KR20210028544A - 인간 ror1에 대한 항체를 포함하는 항체 약물 접합체 및 이의 용도 - Google Patents
인간 ror1에 대한 항체를 포함하는 항체 약물 접합체 및 이의 용도 Download PDFInfo
- Publication number
- KR20210028544A KR20210028544A KR1020190109807A KR20190109807A KR20210028544A KR 20210028544 A KR20210028544 A KR 20210028544A KR 1020190109807 A KR1020190109807 A KR 1020190109807A KR 20190109807 A KR20190109807 A KR 20190109807A KR 20210028544 A KR20210028544 A KR 20210028544A
- Authority
- KR
- South Korea
- Prior art keywords
- ser
- pharmaceutically acceptable
- solvate
- acceptable salt
- antibody conjugate
- Prior art date
Links
- 230000027455 binding Effects 0.000 title claims abstract description 92
- 101001103039 Homo sapiens Inactive tyrosine-protein kinase transmembrane receptor ROR1 Proteins 0.000 title claims abstract description 33
- 229940049595 antibody-drug conjugate Drugs 0.000 title abstract description 63
- 239000000611 antibody drug conjugate Substances 0.000 title abstract description 58
- 102000049583 human ROR1 Human genes 0.000 title description 26
- 239000000427 antigen Substances 0.000 claims abstract description 112
- 102000036639 antigens Human genes 0.000 claims abstract description 111
- 108091007433 antigens Proteins 0.000 claims abstract description 111
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 110
- 201000011510 cancer Diseases 0.000 claims abstract description 82
- 239000012634 fragment Substances 0.000 claims abstract description 67
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims abstract description 20
- 201000010099 disease Diseases 0.000 claims abstract description 18
- 239000008194 pharmaceutical composition Substances 0.000 claims abstract description 17
- 230000002018 overexpression Effects 0.000 claims abstract description 13
- 101001103036 Homo sapiens Nuclear receptor ROR-alpha Proteins 0.000 claims abstract description 8
- 102100039614 Nuclear receptor ROR-alpha Human genes 0.000 claims abstract 5
- 210000004027 cell Anatomy 0.000 claims description 182
- 150000003839 salts Chemical class 0.000 claims description 143
- 239000012453 solvate Substances 0.000 claims description 139
- 229940127121 immunoconjugate Drugs 0.000 claims description 135
- 125000000217 alkyl group Chemical group 0.000 claims description 78
- 229910052739 hydrogen Inorganic materials 0.000 claims description 70
- 238000000034 method Methods 0.000 claims description 70
- 125000001072 heteroaryl group Chemical group 0.000 claims description 67
- 125000005647 linker group Chemical group 0.000 claims description 67
- 125000003118 aryl group Chemical group 0.000 claims description 65
- 150000001413 amino acids Chemical group 0.000 claims description 63
- 235000001014 amino acid Nutrition 0.000 claims description 57
- 239000001257 hydrogen Substances 0.000 claims description 55
- -1 isoprenyl Chemical class 0.000 claims description 53
- 229940024606 amino acid Drugs 0.000 claims description 49
- 239000013543 active substance Substances 0.000 claims description 41
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical group [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 claims description 39
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 39
- 125000000592 heterocycloalkyl group Chemical group 0.000 claims description 38
- 108090000623 proteins and genes Proteins 0.000 claims description 36
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 claims description 34
- 150000007523 nucleic acids Chemical class 0.000 claims description 33
- 125000003545 alkoxy group Chemical group 0.000 claims description 30
- 150000001875 compounds Chemical class 0.000 claims description 30
- YUOCYTRGANSSRY-UHFFFAOYSA-N pyrrolo[2,3-i][1,2]benzodiazepine Chemical compound C1=CN=NC2=C3C=CN=C3C=CC2=C1 YUOCYTRGANSSRY-UHFFFAOYSA-N 0.000 claims description 30
- 102000004169 proteins and genes Human genes 0.000 claims description 29
- 101100038118 Mus musculus Ror1 gene Proteins 0.000 claims description 28
- 235000018102 proteins Nutrition 0.000 claims description 28
- 125000005913 (C3-C6) cycloalkyl group Chemical group 0.000 claims description 26
- 229910052799 carbon Inorganic materials 0.000 claims description 26
- 229920001184 polypeptide Polymers 0.000 claims description 26
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 26
- 125000000882 C2-C6 alkenyl group Chemical group 0.000 claims description 24
- 208000025205 Mantle-Cell Lymphoma Diseases 0.000 claims description 23
- 125000002947 alkylene group Chemical group 0.000 claims description 23
- 206010006187 Breast cancer Diseases 0.000 claims description 22
- 208000026310 Breast neoplasm Diseases 0.000 claims description 22
- 238000006243 chemical reaction Methods 0.000 claims description 21
- 125000003601 C2-C6 alkynyl group Chemical group 0.000 claims description 20
- 238000006467 substitution reaction Methods 0.000 claims description 19
- 125000006552 (C3-C8) cycloalkyl group Chemical group 0.000 claims description 18
- 125000005843 halogen group Chemical group 0.000 claims description 18
- 239000002253 acid Substances 0.000 claims description 17
- 229910052717 sulfur Inorganic materials 0.000 claims description 17
- 125000003342 alkenyl group Chemical group 0.000 claims description 16
- 125000000304 alkynyl group Chemical group 0.000 claims description 16
- 235000018417 cysteine Nutrition 0.000 claims description 16
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 claims description 16
- 125000000623 heterocyclic group Chemical group 0.000 claims description 16
- 150000002431 hydrogen Chemical class 0.000 claims description 16
- 239000002246 antineoplastic agent Substances 0.000 claims description 15
- 102000039446 nucleic acids Human genes 0.000 claims description 15
- 108020004707 nucleic acids Proteins 0.000 claims description 15
- 239000003053 toxin Substances 0.000 claims description 15
- 231100000765 toxin Toxicity 0.000 claims description 15
- 108700012359 toxins Proteins 0.000 claims description 15
- 125000004414 alkyl thio group Chemical group 0.000 claims description 14
- 239000000203 mixture Substances 0.000 claims description 14
- 206010009944 Colon cancer Diseases 0.000 claims description 13
- 239000004471 Glycine Substances 0.000 claims description 13
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 claims description 13
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 claims description 13
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 claims description 13
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 claims description 12
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 claims description 12
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 12
- 206010025323 Lymphomas Diseases 0.000 claims description 12
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 claims description 12
- 125000003282 alkyl amino group Chemical group 0.000 claims description 12
- 239000003795 chemical substances by application Substances 0.000 claims description 12
- 208000029742 colonic neoplasm Diseases 0.000 claims description 12
- 229940127089 cytotoxic agent Drugs 0.000 claims description 12
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 claims description 11
- 102000004357 Transferases Human genes 0.000 claims description 11
- 108090000992 Transferases Proteins 0.000 claims description 11
- 125000000753 cycloalkyl group Chemical group 0.000 claims description 11
- 201000005202 lung cancer Diseases 0.000 claims description 11
- 208000020816 lung neoplasm Diseases 0.000 claims description 11
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 claims description 10
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 claims description 10
- 125000004093 cyano group Chemical group *C#N 0.000 claims description 10
- 229930195712 glutamate Natural products 0.000 claims description 10
- 125000004474 heteroalkylene group Chemical group 0.000 claims description 10
- 208000002154 non-small cell lung carcinoma Diseases 0.000 claims description 10
- 235000004400 serine Nutrition 0.000 claims description 10
- 125000004434 sulfur atom Chemical group 0.000 claims description 10
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 claims description 10
- 229910052727 yttrium Inorganic materials 0.000 claims description 10
- 239000004475 Arginine Substances 0.000 claims description 9
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 claims description 9
- 235000009697 arginine Nutrition 0.000 claims description 9
- 201000003444 follicular lymphoma Diseases 0.000 claims description 9
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 claims description 9
- 208000031261 Acute myeloid leukaemia Diseases 0.000 claims description 8
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 claims description 8
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 claims description 8
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 claims description 8
- 125000004429 atom Chemical group 0.000 claims description 8
- 150000001721 carbon Chemical group 0.000 claims description 8
- 229960004679 doxorubicin Drugs 0.000 claims description 8
- 206010017758 gastric cancer Diseases 0.000 claims description 8
- 239000003446 ligand Substances 0.000 claims description 8
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 claims description 8
- HXCHCVDVKSCDHU-PJKCJEBCSA-N s-[(2r,3s,4s,6s)-6-[[(2r,3s,4s,5r,6r)-5-[(2s,4s,5s)-5-(ethylamino)-4-methoxyoxan-2-yl]oxy-4-hydroxy-6-[[(2s,5z,9r,13e)-9-hydroxy-12-(methoxycarbonylamino)-13-[2-(methyltrisulfanyl)ethylidene]-11-oxo-2-bicyclo[7.3.1]trideca-1(12),5-dien-3,7-diynyl]oxy]-2-m Chemical compound C1[C@H](OC)[C@@H](NCC)CO[C@H]1O[C@H]1[C@H](O[C@@H]2C\3=C(NC(=O)OC)C(=O)C[C@@](C/3=C/CSSSC)(O)C#C\C=C/C#C2)O[C@H](C)[C@@H](NO[C@@H]2O[C@H](C)[C@@H](SC(=O)C=3C(=C(OC)C(O[C@H]4[C@@H]([C@H](OC)[C@@H](O)[C@H](C)O4)O)=C(I)C=3C)OC)[C@@H](O)C2)[C@@H]1O HXCHCVDVKSCDHU-PJKCJEBCSA-N 0.000 claims description 8
- 239000002904 solvent Substances 0.000 claims description 8
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 claims description 7
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 claims description 7
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 claims description 7
- 239000004472 Lysine Substances 0.000 claims description 7
- 108020005497 Nuclear hormone receptor Proteins 0.000 claims description 7
- 102000007399 Nuclear hormone receptor Human genes 0.000 claims description 7
- 229930012538 Paclitaxel Natural products 0.000 claims description 7
- 239000002202 Polyethylene glycol Substances 0.000 claims description 7
- 235000004279 alanine Nutrition 0.000 claims description 7
- 229940009098 aspartate Drugs 0.000 claims description 7
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 claims description 7
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 claims description 7
- 125000003827 glycol group Chemical group 0.000 claims description 7
- 229910052757 nitrogen Inorganic materials 0.000 claims description 7
- 229960001592 paclitaxel Drugs 0.000 claims description 7
- 229920001223 polyethylene glycol Polymers 0.000 claims description 7
- 125000001424 substituent group Chemical group 0.000 claims description 7
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 claims description 7
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 claims description 6
- AHLPHDHHMVZTML-BYPYZUCNSA-N L-Ornithine Chemical compound NCCC[C@H](N)C(O)=O AHLPHDHHMVZTML-BYPYZUCNSA-N 0.000 claims description 6
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 claims description 6
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 claims description 6
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 claims description 6
- AHLPHDHHMVZTML-UHFFFAOYSA-N Orn-delta-NH2 Natural products NCCCC(N)C(O)=O AHLPHDHHMVZTML-UHFFFAOYSA-N 0.000 claims description 6
- UTJLXEIPEHZYQJ-UHFFFAOYSA-N Ornithine Natural products OC(=O)C(C)CCCN UTJLXEIPEHZYQJ-UHFFFAOYSA-N 0.000 claims description 6
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 6
- 238000007792 addition Methods 0.000 claims description 6
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 claims description 6
- AMRJKAQTDDKMCE-UHFFFAOYSA-N dolastatin Chemical compound CC(C)C(N(C)C)C(=O)NC(C(C)C)C(=O)N(C)C(C(C)C)C(OC)CC(=O)N1CCCC1C(OC)C(C)C(=O)NC(C=1SC=CN=1)CC1=CC=CC=C1 AMRJKAQTDDKMCE-UHFFFAOYSA-N 0.000 claims description 6
- 229910052736 halogen Inorganic materials 0.000 claims description 6
- 150000002367 halogens Chemical class 0.000 claims description 6
- 235000005772 leucine Nutrition 0.000 claims description 6
- 201000007270 liver cancer Diseases 0.000 claims description 6
- 208000014018 liver neoplasm Diseases 0.000 claims description 6
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 claims description 6
- 229930182817 methionine Natural products 0.000 claims description 6
- 235000006109 methionine Nutrition 0.000 claims description 6
- 229960001156 mitoxantrone Drugs 0.000 claims description 6
- 125000000449 nitro group Chemical group [O-][N+](*)=O 0.000 claims description 6
- 229960003104 ornithine Drugs 0.000 claims description 6
- UOWVMDUEMSNCAV-WYENRQIDSA-N rachelmycin Chemical compound C1([C@]23C[C@@H]2CN1C(=O)C=1NC=2C(OC)=C(O)C4=C(C=2C=1)CCN4C(=O)C1=CC=2C=4CCN(C=4C(O)=C(C=2N1)OC)C(N)=O)=CC(=O)C1=C3C(C)=CN1 UOWVMDUEMSNCAV-WYENRQIDSA-N 0.000 claims description 6
- OWPCHSCAPHNHAV-LMONGJCWSA-N rhizoxin Chemical compound C/C([C@H](OC)[C@@H](C)[C@@H]1C[C@H](O)[C@]2(C)O[C@@H]2/C=C/[C@@H](C)[C@]2([H])OC(=O)C[C@@](C2)(C[C@@H]2O[C@H]2C(=O)O1)[H])=C\C=C\C(\C)=C\C1=COC(C)=N1 OWPCHSCAPHNHAV-LMONGJCWSA-N 0.000 claims description 6
- 201000011549 stomach cancer Diseases 0.000 claims description 6
- 239000000126 substance Substances 0.000 claims description 6
- 208000004736 B-Cell Leukemia Diseases 0.000 claims description 5
- 206010005003 Bladder cancer Diseases 0.000 claims description 5
- 208000003174 Brain Neoplasms Diseases 0.000 claims description 5
- 208000011691 Burkitt lymphomas Diseases 0.000 claims description 5
- 206010008342 Cervix carcinoma Diseases 0.000 claims description 5
- 102000004190 Enzymes Human genes 0.000 claims description 5
- 108090000790 Enzymes Proteins 0.000 claims description 5
- 208000008839 Kidney Neoplasms Diseases 0.000 claims description 5
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 claims description 5
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 claims description 5
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 claims description 5
- 206010029260 Neuroblastoma Diseases 0.000 claims description 5
- 206010033128 Ovarian cancer Diseases 0.000 claims description 5
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 5
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 5
- 206010035226 Plasma cell myeloma Diseases 0.000 claims description 5
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 claims description 5
- 206010060862 Prostate cancer Diseases 0.000 claims description 5
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 5
- 206010038389 Renal cancer Diseases 0.000 claims description 5
- 206010039509 Scab Diseases 0.000 claims description 5
- 208000000453 Skin Neoplasms Diseases 0.000 claims description 5
- 208000024313 Testicular Neoplasms Diseases 0.000 claims description 5
- 206010057644 Testis cancer Diseases 0.000 claims description 5
- 208000024770 Thyroid neoplasm Diseases 0.000 claims description 5
- 108060008682 Tumor Necrosis Factor Proteins 0.000 claims description 5
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 claims description 5
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 claims description 5
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 claims description 5
- 208000002495 Uterine Neoplasms Diseases 0.000 claims description 5
- 201000005188 adrenal gland cancer Diseases 0.000 claims description 5
- 208000024447 adrenal gland neoplasm Diseases 0.000 claims description 5
- 150000001408 amides Chemical group 0.000 claims description 5
- 239000003242 anti bacterial agent Substances 0.000 claims description 5
- 235000003704 aspartic acid Nutrition 0.000 claims description 5
- 108010044540 auristatin Proteins 0.000 claims description 5
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 claims description 5
- 239000011203 carbon fibre reinforced carbon Substances 0.000 claims description 5
- 125000002915 carbonyl group Chemical group [*:2]C([*:1])=O 0.000 claims description 5
- 201000010881 cervical cancer Diseases 0.000 claims description 5
- PSNOPSMXOBPNNV-VVCTWANISA-N cryptophycin 1 Chemical compound C1=C(Cl)C(OC)=CC=C1C[C@@H]1C(=O)NC[C@@H](C)C(=O)O[C@@H](CC(C)C)C(=O)O[C@H]([C@H](C)[C@@H]2[C@H](O2)C=2C=CC=CC=2)C/C=C/C(=O)N1 PSNOPSMXOBPNNV-VVCTWANISA-N 0.000 claims description 5
- PSNOPSMXOBPNNV-UHFFFAOYSA-N cryptophycin-327 Natural products C1=C(Cl)C(OC)=CC=C1CC1C(=O)NCC(C)C(=O)OC(CC(C)C)C(=O)OC(C(C)C2C(O2)C=2C=CC=CC=2)CC=CC(=O)N1 PSNOPSMXOBPNNV-UHFFFAOYSA-N 0.000 claims description 5
- 206010012818 diffuse large B-cell lymphoma Diseases 0.000 claims description 5
- 238000009472 formulation Methods 0.000 claims description 5
- 201000010536 head and neck cancer Diseases 0.000 claims description 5
- 208000014829 head and neck neoplasm Diseases 0.000 claims description 5
- 125000002887 hydroxy group Chemical group [H]O* 0.000 claims description 5
- 230000002519 immonomodulatory effect Effects 0.000 claims description 5
- 201000010982 kidney cancer Diseases 0.000 claims description 5
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 5
- 201000001441 melanoma Diseases 0.000 claims description 5
- 201000000050 myeloid neoplasm Diseases 0.000 claims description 5
- 201000002528 pancreatic cancer Diseases 0.000 claims description 5
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 5
- 125000006239 protecting group Chemical group 0.000 claims description 5
- 201000000849 skin cancer Diseases 0.000 claims description 5
- 206010041823 squamous cell carcinoma Diseases 0.000 claims description 5
- 201000003120 testicular cancer Diseases 0.000 claims description 5
- 201000002510 thyroid cancer Diseases 0.000 claims description 5
- 201000005112 urinary bladder cancer Diseases 0.000 claims description 5
- 206010046766 uterine cancer Diseases 0.000 claims description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 claims description 4
- RCFNNLSZHVHCEK-IMHLAKCZSA-N (7s,9s)-7-(4-amino-6-methyloxan-2-yl)oxy-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-4-methoxy-8,10-dihydro-7h-tetracene-5,12-dione;hydrochloride Chemical compound [Cl-].O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)C1CC([NH3+])CC(C)O1 RCFNNLSZHVHCEK-IMHLAKCZSA-N 0.000 claims description 4
- IEXUMDBQLIVNHZ-YOUGDJEHSA-N (8s,11r,13r,14s,17s)-11-[4-(dimethylamino)phenyl]-17-hydroxy-17-(3-hydroxypropyl)-13-methyl-1,2,6,7,8,11,12,14,15,16-decahydrocyclopenta[a]phenanthren-3-one Chemical compound C1=CC(N(C)C)=CC=C1[C@@H]1C2=C3CCC(=O)C=C3CC[C@H]2[C@H](CC[C@]2(O)CCCO)[C@@]2(C)C1 IEXUMDBQLIVNHZ-YOUGDJEHSA-N 0.000 claims description 4
- QCXJFISCRQIYID-IAEPZHFASA-N 2-amino-1-n-[(3s,6s,7r,10s,16s)-3-[(2s)-butan-2-yl]-7,11,14-trimethyl-2,5,9,12,15-pentaoxo-10-propan-2-yl-8-oxa-1,4,11,14-tetrazabicyclo[14.3.0]nonadecan-6-yl]-4,6-dimethyl-3-oxo-9-n-[(3s,6s,7r,10s,16s)-7,11,14-trimethyl-2,5,9,12,15-pentaoxo-3,10-di(propa Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N=C2C(C(=O)N[C@@H]3C(=O)N[C@H](C(N4CCC[C@H]4C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]3C)=O)[C@@H](C)CC)=C(N)C(=O)C(C)=C2O2)C2=C(C)C=C1 QCXJFISCRQIYID-IAEPZHFASA-N 0.000 claims description 4
- FDAYLTPAFBGXAB-UHFFFAOYSA-N 2-chloro-n,n-bis(2-chloroethyl)ethanamine Chemical compound ClCCN(CCCl)CCCl FDAYLTPAFBGXAB-UHFFFAOYSA-N 0.000 claims description 4
- NDMPLJNOPCLANR-UHFFFAOYSA-N 3,4-dihydroxy-15-(4-hydroxy-18-methoxycarbonyl-5,18-seco-ibogamin-18-yl)-16-methoxy-1-methyl-6,7-didehydro-aspidospermidine-3-carboxylic acid methyl ester Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 NDMPLJNOPCLANR-UHFFFAOYSA-N 0.000 claims description 4
- YCWQAMGASJSUIP-YFKPBYRVSA-N 6-diazo-5-oxo-L-norleucine Chemical compound OC(=O)[C@@H](N)CCC(=O)C=[N+]=[N-] YCWQAMGASJSUIP-YFKPBYRVSA-N 0.000 claims description 4
- 229960005538 6-diazo-5-oxo-L-norleucine Drugs 0.000 claims description 4
- VVIAGPKUTFNRDU-UHFFFAOYSA-N 6S-folinic acid Natural products C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 VVIAGPKUTFNRDU-UHFFFAOYSA-N 0.000 claims description 4
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 claims description 4
- 208000003950 B-cell lymphoma Diseases 0.000 claims description 4
- KLWPJMFMVPTNCC-UHFFFAOYSA-N Camptothecin Natural products CCC1(O)C(=O)OCC2=C1C=C3C4Nc5ccccc5C=C4CN3C2=O KLWPJMFMVPTNCC-UHFFFAOYSA-N 0.000 claims description 4
- GAGWJHPBXLXJQN-UORFTKCHSA-N Capecitabine Chemical compound C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 GAGWJHPBXLXJQN-UORFTKCHSA-N 0.000 claims description 4
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 claims description 4
- 102000007644 Colony-Stimulating Factors Human genes 0.000 claims description 4
- 108010071942 Colony-Stimulating Factors Proteins 0.000 claims description 4
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 claims description 4
- 108010092160 Dactinomycin Proteins 0.000 claims description 4
- WEAHRLBPCANXCN-UHFFFAOYSA-N Daunomycin Natural products CCC1(O)CC(OC2CC(N)C(O)C(C)O2)c3cc4C(=O)c5c(OC)cccc5C(=O)c4c(O)c3C1 WEAHRLBPCANXCN-UHFFFAOYSA-N 0.000 claims description 4
- SAMRUMKYXPVKPA-VFKOLLTISA-N Enocitabine Chemical compound O=C1N=C(NC(=O)CCCCCCCCCCCCCCCCCCCCC)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 SAMRUMKYXPVKPA-VFKOLLTISA-N 0.000 claims description 4
- 229930189413 Esperamicin Natural products 0.000 claims description 4
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 claims description 4
- OAKJQQAXSVQMHS-UHFFFAOYSA-N Hydrazine Chemical compound NN OAKJQQAXSVQMHS-UHFFFAOYSA-N 0.000 claims description 4
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 claims description 4
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 claims description 4
- 108010063738 Interleukins Proteins 0.000 claims description 4
- 102000015696 Interleukins Human genes 0.000 claims description 4
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 claims description 4
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 claims description 4
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 claims description 4
- 102000003946 Prolactin Human genes 0.000 claims description 4
- 108010057464 Prolactin Proteins 0.000 claims description 4
- OWPCHSCAPHNHAV-UHFFFAOYSA-N Rhizoxin Natural products C1C(O)C2(C)OC2C=CC(C)C(OC(=O)C2)CC2CC2OC2C(=O)OC1C(C)C(OC)C(C)=CC=CC(C)=CC1=COC(C)=N1 OWPCHSCAPHNHAV-UHFFFAOYSA-N 0.000 claims description 4
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 claims description 4
- FOCVUCIESVLUNU-UHFFFAOYSA-N Thiotepa Chemical compound C1CN1P(N1CC1)(=S)N1CC1 FOCVUCIESVLUNU-UHFFFAOYSA-N 0.000 claims description 4
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 claims description 4
- 239000004473 Threonine Substances 0.000 claims description 4
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 claims description 4
- 125000004450 alkenylene group Chemical group 0.000 claims description 4
- 229960003437 aminoglutethimide Drugs 0.000 claims description 4
- ROBVIMPUHSLWNV-UHFFFAOYSA-N aminoglutethimide Chemical compound C=1C=C(N)C=CC=1C1(CC)CCC(=O)NC1=O ROBVIMPUHSLWNV-UHFFFAOYSA-N 0.000 claims description 4
- 239000003429 antifungal agent Substances 0.000 claims description 4
- 229940121375 antifungal agent Drugs 0.000 claims description 4
- 239000003096 antiparasitic agent Substances 0.000 claims description 4
- 229940125687 antiparasitic agent Drugs 0.000 claims description 4
- 239000003443 antiviral agent Substances 0.000 claims description 4
- 235000009582 asparagine Nutrition 0.000 claims description 4
- 229960001230 asparagine Drugs 0.000 claims description 4
- 108700002839 cactinomycin Proteins 0.000 claims description 4
- 229950009908 cactinomycin Drugs 0.000 claims description 4
- 229930195731 calicheamicin Natural products 0.000 claims description 4
- VSJKWCGYPAHWDS-FQEVSTJZSA-N camptothecin Chemical compound C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-FQEVSTJZSA-N 0.000 claims description 4
- 229940127093 camptothecin Drugs 0.000 claims description 4
- 229960005243 carmustine Drugs 0.000 claims description 4
- 229960004630 chlorambucil Drugs 0.000 claims description 4
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 claims description 4
- 230000000295 complement effect Effects 0.000 claims description 4
- 229960004397 cyclophosphamide Drugs 0.000 claims description 4
- VSJKWCGYPAHWDS-UHFFFAOYSA-N dl-camptothecin Natural products C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)C5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-UHFFFAOYSA-N 0.000 claims description 4
- 229930188854 dolastatin Natural products 0.000 claims description 4
- 229960005501 duocarmycin Drugs 0.000 claims description 4
- VQNATVDKACXKTF-XELLLNAOSA-N duocarmycin Chemical compound COC1=C(OC)C(OC)=C2NC(C(=O)N3C4=CC(=O)C5=C([C@@]64C[C@@H]6C3)C=C(N5)C(=O)OC)=CC2=C1 VQNATVDKACXKTF-XELLLNAOSA-N 0.000 claims description 4
- 229930184221 duocarmycin Natural products 0.000 claims description 4
- 229950011487 enocitabine Drugs 0.000 claims description 4
- LJQQFQHBKUKHIS-WJHRIEJJSA-N esperamicin Chemical compound O1CC(NC(C)C)C(OC)CC1OC1C(O)C(NOC2OC(C)C(SC)C(O)C2)C(C)OC1OC1C(\C2=C/CSSSC)=C(NC(=O)OC)C(=O)C(OC3OC(C)C(O)C(OC(=O)C=4C(=CC(OC)=C(OC)C=4)NC(=O)C(=C)OC)C3)C2(O)C#C\C=C/C#C1 LJQQFQHBKUKHIS-WJHRIEJJSA-N 0.000 claims description 4
- 229960002949 fluorouracil Drugs 0.000 claims description 4
- 235000008191 folinic acid Nutrition 0.000 claims description 4
- 239000011672 folinic acid Substances 0.000 claims description 4
- CHPZKNULDCNCBW-UHFFFAOYSA-N gallium nitrate Chemical compound [Ga+3].[O-][N+]([O-])=O.[O-][N+]([O-])=O.[O-][N+]([O-])=O CHPZKNULDCNCBW-UHFFFAOYSA-N 0.000 claims description 4
- HOMGKSMUEGBAAB-UHFFFAOYSA-N ifosfamide Chemical compound ClCCNP1(=O)OCCCN1CCCl HOMGKSMUEGBAAB-UHFFFAOYSA-N 0.000 claims description 4
- 229960001101 ifosfamide Drugs 0.000 claims description 4
- 239000003112 inhibitor Substances 0.000 claims description 4
- 229960003881 letrozole Drugs 0.000 claims description 4
- HPJKCIUCZWXJDR-UHFFFAOYSA-N letrozole Chemical compound C1=CC(C#N)=CC=C1C(N1N=CN=C1)C1=CC=C(C#N)C=C1 HPJKCIUCZWXJDR-UHFFFAOYSA-N 0.000 claims description 4
- 229960001691 leucovorin Drugs 0.000 claims description 4
- 229960001428 mercaptopurine Drugs 0.000 claims description 4
- 229960000485 methotrexate Drugs 0.000 claims description 4
- QZGIWPZCWHMVQL-UIYAJPBUSA-N neocarzinostatin chromophore Chemical compound O1[C@H](C)[C@H](O)[C@H](O)[C@@H](NC)[C@H]1O[C@@H]1C/2=C/C#C[C@H]3O[C@@]3([C@@H]3OC(=O)OC3)C#CC\2=C[C@H]1OC(=O)C1=C(O)C=CC2=C(C)C=C(OC)C=C12 QZGIWPZCWHMVQL-UIYAJPBUSA-N 0.000 claims description 4
- 230000007935 neutral effect Effects 0.000 claims description 4
- 229950011093 onapristone Drugs 0.000 claims description 4
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 claims description 4
- 229960001756 oxaliplatin Drugs 0.000 claims description 4
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 claims description 4
- 229940097325 prolactin Drugs 0.000 claims description 4
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 claims description 4
- 229960004622 raloxifene Drugs 0.000 claims description 4
- GZUITABIAKMVPG-UHFFFAOYSA-N raloxifene Chemical compound C1=CC(O)=CC=C1C1=C(C(=O)C=2C=CC(OCCN3CCCCC3)=CC=2)C2=CC=C(O)C=C2S1 GZUITABIAKMVPG-UHFFFAOYSA-N 0.000 claims description 4
- 229960001196 thiotepa Drugs 0.000 claims description 4
- WYWHKKSPHMUBEB-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 claims description 4
- 229960004355 vindesine Drugs 0.000 claims description 4
- UGGWPQSBPIFKDZ-KOTLKJBCSA-N vindesine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(N)=O)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1N=C1[C]2C=CC=C1 UGGWPQSBPIFKDZ-KOTLKJBCSA-N 0.000 claims description 4
- NOWKCMXCCJGMRR-UHFFFAOYSA-N Aziridine Chemical compound C1CN1 NOWKCMXCCJGMRR-UHFFFAOYSA-N 0.000 claims description 3
- 229930188224 Cryptophycin Natural products 0.000 claims description 3
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 claims description 3
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 claims description 3
- 241000283973 Oryctolagus cuniculus Species 0.000 claims description 3
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 claims description 3
- HSFWRNGVRCDJHI-UHFFFAOYSA-N alpha-acetylene Natural products C#C HSFWRNGVRCDJHI-UHFFFAOYSA-N 0.000 claims description 3
- YBBLVLTVTVSKRW-UHFFFAOYSA-N anastrozole Chemical compound N#CC(C)(C)C1=CC(C(C)(C#N)C)=CC(CN2N=CN=C2)=C1 YBBLVLTVTVSKRW-UHFFFAOYSA-N 0.000 claims description 3
- 239000007864 aqueous solution Substances 0.000 claims description 3
- CREMABGTGYGIQB-UHFFFAOYSA-N carbon carbon Chemical compound C.C CREMABGTGYGIQB-UHFFFAOYSA-N 0.000 claims description 3
- 239000003153 chemical reaction reagent Substances 0.000 claims description 3
- 238000012650 click reaction Methods 0.000 claims description 3
- 108010006226 cryptophycin Proteins 0.000 claims description 3
- VLCYCQAOQCDTCN-UHFFFAOYSA-N eflornithine Chemical compound NCCCC(N)(C(F)F)C(O)=O VLCYCQAOQCDTCN-UHFFFAOYSA-N 0.000 claims description 3
- 125000002485 formyl group Chemical group [H]C(*)=O 0.000 claims description 3
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 claims description 3
- 230000007062 hydrolysis Effects 0.000 claims description 3
- 238000006460 hydrolysis reaction Methods 0.000 claims description 3
- 229960000310 isoleucine Drugs 0.000 claims description 3
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 claims description 3
- 235000014705 isoleucine Nutrition 0.000 claims description 3
- 230000002197 limbic effect Effects 0.000 claims description 3
- 150000002632 lipids Chemical class 0.000 claims description 3
- MQXVYODZCMMZEM-ZYUZMQFOSA-N mannomustine Chemical compound ClCCNC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CNCCCl MQXVYODZCMMZEM-ZYUZMQFOSA-N 0.000 claims description 3
- 229950008612 mannomustine Drugs 0.000 claims description 3
- 238000007254 oxidation reaction Methods 0.000 claims description 3
- 229910052760 oxygen Inorganic materials 0.000 claims description 3
- 239000000758 substrate Substances 0.000 claims description 3
- NRUKOCRGYNPUPR-QBPJDGROSA-N teniposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@@H](OC[C@H]4O3)C=3SC=CC=3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 NRUKOCRGYNPUPR-QBPJDGROSA-N 0.000 claims description 3
- 229960001278 teniposide Drugs 0.000 claims description 3
- 239000004474 valine Substances 0.000 claims description 3
- 235000014393 valine Nutrition 0.000 claims description 3
- NNJPGOLRFBJNIW-HNNXBMFYSA-N (-)-demecolcine Chemical compound C1=C(OC)C(=O)C=C2[C@@H](NC)CCC3=CC(OC)=C(OC)C(OC)=C3C2=C1 NNJPGOLRFBJNIW-HNNXBMFYSA-N 0.000 claims description 2
- WDQLRUYAYXDIFW-RWKIJVEZSA-N (2r,3r,4s,5r,6r)-4-[(2s,3r,4s,5r,6r)-3,5-dihydroxy-4-[(2r,3r,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-6-[[(2r,3r,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxymethyl]oxan-2-yl]oxy-6-(hydroxymethyl)oxane-2,3,5-triol Chemical compound O[C@@H]1[C@@H](CO)O[C@@H](O)[C@H](O)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)O)[C@H](O)[C@@H](CO[C@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)O)O1 WDQLRUYAYXDIFW-RWKIJVEZSA-N 0.000 claims description 2
- FLWWDYNPWOSLEO-HQVZTVAUSA-N (2s)-2-[[4-[1-(2-amino-4-oxo-1h-pteridin-6-yl)ethyl-methylamino]benzoyl]amino]pentanedioic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1C(C)N(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FLWWDYNPWOSLEO-HQVZTVAUSA-N 0.000 claims description 2
- DLKUYSQUHXBYPB-NSSHGSRYSA-N (2s,4r)-4-[[2-[(1r,3r)-1-acetyloxy-4-methyl-3-[3-methylbutanoyloxymethyl-[(2s,3s)-3-methyl-2-[[(2r)-1-methylpiperidine-2-carbonyl]amino]pentanoyl]amino]pentyl]-1,3-thiazole-4-carbonyl]amino]-2-methyl-5-(4-methylphenyl)pentanoic acid Chemical compound N([C@@H]([C@@H](C)CC)C(=O)N(COC(=O)CC(C)C)[C@H](C[C@@H](OC(C)=O)C=1SC=C(N=1)C(=O)N[C@H](C[C@H](C)C(O)=O)CC=1C=CC(C)=CC=1)C(C)C)C(=O)[C@H]1CCCCN1C DLKUYSQUHXBYPB-NSSHGSRYSA-N 0.000 claims description 2
- CGMTUJFWROPELF-YPAAEMCBSA-N (3E,5S)-5-[(2S)-butan-2-yl]-3-(1-hydroxyethylidene)pyrrolidine-2,4-dione Chemical compound CC[C@H](C)[C@@H]1NC(=O)\C(=C(/C)O)C1=O CGMTUJFWROPELF-YPAAEMCBSA-N 0.000 claims description 2
- TVIRNGFXQVMMGB-OFWIHYRESA-N (3s,6r,10r,13e,16s)-16-[(2r,3r,4s)-4-chloro-3-hydroxy-4-phenylbutan-2-yl]-10-[(3-chloro-4-methoxyphenyl)methyl]-6-methyl-3-(2-methylpropyl)-1,4-dioxa-8,11-diazacyclohexadec-13-ene-2,5,9,12-tetrone Chemical compound C1=C(Cl)C(OC)=CC=C1C[C@@H]1C(=O)NC[C@@H](C)C(=O)O[C@@H](CC(C)C)C(=O)O[C@H]([C@H](C)[C@@H](O)[C@@H](Cl)C=2C=CC=CC=2)C/C=C/C(=O)N1 TVIRNGFXQVMMGB-OFWIHYRESA-N 0.000 claims description 2
- AESVUZLWRXEGEX-DKCAWCKPSA-N (7S,9R)-7-[(2S,4R,5R,6R)-4-amino-5-hydroxy-6-methyloxan-2-yl]oxy-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-4-methoxy-8,10-dihydro-7H-tetracene-5,12-dione iron(3+) Chemical compound [Fe+3].COc1cccc2C(=O)c3c(O)c4C[C@@](O)(C[C@H](O[C@@H]5C[C@@H](N)[C@@H](O)[C@@H](C)O5)c4c(O)c3C(=O)c12)C(=O)CO AESVUZLWRXEGEX-DKCAWCKPSA-N 0.000 claims description 2
- JXVAMODRWBNUSF-KZQKBALLSA-N (7s,9r,10r)-7-[(2r,4s,5s,6s)-5-[[(2s,4as,5as,7s,9s,9ar,10ar)-2,9-dimethyl-3-oxo-4,4a,5a,6,7,9,9a,10a-octahydrodipyrano[4,2-a:4',3'-e][1,4]dioxin-7-yl]oxy]-4-(dimethylamino)-6-methyloxan-2-yl]oxy-10-[(2s,4s,5s,6s)-4-(dimethylamino)-5-hydroxy-6-methyloxan-2 Chemical compound O([C@@H]1C2=C(O)C=3C(=O)C4=CC=CC(O)=C4C(=O)C=3C(O)=C2[C@@H](O[C@@H]2O[C@@H](C)[C@@H](O[C@@H]3O[C@@H](C)[C@H]4O[C@@H]5O[C@@H](C)C(=O)C[C@@H]5O[C@H]4C3)[C@H](C2)N(C)C)C[C@]1(O)CC)[C@H]1C[C@H](N(C)C)[C@H](O)[C@H](C)O1 JXVAMODRWBNUSF-KZQKBALLSA-N 0.000 claims description 2
- FPVKHBSQESCIEP-UHFFFAOYSA-N (8S)-3-(2-deoxy-beta-D-erythro-pentofuranosyl)-3,6,7,8-tetrahydroimidazo[4,5-d][1,3]diazepin-8-ol Natural products C1C(O)C(CO)OC1N1C(NC=NCC2O)=C2N=C1 FPVKHBSQESCIEP-UHFFFAOYSA-N 0.000 claims description 2
- 125000003161 (C1-C6) alkylene group Chemical group 0.000 claims description 2
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 claims description 2
- LKJPYSCBVHEWIU-KRWDZBQOSA-N (R)-bicalutamide Chemical compound C([C@@](O)(C)C(=O)NC=1C=C(C(C#N)=CC=1)C(F)(F)F)S(=O)(=O)C1=CC=C(F)C=C1 LKJPYSCBVHEWIU-KRWDZBQOSA-N 0.000 claims description 2
- AGNGYMCLFWQVGX-AGFFZDDWSA-N (e)-1-[(2s)-2-amino-2-carboxyethoxy]-2-diazonioethenolate Chemical compound OC(=O)[C@@H](N)CO\C([O-])=C\[N+]#N AGNGYMCLFWQVGX-AGFFZDDWSA-N 0.000 claims description 2
- FONKWHRXTPJODV-DNQXCXABSA-N 1,3-bis[2-[(8s)-8-(chloromethyl)-4-hydroxy-1-methyl-7,8-dihydro-3h-pyrrolo[3,2-e]indole-6-carbonyl]-1h-indol-5-yl]urea Chemical compound C1([C@H](CCl)CN2C(=O)C=3NC4=CC=C(C=C4C=3)NC(=O)NC=3C=C4C=C(NC4=CC=3)C(=O)N3C4=CC(O)=C5NC=C(C5=C4[C@H](CCl)C3)C)=C2C=C(O)C2=C1C(C)=CN2 FONKWHRXTPJODV-DNQXCXABSA-N 0.000 claims description 2
- VSNHCAURESNICA-NJFSPNSNSA-N 1-oxidanylurea Chemical compound N[14C](=O)NO VSNHCAURESNICA-NJFSPNSNSA-N 0.000 claims description 2
- CJHKJXZMFZKGHI-UHFFFAOYSA-N 1h-pyrido[2,3-i][1,2]benzodiazepine Chemical compound N1N=CC=CC2=CC=C(N=CC=C3)C3=C12 CJHKJXZMFZKGHI-UHFFFAOYSA-N 0.000 claims description 2
- BTOTXLJHDSNXMW-POYBYMJQSA-N 2,3-dideoxyuridine Chemical compound O1[C@H](CO)CC[C@@H]1N1C(=O)NC(=O)C=C1 BTOTXLJHDSNXMW-POYBYMJQSA-N 0.000 claims description 2
- BOMZMNZEXMAQQW-UHFFFAOYSA-N 2,5,11-trimethyl-6h-pyrido[4,3-b]carbazol-2-ium-9-ol;acetate Chemical compound CC([O-])=O.C[N+]1=CC=C2C(C)=C(NC=3C4=CC(O)=CC=3)C4=C(C)C2=C1 BOMZMNZEXMAQQW-UHFFFAOYSA-N 0.000 claims description 2
- VNBAOSVONFJBKP-UHFFFAOYSA-N 2-chloro-n,n-bis(2-chloroethyl)propan-1-amine;hydrochloride Chemical compound Cl.CC(Cl)CN(CCCl)CCCl VNBAOSVONFJBKP-UHFFFAOYSA-N 0.000 claims description 2
- YIMDLWDNDGKDTJ-QLKYHASDSA-N 3'-deamino-3'-(3-cyanomorpholin-4-yl)doxorubicin Chemical compound N1([C@H]2C[C@@H](O[C@@H](C)[C@H]2O)O[C@H]2C[C@@](O)(CC=3C(O)=C4C(=O)C=5C=CC=C(C=5C(=O)C4=C(O)C=32)OC)C(=O)CO)CCOCC1C#N YIMDLWDNDGKDTJ-QLKYHASDSA-N 0.000 claims description 2
- PWMYMKOUNYTVQN-UHFFFAOYSA-N 3-(8,8-diethyl-2-aza-8-germaspiro[4.5]decan-2-yl)-n,n-dimethylpropan-1-amine Chemical compound C1C[Ge](CC)(CC)CCC11CN(CCCN(C)C)CC1 PWMYMKOUNYTVQN-UHFFFAOYSA-N 0.000 claims description 2
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 claims description 2
- DODQJNMQWMSYGS-QPLCGJKRSA-N 4-[(z)-1-[4-[2-(dimethylamino)ethoxy]phenyl]-1-phenylbut-1-en-2-yl]phenol Chemical compound C=1C=C(O)C=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 DODQJNMQWMSYGS-QPLCGJKRSA-N 0.000 claims description 2
- TVZGACDUOSZQKY-LBPRGKRZSA-N 4-aminofolic acid Chemical compound C1=NC2=NC(N)=NC(N)=C2N=C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 TVZGACDUOSZQKY-LBPRGKRZSA-N 0.000 claims description 2
- IDPUKCWIGUEADI-UHFFFAOYSA-N 5-[bis(2-chloroethyl)amino]uracil Chemical compound ClCCN(CCCl)C1=CNC(=O)NC1=O IDPUKCWIGUEADI-UHFFFAOYSA-N 0.000 claims description 2
- NMUSYJAQQFHJEW-KVTDHHQDSA-N 5-azacytidine Chemical compound O=C1N=C(N)N=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 NMUSYJAQQFHJEW-KVTDHHQDSA-N 0.000 claims description 2
- WYXSYVWAUAUWLD-SHUUEZRQSA-N 6-azauridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=N1 WYXSYVWAUAUWLD-SHUUEZRQSA-N 0.000 claims description 2
- ZGXJTSGNIOSYLO-UHFFFAOYSA-N 88755TAZ87 Chemical compound NCC(=O)CCC(O)=O ZGXJTSGNIOSYLO-UHFFFAOYSA-N 0.000 claims description 2
- HDZZVAMISRMYHH-UHFFFAOYSA-N 9beta-Ribofuranosyl-7-deazaadenin Natural products C1=CC=2C(N)=NC=NC=2N1C1OC(CO)C(O)C1O HDZZVAMISRMYHH-UHFFFAOYSA-N 0.000 claims description 2
- 108010059616 Activins Proteins 0.000 claims description 2
- 102000005606 Activins Human genes 0.000 claims description 2
- 101800002638 Alpha-amanitin Proteins 0.000 claims description 2
- CEIZFXOZIQNICU-UHFFFAOYSA-N Alternaria alternata Crofton-weed toxin Natural products CCC(C)C1NC(=O)C(C(C)=O)=C1O CEIZFXOZIQNICU-UHFFFAOYSA-N 0.000 claims description 2
- 108010005853 Anti-Mullerian Hormone Proteins 0.000 claims description 2
- 108020000948 Antisense Oligonucleotides Proteins 0.000 claims description 2
- BFYIZQONLCFLEV-DAELLWKTSA-N Aromasine Chemical compound O=C1C=C[C@]2(C)[C@H]3CC[C@](C)(C(CC4)=O)[C@@H]4[C@@H]3CC(=C)C2=C1 BFYIZQONLCFLEV-DAELLWKTSA-N 0.000 claims description 2
- MLDQJTXFUGDVEO-UHFFFAOYSA-N BAY-43-9006 Chemical compound C1=NC(C(=O)NC)=CC(OC=2C=CC(NC(=O)NC=3C=C(C(Cl)=CC=3)C(F)(F)F)=CC=2)=C1 MLDQJTXFUGDVEO-UHFFFAOYSA-N 0.000 claims description 2
- VGGGPCQERPFHOB-MCIONIFRSA-N Bestatin Chemical compound CC(C)C[C@H](C(O)=O)NC(=O)[C@@H](O)[C@H](N)CC1=CC=CC=C1 VGGGPCQERPFHOB-MCIONIFRSA-N 0.000 claims description 2
- 108010006654 Bleomycin Proteins 0.000 claims description 2
- 108030001720 Bontoxilysin Proteins 0.000 claims description 2
- MBABCNBNDNGODA-LTGLSHGVSA-N Bullatacin Natural products O=C1C(C[C@H](O)CCCCCCCCCC[C@@H](O)[C@@H]2O[C@@H]([C@@H]3O[C@H]([C@@H](O)CCCCCCCCCC)CC3)CC2)=C[C@H](C)O1 MBABCNBNDNGODA-LTGLSHGVSA-N 0.000 claims description 2
- KGGVWMAPBXIMEM-ZRTAFWODSA-N Bullatacinone Chemical compound O1[C@@H]([C@@H](O)CCCCCCCCCC)CC[C@@H]1[C@@H]1O[C@@H]([C@H](O)CCCCCCCCCC[C@H]2OC(=O)[C@H](CC(C)=O)C2)CC1 KGGVWMAPBXIMEM-ZRTAFWODSA-N 0.000 claims description 2
- KGGVWMAPBXIMEM-JQFCFGFHSA-N Bullatacinone Natural products O=C(C[C@H]1C(=O)O[C@H](CCCCCCCCCC[C@H](O)[C@@H]2O[C@@H]([C@@H]3O[C@@H]([C@@H](O)CCCCCCCCCC)CC3)CC2)C1)C KGGVWMAPBXIMEM-JQFCFGFHSA-N 0.000 claims description 2
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 claims description 2
- GAGWJHPBXLXJQN-UHFFFAOYSA-N Capecitabine Natural products C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1C1C(O)C(O)C(C)O1 GAGWJHPBXLXJQN-UHFFFAOYSA-N 0.000 claims description 2
- SHHKQEUPHAENFK-UHFFFAOYSA-N Carboquone Chemical compound O=C1C(C)=C(N2CC2)C(=O)C(C(COC(N)=O)OC)=C1N1CC1 SHHKQEUPHAENFK-UHFFFAOYSA-N 0.000 claims description 2
- AOCCBINRVIKJHY-UHFFFAOYSA-N Carmofur Chemical compound CCCCCCNC(=O)N1C=C(F)C(=O)NC1=O AOCCBINRVIKJHY-UHFFFAOYSA-N 0.000 claims description 2
- 102000053642 Catalytic RNA Human genes 0.000 claims description 2
- 108090000994 Catalytic RNA Proteins 0.000 claims description 2
- JWBOIMRXGHLCPP-UHFFFAOYSA-N Chloditan Chemical compound C=1C=CC=C(Cl)C=1C(C(Cl)Cl)C1=CC=C(Cl)C=C1 JWBOIMRXGHLCPP-UHFFFAOYSA-N 0.000 claims description 2
- XCDXSSFOJZZGQC-UHFFFAOYSA-N Chlornaphazine Chemical compound C1=CC=CC2=CC(N(CCCl)CCCl)=CC=C21 XCDXSSFOJZZGQC-UHFFFAOYSA-N 0.000 claims description 2
- 102000009016 Cholera Toxin Human genes 0.000 claims description 2
- 108010049048 Cholera Toxin Proteins 0.000 claims description 2
- 102100021809 Chorionic somatomammotropin hormone 1 Human genes 0.000 claims description 2
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 claims description 2
- XUIIKFGFIJCVMT-GFCCVEGCSA-N D-thyroxine Chemical compound IC1=CC(C[C@@H](N)C(O)=O)=CC(I)=C1OC1=CC(I)=C(O)C(I)=C1 XUIIKFGFIJCVMT-GFCCVEGCSA-N 0.000 claims description 2
- NNJPGOLRFBJNIW-UHFFFAOYSA-N Demecolcine Natural products C1=C(OC)C(=O)C=C2C(NC)CCC3=CC(OC)=C(OC)C(OC)=C3C2=C1 NNJPGOLRFBJNIW-UHFFFAOYSA-N 0.000 claims description 2
- AUGQEEXBDZWUJY-ZLJUKNTDSA-N Diacetoxyscirpenol Chemical compound C([C@]12[C@]3(C)[C@H](OC(C)=O)[C@@H](O)[C@H]1O[C@@H]1C=C(C)CC[C@@]13COC(=O)C)O2 AUGQEEXBDZWUJY-ZLJUKNTDSA-N 0.000 claims description 2
- AUGQEEXBDZWUJY-UHFFFAOYSA-N Diacetoxyscirpenol Natural products CC(=O)OCC12CCC(C)=CC1OC1C(O)C(OC(C)=O)C2(C)C11CO1 AUGQEEXBDZWUJY-UHFFFAOYSA-N 0.000 claims description 2
- 102000016607 Diphtheria Toxin Human genes 0.000 claims description 2
- 108010053187 Diphtheria Toxin Proteins 0.000 claims description 2
- ZQZFYGIXNQKOAV-OCEACIFDSA-N Droloxifene Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=C(O)C=CC=1)\C1=CC=C(OCCN(C)C)C=C1 ZQZFYGIXNQKOAV-OCEACIFDSA-N 0.000 claims description 2
- 229930193152 Dynemicin Natural products 0.000 claims description 2
- AFMYMMXSQGUCBK-UHFFFAOYSA-N Endynamicin A Natural products C1#CC=CC#CC2NC(C=3C(=O)C4=C(O)C=CC(O)=C4C(=O)C=3C(O)=C3)=C3C34OC32C(C)C(C(O)=O)=C(OC)C41 AFMYMMXSQGUCBK-UHFFFAOYSA-N 0.000 claims description 2
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 claims description 2
- OBMLHUPNRURLOK-XGRAFVIBSA-N Epitiostanol Chemical compound C1[C@@H]2S[C@@H]2C[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CC[C@H]21 OBMLHUPNRURLOK-XGRAFVIBSA-N 0.000 claims description 2
- 102000003951 Erythropoietin Human genes 0.000 claims description 2
- 108090000394 Erythropoietin Proteins 0.000 claims description 2
- JOYRKODLDBILNP-UHFFFAOYSA-N Ethyl urethane Chemical compound CCOC(N)=O JOYRKODLDBILNP-UHFFFAOYSA-N 0.000 claims description 2
- 102000018233 Fibroblast Growth Factor Human genes 0.000 claims description 2
- 108050007372 Fibroblast Growth Factor Proteins 0.000 claims description 2
- MPJKWIXIYCLVCU-UHFFFAOYSA-N Folinic acid Natural products NC1=NC2=C(N(C=O)C(CNc3ccc(cc3)C(=O)NC(CCC(=O)O)CC(=O)O)CN2)C(=O)N1 MPJKWIXIYCLVCU-UHFFFAOYSA-N 0.000 claims description 2
- 102000012673 Follicle Stimulating Hormone Human genes 0.000 claims description 2
- 108010079345 Follicle Stimulating Hormone Proteins 0.000 claims description 2
- VWUXBMIQPBEWFH-WCCTWKNTSA-N Fulvestrant Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3[C@H](CCCCCCCCCS(=O)CCCC(F)(F)C(F)(F)F)CC2=C1 VWUXBMIQPBEWFH-WCCTWKNTSA-N 0.000 claims description 2
- JRZJKWGQFNTSRN-UHFFFAOYSA-N Geldanamycin Natural products C1C(C)CC(OC)C(O)C(C)C=C(C)C(OC(N)=O)C(OC)CCC=C(C)C(=O)NC2=CC(=O)C(OC)=C1C2=O JRZJKWGQFNTSRN-UHFFFAOYSA-N 0.000 claims description 2
- 102000003886 Glycoproteins Human genes 0.000 claims description 2
- 108090000288 Glycoproteins Proteins 0.000 claims description 2
- 102000006771 Gonadotropins Human genes 0.000 claims description 2
- 108010086677 Gonadotropins Proteins 0.000 claims description 2
- BLCLNMBMMGCOAS-URPVMXJPSA-N Goserelin Chemical compound C([C@@H](C(=O)N[C@H](COC(C)(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(=O)NNC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 BLCLNMBMMGCOAS-URPVMXJPSA-N 0.000 claims description 2
- 108010069236 Goserelin Proteins 0.000 claims description 2
- 238000006736 Huisgen cycloaddition reaction Methods 0.000 claims description 2
- MPBVHIBUJCELCL-UHFFFAOYSA-N Ibandronate Chemical compound CCCCCN(C)CCC(O)(P(O)(O)=O)P(O)(O)=O MPBVHIBUJCELCL-UHFFFAOYSA-N 0.000 claims description 2
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 claims description 2
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 claims description 2
- 102000006992 Interferon-alpha Human genes 0.000 claims description 2
- 108010047761 Interferon-alpha Proteins 0.000 claims description 2
- 102000003996 Interferon-beta Human genes 0.000 claims description 2
- 108090000467 Interferon-beta Proteins 0.000 claims description 2
- 102000008070 Interferon-gamma Human genes 0.000 claims description 2
- 108010074328 Interferon-gamma Proteins 0.000 claims description 2
- 102000014150 Interferons Human genes 0.000 claims description 2
- 108010050904 Interferons Proteins 0.000 claims description 2
- 108010002352 Interleukin-1 Proteins 0.000 claims description 2
- 108090000174 Interleukin-10 Proteins 0.000 claims description 2
- 102000013462 Interleukin-12 Human genes 0.000 claims description 2
- 108010065805 Interleukin-12 Proteins 0.000 claims description 2
- 108010002350 Interleukin-2 Proteins 0.000 claims description 2
- 108010002386 Interleukin-3 Proteins 0.000 claims description 2
- 108090000978 Interleukin-4 Proteins 0.000 claims description 2
- 108010002616 Interleukin-5 Proteins 0.000 claims description 2
- 108090001005 Interleukin-6 Proteins 0.000 claims description 2
- 108010002586 Interleukin-7 Proteins 0.000 claims description 2
- 108090001007 Interleukin-8 Proteins 0.000 claims description 2
- 108010002335 Interleukin-9 Proteins 0.000 claims description 2
- 102100020880 Kit ligand Human genes 0.000 claims description 2
- 239000005411 L01XE02 - Gefitinib Substances 0.000 claims description 2
- 239000005551 L01XE03 - Erlotinib Substances 0.000 claims description 2
- 239000002147 L01XE04 - Sunitinib Substances 0.000 claims description 2
- 239000005511 L01XE05 - Sorafenib Substances 0.000 claims description 2
- 239000002136 L01XE07 - Lapatinib Substances 0.000 claims description 2
- JLERVPBPJHKRBJ-UHFFFAOYSA-N LY 117018 Chemical compound C1=CC(O)=CC=C1C1=C(C(=O)C=2C=CC(OCCN3CCCC3)=CC=2)C2=CC=C(O)C=C2S1 JLERVPBPJHKRBJ-UHFFFAOYSA-N 0.000 claims description 2
- 229920001491 Lentinan Polymers 0.000 claims description 2
- 108010000817 Leuprolide Proteins 0.000 claims description 2
- GQYIWUVLTXOXAJ-UHFFFAOYSA-N Lomustine Chemical compound ClCCN(N=O)C(=O)NC1CCCCC1 GQYIWUVLTXOXAJ-UHFFFAOYSA-N 0.000 claims description 2
- 102000009151 Luteinizing Hormone Human genes 0.000 claims description 2
- 108010073521 Luteinizing Hormone Proteins 0.000 claims description 2
- 102000004083 Lymphotoxin-alpha Human genes 0.000 claims description 2
- 108090000542 Lymphotoxin-alpha Proteins 0.000 claims description 2
- VJRAUFKOOPNFIQ-UHFFFAOYSA-N Marcellomycin Natural products C12=C(O)C=3C(=O)C4=C(O)C=CC(O)=C4C(=O)C=3C=C2C(C(=O)OC)C(CC)(O)CC1OC(OC1C)CC(N(C)C)C1OC(OC1C)CC(O)C1OC1CC(O)C(O)C(C)O1 VJRAUFKOOPNFIQ-UHFFFAOYSA-N 0.000 claims description 2
- 229930126263 Maytansine Natural products 0.000 claims description 2
- IVDYZAAPOLNZKG-KWHRADDSSA-N Mepitiostane Chemical compound O([C@@H]1[C@]2(CC[C@@H]3[C@@]4(C)C[C@H]5S[C@H]5C[C@@H]4CC[C@H]3[C@@H]2CC1)C)C1(OC)CCCC1 IVDYZAAPOLNZKG-KWHRADDSSA-N 0.000 claims description 2
- 102100026632 Mimecan Human genes 0.000 claims description 2
- VFKZTMPDYBFSTM-KVTDHHQDSA-N Mitobronitol Chemical compound BrC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CBr VFKZTMPDYBFSTM-KVTDHHQDSA-N 0.000 claims description 2
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 claims description 2
- KGTDRFCXGRULNK-UHFFFAOYSA-N Nogalamycin Natural products COC1C(OC)(C)C(OC)C(C)OC1OC1C2=C(O)C(C(=O)C3=C(O)C=C4C5(C)OC(C(C(C5O)N(C)C)O)OC4=C3C3=O)=C3C=C2C(C(=O)OC)C(C)(O)C1 KGTDRFCXGRULNK-UHFFFAOYSA-N 0.000 claims description 2
- 229930187135 Olivomycin Natural products 0.000 claims description 2
- 101800002327 Osteoinductive factor Proteins 0.000 claims description 2
- VREZDOWOLGNDPW-ALTGWBOUSA-N Pancratistatin Chemical compound C1=C2[C@H]3[C@@H](O)[C@H](O)[C@@H](O)[C@@H](O)[C@@H]3NC(=O)C2=C(O)C2=C1OCO2 VREZDOWOLGNDPW-ALTGWBOUSA-N 0.000 claims description 2
- VREZDOWOLGNDPW-MYVCAWNPSA-N Pancratistatin Natural products O=C1N[C@H]2[C@H](O)[C@H](O)[C@H](O)[C@H](O)[C@@H]2c2c1c(O)c1OCOc1c2 VREZDOWOLGNDPW-MYVCAWNPSA-N 0.000 claims description 2
- 102000003982 Parathyroid hormone Human genes 0.000 claims description 2
- 108090000445 Parathyroid hormone Proteins 0.000 claims description 2
- 108010057150 Peplomycin Proteins 0.000 claims description 2
- 102000015731 Peptide Hormones Human genes 0.000 claims description 2
- 108010038988 Peptide Hormones Proteins 0.000 claims description 2
- KMSKQZKKOZQFFG-HSUXVGOQSA-N Pirarubicin Chemical compound O([C@H]1[C@@H](N)C[C@@H](O[C@H]1C)O[C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1CCCCO1 KMSKQZKKOZQFFG-HSUXVGOQSA-N 0.000 claims description 2
- 108010003044 Placental Lactogen Proteins 0.000 claims description 2
- 239000000381 Placental Lactogen Substances 0.000 claims description 2
- HFVNWDWLWUCIHC-GUPDPFMOSA-N Prednimustine Chemical compound O=C([C@@]1(O)CC[C@H]2[C@H]3[C@@H]([C@]4(C=CC(=O)C=C4CC3)C)[C@@H](O)C[C@@]21C)COC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 HFVNWDWLWUCIHC-GUPDPFMOSA-N 0.000 claims description 2
- XBDQKXXYIPTUBI-UHFFFAOYSA-M Propionate Chemical compound CCC([O-])=O XBDQKXXYIPTUBI-UHFFFAOYSA-M 0.000 claims description 2
- 108090000103 Relaxin Proteins 0.000 claims description 2
- 102000003743 Relaxin Human genes 0.000 claims description 2
- 108010039491 Ricin Proteins 0.000 claims description 2
- NSFWWJIQIKBZMJ-YKNYLIOZSA-N Roridin A Chemical compound C([C@]12[C@]3(C)[C@H]4C[C@H]1O[C@@H]1C=C(C)CC[C@@]13COC(=O)[C@@H](O)[C@H](C)CCO[C@H](\C=C\C=C/C(=O)O4)[C@H](O)C)O2 NSFWWJIQIKBZMJ-YKNYLIOZSA-N 0.000 claims description 2
- 108010003723 Single-Domain Antibodies Proteins 0.000 claims description 2
- 229920000519 Sizofiran Polymers 0.000 claims description 2
- 108010039445 Stem Cell Factor Proteins 0.000 claims description 2
- 108010090804 Streptavidin Proteins 0.000 claims description 2
- BXFOFFBJRFZBQZ-QYWOHJEZSA-N T-2 toxin Chemical compound C([C@@]12[C@]3(C)[C@H](OC(C)=O)[C@@H](O)[C@H]1O[C@H]1[C@]3(COC(C)=O)C[C@@H](C(=C1)C)OC(=O)CC(C)C)O2 BXFOFFBJRFZBQZ-QYWOHJEZSA-N 0.000 claims description 2
- CGMTUJFWROPELF-UHFFFAOYSA-N Tenuazonic acid Natural products CCC(C)C1NC(=O)C(=C(C)/O)C1=O CGMTUJFWROPELF-UHFFFAOYSA-N 0.000 claims description 2
- 108010055044 Tetanus Toxin Proteins 0.000 claims description 2
- 102000036693 Thrombopoietin Human genes 0.000 claims description 2
- 108010041111 Thrombopoietin Proteins 0.000 claims description 2
- 102000011923 Thyrotropin Human genes 0.000 claims description 2
- 108010061174 Thyrotropin Proteins 0.000 claims description 2
- UMILHIMHKXVDGH-UHFFFAOYSA-N Triethylene glycol diglycidyl ether Chemical compound C1OC1COCCOCCOCCOCC1CO1 UMILHIMHKXVDGH-UHFFFAOYSA-N 0.000 claims description 2
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 claims description 2
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 claims description 2
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 claims description 2
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 claims description 2
- ZYVSOIYQKUDENJ-ASUJBHBQSA-N [(2R,3R,4R,6R)-6-[[(6S,7S)-6-[(2S,4R,5R,6R)-4-[(2R,4R,5R,6R)-4-[(2S,4S,5S,6S)-5-acetyloxy-4-hydroxy-4,6-dimethyloxan-2-yl]oxy-5-hydroxy-6-methyloxan-2-yl]oxy-5-hydroxy-6-methyloxan-2-yl]oxy-7-[(3S,4R)-3,4-dihydroxy-1-methoxy-2-oxopentyl]-4,10-dihydroxy-3-methyl-5-oxo-7,8-dihydro-6H-anthracen-2-yl]oxy]-4-[(2R,4R,5R,6R)-4-hydroxy-5-methoxy-6-methyloxan-2-yl]oxy-2-methyloxan-3-yl] acetate Chemical class COC([C@@H]1Cc2cc3cc(O[C@@H]4C[C@@H](O[C@@H]5C[C@@H](O)[C@@H](OC)[C@@H](C)O5)[C@H](OC(C)=O)[C@@H](C)O4)c(C)c(O)c3c(O)c2C(=O)[C@H]1O[C@H]1C[C@@H](O[C@@H]2C[C@@H](O[C@H]3C[C@](C)(O)[C@@H](OC(C)=O)[C@H](C)O3)[C@H](O)[C@@H](C)O2)[C@H](O)[C@@H](C)O1)C(=O)[C@@H](O)[C@@H](C)O ZYVSOIYQKUDENJ-ASUJBHBQSA-N 0.000 claims description 2
- SPJCRMJCFSJKDE-ZWBUGVOYSA-N [(3s,8s,9s,10r,13r,14s,17r)-10,13-dimethyl-17-[(2r)-6-methylheptan-2-yl]-2,3,4,7,8,9,11,12,14,15,16,17-dodecahydro-1h-cyclopenta[a]phenanthren-3-yl] 2-[4-[bis(2-chloroethyl)amino]phenyl]acetate Chemical compound O([C@@H]1CC2=CC[C@H]3[C@@H]4CC[C@@H]([C@]4(CC[C@@H]3[C@@]2(C)CC1)C)[C@H](C)CCCC(C)C)C(=O)CC1=CC=C(N(CCCl)CCCl)C=C1 SPJCRMJCFSJKDE-ZWBUGVOYSA-N 0.000 claims description 2
- IFJUINDAXYAPTO-UUBSBJJBSA-N [(8r,9s,13s,14s,17s)-17-[2-[4-[4-[bis(2-chloroethyl)amino]phenyl]butanoyloxy]acetyl]oxy-13-methyl-6,7,8,9,11,12,14,15,16,17-decahydrocyclopenta[a]phenanthren-3-yl] benzoate Chemical compound C([C@@H]1[C@@H](C2=CC=3)CC[C@]4([C@H]1CC[C@@H]4OC(=O)COC(=O)CCCC=1C=CC(=CC=1)N(CCCl)CCCl)C)CC2=CC=3OC(=O)C1=CC=CC=C1 IFJUINDAXYAPTO-UUBSBJJBSA-N 0.000 claims description 2
- IHGLINDYFMDHJG-UHFFFAOYSA-N [2-(4-methoxyphenyl)-3,4-dihydronaphthalen-1-yl]-[4-(2-pyrrolidin-1-ylethoxy)phenyl]methanone Chemical compound C1=CC(OC)=CC=C1C(CCC1=CC=CC=C11)=C1C(=O)C(C=C1)=CC=C1OCCN1CCCC1 IHGLINDYFMDHJG-UHFFFAOYSA-N 0.000 claims description 2
- ZOZKYEHVNDEUCO-XUTVFYLZSA-N aceglatone Chemical compound O1C(=O)[C@H](OC(C)=O)[C@@H]2OC(=O)[C@@H](OC(=O)C)[C@@H]21 ZOZKYEHVNDEUCO-XUTVFYLZSA-N 0.000 claims description 2
- 229950002684 aceglatone Drugs 0.000 claims description 2
- 229930183665 actinomycin Natural products 0.000 claims description 2
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 claims description 2
- 239000012190 activator Substances 0.000 claims description 2
- 239000000488 activin Substances 0.000 claims description 2
- 229950004955 adozelesin Drugs 0.000 claims description 2
- BYRVKDUQDLJUBX-JJCDCTGGSA-N adozelesin Chemical compound C1=CC=C2OC(C(=O)NC=3C=C4C=C(NC4=CC=3)C(=O)N3C[C@H]4C[C@]44C5=C(C(C=C43)=O)NC=C5C)=CC2=C1 BYRVKDUQDLJUBX-JJCDCTGGSA-N 0.000 claims description 2
- 150000001299 aldehydes Chemical class 0.000 claims description 2
- SHGAZHPCJJPHSC-YCNIQYBTSA-N all-trans-retinoic acid Chemical compound OC(=O)\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-YCNIQYBTSA-N 0.000 claims description 2
- CIORWBWIBBPXCG-SXZCQOKQSA-N alpha-amanitin Chemical compound O=C1N[C@@H](CC(N)=O)C(=O)N2C[C@H](O)C[C@H]2C(=O)N[C@@H]([C@@H](C)[C@@H](O)CO)C(=O)N[C@@H](C2)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@H]1C[S@@](=O)C1=C2C2=CC=C(O)C=C2N1 CIORWBWIBBPXCG-SXZCQOKQSA-N 0.000 claims description 2
- 229960000473 altretamine Drugs 0.000 claims description 2
- 229960002749 aminolevulinic acid Drugs 0.000 claims description 2
- 229960003896 aminopterin Drugs 0.000 claims description 2
- XCPGHVQEEXUHNC-UHFFFAOYSA-N amsacrine Chemical compound COC1=CC(NS(C)(=O)=O)=CC=C1NC1=C(C=CC=C2)C2=NC2=CC=CC=C12 XCPGHVQEEXUHNC-UHFFFAOYSA-N 0.000 claims description 2
- 229960001220 amsacrine Drugs 0.000 claims description 2
- 229960002932 anastrozole Drugs 0.000 claims description 2
- BBDAGFIXKZCXAH-CCXZUQQUSA-N ancitabine Chemical compound N=C1C=CN2[C@@H]3O[C@H](CO)[C@@H](O)[C@@H]3OC2=N1 BBDAGFIXKZCXAH-CCXZUQQUSA-N 0.000 claims description 2
- 229950000242 ancitabine Drugs 0.000 claims description 2
- 239000004037 angiogenesis inhibitor Substances 0.000 claims description 2
- 239000000868 anti-mullerian hormone Substances 0.000 claims description 2
- 229940045988 antineoplastic drug protein kinase inhibitors Drugs 0.000 claims description 2
- 239000000074 antisense oligonucleotide Substances 0.000 claims description 2
- 238000012230 antisense oligonucleotides Methods 0.000 claims description 2
- 150000008209 arabinosides Chemical class 0.000 claims description 2
- 239000003886 aromatase inhibitor Substances 0.000 claims description 2
- 229940046844 aromatase inhibitors Drugs 0.000 claims description 2
- 229960002756 azacitidine Drugs 0.000 claims description 2
- 229950011321 azaserine Drugs 0.000 claims description 2
- 150000001540 azides Chemical class 0.000 claims description 2
- 229960000997 bicalutamide Drugs 0.000 claims description 2
- 230000003115 biocidal effect Effects 0.000 claims description 2
- 229960002685 biotin Drugs 0.000 claims description 2
- 235000020958 biotin Nutrition 0.000 claims description 2
- 239000011616 biotin Substances 0.000 claims description 2
- 229950008548 bisantrene Drugs 0.000 claims description 2
- 229950006844 bizelesin Drugs 0.000 claims description 2
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical class N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 claims description 2
- 229960001467 bortezomib Drugs 0.000 claims description 2
- GXJABQQUPOEUTA-RDJZCZTQSA-N bortezomib Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)B(O)O)NC(=O)C=1N=CC=NC=1)C1=CC=CC=C1 GXJABQQUPOEUTA-RDJZCZTQSA-N 0.000 claims description 2
- 229940053031 botulinum toxin Drugs 0.000 claims description 2
- 229960005520 bryostatin Drugs 0.000 claims description 2
- MJQUEDHRCUIRLF-TVIXENOKSA-N bryostatin 1 Chemical compound C([C@@H]1CC(/[C@@H]([C@@](C(C)(C)/C=C/2)(O)O1)OC(=O)/C=C/C=C/CCC)=C\C(=O)OC)[C@H]([C@@H](C)O)OC(=O)C[C@H](O)C[C@@H](O1)C[C@H](OC(C)=O)C(C)(C)[C@]1(O)C[C@@H]1C\C(=C\C(=O)OC)C[C@H]\2O1 MJQUEDHRCUIRLF-TVIXENOKSA-N 0.000 claims description 2
- MUIWQCKLQMOUAT-AKUNNTHJSA-N bryostatin 20 Natural products COC(=O)C=C1C[C@@]2(C)C[C@]3(O)O[C@](C)(C[C@@H](O)CC(=O)O[C@](C)(C[C@@]4(C)O[C@](O)(CC5=CC(=O)O[C@]45C)C(C)(C)C=C[C@@](C)(C1)O2)[C@@H](C)O)C[C@H](OC(=O)C(C)(C)C)C3(C)C MUIWQCKLQMOUAT-AKUNNTHJSA-N 0.000 claims description 2
- MBABCNBNDNGODA-LUVUIASKSA-N bullatacin Chemical compound O1[C@@H]([C@@H](O)CCCCCCCCCC)CC[C@@H]1[C@@H]1O[C@@H]([C@H](O)CCCCCCCCCC[C@@H](O)CC=2C(O[C@@H](C)C=2)=O)CC1 MBABCNBNDNGODA-LUVUIASKSA-N 0.000 claims description 2
- 229960002092 busulfan Drugs 0.000 claims description 2
- 125000004106 butoxy group Chemical group [*]OC([H])([H])C([H])([H])C(C([H])([H])[H])([H])[H] 0.000 claims description 2
- IVFYLRMMHVYGJH-PVPPCFLZSA-N calusterone Chemical compound C1C[C@]2(C)[C@](O)(C)CC[C@H]2[C@@H]2[C@@H](C)CC3=CC(=O)CC[C@]3(C)[C@H]21 IVFYLRMMHVYGJH-PVPPCFLZSA-N 0.000 claims description 2
- 229950009823 calusterone Drugs 0.000 claims description 2
- 229960004117 capecitabine Drugs 0.000 claims description 2
- 229960004562 carboplatin Drugs 0.000 claims description 2
- 229960002115 carboquone Drugs 0.000 claims description 2
- 229960003261 carmofur Drugs 0.000 claims description 2
- BBZDXMBRAFTCAA-AREMUKBSSA-N carzelesin Chemical compound C1=2NC=C(C)C=2C([C@H](CCl)CN2C(=O)C=3NC4=CC=C(C=C4C=3)NC(=O)C3=CC4=CC=C(C=C4O3)N(CC)CC)=C2C=C1OC(=O)NC1=CC=CC=C1 BBZDXMBRAFTCAA-AREMUKBSSA-N 0.000 claims description 2
- 229950007509 carzelesin Drugs 0.000 claims description 2
- 108010047060 carzinophilin Proteins 0.000 claims description 2
- 229950008249 chlornaphazine Drugs 0.000 claims description 2
- 229960001480 chlorozotocin Drugs 0.000 claims description 2
- VYVRIXWNTVOIRD-UHFFFAOYSA-N ciguatoxin Natural products O1C(C(C(C)C2OC3CC(C)CC4OC5(C)C(O)CC6OC7C=CC8OC9CC%10C(C(C%11OC(C=CCC%11O%10)C=CC(O)CO)O)OC9C=CC8OC7CC=CCC6OC5CC4OC3CC2O2)O)C2C(C)C(C)C21CC(O)CO2 VYVRIXWNTVOIRD-UHFFFAOYSA-N 0.000 claims description 2
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 claims description 2
- 229960004316 cisplatin Drugs 0.000 claims description 2
- 229960002286 clodronic acid Drugs 0.000 claims description 2
- 108010089438 cryptophycin 1 Proteins 0.000 claims description 2
- 108010090203 cryptophycin 8 Proteins 0.000 claims description 2
- 229960000684 cytarabine Drugs 0.000 claims description 2
- 229960003901 dacarbazine Drugs 0.000 claims description 2
- 229960000640 dactinomycin Drugs 0.000 claims description 2
- 229960000975 daunorubicin Drugs 0.000 claims description 2
- 229960005052 demecolcine Drugs 0.000 claims description 2
- WVYXNIXAMZOZFK-UHFFFAOYSA-N diaziquone Chemical compound O=C1C(NC(=O)OCC)=C(N2CC2)C(=O)C(NC(=O)OCC)=C1N1CC1 WVYXNIXAMZOZFK-UHFFFAOYSA-N 0.000 claims description 2
- 229950002389 diaziquone Drugs 0.000 claims description 2
- 239000003534 dna topoisomerase inhibitor Substances 0.000 claims description 2
- 229960003668 docetaxel Drugs 0.000 claims description 2
- ZWAOHEXOSAUJHY-ZIYNGMLESA-N doxifluridine Chemical compound O[C@@H]1[C@H](O)[C@@H](C)O[C@H]1N1C(=O)NC(=O)C(F)=C1 ZWAOHEXOSAUJHY-ZIYNGMLESA-N 0.000 claims description 2
- 229950005454 doxifluridine Drugs 0.000 claims description 2
- 229950004203 droloxifene Drugs 0.000 claims description 2
- 229940017825 dromostanolone Drugs 0.000 claims description 2
- NOTIQUSPUUHHEH-UXOVVSIBSA-N dromostanolone propionate Chemical compound C([C@@H]1CC2)C(=O)[C@H](C)C[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H](OC(=O)CC)[C@@]2(C)CC1 NOTIQUSPUUHHEH-UXOVVSIBSA-N 0.000 claims description 2
- AFMYMMXSQGUCBK-AKMKHHNQSA-N dynemicin a Chemical compound C1#C\C=C/C#C[C@@H]2NC(C=3C(=O)C4=C(O)C=CC(O)=C4C(=O)C=3C(O)=C3)=C3[C@@]34O[C@]32[C@@H](C)C(C(O)=O)=C(OC)[C@H]41 AFMYMMXSQGUCBK-AKMKHHNQSA-N 0.000 claims description 2
- FSIRXIHZBIXHKT-MHTVFEQDSA-N edatrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CC(CC)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FSIRXIHZBIXHKT-MHTVFEQDSA-N 0.000 claims description 2
- 229950006700 edatrexate Drugs 0.000 claims description 2
- 229960002759 eflornithine Drugs 0.000 claims description 2
- XOPYFXBZMVTEJF-PDACKIITSA-N eleutherobin Chemical compound C(/[C@H]1[C@H](C(=CC[C@@H]1C(C)C)C)C[C@@H]([C@@]1(C)O[C@@]2(C=C1)OC)OC(=O)\C=C\C=1N=CN(C)C=1)=C2\CO[C@@H]1OC[C@@H](O)[C@@H](O)[C@@H]1OC(C)=O XOPYFXBZMVTEJF-PDACKIITSA-N 0.000 claims description 2
- XOPYFXBZMVTEJF-UHFFFAOYSA-N eleutherobin Natural products C1=CC2(OC)OC1(C)C(OC(=O)C=CC=1N=CN(C)C=1)CC(C(=CCC1C(C)C)C)C1C=C2COC1OCC(O)C(O)C1OC(C)=O XOPYFXBZMVTEJF-UHFFFAOYSA-N 0.000 claims description 2
- 229950000549 elliptinium acetate Drugs 0.000 claims description 2
- JOZGNYDSEBIJDH-UHFFFAOYSA-N eniluracil Chemical compound O=C1NC=C(C#C)C(=O)N1 JOZGNYDSEBIJDH-UHFFFAOYSA-N 0.000 claims description 2
- 229950010213 eniluracil Drugs 0.000 claims description 2
- 229960001904 epirubicin Drugs 0.000 claims description 2
- 229950002973 epitiostanol Drugs 0.000 claims description 2
- 229930013356 epothilone Natural products 0.000 claims description 2
- 150000003883 epothilone derivatives Chemical class 0.000 claims description 2
- 229960001433 erlotinib Drugs 0.000 claims description 2
- AAKJLRGGTJKAMG-UHFFFAOYSA-N erlotinib Chemical compound C=12C=C(OCCOC)C(OCCOC)=CC2=NC=NC=1NC1=CC=CC(C#C)=C1 AAKJLRGGTJKAMG-UHFFFAOYSA-N 0.000 claims description 2
- 229940105423 erythropoietin Drugs 0.000 claims description 2
- ITSGNOIFAJAQHJ-BMFNZSJVSA-N esorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)C[C@H](C)O1 ITSGNOIFAJAQHJ-BMFNZSJVSA-N 0.000 claims description 2
- 229950002017 esorubicin Drugs 0.000 claims description 2
- 229960001842 estramustine Drugs 0.000 claims description 2
- FRPJXPJMRWBBIH-RBRWEJTLSA-N estramustine Chemical compound ClCCN(CCCl)C(=O)OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 FRPJXPJMRWBBIH-RBRWEJTLSA-N 0.000 claims description 2
- QSRLNKCNOLVZIR-KRWDZBQOSA-N ethyl (2s)-2-[[2-[4-[bis(2-chloroethyl)amino]phenyl]acetyl]amino]-4-methylsulfanylbutanoate Chemical compound CCOC(=O)[C@H](CCSC)NC(=O)CC1=CC=C(N(CCCl)CCCl)C=C1 QSRLNKCNOLVZIR-KRWDZBQOSA-N 0.000 claims description 2
- 229960005237 etoglucid Drugs 0.000 claims description 2
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 claims description 2
- 229960005420 etoposide Drugs 0.000 claims description 2
- 229960000255 exemestane Drugs 0.000 claims description 2
- 229940126864 fibroblast growth factor Drugs 0.000 claims description 2
- ODKNJVUHOIMIIZ-RRKCRQDMSA-N floxuridine Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(F)=C1 ODKNJVUHOIMIIZ-RRKCRQDMSA-N 0.000 claims description 2
- 229960000961 floxuridine Drugs 0.000 claims description 2
- 229960000390 fludarabine Drugs 0.000 claims description 2
- GIUYCYHIANZCFB-FJFJXFQQSA-N fludarabine phosphate Chemical compound C1=NC=2C(N)=NC(F)=NC=2N1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@@H]1O GIUYCYHIANZCFB-FJFJXFQQSA-N 0.000 claims description 2
- MKXKFYHWDHIYRV-UHFFFAOYSA-N flutamide Chemical compound CC(C)C(=O)NC1=CC=C([N+]([O-])=O)C(C(F)(F)F)=C1 MKXKFYHWDHIYRV-UHFFFAOYSA-N 0.000 claims description 2
- 229960002074 flutamide Drugs 0.000 claims description 2
- 229940028334 follicle stimulating hormone Drugs 0.000 claims description 2
- 229960004783 fotemustine Drugs 0.000 claims description 2
- YAKWPXVTIGTRJH-UHFFFAOYSA-N fotemustine Chemical compound CCOP(=O)(OCC)C(C)NC(=O)N(CCCl)N=O YAKWPXVTIGTRJH-UHFFFAOYSA-N 0.000 claims description 2
- 229960002258 fulvestrant Drugs 0.000 claims description 2
- 229940044658 gallium nitrate Drugs 0.000 claims description 2
- XGALLCVXEZPNRQ-UHFFFAOYSA-N gefitinib Chemical compound C=12C=C(OCCCN3CCOCC3)C(OC)=CC2=NC=NC=1NC1=CC=C(F)C(Cl)=C1 XGALLCVXEZPNRQ-UHFFFAOYSA-N 0.000 claims description 2
- 229960002584 gefitinib Drugs 0.000 claims description 2
- QTQAWLPCGQOSGP-GBTDJJJQSA-N geldanamycin Chemical compound N1C(=O)\C(C)=C/C=C\[C@@H](OC)[C@H](OC(N)=O)\C(C)=C/[C@@H](C)[C@@H](O)[C@H](OC)C[C@@H](C)CC2=C(OC)C(=O)C=C1C2=O QTQAWLPCGQOSGP-GBTDJJJQSA-N 0.000 claims description 2
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 claims description 2
- 229960005277 gemcitabine Drugs 0.000 claims description 2
- 229930182470 glycoside Natural products 0.000 claims description 2
- 239000002622 gonadotropin Substances 0.000 claims description 2
- 229960002913 goserelin Drugs 0.000 claims description 2
- 239000003102 growth factor Substances 0.000 claims description 2
- 230000002440 hepatic effect Effects 0.000 claims description 2
- 125000004404 heteroalkyl group Chemical group 0.000 claims description 2
- UUVWYPNAQBNQJQ-UHFFFAOYSA-N hexamethylmelamine Chemical compound CN(C)C1=NC(N(C)C)=NC(N(C)C)=N1 UUVWYPNAQBNQJQ-UHFFFAOYSA-N 0.000 claims description 2
- 229940088597 hormone Drugs 0.000 claims description 2
- 239000005556 hormone Substances 0.000 claims description 2
- 229940015872 ibandronate Drugs 0.000 claims description 2
- 229960003685 imatinib mesylate Drugs 0.000 claims description 2
- YLMAHDNUQAMNNX-UHFFFAOYSA-N imatinib methanesulfonate Chemical compound CS(O)(=O)=O.C1CN(C)CCN1CC1=CC=C(C(=O)NC=2C=C(NC=3N=C(C=CN=3)C=3C=NC=CC=3)C(C)=CC=2)C=C1 YLMAHDNUQAMNNX-UHFFFAOYSA-N 0.000 claims description 2
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Substances C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 claims description 2
- 230000002163 immunogen Effects 0.000 claims description 2
- 229950008097 improsulfan Drugs 0.000 claims description 2
- DBIGHPPNXATHOF-UHFFFAOYSA-N improsulfan Chemical compound CS(=O)(=O)OCCCNCCCOS(C)(=O)=O DBIGHPPNXATHOF-UHFFFAOYSA-N 0.000 claims description 2
- 229940079322 interferon Drugs 0.000 claims description 2
- 229960003130 interferon gamma Drugs 0.000 claims description 2
- 229960001388 interferon-beta Drugs 0.000 claims description 2
- 125000000468 ketone group Chemical group 0.000 claims description 2
- 229940043355 kinase inhibitor Drugs 0.000 claims description 2
- 229960004891 lapatinib Drugs 0.000 claims description 2
- 229940115286 lentinan Drugs 0.000 claims description 2
- GFIJNRVAKGFPGQ-LIJARHBVSA-N leuprolide Chemical compound CCNC(=O)[C@@H]1CCCN1C(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)CC1=CC=C(O)C=C1 GFIJNRVAKGFPGQ-LIJARHBVSA-N 0.000 claims description 2
- 229960004338 leuprorelin Drugs 0.000 claims description 2
- 229960002247 lomustine Drugs 0.000 claims description 2
- DHMTURDWPRKSOA-RUZDIDTESA-N lonafarnib Chemical compound C1CN(C(=O)N)CCC1CC(=O)N1CCC([C@@H]2C3=C(Br)C=C(Cl)C=C3CCC3=CC(Br)=CN=C32)CC1 DHMTURDWPRKSOA-RUZDIDTESA-N 0.000 claims description 2
- 229950001750 lonafarnib Drugs 0.000 claims description 2
- YROQEQPFUCPDCP-UHFFFAOYSA-N losoxantrone Chemical compound OCCNCCN1N=C2C3=CC=CC(O)=C3C(=O)C3=C2C1=CC=C3NCCNCCO YROQEQPFUCPDCP-UHFFFAOYSA-N 0.000 claims description 2
- 229950008745 losoxantrone Drugs 0.000 claims description 2
- 229940040129 luteinizing hormone Drugs 0.000 claims description 2
- WKPWGQKGSOKKOO-RSFHAFMBSA-N maytansine Chemical compound CO[C@@H]([C@@]1(O)C[C@](OC(=O)N1)([C@H]([C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(C)=O)CC(=O)N1C)C)[H])\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 WKPWGQKGSOKKOO-RSFHAFMBSA-N 0.000 claims description 2
- QZIQJVCYUQZDIR-UHFFFAOYSA-N mechlorethamine hydrochloride Chemical compound Cl.ClCCN(C)CCCl QZIQJVCYUQZDIR-UHFFFAOYSA-N 0.000 claims description 2
- RQZAXGRLVPAYTJ-GQFGMJRRSA-N megestrol acetate Chemical compound C1=C(C)C2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(C)=O)(OC(=O)C)[C@@]1(C)CC2 RQZAXGRLVPAYTJ-GQFGMJRRSA-N 0.000 claims description 2
- 229960004296 megestrol acetate Drugs 0.000 claims description 2
- 229960001924 melphalan Drugs 0.000 claims description 2
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 claims description 2
- 229950009246 mepitiostane Drugs 0.000 claims description 2
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 claims description 2
- VJRAUFKOOPNFIQ-TVEKBUMESA-N methyl (1r,2r,4s)-4-[(2r,4s,5s,6s)-5-[(2s,4s,5s,6s)-5-[(2s,4s,5s,6s)-4,5-dihydroxy-6-methyloxan-2-yl]oxy-4-hydroxy-6-methyloxan-2-yl]oxy-4-(dimethylamino)-6-methyloxan-2-yl]oxy-2-ethyl-2,5,7,10-tetrahydroxy-6,11-dioxo-3,4-dihydro-1h-tetracene-1-carboxylat Chemical compound O([C@H]1[C@@H](O)C[C@@H](O[C@H]1C)O[C@H]1[C@H](C[C@@H](O[C@H]1C)O[C@H]1C[C@]([C@@H](C2=CC=3C(=O)C4=C(O)C=CC(O)=C4C(=O)C=3C(O)=C21)C(=O)OC)(O)CC)N(C)C)[C@H]1C[C@H](O)[C@H](O)[C@H](C)O1 VJRAUFKOOPNFIQ-TVEKBUMESA-N 0.000 claims description 2
- HPNSFSBZBAHARI-UHFFFAOYSA-N micophenolic acid Natural products OC1=C(CC=C(C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-UHFFFAOYSA-N 0.000 claims description 2
- 229960005485 mitobronitol Drugs 0.000 claims description 2
- 229960003539 mitoguazone Drugs 0.000 claims description 2
- MXWHMTNPTTVWDM-NXOFHUPFSA-N mitoguazone Chemical compound NC(N)=N\N=C(/C)\C=N\N=C(N)N MXWHMTNPTTVWDM-NXOFHUPFSA-N 0.000 claims description 2
- VFKZTMPDYBFSTM-GUCUJZIJSA-N mitolactol Chemical compound BrC[C@H](O)[C@@H](O)[C@@H](O)[C@H](O)CBr VFKZTMPDYBFSTM-GUCUJZIJSA-N 0.000 claims description 2
- 229950010913 mitolactol Drugs 0.000 claims description 2
- 229960004857 mitomycin Drugs 0.000 claims description 2
- 229960000350 mitotane Drugs 0.000 claims description 2
- 229960000951 mycophenolic acid Drugs 0.000 claims description 2
- HPNSFSBZBAHARI-RUDMXATFSA-N mycophenolic acid Chemical compound OC1=C(C\C=C(/C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-RUDMXATFSA-N 0.000 claims description 2
- NJSMWLQOCQIOPE-OCHFTUDZSA-N n-[(e)-[10-[(e)-(4,5-dihydro-1h-imidazol-2-ylhydrazinylidene)methyl]anthracen-9-yl]methylideneamino]-4,5-dihydro-1h-imidazol-2-amine Chemical compound N1CCN=C1N\N=C\C(C1=CC=CC=C11)=C(C=CC=C2)C2=C1\C=N\NC1=NCCN1 NJSMWLQOCQIOPE-OCHFTUDZSA-N 0.000 claims description 2
- LBWFXVZLPYTWQI-IPOVEDGCSA-N n-[2-(diethylamino)ethyl]-5-[(z)-(5-fluoro-2-oxo-1h-indol-3-ylidene)methyl]-2,4-dimethyl-1h-pyrrole-3-carboxamide;(2s)-2-hydroxybutanedioic acid Chemical compound OC(=O)[C@@H](O)CC(O)=O.CCN(CC)CCNC(=O)C1=C(C)NC(\C=C/2C3=CC(F)=CC=C3NC\2=O)=C1C LBWFXVZLPYTWQI-IPOVEDGCSA-N 0.000 claims description 2
- 239000002105 nanoparticle Substances 0.000 claims description 2
- 239000002858 neurotransmitter agent Substances 0.000 claims description 2
- XWXYUMMDTVBTOU-UHFFFAOYSA-N nilutamide Chemical compound O=C1C(C)(C)NC(=O)N1C1=CC=C([N+]([O-])=O)C(C(F)(F)F)=C1 XWXYUMMDTVBTOU-UHFFFAOYSA-N 0.000 claims description 2
- 229960002653 nilutamide Drugs 0.000 claims description 2
- 229960001420 nimustine Drugs 0.000 claims description 2
- VFEDRRNHLBGPNN-UHFFFAOYSA-N nimustine Chemical compound CC1=NC=C(CNC(=O)N(CCCl)N=O)C(N)=N1 VFEDRRNHLBGPNN-UHFFFAOYSA-N 0.000 claims description 2
- KGTDRFCXGRULNK-JYOBTZKQSA-N nogalamycin Chemical compound CO[C@@H]1[C@@](OC)(C)[C@@H](OC)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=C(O)C=C4[C@@]5(C)O[C@H]([C@H]([C@@H]([C@H]5O)N(C)C)O)OC4=C3C3=O)=C3C=C2[C@@H](C(=O)OC)[C@@](C)(O)C1 KGTDRFCXGRULNK-JYOBTZKQSA-N 0.000 claims description 2
- 229950009266 nogalamycin Drugs 0.000 claims description 2
- CZDBNBLGZNWKMC-MWQNXGTOSA-N olivomycin Chemical class O([C@@H]1C[C@@H](O[C@H](C)[C@@H]1O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1)O[C@H]1O[C@@H](C)[C@H](O)[C@@H](OC2O[C@@H](C)[C@H](O)[C@@H](O)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@H]1C[C@H](O)[C@H](OC)[C@H](C)O1 CZDBNBLGZNWKMC-MWQNXGTOSA-N 0.000 claims description 2
- VREZDOWOLGNDPW-UHFFFAOYSA-N pancratistatine Natural products C1=C2C3C(O)C(O)C(O)C(O)C3NC(=O)C2=C(O)C2=C1OCO2 VREZDOWOLGNDPW-UHFFFAOYSA-N 0.000 claims description 2
- 239000000199 parathyroid hormone Substances 0.000 claims description 2
- 229960001319 parathyroid hormone Drugs 0.000 claims description 2
- 229960002340 pentostatin Drugs 0.000 claims description 2
- FPVKHBSQESCIEP-JQCXWYLXSA-N pentostatin Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC[C@H]2O)=C2N=C1 FPVKHBSQESCIEP-JQCXWYLXSA-N 0.000 claims description 2
- QIMGFXOHTOXMQP-GFAGFCTOSA-N peplomycin Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCCN[C@@H](C)C=1C=CC=CC=1)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1NC=NC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C QIMGFXOHTOXMQP-GFAGFCTOSA-N 0.000 claims description 2
- 229950003180 peplomycin Drugs 0.000 claims description 2
- 239000000813 peptide hormone Substances 0.000 claims description 2
- RLZZZVKAURTHCP-UHFFFAOYSA-N phenanthrene-3,4-diol Chemical compound C1=CC=C2C3=C(O)C(O)=CC=C3C=CC2=C1 RLZZZVKAURTHCP-UHFFFAOYSA-N 0.000 claims description 2
- 239000003757 phosphotransferase inhibitor Substances 0.000 claims description 2
- NJBFOOCLYDNZJN-UHFFFAOYSA-N pipobroman Chemical compound BrCCC(=O)N1CCN(C(=O)CCBr)CC1 NJBFOOCLYDNZJN-UHFFFAOYSA-N 0.000 claims description 2
- 229960000952 pipobroman Drugs 0.000 claims description 2
- 229950001100 piposulfan Drugs 0.000 claims description 2
- NUKCGLDCWQXYOQ-UHFFFAOYSA-N piposulfan Chemical compound CS(=O)(=O)OCCC(=O)N1CCN(C(=O)CCOS(C)(=O)=O)CC1 NUKCGLDCWQXYOQ-UHFFFAOYSA-N 0.000 claims description 2
- 229960001221 pirarubicin Drugs 0.000 claims description 2
- 229910052697 platinum Inorganic materials 0.000 claims description 2
- 108010001062 polysaccharide-K Proteins 0.000 claims description 2
- 229940034049 polysaccharide-k Drugs 0.000 claims description 2
- OXCMYAYHXIHQOA-UHFFFAOYSA-N potassium;[2-butyl-5-chloro-3-[[4-[2-(1,2,4-triaza-3-azanidacyclopenta-1,4-dien-5-yl)phenyl]phenyl]methyl]imidazol-4-yl]methanol Chemical compound [K+].CCCCC1=NC(Cl)=C(CO)N1CC1=CC=C(C=2C(=CC=CC=2)C2=N[N-]N=N2)C=C1 OXCMYAYHXIHQOA-UHFFFAOYSA-N 0.000 claims description 2
- 229960004694 prednimustine Drugs 0.000 claims description 2
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 claims description 2
- 229960000624 procarbazine Drugs 0.000 claims description 2
- 108010087851 prorelaxin Proteins 0.000 claims description 2
- 239000003909 protein kinase inhibitor Substances 0.000 claims description 2
- WOLQREOUPKZMEX-UHFFFAOYSA-N pteroyltriglutamic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(=O)NC(CCC(=O)NC(CCC(O)=O)C(O)=O)C(O)=O)C(O)=O)C=C1 WOLQREOUPKZMEX-UHFFFAOYSA-N 0.000 claims description 2
- 229950010131 puromycin Drugs 0.000 claims description 2
- 230000002285 radioactive effect Effects 0.000 claims description 2
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 claims description 2
- BMKDZUISNHGIBY-UHFFFAOYSA-N razoxane Chemical compound C1C(=O)NC(=O)CN1C(C)CN1CC(=O)NC(=O)C1 BMKDZUISNHGIBY-UHFFFAOYSA-N 0.000 claims description 2
- 229960000460 razoxane Drugs 0.000 claims description 2
- 229930002330 retinoic acid Natural products 0.000 claims description 2
- 108091092562 ribozyme Proteins 0.000 claims description 2
- 229950004892 rodorubicin Drugs 0.000 claims description 2
- MBABCNBNDNGODA-WPZDJQSSSA-N rolliniastatin 1 Natural products O1[C@@H]([C@@H](O)CCCCCCCCCC)CC[C@H]1[C@H]1O[C@@H]([C@H](O)CCCCCCCCCC[C@@H](O)CC=2C(O[C@@H](C)C=2)=O)CC1 MBABCNBNDNGODA-WPZDJQSSSA-N 0.000 claims description 2
- IMUQLZLGWJSVMV-UOBFQKKOSA-N roridin A Natural products CC(O)C1OCCC(C)C(O)C(=O)OCC2CC(=CC3OC4CC(OC(=O)C=C/C=C/1)C(C)(C23)C45CO5)C IMUQLZLGWJSVMV-UOBFQKKOSA-N 0.000 claims description 2
- VHXNKPBCCMUMSW-FQEVSTJZSA-N rubitecan Chemical compound C1=CC([N+]([O-])=O)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VHXNKPBCCMUMSW-FQEVSTJZSA-N 0.000 claims description 2
- 229930182947 sarcodictyin Natural products 0.000 claims description 2
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 claims description 2
- 229960002930 sirolimus Drugs 0.000 claims description 2
- 229950001403 sizofiran Drugs 0.000 claims description 2
- 229960003787 sorafenib Drugs 0.000 claims description 2
- 229950006315 spirogermanium Drugs 0.000 claims description 2
- ICXJVZHDZFXYQC-UHFFFAOYSA-N spongistatin 1 Natural products OC1C(O2)(O)CC(O)C(C)C2CCCC=CC(O2)CC(O)CC2(O2)CC(OC)CC2CC(=O)C(C)C(OC(C)=O)C(C)C(=C)CC(O2)CC(C)(O)CC2(O2)CC(OC(C)=O)CC2CC(=O)OC2C(O)C(CC(=C)CC(O)C=CC(Cl)=C)OC1C2C ICXJVZHDZFXYQC-UHFFFAOYSA-N 0.000 claims description 2
- 229960001052 streptozocin Drugs 0.000 claims description 2
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 claims description 2
- 229940034785 sutent Drugs 0.000 claims description 2
- 229960001603 tamoxifen Drugs 0.000 claims description 2
- 229960005353 testolactone Drugs 0.000 claims description 2
- BPEWUONYVDABNZ-DZBHQSCQSA-N testolactone Chemical compound O=C1C=C[C@]2(C)[C@H]3CC[C@](C)(OC(=O)CC4)[C@@H]4[C@@H]3CCC2=C1 BPEWUONYVDABNZ-DZBHQSCQSA-N 0.000 claims description 2
- 229940118376 tetanus toxin Drugs 0.000 claims description 2
- CFMYXEVWODSLAX-UHFFFAOYSA-N tetrodotoxin Natural products C12C(O)NC(=N)NC2(C2O)C(O)C3C(CO)(O)C1OC2(O)O3 CFMYXEVWODSLAX-UHFFFAOYSA-N 0.000 claims description 2
- 229940034208 thyroxine Drugs 0.000 claims description 2
- XUIIKFGFIJCVMT-UHFFFAOYSA-N thyroxine-binding globulin Natural products IC1=CC(CC([NH3+])C([O-])=O)=CC(I)=C1OC1=CC(I)=C(O)C(I)=C1 XUIIKFGFIJCVMT-UHFFFAOYSA-N 0.000 claims description 2
- YFTWHEBLORWGNI-UHFFFAOYSA-N tiamiprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC(N)=NC2=C1NC=N2 YFTWHEBLORWGNI-UHFFFAOYSA-N 0.000 claims description 2
- 229950011457 tiamiprine Drugs 0.000 claims description 2
- 229960003087 tioguanine Drugs 0.000 claims description 2
- 229940044693 topoisomerase inhibitor Drugs 0.000 claims description 2
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 claims description 2
- 229960000303 topotecan Drugs 0.000 claims description 2
- 229960005026 toremifene Drugs 0.000 claims description 2
- XFCLJVABOIYOMF-QPLCGJKRSA-N toremifene Chemical compound C1=CC(OCCN(C)C)=CC=C1C(\C=1C=CC=CC=1)=C(\CCCl)C1=CC=CC=C1 XFCLJVABOIYOMF-QPLCGJKRSA-N 0.000 claims description 2
- IUCJMVBFZDHPDX-UHFFFAOYSA-N tretamine Chemical compound C1CN1C1=NC(N2CC2)=NC(N2CC2)=N1 IUCJMVBFZDHPDX-UHFFFAOYSA-N 0.000 claims description 2
- 229950001353 tretamine Drugs 0.000 claims description 2
- 229960001727 tretinoin Drugs 0.000 claims description 2
- 229960004560 triaziquone Drugs 0.000 claims description 2
- PXSOHRWMIRDKMP-UHFFFAOYSA-N triaziquone Chemical compound O=C1C(N2CC2)=C(N2CC2)C(=O)C=C1N1CC1 PXSOHRWMIRDKMP-UHFFFAOYSA-N 0.000 claims description 2
- KVJXBPDAXMEYOA-CXANFOAXSA-N trilostane Chemical compound OC1=C(C#N)C[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CC[C@@]32O[C@@H]31 KVJXBPDAXMEYOA-CXANFOAXSA-N 0.000 claims description 2
- 229960001670 trilostane Drugs 0.000 claims description 2
- 229960001099 trimetrexate Drugs 0.000 claims description 2
- 229950000212 trioxifene Drugs 0.000 claims description 2
- 229960000875 trofosfamide Drugs 0.000 claims description 2
- UMKFEPPTGMDVMI-UHFFFAOYSA-N trofosfamide Chemical compound ClCCN(CCCl)P1(=O)OCCCN1CCCl UMKFEPPTGMDVMI-UHFFFAOYSA-N 0.000 claims description 2
- 229950010147 troxacitabine Drugs 0.000 claims description 2
- RXRGZNYSEHTMHC-BQBZGAKWSA-N troxacitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1O[C@@H](CO)OC1 RXRGZNYSEHTMHC-BQBZGAKWSA-N 0.000 claims description 2
- HDZZVAMISRMYHH-LITAXDCLSA-N tubercidin Chemical compound C1=CC=2C(N)=NC=NC=2N1[C@@H]1O[C@@H](CO)[C@H](O)[C@H]1O HDZZVAMISRMYHH-LITAXDCLSA-N 0.000 claims description 2
- 229930184737 tubulysin Natural products 0.000 claims description 2
- GFNNBHLJANVSQV-UHFFFAOYSA-N tyrphostin AG 1478 Chemical compound C=12C=C(OC)C(OC)=CC2=NC=NC=1NC1=CC=CC(Cl)=C1 GFNNBHLJANVSQV-UHFFFAOYSA-N 0.000 claims description 2
- 229950009811 ubenimex Drugs 0.000 claims description 2
- 229960001055 uracil mustard Drugs 0.000 claims description 2
- 229960005088 urethane Drugs 0.000 claims description 2
- 229960005486 vaccine Drugs 0.000 claims description 2
- LLDWLPRYLVPDTG-UHFFFAOYSA-N vatalanib succinate Chemical compound OC(=O)CCC(O)=O.C1=CC(Cl)=CC=C1NC(C1=CC=CC=C11)=NN=C1CC1=CC=NC=C1 LLDWLPRYLVPDTG-UHFFFAOYSA-N 0.000 claims description 2
- 229960003048 vinblastine Drugs 0.000 claims description 2
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 claims description 2
- 229960004528 vincristine Drugs 0.000 claims description 2
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 claims description 2
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 claims description 2
- GBABOYUKABKIAF-GHYRFKGUSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-GHYRFKGUSA-N 0.000 claims description 2
- 229960002066 vinorelbine Drugs 0.000 claims description 2
- 229940053867 xeloda Drugs 0.000 claims description 2
- 229950009268 zinostatin Drugs 0.000 claims description 2
- 229960000641 zorubicin Drugs 0.000 claims description 2
- FBTUMDXHSRTGRV-ALTNURHMSA-N zorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(\C)=N\NC(=O)C=1C=CC=CC=1)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 FBTUMDXHSRTGRV-ALTNURHMSA-N 0.000 claims description 2
- 150000002923 oximes Chemical class 0.000 claims 13
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 claims 4
- 125000004433 nitrogen atom Chemical group N* 0.000 claims 3
- VVIAGPKUTFNRDU-ABLWVSNPSA-N folinic acid Chemical compound C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 VVIAGPKUTFNRDU-ABLWVSNPSA-N 0.000 claims 2
- 125000005549 heteroarylene group Chemical group 0.000 claims 2
- QJGQUHMNIGDVPM-UHFFFAOYSA-N nitrogen group Chemical group [N] QJGQUHMNIGDVPM-UHFFFAOYSA-N 0.000 claims 2
- 125000004430 oxygen atom Chemical group O* 0.000 claims 2
- 229910052698 phosphorus Inorganic materials 0.000 claims 2
- HPWBMFITLVBZLG-LURJTMIESA-N (2R)-5-amino-2-[difluoromethyl(fluoro)amino]-2-fluoropentanoic acid Chemical compound F[C@](N(C(F)F)F)(CCCN)C(=O)O HPWBMFITLVBZLG-LURJTMIESA-N 0.000 claims 1
- MKQWTWSXVILIKJ-LXGUWJNJSA-N Chlorozotocin Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](C=O)NC(=O)N(N=O)CCCl MKQWTWSXVILIKJ-LXGUWJNJSA-N 0.000 claims 1
- AVXURJPOCDRRFD-UHFFFAOYSA-N Hydroxylamine Chemical compound ON AVXURJPOCDRRFD-UHFFFAOYSA-N 0.000 claims 1
- 125000001429 N-terminal alpha-amino-acid group Chemical group 0.000 claims 1
- 235000010627 Phaseolus vulgaris Nutrition 0.000 claims 1
- 244000046052 Phaseolus vulgaris Species 0.000 claims 1
- IAJILQKETJEXLJ-QTBDOELSSA-N aldehydo-D-glucuronic acid Chemical group O=C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C(O)=O IAJILQKETJEXLJ-QTBDOELSSA-N 0.000 claims 1
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 claims 1
- ACSIXWWBWUQEHA-UHFFFAOYSA-N clodronic acid Chemical compound OP(O)(=O)C(Cl)(Cl)P(O)(O)=O ACSIXWWBWUQEHA-UHFFFAOYSA-N 0.000 claims 1
- 125000005677 ethinylene group Chemical group [*:2]C#C[*:1] 0.000 claims 1
- 125000004030 farnesyl group Chemical group [H]C([*])([H])C([H])=C(C([H])([H])[H])C([H])([H])C([H])([H])C([H])=C(C([H])([H])[H])C([H])([H])C([H])([H])C([H])=C(C([H])([H])[H])C([H])([H])[H] 0.000 claims 1
- 125000002686 geranylgeranyl group Chemical group [H]C([*])([H])/C([H])=C(C([H])([H])[H])/C([H])([H])C([H])([H])/C([H])=C(C([H])([H])[H])/C([H])([H])C([H])([H])/C([H])=C(C([H])([H])[H])/C([H])([H])C([H])([H])C([H])=C(C([H])([H])[H])C([H])([H])[H] 0.000 claims 1
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 claims 1
- BCFGMOOMADDAQU-UHFFFAOYSA-N lapatinib Chemical compound O1C(CNCCS(=O)(=O)C)=CC=C1C1=CC=C(N=CN=C2NC=3C=C(Cl)C(OCC=4C=C(F)C=CC=4)=CC=3)C2=C1 BCFGMOOMADDAQU-UHFFFAOYSA-N 0.000 claims 1
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 claims 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 claims 1
- NOYPYLRCIDNJJB-UHFFFAOYSA-N trimetrexate Chemical compound COC1=C(OC)C(OC)=CC(NCC=2C(=C3C(N)=NC(N)=NC3=CC=2)C)=C1 NOYPYLRCIDNJJB-UHFFFAOYSA-N 0.000 claims 1
- 239000003814 drug Substances 0.000 abstract description 46
- 238000004519 manufacturing process Methods 0.000 abstract description 8
- 230000008685 targeting Effects 0.000 abstract description 7
- 239000002207 metabolite Substances 0.000 abstract description 2
- 101000928535 Homo sapiens Protein delta homolog 1 Proteins 0.000 abstract 2
- 102100036467 Protein delta homolog 1 Human genes 0.000 abstract 2
- 125000003275 alpha amino acid group Chemical group 0.000 description 49
- 229940079593 drug Drugs 0.000 description 38
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 description 32
- 241000699666 Mus <mouse, genus> Species 0.000 description 30
- 239000002953 phosphate buffered saline Substances 0.000 description 30
- 230000014509 gene expression Effects 0.000 description 23
- 239000000562 conjugate Substances 0.000 description 22
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 22
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 19
- 238000011282 treatment Methods 0.000 description 19
- 238000004458 analytical method Methods 0.000 description 18
- 230000005907 cancer growth Effects 0.000 description 18
- 238000010172 mouse model Methods 0.000 description 18
- 241000699670 Mus sp. Species 0.000 description 17
- 108010068265 aspartyltyrosine Proteins 0.000 description 17
- 230000000694 effects Effects 0.000 description 17
- 108091033319 polynucleotide Proteins 0.000 description 17
- 102000040430 polynucleotide Human genes 0.000 description 17
- 239000002157 polynucleotide Substances 0.000 description 17
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 16
- WLJPJRGQRNCIQS-ZLUOBGJFSA-N Ser-Ser-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O WLJPJRGQRNCIQS-ZLUOBGJFSA-N 0.000 description 16
- 239000002609 medium Substances 0.000 description 16
- 241000880493 Leptailurus serval Species 0.000 description 15
- 230000001225 therapeutic effect Effects 0.000 description 15
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 14
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 14
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 13
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 13
- 108091028043 Nucleic acid sequence Proteins 0.000 description 13
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 13
- 108010087924 alanylproline Proteins 0.000 description 13
- 230000006907 apoptotic process Effects 0.000 description 13
- 230000002401 inhibitory effect Effects 0.000 description 13
- 230000005764 inhibitory process Effects 0.000 description 13
- 125000006413 ring segment Chemical group 0.000 description 12
- 239000000243 solution Substances 0.000 description 12
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 11
- VKKYFICVTYKFIO-CIUDSAMLSA-N Arg-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N VKKYFICVTYKFIO-CIUDSAMLSA-N 0.000 description 11
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 11
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 11
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 11
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 11
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 11
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 11
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 11
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 11
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 11
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 11
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 11
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 11
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 11
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 11
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 11
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 11
- 108010008355 arginyl-glutamine Proteins 0.000 description 11
- 125000004432 carbon atom Chemical group C* 0.000 description 11
- 230000009260 cross reactivity Effects 0.000 description 11
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 11
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 10
- UGXYFDQFLVCDFC-CIUDSAMLSA-N Asn-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O UGXYFDQFLVCDFC-CIUDSAMLSA-N 0.000 description 10
- JBDLMLZNDRLDIX-HJGDQZAQSA-N Asn-Thr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O JBDLMLZNDRLDIX-HJGDQZAQSA-N 0.000 description 10
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 10
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 10
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 10
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 10
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 10
- 238000002474 experimental method Methods 0.000 description 10
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 10
- 238000001727 in vivo Methods 0.000 description 10
- 239000013642 negative control Substances 0.000 description 10
- 108010051242 phenylalanylserine Proteins 0.000 description 10
- 239000013598 vector Substances 0.000 description 10
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 9
- POJJAZJHBGXEGM-YUMQZZPRSA-N Gly-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)CN POJJAZJHBGXEGM-YUMQZZPRSA-N 0.000 description 9
- 230000007246 mechanism Effects 0.000 description 9
- 238000002054 transplantation Methods 0.000 description 9
- VNYMOTCMNHJGTG-JBDRJPRFSA-N Ala-Ile-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O VNYMOTCMNHJGTG-JBDRJPRFSA-N 0.000 description 8
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 8
- ATABBWFGOHKROJ-GUBZILKMSA-N Arg-Pro-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O ATABBWFGOHKROJ-GUBZILKMSA-N 0.000 description 8
- QLSRIZIDQXDQHK-RCWTZXSCSA-N Arg-Val-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QLSRIZIDQXDQHK-RCWTZXSCSA-N 0.000 description 8
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 8
- IOXWDLNHXZOXQP-FXQIFTODSA-N Asp-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N IOXWDLNHXZOXQP-FXQIFTODSA-N 0.000 description 8
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 8
- 238000002965 ELISA Methods 0.000 description 8
- ZBKUIQNCRIYVGH-SDDRHHMPSA-N Gln-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N ZBKUIQNCRIYVGH-SDDRHHMPSA-N 0.000 description 8
- OTQSTOXRUBVWAP-NRPADANISA-N Gln-Ser-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O OTQSTOXRUBVWAP-NRPADANISA-N 0.000 description 8
- WZZSKAJIHTUUSG-ACZMJKKPSA-N Glu-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O WZZSKAJIHTUUSG-ACZMJKKPSA-N 0.000 description 8
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 8
- NSTUFLGQJCOCDL-UWVGGRQHSA-N Gly-Leu-Arg Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NSTUFLGQJCOCDL-UWVGGRQHSA-N 0.000 description 8
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 8
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 8
- 101001103033 Homo sapiens Tyrosine-protein kinase transmembrane receptor ROR2 Proteins 0.000 description 8
- SLQVFYWBGNNOTK-BYULHYEWSA-N Ile-Gly-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N SLQVFYWBGNNOTK-BYULHYEWSA-N 0.000 description 8
- LBRCLQMZAHRTLV-ZKWXMUAHSA-N Ile-Gly-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LBRCLQMZAHRTLV-ZKWXMUAHSA-N 0.000 description 8
- FBGXMKUWQFPHFB-JBDRJPRFSA-N Ile-Ser-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N FBGXMKUWQFPHFB-JBDRJPRFSA-N 0.000 description 8
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 8
- OIQSIMFSVLLWBX-VOAKCMCISA-N Lys-Leu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OIQSIMFSVLLWBX-VOAKCMCISA-N 0.000 description 8
- 101100068676 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gln-1 gene Proteins 0.000 description 8
- RMODQFBNDDENCP-IHRRRGAJSA-N Pro-Lys-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O RMODQFBNDDENCP-IHRRRGAJSA-N 0.000 description 8
- HJEBZBMOTCQYDN-ACZMJKKPSA-N Ser-Glu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJEBZBMOTCQYDN-ACZMJKKPSA-N 0.000 description 8
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 8
- OQPNSDWGAMFJNU-QWRGUYRKSA-N Ser-Gly-Tyr Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 OQPNSDWGAMFJNU-QWRGUYRKSA-N 0.000 description 8
- MXDOAJQRJBMGMO-FJXKBIBVSA-N Thr-Pro-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O MXDOAJQRJBMGMO-FJXKBIBVSA-N 0.000 description 8
- PKZIWSHDJYIPRH-JBACZVJFSA-N Trp-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKZIWSHDJYIPRH-JBACZVJFSA-N 0.000 description 8
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 8
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 8
- CKTMJBPRVQWPHU-JSGCOSHPSA-N Val-Phe-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)O)N CKTMJBPRVQWPHU-JSGCOSHPSA-N 0.000 description 8
- 108010092854 aspartyllysine Proteins 0.000 description 8
- 229940098773 bovine serum albumin Drugs 0.000 description 8
- 238000011161 development Methods 0.000 description 8
- 230000018109 developmental process Effects 0.000 description 8
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 8
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 8
- 238000002360 preparation method Methods 0.000 description 8
- 238000000926 separation method Methods 0.000 description 8
- 125000004209 (C1-C8) alkyl group Chemical group 0.000 description 7
- QXHVOUSPVAWEMX-ZLUOBGJFSA-N Asp-Asp-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXHVOUSPVAWEMX-ZLUOBGJFSA-N 0.000 description 7
- JSHWXQIZOCVWIA-ZKWXMUAHSA-N Asp-Ser-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JSHWXQIZOCVWIA-ZKWXMUAHSA-N 0.000 description 7
- NXRNRBOKDBIVKQ-CXTHYWKRSA-N Ile-Tyr-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N NXRNRBOKDBIVKQ-CXTHYWKRSA-N 0.000 description 7
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 7
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 7
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 7
- MWUYSCVVPVITMW-IGNZVWTISA-N Tyr-Tyr-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 MWUYSCVVPVITMW-IGNZVWTISA-N 0.000 description 7
- 239000000872 buffer Substances 0.000 description 7
- 108010016616 cysteinylglycine Proteins 0.000 description 7
- 238000005516 engineering process Methods 0.000 description 7
- 125000004435 hydrogen atom Chemical group [H]* 0.000 description 7
- 238000012360 testing method Methods 0.000 description 7
- 108010073969 valyllysine Proteins 0.000 description 7
- CZIVKMOEXPILDK-SRVKXCTJSA-N Asp-Tyr-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O CZIVKMOEXPILDK-SRVKXCTJSA-N 0.000 description 6
- 201000009030 Carcinoma Diseases 0.000 description 6
- LERGJIVJIIODPZ-ZANVPECISA-N Gly-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)CN)C)C(O)=O)=CNC2=C1 LERGJIVJIIODPZ-ZANVPECISA-N 0.000 description 6
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 6
- MUBZPKHOEPUJKR-UHFFFAOYSA-N Oxalic acid Chemical compound OC(=O)C(O)=O MUBZPKHOEPUJKR-UHFFFAOYSA-N 0.000 description 6
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 6
- ZMANZCXQSJIPKH-UHFFFAOYSA-N Triethylamine Chemical compound CCN(CC)CC ZMANZCXQSJIPKH-UHFFFAOYSA-N 0.000 description 6
- FPPNZSSZRUTDAP-UWFZAAFLSA-N carbenicillin Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)C(C(O)=O)C1=CC=CC=C1 FPPNZSSZRUTDAP-UWFZAAFLSA-N 0.000 description 6
- 229960003669 carbenicillin Drugs 0.000 description 6
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 6
- 230000001419 dependent effect Effects 0.000 description 6
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 6
- 239000006228 supernatant Substances 0.000 description 6
- 210000001519 tissue Anatomy 0.000 description 6
- 230000001988 toxicity Effects 0.000 description 6
- 231100000419 toxicity Toxicity 0.000 description 6
- 125000004169 (C1-C6) alkyl group Chemical group 0.000 description 5
- HTSSXFASOUSJQG-IHPCNDPISA-N Asp-Tyr-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HTSSXFASOUSJQG-IHPCNDPISA-N 0.000 description 5
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 5
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 5
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 5
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 5
- KFZMGEQAYNKOFK-UHFFFAOYSA-N Isopropanol Chemical compound CC(C)O KFZMGEQAYNKOFK-UHFFFAOYSA-N 0.000 description 5
- RGUXWMDNCPMQFB-YUMQZZPRSA-N Leu-Ser-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RGUXWMDNCPMQFB-YUMQZZPRSA-N 0.000 description 5
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 5
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 5
- PJIQEIFXZPCWOJ-FXQIFTODSA-N Ser-Pro-Asp Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O PJIQEIFXZPCWOJ-FXQIFTODSA-N 0.000 description 5
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 5
- 101150042711 adc2 gene Proteins 0.000 description 5
- 230000001093 anti-cancer Effects 0.000 description 5
- 230000008901 benefit Effects 0.000 description 5
- 230000003013 cytotoxicity Effects 0.000 description 5
- 231100000135 cytotoxicity Toxicity 0.000 description 5
- 230000034994 death Effects 0.000 description 5
- 230000006870 function Effects 0.000 description 5
- 230000004927 fusion Effects 0.000 description 5
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 5
- 108010087823 glycyltyrosine Proteins 0.000 description 5
- 102000049622 human ROR2 Human genes 0.000 description 5
- 230000003993 interaction Effects 0.000 description 5
- 201000007924 marginal zone B-cell lymphoma Diseases 0.000 description 5
- 208000021937 marginal zone lymphoma Diseases 0.000 description 5
- 238000005259 measurement Methods 0.000 description 5
- 108010026333 seryl-proline Proteins 0.000 description 5
- 108010038745 tryptophylglycine Proteins 0.000 description 5
- 125000006736 (C6-C20) aryl group Chemical group 0.000 description 4
- FCEHBMOGCRZNNI-UHFFFAOYSA-N 1-benzothiophene Chemical compound C1=CC=C2SC=CC2=C1 FCEHBMOGCRZNNI-UHFFFAOYSA-N 0.000 description 4
- HZAXFHJVJLSVMW-UHFFFAOYSA-N 2-Aminoethan-1-ol Chemical compound NCCO HZAXFHJVJLSVMW-UHFFFAOYSA-N 0.000 description 4
- 108090000672 Annexin A5 Proteins 0.000 description 4
- 102000004121 Annexin A5 Human genes 0.000 description 4
- RGHNJXZEOKUKBD-SQOUGZDYSA-N D-gluconic acid Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C(O)=O RGHNJXZEOKUKBD-SQOUGZDYSA-N 0.000 description 4
- 241000588724 Escherichia coli Species 0.000 description 4
- VZCYOOQTPOCHFL-OWOJBTEDSA-N Fumaric acid Chemical compound OC(=O)\C=C\C(O)=O VZCYOOQTPOCHFL-OWOJBTEDSA-N 0.000 description 4
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 4
- WSWWTQYHFCBKBT-DVJZZOLTSA-N Gly-Thr-Trp Chemical compound C[C@@H](O)[C@H](NC(=O)CN)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O WSWWTQYHFCBKBT-DVJZZOLTSA-N 0.000 description 4
- AEMRFAOFKBGASW-UHFFFAOYSA-N Glycolic acid Chemical compound OCC(O)=O AEMRFAOFKBGASW-UHFFFAOYSA-N 0.000 description 4
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 4
- 206010061598 Immunodeficiency Diseases 0.000 description 4
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 4
- FPQMQEOVSKMVMA-ACRUOGEOSA-N Lys-Tyr-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)NC(=O)[C@H](CCCCN)N)O FPQMQEOVSKMVMA-ACRUOGEOSA-N 0.000 description 4
- 241001465754 Metazoa Species 0.000 description 4
- 241001024304 Mino Species 0.000 description 4
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 description 4
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 4
- GLUUGHFHXGJENI-UHFFFAOYSA-N Piperazine Chemical compound C1CNCCN1 GLUUGHFHXGJENI-UHFFFAOYSA-N 0.000 description 4
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 4
- JCLAFVNDBJMLBC-JBDRJPRFSA-N Ser-Ser-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JCLAFVNDBJMLBC-JBDRJPRFSA-N 0.000 description 4
- ATEQEHCGZKBEMU-GQGQLFGLSA-N Ser-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CO)N ATEQEHCGZKBEMU-GQGQLFGLSA-N 0.000 description 4
- DJDSEDOKJTZBAR-ZDLURKLDSA-N Thr-Gly-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O DJDSEDOKJTZBAR-ZDLURKLDSA-N 0.000 description 4
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 4
- 230000009471 action Effects 0.000 description 4
- 239000004480 active ingredient Substances 0.000 description 4
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 4
- 150000001491 aromatic compounds Chemical class 0.000 description 4
- WPYMKLBDIGXBTP-UHFFFAOYSA-N benzoic acid Chemical compound OC(=O)C1=CC=CC=C1 WPYMKLBDIGXBTP-UHFFFAOYSA-N 0.000 description 4
- 230000037396 body weight Effects 0.000 description 4
- 150000001768 cations Chemical class 0.000 description 4
- 239000002254 cytotoxic agent Substances 0.000 description 4
- 231100000599 cytotoxic agent Toxicity 0.000 description 4
- XBDQKXXYIPTUBI-UHFFFAOYSA-N dimethylselenoniopropionate Natural products CCC(O)=O XBDQKXXYIPTUBI-UHFFFAOYSA-N 0.000 description 4
- 239000013604 expression vector Substances 0.000 description 4
- 108010089804 glycyl-threonine Proteins 0.000 description 4
- 125000005842 heteroatom Chemical group 0.000 description 4
- 230000002209 hydrophobic effect Effects 0.000 description 4
- 238000011534 incubation Methods 0.000 description 4
- JVTAAEKCZFNVCJ-UHFFFAOYSA-N lactic acid Chemical compound CC(O)C(O)=O JVTAAEKCZFNVCJ-UHFFFAOYSA-N 0.000 description 4
- 238000002823 phage display Methods 0.000 description 4
- 239000002243 precursor Substances 0.000 description 4
- 239000011541 reaction mixture Substances 0.000 description 4
- 108010048818 seryl-histidine Proteins 0.000 description 4
- 239000011780 sodium chloride Substances 0.000 description 4
- 238000010186 staining Methods 0.000 description 4
- 229940124597 therapeutic agent Drugs 0.000 description 4
- VZCYOOQTPOCHFL-UHFFFAOYSA-N trans-butenedioic acid Natural products OC(=O)C=CC(O)=O VZCYOOQTPOCHFL-UHFFFAOYSA-N 0.000 description 4
- 210000004881 tumor cell Anatomy 0.000 description 4
- 238000005406 washing Methods 0.000 description 4
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 4
- VZSRBBMJRBPUNF-UHFFFAOYSA-N 2-(2,3-dihydro-1H-inden-2-ylamino)-N-[3-oxo-3-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)propyl]pyrimidine-5-carboxamide Chemical compound C1C(CC2=CC=CC=C12)NC1=NC=C(C=N1)C(=O)NCCC(N1CC2=C(CC1)NN=N2)=O VZSRBBMJRBPUNF-UHFFFAOYSA-N 0.000 description 3
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 3
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 3
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 3
- IYVSIZAXNLOKFQ-BYULHYEWSA-N Asn-Asp-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O IYVSIZAXNLOKFQ-BYULHYEWSA-N 0.000 description 3
- QUAWOKPCAKCHQL-SRVKXCTJSA-N Asn-His-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N QUAWOKPCAKCHQL-SRVKXCTJSA-N 0.000 description 3
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 3
- UHOVQNZJYSORNB-UHFFFAOYSA-N Benzene Chemical compound C1=CC=CC=C1 UHOVQNZJYSORNB-UHFFFAOYSA-N 0.000 description 3
- 241000283707 Capra Species 0.000 description 3
- RGSFGYAAUTVSQA-UHFFFAOYSA-N Cyclopentane Chemical compound C1CCCC1 RGSFGYAAUTVSQA-UHFFFAOYSA-N 0.000 description 3
- NDUSUIGBMZCOIL-ZKWXMUAHSA-N Cys-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CS)N NDUSUIGBMZCOIL-ZKWXMUAHSA-N 0.000 description 3
- SMEYEQDCCBHTEF-FXQIFTODSA-N Cys-Pro-Ala Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O SMEYEQDCCBHTEF-FXQIFTODSA-N 0.000 description 3
- KSMSFCBQBQPFAD-GUBZILKMSA-N Cys-Pro-Pro Chemical compound SC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 KSMSFCBQBQPFAD-GUBZILKMSA-N 0.000 description 3
- ALTQTAKGRFLRLR-GUBZILKMSA-N Cys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N ALTQTAKGRFLRLR-GUBZILKMSA-N 0.000 description 3
- 208000006402 Ductal Carcinoma Diseases 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- XEKOWRVHYACXOJ-UHFFFAOYSA-N Ethyl acetate Chemical compound CCOC(C)=O XEKOWRVHYACXOJ-UHFFFAOYSA-N 0.000 description 3
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 3
- BFEZQZKEPRKKHV-SRVKXCTJSA-N Glu-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O BFEZQZKEPRKKHV-SRVKXCTJSA-N 0.000 description 3
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 3
- WGYHAAXZWPEBDQ-IFFSRLJSSA-N Glu-Val-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGYHAAXZWPEBDQ-IFFSRLJSSA-N 0.000 description 3
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 3
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 3
- AFWYPMDMDYCKMD-KBPBESRZSA-N Gly-Leu-Tyr Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AFWYPMDMDYCKMD-KBPBESRZSA-N 0.000 description 3
- CQMFNTVQVLQRLT-JHEQGTHGSA-N Gly-Thr-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O CQMFNTVQVLQRLT-JHEQGTHGSA-N 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- ALPXXNRQBMRCPZ-MEYUZBJRSA-N His-Thr-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ALPXXNRQBMRCPZ-MEYUZBJRSA-N 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- DTPGSUQHUMELQB-GVARAGBVSA-N Ile-Tyr-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=C(O)C=C1 DTPGSUQHUMELQB-GVARAGBVSA-N 0.000 description 3
- 208000029462 Immunodeficiency disease Diseases 0.000 description 3
- 108060003951 Immunoglobulin Proteins 0.000 description 3
- SIKJAQJRHWYJAI-UHFFFAOYSA-N Indole Chemical compound C1=CC=C2NC=CC2=C1 SIKJAQJRHWYJAI-UHFFFAOYSA-N 0.000 description 3
- 108010065920 Insulin Lispro Proteins 0.000 description 3
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 3
- QJUWBDPGGYVRHY-YUMQZZPRSA-N Leu-Gly-Cys Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N QJUWBDPGGYVRHY-YUMQZZPRSA-N 0.000 description 3
- VWHGTYCRDRBSFI-ZETCQYMHSA-N Leu-Gly-Gly Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)NCC(O)=O VWHGTYCRDRBSFI-ZETCQYMHSA-N 0.000 description 3
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 3
- KWUKZRFFKPLUPE-HJGDQZAQSA-N Lys-Asp-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWUKZRFFKPLUPE-HJGDQZAQSA-N 0.000 description 3
- QQPSCXKFDSORFT-IHRRRGAJSA-N Lys-Lys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN QQPSCXKFDSORFT-IHRRRGAJSA-N 0.000 description 3
- MIFFFXHMAHFACR-KATARQTJSA-N Lys-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN MIFFFXHMAHFACR-KATARQTJSA-N 0.000 description 3
- IEVXCWPVBYCJRZ-IXOXFDKPSA-N Lys-Thr-His Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 IEVXCWPVBYCJRZ-IXOXFDKPSA-N 0.000 description 3
- QLFAPXUXEBAWEK-NHCYSSNCSA-N Lys-Val-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QLFAPXUXEBAWEK-NHCYSSNCSA-N 0.000 description 3
- 206010027476 Metastases Diseases 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 3
- 108010047562 NGR peptide Proteins 0.000 description 3
- CUMXHKAOHNWRFQ-BZSNNMDCSA-N Phe-Asp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 CUMXHKAOHNWRFQ-BZSNNMDCSA-N 0.000 description 3
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 3
- YMIZSYUAZJSOFL-SRVKXCTJSA-N Phe-Ser-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O YMIZSYUAZJSOFL-SRVKXCTJSA-N 0.000 description 3
- XDMMOISUAHXXFD-SRVKXCTJSA-N Phe-Ser-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O XDMMOISUAHXXFD-SRVKXCTJSA-N 0.000 description 3
- OOLOTUZJUBOMAX-GUBZILKMSA-N Pro-Ala-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O OOLOTUZJUBOMAX-GUBZILKMSA-N 0.000 description 3
- NXEYSLRNNPWCRN-SRVKXCTJSA-N Pro-Glu-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NXEYSLRNNPWCRN-SRVKXCTJSA-N 0.000 description 3
- ULWBBFKQBDNGOY-RWMBFGLXSA-N Pro-Lys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@@H]2C(=O)O ULWBBFKQBDNGOY-RWMBFGLXSA-N 0.000 description 3
- OWQXAJQZLWHPBH-FXQIFTODSA-N Pro-Ser-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O OWQXAJQZLWHPBH-FXQIFTODSA-N 0.000 description 3
- RWRDLPDLKQPQOW-UHFFFAOYSA-N Pyrrolidine Chemical compound C1CCNC1 RWRDLPDLKQPQOW-UHFFFAOYSA-N 0.000 description 3
- KNCJWSPMTFFJII-ZLUOBGJFSA-N Ser-Cys-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O KNCJWSPMTFFJII-ZLUOBGJFSA-N 0.000 description 3
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 3
- HMRAQFJFTOLDKW-GUBZILKMSA-N Ser-His-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O HMRAQFJFTOLDKW-GUBZILKMSA-N 0.000 description 3
- UIPXCLNLUUAMJU-JBDRJPRFSA-N Ser-Ile-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UIPXCLNLUUAMJU-JBDRJPRFSA-N 0.000 description 3
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 3
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 3
- 239000004098 Tetracycline Substances 0.000 description 3
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 3
- JLNMFGCJODTXDH-WEDXCCLWSA-N Thr-Lys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O JLNMFGCJODTXDH-WEDXCCLWSA-N 0.000 description 3
- RPECVQBNONKZAT-WZLNRYEVSA-N Thr-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H]([C@@H](C)O)N RPECVQBNONKZAT-WZLNRYEVSA-N 0.000 description 3
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 3
- QNXZCKMXHPULME-ZNSHCXBVSA-N Thr-Val-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O QNXZCKMXHPULME-ZNSHCXBVSA-N 0.000 description 3
- UKINEYBQXPMOJO-UBHSHLNASA-N Trp-Asn-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N UKINEYBQXPMOJO-UBHSHLNASA-N 0.000 description 3
- WURLIFOWSMBUAR-SLFFLAALSA-N Tyr-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)C(=O)O WURLIFOWSMBUAR-SLFFLAALSA-N 0.000 description 3
- 102100039616 Tyrosine-protein kinase transmembrane receptor ROR2 Human genes 0.000 description 3
- SCBITHMBEJNRHC-LSJOCFKGSA-N Val-Asp-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N SCBITHMBEJNRHC-LSJOCFKGSA-N 0.000 description 3
- KTEZUXISLQTDDQ-NHCYSSNCSA-N Val-Lys-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)O)C(=O)O)N KTEZUXISLQTDDQ-NHCYSSNCSA-N 0.000 description 3
- QHSSPPHOHJSTML-HOCLYGCPSA-N Val-Trp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)NCC(=O)O)N QHSSPPHOHJSTML-HOCLYGCPSA-N 0.000 description 3
- IEDXPSOJFSVCKU-HOKPPMCLSA-N [4-[[(2S)-5-(carbamoylamino)-2-[[(2S)-2-[6-(2,5-dioxopyrrolidin-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl N-[(2S)-1-[[(2S)-1-[[(3R,4S,5S)-1-[(2S)-2-[(1R,2R)-3-[[(1S,2R)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]-N-methylcarbamate Chemical compound CC[C@H](C)[C@@H]([C@@H](CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)c1ccccc1)OC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCc1ccc(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN2C(=O)CCC2=O)C(C)C)cc1)C(C)C IEDXPSOJFSVCKU-HOKPPMCLSA-N 0.000 description 3
- 238000002835 absorbance Methods 0.000 description 3
- 235000011054 acetic acid Nutrition 0.000 description 3
- 230000004913 activation Effects 0.000 description 3
- 125000000539 amino acid group Chemical group 0.000 description 3
- 150000001450 anions Chemical class 0.000 description 3
- 108010047857 aspartylglycine Proteins 0.000 description 3
- 230000004900 autophagic degradation Effects 0.000 description 3
- 239000011230 binding agent Substances 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 229910002091 carbon monoxide Inorganic materials 0.000 description 3
- 238000002659 cell therapy Methods 0.000 description 3
- 238000005119 centrifugation Methods 0.000 description 3
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 3
- 230000021615 conjugation Effects 0.000 description 3
- 231100000433 cytotoxic Toxicity 0.000 description 3
- 230000001472 cytotoxic effect Effects 0.000 description 3
- 238000010494 dissociation reaction Methods 0.000 description 3
- 230000005593 dissociations Effects 0.000 description 3
- POULHZVOKOAJMA-UHFFFAOYSA-N dodecanoic acid Chemical compound CCCCCCCCCCCC(O)=O POULHZVOKOAJMA-UHFFFAOYSA-N 0.000 description 3
- 230000000857 drug effect Effects 0.000 description 3
- 201000006585 gastric adenocarcinoma Diseases 0.000 description 3
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 3
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 3
- 108010010147 glycylglutamine Proteins 0.000 description 3
- 239000001963 growth medium Substances 0.000 description 3
- DMEGYFMYUHOHGS-UHFFFAOYSA-N heptamethylene Natural products C1CCCCCC1 DMEGYFMYUHOHGS-UHFFFAOYSA-N 0.000 description 3
- IPCSVZSSVZVIGE-UHFFFAOYSA-N hexadecanoic acid Chemical compound CCCCCCCCCCCCCCCC(O)=O IPCSVZSSVZVIGE-UHFFFAOYSA-N 0.000 description 3
- 210000002865 immune cell Anatomy 0.000 description 3
- 230000007813 immunodeficiency Effects 0.000 description 3
- 102000018358 immunoglobulin Human genes 0.000 description 3
- 230000001965 increasing effect Effects 0.000 description 3
- 230000006698 induction Effects 0.000 description 3
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 3
- 108010027338 isoleucylcysteine Proteins 0.000 description 3
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 3
- 108010064235 lysylglycine Proteins 0.000 description 3
- 210000004962 mammalian cell Anatomy 0.000 description 3
- 239000003550 marker Substances 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 230000009401 metastasis Effects 0.000 description 3
- 150000007522 mineralic acids Chemical class 0.000 description 3
- 230000035772 mutation Effects 0.000 description 3
- 150000007524 organic acids Chemical class 0.000 description 3
- 238000004091 panning Methods 0.000 description 3
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 3
- 239000008057 potassium phosphate buffer Substances 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 229940002612 prodrug Drugs 0.000 description 3
- 239000000651 prodrug Substances 0.000 description 3
- 108010077112 prolyl-proline Proteins 0.000 description 3
- 108010031719 prolyl-serine Proteins 0.000 description 3
- 108010070643 prolylglutamic acid Proteins 0.000 description 3
- XSCHRSMBECNVNS-UHFFFAOYSA-N quinoxaline Chemical compound N1=CC=NC2=CC=CC=C21 XSCHRSMBECNVNS-UHFFFAOYSA-N 0.000 description 3
- 229920006395 saturated elastomer Polymers 0.000 description 3
- 238000003998 size exclusion chromatography high performance liquid chromatography Methods 0.000 description 3
- 229960002180 tetracycline Drugs 0.000 description 3
- CXWXQJXEFPUFDZ-UHFFFAOYSA-N tetralin Chemical compound C1=CC=C2CCCCC2=C1 CXWXQJXEFPUFDZ-UHFFFAOYSA-N 0.000 description 3
- 238000012447 xenograft mouse model Methods 0.000 description 3
- GHOKWGTUZJEAQD-ZETCQYMHSA-N (D)-(+)-Pantothenic acid Chemical compound OCC(C)(C)[C@@H](O)C(=O)NCCC(O)=O GHOKWGTUZJEAQD-ZETCQYMHSA-N 0.000 description 2
- RYHBNJHYFVUHQT-UHFFFAOYSA-N 1,4-Dioxane Chemical compound C1COCCO1 RYHBNJHYFVUHQT-UHFFFAOYSA-N 0.000 description 2
- CTMHWPIWNRWQEG-UHFFFAOYSA-N 1-methylcyclohexene Chemical compound CC1=CCCCC1 CTMHWPIWNRWQEG-UHFFFAOYSA-N 0.000 description 2
- YBYIRNPNPLQARY-UHFFFAOYSA-N 1H-indene Chemical compound C1=CC=C2CC=CC2=C1 YBYIRNPNPLQARY-UHFFFAOYSA-N 0.000 description 2
- VEPOHXYIFQMVHW-XOZOLZJESA-N 2,3-dihydroxybutanedioic acid (2S,3S)-3,4-dimethyl-2-phenylmorpholine Chemical compound OC(C(O)C(O)=O)C(O)=O.C[C@H]1[C@@H](OCCN1C)c1ccccc1 VEPOHXYIFQMVHW-XOZOLZJESA-N 0.000 description 2
- LDXJRKWFNNFDSA-UHFFFAOYSA-N 2-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)-1-[4-[2-[[3-(trifluoromethoxy)phenyl]methylamino]pyrimidin-5-yl]piperazin-1-yl]ethanone Chemical compound C1CN(CC2=NNN=C21)CC(=O)N3CCN(CC3)C4=CN=C(N=C4)NCC5=CC(=CC=C5)OC(F)(F)F LDXJRKWFNNFDSA-UHFFFAOYSA-N 0.000 description 2
- XXZCIYUJYUESMD-UHFFFAOYSA-N 2-[4-[2-(2,3-dihydro-1H-inden-2-ylamino)pyrimidin-5-yl]-3-(morpholin-4-ylmethyl)pyrazol-1-yl]-1-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)ethanone Chemical compound C1C(CC2=CC=CC=C12)NC1=NC=C(C=N1)C=1C(=NN(C=1)CC(=O)N1CC2=C(CC1)NN=N2)CN1CCOCC1 XXZCIYUJYUESMD-UHFFFAOYSA-N 0.000 description 2
- VHMICKWLTGFITH-UHFFFAOYSA-N 2H-isoindole Chemical compound C1=CC=CC2=CNC=C21 VHMICKWLTGFITH-UHFFFAOYSA-N 0.000 description 2
- HSJKGGMUJITCBW-UHFFFAOYSA-N 3-hydroxybutanal Chemical compound CC(O)CC=O HSJKGGMUJITCBW-UHFFFAOYSA-N 0.000 description 2
- YRNWIFYIFSBPAU-UHFFFAOYSA-N 4-[4-(dimethylamino)phenyl]-n,n-dimethylaniline Chemical compound C1=CC(N(C)C)=CC=C1C1=CC=C(N(C)C)C=C1 YRNWIFYIFSBPAU-UHFFFAOYSA-N 0.000 description 2
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 2
- UJOBWOGCFQCDNV-UHFFFAOYSA-N 9H-carbazole Chemical compound C1=CC=C2C3=CC=CC=C3NC2=C1 UJOBWOGCFQCDNV-UHFFFAOYSA-N 0.000 description 2
- 229920001817 Agar Polymers 0.000 description 2
- UCIYCBSJBQGDGM-LPEHRKFASA-N Ala-Arg-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N UCIYCBSJBQGDGM-LPEHRKFASA-N 0.000 description 2
- AJBVYEYZVYPFCF-CIUDSAMLSA-N Ala-Lys-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O AJBVYEYZVYPFCF-CIUDSAMLSA-N 0.000 description 2
- VHEVVUZDDUCAKU-FXQIFTODSA-N Ala-Met-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O VHEVVUZDDUCAKU-FXQIFTODSA-N 0.000 description 2
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 2
- LTTLSZVJTDSACD-OWLDWWDNSA-N Ala-Thr-Trp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O LTTLSZVJTDSACD-OWLDWWDNSA-N 0.000 description 2
- SBVJJNJLFWSJOV-UBHSHLNASA-N Arg-Ala-Phe Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SBVJJNJLFWSJOV-UBHSHLNASA-N 0.000 description 2
- OVVUNXXROOFSIM-SDDRHHMPSA-N Arg-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O OVVUNXXROOFSIM-SDDRHHMPSA-N 0.000 description 2
- FKQITMVNILRUCQ-IHRRRGAJSA-N Arg-Phe-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O FKQITMVNILRUCQ-IHRRRGAJSA-N 0.000 description 2
- PSUXEQYPYZLNER-QXEWZRGKSA-N Arg-Val-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O PSUXEQYPYZLNER-QXEWZRGKSA-N 0.000 description 2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 2
- SLKLLQWZQHXYSV-CIUDSAMLSA-N Asn-Ala-Lys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O SLKLLQWZQHXYSV-CIUDSAMLSA-N 0.000 description 2
- JJGRJMKUOYXZRA-LPEHRKFASA-N Asn-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)N)N)C(=O)O JJGRJMKUOYXZRA-LPEHRKFASA-N 0.000 description 2
- BVLIJXXSXBUGEC-SRVKXCTJSA-N Asn-Asn-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BVLIJXXSXBUGEC-SRVKXCTJSA-N 0.000 description 2
- QHBMKQWOIYJYMI-BYULHYEWSA-N Asn-Asn-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O QHBMKQWOIYJYMI-BYULHYEWSA-N 0.000 description 2
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 2
- WQLJRNRLHWJIRW-KKUMJFAQSA-N Asn-His-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)N)N)O WQLJRNRLHWJIRW-KKUMJFAQSA-N 0.000 description 2
- RCFGLXMZDYNRSC-CIUDSAMLSA-N Asn-Lys-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O RCFGLXMZDYNRSC-CIUDSAMLSA-N 0.000 description 2
- KBQOUDLMWYWXNP-YDHLFZDLSA-N Asn-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KBQOUDLMWYWXNP-YDHLFZDLSA-N 0.000 description 2
- NJIKKGUVGUBICV-ZLUOBGJFSA-N Asp-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O NJIKKGUVGUBICV-ZLUOBGJFSA-N 0.000 description 2
- YNQIDCRRTWGHJD-ZLUOBGJFSA-N Asp-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(O)=O YNQIDCRRTWGHJD-ZLUOBGJFSA-N 0.000 description 2
- WSGVTKZFVJSJOG-RCOVLWMOSA-N Asp-Gly-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O WSGVTKZFVJSJOG-RCOVLWMOSA-N 0.000 description 2
- KTTCQQNRRLCIBC-GHCJXIJMSA-N Asp-Ile-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O KTTCQQNRRLCIBC-GHCJXIJMSA-N 0.000 description 2
- NBKLEMWHDLAUEM-CIUDSAMLSA-N Asp-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N NBKLEMWHDLAUEM-CIUDSAMLSA-N 0.000 description 2
- YUELDQUPTAYEGM-XIRDDKMYSA-N Asp-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)O)N YUELDQUPTAYEGM-XIRDDKMYSA-N 0.000 description 2
- QOJJMJKTMKNFEF-ZKWXMUAHSA-N Asp-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O QOJJMJKTMKNFEF-ZKWXMUAHSA-N 0.000 description 2
- 238000011729 BALB/c nude mouse Methods 0.000 description 2
- 239000005711 Benzoic acid Substances 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- 206010052360 Colorectal adenocarcinoma Diseases 0.000 description 2
- ZKAUCGZIIXXWJQ-BZSNNMDCSA-N Cys-Tyr-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)NC(=O)[C@H](CS)N)O ZKAUCGZIIXXWJQ-BZSNNMDCSA-N 0.000 description 2
- RGHNJXZEOKUKBD-UHFFFAOYSA-N D-gluconic acid Natural products OCC(O)C(O)C(O)C(O)C(O)=O RGHNJXZEOKUKBD-UHFFFAOYSA-N 0.000 description 2
- 108020004414 DNA Proteins 0.000 description 2
- FEWJPZIEWOKRBE-JCYAYHJZSA-N Dextrotartaric acid Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O FEWJPZIEWOKRBE-JCYAYHJZSA-N 0.000 description 2
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 2
- QUSNBJAOOMFDIB-UHFFFAOYSA-N Ethylamine Chemical compound CCN QUSNBJAOOMFDIB-UHFFFAOYSA-N 0.000 description 2
- XOKGKOQWADCLFQ-GARJFASQSA-N Gln-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XOKGKOQWADCLFQ-GARJFASQSA-N 0.000 description 2
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 2
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 2
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 2
- HNVFSTLPVJWIDV-CIUDSAMLSA-N Glu-Glu-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HNVFSTLPVJWIDV-CIUDSAMLSA-N 0.000 description 2
- YHOJJFFTSMWVGR-HJGDQZAQSA-N Glu-Met-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YHOJJFFTSMWVGR-HJGDQZAQSA-N 0.000 description 2
- AAJHGGDRKHYSDH-GUBZILKMSA-N Glu-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O AAJHGGDRKHYSDH-GUBZILKMSA-N 0.000 description 2
- ALMBZBOCGSVSAI-ACZMJKKPSA-N Glu-Ser-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ALMBZBOCGSVSAI-ACZMJKKPSA-N 0.000 description 2
- MFYLRRCYBBJYPI-JYJNAYRXSA-N Glu-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O MFYLRRCYBBJYPI-JYJNAYRXSA-N 0.000 description 2
- ZALGPUWUVHOGAE-GVXVVHGQSA-N Glu-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZALGPUWUVHOGAE-GVXVVHGQSA-N 0.000 description 2
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 2
- KRRMJKMGWWXWDW-STQMWFEESA-N Gly-Arg-Phe Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KRRMJKMGWWXWDW-STQMWFEESA-N 0.000 description 2
- IALQAMYQJBZNSK-WHFBIAKZSA-N Gly-Ser-Asn Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O IALQAMYQJBZNSK-WHFBIAKZSA-N 0.000 description 2
- VNNRLUNBJSWZPF-ZKWXMUAHSA-N Gly-Ser-Ile Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNNRLUNBJSWZPF-ZKWXMUAHSA-N 0.000 description 2
- JSLVAHYTAJJEQH-QWRGUYRKSA-N Gly-Ser-Phe Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JSLVAHYTAJJEQH-QWRGUYRKSA-N 0.000 description 2
- WCORRBXVISTKQL-WHFBIAKZSA-N Gly-Ser-Ser Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WCORRBXVISTKQL-WHFBIAKZSA-N 0.000 description 2
- IMRNSEPSPFQNHF-STQMWFEESA-N Gly-Ser-Trp Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=CC=CC=C12)C(=O)O IMRNSEPSPFQNHF-STQMWFEESA-N 0.000 description 2
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 2
- PROLDOGUBQJNPG-RWMBFGLXSA-N His-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O PROLDOGUBQJNPG-RWMBFGLXSA-N 0.000 description 2
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 2
- OMDWJWGZGMCQND-CFMVVWHZSA-N Ile-Tyr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N OMDWJWGZGMCQND-CFMVVWHZSA-N 0.000 description 2
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 2
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 2
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 2
- AUNMOHYWTAPQLA-XUXIUFHCSA-N Leu-Met-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AUNMOHYWTAPQLA-XUXIUFHCSA-N 0.000 description 2
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 2
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 2
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 2
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 2
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 2
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 description 2
- WSXTWLJHTLRFLW-SRVKXCTJSA-N Lys-Ala-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O WSXTWLJHTLRFLW-SRVKXCTJSA-N 0.000 description 2
- FUKDBQGFSJUXGX-RWMBFGLXSA-N Lys-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)N)C(=O)O FUKDBQGFSJUXGX-RWMBFGLXSA-N 0.000 description 2
- YKIRNDPUWONXQN-GUBZILKMSA-N Lys-Asn-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YKIRNDPUWONXQN-GUBZILKMSA-N 0.000 description 2
- PBLLTSKBTAHDNA-KBPBESRZSA-N Lys-Gly-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PBLLTSKBTAHDNA-KBPBESRZSA-N 0.000 description 2
- ODTZHNZPINULEU-KKUMJFAQSA-N Lys-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N ODTZHNZPINULEU-KKUMJFAQSA-N 0.000 description 2
- AFLBTVGQCQLOFJ-AVGNSLFASA-N Lys-Pro-Arg Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O AFLBTVGQCQLOFJ-AVGNSLFASA-N 0.000 description 2
- WQDKIVRHTQYJSN-DCAQKATOSA-N Lys-Ser-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N WQDKIVRHTQYJSN-DCAQKATOSA-N 0.000 description 2
- DLCAXBGXGOVUCD-PPCPHDFISA-N Lys-Thr-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DLCAXBGXGOVUCD-PPCPHDFISA-N 0.000 description 2
- CAVRAQIDHUPECU-UVOCVTCTSA-N Lys-Thr-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAVRAQIDHUPECU-UVOCVTCTSA-N 0.000 description 2
- GILLQRYAWOMHED-DCAQKATOSA-N Lys-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN GILLQRYAWOMHED-DCAQKATOSA-N 0.000 description 2
- 239000012515 MabSelect SuRe Substances 0.000 description 2
- TWRXJAOTZQYOKJ-UHFFFAOYSA-L Magnesium chloride Chemical compound [Mg+2].[Cl-].[Cl-] TWRXJAOTZQYOKJ-UHFFFAOYSA-L 0.000 description 2
- AFVFQIVMOAPDHO-UHFFFAOYSA-N Methanesulfonic acid Chemical compound CS(O)(=O)=O AFVFQIVMOAPDHO-UHFFFAOYSA-N 0.000 description 2
- YNAVUWVOSKDBBP-UHFFFAOYSA-N Morpholine Chemical compound C1COCCN1 YNAVUWVOSKDBBP-UHFFFAOYSA-N 0.000 description 2
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 2
- UFWIBTONFRDIAS-UHFFFAOYSA-N Naphthalene Chemical compound C1=CC=CC2=CC=CC=C21 UFWIBTONFRDIAS-UHFFFAOYSA-N 0.000 description 2
- JDMKQHSHKJHAHR-UHFFFAOYSA-N Phe-Phe-Leu-Tyr Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)CC1=CC=CC=C1 JDMKQHSHKJHAHR-UHFFFAOYSA-N 0.000 description 2
- PCNDJXKNXGMECE-UHFFFAOYSA-N Phenazine Natural products C1=CC=CC2=NC3=CC=CC=C3N=C21 PCNDJXKNXGMECE-UHFFFAOYSA-N 0.000 description 2
- NQRYJNQNLNOLGT-UHFFFAOYSA-N Piperidine Chemical compound C1CCNCC1 NQRYJNQNLNOLGT-UHFFFAOYSA-N 0.000 description 2
- 229920001213 Polysorbate 20 Polymers 0.000 description 2
- SGCZFWSQERRKBD-BQBZGAKWSA-N Pro-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 SGCZFWSQERRKBD-BQBZGAKWSA-N 0.000 description 2
- KWMUAKQOVYCQJQ-ZPFDUUQYSA-N Pro-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@@H]1CCCN1 KWMUAKQOVYCQJQ-ZPFDUUQYSA-N 0.000 description 2
- KBUAPZAZPWNYSW-SRVKXCTJSA-N Pro-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KBUAPZAZPWNYSW-SRVKXCTJSA-N 0.000 description 2
- OFOBLEOULBTSOW-UHFFFAOYSA-N Propanedioic acid Natural products OC(=O)CC(O)=O OFOBLEOULBTSOW-UHFFFAOYSA-N 0.000 description 2
- JUJWROOIHBZHMG-UHFFFAOYSA-N Pyridine Chemical compound C1=CC=NC=C1 JUJWROOIHBZHMG-UHFFFAOYSA-N 0.000 description 2
- LCTONWCANYUPML-UHFFFAOYSA-N Pyruvic acid Chemical compound CC(=O)C(O)=O LCTONWCANYUPML-UHFFFAOYSA-N 0.000 description 2
- SMWDFEZZVXVKRB-UHFFFAOYSA-N Quinoline Chemical compound N1=CC=CC2=CC=CC=C21 SMWDFEZZVXVKRB-UHFFFAOYSA-N 0.000 description 2
- 239000012980 RPMI-1640 medium Substances 0.000 description 2
- 241000700159 Rattus Species 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- UEJYSALTSUZXFV-SRVKXCTJSA-N Rigin Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O UEJYSALTSUZXFV-SRVKXCTJSA-N 0.000 description 2
- YUSRGTQIPCJNHQ-CIUDSAMLSA-N Ser-Arg-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O YUSRGTQIPCJNHQ-CIUDSAMLSA-N 0.000 description 2
- OYEDZGNMSBZCIM-XGEHTFHBSA-N Ser-Arg-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OYEDZGNMSBZCIM-XGEHTFHBSA-N 0.000 description 2
- OHKLFYXEOGGGCK-ZLUOBGJFSA-N Ser-Asp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OHKLFYXEOGGGCK-ZLUOBGJFSA-N 0.000 description 2
- MOVJSUIKUNCVMG-ZLUOBGJFSA-N Ser-Cys-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N)O MOVJSUIKUNCVMG-ZLUOBGJFSA-N 0.000 description 2
- XUDRHBPSPAPDJP-SRVKXCTJSA-N Ser-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO XUDRHBPSPAPDJP-SRVKXCTJSA-N 0.000 description 2
- RHAPJNVNWDBFQI-BQBZGAKWSA-N Ser-Pro-Gly Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O RHAPJNVNWDBFQI-BQBZGAKWSA-N 0.000 description 2
- GSCVDSBEYVGMJQ-SRVKXCTJSA-N Ser-Tyr-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N)O GSCVDSBEYVGMJQ-SRVKXCTJSA-N 0.000 description 2
- OSFZCEQJLWCIBG-BZSNNMDCSA-N Ser-Tyr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OSFZCEQJLWCIBG-BZSNNMDCSA-N 0.000 description 2
- KDYFGRWQOYBRFD-UHFFFAOYSA-N Succinic acid Natural products OC(=O)CCC(O)=O KDYFGRWQOYBRFD-UHFFFAOYSA-N 0.000 description 2
- 210000001744 T-lymphocyte Anatomy 0.000 description 2
- FEWJPZIEWOKRBE-UHFFFAOYSA-N Tartaric acid Natural products [H+].[H+].[O-]C(=O)C(O)C(O)C([O-])=O FEWJPZIEWOKRBE-UHFFFAOYSA-N 0.000 description 2
- YTPLMLYBLZKORZ-UHFFFAOYSA-N Thiophene Chemical compound C=1C=CSC=1 YTPLMLYBLZKORZ-UHFFFAOYSA-N 0.000 description 2
- ASJDFGOPDCVXTG-KATARQTJSA-N Thr-Cys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O ASJDFGOPDCVXTG-KATARQTJSA-N 0.000 description 2
- LAFLAXHTDVNVEL-WDCWCFNPSA-N Thr-Gln-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O LAFLAXHTDVNVEL-WDCWCFNPSA-N 0.000 description 2
- KCRQEJSKXAIULJ-FJXKBIBVSA-N Thr-Gly-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O KCRQEJSKXAIULJ-FJXKBIBVSA-N 0.000 description 2
- BEZTUFWTPVOROW-KJEVXHAQSA-N Thr-Tyr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O BEZTUFWTPVOROW-KJEVXHAQSA-N 0.000 description 2
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 2
- DTQVDTLACAAQTR-UHFFFAOYSA-N Trifluoroacetic acid Chemical compound OC(=O)C(F)(F)F DTQVDTLACAAQTR-UHFFFAOYSA-N 0.000 description 2
- OFSLQLHHDQOWDB-QEJZJMRPSA-N Trp-Cys-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 OFSLQLHHDQOWDB-QEJZJMRPSA-N 0.000 description 2
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 2
- SAKLWFSRZTZQAJ-GQGQLFGLSA-N Trp-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N SAKLWFSRZTZQAJ-GQGQLFGLSA-N 0.000 description 2
- SSSDKJMQMZTMJP-BVSLBCMMSA-N Trp-Tyr-Val Chemical compound C([C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CC=C(O)C=C1 SSSDKJMQMZTMJP-BVSLBCMMSA-N 0.000 description 2
- SCCKSNREWHMKOJ-SRVKXCTJSA-N Tyr-Asn-Ser Chemical compound N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O SCCKSNREWHMKOJ-SRVKXCTJSA-N 0.000 description 2
- DANHCMVVXDXOHN-SRVKXCTJSA-N Tyr-Asp-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 DANHCMVVXDXOHN-SRVKXCTJSA-N 0.000 description 2
- OGPKMBOPMDTEDM-IHRRRGAJSA-N Tyr-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N OGPKMBOPMDTEDM-IHRRRGAJSA-N 0.000 description 2
- YYLHVUCSTXXKBS-IHRRRGAJSA-N Tyr-Pro-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YYLHVUCSTXXKBS-IHRRRGAJSA-N 0.000 description 2
- RKIGNDAHUOOIMJ-BQFCYCMXSA-N Val-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 RKIGNDAHUOOIMJ-BQFCYCMXSA-N 0.000 description 2
- SBJCTAZFSZXWSR-AVGNSLFASA-N Val-Met-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SBJCTAZFSZXWSR-AVGNSLFASA-N 0.000 description 2
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 2
- BGTDGENDNWGMDQ-KJEVXHAQSA-N Val-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N)O BGTDGENDNWGMDQ-KJEVXHAQSA-N 0.000 description 2
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- DZBUGLKDJFMEHC-UHFFFAOYSA-N acridine Chemical compound C1=CC=CC2=CC3=CC=CC=C3N=C21 DZBUGLKDJFMEHC-UHFFFAOYSA-N 0.000 description 2
- 239000002671 adjuvant Substances 0.000 description 2
- 239000008272 agar Substances 0.000 description 2
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 2
- 230000033115 angiogenesis Effects 0.000 description 2
- MWPLVEDNUUSJAV-UHFFFAOYSA-N anthracene Chemical compound C1=CC=CC2=CC3=CC=CC=C3C=C21 MWPLVEDNUUSJAV-UHFFFAOYSA-N 0.000 description 2
- 238000011230 antibody-based therapy Methods 0.000 description 2
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 2
- 102000025171 antigen binding proteins Human genes 0.000 description 2
- 108091000831 antigen binding proteins Proteins 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 2
- 238000003556 assay Methods 0.000 description 2
- CUFNKYGDVFVPHO-UHFFFAOYSA-N azulene Chemical compound C1=CC=CC2=CC=CC2=C1 CUFNKYGDVFVPHO-UHFFFAOYSA-N 0.000 description 2
- 210000003719 b-lymphocyte Anatomy 0.000 description 2
- RFRXIWQYSOIBDI-UHFFFAOYSA-N benzarone Chemical compound CCC=1OC2=CC=CC=C2C=1C(=O)C1=CC=C(O)C=C1 RFRXIWQYSOIBDI-UHFFFAOYSA-N 0.000 description 2
- 235000010233 benzoic acid Nutrition 0.000 description 2
- IOJUPLGTWVMSFF-UHFFFAOYSA-N benzothiazole Chemical compound C1=CC=C2SC=NC2=C1 IOJUPLGTWVMSFF-UHFFFAOYSA-N 0.000 description 2
- WGQKYBSKWIADBV-UHFFFAOYSA-N benzylamine Chemical compound NCC1=CC=CC=C1 WGQKYBSKWIADBV-UHFFFAOYSA-N 0.000 description 2
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 2
- 230000000903 blocking effect Effects 0.000 description 2
- 210000000481 breast Anatomy 0.000 description 2
- 239000007853 buffer solution Substances 0.000 description 2
- HQABUPZFAYXKJW-UHFFFAOYSA-N butan-1-amine Chemical compound CCCCN HQABUPZFAYXKJW-UHFFFAOYSA-N 0.000 description 2
- KVUAALJSMIVURS-ZEDZUCNESA-L calcium folinate Chemical compound [Ca+2].C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC([O-])=O)C([O-])=O)C=C1 KVUAALJSMIVURS-ZEDZUCNESA-L 0.000 description 2
- 239000001506 calcium phosphate Substances 0.000 description 2
- 229910000389 calcium phosphate Inorganic materials 0.000 description 2
- 235000011010 calcium phosphates Nutrition 0.000 description 2
- 125000005488 carboaryl group Chemical group 0.000 description 2
- 230000032823 cell division Effects 0.000 description 2
- 230000010261 cell growth Effects 0.000 description 2
- 210000000170 cell membrane Anatomy 0.000 description 2
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 description 2
- WCZVZNOTHYJIEI-UHFFFAOYSA-N cinnoline Chemical compound N1=NC=CC2=CC=CC=C21 WCZVZNOTHYJIEI-UHFFFAOYSA-N 0.000 description 2
- 235000015165 citric acid Nutrition 0.000 description 2
- 238000003776 cleavage reaction Methods 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- HGCIXCUEYOPUTN-UHFFFAOYSA-N cyclohexene Chemical compound C1CCC=CC1 HGCIXCUEYOPUTN-UHFFFAOYSA-N 0.000 description 2
- LPIQUOYDBNQMRZ-UHFFFAOYSA-N cyclopentene Chemical compound C1CC=CC1 LPIQUOYDBNQMRZ-UHFFFAOYSA-N 0.000 description 2
- 238000012217 deletion Methods 0.000 description 2
- 230000037430 deletion Effects 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- UQLDLKMNUJERMK-UHFFFAOYSA-L di(octadecanoyloxy)lead Chemical compound [Pb+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O UQLDLKMNUJERMK-UHFFFAOYSA-L 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- TXCDCPKCNAJMEE-UHFFFAOYSA-N dibenzofuran Chemical compound C1=CC=C2C3=CC=CC=C3OC2=C1 TXCDCPKCNAJMEE-UHFFFAOYSA-N 0.000 description 2
- IYYZUPMFVPLQIF-UHFFFAOYSA-N dibenzothiophene Chemical compound C1=CC=C2C3=CC=CC=C3SC2=C1 IYYZUPMFVPLQIF-UHFFFAOYSA-N 0.000 description 2
- 239000003085 diluting agent Substances 0.000 description 2
- QWHNJUXXYKPLQM-UHFFFAOYSA-N dimethyl cyclopentane Natural products CC1(C)CCCC1 QWHNJUXXYKPLQM-UHFFFAOYSA-N 0.000 description 2
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 2
- 230000006806 disease prevention Effects 0.000 description 2
- 239000012636 effector Substances 0.000 description 2
- 239000003995 emulsifying agent Substances 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 2
- 125000002534 ethynyl group Chemical group [H]C#C* 0.000 description 2
- 230000029142 excretion Effects 0.000 description 2
- 239000001530 fumaric acid Substances 0.000 description 2
- 235000011087 fumaric acid Nutrition 0.000 description 2
- 125000000524 functional group Chemical group 0.000 description 2
- 208000010749 gastric carcinoma Diseases 0.000 description 2
- 239000000174 gluconic acid Substances 0.000 description 2
- 235000012208 gluconic acid Nutrition 0.000 description 2
- 239000004220 glutamic acid Substances 0.000 description 2
- 235000013922 glutamic acid Nutrition 0.000 description 2
- 108010078144 glutaminyl-glycine Proteins 0.000 description 2
- 108010019832 glycyl-asparaginyl-glycine Proteins 0.000 description 2
- 108010074027 glycyl-seryl-phenylalanine Proteins 0.000 description 2
- 108010015792 glycyllysine Proteins 0.000 description 2
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 2
- 201000005787 hematologic cancer Diseases 0.000 description 2
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 description 2
- 238000004128 high performance liquid chromatography Methods 0.000 description 2
- 210000004408 hybridoma Anatomy 0.000 description 2
- 210000000987 immune system Anatomy 0.000 description 2
- 230000036039 immunity Effects 0.000 description 2
- PQNFLJBBNBOBRQ-UHFFFAOYSA-N indane Chemical compound C1=CC=C2CCCC2=C1 PQNFLJBBNBOBRQ-UHFFFAOYSA-N 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- SUMDYPCJJOFFON-UHFFFAOYSA-N isethionic acid Chemical compound OCCS(O)(=O)=O SUMDYPCJJOFFON-UHFFFAOYSA-N 0.000 description 2
- 150000008372 isochromenes Chemical class 0.000 description 2
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 2
- AWJUIBRHMBBTKR-UHFFFAOYSA-N isoquinoline Chemical compound C1=NC=CC2=CC=CC=C21 AWJUIBRHMBBTKR-UHFFFAOYSA-N 0.000 description 2
- 239000004310 lactic acid Substances 0.000 description 2
- 235000014655 lactic acid Nutrition 0.000 description 2
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 201000009546 lung large cell carcinoma Diseases 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- VZCYOOQTPOCHFL-UPHRSURJSA-N maleic acid Chemical compound OC(=O)\C=C/C(O)=O VZCYOOQTPOCHFL-UPHRSURJSA-N 0.000 description 2
- 239000011976 maleic acid Substances 0.000 description 2
- 230000010534 mechanism of action Effects 0.000 description 2
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 2
- BDJAEZRIGNCQBZ-UHFFFAOYSA-N methylcyclobutane Chemical compound CC1CCC1 BDJAEZRIGNCQBZ-UHFFFAOYSA-N 0.000 description 2
- UAEPNZWRGJTJPN-UHFFFAOYSA-N methylcyclohexane Chemical compound CC1CCCCC1 UAEPNZWRGJTJPN-UHFFFAOYSA-N 0.000 description 2
- GDOPTJXRTPNYNR-UHFFFAOYSA-N methylcyclopentane Chemical compound CC1CCCC1 GDOPTJXRTPNYNR-UHFFFAOYSA-N 0.000 description 2
- 238000002156 mixing Methods 0.000 description 2
- 150000002772 monosaccharides Chemical class 0.000 description 2
- 125000000740 n-pentyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 2
- 150000002891 organic anions Chemical class 0.000 description 2
- 235000006408 oxalic acid Nutrition 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- YNPNZTXNASCQKK-UHFFFAOYSA-N phenanthrene Chemical compound C1=CC=C2C3=CC=CC=C3C=CC2=C1 YNPNZTXNASCQKK-UHFFFAOYSA-N 0.000 description 2
- RDOWQLZANAYVLL-UHFFFAOYSA-N phenanthridine Chemical compound C1=CC=C2C3=CC=CC=C3C=NC2=C1 RDOWQLZANAYVLL-UHFFFAOYSA-N 0.000 description 2
- 239000013612 plasmid Substances 0.000 description 2
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 2
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 2
- 238000010837 poor prognosis Methods 0.000 description 2
- 239000003755 preservative agent Substances 0.000 description 2
- 230000002335 preservative effect Effects 0.000 description 2
- 230000002062 proliferating effect Effects 0.000 description 2
- 238000011321 prophylaxis Methods 0.000 description 2
- 235000019260 propionic acid Nutrition 0.000 description 2
- BBEAQIROQSPTKN-UHFFFAOYSA-N pyrene Chemical compound C1=CC=C2C=CC3=CC=CC4=CC=C1C2=C43 BBEAQIROQSPTKN-UHFFFAOYSA-N 0.000 description 2
- IUVKMZGDUIUOCP-BTNSXGMBSA-N quinbolone Chemical compound O([C@H]1CC[C@H]2[C@H]3[C@@H]([C@]4(C=CC(=O)C=C4CC3)C)CC[C@@]21C)C1=CCCC1 IUVKMZGDUIUOCP-BTNSXGMBSA-N 0.000 description 2
- 108091008598 receptor tyrosine kinases Proteins 0.000 description 2
- 102000027426 receptor tyrosine kinases Human genes 0.000 description 2
- 102000005962 receptors Human genes 0.000 description 2
- 108020003175 receptors Proteins 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- YGSDEFSMJLZEOE-UHFFFAOYSA-N salicylic acid Chemical compound OC(=O)C1=CC=CC=C1O YGSDEFSMJLZEOE-UHFFFAOYSA-N 0.000 description 2
- 230000007017 scission Effects 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 2
- 150000003384 small molecules Chemical class 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 201000000498 stomach carcinoma Diseases 0.000 description 2
- 208000024891 symptom Diseases 0.000 description 2
- 239000011975 tartaric acid Substances 0.000 description 2
- 235000002906 tartaric acid Nutrition 0.000 description 2
- 238000010361 transduction Methods 0.000 description 2
- 230000026683 transduction Effects 0.000 description 2
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 2
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 2
- 108010051110 tyrosyl-lysine Proteins 0.000 description 2
- NQPDZGIKBAWPEJ-UHFFFAOYSA-N valeric acid Chemical compound CCCCC(O)=O NQPDZGIKBAWPEJ-UHFFFAOYSA-N 0.000 description 2
- 229910052720 vanadium Inorganic materials 0.000 description 2
- 125000000391 vinyl group Chemical group [H]C([*])=C([H])[H] 0.000 description 2
- 229920002554 vinyl polymer Polymers 0.000 description 2
- MFRNYXJJRJQHNW-DEMKXPNLSA-N (2s)-2-[[(2r,3r)-3-methoxy-3-[(2s)-1-[(3r,4s,5s)-3-methoxy-5-methyl-4-[methyl-[(2s)-3-methyl-2-[[(2s)-3-methyl-2-(methylamino)butanoyl]amino]butanoyl]amino]heptanoyl]pyrrolidin-2-yl]-2-methylpropanoyl]amino]-3-phenylpropanoic acid Chemical compound CN[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFRNYXJJRJQHNW-DEMKXPNLSA-N 0.000 description 1
- OMRPLUKQNWNZAV-CONSDPRKSA-N (6as)-3-[3-[[(6as)-2-methoxy-8-(4-methoxyphenyl)-11-oxo-6a,7-dihydropyrrolo[2,1-c][1,4]benzodiazepin-3-yl]oxy]propoxy]-8-(4-aminophenyl)-2-methoxy-6a,7-dihydropyrrolo[2,1-c][1,4]benzodiazepin-11-one Chemical compound C1=CC(OC)=CC=C1C1=CN2C(=O)C3=CC(OC)=C(OCCCOC=4C(=CC=5C(=O)N6C=C(C[C@H]6C=NC=5C=4)C=4C=CC(N)=CC=4)OC)C=C3N=C[C@@H]2C1 OMRPLUKQNWNZAV-CONSDPRKSA-N 0.000 description 1
- WRIDQFICGBMAFQ-UHFFFAOYSA-N (E)-8-Octadecenoic acid Natural products CCCCCCCCCC=CCCCCCCC(O)=O WRIDQFICGBMAFQ-UHFFFAOYSA-N 0.000 description 1
- MIOPJNTWMNEORI-GMSGAONNSA-N (S)-camphorsulfonic acid Chemical compound C1C[C@@]2(CS(O)(=O)=O)C(=O)C[C@@H]1C2(C)C MIOPJNTWMNEORI-GMSGAONNSA-N 0.000 description 1
- BJEPYKJPYRNKOW-REOHCLBHSA-N (S)-malic acid Chemical compound OC(=O)[C@@H](O)CC(O)=O BJEPYKJPYRNKOW-REOHCLBHSA-N 0.000 description 1
- UWYVPFMHMJIBHE-OWOJBTEDSA-N (e)-2-hydroxybut-2-enedioic acid Chemical compound OC(=O)\C=C(\O)C(O)=O UWYVPFMHMJIBHE-OWOJBTEDSA-N 0.000 description 1
- WBYWAXJHAXSJNI-VOTSOKGWSA-M .beta-Phenylacrylic acid Natural products [O-]C(=O)\C=C\C1=CC=CC=C1 WBYWAXJHAXSJNI-VOTSOKGWSA-M 0.000 description 1
- OFZYBEBWCZBCPM-UHFFFAOYSA-N 1,1-dimethylcyclobutane Chemical compound CC1(C)CCC1 OFZYBEBWCZBCPM-UHFFFAOYSA-N 0.000 description 1
- PBIJFSCPEFQXBB-UHFFFAOYSA-N 1,1-dimethylcyclopropane Chemical compound CC1(C)CC1 PBIJFSCPEFQXBB-UHFFFAOYSA-N 0.000 description 1
- FNQJDLTXOVEEFB-UHFFFAOYSA-N 1,2,3-benzothiadiazole Chemical compound C1=CC=C2SN=NC2=C1 FNQJDLTXOVEEFB-UHFFFAOYSA-N 0.000 description 1
- KTZQTRPPVKQPFO-UHFFFAOYSA-N 1,2-benzoxazole Chemical compound C1=CC=C2C=NOC2=C1 KTZQTRPPVKQPFO-UHFFFAOYSA-N 0.000 description 1
- PUAKTHBSHFXVAG-UHFFFAOYSA-N 1,2-dimethylcyclobutene Chemical compound CC1=C(C)CC1 PUAKTHBSHFXVAG-UHFFFAOYSA-N 0.000 description 1
- SZZWLAZADBEDQP-UHFFFAOYSA-N 1,2-dimethylcyclopentene Chemical compound CC1=C(C)CCC1 SZZWLAZADBEDQP-UHFFFAOYSA-N 0.000 description 1
- CIISBYKBBMFLEZ-UHFFFAOYSA-N 1,2-oxazolidine Chemical compound C1CNOC1 CIISBYKBBMFLEZ-UHFFFAOYSA-N 0.000 description 1
- BGJSXRVXTHVRSN-UHFFFAOYSA-N 1,3,5-trioxane Chemical compound C1OCOCO1 BGJSXRVXTHVRSN-UHFFFAOYSA-N 0.000 description 1
- FTNJQNQLEGKTGD-UHFFFAOYSA-N 1,3-benzodioxole Chemical compound C1=CC=C2OCOC2=C1 FTNJQNQLEGKTGD-UHFFFAOYSA-N 0.000 description 1
- BCMCBBGGLRIHSE-UHFFFAOYSA-N 1,3-benzoxazole Chemical compound C1=CC=C2OC=NC2=C1 BCMCBBGGLRIHSE-UHFFFAOYSA-N 0.000 description 1
- WNXJIVFYUVYPPR-UHFFFAOYSA-N 1,3-dioxolane Chemical compound C1COCO1 WNXJIVFYUVYPPR-UHFFFAOYSA-N 0.000 description 1
- OGYGFUAIIOPWQD-UHFFFAOYSA-N 1,3-thiazolidine Chemical compound C1CSCN1 OGYGFUAIIOPWQD-UHFFFAOYSA-N 0.000 description 1
- YNGDWRXWKFWCJY-UHFFFAOYSA-N 1,4-Dihydropyridine Chemical compound C1C=CNC=C1 YNGDWRXWKFWCJY-UHFFFAOYSA-N 0.000 description 1
- VMLKTERJLVWEJJ-UHFFFAOYSA-N 1,5-naphthyridine Chemical compound C1=CC=NC2=CC=CN=C21 VMLKTERJLVWEJJ-UHFFFAOYSA-N 0.000 description 1
- FLBAYUMRQUHISI-UHFFFAOYSA-N 1,8-naphthyridine Chemical compound N1=CC=CC2=CC=CN=C21 FLBAYUMRQUHISI-UHFFFAOYSA-N 0.000 description 1
- MYBLAOJMRYYKMS-RTRLPJTCSA-N 1-(2-chloroethyl)-1-nitroso-3-[(3r,4r,5s,6r)-2,4,5-trihydroxy-6-(hydroxymethyl)oxan-3-yl]urea Chemical compound OC[C@H]1OC(O)[C@H](NC(=O)N(CCCl)N=O)[C@@H](O)[C@@H]1O MYBLAOJMRYYKMS-RTRLPJTCSA-N 0.000 description 1
- TUSDEZXZIZRFGC-UHFFFAOYSA-N 1-O-galloyl-3,6-(R)-HHDP-beta-D-glucose Natural products OC1C(O2)COC(=O)C3=CC(O)=C(O)C(O)=C3C3=C(O)C(O)=C(O)C=C3C(=O)OC1C(O)C2OC(=O)C1=CC(O)=C(O)C(O)=C1 TUSDEZXZIZRFGC-UHFFFAOYSA-N 0.000 description 1
- HMUNWXXNJPVALC-UHFFFAOYSA-N 1-[4-[2-(2,3-dihydro-1H-inden-2-ylamino)pyrimidin-5-yl]piperazin-1-yl]-2-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)ethanone Chemical compound C1C(CC2=CC=CC=C12)NC1=NC=C(C=N1)N1CCN(CC1)C(CN1CC2=C(CC1)NN=N2)=O HMUNWXXNJPVALC-UHFFFAOYSA-N 0.000 description 1
- MUPYMRJBEZFVMT-UHFFFAOYSA-N 1-chloro-4-dimethoxyphosphorylsulfanylbenzene Chemical compound COP(=O)(OC)SC1=CC=C(Cl)C=C1 MUPYMRJBEZFVMT-UHFFFAOYSA-N 0.000 description 1
- AVPHQXWAMGTQPF-UHFFFAOYSA-N 1-methylcyclobutene Chemical compound CC1=CCC1 AVPHQXWAMGTQPF-UHFFFAOYSA-N 0.000 description 1
- ATQUFXWBVZUTKO-UHFFFAOYSA-N 1-methylcyclopentene Chemical compound CC1=CCCC1 ATQUFXWBVZUTKO-UHFFFAOYSA-N 0.000 description 1
- SHDPRTQPPWIEJG-UHFFFAOYSA-N 1-methylcyclopropene Chemical compound CC1=CC1 SHDPRTQPPWIEJG-UHFFFAOYSA-N 0.000 description 1
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 1
- 125000006017 1-propenyl group Chemical group 0.000 description 1
- WJFKNYWRSNBZNX-UHFFFAOYSA-N 10H-phenothiazine Chemical compound C1=CC=C2NC3=CC=CC=C3SC2=C1 WJFKNYWRSNBZNX-UHFFFAOYSA-N 0.000 description 1
- TZMSYXZUNZXBOL-UHFFFAOYSA-N 10H-phenoxazine Chemical compound C1=CC=C2NC3=CC=CC=C3OC2=C1 TZMSYXZUNZXBOL-UHFFFAOYSA-N 0.000 description 1
- HYZJCKYKOHLVJF-UHFFFAOYSA-N 1H-benzimidazole Chemical compound C1=CC=C2NC=NC2=C1 HYZJCKYKOHLVJF-UHFFFAOYSA-N 0.000 description 1
- BAXOFTOLAUCFNW-UHFFFAOYSA-N 1H-indazole Chemical compound C1=CC=C2C=NNC2=C1 BAXOFTOLAUCFNW-UHFFFAOYSA-N 0.000 description 1
- AAQTWLBJPNLKHT-UHFFFAOYSA-N 1H-perimidine Chemical compound N1C=NC2=CC=CC3=CC=CC1=C32 AAQTWLBJPNLKHT-UHFFFAOYSA-N 0.000 description 1
- SVUOLADPCWQTTE-UHFFFAOYSA-N 1h-1,2-benzodiazepine Chemical compound N1N=CC=CC2=CC=CC=C12 SVUOLADPCWQTTE-UHFFFAOYSA-N 0.000 description 1
- FJRPOHLDJUJARI-UHFFFAOYSA-N 2,3-dihydro-1,2-oxazole Chemical compound C1NOC=C1 FJRPOHLDJUJARI-UHFFFAOYSA-N 0.000 description 1
- ZABMHLDQFJHDSC-UHFFFAOYSA-N 2,3-dihydro-1,3-oxazole Chemical compound C1NC=CO1 ZABMHLDQFJHDSC-UHFFFAOYSA-N 0.000 description 1
- JECYNCQXXKQDJN-UHFFFAOYSA-N 2-(2-methylhexan-2-yloxymethyl)oxirane Chemical compound CCCCC(C)(C)OCC1CO1 JECYNCQXXKQDJN-UHFFFAOYSA-N 0.000 description 1
- GVNVAWHJIKLAGL-UHFFFAOYSA-N 2-(cyclohexen-1-yl)cyclohexan-1-one Chemical compound O=C1CCCCC1C1=CCCCC1 GVNVAWHJIKLAGL-UHFFFAOYSA-N 0.000 description 1
- LBLYYCQCTBFVLH-UHFFFAOYSA-N 2-Methylbenzenesulfonic acid Chemical compound CC1=CC=CC=C1S(O)(=O)=O LBLYYCQCTBFVLH-UHFFFAOYSA-N 0.000 description 1
- NPHULPIAPWNOOH-UHFFFAOYSA-N 2-[4-[2-(2,3-dihydro-1H-inden-2-ylamino)pyrimidin-5-yl]-3-(2,3-dihydroindol-1-ylmethyl)pyrazol-1-yl]-1-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)ethanone Chemical compound C1C(CC2=CC=CC=C12)NC1=NC=C(C=N1)C=1C(=NN(C=1)CC(=O)N1CC2=C(CC1)NN=N2)CN1CCC2=CC=CC=C12 NPHULPIAPWNOOH-UHFFFAOYSA-N 0.000 description 1
- UBDZFAGVPPMTIT-UHFFFAOYSA-N 2-aminoguanidine;hydron;chloride Chemical compound [Cl-].NC(N)=N[NH3+] UBDZFAGVPPMTIT-UHFFFAOYSA-N 0.000 description 1
- UXGVMFHEKMGWMA-UHFFFAOYSA-N 2-benzofuran Chemical compound C1=CC=CC2=COC=C21 UXGVMFHEKMGWMA-UHFFFAOYSA-N 0.000 description 1
- UPHOPMSGKZNELG-UHFFFAOYSA-N 2-hydroxynaphthalene-1-carboxylic acid Chemical compound C1=CC=C2C(C(=O)O)=C(O)C=CC2=C1 UPHOPMSGKZNELG-UHFFFAOYSA-N 0.000 description 1
- WLJVXDMOQOGPHL-PPJXEINESA-N 2-phenylacetic acid Chemical compound O[14C](=O)CC1=CC=CC=C1 WLJVXDMOQOGPHL-PPJXEINESA-N 0.000 description 1
- VSWICNJIUPRZIK-UHFFFAOYSA-N 2-piperideine Chemical compound C1CNC=CC1 VSWICNJIUPRZIK-UHFFFAOYSA-N 0.000 description 1
- 125000003903 2-propenyl group Chemical group [H]C([*])([H])C([H])=C([H])[H] 0.000 description 1
- 125000001494 2-propynyl group Chemical group [H]C#CC([H])([H])* 0.000 description 1
- RSEBUVRVKCANEP-UHFFFAOYSA-N 2-pyrroline Chemical compound C1CC=CN1 RSEBUVRVKCANEP-UHFFFAOYSA-N 0.000 description 1
- LQJBNNIYVWPHFW-UHFFFAOYSA-N 20:1omega9c fatty acid Natural products CCCCCCCCCCC=CCCCCCCCC(O)=O LQJBNNIYVWPHFW-UHFFFAOYSA-N 0.000 description 1
- BQTJMKIHKULPCZ-UHFFFAOYSA-N 2H-indene Chemical compound C1=CC=CC2=CCC=C21 BQTJMKIHKULPCZ-UHFFFAOYSA-N 0.000 description 1
- MGADZUXDNSDTHW-UHFFFAOYSA-N 2H-pyran Chemical compound C1OC=CC=C1 MGADZUXDNSDTHW-UHFFFAOYSA-N 0.000 description 1
- JZIBVTUXIVIFGC-UHFFFAOYSA-N 2H-pyrrole Chemical compound C1C=CC=N1 JZIBVTUXIVIFGC-UHFFFAOYSA-N 0.000 description 1
- CMLFRMDBDNHMRA-UHFFFAOYSA-N 2h-1,2-benzoxazine Chemical compound C1=CC=C2C=CNOC2=C1 CMLFRMDBDNHMRA-UHFFFAOYSA-N 0.000 description 1
- QMEQBOSUJUOXMX-UHFFFAOYSA-N 2h-oxadiazine Chemical compound N1OC=CC=N1 QMEQBOSUJUOXMX-UHFFFAOYSA-N 0.000 description 1
- BCHZICNRHXRCHY-UHFFFAOYSA-N 2h-oxazine Chemical compound N1OC=CC=C1 BCHZICNRHXRCHY-UHFFFAOYSA-N 0.000 description 1
- BOLMDIXLULGTBD-UHFFFAOYSA-N 3,4-dihydro-2h-oxazine Chemical compound C1CC=CON1 BOLMDIXLULGTBD-UHFFFAOYSA-N 0.000 description 1
- YLZOPXRUQYQQID-UHFFFAOYSA-N 3-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)-1-[4-[2-[[3-(trifluoromethoxy)phenyl]methylamino]pyrimidin-5-yl]piperazin-1-yl]propan-1-one Chemical compound N1N=NC=2CN(CCC=21)CCC(=O)N1CCN(CC1)C=1C=NC(=NC=1)NCC1=CC(=CC=C1)OC(F)(F)F YLZOPXRUQYQQID-UHFFFAOYSA-N 0.000 description 1
- BMYNFMYTOJXKLE-UHFFFAOYSA-N 3-azaniumyl-2-hydroxypropanoate Chemical compound NCC(O)C(O)=O BMYNFMYTOJXKLE-UHFFFAOYSA-N 0.000 description 1
- UOQHWNPVNXSDDO-UHFFFAOYSA-N 3-bromoimidazo[1,2-a]pyridine-6-carbonitrile Chemical compound C1=CC(C#N)=CN2C(Br)=CN=C21 UOQHWNPVNXSDDO-UHFFFAOYSA-N 0.000 description 1
- VXIKDBJPBRMXBP-UHFFFAOYSA-N 3H-pyrrole Chemical compound C1C=CN=C1 VXIKDBJPBRMXBP-UHFFFAOYSA-N 0.000 description 1
- ZBWXZZIIMVVCNZ-UHFFFAOYSA-N 4,5-dihydroacephenanthrylene Chemical compound C1=CC(CC2)=C3C2=CC2=CC=CC=C2C3=C1 ZBWXZZIIMVVCNZ-UHFFFAOYSA-N 0.000 description 1
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 1
- GDRVFDDBLLKWRI-UHFFFAOYSA-N 4H-quinolizine Chemical compound C1=CC=CN2CC=CC=C21 GDRVFDDBLLKWRI-UHFFFAOYSA-N 0.000 description 1
- FHVDTGUDJYJELY-UHFFFAOYSA-N 6-{[2-carboxy-4,5-dihydroxy-6-(phosphanyloxy)oxan-3-yl]oxy}-4,5-dihydroxy-3-phosphanyloxane-2-carboxylic acid Chemical compound O1C(C(O)=O)C(P)C(O)C(O)C1OC1C(C(O)=O)OC(OP)C(O)C1O FHVDTGUDJYJELY-UHFFFAOYSA-N 0.000 description 1
- NJBMMMJOXRZENQ-UHFFFAOYSA-N 6H-pyrrolo[2,3-f]quinoline Chemical compound c1cc2ccc3[nH]cccc3c2n1 NJBMMMJOXRZENQ-UHFFFAOYSA-N 0.000 description 1
- QSBYPNXLFMSGKH-UHFFFAOYSA-N 9-Heptadecensaeure Natural products CCCCCCCC=CCCCCCCCC(O)=O QSBYPNXLFMSGKH-UHFFFAOYSA-N 0.000 description 1
- PQJUJGAVDBINPI-UHFFFAOYSA-N 9H-thioxanthene Chemical compound C1=CC=C2CC3=CC=CC=C3SC2=C1 PQJUJGAVDBINPI-UHFFFAOYSA-N 0.000 description 1
- GJCOSYZMQJWQCA-UHFFFAOYSA-N 9H-xanthene Chemical compound C1=CC=C2CC3=CC=CC=C3OC2=C1 GJCOSYZMQJWQCA-UHFFFAOYSA-N 0.000 description 1
- 244000215068 Acacia senegal Species 0.000 description 1
- 235000006491 Acacia senegal Nutrition 0.000 description 1
- 239000005964 Acibenzolar-S-methyl Substances 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- SSSROGPPPVTHLX-FXQIFTODSA-N Ala-Arg-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSROGPPPVTHLX-FXQIFTODSA-N 0.000 description 1
- JBGSZRYCXBPWGX-BQBZGAKWSA-N Ala-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N JBGSZRYCXBPWGX-BQBZGAKWSA-N 0.000 description 1
- LWUWMHIOBPTZBA-DCAQKATOSA-N Ala-Arg-Lys Chemical compound NC(=N)NCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O LWUWMHIOBPTZBA-DCAQKATOSA-N 0.000 description 1
- FXKNPWNXPQZLES-ZLUOBGJFSA-N Ala-Asn-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O FXKNPWNXPQZLES-ZLUOBGJFSA-N 0.000 description 1
- QQACQIHVWCVBBR-GVARAGBVSA-N Ala-Ile-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QQACQIHVWCVBBR-GVARAGBVSA-N 0.000 description 1
- LDLSENBXQNDTPB-DCAQKATOSA-N Ala-Lys-Arg Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N LDLSENBXQNDTPB-DCAQKATOSA-N 0.000 description 1
- BLTRAARCJYVJKV-QEJZJMRPSA-N Ala-Lys-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](Cc1ccccc1)C(O)=O BLTRAARCJYVJKV-QEJZJMRPSA-N 0.000 description 1
- AWNAEZICPNGAJK-FXQIFTODSA-N Ala-Met-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(O)=O AWNAEZICPNGAJK-FXQIFTODSA-N 0.000 description 1
- BFMIRJBURUXDRG-DLOVCJGASA-N Ala-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 BFMIRJBURUXDRG-DLOVCJGASA-N 0.000 description 1
- FSXDWQGEWZQBPJ-HERUPUMHSA-N Ala-Trp-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC(=O)O)C(=O)O)N FSXDWQGEWZQBPJ-HERUPUMHSA-N 0.000 description 1
- XSLGWYYNOSUMRM-ZKWXMUAHSA-N Ala-Val-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O XSLGWYYNOSUMRM-ZKWXMUAHSA-N 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- COXMUHNBYCVVRG-DCAQKATOSA-N Arg-Leu-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O COXMUHNBYCVVRG-DCAQKATOSA-N 0.000 description 1
- NPAVRDPEFVKELR-DCAQKATOSA-N Arg-Lys-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O NPAVRDPEFVKELR-DCAQKATOSA-N 0.000 description 1
- PRLPSDIHSRITSF-UNQGMJICSA-N Arg-Phe-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PRLPSDIHSRITSF-UNQGMJICSA-N 0.000 description 1
- BECXEHHOZNFFFX-IHRRRGAJSA-N Arg-Ser-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BECXEHHOZNFFFX-IHRRRGAJSA-N 0.000 description 1
- ORXCYAFUCSTQGY-FXQIFTODSA-N Asn-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(=O)N)N ORXCYAFUCSTQGY-FXQIFTODSA-N 0.000 description 1
- QEYJFBMTSMLPKZ-ZKWXMUAHSA-N Asn-Ala-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O QEYJFBMTSMLPKZ-ZKWXMUAHSA-N 0.000 description 1
- NLRJGXZWTKXRHP-DCAQKATOSA-N Asn-Leu-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NLRJGXZWTKXRHP-DCAQKATOSA-N 0.000 description 1
- OSZBYGVKAFZWKC-FXQIFTODSA-N Asn-Pro-Cys Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CS)C(O)=O OSZBYGVKAFZWKC-FXQIFTODSA-N 0.000 description 1
- JWQWPRCDYWNVNM-ACZMJKKPSA-N Asn-Ser-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N JWQWPRCDYWNVNM-ACZMJKKPSA-N 0.000 description 1
- BCADFFUQHIMQAA-KKHAAJSZSA-N Asn-Thr-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O BCADFFUQHIMQAA-KKHAAJSZSA-N 0.000 description 1
- JPPLRQVZMZFOSX-UWJYBYFXSA-N Asn-Tyr-Ala Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=C(O)C=C1 JPPLRQVZMZFOSX-UWJYBYFXSA-N 0.000 description 1
- SKQTXVZTCGSRJS-SRVKXCTJSA-N Asn-Tyr-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O SKQTXVZTCGSRJS-SRVKXCTJSA-N 0.000 description 1
- DPSUVAPLRQDWAO-YDHLFZDLSA-N Asn-Tyr-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC(=O)N)N DPSUVAPLRQDWAO-YDHLFZDLSA-N 0.000 description 1
- MJIJBEYEHBKTIM-BYULHYEWSA-N Asn-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N MJIJBEYEHBKTIM-BYULHYEWSA-N 0.000 description 1
- PQKSVQSMTHPRIB-ZKWXMUAHSA-N Asn-Val-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O PQKSVQSMTHPRIB-ZKWXMUAHSA-N 0.000 description 1
- UQBGYPFHWFZMCD-ZLUOBGJFSA-N Asp-Asn-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O UQBGYPFHWFZMCD-ZLUOBGJFSA-N 0.000 description 1
- JDHOJQJMWBKHDB-CIUDSAMLSA-N Asp-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N JDHOJQJMWBKHDB-CIUDSAMLSA-N 0.000 description 1
- KNMRXHIAVXHCLW-ZLUOBGJFSA-N Asp-Asn-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)C(=O)O KNMRXHIAVXHCLW-ZLUOBGJFSA-N 0.000 description 1
- XXAMCEGRCZQGEM-ZLUOBGJFSA-N Asp-Ser-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O XXAMCEGRCZQGEM-ZLUOBGJFSA-N 0.000 description 1
- ZVGRHIRJLWBWGJ-ACZMJKKPSA-N Asp-Ser-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZVGRHIRJLWBWGJ-ACZMJKKPSA-N 0.000 description 1
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 1
- JJQGZGOEDSSHTE-FOHZUACHSA-N Asp-Thr-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O JJQGZGOEDSSHTE-FOHZUACHSA-N 0.000 description 1
- USENATHVGFXRNO-SRVKXCTJSA-N Asp-Tyr-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(O)=O)C(O)=O)CC1=CC=C(O)C=C1 USENATHVGFXRNO-SRVKXCTJSA-N 0.000 description 1
- ALMIMUZAWTUNIO-BZSNNMDCSA-N Asp-Tyr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ALMIMUZAWTUNIO-BZSNNMDCSA-N 0.000 description 1
- RKXVTTIQNKPCHU-KKHAAJSZSA-N Asp-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O RKXVTTIQNKPCHU-KKHAAJSZSA-N 0.000 description 1
- GYNUXDMCDILYIQ-QRTARXTBSA-N Asp-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N GYNUXDMCDILYIQ-QRTARXTBSA-N 0.000 description 1
- ZUNMTUPRQMWMHX-LSJOCFKGSA-N Asp-Val-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O ZUNMTUPRQMWMHX-LSJOCFKGSA-N 0.000 description 1
- 102000006942 B-Cell Maturation Antigen Human genes 0.000 description 1
- 108010008014 B-Cell Maturation Antigen Proteins 0.000 description 1
- 206010055113 Breast cancer metastatic Diseases 0.000 description 1
- WKBOTKDWSSQWDR-UHFFFAOYSA-N Bromine atom Chemical group [Br] WKBOTKDWSSQWDR-UHFFFAOYSA-N 0.000 description 1
- 101100315624 Caenorhabditis elegans tyr-1 gene Proteins 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 1
- GHOKWGTUZJEAQD-UHFFFAOYSA-N Chick antidermatitis factor Natural products OCC(C)(C)C(O)C(=O)NCCC(O)=O GHOKWGTUZJEAQD-UHFFFAOYSA-N 0.000 description 1
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 description 1
- ZAMOUSCENKQFHK-UHFFFAOYSA-N Chlorine atom Chemical group [Cl] ZAMOUSCENKQFHK-UHFFFAOYSA-N 0.000 description 1
- 101150065749 Churc1 gene Proteins 0.000 description 1
- WBYWAXJHAXSJNI-SREVYHEPSA-N Cinnamic acid Chemical compound OC(=O)\C=C/C1=CC=CC=C1 WBYWAXJHAXSJNI-SREVYHEPSA-N 0.000 description 1
- BYMMIQCVDHHYGG-UHFFFAOYSA-N Cl.OP(O)(O)=O Chemical compound Cl.OP(O)(O)=O BYMMIQCVDHHYGG-UHFFFAOYSA-N 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- 241000557626 Corvus corax Species 0.000 description 1
- PMPVIKIVABFJJI-UHFFFAOYSA-N Cyclobutane Chemical compound C1CCC1 PMPVIKIVABFJJI-UHFFFAOYSA-N 0.000 description 1
- XDTMQSROBMDMFD-UHFFFAOYSA-N Cyclohexane Chemical compound C1CCCCC1 XDTMQSROBMDMFD-UHFFFAOYSA-N 0.000 description 1
- LVZWSLJZHVFIQJ-UHFFFAOYSA-N Cyclopropane Chemical compound C1CC1 LVZWSLJZHVFIQJ-UHFFFAOYSA-N 0.000 description 1
- DCJNIJAWIRPPBB-CIUDSAMLSA-N Cys-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CS)N DCJNIJAWIRPPBB-CIUDSAMLSA-N 0.000 description 1
- SQJSYLDKQBZQTG-FXQIFTODSA-N Cys-Asn-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CS)N SQJSYLDKQBZQTG-FXQIFTODSA-N 0.000 description 1
- IXPSSIBVVKSOIE-SRVKXCTJSA-N Cys-Ser-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CS)N)O IXPSSIBVVKSOIE-SRVKXCTJSA-N 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- XBPCUCUWBYBCDP-UHFFFAOYSA-N Dicyclohexylamine Chemical compound C1CCCCC1NC1CCCCC1 XBPCUCUWBYBCDP-UHFFFAOYSA-N 0.000 description 1
- XTAHYROJKCXMOF-UHFFFAOYSA-N Dihydroaceanthrylene Chemical compound C1=CC=C2C(CCC3=CC=C4)=C3C4=CC2=C1 XTAHYROJKCXMOF-UHFFFAOYSA-N 0.000 description 1
- BUDQDWGNQVEFAC-UHFFFAOYSA-N Dihydropyran Chemical compound C1COC=CC1 BUDQDWGNQVEFAC-UHFFFAOYSA-N 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- 241000283074 Equus asinus Species 0.000 description 1
- 239000004386 Erythritol Substances 0.000 description 1
- UNXHWFMMPAWVPI-UHFFFAOYSA-N Erythritol Natural products OCC(O)C(O)CO UNXHWFMMPAWVPI-UHFFFAOYSA-N 0.000 description 1
- OTMSDBZUPAUEDD-UHFFFAOYSA-N Ethane Chemical compound CC OTMSDBZUPAUEDD-UHFFFAOYSA-N 0.000 description 1
- PIICEJLVQHRZGT-UHFFFAOYSA-N Ethylenediamine Chemical compound NCCN PIICEJLVQHRZGT-UHFFFAOYSA-N 0.000 description 1
- 239000001263 FEMA 3042 Substances 0.000 description 1
- YLQBMQCUIZJEEH-UHFFFAOYSA-N Furan Chemical compound C=1C=COC=1 YLQBMQCUIZJEEH-UHFFFAOYSA-N 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- KLJMRPIBBLTDGE-ACZMJKKPSA-N Glu-Cys-Asn Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(O)=O KLJMRPIBBLTDGE-ACZMJKKPSA-N 0.000 description 1
- GGEJHJIXRBTJPD-BYPYZUCNSA-N Gly-Asn-Gly Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GGEJHJIXRBTJPD-BYPYZUCNSA-N 0.000 description 1
- OCDLPQDYTJPWNG-YUMQZZPRSA-N Gly-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)CN OCDLPQDYTJPWNG-YUMQZZPRSA-N 0.000 description 1
- KMSGYZQRXPUKGI-BYPYZUCNSA-N Gly-Gly-Asn Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(N)=O KMSGYZQRXPUKGI-BYPYZUCNSA-N 0.000 description 1
- HAXARWKYFIIHKD-ZKWXMUAHSA-N Gly-Ile-Ser Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HAXARWKYFIIHKD-ZKWXMUAHSA-N 0.000 description 1
- OJNZVYSGVYLQIN-BQBZGAKWSA-N Gly-Met-Asp Chemical compound [H]NCC(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O OJNZVYSGVYLQIN-BQBZGAKWSA-N 0.000 description 1
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 1
- 229920000084 Gum arabic Polymers 0.000 description 1
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 1
- 101100356020 Haemophilus influenzae (strain ATCC 51907 / DSM 11121 / KW20 / Rd) recA gene Proteins 0.000 description 1
- 229920000209 Hexadimethrine bromide Polymers 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- HRGGKHFHRSFSDE-CIUDSAMLSA-N His-Asn-Ser Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N HRGGKHFHRSFSDE-CIUDSAMLSA-N 0.000 description 1
- FYTCLUIYTYFGPT-YUMQZZPRSA-N His-Gly-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FYTCLUIYTYFGPT-YUMQZZPRSA-N 0.000 description 1
- ZHHLTWUOWXHVQJ-YUMQZZPRSA-N His-Ser-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZHHLTWUOWXHVQJ-YUMQZZPRSA-N 0.000 description 1
- 241001272567 Hominoidea Species 0.000 description 1
- 101100038117 Homo sapiens ROR1 gene Proteins 0.000 description 1
- 101000801255 Homo sapiens Tumor necrosis factor receptor superfamily member 17 Proteins 0.000 description 1
- 102000003839 Human Proteins Human genes 0.000 description 1
- 108090000144 Human Proteins Proteins 0.000 description 1
- 102000009490 IgG Receptors Human genes 0.000 description 1
- 108010073807 IgG Receptors Proteins 0.000 description 1
- YKZAMJXNJUWFIK-JBDRJPRFSA-N Ile-Ser-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)O)N YKZAMJXNJUWFIK-JBDRJPRFSA-N 0.000 description 1
- WRYCSMQKUKOKBP-UHFFFAOYSA-N Imidazolidine Chemical compound C1CNCN1 WRYCSMQKUKOKBP-UHFFFAOYSA-N 0.000 description 1
- 102000012745 Immunoglobulin Subunits Human genes 0.000 description 1
- 108010079585 Immunoglobulin Subunits Proteins 0.000 description 1
- LRQKBLKVPFOOQJ-YFKPBYRVSA-N L-norleucine Chemical compound CCCC[C@H]([NH3+])C([O-])=O LRQKBLKVPFOOQJ-YFKPBYRVSA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- XNRVGTHNYCNCFF-UHFFFAOYSA-N Lapatinib ditosylate monohydrate Chemical compound O.CC1=CC=C(S(O)(=O)=O)C=C1.CC1=CC=C(S(O)(=O)=O)C=C1.O1C(CNCCS(=O)(=O)C)=CC=C1C1=CC=C(N=CN=C2NC=3C=C(Cl)C(OCC=4C=C(F)C=CC=4)=CC=3)C2=C1 XNRVGTHNYCNCFF-UHFFFAOYSA-N 0.000 description 1
- 206010023774 Large cell lung cancer Diseases 0.000 description 1
- 239000005639 Lauric acid Substances 0.000 description 1
- BABSVXFGKFLIGW-UWVGGRQHSA-N Leu-Gly-Arg Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N BABSVXFGKFLIGW-UWVGGRQHSA-N 0.000 description 1
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 1
- QUCDKEKDPYISNX-HJGDQZAQSA-N Lys-Asn-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QUCDKEKDPYISNX-HJGDQZAQSA-N 0.000 description 1
- HGNRJCINZYHNOU-LURJTMIESA-N Lys-Gly Chemical compound NCCCC[C@H](N)C(=O)NCC(O)=O HGNRJCINZYHNOU-LURJTMIESA-N 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- IHITVQKJXQQGLJ-LPEHRKFASA-N Met-Asn-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N IHITVQKJXQQGLJ-LPEHRKFASA-N 0.000 description 1
- CAODKDAPYGUMLK-FXQIFTODSA-N Met-Asn-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CAODKDAPYGUMLK-FXQIFTODSA-N 0.000 description 1
- 101100042680 Mus musculus Slc7a1 gene Proteins 0.000 description 1
- 102000008300 Mutant Proteins Human genes 0.000 description 1
- 108010021466 Mutant Proteins Proteins 0.000 description 1
- AFCARXCZXQIEQB-UHFFFAOYSA-N N-[3-oxo-3-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)propyl]-2-[[3-(trifluoromethoxy)phenyl]methylamino]pyrimidine-5-carboxamide Chemical compound O=C(CCNC(=O)C=1C=NC(=NC=1)NCC1=CC(=CC=C1)OC(F)(F)F)N1CC2=C(CC1)NN=N2 AFCARXCZXQIEQB-UHFFFAOYSA-N 0.000 description 1
- MBBZMMPHUWSWHV-BDVNFPICSA-N N-methylglucamine Chemical compound CNC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO MBBZMMPHUWSWHV-BDVNFPICSA-N 0.000 description 1
- GRYLNZFGIOXLOG-UHFFFAOYSA-N Nitric acid Chemical compound O[N+]([O-])=O GRYLNZFGIOXLOG-UHFFFAOYSA-N 0.000 description 1
- IOVCWXUNBOPUCH-UHFFFAOYSA-N Nitrous acid Chemical compound ON=O IOVCWXUNBOPUCH-UHFFFAOYSA-N 0.000 description 1
- 239000005642 Oleic acid Substances 0.000 description 1
- ZQPPMHVWECSIRJ-UHFFFAOYSA-N Oleic acid Natural products CCCCCCCCC=CCCCCCCCC(O)=O ZQPPMHVWECSIRJ-UHFFFAOYSA-N 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 239000012124 Opti-MEM Substances 0.000 description 1
- 101710160107 Outer membrane protein A Proteins 0.000 description 1
- 208000012868 Overgrowth Diseases 0.000 description 1
- WYNCHZVNFNFDNH-UHFFFAOYSA-N Oxazolidine Chemical compound C1COCN1 WYNCHZVNFNFDNH-UHFFFAOYSA-N 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 235000021314 Palmitic acid Nutrition 0.000 description 1
- 241000282579 Pan Species 0.000 description 1
- LRBQNJMCXXYXIU-PPKXGCFTSA-N Penta-digallate-beta-D-glucose Natural products OC1=C(O)C(O)=CC(C(=O)OC=2C(=C(O)C=C(C=2)C(=O)OC[C@@H]2[C@H]([C@H](OC(=O)C=3C=C(OC(=O)C=4C=C(O)C(O)=C(O)C=4)C(O)=C(O)C=3)[C@@H](OC(=O)C=3C=C(OC(=O)C=4C=C(O)C(O)=C(O)C=4)C(O)=C(O)C=3)[C@H](OC(=O)C=3C=C(OC(=O)C=4C=C(O)C(O)=C(O)C=4)C(O)=C(O)C=3)O2)OC(=O)C=2C=C(OC(=O)C=3C=C(O)C(O)=C(O)C=3)C(O)=C(O)C=2)O)=C1 LRBQNJMCXXYXIU-PPKXGCFTSA-N 0.000 description 1
- 206010057249 Phagocytosis Diseases 0.000 description 1
- CWFGECHCRMGPPT-MXAVVETBSA-N Phe-Ile-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O CWFGECHCRMGPPT-MXAVVETBSA-N 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- 229920002594 Polyethylene Glycol 8000 Polymers 0.000 description 1
- ZCXQTRXYZOSGJR-FXQIFTODSA-N Pro-Asp-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZCXQTRXYZOSGJR-FXQIFTODSA-N 0.000 description 1
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 1
- SBVPYBFMIGDIDX-SRVKXCTJSA-N Pro-Pro-Pro Chemical compound OC(=O)[C@@H]1CCCN1C(=O)[C@H]1N(C(=O)[C@H]2NCCC2)CCC1 SBVPYBFMIGDIDX-SRVKXCTJSA-N 0.000 description 1
- DCHQYSOGURGJST-FJXKBIBVSA-N Pro-Thr-Gly Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O DCHQYSOGURGJST-FJXKBIBVSA-N 0.000 description 1
- 102100038239 Protein Churchill Human genes 0.000 description 1
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 1
- 108010079005 RDV peptide Proteins 0.000 description 1
- 101150001095 ROR1 gene Proteins 0.000 description 1
- 102000005435 Receptor Tyrosine Kinase-like Orphan Receptors Human genes 0.000 description 1
- 108010006700 Receptor Tyrosine Kinase-like Orphan Receptors Proteins 0.000 description 1
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 1
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 1
- 229920002684 Sepharose Polymers 0.000 description 1
- WTWGOQRNRFHFQD-JBDRJPRFSA-N Ser-Ala-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WTWGOQRNRFHFQD-JBDRJPRFSA-N 0.000 description 1
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 1
- UGJRQLURDVGULT-LKXGYXEUSA-N Ser-Asn-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UGJRQLURDVGULT-LKXGYXEUSA-N 0.000 description 1
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 1
- IOVHBRCQOGWAQH-ZKWXMUAHSA-N Ser-Gly-Ile Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOVHBRCQOGWAQH-ZKWXMUAHSA-N 0.000 description 1
- RJHJPZQOMKCSTP-CIUDSAMLSA-N Ser-His-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O RJHJPZQOMKCSTP-CIUDSAMLSA-N 0.000 description 1
- QGAHMVHBORDHDC-YUMQZZPRSA-N Ser-His-Gly Chemical compound OC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CN=CN1 QGAHMVHBORDHDC-YUMQZZPRSA-N 0.000 description 1
- MQQBBLVOUUJKLH-HJPIBITLSA-N Ser-Ile-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MQQBBLVOUUJKLH-HJPIBITLSA-N 0.000 description 1
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 1
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 1
- OZPDGESCTGGNAD-CIUDSAMLSA-N Ser-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CO OZPDGESCTGGNAD-CIUDSAMLSA-N 0.000 description 1
- VVKVHAOOUGNDPJ-SRVKXCTJSA-N Ser-Tyr-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VVKVHAOOUGNDPJ-SRVKXCTJSA-N 0.000 description 1
- MFQMZDPAZRZAPV-NAKRPEOUSA-N Ser-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CO)N MFQMZDPAZRZAPV-NAKRPEOUSA-N 0.000 description 1
- 206010041067 Small cell lung cancer Diseases 0.000 description 1
- VMHLLURERBWHNL-UHFFFAOYSA-M Sodium acetate Chemical compound [Na+].CC([O-])=O VMHLLURERBWHNL-UHFFFAOYSA-M 0.000 description 1
- 229920002472 Starch Polymers 0.000 description 1
- 235000021355 Stearic acid Nutrition 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- LSNNMFCWUKXFEE-UHFFFAOYSA-N Sulfurous acid Chemical compound OS(O)=O LSNNMFCWUKXFEE-UHFFFAOYSA-N 0.000 description 1
- WYURNTSHIVDZCO-UHFFFAOYSA-N Tetrahydrofuran Chemical compound C1CCOC1 WYURNTSHIVDZCO-UHFFFAOYSA-N 0.000 description 1
- DHXVGJBLRPWPCS-UHFFFAOYSA-N Tetrahydropyran Chemical compound C1CCOCC1 DHXVGJBLRPWPCS-UHFFFAOYSA-N 0.000 description 1
- YPWFISCTZQNZAU-UHFFFAOYSA-N Thiane Chemical compound C1CCSCC1 YPWFISCTZQNZAU-UHFFFAOYSA-N 0.000 description 1
- ZTPXSEUVYNNZRB-CDMKHQONSA-N Thr-Gly-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ZTPXSEUVYNNZRB-CDMKHQONSA-N 0.000 description 1
- BPGDJSUFQKWUBK-KJEVXHAQSA-N Thr-Val-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BPGDJSUFQKWUBK-KJEVXHAQSA-N 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- BURPTJBFWIOHEY-UWJYBYFXSA-N Tyr-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 BURPTJBFWIOHEY-UWJYBYFXSA-N 0.000 description 1
- VFJIWSJKZJTQII-SRVKXCTJSA-N Tyr-Asp-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O VFJIWSJKZJTQII-SRVKXCTJSA-N 0.000 description 1
- JHORGUYURUBVOM-KKUMJFAQSA-N Tyr-His-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O JHORGUYURUBVOM-KKUMJFAQSA-N 0.000 description 1
- NKUGCYDFQKFVOJ-JYJNAYRXSA-N Tyr-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NKUGCYDFQKFVOJ-JYJNAYRXSA-N 0.000 description 1
- RVGVIWNHABGIFH-IHRRRGAJSA-N Tyr-Val-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O RVGVIWNHABGIFH-IHRRRGAJSA-N 0.000 description 1
- UDNYEPLJTRDMEJ-RCOVLWMOSA-N Val-Asn-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)NCC(=O)O)N UDNYEPLJTRDMEJ-RCOVLWMOSA-N 0.000 description 1
- OVBMCNDKCWAXMZ-NAKRPEOUSA-N Val-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N OVBMCNDKCWAXMZ-NAKRPEOUSA-N 0.000 description 1
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 1
- NLNCNKIVJPEFBC-DLOVCJGASA-N Val-Val-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O NLNCNKIVJPEFBC-DLOVCJGASA-N 0.000 description 1
- TVXBFESIOXBWNM-UHFFFAOYSA-N Xylitol Natural products OCCC(O)C(O)C(O)CCO TVXBFESIOXBWNM-UHFFFAOYSA-N 0.000 description 1
- DGEZNRSVGBDHLK-UHFFFAOYSA-N [1,10]phenanthroline Chemical compound C1=CN=C2C3=NC=CC=C3C=CC2=C1 DGEZNRSVGBDHLK-UHFFFAOYSA-N 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 230000009102 absorption Effects 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 235000010489 acacia gum Nutrition 0.000 description 1
- CWRYPZZKDGJXCA-UHFFFAOYSA-N acenaphthene Chemical compound C1=CC(CC2)=C3C2=CC=CC3=C1 CWRYPZZKDGJXCA-UHFFFAOYSA-N 0.000 description 1
- 239000008351 acetate buffer Substances 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 230000001154 acute effect Effects 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 210000001789 adipocyte Anatomy 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 229940072056 alginate Drugs 0.000 description 1
- 235000010443 alginic acid Nutrition 0.000 description 1
- 229920000615 alginic acid Polymers 0.000 description 1
- 125000002723 alicyclic group Chemical group 0.000 description 1
- 125000001931 aliphatic group Chemical group 0.000 description 1
- 229910001413 alkali metal ion Inorganic materials 0.000 description 1
- 229910052784 alkaline earth metal Inorganic materials 0.000 description 1
- 125000005262 alkoxyamine group Chemical group 0.000 description 1
- BJEPYKJPYRNKOW-UHFFFAOYSA-N alpha-hydroxysuccinic acid Natural products OC(=O)C(O)CC(O)=O BJEPYKJPYRNKOW-UHFFFAOYSA-N 0.000 description 1
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical compound N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 1
- 229910052921 ammonium sulfate Inorganic materials 0.000 description 1
- 235000011130 ammonium sulphate Nutrition 0.000 description 1
- 238000000540 analysis of variance Methods 0.000 description 1
- 150000001449 anionic compounds Chemical class 0.000 description 1
- 239000005557 antagonist Substances 0.000 description 1
- 230000002744 anti-aggregatory effect Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 229940125644 antibody drug Drugs 0.000 description 1
- 238000009175 antibody therapy Methods 0.000 description 1
- 230000005888 antibody-dependent cellular phagocytosis Effects 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 229940041181 antineoplastic drug Drugs 0.000 description 1
- 235000010323 ascorbic acid Nutrition 0.000 description 1
- 239000011668 ascorbic acid Substances 0.000 description 1
- 229960005070 ascorbic acid Drugs 0.000 description 1
- XYOVOXDWRFGKEX-UHFFFAOYSA-N azepine Chemical compound N1C=CC=CC=C1 XYOVOXDWRFGKEX-UHFFFAOYSA-N 0.000 description 1
- HONIICLYMWZJFZ-UHFFFAOYSA-N azetidine Chemical compound C1CNC1 HONIICLYMWZJFZ-UHFFFAOYSA-N 0.000 description 1
- SRSXLGNVWSONIS-UHFFFAOYSA-N benzenesulfonic acid Chemical compound OS(=O)(=O)C1=CC=CC=C1 SRSXLGNVWSONIS-UHFFFAOYSA-N 0.000 description 1
- 125000005605 benzo group Chemical group 0.000 description 1
- 229940049706 benzodiazepine Drugs 0.000 description 1
- QRUDEWIWKLJBPS-UHFFFAOYSA-N benzotriazole Chemical compound C1=CC=C2N[N][N]C2=C1 QRUDEWIWKLJBPS-UHFFFAOYSA-N 0.000 description 1
- 239000012964 benzotriazole Substances 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- SXDBWCPKPHAZSM-UHFFFAOYSA-N bromic acid Chemical compound OBr(=O)=O SXDBWCPKPHAZSM-UHFFFAOYSA-N 0.000 description 1
- GDTBXPJZTBHREO-UHFFFAOYSA-N bromine Chemical group BrBr GDTBXPJZTBHREO-UHFFFAOYSA-N 0.000 description 1
- 229910052794 bromium Inorganic materials 0.000 description 1
- KDYFGRWQOYBRFD-NUQCWPJISA-N butanedioic acid Chemical compound O[14C](=O)CC[14C](O)=O KDYFGRWQOYBRFD-NUQCWPJISA-N 0.000 description 1
- 125000004369 butenyl group Chemical group C(=CCC)* 0.000 description 1
- 125000000484 butyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 239000000378 calcium silicate Substances 0.000 description 1
- 229910052918 calcium silicate Inorganic materials 0.000 description 1
- 235000012241 calcium silicate Nutrition 0.000 description 1
- OYACROKNLOSFPA-UHFFFAOYSA-N calcium;dioxido(oxo)silane Chemical compound [Ca+2].[O-][Si]([O-])=O OYACROKNLOSFPA-UHFFFAOYSA-N 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- YAYRGNWWLMLWJE-UHFFFAOYSA-L carboplatin Chemical compound O=C1O[Pt](N)(N)OC(=O)C11CCC1 YAYRGNWWLMLWJE-UHFFFAOYSA-L 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 1
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 1
- 150000001767 cationic compounds Chemical class 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000012292 cell migration Effects 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 235000010980 cellulose Nutrition 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 238000002512 chemotherapy Methods 0.000 description 1
- 239000000460 chlorine Chemical group 0.000 description 1
- 229910052801 chlorine Inorganic materials 0.000 description 1
- OEYIOHPDSNJKLS-UHFFFAOYSA-N choline Chemical compound C[N+](C)(C)CCO OEYIOHPDSNJKLS-UHFFFAOYSA-N 0.000 description 1
- 229960001231 choline Drugs 0.000 description 1
- VZWXIQHBIQLMPN-UHFFFAOYSA-N chromane Chemical compound C1=CC=C2CCCOC2=C1 VZWXIQHBIQLMPN-UHFFFAOYSA-N 0.000 description 1
- 150000001843 chromanes Chemical class 0.000 description 1
- 235000013985 cinnamic acid Nutrition 0.000 description 1
- 229930016911 cinnamic acid Natural products 0.000 description 1
- ACSIXWWBWUQEHA-UHFFFAOYSA-L clondronate(2-) Chemical compound OP([O-])(=O)C(Cl)(Cl)P(O)([O-])=O ACSIXWWBWUQEHA-UHFFFAOYSA-L 0.000 description 1
- 238000013373 clone screening Methods 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 201000010989 colorectal carcinoma Diseases 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 235000008504 concentrate Nutrition 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- JZCCFEFSEZPSOG-UHFFFAOYSA-L copper(II) sulfate pentahydrate Chemical compound O.O.O.O.O.[Cu+2].[O-]S([O-])(=O)=O JZCCFEFSEZPSOG-UHFFFAOYSA-L 0.000 description 1
- 238000004132 cross linking Methods 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- CFBGXYDUODCMNS-UHFFFAOYSA-N cyclobutene Chemical compound C1CC=C1 CFBGXYDUODCMNS-UHFFFAOYSA-N 0.000 description 1
- OOXWYYGXTJLWHA-UHFFFAOYSA-N cyclopropene Chemical compound C1C=C1 OOXWYYGXTJLWHA-UHFFFAOYSA-N 0.000 description 1
- 239000000824 cytostatic agent Substances 0.000 description 1
- 230000001085 cytostatic effect Effects 0.000 description 1
- 238000000354 decomposition reaction Methods 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 239000000032 diagnostic agent Substances 0.000 description 1
- 229940039227 diagnostic agent Drugs 0.000 description 1
- ZBCBWPMODOFKDW-UHFFFAOYSA-N diethanolamine Chemical compound OCCNCCO ZBCBWPMODOFKDW-UHFFFAOYSA-N 0.000 description 1
- HPNMFZURTQLUMO-UHFFFAOYSA-N diethylamine Chemical compound CCNCC HPNMFZURTQLUMO-UHFFFAOYSA-N 0.000 description 1
- 150000004683 dihydrates Chemical class 0.000 description 1
- 125000004276 dioxalanyl group Chemical group 0.000 description 1
- HGGNZMUHOHGHBJ-UHFFFAOYSA-N dioxepane Chemical compound C1CCOOCC1 HGGNZMUHOHGHBJ-UHFFFAOYSA-N 0.000 description 1
- ADDTYLVLXWBJNH-UHFFFAOYSA-M disodium 4-[2-(2-methoxy-4-nitrophenyl)-3-(4-nitrophenyl)tetrazol-2-ium-5-yl]benzene-1,3-disulfonate Chemical compound [Na]OS(=O)(=O)C1=C(C=CC(=C1)S(=O)(=O)O[Na])C=1N=[N+](N(N=1)C1=CC=C(C=C1)[N+](=O)[O-])C1=C(C=C(C=C1)[N+](=O)[O-])OC ADDTYLVLXWBJNH-UHFFFAOYSA-M 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 239000003937 drug carrier Substances 0.000 description 1
- 229960001484 edetic acid Drugs 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 238000010828 elution Methods 0.000 description 1
- 230000013020 embryo development Effects 0.000 description 1
- 238000005538 encapsulation Methods 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- 238000011067 equilibration Methods 0.000 description 1
- 239000006167 equilibration buffer Substances 0.000 description 1
- UNXHWFMMPAWVPI-ZXZARUISSA-N erythritol Chemical compound OC[C@H](O)[C@H](O)CO UNXHWFMMPAWVPI-ZXZARUISSA-N 0.000 description 1
- 229940009714 erythritol Drugs 0.000 description 1
- 235000019414 erythritol Nutrition 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- CCIVGXIOQKPBKL-UHFFFAOYSA-M ethanesulfonate Chemical compound CCS([O-])(=O)=O CCIVGXIOQKPBKL-UHFFFAOYSA-M 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 230000008175 fetal development Effects 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 239000000796 flavoring agent Substances 0.000 description 1
- 238000000684 flow cytometry Methods 0.000 description 1
- GVEPBJHOBDJJJI-UHFFFAOYSA-N fluoranthrene Natural products C1=CC(C2=CC=CC=C22)=C3C2=CC=CC3=C1 GVEPBJHOBDJJJI-UHFFFAOYSA-N 0.000 description 1
- RMBPEFMHABBEKP-UHFFFAOYSA-N fluorene Chemical compound C1=CC=C2C3=C[CH]C=CC3=CC2=C1 RMBPEFMHABBEKP-UHFFFAOYSA-N 0.000 description 1
- 229910052731 fluorine Inorganic materials 0.000 description 1
- 239000011737 fluorine Substances 0.000 description 1
- 125000001153 fluoro group Chemical group F* 0.000 description 1
- 230000003325 follicular Effects 0.000 description 1
- 235000013355 food flavoring agent Nutrition 0.000 description 1
- 235000019253 formic acid Nutrition 0.000 description 1
- 125000002541 furyl group Chemical group 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 1
- 239000008187 granular material Substances 0.000 description 1
- 229940093915 gynecological organic acid Drugs 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 125000003187 heptyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 238000006077 hetero Diels-Alder cycloaddition reaction Methods 0.000 description 1
- 150000002391 heterocyclic compounds Chemical class 0.000 description 1
- 125000006038 hexenyl group Chemical group 0.000 description 1
- 125000004051 hexyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 102000046935 human TNFRSF17 Human genes 0.000 description 1
- 238000009396 hybridization Methods 0.000 description 1
- 150000002430 hydrocarbons Chemical class 0.000 description 1
- XMBWDFGMSWQBCA-UHFFFAOYSA-N hydrogen iodide Chemical compound I XMBWDFGMSWQBCA-UHFFFAOYSA-N 0.000 description 1
- 229940071870 hydroiodic acid Drugs 0.000 description 1
- MTNDZQHUAFNZQY-UHFFFAOYSA-N imidazoline Chemical compound C1CN=CN1 MTNDZQHUAFNZQY-UHFFFAOYSA-N 0.000 description 1
- 125000000879 imine group Chemical group 0.000 description 1
- 230000036737 immune function Effects 0.000 description 1
- 230000003053 immunization Effects 0.000 description 1
- 230000016784 immunoglobulin production Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 239000012535 impurity Substances 0.000 description 1
- 238000000338 in vitro Methods 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- PZOUSPYUWWUPPK-UHFFFAOYSA-N indole Natural products CC1=CC=CC2=C1C=CN2 PZOUSPYUWWUPPK-UHFFFAOYSA-N 0.000 description 1
- RKJUIXBNRJVNHR-UHFFFAOYSA-N indolenine Natural products C1=CC=C2CC=NC2=C1 RKJUIXBNRJVNHR-UHFFFAOYSA-N 0.000 description 1
- HOBCFUWDNJPFHB-UHFFFAOYSA-N indolizine Chemical compound C1=CC=CN2C=CC=C21 HOBCFUWDNJPFHB-UHFFFAOYSA-N 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 229910001412 inorganic anion Inorganic materials 0.000 description 1
- 229910001411 inorganic cation Inorganic materials 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- PNDPGZBMCMUPRI-UHFFFAOYSA-N iodine Chemical group II PNDPGZBMCMUPRI-UHFFFAOYSA-N 0.000 description 1
- KLEAIHJJLUAXIQ-JDRGBKBRSA-N irinotecan hydrochloride hydrate Chemical compound O.O.O.Cl.C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 KLEAIHJJLUAXIQ-JDRGBKBRSA-N 0.000 description 1
- 229940045996 isethionic acid Drugs 0.000 description 1
- 125000000959 isobutyl group Chemical group [H]C([H])([H])C([H])(C([H])([H])[H])C([H])([H])* 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- QXJSBBXBKPUZAA-UHFFFAOYSA-N isooleic acid Natural products CCCCCCCC=CCCCCCCCCC(O)=O QXJSBBXBKPUZAA-UHFFFAOYSA-N 0.000 description 1
- 125000001972 isopentyl group Chemical group [H]C([H])([H])C([H])(C([H])([H])[H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000000555 isopropenyl group Chemical group [H]\C([H])=C(\*)C([H])([H])[H] 0.000 description 1
- 229930027917 kanamycin Natural products 0.000 description 1
- 229960000318 kanamycin Drugs 0.000 description 1
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 1
- 229930182823 kanamycin A Natural products 0.000 description 1
- 230000002147 killing effect Effects 0.000 description 1
- 229960000448 lactic acid Drugs 0.000 description 1
- 229940099563 lactobionic acid Drugs 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 229940033355 lauric acid Drugs 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- QDLAGTHXVHQKRE-UHFFFAOYSA-N lichenxanthone Natural products COC1=CC(O)=C2C(=O)C3=C(C)C=C(OC)C=C3OC2=C1 QDLAGTHXVHQKRE-UHFFFAOYSA-N 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 238000011068 loading method Methods 0.000 description 1
- 239000000314 lubricant Substances 0.000 description 1
- 201000005296 lung carcinoma Diseases 0.000 description 1
- 239000011777 magnesium Substances 0.000 description 1
- 229910001629 magnesium chloride Inorganic materials 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 229940098895 maleic acid Drugs 0.000 description 1
- 239000001630 malic acid Substances 0.000 description 1
- 235000011090 malic acid Nutrition 0.000 description 1
- 229940099690 malic acid Drugs 0.000 description 1
- 239000000845 maltitol Substances 0.000 description 1
- 235000010449 maltitol Nutrition 0.000 description 1
- VQHSOMBJVWLPSR-WUJBLJFYSA-N maltitol Chemical compound OC[C@H](O)[C@@H](O)[C@@H]([C@H](O)CO)O[C@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@H]1O VQHSOMBJVWLPSR-WUJBLJFYSA-N 0.000 description 1
- 229940035436 maltitol Drugs 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 229960003194 meglumine Drugs 0.000 description 1
- HEBKCHPVOIAQTA-UHFFFAOYSA-N meso ribitol Natural products OCC(O)C(O)C(O)CO HEBKCHPVOIAQTA-UHFFFAOYSA-N 0.000 description 1
- 206010061289 metastatic neoplasm Diseases 0.000 description 1
- 229940098779 methanesulfonic acid Drugs 0.000 description 1
- 229920000609 methyl cellulose Polymers 0.000 description 1
- WBYWAXJHAXSJNI-UHFFFAOYSA-N methyl p-hydroxycinnamate Natural products OC(=O)C=CC1=CC=CC=C1 WBYWAXJHAXSJNI-UHFFFAOYSA-N 0.000 description 1
- GYNNXHKOJHMOHS-UHFFFAOYSA-N methyl-cycloheptane Natural products CC1CCCCCC1 GYNNXHKOJHMOHS-UHFFFAOYSA-N 0.000 description 1
- 239000001923 methylcellulose Substances 0.000 description 1
- 235000010981 methylcellulose Nutrition 0.000 description 1
- VNXBKJFUJUWOCW-UHFFFAOYSA-N methylcyclopropane Chemical compound CC1CC1 VNXBKJFUJUWOCW-UHFFFAOYSA-N 0.000 description 1
- LXCFILQKKLGQFO-UHFFFAOYSA-N methylparaben Chemical compound COC(=O)C1=CC=C(O)C=C1 LXCFILQKKLGQFO-UHFFFAOYSA-N 0.000 description 1
- 230000000813 microbial effect Effects 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 239000002480 mineral oil Substances 0.000 description 1
- 235000010446 mineral oil Nutrition 0.000 description 1
- 239000012046 mixed solvent Substances 0.000 description 1
- 125000002950 monocyclic group Chemical group 0.000 description 1
- 150000004682 monohydrates Chemical class 0.000 description 1
- WQEPLUUGTLDZJY-UHFFFAOYSA-N n-Pentadecanoic acid Natural products CCCCCCCCCCCCCCC(O)=O WQEPLUUGTLDZJY-UHFFFAOYSA-N 0.000 description 1
- GTWJETSWSUWSEJ-UHFFFAOYSA-N n-benzylaniline Chemical compound C=1C=CC=CC=1CNC1=CC=CC=C1 GTWJETSWSUWSEJ-UHFFFAOYSA-N 0.000 description 1
- 125000004108 n-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000003136 n-heptyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000001280 n-hexyl group Chemical group C(CCCCC)* 0.000 description 1
- 125000004123 n-propyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000001971 neopentyl group Chemical group [H]C([*])([H])C(C([H])([H])[H])(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 230000014511 neuron projection development Effects 0.000 description 1
- 230000003472 neutralizing effect Effects 0.000 description 1
- 229910017604 nitric acid Inorganic materials 0.000 description 1
- 230000009871 nonspecific binding Effects 0.000 description 1
- UMRZSTCPUPJPOJ-KNVOCYPGSA-N norbornane Chemical compound C1C[C@H]2CC[C@@H]1C2 UMRZSTCPUPJPOJ-KNVOCYPGSA-N 0.000 description 1
- 239000012038 nucleophile Substances 0.000 description 1
- 238000010534 nucleophilic substitution reaction Methods 0.000 description 1
- 239000002773 nucleotide Substances 0.000 description 1
- 125000003729 nucleotide group Chemical group 0.000 description 1
- NIHNNTQXNPWCJQ-UHFFFAOYSA-N o-biphenylenemethane Natural products C1=CC=C2CC3=CC=CC=C3C2=C1 NIHNNTQXNPWCJQ-UHFFFAOYSA-N 0.000 description 1
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 1
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 1
- ZQPPMHVWECSIRJ-KTKRTIGZSA-N oleic acid Chemical compound CCCCCCCC\C=C/CCCCCCCC(O)=O ZQPPMHVWECSIRJ-KTKRTIGZSA-N 0.000 description 1
- 235000021313 oleic acid Nutrition 0.000 description 1
- 229920001542 oligosaccharide Polymers 0.000 description 1
- 150000002482 oligosaccharides Chemical class 0.000 description 1
- 239000006186 oral dosage form Substances 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 150000002892 organic cations Chemical class 0.000 description 1
- AZHVQJLDOFKHPZ-UHFFFAOYSA-N oxathiazine Chemical compound O1SN=CC=C1 AZHVQJLDOFKHPZ-UHFFFAOYSA-N 0.000 description 1
- 125000002971 oxazolyl group Chemical group 0.000 description 1
- ATYBXHSAIOKLMG-UHFFFAOYSA-N oxepin Chemical compound O1C=CC=CC=C1 ATYBXHSAIOKLMG-UHFFFAOYSA-N 0.000 description 1
- AHHWIHXENZJRFG-UHFFFAOYSA-N oxetane Chemical compound C1COC1 AHHWIHXENZJRFG-UHFFFAOYSA-N 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000012856 packing Methods 0.000 description 1
- 238000002638 palliative care Methods 0.000 description 1
- 239000011713 pantothenic acid Substances 0.000 description 1
- 229940055726 pantothenic acid Drugs 0.000 description 1
- 235000019161 pantothenic acid Nutrition 0.000 description 1
- FJKROLUGYXJWQN-UHFFFAOYSA-N papa-hydroxy-benzoic acid Natural products OC(=O)C1=CC=C(O)C=C1 FJKROLUGYXJWQN-UHFFFAOYSA-N 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- 125000002255 pentenyl group Chemical group C(=CCCC)* 0.000 description 1
- 125000001147 pentyl group Chemical group C(CCCC)* 0.000 description 1
- 230000008782 phagocytosis Effects 0.000 description 1
- XDJOIMJURHQYDW-UHFFFAOYSA-N phenalene Chemical compound C1=CC(CC=C2)=C3C2=CC=CC3=C1 XDJOIMJURHQYDW-UHFFFAOYSA-N 0.000 description 1
- 229950000688 phenothiazine Drugs 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- LFSXCDWNBUNEEM-UHFFFAOYSA-N phthalazine Chemical compound C1=NN=CC2=CC=CC=C21 LFSXCDWNBUNEEM-UHFFFAOYSA-N 0.000 description 1
- 230000000704 physical effect Effects 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 239000002504 physiological saline solution Substances 0.000 description 1
- 239000006187 pill Substances 0.000 description 1
- 230000036470 plasma concentration Effects 0.000 description 1
- 231100000614 poison Toxicity 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 230000013823 prenylation Effects 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 239000000047 product Substances 0.000 description 1
- 230000000069 prophylactic effect Effects 0.000 description 1
- 229940095574 propionic acid Drugs 0.000 description 1
- 125000001436 propyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- QELSKZZBTMNZEB-UHFFFAOYSA-N propylparaben Chemical compound CCCOC(=O)C1=CC=C(O)C=C1 QELSKZZBTMNZEB-UHFFFAOYSA-N 0.000 description 1
- 229960003415 propylparaben Drugs 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- CPNGPNLZQNNVQM-UHFFFAOYSA-N pteridine Chemical compound N1=CN=CC2=NC=CN=C21 CPNGPNLZQNNVQM-UHFFFAOYSA-N 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- USPWKWBDZOARPV-UHFFFAOYSA-N pyrazolidine Chemical compound C1CNNC1 USPWKWBDZOARPV-UHFFFAOYSA-N 0.000 description 1
- DNXIASIHZYFFRO-UHFFFAOYSA-N pyrazoline Chemical compound C1CN=NC1 DNXIASIHZYFFRO-UHFFFAOYSA-N 0.000 description 1
- 125000002098 pyridazinyl group Chemical group 0.000 description 1
- UMJSCPRVCHMLSP-UHFFFAOYSA-N pyridine Natural products COC1=CC=CN=C1 UMJSCPRVCHMLSP-UHFFFAOYSA-N 0.000 description 1
- 125000004076 pyridyl group Chemical group 0.000 description 1
- ZVJHJDDKYZXRJI-UHFFFAOYSA-N pyrroline Natural products C1CC=NC1 ZVJHJDDKYZXRJI-UHFFFAOYSA-N 0.000 description 1
- 125000000168 pyrrolyl group Chemical group 0.000 description 1
- 229940107700 pyruvic acid Drugs 0.000 description 1
- 125000001453 quaternary ammonium group Chemical group 0.000 description 1
- JWVCLYRUEFBMGU-UHFFFAOYSA-N quinazoline Chemical compound N1=CN=CC2=CC=CC=C21 JWVCLYRUEFBMGU-UHFFFAOYSA-N 0.000 description 1
- 239000000941 radioactive substance Substances 0.000 description 1
- 238000001959 radiotherapy Methods 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000002829 reductive effect Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000004043 responsiveness Effects 0.000 description 1
- 229960004889 salicylic acid Drugs 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 125000002914 sec-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 238000013207 serial dilution Methods 0.000 description 1
- 208000002491 severe combined immunodeficiency Diseases 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 208000000587 small cell lung carcinoma Diseases 0.000 description 1
- 229940126586 small molecule drug Drugs 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 239000001632 sodium acetate Substances 0.000 description 1
- 235000017281 sodium acetate Nutrition 0.000 description 1
- PPASLZSBLFJQEF-RKJRWTFHSA-M sodium ascorbate Substances [Na+].OC[C@@H](O)[C@H]1OC(=O)C(O)=C1[O-] PPASLZSBLFJQEF-RKJRWTFHSA-M 0.000 description 1
- 235000010378 sodium ascorbate Nutrition 0.000 description 1
- 229960005055 sodium ascorbate Drugs 0.000 description 1
- PPASLZSBLFJQEF-RXSVEWSESA-M sodium-L-ascorbate Chemical compound [Na+].OC[C@H](O)[C@H]1OC(=O)C(O)=C1[O-] PPASLZSBLFJQEF-RXSVEWSESA-M 0.000 description 1
- 210000001082 somatic cell Anatomy 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 235000010356 sorbitol Nutrition 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 239000008107 starch Substances 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 239000008117 stearic acid Substances 0.000 description 1
- 229960004274 stearic acid Drugs 0.000 description 1
- 239000000021 stimulant Substances 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 235000011149 sulphuric acid Nutrition 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 239000006188 syrup Substances 0.000 description 1
- 235000020357 syrup Nutrition 0.000 description 1
- 238000007910 systemic administration Methods 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 231100000057 systemic toxicity Toxicity 0.000 description 1
- 239000003826 tablet Substances 0.000 description 1
- 239000000454 talc Substances 0.000 description 1
- 229910052623 talc Inorganic materials 0.000 description 1
- 235000012222 talc Nutrition 0.000 description 1
- 235000015523 tannic acid Nutrition 0.000 description 1
- LRBQNJMCXXYXIU-NRMVVENXSA-N tannic acid Chemical compound OC1=C(O)C(O)=CC(C(=O)OC=2C(=C(O)C=C(C=2)C(=O)OC[C@@H]2[C@H]([C@H](OC(=O)C=3C=C(OC(=O)C=4C=C(O)C(O)=C(O)C=4)C(O)=C(O)C=3)[C@@H](OC(=O)C=3C=C(OC(=O)C=4C=C(O)C(O)=C(O)C=4)C(O)=C(O)C=3)[C@@H](OC(=O)C=3C=C(OC(=O)C=4C=C(O)C(O)=C(O)C=4)C(O)=C(O)C=3)O2)OC(=O)C=2C=C(OC(=O)C=3C=C(O)C(O)=C(O)C=3)C(O)=C(O)C=2)O)=C1 LRBQNJMCXXYXIU-NRMVVENXSA-N 0.000 description 1
- 229920002258 tannic acid Polymers 0.000 description 1
- 229940033123 tannic acid Drugs 0.000 description 1
- ISIJQEHRDSCQIU-UHFFFAOYSA-N tert-butyl 2,7-diazaspiro[4.5]decane-7-carboxylate Chemical compound C1N(C(=O)OC(C)(C)C)CCCC11CNCC1 ISIJQEHRDSCQIU-UHFFFAOYSA-N 0.000 description 1
- 125000000999 tert-butyl group Chemical group [H]C([H])([H])C(*)(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- IFLREYGFSNHWGE-UHFFFAOYSA-N tetracene Chemical compound C1=CC=CC2=CC3=CC4=CC=CC=C4C=C3C=C21 IFLREYGFSNHWGE-UHFFFAOYSA-N 0.000 description 1
- KHVCOYGKHDJPBZ-WDCZJNDASA-N tetrahydrooxazine Chemical compound OC[C@H]1ONC[C@@H](O)[C@@H]1O KHVCOYGKHDJPBZ-WDCZJNDASA-N 0.000 description 1
- RAOIDOHSFRTOEL-UHFFFAOYSA-N tetrahydrothiophene Chemical compound C1CCSC1 RAOIDOHSFRTOEL-UHFFFAOYSA-N 0.000 description 1
- GVIJJXMXTUZIOD-UHFFFAOYSA-N thianthrene Chemical compound C1=CC=C2SC3=CC=CC=C3SC2=C1 GVIJJXMXTUZIOD-UHFFFAOYSA-N 0.000 description 1
- JWCVYQRPINPYQJ-UHFFFAOYSA-N thiepane Chemical compound C1CCCSCC1 JWCVYQRPINPYQJ-UHFFFAOYSA-N 0.000 description 1
- VOVUARRWDCVURC-UHFFFAOYSA-N thiirane Chemical compound C1CS1 VOVUARRWDCVURC-UHFFFAOYSA-N 0.000 description 1
- BRNULMACUQOKMR-UHFFFAOYSA-N thiomorpholine Chemical compound C1CSCCN1 BRNULMACUQOKMR-UHFFFAOYSA-N 0.000 description 1
- 229930192474 thiophene Natural products 0.000 description 1
- JOXIMZWYDAKGHI-UHFFFAOYSA-N toluene-4-sulfonic acid Chemical compound CC1=CC=C(S(O)(=O)=O)C=C1 JOXIMZWYDAKGHI-UHFFFAOYSA-N 0.000 description 1
- 239000012049 topical pharmaceutical composition Substances 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 239000003440 toxic substance Substances 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 150000004684 trihydrates Chemical class 0.000 description 1
- NOYPYLRCIDNJJB-UHFFFAOYSA-O trimetrexate Chemical compound COC1=C(OC)C(OC)=CC(NCC=2C(=C3C(N)=[NH+]C(N)=NC3=CC=2)C)=C1 NOYPYLRCIDNJJB-UHFFFAOYSA-O 0.000 description 1
- 229960000281 trometamol Drugs 0.000 description 1
- 230000004614 tumor growth Effects 0.000 description 1
- 230000005760 tumorsuppression Effects 0.000 description 1
- 229940005605 valeric acid Drugs 0.000 description 1
- 230000004584 weight gain Effects 0.000 description 1
- 235000019786 weight gain Nutrition 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 239000000811 xylitol Substances 0.000 description 1
- 235000010447 xylitol Nutrition 0.000 description 1
- HEBKCHPVOIAQTA-SCDXWVJYSA-N xylitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)CO HEBKCHPVOIAQTA-SCDXWVJYSA-N 0.000 description 1
- 229960002675 xylitol Drugs 0.000 description 1
- 239000011592 zinc chloride Substances 0.000 description 1
- 235000005074 zinc chloride Nutrition 0.000 description 1
- JIAARYAFYJHUJI-UHFFFAOYSA-L zinc dichloride Chemical compound [Cl-].[Cl-].[Zn+2] JIAARYAFYJHUJI-UHFFFAOYSA-L 0.000 description 1
Images
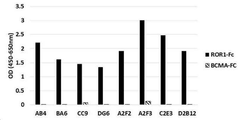









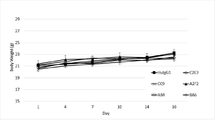









Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6849—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a receptor, a cell surface antigen or a cell surface determinant
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7042—Compounds having saccharide radicals and heterocyclic rings
- A61K31/7052—Compounds having saccharide radicals and heterocyclic rings having nitrogen as a ring hetero atom, e.g. nucleosides, nucleotides
- A61K31/706—Compounds having saccharide radicals and heterocyclic rings having nitrogen as a ring hetero atom, e.g. nucleosides, nucleotides containing six-membered rings with nitrogen as a ring hetero atom
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K45/00—Medicinal preparations containing active ingredients not provided for in groups A61K31/00 - A61K41/00
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/68031—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being an auristatin
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/68035—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being a pyrrolobenzodiazepine
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6851—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a determinant of a tumour cell
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6889—Conjugates wherein the antibody being the modifying agent and wherein the linker, binder or spacer confers particular properties to the conjugates, e.g. peptidic enzyme-labile linkers or acid-labile linkers, providing for an acid-labile immuno conjugate wherein the drug may be released from its antibody conjugated part in an acidic, e.g. tumoural or environment
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- A61P35/02—Antineoplastic agents specific for leukemia
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
Abstract
본 발명은 ROR1을 타겟팅하는 신규한 항체-약물 접합체(antibody-drug conjugate, ADC), 이들 ADC의 활성 대사물, 이들 ADC의 제조방법, 병의 치료 및/또는 예방을 위한 이들 ADC의 용도, 및 또한 병, 더 상세하게는 ROR1의 과발현과 관련된 질환 예컨대, 암 질환의 치료 및/또는 예방을 위한 약제를 생산하기 위한 이들 ADC의 용도에 관한 것이며, 보다 구체적으로, ROR1에 결합하는 항체 또는 이의 항원 결합 단편을 포함하는 항체-약물 접합체 및 이를 포함하는 약학 조성물에 관한 것이다.
Description
본 발명은 ROR1을 타겟팅하는 신규한 항체-약물 접합체(antibody-drug conjugate, ADC), 이들 ADC의 활성 대사물, 이들 ADC의 제조방법, 병의 치료 및/또는 예방을 위한 이들 ADC의 용도, 및 또한 병, 더 상세하게는 ROR1의 과발현과 관련된 질환 예컨대, 암 질환의 치료 및/또는 예방을 위한 약제를 생산하기 위한 이들 ADC의 용도에 관한 것이며, 보다 구체적으로, ROR1에 결합하는 항체 또는 이의 항원 결합 단편을 포함하는 항체-약물 접합체 및 이를 포함하는 약학 조성물에 관한 것이다.
암(cancer)은 신체 조직의 자율적인 과잉 성장에 의해 비정상적으로 자라난 덩어리로 인한 질환을 말하며, 다양한 조직에서 조절되지 않는 세포 성장의 결과이다. 초기 단계 종양은 수술 및 방사선치료 조치에 의해 제거될 수 있으며, 전이된 종양의 경우 일반적으로 화학요법제에 의해 완화치료를 하게 된다.
비경구로 투여되는 대다수 화학요법제는 전신 투여의 결과로서 원치 않는 부작용 및 심지어 독성이라는 심각한 효과를 유도할 수 있으며, 따라서 종양 세포 또는 바로 인접한 조직에서 이들 화학요법제의 개선되었으면서도 선택적인 적용을 통해 약효 증가 및 독성/부작용의 최소화를 동시에 이루기 위한 신규한 화학 요법제의 개발에 초점이 맞추어져 왔다.
항체-약물 접합체(ADC, antibody-drug conjugate)는 항원과 결합하는 항체에 독소 또는 약물을 결합시킨 후 세포 내부에서 독성물질을 방출하면서 암세포 등을 사멸에 이르게 하는 표적지향성 신기술이다. 건강한 세포에는 최소한으로 영향을 주면서 약물을 타겟 암세포에 정확하게 전달하고, 특정한 조건하에서만 방출되도록 해주기 때문에 항체 치료제 자체보다 효능이 우수하고 기존의 항암제들에 비해 부작용의 위험성을 크게 낮출 수 있는 기술이다.
이러한 항체-약물 접합체의 기본 구조는 "항체-링커-저분자 약물(독소)"로 구성되어 있다. 여기서 링커는 단순히 항체와 약물을 연결시켜 주는 기능적인 역할뿐 아니라, 체내 순환시 안정하게 타겟 세포까지 도달 후 항체-약물 접합체가 세포 내로 들어가 항체-약물간 해리현상(예, 효소에 의한 가수분해에 의한 결과)에 의해 약물이 잘 떨어지면서 타겟 암세포에 약효를 나타내도록 해야 한다. 즉 링커의 안정성에 따라 항체-약물 접합체의 효능 및 전신독성(systemic toxicity) 등의 안전성 면에서 링커는 매우 중요한 역할을 한다 (Discovery Medicine 2010, 10(53): 329-39) 85-8 2018-08-14).
본 발명의 발명자는 혈장 내에서 보다 안정하고 체내 순환시에도 안정적이며 약물이 암세포 내에서 쉽게 방출되어 약효를 나타낼 수 있는 효과적인 자가-희생 기(self-immolative group)을 포함하는 링커를 개발하여 이에 대해 특허를 확보한바 있다(한국등록특허 제1,628,872호 등). 한편 암 치료를 위한 단일클론 항체의 사용은 상당한 성공을 거두고 있다. 단일클론 항체는 종양 조직 및 종양 세포의 표적-지향된 어드레싱 (addressing)에 적당하다. 항체 약물 접합체들은 림프종과 고형암 치료를 위해 강력하고 새로운 치료의 옵션이 되었으며, 최근 들어 면역 조절 항체들도 임상에서 상당한 성공을 거두고 있다. 치료 항체들의 개발은 암 혈청학, 단백질 엔지니어링 기술과 그 작용, 저항성의 기작들 및 면역 시스템과 암세포들 간의 상호 작용에 대한 깊은 이해를 바탕으로 한다.
인간 암의 세포 표면에서 발현되는 항원의 정의는 정상 조직에 비해 과다 발현되거나 돌연변이 및 선택적으로 발현되는 광범위한 목표물들을 의미한다. 핵심적인 문제는 항체를 기반으로 한 치료법들에 적절한 항원을 동정하는 것이다. 이러한 치료제들은 항원이나 수용체 기능 (즉 자극제로서나 길항제로서의 기능)의 변화를 매개하고 Fc 과 T 세포 활성화를 통해 면역 시스템을 조절하며 특정한 항원을 목표로 하는 항체에 결합되는 특정한 약물의 전달을 통해 그 효능을 발휘한다. 항체 약동학 (pharmacokinetics), 작용 기능, 사이즈와 면역 자극성을 변화시킬 수 있는 분자 기술들은 새로운 항체를 기반으로 한 치료법들의 개발에서 핵심적인 요소로 등장하고 있다. 암 환자들을 대상으로 한 치료 항체들의 임상 시도에서 얻은 증거들은 목표 항원과 항체들의 친화성 및 결합성, 항체 구조의 선택, 치료적 접근법(신호전달 차단이나 면역 작용 기능)을 포함하는 최적화된 항체들의 선택을 위한 접근법들의 중요성을 강조하고 있다.
이와 관련하여, ROR1을 항원으로 삼는 항체에 대한 연구가 진행되고 있다.
ROR1은 배아 및 태아 발생과정에서 발현되어 세포 극성, 세포 이동, 및 신경돌기 성장 등을 조절한다. 발생의 진행에 따라 발현이 점차 감소하며 성체에서는 거의 발현되지 않고, B 세포의 발달과정에서 일시적으로 발현되고, 지방세포에서 약간의 발현만이 보고되고 있다 (Hudecek et al, 2010, Blood 116:4532, Matsuda et al, 2001, Mech Dev 105:153).
하지만 다양한 암세포에서 ROR1의 과발현이 관찰됨에 따라 종양태아성 유전자(oncofetal gene)로 분류되었다. 특히 ROR1은 만성 림프구성 백혈병(CLL: chronic lymphocytic leukemia)에 과발현 한다는 것이 밝혀지면서 항암 항체 타겟으로 주목을 받기 시작하였다 (Klein et al, 2001, J Exp Med 194:1625). 만성 림프구성 백혈병(CLL) 외에도 B세포 백혈병, 림프종, 급성 골수성 백혈병(AML), 버킷 림프종, 외투세포림프종(MCL), 급성림프구성백혈병(ALL), 미만성거대B세포림프종(DLBCL), 여포성림프종(FL), 변연부림프종(MZL) 등의 혈액암은 물론 유방암, 신장암, 난소암, 위암, 간암, 폐암, 대장암, 췌장암, 피부암, 방광암, 고환암, 자궁암, 전립선암, 비소세포 폐암(NSCLC), 신경모세포종, 뇌암, 결장암, 상피 편평세포암, 흑색종, 골수종, 자궁경부암, 갑상선암, 두경부암 및 부신암 등의 다양한 고형암에서도 과발현되는 것으로 보고되었다. 이와 같은 암에서 ROR1의 발현은 암환자의 좋지 않은 예후와 관련이 있으며, 암 전이에도 영향을 미치는 것으로 알려져 있다.
이러한 ROR1의 암세포 특이적 발현은 ROR1이 효과적인 암 표적이 될 수 있어, 이를 특이적으로 인식하는 항체의 개발이 필요하다는 것을 나타낸다.
미국 특허 제9,316,646호는 항-ROR1 항체에 관한 것으로 인간 세포 외 영역 ROR1을 특이적으로 인식할 수 있는 단클론 항체를 개시한다.
미국 특허 제9,266,952호는 ROR1에 대한 항체 및 그 용도에 관한 것으로, CLL 세포에 특이적으로 결합하여, CLL 사멸을 유도하는 항체를 개시한다.
동일한 ROR1 항원에 대한 항체라도 각 항체의 특성 또는 용도에 따라 다양한 항암항체로 개발이 가능하므로, 이러한 ROR1의 암특이적 발현, 다양한 암에서의 발현을 고려하면, 기존의 항체를 대체 또는 보완할 수 있는 다양한 항체의 개발이 필요하다.
이러한 기술적 배경하에서, 본 발명의 발명자는 ROR1에 특이적으로 결합하는 항체를 개발하기 위하여 노력한 결과 ROR1에 우수한 결합력을 나타내는 항-ROR1 항체를 개발하였으며, 항체의 효과를 더욱 강화하기 위하여 혈장 내에서 보다 안정하고 체내 순환시에도 안정적이며 약물이 암세포 내에서 쉽게 방출되어 약효를 나타낼 수 있는 효과적인 자가-희생기(self-immolative group)을 포함하는 링커를 상기 항-ROR1 항체에 적용하여, 암 질환의 치료 및/또는 예방에 효과적인 ROR1을 타겟팅하는 신규한 항체-약물접합체(ADC)를 제공할 수 있음을 확인하고, 본 발명을 완성하게 되었다.
본 발명은 ROR1을 타겟팅하는 신규한 항체-약물 접합체 또는 이의 염, 용매화물을 제공하고자 한다.
본 발명은 ROR1에 특이적으로 결합하는 항체 및 이에 결합하는 약물을 포함하는 항체-약물 접합체 및 이를 포함하는 약학 조성물을 제공하고자 한다.
본 발명은 또한 혈장 내에서 보다 안정하고 체내 순환시에도 안정적이며, 약물이 암세포 내에서 쉽게 방출되어 약효를 극대화할 수 있는 자가-희생기를 포함하는 링커 기술을 접목시켜, 약물 및/또는 톡신이 표적 세포에 안정적으로 도달하여 약효를 효과적으로 발휘하면서도 독성을 크게 낮출 수 있는, 항체-링커-약물(톡신) 시스템을 제공하고자 한다.
본 발명의 일 양태에서 본 발명은 일반식 I의 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물을 제공한다.
[일반식 I]
Ab - (X)y
상기 식에서,
Ab는 중쇄 가변영역 및 경쇄 가변영역을 포함하는 ROR1의 세포외영역을 특이적으로 결합하는 항체 또는 이의 항원 결합 단편이고,
상기 항체 또는 이의 항원 결합 단편은
서열번호 1 내지 5로 구성된 군에서 선택된 하나 이상의 CDRH1,
서열번호 6 내지 13, 및 96으로 구성된 군에서 선택된 하나 이상의 CDRH2, 및
서열번호 14 내지 21, 및 97로 구성된 군에서 선택된 하나 이상의 CDRH3를 포함하는 중쇄 가변영역; 및
서열번호 22 내지 29로 구성된 군에서 선택된 하나 이상의 CDRL1,
서열번호 30 내지 37로 구성된 군에서 선택된 하나 이상의 CDRL2, 및
서열번호 38 내지 42로 구성된 군에서 선택된 하나 이상의 CDRL3를 포함하는 경쇄 가변영역을 포함하고,
상기 X는 독립적으로 하나 이상의 활성제 및 링커를 포함하는 화학적 잔기이며, 및
상기 링커는 항체와 활성제를 연결하고,
상기 y는 1 내지 20의 정수이다.
본 발명의 일 양태에서 본 발명에 따른 항체는 예를 들어, 인간 ROR1의 세포외영역을 특이적으로 인식하고, 마우스 ROR1에 대한 교차 반응성을 나타낸다.
본 발명의 범위에는 ROR1에 특이적으로 결합하는 완전한 항체 형태뿐 아니라, 상기 항체 분자의 항원 결합 단편도 포함된다.
일 구현예에서 본 발명에 따른 항체 또는 항원결합 단편은 (i) CDRH1, CDRH2 및 CDRH3의 상보성 결정부위 및/또는 (ii) CDRL1, CDRL2 및 CDRL3의 상보성 결정부위를 포함하며, 상기 CDRH1은 서열번호 1 내지 5로부터 선택되는 어느 하나이고; 상기 CDRH2는 서열번호 6 내지 13, 및 96으로부터 선택되는 어느 하나이고; 상기 CDRH3은 서열번호 14 내지 21, 및 97로부터 선택되는 어느 하나이고, 상기 CDRL1은 서열번호 22 내지 29로부터 선택되는 어느 하나이고; 상기 CDRL2는 서열번호 30 내지 37로부터 선택되는 어느 하나이고; 상기 CDRL3은 서열번호 38 내지 42로부터 선택된다. CDRH는 중쇄 가변영역에 포함된 CDR을 나타내고, CDRL은 경쇄 가변영역에 포함된 CDR을 나타낸다.
이런 관점에서, 다른 구현예에서 본 발명에 따른 항체 또는 항원결합 단편은 (i) CDRH1, CDRH2 및 CDRH3의 상보성 결정부위를 포함하는 중쇄 가변영역 및/또는 (ii) CDRL1, CDRL2 및 CDRL3의 상보성 결정부위를 포함하는 경쇄 가변영역을 포함하며, 상기 CDRH1은 서열번호 1 내지 5로부터 선택되는 어느 하나이고; 상기 CDRH2는 서열번호 6 내지 13, 및 96으로부터 선택되는 어느 하나이고; 상기 CDRH3은 서열번호 14 내지 21, 및 97로부터 선택되는 어느 하나이고, 상기 CDRL1은 서열번호 22 내지 29로부터 선택되는 어느 하나이고; 상기 CDRL2는 서열번호 30 내지 37로부터 선택되는 어느 하나이고; 상기 CDRL3은 서열번호 38 내지 42로부터 선택된다.
다른 구현예에서 상기 CDRH1, CDRH2 및 CDRH3은 하기로부터 선택되는 하나의 조합이다: 각각 서열번호 1, 6, 및 14; 각각 서열번호 2, 7, 및 15; 각각 서열번호 1, 8, 및 16; 각각 서열번호 3, 9, 및 17; 각각 서열번호 1, 10, 및 18; 각각 서열번호 4, 11, 및 19; 각각 서열번호 5, 12, 및 20; 각각 서열번호 3, 13, 및 21; 각각 서열번호 2, 96, 및 15; 또는 각각 서열번호 3, 9, 및 97.
다른 구현예에서 상기 CDRL1, CDRL2 및 CDRL3은 하기로부터 선택되는 하나의 조합이다: 각각 서열번호 22, 30 및 38; 각각 서열번호 23, 31 및 39; 각각 서열번호 24, 32 및 40; 각각 서열번호 25, 33 및 41; 각각 서열번호 26, 34 및 41; 각각 서열번호 27, 35 및 42; 각각 서열번호 28, 36 및 41; 또는 각각 서열번호 29, 37 및 41.
다른 구현예에서, 상기 CDRH1, CDRH2 및 CDRH3; 및 상기 CDRL1, CDRL2 및 CDRL3의 서열은 다음 중 어느 하나의 조합이다:
(a) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 1, 6, 및 14, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 22, 30 및 38;
(b) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 2, 7, 및 15, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 23, 31 및 39;
(c) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 1, 8, 및 16, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 24, 32 및 40;
(d) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 3, 9, 및 17, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 25, 33 및 41;
(e) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 1, 10, 및 18, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 26, 34 및 41;
(f) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 4, 11, 및 19, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 27, 35 및 42;
(g) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 5, 12, 및 20, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 28, 36 및 41;
(h) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 3, 13, 및 21, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 29, 37 및 41;
(i) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 2, 96, 및 15, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 23, 31 및 39; 또는
(j) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 3, 9, 및 97, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 25, 33 및 41.
다른 구현예에서 본 발명에 따른 항체 또는 항원결합 단편은 하기 서열로 표시되는 중쇄 가변영역을 포함한다: 서열번호 43 내지 50, 98 및 99로부터 선택되는 어느 하나의 아미노산 서열; 상기 서열번호 43 내지 50, 98 및 99로부터 선택되는 어느 하나의 아미노산 서열과 적어도 90% 이상; 또는 상기 서열번호 43 내지 50, 98 및 99로부터 선택되는 어느 하나의 아미노산 서열과 적어도 95% 이상의 상동성을 갖는 서열.
다른 구현예에서 본 발명에 따른 항체 또는 항원결합 단편은 하기 서열로 표시되는 경쇄 가변영역을 포함한다: 서열번호 51 내지 58로부터 선택되는 어느 하나의 아미노산 서열; 상기 서열번호 51 내지 58로부터 선택되는 어느 하나의 아미노산 서열과 적어도 90% 이상; 또는 상기 서열번호 51 내지 58로부터 선택되는 어느 하나의 아미노산 서열과 적어도 95% 이상의 상동성을 갖는 서열.
다른 구현예에서 본 발명에 따른 항체 또는 항원결합 단편은 하기 서열로 표시되는 중쇄 및 경쇄 가변영역 조합을 포함한다: 서열번호 43 및 51; 서열번호 44 및 52; 서열번호 45 및 53; 서열번호 46 및 54; 서열번호 47 및 55; 서열번호 48 및 56; 서열번호 49 및 57; 서열번호 50 및 58; 서열번호 98 및 52; 또는 서열번호 99 및 54로 표시되는 서열; 상기 어느 하나의 아미노산 서열과 적어도 90% 이상; 또는 상기 어느 하나의 아미노산 서열과 적어도 95% 이상의 상동성을 갖는 서열.
다른 구현예에서 본 발명에 따른 항체 또는 항원결합 단편은 인간 항체, 완전 인간 항체 또는 항원결합 단편이고, 마우스 ROR1에 교차반응성을 가진다.
다른 구현예에서 본 발명에 따른 항체는 모노클로날 항체, 특히 인간 모노클로날 항체이고, 마우스 ROR1에 교차반응성을 가진다.
다른 구현예에서 본 발명에 따른 항체 또는 항원결합 단편은 인간 및 마우스 ROR1을 특이적으로 인식 및/또는 결합한다.
다른 구현예에서 본 발명에 따른 항체는 IgG1, IgG2, IgG3 또는 IgG4형이다.
다른 구현예에서 본 발명에 따른 항체는 하기 서열의 중쇄 및 경쇄 조합을 포함한다: 서열번호 59 및 67; 서열번호 60 및 68; 서열번호 61 및 69; 서열번호 62 및 70; 서열번호 63 및 71; 서열번호 64 및 72; 서열번호 65 및 73; 또는 서열번호 66 및 74.
다른 구현예에서 본 발명에 따른 항체 또는 항원결합 단편은 단일클론 항체(monoclonal antibody), 도메인 항체(domain antibody; dAb), 단일 사슬 항체(single chain antibody; scAb), Fab 단편, Fab' 단편, F(ab')2 단편, scFab 단편, Fv 단편, dsFv 단편, 단일 사슬 가변 항체(single chain variable fragment; scFv), scFv-Fc 단편, 단일 도메인 중쇄 항체(single domain heavy chain antibody), 단일 도메인 경쇄 항체(single domain light chain antibody), 항체 변이체(variant antibody), 다중 결합 항체(multimeric antibody), 미니바디, 다이아바디, 이중 특이적 항체(bispecific antibody) 또는 다중 특이적 항체를 포함하나 이로 제한하는 것은 아니다.
다른 구현예에서 본 발명에 따른 항체 또는 항원결합 단편은 상기 ROR1 항원에 부가하여 하나 이상의 항원에 대한 특이성을 갖는다. 일 구현예에서 하나 이상의 항원은 ROR1과 상이한 것으로 예를 들면 암 항원을 포함하며, 이 경우 항체는 이중특이성을 가질 수 있다. 당업자라면 이중특이항체의 구체적 목적에 따라 적절한 암 항원을 선택할 수 있을 것이다.
다른 양태에서 본 발명은 또한 본 발명에 따른 항체 또는 항원결합 단편을 코딩하는 분리된 폴리뉴클레오타이드를 제공한다.
일 구현예에서 본 발명에 따른 폴리뉴클레오타이드는 본 발명에 개시된 CDR를 코딩하는 폴리뉴클레오타이드이다.
다른 구현예에서 본 발명에 따른 폴리뉴클레오타이드는 본 발명에 개시된 중쇄 또는 경쇄 가변영역을 코딩하는 폴리뉴클레오타이드이다.
또 다른 구현예에서 본 발명에 따른 폴리뉴클레오타이드는 본 발명에 개시된 중쇄 또는 경쇄를 코딩하는 폴리뉴클레오타이드이다.
일 구현예에서 본 발명에 따른 폴리뉴클레오타이드는 본 발명에 개시된 전장 중쇄를 코딩하는 서열번호 75 내지 82번, 102번 및 103번 중 어느 하나로 표시된다.
다른 구현예에서 본 발명에 따른 폴리뉴클레오타이드는 본 발명에 개시된 전장 경쇄를 코딩하는 서열번호 83 내지 90번 중 어느 하나로 표시된다.
본 발명에 따른 CDR 및 가변영역을 코딩하는 폴리뉴클레오타이드는 상기 전장 중쇄 및 경쇄를 코딩하는 핵산 서열로부터, 본 발명에 개시된 CDR 및 가변영역의 아미노산 서열을 기초로 용이하게 결정할 수 있을 것이다.
다른 양태에서는 본 발명에 따른 폴리뉴클레오타이드를 포함하는 벡터를 제공한다. 일 구현예에서 본 발명에 따른 벡터는 항체 생산을 위한 발현 벡터 또는 CAR-T 세포 (Chimeric Antigen receptor redirected T cells) 또는 CAR-NK 세포용 벡터를 포함한다.
다른 양태에서 본 발명에 따른 벡터로 형질전환된 세포주를 제공한다.
또 다른 양태에서 본 발명은 본 발명에 따른 상기 세포주로부터 항체 또는 그 항원결합 단편을 분리하는 단계를 포함하는, ROR1에 특이적으로 결합하는 분리된 항체 또는 그 항원결합 단편의 제조 방법을 제공한다.
본 발명의 일 양태에서, Linker는 하기 화학식 (IIa)의 구조를 갖는다:
[화학식 (IIa)]

상기 식에서,
G는 당(sugar), 당산(sugar acid), 또는 당 유도체(sugar derivatives)이고,
W는 -C(O)-, -C(O)NR'-, -C(O)O-, -S(O)2NR'-, -P(O)R''NR'-, -S(O)NR'-, 또는 -PO2NR'-이고,
C(O), S, 또는 P가 페닐환과 바로 연결되는 경우, R' 및 R''은 각각 독립적으로 수소, (C1-C8)알킬, (C3-C8)사이클로알킬, (C1-C8)알콕시, (C1-C8)알킬티오, 모노- 또는 디-(C1-C8)알킬아미노, (C3-C20)헤테로아릴, 또는 (C6-C20)아릴이며,
각 Z는 각각 독립적으로 수소, (C1-C8)알킬, 할로겐, 시아노 또는 나이트로이고,
n은 1 내지 3의 정수이며,
m은 0 또는 1이고,
L은 부존재하거나, 또는
최소 하나의 브랜칭 유닛(branching unit, BR) 및 최소 하나의 커넥션 유닛(connection unit)을 함유하며,
R1 및 R2는 각각 독립적으로 수소, (C1-C8)알킬 또는 (C3-C8)사이클로알킬이거나, 또는 R1 및 R2는 이들이 부착된 탄소 원자와 함께 (C3-C8)사이클로알킬 환을 형성하며,
상기 식에서 물결표시는 항체 또는 이의 항원결합 단편과 연결되는 부위, * 표시는 약물 또는 톡신과 연결되는 부위를 나타낸다.
본 발명의 일 양태에서, 상기 당 또는 당산은 모노사카라이드이다.
본 발명의 일 양태에서, G는 하기 화학식 (IIIa) 구조의 화합물이다:
[화학식 (IIIa)]

여기에서,
R3는 수소 또는 카르복실 보호기이고,
각 R4는 각각 독립적으로 수소 또는 하이드록실 보호기이다.
본 발명의 일 양태에서, R3는 수소이고, 각 R4는 수소이다.
본 발명의 일 양태에서, W는 -C(O)NR'-이고, 여기에서 C(O)가 페닐환과 연결되며, NR'은 L과 연결된다.
본 발명의 일 양태에서, Z는 수소이고, n은 3이다.
본 발명의 일 양태에서, R1 및 R2는 각각 수소이다.
본 발명의 일 양태에서, G는 하기 화학식 (IIIa) 구조의 화합물이고:
[화학식 (IIIa)]

여기에서,
R3는 수소 또는 카르복실 보호기이고,
각 R4는 각각 독립적으로 수소 또는 하이드록실 보호기이며,
W는 -C(O)NR'-이고, 여기에서 C(O)가 페닐환과 연결되며 NR'은 L과 연결되고, 각 Z는 수소이며, n은 3이고, m은 1이며, R1 및 R2는 각각 수소이다.
본 발명의 일 양태에서, 최소 하나의 브랜칭 유닛은 1 내지 100개의 탄소 원자를 갖는 알킬렌이고, 여기에서 알킬렌의 탄소 원자는, N, O 및 S로 이루어진 그룹으로부터 선택되는 하나 또는 그 이상의 헤테로원자로 치환될 수 있으며, 알킬렌은 1 내지 20개의 탄소원자를 갖는 하나 이상의 알킬로 더 치환될 수 있다.
본 발명의 일 양태에서, 최소 하나의 브랜칭 유닛은 친수성 아미노산(hydrophilic amino acid)이다.
본 발명의 일 양태에서, 친수성 아미노산은 아르기닌, 아스파테이트, 아스파라긴, 글루타메이트, 글루타민, 히스티딘, 리신, 오르니틴, 프롤린, 세린, 또는 트레오닌일 수 있다.
본 발명의 일 양태에서, 친수성 아미노산은 수용액에서 중성 pH에서 전하를 갖는 잔기를 갖는 측쇄를 포함하는 아미노산일 수 있다.
본 발명의 일 양태에서, 친수성 아미노산은 아스파테이트 또는 글루타메이트이다.
본 발명의 일 양태에서, 친수성 아미노산은 오르니틴 또는 리신이다.
본 발명의 일 양태에서, 친수성 아미노산은 아르기닌이다.
본 발명의 일 양태에서, 최소 하나의 브랜칭 유닛은 -C(O)-, -C(O)NR'-, -C(O)O-, -S(O)2NR'-, -P(O)R''NR'-, -S(O)NR'-, 또는 -PO2NR'-이고, R' 및 R''은 각각 독립적으로 수소, (C1-C8)알킬, (C3-C8)사이클로알킬, (C1-C8)알콕시, (C1-C8)알킬티오, 모노- 또는 디-(C1-C8)알킬아미노, (C3-C20)헤테로아릴, 또는 (C6-C20)아릴이다.
본 발명의 일 양태에서, 최소 하나의 브랜칭 유닛은 -C(O)NR'-이고, R'은 수소이다.
본 발명의 일 양태에서, 최소 하나의 커넥션 유닛은 -(CH2)r(V(CH2)p)q- 이고, 여기에서 r은 0 내지 10의 정수이며, p은 0 내지 12의 정수이고, q는 1 내지 20의 정수이며, V는 단일결합, -O- 또는 -S-이다.
본 발명의 일 양태에서, r은 2이다.
본 발명의 일 양태에서, p은 2이다.
본 발명의 일 양태에서, q는 6 내지 20의 정수이다.
본 발명의 일 양태에서, r은 2이고, p은 2이며, q는 2, 4, 5 또는 11이고, V는 -O-이다.
본 발명의 일 양태에서, 최소 하나의 커넥션 유닛은 최소 하나의 폴리에틸렌 글리콜 유닛이고,  또는
또는  의 구조를 갖는다.
의 구조를 갖는다.
본 발명의 일 양태에서, 최소 하나의 커넥션 유닛은 1 내지 12 -OCH2CH2-유닛, 또는 5 내지 12 -OCH2CH2-유닛, 또는 6 내지 12 -OCH2CH2-유닛이다.
본 발명의 일 양태에서, 최소 하나의 커넥션 유닛은 -(CH2CH2X)w-이고,
여기에서 X는 단일 결합, -O-, (C1-C8)알킬렌, 또는 -NR21-이고;
R21은 수소, (C1-C6)알킬, (C1-C6)알킬(C6-C20)아릴, 또는 (C1-C6)알킬 (C3-C20)헤테로아릴이며,
w는 1 내지 20의 정수이고, 구체적으로는 1, 3, 6, 또는 12이다.
본 발명의 일 양태에서 X는 -O-이고, w는 6 내지 20의 정수이다.
본 발명의 일 양태에서, Linker는 1,3-dipolar cycloaddition 반응, hetero-Diels-Alder 반응, 친핵성 치환(nucleophilic substitution) 반응, 비-알돌형 카르보닐 반응, 탄소-탄소 다중 결합 첨가(addition to carbon-carbon multiple bond), 산화 반응 또는 클릭 반응에 의해 형성된 바인딩 유닛을 추가로 포함한다.
본 발명의 일 양태에서, 바인딩 유닛은 아세틸렌 및 아자이드 사이의 반응, 또는 알데하이드 또는 케톤기 및 하이드라진 또는 알콕시아민 사이의 반응에 의해 형성된다.
본 발명의 일 양태에서, 바인딩 유닛은,

이고,
여기에서,
L1은 단일 결합 또는 1 내지 30개의 탄소원자를 갖는 알킬렌이고,
R11은 수소 또는 1 내지 10개의 탄소원자를 갖는 알킬이며, 구체적으로 메틸이고,
L2는 1 내지 30개의 탄소원자를 갖는 알킬렌이다.
본 발명의 일 양태에서, Linker는  의 구조를 갖는 최소 하나 이상의 이소프레닐 유닛을 추가로 함유할 수 있으며, 여기에서 n은 최소 2 이상이다.
의 구조를 갖는 최소 하나 이상의 이소프레닐 유닛을 추가로 함유할 수 있으며, 여기에서 n은 최소 2 이상이다.
본 발명의 일 양태에서, 최소 하나의 이소프레닐 유닛은 이소프레노이드 트랜스퍼라제의 기질 또는 이소프레노이드 트랜스퍼라제의 생성물이다.
본 발명의 일 양태에서, Linker의 이소프레닐 유닛은 티오에테르 결합에 의해 항체와 공유결합하며, 티오에테르 결합은 항체의 시스테인의 황원자를 포함한다.
본 발명의 일 양태에서, 항체는 이소프레노이드 트랜스퍼라제에 의해 인식되는 아미노산 모티프를 포함하고, 티오에테르 결합은 아미노산 모티프의 시스테인의 황원자를 포함한다.
본 발명의 일 양태에서, ROR1에 결합하는 항체 또는 이의 항원 결합 단편은 이소프레노이드 트랜스퍼라제에 의해 인식되는 아미노산 모티프를 포함하고, 티오에테르 결합은 아미노산 모티프의 시스테인의 황원자를 포함한다.
본 발명의 일 양태에서, 아미노산 모티프는 CXX, CXC, XCXC, XXCC, 및 CYYX로 이루어진 그룹으로부터 선택되는 서열이고, 여기에서 C는 시스테인을 나타내며; Y는 각 경우 독립적으로 지방족 아미노산을 나타내고; X는 각 경우 독립적으로 글루타민, 글루타메이트, 세린, 시스테인, 메티오닌, 알라닌, 또는 루신을 나타내고; 티오에테르 결합은 아미노산 모티프의 시스테인의 황원자를 포함한다.
본 발명의 일 양태에서, 아미노산 모티프는 CYYX 서열이고, Y는 각 경우 독립적으로 알라닌, 이소루신, 루신, 메티오닌 또는 발린이다.
본 발명의 일 양태에서, 아미노산 모티프는 CVIM 또는 CVLL 서열이다.
본 발명의 일 양태에서, 아미노산 모티프에 선행하는 1 내지 20개의 아미노산 중 적어도 하나는 글리신이다.
본 발명의 일 양태에서, 아미노산 모티프에 선행하는 1 내지 20개의 아미노산 중 1개 이상이 글리신, 아르기닌, 아스파르트산 및 세린으로부터 각각 독립적으로 선택될 수 있다.
본 발명의 일 양태에서, 아미노산 모티프에 선행하는 1 내지 20개의 아미노산이 글리신, 구체적으로는 아미노산 모티프에 선행하는 최소 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 또는 20개의 아미노산은 글리신이다.
본 발명의 일 양태에서, 항체는 GGGGGGGCVIM의 아미노산 서열을 포함할 수 있다.
본 발명의 또 다른 일 양태에서, Linker는,
(a) 하나 이상의 브랜칭 유닛; (b) 하나 이상의 커넥션 유닛; (c)하나 이상의 바인딩 유닛(binding unit, BU); 및 (d) 하나 이상의 트리거 유닛(trigger unit, TU)을 함유하는 것일 수 있다.
여기에서 커넥션 유닛은 트리거 유닛과 바인딩 유닛, 트리거 유닛과 브랜칭 유닛 또는 브랜칭 유닛과 바인딩 유닛을 연결하고,
여기에서 하나 이상의 트리거 유닛은 하나 이상의 약물 또는 톡신을 방출할 수 있으며,
여기에서 브랜칭 유닛은 커넥션 유닛과 트리거 유닛, 또는 커넥션 유닛을 또 다른 커넥션 유닛과 연결하는 것이다.
본 발명의 일 양태에서, 트리거 유닛은 다음 화학식 (IIb)의 구조를 갖는다:
[화학식 (IIb)]

상기 식에서,
G는 당(sugar), 당산(sugar acid), 또는 당 유도체(sugar derivatives)이고,
W는 -C(O)-, -C(O)NR'-, -C(O)O-, -S(O)2NR'-, -P(O)R''NR'-, -S(O)NR'-, 또는 -PO2NR'-이고,
C(O), S, 또는 P가 페닐환과 바로 연결되는 경우, R' 및 R''은 각각 독립적으로 수소, (C1-C8)알킬, (C3-C8)사이클로알킬, (C1-C8)알콕시, (C1-C8)알킬티오, 모노- 또는 디-(C1-C8)알킬아미노, (C3-C20)헤테로아릴, 또는 (C6-C20)아릴이며, W는 커넥션 유닛 또는 브랜칭 유닛과 연결되고,
각 Z는 각각 독립적으로 수소, (C1-C8)알킬, 할로겐, 시아노 또는 나이트로이고,
n은 1 내지 3의 정수이며,
m은 0 또는 1이고,
R1 및 R2는 각각 독립적으로 수소, (C1-C8)알킬 또는 (C3-C8)사이클로알킬이거나, 또는 R1 및 R2는 이들이 부착된 탄소 원자와 함께 (C3-C8)사이클로알킬 환을 형성한다.
본 발명의 일 양태에서, 상기 당 또는 당산은 모노사카라이드이다.
본 발명의 일 양태에서, G는 하기 화학식 (IIIa) 구조의 화합물이다:
[화학식 (IIIa)]

여기에서,
R3는 수소 또는 카르복실 보호기이고,
각 R4는 각각 독립적으로 수소 또는 하이드록실 보호기이다.
본 발명의 일 양태에서, R3는 수소이고, 각 R4는 수소이다.
본 발명의 일 양태에서, W는 -C(O)NR'-이고, 여기에서 C(O)가 페닐환과 연결되며, NR'은 커넥션 유닛과 연결된다.
본 발명의 일 양태에서, Z는 수소이다.
본 발명의 일 양태에서, R1 및 R2는 각각 수소이다.
본 발명의 일 양태에서, 커넥션 유닛은 -(CH2)r(V(CH2)p)q-, -((CH2)pV)q-, -(CH2)r(V(CH2)p)qY-, -((CH2)pV)q(CH2)r-, -Y((CH2)pV)q- 또는 -(CH2)r(V(CH2)p)qYCH2-로 나타내지며,
여기에서,
r은 0 내지 10의 정수이고;
p는 1 내지 10의 정수이며;
q는 1 내지 20의 정수이고,
V 및 Y는 각각 독립적으로 단일결합, -O-, -S-, -NR21-, -C(O)NR22-, -NR23C(O)-, -NR24SO2-, 또는 -SO2NR25-이고,
R21 내지 R25는 각각 독립적으로 수소, (C1-C6)알킬, (C1-C6)알킬(C6-C20)아릴 또는 (C1-C6)알킬(C3-C20)헤테로아릴이다.
본 발명의 일 양태에서, r은 2이다.
본 발명의 일 양태에서, p는 2이다.
본 발명의 일 양태에서, q는 6 내지 20의 정수이다.
본 발명의 일 양태에서, q는 2, 5, 또는 11이다.
본 발명의 일 양태에서, V 및 Y는 각각 독립적으로 -O-이다.
본 발명의 일 양태에서, 브랜칭 유닛은,

이고,
여기에서,
L1, L2, 및 L3는 각각 독립적으로 직접 결합(direct bond) 또는 -CnH2n- 이고,
여기에서 n은 1 내지 30의 정수이며,
여기에서, G1, G2, G3는 각각 독립적으로 직접 결합,  이고,
이고,
여기에서 R3는 수소 또는 C1-C30알킬이며,
여기에서 R4는 수소 또는 -L4-COOR5이고, 여기에서 L4는 직접 결합 또는 -CnH2n- 이고 여기에서 n은 1 내지 10의 정수이며, R5는 수소 또는 C1-C30 알킬이다.
본 발명의 일 양태에서, 브랜칭 유닛은  이고,
이고,
여기에서 L1은 직접 결합 또는 1 내지 30개의 탄소원자를 갖는 알킬렌이고,
R11은 수소 또는 1 내지 10개의 탄소원자를 갖는 알킬이며, 구체적으로 메틸이고,
L2는 1 내지 30개의 탄소원자를 갖는 알킬렌이고,
여기에서 브랜칭 유닛은 커넥션 유닛과 항체를 연결한다.
본 발명의 일 양태에서, L1은 12개의 탄소원자를 갖는 알킬렌이다.
본 발명의 일 양태에서, R11은 메틸이다.
본 발명의 일 양태에서, L2는 11개의 탄소원자를 갖는 알킬렌이다.
본 발명의 일 양태에서, 바인딩 유닛은 티오에테르 결합에 의해 항체와 공유결합하며, 티오에테르 결합은 항체의 시스테인의 황원자를 포함한다.
본 발명의 일 양태에서, 항체는 이소프레노이드 트랜스퍼라제에 의해 인식되는 아미노산 모티프를 포함하고, 티오에테르 결합은 아미노산 모티프의 시스테인의 황원자를 포함한다.
본 발명의 일 양태에서, 아미노산 모티프는 CXX, CXC, XCXC, XXCC, 및 CYYX로 이루어진 그룹으로부터 선택되는 서열이고, 여기에서 C는 시스테인을 나타내며; Y는 각 경우 독립적으로 지방족 아미노산을 나타내고; X는 각 경우 독립적으로 글루타민, 글루타메이트, 세린, 시스테인, 메티오닌, 알라닌, 또는 루신을 나타내고; 티오에테르 결합은 아미노산 모티프의 시스테인의 황원자를 포함한다.
본 발명의 일 양태에서, 아미노산 모티프는 CYYX 서열이고, Y는 각 경우 독립적으로 알라닌, 이소루신, 루신, 메티오닌 또는 발린이다.
본 발명의 일 양태에서, 아미노산 모티프는 CVIM 또는 CVLL 서열이다.
본 발명의 일 양태에서, 아미노산 모티프에 선행하는 1 내지 20개의 아미노산 중 적어도 하나는 글리신이다.
본 발명의 일 양태에서, 아미노산 모티프에 선행하는 1 내지 20개의 아미노산 중 1개 이상이 글리신, 아르기닌, 아스파르트산 및 세린으로부터 각각 독립적으로 선택될 수 있다.
본 발명의 일 양태에서, 아미노산 모티프에 선행하는 1 내지 20개의 아미노산이 글리신, 구체적으로는 아미노산 모티프에 선행하는 최소 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 또는 20개의 아미노산은 글리신이다.
본 발명의 일 양태에서, 항체는 GGGGGGGCVIM의 아미노산 서열을 포함할 수 있다.
또한, 본 발명의 일 양태에서, 활성제는 화학요법제 또는 톡신일 수 있다.
또한, 활성제는 면역 조절 화합물, 항암제, 항바이러스제, 항균제, 항진균제, 항기생충제 또는 이들의 조합일 수 있고, 하기 나열된 활성제 중 선택적으로 사용할 수 있다:
(a) 엘로티닙(erlotinib), 보르테조밉(bortezomib), 풀베스트란트(fulvestrant), 수텐트(sutent), 레트로졸(letrozole), 이마티닙 메실레이트(imatinib mesylate), PTK787/ZK 222584, 옥살리플라틴(oxaliplatin), 5-플루오로우라실(5-fluorouracil), 루코보린(leucovorin), 라파마이신(rapamycin), 라파티닙(lapatinib), 로나파르닙(lonafarnib), 소라페닙(sorafenib), 제피티닙(gefitinib), AG1478, AG1571, 티오테파(thiotepa), 사이클로포스파마이드(cyclophosphamide), 부술판(busulfan), 임프로술판(improsulfan), 피포술판(piposulfan), 벤조도파(benzodopa), 카르보콘(carboquone), 메츄도파(meturedopa), 유레도파(uredopa), 에틸렌이민(ethylenimine), 알트레타민(altretamine), 트리에틸렌멜라민(triethylenemelamine), 트리에틸렌포스포라미드(trietylenephosphoramide), 트리에틸렌티오포스포라미드(triethiylenethiophosphoramide), 트리메틸롤로멜라민(trimethylolomelamine), 불라타신(bullatacin), 불라타시논(bullatacinone), 캄토테신(camptothecin), 토포테칸(topotecan), 브리오스타틴(bryostatin), 칼리스타틴(callystatin), CC-1065, 아도젤레신(adozelesin), 카르젤레신(carzelesin), 비젤레신(bizelesin), 크립토피신 1(cryptophycin 1), 크립토피신 8(cryptophycin 8), 돌라스타틴(dolastatin), 듀오카마이신(duocarmycin), KW-2189, CB1-TM1, 엘루테로빈(eleutherobin), 판크라티스타틴(pancratistatin), 사르코딕티인(sarcodictyin), 스폰지스타틴(spongistatin), 클로람부실(chlorambucil), 클로르나파진(chlornaphazine), 클로로포스파미드(cholophosphamide), 에스트라무스틴(estramustine), 이포스파미드(ifosfamide), 메클로르에타민(mechlorethamine), 멜팔란(melphalan), 노벰비킨(novembichin), 페네스테린(phenesterine), 프레드니무스틴(prednimustine), 트로포스파미드(trofosfamide), 우라실 머스타드(uracil mustard), 카르무스틴(carmustine), 클로로코토신(chlorozotocin), 포테쿠스틴(fotemustine), 로무스틴(lomustine), 니무스틴(nimustine), 라니무스틴(ranimnustine), 칼리키아미신(calicheamicin), 칼리키아미신 감마 1(calicheamicin gamma 1), 칼리키아미신 오메가 1(calicheamicin omega 1), 디네미신(dynemicin), 디네미신 A(dynemicin A), 클로드로네이트(clodronate), 에스페르아미신(esperamicin), 네오카르지노스타틴크로모포어(neocarzinostatin chromophore), 아클라시노마이신(aclacinomysins), 악티노마이신(actinomycin), 안트르마이신(antrmycin), 아자세린(azaserine), 블레오마이신(bleomycins), 칵티노마이신(cactinomycin), 카라비신(carabicin), 카르니노마이신(carninomycin), 카르지노필린(carzinophilin), 크로모마이신(chromomycins), 닥티노마이신(dactinomycin), 다우노루비신(daunorubicin), 데토루부신(detorubucin), 6-디아조-5-옥소-L-노르루신(6-diazo-5-oxo-L-norleucine), 독소루비신(doxorubicin), 모르폴리노-독소루비신(morpholino-doxorubicin), 시아노모르폴리노-독소루비신(cyanomorpholino-doxorubicin), 2-피롤리노-독소루비신(2-pyrrolino-doxorubucin), 리포소말 독소루비신(liposomal doxorubicin), 데옥시독소루비신(deoxydoxorubicin), 에피루비신(epirubicin), 에소루비신(esorubicin), 마르셀로마이신(marcellomycin), 미토마이신 C(mitomycin C), 미코페놀산(mycophenolic acid), 노갈라마이신(nogalamycin), 올리보마이신(olivomycins), 페플로마이신(peplomycin), 포트피로마이신(potfiromycin), 퓨로마이신(puromycin), 쿠엘라마이신(quelamycin), 로도루비신(rodorubicin), 스트렙토미그린(streptomigrin), 스트렙토조신(streptozocin), 투베르시딘(tubercidin), 우베니멕스(ubenimex), 지노스타틴(zinostatin), 조루비신(zorubicin), 5-플루오로우라신(5-fluorouracil), 데노프테린(denopterin), 메토트렉세이트(methotrexate), 프테로프테린(pteropterin), 트리메트렉세이트(trimetrexate), 플루다라빈(fludarabine), 6-머캅토퓨린(6-mercaptopurine), 티아미프린(thiamiprine), 티구아닌(thiguanine), 안시타빈(ancitabine), 아자시티딘(azacitidine), 6-아자유리딘(6-azauridine), 카르모푸르(carmofur), 시타라빈(cytarabine), 디데옥시유리딘(dideoxyuridine), 독시플루리딘(doxifluridine), 에노시타빈(enocitabine), 플록수리딘(floxuridine), 칼루스테론(calusterone), 드로모스타놀론(dromostanolone), 프로피오네이트(propionate), 에피티오스타놀(epitiostanol), 메피티오스테인(mepitiostane), 테스토락톤(testolactone), 아미노글루테티미드(aminoglutethimide), 미토테인(mitotane), 트릴로스테인(trilostane), 폴린산(folinic acid), 아세글라톤(aceglatone), 알도포스파미드 글리코사이드(aldophosphamide glycoside), 아미노레불린산(aminolevulinic acid), 에닐우라실(eniluracil), 암사크린(amsacrine), 베스트라부실(bestrabucil), 비산트렌(bisantrene), 에다트락세이트(edatraxate), 데포파민(defofamine), 데메콜신(demecolcine), 디아지콘(diaziquone), 엘포르니틴(elfornithine), 엘립티니움 아세테이트(elliptinium acetate), 에토글루시드(etoglucid), 갈리움 나이트레이트(gallium nitrate), 하이드록시우레아(hydroxyurea), 렌티난(lentinan), 로니다이닌(lonidainine), 메이탄신(maytansine), 안사미토신(ansamitocins), 미토구아존(mitoguazone), 미토잔트론(mitoxantrone), 모피단몰(mopidanmol), 니트라에린(nitraerine), 펜토스타틴(pentostatin), 페나메트(phenamet), 피라루비신(pirarubicin), 로소잔트론(losoxantrone), 2-에틸하이드라지드(2-ethylhydrazide), 프로카르바진(procarbazine), 폴리사카라이드-k(polysaccharidek), 라족세인(razoxane), 리조신(rhizoxin), 시조피란(sizofiran), 스피로게르마늄(spirogermanium), 테누아존산(tenuazonic acid), 트리아지콘(triaziquone), 2,2',2''-트리클로로트리에틸아민(2,2',2''-trichlorotriethylamine), T-2 톡신, 베라큐린 A(verracurin A), 로리딘 A(roridin A), 안구이딘(anguidine), 우레탄(urethane), 빈데신(vindesine), 다카르바진(dacarbazine), 만노무스틴(mannomustine), 미토브로니톨(mitobronitol), 미토락톨(mitolactol), 피포브로만(pipobroman), 가시토신(gacytosine), 아라비노사이드(arabinoside), 사이클로포스파미드(cyclophosphamide), 티오테파(thiotepa), 파클리탁셀(paclitaxel), 파클리탁셀, 파클리탁셀의 알부민-엔지니어드 나노파티클(albumin-engineered nanoparticle formulation of paclitaxel), 도세탁셀, 클로람부실, 젬시타빈, 6-티오구아닌, 머캅토퓨린, 시스플라틴, 카보플라틴(carboplatin), 빈블라스틴(vinblastine), 플래티늄(platinum), 에토포사이드(etoposide), 이포스파미드(ifosfamide), 미톡산트론(mitoxantrone), 빈크리스틴, 비노렐빈(vinorelbine), 노반트론(novantrone), 테니포사이드(teniposide), 에다트렉세이트(edatrexate), 다우노마이신(daunomycin), 아미노프테린(aminopterin), 젤로다(xeloda), 이반드로네이트(ibandronate), CPT-11, 토포이소머라아제 저해제 RFS 2000, 디플루오로메틸오르니틴(difluoromethylornithine), 레티노산(retinoic acid), 카페시타빈(capecitabine), 또는 이의 약학적으로 허용되는 염, 용매화물 또는 산;
(b) 모노카인(monokine), 림포카인(lympokine), 폴리펩타이드 호르몬(traditional polypeptide hormone), 부갑상선 호르몬(parathyroid hormone), 티록신(thyroxine), 릴렉신(relaxin), 프로릴렉신(prorelaxin), 당단백 호르몬(glycoprotein hormone), 여포자극호르몬(follicle stimulating hormone), 갑상샘자극호르몬(thyroid stimulating hormone), 황체형성호르몬(luteinizing hormone), 간 성장인자 섬유모세포성장인자(hepatic growth factor fibroblast growth factor), 프롤락틴(prolactin), 태반성 락토젠(placental lactogen), 종양괴사인자 (tumor necrosis factor), 종양괴사인자-α, 종양괴사인자-β, 뮐러관 억제물질(mullerian inhibiting substance), 마우스 고나도트로핀-연관 펩타이드(mouse gonadotropin associated peptide), 인히빈(inhibin), 액티빈(activin), 혈관내피증식인자(vascular endothelial growth factor), 트롬보포이에틴(thrombopoietin), 에리스로포이에틴(erythropoietin), 골유도 인자(osteoinductive factor), 인터페론, 인터페론-α, 인터페론-β, 인터페론-γ, 콜로니자극인자(colony stimulating factor, CSF), 마크로파지-CSF, 과립구-마크로파지-CSF(granulocyte-macrophage-CSF), 과립구-CSF, 인터루킨(IL), IL-1, IL-1α, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8, IL-9, IL-10, IL-11, IL-12, 종양괴사인자(tumor necrosis factor), 폴리펩타이드 인자, LIF, 키트 리간드(kit ligand), 또는 이들의 배합물;
(c) 디프테리아 톡신, 보툴리눔 톡신, 테타누스 톡신, 디센터리 톡신, 콜레라 톡신, 아마니틴, α-아마니틴, 피롤로벤조디아제핀, 피롤로벤조디아제핀 유도체, 인돌리노벤조디아제핀, 피리디노벤조디아제핀, 테트로도톡신, 브레베톡신(brevetoxin), 시구아톡신(ciguatoxin), 리신(ricin), AM 톡신, 오리스타틴(auristatin), 투불리신(tubulysin), 겔다나마이신(geldanamycin), 메이탄시노이드(maytansinoid), 칼리케아마이신(calicheamycin), 다우노마이신(daunomycin), 독소루비신(doxorubicin), 메토트렉세이트(methotrexate), 빈데신(vindesine), SG2285, 돌라스타틴(dolastatin), 돌라스타틴 유사체(dolastatin analog), 오리스타틴(auristatin), 크립토피신(cryptophycin), 캄토테신(camptothecin), 리족신(rhizoxin), 리족신 유도체(rhizoxin derivatives), CC-1065, CC-1065, 유사체 또는 유도체, 듀오카마이신(duocarmycin), 에네다인 항생제(enediyne antibiotic), 에스페라마이신(esperamicin), 에포틸론(epothilone), 톡소이드(toxoid), 또는 이들의 배합물;
(d) 친화성 리간드(affinity ligand), 여기에서 친화성 리간드는 기질, 저해제, 활성화제, 신경전달물질, 방사성 동위원소, 또는 이들의 배합물;
(e) 방사능표지(radioactive label), 32P, 35S, 형광다이, 전자밀도 반응제(electron dense reagent), 효소, 비오틴, 스트렙타비딘(streptavidin), 디옥시제닌(dioxigenin), 햅텐(hapten), 면역성 단백질(immunogenic protein), 타겟에 컴플러멘터리한 서열을 갖는 핵산 분자(nucleic acid molecule with a sequence complementary to a target) 또는 이들의 배합물;
(f) 면역조절 화합물(immunomodulatory compound), 항-암제(anticancer agent), 항-바이러스제(anti-viral agent), 항-박테리아제(anti-bacterial agent), 항-곰팡이제(anti-fungal agent), 및 항-기생충제(anti-parasitic agent), 또는 이들의 배합물;
(g) 타목시펜(tamoxifen), 랄록시펜(raloxifene), 드롤록시펜(droloxifene), 4-하이드록시타목시펜(4-hydroxytamoxifen), 트리옥시펜(trioxifene), 케옥시펜(keoxifene), LY117018, 오나프리스톤(onapristone) 또는 토레미펜(toremifene);
(h) 4(5)-이미다졸, 아미노글루테티미드(aminoglutethimide), 메제스톨 아세테이트(megestrol acetate), 엑스메스탄(exemestane), 레트로졸(letrozole)Ehsms 아나스트로졸(anastrozole)
(i) 플루타미드(flutamide), 닐루타미드(nilutamide), 비칼루타미드(bicalutamide), 리우프롤라이드(leuprolide), 고세렐린(goserelin), 또는 트록사시타빈(troxacitabine);
(j) 아로마타아제 저해제;
(k) 단백질 키나아제 저해제;
(l) 리피드 키나아제 저해제;
(m) 안티센스 올리고뉴클레오티드;
(n) 리보자임;
(o) 백신; 및
(p) 항-맥관형성제(anti-angiogenic agent)
다른 일 양태에서 본 발명은 다음 일반식 Ia의 항체-약물 접합체를 제공한다:
[일반식 Ia]
Ab-(Linker-D)n
상기 식에서,
Ab는 항-ROR1 항체이고,
Linker는 링커이며,
D는 활성제로 피롤로벤조디아제핀 이량체이고,
상기 피롤로벤조디아제핀 이량체의 N10 또는 N10' 위치를 통해 링커와 항체가 연결된다.
피롤로벤조디아제핀 이량체의 N10 및 N10' 위치에 각각 독립적으로 -C(O)O-*, -S(O)O-*, -C(O)-*, -C(O)NR-*, -S(O)2NR-*, -(P(O)R')NR-*, -S(O)NR-*, 및 -PO2NR-*기로 이루어진 그룹으로부터 선택되는 어느 하나가 부착되며,
RX 및 RX'는 독립적으로 H, OH, N3, CN, NO2, SH, NH2, ONH2, NHNH2, 할로, C1-8 알킬, C3-8 사이클로알킬, C1-8 알콕시, C1-8 알킬티오, C3-20 헤테로아릴, C5-20 아릴 또는 모노- 또는 디(di)-C1-8 알킬아미노로부터 선택되며;
여기에서 *은 링커가 부착되는 부분이고,
여기에서, R 및 R'은 각각 독립적으로 H, OH, N3, CN, NO2, SH, NH2, ONH2, NHNH2, 할로, 치환되거나 비치환된 C1-8알킬, 치환되거나 비치환된 C3-8사이클로알킬, 치환되거나 비치환된 C1-8알콕시, 치환되거나 비치환된 C1-8알킬티오, 치환되거나 비치환된 C3-20헤테로아릴, 치환되거나 비치환된 C5-20아릴 또는 모노- 또는 다이-C1-8알킬아미노이고,
여기에서 C1-8알킬, C3-8사이클로알킬, C1-8알콕시, C1-8알킬티오, C3-20헤테로아릴, C5-20아릴이 치환되는 경우, H, OH, N3, CN, NO2, SH, NH2, ONH2, NNH2, 할로, C1-6알킬, C1-6알콕시 및 C6-12아릴로 이루어진 그룹으로부터 선택되는 치환기로 치환되는,
피롤로벤조디아제핀 이량체 전구체(pyrrolobenzodiazepine dimer prodrug), 이의 약학적으로 허용되는 염 또는 용매화물은 활성제로 사용할 수 있다.
보다 구체적으로, 피롤로벤조디아제핀 이량체의 N10 위치에서 X 또는 N'10 위치에서 X '로 치환되고, 여기서 X 또는 X'는 피롤로벤조디아제핀 다이머를 링커에 연결하며;
X 및 X'는 각각 독립적으로 -C(O)O*, -S(O)O-*, -C(O)-*, -C(O)NRX-*, -S(O)2NRX-*, -P(O)R'NRX-*, -S(O)NRX-*, 또는 -PO2NRX-*로부터 선택되고;
RX 및 RX'는 독립적으로 H, OH, N3, CN, NO2, SH, NH2, ONH2, NHNH2, 할로, C1-8 알킬, C3-8 사이클로알킬, C1-8 알콕시, C1-8 알킬티오, C3-20 헤테로아릴, C5-20 아릴 또는 모노- 또는 디(di)-C1-8 알킬아미노로부터 선택된다.
본 발명의 일 양태에서, 피롤로벤조디아제핀 이량체 전구체가 제공된다. 본 발명에 따른 전구체 형태로 투여하는 경우, 혈중 노출 시 추가적인 반응에 의해 유효한 약물로 전환되어야 할 필요가 있기 때문에 예상치 못한 링커의 분해 시에 생길 수 있는 부작용의 발생가능성을 미연에 방지할 수 있고, 정상세포에 대한 독성이 감소하며, 약물이 보다 안정적이라는 점에서 기존 PBD 약물에 비해 유리한 점이 있다.
또한 항체-약물 접합체 제조 시, 기존 방법으로 제조한 항체-약물 접합체의 경우 불순물의 함량이 높고 노출된 이민 그룹이 뉴클레오필(nucleophile)의 공격을 받아 원치 않는 구조의 약물이 생성될 우려가 있는 반면, 본 발명에 따른 방법으로 제조된 항체-약물 접합체는 순도가 높아 분리가 용이하다는 장점이 있고, 기존 PBD 또는 PBD 이량체에 비하여 물성이 보다 향상되는 것으로 나타났다.
본 발명의 일 양태에서, 피롤로벤조디아제핀 이량체 전구체는 하기 일반식 X 또는 일반식 XI 구조를 갖는 것을 특징으로 하는, 피롤로벤조디아제핀 이량체 전구체, 이의 약학적으로 허용되는 염 또는 용매화물이다:
[일반식 X]

[일반식 XI]

상기 식에서,
상기 점선은 C1과 C2 사이, C2와 C3 사이, C'1과 C'2 사이, 또는 C'2과 C'3 사이의 이중 결합의 선택적 존재를 나타내며;
RX1 및 RX1'는 독립적으로 H, OH, =O, =CH2, CN, Rm, ORm, =CH-Rm'
=C(Rm')2, O-SO2-Rm, CO2Rm, CORm, 할로 및 디할로로부터 선택되고;
Rm'는 Rm, CO2Rm, CORm, CHO, CO2H, 및 할로로부터 선택되며,
각각의 Rm는 독립적으로 C1-12 알킬, C2-12 알케닐, C2-12 알키닐, C5-20 아릴, C5-20 헤테로아릴, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클릴, 3 내지 7-원 헤테로사이클로알킬, 및 5 내지 7-원 헤테로아릴로 이루어진 군으로부터 선택되고;
RX2, RX2' RX3, RX3', RX5, 및 RX5'는 독립적으로 H, Rm, OH, ORm, SH, SRm, NH2, NHRm, NRm 2, NO2, Me3Sn 및 할로로부터 선택되며;
RX4 및 RX4'는 독립적으로 H, Rm, OH, ORm, SH, SRm, NH2, NHRm, NRm 2, NO2, Me3Sn, 할로, C1-6 알킬 C1-6 알콕시, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-12 아릴, 5 내지 7-원 헤테로아릴, -CN, -NCO, -ORn, -OC(O)Rn, -OC(O)NRnRn', -OS(O)Rn, -OS(O)2Rn, -SRn, -S(O)Rn, -S(O)2Rn, -S(O)NRnRn', -S(O)2NRnRn', -OS(O)NRnRn', -OS(O)2NRnRn', -NRnRn', -NRnC(O)Ro, -NRnC(O)ORo, -NRnC(O)NRoRo', -NRnS(O)Ro, -NRnS(O)2Ro, -NRnS(O)NRoRo', -NRnS(O)2NRoRo', -C(O)Rn, -C(O)ORn 및 -C(O)NRnRn'로 부터 선택되고;
X 및 X'는 독립적으로 -C(O)O*, -S(O)O-*, -C(O)-*, -C(O)NRX-*, -S(O)2NRX-*, -P(O)R'NRX-*, -S(O)NRX-*, 또는 -PO2NRX-*로부터 선택되며;
RX 및 RX'는 독립적으로 H, OH, N3, CN, NO2, SH, NH2, ONH2, NHNH2, 할로, C1-8 알킬, C3-8 사이클로알킬, C1-8 알콕시, C1-8 알킬티오, C3-20 헤테로아릴, C5-20 아릴 또는 모노- 또는 디(di)-C1-8 알킬아미노로 부터 선택되며;
Y 및 Y'는 독립적으로 O, S, 및 N(H)으로 부터 선택되고;
RX6는 독립적으로 C3-12 알킬렌, C3-12 알케닐렌, 또는 C3-12 헤테로알킬렌으로 부터 선택되며;
RX7 및 RX7' 는 독립적으로 H, C1-6 알킬, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로 알킬, 3 내지 7-원 헤테로사이클로알킬, C6-10 아릴, 5 내지 7-원 헤테로아릴, -ORr, -OC(O)Rr, -OC(O)NRrRr', -OS(O)Rr, -OS(O)2Rr, -SRr, -S(O)Rr, -S(O)2Rr, -S(O)NRrRr', -S(O)2NRrRr', -OS(O)NRrRr', -OS(O)2NRrRr', -NRrRr', -NRrC(O)Rs, -NRrC(O)ORs, -NRrC(O)NRsRs', -NRrS(O)Rs, -NRrS(O)2Rs, -NRrS(O)NRsRs', -NRrS(O)2NRsRs, -C(O)Rr, -C(O)ORs 또는 -C(O)NRrRr'으로 부터 선택되고;
각각의 Rr, Rr', Rs, 및 Rs' 은 독립적으로 H, C1-7 알킬, C2-7 알케닐, C2-7 알키닐, C3-13 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-10 아릴, 및 5 내지 7-원 헤테로아릴로 부터 선택되며;
각 RX8 및 RX8'는 독립적으로 H, C1-6 알킬, C2-6 알케닐, C2-6 알키닐, C3-6 헤테로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-10 아릴, 5 내지 7-원 헤테로아릴, -S(O)Rm, -S(O)2Rm, -S(O)NRmRm', -S(O)2NRmRm', -NRmRm', -NRmC(O)Rm, -NRmC(O)ORn, -NRmC(O)NRnRn', -NRmS(O)Rn, -NRmS(O)2Rn, -NRmS(O)NRnRn', -NRmS(O)2NRnRn', -C(O)Rm, -C(O)ORm 및 -C(O)NRmRm'로 부터 선택되고;
Za 는 ORX12a, NRX12aRX12a, 또는 SRX12a로 부터 선택되며;
Zb 는 ORX13a, NRX13aRX13a, 또는 SRX13a로 부터 선택되고;
Za'는 ORX12a, NRX12aRX12a, 또는 SRX12a로 부터 선택되며;
Zb'는 ORX13a', NRX13'RX13a' 또는 SRX13a'로 부터 선택되고;
각 RX12a, RX12a', RX13a' 및 RX13a'는 독립적으로 H, C1-6 알킬, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-10 아릴, 5 내지 7-원 헤테로아릴, -C(O)RX15a, -C(O)ORX15a 및 -C(O)NRX15aRX15a'로 부터 선택되고; 및
각각의 RX15a 및 RX15a' 는 독립적으로 C1-12 알킬, C2-12 알케닐, C2-12 알키닐, C5-20 아릴, C5-20 헤테로아릴, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클릴, 3 내지 7-원 헤테로사이클로알킬, 및 5 내지 7-원 헤테로아릴로부터 선택되며;
상기 RX13a 및 RX14a 는 이들이 부착된 원자와 함께 임의적으로 결합하여 3 내지 7-원 헤테로사이클릴, 3 내지 7-원 헤테로사이클로알킬, 또는 3 내지 7-원 헤테로아릴을 형성하고, 및 RX13a' 및 RX14a'이들이 부착된 원자와 함께 임의적으로 결합하여 3 내지 7-원 헤테로사이클릴, 3 내지 7-원 헤테로사이클로알킬, 또는 3 내지 7-원 헤테로 아릴을 형성하며; 및
상기 각각의 Rn, Rn', Ro, Ro', Rp, 및 Rp' 는 독립적으로 H, C1-7 알킬, C2-7 알케닐, C2-7 알키닐, C3-13 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-10 아릴, 및 5 내지 7-원 헤테로아릴로부터 선택된다.
또한, 상기 Rm는 독립적으로 C1-12 알킬, C2-12 알케닐, C2-12 알키닐, C5-20 아릴, C5-20 헤테로아릴, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클릴, 3 내지 7-원 헤테로사이클로알킬, 및 5 내지 7-원 헤테로아릴로 이루어진 군으로부터 선택되고,
상기 Rm는 추가적으로 C1-12 알킬, C2-12 알케닐, C2-12 알키닐, C5-20 아릴, C5-20 헤테로아릴, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클릴, 3 내지 7-원 헤테로사이클로알킬, 또는 5 내지 7-원 헤테로아릴로 치환된다.
또한, 상기 RX4 및 RX4'는 독립적으로 H, Rm, OH, ORm, SH, SRm, NH2, NHRm, NRmRm', NO2, Me3Sn, 할로, C1-6 알킬 C1-6 알콕시, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-12 아릴, 5 내지 7-원 헤테로아릴, -CN, -NCO, -ORn, -OC(O)Rn, -OC(O)NRnRn', -OS(O)Rn, -OS(O)2Rn, -SRn, -S(O)Rn, -S(O)2Rn, -S(O)NRnRn', -S(O)2NRnRn', -OS(O)NRnRn', -OS(O)2NRnRn', -NRnRn', -NRnC(O)Ro, -NRnC(O)ORo, -NRnC(O)NRoRo', -NRnS(O)Ro, -NRnS(O)2Ro, -NRnS(O)NRoRo', -NRnS(O)2NRoRo', -C(O)Rn, -C(O)ORn 및 -C(O)NRnRn'로 부터 선택되고,
상기 RX4 또는 RX4'는 C1-6 알킬, C1-6 알콕시, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-12 아릴 또는 5 내지 7-원 헤테로아릴이고, 추가적으로 하나 이상의 C1-6 알킬, C1-6 알콕시, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-10 아릴, 5 내지 7-원 헤테로아릴, -ORp, -OC(O)Rp, -OC(O)NRpRp', -OS(O)Rp, -OS(O)2Rp, -SRp, -S(O)Rp, -S(O)2Rp, -S(O)NRpRp', -S(O)2NRpRp', -OS(O)NRpRp', -OS(O)2NRpRp', -NRpRp', -NRpC(O)Rq, -NRpC(O)ORq, -NRpC(O)NRqRq', -NRpS(O)Rq, -NRpS(O)2Rq, -NRpS(O)NRqRq', -NRpS(O)2NRqRq', -C(O)Rp, -C(O)ORp 또는 -C(O)NRpRp로 치환된다.
또한, 상기 RX7 및 RX7' 는 독립적으로 H, C1-6 알킬, C2-6 알케닐, C2-6알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C6-10 아릴, 5 내지 7-원 헤테로아릴, -ORr, -OC(O)Rr, -OC(O)NRrRr', -OS(O)Rr, -OS(O)2Rr, -SRr, -S(O)Rr, -S(O)2Rr, -S(O)NRrRr', -S(O)2NRrRr', -OS(O)NRrRr', -OS(O)2NRrRr', -NRrRr', -NRrC(O)Rs, -NRrC(O)ORs, -NRrC(O)NRsRs', -NRrS(O)Rs, -NRrS(O)2Rs, -NRrS(O)NRsRs', -NRrS(O)2NRsRs, -C(O)Rr, -C(O)ORs 또는 -C(O)NRrRr'으로부터 선택되고,
상기 RX7 또는 RX7' 는 C1-6 알킬, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C6-10 아릴, 5 내지 7-원 헤테로아릴이고, 추가적으로 C1-6 알킬, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C6-10 아릴, 5 내지 7-원 헤테로아릴, -ORt, -OC(O)Rt, -OC(O)NRtRt', -OS(O)Rt, -OS(O)2Rt, -SRt, -S(O)Rt, -S(O)2Rt, -S(O)NRtRt', -S(O)2NRtRt', -OS(O)NRtRt', -OS(O)2NRtRt', -NRtRt', -NRtC(O)Ru, -NRtC(O)ORu, -NRtC(O)NRuRu', -NRtS(O)Ru, -NRtS(O)2Ru, -NRtS(O)NRuRu', -NRtS(O)2NRuRu', -C(O)Rt, -C(O)ORt 또는 -C(O)NRtRt'로 치환되며,
상기 Rr, Rr', Rs, Rs', Rt, Rt', Ru 및 Ru'는 독립적으로 H, C1-7 알킬, C2-7 알케닐, C2-7 알키닐, C3-13 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-10 아릴, 및 5 내지 7-원 헤테로아릴로부터 선택된다.
또한, 상기 RX1 및 RX1' 는 독립적으로 Rm 으로부터 선택되고; 및
Rm은 C1-6 알킬, C2-6 알케닐, C5-7 아릴 및 C3-6 헤테로아릴로부터 선택된다.
또한, 상기 RX2 , RX2', RX3, RX3', RX5, 및 RX5'은 독립적으로 H 또는 OH로부터 선택된다.
또한, RX4 및 RX4' 는 독립적으로 Rm으로부터 선택되고; 및
Rm 은 C1-6 알콕시이다.
또한, 상기 RX4 및 RX4' 는 독립적으로 메톡시, 에톡시 및 부톡시로 이루어진 군으로부터 선택되는 어느 하나이다.
또한, 상기 Y 및 Y'는 O이다.
또한, 상기 RX6 는 C3-12 알킬렌, C3-12 알케닐렌 또는 C3-12 헤테로알킬렌이고, 상기 RX6은 -NH2, -NHRm, -NHC(O)Rm, -NHC(O)CH2-[OCH2CH2]n-RXX, 또는 -[CH2CH2O]n-RXX치환되고;
상기 RXX는 H, OH, N3, CN, NO2, SH, NH2, ONH2, NHNH2, 할로, C1-8 알킬, C3-8 사이클로알킬, C1-8 알콕시, C1-8 알킬티오, C3-20 헤테로아릴, C5-20 아릴 또는 모노- 또는 디-C1-8 알킬 아미노; 및
n은 1 내지 6의 정수이다.
또한, 본 발명의 일 양태에서, 상기 활성제는 일반식 XII 또는 일반식 XIII로 기재되는 피롤로벤조디아제핀 이량체이다:
[일반식 XII]

[일반식 XIII]

상기 Xa 및 Xa'는 독립적으로 결합 또는 C1-6 알킬렌으로부터 선택되고;
ZX' 및 ZX 는 독립적으로 수소, C1-8 알킬, 할로겐, 시아노, 나이트로,  ,
,  또는 -(CH2)m-OCH3로부터 선택되며;
또는 -(CH2)m-OCH3로부터 선택되며;
각각의 R80, R90 및 R100 는 수소, C1-8 알킬, C2-6 알케닐, 및 C1-6 알콕시로부터 선택되고; 및
m은 0 내지 12의 정수임.
상기 ZX' 및 ZX 는 독립적으로 수소,  ,
,  및 -(CH2)m-OCH3로 이루어진 군으로 부터 선택되는 어느 하나이고,
및 -(CH2)m-OCH3로 이루어진 군으로 부터 선택되는 어느 하나이고,
상기 각각의 R80, R90 및 R100 는 수소, C1-3 알킬 및 C1-3 알콕시로 이루어진 군으로부터 선택되는 어느 하나이며,
m은 1 내지 6의 정수이고,
상기 활성제는


























으로 이루어진 군으로부터 선택되는 어느 하나이다.
다른 양태에서 본 발명은 또한 ROR1의 과발현과 관련된 질환의 예방 또는 치료를 위한 약제의 제조에 있어서, 본 발명에 따른 항체-약물 접합체 또는 이의 약학적으로 허용되는 염 또는 용매화물의 용도가 제공한다.
여기서 ROR1의 과발현과 관련된 질환은 암을 들 수 있고, 암의 예로는 만성 림프구성 백혈병(CLL), B세포 백혈병, 림프종, 급성 골수성 백혈병(AML), 버킷 림프종, 외투세포림프종(MCL), 급성림프구성백혈병(ALL), 미만성거대B세포림프종(DLBCL), 여포성림프종(FL), 변연부림프종(MZL), 유방암, 신장암, 난소암, 위암, 간암, 폐암, 대장암, 췌장암, 피부암, 방광암, 고환암, 자궁암, 전립선암, 비소세포 폐암(NSCLC), 신경모세포종, 뇌암, 결장암, 상피 편평세포암, 흑색종, 골수종, 자궁경부암, 갑상선암, 두경부암, 또는 부신암을 들 수 있으나, 이로 제한하는 것은 아니다.
본 발명의 다른 양태에서 본 발명은 본 발명에 따른 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물을 포함하는 ROR1의 과발현과 관련된 질환의 예방 또는 치료용 약학 조성물을 제공한다.
또한, 약학적으로 유효한 양의 화학 치료제(chemotherapeutic agent), 예를 들어 1종 이상의 치료적 공동-작용제(therapeutic co-agent); 및 약학적으로 허용되는 부형제를 추가적으로 포함할 수 있다.
본 발명의 일 양태에서, 상기 치료적 공동-작용제는 ROR1의 과발현과 관련된 질환에 대한 예방, 개선 또는 치료효과를 나타내는 작용제, 또는 ROR1의 과발현과 관련된 질환 치료제 투약 시 나타나는 부작용의 발현을 감소시킬 수 있는 작용제, 또는 면역력 증진 효과를 나타내는 작용제 등일 수 있으나 이로 제한되는 것은 아니고, 예를 들어 피롤로벤조디아제핀과 함께 배합제의 형태로 적용하였을 때 치료적으로 유용한 효과를 나타내고/거나, 피롤로벤조디아제핀의 안정성을 보다 향상시키고/거나, 피롤로벤조디아제핀 투여 시 나타날 수 있는 부작용을 감소시키고/거나, 면역력의 증진을 통해 치료효과를 극대화할 수 있는 효과를 나타내는 제제라면 어떤 것이든 배합하여 적용할 수 있음을 의미한다.
본 발명의 다른 양태에서 본 발명은 ROR1의 과발현과 관련된 질환을 치료하기 위한 유효량의 본 발명에 따른 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물을 대상체에게 투여하는 단계를 포함하는 ROR1의 과발현과 관련된 질환을 갖는 대상체에서의 ROR1의 과발현과 관련된 질환의 치료 방법을 제공하며, 이 때 하나 이상의 항-과증식, 세포정지성 또는 세포독성물질을 배합하여 투여하는 방법을 또한 제공한다.
본 발명의 일 양태에서, 상기 약학적 조성물을 환자에 투여하는 단계를 포함하는, 암 치료방법이 제공된다.
본 발명에 따른 접합체는 대상체의 목표 위치에 활성제, 보다 구체적으로 피롤로벤조디아제핀을 제공하는데 사용하기에 적합하다. 본 발명에 따른 접합체는 링커 부분을 전혀 보유하지 않는 활성 피롤로벤조디아제핀을 방출시키며, 피롤로벤조디아제핀 화합물의 반응성에 영향을 줄 수 있는 것은 존재하지 않는다.
본 발명에 따른 항체-약물 접합체는 본 발명에 따른 항체를 포함함으로써, ROR1 발현 세포에 약물을 효과적이면서도 특이적 및 선택적으로 전달할 수 있고, 항체에 약물이 안정적으로 결합되어 생체내 안정성을 유지하면서 목적하는 세포독성을 나타낼 수 있도록 하며, 특히 혈장 내에서 보다 안정하고 체내 순환시에도 안정적이며, 약물이 암세포 내에서 쉽게 방출되어 약효를 극대화할 수 있는 자가-희생기를 포함하는 링커 기술을 접목시킴으로써, 약물 및/또는 톡신이 표적 세포에 안정적으로 도달하여 약효를 효과적으로 발휘하면서도 독성을 크게 낮출 수 있는, 약물-링커-리간드 시스템을 제공하는 효과를 나타낸다.
도 1은 본 발명의 일 구현예에 따라 제조된 항-ROR1 단일클론 파아지항체의 ROR1 항원에 대한 결합능 분석 (ELISA) 결과이다. 각 항-ROR1 단일클론 항체가 세포외영역 ROR1 항원에 특이적으로 결합하는 것을 나타낸다. 도 1에 BCMA-Fc는 음성 대조군으로 각 항-ROR1 단일클론 항체가 ROR1 항원에만 특이적으로 결합하고 BCMA 단백질 또는 태그로 사용한 Fc에는 결합하지 않음을 나타낸다.
도 2는 본 발명의 일 구현예에 따른 항-ROR1 단일클론 파아지 항체의 세포 표면발현 ROR1 항원에 대한 결합능 측정 (FACS) 결과이며, ROR1을 세포 표면에서 발현하는 세포로는 JeKo-1 세포주를 사용하였다. 각 항-ROR1 단일클론 항체가 세포 표면에서 발현되는 ROR1에 특이적으로 결합하는 것을 나타낸다.
도 3은 본 발명의 일 구현예에 따라 제조된 항-ROR1 IgG 항체의 인간 ROR1 항원에 대한 결합능 분석 (ELISA) 결과이다. 각 항체들이 농도의존적으로 인간 ROR1 항원에 결합하는 것을 나타낸다. 상기 결과는 단일클론 파아지 항체를 IgG 형태로 변경한 후에도 ROR1에 대한 결합능을 유지하는 것을 나타낸다.
도 4는 본 발명의 일 구현예에 따라 제조된 항-ROR1 IgG 항체의 마우스 ROR1 항원에 대한 결합능 분석 (ELISA) 결과이다. 각 항체들이 농도의존적으로 마우스 ROR1 항원에 결합하는 것을 나타낸다. 본 실험을 통해 본 발명의 항-ROR1 항체가 마우스 ROR1에 대한 교차반응성이 있음을 확인하였다. 비교군으로 사용한 2A2 항체는 마우스 ROR1에 교차반응성이 있으나 본 발명의 항-ROR1 항체 대비 결합 정도가 상대적으로 미약한 것으로 나타났다.
도 5는 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체의 세포 표면 발현ROR1 항원에 대한 결합능 측정 (FACS) 결과로, CHO-human ROR1 세포주는 인간 ROR1을, CHO-human ROR2는 인간 ROR2를, CHO-mouse ROR1은 마우스 ROR1을 인위적으로 과발현시킨 세포주이다. 각 항체는 세포 표면에서 발현되는 인간 ROR1에 특이적으로 결합하고 패밀리 단백질인 인간 ROR2에는 결합하지 않는 것으로 나타났다. 또한, 마우스 ROR1을 인위적으로 과발현시킨 세포주에도 결합하는 것을 확인함으로써 본 발명의 항-ROR1 항체가 마우스 ROR1에 대한 종간 교차반응성이 있음을 확인하였다. 비교군으로 사용한 2A2 항체는 마우스 ROR1에 교차반응성이 있으나 본 발명의 항-ROR1 항체 대비 결합 정도가 상대적으로 미약한 것으로 나타났다.
도 6은 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체의 세포 표면 발현 ROR1 항원에 대한 결합능 측정 (FACS) 결과로, ROR1 발현 양성 세포주로 JeKo-1 및 Mino 세포주, ROR1 음성 세포주로 MCF7 세포주를 사용하였다. 각 항체들은 세포 표면에서 발현되는 ROR1에 특이적으로 결합하고, ROR1을 발현하지 않는 세포주인 MCF7에서는 결합하지 않는 것으로 나타났다.
도 7은 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체의 세포 표면 발현 ROR1 항원에 대한 결합능 측정 (FACS) 결과이다. 인간 ROR1을 마우스 대장암 세포주인 MC38에 인위적으로 과발현시킨 MC38 human ROR1 세포주를 사용하였다. 각 항체들은 인간 ROR1을 과발현한 세포주에 농도의존적으로 결합하는 것으로 나타났다.
도 8은 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체의 세포발현 ROR1 항원에 대한 결합능을 다양한 암세포주에서 측정한 결과이다(FACS).
도 9는 본 발명의 일 구현예에 따른 항-ROR1 항체의 마우스 이종종양이식 모델에서의 암억제 효능을 분석한 결과이다.
도 10은 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체의 작용기전을 분석한 결과이다. 항체에 의한 암의 성장 억제는 다양한 기전 예를 들면 자가세포사멸 유도, 암세포 분열 억제, 암혈관형성 억제, 및/또는 면역세포 활성화 등에 의해 나타날 수 있으며, 항체별로 동일 또는 상이한 기전을 나타낼 수 있다. 도 10에서는 가능한 한 가지 기전으로서 세포사멸 여부를 분석하였으며, ROR1을 발현하는 세포주에서 본 발명에 따른 항-ROR1 항체를 처리한 결과 항체가 다량체를 형성하면서 세포사멸을 유도할 수 있는 것으로 나타났으며, 비교군으로 사용한 2A2 항체는 다량체를 형성하는 경우에도 세포사멸을 유도하지 못하는 것으로 나타났다.
도 11a는 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체-MMAE 컨쥬게이트(DAR4)의 특성을 나타낸 도이다.
도 11b는 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체-dPBD 컨쥬게이트(DAR2)의 특성을 나타낸 도이다.
도 12는 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체-dPBD 컨쥬게이트(DAR2)의 MDA-MB-468 유방암 세포주 이식 마우스 모델에서의 암억제 효능을 분석한 결과이다. 본 발명에 따른 항-ROR1 항체-dPBD 컨쥬게이트(DAR2)이 ROR1 발현 유방암 세포주 이식 마우스 모델에서 암종 제거에 효과적임을 나타낸다.
도 13은 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체-dPBD 컨쥬게이트(DAR2)의 MDA-MB-231 유방암 세포주 이식 마우스 모델에서의 암억제 효능을 분석한 결과이다. 본 발명에 따른 항-ROR1 항체-dPBD 컨쥬게이트(DAR2)이 ROR1 발현 유방암 세포주 이식 마우스 모델에서 암종 제거에 효과적임을 나타낸다.
도 14는 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체-dPBD 컨쥬게이트(DAR2)의 HCC1187 폐암 세포주 이식 마우스 모델에서의 암억제 효능을 분석한 결과이다. 본 발명에 따른 항-ROR1 항체-dPBD 컨쥬게이트(DAR2)이 ROR1 발현 폐암 세포주 이식 마우스 모델에서 암종 제거에 효과적임을 나타낸다.
도 15는 본 발명의 일 구현예에 따라 제조된 ROR1 항체-dPBD 컨쥬게이트(DAR2) 및 항-ROR1 항체-MMAE 컨쥬게이트(DAR4)의 Calu-3 유방암 세포주 이식 마우스 모델에서의 암억제 효능을 분석한 결과이다. 본 발명에 따른 항-ROR1 항체-dPBD 컨쥬게이트(DAR2) 및 항-ROR1 항체-MMAE 컨쥬게이트(DAR4)가 ROR1 발현 유방암 세포주 이식 마우스 모델에서 암종 제거에 효과적임을 나타낸다.
도 16은 본 발명 따른 항-ROR1 항체-약물 컨쥬게이트 간 Jeko-1 외투세포림프종 세포주 이식 마우스 모델에서의 암억제 효능을 비교한 결과이다.
도 17은 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체-dPBD 컨쥬게이트(DAR2) 및 항-ROR1 항체-MMAE 컨쥬게이트(DAR4)의 본 발명에 따른 항-ROR1 항체-dPBD 컨쥬게이트(DAR2) 및 항-ROR1 항체-MMAE 컨쥬게이트(DAR4)이 ROR1 발현 외투세포림프종 세포주 이식 마우스 모델에서 암종 제거에 효과적임을 나타낸다.
도 2는 본 발명의 일 구현예에 따른 항-ROR1 단일클론 파아지 항체의 세포 표면발현 ROR1 항원에 대한 결합능 측정 (FACS) 결과이며, ROR1을 세포 표면에서 발현하는 세포로는 JeKo-1 세포주를 사용하였다. 각 항-ROR1 단일클론 항체가 세포 표면에서 발현되는 ROR1에 특이적으로 결합하는 것을 나타낸다.
도 3은 본 발명의 일 구현예에 따라 제조된 항-ROR1 IgG 항체의 인간 ROR1 항원에 대한 결합능 분석 (ELISA) 결과이다. 각 항체들이 농도의존적으로 인간 ROR1 항원에 결합하는 것을 나타낸다. 상기 결과는 단일클론 파아지 항체를 IgG 형태로 변경한 후에도 ROR1에 대한 결합능을 유지하는 것을 나타낸다.
도 4는 본 발명의 일 구현예에 따라 제조된 항-ROR1 IgG 항체의 마우스 ROR1 항원에 대한 결합능 분석 (ELISA) 결과이다. 각 항체들이 농도의존적으로 마우스 ROR1 항원에 결합하는 것을 나타낸다. 본 실험을 통해 본 발명의 항-ROR1 항체가 마우스 ROR1에 대한 교차반응성이 있음을 확인하였다. 비교군으로 사용한 2A2 항체는 마우스 ROR1에 교차반응성이 있으나 본 발명의 항-ROR1 항체 대비 결합 정도가 상대적으로 미약한 것으로 나타났다.
도 5는 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체의 세포 표면 발현ROR1 항원에 대한 결합능 측정 (FACS) 결과로, CHO-human ROR1 세포주는 인간 ROR1을, CHO-human ROR2는 인간 ROR2를, CHO-mouse ROR1은 마우스 ROR1을 인위적으로 과발현시킨 세포주이다. 각 항체는 세포 표면에서 발현되는 인간 ROR1에 특이적으로 결합하고 패밀리 단백질인 인간 ROR2에는 결합하지 않는 것으로 나타났다. 또한, 마우스 ROR1을 인위적으로 과발현시킨 세포주에도 결합하는 것을 확인함으로써 본 발명의 항-ROR1 항체가 마우스 ROR1에 대한 종간 교차반응성이 있음을 확인하였다. 비교군으로 사용한 2A2 항체는 마우스 ROR1에 교차반응성이 있으나 본 발명의 항-ROR1 항체 대비 결합 정도가 상대적으로 미약한 것으로 나타났다.
도 6은 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체의 세포 표면 발현 ROR1 항원에 대한 결합능 측정 (FACS) 결과로, ROR1 발현 양성 세포주로 JeKo-1 및 Mino 세포주, ROR1 음성 세포주로 MCF7 세포주를 사용하였다. 각 항체들은 세포 표면에서 발현되는 ROR1에 특이적으로 결합하고, ROR1을 발현하지 않는 세포주인 MCF7에서는 결합하지 않는 것으로 나타났다.
도 7은 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체의 세포 표면 발현 ROR1 항원에 대한 결합능 측정 (FACS) 결과이다. 인간 ROR1을 마우스 대장암 세포주인 MC38에 인위적으로 과발현시킨 MC38 human ROR1 세포주를 사용하였다. 각 항체들은 인간 ROR1을 과발현한 세포주에 농도의존적으로 결합하는 것으로 나타났다.
도 8은 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체의 세포발현 ROR1 항원에 대한 결합능을 다양한 암세포주에서 측정한 결과이다(FACS).
도 9는 본 발명의 일 구현예에 따른 항-ROR1 항체의 마우스 이종종양이식 모델에서의 암억제 효능을 분석한 결과이다.
도 10은 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체의 작용기전을 분석한 결과이다. 항체에 의한 암의 성장 억제는 다양한 기전 예를 들면 자가세포사멸 유도, 암세포 분열 억제, 암혈관형성 억제, 및/또는 면역세포 활성화 등에 의해 나타날 수 있으며, 항체별로 동일 또는 상이한 기전을 나타낼 수 있다. 도 10에서는 가능한 한 가지 기전으로서 세포사멸 여부를 분석하였으며, ROR1을 발현하는 세포주에서 본 발명에 따른 항-ROR1 항체를 처리한 결과 항체가 다량체를 형성하면서 세포사멸을 유도할 수 있는 것으로 나타났으며, 비교군으로 사용한 2A2 항체는 다량체를 형성하는 경우에도 세포사멸을 유도하지 못하는 것으로 나타났다.
도 11a는 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체-MMAE 컨쥬게이트(DAR4)의 특성을 나타낸 도이다.
도 11b는 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체-dPBD 컨쥬게이트(DAR2)의 특성을 나타낸 도이다.
도 12는 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체-dPBD 컨쥬게이트(DAR2)의 MDA-MB-468 유방암 세포주 이식 마우스 모델에서의 암억제 효능을 분석한 결과이다. 본 발명에 따른 항-ROR1 항체-dPBD 컨쥬게이트(DAR2)이 ROR1 발현 유방암 세포주 이식 마우스 모델에서 암종 제거에 효과적임을 나타낸다.
도 13은 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체-dPBD 컨쥬게이트(DAR2)의 MDA-MB-231 유방암 세포주 이식 마우스 모델에서의 암억제 효능을 분석한 결과이다. 본 발명에 따른 항-ROR1 항체-dPBD 컨쥬게이트(DAR2)이 ROR1 발현 유방암 세포주 이식 마우스 모델에서 암종 제거에 효과적임을 나타낸다.
도 14는 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체-dPBD 컨쥬게이트(DAR2)의 HCC1187 폐암 세포주 이식 마우스 모델에서의 암억제 효능을 분석한 결과이다. 본 발명에 따른 항-ROR1 항체-dPBD 컨쥬게이트(DAR2)이 ROR1 발현 폐암 세포주 이식 마우스 모델에서 암종 제거에 효과적임을 나타낸다.
도 15는 본 발명의 일 구현예에 따라 제조된 ROR1 항체-dPBD 컨쥬게이트(DAR2) 및 항-ROR1 항체-MMAE 컨쥬게이트(DAR4)의 Calu-3 유방암 세포주 이식 마우스 모델에서의 암억제 효능을 분석한 결과이다. 본 발명에 따른 항-ROR1 항체-dPBD 컨쥬게이트(DAR2) 및 항-ROR1 항체-MMAE 컨쥬게이트(DAR4)가 ROR1 발현 유방암 세포주 이식 마우스 모델에서 암종 제거에 효과적임을 나타낸다.
도 16은 본 발명 따른 항-ROR1 항체-약물 컨쥬게이트 간 Jeko-1 외투세포림프종 세포주 이식 마우스 모델에서의 암억제 효능을 비교한 결과이다.
도 17은 본 발명의 일 구현예에 따라 제조된 항-ROR1 항체-dPBD 컨쥬게이트(DAR2) 및 항-ROR1 항체-MMAE 컨쥬게이트(DAR4)의 본 발명에 따른 항-ROR1 항체-dPBD 컨쥬게이트(DAR2) 및 항-ROR1 항체-MMAE 컨쥬게이트(DAR4)이 ROR1 발현 외투세포림프종 세포주 이식 마우스 모델에서 암종 제거에 효과적임을 나타낸다.
본 발명은 ROR1에 특이적으로 결합할 수 있는 항체의 개발을 근거로 한 것이다.
본 항목에서 사용된 제목은 명세서 기재의 편리성을 위한 것일 뿐, 본 발명을 이로 제한하는 것은 아니다.
본 발명에서 달리 정의하지 않는 한, 본 발명에서 사용된 과학 및 기술적 용어는 본 기술분야의 당업자가 통상적으로 이해하는 대로의 의미를 가진다. 나아가 문맥상 특별히 요구되지 않는다면, 단수는 복수를 포함하고, 복수는 단수를 포함한다.
[정의]
본 명세서에서 하기 정의가 적용된다:
본 명세서에서 "접합체(conjugates)"는 세포독성 화합물의 하나 이상의 분자에 공유결합되는 세포 결합제를 말한다. 여기서, "세포 결합제"는 생물학적 타깃에 대한 친화도를 갖는 분자로서, 예를 들어 리간드, 단백질, 항체, 구체적으로 모노클로날 항체, 단백질 또는 항체 단편, 펩타이드, 올리고뉴클레오티드, 올리고사카라이드일 수 있으며, 결합제는 생물학적 활성 화합물을 생물학적 타깃으로 유도하는 기능을 한다. 본 발명의 일 양태에서, 접합체는 세포 표면 항원을 통해 종양 세포를 표적화하도록 설계될 수 있다. 항원은 비정상적인 세포 타입에서 과다발현되거나 또는 발현되는 세포 표면 항원일 수 있다. 구체적으로, 표적 항원은 증식성 세포(예컨대 종양 세포) 상에서만 발현되는 것일 수 있다. 표적 항원은 통상 증식성 조직 및 정상 조직 사이의 상이한 발현에 기초하여 선택될 수 있다. 본 발명에서 리간드는 링커에 결합된다.
본 발명에서 예를 들면 항원 결합 단편, 단백질, 또는 항체와 같은 폴리펩타이드의 "변이체"는 다른 폴리펩타이드 서열과 비교하여 하나 이상의 아미노산 잔기에 삽입, 결실, 부가 및/또는 치환이 발생한 폴리펩타이드이며, 융합 폴리펩타이드를 포함한다. 또한 단백질 변이체는 단백질 효소 절단, 인산화 또는 기타 후번역 변형에 의해 변형되었으나, 본 발명에 개시된 항체의 생물학적 활성 예를 들면 ROR1에 결합 및 특이성을 유지하는 것을 포함한다. 변이체는 본 발명에 개시된 항체 또는 그 항원 결합단편의 서열과 약 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 또는 80% 동일한 것일 수 있다. 퍼센트 동일성(%) 또는 상동성은 후술하는 바를 참조하여 계산할 수 있다.
일 구현예에서 퍼센트 상동성 또는 동일성은 100Х[(동일한 위치)/min(TGA, TGB)]으로 계산될 수 있으며, 상기 식에서 TGA, TGB 는 비교되는 서열 A 및 B의 잔기의 수 및 내부갭 위치의 합이다 (Russell et al., J. Mol Biol., 244: 332-350 (1994).
본 발명에서 보존적 아미노산 치환은 폴리펩타이드의 활성 또는 항원선을 실질적으로 영향을 미치지 않는 치환을 의미한다. 폴리펩타이드는 하나 이상의 보존적 치환을 포함할 수 있다. 비제한적 예는 하기 표 3에 개시되어 있다.
본 발명에서 폴리펩타이드의 "유도체"는, 삽입, 결실, 부가 또는 치환 변이체와는 상이한, 다른 화학적 모이어티와의 컨쥬게에션을 통해 하나 이상의 잔기에서 화학적으로 변형된 폴리펩타이드를 의미한다.
본 발명에서 폴리펩타이드, 핵산, 숙주 세포 등과 관련하여 사용된 용어 "자연에서 발견되는"은 자연적으로 존재하는 물질을 의미한다.
본 발명에 따른 항체가 인식하는 ROR1 (Receptor Receptor Tyrosine Kinase-Like Orphan Receptor)은 RTK (Receptor Tyrosine Kinase) 패밀리의 막관통 단백질을 지칭한다. 일 구현예에서는 특히 세포외영역을 인식한다. 본 발명에 따른 항체가 인식하는 ROR1은 세포막에 존재하거나 또는 세포막에 존재하지 않은 상태의 세포외영역 일 수 있다. ROR1의 인간 단백질은 937개의 아미노산으로 구성되어 있으며, 아미노산 서열은 NCBI Reference Sequence ID: NP_005003.2, 핵산 서열은 NM_005012.3이다. 본 발명에서 사용된 문맥으로부터 명백하지 않는 한, ROR1은 인간 hROR1을 지칭하나, 본 발명에 따른 항체는 마우스 ROR1도 특이적으로 결합능을 가진다. 마우스 ROR1 아미노산 서열은 GenBank: BAA75480.1로 표시된다.
본 발명에서 "동일성"은 두 개 이상의 폴리펩타이드 또는 두 개 이상의 폴리뉴클레오타이드 서열을 정렬하고 비교하여 결정되는, 두 개 이상 폴리펩타이드 또는 두 개 이상 폴리뉴클레오타이드의 서열 유사성을 의미한다. 이러한 서열간 동일성은 일반적으로 "동일성 퍼센트"로 표시되며, 이는 비교되는 분자 간의 동일한 아미노산 또는 뉴클레오타이드 비율을 의미하며, 비교되는 분자 중, 가장 작은 크기의 분자를 기초로 계산된다. 핵산 또는 폴리펩타이드를 정렬하여 다 분자간의 동일성을 계산하는데 사용될 수 있는 방법은 당업자에게 공지되어 있다.
본 발명에서 "친화성" 또는 "친화도"는 항체 또는 그 항원 결합단편과 항원 사이의 상호작용의 강도이며, 항원의 크기, 모양 및/또는 전하와 같은 항원의 특징 및 항체 또는 항원결합 단편의 CDR 서열에 의해 결정된다. 이러한 친화도를 결정하는 방법은 당업계에 공지되어 있으며, 또한 하기를 참조할 수 있다.
항체 또는 이의 항원 결합 단편은 해리 상수(dissociation constant, KD)가 ≤10-6 M일 때, 항원과 같은 이의 표적에 "특이적으로 결합한다"라고 일컬어진다. 항체는 KD가 ≤1x 10-8 M일 때, "높은 친화성"으로 표적에 특이적으로 결합한다.
본 발명에 사용된, 항체 또는 면역글로불린의 사슬(중쇄 또는 경쇄)의 "항원 결합 단편"은 전장 사슬과 비교하여 일부 아미노산이 결여되었지만, 항원에 특이적으로 결합할 수 있는 항체의 일부를 포함하는 것이다. 이러한 단편은 표적 항원에 특이적으로 결합할 수 있고, 또는 다른 항체 또는 항원 결합 단편과 특정 에피토프에 결합하기 위해 경쟁할 수 있다는 측면에서 생물학적으로 활성이 있다고 할 수 있다. 한 양태에서, 이러한 단편은 전장 경쇄 또는 중쇄 내에 존재하는 적어도 하나의 CDR을 포함하고, 일부 구현예에서, 단쇄 중쇄 및/또는 경쇄, 또는 이의 일부를 포함한다. 이러한 생물학적 활성 단편은 재조합 DNA 기술에 의해 생산되거나, 또는 예를 들면 온전한 항체를 효소적 또는 화학적 절단하여 생산될 수 있다. 면역학적으로 기능적인 면역글로불린 단편에는 이로 제한하는 것은 아니나, Fab, Fab, F(ab)2, scFab, dsFv, Fv, scFV, scFV-Fc, 다이아바디, 미니바디, scAb, 및 dAb를 포함하나 이로 제한하는 것은 아니나, 인간, 마우스, 랫트, 카멜리드 또는 토끼를 포함하는 임의의 포유동물에서 유래될 수 있다. 본 발명에 개시된 하나 이상의 CDR과 같은 항체의 기능적인 부분은 제2의 단백질 또는 저분자 화합물과 공유결합으로 연결되어 특정 표적에 대한 표적 치료제로서 사용될 수 있다.
본 발명에서 "Fc" 영역은 항체의 CH2 및 CH3 도메인을 포함하는 2개의 중쇄 단편을 포함한다. 이들 2개의 중쇄 단편은 2개 이상의 디설파이드 결합 및 CH3 도메인의 소수성 상호작용에 의해 서로 결합되어 있다.
본 발명에서 "Fab 단편"은 1개의 경쇄와 가변 영역 및 CH1만을 포함하는 1개 중쇄로 구성된다. Fab 분자의 중쇄는 다른 중쇄 분자와 디설파이드 결합을 형성할 수 없다. scFab은 두 분자의 Fab이 유연한 링커에 의해 연결된 것이다.
본 발명에서 "Fab' 단편"은 Fab 단편에 추가적으로 중쇄의 CH1과 CH2 도메인 사이의 영역을 포함하여, 두 분자의 Fab' 단편의 두 개의 중쇄사이에서 사슬간 다이설파이드 결합이 형성되어, F(ab')2 분자를 형성할 수 있다.
본 발명에서 "F(ab')2 단편"은 앞서 기술한 바와 같이, 2개의 경쇄, 및 가변영역, CH1 및 CH1과 CH2 도메인 사이에 불변 영역의 일부를 포함하는 2개의 중쇄를 포함하여, 2개의 중쇄 사이에서 사슬간 다이설파이드 결합이 형성된다. 따라서, F(ab')2 단편은 2개의 Fab' 단편으로 구성되며, 상기 두 개의 Fab' 단편은 이들 간의 다이설파이드 결합에 의해 서로 회합되어 있다.
본 발명에서 "Fv 영역"은 중쇄 및 경쇄의 각 가변 영역을 포함하지만 불변 영역은 포함하지 않는 항체의 단편이다. sdFV는 중쇄 및 경쇄가 이황화결합에 의해 연결된 것이다. scFv는 Fv가 유연한 링커에 의해 연결된 것이다. scFv-Fc는 scFV에 Fc가 연결된 것이다. 미니바디는 scFV에 CH3가 연결된 것이다. 다이아바디는 두분자의 scFV를 포함한다.
본 발명에서 "단일쇄 Fv" 또는 "scFv" 항체 단편은 항체의 VH 및 VL 도메인을 포함하는데, 이들 도메인은 단일 폴리펩티드 쇄 내에 존재한다. Fv 폴리펩티드는 scFv가 항원 결합을 위해 목적하는 구조를 형성할 수 있도록 하는 VH 도메인과 VL 도메인 사이에 폴리펩티드 링커를 추가로 포함할 수 있다.
본 발명에서 "단쇄항체"(scAb)는 중쇄 및 경쇄 가변영역이 유연한 링커에 의해 연결된 중쇄의 하나의 불변영역 또는 경쇄 불변영역을 포함하는 단일 폴리펩타이드 사슬이다. 단쇄 항체는 예를 들면 미국 특허 제5,260,203호를 참조할 수 있으며, 이는 참조에 의해 본 발명에 개시된다.
본 발명에서 "도메인 항체"(dAb)는 중쇄의 가변 영역 또는 경쇄의 가변 영역만을 포함하는 면역학적으로 기능적인 면역글로불린 단편이다. 일 구현예에서는 2개 이상의 VH 영역이 펩타이드 링커에 의한 공유결합으로 연결되어, 2가(bivalent)의 도메인 항체를 형성한다. 이러한 2가 도메인 항체의 2개의 VH 영역은 동일 또는 상이한 항원을 표적으로 할 수 있다.
본 발명에서 "상보성 결정 영역" (CDR; 즉, CDR1, CDR2, 및 CDR3)은 항원 결합을 위해 필요한 존재인 항체 가변 도메인의 아미노산 잔기를 지칭한다. 각 가변 도메인은 전형적으로 CDR1, CDR2 및 CDR3으로서 확인된 3개의 CDR 영역을 갖는다.
본 발명에서 "골격 영역" (FR)은 CDR 잔기 이외의 가변 도메인 잔기이다. 각 가변 도메인은 전형적으로, FR1, FR2, FR3 및 FR4로서 확인된 4개의 FR을 가진다.
본 발명에서 "2가의 항원 결합 단백질" 또는 "2가 항체"는 2개의 항원 결합 부위를 포함한다. 이러한 2가 항체에 포함된 2개의 항원 결합 부위는 동일한 항원 특이성을 갖거나, 또는 각각 상이한 항원에 결합하는 이중특이적 항체일 수 있다.
본 발명에서 "다중 특이적 항원 결합 단백질" 또는 "다중 특이적 항체"는 두 개 이상의 항원 또는 에피토프를 표적으로 하는 것이다.
본 발명에서 "링커"는 세포독성 화합물을 리간드에 공유결합시키는 화합물을 말한다. 본 발명의 일 양태에서, 링커로는 PCT/US2016/063564호 및 PCT/US2016/063595호에 개시된 링커를 사용할 수 있다.
본 발명에서 "비치환되거나 치환된"은 비치환될 수 있거나 또는 치환될 수 있는 모기(parent group)를, "치환된"은 1 이상의 치환기를 갖는 모기(parent group)를, 치환기는 모기(parent group)에 공유결합되거나 모기(parent group)에 융합된 화학적 부분을 의미한다.
본 발명에서 "할로"는 플루오린, 클로라인, 브로마인, 요오드 등을 말한다.
본 발명에서 "알킬"은 지방족 또는 지환족, 포화 또는 불포화(불포화, 완전 불포화) 탄화수소 화합물의 탄소 원자로부터 수소 원자를 제거하여 얻어진 1가 부분으로서, 포화 알킬의 예로는 메틸, 에틸, 프로필, 부틸, 펜틸, 헥실, 헵틸 등을, 포화 직쇄형 알킬의 예로는 메틸, 에틸, n-프로필, n-부틸, n-펜틸(아밀), n-헥실, n-헵틸 등, 포화 분지쇄형 알킬의 예로는 이소프로필, 이소부틸, sec-부틸, tert-부틸, 이소펜틸, 네오펜틸 등을 들 수 있다.
본 발명에서 "알콕시"는 -OR[여기서, R은 알킬기]을 의미하며, 예로는 메톡시, 에톡시, n-프로폭시, 이소프로폭시, n-부톡시, sec-부톡시, 이소부톡시, tert-부톡시 등을 들 수 있다.
본 발명에서 "아릴"은 고리 원자를 갖는 방향족 화합물의 방향족 고리 원자로부터 수소 원자를 제거하여 얻어진 1가 부분을 의미한다.
본 발명에서 "알케닐"은 1 이상의 탄소-탄소 이중 결합을 갖는 알킬로서, 불포화 알케닐기의 예로는 에테닐(비닐, -CH=CH2), 1-프로페닐(-CH=CHCH3), 2-프로페닐, 이소프로페닐, 부테닐, 펜테닐, 헥세닐 등을 들 수 있다.
본 발명에서 "알키닐"은 1 이상의 탄소-탄소 삼중 결합을 갖는 알킬기로서, 불포화 알키닐기의 예는 에티닐 및 2-프로피닐 등을 들 수 있다.
본 발명에서 "카르복시"는 -C(=O)OH를 말한다.
본 발명에서 "포르밀"은 -C(=O)H를 말한다.
본 발명에서 "아릴"은 방향족 화합물의 방향족 고리 원자로부터 수소 원자를 제거하여 얻어진 1가 모이어티에 관한 것이다. 예를 들어 "C5-7아릴"은 모이어티가 5 내지 7 개의 고리 원자를 갖는 것으로서, 방향족 화합물의 방향족 고리 원자로부터 수소 원자를 제거함으로써 수득되는 1 가 모이어티를 의미하고,"C5-10 아릴"은 모이어티가 5 내지 10 개의 고리 원자를 갖는 것으로서, 방향족 화합물의 방향족 고리 원자로부터 수소 원자를 제거함으로써 수득되는 1 가 모이어티를 의미한다. 여기에서 접두사(C5-7, C5-10 등)는 탄소 원자 또는 헤테로 원자인지 여부와 상관없이 고리원자의 수 또는 고리 원자의 수의 범위를 지칭한다. 예를 들어 "C5-6아릴"은 5 또는 6개의 고리 원자를 갖는 아릴기에 관한 것이다. 여기에서, 고리 원자는 "카르보아릴기"에서와 같이 모두 탄소 원자일 수 있다. 카르보아릴기의 예는 벤젠, 나프탈렌, 아줄렌, 안트라센, 페난트렌, 나프타센 및 피렌으로부터 유도된 것들을 포함하나, 이로 제한되지 않는다. 적어도 하나가 방향족 고리인 융합 고리를 포함하는 아릴기의 예는 인단, 인덴, 이소인덴, 테트랄린, 아세나프텐, 플루오렌, 페날렌, 아세페난트렌 및 아세안트렌으로부터 유도된 기를 포함하나, 이로 제한되지 않는다. 또는, 고리 원자는 "헤테로아릴기"에서와 같이 하나 이상의 헤테로 원자를 포함할 수 있다.
본 발명에서 "헤테로아릴"은 1 이상의 헤테로 원자를 포함하는 아릴로서, 예로는 피리딘, 피리미딘, 벤조티오펜, 푸릴, 디옥살라닐, 피롤릴, 옥사졸릴, 피리딜, 피리다지닐, 피리미디닐 등, 보다 구체적으로 벤조푸란, 이소벤조푸란, 인돌, 이소인돌, 인돌리진, 인돌린, 이소인돌린, 푸린(아데닌 또는 구아닌), 벤즈이미다졸, 인다졸, 벤즈옥사졸, 벤즈이속사졸, 벤조디옥솔, 벤조푸란, 벤조트리아졸, 벤조티오푸란, 벤조티아졸, 벤조티아디아졸로부터 유도된 2개의 융합고리를 갖는 C9, 크로멘, 이소크로멘, 크로만, 이소크로만, 벤조디옥산, 퀴놀린, 이소퀴놀린, 퀴놀리진, 벤족사진, 벤조디아진, 피리도피리딘, 퀴녹살린, 퀴나졸린, 신놀린, 프탈라진, 나프티리딘, 프테리딘으로부터 유도된 2개의 융합고리를 갖는 C10, 벤조디아제핀으로부터 유도된 2개의 융합고리를 갖는 C11, 카르바졸, 디벤조푸란, 디벤조티오펜, 카르볼린, 페리미딘, 피리도인돌로부터 유도된 3개의 융합고리를 갖는 C13, 아크리딘, 크산텐, 티오크산텐, 옥산트렌, 페녹사티인, 페나진, 페녹사진, 페노티아진, 티안트렌, 페난트리딘, 페난트롤린, 페나진으로부터 유도된 3개의 융합고리를 갖는 C14를 들 수 있다.
본 발명에서 "사이클로알킬"은 시클릴기인 알킬기이고, 고리(cyclic) 탄화수소 화합물의 지환족 고리 원자로부터 수소 원자를 제거하여 얻어진 1가 부분에 관한 것이다. 사이클로알킬기의 예는 하기로부터 유도된 것들을 포함하나, 이로 제한되지 않는다:
포화 단일고리 탄화수소 화합물: 사이클로프로판, 사이클로부탄, 사이클로펜탄, 사이클로헥산, 사이클로헵탄, 메틸사이클로프로판, 디메틸사이클로프로판, 메틸사이클로부탄, 디메틸사이클로부탄, 메틸사이클로펜탄, 디메틸사이클로펜탄 및 메틸사이클로헥산;
불포화 단일고리 탄화수소 화합물: 사이클로프로펜, 사이클로부텐, 사이클로펜텐, 사이클로헥센, 메틸사이클로프로펜, 디메틸사이클로프로펜, 메틸사이클로부텐, 디메틸사이클로부텐, 메틸사이클로펜텐, 디메틸사이클로펜텐 및 메틸사이클로헥센; 및 포화 헤테로사이클릭 탄화수소 화합물: 노르카란, 노르피난, 노르보르난.
본 발명에서 "헤테로사이클릴"은 헤테로사이클릭 화합물의 고리 원자로부터 수소 원자를 제거하여 얻어진 1가 부분에 관한 것이다.
본 발명에서 접두사(예를 들어 C1-12, C3-8 등)는 탄소 원자 또는 헤테로 원자인지 여부와 상관없이 고리 원자의 수 또는 고리 원자의 수의 범위를 지칭한다. 예를 들어 본 명세서에서 사용된 용어 "C3-6헤테로사이클릴"은 3 내지 6개의 고리 원자를 갖는 헤테로사이클릴기에 관한 것이다.
단일고리 헤테로사이클릴기의 예는 하기로부터 유도된 것들을 포함하지만, 이로 제한되지 않는다:
N1: 아지리딘, 아제티딘, 피롤리딘, 피롤린, 2H- 또는 3H-피롤, 피페리딘, 디하이드로피리딘, 테트라하이드로피리딘, 아제핀;
N2: 이미다졸리딘, 피라졸리딘, 이미다졸린, 피라졸린, 피페라진;
O1: 옥시란, 옥세탄, 옥솔란, 옥솔, 옥산, 디하이드로피란, 피란, 옥세핀;
O2: 디옥솔란, 디옥산 및 디옥세판;
O3: 트리옥산;
N1O1: 테트라하이드로옥사졸, 디하이드로옥사졸, 테트라하이드로이속사졸, 디하이드로이속사졸, 모르폴린, 테트라하이드로옥사진, 디하이드로옥사진, 옥사진
S1: 티이란, 티에탄, 티올란, 티안, 티에판;
N1S1: 티아졸린, 티아졸리딘, 티오모르폴린;
N2O1: 옥사디아진;
O1S1: 옥사티올, 옥사티안; 및
N1O1S1: 옥사티아진.
본 발명에서 "전구체(prodrug)"는 생체내 생리학적 조건 하(예를 들어 효소 산화(enzymatic oxidation), 환원(reduction) 및/또는 가수분해 등)에서 효소, 위산의 작용에 의해 피롤로벤조다이아제핀 약물로 직접적으로 또는 간접적으로 변환할 수 있는 화합물을 말한다.
본 발명에서 "약학적으로 허용되는 염"으로는 약학적으로 허용가능한 유리산(free acid)에 의하여 형성된 산 부가염을 사용할 수 있고, 상기 유리 산으로는 유기산 또는 무기산을 사용할 수 있다.
상기 유기산은 이로 제한되는 것은 아니나, 구연산, 초산, 젖산, 주석산, 말레인산, 푸마르산, 포름산, 프로피온산, 옥살산, 트리플로오로아세트산, 벤조산, 글루콘산, 메타술폰산, 글리콜산, 숙신산, 4-톨루엔술폰산, 글루탐산 및 아스파르트산을 포함한다. 또한 상기 무기산은 이로 제한되는 것은 아니나, 염산, 브롬산, 황산 및 인산을 포함한다.
예컨대, 화합물이 음이온이거나 또는 음이온일 수 있는 작용기를 갖는 경우(예컨대 -COOH는 -COO-일 수 있음), 적절한 양이온으로 염을 형성할 수 있다. 적절한 무기 양이온의 예는 알칼리 금속 이온, 예컨대 Na+ 및 K+, 알칼리 토금속 양이온, 예컨대 Ca2+ 및 Mg2+ 및 다른 양이온, 예컨대 Al3+을 포함하지만, 이에 한정되지 않는다. 적절한 유기 양이온의 예는 암모늄 이온(즉, NH4 +) 및 치환된 암모늄 이온(예컨대 NH3R+, NH2R2 +, NHR3 +, NR4 +)을 포함하지만, 이에 한정되지 않는다.
일부 적절한 치환된 암모늄 이온의 예는 하기로부터 유도된 것들이다: 에틸아민, 디에틸아민, 디사이클로헥실아민, 트리에틸아민, 부틸아민, 에틸렌디아민, 에탄올아민, 디에탄올아민, 피페라진, 벤질아민, 페닐벤질아민, 콜린, 메글루민 및 트로메타민 뿐 아니라, 아미노산, 예컨대 리신 및 아르기닌. 통상적인 4급 암모늄 이온의 예는 N(CH3)4+이다.
화합물이 양이온이거나 또는 양이온일 수 있는 작용기를 갖는 경우(예컨대 -NH2는 -NH3 +일 수 있음), 적절한 음이온으로 염을 형성할 수 있다. 적절한 무기 음이온의 예는 하기 무기 산으로부터 유도된 것들을 포함하지만, 이에 한정되지 않는다: 염산, 브롬화수소산, 요오드화수소산, 황산, 아황산, 질산, 아질산, 인산 및 아인산 등을 예로 들 수 있다.
적절한 유기 음이온의 예는 하기 유기산으로부터 유도된 것들을 포함하지만, 이로 한정되지 않는다: 2-아세티옥시벤조산, 아세트산, 아스코르브산, 아스파르트산, 벤조산, 캠퍼설폰산, 신남산, 시트르산, 에데트산, 에탄디설폰산, 에탄설폰산, 푸마르산, 글루쳅톤산, 글루콘산, 글루탐산, 글리콜산, 히드록시말레산, 히드록시나프탈렌 카르복실산, 이세티온산, 락트산, 락토비온산, 라우르산, 말레산, 말산, 메탄설폰산, 점액산, 올레산, 옥살산, 팔미트산, 팜산, 판토텐산, 페닐아세트산, 페닐설폰산, 프로피온산, 피루브산, 살리실산, 스테아르산, 숙신산, 설파닐산, 타르타르산, 톨루엔설폰산 및 발레르산 등을 예로 들 수 있다. 적절한 중합체 유기 음이온의 예는 하기 중합체 산으로부터 유도된 것들을 포함하지만, 이에 한정되지 않는다: 타닌산, 카르복시메틸 셀룰로오스 등을 예로 들 수 있다.
본 발명에서 "용매화물(solvate)"은 본 발명에 따른 화합물과 용매 분자(solvent molecules) 사이의 분자 복합체(molecular complex)를 말하며, 용매화물의 예는 물, 이소프로판올, 에탄올, 메탄올, 디메틸설폭사이드(dimethylsulfoxide), 에틸 아세테이트, 아세트산, 에탄올아민 또는 이의 혼합용매와 결합한 본 발명에 따른 화합물을 포함하나, 이로 제한되는 것은 아니다.
활성 화합물의 상당하는 용매화물을 제조, 정제 및/또는 취급하는 것이 편리하거나 또는 바람직할 수 있다. 용어 "용매화물"은 본 명세서에서 용질(예컨대 활성 화합물, 활성 화합물의 염) 및 용매의 착체를 지칭하기 위해 통상적인 의미로 사용된다. 용매가 물인 경우, 용매화물을 편리하게 수화물, 예컨대 일수화물, 이수화물, 삼수화물 등으로 지칭할 수 있다.
본 발명에서 사용된 어구 "유효량" 또는 "치료 유효량"은 목적 치료결과를 달성하는데 (투여량 및 투여 기간 및 수단에 대해) 필요한 양을 지칭한다. 유효량은 적어도 대상체에게 치료 이익을 부여하는데 필요한 활성제의 최소량이며, 독성량 미만이다. 예를 들어 투여량은 환자 당 약 100 ng 내지 약 100 mg/kg 범위로, 보다 전형적으로 약 1 μg/kg 내지 약 10 mg/kg의 범위로 투여할 수 있다. 활성 화합물이 염, 에스테르, 아미드, 전구체약물(prodrug) 등인 경우에 투여양은 모화합물을 기준으로 계산되므로, 사용되는 실제 중량은 비례하여 증가된다. 본 발명에 따른 피롤로벤조디아제핀 화합물은 단위 제형(dosage form)당 활성 성분 0.1 mg 내지 3000 mg, 1 mg 내지 2000 mg, 10 mg 내지 1000 mg을 포함하도록 제형화될 수 있으나 이로 한정되지 않는다. 활성 성분은 약 0.05 μM 내지 100 μM, 1 μM 내지 50 μM, 5 μM 내지 30 μM의 활성 화합물의 피크 플라즈마 농도를 얻도록 투여될 수 있다. 예를 들어 임의로 식염수내에서 활성 성분 0.1 w/v% 내지 5 w/v% 용액의 정맥 주사에 의해 투여될 수 있다.
약학 조성물에서 활성 화합물의 농도는 약물의 흡수, 불활성화 및 배출율 및 당 기술분야의 숙련자에게 알려진 다른 인자에 의해 결정될 수 있다. 투여량은 증상/질환의 심각도에 따라 달라질 수 있다. 또한 어떤 특정 환자에 대한 투여량 및 투여요법은 환자의 증상/질환의 정도, 필요성, 나이, 약물에 대한 반응성 등을 종합적으로 고려하여 투여 감독자의 직업적 판단에 따라 조정될 수 있으며, 본 발명에서 제시된 농도 범위는 단지 일 예이며 청구된 조성물의 실시양태를 이로 한정하는 것을 의도하지 않는다. 또한 활성 성분은 1회 투여될 수 있거나, 보다 적은 투여량을 수 회 나누어 투여할 수도 있다.
항체 또는 항원 결합 단편
본 발명은 ROR1 단백질의 세포외영역에 특이적으로 결합하는 항체를 개시한다. 본 발명에 따른 항체는 본 발명에 개시된 바와 같이, 하나 이상의 상보성 결정영역 또는 부위(CDR)를 포함하는 폴리펩타이드이다.
일부 구현예에서, CDR은 "프레임워크" 영역에 포함되며, 프레임워크는 이러한 CDR(들)이 적절한 항원 결합 특성을 가질 수 있도록 CDR(들)을 배향한다.
본 발명에 따른 항체는 인간 및 마우스 유래의 ROR1 세포외 도메인(Extracellular domain)에 특이적으로 결합하며, 분리된 형태의 세포외도메인 또는 세포 표면에서 발현되는 ROR1의 세포외도메인에 특이적으로 결합할 수 있다.
본 발명에 개시된 항체는 ROR1, 특히 인간 ROR1 및 마우스 ROR1에 결합한다. 본 발명에 개시된 항체는 인간 및 마우스 유래의, ROR1 세포외 도메인(Extracellular domain) 또는, 세포 표면에서 발현되는 ROR1에 특이적으로 결합할 수 있어, ROR1을 표적으로 하는 암의 표적 치료에 유용하게 사용될 수 있다. 예를들면 본 발명에 따른 항체와 항암제를 결합시켜, 특정 암의 치료에 사용될 수 있다.
또한 마우스 ROR1에 결합하므로 on-target tox를 마우스 실험을 통해 확인 가능하고, 마우스 ROR1을 과발현하는 마우스 암세포주를 이용하여 syngenic model을 통한 in vivo efficacy 확인이 가능하여 ROR1과 관련된 다양한 약물개발에 유용하게 사용될 수 있다.
일 구현예에서, 항체는 모노클로날 항체, 이중특이적 항체, 이중항체, 다중특이적 항체, 다중항체, 미니바디, 도메인 항체, 항체 모방체(또는 합성 항체), 키메라 항체, 또는 항체 융합체(또는 항체 접합체), 및 이의 단편을 포함하나, 이에 국한되지 않으며 본 발명에 개시된 다양한 형태의 항체를 포함한다.
일 구현예에서, 본 발명에 개시된 항체의 항체 단편은 Fab, Fab', F(ab')2, scFab, Fv, dsFv, scFV, scFV-Fc, 미니바디, 다이아바디, scAb 또는 dAb를 포함한다.
또 다른 구현예에서, 본 발명에 개시된 항체는 표 2a 및 표 2b에 개시된 가변영역을 포함하는 경쇄만의 또는 중쇄만의 폴리펩타이드로 이루어질 수 있다.
본 발명에 개시된 일 항체는 본 발명에 개시된 다른 항체와 특정 영역 또는 서열을 공유한다. 일 구현예에서는 항체 또는 항원결합단편의 불변영역을 공유할 수 있다. 다른 구현예에서는 Fc 영역을 공유할 수 있다. 또 다른 구현예에서는 가변영역의 프레임을 공유할 수 있다.
일 구현예에서 본 발명에 따른 항체는 자연에서 발견되는 항체의 전형적인 구조를 가진다. 이러한 항체의 구조적 단위체는, 낙타과 동물이 단일 중쇄로 구성된 항체를 생산하지만, 일반적으로 사량체 폴리펩타이드를 포함하며, 사량체는 상이한 두 개의 폴리펩타이드 사슬로 구성된 한 쌍의 폴리펩타드 사슬체를 두 개 포함한다. 전형적인 항체에서, 상기 한 쌍의 폴리펩타이드 사슬체는 하나의 전장 경쇄(약 25kDa) 및 하나의 전장 중쇄(약 50 내지 70kDa)를 포함한다. 각 사슬은, 특징적인 접힘 패턴을 나타내며, 약 90 내지 110개 아미노산으로 이루어진, 수 개의 면역글로불린 도메인으로 구성되어 있다. 이러한 도메인은 항체 폴리펩타이드를 구성하고 있는 기본 단위체이다. 각 사슬의 아미노-말단 부분은 전형적으로 항원을 인식하는 부분인 가변 영역 또는 V 영역으로 지칭되는 부분을 포함한다. 카복시-말단 부분은 아미노-말단 보다 진화적으로 보다 보존되었으며 불변 영역 또는 C 영역으로 지칭되는 부분을 포함한다. 인간 경쇄는 일반적으로 카파(κ) 및 람다(λ) 경쇄로서 분류되고, 이들 각각은 하나의 가변 영역 및 하나의 불변 영역을 포함한다.
중쇄는 전형적으로 뮤(μ), 델타(δ), 감마(γ), 알파(α) 또는 엡실론(ε) 쇄로서 분류되고, 이들은 각각 IgM, IgD, IgG, IgA 및 IgE 이소타입으로 정의된다. IgG는 IgG1, IgG2, IgG3 및 IgG4를 포함하나, 이에 제한되지 않는 다수의 서브타입을 갖는다. IgM 서브타입은 IgM 및 IgM2를 포함한다. IgA 서브타입은 IgA1 및 IgA2를 포함한다. 인간에서, IgA 및 IgD 이소타입은 4개의 중쇄 및 4개의 경쇄를 포함하고;
IgG 및 IgE 이소타입은 2개의 중쇄 및 2개의 경쇄를 포함하고, IgM 이소타입은 5개의 중쇄 및 5개의 경쇄를 포함한다. 중쇄 불변 영역은 전형적으로 효과기 기능을 나타내는 하나 이상의 도메인을 포함한다. 중쇄 불변 영역 도메인의 수는 이소타입에 따라 달라진다. IgG 중쇄는, 예를 들면, 각각 CH1, CH2 및 CH3으로 공지된 3개의 C 영역 도메인을 포함한다. 본 발명에 개시된 항체는 이러한 이소타입 및 서브타입 중의 임의의 하나일 수 있다. 일 구현예에서, 본 발명에 따른 항체는 IgG1, IgG2a, IgG2b, IgG3 또는 IgG4 서브타입이다. 추가의 구현예에서, 본 발명의 항체는 IgG1- 또는 IgG2-형이다. 추가의 구현예에서, 본 발명의 항체는 IgG1-형이다.
본 발명에 따른 중쇄 가변 영역 및 경쇄 가변 영역은 인간 불변 영역의 적어도 일부에 연결될 수 있다. 불변영역의 선택은 부분적으로 항체 의존적 세포 매개 세포독성, 항체 의존적 세포 식균작용 및/또는 보체 의존적 세포독성이 요구되는지에 의해 결정될 수 있다. 예를 들면, 인간 동종형 IgG1 및 IgG3은 보체 의존적 세포독성을 갖고, 인간 동종형 IgG2 및 IgG4는 이러한 세포독성을 갖지 않는다. 또한, 인간 IgG1 및 IgG3은 인간 IgG2 및 IgG4보다 더 강한 세포 매개 이펙터 기능을 유도한다. 경쇄 불변 영역은 람다 또는 카파일 수 있다.
일 구현예에서, 본 발명에 따른 항체는 인간 항체이고, 중쇄 불변영역은 IgG1-, IgG2- IgG3- 또는 IgG4-형 일 수 있다. 추가의 구현예에서, 본 발명의 항체는 IgG1- 또는 IgG2-형이다.
다른 구현예에서, 본 발명에 따른 항체는 인간 항체이고, 마우스 ROR1을 특이적으로 인식한다.
전장의 경쇄 및 중쇄에서, 가변 영역 및 불변 영역은 약 12개 이상의 아미노산 길이인 "J" 영역에 의해 결합되고, 중쇄는 또한 약 10개 이상의 아미노산의 "D" 영역을 포함한다. 예를 들면, Fundamental Immunology, 2nd ed, Ch 7(Paul, W, ed) 1989, New York: Raven Press를 참조할 수 있다. 전형적으로 항체의 경쇄/중쇄 쌍의 가변 영역이 항원 결합 부위를 형성한다.
면역글로불린 사슬의 가변 영역은 일반적으로 전체적 구조가 동일하며, "상보적 결정부위 또는 영역 또는 도메인" 또는 CDR(Complementary Determining Region)로 지칭되는 3개의 초가변 영역에 의해 이어지는 비교적 보존된 프레임워크 영역(FR)을 포함한다. 중쇄/경쇄 쌍을 구성하는 각 사슬 유래의 가변영역의 CDR은 전형적으로 프레임워크 영역에 의해 정렬되어 표적 단백질(ROR1)의 특정 에피토프와 특이적으로 결합하는 구조를 형성한다. 자연 발생 경쇄 및 중쇄가변 영역의 이러한 요소는 N-말단으로부터 C-말단까지 전형적으로 다음 순서로 포함된다: FR1, CDR1, FR2, CDR2, FR3, CDR3 및 FR4 가변영역에서 이들 각각에 해당하는 아미노산 서열의 위치는 Kabat에 의해 결정될 수 있다. 상기 각 정의에 의해 결정된 CDR은 서로 비교하면, 중첩되거나 하나가 다른 하나를 포함하는 서브세트일 수 있다. 하지만 본 발명에는 상기 각 방법에 의해 정의되는 모든 CDR이 본 발명의 범위에 포함된다. 당업자라면 항체의 가변영역서열이 주어지면, 여기에서 상기 각 정의에 의한 CDR 서열을 용이하게 선택할 수 있을 것이다.
본 발명의 일 구현예에 따른 항체 또는 항원 결합 단편의 중쇄 및 경쇄가변 영역에 포함될 수 있는 CDR 서열은 각각 표 1a 내지 표 1f에 개시된다.
[표 1a]

[표 1b]

[표 1c]

[표 1d]

[표 1e]

[표 1f]

본 발명의 일 구현예에서, 상기 경쇄 및 중쇄의 CDR 서열을 포함하는 항체 또는 항원 결합 단편의 중쇄 및 경쇄 가변영역 서열을 각각 하기 표 2a 및 표 2b로 개시된다.
[표 2a]

[표 2b]

일 구현예에서 상기 표 1a 내지 표 1f에 개시된 개시된 경쇄의 각 가변영역의 CDR과 중쇄의 각 가변영역의 CDR은 자유롭게 조합될 수 있다.
다른 구현예에서 상기 표 2a 및 표 2b에 개시된 중쇄 및 경쇄의 가변영역은 다양한 형태의 항체의 제조를 위해 자유롭게 조합될 수 있으며, 예를 들면 ScFV와 같은 단쇄 항체, 또는 도메인 항체 또는 전장 항체를 형성할 수 있다.
본 발명에 개시된 각각의 중쇄 및 경쇄 가변 영역은 온전한 항체의 각각 중쇄 및 경쇄를 형성하기 위해 목적하는 다양한 중쇄 및 경쇄 불변 영역에 결합될 수 있다. 또한, 이렇게 불변영역에 결합된 각각의 중쇄 및 경쇄 서열은 또한 온전한 항체 구조를 형성하기 위해 조합될 수 있다.
본 발명에 따른 항체의 중쇄 및 경쇄의 임의의 가변 영역은 불변 영역의 적어도 일부에 연결될 수 있다. 불변 영역은 항체 의존성 세포 매개 세포 독성, 항체 의존성 세포성 포식작용 및/또는 보체 의존성 세포 독성 등이 필요한지에 따라 선택될 수 있다.
상기 불변영역은 목적하는 바에 따라 적절한 것이 사용될 수 있으며, 예를 들면 인간 또는 마우스 유래의 것이 사용될 수 있다. 일 구현예에서는 인간 중쇄 불변영역 IgG1이 사용되며, 이는 서열번호 91의 서열로 나타낼 수 있다. 다른 구현예에서 경쇄 불변영역은 인간 람다 영역이 사용되며, 이는 서열번호 93으로 나타낼 수 있다.
본 발명에 개시된 임의의 가변 영역은 불변 영역에 결합되어 중쇄 및 경쇄 서열을 형성할 수 있다. 일 구현예에서 본 발명에 개시된 중쇄 가변영역은 인간 IgG1 불변영역에 연결될 수 있으며, 이는 서열번호 59 내지 66, 100 및 101으로 나타낼 수 있다. 다른 구현예에서, 본 발명에 개시된 경쇄 가변영역은 인간 람다 불변영역에 연결될 수 있으며, 이는 각각 서열번호 67 내지 74로 나타낼 수 있다. 상기 본 발명에 따른 경쇄 및 중쇄는 다양한 조합으로 조합되어 두 개의 경쇄 및 두 개의 중쇄로 이루어진 온전한 항체를 형성할 수 있다.
하지만 본 발명에 개시된 가변 영역과 조합될 수 있는 이러한 불변 영역 서열은 예시적인 것이고, 당업자라면, IgG1 중쇄 불변 영역, IgG3 또는 IgG4 중쇄 불변 영역, 임의의 카파 또는 람다 경쇄 불변 영역, 안정성, 발현, 제조 가능성 또는 다른 목적하는 특징 등을 위해 변형된 불변 영역을 포함하는 다른 불변 영역이 사용될 수 있음을 알 수 있을 것이다.
본 발명은 또한 본 발명에 개시된 하나 이상의 아미노산 서열과 실질적인 서열 동일성을 갖는 하나 이상의 아미노산 서열을 포함한다. 실질적 동일성이란 본 발명은 서열변이가 존재하는 본 발명에 개시된 효과를 유지하는 것을 의미한다. 일 구현예에서 표 2a에 개시된 중쇄 가변영역과 약 90%, 95%, 또는 99% 동일성을 가진다. 다른 구현예에서 표 2b에 개시된 경쇄 가변영역과 약 90%, 95%, 또는 99% 동일성을 가진다. 예를 들면 본 발명에 개시된 항체 또는 항원 결합단편의 서열과 90%, 95%, 또는 99% 동일성을 나타내는 변이체의 경우, 임의의 변이는 CDR 보다는 가변영역의 골격에서 발생된다.
일 구현예에서 본 발명에 개시된 항체 또는 그 단편을 코딩하는 핵산은 본 발명에 개시된 CDR, 상기 CDR을 포함하는 가변영역, 상기 가변영역 및 불변영역을 포함하는 전장 항체를 코딩하는 핵산이다. 아미노산 서열이 결정되면, 핵산서열은 공지의 역전사 프로그램 및 코돈사용빈도(codon usage) 등을 고려하여 용이하게 결정될 수 있다. 인간 IgG1을 코딩하는 중쇄 불변영역의 예시적인 핵산 서열은 서열번호 92로 표시될 수 있다. 인간 람다를 코딩하는 경쇄 불변영역의 예시적인 핵산서열은 서열번호 94 또는 95로 표시될 수 있다. 상기와 같은 불변영역의 핵산서열을 포함하는 전장 중쇄의 예시적인 핵산 서열은 서열번호 75 내지 82, 102 및 103 (인간 IgG1 불변영역을 포함하는 중쇄), 전장 경쇄의 예시적인 핵산 서열은 서열번호 83 내지 90 (인간 람다 불변 영역을 포함하는 경쇄)를 들 수 있다.
또한 표 1a 내지 표 1f의 CDR 서열, 및 표 2a 및 표 2b의 가변 영역을 코딩하는 핵산 서열이 포함된다. 이러한 핵산 서열은 상기 개시된 전장 항체를 코딩하는 핵산 서열에 포함되기 때문에, 별도로 기재되지 않으며, 당업자라면, 본 발명에 개시된 CDR 및 가변 영역의 단백질 서열을 기초로, 이를 코딩하는 핵산 서열을 상기 서열번호 75 내지 90으로부터 용이하게 확인할 수 있을 것이다.
본 발명은 또한 본 발명에 개시된 하나 이상의 핵산 서열과 실질적인 서열 동일성을 갖는 하나 이상의 핵산 서열을 포함한다. 실질적 동일성이란 핵산의 변이가 아미노산 치환을 수반하지 않는 보존적 치환 또는 아미노산의 변이를 초래하는 경우라도 상기 핵산에 의해 코딩되는 항체 또는 항원결합 단편이 본 발명에 개시된 효과를 유지하는 것을 의미한다.
항체의 항원 대한 특이성 및 친화도
본 발명에 따른 항체 또는 항원 결합단편은 특히 ROR1 항원의 ECD에 대한 특이성 및 항체 치료제/진단제로서 사용되기에 적절한 친화도를 가진다. 일 구현예에서, 표 6에 따르면, 응집체에 대한 친화도는 KD < 1.0 x 10-9 M; 또 다른 구현예에서, KD ≤ 1.0 x 10-10 M이다. 이러한 친화도를 갖는 본 발명에 따른 항체 또는 항원 결합 단편은 이 보다 낮은 친화도 예를 들면 친화도가 10-8 M 또는 10-9 M의 항체와 비교하여 더 낮은 투여량으로 투여될 수 있는 장점이 있다. 이는 항체를 예를 들면 이로 제한하는 것은 아니나, 보다 간편한 피하주사와 같은 방식으로 투여해도 충분한 효능을 얻을 수 있기 때문에, 임상에서 큰 장점이 있다.
항체의 가변영역
본 발명은 항체 상기 표 2a 및 표 2b에 개시된 중쇄 및 경쇄의 가변영역을 포함한다. 또한, 면역학적 기능성 단편, 유도체, 돌연변이 단백질 및 중쇄 및 경쇄의 가변영역 변이체를 포함하는 항체 (및 상응하는 핵산 서열)를 포함하다. 본 발명에 따른 중쇄 및 경쇄의 가변 영역이 다양하게 조합된 항체는 "VHx / VLy"로 표현될 수 있으며, 여기서 "x"는 중쇄 가변 영역 서열 번호, "y"는 경쇄에 해당한다. 일 구현예에서, 가변 영역은 다음 조합을 포함할 수 있다: VH43/VL51, VH43/VL52, VH43/VL53, VH43/VL54, VH43/VL55, VH43/VL56, VH43/VL57, VH43/VL58, VH44/VL51, VH44/VL52, VH44/VL53, VH44/VL54, VH44/VL55, VH44/VL56, VH44/VL57, VH44/VL58, VH45/VL51, VH45/VL52, VH45/VL53, VH45/VL54, VH45/VL55, VH45/VL56, VH45/VL57, VH45/VL58, VH46/VL51, VH46/VL52, VH46/VL53, VH46/VL54, VH46/VL55, VH46/VL56, VH46/VL57, VH46/VL58, VH47/VL51, VH47/VL52, VH47/VL53, VH47/VL54, VH47/VL55, VH47/VL56, VH47/VL57, VH47/VL58, VH48/VL51, VH48/VL52, VH48/VL53, VH48/VL54, VH48/VL55, VH48/VL56, VH48/VL57, VH48/VL58, VH49/VL51, VH49/VL52, VH49/VL53, VH49/VL54, VH49/VL55, VH49/VL56, VH49/VL57, VH49/VL58, VH50/VL51, VH50/VL52, VH50/VL53, VH50/VL54, VH50/VL55, VH50/VL56, VH50/VL57, VH50/VL58, VH98/VL51, VH98/VL52, VH98/VL53, VH98/VL54, VH98/VL55, VH98/VL56, VH98/VL57, VH98/VL58, VH99/VL51, VH99/VL52, VH99/VL53, VH99/VL54, VH99/VL55, VH99/VL56, VH99/VL57, 또는 VH99/VL58.
다양한 다른 형태의 항체
본 발명에 개시된 항체는 또한 상기 본 발명에 개시된 항체의 변이체이다. 예를 들면, 항원의 일부는 상기 개시된 중쇄 또는 경쇄, 가변 영역 또는 CDR 서열의 하나 이상의 잔기에서 보존적 아미노산 치환을 포함한다. 보존적 아미노산 치환은 폴리펩타이드의 활성 또는 항원선을 실질적으로 영향을 미치지 않는 치환을 의미한다. 일 구현예에서 보존적 아미노산 치환은 하기 아미노산 분류 중에서 동일한 분류에 속하는 다른 잔기로의 치환을 일컫는다. 자연-발생 아미노산은 측쇄 특성에 공통적 특징에 기초하여 다음과 같이 분류될 수 있다: 1) 소수성: 노르류신, Met, Ala, Val, Leu, Ile; 2) 중성 친수성: Cys, Ser, Thr, Asn, Gln; 3) 산성: Asp, Glu; 4) 염기성: His, Lys, Arg; 5) 사슬 방향에 영향을 주는 잔기: Gly, Pro; 및 6) 방향족: Trp, Tyr, Phe 보존적 아미노산 치환은 또한 펩타이드 모방체와 같은 비-자연-발생 아미노산 잔기를 포함할 수 있고, 이러한 잔기는 전형적으로 세포가 아닌, 화학적 합성에 의해 도입된다.
비제한적인 예시적인 보존적 아미노산 치환의 예는 표 3에 나타내나 이로 제한하는 것은 아니다.
[표 3] 보존적 아미노산 치환

비-보존적 치환은 상기 분류 중에서 다른 분류에 속하는 잔기로 치환을 포함한다. 이러한 치환은 인간 항체와 상동성인 항체의 영역 또는 비-상동성 영역 내로 도입될 수 있다.
항체의 제조
본 발명에서 비-인간 항체는, 예를 들면, 임의의 항체-생성 동물, 예를 들면, 마우스, 랫트, 토끼, 염소, 당나귀, 또는 비-인간 영장류(예를 들면, 시노몰구스 또는 붉은털 원숭이와 같은 원숭이) 또는 유인원(예를 들면 침팬지))로부터유래될 수 있다. 비인간 항체는 당해 기술 분야에 공지된 방법을 사용하여 동물을 면역화시킴으로써 생성될 수 있다. 항체는 폴리클로날, 모노클로날일 수 있거나, 또는 재조합 DNA를 발현시킴으로써 숙주 세포 내에서 합성될 수 있다. 완전 인간항체는 인간 면역글로불린 유전자 좌를 포함하는 형질전환 동물에 항원을 투여하거나, 또는 인간 항체의 레퍼토리를 발현하는 파지 디스플레이 라이브러리를 항원으로 처리하여, 목적하는 항체를 선택함으로써 제조될 수 있다.
모노클로날 항체(mAb)는 종래의 모노클로날 항체 방법, 예를 들면, 문헌(참조: Kohler and Milstein, 1975, Nature 256:495)의 표준 체세포 혼성화 기술을 비롯한 다양한 기술에 의해 생성될 수 있다.
본 발명에 개시된 단쇄 항체는 아미노산 가교(짧은 펩타이드 링커)를 이용하여, 중쇄 및 경쇄 가변 도메인(Fv 영역) 단편을 연결하여 생성될 수 있다. 본 발명에 개시된 단쇄 항체는 표 1a 내지 1f에 기재된 중쇄 및 경쇄 가변 영역의 도메인 조합을 포함하는 scFv, 또는 표 1a 내지 표 1f에 개시된 CDR을 포함하는 경쇄 및 중쇄 가변 도메인의 조합이 포함되지만 이로 제한되는 것은 아니다.
본 발명에 개시된 항체는 또한 서브타입 스위칭을 통해, 상이한 서브타입 항체로 변경될 수 있다. 따라서 IgG 항체는, 예를 들면, IgM 항체로부터 유래될 수 있고, 그 역도 가능하다.
따라서, 본 발명에 개시된 항체에는, 예를 들면, 목적하는 아이소타입(예를 들면, IgA, IgG1, IgG2, IgG3, IgG4, IgE, 및 IgD)으로 스위칭된 본 발명에 개시된 가변 도메인 조합 항체가 포함된다.
항체를 발현하는 방법
본 발명은 또한 상술한 바와 같은 적어도 하나의 폴리뉴클레오티드를 포함하는 플라스미드, 발현 벡터, 전사 또는 발현 카세트의 형태의 발현 시스템 및 구축물, 그리고, 상기 발현 시스템 또는 구축물을 포함하는 숙주 세포, 및 상기 발현시스템 또는 숙주세포를 이용한 항체의 생산방법에 관한 것이다.
본 발명에 개시된 항체는 하이브리도마 세포주 또는 하이브리도마 이외의 발현 세포주에서 발현될 수 있다. 항체를 코딩하는 발현 구축물은 포유동물, 곤충 또는 미생물 숙주 세포를 형질전환시키는데 사용될 수 있다. 플라스미드와 같은 구축물은 앞서 기술된 바와 같이 폴리뉴클레오티드를 숙주 세포 내로 도입하기 위한 다양한 임의의 공지된 방법을 사용하여 수행될 수 있다. 구체적인 방법은 숙주세포의 종류에 따라 달라질 수 있을 것이다. 이종 폴리뉴클레오티드를 포유동물 세포 내로 도입하는 방법은 당해 기술 분야에 널리 공지되어 있고, 예를 들면 덱스트란 매개 전달이입, 인산칼슘 침전, 폴리브렌 매개 전달이입, 원형질체(protoplast) 융합, 전기천공, 리포좀을 이용한 전달되는 폴리뉴클레오티드의 캡슐화, 핵산과 양으로 하전된 지질의 혼합, 및 핵 내로 DNA의 직접적인 미세주입에 의해 수행될 수 있지만, 이로 제한되는 것은 아니다.
진단 및 치료 목적을 위한 인간 ROR1 항체의 용도
암에서 ROR1의 발현은 암환자의 좋지 않은 예후와 관련이 있으며, 암 전이에도 영향을 미치는 것으로 알려져 있다. 예를 들면 ROR1은 B세포 백혈병, 림프종, 급성 골수성 백혈병(AML), 버킷 림프종, 만성 림프구성 백혈병(CLL), 외투세포림프종(MCL), 급성림프구성백혈병(ALL), 미만성거대B세포림프종(DLBCL), 여포성림프종(FL), 변연부림프종(MZL) 등의 혈액암은 물론 유방암, 신장암, 난소암, 위암, 간암, 폐암, 대장암, 췌장암, 피부암, 방광암, 고환암, 자궁암, 전립선암, 비소세포 폐암(NSCLC), 신경모세포종, 뇌암, 결장암, 상피 편평세포암, 흑색종, 골수종, 자궁경부암, 갑상선암, 두경부암 및 부신암 등의 고형암에서도 과발현된다. 항암 항체 치료를 위해 예를 들면 ROR1 항체는 본 발명에 기술한 바와 같이 항체 단독 또는 다양한 세포독성제제와 연결된 형태로 ROR1을 과발현하는 암 세포의 제거에 사용될 수 있다. 따라서, ROR1에 결합하는 항체는 항체 단독 또는 항암화학요법제, 세포독성제 또는 방사선 물질과 결합되어 사용될 수 있거나 또는 CAR-T 세포와 같은 세포치료제로서, 항암 표적에 대한 표적화의 목적으로 구현되어, 본 발명에 개시된 항체 유래 치료제를 ROR1을 발현하는 세포로 유도하는 표적 치료제로 사용될 수 있다.
치료 방법: 약학적 제형, 투여 경로
항체, 또는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물을 사용한 치료 방법이 또한 제공된다. 일 구현예에서 항체, 또는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물은 환자에 제공된다. 항체, 또는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물은 암세포 표면에 발현되는 인간 ROR1에 결합함으로써, 암세포의 전이를 억제한다. 일 구현예에서 항체는 세포독성제와 결합한 형태로 암세포 표면에 발현되는 인간 ROR1에 결합함으로써, 항체에 결합된 세포독성제를 암세포에 특이적으로 전달하여 암세포의 사멸을 유도한다. 일 구현예에서 항체는 같은 표적 또는 다른 표적에 특이적인 항체의 형태로 암세포 표면에 발현되는 인간 ROR1에 결합함으로써, 다중항체의 암세포에 대한 특이성을 높이거나 암세포와 면역세포등의 다른 종류의 세포간의 연결을 유도하여 암세포의 사멸을 유도한다. 일 구현예에서 항체는 CAR-T등의 세포치료제의 표면에 발현하여 항체가 인간 ROR1에 결합함으로써, 세포치료제를 암세포에 특이적으로 전달하여 암세포의 사멸을 유도한다.
항체, 또는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물의 치료적 유효량, 및 약학적으로 허용가능한 희석제, 담체, 가용화제, 유화제, 방부제 및/또는 보조제를 포함하는 약학적 조성물도 또한 제공된다. 또한, 예를 들면, 이러한 약학적 조성물을 투여함으로써 암 환자를 치료하는 방법이 포함된다. 용어 "환자"는 인간 환자를 포함한다.
상기 약학적 조성물은 약학적으로 허용가능한 담체를 포함할 수 있다. 상기 담체는 부형제, 희석제 또는 보조제를 포함하는 의미로 사용된다. 상기 담체는 예를 들면, 락토스, 덱스트로스, 수크로스, 소르비톨, 만니톨, 자일리톨, 에리트리톨, 말티톨, 전분, 아카시아 고무, 알기네이트, 젤라틴, 칼슘 포스페이트, 칼슘 실리케이트, 셀룰로스, 메틸 셀룰로스, 폴리비닐 피롤리돈, 물, 생리식염수, PBS와 같은 완충액, 메틸히드록시 벤조에이트, 프로필히드록시 벤조에이트, 탈크, 마그네슘 스테아레이트, 및 미네랄 오일로 이루어진 군으로부터 선택된 것일 수 있다. 상기 조성물은 충진제, 항응집제, 윤활제, 습윤제, 풍미제, 유화제, 보존제, 또는 이들의 조합을 포함할 수 있다.
상기 약학적 조성물은 통상의 방법에 따라 임의의 제형으로 준비될 수 있다. 상기 조성물은 예를 들면, 경구 투여 제형(예를 들면, 분말, 정제, 캡슐, 시럽, 알약, 또는 과립), 또는 비경구 제형(예를 들면, 주사제)으로 제형화될 수 있다. 또한, 상기 조성물은 전신 제형, 또는 국부 제형으로 제조될 수 있다.
상기 약학적 조성물은 상기 항체 또는 그의 항원 결합 단편, 항암제, 또는 이들의 조합을 유효한 양으로 포함할 수 있다. 용어 "유효한 양"은 예방 또는 치료를 필요로 하는 개체에게 투여되는 경우 예방 또는 치료의 효과를 나타내기에 충분한 양을 말한다. 상기 유효한 양은 당업자가 선택되는 세포 또는 개체에 따라 적절하게 선택할 수 있다. 질환의 중증도, 환자의 연령, 체중, 건강, 성별, 환자의 약물에 대한 민감도, 투여 시간, 투여 경로 및 배출 비율, 치료 기간, 사용된 조성물과 배합 또는 동시 사용되는 약물을 포함한 요소 및 기타 의학 분야에 잘 알려진 요소에 따라 결정될 수 있다. 상기 유효한 양은 상기 약학적 조성물 당 약 0.1 ㎍ 내지 약 2 g일 수 있다.
상기 약학적 조성물의 투여량은 예를 들어, 성인 기준으로 10 ㎍/kg 내지 약 30 ㎎/kg, 선택적으로 0.1 ㎎/kg 내지 약 30 ㎎/kg, 또는 대안적으로 0.3 ㎎/kg 내지 약 20 ㎎/kg의 범위일 수 있다. 상기 투여는 1일 1회, 1일 다회, 또는 1주일 내지 4주일에 1회, 또는 1년에 1회 내지 12회 투여될 수 있다.
이하, 본 발명의 이해를 돕기 위하여 바람직한 실시예를 제시한다. 그러나 하기의 실시예는 본 발명을 보다 쉽게 이해하기 위하여 제공되는 것일 뿐, 하기 실시예에 의해 본 발명의 내용이 한정되는 것은 아니다.
실시예 1: ROR1 항체의 제조
실시예 1-1: 항원
항원으로서는 인간 ROR1의 세포외영역(ECD)의 C-말단에 Fc가 연결된 ROR1 ECD-Fc 형태의 단백질을 사용하였다.
상기 항원의 제조를 위해 구체적으로 ROR1의 세포외도메인을 포함하는 단백질로서 NCBI 참조번호 NP_0050032로 표시되는 ROR1 아미노산 서열의 1번 아미노산 내지 406번 아미노산에 해당하는 잔기를 이용하였다. 상기 ROR1의 세포외 도메인을 코딩하는 유전자는 Origene사의 cDNA를 구매하여 사용하였다(Origene, RC214967) 또한, 추후 ROR1 세포외도메인을 정제하기 위하여 ROR1 세포외도메인을 코딩하는 유전자의 3'말단에는 인간 IgG1 유래의 Fc 단백질을 코딩하는 유전자를 합성하여 연결하였다(하기 'ROR1-Fc'로 명명) 상기 유전자를 pcDNA3.1 벡터에 도입하여, 포유동물 세포주에서 ROR1-Fc 핵산을 암호화하는 벡터를 확보하였다.
상기 발현벡터를 HEK 293E세포에 일시적으로 트랜스펙션 시켜 DMEM/F-12 배지에서 8% CO2, 37℃ 조건에서 배양함으로써 ROR1-Fc 발현하고, 매 72시간 마다 배지를 수집하였으며, 이어 배지를 합하고 단백질 A 친화성 크로마토그래피를 사용하여 Fc-ROR1 ECD 단백질을 정제하였다.
실시예 1-2: 파이지 라이브러리 스크리닝을 통한 항체 선별
라이브러리 파아지(Library phage)의 제조
다양한 항원에 대한 결합 다양성을 가진 인간 유래 scFv(single chain variable fragment) 라이브러리(Yang et al, 2009 Mol Cells 27:225) 유전자를 가진 대장균 2 x 1010을 2X YT(Amresco, J902-500G), 카베니실린(Duchefa, C01090025) 100 ㎍/㎖, 2% 글루코스(sigma, G7021)를 포함하는 배지에서 37℃에서 2시간 내지 3시간 동안 배양한 후(OD600=0.5~0.7) 헬퍼 파아지(helper phage)를 감염시켜 2X YT [2X YT, 카베니실린, 카나마이신(Duchfa, K0126) 70 ㎍/㎖, 1 mM IPTG(Duchefa, I1401)] 배지에 30℃에서 16시간 동안 배양하여 파이지 패킹을 유도하였다. 이어 배양한 세포를 원심분리(6000 rpm, 15분, 4℃)한 후, 상등액에 4% PEG8000(sigma, P2139)과 3% NaCl(Samchun, S2097)을 첨가하여 잘 녹인 후 얼음에서 1시간 동안 반응시켰다. 다시 원심분리(8000rpm, 20분, 4℃)한 후, 펠렛에 PBS(Phosphate buffered saline, Gibco 10010-023)를 첨가하여 현탁한 다음 원심분리(12000rpm, 10분, 4℃)하여 라이브러리 파아지를 포함하는 상등액을 새 튜브에 넣어 사용시까지 4℃에서 보관하였다.
파아지 디스플레이(Phage display)를 통한 패닝(panning)
인간 ROR1 단백질과 결합하는 항체를 선별하기 위해 실시예 1-1에서 제조된 ROR1-Fc 단백질을 이용하여 다음과 같이 패닝을 총 3회 진행하였다.
구체적으로 면역시험관(immunotube, maxisorp 444202)에 10 ㎍/㎖ 농도의 ROR1-Fc와 음성대조군-Fc(BCMA-Fc)를 PBS에 첨가하여 4℃에서 밤새 시험관 표면에 단백질을 흡착시킨 후 우혈청 알부민(BSA, Bovine serum albumin) 3% 용액을 시험관에 첨가하여 ROR1-Fc가 흡착되지 않은 표면을 보호하였다. 시험관을 비운 후 BSA 3% 용액에 분산된 1012 CFU의 항체 파지 라이브러리를 대조군 Fc 단백질이 흡착되어 있는 면역시험관에 넣고 상온에서 1시간 반응시켰다(negative selection). 이어 음성대조군 Fc에 비결합된 파지들을 회수하여 ROR1-Fc가 협착된 면역시험관에 결합시켰다. 비특이적으로 결합한 파지를 PBS-T(Phosphate buffered saline-0.05% Tween 20) 용액으로 5회~30회 씻어내어 제거하고, 남아있는 항원 특이적 파지항체를 100 mM 트리에틸아민 용액을 이용하여 회수하였다. 회수된 파지를 1M 트리스 버퍼(pH 7.4)로 중화시킨 후 ER2537 대장균에 37℃에서 1시간 감염시키고 감염된 대장균을 카베니실린을 포함하는 2X YT 한천배지에 도말하여 37℃에서 밤새 배양하였다. 다음날 배양된 대장균을 4 ㎖의 2X YT 카베니실린 배양액에 현탁하고 15% 글리세롤을 첨가하여 일부는 -80℃에 보관하고 나머지는 다음 실험을 위해 파아지를 제조하였다. 이러한 과정을 총 3라운드 반복하여 ROR1 항원 특이적인 파아지 풀(phage pool)을 증폭 및 농축하였다.
단일클론 파아지 항체 선별(single clone screening)
상기 패닝을 통해 얻은 파아지 풀(phage pool)로부터 ROR1에 특이적으로 결합하는 단일클론항체를 선별하기 위해 다음과 같은 실험을 수행하였다.
농축된 풀로부터 단일클론을 분리하기 위해, LB-테트라사이클린/카베니실린 한천배지에 상기 파아지 풀을 도말한 후 배양하여 단일 콜로니를 확보하였다. 이어 단일 클론을 웰당 400 ㎕의 2 X YT-테트라사이클린/카베니실린 배지가 들어간 96 깊은 웰 플레이트에 접종하여 밤새 키운 후, 배양액 10 ㎕를 새로운 390㎕의 2 X YT-테트라사이클린/카베니실린 배지가 포함된 96 깊은 웰 플레이트에 넣어 37℃에서 4시간 배양했다. 상기 배양액에 1 mM IPTG 되게 넣어 주고 30℃에서 밤새 배양했다. 밤새 배양한 배양액을 원심분리하여 상등액을 취하였다.
이어 다음과 같이 ELISA 방법을 사용하여 인간 ROR1-Fc 항원과 결합하는 단일클론 가용성 scFv를 발현하는 클론을 선택하였다(Steinberger Rader and Barbas III 2000 Phage display vectors In: Phage Display Laboratory Manual 1sted ColdSpringHarborLaboratoryPress NY USA pp119-1112) 구체적으로 96-웰 미세역가 플레이트(Nunc-Immuno Plates, NUNC, USA)에 실시예 1-1에서 준비한 재조합 인간 ROR1-Fc 또는 BCMA-Fc를 well당 100 ng 넣고, 4℃에서 밤새 코팅하였다. BCMA-Fc는 음성대조군으로 사용한 단백질로 인간 BCMA 단백질의 세포외도메인 영역을 인간 Fc에 연결한 재조합 단백질이다. 3% BSA를 각 웰당 200 μL씩 넣어 37℃에서 2시간 블록킹 하였다. 상기 단일클론 파지 상등액은 3% BSA와 1:1로 섞어서 준비하여, 이 혼합액을 100 μL씩 상기 웰에 로딩한 뒤 37℃에서 2시간 반응시켰다. PBST 300 μL로 5회 세척한 후, 항-HA HRP 결합 항체를 넣고 37℃에서 1시간 반응시킨 후, PBST로 5회 세척하였다. TMB(Tetramethylbenzidine, Sigma, T0440) 100 μL를 넣어 발색한 후, 1N H2SO4 50 μL를 넣어 반응을 정지한 후, 450 nm 및 650 nm에서 흡광도를 측정하여, ROR1 1 ㎍/mL 코팅했을 때 흡광도 값이 450 nm 및 650 nm에서 10 이상인 클론을 선별하였다(도 1)
이어 ROR1을 발현하는 세포주에 결합하는 클론은 유세포분석으로 선별하였다. 구체적으로 상기 단일 클론 scFv 상등액 100 ㎕를 ROR1을 과발현하는 암세포주(JeKo-1)와 반응시킨 후 PBS로 2회 세척하였다. 항-HA-FITC 항체(Sigma, H7411)와 4℃에서 30분간 반응한 후 PBS로 2회 세척 후 PBS 200 ㎕로 현탁하여 FACSCalibur flow cytometer(BD Bioscience)를 이용하여 JeKo-1 세포주에 결합하는 클론을 선별하였다(도 2)
이로부터 재조합 인간 ROR1 단백질 및 ROR1을 발현하는 세포주에 결합하는 10개 항체 클론(AB4, A2F2, A2F3, BA6, CC9, C2E3, DG6, D2B12, A2F2 M1 및 BA6 M1)을 선별하였으며, 상기 각 항체의 중쇄가변 및 경쇄 가변영역의 아미노산 서열 및 CDR 서열은 다음 표와 같다.
[표 4a]

[표 4b]

상기 가변영역 및 CDR 서열을 코딩하는 핵산 서열은 AB4, A2F2, A2F3, BA6, CC9, C2E3, DG6, D2B12, A2F2 M1 및 BA6 M1의 순서대로 하기 중쇄 및 경쇄 전장을 코딩하는 핵산서열의 일부로 포함되어 있다: 서열번호 75(중쇄) 및 83(경쇄); 서열번호 76(중쇄) 및 84(경쇄); 서열번호 77(중쇄) 및 85(경쇄); 서열번호 78(중쇄) 및 86(경쇄); 서열번호 79(중쇄) 및 87(경쇄); 서열번호 80(중쇄) 및 88(경쇄); 서열번호 81(중쇄) 및 89(경쇄); 서열번호 82(중쇄) 및 90(경쇄); 서열번호 102(중쇄) 및 84(경쇄); 서열번호 103(중쇄) 및 86(경쇄) 상기 핵산 서열에서 불변영역을 코딩하는 핵산서열은 서열번호 92(중쇄), 및 서열번호 94(경쇄) 또는 95(경쇄) 이다.
실시예 2: 항-ROR1 scFv의 전체 IgG 형태로 변환 및 생산
실시예 2-1: 항-ROR1 scFv의 전체 IgG 형태로의 클로닝
상기 실시예 1에서 확보한, 각 ROR1 특이적 단일클론 파아지 항체의 서열을 전체 IgG(full IgG) 형태로 변환하기 위해, 실시예 1에서 확보한 각 클론의 중쇄 및 경쇄 가변영역을 코딩하는 핵산을 합성하였다(제노텍, 대한민국) 인간 IgG1 서브타입의 중쇄와 경쇄 불변영역(각각 서열번호 91 및 93) 단백질을 코딩하는 유전자를 합성하여 상기 각 중쇄와 경쇄 가변영역을 코딩하는 핵산과 연결하였다. 각 항체의 경쇄와 중쇄를 암호화하는 핵산은 각각 pcDNA3.1 기반의 발현 벡터에 클로닝하여 CHO-S 포유동물세포주에서 항체 핵산을 암호화하는 벡터를 확보하였다.
비교군 항체로는 기존 항-ROR1 항체인 2A2(US 9,316,646)의 가변영역에 인간 IgG1을 연결한 키메라 항체를 비교군 항체로 사용하였다.
IgG 형태의 본 발명에 따른 항체는 AB4, A2F2, A2F3, BA6, CC9, C2E3, DG6, D2B12, A2F2 M1 및 BA6 M1의 순서대로 하기 중쇄 및 경쇄 전장 서열로 개시된다: 서열번호 59(중쇄) 및 67 (경쇄); 서열번호 60 (중쇄) 및 68 (경쇄); 서열번호 61 (중쇄) 및 69 (경쇄); 서열번호 62 (중쇄) 및 70 (경쇄); 서열번호 63 (중쇄) 및 71 (경쇄); 서열번호 64 (중쇄) 및 72 (경쇄); 서열번호 65 (중쇄) 및 73 (경쇄); 서열번호 66(중쇄) 및 74 (경쇄); 서열번호 100(중쇄) 및 68(경쇄); 서열번호 101(중쇄) 및 70(경쇄)
실시예 2-2: 항-ROR1 IgG 항체의 발현
CHO-S 세포를 CD-CHO(Gibco, 10743) 배지에 1.5X106 cells/ml로 농도를 맞춘 후, 8% CO2, 37℃에서 1일 동안 배양하였다. DNA 트랜스펙션 당일 2.5~3X106 cells/ml로 자란 세포를 1% DMSO가 포함되어 있는 CD-CHO 배지를 이용하여 2.1X106 cells/ml의 농도로 준비한 후, 8% CO2, 37℃에서 3 hr 배양하였다. 3000rpm에서 15 min 원심분리 후, 상등액을 제거한 후, 25% FBS가 포함된 RPMI 1640 배지에 재현탁 하였다. 이어 실시예 2-1의 중쇄와 경쇄를 발현하는 각 벡터를 각각 배지 ml당 1 ㎍씩 Opti-MEM 배지에 희석하고, PEI(Polysciences, 23966, stock 농도: 1 mg/ml)는 배양 배지 ml당 8 ㎍ 희석하였다. 상기 벡터 및 PEI 혼합물을 섞어 상온에서 10 min 동안 정치한 후, 상기와 같이 준비된 세포가 포함된 플라스크에 넣은 후, 5% CO2, 37℃, 100 rpm으로 4 hr 배양한 후, 배양부피와 동일한 부피의 CD-CHO 배지를 넣어준 후, 8% CO2, 37℃, 110 rpm에서 4일 동안 배양하였다.
실시예 2-3: 항-ROR1 IgG 항체의 분리 정제
평형화 완충액(50 mM Tris-HCl, pH7.5, 100 mM NaCl)을 Mab selectsure(GE healthcare, 5mL)에 통과시켜 평형시킨 이후, 실시예 3-2의 배양액을 컬럼(Mab selectsure(GE healthcare, 5mL))에 통과하여 발현된 항체가 컬럼에 결합하도록 하였다. 이 후, 50 mM Na-citrate(pH 3.4), 100 mM NaCl 용액으로 용출시킨 후, 1M Tris-HCl(pH 9.0)을 이용하여 중화시켜 최종 pH가 7.2가 되게 하였다. 완충액을 PBS(phosphate buffered saline, pH 7.4)로 교환하였다.
실시예 3: 항-ROR1 IgG 항체의 ROR1에 대한 결합 특이성 분석
실시예 3-1: 항-ROR1 IgG 항체의 ROR1 항원(세포외 영역)에 대한 결합능 분석(ELISA)
상기 실시예 2에서 제조된, 실시예 2에서 선별된 각 클론의 IgG 항체의 항원에 대한 특이적 결합능을 하기와 같이 분석하였다.
항-ROR1 항체-항원 결합 친화도는 ELISA-기반 용액 결합시험을 사용하여 평가하였다. 구체적으로 96-웰 미세역가 플레이트(Nunc-Immuno Plates, NUNC)를 4℃에서 16시간 동안 PBS 용액 중의 1 ㎍/㎖ 농도의 아래 기술한 ROR1 단백질로 코팅하고, 비특이적 결합부위는 3% BSA(bovine serum albumin)로 2시간 동안 차단시켰다. 이때 ROR1 단백질은 인간 ROR1의 경우 실시예 1의 ROR1-Fc 또는 재조합 인간 ROR1-His(Sino Biological, 13968-H08H)을 사용하였다. ELISA에서 사용한 ROR1-His는 위의 문장에 기재한 바와 같이 sino biological사(13968-H08H)의 단백질로 실시예 1의 ROR1-His, 또는 재조합 마우스 ROR1 단백질을 사용하였다(Acrobiosystems, RO1-M5221-100㎍)
이어 96-웰 미세역가 플레이트상에서 실시예 3에서 준비한 항-ROR1 항체를 도 2에 기재된 농도로 미세역가 플레이트 추가한 후 결합능을 다음과 같이 ELISA로 분석하였다. 구체적으로 2시간 항온처리 한 후에, 상기 플레이트를 0.05%의 트윈 20(tween 20)을 포함하는 PBS로 5회 세척한 후, HRP-접합된 Fab 다중클로날 항체 시약(Pierce, 31414)을 1:10,000 비율로 희석하여 상기 세척된 미세역가플레이트에 넣고, 1시간 동안 37℃에서 반응시켜, 플레이트에 결합된 ROR1 항체를 검출하였다. 반응 후 TMB(Tetramethylbenzidine, Sigma, T0440)를 사용하여 발색시켰다. 효소반응을 0.5 mol/L의 황산에 의해서 중지시키고, 마이크로 플레이트 리더기(molecular device)를 이용하여 450nm 및 650nm에서 흡광도를 측정하였다(450 nm - 650 nm)
결과는 도 3a 및 도 3b, 및 도 4에 기재되어 있으며, 본 발명의 항-ROR1 항체는 인간 ROR1과 마우스 ROR1에 농도 의존적으로 결합함을 확인하였다. 또한 마우스 ROR1 단백질에 대한 교차반응성을 비교하였을 때 본 발명 ROR1 항체가 비교군으로 사용한 2A2 대조항체 대비 결합력이 우수한 것으로 나타났다.
실시예
3-2: 항-
ROR1
IgG
항체의 세포 표면 발현
ROR1
항원에 대한 특이적 결합능 측정(
FACS
)
특정 항원에 대한 항체가 치료용 항체 등 생체 내에서 사용되기 위해서는 세포 표면 발현 항원에 결합하는 것이 필수적인 요소이다. 일부 항체의 경우 정제된 항원에는 결합하지만 세포 표면 발현 항원에는 결합하지 않는다. 이런 경우 생체 내로 항체를 투여하여도 항원에 대한 결합이 불가능 하므로 항원을 발현하고 있는 세포에 항체가 결합하지 못하여 치료용 항체 등 생체 내에서의 활성을 보일 수 없다.
이에 본 발명의 항-ROR1 항체가 세포 표면 발현 ROR1에 결합하는지 여부를 FACS 분석을 통하여 확인하였다.
이 실험을 위하여 ROR1 유전자를 일시적으로(CHO-human ROR1, CHO-human ROR2, CHO-mouse ROR1) 또는 안정적으로(MC38-human ROR1) 트렌스펙션시켜 ROR1 단백질의 발현을 인위적으로 과발현시킨 세포주(각각 도 5 및 도 7) 또는 ROR1을 발현하는 세포주(JeKo-1, Mino)(도 6) 또는 ROR1을 발현하지 않는 세포주(MCF7)(도 6)와 FACSCalibur(BD Biosciences) 기기를 이용하여 항-ROR1 항체와 ROR1의 결합된 정도를 다음과 같이 측정하였다. MCF7는 ROR1을 발현하지 않는 음성대조군이고, CHO-human ROR2는 인간 ROR2를 발현하는 음성대조군이다. JeKo-1, Mino, CHO-human ROR1, CHO-mouse ROR1, MC38-human ROR1은 모두 인간 ROR1 또는 마우스 ROR1을 발현 하는 세포주이다.
구체적으로 각 세포주를 해리시키고 PBS에서 세척한 후, 세포수를 계수하여 2x105 cells/200㎕ PBS로 맞춘 뒤, 실시예 3에서 준비된 각 ROR1 단일클론항체를 10 μg/mL 또는 10 μg/mL으로부터 5배씩 희석하여 처리 후 4℃에서 1시간 반응하였다. 반응 후 세포를 PBS에서 세척한 뒤 FITC 표지된 불가변영역(Fc) 특이적인 항체(Goat anti-human IgG FITC conjugate, Fc specific, Sigma, F9512, 농도:20 mg/ml)를 2 ㎕/1x105 cells/200㎕ PBS로 현탁하여 4℃에서 1시간 반응하였다. 일시적으로 과발현시킨 인간 ROR1, 인간 ROR2, 마우스 ROR1의 발현 정도의 확인은 상업적으로 판매되는 FACS 분석용 항체(anti-ROR1 : R&D Systems, FAB2000G, anti-ROR2 : R&D, FAB20641P)를 이용하여 분석하였다. 반응 후 세포를 PBS에서 세척하고 FACSCalibur 기기를 이용하여 판독하였다. 음성대조군(2nd Ab)은 FITC 라벨링된 불가변영역(Fc) 특이적인 항체만 처리하였다. 각각의 ROR1 단일클론항체를 처리한 실험군에서 이동된 판독 결과를 대조군의 이동된 판독 결과와 비교하였다(MFI Ratio:MFI of anti-ROR1 / MFI of 2nd Ab).
결과는 도 5, 도 6 및 도 7에 기재되어 있다. 그 결과 본 발명의 항-ROR1 항체는 세포에서 원래 발현되는 인간 ROR1(도 6) 및 세포에서 인위적으로 과발현 된 인간 ROR1(도 5, 도 7)의 세포외영역에 특이적으로, 농도의존적인 양상으로 결합함을 확인하였다. 또한 패밀리 단백질인 인간 ROR2에는 결합하지 않고, 마우스 ROR1에 대해서는 종간 교차반응성이 있음을 확인하였다(도 5). 세포표면에 발현하는 마우스 ROR1에 대한 교차반응성을 비교하였을 때 본 발명의 ROR1 항체가 비교군으로 사용한 항체인 2A2 대비 결합정도가 더 우수함을 확인하였다 (도 5).
실시예
3-3: 항-
ROR1
IgG
항체의 다양한
암종에서의
세포 표면 발현
ROR1
항원에 대한
결합능
측정(
FACS
)
이어 FACS 분석을 통하여 본 발명의 항-ROR1 항체가 다양한 종류의 암세포주에서 세포 표면 발현 ROR1에 결합하는지 여부를 확인하였다. ROR1은 다양한 암세포에서 발현하는데 만성 림프구성 백혈병(CLL), B세포 백혈병, 림프종, 급성골수성 백혈병(AML), 버킷 림프종, 외투세포림프종(MCL), 급성림프구성백혈병(ALL), 미만성거대B세포림프종(DLBCL), 여포성림프종(FL), 변연부림프종(MZL) 등의 혈액암은 물론 유방암, 신장암, 난소암, 위암, 간암, 폐암, 대장암, 췌장암, 피부암, 방광암, 고환암, 자궁암, 전립선암, 비소세포 폐암(NSCLC), 신경모세포종, 뇌암, 결장암, 상피 편평세포암, 흑색종, 골수종, 자궁경부암, 갑상선암, 두경부암 및 부신암 등의 다양한 고형암에서도 과발현되는 것으로 보고 되어있다.
이 실험을 위하여 다음과 같은 다양한 종류의 암세포주를 사용하였다: AGS (ATCC CRL-1739™, huamn gastric adenocarcinoma), NCI-N87 (ATCC CRL-5822™, human gastric carcinoma), MKN-28 (KCLB 80102, human gastric adenocarcinoma), SNU-1750 (KCLB 01750, human gastric adenocarcinoma), SNU-16 (ATCC CRL5974™, human gastric carcinoma), HCC1187 (ATCC CRL-2322™, huamn breast canccer TNM stage IIA grade 3), MDA-MB-231 ATCC HTB-26™, human breast cancer), MDA-MB-468 (ATCC HTB-132™, human breast cancer), HCC70 (ATCC CRL2315™, human breast cancer TNM stage IIIA, grade 3), HCC1143 (ATCC CRL-2321™, TNMstageIIA, grade3, primary ductal carcinoma), BT20(ATCC HTB-19™ human breast cancer), HCC1806 (ATCC CRL-2335™, huamn breast canccer TNM stage IIB grade 2), HCC1937 (ATCC CRL2336™, TNMstageIIB, grade3, primary ductal carcinoma), BT474 (ATCC HTB-20™, ductal carcinoma), MCF7 (ATCC HTB-22™, breast cancer metastatic site), H460 (ATCC HTB-177™, large cell lung cancer), A549 (ATCC CCL-185™, lung carcinoma), NCI-H1975 (ATCC CRL-5908™, non-small cell lung cancer), H1437 (ATCC CRL5872™, stage1,adenocarcinomanonsmallcelllungcancer),Calu-6(ATCC HTB-56™, anaplastic lung carcinoma), HCT116 (ATCC CCL-247™, colorectal carcinoma), DLD-1 (ATCC CCL-221™, Dukes' type C, colorectal adenocarcinoma), HT29 (ATCC HTB-38™, colorectal adenocarcinoma), 697 (DSMZACC 42, acute myeloblastic leukemia), Kasumi-2 (ATCC CRL-2724™, acute myeloblastic leukemia), Mino (ATCC CRL3000™, Mantle Cell Lymphoma), JeKo-1(ATCC CRL3006™, Mantle Cell Lymphoma), Jurkat (ATCC TIB-152™, acute Tcell leukemia) 상기 세포주에 대하여 본 발명의 항-ROR1 항체를 이용하여 ROR1에 대한 결합을 FACS (FACSCalibur, BD Biosciences)로 분석하였다.
구체적으로 각 세포주를 해리시키고 PBS에서 세척한 후, 세포수를 계수하여 2x105 cells/200㎕ PBS로 맞춘 뒤, 실시예 3에서 준비된 각 ROR1 단일클론 항체중 클론명 C2E3 항체를 10 μg/mL으로 처리 후 4℃에서 1시간 반응하였다. 반응 후 세포를 PBS에서 세척한 뒤 FITC 표지된 불가변영역(Fc) 특이적인 항체(Goat anti-human IgG FITC conjugate, Fc specific, Sigma, F9512, 농도: 20 mg/ml)를 2 ㎕/1x105 cells/200㎕ PBS로 현탁하여 4℃에서 1시간 반응하였다. 반응 후 세포를 PBS에서 세척하고 FACSCalibur 기기를 이용하여 판독하였다. 음성대조군은 FITC 라벨링된 불가변영역(Fc) 특이적인 항체만 처리하였다. 각 암세포주간 ROR1의 발현정도를 비교하기 위하여 본 발명의 ROR1 단일클론항체(C2E3)를 처리한 실험군에서 이동된 판독 결과를 대조군에서 이동된 판독 결과로 나눈 값(MFI Ratio : MFI of anti-ROR1 / MFI of 2nd Ab)을 표기하였다.
결과는 도 8에 기재되어 있다. 그 결과 본 발명의 항-ROR1 항체는 위암, 유방암, 폐암, 대장암, 급성림프구성백혈병(ALL), 및 외투세포림프종(MCL)유래의 다양한 암세포주에서 발현되는 ROR1에 결합이 확인되었다.
실시예 4: 항-ROR1 IgG 항체의 ROR1에 대한 친화도(Affinity) 측정
바이오센서 트레이 케이스에 96 well black microplate(greiner bioone)를 장착하고 8개 well 각각에 10X KB 또는 DW로 200 ㎕을 넣는 다음 Anti Penta His biosensor 또는 AR2G biosensor(ForteBio, USA) 8개를 꽂아서 10분 동안 수화하였다. 분석 시료는 희석할 농도에 맞게 600 ㎕씩 2배 또는 3배로 희석하였다. 분석 농도는 30 ~ 0.021 nM까지 1X KB 또는 10X KB를 사용하여 희석하였다. 항원 고정을 위해서 재조합 인간 ROR1-His(Sino Biological, 13968-H08H)을 1 ㎍/mL로 10XKB 또는 Sodium Acetate pH5 버퍼로 희석하였다. 고정화는 로딩단계에서 문턱값 0.3 nm로 고정하였다. Association은 3분~10분, Dissociation은 20분으로 실험 진행하였다. Octet program template에 맞추어서 새로운 96 well black microplate에 준비된 buffer를 순서에 맞게 넣었다. Baseline1으로 사용 되는 10X KB 또는 DW로 200 ㎕을 넣었다. Loading 할 항원 ROR1-His 단백질, 1 ㎍/mL을 200㎕씩 넣었다. Baseline2로 사용되는 10X KB 또는 1X KB, 200 ㎕을 넣었다. 희석한 항체 30 ~ 0.021 nM, Reference blank에 해당되는 10X KB buffer 또는 1X KB를 각 well에 200㎕씩 넣었다. 실험 plate의 온도는 30℃로 고정하였다. 시료를 모두 넣은 후 기기를 작동시긴 후 실험이 종료하여 Octet Analysis 90 software로 결과를 업로드 한 후 1:1 핏팅으로 KD값을 분석하였으며, 결과는 아래 표 6에 기재되어 있다. Octet 분석법을 이용한 KD값 획득을 통해 항-ROR1 항체가 ROR1 항원에 대한 강한 결합력을 가짐을 확인하였다.
[표 6] 항-ROR1 IgG 항체의 ROR1에 대한 친화도 측정

실시예 5: 항-ROR1 IgG 항체의 마우스 이종종양이식 모델에서의 암 성장 억제 효능 분석
중증면역 부전 마우스(The severe combined immunodeficiency mouse, SCID)에 ROR-1을 발현하는 인간 외투세포림프종인 JeKo-1 세포주를 1 x 107 cells/head 이식하여 인간 암 이식 종양 마우스를 제작했다. 이식후 종양 크기가 평균 170 mm3 에 도달하였을 때 (Day 1) 군분리를 실시하고 항 ROR-1 항체 5종을 10 mg/kg씩 주 2회, 총 5회 1 mL 실린지를 이용하여 마우스 복강내로 투여했다 (Day 1, 4, 7, 10 및 14) 음성대조군은 항 ROR-1 항체의 구조와 유사한 인간 IgG1(InVivoPlus human IgG1 isotype control, BioXCell, BP0297)을 10 mg/kg씩 주 2회, 총 5회 복강내로 투여하였다. 마우스에 이식된 종양크기 및 체중은 최초 투여(Day 1) 직전에 측정되고, 그 후 각 투여일의 투여 직전 및 최후 투여 후 2일 후(Day 16)에 측정하였다.
결과는 도 9a 및 도 9b에 기재되어 있다. 본 발명에 따른 항 ROR-1 항체는 암의 성장을 억제하였으며, 음성 대조군인 인간 IgG1 항체(HuIgG1) 대비 본 발명에 따른 암의 성장억제 효과(% Tumor Growth Inhibition, %TGI)는 실험종료일인 Day 16을 기준으로 C2E3 360%, A2F2 289%, AB4 361%, BA6 317%, CC9 294% 인 것으로 나타났다. 본 발명에 따른 항-ROR1 항체는 HuIgG 투여군 대비 통계학적 유의성 있는 차이를 갖는 것으로 나타났다(일원배치 분산분석, P value < 0.05) (도 9a) 체중 측정 결과(도 9b) 투여군간의 유의미한 차이는 관찰되지 않았다. 실시예 3-1과 3-2에 기재된 바와 같이 본 발명의 항-ROR1 항체는 마우스 ROR1 항원에 교차반응성을 가진다. 그러므로 투여한 본 발명의 항-ROR1 항체는 이종이식한 인간 외투세포림프종인 JeKo-1 세포주가 발현하는 인간 ROR1과 함께 마우스가 자체적으로 발현하는 마우스 ROR1에도 결합할 수 있다. 체중 측정 결과 음성 대조군(HuIgG1)과 본 발명의 항-ROR1 항체 간에 체중 증가양상이 유사한 것은 본 발명의 항-ROR1 항체 투여에 의해 독성을 유도하지 않음을 의미한다고 할 수 있다. 상기 결과는 본 발명에 따른 항체가 암치료제로서 유용하게 사용될 수 있음을 나타낸다.
마우스 이종종양이식 모델에서는 본 발명의 ROR1 항체 5종 모두 암의 성장을 억제하는 것으로 나타났다. 이들 중 일부 항체(C2E3, AB4)는 하기 실시예 6 및 도 10에 기재된 바와 같이 anti-human Fc 항체에 의해 다량체화 될 때 ROR1 과발현 암세포주의 자가세포 사멸을 유도할 수 있는 것으로 나타났다. 그러나 암의 저해기전은 자가세포사멸 유도, 암세포 분열 및 성장 억제, 암혈관형성 억제, 면역 세포 활성화 등 다양한 기전을 통해 가능하기 때문에, 후술하는 도 10의 결과는 본 발명에 따른 항-ROR1 항체들이 각 항체별로 상이한 작용기작에 의해 생체내에서 암성장을 억제할 수 있음을 의미한다.
실시예 6: 항-ROR1 IgG 항체의 자가세포사멸 유도능 분석
실시예 5에서와 같은 종양 억제능을 나타내는 본 발명에 따른 항체의 가능한 기전을 분석하기 위해, 세포사멸 유도능을 분석하였다.
이를 위해 ROR1 고발현 세포주인 JeKo-1을 원심분리하여 혈청이 포함된 배지를 제거하고, PBS를 이용하여 1회 세척한 후, 6 well plate에 각 well당 5X10^6개의 세포를 혈청이 없는 RPMI1640 배지를 이용하여 seeding 하였다. 본 발명의 항-ROR1 항체 100 ㎍/mL과 anti-human Fc 항체(Thermo Fisher, 31125) 300 ㎍/ml을 1:1로 동량 tube에 넣어 준 후, 상온에서 10분간 반응시켜, anti-human Fc 항체에 의해 항-ROR1 항체가 다량체를(cross-linking) 이루게 하였다. 15 ml의 배지가 들어있는 각 well에 상기 혼합물을 150 ㎕ 넣어 최종 항체 처리양이 ROR1의 항체의 경우 10 ㎍/mL, anti-human Fc 항체는 30 ㎍/mL이 되도록 한 후, 5% CO2, 37℃ 조건에서 24 hr 배양하여 반응시켰다.
이어 ROR1 항체의 단독처리 및 다량체를 이룬 항-ROR1 항체가 자가 세포 사멸능이 있는지 확인하기 위해 각 well의 세포를 수거하여 PBS로 1회 세척하였다. 이후, 자가세포사멸의 표지인 Annexin V와 세포사멸 표지인 PI를 각 군에 반응시켜 염색된 정도를 FACS 분석을 통해 확인하였다.
결과는 도 10에 기재되어있다. 실험 결과 항-ROR1 항체 단독 처리에 의해서는 자가세포사멸이 관찰되지 않았으나, anti-human Fc 항체에 의해 다량체를 이룬 일부 항-ROR1 항체 클론(C2E3, AB4)의 경우 대조군에 비해 Annexin V와 PI의 염색정도가 증가함을 확인하였으며, 특히 자가세포사멸능의 표지인 Annexin V의 염색정도의 경우 대조군에 비해 C2E3 클론은 23%, AB4 클론은 10% 증가함을 확인하였다. 이와 같은 자가세포사멸능이 ROR1에 의한 특이적 반응인지 확인하기 위해, ROR1 미발현 세포주인 U266에 C2E3 클론을 이용하여 상기와 같은 방법으로 AnnexinV와 PI 염색정도를 확인하였고, ROR1 미발현 세포주인 U266에는 자가세포사멸능이 유도되지 못함을 확인하여, 다량체를 이룬 일 항-ROR1의 항체에 의한 자가세포사멸능이 ROR1을 통한 특이적 반응임을 증명하였다. 항체는 생체 내에서 Fc 영역을 통해 Fc 감마 수용체와 결합하면서 다량체를 이룰 수 있으므로 anti-human Fc 항체를 이용한 항-ROR1 항체의 다량체 형성은 생체 내 현상을 유사하게 만든 조건이라 할 수 있다. 상기 분석결과는 일 기전으로, 본 발명에 따른 항-ROR1 항체에 의해 ROR1을 과발현 하는 암세포주에서 자가세포사멸이 유도될 수 있음을 의미한다.
참고로 ROR1 항체의 다량체화에 의한 암세포주의 자가세포사멸 유도는 모든 종류의 ROR1 항체에서 나타나는 현상은 아니다. 예로 본 발명의 ROR1 항체 중 BA6 클론 및 비교군으로 사용한 항체인 2A2는 anti-human Fc 항체에 의해 다량체화를 이루어도 ROR1 과발현 암세포주의 자가세포사멸을 유도하지 않았다. 이는 본 발명에 따른 ROR1 항체들이 서로 상이한 작용기작에 의해 암세포 억제능을 가짐을 의미한다. 이러한 차이는 본 이론으로 한정하는 것은 아니지만 각 ROR1 항체들이 결합하는 에피토프의 상이성에 기인할 수 있다.
실시예 7: 화합물 1, 2, 3 및 4의 제조




상기 화합물 1, 2, 3 및 4는 특허 WO2017-089895에 기재된 방법으로 제조하였다.
상기 상기 화합물 1, 2, 3 및 4에서 MMAE 또는 MMAF의 구조는 다음과 같다 :


실시예 8: 화합물 5, 6 및 7의 제조



상기 화합물 5, 6 및 7은 대한민국 출원번호 10-2018-0036895호에 기재된 방법으로 제조하였다.
실시예 9: ADC의 제조
ADC의 제조는 다음의 두 단계를 거쳐 제조되었으며, 공통적으로 사용한 LCB14-0511 및 LCB14-0606은 한국공개특허 제10-2014-0035393호에 기재된 방법으로 제조하였다. LCB14-0511 및 LCB14-0606 구조식은 다음과 같다:


1단계 : prenylated antibody의 제조
본 발명의 ROR1 단일클론항체(C2E3)의 프레닐레이션 반응 혼합물을 제조하여 30℃에서 16시간 반응하였다. 반응혼합물은 24 μM 항체, 200 nM FTase (Calbiochem #344145)와 0.144 mM LCB14-0511 또는 LCB14-0606을 포함하는 완충용액 (50 mM Tris-HCl (pH 7.4), 5 mM MgCl2, 10 μM ZnCl2, 0.144 mM DTT)으로 구성하였다. 반응 종료 후 프레닐레이션된 항체는 PBS 완충용액으로 평형화된 G25 Sepharose 컬럼 (AKTA purifier, GE healthcare)으로 제염시켰다.
비교군 항체로 기존 항-ROR1 항체인 2A2(US 9,316,646)의 가변영역에 인간 IgG1을 연견할 키메라 항체(2A2)를 사용하였다.
2단계 : drug-conjugation 방법
<옥심 결합 반응 (conjugation by oxime bond formation)>
프레닐레이션된 항체와 링커-약물간의 옥심결합 생성반응 혼합물은 100 mM Na-아세테이트 완충용액 pH 5.2, 10% DMSO, 20 μM 항체와 200 μM 링커-약물(in house, 실시예 7, 8의 화합물 1, 2, 3, 4, 5 및 7번)을 섞어 제조하였으며 30℃에서 약하게 교반하였다. 6시간 또는 24시간 반응 후에 FPLC(AKTA purifier, GE healthcare) 과정을 거쳐 사용된 과량의 저분자 화합물들을 제거하였으며 단백질 분획은 수집하여 농축하였다.
<클릭 결합 반응 (conjugation by click reaction)>
프레닐레이션된 항체와 링커-약물간의 옥심결합 생성반응 혼합물은 10% DMSO, 20 μM 항체와 200 μM 링커-약물(in house, 실시예 8의 화합물 6번), 1mM 카퍼(II) 설페이트 펜타하이드레이트, 2 mM (BimC4A)3 (Sigma-Aldrich 696854), 10 mM 소듐 아스코르베이트 (sodium ascorbate) 및 10 mM 아미노구아니딘 염산염을 섞어 제조하였으며 25 ℃에서 3 시간 반응 후에 20 mM EDTA를 처리하여 30 분 동안 반응하였다. 반응 종료 후, FPLC(AKTA purifier, GE healthcare) 과정을 거쳐 사용된 과량의 저분자 화합물들을 제거하였으며 단백질 분획은 수집하여 농축하였다.
[표 7]
ADC 제조목록

실시예 10: ADC의 특성 분석
실시예 9에서 제조한 ADC를 이용하여 본 발명에 따른 ADC의 특성을 분석하였다.
이를 위해 소수성 상호작용 크로마토그래피-고성능 액체 크로마토그래피(HIC-HPLC) 분석을 수행하였다. ADC를 페닐-5PW 컬럼(7.5×75 mm, 10 μm, Tosoh Bioscience, USA)으로 소수성 상호 작용 크로마토그래피-고성능 액체 크로마토그래피시켰다. 1.5M 황산암모늄을 함유하는 50 mM 인산칼륨 완충액(pH 7.0)을 완충액 A로서 사용하고, 30% 아세토나이트릴을 함유하는 50 mM 인산칼륨 완충액(pH 7.0)을 완충액 B로서 사용하였여 70% A/30% B를 초기 조건으로 안정화시켰다. 70% A/30% B 대 10% A/90% B의 선형 구배를 사용하여 그 다음 25분 동안 용출을 하고 10% A/90% B로 5분간 추가적으로 용출을 수행하였다. 유량 및 온도를 각각 1.0 ㎖/min 및 25℃로 설정하였다. 검출을 254 및 280 nm 둘 다에서 후속하였다. ROR1 항체 및 프레닐화 ROR1 항체를 대조군으로 사용하였다.
또한, 및 크기 배제 크로마토그래피-고성능 액체 크로마토그래피(SEC-HPLC) 분석을 수행하였다. ADC를 SWXL(6.0×40 mm, Tosoh Bioscience, USA) 가드컬럼과 G3000SWxl 컬럼(7.8×300mm, 5μm, Tosoh Bioscience, USA)을 이용하여 크기 배제 크로마토그래피-고성능 액체 크로마토그래피시켰다. 250 mM 인산 클로라이드와 15% 이소프로필 알콜을 포함하는 200 mM 인산 칼륨 완충액(pH 7.0)을 이동상으로 하여 0.5 ㎖/min의 유속, 25℃ 조건에서 30분 동안 분석하였다. 검출을 254 및 280 nm 둘 다에서 후속하였다. ROR1 항체 및 프레닐화 ROR1 항체를 대조군으로 사용하였다.
실시예 9에서 제조한 ADC 중 ADC2 및 ADC5의 특성 분석 결과를 도 11a 및 도 11b에 기재하였다.
실시예 11:
In vitro
세포 독성 평가
실시예 9에서 제조한 ADC의 암세포주에 대한 세포증식억제 활성을 측정하였다.
이를 위해 시판 중인 암세포주(Mino, Jeko-1, REC-1, H2228, NCI-N87, HCC1806, MDA-MB-231, MCF-7 및 Daudi 세포주)를 사용하였다. 96-웰 플레이트에 각 암세포주를 웰(well)당 4,000~5,000개씩 접종(seeding)하여 24시간 동안 배양한 뒤에 표_에 기재된 ADC를 0.0015~10.0 nM (3배 연속 희석) 농도로 처리하였다. 72시간 뒤에 살아있는 세포수를 WST-8 (Dojindo molecular technology inc.) 염료를 사용하여 정량하였다.
결과는 아래 표 8에 기재되어 있다. ROR1이 과발현된 암세포주에서 본 발명의 항-ROR1 단일클론항체가 접합된 ADC가 기존 항-ROR1 항체가 접합된 ADC(ADC8, 9, 10)보다 세포 독성이 매우 뛰어남을 확인하였다. 또한, 피롤로벤조디아제핀 계열의 ADC는 오리스타틴 계열의 ADC에 비해 세포독성이 강하게 나타나는 것을 확인하였다.
[표 8]
ADC 시료의 세포 독성 비교

실시예 12:
In vivo
암 성장 억제 효능 분석
실시예 12-1: ROR1 발현 유방암 세포주 이식 마우스 모델에서 ADC에 의한 암 성장 억제 효능 분석
실시예 12-1: ROR1 발현 유방암 세포주 이식 마우스 모델에서 ADC에 의한 암 성장 억제 효능 분석
암컷 Balb/C 누드 마우스에 ROR-1을 발현하는 인간 유방암 세포주인 MDA-MB-468 세포주를 1 x 107 cells/head 이식하여 인간 암 이식 종양 마우스를 제작했다. 이식후 종양 크기가 평균 166 mm3 에 도달하였을 때 (Day 1) 군분리를 실시하고 실시예 9에서 제조한 ADC5 1 mg/kg을 1회 마우스 정맥내로 투여하였다. 대조군은 PBS 10 ml/kg을 마우스 정맥내로 투여하였다. 마우스에 이식된 종양크기 및 체중은 최초 투여(Day 1) 직전에 측정되고, 그 후 56일 동안 주기적으로 측정하였다.
또한, 중증면역 부전 마우스(SCID)에 ROR-1을 발현하는 인간 유방암 세포주인 MDA-MB-231 세포주를 1 x 107 cells/head 이식하여 인간 암 이식 종양 마우스를 제작했다. 이식후 종양 크기가 평균 110 mm3 에 도달하였을 때 (Day 1) 군분리를 실시하고 실시예 9에서 제조한 ADC5 0.5, 1.0 또는 2.0 mg/kg을 1회 마우스 정맥 내로 투여하였다. 또는 ADC5 0.33 mg/kg을 주 2회, 총 3회 마우스 정맥 내로 투여하였다(Day 1, 7, 14). 대조군은 PBS 10 ml/kg을 마우스 정맥내로 투여하였다. 마우스에 이식된 종양크기 및 체중은 최초 투여(Day 1) 직전에 측정되고, 그 후 22일 동안 주기적으로 측정하였다.
또한, 중증면역 부전 마우스(SCID)에 ROR-1을 발현하는 인간 유방암 세포주인 HCC1187 세포주를 1 x 107 cells/head 이식하여 인간 암 이식 종양 마우스를 제작했다. 이식후 종양 크기가 평균 110 mm3 에 도달하였을 때 (Day 1) 군분리를 실시하고 실시예 9에서 제조한 ADC5 1.25 또는 0.31 mg/kg을 1회 마우스 정맥내로 투여하였다. 또는 ADC2 3.75 mg/kg을 1회 마우스 정맥내로 투여하였다. 대조군은 PBS 10 ml/kg을 마우스 정맥내로 투여하였다. 마우스에 이식된 종양크기 및 체중은 최초 투여(Day 1) 직전에 측정되고, 그 후 41일 동안 주기적으로 측정하였다.
결과는 도 12, 13 및 도 14에 기재되어 있다. ROR1 발현 유방암 세포주 이식 마우스 모델에서 본 발명의 ADC가 암의 성장을 억제하는 것을 확인하였다.
실시예 12-2: ROR1 발현 페암 세포주 이식 마우스 모델에서 ADC에 의한 암 성장 억제 효능 분석
암컷 Balb/C 누드 마우스에 ROR-1을 발현하는 인간 폐암 세포주인 Calu-3 세포주를 1 x 107 cells/head 이식하여 인간 암 이식 종양 마우스를 제작했다. 이식후 종양 크기가 평균 184 mm3 에 도달하였을 때 (Day 1) 군분리를 실시하고 실시예 9에서 제조한 ADC2 3 mg/kg을 1회 마우스 정맥내로 투여하였다. 또는, 실시예 9에서 제조한 ADC5 0.25 또는 1.0 mg/kg을 1회 마우스 정맥내로 투여하였다. 대조군은 PBS 10 ml/kg을 마우스 정맥내로 투여하였다. 마우스에 이식된 종양크기 및 체중은 최초 투여(Day 1) 직전에 측정되고, 그 후 35일 동안 주기적으로 측정하였다.
결과는 도 15에 기재되어 있다. ROR1 발현 폐암 세포주 이식 마우스 모델에서 본 발명의 ADC가 암의 성장을 억제하는 것을 확인하였다.
실시예 12-3: ROR1 발현 외투세포림프종 세포주 이식 마우스 모델에서 ADC에 의한 암 성장 억제 효능 분석
중증면역 부전 마우스(SCID)에 ROR-1을 발현하는 인간 외투세포림프종 세포주인 Jeko-1 세포주를 1 x 107 cells/head 이식하여 인간 암 이식 종양 마우스를 제작했다. 이식후 종양 크기가 평균 110 mm3 에 도달하였을 때 (Day 1) 군분리를 실시하고 실시예 9에서 제조한 ADC2 3 mg/kg을 1회 마우스 정맥내로 투여하였다. 또는, 실시예 9에서 제조한 ADC5 0.25 또는 1.0 mg/kg을 1회 마우스 정맥내로 투여하였다. 대조군은 PBS 10 ml/kg을 마우스 정맥내로 투여하였다. 마우스에 이식된 종양크기 및 체중은 최초 투여(Day 1) 직전에 측정되고, 그 후 33일 동안 주기적으로 측정하였다.
결과는 도 16에 기재되어 있다. ROR1 발현 외투세포림프종 세포주 이식 마우스 모델에서 본 발명의 ADC가 암의 성장을 억제하는 것을 확인하였다.
실시예 12-4: ROR1 발현 외투세포림프종 세포주 이식 마우스 모델에서 ADC 간 암 성장 억제 효능 비교
ADC를 구성하는 항체 및 약물에 따른 암 성장 억제 효능을 비교하였다.
이를 위해 중증면역 부전 마우스(SCID)에 ROR-1을 발현하는 인간 외투세포림프종 세포주인 Jeko-1 세포주를 1 x 107 cells/head 이식하여 인간 암 이식 종양 마우스를 제작했다. 이식후 종양 크기가 평균 110 mm3 에 도달하였을 때 (Day 1) 군분리를 실시하고 실시예 9에서 제조한 ADC2(C2 MMAE) 또는 ADC9(2A2 MMAE)를 1mg/kg 또는 4 mg/kg 농도로 1회 마우스 정맥내로 투여하였다. 또는, 실시예 9에서 제조한 ADC5(dPBD-ADC) 또는 ADC10(2A2 dPBD)을 0.25 mg/kg 또는 1 mg/kg 농도로 1회 마우스 정맥내로 투여하였다. 대조군은 PBS 10 ml/kg을 마우스 정맥내로 투여하였다. 마우스에 이식된 종양크기 및 체중은 최초 투여(Day 1) 직전에 측정되고, 그 후 37일 동안 주기적으로 측정하였다.
결과는 도 17에 기재되어 있다. 본 발명의 항-ROR1 단일클론항체가 접합된 ADC가 기존 항-ROR1 항체가 접합된 ADC(ADC9, 10)보다 암의 성장 억제 효과가 우수함을 확인하였다. 또한, 피롤로벤조디아제핀 계열의 ADC에 의한 암의 성장 억제가 오리스타틴 계열의 ADC보다 강하게 나타나는 것을 확인하였다.
<110> ABL Bio Inc.
LEGOCHEM BIOSCIENCES, INC.
<120> Antibody-drug conjugate comprising antibody binding to antibody
against human ROR1 and its use
<130> PB2019-070
<160> 103
<170> KopatentIn 3.0
<210> 1
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR1
<400> 1
Ser Tyr Asp Met Ser
1 5
<210> 2
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR1
<400> 2
Asp Tyr Tyr Met Ser
1 5
<210> 3
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR1
<400> 3
Asn Tyr Asp Met Ser
1 5
<210> 4
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR1
<400> 4
Asn Tyr Ala Met Ser
1 5
<210> 5
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR1
<400> 5
Asp Tyr Asp Met Ser
1 5
<210> 6
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR2
<400> 6
Trp Ile Ser Pro Asp Ser Gly Ser Ile Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 7
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR2
<400> 7
Ser Ile Ser Pro Asp Gly Ser Asn Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 8
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR2
<400> 8
Trp Ile Ser Pro Gly Gly Gly Ser Lys Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 9
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR2
<400> 9
Ala Ile Tyr His Ser Gly Ser Ser Lys Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 10
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR2
<400> 10
Gly Ile Ser His Gly Ser Gly Asn Lys Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 11
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR2
<400> 11
Ser Ile Ser His Asn Ser Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 12
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR2
<400> 12
Val Ile Ser Pro Asp Gly Gly Ser Ile Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 13
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR2
<400> 13
Ser Ile Ser Pro Ser Ser Gly Ser Ser Ile Tyr Tyr Ala Asp Ser Val
1 5 10 15
Lys Gly
<210> 14
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR3
<400> 14
Pro Thr Gly Arg Phe Asp Tyr
1 5
<210> 15
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR3
<400> 15
Asn Leu Arg Ala Phe Asp Tyr
1 5
<210> 16
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR3
<400> 16
Val Asn Gly Arg Phe Asp Tyr
1 5
<210> 17
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR3
<400> 17
Gly Gly Asn Gly Ala Trp Asp Thr Gly Phe Asp Tyr
1 5 10
<210> 18
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR3
<400> 18
Arg Leu Ser Leu Arg Arg Arg Pro Ser Tyr Tyr Ser Asp Asn Ala Met
1 5 10 15
Asp Val
<210> 19
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR3
<400> 19
Phe Ile Ser Ala Arg Lys Ser Leu Gly Arg Ser Tyr Ser Asn Gly Met
1 5 10 15
Asp Val
<210> 20
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR3
<400> 20
Asp Val Val Glu Cys Asn Met Asn Pro Cys Ser Tyr Asp Asn Ala Met
1 5 10 15
Asp Val
<210> 21
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR3
<400> 21
Ala Pro Gly Trp Cys Gln Ala Pro Ser Cys Tyr Tyr Asp Asn Ala Met
1 5 10 15
Asp Val
<210> 22
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR1
<400> 22
Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn Asn Val Asn
1 5 10
<210> 23
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR1
<400> 23
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Thr Val Tyr
1 5 10
<210> 24
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR1
<400> 24
Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn Asn Val Ser
1 5 10
<210> 25
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR1
<400> 25
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Asp Val Ser
1 5 10
<210> 26
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR1
<400> 26
Thr Gly Ser Ser Ser Asn Ile Gly Asn Asn Ala Val Asn
1 5 10
<210> 27
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR1
<400> 27
Thr Gly Ser Ser Ser Asn Ile Gly Ser Asn Asp Val Thr
1 5 10
<210> 28
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR1
<400> 28
Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn Tyr Val Ser
1 5 10
<210> 29
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR1
<400> 29
Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn Asp Val Ser
1 5 10
<210> 30
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR2
<400> 30
Tyr Asp Asn Lys Arg Pro Ser
1 5
<210> 31
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR2
<400> 31
Ala Asn Ser Gln Arg Pro Ser
1 5
<210> 32
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR2
<400> 32
Ala Asp Ser His Arg Pro Ser
1 5
<210> 33
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR2
<400> 33
Tyr Asp Asn Asn Arg Pro Ser
1 5
<210> 34
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR2
<400> 34
Tyr Asp Ser Asn Arg Pro Ser
1 5
<210> 35
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR2
<400> 35
Ala Asp Ser Lys Arg Pro Ser
1 5
<210> 36
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR2
<400> 36
Asp Asp Ser His Arg Pro Ser
1 5
<210> 37
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR2
<400> 37
Asp Asp Ser Gln Arg Pro Ser
1 5
<210> 38
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR3
<400> 38
Gly Thr Trp Asp Ala Ser Leu Ser Gly Tyr Val
1 5 10
<210> 39
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR3
<400> 39
Gly Ser Trp Asp Tyr Ser Leu Ser Gly Tyr Val
1 5 10
<210> 40
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR3
<400> 40
Ala Thr Trp Asp Tyr Ser Leu Ser Gly Tyr Val
1 5 10
<210> 41
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR3
<400> 41
Gly Ala Trp Asp Asp Ser Leu Ser Gly Tyr Val
1 5 10
<210> 42
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain CDR3
<400> 42
Gly Thr Trp Asp Tyr Ser Leu Ser Gly Tyr Val
1 5 10
<210> 43
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain variable region
<400> 43
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Trp Ile Ser Pro Asp Ser Gly Ser Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Pro Thr Gly Arg Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 44
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain variable region
<400> 44
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Pro Asp Gly Ser Asn Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asn Leu Arg Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 45
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain variable region
<400> 45
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Trp Ile Ser Pro Gly Gly Gly Ser Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Val Asn Gly Arg Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 46
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain variable region
<400> 46
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Tyr His Ser Gly Ser Ser Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Asn Gly Ala Trp Asp Thr Gly Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 47
<211> 127
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain variable region
<400> 47
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser His Gly Ser Gly Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Arg Leu Ser Leu Arg Arg Arg Pro Ser Tyr Tyr Ser Asp Asn
100 105 110
Ala Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 48
<211> 127
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain variable region
<400> 48
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser His Asn Ser Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Phe Ile Ser Ala Arg Lys Ser Leu Gly Arg Ser Tyr Ser Asn
100 105 110
Gly Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 49
<211> 127
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain variable region
<400> 49
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Ser Pro Asp Gly Gly Ser Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Val Val Glu Cys Asn Met Asn Pro Cys Ser Tyr Asp Asn
100 105 110
Ala Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 50
<211> 128
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain variable region
<400> 50
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Pro Ser Ser Gly Ser Ser Ile Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Lys Ala Pro Gly Trp Cys Gln Ala Pro Ser Cys Tyr Tyr Asp
100 105 110
Asn Ala Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 51
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain variable region
<400> 51
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn
20 25 30
Asn Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asn Lys Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Thr Trp Asp Ala Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 52
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain variable region
<400> 52
Gln Ser Val Leu Thr Gln Pro Pro Pro Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Tyr Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Ala Asn Ser Gln Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ser Trp Asp Tyr Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 53
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain variable region
<400> 53
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn
20 25 30
Asn Val Ser Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Ala Asp Ser His Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Thr Trp Asp Tyr Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 54
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain variable region
<400> 54
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Asp Val Ser Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asn Asn Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ala Trp Asp Asp Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 55
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain variable region
<400> 55
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Asn Asn
20 25 30
Ala Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ala Trp Asp Asp Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 56
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain variable region
<400> 56
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Asp Val Thr Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Ala Asp Ser Lys Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Thr Trp Asp Tyr Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 57
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain variable region
<400> 57
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Tyr Val Ser Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Asp Asp Ser His Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ala Trp Asp Asp Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 58
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain variable region
<400> 58
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn
20 25 30
Asp Val Ser Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Asp Asp Ser Gln Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ala Trp Asp Asp Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly
100 105 110
<210> 59
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain
<400> 59
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Trp Ile Ser Pro Asp Ser Gly Ser Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Pro Thr Gly Arg Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 60
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain
<400> 60
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Pro Asp Gly Ser Asn Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asn Leu Arg Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 61
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain
<400> 61
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Trp Ile Ser Pro Gly Gly Gly Ser Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Val Asn Gly Arg Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 62
<211> 451
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain
<400> 62
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Tyr His Ser Gly Ser Ser Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Asn Gly Ala Trp Asp Thr Gly Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
225 230 235 240
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
245 250 255
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
260 265 270
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
275 280 285
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
290 295 300
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
305 310 315 320
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
325 330 335
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
340 345 350
Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser
355 360 365
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
370 375 380
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
385 390 395 400
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
405 410 415
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
420 425 430
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
435 440 445
Pro Gly Lys
450
<210> 63
<211> 457
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain
<400> 63
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser His Gly Ser Gly Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Arg Leu Ser Leu Arg Arg Arg Pro Ser Tyr Tyr Ser Asp Asn
100 105 110
Ala Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala
115 120 125
Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser
130 135 140
Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe
145 150 155 160
Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly
165 170 175
Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu
180 185 190
Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr
195 200 205
Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys
210 215 220
Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro
225 230 235 240
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
245 250 255
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
260 265 270
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
275 280 285
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
290 295 300
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
305 310 315 320
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
325 330 335
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
340 345 350
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met
355 360 365
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
370 375 380
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
385 390 395 400
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
405 410 415
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
420 425 430
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
435 440 445
Lys Ser Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 64
<211> 457
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain
<400> 64
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser His Asn Ser Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Phe Ile Ser Ala Arg Lys Ser Leu Gly Arg Ser Tyr Ser Asn
100 105 110
Gly Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala
115 120 125
Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser
130 135 140
Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe
145 150 155 160
Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly
165 170 175
Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu
180 185 190
Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr
195 200 205
Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys
210 215 220
Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro
225 230 235 240
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
245 250 255
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
260 265 270
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
275 280 285
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
290 295 300
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
305 310 315 320
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
325 330 335
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
340 345 350
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met
355 360 365
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
370 375 380
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
385 390 395 400
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
405 410 415
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
420 425 430
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
435 440 445
Lys Ser Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 65
<211> 457
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain
<400> 65
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Ser Pro Asp Gly Gly Ser Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Val Val Glu Cys Asn Met Asn Pro Cys Ser Tyr Asp Asn
100 105 110
Ala Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala
115 120 125
Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser
130 135 140
Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe
145 150 155 160
Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly
165 170 175
Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu
180 185 190
Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr
195 200 205
Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys
210 215 220
Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro
225 230 235 240
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
245 250 255
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
260 265 270
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
275 280 285
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
290 295 300
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
305 310 315 320
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
325 330 335
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
340 345 350
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met
355 360 365
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
370 375 380
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
385 390 395 400
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
405 410 415
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
420 425 430
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
435 440 445
Lys Ser Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 66
<211> 458
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain
<400> 66
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Pro Ser Ser Gly Ser Ser Ile Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Lys Ala Pro Gly Trp Cys Gln Ala Pro Ser Cys Tyr Tyr Asp
100 105 110
Asn Ala Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
130 135 140
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
145 150 155 160
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
165 170 175
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
180 185 190
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
195 200 205
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
210 215 220
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
225 230 235 240
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
245 250 255
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
260 265 270
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
275 280 285
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
290 295 300
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
305 310 315 320
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
325 330 335
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
340 345 350
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
355 360 365
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
370 375 380
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
385 390 395 400
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
405 410 415
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
420 425 430
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
435 440 445
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 67
<211> 216
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain
<400> 67
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn
20 25 30
Asn Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asn Lys Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Thr Trp Asp Ala Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Ala Glu Cys Ser
210 215
<210> 68
<211> 216
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain
<400> 68
Gln Ser Val Leu Thr Gln Pro Pro Pro Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Thr Val Tyr Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Ala Asn Ser Gln Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ser Trp Asp Tyr Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Ala Glu Cys Ser
210 215
<210> 69
<211> 216
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain
<400> 69
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn
20 25 30
Asn Val Ser Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Ala Asp Ser His Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Thr Trp Asp Tyr Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Ala Glu Cys Ser
210 215
<210> 70
<211> 216
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain
<400> 70
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Asp Val Ser Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Asn Asn Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ala Trp Asp Asp Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Ala Glu Cys Ser
210 215
<210> 71
<211> 216
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain
<400> 71
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Asn Asn
20 25 30
Ala Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Tyr Asp Ser Asn Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ala Trp Asp Asp Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Ala Glu Cys Ser
210 215
<210> 72
<211> 216
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain
<400> 72
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Asp Val Thr Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Ala Asp Ser Lys Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Thr Trp Asp Tyr Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Ala Glu Cys Ser
210 215
<210> 73
<211> 216
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain
<400> 73
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Asn
20 25 30
Tyr Val Ser Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Asp Asp Ser His Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ala Trp Asp Asp Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Ala Glu Cys Ser
210 215
<210> 74
<211> 216
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain
<400> 74
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Asn Asn
20 25 30
Asp Val Ser Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Asp Asp Ser Gln Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Arg
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Gly Ala Trp Asp Asp Ser Leu
85 90 95
Ser Gly Tyr Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Ala Glu Cys Ser
210 215
<210> 75
<211> 1338
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain coding gene
<400> 75
gaagtacaac ttctggagtc aggtggagga cttgttcagc ccggcgggtc cctgaggctg 60
agttgcgcag caagcgggtt cacattctcc tcttatgata tgtcttgggt aagacaggct 120
cctggtaagg gtctggaatg ggtatcctgg ataagtcctg actccggttc aatatactac 180
gccgatagtg tgaagggacg tttcaccatc agccgggaca acagcaaaaa taccttgtat 240
ctccaaatga atagcctccg ggctgaagac actgccgtat attactgcgc cagacctact 300
ggtcgttttg actattgggg gcaaggaaca ctggtaaccg tttcaagcgc ctccaccaag 360
ggcccctccg tgttccccct ggccccctcc tccaagtcca cctccggcgg caccgccgcc 420
ctgggctgcc tggtgaagga ctacttcccc gagcccgtga ccgtgtcctg gaactccggc 480
gccctgacct ccggcgtgca caccttcccc gccgtgctgc agtcctccgg cctgtactcc 540
ctgtcctccg tcgtgaccgt gccctcctcc tccctgggca cccagaccta catctgcaac 600
gtgaaccaca agccctccaa caccaaggtg gacaagaagg tggagcccaa gtcctgcgac 660
aagacccaca cctgccctcc ctgccccgcc cccgagctgc tgggcggccc ctccgtgttc 720
ctgttccctc ctaagcccaa ggacaccctg atgatctccc ggacccccga ggtgacttgc 780
gtggtggtgg acgtgtccca cgaggacccc gaggtgaagt tcaactggta cgtggacggc 840
gtggaggtgc acaacgccaa gaccaagccc cgggaggagc agtacaactc cacctaccgg 900
gtggtgtccg tgctgaccgt gctgcaccag gactggctga acggcaagga gtacaagtgc 960
aaggtgtcca acaaggccct gcccgccccc atcgagaaga ccatctccaa ggccaagggc 1020
cagccccggg agccccaggt gtacaccctg cccccctccc gggaggagat gaccaagaac 1080
caggtgtccc tgacctgcct ggtgaagggc ttctacccct ccgacatcgc cgtggagtgg 1140
gagtccaacg gccagcccga gaacaactac aagaccaccc cccccgtgct ggactccgac 1200
ggctccttct tcctgtactc caagctgacc gtggacaagt cccggtggca gcagggcaac 1260
gtgttctcct gctccgtgat gcacgaggcc ctgcacaacc actacaccca gaagtccctg 1320
tccctgtccc ccggcaag 1338
<210> 76
<211> 1338
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain coding gene
<400> 76
gaagtgcagc tgctggaatc cggcggaggc ctggtgcagc ctggcggctc tctgagactg 60
tcttgcgccg cctccggctt caccttctcc gactactaca tgtcctgggt gcgacaggcc 120
cctggcaagg gcctggaatg ggtgtcctcc atctcccccg acggctccaa cacctactac 180
gccgactccg tgaagggccg gttcaccatc tcccgggaca actccaagaa caccctgtac 240
ctgcagatga actccctgcg ggccgaggac accgccgtgt actactgcgc caagaacctg 300
cgggccttcg actactgggg ccagggcaca ctggtgaccg tgtcctccgc ctccaccaag 360
ggcccctccg tgttccccct ggccccctcc tccaagtcca cctccggcgg caccgccgcc 420
ctgggctgcc tggtgaagga ctacttcccc gagcccgtga ccgtgtcctg gaactccggc 480
gccctgacct ccggcgtgca caccttcccc gccgtgctgc agtcctccgg cctgtactcc 540
ctgtcctccg tcgtgaccgt gccctcctcc tccctgggca cccagaccta catctgcaac 600
gtgaaccaca agccctccaa caccaaggtg gacaagaagg tggagcccaa gtcctgcgac 660
aagacccaca cctgccctcc ctgccccgcc cccgagctgc tgggcggccc ctccgtgttc 720
ctgttccctc ctaagcccaa ggacaccctg atgatctccc ggacccccga ggtgacttgc 780
gtggtggtgg acgtgtccca cgaggacccc gaggtgaagt tcaactggta cgtggacggc 840
gtggaggtgc acaacgccaa gaccaagccc cgggaggagc agtacaactc cacctaccgg 900
gtggtgtccg tgctgaccgt gctgcaccag gactggctga acggcaagga gtacaagtgc 960
aaggtgtcca acaaggccct gcccgccccc atcgagaaga ccatctccaa ggccaagggc 1020
cagccccggg agccccaggt gtacaccctg cccccctccc gggaggagat gaccaagaac 1080
caggtgtccc tgacctgcct ggtgaagggc ttctacccct ccgacatcgc cgtggagtgg 1140
gagtccaacg gccagcccga gaacaactac aagaccaccc cccccgtgct ggactccgac 1200
ggctccttct tcctgtactc caagctgacc gtggacaagt cccggtggca gcagggcaac 1260
gtgttctcct gctccgtgat gcacgaggcc ctgcacaacc actacaccca gaagtccctg 1320
tccctgtccc ccggcaag 1338
<210> 77
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain coding gene
<400> 77
gaagtgcaac ttcttgagag tggtggagga ttggtacaac ctgggggtag tttgcgtctc 60
tcctgtgctg cttctggttt cacattttcc tcctatgaca tgagctgggt acggcaagct 120
ccaggaaaag ggcttgagtg ggtctcctgg atctctcccg gtggaggcag caagtattat 180
gcagactctg taaagggtag gtttactata tcacgcgata atagtaagaa tactttgtat 240
ttgcaaatga actccctccg agctgaggac acagcagtct attattgcgc ccgagttaac 300
ggtcgcttcg attactgggg ccaaggcaca ctggttacag tgtcctcagc ctccaccaag 360
ggcccctccg tgttccccct ggccccctcc tccaagtcca cctccggcgg caccgccgcc 420
ctgggctgcc tggtgaagga ctacttcccc gagcccgtga ccgtgtcctg gaactccggc 480
gccctgacct ccggcgtgca caccttcccc gccgtgctgc agtcctccgg cctgtactcc 540
ctgtcctccg tcgtgaccgt gccctcctcc tccctgggca cccagaccta catctgcaac 600
gtgaaccaca agccctccaa caccaaggtg gacaagaagg tggagcccaa gtcctgcgac 660
aagacccaca cctgccctcc ctgccccgcc cccgagctgc tgggcggccc ctccgtgttc 720
ctgttccctc ctaagcccaa ggacaccctg atgatctccc ggacccccga ggtgacttgc 780
gtggtggtgg acgtgtccca cgaggacccc gaggtgaagt tcaactggta cgtggacggc 840
gtggaggtgc acaacgccaa gaccaagccc cgggaggagc agtacaactc cacctaccgg 900
gtggtgtccg tgctgaccgt gctgcaccag gactggctga acggcaagga gtacaagtgc 960
aaggtgtcca acaaggccct gcccgccccc atcgagaaga ccatctccaa ggccaagggc 1020
cagccccggg agccccaggt gtacaccctg cccccctccc gggaggagat gaccaagaac 1080
caggtgtccc tgacctgcct ggtgaagggc ttctacccct ccgacatcgc cgtggagtgg 1140
gagtccaacg gccagcccga gaacaactac aagaccaccc cccccgtgct ggactccgac 1200
ggctccttct tcctgtactc caagctgacc gtggacaagt cccggtggca gcagggcaac 1260
gtgttctcct gctccgtgat gcacgaggcc ctgcacaacc actacaccca gaagtccctg 1320
tccctgtccc ccggcaagtg a 1341
<210> 78
<211> 1353
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain coding gene
<400> 78
gaggtgcagc tgctggagtc cggcggcggc ctggtgcagc ccggcggctc cctgcggctg 60
tcctgcgccg cctccggctt caccttctcc aactacgaca tgtcctgggt gcggcaggcc 120
cccggcaagg gcctggagtg ggtgtccgcc atctaccact ccggctcctc caagtactac 180
gccgactccg tgaagggccg gttcaccatc tcccgggaca actccaagaa caccctgtac 240
ctgcagatga actccctgcg ggccgaggac accgccgtgt actactgcgc ccggggcggc 300
aacggcgcct gggacaccgg cttcgactac tggggccagg gcaccctggt gaccgtgtcc 360
tccgcctcca ccaagggccc ctccgtgttc cccctggccc cctcctccaa gtccacctcc 420
ggcggcaccg ccgccctggg ctgcctggtg aaggactact tccccgagcc cgtgaccgtg 480
tcctggaact ccggcgccct gacctccggc gtgcacacct tccccgccgt gctgcagtcc 540
tccggcctgt actccctgtc ctccgtcgtg accgtgccct cctcctccct gggcacccag 600
acctacatct gcaacgtgaa ccacaagccc tccaacacca aggtggacaa gaaggtggag 660
cccaagtcct gcgacaagac ccacacctgc cctccctgcc ccgcccccga gctgctgggc 720
ggcccctccg tgttcctgtt ccctcctaag cccaaggaca ccctgatgat ctcccggacc 780
cccgaggtga cttgcgtggt ggtggacgtg tcccacgagg accccgaggt gaagttcaac 840
tggtacgtgg acggcgtgga ggtgcacaac gccaagacca agccccggga ggagcagtac 900
aactccacct accgggtggt gtccgtgctg accgtgctgc accaggactg gctgaacggc 960
aaggagtaca agtgcaaggt gtccaacaag gccctgcccg cccccatcga gaagaccatc 1020
tccaaggcca agggccagcc ccgggagccc caggtgtaca ccctgccccc ctcccgggag 1080
gagatgacca agaaccaggt gtccctgacc tgcctggtga agggcttcta cccctccgac 1140
atcgccgtgg agtgggagtc caacggccag cccgagaaca actacaagac cacccccccc 1200
gtgctggact ccgacggctc cttcttcctg tactccaagc tgaccgtgga caagtcccgg 1260
tggcagcagg gcaacgtgtt ctcctgctcc gtgatgcacg aggccctgca caaccactac 1320
acccagaagt ccctgtccct gtcccccggc aag 1353
<210> 79
<211> 1374
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain coding gene
<400> 79
gaagttcaac tgttggaatc cgggggtggt ctggtccaac ctggagggtc tcttagactg 60
agttgtgctg cttcaggctt cacatttagc tcatatgata tgtcctgggt cagacaggcc 120
cccggcaaag gtcttgaatg ggtatctggt attagtcatg gatctggcaa caagtactac 180
gctgatagtg tcaaaggacg attcaccata tctcgtgaca actctaaaaa cactttgtac 240
ttgcagatga actcactgcg tgccgaagac acagccgtgt attattgcgc taagcgtctc 300
tcactccgca ggcgaccttc ctattacagc gacaacgcta tggatgtctg ggggcagggt 360
acactcgtca ccgtgtcatc agcctccacc aagggcccct ccgtgttccc cctggccccc 420
tcctccaagt ccacctccgg cggcaccgcc gccctgggct gcctggtgaa ggactacttc 480
cccgagcccg tgaccgtgtc ctggaactcc ggcgccctga cctccggcgt gcacaccttc 540
cccgccgtgc tgcagtcctc cggcctgtac tccctgtcct ccgtcgtgac cgtgccctcc 600
tcctccctgg gcacccagac ctacatctgc aacgtgaacc acaagccctc caacaccaag 660
gtggacaaga aggtggagcc caagtcctgc gacaagaccc acacctgccc tccctgcccc 720
gcccccgagc tgctgggcgg cccctccgtg ttcctgttcc ctcctaagcc caaggacacc 780
ctgatgatct cccggacccc cgaggtgact tgcgtggtgg tggacgtgtc ccacgaggac 840
cccgaggtga agttcaactg gtacgtggac ggcgtggagg tgcacaacgc caagaccaag 900
ccccgggagg agcagtacaa ctccacctac cgggtggtgt ccgtgctgac cgtgctgcac 960
caggactggc tgaacggcaa ggagtacaag tgcaaggtgt ccaacaaggc cctgcccgcc 1020
cccatcgaga agaccatctc caaggccaag ggccagcccc gggagcccca ggtgtacacc 1080
ctgcccccct cccgggagga gatgaccaag aaccaggtgt ccctgacctg cctggtgaag 1140
ggcttctacc cctccgacat cgccgtggag tgggagtcca acggccagcc cgagaacaac 1200
tacaagacca ccccccccgt gctggactcc gacggctcct tcttcctgta ctccaagctg 1260
accgtggaca agtcccggtg gcagcagggc aacgtgttct cctgctccgt gatgcacgag 1320
gccctgcaca accactacac ccagaagtcc ctgtccctgt cccccggcaa gtga 1374
<210> 80
<211> 1371
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain coding gene
<400> 80
gaggtgcagc tgctggagtc cggcggcggc ctggtgcagc ccggcggctc cctgcggctg 60
tcctgcgccg cctccggctt caccttctcc aactacgcca tgtcctgggt gcggcaggcc 120
cccggcaagg gcctggagtg ggtgtcctcc atctcccaca actccggctc cacctactac 180
gccgactccg tgaagggccg gttcaccatc tcccgggaca actccaagaa caccctgtac 240
ctgcagatga actccctgcg ggccgaggac accgccgtgt actactgcgc caagttcatc 300
tccgcccgga agtccctggg ccggtcctac tccaacggca tggacgtgtg gggccagggc 360
accctggtga ccgtgtcctc cgcctccacc aagggcccct ccgtgttccc cctggccccc 420
tcctccaagt ccacctccgg cggcaccgcc gccctgggct gcctggtgaa ggactacttc 480
cccgagcccg tgaccgtgtc ctggaactcc ggcgccctga cctccggcgt gcacaccttc 540
cccgccgtgc tgcagtcctc cggcctgtac tccctgtcct ccgtcgtgac cgtgccctcc 600
tcctccctgg gcacccagac ctacatctgc aacgtgaacc acaagccctc caacaccaag 660
gtggacaaga aggtggagcc caagtcctgc gacaagaccc acacctgccc tccctgcccc 720
gcccccgagc tgctgggcgg cccctccgtg ttcctgttcc ctcctaagcc caaggacacc 780
ctgatgatct cccggacccc cgaggtgact tgcgtggtgg tggacgtgtc ccacgaggac 840
cccgaggtga agttcaactg gtacgtggac ggcgtggagg tgcacaacgc caagaccaag 900
ccccgggagg agcagtacaa ctccacctac cgggtggtgt ccgtgctgac cgtgctgcac 960
caggactggc tgaacggcaa ggagtacaag tgcaaggtgt ccaacaaggc cctgcccgcc 1020
cccatcgaga agaccatctc caaggccaag ggccagcccc gggagcccca ggtgtacacc 1080
ctgcccccct cccgggagga gatgaccaag aaccaggtgt ccctgacctg cctggtgaag 1140
ggcttctacc cctccgacat cgccgtggag tgggagtcca acggccagcc cgagaacaac 1200
tacaagacca ccccccccgt gctggactcc gacggctcct tcttcctgta ctccaagctg 1260
accgtggaca agtcccggtg gcagcagggc aacgtgttct cctgctccgt gatgcacgag 1320
gccctgcaca accactacac ccagaagtcc ctgtccctgt cccccggcaa g 1371
<210> 81
<211> 1371
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain coding gene
<400> 81
gaagtacagt tgcttgaaag tggcggtggt cttgtccagc caggcggttc ccttcggctg 60
tcttgcgccg caagtggctt cactttcagc gactatgata tgtcttgggt ccgccaagca 120
ccaggaaagg gacttgaatg ggtgagtgta atcagtcctg acggagggtc aatttattat 180
gcagattcag tcaagggtcg attcactata tcccgagaca actccaaaaa tactctttat 240
cttcagatga actctttgag agctgaagac accgcagttt attactgtgc tcgggatgta 300
gtggagtgca atatgaatcc ctgctcatac gacaacgcaa tggatgtttg ggggcagggg 360
actctggtga cagtcagctc tgcctccacc aagggcccct ccgtgttccc cctggccccc 420
tcctccaagt ccacctccgg cggcaccgcc gccctgggct gcctggtgaa ggactacttc 480
cccgagcccg tgaccgtgtc ctggaactcc ggcgccctga cctccggcgt gcacaccttc 540
cccgccgtgc tgcagtcctc cggcctgtac tccctgtcct ccgtcgtgac cgtgccctcc 600
tcctccctgg gcacccagac ctacatctgc aacgtgaacc acaagccctc caacaccaag 660
gtggacaaga aggtggagcc caagtcctgc gacaagaccc acacctgccc tccctgcccc 720
gcccccgagc tgctgggcgg cccctccgtg ttcctgttcc ctcctaagcc caaggacacc 780
ctgatgatct cccggacccc cgaggtgact tgcgtggtgg tggacgtgtc ccacgaggac 840
cccgaggtga agttcaactg gtacgtggac ggcgtggagg tgcacaacgc caagaccaag 900
ccccgggagg agcagtacaa ctccacctac cgggtggtgt ccgtgctgac cgtgctgcac 960
caggactggc tgaacggcaa ggagtacaag tgcaaggtgt ccaacaaggc cctgcccgcc 1020
cccatcgaga agaccatctc caaggccaag ggccagcccc gggagcccca ggtgtacacc 1080
ctgcccccct cccgggagga gatgaccaag aaccaggtgt ccctgacctg cctggtgaag 1140
ggcttctacc cctccgacat cgccgtggag tgggagtcca acggccagcc cgagaacaac 1200
tacaagacca ccccccccgt gctggactcc gacggctcct tcttcctgta ctccaagctg 1260
accgtggaca agtcccggtg gcagcagggc aacgtgttct cctgctccgt gatgcacgag 1320
gccctgcaca accactacac ccagaagtcc ctgtccctgt cccccggcaa g 1371
<210> 82
<211> 1374
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain coding gene
<400> 82
gaagtgcagc tgcttgaatc aggaggcggc ctcgtacaac cagggggatc tctcagactg 60
tcctgcgctg ccagtggctt cactttcagc aactacgata tgtcatgggt gaggcaggca 120
cctggcaagg gtctggagtg ggtctcaagc ataagtccca gtagtggaag ctcaatttat 180
tacgccgaca gtgtaaaggg ccggttcacc attagtagag acaattctaa gaataccttg 240
taccttcaaa tgaatagtct gagagccgaa gataccgcag tttattattg cgctaaggcc 300
ccagggtggt gtcaggcccc ttcatgctat tatgataatg caatggacgt gtggggtcag 360
ggtactctgg tcacagtcag tagtgcctcc accaagggcc cctccgtgtt ccccctggcc 420
ccctcctcca agtccacctc cggcggcacc gccgccctgg gctgcctggt gaaggactac 480
ttccccgagc ccgtgaccgt gtcctggaac tccggcgccc tgacctccgg cgtgcacacc 540
ttccccgccg tgctgcagtc ctccggcctg tactccctgt cctccgtcgt gaccgtgccc 600
tcctcctccc tgggcaccca gacctacatc tgcaacgtga accacaagcc ctccaacacc 660
aaggtggaca agaaggtgga gcccaagtcc tgcgacaaga cccacacctg ccctccctgc 720
cccgcccccg agctgctggg cggcccctcc gtgttcctgt tccctcctaa gcccaaggac 780
accctgatga tctcccggac ccccgaggtg acttgcgtgg tggtggacgt gtcccacgag 840
gaccccgagg tgaagttcaa ctggtacgtg gacggcgtgg aggtgcacaa cgccaagacc 900
aagccccggg aggagcagta caactccacc taccgggtgg tgtccgtgct gaccgtgctg 960
caccaggact ggctgaacgg caaggagtac aagtgcaagg tgtccaacaa ggccctgccc 1020
gcccccatcg agaagaccat ctccaaggcc aagggccagc cccgggagcc ccaggtgtac 1080
accctgcccc cctcccggga ggagatgacc aagaaccagg tgtccctgac ctgcctggtg 1140
aagggcttct acccctccga catcgccgtg gagtgggagt ccaacggcca gcccgagaac 1200
aactacaaga ccaccccccc cgtgctggac tccgacggct ccttcttcct gtactccaag 1260
ctgaccgtgg acaagtcccg gtggcagcag ggcaacgtgt tctcctgctc cgtgatgcac 1320
gaggccctgc acaaccacta cacccagaag tccctgtccc tgtcccccgg caag 1374
<210> 83
<211> 648
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain coding gene
<400> 83
cagtctgtgc tgacacaacc accttctgcc tctgggactc caggccagcg ggttaccatt 60
agctgttctg gtagttctag taatatcggt aacaacaatg tgaattggta tcaacaactg 120
ccaggaaccg cccctaagtt gctcatatat tatgataaca agcggccttc aggcgttcct 180
gatcgtttct ccggctctaa aagtggcaca tccgccagtc ttgctatcag cggtctcaga 240
tccgaggacg aggccgacta ttattgtggt acatgggacg cttccctgtc aggttacgtc 300
tttggcggcg gcacaaaact gacagttctt ggccagccca aggccgcccc ctccgtgacc 360
ctgttccccc cctcctccga ggagctgcag gccaacaagg ccaccctggt gtgcctgatc 420
tccgacttct accccggcgc cgtgaccgtg gcctggaagg ccgactcctc ccccgtgaag 480
gccggcgtgg agaccaccac cccctccaag cagtccaaca acaagtacgc cgcctcctcc 540
tacctgtccc tgacccccga gcagtggaag tcccaccggt cctactcctg ccaggtgacc 600
cacgagggct ccaccgtgga gaagaccgtg gcccccgccg agtgctcc 648
<210> 84
<211> 648
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain coding gene
<400> 84
cagtctgtgc tgacccagcc tccccctgct tctggcaccc ctggccagag agtgaccatc 60
tcctgctccg gctcctcctc caacatcggc tccaacaccg tgtactggta tcagcagctg 120
cccggcaccg cccccaagct gctgatctac gccaactccc agcggccctc cggcgtgccc 180
gacagattct ccggctccaa gtccggcacc tccgcctccc tggccatctc cggcctgaga 240
tctgaggacg aggccgacta ctactgcggc tcctgggact actccctgtc cggctacgtg 300
ttcggcggag gcaccaagct gaccgtgctg ggccagccta aggccgctcc ctccgtgacc 360
ctgttccccc catcctccga ggaactgcag gccaacaagg ccaccctggt ctgcctgatc 420
tccgacttct accctggcgc cgtgaccgtg gcctggaagg ccgacagctc tcctgtgaag 480
gccggcgtgg aaaccaccac cccctccaag cagtccaaca acaaatacgc cgcctcctcc 540
tacctgtccc tgacccccga gcagtggaag tcccaccggt cctacagctg ccaggtcaca 600
cacgagggct ccaccgtgga aaagaccgtg gcccctgccg agtgctcc 648
<210> 85
<211> 648
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain coding gene
<400> 85
cagagtgttt tgacccagcc tccttccgcc agcggcaccc ctgggcaacg ggttacaatc 60
agctgttccg ggagcagcag taacattggt aataataacg tctcttggta tcagcagttg 120
cctggcacag cacctaagct cctgatttac gctgactccc accggccttc cggcgtccct 180
gatcgtttct ccgggtcaaa aagtggaacc tcagcaagcc ttgcaatcag cggactgcgg 240
tccgaagatg aagctgacta ctactgcgct acctgggatt actcattgtc cggctacgtc 300
tttggggggg gaaccaaatt gacagtcttg ggtcagccca aggccgcccc ctccgtgacc 360
ctgttccccc cctcctccga ggagctgcag gccaacaagg ccaccctggt gtgcctgatc 420
tccgacttct accccggcgc cgtgaccgtg gcctggaagg ccgactcctc ccccgtgaag 480
gccggcgtgg agaccaccac cccctccaag cagtccaaca acaagtacgc cgcctcctcc 540
tacctgtccc tgacccccga gcagtggaag tcccaccggt cctactcctg ccaggtgacc 600
cacgagggct ccaccgtgga gaagaccgtg gcccccgccg agtgctcc 648
<210> 86
<211> 648
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain coding gene
<400> 86
cagtccgtgc tgacccagcc cccctccgcc tccggcaccc ccggccagcg ggtgaccatc 60
tcctgctccg gctcctcctc caacatcggc tccaacgacg tgtcctggta ccagcagctg 120
cccggcaccg cccccaagct gctgatctac tacgacaaca accggccctc cggcgtgccc 180
gaccggttct ccggctccaa gtccggcacc tccgcctccc tggccatctc cggcctgcgg 240
tccgaggacg aggccgacta ctactgcggc gcctgggacg actccctgtc cggctacgtg 300
ttcggcggcg gcaccaagct gaccgtgctg ggccagccca aggccgcccc ctccgtgacc 360
ctgttccccc cctcctccga ggagctgcag gccaacaagg ccaccctggt gtgcctgatc 420
tccgacttct accccggcgc cgtgaccgtg gcctggaagg ccgactcctc ccccgtgaag 480
gccggcgtgg agaccaccac cccctccaag cagtccaaca acaagtacgc cgcctcctcc 540
tacctgtccc tgacccccga gcagtggaag tcccaccggt cctactcctg ccaggtgacc 600
cacgagggct ccaccgtgga gaagaccgtg gcccccgccg agtgctcc 648
<210> 87
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain coding gene
<400> 87
caaagcgtac tcacccagcc cccatccgca tctggcactc ctggtcaacg ggttacaatc 60
tcttgtactg ggtcaagttc caatattgga aataacgcag tgaactggta tcagcagctc 120
cctggcaccg cccctaaact cttgatatac tatgactcta atcggccaag tggagtcccc 180
gataggttct caggttctaa gagtggcaca agtgccagcc tggcaatctc agggctcagg 240
tccgaagatg aggctgatta ttactgcgga gcttgggatg atagcctgag tggctacgtc 300
ttcgggggag gaacaaaatt gaccgtactt ggccagccca aggccgcccc ctccgtgacc 360
ctgttccccc cctcctccga ggagctgcag gccaacaagg ccaccctggt gtgcctgatc 420
tccgacttct accccggcgc cgtgaccgtg gcctggaagg ccgactcctc ccccgtgaag 480
gccggcgtgg agaccaccac cccctccaag cagtccaaca acaagtacgc cgcctcctcc 540
tacctgtccc tgacccccga gcagtggaag tcccaccggt cctactcctg ccaggtgacc 600
cacgagggct ccaccgtgga gaagaccgtg gcccccgccg agtgctcctg a 651
<210> 88
<211> 648
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain coding gene
<400> 88
cagtccgtgc tgacccagcc cccctccgcc tccggcaccc ccggccagcg ggtgaccatc 60
tcctgcaccg gctcctcctc caacatcggc tccaacgacg tgacctggta ccagcagctg 120
cccggcaccg cccccaagct gctgatctac gccgactcca agcggccctc cggcgtgccc 180
gaccggttct ccggctccaa gtccggcacc tccgcctccc tggccatctc cggcctgcgg 240
tccgaggacg aggccgacta ctactgcggc acctgggact actccctgtc cggctacgtg 300
ttcggcggcg gcaccaagct gaccgtgctg ggccagccca aggccgcccc ctccgtgacc 360
ctgttccccc cctcctccga ggagctgcag gccaacaagg ccaccctggt gtgcctgatc 420
tccgacttct accccggcgc cgtgaccgtg gcctggaagg ccgactcctc ccccgtgaag 480
gccggcgtgg agaccaccac cccctccaag cagtccaaca acaagtacgc cgcctcctcc 540
tacctgtccc tgacccccga gcagtggaag tcccaccggt cctactcctg ccaggtgacc 600
cacgagggct ccaccgtgga gaagaccgtg gcccccgccg agtgctcc 648
<210> 89
<211> 648
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain coding gene
<400> 89
caaagtgtat tgactcaacc tccctccgct tccggtacac cagggcagcg agtaaccatc 60
agttgcagtg gcagcagctc caatatcgga agcaattatg taagttggta tcaacagttg 120
ccagggaccg ctccaaaact gttgatctat gacgacagtc accgtccttc aggtgtgccc 180
gaccgatttt caggcagcaa gagcggcaca tccgcctccc tcgctatctc cggcctccga 240
tccgaagatg aggccgacta ctattgtgga gcctgggacg actcccttag tggctatgtg 300
tttgggggag ggacaaagtt gaccgtactt ggccagccca aggccgcccc ctccgtgacc 360
ctgttccccc cctcctccga ggagctgcag gccaacaagg ccaccctggt gtgcctgatc 420
tccgacttct accccggcgc cgtgaccgtg gcctggaagg ccgactcctc ccccgtgaag 480
gccggcgtgg agaccaccac cccctccaag cagtccaaca acaagtacgc cgcctcctcc 540
tacctgtccc tgacccccga gcagtggaag tcccaccggt cctactcctg ccaggtgacc 600
cacgagggct ccaccgtgga gaagaccgtg gcccccgccg agtgctcc 648
<210> 90
<211> 648
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain coding gene
<400> 90
cagtcagttc ttacacaacc cccatccgct tctggcactc ccggccagcg cgtaactata 60
tcttgctctg ggagtagtag caatatcggt aataatgatg tctcatggta ccaacagctg 120
cctggaacag cccccaaact cctcatttat gatgactctc aaaggccaag tggtgtgcca 180
gacagatttt ccggtagcaa gagtggaaca tcagcaagtc ttgctataag tggcttgcgt 240
tccgaggacg aggccgacta ttattgtggc gcatgggatg actcactgag cggctacgtt 300
ttcgggggcg gtactaagtt gaccgttttg ggacagccca aggccgcccc ctccgtgacc 360
ctgttccccc cctcctccga ggagctgcag gccaacaagg ccaccctggt gtgcctgatc 420
tccgacttct accccggcgc cgtgaccgtg gcctggaagg ccgactcctc ccccgtgaag 480
gccggcgtgg agaccaccac cccctccaag cagtccaaca acaagtacgc cgcctcctcc 540
tacctgtccc tgacccccga gcagtggaag tcccaccggt cctactcctg ccaggtgacc 600
cacgagggct ccaccgtgga gaagaccgtg gcccccgccg agtgctcc 648
<210> 91
<211> 330
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain constant region
<400> 91
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
225 230 235 240
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 92
<211> 993
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain constant region coding gene
<400> 92
gcctccacca agggcccctc cgtgttcccc ctggccccct cctccaagtc cacctccggc 60
ggcaccgccg ccctgggctg cctggtgaag gactacttcc ccgagcccgt gaccgtgtcc 120
tggaactccg gcgccctgac ctccggcgtg cacaccttcc ccgccgtgct gcagtcctcc 180
ggcctgtact ccctgtcctc cgtcgtgacc gtgccctcct cctccctggg cacccagacc 240
tacatctgca acgtgaacca caagccctcc aacaccaagg tggacaagaa ggtggagccc 300
aagtcctgcg acaagaccca cacctgccct ccctgccccg cccccgagct gctgggcggc 360
ccctccgtgt tcctgttccc tcctaagccc aaggacaccc tgatgatctc ccggaccccc 420
gaggtgactt gcgtggtggt ggacgtgtcc cacgaggacc ccgaggtgaa gttcaactgg 480
tacgtggacg gcgtggaggt gcacaacgcc aagaccaagc cccgggagga gcagtacaac 540
tccacctacc gggtggtgtc cgtgctgacc gtgctgcacc aggactggct gaacggcaag 600
gagtacaagt gcaaggtgtc caacaaggcc ctgcccgccc ccatcgagaa gaccatctcc 660
aaggccaagg gccagccccg ggagccccag gtgtacaccc tgcccccctc ccgggaggag 720
atgaccaaga accaggtgtc cctgacctgc ctggtgaagg gcttctaccc ctccgacatc 780
gccgtggagt gggagtccaa cggccagccc gagaacaact acaagaccac cccccccgtg 840
ctggactccg acggctcctt cttcctgtac tccaagctga ccgtggacaa gtcccggtgg 900
cagcagggca acgtgttctc ctgctccgtg atgcacgagg ccctgcacaa ccactacacc 960
cagaagtccc tgtccctgtc ccccggcaag tga 993
<210> 93
<211> 105
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain constant region
<400> 93
Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu
1 5 10 15
Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe
20 25 30
Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val
35 40 45
Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys
50 55 60
Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser
65 70 75 80
His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu
85 90 95
Lys Thr Val Ala Pro Ala Glu Cys Ser
100 105
<210> 94
<211> 318
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain constant region coding gene
<400> 94
cagcccaagg ccgccccctc cgtgaccctg ttccccccct cctccgagga gctgcaggcc 60
aacaaggcca ccctggtgtg cctgatctcc gacttctacc ccggcgccgt gaccgtggcc 120
tggaaggccg actcctcccc cgtgaaggcc ggcgtggaga ccaccacccc ctccaagcag 180
tccaacaaca agtacgccgc ctcctcctac ctgtccctga cccccgagca gtggaagtcc 240
caccggtcct actcctgcca ggtgacccac gagggctcca ccgtggagaa gaccgtggcc 300
cccgccgagt gctcctga 318
<210> 95
<211> 318
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Light chain constant region coding gene
<400> 95
cagcctaagg ccgctccctc cgtgaccctg ttccccccat cctccgagga actgcaggcc 60
aacaaggcca ccctggtctg cctgatctcc gacttctacc ctggcgccgt gaccgtggcc 120
tggaaggccg acagctctcc tgtgaaggcc ggcgtggaaa ccaccacccc ctccaagcag 180
tccaacaaca aatacgccgc ctcctcctac ctgtccctga cccccgagca gtggaagtcc 240
caccggtcct acagctgcca ggtcacacac gagggctcca ccgtggaaaa gaccgtggcc 300
cctgccgagt gctcctga 318
<210> 96
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR2
<400> 96
Ser Ile Ser Pro Asp Ala Ser Asn Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 97
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain CDR3
<400> 97
Gly Gly Asn Ala Ala Trp Asp Thr Gly Phe Asp Tyr
1 5 10
<210> 98
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain variable region
<400> 98
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Pro Asp Ala Ser Asn Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asn Leu Arg Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 99
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain variable region
<400> 99
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Tyr His Ser Gly Ser Ser Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Asn Ala Ala Trp Asp Thr Gly Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 100
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain
<400> 100
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Pro Asp Ala Ser Asn Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asn Leu Arg Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 101
<211> 451
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain
<400> 101
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Tyr His Ser Gly Ser Ser Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Asn Ala Ala Trp Asp Thr Gly Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
225 230 235 240
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
245 250 255
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
260 265 270
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
275 280 285
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
290 295 300
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
305 310 315 320
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
325 330 335
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
340 345 350
Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser
355 360 365
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
370 375 380
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
385 390 395 400
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
405 410 415
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
420 425 430
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
435 440 445
Pro Gly Lys
450
<210> 102
<211> 1338
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain coding gene
<400> 102
gaagtgcagc tgctggaatc cggcggaggc ctggtgcagc ctggcggctc tctgagactg 60
tcttgcgccg cctccggctt caccttctcc gactactaca tgtcctgggt gcgacaggcc 120
cctggcaagg gcctggaatg ggtgtcctcc atctcccccg acgcctccaa cacctactac 180
gccgactccg tgaagggccg gttcaccatc tcccgggaca actccaagaa caccctgtac 240
ctgcagatga actccctgcg ggccgaggac accgccgtgt actactgcgc caagaacctg 300
cgggccttcg actactgggg ccagggcaca ctggtgaccg tgtcctccgc ctccaccaag 360
ggcccctccg tgttccccct ggccccctcc tccaagtcca cctccggcgg caccgccgcc 420
ctgggctgcc tggtgaagga ctacttcccc gagcccgtga ccgtgtcctg gaactccggc 480
gccctgacct ccggcgtgca caccttcccc gccgtgctgc agtcctccgg cctgtactcc 540
ctgtcctccg tcgtgaccgt gccctcctcc tccctgggca cccagaccta catctgcaac 600
gtgaaccaca agccctccaa caccaaggtg gacaagaagg tggagcccaa gtcctgcgac 660
aagacccaca cctgccctcc ctgccccgcc cccgagctgc tgggcggccc ctccgtgttc 720
ctgttccctc ctaagcccaa ggacaccctg atgatctccc ggacccccga ggtgacttgc 780
gtggtggtgg acgtgtccca cgaggacccc gaggtgaagt tcaactggta cgtggacggc 840
gtggaggtgc acaacgccaa gaccaagccc cgggaggagc agtacaactc cacctaccgg 900
gtggtgtccg tgctgaccgt gctgcaccag gactggctga acggcaagga gtacaagtgc 960
aaggtgtcca acaaggccct gcccgccccc atcgagaaga ccatctccaa ggccaagggc 1020
cagccccggg agccccaggt gtacaccctg cccccctccc gggaggagat gaccaagaac 1080
caggtgtccc tgacctgcct ggtgaagggc ttctacccct ccgacatcgc cgtggagtgg 1140
gagtccaacg gccagcccga gaacaactac aagaccaccc cccccgtgct ggactccgac 1200
ggctccttct tcctgtactc caagctgacc gtggacaagt cccggtggca gcagggcaac 1260
gtgttctcct gctccgtgat gcacgaggcc ctgcacaacc actacaccca gaagtccctg 1320
tccctgtccc ccggcaag 1338
<210> 103
<211> 1353
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic: Heavy chain coding gene
<400> 103
gaggtgcagc tgctggagtc cggcggcggc ctggtgcagc ccggcggctc cctgcggctg 60
tcctgcgccg cctccggctt caccttctcc aactacgaca tgtcctgggt gcggcaggcc 120
cccggcaagg gcctggagtg ggtgtccgcc atctaccact ccggctcctc caagtactac 180
gccgactccg tgaagggccg gttcaccatc tcccgggaca actccaagaa caccctgtac 240
ctgcagatga actccctgcg ggccgaggac accgccgtgt actactgcgc ccggggcggc 300
aacgccgcct gggacaccgg cttcgactac tggggccagg gcaccctggt gaccgtgtcc 360
tccgcctcca ccaagggccc ctccgtgttc cccctggccc cctcctccaa gtccacctcc 420
ggcggcaccg ccgccctggg ctgcctggtg aaggactact tccccgagcc cgtgaccgtg 480
tcctggaact ccggcgccct gacctccggc gtgcacacct tccccgccgt gctgcagtcc 540
tccggcctgt actccctgtc ctccgtcgtg accgtgccct cctcctccct gggcacccag 600
acctacatct gcaacgtgaa ccacaagccc tccaacacca aggtggacaa gaaggtggag 660
cccaagtcct gcgacaagac ccacacctgc cctccctgcc ccgcccccga gctgctgggc 720
ggcccctccg tgttcctgtt ccctcctaag cccaaggaca ccctgatgat ctcccggacc 780
cccgaggtga cttgcgtggt ggtggacgtg tcccacgagg accccgaggt gaagttcaac 840
tggtacgtgg acggcgtgga ggtgcacaac gccaagacca agccccggga ggagcagtac 900
aactccacct accgggtggt gtccgtgctg accgtgctgc accaggactg gctgaacggc 960
aaggagtaca agtgcaaggt gtccaacaag gccctgcccg cccccatcga gaagaccatc 1020
tccaaggcca agggccagcc ccgggagccc caggtgtaca ccctgccccc ctcccgggag 1080
gagatgacca agaaccaggt gtccctgacc tgcctggtga agggcttcta cccctccgac 1140
atcgccgtgg agtgggagtc caacggccag cccgagaaca actacaagac cacccccccc 1200
gtgctggact ccgacggctc cttcttcctg tactccaagc tgaccgtgga caagtcccgg 1260
tggcagcagg gcaacgtgtt ctcctgctcc gtgatgcacg aggccctgca caaccactac 1320
acccagaagt ccctgtccct gtcccccggc aag 1353
Claims (131)
- 일반식 I의 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물:
[일반식 I]
Ab - (X)y
상기 식에서,
Ab는 중쇄 가변영역 및 경쇄 가변영역을 포함하는 ROR1의 세포외영역을 특이적으로 결합하는 항체 또는 이의 항원 결합단편이고,
상기 항체 또는 이의 항원 결합 단편은
서열번호 1 내지 5로 구성된 군에서 선택된 하나 이상의 CDRH1,
서열번호 6 내지 13, 및 96으로 구성된 군에서 선택된 하나 이상의 CDRH2, 및
서열번호 14 내지 21, 및 97로 구성된 군에서 선택된 하나 이상의 CDRH3를 포함하는 중쇄 가변영역; 및
서열번호 22 내지 29로 구성된 군에서 선택된 하나 이상의 CDRL1,
서열번호 30 내지 37로 구성된 군에서 선택된 하나 이상의 CDRL2, 및
서열번호 38 내지 42로 구성된 군에서 선택된 하나 이상의 CDRL3를 포함하는 경쇄 가변영역을 포함하고,
상기 X는 독립적으로 하나 이상의 활성제 및 링커를 포함하는 화학적 잔기이며, 및
상기 링커는 항체와 활성제를 연결하고,
상기 y는 1 내지 20의 정수이다.
- 제 1항에 있어서, 상기 CDRH1, CDRH2 및 CDRH3; 및 CDRL1, CDRL2 및 CDRL3의 서열은 다음 중 어느 하나의 조합인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물;
(a) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 1, 6, 및 14, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 22, 30 및 38;
(b) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 2, 7, 및 15, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 23, 31 및 39;
(c) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 1, 8, 및 16, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 24, 32 및 40;
(d) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 3, 9, 및 17, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 25, 33 및 41;
(e) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 1, 10, 및 18, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 26, 34 및 41;
(f) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 4, 11, 및 19, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 27, 35 및 42;
(g) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 5, 12, 및 20, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 28, 36 및 41;
(h) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 3, 13, 및 21, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 29, 37 및 41;
(i) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 2, 96, 및 15, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 23, 31 및 39; 또는
(j) CDRH1, CDRH2 및 CDRH3은 각각 서열번호 3, 9, 및 97, 그리고 상기 CDRL1, CDRL2, 및 CDRL3은 각각 서열번호 25, 33 및 41.
- 제 1 항에 있어서, 상기 항체는
서열번호 43 내지 50, 98 및 99로 구성된 군에서 선택된 어느 하나의 아미노산 서열;
상기 서열번호 43 내지 50, 98 및 99로 구성된 군에서 선택된 어느 하나의 아미노산 서열과 적어도 90% 이상의 상동성을 갖는 서열; 또는
상기 서열번호 43 내지 50, 98 및 99로 구성된 군에서 선택된 어느 하나의 아미노산 서열과 적어도 95% 이상의 상동성을 갖는 서열로 표시되는 중쇄 가변영역을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 1항에 있어서, 상기 항체는
서열번호 51 내지 58로 구성된 군에서 선택된 어느 하나의 아미노산 서열;
상기 서열번호 51 내지 58로 구성된 군에서 선택된 어느 하나의 아미노산 서열과 적어도 90% 이상의 상동성을 갖는 서열; 또는
상기 서열번호 51 내지 58로 구성된 군에서 선택된 어느 하나의 아미노산 서열과 적어도 95% 이상의 상동성을 갖는 서열로 표시되는 경쇄 가변영역을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 1 항에 있어서, 상기 항체는 하기 서열로 표시되는 중쇄 가변영역 및 경쇄 가변영역 조합을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물:
서열번호 43 및 51; 서열번호 44 및 52; 서열번호 45 및 53; 서열번호 46 및 54; 서열번호 47 및 55; 서열번호 48 및 56; 서열번호 49 및 57; 서열번호 50 및 58; 서열번호 98 및 52 또는 서열번호 99 및 54.
- 제 1 항에 있어서, 상기 항체는 하기 서열로 표시되는 중쇄 및 경쇄 조합을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물:
서열번호 59 및 67; 서열번호 60 및 68; 서열번호 61 및 69; 서열번호 62 및 70; 서열번호 63 및 71; 서열번호 64 및 72; 서열번호 65 및 73; 또는 서열번호 66 및 74.
- 제 1항에 있어서, 상기 항체는 단일클론 항체(monoclonal antibody), 도메인 항체(domain antibody; dAb), 단일 사슬 항체(single chain antibody; scAb), Fab 단편, Fab'단편, F(ab')2 단편, scFab 단편, Fv 단편, dsFv 단편, 단일 사슬 가변 항체(single chain variable fragment; scFv), scFv-Fc 단편, 단일 도메인 중쇄 항체(single domain heavy chain antibody), 단일 도메인 경쇄 항체(single domain light chain antibody), 항체 변이체(variant antibody), 다중 결합 항체(multimeric antibody), 미니바디, 다이아바디, 이중 특이적 항체(bispecific antibody) 및 다중 특이적 항체로 이루어진 군으로부터 선택되는 어느 하나인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 1항에 있어서, 상기 항체는 래빗(rabbit), 마우스(mouse), 키메릭(chimeric), 인간화(humanized) 및 완전 인간 단일큰론 항체(fully human monoclonal antibody)로 구성된 군으로부터 선택되는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 1항에 있어서, 상기 항체는 IgG1, IgG2, IgG3 또는 IgG4 형인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 1 항에 있어서, 상기 ROR1은 인간 또는 마우스 ROR1인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 1항에 있어서, 상기 항체와 활성제 사이의 링커는 절단 가능한 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 1항에 있어서, 상기 링커는 일반식 Ⅱ의 구조를 갖는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물:
[일반식 Ⅱ]

상기 식에서,
G는 글루쿠론산(glucuronic acid) moiety 또는이고; 상기 R3은 수소 또는 카복실 보호기이고, 상기 각각의 R4는 독립적으로 수소 또는 하이드록실 보호기이고;
B는 활성제이며;
R1 및 R2는 각각 독립적으로 수소, C1-C8 알킬 또는 C3-C8 사이클로알킬이고;
W는 -C(O)-, -C(O)NR'-, -C(O)O-, -SO2NR'-, -P(O)R''NR'-, -SONR'- 또는 -PO2NR'-이고, 상기 C, S 또는 P는 직접적으로 페닐링(phenyl ring)에 결합하며, 상기 R' 및 R''는 각각 독립적으로 수소, C1-C8 알킬, C3-C8 사이클로알킬, C1-C8 알콕시, C1-C8 알킬티오, 모노- 또는 다이- C1-C8 알킬아미노, C3-C20 헤테로아릴 또는 C6-C20아릴인 화합물이며;
Z는 독립적으로 C1-C8 알킬, 할로겐, 시아노 또는 나이트로이고;
n은 0 내지 3의 정수이며;
L은, 하기 중 어느 하나이다:
A) C1-C50 알킬렌 또는 1-50 원자 헤테로알킬렌이며, 하기 중 하나 이상을 만족한다:
(i) L은 하나 이상의 불포화 결합을 포함하고;
(ii) L 내의 2 개의 원자가 치환체와 같은 2가 치환체로 치환되고; 이는 헤테로아릴렌(heteroarylene)을 완성시키며;
(iii) L은 1 내지 50 원자 헤테로알킬렌이고;
(iv) 상기 알킬렌은 하나 이상의 C1-20 알킬로 치환되고;
B) 이소프레노이드 트랜스퍼라제에 의하여 인식될 수 있는 하기 일반식 Ⅲ의 이소프레닐 유도체 유닛을 적어도 하나 이상 포함한다:
[일반식 Ⅲ]

- 제12항에 있어서, 상기 G는이고,

R3은 수소 또는 카복실 보호기이고,
상기 각각의 R4는 독립적으로 수소 또는 하이드록실 보호기인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 R3은 수소이고, 상기 각각의 R4는 수소인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 R1 및 R2는 수소인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 Z는 독립적으로 C1-C8 알킬, 할로겐, 시아노 또는 나이트로인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 n은 0인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 W는 -C(O)-, -C(O)NR'-, -C(O)O-, -SO2NR'-, -P(O)R''NR'-, -SONR'- 또는 -PO2NR'-이고, 상기 C, S 또는 P는 직접적으로 페닐링(phenyl ring)에 결합하며, 상기 R' 및 R''는 각각 독립적으로 수소, C1-C8 알킬, C3-C8 사이클로알킬, C1-C8 알콕시, C1-C8 알킬티오, 모노- 또는 다이- C1-C8 알킬아미노, C3-C20 헤테로아릴 또는 C6-C20아릴인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 W는 -C(O)-, -C(O)NR'- 또는 -C(O)O-인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 19항에 있어서, 상기 W는 -C(O)NR'- 이고, 상기 C(O)는 페닐링에 결합하고, NR'은 L에 결합하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 G는이고,

W는 -C(O)NR'- 이고, 상기 C(O)는 페닐링에 결합하고, NR'은 L에 결합하며,
R3 및 R4는 수소인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, L은 C1-C50 알킬렌 또는 1-50 원자 헤테로알킬렌이며, 하기 중 하나 이상을 만족하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물:
(i) L은 하나 이상의 불포화 결합을 포함하고;
(ii) L 내의 2 개의 원자가 치환체와 같은 2가 치환체로 치환되고; 이는 헤테로아릴렌(heteroarylene)을 완성시키며;
(iii) L은 1 내지 50 원자 헤테로알킬렌이고; 및
(iv) 상기 알킬렌은 하나 이상의 C1-20 알킬로 치환된다.
- 제 22항에 있어서, 상기 L은 질소 함유 1-50 원자 헤테로 알킬렌이고, 상기 링커는 친수성 아미노산의 2 이상의 원자를 포함하고, 상기 질소는 친수성 아미노산의 카르보닐과 펩타이드 결합을 형성하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 W는 -C(O)NR'- 이고, 상기 W의 질소는 친수성 아미노산의 질소 원자인 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 23항 또는 제 24항에 있어서, 상기 친수성 아미노산은 아르기닌, 아스파테이트, 아스파라긴, 글루타메이트, 글루타민, 히스티딘, 라이신, 오르니틴, 프롤린, 세린 및 트레오닌으로 이루어진 군으로부터 선택되는 어느 하나인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 20항 또는 제 21항에 있어서, 상기 아미노산은 링커의 옥심(oxime)을 링커의 폴리에틸렌 글리콜 유닛에 공유 결합시키는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제26항에 있어서, 상기 아미노산은 아르기닌, 아스파테이트, 아스파라긴, 글루타메이트, 글루타민, 히스티딘, 라이신, 오르니틴, 프롤린, 세린 및 트레오닌으로 이루어진 군으로부터 선택되는 어느 하나인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 23항 또는 24항에 있어서, 상기 친수성 아미노산은 수용액에서 중성 pH에서 전하를 나타내는 moiety를 갖는 측쇄를 포함하는 아미노산인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제28항에 있어서, 상기 친수성 아미노산은 아스파테이트 또는 글루타메이트인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제28항에 있어서, 상기 친수성 아미노산은 오르니틴 또는 라이신인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제28항에 있어서, 상기 친수성 아미노산은 아르기닌인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 링커는 펩타이드를 포함하고, 상기 펩타이드는 하나이상의 친수성 아미노산을 포함하며, 수용액에서 중성 pH에서 전하를 나타내는 모이어티(moiety)를 갖는 측쇄를 포함하는 아미노산인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제32항에 있어서, 상기 펩타이드의 각각의 아미노산은 알라닌, 아스파테이트, 아스파라긴, 글루타메이트, 글루타민, 글리신, 라이신, 오르니틴, 프롤린, 세린 및 트레오닌으로 구성된 군으로부터 선택되는 어느 하나인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제33항에 있어서, 상기 펩타이드는 적어도 하나의 아스파테이트 또는 글루타메이트를 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, W는 -C(O)NR'- 이고, 상기 W의 질소는 펩타이드의 N-말단 아미노산의 질소 원자인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제33항에 있어서, 상기 펩타이드는 링커의 옥심(oxime)을 링커의 폴리에틸렌 글리콜 유닛에 공유 결합시키는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제33항 내지 제36항 중 어느 한 항에 있어서, 상기 펩타이드는 2 내지 20개의 아미노산을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 L은 티오에테르 결합에 의해 항체와 공유결합하고, 상기 티오에테르 결합은 항체의 시스테인의 황원자를 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제38항에 있어서, 상기 항체는 이소프레노이드 트랜스퍼라제에 의하여 인식될 수 있는 항체의 C-말단에 아미노산 모티프를 포함하고, 상기 티오에테르 결합은 상기 아미노산 모티프의 시스테인의 황원자를 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제39항에 있어서, 상기 아미노산 모티프는 CYYX 서열이고, C가 시스테인이고, Y가 지방족 아미노산이며, X가 글루타민, 글루타메이트, 세린, 시스테인, 메티오닌, 알라닌 및 루신으로 이루어진 군으로부터 선택되는 어느 하나이며; 및
상기 티오에테르 결합은 상기 아미노산 모티프의 시스테인의 황원자를 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제40항에 있어서, 상기 아미노산 모티프는 CYYX 서열이고, Y가 알라닌, 이소루이신, 류신, 메티오닌 및 발린으로 이루어진 군으로부터 선택되는 어느 하나인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제41항에 있어서, 상기 아미노산 모티프는 CVIM 또는 CVLL 서열인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 39항 내지 제 42항 중 어느 한 항에 있어서, 아미노산 모티프에 선행하는 1 내지 20 개의 아미노산 중 적어도 하나가 글리신인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제43항에 있어서, 아미노산 모티프에 선행하는 1 내지 20 개의 아미노산 중 적어도 세 개가 글리신 또는 프롤린인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제43항에 있어서, 아미노산 모티프에 선행하는 1 내지 20 개의 아미노산 중 적어도 1개가 글리신, 아스파르트 산, 아르기닌 및 세린으로 이루어진 군으로부터 선택되는 어느 하나인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제39항 내지 제42항 중 어느 한 항에 있어서, 아미노산 모티프에 선행하는 1, 2, 3, 4, 5, 6, 7, 8, 9 또는 10 개의 아미노산은 각각 글리신인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 L은 C-말단에 아미노산 서열 GGGGGGGCVIM을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 L은 이소프레노이드 트랜스퍼라제에 의하여 인식될 수 있는 하기 일반식 Ⅲ의 이소프레닐 유도체 유닛을 적어도 하나 이상 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물:
[일반식 Ⅲ]

- 제12항에 있어서, 상기 L은 옥심을 포함하는 3 내지 50 헤테로알킬렌이고, 상기 옥심의 산소 원자는 W와 연결된 L의 측면에 있고, 옥심의 탄소 원자는 Ab에 연결된 L의 측면에 있으며; 또는 상기 옥심의 탄소 원자는 W에 연결된 L의 측면에 있고, 옥심의 산소 원자는 Ab에 연결된 L의 측면에 있는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제48항 또는 제49항에 있어서, 상기 L은 옥심을 포함하고, 하나 이상의 이소프레닐 유닛은 옥심을 Ab에 공유 결합시키는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 L은 일반식 VIII 또는 일반식 IX로 표시되는 연결 유닛을 더 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물:
[일반식 VIII]
-(CH2)r(V(CH2)p)q-
[일반식 IX]
-(CH2CH2X)w-
상기 V는 단일결합, -O-, -S-, -NR21-, -C(O)NR22-, -NR23C(O)-, -NR24SO2- 또는 -SO2NR25-이고;
X는 -O-, C1-C8 알킬렌 또는 -NR21-이고;
R21 내지 R25는 각각 독립적으로 수소, C1-C6 알킬, C1-C6 알킬 C6-C20 아릴 또는 C1-C6 알킬C3-C20 헤테로아릴이고;
r은 0 내지 10의 정수이고;
p는 0 내지 10의 정수이고;
q는 1 내지 20의 정수이고; 및
w는 1 내지 20의 정수이다.
- 제51항에 있어서, 상기 q는 4 내지 20의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제51항에 있어서, 상기 q는 2 내지 12의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제51항에 있어서, 상기 q는 6 내지 20의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제53항에 있어서, 상기 q는 2, 5 또는 11의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제51항에 있어서, 상기 r은 2의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제51항에 있어서, 상기 p은 2의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제51항에 있어서, 상기 V는 -O-인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제51항에 있어서,
상기 r은 2의 정수이고;
상기 p은 2의 정수이며;
상기 q는 2, 5 또는 11의 정수이고; 및
상기 V는 -O-인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제51항에 있어서, 상기 X는 -O-인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제51항에 있어서, 상기 w는 6 내지 20의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제51항에 있어서, 상기 X는 -O-이고, w는 6 내지 20의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제51항에 있어서, 상기 L은또는
 로 표시되는 적어도 하나의 폴리에틸렌 글리콜 유닛을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
로 표시되는 적어도 하나의 폴리에틸렌 글리콜 유닛을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제63항에 있어서, 상기 L은 1 내지 12 -OCH2CH2- 유닛을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제63항에 있어서, 상기 L은 3 내지 12 -OCH2CH2- 유닛을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제63항에 있어서, 상기 L은 5 내지 12 -OCH2CH2- 유닛을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제63항에 있어서, 상기 L은 6 내지 12 -OCH2CH2- 유닛을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제63항에 있어서, 상기 L은 3 -OCH2CH2- 유닛을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제51항에 있어서, 상기 L은 옥심을 포함하고, 적어도 하나의 폴리에틸렌 글리콜 유닛은 옥심을 활성제에 공유 결합시키는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 L은 1,3-양극성고리 첨가반응(1,3-dipolar cycloaddition reactions), 헤테로-디엘스 반응(hetero-diels reactions), 친핵성 치환 반응(nucloephilic substitution reactions), 논-알돌 형 카보닐 반응(nonaldol type carbonyl reactions), 탄소-탄소 다중 결합에 대한 첨가(additions to carbon-carbon multiple bonds), 산화 반응(oxidation reactions) 또는 클릭 반응(click reactions)에 의하여 형성된 결합 유닛을 더 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제70항에 있어서, 상기 결합 유닛은 아세틸렌과 아지드와의 반응, 또는 알데히드 또는 케톤 그룹과 하이드라진 또는 하이드록실아민과의 반응으로 형성되는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 L은 하기 일반식 Ⅳ, Ⅴ, Ⅵ 또는 Ⅶ로 표시되는 결합 유닛을 더 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물:
[일반식 Ⅳ]

[일반식 Ⅴ]

[일반식 Ⅵ]

[일반식 Ⅶ]

상기 식에서,
상기 L1은 단일결합 또는 C1-C30의 알킬렌이고;
R11은 수소 또는 C1-C10의 알킬이다.
- 제72항에 있어서, 상기 L1은 단일결합인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제72항에 있어서, 상기 L1은 C11의 알킬렌인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제72항에 있어서, 상기 L1은 C12의 알킬렌인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제72항에 있어서, 상기 L은또는
 을 포함하고,
을 포함하고,
상기 V는 단일 결합 , -O-, -S-, -NR21-, -C(O)NR22-, -NR23C(O)-, -NR24SO2-, 또는 -SO2NR25- 이고;
R21 내지 R25 는 독립적으로 수소, C1-6 알킬, C1-6 알킬 C6-20 아릴, 또는 C1-6알킬 C3-20 헤테로아릴이며;
r은 1 내지 10의 정수이고;
p는 0 내지 10의 정수이며;
q는 1 내지 20의 정수이고; 및
L1은 단일결합인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제76항에 있어서, 상기 r은 2 또는 3의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제76항에 있어서, 상기 p는 1 또는 2의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제76항에 있어서, 상기 q는 1 내지 6의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제76항에 있어서, 상기 r은 2 또는 3의 정수; p는 1 또는 2의 정수 및 q는 1 내지 6의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제76항에 있어서,
을 포함하며,
상기 Ab는 항-ROR1 항체이고; B는 활성제이며, n은 1 내지 20의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제76항에 있어서,
을 포함
하며, 상기 Ab는 항-ROR1 항체이고; B는 활성제이며, n은 1 내지 20의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제76항에 있어서,
을 포함하며,
상기 Ab는 항-ROR1 항체이고; B는 활성제이며, n은 0 내지 20의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제76항에 있어서,
을 포함하며, 상기 Ab는 항-ROR1 항체이고; B는 활성제이며, n은 1 내지 20의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 이소프레노이드 트랜스퍼라제는 파네실 단백질 트랜스퍼라아제(FTase) 또는 게라닐게라닐 트랜스퍼라제(GGTase)인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, L은 Ab에 공유 결합된 하나 이상의 분지형 링커를 포함하고,
i) 각각의 분지형 링커는 주링커(PL)에 의해 Ab에 공유 결합된 분지 유닛(BR)을 포함하고;
ii) 각각의 분지형 링커는 제 1 활성제를 분지 유닛에 결합시키고, 제 2 링커 (SL) 및 절단기(CG)를 포함하는 제 1 분지(B1)를 포함하며; 및
iii) 각각의 분지형 링커는 a) 제 2 활성제가 제 2 링커 (SL) 및 절단기(CG)에 의해 분지 유닛에 공유 결합 된 제 2 분지 (B2); 또는 b) 폴리에틸렌 글리콜 모이어티(moiety)가 분지 유닛에 공유 결합되어 있는 제 2 분지를 포함하고,
상기 각각의 절단기는 항체 접합체부터 활성제를 방출하기 위해 가수분해되는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제86항에 있어서, 상기 분지형 링커는,
 ,
, 또는
또는 이고,
이고,
상기 L2, L3, L4 는 각각 독립적으로 직접 결합 또는 -CnH2n-이며, 상기 n은 1 내지 30의 정수이고,
상기 G1, G2, G3은 독립적으로 직접 결합,, ,
, 또는
또는 이며,
이며,
상기 R30은 수소 또는 C1-30 알킬; 및
상기 L5는 직접 결합 또는 C1-10 알킬렌, R50은 수소 C1-30 알킬인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제87항 있어서,
를 포함하고,
상기 B 및 B'는 동일하거나 상이할 수 있는 활성제를 나타내고;
n은 각각 독립적으로 0 내지 30의 정수를 나타내며;
f는 각각 독립적으로 0 내지 30의 정수를 나타내고; 및
L은 Ab에 대한 결합을 나타내는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제88항에 있어서, 상기 n은 1 내지 10의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제88항에 있어서, 상기 n은 4 내지 20의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제88항에 있어서, 상기 L은 옥심을 포함하고, 적어도 하나의 폴리에틸렌 글리콜 유닛은 옥심을 활성제에 공유 결합시키는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제86항에 있어서, 상기 절단기는 표적 세포 내에서 절단될 수 있는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제86항에 있어서, 상기 절단기는 하나 이상의 활성제를 방출시킬 수 있는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제86항에 있어서, 항체 접합체는 Ab를 포함하고; Ab에 공유 결합 된 하나 이상의 분지형 링커를 포함하며; 및 분지형 링커에 공유 결합 된 2개 이상의 활성제를 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제94항에 있어서, 2 이상의 분지형 링커가 Ab와 결합되고, 각각의 분지형 링커가 2개 이상의 활성제와 결합하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제95항에 있어서, 3개 분지형 링커는 Ab와 결합되는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제95항에 있어서, 4개 분지형 링커는 Ab와 결합되는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제94항에 있어서, 1개 분지형 링커는 Ab와 결합되는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제94항에 있어서, 각각의 분지형 링커는 두 개의 활성제와 결합되는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제94항에 있어서, 상기 접합체는 2개 이상의 상이한 활성제를 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제100항에 있어서, 하나 이상의 분지형 링커는 2개 이상의 활성제와 결합되는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제94항에 있어서, 각각의 활성제는 절단 가능한 결합에 의해 분지형 링커에 결합된 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 94항에 있어서, 각각의 분지형 링커는 분지형 유닛을 포함하고, 각각의 활성제는 2차 링커를 통해 분지형 유닛에 결합하고, 상기 분지형 유닛 1차 링커에 의해 항-ROR1 항체에 결합되는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제103항에 있어서, 상기 분지형 유닛은 질소 원자인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제103항에 있어서, 상기 분지형 유닛은 아미드이고, 1차 링커는 아미드의 카르보닐을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제103항에 있어서, 상기 분지형 유닛은 아미드이고, 2차 링커는 아미드의 카르보닐을 포함하는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제103항에 있어서, 상기 분지형 유닛은 라이신 유닛인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제12항에 있어서, 상기 B는 활성제인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 108항에 있어서, 상기 활성제는 화학요법제 또는 톡신인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제 108항에 있어서, 상기 활성제는 면역 조절 화합물, 항암제, 항바이러스제, 항균제, 항진균제, 항기생충제 또는 이들의 조합인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제108항에 있어서, 상기 활성제는 하기로부터 선택되는 어느 하나인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물:
(a) 엘로티닙(erlotinib), 보르테조밉(bortezomib), 풀베스트란트(fulvestrant), 수텐트(sutent), 레트로졸(letrozole), 이마티닙 메실레이트(imatinib mesylate), PTK787/ZK 222584, 옥살리플라틴(oxaliplatin), 5-플루오로우라실(5-fluorouracil), 루코보린(leucovorin), 라파마이신(rapamycin), 라파티닙(lapatinib), 로나파르닙(lonafarnib), 소라페닙(sorafenib), 제피티닙(gefitinib), AG1478, AG1571, 티오테파(thiotepa), 사이클로포스파마이드(cyclophosphamide), 부술판(busulfan), 임프로술판(improsulfan), 피포술판(piposulfan), 벤조도파(benzodopa), 카르보콘(carboquone), 메츄도파(meturedopa), 유레도파(uredopa), 에틸렌이민(ethylenimine), 알트레타민(altretamine), 트리에틸렌멜라민(triethylenemelamine), 트리에틸렌포스포라미드(trietylenephosphoramide), 트리에틸렌티오포스포라미드(triethiylenethiophosphoramide), 트리메틸롤로멜라민(trimethylolomelamine), 불라타신(bullatacin), 불라타시논(bullatacinone), 캄토테신(camptothecin), 토포테칸(topotecan), 브리오스타틴(bryostatin), 칼리스타틴(callystatin), CC-1065, 아도젤레신(adozelesin), 카르젤레신(carzelesin), 비젤레신(bizelesin), 크립토피신 1(cryptophycin 1), 크립토피신 8(cryptophycin 8), 돌라스타틴(dolastatin), 듀오카마이신(duocarmycin), KW-2189, CB1-TM1, 엘루테로빈(eleutherobin), 판크라티스타틴(pancratistatin), 사르코딕티인(sarcodictyin), 스폰지스타틴(spongistatin), 클로람부실(chlorambucil), 클로르나파진(chlornaphazine), 클로로포스파미드(cholophosphamide), 에스트라무스틴(estramustine), 이포스파미드(ifosfamide), 메클로르에타민(mechlorethamine), 멜팔란(melphalan), 노벰비킨(novembichin), 페네스테린(phenesterine), 프레드니무스틴(prednimustine), 트로포스파미드(trofosfamide), 우라실 머스타드(uracil mustard), 카르무스틴(carmustine), 클로로코토신(chlorozotocin), 포테쿠스틴(fotemustine), 로무스틴(lomustine), 니무스틴(nimustine), 라니무스틴(ranimnustine), 칼리키아미신(calicheamicin), 칼리키아미신 감마 1(calicheamicin gamma 1), 칼리키아미신 오메가 1(calicheamicin omega 1), 디네미신(dynemicin), 디네미신 A(dynemicin A), 클로드로네이트(clodronate), 에스페르아미신(esperamicin), 네오카르지노스타틴크로모포어(neocarzinostatin chromophore), 아클라시노마이신(aclacinomysins), 악티노마이신(actinomycin), 안트르마이신(antrmycin), 아자세린(azaserine), 블레오마이신(bleomycins), 칵티노마이신(cactinomycin), 카라비신(carabicin), 카르니노마이신(carninomycin), 카르지노필린(carzinophilin), 크로모마이신(chromomycins), 닥티노마이신(dactinomycin), 다우노루비신(daunorubicin), 데토루부신(detorubucin), 6-디아조-5-옥소-L-노르루신(6-diazo-5-oxo-L-norleucine), 독소루비신(doxorubicin), 모르폴리노-독소루비신(morpholino-doxorubicin), 시아노모르폴리노-독소루비신(cyanomorpholino-doxorubicin), 2-피롤리노-독소루비신(2-pyrrolino-doxorubucin), 리포소말 독소루비신(liposomal doxorubicin), 데옥시독소루비신(deoxydoxorubicin), 에피루비신(epirubicin), 에소루비신(esorubicin), 마르셀로마이신(marcellomycin), 미토마이신 C(mitomycin C), 미코페놀산(mycophenolic acid), 노갈라마이신(nogalamycin), 올리보마이신(olivomycins), 페플로마이신(peplomycin), 포트피로마이신(potfiromycin), 퓨로마이신(puromycin), 쿠엘라마이신(quelamycin), 로도루비신(rodorubicin), 스트렙토미그린(streptomigrin), 스트렙토조신(streptozocin), 투베르시딘(tubercidin), 우베니멕스(ubenimex), 지노스타틴(zinostatin), 조루비신(zorubicin), 5-플루오로우라신(5-fluorouracil), 데노프테린(denopterin), 메토트렉세이트(methotrexate), 프테로프테린(pteropterin), 트리메트렉세이트(trimetrexate), 플루다라빈(fludarabine), 6-머캅토퓨린(6-mercaptopurine), 티아미프린(thiamiprine), 티구아닌(thiguanine), 안시타빈(ancitabine), 아자시티딘(azacitidine), 6-아자유리딘(6-azauridine), 카르모푸르(carmofur), 시타라빈(cytarabine), 디데옥시유리딘(dideoxyuridine), 독시플루리딘(doxifluridine), 에노시타빈(enocitabine), 플록수리딘(floxuridine), 칼루스테론(calusterone), 드로모스타놀론(dromostanolone),프로피오네이트(propionate), 에피티오스타놀(epitiostanol), 메피티오스테인(mepitiostane), 테스토락톤(testolactone), 아미노글루테티미드(aminoglutethimide), 미토테인(mitotane), 트릴로스테인(trilostane), 폴린산(folinic acid), 아세글라톤(aceglatone), 알도포스파미드 글리코사이드(aldophosphamide glycoside), 아미노레불린산(aminolevulinic acid), 에닐우라실(eniluracil), 암사크린(amsacrine), 베스트라부실(bestrabucil), 비산트렌(bisantrene), 에다트락세이트(edatraxate), 데포파민(defofamine), 데메콜신(demecolcine), 디아지콘(diaziquone), 엘포르니틴(elfornithine), 엘립티니움 아세테이트(elliptinium acetate), 에토글루시드(etoglucid), 갈리움 나이트레이트(gallium nitrate), 하이드록시우레아(hydroxyurea), 렌티난(lentinan), 로니다이닌(lonidainine), 메이탄신(maytansine), 안사미토신(ansamitocins), 미토구아존(mitoguazone), 미토잔트론(mitoxantrone), 모피단몰(mopidanmol), 니트라에린(nitraerine), 펜토스타틴(pentostatin), 페나메트(phenamet), 피라루비신(pirarubicin), 로소잔트론(losoxantrone), 2-에틸하이드라지드(2-ethylhydrazide), 프로카르바진(procarbazine), 폴리사카라이드-k(polysaccharidek), 라족세인(razoxane), 리조신(rhizoxin), 시조피란(sizofiran), 스피로게르마늄(spirogermanium), 테누아존산(tenuazonic acid), 트리아지콘(triaziquone),2,2',2''-트리클로로트리에틸아민(2,2',2''-trichlorotriethylamine), T-2 톡신, 베라큐린 A(verracurin A), 로리딘 A(roridin A), 안구이딘(anguidine), 우레탄(urethane), 빈데신(vindesine), 다카르바진(dacarbazine), 만노무스틴(mannomustine), 미토브로니톨(mitobronitol), 미토락톨(mitolactol), 피포브로만(pipobroman), 가시토신(gacytosine), 아라비노사이드(arabinoside), 사이클로포스파미드(cyclophosphamide), 티오테파(thiotepa), 파클리탁셀(paclitaxel), 파클리탁셀, 파클리탁셀의 알부민-엔지니어드 나노파티클(albumin-engineered nanoparticle formulation of paclitaxel), 도세탁셀, 클로람부실, 젬시타빈, 6-티오구아닌, 머캅토퓨린, 시스플라틴, 카보플라틴(carboplatin), 빈블라스틴(vinblastine), 플래티늄(platinum), 에토포사이드(etoposide), 이포스파미드(ifosfamide), 미톡산트론(mitoxantrone), 빈크리스틴, 비노렐빈(vinorelbine), 노반트론(novantrone), 테니포사이드(teniposide), 에다트렉세이트(edatrexate), 다우노마이신(daunomycin), 아미노프테린(aminopterin), 젤로다(xeloda), 이반드로네이트(ibandronate), CPT-11, 토포이소머라아제 저해제 RFS 2000, 디플루오로메틸오르니틴(difluoromethylornithine), 레티노산(retinoic acid), 카페시타빈(capecitabine), 또는 이의 약학적으로 허용되는 염, 용매화물 또는 산;
(b) 모노카인(monokine), 림포카인(lympokine), 폴리펩타이드 호르몬(traditional polypeptide hormone), 부갑상선 호르몬(parathyroid hormone), 티록신(thyroxine), 릴렉신(relaxin), 프로릴렉신(prorelaxin), 당단백 호르몬(glycoprotein hormone), 여포자극호르몬(follicle stimulating hormone), 갑상샘자극호르몬(thyroid stimulating hormone), 황체형성호르몬(luteinizing hormone), 간 성장인자 섬유모세포성장인자(hepatic growth factor fibroblast growth factor), 프롤락틴(prolactin), 태반성 락토젠(placental lactogen), 종양괴사인자 (tumor necrosis factor), 종양괴사인자-α, 종양괴사인자-β, 뮐러관 억제물질(mullerian inhibiting substance), 마우스 고나도트로핀-연관 펩타이드(mouse gonadotropin associated peptide), 인히빈(inhibin), 액티빈(activin), 혈관내피증식인자(vascular endothelial growth factor), 트롬보포이에틴(thrombopoietin), 에리스로포이에틴(erythropoietin), 골유도 인자(osteoinductive factor), 인터페론, 인터페론-α, 인터페론-β, 인터페론-γ, 콜로니자극인자(colony stimulating factor, CSF), 마크로파지-CSF, 과립구-마크로파지-CSF(granulocyte-macrophage-CSF), 과립구-CSF, 인터루킨(IL), IL-1, IL-1α, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8, IL-9, IL-10, IL-11, IL-12, 폴리펩타이드 인자, LIF, 키트 리간드(kit ligand), 또는 이들의배합물;
(c) 디프테리아 톡신, 보툴리눔 톡신, 테타누스 톡신, 디센터리 톡신, 콜레라 톡신, 아마니틴, α-아마니틴, 피롤로벤조디아제핀, 피롤로벤조디아제핀 유도체, 인돌리노벤조디아제핀, 피리디노벤조디아제핀, 테트로도톡신, 브레베톡신(brevetoxin), 시구아톡신(ciguatoxin), 리신(ricin), AM 톡신, 오리스타틴(auristatin), 투불리신(tubulysin), 겔다나마이신(geldanamycin), 메이탄시노이드(maytansinoid), 칼리케아마이신(calicheamycin), 다우노마이신(daunomycin), 독소루비신(doxorubicin), 메토트렉세이트(methotrexate), 빈데신(vindesine), SG2285, 돌라스타틴(dolastatin), 돌라스타틴유사체(dolastatin analog), 크립토피신(cryptophycin), 캄토테신(camptothecin), 리족신(rhizoxin), 리족신 유도체(rhizoxin derivatives), CC-1065, CC-1065 유사체 또는 유도체, 듀오카마이신(duocarmycin), 에네다인 항생제(enediyne antibiotic), 에스페라마이신(esperamicin), 에포틸론(epothilone), 톡소이드(toxoid), 또는 이들의 배합물;
(d) 친화성 리간드(affinity ligand), 여기에서 친화성 리간드는 기질, 저해제, 활성화제, 신경전달물질, 방사성 동위원소, 또는 이들의 배합물;
(e) 방사능표지(radioactive label), 32P, 35S, 형광다이, 전자밀도 반응제(electron dense reagent), 효소, 비오틴, 스트렙타비딘(streptavidin), 디옥시제닌(dioxigenin), 햅텐(hapten), 면역성 단백질(immunogenic protein), 타겟에 컴플러멘터리한 서열을 갖는 핵산 분자(nucleic acid molecule with a sequence complementary to a target) 또는 이들의 배합물;
(f) 면역조절 화합물(immunomodulatory compound), 항-암제(anti-cancer agent), 항-바이러스제(anti-viral agent), 항-박테리아제(anti-bacterial agent), 항-곰팡이제(anti-fungal agent), 및 항-기생충제(anti-parasitic agent), 또는 이들의 배합물;
(g) 타목시펜(tamoxifen), 랄록시펜(raloxifene), 드롤록시펜(droloxifene), 4-하이드록시타목시펜(4-hydroxytamoxifen), 트리옥시펜(trioxifene), 케옥시펜(keoxifene), LY117018, 오나프리스톤(onapristone) 또는 토레미펜(toremifene);
(h) 4(5)-이미다졸, 아미노글루테티미드(aminoglutethimide), 메제스톨 아세테이트(megestrol acetate), 엑스메스탄(exemestane), 레트로졸(letrozole), 또는 아나스트로졸(anastrozole)
(i) 플루타미드(flutamide), 닐루타미드(nilutamide), 비칼루타미드(bicalutamide), 리우프롤라이드(leuprolide), 고세렐린(goserelin), 또는 트록사시타빈(troxacitabine);
(j) 아로마타아제 저해제;
(k) 단백질 키나아제 저해제;
(l) 리피드 키나아제 저해제;
(m) 안티센스 올리고뉴클레오티드;
(n) 리보자임;
(o) 백신; 및
(p) 항-맥관형성제(anti-angiogenic agent).
- 제 1항에 있어서,
상기 Ab는 항-ROR1 항체이고;
상기 활성제는 피롤로벤조디아제핀(pyrrolobenzodiazepine) 이량체이며;
상기 링커는 Ab를 피롤로벤조디아제핀 이량체의 N10 또는 N'10 위치와 연결시키고; 및
y는 1 내지 20의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제112항에 있어서,
상기 활성제는 피롤로벤조디아제핀 이량체이고;
상기 피롤로벤조디아제핀 이량체는 N10 위치에서 X 또는 N'10 위치에서 X '로 치환되고, 여기서 X 또는 X'는 피롤로벤조디아제핀 이량체를 링커에 연결하며;
X 및 X'는 각각 독립적으로 -C(O)O-*, -S(O)O-*, -C(O)-*, -C(O)NRX-*, -S(O)2NRX-*, -(P(O)R')NRX-*, -S(O)NRX-*, 또는 PO2NRX-*이고;
RX는 H, C1-8 알킬, C3-8 사이클로알킬, C3-20 헤테로아릴, 또는 C5-20 아릴이며;
RX'는 OH, N3, CN, SH, C1-8 알킬, C3-8 사이클로알킬, C1-8 알콕시, C1-8 알킬티오, C3-20 헤테로아릴, C5-20 아릴, 또는 아미노이고; 및
*는 피롤로벤조디아제핀 이량체와 링커 사이의 결합 지점인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제113항에 있어서, 상기 X 및 X'는 각각 독립적으로 -C(O)O-*, -C(O)-* 또는 -C(O)NRX-*인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제113항에 있어서, 상기 피롤로벤조디아제핀 이량체는 하기 일반식 X 또는 일반식 XI로 기재되는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물:
[일반식 X]

[일반식 XI]

상기 식에서,
상기 점선은 C1과 C2 사이, C2와 C3 사이, C'1과 C'2 사이, 또는 C'2과 C'3 사이의 이중 결합의 선택적 존재를 나타내며;
RX1 및 RX1'는 독립적으로 H, OH, =O, =CH2, CN, Rm, ORm, =CH-Rm' =C(Rm')2, OSO2-Rm, CO2Rm, CORm, 할로 또는 디할로이고;
Rm'는 Rm, CO2Rm, CORm, CHO, CO2H 또는 할로이며,
각각의 Rm는 독립적으로 C1-12 알킬, C2-12 알케닐, C2-12 알키닐, C5-20 아릴, C5-20 헤테로아릴, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클릴, 3 내지 7-원 헤테로사이클로알킬, 또는 5 내지 7-원 헤테로아릴로이고;
RX2, RX2' RX3, RX3', RX5, 및 RX5'는 독립적으로 H, Rm, OH, ORm, SH, SRm, NH2, NHRm, NRm 2, NO2, Me3Sn 또는 할로이며;
RX4 및 RX4'는 독립적으로 H, Rm, OH, ORm, SH, SRm, NH2, NHRm, NRm 2, NO2, Me3Sn, 할로, C1-6 알킬 C1-6 알콕시, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-12 아릴, 5 내지 7-원 헤테로아릴, -CN, -NCO, -ORn, -OC(O)Rn, -OC(O)NRnRn', -OS(O)Rn, -OS(O)2Rn, -SRn, -S(O)Rn, -S(O)2Rn, -S(O)NRnRn', -S(O)2NRnRn', -OS(O)NRnRn', -OS(O)2NRnRn', -NRnRn', -NRnC(O)Ro, -NRnC(O)ORo, -NRnC(O)NRoRo', -NRnS(O)Ro, -NRnS(O)2Ro, -NRnS(O)NRoRo', -NRnS(O)2NRoRo', -C(O)Rn, -C(O)ORn 또는 -C(O)NRnRn'이고;
RX 및 RX'는 독립적으로 H, OH, N3, CN, NO2, SH, NH2, ONH2, NHNH2, 할로, C1-8 알킬, C3-8 사이클로 알킬, C1-8 알콕시, C1-8 알킬티오, C3-20 헤테로아릴, C5-20 아릴 또는 모노- 또는 디(di)-C1-8 알킬아미노이며;
Y 및 Y'는 독립적으로 O, S, 또는 N(H)이고;
RX6는 독립적으로 C3-12 알킬렌, C3-12 알케닐렌, 또는 C3-12 헤테로알킬렌이며;
RX7 및 RX7'는 독립적으로 H, C1-6 알킬, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C6-10 아릴, 5 내지 7-원 헤테로아릴, -ORr, -OC(O)Rr, -OC(O)NRrRr', -OS(O)Rr, -OS(O)2Rr, -SRr, -S(O)Rr, -S(O)2Rr, -S(O)NRrRr', -S(O)2NRrRr', -OS(O)NRrRr', -OS(O)2NRrRr', -NRrRr', -NRrC(O)Rs, -NRrC(O)ORs, -NRrC(O)NRsRs', -NRrS(O)Rs, -NRrS(O)2Rs, -NRrS(O)NRsRs', -NRrS(O)2NRsRs, -C(O)Rr, -C(O)ORs 또는 -C(O)NRrRr'이고;
각각의 Rr, Rr', Rs, 및 Rs' 은 독립적으로 H, C1-7 알킬, C2-7 알케닐, C2-7 알키닐, C3-13 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-10 아릴 또는 5 내지 7-원 헤테로아릴로이며;
각 RX8 및 RX8'는 독립적으로 H, C1-6 알킬, C2-6 알케닐, C2-6 알키닐, C3-6 헤테로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-10 아릴, 5 내지 7-원 헤테로아릴, -S(O)Rm, -S(O)2Rm, -S(O)NRmRm', -S(O)2NRmRm', -NRmRm', -NRmC(O)Rm, -NRmC(O)ORn, -NRmC(O)NRnRn', -NRmS(O)Rn, -NRmS(O)2Rn, -NRmS(O)NRnRn', -NRmS(O)2NRnRn', -C(O)Rm, -C(O)ORm 또는 -C(O)NRmRm'이고;
Za 는 ORX12a, NRX12aRX12a, 또는 SRX12a이며;
Zb 는 ORX13a, NRX13aRX13a, 또는 SRX13a이고;
Za'는 ORX12a, NRX12aRX12a, 또는 SRX12a이며;
Zb'는 ORX13a', NRX13'RX13a' 또는 SRX13a'이고;
각 RX12a, RX12a', RX13a' 및 RX13a'는 독립적으로 H, C1-6 알킬, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 to 7-원 헤테로사이클로알킬, C5-10 아릴, 5 내지 7-원 헤테아릴, -C(O)RX15a, -C(O)ORX15a 또는 -C(O)NRX15aRX15a'이며; 및
각각의 RX15a 및 RX15a' 는 독립적으로 C1-12 알킬, C2-12 알케닐, C2-12 알키닐, C5-20 아릴, C5-20 헤테로 아릴, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클릴, 3 내지 7-원 헤테로사이클로알킬, 또는 5 내지 7-원 헤테로아릴이고;
상기 RX13a 및 RX14a 는 이들이 부착된 원자와 함께 임의적으로 결합하여 3 내지 7-원 헤테로 사이클릴, 3 내지 7-원 헤테로 사이클로알킬, 또는 3 내지 7-원 헤테로 아릴을 형성하고, 및 RX13a' 및 RX14a'이들이 부착된 원자와 함께 임의적으로 결합하여 3 내지 7-원 헤테로 사이클릴, 3 내지 7-원 헤테로사이클로알킬, 또는 3 내지 7-원 헤테로 아릴을 형성하며; 및
상기 각각의 Rn, Rn', Ro, Ro', Rp, 및 Rp' 는 독립적으로 H, C1-7 알킬, C2-7 알케닐, C2-7 알키닐, C3-13 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-10 아릴, 또는 5 내지 7-원 헤테로아릴이다.
- 제115항에 있어서, 상기 Rm는 독립적으로 C1-12 알킬, C2-12 알케닐, C2-12알키닐, C5-20 아릴, C5-20 헤테로아릴, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클릴, 3 내지 7-원 헤테로사이클로알킬, 및 5 내지 7-원 헤테로아릴로 이루어진 군으로부터 선택되고,
상기 Rm는 추가적으로 C1-12 알킬, C2-12 알케닐, C2-12 알키닐, C5-20 아릴, C5-20 헤테로아릴, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클릴, 3 내지 7-원 헤테로사이클로알킬, 또는 5 내지 7-원 헤테로아릴로 치환되는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제115항에 있어서, 상기 RX4 및 RX4'는 독립적으로 H, Rm, OH, ORm, SH, SRm, NH2, NHRm, NRmRm', NO2, Me3Sn, 할로, C1-6 알킬, C1-6 알콕시, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-12 아릴, 5 내지 7-원 헤테로아릴, -CN, -NCO, -ORn, -OC(O)Rn, -OC(O)NRnRn', -OS(O)Rn, -OS(O)2Rn, -SRn, -S(O)Rn, -S(O)2Rn, -S(O)NRnRn', -S(O)2NRnRn', -OS(O)NRnRn', -OS(O)2NRnRn', -NRnRn', -NRnC(O)Ro, -NRnC(O)ORo, -NRnC(O)NRoRo', -NRnS(O)Ro, -NRnS(O)2Ro, -NRnS(O)NRoRo', -NRnS(O)2NRoRo', -C(O)Rn, -C(O)ORn 및 -C(O)NRnRn'로 부터 선택되고,
상기 RX4 또는 RX4'는 C1-6 알킬, C1-6 알콕시, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-12 아릴 또는 5 내지 7-원 헤테로아릴이고, 추가적으로 하나 이상의 C1-6 알킬, C1-6 알콕시, C2-6 알케닐, C2-6 알키닐, C3-C6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-10 아릴, 5 내지 7-원 헤테로아릴, -ORp, -OC(O)Rp, -OC(O)NRpRp', -OS(O)Rp, -OS(O)2Rp, -SRp, -S(O)Rp, -S(O)2Rp, -S(O)NRpRp', -S(O)2NRpRp', -OS(O)NRpRp', -OS(O)2NRpRp', -NRpRp', -NRpC(O)Rq, -NRpC(O)ORq, -NRpC(O)NRqRq', -NRpS(O)Rq, -NRpS(O)2Rq, -NRpS(O)NRqRq', -NRpS(O)2NRqRq', -C(O)Rp, -C(O)ORp 또는 -C(O)NRpRp로 치환되는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제115항에 있어서, 상기 RX7 및 RX7' 는 독립적으로 H, C1-6 알킬, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C6-10 아릴, 5 내지 7-원 헤테로아릴, -ORr, -OC(O)Rr, -OC(O)NRrRr', -OS(O)Rr, -OS(O)2Rr, -SRr, -S(O)Rr, -S(O)2Rr, -S(O)NRrRr', -S(O)2NRrRr', -OS(O)NRrRr', -OS(O)2NRrRr', -NRrRr', -NRrC(O)Rs, -NRrC(O)ORs, -NRrC(O)NRsRs', -NRrS(O)Rs, -NRrS(O)2Rs, -NRrS(O)NRsRs', -NRrS(O)2NRsRs, -C(O)Rr, -C(O)ORs 또는 -C(O)NRrRr'으로부터 선택되고,
상기 RX7 또는 RX7' 는 C1-6 알킬, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C6-10 아릴, 5 내지 7-원 헤테로아릴이고, 추가적으로 C1-6 알킬, C2-6 알케닐, C2-6 알키닐, C3-6 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C6-10 아릴, 5 내지 7-원 헤테로아릴, -ORt, -OC(O)Rt, -OC(O)NRtRt', -OS(O)Rt, -OS(O)2Rt, -SRt, -S(O)Rt, -S(O)2Rt, -S(O)NRtRt', -S(O)2NRtRt', -OS(O)NRtRt', -OS(O)2NRtRt', -NRtRt', -NRtC(O)Ru, -NRtC(O)ORu, -NRtC(O)NRuRu', -NRtS(O)Ru, -NRtS(O)2Ru, -NRtS(O)NRuRu', -NRtS(O)2NRuRu', -C(O)Rt, -C(O)ORt 또는 -C(O)NRtRt'로 치환되며,
상기 Rr, Rr', Rs, Rs', Rt, Rt', Ru 및 Ru'는 독립적으로 H, C1-7 알킬, C2-7 알케닐, C2-7 알키닐, C3-13 사이클로알킬, 3 내지 7-원 헤테로사이클로알킬, C5-10 아릴, 및 5 내지 7-원 헤테로아릴로 부터 선택되는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제115항에 있어서, 상기 RX1 및 RX1' 는 독립적으로 Rm 으로부터 선택되고; 및
Rm은 C1-6 알킬, C2-6 알케닐, C5-7 아릴 및 C3-6 헤테로아릴로 부터 선택되는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제115항에 있어서, 상기 RX2, RX2', RX3, RX3', RX5, 및 RX5'은 독립적으로 H 또는 OH로부터 선택되는 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제115항에 있어서, 상기 RX4 및 RX4' 는 독립적으로 Rm으로부터 선택되고; 및
Rm 은 C1-6 알콕시인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제115항에 있어서, 상기 RX4 및 RX4' 는 독립적으로 메톡시, 에톡시 및 부톡시로 이루어진 군으로부터 선택되는 어느 하나인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제115항에 있어서, 상기 Y 및 Y'는 O인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제115항에 있어서, RX6 는 C3-12 알킬렌, C3-12 알케닐렌 또는 C3-12 헤테로알킬렌이고, 상기 RX6은 -NH2, -NHRm, -NHC(O)Rm, -NHC(O)CH2-[OCH2CH2]n-RXX, 또는 -[CH2CH2O]n-RXX로 치환되고;
상기 RXX는 H, OH, N3, CN, NO2, SH, NH2, ONH2, NHNH2, 할로, C1-8 알킬, C3-8 사이클로알킬, C1-8 알콕시, C1-8 알킬티오, C3-20 헤테로아릴, C5-20 아릴 또는 모노- 또는 디-C1-8 알킬 아미노이며; 및
n은 1 내지 6의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제115항에 있어서, 상기 활성제는 하기 일반식 XII 또는 일반식 XIII로 기재되는 피롤로벤조디아제핀 이량체인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물:
[일반식 XII]

[일반식 XIII]

상기 Xa 및 Xa'는 독립적으로 결합 또는 C1-6 알킬렌으로부터 선택되고;
ZX' 및 ZX 는 독립적으로 수소, C1-8 알킬, 할로겐, 시아노, 나이트로,, 또는 -(CH2)m-OCH3로부터 선택되며;
또는 -(CH2)m-OCH3로부터 선택되며;
각각의 R80, R90 및 R100 는 수소, C1-8 알킬, C2-6 알케닐, 및 C1-6 알콕시로부터 선택되고; 및
m은 0 내지 12의 정수임.
- 제125항에 있어서, 상기 ZX' 및 ZX 는 독립적으로 수소,,
 및 -(CH2)m-OCH3로 이루어진 군으로부터 선택되는 어느 하나이고,
및 -(CH2)m-OCH3로 이루어진 군으로부터 선택되는 어느 하나이고,
상기 각각의 R80, R90 및 R100 는 수소, C1-3 알킬 및 C1-3 알콕시로 이루어진 군으로부터 선택되는 어느 하나이며,
m은 1 내지 6의 정수인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제1항에 있어서, 상기 활성제는
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
및
으로 이루어진 군으로부터 선택되는 어느 하나인 것을 특징으로 하는 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물.
- 제1항의 항체 접합체 또는 이의 약학적으로 허용되는 염 또는 이의 용매화물를 포함하는 ROR1의 과발현과 관련된 질환의 예방 또는 치료 예방 및 치료용 약학적 조성물.
- 제128항에 있어서, 추가적으로 약학적으로 유효한 양의 화학 치료제(chemotherapeutic agent)를 포함하는 것을 특징으로 하는 약학적 조성물.
- 제128항에 있어서, 상기 ROR1의 과발현과 관련된 질환은 암인 것을 특징으로 하는 약학적 조성물.
- 제130항에 있어서, 상기 암은 만성 림프구성 백혈병(CLL), B세포 백혈병, 림프종, 급성 골수성 백혈병(AML), 버킷 림프종, 외투세포림프종(MCL), 급성림프구성백혈병(ALL), 미만성거대B세포림프종(DLBCL), 여포성림프종(FL), 변연부림프종(MZL), 유방암, 신장암, 난소암, 위암, 간암, 폐암, 대장암, 췌장암, 피부암, 방광암, 고환암, 자궁암, 전립선암, 비소세포 폐암(NSCLC), 신경모세포종, 뇌암, 결장암, 상피 편평세포암, 흑색종, 골수종, 자궁경부암, 갑상선암, 두경부암, 또는 부신암으로 이루어진 군으로부터 선택되는 어느 하나인 것을 특징으로 하는 약학적 조성물.
Priority Applications (15)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020190109807A KR20210028544A (ko) | 2019-09-04 | 2019-09-04 | 인간 ror1에 대한 항체를 포함하는 항체 약물 접합체 및 이의 용도 |
| BR112022003589A BR112022003589A2 (pt) | 2019-09-04 | 2020-07-27 | Conjugado de anticorpo-fármaco compreendendo anticorpo contra ror1 humano e uso para o mesmo |
| EP20861806.6A EP4025257A4 (en) | 2019-09-04 | 2020-07-27 | ANTIBODY-DRUG CONJUGATE COMPRISING AN ANTIBODY AGAINST HUMAN ROR1, AND USE THEREOF |
| AU2020343888A AU2020343888A1 (en) | 2019-09-04 | 2020-07-27 | Antibody-drug conjugate comprising antibody against human ROR1, and use for the same |
| PCT/IB2020/000649 WO2021044208A1 (en) | 2019-09-04 | 2020-07-27 | Antibody-drug conjugate comprising antibody against human ror1, and use for the same |
| US16/940,326 US11707533B2 (en) | 2019-09-04 | 2020-07-27 | Antibody-drug conjugate comprising antibody against human ROR1 and use for the same |
| CA3153069A CA3153069A1 (en) | 2019-09-04 | 2020-07-27 | Antibody-drug conjugate comprising antibody against human ror1, and use for the same |
| MX2022002592A MX2022002592A (es) | 2019-09-04 | 2020-07-27 | Conjugado de anticuerpo-farmaco que comprende un anticuerpo contra el gen del receptor huerfano 1 similar a tirosina cinasa receptora (ror1) humano y uso para el mismo. |
| CN202010852078.1A CN112439075A (zh) | 2019-09-04 | 2020-08-21 | 包含抗人类ror1抗体的抗体-药物结合物和其用途 |
| CN202110805667.9A CN113521300A (zh) | 2019-09-04 | 2020-08-21 | 包含抗人类ror1抗体的抗体-药物结合物和其用途 |
| TW109128698A TW202122115A (zh) | 2019-09-04 | 2020-08-21 | 包含抗人類ror1抗體之抗體—藥物結合物及其用途 |
| JP2020143359A JP2021063058A (ja) | 2019-09-04 | 2020-08-27 | ヒトror1に対する抗体を含む抗体−薬物コンジュゲートおよびその使用 |
| IL290979A IL290979A (en) | 2019-09-04 | 2022-02-28 | Antibody-drug conjugates containing anti-human ror1 antibody and use thereof |
| US18/209,299 US20230405139A1 (en) | 2019-09-04 | 2023-06-13 | Antibody-drug conjugate comprising antibody against human ror1 and use for the same |
| JP2023135580A JP2023179421A (ja) | 2019-09-04 | 2023-08-23 | ヒトror1に対する抗体を含む抗体-薬物コンジュゲートおよびその使用 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020190109807A KR20210028544A (ko) | 2019-09-04 | 2019-09-04 | 인간 ror1에 대한 항체를 포함하는 항체 약물 접합체 및 이의 용도 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020200041527A Division KR20210028556A (ko) | 2019-09-04 | 2020-04-06 | 인간 ror1에 대한 항체를 포함하는 항체 약물 접합체 및 이의 용도 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210028544A true KR20210028544A (ko) | 2021-03-12 |
Family
ID=74733383
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020190109807A KR20210028544A (ko) | 2019-09-04 | 2019-09-04 | 인간 ror1에 대한 항체를 포함하는 항체 약물 접합체 및 이의 용도 |
Country Status (12)
| Country | Link |
|---|---|
| US (2) | US11707533B2 (ko) |
| EP (1) | EP4025257A4 (ko) |
| JP (2) | JP2021063058A (ko) |
| KR (1) | KR20210028544A (ko) |
| CN (2) | CN112439075A (ko) |
| AU (1) | AU2020343888A1 (ko) |
| BR (1) | BR112022003589A2 (ko) |
| CA (1) | CA3153069A1 (ko) |
| IL (1) | IL290979A (ko) |
| MX (1) | MX2022002592A (ko) |
| TW (1) | TW202122115A (ko) |
| WO (1) | WO2021044208A1 (ko) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022245186A1 (ko) * | 2021-05-21 | 2022-11-24 | 주식회사 레고켐바이오사이언스 | Ror1 및 b7-h3에 결합하는 항체-약물 접합체 및 그 용도 |
| WO2024014930A1 (ko) * | 2022-07-15 | 2024-01-18 | 에이비엘바이오 주식회사 | 항-ror1 항체, 이를 포함하는 이중특이성 항체, 및 이들의 용도 |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2016359230B2 (en) | 2015-11-25 | 2020-04-23 | Legochem Biosciences, Inc. | Conjugates comprising self-immolative groups and methods related thereto |
| CN113599533A (zh) | 2015-11-25 | 2021-11-05 | 乐高化学生物科学股份有限公司 | 包含分支接头的抗体-药物缀合物及其相关方法 |
| KR101938800B1 (ko) | 2017-03-29 | 2019-04-10 | 주식회사 레고켐 바이오사이언스 | 피롤로벤조디아제핀 이량체 전구체 및 이의 리간드-링커 접합체 화합물 |
| WO2019215510A2 (en) | 2018-05-09 | 2019-11-14 | Legochem Biosciences, Inc. | Compositions and methods related to anti-cd19 antibody drug conjugates |
| KR20210028544A (ko) | 2019-09-04 | 2021-03-12 | 주식회사 레고켐 바이오사이언스 | 인간 ror1에 대한 항체를 포함하는 항체 약물 접합체 및 이의 용도 |
| US11806405B1 (en) | 2021-07-19 | 2023-11-07 | Zeno Management, Inc. | Immunoconjugates and methods |
| TW202330620A (zh) * | 2022-01-29 | 2023-08-01 | 大陸商杭州中美華東製藥有限公司 | 一種靶向ror1的抗體或其抗原結合片段及其應用 |
| WO2024008112A1 (en) * | 2022-07-06 | 2024-01-11 | Nona Biosciences (Suzhou) Co., Ltd. | Anti-ror1 antibodies |
| WO2024032761A1 (en) * | 2022-08-11 | 2024-02-15 | Hansoh Bio Llc | Ligand-cytotoxicity drug conjugates and pharmaceutical uses thereof |
Family Cites Families (70)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5112739A (en) | 1988-08-02 | 1992-05-12 | Polaroid Corporation | Enzyme controlled release system |
| DE19512484A1 (de) | 1995-04-04 | 1996-10-17 | Bayer Ag | Kohlenhydratmodifizierte Cytostatika |
| ES2257756T3 (es) | 1996-03-12 | 2006-08-01 | Sanofi-Aventis Deutschland Gmbh | Nuevos profarmacos para la terapia de tumores y enfermedades inflamatorias. |
| US6218519B1 (en) | 1996-04-12 | 2001-04-17 | Pro-Neuron, Inc. | Compounds and methods for the selective treatment of cancer and bacterial infections |
| AU5159798A (en) | 1996-11-05 | 1998-05-29 | Bristol-Myers Squibb Company | Branched peptide linkers |
| US6759509B1 (en) | 1996-11-05 | 2004-07-06 | Bristol-Myers Squibb Company | Branched peptide linkers |
| US6613897B1 (en) | 1998-04-30 | 2003-09-02 | Maruha Corporation | Compounds having glucuronic acid derivatives and glucosamine derivative in the structure, process for producing the same and utilization thereof |
| JP2006510626A (ja) | 2002-12-05 | 2006-03-30 | シエーリング アクチエンゲゼルシャフト | 増殖疾患の処理における部位特異的供給のためのエポチロン類似体 |
| PT2489364E (pt) | 2003-11-06 | 2015-04-16 | Seattle Genetics Inc | Compostos de monometilvalina conjugados com anticorpos |
| CN101035564A (zh) | 2004-09-10 | 2007-09-12 | 惠氏公司 | 人源化的抗5t4抗体和抗5t4抗体/加利车霉素缀合物 |
| SI1912671T1 (en) | 2005-07-18 | 2018-01-31 | Seattle Genetics, Inc. | Conjugates beta-glucuronide linker-drug |
| CN101287500A (zh) | 2005-08-19 | 2008-10-15 | 恩多塞特公司 | 多药物配体缀合物 |
| KR20090057235A (ko) | 2006-09-15 | 2009-06-04 | 엔존 파마슈티컬즈, 인코포레이티드 | 리신계 폴리머 링커 |
| CN103073641B (zh) | 2006-11-10 | 2015-01-21 | 株式会社立富泰克 | 在体内具有抗肿瘤活性的抗人Dlk-1抗体 |
| CL2007003622A1 (es) | 2006-12-13 | 2009-08-07 | Medarex Inc | Anticuerpo monoclonal humano anti-cd19; composicion que lo comprende; y metodo de inhibicion del crecimiento de celulas tumorales. |
| EP2188297B1 (en) | 2007-08-01 | 2012-02-01 | Council of Scientific & Industrial Research | Pyrrolo [2,1-c][1, 4] benzodiazepine-glycoside prodrugs useful as a selective anti tumor agent |
| EP2421899B1 (en) * | 2009-04-23 | 2016-06-08 | The United States of America, as represented by The Secretary, Department of Health and Human Services | Anti-human ror1 antibodies |
| US9353140B2 (en) | 2009-11-25 | 2016-05-31 | Academia Sinica | BQC-G, a tumor-selective anti-cancer prodrug |
| SI2528625T1 (sl) | 2010-04-15 | 2013-11-29 | Spirogen Sarl | Pirolobenzodiazepini in njihovi konjugati |
| FR2960153B1 (fr) | 2010-05-20 | 2012-08-17 | Centre Nat Rech Scient | Nouveaux bras autoreactifs et prodrogues les comprenant |
| US9591882B2 (en) | 2010-08-05 | 2017-03-14 | Robert LaGrand Duffin | Absorbent sleeve |
| EP2621954A1 (en) * | 2010-10-01 | 2013-08-07 | Oxford Biotherapeutics Ltd. | Anti-rori antibodies |
| GB201020995D0 (en) | 2010-12-10 | 2011-01-26 | Bioinvent Int Ab | Biological materials and uses thereof |
| KR20120107741A (ko) | 2011-03-22 | 2012-10-04 | 한국생명공학연구원 | 패혈증 단백질 치료제의 효능 분석 및 스크리닝 방법 |
| KR101438265B1 (ko) | 2011-04-04 | 2014-09-05 | 한국생명공학연구원 | Dlk1 특이적 인간 항체 및 이를 포함하는 약학적 조성물 |
| EP2702522A4 (en) | 2011-04-29 | 2015-03-25 | Hewlett Packard Development Co | SYSTEMS AND METHOD FOR IN-STORAGE PROCESSING OF EVENTS |
| JP6196613B2 (ja) | 2011-05-08 | 2017-09-13 | レゴケム バイオサイエンシズ, インク.Legochem Biosciences, Inc. | タンパク質−活性剤コンジュゲートおよびこれを調製するための方法 |
| EP2755642B1 (en) | 2011-10-14 | 2018-07-18 | Seattle Genetics, Inc. | Pyrrolobenzodiazepines and targeted conjugates |
| US9884123B2 (en) | 2012-01-03 | 2018-02-06 | Invictus Oncology Pvt. Ltd. | Ligand-targeted molecules and methods thereof |
| JP6307519B2 (ja) | 2012-12-21 | 2018-04-04 | メドイミューン・リミテッドMedImmune Limited | ピロロベンゾジアゼピンおよびその結合体 |
| ES2727134T3 (es) | 2013-03-15 | 2019-10-14 | Abbvie Deutschland | Formulaciones de conjugado de fármaco y anticuerpo anti-EGFR |
| WO2014194030A2 (en) | 2013-05-31 | 2014-12-04 | Immunogen, Inc. | Conjugates comprising cell-binding agents and cytotoxic agents |
| US20160256561A1 (en) | 2013-10-11 | 2016-09-08 | Medimmune Limited | Pyrrolobenzodiazepine-antibody conjugates |
| GB201317982D0 (en) | 2013-10-11 | 2013-11-27 | Spirogen Sarl | Pyrrolobenzodiazepines and conjugates thereof |
| EA201690780A1 (ru) | 2013-10-15 | 2016-08-31 | Сиэтл Дженетикс, Инк. | Пегилированные лекарственные средства-линкеры для улучшенной фармакокинетики конъюгатов лиганд-лекарственное средство |
| EP3074048B1 (en) | 2013-11-26 | 2019-03-06 | Novartis AG | Methods for oxime conjugation to ketone-modified polypeptides |
| KR102442906B1 (ko) | 2013-12-19 | 2022-09-14 | 씨젠 인크. | 표적화된-약물 컨쥬게이트와 함께 사용되는 메틸렌 카바메이트 링커 |
| EP2913064A1 (en) | 2014-02-26 | 2015-09-02 | celares GmbH | Branched drug-linker conjugates for the coupling to biological targeting molecules |
| KR101628872B1 (ko) | 2014-05-28 | 2016-06-09 | 주식회사 레고켐 바이오사이언스 | 자가-희생 기를 포함하는 화합물 |
| TWI751102B (zh) | 2014-08-28 | 2022-01-01 | 美商奇諾治療有限公司 | 對cd19具專一性之抗體及嵌合抗原受體 |
| CN113827737A (zh) | 2014-09-11 | 2021-12-24 | 西雅图基因公司 | 含叔胺药物物质的靶向递送 |
| CA2970161A1 (en) | 2014-12-09 | 2016-06-16 | Abbvie Inc. | Bcl-xl inhibitory compounds and antibody drug conjugates including the same |
| KR20160080832A (ko) | 2014-12-29 | 2016-07-08 | 주식회사 레고켐 바이오사이언스 | 리피바디 유도체-약물 복합체, 그 제조방법 및 용도 |
| JP7152156B2 (ja) * | 2015-01-14 | 2022-10-12 | ザ・ブリガーム・アンド・ウーメンズ・ホスピタル・インコーポレーテッド | 抗lapモノクローナル抗体による癌の処置 |
| AR103442A1 (es) | 2015-01-16 | 2017-05-10 | Juno Therapeutics Inc | Anticuerpos y receptores de antígenos quiméricos específicos de ror1 |
| EP3892305A1 (en) | 2015-01-30 | 2021-10-13 | Sutro Biopharma, Inc. | Hemiasterlin derivatives for conjugation and therapy |
| US11673957B2 (en) * | 2015-03-10 | 2023-06-13 | Eureka Therapeutics, Inc. | Anti-ROR2 antibodies |
| WO2016187220A2 (en) * | 2015-05-18 | 2016-11-24 | Five Prime Therapeutics, Inc. | Anti-ror1 antibodies |
| WO2017051254A1 (en) | 2015-09-25 | 2017-03-30 | Legochem Biosciences, Inc. | Compositions and methods related to anti-egfr antibody drug conjugates |
| WO2017051249A1 (en) | 2015-09-25 | 2017-03-30 | Legochem Biosciences, Inc. | Compositions and methods related to anti-cd19 antibody drug conjugates |
| EP3362479A4 (en) | 2015-10-13 | 2019-05-15 | Eureka Therapeutics, Inc. | FOR HUMANESE CD19 SPECIFIC ANTIBODY AGENTS AND USES THEREOF |
| AU2016359230B2 (en) | 2015-11-25 | 2020-04-23 | Legochem Biosciences, Inc. | Conjugates comprising self-immolative groups and methods related thereto |
| CN113599533A (zh) | 2015-11-25 | 2021-11-05 | 乐高化学生物科学股份有限公司 | 包含分支接头的抗体-药物缀合物及其相关方法 |
| CA3006247A1 (en) | 2015-11-25 | 2017-06-01 | Legochem Biosciences, Inc. | Conjugates comprising peptide groups and methods related thereto |
| RU2651776C2 (ru) | 2015-12-01 | 2018-04-23 | Общество с ограниченной ответственностью "Международный биотехнологический центр "Генериум" ("МБЦ "Генериум") | Биспецифические антитела против cd3*cd19 |
| RU2766190C2 (ru) * | 2016-01-20 | 2022-02-09 | Дзе Скриппс Рисерч Инститьют | Композиции антител к ror1 и соответствующие способы |
| GB201617466D0 (en) | 2016-10-14 | 2016-11-30 | Medimmune Ltd | Pyrrolobenzodiazepine conjugates |
| US20180142018A1 (en) | 2016-11-04 | 2018-05-24 | Novimmune Sa | Anti-cd19 antibodies and methods of use thereof |
| US20200338210A1 (en) * | 2016-12-22 | 2020-10-29 | Ardeagen Corporation | Anti-ror1 antibody and conjugates thereof |
| ES2890934T3 (es) | 2017-02-08 | 2022-01-25 | Adc Therapeutics Sa | Conjugados de pirrolobenzodiazepinas y anticuerpos |
| KR101938800B1 (ko) | 2017-03-29 | 2019-04-10 | 주식회사 레고켐 바이오사이언스 | 피롤로벤조디아제핀 이량체 전구체 및 이의 리간드-링커 접합체 화합물 |
| AR113224A1 (es) * | 2017-04-28 | 2020-02-19 | Novartis Ag | Conjugados de anticuerpo que comprenden un agonista de sting |
| TWI804499B (zh) * | 2017-06-23 | 2023-06-11 | 美商維洛斯生物公司 | Ror1抗體免疫接合物 |
| KR20190018400A (ko) | 2017-08-14 | 2019-02-22 | 주식회사 레고켐 바이오사이언스 | EGFRvIII에 대한 항체를 포함하는 항체 약물 접합체 |
| WO2019050362A2 (ko) | 2017-09-08 | 2019-03-14 | 주식회사 와이바이오로직스 | 인간 dlk1에 대한 항체 및 이의 용도 |
| US11638760B2 (en) * | 2017-11-27 | 2023-05-02 | Mersana Therapeutics, Inc. | Pyrrolobenzodiazepine antibody conjugates |
| WO2019215510A2 (en) | 2018-05-09 | 2019-11-14 | Legochem Biosciences, Inc. | Compositions and methods related to anti-cd19 antibody drug conjugates |
| WO2019225777A1 (ko) * | 2018-05-23 | 2019-11-28 | 에이비엘바이오 주식회사 | 항-ror1 항체 및 그 용도 |
| WO2020180121A1 (ko) | 2019-03-06 | 2020-09-10 | 주식회사 레고켐 바이오사이언스 | 인간 dlk1에 대한 항체를 포함하는 항체 약물 접합체 및 이의 용도 |
| KR20210028544A (ko) | 2019-09-04 | 2021-03-12 | 주식회사 레고켐 바이오사이언스 | 인간 ror1에 대한 항체를 포함하는 항체 약물 접합체 및 이의 용도 |
-
2019
- 2019-09-04 KR KR1020190109807A patent/KR20210028544A/ko unknown
-
2020
- 2020-07-27 AU AU2020343888A patent/AU2020343888A1/en active Pending
- 2020-07-27 WO PCT/IB2020/000649 patent/WO2021044208A1/en active Application Filing
- 2020-07-27 US US16/940,326 patent/US11707533B2/en active Active
- 2020-07-27 CA CA3153069A patent/CA3153069A1/en active Pending
- 2020-07-27 MX MX2022002592A patent/MX2022002592A/es unknown
- 2020-07-27 EP EP20861806.6A patent/EP4025257A4/en active Pending
- 2020-07-27 BR BR112022003589A patent/BR112022003589A2/pt unknown
- 2020-08-21 CN CN202010852078.1A patent/CN112439075A/zh active Pending
- 2020-08-21 CN CN202110805667.9A patent/CN113521300A/zh active Pending
- 2020-08-21 TW TW109128698A patent/TW202122115A/zh unknown
- 2020-08-27 JP JP2020143359A patent/JP2021063058A/ja active Pending
-
2022
- 2022-02-28 IL IL290979A patent/IL290979A/en unknown
-
2023
- 2023-06-13 US US18/209,299 patent/US20230405139A1/en active Pending
- 2023-08-23 JP JP2023135580A patent/JP2023179421A/ja active Pending
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022245186A1 (ko) * | 2021-05-21 | 2022-11-24 | 주식회사 레고켐바이오사이언스 | Ror1 및 b7-h3에 결합하는 항체-약물 접합체 및 그 용도 |
| WO2024014930A1 (ko) * | 2022-07-15 | 2024-01-18 | 에이비엘바이오 주식회사 | 항-ror1 항체, 이를 포함하는 이중특이성 항체, 및 이들의 용도 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113521300A (zh) | 2021-10-22 |
| EP4025257A1 (en) | 2022-07-13 |
| JP2023179421A (ja) | 2023-12-19 |
| US20230405139A1 (en) | 2023-12-21 |
| TW202122115A (zh) | 2021-06-16 |
| EP4025257A4 (en) | 2023-11-22 |
| CA3153069A1 (en) | 2021-03-11 |
| MX2022002592A (es) | 2022-03-25 |
| US20210069342A1 (en) | 2021-03-11 |
| WO2021044208A1 (en) | 2021-03-11 |
| WO2021044208A8 (en) | 2021-04-01 |
| US11707533B2 (en) | 2023-07-25 |
| BR112022003589A2 (pt) | 2022-05-24 |
| AU2020343888A1 (en) | 2022-03-17 |
| JP2021063058A (ja) | 2021-04-22 |
| CN112439075A (zh) | 2021-03-05 |
| IL290979A (en) | 2022-05-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20210028544A (ko) | 인간 ror1에 대한 항체를 포함하는 항체 약물 접합체 및 이의 용도 | |
| JP7064629B2 (ja) | 抗cdh6抗体及び抗cdh6抗体-薬物コンジュゲート | |
| US11008398B2 (en) | Anti-TROP2 antibody-drug conjugate | |
| JP2013507968A (ja) | 抗gcc分子と関連組成物および方法 | |
| KR102503143B1 (ko) | 인간 dlk1에 대한 항체를 포함하는 항체 약물 접합체 및 이의 용도 | |
| KR20230038738A (ko) | 단백질에서 글루타민 잔기에 접합된 캄토테신 유사체 및 그의 용도 | |
| JP2022515760A (ja) | Pmel17に対する抗体及びその結合体 | |
| KR20230138444A (ko) | Mcl-1 억제제 항체-약물 접합체 및 사용 방법 | |
| CA3231632A1 (en) | Antibody-drug conjugate for use in methods of treating chemotherapy-resistant cancer | |
| JP2016511257A (ja) | 癌の治療における抗gcc抗体−薬物複合体及びdna損傷剤の投与 | |
| KR20210028556A (ko) | 인간 ror1에 대한 항체를 포함하는 항체 약물 접합체 및 이의 용도 | |
| TW202408591A (zh) | 包含抗人類ror1抗體之抗體-藥物結合物及其用途 | |
| KR20210063070A (ko) | 항-b7-h3 항체를 포함하는 항체-약물 접합체 및 이의 용도 | |
| KR20220158181A (ko) | Ror1 및 b7-h3에 결합하는 항체-약물 접합체 및 그 용도 | |
| RU2801630C2 (ru) | Коньюгаты антитело-лекарственное средство, включающие антитело против человеческого dlk1, и их применение | |
| WO2023041041A1 (en) | D3-binding molecules and uses thereof | |
| TW202237650A (zh) | 抗cd48抗體、抗體藥物軛合物及其用途 | |
| KR20230143869A (ko) | 인간 trop2에 대한 항체를 포함하는 항체-약물 접합체 및 이의 용도 | |
| KR20240052881A (ko) | Pmel17에 대한 항체 및 이의 접합체 |