650-660 bp 상동성 아암을 갖는 항-CD38A2 CAR 작제물(서열번호 4)은 통합된 DNA 기술(IDT, Coralville, IA)에 의해 합성하였다. 인-융합(in-fusion) 클로닝 반응은 실온에서 수행하였고, Mlul 및 BstEII (50ng)으로 이중 분해된 pAAV-MCS 벡터, 플랭킹 상동성 아암을 갖는 항-CD38A2 CAR 단편(서열번호 4) (50ng), 1ul 5X의 인-융합 HD 효소 프레믹스(Enzyme Premix) (Takara Bio), 및 뉴클레아제 부재 물을 함유한다. 반응물을 간략하게 볼텍싱하고 50 ℃에서 30분 동안 항온처리 전에 원심분리하였다. Stellar™ 컴피턴트 세포 (Takara Bio USA)는 이어서 인-융합 생성물로 형질전환시키고, 암피실린-처리된 한천 플레이트 상에 분주하였다. 다수의 콜로니는 생거 서열분석(Genewiz, South Plainfield, Nj)을 위해 선택하여 서열분석 프라이머 CTTAGGCTGGGCATTAGCAG (서열번호 5), CATGGAATGGTCATGGGTCT (서열번호 6), 및 GGCTACGTATTCGGTTCAGG (서열번호 7)을 사용하여 올바른 클론을 동정하였다. 올바른 클론을 배양하고 이들 클론으로부터의 DNA 플라스미드를 정제하였다.
TCR 알파 (TRAC) 유전자의 RNA 가이드-지시된 표적화를 위해, tracr RNA (ALT-R® CRISPR-Cas9 tracrRNA) 및 crRNA (ALT-R® CRISPR-Cas9 crRNA)는 IDT (Coralville, IA)로부터 구입하였고, 여기서, 상기 crRNA는 TRAC 유전자의 제1 엑손 내 Cas9 PAM 서열 (GGG)의 바로 업스트림에 존재하는 표적 서열 CAGGGTTCTGGATATCTGT (서열번호 1)을 포함하도록 디자인하였다.
공여자 단편 DNA를 제조하기 위해, PrimeSTAR 맥스 프레믹스 (Takara Bio USA)는 PCR 반응을 위해 사용하였다. 상기된 AAV 공여자 플라스미드 pAAV-항-CD38A2는 주형으로서 사용하였다. 660nt (서열번호 44) 및 650nt (서열번호 45)의 상동성 아암을 갖는 공여자 단편을 생성하기 위해, 정배향 프라이머는 서열: TGGAGCTAGGGCACCATATT (서열번호 36)을 갖고, 역배향 프라이머는 서열: CAACTTGGAGAAGGGGCTTA (서열번호 9)를 갖는다. 상이한 상동성 아암 길이의 효과를 시험하기 위한 다양한 실험에서, pAAV-항-CD38A2 작제물의 상동성 아암 내 특정 위치에 하이브리드화하는 서열을 갖는 프라이머를 사용하여 PCR에 의해 목적하는 길이의 상동성 아암을 갖는 공여자 단편을 생성하였다. 포스포로티오에이트 결합(도 2a)은 정배향 프라이머 (서열번호 36)의 5’ 말단에서 말단 3개의 뉴클레오타이드에 도입하여 엑소뉴클레아제 분해 (5’ 말단으로부터 첫번째와 두번째, 두번째와 세번째, 및 세번째와 네번째 뉴클레오타이드 사이에)를 억제하였다. 정배향 올리고뉴클레오타이드 프라이머의 5’ 말단으로부터 두번째, 세번째 및 네번째 위치에서 뉴클레오타이드는 또한 2'-O-메틸 변형시켰다(도 2b) (서열번호 8, 표 1 참조). 역배향 프라이머(서열번호 9)는 5'-말단 포스페이트를 포함하였다. 공여자 DNA 단편을 생성하기 위해, 열순환기 세팅은 다음과 같다: 30s 동안 98 ℃의 1회 사이클, 10s 동안 98℃, 5 내지 15s 동안 64 내지 66℃, 30s 동안 72 ℃의 35회 사이클 및 7 내지 10분동안 72 ℃의 1회 사이클. 단일 가닥 주형을 생성하기 위한 스트랜다제를 사용한 분해는 Guide-it™ 롱 ssDNA 제조 시스템(Long ssDNA Production System) 키트 (Takara Bio USA)를 사용하여 제조업자의 지침(Takara Bio USA)에 따라 수행하였고, ssDNA는 뉴클레오스핀 겔(NucleoSpin Gel) 및 PCR 클린-업 키트(Clean-Up kits) (Takara Bio USA)를 사용하여 정제하였다. ssDNA의 농도는 NanoDrop (Denovix, Wilmington, De)에 의해 결정하였다. 대조군으로서, 공여자 단편은 수득한 공여자 단편이 어떠한 화학적 변형을 갖지 않도록 (PS 또는 2’-O-메틸 그룹 부재) 변형되지 않은 프라이머 또는 단지 PS 변형 (2’-O-메틸 그룹 부재)을 갖는 정배향 프라이머로 생성하였다.
TCR 녹아웃/항-CD38 CAR 녹인을 생성하기 위해, T 세포는 CD3을 배양물에 첨가함에 의해 활성화시켰다. CD3을 사용한 T-세포 활성화 개시 후 대략 48 내지 72시간에, 활성화된 T 세포를 포함하는 PBMC 배양물을 Neon® 형질감염 시스템(ThermoFisher Scientific) 및 10-μl의 팁 또는 100-μl 팁을 사용하여 SpCas9 단백질(핵 국소화 서열을 포함하는; IDT) + crRNA(가이드 서열 서열번호 1을 포함하는) 및 tracrRNA을 포함하는 SpCas9 리보뉴클레오단백질 복합체(RNP)와 함께 전기천공하였다. 간략하게, Alt-R® CRISPR-Cas9 crRNA 및 Alt-R tracrRNA (둘다 IDT로부터)는 먼저 혼합하고 95 ℃에서 5분동안 가열하였다. 혼합물을 이어서 가열로부터 제거하고 약 20분동안 벤치 탑 (bench top) 상에서 실온(15-25 ℃)으로 냉각되도록 방치하여 crRNA:tracrRNA 듀플렉스를 제조한다. 각각의 형질감염을 위해, 10 μg SpCas9 단백질 (IDT)은 200 pmol의 crRNA:tracrRNA 듀플렉스와 혼합하고, 30분동안 4℃에서 함께 항온처리하여 RNP를 형성하였다. 1 x 106 세포를 RNP와 혼합하고 1700 V, 20 ms 펄스 폭, 1 펄스로 전기천공하였다. 1 내지 2시간 후에, 10ug의 단일-가닥의 공여자 DNA를 1600 V, 20ms 펄스 폭, 1 펄스로 세포에 전기천공하였다. 일부 경우에, T 세포는 RNP 및 공여자 DNA와 혼합하고 RNP + 공여자 DNA를 동시에 세포에 전기천공하였다. 전기천공 후, 세포는 배양 배지에 희석시키고, 37℃, 5% CO2에서 항온처리하였다.
FACS에 의한 형질전환된 세포의 CAR 발현을 검출함에 의한 녹-인 효율을 결정하기 위해, 형질감염되거나 레트로바이러스적으로 형질도입된 PBMC는 DPBS/5% 사람 혈청 알부민으로 세척하고, 이어서 항-CD3-BV421 항체 SK7 (BioLegend) 및 PE 접합된 항-CD38-Fc 단백질(Chimerigen Laboratories, Allston, MA)로 4 ℃에서 30 내지 60분 동안 염색시켰다. CD3 및 항-CD38 CAR 발현은 iQue 스크리너 플러스 (Intellicyte Co.)를 사용하여 분석하였다. 항-CD38 작제물 녹-인을 위한 음성 대조군은 하이브리드화된 tracrRNA 및 TRAC 유전자의 제1 엑손을 표적화하는 crRNA와 복합체화된 Cas9 단백질을 포함하는 RNP로 형질감염시켰지만 항-CD38 CAR 공여자 DNA로 형질감염되지 않은 세포이다. 녹-인 세포에 의한 항-CD38 CAR 작제물의 발현을 위한 대조군으로서, 항-CD38 CAR-발현 PBMC는 비-Cas9 방법에 의해 생성하였다. TRAC 유전자좌를 표적화하는 가이드를 포함하지만 (TCR 녹아웃 세포) 어떠한 공여자 DNA가 없는 RNP로 형질감염된 PBMC에는 CRISPR/Cas9 표적화에 사용된 공여자 단편을 제조하기 위해 사용된 동일한 항-CD38A2 발현 카세트 (서열번호 2)를 갖는 레트로바이러스 벡터를 포함하는 레트로바이러스를 형질도입하였다.
도 3a는 형질감염 후 8일째에 항-CD38 작제물의 발현이 항-CD38 CAR의 발현을 위한 공여자 단편의 부재하에 RNP (TRAC 유전자를 녹킹아웃하기 위해) RNP로 형질감염된 세포에서 검출되지 않았음을 보여준다(최좌측 패널). 한편, TRAC 녹아웃을 갖고 후속적으로 항-CD38 CAR을 발현하기 위해 작제물을 포함하는 레트로바이러스가 형질도입된 PBMC는 형질감염 후 8일째에 세포의 약 70%에서 항-CD38 CAR의 발현을 보여주었다(도 3a의 최우측 패널). TRAC 유전자의 RNP 표적화 엑손 1에 추가로 항-CD38 CAR ss 공여자 DNA로 형질전환된 배양물에 대해, 어떠한 화학적 변형을 갖지 않은 ss 공여자 DNA를 수용한 집단의 대략 12% 및 공여자 DNA의 5’ 말단 근처의 뉴클레오타이드 상에 PS 골격 변형만을 갖는 (5’ 말단으로부터 넘버링되는 뉴클레오타이드 1과 2, 2와 3 및 3과 4 사이에 PS 결합을 갖는 PCR 프라이머를 사용함에 의해 도입된) ss 공여자 DNA가 형질도입된 배양물의 대략 13%는 항-CD38 작제물의 발현을 입증하였다. 또한 PS 변형을 포함하는 (PCR에 의해 공여자 DNA를 생성하기 위해 이들 변형을 포함하는 서열번호 8의 프라이머를 사용함에 의해) 공여자 단편 가닥의 5’ 말단으로부터 제2, 제3 및 제4 뉴클레오타이드에서 3개 뉴클레오타이드의 2’ 산소로의 메틸 그룹의 부가는 형질감염된 집단에서 항-CD38 CAR의 유의적으로 보다 높은 발현을 유도하였고, 여기서, 항-CD38 CAR의 발현은 8일째에 ‘이중 변형된 (2’-O-메틸 및 PS) 단일 가닥의 공여자 단편을 수용한 세포의 대략 20%에서 나타났다. 현저하게, 공여자 DNA의 화학적 변형은 형질감염된 배양물의 생존률에 영향을 미치지 않았다.
항-CD38 CAR의 증가된 발현은 항-CD38 CAR 공여자 단편 + 상기 TRAC 유전자를 표적화하는 RNP로 형질감염된 배양물에서 시간 경과에 따라서 관찰되었고, 반대로 레트로바이러스가 형질도입된 배양물에 대해서도 사실이다. 형질감염 후 10일째에(도 3b), 유동 세포측정은 모두 TRAC-표적화 RNP로 형질감염된 배양물 모두에 대해, 상기 세포의 적어도 80%가 TCR을 발현하지 않았음을 입증하였다. 더욱이, TRAC-표적화 RNP에 추가로 항-CD38 CAR 공여자 단편으로 형질감염된 배양물에서, TCR을 발현하지 않은 세포의 적어도 42%는 형질감염 후 10일째에 항-CD38 작제물을 발현하였다(도 3b, 패널 2-4). 5’-근접 뉴클레오타이드 상에 PS 및 2’-O-메틸 그룹 둘다를 갖는 항-CD38 CAR 공여자 단편으로 형질감염된 배양물에 대해, 세포의 57%는 10일까지 임의의 시험 배양물 중 최고의 퍼센트로 항-CD38 작제물을 발현하였다(도 3b, 패널 4). 동시에, 레트로바이러스로 형질도입된 배양물 중에 항-CD38 CAR의 발현은 8일째에 나타났던 것의 약 절반으로, 형질도입 후 10일째에 세포의 대략 34%까지 떨어졌다 (도 3b. 패널 5). 20일째에 이중으로 변형된 ss 공여자로 형질감염된 배양물 및 레트로바이러스 형질도입된 배양물의 분석(도 3c)은 배양물 중에 항-CD38 작제물의 발현이 안정화되고, 5’ 말단에서 PS 및 2’-O-메틸 변형 둘다를 갖는 ss 공여자로 형질감염된 Cas9-변형된 배양물은 TCR-음성 세포의 54%가 작제물을 발현함(중간 패널)을 입증하고 레트로바이러스가 형질도입된 배양물은 TCR-음성 세포의 31%가 작제물을 발현함(우측 패널)을 입증함을 보여주었다.
TRAC 유전자의 엑손 1에서 표적화된 유전자좌에서 상동성 지시된 복구 (HDR)의 존재를 확인하기 위해, PCR은 공여자 단편이 가이드 RNA에 의해 표적화된 TRAC 부위로 삽입되었는지를 입증하기 위해 배양물로부터 단리된 DNA에 대해 수행하였다. 게놈 DNA는 비-형질감염된 활성화된 T 세포(ATC), TRAC 엑손 1 가이드 RNA를 포함한 RNP로 형질전환된 TRAC 녹아웃 세포, 및 RNP + 포스포로티오에이트 및 2’ O-메틸 변형된 공여자 DNA로 형질감염된 T 세포로부터 증폭시켜 TRAC 유전자좌로의 항-CD38 CAR 전이유전자의 표적화된 삽입을 검출하였다. 게놈 내 공여자 DNA의 위치를 확인하기 위해, 올리고뉴클레오타이드 프라이머는 TRAC 상동성 아암의 외부이지만 게놈 내 상동성 아암 서열에 인접한 (이의 외부) 서열에 표적화하였다. 총 1 x 105 세포를 30 μL의 퀵 추출 용액(Quick Extraction solution) (Epicenter)에 재현탁시켜 게놈 DNA를 추출하였다. 세포 용해물을 5분동안 65 ℃에서 및 이어서 2분동안 95 ℃에서 항온처리하고 -20 ℃에서 저장하였다. 게놈 DNA의 농도는 NanoDrop (Denovix)에 의해 결정하였다. TRAC 표적 부위를 함유하는 게놈 영역은 하기의 프라이머 세트를 사용하여 PCR-증폭시켰다: TRAC 상에 5’ PCR 정배향 프라이머: CCTGCTTTCTGAGGGTGAAG (서열번호 10), CAR 상에 역배향 프라이머: CTTTCGACCAACTGGACCTG (서열번호 11); CAR 상에 3’ 정배향 프라이머: CGTTCTGGGTACTCGTGGTT (서열번호 12), TRAC 상에 3’ 역배향 프라이머: GAGAGCCCTTCCCTGACTTT (서열번호 13) (도 1b 참조). 프라이머 세트 둘다는 상동성 아암의 외부를 어닐링함에 의해 HDR 주형의 증폭을 회피하도록 디자인하였다.
게놈 DNA의 농도는 NanoDrop (Denovix)에 의해 결정하였다. 프라이머 세트 둘다는 쌍의 하나의 프라이머가 상동성 아암의 외부의 게놈 내 부위에 어닐링하도록 하고 상기 쌍의 다른 프라이머가 작제물의 암호화 영역 (즉, 상동성 아암에서의 영역이 아닌) 내 부위로 어닐링하도록 디자인하였다. PCR은 400ng의 게놈 DNA 및 Q5 고충실도 2X 믹스 (New England Biolabs)를 함유하였다. 열순환기 세팅은 2분동안 98 ℃에서 1 사이클, 10s 동안 98 ℃에서, 15s 동안 65 ℃에서, 45s 동안 72 ℃에서 35 사이클 및 10분동안 72 ℃에서 1 사이클로 이루어졌다. PCR 생성물은 SYBR Safe를 함유하는 1% 아가로스 겔 (Life Technologies) 상에서 정제하였다. PCR 생성물은 이어서 아가로스 겔로부터 용출시키고 NucleoSpin® 겔 및 PCR 클린-업 키트(MACHEREY-NAGEL GmbH & Co. Kg)를 사용하여 단리하였다. PCR 생성물은 생거 서열분석 (Genewiz)을 위해 제출하였다. 도 4는 겔 분리 PCR 생성물의 사진을 제공한다. 작제물의 5’ 및 3’ 말단에서 게놈 내 상동성 아암에 인접한 게놈 서열에 인접한 항-CD38 작제물에 상응하는 양성 밴드는 공여자 DNA로 형질감염된 세포 (레인 3 및 6)에서 나타났고 비-형질감염된 ATC (레인 1 및 4) 또는 TRAC 녹아웃 유일 세포 (레인 2 및 5)에서 나타나지 않았다. 이들 PCR 생성물의 서열분석은 예측된 부위에 삽입된 항-CD38 CAR 작제물이 예측된 부위에 삽입됨을 확인시켜주었고, 여기서, 상동성 아암의 영역 외부에 게놈 서열 및 작제물의 5’ 및 3’ 말단 둘다에서 상동성 아암 서열 내부에서 작제물 서열에 어닐링하는 프라이머를 사용한 통합된 항-CD38 CAR 작제물을 갖는 세포의 게놈 DNA로부터 생성된 상기 PCR 단편들은 표적화된 부위에 통합된 작제물에 대해 예측된 서열을 가졌다. 삽입 유전자좌를 진단하기 위해 프라이머를 사용하여 생성된 PCR 생성물의 서열분석(도 1b 참조)은 TRAC 유전자의 엑손 1에 통합된 항-CD38 CAR 공여자 단편을 입증하는 서열을 제공하였다. PCR 생성물 서열(예를 들어, 서열번호 39 및 서열번호 40)은 게놈 내 상동성 아암 (의 외부)에 인접한 서열, 공여자 단편내에 존재하는 상동성 아암에 인접한 서열 및 단일 PCR 생성물 내 항-CD38 CAR의 일부를 포함하였고, 이는 예상된 부위에서의 삽입을 입증한다.
형질감염된 세포의 기능에 대해 시험하기 위해, 전기천공 3주 후에, TRAC 유전자좌에 표적화된 항-CD38 CAR로 형질감염된 활성화된 T 세포는 밤새 IL-2로 단식시키고, 특이적 사멸 검정에서 시험하였다. 활성화된 T 세포는 CD38 양성 RPMI-8226/GFP 세포 및 CD38 음성 K562/RPE 세포의 표적 세포 혼합물과 동시 배양하였다. 항온처리 이펙터-대-표적 세포 비율은 10:1 내지 0.08:1 범위였다. 밤새 항온처리 후, 세포는 유동 세포측정에 의해 분석하여 GFP-양성 및 RPE-양성 세포 집단을 측정하여 항-CD38A2 CART 세포에 의한 특이적 표적 세포 사멸을 결정하였다. 도 5는 CD38-발현 RPMI8226 세포에 대한 각각의 세포 집단의 특이적 세포독성의 그래프를 제공한다(CD38을 발현하지 않는 K562 세포에 대한 관찰된 세포독성으로부터 공제한 후 CD38-발현 RPMI8226에 대해 관찰된 세포독성). 상기 그래프는 비-형질감염된 ATC 세포가 최고의 이펙터 대 표적 비율에서 일부 독성을 보여주었지만, TRAC 녹아웃 세포는 이펙터 대 표적 세포 비율에 상관 없이 실질적으로 어떠한 사멸을 보여주지 않았음을 보여준다. 항-CD38A2 CART 세포는 그러나 CD38 양성 세포- RPMI8226에 대해 강력하고 특이적인 사멸 활성을 나타냈지만 CD38 음성 세포 - K562에 대해서는 활성이 나타나지 않았다(도 5). 항-CD38 CAR 카세트를 함유한 화학적으로 변형된 공여자를 통합한 T 세포는 항-CD38 CAR 작제물을 포함하는 레트로바이러스가 형질도입된 세포의 것과 유사하게 표적 세포에 대한 세포독성을 입증하였다.
형질감염된 활성화된 T 세포 (ATC)는 또한 사이토킨 분비에 대해 시험하였다(도 6). T 세포는 밤새 IL-2 부재 배지에서 단식시켰다. 항-CD38 CAR-T 세포 또는 ATC 대조군은 이어서 CD38 음성 K562 또는 CD38 양성 RPMI8226 세포와 동시 배양하였다. 항온처리 이펙터 대 표적 세포 비율은 2:1이었다. 밤새 항온처리 후, 세포는 제조업자의 지침에 따라 원심분리하고 상등액을 수거하여 사이토킨 IL-2, IFN-감마 및 TNF 알파(Affymetrix eBioscience)를 정량하였다. 유전자-편집된 TCR 녹아웃 항-CD38A2 CART 세포는 또한 CD38 음성 세포 (K562)가 아닌 CD38 양성 종양 세포 (RPMI8226)와 동시 배양하는 경우 유사한 양의 IFN-γ 및 다른 염증 촉진 사이토킨을 방출하였다.
요약하면, 시험관내 세포 기능성 연구는 특이적 사멸 검정 (도 5) 및 사이토킨 분비 검정(도 6) 둘다의 측면에서, 상기 신규 및 효율적인 공정에 의해 성취된 TRAC-부위-특이적 통합된 항-CD38A2 CAR과 바이러스-매개된 무작위로 통합된 항-CD38A2 CAR 간에 임의의 현저한 차이를 밝히지 못했다.
실시예 2. 공여자 DNA의 상동성 아암의 길이의 감소
항-CD38 CAR 작제물의 녹-인을 위해, 상이한 길이의 상동성 아암 (HA)을 갖는 공여자 단편을 생성하고 시험하였다. 항-CD38 카세트 + 660과 650nt의 TRAC 엑손 1 상동성 아암을 포함한 실시예 1에서 기재된 pAAV-TRAC-항-CD38 작제물은 주형(서열번호 4)으로서 사용하였다. 프라이머, 서열번호 8 및 서열번호 9의 제1 세트를 사용하여 실시예 1에 제공된 바와 같은 상기 주형으로부터 660 nt 및 650 nt의 상동성 아암을 갖는 공여자 단편을 생성하였다. 제2 세트의 프라이머, 서열번호 14 및 서열번호 15를 사용하여 대략 350nt (375 및 321 뉴클레오타이드)의 상동성 아암을 갖는 공여자 단편을 생성하였고, 여기서, 서열번호 14의 프라이머는 5’ 말단으로부터 제1과 제2, 제2와 제3, 및 제3과 제4 뉴클레오타이드 사이에 PS 연결을 갖고 위치 2, 3, 및 5에서 2’-O-메틸-변형된 뉴클레오타이드를 가졌다. 제3 세트의 프라이머, 서열번호 18 및 서열번호 19를 사용하여 대략 165nt (171 및 161nt)의 상동성 아암을 갖는 공여자 단편을 생성하였고, 여기서, 서열번호 18의 프라이머는 5’ 말단으로부터 제1과 제2, 제3과 제4, 및 제4와 제5 뉴클레오타이드 사이에 PS 연결을 갖고 위치 3, 4 및 5에서 2’-O-메틸-변형된 뉴클레오타이드를 가졌다. 각각의 경우에, 정배향 프라이머 (서열번호 8, 14, 및 18)는 5’말단 최외곽 5개 뉴클레오타이드 내 3개의 PS 연결 (예를 들어, 프라이머의 5’ 말단으로부터 임의의 제1과 제2, 제2와 제3, 제3과 제4, 및 제4와 제5 뉴클레오타이드 사이에) 및 임의의 5개의 5’ 말단 최외곽 뉴클레오타이드에 존재하는 3개의 2’-O-메틸 그룹을 갖도록 디자인하였다. 각각의 경우에, 역배향 프라이머(서열번호 9, 15, 및 17)는 5’ 말단 포스페이트를 가졌다(표 1 참조).
프라이머 세트 각각은 공여자의 하나의 가닥의 5’ 말단에 근접한 다중 PS 및 2’-O 메틸 변형 및 공여자의 반대 가닥의 5’ 말단에서 5’ 포스페이트를 갖는 공여자 DNA 분자를 생성하기 위해 주형으로서 pAAV CD38 DAR 작제물과 함께 사용하였다. RNP는 실시예 1에 기재된 바와 같은 tracr 및 crRNA를 포함하도록 어셈블리하였고, 여기서, 상기 crRNA는 TRAC 유전자의 엑손 1에 발견된 서열인 서열번호 1의 표적 서열을 포함하였다. PCR에 의해 공여자 DNA를 합성하는 경우, 단일 가닥의 공여자 단편을 생성하기 위한 뉴클레아제 반응 및 상기 단일 가닥의 DNA의 후속 정제는 시간 소모적이고 전형적으로 형질감염에 대한 공여자 단편의 수율에서 유의적 상실을 유도한다. 추가로, 뉴클레아제 반응은 공여자 단편의 말단이 분해될 수 있어 제어하기가 어려울 수 있다. 지시된 유전자 녹아웃 및 항체 작제물 녹인의 효율을 시험하는 추가의 실험에서, 이중 가닥 공여자 DNA는 PCR 합성된 공여자의 뉴클레아제 분해 및 단일 가닥 정제를 제거하기 위해 형질감염에서 시험하였다.
길이가 대략 665, 350 및 165 염기쌍인 상동성 아암을 갖는 이중 가닥 공여자 분자는 독립적으로 실시예 1에 기재된 바와 같이 활성화된 T 세포에 형질감염시켰고, 단, 공여자 단편 및 RNP는 RNP를 전기천공시키기 위한 (Neon® 형질감염 시스템(ThermoFisher Scientific) 1700 V, 20 ms 펄스 폭, 1 펄스) 조건하에서 동일한 전기천공으로 형질감염시켰다. 대조군으로서, 활성화된 T 세포에는 공여자 단편의 부재하에 RNP로 형질감염시키고, 이는 공여자 DNA 삽입 없이 표적화된 TRAC 유전자좌의 녹아웃을 유도해야만 하였다. T 세포 수용체 및 항-CD38 CAR 작제물의 발현에 대해 시험하기 위해, 유동 세포측정은 실시예 1에 제공된 바와 같이 수행하였다. 도 7은 예상된 바와 같이, 단지 RNP로 형질감염된 T 세포 배양물이 T 세포 수용체의 저수준의 발현을 가짐을 보여주고 또한 항-CD38 CAR이 발현되지 않음을 입증하였다. RNP + 상이한 크기의 상동성 아암을 갖는 공여자 DNA로 형질감염된 T 세포는 그러나 배양물에서 저수준의 T 세포 수용체 발현 및 항-CD38 CAR의 양호한 발현을 보여주고, 이는 이중 가닥 DNA의 형질감염이 표적화된 녹-인을 위해 매우 효과적임을 입증한다. 추가로, 놀랍게도, 시험된 최단 HA 길이 161/171 nt는 보다 긴 HA 길이 보다 양호하게 작동하였고, 도입된 작제물을 발현하는 녹아웃 세포의 퍼센트는 대략 665 nt 아암에 대해 대략 24%, 대략 350nt 아암에 대해 대략 30% 및 대략 165 nt 아암에 대해 대략 38%이다. 짧은 상동성 아암은 다라서 이중 가닥 DNA 공여자를 사용한 표적화된 녹-인 게놈 변형에 매우 효과적인 것으로 밝혀졌고, 이는 보다 작은 작제물을 가능하고/하거나 작제물 내 보다 높은 용량을 가능하게 하여 공여자 DNA에 포함될 추가의 또는 보다 긴 서열의 내포를 가능하게 한다는 이득을 갖는다.
실시예 3. 변형된 것 대 비-변형된 이중 가닥 공여자 DNA
항-CD38 CAR을 포함하고 상기 실시예 2에 제시된 바와 같이 대략 165 nt TRAC 엑손 1 상동성 아암을 갖는 공여자 DNA는 HDR을 촉진시키는데 이들의 상대적 효과를 시험하기 위해 뉴클레오타이드 변형의 존재 및 부재하에 프라이머를 사용하여 합성하였다. 첫번째의 경우에, 프라이머 서열번호 18은 프라이머(뉴클레오타이드 위치 3, 4 및 5에서) 및 프라이머 서열번호 19의 처음 5개 뉴클레오타이드 내 제1과 제2, 제3과 제4 및 제4와 제5의 뉴클레오사이드, 및 3개의 2’-O-메틸-변형된 뉴클레오타이드 사이에 존재하는 3개의 PS 연결을 갖고, 프라이머 서열번호 19는 5’ 말단 포스페이트를 갖는다(표 1). 이들 프라이머를 사용하여 각각 171 bp 및 161 bp의 HA를 갖고, 상응하는 뉴클레오타이드 변형 (즉, 공여자 DNA 생성물의 제1 가닥의 5’ 말단의 5개 뉴클레오타이드 내 3개의 PS 연결 및 3개의 2’-O-메틸 그룹, 및 공여자 DNA 생성물의 제2 가닥의 5’ 말단 상에 포스페이트)을 갖는 공여자 DNA를 생성하였다. 제2의 경우에, 프라이머 서열번호 37은 프라이머 서열번호 18과 동일하고, 단, 프라이머 서열번호 37은 화학적 변형이 부재이다(표 1 참조). 5’ 말단 포스페이트가 부재인 서열번호 37 프라이머 및 서열번호 19 프라이머를 사용하여 항-CD38 CAR 카세트를 갖는 어떠한 뉴클레오타이드 변형을 갖지 않는 공여자 DNA를 생성하였다. 이들 공여자 DNA는 활성화된 T 세포에 서열번호 1의 표적 서열 (TRAC 유전자의 엑손 1 내)을 포함하는 trRNA 및 crRNA를 포함하는 RNP와 함께 이중 가닥 DNA 분자 (어느 한 가닥의 변성 또는 뉴클레아제 분해가 없음)로서 형질감염시켰다. 공여자로서 이중 가닥의 DNA를 사용한 전기 천공에서, 5ug의 dsDNA를 사용하여 100만개의 활성화된 T 세포를 형질감염시켰다.
실시예 2에서와 같이, 대조군 활성화된 T 세포에는 공여자 단편의 부재하에 RNP를 형질감염시키고, 이는 작제물 삽입 없이 표적화된 TRAC 유전자좌의 녹아웃을 유도해야만 하였다. T 세포 수용체 및 항-CD3 CAR 작제물의 발현에 대해 시험하기 위해, 유동 세포측정은 필수적으로 실시예 1에 제공된 바와 같이 수행하였다. 도 8에 나타낸 결과는 RNP 및 변형된 이중 가닥 공여자를 사용한 형질감염이 항-CD38 CAR을 발현하는 세포의 50% 초과를 유도하였음을 보여주고, 이는 TCR 발현 부재, RNP 및 비변형된 이중 가닥 공여자 (22%)로 형질감염된 배양물에서 관찰된 바와 같이 항-CD38 작제물을 발현하는 TCR 음성 세포 퍼센트의 적어도 2배를 입증한다.
실시예 4. 동시 TCR 녹아웃과 함께 항-CD19 및 항-BCMA CAR 작제물의 HDR-매개된 녹인
항-CD19 CAR 및 항-BCMA CAR 발현 작제물을 포함한 추가의 공여자 DNA는 또한 TRAC 유전자좌로의 삽입에 대해 시험하였다.
Jet 프로모터 (서열번호 3), 및 인트론, 항-CD19 CAR 작제물 및 SV40 폴리A 서열을 포함하는 항-CD19 CAR 카세트(서열번호 22)를 포함하는 항-CD19 CAR 작제물은 필수적으로 실시예 1에 기재된 항-CD38 CAR pAAV 작제물에 대해 기재된 바와 같이 제조하였고, 서열번호 20 및 서열번호 21의 TRAC 유전자 엑손 1 상동성 아암(HA)에 의해 플랭킹된 벡터에 클로닝하였다. HA pAAV 작제물을 갖는 항-CD19 CAR은 대략 170개 및 160개 뉴클레오타이드의 HA를 갖는 변형된 공여자 DNA의 생성을 유도하는 서열번호 18 및 서열번호 19로서 제공된 프라이머를 사용하여 실시예 1에 제공된 바와 같은 PCR 반응에서 주형으로서 사용하였다(표 1 참조). 정배향 프라이머(서열번호 18)는 첫번째와 두번째, 세번째와 네번째, 및 네번째와 다섯번째 뉴클레오사이드 사이에 3개의 PS 결합 및 프라이머의 5’ 말단으로부터 넘버링하는 경우 뉴클레오타이드 3, 4 및 5에서 3개의 2’-O-메틸 변형을 갖고, 역배향 프라이머(서열번호 19)는 5’ 말단 포스페이트를 가졌다(표 1). 따라서, 수득한 이중 가닥 공여자 DNA는 상응하는 변형을 갖도록 합성하였고, 제1 가닥은 5’ 말단의 5개 뉴클레오타이드 내 3개의 PS 및 3개의 2’-O-메틸 변형을 가졌고, 제2 가닥은 5’ 말단 포스페이트를 가졌다.
도입된 상기된 프라이머 서열번호 18 및 서열번호 19의 뉴클레오타이드 변형을 갖는서열번호 38의 서열을 갖는 이중 가닥의 화학적으로 변형된 공여자 단편을 사용하여 실시예 1에 제공된 방법에 따라 생성된 RNP와 함께 세포를 형질감염시키고, 여기서, 상기 RNP의 crRNA는 TRAC 유전자의 엑손 1을 표적화하는 서열번호 1의 표적 서열을 포함하였다. 대조군으로서, 활성화된 T 세포에는 공여자 단편의 부재하에 RNP로 형질감염시키고, 이는 작제물 삽입 없이 표적화된 TRAC 유전자좌의 녹아웃을 유도해야만 하였다. 유동 세포측정은 필수적으로 실시예 1에 기재된 바와 같이 수행하여 상이한 작제물의 TRAC 유전자좌로의 도입 효율을 평가하였고, 단, 항-CD19 CAR 발현은 CD19-Fc (Speed Biosystem)에 이어서 APC 항-사람 IgG Fcγ (Jackson Immunoresearch)에 의해 검출하였다. 상기 결과는 도 9에 나타내고, 여기서, 항-CD19 CAR이 배양물 중의 세포의 대략 42%에서 T 세포 수용체 발현의 부재하에 발현됨을 알 수 있다.
항-BCMA CAR 작제물은 항-CD38 CAR을, 실시예 1에 기재된 항-CD38 CAR pAAV 작제물을 기초로 하는 항-BCMA CAR로 대체함에 의해 생성하였다. 항-BCMA CAR 단편은 IDT에 의해 합성하였다. 삽입체의 서열은 서열번호 23으로서 제공된다. 항-BCMA CAR 작제물은 대략 160개 -170개 뉴클레오타이드의 TRAC 엑손 1 유전자좌 HA를 갖는 공여자 DNA의 생성을 유도하는 서열번호 18 및 서열번호 19로서 제공된 프라이머를 사용하여 실시예 1에 제시된 바와 같은 PCR 반응에서 주형으로서 사용하였다(표 1 참조). 정배향 프라이머(서열번호 18)는 프라이머의 5’-말단의 5개 뉴클레오타이드 내 3개의 PS 및 3개의 2’-O-메틸 변형을 가졌다. 역배향 프라이머 (서열번호 19)는 5’ 말단 포스페이트를 가졌다. 따라서, 수득한 이중 가닥 공여자 DNA는 5’ 말단의 5개 뉴클레오타이드 내 3개의 PS 및 3개의 2’-O-메틸 변형을 갖는 제1 가닥 및 5’ 말단 포스페이트를 갖는 제2 가닥을 갖도록 합성하였다.
상기 제공된 바와 같은 화학적으로 변형된 프라이머의 도입에 의해 변형된 뉴클레오타이드 변형을 갖는 서열번호 37의 서열을 갖는 이중 가닥의 공여자 단편을 사용하여 실시예 1에 제공된 방법에 따라 생성된 RNP와 함께 세포를 형질감염시키고, 여기서, 상기 RNP의 crRNA는 TRAC 유전자의 엑손 1을 표적화하는 서열번호 1의 표적 서열을 포함하였다. 대조군으로서, 활성화된 T 세포에는 공여자 단편의 부재하에 RNP로 형질감염시키고, 이는 작제물 삽입 없이 표적화된 TRAC 유전자좌의 녹아웃을 유도해야만 하였다. 유동 세포측정은 실시예 1에 기재된 바와 같이 수행하여 상이한 작제물의 TRAC 유전자좌로의 도입 효율을 평가하였고, 단, 항-BCMA CAR 발현은 PE 또는 APC 접합된 BCMA-Fc (R&D)에 의해 검출하였다. 상기 결과는 도 10에 나타내고, 여기서, 항-BCMA CAR이 배양물 중의 세포의 대략 66%에서 T 세포 수용체 발현의 부재하에 발현됨을 알 수 있다.
실시예 5. TRAC 엑손 3을 표적화하는 HDR 매개된 녹인
본원에 제공된 공여자 삽입을 위한 방법을 사용하여 추가의 유전자좌에 공여자 DNA를 삽입하는 효율을 시험하기 위해, 항-CD38 CAR 작제물은 TRAC 유전자의 엑손 3으로부터의 HA를 갖는 공여자 DNA를 생성하기 위해 제조하였다. 상기 경우에, 작제물은 필수적으로 TRAC 엑손 1 표적화 작제물에 대해 실시예 1에 기재된 바와 같이 제조하였고, 단, HA (5’ HA 서열번호 24 (183 nt) 및 3’ HA 서열번호 25 (140 nt))는 엑손 3 표적 부위 주변의 서열 (서열번호 26)이다. 이어서 TRAC 유전자 엑손 3 상동성 아암을 갖는 공여자 DNA로서 생성된 pAAV 작제물의 삽입체의 서열은 서열번호 27로서 제공된다. 공여자 단편을 생성하기 위해, 정배향 프라이머 (서열번호 28)는 제1과 제2, 제2와 제3, 제3과 제4 뉴클레오타이드 사이에 PS 연결, 및 5’ 말단으로부터 제2, 제4 및 제5 위치 상에 2’-O-메틸 변형을 포함하였고, 역배향 프라이머(서열번호 29)는 5’-말단 포스페이트를 가졌다. 프라이머가 혼입된 수득한 이중 가닥 공여자 DNA는 5’ 말단 최외곽 뉴클레오타이드 상에 상응하는 PS 및 2’-O-메틸 변형을 갖는 제1 가닥 및 5’ 말단 포스페이트를 갖는 제2 가닥을 가졌다.
상기 프라이머의 도입에 의해 변형된 뉴클레오타이드를 갖고 서열번호 27의 서열을 갖는 이중 가닥의 공여자 단편을 사용하여 실시예 1에 제공된 방법에 따라 생성된 RNP와 함께 세포를 형질감염시키고, 여기서, crRNA는 TRAC 유전자의 엑손 3을 표적화하는 서열번호 26의 표적 서열을 포함하였다. 대조군으로서, 활성화된 T 세포에는 공여자 단편의 부재하에 RNP로 형질감염시키고, 이는 작제물 삽입 없이 표적화된 TRAC 유전자좌의 녹아웃을 유도해야만 하였다. 추가의 대조군은 비-형질감염된 활성화된 T 세포 (ATC)였다. 유동 세포측정은 필수적으로 실시예 1에 기재된 바와 같이 수행하였다. 상기 결과는 도 11에 나타내고, 여기서, RNP 또는 RNP + 공여자 DNA를 사용한 형질감염이 배양물에 걸쳐 80% 초과의 세포가 TCR 발현을 상실시킴을 알 수 있다. 추가로, 항-CD38 CAR은 표적화 RNA + TRAC 유전자 엑손 3으로부터 유래된 HA를 갖는 공여자 DNA로 형질감염된 배양물에서 세포의 대략 42%에서 T 세포 수용체 발현의 부재하에 발현되었다.
PCR 생성물은 삽입 유전자좌를 진단하도록 디자인된 프라이머를 사용하여 생성하였다(도 2b 참조): 5’- CTCCTGAATCCCTCTCACCA-3’ (서열번호 64, TRAC 엑손 3 유전자좌에서 항-CD38 CAR의 5’ 상동성 아암에 걸쳐 서열분석을 위한 정배향 프라이머) 및 5’-GCGGATCCAGCTCATGTAGT-3’ (서열번호 65, TRAC 엑손 3 유전자좌에서 항-CD38 CAR의 5’ 상동성 아암에 걸쳐 서열분석하기 위한 역배향 프라이머) 및 반대 연결을 위해, 5’-CGTTCTGGGTACTCGTGGTT -3’ (서열번호 66, TRAC 엑손 3 유전자좌에서 항-CD38 CAR의 3’ 상동성 아암에 걸쳐 서열분석을 위한 정배향 프라이머) 및 5’- GGAGCACAGGCTGTCTTACA-3’ (서열번호 67, TRAC 엑손 3 유전자좌에서 항-CD38 CAR의 3’ 상동성 아암에 걸쳐 서열분석을 위한 역배향 프라이머). 수득한 PCR 생성물을 서열분석하였다. PCR 생성물 서열(예를 들어, 서열번호 41 및 서열번호 42)은 게놈 내 상동성 아암에 인접한 서열, 공여자 단편내에 존재하는 상동성 아암에 인접한 서열 및 단일 PCR 생성물 내 항-CD38 CAR의 일부를 포함하였고, 이는 예상된 삽입을 입증한다.
도 12는 항-CD19 CAR의 TRAC 유전자의 엑손 3 및 엑손 1로의 표적화를 비교한다. 엑손 3으로 지시된 항-CD19 CAR 공여자 DNA는 상기 실시예에 제시된 바와 같이 항-CD19 CAR 카세트 (서열번호 22)를 포함하도록 합성하였고, 여기서, 상기 항-CD19 발현 카세트는 상기 제시된 바와 같이 엑손 3 유전자좌로부터의 서열 (서열번호 24 및 서열번호 25)에 의해 플랭킹된다. 엑손 1 (서열번호 38의 서열을 갖는)로 지시된 항-CD19 CAR 공여자는 실시예 4에 제공된다. 이들 작제물 각각 - TRAC 엑손 1 HA (서열번호 18 및 서열번호 19)에 의해 플랭킹된 항-CD19 CAR 카세트 (서열번호 22)를 갖는 작제물 및 TRAC 엑손 3 HA (서열번호 24 및 서열번호 25)에 의해 플랭킹된 항-CD19 CAR 카세트 (서열번호 22)를 갖는 다른 작제물을 사용하여 3개의 5’ 말단의 최외곽 뉴클레오타이드 상에 PS 및 2’-O-메틸 변형을 갖는 변형된 정배향 프라이머를 사용한 공여자 단편을 생성하였다. 역배향 프라이머는 5’-말단 포스페이트를 가졌다. 엑손 1 HA에 의해 플랭킹된 항-CD19 CAR 공여자를 제조하기 위한 프라이머는 서열번호 18 및 서열번호 19이고, 여기서, 서열번호 18 프라이머는 제1과 제2, 제3과 제4, 및 제4와 제5 뉴클레오사이드 사이에 PS 연결 및 5’ 말단으로부터 위치 3, 위치 4 및 위치 5에 2’-O 메틸 그룹을 포함하였다. 엑손 3 HA에 의해 플랭킹된 항-CD19 CAR 공여자를 제조하기 위한 프라이머는 서열번호 28 및 서열번호 29이고, 여기서, 서열번호 28 프라이머는 5’ 말단으로부터 제1과 제2, 제2와 제3, 및 제3과 제4 뉴클레오사이드 사이에 PS 연결 및 5’ 말단으로부터 위치 2, 위치 4 및 위치 5에 2’-O 메틸 그룹을 가졌다. 따라서 수득한 이중 가닥 공여자 DNA는 5’ 말단 뉴클레오타이드 상에 상응하는 PS 및 2’-O-메틸 변형을 갖는 제1 가닥 및 5’ 말단 포스페이트를 갖는 제2 가닥을 가졌다.
공여자 단편을 독립적으로 RNP와 함께 활성화된 T 세포에 형질감염시켰다. RNP는 실시예 1에 기재된 바와 같이 생성하였고, 여기서, TRAC 유전자 엑손 1을 표적화하기 위한 crRNA의 표적 서열은 서열번호 1이고, TRAC 유전자 엑손 3을 표적화하기 위한 crRNA의 표적 서열은 서열번호 26이었다. 도 12에서 알 수있는 바와 같이, TRAC 유전자의 엑손 3을 표적화하는 RNP 및 항-CD19 CAR을 발현시키기 위한 공여자 단편으로 형질감염된 배양물의 대략 41%는 둘다 항-CD19 CAR에 대해 TCR 음성 및 양성이었고, TRAC 유전자의 엑손 1을 표적화하는 RNP 및 항-CD19 CAR을 발현하기 위한 공여자 단편으로 형질감염된 배양물의 대략 20%는 둘다 항-CD19 CAR에 대해 TCR 음성 및 양성이었다. 항-CD19 CAR 발현 카세트를 포함하는 레트로바이러스가 형질도입된 T 세포 배양물은 보다 높은 퍼센트의 항-CD19 CAR 발현 세포를 입증하였지만, 이들 세포는 TCR 녹아웃을 갖지 않았다.
실시예 6. PD-1 유전자를 표적화하는 HDR 매개된 녹-인
PD-1 유전자좌는 또한 CAR 작제물로 표적화하였다. 이 경우에, 항-CD38 CAR 카세트 (서열번호 2)는 공여자 DNA를 생성하기 위한 주형을 제공하기 위해 필수적으로 실시예 1에 기재된 바와 같은 방법을 사용하여 표적 부위 (서열번호 32)를 둘러싸는 PD-1 유전자좌의 서열을 갖는 상동성 아암(서열번호 30 및 서열번호 31)에 바로 인접해있다.
공여자 DNA는 5’ 포스페이트를 포함하는 정배향 프라이머 (서열번호 34) 및 5’ 말단으로부터 제1, 제2 및 제4 뉴클레오사이드 (서열번호 35) 상에 2’-O-메틸 그룹 뿐만 아니라 5’ 말단으로부터 제1과 제2, 제2와 제3, 및 제3과 제4 뉴클레오사이드 사이의 포스포로티오에이트 연결을 포함하는 역배향 프라이머를 사용하여 필수적으로 실시예 1에 기재된 바와 같이 생성하였다. 표 1을 참조한다.
상기 이중 가닥의 화학적으로 변형된 공여자 단편 (서열번호 33)을 사용하여 실시예 1에 제공된 방법에 따라 생성된 RNP와 함께 세포를 형질감염시키고, 여기서, crRNA는 PD-1 유전자를 표적화하는 서열번호 32의 표적 서열을 포함하였다. 대조군으로서, 활성화된 T 세포에는 공여자 단편의 부재하에 RNP로 형질감염시키고, 이는 CAR 작제물 삽입 없이 표적화된 TRAC 유전자좌의 녹아웃을 생성한다. 추가의 대조군은 비-형질감염된 활성화된 T 세포 (ATC)였다. 유동 세포측정은 필수적으로 실시예 1에 기재된 바와 같이 수행하였고, 여기서, 비형질감염된 활성화된 T 세포 (ATC)의 추가의 제어가 포함되었다. PD-1에 대한 BV421-접합된 항체(EH12.2H7, BioLegend)를 사용하여 PD-1 발현을 검출하였다.
상기 결과는 도 13에 나타내고, 여기서, PD-1을 발현하는 세포의 퍼센트는 ATC에서 대략 19%로부터 PD-1 유전자좌를 표적화하는 RNP (PD-1 RNP)로 형질감염된 배양물의 세포에서 대략 4%로 하강함을 알 수 있다. 항-CD38 CAR은 PD-1 표적화 RNA + PD-1 유전자좌와 상동성을 갖는 HA를 갖는 공여자로 형질감염된 배양물에서 세포의 대략 27%에서 T 세포 수용체 발현의 부재하에 발현시켰다. 비교로서, 배양물의 세포의 약 32%는 TCR의 엑손 1을 표적화하는 RNP 및 TRAC 유전자의 엑손 1의 서열과 상동성을 갖는 HA를 갖는 항-CD38 CAR 공여자 단편으로 형질감염시켰다.
삽입 유전자좌를 진단하기 위해 프라이머를 사용하여 생성된 PCR 생성물의 서열분석(도 2b 참조)은 PD-1 유전자에 통합된 항-CD38 CAR 공여자 단편을 입증하는 서열을 제공하였다. 연결 서열을 수득하기 위해, 총 1 x 107 세포를 500 μL의 퀵 추출 용액(Quick Extraction solution) (Epicenter)에 재현탁시켜 게놈 DNA를 추출하였다. 세포 용해물을 5분동안 65 ℃에서 및 이어서 2분동안 95 ℃에서 항온처리하고 -20 ℃에서 저장하였다. 게놈 DNA의 농도는 NanoDrop (Denovix)에 의해 결정하였다. 표적 부위를 함유하는 게놈 영역은 PCR 증폭시켰다. 5’ 연결 및 3’ 연결 둘다를 위한 프라이머 세트는 상동성 아암의 외부에서 어닐링하도록 디자인하였다. PCR 생성물은 삽입 유전자좌를 진단하도록 디자인된 프라이머를 사용하여 생성하였다(도 2b 참조): 5’- GTGTGAGGCCATCCACAAG-3’ (서열번호 68, TRAC 엑손 3 유전자좌에서 항-CD38 CAR의 5’ 상동성 아암에 걸쳐 서열분석을 위한 정배향 프라이머) 및 5’-ACACACTTGCGACCCATTC-3’ (서열번호 69, TRAC 엑손 3 유전자좌에서 항-CD38 CAR의 5’ 상동성 아암에 걸쳐 서열분석하기 위한 역배향 프라이머) 및 반대 연결을 위해, 5’-CGTTCTGGGTACTCGTGGTT -3’ (서열번호 70, TRAC 엑손 3 유전자좌에서 항-CD38 CAR의 3’ 상동성 아암에 걸쳐 서열분석을 위한 정배향 프라이머) 및 5’- GGGACTGTCTTAGGCTTGG-3’ (서열번호 71, TRAC 엑손 3 유전자좌에서 항-CD38 CAR의 3’ 상동성 아암에 걸쳐 서열분석을 위한 역배향 프라이머).
PCR은 400ng의 게놈 DNA 및 Q5 고충실도 2X PCR 믹스 (New England Biolabs)를 함유하였다. 열순환기 세팅은 2분동안 98 ℃에서 1 사이클, 10s 동안 98 ℃에서, 15s 동안 65 ℃에서, 45s 동안 72 ℃에서 35 사이클 및 10분동안 72 ℃에서 1 사이클로 이루어졌다. PCR 생성물은 SYBR Safe를 함유하는 1% 아가로스 겔 (Life Technologies) 상에서 정제하였다. PCR 생성물은 이어서 NucleoSpin® 겔 및 PCR 클린-업 키트(MACHEREY-NAGEL GmbH & Co. Kg)를 사용하여 아가로스 겔로부터 용출시켰다. PCR 생성물은 생거 서열분석 (Genewiz)을 위해 제출하였다. PCR 생성물 서열은 게놈 내 상동성 아암에 인접한 서열, 공여자 단편에 존재하는 상동성 아암 및 단일 PCR 생성물 내 항-CD38 CAR의 일부를 포함하였고, 이는 예상된 삽입을 입증한다.
도 14는 항-CD38 CAR을 발현하고, PD-1 유전자에서 녹아웃된 세포의 기능을 결정하기 위해, PBMC, 및 항-CD38 CAR 공여자 단편 및 PD-1 유전자좌를 표적화하는 RNP로 형질감염된 배양물로부터 단리된 T 세포(각각 “PD-1 KOKI PBMC” 및 “PD-1 KOKI T세포”)를 사용하여 수행된 세포독성 검정의 결과를 제공한다. 이들 변형된 세포는 PD-1 유전자 녹아웃을 갖지만 CAR 작제물을 수용하지 않은 대조군 세포(“PD-1 KO”) 및 TRAC 유전자 녹아웃을 갖지만 CAR 작제물을 수용하지 않은 대조군 세포 (“TRAC-1 KO”)와 관련하여 검정에서 표적 세포에 대해 고수준의 세포독성을 보여주었고 관찰된 PD-1 부위에서 능히 공여자 CAR 작제물 통합의 보다 낮은 효율로 인해 항-CD38 CAR 공여자 단편 및 TRAC 유전자좌를 표적화하는 RNP(“TRAC KOKI”)로 형질감염된 세포에 의해 어느정도 능가되었다(도 13).
실시예 7. Cas9 및 Cas12a를 사용한 항-CD38 이량체 항체 수용체 (DAR) 작제물의 TRAC 엑손 1 유전자좌로의 표적화된 삽입.
추가의 실험에서, 합성 항체-수용체의 추가의 구성은 T 세포에서 발현시켰다. 작제물은 이량체 항체 수용체의 발현을 위해 제조하였고(DAR, 예를 들어, 본원에 참조로 인용된 WO 2019/173837을 참조한다), 여기서, 상기 DAR 작제물은 단일 개방 판독 프레임으로부터 2개의 폴리펩타이드를 생성하기 위해 사용된 “자가-말단” 2A 서열에 의해 연결된 2개의 폴리펩타이드를 암호화하는 핵산 서열을 포함하였다. 제1 암호화된 폴리펩타이드는 중쇄 가변 영역 및 제1 중쇄 불변 영역 (CH1), 힌지 영역, CD28의 막관통 도메인 및 4-1BB 및 CDζ의 세포질 도메인을 포함하는 중쇄 폴리펩타이드이다. 이에 이어서, 토세아 아시그나(Thosea asigna) 바이러스 T2A 펩타이드 암호화 서열 (서열번호 46)이 있고 이어서 상기 제2 폴리펩타이드를 암호화하는 서열이 있고, 여기서, 상기 제2 폴리펩타이드는 N 말단에서 C-말단으로 진행하여 면역글로불린 경쇄 가변 영역 (VL) + 불변 영역 (람다)을 포함하였다. 중쇄 폴리펩타이드 서열, 2A 펩타이드, 및 경쇄 서열을 암호화하는 핵산 서열은 DAR-암호화 서열의 5’ 말단에서 JeT 프로모터 (서열번호 3) 및 DAR-암호화 서열의 3’ 말단에서 SV40 폴리A 첨가 서열(서열번호 47)에 작동적으로 연결되어 있다. 전체 항-CD38 DAR 작제물 (JeT 포로모터, 힌지, CD28 막관통 도메인, 및 4-1BB 및 CDζ의 세포질 도메인, T2A, 경쇄, 및 SV40 서열(서열번호 48)을 갖는 중쇄 암호화 서열)은 벡터 내 660 bp (서열번호 44)와 650 bp (서열번호 45)의 상동성 아암 사이에 클로닝하였다. 상동성 아암은 표적 서열의 어느 한 측면 상에 TRAC 엑손 1 유전자좌의 서열을 포함하였다. 형질감염 실험에 사용하기 위한 공여자 단편은 첫번째와 두번째, 세번째와 네번째, 네번째와 다섯번째 뉴클레오타이드 사이에 3개의 PS 결합 및 프라이머의 5’ 말단으로부터 넘버링하는 경우 뉴클레오타이드 3, 4 및 5에 2’-O-메틸 변형을 포함하는 정배향 프라이머(서열번호 18), 및 5’ 말단 포스페이트를 포함하는 역배향 프라이머 (서열번호 19)를 사용하는 PCR에 의해 합성하였다(표 1). 수득한 PCR 생성물(서열번호 49)은 항-CD38 DAR-암호화 작제물 (서열번호 48)을 플랭킹하는 상동성 아암 (서열번호 20 및 서열번호 21)을 포함하였고, 제1 가닥 및 5’ 말단 포스페이트에 혼입되었지만 반대 가닥, 제2 가닥에 첨가된 화학적 변형이 도입되지 않은 서열번호 18의 프라이머 변형을 가졌다.
녹아웃/녹인 (“KOKI”) 전략은 또한 tracrRNA를 사용하지 않고 서열 TTTV를 갖는 PAM을 인지하는 RNA-가이드된 엔도뉴클레아제인 Cas12a와 함께 시험하였고, 여기서, V는 A, C, 또는 G이고, PAM은 표적 부위의 바로 업스트림에 있다. 이들 실험에서, 동일한 항-CD38 DAR 작제물(서열번호 48)은 상동성 아암 사이에 클로닝하였고, 여기서, 상기 상동성 아암 서열 (서열번호 50 및 서열번호 51)은 TRAC 유전자의 엑손 1에서 Cas12a 표적 부위 (서열번호 52)의 어느 한 측면 상의 게놈 서열과 상동성을 가졌다. 이들 상동성 서열(서열번호 53)에 의해 플랭킹된 항-CD38 DAR 작제물은 항-CD38 CAR 작제물에 대해 실시예 1에 기재된 바와 같이 벡터에 클로닝하였고, 수득한 클론은 5’ 말단 포스페이트를 포함하는 정배향 프라이머 서열번호 20, 및 5’ 말단 2’-O-메틸화된 (2’-O-메틸 데옥시구아노신, 2’-O-메틸 데옥시시티딘, 및 2’-O-메틸 데옥시아데노신)으로부터 처음 3개의 뉴클레오타이드를 갖고, 상기 처음 3개의 뉴클레오타이드가 PS 결합을 통해 다음 뉴클레오타이드에 연결되어 있는 역배향 프라이머 서열번호 54 (즉, 5’ 말단으로부터 첫번째와 두번째, 두번째와 세번째, 세번째와 네번째 뉴클레오타이드 사이에 PS 연결이 있다)를 사용한 PCR 반응을 위해 주형으로서 사용하였다(표 1 참조). PCR은 192 및 159nt (서열번호 55 및 서열번호 56)의 상동성 아암에 의해 플랭킹된 항-CD38 DAR 작제물 (서열번호 48)을 갖는 이중 가닥 공여자 DNA 분자를 생성하기 위해 플랭킹 상동성 서열 서열번호 50 및 서열번호 51 내 하이브리드화하는 정배향 프라이머 (서열번호 20) 및 변형된 역배향 프라이머 (서열번호 54)를 사용하여 실시예 1에 제공된 바와 같이 필수적으로 수행하였다. 수득한 이중 가닥 항-CD38 DAR 공여자 DNA 단편 (서열번호 57)은 3킬로베이스 크기이고, 표적 서열 (서열번호 52)을 포함하는 crRNA (가이드 RNA)와 복합체화된 Cas12a 단백질과 함께 이중 가닥 분자로서 활성화된 PBMC를 형질감염시키기 위해 사용된 공여자 DNA 분자에 역배향 프라이머 (서열번호 54)의 2’-O-메틸 및 PS 변형 및 정배향 프라이머 (서열번호 20)의 5’ 말단 포스페이트를 혼입시켰다. crRNA는 IDT (Coralville, IA)로부터 구입한 AltR® RNA였다. Cas12a 및 가이드 RNA RNP의 형성은 필수적으로 Cas9 RNP에 대해 실시예 1에 기재된 바와 같이 필수적으로 수행하였고, 단, 어떠한 tracrRNA도 사용되지 않았고, RNA 종의 사전 하이브리드화는 없었다. Cas12a RNP 및 이중 가닥 공여자 DNA의 T 세포로의 전기천공은 또한 필수적으로 실시예 1에 따라 수행하였다. 대조군으로서, 하나의 T 세포 집단은 Cas9 RNP로 형질전환시켰지만 어떠한 공여자 단편으로는 형질전환시키지 않았고, 또는 T 세포 집단은 Cas12a RNP로 형질전환시켰지만 어떠한 공여자 단편으로는 형질전환시키지 않았다. 공여자 단편의 부재하에, RNP는 표적화된 유전자를 붕괴시키는 것으로 예측되고, 어떠한 발현 작제물은 삽입되지 않았다. 따라서, 형질감염된 세포는 녹아웃(KO) 대조군으로서 언급된다.
형질감염 후 14일에, Cas9 RNP + Cas9 표적 부위 (서열번호 49)를 표적화하기 위해 상동성 아암을 갖는 공여자 DNA 또는 Cas12a RNP 및 Cas12a 표적 부위 (서열번호 57)를 표적화하기 우한 상동성 아암을 갖는 공여자 DNA 중 어느 하나로 형질감된 T 세포 집단은 실시예 1에 기재된 바와 같이 녹아웃 대조군과 함께 유동 세포측정에 의해 분석하였다(도 15). 공여자 단편의 부재하에 TRAC 유전자를 표적화하는 Cas9 RNA로 형질감염된 세포 집단의 단지 약 32% 및 공여자 단편의 부재하에 TRAC 유전자 (“TRAC KO”)를 표적화하는 Cas12a RNP로 형질감염된 세포 집단의 약 22%는 TCR을 발현하였다. 대조적으로, 도 15의 최좌측 패널에 나타낸 필수적으로 모든 비변형된 활성화된 T 세포 (활성화된 T 세포 “ATC”)는 TCR을 발현하였다. 예상된 바와 같이, 공여자 DNA를 받지 않은 세포의 어떠한 것도 항-CD38 작제물에 대해 양성이 아니었다(도 15, 제2 및 제3 패널). 한편, Cas9 또는 Cas12a RNP에 추가로 항-CD38 DAR 작제물 공여자 DNA로 형질감염된 세포 집단의 유의적 퍼센트는 DAR 작제물의 발현을 입증하였다: Cas9 RNP와 함께 항-CD38 DAR 작제물 공여자 DNA로 형질감염된 집단의 대략 54%(도 15, 네번째 패널)는 항-CD38 DAR을 발현하였고, Cas12a RNP와 함께 항-CD38 DAR 작제물 공여자 DNA로 형질감염된 세포 집단의 대략 77%(도 15, 다섯번째 패널)도 발현하였다.
항-CD38 DAR 작제물의 TRAC 유전자의 엑손 1의 Cas9 표적 부위로의 삽입, 및 항-CD38 DAR 작제물의 TRAC 유전자의 엑손 1의 Cas12a 표적 부위로의 삽입은 둘다, 형질감염된 세포 집단 둘다로부터 단리된 게놈 DNA에 대해 수행된 PCR 및 연결 단편의 서열분석에 의해 확인하였다. Cas9 매개된 삽입을 위해, 5’ 상동성 아암 영역의 PCR은 정배향 프라이머로서 서열번호 72 및 역배향 프라이머로서 서열번호 73을 사용하였다. 3’ 상동성 아암 영역의 PCR은 정배향 프라이머로서 서열번호 74 및 역배향 프라이머로서 서열번호 75를 사용하였다. 수득한 PCR 단편의 서열분석은 항-CD38 DAR 작제물이 표적화된 Cas9 표적 부위에 삽입되었음을 입증하였다. Cas12a 매개된 삽입을 위해, 5’ 상동성 아암 영역의 PCR은 정배향 프라이머로서 서열번호 76 및 역배향 프라이머로서 서열번호 77을 사용하였다. 3’ 상동성 아암 영역의 PCR은 정배향 프라이머로서 서열번호 78 및 역배향 프라이머로서 서열번호 79를 사용하였다. 수득한 PCR 단편의 서열분석은 항-CD38 DAR 작제물이 표적화된 Cas12a 표적 부위에 삽입되었음을 입증하였다.
RPMI8226 세포와 동시 배양된 형질감염된 집단을 사용한 세포독성 검정의 결과는 도 16에 제공되고, Cas9 또는 Cas12a 시스템을 사용함에 의해 DAR 작제물로 형질감염된 T 세포가 예상된 생리학적 거동을 가짐을 입증하였다. Cas9 RNP + 항-CD38 DAR 작제물 공여자 DNA (서열번호 49) 및 Cas12a RNP + 항-CD38 DAR 작제물 공여자 DNA (서열번호 57)로 형질감염된 세포 둘다는 녹아웃된 TCR 유전자를 갖지만, 항-CD38 DAR 작제물 공여자 DNA로 형질감염되지 않은 대조군 집단과 실제로 동일하고, 이 보다 급격하게 높은 RPMI88226 세포의 사멸을 보여주었다.
실시예 8. 오프-표적 돌연변이의 분석.
본원에 제공된 바와 같은 RNP 및 공여자 단편으로 배양물의 형질감염으로부터 비롯된 오프-부위 돌연변이의 빈도를 결정하기 위해, TRAC 유전자의 cas9 RNP 표적화 엑손 1 및 서열번호 7에 제공된 바와 같이 변형된 프라이머 (서열번호 18 및 서열번호 19)를 사용하여 합성된 171 및 161bp의 HA를 갖는 이중 가닥 항-CD38 DAR 공여자 DNA로 PBMC의 형질감염으로부터 비롯된 세포로부터 단리된 DNA는 서열분석되었다.
게놈 DNA는 제조업자의 지침에 따라 QIAamp® DNA 소형 키트 (QIAGEN 51104)를 사용하여 T 세포로부터 추출하였다. 간략하게, 200 μL PBS 중에 총 5 x 106 세포는 20 μl QIAGEN 프로테아제 및 200 μl 완충액 AL에 첨가하고, 56℃에서 10분동안 항온처리하였다. 게놈 DNA는 에탄올에 의해 침전시키고 소형-컬럼으로부터 용출하였다. 게놈 DNA의 농도는 Qubit dsDNA HS 검정 키트 (Thermofisher)를 사용하여 Qubit 4 형광측정기에 의해 결정하였다.
DNA 샘플의 전체 게놈 서열분석은 Novagene (Sacramento, Ca)에 의해 수행하였다. 상기 결과는 도 17 및 표 2에 요약한다. 총 4개의 삽입결실이 검출되었다. 검출된 삽입결실의 어느 것도 유전자의 암호화 영역 내에 있는 것으로 밝혀지지 않았고, 오프-부위 돌연변이 중 2개는 유전자 간 영역에서 발견되었고, 오프-부위 돌연변이 중 2개는 인트론에 존재한다.
| 돌연변이의 유형 | 이벤트의 수 |
| CDS: | 0 |
| · 판독전환 결실 | 0 |
| · 판독전환 삽입 | 0 |
| · 비판독전환 결실 | 0 |
| · 비판독전환 삽입 | 0 |
| · 정지 획득(Stopgain) | 0 |
| · 정지 상실(Stoploss) | 0 |
| · 공지되지 않음 | 0 |
| 인트론 | 1 |
| UTR3 | 0 |
| UTR5 | 0 |
| 스플라이싱 | 0 |
| ncRNA 엑손 | 0 |
| ncRNA 인트론 | 1 |
| ncRNA 스플라이싱 | 0 |
| 업스트림 | 0 |
| 다운스트림 | 0 |
| 유전자간 | 2 |
| 합계 | 4 |
실시예 9. Cas12a를 사용한 항-CD38 이량체 항체 수용체 (DAR) 작제물의 TIM3 유전자좌로의 표적화된 삽입.
추가의 실험에서, 항-CD38 DAR 작제물은 T 세포 소진에서의 역할을 수행할 수 있는 Tim-3 유전자를 동시 녹아웃시키고 Cas12a를 사용한 항-CD38 DAR을 녹인시키기 위한 Tim-3 유전자좌로부터 유래된 플랭킹 서열 사이에 클로닝하였다. 항-CD38 DAR 작제물 (서열번호 48)은 TIM3 유전자좌로부터 유래되고, Cas12a PAM 서열의 바로 다운스트림에 있는 Cas12a 표적 부위 (서열번호 60)의 어느 하나의 측면에 존재하는 DNA 서열(5’ 플랭킹 서열, 서열번호 58; 3’ 플랭킹 서열, 서열번호 59) 사이에 클로닝하였다. 클로닝된 DAR 작제물 + 플랭킹 서열은 정배향 프라이머 5’-p-TGGAATACAGAGCGGAGGTC (서열번호 60) 및 5’ 말단으로부터 제1, 제2 및 제3 뉴클레오타이드 상에 2’-O-메틸 그룹을 포함하도록 변형되고, 5’ 말단으로부터 첫번째와 두번째, 두번째와 세번째 및 세번째와 네번째 뉴클레오타이드 사이에 PS 결합: 하나의 가닥의 5’ 말단으로 역배향 프라이머 (서열번호 61)의 변형을 혼입시키는 공여자 DNA 분자 (서열번호 62)를 생성하기 위한 mG*mC*mA*TGCAAATGTCCACTCAC (서열번호 61)을 갖는 역배향 프라이머를 사용한, PCR 반응을 위한 주형으로서 사용하였다.
T 세포의 형질감염은 실시예 1에 수행된 바와 같이 수행하였고, 단, Cas12a 형질감염에서, Cas12a 단백질은 AltR crRNA와 복합체화되어 있고 어떠한 tracr RNA를 사용하지 않았다. 공여자 단편은 Cas12a RNP와 함께 전기천공하였다. 대조군으로서, 형질감연은 또한 공여자 DNA의 부재 (TRAC 녹아웃 대조군) 하에 RNP로 수행하였다.
Tim-3 유전자좌로 표적화된 DAR 작제물로 형질감염된 T 세포 집단의 유동 세포측정 분석의 결과는 도 18에 제공된다. 대조군으로서 포함된, 비-형질감염된 활성화된 T 세포 (ATC)는 항-CD38 DAR 작제물을 발현하지 않으면서 형질감염된 세포의 대략 84%까지 Tim-3 유전자의 발현을 입증하였다. 녹아웃/녹인 세포에 대해, 집단의 대략 17%는 Tim-3 유전자 생성물을 발현하지 않으면서 CD38 DAR 작제물을 발현하였다.
실시예 10. Cas9 및 Cas12a를 사용한 GM-CSF 유전자의 제2 부위 녹아웃과 함께 항-CD38 이량체 항체 수용체 (DAR) 작제물의 TRAC 유전자좌로의 표적화된 삽입.
T 세포에 의한 과립구 대식세포-콜로니 자극 인자 (GM-CSF)의 방출은 사이토킨 방출 증후군 및 신경독성에 기여할 수 있어, 이는 CAR-T 치료요법의 치료학적 이득을 제한할 수 있다(문헌참조: Sterner et al. 2018 Blood 132:961). T 세포 수용체 대신 항-CD38 DAR을 발현하고, GM-CSF의 발현이 감소된 T 세포의 집단을 제공하기 위해, 본원 발명자들은 동일한 세포 집단에서 1) 내인성 T 세포 수용체 유전자를 녹아웃시키고 (TRAC 유전자좌에서) 항-CD38 DAR 작제물을 녹인시키고, 또한 2) GM-CSF 유전자를 녹아웃시키고자 하였다.
실시예 7에 기재된 항-CD38 DAR 작제물은 TRAC 녹아웃 및 항-CD38 DAR 발현을 위한 공여자 단편을 생성하기 위해 PCR용 주형으로서 사용하였다. 상기 작제물은 힌지, CD28 막관통 도메인, 및 4-1BB 및 CD3ζ 세포질 도메인를 갖는 중쇄 폴리펩타이드 서열, 및 이어서 2A 펩타이드, 및 이어서 경쇄 폴리펩타이드 서열을 암호화하는 핵산 서열에 작동적으로 연결된 JeT 프로모터 (서열번호 3)를 포함하였고, 또한, DAR-암호화 서열 (서열번호 48에 제공된 항-CD38 DAR-암호화 어셈블리)의 3’ 말단에서 SV40 폴리A 첨가 서열을 포함하였고, 플라스미드 벡터 pAAV-MCS에서 660 bp (서열번호 44) 및 650 bp (서열번호 45)의 TRAC 유전자좌 상동성 아암 사이에 클로닝하였다. 형질감염 실험에 사용하기 위한 공여자 단편은 첫번째와 두번째, 세번째와 네번째, 네번째와 다섯번째 뉴클레오타이드 사이에 3개의 PS 결합 및 프라이머의 5’ 말단으로부터 넘버링하는 경우 뉴클레오타이드 3, 4 및 5에 3개의 2’-O-메틸 변형을 포함하는 정배향 프라이머(서열번호 18), 및 5’ 말단 포스페이트를 포함하는 역배향 프라이머 (서열번호 19)를 사용하는, 실시예 7에 기재된 바와 같이 PCR에 의해 합성하였다(표 1). 수득한 PCR 생성물(서열번호 49)은 항-CD38 DAR-암호화 작제물 (서열번호 48)을 플랭킹하는 대략적으로 170bp 및 160bp의 상동성 아암(서열번호 20 및 서열번호 21)을 포함하였고, 제1 가닥 및 5’ 말단 포스페이트에 혼입되었지만 반대 가닥, 또는 제2 가닥에 첨가된 화학적 변형이 도입되지 않은 서열번호 18의 프라이머 변형을 가졌다.
TRAC 유전자좌를 녹아웃시키기 위한 가이드 RNA는 에스. 피오게네스(S. pyogenes)(Sp) cas9 단백질과 함께 사용하기 위해 가공된 2개의 RNA: 서열번호 1의 표적 서열을 포함한 TRAC 유전자의 엑손 1을 표적화하기 위한 crRNA 및 tracrRNA로 이루어져 있고, 이들 둘다는 Spcas9과 함께 사용하기 위해 가공되고, IDT (Coralville, IA)에 의해 합성된 “AltR” RNA이다.
GM-CSF 유전자좌를 녹아웃시키기 위해, 사람 GM-CSF 유전자 (표적 서열 TACAGAATGAAACAGTAGAAG, 서열번호 80)에 특이적인 Cas12a 가이드를 사용하였다. Cas12a (Cpf1) 뉴클레아제와 함께 사용하기 위해 디자인된 crRNA는 IDT에 의해 합성하였다.
2개의 구분된 부위에서 게놈을 변형시키기 위해, 2개의 RNP를 생성하였다. 제1 RNP는 Cas9 단백질을 하이브리드화된 TRAC 유전자좌-가이드된 crRNMA (표적 서열 서열번호 1을 갖는) 및 Cas9 tracrRNA와 항온처리함에 의해 형성된 Cas9 RNP이었다. Cas9 crRNA와 tracrRNA의 하이브리드화 및 이어서 Cas9 단백질과 TRAC 유전자의 하이브리드화된 crRNA:tracrRNA 표적화 엑손 1의 항온처리는 실시예 1에 제공된 바와 같이 수행하였다. 제2 RNP는 동일한 방식(4℃에서 30분 항온처리)으로 Cas12a 단백질(단백질 IDT의 N-말단 및 C-말단 영역 각각에서 NLS를 포함하는)을 GM-CSF-표적화 crRNA (표적 서열 서열번호 80을 갖는)로 항온처리함에 의해 형성된 Cas12a RNP이었다.
항-CD38 DAR 작제물의 녹인 및 GM-CSF 유전자의 녹아웃과 함께 TCR 수용체 유전자의 녹아웃을 위한 T 세포의 단일 형질감염은 TRAC 유전자로의 삽입을 위한 HA를 갖는 공여자 단편과 함께, TRAC 유전자를 표적화하는 가이드 RNA 및 GM-CSF 유전자를 표적화하는 Cas12a RNP와 어셈블리된 Cas9 RNP를 사용하여 수행하였다. 형질감염은 실시예 1에 제공된 바와 동일한 조건을 사용한 전기천공에 의해 수행하였다.
실시예 7에 기재된 프라이머 서열번호 18 및 서열번호 19의 뉴클레오타이드 변형과 함께 서열번호 48의 서열을 갖는 이중 가닥의 화학적으로 변형된 공여자 단편을 사용하여 RNP와 함께 세포를 형질감염시켰다. 이중 가닥 공여자 단편은 171 및 161 bp의 HA를 가졌다.
3개의 T 세포 집단을 생성하였다. 제1 형질감염에서, 활성화된 T 세포는 TRAC 유전자-표적화 Cas9 RNP 및 항-CD38 DAR을 암호화하고 TRAC HA를 갖는 이중 가닥 공여자 단편으로 형질감염시켰다. 제2 형질감염은 TRAC 유전자-표적화 Cas9 RNP, 항-CD38 DAR을 암호화하고 TRAC HA를 갖는 이중 가닥 공여자 단편, 및 추가로, the Cas12a RNP targeting the GM-CSF 유전자를 표적화하는 Cas12a RNP를 포함하였다. 최종적으로, 대조군으로서, 활성화된 T 세포에는 공여자 단편의 부재하에 TRAC-특이적 Cas9 RNP로 형질감염시키고, 이는 작제물 삽입 없이 표적화된 TRAC 유전자좌의 녹아웃을 유도해야만 하였다. 전기천공은 실시예 1에 상세히 기재된 바와 같이 수행하였고, 여기서, 각각의 경우에, 단일 전기천공을 수행하였고, 각각 3개의 집단에 대해, 1) TRAC-표적화 RNP 및 항-CD38 공여자 단편; 2) TRAC-표적화 RNP 및 항-CD38 공여자 단편에 추가로 GM-CSF-표적화 RNP; 및, 3) TRAC 녹아웃 유일 대조군을 위해, TRAC-표적화 RNP 단독을 포함하였다.
유동 세포측정은 필수적으로 실시예 1에 기재된 바와 같이 수행하여 상이한 작제물을 TRAC 유전자좌에 도입하는 효율을 평가하였고, 여기서, 세포내 GM-CSF는 eBioscience™ 세포내 고정화 & 투과 완충액 세트 (ThermoFisher, 88-8824-00)를 사용하여 검출하였고, PE-GM-CSF 항체[BioLegend, 502306]로 염색시켰다. CD3 (T 세포 수용체)는 항-CD3-BV421 항체 SK7 (BioLegend)으로 검출하였고, 항-CD38 DAR 발현은 PE 접합된 항-CD38-Fc 단백질(Chimerigen Laboratories, Allston, Ma)로 검출하였다.
배양물이 GM-CSF 발현을 유도하기 위해 자극된 경우, 배양물은 DMSO 중에 포르볼-12-미리스테이트 13-아세테이트(PMA, 40.5 μM), 이오노마이신(669.3 μM), 및 브레펠딘 A (2.5 mg/ml)를 함유하는 세포 활성화 칵테일 (BioLegend, 423304)로 6시간 동안 처리하였다.
도 19는 패널 A 및 B에서, TRAC-표적화 RNP 및 항-CD38 DAR 공여자 작제물로 형질감염된 T 세포의 대략 2%만이 PMA 및 이오노마이신으로 자극되지 않는 경우 GM-CSF를 발현하는 반면, 상기 형질감염된 세포의 이들 약물로의 자극은 GM-CSF를 생성하는 세포의 대략 53%를 유도한다. 한편, 패널 C에 나타낸 바와 같이, TRAC-표적화 RNP 및 항-CD38 DAR 공여자 작제물에 추가로 GM-CSF 표적화 RNP로 형질감염된 T 세포의 대략 29%만이 자극시 GM-CSF를 생성하고, 이는 제2 유전자의 동시 녹아웃이 상기 경우에 45% (52.78-29.07/52.78)로 평가되는 빈도로 수행됨을 입증한다.
동일한 세포 집단은 도 19의 패널 E-G에서 T 세포 수용체 및 항-CD38 DAR 발현에 대해 분석되었다. 패널 D는, 항-CD38 DAR 공여자 단편의 부재하에 TRAC 표적화 RNP로 형질감염되는 경우, 세포의 거의 80% (78.57%)가 T 세포 수용체를 발현하지 않았고, 예상된 바와 같이 항-CD38 DAR 작제물의 발현도 검출되지 않았음을 보여준다. 대조적으로, 세포가 항-CD38 DAR 공여자 단편과 함께 TRAC 표적화 RNP로 형질감염되는 경우, 세포 집단의 대략 70%는 고유 T 세포 수용체의 발현의 부재하에 항-CD38 DAR의 발현을 입증하였다(패널 E). 최종적으로, 제2 유전자 표적화 RNP, GM-CSF 표적화 RNP의 첨가는 TCR 녹아웃/녹인 비율을 급격히 저하시키지 않았고, 여기서, RNP (항-TRAC 및 항-GM-CSF) + 항-CD38 DAR 작제물 둘다로 형질감염된 세포의 대략 50%는 내인성 T 세포 수용체를 발현하는데 실패하면서 항-CD38 DAR 작제물을 발현하였다(패널 F). 이들 배양물에서, 집단의 고비율(~45%)이 형질감염에 대한 항-GM-CSF RNP의 내포로부터 비롯되는 GM-CSF 녹아웃인 것으로 계산된다.
실시예 11. Cas12a를 사용한 GM-CSF 유전자의 제2 부위 녹아웃과 함께 항-CD38 이량체 항체 수용체 (DAR) 작제물의 TRAC 유전자좌로의 표적화된 삽입.
항-CD38 DAR의 TRAC 유전자좌로의 이중 녹아웃 및 동시 녹인이 또한 이의 각각이 상이한 가이드 RNA (crRNA)를 포함하는 2개의 Cas12a RNP를 사용하여 시도되었다.
항-CD38 DAR 공여자 단편은 첫번째와 두번째, 세번째와 네번째, 네번째와 다섯번째 뉴클레오타이드 사이에 3개의 PS 결합 및 프라이머의 5’ 말단으로부터 넘버링하는 경우 뉴클레오타이드 3, 4 및 5에 3개의 2’-O-메틸 변형을 포함하는 정배향 프라이머(서열번호 18), 및 5’ 말단 포스페이트를 포함하는 역배향 프라이머 (서열번호 19)를 사용하여 상기 실시예 7 및 10에 기재된 바와 같이 생성하였다(표 1). 수득한 PCR 생성물(서열번호 49)은 항-CD38 DAR-암호화 작제물 (서열번호 48)을 플랭킹하는 대략적으로 170bp 및 160bp의 상동성 아암(서열번호 20 및 서열번호 21)을 포함하였고, 제1 가닥 및 5’ 말단 포스페이트에 혼입되었지만 반대 가닥, 또는 제2 가닥에 첨가된 화학적 변형이 도입되지 않은 서열번호 18의 프라이머 변형을 가졌다.
TRAC 유전자좌를 녹아웃시키기 위한 가이드 RNA는 TRAC 유전자의 엑손 1을 표적화하기 위한 Cas12a (Cpf1)에 대해 가공된 crRNA이었고 서열번호 26의 표적 서열을 포함하였다. TRAC 유전자를 녹아웃시키기 위한 가이드 RNA는 TRAC 유전자의 엑손 1을 표적화하기 위한 Cas12a (Cpf1)에 대해 가공된 crRNA이었고 서열번호 52의 표적 서열을 포함하였다. GM-CSF 유전자를 녹아웃시키기 위한 가이드 RNA는 서열번호 80의 표적 서열을 포함하는 Cas12a (Cpf1)에 대해 가공된 crRNA이었다. Cas12a crRNA 둘다는 IDT (Coralville, Ia)에 의해 합성하였다.
2개의 RNP는 단백질 (IDT)의 N-말단 및 C-말단 영역 각각에서 NLS를 포함하는 Cas12a 단백질과 함께 제조하였다. 제1 RNP는 상기 Cas12a 단백질을 TRAC 유전자좌를 표적화하고 서열번호 52 방식의 표적 서열(4℃에서 30분 항온처리)을 갖는 crRNA로 항온처리함에 의해 형성되었다. 제2 RNP는 동일한 방식으로 Cas12a 단백질을 GM-CSF-표적화 crRNA (표적 서열 서열번호 80을 갖는)로 항온처리함에 의해 형성되었다.
항-CD38 DAR 작제물의 녹인 및 GM-CSF 유전자의 녹아웃과 함께 TCR 수용체 유전자의 녹아웃을 위한 T 세포의 단일 형질감염은 TRAC 유전자로의 삽입을 위한 HA를 갖는 공여자 단편과 함께, 2개의 어셈블리된 Cas12a RNP를 사용하여 수행하였다. 형질감염은 실시예 1에 제공된 바와 동일한 조건을 사용한 전기천공에 의해 수행하였다.
실시예 7에 기재된 프라이머 서열번호 18 및 서열번호 19의 뉴클레오타이드 변형과 함께 서열번호 48의 서열을 갖는 이중 가닥의 화학적으로 변형된 공여자 단편을 사용하여 RNP와 함께 세포를 형질감염시켰다. 이중 가닥 공여자 단편은 171 및 161 bp의 HA를 가졌다.
유동 세포측정은 필수적으로 실시예 10에 기재된 바와 같이 수행하여 상이한 작제물을 TRAC 유전자좌에 도입하는 효율을 평가하였고, 여기서, 세포내 GM-CSF는 eBioscience™ 세포내 고정화 & 투과 완충액 세트 (ThermoFisher, 88-8824-00)를 사용하여 검출하였고, PE-GM-CSF 항체[BioLegend, 502306]로 염색시켰다. CD3 (T 세포 수용체)는 항-CD3-BV421 항체 SK7 (BioLegend)으로 검출하였고, 항-CD38 DAR 발현은 PE 접합된 항-CD38-Fc 단백질(Chimerigen Laboratories, Allston, Ma)로 검출하였다.
도 19는 패널 A 및 B에서, TRAC-표적화 RNP 및 항-CD38 DAR 공여자 작제물로 형질감염된 T 세포의 대략 2%만이 자극되지 않는 경우 GM-CSF를 발현하는 반면, 상기 형질감염된 세포의 이들 약물로의 자극은 GM-CSF를 생성하는 세포의 대략 53%를 유도한다. 한편, 패널 D에 나타낸 바와 같이, TRAC-표적화 RNP 및 항-CD38 DAR 공여자 작제물에 추가로 GM-CSF 표적화 RNP로 형질감염된 T 세포의 대략 15%만이 자극시 GM-CSF를 생성하고, 이는 제2 유전자의 동시 녹아웃이 상기 경우에 72% (52.78-14.9/52.78)로 평가되는 빈도로 수행됨을 입증한다.
동일한 세포 집단은 도 19의 패널 H에서 T 세포 수용체 및 항-CD38 DAR 발현에 대해 분석되었다. 패널 E는, 항-CD38 DAR 공여자 단편의 부재하에 TRAC 표적화 RNP로 형질감염되는 경우, 세포의 거의 80% (78.57%)가 T 세포 수용체를 발현하지 않았고, 예상된 바와 같이 항-CD38 DAR 작제물의 어떠한 발현도 검출되지 않았음을 보여준다. 대조적으로, 세포가 항-CD38 DAR 공여자 단편과 함께 TRAC 표적화 RNP로 형질감염되는 경우, 세포 집단의 대략 70%는 고유 T 세포 수용체의 발현의 부재하에 항-CD38 DAR의 발현을 입증하였다(패널 F). 최종적으로, 제2 유전자 표적화 RNP, GM-CSF 표적화 RNP의 첨가는 TCR 녹아웃/녹인 비율을 급격히 저하시키지 않았고, 여기서, RNP (항-TRAC 및 항-GM-CSF) + 항-CD38 DAR 작제물 둘다로 형질감염된 세포의 대략 60%는 내인성 T 세포 수용체를 발현하는데 실패하면서 항-CD38 DAR 작제물을 발현하였다(패널 H). 이들 배양물에서, 집단의 고비율(~49%)이 형질감염에 대한 항-GM-CSF RNP의 내포로부터 비롯되는 GM-CSF 녹아웃인 것으로 계산된다.
실시예 12. Cas12a를 사용한 항-CD20 이량체 항체 수용체 (DAR) 작제물의 TRAC 유전자로의 표적화된 삽입.
T 세포 수용체 알파 불변 (TRAC) 유전자는 또한 공여자 DNA로서 항-CD20 DAR 작제물로 표적화하였다. 항-CD20 DAR 작제물 (서열번호 81)은 단일 개방 판독 프레임으로부터 2개의 폴리펩타이드를 생성하기 위해 사용된 “자가-절단” 2A 서열에 의해 연결된 2개의 폴리펩타이드를 암호화하는 핵산을 포함하였다. 제1 암호화된 폴리펩타이드는 중쇄 가변 영역 (VH) 및 제1 중쇄 불변 영역 (CH1), 힌지 영역, CD28의 막관통 도메인 및 4-1BB 및 CD3ζ의 제3 ITAM의 세포질 도메인을 포함하는 중쇄 폴리펩타이드이다. 이에 이어서, 토세아 아시그나(Thosea asigna) 바이러스 T2A 펩타이드 암호화 서열 (서열번호 46)이 있고 이어서 상기 제2 폴리펩타이드를 암호화하는 서열이 있고, 여기서, 상기 제2 폴리펩타이드는 N 말단에서 C-말단으로 진행하여 면역글로불린 경쇄 가변 영역 (VL) + 불변 영역 (카파)을 포함하였다. 중쇄 폴리펩타이드 서열, 2A 펩타이드, 및 경쇄 서열을 암호화하는 핵산 서열은 DAR-암호화 서열의 5’ 말단에서 JeT 프로모터 (서열번호 3) 및 DAR-암호화 서열의 3’ 말단에서 SV40 폴리A 첨가 서열(서열번호 47)에 작동적으로 연결되어 있다. 전체 항-CD20 DAR 작제물 (JeT 프로모터, 힌지, CD28 막관통 도메인, 및 4-1BB 및 CDζ의 세포질 도메인을 갖는 중쇄 암호화 서열에 이어서, T2A, 경쇄, 및 SV40 서열(서열번호 48))은 pAAV 벡터 내 645 bp (서열번호 50)와 600 bp (서열번호 51)의 상동성 아암 사이에 클로닝하였다. 상동성 아암(HA)은 TRAC 유전자의 엑손 1에서 표적 서열(서열번호 52)의 어느 한 측면 상에 TRAC 엑손 1 유전자좌의 서열이다.
형질감염 실험에 사용하기 위한 공여자 단편은 플랭킹 TRAC HA를 포함하는 pAAV 항-CD20 DAR 벡터 작제물을 사용하여 실시예 1에 기재된 바와 같이 PCR에 의해 합성하였다. 사용된 프라이머는 5’ 인산화된 서열번호 82 (정배향 프라이머) 및 프라이머의 3개의 5’ 최외곽 뉴클레오타이드 상에 2’-O-메틸 변형 및 프라이머의 5’ 말단으로부터 첫번째와 두번째, 두번째와 세번째, 및 세번째와 네번째 뉴클레오타이드 사이에 포스포로티오에이트 결합을 포함하는 서열번호 54 (역배향 프라이머)이다(표 1). 이들 프라이머는 벡터 작제물 내 645 bp 내지 600bp 상동성 아암 내 하이브리드화하여 DAR 작제물을 플랭킹하는 192bp 및 159 bp의 상동성 아암을 갖는 단편을 생성하였다. 수득한 PCR 생성물인, 이중 가닥 항-CD20 DAR 공여자 DNA 단편 (서열번호 83)은 2.8 kb크기이고, 2.457 kb 항-CD20 DAR 작제물 (서열번호 81), 192 bp 상동성 아암(서열번호 55), 및 항-CD20 DAR-암호화 작제물 (서열번호 81)을 플랭킹하는 159 bp 상동성 아암 (서열번호 56)을 포함하고, 공여자 DNA 분자에 역배향 프라이머 (서열번호 54)의 2’-O-메틸 및 PS 변형 및 정배향 프라이머 (서열번호 82)의 5’ 말단 포스페이트를 혼입시켰다. 제1 가닥에 혼입되지만 어떠한 화학적 변형을 갖지 않는 서열번호 54의 프라이머 변형은 프라이머의 5’ 말단 포스페이트를 포함하는, 반대, 또는 제2 가닥 상에 도입하였다. 공여자 분자를 사용하여 표적 서열 (서열번호 52)을 포함하는 crRNA (가이드 RNA)와 복합체화된 Cas12a 단백질과 함께 이중 가닥 분자로서 활성화된 T 세포를 형질감염시켰다.
TCR 알파 (TRAC) 유전자의 RNA 가이드-지시된 표적화를 위해, crRNA (ALT-R® CRISPR-Cas9 tracrRNA)는 IDT (Coralville, IA)로부터 구입하였고, 여기서, 상기 crRNA는 TRAC 유전자의 제1 엑손 내 Cas12a PAM 서열 (TTTA)의 바로 다운스트림에 존재하는 표적 서열 (서열번호 52)을 포함하도록 디자인하였다.
Cas12a 및 가이드 RNA RNP의 형성은 필수적으로 실시예 7에 기재된 바와 같이 수행하였다. Cas12a RNP 및 이중 가닥 공여자 DNA의 T 세포로의 전기천공은 또한 필수적으로 실시예 7에 따라 수행하였다. 대조군으로서, 하나의 T 세포 집단은 Cas12a RNP로 형질감염시켰지만, 어떠한 공여자 단편으로는 형질감염시키지 않았고, TRAC 녹아웃 (KO) 대조군으로서 언급된다. 형질감염 후, T 세포는 확장을 위해 완전한 세포 배양 배지에 옮겼다.
10일 후, 배양물은 실시예 1에 기재된 바와 같이 TRAC 녹아웃 대조군 집단과 함께 유동 세포측정에 의해 분석하였고, 단, CD20 DAR 발현은 항-리툭시맙 항체(Acro)에 의해 검출되었다(도 20a 및 b). 공여자 단편 (“TRAC KO”)의 부재하에 TRAC 유전자를 표적화하는 Cas12a RNP로 형질감염된 세포 집단의 약 16.6%만이 TCR을 발현하였다. 심지어 보다 작은 퍼센트로서, CD20 DAR 공여자 단편(“CD20 DAR-T”)과 함께 TRAC 유전자를 표적화하는 Cas12a RNP 유전자로 형질감염된 세포 집단의 약 3.5%는 TCR을 발현하였다. 예상된 바와 같이, 공여자 DNA를 받지 않은 세포의 어떠한 것도 항-CD20 작제물에 대해 양성이 아니었다(도 20a). 한편, Cas12a RNP와 함께 항-CD20 DAR 작제물 공여자 DNA로 형질감염된 집단의 28.7% (도 20b)는 TCR을 발현하지 않으면서 항-CD20 DAR을 발현하였다.
세포는 필수적으로 실시예 1에서와 같이 수행된 세포독성 검정에서 시험하였고, 단, 상기 항-CD20 DAR 세포는 2일 동안 표적으로서 CD20+ Daudi 세포로 항온처리하였다. 도 21은 사멸 수준이 매우 높아 0.625:1 내지 5:1 범위의 이펙터:표적 비율에 대해 90%에 근접하여 매우 높고, 심지어 0.16:1의 최저 이펙터:표적 비율에서 대략 70%임을 보여준다. 도 22는 항-CD20 CAR-T 세포가 CD20+ Daudi 세포에 의해 자극되는 경우 고수준의 인터페론 감마 (IFNγ) 및 GM-CSF을 분비함을 입증하였다. 항-CD19 CAR-T 세포에 의한 사이토킨의 분비(실시예 4 참조)를 또한 나타낸다.
실시예 13. Cas12a를 사용한 항-CEA CAR 작제물의 TRAC 및 CD7 유전자로의 표적화된 삽입.
항-CEA CAR 작제물은 또한 Cas12a를 사용하여 TRAC 유전자에 삽입하였다. CAR 암호화 서열의 5’ 말단에서 JeT 프로모터 (서열번호 3) 및 CAR-암호화 서열의 3’ 말단에서 SV40 폴리A 첨가 서열 (서열번호 47)을 포함하는 항-CEA CAR 작제물 (서열번호 84)은 pAAV 벡터에서 645 bp (서열번호 50) 및 600 bp (서열번호 51)의 상동성 아암 사이에 클로닝하였다. 상동성 아암은 TRAC 유전자의 엑손 1에서 표적 서열(서열번호 52)의 어느 한 측면 상에 TRAC 엑손 1 유전자좌의 서열이다.
형질감염 실험에 사용하기 위한 공여자 단편은 실시예 1에 기재된 바와 같이 PCR에 의해 합성하였다. 사용된 프라이머는 5’ 인산화된 서열번호 82 (정배향 프라이머) 및 프라이머의 3개의 5’ 최외곽 뉴클레오타이드 상에 2’-O-메틸 변형 및 프라이머의 5’ 말단으로부터 첫번째와 두번째, 두번째와 세번째, 및 세번째와 네번째 뉴클레오타이드 사이에 포스포로티오에이트 결합을 포함하는 서열번호 54 (역배향 프라이머)이다(표 1). 이들 프라이머는 벡터 작제물 내 645 bp 내지 600bp 상동성 아암 내 하이브리드화하여 DAR 작제물을 플랭킹하는 192bp 및 159 bp의 상동성 아암을 갖는 작제물을 생성하였다. 수득한 PCR 생성물인, 이중 가닥 항-CEA CAR 공여자 DNA 단편 (서열번호 85)은 2.4 kb크기이고, 2.077 kb 항-CEA CAR 작제물 (서열번호 84), 192 bp 상동성 아암(서열번호 55), 및 항-CEA CAR 작제물을 플랭킹하는 159 bp 상동성 아암 (서열번호 56)을 포함하고, 공여자 DNA 분자에 역배향 프라이머 (서열번호 54)의 2’-O-메틸 및 PS 변형 및 정배향 프라이머 (서열번호 82)의 5’ 말단 포스페이트를 혼입시켰다. 서열번호 54의 프라이머 변형은 이중 가닥 공여자 DNA의 제1 가닥에 혼입하였지만, 어떠한 화학적 변형도 프라이머의 5’ 말단 포스페이트를 포함하는, 반대, 또는 제2 가닥 상에 도입하지 않았다. 공여자 분자를 사용하여 표적 서열 (서열번호 52)을 포함하는 crRNA (가이드 RNA)와 복합체화된 Cas12a 단백질과 함께 이중 가닥 분자로서 활성화된 T 세포를 형질감염시켰다.
TCR 알파 (TRAC) 유전자의 RNA 가이드-지시된 표적화를 위해, crRNA (ALT-R® CRISPR-Cas12a crRNA)는 IDT (Coralville, IA)로부터 구입하였고, 여기서, 상기 crRNA는 TRAC 유전자의 제1 엑손 내 Cas12a PAM 서열 (TTTA)의 바로 다운스트림에 존재하는 표적 서열 (서열번호 52)을 포함하도록 디자인하였다.
Cas12a 및 가이드 RNA RNP의 형성 및 Cas12a RNP 및 이중 가닥 공여자 DNA의 T 세포로의 전기천공은 또한 실시예 7에 따라 필수적으로 수행하였다. 대조군으로서, 하나의 T 세포 집단은 Cas12a RNP로 형질전환시켰지만, 어떠한 공여자 단편으로는 형질감염시키지 않았고, TRAC 녹아웃 (KO) 대조군으로서 언급된다.
별도의 실험에서, 동일한 항-CEA CAR 작제물은 Cas12a를 사용하여 CD7 유전자에 삽입하였다. 상기 경우에 항-CEA CAR 작제물 (서열번호 84)은 pAAV 벡터 내 CD7 표적 부위 (서열번호 86) 주변의 서열을 포함하는 상동성 아암 사이에 클로닝하였다.
CD7 유전자 내 표적 부위를 선택하기 위해, Cas12a PAM 서열의 업스트림에 2개의 잠재적 부위를 조사하였고, 이들 각각은 Cpf1(Cas12a)에 대한 온라인 가이드 분석 도구를 사용하여 녹아웃을 성취하기 위해 높은 스코어를 받았다. 제1 표적 부위 (서열번호 86)를 사용하여 RNA 가이드 “crRNA-1”을 디자인하였고; 상기 표적 서열은 표적화된 CD7 유전자좌의 외부의 사람 게놈에 단지 하나의 부위 매칭을 가졌고 상기 게놈 내 추가의 부위는 엑손 내에 있지 않았다. Cas12a PAM 부위의 업스트림에 있는 것으로서 CD7 유전자에서 동정된 제2 표적 서열(서열번호 87)을 사용하여 가이드 RNA “crRNA-2”를 디자인하였다. 상기 부위는 사람 게놈내 103개 매칭 서열을 가졌고, 이중 5개는 엑손에 존재하였다. 흥미롭게도, 2개의 가이드 및 유동 세포측정 분석을 사용한 녹아웃 실험 (어떠한 공여자도 전기천공에 포함되지 않음)은 가이드로서 crRNA-2의 사용이 형질감염된 집단의 약 80%가 CD7 발현을 상실하도록 하는 반면, 가이드로서 crRNA-1은 형질감염된 집단의 대략 96%가 CD7 발현을 상실하도록 함을 보여주었다. 표적 서열 (서열번호 86)에 지시된 crRNA-1 가이드 RNA는 따라서 CD7 유전자 내 녹아웃/녹인에 대해 선택되었다.
CD7 유전자좌로의 삽입을 위한 공여자 단편은 실시예 1에 기재된 바와 같이 PCR에 의해 합성하였다. 사용된 프라이머는 프라이머의 5’ 말단으로부터 첫번째, 세번째 및 네번째 뉴클레오타이드 상에 2’-O-메틸 변형, 및 5’ 말단으로부터 첫번째와 두번째, 두번째와 세번째, 및 세번째와 네번째 뉴클레오타이드 사이에 포스포로티오에이트 결합을 포함하는 서열번호 88 (정배향 프라이머) 및 5’ 인산화된 서열번호 89 (역배향 프라이머)이다(표 1). 이들 프라이머는 CD7 표적 부위 (서열번호 86)을 플랭킹하는 연장된 상동성 아암에 의해 플랭킹된 항-CEA CAR 작제물 (서열번호 84)을 포함하는 벡터 작제물 내 상동성 아암내에서 하이브리드화하여 CAR 작제물을 플랭킹하는 212 bp (서열번호 90) 및 170 bp (서열번호 91)의 상동성 아암을 갖는 공여자 단편을 생성하였다. 수득한 PCR 생성물인, 이중 가닥 항-CEA CAR 공여자 DNA 단편 (서열번호 92)은 2.46 kb크기이고, 2.077 kb 항-CEA CAR 작제물 (서열번호 84), 212 bp 상동성 아암(서열번호 90), 및 170 bp 상동성 아암 (서열번호 91)을 포함하고, 공여자 DNA 분자에 정배향 프라이머 (서열번호 88)의 2’-O-메틸 및 PS 변형 및 역배향 프라이머 (서열번호 89)의 5’ 말단 포스페이트를 혼입시켰다. 서열번호 88의 프라이머 변형은 제1 가닥에 혼입되지만 어떠한 화학적 변형도 프라이머의 5’ 말단 포스페이트를 포함하는, 반대, 또는 제2 가닥 상에 도입되지 않았다. 공여자 DNA를 사용하여 표적 서열 (서열번호 87)을 포함하는 crRNA (가이드 RNA)와 복합체화된 Cas12a 단백질과 함께 이중 가닥 분자로서 활성화된 T 세포를 형질감염시켰다.
CD7 유전자의 RNA 가이드-지시된 표적화를 위해, crRNA (ALT-R® CRISPR-Cas12a crRNA)는 IDT (Coralville, IA)로부터 구입하였고, 여기서, 상기 crRNA는 TRAC 유전자의 제1 엑손 내 Cas12a PAM 서열 (TTTA)의 바로 다운스트림에 존재하는 표적 서열 (서열번호 86)을 포함하도록 디자인하였다.
Cas12a 및 가이드 RNA RNP의 형성 및 Cas12a RNP 및 이중 가닥 공여자 DNA의 T 세포로의 전기천공은 또한 실시예 7에 따라 필수적으로 수행하였다. 대조군으로서, 하나의 T 세포 집단은 Cas12a RNP로 형질전환시켰지만, 어떠한 공여자 단편으로는 형질전환시키지 않았고, TRAC 녹아웃 (KO) 대조군으로서 언급된다.
형질감염된 배양물은 상기된 바와 같이 TRAC 녹아웃 대조군 집단과 함께 유동 세포측정에 의해 분석하였다(도 23a-d). 도 23a는 공여자 DNA로 형질감염되지 않은 세포에서 CEA CAR의 어떠한 검출된 발현도 없었지만, TRAC 가이드-RNP로 전기천공된 집단의 89%는 TRAC 유전자의 발현을 상실시켰음 (녹아웃)을 보여준다. 그러나, 공여자가 전기천공에 포함되는 경우, 집단의 대략 28.7%는 항-CEA CAR을 발현하지만 TCR을 발현하는데 실패하였다(도 23b). 항-CEA CAR 공여자 및 Cas12a RNP를 사용한 CD7 유전자좌의 표적화는 보다 더 효율적이었다: 집단의 대략 38%는 녹인/녹아웃 세포(CD7 발현의 부재하에 항-CEA CAR의 발현) (도 23d)이다. 도 23c는 세포에서 CD7 발현의 비교를 위한 기초를 제공하고, 여기서, 상기 CD7 유전자좌는 표적화되지 않았다(상기 세포에는 TRAC 유전자좌를 표적화하는 RNP로 형질감염시켰다). 상기 집단에서, 세포 집단의 약 65%는 CD7 유전자좌가 RNP로 표적화된 집단의 단지 약 8%와 비교하여 CD7을 발현하였다(도 23d).
상기 세포는 표적으로서 CEA 양성 LS174T 세포를 사용하여 실시예 1에서와 같이 필수적으로 수행된 세포독성 검정에서 시험하였다. 도 24는 예상된 바와 같이, 항-CEA CAR을 발현하지 않은 TRAC 녹아웃 세포가 표적을 사멸시키지 않음을 보여준다. 한편, TRAC 유전자좌에서 항-CEA CAR의 Cas12a-매개된 녹인은 이펙터:표적 비율에 의존하는 세포독성을 유도하였고, 2.5:1 초과의 이펙터:표적 비율에서 60% 사멸 수준에 이른다. 놀랍게도, CD7 유전자좌에서 항-CEA CAR 녹인은 특히 낮은 표적:이펙터 비율에서 TRAC 유전자좌에서 녹인 보다 표적을 사멸시키는데 보다 효과적이고, 이는 최저 표적 대 이펙터 비율 0.625:1에서 대략 80% 사멸을 입증한다.
도 25는 Cas12a-매개된 항-CEA CAR 녹인/CD7 녹아웃 및 항-CEA CAR 녹인/TRAC 녹아웃 T 세포 둘다가 인터페론 감마를 분비하였고, CD7 녹아웃/항-CEA CAR 녹인 T 세포가 TRAC 녹아웃/항-CEA CAR 녹인 T 세포 보다 약간 적은 인터페론 감마를 분비함을 보여준다.
서열
서열번호 1
DNA
호모 사피엔스
TRAC 유전자 (엑손 1) 내 표적 서열
CAGGGTTCTGGATATCTGT
서열번호 2
DNA
인공
TRAC 유전자좌로의 삽입을 위한 항-CD38 CAR 작제물은: JeT 포로모터에 이어서 CD8a 리더 펩타이드에 이어서 항-CD38 CAR (사람 CD38에 특이적인 단일쇄 가변 단편 (scFv))에 이어서 CD28 힌지-막관통-세포 내 영역 및 CD3 제타 세포내 도메인을 암호화하는 DNA 서열을 포함한다. GAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAATGGTCATGGGTCTTTCTCTTTTTTCTCAGCGTGACCACCGGAGTCCACTCCCAGGTAGAGCAGAAATTGATCTCTGAGGAAGACCTGCAGGTCCAGTTGGTCGAAAGTGGCGGCGGATTGGTGAAACCAGGCGGATCTTTGAGGCTTAGTTGCGCGGCTTCCGGATTTACGTTCAGTGATGACTACATGAGCTGGATAAGGCAAGCACCTGGTAAGGGCCTGGAATGGGTCGCAAGTGTGTCTAATGGAAGGCCCACTACCTACTATGCTGATTCCGTCCGCGGACGCTTTACTATTTCAAGAGATAATGCTAAGAATAGTCTGTACCTGCAGATGAACAGTCTGCGCGCGGAAGATACCGCAGTATATTACTGTGCACGAGAGGATTGGGGTGGGGAGTTCACGGATTGGGGCAGGGGAACTCTTGTAACGGTGTCTAGCGGAGGAGGTGGGTCAGGTGGAGGTGGCAGTGGAGGTGGAGGCTCTCAGGCCGGCTTGACCCAACCGCCATCTGCGTCAGGAACATCAGGCCAGAGGGTGACTATCAGTTGTTCTGGCAGTTCATCCAATATTGGGATCAATTTCGTGTACTGGTATCAGCACCTGCCAGGTACCGCGCCGAAGCTGCTGATCTATAAGAATAATCAACGCCCATCAGGCGTTCCAGATAGGTTCAGTGGGAGCAAGTCCGGAAACTCCGCGTCACTCGCGATCTCAGGTCTGCGGTCTGAGGATGAAGCTGATTATTACTGCGCGGCGTGGGATGATTCTCTGTCAGGCTACGTATTCGGTTCAGGGACTAAGGTAACTGTGTTGGCGAAACCGACCACGACACCGGCTCCAAGACCTCCGACGCCAGCTCCAACGATAGCGTCACAGCCATTGTCTCTCCGCCCTGAAGCCTGCCGGCCCGCTGCGGGCGGCGCGGTTCATACCCGGGGATTGGACTTTGCCCCCAGAAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTCGATCTAAGCGAAGCCGCTTGTTGCATTCTGACTACATGAATATGACGCCAAGACGGCCAGGGCCAACAAGAAAGCATTACCAACCGTACGCCCCCCCGCGAGACTTCGCGGCCTACCGCAGCAGGGTAAAATTTAGCAGGTCTGCAGATGCGCCTGCGTATCAACAGGGTCAGAATCAGCTCTATAATGAGCTGAACCTCGGGCGGCGGGAAGAGTATGATGTTCTCGATAAAAGGAGAGGACGAGACCCCGAAATGGGCGGCAAACCGAGACGCAAAAATCCTCAGGAGGGGCTCTACAATGAACTTCAAAAAGACAAAATGGCCGAAGCATACTCAGAAATCGGAATGAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACGGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCGCTGCCGCCTAGATGATAAAATTGTTGTTGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTA
서열번호 3
DNA
인공
Jet 프로모터
GAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACA
서열번호 4
DNA
인공
상동성 아암을 갖는 항-CD38A2 CAR 카세트
GGCACCATATTCATTTTGCAGGTGAAATTCCTGAGATGTAAGGAGCTGCTGTGACTTGCTCAAGGCCTTATATCGAGTAAACGGTAGTGCTGGGGCTTAGACGCAGGTGTTCTGATTTATAGTTCAAAACCTCTATCAATGAGAGAGCAATCTCCTGGTAATGTGATAGATTTCCCAACTTAATGCCAACATACCATAAACCTCCCATTCTGCTAATGCCCAGCCTAAGTTGGGGAGACCACTCCAGATTCCAAGATGTACAGTTTGCTTTGCTGGGCCTTTTTCCCATGCCTGCCTTTACTCTGCCAGAGTTATATTGCTGGGGTTTTGAAGAAGATCCTATTAAATAAAAGAATAAGCAGTATTATTAAGTAGCCCTGCATTTCAGGTTTCCTTGAGTGGCAGGCCAGGCCTGGCCGTGAACGTTCACTGAAATCATGGCCTCTTGGCCAAGATTGATAGCTTGTGCCTGTCCCTGAGTCCCAGTCCATCACGAGCAGCTGGTTTCTAAGATGCTATTTCCCGTATAAAGCATGAGACCGTGACTTGCCAGCCCCACAGAGCCCCGCCCTTGTCCATCACTGGCATCTGGACTCCAGCCTGGGTTGGGGCAAAGAGGGAAATGAGATCATGTCCTAACCCTGATCCTCTTGTCCCACAGAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAATGGTCATGGGTCTTTCTCTTTTTTCTCAGCGTGACCACCGGAGTCCACTCCCAGGTAGAGCAGAAATTGATCTCTGAGGAAGACCTGCAGGTCCAGTTGGTCGAAAGTGGCGGCGGATTGGTGAAACCAGGCGGATCTTTGAGGCTTAGTTGCGCGGCTTCCGGATTTACGTTCAGTGATGACTACATGAGCTGGATAAGGCAAGCACCTGGTAAGGGCCTGGAATGGGTCGCAAGTGTGTCTAATGGAAGGCCCACTACCTACTATGCTGATTCCGTCCGCGGACGCTTTACTATTTCAAGAGATAATGCTAAGAATAGTCTGTACCTGCAGATGAACAGTCTGCGCGCGGAAGATACCGCAGTATATTACTGTGCACGAGAGGATTGGGGTGGGGAGTTCACGGATTGGGGCAGGGGAACTCTTGTAACGGTGTCTAGCGGAGGAGGTGGGTCAGGTGGAGGTGGCAGTGGAGGTGGAGGCTCTCAGGCCGGCTTGACCCAACCGCCATCTGCGTCAGGAACATCAGGCCAGAGGGTGACTATCAGTTGTTCTGGCAGTTCATCCAATATTGGGATCAATTTCGTGTACTGGTATCAGCACCTGCCAGGTACCGCGCCGAAGCTGCTGATCTATAAGAATAATCAACGCCCATCAGGCGTTCCAGATAGGTTCAGTGGGAGCAAGTCCGGAAACTCCGCGTCACTCGCGATCTCAGGTCTGCGGTCTGAGGATGAAGCTGATTATTACTGCGCGGCGTGGGATGATTCTCTGTCAGGCTACGTATTCGGTTCAGGGACTAAGGTAACTGTGTTGGCGAAACCGACCACGACACCGGCTCCAAGACCTCCGACGCCAGCTCCAACGATAGCGTCACAGCCATTGTCTCTCCGCCCTGAAGCCTGCCGGCCCGCTGCGGGCGGCGCGGTTCATACCCGGGGATTGGACTTTGCCCCCAGAAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTCGATCTAAGCGAAGCCGCTTGTTGCATTCTGACTACATGAATATGACGCCAAGACGGCCAGGGCCAACAAGAAAGCATTACCAACCGTACGCCCCCCCGCGAGACTTCGCGGCCTACCGCAGCAGGGTAAAATTTAGCAGGTCTGCAGATGCGCCTGCGTATCAACAGGGTCAGAATCAGCTCTATAATGAGCTGAACCTCGGGCGGCGGGAAGAGTATGATGTTCTCGATAAAAGGAGAGGACGAGACCCCGAAATGGGCGGCAAACCGAGACGCAAAAATCCTCAGGAGGGGCTCTACAATGAACTTCAAAAAGACAAAATGGCCGAAGCATACTCAGAAATCGGAATGAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACGGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCGCTGCCGCCTAGATGATAAAATTGTTGTTGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTAGATATCCAGAACCCTGACCCTGCCGTGTACCAGCTGAGAGACTCTAAATCCAGTGACAAGTCTGTCTGCCTATTCACCGATTTTGATTCTCAAACAAATGTGTCACAAAGTAAGGATTCTGATGTGTATATCACAGACAAAACTGTGCTAGACATGAGGTCTATGGACTTCAAGAGCAACAGTGCTGTGGCCTGGAGCAACAAATCTGACTTTGCATGTGCAAACGCCTTCAACAACAGCATTATTCCAGAGGACACCTTCTTCCCCAGCCCAGGTAAGGGCAGCTTTGGTGCCTTCGCAGGCTGTTTCCTTGCTTCAGGAATGGCCAGGTTCTGCCCAGAGCTCTGGTCAATGATGTCTAAAACTCCTCTGATTGGTGGTCTCGGCCTTATCCATTGCCACCAAAACCCTCTTTTTACTAAGAAACAGTGAGCCTTGTTCTGGCAGTCCAGAGAATGACACGGGAAAAAAGCAGATGAAGAGAAGGTGGCAGGAGAGGGCACGTGGCCCAGCCTCAGTCTCTCCAACTGAGTTCCTGCCTGCCTGCCTTTGCTCAGACTGTTTGCCCCTTACTGCTCTTCTAGGCCTCATTCTAAGCCCCTTCTCCAAGTTGCCTCTCCTTATTTCTCCCTGTCTGCCAAAAAATCTTT
서열번호 5
DNA
인공
pAAV-MCS 벡터 내 항-CD38 CAR-TRAC 상동성 아암 삽입체를 갖는 클론을 서열분석하기 위한 프라이머
CTTAGGCTGGGCATTAGCAG
서열번호 6
DNA
인공
pAAV-MCS 벡터 내 항-CD38 CAR-TRAC 상동성 아암 삽입체를 갖는 클론을 서열분석하기 위한 프라이머
CATGGAATGGTCATGGGTCT
서열번호 7
DNA
인공
pAAV-MCS 벡터 내 항-CD38 CAR-TRAC 상동성 아암 삽입체를 갖는 클론을 서열분석하기 위한 프라이머
GGCTACGTATTCGGTTCAGG
서열번호 8
DNA
인공
pAAV 항-CD38 CAR-TRAC 작제물(660 & 650 HA)로부터 공여자 DNA PCR 단편을 생성하기 위한 정배향 프라이머
첫번째와 두번째, 두번째와 세번째, 및 세번째와 네번째 뉴클레오사이드 사이에 포스포로티오에이트 결합; 위치 2 및 3에서 G 및 위치 4에서 A는 2’-O-메틸화됨
T gm gm am GCTAGGGCACCATATT
서열번호 9
DNA
인공
pAAV 항-CD38 CAR-TRAC 작제물 (660 및 650 HA)로부터 공여자 DNA PCR 단편을 생성하기 위한 역배향 프라이머, 5’-최외곽 뉴클레오사이드 (C)는 5’ 포스페이트를 가짐
CAACTTGGAGAAGGGGCTTA
서열번호 10
DNA
인공
항-CD38 CAR의 부위-특이적 삽입(업스트림 접합)을 입증하기 위한 TRAC 유전자좌에 대해 상동성을 갖는 PCR 정배향 프라이머
CCTGCTTTCTGAGGGTGAAG
서열번호 11
DNA
인공
항-CD38 CAR의 부위-특이적 삽입(업스트림 접합)을 입증하기 위한 CAR 작제물에 대해 상동성을 갖는 PCR 역배향 프라이머
CTTTCGACCAACTGGACCTG
서열번호 12
DNA
인공
항-CD38 CAR의 부위-특이적 삽입(다운스트림 접합)을 입증하기 위한 CAR 유전자좌에 대해 상동성을 갖는 PCR 정배향 프라이머
CGTTCTGGGTACTCGTGGTT
서열번호 13
DNA
인공
TRAC 유전자좌에 대한 상동성을 갖는 PCR 역배향 프라이머(다운스트림 접합)
GAGAGCCCTTCCCTGACTTT
서열번호 14
DNA
인공
300nt HA를 갖는 공여자 단편을 생성하기 위한 정배향 프라이머
첫번째와 두번째, 두번째와 세번째, 및 세번째와 네번째 뉴클레오사이드 사이에 포스포로티오에이트 결합; 위치 2에서 C, 위치 3에서 A 및 위치 5에서 G는 2’-O-메틸화됨
C cm am T gm CCTGCCTTTACTCTG
서열번호 15
DNA
인공
300 nt HA를 갖는 공여자 단편을 생성하기 위한 역배향 프라이머, 5’-최외곽 뉴클레오사이드(T)는 5’ 포스페이트를 가짐
TCCTGAAGCAAGGAAACAGC
서열번호 16
DNA
호모 사피엔스
375 nt
5’ 상동성 아암, 엑손 1 TRAC 유전자
CCATGCCTGCCTTTACTCTGCCAGAGTTATATTGCTGGGGTTTTGAAGAAGATCCTATTAAATAAAAGAATAAGCAGTATTATTAAGTAGCCCTGCATTTCAGGTTTCCTTGAGTGGCAGGCCAGGCCTGGCCGTGAACGTTCACTGAAATCATGGCCTCTTGGCCAAGATTGATAGCTTGTGCCTGTCCCTGAGTCCCAGTCCATCACGAGCAGCTGGTTTCTAAGATGCTATTTCCCGTATAAAGCATGAGACCGTGACTTGCCAGCCCCACAGAGCCCCGCCCTTGTCCATCACTGGCATCTGGACTCCAGCCTGGGTTGGGGCAAAGAGGGAAATGAGATCATGTCCTAACCCTGATCCTCTTGTCCCACA
서열번호 17
DNA
호모 사피엔스
321 nt
3’ 상동성 아암, 엑손 1 TRAC 유전자
GATATCCAGAACCCTGACCCTGCCGTGTACCAGCTGAGAGACTCTAAATCCAGTGACAAGTCTGTCTGCCTATTCACCGATTTTGATTCTCAAACAAATGTGTCACAAAGTAAGGATTCTGATGTGTATATCACAGACAAAACTGTGCTAGACATGAGGTCTATGGACTTCAAGAGCAACAGTGCTGTGGCCTGGAGCAACAAATCTGACTTTGCATGTGCAAACGCCTTCAACAACAGCATTATTCCAGAGGACACCTTCTTCCCCAGCCCAGGTAAGGGCAGCTTTGGTGCCTTCGCAGGCTGTTTCCTTGCTTCAGGA
서열번호 18
DNA
인공
150nt HA를 갖는 공여자 단편을 생성하기 위한 정배향 프라이머
첫번째와 두번째, 세번째와 네번째 및 네번째와 다섯번째 뉴클레오사이드 사이에 포스포로티오에이트 연결; 위치 3에서 C, 위치 4에서 A 및 위치 5에서 G는 2’-O-메틸화됨
AT cm am cm GAGCAGCTGGTTTCT
서열번호 19
DNA
인공
150 nt HA를 갖는 공여자 단편을 생성하기 위한 역배향 프라이머, 5’-최외곽 뉴클레오사이드(G)는 5’ 포스페이트를 가짐
GACCTCATGTCTAGCACAGTTTTG
서열번호 20
DNA
호모 사피엔스
5’ 171 nt 상동성 아암, 엑손 1 TRAC 유전자
ATCACGAGCAGCTGGTTTCTAAGATGCTATTTCCCGTATAAAGCATGAGACCGTGACTTGCCAGCCCCACAGAGCCCCGCCCTTGTCCATCACTGGCATCTGGACTCCAGCCTGGGTTGGGGCAAAGAGGGAAATGAGATCATGTCCTAACCCTGATCCTCTTGTCCCACA
서열번호 21
DNA
호모 사피엔스
3’ 161 nt 상동성 아암, 엑손 1 TRAC 유전자
GATATCCAGAACCCTGACCCTGCCGTGTACCAGCTGAGAGACTCTAAATCCAGTGACAAGTCTGTCTGCCTATTCACCGATTTTGATTCTCAAACAAATGTGTCACAAAGTAAGGATTCTGATGTGTATATCACAGACAAAACTGTGCTAGACATGAGGTC
서열번호 22
DNA
인공
JeT 프로모터, 인트론, 항-CD19 CAR, SV40 서열을 포함하는 항-CD19 CAR 카세트
GAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAATGGTCATGGGTCTTTCTCTTTTTTCTCAGCGTGACCACCGGAGTCCACTCCGATATCCAGATGACACAGACCACCAGCAGCCTGAGCGCCAGCCTGGGCGACCGAGTGACTATCAGCTGCCGGGCATCCCAGGATATTTCTAAGTATCTGAACTGGTACCAGCAGAAGCCCGACGGCACTGTCAAACTGCTGATCTACCACACCAGTAGACTGCATTCAGGGGTGCCTAGCAGGTTCTCCGGATCTGGCAGTGGGACTGACTACTCCCTGACCATCTCTAACCTGGAGCAGGAAGATATTGCCACCTATTTCTGCCAGCAGGGCAATACACTGCCTTACACTTTTGGCGGGGGAACAAAGCTGGAGATCACTGGCGGAGGAGGATCTGGAGGAGGAGGAAGTGGAGGAGGAGGATCAGAGGTGAAACTGCAGGAAAGCGGACCAGGACTGGTCGCACCTTCACAGAGCCTGTCCGTGACATGTACTGTCTCCGGAGTGTCTCTGCCCGATTACGGCGTCTCTTGGATCCGGCAGCCCCCTAGAAAGGGACTGGAGTGGCTGGGCGTGATCTGGGGAAGTGAAACTACCTACTATAATAGTGCTCTGAAATCAAGACTGACCATCATTAAGGACAACTCTAAAAGTCAGGTGTTTCTGAAGATGAATTCCCTGCAGACCGACGATACAGCAATCTACTATTGCGCCAAACACTACTATTACGGCGGGAGCTATGCCATGGATTACTGGGGGCAGGGAACTTCCGTCACCGTGAGCAGCgcTAAGCCGACCACGACACCGGCTCCAAGACCTCCGACGCCAGCTCCAACGATAGCGTCACAGCCATTGTCTCTCCGCCCTGAAGCCTGCCGGCCCGCTGCGGGCGGCGCGGTTCATACCCGGGGATTGGACTTTGCCCCCAGAAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTCGATCTAAGCGAAGCCGCTTGTTGCATTCTGACTACATGAATATGACGCCAAGACGGCCAGGGCCAACAAGAAAGCATTACCAACCGTACGCCCCCCCGCGAGACTTCGCGGCCTACCGCAGCAGGGTAAAATTTAGCAGGTCTGCAGATGCGCCTGCGTATCAACAGGGTCAGAATCAGCTCTATAATGAGCTGAACCTCGGGCGGCGGGAAGAGTATGATGTTCTCGATAAAAGGAGAGGACGAGACCCCGAAATGGGCGGCAAACCGAGACGCAAAAATCCTCAGGAGGGGCTCTACAATGAACTTCAAAAAGACAAAATGGCCGAAGCATACTCAGAAATCGGAATGAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACAGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCGCTGCCGCCTAGATGATAAAATTGTTGTTGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTA
서열번호 23
DNA
인공
JeT 프로모터, 인트론, 항-BCMA CAR 작제물, SV40 서열을 포함하는 항-BCMA CAR 작제물
GAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAGTGGTCCTGGGTGTTCCTGTTCTTTCTGTCCGTGACCACCGGTGTCCACTCTCAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTAAAGCCTGGGGGGTCCCTTAGACTCTCCTGTGCAGCCTCTGGATTCACTTCCAGTACCGCCTGGATGAGCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGGTTGGCCGTATTAAAAGCAAAAGTGATGGTGGGACAACAGACTACGCTGCACCCGTGAAAGGCAGATTCACCATCTCAAGAGATGATTCAAAAAACACGCTGTTTCTGCAAATGAACAGCCTGAAAACCGAGGACACAGCCGTGTATTACTGTGCCAAGGGAGGCGGGACCTACGGCTACTGGGGCCAGGGAACCCTGGTCACCGTCTCCTCCGGCGGCGGCGGCAGCGGTGGCGGTGGCTCAGGTGGTGGTGGTTCTTCCTATGTGCTGACTCAGCCTGCCTCCGTGTCTGGGTCTCCTGGACAGTCAGTCACCATCTCCTGCACTGGAACCAGCAGTGATGGTGGTGGTCACACCTATGTCTCCTGGTACCAACAGCACCCAGGCAAAGCCCCCAAACTCATGATTTATGATGTCAGTAATCGGCCCTCATGGGTTTCTAATCGCTTCTCTGGCTCCAAGTCTGGCAACACGGCCTCCCTGACCATCTCTGGGCTCCAGGCTGANGACGAGGCTGATTATTACTGCGGCTCATATACAAGCAGCGNCTCTTATGTCTTCGGAACTGGNACCAAGCTGACCGTCCTGGCTAAGCCCACCACGACGCCAGCGCCGCGACCACCAACACCGGCGCCCACCATCGCGTCGCAGCCCCTGTCCCTGCGCCCAGAGGCGTGCCGGCCAGCGGCGGGGGGCGCAGTGCACACGAGGGGGCTGGACTTCGCCCCTAGGAAAATTGAAGTTATGTATCCTCCTCCTTACCTAGACAATGAGAAGAGCAATGGAACCATTATCCATGTGAAAGGGAAACACCTTTGTCCAAGTCCCCTATTTCCCGGACCTTCTAAGCCCTTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGCTCCTGCACAGTGACTACATGAACATGACTCCCCGCCGCCCCGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCCAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTACAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTACAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTACCAGGGTCTCAGTACAGCCACCAAGGACACCTACGACGCCCTTCACATGCAGGCCCTGCCGCCTAGATGATAAAATTGTTGTTGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTA
서열번호 24
DNA
호모 사피엔스
5’ 상동성 아암, TRAC 유전자 엑손 3, 183 nt
TATGCACAGAAGCTGCAAGGGACAGGAGGTGCAGGAGCTGCAGGCCTCCCCCACCCAGCCTGCTCTGCCTTGGGGAAAACCGTGGGTGTGTCCTGCAGGCCATGCAGGCCTGGGACATGCAAGCCCATAACCGCTGTGGCCTCTTGGTTTTACAGATACGAACCTAAACTTTCAAAACCTGTC
서열번호 25
DNA
호모 사피엔스
3’ 상동성 아암, TRAC 유전자 엑손 3
140 nt
AGTGATTGGGTTCCGAATCCTCCTCCTGAAAGTGGCCGGGTTTAATCTGCTCATGACGCTGCGGCTGTGGTCCAGCTGAGGTGAGGGGCCTTGAAGCTGGGAGTGGGGTTTAGGGACGCGGGTCTCTGGGTGCATCCTAA
서열번호 26
DNA
호모 사피엔스
엑손 3 표적 서열 (가이드 서열)
TTCGGAACCCAATCACTGAC
서열번호 27
DNA
인공
전체 공여자 DNA 항-CD38 CAR + 양 말단 상에 엑손 3 HA
TATGCACAGAAGCTGCAAGGGACAGGAGGTGCAGGAGCTGCAGGCCTCCCCCACCCAGCCTGCTCTGCCTTGGGGAAAACCGTGGGTGTGTCCTGCAGGCCATGCAGGCCTGGGACATGCAAGCCCATAACCGCTGTGGCCTCTTGGTTTTACAGATACGAACCTAAACTTTCAAAACCTGTCGAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAATGGTCATGGGTCTTTCTCTTTTTTCTCAGCGTGACCACCGGAGTCCACTCCCAGGTAGAGCAGAAATTGATCTCTGAGGAAGACCTGCAGGTCCAGTTGGTCGAAAGTGGCGGCGGATTGGTGAAACCAGGCGGATCTTTGAGGCTTAGTTGCGCGGCTTCCGGATTTACGTTCAGTGATGACTACATGAGCTGGATAAGGCAAGCACCTGGTAAGGGCCTGGAATGGGTCGCAAGTGTGTCTAATGGAAGGCCCACTACCTACTATGCTGATTCCGTCCGCGGACGCTTTACTATTTCAAGAGATAATGCTAAGAATAGTCTGTACCTGCAGATGAACAGTCTGCGCGCGGAAGATACCGCAGTATATTACTGTGCACGAGAGGATTGGGGTGGGGAGTTCACGGATTGGGGCAGGGGAACTCTTGTAACGGTGTCTAGCGGAGGAGGTGGGTCAGGTGGAGGTGGCAGTGGAGGTGGAGGCTCTCAGGCCGGCTTGACCCAACCGCCATCTGCGTCAGGAACATCAGGCCAGAGGGTGACTATCAGTTGTTCTGGCAGTTCATCCAATATTGGGATCAATTTCGTGTACTGGTATCAGCACCTGCCAGGTACCGCGCCGAAGCTGCTGATCTATAAGAATAATCAACGCCCATCAGGCGTTCCAGATAGGTTCAGTGGGAGCAAGTCCGGAAACTCCGCGTCACTCGCGATCTCAGGTCTGCGGTCTGAGGATGAAGCTGATTATTACTGCGCGGCGTGGGATGATTCTCTGTCAGGCTACGTATTCGGTTCAGGGACTAAGGTAACTGTGTTGGCGAAACCGACCACGACACCGGCTCCAAGACCTCCGACGCCAGCTCCAACGATAGCGTCACAGCCATTGTCTCTCCGCCCTGAAGCCTGCCGGCCCGCTGCGGGCGGCGCGGTTCATACCCGGGGATTGGACTTTGCCCCCAGAAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTCGATCTAAGCGAAGCCGCTTGTTGCATTCTGACTACATGAATATGACGCCAAGACGGCCAGGGCCAACAAGAAAGCATTACCAACCGTACGCCCCCCCGCGAGACTTCGCGGCCTACCGCAGCAGGGTAAAATTTAGCAGGTCTGCAGATGCGCCTGCGTATCAACAGGGTCAGAATCAGCTCTATAATGAGCTGAACCTCGGGCGGCGGGAAGAGTATGATGTTCTCGATAAAAGGAGAGGACGAGACCCCGAAATGGGCGGCAAACCGAGACGCAAAAATCCTCAGGAGGGGCTCTACAATGAACTTCAAAAAGACAAAATGGCCGAAGCATACTCAGAAATCGGAATGAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACGGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCGCTGCCGCCTAGATGATAAAATTGTTGTTGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTAAGTGATTGGGTTCCGAATCCTCCTCCTGAAAGTGGCCGGGTTTAATCTGCTCATGACGCTGCGGCTGTGGTCCAGCTGAGGTGAGGGGCCTTGAAGCTGGGAGTGGGGTTTAGGGACGCGGGTCTCTGGGTGCATCCTAA
서열번호 28
인공
서열번호 27의 공여자 단편을 생성하기 위한 정배향 프라이머
첫번째와 두번째, 두번째와 세번째, 및 세번째와 네번째 뉴클레오사이드 사이에 포스포로티오에이트 연결; 위치 2에서 A, 위치 4에서 G 및 위치 5에서 C는 2’-O-메틸화됨
T am T gm cm CACAGAAGCTGCAAGG
서열번호 29
인공
서열번호 27의 공여자 단편을 생성하기 위한 역배향 프라이머, 5’-최외곽 뉴클레오사이드(T)는 5’ 포스페이트를 가짐
TTAGGATGCACCCAGAGACC
서열번호 30
DNA PD-1 유전자좌 5’ HA
호모 사피엔스
326 nt
CTCCCCATCTCCTCTGTCTCCCTGTCTCTGTCTCTCTCTCCCTCCCCCACCCTCTCCCCAGTCCTACCCCCTCCTCACCCCTCCTCCCCCAGCACTGCCTCTGTCACTCTCGCCCACGTGGATGTGGAGGAAGAGGGGGCGGGAGCAAGGGGCGGGCACCCTCCCTTCAACCTGACCTGGGACAGTTTCCCTTCCGCTCACCTCCGCCTGAGCAGTGGAGAAGGCGGCACTCTGGTGGGGCTGCTCCAGGCATGCAGATCCCACAGGCGCCCTGGCCAGTCGTCTGGGCGGTGCTACAACTGGGCTGGCGGCCAGGATGGTTCTTA
서열번호 31
DNA PD-1 유전자좌 3’ HA
호모 사피엔스
380 nt
GGTAGGTGGGGTCGGCGGTCAGGTGTCCCAGAGCCAGGGGTCTGGAGGGACCTTCCACCCTCAGTCCCTGGCAGGTCGGGGGGTGCTGAGGCGGGCCTGGCCCTGGCAGCCCAGGGGTCCCGGAGCGAGGGGTCTGGAGGGACCTTTCACTCTCAGTCCCTGGCAGGTCGGGGGGTGCTGTGGCAGGCCCAGCCTTGGCCCCCAGCTCTGCCCCTTACCCTGAGCTGTGTGGCTTTGGGCAGCTCGAACTCCTGGGTTCCTCTCTGGGCCCCAACTCCTCCCCTGGCCCAAGTCCCCTCTTTGCTCCTGGGCAGGCAGGACCTCTGTCCCCTCTCAGCCGGTCCTTGGGGCTGCGTGTTTCTGTAGAATGACGGGTCAGG
서열번호 32
DNA
호모 사피엔스
PD-1 표적 부위
GGCCAGGATGGTTCTTAGGT
서열번호 33
DNA
인공
PD-1 HA에 의해 플랭킹된 CD38 카세트(서열번호 2)를 갖는 공여자 DNA 단편
CTCCCCATCTCCTCTGTCTCCCTGTCTCTGTCTCTCTCTCCCTCCCCCACCCTCTCCCCAGTCCTACCCCCTCCTCACCCCTCCTCCCCCAGCACTGCCTCTGTCACTCTCGCCCACGTGGATGTGGAGGAAGAGGGGGCGGGAGCAAGGGGCGGGCACCCTCCCTTCAACCTGACCTGGGACAGTTTCCCTTCCGCTCACCTCCGCCTGAGCAGTGGAGAAGGCGGCACTCTGGTGGGGCTGCTCCAGGCATGCAGATCCCACAGGCGCCCTGGCCAGTCGTCTGGGCGGTGCTACAACTGGGCTGGCGGCCAGGATGGTTCTTAGAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAATGGTCATGGGTCTTTCTCTTTTTTCTCAGCGTGACCACCGGAGTCCACTCCCAGGTAGAGCAGAAATTGATCTCTGAGGAAGACCTGCAGGTCCAGTTGGTCGAAAGTGGCGGCGGATTGGTGAAACCAGGCGGATCTTTGAGGCTTAGTTGCGCGGCTTCCGGATTTACGTTCAGTGATGACTACATGAGCTGGATAAGGCAAGCACCTGGTAAGGGCCTGGAATGGGTCGCAAGTGTGTCTAATGGAAGGCCCACTACCTACTATGCTGATTCCGTCCGCGGACGCTTTACTATTTCAAGAGATAATGCTAAGAATAGTCTGTACCTGCAGATGAACAGTCTGCGCGCGGAAGATACCGCAGTATATTACTGTGCACGAGAGGATTGGGGTGGGGAGTTCACGGATTGGGGCAGGGGAACTCTTGTAACGGTGTCTAGCGGAGGAGGTGGGTCAGGTGGAGGTGGCAGTGGAGGTGGAGGCTCTCAGGCCGGCTTGACCCAACCGCCATCTGCGTCAGGAACATCAGGCCAGAGGGTGACTATCAGTTGTTCTGGCAGTTCATCCAATATTGGGATCAATTTCGTGTACTGGTATCAGCACCTGCCAGGTACCGCGCCGAAGCTGCTGATCTATAAGAATAATCAACGCCCATCAGGCGTTCCAGATAGGTTCAGTGGGAGCAAGTCCGGAAACTCCGCGTCACTCGCGATCTCAGGTCTGCGGTCTGAGGATGAAGCTGATTATTACTGCGCGGCGTGGGATGATTCTCTGTCAGGCTACGTATTCGGTTCAGGGACTAAGGTAACTGTGTTGGCGAAACCGACCACGACACCGGCTCCAAGACCTCCGACGCCAGCTCCAACGATAGCGTCACAGCCATTGTCTCTCCGCCCTGAAGCCTGCCGGCCCGCTGCGGGCGGCGCGGTTCATACCCGGGGATTGGACTTTGCCCCCAGAAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTCGATCTAAGCGAAGCCGCTTGTTGCATTCTGACTACATGAATATGACGCCAAGACGGCCAGGGCCAACAAGAAAGCATTACCAACCGTACGCCCCCCCGCGAGACTTCGCGGCCTACCGCAGCAGGGTAAAATTTAGCAGGTCTGCAGATGCGCCTGCGTATCAACAGGGTCAGAATCAGCTCTATAATGAGCTGAACCTCGGGCGGCGGGAAGAGTATGATGTTCTCGATAAAAGGAGAGGACGAGACCCCGAAATGGGCGGCAAACCGAGACGCAAAAATCCTCAGGAGGGGCTCTACAATGAACTTCAAAAAGACAAAATGGCCGAAGCATACTCAGAAATCGGAATGAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACGGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCGCTGCCGCCTAGATGATAAAATTGTTGTTGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTAGGTAGGTGGGGTCGGCGGTCAGGTGTCCCAGAGCCAGGGGTCTGGAGGGACCTTCCACCCTCAGTCCCTGGCAGGTCGGGGGGTGCTGAGGCGGGCCTGGCCCTGGCAGCCCAGGGGTCCCGGAGCGAGGGGTCTGGAGGGACCTTTCACTCTCAGTCCCTGGCAGGTCGGGGGGTGCTGTGGCAGGCCCAGCCTTGGCCCCCAGCTCTGCCCCTTACCCTGAGCTGTGTGGCTTTGGGCAGCTCGAACTCCTGGGTTCCTCTCTGGGCCCCAACTCCTCCCCTGGCCCAAGTCCCCTCTTTGCTCCTGGGCAGGCAGGACCTCTGTCCCCTCTCAGCCGGTCCTTGGGGCTGCGTGTTTCTGTAGAATGACGGGTCAGG
서열번호 34
DNA
인공
서열번호 33의 공여자 단편을 생성하기 위한 정배향 프라이머, 5’-최외곽 뉴클레오사이드(C)는 5’ 포스페이트를 가짐
CTCCCCATCTCCTCTGTCTC
서열번호 35
DNA
인공
서열번호 33의 공여자 단편을 생성하기 위한 역배향 프라이머, 첫번째와 두번째, 두번째와 세번째, 및 세번째와 네번째 뉴클레오사이드 사이에 포스포로티오에이트 연결; 위치 1에서 C, 위치 2에서 C, 위치 4에서 G는 2’-O-메틸화됨
cm cm T gm GACCCGTCATTCTACAG
서열번호 36
DNA
호모 사피엔스
pAAV 항-CD38 CAR-TRAC 작제물(660 & 650 HA)로부터 공여자 DNA PCR 단편을 생성하기 위한 정배향 프라이머
TGGAGCTAGGGCACCATATT
서열번호 37
DNA
인공
5’ 및 3’ TRAC 유전자 엑손 1 상동성 아암을 갖는, JeT 프로모터, 인트론, 항-BCMA CAR 작제물, SV40 서열을 포함하는 항-BCMA CAR 작제물 공여자 단편 서열
ATCACGAGCAGCTGGTTTCTAAGATGCTATTTCCCGTATAAAGCATGAGACCGTGACTTGCCAGCCCCACAGAGCCCCGCCCTTGTCCATCACTGGCATCTGGACTCCAGCCTGGGTTGGGGCAAAGAGGGAAATGAGATCATGTCCTAACCCTGATCCTCTTGTCCCACAGAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAGTGGTCCTGGGTGTTCCTGTTCTTTCTGTCCGTGACCACCGGTGTCCACTCTCAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTAAAGCCTGGGGGGTCCCTTAGACTCTCCTGTGCAGCCTCTGGATTCACTTCCAGTACCGCCTGGATGAGCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGGTTGGCCGTATTAAAAGCAAAAGTGATGGTGGGACAACAGACTACGCTGCACCCGTGAAAGGCAGATTCACCATCTCAAGAGATGATTCAAAAAACACGCTGTTTCTGCAAATGAACAGCCTGAAAACCGAGGACACAGCCGTGTATTACTGTGCCAAGGGAGGCGGGACCTACGGCTACTGGGGCCAGGGAACCCTGGTCACCGTCTCCTCCGGCGGCGGCGGCAGCGGTGGCGGTGGCTCAGGTGGTGGTGGTTCTTCCTATGTGCTGACTCAGCCTGCCTCCGTGTCTGGGTCTCCTGGACAGTCAGTCACCATCTCCTGCACTGGAACCAGCAGTGATGGTGGTGGTCACACCTATGTCTCCTGGTACCAACAGCACCCAGGCAAAGCCCCCAAACTCATGATTTATGATGTCAGTAATCGGCCCTCATGGGTTTCTAATCGCTTCTCTGGCTCCAAGTCTGGCAACACGGCCTCCCTGACCATCTCTGGGCTCCAGGCTGANGACGAGGCTGATTATTACTGCGGCTCATATACAAGCAGCGNCTCTTATGTCTTCGGAACTGGNACCAAGCTGACCGTCCTGGCTAAGCCCACCACGACGCCAGCGCCGCGACCACCAACACCGGCGCCCACCATCGCGTCGCAGCCCCTGTCCCTGCGCCCAGAGGCGTGCCGGCCAGCGGCGGGGGGCGCAGTGCACACGAGGGGGCTGGACTTCGCCCCTAGGAAAATTGAAGTTATGTATCCTCCTCCTTACCTAGACAATGAGAAGAGCAATGGAACCATTATCCATGTGAAAGGGAAACACCTTTGTCCAAGTCCCCTATTTCCCGGACCTTCTAAGCCCTTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGCTCCTGCACAGTGACTACATGAACATGACTCCCCGCCGCCCCGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCCAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTACAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTACAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTACCAGGGTCTCAGTACAGCCACCAAGGACACCTACGACGCCCTTCACATGCAGGCCCTGCCGCCTAGATGATAAAATTGTTGTTGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTAGATATCCAGAACCCTGACCCTGCCGTGTACCAGCTGAGAGACTCTAAATCCAGTGACAAGTCTGTCTGCCTATTCACCGATTTTGATTCTCAAACAAATGTGTCACAAAGTAAGGATTCTGATGTGTATATCACAGACAAAACTGTGCTAGACATGAGGTC
서열번호 38
DNA
인공
JeT 프로모터, 인트론, 항-CD19 CAR, 서열번호 20 및 서열번호 21의 5’ 및 3’ TRAC 유전자 엑손 1 상동성 아암에 의해 플랭킹된 SV40 서열을 포함하는 항-CD19 CAR 카세트
ATCACGAGCAGCTGGTTTCTAAGATGCTATTTCCCGTATAAAGCATGAGACCGTGACTTGCCAGCCCCACAGAGCCCCGCCCTTGTCCATCACTGGCATCTGGACTCCAGCCTGGGTTGGGGCAAAGAGGGAAATGAGATCATGTCCTAACCCTGATCCTCTTGTCCCACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAATGGTCATGGGTCTTTCTCTTTTTTCTCAGCGTGACCACCGGAGTCCACTCCGATATCCAGATGACACAGACCACCAGCAGCCTGAGCGCCAGCCTGGGCGACCGAGTGACTATCAGCTGCCGGGCATCCCAGGATATTTCTAAGTATCTGAACTGGTACCAGCAGAAGCCCGACGGCACTGTCAAACTGCTGATCTACCACACCAGTAGACTGCATTCAGGGGTGCCTAGCAGGTTCTCCGGATCTGGCAGTGGGACTGACTACTCCCTGACCATCTCTAACCTGGAGCAGGAAGATATTGCCACCTATTTCTGCCAGCAGGGCAATACACTGCCTTACACTTTTGGCGGGGGAACAAAGCTGGAGATCACTGGCGGAGGAGGATCTGGAGGAGGAGGAAGTGGAGGAGGAGGATCAGAGGTGAAACTGCAGGAAAGCGGACCAGGACTGGTCGCACCTTCACAGAGCCTGTCCGTGACATGTACTGTCTCCGGAGTGTCTCTGCCCGATTACGGCGTCTCTTGGATCCGGCAGCCCCCTAGAAAGGGACTGGAGTGGCTGGGCGTGATCTGGGGAAGTGAAACTACCTACTATAATAGTGCTCTGAAATCAAGACTGACCATCATTAAGGACAACTCTAAAAGTCAGGTGTTTCTGAAGATGAATTCCCTGCAGACCGACGATACAGCAATCTACTATTGCGCCAAACACTACTATTACGGCGGGAGCTATGCCATGGATTACTGGGGGCAGGGAACTTCCGTCACCGTGAGCAGCgcTAAGCCGACCACGACACCGGCTCCAAGACCTCCGACGCCAGCTCCAACGATAGCGTCACAGCCATTGTCTCTCCGCCCTGAAGCCTGCCGGCCCGCTGCGGGCGGCGCGGTTCATACCCGGGGATTGGACTTTGCCCCCAGAAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTCGATCTAAGCGAAGCCGCTTGTTGCATTCTGACTACATGAATATGACGCCAAGACGGCCAGGGCCAACAAGAAAGCATTACCAACCGTACGCCCCCCCGCGAGACTTCGCGGCCTACCGCAGCAGGGTAAAATTTAGCAGGTCTGCAGATGCGCCTGCGTATCAACAGGGTCAGAATCAGCTCTATAATGAGCTGAACCTCGGGCGGCGGGAAGAGTATGATGTTCTCGATAAAAGGAGAGGACGAGACCCCGAAATGGGCGGCAAACCGAGACGCAAAAATCCTCAGGAGGGGCTCTACAATGAACTTCAAAAAGACAAAATGGCCGAAGCATACTCAGAAATCGGAATGAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACAGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCGCTGCCGCCTAGATGATAAAATTGTTGTTGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTAGATATCCAGAACCCTGACCCTGCCGTGTACCAGCTGAGAGACTCTAAATCCAGTGACAAGTCTGTCTGCCTATTCACCGATTTTGATTCTCAAACAAATGTGTCACAAAGTAAGGATTCTGATGTGTATATCACAGACAAAACTGTGCTAGACATGAGGTC
서열번호 39
DNA
인공
공여자 DNA의 5’ 말단의 서열분석된 PCR 생성물 + 항-CD38 CAR 작제물 및 660nt 상동성 아암 부분을 포함하는 인접한 TRAC 유전자 엑손 1 게놈 서열
NNNNNNNNNNNNNNNGCNNGACTCACTAGCACTCTATCACGGCCATATTCTGGCAGGGTCAGTGGCTCCAACTAACATTTGTTTGGTACTTTACAGTTTATTAAATAGATGTTTATATGGAGAAGCTCTCATTTCTTTCTCAGAAGAGCCTGGCTAGGAAGGTGGATGAGGCACCATATTCATTTTGCAGGTGAAATTCCTGAGATGTAAGGAGCTGCTGTGACTTGCTCAAGGCCTTATATCGAGTAAACGGTAGCGCTGGGGCTTAGACGCAGGTGTTCTGATTTATAGTTCAAAACCTCTATCAATGAGAGAGCAATCTCCTGGTAATGTGATAGATTTCCCAACTTAATGCCAACATACCATAAACCTCCCATTCTGCTAATGCCCAGCCTAAGTTGGGGAGACCACTCCAGATTCCAAGATGTACAGTTTGCTTTGCTGGGCCTTTTTCCCATGCCTGCCTTTACTCTGCCAGAGTTATATTGCTGGGGTTTTGAAGAAGATCCTATTAAATAAAAGAATAAGCAGTATTATTAAGTAGCCCTGCATTTCAGGTTTCCTTGAGTGGCAGGCCAGGCCTGGCCGTGAACGTTCACTGAAATCATGGCCTCTTGGCCAAGATTGATAGCTTGTGCCTGTCCCTGAGTCCCAGTCCATCACGAGCAGCTGGTTTCTAAGATGCTATTTCCCGTATAAAGCATGAGACCGTGACTTGCCAGCCCCACAGAGCCCCGCCCTTGTCCATCACTGGCATCTGGACTCCAGCCTGGGTTGGGGCAAAGAGGGNNNGAGATCATGTCCTAACCCTGATCCTCTTGTCCCACAGAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGANTATATNANNACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGN
서열번호 40
DNA
인공
공여자 DNA의 3’ 말단의 서열분석된 PCR 생성물 + 항-CD38 CAR 작제물 및 650nt 상동성 아암 부분을 포함하는 인접한 TRAC 유전자 엑손 1 게놈 서열
NNNNNNNNNNNNNNNNTTCTGCTCTACCTGGGAGTGGACTCCGGTGGTCACGCTGAGAAAAAAGAGAAAGACCCATGACCATTCCATGGTGGCGGCCTCGAGGCCTGTCAGGAGAGGAAAGAGAAGAAGGTTAGTACAATTGTCTAGATGCATTCCTAGGGCTGCAGGGTTCATAGTGCCACTTTTCCTGCACTGCCCCATCTCCTGCCCACCCTTTCCCAGGCATAGACAGTCAGTGACTTACTGTCAAGTGACGATCACAGGGATCCACAAACAAGAACCGCGACCCAAATCCCGGCTGCGACGGAACTAGCTGTGCCACACCCGGCGCGTCCTTATATAATCATCGGCGTTCACCGCCCATTCTCCGCCCAGCCATAAAAGGCAACTTTCGGAACGGCGCACGCTGATTGGCTCCGCCCTAACTCCGCCCGAATTCTGTGGGACAAGAGGATCAGGGTTAGGACATGATCTCATTTCCCTCTTTGCCCCAACCCAGGCTGGAGTCCAGATGCCAGTGATGGACAAGGGCGGGGCTCTGTGGGGCTGGCAAGTCACGGTCTCATGCTTTATACGGGAAATAGCATCTTAGAAACCAGCTGCTCGTGATGGACTGGGACTCAGGGACAGGCACAAGCTATCAATCTTGGCCAAGAGGCCATGATTTCAGTGAACGTTCACGGCCAGGCCTGGCCTGCCACTCAAGGAAACCTGAAATGCAGGGCTACTTAATAATACTGCTTATTCTTTTATTTAATAGGATCTTCTTCAAAACCCCAGCAATATAACTCTGGCAGAGTAAAGGCAGGCATGGGAAAAAGGCCCAGCAAAGCAAACTGTACATCTTGGAATCTGGAGTGGTCTCCCCAACTTAGGCTGGGCATTAGCAGAATGGGAGGTTTATGGTATGTTGGCATTAAGTTGGGAAATCTATCACATTACCAGGAGATTGCTCTCTCATTGATAGAGGTTTTGAACTATAAATCANAACACCTGCGTCTAAGCCCCAGCGCTA
서열번호 41
DNA
인공
공여자 DNA의 5’ 말단의 서열분석된 PCR 생성물 + 항-CD38 CAR 작제물 및 660nt 상동성 아암 부분을 포함하는 인접한 TRAC 유전자 엑손 3 게놈 서열
엑손3 5HA F 서열 결과:
CNNNNNNNNNNNNNNNNNNNNCTTTGAGGANGAGTTTCTAGCTTCAATAGACCAAGGACTCTCTCCTAGGCCTCTGTATTCCTTTCAACAGCTCCACTGTCAAGAGAGCCAGAGAGAGCTTCTGGGTGGCCCAGCTGTGAAATTTCTGAGTCCCTTAGGGATAGCCCTAAACGAACCAGATCATCCTGAGGACAGCCAAGAGGTTTTGCCTTCTTTCAAGACAAGCAACAGTACTCACATAGGCTGTGGGCAATGGTCCTGTCTCTCAAGAATCCCCTGCCACTCCTCACACCCACCCTGGGCCCATATTCATTTCCATTTGAGTTGTTCTTATTGAGTCATCCTTCCTGTGGTAGCGGAACTCACTAAGGGGCCCATCTGGACCCGAGGTATTGTGATGATAAATTCTGAGCACCTACCCCATCCCCAGAAGGGCTCAGAAATAAAATAAGAGCCAAGTCTAGTCGGTGTTTCCTGTCTTGAAACACAATACTGTTGGCCCTGGAAGAATGCACAGAATCTGTTTGTAAGGGGATATGCACAGAAGCTGCAAGGGACAGGAGGTGCAGGAGCTGCAGGCCTCCCCCACCCAGCCTGCTCTGCCTTGGGGAAAACCGTGGGTGTGTCCTGCAGGCCATGCAGGCCTGGGACATGCAAGCCCATAACCGCTGTGGCCTCTTGGTTTTACAGATACGAACCTAAACTTTCAAAACCTGTCGAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCNTNNNN
서열번호 42
DNA
인공
공여자 DNA의 3’ 말단의 서열분석된 PCR 생성물 + 항-CD38 CAR 작제물 및 650nt 상동성 아암 부분을 포함하는 인접한 게놈 TRAC 유전자 엑손 3 서열
NNNNNNNNNNNNNNNNNNGCTGCACAGGAGAGTCTCAGGGACCCTCCAGGCTTGACCAAGCCTCCCCCAGACTCCACCAGCTGCACCTGAGAGTGGACACCGGTGGTCACGGACAGAAAGAACAGGAACACCCAGGACCACTCCATGGTGGCGGCCTCGAGGCCTGTCAGGAGAGGAAAGAGAAGAAGGTTAGTACAATTGTCTAGATGCATTCCTAGGGCTGCAGGGTTCATAGTGCCACTTTTCCTGCACTGCCCCATCTCCTGCCCACCCTTTCCCAGGCATAGACAGTCAGTGACTTACTGTCAAGTGACGATCACAGGGATCCACAAACAAGAACCGCGACCCAAATCCCGGCTGCGACGGAACTAGCTGTGCCACACCCGGCGCGTCCTTATATAATCATCGGCGTTCACCGCCCATTCTCCGCCCAGCCATAAAAGGCAACTTTCGGAACGGCGCACGCTGATTGGCTCCGCCCTAACTCCGCCCGAATTCGACAGGTTTTGAAAGTTTAGGTTCGTATCTGTAAAACCAAGAGGCCACAGCGGTTATGGGCTTGCATGTCCCAGGCCTGCATGGCCTGCAGGACACACCCACGGTTTTCCCCAAGGCAGAGCAGGCTGGGTGGGGGAGGCCTGCAGCTCCTGCACCTCCTGTCCCTTGCAGCTTCTGTGCATATCCCCTTACAAACAGATTCTGTGCATTCTTCCAGGGCCAACAGTATTGTGTTTCAAGACAGGAAACACCGACTAGACTTGGCTCTTATTTTATTTCTGAGCCCTTCTGGGGATGGGGTAGGTGCTCAGAATTTATCATCACAATACCTCGGGTCCAGATGGGCCCCTTAGTGAGTTCCGCTACCACAGGAAGGATGACTCAATAAGAACAACTCAAATGGAAATGAATATGGGCCCAGGGTGGGTGTGAGGAGTGGCAGGGGATTCTTGANAGACAGGACCATTGCCCACAGCCTATGTGAGTACTGTTGCTTGTCTTGAAAGAANGCAAAACCTCTTGGCTGTCCTCN
서열번호 43
DNA
인공
공여자 DNA의 3’ 말단의 서열분석된 PCR 생성물 + 항-CD38 CAR 작제물 및 660nt 상동성 아암 부분을 포함하는 인접한 PD-1 게놈 서열
NNNNNNNNNNNNNNNNNNNTCNTGCTGGTGANGGTGGCCTTTATTATTTTCTGGGTTCGATCTAAGCGAAGCCGCTTGTTGCATTCTGACTACATGAATATGACGCCAAGACGGCCAGGGCCAACAAGAAAGCATTACCAACCGTACGCCCCCCCGCGAGACTACGCGGCCTACCGCAGCAGGGTAAAATTTAGCAGGTCTGCAGATGCGCCTGCGTATCAACAGGGTCAGAATCAGCTCTATAATGAGCTGAACCTCGGGCGGCGGGAAGAGTATGATGTTCTCGATAAAAGGAGAGGACGAGACCCCGAAATGGGCGGCAAACCGAGACGCAAAAATCCTCAGGAGGGGCTCTACAATGAACTTCAAAAAGACAAAATGGCCGAAGCATACTCAGAAATCGGAATGAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACAGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCGCTGCCGCCTAGATGATAAAATTGTTGTTGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTAGGTAGGTGGGGTCGGCGGTCAGGTGTCCCAGAGCCAGGGGTCTGGAGGGACCTTCCACCCTCAGTCCCTGGCAGGTCGGGGGGTGCTGAGGCGGGCCTGGCCCTGGCAGCCCAGGGGTCCCGGAGCGAGGGGTCTGGAGGGACCTTTCACTCTCAGTCCCTGGCAGGTCGGGGGGTGCTGTGGCAGGCCCAGCCTTGGCCCCCAGCTCTGCCCCTTACCCTGAGCTGTGTGGCTTTGGGCAGCTCAAACTCCTGGGTTCCTCTCTGGNNCCCNACTCNNCCCCTGNCCCNAGTCCCCTCTTTNNTCCTGGGCANGCNNNANCTCTNNNCCCTNNCAGCCGGNCCTTGGGGCTGCNNGN
서열번호 44
DNA
호모 사피엔스
TRAC 유전자의 엑손 1로부터의 5’ 상동성 아암, 660nt
GGCACCATATTCATTTTGCAGGTGAAATTCCTGAGATGTAAGGAGCTGCTGTGACTTGCTCAAGGCCTTATATCGAGTAAACGGTAGTGCTGGGGCTTAGACGCAGGTGTTCTGATTTATAGTTCAAAACCTCTATCAATGAGAGAGCAATCTCCTGGTAATGTGATAGATTTCCCAACTTAATGCCAACATACCATAAACCTCCCATTCTGCTAATGCCCAGCCTAAGTTGGGGAGACCACTCCAGATTCCAAGATGTACAGTTTGCTTTGCTGGGCCTTTTTCCCATGCCTGCCTTTACTCTGCCAGAGTTATATTGCTGGGGTTTTGAAGAAGATCCTATTAAATAAAAGAATAAGCAGTATTATTAAGTAGCCCTGCATTTCAGGTTTCCTTGAGTGGCAGGCCAGGCCTGGCCGTGAACGTTCACTGAAATCATGGCCTCTTGGCCAAGATTGATAGCTTGTGCCTGTCCCTGAGTCCCAGTCCATCACGAGCAGCTGGTTTCTAAGATGCTATTTCCCGTATAAAGCATGAGACCGTGACTTGCCAGCCCCACAGAGCCCCGCCCTTGTCCATCACTGGCATCTGGACTCCAGCCTGGGTTGGGGCAAAGAGGGAAATGAGATCATGTCCTAACCCTGATCCTCTTGTCCCACA
서열번호 45
DNA
호모 사피엔스
TRAC 유전자의 엑손 1로부터의 3’ 상동성 아암, 650nt
GATATCCAGAACCCTGACCCTGCCGTGTACCAGCTGAGAGACTCTAAATCCAGTGACAAGTCTGTCTGCCTATTCACCGATTTTGATTCTCAAACAAATGTGTCACAAAGTAAGGATTCTGATGTGTATATCACAGACAAAACTGTGCTAGACATGAGGTCTATGGACTTCAAGAGCAACAGTGCTGTGGCCTGGAGCAACAAATCTGACTTTGCATGTGCAAACGCCTTCAACAACAGCATTATTCCAGAGGACACCTTCTTCCCCAGCCCAGGTAAGGGCAGCTTTGGTGCCTTCGCAGGCTGTTTCCTTGCTTCAGGAATGGCCAGGTTCTGCCCAGAGCTCTGGTCAATGATGTCTAAAACTCCTCTGATTGGTGGTCTCGGCCTTATCCATTGCCACCAAAACCCTCTTTTTACTAAGAAACAGTGAGCCTTGTTCTGGCAGTCCAGAGAATGACACGGGAAAAAAGCAGATGAAGAGAAGGTGGCAGGAGAGGGCACGTGGCCCAGCCTCAGTCTCTCCAACTGAGTTCCTGCCTGCCTGCCTTTGCTCAGACTGTTTGCCCCTTACTGCTCTTCTAGGCCTCATTCTAAGCCCCTTCTCCAAGTTGCCTCTCCTTATTTCTCCCTGTCTGCCAAAAAATCTTT
서열번호 46
DNA
인공
토세아 아시그나(Thosea asigna) 바이러스의 T2A 펩타이드 서열을 암호화함
GGAAGCGGAGAGGGCAGAGGAAGTCTGCTAACATGCGGTGACGTCGAGGAGAATCCTGGACCT
서열번호 47
DNA
SV40
폴리A 첨가 서열
AACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTA
서열번호 48
DNA
인공
CD38 DAR 삽입체 2652 nt
GAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAGTGGAGCTGGGTGTTTCTGTTCTTCCTCTCCGTCACAACCGGCGTGCATAGCCAGGTGCAGCTGGTGGAGTCCGGAGGCGGCCTGGTGAAACCTGGCGGATCCCTGAGGCTGTCCTGCGCCGCTAGCGGATTCACCTTCAGCGACGACTACATGAGCTGGATCAGGCAGGCTCCCGGAAAGGGCCTGGAGTGGGTCGCTAGCGTGAGCAATGGCCGGCCCACAACCTACTATGCCGACTCCGTGCGGGGCAGGTTTACCATCTCCAGGGATAACGCTAAGAACTCCCTGTACCTGCAGATGAACAGCCTGCGGGCCGAAGATACCGCCGTCTACTATTGCGCCAGGGAGGATTGGGGCGGCGAGTTCACAGACTGGGGAAGGGGCACCCTGGTGACCGTGAGCAGCGCTTCCACCAAGGGCCCCTCCGTGTTCCCTCTGGCCCCCAGCAGCAAGAGCACATCCGGAGGCACCGCCGCCCTCGGATGTCTGGTGAAGGACTACTTCCCCGAGCCTGTCACCGTGTCCTGGAATAGCGGCGCCCTCACCTCCGGCGTGCACACCTTCCCCGCTGTCCTGCAGTCCTCCGGACTGTACAGCCTGTCCTCCGTCGTGACCGTGCCTAGCTCCTCCCTCGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCTTCCAACACAAAGGTGGACAAACGGGTGGAGCCCAAGTCCTGCGACAAAACCCACACCAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTAAACGGGGCAGAAAGAAACTCCTGTATATATTCAAACAACCATTTATGAGACCAGTACAAACTACTCAAGAGGAAGATGGCTGTAGCTGCCGATTTCCAGAAGAAGAAGAAGGAGGATGTGAACTGAGGGTAAAATTTAGCAGGTCTGCAGATGCGCCTGCGTATCAACAGGGTCAGAATCAGCTCTATAATGAGCTGAACCTCGGGCGGCGGGAAGAGTATGATGTTCTCGATAAAAGGAGAGGACGAGACCCCGAAATGGGCGGCAAACCGAGACGCAAAAATCCTCAGGAGGGGCTCTACAATGAACTTCAAAAAGACAAAATGGCCGAAGCATACTCAGAAATCGGAATGAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACAGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCCCTGCCCCCTCGCGGAAGCGGAGAGGGCAGAGGAAGTCTGCTAACATGCGGTGACGTCGAGGAGAATCCTGGACCTATGTCCGTCCCTACCCAGGTGCTGGGCCTGCTGCTGCTGTGGCTGACCGATGCTAGATGCCAGTCCGTTCTGACCCAGCCTCCTTCCGCCTCTGGCACATCCGGCCAGAGAGTGACCATCTCCTGCAGCGGCTCCAGCTCTAACATCGGCATCAATTTCGTGTACTGGTATCAGCACCTGCCAGGCACAGCTCCCAAGCTGCTGATCTACAAGAACAATCAGAGGCCTTCCGGCGTGCCAGACCGGTTCTCTGGCTCCAAGAGCGGCAACTCTGCCTCCCTGGCTATCTCCGGCCTGCGCAGCGAGGACGAGGCTGATTACTATTGCGCCGCTTGGGACGATAGCCTGTCTGGCTACGTGTTCGGCAGCGGCACAAAGGTGACCGTGCTGGGACAGCCAAAGGCTGCTCCTTCTGTGACACTGTTTCCCCCTTCCAGCGAGGAGCTGCAGGCCAATAAGGCCACCCTGGTGTGCCTGATCAGCGACTTCTATCCTGGAGCTGTGACCGTGGCTTGGAAGGCTGATTCTTCCCCAGTGAAGGCTGGCGTGGAGACAACAACCCCCAGCAAGCAGTCTAACAATAAGTACGCCGCTAGCTCTTATCTGTCTCTGACCCCAGAGCAGTGGAAGTCCCATAGGTCCTATAGCTGTCANGTCACCCACGAAGGGAGCACAGTCGAAAAAACCGTCGCACCAACCGAGTGTTCCTGATAAGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTA
서열번호 49
DNA
인공
5’ 171 nt 및 3’ 161 nt TRAC 엑손 1 상동성 아암에 의해 플랭킹된 CD28 DAR 삽입체 2652 nt
ATCACGAGCAGCTGGTTTCTAAGATGCTATTTCCCGTATAAAGCATGAGACCGTGACTTGCCAGCCCCACAGAGCCCCGCCCTTGTCCATCACTGGCATCTGGACTCCAGCCTGGGTTGGGGCAAAGAGGGAAATGAGATCATGTCCTAACCCTGATCCTCTTGTCCCACAGAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAGTGGAGCTGGGTGTTTCTGTTCTTCCTCTCCGTCACAACCGGCGTGCATAGCCAGGTGCAGCTGGTGGAGTCCGGAGGCGGCCTGGTGAAACCTGGCGGATCCCTGAGGCTGTCCTGCGCCGCTAGCGGATTCACCTTCAGCGACGACTACATGAGCTGGATCAGGCAGGCTCCCGGAAAGGGCCTGGAGTGGGTCGCTAGCGTGAGCAATGGCCGGCCCACAACCTACTATGCCGACTCCGTGCGGGGCAGGTTTACCATCTCCAGGGATAACGCTAAGAACTCCCTGTACCTGCAGATGAACAGCCTGCGGGCCGAAGATACCGCCGTCTACTATTGCGCCAGGGAGGATTGGGGCGGCGAGTTCACAGACTGGGGAAGGGGCACCCTGGTGACCGTGAGCAGCGCTTCCACCAAGGGCCCCTCCGTGTTCCCTCTGGCCCCCAGCAGCAAGAGCACATCCGGAGGCACCGCCGCCCTCGGATGTCTGGTGAAGGACTACTTCCCCGAGCCTGTCACCGTGTCCTGGAATAGCGGCGCCCTCACCTCCGGCGTGCACACCTTCCCCGCTGTCCTGCAGTCCTCCGGACTGTACAGCCTGTCCTCCGTCGTGACCGTGCCTAGCTCCTCCCTCGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCTTCCAACACAAAGGTGGACAAACGGGTGGAGCCCAAGTCCTGCGACAAAACCCACACCAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTAAACGGGGCAGAAAGAAACTCCTGTATATATTCAAACAACCATTTATGAGACCAGTACAAACTACTCAAGAGGAAGATGGCTGTAGCTGCCGATTTCCAGAAGAAGAAGAAGGAGGATGTGAACTGAGGGTAAAATTTAGCAGGTCTGCAGATGCGCCTGCGTATCAACAGGGTCAGAATCAGCTCTATAATGAGCTGAACCTCGGGCGGCGGGAAGAGTATGATGTTCTCGATAAAAGGAGAGGACGAGACCCCGAAATGGGCGGCAAACCGAGACGCAAAAATCCTCAGGAGGGGCTCTACAATGAACTTCAAAAAGACAAAATGGCCGAAGCATACTCAGAAATCGGAATGAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACAGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCCCTGCCCCCTCGCGGAAGCGGAGAGGGCAGAGGAAGTCTGCTAACATGCGGTGACGTCGAGGAGAATCCTGGACCTATGTCCGTCCCTACCCAGGTGCTGGGCCTGCTGCTGCTGTGGCTGACCGATGCTAGATGCCAGTCCGTTCTGACCCAGCCTCCTTCCGCCTCTGGCACATCCGGCCAGAGAGTGACCATCTCCTGCAGCGGCTCCAGCTCTAACATCGGCATCAATTTCGTGTACTGGTATCAGCACCTGCCAGGCACAGCTCCCAAGCTGCTGATCTACAAGAACAATCAGAGGCCTTCCGGCGTGCCAGACCGGTTCTCTGGCTCCAAGAGCGGCAACTCTGCCTCCCTGGCTATCTCCGGCCTGCGCAGCGAGGACGAGGCTGATTACTATTGCGCCGCTTGGGACGATAGCCTGTCTGGCTACGTGTTCGGCAGCGGCACAAAGGTGACCGTGCTGGGACAGCCAAAGGCTGCTCCTTCTGTGACACTGTTTCCCCCTTCCAGCGAGGAGCTGCAGGCCAATAAGGCCACCCTGGTGTGCCTGATCAGCGACTTCTATCCTGGAGCTGTGACCGTGGCTTGGAAGGCTGATTCTTCCCCAGTGAAGGCTGGCGTGGAGACAACAACCCCCAGCAAGCAGTCTAACAATAAGTACGCCGCTAGCTCTTATCTGTCTCTGACCCCAGAGCAGTGGAAGTCCCATAGGTCCTATAGCTGTCANGTCACCCACGAAGGGAGCACAGTCGAAAAAACCGTCGCACCAACCGAGTGTTCCTGATAAGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTAGATATCCAGAACCCTGACCCTGCCGTGTACCAGCTGAGAGACTCTAAATCCAGTGACAAGTCTGTCTGCCTATTCACCGATTTTGATTCTCAAACAAATGTGTCACAAAGTAAGGATTCTGATGTGTATATCACAGACAAAACTGTGCTAGACATGAGGTC
서열번호 50
DNA
5’ 엑손 1 TRAC 유전자 상동성 플랭킹 서열, 645 bp
TGTAAGGAGCTGCTGTGACTTGCTCAAGGCCTTATATCGAGTAAACGGTAGTGCTGGGGCTTAGACGCAGGTGTTCTGATTTATAGTTCAAAACCTCTATCAATGAGAGAGCAATCTCCTGGTAATGTGATAGATTTCCCAACTTAATGCCAACATACCATAAACCTCCCATTCTGCTAATGCCCAGCCTAAGTTGGGGAGACCACTCCAGATTCCAAGATGTACAGTTTGCTTTGCTGGGCCTTTTTCCCATGCCTGCCTTTACTCTGCCAGAGTTATATTGCTGGGGTTTTGAAGAAGATCCTATTAAATAAAAGAATAAGCAGTATTATTAAGTAGCCCTGCATTTCAGGTTTCCTTGAGTGGCAGGCCAGGCCTGGCCGTGAACGTTCACTGAAATCATGGCCTCTTGGCCAAGATTGATAGCTTGTGCCTGTCCCTGAGTCCCAGTCCATCACGAGCAGCTGGTTTCTAAGATGCTATTTCCCGTATAAAGCATGAGACCGTGACTTGCCAGCCCCACAGAGCCCCGCCCTTGTCCATCACTGGCATCTGGACTCCAGCCTGGGTTGGGGCAAAGAGGGAAATGAGATCATGTCCTAACCCTGATCCTCTTGTCCCACAGATATCCAGAACCCTGACCCT
서열번호 51
DNA
3’ 엑손 1 TRAC 유전자 상동성 플랭킹 서열, 엑손 1 TRAC 유전자 600bp
GTACCAGCTGAGAGACTCACTATCCAGTGACAAGTCTGTCTGCCTATTCACCGATTTTGATTCTCAAACAAATGTGTCACAAAGTAAGGATTCTGATGTGTATATCACAGACAAAACTGTGCTAGACATGAGGTCTATGGACTTCAAGAGCAACAGTGCTGTGGCCTGGAGCAACAAATCTGACTTTGCATGTGCAAACGCCTTCAACAACAGCATTATTCCAGAGGACACCTTCTTCCCCAGCCCAGGTAAGGGCAGCTTTGGTGCCTTCGCAGGCTGTTTCCTTGCTTCAGGAATGGCCAGGTTCTGCCCAGAGCTCTGGTCAATGATGTCTAAAACTCCTCTGATTGGTGGTCTCGGCCTTATCCATTGCCACCAAAACCCTCTTTTTACTAAGAAACAGTGAGCCTTGTTCTGGCAGTCCAGAGAATGACACGGGAAAAAAGCAGATGAAGAGAAGGTGGCAGGAGAGGGCACGTGGCCCAGCCTCAGTCTCTCCAACTGAGTTCCTGCCTGCCTGCCTTTGCTCAGACTGTTTGCCCCTTACTGCTCTTCTAGGCCTCATTCTAAGCCCCTTCTCCAAGTTGCCTCTCCTTATTT
서열번호 52
DNA
TRAC 유전자의 엑손 1에서 Cas12a 표적 부위
GAGTCTCTCAGCTGGTACACG
서열번호 53
DNA
인공
TRAC 유전자좌로부터 645 bp 및 600 bp 상동성 서열에 의해 플랭킹된 항-CD38 DAR 작제물
TGTAAGGAGCTGCTGTGACTTGCTCAAGGCCTTATATCGAGTAAACGGTAGTGCTGGGGCTTAGACGCAGGTGTTCTGATTTATAGTTCAAAACCTCTATCAATGAGAGAGCAATCTCCTGGTAATGTGATAGATTTCCCAACTTAATGCCAACATACCATAAACCTCCCATTCTGCTAATGCCCAGCCTAAGTTGGGGAGACCACTCCAGATTCCAAGATGTACAGTTTGCTTTGCTGGGCCTTTTTCCCATGCCTGCCTTTACTCTGCCAGAGTTATATTGCTGGGGTTTTGAAGAAGATCCTATTAAATAAAAGAATAAGCAGTATTATTAAGTAGCCCTGCATTTCAGGTTTCCTTGAGTGGCAGGCCAGGCCTGGCCGTGAACGTTCACTGAAATCATGGCCTCTTGGCCAAGATTGATAGCTTGTGCCTGTCCCTGAGTCCCAGTCCATCACGAGCAGCTGGTTTCTAAGATGCTATTTCCCGTATAAAGCATGAGACCGTGACTTGCCAGCCCCACAGAGCCCCGCCCTTGTCCATCACTGGCATCTGGACTCCAGCCTGGGTTGGGGCAAAGAGGGAAATGAGATCATGTCCTAACCCTGATCCTCTTGTCCCACAGATATCCAGAACCCTGACCCTGAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAGTGGAGCTGGGTGTTTCTGTTCTTCCTCTCCGTCACAACCGGCGTGCATAGCCAGGTGCAGCTGGTGGAGTCCGGAGGCGGCCTGGTGAAACCTGGCGGATCCCTGAGGCTGTCCTGCGCCGCTAGCGGATTCACCTTCAGCGACGACTACATGAGCTGGATCAGGCAGGCTCCCGGAAAGGGCCTGGAGTGGGTCGCTAGCGTGAGCAATGGCCGGCCCACAACCTACTATGCCGACTCCGTGCGGGGCAGGTTTACCATCTCCAGGGATAACGCTAAGAACTCCCTGTACCTGCAGATGAACAGCCTGCGGGCCGAAGATACCGCCGTCTACTATTGCGCCAGGGAGGATTGGGGCGGCGAGTTCACAGACTGGGGAAGGGGCACCCTGGTGACCGTGAGCAGCGCTTCCACCAAGGGCCCCTCCGTGTTCCCTCTGGCCCCCAGCAGCAAGAGCACATCCGGAGGCACCGCCGCCCTCGGATGTCTGGTGAAGGACTACTTCCCCGAGCCTGTCACCGTGTCCTGGAATAGCGGCGCCCTCACCTCCGGCGTGCACACCTTCCCCGCTGTCCTGCAGTCCTCCGGACTGTACAGCCTGTCCTCCGTCGTGACCGTGCCTAGCTCCTCCCTCGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCTTCCAACACAAAGGTGGACAAACGGGTGGAGCCCAAGTCCTGCGACAAAACCCACACCAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTAAACGGGGCAGAAAGAAACTCCTGTATATATTCAAACAACCATTTATGAGACCAGTACAAACTACTCAAGAGGAAGATGGCTGTAGCTGCCGATTTCCAGAAGAAGAAGAAGGAGGATGTGAACTGAGGGTAAAATTTAGCAGGTCTGCAGATGCGCCTGCGTATCAACAGGGTCAGAATCAGCTCTATAATGAGCTGAACCTCGGGCGGCGGGAAGAGTATGATGTTCTCGATAAAAGGAGAGGACGAGACCCCGAAATGGGCGGCAAACCGAGACGCAAAAATCCTCAGGAGGGGCTCTACAATGAACTTCAAAAAGACAAAATGGCCGAAGCATACTCAGAAATCGGAATGAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACAGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCCCTGCCCCCTCGCGGAAGCGGAGAGGGCAGAGGAAGTCTGCTAACATGCGGTGACGTCGAGGAGAATCCTGGACCTATGTCCGTCCCTACCCAGGTGCTGGGCCTGCTGCTGCTGTGGCTGACCGATGCTAGATGCCAGTCCGTTCTGACCCAGCCTCCTTCCGCCTCTGGCACATCCGGCCAGAGAGTGACCATCTCCTGCAGCGGCTCCAGCTCTAACATCGGCATCAATTTCGTGTACTGGTATCAGCACCTGCCAGGCACAGCTCCCAAGCTGCTGATCTACAAGAACAATCAGAGGCCTTCCGGCGTGCCAGACCGGTTCTCTGGCTCCAAGAGCGGCAACTCTGCCTCCCTGGCTATCTCCGGCCTGCGCAGCGAGGACGAGGCTGATTACTATTGCGCCGCTTGGGACGATAGCCTGTCTGGCTACGTGTTCGGCAGCGGCACAAAGGTGACCGTGCTGGGACAGCCAAAGGCTGCTCCTTCTGTGACACTGTTTCCCCCTTCCAGCGAGGAGCTGCAGGCCAATAAGGCCACCCTGGTGTGCCTGATCAGCGACTTCTATCCTGGAGCTGTGACCGTGGCTTGGAAGGCTGATTCTTCCCCAGTGAAGGCTGGCGTGGAGACAACAACCCCCAGCAAGCAGTCTAACAATAAGTACGCCGCTAGCTCTTATCTGTCTCTGACCCCAGAGCAGTGGAAGTCCCATAGGTCCTATAGCTGTCANGTCACCCACGAAGGGAGCACAGTCGAAAAAACCGTCGCACCAACCGAGTGTTCCTGATAAGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTAGTACCAGCTGAGAGACTCACTATCCAGTGACAAGTCTGTCTGCCTATTCACCGATTTTGATTCTCAAACAAATGTGTCACAAAGTAAGGATTCTGATGTGTATATCACAGACAAAACTGTGCTAGACATGAGGTCTATGGACTTCAAGAGCAACAGTGCTGTGGCCTGGAGCAACAAATCTGACTTTGCATGTGCAAACGCCTTCAACAACAGCATTATTCCAGAGGACACCTTCTTCCCCAGCCCAGGTAAGGGCAGCTTTGGTGCCTTCGCAGGCTGTTTCCTTGCTTCAGGAATGGCCAGGTTCTGCCCAGAGCTCTGGTCAATGATGTCTAAAACTCCTCTGATTGGTGGTCTCGGCCTTATCCATTGCCACCAAAACCCTCTTTTTACTAAGAAACAGTGAGCCTTGTTCTGGCAGTCCAGAGAATGACACGGGAAAAAAGCAGATGAAGAGAAGGTGGCAGGAGAGGGCACGTGGCCCAGCCTCAGTCTCTCCAACTGAGTTCCTGCCTGCCTGCCTTTGCTCAGACTGTTTGCCCCTTACTGCTCTTCTAGGCCTCATTCTAAGCCCCTTCTCCAAGTTGCCTCTCCTTATTTGTACCAGCTGAGAGACTCACTATCCAGTGACAAGTCTGTCTGCCTATTCACCGATTTTGATTCTCAAACAAATGTGTCACAAAGTAAGGATTCTGATGTGTATATCACAGACAAAACTGTGCTAGACATGAGGTCTATGGACTTCAAGAGCAACAGTGCTGTGGCCTGGAGCAACAAATCTGACTTTGCATGTGCAAACGCCTTCAACAACAGCATTATTCCAGAGGACACCTTCTTCCCCAGCCCAGGTAAGGGCAGCTTTGGTGCCTTCGCAGGCTGTTTCCTTGCTTCAGGAATGGCCAGGTTCTGCCCAGAGCTCTGGTCAATGATGTCTAAAACTCCTCTGATTGGTGGTCTCGGCCTTATCCATTGCCACCAAAACCCTCTTTTTACTAAGAAACAGTGAGCCTTGTTCTGGCAGTCCAGAGAATGACACGGGAAAAAAGCAGATGAAGAGAAGGTGGCAGGAGAGGGCACGTGGCCCAGCCTCAGTCTCTCCAACTGAGTTCCTGCCTGCCTGCCTTTGCTCAGACTGTTTGCCCCTTACTGCTCTTCTAGGCCTCATTCTAAGCCCCTTCTCCAAGTTGCCTCTCCTTATTT
서열번호 54
DNA
cas12a를 사용한 TRAC 엑손 1로의 삽입을 위한 공여자 DNA를 생성하기 위한 역배향 프라이머
mG*mC*mA*CTGTTGCTCTTGAAGTCC
서열번호 55
DNA
PCR 합성된 5’ 상동성 아암, 192 nts
ATCACGAGCAGCTGGTTTCTAAGATGCTATTTCCCGTATAAAGCATGAGACCGTGACTTGCCAGCCCCACAGAGCCCCGCCCTTGTCCATCACTGGCATCTGGACTCCAGCCTGGGTTGGGGCAAAGAGGGAAATGAGATCATGTCCTAACCCTGATCCTCTTGTCCCACAGATATCCAGAACCCTGACCCT
서열번호 56
DNA
PCR 합성된 3’ 상동성 아암, 159 nts
GTACCAGCTGAGAGACTCACTATCCAGTGACAAGTCTGTCTGCCTATTCACCGATTTTGATTCTCAAACAAATGTGTCACAAAGTAAGGATTCTGATGTGTATATCACAGACAAAACTGTGCTAGACATGAGGTCTATGGACTTCAAGAGCAACAGTGC
서열번호 57
DNA
인공
항-CD38 DAR 공여자 DNA, 30003 뉴클레오타이드
ATCACGAGCAGCTGGTTTCTAAGATGCTATTTCCCGTATAAAGCATGAGACCGTGACTTGCCAGCCCCACAGAGCCCCGCCCTTGTCCATCACTGGCATCTGGACTCCAGCCTGGGTTGGGGCAAAGAGGGAAATGAGATCATGTCCTAACCCTGATCCTCTTGTCCCACAGATATCCAGAACCCTGACCCTGAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAGTGGAGCTGGGTGTTTCTGTTCTTCCTCTCCGTCACAACCGGCGTGCATAGCCAGGTGCAGCTGGTGGAGTCCGGAGGCGGCCTGGTGAAACCTGGCGGATCCCTGAGGCTGTCCTGCGCCGCTAGCGGATTCACCTTCAGCGACGACTACATGAGCTGGATCAGGCAGGCTCCCGGAAAGGGCCTGGAGTGGGTCGCTAGCGTGAGCAATGGCCGGCCCACAACCTACTATGCCGACTCCGTGCGGGGCAGGTTTACCATCTCCAGGGATAACGCTAAGAACTCCCTGTACCTGCAGATGAACAGCCTGCGGGCCGAAGATACCGCCGTCTACTATTGCGCCAGGGAGGATTGGGGCGGCGAGTTCACAGACTGGGGAAGGGGCACCCTGGTGACCGTGAGCAGCGCTTCCACCAAGGGCCCCTCCGTGTTCCCTCTGGCCCCCAGCAGCAAGAGCACATCCGGAGGCACCGCCGCCCTCGGATGTCTGGTGAAGGACTACTTCCCCGAGCCTGTCACCGTGTCCTGGAATAGCGGCGCCCTCACCTCCGGCGTGCACACCTTCCCCGCTGTCCTGCAGTCCTCCGGACTGTACAGCCTGTCCTCCGTCGTGACCGTGCCTAGCTCCTCCCTCGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCTTCCAACACAAAGGTGGACAAACGGGTGGAGCCCAAGTCCTGCGACAAAACCCACACCAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTAAACGGGGCAGAAAGAAACTCCTGTATATATTCAAACAACCATTTATGAGACCAGTACAAACTACTCAAGAGGAAGATGGCTGTAGCTGCCGATTTCCAGAAGAAGAAGAAGGAGGATGTGAACTGAGGGTAAAATTTAGCAGGTCTGCAGATGCGCCTGCGTATCAACAGGGTCAGAATCAGCTCTATAATGAGCTGAACCTCGGGCGGCGGGAAGAGTATGATGTTCTCGATAAAAGGAGAGGACGAGACCCCGAAATGGGCGGCAAACCGAGACGCAAAAATCCTCAGGAGGGGCTCTACAATGAACTTCAAAAAGACAAAATGGCCGAAGCATACTCAGAAATCGGAATGAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACAGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCCCTGCCCCCTCGCGGAAGCGGAGAGGGCAGAGGAAGTCTGCTAACATGCGGTGACGTCGAGGAGAATCCTGGACCTATGTCCGTCCCTACCCAGGTGCTGGGCCTGCTGCTGCTGTGGCTGACCGATGCTAGATGCCAGTCCGTTCTGACCCAGCCTCCTTCCGCCTCTGGCACATCCGGCCAGAGAGTGACCATCTCCTGCAGCGGCTCCAGCTCTAACATCGGCATCAATTTCGTGTACTGGTATCAGCACCTGCCAGGCACAGCTCCCAAGCTGCTGATCTACAAGAACAATCAGAGGCCTTCCGGCGTGCCAGACCGGTTCTCTGGCTCCAAGAGCGGCAACTCTGCCTCCCTGGCTATCTCCGGCCTGCGCAGCGAGGACGAGGCTGATTACTATTGCGCCGCTTGGGACGATAGCCTGTCTGGCTACGTGTTCGGCAGCGGCACAAAGGTGACCGTGCTGGGACAGCCAAAGGCTGCTCCTTCTGTGACACTGTTTCCCCCTTCCAGCGAGGAGCTGCAGGCCAATAAGGCCACCCTGGTGTGCCTGATCAGCGACTTCTATCCTGGAGCTGTGACCGTGGCTTGGAAGGCTGATTCTTCCCCAGTGAAGGCTGGCGTGGAGACAACAACCCCCAGCAAGCAGTCTAACAATAAGTACGCCGCTAGCTCTTATCTGTCTCTGACCCCAGAGCAGTGGAAGTCCCATAGGTCCTATAGCTGTCANGTCACCCACGAAGGGAGCACAGTCGAAAAAACCGTCGCACCAACCGAGTGTTCCTGATAAGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTAGTACCAGCTGAGAGACTCACTATCCAGTGACAAGTCTGTCTGCCTATTCACCGATTTTGATTCTCAAACAAATGTGTCACAAAGTAAGGATTCTGATGTGTATATCACAGACAAAACTGTGCTAGACATGAGGTCTATGGACTTCAAGAGCAACAGTGC
서열번호 58
DNA
호모 사피엔스
5’HA 645bp, Tim3 유전자좌
GTTAGGAGAGCCTCCCTTTGTTGATGAACAAGCAAGTAGCCCAGATGGGCGGGCCGTTTCCTGGCTGACCATGACTAATTTTCTGATTGTCTGTTTCCATCAGCCCTGTTCTCCCGTGTTCACAGAATTGGGCCACAATTCTCTCCTAGGGCAGTGTTTCTGAAAGTGAGGTTCTGAGACCAGCCACTTCAGCAACACTTGAGAACTTGTTAGAAATAAAAGTTCTCAGGCTCTACCACAGGCCAACTGAGTCAGGAACTCTAGCAGTTGAGCCCAGCAATCTGTGTTTTCGCAAGGCTTCCCAGTGATTCTGATGGCCTTCACATCTGAGAAGCATTGTCACAGCGAATCATCCTCCAAACAGGACTGCAGCAGTAGCTTCCTCTTTATTCTGTAAGACATGGCTTGCAGTTTTCCTGAAATGGAGTAACCTCACTCACCGCTTGAGTCTTGGCTCTCCTTCTCTCTCTATGCAGGGTCCTCAGAAGTGGAATACAGAGCGGAGGTCGGTCAGAATGCCTATCTGCCCTGCTTCTACACCCCAGCCGCCCCAGGGAACCTCGTGCCCGTCTGCTGGGGCAAAGGAGCCTGTCCTGTGTTTGAATGTGGCAACGTGGTGCTCAGGACTGATGAAAGGGATGTGAA
서열번호 59
DNA
호모 사피엔스
3’HA 600bp, Tim3 유전자좌
GGACATCCAGATACTGGCTTCTTGGGGATTTCCGCAAAGGAGATGTGTCCCTGACCATAGAGAATGTGACTCTAGCAGACAGTGGGATCTACTGCTGCCGGATCCAAATCCCAGGCATAATGAATGATGAAAAATTTAACCTGAAGTTGGTCATCAAACCAGGTGAGTGGACATTTGCATGCCATCTTTATGAATAAGATTTATCTGTGGATCATATTAAAGGTACTGATTGTTCTCATCTCTGACTTCCCTAATTATAGCCCTGGAGGAGGGCCACTAAGACCTAAAGTTTAACAGGCCCCATTGGTGATGCTCAGTGATATTTAACACCTTCTCTCTGTTTTAAAACTCATGGGTGTGCCTGGGCGTGGTGGCTCACACCTCTAATCCCAGCACTTTGGGAGGCTGAGGCCGGTGGATCATGAGGTCAGGAATTCGAGACCAGCCTGGCCAACATAGTAAAACCTTGTCTCCACTAAAAATACAAAAAATTAGCCAGGCATGGTTACGGGAGCCTGTAATTCTAGCTACTTGGGGGGCTGAAGCAGGAGAATCACTTGAACCTGGGAGTCGGAGGTTGTGGTAAGCCAAGATCTCGCC
서열번호 60
DNA
호모 사피엔스
TIM-3 cas12a 표적 부위
GCCAGTATCTGGATGTCCAAT
서열번호 61
DNA
호모 사피엔스
공여자 DNA를 제조하기 위한 TIM3 정배향 프라이머
5’-p-TGGAATACAGAGCGGAGGTC
서열번호 62
DNA
호모 사피엔스
공여자 DNA를 제조하기 위한 TIM3 역배향 프라이머
mG*mC*mA*TGCAAATGTCCACTCAC
서열번호 63
DNA
인공
TIM3 공여자 DNA
TGGAATACAGAGCGGAGGTCGGTCAGAATGCCTATCTGCCCTGCTTCTACACCCCAGCCGCCCCAGGGAACCTCGTGCCCGTCTGCTGGGGCAAAGGAGCCTGTCCTGTGTTTGAATGTGGCAACGTGGTGCTCAGGACTGATGAAAGGGATGTGAAGAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAGTGGAGCTGGGTGTTTCTGTTCTTCCTCTCCGTCACAACCGGCGTGCATAGCCAGGTGCAGCTGGTGGAGTCCGGAGGCGGCCTGGTGAAACCTGGCGGATCCCTGAGGCTGTCCTGCGCCGCTAGCGGATTCACCTTCAGCGACGACTACATGAGCTGGATCAGGCAGGCTCCCGGAAAGGGCCTGGAGTGGGTCGCTAGCGTGAGCAATGGCCGGCCCACAACCTACTATGCCGACTCCGTGCGGGGCAGGTTTACCATCTCCAGGGATAACGCTAAGAACTCCCTGTACCTGCAGATGAACAGCCTGCGGGCCGAAGATACCGCCGTCTACTATTGCGCCAGGGAGGATTGGGGCGGCGAGTTCACAGACTGGGGAAGGGGCACCCTGGTGACCGTGAGCAGCGCTTCCACCAAGGGCCCCTCCGTGTTCCCTCTGGCCCCCAGCAGCAAGAGCACATCCGGAGGCACCGCCGCCCTCGGATGTCTGGTGAAGGACTACTTCCCCGAGCCTGTCACCGTGTCCTGGAATAGCGGCGCCCTCACCTCCGGCGTGCACACCTTCCCCGCTGTCCTGCAGTCCTCCGGACTGTACAGCCTGTCCTCCGTCGTGACCGTGCCTAGCTCCTCCCTCGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCTTCCAACACAAAGGTGGACAAACGGGTGGAGCCCAAGTCCTGCGACAAAACCCACACCAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTAAACGGGGCAGAAAGAAACTCCTGTATATATTCAAACAACCATTTATGAGACCAGTACAAACTACTCAAGAGGAAGATGGCTGTAGCTGCCGATTTCCAGAAGAAGAAGAAGGAGGATGTGAACTGAGGGTAAAATTTAGCAGGTCTGCAGATGCGCCTGCGTATCAACAGGGTCAGAATCAGCTCTATAATGAGCTGAACCTCGGGCGGCGGGAAGAGTATGATGTTCTCGATAAAAGGAGAGGACGAGACCCCGAAATGGGCGGCAAACCGAGACGCAAAAATCCTCAGGAGGGGCTCTACAATGAACTTCAAAAAGACAAAATGGCCGAAGCATACTCAGAAATCGGAATGAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACAGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCCCTGCCCCCTCGCGGAAGCGGAGAGGGCAGAGGAAGTCTGCTAACATGCGGTGACGTCGAGGAGAATCCTGGACCTATGTCCGTCCCTACCCAGGTGCTGGGCCTGCTGCTGCTGTGGCTGACCGATGCTAGATGCCAGTCCGTTCTGACCCAGCCTCCTTCCGCCTCTGGCACATCCGGCCAGAGAGTGACCATCTCCTGCAGCGGCTCCAGCTCTAACATCGGCATCAATTTCGTGTACTGGTATCAGCACCTGCCAGGCACAGCTCCCAAGCTGCTGATCTACAAGAACAATCAGAGGCCTTCCGGCGTGCCAGACCGGTTCTCTGGCTCCAAGAGCGGCAACTCTGCCTCCCTGGCTATCTCCGGCCTGCGCAGCGAGGACGAGGCTGATTACTATTGCGCCGCTTGGGACGATAGCCTGTCTGGCTACGTGTTCGGCAGCGGCACAAAGGTGACCGTGCTGGGACAGCCAAAGGCTGCTCCTTCTGTGACACTGTTTCCCCCTTCCAGCGAGGAGCTGCAGGCCAATAAGGCCACCCTGGTGTGCCTGATCAGCGACTTCTATCCTGGAGCTGTGACCGTGGCTTGGAAGGCTGATTCTTCCCCAGTGAAGGCTGGCGTGGAGACAACAACCCCCAGCAAGCAGTCTAACAATAAGTACGCCGCTAGCTCTTATCTGTCTCTGACCCCAGAGCAGTGGAAGTCCCATAGGTCCTATAGCTGTCANGTCACCCACGAAGGGAGCACAGTCGAAAAAACCGTCGCACCAACCGAGTGTTCCTGATAAGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTAGGACATCCAGATACTGGCTTCTTGGGGATTTCCGCAAAGGAGATGTGTCCCTGACCATAGAGAATGTGACTCTAGCAGACAGTGGGATCTACTGCTGCCGGATCCAAATCCCAGGCATAATGAATGATGAAAAATTTAACCTGAAGTTGGTCATCAAACCAGGTGAGTGGACATTTGCATGC
서열번호 64
DNA
TRAC 엑손 3 유전자좌에서 항-CD38 CAR의 5’ 상동성 아암에 걸친 서열분석을 위한 정배향 프라이머
CTCCTGAATCCCTCTCACCA
서열번호 65
DNA
TRAC 엑손 3 유전자좌에서 항-CD38 CAR의 5’ 상동성 아암에 걸친 서열분석을 위한 역배향 프라이머
GCGGATCCAGCTCATGTAGT
서열번호 66
DNA
TRAC 엑손 3 유전자좌에서 항-CD38 CAR의 3’ 상동성 아암에 걸친 서열분석을 위한 정배향 프라이머
CGTTCTGGGTACTCGTGGTT
서열번호 67
DNA
TRAC 엑손 3 유전자좌에서 항-CD38 CAR의 3’ 상동성 아암에 걸친 서열분석을 위한 역배향 프라이머
GGAGCACAGGCTGTCTTACA
서열번호 68
DNA
PD-1 유전자좌에서 항-CD38 CAR의 5’ 상동성 아암에 걸친 서열분석을 위한 정배향 프라이머
GTGTGAGGCCATCCACAAG
서열번호 69
DNA
PD-1 유전자좌에서 항-CD38 CAR의 5’ 상동성 아암에 걸친 서열분석을 위한 역배향 프라이머
ACACACTTGCGACCCATTC
서열번호 70
DNA
PD-1 유전자좌에서 항-CD38 CAR의 3’ 상동성 아암에 걸친 서열분석을 위한 정배향 프라이머
CGTTCTGGGTACTCGTGGTT
서열번호 71
DNA
PD-1 유전자좌에서 항-CD38 CAR의 3’ 상동성 아암에 걸친 서열분석을 위한 역배향 프라이머
GGGACTGTCTTAGGCTTGG
서열번호 72
DNA
TRAC 엑손 1 유전자좌에서 항-CD38 DAR의 5’ 상동성 아암에 걸친 서열분석을 위한 정배향 프라이머
CCTGCTTTCTGAGGGTGAAG
서열번호 73
DNA
TRAC 엑손 1 유전자좌에서 항-CD38 DAR의 5’ 상동성 아암에 걸친 서열분석을 위한 역배향 프라이머
CAGCTCATGTAGTCGTCGCT
서열번호 74
DNA
TRAC 엑손 1 유전자좌에서 항-CD38 DAR의 3’ 상동성 아암에 걸친 서열분석을 위한 정배향 프라이머
GGAATGAAAGGGGAGAGGAG
서열번호 75
DNA
TRAC 엑손 1 유전자좌에서 항-CD38 DAR의 3’ 상동성 아암에 걸친 서열분석을 위한 역배향 프라이머
GAGAGCCCTTCCCTGACTTT
서열번호 76
DNA
Cas12a 표적 부위에서 TRAC 엑손 1 유전자좌에서 항-CD38 DAR의 5’ 상동성 아암에 걸친 서열분석을 위한 정배향 프라이머
CCTGCTTTCTGAGGGTGAAG
서열번호 77
DNA
Cas12a 표적 부위에서 TRAC 엑손 1 유전자좌에서 항-CD38 DAR의 5’ 상동성 아암에 걸친 서열분석을 위한 역배향 프라이머
CAGCTCATGTAGTCGTCGCT
서열번호 78
DNA
Cas12a 표적 부위에서 TRAC 엑손 1 유전자좌에서 항-CD38 DAR의 3’ 상동성 아암에 걸친 서열분석을 위한 정배향 프라이머
GGAATGAAAGGGGAGAGGAG
서열번호 79
DNA
TRAC 엑손 1 유전자좌에서 항-CD38 DAR의 3’ 상동성 아암에 걸친 서열분석을 위한 역배향 프라이머
GAGAGCCCTTCCCTGACTTT
서열번호 80
DNA
GM-CSF
cas12a 표적 부위
TACAGAATGAAACAGTAGAAG
서열번호 81
DNA
항-CD20 DAR 작제물
GAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAGTGGAGCTGGGTGTTTCTGTTCTTCCTCTCCGTCACAACCGGCGTGCATAGCCAAGTGCAATTGCAGCAGCCCGGTGCCGAACTCGTGAAACCAGGAGCAAGCGTAAAGATGTCCTGTAAGGCATCAGGTTATACCTTTACCAGCTACAACATGCACTGGGTGAAACAAACGCCGGGGCGGGGCCTCGAATGGATAGGCGCGATATATCCCGGAAATGGCGATACCAGTTACAATCAGAAGTTCAAAGGCAAAGCGACACTGACAGCTGATAAGTCTTCAAGCACCGCCTATATGCAACTTTCTAGCCTGACCAGCGAAGACTCCGCCGTTTATTACTGTGCTCGGTCCACATACTACGGAGGCGATTGGTACTTTAATGTGTGGGGTGCGGGCACCACTGTCACTGTATCAGCGGCTTCCACCAAGGGCCCCTCCGTGTTCCCTCTGGCCCCCAGCAGCAAGAGCACATCCGGAGGCACCGCCGCCCTCGGATGTCTGGTGAAGGACTACTTCCCCGAGCCTGTCACCGTGTCCTGGAATAGCGGCGCCCTCACCTCCGGCGTGCACACCTTCCCCGCTGTCCTGCAGTCCTCCGGACTGTACAGCCTGTCCTCCGTCGTGACCGTGCCTAGCTCCTCCCTCGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCTTCCAACACAAAGGTGGACAAACGGGTGGAGCCCAAGTCCTGCGACAAAACCCACACCCCCAGAAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTAAACGGGGCAGAAAGAAACTCCTGTATATATTCAAACAACCATTTATGAGACCAGTACAAACTACTCAAGAGGAAGATGGCTGTAGCTGCCGATTTCCAGAAGAAGAAGAAGGAGGATGTGAACTGAGGGTAAAATTTAGCAGGTCTGCAGATAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACAGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCCCTGCCCCCTCGCGGAAGCGGAGAGGGCAGAGGAAGTCTGCTAACATGCGGTGACGTCGAGGAGAATCCTGGACCTATGTCCGTCCCTACCCAGGTGCTGGGCCTGCTGCTGCTGTGGCTGACCGATGCTAGATGCCAGATAGTCCTGAGCCAATCACCGGCCATCTTGTCTGCCTCTCCTGGCGAAAAGGTGACGATGACTTGCAGAGCCAGTAGCTCTGTAAGCTATATACACTGGTTCCAGCAAAAACCGGGCTCTTCTCCGAAGCCGTGGATATACGCAACTTCAAACCTGGCGTCTGGGGTTCCTGTAAGGTTTAGCGGCAGCGGTTCAGGCACGAGCTACAGCCTTACTATCTCCCGGGTTGAGGCTGAAGATGCAGCCACATACTACTGTCAGCAGTGGACTTCAAATCCACCTACATTCGGGGGAGGCACGAAGCTGGAGATTAAACGAACCGTTGCGGCGCCTAGTGTGTTCATATTCCCGCCGTCTGATGAACAACTCAAGTCTGGAACGGCAAGTGTGGTGTGTCTCCTGAATAATTTTTATCCTAGGGAAGCAAAGGTGCAGTGGAAAGTCGATAACGCATTGCAAAGCGGTAACAGTCAAGAATCTGTAACTGAACAAGATTCTAAAGATTCTACCTACAGTCTCTCCTCCACATTGACCCTGTCAAAAGCAGATTATGAGAAGCACAAGGTGTACGCATGTGAGGTAACACATCAAGGACTCAGCAGCCCAGTTACAAAAAGTTTCAATCGCGGGGAATGTTGATAAGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTA
서열번호 82
DNA
공여자 DNA를 생성하기 위한 정배향 프라이머는 5’포스페이트를 포함한다
5’-p-ATCACGAGCAGCTGGTTTCT-3’
서열번호 83
DNA
5’상동성 아암, 항-CD20 DAR 작제물 및 3’상동성 아암을 포함하는 항-CD20 DAR 공여자 DNA
ATCACGAGCAGCTGGTTTCTAAGATGCTATTTCCCGTATAAAGCATGAGACCGTGACTTGCCAGCCCCACAGAGCCCCGCCCTTGTCCATCACTGGCATCTGGACTCCAGCCTGGGTTGGGGCAAAGAGGGAAATGAGATCATGTCCTAACCCTGATCCTCTTGTCCCACAGATATCCAGAACCCTGACCCTGAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGAGTGGAGCTGGGTGTTTCTGTTCTTCCTCTCCGTCACAACCGGCGTGCATAGCCAAGTGCAATTGCAGCAGCCCGGTGCCGAACTCGTGAAACCAGGAGCAAGCGTAAAGATGTCCTGTAAGGCATCAGGTTATACCTTTACCAGCTACAACATGCACTGGGTGAAACAAACGCCGGGGCGGGGCCTCGAATGGATAGGCGCGATATATCCCGGAAATGGCGATACCAGTTACAATCAGAAGTTCAAAGGCAAAGCGACACTGACAGCTGATAAGTCTTCAAGCACCGCCTATATGCAACTTTCTAGCCTGACCAGCGAAGACTCCGCCGTTTATTACTGTGCTCGGTCCACATACTACGGAGGCGATTGGTACTTTAATGTGTGGGGTGCGGGCACCACTGTCACTGTATCAGCGGCTTCCACCAAGGGCCCCTCCGTGTTCCCTCTGGCCCCCAGCAGCAAGAGCACATCCGGAGGCACCGCCGCCCTCGGATGTCTGGTGAAGGACTACTTCCCCGAGCCTGTCACCGTGTCCTGGAATAGCGGCGCCCTCACCTCCGGCGTGCACACCTTCCCCGCTGTCCTGCAGTCCTCCGGACTGTACAGCCTGTCCTCCGTCGTGACCGTGCCTAGCTCCTCCCTCGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCTTCCAACACAAAGGTGGACAAACGGGTGGAGCCCAAGTCCTGCGACAAAACCCACACCCCCAGAAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTAAACGGGGCAGAAAGAAACTCCTGTATATATTCAAACAACCATTTATGAGACCAGTACAAACTACTCAAGAGGAAGATGGCTGTAGCTGCCGATTTCCAGAAGAAGAAGAAGGAGGATGTGAACTGAGGGTAAAATTTAGCAGGTCTGCAGATAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACAGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCCCTGCCCCCTCGCGGAAGCGGAGAGGGCAGAGGAAGTCTGCTAACATGCGGTGACGTCGAGGAGAATCCTGGACCTATGTCCGTCCCTACCCAGGTGCTGGGCCTGCTGCTGCTGTGGCTGACCGATGCTAGATGCCAGATAGTCCTGAGCCAATCACCGGCCATCTTGTCTGCCTCTCCTGGCGAAAAGGTGACGATGACTTGCAGAGCCAGTAGCTCTGTAAGCTATATACACTGGTTCCAGCAAAAACCGGGCTCTTCTCCGAAGCCGTGGATATACGCAACTTCAAACCTGGCGTCTGGGGTTCCTGTAAGGTTTAGCGGCAGCGGTTCAGGCACGAGCTACAGCCTTACTATCTCCCGGGTTGAGGCTGAAGATGCAGCCACATACTACTGTCAGCAGTGGACTTCAAATCCACCTACATTCGGGGGAGGCACGAAGCTGGAGATTAAACGAACCGTTGCGGCGCCTAGTGTGTTCATATTCCCGCCGTCTGATGAACAACTCAAGTCTGGAACGGCAAGTGTGGTGTGTCTCCTGAATAATTTTTATCCTAGGGAAGCAAAGGTGCAGTGGAAAGTCGATAACGCATTGCAAAGCGGTAACAGTCAAGAATCTGTAACTGAACAAGATTCTAAAGATTCTACCTACAGTCTCTCCTCCACATTGACCCTGTCAAAAGCAGATTATGAGAAGCACAAGGTGTACGCATGTGAGGTAACACATCAAGGACTCAGCAGCCCAGTTACAAAAAGTTTCAATCGCGGGGAATGTTGATAAGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTAGTACCAGCTGAGAGACTCACTATCCAGTGACAAGTCTGTCTGCCTATTCACCGATTTTGATTCTCAAACAAATGTGTCACAAAGTAAGGATTCTGATGTGTATATCACAGACAAAACTGTGCTAGACATGAGGTCTATGGACTTCAAGAGCAACAGTGC
서열번호 84
DNA
항-CEA CAR 작제물
GAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGGATGGAGCTGTATCATCCTCTTCTTGGTAGCAACAGCTACAGGTGTCCACTCCGACATCCAGCTGACCCAGAGCCCAAGCAGCCTGAGCGCCAGCGTGGGTGACAGAGTGACCATCACCTGTAAGGCCAGTCAGGATGTGGGTACTTCTGTAGCTTGGTACCAGCAGAAGCCAGGTAAGGCTCCAAAGCTGCTGATCTACTGGACATCCACCCGGCACACTGGTGTGCCAAGCAGATTCAGCGGTAGCGGTAGCGGTACCGACTTCACCTTCACCATCAGCAGCCTCCAGCCAGAGGACATCGCCACCTACTACTGCCAGCAATATAGCCTCTATCGGTCGTTCGGCCAAGGGACCAAGGTGGAAATCAAACGAGGTGGCTCAGGATCGGGTGGATCCGGCTCTGGTGGCTCAGGATCGGAGGTCCAACTGGTGGAGAGCGGTGGAGGTGTTGTGCAACCTGGCCGGTCCCTGCGCCTGTCCTGCTCCGCATCTGGCTTCGATTTCACCACATATTGGATGAGTTGGGTGAGACAGGCACCTGGAAAAGGTCTTGAGTGGATTGGAGAAATTCATCCAGATAGCAGTACGATTAACTATGCGCCGTCTCTAAAGGATAGATTTACAATATCGCGAGACAACGCCAAGAACACATTGTTCCTGCAAATGGACAGCCTGAGACCCGAAGACACCGGGGTCTATTTTTGTGCAAGCCTTTACTTCGGCTTCCCCTGGTTTGCTTATTGGGGCCAAGGGACCCCGGTCACCGTCTCCAGTGCTAAGCCGACCACGACACCGGCTCCAAGACCTCCGACGCCAGCTCCAACGATAGCGTCACAGCCATTGTCTCTCCGCCCTGAAGCCTGCCGGCCCGCTGCGGGCGGCGCGGTTCATACCCGGGGATTGGACTTTGCCCCCAGAAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTCGATCTAAGCGAAGCCGCTTGTTGCATTCTGACTACATGAATATGACGCCAAGACGGCCAGGGCCAACAAGAAAGCATTACCAACCGTACGCCCCCCCGCGAGACTTCGCGGCCTACCGCAGCAGGGTAAAATTTAGCAGGTCTGCAGATGCGCCTGCGTATCAACAGGGTCAGAATCAGCTCTATAATGAGCTGAACCTCGGGCGGCGGGAAGAGTATGATGTTCTCGATAAAAGGAGAGGACGAGACCCCGAAATGGGCGGCAAACCGAGACGCAAAAATCCTCAGGAGGGGCTCTACAATGAACTTCAAAAAGACAAAATGGCCGAAGCATACTCAGAAATCGGAATGAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACAGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCGCTGCCGCCTAGATGATAAAATTGTTGTTGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTA
서열번호 85
DNA
5’ 상동성 아암, 항-CD20 DAR 작제물 및 3’ 상동성 아암을 포함하는 항-CD20 DAR 공여자 DNA
ATCACGAGCAGCTGGTTTCTAAGATGCTATTTCCCGTATAAAGCATGAGACCGTGACTTGCCAGCCCCACAGAGCCCCGCCCTTGTCCATCACTGGCATCTGGACTCCAGCCTGGGTTGGGGCAAAGAGGGAAATGAGATCATGTCCTAACCCTGATCCTCTTGTCCCACAGATATCCAGAACCCTGACCCTGAATTCGGGCGGAGTTAGGGCGGAGCCAATCAGCGTGCGCCGTTCCGAAAGTTGCCTTTTATGGCTGGGCGGAGAATGGGCGGTGAACGCCGATGATTATATAAGGACGCGCCGGGTGTGGCACAGCTAGTTCCGTCGCAGCCGGGATTTGGGTCGCGGTTCTTGTTTGTGGATCCCTGTGATCGTCACTTGACAGTAAGTCACTGACTGTCTATGCCTGGGAAAGGGTGGGCAGGAGATGGGGCAGTGCAGGAAAAGTGGCACTATGAACCCTGCAGCCCTAGGAATGCATCTAGACAATTGTACTAACCTTCTTCTCTTTCCTCTCCTGACAGGCCTCGAGGCCGCCACCATGGGATGGAGCTGTATCATCCTCTTCTTGGTAGCAACAGCTACAGGTGTCCACTCCGACATCCAGCTGACCCAGAGCCCAAGCAGCCTGAGCGCCAGCGTGGGTGACAGAGTGACCATCACCTGTAAGGCCAGTCAGGATGTGGGTACTTCTGTAGCTTGGTACCAGCAGAAGCCAGGTAAGGCTCCAAAGCTGCTGATCTACTGGACATCCACCCGGCACACTGGTGTGCCAAGCAGATTCAGCGGTAGCGGTAGCGGTACCGACTTCACCTTCACCATCAGCAGCCTCCAGCCAGAGGACATCGCCACCTACTACTGCCAGCAATATAGCCTCTATCGGTCGTTCGGCCAAGGGACCAAGGTGGAAATCAAACGAGGTGGCTCAGGATCGGGTGGATCCGGCTCTGGTGGCTCAGGATCGGAGGTCCAACTGGTGGAGAGCGGTGGAGGTGTTGTGCAACCTGGCCGGTCCCTGCGCCTGTCCTGCTCCGCATCTGGCTTCGATTTCACCACATATTGGATGAGTTGGGTGAGACAGGCACCTGGAAAAGGTCTTGAGTGGATTGGAGAAATTCATCCAGATAGCAGTACGATTAACTATGCGCCGTCTCTAAAGGATAGATTTACAATATCGCGAGACAACGCCAAGAACACATTGTTCCTGCAAATGGACAGCCTGAGACCCGAAGACACCGGGGTCTATTTTTGTGCAAGCCTTTACTTCGGCTTCCCCTGGTTTGCTTATTGGGGCCAAGGGACCCCGGTCACCGTCTCCAGTGCTAAGCCGACCACGACACCGGCTCCAAGACCTCCGACGCCAGCTCCAACGATAGCGTCACAGCCATTGTCTCTCCGCCCTGAAGCCTGCCGGCCCGCTGCGGGCGGCGCGGTTCATACCCGGGGATTGGACTTTGCCCCCAGAAAGATAGAGGTGATGTACCCTCCCCCCTACTTGGACAACGAAAAGTCTAATGGCACTATCATTCACGTAAAGGGCAAACACCTTTGTCCAAGTCCTTTGTTCCCAGGCCCATCTAAGCCGTTCTGGGTACTCGTGGTTGTGGGGGGCGTGCTCGCTTGTTACTCACTGCTGGTGACGGTGGCCTTTATTATTTTCTGGGTTCGATCTAAGCGAAGCCGCTTGTTGCATTCTGACTACATGAATATGACGCCAAGACGGCCAGGGCCAACAAGAAAGCATTACCAACCGTACGCCCCCCCGCGAGACTTCGCGGCCTACCGCAGCAGGGTAAAATTTAGCAGGTCTGCAGATGCGCCTGCGTATCAACAGGGTCAGAATCAGCTCTATAATGAGCTGAACCTCGGGCGGCGGGAAGAGTATGATGTTCTCGATAAAAGGAGAGGACGAGACCCCGAAATGGGCGGCAAACCGAGACGCAAAAATCCTCAGGAGGGGCTCTACAATGAACTTCAAAAAGACAAAATGGCCGAAGCATACTCAGAAATCGGAATGAAAGGGGAGAGGAGACGCGGGAAGGGCCATGATGGACTGTATCAGGGACTTTCCACAGCCACCAAGGACACCTATGACGCTCTCCACATGCAGGCGCTGCCGCCTAGATGATAAAATTGTTGTTGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTCATCAATGTATCTTAGTACCAGCTGAGAGACTCACTATCCAGTGACAAGTCTGTCTGCCTATTCACCGATTTTGATTCTCAAACAAATGTGTCACAAAGTAAGGATTCTGATGTGTATATCACAGACAAAACTGTGCTAGACATGAGGTCTATGGACTTCAAGAGCAACAGTGC
서열번호 86
DNA
CD7 유전자좌 Cas12a 표적 부위
CTACGAGGACGGGGTGGTGCC
서열번호 87
DNA
CD7 유전자좌 Cas12a 대안적 표적 부위
CTTCTCAGAGGAACAGTCCCA
서열번호 88
DNA
CD7 유전자좌로의 삽입을 위한 공여자 단편을 생성하는 정배향 프라이머
mC*T*mG* mCAG GGA GGA CAT TCT CT
서열번호 89
DNA
CD7 유전자좌로의 삽입을 위한 공여자 단편을 생성하는 역배향 프라이머
5’-p-TTCCCTA CTGTCACCAGGA
서열번호 90
DNA
CD7 유전자좌 삽입을 위한 5’상동성 아암
CTGCAGGGAGGACATTCTCTGTCCTTCTGGCCAGACTGATGGTGACAGCCCAGGTCCTCCCCAGAGGTGCAGCAGTCTCCCCACTGCACGACTGTCCCCGTGGGAGCCTCCGTCAACATCACCTGCTCCACCAGCGGGGGCCTGCGTGGGATCTACCTGAGGCAGCTCGGGCCACAGCCCCAAGACATCATAGTCTACGAGGACGGGGTGGT
서열번호 91
DNA
CD7 유전자좌 삽입을 위한 3’ 상동성 아암
CTACGGACAGACGGTTCCGGGGCCGCATCGACTTCTCAGGGTCCCAGGACAACCTGACTATCACCATGCACCGCCTGCAGCTGTCGGACACTGGCACCTACACCTGCCAGGCCATCACGGAGGTCAATGTCTACGGCTCCGGCACCCTGGTCCTGGTGACAGGTAGGGAA
SEQUENCE LISTING
<110> SORRENTO THERAPEUTICS, INC.
<120> IMPROVED PROCESS FOR INTEGRATION OF DNA CONSTRUCTS USING
RNA-GUIDED ENDONUCLEASES
<130> 087735.0131
<140> PCT/US2020/022056
<141> 2020-03-11
<150> US 62/816,836
<151> 2019-03-11
<150> US 62/901,735
<151> 2019-09-17
<160> 91
<170> PatentIn version 3.5
<210> 1
<211> 19
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(19)
<223> Target sequence in TRAC gene (exon 1)
<400> 1
cagggttctg gatatctgt 19
<210> 2
<211> 2119
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: anti-CD38 CAR Construct for insertion into TRAC locus
<220>
<221> misc_feature
<223> includes the JeT promoter followed by a DNA sequence encoding
CD8a leader peptide followed by anti-CD38 CAR (single chain
variable fragment (scFv) specific for human CD38)
<220>
<221> misc_feature
<223> followed by CD28 hinge-transmembrane-intracellular regions and
CD3 zeta intracellular domain
<400> 2
gaattcgggc ggagttaggg cggagccaat cagcgtgcgc cgttccgaaa gttgcctttt 60
atggctgggc ggagaatggg cggtgaacgc cgatgattat ataaggacgc gccgggtgtg 120
gcacagctag ttccgtcgca gccgggattt gggtcgcggt tcttgtttgt ggatccctgt 180
gatcgtcact tgacagtaag tcactgactg tctatgcctg ggaaagggtg ggcaggagat 240
ggggcagtgc aggaaaagtg gcactatgaa ccctgcagcc ctaggaatgc atctagacaa 300
ttgtactaac cttcttctct ttcctctcct gacaggcctc gaggccgcca ccatggaatg 360
gtcatgggtc tttctctttt ttctcagcgt gaccaccgga gtccactccc aggtagagca 420
gaaattgatc tctgaggaag acctgcaggt ccagttggtc gaaagtggcg gcggattggt 480
gaaaccaggc ggatctttga ggcttagttg cgcggcttcc ggatttacgt tcagtgatga 540
ctacatgagc tggataaggc aagcacctgg taagggcctg gaatgggtcg caagtgtgtc 600
taatggaagg cccactacct actatgctga ttccgtccgc ggacgcttta ctatttcaag 660
agataatgct aagaatagtc tgtacctgca gatgaacagt ctgcgcgcgg aagataccgc 720
agtatattac tgtgcacgag aggattgggg tggggagttc acggattggg gcaggggaac 780
tcttgtaacg gtgtctagcg gaggaggtgg gtcaggtgga ggtggcagtg gaggtggagg 840
ctctcaggcc ggcttgaccc aaccgccatc tgcgtcagga acatcaggcc agagggtgac 900
tatcagttgt tctggcagtt catccaatat tgggatcaat ttcgtgtact ggtatcagca 960
cctgccaggt accgcgccga agctgctgat ctataagaat aatcaacgcc catcaggcgt 1020
tccagatagg ttcagtggga gcaagtccgg aaactccgcg tcactcgcga tctcaggtct 1080
gcggtctgag gatgaagctg attattactg cgcggcgtgg gatgattctc tgtcaggcta 1140
cgtattcggt tcagggacta aggtaactgt gttggcgaaa ccgaccacga caccggctcc 1200
aagacctccg acgccagctc caacgatagc gtcacagcca ttgtctctcc gccctgaagc 1260
ctgccggccc gctgcgggcg gcgcggttca tacccgggga ttggactttg cccccagaaa 1320
gatagaggtg atgtaccctc ccccctactt ggacaacgaa aagtctaatg gcactatcat 1380
tcacgtaaag ggcaaacacc tttgtccaag tcctttgttc ccaggcccat ctaagccgtt 1440
ctgggtactc gtggttgtgg ggggcgtgct cgcttgttac tcactgctgg tgacggtggc 1500
ctttattatt ttctgggttc gatctaagcg aagccgcttg ttgcattctg actacatgaa 1560
tatgacgcca agacggccag ggccaacaag aaagcattac caaccgtacg cccccccgcg 1620
agacttcgcg gcctaccgca gcagggtaaa atttagcagg tctgcagatg cgcctgcgta 1680
tcaacagggt cagaatcagc tctataatga gctgaacctc gggcggcggg aagagtatga 1740
tgttctcgat aaaaggagag gacgagaccc cgaaatgggc ggcaaaccga gacgcaaaaa 1800
tcctcaggag gggctctaca atgaacttca aaaagacaaa atggccgaag catactcaga 1860
aatcggaatg aaaggggaga ggagacgcgg gaagggccat gatggactgt atcagggact 1920
ttccacggcc accaaggaca cctatgacgc tctccacatg caggcgctgc cgcctagatg 1980
ataaaattgt tgttgttaac ttgtttattg cagcttataa tggttacaaa taaagcaata 2040
gcatcacaaa tttcacaaat aaagcatttt tttcactgca ttctagttgt ggtttgtcca 2100
aactcatcaa tgtatctta 2119
<210> 3
<211> 195
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Jet promoter
<400> 3
gaattcgggc ggagttaggg cggagccaat cagcgtgcgc cgttccgaaa gttgcctttt 60
atggctgggc ggagaatggg cggtgaacgc cgatgattat ataaggacgc gccgggtgtg 120
gcacagctag ttccgtcgca gccgggattt gggtcgcggt tcttgtttgt ggatccctgt 180
gatcgtcact tgaca 195
<210> 4
<211> 3429
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: anti-CD38A2 CAR cassette with homology arms
<400> 4
ggcaccatat tcattttgca ggtgaaattc ctgagatgta aggagctgct gtgacttgct 60
caaggcctta tatcgagtaa acggtagtgc tggggcttag acgcaggtgt tctgatttat 120
agttcaaaac ctctatcaat gagagagcaa tctcctggta atgtgataga tttcccaact 180
taatgccaac ataccataaa cctcccattc tgctaatgcc cagcctaagt tggggagacc 240
actccagatt ccaagatgta cagtttgctt tgctgggcct ttttcccatg cctgccttta 300
ctctgccaga gttatattgc tggggttttg aagaagatcc tattaaataa aagaataagc 360
agtattatta agtagccctg catttcaggt ttccttgagt ggcaggccag gcctggccgt 420
gaacgttcac tgaaatcatg gcctcttggc caagattgat agcttgtgcc tgtccctgag 480
tcccagtcca tcacgagcag ctggtttcta agatgctatt tcccgtataa agcatgagac 540
cgtgacttgc cagccccaca gagccccgcc cttgtccatc actggcatct ggactccagc 600
ctgggttggg gcaaagaggg aaatgagatc atgtcctaac cctgatcctc ttgtcccaca 660
gaattcgggc ggagttaggg cggagccaat cagcgtgcgc cgttccgaaa gttgcctttt 720
atggctgggc ggagaatggg cggtgaacgc cgatgattat ataaggacgc gccgggtgtg 780
gcacagctag ttccgtcgca gccgggattt gggtcgcggt tcttgtttgt ggatccctgt 840
gatcgtcact tgacagtaag tcactgactg tctatgcctg ggaaagggtg ggcaggagat 900
ggggcagtgc aggaaaagtg gcactatgaa ccctgcagcc ctaggaatgc atctagacaa 960
ttgtactaac cttcttctct ttcctctcct gacaggcctc gaggccgcca ccatggaatg 1020
gtcatgggtc tttctctttt ttctcagcgt gaccaccgga gtccactccc aggtagagca 1080
gaaattgatc tctgaggaag acctgcaggt ccagttggtc gaaagtggcg gcggattggt 1140
gaaaccaggc ggatctttga ggcttagttg cgcggcttcc ggatttacgt tcagtgatga 1200
ctacatgagc tggataaggc aagcacctgg taagggcctg gaatgggtcg caagtgtgtc 1260
taatggaagg cccactacct actatgctga ttccgtccgc ggacgcttta ctatttcaag 1320
agataatgct aagaatagtc tgtacctgca gatgaacagt ctgcgcgcgg aagataccgc 1380
agtatattac tgtgcacgag aggattgggg tggggagttc acggattggg gcaggggaac 1440
tcttgtaacg gtgtctagcg gaggaggtgg gtcaggtgga ggtggcagtg gaggtggagg 1500
ctctcaggcc ggcttgaccc aaccgccatc tgcgtcagga acatcaggcc agagggtgac 1560
tatcagttgt tctggcagtt catccaatat tgggatcaat ttcgtgtact ggtatcagca 1620
cctgccaggt accgcgccga agctgctgat ctataagaat aatcaacgcc catcaggcgt 1680
tccagatagg ttcagtggga gcaagtccgg aaactccgcg tcactcgcga tctcaggtct 1740
gcggtctgag gatgaagctg attattactg cgcggcgtgg gatgattctc tgtcaggcta 1800
cgtattcggt tcagggacta aggtaactgt gttggcgaaa ccgaccacga caccggctcc 1860
aagacctccg acgccagctc caacgatagc gtcacagcca ttgtctctcc gccctgaagc 1920
ctgccggccc gctgcgggcg gcgcggttca tacccgggga ttggactttg cccccagaaa 1980
gatagaggtg atgtaccctc ccccctactt ggacaacgaa aagtctaatg gcactatcat 2040
tcacgtaaag ggcaaacacc tttgtccaag tcctttgttc ccaggcccat ctaagccgtt 2100
ctgggtactc gtggttgtgg ggggcgtgct cgcttgttac tcactgctgg tgacggtggc 2160
ctttattatt ttctgggttc gatctaagcg aagccgcttg ttgcattctg actacatgaa 2220
tatgacgcca agacggccag ggccaacaag aaagcattac caaccgtacg cccccccgcg 2280
agacttcgcg gcctaccgca gcagggtaaa atttagcagg tctgcagatg cgcctgcgta 2340
tcaacagggt cagaatcagc tctataatga gctgaacctc gggcggcggg aagagtatga 2400
tgttctcgat aaaaggagag gacgagaccc cgaaatgggc ggcaaaccga gacgcaaaaa 2460
tcctcaggag gggctctaca atgaacttca aaaagacaaa atggccgaag catactcaga 2520
aatcggaatg aaaggggaga ggagacgcgg gaagggccat gatggactgt atcagggact 2580
ttccacggcc accaaggaca cctatgacgc tctccacatg caggcgctgc cgcctagatg 2640
ataaaattgt tgttgttaac ttgtttattg cagcttataa tggttacaaa taaagcaata 2700
gcatcacaaa tttcacaaat aaagcatttt tttcactgca ttctagttgt ggtttgtcca 2760
aactcatcaa tgtatcttag atatccagaa ccctgaccct gccgtgtacc agctgagaga 2820
ctctaaatcc agtgacaagt ctgtctgcct attcaccgat tttgattctc aaacaaatgt 2880
gtcacaaagt aaggattctg atgtgtatat cacagacaaa actgtgctag acatgaggtc 2940
tatggacttc aagagcaaca gtgctgtggc ctggagcaac aaatctgact ttgcatgtgc 3000
aaacgccttc aacaacagca ttattccaga ggacaccttc ttccccagcc caggtaaggg 3060
cagctttggt gccttcgcag gctgtttcct tgcttcagga atggccaggt tctgcccaga 3120
gctctggtca atgatgtcta aaactcctct gattggtggt ctcggcctta tccattgcca 3180
ccaaaaccct ctttttacta agaaacagtg agccttgttc tggcagtcca gagaatgaca 3240
cgggaaaaaa gcagatgaag agaaggtggc aggagagggc acgtggccca gcctcagtct 3300
ctccaactga gttcctgcct gcctgccttt gctcagactg tttgcccctt actgctcttc 3360
taggcctcat tctaagcccc ttctccaagt tgcctctcct tatttctccc tgtctgccaa 3420
aaaatcttt 3429
<210> 5
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: primer for sequencing clones with anti-CD38 CAR-TRAC
homology arms insert in pAAV-MCS vector
<400> 5
cttaggctgg gcattagcag 20
<210> 6
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: primer for sequencing clones with anti-CD38 CAR-TRAC
homology arms insert in pAAV-MCS vector
<400> 6
catggaatgg tcatgggtct 20
<210> 7
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: primer for sequencing clones with anti-CD38 CAR-TRAC
homology arms insert in pAAV-MCS vector
<400> 7
ggctacgtat tcggttcagg 20
<210> 8
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Forward primer for generating donor DNA PCR fragment
from pAAV anti-CD38 CAR-TRAC construct (660 & 650 HAs)
<220>
<221> modified_base
<222> (1)..(2)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (2)..(3)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (2)..(3)
<223> 2'-O-methylated
<220>
<221> modified_base
<222> (3)..(4)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (4)..(4)
<223> 2'-O-methylated
<400> 8
tggagctagg gcaccatatt 20
<210> 9
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Reverse primer for generating donor DNA PCR fragment
from pAAV anti-CD38 CAR-TRAC construct (660 & 650 HAs), the
5'-most nucleoside (C) has a 5' phosphate
<220>
<221> misc_feature
<223> 5' phosphate
<400> 9
caacttggag aaggggctta 20
<210> 10
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: PCR forward primer with homology to TRAC locus for
verifying site-specific insertion of anti-CD38 CAR (upstream
junction)
<400> 10
cctgctttct gagggtgaag 20
<210> 11
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: PCR reverse primer with homology to CAR construct for
verifying site-specific insertion of anti-CD38 CAR (upstream
junction)
<400> 11
ctttcgacca actggacctg 20
<210> 12
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: PCR forward primer with homology to CAR locus for
verifying site-specific insertion of anti-CD38 CAR (downstream
junction)
<400> 12
cgttctgggt actcgtggtt 20
<210> 13
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: PCR reverse primer with homology to TRAC locus
(downstream junction)
<400> 13
gagagccctt ccctgacttt 20
<210> 14
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Forward primer for generating donor fragment with 300
nt HAs
<220>
<221> modified_base
<222> (1)..(2)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (2)..(3)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (2)..(3)
<223> 2'-O-methylated
<220>
<221> modified_base
<222> (3)..(4)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (5)..(5)
<223> 2'-O-methylated
<400> 14
ccatgcctgc ctttactctg 20
<210> 15
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Reverse primer for generating donor fragment with 300
nt HAs, the 5'-most nucleoside (T) has a 5' phosphate
<220>
<221> misc_feature
<223> 5' phosphate
<400> 15
tcctgaagca aggaaacagc 20
<210> 16
<211> 375
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(375)
<223> 5' homology arm, exon 1 TRAC gene
<400> 16
ccatgcctgc ctttactctg ccagagttat attgctgggg ttttgaagaa gatcctatta 60
aataaaagaa taagcagtat tattaagtag ccctgcattt caggtttcct tgagtggcag 120
gccaggcctg gccgtgaacg ttcactgaaa tcatggcctc ttggccaaga ttgatagctt 180
gtgcctgtcc ctgagtccca gtccatcacg agcagctggt ttctaagatg ctatttcccg 240
tataaagcat gagaccgtga cttgccagcc ccacagagcc ccgcccttgt ccatcactgg 300
catctggact ccagcctggg ttggggcaaa gagggaaatg agatcatgtc ctaaccctga 360
tcctcttgtc ccaca 375
<210> 17
<211> 321
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(321)
<223> 3' homology arm, exon 1 TRAC gene
<400> 17
gatatccaga accctgaccc tgccgtgtac cagctgagag actctaaatc cagtgacaag 60
tctgtctgcc tattcaccga ttttgattct caaacaaatg tgtcacaaag taaggattct 120
gatgtgtata tcacagacaa aactgtgcta gacatgaggt ctatggactt caagagcaac 180
agtgctgtgg cctggagcaa caaatctgac tttgcatgtg caaacgcctt caacaacagc 240
attattccag aggacacctt cttccccagc ccaggtaagg gcagctttgg tgccttcgca 300
ggctgtttcc ttgcttcagg a 321
<210> 18
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Forward primer for generating donor fragment with 150
nt HAs
<220>
<221> modified_base
<222> (1)..(2)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (3)..(4)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (3)..(5)
<223> 2'-O-methylated
<220>
<221> modified_base
<222> (4)..(5)
<223> Phosphorothioate linkage
<400> 18
atcacgagca gctggtttct 20
<210> 19
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Reverse primer for generating donor fragment with 150
nt HAs, the 5'-most nucleoside (G) has a 5' phosphate
<220>
<221> misc_feature
<223> 5' phosphate
<400> 19
gacctcatgt ctagcacagt tttg 24
<210> 20
<211> 171
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(171)
<223> 5' 171 nt homology arm, exon 1 TRAC gene
<400> 20
atcacgagca gctggtttct aagatgctat ttcccgtata aagcatgaga ccgtgacttg 60
ccagccccac agagccccgc ccttgtccat cactggcatc tggactccag cctgggttgg 120
ggcaaagagg gaaatgagat catgtcctaa ccctgatcct cttgtcccac a 171
<210> 21
<211> 161
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(161)
<223> 3' 161 nt homology arm, exon 1 TRAC gene
<400> 21
gatatccaga accctgaccc tgccgtgtac cagctgagag actctaaatc cagtgacaag 60
tctgtctgcc tattcaccga ttttgattct caaacaaatg tgtcacaaag taaggattct 120
gatgtgtata tcacagacaa aactgtgcta gacatgaggt c 161
<210> 22
<211> 2080
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: anti-CD19 CAR cassette including JeT promoter, intron,
anti-CD19 CAR, SV40 sequence
<400> 22
gaattcgggc ggagttaggg cggagccaat cagcgtgcgc cgttccgaaa gttgcctttt 60
atggctgggc ggagaatggg cggtgaacgc cgatgattat ataaggacgc gccgggtgtg 120
gcacagctag ttccgtcgca gccgggattt gggtcgcggt tcttgtttgt ggatccctgt 180
gatcgtcact tgacagtaag tcactgactg tctatgcctg ggaaagggtg ggcaggagat 240
ggggcagtgc aggaaaagtg gcactatgaa ccctgcagcc ctaggaatgc atctagacaa 300
ttgtactaac cttcttctct ttcctctcct gacaggcctc gaggccgcca ccatggaatg 360
gtcatgggtc tttctctttt ttctcagcgt gaccaccgga gtccactccg atatccagat 420
gacacagacc accagcagcc tgagcgccag cctgggcgac cgagtgacta tcagctgccg 480
ggcatcccag gatatttcta agtatctgaa ctggtaccag cagaagcccg acggcactgt 540
caaactgctg atctaccaca ccagtagact gcattcaggg gtgcctagca ggttctccgg 600
atctggcagt gggactgact actccctgac catctctaac ctggagcagg aagatattgc 660
cacctatttc tgccagcagg gcaatacact gccttacact tttggcgggg gaacaaagct 720
ggagatcact ggcggaggag gatctggagg aggaggaagt ggaggaggag gatcagaggt 780
gaaactgcag gaaagcggac caggactggt cgcaccttca cagagcctgt ccgtgacatg 840
tactgtctcc ggagtgtctc tgcccgatta cggcgtctct tggatccggc agccccctag 900
aaagggactg gagtggctgg gcgtgatctg gggaagtgaa actacctact ataatagtgc 960
tctgaaatca agactgacca tcattaagga caactctaaa agtcaggtgt ttctgaagat 1020
gaattccctg cagaccgacg atacagcaat ctactattgc gccaaacact actattacgg 1080
cgggagctat gccatggatt actgggggca gggaacttcc gtcaccgtga gcagcgctaa 1140
gccgaccacg acaccggctc caagacctcc gacgccagct ccaacgatag cgtcacagcc 1200
attgtctctc cgccctgaag cctgccggcc cgctgcgggc ggcgcggttc atacccgggg 1260
attggacttt gcccccagaa agatagaggt gatgtaccct cccccctact tggacaacga 1320
aaagtctaat ggcactatca ttcacgtaaa gggcaaacac ctttgtccaa gtcctttgtt 1380
cccaggccca tctaagccgt tctgggtact cgtggttgtg gggggcgtgc tcgcttgtta 1440
ctcactgctg gtgacggtgg cctttattat tttctgggtt cgatctaagc gaagccgctt 1500
gttgcattct gactacatga atatgacgcc aagacggcca gggccaacaa gaaagcatta 1560
ccaaccgtac gcccccccgc gagacttcgc ggcctaccgc agcagggtaa aatttagcag 1620
gtctgcagat gcgcctgcgt atcaacaggg tcagaatcag ctctataatg agctgaacct 1680
cgggcggcgg gaagagtatg atgttctcga taaaaggaga ggacgagacc ccgaaatggg 1740
cggcaaaccg agacgcaaaa atcctcagga ggggctctac aatgaacttc aaaaagacaa 1800
aatggccgaa gcatactcag aaatcggaat gaaaggggag aggagacgcg ggaagggcca 1860
tgatggactg tatcagggac tttccacagc caccaaggac acctatgacg ctctccacat 1920
gcaggcgctg ccgcctagat gataaaattg ttgttgttaa cttgtttatt gcagcttata 1980
atggttacaa ataaagcaat agcatcacaa atttcacaaa taaagcattt ttttcactgc 2040
attctagttg tggtttgtcc aaactcatca atgtatctta 2080
<210> 23
<211> 2083
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: anti-BCMA CAR construct including JeT promoter,
intron, anti-BCMA CAR construct, SV40 sequence
<220>
<221> misc_feature
<222> (1057)..(1057)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (1098)..(1098)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (1120)..(1120)
<223> n is a, c, g, or t
<400> 23
gaattcgggc ggagttaggg cggagccaat cagcgtgcgc cgttccgaaa gttgcctttt 60
atggctgggc ggagaatggg cggtgaacgc cgatgattat ataaggacgc gccgggtgtg 120
gcacagctag ttccgtcgca gccgggattt gggtcgcggt tcttgtttgt ggatccctgt 180
gatcgtcact tgacagtaag tcactgactg tctatgcctg ggaaagggtg ggcaggagat 240
ggggcagtgc aggaaaagtg gcactatgaa ccctgcagcc ctaggaatgc atctagacaa 300
ttgtactaac cttcttctct ttcctctcct gacaggcctc gaggccgcca ccatggagtg 360
gtcctgggtg ttcctgttct ttctgtccgt gaccaccggt gtccactctc aggtgcagct 420
ggtggagtct gggggaggct tggtaaagcc tggggggtcc cttagactct cctgtgcagc 480
ctctggattc acttccagta ccgcctggat gagctgggtc cgccaggctc cagggaaggg 540
gctggagtgg gttggccgta ttaaaagcaa aagtgatggt gggacaacag actacgctgc 600
acccgtgaaa ggcagattca ccatctcaag agatgattca aaaaacacgc tgtttctgca 660
aatgaacagc ctgaaaaccg aggacacagc cgtgtattac tgtgccaagg gaggcgggac 720
ctacggctac tggggccagg gaaccctggt caccgtctcc tccggcggcg gcggcagcgg 780
tggcggtggc tcaggtggtg gtggttcttc ctatgtgctg actcagcctg cctccgtgtc 840
tgggtctcct ggacagtcag tcaccatctc ctgcactgga accagcagtg atggtggtgg 900
tcacacctat gtctcctggt accaacagca cccaggcaaa gcccccaaac tcatgattta 960
tgatgtcagt aatcggccct catgggtttc taatcgcttc tctggctcca agtctggcaa 1020
cacggcctcc ctgaccatct ctgggctcca ggctgangac gaggctgatt attactgcgg 1080
ctcatataca agcagcgnct cttatgtctt cggaactggn accaagctga ccgtcctggc 1140
taagcccacc acgacgccag cgccgcgacc accaacaccg gcgcccacca tcgcgtcgca 1200
gcccctgtcc ctgcgcccag aggcgtgccg gccagcggcg gggggcgcag tgcacacgag 1260
ggggctggac ttcgccccta ggaaaattga agttatgtat cctcctcctt acctagacaa 1320
tgagaagagc aatggaacca ttatccatgt gaaagggaaa cacctttgtc caagtcccct 1380
atttcccgga ccttctaagc ccttttgggt gctggtggtg gttggtggag tcctggcttg 1440
ctatagcttg ctagtaacag tggcctttat tattttctgg gtgaggagta agaggagcag 1500
gctcctgcac agtgactaca tgaacatgac tccccgccgc cccgggccca cccgcaagca 1560
ttaccagccc tatgccccac cacgcgactt cgcagcctat cgctccagag tgaagttcag 1620
caggagcgca gacgcccccg cgtaccagca gggccagaac cagctctata acgagctcaa 1680
tctaggacga agagaggagt acgatgtttt ggacaagaga cgtggccggg accctgagat 1740
ggggggaaag ccgagaagga agaaccctca ggaaggcctg tacaatgaac tgcagaaaga 1800
taagatggcg gaggcctaca gtgagattgg gatgaaaggc gagcgccgga ggggcaaggg 1860
gcacgatggc ctttaccagg gtctcagtac agccaccaag gacacctacg acgcccttca 1920
catgcaggcc ctgccgccta gatgataaaa ttgttgttgt taacttgttt attgcagctt 1980
ataatggtta caaataaagc aatagcatca caaatttcac aaataaagca tttttttcac 2040
tgcattctag ttgtggtttg tccaaactca tcaatgtatc tta 2083
<210> 24
<211> 183
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(183)
<223> 5' homology arm, TRAC gene exon 3, 183 nt
<400> 24
tatgcacaga agctgcaagg gacaggaggt gcaggagctg caggcctccc ccacccagcc 60
tgctctgcct tggggaaaac cgtgggtgtg tcctgcaggc catgcaggcc tgggacatgc 120
aagcccataa ccgctgtggc ctcttggttt tacagatacg aacctaaact ttcaaaacct 180
gtc 183
<210> 25
<211> 140
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(140)
<223> 3' homology arm, TRAC gene exon 3
<400> 25
agtgattggg ttccgaatcc tcctcctgaa agtggccggg tttaatctgc tcatgacgct 60
gcggctgtgg tccagctgag gtgaggggcc ttgaagctgg gagtggggtt tagggacgcg 120
ggtctctggg tgcatcctaa 140
<210> 26
<211> 20
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(20)
<223> Exon 3 target sequence (guide sequence)
<400> 26
ttcggaaccc aatcactgac 20
<210> 27
<211> 2442
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Entire donor DNA anti-CD38 CAR plus exon 3 HAs on both
ends
<400> 27
tatgcacaga agctgcaagg gacaggaggt gcaggagctg caggcctccc ccacccagcc 60
tgctctgcct tggggaaaac cgtgggtgtg tcctgcaggc catgcaggcc tgggacatgc 120
aagcccataa ccgctgtggc ctcttggttt tacagatacg aacctaaact ttcaaaacct 180
gtcgaattcg ggcggagtta gggcggagcc aatcagcgtg cgccgttccg aaagttgcct 240
tttatggctg ggcggagaat gggcggtgaa cgccgatgat tatataagga cgcgccgggt 300
gtggcacagc tagttccgtc gcagccggga tttgggtcgc ggttcttgtt tgtggatccc 360
tgtgatcgtc acttgacagt aagtcactga ctgtctatgc ctgggaaagg gtgggcagga 420
gatggggcag tgcaggaaaa gtggcactat gaaccctgca gccctaggaa tgcatctaga 480
caattgtact aaccttcttc tctttcctct cctgacaggc ctcgaggccg ccaccatgga 540
atggtcatgg gtctttctct tttttctcag cgtgaccacc ggagtccact cccaggtaga 600
gcagaaattg atctctgagg aagacctgca ggtccagttg gtcgaaagtg gcggcggatt 660
ggtgaaacca ggcggatctt tgaggcttag ttgcgcggct tccggattta cgttcagtga 720
tgactacatg agctggataa ggcaagcacc tggtaagggc ctggaatggg tcgcaagtgt 780
gtctaatgga aggcccacta cctactatgc tgattccgtc cgcggacgct ttactatttc 840
aagagataat gctaagaata gtctgtacct gcagatgaac agtctgcgcg cggaagatac 900
cgcagtatat tactgtgcac gagaggattg gggtggggag ttcacggatt ggggcagggg 960
aactcttgta acggtgtcta gcggaggagg tgggtcaggt ggaggtggca gtggaggtgg 1020
aggctctcag gccggcttga cccaaccgcc atctgcgtca ggaacatcag gccagagggt 1080
gactatcagt tgttctggca gttcatccaa tattgggatc aatttcgtgt actggtatca 1140
gcacctgcca ggtaccgcgc cgaagctgct gatctataag aataatcaac gcccatcagg 1200
cgttccagat aggttcagtg ggagcaagtc cggaaactcc gcgtcactcg cgatctcagg 1260
tctgcggtct gaggatgaag ctgattatta ctgcgcggcg tgggatgatt ctctgtcagg 1320
ctacgtattc ggttcaggga ctaaggtaac tgtgttggcg aaaccgacca cgacaccggc 1380
tccaagacct ccgacgccag ctccaacgat agcgtcacag ccattgtctc tccgccctga 1440
agcctgccgg cccgctgcgg gcggcgcggt tcatacccgg ggattggact ttgcccccag 1500
aaagatagag gtgatgtacc ctccccccta cttggacaac gaaaagtcta atggcactat 1560
cattcacgta aagggcaaac acctttgtcc aagtcctttg ttcccaggcc catctaagcc 1620
gttctgggta ctcgtggttg tggggggcgt gctcgcttgt tactcactgc tggtgacggt 1680
ggcctttatt attttctggg ttcgatctaa gcgaagccgc ttgttgcatt ctgactacat 1740
gaatatgacg ccaagacggc cagggccaac aagaaagcat taccaaccgt acgccccccc 1800
gcgagacttc gcggcctacc gcagcagggt aaaatttagc aggtctgcag atgcgcctgc 1860
gtatcaacag ggtcagaatc agctctataa tgagctgaac ctcgggcggc gggaagagta 1920
tgatgttctc gataaaagga gaggacgaga ccccgaaatg ggcggcaaac cgagacgcaa 1980
aaatcctcag gaggggctct acaatgaact tcaaaaagac aaaatggccg aagcatactc 2040
agaaatcgga atgaaagggg agaggagacg cgggaagggc catgatggac tgtatcaggg 2100
actttccacg gccaccaagg acacctatga cgctctccac atgcaggcgc tgccgcctag 2160
atgataaaat tgttgttgtt aacttgttta ttgcagctta taatggttac aaataaagca 2220
atagcatcac aaatttcaca aataaagcat ttttttcact gcattctagt tgtggtttgt 2280
ccaaactcat caatgtatct taagtgattg ggttccgaat cctcctcctg aaagtggccg 2340
ggtttaatct gctcatgacg ctgcggctgt ggtccagctg aggtgagggg ccttgaagct 2400
gggagtgggg tttagggacg cgggtctctg ggtgcatcct aa 2442
<210> 28
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Forward primer for generating donor fragment of SEQ ID
NO:27
<220>
<221> modified_base
<222> (1)..(2)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (2)..(3)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (2)..(2)
<223> 2'-O-methylated
<220>
<221> modified_base
<222> (3)..(4)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (4)..(5)
<223> 2'-O-methylated
<400> 28
tatgccacag aagctgcaag g 21
<210> 29
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Reverse primer for generating donor fragment of SEQ ID
NO:27, the 5'-most nucleoside (T) has a 5' phosphate
<220>
<221> misc_feature
<223> 5' phosphate
<400> 29
ttaggatgca cccagagacc 20
<210> 30
<211> 326
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(326)
<223> DNA PD-1 locus 5' HA
<400> 30
ctccccatct cctctgtctc cctgtctctg tctctctctc cctcccccac cctctcccca 60
gtcctacccc ctcctcaccc ctcctccccc agcactgcct ctgtcactct cgcccacgtg 120
gatgtggagg aagagggggc gggagcaagg ggcgggcacc ctcccttcaa cctgacctgg 180
gacagtttcc cttccgctca cctccgcctg agcagtggag aaggcggcac tctggtgggg 240
ctgctccagg catgcagatc ccacaggcgc cctggccagt cgtctgggcg gtgctacaac 300
tgggctggcg gccaggatgg ttctta 326
<210> 31
<211> 380
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(380)
<223> DNA PD-1 locus 3' HA
<400> 31
ggtaggtggg gtcggcggtc aggtgtccca gagccagggg tctggaggga ccttccaccc 60
tcagtccctg gcaggtcggg gggtgctgag gcgggcctgg ccctggcagc ccaggggtcc 120
cggagcgagg ggtctggagg gacctttcac tctcagtccc tggcaggtcg gggggtgctg 180
tggcaggccc agccttggcc cccagctctg ccccttaccc tgagctgtgt ggctttgggc 240
agctcgaact cctgggttcc tctctgggcc ccaactcctc ccctggccca agtcccctct 300
ttgctcctgg gcaggcagga cctctgtccc ctctcagccg gtccttgggg ctgcgtgttt 360
ctgtagaatg acgggtcagg 380
<210> 32
<211> 20
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(20)
<223> PD-1 target site
<400> 32
ggccaggatg gttcttaggt 20
<210> 33
<211> 2825
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Donor DNA fragment having CD38 cassette (SEQ ID NO:2)
flanked by PD-1 Has
<400> 33
ctccccatct cctctgtctc cctgtctctg tctctctctc cctcccccac cctctcccca 60
gtcctacccc ctcctcaccc ctcctccccc agcactgcct ctgtcactct cgcccacgtg 120
gatgtggagg aagagggggc gggagcaagg ggcgggcacc ctcccttcaa cctgacctgg 180
gacagtttcc cttccgctca cctccgcctg agcagtggag aaggcggcac tctggtgggg 240
ctgctccagg catgcagatc ccacaggcgc cctggccagt cgtctgggcg gtgctacaac 300
tgggctggcg gccaggatgg ttcttagaat tcgggcggag ttagggcgga gccaatcagc 360
gtgcgccgtt ccgaaagttg ccttttatgg ctgggcggag aatgggcggt gaacgccgat 420
gattatataa ggacgcgccg ggtgtggcac agctagttcc gtcgcagccg ggatttgggt 480
cgcggttctt gtttgtggat ccctgtgatc gtcacttgac agtaagtcac tgactgtcta 540
tgcctgggaa agggtgggca ggagatgggg cagtgcagga aaagtggcac tatgaaccct 600
gcagccctag gaatgcatct agacaattgt actaaccttc ttctctttcc tctcctgaca 660
ggcctcgagg ccgccaccat ggaatggtca tgggtctttc tcttttttct cagcgtgacc 720
accggagtcc actcccaggt agagcagaaa ttgatctctg aggaagacct gcaggtccag 780
ttggtcgaaa gtggcggcgg attggtgaaa ccaggcggat ctttgaggct tagttgcgcg 840
gcttccggat ttacgttcag tgatgactac atgagctgga taaggcaagc acctggtaag 900
ggcctggaat gggtcgcaag tgtgtctaat ggaaggccca ctacctacta tgctgattcc 960
gtccgcggac gctttactat ttcaagagat aatgctaaga atagtctgta cctgcagatg 1020
aacagtctgc gcgcggaaga taccgcagta tattactgtg cacgagagga ttggggtggg 1080
gagttcacgg attggggcag gggaactctt gtaacggtgt ctagcggagg aggtgggtca 1140
ggtggaggtg gcagtggagg tggaggctct caggccggct tgacccaacc gccatctgcg 1200
tcaggaacat caggccagag ggtgactatc agttgttctg gcagttcatc caatattggg 1260
atcaatttcg tgtactggta tcagcacctg ccaggtaccg cgccgaagct gctgatctat 1320
aagaataatc aacgcccatc aggcgttcca gataggttca gtgggagcaa gtccggaaac 1380
tccgcgtcac tcgcgatctc aggtctgcgg tctgaggatg aagctgatta ttactgcgcg 1440
gcgtgggatg attctctgtc aggctacgta ttcggttcag ggactaaggt aactgtgttg 1500
gcgaaaccga ccacgacacc ggctccaaga cctccgacgc cagctccaac gatagcgtca 1560
cagccattgt ctctccgccc tgaagcctgc cggcccgctg cgggcggcgc ggttcatacc 1620
cggggattgg actttgcccc cagaaagata gaggtgatgt accctccccc ctacttggac 1680
aacgaaaagt ctaatggcac tatcattcac gtaaagggca aacacctttg tccaagtcct 1740
ttgttcccag gcccatctaa gccgttctgg gtactcgtgg ttgtgggggg cgtgctcgct 1800
tgttactcac tgctggtgac ggtggccttt attattttct gggttcgatc taagcgaagc 1860
cgcttgttgc attctgacta catgaatatg acgccaagac ggccagggcc aacaagaaag 1920
cattaccaac cgtacgcccc cccgcgagac ttcgcggcct accgcagcag ggtaaaattt 1980
agcaggtctg cagatgcgcc tgcgtatcaa cagggtcaga atcagctcta taatgagctg 2040
aacctcgggc ggcgggaaga gtatgatgtt ctcgataaaa ggagaggacg agaccccgaa 2100
atgggcggca aaccgagacg caaaaatcct caggaggggc tctacaatga acttcaaaaa 2160
gacaaaatgg ccgaagcata ctcagaaatc ggaatgaaag gggagaggag acgcgggaag 2220
ggccatgatg gactgtatca gggactttcc acggccacca aggacaccta tgacgctctc 2280
cacatgcagg cgctgccgcc tagatgataa aattgttgtt gttaacttgt ttattgcagc 2340
ttataatggt tacaaataaa gcaatagcat cacaaatttc acaaataaag catttttttc 2400
actgcattct agttgtggtt tgtccaaact catcaatgta tcttaggtag gtggggtcgg 2460
cggtcaggtg tcccagagcc aggggtctgg agggaccttc caccctcagt ccctggcagg 2520
tcggggggtg ctgaggcggg cctggccctg gcagcccagg ggtcccggag cgaggggtct 2580
ggagggacct ttcactctca gtccctggca ggtcgggggg tgctgtggca ggcccagcct 2640
tggcccccag ctctgcccct taccctgagc tgtgtggctt tgggcagctc gaactcctgg 2700
gttcctctct gggccccaac tcctcccctg gcccaagtcc cctctttgct cctgggcagg 2760
caggacctct gtcccctctc agccggtcct tggggctgcg tgtttctgta gaatgacggg 2820
tcagg 2825
<210> 34
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Forward primer for generating donor fragment of SEQ ID
NO:33, the 5'-most nucleoside (C) has a 5' phosphate
<220>
<221> misc_feature
<223> 5' phosphate
<400> 34
ctccccatct cctctgtctc 20
<210> 35
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Reverse primer for generating donor fragment of SEQ ID
NO:33, Phosphorothioate linkage between first and second, second
and third, and third and fourth nucleosides; C at position 1, C
at position 2, and G at position 4 are 2'-O-methylated
<220>
<221> modified_base
<222> (1)..(2)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (1)..(2)
<223> 2'-O-methylated
<220>
<221> modified_base
<222> (2)..(3)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (3)..(4)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (4)..(4)
<223> 2'-O-methylated
<400> 35
cctggacccg tcattctaca g 21
<210> 36
<211> 20
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(20)
<223> Forward primer for generating donor DNA PCR fragment from pAAV
anti-CD38 CAR-TRAC construct (660 & 650 HAs)
<400> 36
tggagctagg gcaccatatt 20
<210> 37
<211> 2415
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: anti-BCMA CAR construct donor fragment sequence,
including JeT promoter, intron, anti-BCMA CAR construct, SV40
sequence, with 5' and 3' TRAC gene exon 1 homology arms
<220>
<221> misc_feature
<222> (1228)..(1228)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (1269)..(1269)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (1291)..(1291)
<223> n is a, c, g, or t
<400> 37
atcacgagca gctggtttct aagatgctat ttcccgtata aagcatgaga ccgtgacttg 60
ccagccccac agagccccgc ccttgtccat cactggcatc tggactccag cctgggttgg 120
ggcaaagagg gaaatgagat catgtcctaa ccctgatcct cttgtcccac agaattcggg 180
cggagttagg gcggagccaa tcagcgtgcg ccgttccgaa agttgccttt tatggctggg 240
cggagaatgg gcggtgaacg ccgatgatta tataaggacg cgccgggtgt ggcacagcta 300
gttccgtcgc agccgggatt tgggtcgcgg ttcttgtttg tggatccctg tgatcgtcac 360
ttgacagtaa gtcactgact gtctatgcct gggaaagggt gggcaggaga tggggcagtg 420
caggaaaagt ggcactatga accctgcagc cctaggaatg catctagaca attgtactaa 480
ccttcttctc tttcctctcc tgacaggcct cgaggccgcc accatggagt ggtcctgggt 540
gttcctgttc tttctgtccg tgaccaccgg tgtccactct caggtgcagc tggtggagtc 600
tgggggaggc ttggtaaagc ctggggggtc ccttagactc tcctgtgcag cctctggatt 660
cacttccagt accgcctgga tgagctgggt ccgccaggct ccagggaagg ggctggagtg 720
ggttggccgt attaaaagca aaagtgatgg tgggacaaca gactacgctg cacccgtgaa 780
aggcagattc accatctcaa gagatgattc aaaaaacacg ctgtttctgc aaatgaacag 840
cctgaaaacc gaggacacag ccgtgtatta ctgtgccaag ggaggcggga cctacggcta 900
ctggggccag ggaaccctgg tcaccgtctc ctccggcggc ggcggcagcg gtggcggtgg 960
ctcaggtggt ggtggttctt cctatgtgct gactcagcct gcctccgtgt ctgggtctcc 1020
tggacagtca gtcaccatct cctgcactgg aaccagcagt gatggtggtg gtcacaccta 1080
tgtctcctgg taccaacagc acccaggcaa agcccccaaa ctcatgattt atgatgtcag 1140
taatcggccc tcatgggttt ctaatcgctt ctctggctcc aagtctggca acacggcctc 1200
cctgaccatc tctgggctcc aggctganga cgaggctgat tattactgcg gctcatatac 1260
aagcagcgnc tcttatgtct tcggaactgg naccaagctg accgtcctgg ctaagcccac 1320
cacgacgcca gcgccgcgac caccaacacc ggcgcccacc atcgcgtcgc agcccctgtc 1380
cctgcgccca gaggcgtgcc ggccagcggc ggggggcgca gtgcacacga gggggctgga 1440
cttcgcccct aggaaaattg aagttatgta tcctcctcct tacctagaca atgagaagag 1500
caatggaacc attatccatg tgaaagggaa acacctttgt ccaagtcccc tatttcccgg 1560
accttctaag cccttttggg tgctggtggt ggttggtgga gtcctggctt gctatagctt 1620
gctagtaaca gtggccttta ttattttctg ggtgaggagt aagaggagca ggctcctgca 1680
cagtgactac atgaacatga ctccccgccg ccccgggccc acccgcaagc attaccagcc 1740
ctatgcccca ccacgcgact tcgcagccta tcgctccaga gtgaagttca gcaggagcgc 1800
agacgccccc gcgtaccagc agggccagaa ccagctctat aacgagctca atctaggacg 1860
aagagaggag tacgatgttt tggacaagag acgtggccgg gaccctgaga tggggggaaa 1920
gccgagaagg aagaaccctc aggaaggcct gtacaatgaa ctgcagaaag ataagatggc 1980
ggaggcctac agtgagattg ggatgaaagg cgagcgccgg aggggcaagg ggcacgatgg 2040
cctttaccag ggtctcagta cagccaccaa ggacacctac gacgcccttc acatgcaggc 2100
cctgccgcct agatgataaa attgttgttg ttaacttgtt tattgcagct tataatggtt 2160
acaaataaag caatagcatc acaaatttca caaataaagc atttttttca ctgcattcta 2220
gttgtggttt gtccaaactc atcaatgtat cttagatatc cagaaccctg accctgccgt 2280
gtaccagctg agagactcta aatccagtga caagtctgtc tgcctattca ccgattttga 2340
ttctcaaaca aatgtgtcac aaagtaagga ttctgatgtg tatatcacag acaaaactgt 2400
gctagacatg aggtc 2415
<210> 38
<211> 2217
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: anti-CD19 CAR cassette including JeT promoter, intron,
anti-CD19 CAR, SV40 sequence flanked by 5' and 3' TRAC gene exon
1 homology arms of SEQ ID NO:20 and SEQ ID NO:21
<400> 38
atcacgagca gctggtttct aagatgctat ttcccgtata aagcatgaga ccgtgacttg 60
ccagccccac agagccccgc ccttgtccat cactggcatc tggactccag cctgggttgg 120
ggcaaagagg gaaatgagat catgtcctaa ccctgatcct cttgtcccac agtaagtcac 180
tgactgtcta tgcctgggaa agggtgggca ggagatgggg cagtgcagga aaagtggcac 240
tatgaaccct gcagccctag gaatgcatct agacaattgt actaaccttc ttctctttcc 300
tctcctgaca ggcctcgagg ccgccaccat ggaatggtca tgggtctttc tcttttttct 360
cagcgtgacc accggagtcc actccgatat ccagatgaca cagaccacca gcagcctgag 420
cgccagcctg ggcgaccgag tgactatcag ctgccgggca tcccaggata tttctaagta 480
tctgaactgg taccagcaga agcccgacgg cactgtcaaa ctgctgatct accacaccag 540
tagactgcat tcaggggtgc ctagcaggtt ctccggatct ggcagtggga ctgactactc 600
cctgaccatc tctaacctgg agcaggaaga tattgccacc tatttctgcc agcagggcaa 660
tacactgcct tacacttttg gcgggggaac aaagctggag atcactggcg gaggaggatc 720
tggaggagga ggaagtggag gaggaggatc agaggtgaaa ctgcaggaaa gcggaccagg 780
actggtcgca ccttcacaga gcctgtccgt gacatgtact gtctccggag tgtctctgcc 840
cgattacggc gtctcttgga tccggcagcc ccctagaaag ggactggagt ggctgggcgt 900
gatctgggga agtgaaacta cctactataa tagtgctctg aaatcaagac tgaccatcat 960
taaggacaac tctaaaagtc aggtgtttct gaagatgaat tccctgcaga ccgacgatac 1020
agcaatctac tattgcgcca aacactacta ttacggcggg agctatgcca tggattactg 1080
ggggcaggga acttccgtca ccgtgagcag cgctaagccg accacgacac cggctccaag 1140
acctccgacg ccagctccaa cgatagcgtc acagccattg tctctccgcc ctgaagcctg 1200
ccggcccgct gcgggcggcg cggttcatac ccggggattg gactttgccc ccagaaagat 1260
agaggtgatg taccctcccc cctacttgga caacgaaaag tctaatggca ctatcattca 1320
cgtaaagggc aaacaccttt gtccaagtcc tttgttccca ggcccatcta agccgttctg 1380
ggtactcgtg gttgtggggg gcgtgctcgc ttgttactca ctgctggtga cggtggcctt 1440
tattattttc tgggttcgat ctaagcgaag ccgcttgttg cattctgact acatgaatat 1500
gacgccaaga cggccagggc caacaagaaa gcattaccaa ccgtacgccc ccccgcgaga 1560
cttcgcggcc taccgcagca gggtaaaatt tagcaggtct gcagatgcgc ctgcgtatca 1620
acagggtcag aatcagctct ataatgagct gaacctcggg cggcgggaag agtatgatgt 1680
tctcgataaa aggagaggac gagaccccga aatgggcggc aaaccgagac gcaaaaatcc 1740
tcaggagggg ctctacaatg aacttcaaaa agacaaaatg gccgaagcat actcagaaat 1800
cggaatgaaa ggggagagga gacgcgggaa gggccatgat ggactgtatc agggactttc 1860
cacagccacc aaggacacct atgacgctct ccacatgcag gcgctgccgc ctagatgata 1920
aaattgttgt tgttaacttg tttattgcag cttataatgg ttacaaataa agcaatagca 1980
tcacaaattt cacaaataaa gcattttttt cactgcattc tagttgtggt ttgtccaaac 2040
tcatcaatgt atcttagata tccagaaccc tgaccctgcc gtgtaccagc tgagagactc 2100
taaatccagt gacaagtctg tctgcctatt caccgatttt gattctcaaa caaatgtgtc 2160
acaaagtaag gattctgatg tgtatatcac agacaaaact gtgctagaca tgaggtc 2217
<210> 39
<211> 1001
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Sequenced PCR product of 5' end of donor DNA plus
adjacent TRAC gene exon 1 genomic sequence that included portion
of anti-CD38 CAR construct and 660 nt homology arm
<220>
<221> misc_feature
<222> (1)..(15)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (18)..(19)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (790)..(792)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (925)..(925)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (931)..(931)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (933)..(934)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (1001)..(1001)
<223> n is a, c, g, or t
<400> 39
nnnnnnnnnn nnnnngcnng actcactagc actctatcac ggccatattc tggcagggtc 60
agtggctcca actaacattt gtttggtact ttacagttta ttaaatagat gtttatatgg 120
agaagctctc atttctttct cagaagagcc tggctaggaa ggtggatgag gcaccatatt 180
cattttgcag gtgaaattcc tgagatgtaa ggagctgctg tgacttgctc aaggccttat 240
atcgagtaaa cggtagcgct ggggcttaga cgcaggtgtt ctgatttata gttcaaaacc 300
tctatcaatg agagagcaat ctcctggtaa tgtgatagat ttcccaactt aatgccaaca 360
taccataaac ctcccattct gctaatgccc agcctaagtt ggggagacca ctccagattc 420
caagatgtac agtttgcttt gctgggcctt tttcccatgc ctgcctttac tctgccagag 480
ttatattgct ggggttttga agaagatcct attaaataaa agaataagca gtattattaa 540
gtagccctgc atttcaggtt tccttgagtg gcaggccagg cctggccgtg aacgttcact 600
gaaatcatgg cctcttggcc aagattgata gcttgtgcct gtccctgagt cccagtccat 660
cacgagcagc tggtttctaa gatgctattt cccgtataaa gcatgagacc gtgacttgcc 720
agccccacag agccccgccc ttgtccatca ctggcatctg gactccagcc tgggttgggg 780
caaagagggn nngagatcat gtcctaaccc tgatcctctt gtcccacaga attcgggcgg 840
agttagggcg gagccaatca gcgtgcgccg ttccgaaagt tgccttttat ggctgggcgg 900
agaatgggcg gtgaacgccg atgantatat nannacgcgc cgggtgtggc acagctagtt 960
ccgtcgcagc cgggatttgg gtcgcggttc ttgtttgtgg n 1001
<210> 40
<211> 1015
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Sequenced PCR product of 3' end of donor DNA plus
adjacent TRAC gene exon 1 genomic sequence that included portion
of anti-CD38 CAR construct and 650 nt homology arm
<220>
<221> misc_feature
<222> (1)..(16)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (988)..(988)
<223> n is a, c, g, or t
<400> 40
nnnnnnnnnn nnnnnnttct gctctacctg ggagtggact ccggtggtca cgctgagaaa 60
aaagagaaag acccatgacc attccatggt ggcggcctcg aggcctgtca ggagaggaaa 120
gagaagaagg ttagtacaat tgtctagatg cattcctagg gctgcagggt tcatagtgcc 180
acttttcctg cactgcccca tctcctgccc accctttccc aggcatagac agtcagtgac 240
ttactgtcaa gtgacgatca cagggatcca caaacaagaa ccgcgaccca aatcccggct 300
gcgacggaac tagctgtgcc acacccggcg cgtccttata taatcatcgg cgttcaccgc 360
ccattctccg cccagccata aaaggcaact ttcggaacgg cgcacgctga ttggctccgc 420
cctaactccg cccgaattct gtgggacaag aggatcaggg ttaggacatg atctcatttc 480
cctctttgcc ccaacccagg ctggagtcca gatgccagtg atggacaagg gcggggctct 540
gtggggctgg caagtcacgg tctcatgctt tatacgggaa atagcatctt agaaaccagc 600
tgctcgtgat ggactgggac tcagggacag gcacaagcta tcaatcttgg ccaagaggcc 660
atgatttcag tgaacgttca cggccaggcc tggcctgcca ctcaaggaaa cctgaaatgc 720
agggctactt aataatactg cttattcttt tatttaatag gatcttcttc aaaaccccag 780
caatataact ctggcagagt aaaggcaggc atgggaaaaa ggcccagcaa agcaaactgt 840
acatcttgga atctggagtg gtctccccaa cttaggctgg gcattagcag aatgggaggt 900
ttatggtatg ttggcattaa gttgggaaat ctatcacatt accaggagat tgctctctca 960
ttgatagagg ttttgaacta taaatcanaa cacctgcgtc taagccccag cgcta 1015
<210> 41
<211> 1035
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Sequenced PCR product of 5' end of donor DNA plus
adjacent TRAC gene exon 3 genomic sequence that included portion
of the anti-CD38 CAR construct and 660 nt homology arm Exon3 5HA
F sequence results
<220>
<221> misc_feature
<222> (2)..(21)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (31)..(31)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (1030)..(1030)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (1032)..(1035)
<223> n is a, c, g, or t
<400> 41
cnnnnnnnnn nnnnnnnnnn nctttgagga ngagtttcta gcttcaatag accaaggact 60
ctctcctagg cctctgtatt cctttcaaca gctccactgt caagagagcc agagagagct 120
tctgggtggc ccagctgtga aatttctgag tcccttaggg atagccctaa acgaaccaga 180
tcatcctgag gacagccaag aggttttgcc ttctttcaag acaagcaaca gtactcacat 240
aggctgtggg caatggtcct gtctctcaag aatcccctgc cactcctcac acccaccctg 300
ggcccatatt catttccatt tgagttgttc ttattgagtc atccttcctg tggtagcgga 360
actcactaag gggcccatct ggacccgagg tattgtgatg ataaattctg agcacctacc 420
ccatccccag aagggctcag aaataaaata agagccaagt ctagtcggtg tttcctgtct 480
tgaaacacaa tactgttggc cctggaagaa tgcacagaat ctgtttgtaa ggggatatgc 540
acagaagctg caagggacag gaggtgcagg agctgcaggc ctcccccacc cagcctgctc 600
tgccttgggg aaaaccgtgg gtgtgtcctg caggccatgc aggcctggga catgcaagcc 660
cataaccgct gtggcctctt ggttttacag atacgaacct aaactttcaa aacctgtcga 720
attcgggcgg agttagggcg gagccaatca gcgtgcgccg ttccgaaagt tgccttttat 780
ggctgggcgg agaatgggcg gtgaacgccg atgattatat aaggacgcgc cgggtgtggc 840
acagctagtt ccgtcgcagc cgggatttgg gtcgcggttc ttgtttgtgg atccctgtga 900
tcgtcacttg acagtaagtc actgactgtc tatgcctggg aaagggtggg caggagatgg 960
ggcagtgcag gaaaagtggc actatgaacc ctgcagccct aggaatgcat ctagacaatt 1020
gtactaaccn tnnnn 1035
<210> 42
<211> 1030
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Sequenced PCR product of 3' end of donor DNA plus
adjacent genomic TRAC gene exon 3 sequence that included portion
of the anti-CD38 CAR construct and 650 nt homology arm
<220>
<221> misc_feature
<222> (1)..(18)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (952)..(952)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (1007)..(1007)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (1030)..(1030)
<223> n is a, c, g, or t
<400> 42
nnnnnnnnnn nnnnnnnngc tgcacaggag agtctcaggg accctccagg cttgaccaag 60
cctcccccag actccaccag ctgcacctga gagtggacac cggtggtcac ggacagaaag 120
aacaggaaca cccaggacca ctccatggtg gcggcctcga ggcctgtcag gagaggaaag 180
agaagaaggt tagtacaatt gtctagatgc attcctaggg ctgcagggtt catagtgcca 240
cttttcctgc actgccccat ctcctgccca ccctttccca ggcatagaca gtcagtgact 300
tactgtcaag tgacgatcac agggatccac aaacaagaac cgcgacccaa atcccggctg 360
cgacggaact agctgtgcca cacccggcgc gtccttatat aatcatcggc gttcaccgcc 420
cattctccgc ccagccataa aaggcaactt tcggaacggc gcacgctgat tggctccgcc 480
ctaactccgc ccgaattcga caggttttga aagtttaggt tcgtatctgt aaaaccaaga 540
ggccacagcg gttatgggct tgcatgtccc aggcctgcat ggcctgcagg acacacccac 600
ggttttcccc aaggcagagc aggctgggtg ggggaggcct gcagctcctg cacctcctgt 660
cccttgcagc ttctgtgcat atccccttac aaacagattc tgtgcattct tccagggcca 720
acagtattgt gtttcaagac aggaaacacc gactagactt ggctcttatt ttatttctga 780
gcccttctgg ggatggggta ggtgctcaga atttatcatc acaatacctc gggtccagat 840
gggcccctta gtgagttccg ctaccacagg aaggatgact caataagaac aactcaaatg 900
gaaatgaata tgggcccagg gtgggtgtga ggagtggcag gggattcttg anagacagga 960
ccattgccca cagcctatgt gagtactgtt gcttgtcttg aaagaangca aaacctcttg 1020
gctgtcctcn 1030
<210> 43
<211> 1015
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Sequenced PCR product of 3' end of donor DNA plus
adjacent PD-1 genomic sequence that included portion of the
anti-CD38 CAR construct and 660 nt homology arm
<220>
<221> misc_feature
<222> (1)..(19)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (22)..(22)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (32)..(32)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (925)..(926)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (930)..(930)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (935)..(936)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (943)..(943)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (947)..(947)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (960)..(961)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (971)..(971)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (974)..(976)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (978)..(978)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (983)..(985)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (990)..(991)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (999)..(999)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (1012)..(1013)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (1015)..(1015)
<223> n is a, c, g, or t
<400> 43
nnnnnnnnnn nnnnnnnnnt cntgctggtg anggtggcct ttattatttt ctgggttcga 60
tctaagcgaa gccgcttgtt gcattctgac tacatgaata tgacgccaag acggccaggg 120
ccaacaagaa agcattacca accgtacgcc cccccgcgag actacgcggc ctaccgcagc 180
agggtaaaat ttagcaggtc tgcagatgcg cctgcgtatc aacagggtca gaatcagctc 240
tataatgagc tgaacctcgg gcggcgggaa gagtatgatg ttctcgataa aaggagagga 300
cgagaccccg aaatgggcgg caaaccgaga cgcaaaaatc ctcaggaggg gctctacaat 360
gaacttcaaa aagacaaaat ggccgaagca tactcagaaa tcggaatgaa aggggagagg 420
agacgcggga agggccatga tggactgtat cagggacttt ccacagccac caaggacacc 480
tatgacgctc tccacatgca ggcgctgccg cctagatgat aaaattgttg ttgttaactt 540
gtttattgca gcttataatg gttacaaata aagcaatagc atcacaaatt tcacaaataa 600
agcatttttt tcactgcatt ctagttgtgg tttgtccaaa ctcatcaatg tatcttaggt 660
aggtggggtc ggcggtcagg tgtcccagag ccaggggtct ggagggacct tccaccctca 720
gtccctggca ggtcgggggg tgctgaggcg ggcctggccc tggcagccca ggggtcccgg 780
agcgaggggt ctggagggac ctttcactct cagtccctgg caggtcgggg ggtgctgtgg 840
caggcccagc cttggccccc agctctgccc cttaccctga gctgtgtggc tttgggcagc 900
tcaaactcct gggttcctct ctggnncccn actcnncccc tgncccnagt cccctctttn 960
ntcctgggca ngcnnnanct ctnnnccctn ncagccggnc cttggggctg cnngn 1015
<210> 44
<211> 660
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(660)
<223> 5' homology arm from exon 1 of TRAC gene, 660 nt
<400> 44
ggcaccatat tcattttgca ggtgaaattc ctgagatgta aggagctgct gtgacttgct 60
caaggcctta tatcgagtaa acggtagtgc tggggcttag acgcaggtgt tctgatttat 120
agttcaaaac ctctatcaat gagagagcaa tctcctggta atgtgataga tttcccaact 180
taatgccaac ataccataaa cctcccattc tgctaatgcc cagcctaagt tggggagacc 240
actccagatt ccaagatgta cagtttgctt tgctgggcct ttttcccatg cctgccttta 300
ctctgccaga gttatattgc tggggttttg aagaagatcc tattaaataa aagaataagc 360
agtattatta agtagccctg catttcaggt ttccttgagt ggcaggccag gcctggccgt 420
gaacgttcac tgaaatcatg gcctcttggc caagattgat agcttgtgcc tgtccctgag 480
tcccagtcca tcacgagcag ctggtttcta agatgctatt tcccgtataa agcatgagac 540
cgtgacttgc cagccccaca gagccccgcc cttgtccatc actggcatct ggactccagc 600
ctgggttggg gcaaagaggg aaatgagatc atgtcctaac cctgatcctc ttgtcccaca 660
<210> 45
<211> 650
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(650)
<223> 3' homology arm from exon 1 of TRAC gene, 650 nt
<400> 45
gatatccaga accctgaccc tgccgtgtac cagctgagag actctaaatc cagtgacaag 60
tctgtctgcc tattcaccga ttttgattct caaacaaatg tgtcacaaag taaggattct 120
gatgtgtata tcacagacaa aactgtgcta gacatgaggt ctatggactt caagagcaac 180
agtgctgtgg cctggagcaa caaatctgac tttgcatgtg caaacgcctt caacaacagc 240
attattccag aggacacctt cttccccagc ccaggtaagg gcagctttgg tgccttcgca 300
ggctgtttcc ttgcttcagg aatggccagg ttctgcccag agctctggtc aatgatgtct 360
aaaactcctc tgattggtgg tctcggcctt atccattgcc accaaaaccc tctttttact 420
aagaaacagt gagccttgtt ctggcagtcc agagaatgac acgggaaaaa agcagatgaa 480
gagaaggtgg caggagaggg cacgtggccc agcctcagtc tctccaactg agttcctgcc 540
tgcctgcctt tgctcagact gtttgcccct tactgctctt ctaggcctca ttctaagccc 600
cttctccaag ttgcctctcc ttatttctcc ctgtctgcca aaaaatcttt 650
<210> 46
<211> 63
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Encodes T2A peptide sequence of Thosea asigna virus
<400> 46
ggaagcggag agggcagagg aagtctgcta acatgcggtg acgtcgagga gaatcctgga 60
cct 63
<210> 47
<211> 122
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: SV40 polyA addition sequence
<400> 47
aacttgttta ttgcagctta taatggttac aaataaagca atagcatcac aaatttcaca 60
aataaagcat ttttttcact gcattctagt tgtggtttgt ccaaactcat caatgtatct 120
ta 122
<210> 48
<211> 2652
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: CD38 DAR insert 2652 nt
<220>
<221> misc_feature
<222> (2467)..(2467)
<223> n is a, c, g, or t
<400> 48
gaattcgggc ggagttaggg cggagccaat cagcgtgcgc cgttccgaaa gttgcctttt 60
atggctgggc ggagaatggg cggtgaacgc cgatgattat ataaggacgc gccgggtgtg 120
gcacagctag ttccgtcgca gccgggattt gggtcgcggt tcttgtttgt ggatccctgt 180
gatcgtcact tgacagtaag tcactgactg tctatgcctg ggaaagggtg ggcaggagat 240
ggggcagtgc aggaaaagtg gcactatgaa ccctgcagcc ctaggaatgc atctagacaa 300
ttgtactaac cttcttctct ttcctctcct gacaggcctc gaggccgcca ccatggagtg 360
gagctgggtg tttctgttct tcctctccgt cacaaccggc gtgcatagcc aggtgcagct 420
ggtggagtcc ggaggcggcc tggtgaaacc tggcggatcc ctgaggctgt cctgcgccgc 480
tagcggattc accttcagcg acgactacat gagctggatc aggcaggctc ccggaaaggg 540
cctggagtgg gtcgctagcg tgagcaatgg ccggcccaca acctactatg ccgactccgt 600
gcggggcagg tttaccatct ccagggataa cgctaagaac tccctgtacc tgcagatgaa 660
cagcctgcgg gccgaagata ccgccgtcta ctattgcgcc agggaggatt ggggcggcga 720
gttcacagac tggggaaggg gcaccctggt gaccgtgagc agcgcttcca ccaagggccc 780
ctccgtgttc cctctggccc ccagcagcaa gagcacatcc ggaggcaccg ccgccctcgg 840
atgtctggtg aaggactact tccccgagcc tgtcaccgtg tcctggaata gcggcgccct 900
cacctccggc gtgcacacct tccccgctgt cctgcagtcc tccggactgt acagcctgtc 960
ctccgtcgtg accgtgccta gctcctccct cggcacccag acctacatct gcaacgtgaa 1020
ccacaagcct tccaacacaa aggtggacaa acgggtggag cccaagtcct gcgacaaaac 1080
ccacaccaag atagaggtga tgtaccctcc cccctacttg gacaacgaaa agtctaatgg 1140
cactatcatt cacgtaaagg gcaaacacct ttgtccaagt cctttgttcc caggcccatc 1200
taagccgttc tgggtactcg tggttgtggg gggcgtgctc gcttgttact cactgctggt 1260
gacggtggcc tttattattt tctgggttaa acggggcaga aagaaactcc tgtatatatt 1320
caaacaacca tttatgagac cagtacaaac tactcaagag gaagatggct gtagctgccg 1380
atttccagaa gaagaagaag gaggatgtga actgagggta aaatttagca ggtctgcaga 1440
tgcgcctgcg tatcaacagg gtcagaatca gctctataat gagctgaacc tcgggcggcg 1500
ggaagagtat gatgttctcg ataaaaggag aggacgagac cccgaaatgg gcggcaaacc 1560
gagacgcaaa aatcctcagg aggggctcta caatgaactt caaaaagaca aaatggccga 1620
agcatactca gaaatcggaa tgaaagggga gaggagacgc gggaagggcc atgatggact 1680
gtatcaggga ctttccacag ccaccaagga cacctatgac gctctccaca tgcaggccct 1740
gccccctcgc ggaagcggag agggcagagg aagtctgcta acatgcggtg acgtcgagga 1800
gaatcctgga cctatgtccg tccctaccca ggtgctgggc ctgctgctgc tgtggctgac 1860
cgatgctaga tgccagtccg ttctgaccca gcctccttcc gcctctggca catccggcca 1920
gagagtgacc atctcctgca gcggctccag ctctaacatc ggcatcaatt tcgtgtactg 1980
gtatcagcac ctgccaggca cagctcccaa gctgctgatc tacaagaaca atcagaggcc 2040
ttccggcgtg ccagaccggt tctctggctc caagagcggc aactctgcct ccctggctat 2100
ctccggcctg cgcagcgagg acgaggctga ttactattgc gccgcttggg acgatagcct 2160
gtctggctac gtgttcggca gcggcacaaa ggtgaccgtg ctgggacagc caaaggctgc 2220
tccttctgtg acactgtttc ccccttccag cgaggagctg caggccaata aggccaccct 2280
ggtgtgcctg atcagcgact tctatcctgg agctgtgacc gtggcttgga aggctgattc 2340
ttccccagtg aaggctggcg tggagacaac aacccccagc aagcagtcta acaataagta 2400
cgccgctagc tcttatctgt ctctgacccc agagcagtgg aagtcccata ggtcctatag 2460
ctgtcangtc acccacgaag ggagcacagt cgaaaaaacc gtcgcaccaa ccgagtgttc 2520
ctgataagtt aacttgttta ttgcagctta taatggttac aaataaagca atagcatcac 2580
aaatttcaca aataaagcat ttttttcact gcattctagt tgtggtttgt ccaaactcat 2640
caatgtatct ta 2652
<210> 49
<211> 2984
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: CD38 DAR insert 2652 nt flanked by 5' 171 nt and 3'
161 nt TRAC exon 1 homology arms
<220>
<221> misc_feature
<222> (2638)..(2638)
<223> n is a, c, g, or t
<400> 49
atcacgagca gctggtttct aagatgctat ttcccgtata aagcatgaga ccgtgacttg 60
ccagccccac agagccccgc ccttgtccat cactggcatc tggactccag cctgggttgg 120
ggcaaagagg gaaatgagat catgtcctaa ccctgatcct cttgtcccac agaattcggg 180
cggagttagg gcggagccaa tcagcgtgcg ccgttccgaa agttgccttt tatggctggg 240
cggagaatgg gcggtgaacg ccgatgatta tataaggacg cgccgggtgt ggcacagcta 300
gttccgtcgc agccgggatt tgggtcgcgg ttcttgtttg tggatccctg tgatcgtcac 360
ttgacagtaa gtcactgact gtctatgcct gggaaagggt gggcaggaga tggggcagtg 420
caggaaaagt ggcactatga accctgcagc cctaggaatg catctagaca attgtactaa 480
ccttcttctc tttcctctcc tgacaggcct cgaggccgcc accatggagt ggagctgggt 540
gtttctgttc ttcctctccg tcacaaccgg cgtgcatagc caggtgcagc tggtggagtc 600
cggaggcggc ctggtgaaac ctggcggatc cctgaggctg tcctgcgccg ctagcggatt 660
caccttcagc gacgactaca tgagctggat caggcaggct cccggaaagg gcctggagtg 720
ggtcgctagc gtgagcaatg gccggcccac aacctactat gccgactccg tgcggggcag 780
gtttaccatc tccagggata acgctaagaa ctccctgtac ctgcagatga acagcctgcg 840
ggccgaagat accgccgtct actattgcgc cagggaggat tggggcggcg agttcacaga 900
ctggggaagg ggcaccctgg tgaccgtgag cagcgcttcc accaagggcc cctccgtgtt 960
ccctctggcc cccagcagca agagcacatc cggaggcacc gccgccctcg gatgtctggt 1020
gaaggactac ttccccgagc ctgtcaccgt gtcctggaat agcggcgccc tcacctccgg 1080
cgtgcacacc ttccccgctg tcctgcagtc ctccggactg tacagcctgt cctccgtcgt 1140
gaccgtgcct agctcctccc tcggcaccca gacctacatc tgcaacgtga accacaagcc 1200
ttccaacaca aaggtggaca aacgggtgga gcccaagtcc tgcgacaaaa cccacaccaa 1260
gatagaggtg atgtaccctc ccccctactt ggacaacgaa aagtctaatg gcactatcat 1320
tcacgtaaag ggcaaacacc tttgtccaag tcctttgttc ccaggcccat ctaagccgtt 1380
ctgggtactc gtggttgtgg ggggcgtgct cgcttgttac tcactgctgg tgacggtggc 1440
ctttattatt ttctgggtta aacggggcag aaagaaactc ctgtatatat tcaaacaacc 1500
atttatgaga ccagtacaaa ctactcaaga ggaagatggc tgtagctgcc gatttccaga 1560
agaagaagaa ggaggatgtg aactgagggt aaaatttagc aggtctgcag atgcgcctgc 1620
gtatcaacag ggtcagaatc agctctataa tgagctgaac ctcgggcggc gggaagagta 1680
tgatgttctc gataaaagga gaggacgaga ccccgaaatg ggcggcaaac cgagacgcaa 1740
aaatcctcag gaggggctct acaatgaact tcaaaaagac aaaatggccg aagcatactc 1800
agaaatcgga atgaaagggg agaggagacg cgggaagggc catgatggac tgtatcaggg 1860
actttccaca gccaccaagg acacctatga cgctctccac atgcaggccc tgccccctcg 1920
cggaagcgga gagggcagag gaagtctgct aacatgcggt gacgtcgagg agaatcctgg 1980
acctatgtcc gtccctaccc aggtgctggg cctgctgctg ctgtggctga ccgatgctag 2040
atgccagtcc gttctgaccc agcctccttc cgcctctggc acatccggcc agagagtgac 2100
catctcctgc agcggctcca gctctaacat cggcatcaat ttcgtgtact ggtatcagca 2160
cctgccaggc acagctccca agctgctgat ctacaagaac aatcagaggc cttccggcgt 2220
gccagaccgg ttctctggct ccaagagcgg caactctgcc tccctggcta tctccggcct 2280
gcgcagcgag gacgaggctg attactattg cgccgcttgg gacgatagcc tgtctggcta 2340
cgtgttcggc agcggcacaa aggtgaccgt gctgggacag ccaaaggctg ctccttctgt 2400
gacactgttt cccccttcca gcgaggagct gcaggccaat aaggccaccc tggtgtgcct 2460
gatcagcgac ttctatcctg gagctgtgac cgtggcttgg aaggctgatt cttccccagt 2520
gaaggctggc gtggagacaa caacccccag caagcagtct aacaataagt acgccgctag 2580
ctcttatctg tctctgaccc cagagcagtg gaagtcccat aggtcctata gctgtcangt 2640
cacccacgaa gggagcacag tcgaaaaaac cgtcgcacca accgagtgtt cctgataagt 2700
taacttgttt attgcagctt ataatggtta caaataaagc aatagcatca caaatttcac 2760
aaataaagca tttttttcac tgcattctag ttgtggtttg tccaaactca tcaatgtatc 2820
ttagatatcc agaaccctga ccctgccgtg taccagctga gagactctaa atccagtgac 2880
aagtctgtct gcctattcac cgattttgat tctcaaacaa atgtgtcaca aagtaaggat 2940
tctgatgtgt atatcacaga caaaactgtg ctagacatga ggtc 2984
<210> 50
<211> 645
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: 5' exon 1 TRAC gene homology flanking sequence, 645 bp
<400> 50
tgtaaggagc tgctgtgact tgctcaaggc cttatatcga gtaaacggta gtgctggggc 60
ttagacgcag gtgttctgat ttatagttca aaacctctat caatgagaga gcaatctcct 120
ggtaatgtga tagatttccc aacttaatgc caacatacca taaacctccc attctgctaa 180
tgcccagcct aagttgggga gaccactcca gattccaaga tgtacagttt gctttgctgg 240
gcctttttcc catgcctgcc tttactctgc cagagttata ttgctggggt tttgaagaag 300
atcctattaa ataaaagaat aagcagtatt attaagtagc cctgcatttc aggtttcctt 360
gagtggcagg ccaggcctgg ccgtgaacgt tcactgaaat catggcctct tggccaagat 420
tgatagcttg tgcctgtccc tgagtcccag tccatcacga gcagctggtt tctaagatgc 480
tatttcccgt ataaagcatg agaccgtgac ttgccagccc cacagagccc cgcccttgtc 540
catcactggc atctggactc cagcctgggt tggggcaaag agggaaatga gatcatgtcc 600
taaccctgat cctcttgtcc cacagatatc cagaaccctg accct 645
<210> 51
<211> 600
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: 3' exon 1 TRAC gene homology flanking sequence, exon 1
TRAC gene 600bp
<400> 51
gtaccagctg agagactcac tatccagtga caagtctgtc tgcctattca ccgattttga 60
ttctcaaaca aatgtgtcac aaagtaagga ttctgatgtg tatatcacag acaaaactgt 120
gctagacatg aggtctatgg acttcaagag caacagtgct gtggcctgga gcaacaaatc 180
tgactttgca tgtgcaaacg ccttcaacaa cagcattatt ccagaggaca ccttcttccc 240
cagcccaggt aagggcagct ttggtgcctt cgcaggctgt ttccttgctt caggaatggc 300
caggttctgc ccagagctct ggtcaatgat gtctaaaact cctctgattg gtggtctcgg 360
ccttatccat tgccaccaaa accctctttt tactaagaaa cagtgagcct tgttctggca 420
gtccagagaa tgacacggga aaaaagcaga tgaagagaag gtggcaggag agggcacgtg 480
gcccagcctc agtctctcca actgagttcc tgcctgcctg cctttgctca gactgtttgc 540
cccttactgc tcttctaggc ctcattctaa gccccttctc caagttgcct ctccttattt 600
<210> 52
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Cas12a target site in exon 1 of the TRAC gene
<400> 52
gagtctctca gctggtacac g 21
<210> 53
<211> 4497
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Anti-CD38 DAR construct flanked by 645 bp and 600 bp
homology sequences from TRAC locus
<220>
<221> misc_feature
<222> (3112)..(3112)
<223> n is a, c, g, or t
<400> 53
tgtaaggagc tgctgtgact tgctcaaggc cttatatcga gtaaacggta gtgctggggc 60
ttagacgcag gtgttctgat ttatagttca aaacctctat caatgagaga gcaatctcct 120
ggtaatgtga tagatttccc aacttaatgc caacatacca taaacctccc attctgctaa 180
tgcccagcct aagttgggga gaccactcca gattccaaga tgtacagttt gctttgctgg 240
gcctttttcc catgcctgcc tttactctgc cagagttata ttgctggggt tttgaagaag 300
atcctattaa ataaaagaat aagcagtatt attaagtagc cctgcatttc aggtttcctt 360
gagtggcagg ccaggcctgg ccgtgaacgt tcactgaaat catggcctct tggccaagat 420
tgatagcttg tgcctgtccc tgagtcccag tccatcacga gcagctggtt tctaagatgc 480
tatttcccgt ataaagcatg agaccgtgac ttgccagccc cacagagccc cgcccttgtc 540
catcactggc atctggactc cagcctgggt tggggcaaag agggaaatga gatcatgtcc 600
taaccctgat cctcttgtcc cacagatatc cagaaccctg accctgaatt cgggcggagt 660
tagggcggag ccaatcagcg tgcgccgttc cgaaagttgc cttttatggc tgggcggaga 720
atgggcggtg aacgccgatg attatataag gacgcgccgg gtgtggcaca gctagttccg 780
tcgcagccgg gatttgggtc gcggttcttg tttgtggatc cctgtgatcg tcacttgaca 840
gtaagtcact gactgtctat gcctgggaaa gggtgggcag gagatggggc agtgcaggaa 900
aagtggcact atgaaccctg cagccctagg aatgcatcta gacaattgta ctaaccttct 960
tctctttcct ctcctgacag gcctcgaggc cgccaccatg gagtggagct gggtgtttct 1020
gttcttcctc tccgtcacaa ccggcgtgca tagccaggtg cagctggtgg agtccggagg 1080
cggcctggtg aaacctggcg gatccctgag gctgtcctgc gccgctagcg gattcacctt 1140
cagcgacgac tacatgagct ggatcaggca ggctcccgga aagggcctgg agtgggtcgc 1200
tagcgtgagc aatggccggc ccacaaccta ctatgccgac tccgtgcggg gcaggtttac 1260
catctccagg gataacgcta agaactccct gtacctgcag atgaacagcc tgcgggccga 1320
agataccgcc gtctactatt gcgccaggga ggattggggc ggcgagttca cagactgggg 1380
aaggggcacc ctggtgaccg tgagcagcgc ttccaccaag ggcccctccg tgttccctct 1440
ggcccccagc agcaagagca catccggagg caccgccgcc ctcggatgtc tggtgaagga 1500
ctacttcccc gagcctgtca ccgtgtcctg gaatagcggc gccctcacct ccggcgtgca 1560
caccttcccc gctgtcctgc agtcctccgg actgtacagc ctgtcctccg tcgtgaccgt 1620
gcctagctcc tccctcggca cccagaccta catctgcaac gtgaaccaca agccttccaa 1680
cacaaaggtg gacaaacggg tggagcccaa gtcctgcgac aaaacccaca ccaagataga 1740
ggtgatgtac cctcccccct acttggacaa cgaaaagtct aatggcacta tcattcacgt 1800
aaagggcaaa cacctttgtc caagtccttt gttcccaggc ccatctaagc cgttctgggt 1860
actcgtggtt gtggggggcg tgctcgcttg ttactcactg ctggtgacgg tggcctttat 1920
tattttctgg gttaaacggg gcagaaagaa actcctgtat atattcaaac aaccatttat 1980
gagaccagta caaactactc aagaggaaga tggctgtagc tgccgatttc cagaagaaga 2040
agaaggagga tgtgaactga gggtaaaatt tagcaggtct gcagatgcgc ctgcgtatca 2100
acagggtcag aatcagctct ataatgagct gaacctcggg cggcgggaag agtatgatgt 2160
tctcgataaa aggagaggac gagaccccga aatgggcggc aaaccgagac gcaaaaatcc 2220
tcaggagggg ctctacaatg aacttcaaaa agacaaaatg gccgaagcat actcagaaat 2280
cggaatgaaa ggggagagga gacgcgggaa gggccatgat ggactgtatc agggactttc 2340
cacagccacc aaggacacct atgacgctct ccacatgcag gccctgcccc ctcgcggaag 2400
cggagagggc agaggaagtc tgctaacatg cggtgacgtc gaggagaatc ctggacctat 2460
gtccgtccct acccaggtgc tgggcctgct gctgctgtgg ctgaccgatg ctagatgcca 2520
gtccgttctg acccagcctc cttccgcctc tggcacatcc ggccagagag tgaccatctc 2580
ctgcagcggc tccagctcta acatcggcat caatttcgtg tactggtatc agcacctgcc 2640
aggcacagct cccaagctgc tgatctacaa gaacaatcag aggccttccg gcgtgccaga 2700
ccggttctct ggctccaaga gcggcaactc tgcctccctg gctatctccg gcctgcgcag 2760
cgaggacgag gctgattact attgcgccgc ttgggacgat agcctgtctg gctacgtgtt 2820
cggcagcggc acaaaggtga ccgtgctggg acagccaaag gctgctcctt ctgtgacact 2880
gtttccccct tccagcgagg agctgcaggc caataaggcc accctggtgt gcctgatcag 2940
cgacttctat cctggagctg tgaccgtggc ttggaaggct gattcttccc cagtgaaggc 3000
tggcgtggag acaacaaccc ccagcaagca gtctaacaat aagtacgccg ctagctctta 3060
tctgtctctg accccagagc agtggaagtc ccataggtcc tatagctgtc angtcaccca 3120
cgaagggagc acagtcgaaa aaaccgtcgc accaaccgag tgttcctgat aagttaactt 3180
gtttattgca gcttataatg gttacaaata aagcaatagc atcacaaatt tcacaaataa 3240
agcatttttt tcactgcatt ctagttgtgg tttgtccaaa ctcatcaatg tatcttagta 3300
ccagctgaga gactcactat ccagtgacaa gtctgtctgc ctattcaccg attttgattc 3360
tcaaacaaat gtgtcacaaa gtaaggattc tgatgtgtat atcacagaca aaactgtgct 3420
agacatgagg tctatggact tcaagagcaa cagtgctgtg gcctggagca acaaatctga 3480
ctttgcatgt gcaaacgcct tcaacaacag cattattcca gaggacacct tcttccccag 3540
cccaggtaag ggcagctttg gtgccttcgc aggctgtttc cttgcttcag gaatggccag 3600
gttctgccca gagctctggt caatgatgtc taaaactcct ctgattggtg gtctcggcct 3660
tatccattgc caccaaaacc ctctttttac taagaaacag tgagccttgt tctggcagtc 3720
cagagaatga cacgggaaaa aagcagatga agagaaggtg gcaggagagg gcacgtggcc 3780
cagcctcagt ctctccaact gagttcctgc ctgcctgcct ttgctcagac tgtttgcccc 3840
ttactgctct tctaggcctc attctaagcc ccttctccaa gttgcctctc cttatttgta 3900
ccagctgaga gactcactat ccagtgacaa gtctgtctgc ctattcaccg attttgattc 3960
tcaaacaaat gtgtcacaaa gtaaggattc tgatgtgtat atcacagaca aaactgtgct 4020
agacatgagg tctatggact tcaagagcaa cagtgctgtg gcctggagca acaaatctga 4080
ctttgcatgt gcaaacgcct tcaacaacag cattattcca gaggacacct tcttccccag 4140
cccaggtaag ggcagctttg gtgccttcgc aggctgtttc cttgcttcag gaatggccag 4200
gttctgccca gagctctggt caatgatgtc taaaactcct ctgattggtg gtctcggcct 4260
tatccattgc caccaaaacc ctctttttac taagaaacag tgagccttgt tctggcagtc 4320
cagagaatga cacgggaaaa aagcagatga agagaaggtg gcaggagagg gcacgtggcc 4380
cagcctcagt ctctccaact gagttcctgc ctgcctgcct ttgctcagac tgtttgcccc 4440
ttactgctct tctaggcctc attctaagcc ccttctccaa gttgcctctc cttattt 4497
<210> 54
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Reverse primer for producing donor DNA for insertion
into TRAC exon 1 using cas12a
<220>
<221> modified_base
<222> (1)..(2)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (1)..(3)
<223> 2'-O-methylated
<220>
<221> modified_base
<222> (2)..(3)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (3)..(4)
<223> Phosphorothioate linkage
<400> 54
gcactgttgc tcttgaagtc c 21
<210> 55
<211> 192
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: PCR synthesized 5' homology arm, 192 nts
<400> 55
atcacgagca gctggtttct aagatgctat ttcccgtata aagcatgaga ccgtgacttg 60
ccagccccac agagccccgc ccttgtccat cactggcatc tggactccag cctgggttgg 120
ggcaaagagg gaaatgagat catgtcctaa ccctgatcct cttgtcccac agatatccag 180
aaccctgacc ct 192
<210> 56
<211> 159
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: PCR synthesized 3' homology arm, 159 nts
<400> 56
gtaccagctg agagactcac tatccagtga caagtctgtc tgcctattca ccgattttga 60
ttctcaaaca aatgtgtcac aaagtaagga ttctgatgtg tatatcacag acaaaactgt 120
gctagacatg aggtctatgg acttcaagag caacagtgc 159
<210> 57
<211> 3003
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Anti-CD38 DAR donor DNA, 30003 nucleotides
<220>
<221> misc_feature
<222> (2659)..(2659)
<223> n is a, c, g, or t
<400> 57
atcacgagca gctggtttct aagatgctat ttcccgtata aagcatgaga ccgtgacttg 60
ccagccccac agagccccgc ccttgtccat cactggcatc tggactccag cctgggttgg 120
ggcaaagagg gaaatgagat catgtcctaa ccctgatcct cttgtcccac agatatccag 180
aaccctgacc ctgaattcgg gcggagttag ggcggagcca atcagcgtgc gccgttccga 240
aagttgcctt ttatggctgg gcggagaatg ggcggtgaac gccgatgatt atataaggac 300
gcgccgggtg tggcacagct agttccgtcg cagccgggat ttgggtcgcg gttcttgttt 360
gtggatccct gtgatcgtca cttgacagta agtcactgac tgtctatgcc tgggaaaggg 420
tgggcaggag atggggcagt gcaggaaaag tggcactatg aaccctgcag ccctaggaat 480
gcatctagac aattgtacta accttcttct ctttcctctc ctgacaggcc tcgaggccgc 540
caccatggag tggagctggg tgtttctgtt cttcctctcc gtcacaaccg gcgtgcatag 600
ccaggtgcag ctggtggagt ccggaggcgg cctggtgaaa cctggcggat ccctgaggct 660
gtcctgcgcc gctagcggat tcaccttcag cgacgactac atgagctgga tcaggcaggc 720
tcccggaaag ggcctggagt gggtcgctag cgtgagcaat ggccggccca caacctacta 780
tgccgactcc gtgcggggca ggtttaccat ctccagggat aacgctaaga actccctgta 840
cctgcagatg aacagcctgc gggccgaaga taccgccgtc tactattgcg ccagggagga 900
ttggggcggc gagttcacag actggggaag gggcaccctg gtgaccgtga gcagcgcttc 960
caccaagggc ccctccgtgt tccctctggc ccccagcagc aagagcacat ccggaggcac 1020
cgccgccctc ggatgtctgg tgaaggacta cttccccgag cctgtcaccg tgtcctggaa 1080
tagcggcgcc ctcacctccg gcgtgcacac cttccccgct gtcctgcagt cctccggact 1140
gtacagcctg tcctccgtcg tgaccgtgcc tagctcctcc ctcggcaccc agacctacat 1200
ctgcaacgtg aaccacaagc cttccaacac aaaggtggac aaacgggtgg agcccaagtc 1260
ctgcgacaaa acccacacca agatagaggt gatgtaccct cccccctact tggacaacga 1320
aaagtctaat ggcactatca ttcacgtaaa gggcaaacac ctttgtccaa gtcctttgtt 1380
cccaggccca tctaagccgt tctgggtact cgtggttgtg gggggcgtgc tcgcttgtta 1440
ctcactgctg gtgacggtgg cctttattat tttctgggtt aaacggggca gaaagaaact 1500
cctgtatata ttcaaacaac catttatgag accagtacaa actactcaag aggaagatgg 1560
ctgtagctgc cgatttccag aagaagaaga aggaggatgt gaactgaggg taaaatttag 1620
caggtctgca gatgcgcctg cgtatcaaca gggtcagaat cagctctata atgagctgaa 1680
cctcgggcgg cgggaagagt atgatgttct cgataaaagg agaggacgag accccgaaat 1740
gggcggcaaa ccgagacgca aaaatcctca ggaggggctc tacaatgaac ttcaaaaaga 1800
caaaatggcc gaagcatact cagaaatcgg aatgaaaggg gagaggagac gcgggaaggg 1860
ccatgatgga ctgtatcagg gactttccac agccaccaag gacacctatg acgctctcca 1920
catgcaggcc ctgccccctc gcggaagcgg agagggcaga ggaagtctgc taacatgcgg 1980
tgacgtcgag gagaatcctg gacctatgtc cgtccctacc caggtgctgg gcctgctgct 2040
gctgtggctg accgatgcta gatgccagtc cgttctgacc cagcctcctt ccgcctctgg 2100
cacatccggc cagagagtga ccatctcctg cagcggctcc agctctaaca tcggcatcaa 2160
tttcgtgtac tggtatcagc acctgccagg cacagctccc aagctgctga tctacaagaa 2220
caatcagagg ccttccggcg tgccagaccg gttctctggc tccaagagcg gcaactctgc 2280
ctccctggct atctccggcc tgcgcagcga ggacgaggct gattactatt gcgccgcttg 2340
ggacgatagc ctgtctggct acgtgttcgg cagcggcaca aaggtgaccg tgctgggaca 2400
gccaaaggct gctccttctg tgacactgtt tcccccttcc agcgaggagc tgcaggccaa 2460
taaggccacc ctggtgtgcc tgatcagcga cttctatcct ggagctgtga ccgtggcttg 2520
gaaggctgat tcttccccag tgaaggctgg cgtggagaca acaaccccca gcaagcagtc 2580
taacaataag tacgccgcta gctcttatct gtctctgacc ccagagcagt ggaagtccca 2640
taggtcctat agctgtcang tcacccacga agggagcaca gtcgaaaaaa ccgtcgcacc 2700
aaccgagtgt tcctgataag ttaacttgtt tattgcagct tataatggtt acaaataaag 2760
caatagcatc acaaatttca caaataaagc atttttttca ctgcattcta gttgtggttt 2820
gtccaaactc atcaatgtat cttagtacca gctgagagac tcactatcca gtgacaagtc 2880
tgtctgccta ttcaccgatt ttgattctca aacaaatgtg tcacaaagta aggattctga 2940
tgtgtatatc acagacaaaa ctgtgctaga catgaggtct atggacttca agagcaacag 3000
tgc 3003
<210> 58
<211> 645
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(645)
<223> 5'HA 645bp, Tim3 locus
<400> 58
gttaggagag cctccctttg ttgatgaaca agcaagtagc ccagatgggc gggccgtttc 60
ctggctgacc atgactaatt ttctgattgt ctgtttccat cagccctgtt ctcccgtgtt 120
cacagaattg ggccacaatt ctctcctagg gcagtgtttc tgaaagtgag gttctgagac 180
cagccacttc agcaacactt gagaacttgt tagaaataaa agttctcagg ctctaccaca 240
ggccaactga gtcaggaact ctagcagttg agcccagcaa tctgtgtttt cgcaaggctt 300
cccagtgatt ctgatggcct tcacatctga gaagcattgt cacagcgaat catcctccaa 360
acaggactgc agcagtagct tcctctttat tctgtaagac atggcttgca gttttcctga 420
aatggagtaa cctcactcac cgcttgagtc ttggctctcc ttctctctct atgcagggtc 480
ctcagaagtg gaatacagag cggaggtcgg tcagaatgcc tatctgccct gcttctacac 540
cccagccgcc ccagggaacc tcgtgcccgt ctgctggggc aaaggagcct gtcctgtgtt 600
tgaatgtggc aacgtggtgc tcaggactga tgaaagggat gtgaa 645
<210> 59
<211> 600
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(600)
<223> 3'HA 600bp, Tim3 locus
<400> 59
ggacatccag atactggctt cttggggatt tccgcaaagg agatgtgtcc ctgaccatag 60
agaatgtgac tctagcagac agtgggatct actgctgccg gatccaaatc ccaggcataa 120
tgaatgatga aaaatttaac ctgaagttgg tcatcaaacc aggtgagtgg acatttgcat 180
gccatcttta tgaataagat ttatctgtgg atcatattaa aggtactgat tgttctcatc 240
tctgacttcc ctaattatag ccctggagga gggccactaa gacctaaagt ttaacaggcc 300
ccattggtga tgctcagtga tatttaacac cttctctctg ttttaaaact catgggtgtg 360
cctgggcgtg gtggctcaca cctctaatcc cagcactttg ggaggctgag gccggtggat 420
catgaggtca ggaattcgag accagcctgg ccaacatagt aaaaccttgt ctccactaaa 480
aatacaaaaa attagccagg catggttacg ggagcctgta attctagcta cttggggggc 540
tgaagcagga gaatcacttg aacctgggag tcggaggttg tggtaagcca agatctcgcc 600
<210> 60
<211> 21
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<222> (1)..(21)
<223> TIM-3 cas12a target site
<400> 60
gccagtatct ggatgtccaa t 21
<210> 61
<211> 20
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<223> 5' phosphate
<220>
<221> misc_feature
<222> (1)..(20)
<223> TIM3 Forward primer for making donor DNA
<400> 61
tggaatacag agcggaggtc 20
<210> 62
<211> 20
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (1)..(2)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (1)..(3)
<223> 2'-O-methylated
<220>
<221> misc_feature
<222> (1)..(20)
<223> TIM3 Reverse primer for making donor DNA
<220>
<221> modified_base
<222> (2)..(3)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (3)..(4)
<223> Phosphorothioate linkage
<400> 62
gcatgcaaat gtccactcac 20
<210> 63
<211> 2991
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: TIM3 donor DNA
<220>
<221> misc_feature
<222> (2624)..(2624)
<223> n is a, c, g, or t
<400> 63
tggaatacag agcggaggtc ggtcagaatg cctatctgcc ctgcttctac accccagccg 60
ccccagggaa cctcgtgccc gtctgctggg gcaaaggagc ctgtcctgtg tttgaatgtg 120
gcaacgtggt gctcaggact gatgaaaggg atgtgaagaa ttcgggcgga gttagggcgg 180
agccaatcag cgtgcgccgt tccgaaagtt gccttttatg gctgggcgga gaatgggcgg 240
tgaacgccga tgattatata aggacgcgcc gggtgtggca cagctagttc cgtcgcagcc 300
gggatttggg tcgcggttct tgtttgtgga tccctgtgat cgtcacttga cagtaagtca 360
ctgactgtct atgcctggga aagggtgggc aggagatggg gcagtgcagg aaaagtggca 420
ctatgaaccc tgcagcccta ggaatgcatc tagacaattg tactaacctt cttctctttc 480
ctctcctgac aggcctcgag gccgccacca tggagtggag ctgggtgttt ctgttcttcc 540
tctccgtcac aaccggcgtg catagccagg tgcagctggt ggagtccgga ggcggcctgg 600
tgaaacctgg cggatccctg aggctgtcct gcgccgctag cggattcacc ttcagcgacg 660
actacatgag ctggatcagg caggctcccg gaaagggcct ggagtgggtc gctagcgtga 720
gcaatggccg gcccacaacc tactatgccg actccgtgcg gggcaggttt accatctcca 780
gggataacgc taagaactcc ctgtacctgc agatgaacag cctgcgggcc gaagataccg 840
ccgtctacta ttgcgccagg gaggattggg gcggcgagtt cacagactgg ggaaggggca 900
ccctggtgac cgtgagcagc gcttccacca agggcccctc cgtgttccct ctggccccca 960
gcagcaagag cacatccgga ggcaccgccg ccctcggatg tctggtgaag gactacttcc 1020
ccgagcctgt caccgtgtcc tggaatagcg gcgccctcac ctccggcgtg cacaccttcc 1080
ccgctgtcct gcagtcctcc ggactgtaca gcctgtcctc cgtcgtgacc gtgcctagct 1140
cctccctcgg cacccagacc tacatctgca acgtgaacca caagccttcc aacacaaagg 1200
tggacaaacg ggtggagccc aagtcctgcg acaaaaccca caccaagata gaggtgatgt 1260
accctccccc ctacttggac aacgaaaagt ctaatggcac tatcattcac gtaaagggca 1320
aacacctttg tccaagtcct ttgttcccag gcccatctaa gccgttctgg gtactcgtgg 1380
ttgtgggggg cgtgctcgct tgttactcac tgctggtgac ggtggccttt attattttct 1440
gggttaaacg gggcagaaag aaactcctgt atatattcaa acaaccattt atgagaccag 1500
tacaaactac tcaagaggaa gatggctgta gctgccgatt tccagaagaa gaagaaggag 1560
gatgtgaact gagggtaaaa tttagcaggt ctgcagatgc gcctgcgtat caacagggtc 1620
agaatcagct ctataatgag ctgaacctcg ggcggcggga agagtatgat gttctcgata 1680
aaaggagagg acgagacccc gaaatgggcg gcaaaccgag acgcaaaaat cctcaggagg 1740
ggctctacaa tgaacttcaa aaagacaaaa tggccgaagc atactcagaa atcggaatga 1800
aaggggagag gagacgcggg aagggccatg atggactgta tcagggactt tccacagcca 1860
ccaaggacac ctatgacgct ctccacatgc aggccctgcc ccctcgcgga agcggagagg 1920
gcagaggaag tctgctaaca tgcggtgacg tcgaggagaa tcctggacct atgtccgtcc 1980
ctacccaggt gctgggcctg ctgctgctgt ggctgaccga tgctagatgc cagtccgttc 2040
tgacccagcc tccttccgcc tctggcacat ccggccagag agtgaccatc tcctgcagcg 2100
gctccagctc taacatcggc atcaatttcg tgtactggta tcagcacctg ccaggcacag 2160
ctcccaagct gctgatctac aagaacaatc agaggccttc cggcgtgcca gaccggttct 2220
ctggctccaa gagcggcaac tctgcctccc tggctatctc cggcctgcgc agcgaggacg 2280
aggctgatta ctattgcgcc gcttgggacg atagcctgtc tggctacgtg ttcggcagcg 2340
gcacaaaggt gaccgtgctg ggacagccaa aggctgctcc ttctgtgaca ctgtttcccc 2400
cttccagcga ggagctgcag gccaataagg ccaccctggt gtgcctgatc agcgacttct 2460
atcctggagc tgtgaccgtg gcttggaagg ctgattcttc cccagtgaag gctggcgtgg 2520
agacaacaac ccccagcaag cagtctaaca ataagtacgc cgctagctct tatctgtctc 2580
tgaccccaga gcagtggaag tcccataggt cctatagctg tcangtcacc cacgaaggga 2640
gcacagtcga aaaaaccgtc gcaccaaccg agtgttcctg ataagttaac ttgtttattg 2700
cagcttataa tggttacaaa taaagcaata gcatcacaaa tttcacaaat aaagcatttt 2760
tttcactgca ttctagttgt ggtttgtcca aactcatcaa tgtatcttag gacatccaga 2820
tactggcttc ttggggattt ccgcaaagga gatgtgtccc tgaccataga gaatgtgact 2880
ctagcagaca gtgggatcta ctgctgccgg atccaaatcc caggcataat gaatgatgaa 2940
aaatttaacc tgaagttggt catcaaacca ggtgagtgga catttgcatg c 2991
<210> 64
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: forward primer for sequencing across 5' homology arm
of anti-CD38 CAR in TRAC exon 3 locus
<400> 64
ctcctgaatc cctctcacca 20
<210> 65
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: reverse primer for sequencing across 5' homology arm
of anti-CD38 CAR in TRAC exon 3 locus
<400> 65
gcggatccag ctcatgtagt 20
<210> 66
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: forward primer for sequencing across 3' homology arm
of anti-CD38 CAR in TRAC exon 3 locus
<400> 66
cgttctgggt actcgtggtt 20
<210> 67
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: reverse primer for sequencing across 3' homology arm
of anti-CD38 CAR in TRAC exon 3 locus
<400> 67
ggagcacagg ctgtcttaca 20
<210> 68
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: forward primer for sequencing across 5' homology arm
of anti-CD38 CAR in PD-1 locus
<400> 68
gtgtgaggcc atccacaag 19
<210> 69
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: reverse primer for sequencing across 5' homology arm
of anti-CD38 CAR in PD-1 locus
<400> 69
acacacttgc gacccattc 19
<210> 70
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: forward primer for sequencing across 3' homology arm
of anti-CD38 CAR in PD-1 locus
<400> 70
cgttctgggt actcgtggtt 20
<210> 71
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: reverse primer for sequencing across 3' homology arm
of anti-CD38 CAR in PD-1 locus
<400> 71
gggactgtct taggcttgg 19
<210> 72
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: forward primer for sequencing across 5' homology arm
of anti-CD38 DAR in TRAC exon 1 locus
<400> 72
cctgctttct gagggtgaag 20
<210> 73
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: reverse primer for sequencing across 5' homology arm
of anti-CD38 DAR in TRAC exon 1 locus
<400> 73
cagctcatgt agtcgtcgct 20
<210> 74
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: forward primer for sequencing across 3' homology arm
of anti-CD38 DAR in TRAC exon 1 locus
<400> 74
ggaatgaaag gggagaggag 20
<210> 75
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: reverse primer for sequencing across 3' homology arm
of anti-CD38 DAR in TRAC exon 1 locus
<400> 75
gagagccctt ccctgacttt 20
<210> 76
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: forward primer for sequencing across 5' homology arm
of anti-CD38 DAR in TRAC exon 1 locus at Cas12a target site
<400> 76
cctgctttct gagggtgaag 20
<210> 77
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: reverse primer for sequencing across 5' homology arm
of anti-CD38 DAR in TRAC exon 1 locus at Cas12a target site
<400> 77
cagctcatgt agtcgtcgct 20
<210> 78
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: forward primer for sequencing across 3' homology arm
of anti-CD38 DAR in TRAC exon 1 locus at Cas12a target site
<400> 78
ggaatgaaag gggagaggag 20
<210> 79
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: reverse primer for sequencing across 3' homology arm
of anti-CD38 DAR in TRAC exon 1 locus
<400> 79
gagagccctt ccctgacttt 20
<210> 80
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: GM-CSF cas12a target site
<400> 80
tacagaatga aacagtagaa g 21
<210> 81
<211> 2457
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Anti-CD20 DAR construct
<400> 81
gaattcgggc ggagttaggg cggagccaat cagcgtgcgc cgttccgaaa gttgcctttt 60
atggctgggc ggagaatggg cggtgaacgc cgatgattat ataaggacgc gccgggtgtg 120
gcacagctag ttccgtcgca gccgggattt gggtcgcggt tcttgtttgt ggatccctgt 180
gatcgtcact tgacagtaag tcactgactg tctatgcctg ggaaagggtg ggcaggagat 240
ggggcagtgc aggaaaagtg gcactatgaa ccctgcagcc ctaggaatgc atctagacaa 300
ttgtactaac cttcttctct ttcctctcct gacaggcctc gaggccgcca ccatggagtg 360
gagctgggtg tttctgttct tcctctccgt cacaaccggc gtgcatagcc aagtgcaatt 420
gcagcagccc ggtgccgaac tcgtgaaacc aggagcaagc gtaaagatgt cctgtaaggc 480
atcaggttat acctttacca gctacaacat gcactgggtg aaacaaacgc cggggcgggg 540
cctcgaatgg ataggcgcga tatatcccgg aaatggcgat accagttaca atcagaagtt 600
caaaggcaaa gcgacactga cagctgataa gtcttcaagc accgcctata tgcaactttc 660
tagcctgacc agcgaagact ccgccgttta ttactgtgct cggtccacat actacggagg 720
cgattggtac tttaatgtgt ggggtgcggg caccactgtc actgtatcag cggcttccac 780
caagggcccc tccgtgttcc ctctggcccc cagcagcaag agcacatccg gaggcaccgc 840
cgccctcgga tgtctggtga aggactactt ccccgagcct gtcaccgtgt cctggaatag 900
cggcgccctc acctccggcg tgcacacctt ccccgctgtc ctgcagtcct ccggactgta 960
cagcctgtcc tccgtcgtga ccgtgcctag ctcctccctc ggcacccaga cctacatctg 1020
caacgtgaac cacaagcctt ccaacacaaa ggtggacaaa cgggtggagc ccaagtcctg 1080
cgacaaaacc cacaccccca gaaagataga ggtgatgtac cctcccccct acttggacaa 1140
cgaaaagtct aatggcacta tcattcacgt aaagggcaaa cacctttgtc caagtccttt 1200
gttcccaggc ccatctaagc cgttctgggt actcgtggtt gtggggggcg tgctcgcttg 1260
ttactcactg ctggtgacgg tggcctttat tattttctgg gttaaacggg gcagaaagaa 1320
actcctgtat atattcaaac aaccatttat gagaccagta caaactactc aagaggaaga 1380
tggctgtagc tgccgatttc cagaagaaga agaaggagga tgtgaactga gggtaaaatt 1440
tagcaggtct gcagataaag gggagaggag acgcgggaag ggccatgatg gactgtatca 1500
gggactttcc acagccacca aggacaccta tgacgctctc cacatgcagg ccctgccccc 1560
tcgcggaagc ggagagggca gaggaagtct gctaacatgc ggtgacgtcg aggagaatcc 1620
tggacctatg tccgtcccta cccaggtgct gggcctgctg ctgctgtggc tgaccgatgc 1680
tagatgccag atagtcctga gccaatcacc ggccatcttg tctgcctctc ctggcgaaaa 1740
ggtgacgatg acttgcagag ccagtagctc tgtaagctat atacactggt tccagcaaaa 1800
accgggctct tctccgaagc cgtggatata cgcaacttca aacctggcgt ctggggttcc 1860
tgtaaggttt agcggcagcg gttcaggcac gagctacagc cttactatct cccgggttga 1920
ggctgaagat gcagccacat actactgtca gcagtggact tcaaatccac ctacattcgg 1980
gggaggcacg aagctggaga ttaaacgaac cgttgcggcg cctagtgtgt tcatattccc 2040
gccgtctgat gaacaactca agtctggaac ggcaagtgtg gtgtgtctcc tgaataattt 2100
ttatcctagg gaagcaaagg tgcagtggaa agtcgataac gcattgcaaa gcggtaacag 2160
tcaagaatct gtaactgaac aagattctaa agattctacc tacagtctct cctccacatt 2220
gaccctgtca aaagcagatt atgagaagca caaggtgtac gcatgtgagg taacacatca 2280
aggactcagc agcccagtta caaaaagttt caatcgcggg gaatgttgat aagttaactt 2340
gtttattgca gcttataatg gttacaaata aagcaatagc atcacaaatt tcacaaataa 2400
agcatttttt tcactgcatt ctagttgtgg tttgtccaaa ctcatcaatg tatctta 2457
<210> 82
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: forward primer for generating donor DNA, includes 5'
phosphate
<220>
<221> misc_feature
<223> 5' phosphate
<400> 82
atcacgagca gctggtttct 20
<210> 83
<211> 2808
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Anti-CD20 DAR donor DNA including 5' homology arm,
anti-CD20 DAR construct, and 3' homology arm
<400> 83
atcacgagca gctggtttct aagatgctat ttcccgtata aagcatgaga ccgtgacttg 60
ccagccccac agagccccgc ccttgtccat cactggcatc tggactccag cctgggttgg 120
ggcaaagagg gaaatgagat catgtcctaa ccctgatcct cttgtcccac agatatccag 180
aaccctgacc ctgaattcgg gcggagttag ggcggagcca atcagcgtgc gccgttccga 240
aagttgcctt ttatggctgg gcggagaatg ggcggtgaac gccgatgatt atataaggac 300
gcgccgggtg tggcacagct agttccgtcg cagccgggat ttgggtcgcg gttcttgttt 360
gtggatccct gtgatcgtca cttgacagta agtcactgac tgtctatgcc tgggaaaggg 420
tgggcaggag atggggcagt gcaggaaaag tggcactatg aaccctgcag ccctaggaat 480
gcatctagac aattgtacta accttcttct ctttcctctc ctgacaggcc tcgaggccgc 540
caccatggag tggagctggg tgtttctgtt cttcctctcc gtcacaaccg gcgtgcatag 600
ccaagtgcaa ttgcagcagc ccggtgccga actcgtgaaa ccaggagcaa gcgtaaagat 660
gtcctgtaag gcatcaggtt atacctttac cagctacaac atgcactggg tgaaacaaac 720
gccggggcgg ggcctcgaat ggataggcgc gatatatccc ggaaatggcg ataccagtta 780
caatcagaag ttcaaaggca aagcgacact gacagctgat aagtcttcaa gcaccgccta 840
tatgcaactt tctagcctga ccagcgaaga ctccgccgtt tattactgtg ctcggtccac 900
atactacgga ggcgattggt actttaatgt gtggggtgcg ggcaccactg tcactgtatc 960
agcggcttcc accaagggcc cctccgtgtt ccctctggcc cccagcagca agagcacatc 1020
cggaggcacc gccgccctcg gatgtctggt gaaggactac ttccccgagc ctgtcaccgt 1080
gtcctggaat agcggcgccc tcacctccgg cgtgcacacc ttccccgctg tcctgcagtc 1140
ctccggactg tacagcctgt cctccgtcgt gaccgtgcct agctcctccc tcggcaccca 1200
gacctacatc tgcaacgtga accacaagcc ttccaacaca aaggtggaca aacgggtgga 1260
gcccaagtcc tgcgacaaaa cccacacccc cagaaagata gaggtgatgt accctccccc 1320
ctacttggac aacgaaaagt ctaatggcac tatcattcac gtaaagggca aacacctttg 1380
tccaagtcct ttgttcccag gcccatctaa gccgttctgg gtactcgtgg ttgtgggggg 1440
cgtgctcgct tgttactcac tgctggtgac ggtggccttt attattttct gggttaaacg 1500
gggcagaaag aaactcctgt atatattcaa acaaccattt atgagaccag tacaaactac 1560
tcaagaggaa gatggctgta gctgccgatt tccagaagaa gaagaaggag gatgtgaact 1620
gagggtaaaa tttagcaggt ctgcagataa aggggagagg agacgcggga agggccatga 1680
tggactgtat cagggacttt ccacagccac caaggacacc tatgacgctc tccacatgca 1740
ggccctgccc cctcgcggaa gcggagaggg cagaggaagt ctgctaacat gcggtgacgt 1800
cgaggagaat cctggaccta tgtccgtccc tacccaggtg ctgggcctgc tgctgctgtg 1860
gctgaccgat gctagatgcc agatagtcct gagccaatca ccggccatct tgtctgcctc 1920
tcctggcgaa aaggtgacga tgacttgcag agccagtagc tctgtaagct atatacactg 1980
gttccagcaa aaaccgggct cttctccgaa gccgtggata tacgcaactt caaacctggc 2040
gtctggggtt cctgtaaggt ttagcggcag cggttcaggc acgagctaca gccttactat 2100
ctcccgggtt gaggctgaag atgcagccac atactactgt cagcagtgga cttcaaatcc 2160
acctacattc gggggaggca cgaagctgga gattaaacga accgttgcgg cgcctagtgt 2220
gttcatattc ccgccgtctg atgaacaact caagtctgga acggcaagtg tggtgtgtct 2280
cctgaataat ttttatccta gggaagcaaa ggtgcagtgg aaagtcgata acgcattgca 2340
aagcggtaac agtcaagaat ctgtaactga acaagattct aaagattcta cctacagtct 2400
ctcctccaca ttgaccctgt caaaagcaga ttatgagaag cacaaggtgt acgcatgtga 2460
ggtaacacat caaggactca gcagcccagt tacaaaaagt ttcaatcgcg gggaatgttg 2520
ataagttaac ttgtttattg cagcttataa tggttacaaa taaagcaata gcatcacaaa 2580
tttcacaaat aaagcatttt tttcactgca ttctagttgt ggtttgtcca aactcatcaa 2640
tgtatcttag taccagctga gagactcact atccagtgac aagtctgtct gcctattcac 2700
cgattttgat tctcaaacaa atgtgtcaca aagtaaggat tctgatgtgt atatcacaga 2760
caaaactgtg ctagacatga ggtctatgga cttcaagagc aacagtgc 2808
<210> 84
<211> 2077
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Anti-CEA CAR construct
<400> 84
gaattcgggc ggagttaggg cggagccaat cagcgtgcgc cgttccgaaa gttgcctttt 60
atggctgggc ggagaatggg cggtgaacgc cgatgattat ataaggacgc gccgggtgtg 120
gcacagctag ttccgtcgca gccgggattt gggtcgcggt tcttgtttgt ggatccctgt 180
gatcgtcact tgacagtaag tcactgactg tctatgcctg ggaaagggtg ggcaggagat 240
ggggcagtgc aggaaaagtg gcactatgaa ccctgcagcc ctaggaatgc atctagacaa 300
ttgtactaac cttcttctct ttcctctcct gacaggcctc gaggccgcca ccatgggatg 360
gagctgtatc atcctcttct tggtagcaac agctacaggt gtccactccg acatccagct 420
gacccagagc ccaagcagcc tgagcgccag cgtgggtgac agagtgacca tcacctgtaa 480
ggccagtcag gatgtgggta cttctgtagc ttggtaccag cagaagccag gtaaggctcc 540
aaagctgctg atctactgga catccacccg gcacactggt gtgccaagca gattcagcgg 600
tagcggtagc ggtaccgact tcaccttcac catcagcagc ctccagccag aggacatcgc 660
cacctactac tgccagcaat atagcctcta tcggtcgttc ggccaaggga ccaaggtgga 720
aatcaaacga ggtggctcag gatcgggtgg atccggctct ggtggctcag gatcggaggt 780
ccaactggtg gagagcggtg gaggtgttgt gcaacctggc cggtccctgc gcctgtcctg 840
ctccgcatct ggcttcgatt tcaccacata ttggatgagt tgggtgagac aggcacctgg 900
aaaaggtctt gagtggattg gagaaattca tccagatagc agtacgatta actatgcgcc 960
gtctctaaag gatagattta caatatcgcg agacaacgcc aagaacacat tgttcctgca 1020
aatggacagc ctgagacccg aagacaccgg ggtctatttt tgtgcaagcc tttacttcgg 1080
cttcccctgg tttgcttatt ggggccaagg gaccccggtc accgtctcca gtgctaagcc 1140
gaccacgaca ccggctccaa gacctccgac gccagctcca acgatagcgt cacagccatt 1200
gtctctccgc cctgaagcct gccggcccgc tgcgggcggc gcggttcata cccggggatt 1260
ggactttgcc cccagaaaga tagaggtgat gtaccctccc ccctacttgg acaacgaaaa 1320
gtctaatggc actatcattc acgtaaaggg caaacacctt tgtccaagtc ctttgttccc 1380
aggcccatct aagccgttct gggtactcgt ggttgtgggg ggcgtgctcg cttgttactc 1440
actgctggtg acggtggcct ttattatttt ctgggttcga tctaagcgaa gccgcttgtt 1500
gcattctgac tacatgaata tgacgccaag acggccaggg ccaacaagaa agcattacca 1560
accgtacgcc cccccgcgag acttcgcggc ctaccgcagc agggtaaaat ttagcaggtc 1620
tgcagatgcg cctgcgtatc aacagggtca gaatcagctc tataatgagc tgaacctcgg 1680
gcggcgggaa gagtatgatg ttctcgataa aaggagagga cgagaccccg aaatgggcgg 1740
caaaccgaga cgcaaaaatc ctcaggaggg gctctacaat gaacttcaaa aagacaaaat 1800
ggccgaagca tactcagaaa tcggaatgaa aggggagagg agacgcggga agggccatga 1860
tggactgtat cagggacttt ccacagccac caaggacacc tatgacgctc tccacatgca 1920
ggcgctgccg cctagatgat aaaattgttg ttgttaactt gtttattgca gcttataatg 1980
gttacaaata aagcaatagc atcacaaatt tcacaaataa agcatttttt tcactgcatt 2040
ctagttgtgg tttgtccaaa ctcatcaatg tatctta 2077
<210> 85
<211> 2428
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Anti-CD20 DAR donor DNA including 5' homology arm,
anti-CD20 DAR construct, and 3' homology arm
<400> 85
atcacgagca gctggtttct aagatgctat ttcccgtata aagcatgaga ccgtgacttg 60
ccagccccac agagccccgc ccttgtccat cactggcatc tggactccag cctgggttgg 120
ggcaaagagg gaaatgagat catgtcctaa ccctgatcct cttgtcccac agatatccag 180
aaccctgacc ctgaattcgg gcggagttag ggcggagcca atcagcgtgc gccgttccga 240
aagttgcctt ttatggctgg gcggagaatg ggcggtgaac gccgatgatt atataaggac 300
gcgccgggtg tggcacagct agttccgtcg cagccgggat ttgggtcgcg gttcttgttt 360
gtggatccct gtgatcgtca cttgacagta agtcactgac tgtctatgcc tgggaaaggg 420
tgggcaggag atggggcagt gcaggaaaag tggcactatg aaccctgcag ccctaggaat 480
gcatctagac aattgtacta accttcttct ctttcctctc ctgacaggcc tcgaggccgc 540
caccatggga tggagctgta tcatcctctt cttggtagca acagctacag gtgtccactc 600
cgacatccag ctgacccaga gcccaagcag cctgagcgcc agcgtgggtg acagagtgac 660
catcacctgt aaggccagtc aggatgtggg tacttctgta gcttggtacc agcagaagcc 720
aggtaaggct ccaaagctgc tgatctactg gacatccacc cggcacactg gtgtgccaag 780
cagattcagc ggtagcggta gcggtaccga cttcaccttc accatcagca gcctccagcc 840
agaggacatc gccacctact actgccagca atatagcctc tatcggtcgt tcggccaagg 900
gaccaaggtg gaaatcaaac gaggtggctc aggatcgggt ggatccggct ctggtggctc 960
aggatcggag gtccaactgg tggagagcgg tggaggtgtt gtgcaacctg gccggtccct 1020
gcgcctgtcc tgctccgcat ctggcttcga tttcaccaca tattggatga gttgggtgag 1080
acaggcacct ggaaaaggtc ttgagtggat tggagaaatt catccagata gcagtacgat 1140
taactatgcg ccgtctctaa aggatagatt tacaatatcg cgagacaacg ccaagaacac 1200
attgttcctg caaatggaca gcctgagacc cgaagacacc ggggtctatt tttgtgcaag 1260
cctttacttc ggcttcccct ggtttgctta ttggggccaa gggaccccgg tcaccgtctc 1320
cagtgctaag ccgaccacga caccggctcc aagacctccg acgccagctc caacgatagc 1380
gtcacagcca ttgtctctcc gccctgaagc ctgccggccc gctgcgggcg gcgcggttca 1440
tacccgggga ttggactttg cccccagaaa gatagaggtg atgtaccctc ccccctactt 1500
ggacaacgaa aagtctaatg gcactatcat tcacgtaaag ggcaaacacc tttgtccaag 1560
tcctttgttc ccaggcccat ctaagccgtt ctgggtactc gtggttgtgg ggggcgtgct 1620
cgcttgttac tcactgctgg tgacggtggc ctttattatt ttctgggttc gatctaagcg 1680
aagccgcttg ttgcattctg actacatgaa tatgacgcca agacggccag ggccaacaag 1740
aaagcattac caaccgtacg cccccccgcg agacttcgcg gcctaccgca gcagggtaaa 1800
atttagcagg tctgcagatg cgcctgcgta tcaacagggt cagaatcagc tctataatga 1860
gctgaacctc gggcggcggg aagagtatga tgttctcgat aaaaggagag gacgagaccc 1920
cgaaatgggc ggcaaaccga gacgcaaaaa tcctcaggag gggctctaca atgaacttca 1980
aaaagacaaa atggccgaag catactcaga aatcggaatg aaaggggaga ggagacgcgg 2040
gaagggccat gatggactgt atcagggact ttccacagcc accaaggaca cctatgacgc 2100
tctccacatg caggcgctgc cgcctagatg ataaaattgt tgttgttaac ttgtttattg 2160
cagcttataa tggttacaaa taaagcaata gcatcacaaa tttcacaaat aaagcatttt 2220
tttcactgca ttctagttgt ggtttgtcca aactcatcaa tgtatcttag taccagctga 2280
gagactcact atccagtgac aagtctgtct gcctattcac cgattttgat tctcaaacaa 2340
atgtgtcaca aagtaaggat tctgatgtgt atatcacaga caaaactgtg ctagacatga 2400
ggtctatgga cttcaagagc aacagtgc 2428
<210> 86
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: CD7 locus Cas12a target site
<400> 86
ctacgaggac ggggtggtgc c 21
<210> 87
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: CD7 locus Cas12a alternate target site
<400> 87
cttctcagag gaacagtccc a 21
<210> 88
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: forward primer producing donor fragment for insertion
into CD7 locus
<220>
<221> modified_base
<222> (1)..(2)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (1)..(1)
<223> 2'-O-methylated
<220>
<221> modified_base
<222> (2)..(3)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (3)..(4)
<223> Phosphorothioate linkage
<220>
<221> modified_base
<222> (3)..(4)
<223> 2'-O-methylated
<400> 88
ctgcagggag gacattctct 20
<210> 89
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: reverse primer producing donor fragment for insertion
into CD7 locus
<220>
<221> misc_feature
<223> 5' phosphate
<400> 89
ttccctactg tcaccagga 19
<210> 90
<211> 212
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: 5' homology arm for CD7 locus insertion
<400> 90
ctgcagggag gacattctct gtccttctgg ccagactgat ggtgacagcc caggtcctcc 60
ccagaggtgc agcagtctcc ccactgcacg actgtccccg tgggagcctc cgtcaacatc 120
acctgctcca ccagcggggg cctgcgtggg atctacctga ggcagctcgg gccacagccc 180
caagacatca tagtctacga ggacggggtg gt 212
<210> 91
<211> 170
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: 3' homology arm for CD7 locus insertion
<400> 91
ctacggacag acggttccgg ggccgcatcg acttctcagg gtcccaggac aacctgacta 60
tcaccatgca ccgcctgcag ctgtcggaca ctggcaccta cacctgccag gccatcacgg 120
aggtcaatgt ctacggctcc ggcaccctgg tcctggtgac aggtagggaa 170
Claims (75)
- 2개의 상이한 유전학적 유전자좌에서 1차 사람 T 세포를 유전학적으로 변형시키기 위한 방법으로서, 상기 방법이 1차 사람 T 세포에
제1 RNA 가이드된 엔도뉴클레아제 및 제1 가이드 RNA를 포함하는 제1 리보뉴클레오단백질 (RNP);
제2 RNA 가이드된 엔도뉴클레아제 및 제2 가이드 RNA를 포함하는 제2 RNP; 및
적어도 2개의 핵산 변형을 포함하는 공여자 DNA 분자를 도입하는 단계를 포함하고;
상기 제1 가이드 RNA가 상기 표적 DNA 내 제1 유전학적 유전자좌에서 제1 표적 부위와 하이브리드화하도록 디자인된 표적 서열을 포함하고, 상기 공여자 DNA가 상기 제1 표적 부위에서 상기 표적 DNA 분자에 삽입되고;
추가로, 상기 제2 가이드 RNA가 상기 표적 DNA에서 제2 유전학적 유전자좌에서 제2 표적 부위와 하이브리드화하도록 디자인되어 상기 제2 표적 부위에서 돌연변이를 유도하는 제2 표적 서열을 포함하는, 방법. - 제1항에 있어서, 상기 적어도 2개의 핵산 변형이 상기 공여자 DNA 분자의 단일 가닥 상에 있는, 방법.
- 제1항 또는 제2항에 있어서, 하나 이상의 핵산 변형이 상기 공여자 DNA 분자의 변형된 가닥의 5’ 말단의 10개 뉴클레오타이드 내 하나 이상의 뉴클레오타이드 또는 뉴클레오타이드 연결의 변형인, 방법.
- 제1항에 있어서, 하나 이상의 핵산 변형이 골격(backbone) 변형인, 방법.
- 제4항에 있어서, 하나 이상의 핵산 변형이 포스포로티오에이트 변형 또는 포스포르아미디트 변형 또는 이의 조합인, 방법.
- 제1항에 있어서, 하나 이상의 핵산 변형이 핵염기의 변형 또는 치환인, 방법.
- 제1항에 있어서, 하나 이상의 핵산 변형이 당의 변형 또는 치환인, 방법.
- 제7항에 있어서, 하나 이상의 핵산 변형이 데옥시리보스의 2’-O-메틸 그룹 변형인, 방법.
- 제1항 또는 제2항에 있어서, 상기 공여자 DNA 분자가 이중 가닥 DNA 분자인, 방법.
- 제9항에 있어서, 상기 공여자 DNA 분자가 상기 변형된 가닥의 반대편 가닥 상에 5’ 말단 포스페이트를 갖는, 방법.
- 제10항에 있어서, 상기 공여자 분자가 상기 공여자 분자의 변형된 가닥의 5’말단의 10개 뉴클레오타이드 내 골격 상에 1 내지 3개의 포스포로티오에이트 변형 및 상기 공여자 분자의 변형된 가닥의 5’말단의 10개 뉴클레오타이드 내 1 내지 3개의 2’-O-메틸 뉴클레오타이드 변형을 갖는, 방법.
- 제11항에 있어서, 상기 공여자 분자가 상기 공여자 분자의 변형된 가닥의 5’ 말단의 5개 뉴클레오타이드 내 골격 상에 1 내지 3개의 포스포로티오에이트 변형 및 상기 공여자 분자의 변형된 가닥의 5’ 말단의 5개 뉴클레오타이드 내 1 내지 3개의 2’-O-메틸 뉴클레오타이드 변형을 갖는, 방법.
- 제1항에 있어서, 상기 공여자 DNA 분자가 게놈으로의 통합을 위한 서열을 플랭킹하는 상동성 아암을 포함하는, 방법.
- 제13항에 있어서, 상기 상동성 아암의 적어도 하나가 50 내지 2000개 뉴클레오타이드 길이인, 방법.
- 제13항에 있어서, 상기 상동성 아암의 적어도 하나가 140 내지 660개 뉴클레오타이드 길이인, 방법.
- 제13항에 있어서, 상기 상동성 아암의 적어도 하나가 140 내지 250개 뉴클레오타이드 길이인, 방법.
- 제13항에 있어서, 상기 공여자 DNA 분자가 변형된 가닥 및 반대편 가닥을 포함하고, 상기 변형된 가닥이 2개 이상의 핵산 변형을 포함하고, 상기 반대편 가닥이 말단 포스페이트를 포함하는, 방법.
- 제1항에 있어서, 상기 공여자 DNA가 약 500 내지 약 5000 bp 길이인, 방법.
- 제18항에 있어서, 상기 공여자 DNA가 약 500 내지 약 3500 bp 길이인, 방법.
- 제1항에 있어서, 상기 공여자 DNA가 키메라 항원 수용체 (CAR) 또는 이량체 항원 수용체 (DAR) 작제물을 포함하는, 방법.
- 제1항에 있어서, 상기 제1 및/또는 제2 RNA 가이드된 엔도뉴클레아제가 Cas9인, 방법.
- 제21항에 있어서, 상기 제1 및/또는 제2 RNA 가이드된 엔도뉴클레아제가 Cas12a인, 방법.
- 제22항에 있어서, 상기 제1 및 제2 RNA 가이드된 엔도뉴클레아제가 Cas12a인, 방법.
- 제21항에 있어서, 상기 제1 RNA 가이드된 엔도뉴클레아제가 Cas12a이고, 상기 제2 RNA 가이드된 엔도뉴클레아제가 Cas9이거나, 상기 제1 RNA 가이드된 엔도뉴클레아제가 Cas9이고, 상기 제2 RNA 가이드된 엔도뉴클레아제가 Cas12a인, 방법.
- 제1항에 있어서, 상기 제1 RNP 및 상기 공여자 DNA가 동시에 도입되는, 방법.
- 제25항에 있어서, 상기 제1 RNP, 상기 공여자 DNA 및 상기 제2 RNP가 동시에 상기 세포에 도입되는, 방법.
- 제1항에 있어서, 상기 제1 RNP 및 상기 공여자 DNA가 동시에 상기 세포에 도입되고, 상기 제2 RNP가 상이한 시점에 상기 세포에 도입되는, 방법.
- 제27항에 있어서, 상기 RNP가 전기천공 또는 리포좀 전달에 의해 상기 세포에 도입된, 방법.
- RNA 가이드된 뉴클레아제의 제1 표적 부위를 포함하는 제1 유전학적 유전자좌에서 게놈으로 통합된 비-고유 유전학적 작제물 및 RNA 가이드된 뉴클레아제의 제2 표적 부위를 포함하는 제2 유전학적 유전자좌에서 돌연변이를 포함하는 가공된 1차 T 세포로서, 상기 가공된 1차 T 세포가 제1항 내지 제28항 중 어느 한 항의 방법에 의해 생성되는, 가공된 1차 T 세포.
- 유전학적 작제물로 형질감염된 1차 사람 T 세포 집단으로서, 상기 세포 집단이 제1 유전학적 유전자좌에서 게놈으로 통합된 비-고유 유전학적 작제물을 갖는 세포를 포함하고, 제2 유전학적 유전자좌에서 유전자 내 돌연변이를 추가로 갖고, 상기 집단 세포의 적어도 25%가 상기 유전학적 작제물을 발현하고, 상기 제2 유전학적 유전자좌에서 상기 유전자의 감소된 발현을 나타내는, 1차 사람 T 세포 집단.
- 제30항에 있어서, 상기 제1 RNA 가이드된 엔도뉴클레아제 표적 부위 및 제2 RNA 가이드된 엔도뉴클레아제 부위가 Cas12a 표적 부위인, 1차 사람 T 세포 집단.
- 제30항에 있어서, 상기 제1 RNA 가이드된 엔도뉴클레아제 표적 부위가 Cas12a 표적 부위이고, 상기 제2 RNA 가이드된 엔도뉴클레아제 부위가 Cas9 표적 부위인, 사람 T 세포 집단.
- 제30항에 있어서, 상기 제1 RNA 가이드된 엔도뉴클레아제 표적 부위가 Cas9 표적 부위이고, 상기 제2 RNA 가이드된 엔도뉴클레아제 부위가 Cas12a 표적 부위인, 사람 T 세포 집단.
- 공여자 DNA의 표적 DNA 분자로의 부위-특이적 통합을 위한 방법으로서, 상기 방법이
Cas12a 엔도뉴클레아제 및 가공된 가이드 RNA를 포함하는 RNP; 및
적어도 2개의 핵산 변형을 포함하는 공여자 DNA 분자를 세포에 도입하는 단계를 포함하고;
상기 가이드 RNA가 상기 표적 DNA 내 표적 부위와 하이브리드화하도록 디자인된 표적 서열을 포함하고, 상기 공여자 DNA가 상기 표적 부위에서 상기 표적 DNA 분자에 삽입되는, 방법. - 제34항에 있어서, 상기 적어도 2개의 핵산 변형이 상기 공여자 DNA 분자의 단일 가닥 상에 있는, 방법.
- 제34항 또는 제35항에 있어서, 하나 이상의 핵산 변형이 상기 공여자 DNA 분자의 변형된 가닥의 5’ 말단의 10개 뉴클레오타이드 내 하나 이상의 뉴클레오타이드 또는 뉴클레오타이드 연결의 변형인, 방법.
- 제34항에 있어서, 하나 이상의 핵산 변형이 골격 변형인, 방법.
- 제37항에 있어서, 하나 이상의 핵산 변형이 포스포로티오에이트 변형 또는 포스포르아미디트 변형 또는 이의 조합인, 방법.
- 제33항에 있어서, 하나 이상의 핵산 변형이 핵염기의 변형 또는 치환인, 방법.
- 제33항에 있어서, 하나 이상의 핵산 변형이 당의 변형 또는 치환인, 방법.
- 제40항에 있어서, 하나 이상의 핵산 변형이 데옥시리보스의 2’-O-메틸 그룹 변형인, 방법.
- 제34항에 있어서, 상기 공여자 DNA 분자가 이중 가닥 DNA 분자인, 방법.
- 제42항에 있어서, 상기 공여자 DNA 분자가 상기 변형된 가닥의 반대편 가닥 상에 5’ 말단 포스페이트를 갖는, 방법.
- 제43항에 있어서, 상기 공여자 분자가 상기 공여자 분자의 변형된 가닥의 5’ 말단의 10개 뉴클레오타이드 내 골격 상에 1 내지 3개의 포스포로티오에이트 변형 및 상기 공여자 분자의 변형된 가닥의 5’ 말단의 10개 뉴클레오타이드 내 1 내지 3개의 2’-O-메틸 뉴클레오타이드 변형을 갖는, 방법.
- 제44항에 있어서, 상기 공여자 분자가 상기 공여자 분자의 변형된 가닥의 5’ 말단의 5개 뉴클레오타이드 내 골격 상에 1 내지 3개의 포스포로티오에이트 변형 및 상기 공여자 분자의 변형된 가닥의 5’ 말단의 5개 뉴클레오타이드 내 1 내지 3개의 2’-O-메틸 뉴클레오타이드 변형을 갖는, 방법.
- 제34항에 있어서, 상기 공여자 DNA 분자가 게놈으로의 통합을 위한 서열을 플랭킹하는 상동성 아암을 포함하는, 방법.
- 제46항에 있어서, 상기 상동성 아암의 적어도 하나가 50 내지 2000개 뉴클레오타이드 길이인, 방법.
- 제47항에 있어서, 상기 상동성 아암의 적어도 하나가 140 내지 660개 뉴클레오타이드 길이인, 방법.
- 제48항에 있어서, 상기 상동성 아암의 적어도 하나가 140 내지 250개 뉴클레오타이드 길이인, 방법.
- 제34항에 있어서, 상기 공여자 DNA 분자가 변형된 가닥 및 반대편 가닥을 포함하고, 상기 변형된 가닥이 2개 이상의 핵산 변형을 포함하고, 상기 반대편 가닥이 말단 포스페이트를 포함하는, 방법.
- 제34항에 있어서, 상기 공여자 DNA가 약 500 내지 약 5000 bp 길이인, 방법.
- 제51항에 있어서, 상기 공여자 DNA가 약 500 내지 약 3500 bp 길이인, 방법.
- 제34항에 있어서, 상기 공여자 DNA가 키메라 항원 수용체 (CAR) 또는 이량체 항원 수용체 (DAR) 작제물을 포함하는, 방법.
- 제34항에 있어서, 상기 가이드 RNA가 crRNA인, 방법.
- 제54항에 있어서, tracrRNA를 상기 세포에 도입하는 단계를 추가로 포함하는, 방법.
- 제34항에 있어서, 상기 RNP가 전기천공 또는 리포좀 전달에 의해 상기 세포에 도입된, 방법.
- 제34항에 있어서, 상기 공여자 DNA 및 상기 RNP가 동시에 또는 별도로 상기 세포에 도입되는, 방법.
- 공여자 DNA의 표적 유전자좌로의 표적화된 통합을 위한 시스템으로서,
Cas12a 엔도뉴클레아제; 가이드 RNA; 및 이중 가닥 공여자 DNA 분자를 포함하고, 상기 공여자 DNA 분자가 상기 이중 가닥 DNA 분자의 변형된 가닥의 5’ 말단의 10개 뉴클레오타이드 내 상기 이중 가닥 DNA 분자의 단일 변형된 가닥 상에 하나 이상의 포스포로티오에이트 결합을 포함하는, 시스템. - 제58항에 있어서, 상기 공여자 DNA 분자가 상기 이중 가닥 DNA 분자의 변형된 가닥의 5’ 말단의 10개 뉴클레오타이드 내 상기 변형된 가닥의 당 모이어티 또는 핵염기의 적어도 하나의 변형을 추가로 포함하는, 시스템.
- 제58항에 있어서, 상기 공여자 DNA가 게놈으로의 통합을 위한 관심 대상의 서열을 플랭킹하는 상동성 아암을 갖는, 시스템.
- 제58항에 있어서, 상기 이중 가닥 DNA 분자의 단일 변형된 가닥 상에 상기 하나 이상의 포스포로티오에이트 결합이 상기 이중 가닥 DNA 분자의 변형된 가닥의 5’ 말단의 5개 뉴클레오타이드 내에 있는, 시스템.
- 제61항에 있어서, 상기 변형된 가닥의 당 모이어티 또는 핵염기의 상기 적어도 하나의 변형이 상기 이중 가닥 DNA 분자의 변형된 가닥의 5’ 말단의 5개 뉴클레오타이드 내에 있는, 시스템.
- 제61항에 있어서, 당 모이어티의 상기 적어도 하나의 변형이 2’-O 메틸화를 포함하는, 시스템.
- 제60항에 있어서, 상기 관심 대상의 서열이 발현 카세트를 포함하는, 시스템.
- 제64항에 있어서, 상기 발현 카세트가 하나 이상의 항체 또는 수용체 도메인을 포함하는 작제물을 포함하는, 시스템.
[청구항 63]
제60항에 있어서, 상기 상동성 아암의 적어도 하나가 50 내지 2000개 뉴클레오타이드 길이인, 방법.
[청구항 64]
제63항에 있어서, 상기 상동성 아암의 적어도 하나가 140 내지 660개 뉴클레오타이드 길이인, 방법.
[청구항 65]
제63항에 있어서, 상기 상동성 아암의 적어도 하나가 140 내지 250개 뉴클레오타이드 길이인, 방법. - 제61항에 있어서, 상기 공여자 DNA 분자가 변형된 가닥 및 반대편 가닥을 포함하고, 상기 변형된 가닥이 2개 이상의 핵산 변형을 포함하고, 상기 반대편 가닥이 말단 포스페이트를 포함하는, 방법.
- 제58항에 있어서, 상기 공여자 DNA가 약 500 내지 약 5000 bp 길이인, 방법.
- 제58항에 있어서, 상기 공여자 DNA가 약 500 내지 약 3500 bp 길이인, 방법.
- 제64항에 있어서, 상기 공여자 DNA가 키메라 항원 수용체 (CAR) 또는 이량체 항원 수용체 (DAR) 작제물을 포함하는, 방법.
- 제58항에 있어서, 상기 가이드 RNA가 crRNA인, 시스템.
- 제58항에 있어서, 상기 가이드 RNA가 하나 이상의 포스포로티오에이트 (PS) 올리고뉴클레오타이드를 포함하는, 시스템.
- 제8항에 있어서, 상기 Cas12a 엔도뉴클레아제 및 상기 가이드 RNA를 포함하는 리보뉴클레오단백질 복합체를 포함하는, 시스템.
- CD7 유전자에 삽입된 CAR 또는 DAR 작제물을 갖는 1차 사람 T 세포.
- 제73항에 있어서, 상기 CAR 또는 DAR 작제물이 CEA CAR 또는 DAR 작제물인, 1차 사람 T 세포.
- 제73항에 따른 T 세포 집단.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201962816836P | 2019-03-11 | 2019-03-11 | |
| US62/816,836 | 2019-03-11 | ||
| US201962901735P | 2019-09-17 | 2019-09-17 | |
| US62/901,735 | 2019-09-17 | ||
| PCT/US2020/022056 WO2020185867A1 (en) | 2019-03-11 | 2020-03-11 | Improved process for integration of dna constructs using rna-guided endonucleases |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210149734A true KR20210149734A (ko) | 2021-12-09 |
Family
ID=70190148
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217032629A KR20210149734A (ko) | 2019-03-11 | 2020-03-11 | Rna-가이드된 엔도뉴클레아제를 사용한 dna 작제물의 통합을 위한 개선된 방법 |
Country Status (11)
| Country | Link |
|---|---|
| US (1) | US20220145333A1 (ko) |
| EP (1) | EP3938510A1 (ko) |
| JP (1) | JP2022524435A (ko) |
| KR (1) | KR20210149734A (ko) |
| CN (1) | CN113825834A (ko) |
| AU (1) | AU2020239050A1 (ko) |
| CA (1) | CA3133226A1 (ko) |
| IL (1) | IL286244A (ko) |
| MX (1) | MX2021010938A (ko) |
| SG (1) | SG11202109972QA (ko) |
| WO (1) | WO2020185867A1 (ko) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP4139345A1 (en) | 2020-04-24 | 2023-03-01 | Sorrento Therapeutics, Inc. | Memory dimeric antigen receptors |
| WO2022015956A1 (en) | 2020-07-15 | 2022-01-20 | Sorrento Therapeutics, Inc. | Improved process for dna integration using rna-guided endonucleases |
| EP4214318A1 (en) * | 2020-09-18 | 2023-07-26 | Vor Biopharma Inc. | Compositions and methods for cd7 modification |
| JP2024513087A (ja) * | 2021-04-07 | 2024-03-21 | アストラゼネカ・アクチエボラーグ | 部位特異的改変のための組成物及び方法 |
| WO2022266538A2 (en) * | 2021-06-18 | 2022-12-22 | Artisan Development Labs, Inc. | Compositions and methods for targeting, editing or modifying human genes |
| WO2023097236A1 (en) * | 2021-11-24 | 2023-06-01 | The Rockefeller University | Compositions and methods for generating immunoglobulin knock-in mice |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5034506A (en) | 1985-03-15 | 1991-07-23 | Anti-Gene Development Group | Uncharged morpholino-based polymers having achiral intersubunit linkages |
| US5489677A (en) | 1990-07-27 | 1996-02-06 | Isis Pharmaceuticals, Inc. | Oligonucleoside linkages containing adjacent oxygen and nitrogen atoms |
| US5602240A (en) | 1990-07-27 | 1997-02-11 | Ciba Geigy Ag. | Backbone modified oligonucleotide analogs |
| US6555674B2 (en) | 2000-08-09 | 2003-04-29 | Nsgene A/S | JeT promoter |
| LT2800811T (lt) | 2012-05-25 | 2017-09-11 | The Regents Of The University Of California | Būdai ir kompozicijos, skirti tikslinės dnr modifikavimui, panaudojant adresuotą rnr, ir transkripcijos moduliavimui, panaudojant adresuotą rnr |
| US8697359B1 (en) | 2012-12-12 | 2014-04-15 | The Broad Institute, Inc. | CRISPR-Cas systems and methods for altering expression of gene products |
| WO2015089427A1 (en) | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Crispr-cas systems and methods for altering expression of gene products, structural information and inducible modular cas enzymes |
| EP3204513A2 (en) * | 2014-10-09 | 2017-08-16 | Life Technologies Corporation | Crispr oligonucleotides and gene editing |
| WO2016182959A1 (en) * | 2015-05-11 | 2016-11-17 | Editas Medicine, Inc. | Optimized crispr/cas9 systems and methods for gene editing in stem cells |
| US9790490B2 (en) | 2015-06-18 | 2017-10-17 | The Broad Institute Inc. | CRISPR enzymes and systems |
| US11873504B2 (en) | 2016-09-30 | 2024-01-16 | The Regents Of The University Of California | RNA-guided nucleic acid modifying enzymes and methods of use thereof |
| JP2021515558A (ja) | 2018-03-09 | 2021-06-24 | ソレント・セラピューティクス・インコーポレイテッドSorrento Therapeutics, Inc. | 二量体抗原受容体(dar) |
-
2020
- 2020-03-11 CN CN202080035087.XA patent/CN113825834A/zh active Pending
- 2020-03-11 CA CA3133226A patent/CA3133226A1/en active Pending
- 2020-03-11 EP EP20717424.4A patent/EP3938510A1/en active Pending
- 2020-03-11 JP JP2021554697A patent/JP2022524435A/ja active Pending
- 2020-03-11 US US17/438,039 patent/US20220145333A1/en active Pending
- 2020-03-11 MX MX2021010938A patent/MX2021010938A/es unknown
- 2020-03-11 KR KR1020217032629A patent/KR20210149734A/ko unknown
- 2020-03-11 SG SG11202109972Q patent/SG11202109972QA/en unknown
- 2020-03-11 WO PCT/US2020/022056 patent/WO2020185867A1/en unknown
- 2020-03-11 AU AU2020239050A patent/AU2020239050A1/en active Pending
-
2021
- 2021-09-09 IL IL286244A patent/IL286244A/en unknown
Also Published As
| Publication number | Publication date |
|---|---|
| EP3938510A1 (en) | 2022-01-19 |
| AU2020239050A1 (en) | 2021-11-04 |
| WO2020185867A1 (en) | 2020-09-17 |
| CA3133226A1 (en) | 2020-09-17 |
| US20220145333A1 (en) | 2022-05-12 |
| MX2021010938A (es) | 2022-01-06 |
| CN113825834A (zh) | 2021-12-21 |
| SG11202109972QA (en) | 2021-10-28 |
| IL286244A (en) | 2021-10-31 |
| JP2022524435A (ja) | 2022-05-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20210149734A (ko) | Rna-가이드된 엔도뉴클레아제를 사용한 dna 작제물의 통합을 위한 개선된 방법 | |
| JP6788573B6 (ja) | メトトレキサートによる選択と組み合わせたSleeping Beautyトランスポゾンによる遺伝子改変T細胞の製造 | |
| KR20210008502A (ko) | 암을 치료하기 위한 방법 및 조성물 | |
| AU2020230334A1 (en) | Compositions and methods for immunooncology | |
| KR20210134000A (ko) | Rna-가이드된 엔도뉴클레아제를 사용한 dna 통합을 위한 개선된 방법 | |
| KR20200005596A (ko) | 세포를 엔지니어링하기 위한 물질 및 방법, 및 면역-종양학에서의 그의 용도 | |
| CN116322716A (zh) | Regnase-1和/或TGFBRII被破坏的基因工程化T细胞具有改善的功能性和持久性 | |
| CA3072777A1 (en) | Compositions and methods for chimeric ligand receptor (clr)-mediated conditional gene expression | |
| WO2021197391A1 (zh) | 一种制备经修饰的免疫细胞的方法 | |
| KR20210089712A (ko) | 항-cd33 면역세포 암 치료법 | |
| KR20210005922A (ko) | 형질 세포 고갈을 위한 항-bcma car-t-세포 | |
| CA3166430A1 (en) | Compositions and methods for targeting, editing or modifying human genes | |
| KR20210089707A (ko) | 항-liv1 면역세포 암 치료법 | |
| KR20230029603A (ko) | 필수 유전자 녹-인에 의한 선택 | |
| KR20210005923A (ko) | 세포독성 t 세포 고갈의 방법 및 조성물 | |
| WO2023010125A1 (en) | Multiplex base editing of primary human natural killer cells | |
| KR20230147109A (ko) | Her2 양성 암을 치료하기 위한 조성물 및 방법 | |
| WO2022015956A1 (en) | Improved process for dna integration using rna-guided endonucleases | |
| KR20230090367A (ko) | 변형된 불변 cd3 이뮤노글로불린 슈퍼패밀리 쇄 유전자좌로부터 키메라 수용체를 발현하는 세포 및 관련 폴리뉴클레오티드 및 방법 | |
| CN116507629A (zh) | Rna支架 | |
| CA3235955A1 (en) | Systems and methods for trans-modulation of immune cells by genetic manipulation of immune regulatory genes | |
| CA3223311A1 (en) | Compositions and methods for targeting, editing or modifying human genes | |
| TW202334421A (zh) | 包含靶向ciita之rna引導之組合物及其用途 | |
| WO2023225035A2 (en) | Compositions and methods for engineering cells | |
| WO2023183434A2 (en) | Compositions and methods for generating cells with reduced immunogenicty |