KR20200104302A - 신규 티오포스포르아미다이트 - Google Patents
신규 티오포스포르아미다이트 Download PDFInfo
- Publication number
- KR20200104302A KR20200104302A KR1020207017875A KR20207017875A KR20200104302A KR 20200104302 A KR20200104302 A KR 20200104302A KR 1020207017875 A KR1020207017875 A KR 1020207017875A KR 20207017875 A KR20207017875 A KR 20207017875A KR 20200104302 A KR20200104302 A KR 20200104302A
- Authority
- KR
- South Korea
- Prior art keywords
- oligonucleotide
- nucleoside
- nucleosides
- formula
- region
- Prior art date
Links
- 108091034117 Oligonucleotide Proteins 0.000 claims abstract description 877
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 claims abstract description 149
- 150000001875 compounds Chemical class 0.000 claims abstract description 101
- 238000002360 preparation method Methods 0.000 claims abstract description 20
- 239000002777 nucleoside Substances 0.000 claims description 820
- 150000003833 nucleoside derivatives Chemical class 0.000 claims description 324
- -1 cyano, thiohydroxyl Chemical group 0.000 claims description 132
- 229910052739 hydrogen Inorganic materials 0.000 claims description 126
- 239000001257 hydrogen Substances 0.000 claims description 126
- 238000000034 method Methods 0.000 claims description 92
- 229910052799 carbon Inorganic materials 0.000 claims description 62
- 125000004435 hydrogen atom Chemical group [H]* 0.000 claims description 62
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 claims description 58
- 150000001721 carbon Chemical group 0.000 claims description 53
- 125000000217 alkyl group Chemical group 0.000 claims description 52
- 229910052760 oxygen Inorganic materials 0.000 claims description 37
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical group [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 claims description 35
- 239000001301 oxygen Substances 0.000 claims description 35
- 229910052736 halogen Inorganic materials 0.000 claims description 32
- 150000002367 halogens Chemical class 0.000 claims description 32
- 238000006243 chemical reaction Methods 0.000 claims description 29
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 claims description 27
- 125000002887 hydroxy group Chemical group [H]O* 0.000 claims description 24
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 claims description 22
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 claims description 22
- 229910052717 sulfur Inorganic materials 0.000 claims description 22
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical group [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 claims description 19
- 239000011593 sulfur Chemical group 0.000 claims description 19
- LRSASMSXMSNRBT-UHFFFAOYSA-N 5-methylcytosine Chemical compound CC1=CNC(=O)N=C1N LRSASMSXMSNRBT-UHFFFAOYSA-N 0.000 claims description 18
- 125000004183 alkoxy alkyl group Chemical group 0.000 claims description 18
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical group CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 claims description 18
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 claims description 16
- 125000003545 alkoxy group Chemical group 0.000 claims description 16
- 125000003342 alkenyl group Chemical group 0.000 claims description 15
- 229940104302 cytosine Drugs 0.000 claims description 15
- 125000000304 alkynyl group Chemical group 0.000 claims description 14
- 125000003302 alkenyloxy group Chemical group 0.000 claims description 13
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 claims description 13
- 239000003795 chemical substances by application Substances 0.000 claims description 12
- 229940035893 uracil Drugs 0.000 claims description 12
- 230000002378 acidificating effect Effects 0.000 claims description 11
- 125000002485 formyl group Chemical group [H]C(*)=O 0.000 claims description 11
- 125000004448 alkyl carbonyl group Chemical group 0.000 claims description 10
- 239000007822 coupling agent Substances 0.000 claims description 10
- 229940113082 thymine Drugs 0.000 claims description 10
- 125000004453 alkoxycarbonyl group Chemical group 0.000 claims description 9
- 125000003118 aryl group Chemical group 0.000 claims description 9
- 125000000753 cycloalkyl group Chemical group 0.000 claims description 9
- 238000004519 manufacturing process Methods 0.000 claims description 9
- 125000000325 methylidene group Chemical group [H]C([H])=* 0.000 claims description 9
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 claims description 9
- 125000000719 pyrrolidinyl group Chemical group 0.000 claims description 9
- 125000001424 substituent group Chemical group 0.000 claims description 9
- 239000002126 C01EB10 - Adenosine Substances 0.000 claims description 8
- 229960005305 adenosine Drugs 0.000 claims description 8
- 125000000852 azido group Chemical group *N=[N+]=[N-] 0.000 claims description 8
- 125000001072 heteroaryl group Chemical group 0.000 claims description 8
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 claims description 8
- VHUUQVKOLVNVRT-UHFFFAOYSA-N Ammonium hydroxide Chemical compound [NH4+].[OH-] VHUUQVKOLVNVRT-UHFFFAOYSA-N 0.000 claims description 7
- 239000000908 ammonium hydroxide Substances 0.000 claims description 7
- 125000000623 heterocyclic group Chemical group 0.000 claims description 7
- 238000002953 preparative HPLC Methods 0.000 claims description 7
- XYFCBTPGUUZFHI-UHFFFAOYSA-N Phosphine Chemical compound P XYFCBTPGUUZFHI-UHFFFAOYSA-N 0.000 claims description 6
- 125000006501 nitrophenyl group Chemical group 0.000 claims description 6
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 claims description 6
- 125000005017 substituted alkenyl group Chemical group 0.000 claims description 6
- 125000005415 substituted alkoxy group Chemical group 0.000 claims description 6
- 125000000547 substituted alkyl group Chemical group 0.000 claims description 6
- 125000004426 substituted alkynyl group Chemical group 0.000 claims description 6
- 125000001731 2-cyanoethyl group Chemical group [H]C([H])(*)C([H])([H])C#N 0.000 claims description 5
- 125000005347 halocycloalkyl group Chemical group 0.000 claims description 5
- 125000003282 alkyl amino group Chemical group 0.000 claims description 4
- 125000003917 carbamoyl group Chemical group [H]N([H])C(*)=O 0.000 claims description 4
- 125000004966 cyanoalkyl group Chemical group 0.000 claims description 4
- 125000004663 dialkyl amino group Chemical group 0.000 claims description 4
- 125000000449 nitro group Chemical group [O-][N+](*)=O 0.000 claims description 4
- 125000003884 phenylalkyl group Chemical group 0.000 claims description 4
- 125000000472 sulfonyl group Chemical group *S(*)(=O)=O 0.000 claims description 4
- 125000004423 acyloxy group Chemical group 0.000 claims description 3
- 125000004457 alkyl amino carbonyl group Chemical group 0.000 claims description 3
- 125000003806 alkyl carbonyl amino group Chemical group 0.000 claims description 3
- 125000005278 alkyl sulfonyloxy group Chemical group 0.000 claims description 3
- 125000005096 aminoalkylaminocarbonyl group Chemical group 0.000 claims description 3
- 125000005129 aryl carbonyl group Chemical group 0.000 claims description 3
- 125000005161 aryl oxy carbonyl group Chemical group 0.000 claims description 3
- 125000004104 aryloxy group Chemical group 0.000 claims description 3
- 125000001797 benzyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])* 0.000 claims description 3
- 125000005223 heteroarylcarbonyl group Chemical group 0.000 claims description 3
- 125000005553 heteroaryloxy group Chemical group 0.000 claims description 3
- 125000005226 heteroaryloxycarbonyl group Chemical group 0.000 claims description 3
- 229910000073 phosphorus hydride Inorganic materials 0.000 claims description 3
- DTGKSKDOIYIVQL-WEDXCCLWSA-N (+)-borneol Chemical group C1C[C@@]2(C)[C@@H](O)C[C@@H]1C2(C)C DTGKSKDOIYIVQL-WEDXCCLWSA-N 0.000 claims description 2
- 150000002431 hydrogen Chemical class 0.000 claims 1
- 125000003835 nucleoside group Chemical group 0.000 description 514
- 239000000074 antisense oligonucleotide Substances 0.000 description 308
- 238000012230 antisense oligonucleotides Methods 0.000 description 308
- 125000003729 nucleotide group Chemical group 0.000 description 284
- 239000002773 nucleotide Substances 0.000 description 264
- 229910052731 fluorine Inorganic materials 0.000 description 195
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical compound [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 149
- 108020004414 DNA Proteins 0.000 description 142
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 131
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 100
- 150000003839 salts Chemical class 0.000 description 82
- 102000039446 nucleic acids Human genes 0.000 description 76
- 108020004707 nucleic acids Proteins 0.000 description 76
- 108020004999 messenger RNA Proteins 0.000 description 75
- 150000007523 nucleic acids Chemical class 0.000 description 72
- 150000001768 cations Chemical class 0.000 description 66
- 210000004027 cell Anatomy 0.000 description 65
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 62
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 55
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 52
- 230000000295 complement effect Effects 0.000 description 46
- ZMANZCXQSJIPKH-UHFFFAOYSA-N Triethylamine Chemical compound CCN(CC)CC ZMANZCXQSJIPKH-UHFFFAOYSA-N 0.000 description 39
- 150000004713 phosphodiesters Chemical class 0.000 description 39
- 125000005647 linker group Chemical group 0.000 description 35
- 239000000203 mixture Substances 0.000 description 32
- 230000014509 gene expression Effects 0.000 description 31
- 238000000338 in vitro Methods 0.000 description 31
- 239000000243 solution Substances 0.000 description 30
- 125000004430 oxygen atom Chemical group O* 0.000 description 29
- 230000000692 anti-sense effect Effects 0.000 description 28
- 238000001727 in vivo Methods 0.000 description 28
- 125000006245 phosphate protecting group Chemical group 0.000 description 28
- 101710163270 Nuclease Proteins 0.000 description 26
- 230000004048 modification Effects 0.000 description 26
- 238000012986 modification Methods 0.000 description 26
- YMWUJEATGCHHMB-UHFFFAOYSA-N Dichloromethane Chemical compound ClCCl YMWUJEATGCHHMB-UHFFFAOYSA-N 0.000 description 24
- 229910052783 alkali metal Inorganic materials 0.000 description 24
- 229910052751 metal Inorganic materials 0.000 description 23
- 239000002184 metal Substances 0.000 description 23
- QGZKDVFQNNGYKY-UHFFFAOYSA-O Ammonium Chemical compound [NH4+] QGZKDVFQNNGYKY-UHFFFAOYSA-O 0.000 description 22
- 230000033228 biological regulation Effects 0.000 description 22
- 230000000694 effects Effects 0.000 description 22
- 239000003814 drug Substances 0.000 description 21
- 108700011259 MicroRNAs Proteins 0.000 description 20
- 239000011734 sodium Substances 0.000 description 19
- 230000008685 targeting Effects 0.000 description 19
- 125000001153 fluoro group Chemical group F* 0.000 description 18
- 239000008194 pharmaceutical composition Substances 0.000 description 18
- 241000282414 Homo sapiens Species 0.000 description 17
- 230000005764 inhibitory process Effects 0.000 description 17
- IMNFDUFMRHMDMM-UHFFFAOYSA-N N-Heptane Chemical compound CCCCCCC IMNFDUFMRHMDMM-UHFFFAOYSA-N 0.000 description 16
- 239000002585 base Substances 0.000 description 16
- 239000002679 microRNA Substances 0.000 description 16
- 230000001105 regulatory effect Effects 0.000 description 16
- 108091028043 Nucleic acid sequence Proteins 0.000 description 14
- 210000001808 exosome Anatomy 0.000 description 14
- 125000006239 protecting group Chemical group 0.000 description 14
- 229910052708 sodium Inorganic materials 0.000 description 14
- 238000003786 synthesis reaction Methods 0.000 description 14
- 238000013461 design Methods 0.000 description 13
- 239000007787 solid Substances 0.000 description 13
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 12
- YXFVVABEGXRONW-UHFFFAOYSA-N Toluene Chemical compound CC1=CC=CC=C1 YXFVVABEGXRONW-UHFFFAOYSA-N 0.000 description 12
- 230000015572 biosynthetic process Effects 0.000 description 12
- 230000008878 coupling Effects 0.000 description 12
- 238000010168 coupling process Methods 0.000 description 12
- 238000005859 coupling reaction Methods 0.000 description 12
- 239000000178 monomer Substances 0.000 description 12
- 241000700159 Rattus Species 0.000 description 11
- 125000000956 methoxy group Chemical group [H]C([H])([H])O* 0.000 description 11
- 108091046869 Telomeric non-coding RNA Proteins 0.000 description 10
- 230000002401 inhibitory effect Effects 0.000 description 10
- 150000003536 tetrazoles Chemical class 0.000 description 10
- 210000001519 tissue Anatomy 0.000 description 10
- 239000013543 active substance Substances 0.000 description 9
- XAEFZNCEHLXOMS-UHFFFAOYSA-M potassium benzoate Chemical compound [K+].[O-]C(=O)C1=CC=CC=C1 XAEFZNCEHLXOMS-UHFFFAOYSA-M 0.000 description 9
- 108090000623 proteins and genes Proteins 0.000 description 9
- 241000282465 Canis Species 0.000 description 8
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical group [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 8
- CDBYLPFSWZWCQE-UHFFFAOYSA-L Sodium Carbonate Chemical compound [Na+].[Na+].[O-]C([O-])=O CDBYLPFSWZWCQE-UHFFFAOYSA-L 0.000 description 8
- WYURNTSHIVDZCO-UHFFFAOYSA-N Tetrahydrofuran Chemical compound C1CCOC1 WYURNTSHIVDZCO-UHFFFAOYSA-N 0.000 description 8
- 102100033733 Tumor necrosis factor receptor superfamily member 1B Human genes 0.000 description 8
- 108020000999 Viral RNA Proteins 0.000 description 8
- 150000003863 ammonium salts Chemical class 0.000 description 8
- 238000003556 assay Methods 0.000 description 8
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 8
- 238000001914 filtration Methods 0.000 description 8
- 210000003494 hepatocyte Anatomy 0.000 description 8
- 238000009396 hybridization Methods 0.000 description 8
- 210000004185 liver Anatomy 0.000 description 8
- 239000002808 molecular sieve Substances 0.000 description 8
- 230000007115 recruitment Effects 0.000 description 8
- URGAHOPLAPQHLN-UHFFFAOYSA-N sodium aluminosilicate Chemical compound [Na+].[Al+3].[O-][Si]([O-])=O.[O-][Si]([O-])=O URGAHOPLAPQHLN-UHFFFAOYSA-N 0.000 description 8
- 239000006188 syrup Substances 0.000 description 8
- 235000020357 syrup Nutrition 0.000 description 8
- 230000001225 therapeutic effect Effects 0.000 description 8
- 125000004172 4-methoxyphenyl group Chemical group [H]C1=C([H])C(OC([H])([H])[H])=C([H])C([H])=C1* 0.000 description 7
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 7
- 101150007028 HTRA1 gene Proteins 0.000 description 7
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 7
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 7
- 201000010099 disease Diseases 0.000 description 7
- NAGJZTKCGNOGPW-UHFFFAOYSA-N dithiophosphoric acid Chemical class OP(O)(S)=S NAGJZTKCGNOGPW-UHFFFAOYSA-N 0.000 description 7
- 238000002515 oligonucleotide synthesis Methods 0.000 description 7
- 108010052833 ribonuclease HI Proteins 0.000 description 7
- 125000000548 ribosyl group Chemical group C1([C@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 7
- 101000801232 Homo sapiens Tumor necrosis factor receptor superfamily member 1B Proteins 0.000 description 6
- 102100034343 Integrase Human genes 0.000 description 6
- 101710203526 Integrase Proteins 0.000 description 6
- YKFRUJSEPGHZFJ-UHFFFAOYSA-N N-trimethylsilylimidazole Chemical compound C[Si](C)(C)N1C=CN=C1 YKFRUJSEPGHZFJ-UHFFFAOYSA-N 0.000 description 6
- 230000009471 action Effects 0.000 description 6
- 150000001340 alkali metals Chemical class 0.000 description 6
- 230000000903 blocking effect Effects 0.000 description 6
- 125000004432 carbon atom Chemical group C* 0.000 description 6
- 230000004700 cellular uptake Effects 0.000 description 6
- 239000000460 chlorine Substances 0.000 description 6
- 230000006872 improvement Effects 0.000 description 6
- 238000007914 intraventricular administration Methods 0.000 description 6
- QZJLJABLDNRKOD-UHFFFAOYSA-N s-(2-sulfanylethyl) benzenecarbothioate Chemical compound SCCSC(=O)C1=CC=CC=C1 QZJLJABLDNRKOD-UHFFFAOYSA-N 0.000 description 6
- 210000002966 serum Anatomy 0.000 description 6
- 238000007920 subcutaneous administration Methods 0.000 description 6
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 5
- 206010013801 Duchenne Muscular Dystrophy Diseases 0.000 description 5
- 108020004459 Small interfering RNA Proteins 0.000 description 5
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical class OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 5
- 239000002253 acid Substances 0.000 description 5
- 206010064930 age-related macular degeneration Diseases 0.000 description 5
- 239000012267 brine Substances 0.000 description 5
- 230000015556 catabolic process Effects 0.000 description 5
- 230000001413 cellular effect Effects 0.000 description 5
- 230000000875 corresponding effect Effects 0.000 description 5
- 238000006731 degradation reaction Methods 0.000 description 5
- 229940079593 drug Drugs 0.000 description 5
- 238000011156 evaluation Methods 0.000 description 5
- 230000001965 increasing effect Effects 0.000 description 5
- 238000007918 intramuscular administration Methods 0.000 description 5
- 238000001990 intravenous administration Methods 0.000 description 5
- 210000003734 kidney Anatomy 0.000 description 5
- 210000004962 mammalian cell Anatomy 0.000 description 5
- 230000007246 mechanism Effects 0.000 description 5
- 230000001404 mediated effect Effects 0.000 description 5
- 210000004940 nucleus Anatomy 0.000 description 5
- 229910052700 potassium Inorganic materials 0.000 description 5
- 230000002829 reductive effect Effects 0.000 description 5
- HPALAKNZSZLMCH-UHFFFAOYSA-M sodium;chloride;hydrate Chemical compound O.[Na+].[Cl-] HPALAKNZSZLMCH-UHFFFAOYSA-M 0.000 description 5
- 238000006467 substitution reaction Methods 0.000 description 5
- PXFLCAQHOZXYED-UHFFFAOYSA-N tripyrrolidin-1-ylphosphane Chemical compound C1CCCN1P(N1CCCC1)N1CCCC1 PXFLCAQHOZXYED-UHFFFAOYSA-N 0.000 description 5
- RHCSKNNOAZULRK-APZFVMQVSA-N 2,2-dideuterio-2-(3,4,5-trimethoxyphenyl)ethanamine Chemical compound NCC([2H])([2H])C1=CC(OC)=C(OC)C(OC)=C1 RHCSKNNOAZULRK-APZFVMQVSA-N 0.000 description 4
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 4
- 229930024421 Adenine Natural products 0.000 description 4
- 108010027006 Apolipoproteins B Proteins 0.000 description 4
- 102000018616 Apolipoproteins B Human genes 0.000 description 4
- HEDRZPFGACZZDS-UHFFFAOYSA-N Chloroform Chemical compound ClC(Cl)Cl HEDRZPFGACZZDS-UHFFFAOYSA-N 0.000 description 4
- RTZKZFJDLAIYFH-UHFFFAOYSA-N Diethyl ether Chemical compound CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 4
- 208000008069 Geographic Atrophy Diseases 0.000 description 4
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 4
- 229940122938 MicroRNA inhibitor Drugs 0.000 description 4
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 4
- JUJWROOIHBZHMG-UHFFFAOYSA-N Pyridine Chemical compound C1=CC=NC=C1 JUJWROOIHBZHMG-UHFFFAOYSA-N 0.000 description 4
- UIIMBOGNXHQVGW-UHFFFAOYSA-M Sodium bicarbonate Chemical class [Na+].OC([O-])=O UIIMBOGNXHQVGW-UHFFFAOYSA-M 0.000 description 4
- 238000010521 absorption reaction Methods 0.000 description 4
- 239000012190 activator Substances 0.000 description 4
- 125000005083 alkoxyalkoxy group Chemical group 0.000 description 4
- 125000004103 aminoalkyl group Chemical group 0.000 description 4
- 230000008901 benefit Effects 0.000 description 4
- 239000002274 desiccant Substances 0.000 description 4
- 238000009472 formulation Methods 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 125000000524 functional group Chemical group 0.000 description 4
- 239000011521 glass Substances 0.000 description 4
- 125000001188 haloalkyl group Chemical group 0.000 description 4
- 239000012535 impurity Substances 0.000 description 4
- 208000002780 macular degeneration Diseases 0.000 description 4
- 235000013336 milk Nutrition 0.000 description 4
- 210000004080 milk Anatomy 0.000 description 4
- 239000008267 milk Substances 0.000 description 4
- 230000001483 mobilizing effect Effects 0.000 description 4
- 239000012044 organic layer Substances 0.000 description 4
- 239000002244 precipitate Substances 0.000 description 4
- 239000000047 product Substances 0.000 description 4
- 235000018102 proteins Nutrition 0.000 description 4
- 102000004169 proteins and genes Human genes 0.000 description 4
- 230000009467 reduction Effects 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 229910000029 sodium carbonate Inorganic materials 0.000 description 4
- 239000000126 substance Substances 0.000 description 4
- 125000000446 sulfanediyl group Chemical group *S* 0.000 description 4
- PXQLVRUNWNTZOS-UHFFFAOYSA-N sulfanyl Chemical group [SH] PXQLVRUNWNTZOS-UHFFFAOYSA-N 0.000 description 4
- YLQBMQCUIZJEEH-UHFFFAOYSA-N tetrahydrofuran Natural products C=1C=COC=1 YLQBMQCUIZJEEH-UHFFFAOYSA-N 0.000 description 4
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 3
- 102100040202 Apolipoprotein B-100 Human genes 0.000 description 3
- 102000005427 Asialoglycoprotein Receptor Human genes 0.000 description 3
- 108010032947 Ataxin-3 Proteins 0.000 description 3
- 102000007371 Ataxin-3 Human genes 0.000 description 3
- 102100026596 Bcl-2-like protein 1 Human genes 0.000 description 3
- 101150008012 Bcl2l1 gene Proteins 0.000 description 3
- 102100035673 Centrosomal protein of 290 kDa Human genes 0.000 description 3
- 101710198317 Centrosomal protein of 290 kDa Proteins 0.000 description 3
- 102100023457 Chloride channel protein 1 Human genes 0.000 description 3
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 3
- 108060002716 Exonuclease Proteins 0.000 description 3
- PXGOKWXKJXAPGV-UHFFFAOYSA-N Fluorine Chemical compound FF PXGOKWXKJXAPGV-UHFFFAOYSA-N 0.000 description 3
- 102100039264 Glycogen [starch] synthase, liver Human genes 0.000 description 3
- 102100039939 Growth/differentiation factor 8 Human genes 0.000 description 3
- 108050006583 Growth/differentiation factor 8 Proteins 0.000 description 3
- 102100037931 Harmonin Human genes 0.000 description 3
- 102100021519 Hemoglobin subunit beta Human genes 0.000 description 3
- 206010019851 Hepatotoxicity Diseases 0.000 description 3
- 101000889953 Homo sapiens Apolipoprotein B-100 Proteins 0.000 description 3
- 101000906651 Homo sapiens Chloride channel protein 1 Proteins 0.000 description 3
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 description 3
- 101001036117 Homo sapiens Glycogen [starch] synthase, liver Proteins 0.000 description 3
- 101000805947 Homo sapiens Harmonin Proteins 0.000 description 3
- 101000899111 Homo sapiens Hemoglobin subunit beta Proteins 0.000 description 3
- 101000960952 Homo sapiens Interleukin-1 receptor accessory protein Proteins 0.000 description 3
- 101001039207 Homo sapiens Low-density lipoprotein receptor-related protein 8 Proteins 0.000 description 3
- 101000982032 Homo sapiens Myosin-binding protein C, cardiac-type Proteins 0.000 description 3
- 101001003584 Homo sapiens Prelamin-A/C Proteins 0.000 description 3
- 101000846336 Homo sapiens Ribitol-5-phosphate transferase FKTN Proteins 0.000 description 3
- 101000617738 Homo sapiens Survival motor neuron protein Proteins 0.000 description 3
- 101000864342 Homo sapiens Tyrosine-protein kinase BTK Proteins 0.000 description 3
- 101000851018 Homo sapiens Vascular endothelial growth factor receptor 1 Proteins 0.000 description 3
- 102100039880 Interleukin-1 receptor accessory protein Human genes 0.000 description 3
- 108090000174 Interleukin-10 Proteins 0.000 description 3
- 102000003814 Interleukin-10 Human genes 0.000 description 3
- 102100040705 Low-density lipoprotein receptor-related protein 8 Human genes 0.000 description 3
- 102000017274 MDM4 Human genes 0.000 description 3
- 108050005300 MDM4 Proteins 0.000 description 3
- 108091027974 Mature messenger RNA Proteins 0.000 description 3
- AFVFQIVMOAPDHO-UHFFFAOYSA-N Methanesulfonic acid Chemical compound CS(O)(=O)=O AFVFQIVMOAPDHO-UHFFFAOYSA-N 0.000 description 3
- 102100026771 Myosin-binding protein C, cardiac-type Human genes 0.000 description 3
- 206010029155 Nephropathy toxic Diseases 0.000 description 3
- MUBZPKHOEPUJKR-UHFFFAOYSA-N Oxalic acid Chemical compound OC(=O)C(O)=O MUBZPKHOEPUJKR-UHFFFAOYSA-N 0.000 description 3
- 108091093037 Peptide nucleic acid Proteins 0.000 description 3
- 102100026531 Prelamin-A/C Human genes 0.000 description 3
- OFOBLEOULBTSOW-UHFFFAOYSA-N Propanedioic acid Natural products OC(=O)CC(O)=O OFOBLEOULBTSOW-UHFFFAOYSA-N 0.000 description 3
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 3
- 102100029981 Receptor tyrosine-protein kinase erbB-4 Human genes 0.000 description 3
- 101710100963 Receptor tyrosine-protein kinase erbB-4 Proteins 0.000 description 3
- 102100031754 Ribitol-5-phosphate transferase FKTN Human genes 0.000 description 3
- 108010017324 STAT3 Transcription Factor Proteins 0.000 description 3
- 102100024040 Signal transducer and activator of transcription 3 Human genes 0.000 description 3
- 102100021947 Survival motor neuron protein Human genes 0.000 description 3
- 102100026260 Titin Human genes 0.000 description 3
- 102100029823 Tyrosine-protein kinase BTK Human genes 0.000 description 3
- 108010053099 Vascular Endothelial Growth Factor Receptor-2 Proteins 0.000 description 3
- 102100033178 Vascular endothelial growth factor receptor 1 Human genes 0.000 description 3
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 description 3
- 229960000643 adenine Drugs 0.000 description 3
- 125000005336 allyloxy group Chemical group 0.000 description 3
- 125000002431 aminoalkoxy group Chemical group 0.000 description 3
- 108010006523 asialoglycoprotein receptor Proteins 0.000 description 3
- 108700000711 bcl-X Proteins 0.000 description 3
- UIJGNTRUPZPVNG-UHFFFAOYSA-N benzenecarbothioic s-acid Chemical compound SC(=O)C1=CC=CC=C1 UIJGNTRUPZPVNG-UHFFFAOYSA-N 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 3
- 238000003776 cleavage reaction Methods 0.000 description 3
- 239000005289 controlled pore glass Substances 0.000 description 3
- 230000001276 controlling effect Effects 0.000 description 3
- 125000001559 cyclopropyl group Chemical group [H]C1([H])C([H])([H])C1([H])* 0.000 description 3
- 238000010511 deprotection reaction Methods 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 230000018109 developmental process Effects 0.000 description 3
- 238000009826 distribution Methods 0.000 description 3
- 238000009509 drug development Methods 0.000 description 3
- 230000002708 enhancing effect Effects 0.000 description 3
- 229940088598 enzyme Drugs 0.000 description 3
- 210000002919 epithelial cell Anatomy 0.000 description 3
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 3
- 102000013165 exonuclease Human genes 0.000 description 3
- 239000011737 fluorine Substances 0.000 description 3
- 230000007686 hepatotoxicity Effects 0.000 description 3
- 231100000304 hepatotoxicity Toxicity 0.000 description 3
- 210000005260 human cell Anatomy 0.000 description 3
- 238000010348 incorporation Methods 0.000 description 3
- 238000003780 insertion Methods 0.000 description 3
- 230000037431 insertion Effects 0.000 description 3
- 238000002844 melting Methods 0.000 description 3
- 230000008018 melting Effects 0.000 description 3
- 125000004184 methoxymethyl group Chemical group [H]C([H])([H])OC([H])([H])* 0.000 description 3
- 230000007694 nephrotoxicity Effects 0.000 description 3
- 231100000417 nephrotoxicity Toxicity 0.000 description 3
- 210000000056 organ Anatomy 0.000 description 3
- 238000007911 parenteral administration Methods 0.000 description 3
- 230000000144 pharmacologic effect Effects 0.000 description 3
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 3
- 150000008300 phosphoramidites Chemical class 0.000 description 3
- 229910052698 phosphorus Inorganic materials 0.000 description 3
- 239000011591 potassium Substances 0.000 description 3
- 230000002265 prevention Effects 0.000 description 3
- 125000001436 propyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])[H] 0.000 description 3
- 125000006413 ring segment Chemical group 0.000 description 3
- 230000007017 scission Effects 0.000 description 3
- 108010062513 snake venom phosphodiesterase I Proteins 0.000 description 3
- 125000001412 tetrahydropyranyl group Chemical group 0.000 description 3
- 231100000419 toxicity Toxicity 0.000 description 3
- 230000001988 toxicity Effects 0.000 description 3
- 125000002023 trifluoromethyl group Chemical group FC(F)(F)* 0.000 description 3
- SDTORDSXCYSNTD-UHFFFAOYSA-N 1-methoxy-4-[(4-methoxyphenyl)methoxymethyl]benzene Chemical compound C1=CC(OC)=CC=C1COCC1=CC=C(OC)C=C1 SDTORDSXCYSNTD-UHFFFAOYSA-N 0.000 description 2
- KJUGUADJHNHALS-UHFFFAOYSA-N 1H-tetrazole Substances C=1N=NNN=1 KJUGUADJHNHALS-UHFFFAOYSA-N 0.000 description 2
- JAAIPIWKKXCNOC-UHFFFAOYSA-N 1h-tetrazol-1-ium-5-thiolate Chemical compound SC1=NN=NN1 JAAIPIWKKXCNOC-UHFFFAOYSA-N 0.000 description 2
- OISVCGZHLKNMSJ-UHFFFAOYSA-N 2,6-dimethylpyridine Chemical compound CC1=CC=CC(C)=N1 OISVCGZHLKNMSJ-UHFFFAOYSA-N 0.000 description 2
- HZAXFHJVJLSVMW-UHFFFAOYSA-N 2-Aminoethan-1-ol Chemical compound NCCO HZAXFHJVJLSVMW-UHFFFAOYSA-N 0.000 description 2
- GXGKKIPUFAHZIZ-UHFFFAOYSA-N 5-benzylsulfanyl-2h-tetrazole Chemical compound C=1C=CC=CC=1CSC=1N=NNN=1 GXGKKIPUFAHZIZ-UHFFFAOYSA-N 0.000 description 2
- GONFBOIJNUKKST-UHFFFAOYSA-N 5-ethylsulfanyl-2h-tetrazole Chemical compound CCSC=1N=NNN=1 GONFBOIJNUKKST-UHFFFAOYSA-N 0.000 description 2
- ZBXNFTFKKOSPLD-UHFFFAOYSA-N 5-methylsulfanyl-2h-tetrazole Chemical compound CSC1=NN=NN1 ZBXNFTFKKOSPLD-UHFFFAOYSA-N 0.000 description 2
- HBAQYPYDRFILMT-UHFFFAOYSA-N 8-[3-(1-cyclopropylpyrazol-4-yl)-1H-pyrazolo[4,3-d]pyrimidin-5-yl]-3-methyl-3,8-diazabicyclo[3.2.1]octan-2-one Chemical class C1(CC1)N1N=CC(=C1)C1=NNC2=C1N=C(N=C2)N1C2C(N(CC1CC2)C)=O HBAQYPYDRFILMT-UHFFFAOYSA-N 0.000 description 2
- LRFVTYWOQMYALW-UHFFFAOYSA-N 9H-xanthine Chemical compound O=C1NC(=O)NC2=C1NC=N2 LRFVTYWOQMYALW-UHFFFAOYSA-N 0.000 description 2
- 208000024827 Alzheimer disease Diseases 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- WKBOTKDWSSQWDR-UHFFFAOYSA-N Bromine atom Chemical compound [Br] WKBOTKDWSSQWDR-UHFFFAOYSA-N 0.000 description 2
- DCERHCFNWRGHLK-UHFFFAOYSA-N C[Si](C)C Chemical compound C[Si](C)C DCERHCFNWRGHLK-UHFFFAOYSA-N 0.000 description 2
- 108090000994 Catalytic RNA Proteins 0.000 description 2
- 102000053642 Catalytic RNA Human genes 0.000 description 2
- ZAMOUSCENKQFHK-UHFFFAOYSA-N Chlorine atom Chemical compound [Cl] ZAMOUSCENKQFHK-UHFFFAOYSA-N 0.000 description 2
- 108020004394 Complementary RNA Proteins 0.000 description 2
- 108091030081 DNA N(4)-methylcytosine Proteins 0.000 description 2
- 206010012689 Diabetic retinopathy Diseases 0.000 description 2
- 102100024108 Dystrophin Human genes 0.000 description 2
- VZCYOOQTPOCHFL-OWOJBTEDSA-N Fumaric acid Chemical compound OC(=O)\C=C\C(O)=O VZCYOOQTPOCHFL-OWOJBTEDSA-N 0.000 description 2
- AEMRFAOFKBGASW-UHFFFAOYSA-N Glycolic acid Chemical compound OCC(O)=O AEMRFAOFKBGASW-UHFFFAOYSA-N 0.000 description 2
- 101000785776 Homo sapiens Artemin Proteins 0.000 description 2
- 101001053946 Homo sapiens Dystrophin Proteins 0.000 description 2
- 101000981336 Homo sapiens Nibrin Proteins 0.000 description 2
- 101001041393 Homo sapiens Serine protease HTRA1 Proteins 0.000 description 2
- 101000645320 Homo sapiens Titin Proteins 0.000 description 2
- WHXSMMKQMYFTQS-UHFFFAOYSA-N Lithium Chemical compound [Li] WHXSMMKQMYFTQS-UHFFFAOYSA-N 0.000 description 2
- 108091007767 MALAT1 Proteins 0.000 description 2
- XCOBLONWWXQEBS-KPKJPENVSA-N N,O-bis(trimethylsilyl)trifluoroacetamide Chemical compound C[Si](C)(C)O\C(C(F)(F)F)=N\[Si](C)(C)C XCOBLONWWXQEBS-KPKJPENVSA-N 0.000 description 2
- QRKUHYFDBWGLHJ-UHFFFAOYSA-N N-(tert-butyldimethylsilyl)-N-methyltrifluoroacetamide Chemical compound FC(F)(F)C(=O)N(C)[Si](C)(C)C(C)(C)C QRKUHYFDBWGLHJ-UHFFFAOYSA-N 0.000 description 2
- MSPCIZMDDUQPGJ-UHFFFAOYSA-N N-methyl-N-(trimethylsilyl)trifluoroacetamide Chemical compound C[Si](C)(C)N(C)C(=O)C(F)(F)F MSPCIZMDDUQPGJ-UHFFFAOYSA-N 0.000 description 2
- 102100024403 Nibrin Human genes 0.000 description 2
- 229910019142 PO4 Inorganic materials 0.000 description 2
- 208000018737 Parkinson disease Diseases 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 2
- NQRYJNQNLNOLGT-UHFFFAOYSA-N Piperidine Chemical compound C1CCNCC1 NQRYJNQNLNOLGT-UHFFFAOYSA-N 0.000 description 2
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 2
- KAESVJOAVNADME-UHFFFAOYSA-N Pyrrole Chemical compound C=1C=CNC=1 KAESVJOAVNADME-UHFFFAOYSA-N 0.000 description 2
- LCTONWCANYUPML-UHFFFAOYSA-N Pyruvic acid Chemical compound CC(=O)C(O)=O LCTONWCANYUPML-UHFFFAOYSA-N 0.000 description 2
- 101001053942 Saccharolobus solfataricus (strain ATCC 35092 / DSM 1617 / JCM 11322 / P2) Diphosphomevalonate decarboxylase Proteins 0.000 description 2
- 102100021119 Serine protease HTRA1 Human genes 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 2
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 2
- 101710187830 Tumor necrosis factor receptor superfamily member 1B Proteins 0.000 description 2
- HIMXYMYMHUAZLW-UHFFFAOYSA-N [[[dimethyl(phenyl)silyl]amino]-dimethylsilyl]benzene Chemical compound C=1C=CC=CC=1[Si](C)(C)N[Si](C)(C)C1=CC=CC=C1 HIMXYMYMHUAZLW-UHFFFAOYSA-N 0.000 description 2
- YFONAHAKNVIHPT-UHFFFAOYSA-N [methyl-[[methyl(diphenyl)silyl]amino]-phenylsilyl]benzene Chemical compound C=1C=CC=CC=1[Si](C=1C=CC=CC=1)(C)N[Si](C)(C=1C=CC=CC=1)C1=CC=CC=C1 YFONAHAKNVIHPT-UHFFFAOYSA-N 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- 150000001412 amines Chemical class 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 206010003246 arthritis Diseases 0.000 description 2
- 125000004429 atom Chemical group 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 2
- 125000003785 benzimidazolyl group Chemical group N1=C(NC2=C1C=CC=C2)* 0.000 description 2
- WPYMKLBDIGXBTP-UHFFFAOYSA-N benzoic acid Chemical compound OC(=O)C1=CC=CC=C1 WPYMKLBDIGXBTP-UHFFFAOYSA-N 0.000 description 2
- 125000001584 benzyloxycarbonyl group Chemical group C(=O)(OCC1=CC=CC=C1)* 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- GDTBXPJZTBHREO-UHFFFAOYSA-N bromine Substances BrBr GDTBXPJZTBHREO-UHFFFAOYSA-N 0.000 description 2
- 229910052794 bromium Inorganic materials 0.000 description 2
- IYYIVELXUANFED-UHFFFAOYSA-N bromo(trimethyl)silane Chemical compound C[Si](C)(C)Br IYYIVELXUANFED-UHFFFAOYSA-N 0.000 description 2
- 125000004106 butoxy group Chemical group [*]OC([H])([H])C([H])([H])C(C([H])([H])[H])([H])[H] 0.000 description 2
- 125000000484 butyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 2
- 125000002915 carbonyl group Chemical group [*:2]C([*:1])=O 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 125000003636 chemical group Chemical group 0.000 description 2
- 229910052801 chlorine Inorganic materials 0.000 description 2
- DCFKHNIGBAHNSS-UHFFFAOYSA-N chloro(triethyl)silane Chemical compound CC[Si](Cl)(CC)CC DCFKHNIGBAHNSS-UHFFFAOYSA-N 0.000 description 2
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 2
- 239000003184 complementary RNA Substances 0.000 description 2
- 125000004093 cyano group Chemical group *C#N 0.000 description 2
- 125000001995 cyclobutyl group Chemical group [H]C1([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 2
- 238000012217 deletion Methods 0.000 description 2
- 230000037430 deletion Effects 0.000 description 2
- 125000001028 difluoromethyl group Chemical group [H]C(F)(F)* 0.000 description 2
- XBDQKXXYIPTUBI-UHFFFAOYSA-N dimethylselenoniopropionate Natural products CCC(O)=O XBDQKXXYIPTUBI-UHFFFAOYSA-N 0.000 description 2
- 239000012636 effector Substances 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 125000004216 fluoromethyl group Chemical group [H]C([H])(F)* 0.000 description 2
- 125000005843 halogen group Chemical group 0.000 description 2
- 210000002216 heart Anatomy 0.000 description 2
- 125000005842 heteroatom Chemical group 0.000 description 2
- UQEAIHBTYFGYIE-UHFFFAOYSA-N hexamethyldisiloxane Chemical compound C[Si](C)(C)O[Si](C)(C)C UQEAIHBTYFGYIE-UHFFFAOYSA-N 0.000 description 2
- 238000004128 high performance liquid chromatography Methods 0.000 description 2
- 150000002430 hydrocarbons Chemical group 0.000 description 2
- FDGQSTZJBFJUBT-UHFFFAOYSA-N hypoxanthine Chemical compound O=C1NC=NC2=C1NC=N2 FDGQSTZJBFJUBT-UHFFFAOYSA-N 0.000 description 2
- 239000003112 inhibitor Substances 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- 150000007529 inorganic bases Chemical class 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- 230000000302 ischemic effect Effects 0.000 description 2
- 125000002183 isoquinolinyl group Chemical group C1(=NC=CC2=CC=CC=C12)* 0.000 description 2
- 238000000111 isothermal titration calorimetry Methods 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 229910052744 lithium Inorganic materials 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- NSPJNIDYTSSIIY-UHFFFAOYSA-N methoxy(methoxymethoxy)methane Chemical compound COCOCOC NSPJNIDYTSSIIY-UHFFFAOYSA-N 0.000 description 2
- 108091070501 miRNA Proteins 0.000 description 2
- 230000003278 mimic effect Effects 0.000 description 2
- KAHVZNKZQFSBFW-UHFFFAOYSA-N n-methyl-n-trimethylsilylmethanamine Chemical compound CN(C)[Si](C)(C)C KAHVZNKZQFSBFW-UHFFFAOYSA-N 0.000 description 2
- 238000007899 nucleic acid hybridization Methods 0.000 description 2
- 239000003921 oil Substances 0.000 description 2
- 150000007530 organic bases Chemical class 0.000 description 2
- 201000008482 osteoarthritis Diseases 0.000 description 2
- 230000003647 oxidation Effects 0.000 description 2
- 238000007254 oxidation reaction Methods 0.000 description 2
- 125000001147 pentyl group Chemical group C(CCCC)* 0.000 description 2
- 239000010452 phosphate Substances 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 2
- 239000011574 phosphorus Substances 0.000 description 2
- 159000000001 potassium salts Chemical class 0.000 description 2
- 230000003389 potentiating effect Effects 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 150000003212 purines Chemical class 0.000 description 2
- UMJSCPRVCHMLSP-UHFFFAOYSA-N pyridine Natural products COC1=CC=CN=C1 UMJSCPRVCHMLSP-UHFFFAOYSA-N 0.000 description 2
- 125000002943 quinolinyl group Chemical group N1=C(C=CC2=CC=CC=C12)* 0.000 description 2
- 108091092562 ribozyme Proteins 0.000 description 2
- YGSDEFSMJLZEOE-UHFFFAOYSA-N salicylic acid Chemical compound OC(=O)C1=CC=CC=C1O YGSDEFSMJLZEOE-UHFFFAOYSA-N 0.000 description 2
- 239000002924 silencing RNA Substances 0.000 description 2
- 210000002027 skeletal muscle Anatomy 0.000 description 2
- 159000000000 sodium salts Chemical class 0.000 description 2
- HJHVQCXHVMGZNC-JCJNLNMISA-M sodium;(2z)-2-[(3r,4s,5s,8s,9s,10s,11r,13r,14s,16s)-16-acetyloxy-3,11-dihydroxy-4,8,10,14-tetramethyl-2,3,4,5,6,7,9,11,12,13,15,16-dodecahydro-1h-cyclopenta[a]phenanthren-17-ylidene]-6-methylhept-5-enoate Chemical compound [Na+].O[C@@H]([C@@H]12)C[C@H]3\C(=C(/CCC=C(C)C)C([O-])=O)[C@@H](OC(C)=O)C[C@]3(C)[C@@]2(C)CC[C@@H]2[C@]1(C)CC[C@@H](O)[C@H]2C HJHVQCXHVMGZNC-JCJNLNMISA-M 0.000 description 2
- 239000007790 solid phase Substances 0.000 description 2
- 210000000952 spleen Anatomy 0.000 description 2
- 230000002269 spontaneous effect Effects 0.000 description 2
- 230000006641 stabilisation Effects 0.000 description 2
- 238000011105 stabilization Methods 0.000 description 2
- 239000007858 starting material Substances 0.000 description 2
- 230000000707 stereoselective effect Effects 0.000 description 2
- 238000003860 storage Methods 0.000 description 2
- 230000002459 sustained effect Effects 0.000 description 2
- 229940124597 therapeutic agent Drugs 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 125000003396 thiol group Chemical group [H]S* 0.000 description 2
- JOXIMZWYDAKGHI-UHFFFAOYSA-N toluene-4-sulfonic acid Chemical compound CC1=CC=C(S(O)(=O)=O)C=C1 JOXIMZWYDAKGHI-UHFFFAOYSA-N 0.000 description 2
- VZCYOOQTPOCHFL-UHFFFAOYSA-N trans-butenedioic acid Natural products OC(=O)C=CC(O)=O VZCYOOQTPOCHFL-UHFFFAOYSA-N 0.000 description 2
- YNJBWRMUSHSURL-UHFFFAOYSA-N trichloroacetic acid Chemical compound OC(=O)C(Cl)(Cl)Cl YNJBWRMUSHSURL-UHFFFAOYSA-N 0.000 description 2
- 125000000025 triisopropylsilyl group Chemical group C(C)(C)[Si](C(C)C)(C(C)C)* 0.000 description 2
- GETQZCLCWQTVFV-UHFFFAOYSA-N trimethylamine Chemical compound CN(C)C GETQZCLCWQTVFV-UHFFFAOYSA-N 0.000 description 2
- 125000000026 trimethylsilyl group Chemical group [H]C([H])([H])[Si]([*])(C([H])([H])[H])C([H])([H])[H] 0.000 description 2
- 125000002221 trityl group Chemical group [H]C1=C([H])C([H])=C([H])C([H])=C1C([*])(C1=C(C(=C(C(=C1[H])[H])[H])[H])[H])C1=C([H])C([H])=C([H])C([H])=C1[H] 0.000 description 2
- 125000000391 vinyl group Chemical group [H]C([*])=C([H])[H] 0.000 description 2
- QBYIENPQHBMVBV-HFEGYEGKSA-N (2R)-2-hydroxy-2-phenylacetic acid Chemical compound O[C@@H](C(O)=O)c1ccccc1.O[C@@H](C(O)=O)c1ccccc1 QBYIENPQHBMVBV-HFEGYEGKSA-N 0.000 description 1
- YIMATHOGWXZHFX-WCTZXXKLSA-N (2r,3r,4r,5r)-5-(hydroxymethyl)-3-(2-methoxyethoxy)oxolane-2,4-diol Chemical compound COCCO[C@H]1[C@H](O)O[C@H](CO)[C@H]1O YIMATHOGWXZHFX-WCTZXXKLSA-N 0.000 description 1
- 125000004209 (C1-C8) alkyl group Chemical group 0.000 description 1
- FBADCSUQBLLAHW-SOFGYWHQSA-N (e)-4-trimethylsilyloxypent-3-en-2-one Chemical compound CC(=O)\C=C(/C)O[Si](C)(C)C FBADCSUQBLLAHW-SOFGYWHQSA-N 0.000 description 1
- 125000003088 (fluoren-9-ylmethoxy)carbonyl group Chemical group 0.000 description 1
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 1
- WBYWAXJHAXSJNI-VOTSOKGWSA-M .beta-Phenylacrylic acid Natural products [O-]C(=O)\C=C\C1=CC=CC=C1 WBYWAXJHAXSJNI-VOTSOKGWSA-M 0.000 description 1
- JYOQNYLFMVKQHO-UHFFFAOYSA-N 1,1-bis(trimethylsilyl)urea Chemical compound C[Si](C)(C)N(C(N)=O)[Si](C)(C)C JYOQNYLFMVKQHO-UHFFFAOYSA-N 0.000 description 1
- DHBXNPKRAUYBTH-UHFFFAOYSA-N 1,1-ethanedithiol Chemical compound CC(S)S DHBXNPKRAUYBTH-UHFFFAOYSA-N 0.000 description 1
- VYMPLPIFKRHAAC-UHFFFAOYSA-N 1,2-ethanedithiol Chemical compound SCCS VYMPLPIFKRHAAC-UHFFFAOYSA-N 0.000 description 1
- UJGJMZVYYVWKOY-UHFFFAOYSA-N 1-(3-nitrophenyl)tetrazole Chemical compound [O-][N+](=O)C1=CC=CC(N2N=NN=C2)=C1 UJGJMZVYYVWKOY-UHFFFAOYSA-N 0.000 description 1
- 125000004973 1-butenyl group Chemical group C(=CCC)* 0.000 description 1
- RRQYJINTUHWNHW-UHFFFAOYSA-N 1-ethoxy-2-(2-ethoxyethoxy)ethane Chemical compound CCOCCOCCOCC RRQYJINTUHWNHW-UHFFFAOYSA-N 0.000 description 1
- GPAAEZIXSQCCES-UHFFFAOYSA-N 1-methoxy-2-(2-methoxyethoxymethoxymethoxy)ethane Chemical compound COCCOCOCOCCOC GPAAEZIXSQCCES-UHFFFAOYSA-N 0.000 description 1
- MCTWTZJPVLRJOU-UHFFFAOYSA-N 1-methyl-1H-imidazole Chemical compound CN1C=CN=C1 MCTWTZJPVLRJOU-UHFFFAOYSA-N 0.000 description 1
- 125000006017 1-propenyl group Chemical group 0.000 description 1
- IWYHWZTYVNIDAE-UHFFFAOYSA-N 1h-benzimidazol-1-ium;trifluoromethanesulfonate Chemical compound OS(=O)(=O)C(F)(F)F.C1=CC=C2NC=NC2=C1 IWYHWZTYVNIDAE-UHFFFAOYSA-N 0.000 description 1
- XGDRLCRGKUCBQL-UHFFFAOYSA-N 1h-imidazole-4,5-dicarbonitrile Chemical compound N#CC=1N=CNC=1C#N XGDRLCRGKUCBQL-UHFFFAOYSA-N 0.000 description 1
- 125000004206 2,2,2-trifluoroethyl group Chemical group [H]C([H])(*)C(F)(F)F 0.000 description 1
- CMXKINNDZCNCEI-UHFFFAOYSA-N 2,2,3,3,4,4,4-heptafluoro-n-methyl-n-trimethylsilylbutanamide Chemical compound C[Si](C)(C)N(C)C(=O)C(F)(F)C(F)(F)C(F)(F)F CMXKINNDZCNCEI-UHFFFAOYSA-N 0.000 description 1
- YQTCQNIPQMJNTI-UHFFFAOYSA-N 2,2-dimethylpropan-1-one Chemical group CC(C)(C)[C]=O YQTCQNIPQMJNTI-UHFFFAOYSA-N 0.000 description 1
- UFBJCMHMOXMLKC-UHFFFAOYSA-N 2,4-dinitrophenol Chemical compound OC1=CC=C([N+]([O-])=O)C=C1[N+]([O-])=O UFBJCMHMOXMLKC-UHFFFAOYSA-N 0.000 description 1
- XQCZBXHVTFVIFE-UHFFFAOYSA-N 2-amino-4-hydroxypyrimidine Chemical compound NC1=NC=CC(O)=N1 XQCZBXHVTFVIFE-UHFFFAOYSA-N 0.000 description 1
- MWBWWFOAEOYUST-UHFFFAOYSA-N 2-aminopurine Chemical compound NC1=NC=C2N=CNC2=N1 MWBWWFOAEOYUST-UHFFFAOYSA-N 0.000 description 1
- 125000004974 2-butenyl group Chemical group C(C=CC)* 0.000 description 1
- HBJGQJWNMZDFKL-UHFFFAOYSA-N 2-chloro-7h-purin-6-amine Chemical compound NC1=NC(Cl)=NC2=C1NC=N2 HBJGQJWNMZDFKL-UHFFFAOYSA-N 0.000 description 1
- 125000004777 2-fluoroethyl group Chemical group [H]C([H])(F)C([H])([H])* 0.000 description 1
- 125000003903 2-propenyl group Chemical group [H]C([*])([H])C([H])=C([H])[H] 0.000 description 1
- QWYTUBPAXJYCTH-UHFFFAOYSA-N 2-trimethylsilylethyl carbamate Chemical compound C[Si](C)(C)CCOC(N)=O QWYTUBPAXJYCTH-UHFFFAOYSA-N 0.000 description 1
- 108020005065 3' Flanking Region Proteins 0.000 description 1
- BMYNFMYTOJXKLE-UHFFFAOYSA-N 3-azaniumyl-2-hydroxypropanoate Chemical compound NCC(O)C(O)=O BMYNFMYTOJXKLE-UHFFFAOYSA-N 0.000 description 1
- 125000004975 3-butenyl group Chemical group C(CC=C)* 0.000 description 1
- XTYLRVPBHHRTMS-UHFFFAOYSA-N 4-chloro-1-isothiocyanato-2-methylbenzene Chemical compound CC1=CC(Cl)=CC=C1N=C=S XTYLRVPBHHRTMS-UHFFFAOYSA-N 0.000 description 1
- 108020005029 5' Flanking Region Proteins 0.000 description 1
- KKJFZIQEWZVVIV-UHFFFAOYSA-N 5-[3,5-bis(trifluoromethyl)phenyl]-2h-tetrazole Chemical compound FC(F)(F)C1=CC(C(F)(F)F)=CC(C2=NNN=N2)=C1 KKJFZIQEWZVVIV-UHFFFAOYSA-N 0.000 description 1
- YWZHEXZIISFIDA-UHFFFAOYSA-N 5-amino-1,2,4-dithiazole-3-thione Chemical compound NC1=NC(=S)SS1 YWZHEXZIISFIDA-UHFFFAOYSA-N 0.000 description 1
- LQLQRFGHAALLLE-UHFFFAOYSA-N 5-bromouracil Chemical compound BrC1=CNC(=O)NC1=O LQLQRFGHAALLLE-UHFFFAOYSA-N 0.000 description 1
- ZLAQATDNGLKIEV-UHFFFAOYSA-N 5-methyl-2-sulfanylidene-1h-pyrimidin-4-one Chemical compound CC1=CNC(=S)NC1=O ZLAQATDNGLKIEV-UHFFFAOYSA-N 0.000 description 1
- UJBCLAXPPIDQEE-UHFFFAOYSA-N 5-prop-1-ynyl-1h-pyrimidine-2,4-dione Chemical compound CC#CC1=CNC(=O)NC1=O UJBCLAXPPIDQEE-UHFFFAOYSA-N 0.000 description 1
- QNNARSZPGNJZIX-UHFFFAOYSA-N 6-amino-5-prop-1-ynyl-1h-pyrimidin-2-one Chemical compound CC#CC1=CNC(=O)N=C1N QNNARSZPGNJZIX-UHFFFAOYSA-N 0.000 description 1
- IELBPRXADXDMJU-UHFFFAOYSA-N 6-nitro-1h-benzimidazol-3-ium;trifluoromethanesulfonate Chemical compound [O-]S(=O)(=O)C(F)(F)F.[O-][N+](=O)C1=CC=C2[NH2+]C=NC2=C1 IELBPRXADXDMJU-UHFFFAOYSA-N 0.000 description 1
- ZIIGSRYPZWDGBT-UHFFFAOYSA-N 610-30-0 Chemical compound OC(=O)C1=CC=C([N+]([O-])=O)C=C1[N+]([O-])=O ZIIGSRYPZWDGBT-UHFFFAOYSA-N 0.000 description 1
- ZCYVEMRRCGMTRW-UHFFFAOYSA-N 7553-56-2 Chemical compound [I] ZCYVEMRRCGMTRW-UHFFFAOYSA-N 0.000 description 1
- VKKXEIQIGGPMHT-UHFFFAOYSA-N 7h-purine-2,8-diamine Chemical compound NC1=NC=C2NC(N)=NC2=N1 VKKXEIQIGGPMHT-UHFFFAOYSA-N 0.000 description 1
- MSSXOMSJDRHRMC-UHFFFAOYSA-N 9H-purine-2,6-diamine Chemical compound NC1=NC(N)=C2NC=NC2=N1 MSSXOMSJDRHRMC-UHFFFAOYSA-N 0.000 description 1
- ZZOKVYOCRSMTSS-UHFFFAOYSA-N 9h-fluoren-9-ylmethyl carbamate Chemical compound C1=CC=C2C(COC(=O)N)C3=CC=CC=C3C2=C1 ZZOKVYOCRSMTSS-UHFFFAOYSA-N 0.000 description 1
- 108091029792 Alkylated DNA Proteins 0.000 description 1
- 108091023037 Aptamer Proteins 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 231100000699 Bacterial toxin Toxicity 0.000 description 1
- 239000005711 Benzoic acid Substances 0.000 description 1
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 1
- ZMVIIAIYFASMPP-UHFFFAOYSA-N C1CN=C[NH2+]1.[O-]S(=O)(=O)C(F)(F)F Chemical compound C1CN=C[NH2+]1.[O-]S(=O)(=O)C(F)(F)F ZMVIIAIYFASMPP-UHFFFAOYSA-N 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 102000000844 Cell Surface Receptors Human genes 0.000 description 1
- 108010001857 Cell Surface Receptors Proteins 0.000 description 1
- 208000029812 Cerebral Small Vessel disease Diseases 0.000 description 1
- 108010077544 Chromatin Proteins 0.000 description 1
- WBYWAXJHAXSJNI-SREVYHEPSA-N Cinnamic acid Chemical compound OC(=O)\C=C/C1=CC=CC=C1 WBYWAXJHAXSJNI-SREVYHEPSA-N 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- FEWJPZIEWOKRBE-JCYAYHJZSA-N Dextrotartaric acid Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O FEWJPZIEWOKRBE-JCYAYHJZSA-N 0.000 description 1
- LCGLNKUTAGEVQW-UHFFFAOYSA-N Dimethyl ether Chemical compound COC LCGLNKUTAGEVQW-UHFFFAOYSA-N 0.000 description 1
- 108010042407 Endonucleases Proteins 0.000 description 1
- 102000004533 Endonucleases Human genes 0.000 description 1
- 239000005977 Ethylene Substances 0.000 description 1
- 108700024394 Exon Proteins 0.000 description 1
- 101100178820 Homo sapiens HTRA1 gene Proteins 0.000 description 1
- UGQMRVRMYYASKQ-UHFFFAOYSA-N Hypoxanthine nucleoside Natural products OC1C(O)C(CO)OC1N1C(NC=NC2=O)=C2N=C1 UGQMRVRMYYASKQ-UHFFFAOYSA-N 0.000 description 1
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 1
- 229930010555 Inosine Natural products 0.000 description 1
- PWKSKIMOESPYIA-BYPYZUCNSA-N L-N-acetyl-Cysteine Chemical compound CC(=O)N[C@@H](CS)C(O)=O PWKSKIMOESPYIA-BYPYZUCNSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- 108020005198 Long Noncoding RNA Proteins 0.000 description 1
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 235000010624 Medicago sativa Nutrition 0.000 description 1
- 240000004658 Medicago sativa Species 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- OVRNDRQMDRJTHS-CBQIKETKSA-N N-Acetyl-D-Galactosamine Chemical compound CC(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@H](O)[C@@H]1O OVRNDRQMDRJTHS-CBQIKETKSA-N 0.000 description 1
- MBLBDJOUHNCFQT-UHFFFAOYSA-N N-acetyl-D-galactosamine Natural products CC(=O)NC(C=O)C(O)C(O)C(O)CO MBLBDJOUHNCFQT-UHFFFAOYSA-N 0.000 description 1
- HTLZVHNRZJPSMI-UHFFFAOYSA-N N-ethylpiperidine Chemical compound CCN1CCCCC1 HTLZVHNRZJPSMI-UHFFFAOYSA-N 0.000 description 1
- 206010029350 Neurotoxicity Diseases 0.000 description 1
- GRYLNZFGIOXLOG-UHFFFAOYSA-N Nitric acid Chemical compound O[N+]([O-])=O GRYLNZFGIOXLOG-UHFFFAOYSA-N 0.000 description 1
- 108010047956 Nucleosomes Proteins 0.000 description 1
- WSDRAZIPGVLSNP-UHFFFAOYSA-N O.P(=O)(O)(O)O.O.O.P(=O)(O)(O)O Chemical group O.P(=O)(O)(O)O.O.O.P(=O)(O)(O)O WSDRAZIPGVLSNP-UHFFFAOYSA-N 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- 102000035195 Peptidases Human genes 0.000 description 1
- 108010010677 Phosphodiesterase I Proteins 0.000 description 1
- 241000360071 Pituophis catenifer Species 0.000 description 1
- IWYDHOAUDWTVEP-UHFFFAOYSA-N R-2-phenyl-2-hydroxyacetic acid Natural products OC(=O)C(O)C1=CC=CC=C1 IWYDHOAUDWTVEP-UHFFFAOYSA-N 0.000 description 1
- 108020005067 RNA Splice Sites Proteins 0.000 description 1
- 108010022999 Serine Proteases Proteins 0.000 description 1
- 102000012479 Serine Proteases Human genes 0.000 description 1
- 108091027967 Small hairpin RNA Proteins 0.000 description 1
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 1
- KDYFGRWQOYBRFD-UHFFFAOYSA-N Succinic acid Natural products OC(=O)CCC(O)=O KDYFGRWQOYBRFD-UHFFFAOYSA-N 0.000 description 1
- FEWJPZIEWOKRBE-UHFFFAOYSA-N Tartaric acid Natural products [H+].[H+].[O-]C(=O)C(O)C(O)C([O-])=O FEWJPZIEWOKRBE-UHFFFAOYSA-N 0.000 description 1
- 206010044221 Toxic encephalopathy Diseases 0.000 description 1
- 229910052770 Uranium Inorganic materials 0.000 description 1
- 108010067390 Viral Proteins Proteins 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 125000002777 acetyl group Chemical group [H]C([H])([H])C(*)=O 0.000 description 1
- CUJRVFIICFDLGR-UHFFFAOYSA-N acetylacetonate Chemical compound CC(=O)[CH-]C(C)=O CUJRVFIICFDLGR-UHFFFAOYSA-N 0.000 description 1
- 229960004308 acetylcysteine Drugs 0.000 description 1
- 150000008043 acidic salts Chemical class 0.000 description 1
- 125000000641 acridinyl group Chemical group C1(=CC=CC2=NC3=CC=CC=C3C=C12)* 0.000 description 1
- 239000008186 active pharmaceutical agent Substances 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 238000012382 advanced drug delivery Methods 0.000 description 1
- 125000005600 alkyl phosphonate group Chemical group 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 1
- 150000001413 amino acids Chemical group 0.000 description 1
- 125000003277 amino group Chemical group 0.000 description 1
- PYMYPHUHKUWMLA-WDCZJNDASA-N arabinose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)C=O PYMYPHUHKUWMLA-WDCZJNDASA-N 0.000 description 1
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 125000003725 azepanyl group Chemical group 0.000 description 1
- 125000002785 azepinyl group Chemical group 0.000 description 1
- 125000002393 azetidinyl group Chemical group 0.000 description 1
- 239000000688 bacterial toxin Substances 0.000 description 1
- 125000000499 benzofuranyl group Chemical group O1C(=CC2=C1C=CC=C2)* 0.000 description 1
- 235000010233 benzoic acid Nutrition 0.000 description 1
- 125000005874 benzothiadiazolyl group Chemical group 0.000 description 1
- 125000001164 benzothiazolyl group Chemical group S1C(=NC2=C1C=CC=C2)* 0.000 description 1
- 125000004196 benzothienyl group Chemical group S1C(=CC2=C1C=CC=C2)* 0.000 description 1
- 125000003354 benzotriazolyl group Chemical group N1N=NC2=C1C=CC=C2* 0.000 description 1
- PASDCCFISLVPSO-UHFFFAOYSA-N benzoyl chloride Chemical compound ClC(=O)C1=CC=CC=C1 PASDCCFISLVPSO-UHFFFAOYSA-N 0.000 description 1
- 125000003236 benzoyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C(*)=O 0.000 description 1
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 1
- IQFYYKKMVGJFEH-UHFFFAOYSA-N beta-L-thymidine Natural products O=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1 IQFYYKKMVGJFEH-UHFFFAOYSA-N 0.000 description 1
- 125000002619 bicyclic group Chemical group 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- KDYFGRWQOYBRFD-NUQCWPJISA-N butanedioic acid Chemical compound O[14C](=O)CC[14C](O)=O KDYFGRWQOYBRFD-NUQCWPJISA-N 0.000 description 1
- 239000006227 byproduct Substances 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 210000000234 capsid Anatomy 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 125000000609 carbazolyl group Chemical group C1(=CC=CC=2C3=CC=CC=C3NC12)* 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 230000008568 cell cell communication Effects 0.000 description 1
- 208000026106 cerebrovascular disease Diseases 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- PQRFRTCWNCVQHI-UHFFFAOYSA-N chloro-dimethyl-(2,3,4,5,6-pentafluorophenyl)silane Chemical compound C[Si](C)(Cl)C1=C(F)C(F)=C(F)C(F)=C1F PQRFRTCWNCVQHI-UHFFFAOYSA-N 0.000 description 1
- 235000012000 cholesterol Nutrition 0.000 description 1
- 210000003483 chromatin Anatomy 0.000 description 1
- 235000013985 cinnamic acid Nutrition 0.000 description 1
- 229930016911 cinnamic acid Natural products 0.000 description 1
- 239000012230 colorless oil Substances 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 125000000582 cycloheptyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])([H])C([H])(*)C([H])([H])C1([H])[H] 0.000 description 1
- 125000000113 cyclohexyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C([H])([H])C1([H])[H] 0.000 description 1
- 125000000640 cyclooctyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])([H])C([H])(*)C([H])([H])C([H])([H])C1([H])[H] 0.000 description 1
- 125000001511 cyclopentyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- CTMZLDSMFCVUNX-VMIOUTBZSA-N cytidylyl-(3'->5')-guanosine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@H](OP(O)(=O)OC[C@@H]2[C@H]([C@@H](O)[C@@H](O2)N2C3=C(C(N=C(N)N3)=O)N=C2)O)[C@@H](CO)O1 CTMZLDSMFCVUNX-VMIOUTBZSA-N 0.000 description 1
- 239000007857 degradation product Substances 0.000 description 1
- 125000005959 diazepanyl group Chemical group 0.000 description 1
- 125000002576 diazepinyl group Chemical group N1N=C(C=CC=C1)* 0.000 description 1
- HPNMFZURTQLUMO-UHFFFAOYSA-N diethylamine Chemical compound CCNCC HPNMFZURTQLUMO-UHFFFAOYSA-N 0.000 description 1
- 125000004852 dihydrofuranyl group Chemical group O1C(CC=C1)* 0.000 description 1
- 125000005050 dihydrooxazolyl group Chemical group O1C(NC=C1)* 0.000 description 1
- 125000005043 dihydropyranyl group Chemical group O1C(CCC=C1)* 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- HPYNZHMRTTWQTB-UHFFFAOYSA-N dimethylpyridine Natural products CC1=CC=CN=C1C HPYNZHMRTTWQTB-UHFFFAOYSA-N 0.000 description 1
- 125000005982 diphenylmethyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C([H])(*)C1=C([H])C([H])=C([H])C([H])=C1[H] 0.000 description 1
- KPUWHANPEXNPJT-UHFFFAOYSA-N disiloxane Chemical class [SiH3]O[SiH3] KPUWHANPEXNPJT-UHFFFAOYSA-N 0.000 description 1
- 208000035475 disorder Diseases 0.000 description 1
- 238000010494 dissociation reaction Methods 0.000 description 1
- 230000005593 dissociations Effects 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 230000003828 downregulation Effects 0.000 description 1
- 238000011304 droplet digital PCR Methods 0.000 description 1
- 229940088679 drug related substance Drugs 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- CCIVGXIOQKPBKL-UHFFFAOYSA-M ethanesulfonate Chemical compound CCS([O-])(=O)=O CCIVGXIOQKPBKL-UHFFFAOYSA-M 0.000 description 1
- 125000001301 ethoxy group Chemical group [H]C([H])([H])C([H])([H])O* 0.000 description 1
- 230000029142 excretion Effects 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 125000006419 fluorocyclopropyl group Chemical group 0.000 description 1
- 239000012458 free base Substances 0.000 description 1
- 239000001530 fumaric acid Substances 0.000 description 1
- 125000002541 furyl group Chemical group 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 210000001035 gastrointestinal tract Anatomy 0.000 description 1
- 210000002064 heart cell Anatomy 0.000 description 1
- 125000003187 heptyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 125000000592 heterocycloalkyl group Chemical group 0.000 description 1
- FFUAGWLWBBFQJT-UHFFFAOYSA-N hexamethyldisilazane Chemical compound C[Si](C)(C)N[Si](C)(C)C FFUAGWLWBBFQJT-UHFFFAOYSA-N 0.000 description 1
- 125000000625 hexosyl group Chemical group 0.000 description 1
- 125000004051 hexyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- BHEPBYXIRTUNPN-UHFFFAOYSA-N hydridophosphorus(.) (triplet) Chemical compound [PH] BHEPBYXIRTUNPN-UHFFFAOYSA-N 0.000 description 1
- 230000003301 hydrolyzing effect Effects 0.000 description 1
- 125000002632 imidazolidinyl group Chemical group 0.000 description 1
- 125000002636 imidazolinyl group Chemical group 0.000 description 1
- 125000002883 imidazolyl group Chemical group 0.000 description 1
- 230000003308 immunostimulating effect Effects 0.000 description 1
- 238000000099 in vitro assay Methods 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 229910052738 indium Inorganic materials 0.000 description 1
- 125000001041 indolyl group Chemical group 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 229960003786 inosine Drugs 0.000 description 1
- 230000000968 intestinal effect Effects 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000007917 intracranial administration Methods 0.000 description 1
- 238000010255 intramuscular injection Methods 0.000 description 1
- 239000007927 intramuscular injection Substances 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 239000007928 intraperitoneal injection Substances 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 229910052740 iodine Inorganic materials 0.000 description 1
- 239000011630 iodine Substances 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- 239000003456 ion exchange resin Substances 0.000 description 1
- 229920003303 ion-exchange polymer Polymers 0.000 description 1
- 125000001977 isobenzofuranyl group Chemical group C=1(OC=C2C=CC=CC12)* 0.000 description 1
- 125000000959 isobutyl group Chemical group [H]C([H])([H])C([H])(C([H])([H])[H])C([H])([H])* 0.000 description 1
- 125000000904 isoindolyl group Chemical group C=1(NC=C2C=CC=CC12)* 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 125000000555 isopropenyl group Chemical group [H]\C([H])=C(\*)C([H])([H])[H] 0.000 description 1
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- JJWLVOIRVHMVIS-UHFFFAOYSA-N isopropylamine Chemical compound CC(C)N JJWLVOIRVHMVIS-UHFFFAOYSA-N 0.000 description 1
- 125000001786 isothiazolyl group Chemical group 0.000 description 1
- 125000003965 isoxazolidinyl group Chemical group 0.000 description 1
- 125000000842 isoxazolyl group Chemical group 0.000 description 1
- 239000003446 ligand Substances 0.000 description 1
- 238000011068 loading method Methods 0.000 description 1
- 159000000003 magnesium salts Chemical class 0.000 description 1
- VZCYOOQTPOCHFL-UPHRSURJSA-N maleic acid Chemical compound OC(=O)\C=C/C(O)=O VZCYOOQTPOCHFL-UPHRSURJSA-N 0.000 description 1
- 239000011976 maleic acid Substances 0.000 description 1
- 229960002510 mandelic acid Drugs 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 239000002609 medium Substances 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 239000002207 metabolite Substances 0.000 description 1
- 229940098779 methanesulfonic acid Drugs 0.000 description 1
- WBYWAXJHAXSJNI-UHFFFAOYSA-N methyl p-hydroxycinnamate Natural products OC(=O)C=CC1=CC=CC=C1 WBYWAXJHAXSJNI-UHFFFAOYSA-N 0.000 description 1
- 230000011987 methylation Effects 0.000 description 1
- 238000007069 methylation reaction Methods 0.000 description 1
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical compound CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 1
- CPZBTYRIGVOOMI-UHFFFAOYSA-N methylsulfanyl(methylsulfanylmethoxy)methane Chemical compound CSCOCSC CPZBTYRIGVOOMI-UHFFFAOYSA-N 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 150000007522 mineralic acids Chemical class 0.000 description 1
- 125000002950 monocyclic group Chemical group 0.000 description 1
- 125000002757 morpholinyl group Chemical group 0.000 description 1
- 210000000663 muscle cell Anatomy 0.000 description 1
- 230000035772 mutation Effects 0.000 description 1
- ZSMNRKGGHXLZEC-UHFFFAOYSA-N n,n-bis(trimethylsilyl)methanamine Chemical compound C[Si](C)(C)N(C)[Si](C)(C)C ZSMNRKGGHXLZEC-UHFFFAOYSA-N 0.000 description 1
- CTGWFRQUULNNIN-OSZGUBSQSA-N n-[1-[(1r,4r,6r,7s)-4-[[bis(4-methoxyphenyl)-phenylmethoxy]methyl]-7-hydroxy-2,5-dioxabicyclo[2.2.1]heptan-6-yl]-5-methyl-2-oxopyrimidin-4-yl]benzamide Chemical compound C([C@]12CO[C@@]([C@@H](O2)N2C(N=C(NC(=O)C=3C=CC=CC=3)C(C)=C2)=O)([C@@H]1O)[H])OC(C=1C=CC(OC)=CC=1)(C=1C=CC(OC)=CC=1)C1=CC=CC=C1 CTGWFRQUULNNIN-OSZGUBSQSA-N 0.000 description 1
- QKRIAIFSTHOZRG-WBZZMTOKSA-N n-[9-[(1r,4r,6r,7s)-4-[[bis(4-methoxyphenyl)-phenylmethoxy]methyl]-7-hydroxy-2,5-dioxabicyclo[2.2.1]heptan-6-yl]purin-6-yl]benzamide Chemical compound C([C@]12CO[C@@]([C@@H](O2)N2C3=NC=NC(NC(=O)C=4C=CC=CC=4)=C3N=C2)([C@@H]1O)[H])OC(C=1C=CC(OC)=CC=1)(C=1C=CC(OC)=CC=1)C1=CC=CC=C1 QKRIAIFSTHOZRG-WBZZMTOKSA-N 0.000 description 1
- QULMGWCCKILBTO-UHFFFAOYSA-N n-[dimethylamino(dimethyl)silyl]-n-methylmethanamine Chemical compound CN(C)[Si](C)(C)N(C)C QULMGWCCKILBTO-UHFFFAOYSA-N 0.000 description 1
- QHUOBLDKFGCVCG-UHFFFAOYSA-N n-methyl-n-trimethylsilylacetamide Chemical compound CC(=O)N(C)[Si](C)(C)C QHUOBLDKFGCVCG-UHFFFAOYSA-N 0.000 description 1
- 125000001624 naphthyl group Chemical group 0.000 description 1
- CMWTZPSULFXXJA-VIFPVBQESA-N naproxen Chemical group C1=C([C@H](C)C(O)=O)C=CC2=CC(OC)=CC=C21 CMWTZPSULFXXJA-VIFPVBQESA-N 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 230000007135 neurotoxicity Effects 0.000 description 1
- 231100000228 neurotoxicity Toxicity 0.000 description 1
- 229910017604 nitric acid Inorganic materials 0.000 description 1
- 108091027963 non-coding RNA Proteins 0.000 description 1
- 102000042567 non-coding RNA Human genes 0.000 description 1
- 210000001623 nucleosome Anatomy 0.000 description 1
- 125000002347 octyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- JRZJOMJEPLMPRA-UHFFFAOYSA-N olefin Natural products CCCCCCCC=C JRZJOMJEPLMPRA-UHFFFAOYSA-N 0.000 description 1
- 229940046166 oligodeoxynucleotide Drugs 0.000 description 1
- 239000006195 ophthalmic dosage form Substances 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 239000012074 organic phase Substances 0.000 description 1
- 125000001715 oxadiazolyl group Chemical group 0.000 description 1
- 235000006408 oxalic acid Nutrition 0.000 description 1
- 125000000160 oxazolidinyl group Chemical group 0.000 description 1
- 125000002971 oxazolyl group Chemical group 0.000 description 1
- 125000005740 oxycarbonyl group Chemical group [*:1]OC([*:2])=O 0.000 description 1
- 125000000636 p-nitrophenyl group Chemical group [H]C1=C([H])C(=C([H])C([H])=C1*)[N+]([O-])=O 0.000 description 1
- FJKROLUGYXJWQN-UHFFFAOYSA-N papa-hydroxy-benzoic acid Natural products OC(=O)C1=CC=C(O)C=C1 FJKROLUGYXJWQN-UHFFFAOYSA-N 0.000 description 1
- 230000035699 permeability Effects 0.000 description 1
- 125000004437 phosphorous atom Chemical group 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 125000004193 piperazinyl group Chemical group 0.000 description 1
- 125000003386 piperidinyl group Chemical group 0.000 description 1
- 210000002381 plasma Anatomy 0.000 description 1
- 229920000768 polyamine Polymers 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 102000040430 polynucleotide Human genes 0.000 description 1
- 108091033319 polynucleotide Proteins 0.000 description 1
- 239000002157 polynucleotide Substances 0.000 description 1
- 231100000683 possible toxicity Toxicity 0.000 description 1
- 150000003141 primary amines Chemical class 0.000 description 1
- 108090000765 processed proteins & peptides Proteins 0.000 description 1
- 235000019260 propionic acid Nutrition 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 229940024999 proteolytic enzymes for treatment of wounds and ulcers Drugs 0.000 description 1
- 125000003373 pyrazinyl group Chemical group 0.000 description 1
- 125000003072 pyrazolidinyl group Chemical group 0.000 description 1
- 125000003226 pyrazolyl group Chemical group 0.000 description 1
- 125000002098 pyridazinyl group Chemical group 0.000 description 1
- AOJFQRQNPXYVLM-UHFFFAOYSA-N pyridin-1-ium;chloride Chemical compound [Cl-].C1=CC=[NH+]C=C1 AOJFQRQNPXYVLM-UHFFFAOYSA-N 0.000 description 1
- 125000004076 pyridyl group Chemical group 0.000 description 1
- 150000003230 pyrimidines Chemical class 0.000 description 1
- 125000000714 pyrimidinyl group Chemical group 0.000 description 1
- 125000000168 pyrrolyl group Chemical group 0.000 description 1
- 229940107700 pyruvic acid Drugs 0.000 description 1
- 238000010791 quenching Methods 0.000 description 1
- 230000000171 quenching effect Effects 0.000 description 1
- 125000002294 quinazolinyl group Chemical group N1=C(N=CC2=CC=CC=C12)* 0.000 description 1
- IUVKMZGDUIUOCP-BTNSXGMBSA-N quinbolone Chemical compound O([C@H]1CC[C@H]2[C@H]3[C@@H]([C@]4(C=CC(=O)C=C4CC3)C)CC[C@@]21C)C1=CCCC1 IUVKMZGDUIUOCP-BTNSXGMBSA-N 0.000 description 1
- 125000001567 quinoxalinyl group Chemical group N1=C(C=NC2=CC=CC=C12)* 0.000 description 1
- 125000004621 quinuclidinyl group Chemical group N12C(CC(CC1)CC2)* 0.000 description 1
- 239000011347 resin Substances 0.000 description 1
- 229920005989 resin Polymers 0.000 description 1
- 230000002207 retinal effect Effects 0.000 description 1
- 238000004366 reverse phase liquid chromatography Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 229960004889 salicylic acid Drugs 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 239000000523 sample Substances 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 150000003335 secondary amines Chemical class 0.000 description 1
- 125000000467 secondary amino group Chemical group [H]N([*:1])[*:2] 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- 230000003584 silencer Effects 0.000 description 1
- 239000004055 small Interfering RNA Substances 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 238000010532 solid phase synthesis reaction Methods 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 210000000278 spinal cord Anatomy 0.000 description 1
- 108010068698 spleen exonuclease Proteins 0.000 description 1
- 230000037423 splicing regulation Effects 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 125000000475 sulfinyl group Chemical group [*:2]S([*:1])=O 0.000 description 1
- 125000004434 sulfur atom Chemical group 0.000 description 1
- 238000005987 sulfurization reaction Methods 0.000 description 1
- 235000002906 tartaric acid Nutrition 0.000 description 1
- 239000011975 tartaric acid Substances 0.000 description 1
- ILMRJRBKQSSXGY-UHFFFAOYSA-N tert-butyl(dimethyl)silicon Chemical compound C[Si](C)C(C)(C)C ILMRJRBKQSSXGY-UHFFFAOYSA-N 0.000 description 1
- 125000001981 tert-butyldimethylsilyl group Chemical group [H]C([H])([H])[Si]([H])(C([H])([H])[H])[*]C(C([H])([H])[H])(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 125000005931 tert-butyloxycarbonyl group Chemical group [H]C([H])([H])C(OC(*)=O)(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 150000003512 tertiary amines Chemical class 0.000 description 1
- 125000001302 tertiary amino group Chemical group 0.000 description 1
- 125000003718 tetrahydrofuranyl group Chemical group 0.000 description 1
- 125000004853 tetrahydropyridinyl group Chemical group N1(CCCC=C1)* 0.000 description 1
- 125000005958 tetrahydrothienyl group Chemical group 0.000 description 1
- 125000004632 tetrahydrothiopyranyl group Chemical group S1C(CCCC1)* 0.000 description 1
- 125000003831 tetrazolyl group Chemical group 0.000 description 1
- 125000001113 thiadiazolyl group Chemical group 0.000 description 1
- 125000001984 thiazolidinyl group Chemical group 0.000 description 1
- 125000000335 thiazolyl group Chemical group 0.000 description 1
- 125000001544 thienyl group Chemical group 0.000 description 1
- 125000005190 thiohydroxy group Chemical group 0.000 description 1
- 125000004568 thiomorpholinyl group Chemical group 0.000 description 1
- ZEMGGZBWXRYJHK-UHFFFAOYSA-N thiouracil Chemical compound O=C1C=CNC(=S)N1 ZEMGGZBWXRYJHK-UHFFFAOYSA-N 0.000 description 1
- 229940104230 thymidine Drugs 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 108700012359 toxins Proteins 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000014616 translation Effects 0.000 description 1
- 125000005208 trialkylammonium group Chemical group 0.000 description 1
- 125000004306 triazinyl group Chemical group 0.000 description 1
- 125000001425 triazolyl group Chemical group 0.000 description 1
- SIOVKLKJSOKLIF-HJWRWDBZSA-N trimethylsilyl (1z)-n-trimethylsilylethanimidate Chemical compound C[Si](C)(C)OC(/C)=N\[Si](C)(C)C SIOVKLKJSOKLIF-HJWRWDBZSA-N 0.000 description 1
- CSRZQMIRAZTJOY-UHFFFAOYSA-N trimethylsilyl iodide Substances C[Si](C)(C)I CSRZQMIRAZTJOY-UHFFFAOYSA-N 0.000 description 1
- DGIJAZGPLFOQJE-UHFFFAOYSA-N trimethylsilyl n-trimethylsilylcarbamate Chemical compound C[Si](C)(C)NC(=O)O[Si](C)(C)C DGIJAZGPLFOQJE-UHFFFAOYSA-N 0.000 description 1
- YFTHZRPMJXBUME-UHFFFAOYSA-N tripropylamine Chemical compound CCCN(CCC)CCC YFTHZRPMJXBUME-UHFFFAOYSA-N 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 229910052720 vanadium Inorganic materials 0.000 description 1
- 229920002554 vinyl polymer Polymers 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 150000003722 vitamin derivatives Chemical class 0.000 description 1
- 229940075420 xanthine Drugs 0.000 description 1
Images





























Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07F—ACYCLIC, CARBOCYCLIC OR HETEROCYCLIC COMPOUNDS CONTAINING ELEMENTS OTHER THAN CARBON, HYDROGEN, HALOGEN, OXYGEN, NITROGEN, SULFUR, SELENIUM OR TELLURIUM
- C07F9/00—Compounds containing elements of Groups 5 or 15 of the Periodic Table
- C07F9/02—Phosphorus compounds
- C07F9/547—Heterocyclic compounds, e.g. containing phosphorus as a ring hetero atom
- C07F9/6558—Heterocyclic compounds, e.g. containing phosphorus as a ring hetero atom containing at least two different or differently substituted hetero rings neither condensed among themselves nor condensed with a common carbocyclic ring or ring system
- C07F9/65586—Heterocyclic compounds, e.g. containing phosphorus as a ring hetero atom containing at least two different or differently substituted hetero rings neither condensed among themselves nor condensed with a common carbocyclic ring or ring system at least one of the hetero rings does not contain nitrogen as ring hetero atom
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07F—ACYCLIC, CARBOCYCLIC OR HETEROCYCLIC COMPOUNDS CONTAINING ELEMENTS OTHER THAN CARBON, HYDROGEN, HALOGEN, OXYGEN, NITROGEN, SULFUR, SELENIUM OR TELLURIUM
- C07F9/00—Compounds containing elements of Groups 5 or 15 of the Periodic Table
- C07F9/02—Phosphorus compounds
- C07F9/547—Heterocyclic compounds, e.g. containing phosphorus as a ring hetero atom
- C07F9/6561—Heterocyclic compounds, e.g. containing phosphorus as a ring hetero atom containing systems of two or more relevant hetero rings condensed among themselves or condensed with a common carbocyclic ring or ring system, with or without other non-condensed hetero rings
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07F—ACYCLIC, CARBOCYCLIC OR HETEROCYCLIC COMPOUNDS CONTAINING ELEMENTS OTHER THAN CARBON, HYDROGEN, HALOGEN, OXYGEN, NITROGEN, SULFUR, SELENIUM OR TELLURIUM
- C07F9/00—Compounds containing elements of Groups 5 or 15 of the Periodic Table
- C07F9/02—Phosphorus compounds
- C07F9/547—Heterocyclic compounds, e.g. containing phosphorus as a ring hetero atom
- C07F9/6561—Heterocyclic compounds, e.g. containing phosphorus as a ring hetero atom containing systems of two or more relevant hetero rings condensed among themselves or condensed with a common carbocyclic ring or ring system, with or without other non-condensed hetero rings
- C07F9/65616—Heterocyclic compounds, e.g. containing phosphorus as a ring hetero atom containing systems of two or more relevant hetero rings condensed among themselves or condensed with a common carbocyclic ring or ring system, with or without other non-condensed hetero rings containing the ring system having three or more than three double bonds between ring members or between ring members and non-ring members, e.g. purine or analogs
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07H—SUGARS; DERIVATIVES THEREOF; NUCLEOSIDES; NUCLEOTIDES; NUCLEIC ACIDS
- C07H1/00—Processes for the preparation of sugar derivatives
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07H—SUGARS; DERIVATIVES THEREOF; NUCLEOSIDES; NUCLEOTIDES; NUCLEIC ACIDS
- C07H19/00—Compounds containing a hetero ring sharing one ring hetero atom with a saccharide radical; Nucleosides; Mononucleotides; Anhydro-derivatives thereof
- C07H19/02—Compounds containing a hetero ring sharing one ring hetero atom with a saccharide radical; Nucleosides; Mononucleotides; Anhydro-derivatives thereof sharing nitrogen
- C07H19/04—Heterocyclic radicals containing only nitrogen atoms as ring hetero atom
- C07H19/06—Pyrimidine radicals
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07H—SUGARS; DERIVATIVES THEREOF; NUCLEOSIDES; NUCLEOTIDES; NUCLEIC ACIDS
- C07H19/00—Compounds containing a hetero ring sharing one ring hetero atom with a saccharide radical; Nucleosides; Mononucleotides; Anhydro-derivatives thereof
- C07H19/02—Compounds containing a hetero ring sharing one ring hetero atom with a saccharide radical; Nucleosides; Mononucleotides; Anhydro-derivatives thereof sharing nitrogen
- C07H19/04—Heterocyclic radicals containing only nitrogen atoms as ring hetero atom
- C07H19/06—Pyrimidine radicals
- C07H19/10—Pyrimidine radicals with the saccharide radical esterified by phosphoric or polyphosphoric acids
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07H—SUGARS; DERIVATIVES THEREOF; NUCLEOSIDES; NUCLEOTIDES; NUCLEIC ACIDS
- C07H19/00—Compounds containing a hetero ring sharing one ring hetero atom with a saccharide radical; Nucleosides; Mononucleotides; Anhydro-derivatives thereof
- C07H19/02—Compounds containing a hetero ring sharing one ring hetero atom with a saccharide radical; Nucleosides; Mononucleotides; Anhydro-derivatives thereof sharing nitrogen
- C07H19/04—Heterocyclic radicals containing only nitrogen atoms as ring hetero atom
- C07H19/16—Purine radicals
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07H—SUGARS; DERIVATIVES THEREOF; NUCLEOSIDES; NUCLEOTIDES; NUCLEIC ACIDS
- C07H19/00—Compounds containing a hetero ring sharing one ring hetero atom with a saccharide radical; Nucleosides; Mononucleotides; Anhydro-derivatives thereof
- C07H19/02—Compounds containing a hetero ring sharing one ring hetero atom with a saccharide radical; Nucleosides; Mononucleotides; Anhydro-derivatives thereof sharing nitrogen
- C07H19/04—Heterocyclic radicals containing only nitrogen atoms as ring hetero atom
- C07H19/16—Purine radicals
- C07H19/20—Purine radicals with the saccharide radical esterified by phosphoric or polyphosphoric acids
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07H—SUGARS; DERIVATIVES THEREOF; NUCLEOSIDES; NUCLEOTIDES; NUCLEIC ACIDS
- C07H21/00—Compounds containing two or more mononucleotide units having separate phosphate or polyphosphate groups linked by saccharide radicals of nucleoside groups, e.g. nucleic acids
- C07H21/04—Compounds containing two or more mononucleotide units having separate phosphate or polyphosphate groups linked by saccharide radicals of nucleoside groups, e.g. nucleic acids with deoxyribosyl as saccharide radical
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/111—General methods applicable to biologically active non-coding nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/11—Antisense
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/313—Phosphorodithioates
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/315—Phosphorothioates
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/321—2'-O-R Modification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/323—Chemical structure of the sugar modified ring structure
- C12N2310/3231—Chemical structure of the sugar modified ring structure having an additional ring, e.g. LNA, ENA
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/34—Spatial arrangement of the modifications
- C12N2310/341—Gapmers, i.e. of the type ===---===
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/34—Spatial arrangement of the modifications
- C12N2310/346—Spatial arrangement of the modifications having a combination of backbone and sugar modifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2330/00—Production
- C12N2330/30—Production chemically synthesised
Landscapes
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- Biotechnology (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Plant Pathology (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Saccharide Compounds (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
Abstract
본 발명은 화학식 (II) 또는 (IIb) 의 화합물에 관한 것이다:


[식 중, X, Y, Rx, Ry, R5 및 Nu 는 설명 및 청구범위에 정의된 바와 같음].
화학식 (II) 의 화합물은 올리고뉴클레오티드의 제조에 사용될 수 있다.
[식 중, X, Y, Rx, Ry, R5 및 Nu 는 설명 및 청구범위에 정의된 바와 같음].
화학식 (II) 의 화합물은 올리고뉴클레오티드의 제조에 사용될 수 있다.
Description
치료제로서 합성 올리고뉴클레오티드의 사용은 최근 수십 년에 걸쳐 RNase H 활성화 갭머, 스플라이스 스위칭 올리고뉴클레오티드, 마이크로RNA 저해제, siRNA 또는 압타머를 포함한 다양한 메커니즘에 의해 작용하는 분자의 발달로 이어지는 현저한 진보를 목격했다 (S. T. Crooke, Antisense drug technology: principles, strategies, and applications, 2nd ed. ed., Boca Raton, FL: CRC Press, 2008). 그러나, 올리고뉴클레오티드는 생물학적 시스템에서 핵분해에 대해 본질적으로 불안정하다. 뿐만 아니라, 이들은 매우 불리한 약동학적 거동을 나타낸다. 이러한 단점을 개선하기 위해 최근 수십 년 동안 다양한 화학적 개질이 연구되어 왔다. 가장 성공적인 개질 중 하나는 포스포로티오에이트 연결의 도입인데, 여기서 비-가교 포스페이트 산소 원자 중 하나가 황 원자로 대체된다 (F. Eckstein, Antisense and Nucleic Acid Drug Development 2009, 10, 117-121.). 이러한 포스포로티오에이트 올리고데옥시뉴클레오티드는 증가된 단백질 결합뿐만 아니라 핵분해에 대한 현저하게 보다 높은 안정성을 나타내므로 개질되지 않은 포스포디에스테르 유사체보다 혈장, 조직 및 세포에서 실질적으로 보다 높은 반감기를 나타낸다. 이러한 중요한 특징은 1 세대 올리고뉴클레오티드 치료제의 개발을 가능하게 했을 뿐만 아니라 잠금 핵산 (LNA) 과 같은 차세대 개질을 통해 추가 개선을 위한 문을 열었다. 그러나, 포스포디에스테르 연결을 포스포로티오에이트로 대체하면, 인 원자에 카이랄 중심이 생성된다. 그 결과, 모든 승인된 포스포로티오에이트 올리고뉴클레오티드 치료제는 다량의 부분입체 이성질체 화합물의 혼합물로서 사용되며, 이들은 모두 잠재적으로 상이한 (및 가능하게는 반대되는) 물리화학적 및 약리학적 특성을 갖는다.
단일 입체 화학적으로 정의된 포스포로티오에이트 올리고뉴클레오티드의 입체 특이적 합성이 이제 가능하지만 (N. Oka, M. Yamamoto, T. Sato, T. Wada, J. Am. Chem. Soc. 2008, 130, 16031-16037), 다수의 가능한 부분입체 이성질체 내에서 최적의 특성을 갖는 입체 이성질체를 확인하는 것은 여전히 어려운 과제이다. 이와 관련하여, 비-카이랄 티오포스페이트 연결의 사용에 의한 부분입체 이성질체 복잡성의 감소가 큰 관심 대상이다. 예를 들어, 포스페이트 연결 내의 둘 모두의 비-가교 산소 원자가 황으로 대체된 대칭 비-가교 디티오에이트 개질 (예를 들어 W. T. Wiesler, M. H. Caruthers, J. Org. Chem. 1996, 61, 4272-4281 참조) 은 면역 자극 올리고뉴클레오티드 (A. M. Krieg, S. Matson, E. Fisher, Antisense Nucleic Acid Drug Dev. 1996, 6, 133-139), siRNA (예를 들어 X. Yang, M. Sierant, M. Janicka, L. Peczek, C. Martinez, T. Hassell, N. Li, X. Li, T. Wang, B. Nawrot, ACS Chem. Biol. 2012, 7, 1214-1220) 및 압타머 (예를 들어 X. Yang, S. Fennewald, B. A. Luxon, J. Aronson, N. K. Herzog, D. G. Gorenstein, Bioorg. Med. Chem. Lett. 1999, 9, 3357-3362) 에 적용되었다. 흥미롭게도, 안티센스 올리고뉴클레오티드와 관련하여 이러한 비-카이랄 개질을 사용하려는 시도는 현재까지 제한된 성공을 거두었다 (예를 들어 M. K. Ghosh, K. Ghosh, O. Dahl, J. S. Cohen, Nucleic Acids Res. 1993, 21, 5761-5766. 및 J. P. Vaughn, J. Stekler, S. Demirdji, J. K. Mills, M. H. Caruthers, J. D. Iglehart, J. R. Marks, Nucleic Acids Res. 1996, 24, 4558-4564 참조).
놀랍게도, 본 발명자들은 비-가교 포스포로디티오에이트가 올리고뉴클레오티드, 특히 올리고뉴클레오티드 갭머 또는 믹스머 일반적으로 및 LNA-DNA-LNA 갭머 또는 특히 LNA/DNA 믹스머에 도입될 수 있음을 발견하였다. 개질은 매우 내성이며 생성된 분자는 치료 적용에 큰 잠재력을 나타내지만, 모든 비-가교 포스포로디티오에이트 개질은 가능한 부분입체 이성질체의 전체 라이브러리 크기를 50% 줄인다. 개질이 갭머의 LNA 플랭크에 위치될 때, 생성된 올리고뉴클레오티드는 일반적으로 상응하는 모든 포스포로티오에이트 모체보다 더 강력한 것으로 밝혀졌다. 일반적으로, 개질은 갭 영역 내에서 추가로 매우 내성이며 더욱 놀랍게도 적절하게 위치될 때 개선된 효능을 야기할 수 있다.
따라서, 본 발명자들은 놀랍게도 본 발명이 예를 들어 개선된 효능을 포함하여 개선된 물리 화학적 및 약리학적 특성을 갖는 올리고뉴클레오티드를 제공한다는 것을 발견하였다. 일부 양태에서, 본 발명의 올리고뉴클레오티드는 활성 또는 효능을 보유하며, 화학식 (IA 또는 IB) 의 포스포디티오에이트 연결이 통상적인 입체 랜덤 포스포로티오에이트 연결로 대체된 동일한 화합물 (포스포로티오에이트 기준 화합물) 만큼 강력할 수 있거나 또는 보다 강력하다. 비-가교 포스포로디티오에이트 개질의 모든 도입은 인에서 카이랄 중심 중 하나를 제거함으로써 화합물의 부분입체 이성질체 복잡성을 50% 감소시킨다. 또한, 디티오에이트 개질이 도입될 때마다, 올리고뉴클레오티드는 예를 들어 세포, 특히 간세포, 근육 세포, 심장 세포로 극적으로 더 잘 흡수되는 것으로 보인다.
갭머의 LNA 플랭크에의 비-가교 디티오에이트 개질의 도입은 특히 유리한 것으로 보이며, 분자가 더 높은 표적 감소 및 실질적으로 더 우수한 흡수 거동, 더 높은 안정성 및 양호한 안전 프로파일을 나타내는 것으로 이끈다.
올리고뉴클레오티드에서 비-가교 포스포로디티오에이트 연결의 화합적 합성은 적절한 티오포스포르아미다이트 빌딩 블록을 사용하는 고체 상 올리고뉴클레오티드 합성 기술에 의해 가장 잘 달성된다. 이러한 티오포스포르아미다이트의 성공적인 적용은 일반 DNA (X. Yang, Curr Protoc Nucleic Acid Chem 2016, 66, 4.71.71-74.71.14.) 뿐만 아니라 RNA (X. Yang, Curr Protoc Nucleic Acid Chem 2017, 70, 4.77.71-74.77.13.) 에 대하여 기술되어 왔으며 필요한 빌딩 블록은 상업적 공급원으로부터 입수 가능하다. 흥미롭게도, 상응하는 LNA 티오포스포르아미다이트의 더욱 도전적인 합성은 보고되지 않았다. 본 출원에서, 본 발명자들은 또한 모든 4 개의 LNA 티오포스포르아미다이트의 성공적인 합성 및 올리고뉴클레오티드로의 이들의 혼입을 보고한다.
본 발명은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 올리고뉴클레오티드에 관한 것이다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, 이때 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 LNA 뉴클레오시드이고, R 은 수소 또는 포스페이트 보호기이다. 본 발명은 또한 특히 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 갭머 올리고뉴클레오티드에 관한 것이다. 본 발명은 또한 본 발명에 따른 올리고뉴클레오티드의 제조 방법 및 특히 본 발명에 따른 올리고뉴클레오티드의 제조에 유용한 LNA 뉴클레오시드 단량체에 관한 것이다.
본 발명은 화학식 (IA) 또는 (IB) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 올리고뉴클레오티드에 관한 것이다:

식 중, 2 개의 산소 원자 중 하나는는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이다.
대안적으로 언급된 M 은 금속, 예컨대 알칼리금속, 예컨대 Na 또는 K 이거나; 또는 M 은 NH4 이다.
본 발명은 본원에 기재된 바와 같은 화학식 IA 또는 IB 의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 안티센스 올리고뉴클레오티드를 제공한다. 본 발명의 올리고뉴클레오티드는 바람직하게는 단일 가닥 안티센스 올리고뉴클레오티드이며, 이는 하나 이상의 2'당 개질된 뉴클레오시드, 예컨대 하나 이상의 LNA 뉴클레오시드 또는 하나 이상의 2' MOE 뉴클레오시드를 포함한다. 본 발명의 안티센스 올리고뉴클레오티드는 생체내 또는 시험관내에서 표적 RNA 를 발현하는 세포에서 표적 핵산, 예컨대 표적 pre-mRNA, 또는 표적 마이크로RNA 의 발현을 조절할 수 있다. 일부 구현예에서, 단일 가닥 안티센스 올리고뉴클레오티드는 포스포로티오에이트 뉴클레오시드간 연결을 추가로 포함한다. 단일 가닥 안티센스 올리고뉴클레오티드는 예를 들어 갭머 올리고뉴클레오티드, 믹스머 올리고뉴클레오티드 또는 토탈머 올리고뉴클레오티드의 형태일 수 있다. 단일 가닥 안티센스 올리고뉴클레오티드 믹스머는 표적 pre-mRNA 에서 스플라이싱 이벤트를 조절하는데 사용될 수 있다. 단일 가닥 안티센스 올리고뉴클레오티드 믹스머는 표적 마이크로RNA 의 발현을 저해하는데 사용될 수 있다.
본 발명은 또한 치료제로서 단일 가닥 안티센스 올리고뉴클레오티드와 같은 본 발명의 올리고뉴클레오티드의 용도에 관한 것이다.
본 발명은 또한 특히 화학식 (IA 또는 IB) 의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 믹스머 올리고뉴클레오티드에 관한 것이다. 본 발명은 또한 특히 화학식 (IA 또는 IB) 의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 토탈머 올리고뉴클레오티드에 관한 것이다.
본 발명은 또한 본 발명에 따른 올리고뉴클레오티드의 제조 방법 및 특히 본 발명에 따른 올리고뉴클레오티드의 제조에 유용한 LNA 뉴클레오시드 단량체에 관한 것이다.
본 발명은 또한 본 발명에 따른 올리고뉴클레오티드의 제조 방법 및 특히 본 발명에 따른 올리고뉴클레오티드의 제조에 유용한 MOE 뉴클레오시드 단량체에 관한 것이다.
본 발명은 또한 본 발명에 따른 올리고뉴클레오티드의 제조에 사용될 수 있는 신규 MOE 및 LNA 단량체를 제공한다.
올리고뉴클레오티드 합성 동안, 보호 R 기가 종종 사용된다. 올리고뉴클레오티드 합성 후, 예를 들어 올리고뉴클레오티드가 염의 형태인 경우 보호기는 전형적으로 수소 원자 또는 양이온, 예컨대 알칼리금속 또는 암모늄 양이온으로 교환된다. 염은 전형적으로 양이온, 예컨대 금속 양이온, 예를 들어 소듐 또는 포타슘 양이온 또는 암모늄 양이온을 함유한다. 안티센스 올리고뉴클레오티드에 관련하여, 바람직하게는 R 은 수소이거나, 또는 안티센스 올리고뉴클레오티드는 염의 형태이다 (IB 에 도시된 바와 같음).
화학식 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결은 예를 들어 하기로 이루어진 군으로부터 선택될 수 있다:

식 중, M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이다. 따라서, 본 발명의 올리고뉴클레오티드는 올리고뉴클레오티드 염, 알칼리금속 염, 예컨대 소듐 염, 포타슘 염 또는 암모늄 염의 형태일 수 있다.
대안적으로, 본 발명의 올리고뉴클레오티드는 화학식 IA' 또는 IB' 의 포스포로디티오에이트 뉴클레오시드간 연결을 포함할 수 있다:

본 발명은 또한 특히 화학식 IA 또는 IB, 또는 화학식 IA' 또는 화학식 IB' 에 대하여 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 갭머 올리고뉴클레오티드에 관한 것이다.
본 발명은 또한 특히 화학식 IA 또는 IB, 또는 화학식 IA' 또는 화학식 IB' 에 대하여 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 믹스머 올리고뉴클레오티드에 관한 것이다.
본 발명은 또한 특히 화학식 IA 또는 IB, 또는 화학식 IA' 또는 화학식 IB' 에 대하여 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 토탈머 올리고뉴클레오티드에 관한 것이다.
본 발명의 올리고뉴클레오티드의 바람직한 구현예에서, 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 LNA 뉴클레오시드이다.
본 발명의 올리고뉴클레오티드의 바람직한 구현예에서, 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 2'-O-MOE 뉴클레오시드이다.
본 발명의 올리고뉴클레오티드의 바람직한 구현예에서, 올리고뉴클레오티드는 단일 가닥 안티센스 올리고뉴클레오티드이고, 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 LNA 뉴클레오시드이다.
본 발명의 올리고뉴클레오티드의 바람직한 구현예에서, 올리고뉴클레오티드는 단일 가닥 안티센스 올리고뉴클레오티드이고, 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 2'-O-MOE 뉴클레오시드이다.
본 발명은 세포에서 표적 RNA 를 저해하기 위한 안티센스 올리고뉴클레오티드를 제공하고, 안티센스 갭머 올리고뉴클레오티드는 화학식 (IA) 또는 (IB) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함한다:

(IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, 안티센스 올리고뉴클레오티드는 안티센스 갭머 올리고뉴클레오티드 (본원에서 갭머 또는 갭머 올리고뉴클레오티드로 지칭됨) 이거나 이를 포함한다.
따라서, 본 발명의 안티센스 올리고뉴클레오티드는 갭머를 포함하거나 이로 이루어질 수 있다.
본 발명은 화학식 (IA) 또는 (IB) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 안티센스 올리고뉴클레오티드를 제공한다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, 이때 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 LNA 뉴클레오시드이고, (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, A2 는 올리고뉴클레오티드의 3' 말단 뉴클레오시드이다.
본 발명은 화학식 (IA) 또는 (IB) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 안티센스 올리고뉴클레오티드를 제공한다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, 이때 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 LNA 뉴클레오시드이고, (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, A1 은 올리고뉴클레오티드의 5' 말단 뉴클레오시드이다.
본 발명은 화학식 (IA) 또는 (IB) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 안티센스 올리고뉴클레오티드를 제공한다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, 이때 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 2-O-MOE 뉴클레오시드이고, (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, A2 는 올리고뉴클레오티드의 3' 말단 뉴클레오시드이다.
본 발명은 화학식 (IA) 또는 (IB) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 안티센스 올리고뉴클레오티드를 제공한다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, 이때 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 2-O-MOE 뉴클레오시드이고, (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, A1 은 올리고뉴클레오티드의 5' 말단 뉴클레오시드이다.
본 발명은 화학식 (IA) 또는 (IB) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 안티센스 올리고뉴클레오티드를 제공한다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, 이때 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 2' 당 개질된 뉴클레오시드이고, (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, A2 는 올리고뉴클레오티드의 3' 말단 뉴클레오시드이다.
본 발명은 화학식 (IA) 또는 (IB) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 안티센스 올리고뉴클레오티드를 제공한다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, 이때 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 2' 당 개질된 뉴클레오시드이고, (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, A1 은 올리고뉴클레오티드의 5' 말단 뉴클레오시드이다.
2' 당 개질된 뉴클레오시드는 2'-알콕시-RNA, 2'-알콕시알콕시-RNA, 2'-아미노-DNA, 2'-플루오로-RNA, 2'-플루오로-ANA 및 LNA 뉴클레오시드로 이루어진 군으로부터 선택되는 2' 당 개질된 뉴클레오시드로 이루어진 군으로부터 독립적으로 선택될 수 있다.
본 발명은 화학식 (IA) 또는 (IB) 의 적어도 하나의 단일 가닥 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 안티센스 올리고뉴클레오티드를 제공한다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, 단일 가닥 올리고뉴클레오티드는 적어도 하나의 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결, (Sp, S) 또는 (Rp, R) 을 추가로 포함한다:

식 중, N1 및 N2 는 뉴클레오시드이다.
본 발명은 또한 세포에서 RNA 표적의 조절을 위한 단일 가닥 안티센스 올리고뉴클레오티드를 제공하고, 안티센스 올리고뉴클레오티드는 길이가 10 - 30 개의 뉴클레오티드인 인접 뉴클레오티드 서열을 포함하거나 이로 이루어지고, 인접 뉴클레오티드 서열은 하나 이상의 2'당 개질된 뉴클레오시드를 포함하고, 인접 뉴클레오티드 서열의 뉴클레오시드 사이에 존재하는 뉴클레오시드간 연결 중 적어도 하나는 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결이다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, R 은 수소 또는 포스페이트 보호기이다.
본 발명은 또한 세포에서 RNA 표적의 조절을 위한 단일 가닥 안티센스 올리고뉴클레오티드를 제공하고, 안티센스 올리고뉴클레오티드는 길이가 10 - 30 개의 뉴클레오티드인 인접 뉴클레오티드 서열을 포함하거나 이로 이루어지고, 인접 뉴클레오티드 서열은 하나 이상의 2'당 개질된 뉴클레오시드를 포함하고, 인접 뉴클레오티드 서열의 뉴클레오시드 사이에 존재하는 뉴클레오시드간 연결 중 적어도 하나는 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결이다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고; (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, 단일 가닥 안티센스 올리고뉴클레오티드는 pre-mRNA 표적 RNA 의 스플라이싱을 조절하는데 사용된다.
본 발명은 또한 세포에서 RNA 표적의 조절을 위한 단일 가닥 안티센스 올리고뉴클레오티드를 제공하고, 안티센스 올리고뉴클레오티드는 길이가 10 - 30 개의 뉴클레오티드인 인접 뉴클레오티드 서열을 포함하거나 이로 이루어지고, 인접 뉴클레오티드 서열은 하나 이상의 2'당 개질된 뉴클레오시드를 포함하고, 인접 뉴클레오티드 서열의 뉴클레오시드 사이에 존재하는 뉴클레오시드간 연결 중 적어도 하나는 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결이다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고; (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, 단일 가닥 안티센스 올리고뉴클레오티드는 긴 비-코팅 RNA 의 발현을 저해하는데 사용된다. 본 발명의 화합물에 의해 표적화될 수 있는 lncRNA 의 예는 WO 2012/065143 참조.
본 발명은 또한 세포에서 RNA 표적의 조절을 위한 단일 가닥 안티센스 올리고뉴클레오티드를 제공하고, 안티센스 올리고뉴클레오티드는 길이가 10 - 30 개의 뉴클레오티드인 인접 뉴클레오티드 서열을 포함하거나 이로 이루어지고, 인접 뉴클레오티드 서열은 하나 이상의 2'당 개질된 뉴클레오시드를 포함하고, 인접 뉴클레오티드 서열의 뉴클레오시드 사이에 존재하는 뉴클레오시드간 연결 중 적어도 하나는 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결이다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고; (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, 단일 가닥 안티센스 올리고뉴클레오티드는 인간 mRNA 또는 pre-mRNA 표적의 발현을 저해하는데 사용된다.
본 발명은 또한 세포에서 RNA 표적의 조절을 위한 단일 가닥 안티센스 올리고뉴클레오티드를 제공하고, 안티센스 올리고뉴클레오티드는 길이가 10 - 30 개의 뉴클레오티드인 인접 뉴클레오티드 서열을 포함하거나 이로 이루어지고, 인접 뉴클레오티드 서열은 하나 이상의 2'당 개질된 뉴클레오시드를 포함하고, 인접 뉴클레오티드 서열의 뉴클레오시드 사이에 존재하는 뉴클레오시드간 연결 중 적어도 하나는 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결이다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고; (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, 단일 가닥 안티센스 올리고뉴클레오티드는 바이러스 RNA 표적의 발현을 저해하는데 사용된다. 적합한 바이러스 RNA 표적은 예를 들어 HCV 또는 HBV 일 수 있다.
본 발명은 또한 세포에서 RNA 표적의 조절을 위한 단일 가닥 안티센스 올리고뉴클레오티드를 제공하고, 안티센스 올리고뉴클레오티드는 길이가 7 - 30 개의 뉴클레오티드인 인접 뉴클레오티드 서열을 포함하거나 이로 이루어지고, 인접 뉴클레오티드 서열은 하나 이상의 2'당 개질된 뉴클레오시드를 포함하고, 인접 뉴클레오티드 서열의 뉴클레오시드 사이에 존재하는 뉴클레오시드간 연결 중 적어도 하나는 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결이다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고; (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, 단일 가닥 안티센스 올리고뉴클레오티드는 마이크로RNA 의 발현을 저해하는데 사용된다.
RNA 표적, 예를 들어 pre-mRNA 표적, mRNA 표적, 바이러스 RNA 표적, 마이크로RNA 또는 긴 비-코딩 RNA 표적을 표적화하기 위해, 본 발명의 올리고뉴클레오티드는 표적 RNA 의 발현을 적합하게 저해할 수 있다. 이는 안티센스 올리고뉴클레오티드와 표적 RNA 사이의 상보성에 의해 달성된다. RNA 표적의 저해는 RNA 표적의 수준을 감소시키거나 RNA 표적의 기능을 차단함으로써 달성될 수 있다. RNA 표적의 RNA 저해는 적합하게 예를 들어 갭머의 사용을 통해 세포 RNAse, 예컨대 RNaseH 의 동원을 통해 달성될 수 있거나, 또는 비-뉴클레아제 매개 메커니즘, 예컨대 입체 차단 메커니즘 (예컨대 마이크로RNA 저해, pre-mRNA 의 스플라이스 조절, 또는 긴 비-코딩 RNA 와 크로마틴 사이의 상호 작용 차단) 을 통해 달성될 수 있다.
본 발명은 또한 본 발명에 따른 올리고뉴클레오티드의 제조 방법 및 특히 본 발명에 따른 올리고뉴클레오티드의 제조에 유용한 LNA 또는 MOE 뉴클레오시드 단량체에 관한 것이다.
본 발명은 본 발명에 따른 올리고뉴클레오티드의 약학적으로 허용되는 염, 또는 이의 컨쥬게이트, 특히 소듐 또는 포타슘 염 또는 암모늄 염을 제공한다.
본 발명은 올리고뉴클레오티드, 또는 이의 약학적으로 허용되는 염을 포함하는 컨쥬게이트, 및 임의로 링커 모이어티를 통해 상기 올리고뉴클레오티드 또는 상기 약학적으로 허용되는 염에 공유 부착된 적어도 하나의 컨쥬게이트 모이어티를 제공한다.
본 발명은 본 발명에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트 및 치료적으로 불활성인 담체를 포함하는 약학 조성물을 제공한다.
본 발명은 치료적으로 활성인 물질로서 사용하기 위한 본 발명에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트를 제공한다.
본 발명은 RNA 를 발현하는 세포에서 표적 RNA 의 조절 방법을 제공하고, 상기 방법은 유효량의 본 발명에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염, 컨쥬게이트 또는 조성물을 세포에 투여하는 단계를 포함하고, 올리고뉴클레오티드는 표적 RNA 에 상보적이다.
본 발명은 표적 pre-mRNA 를 발현하는 세포에서 표적 pre-RNA 의 스플라이싱 조절 방법을 제공하고, 상기 방법은 유효량의 본 발명에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염, 컨쥬게이트 또는 조성물을 세포에 투여하는 단계를 포함하고, 올리고뉴클레오티드는 표적 RNA 에 상보적이고 pre-mRNA 에서 스플라이싱 이벤트를 조절할 수 있다.
본 발명은 세포, 예컨대 인간 세포에서 pre-mRNA, mRNA, 또는 긴 비-코딩 RNA 의 저해를 위한 본 발명의 올리고뉴클레오티드, 약학적 염, 컨쥬게이트, 또는 조성물의 용도를 제공한다.
상기 방법 또는 용도는 시험관내 방법 또는 생체내 방법일 수 있다.
본 발명은 약제의 제조에서 본 발명의 올리고뉴클레오티드, 약학적 염, 컨쥬게이트, 또는 조성물의 용도를 제공한다.
본 발명은 단일 가닥 포스포로티오에이트 안티센스 올리고뉴클레오티드의 시험관내 또는 생체내 안정성을 향상시키기 위해 사용하기 위한 화학식 IA 또는 IB 의 포스포로디티오에이트 뉴클레오시드간 연결의 용도를 제공한다.
본 발명은 단일 가닥 포스포로티오에이트 안티센스 올리고뉴클레오티드의 시험관내 또는 생체내 작용 기간을 향상시키기 위해 사용하기 위한 화학식 IA 또는 IB 의 포스포로디티오에이트 뉴클레오시드간 연결의 용도를 제공한다.
본 발명은 단일 가닥 포스포로티오에이트 안티센스 올리고뉴클레오티드의 세포 흡수 또는 조직 분포를 향상시키기 위해 사용하기 위한 화학식 IA 또는 IB 의 포스포로디티오에이트 뉴클레오시드간 연결의 용도를 제공한다.
본 발명은 골격근, 심장, 망막 상피 세포를 포함하는 상피 세포 (예를 들어 Htra1 표적화 화합물에 대하여), 간, 신장, 또는 비장으로 이루어진 군으로부터 선택되는 조직에의 단일 가닥 포스포로티오에이트 안티센스 올리고뉴클레오티드의 흡수를 향상시키기 위해 사용하기 위한 화학식 IA 또는 IB 의 포스포로디티오에이트 뉴클레오시드간 연결의 용도를 제공한다.
생체내 사용을 위해 단일 가닥 포스포로티오에이트 안티센스 올리고뉴클레오티드는 치료용 올리고뉴클레오티드일 수 있다.
도 1-4 는 본 발명에 따른 올리고뉴클레오티드의 투여 24 시간 및 74 시간 후 1차 랫트 간세포에서의 표적 mRNA 수준을 도시한다.
도 1 은 갭에서 본 발명에 따른 단일 포스포로디티오에이트 뉴클레오시드 간 연결을 갖는 올리고뉴클레오티드 갭머의 24 및 74 시간의 투여 후 1차 랫트 간세포에서의 표적 mRNA 수준을 보여준다.
도 2 는 갭에서 본 발명에 따른 다수의 포스포로디티오에이트 뉴클레오시드간 연결을 갖는 올리고뉴클레오티드 갭머의 24 및 74 시간의 투여 후 1차 랫트 간세포에서의 표적 mRNA 수준을 보여준다.
도 3 은 갭에서 본 발명에 따른 다수의 포스포로디티오에이트 뉴클레오시드간 연결을 갖는 올리고뉴클레오티드 갭머의 24 및 74 시간의 투여 후 1차 랫트 간세포에서의 표적 mRNA 수준을 보여준다.
도 4 는 플랭크에서 본 발명에 따른 포스포로디티오에이트 뉴클레오시드간 연결을 갖는 올리고뉴클레오티드 갭머의 24 및 74 시간의 투여 후 1차 랫트 간세포에서의 표적 mRNA 수준을 보여준다.
도 5 는 RNA 및 DNA 에 하이브리드화된 본 발명에 따른 포스포로디티오에이트 뉴클레오시드간 연결을 함유하는 올리고뉴클레오티드의 열 용융 (Tm) 을 나타낸다.
도 6 은 랫트 혈청에서 본 발명에 따른 포스포로디티오에이트 뉴클레오시드간 연결을 함유하는 올리고뉴클레오티드의 안정성을 나타낸다.
도 7: 갭머의 갭 및 플랭크 영역에서 아카이랄 포스포디티오에이트의 탐색 - 1차 랫트 간세포의 처리 후 잔류 mRNA 수준.
도 8: 갭머의 갭 영역에서 아카이랄 포스포디티오에이트의 위치 의존성 및 최적화 탐색 - 1차 랫트 간세포의 처리 후 잔류 mRNA 수준.
도 9A 및 9B: 갭머의 갭 영역에서 아카이랄 포스포디티오에이트의 탐색 - 세포 흡수에 대한 효과.
도 10A 및 10B: 갭머의 플랭크 영역에의 아카이랄 포스포로디티오에이트의 도입은 증가된 효능을 갖는 포스포로티오에이트 로드 사이의 상관 관계와 함께 증가된 효능을 제공한다 (4 연결 > 3 연결 >2 연결 >1 연결>플랭크에 포스포로디티오에이트 연결 없음).
도 11: 상이한 세포 유형에서의 IC50 값
도 12: 3' 말단 보호된 LNA 올리고뉴클레오티드의 시험관내 랫트 혈청 안정성.
도 13: 플랭크 및 갭 영역에 아카이랄 포스포로디티오에이트 연결을 함유하는 갭머의 생체내 평가 - 표적 저해.
도 14A: 플랭크 및 갭 영역에 아카이랄 포스포로디티오에이트 연결을 함유하는 갭머의 생체내 평가 - 조직 흡수.
도 14B: 플랭크 및 갭 영역에 아카이랄 포스포로디티오에이트 연결을 함유하는 갭머의 생체내 평가 - 간/신장 비.
도 15A 및 15B: 플랭크 및 갭 영역에 아카이랄 포스포로디티오에이트 연결을 함유하는 갭머의 생체내 평가 - 대사 산물 분석.
도 16: 아카이랄 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 안티센스 올리고뉴클레오티드에 의한 지속되는 작용 기간은 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결과의 조합에 의해 추가로 향상될 수 있다.
도 17A: MALAT-1 을 표적으로 하는 아카이랄 포스포로디티오에이트 갭머의 시험관내 EC50 측정.
도 17B: MALAT-1 을 표적으로 하는 아카이랄 포스포로디티오에이트 갭머의 생체내 효능.
도 17C: MALAT-1 을 표적으로 하는 아카이랄 포스포로디티오에이트 갭머의 생체내 연구 - 조직 함량
도 18A: ApoB 를 표적으로 하는 아카이랄 모노포스포로티오에이트 개질된 갭머 올리고뉴클레오티드의 시험관내 연구. 활성 데이터.
도 18B: ApoB 를 표적으로 하는 아카이랄 모노포스포로티오에이트 개질된 갭머 올리고뉴클레오티드의 시험관내 연구. 세포 함량 데이터.
도 19A: ApoB 를 표적으로 하는 카이랄 포스포로디티오에이트 개질된 갭머 올리고뉴클레오티드의 시험관내 연구. 활성 데이터.
도 19B: ApoB 를 표적으로 하는 카이랄 포스포로디티오에이트 개질된 갭머 올리고뉴클레오티드의 시험관내 연구. 세포 함량 데이터.
도 20: TNFRSF1B 의 3'스플라이스 부위를 표적으로 하는 스플라이스-스위칭 올리고뉴클레오티드에 존재하는 아카이랄 포스포로디티오에이트 (P2S) 뉴클레오시드간 연결의 효과. 인간 Colo 205 세포를 96 웰 플레이트에 시딩하고 각각 5 μM (A) 및 25 μM (B) 의 올리고에 적용하였다. 엑손 7 스키핑의 백분율을 엑손 6-8 접합부를 표적으로 하는 프로브를 사용하여 액적 디지털 PCR 에 의해 분석하고 엑손 2-3 을 표적으로 하는 검정에 의해 TNFRSF1B 의 총량과 비교하였다. SSO#26 은 모체 올리고이고, SSO#27 은 TNFRSF1B 를 표적으로 하지 않는 음성 대조군이다.
도 21: S1 뉴클레아제를 사용한 안정성 분석. 디티오에이트 함유 올리고를 각각 30 분 및 120 분 동안 S1 뉴클레아제와 배양하였다. 올리고를 15% TBE-우레아 겔에서 시각화하였다. 온전한 올리고 (SSO#14) 의 이동의 마커로서 S1 뉴클레아제에 적용하지 않고 포함시켰다.
도 1 은 갭에서 본 발명에 따른 단일 포스포로디티오에이트 뉴클레오시드 간 연결을 갖는 올리고뉴클레오티드 갭머의 24 및 74 시간의 투여 후 1차 랫트 간세포에서의 표적 mRNA 수준을 보여준다.
도 2 는 갭에서 본 발명에 따른 다수의 포스포로디티오에이트 뉴클레오시드간 연결을 갖는 올리고뉴클레오티드 갭머의 24 및 74 시간의 투여 후 1차 랫트 간세포에서의 표적 mRNA 수준을 보여준다.
도 3 은 갭에서 본 발명에 따른 다수의 포스포로디티오에이트 뉴클레오시드간 연결을 갖는 올리고뉴클레오티드 갭머의 24 및 74 시간의 투여 후 1차 랫트 간세포에서의 표적 mRNA 수준을 보여준다.
도 4 는 플랭크에서 본 발명에 따른 포스포로디티오에이트 뉴클레오시드간 연결을 갖는 올리고뉴클레오티드 갭머의 24 및 74 시간의 투여 후 1차 랫트 간세포에서의 표적 mRNA 수준을 보여준다.
도 5 는 RNA 및 DNA 에 하이브리드화된 본 발명에 따른 포스포로디티오에이트 뉴클레오시드간 연결을 함유하는 올리고뉴클레오티드의 열 용융 (Tm) 을 나타낸다.
도 6 은 랫트 혈청에서 본 발명에 따른 포스포로디티오에이트 뉴클레오시드간 연결을 함유하는 올리고뉴클레오티드의 안정성을 나타낸다.
도 7: 갭머의 갭 및 플랭크 영역에서 아카이랄 포스포디티오에이트의 탐색 - 1차 랫트 간세포의 처리 후 잔류 mRNA 수준.
도 8: 갭머의 갭 영역에서 아카이랄 포스포디티오에이트의 위치 의존성 및 최적화 탐색 - 1차 랫트 간세포의 처리 후 잔류 mRNA 수준.
도 9A 및 9B: 갭머의 갭 영역에서 아카이랄 포스포디티오에이트의 탐색 - 세포 흡수에 대한 효과.
도 10A 및 10B: 갭머의 플랭크 영역에의 아카이랄 포스포로디티오에이트의 도입은 증가된 효능을 갖는 포스포로티오에이트 로드 사이의 상관 관계와 함께 증가된 효능을 제공한다 (4 연결 > 3 연결 >2 연결 >1 연결>플랭크에 포스포로디티오에이트 연결 없음).
도 11: 상이한 세포 유형에서의 IC50 값
도 12: 3' 말단 보호된 LNA 올리고뉴클레오티드의 시험관내 랫트 혈청 안정성.
도 13: 플랭크 및 갭 영역에 아카이랄 포스포로디티오에이트 연결을 함유하는 갭머의 생체내 평가 - 표적 저해.
도 14A: 플랭크 및 갭 영역에 아카이랄 포스포로디티오에이트 연결을 함유하는 갭머의 생체내 평가 - 조직 흡수.
도 14B: 플랭크 및 갭 영역에 아카이랄 포스포로디티오에이트 연결을 함유하는 갭머의 생체내 평가 - 간/신장 비.
도 15A 및 15B: 플랭크 및 갭 영역에 아카이랄 포스포로디티오에이트 연결을 함유하는 갭머의 생체내 평가 - 대사 산물 분석.
도 16: 아카이랄 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 안티센스 올리고뉴클레오티드에 의한 지속되는 작용 기간은 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결과의 조합에 의해 추가로 향상될 수 있다.
도 17A: MALAT-1 을 표적으로 하는 아카이랄 포스포로디티오에이트 갭머의 시험관내 EC50 측정.
도 17B: MALAT-1 을 표적으로 하는 아카이랄 포스포로디티오에이트 갭머의 생체내 효능.
도 17C: MALAT-1 을 표적으로 하는 아카이랄 포스포로디티오에이트 갭머의 생체내 연구 - 조직 함량
도 18A: ApoB 를 표적으로 하는 아카이랄 모노포스포로티오에이트 개질된 갭머 올리고뉴클레오티드의 시험관내 연구. 활성 데이터.
도 18B: ApoB 를 표적으로 하는 아카이랄 모노포스포로티오에이트 개질된 갭머 올리고뉴클레오티드의 시험관내 연구. 세포 함량 데이터.
도 19A: ApoB 를 표적으로 하는 카이랄 포스포로디티오에이트 개질된 갭머 올리고뉴클레오티드의 시험관내 연구. 활성 데이터.
도 19B: ApoB 를 표적으로 하는 카이랄 포스포로디티오에이트 개질된 갭머 올리고뉴클레오티드의 시험관내 연구. 세포 함량 데이터.
도 20: TNFRSF1B 의 3'스플라이스 부위를 표적으로 하는 스플라이스-스위칭 올리고뉴클레오티드에 존재하는 아카이랄 포스포로디티오에이트 (P2S) 뉴클레오시드간 연결의 효과. 인간 Colo 205 세포를 96 웰 플레이트에 시딩하고 각각 5 μM (A) 및 25 μM (B) 의 올리고에 적용하였다. 엑손 7 스키핑의 백분율을 엑손 6-8 접합부를 표적으로 하는 프로브를 사용하여 액적 디지털 PCR 에 의해 분석하고 엑손 2-3 을 표적으로 하는 검정에 의해 TNFRSF1B 의 총량과 비교하였다. SSO#26 은 모체 올리고이고, SSO#27 은 TNFRSF1B 를 표적으로 하지 않는 음성 대조군이다.
도 21: S1 뉴클레아제를 사용한 안정성 분석. 디티오에이트 함유 올리고를 각각 30 분 및 120 분 동안 S1 뉴클레아제와 배양하였다. 올리고를 15% TBE-우레아 겔에서 시각화하였다. 온전한 올리고 (SSO#14) 의 이동의 마커로서 S1 뉴클레아제에 적용하지 않고 포함시켰다.
정의
본 명세서에서 용어 "알킬" 은 단독으로 또는 조합으로 1 내지 8 개의 탄소 원자를 갖는 직쇄 또는 분지쇄 알킬 기, 특히 1 내지 6 개의 탄소 원자를 갖는 직쇄 또는 분지쇄 알킬 기 및 보다 특히 1 내지 4 개의 탄소 원자를 갖는 직쇄 또는 분지쇄 알킬 기를 의미한다. 직쇄 및 분지쇄 C1-C8 알킬 기의 예는 메틸, 에틸, 프로필, 이소프로필, 부틸, 이소부틸, tert.-부틸, 이성질체 펜틸, 이성질체 헥실, 이성질체 헵틸 및 이성질체 옥틸, 특히 메틸, 에틸, 프로필, 부틸 및 펜틸이다. 알킬의 특정 예는 메틸, 에틸 및 프로필이다.
용어 "시클로알킬" 은 단독으로 또는 조합으로 3 내지 8 개의 탄소 원자를 갖는 시클로알킬 고리 및 특히 3 내지 6 개의 탄소 원자를 갖는 시클로알킬 고리를 의미한다. 시클로알킬의 예는 시클로프로필, 시클로부틸, 시클로펜틸, 시클로헥실, 시클로헵틸 및 시클로옥틸, 보다 특히 시클로프로필 및 시클로부틸이다. "시클로알킬" 의 특정 예는 시클로프로필이다.
용어 "알콕시" 는 단독으로 또는 조합으로 화학식 알킬-O- 의 기를 의미하며, 여기서 용어 "알킬" 은 메톡시, 에톡시, n-프로폭시, 이소프로폭시, n-부톡시, 이소부톡시, sec.부톡시 및 tert.부톡시와 같은 앞서 주어진 의미를 갖는다. 특정 "알콕시" 는 메톡시 및 에톡시이다. 메톡시에톡시는 "알콕시알콕시" 의 특정 예이다.
용어 "옥시" 는 단독으로 또는 조합으로 -O- 기를 의미한다.
용어 "알케닐" 은 단독으로 또는 조합으로 올레핀 결합 및 8 개 이하, 바람직하게는 6 개 이하, 특히 바람직하게는 4 개 이하의 탄소 원자를 포함하는 직쇄 또는 분지쇄 탄화수소 잔기를 의미한다. 알케닐 기의 예는 에테닐, 1-프로페닐, 2-프로페닐, 이소프로페닐, 1-부테닐, 2-부테닐, 3-부테닐 및 이소부테닐이다.
용어 "알키닐" 은 단독으로 또는 조합으로 삼중 결합 및 8 개 이하, 특히 2 개 이하의 탄소 원자를 포함하는 직쇄 또는 분지쇄 탄화수소 잔기를 의미한다.
용어 "할로겐" 또는 "할로" 는 단독으로 또는 조합으로 불소, 염소, 브롬 또는 요요드 및 특히 불소, 염소 또는 브롬, 보다 특히 불소를 의미한다. 용어 "할로" 는 다른 기와 조합으로 적어도 1 개의 할로겐, 특히 1 내지 5 개의 할로겐, 특히 1 내지 4 개의 할로겐, 즉 1, 2, 3 또는 4 개의 할로겐으로 치환된 상기 기의 치환을 의미한다.
용어 "할로알킬" 은 단독으로 또는 조합으로 적어도 1 개의 할로겐으로 치환된, 특히 1 내지 5 개의 할로겐, 특히 1 내지 3 개의 할로겐으로 치환된 알킬 기를 의미한다. 할로알킬의 예는 모노플루오로-, 디플루오로- 또는 트리플루오로-메틸, -에틸 또는 -프로필, 예를 들어 3,3,3-트리플루오로프로필, 2-플루오로에틸, 2,2,2-트리플루오로에틸, 플루오로메틸 또는 트리플루오로메틸을 포함한다. 플루오로메틸, 디플루오로메틸 및 트리플루오로메틸이 특정 "할로알킬" 이다.
용어 "할로시클로알킬" 은 단독으로 또는 조합으로 적어도 1 개의 할로겐으로 치환된, 특히 1 내지 5 개의 할로겐, 특히 1 내지 3 개의 할로겐으로 치환된 상기 정의된 바와 같은 시클로알킬 기를 의미한다. "할로시클로알킬" 의 특정 예는 할로시클로프로필, 특히 플루오로시클로프로필, 디플루오로시클로프로필 및 트리플루오로시클로프로필이다.
용어 "하이드록실" 및 "하이드록시" 는 단독으로 또는 조합으로 -OH 기를 의미한다.
용어 "티오하이드록실" 및 "티오하이드록시" 는 단독으로 또는 조합으로 -SH 기를 의미한다.
용어 "카르보닐" 은 단독으로 또는 조합으로 -C(O)- 기를 의미한다.
용어 "카복시" 또는 "카르복실" 은 단독으로 또는 조합으로 -COOH 기를 의미한다.
용어 "아미노" 는 단독으로 또는 조합으로 1차 아미노 기 (-NH2), 2차 아미노 기 (-NH-), 또는 3차 아미노 기 (-N-) 를 의미한다.
용어 "알킬아미노" 는 단독으로 또는 조합으로 상기 정의된 바와 같은 1 또는 2 개의 알킬 기로 치환된 상기 정의된 바와 같은 아미노 기를 의미한다.
용어 "설포닐" 은 단독으로 또는 조합으로 -SO2 기를 의미한다.
용어 "설피닐" 은 단독으로 또는 조합으로 -SO- 기를 의미한다.
용어 "설파닐" 은 단독으로 또는 조합으로 -S- 기를 의미한다.
용어 "시아노" 는 단독으로 또는 조합으로 -CN 기를 의미한다.
용어 "아지도" 는 단독으로 또는 조합으로 -N3 기를 의미한다.
용어 "니트로" 는 단독으로 또는 조합으로 NO2 기를 의미한다.
용어 "포르밀" 은 단독으로 또는 조합으로 -C(O)H 기를 의미한다.
용어 "카르바모일" 은 단독으로 또는 조합으로 -C(O)NH2 기를 의미한다.
용어 "카바미도" 는 단독으로 또는 조합으로 -NH-C(O)-NH2 기를 의미한다.
용어 "아릴" 은 단독으로 또는 조합으로 할로겐, 하이드록실, 알킬, 알케닐, 알키닐, 알콕시, 알콕시알킬, 알케닐옥시, 카르복실, 알콕시카르보닐, 알킬카르보닐 및 포르밀로부터 독립적으로 선택된 1 내지 3 개의 치환기로 임의 치환된 6 내지 10 개의 탄소 고리 원자를 포함하는 1가 방향족 카르보시클릭 모노- 또는 바이시클릭 고리 시스템을 의미한다. 아릴의 예는 페닐 및 나프틸, 특히 페닐을 포함한다.
용어 "헤테로아릴" 은 단독으로 또는 조합으로 할로겐, 하이드록실, 알킬, 알케닐, 알키닐, 알콕시, 알콕시알킬, 알케닐옥시, 카르복실, 알콕시카르보닐, 알킬카르보닐 및 포르밀로부터 독립적으로 선택된 1 내지 3 개의 치환기로 임의 치환된, N, O 및 S 에서 선택되는 1, 2, 3 또는 4 개의 헤테로원자를 포함하며, 나머지 고리 원자는 탄소인, 5 내지 12 개의 고리 원자의 1가 방향족 헤테로시클릭 모노- 또는 바이시클릭 고리 시스템을 의미한다. 헤테로아릴의 예는 피롤릴, 푸라닐, 티에닐, 이미다졸릴, 옥사졸릴, 티아졸릴, 트리아졸릴, 옥사디아졸릴, 티아디아졸릴, 테트라졸릴, 피리디닐, 피라지닐, 피라졸릴, 피리다지닐, 피리미디닐, 트리아지닐, 아제피닐, 디아제피닐, 이속사졸릴, 벤조푸라닐, 이소티아졸릴, 벤조티에닐, 인돌릴, 이소인돌릴, 이소벤조푸라닐, 벤즈이미다졸릴, 벤족사졸릴, 벤조이속사졸릴, 벤조티아졸릴, 벤조이소티아졸릴, 벤조옥사디아졸릴, 벤조티아디아졸릴, 벤조트리아졸릴, 푸리닐, 퀴놀리닐, 이소퀴놀리닐, 푸리닐, 퀴놀리닐, 이소퀴놀리닐, 퀴나졸리닐, 퀴녹살리닐, 카바졸릴 또는 아크리디닐을 포함한다.
용어 "헤테로시클릴" 은 단독으로 또는 조합으로 할로겐, 하이드록실, 알킬, 알케닐, 알키닐, 알콕시, 알콕시알킬, 알케닐옥시, 카르복실, 알콕시카르보닐, 알킬카르보닐 및 포르밀로부터 독립적으로 선택된 1 내지 3 개의 치환기로 임의 치환된, N, O 및 S 에서 선택되는 1, 2, 3 또는 4 개의 헤테로원자이며, 나머지 고리 원자는 탄소인, 4 내지 12, 특히 4 내지 9 개의 고리 원자의 1가 포화 또는 부분 불포화 모노- 또는 바이시클릭 고리 시스템을 의미한다. 모노시클릭 포화 헤테로시클릴의 예는 아제티디닐, 피롤리디닐, 테트라하이드로푸라닐, 테트라하이드로-티에닐, 피라졸리디닐, 이미다졸리디닐, 옥사졸리디닐, 이속사졸리디닐, 티아졸리디닐, 피페리디닐, 테트라하이드로피라닐, 테트라하이드로티오피라닐, 피페라지닐, 모르폴리닐, 티오모르폴리닐, 1,1-디옥소-티오모르폴린-4-일, 아제파닐, 디아제파닐, 호모피페라지닐, 또는 옥사제파닐이다. 바이시클릭 포화 헤테로시클로알킬의 예는 8-아자-바이시클로[3.2.1]옥틸, 퀴누클리디닐, 8-옥사-3-아자-바이시클로[3.2.1]옥틸, 9-아자-바이시클로[3.3.1]노닐, 3-옥사-9-아자-바이시클로[3.3.1]노닐, 또는 3-티아-9-아자-바이시클로[3.3.1]노닐이다. 부분 불포화 헤테로시클로알킬의 예는 디하이드로푸릴, 이미다졸리닐, 디하이드로-옥사졸릴, 테트라하이드로-피리디닐 또는 디하이드로피라닐이다.
용어 "약학적으로 허용되는 염" 은 생물학적으로 또는 그 외에 바람직하지 않은 유리 염기 또는 유리 산의 생물학적 효과 및 특성을 보유하는 염을 지칭한다. 염은 무기 산, 예컨대 염산, 브롬화수소산, 황산, 질산, 인산, 특히 염산, 및 유기 산, 예컨대 아세트산, 프로피온산, 글리콜산, 피루브산, 옥살산, 말레산, 말론산, 숙신산, 푸마르산, 타르타르산, 시트르산, 벤조산, 신남산, 만델산, 메탄설폰산, 에탄설폰산, p-톨루엔설폰산, 살리실산, N-아세틸 시스테인에 의해 형성된다. 또한 이들 염은 유리 산에 무기 염기 또는 유기 염기를 첨가하여 제조될 수 있다. 무기 염기로부터 유도된 염은 소듐, 포타슘, 리튬, 암모늄, 칼슘, 마그네슘 염을 포함하지만 이에 제한되지는 않는다. 유기 염기로부터 유도된 염은 1차, 2차, 및 3차 아민, 자연 발생 치환된 아민을 포함하는 치환된 아민, 시클릭 아민 및 염기성 이온 교환 수지, 예컨대 이소프로필아민, 트리메틸아민, 디에틸아민, 트리에틸아민, 트리프로필아민, 에탄올아민, 리신, 아르기닌, N-에틸피페리딘, 피페리딘, 폴리아민 수지의 염을 포함하지만 이에 제한되지는 않는다. 본 발명의 올리고뉴클레오티드는 또한 양쪽성 이온의 형태로 존재할 수 있다. 본 발명의 특히 바람직한 약학적으로 허용되는 염은 소듐, 리튬, 포타슘 및 트리알킬암모늄 염이다.
용어 "보호기" 는 단독으로 또는 조합으로 다작용성 화합물에서 반응성 부위를 선택적으로 차단하여 화학 반응이 다른 비보호된 반응성 부위에서 선택적으로 수행될 수 있게 하는 기를 의미한다. 보호기는 제거될 수 있다. 예시적인 보호기는 아미노-보호기, 카복시-보호기 또는 하이드록시-보호기이다.
"포스페이트 보호기" 는 포스페이트 기의 보호기이다. 포스페이트 보호기의 예는 2-시아노에틸 및 메틸이다. 포스페이트 보호기의 특정 예는 2-시아노에틸이다.
"하이드록실 보호기" 는 하이드록실 기의 보호기이며 또한 티올 기를 보호하는데 사용된다. 하이드록실 보호기의 예는 아세틸 (Ac), 벤조일 (Bz), 벤질 (Bn), β-메톡시에톡시메틸 에테르 (MEM), 디메톡시트리틸 (또는 비스-(4-메톡시페닐)페닐메틸) (DMT), 트리메톡시트리틸 (또는 트리스-(4-메톡시페닐)페닐메틸) (TMT), 메톡시메틸 에테르 (MOM), 메톡시트리틸 [(4-메톡시페닐)디페닐메틸 (MMT), p-메톡시벤질 에테르 (PMB), 메틸티오메틸 에테르, 피발로일 (Piv), 테트라하이드로피라닐 (THP), 테트라하이드로푸란 (THF), 트리틸 또는 트리페닐메틸 (Tr), 실릴 에테르 (예를 들어 트리메틸실릴 (TMS), tert-부틸디메틸실릴 (TBDMS), 트리-이소-프로필실릴옥시메틸 (TOM) 및 트리이소프로필실릴 (TIPS) 에테르), 메틸 에테르 및 에톡시에틸 에테르 (EE) 이다. 하이드록실 보호기의 특정 예는 DMT 및 TMT, 특히 DMT 이다.
"티오하이드록실 보호기" 는 티오하이드록실 기의 보호기이다. 티오하이드록실 보호기의 예는 "하이드록실 보호기" 의 것들이다.
본 발명의 출발 물질 또는 화합물 중 하나가 하나 이상의 반응 단계의 반응 조건 하에서 안정하지 않거나 반응성인 하나 이상의 작용기를 함유하는 경우, 적절한 보호기 (예를 들어 "Protective Groups in Organic Chemistry" by T. W. Greene and P. G. M. Wuts, 3rd Ed., 1999, Wiley, New York 에 기재되어 있는 바와 같음) 가 당업계에 익히 공지된 방법을 적용하는 중요한 단계 전에 도입될 수 있다. 이러한 보호기는 문헌에 기재된 표준 방법을 사용하여 합성의 후기 단계에서 제거될 수 있다. 보호기의 예는 tert-부톡시카르보닐 (Boc), 9-플루오레닐메틸 카바메이트 (Fmoc), 2-트리메틸실릴에틸 카바메이트 (Teoc), 카르보벤질옥시 (Cbz) 및 p-메톡시벤질옥시카르보닐 (Moz) 이다.
본원에 기재된 화합물은 여러 비대칭 중심을 함유할 수 있고 광학적으로 순수한 거울상 이성질체, 거울상 이성질체의 혼합물, 예를 들어 라세미체, 부분 입체 이성질체의 혼합물, 부분 입체 이성질체 라세미체 또는 부분 입체 이성질체 라세미체의 혼합물로 존재할 수 있다.
올리고뉴클레오티드
본원에서 사용된 용어 "올리고뉴클레오티드" 는 2 개 이상의 공유 결합으로 연결된 뉴클레오시드를 포함하는 분자로서 당업자에 의해 일반적으로 이해되는 바와 같이 정의된다. 이러한 공유 결합으로 연결된 뉴클레오시드는 또한 핵산 분자 또는 올리고머로 지칭될 수 있다. 올리고뉴클레오티드는 통상적으로 고체-상 화학 합성 이후 정제에 의해 실험실에서 제조된다. 올리고뉴클레오티드의 서열을 언급할 때, 공유 결합으로 연결된 뉴클레오티드 또는 뉴클레오시드의 핵염기 모이어티, 또는 이의 개질물의 서열 또는 순서가 언급된다. 본 발명의 올리고뉴클레오티드는 인공적이고, 화학적으로 합성되고, 전형적으로 정제 또는 단리된다. 본 발명의 올리고뉴클레오티드는 하나 이상의 개질된 뉴클레오시드 또는 뉴클레오티드를 포함할 수 있다.
안티센스 올리고뉴클레오티드
본원에서 사용된 용어 "안티센스 올리고뉴클레오티드" 는 표적 핵산, 특히 표적 핵산 상의 인접 서열에 대한 하이브리드화에 의한 표적 유전자의 발현을 조절할 수 있는 올리고뉴클레오티드로서 정의된다. 안티센스 올리고뉴클레오티드는 본질적으로 이중 가닥이 아니므로 siRNA 또는 shRNA 가 아니다. 바람직하게는, 본 발명의 안티센스 올리고뉴클레오티드는 단일 가닥이다. 본 발명의 단일 가닥 올리고뉴클레오티드는, 내부 또는 상호 자기 상보성(intra or inter self complementarity)의 정도가 올리고뉴클레오티드의 전체 길이에 걸쳐 50% 미만인 한, 헤어핀 또는 분자간 듀플렉스 구조 (동일한 올리고뉴클레오티드 분자 2 개 사이의 듀플렉스) 를 형성할 수 있는 것으로 이해된다.
발현의 조절
본원에서 사용된 용어 "발현의 조절" 은 표적 핵산의 발현을 변화시키거나 표적 핵산의 수준을 변화시키는 올리고뉴클레오티드의 능력에 대한 전반적인 용어로 이해되어야 한다. 발현의 조절은 올리고뉴클레오티드의 투여 이전의 표적 핵산의 발현 또는 수준과 비교하여 결정될 수 있거나, 발현의 조절은 본 발명의 올리고뉴클레오티드가 투여되지 않은 대조군 실험을 참조하여 결정될 수 있다. 일반적으로 대조군은 염수 조성물로 처리된 개체 또는 표적 세포 또는 비-표적화 올리고뉴클레오티드 (모의 (mock)) 로 처리된 개체 또는 표적 세포인 것으로 이해된다.
조절의 한 유형은 예를 들어 표적 핵산의 분해 (예를 들어 RNaseH1 매개 분해를 통해) 또는 전사의 차단에 의해 표적 핵산의 발현을 저해, 하향-조정, 감소, 억제, 제거, 중단, 차단, 방지, 경감, 저하, 회피 또는 종료시키는 올리고뉴클레오티드의 능력이다. 조절의 또 다른 유형은 예를 들어 표적 pre-mRNA 에서의 스플라이싱 이벤트의 조절, 또는 mRNA 의 마이크로RNA 억제와 같은 저해 메커니즘의 차단을 통해 표적 RNA 의 발현을 회복, 증가 또는 향상시키는 올리고뉴클레오티드의 능력이다.
인접 뉴클레오티드 서열
용어 "인접 뉴클레오티드 서열" 은 표적 핵산에 상보적인, 예컨대 완전히 상보적인 올리고뉴클레오티드의 영역을 지칭한다. 상기 용어는 본원에서 용어 "인접 핵염기 서열" 및 용어 "올리고뉴클레오티드 모티프 서열" 과 상호 교환적으로 사용된다. 일부 구현예에서 올리고뉴클레오티드의 모든 뉴클레오티드는 인접 뉴클레오티드 서열을 구성한다. 일부 구현예에서 올리고뉴클레오티드는 인접 뉴클레오티드 서열, 예컨대 F-G-F' 갭머 영역을 포함하고, 추가의 뉴클레오티드(들), 예를 들어 작용기를 인접 뉴클레오티드 서열에 부착시키는데 사용될 수 있는 뉴클레오티드 링커 영역, 예를 들어 영역 D 또는 D' 를 임의로 포함할 수 있다. 뉴클레오티드 링커 영역은 표적 핵산에 상보적일 수 있거나 그렇지 않을 수 있다. 본원에서 언급된 안티센스 올리고뉴클레오티드 믹스머는 인접 뉴클레오티드 서열을 포함할 수 있거나 이로 이루어질 수 있다.
뉴클레오티드
뉴클레오티드는 올리고뉴클레오티드 및 폴리뉴클레오티드의 빌딩 블록이고, 본 발명의 목적 상, 자연 발생 및 비-자연 발생 뉴클레오티드 둘 모두를 포함한다. 자연에서, 뉴클레오티드, 예컨대 DNA 및 RNA 뉴클레오티드는 리보오스 당 모이어티, 핵염기 모이어티 및 하나 이상의 포스페이트 기 (이는 뉴클레오시드에는 없음) 를 포함한다. 뉴클레오시드 및 뉴클레오티드는 또한 "단위" 또는 "단량체" 로 상호 교환적으로 지칭될 수 있다.
개질된 뉴클레오시드
본원에서 사용되는 용어 "개질된 뉴클레오시드" 또는 "뉴클레오시드 개질" 은 당 모이어티 또는 (핵)염기 모이어티의 하나 이상의 개질의 도입에 의해 동등한 DNA 또는 RNA 뉴클레오시드와 비교하여 개질된 뉴클레오시드를 지칭한다. 바람직한 구현예에서 개질된 뉴클레오시드는 개질된 당 모이어티를 포함한다. 용어 개질된 뉴클레오시드는 또한 본원에서 용어 "뉴클레오시드 유사체" 또는 개질된 "단위" 또는 개질된 "단량체" 와 상호 교환적으로 사용될 수 있다. 개질되지 않은 DNA 또는 RNA 당 모이어티는를 갖는 뉴클레오시드는 본원에서 DNA 또는 RNA 뉴클레오시드로 지칭된다. DNA 또는 RNA 뉴클레오시드의 염기 영역에서 개질된 뉴클레오시드는 이들이 왓슨 크릭 염기쌍을 허용하는 경우 여전히 일반적으로 DNA 또는 RNA 로 지칭된다.
개질된 뉴클레오시드간 연결
용어 "개질된 뉴클레오시드간 연결" 은 2 개의 뉴클레오시드를 함께 공유결합적으로 커플링시키는 포스포디에스테르 (PO) 연결 이외의 연결로서 당업자에 의해 일반적으로 이해되는 바와 같이 정의된다. 따라서, 본 발명의 올리고뉴클레오티드는 개질된 뉴클레오시드간 연결을 포함할 수 있다. 일부 구현예에서, 개질된 뉴클레오시드간 연결은 포스포디에스테르 연결에 비해 올리고뉴클레오티드의 뉴클레아제 내성을 증가시킨다. 자연 발생 올리고뉴클레오티드의 경우, 뉴클레오시드간 연결은 인접 뉴클레오시드 사이에 포스포디에스테르 결합을 발생시키는 포스페이트 기를 포함한다. 개질된 뉴클레오시드간 연결은 생체내 사용을 위한 올리고뉴클레오티드를 안정화시키는데 있어서 특히 유용하고, 본 발명의 올리고뉴클레오티드에서의 DNA 또는 RNA 뉴클레오시드의 영역에서, 예를 들어 갭머 올리고뉴클레오티드의 갭 영역 내에서, 뿐만 아니라 개질된 뉴클레오시드의 영역, 예컨대 영역 F 및 F' 에서 뉴클레아제 절단에 대해 보호하는 역할을 할 수 있다.
일 구현예에서, 올리고뉴클레오티드는 예를 들어 뉴클레아제 공격에 대해 더 내성인 하나 이상의 개질된 뉴클레오시드간 연결과 같은 천연 포스포디에스테르로부터 개질된 하나 이상의 뉴클레오시드간 연결을 포함한다. 뉴클레아제 내성은 혈청 중 올리고뉴클레오티드의 배양에 의해 또는 뉴클레아제 내성 검정 (예를 들어 뱀독 포스포디에스테라제 (SVPD)) 을 사용하여 측정될 수 있는데, 둘 모두는 당업계에 공지되어 있다. 올리고뉴클레오티드의 뉴클레아제 내성을 향상시킬 수 있는 뉴클레오시드간 연결은 뉴클레아제 내성 뉴클레오시드간 연결로 지칭된다. 일부 구현예에서 올리고뉴클레오티드, 또는 이의 인접 뉴클레오티드 서열에서 뉴클레오시드간 연결 중 적어도 50% 가 개질되고, 올리고뉴클레오티드, 또는 이의 인접 뉴클레오티드 서열에서 뉴클레오시드간 연결 중 예컨대 적어도 60%, 예컨대 적어도 70%, 예컨대 적어도 80% 또는 예컨대 적어도 90% 는 뉴클레아제 내성 뉴클레오시드간 연결이다. 일부 구현예에서 올리고뉴클레오티드, 또는 이의 인접 뉴클레오티드 서열의 모든 뉴클레오시드간 연결은 뉴클레아제 내성 뉴클레오시드간 연결이다. 일부 구현예에서 컨쥬게이트와 같은 비-뉴클레오티드 작용기에 본 발명의 올리고뉴클레오티드를 연결하는 뉴클레오시드는 포스포디에스테르일 수 있음이 인식될 것이다.
본 발명의 올리고뉴클레오티드에서의 사용에 바람직한 개질된 뉴클레오시드간 연결은 포스포로티오에이트이다.
포스포로티오에이트 뉴클레오시드간 연결은 뉴클레아제 내성, 유익한 약동학 및 제조의 용이함으로 인해 특히 유용하다. 일부 구현예에서 올리고뉴클레오티드, 또는 이의 인접 뉴클레오티드 서열에서 뉴클레오시드간 연결 중 적어도 50% 는 포스포로티오에이트이고, 올리고뉴클레오티드, 또는 이의 인접 뉴클레오티드 서열에서 뉴클레오시드간 연결 중 예컨대 적어도 60%, 예컨대 적어도 70%, 예컨대 적어도 80% 또는 예컨대 적어도 90% 는 포스포로티오에이트이다. 일부 구현예에서, 포스포로디티오에이트 뉴클레오시드간 연결 이외의, 올리고뉴클레오티드, 또는 이의 인접 뉴클레오티드 서열의 모든 뉴클레오시드간 연결은 포스포로티오에이트이다. 일부 구현예에서, 본 발명의 올리고뉴클레오티드는 포스포로디티오에이트 연결(들)에 추가하여 포스포로티오에이트 뉴클레오시드간 연결 및 적어도 하나의 포스포디에스테르 연결, 예컨대 2, 3 또는 4 개의 포스포디에스테르 연결을 포함한다. 갭머 올리고뉴클레오티드에서, 포스포디에스테르 연결은, 존재하는 경우, 갭 영역 G 에서 인접 DNA 뉴클레오시드 사이에 적절하게 위치하지 않는다.
뉴클레아제 내성 연결, 예컨대 포스포로티오에이트 연결은 갭머를 위한 영역 G 와 같은 표적 핵산과 듀플렉스를 형성할 때 뉴클레아제를 동원할 수 있는 올리고뉴클레오티드 영역에서 특히 유용하다. 그러나, 포스포로티오에이트 연결은 또한 갭머를 위한 영역 F 및 F' 와 같은 비-뉴클레아제 동원 영역 및/또는 친화도 향상 영역에서 유용할 수 있다. 갭머 올리고뉴클레오티드는 일부 구현예에서 영역 F 또는 F' 에서, 또는 영역 F 및 F' 둘 다에서 하나 이상의 포스포디에스테르 연결을 포함할 수 있으며, 영역 G 에서의 뉴클레오시드간 연결은 완전히 포스포로티오에이트일 수 있다.
유리하게는, 올리고뉴클레오티드의 인접 뉴클레오티드 서열에서 모든 뉴클레오시드간 연결, 또는 올리고뉴클레오티드의 모든 뉴클레오시드간 연결은 포스포로티오에이트 연결이다.
EP 2 742 135 에 개시된 바와 같이, 안티센스 올리고뉴클레오티드는 다른 뉴클레오시드간 연결 (포스포디에스테르 및 포스포로티오에이트 이외의), 예를 들어 알킬 포스포네이트/메틸 포스포네이트 뉴클레오시드간 연결을 포함할 수 있으며, 이는 EP 2 742 135 에 따라 예를 들어 그렇지 않으면 DNA 포스포로티오에이트 갭 영역에서 용인될 수 있는 것으로 인식된다.
입체 랜덤 포스포로티오에이트 연결
포스포로티오에이트 연결은 비-가교 산소 중 하나가 황으로 치환된 뉴클레오시드간 포스페이트 연결이다. 비-가교 산소 중 하나의 황으로의 치환은 카이랄 중심을 도입하고, 단일 포스포로티오에이트 올리고뉴클레오티드 내에서와 같이, 각각의 포스포로티오에이트 뉴클레오시드간 연결은 S (Sp) 또는 R (Rp) 입체 이성질체 형태일 것이다. 이러한 뉴클레오시드간 연결은 "카이랄 뉴클레오시드간 연결" 로 지칭된다. 그에 비해, 포스포디에스테르 뉴클레오시드간 연결은 이들이 2 개의 비-말단 산소 원자를 갖기 때문에 비-카이랄이다.
입체 중심의 카이랄성의 지정은 표준 Cahn- Ingold-Prelog rules (CIP priority rules) first published in Cahn, R.S.; Ingold, C.K.; Prelog, V. (1966) "Specification of Molecular Chirality" Angewandte Chemie International Edition 5 (4): 385-415. doi:10.1002/anie.196603851 에 의해 결정된다.
표준 올리고뉴클레오티드 합성 동안 커플링 및 후속 황화의 입체 선택성은 제어되지 않는다. 이러한 이유로, 각각의 포스포로티오에이트 뉴클레오시드간 연결의 입체 화학은 랜덤하게 Sp 또는 Rp 이고, 전통적인 올리고뉴클레오티드 합성에 의해 제조된 포스포로티오에이트 올리고뉴클레오티드는 실제로 2X 개의 상이한 포스포로티오에이트 부분입체 이성질체 (여기서 X 는 포스포로티오에이트 뉴클레오시드간 연결의 수임) 가 존재할 수 있다. 이러한 올리고뉴클레오티드는 입체 랜덤 포스포로티오에이트 올리고뉴클레오티드로 본원에서 지칭되고, 임의의 입체 정의된 뉴클레오시드간 연결을 함유하지 않는다. 따라서, 입체 랜덤 포스포로티오에이트 올리고뉴클레오티드는 비-입체 정의된 합성에서 유래하는 개별 부분입체 이성질체의 혼합물이다. 이러한 맥락에서 혼합물은 최대 2X 개의 상이한 포스포로티오에이트 부분입체 이성질체로 정의된다.
입체 정의된 뉴클레오시드간 연결
입체 정의된 뉴클레오시드간 연결은 2 개의 부분입체 이성질체 형태 중 하나, Rp 또는 Sp 에 대해 부분입체 이성질체 과잉을 갖는 카이랄 뉴클레오시드간 연결이다.
당업계에서 사용되는 입체 선택적 올리고뉴클레오티드 합성 방법은 전형적으로 각각의 카이랄 뉴클레오시드간 연결에서 적어도 약 90% 또는 적어도 약 95% 부분입체 선택성을 제공하고, 약 10% 이하, 예컨대 약 5% 의 올리고뉴클레오티드 분자는 대안적인 부분입체 이성질체 형태를 가질 수 있다는 것이 인식되어야 한다.
일부 구현예에서 각각의 입체 정의된 카이랄 뉴클레오시드간 연결의 부분입체 이성질체 비는 적어도 약 90:10 이다. 일부 구현예에서 각각의 카이랄 뉴클레오시드간 연결의 부분입체 이성질체 비는 적어도 약 95:5 이다.
입체 정의된 포스포로티오에이트 연결은 입체 정의된 뉴클레오시드간 연결의 특정 예이다.
입체 정의된 포스포로티오에이트 연결
입체 정의된 포스포로티오에이트 연결은 2 개의 부분입체 이성질체 형태 중 하나, Rp 또는 Sp 에 대해 부분입체 이성질체 과잉을 갖는 포스포로티오에이트 연결이다.
포스포로티오에이트 뉴클레오시드간 연결의 Rp 및 Sp 배열은 하기에 제시되어 있다:

여기서 3' R 기는 인접뉴클레오시드 (5' 뉴클레오시드) 의 3' 위치를 나타내고, 5' R 기는 인접 뉴클레오시드 (3' 뉴클레오시드) 의 5' 위치를 나타낸다.
Rp 뉴클레오시드간 연결은 또한 srP 표현될 수 있고, Sp 뉴클레오시드간 연결은 본원에서 ssP 로 표현될 수 있다.
특정 구현예에서, 각각의 입체 정의된 포스포로티오에이트 연결의 부분입체 이성질체 비는 적어도 약 90:10 또는 적어도 95:5 이다.
일부 구현예에서 각각의 입체 정의된 포스포로티오에이트 연결의 부분입체 이성질체 비는 적어도 약 97:3 이다. 일부 구현예에서 각각의 입체 정의된 포스포로티오에이트 연결의 부분입체 이성질체 비는 적어도 약 98:2 이다. 일부 구현예에서 각각의 입체 정의된 포스포로티오에이트 연결의 부분입체 이성질체 비는 적어도 약 99:1 이다.
일부 구현예에서 입체 정의된 뉴클레오시드간 연결은 올리고뉴클레오티드 분자의 집단에 존재하는 올리고뉴클레오티드 분자 중 적어도 97%, 예컨대 적어도 98%, 예컨대 적어도 99%, 또는 (본질적으로) 전부가 동일한 부분입체 이성질체 형태 (Rp 또는 Sp) 로 존재한다.
부분입체 이성질체 순도는 아카이랄 백본만 갖는 모델 시스템 (즉 포스포디에스테르) 에서 측정될 수 있다. 예를 들어 입체 정의된 뉴클레오시드간 연결을 갖는 단량체를 하기 모델 시스템 "5' t-po-t-po-t-po 3'" 에 커플링시킴으로써 각각의 단량체의 부분입체 이성질체 순도를 측정할 수 있다. 이의 결과는 다음과 같다: HPLC 를 사용하여 분리될 수 있는 5' DMTr-t-srp-t-po-t-po-t-po 3' 또는 5' DMTr-t-ssp-t-po-t-po-t-po 3'. 부분입체 이성질체 순도는 2 개의 가능한 부분입체 이성질체로부터의 UV 신호를 통합하고 예를 들어 98:2, 99:1 또는 >99:1 의 이들의 비를 제공함으로써 결정된다.
특정 단일 부분입체 이성질체 (단일 입체 정의된 올리고뉴클레오티드 분자) 의 부분입체 이성질체 순도는 각각의 뉴클레오시드간 위치에서 정의된 입체 중심에 대한 커플링 선택성, 및 도입될 입체 정의된 뉴클레오시드간 연결의 수의 함수인 것으로 이해될 것이다. 예를 들어, 각각의 위치에서 커플링 선택성이 97% 인 경우, 15 개의 입체 정의된 뉴클레오시드간 연결을 갖는 입체 정의된 올리고뉴클레오티드의 수득되는 순도는 0.9715, 즉 37% 의 다른 부분입체 이성질체와 비교하여 63% 의 원하는 부분입체 이성질체이다. 정의된 부분입체 이성질체의 순도는 합성 후 정제에 의해, 예를 들어 HPLC, 예컨대 이온 교환 크로마토그래피 또는 역상 크로마토그래피에 의해 개선될 수 있다.
일부 구현예에서, 입체 정의된 올리고뉴클레오티드는 집단 중 적어도 약 40%, 예컨대 적어도 약 50% 가 원하는 부분입체 이성질체인 올리고뉴클레오티드의 집단을 지칭한다.
대안적으로 언급하면, 일부 구현예에서, 입체 정의된 올리고뉴클레오티드는 집단 중 적어도 약 40%, 예컨대 적어도 약 50% 가 원하는 (특정) 입체 정의된 뉴클레오시드간 연결 모티프 (입체 정의된 모티프라고도 함) 로 이루어진 올리고뉴클레오티드의 집단을 지칭한다.
입체 랜덤 및 입체 정의된 뉴클레오시드간 카이랄 중심 둘 모두를 포함하는 입체 정의된 올리고뉴클레오티드의 경우, 입체 정의된 올리고뉴클레오티드의 순도는 원하는 입체 정의된 뉴클레오시드간 연결 모티프(들)을 유지하는 올리고뉴클레오티드의 집단의 % 에 대하여 측정된다 (입체 랜덤 연결은 계산에서 무시됨).
핵염기
용어 핵염기는 핵산 하이브리드화에서 수소 결합을 형성하는 뉴클레오시드 및 뉴클레오티드에 존재하는 푸린 (예를 들어 아데닌 및 구아닌) 및 피리미딘 (예를 들어 우라실, 티민 및 시토신) 모이어티를 포함한다. 본 발명의 맥락에서, 용어 핵염기는 또한 자연 발생 핵염기와 상이할 수 있지만 핵산 하이브리드화 동안 기능적인 개질된 핵염기를 포함한다. 이러한 맥락에서, "핵염기" 는 자연 발생 핵염기, 예컨대 아데닌, 구아닌, 시토신, 티미딘, 우라실, 잔틴 및 하이포잔틴, 뿐만 아니라 비-자연 발생 변이체 모두를 나타낸다. 이러한 변이체는 예를 들어 Hirao et al (2012) Accounts of Chemical Research vol 45 page 2055 및 Bergstrom (2009) Current Protocols in Nucleic Acid Chemistry Suppl. 37 1.4.1 에 기재되어 있다.
일부 구현예에서, 핵염기 모이어티는 푸린 또는 피리미딘을 개질된 푸린 또는 피리미딘, 예컨대 치환된 푸린 또는 치환된 피리미딘으로 바꿈으로써 개질되고, 예컨대 이소시토신, 슈도이소시토신, 5-메틸 시토신, 5-티오졸로-시토신, 5-프로피닐-시토신, 5-프로피닐-우라실, 5-브로모우라실 5-티아졸로-우라실, 2-티오-우라실, 2'티오-티민, 이노신, 디아미노푸린, 6-아미노푸린, 2-아미노푸린, 2,6-디아미노푸린 및 2-클로로-6-아미노푸린으로부터 선택되는 핵염기이다.
핵염기 모이어티는 각각의 상응하는 핵염기에 대하여 문자 코드, 예를 들어 A, T, G, C 또는 U 로 나타내어질 수 있고, 여기서 각각의 문자는 임의로는 동등한 기능의 개질된 핵염기를 포함할 수 있다. 예를 들어, 예시된 올리고뉴클레오티드에서, 핵염기 모이어티는 A, T, G, C, 및 5-메틸 시토신으로부터 선택된다. 임의로는, LNA 갭머의 경우, 5-메틸 시토신 LNA 뉴클레오시드가 사용될 수 있다.
개질된 올리고뉴클레오티드
용어 개질된 올리고뉴클레오티드는 하나 이상의 당-개질된 뉴클레오시드 및/또는 개질된 뉴클레오시드간 연결을 포함하는 올리고뉴클레오티드를 설명한다. 용어 "키메라성 올리고뉴클레오티드" 는 개질된 뉴클레오시드를 갖는 올리고뉴클레오티드를 기재하기 위해 문헌에서 사용되는 용어이다.
입체 정의된 올리고뉴클레오티드
입체 정의된 올리고뉴클레오티드는 뉴클레오시드간 연결 중 적어도 하나가 입체 정의된 뉴클레오시드간 연결인 올리고뉴클레오티드이다.
입체 정의된 포스포로티오에이트 올리고뉴클레오티드는 뉴클레오시드간 연결 중 적어도 하나가 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인 올리고뉴클레오티드이다.
상보성
용어 "상보성" 은 뉴클레오시드/뉴클레오티드의 왓슨-크릭 (Watson-Crick) 염기쌍의 용량 (capacity) 을 기재하고 있다. 왓슨-크릭 염기쌍은 구아닌 (G)-시토신 (C) 및 아데닌 (A) - 티민 (T)/우라실 (U) 이다. 올리고뉴클레오티드는 개질된 핵염기를 갖는 뉴클레오시드를 포함할 수 있고, 예를 들어 5-메틸 시토신이 흔히 시토신 대신에 사용되고, 이와 같이 용어 상보성은 비-개질된 핵염기와 개질된 핵염기 사이에 왓슨 크릭 염기쌍을 포함하는 것으로 이해될 것이다 (예를 들어 Hirao et al (2012) Accounts of Chemical Research vol 45 page 2055 및 Bergstrom (2009) Current Protocols in Nucleic Acid Chemistry Suppl. 37 1.4.1 참조).
본원에서 사용된 바와 같은 용어 "% 상보성" 은 별개의 핵산 분자 (예를 들어 표적 핵산) 의 주어진 위치에서, 인접 뉴클레오티드 서열과 주어진 위치에서 상보적인 (즉, 이와 왓슨 크릭 염기쌍을 형성함) 핵산 분자 (예를 들어 올리고뉴클레오티드) 중 인접 뉴클레오티드 서열의 뉴클레오티드의 비율을 나타낸다. 백분율은 두 서열 사이에서 쌍을 형성하는 정렬된 염기의 수를 계수하고 (표적 서열 5'-3' 및 3'-5' 의 올리고뉴클레오티드 서열과 정렬될 때), 올리고뉴클레오티드 중 뉴클레오티드의 총 수로 나누고 100 을 곱함으로써 계산된다. 상기 비교에서, 정렬되지 않은 핵염기/뉴클레오티드 (염기쌍을 형성함) 는 미스매치 (mismatch) 로 지칭된다. 바람직하게는, 인접 뉴클레오티드 서열의 % 상보성의 계산에서 삽입 및 결실이 허용되지 않는다.
용어 "완전히 상보적" 은 100% 상보성을 나타낸다.
동일성
본원에서 사용된 바와 같은 용어 "동일성" 은, 별개의 핵산 분자 (예를 들어 표적 핵산) 의 주어진 위치에서 인접 뉴클레오티드 서열과 주어진 위치에서 동일한 (즉, 상보적 뉴클레오시드와 왓슨 크릭 염기쌍을 형성하는 이의 능력에 있어서) 핵산 분자 (예를 들어, 올리고뉴클레오티드) 중 인접 뉴클레오티드 서열의 백분율로의 뉴클레오티드의 수를 나타낸다. 백분율은 두 서열 사이에서 동일한 정렬된 염기의 수를 계수하고, 올리고뉴클레오티드 중 뉴클레오티드의 총 수로 나누고 100 을 곱함으로써 계산된다. % 동일성 = (일치 × 100)/정렬된 영역의 길이. 바람직하게는, 인접 뉴클레오티드 서열의 % 상보성의 계산에서 삽입 및 결실이 허용되지 않는다.
하이브리드화
본원에 사용된 바와 같은 용어 "하이브리드화하는" 또는 "하이브리드화" 는 반대편 가닥 상의 염기쌍 사이에 수소 결합을 형성하여 듀플렉스를 형성하는 2 개의 핵산 가닥 (예를 들어 올리고뉴클레오티드 및 표적 핵산) 으로서 이해되어야 한다. 2 개의 핵산 가닥 사이의 결합의 친화성은 하이브리드화의 강도이다. 이는 흔히 올리고뉴클레오티드의 절반이 표적 핵산과 듀플렉스되는 온도로서 정의된 용융 온도 (Tm) 에 관하여 기재된다. 생리학적 조건에서, Tm 은 친화성에 엄격하게 비례하지는 않는다 (Mergny and Lacroix, 2003, Oligonucleotides 13:515-537). 표준 상태 깁스 자유 에너지 (Gibbs free energy) △G°는 결합 친화성의 더 정확한 표현이고, △G°= -RTln(Kd) (여기서, R 은 기체 상수이고, T 는 절대 온도임) 에 의한 반응의 해리 상수 (Kd) 와 관련된다. 따라서, 올리고뉴클레오티드와 표적 핵산 사이의 반응의 초저 △G°는 올리고뉴클레오티드 및 표적 핵산 사이의 강한 하이브리화를 반영한다. △G°는 수성 농도가 1 M 이고, pH 가 7 이고, 온도가 37 ℃ 인 반응과 관련된 에너지이다. 올리고뉴클레오티드의 표적 핵산에 대한 하이브리드화는 자발적 반응이고, 자발적 반응의 경우 △G°는 0 미만이다. △G°는 예를 들어 Hansen et al., 1965, Chem. Comm. 36-38 및 Holdgate et al., 2005, Drug Discov Today 에 기재되어 있는 바와 같은 등온 적정 열량 측정법 (ITC) 방법을 사용하여 실험적으로 측정될 수 있다. 당업자는 시판 장비가 △G°측정에 이용가능함을 알 것이다. △G°는, 또한 Sugimoto et al., 1995, Biochemistry 34:11211-11216 및 McTigue et al., 2004, Biochemistry 43:5388-5405 에 의해 기재된 적절하게 유래된 열역학적 파라미터를 사용하여, SantaLucia, 1998, Proc Natl Acad Sci USA. 95: 1460-1465 에 의해 기재된 바와 같은 가장 가까운 이웃 모델을 사용하여 수치적으로 추정될 수 있다. 하이브리드화에 의해 이의 의도된 핵산 표적을 조절할 가능성을 갖기 위해, 본 발명의 올리고뉴클레오티드는 길이가 10-30 개의 뉴클레오티드인 올리고뉴클레오티드에 대해 -10 kcal 미만의 추정된 △G°값을 갖는 표적 핵산에 하이브리드화된다. 일부 구현예에서, 하이브리드화의 정도 또는 강도는 표준 상태 깁스 자유 에너지 △G°에 의해 측정된다. 올리고뉴클레오티드는 길이가 8-30 개의 뉴클레오티드인 올리고뉴클레오티드에 대해 -10 kcal 의 범위 미만, 예컨대 -15 kcal 미만, 예컨대 -20 kcal 미만 및 예컨대 -25 kcal 미만의 추정된 △G°값을 갖는 표적 핵산에 대해 하이브리드화될 수 있다. 일부 구현예에서, 올리고뉴클레오티드는 -10 내지 -60 kcal, 예컨대 -12 내지 -40, 예컨대 -15 내지 -30 kcal 또는 -16 내지 -27 kcal, 예컨대 -18 내지 -25 kcal 의 추정된 △G°값을 갖는 표적 핵산에 대해 하이브리드화된다.
당 개질물
본 발명의 올리고머는 개질된 당 모이어티, 즉 DNA 및 RNA 에서 발견되는 리보오스 당 모이어티와 비교했을 때 당 모이어티의 개질물을 갖는 하나 이상의 뉴클레오시드를 포함할 수 있다.
리보오스 당 모이어티의 개질물을 갖는 수많은 뉴클레오시드는 주로 올리고뉴클레오티드의 특정 특성, 예컨대 친화성 및/또는 뉴클레아제 내성의 개선을 목적으로 제조된다.
상기 개질물은 리보오스 고리 구조가 예를 들어 헥소오스 고리 (HNA), 또는 바이시클릭 고리 (이는 전형적으로 리보오스 고리 (LNA) 상의 C2 탄소와 C4 탄소 사이에 바이라디칼 가교를 가짐) 또는 C2 탄소와 C3 탄소 사이에 결합이 전형적으로 결여된 비연결된 리보오스 고리 (예를 들어 UNA) 로의 대체에 의해 개질된 것이다. 다른 당 개질된 뉴클레오시드는 예를 들어 바이시클로헥소오스 핵산 (WO2011/017521) 또는 트리시클릭 핵산 (WO2013/154798) 을 포함한다. 개질된 뉴클레오시드는 또한 당 모이어티가 예를 들어 펩티드 핵산 (PNA), 또는 모르폴리노 핵산의 경우 비(非)-당 모이어티로 대체되는 뉴클레오시드를 포함한다.
당 개질물은 또한 리보오스 고리 상의 치환기를 DNA 및 RNA 뉴클레오시드에서 자연적으로 발견되는 2'-OH 기 또는 수소 이외의 기로 바꾸는 것을 통해 제조된 개질물을 포함한다. 치환기는 예를 들어 2', 3', 4' 또는 5' 위치에서 도입될 수 있다.
2' 당 개질된 뉴클레오시드
2' 당 개질된 뉴클레오시드는 2' 위치에 H 또는 -OH 이외의 치환기를 갖는 뉴클레오시드 (2' 치환된 뉴클레오시드) 이거나 또는 리보오스 고리에서 2' 탄소와 제 2 탄소 사이에서 가교를 형성할 수 있는 2' 연결된 바이라디칼, 예컨대 LNA (2' - 4' 바이라디칼 가교된) 뉴클레오시드를 포함한다.
실제로, 2' 치환된 뉴클레오시드의 개발에 많은 관심이 집중되어 왔으며, 다수의 2' 치환된 뉴클레오시드는 올리고뉴클레오티드에 혼입될 때 유리한 특성을 갖는 것으로 밝혀졌다. 예를 들어, 2' 개질된 당은 올리고뉴클레오티드에 대해 향상된 결합 친화성 및/또는 증가된 뉴클레아제 내성을 제공할 수 있다. 2' 치환된 개질된 뉴클레오시드의 예는 2'-O-알킬-RNA, 2'-O-메틸-RNA, 2'-알콕시-RNA, 2'-O-메톡시에틸-RNA (MOE), 2'-아미노-DNA, 2'-플루오로-RNA 및 2'-F-ANA 뉴클레오시드이다. 추가 예는 예를 들어 Freier & Altmann; Nucl. Acid Res., 1997, 25, 4429-4443 및 Uhlmann; Curr. Opinion in Drug Development, 2000, 3(2), 293-213 및 Deleavey and Damha, Chemistry and Biology 2012, 19, 937 에서 확인할 수 있다. 하기는 일부 2' 치환된 개질된 뉴클레오시드의 예시이다.

본 발명과 관련하여, 2'치환은 LNA 와 같은 2' 가교된 분자를 포함하지 않는다.
잠금 핵산 뉴클레오시드 (LNA 뉴클레오시드)
"LNA 뉴클레오시드" 는 상기 뉴클레오시드의 리보오스 당 고리의 C2' 및 C4' 를 연결하는 바이라디칼 ("2'- 4' 가교" 로도 지칭됨) 을 포함하는 2'-개질된 뉴클레오시드이며, 리보오스 고리의 형태를 제한하거나 잠근다. 이러한 뉴클레오시드는 또한 문헌에서 가교된 핵산 또는 바이시클릭 핵산 (BNA) 으로 지칭된다. 리보오스의 형태의 잠금은 LNA 가 상보적 RNA 또는 DNA 분자를 위해 올리고뉴클레오티드에 혼입될 때 하이브리드화 (듀플렉스 안정화) 의 향상된 친화도와 관련이 있다. 이는 올리고뉴클레오티드/상보적 듀플렉스의 용융 온도를 측정함으로써 일상적으로 결정될 수 있다.
비제한적이고 예시적인 LNA 뉴클레오시드는 WO 99/014226, WO 00/66604, WO 98/039352, WO 2004/046160, WO 00/047599, WO 2007/134181, WO 2010/077578, WO 2010/036698, WO 2007/090071, WO 2009/006478, WO 2011/156202, WO 2008/154401, WO 2009/067647, WO 2008/150729, Morita et al., Bioorganic & Med.Chem. Lett. 12, 73-76, Seth et al. J. Org. Chem. 2010, Vol 75(5) pp. 1569-81 및 Mitsuoka et al., Nucleic Acids Research 2009, 37(4), 1225-1238 에 개시되어 있다.
2'-4' 가교는 2 내지 4 개의 가교 원자를 포함하고 특히 X 는 C4' 에 연결되어 있고 Y 는 C2' 에 연결되어 있는 화학식 -X-Y- 을 갖는다.
식 중,
X 는 산소, 황, -CRaRb-, -C(Ra)=C(Rb)-, -C(=CRaRb)-, -C(Ra)=N-, -Si(Ra)2-, -SO2-, -NRa-; -O-NRa-, -NRa-O-, -C(=J)-, Se, -O-NRa-, -NRa-CRaRb-, -N(Ra)-O- 또는 -O-CRaRb- 이고;
Y 는 산소, 황, -(CRaRb)n-, -CRaRb-O-CRaRb-, -C(Ra)=C(Rb)-, -C(Ra)=N-, -Si(Ra)2-, -SO2-, -NRa-, -C(=J)-, Se, -O-NRa-, -NRa-CRaRb-, -N(Ra)-O- 또는 -O-CRaRb- 이고;
단, -X-Y- 는 -O-O-, Si(Ra)2-Si(Ra)2-, -SO2-SO2-, -C(Ra)=C(Rb)-C(Ra)=C(Rb), -C(Ra)=N-C(Ra)=N-, -C(Ra)=N-C(Ra)=C(Rb), -C(Ra)=C(Rb)-C(Ra)=N- 또는 -Se-Se- 가 아니고;
J 는 산소, 황, =CH2 또는 =N(Ra) 이고;
Ra 및 Rb 는 수소, 할로겐, 하이드록실, 시아노, 티오하이드록실, 알킬, 치환된 알킬, 알케닐, 치환된 알케닐, 알키닐, 치환된 알키닐, 알콕시, 치환된 알콕시, 알콕시알킬, 알케닐옥시, 카르복실, 알콕시카르보닐, 알킬카르보닐, 포르밀, 아릴, 헤테로시클릴, 아미노, 알킬아미노, 카르바모일, 알킬아미노카르보닐, 아미노알킬아미노카르보닐, 알킬아미노알킬아미노카르보닐, 알킬카르보닐아미노, 카르바미도, 알카노일옥시, 설포닐, 알킬설포닐옥시, 니트로, 아지도, 티오하이드록실설파이드알킬설파닐, 아릴옥시카르보닐, 아릴옥시, 아릴카르보닐, 헤테로아릴, 헤테로아릴옥시카르보닐, 헤테로아릴옥시, 헤테로아릴카르보닐, -OC(=Xa)Rc, -OC(=Xa)NRcRd 및 -NReC(=Xa)NRcRd 로부터 독립적으로 선택되고;
또는 2 개의 제미날 Ra 및 Rb 는 함께 임의 치환된 메틸렌을 형성하고;
또는 2 개의 제미날 Ra 및 Rb 는, 이들이 부착된 탄소 원자와 함께, -X-Y- 의 오직 하나의 탄소 원자와 시클로알킬 또는 할로시클로알킬을 형성하고;
치환된 알킬, 치환된 알케닐, 치환된 알키닐, 치환된 알콕시 및 치환된 메틸렌은 할로겐, 하이드록실, 알킬, 알케닐, 알키닐, 알콕시, 알콕시알킬, 알케닐옥시, 카르복실, 알콕시카르보닐, 알킬카르보닐, 포르밀, 헤테로시클릴, 아릴 및 헤테로아릴로부터 독립적으로 선택된 1 내지 3 개의 치환기로 치환된 알킬, 알케닐, 알키닐 및 메틸렌이고;
Xa 는 산소, 황 또는 -NRc 이고;
Rc, Rd 및 Re 는 수소 및 알킬로부터 독립적으로 선택되고;
n 은 1, 2 또는 3 이다.
본 발명의 추가의 특정 구현예에서, X 는 산소, 황, -NRa-, -CRaRb- 또는 -C(=CRaRb)-, 특히 산소, 황, -NH-, -CH2- 또는 -C(=CH2)-, 보다 특히 산소이다.
본 발명의 또 다른 특정 구현예에서, Y 는 -CRaRb-, -CRaRb-CRaRb- 또는 -CRaRb-CRaRb-CRaRb-, 특히 -CH2-CHCH3-, -CHCH3-CH2-, -CH2-CH2- 또는 -CH2-CH2-CH2- 이다.
본 발명의 특정 구현예에서, -X-Y- 는 -O-(CRaRb)n-, -S-CRaRb-, -N(Ra)CRaRb-, -CRaRb-CRaRb-, -O-CRaRb-O-CRaRb-, -CRaRb-O-CRaRb-, -C(=CRaRb)-CRaRb-, -N(Ra)CRaRb-, -O-N(Ra)-CRaRb- 또는 -N(Ra)-O-CRaRb- 이다.
본 발명의 특정 구현예에서, Ra 및 Rb 는 수소, 할로겐, 하이드록실, 알킬 및 알콕시알킬, 특히 수소, 할로겐, 알킬 및 알콕시알킬로 이루어진 군으로부터 독립적으로 선택된다.
본 발명의 또 다른 구현예에서, Ra 및 Rb 는 수소, 플루오로, 하이드록실, 메틸 및 -CH2-O-CH3, 특히 수소, 플루오로, 메틸 및 -CH2-O-CH3 로 이루어진 군으로부터 독립적으로 선택된다.
유리하게는, -X-Y- 의 Ra 및 Rb 중 하나는 상기 정의된 바와 같고 다른 것들은 모두 동시에 수소이다.
본 발명의 추가의 특정 구현예에서, Ra 는 수소 또는 알킬, 특히 수소 또는 메틸이다.
본 발명의 또 다른 특정 구현예에서, Rb 는 수소 또는 또는 알킬, 특히 수소 또는 메틸이다.
본 발명의 특정 구현예에서, Ra 및 Rb 중 하나 또는 모두는 수소이다.
본 발명의 특정 구현예에서, Ra 및 Rb 중 오직 하나는 수소이다.
본 발명의 한 특정 구현예에서, Ra 및 Rb 중 하나는 메틸이고 다른 하나는 수소이다.
본 발명의 특정 구현예에서, Ra 및 Rb 는 모두 동시에 메틸이다.
본 발명의 특정 구현예에서, -X-Y- 는 -O-CH2-, -S-CH2-, -S-CH(CH3)-, -NH-CH2-, -O-CH2CH2-, -O-CH(CH2-O-CH3)-, -O-CH(CH2CH3)-, -O-CH(CH3)-, -O-CH2-O-CH2-, -O-CH2-O-CH2-, -CH2-O-CH2-, -C(=CH2)CH2-, -C(=CH2)CH(CH3)-, -N(OCH3)CH2- 또는 -N(CH3)CH2- 이고;
본 발명의 특정 구현예에서, -X-Y- 는 -O-CRaRb- 이고, 여기서 Ra 및 Rb 는 수소, 알킬 및 알콕시알킬, 특히 수소, 메틸 및 -CH2-O-CH3 로 이루어진 군으로부터 독립적으로 선택된다.
특정 구현예에서, -X-Y- 는 -O-CH2- 또는 -O-CH(CH3)-, 특히 -O-CH2- 이다.
2'- 4' 가교는 각각 화학식 (A) 및 화학식 (B) 에 예시된 바와 같이 리보오스 고리의 평면 아래 (베타-D-배열), 또는 고리의 평면 위 (알파-L-배열) 에 위치할 수 있다.
본 발명에 따른 LNA 뉴클레오시드는 특히 화학식 (B1) 또는 (B2) 을 갖는다:

식 중,
W 는 산소, 황, -N(Ra)- 또는 -CRaRb-, 특히 산소이고;
B 는 핵염기 또는 개질된 핵염기이고;
Z 는 인접 뉴클레오시드에 대한 뉴클레오시드간 연결 또는 5'-말단기이고;
Z* 는 인접 뉴클레오시드에 대한 뉴클레오시드간 연결 또는 3'-말단기이고;
R1, R2, R3, R5 및 R5* 는 수소, 할로겐, 알킬, 할로알킬, 알케닐, 알키닐, 하이드록시, 알콕시, 알콕시알킬, 아지도, 알케닐옥시, 카르복실, 알콕시카르보닐, 알킬카르보닐, 포르밀 및 아릴로부터 독립적으로 선택되고;
X, Y, Ra 및 Rb 는 상기 정의된 바와 같다.
특정 구현예에서, -X-Y- 의 정의에서, Ra 는 수소 또는 알킬, 특히 수소 또는 메틸이다. 또 다른 특정 구현예에서, -X-Y- 의 정의에서, Rb 는 수소 또는 알킬, 특히 수소 또는 메틸이다. 추가의 특정 구현예에서, -X-Y- 의 정의에서, Ra 및 Rb 중 하나 또는 둘 모두는 수소이다. 특정 구현예에서, -X-Y- 의 정의에서, Ra 및 Rb 중 오직 하나는 수소이다. 한 특정 구현예에서, -X-Y- 의 정의에서, Ra 및 Rb 중 하나는 메틸이고 다른 하나는 수소이다. 특정 구현예에서, -X-Y- 의 정의에서, Ra 및 Rb 둘 모두는 동시에 메틸이다.
추가의 특정 구현예에서, X 의 정의에서, Ra 는 수소 또는 알킬, 특히 수소 또는 메틸이다. 또 다른 특정 구현예에서, X 의 정의에서, Rb 는 수소 또는 알킬, 특히 수소 또는 메틸이다. 특정 구현예에서, X 의 정의에서, Ra 및 Rb 중 하나 또는 둘 모두는 수소이다. 특정 구현예에서, X 의 정의에서, Ra 및 Rb 중 오직 하나는 수소이다. 한 특정 구현예에서, X 의 정의에서, Ra 및 Rb 중 하나는 메틸이고 다른 하나는 수소이다. 특정 구현예에서, X 의 정의에서, Ra 및 Rb 둘 모두는 동시에 메틸이다.
추가의 특정 구현예에서, Y 의 정의에서, Ra 는 수소 또는 알킬, 특히 수소 또는 메틸이다. 또 다른 특정 구현예에서, Y 의 정의에서, Rb 는 수소 또는 알킬, 특히 수소 또는 메틸이다. 특정 구현예에서, Y 의 정의에서, Ra 및 Rb 중 하나 또는 둘 모두는 수소이다. 특정 구현예에서, Y 의 정의에서, Ra 및 Rb 중 오직 하나는 수소이다. 한 특정 구현예에서, Y 의 정의에서, Ra 및 Rb 중 하나는 메틸이고 다른 하나는 수소이다. 특정 구현예에서, Y 의 정의에서, Ra 및 Rb 둘 모두는 동시에 메틸이다.
본 발명의 특정 구현예에서, R1, R2, R3, R5 및 R5* 는 수소 및 알킬, 특히 수소 및 메틸로부터 독립적으로 선택된다.
본 발명의 추가의 특정 유리한 구현예에서, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다.
본 발명의 또 다른 특정 구현예에서, R1, R2, R3 은 동시에 모두 수소이고, R5 및 R5* 중 하나는 수소이고 다른 하나는 상기 정의된 바와 같이, 특히 알킬, 보다 특히 메틸이다.
본 발명의 특정 구현예에서, R5 및 R5* 는 수소, 할로겐, 알킬, 알콕시알킬 및 아지도, 특히 수소, 플루오로, 메틸, 메톡시에틸 및 아지도로부터 독립적으로 선택된다. 본 발명의 특정 유리한 구현예에서, R5 및 R5* 중 하나는 수소이고 다른 하나는 알킬, 특히 메틸, 할로겐, 특히 플루오로, 알콕시알킬, 특히 메톡시에틸 또는 아지도이거나; 또는 R5 및 R5* 둘 모두는 동시에 수소 또는 할로겐, 특히 둘 모두는 동시에 수소 또는 플루오로이다. 이러한 특정 구현예에서, W 는 유리하게는 산소일 수 있고, -X-Y- 는 유리하게는 -O-CH2- 일 수 있다.
본 발명의 특정 구현예에서, -X-Y- 는 -O-CH2- 이고, W 는 산소이고, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다. 이러한 LNA 뉴클레오시드는 모두 본원에 참조로 포함되는 WO 99/014226, WO 00/66604, WO 98/039352 및 WO 2004/046160 에 개시되어 있고 베타-D-옥시 LNA 및 알파-L-옥시 LNA 뉴클레오시드로 당업계에 통상적으로 공지된 것을 포함한다.
본 발명의 또 다른 특정 구현예에서, -X-Y- 는 -S-CH2- 이고, W 는 산소이고, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다. 이러한 티오 LNA 뉴클레오시드는 본원에 참조로 포함되는 WO 99/014226 및 WO 2004/046160 개시되어 있다.
본 발명의 또 다른 특정 구현예에서, -X-Y- 는 -NH-CH2- 이고, W 는 산소이고, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다. 이러한 아미노 LNA 뉴클레오시드는 본원에 참조로 포함되는 WO 99/014226 및 WO 2004/046160 에 개시되어 있다.
본 발명의 또 다른 특정 구현예에서, -X-Y- 는 -O-CH2CH2- 또는 -OCH2CH2CH2- 이고, W 는 산소이고, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다. 이러한 LNA 뉴클레오시드는 본원에 참조로 포함되는 WO 00/047599 및 Morita et al., Bioorganic & Med.Chem. Lett. 12, 73-76 에 개시되어 있고, 2'-O-4'C-에틸렌 가교 핵산 (ENA) 으로 당업계에 통상적으로 공지된 것을 포함한다.
본 발명의 또 다른 특정 구현예에서, -X-Y- 는 -O-CH2- 이고, W 는 산소이고, R1, R2, R3 은 동시에 모두 수소이고, R5 및 R5* 중 하나는 수소이고 다른 하나는 수소가 아니고, 예컨대 알킬, 예를 들어 메틸이다. 이러한 5' 치환된 LNA 뉴클레오시드는 본원에 참조로 포함되는 WO 2007/134181 에 개시되어 있다.
본 발명의 또 다른 특정 구현예에서, -X-Y- 는 -O-CRaRb- 이고, Ra 및 Rb 중 하나 또는 둘 모두는 수소가 아니고, 특히 알킬, 예컨대 메틸이고, W 는 산소이고, R1, R2, R3 은 동시에 모두 수소이고, R5 및 R5* 중 하나는 수소이고 다른 하나는 수소가 아니고, 특히 알킬, 예를 들어 메틸이다. 이러한 비스 개질된 LNA 뉴클레오시드는 본원에 참조로 포함되는 WO 2010/077578 에 개시되어 있다.
본 발명의 또 다른 특정 구현예에서, -X-Y- 는 -O-CHRa- 이고, W 는 산소이고, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다. 이러한 6'-치환된 LNA 뉴클레오시드는 모두 본원에 참조로 포함되는 WO 2010/036698 및 WO 2007/090071 에 개시되어 있다. 이러한 6'-치환된 LNA 뉴클레오시드에서, Ra 는 특히 C1-C6 알킬, 예컨대 메틸이다.
본 발명의 또 다른 특정 구현예에서, -X-Y- 는 -O-CH(CH2-O-CH3)- ("2' O-메톡시에틸 바이시클릭 핵산" Seth et al. J. Org. Chem. 2010, Vol 75(5) pp. 1569-81) 이다.
본 발명의 또 다른 특정 구현예에서, -X-Y- 는 -O-CH(CH2CH3)- 이고;
본 발명의 또 다른 특정 구현예에서, -X-Y- 는 -O-CH(CH2-O-CH3)- 이고, W 는 산소이고, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다. 이러한 LNA 뉴클레오시드는 또한 시클릭 MOE (cMOE) 로 당업계에 공지되어 있고, WO 2007/090071 에 개시되어 있다.
본 발명의 또 다른 특정 구현예에서, -X-Y- 는 -O-CH(CH3)- ("2'O-에틸 바이시클릭 핵산" Seth at al., J. Org. Chem. 2010, Vol 75(5) pp. 1569-81) 이다.
본 발명의 또 다른 특정 구현예에서, -X-Y- 는 -O-CH2-O-CH2- (Seth et al., J. Org. Chem 2010 op. cit.) 이다.
본 발명의 또 다른 특정 구현예에서, -X-Y- 는 -O-CH(CH3)- 이고, W 는 산소이고, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다. 이러한 6'-메틸 LNA 뉴클레오시드는 또한 cET 뉴클레오시드로 당업계에 공지되어 있고, 모두 본원에 참조로 포함되는 WO 2007/090071 (베타-D) 및 WO 2010/036698 (알파-L) 에 개시되어 있는 바와 같이 (S)-cET 또는 (R)-cET 부분입체 이성질체일 수 있다.
본 발명의 또 다른 특정 구현예에서, -X-Y- 는 -O-CRaRb- 이고, Ra 또는 Rb 둘 모두는 수소가 아니고, W 는 산소이고, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다. 특정 구현예에서, Ra 및 Rb 둘 모두는 동시에 알킬, 특히 둘 모두는 동시에 메틸이다. 이러한 6'-디-치환된 LNA 뉴클레오시드는 본원에 참조로 포함되는 WO 2009/006478 에 개시되어 있다.
본 발명의 또 다른 특정 구현예에서, -X-Y- 는 -S-CHRa- 이고, W 는 산소이고, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다. 이러한 6'-치환된 티오 LNA 뉴클레오시드는 본원에 참조로 포함되는 WO 2011/156202 에 개시되어 있다. 이러한 6'-치환된 티오 LNA 의 특정 구현예에서, Ra 는 알킬, 특히 메틸이다.
본 발명의 특정 구현예에서, -X-Y- 는 -C(=CH2)C(RaRb)-, -C(=CHF)C(RaRb)- 또는 -C(=CF2)C(RaRb)- 이고, W 는 산소이고, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다. Ra 및 Rb 는 유리하게는 수소, 할로겐, 알킬 및 알콕시알킬, 특히 수소, 메틸, 플루오로 및 메톡시메틸로부터 독립적으로 선택된다. Ra 및 Rb 둘 모두는 동시에 특히 수소 또는 메틸이거나 또는 Ra 및 Rb 중 하나는 수소이고 다른 하나는 메틸이다. 이러한 비닐 카르보 LNA 뉴클레오시드는 본원에 참조로 포함되는 WO 2008/154401 및 WO 2009/067647 에 개시되어 있다.
본 발명의 특정 구현예에서, -X-Y- 는 -N(ORa)-CH2- 이고, W 는 산소이고, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다. 특정 구현예에서, Ra 는 알킬, 예컨대 메틸이다. 이러한 LNA 뉴클레오시드는 N 치환된 LNA 로도 공지되어 있고 본원에 참조로 포함되는 WO 2008/150729 에 개시되어 있다.
본 발명의 특정 구현예에서, -X-Y- 는 -O-N(Ra)-, -N(Ra)-O-, -NRa-CRaRb-CRaRb- 또는 -NRa-CRaRb- 이고, W 는 산소이고, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다. Ra 및 Rb 는 유리하게는 수소, 할로겐, 알킬 및 알콕시알킬, 특히 수소, 메틸, 플루오로 및 메톡시메틸로부터 독립적으로 선택된다. 특정 구현예에서, Ra 는 알킬, 예컨대 메틸이고, Rb 는 수소 또는 메틸, 특히 수소이다 (Seth et al., J. Org. Chem 2010 op. cit.).
본 발명의 특정 구현예에서, -X-Y- 는 -O-N(CH3)- 이다 (Seth et al., J. Org. Chem 2010 op. cit.).
본 발명의 특정 구현예에서, R5 및 R5* 둘 모두는 동시에 수소이다. 본 발명의 또 다른 특정 구현에서, R5 및 R5* 중 하나는 수소이고 다른 하나는 알킬, 예컨대 메틸이다. 이러한 구현예에서, R1, R2 및 R3 는 특히 수소일 수 있고 -X-Y- 는 특히 -O-CH2- 또는 -O-CHC(Ra)3-, 예컨대 -O-CH(CH3)- 일 수 있다.
본 발명의 특정 구현예에서, -X-Y- 는 -CRaRb-O-CRaRb-, 예컨대 -CH2-O-CH2- 이고, W 는 산소이고, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다. 이러한 특정 구현예에서, Ra 는 특히 알킬, 예컨대 메틸일 수 있고, Rb 는 수소 또는 메틸, 특히 수소일 수 있다. 이러한 LNA 뉴클레오시드는 형태적으로 제한된 뉴클레오티드 (CRN) 로도 알려져 있고 본원에 참조로 포함되는 WO 2013/036868 에 개시되어 있다.
본 발명의 특정 구현예에서, -X-Y- 는 -O-CRaRb-O-CRaRb-, 예컨대 -O-CH2-O-CH2- 이고, W 는 산소이고, R1, R2, R3, R5 및 R5* 는 동시에 모두 수소이다. Ra 및 Rb 는 유리하게는 수소, 할로겐, 알킬 및 알콕시알킬, 특히 수소, 메틸, 플루오로 및 메톡시메틸로부터 독립적으로 선택된다. 이러한 특정 구현예에서, Ra 는 특히 알킬, 예컨대 메틸일 수 있고, Rb 는 수소 또는 메틸, 특히 수소일 수 있다. 이러한 LNA 뉴클레오시드는 COC 뉴클레오티드로도 공지되어 있고 본원에 참조로 포함되는 Mitsuoka et al., Nucleic Acids Research 2009, 37(4), 1225-1238 에 개시되어 있다.
달리 명시되지 않는 한, LNA 뉴클레오시드는 베타-D 또는 알파-L 입체 이성질체 형태일 수 있음이 인식될 것이다.
본 발명의 LNA 뉴클레오시드의 특정 예는 반응식 1 에 제시되어 있다 (여기서 B 는 상기 정의된 바와 같음).
반응식 1



특정 LNA 뉴클레오시드는 베타-D-옥시-LNA, 6'-메틸-베타-D-옥시 LNA, 예컨대 (S)-6'-메틸-베타-D-옥시-LNA ((S)-cET) 및 ENA 이다.
MOE 뉴클레오시드
용어 "MOE" 는 "메톡시-에틸" 을 나타내고, 하기에 나타낸 바와 같이 메톡시-에톡시 기로 2 '위치에서 치환된 뉴클레오시드에 대한 약어를 의미한다.

따라서, 상기 뉴클레오시드는 "MOE" 또는 "2'-O-MOE 뉴클레오시드" 로 명명될 수 있다.
RNase H 활성 및 동원
안티센스 올리고뉴클레오티드의 RNase H 활성은 상보적 RNA 분자와의 듀플렉스일 때 RNase H 를 동원하는 이의 능력을 지칭한다. WO01/23613 은 RNaseH 를 동원하는 능력을 측정하는데 사용될 수 있는 RNaseH 활성을 측정하기 위한 시험관내 방법을 제공한다. 전형적으로 올리고뉴클레오티드는 이것이 상보적 표적 핵산 서열과 함께 제공될 때, 시험되는 개질된 올리고뉴클레오티드와 동일한 염기 서열을 갖지만 올리고뉴클레오티드에서의 모든 단량체 사이에 포스포로티오에이트 연결을 갖는 DNA 단량체만을 함유하는 올리고뉴클레오티드를 사용하고, WO01/23613 (본원에서 참조 인용됨) 의 실시예 91-95 에 의해 제공된 방법론을 사용하였을 때 측정된 초기 속도의 적어도 5%, 예컨대 적어도 10% 또는 20% 초과의 초기 속도 (pmol/l/min 으로 측정됨) 를 갖는다. RHase H 활성을 측정하는데 사용하기 위해, 재조합 인간 RNase H1 은 Lubio Science GmbH, Lucerne, Switzerland 로부터 입수 가능하다.
갭머
본 발명의 안티센스 올리고뉴클레오티드, 또는 이의 인접 뉴클레오티드 서열은 갭머일 수 있다. 안티센스 갭머는 RNase H 매개 분해를 통해 표적 핵산을 저해하기 위해 일반적으로 사용된다. 갭머 올리고뉴클레오티드는 '5 -> 3' 방향으로 적어도 3 개의 별개의 구조 영역 5'-플랭크, 갭 및 3'-플랭크, F-G-F' 를 포함한다. "갭" 영역 (G) 은 올리고뉴클레오티드가 RNase H 를 동원할 수 있게 하는 인접 DNA 뉴클레오티드의 스트레치를 포함한다. 갭 영역은 하나 이상의 당 개질된 뉴클레오시드, 유리하게는 높은 친화도 당 개질된 뉴클레오시드를 포함하는 5' 플랭킹 영역 (F) 에 의해, 및 하나 이상의 당 개질된 뉴클레오시드, 유리하게는 높은 친화도 당 개질된 뉴클레오시드를 포함하는 3' 플랭킹 영역 (F') 에 의해 플랭킹된다. 영역 F 및 F' 에서 하나 이상의 당 개질된 뉴클레오시드는 표적 핵산에 대한 올리고뉴클레오티드의 친화도를 향상시킨다 (즉, 친화도 향상 당 개질된 뉴클레오시드임). 일부 구현예에서, 영역 F 및 F' 에서 하나 이상의 당 개질된 뉴클레오시드는 2' 당 개질된 뉴클레오시드, 예컨대 높은 친화도 2' 당 개질물, 예컨대 LNA 및 2'-MOE 로부터 독립적으로 선택되는 것이다.
갭머 디자인에서, 갭 영역의 5' 및 3' 말단 뉴클레오시드는 DNA 뉴클레오시드이고, 각각 5' (F) 또는 3' (F') 영역의 당 개질된 뉴클레오시드에 인접하여 위치한다. 플랭크는 갭 영역으로부터 가장 먼 말단, 즉 5' 플랭크의 5' 말단 및 3' 플랭크의 3' 말단에 적어도 하나의 당 개질된 뉴클레오시드를 갖는 것에 의해 추가로 정의될 수 있다.
영역 F-G-F' 는 인접 뉴클레오티드 서열을 형성한다. 본 발명의 안티센스 올리고뉴클레오티드, 또는 이의 인접 뉴클레오티드 서열은 화학식 F-G-F' 의 갭머 영역을 포함할 수 있다.
갭머 디자인 F-G-F' 의 전체 길이는 예를 들어 12 내지 32 개의 뉴클레오시드, 예컨대 13 내지 24 개, 예컨대 14 내지 22 개의 뉴클레오시드, 예컨대 14 내지 17 개, 예컨대 16 내지 18 개의 뉴클레오시드일 수 있다.
예를 들어, 본 발명의 갭머 올리고뉴클레오티드는 하기 화학식으로 나타낼 수 있다:
F1-8-G5-16-F'1-8, 예컨대
F1-8-G7-16-F'2-8
단, 갭머 영역 F-G-F' 의 전체 길이는 적어도 12 개, 예컨대 적어도 14 개의 뉴클레오티드 길이이다.
영역 F, G 및 F' 는 하기에 추가로 정의되고 F-G-F' 화학식에 혼입될 수 있다.
갭머 - 영역 G
갭머의 영역 G (갭 영역) 는 RNaseH, 예컨대 인간 RNase H1, 전형적으로 DNA 뉴클레오시드를 동원할 수 있게 하는 뉴클레오시드의 영역이다. RNaseH 는 DNA 와 RNA 사이의 듀플렉스를 인식하고 RNA 분자를 효소적으로 절단하는 세포 효소이다. 적합한 갭머는 적어도 5 또는 6 개의 인접 DNA 뉴클레오시드, 예컨대 5 - 16 개의 인접 DNA 뉴클레오시드, 예컨대 6 - 15 개의 인접 DNA 뉴클레오시드, 예컨대 7 - 14 개의 인접 DNA 뉴클레오시드, 예컨대 8 - 12 개의 인접 DNA 뉴클레오티드, 예컨대 8 - 12 개의 인접 DNA 뉴클레오티드 길이의 갭 영역 (G) 일 수 있다. 갭 영역 G 는 일부 구현예에서 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 또는 16 개의 인접 DNA 뉴클레오시드로 이루어질 수 있다. 갭 영역의 시토신 (C) DNA 는 일부 경우 메틸화될 수 있으며, 이러한 잔기는 5-메틸-시토신으로 (meC 또는 c 대신에 e 로) 주석을 달 수 있다. 갭의 시토신 DNA 의 메틸화는 cg 디뉴클레오티드가 갭에 존재하여 잠재적 독성을 감소시키는 경우 유리하며, 개질은 올리고뉴클레오티드의 효능에 큰 영향을 미치지 않는다.
일부 구현예에서 갭 영역 G 은 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 또는 16 개의 인접 포스포로티오에이트 연결된 DNA 뉴클레오시드로 이루어질 수 있다. 일부 구현예에서, 갭의 모든 뉴클레오시드간 연결은 포스포로티오에이트 연결이다.
전통적인 갭머는 DNA 갭 영역을 갖지만, 갭 영역 내에서 사용될 때 RNaseH 동원을 가능하게 하는 개질된 뉴클레오시드의 많은 예가 존재한다. 갭 영역 내에 포함될 때 RNaseH 를 동원할 수 있는 것으로 보고된 개질된 뉴클레오시드는 예를 들어, 알파-L-LNA, C4' 알킬화 DNA (본원에 참조로 포함되는 PCT/EP2009/050349 및 Vester et al., Bioorg. Med. Chem. Lett. 18 (2008) 2296 - 2300 에 기재되어 있는 바와 같음), 아라비노스 유래 뉴클레오시드, 예컨대 ANA 및 2'F-ANA (Mangos et al. 2003 J. AM. CHEM. SOC. 125, 654-661), UNA (비잠금 핵산) (본원에 참조로 포함되는 Fluiter et al., Mol. Biosyst., 2009, 10, 1039 에 기재되어 있는 바와 같음) 를 포함한다. UNA 는 비잠금 핵산이고, 전형적으로 여기서 리보오스의 C2 와 C3 사이의 결합이 제거되어, 비잠금 "당" 잔기를 형성한다. 이러한 갭머에 사용된 개질된 뉴클레오시드는 갭 영역으로 도입될 때 2' 엔도 (DNA 유사) 구조를 채택하는 뉴클레오시드일 수 있으며, 즉 개질은 RNaseH 동원을 허용한다. 일부 구현예에서 본원에 기재된 DNA 갭 영역 (G) 은 임의로 갭 영역으로 도입될 때 2' 엔도 (DNA 유사) 구조를 채택하는 1 내지 3 개의 당 개질된 뉴클레오시드를 함유할 수 있다.
영역 G - "갭-브레이커"
대안적으로, 일부 RNaseH 활성을 유지하면서, 갭머의 갭 영역으로 3' 엔도 형태를 부여하는 개질된 뉴클레오사시의 삽입에 대한 수많은 보고가 있다. 이러한 하나 이상의 3'엔도 개질된 뉴클레오시드를 포함하는 갭 영역을 갖는 갭머는 "갭-브레이커" 또는 "갭-분열된" 갭머로 지칭된다 (예를 들어 WO2013/022984 참조). 갭-브레이커 올리고뉴클레오티드는 RNaseH 동원을 허용하기 위해 갭 영역 내에 충분한 DNA 뉴클레오시드 영역을 보유한다. RNaseH 를 동원하는 갭브레이커 올리고뉴클레오티드 디자인의 능력은 전형적으로 서열 또는 심지어 화합물 특이적이다 (일부 경우에서 표적 RNA 의 더 많은 특이적 절단을 제공하는 RNaseH 를 동원하는 "갭브레이커" 올리고뉴클레오티드를 개시하고 있는 Rukov et al. 2015 Nucl. Acids Res. Vol. 43 pp. 8476-8487 참조). 갭-브레이커 올리고뉴클레오티드의 갭 영역 내에 사용된 개질된 뉴클레오시드는 예를 들어 3'엔도 형태를 부여한는 개질된 뉴클레오시드, 예컨대 2'-O-메틸 (OMe) 또는 2'-O-MOE (MOE) 뉴클레오시드, 또는 베타-D LNA 뉴클레오시드 (뉴클레오시드의 리보오스 당 고리의 C2' 와 C4' 사이의 가교는 베타 형태임), 예컨대 베타-D-옥시 LNA 또는 ScET 뉴클레오시드일 수 있다.
상기 기재된 영역 G 를 함유하는 갭머와 마찬가지로, 갭-브레이커 또는 갭-분열된 갭머의 갭 영역은 갭의 5' 말단에 DNA 뉴클레오시드 (영역 F 의 3' 뉴클레오시드에 인접함), 및 갭의 3' 말단에 DNA 뉴클레오시드 (영역 F' 의 5' 뉴클레오시드에 인접함) 을 갖는다. 분열된 갭을 포함하는 갭머는 전형적으로 갭 영역의 5' 말단 또는 3' 말단에 적어도 3 또는 4 개의 인접 DNA 뉴클레오시드의 영역을 보유한다.
갭-브레이커 올리고뉴클레오티드에 대한 예시적인 디자인은 하기를 포함한다:

여기서, 영역 G 는 괄호 [Dn-Er- Dm] 안에 있고, D 는 DNA 뉴클레오시드의 인접 서열이고, E 는 개질된 뉴클레오시드 (갭-브레이커 또는 갭-분열 뉴클레오시드) 이고, F 및 F' 는 본원에서 정의된 바와 같은 플랭킹 영역이고, 단, 갭머 영역 F-G-F' 의 전체 길이는 적어도 12 개, 예컨대 적어도 14 개의 뉴클레오티드 길이이다.
일부 구현예에서, 갭 분열된 갭머의 영역 G 는 적어도 6 개의 DNA 뉴클레오시드, 예컨대 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 또는 16 개의 DNA 뉴클레오시드를 포함한다. 상기 기재한 바와 같이, DNA 뉴클레오시드는 인접일 수 있거나 또는 임의로 하나 이상의 개질된 뉴클레오시드함께 산재될 수 있으며, 단, 갭 영역 G 는 RNaseH 동원을 매개할 수 있다.
갭머 - 플랭킹 영역, F 및 F'
영역 F 는 영역 G 의 5' DNA 뉴클레오시드에 바로 인접하여 위치한다. 영역 F 의 3' 말단 뉴클레오시드는 당 개질된 뉴클레오시드, 예컨대 고 친화도 당 개질된 뉴클레오시드, 예를 들어 2' 치환된 뉴클레오시드, 예컨대 MOE 뉴클레오시드, 또는 LNA 뉴클레오시드이다.
영역 F' 는 영역 G 의 3' DNA 뉴클레오시드에 바로 인접하여 위치한다. F' 영역의 5' 말단 뉴클레오시드는 당 개질된 뉴클레오시드, 예컨대 고 친화도 당 개질된 뉴클레오시드, 예를 들어 2' 치환된 뉴클레오시드, 예컨대 MOE 뉴클레오시드, 또는 LNA 뉴클레오시드이다.
영역 F 는 1-8 개의 인접 뉴클레오티드 길이, 예컨대 2-6 개, 예컨대 3-4 개의 인접 뉴클레오티드 길이이다. 유리하게는 영역 F 의 5' 말단 뉴클레오시드는 당 개질된 뉴클레오시드이다. 일부 구현예에서 영역 F 의 2 개의 5' 말단 뉴클레오시드는 당 개질된 뉴클레오시드이다. 일부 구현예에서 영역 F 의 5' 말단 뉴클레오시드는 LNA 뉴클레오시드이다. 일부 구현예에서 영역 F 의 2 개의 5' 말단 뉴클레오시드는 LNA 뉴클레오시드이다. 일부 구현예에서 영역 F 의 2 개의 5' 말단 뉴클레오시드는 2' 치환된 뉴클레오시드, 예컨대 2 개의 3' MOE 뉴클레오시드이다. 일부 구현예에서 영역 F 의 5' 말단 뉴클레오시는 2' 치환된 뉴클레오시드, 예컨대 MOE 뉴클레오시드이다.
영역 F' 는 2-8 개의 인접 뉴클레오티드 길이, 예컨대 3-6 개, 예컨대 4-5 개의 인접 뉴클레오티드 길이이다. 유리하게는, 영역 F' 의 3' 말단 뉴클레오시드는 당 개질된 뉴클레오시드이다. 일부 구현예에서 F' 영역의 2 개의 3' 말단 뉴클레오시드는 당 개질된 뉴클레오시드이다. 일부 구현예에서 F' 영역의 2 개의 3' 말단 뉴클레오시드는 LNA 뉴클레오시드이다. 일부 구현예에서 영역 F' 의 3' 말단 뉴클레오시드는 LNA 뉴클레오시드이다. 일부 구현예에서 F' 영역의 2 개의 3' 말단 뉴클레오시드는 2' 치환된 뉴클레오시드, 예컨대 2 개의 3' MOE 뉴클레오시드이다. 일부 구현예에서 영역 F' 의 3' 말단 뉴클레오시드는 2' 치환된 뉴클레오시드, 예컨대 MOE 뉴클레오시드이다.
영역 F 또는 F' 의 길이가 1 인 경우, 이는 유리하게는 LNA 뉴클레오시드인 것이 주목되어야 한다.
일부 구현예에서, 영역 F 및 F' 는 독립적으로 당 개질된 뉴클레오시드의 인접 서열을 포함하거나 이로 이루어진다. 일부 구현예에서, 영역 F 의 당 개질된 뉴클레오시드는 2'-O-알킬-RNA 단위, 2'-O-메틸-RNA, 2'-아미노-DNA 단위, 2'-플루오로-DNA 단위, 2'-알콕시-RNA, MOE 단위, LNA 단위, 아라비노 핵산 (ANA) 단위 및 2'-플루오로-ANA 단위로부터 독립적으로 선택될 수 있다.
일부 구현예에서, 영역 F 및 F' 는 독립적으로 LNA 및 2' 치환된 개질된 뉴클레오시드 (혼합 윙 디자인) 를 포함한다.
일부 구현예에서, 영역 F 및 F' 는 오직 한 유형의 당 개질된 뉴클레오시드, 예컨대 MOE 만 또는 베타-D-옥시 LNA 만 또는 ScET 만으로 이루어진다. 이러한 디자인은 또한 균일한 플랭크 또는 균일한 갭머 디자인으로 지칭된다.
일부 구현예에서, 영역 F 또는 F', 또는 F 및 F' 의 모든 뉴클레오시드는 베타-D-옥시 LNA, ENA 또는 ScET 뉴클레오시드로부터 독립적으로 선택되는 것과 같은 LNA 뉴클레오시드이다. 일부 구현예에서 영역 F 는 1-5 개, 예컨대 2-4 개, 예컨대 3-4 개, 예컨대 1, 2, 3, 4 또는 5 개의 인접 LNA 뉴클레오시드로 이루어진다. 일부 구현예에서, 영역 F 및 F' 의 모든 뉴클레오시드는 베타-D-옥시 LNA 뉴클레오시드이다.
일부 구현예에서, 영역 F 또는 F', 또는 F 및 F' 의 모든 뉴클레오시드는 2' 치환된 뉴클레오시드, 예컨대 OMe 또는 MOE 뉴클레오시드이다. 일부 구현예에서 영역 F 는 1, 2, 3, 4, 5, 6, 7, 또는 8 개의 인접 OMe 또는 MOE 뉴클레오시드로 이루어진다. 일부 구현예에서 플랭킹 영역 중 오직 하나만 2' 치환된 뉴클레오시드, 예컨대 OMe 또는 MOE 뉴클레오시드로 이루어질 수 있다. 일부 구현예에서, 2' 치환된 뉴클레오시드, 예컨대 OMe 또는 MOE 뉴클레오시드를 이루는 것은 5' (F) 플랭킹 영역이고, 3' (F') 플랭킹 영역은 적어도 하나의 LNA 뉴클레오시드, 예컨대 베타-D-옥시 LNA 뉴클레오시드 또는 cET 뉴클레오시드를 포함한다. 일부 구현예에서, 2' 치환된 뉴클레오시드, 예컨대 OMe 또는 MOE 뉴클레오시드를 이루는 것은 3' (F') 플랭킹 영역이고, 5' (F) 플랭킹 영역은 적어도 하나의 LNA 뉴클레오시드, 예컨대 베타-D-옥시 LNA 뉴클레오시드 또는 cET 뉴클레오시드를 포함한다.
일부 구현예에서, 영역 F 및 F' 의 모든 개질된 뉴클레오시드는 베타-D-옥시 LNA, ENA 또는 ScET 뉴클레오시드로부터 독립적으로 선택되는 것과 같은 LNA 뉴클레오시드이고, 영역 F 또는 F', 또는 F 및 F' 는 임의로 DNA 뉴클레오시드 (교대 플랭크, 자세한 내용은 이들의 정의 참조) 를 포함할 수 있다. 일부 구현예에서, 영역 F 및 F' 의 모든 개질된 뉴클레오시드는 베타-D-옥시 LNA 뉴클레오시드이고, 영역 F 또는 F', 또는 F 및 F' 는 임의로 DNA 뉴클레오시드 (교대 플랭크, 자세한 내용은 이들의 정의 참조) 를 포함할 수 있다.
일부 구현예에서 영역 F 및 F' 의 5' 말단 및 3' 말단 뉴클레오시드는 LNA 뉴클레오시드, 예컨대 베타-D-옥시 LNA 뉴클레오시드 또는 ScET 뉴클레오시드이다.
일부 구현예에서, 영역 F 와 영역 G 사이의 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결이다. 일부 구현예에서, 영역 F' 와 영역 G 사이의 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결이다. 일부 구현예에서, 영역 F 또는 F', F 및 F' 의 뉴클레오시드 사이의 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결이다.
추가의 갭머 디자인은 본원에 참조로 포함되는 WO 2004/046160, WO 2007/146511 및 WO 2008/113832 에 개시되어 있다.
LNA 갭머
LNA 갭머는 영역 F 및 F' 중 하나 또는 둘 모두가 LNA 뉴클레오시드를 포함하거나 이로 이루어지는 갭머이다. 베타-D-옥시 갭머는 영역 F 및 F' 중 하나 또는 둘 모두가 베타-D-옥시 LNA 뉴클레오시드를 포함하거나 이로 이루어지는 갭머이다.
일부 구현예에서, LNA 갭머는 화학식: [LNA]1-5-[영역 G] -[LNA]1-5 (여기서, 영역 G 는 갭머 영역 G 정의에 정의된 바와 같음) 을 갖는다.
MOE 갭머
MOE 갭머는 영역 F 및 F' 가 MOE 뉴클레오시드로 이루어진 갭머이다. 일부 구현예에서 MOE 갭머는 디자인 [MOE]1-8-[영역 G]-[MOE] 1-8, 예컨대 [MOE]2-7-[영역 G]5-16-[MOE] 2-7, 예컨대 [MOE]3-6-[영역 G]-[MOE] 3-6 를 갖고, 여기서 영역 G 는 갭머 정의에 정의된 바와 같다. 5-10-5 디자인 (MOE-DNA-MOE) 을 갖는 MOE 갭머는 당업계에서 널리 사용되어 왔다.
혼합 윙 갭머
혼합 윙 갭머는 영역 F 및 F' 중 하나 또는 둘 모두가 2' 치환된 뉴클레오시드, 예컨대 2'-O-알킬-RNA 단위, 2'-O-메틸-RNA, 2'-아미노-DNA 단위, 2'-플루오로-DNA 단위, 2'-알콕시-RNA, MOE 단위, 아라비노 핵산 (ANA) 단위 및 2'-플루오로-ANA 단위, 예컨대 MOE 뉴클레오시드로 이루어진 군으로부터 독립적으로 선택되는 2' 치환된 뉴클레오시드를 포함하는 LNA 갭머이다. 일부 구현예에서, 영역 F 및 F' 중 적어도 하나, 또는 영역 F 및 F' 둘 모두는 적어도 하나의 LNA 뉴클레오시드를 포함하고, 영역 F 및 F' 의 나머지 뉴클레오시드는 MOE 및 LNA 로 이루어진 군으로부터 독립적으로 선택된다. 일부 구현예에서, 영역 F 및 F' 중 적어도 하나, 또는 영역 F 및 F' 둘 모두는 적어도 2 개의 LNA 뉴클레오시드를 포함하고, 영역 F 및 F' 의 나머지 뉴클레오시드는 MOE 및 LNA 로 이루어진 군으로부터 독립적으로 선택된다. 일부 혼합 윙 구현예에서, 영역 F 및 F' 중 하나 또는 둘 모두는 하나 이상의 DNA 뉴클레오시드를 추가로 포함할 수 있다.
혼합 윙 갭머 디자인은 본원에 참조로 포함되는 WO 2008/049085 및 WO 2012/109395 에 개시되어 있다.
교대 플랭크 갭머
플랭킹 영역은 LNA 및 DNA 뉴클레오시드 둘 모두를 포함할 수 있고 이들이 LNA-DNA-LNA 뉴클레오시드의 교대 모티프를 포함하기 때문에 "교대 플랭크" 로 지칭된다. 이러한 교대 플랭크를 포함하는 갭머는 "교대 플랭크 갭머" 로 지칭된다. 따라서, "대안적인 플랭크 갭머" 는 플랭크 (F 또는 F') 중 적어도 하나가 LNA 뉴클레오시드(들) 이외에 DNA 를 포함하는 LNA 갭머 올리고뉴클레오티드이다. 일부 구현예에서 영역 F 또는 F' 중 적어도 하나, 또는 영역 F 및 F' 둘 모두는 LNA 뉴클레오시드 및 DNA 뉴클레오시드 둘 모두를 포함한다. 이러한 구현예에서, 플랭킹 영역 F 또는 F', 또는 F 및 F' 둘 모두는 적어도 3 개의 뉴클레오시드를 포함하고, F 및/또는 F' 영역의 5' 및 3' 말단 뉴클레오시드는 LNA 뉴클레오시드이다.
교대 플랭크 LNA 갭머는 WO 2016/127002 에 개시되어 있다.
교대 플랭크 영역은 3 개 이하의 인접 DNA 뉴클레오시드, 예컨대 1 내지 2 개 또는 1 또는 2 개 또는 3 개의 인접 DNA 뉴클레오시드를 포함할 수 있다.
교대 플랭크 영역은 예를 들어 다음과 같이 LNA 뉴클레오시드 (L) 의 수 다음에 DNA 뉴클레오시드 (D) 의 수를 나타내는 일련의 정수로 주석을 달 수 있다:

올리고뉴클레오티드 디자인에서, 이들은 종종 2-2-1 이 5' [L]2-[D]2-[L] 3' 를 나타내고, 1-1-1-1-1 이 5' [L]-[D]-[L]-[D]-[L] 3' 을 나타내도록 숫자로 표현될 것이다. 교대 플랭크를 갖는 올리고뉴클레오티드에서 플랭크 (영역 F 및 F') 의 길이는 독립적으로 3 내지 10 개의 뉴클레오시드, 예컨대 4 내지 8 개, 예컨대 5 내지 6 개의 뉴클레오시드, 예컨대 4, 5, 6 또는 7 개의 개질된 뉴클레오시드일 수 있다. 일부 구현예에서 갭머 올리고뉴클레오티드에서 플랭크 중 오직 하나만 교대인 반면, 다른 하나는 LNA 뉴클레오티드로 구성된다. 추가적인 엑소뉴클레아제 내성을 부여하기 위해, 플랭크 (F') 의 3' 말단에 적어도 2 개의 LNA 뉴클레오시드를 갖는 것이 유리할 수 있다. 교대 플랭크를 갖는 올리고뉴클레오티드의 일부 예는 다음과 같다:

단, 갭머의 전체 길이는 적어도 12 개, 예컨대 적어도 14 개의 뉴클레오티드 길이이다.
올리고뉴클레오티드의 영역 D' 또는 D"
일부 구현예에서 본 발명의 올리고뉴클레오티드는 표적 핵산, 예컨대 갭머 F-G-F' 에 상보적인 올리고뉴클레오티드의 인접 뉴클레오티드 서열, 및 추가의 5' 및/또는 3' 뉴클레오시드를 포함하거나 이로 이루어질 수 있다. 추가의 5' 및/또는 3' 뉴클레오시드는 표적 핵산에 완전히 상보적이거나 상보적이지 않을 수 있다. 이러한 추가의 5' 및/또는 3' 뉴클레오시드는 본원에서 영역 D' 및 D" 로 지칭될 수 있다.
영역 D' 또는 D" 의 첨가는 인접 뉴클레오티드 서열, 예컨대 갭머를, 컨쥬게이트 모이어티 또는 또 다른 작용기에 결합시키기 위해 사용될 수 있다. 인접 뉴클레오티드 서열을 컨쥬게이트 모이어티와 결합시키기 위해 사용되는 경우 이는 생물 절단성 링커로서 작용할 수있다. 대안적으로, 이는 엑소뉴클레아제 보호를 제공하거나 또는 합성 또는 제조의 용이함을 위해 사용될 수 있다.
영역 D' 및 D" 는 영역 F 의 5' 말단 또는 영역 F' 의 3' 말단에 부착되어 각각 하기 화학식 D'-F-G-F', F-G-F'-D" 또는 D'-F-G-F'-D" 의 디자인을 생성할 수 있다. 이러한 경우에, F-G-F' 는 올리고뉴클레오티드의 갭머 부분이고 영역 D' 또는 D" 는 올리고뉴클레오티드의 개별 부분을 구성한다.
영역 D' 또는 D" 는 독립적으로 1, 2, 3, 4 또는 5 개의 추가 뉴클레오티드를 포함할 수 있거나 또는 이로 이루어질 수 있고, 이는 표적 핵산에 대해 상보적 또는 비-상보적일 수 있다. F 또는 F' 영역에 인접한 뉴클레오티드는 당-개질된 뉴클레오티드, 예컨대 DNA 또는 RNA 또는 이들의 염기 개질된 버젼이 아니다. D' 또는 D' 영역은 뉴클레아제 민감성 생물 절단성 링커로서 작용할 수 있다 (링커의 정의 참조). 일부 구현예에서, 추가의 5' 및/또는 3' 말단 뉴클레오티드는 포스포디에스테르 연결로 연결되고, DNA 또는 RNA 이다. 영역 D' 또는 D" 로 사용하기에 적합한 뉴클레오티드 기반 생물 절단성 링커는 예를 들어 포스포디에스테르 연결된 DNA 디뉴클레오티드를 포함하는 WO 2014/076195 에 개시되어 있다. 폴리-올리고뉴클레오티드 구조물에서 생물 절단성 링커의 사용은 단일 올리고뉴클레오티드 내에서 다수의 안티센스 구조물 (예를 들어 갭머 영역) 을 연결하는데 사용되는 WO 2015/113922 에 개시되어 있다.
일 구현예에서, 본 발명의 올리고뉴클레오티드는 갭머를 구성하는 인접 뉴클레오티드 서열 이외에 영역 D' 및/또는 D" 를 포함한다.
일부 구현예에서, 본 발명의 올리고뉴클레오티드는 하기 화학식으로 나타낼 수 있다:
F-G-F'; 특히 F1-8-G5-16-F'2-8
D'-F-G-F', 특히 D'1-3-F1-8-G5-16-F'2-8
F-G-F'-D", 특히 F1-8-G5-16-F'2-8-D"1-3
D'-F-G-F'-D", 특히 D'1-3- F1-8-G5-16-F'2-8-D"1-3
일부 구현예에서, 영역 D' 와 영역 F 사이에 위치한 뉴클레오시드간 연결은 포스포디에스테르 연결이다. 일부 구현예에서 영역 F' 와 영역 D" 사이에 위치한 뉴클레오시드간 연결은 포스포디에스테르 연결이다.
토탈머
일부 구현예에서, 올리고뉴클레오티드, 또는 이의 인접 뉴클레오티드 서열의 모든 뉴클레오시드는 당 개질된 뉴클레오시드이다. 이러한 올리고뉴클레오티드는 본원에서 토탈머로 지칭된다.
일부 구현예에서 토탈머의 모든 당 개질된 뉴클레오시드는 동일한 당 개질을 포함하며, 예를 들어 이들은 모두 LNA 뉴클레오시드일 수 있거나, 또는 모두 2'O-MOE 뉴클레오시드일 수 있다. 일부 구현예에서 토탈머의 당 개질된 뉴클레오시드는 LNA 뉴클레오시드 및 2' 치환된 뉴클레오시드, 예컨대 2'-O-알킬-RNA, 2'-O-메틸-RNA, 2'-알콕시-RNA, 2'-O-메톡시에틸-RNA (MOE), 2'-아미노-DNA, 2'-플루오로-RNA, 및 2'-F-ANA 뉴클레오시드로 이루어진 군으로부터 선택되는 2' 치환된 뉴클레오시드로부터 독립적으로 선택된다. 일부 구현예에서 올리고뉴클레오티드는 LNA 뉴클레오시드 및 2' 치환된 뉴클레오시드, 예컨대 2'-O-알킬-RNA, 2'-O-메틸-RNA, 2'-알콕시-RNA, 2'-O-메톡시에틸-RNA (MOE), 2'-아미노-DNA, 2'-플루오로-RNA, 및 2'-F-ANA 뉴클레오시드로 이루어진 군으로부터 선택되는 2' 치환된 뉴클레오시드 둘 모두를 포함한다. 일부 구현예에서, 올리고뉴클레오티드는 LNA 뉴클레오시드 및 2'-O-MOE 뉴클레오시드를 포함한다. 일부 구현예에서, 올리고뉴클레오티드는 (S)cET LNA 뉴클레오시드 및 2'-O-MOE 뉴클레오시드를 포함한다. 일부 구현예에서, 올리고뉴클레오티드의 각각의 뉴클레오시드 단위는 2'치환된 뉴클레오시드이다. 일부 구현예에서, 올리고뉴클레오티드의 각각의 뉴클레오시드 단위는 2'-O-MOE 뉴클레오시드이다.
일부 구현예에서, 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열의 모든 뉴클레오시드는 LNA 뉴클레오시드, 예컨대 베타-D-옥시-LNA 뉴클레오시드 및/또는 (S)cET 뉴클레오시드이다. 일부 구현예에서 이러한 LNA 토탈머 올리고뉴클레오티드는 7 - 12 개의 뉴클레오시드 길이이다 (예를 들어, WO 2009/043353 참조). 이러한 짧은 완전 LNA 올리고뉴클레오티드는 특히 마이크로RNA 의 저해에 효과적이다.
다양한 토탈머 화합물은 특히 마이크로RNA (antimiR) 를 표적화할 때 치료용 올리고머로서 또는 스플라이스 스위칭 올리고머 (SSO) 로서 매우 효과적이다.
일부 구현예에서, 토탈머는 적어도 하나의 XYX 또는 YXY 서열 모티프, 예컨대 반복 서열 XYX 또는 YXY 를 포함하거나 이로 이루어지고, X 는 LNA 이고 Y 는 대안적인 (즉 비-LNA) 뉴클레오티드 유사체, 예컨대 2'-OMe RNA 단위 및 2'-플루오로 DNA 단위이다. 상기 서열 모티프는 일부 구현예에서 예를 들어 XXY, XYX, YXY 또는 YYX 일 수 있다.
일부 구현예에서, 토탈머는 7 내지 24 개의 뉴클레오티드, 예컨대 7, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22 또는 23 개의 뉴클레오티드의 인접 뉴클레오티드 서열을 포함하거나 이로 이루어질 수 있다.
일부 구현예에서, 토탈머의 인접 뉴클레오티드 서열은 적어도 30%, 예컨대 적어도 40%, 예컨대 적어도 50%, 예컨대 적어도 60%, 예컨대 적어도 70%, 예컨대 적어도 80%, 예컨대 적어도 90%, 예컨대 95%, 예컨대 100% 의 LNA 단위를 포함한다. 완전 LNA 화합물의 경우, 12 개 미만, 예컨대 7 - 10 개의 뉴클레오티드 길이인 것이 유리하다.
나머지 단위는 2'-O-알킬-RNA 단위, 2'-OMe-RNA 단위, 2'-아미노-DNA 단위, 2'-플루오로-DNA 단위, LNA 단위, PNA 단위, HNA 단위, INA 단위 및 2' MOE RNA 단위로 이루어지는 군, 또는 2'-OMe RNA 단위 및 2'-플루오로 DNA 단위로 이루어지는 군으로부터 선택된 것들과 같은 본원에서 언급되는 비-LNA 뉴클레오티드 유사체로부터 선택될 수 있다.
믹스머
용어 '믹스머' 는 DNA 뉴클레오시드 및 당 개질된 뉴클레오시드 둘 모두를 포함하는 올리고머를 지칭하며, 여기서 RNaseH 를 동원하기에는 불충분한 길이의 인접 DNA 뉴클레오시드가 존재한다. 적합한 믹스머는 3 개 이하 또는 4 개 이하의 인접 DNA 뉴클레오시드를 포함할 수 있다. 일부 구현예에서, 믹스머, 또는 이의 인접 뉴클레오티드 서열은 DNA 뉴클레오시드 및 당 개질된 뉴클레오시드의 교대 영역을 포함한다. DNA 뉴클레오시드의 짧은 영역과 함께 올리고뉴클레오티드 내로 혼입될 때 RNA 유사 (3'엔도) 형태를 형성하는 당 개질된 뉴클레오시드의 교대 영역에 의해, 비-RNaseH 동원 올리고뉴클레오티드가 제조될 수 있다. 유리하게는, 당 개질된 뉴클레오시드는 친화도 향상 당 개질된 뉴클레오시드이다.
올리고뉴클레오티드 믹스머는 종종 스플라이스 조절제 또는 마이크로RNA 저해제와 같은 표적 유전자의 점유 기반 조절을 제공하기 위해 사용된다.
일부 구현예에서 믹스머, 또는 이의 인접 뉴클레오티드 서열에서 당 개질된 뉴클레오시드는 LNA 뉴클레오시드, 예컨대 (S)cET 또는 베타-D-옥시 LNA 뉴클레오시드를 포함하거나 모두 LNA 뉴클레오시드, 예컨대 (S)cET 또는 베타-D-옥시 LNA 뉴클레오시드이다.
일부 구현예에서 믹스머의 모든 당 개질된 뉴클레오시드는 동일한 당 개질을 포함하며, 예를 들어 이들은 모두 LNA 뉴클레오시드일 수 있거나, 또는 모두 2'O-MOE 뉴클레오시드일 수 있다. 일부 구현예에서 믹스머의 당 개질된 뉴클레오시드는 LNA 뉴클레오시드 및 2' 치환된 뉴클레오시드, 예컨대 2'-O-알킬-RNA, 2'-O-메틸-RNA, 2'-알콕시-RNA, 2'-O-메톡시에틸-RNA (MOE), 2'-아미노-DNA, 2'-플루오로-RNA, 및 2'-F-ANA 뉴클레오시드로 이루어진 군으로부터 선택되는 2' 치환된 뉴클레오시드로부터 독립적으로 선택될 수 있다. 일부 구현예에서 올리고뉴클레오티드는 LNA 뉴클레오시드 및 2' 치환된 뉴클레오시드, 예컨대 2'-O-알킬-RNA, 2'-O-메틸-RNA, 2'-알콕시-RNA, 2'-O-메톡시에틸-RNA (MOE), 2'-아미노-DNA, 2'-플루오로-RNA, 및 2'-F-ANA 뉴클레오시드로 이루어진 군으로부터 선택되는 2' 치환된 뉴클레오시드 둘 모두를 포함한다. 일부 구현예에서, 올리고뉴클레오티드는 LNA 뉴클레오시드 및 2'-O-MOE 뉴클레오시드를 포함한다. 일부 구현예에서, 올리고뉴클레오티드는 (S)cET LNA 뉴클레오시드 및 2'-O-MOE 뉴클레오시드를 포함한다.
일부 구현예에서, 믹스머, 또는 이의 인접 뉴클레오티드 서열은 LNA 및 DNA 뉴클레오시드만 포함하며, 이러한 LNA 믹스머 올리고뉴클레오티드는 예를 들어 8 - 24 개의 뉴클레오시드 길이일 수 있다 (예를 들어, 마이크로RNA 의 LNA antmiR 저해제를 개시하는 WO2007112754 참조).
다양한 믹스머 화합물은 특히 마이크로RNA (antimiR) 를 표적화할 때 치료용 올리고머로서 또는 스플라이스 스위칭 올리고머 (SSO) 로서 매우 효과적이다.
일부 구현예에서, 믹스머는 하기 모티프를 포함한다:

여기서, L 은 당 개질된 뉴클레오시드, 예컨대 LNA 또는 2' 치환된 뉴클레오시드 (예를 들어 2'-O-MOE) 를 나타내고, D 는 DNA 뉴클레오시드를 나타내고, 각각의 m 은 1 - 6 으로부터 독립적으로 선택되고, 각각의 n 은 1, 2, 3 및 4, 예컨대 1- 3 으로부터 독립적으로 선택된다. 일부 구현예에서 각각의 L 은 LNA 뉴클레오시드이다. 일부 구현예에서, 적어도 하나의 L 은 LNA 뉴클레오시드이고 적어도 하나의 L 은 2'-O-MOE 뉴클레오시드이다. 일부 구현예에서, 각각의 L 은 LNA 및 2'-O-MOE 뉴클레오시드로부터 독립적으로 선택된다.
일부 구현예에서, 믹스머는 10 내지 24 개의 뉴클레오티드, 예컨대 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22 또는 23 개의 뉴클레오티드의 인접 뉴클레오티드 서열을 포함할 수 있거나 이로 이루어질 수 있다.
일부 구현예에서, 믹스머의 인접 뉴클레오티드 서열은 적어도 30%, 예컨대 적어도 40%, 예컨대 적어도 50% 의 LNA 단위를 포함한다.
일부 구현예에서, 믹스머는 뉴클레오티드 유사체 및 자연 발생 뉴클레오티드, 또는 뉴클레오티드 유사체의 하나의 유형 및 뉴클레오티드 유사체의 두 번째 유형의 반복 패턴의 인접 뉴클레오티드 서열을 포함하거나 이들로 이루어진다. 반복 패턴은, 예를 들어 매 두 번째 또는 매 세 번째 뉴클레오티드 또는 뉴클레오티드 유사체, 예를 들어 LNA 이고, 나머지 뉴클레오티드는 자연 발생 뉴클레오티드, 예를 들어 DNA 이거나, 2' 치환된 뉴클레오티드 유사체, 예를 들어 본원에서 언급된 2' 플루오로 유사체의 2' MOE 이거나, 일부 구현예에서, 본원에서 언급된 뉴클레오티드 유사체의 군으로부터 선택된다. 뉴클레오티드 유사체, 예컨대 LNA 단위의 반복 패턴은 고정 위치에서 - 예를 들어 5' 또는 3' 말단에서 - 뉴클레오티드 유사체와 조합될 수 있는 것으로 인지된다.
일부 구현예에서, 3' 말단으로부터 세는 올리고머의 제 1 뉴클레오티드는 뉴클레오티드 유사체, 예컨대 LNA 뉴클레오티드 또는 2'-O-MOE 뉴클레오시드이다.
일부 구현예에서, 동일하거나 상이할 수 있는, 3' 말단으로부터 세는 올리고머의 두 번째 뉴클레오티드는 뉴클레오티드 유사체, 예컨대 LNA 뉴클레오티드 또는 2'-O-MOE 뉴클레오시드이다.
일부 구현예에서, 동일하거나 상이할 수 있는, 올리고머의 5' 말단은 뉴클레오티드 유사체, 예컨대 LNA 뉴클레오티드 또는 2'-O-MOE 뉴클레오시드이다.
일부 구현예에서, 믹스머는 2 개 이상의 연속적 뉴클레오티드 유사체 단위, 예를 들어 2 개 이상의 연속적 LNA 단위를 포함하는 영역을 적어도 포함한다.
일부 구현예에서, 믹스머는 3 개 이상의 연속적 뉴클레오티드 유사체 단위, 예를 들어 3 개 이상의 연속적 LNA 단위를 포함하는 영역을 적어도 포함한다.
엑소좀
엑소좀은 기능적으로 활성인 카고 (예컨대 miRNA, mRNA, DNA 및 단백질) 를 통한 세포-세포 통신에 관여하는 전형적으로 30 내지 500 nm 범위의 천연 생물학적 나노 소포이다.
엑소좀은 모든 유형의 세포에 의해 분비되며 타액, 혈액, 소변 및 젖과 같은 체액에서 풍부하게 발견된다. 엑소좀의 주요 역할은 특정 세포 사이에 다양한 이펙터 또는 신호 분자를 전달하여 정보를 전달하는 것이다 (Acta Pol Pharm. 2014 Jul-Aug;71(4):537-43.). 이러한 이펙터 또는 신호 분자는 예를 들어 단백질, miRNA 또는 mRNA 일 수 있다. 엑소좀은 현재 이러한 분자의 치료 및 진단 적용을 확장시키기 위해 RNA 치료 분자를 포함하는 다양한 약물 분자에 대한 전달 비히클로서 탐구되고 있다. 유리 약물 분자와 비교하여 이러한 분자의 전달 및 효능면에서 이점을 제시하거나 나타내는 siRNA, 안티센스 올리고뉴클레오티드 및 소분자와 같은 합성 분자가 로딩된 엑소좀의 개시가 선행 기술에 있다 (예를 들어 Andaloussi et al 2013 Advanced Drug Delivery Reviews 65: 391-397, WO2014/168548, WO2016/172598, WO2017/173034 및 WO 2018/102397 참조).
엑소좀은 생물학적 공급원, 예컨대 젖 (젖 엑소좀) 으로부터 단리될 수 있으며, 특히 소 젖은 소 젖 엑소좀 단리에 대한 풍부한 공급원이다. 예를 들어 Manca et al., Scientific Reports (2018) 8:11321 참조.
본 발명의 일부 구현예에서, 단일 가닥 올리고뉴클레오티드는 엑소좀 (엑소좀 제형) 으로 캡슐화되고, 단일 가닥 안티센스 올리고뉴클레오티드로 엑소좀을 로딩하는 예는 EP 출원 No. 18192614.8 에 기재되어 있다. 본 발명의 방법에서 안티센스 올리고뉴클레오티드는 엑소좀 제형의 형태로 세포 또는 대상에게 투여될 수 있으며, 특히 엑소좀 제형의 경구 투여가 예상된다.
일부 구현예에서, 안티센스 올리고뉴클레오티드는, 예를 들어, 콜레스테롤과 같은 친유성 컨쥬게이트와 컨쥬게이트될 수 있으며, 이는 생물 절단성 링커 (예를 들어, 포스포디에스테르 연결된 DNA 뉴클레오티드의 영역) 를 통해 안티센스 올리고뉴클레오티드에 공유 부착될 수 있다. 이러한 친유성 컨쥬게이트는 안티센스 올리고뉴클레오티드의 엑소좀으로의 제형화를 용이하게 할 수 있고 표적 세포로의 전달을 추가로 향상시킬 수 있다.
컨쥬게이트
본원에서 사용된 용어 컨쥬게이트는 비-뉴클레오티드 모이어티 (컨쥬게이트 모이어티 또는 영역 C 또는 제 3 영역) 에 공유 결합으로 연결된 올리고뉴클레오티드를 지칭한다.
본 발명의 올리고뉴클레오티드의 하나 이상의 비-뉴클레오티드 모이어티에의 컨쥬게이션은 예를 들어 올리고뉴클레오티드의 활성, 세포 분포, 세포 흡수 또는 안정성에 영향을 미침으로써 올리고뉴클레오티드의 약리학을 개선할 수 있다. 일부 구현예에서 컨쥬게이트 모이어티는 올리고뉴클레오티드의 세포 분포, 생체이용률, 대사, 배설, 투과성, 및/또는 세포 흡수를 개선함으로써 올리고뉴클레오티드의 약동학적 특성을 변경 또는 개선한다. 특히 컨쥬게이트는 표적 올리고뉴클레오티드를 특정 기관, 조직 또는 세포 유형에 표적화하여 기관, 조직 또는 세포 유형에서 올리고뉴클레오티드의 효과를 향상시킬 수 있다. 이때, 컨쥬게이트는 올리고뉴클레오티드의 활성을 감소시키는 역할을 할 수 있으며, 예를 들어 비-표적 세포 유형, 조직 또는 기관에서 표적 활성 또는 활성을 제거하는 역할을 할 수 있다.
WO 93/07883 및 WO 2013/033230 은 본원에 참조로 포함되는 적합한 컨쥬게이트 모이어티를 제공한다. 추가의 적합한 컨쥬게이트 모이어티는 아시알로당단백질 수용체 (ASGPR) 에 결합할 수 있는 것들이다. 특히 3가 N-아세틸갈락토사민 컨쥬게이트 모이어티는 ASGPR 에 결합하기에 적합하다 (예를 들어 WO 2014/076196, WO 2014/207232 및 WO 2014/179620 (본원에 참조로 포함됨) 참조). 이러한 컨쥬게이트는 신장에서 그의 존재를 감소시키면서 올리고뉴클레오티드의 간으로의 흡수를 향상시켜, 컨쥬게이트되지 않은 버전의 동일한 올리고뉴클레오티드와 비교하여 컨쥬게이트된 올리고뉴클레오티드의 간/신장 비를 증가시키는 역할을 한다.
올리고뉴클레오티드 컨쥬게이트 및 그 합성은 또한 각각 그 전문이 본원에 참조로 포함되는 [Manoharan in Antisense Drug Technology, Principles, Strategies, and Applications, S.T. Crooke, ed., Ch. 16, Marcel Dekker, Inc., 2001 and Manoharan, Antisense and Nucleic Acid Drug Development, 2002, 12, 103] 에 의한 포괄적 검토에서 보고되어 있다.
일 구현예에서, 비-뉴클레오티드 모이어티 (컨쥬게이트 모이어티) 는 탄수화물, 세포 표면 수용체 리간드, 약물 물질, 호르몬, 친유성 물질, 중합체, 단백질, 펩티드, 독소 (예를 들어 박테리아 독소), 비타민, 바이러스 단백질 (예를 들어 캡시드) 또는 이들의 조합으로 이루어진 군으로부터 선택된다.
링커
연결 또는 링커는 하나 이상의 공유 결합을 통해 관심 대상의 하나의 화학기 또는 분절을 관심 대상의 또 다른 화학기 또는 분절에 연결하는 2 개의 원자 사이의 연결이다. 컨쥬게이트 모이어티는 올리고뉴클레오티드에 직접 또는 연결 모이어티 (예를 들어 링커 또는 테더) 를 통해 부착될 수 있다. 링커는 제 3 영역, 예를 들어 컨쥬게이트 모이어티 (영역 C) 를 제 1 영역, 예를 들어 표적 핵산에 상보적인 올리고뉴클레오티드 또는 인접 뉴클레오티드 서열 (영역 A) 에 공유적으로 연결시키는 역할을 한다.
본 발명의 일부 구현예에서 본 발명의 컨쥬게이트 또는 올리고뉴클레오티드 컨쥬게이트는 임의로 표적 핵산에 상보적인 올리고뉴클레오티드 또는 인접 뉴클레오티드 서열 (영역 A 또는 제 1 영역) 과 컨쥬게이트 모이어티 (영역 C 또는 제 3 영역) 사이에 위치한 링커 영역 (제 2 영역 또는 영역 B 및/또는 영역 Y) 를 포함할 수 있다.
영역 B 는 포유류 신체 내에서 일반적으로 발생되거나 또는 발생되는 것들과 유사한 조건 하에서 절단될 수 있는 생리학적으로 불안정한 결합을 포함하거나 이로 이루어지는 생물 절단성 링커를 지칭한다. 생리학적으로 불안정한 링커가 화학적 변형 (예를 들어, 절단) 되는 조건은, 화학적 조건, 예컨대 pH, 온도, 산화 또는 환원 조건 또는 작용제, 및 포유류 세포에서 발견되는 염 농도 또는 포유류 세포에서 발생되는 것들과 유사한 염 농도를 포함한다. 포유류의 세포내 조건은 또한 단백분해 효소 또는 가수분해 효소 또는 뉴클레아제로부터와 같은 포유류 세포에 정상적으로 존재하는 효소 활성의 존재를 포함한다. 일 구현예에서, 생물 절단성 링커는 S1 뉴클레아제 절단되기 쉽다. 바람직한 구현예에서, 뉴클레아제 민감성 링커는 1 내지 10 개의 뉴클레오시드, 예컨대 1, 2, 3, 4, 5, 6, 7, 8, 9 또는 10 개의 뉴클레오시드, 더 바람직하게는 2 내지 6 개의 뉴클레오시드 및 가장 바람직하게는 2 내지 4 개의 연결된 뉴클레오시드 (적어도 2 개의 연속적 포스포디에스테르 연결, 예컨대 적어도 3 또는 4 또는 5 개의 연속적 포스포디에스테르 연결을 포함함) 를 포함한다. 바람직하게는, 뉴클레오시드는 DNA 또는 RNA 이다. 포스포디에스테르 함유 생물 절단성 링커는 WO 2014/076195 (본원에 참조로 포함됨) 에 더 상세하게 기재되어 있다.
영역 Y 는 반드시 생물 절단성일 필요는 없지만 주로 컨쥬게이트 모이어티 (영역 C 또는 제 3 영역) 를 올리고뉴클레오티드 (영역 A 또는 제 1 영역) 에 공유 연결하는 역할을 하는 링커를 지칭한다. 영역 Y 링커는 사슬 구조 또는 에틸렌 글리콜, 아미노산 단위 또는 아미노 알킬 기와 같은 반복 단위의 올리고머를 포함할 수 있다. 본 발명의 올리고뉴클레오티드 컨쥬게이트는 하기 영역 요소 A-C, A-B-C, A-B-Y-C, A-Y-B-C 또는 A-Y-C 로 구성될 수 있다. 일부 구현예에서 링커 (영역 Y) 는 예를 들어 C6 내지 C12 아미노 알킬 기를 포함하는 C2 - C36 아미노 알킬 기와 같은 아미노 알킬이다. 바람직한 구현예에서 링커 (영역 Y) 는 C6 아미노 알킬 기이다.
투여
본 발명의 올리고뉴클레오티드 또는 약학적 조성물은 국소 (예컨대, 피부, 흡입, 눈 또는 귀) 또는 장내 (예컨대, 경구 또는 위장관을 통해) 또는 비경구 (예컨대, 정맥 내, 피하, 근육 내, 대뇌 내, 뇌실 내 또는 뇌척수 내) 로 투여될 수 있다.
일부 구현예에서 본 발명의 올리고뉴클레오티드 또는 약학적 조성물은 정맥 내, 동맥 내, 피하, 복강 내 또는 근육 내 주사 또는 주입, 척추 강내 또는 두개 내, 예를 들어 대뇌 내 또는 뇌실 내, 유리 체내 투여를 포함하는 비경구 경로에 의해 투여된다. 일 구현예에서, 활성 올리고뉴클레오티드 또는 올리고뉴클레오티드 컨쥬게이트 정맥 내 투여된다. 또 다른 구현예에서, 활성 올리고뉴클레오티드 또는 올리고뉴클레오티드 컨쥬게이트는 피하 투여된다.
일부 구현예에서, 본 발명의 올리고뉴클레오티드, 올리고뉴클레오티드 컨쥬게이트 또는 약학 조성물은 0.1 - 15 mg/kg, 예컨대 0.2 - 10 mg/kg, 예컨대 0.25 - 5 mg/kg 의 용량으로 투여된다. 투여는 1 주일에 1 회, 2 주 마다, 3 주 마다 또는 1 개월에 1 회 또는 2 개월에 1 회일 수 있다.
본 발명은 또한 약제가 유리 체내 주사와 같은 안과용 투여 형태인 약제의 제조를 위해 기재된 본 발명의 올리고뉴클레오티드 또는 올리고뉴클레오티드 컨쥬게이트의 용도를 제공한다. 일부 구현예에서, 안과 표적용 올리고뉴클레오티드는 Htra-1 이다.
본 발명은 또한 약제가 정맥 내, 피하, 근육 내, 대뇌 내, 뇌실 내 또는 뇌척수 내 투여 (예를 들어 주사) 를 위한 투여 형태인 약제의 제조를 위해 기재된 본 발명의 올리고뉴클레오티드 또는 올리고뉴클레오티드 컨쥬게이트의 용도를 제공한다.
예시적인 장점
본원에 예시된 바와 같이, 본 발명의 화합물에 사용된 아카이랄 포스포로디티오에이트 뉴클레오시드간 연결은 비-입체 정의된 포스포로티오에이트 올리고뉴클레오티드의 복잡성을 감소시키면서 올리고뉴클레오티드의 활성, 효능 또는 효력을 유지하게 한다.
실제로, 본원에 예시된 바와 같이, 본 발명의 화합물에 사용된 것은 입체 정의된 포스포로티오에이트와 조합으로 독특한 이점을 제공하여, 포스포로티오에이트 올리고뉴클레오티드의 복잡성을 추가로 감소시키면서 올리고뉴클레오티드의 활성, 효능 또는 효력을 유지 또는 개선할 수 있는 기회를 제공한다.
본원에 예시된 바와 같이, 본 발명의 화합물에 사용된 아카이랄 포스포로디티오에이트 뉴클레오시드간 연결은 시험관내 또는 생체내 세포 흡수의 개선을 허용한다.
본원에 예시된 바와 같이, 본 발명의 화합물에 사용된 아카이랄 포스포로디티오에이트 뉴클레오시드간 연결은 시험관내 생체 분포의 변경 또는 개선을 허용한다 (조직 또는 세포 함량, 또는 표적 조직에서의 활성/효능으로 측정됨). 특히, 본 발명자들은 골격근, 심장, 비장, 간, 신장, 섬유아세포, 상피 세포에서 조직 흡수, 함량 및/또는 효능의 개선을 관찰하였다.
믹스머 올리고뉴클레오티드와 관련하여, 본 발명자들은 포스포로디티오에이트 연결 (IA 또는 IB 에 도시됨) 을 하나 이상의 DNA 뉴클레오시드의 사이 또는 이에 인접하여 혼입시키는 것이 향상된 안정성 및/또는 개선된 효능과 같은 개선을 제공한다는 것을 확인하였다. 갭머 올리고뉴클레오티드와 관련하여, 본 발명자들은 포스포로디티오에이트 연결 (IA 또는 IB 에 도시됨) 을 플랭크 영역의 뉴클레오시드 사이 (예컨대 2'당 개질된 뉴클레오시드 사이) 에 혼입시키는 것도 향상된 안정성 및/또는 개선된 효능과 같은 개선을 제공한다는 것을 확인하였다.
본원에 예시된 바와 같이, 본 발명의 화합물에 사용된 아카이랄 포스포로디티오에이트 뉴클레오시드간 연결은 올리고뉴클레오티드 안정성의 개선을 허용한다. 본 발명의 화합물에서 아카이랄 포스포로디티오에이트 뉴클레오시드간의 혼입은 혈청 및 세포 엑소뉴클레아제, 특히 3' 엑소뉴클레아제, 뿐만 아니라 5'엑소뉴클레아제에 대한 향상된 내성을 제공하고, 본 발명의 화합물의 현저한 안정성은 아카이랄 포스포로디티오에이트 연결을 포함하는 화합물의 엔도뉴클레아제에 대한 내성을 추가로 나타낸다. 올리고뉴클레오티드의 안정화는 독성 분해 산물의 축적을 감소 또는 예방하고 안티센스 올리고뉴클레오티드의 작용 기간을 연장시키는데 특히 중요하다. 실시예에 예시된 바와 같이, 랫트 혈청 안정성은 개선된 안정성을 분석하기 위해 사용될 수 있다. 세포 안정성의 평가를 위해, 조직 (예를 들어 간) 균질액 추출물이 사용될 수 있다 (예를 들어 이러한 방법을 제공하는 WO2014076195 참조). 올리고뉴클레오티드 안정성의 측정을 위한 다른 분석은 뱀독 포스포디에스테라제 안정성 분석 및 S1 뉴클레아제 안정성을 포함한다.
청구된 올리고뉴클레오티드의 감소된 독성 위험은 시험관내 간독성 분석 (예를 들어 WO 2017/067970 에 개시된 바와 같음) 또는 시험관내 신독성 분석 (예를 들어 WO 2017/216340 에 개시된 바와 같음), 또는 시험관내 신경독성 분석 (예를 들어 WO2016127000 에 개시된 바와 같음) 으로 시험된다. 대안적으로 독성은 생체내, 예를 들어 마우스 또는 랫트에서 분석될 수 있다.
향상된 안정성은 본 발명의 올리고뉴클레오티드의 작용 기간에 이점을 제공할 수 있으며, 이는 투여 경로가 침습성인 경우, 예를 들어 비경구 투여, 예컨대, 정맥 내, 피하, 근육 내, 대뇌 내, 안구 내, 뇌실 내 또는 뇌척수 내 투여인 경우, 특히 유리하다.
일반적인 올리고뉴클레오티드 구현예
1. 화학식 (IA) 또는 (IB) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 올리고뉴클레오티드:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, 이때 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 LNA 뉴클레오시드이고, (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이다.
2. 구현예 1 에 있어서, (A1) 및 (A2) 중 하나는 LNA 뉴클레오시드이고 다른 하나는 DNA 뉴클레오시드, RNA 뉴클레오시드 또는 당 개질된 뉴클레오시드인, 올리고뉴클레오티드.
3. 구현예 1 또는 2 에 있어서, (A1) 및 (A2) 중 하나는 LNA 뉴클레오시드이고 다른 하나는 DNA 뉴클레오시드 또는 당 개질된 뉴클레오시드인, 올리고뉴클레오티드.
4. 구현예 1 - 3 중 어느 하나에 있어서, (A1) 및 (A2) 중 하나는 LNA 뉴클레오시드이고 다른 하나는 DNA 뉴클레오시드인, 올리고뉴클레오티드.
6. 구현예 1 - 3 중 어느 하나에 있어서, (A1) 및 (A2) 중 하나는 LNA 뉴클레오시드이고 다른 하나는 당 개질된 뉴클레오시드인, 올리고뉴클레오티드.
7. 구현예 2 내지 6 중 어느 하나에 있어서, 상기 당 개질된 뉴클레오시드는 2'-당 개질된 뉴클레오시드인, 올리고뉴클레오티드.
8. 구현예 7 에 있어서, 상기 2'-당 개질된 뉴클레오시드는 2'-알콕시-RNA, 2'-알콕시알콕시-RNA, 2'-아미노-DNA, 2'-플루오로-RNA, 2'-플루오로-ANA 또는 LNA 뉴클레오시드인, 올리고뉴클레오티드.
9. 구현예 7 또는 8 에 있어서, 상기 2'-당 개질된 뉴클레오시드는 LNA 뉴클레오시드인, 올리고뉴클레오티드.
10. 구현예 1 - 9 중 어느 하나에 있어서, LNA 뉴클레오시드는 베타-D-옥시 LNA, 6'-메틸-베타-D-옥시 LNA 및 ENA 로부터 독립적으로 선택되는, 올리고뉴클레오티드.
11. 구현예 9 또는 10 에 있어서, LNA 뉴클레오시드 둘 모두는 베타-D-옥시 LNA 인, 올리고뉴클레오티드.
12. 구현예 7 또는 8 에 있어서, 상기 2'-당 개질된 뉴클레오시드는 2'-알콕시알콕시-RNA 인, 올리고뉴클레오티드.
13. 구현예 10 에 있어서, 2'-알콕시-RNA 는 2'-메톡시-RNA 인, 올리고뉴클레오티드.
14. 구현예 1 - 12 중 어느 하나에 있어서, 2'-알콕시알콕시-RNA 는 2'-메톡시에톡시-RNA 인, 올리고뉴클레오티드.
15. 구현예 1 - 14 중 어느 하나에 있어서, 1 내지 15 개, 특히 1 내지 5 개, 보다 특히 1, 2, 3, 4 또는 5 개의 구현예 1 에 정의된 바와 같은 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는, 올리고뉴클레오티드.
16. 구현예 1 - 15 중 어느 하나에 있어서, 포스포디에스테르 뉴클레오시드간 연결, 포스포로티오에이트 뉴클레오시드간 연결 및 구현예 1 에 정의된 바와 같은 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택되는 뉴클레오시드간 연결을 추가로 포함하는, 올리고뉴클레오티드.
17. 구현예 16 에 있어서, 추가의 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결 및 구현예 1 에 정의된 바와 같은 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택되는, 올리고뉴클레오티드.
18. 구현예 16 또는 17 에 있어서, 추가의 뉴클레오시드간 연결은 모두 포스포로티오에이트 뉴클레오시드간 연결인, 올리고뉴클레오티드.
19. 구현예 16 또는 17 에 있어서, 추가의 뉴클레오시드간 연결은 모두 구현예 1 에 정의된 바와 같은 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결인, 올리고뉴클레오티드.
20. 구현예 1 - 19 중 어느 하나에 있어서, 올리고뉴클레오티드는 길이가 7 내지 30 개의 뉴클레오티드인, 올리고뉴클레오티드.
21. 구현예 1 - 20 중 어느 하나에 있어서, 하나 이상의 뉴클레오시드는 핵염기 개질된 뉴클레오시드인, 올리고뉴클레오티드.
22. 구현예 1 - 21 중 어느 하나에 있어서, 올리고뉴클레오티드는 안티센스 올리고뉴클레오티드, siRNA, 마이크로RNA 미믹 또는 리보자임인, 올리고뉴클레오티드.
23. 구현예 1 - 22 중 어느 하나에 따른 올리고뉴클레오티드의 약학적으로 허용되는 염, 특히 소듐 또는 포타슘 염 또는 암모늄 염.
24. 구현예 1 - 23 중 어느 하나에 따른 올리고뉴클레오티드 또는 약학적으로 허용되는 염을 포함하는 컨쥬게이트 및 임의로 링커 모이어티를 통해 상기 올리고뉴클레오티드 또는 상기 약학적으로 허용되는 염에 공유 부착된 적어도 하나의 컨쥬게이트 모이어티.
25. 구현예 1 - 24 중 어느 하나에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트 및 치료적으로 불활성인 담체를 포함하는 약학 조성물.
26. 치료적으로 활성인 물질로서 사용하기 위한, 구현예 1 - 24 중 어느 하나에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트.
27. 하기 단계를 포함하는 구현예 1 - 24 중 어느 하나에 따른 올리고뉴클레오티드의 제조 방법:
(a) 티오포스포르아미다이트 뉴클레오시드를 뉴클레오티드 또는 올리고뉴클레오티드의 말단 5' 산소 원자에 커플링시켜 티오포스파이트 트리에스테르 중간체를 생성하는 단계;
(b) 단계 a) 에서 수득된 티오포스파이트 트리에스테르 중간체를 티오산화시키는 단계; 및
(c) 임의로 올리고뉴클레오티드를 추가로 연장하는 단계.
28. 구현예 27 의 방법에 따라 제조된 올리고뉴클레오티드.
갭머 구현예
1. 세포에서 표적 RNA 의 저해를 위한, 화학식 (IA) 또는 (IB) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는, 안티센스 갭머 올리고뉴클레오티드:

(IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이다.
2. 구현예 1 에 있어서, 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결은 화학식 (IA) 을 갖고, R 은 수소이거나; 또는 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결은 화학식 (IB) 을 갖고, M+ 은 Na+, K+ 또는 암모늄인, 안티센스 갭머 올리고뉴클레오티드.
3. 구현예 1 또는 2 에 있어서, 상기 화학식 (I) 의 적어도 하나의 뉴클레오시드간 연결의 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 2'-당 개질된 뉴클레오시드인, 갭머 올리고뉴클레오티드.
4. 구현예 1 - 3 중 어느 하나에 있어서, (A1) 및 (A2) 중 하나는 2'-당 개질된 뉴클레오시드이고 다른 하나는 DNA 뉴클레오시드인, 갭머 올리고뉴클레오티드.
5.구현예 1 - 3 중 어느 하나에 있어서, (A1) 및 (A2) 둘 모두는 동시에 2'- 개질된 뉴클레오시드인, 갭머 올리고뉴클레오티드.
6. 구현예 1 - 3 중 어느 하나에 있어서, (A1) 및 (A2) 둘 모두는 동시에 DNA 뉴클레오시드인, 갭머 올리고뉴클레오티드.
7. 구현예 1 - 6 중 어느 하나에 있어서, 갭머 올리고뉴클레오티드는 화학식 5'-F-G-F'-3' 의 인접 뉴클레오티드 서열을 포함하고, G 는 RNaseH 를 동원할 수 있는 5 내지 18 개의 뉴클레오시드의 영역이고, 상기 영역 G 는 플랭킹 영역 F 및 F' 각각에 의해 5' 및 3' 플랭킹되고, 영역 F 및 F' 는 독립적으로 1 내지 7 개의 2'-당 개질된 뉴클레오티드를 포함하거나 이로 이루어지고, 영역 G 에 인접한 영역 F 의 뉴클레오시드는 2'-당 개질된 뉴클레오시드이고, 영역 G 에 인접한 영역 F' 의 뉴클레오시드는 2'-당 개질된 뉴클레오시드인, 갭머 올리고뉴클레오티드.
8. 구현예 1 - 7 중 어느 하나에 있어서, 2'-당 개질된 뉴클레오시드는 2'-알콕시-RNA, 2'-알콕시알콕시-RNA, 2'-아미노-DNA, 2'-플루오로-RNA, 2'-플루오로-ANA 및 LNA 뉴클레오시드로부터 독립적으로 선택되는, 갭머 올리고뉴클레오티드.
9.구현예 8 에 있어서, 2'-알콕시알콕시-RNA 는 2'-메톡시에톡시-RNA (2'-O-MOE) 인, 갭머 올리고뉴클레오티드.
10. 구현예 7 또는 8 에 있어서, 영역 F 및 영역 F' 는 2'-메톡시에톡시-RNA 뉴클레오티드를 포함하거나 이로 이루어지는, 갭머 올리고뉴클레오티드.
11. 구현예 7 내지 10 중 어느 하나에 있어서, 영역 F 또는 영역 F', 또는 영역 F 및 F' 둘 모두의 2'-당 개질된 뉴클레오시드 중 적어도 하나 또는 전부가 LNA 뉴클레오시드인, 갭머 올리고뉴클레오티드.
12. 구현예 7 내지 11 중 어느 하나에 있어서, 영역 F 또는 영역 F', 또는 영역 F 및 F' 둘 모두가 적어도 하나의 LNA 뉴클레오시드 및 적어도 하나의 DNA 뉴클레오시드를 포함하는, 갭머 올리고뉴클레오티드.
13. 구현예 7 내지 12 중 어느 하나에 있어서, 영역 F 또는 영역 F', 또는 영역 F 및 F' 둘 모두가 적어도 하나의 LNA 뉴클레오시드 및 적어도 하나의 비-LNA 2'-당 개질된 뉴클레오시드, 예컨대 적어도 하나의 2'-메톡시에톡시-RNA 뉴클레오시드를 포함하는, 갭머 올리고뉴클레오티드.
14. 구현예 1 - 13 중 어느 하나에 있어서, 갭 영역이 5 내지 16 개, 특히 8 내지 16 개, 보다 특히 8, 9, 10, 11, 12, 13 또는 14 개의 인접 DNA 뉴클레오시드를 포함하는, 갭머 올리고뉴클레오티드.
15. 구현예 1 - 14 중 어느 하나에 있어서, 영역 F 및 영역 F' 가 독립적으로 1, 2, 3, 4, 5, 6, 7 또는 8 개의 뉴클레오시드 길이인, 갭머 올리고뉴클레오티드.
16. 구현예 1 - 15 중 어느 하나에 있어서, 영역 F 및 영역 F' 가 각각 독립적으로 1, 2, 3 또는 4 개의 LNA 뉴클레오시드를 포함하는, 갭머 올리고뉴클레오티드.
17. 구현예 8 내지 16 중 어느 하나에 있어서, LNA 뉴클레오시드가 베타-D-옥시 LNA, 6'-메틸-베타-D-옥시 LNA 및 ENA 로부터 독립적으로 선택되는, 갭머 올리고뉴클레오티드.
18. 구현예 8 - 18 중 어느 하나에 있어서, LNA 뉴클레오시드가 베타-D-옥시 LNA 인, 갭머 올리고뉴클레오티드.
19. 구현예 1 - 18 중 어느 하나에 있어서, 올리고뉴클레오티드, 또는 이의 인접 뉴클레오티드 서열 (F-G-F') 이, 10 내지 30 개의 뉴클레오티드 길이, 특히 12 내지 22 개, 보다 특히 14 내지 20 개의 올리고뉴클레오티드 길이인, 갭머 올리고뉴클레오티드.
20. 구현예 1 - 19 중 어느 하나에 있어서, 영역 F 및 F' 와 같은 플랭크 영역 중 적어도 하나가 구현예 1 - 19 중 어느 하나에 정의된 바와 같은 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결을 포함하는, 갭머 올리고뉴클레오티드.
21. 구현예 1 - 19 중 어느 하나에 있어서, 영역 F 및 F' 와 같은 플랭크 영역 둘 모두가 구현예 1 - 19 중 어느 하나에 정의된 바와 같은 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결을 포함하는, 갭머 올리고뉴클레오티드.
22. 구현예 1 - 21 중 어느 하나에 있어서, F 또는 F' 와 같은 플랭크 영역 중 적어도 하나가 구현예 1 - 19 중 어느 하나에 정의된 바와 같은 화학식 (IA) 또는 (IB) 의 적어도 2 개의 포스포로디티오에이트 연결을 포함하는, 갭머 올리고뉴클레오티드.
23. 구현예 1 - 21 중 어느 하나에 있어서, 플랭크 영역, F 및 F' 둘 모두가 구현예 1 - 19 중 어느 하나에 정의된 바와 같은 화학식 (IA) 또는 (IB) 의 적어도 2 개의 포스포로디티오에이트 연결을 포함하는, 갭머 올리고뉴클레오티드.
24. 구현예 1 - 23 중 어느 하나에 있어서, 플랭크 영역 중 하나 또는 둘 모두가 각각 LNA 를 3' 뉴클레오시드에 연결하는 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결을 갖는 LNA 뉴클레오시드를 포함하는, 갭머 올리고뉴클레오티드.
25. 구현예 1 - 24 중 어느 하나에 있어서, 플랭크 영역 중 하나 또는 둘 모두가 각각 LNA 를 3' 뉴클레오시드에 연결하는 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결에 의해 연결된 2 개 이상의 인접 LNA 뉴클레오시드를 포함하는, 갭머 올리고뉴클레오티드.
26. 구현예 1 - 25 중 어느 하나에 있어서, 플랭크 영역 중 하나 또는 둘 모두가 각각 MOE 를 3' 뉴클레오시드에 연결하는 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결을 갖는 MOE 뉴클레오시드를 포함하는, 갭머 올리고뉴클레오티드.
27. 구현예 1 - 26 중 어느 하나에 있어서, 플랭크 영역 중 하나 또는 둘 모두가 각각 MOE 를 3' 뉴클레오시드에 연결하는 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결에 의해 연결된 2 개 이상의 인접 MOE 뉴클레오시드를 포함하는, 갭머 올리고뉴클레오티드.
28. 구현예 1 - 27 중 어느 하나에 있어서, 플랭크 영역, F 및 F' 가 함께 화학식 (IA) 또는 (IB) 의 1, 2, 3, 4 또는 5 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 임의로, 영역 F 의 3' 말단 뉴클레오시드와 영역 G 의 5' 말단 뉴클레오시드 사이의 뉴클레오시드간 연결은 또한 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결인, 갭머 올리고뉴클레오티드.
29. 구현예 1 - 28 중 어느 하나에 있어서, 영역 F 또는 영역 F', 영역 F 와 영역 G 사이 또는 영역 G 와 영역 F' 사이의 인접 뉴클레오시드에 위치한 화학식 (IA) 또는 (IB) 의 1 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는, 갭머 올리고뉴클레오티드.
30. 구현예 1 - 29 중 어느 하나에 있어서, 갭 영역이 화학식 (IA) 또는 (IB) 의 1, 2, 3 또는 4 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 나머지 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결인, 갭머 영역
31. 구현예 1 - 30 중 어느 하나에 있어서, 갭 영역이 적어도 5 개의 인접 DNA 뉴클레오티드의 영역, 예컨대 6 - 18 개의 DNA 인접 뉴클레오티드, 또는 8 - 14 개의 인접 DNA 뉴클레오티드의 영역을 포함하는, 갭머.
32. 구현예 1 - 31 중 어느 하나에 있어서, 하나 이상의 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결 (Sp, S) 또는 (Rp, R) 을 추가로 포함하는, 갭머:

여기서, N1 및 N2 는 뉴클레오시드이다.
33. 구현예 32 에 있어서, 갭머가 2 개의 DNA 뉴클레오시드 사이, 예컨대 갭 영역에서 2 개의 DNA 뉴클레오시드 사이에 적어도 하나의 입체 정의된 뉴클레오시드간 연결 (Sp, S) 또는 (Rp, R) 을 포함하는, 갭머.
34. 구현예 32 또는 33 에 있어서, 갭 영역이 Rp 및 Sp 뉴클레오시드간 연결로부터 독립적으로 선택되는 2, 3, 4, 5, 6, 7 또는 8 개의 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결을 포함하는, 갭머 올리고뉴클레오티드.
35. 구현예 32 - 33 중 어느 하나에 있어서, 영역 G 가 화학식 IB 의 적어도 2, 3, 또는 4 개의 뉴클레오시드간 연결을 추가로 포함하는, 갭머 올리고뉴클레오티드.
34. 구현예 32 - 35 중 어느 하나에 있어서, (i) 영역 G 내의 모든 나머지 뉴클레오시드간 연결 (즉 영역 G 에서의 뉴클레오시드 사이) 이 Rp 및 Sp 뉴클레오시드간 연결로부터 독립적으로 선택되는 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결이거나, 또는 (ii) 영역 G 내의 모든 뉴클레오시드간 연결이 Rp 및 Sp 뉴클레오시드간 연결로부터 독립적으로 선택되는 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인, 갭머 올리고뉴클레오티드.
35. 구현예 1 - 34 중 어느 하나에 있어서, 플랭크 영역 내의 모든 뉴클레오시드간 연결이 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결이고, 임의로 영역 F 의 3' 말단 뉴클레오시드와 영역 G 의 5' 말단 뉴클레오시드 사이의 뉴클레오시드간 연결이 또한 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결이고, 영역 G 의 3' 말단 뉴클레오시드와 영역 F' 의 5' 말단 뉴클레오시드 사이의 뉴클레오시드간 연결이 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인, 갭머 올리고뉴클레오티드.
36. 구현예 6 내지 35 중 어느 하나에 있어서, 영역 G 의 뉴클레오시드 사이의 뉴클레오시드간 연결이 포스포로티오에이트 뉴클레오시드간 연결 및 구현예 1 에 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택되는, 갭머 올리고뉴클레오티드.
37. 구현예 7 내지 36 중 어느 하나에 있어서, 영역 G 의 뉴클레오시드 사이의 뉴클레오시드간 연결이 구현예 1 에 정의된 바와 같은 화학식 (I) 의 0, 1, 2 또는 3 개의 포스포로디티오에이트 뉴클레오시드간 연결, 특히 화학식 (I) 의 0 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는, 갭머 올리고뉴클레오티드.
38. 구현예 1 - 37 중 어느 하나에 있어서, 나머지 뉴클레오시드간 연결이 포스포로티오에이트, 포스포디에스테르 및 구현예 1 에 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결로 이루어진 군으로부터 독립적으로 선택되는, 갭머 올리고뉴클레오티드.
39. 구현예 7 내지 38 중 어느 하나에 있어서, 영역 F 의 뉴클레오시드 사이의 뉴클레오시드간 연결 및 영역 F' 의 뉴클레오시드 사이의 뉴클레오시드간 연결이 포스포로티오에이트 및 구현예 1 에 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택되는, 갭머 올리고뉴클레오티드.
40. 구현예 7 내지 39 중 어느 하나에 있어서, 각각의 플랭킹 영역 F 및 F' 는 구현예 1 에 정의된 바와 같은 화학식 (I) 의 1, 2, 3, 4, 5, 6 또는 7 개의 포스포로디티오에이트 뉴클레오시드간 연결을 독립적으로 포함하는, 갭머 올리고뉴클레오티드.
41. 구현예 7 내지 40 중 어느 하나에 있어서, 플랭킹 영역 F 및/또는 F' 의 모든 뉴클레오시드간 연결은 구현예 1 에 정의된 바와 같은 화학식 (I) 의 포스포르디티오에이트 뉴클레오시드간 연결인, 갭머 올리고뉴클레오티드.
42. 구현예 1 - 41 중 어느 하나에 있어서, 갭머 올리고뉴클레오티드가 적어도 하나의 입체 정의된 뉴클레오시드간 연결, 예컨대 적어도 하나의 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결을 포함하는, 갭머 올리고뉴클레오티드.
43. 구현예 1 - 42 중 어느 하나에 있어서, 갭 영역이 1, 2, 3, 4 또는 5 개의 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결을 포함하는, 갭머 올리고뉴클레오티드.
44. 구현예 1 - 43 중 어느 하나에 있어서, 갭 영역의 뉴클레오시드 사이의 모든 뉴클레오시드간 연결이 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인, 갭머 올리고뉴클레오티드.
45. 구현예 7 내지 44 중 어느 하나에 있어서, 화학식 (IA) 또는 (IB) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결은 영역 F 의 뉴클레오시드 사이, 또는 영역 F' 의 뉴클레오시드 사이, 또는 영역 F 와 영역 G 사이, 또는 영역 G 와 영역 F' 사이에 위치하고, 영역 F 및 F' 내, 영역 F 와 영역 G 사이 및 영역 G 와 영역 F' 사이의 나머지 뉴클레오시드간 연결은 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결, 입체 랜덤 뉴클레오시드간 연결, 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결 및 포스포디에스테르 뉴클레오시드간 연결로부터 독립적으로 선택되는, 갭머 올리고뉴클레오티드.
46. 구현예 45 에 있어서, 영역 F 내, 영역 F' 내 또는 영역 F 및 영역 F' 내의 나머지 뉴클레오시드간 연결은 모두 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결인, 갭머 올리고뉴클레오티드.
47. 구현예 6 내지 33 중 어느 하나에 있어서, 영역 G 의 뉴클레오시드 사이의 뉴클레오시드간 연결은 구현예 1 에 정의된 바와 같은 화학식 (I) 의 0, 1, 2 또는 3 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 G 내의 나머지 뉴클레오시드간 연결은 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결, 입체 랜덤 뉴클레오시드간 연결 및 포스포디에스테르 뉴클레오시드간 연결로부터 독립적으로 선택되는, 갭머 올리고뉴클레오티드.
48. 구현예 1 - 47 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 3' 말단 뉴클레오시드는 LNA 뉴클레오시드 또는 2'-O-MOE 뉴클레오시드인, 갭머 올리고뉴클레오티드.
49. 구현예 1 - 48 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 5' 말단 뉴클레오시드는 LNA 뉴클레오시드 또는 2'-O-MOE 뉴클레오시드인, 갭머 올리고뉴클레오티드.
50. 구현예 1 - 49 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 2 개의 3' 최말단 뉴클레오시드는 LNA 뉴클레오시드 및 2'-O-MOE 뉴클레오시드로부터 독립적으로 선택되는, 갭머 올리고뉴클레오티드.
51. 구현예 1 - 50 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 2 개의 5' 최말단 뉴클레오시드는 LNA 뉴클레오시드 및 2'-O-MOE 뉴클레오시드로부터 독립적으로 선택되는, 갭머 올리고뉴클레오티드.
52. 구현예 1 - 51 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 3 개의 3' 최말단 뉴클레오시드는 LNA 뉴클레오시드 및 2'-O-MOE 뉴클레오시드로부터 독립적으로 선택되는, 갭머 올리고뉴클레오티드.
53. 구현예 1 - 52 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 3 개의 5' 최말단 뉴클레오시드는 LNA 뉴클레오시드 및 2'-O-MOE 뉴클레오시드로부터 독립적으로 선택되는, 갭머 올리고뉴클레오티드.
54. 구현예 1 - 53 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 2 개의 3' 최말단 뉴클레오시드는 LNA 뉴클레오시드인, 갭머 올리고뉴클레오티드.
55. 구현예 1 - 54 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 2 개의 5' 최말단 뉴클레오시드는 LNA 뉴클레오시드인, 갭머 올리고뉴클레오티드.
56. 구현예 1 - 55 중 어느 하나에 있어서, 화학식 (IA) 또는 (IB) 의 뉴클레오시드 (A2) 는 올리고뉴클레오티드의 3' 말단 뉴클레오시드인, 갭머 올리고뉴클레오티드.
57. 구현예 1 - 56 중 어느 하나에 있어서, 화학식 (IA) 또는 (IB) 의 뉴클레오시드 (A1) 는 올리고뉴클레오티드의 5' 말단 뉴클레오시드인, 갭머 올리고뉴클레오티드.
58. 구현예 7 - 57 중 어느 하나에 있어서, 갭머 올리고뉴클레오티드는 화학식 5'-D'-F-G-F'-D"-3' 의 인접 뉴클레오티드 서열을 포함하고, F, G 및 F' 는 구현예 7 내지 45 중 어느 하나에 정의된 바와 같고, 영역 D' 및 D" 는 각각 독립적으로 0 내지 5 개의 뉴클레오티드, 특히 2, 3 또는 4 개의 뉴클레오티드, 특히 DNA 뉴클레오티드, 예컨대 포스포디에스테르 연결된 DNA 뉴클레오시드로 이루어지는, 갭머 올리고뉴클레오티드 [갭머 올리고뉴클레오티드, 및 플랭킹 서열을 포함하는 올리고뉴클레오티드].
59. 구현예 1 - 58 중 어느 하나에 있어서, 갭머 올리고뉴클레오티드는 인간 RNaseH1 를 동원할 수 있는, 갭머 올리고뉴클레오티드.
60. 구현예 1 - 59 중 어느 하나에 있어서, 갭머 올리고뉴클레오티드는 포유류, 예컨대 인간, mRNA 또는 pre-mRNA 표적, 또는 바이러스 표적, 또는 긴 비-코딩 RNA 의 시험관내 또는 생체내 저해를 위한 것인, 갭머 올리고뉴클레오티드.
61. 구현예 1 - 60 중 어느 하나에 따른 갭머 올리고뉴클레오티드의 약학적으로 허용되는 염, 특히 소듐 또는 포타슘 염.
62. 구현예 1 - 61 중 어느 하나에 따른 갭머 올리고뉴클레오티드 또는 약학적으로 허용되는 염을 포함하는 컨쥬게이트 및 임의로 링커 모이어티를 통해 상기 올리고뉴클레오티드 또는 상기 약학적으로 허용되는 염에 공유 부착된 적어도 하나의 컨쥬게이트 모이어티.
63. 구현예 1 - 62 중 어느 하나에 따른 갭머 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트 및 치료적으로 불활성인 담체를 포함하는 약학 조성물.
64. 치료적으로 활성인 물질로서 사용하기 위한 구현예 1 내지 63 중 어느 하나에 따른 갭머 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트.
안티센스 올리고뉴클레오티드 구현예
본 발명은 화학식 (IA) 또는 (IB) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 올리고뉴클레오티드에 관한 것이다:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이다.
대안적으로 언급하면 M 은 금속, 예컨대 알칼리금속, 예컨대 Na 또는 K 이거나; 또는 M 은 NH4 이다.
올리고뉴클레오티드는 예를 들어 단일 가닥 안티센스 올리고뉴클레오티드일 수 있으며, 이는 표적 핵산, 예컨대 표적 마이크로RNA 의 발현을 조절할 수 있거나 또는 인접 뉴클레오티드 서열을 포함하는 표적 pre-mRNA 의 스플라이싱을 조절할 수 있다. 본 발명의 안티센스 올리고뉴클레오티드는 표적 핵산에 상보적이고 표적 핵산에 하이브리드화될 수 있고 표적 핵산의 발현을 조절할 수 있는 인접 뉴클레오티드 서열을 포함한다. 바람직한 구현예에서, 안티센스 올리고뉴클레오티드, 또는 이의 인접 뉴클레오티드 서열은 (A1) 또는 (A2) 가 DNA 뉴클레오시드이거나, 또는 (A1) 및 (A2) 둘 모두가 DNA 뉴클레오시드인 믹스머 올리고뉴클레오티드이다.
본 발명의 맥락에서, 안티센스 올리고뉴클레오티드는 핵산 표적, 예컨대 표적 RNA 에 상보적이고 핵산 표적 (예를 들어 mRNA 표적, premRNA 표적, 바이러스 RNA 표적, 또는 긴 비-코딩 RNA 표적) 의 발현을 조절 (예를 들어 pre-mRNA 표적의 스플라이스 조절) 또는 저해할 수 있는 단일 가닥 올리고뉴클레오티드이다. 표적에 따라, 올리고뉴클레오티드의 길이 또는 그에 상보적인 영역의 길이 (즉 안티센스 - 바람직하게는 상보적 영역은 표적에 완전히 상보적임) 는 7 - 30 개의 뉴클레오티드 (인접 뉴클레오티드 서열로 지칭되는 영역) 일 수 있다. 예를 들어, 마이크로RNA 의 LNA 뉴클레오티드 저해제는 7 개의 인접 상보적 뉴클레오티드만큼 짧을 수 있고 (및 30 개의 뉴클레오티드만큼 길 수 있음), RNaseH 동원 올리고뉴클레오티드는 전형적으로 적어도 12 개의 인접 상보적 뉴클레오티드 길이, 예컨대 12- 26 개의 뉴클레오티드 길이이다. 스플라이스 조절 안티센스 올리고뉴클레오티드는 전형적으로 10 - 30 개의 상보적 뉴클레오티드의 인접 뉴클레오티드 영역을 갖는다.
스플라이스-스위칭 올리고뉴클레오티드 (SSO) 로도 알려진 스플라이스 조절 올리고뉴클레오티드는 pre-mRNA 와 염기쌍을 이루고 스플라이싱 머시너리 구성 요소와 pre-mRNA 사이에 일어나는 단백질-RNA 결합 상호 작용 또는 RNA-RNA 염기쌍을 차단하여 전사체의 정상적인 스플라이싱 레퍼토리를 방해하는 짧은 합성, 안티센스, 개질된 핵산이다. pre-mRNA 의 스플라이싱은 다수의 단백질 코딩 유전자의 적절한 발현을 위해 필요하므로, 표적화 방법은 유전자에서 단백질 생산을 조작하는 수단을 제공한다. 스플라이싱 조절은 정상 스플라이싱을 방해하는 돌연변이에 의해 야기된 질환의 경우 특히 가치가 있거나 또는 유전자 전사체의 정상 스플라이싱 과정을 방해하는 경우 치료적일 수 있다. SSO 는 치료 방식으로 스플라이싱을 표적화하고 변경하는 효과적이고 구체적인 방법을 제공한다. Haven's and Hasting NAR (2016) 44, 6549-6563 참조. SSO 는 표적 pre-mRNA 에서 엑손/인트론 경계에 상보적일 수 있거나 또는 pre-mRNA 의 스플라이싱을 조절하는 pre-mRNA 내의 표적 스플라이싱 향상된 또는 사일렌서 요소 (총체적으로 시스-작용 스플라이스 요소로 지칭됨) 를 표적으로 할 수 있다. 스플라이스 조절은 엑손 스키핑, 또는 엑손 포함을 야기할 수 있으며, 이에 의해 pre-mRNA 의 대안적 스플라이싱을 조절한다. SSO 는 표적 pre-mRNA 의 비-뉴클레아제 매개 조절에 의해 기능하며, 따라서 RNaseH 를 동원할 수 없으며, 이들은 종종 완전히 개질된 올리고뉴클레오티드이며, 즉 각각의 뉴클레오시드는 개질된 당 모이어티, 예컨대 2'당 치환된 당 모이어티 (예를 들어 포스포로티오에이트 백본을 기준으로 예를 들어 15 - 25 개의 뉴클레오티드 길이, 종종 18 - 22 개 또는 20 개의 뉴클레오티드 길이의 완전히 2'-O-MOE 올리고뉴클레오티드), 또는 LNA 믹스머 올리고뉴클레오티드 (DNA 및 LNA 뉴클레오시드를 포함하는 10 - 30 개의 뉴클레오티드 길이의 올리고뉴클레오티드), 및 임의로 다른 2' 당 개질된 뉴클레오시드, 예컨대 2'-O-MOE 를 포함한다. DNA 뉴클레오시드를 포함하지 않지만, LNA 및 다른 2'당 개질된 뉴클레오시드, 예컨대 2'-O-MOE 뉴클레오시드는 포함하는 LNA 올리고뉴클레오티드가 또한 예상된다. 본원에 참조로 포함되는 Haven's and Hasting NAR (2016) 44, 6549-6563 의 표 1 은 생체내 활성을 보고하고 하기 표 A 에 재현된 사용된 올리고뉴클레오티드의 화학 및 SSO 표적의 범위를 예시한다:
표 A




본 발명의 일부 구현예에서, 안티센스 올리고뉴클레오티드는 HBB, FKTN, LMNA, CEP290, CLCN1, USH1C, BTK, LRP8, CTLA4, BCL2L1, ERBB4, MDM4, STAT3, IL1RAP, TNFRSF1B, FLT1, KDR, SMN2, MYBPC3, TTN, DMD, NBN, IL10, HTT, APOB, MSTN, GYS2, 및 ATXN3 로 이루어진 군으로부터 선택되는 pre-mRNA 에 상보적인 스플라이스 조절 올리고뉴클레오티드이다. 표적 기준으로 본 발명의 SSO 로 치료될 수 있는 예시적인 질환이 표 A 에 제공되어 있다.
하기 구현예는 일반적으로 본 발명의 단일 가닥 안티센스 올리고뉴클레오티드, 및 특히 스플라이스 조절 안티센스 올리고뉴클레오티드 (SSO) 에 관한 것이다:
1. 세포에서 RNA 표적의 조절을 위한 단일 가닥 안티센스 올리고뉴클레오티드로서, 안티센스 올리고뉴클레오티드는 길이가 10 - 30 개의 뉴클레오티드인 인접 뉴클레오티드 서열을 포함하거나 이로 이루어지고, 인접 뉴클레오티드 서열은 하나 이상의 2'당 개질된 뉴클레오시드를 포함하고, 인접 뉴클레오티드 서열의 뉴클레오시드 사이에 존재하는 뉴클레오시드간 연결 중 적어도 하나는 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결인, 단일 가닥 안티센스 올리고뉴클레오티드:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, R 은 수소 또는 포스페이트 보호기이다.
2. 구현예 1 에 있어서, 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 2' 당 개질된 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
3. 구현예 1 에 있어서, 뉴클레오시드 (A1) 및 (A2) 둘 모두는 2' 당 개질된 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
4. 구현예 1 - 3 중 어느 하나에 있어서, 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나, 또는 뉴클레오시드 (A1) 및 (A2) 둘 모두는 DNA 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
5. 구현예 1 - 4 중 어느 하나에 있어서, (A1) 및 (A2) 중 적어도 하나는 2'-당 개질된 뉴클레오시드 또는 2'-알콕시-RNA, 2'-알콕시알콕시-RNA, 2'-아미노-DNA, 2'-플루오로-RNA, 2'-플루오로-ANA 또는 LNA 뉴클레오시드로부터 독립적으로 선택된 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
6. 구현예 1 - 5 중 어느 하나에 있어서, (A1) 및 (A2) 중 적어도 하나는 LNA 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
7. 구현예 1 - 5 중 어느 하나에 있어서, (A1) 및 (A2) 둘 모두는 LNA 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
8. 구현예 1 - 6 중 어느 하나에 있어서, (A1) 및 (A2) 중 적어도 하나는 2'-O-메톡시에틸 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
9. 구현예 1 - 5 중 어느 하나에 있어서, (A1) 및 (A2) 둘 모두는 2'-O-메톡시에틸 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
10. 구현예 1 - 8 중 어느 하나에 있어서, LNA 뉴클레오시드는 베타-D-옥시 LNA, 6'-메틸-베타-D-옥시 LNA 및 ENA 로 이루어진 군으로부터 선택되는, 안티센스 올리고뉴클레오티드.
11. 구현예 1 - 8 중 어느 하나에 있어서, LNA 뉴클레오시드는 베타-D-옥시 LNA 인, 안티센스 올리고뉴클레오티드.
12. 구현예 1 - 11 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 하나 이상의 추가의 2'-당 개질된 뉴클레오시드, 예컨대 2'-알콕시-RNA, 2'-알콕시알콕시-RNA, 2'-아미노-DNA, 2'-플루오로-RNA, 2'-플루오로-ANA 또는 LNA 뉴클레오시드로 이루어진 군으로부터 선택되는 하나 이상의 추가의 2'당 개질된 뉴클레오시드를 포함하는, 안티센스 올리고뉴클레오티드.
13. 구현예 1 - 12 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 LNA 뉴클레오시드 및 DNA 뉴클레오시드 둘 모두를 포함하는, 안티센스 올리고뉴클레오티드.
14. 구현예 1 - 12 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 LNA 뉴클레오시드 및 2'-O-메톡시에틸 뉴클레오시드 둘 모두를 포함하는, 안티센스 올리고뉴클레오티드.
15. 구현예 1 - 13 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 LNA 뉴클레오시드 및 2'플루오로 RNA 뉴클레오시드 둘 모두를 포함하는, 안티센스 올리고뉴클레오티드.
16. 구현예 1 - 13 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 하기를 포함하는, 안티센스 올리고뉴클레오티드:
(i) LNA 및 DNA 뉴클레오시드만
(ii) LNA 및 2'-O-메톡시에틸 뉴클레오시드만
(iii) LNA, DNA 및 2'-O-메톡시에틸 뉴클레오시드만
(iv) LNA, 2'플루오로 RNA 및 2'-O-메톡시에틸 뉴클레오시드만
(v) LNA, DNA, 2'플루오로 RNA 및 2'-O-메톡시에틸 뉴클레오시드만 또는 LNA, 2'플루오로 RNA 및 2'-O-메톡시에틸 뉴클레오시드만
(vi) 2'-O-메톡시에틸 뉴클레오시드만.
17. 구현예 1 - 16 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 4 개 이상의 인접 DNA 뉴클레오시드의 서열을 포함하지 않거나, 또는 3 개 이상의 인접 DNA 뉴클레오시드의 서열을 포함하지 않는, 안티센스 올리고뉴클레오티드.
18. 구현예 1 - 17 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열이 믹스머 올리고뉴클레오티드 또는 토탈머 올리고뉴클레오티드인, 안티센스 올리고뉴클레오티드.
19. 구현예 1 - 18 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드가 인간 RNAseH1 을 동원할 수 없는, 안티센스 올리고뉴클레오티드.
20. 구현예 1 - 19 중 어느 하나에 있어서, 뉴클레오시드 (A2) 가 인접 뉴클레오티드 서열 또는 올리고뉴클레오티드의 3' 말단 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
21. 구현예 1 - 20 중 어느 하나에 있어서, 뉴클레오시드 (A1) 가 인접 뉴클레오티드 서열 또는 올리고뉴클레오티드의 5' 말단 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
22. 구현예 1 - 21 중 어느 하나에 있어서, 화학식 I 의 적어도 2 개의 포스포로디티오에이트 뉴클레오시드간 연결, 예컨대 화학식 I 의 2, 3, 4, 5, 또는 6 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는, 안티센스 올리고뉴클레오티드.
23. 구현예 1 - 22 중 어느 하나에 있어서, 인접 뉴클레오티드 서열의 2 개의 3' 말단 뉴클레오시드 사이의 뉴클레오시드간 연결이 화학식 I 의 포스포로디티오에이트 뉴클레오시드간 연결이고, 인접 뉴클레오티드 서열의 2 개의 5' 말단 뉴클레오시드 사이의 뉴클레오시드간 연결이 화학식 I 의 포스포로디티오에이트 뉴클레오시드간 연결인, 안티센스 올리고뉴클레오티드.
24. 구현예 1 - 23 중 어느 하나에 있어서, 포스포로티오에이트 뉴클레오시드간 연결을 추가로 포함하는, 안티센스 올리고뉴클레오티드.
25. 구현예 1 - 24 중 어느 하나에 있어서, 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결을 추가로 포함하는, 안티센스 올리고뉴클레오티드.
26. 구현예 1 - 25 중 어느 하나에 있어서, 나머지 뉴클레오시드간 연결이 포스포로디티오에이트 뉴클레오시드간 연결, 포스포로티오에이트 뉴클레오시드간 연결, 및 포스포디에스테르 뉴클레오시드간 연결로 이루어진 군으로부터 독립적으로 선택되는, 안티센스 올리고뉴클레오티드.
27. 구현예 1 - 26 중 어느 하나에 있어서, 나머지 뉴클레오시드간 연결이 포스포로티오에이트 뉴클레오시드간 연결인, 안티센스 올리고뉴클레오티드.
28. 구현예 1 - 27 중 어느 하나에 있어서, 상기 인접 뉴클레오티드 서열이 포유류 pre-mRNA, 포유류 성숙 mRNA 표적, 바이러스 RNA 표적, 또는 포유류 긴 비-코딩 RNA 에 상보적, 예컨대 100% 상보적인, 안티센스 올리고뉴클레오티드.
29. 구현예 28 에 있어서, RNA 표적이 인간 RNA 표적인, 안티센스 올리고뉴클레오티드.
30. 구현예 1 - 29 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드가 포유류, 예컨대 인간 pre-mRNA 표적의 스플라이싱을 조절하며, 예를 들어 스플라이스 스키핑 또는 스플라이스 조절 안티센스 올리고뉴클레오티드인, 안티센스 올리고뉴클레오티드.
31. 구현예 1 - 30 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드가 인간 pre-mRNA 의 인트론/엑손 스플라이스 부위, 또는 인간 pre-mRNA 의 스플라이스 조절 영역에 상보적, 예컨대 100% 상보적인, 안티센스 올리고뉴클레오티드.
32. 구현예 1 - 30 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열이 TNFR2, HBB, FKTN, LMNA, CEP290, CLCN1, USH1C, BTK, LRP8, CTLA4, BCL2L1, ERBB4, MDM4, STAT3, IL1RAP, TNFRSF1B, FLT1, KDR, SMN2, MYBPC3, TTN, DMD, NBN, IL10, HTT, APOB, MSTN, GYS2, 및 ATXN3 로 이루어진 군으로부터 선택되는 인간 pre-mRNA 서열에 상보적, 예컨대 완전히 상보적인, 안티센스 올리고뉴클레오티드.
33. 구현예 1 - 32 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드가 SSO#1 - SSO#25 로 이루어진 군으로부터 선택된 인접 뉴클레오티드 서열을 포함하거나 이로 이루어지는, 안티센스 올리고뉴클레오티드.
34. 구현예 1 - 33 중 어느 하나에 있어서, 세포가 인간 세포인, 안티센스 올리고뉴클레오티드.
35. 구현예 1 - 34 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 길이가 10 - 30 개의 뉴클레오티드 길이인, 안티센스 올리고뉴클레오티드.
36. 구현예 1 - 34 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 길이가 12 - 24 개의 뉴클레오티드 길이인, 안티센스 올리고뉴클레오티드.
37. 구현예 1 - 36 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열의 3' 말단 뉴클레오시드가 LNA 뉴클레오시드 또는 2-O-메톡시에틸 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
38. 구현예 1 - 27 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열의 5' 말단 뉴클레오시드가 LNA 뉴클레오시드 또는 2-O-메톡시에틸 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
39. 구현예 1 - 38 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열의 5' 말단 뉴클레오시드 및 3' 말단 뉴클레오시드 둘 모두가 LNA 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
40. 구현예 1 - 39 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 2 또는 3 개의 LNA 인접 뉴클레오티드의 적어도 하나의 영역, 및/또는 2 또는 3 개의 인접 2'-O-메톡시에틸 인접 뉴클레오티드의 적어도 하나의 영역을 포함하는, 안티센스 올리고뉴클레오티드.
41. 구현예 1 - 40 중 어느 하나에 따른 올리고뉴클레오티드의 약학적으로 허용되는 염, 특히 소듐 또는 포타슘 염 또는 암모늄 염.
42. 구현예 1 - 41 중 어느 하나에 따른 올리고뉴클레오티드 또는 약학적으로 허용되는 염을 포함하는 컨쥬게이트 및 임의로 링커 모이어티를 통해 상기 올리고뉴클레오티드 또는 상기 약학적으로 허용되는 염에 공유 부착된 적어도 하나의 컨쥬게이트 모이어티.
43. 구현예 1 - 42 중 어느 하나에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트 및 치료적으로 불활성인 담체를 포함하는 약학 조성물.
44. 치료적으로 활성인 물질로서 사용하기 위한 구현예 1 - 43 중 어느 하나에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트.
45. 유효량의 구현예 1 - 44 중 어느 하나에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염, 컨쥬게이트 또는 조성물을 세포에 투여하는 단계를 포함하는, RNA 를 발현하는 세포에서 표적 RNA 의 조절 방법.
46. 유효량의 구현예 1 - 44 중 어느 하나에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염, 컨쥬게이트 또는 조성물을 세포에 투여하는 단계를 포함하는, 표적 pre-mRNA 를 발현하는 세포에서 표적 pre-RNA 의 스플라이싱의 조절 방법.
47. 구현예 45 또는 46 에 있어서, 상기 방법이 시험관내 방법 또는 생체내 방법인, 방법.
48. 세포에서, 예컨대 인간 세포에서 RNA 의 저해를 위한, 구현예 1 - 44 중 어느 하나에 따른 올리고뉴클레오티드, 약학적 염, 컨쥬게이트, 또는 조성물의 용도로서, 상기 용도는 시험관내 또는 생체내인 용도.
특정 믹스머 구현예
1. 세포에서 RNA 표적의 조절을 위한, 단일 가닥 안티센스 올리고뉴클레오티드로서, 안티센스 올리고뉴클레오티드는 10 - 30 개의 뉴클레오티드 길이의 인접 뉴클레오티드 서열을 포함하거나 이로 이루어지고, 인접 뉴클레오티드 서열은 2'당 개질된 뉴클레오시드의 교대 영역을 포함하고, 인접 뉴클레오티드 서열을 갖는 인접 DNA 뉴클레오시드의 최대 길이는 3 또는 4 이고, 인접 뉴클레오티드 서열의 뉴클레오시드 사이에 존재하는 뉴클레오시드간 연결 중 적어도 하나는 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결인, 단일 가닥 안티센스 올리고뉴클레오티드:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, R 은 수소 또는 포스페이트 보호기이다.
2. 구현예 1 에 있어서, 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 2' 당 개질된 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
3. 구현예 1 에 있어서, 뉴클레오시드 (A1) 및 (A2) 둘 모두는 2' 당 개질된 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
4. 구현예 1 - 3 중 어느 하나에 있어서, 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나, 또는 뉴클레오시드 (A1) 및 (A2) 둘 모두는 DNA 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
5. 구현예 1 - 4 중 어느 하나에 있어서, (A1) 및 (A2) 중 적어도 하나는 2'-당 개질된 뉴클레오시드 또는 2'-알콕시-RNA, 2'-알콕시알콕시-RNA, 2'-아미노-DNA, 2'-플루오로-RNA, 2'-플루오로-ANA 또는 LNA 뉴클레오시드로부터 독립적으로 선택된 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
6. 구현예 1 - 5 중 어느 하나에 있어서, (A1) 및 (A2) 중 적어도 하나는 LNA 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
7. 구현예 1 - 5 중 어느 하나에 있어서, (A1) 및 (A2) 둘 모두는 LNA 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
8. 구현예 1 - 6 중 어느 하나에 있어서, (A1) 및 (A2) 중 적어도 하나는 2'-O-메톡시에틸 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
9. 구현예 1 - 5 중 어느 하나에 있어서, (A1) 및 (A2) 둘 모두는 2'-O-메톡시에틸 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
10. 구현예 1 - 8 중 어느 하나에 있어서, LNA 뉴클레오시드는 베타-D-옥시 LNA, 6'-메틸-베타-D-옥시 LNA 및 ENA 로 이루어진 군으로부터 선택되는, 안티센스 올리고뉴클레오티드.
11. 구현예 1 - 8 중 어느 하나에 있어서, LNA 뉴클레오시드는 베타-D-옥시 LNA 인, 안티센스 올리고뉴클레오티드.
12. 구현예 1 - 11 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 하나 이상의 추가의 2'-당 개질된 뉴클레오시드, 예컨대 2'-알콕시-RNA, 2'-알콕시알콕시-RNA, 2'-아미노-DNA, 2'-플루오로-RNA, 2'-플루오로-ANA 또는 LNA 뉴클레오시드로 이루어진 군으로부터 선택되는 하나 이상의 추가의 2'당 개질된 뉴클레오시드를 포함하는, 안티센스 올리고뉴클레오티드.
13. 구현예 1 -12 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 LNA 뉴클레오시드 및 DNA 뉴클레오시드 둘 모두를 포함하는, 안티센스 올리고뉴클레오티드.
14. 구현예 1 - 12 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 LNA 뉴클레오시드 및 2'-O-메톡시에틸 뉴클레오시드 둘 모두를 포함하는, 안티센스 올리고뉴클레오티드.
15. 구현예 1 - 13 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 LNA 뉴클레오시드 및 2'플루오로 RNA 뉴클레오시드 둘 모두를 포함하는, 안티센스 올리고뉴클레오티드.
16. 구현예 1 - 13 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 하기를 포함하는, 안티센스 올리고뉴클레오티드:
(i) LNA 및 DNA 뉴클레오시드
(ii) LNA, DNA 및 2'-O-메톡시에틸 뉴클레오시드
(iii) LNA, DNA, 2'플루오로 RNA 및 2'-O-메톡시에틸 뉴클레오시드.
17. 구현예 1 - 16 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 3 개 이상의 인접 DNA 뉴클레오시드의 서열을 포함하지 않거나, 또는 2 개 이상의 인접 DNA 뉴클레오시드의 서열을 포함하지 않는, 안티센스 올리고뉴클레오티드.
18. 구현예 1 - 17 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열이 믹스머 올리고뉴클레오티드, 예컨대 스플라이스 조절 올리고뉴클레오티드 또는 마이크로RNA 저해제 올리고뉴클레오티드인, 안티센스 올리고뉴클레오티드.
19. 구현예 18 에 있어서, 믹스머가 교대 영역 모티프를 포함하거나 이로 이루어지는, 안티센스 올리고뉴클레오티드:

여기서, L 은 2' 당 개질된 뉴클레오시드를 나타내고, D 는 DNA 뉴클레오시드를 나타내고, 각각의 m 은 1 - 6 으로부터 독립적으로 선택되고, 각각의 n 은 1, 2, 3 및 4, 예컨대 1 - 3 으로부터 독립적으로 선택된다.
20. 구현예 19 에 있어서, 각각의 L 뉴클레오시드는 LNA, 2'-O-MOE 또는 2'플루오로 뉴클레오시드로 이루어진 군으로부터 독립적으로 선택되거나, 또는 각각의 L 은 독립적으로 LNA 또는 2'-O-MOE 인, 안티센스 올리고뉴클레오티드.
21. 구현예 20 에 있어서, 각각의 L 은 LNA 인, 안티센스 올리고뉴클레오티드.
22. 구현예 1 - 21 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드는 인간 RNAseH1 을 동원할 수 없는, 안티센스 올리고뉴클레오티드.
23. 구현예 1 - 22 중 어느 하나에 있어서, 뉴클레오시드 (A2) 가 인접 뉴클레오티드 서열 또는 올리고뉴클레오티드의 3' 말단 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
24. 구현예 1 - 23 중 어느 하나에 있어서, 뉴클레오시드 (A1) 가 인접 뉴클레오티드 서열 또는 올리고뉴클레오티드의 5' 말단 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
25. 구현예 1 - 24 중 어느 하나에 있어서, 화학식 I 의 적어도 2 개의 포스포로디티오에이트 뉴클레오시드간 연결, 예컨대 화학식 I 의 2, 3, 4, 5, 또는 6 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는, 안티센스 올리고뉴클레오티드.
26. 구현예 1 - 25 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 2 개의 인접 DNA 뉴클레오티드를 포함하고, 2 개의 인접 DNA 뉴클레오티드 사이의 뉴클레오시드 연결이 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결, 즉 P2S 연결된 DNA 뉴클레오티드 쌍인, 안티센스 올리고뉴클레오티드.
27. 구현예 1 - 26 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 1 개 초과의 P2S 연결된 DNA 뉴클레오티드 쌍을 포함하는, 안티센스 올리고뉴클레오티드.
28. 구현예 1 - 26 중 어느 하나에 있어서, 인접 뉴클레오티드 서열에 존재하는 2 개의 인접 DNA 뉴클레오티드 사이의 모든 뉴클레오시드 연결이 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결인, 안티센스 올리고뉴클레오티드.
29. 구현예 1 - 27 중 어느 하나에 있어서, 2'당 개질된 뉴클레오시드와 DNA 뉴클레오시드 사이의 적어도 하나의 뉴클레오시드간 연결이 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결인, 안티센스 올리고뉴클레오티드.
30. 구현예 1 - 27 중 어느 하나에 있어서, 2'당 개질된 뉴클레오시드와 DNA 뉴클레오시드 사이의 1 개 초과의 뉴클레오시드간 연결이 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결인, 안티센스 올리고뉴클레오티드.
31. 구현예 1 - 27 중 어느 하나에 있어서, 2'당 개질된 뉴클레오시드와 DNA 뉴클레오시드 사이의 모든 뉴클레오시드간 연결이 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결인, 안티센스 올리고뉴클레오티드.
32. 구현예 1 - 27 중 어느 하나에 있어서, 2 개의 2'당 개질된 뉴클레오시드 사이의 뉴클레오시드간 연결 중 적어도 하나가 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결이 아니고, 예컨대 포스포로티오에이트 뉴클레오시드간 연결인, 안티센스 올리고뉴클레오티드.
33. 구현예 1 - 27 중 어느 하나에 있어서, 2 개의 2'당 개질된 뉴클레오시드 사이의 뉴클레오시드간 연결 모두가 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 뉴클레오시드간 연결이 아니고, 예컨대 포스포로티오에이트 뉴클레오시드간 연결인, 안티센스 올리고뉴클레오티드.
34. 구현예 1 - 33 중 어느 하나에 있어서, 인접 뉴클레오티드 서열의 2 개의 3' 말단 뉴클레오시드 사이의 뉴클레오시드간 연결이 화학식 I 의 포스포로디티오에이트 뉴클레오시드간 연결이고, 인접 뉴클레오티드 서열의 2 개의 5' 말단 뉴클레오시드 사이의 뉴클레오시드간 연결이 화학식 I 의 포스포로디티오에이트 뉴클레오시드간 연결인, 안티센스 올리고뉴클레오티드.
35. 구현예 1 - 34 중 어느 하나에 있어서, 포스포로티오에이트 뉴클레오시드간 연결을 추가로 포함하는, 안티센스 올리고뉴클레오티드.
36. 구현예 1 - 35 중 어느 하나에 있어서, 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결을 추가로 포함하는, 안티센스 올리고뉴클레오티드.
37. 구현예 1 - 35 중 어느 하나에 있어서, 나머지 뉴클레오시드간 연결이 포스포로디티오에이트 뉴클레오시드간 연결, 포스포로티오에이트 뉴클레오시드간 연결, 및 포스포디에스테르 뉴클레오시드간 연결로 이루어진 군으로부터 독립적으로 선택되는, 안티센스 올리고뉴클레오티드.
38. 구현예 1 -36 중 어느 하나에 있어서, 나머지 뉴클레오시드간 연결이 포스포로티오에이트 뉴클레오시드간 연결인, 안티센스 올리고뉴클레오티드.
39. 구현예 1 -37 중 어느 하나에 있어서, 상기 인접 뉴클레오티드 서열이 포유류, 예컨대 인간 pre-mRNA 에 상보적, 예컨대 100% 상보적인, 안티센스 올리고뉴클레오티드.
40. 구현예 1 - 38 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드가 포유류, 예컨대 인간 pre-mRNA 표적의 스플라이싱을 조절하며, 예를 들어 스플라이스 스키핑 또는 스플라이스 조절 안티센스 올리고뉴클레오티드인, 안티센스 올리고뉴클레오티드.
41. 구현예 1 - 39 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드가 인간 pre-mRNA 의 인트론/엑손 스플라이스 부위, 또는 인간 pre-mRNA 의 스플라이스 조절 영역에 상보적, 예컨대 100% 상보적인, 안티센스 올리고뉴클레오티드.
42. 구현예 1 - 41 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열이 TNFR2, HBB, FKTN, LMNA, CEP290, CLCN1, USH1C, BTK, LRP8, CTLA4, BCL2L1, ERBB4, MDM4, STAT3, IL1RAP, TNFRSF1B, FLT1, KDR, SMN2, MYBPC3, TTN, DMD, NBN, IL10, HTT, APOB, MSTN, GYS2, 및 ATXN3 로 이루어진 군으로부터 선택되는 인간 pre-mRNA 서열에 상보적, 예컨대 완전히 상보적인, 안티센스 올리고뉴클레오티드.
43. 구현예 1 - 42 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드가 SSO#1 - SSO#25 로 이루어진 군으로부터 선택된 인접 뉴클레오티드 서열을 포함하거나 이로 이루어지는, 안티센스 올리고뉴클레오티드.
44. 구현예 1 - 43 중 어느 하나에 있어서, 세포가 포유류 세포인, 안티센스 올리고뉴클레오티드.
45. 구현예 1 - 44 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 길이가 10 - 30 개의 뉴클레오티드 길이인, 안티센스 올리고뉴클레오티드.
46. 구현예 1 - 44 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 길이가 12 - 24 개의 뉴클레오티드 길이인, 안티센스 올리고뉴클레오티드.
47. 구현예 1 - 46 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열의 3' 말단 뉴클레오시드가 LNA 뉴클레오시드 또는 2-O-메톡시에틸 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
48. 구현예 1 - 47 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열의 5' 말단 뉴클레오시드가 LNA 뉴클레오시드 또는 2-O-메톡시에틸 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
49. 구현예 1 - 48 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열의 5' 말단 뉴클레오시드 및 3' 말단 뉴클레오시드 둘 모두가 LNA 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
50. 구현예 1 - 49 중 어느 하나에 있어서, 인접 뉴클레오티드 서열이 2 또는 3 개의 LNA 인접 뉴클레오티드의 적어도 하나의 영역, 및/또는 2 또는 3 개의 인접 2'-O-메톡시에틸 인접 뉴클레오티드의 적어도 하나의 영역을 포함하는, 안티센스 올리고뉴클레오티드.
51. 구현예 1 - 50 중 어느 하나에 따른 올리고뉴클레오티드의 약학적으로 허용되는 염, 특히 소듐 또는 포타슘 염 또는 암모늄 염.
52. 구현예 1 - 51 중 어느 하나에 따른 올리고뉴클레오티드 또는 약학적으로 허용되는 염을 포함하는 컨쥬게이트 및 임의로 링커 모이어티를 통해 상기 올리고뉴클레오티드 또는 상기 약학적으로 허용되는 염에 공유 부착된 적어도 하나의 컨쥬게이트 모이어티.
53. 구현예 1 - 52 중 어느 하나에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트 및 치료적으로 불활성인 담체를 포함하는 약학 조성물.
54. 치료적으로 활성인 물질로서 사용하기 위한 구현예 1 - 53 중 어느 하나에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트.
55. 유효량의 구현예 1 - 54 중 어느 하나에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염, 컨쥬게이트 또는 조성물을 세포에 투여하는 단계를 포함하는, RNA 를 발현하는 세포에서 표적 RNA 의 조절 방법.
56. 유효량의 구현예 1 - 54 중 어느 하나에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염, 컨쥬게이트 또는 조성물을 세포에 투여하는 단계를 포함하는, 표적 pre-mRNA 를 발현하는 세포에서 표적 pre-RNA 의 스플라이싱의 조절 방법.
57. 구현예 55 또는 56 에 있어서, 상기 방법이 시험관내 방법 또는 생체내 방법인, 방법.
58. 세포에서, 예컨대 포유류 세포에서 RNA 의 저해를 위한, 구현예 1 - 54 중 어느 하나에 따른 올리고뉴클레오티드, 약학적 염, 컨쥬게이트, 또는 조성물의 용도로서, 상기 용도는 시험관내 또는 생체내인 용도.
3' 말단 보호에 관한 특정 구현예
1. 화학식 (IA) 또는 (IB) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 단일 가닥 안티센스 올리고뉴클레오티드:
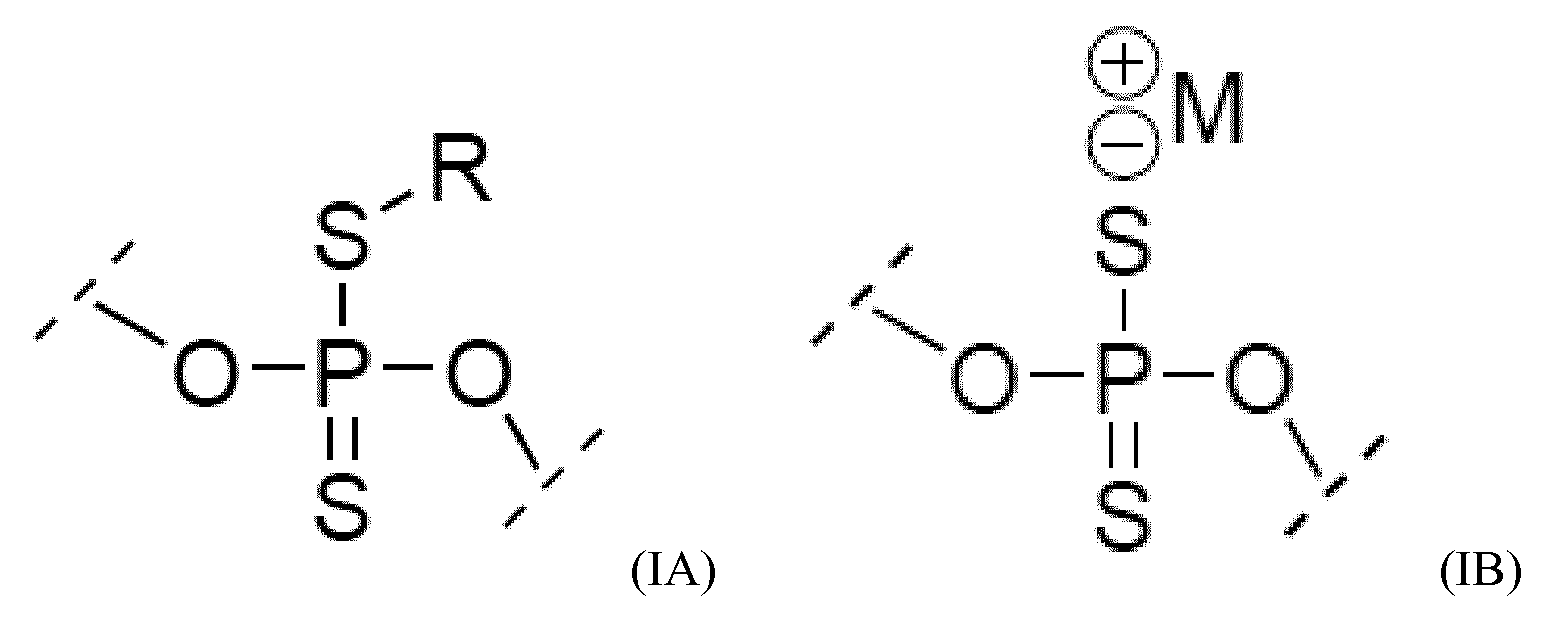
식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 2' 당 개질된 뉴클레오시드, 예컨대 LNA 뉴클레오시드 또는 2'-O-MOE 뉴클레오시드이고, R 은 수소 또는 포스페이트 보호기이고, A2 는 올리고뉴클레오티드의 3' 말단 뉴클레오시드이다.
2. 구현예 1 에 있어서, (A2) 는 LNA 뉴클레오시드이거나, 또는 (A1) 및 (A2) 둘 모두는 LNA 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
3. 구현예 1 에 있어서, (A2) 는 LNA 뉴클레오시드이고 (A1) 는 당 개질된 뉴클레오티드인, 단일 가닥 안티센스 올리고뉴클레오티드.
4.구현예 1 에 있어서, (A2) 는 LNA 뉴클레오시드이고 (A1) 는 DNA 뉴클레오티드인, 단일 가닥 안티센스 올리고뉴클레오티드.
5.구현예 1 에 있어서, (A1) 는 LNA 뉴클레오시드이고 (A2) 는 당 개질된 뉴클레오티드인, 단일 가닥 안티센스 올리고뉴클레오티드.
6.구현예 1 에 있어서, (A1) 는 LNA 뉴클레오시드이고 (A2) 는 DNA 뉴클레오티드인, 단일 가닥 안티센스 올리고뉴클레오티드.
7. 구현예 3 또는 5 중 어느 하나에 있어서, 상기 당 개질된 뉴클레오시드는 2'-당 개질된 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
8. 구현예 7 에 있어서, 상기 2'-당 개질된 뉴클레오시드는 2'-알콕시-RNA, 2'-알콕시알콕시-RNA, 2'-아미노-DNA, 2'-플루오로-RNA, 2'-플루오로-ANA 또는 LNA 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
9. 구현예 7 또는 8 중 어느 하나에 있어서, 상기 2'-당 개질된 뉴클레오시드는 2'-O-메톡시에틸 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
10. 구현예 1 - 9 중 어느 하나에 있어서, LNA 뉴클레오시드 또는 뉴클레오티드는 베타-D 배열인, 단일 가닥 안티센스 올리고뉴클레오티드.
11. 구현예 1 - 10 중 어느 하나에 있어서, LNA 뉴클레오시드는 베타-D-옥시 LNA, 6'-메틸-베타-D-옥시 LNA 및 ENA 로부터 독립적으로 선택되는, 단일 가닥 안티센스 올리고뉴클레오티드.
12. 구현예 1 - 11 중 어느 하나에 있어서, LNA 는 베타-D-옥시 LNA 인, 단일 가닥 안티센스 올리고뉴클레오티드.
13. 구현예 1 - 12 중 어느 하나에 있어서, 단일 가닥 안티센스가 표적 핵산, 예컨대 pre-mRNA, 및 mRNA, 마이크로RNA, 바이러스 RNA, 및 긴 비-코딩 RNA 로 이루어진 군으로부터 선택되는 표적 핵산에 상보적인 7 - 30 개의 인접 뉴클레오티드를 포함하거나 이로 이루어지는 [안티센스 단일 가닥 안티센스의 인접 뉴클레오티드 서열로 지칭됨], 단일 가닥 안티센스 올리고뉴클레오티드.
14. 구현예 1 - 13 중 어느 하나에 있어서, 인접 뉴클레오티드 서열은 화학식 5'-F-G-F'-3' 의 갭머 영역을 포함하고, G 는 RnaseH 를 동원할 수 있는 5 내지 18 개의 뉴클레오시드의 영역이고, 상기 영역 G 는 플랭킹 영역 F 및 F' 각각에 의해 5' 및 3' 플랭킹되고, 영역 F 및 F' 는 독립적으로 1 내지 7 개의 2'-당 개질된 뉴클레오티드를 포함하거나 이로 이루어지고, 영역 G 에 인접한 영역 F 의 뉴클레오시드는 2'-당 개질된 뉴클레오시드이고, 영역 G 에 인접한 영역 F' 의 뉴클레오시드는 2'-당 개질된 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
14. 구현예 1 - 13 중 어느 하나에 있어서, 인접 뉴클레오티드 서열은 믹스머 올리고뉴클레오티드이고, 믹스머 올리고뉴클레오티드는 LNA 뉴클레오시드 및 DNA 뉴클레오시드 둘 모두, 및 임의로 2'당 개질된 뉴클레오시드 [예컨대 구현예 8 - 9 에 따른 것들] 를 포함하고, 단일 가닥 안티센스는 4 개 이상의 인접 DNA 뉴클레오시드의 영역을 포함하지 않는, 단일 가닥 안티센스 올리고뉴클레오티드.
15. 구현예 1 - 13 중 어느 하나에 있어서, 인접 뉴클레오티드 서열은 당 개질된 뉴클레오시드만 포함하는, 단일 가닥 안티센스 올리고뉴클레오티드.
16. 구현예 14 또는 15 에 있어서, 올리고뉴클레오티드는 스플라이스 조절 올리고뉴클레오티드 [pre-mRNA 스플라이스 이벤트의 스플라이싱을 조절할 수 있음] 인, 단일 가닥 안티센스 올리고뉴클레오티드.
17. 구현예 14 또는 15 에 있어서, 올리고뉴클레오티드가 마이크로RNA 에 상보적이며, 예컨대 마이크로RNA 저해제인, 단일 가닥 안티센스 올리고뉴클레오티드.
18. 구현예 1 - 17 중 어느 하나에 있어서, 포스포디에스테르 뉴클레오시드간 연결, 포스포로티오에이트 뉴클레오시드간 연결 및 포스포로디티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택되는 뉴클레오시드간 연결; 또는 포스포로티오에이트 뉴클레오시드간 연결 및 포스포로디티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택되는 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열 내의 추가의 뉴클레오시드간 연결을 추가로 포함하는, 단일 가닥 안티센스 올리고뉴클레오티드.
18. 구현예 1 - 18 중 어느 하나에 있어서, 올리고뉴클레오티드, 또는 이의 인접 뉴클레오티드 서열의 추가의 뉴클레오시드간 연결이 모두 포스포로티오에이트 뉴클레오시드간 연결인, 단일 가닥 안티센스 올리고뉴클레오티드.
19. 구현예 1 - 18 중 어느 하나에 있어서, 올리고뉴클레오티드는 인접 뉴클레오티드 서열에 대한 5' 영역 위치 5' 를 포함하고, 5' 뉴클레오시드 영역은 적어도 하나의 포스포디에스테르 연결을 포함하는, 단일 가닥 안티센스 올리고뉴클레오티드.
20. 구현예 19 에 있어서, 5' 영역은 1 - 5 개의 포스포디에스테르 연결된 DNA 뉴클레오시드를 포함하고, 임의로 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열을 컨쥬게이트 모이어티에 연결할 수 있는, 단일 가닥 안티센스 올리고뉴클레오티드.
21. 구현예 1 - 20 중 어느 하나에 있어서, 하나 이상의 뉴클레오시드가 핵염기 개질된 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
22. 구현예 1 - 21 중 어느 하나에 있어서, 하나 이상의 뉴클레오시드가 5-메틸 시토신, 예컨대 LNA 5-메틸 시토신 또는 DNA 5-메틸 시토신인, 단일 가닥 안티센스 올리고뉴클레오티드.
23. 구현예 1 - 22 중 어느 하나에 따른 올리고뉴클레오티드의 약학적으로 허용되는 염, 특히 소듐 또는 포타슘 염 또는 암모늄 염.
24. 구현예 1 - 23 중 어느 하나에 따른 올리고뉴클레오티드 또는 약학적으로 허용되는 염을 포함하는 컨쥬게이트 및 임의로 링커 모이어티를 통해 상기 올리고뉴클레오티드 또는 상기 약학적으로 허용되는 염에 공유 부착된 적어도 하나의 컨쥬게이트 모이어티.
25. 구현예 1 - 24 중 어느 하나에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트 및 치료적으로 불활성인 담체를 포함하는 약학 조성물.
26. 치료적으로 활성인 물질로서 사용하기 위한 구현예 1 - 25 중 어느 하나에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트.
27. 비경구 투여, 예컨대, 정맥 내, 피하, 근육 내, 대뇌 내, 뇌실 내 또는 뇌척수 내 투여를 통해 대상에게 투여하기 위한, 치료에 사용하기 위한, 구현예 1 - 24 중 어느 하나에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트.
아카이랄 포스포로디티오에이트 및 입체 정의된 포스포로티오에이트 연결을 갖는 올리고뉴클레오티드에 관한 구현예
1. 화학식 (IA) 또는 (IB) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 단일 가닥 안티센스 올리고뉴클레오티드:

식 중, 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 인접 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, (IA) 에서 R 은 수소 또는 포스페이트 보호기이고, (IB) 에서 M+ 은 양이온, 예컨대 금속 양이온, 예컨대 알칼리금속 양이온, 예컨대 Na+ 또는 K+ 양이온이거나; 또는 M+ 은 암모늄 양이온이고, 단일 가닥 올리고뉴클레오티드는 적어도 하나의 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결, (Sp, S) 또는 (Rp, R) 을 추가로 포함한다:

여기서, N1 및 N2 는 뉴클레오시드이다. (참고: 일부 비제한적인 구현예에서 N1 및/또는 N2 는 DNA 뉴클레오티드이다).
2. 구현예 1 에 있어서, A2 가 올리고뉴클레오티드의 3' 말단 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
3. 구현예 1 에 있어서, A1 이 올리고뉴클레오티드의 5' 말단 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
4. 구현예 1 - 3 중 어느 하나에 있어서, 상기 단일 가닥 올리고뉴클레오티드가 화학식 IB 의 1, 2, 3, 4, 5, 또는 6 개의 뉴클레오시드간 연결을 포함하는, 단일 가닥 안티센스 올리고뉴클레오티드.
5. 구현예 1 - 4 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 5' 말단 뉴클레오시드간 연결 및 안티센스 올리고뉴클레오티드의 3' 말단 뉴클레오시드간 연결 둘 모두가 화학식 IB 의 뉴클레오시드간 연결인, 단일 가닥 안티센스 올리고뉴클레오티드.
6. 구현예 1 - 5 중 어느 하나에 있어서, 화학식 IB 의 뉴클레오시드간 연결 중 적어도 하나에서, 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 2' 당 개질된 뉴클레오시드, 예컨대 2'-알콕시-RNA, 2'-알콕시알콕시-RNA, 2'-아미노-DNA, 2'-플루오로-RNA, 2'-플루오로-ANA 및 LNA 뉴클레오시드로 이루어진 군으로부터 선택되는 2' 당 개질된 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
7. 구현예 1 - 6 중 어느 하나에 있어서, 화학식 IB 의 뉴클레오시드간 연결 중 적어도 하나에서, 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 LNA 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
8. 구현예 1 - 6 중 어느 하나에 있어서, 화학식 IB 의 뉴클레오시드간 연결 중 적어도 하나에서, 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 2'-O-MOE 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
9. 구현예 1 - 8 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 3' 말단 뉴클레오시드가 LNA 뉴클레오시드 또는 2'-O-MOE 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
10. 구현예 1 - 9 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 5' 말단 뉴클레오시드가 LNA 뉴클레오시드 또는 2'-O-MOE 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
11. 구현예 1 - 10 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 2 개의 3' 최말단 뉴클레오시드가 LNA 뉴클레오시드 및 2'-O-MOE 뉴클레오시드로부터 독립적으로 선택되는, 단일 가닥 안티센스 올리고뉴클레오티드.
12. 구현예 1 - 11 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 2 개의 5' 최말단 뉴클레오시드가 LNA 뉴클레오시드 및 2'-O-MOE 뉴클레오시드로부터 독립적으로 선택되는, 단일 가닥 안티센스 올리고뉴클레오티드.
13. 구현예 1 - 12 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 3 개의 3' 최말단 뉴클레오시드가 LNA 뉴클레오시드 및 2'-O-MOE 뉴클레오시드로부터 독립적으로 선택되는, 단일 가닥 안티센스 올리고뉴클레오티드.
14. 구현예 1 - 13 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 3 개의 5' 최말단 뉴클레오시드가 LNA 뉴클레오시드 및 2'-O-MOE 뉴클레오시드로부터 독립적으로 선택되는, 단일 가닥 안티센스 올리고뉴클레오티드.
15. 구현예 1 - 14 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 2 개의 3' 최말단 뉴클레오시드가 LNA 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
16. 구현예 1 - 15 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드의 2 개의 5' 최말단 뉴클레오시드가 LNA 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
17. 구현예 1 - 16 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드는 2 - 16 개의 DNA 뉴클레오티드의 영역을 추가로 포함하고, DNA 뉴클레오티드 사이의 뉴클레오시드간 연결은 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인, 단일 가닥 안티센스 올리고뉴클레오티드.
18. 구현예 1 - 17 중 어느 하나에 있어서, LNA 뉴클레오시드는 베타-D-옥시 LNA, 6'-메틸-베타-D-옥시 LNA 및 ENA 로부터 독립적으로 선택되는, 단일 가닥 안티센스 올리고뉴클레오티드.
19. 구현예 1 - 17 중 어느 하나에 있어서, LNA 뉴클레오시드는 베타-D-옥시 LNA 인, 단일 가닥 안티센스 올리고뉴클레오티드.
20. 구현예 1 - 19 중 어느 하나에 있어서, 올리고뉴클레오티드가 표적 핵산, 예컨대 pre-mRNA, 및 mRNA, 마이크로RNA, 바이러스 RNA, 및 긴 비-코딩 RNA 로 이루어진 군으로부터 선택되는 표적 핵산에 상보적인, 예컨대 완전히 상보적인 7 - 30 개의 인접 뉴클레오티드를 포함하거나 이로 이루어지는 [안티센스 올리고뉴클레오티드], 단일 가닥 안티센스 올리고뉴클레오티드.
21. 구현예 1 - 20 중 어느 하나에 있어서, 단일 가닥 올리고뉴클레오티드가 RNA 표적을 조절할 수 있는, 단일 가닥 안티센스 올리고뉴클레오티드.
22. 구현예 1 - 20 중 어느 하나에 있어서, 단일 가닥 안티센스 올리고뉴클레오티드는 예컨대 RNAseH1 동원을 통해 RNA 표적을 저해할 수 있는, 단일 가닥 안티센스 올리고뉴클레오티드.
23. 구현예 1 - 22 중 어느 하나에 있어서, 올리고뉴클레오티드의 인접 뉴클레오티드 서열은 화학식 5'-F-G-F'-3' 의 갭머 영역을 포함하고, G 는 RnaseH1 를 동원할 수 있는 5 내지 18 개의 뉴클레오시드의 영역이고, 상기 영역 G 는 플랭킹 영역 F 및 F' 각각에 의해 5' 및 3' 플랭킹되고, 영역 F 및 F' 는 독립적으로 1 내지 7 개의 2'-당 개질된 뉴클레오티드를 포함하거나 이로 이루어지고, 영역 G 에 인접한 영역 F 의 뉴클레오시드는 2'-당 개질된 뉴클레오시드이고, 영역 G 에 인접한 영역 F' 의 뉴클레오시드는 2'-당 개질된 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
24. 구현예 23 에 있어서, 영역 F 또는 영역 F' 는 구현예 1 - 19 중 어느 하나에 따른 화학식 IB 의 뉴클레오시드간 연결을 포함하는, 단일 가닥 안티센스 올리고뉴클레오티드.
25. 구현예 24 에 있어서, 영역 F 및 F' 둘 모두는 구현예 1 - 19 중 어느 하나에 따른 화학식 IB 의 뉴클레오시드간 연결을 포함하는, 단일 가닥 안티센스 올리고뉴클레오티드.
26. 구현예 23 - 25 중 어느 하나에 있어서, 영역 F 및/또는 F' 내의 모든 뉴클레오시드간 연결은 구현예 1 - 19 중 어느 하나에 따른 화학식 IB 의 뉴클레오시드간 연결인, 단일 가닥 안티센스 올리고뉴클레오티드.
27. 구현예 23 - 26 중 어느 하나에 있어서, 영역 F 및 F' 둘 모두는 LNA 뉴클레오시드를 포함하거나 이로 이루어지는, 단일 가닥 안티센스 올리고뉴클레오티드.
28. 구현예 23 - 27 중 어느 하나에 있어서, 영역 F 및 F' 둘 모두는 MOE 뉴클레오시드를 포함하거나 이로 이루어지는, 단일 가닥 안티센스 올리고뉴클레오티드.
29. 구현예 23 - 28 중 어느 하나에 있어서, 영역 F 는 LNA 뉴클레오시드(들)을 포함하고 F' 는 MOE 뉴클레오시드를 포함하거나 이로 이루어지는, 단일 가닥 안티센스 올리고뉴클레오티드.
30. 구현예 23 - 29 중 어느 하나에 있어서, 영역 G 는 영역 F 의 3' 말단 뉴클레오시드와 영역 G 의 5' 말단 뉴클레오시드 사이에 위치한 화학식 IB 의 적어도 하나의 뉴클레오시드간 연결을 추가로 포함하는, 단일 가닥 안티센스 올리고뉴클레오티드.
31. 구현예 23 - 30 중 어느 하나에 있어서, 영역 G 는 2 개의 DNA 뉴클레오시드 사이에 위치한 적어도 하나의 입체 정의된 포스포로티오에이트 연결을 포함하는, 단일 가닥 안티센스 올리고뉴클레오티드.
32. 구현예 23 - 31 중 어느 하나에 있어서, 영역 G 는 2 개의 DNA 뉴클레오시드 사이에 위치한 화학식 IB 의 적어도 하나의 뉴클레오시드간 연결을 포함하는, 단일 가닥 안티센스 올리고뉴클레오티드.
33. 구현예 23 - 32 중 어느 하나에 있어서, 영역 G 는 화학식 IB 의 적어도 2, 3, 또는 4 개의 뉴클레오시드간 연결을 추가로 포함하는, 단일 가닥 안티센스 올리고뉴클레오티드.
34. 구현예 23 - 31 중 어느 하나에 있어서, 영역 G 내의 모든 나머지 뉴클레오시드간 연결은 Rp 및 Sp 뉴클레오시드간 연결로부터 독립적으로 선택되는 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인, 단일 가닥 안티센스 올리고뉴클레오티드.
35. 구현예 23 - 31 중 어느 하나에 있어서, 영역 G 내의 모든 뉴클레오시드간 연결은 임의로 영역 F 의 3' 말단 뉴클레오시드와 영역 G 의 5' 말단 뉴클레오시드 사이의 뉴클레오시드간 연결 이외의 Rp 및 Sp 뉴클레오시드간 연결로부터 독립적으로 선택되는 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인, 단일 가닥 안티센스 올리고뉴클레오티드.
36. 구현예 1 - 22 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드가 4 개 미만의 인접 DNA 뉴클레오티드를 포함하는, 단일 가닥 안티센스 올리고뉴클레오티드.
37. 구현예 1 - 22 또는 36 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드가 믹스머 또는 토탈머 올리고뉴클레오티드인, 단일 가닥 안티센스 올리고뉴클레오티드.
38. 구현예 37 에 있어서, 믹스머 올리고뉴클레오티드가 LNA 뉴클레오시드 및 DNA 뉴클레오시드 둘 모두, 및 임의로 2'당 개질된 뉴클레오시드 (예를 들어 구현예 6 의 목록 참조), 예컨대 2'-O-MOE 뉴클레오시드(들)를 포함하는, 단일 가닥 안티센스 올리고뉴클레오티드.
39. 구현예 1 - 38 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드가 3 개 이상의 인접 MOE 뉴클레오시드의 영역을 포함하고, 임의로 올리고뉴클레오티드의 모든 뉴클레오시드는 2'MOE 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
40. 구현예 1 - 39 중 어느 하나에 있어서, 표적이 mRNA 또는 pre-mRNA 표적인, 단일 가닥 안티센스 올리고뉴클레오티드.
41. 구현예 1 - 40 중 어느 하나에 있어서, 올리고뉴클레오티드가 pre-mRNA 스플라이스 부위에서 스플라이싱 이벤트를 조절하는 pre-mRNA 의 영역 또는 pre-mRNA 스플라이스 부위를 표적으로 하는, 단일 가닥 안티센스 올리고뉴클레오티드.
42. 구현예 1 - 41 중 어느 하나에 있어서, pre-mRNA 표적의 스플라이싱을 조절할 수 있는 스플라이스 조절 올리고뉴클레오티드인, 단일 가닥 안티센스 올리고뉴클레오티드.
43. 구현예 1 - 42 중 어느 하나에 있어서, 표적이 마이크로RNA 인, 단일 가닥 안티센스 올리고뉴클레오티드.
44. 구현예 1 - 42 중 어느 하나에 있어서, 안티센스 올리고뉴클레오티드가 10 - 20 개의 뉴클레오티드 길이, 예컨대 12 - 24 개의 뉴클레오티드 길이인, 단일 가닥 안티센스 올리고뉴클레오티드.
45. 구현예 43 에 있어서, 안티센스 올리고뉴클레오티드의 길이가 7 - 30 개, 예컨대 8 - 12 개 또는 12 내지 23 개의 뉴클레오티드 길이인, 단일 가닥 안티센스 올리고뉴클레오티드.
46. 구현예 1 - 45 중 어느 하나에 따른 안티센스 올리고뉴클레오티드를 포함하는 단일 가닥 안티센스 올리고뉴클레오티드로서, 올리고뉴클레오티드는 인접 뉴클레오티드 서열에 대한 5' 영역 위치 5' 를 추가로 포함하고, 5' 뉴클레오시드 영역은 적어도 하나의 포스포디에스테르 연결을 포함하는, 단일 가닥 안티센스 올리고뉴클레오티드.
47. 구현예 46 에 있어서, 5' 영역은 1 - 5 개의 포스포디에스테르 연결된 DNA 뉴클레오시드를 포함하고, 임의로 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열을 컨쥬게이트 모이어티에 연결할 수 있는, 단일 가닥 안티센스 올리고뉴클레오티드.
48. 구현예 1 - 47 중 어느 하나에 있어서, 하나 이상의 뉴클레오시드는 핵염기 개질된 뉴클레오시드인, 단일 가닥 안티센스 올리고뉴클레오티드.
49. 구현예 1 - 48 중 어느 하나에 있어서, 하나 이상의 뉴클레오시드는 5-메틸 시토신, 예컨대 LNA 5-메틸 시토신 또는 DNA 5-메틸 시토신인, 단일 가닥 안티센스 올리고뉴클레오티드.
50. 구현예 1 - 49 중 어느 하나에 따른 단일 가닥 안티센스 올리고뉴클레오티드의 약학적으로 허용되는 염, 특히 소듐 또는 포타슘 염 또는 암모늄 염.
51. 구현예 1 - 49 중 어느 하나에 따른 단일 가닥 안티센스 올리고뉴클레오티드, 또는 약학적으로 허용되는 염을 포함하는 컨쥬게이트 및 임의로 링커 모이어티를 통해 상기 올리고뉴클레오티드 또는 상기 약학적으로 허용되는 염에 공유 부착된 적어도 하나의 컨쥬게이트 모이어티.
52. 구현예 1 - 51 중 어느 하나에 따른 단일 가닥 안티센스 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트 및 치료적으로 불활성인 담체를 포함하는 약학 조성물.
53. 치료적으로 활성인 물질로서 사용하기 위한 구현예 1 - 52 중 어느 하나에 따른 단일 가닥 안티센스 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트.
54. 비경구 투여, 예컨대, 정맥 내, 피하, 근육 내, 대뇌 내, 뇌실 내 또는 뇌척수 내 투여를 통해 대상에게 투여하기 위한, 치료에 사용하기 위한, 구현예 1 - 53 중 어느 하나에 따른 단일 가닥 안티센스 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트.
55. 세포에서 표적 RNA 의 저해에서 사용하기 위한 구현예 1 - 54 중 어느 하나에 따른 단일 가닥 안티센스 올리고뉴클레오티드, 염, 또는 조성물의 시험관내 용도로서, 단일 가닥 안티센스 올리고뉴클레오티드는 표적 RNA 에 대하여 상보적, 예컨대 완전히 상보적인, 용도.
56. 유효량의 구현예 1 - 55 중 어느 하나에 따른 안티센스 올리고뉴클레오티드, 염, 컨쥬게이트 또는 조성물을 세포에 투여하여, 표적 RNA 를 저해하는 것을 포함하는, 표적 RNA 를 발현하는 세포에서 표적 RNA 의 저해를 위한 생체내 또는 시험관내 방법.
57. 세포에서 표적 pre-mRNA 의 스플라이싱을 조절하는데 사용하기 위한, 구현예 1 - 56 중 어느 하나에 따른 단일 가닥 안티센스 올리고뉴클레오티드, 염, 또는 조성물의 시험관내 또는 생체내 용도.
58. 유효량의 구현예 1 - 57 중 어느 하나에 따른 안티센스 올리고뉴클레오티드, 염, 컨쥬게이트 또는 조성물을 세포에 투여하여, 표적 RNA 의 스플라이싱을 조절하는 것을 포함하는, 표적 pre-RNA 를 발현하는 세포에서 표적 pre-RNA 의 스플라이싱을 조절하기 위한 생체내 또는 시험관내 방법.
본 발명의 안티센스 올리고뉴클레오티드를 표적으로 하는 Htra-1
일부 구현예에서, 본 발명의 안티센스 올리고뉴클레오티드는 인간 고온 요건 A1 세린 프로테아제 (Htra1) 를 코딩하는 mRNA 또는 pre-mRNA 에 상보적이다 - 예를 들어 WO 2018/002105 참조. Htra1 mRNa 또는 premRNA 를 표적으로 하는 본 발명의 안티센스 올리고뉴클레오티드를 사용하는 Htra1 발현의 저해는 황반 변성, 예를 들어 연령 관련 황반 변성 (지도형 위축) 과 같은 다양한 의학적 장애의 치료에 유익하다. 인간 Htra1 pre-mRNA 및 mRNA 표적 서열은 다음과 같이 이용 가능하다:

Htra-1 을 표적으로 하는 본 발명의 화합물은 실시예에서 Htra1#1 - 38 로 열거된다.
1. 길이가 10 - 30 개의 뉴클레오티드인 본 발명의 안티센스 올리고뉴클레오티드로서, 상기 안티센스 올리고뉴클레오티드는 인간 HTRA1 mRNA 또는 pre-mRNA 를 표적으로 하고, 상기 안티센스 올리고뉴클레오티드는 SEQ ID NO 9 및 10 로서 서열 목록에 개시되어 있는 WO 2018/002105 의 SEQ ID NO 1 또는 2 에 대하여 적어도 90%, 예컨대 100% 상보성인 10 - 22 개 뉴클레오티드의 인접 뉴클레오티드 영역을 포함하고, 상기 안티센스 올리고뉴클레오티드는 화학식 IA 또는 화학식 IB 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는, 안티센스 올리고뉴클레오티드.
2. 구현예 1 또는 2 에 있어서, 인접 뉴클레오티드 영역이 하기로 이루어진 군으로부터 선택된 서열에 존재하는 서열과 동일한, 안티센스 올리고뉴클레오티드:

3. 구현예 1 - 3 중 어느 하나에 있어서, 인접 뉴클레오티드 영역이 하기 서열을 포함하는, 안티센스 올리고뉴클레오티드:
4. 구현예 1 - 4 중 어느 하나에 있어서, 올리고뉴클레오티드의 인접 뉴클레오티드 영역이 SEQ ID NO 11, 12, 13, 14, 15, 16, 17 및 18 중 어느 하나로부터 선택된 서열로 이루어지거나 또는 이를 포함하는, 안티센스 올리고뉴클레오티드.
5. 구현예 1 - 5 중 어느 하나에 있어서, 올리고뉴클레오티드의 인접 뉴클레오티드 영역이 하나 이상의 2' 당 개질된 뉴클레오시드, 예컨대 2'-O-알킬-RNA, 2'-O-메틸-RNA, 2'-알콕시-RNA, 2'-O-메톡시에틸-RNA, 2'-아미노-DNA, 2'-플루오로-DNA, 아라비노 핵산 (ANA), 2'-플루오로-ANA 및 LNA 뉴클레오시드로 이루어진 군으로부터 독립적으로 선택된 하나 이상의 2' 당 개질된 뉴클레오시드를 포함하는, 안티센스 올리고뉴클레오티드.
6. 구현예 1 - 5 중 어느 하나에 있어서, 올리고뉴클레오티드의 인접 뉴클레오티드 영역이 적어도 하나의 개질된 뉴클레오시드간 연결, 예컨대 하나 이상의 포스포로티오에이트 뉴클레오시드간 연결을 포함하거나, 또는 예컨대 인접 뉴클레오티드 영역 내 모든 뉴클레오시드간 연결이 포스포로티오에이트 뉴클레오시드간 연결인, 안티센스 올리고뉴클레오티드.
7. 구현예 1 - 6 중 어느 하나에 있어서, 올리고뉴클레오티드 또는 이의 인접 뉴클레오티드 서열이 갭머, 예컨대 화학식 5'-F-G-F'-3' 의 갭머이거나 또는 이를 포함하고, 여기서 영역 F 및 F' 는 독립적으로 1 - 7 개의 당 개질된 뉴클레오시드를 포함하고, G 는 RNaseH 를 동원할 수 있는 6 - 16 개의 뉴클레오시드 영역이고, 영역 G 에 인접한 영역 F 및 F' 의 뉴클레오시드는 당 개질된 뉴클레오시드인, 안티센스 올리고뉴클레오티드.
8. 구현예 7 에 있어서, 영역 F 및 F' 중 적어도 하나 또는 둘 모두가 각각 적어도 하나의 LNA 뉴클레오시드를 포함하는, 안티센스 올리고뉴클레오티드.
9. 구현예 1 - 8 중 어느 하나에 있어서, 하기로부터 선택된 군으로부터 선택된, 안티센스 올리고뉴클레오티드:
Htra1#1 - 38, 여기서 대문자는 베타-D-옥시 LNA 뉴클레오시드 단위를 나타내고, 소문자는 DNA 뉴클레오시드 단위를 나타내고, 아래 첨자 s 는 포스포로티오에이트 뉴클레오시드간 연결을 나타내고, 모든 LNA 시토신은 5-메틸 시토신이고, P 는 화학식 IB 의 포스포로디티오에이트 뉴클레오시드간 연결을 나타내고, S 는 Sp 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결을 나타내고, R 은 Rp 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결을 나타내고, X 는 입체 랜덤 포스포로티오에이트 연결을 나타냄.
10. 구현예 1 - 9 중 어느 하나에 있어서, 염, 예컨대 소듐 염, 포타슘 염 또는 암모늄 염 (예를 들어 약학적으로 허용되는 염) 의 형태인, 안티센스 올리고뉴클레오티드.
11. 구현예 1 - 10 중 어느 하나에 따른 올리고뉴클레오티드를 포함하는 컨쥬게이트, 및 상기 올리고뉴클레오티드, 또는 이의 염에 공유 부착된 적어도 하나의 컨쥬게이트 모이어티.
12. 구현예 1 - 10 의 올리고뉴클레오티드 또는 구현예 11 의 컨쥬게이트 및 약학적으로 허용되는 희석제, 용매, 담체, 염 및/또는 아쥬반트를 포함하는 약학 조성물.
13. HTRA1 을 발현하는 표적 세포에서 HTRA1 발현을 조절하기 위한 생체내 또는 시험관내 방법으로서, 상기 방법은 구현예 1 - 10 중 어느 하나의 올리고뉴클레오티드 또는 구현예 11 에 따른 컨쥬게이트 또는 구현예 12 의 약학 조성물을 상기 세포에 유효량으로 투여하는 것을 포함하는 방법.
14. 치료적 또는 예방적 유효량의 구현예 1 - 10 중 어느 하나의 올리고뉴클레오티드 또는 구현예 11 에 따른 컨쥬게이트 또는 구현예 12 의 약학 조성물을 질환을 앓고 있거나 질환에 걸리기 쉬운 대상에게 투여하는 것을 포함하는 질환의 치료 또는 예방 방법.
15. 의약에 사용하기 위한 구현예 1 - 10 중 어느 하나의 올리고뉴클레오티드 또는 구현예 11 에 따른 컨쥬게이트 또는 구현예 12 의 약학 조성물.
16. 황반 변성 (예컨대 wetAMD, dryAMD, 지도형 위축, 중간체 dAMD, 당뇨 망막병증), 파킨슨병, 알츠하이머병, 뒤쉔 근육 영양장애, 관절염, 예컨대 골관절염, 및 가족 허혈성 뇌 소혈관 질환으로 이루어진 군으로부터 선택되는 질환의 치료 또는 예방에 사용하기 위한, 구현예 1 - 10 중 어느 하나의 올리고뉴클레오티드 또는 구현예 11 에 따른 컨쥬게이트 또는 구현예 12 의 약학 조성물.
17. 황반 변성 (예컨대 wetAMD, dryAMD, 지도형 위축, 중간체 dAMD, 당뇨 망막병증), 파킨슨병, 알츠하이머병, 뒤쉔 근육 영양장애, 관절염, 예컨대 골관절염, 및 가족 허혈성 뇌 소혈관 질환으로 이루어진 군으로부터 선택되는 질환의 치료 또는 예방을 위한, 약제의 제조를 위한, 구현예 1 - 10 의 올리고뉴클레오티드 또는 구현예 11 에 따른 컨쥬게이트 또는 구현예 12 의 약학 조성물의 용도.
18. 지도형 위축의 치료에 사용하기 위한, 구현예 1 - 17 중 어느 하나에 따른 올리고뉴클레오티드, 컨쥬게이트, 염 또는 조성물 또는 용도.
본 발명의 추가 구현예
따라서 본 발명은 특히 하기에 관한 것이다:
올리고뉴클레오티드가 상기 표적 RNA 를 발현하는 세포에서 표적 RNA 의 발현을 조절할 수 있는 안티센스 올리고뉴클레오티드인 본 발명에 따른 올리고뉴클레오티드;
올리고뉴클레오티드가 상기 표적 RNA 를 발현하는 세포에서 표적 RNA 의 발현을 저해할 수 있는 안티센스 올리고뉴클레오티드인 본 발명에 따른 올리고뉴클레오티드;
(A1) 및 (A2) 중 하나는 LNA 뉴클레오시드이고 다른 하나는 DNA 뉴클레오시드, RNA 뉴클레오시드 또는 당 개질된 뉴클레오시드인 본 발명에 따른 올리고뉴클레오티드;
(A1) 및 (A2) 중 하나는 LNA 뉴클레오시드이고 다른 하나는 DNA 뉴클레오시드 또는 당 개질된 뉴클레오시드인 본 발명에 따른 올리고뉴클레오티드;
(A1) 및 (A2) 중 하나는 LNA 뉴클레오시드이고 다른 하나는 DNA 뉴클레오시드인 본 발명에 따른 올리고뉴클레오티드;
(A1) 및 (A2) 중 하나는 LNA 뉴클레오시드이고 다른 하나는 당 개질된 뉴클레오시드인 본 발명에 따른 올리고뉴클레오티드;
상기 당 개질된 뉴클레오시드가 2'-당 개질된 뉴클레오시드인 본 발명에 따른 올리고뉴클레오티드;
상기 2'-당 개질된 뉴클레오시드가 2'-알콕시-RNA, 2'-알콕시알콕시-RNA, 2'-아미노-DNA, 2'-플루오로-RNA, 2'-플루오로-ANA 또는 LNA 뉴클레오시드인 본 발명에 따른 올리고뉴클레오티드;
상기 2'-당 개질된 뉴클레오시드가 LNA 뉴클레오시드인 본 발명에 따른 올리고뉴클레오티드;
LNA 뉴클레오시드가 베타-D-옥시 LNA, 6'-메틸-베타-D-옥시 LNA 및 ENA 로부터 독립적으로 선택되는 본 발명에 따른 올리고뉴클레오티드;
LNA 뉴클레오시드가 모두 베타-D-옥시 LNA 인 본 발명에 따른 올리고뉴클레오티드;
상기 2'-당 개질된 뉴클레오시드가 2'-알콕시알콕시-RNA 인 본 발명에 따른 올리고뉴클레오티드;
2'-알콕시-RNA 가 2'-메톡시-RNA 인 본 발명에 따른 올리고뉴클레오티드;
2'-알콕시알콕시-RNA 가 2'-메톡시에톡시-RNA 인 본 발명에 따른 올리고뉴클레오티드;
1 내지 15, 특히 1 내지 5, 보다 특히 1, 2, 3, 4 또는 5 개의 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 본 발명에 따른 올리고뉴클레오티드;
포스포디에스테르 뉴클레오시드간 연결, 포스포로티오에이트 뉴클레오시드간 연결 및 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택되는 뉴클레오시드간 연결을 추가로 포함하는 본 발명에 따른 올리고뉴클레오티드;
추가의 뉴클레오시드간 연결이 포스포로티오에이트 뉴클레오시드간 연결 및 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택되는 본 발명에 따른 올리고뉴클레오티드;
추가의 뉴클레오시드간 연결이 모두 포스포로티오에이트 뉴클레오시드간 연결인 본 발명에 따른 올리고뉴클레오티드;
추가의 뉴클레오시드간 연결이 모두 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결인 본 발명에 따른 올리고뉴클레오티드;
올리고뉴클레오티드가 갭머, 특히 LNA 갭머, 혼합 윙 갭머, 교대 플랭크 갭머, 스플라이스 스위칭 올리고머, 믹스머 또는 토탈머인 본 발명에 따른 올리고뉴클레오티드;
갭머이고 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결이 갭머의 하나 이상의 플랭킹 영역 및/또는 갭 영역에 포함되는 본 발명에 따른 올리고뉴클레오티드;
포스포디에스테르 뉴클레오시드간 연결을 통해 올리고뉴클레오티드의 나머지에 연결된 하나 이상의 DNA 뉴클레오시드를 포함하는, 인접 뉴클레오티드 서열, 예컨대 갭머 영역 F-G-F' 가 플랭킹 영역 D' 또는 D" 또는 D' 및 D" 에 의해 플랭킹된, 본 발명에 따른 올리고뉴클레오티드;
플랭킹 영역 F 및 F' 중 하나 또는 둘 모두, 특히 하나가 포스포디에스테르 연결된 DNA 뉴클레오시드, 특히 1 내지 5 개의 포스포디에스테르 연결된 DNA 뉴클레오시드 (영역 D' 및 D") 에 의해 추가로 플랭킹된 갭머인, 본 발명에 따른 올리고뉴클레오티드;
올리고뉴클레오티드가 7 내지 30 개의 뉴클레오티드 길이인, 본 발명에 따른 올리고뉴클레오티드.
본 발명의 올리고뉴클레오티드가 갭머인 경우, 이는 유리하게는 12 내지 26 개의 뉴클레오티드 길이이다. 16 개의 뉴클레오티드가 특히 유리한 갭머 올리고뉴클레오티드 길이이다.
올리고뉴클레오티드가 완전한 LNA 올리고뉴클레오티드인 경우, 이는 유리하게는 7 내지 10 개의 뉴클레오티드 길이이다.
올리고뉴클레오티드가 믹스머 올리고뉴클레오티드인 경우, 이는 유리하게는 8 내지 30 개의 뉴클레오티드 길이이다.
따라서 본 발명은 특히 하기에 관한 것이다:
하나 이상의 뉴클레오시드가 핵염기 개질된 뉴클레오시드인 본 발명에 따른 올리고뉴클레오티드;
올리고뉴클레오티드가 안티센스 올리고뉴클레오티드, siRNA, 마이크로RNA 미믹 또는 리보자임인 본 발명에 따른 올리고뉴클레오티드;
본 발명에 따른 올리고뉴클레오티드의 약학적으로 허용되는 염, 특히 소듐 또는 포타슘 염;
본 발명에 따른 올리고뉴클레오티드 또는 약학적으로 허용되는 염을 포함하는 컨쥬게이트 및 임의로 링커 모이어티를 통해 상기 올리고뉴클레오티드 또는 상기 약학적으로 허용되는 염에 공유 부착된 적어도 하나의 컨쥬게이트 모이어티;
본 발명에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트 및 치료적으로 불활성인 담체를 포함하는 약학 조성물;
치료적으로 활성인 물질로서 사용하기 위한, 본 발명에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트; 및
약제로서의 본 발명에 따른 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트의 용도;
일부 구현예에서, 본 발명의 올리고뉴클레오티드는 상응하는 완전 포스포로티오에이트 연결된 올리고뉴클레오티드와 비교하여 표적 핵산을 조절하는데 보다 높은 활성을 갖는다. 일부 구현예에서, 본 발명은 향상된 활성, 향상된 효능, 향상된 특이적 활성 또는 향상된 세포 흡수를 갖는 올리고뉴클레오티드를 제공한다. 일부 구현예에서, 본 발명은 변경된 시험관내 또는 생체내 작용 기간, 예컨대 지속되는 시험관내 또는 생체내 작용 기간을 갖는 올리고뉴클레오티드를 제공한다. 일부 구현예에서, 표적 핵산 조절에서 보다 높은 활성은 표적 핵산을 발현하는 세포에서 시험관내 또는 생체내에서 결정된다.
일부 구현예에서, 본 발명의 올리고뉴클레오티드 변경된 약리학적 특성, 예컨대 감소된 독성, 예를 들어 감소된 신독성, 감소된 간독성 또는 감소된 면역 자극을 갖는다. 간독성은 예를 들어 생체내에서, 또는 본원에 참조로 포함되는 WO 2017/067970 에 개시된 시험관내 분석을 사용하여 결정될 수 있다. 신독성은 예를 들어 시험관내에서, 또는 본원에 참조로 포함되는 PCT/EP2017/064770 에 개시된 분석을 사용하여 결정될 수 있다. 일부 구현예에서 본 발명의 올리고뉴클레오티드는 5' CG 3' 디뉴클레오티드, 예컨대 DNA 5' CG 3' 디뉴클레오티드를 포함하며, 여기서 C 와 G 사이의 뉴클레오시드간 연결은 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결이다.
일부 구현예에서, 본 발명의 올리고뉴클레오티드는 혈청에서 개선된 생체 안정성과 같은 개선된 뉴클레아제 내성을 갖는다. 일부 구현예에서, 본 발명의 올리고뉴클레오티드의 3' 말단 뉴클레오시드는 A 또는 G 염기, 예컨대 3' 말단 LNA-A 또는 LNA-G 뉴클레오시드를 갖는다. 적합하게는, 올리고뉴클레오티드의 2 개의 3' 말단 뉴클레오시드 사이의 뉴클레오시드간 연결은 상기 정의된 바와 같은 화학식 (I) 에 따른 포스포로디티오에이트 뉴클레오시드간 연결일 수 있다.
일부 구현예에서 본 발명의 올리고뉴클레오티드는 향상된 생체이용률을 갖는다. 일부 구현예에서 본 발명의 올리고뉴클레오티드는 혈액에서 보다 긴 체류 시간과 같은 보다 큰 혈액 노출을 갖는다.
비-가교 포스포로디티오에이트 개질은 포스포르아미다이트 방법을 사용하여 고체 상 합성에 의해 올리고뉴클레오티드에 도입된다. 합성은 범용 링커가 장착된 제어된 기공 유리 (CPG) 를 지지체로 사용하여 수행된다. 이러한 고체 지지체 상에 올리고뉴클레오티드는 전형적으로 5'O-DMT 보호된 뉴클레오시드 포스포르아미다이트 빌딩 블록의 커플링 이어서 DMT 기의 (티오)산화, 캡핑 및 탈보호로 이루어진 순차적 사이클에 의해 3' 에서 5' 방향으로 형성된다. 비-가교 포스포로디티오에이트의 도입은 적절한 티오포스포르아미다이트 빌딩 블록 이어서 1차 중간체의 티오산화를 사용하여 달성된다.
상응하는 DNA 티오포스포르아미다이트는 상업적으로 입수 가능하지만, 각각의 LNA 빌딩 블록은 이전에 설명되지 않았다. 이들은 5'-O-DMT-보호된 뉴클레오시드 3'-알코올로부터 예를 들어 모노-벤조일 보호된 에탄디티올 및 트리피롤리딘-1-일포스판과의 반응에 의해 제조될 수 있다.
따라서 본 발명에 따른 올리고뉴클레오티드는 예를 들어 반응식 2 에 따라 제조될 수 있으며, 여기서 R1, R2a, R2b, R4a, R4b, R5, Rx, Ry 및 V 는 아래에 정의된 바와 같다.
반응식 2

따라서 본 발명은 또한 하기 단계를 포함하는 본 발명에 따른 올리고뉴클레오티드의 제조 방법에 관한 것이다:
(a) 티오포스포르아미다이트 뉴클레오시드를 뉴클레오티드 또는 올리고뉴클레오티드의 말단 5' 산소 원자에 커플링시켜 티오포스파이트 트리에스테르 중간체를 생성하는 단계;
(b) 단계 (a) 에서 수득된 티오포스파이트 트리에스테르 중간체를 티오산화시키는 단계; 및
(c) 임의로 올리고뉴클레오티드를 추가로 연장하는 단계.
본 발명은 특히 하기 단계를 포함하는 본 발명에 따른 올리고뉴클레오티드의 제조 방법에 관한 것이다:
(a1) 하기 화학식 (A) 의 화합물을 하기 화학식 (B) 의 뉴클레오티드 또는 올리고뉴클레오티드의 5' 산소 원자에 커플링시키는 단계:


(b1) 단계 (a1) 에서 수득된 티오포스파이트 트리에스테르 중간체를 티오산화시키는 단계; 및
(c1) 임의로 올리고뉴클레오티드를 추가로 연장하는 단계;
[식 중,
R2a 및 R4a 는 함께 상기 정의된 바와 같은 -X-Y- 를 형성하거나; 또는
R4a 는 수소이고 R2a 는 알콕시, 특히 메톡시, 할로겐, 특히 플루오로, 알콕시알콕시, 특히 메톡시에톡시, 알케닐옥시, 특히 알릴옥시 및 아미노알콕시, 특히 아미노에틸옥시로부터 선택되고;
R2b 및 R4b 는 함께 상기 정의된 바와 같은 -X-Y- 를 형성하거나; 또는
R2b 및 R4b 둘 모두는 동시에 수소이거나; 또는
R4b 는 수소이고 R2b 는 알콕시, 특히 메톡시, 할로겐, 특히 플루오로, 알콕시알콕시, 특히 메톡시에톡시, 알케닐옥시, 특히 알릴옥시 및 아미노알콕시, 특히 아미노에틸옥시로부터 선택되고;
V 는 산소 또는 황이고; 및
R5, Rx, Ry 및 Nu 는 아래에 정의된 바와 같음].
본 발명은 특히 하기 단계를 포함하는 본 발명에 따른 올리고뉴클레오티드의 제조 방법에 관한 것이다:
(a2) 하기 화학식 (A1) 의 화합물을 하기 화학식 (B1) 의 뉴클레오티드 또는 올리고뉴클레오티드의 5' 산소 원자에 커플링시키는 단계:


(b2) 단계 (a2) 에서 수득된 티오포스파이트 트리에스테르 중간체를 티오산화시키는 단계; 및
(c2) 임의로 올리고뉴클레오티드를 추가로 연장하는 단계;
[식 중,
R2b 및 R4b 는 함께 상기 정의된 바와 같은 -X-Y- 를 형성하거나; 또는
R2b 및 R4b 둘 모두는 동시에 수소이거나; 또는
R4b 는 수소이고 R2b 는 알콕시, 특히 메톡시, 할로겐, 특히 플루오로, 알콕시알콕시, 특히 메톡시에톡시, 알케닐옥시, 특히 알릴옥시 및 아미노알콕시, 특히 아미노에틸옥시로부터 선택되고;
R5, Rx, Ry 및 Nu 는 아래에 정의된 바와 같음].
본 발명은 또한 본 발명의 방법에 따라 제조된 올리고뉴클레오티드에 관한 것이다.
본 발명은 또한 하기에 관한 것이다:
화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는 갭머 올리고뉴클레오티드:

[식 중, R 은 수소 또는 포스페이트 보호기임];
올리고뉴클레오티드가 상기 표적 RNA 를 발현하는 세포에서 표적 RNA 의 발현을 조절할 수 있는 안티센스 올리고뉴클레오티드인 상기 정의된 바와 같은 갭머 올리고뉴클레오티드;
올리고뉴클레오티드가 상기 표적 RNA 를 발현하는 세포에서 표적 RNA 의 발현을 저해할 수 있는 안티센스 올리고뉴클레오티드인 상기 정의된 바와 같은 갭머 올리고뉴클레오티드;
RNAseH, 예컨대 인간 RNaseH1 를 동원할 수 있는 상기 정의된 바와 같은 갭머 올리고뉴클레오티드;
상기 화학식 (I) 의 적어도 하나의 뉴클레오시드간 연결의 2 개의 산소 원자 중 하나는 인접 뉴클레오시드 (A1) 의 3'탄소 원자에 연결되고 다른 하나는 또 다른 뉴클레오시드 (A2) 의 5'탄소 원자에 연결되고, 2 개의 뉴클레오시드 (A1) 및 (A2) 중 적어도 하나는 2'-당 개질된 뉴클레오시드인 본 발명에 따른 갭머 올리고뉴클레오티드;
(A1) 및 (A2) 중 하나는 2'-당 개질된 뉴클레오시드이고 다른 하나는 DNA 뉴클레오시드인 본 발명에 따른 갭머 올리고뉴클레오티드;
(A1) 및 (A2) 둘 모두는 동시에 2'- 개질된 뉴클레오시드인, 본 발명에 따른 갭머 올리고뉴클레오티드;
(A1) 및 (A2) 둘 모두는 동시에 DNA 뉴클레오시드인, 본 발명에 따른 갭머 올리고뉴클레오티드;
갭머 올리고뉴클레오티드는 화학식 5'-F-G-F'-3' 의 인접 뉴클레오티드 서열을 포함하고, G 는 RnaseH 를 동원할 수 있는 5 내지 18 개의 뉴클레오시드의 영역이고, 상기 영역 G 는 플랭킹 영역 F 및 F' 각각에 의해 5' 및 3' 플랭킹되고, 영역 F 및 F' 는 독립적으로 1 내지 7 개의 2'-당 개질된 뉴클레오티드를 포함하거나 이로 이루어지고, 영역 G 에 인접한 영역 F 의 뉴클레오시드는 2'-당 개질된 뉴클레오시드이고, 영역 G 에 인접한 영역 F' 의 뉴클레오시드는 2'-당 개질된 뉴클레오시드인, 본 발명에 따른 갭머 올리고뉴클레오티드;
2'-당 개질된 뉴클레오시드가 2'-알콕시-RNA, 2'-알콕시알콕시-RNA, 2'-아미노-DNA, 2'-플루오로-RNA, 2'-플루오로-ANA 및 LNA 뉴클레오시드로부터 독립적으로 선택되는, 본 발명에 따른 갭머 올리고뉴클레오티드;
2'-알콕시알콕시-RNA 가 2'-메톡시에톡시-RNA (2'-O-MOE) 인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 및 영역 F' 가 2'-메톡시에톡시-RNA 뉴클레오티드를 포함하거나 이로 이루어지는, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 및 F' 둘 모두가 2'-메톡시에톡시-RNA 뉴클레오티드, 예컨대 화학식 [MOE]3-8[DNA]8-16[MOE]3-8, 예를 들어 [MOE]5[DNA]10[MOE]5 (즉, 여기서 영역 F 및 F' 는 각각 5 개의 2'-메톡시에톡시-RNA 뉴클레오티드로 이루어지고, 영역 G 는 10 개의 DNA 뉴클레오티드로 이루어짐) 의 F-G-F' 를 포함하는 갭머로 이루어지는, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 또는 영역 F' 내, 또는 영역 F 및 F' 내의 2'-당 개질된 뉴클레오시드 중 적어도 하나 또는 모두가 LNA 뉴클레오시드인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 또는 영역 F', 또는 영역 F 및 F' 가 적어도 하나의 LNA 뉴클레오시드 및 적어도 하나의 DNA 뉴클레오시드를 포함하는, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 또는 영역 F', 또는 영역 F 및 F' 가 적어도 하나의 LNA 뉴클레오시드 및 적어도 하나의 비-LNA 2'-당 개질된 뉴클레오시드, 예컨대 적어도 하나의 2'-메톡시에톡시-RNA 뉴클레오시드를 포함하는, 본 발명에 따른 갭머 올리고뉴클레오티드;
갭 영역이 5 내지 16 개, 특히 8 내지 16 개, 보다 특히 8, 9, 10, 11, 12, 13 또는 14 개의 인접 DNA 뉴클레오시드를 포함하는, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 및 영역 F' 가 독립적으로 1, 2, 3, 4, 5, 6, 7 또는 8 개의 뉴클레오시드 길이인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 및 영역 F' 가 각각 독립적으로 1, 2, 3 또는 4 개의 LNA 뉴클레오시드를 포함하는, 본 발명에 따른 갭머 올리고뉴클레오티드;
LNA 뉴클레오시드가 베타-D-옥시 LNA, 6'-메틸-베타-D-옥시 LNA 및 ENA 로부터 독립적으로 선택되는 본 발명에 따른 갭머 올리고뉴클레오티드;
LNA 뉴클레오시드가 베타-D-옥시 LNA 인, 본 발명에 따른 갭머 올리고뉴클레오티드;
올리고뉴클레오티드, 또는 이의 인접 뉴클레오티드 서열 (F-G-F') 이 10 내지 30 개의 뉴클레오티드 길이, 특히 12 내지 22 개, 보다 특히 14 내지 20 개의 올리고뉴클레오티드 길이인, 본 발명에 따른 갭머 올리고뉴클레오티드;
갭머 올리고뉴클레오티드는 화학식 5'-D'-F-G-F'-D"-3' 의 인접 뉴클레오티드 서열을 포함하고, F, G 및 F' 는 제 4 항 내지 제 17 항 중 어느 한 항에 정의된 바와 같고, 영역 D' 및 D" 는 각각 독립적으로 0 내지 5 개의 뉴클레오티드, 특히 2, 3 또는 4 개의 뉴클레오티드, 특히 DNA 뉴클레오티드, 예컨대 포스포디에스테르 연결된 DNA 뉴클레오시드로 이루어지는, 본 발명에 따른 갭머 올리고뉴클레오티드;
갭머 올리고뉴클레오티드가 인간 RNaseH1 을 동원할 수 있는 본 발명에 따른 갭머 올리고뉴클레오티드;
상기 정의된 바와 같은 화학식 (I) 의 상기 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결이 영역 F 또는 영역 F', 영역 F 와 영역 G 사이 또는 영역 G 와 F' 영역 사이의 인접 뉴클레오시드 사이에 위치하는, 본 발명에 따른 갭머 올리고뉴클레오티드;
포스포로티오에이트 뉴클레오시드간 연결을 추가로 포함하는, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 G 의 뉴클레오시드 사이의 뉴클레오시드간 연결이 포스포로티오에이트 뉴클레오시드간 연결 및 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택되는, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 G 의 뉴클레오시드 사이의 뉴클레오시드간 연결이 상기 정의된 바와 같은 화학식 (I) 의 0, 1, 2 또는 3 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는, 본 발명에 따른 갭머 올리고뉴클레오티드;
나머지 뉴클레오시드간 연결이 포스포로티오에이트, 포스포디에스테르 및 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결로 이루어진 군으로부터 독립적으로 선택되는, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 의 뉴클레오시드 사이의 뉴클레오시드간 연결 및 영역 F' 의 뉴클레오시드 사이의 뉴클레오시드간 연결이 포스포로티오에이트 및 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택되는, 본 발명에 따른 갭머 올리고뉴클레오티드;
각각의 플랭킹 영역 F 및 F' 가 독립적으로 상기 정의된 바와 같은 화학식 (I) 의 1, 2, 3, 4, 5, 6 또는 7 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는, 본 발명에 따른 갭머 올리고뉴클레오티드;
플랭킹 영역 F 및 F' 가 함께 또는 개별적으로 상기 정의된 바와 같은 화학식 (I) 의 1, 2, 3, 4, 5 또는 6 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하거나, 또는 영역 F 및/또는 영역 F' 의 모든 뉴클레오시드간 연결이 상기 정의된 바와 같은 화학식 (I) 의 포스포르디티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
플랭킹 영역 F 및 F' 가 함께 상기 정의된 바와 같은 화학식 (I) 의 1, 2, 3 또는 4 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는, 본 발명에 따른 갭머 올리고뉴클레오티드;
플랭킹 영역 F 및 F' 가 각각 상기 정의된 바와 같은 화학식 (I) 의 2 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하는, 본 발명에 따른 갭머 올리고뉴클레오티드;
플랭킹 영역 F 및/또는 F' 의 모든 뉴클레오시드간 연결이 상기 정의된 바와 같은 화학식 (I) 의 포스포르디티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
갭머 올리고뉴클레오티드가 적어도 하나의 입체 정의된 뉴클레오시드간 연결, 예컨대 적어도 하나의 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결을 포함하는, 본 발명에 따른 갭머 올리고뉴클레오티드;
갭 영역이 1, 2, 3, 4 또는 5 개의 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결을 포함하는, 본 발명에 따른 갭머 올리고뉴클레오티드;
갭 영역의 뉴클레오시드 사이의 모든 뉴클레오시드간 연결이 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결은 영역 F 의 뉴클레오시드 사이, 또는 영역 F' 의 뉴클레오시드 사이, 또는 영역 F 와 영역 G 사이, 또는 영역 G 와 영역 F' 사이에 위치하고, 영역 F 및 F' 내, 영역 F 와 영역 G 사이 및 영역 G 와 영역 F' 사이의 나머지 뉴클레오시드간 연결은 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결, 입체 랜덤 뉴클레오시드간 연결, 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결 및 포스포디에스테르 뉴클레오시드간 연결로부터 독립적으로 선택되는, 본 발명에 따른 갭머 올리고뉴클레오티드;
상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결은 영역 F 의 적어도 2 개의 인접 뉴클레오시드 사이, 또는 영역 F', 또는 영역 F 와 영역 G 사이, 또는 영역 G 와 영역 F' 사이의 2 개의 인접 뉴클레오시드 사이에 위치하고, 영역 F 및 F' 의 뉴클레오티드 사이의 나머지 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결, 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결 및 포스포디에스테르 뉴클레오시드간 연결로부터 독립적으로 선택되고, 영역 F 및 F' 의 포스포로티오에이트 뉴클레오시드간 연결은 입체 랜덤 또는 입체 정의일 수 있거나, 또는 입체 랜덤 및 입체 정의로부터 독립적으로 선택될 수 있는, 본 발명에 따른 갭머 올리고뉴클레오티드;
상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결은 영역 F 의 적어도 2 개의 인접 뉴클레오시드 사이, 또는 영역 F', 또는 영역 F 와 영역 G 사이, 또는 영역 G 와 영역 F' 사이의 적어도 2 개의 인접 뉴클레오시드 사이에 위치하고, 영역 F 및 F' 의 뉴클레오티드 사이의 나머지 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결, 및 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택되고, 영역 F 및 F' 의 포스포로티오에이트 뉴클레오시드간 연결은 입체 랜덤 또는 입체 정의일 수 있거나, 또는 입체 랜덤 및 입체 정의로부터 독립적으로 선택될 수 있는, 본 발명에 따른 갭머 올리고뉴클레오티드;
상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결은 영역 F 의 적어도 2 개의 인접 뉴클레오시드 사이, 또는 영역 F', 또는 영역 F 와 영역 G 사이, 또는 영역 G 와 영역 F' 사이의 적어도 2 개의 인접 뉴클레오시드 사이에 위치하고, 영역 F 및 F' 의 뉴클레오티드 사이, 영역 F 와 영역 G 사이 및 영역 G 와 영역 F' 사이의 나머지 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결 및 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택되고; 영역 F 및 F' 의 포스포로티오에이트 뉴클레오시드간 연결은 입체 랜덤 또는 입체 정의일 수 있거나, 또는 입체 랜덤 및 입체 정의로부터 독립적으로 선택될 수 있는, 본 발명에 따른 갭머 올리고뉴클레오티드;
상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결은 영역 F 의 적어도 2 개의 인접 뉴클레오시드 사이, 또는 영역 F', 또는 영역 F 와 영역 G 사이, 또는 영역 G 와 영역 F' 사이의 적어도 2 개의 인접 뉴클레오시드 사이에 위치하고, 영역 F 및 F' 의 뉴클레오티드 사이 및 영역 F 와 영역 G 사이 및 영역 G 와 영역 F' 사이의 나머지 뉴클레오시드간 연결은 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결 및 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택되는, 본 발명에 따른 갭머 올리고뉴클레오티드;
상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결은 영역 F 의 적어도 2 개의 인접 뉴클레오시드 사이, 또는 영역 F', 또는 영역 F 와 영역 G 사이, 또는 영역 G 와 영역 F' 사이의 적어도 2 개의 인접 뉴클레오시드 사이에 위치하고, 영역 F 및 F' 내, 영역 F 와 영역 G 사이 및 영역 G 와 영역 F' 사이의 나머지 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결이며, 이는 모두 입체 랜덤 포스포로티오에이트 뉴클레오시드간 연결, 모두 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결일 수 있거나, 또는 입체 랜덤 및 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택될 수 있는, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 내, 영역 F' 내 또는 영역 F 및 영역 F' 내의 나머지 뉴클레오시드간 연결은 모두 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 G 의 뉴클레오시드 사이의 뉴클레오시드간 연결은 상기 정의된 바와 같은 화학식 (I) 의 0, 1, 2 또는 3 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 G 내의 나머지 뉴클레오시드간 연결은 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결 및 입체 랜덤 포스포로티오에이트 뉴클레오시드간 연결로부터 독립적으로 선택되는, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 G 의 뉴클레오시드 사이의 뉴클레오시드간 연결은 상기 정의된 바와 같은 화학식 (I) 의 0, 1, 2 또는 3 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 G 내의 나머지 뉴클레오시드간 연결 중 적어도 하나, 또는 영역 G 내의 모든 나머지 뉴클레오시드간 연결은 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 G 의 뉴클레오시드 사이의 뉴클레오시드간 연결은 상기 정의된 바와 같은 화학식 (I) 의 0, 1, 2 또는 3 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 G 내의 나머지 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결, 예컨대 입체 랜덤 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 또는 F' 중 적어도 하나는 상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 G 내의 모든 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결, 예컨대 입체 랜덤 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 또는 F' 중 적어도 하나는 상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 G 내의 모든 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결이고, 영역 G 내의 포스포로티오에이트 뉴클레오시드간 연결중 적어도 하나는 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 또는 F' 중 적어도 하나는 상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 G 내의 모든 뉴클레오시드간 연결은 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 와 G 사이의 뉴클레오시드간 연결, 또는 영역 G 와 F' 사이의 뉴클레오시드간 연결, 또는 영역 F 와 G 사이 및 영역 G 와 F' 사이의 뉴클레오시드간 연결은 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결이고, 영역 F 와 G 사이 및 영역 G 와 F' 사이의 뉴클레오시드간 연결 중 하나만 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결인 경우, 영역 F 와 G 사이 또는 영역 G 와 F' 사이의 다른 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 또는 F' 중 적어도 하나는 상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 F 와 G 사이의 뉴클레오시드간 연결, 또는 영역 G 와 F' 사이의 뉴클레오시드간 연결, 또는 영역 F 와 G 사이 및 영역 G 와 F' 사이의 뉴클레오시드간 연결은 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결이고, 영역 F 와 G 사이 및 영역 G 와 F' 사이의 뉴클레오시드간 연결 중 하나만 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결인 경우, 영역 F 와 G 사이 또는 영역 G 와 F' 사이의 다른 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 G 의 뉴클레오시드 사이의 뉴클레오시드간 연결은 상기 정의된 바와 같은 화학식 (I) 의 0, 1, 2 또는 3 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 G 내의 나머지 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결이고, 영역 F 와 G 사이의 뉴클레오시드간 연결, 또는 영역 G 와 F' 사이의 뉴클레오시드간 연결, 또는 영역 F 와 G 사이 및 영역 G 와 F' 사이의 뉴클레오시드간 연결은 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결이고, 영역 F 와 G 사이 및 영역 G 와 F' 사이의 뉴클레오시드간 연결 중 하나만 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결인 경우, 영역 F 와 G 사이 또는 영역 G 와 F' 사이의 다른 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 또는 F' 중 적어도 하나는 상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 G 의 뉴클레오시드 사이의 뉴클레오시드간 연결은 상기 정의된 바와 같은 화학식 (I) 의 0, 1, 2 또는 3 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 G 내의 나머지 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결이고, 영역 F 와 G 사이의 뉴클레오시드간 연결, 또는 영역 G 와 F' 사이의 뉴클레오시드간 연결, 또는 영역 F 와 G 사이 및 영역 G 와 F' 사이의 뉴클레오시드간 연결은 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결이고, 영역 F 와 G 사이 및 영역 G 와 F' 사이의 뉴클레오시드간 연결 중 하나만 상기 정의된 바와 같은 화학식 (I) 의 포스포로디티오에이트 뉴클레오시드간 연결인 경우, 영역 F 와 G 사이 또는 영역 G 와 F' 사이의 다른 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 또는 영역 F' 은 상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하거나, 또는 영역 F 와 영역 G 사이, 또는 영역 G 와 영역 F' 사이의 뉴클레오시드간 연결은 상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 G 는 상기 정의된 바와 같은 화학식 (I) 의 1, 2 또는 3 개의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 G 내의 나머지 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 또는 영역 F' 은 상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하거나, 또는 영역 F 와 영역 G 사이, 또는 영역 G 와 영역 F' 사이의 뉴클레오시드간 연결은 상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 G 내의 모든 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결이고, 영역 G 내의 포스포로티오에이트 뉴클레오시드간 연결중 적어도 하나는 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 또는 영역 F' 은 상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하거나, 또는 영역 F 와 영역 G 사이, 또는 영역 G 와 영역 F' 사이의 뉴클레오시드간 연결은 상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고, 영역 G 내의 모든 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결이고, 영역 G 내의 모든 포스포로티오에이트 뉴클레오시드간 연결은 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결 이외의 갭머 영역 F-G-F' 내의 모든 나머지 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
영역 F 또는 F' 중 적어도 하나는 상기 정의된 바와 같은 화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 포함하고 영역 G 내의 모든 뉴클레오시드간 연결은 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
화학식 (I) 의 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결 이외의 갭머 영역 F-G-F' 내의 모든 나머지 뉴클레오시드간 연결은 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결인, 본 발명에 따른 갭머 올리고뉴클레오티드;
LNA 갭머, 혼합 윙 갭머, 교대 플랭크 갭머 또는 갭-브레이커 갭머인, 본 발명에 따른 갭머 올리고뉴클레오티드;
본 발명에 따른 갭머 올리고뉴클레오티드의 약학적으로 허용되는 염, 특히 소듐 또는 포타슘 염;
본 발명에 따른 갭머 올리고뉴클레오티드 또는 약학적으로 허용되는 염을 포함하는 컨쥬게이트 및 임의로 링커 모이어티를 통해, 특히 생물 절단성 링커를 통해, 특히 2 내지 4 개의 포스포디에스테르 연결된 DNA 뉴클레오시드 (예를 들어 영역 D' 또는 D") 를 통해 상기 올리고뉴클레오티드 또는 상기 약학적으로 허용되는 염에 공유 부착된 적어도 하나의 컨쥬게이트 모이어티;
본 발명에 따른 갭머 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트 및 치료적으로 불활성인 담체를 포함하는 약학 조성물;
치료적으로 활성인 물질로서 사용하기 위한, 본 발명에 따른 갭머 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트;
약제로서의 갭머 올리고뉴클레오티드, 약학적으로 허용되는 염 또는 컨쥬게이트의 용도;
본 발명에 따른 올리고뉴클레오티드 또는 갭머 올리고뉴클레오티드를 표적 RNA 를 발현하는 세포에 투여하여 상기 표적 RNA 의 발현을 조절하는 것을 포함하는, 세포에서 표적 RNA 의 발현의 조절 방법;
본 발명에 따른 올리고뉴클레오티드 또는 갭머 올리고뉴클레오티드를 표적 RNA 를 발현하는 세포에 투여하여 상기 표적 RNA 의 발현을 저해하는 것을 포함하는, 세포에서 표적 RNA 의 발현의 저해 방법; 및
본 발명에 따른 올리고뉴클레오티드 또는 갭머 올리고뉴클레오티드를 표적 RNA 를 발현하는 세포에 투여하여 상기 세포에서 상기 표적 RNA 를 조절 또는 저해하는 것을 포함하는, 세포에서 표적 RNA 의 조절 또는 저해하는 시험관내 방법.
표적 RNA 는 예를 들어 포유류 mRNA, 예컨대 pre-mRNA 또는 성숙 mRNA, 인간 mRNA, 바이러스 RNA 또는 비-코딩 RNA, 예컨대 마이크로RNA 또는 긴 비-코딩 RNA 일 수 있다.
일부 구현예에서, 조절은 표적 pre-mRNA 의 스플라이싱 패턴을 변경하는 pre-mRNA 의 스플라이스 조절이다.
일부 구현예에서, 조절은 표적 분해를 통해 (예를 들어 RNaseH, 예컨대 RNaseH1 또는 RISC 의 동원을 통해) 일어날 수 있는 저해, 또는 표적 RNA 의 정상적인 생물학적 기능을 억제하는 점유 매개 메커니즘을 통해 일어날 수 있는 저해 (예를 들어 마이크로RNA 또는 긴 비-코딩 RNA 의 믹스머 또는 토탈머 저해) 이다.
인간 mRNA 는 성숙 RNA 또는 pre-mRNA 일 수 있다.
본 발명은 또한 화학식 (II) 의 화합물에 관한 것이다:

식 중,
X 는 산소, 황, -CRaRb-, -C(Ra)=C(Rb)-, -C(=CRaRb)-, -C(Ra)=N-, -Si(Ra)2-, -SO2-, -NRa-; -O-NRa-, -NRa-O-, -C(=J)-, Se, -O-NRa-, -NRa-CRaRb-, -N(Ra)-O- 또는 -O-CRaRb- 이고;
Y 는 산소, 황, -(CRaRb)n-, -CRaRb-O-CRaRb-, -C(Ra)=C(Rb)-, -C(Ra)=N-, -Si(Ra)2-, -SO2-, -NRa-, -C(=J)-, Se, -O-NRa-, -NRa-CRaRb-, -N(Ra)-O- 또는 -O-CRaRb- 이고;
단, -X-Y- 는 -O-O-, Si(Ra)2-Si(Ra)2-, -SO2-SO2-, -C(Ra)=C(Rb)-C(Ra)=C(Rb), -C(Ra)=N-C(Ra)=N-, -C(Ra)=N-C(Ra)=C(Rb), -C(Ra)=C(Rb)-C(Ra)=N- 또는 -Se-Se- 가 아니고;
J 는 산소, 황, =CH2 또는 =N(Ra) 이고;
Ra 및 Rb 는 수소, 할로겐, 하이드록실, 시아노, 티오하이드록실, 알킬, 치환된 알킬, 알케닐, 치환된 알케닐, 알키닐, 치환된 알키닐, 알콕시, 치환된 알콕시, 알콕시알킬, 알케닐옥시, 카르복실, 알콕시카르보닐, 알킬카르보닐, 포르밀, 아릴, 헤테로시클릴, 아미노, 알킬아미노, 카르바모일, 알킬아미노카르보닐, 아미노알킬아미노카르보닐, 알킬아미노알킬아미노카르보닐, 알킬카르보닐아미노, 카르바미도, 알카노일옥시, 설포닐, 알킬설포닐옥시, 니트로, 아지도, 티오하이드록실설파이드알킬설파닐, 아릴옥시카르보닐, 아릴옥시, 아릴카르보닐, 헤테로아릴, 헤테로아릴옥시카르보닐, 헤테로아릴옥시, 헤테로아릴카르보닐, -OC(=Xa)Rc, -OC(=Xa)NRcRd 및 -NReC(=Xa)NRcRd 로부터 독립적으로 선택되거나;
또는 2 개의 제미날 Ra 및 Rb 는 함께 임의 치환된 메틸렌을 형성하거나;
또는 2 개의 제미날 Ra 및 Rb 는, 이들이 부착된 탄소 원자와 함께, -X-Y- 의 오직 하나의 탄소 원자와 시클로알킬 또는 할로시클로알킬을 형성하고;
치환된 알킬, 치환된 알케닐, 치환된 알키닐, 치환된 알콕시 및 치환된 메틸렌은 할로겐, 하이드록실, 알킬, 알케닐, 알키닐, 알콕시, 알콕시알킬, 알케닐옥시, 카르복실, 알콕시카르보닐, 알킬카르보닐, 포르밀, 헤테로시클릴, 아릴 및 헤테로아릴로부터 독립적으로 선택된 1 내지 3 개의 치환기로 치환된 알킬, 알케닐, 알키닐 및 메틸렌이고;
Xa 는 산소, 황 또는 -NRc 이고;
Rc, Rd 및 Re 는 수소 및 알킬로부터 독립적으로 선택되고;
n 은 1, 2 또는 3 이고;
R5 는 하이드록실 보호기이고;
Rx 는 페닐, 니트로페닐, 페닐알킬, 할로페닐알킬, 시아노알킬, 페닐카르보닐설파닐알킬, 할로페닐카르보닐설파닐알킬 알킬카르보닐설파닐알킬 또는 알킬카르보닐카르보닐설파닐알킬이고;
Ry 는 디알킬아미노 또는 피롤리디닐이고;
Nu 는 핵염기 또는 보호된 핵염기이다.
본 발명은 또한 하기에 관한 것이다:
-X-Y- 는 -CH2-O-, -CH(CH3)-O- 또는 -CH2CH2-O- 인 화학식 (II) 의 화합물;
본 발명은 또한 화학식 (IIb) 의 화합물을 제공한다:

식 중, R5 는 하이드록실 보호기이고,
Rx 는 페닐, 니트로페닐, 페닐알킬, 할로페닐알킬, 시아노알킬, 페닐카르보닐설파닐알킬, 할로페닐카르보닐설파닐알킬 알킬카르보닐설파닐알킬 또는 알킬카르보닐카르보닐설파닐알킬이고;
Ry 는 디알킬아미노 또는 피롤리디닐이고;
Nu 는 핵염기 또는 보호된 핵염기이다.
화학식 (III) 또는 (IV) 를 갖는 화학식 (II) 의 화합물:

식 중, R5, Rx, Ry 및 Nu 는 상기와 같다;
식 중, Rx 는 페닐, 니트로페닐, 페닐메틸, 디클로로페닐메틸, 시아노에틸, 메틸카르보닐설파닐에틸, 에틸카르보닐설파닐에틸, 이소프로필카르보닐설파닐에틸, tert.-부틸카르보닐설파닐에틸, 메틸카르보닐카르보닐설파닐에틸 또는 디플루오로페닐카르보닐설파닐에틸인, 화학식 (II), (IIb), (III) 또는 (IV) 의 화합물;
식 중, Rx 는 페닐, 4-니트로페닐, 2,4-디클로로페닐메틸, 시아노에틸, 메틸카르보닐설파닐에틸, 에틸카르보닐설파닐에틸, 이소프로필카르보닐설파닐에틸, tert.-부틸카르보닐설파닐에틸, 메틸카르보닐카르보닐설파닐에틸 또는 2,4-디플루오로페닐카르보닐설파닐에틸인, 화학식 (II), (IIb), (III) 또는 (IV) 의 화합물;
식 중, Rx 는 페닐카르보닐설파닐알킬인, 화학식 (II), (IIb), (III) 또는 (IV) 의 화합물;
식 중, Rx 는 페닐카르보닐설파닐에틸인, 화학식 (II), (IIb), (III) 또는 (IV) 의 화합물;
식 중, Ry 는 디이소프로필아미노 또는 피롤리디닐인, 화학식 (II), (IIb), (III) 또는 (IV) 의 화합물;
식 중, Ry 는 피롤리디닐인, 화학식 (II), (IIb), (III) 또는 (IV) 의 화합물;
화학식 (V) 을 갖는 화학식 (II) 의 화합물:

식 중, R5 및 Nu 는 상기 정의된 바와 같다;
화학식 (Vb) 을 갖는 화학식 (IIb) 의 화합물:

식 중, R5 및 Nu 는 상기 정의된 바와 같다;
Nu 는 티민, 보호된 티민, 아데노신, 보호된 아데노신, 시토신, 보호된 시토신, 5-메틸시토신, 보호된 5-메틸시토신, 구아닌, 보호된 구아닌, 우라실 또는 보호된 우라실인, 화학식 (II), (IIb), (III), (IV) 또는 (V) 또는 (Vb) 의 화합물;
Nu 는 티민, 보호된 티민, 아데노신, 보호된 아데노신, 시토신, 보호된 시토신, 5-메틸시토신, 보호된 5-메틸시토신, 구아닌, 보호된 구아닌, 우라실 또는 보호된 우라실인, 화학식 (IIb) 의 화합물;
Nu 는 티민, 보호된 티민, 아데노신, 보호된 아데노신, 시토신, 보호된 시토신, 5-메틸시토신, 보호된 5-메틸시토신, 구아닌, 보호된 구아닌, 우라실 또는 보호된 우라실인, 화학식 (Vb) 의 화합물;
하기로부터 선택되는 화학식 (II) 의 화합물:


하기로부터 선택되는 화학식 (IIb) 의 화합물:


화학식 (II) 및 (IIb) 의 화합물에서 불순물의 존재는 올리고뉴클레오티드의 제조 동안 부산물을 생성하고 합성의 성공을 방해한다. 또한, 불순물이 존재하는 경우, 화학식 (II) 또는 (IIb) 의 화합물은 저장시 불안정하다.
화학식 (X1), (X2), (X11) 및 (X21) 의 화합물은 특히 이러한 불순물의 예이다:

따라서, 저장 및 올리고뉴클레오티드 제조 목적을 위해 충분히 순수한 형태의 화학식 (II) 또는 (IIb) 의 화합물이 필요하다.
따라서, 본 발명은 또한 적어도 98 %, 특히 99 %, 보다 특히 100 % 의 순도를 갖는 화학식 (II) (IIb) 의 화합물에 관한 것이다.
따라서, 본 발명은 특히 불순물로서 1 % 미만, 특히 0 % 의 화학식 (X1) 의 화합물 및/또는 (X2) 의 화합물을 포함하는 화학식 (II) 의 화합물에 관한 것이다.
본 발명은 또한 산성 커플링제 및 실릴화제의 존재하의 5'-보호된 LNA 뉴클레오시드와 포스핀 및 모노-보호된 디티올의 반응을 포함하는 상기 정의된 바와 같은 화학식 (II) 의 화합물의 제조 방법에 관한 것이다.
본 발명은 또한 산성 커플링제 및 실릴화제의 존재하의 5'-보호된 MOE 뉴클레오시드와 포스핀 및 모노-보호된 디티올의 반응을 포함하는 상기 정의된 바와 같은 화학식 (IIb) 의 화합물의 제조 방법에 관한 것이다.
본 발명은 산성 커플링제 및 실릴화제의 존재하의 화학식 (C) 의 화합물과 화학식 P(Ry)3 의 화합물 및 화학식 HSRx 의 화합물의 반응을 포함하는 화학식 (II) 의 화합물의 제조 방법에 관한 것이다:

식 중, X, Y, R5, Nu, Rx 및 Ry 는 상기 정의된 바와 같다.
본 발명은 또한 산성 커플링제 및 실릴화제의 존재하의 화학식 (C1) 의 화합물과 화학식 P(Ry)3 의 화합물 및 화학식 HSRx 의 화합물의 반응을 포함하는 화학식 (II) 의 화합물의 제조 방법에 관한 것이다:

식 중, R5, Nu, Rx 및 Ry 는 상기 정의된 바와 같다.
본 발명은 또한 산성 커플링제 및 실릴화제의 존재하의 화학식 (Cb) 의 화합물과 화학식 P(Ry)3 의 화합물 및 화학식 HSRx 의 화합물의 반응을 포함하는 화학식 (IIb) 의 화합물의 제조 방법에 관한 것이다:

식 중, R5, Nu, Rx 및 Ry 는 상기 정의된 바와 같다.
산성 활성화제로도 알려진 산성 커플링제의 예는 아졸 기반 활성화제, 예컨대 테트라졸, 5-니트로페닐-1H-테트라졸 (NPT), 5-에틸티오-1H-테트라졸 (ETT), 5-벤질티오-1H-테트라졸 (BTT), 5-메틸티오-1H-테트라졸 (MTT), 5-머캡토-테트라졸 (MCT), 5-(3,5-비스(트리플루오로메틸)페닐)-1H-테트라졸 및 4,5-디시아노이미다졸 (DCI), 또는 산성 염, 예컨대 피리디늄 하이드로클로라이드, 이미다졸리늄 트리플레이트, 벤지미다졸륨 트리플레이트, 5-니트로벤지미다졸륨 트리플레이트, 또는 약산, 예컨대 2,4-디니트로벤조산 또는 2,4-디니트로페놀이다. 테트라졸은 특정 산성 커플링제이다.
하이드록실 기 소광제로도 알려진 실릴화제의 예는 비스(디메틸아미노)디메틸실란, N,O-비스(트리메틸실릴)아세트아미드 (BSA), N,O-비스(트리메틸실릴)카바메이트 (BSC), N,N-비스(트리메틸실릴)메틸아민, N,O-비스(트리메틸실릴)트리플루오로아세트아미드 (BSTFA), N,N-비스(트리메틸실릴)우레아 (BSU), 브로모트리메틸실란 (TMBS), N-tert-부틸디메틸실릴-N-메틸트리플루오로아세트아미드 (MTBSTFA), 클로로디메틸(펜타플루오로페닐)실란, 클로로트리에틸실란 (TESCI), 클로로트리메틸실란 (TMCS), 1,3-디메틸-1,1,3,3-테트라페닐디실라잔 (TPDMDS), N,N-디메틸트리메틸실릴아민 (TMSDMA), 헥사메틸디실라잔 (HMDS), 헥사메틸디실록산 (HMDSO), N-메틸-N-트리메틸실릴아세트아미드 (MSA), N-메틸-N-트리메틸실릴헵타플루오로부티르아미드 (MSHFA), N-메틸-N-(트리메틸실릴)트리플루오로아세트아미드 (MSTFA), 1,1,3,3-테트라메틸-1,3-디페닐디실라잔 (DPTMDS), 4-(트리메틸실록시)-3-펜텐-2-온 (TMS acac), 1-(트리메틸실릴)이미다졸 (TMSI) 또는 트리메틸실릴 메탈릴설피네이트 (SILMAS-TMS) 이다. 1-(트리메틸실릴)이미다졸은 특정 실릴화제이다.
본 발명은 또한 화학식 (II) 또는 (IIb) 의 미정제 화합물이 분취용 HPLC 에 의해 정제되는 화학식 (II), (IIb) 또는 (III) 의 화합물의 제조 방법에 관한 것이다.
본 발명은 또한 미정제 화학식 (II), (IIb) 또는 (III) 의 화합물이 분취용 HPLC 에 의해 정제되고 아세토니트릴 대 물 중 암모늄 하이드록사이드의 구배로 용리되는 화학식 (II), (IIb) 또는 (III) 의 화합물의 제조 방법에 관한 것이다.
물 중 암모늄 하이드록사이드 함량은 특히 적어도 약 0.05 % v/v, 특히 약 0.0 5% 내지 1 % v/v, 보다 특히 약 0.05 % 내지 0.5 % v/v, 보다 특히 약 0.05 % v/v 이다.
아세토니트릴의 구배는 특히 0 % 에서 25 % 내지 75 % 에서 100 % 아세토니트릴, 특히 20 min 내지 120 min 이내, 보다 특히 10 % 에서 20 % 내지 75 % 에서 90 % 아세토니트릴, 특히 25 min 내지 60 min 이내, 보다 특히 약 25 % 내지 75 % 아세토니트릴, 특히 30 min 이내이다.
본 발명은 또한 올리고뉴클레오티드, 특히 본 발명에 따른 올리고뉴클레오티드 또는 갭머 올리고뉴클레오티드의 제조에서의 화학식 (II), (IIb) 또는 (III) 의 화합물의 용도에 관한 것이다.
본 발명은 이제 제한적인 특성을 갖지 않는 하기 실시예에 의해 설명될 것이다.
실시예
실시예 1: 단량체 합성
1.1: S-(2-설파닐에틸) 벤젠카르보티오에이트

클로로포름 (200 mL) 중 1,2-에탄디티올 (133.57 mL, 1592 mmol, 1 eq) 및 피리딘 (64.4 mL, 796 mmol, 0.5 eq) 의 용액에 클로로포름 (200 mL) 중 벤조일 클로라이드 (92.4 mL, 796 mmol, 0.5 eq) 를 1 시간 동안 적가하고, 반응물을 0 ℃ 에서 1 시간 동안 교반하였다. 혼합물을 물 (300 mL) 및 염수 (300 mL) 로 세척하였다. 유기상을 Na2SO4 상에서 건조시키고 황색 오일로 농축시켰다. 오일을 증류 (135~145℃) 하여 S-(2-설파닐에틸) 벤젠카르보티오에이트 (40 g, 202 mmol, 13% 수율) 를 무색 오일로 수득하였다.

1.2: S-[2-[[(1R,3R,4R,7S)-1-[[비스(4-메톡시페닐)-페닐-메톡시]메틸]-3-(5-메틸-2,4-디옥소-피리미딘-1-일)-2,5-디옥사바이시클로[2.2.1]헵탄-7-일]옥시-피롤리딘-1-일-포스파닐]설파닐에틸] 벤젠카르보티오에이트

1-[(1R,4R,6R,7S)-4-[[비스(4-메톡시페닐)-페닐-메톡시]메틸]-7-하이드록시-2,5-디옥사바이시클로[2.2.1]헵탄-6-일]-5-메틸-피리미딘-2,4-디온 (2.29 g, 4.00 mmol, 1.0 eq) 을 3 Å 분자체 한 스패츌라를 첨가한 60 mL 의 무수 디클로로메탄에 용해시켰다. 트리피롤리딘-1-일포스판 (960 mg, 3.98 mmol, 0.99 eq) 을 주사기를 통해 첨가한 후 0.1 mmol 분취량의 테트라졸 (7 * 3 Å 분자체에 저장된 무수 아세토니트릴 중 0.5 M 용액 0.4 mL) 을 2 min 간격으로 7 회 첨가하였다. 이어서, N-트리메틸실릴이미다졸 (56.0 mg, 0.400 mmol, 0.1 eq) 을 반응에 첨가하였다. 5 min 후, 테트라졸 (무수 아세토니트릴 중 0.5 M 용액 21.6 mL) 을 첨가한 후, 즉시 S-(2-설파닐에틸) 벤젠카르보티오에이트 (1.04 g, 5.24 mmol, 1.31 eq) 를 첨가하였다. 반응을 120 초 동안 진행시켰다. 4 개의 동일한 배치의 반응을 합치고 40 mL 의 트리에틸아민을 함유하는 600 mL 의 디클로로메탄에 용액을 부어 켄칭시켰다. 포화 소듐 바이카르보네이트 (800 mL) 이어서 10% 소듐 카르보네이트 (2 * 800 mL) 및 염수 (800 mL) 로 혼합물을 즉시 세척하였다. 유기층을 Na2SO4 상에서 건조시켰다. 10-15 min 후, 여과에 의해 건조제를 제거하였다. 트리에틸아민 (40 mL) 을 용액에 첨가하고 회전 증발기를 사용하여 용액을 시럽으로 농축시켰다. 시럽을 톨루엔 (200 mL) 및 트리에틸아민 (40mL) 에 용해시키고 이 용액을 4500 mL 의 격렬하게 교반된 헵탄에 피펫팅하여 솜털 같은 백색 생성물을 침전시켰다. 대부분의 헵탄을 디캔팅한 후, 백색 침전물을 중간 소결된(medium sintered) 유리 깔때기를 통한 여과에 의해 수집한 후 진공하에 건조시켜 백색 고체를 수득하였다. 고체를 prep-HPLC (Phenomenex Gemini C18, 250x50 mm, 10 mm 컬럼, 물 중 0.05% 암모늄 하이드록사이드 / CH3CN) 에 의해 정제하고, 동결 건조시켜 4.58 g 의 표적 화합물을 백색 고체로 수득하였다.

1.3: S-[2-[[(1R,3R,4R,7S)-3-(6-벤즈아미도푸린-9-일)-1-[[비스(4-메톡시페닐)-페닐-메톡시]메틸]-2,5-디옥사바이시클로[2.2.1]헵탄-7-일]옥시-피롤리딘-1-일-포스파닐]설파닐에틸] 벤젠카르보티오에이트

N-[9-[(1R,4R,6R,7S)-4-[[비스(4-메톡시페닐)-페닐-메톡시]메틸]-7-하이드록시-2,5-디옥사바이시클로[2.2.1]헵탄-6-일]푸린-6-일]벤즈아미드 (2.74g, 4.00 mmol, 1.0 eq) 를 3 Å 분자체 한 스패츌라를 첨가한 60 mL 의 무수 디클로로메탄에 용해시켰다. 트리피롤리딘-1-일포스판 (960 mg, 3.98 mmol, 0.99 eq) 을 주사기를 통해 첨가한 후 0.1 mmol 분취량의 테트라졸 (7 * 3 Å 분자체에 저장된 무수 아세토니트릴 중 0.5 M 용액 0.4 mL) 을 2 min 간격으로 7 회 첨가하였다. 이어서, 1-(트리메틸실릴)-1H-이미다졸 (56.0 mg, 0.400 mmol, 0.1 eq) 을 반응에 첨가하였다. 5 min 후, 테트라졸 (무수 아세토니트릴 중 0.5 M 용액 21.6 mL) 을 첨가한 후, 즉시 S-(2-설파닐에틸) 벤젠카르보티오에이트 (1.04 g, 5.24 mmol, 1.31 eq) 를 첨가하였다. 반응을 120 초 동안 진행시켰다. 4 개의 동일한 배치의 반응을 합치고 40 mL 의 트리에틸아민을 함유하는 600 mL 의 디클로로메탄에 용액을 부어 켄칭시켰다. 포화 소듐 바이카르보네이트 (800 mL) 이어서 10% 소듐 카르보네이트 (2 * 800 mL) 및 염수 (800 mL) 로 혼합물을 즉시 세척하였다. 유기층을 Na2SO4 상에서 건조시켰다. 10-15 min 후, 여과에 의해 건조제를 제거하였다. 트리에틸아민 (10 mL) 을 용액에 첨가하고 회전 증발기를 사용하여 용액을 시럽으로 농축시켰다. 시럽을 톨루엔 (100 mL) 및 트리에틸아민 (20mL) 에 용해시키고 이 용액을 4500 mL 의 격렬하게 교반된 헵탄에 피펫팅하여 솜털 같은 백색 생성물을 침전시켰다. 대부분의 헵탄을 디캔팅한 후, 백색 침전물을 중간 소결된 유리 깔때기를 통한 여과에 의해 수집한 후 진공하에 건조시켜 백색 고체를 수득하였다. 고체를 prep-HPLC (Phenomenex Gemini C18, 250x50 mm, 10 mm 컬럼, 물 중 0.05% 암모늄 하이드록사이드 / CH3CN) 에 의해 정제하고, 동결 건조시켜 5.26 g 의 표적 화합물을 백색 고체로 수득하였다.

1.4: S-[2-[[(1R,3R,4R,7S)-3-(4-벤즈아미도-5-메틸-2-옥소-피리미딘-1-일)-1-[[비스(4-메톡시페닐)-페닐-메톡시]메틸]-2,5-디옥사바이시클로[2.2.1]헵탄-7-일]옥시-피롤리딘-1-일-포스파닐]설파닐에틸] 벤젠카르보티오에이트

N-[1-[(1R,4R,6R,7S)-4-[[비스(4-메톡시페닐)-페닐-메톡시]메틸]-7-하이드록시-2,5-디옥사바이시클로[2.2.1]헵탄-6-일]-5-메틸-2-옥소-피리미딘-4-일]벤즈아미드 (2.70 g, 4.00 mmol, 1.0 eq) 를 3 Å 분자체 한 스패츌라를 첨가한 60 mL 의 무수 디클로로메탄에 용해시켰다. 트리피롤리딘-1-일포스판 (965 mg, 4.00 mmol, 1.0 eq) 을 주사기를 통해 첨가한 후 0.1 mmol 분취량의 테트라졸 (7 * 3 Å 분자체에 저장된 무수 아세토니트릴 중 0.5 M 용액 0.4 mL) 을 2 min 간격으로 7 회 첨가하였다. 이어서, 1-(트리메틸실릴)-1H-이미다졸 (56.0 mg, 0.400 mmol, 0.1 eq) 을 반응에 첨가하였다. 5 min 후, 테트라졸 (무수 아세토니트릴 중 0.5 M 용액 21.6 mL) 을 첨가한 후, 즉시 S-(2-설파닐에틸) 벤젠카르보티오에이트 (1.04 g, 5.24 mmol, 1.31 eq) 를 첨가하였다. 반응을 120 초 동안 진행시켰다. 4 개의 동일한 배치의 반응을 40 mL 의 트리에틸아민을 함유하는 600 mL 의 디클로로메탄에 용액을 부어 켄칭시키고 합쳤다. 포화 소듐 바이카르보네이트 (800 mL) 이어서 10% 소듐 카르보네이트 (2 * 800 mL) 및 염수 (800 mL) 로 혼합물을 즉시 세척하였다. 유기층을 Na2SO4 상에서 건조시켰다. 10-15 min 후, 여과에 의해 건조제를 제거하였다. 트리에틸아민 (40 mL) 을 용액에 첨가하고 회전 증발기를 사용하여 용액을 시럽으로 농축시켰다. 시럽을 톨루엔 (100 mL) 및 트리에틸아민 (30 mL) 에 용해키시고, 이 용액을 4500 mL 의 격렬하게 교반된 헵탄에 피펫팅하여 솜털 같은 백색 생성물을 침전시켰다. 대부분의 헵탄을 디캔팅한 후, 백색 침전물을 중간 소결된 유리 깔때기를 통한 여과에 의해 수집한 후 진공하에 건조시켜 백색 고체를 수득하였다. 고체를 prep-HPLC (Phenomenex Gemini C18, 250x50 mm, 10 mm 컬럼, 물 중 0.05% 암모늄 하이드록사이드 / CH3CN) 에 의해 정제하고, 동결 건조시켜 2.05 g 의 표적 화합물을 백색 고체로 수득하였다.

1.5: S-[2-[[(1R,3R,4R,7S)-1-[[비스(4-메톡시페닐)-페닐-메톡시]메틸]-3-[2-[(E)-디메틸아미노메틸렌아미노]-6-옥소-1H-푸린-9-일]-2,5-디옥사바이시클로[2.2.1]헵탄-7-일]옥시-피롤리딘-1-일-포스파닐]설파닐에틸] 벤젠카르보티오에이트

N'-[9-[(1R,4R,6R,7S)-4-[[비스(4-메톡시페닐)-페닐-메톡시]메틸]-7-하이드록시-2,5-디옥사바이시클로[2.2.1]헵탄-6-일]-6-옥소-1H-푸린-2-일]-N,N-디메틸-포름아미딘 (2.62 mg, 4.00 mmol, 1.0 eq) 를 3 Å 분자체 한 스패츌라를 첨가한 200 mL 의 무수 디클로로메탄에 용해시켰다. 트리피롤리딘-1-일포스판 (965 mg, 4.00 mmol, 1.0 eq) 을 주사기를 통해 첨가한 후 0.1 mmol 분취량의 테트라졸 (7 * 3 Å 분자체에 저장된 무수 아세토니트릴 중 0.5 M 용액 0.4 mL) 을 2 min 간격으로 7 회 첨가하였다. 이어서, 1-(트리메틸실릴)-1H-이미다졸 (56.0 mg, 0.400 mmol, 0.1 eq) 을 반응에 첨가하였다. 5 min 후, 테트라졸 (무수 아세토니트릴 중 0.5 M 용액 21.6 mL) 을 첨가한 후, 즉시 S-(2-설파닐에틸) 벤젠카르보티오에이트 (1.04 g, 5.24 mmol, 1.31 eq) 를 첨가하였다. 반응을 180 초 동안 진행시켰다. 4 개의 동일한 배치를 합치고 40 mL 의 트리에틸아민을 함유하는 600 mL 의 디클로로메탄에 용액을 부어 켄칭시켰다. 포화 소듐 바이카르보네이트 (800 mL) 이어서 10% 소듐 카르보네이트 (2 * 800 mL) 및 염수 (800 mL) 로 혼합물을 즉시 세척하였다. 유기층을 Na2SO4 상에서 건조시켰다. 10-15 min 후, 여과에 의해 건조제를 제거하였다. 트리에틸아민 (40 mL) 을 용액에 첨가하고 회전 증발기를 사용하여 용액을 시럽으로 농축시켰다. 시럽을 톨루엔 (100 mL) 및 트리에틸아민 (30mL) 에 용해시키고 이 용액을 4500 mL 의 격렬하게 교반된 헵탄에 피펫팅하여 솜털 같은 백색 생성물을 침전시켰다. 대부분의 헵탄을 디캔팅한 후, 백색 침전물을 중간 소결된 유리 깔때기를 통한 여과에 의해 수집한 후 진공하에 건조시켜 백색 고체를 수득하였다. 고체를 prep-HPLC (Phenomenex Gemini C18, 250x50 mm, 10 mm 컬럼, 물 중 0.05% 암모늄 하이드록사이드 / CH3CN) 에 의해 정제하고, 동결 건조시켜 3.82 g 의 표적 화합물을 황색 고체로 수득하였다.

실시예 2: 올리고뉴클레오티드 합성
올리고뉴클레오티드는 Bioautomation 의 MerMade 12 자동 DNA 합성기를 사용하여 합성되었다. 범용 링커를 갖는 제어된 기공 유리 지지체 (500Å) 를 사용하여 1 μmol 규모로 합성을 수행하였다.
DNA 및 LNA 포스포르아미다이트의 커플링을 위한 표준 사이클 절차에서, DMT 탈보호는 CH2Cl2 중 3% (w/v) 트리클로로아세트산을 사용하여 30 초 동안 200 μL 의 3 회 적용으로 수행되었다. 각각의 포스포르아미다이트를 180 초의 커플링 시간 및 활성화제로서 아세토니트릴 중 5-(3,5-비스(트리플루오로메틸페닐))-1H-테트라졸의 0.1 M 용액 110 μL 및 아세토니트릴 (또는 LNA-MeC 빌딩 블록의 경우 아세토니트릴/CH2Cl2 1:1) 중 0.1 M 용액 100 μL 를 사용하여 3 회 커플링하였다. 티오산화를 위해, 아세토니트릴/피리딘 1:1 중 3-아미노-1,2,4-디티아졸-5-티온의 0.1m 용액을 사용하였다 (3x190 μL, 55 초). THF/루티딘/Ac2O 8:1:1 (CapA, 75 μmol) 및 THF/N-메틸이미다졸 8:2 (CapB, 75 μmol) 를 55 초 동안 사용하여 캡핑을 수행하였다.
티오포스포르아미다이트의 도입을 위한 합성 사이클은 CH2Cl2 중 3% (w/v) 트리클로로아세트산을 30 초 동안 200 μL 의 3 회 적용으로 사용하는 DMT 탈보호를 포함하였다. 상업적으로 입수 가능한 DNA 티오포스포르아미다이트 또는 갓 제조된 LNA 티오포스포르아미다이트는 각각 600 초의 커플링 시간 및 활성화제로서 아세토니트릴 중 10% (v/v) CH2Cl2 중 0.15 M 용액 100 μL 및 아세토니트릴 중 5-(3,5-비스(트리플루오로메틸페닐))-1H-테트라졸의 0.1 M 용액 110 μL 를 사용하여 3 회 커플링되었다. 티오산화는 아세토니트릴/피리딘 중 3-아미노-1,2,4-디티아졸-5-티온의 0.1 M 용액을 55 초 동안 3 회의 적용으로 사용하여 수행하였다. THF/루티딘/Ac2O 8:1:1 (CapA, 75 μmol) 및 THF/N-메틸이미다졸 8:2 (CapB, 75 μmol) 를 55 초 동안 사용하여 캡핑을 수행하였다.
자동 합성이 완료되면, 핵염기 보호기의 제거 및 고체 지지체로부터의 절단이 55℃ 에서 15-16 h 동안 20 mM DTT 를 함유하는 암모니아 (32%):에탄올 (3:1, v:v) 혼합물을 사용하여 수행되었다.
미정제 DMT-온 올리고뉴클레오티드는 고체 상 추출 카트리지 및 이온 교환 크로마토그래피에 의한 재정제를 사용하여 또는 C18 컬럼을 사용하는 RP-HPLC 정제에 의해 정제된 다음 80% 수성 아세트산 및 에탄올 침전으로 DMT 를 제거하였다.
하기 실시예에서 본 발명자들은 하기 티오 연결 화학을 사용하였다:

하기 실시예에서, 달리 지시되지 않는 한, 아카이랄 포스포로디티오에이트 연결 (P2S 로도 지칭됨) 은 비-가교 디티오에이트 (화학식 (IA) 또는 (IB) 에 예시된 바와 같음) 이며, * 로 표시되어 있다. 실시예에서 사용된 화합물은 하기 핵염기 서열을 갖는 화합물을 포함한다:

상기 절차에 따라 하기 분자가 제조되었다.


* 인접 뉴클레오티드 사이의 디티오에이트 개질
A, G, mC, T 는 LNA 뉴클레오티드를 나타냄
a, g, c, t 는 DNA 뉴클레오티드를 나타냄
모든 다른 연결은 포스포로티오에이트로서 제조됨
실시예 3: 시험관내 효능 및 세포 흡수 실험
1차 랫트 간세포를 96-웰 플레이트에 플레이팅하고 항생제 없이 10% FCS 를 함유하는 윌리엄스 배지 E 에서 처리하였다. 세포를 전체 세포 배양 배지에서 지시된 농도의 LNA 용액으로 처리하였다. 각각, 24 및 72 시간의 배양 시간 후, Ca2+ 및 Mg2+ 를 함유하는 PBS 로 세포를 3 회 세척하고, 165 uL PureLink Pro 용해 완충액으로 용해시켰다. Thermo Fisher 의 PureLink PRO 96 RNA Kit 를 사용하여 제조사의 지침에 따라 전체 RNA 를 단리하고, RnApoB (Invitrogen) 에 대하여 Primer Primer Sets 와 LightCycler Multiplex RNA Virus Master (Roche) 를 사용하여 RT-qPCR 을 수행하였다. 수득된 데이터를 리보그린 (Ribogreen) 에 대하여 정규화하였다.
LNA 올리고뉴클레오티드의 세포내 농도는 다양한 화합물에 대하여 하이브리드화 기반 ELISA 분석을 사용하여 결정되었다. 모든 데이터 포인트는 3 회 수행되었고 데이터는 평균으로 제공된다.
결과는 도 1 내지 4 에 도시되어 있다.
실시예 4: RNA 및 DNA 에 하이브리드화된 포스포로디티오에이트 뉴클레오시드간 연결을 함유하는 올리고뉴클레오티드의 열 용융 (Tm)
하기 올리고뉴클레오티드가 제조되었다. 포스포로티오에이트 연결은 아래 첨자 S 로 지정된다; 본 발명에 따른 포스포로디티오에이트 연결은 아래 첨자 PS2 로 지정된다.

화합물 1 - 6 은 서열 모티프 SEQ ID NO 1 을 갖는다.
RNA 및 DNA 에 하이브리드화된 화합물 1-6 의 열 용융 (Tm) 은 하기 절차에 따라 측정되었다.
완충액 (100 mM NaCl, 0.1 mM EDTA, 10 mM Na2HPO4, pH 7) 중 등몰량의 RNA 또는 DNA 및 LNA 올리고뉴클레오티드 (1.5 μM) 의 용액을 1 분 동안 90 ℃ 로 가열한 다음 실온으로 냉각시켰다. Cary Series UV-Vis 분광 광도계를 사용하여 260 nm 에서의 UV 흡광도를 기록하였다 (가열 속도 1 분 당 1 ℃; 판독 속도 1 분 당 1 회). 흡광도는 온도에 대해 플롯팅되었고 Tm 값은 각 곡선의 1차 미분을 취함으로써 계산되었다.
결과는 아래 표와 도 5 에 요약되어 있다.

Td: 해리 (변성) 온도; Ta: 회합 (재생) 온도
본 발명에 따른 화합물은 대조군의 RNA 및 DNA 에 대한 높은 친화성을 유지한다.
실시예 5: 포스포로디티오에이트 뉴클레오시드간 연결을 함유하는 올리고뉴클레오티드의 혈청 안정성
수컷 스프라그-다울링(Sprague-Dawling) 랫트로부터의 혈청에서의 올리고뉴클레오티드 1-6 의 안정성을 하기 절차에 따라 측정하였다.
뉴클레아제 완충액 (30 mM 소듐 아세테이트, 1 mM 아연 설페이트, 300 mM NaCl, pH 4.6) 와 3:1 혼합된 랫트 혈청 중 25 μM 올리고뉴클레오티드 용액을 37 ℃ 에서 0, 5, 25, 52 또는 74 시간 동안 배양하였다. UPLC-MS 분석을 위해 Water Acquity BEH C18, 1.7 μm 컬럼이 장착된 Water Acquity UPLC 에서 샘플 2μL 를 주입하였다. 상이한 분해 길이의 확장 상수로 보상된 260 nm 에서 측정된 유사체 피크 면적을 사용하여 절단되지 않은 올리고뉴클레오티드의 % 를 확립하였다.
UPLC 용리액: A: 2.5% MeOH, 0.2 M HEP, 16.3 mM TEA B: 60% MeOH, 0.2 M HEP, 16.3 mM TEA

결과는 도 6 에 요약되어 있다.
본 발명에 따른 적어도 하나의 포스포로디티오에이트 뉴클레오시드간 연결을 갖는 화합물은 포스포로티오에이트 뉴클레오시드간 연결만 갖는 화합물보다 우수한 뉴클레아제 내성을 갖는다.
화합물 1-6 에서 5 시간 후에 나타나는 초기 올리고뉴클레오티드 분해는 모노티오에이트 불순물의 존재에 의해 야기되는 것으로 밝혀졌다.
실시예 7: 디티오에이트 개질된 갭머: LNA 갭머의 갭 영역에서 디티오에이트 탐색
시험된 화합물

실험: ApoB mRNA 를 표적으로 하는 상기 화합물은 짐노틱 흡수를 사용하여 2 μM 의 화합물 농도와 72 시간 동안의 배양에 의해 1차 랫트 간세포에서 시험되었다. 이어서, 표적 mRNA 수준을 RT-PCR 을 사용하여 측정하였다. 결과는 도 7 에 도시되어 있다.
도 7 에 도시된 결과는 단일 및 다수의 아카이랄 포스포로디티오에이트가 갭 및 플랭크 영역에 수용된다는 것을 예시한다. 갭에서 3 또는 4 개 초과의 아카이랄 포스포로디티오에이트를 사용하는 것은 플랭크 영역에서 다수의 아카이랄 포스포로디티오에이트를 사용하는 것에 비해 효능을 감소시키는 경향이 있을 수 있다.
실시예 8: 활성에 대한 위치 의존성 - 디자인 최적화
시험된 화합물

실험: ApoB mRNA 를 표적으로 하는 상기 화합물은 짐노틱 흡수를 사용하여 2 μM 의 화합물 농도와 72 시간 동안의 배양에 의해 1차 랫트 간세포에서 시험되었다. 이어서, 표적 mRNA 수준을 RT-PCR 을 사용하여 측정하였다. 결과는 도 8 에 도시되어 있다.
실시예 9: 아카이랄 포스포로디티오에이트 갭머의 세포 흡수
시험된 화합물

실험: ApoB mRNA 를 표적으로 하는 상기 화합물은 짐노틱 흡수를 사용하여 2 μM 의 화합물 농도와 72 시간 동안의 배양에 의해 1차 랫트 간세포에서 시험되었다. 올리고뉴클레오티드 함량은 하이브리드화 기반 ELISA 분석을 사용하여 결정되었다. 결과는 도 9A 및 9B 에 도시되어 있다.
예외 없이, 아카이랄 포스포로디티오에이트의 포함은 향상된 세포 흡수를 제공하였다. 그러나, 아카이랄 포스포로디티오에이트 연결의 위치에 따라 흡수 개선이 다양하였다.
실시예 10: 갭머의 플랭크 영역에서 아카이랄 포스포로디티오에이트 로드의 증가
시험된 화합물 (서열 모티프 = SEQ ID NO 1)

실험: ApoB mRNA 를 표적으로 하는 상기 화합물은 짐노틱 흡수를 사용하여 2 μM 의 화합물 농도와 72 시간 동안의 배양에 의해 1차 랫트 간세포에서 시험되었다. 이어서, 표적 mRNA 수준을 RT-PCR 을 사용하여 측정하였다. 결과는 도 10A 및 10B 에 도시되어 있다.
갭머의 플랭크 영역에서 아카이랄 포스포로디티오에이트 개질의 도입은 예외 없이 3 - 7 x 의 IC50 감소와 함께 현저한 효능 증가를 제공하였다. 흥미롭게도, 플랭크에서 카이랄 포스포로디티오에이트 개질의 수가 증가하면 IC50 은 낮아진다.
실시예 11: 시험관내에서 상이한 세포 유형에서의 아카이랄 포스포로디티오에이트 연결의 효과.
시험된 화합물 (서열 모티프 = SEQ ID NO 3)

Malat-1 을 표적으로 하는 상기 화합물을 화합물 효능 (IC50) 을 결정하기 위한 농도 범위에서 72 시간 동안 짐노틱 흡수를 사용하여 3 가지 시험관내 세포 시스템: 인간 1차 골격근, 인간 1차 기관지 상피 세포 및 마우스 섬유아세포 (LTK 세포) 에서 시험하였다.
LTK 세포에 대한 농도 범위: 50 μM, ½log 희석, 8 가지 농도.
Malat1 의 RNA 수준을 qPCR (GAPDH 수준에 대하여 정규화) 을 사용하여 정량화하고 IC50 값을 결정하였다.
IC50 결과는 도 11 에 도시되어 있다. 아카이랄 포스포로디티오에이트의 도입은 골격근 세포에서 신뢰할 수 있는 향상된 효능을 제공하였고, 일반적으로 마우스 섬유아세포에 개선된 효능을 제공하였다. 그러나, 인간 기관지 상피 세포에서의 효과는 보다 화합물 특이적이었지만, 일부 화합물 (#5) 에서는 기준 화합물보다 현저하게 더 강력하였다.
실시예 12: 5' 및 3' 말단 보호된 LNA 올리고뉴클레오티드의 시험관내 랫트 혈청 안정성.
시험된 화합물 (서열 모티프 = SEQ ID NO 1)

실험 - 실시예 5 참조.
결과는 도 12 에 도시되어 있다. 본 발명자들은 LNA 포스포로티오에이트 올리고뉴클레오티드의 3' 말단이 이전에 생각된 것보다 혈청 뉴클레아제에 더 민감하고 올리고뉴클레오티드의 3' 말단에서 포스포로티오에이트 연결(들)의 카이랄성과 관련이 있는 것으로 보임 (50% 의 모체 올리고뉴클레오티드 #1 의 신속한 절단에 의해 설명되는 바와 같음) 을 확인하였다. 아카이랄 포스포로디티오에이트에 의한 5' 말단 보호는 개선된 보호를 제공하였다. 아카이랄 포스포로디티오에이트에 의한 3' 말단 보호는 랫트 혈청 엑소뉴클레아제에 대한 완전한 보호를 제공하였다 - 화합물 #4 - #8 에서 관찰되는 약간의 감소는 모노티오에이트 불순물과 상관 관계가 있었다.
따라서, 아카이랄 포스포로티오에이트 연결에 의한 안티센스 올리고뉴클레오티드의 5' 및/또는 3' 말단 보호는 입체 랜덤 및 입체 정의된 포스포로티오에이트와의 주요 불안정성 문제에 대한 해결책을 제공하는 것으로 간주된다.
실시예 13: 플랭크에 아카이랄 포스포로디티오에이트 연결을 갖는 갭머의 생체내 평가
시험된 화합물 (서열 모티프 = SEQ ID NO 1)

실험: ApoB 를 표적으로 하는 상기 화합물을 1 mg/kg 단일 iv 용량을 사용하여 암컷 C57BL/6JBom 마우스에 투여하고, 7 일 째에 희생시켰다, n=5. 간에서의 mRNA 감소는 RT-PCR 을 사용하여 측정되었고 그 결과는 도 13 에 도시되어 있다.
결과는 일반적으로 아카이랄 포스포로디티오에이트 뉴클레오시드간 연결의 도입이 개선된 효능을 제공하고, 특히 플랭크 영역에 아카이랄 포스포로디티오에이트 연결을 갖는 모든 화합물이 개선된 효능을 나타낸다는 것을 보여준다. 시험관내 실험에 나타낸 바와 같이, 갭 영역 (#8) 에서의 다수의 포스포로디티오에이트 연결의 사용은 현저한 효능 손실 없이 수용되었다. 연결 기술을 안티센스 올리고뉴클레오티드와 조합할 때 시너지를 나타내는, 갭 영역에 입체 정의된 포스포로티오에이트 연결을 갖고 플랭크에 아카이랄 포스포로디티오에이트 연결을 갖는 갭머 디자인의 조합된 효과가 특히 흥미롭다.
실시예 14: 개질된 플랭크 및 갭 영역을 갖는 아카이랄 포스포로디티오에이트를 갖는 갭머의 간에서의 생체내 조직 함량.
화합물 및 실험 - 실시예 13 참조. 조직 함량의 결과 (희생된 동물로부터 간 및 신장 샘플에서의 함량을 측정하기 위해 하이브리드화 기반 ELISA 에 의해 결정됨) 가 도 14A 및 B 에 도시되어 있다. 화합물 #1 에 대하여 실험적 오류가 있음을 유의 - 도 14B 데이터 참조.
결과: 도 14A. 아카이랄 포스포로디티오에이트 연결을 함유한 모든 안티센스 올리고뉴클레오티드는 기준 화합물과 비교하여 보다 높은 조직 흡수/함량을 가졌다. 도 14B 는 아카이랄 포스포로디티오에이트 연결의 도입이 모든 시험된 화합물의 생체 분포 (간/신장 비에 의해 결정됨) 을 향상시켰음을 보여준다.
실시예 15: 생체내 실험의 대사 산물 분석
화합물 및 실험 - 실시예 13 참조. 대사 산물 분석은 C. Husser et al., Anal. Chem. 2017, 89, 6821 에 개시된 방법을 사용하여 수행하였다.
결과는 도 15A 및 15B 에 도시되어 있다. 포스포로디티오에이트 개질은 생체내 3'-엑소핵산 분해(exonucleolytic degradation)를 효과적으로 방지한다. 일부 엔도뉴클레아제 절단이 남아있다 (시험된 화합물 #1 - 6 모두는 DNA 포스포로티오에이트 갭 영역을 가지므로 이는 예상되었음). 현저한 엑소뉴클레아제 보호가 주어지면, 안티센스 올리고뉴클레오티드 내 아카이랄 포스포로디티오에이트 연결의 사용은 엔도뉴클레아제 절단을 방지 또는 제한할 수 있는 것으로 고려된다. 아카이랄 포스포르디티오에이트의 향상된 뉴클레아제 내성은 눈에 띄는 약리학적 이점, 예컨대 향상된 활성 및 지속되는 작용 기간, 및 가능하게는 독성 분해 산물의 회피를 제공할 것으로 예상된다.
실시예 16: 생체내 - 장기간 간 활성 (ApoB)
시험된 화합물 (서열 모티프 = SEQ ID NO 1):

실험: 그러나, 실시예 13 에서와 같이, 희생은 7 일 또는 21 일에 수행되었다.
결과는 도 16 에 도시되어 있다. 포스포로티오에이트 기준 화합물과 비교하여, 아카이랄 포스포로디티오에이트의 도입은 간에서 지속되는 작용 기간을 제공하였고, 이는 21 일에 보다 높은 조직 함량과 상관 관계가 있었다. 특히, 갭 영역에서 입체 정의된 포스포로티오에이트 연결과 포스포로디티오에이트 연결된 플랭크 영역의 조합은 지속되는 효능 및 작용 기간과 관련하여 추가의 이점을 제공하였고, 안티센스 올리고뉴클레오티드에서 입체 정의된 포스포로티오에이트 연결과 아카이랄 포스포로디티오에이트 뉴클레오시드간 연결을 조합하는 것에 있어서 현저한 시너지를 다시 강조한다.
실시예 17: 아카이랄 포스포로디티오에이트 개질된 갭머를 표적으로 하는 Malat-1 을 사용한 생체내 연구.
시험된 화합물 (서열 모티프 = SEQ ID NO 3)

실험:
시험관내: 마우스 LTK 세포를 사용하여 시험관내 농도 용량 반응 곡선을 결정하여 MALAT-1 mRNA 저해를 측정하였다.
생체내: 마우스 (C57/BL6) 에 1, 2 및 3 일에 3 회 용량으로 올리고뉴클레오티드의 15 mg/kg 용량을 피하 투여하였다 (n = 5). 마우스를 8 일에 희생시키고, MALAT-1 RNA 감소 및 조직 함량을 간, 심장, 신장, 비장 및 폐에 대해 측정하였다. 모체 화합물은 2 가지 용량 3*15mg/kg 및 3*30mg/kg 으로 투여되었다.
결과: 시험관내 결과는 도 17 에 도시되어 있다 - 플랭크에 1, 2, 3 및 4 개의 아카이랄 포스포로디티오에이트를 갖는 화합물은 시험관내에서 매우 강력한 것으로 밝혀졌다. 플랭크에 5 개의 아카이랄 포스포로디티오에이트를 갖는 화합물 #7 은 플랭크에 1 - 4 개의 아카이랄 포스포로디티오에이트를 갖는 것들보다 낮은 효능을 갖는 것으로 밝혀졌다. 가장 강력한 화합물 #1, #2 및 #6 이 생체내 연구를 위해 선택되었다. 생체내 결과는 도 17B (심장) 에 도시되어 있으며, 이는 기준 화합물로서 심장에서 MALAT-1 을 노킹 다운(knocking down)시키는데 약 2 배 강력함을 나타낸다. 특히 안티센스 올리고뉴클레오티드의 2 개의 3' 말단 뉴클레오시드 사이의 아카이랄 포스포로디티오에이트 뉴클레오시드간 연결의 사용은 동등한 5' 말단 보호된 올리고뉴클레오티드에 비해 현저한 개선을 제공하였다.
도 17C 는 생체내 연구로부터의 조직 함량 분석의 결과를 도시한다. 아카이랄 포스포로디티오에이트 뉴클레오시드간 연결을 함유하는 3 개의 올리고뉴클레오티드 모두 간에서 보다 높은 조직 함량을 가졌다. 디티오에이트는 심장 및 간에서 유사하거나 보다 높은 함량, 및 신장에서 보다 낮은 함량을 야기하여 PS-개질된 안티센스 올리고뉴클레오티드에 비해 우수성을 다시 나타낸다. 특히 심장에서 조직 함량은 화합물 1 에 대해서만 높았으며, 이는 향상된 생체내 효능이 조직 함량의 결과가 아니라, 보다 높은 특이적 활성일 수 있음을 나타낸다.
실시예 18: 시험된 아카이랄 모노포스포티오에이트 개질은 아카이랄 포스포로디티오에이트 연결로 관찰되는 이동성(portable) 이점을 제공하지 않는다.
시험된 화합물 (서열 모티프 = SEQ ID NO 1)

이 연구에서 본 발명자들은 ApoB 를 표적으로 하는 일련의 3' 또는 5' S 개질된 포스포로티오에이트 올리고뉴클레오티드 갭머를 합성하였다 - 백본 연결에서 황의 위치는 아카이랄 뉴클레오시드간 연결을 야기한다. 합성 방법은 WO2018/019799 참조.
상기 기재된 바와 같이 화합물을 시험관내에서 시험하였다 - 예를 들어 실시예 8 참조.
결과는 도 18A 에 도시되어 있다: 결과는 일반적으로 아카이랄 모노포스포로티오에이트가 화합물의 효능에 대해 불리하였지만, 일부 경우에는 화합물이 효능을 유지하였음을 보여준다. 이는 세포 함량과 관련이 있는 것으로 보인다 (도 18B).
실시예 19: 카이랄 포스포로디티오에이트 개질은 안티센스 올리고뉴클레오티드 갭머에 이점을 제공할 수 있다.
시험된 화합물 (서열 모티프 = SEQ ID NO 1)

이 연구에서 본 발명자들은 ApoB 를 표적으로 하는 일련의 입체 랜덤 카이랄 포스포로디티오에이트 올리고뉴클레오티드 갭머를 합성하였다 - 백본 연결에서 황의 위치는 카이랄 뉴클레오시드간 연결을 야기한다.
상기 기재된 바와 같이 화합물을 시험관내에서 시험하였다 - 예를 들어 실시예 8 참조.
결과는 도 19A 에 도시되어 있다: 결과는 일부 위치에서 카이랄 포스포로디티오에이트 화합물이 기준 화합물만큼 강력하여, 카이랄 포스포로디티오에이트가 안티센스 기능과 양립할 수 없음을 나타내지만, 이점은 화합물 특이적이었다 (즉, 이동성을 나타내지 않음). 안티센스 활성과 세포 흡수 사이에는 상관 관계가 없는 것으로 보이지만, 세포 흡수와 관련하여 유사한 그림을 볼 수 있다 (도 19B).
실시예 20: 아카이랄 포스포로디티오에이트 개질된 갭머를 표적으로 하는 Htra-1 을 사용한 생체내 연구.
시험된 화합물
모든 화합물은 서열: TATttacctggtTGTT (SEQ ID NO 4) 를 가지며, 여기서 대문자는 베타-D-옥시 LNA 뉴클레오시드이고, 소문자는 DNA 뉴클레오시드이다. 하기 표에서, 백본 모티프는 5' 디뉴클레오티드 사이의 연결에서 시작하여 3' 디뉴클레오티드 사이의 뉴클레오시드간 연결로 끝나는 (왼쪽에서 오른쪽으로) 각각의 뉴클레오시드간 연결에 대한 백본 개질의 패턴을 나타낸다. X = 입체 랜덤 포스포로티오에이트 뉴클레오시드간 연결, P = 아카이랄 포스포로디티오에이트 (*), S = Sp 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결, R = Rp 입체 정의된 포스포로티오에이트 뉴클레오시드간 연결.



실험:
인간 교모세포종 U251 세포주는 ECACC 에서 구입하였고 5% CO2 로 37℃ 에서 가습 인큐베이터에서 공급자가 권장한 대로 유지하였다. 분석을 위해, 15000 U251 세포/웰을 기아 배지에서 96 다중 웰 플레이트에 시딩하였다 (10% 대신 1% FBS 를 제외하고 공급자가 권장하는 배지). PBS 에 용해된 올리고뉴클레오티드를 첨가하기 전에 세포를 24 시간 동안 배양하였다. 올리고뉴클레오티드의 농도: 5, 1 및 0.2 μM. 올리고뉴클레오티드의 첨가 4 일 후, 세포를 수확하였다. PureLink Pro 96 RNA 정제 키트 (Ambion, 제조사의 지침에 따름) 를 사용하여 RNA 를 추출하였다. 이어서, cDNA 를 M-MLT 역전사 효소, 랜덤 데카머 RETRO스크립트, RNase 저해제 (Ambion, 제조사의 지침에 따름) 와 100mM dNTP 세트 PCR 등급 (Invitrogen) 및 DNase/RNase 유리수 (Gibco) 를 사용하여 합성하였다. 유전자 발현 분석을 위해, qPCR 을 이중 설정에서 TagMan Fast Advanced Master Mix (2X) (Ambion) 를 사용하여 수행하였다. 다음의 TaqMan 프라이머 분석을 qPCR 에 사용하였다: HTRA1, Hs01016151_ m1 (FAM-MGB) 및 하우스 키핑 유전자, TBP, Hs4326322E (VIC-MGB) (Life Technologies). EC50 결정은 Graph Pad Prism6 에서 수행되었다. 표에서 상대적 HTRA1 mRNA 발현 수준은 대조군 (PBS-처리된 세포) 의 % 로 표시된다.
결과:


실시예 21: TNFRSF1B 엑손 7 스키핑을 표적으로 하는 LNA 믹스머에서의 PS2 보행
믹스머 (13'mer) SSO#26 를 사용하는 TNFRSF1B 엑손 7 의 스키핑이 TNFRSF1B 의 인트론 6 - 엑손 7 의 3' 스플라이스 부위를 표적으로 하는데 매우 효과적임을 앞서 확인하였다 (배경 정보는 WO2008131807 & WO2007058894 참조).
이 실험은 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 연결 (PS2) 의 존재가 스플라이스 스위칭 올리고뉴클레오티드의 스플라이스 조절 활성을 추가로 향상시키는데 유용할 수 있는지를 결정하기 위해 확립되었다. 효과를 결정하기 위해, 모체 올리고뉴클레오티드 SSO#26 의 상이한 위치에 화학식 (IA) 또는 (IB) 의 포스포로디티오에이트 결합을 도입하고 하기 화합물을 합성하였다 (하기 표).
시험된 화합물: 모체 올리고뉴클레오티드 (SSO#26) 의 디티오에이트 개질된 올리고뉴클레오티드. 화학식 ((IA) 또는 (IB)) 의 포스포로디티오에이트 뉴클레오시드간 연결은 * 로 표시된 위치에 도입되었고, 모든 다른 뉴클레오시드간 연결은 포스포로티오에이트 뉴클레오시드간 연결 (입체 랜덤) 이고, 대문자는 베타-D-옥시 LNA 뉴클레오시드를 나타내고, LNA C 는 5-메틸-시토신이고, 소문자는 DNA 뉴클레오시드를 나타낸다.

실험:
Colo 205 세포 (인간 결장 직장 선암종) 에서 올리고뉴클레오티드 흡수 및 엑손 스키핑은 두 가지 상이한 농도 (5 μM 및 25 μM) 에서 짐노틱 흡수에 의해 분석되었다. 세포를 96 웰 플레이트 (웰 당 25,000 세포) 에 시딩하고 올리고뉴클레오티드를 첨가하였다. 올리고뉴클레오티드의 첨가 3 일 후, Qiagen 설정을 사용하여 96 웰 플레이트로부터 전체 RNA 를 단리하였다. 스플라이스-스위칭의 백분율은 엑손 6-8 접합부 (엑손 7 스키핑) 에 걸쳐 FAM-표지된 프로브와 액적 디지털 PCR (BioRad) 에 의해 분석되었고 TNFRSF1B 의 총량 (야생형 및 스키핑된 엑손 7) 은 엑손 2-3 에 걸쳐 HEX-표지된 프로브 및 IDT 의 프라이머에 의해 분석되었다. 포스포로디티오에이트 연결의 존재는 올리고뉴클레오티드가 엑손 스키핑을 도입하는 능력에 영향을 미친다 (도 20). 5 μM 에서, 가장 강력한 PS2 올리고뉴클레오티드는 엑손 스키핑을 2 배 넘게 증가시키고, 모체 (SSO#26) 는 약 10% 엑손 스키핑을 나타내고, SSO#25 는 20% 초과의 엑손 7 스키핑을 나타낸다. 25 μM 에서, 가장 강력한 올리고뉴클레오티드는 60% 초과의 엑손 스키핑 (SSO#7) 에 도달하고, 마찬가지로 모체보다 2 배 넘게 증가시킨다. 모든 DNA 뉴클레오티드가 포스포로티오에이트 개질 (PS) 대신에 디티오에이트 개질 (PS2) 을 갖는 올리고뉴클레오티드 SSO#22 는 모체와 비교하여 증가된 활성을 나타내고, 세 번째로 가장 강력한 올리고뉴클레오티드는 5 μM 에서 나타내고, 두 번째로 가장 강력한 스플라이스 스위칭 올리고뉴클레오티드는 25 μM 에서 나타낸다 (도 20). 그러나, PS2 연결 (SSO#16) 로 LNA 뉴클레오시드 사이의 모든 연결을 교환하는 것은 모체 올리고뉴클레오티드와 비교하여 스플라이스 스위칭의 효능을 감소시켰다 (도 20). 뿐만 아니라, 특정 위치에 PS2 를 도입하는 것은 엑손 스키핑 활성에 유리하지 않을 수 있고 5 μM 에서, SSO#1, SSO#9, SSO#11, SSO#12 및 SSO#14 는 보다 낮은 농도에서 유의한 스플라이스 스위칭 활성을 나타내지 않지만, 모두 보다 높은 농도에서 효과적이었음은 명백하다 (도 20). 이 실시예는 PS2 연결이 스플라이스 조절 올리고뉴클레오티드와 양립될 수 있고 또한 LNA 믹스머와 같은 믹스머 올리고뉴클레오티드 내에서 DNA 뉴클레오시드에 인접하거나 또는 인접 DNA 뉴클레오시드 사이에 PS2 연결을 도입함에 있어서 명백한 이점을 강조한다 (이러한 디자인은 스플라이싱 조절에서 특히 더 효과적이었음).
재료 및 방법
액적 디지털 PCR 에 의한 TNFRSF1B 엑손 7 스키핑을 검출하기 위한 분석

TNFRSF1B 의 총량을 검출하기 위한 분석
엑손 2-3 에 걸친 Hs.PT.58.40638488 IDT 분석
실시예 22: 포스포로디티오에이트 개질을 함유하는 믹스머 올리고의 안정성
모체 올리고뉴클레오티드 (SSO#26) 의 3 가지 디티오에이트 개질된 올리고뉴클레오티드를 S1 뉴클레아제 (표 2) 를 사용한 안정성 분석에 선택하였다. 선택된 올리고뉴클레오티드를 제조사의 지침 (Invitrogen, Catalogue no. 18001-016) 에 따라 1x S1 뉴클레아제 완충액, 및 10U 의 S1 뉴클레아제를 함유하는 100 μL 반응 완충액에서 30 min 또는 2h 동안 25 μM 에서 37℃ 에서 배양하였다. 2 μL 의 500 mM EDTA 용액을 100 μL 반응 혼합물에 첨가하여 S1 뉴클레아제 반응을 중단시켰다. 2.5 μL 의 반응 혼합물을 Novex™ TBE-우레아 2x 샘플 완충액 (LC6876 Invitrogen) 에 희석하고 Novex™ 15% TBE-우레아 겔 (EC6885BOX, Invitrogen) 에 로딩 하였다. 180V 에서 약 1 시간 동안 겔을 작동시킨 후, SYBR 금 염색 (S11494, Invitrogen) 및 ChemiDoc™ Touch Imaging System (BIO-RAD) 으로 겔 이미지를 획득하였다.
PS2 함유 올리고뉴클레오티드의 안정성을 S1 뉴클레아제의 30 및 120 분 배양에 의해 시험하였다. PS2 연결의 위치는 안정성에 영향을 미치며, DNA 뉴클레오티드 (SSO#14) 에 대한 PS2 3' 의 존재가 가장 큰 영향을 미친다 (도 21). S1 뉴클레아제와의 함께 30 분의 배양 후, 모체 올리고뉴클레오티드는 거의 분해되는 반면, PS2 개질된 올리고는 13'mer 을 나타내는 강한 밴드를 나타낸다. 또한, SSO#14 는 S1 뉴클레아제에 의한 초기 절단 후에도, 잔류 올리고의 안정화를 나타내는 분해 산물을 나타내는 보다 강한 밴드를 나타낸다 (도 21, 레인 5+9).
이들 데이터는 믹스머 올리고뉴클레오티드와 같은 올리고뉴클레오티드에 도입될 때 포스포로디티오에이트의 존재가 엔도뉴클레아제 활성에 대한 보호를 제공하고 놀랍게도 이는 본 발명의 실험에 도시된 바와 같이 올리고뉴클레오티드의 효능을 유지하면서 스플라이스 조절 활성을 현저하게 개선한다는 것을 나타낸다. 본원에서 LNA 및 DNA 뉴클레오시드를 포함하는 믹스머에 의해 예시된 믹스머 올리고뉴클레오티드에서 DNA 뉴클레오시드에 인접하거나 DNA 뉴클레오시드 사이의 PS2 연결은 엔도뉴클레아제 안정성을 향상시키는 것으로 간주된다. 안티센스 올리고뉴클레오티드, 예컨대 믹스머 (예를 들어 SSO 또는 antimiR) 에서의 사용을 위해, 따라서 인접 DNA 뉴클레오시드 사이의 PS2 연결을 사용하는 것이 유리한 것으로 간주된다. 이러한 이점은 또한 LNA 또는 MOE 와 같은 2'당 개질된 뉴클레오시드에 의해 (각각) 5' 또는 3' 플랭킹된 DNA 뉴클레오시드에 인접한 5' 또는 3' PS2 연결을 사용함으로써 제공될 수 있다.
따라서, 본 발명은 스플라이스 조절 또는 마이크로RNA 저해와 같은 점유 기반 메카니즘에 사용하기 위한 개선된 안티센스 올리고뉴클레오티드를 추가로 제공한다.
SEQUENCE LISTING
<110> F. Hoffmann-La Roche AG
Roche Innovation Center Copenhagen A/S
<120> Novel thiophosphoramidites
<130> P34610-WO-1
<150> PCT/CN2017/118043
<151> 2017-12-22
<150> EP18198487
<151> 2018-10-03
<160> 19
<170> PatentIn version 3.5
<210> 1
<211> 13
<212> DNA
<213> Artificial
<220>
<223> Oligonucleotide motif
<400> 1
gcattggtat tca 13
<210> 2
<211> 18
<212> DNA
<213> artificial
<220>
<223> Oligonucleotide motif
<400> 2
tctcccagcg tgcgccat 18
<210> 3
<211> 16
<212> DNA
<213> artificial
<220>
<223> Oligonucleotide motif
<400> 3
gagttacttg ccaact 16
<210> 4
<211> 16
<212> DNA
<213> artificial
<220>
<223> TATTTACCTGGTTGTT
<400> 4
tatttacctg gttgtt 16
<210> 5
<211> 13
<212> DNA
<213> artificial
<220>
<223> Oligonucleotide motif
<400> 5
caatcagtcc tag 13
<210> 6
<211> 20
<212> DNA
<213> artificial
<220>
<223> Primer sequence
<400> 6
caactccaga acccagcact 20
<210> 7
<211> 20
<212> DNA
<213> artificial
<220>
<223> Primer sequence
<400> 7
cttatcggca ggcaagtgag 20
<210> 8
<211> 26
<212> DNA
<213> artificial
<220>
<223> Primer sequence
<400> 8
gcacaagggc ttctcaactg gaagag 26
<210> 9
<211> 2138
<212> DNA
<213> homo sapiens
<400> 9
caatgggctg ggccgcgcgg ccgcgcgcac tcgcacccgc tgcccccgag gccctcctgc 60
actctccccg gcgccgctct ccggccctcg ccctgtccgc cgccaccgcc gccgccgcca 120
gagtcgccat gcagatcccg cgcgccgctc ttctcccgct gctgctgctg ctgctggcgg 180
cgcccgcctc ggcgcagctg tcccgggccg gccgctcggc gcctttggcc gccgggtgcc 240
cagaccgctg cgagccggcg cgctgcccgc cgcagccgga gcactgcgag ggcggccggg 300
cccgggacgc gtgcggctgc tgcgaggtgt gcggcgcgcc cgagggcgcc gcgtgcggcc 360
tgcaggaggg cccgtgcggc gaggggctgc agtgcgtggt gcccttcggg gtgccagcct 420
cggccacggt gcggcggcgc gcgcaggccg gcctctgtgt gtgcgccagc agcgagccgg 480
tgtgcggcag cgacgccaac acctacgcca acctgtgcca gctgcgcgcc gccagccgcc 540
gctccgagag gctgcaccgg ccgccggtca tcgtcctgca gcgcggagcc tgcggccaag 600
ggcaggaaga tcccaacagt ttgcgccata aatataactt tatcgcggac gtggtggaga 660
agatcgcccc tgccgtggtt catatcgaat tgtttcgcaa gcttccgttt tctaaacgag 720
aggtgccggt ggctagtggg tctgggttta ttgtgtcgga agatggactg atcgtgacaa 780
atgcccacgt ggtgaccaac aagcaccggg tcaaagttga gctgaagaac ggtgccactt 840
acgaagccaa aatcaaggat gtggatgaga aagcagacat cgcactcatc aaaattgacc 900
accagggcaa gctgcctgtc ctgctgcttg gccgctcctc agagctgcgg ccgggagagt 960
tcgtggtcgc catcggaagc ccgttttccc ttcaaaacac agtcaccacc gggatcgtga 1020
gcaccaccca gcgaggcggc aaagagctgg ggctccgcaa ctcagacatg gactacatcc 1080
agaccgacgc catcatcaac tatggaaact cgggaggccc gttagtaaac ctggacggtg 1140
aagtgattgg aattaacact ttgaaagtga cagctggaat ctcctttgca atcccatctg 1200
ataagattaa aaagttcctc acggagtccc atgaccgaca ggccaaagga aaagccatca 1260
ccaagaagaa gtatattggt atccgaatga tgtcactcac gtccagcaaa gccaaagagc 1320
tgaaggaccg gcaccgggac ttcccagacg tgatctcagg agcgtatata attgaagtaa 1380
ttcctgatac cccagcagaa gctggtggtc tcaaggaaaa cgacgtcata atcagcatca 1440
atggacagtc cgtggtctcc gccaatgatg tcagcgacgt cattaaaagg gaaagcaccc 1500
tgaacatggt ggtccgcagg ggtaatgaag atatcatgat cacagtgatt cccgaagaaa 1560
ttgacccata ggcagaggca tgagctggac ttcatgtttc cctcaaagac tctcccgtgg 1620
atgacggatg aggactctgg gctgctggaa taggacactc aagacttttg actgccattt 1680
tgtttgttca gtggagactc cctggccaac agaatccttc ttgatagttt gcaggcaaaa 1740
caaatgtaat gttgcagatc cgcaggcaga agctctgccc ttctgtatcc tatgtatgca 1800
gtgtgctttt tcttgccagc ttgggccatt cttgcttaga cagtcagcat ttgtctcctc 1860
ctttaactga gtcatcatct tagtccaact aatgcagtcg atacaatgcg tagatagaag 1920
aagccccacg ggagccagga tgggactggt cgtgtttgtg cttttctcca agtcagcacc 1980
caaaggtcaa tgcacagaga ccccgggtgg gtgagcgctg gcttctcaaa cggccgaagt 2040
tgcctctttt aggaatctct ttggaattgg gagcacgatg actctgagtt tgagctatta 2100
aagtacttct tacacattgc aaaaaaaaaa aaaaaaaa 2138
<210> 10
<211> 53384
<212> DNA
<213> homo sapiens
<400> 10
caatgggctg ggccgcgcgg ccgcgcgcac tcgcacccgc tgcccccgag gccctcctgc 60
actctccccg gcgccgctct ccggccctcg ccctgtccgc cgccaccgcc gccgccgcca 120
gagtcgccat gcagatcccg cgcgccgctc ttctcccgct gctgctgctg ctgctggcgg 180
cgcccgcctc ggcgcagctg tcccgggccg gccgctcggc gcctttggcc gccgggtgcc 240
cagaccgctg cgagccggcg cgctgcccgc cgcagccgga gcactgcgag ggcggccggg 300
cccgggacgc gtgcggctgc tgcgaggtgt gcggcgcgcc cgagggcgcc gcgtgcggcc 360
tgcaggaggg cccgtgcggc gaggggctgc agtgcgtggt gcccttcggg gtgccagcct 420
cggccacggt gcggcggcgc gcgcaggccg gcctctgtgt gtgcgccagc agcgagccgg 480
tgtgcggcag cgacgccaac acctacgcca acctgtgcca gctgcgcgcc gccagccgcc 540
gctccgagag gctgcaccgg ccgccggtca tcgtcctgca gcgcggagcc tgcggccaag 600
gtactccgcc gcgctcctgg gcagctcccc actctctcca tcccagctcg gacctgcttc 660
tgcgggactg gtgggcaggt tgaggggcag cgaagcgttg tggggtggcc agggcaactc 720
tcggggacag gcaggtgggc cccggggtgg cggatttccg cgggctgcct cggaaccgag 780
cttcgcgccc agcccggggc cggttctgcg cccagacgat gccagtacgc ccggcctgca 840
ctctggggct cgagacgccg ggcgaccggc catggagtgc cctgagggca accacacagc 900
gcggggaccc caggacaaat aagaggaatg ggggcataaa ggaaggagag aagttcagga 960
ctgggaattg gcgcctcgca gagcggcttc aggaccacaa gaagtcattt cggttgcttt 1020
ttcttctatt tacgtcctcc gtccccttta aaattcactg ctttgatcac gggaccgctc 1080
agtgaaaact gtatgtaact cttttggaaa ggaacagtgt ttgccggccc gccccggagt 1140
ttctccaaaa agtctacccc gagcagggaa cggtttggca ccgctctcgt ttcggcggcg 1200
ttgctgcctg tcttgctttc ctcgttttga gccagcccta caaaaatgaa agtggctcct 1260
tttgaataag ctgaatcggg ctttggatca cgaaatctgc agaggcggag aagggaccgg 1320
gttagtgatg aggaagaagt ctacccctct gttcctacag ccgcacacag gacctgttct 1380
ggcaggggag acggtggtga tgggggaagg agtggaatgg agcaatgtct aactctctcg 1440
cgggaccttc cggagagatg ctcctcatct tcaggcagag gccatgtgga aaaataatat 1500
cgagttcagc agcggccagc cccgcgttgt aggaaccaga cagcggggct tggcagtgcg 1560
cttgggcgca gccgtgccgc tgctgccgga ccccagtgct gcctcctcaa cacgggcagt 1620
gccaggagag gggcataggg gagcacagtg cagagggact ggtctagagt ttactttata 1680
ggaatatggt tcggtgtgac caactagggc ttagcatagt ttggcttacg tggacgggaa 1740
gatgccagag ccgaactggg tgaaattcga gattgcgtat ttcaccaaca caggagcaca 1800
gccctcggga aactcagcct agtcaggcag tagagagttg tcccggagag aagtgatcct 1860
gcagactcga gaaggggcat gatgatagca cacgtctgtt gagcacccag tctgtgtgcc 1920
gggtgtgtta cctctgtgac ctcatttggt caaacgagga ggcagttgct cctctctctc 1980
tctttttttt tcttaagaga cagggtctcc ctctgtcgcc catgctggag tgtagtggtg 2040
tgatcatggc tcactgcagc ctccgacccc tgggctcaat gattctcctg cttcagcctc 2100
ccaagtggct gggactacag gcggatgcca ccacacccag cttctcattc ccgttttaca 2160
gatagcggag ctaaggttga aaaacttgcc caaggtcatt cagctggaat ttaaacccag 2220
acagcctcat tcagaggagt cagcccagca cttaactcca agggtgtggg agaggggtca 2280
ggtgctgtaa atttcctggt gggctggacg tgcatccccc tcagagctgg gaacagcata 2340
cacaaagcct aagacttgtt tggaggtgaa tagatcagtg tggctgggga acgttttggg 2400
agggcagcag gagtgagcca ggctggtggc ccagagtccc agggctgaag aggctggctg 2460
tgccccgtgc cctgtgcgca gatgttcttg aactggagca actcaaagcc tagtgtagtg 2520
tagggctgac ctagcagtgg agtgcggaat gcatccaggg tggagagttt agactactgc 2580
aataatctgg gtgtgaggcg acaacattga aaaagcatgt ttttgtccaa aacaagccag 2640
ctgttactgg tctcgctgtt tgtggtctca tcgcacgggg tcctgagttg ctggcaccat 2700
gcgagccgcc taatttattg ctagtgaggc aagttgctta acaagttttg gagttggctg 2760
agtccctgtg tggaggaaaa caggtccccc attggccatc gggctcacag cgggcccccg 2820
gtgtaccagt gaggggacag ccacagaggg ataagcatgg tggctttgaa aggagggaga 2880
gacagagtgg gtacaatgct tttcttatcc ctccctcctt cttttgcaaa tatttattga 2940
gctctgtagg gtgtctgaca ccgtttgcat gtttgtctgt ctggcacatc ggaggtactt 3000
ggtacgagtg gattagtgaa tgaataaatg aatgaatgaa gacaaacggg aggtgcttgc 3060
gatacacagc cattctgttt ttccttagtg gaaggcactg ctttgctgcg ccccctctct 3120
ggatctcaca ctccaccctt gacttttcgg aggtgtttcc gaggacaggc gcctgggagc 3180
cagcagactt cattcagtcc aagccaggct ccaggactca acagctggtg cccacgggca 3240
ggtcacttga cgtcactgtt aaatgaggtg aattggctgc ctgctctggc tggaagattg 3300
gcgggagagt cactttagct gccatggaca tgagcctttt ctaggggtgc cacttgacta 3360
gaggcctgga gttggagcaa gtcatacacg gatctggaga cagagctctc gaggcaggag 3420
cgggtgctgc gatttcaaat attataaggt ggctttgtct ggggcagagc atgccagggg 3480
atgagaggta gaaatgtcat cagatcaggg gtccccaggg aggtgactag cactttgggt 3540
cacagtagat ctttggatag aggaacatgt caccattcaa aggaaagcac tttcatctgt 3600
aagctgttta ttgaatagac ctcagagaac atctctgctc accgctctgg aaatgaaggc 3660
aaatcatcta tttcagaagt caatgcactg gcagggtttg gatgggaaag tatacaattc 3720
agctagagaa caaagatctg tcatctccag ctgtactggt cagatgatta caaaaaagaa 3780
aggaattgaa atactaatag ggtactaata atgagggcta acatatatgt tgtgcttatt 3840
ctatgccggg tgcatactaa ttcatttgat cctccggaca gtcctatgag tgagtgctgt 3900
agtcttccct gggttacagc tgggcagcta agtcacagag aagtaccttg ctcaggactg 3960
gtggtcccac acaactggat ggagagcctc gttcataacc accatgctgt gctgttgaca 4020
gagcaacaga gattttaaac caaccccagc taagccccag ctaatagctg aaataaacag 4080
ggctccagat ggctgtggct tagagatgga acaggacaga tcacagcctt cactctgcag 4140
gctcaggagc ctgaagacaa ggttgcctcc agttgccgtc agtgcagccc tcactaaaga 4200
aaagcaaaaa gagccgaggg actgtaggaa ggctgtttcc aagccagaga tccagacaaa 4260
ctgctcttga agagagaaag cccttccaga ttcccccatg tcccaaaaga ccagccggga 4320
ttccggacct ctgctaaaac atggacaaga agccaggaac gagacctgaa acagacttcc 4380
caaacagcag aagcctcatc catttctcct gctagtacat cctccaggaa agcccaccct 4440
actccatgca gcagcccaga caagcttgga ggtctgcaag ctgcaggggt gcccagaaac 4500
tccacccctg gaggttttta ggatcgcctg ctcctggtct caccccagag cctctaaagg 4560
cagaggctgt atgtacatac ctggtgaaga accaagggct tagatggttg ctttacttct 4620
tggagccctg gaatgtttgt aaaatttact tttttttttg agacagtgtc tcgttctgtc 4680
gcctacgctg gagtgcagtg gcgcgatctc ggctcactgc aagctccacc tcccgggttc 4740
atgccattct cctgccttag cctccagagt agctgggact acaggcaccc gccaccacgc 4800
ccagctaatt tttttgtatt ttttggtaga gacggggttt caccgtgtta gccaggatgg 4860
tctccatctc ctgaccttgt gatccgcccg ctttggcctc ccaaagtgct gggattacag 4920
gagtgagcca ctgcacccgt gccaaaatgt actttattta ggtgactctt tcgtgggaac 4980
ctcaaacaag caatcattgc tagctgagtg ctgaccctgt actgagctct ggggagacag 5040
ggttgaataa aacaaagtca ctgcccacag gtaacttata ttcaatacaa tgggggaaaa 5100
tacaatcact gcttccctgg ggttgtattt ttccattgtt aaagtgggca gtttgctcga 5160
gagtcatttt cactattggc aattcaaata caccttttgt cagttaaaaa acaagtgtgc 5220
cagggacctg agcttcatct tagggcaggg tgggtggaaa catttgtgag tctccagctt 5280
ttagtcacct gaaacttgga aacttggagg tcttttgagc agtttatgag tctctgcctg 5340
ctctggtcgg ctgccttctt ttattgctct gttggttttg ctaaagagtt aaaatattaa 5400
ggcttcataa aattaggaag ttaacaagct caaaaaccaa gtgtttgagt tacttcattc 5460
cactgagaga gctgtaaatg ggttgcattg gaacttaaaa taactgcatt gagtaagtga 5520
tggtggcggg caccatgagc taactgtggt cagaagcctg atggcctccg ctttggggct 5580
ggattctccg tttggagctg tgtgatcctg gatgagtttc atgccttgga ttcagaaatc 5640
agactttcca tgagcttata tttcaagtga ataaatagct ctggtcaggc ttaatttgaa 5700
gaagaagtaa gcttggcagt gggtgagggt tccttggaag gccaactggg gcggaggggc 5760
tgagggcaag cggctctggc ccttcctggg gtgttacctg accaggtaac agctccctcg 5820
acctctcgga gcctcggcag tgaggggatt gggccagttg atctctgagg ctccttttaa 5880
ctagaatggt ctgggatttt tctaagaaaa caagtctttg aggaggttgt ggtcacctca 5940
ttcctaattt aaagcctggg gaggcttcct tatgagctac ttctttttcc taaattattg 6000
atggttaaag ccaaggctgg catcgaatag atgtgatcca tcttgagcct ggttgctttg 6060
tgtttcagct ttgtactggc tgctgaagtc cccgggagac cacaggggtg acatgttcat 6120
ctccaagaga tgagcttcca cgagactcat accccttgct ccttccctgg ggctccaagg 6180
cctttgggtc atctgaagtg agataccctt gtgtcatttc atcttttcct tctccacctt 6240
ctctgccgtt aaaaaaaaaa gaagaaagag aaaaatccta ttaatagaga aaccgagaag 6300
tgtagccatt ctgaatgtgt ttccaaaagg ctcctggaag tggcatggaa gttacagtga 6360
ttcagcacta cttggtgacg tgtgcctaga accacagggg gacattagcc aggacaacac 6420
gcctcaggac agaagtaagt ggctgcgaag aggcatgtcc atcactgccg gaaagatgca 6480
gagttcagtt tttggagtca gtgctgagag ttccatttct aaattcattc agagcattta 6540
tttaacacct actgtgtgct cagaagtgta tcaggtatgg ggactcagag gtaagggctg 6600
gtggcccctg atctcaaggt actcgtggta gatagtatga tgctcagctt aagggctggg 6660
cttctgaagt cggattgcca ttttctggat gtgtggtgtt tcttgggtga cttcatctct 6720
aagtctcagt ttccccatca gtaagataag agaagtaata gcagatacat acgtagctct 6780
tagggcattg cagaatggaa ggacctcctt atatgaaacg caaagcactg tgcctgatgc 6840
attgctagaa ctcaggcaat attagcgtgt tgtcattgtc atcatcatca tcatcatcat 6900
catcatcatc atcatcatct tcaaggcact gacaaaggag tcagctgtgt gggaggagtg 6960
ctgggacact cttgtctccc tggggatgag gtgggtgggt gggttaggaa atcttcacag 7020
agaaggaggg tgatgtgaga cttctgtccg ggagctgact cggaatttgc catctaatat 7080
gttggaaaag gttctctggg cagaggtatc caaagtcact ttgcctgtca ccctttgagg 7140
tcccagttgt tgcctatatc atgtgaccag tgtgtggctt ctcttgaatt aagagctgca 7200
tgtctggact gcctgggatt ttacagatgt catctcgtta actctccctg gagcttgtga 7260
cacccaggag atggcagttt atagaagccc tggcaccttc ttgaatgatg cttggtttgg 7320
tttctatgca ctgggaattc ctcacaagga aagatttgtc acatcttaag gaaggaaaaa 7380
aaggcaaatt tgggagtcca tggataccct attattttag attccaggac aaattgtcga 7440
ataagcacgt ttcataaaaa caatcctccg cagcatcccg tgacagcagc tggtccctcg 7500
ccacaggata attatgtctc cttgtgcaca caaaagtctc cgagggcata ttgttgtggc 7560
tggagtttct gataatttcc aaattgaaca acctcagtcc taatgagtca gaggcttgtg 7620
caatattttc aaacctcagg aacatctttt tcattagttg tgcaataaag atggtaggcc 7680
tatctctgtg atgagctgtt tttttttctc aaagtttgat gagattcgcc gtagaattcc 7740
ttctcacata gtcttgggca agattttacc cgatcttcca acacatgagt catctcatat 7800
cctgtgacta agaagagctg tctctttggt gccagttttc taagtgcagt caccacttga 7860
tggagacgga tggacacagt tgggattgcc caggcagatg ggcaatcttg ccagctagac 7920
ataggggagg gaagcctcaa tgttcagcgg tcacatctgc ttttctgtgg cacagagtga 7980
gctatacagg aatattgtat tctccaggac agttagggca gtgggaaatg tcatcaaaca 8040
gaacagtgac ccaaagagcc actgccactg ggtgctctgt gggagctggg cactgtgctc 8100
attgtgttat gggccttgct ttgttcttac cttgtagcca cccagagagg cagggcatta 8160
tccttgcttc ctagctgagg ccacagaaga ggctcctaga ggttagctgt aacttgtcca 8220
aggccagcca gtgcaaggag gcagagccag gatttgagcc catgtctgtt tcactcccaa 8280
actattcttc agatttcttt aagtcaagtg ttatttagaa atgttttgtt tattcatcaa 8340
atatttggtg ggtgtttcca gctatctttc tgttattaat ttctagttta attctattgt 8400
gggctgagaa tatattttgt atgatttcta ttctattacg tttgttaggg tgtattttct 8460
ggtctagaat gtggtctgtc ttggtgagtg ttccctgtgt gcttgagagg aatgtgtgtt 8520
ctgtcattgt tgaatggagt gttctataaa tgtcacttag gtctagtgga ttgatagtgc 8580
ggttcaggtc aactgtatcc ttcctgattt tctgcctact gatctatcaa ttcctgaaag 8640
agaagtgttg acgtctcctg agtctattct gaaacactga attgcggtct ccatgatgaa 8700
ccactagagt tagaaaacct gggtcctagc cccatttggg cctttgggat gactcccttc 8760
tgcctcagtt tcctcatcta caacaggggg acaatgatgc tgcctaggag acatcagcag 8820
gatactgtga aagtccagtg gcataagggg tatggaggag cttcgtcaac tcctaaagct 8880
tcagtgctag gaatcctaaa gcattgaaat ccaaagatat aaggaatatg aaggagtttt 8940
gtcaattcct aatgcttcag tgctaggaat cctaaagcat taaagtccaa tgatataagg 9000
aatatgaagg agctttgtca actcctaaag cttcaatgct aggaatccta aagcattgaa 9060
gtccagtgat ataaggaata tgaaggagtt ttatcaactc ccaatgcttc agtgctagga 9120
atcctaaagc actgaagtcc aatgatacaa ggaatatgaa ggagctttgt caactcctaa 9180
agcttcagtg ctttaggagt cctaaagcat tgaagctgta agagattagg acctctagtt 9240
ggcaattcca gactcttcca ggactcctga tagagccaac accaagaata gtgaagccag 9300
aaggatggaa atagtaaaat gcctcctggg tgtcaaagca tgggtctcct ctgggcatgt 9360
tctcttgtcc tactgagaca tgatagctct tggccaaagt gactgaactt gaccctctgt 9420
ttcaggaagg ccaaatgcag ggttcactac catcatgtcc aagggcagat gcgttggtcc 9480
agaacatcag catcccaatc attataccaa gcaaacagcc gtctctgcct gcaccgtgga 9540
gagcacacgc tcctcctggg gtggcctgca tcctgtgttc ttctcaggcc gactttctgt 9600
ttaatgtttg ctggtcagga aatggcctga gctgaggttc ttcagatccc agtctgacct 9660
ttctccacca gcatttgtgg ctctgaaaaa tatagcccag tgtggtttag ccccactgga 9720
tgaaacccag taggaaaagt ctgataatag cagaagacgc acaggaggaa gagtgaggat 9780
ttgagagcat ctgggaagga ccatgtgcct ggatatcgtt ctgtctgtgg gattctgtga 9840
cacttgtcat ttacagtctg ttcccatgga attctcatca ttggccaaac atatagtcct 9900
tctgtcctct gaaaaatatc attctgctcc gacctttcac acccatctct gaccacatca 9960
actccctgtt tgcatgcatc ttgtggatga aggacaccac tttacctgta aagacactgg 10020
tggcttccca aagccaccaa ctgacttgta gagaagacag aatcccagag tatgaaacct 10080
gagggtgaag ggtcctggca ggtcctagag ctcaaccctt cacttcacag gtggggaaac 10140
tgagggagcc aatgggaaca tgactctcac aagctgcaca gctcatctgt aggggccagt 10200
gtggagtctg tttgtcctga gacccagggc tgagcctttg agccctccgc atctcagccg 10260
catcctcctg ttggagcagt taggtgtttg ggagaggcca cggtccatgc tcatggtttt 10320
cctgtaaggc tggagaaaca ggccttgttc ccttagtctc tctaatcaaa atgaggttgc 10380
agaaaaccct tctccctact tctccctaaa ataatttcct tgggttagaa gatgactaaa 10440
agactattca tccgatgact gatgtctccc ttcaagagtt ataagcacat ataaatgcct 10500
ttgaatggta attataataa ttttgctgaa gggaaaatat cagtataaat atcatggtgg 10560
acacatggaa tgaggactga gatgctttca tgtcttttca gctgtggtta gattttcttt 10620
aagcagaata tacaagtttt tcctctccta gcataaggac tctttttttt tgtatctttt 10680
ctctctactt tttagacatg atggaaaatg catttataca tttgatgaca tattgtacta 10740
tctcagttgt ttaaaattat aaatgtaatt taatcatatg aaaaattaag aaaagaagat 10800
tcatatttca ccatcatctc cccagaaata tcatttcttt attactatta ttattattat 10860
tattattatt attattatta ttattatttt gagacagggt cttgctccat cacccaggct 10920
ggagtaaggg gcacgatctt gactccctgc aacctccacc tcccaggttc aagcagttct 10980
catgcctcag cctcctcagt agctgggatt acaggcctgc accaccacac ccagctacct 11040
tttatatttt taagtagaga cagtttcgcc atgttggcca gactggtctc gaactcctgg 11100
cctcaagtga ttggcctgct tcagcctccc aaagtgtggg gattacaggc atgagctacc 11160
atgcctggcc taattccatc atttctgtcc caagtgttgc caccgtttgg ttaactgttc 11220
ccctgttcac atccatttgg gccaaggttg caatgttaaa caatcctgag atggacattt 11280
tcatgtttat ggctatttct gtatctaggg tcattctctt aggagaggta ctaaggagta 11340
caaaaactgg gaagaaggat atggaatttt tatggatctg gtataaattg ccaaattatt 11400
ttccagaagg gttgtagcca tatttgttgc catcagctct agaatttcaa cctcgtaagt 11460
cactgaaaga aattctccca aaatcaatcc ttcaggaata atggaagaag atggtgccaa 11520
accccagcca ttctgctcac tgttagattc cttttttggt cttacaggtt acttttattc 11580
tcaggttgat ggctcttaga gttgagcaat gtttggggta gaataacgag cacttttaaa 11640
acttggttct acctggggag ggggtgagtt gtgatcacag acagtctcac ctgggagggg 11700
cttgggtgtt tgtcggcttg tccttctaac actcgtgtct caggcgagca gcctgggacc 11760
agtgaggtga cctgaaggct ggaggtcaca agctaagagg cgacagagaa cccaggtctc 11820
aggaagccca gcccagagct cgctgcactg agcctctcgg atgccagctc tgtccaggat 11880
gcgggaggag gccagactga tttggtctgt tttgaaaagt gatgaaaata tttattcaaa 11940
tgttttgtac tcataggcag aagtataaca ggagctgcat atacaaaatt attttctagt 12000
agtcacatta aaaaagtaaa aagaaagaac acgattattt ttctttttaa aacagcttta 12060
ttgagagata atttacatac tataaaattt acccctttaa agtgtacaat ttgctgttct 12120
tatatattca caatcatgca cgtatcacta ccagctccag gacactttca tcaccgtaaa 12180
aagaaacccc gtatccatta gtagccaccc catacttctc ctctgcccag ccctaggaaa 12240
ccaccggttc attttctatt tctatgaatt tgcttattct ggacatttca tataaatgga 12300
atcaaagaat acgtaacggg cttctgtctc ttagcataat gttttcaagg ttgtccacat 12360
tgtagcatgg atcattattt cattccattt tatgattaaa aatatgcctt ttaagggata 12420
cagggagacc agacgtctat tttatctccc ctccctgatg gggaatccta atttcagcct 12480
ggaaagtcac tgcgaaagtc taaactgcag aggtgatact gtttccactg gaagaaactg 12540
tagcacctga ctcaggaagc cagcattaaa accaagaata ttctatatgg atggggatta 12600
cgcactgaaa ggaaaacatg aggaaatgca cttttcagat ttattagatc atagaacttt 12660
tttggagctg gaaaggatgt cggaaaccgt ctagcctacc ccctcatctt accactgagg 12720
taactgaggc ccaggaaggg gaagtggctt gttttgggtc cgggaccact cttcatttct 12780
tatttgagcc aaagcttcct tctggcgtct gtctctgttt cacaagttcc cctcgcatgg 12840
gggctgggta ctgcttggaa gaactggctt cttccttgat acaggggctc gttcaccatc 12900
acctccctcc ctcacgtctc ttctgcctct ctgcagcctc aggccctcct cctgcaccag 12960
gggggcagac tcaacccggg tgggcactgc ctcccagtcc gtggccagag gctggagggc 13020
tagggagact gaacagcccc ggcagctcca gacataacaa cctatgttga ggagtcaggg 13080
caggaagcga acccagctga gaaatctgcg aaggtcagga ccagagccag acgcttatca 13140
agagcaaagt taatggtttt tgtgaaccga gcagtcagct gtttccccga agataataat 13200
agacacatca tgttgggcat tcaggaggca tctgaaaaaa aaaatgtgca gtggaattga 13260
ttggaagctt ttccctaatg cataaaatag gccagaaaag actatcaaat gtaacagcac 13320
cgatcaaacc caatagatca agcaaggact gaaaaacaca attttttttt tctttgccag 13380
tgagtctgaa aagtgatttt caatgacagg cgcctttaaa catagacaac ataaacaaca 13440
acatagttgt tctggaagag gcatcttttc ccagtaaagc caaagatgca gatctaggct 13500
gtgcttgtga ctgacagcac agtgaggggt tcacagccag ctggccaggt gccccccgaa 13560
agcacatttc gaatctactc tatttgagag agactgcctt agccttgttt gggtaagtct 13620
tcctccttca cttcacctgc cacagacttt tccaggcacc atctgctgca gtcttggccc 13680
agcccctgca acagttactg ctcaaggcac ccgggacatg caggacgggg gagcagcctg 13740
aggtctggcg tccggcgagc ttttcccact tggagccgtc tgggagactg tcccggaaag 13800
agaggggctg ccaacacttg gaagtgccaa tgtgtgctgc aagtcgaggc caggctcccg 13860
gctcccccgc ctcttcctcc ttgattcatt aaaaggaaag aaagaggcca cacgaaactc 13920
tcctgaattt catttctttg tttctatgca aaagacagag cgtggtcatt catcattcaa 13980
attttagcct ttttaaacaa ataataattc ctgcttgtga attcagtgta ttttaacaag 14040
agtaggtctg agggccgttg gccgtgtctt tccttagatt tgcagacagc ggccctgatg 14100
gtgcataggg tttcaggttt cctttagacc tcagctggct gcctgggcca ccacttagca 14160
atgccattgt ccttcctgtg cattttcttt gcagaattcg aggaaatcca gtcgcacagg 14220
cccctctgtg cccatgtccc cggcgccctg gaatgtgcag taccagcagc agcgattaga 14280
atgggggtct ggtttcccgg aatgtgcaag gtctggcttc tgtttctgct gcctccatgc 14340
cccagaccag tgctgggccg ggctctgggc tggagccgtg gctgacaagt ttccttggaa 14400
tttaatggag cgggccagac agcatgcagc cactcaaact gaaaacctgg gaaagaaatg 14460
agtgttgtgg ggcagctttg ctgcattcac tgggtcatat atgcttcttt ttcttttcct 14520
caggcaaccc ctcttgcaga caggaggccc cctccccttt cgcttcatgc ctcactggcc 14580
attaggaacc ttttaaaact gatttctctc ctgaccctca gagagaacat agtccaagtt 14640
ccctggagga ggaggaagcg ctctgtgttt ctctgcagtt cacggctcag ttaaatgcag 14700
cctacgtgct gtctttcccc actcctctgc ctgctcccgt tgtgcttctc atgatcattc 14760
tcaaattcag cgagaaacct cacaaaggga gcttttctta gggaagagtc atccttggcc 14820
tcccgaatgt ggaccagccc ctctccccag ctgcacagca tcaggttagt taaccacctg 14880
cctccatctg ggtcctgtct ggacaggcct actcacacct gctgcaggca tccaacttgc 14940
cctcaggtgc ctgtggctcg tccagagggg tggagcccac attccagtcc tgacaggtaa 15000
agttcagtgg cggggaccct gcatttagtg taaagatcaa tattccaggt cctctcttcc 15060
tgccacccag cgactggccg tttgcaggca ctcggtccca gttgtcctgg gcctgcagcc 15120
cttgcattct ctctgctttg tctctgctat tgcacccctg ccccatcaga aatgcaggtg 15180
ggggggcctt ccgctgggac agtgagagac tgggtagtaa ggggagcgct agagggatgg 15240
ttgcgcttgc atccagccct gactgcattc gctctccccc gcctctctgt gaaggtgctg 15300
agctgtgagt ggaaccaagt ggatgagagt ggccttgggc acctgccgat aaatttcccg 15360
gtgtgtcttc tcctcctggg agtcccatct ggatttgggt ctggatttat ttattcagca 15420
agtagcctct ttatagttac tttttttttt tttttttttt tgagatggag tttcactttg 15480
tcacccaggc tggagtgcac tggcgcaatc ttggctcact gcaagctccg ccttccaggt 15540
tcacgccatt ctcctgcctc agcctcccga gtagctggga ccacaggtgc ctgccaccat 15600
gcctggctaa ttttttgtat ttttagtaga gactgggttt cactgtgtta gccaggacgg 15660
tctcgatctc ctgacctcat gatctgccca ccttggcctc ccaaagcgct gggattacag 15720
gtgtgagcca ccatgcccgg cctgtagtta cttttaattt agccatgctc ggggctgaag 15780
gggatgccaa agaaatataa gatgagcccc tcagacggct aaagatgaag atgaggcctc 15840
cagtatgtac ctcccacata caccccagga aattctgggt gtcactggat tctggacctc 15900
ccaaaagctg ctggcacctg gaggatgggg ccccgaggct ggacctcact cctgctgggt 15960
tgctggactg ggaaagtact gatggcagct gaggagtgtg tcccagactt cactgagcca 16020
ttcccaaaga ttattccaag ttctcctgac actgcactgg aggcctgctg tgctggcctt 16080
ctttatttac agtttctgac tggtgtctag cagccctgcc agagagagcg gcagtgtgtc 16140
tgcaggcgac caggagaaat gtctcaggct ttagagcagg actttgagca catagctgtg 16200
ggggcccagc aggctgtctc ctgcacggtt acttctcctt gtcctttcat ggtcgagagg 16260
ttgctgcctg gcccttcaag tgaggatggg acatgctatc cattggcctt aatttccaac 16320
ctctgcatga tgcattttat gctcctgcct ttgaaagaac ttttattttc ttgtcattta 16380
tgcccagacc ccacatggca gaaggaaggg aggctgggac aggggaggcg gataagctgc 16440
cgctgacaga cctgcccagt ttcttagctc atcccggcct ccatcctggt gagcagacac 16500
tggcccaatc cagccatatt tttggctgag tttctgtctt cacatctcat ccttaaccct 16560
gaatcctggc catagttggt actgggttgt attcttattt gtaatcttta aagtaggaat 16620
acctttgctg gtatttaaag tggaagaaat caggtgaaga atcacaagtg atttgcaaac 16680
tggaagagac attagaatgt aaatgtgagg aagcgtcagc atgaggggct tgcctgggct 16740
gcacagcttg ccttggctgg agtatgcact gttctggcat tgcagagagg atgggtacct 16800
tgcctccctg caggtggggg actgtatcag cccccgcaga ctgctcctgg gctcctgagt 16860
ttgacagatt tttttttttt ttttttgaga cggactctca ctctgttgcc caggctggag 16920
tgcagtggtg cgatctcggc tcactgcaag ctccacctcc tgggttcacg ccattctcct 16980
gcctcagcct cccgagtagc tgggactaca ggcgcctgcc accacgcctg gctaattttt 17040
tgtattttta gtagagacag ggtttcaccg tgttagccag gatggtctcg atttcctgac 17100
ctcatgatct gcctgccttg gcctcccaaa gtgctgggat tacaggcttg agccactcgc 17160
ccggctgagt ttgaccagat taaggcagca tctccagtgg cacctgagca gctcctgaga 17220
tgcttttctg tgctaaatct ggatttgggg tattaaatca aatgaatttg aaatgcaggc 17280
acagctggcc ccatgggcat ggacctgtgc agtcacacct tgccccgtgt tcagaagggt 17340
gctgtgcctg ttttaatgct ctgctgttgc tctcttgaga ttcttaataa tttttgaaca 17400
aagggcccca catactcatt ttgtactggg tactgcatat tatgtagcta gtcttgaatc 17460
taggacagtg cattaaaatg ccattgattg gatcaatctg ctcttgcaac tgatttgaat 17520
tttgggaaca tgctgtttcc tgtgaataaa ggaggattca tttcttttcc ctcgaataca 17580
ctgcgttctg ttttccaaat tagctctacg tatcaactca gctgagaaat tggaagcggg 17640
gattgttctg gctggaaggg aaggttagat tgttaatcct gcatcctggc cctgatctca 17700
ccgagtgtga agcatgttcc cacaatggtg tgggctgcgg ggggctggag gctggctgag 17760
aaggtgggga ccaaggaggg aggctagcct gggagccaga cagatggggt taggctcttg 17820
cttttgccac tcgccagctc tgaggcttag ggcaacatga tttaattctc tgatccttgt 17880
ttttttcatc tttctgtaga ctggtgatga gatgcaccct gcaggcttgc aggcttgcag 17940
gagtaattaa aggtaatatt tgtgcctatt attgggcttg acatatagta gatgctctac 18000
aataaataga tcctattatt cttattgata atattatttt attgctaaca ttgaaggttg 18060
ggtgggattt gactagctgg aggcgaggag aatgagatca tccaggccgg aaggaaaaga 18120
gacatgaatg cagggggatg gggtggagca ctttggaggt gtggggagag gtctgcaggg 18180
tgggagttgt gcattaagga gtcgtgggga gagtggagga atcagtgcca catggtgaat 18240
gagaggggat cgtgggcccg aggagatggc gatggctgcg gggatcctgc aggaagttta 18300
tgtgccccaa agtggcatta tcagttaggg ggagacactg aagacagagg tgaggcctgc 18360
ctgaattagc gtagagtggg attcttggaa gcttcagaag cttgagaaga gccacttgga 18420
ggtgttgaaa tgcacctggg agggacgtgg ggacccagct ctgggctgag agctgggaga 18480
cggaaacgca ggtgaccttg gccttgaaga tggggcatga tatttagtgc tttatgtgca 18540
atctcaccta ggactcccaa gccctttgga gtaggtgata ttagctccgt gttacagaaa 18600
gggagactga ggctgaagca gggacattca tgatctgaag tcacacagct gtacggggca 18660
gaagtgggca tggaggcatt aacttagagc cgaaaggtgt gacctttctt agtgtggctg 18720
gccccacggg gaacgtgtgt gggttggagt acaacttggt gttcctaccc atcccagatg 18780
ctctgcgttt gtgaacccca gttgccacat cagggcgggc gagggcagga agctctgcag 18840
ggagaaggga caagggacag agccaagaac aggggcagtg ccccagggtc ctgcaggggc 18900
aatgaagggg gttggcacac ctgggttagt tgctggccag tgtggggaga gagctggcct 18960
gggagtctaa tgggaatgcc agggaaagct gccttggtcc cctaaagtga agcccccatg 19020
ctggccatgg agtgttggtg attgagggtc cctgctagtt gtctggccga ggcagcatgt 19080
cctataggca tagctctggt gtcctgctgg cgtggcgtga gtgcccctca tgctgggagc 19140
cagccctgtg ctctggaggg aggtggtggg aggacaaggg acagtgggac ctgccacctg 19200
agcaggaatt ggcaccttct cccactggca ggtccaggtt ttatggaatc tgaaacttgt 19260
acaattcagt ataccctctt caagaaaaac acccctcaaa attatgaata taacattagg 19320
tatgaaacta ttattgatat agattgaaaa aagaaaatgc ccaaaatgac aaacttcaga 19380
aaatagacaa atactgcaaa catcacaaaa tcagaaaaat aagattaaaa aaagctaact 19440
gctgaacact ccgtcatctt gaaaatgccc ctctctcctc ctctattttt tggctgtgaa 19500
ctctttgctc accttttcat gtgacaatgc ttttgtaata tttcctacag agaaaataga 19560
ataatttatt attactttta ttgtttttgg attattatta tgatcaattc aatatttttc 19620
tgctacccac acactcactg tcttctgtcc aacctctggc ctgcaccagg ggaaccagca 19680
gtttcccctg ccatagggtg tccctggaga ccacacatat agcaggatag atatagcaat 19740
ttaactagac acagaaggga cttcaaagcc acaaatatat ctcatttaac ctgaacaaaa 19800
tgattatcca gttttacttt tcccttagcc tcttccccca aatgctggca gccaccctga 19860
tgggatagat gtgtgacaga gggcaagaga ccgtggcccc aaccagctgc agcttcactc 19920
tttcatttct gtatactctc tacaagctgt gatgatagca ctttgctagg gcccctcaca 19980
gggcagatgg agggctccac gctgaagctt tgtggatgtt tgctgtctat ccacctctgc 20040
tccttgtgcc tatgcaggga ttcaggccca accactgcag agagcccaag agcatcaggc 20100
agaggttccc aaactgtcat gattggtggc acctttagta gttgatacgg tttggttgtg 20160
tcctcaccca aatctcatct tgaattccca catgttgtgg gagggacccg gttggtggta 20220
attgaatcat gggggcagat ctttcccgca ctgttctcat gatagtgaat aagtctccca 20280
agatctgttg gctttataaa ggggagtttc cctgcacaag ctctctctct gactgctgcc 20340
atccatgtaa gacatgacat gctcctcctt gcctcccacc atgattgtga ggcttcccca 20400
gccacgtgga actggaagtc caataaaacc tccttctttt gtaaatcacc cagtctcagg 20460
tatgtcttta tcagcagtgt gaaaatggac taatacagta gtgcagtcat tttttcatgg 20520
tccccagtaa ggccaaaaaa tacccaacag ttccatttat caattagtgg aggccaaaca 20580
atttgataag tatttgtgtc cctataacac agtggtcatt aaaaaaagac attttaattt 20640
cattattcaa taagcatgat tacttatgaa tgggatatgt gcacctgttg ggtgtcacat 20700
gacctttcaa atcttggagt cagattggac accaccatgc ccatttccag ttcaactctg 20760
atttttgtgt ggtacatgct ttttatcaca gtgactgcca gaaatccaac ttcatatgga 20820
atcatgaaaa gggatgtagt gtgatctgat ttcaaaacta tgatcaatct agagctagtt 20880
tacaaggtgt ctaacagtga tcaagtatca ctgtatttcc ctagaaaacc tgaaatatcg 20940
atgaattttc tgtggcactc tggggtccct tggggcacac tatgggaacc atgggattag 21000
gaccataagg atatgatttt ggcttcttcc tgcctcagat ctaatcttta cctggcattt 21060
ttgccttaaa gatgaaagaa gcatacattt tgatgtattt aaagcacata ttcggccagg 21120
tgcggtggct cacacctgta gtcccagcac tttgggtggc tgaggcaggc agatcacaag 21180
gttggaagtt tgagaccagc ctgaccaaca tggtgaaacc ccatctctac taaaaataca 21240
aaaaatagct gggtgtggtg gcatgtgcct gtaatcccag ctactcagga ggctgaggca 21300
ggagaatcac ttgaacccag gaggcagagg ttgcagtgaa ccaagattgc accactgcac 21360
tccagcctgg gctacagagc aagactctgt ctcaaaaaaa aaaaaaaaaa aaaaaaagca 21420
catattcatt ttgtgcttat tcttttgaga gaaacacaga taaaagccta tcctttaatt 21480
catactcccc atactgtgat tttcattttt actgcaacaa attttgttca gtgtgataat 21540
gaatgtcaaa cacttaatgc cttgctcttt tcagtaacat gacatattgg agaataatga 21600
ctgaagctta tctacactgc ctacgtctgt tttcttccac cttgaaagaa gttgttgaaa 21660
gtaattaaga agtattatgt gtaaaactcc agggatgatg tgcttcaagg aagcaacatt 21720
tatgaagttg tgtgcttgac tagtagttta taaagaggaa agacgaatca tttattgtct 21780
tgggattgaa tcttggcaat ttttaaacta taaagttaca ggaaatgttg gctgctctta 21840
atgggccatt tgttgtgtta aaaatcagta atgagaaata tttactaggt aagtggaaag 21900
atccatctct ataaattgtt gtaacttacc attttacaaa tcttagttac tcagtttttc 21960
tgcttaaaaa tgaaatcatg tagcactgta taagtcattc agttttttat tttggagaat 22020
tactctggat tgtctaggct ctgtgctctc cacatatatt tttgaaatag tttgtgaatt 22080
tctacaaaaa ctcctgctca gaattttcac tgagagtatg cttaatctat gggttaattt 22140
gtgagaaatt gatagcttaa caatagtgaa tcttctgatc tacaagtgtg gtatttctct 22200
ccatttattt aggtcttctt tattttgata gcgttttgta gctttcaatg tacagatctt 22260
gcaaatatct tgttaaatat ttccctaatt acttgatatt tatttttgat gctgttatag 22320
ttatatttta aaaattttga ttccaattgt tgctaataca tagaaatgaa attatttatt 22380
gacctcttat cctgtgacat tgataaacgc agtcatatat tcgtagattt ctagaatttt 22440
tctatataga ctatcatata tatcatctgc aaataaagac ggttttacat tttcctttcc 22500
aatctctatg ccttttgttt ctttctcatg cctcattgtg tggtccatta ctgaacggca 22560
gccagttcca gctttctgtt caattaagga gcaggtaaaa tggccaggcc ttgacctttc 22620
agggggcttc ccgtcctcat tgccttctgc tgcctcagtt ctggcttaac agaacagtgt 22680
ggggaggagg catggtcctt acctactagg gcgttacttg gccttcttca ggttggttgc 22740
ttcgtcaggt ttaagagctc acctgggctg cagttcaggc taggttatct gctgacctgg 22800
ccctgtctcc cttctgtagt gtctgtgggg tacccttgta agctagggag aagagacaca 22860
cgtgaaggcc agaaaaaaca gcctgccaca cagcttccct ggatcatacc ttcgcagtga 22920
catgacgacg tcgttaggag gcgccgaggt ggctgagtgg gtctccagac acctcccttt 22980
acctctctgc tgtgccactg atgtgtgact tgcttacacc tatgcagagc tgccactgag 23040
cagcactgtg gccagtcctt tggattttct tctttctaaa ttgtatgccg tggcttgatc 23100
aagcatttca tatacagtag atcatgaaat cagcatagaa aacacattga ggtaggtggt 23160
gttaccacat tttatggatg agaggctaac acttggagga gtcaggtaac atgtccaagg 23220
ccacacagct agtgagtacc ctgctgaggg tcacactctg gtccatctga ggccagagcc 23280
tgtgccagcc ttctcctcat gctgatagac gaggaaacag aaagaaggag cagtggacgc 23340
ccccaccctc tgtcccctga accccttgga gagtaggcag tggcagagcc agcctgggcc 23400
catctatggg aattctccat cgggattgac tcctctggaa ggaagacagt tgacccacag 23460
ttgagatcac agcagatggg ccagccaggg tgtctgtaga ccatcaggca gtggccactc 23520
catgtagttt aatggacaag cccttttaat ggaacaggaa tctaacactg aaccaagctg 23580
cttttagaca cacttttatt cctcactctg aaatggcgtt tggacaagcc aaatatttct 23640
tcttctttca gttgacattt tgtccatctt tgaactgtta gttgatgctt cttctgttta 23700
gttattcctg ttctattttc ctgttgccac tagtccaccc agggatggta agaatggaag 23760
tcaatggttg ctttttcatc tgagatgcac cacgaaggct tgtcagtcag ccttgtcata 23820
tggtctgtgc tcccactgct ccttctttct gtttcctcat ctgcagaatt tggagagtcc 23880
tggacctgat ctcaaatttc acatgttatt tatcttcctg cagcacgctg gggagaggaa 23940
gagacaggga catagaaggt tggagctgga acagacttca catctcattc cagaggcatt 24000
tggtccatct tacagatgag gaaatggagg ctgctcagtg gactgaggct ggaactgggc 24060
cttccagtgg ccaggccaga tcctccttga tctcccttgt tgctttcctg gtgggaagac 24120
cctggaacca ctttatgtga ctgtgtgaga agggaactgc ctctcatttt acccagcaaa 24180
atccaccttc aatccatctt catttttgcc cctggtgtgg gcaaattctc ccatacctaa 24240
ttcaggaagc cagaaagagg aagtgagtta atgatcctta gtgggaaggc gctggtaatg 24300
gtccttcttg tgagagtttc tgaaacacca cgctgtctct gtgttctggc ctggctggag 24360
ttaaacctct tcttggcctt tccccaggaa gctggtctga ggaagcccag atgcgtttgt 24420
ttacagctgt ctggtgacat tcgccaggct ctgttttcag aaggaacatt tccattccct 24480
tatttacacc tcccattgga gtgctcgggg ggacacacca attatttgca actacctgga 24540
aacctaggag ggtagcagat ctgtaggagg ccagtgttga agtgagaagc tgtagatctg 24600
gtgacactgt gggcttggga gggcttgccc agatctgtta cttatactct ctattaagaa 24660
acttcagtgt ccatggagaa gttatttaaa gtctgcgagc ctcagtttcc ccatatataa 24720
tatgggaagg atacctgatt ttcctattcc acatgaaggt agaaaaaatt aaattaaggc 24780
agccaatgaa agggttttga aagcaaaaat aataatatga tactgttctg aatttgttaa 24840
attattcttc caagtagttg cagatctttt tctgtacctt agaaaaaaac catgctatgt 24900
aaaaggagat gattccaatc tttaaataaa gcaactcaga ggtcaggggc taggacagaa 24960
aacggccctt tgttcacaga agcgctctca cttccaagaa agcaagcgtg ggagaggcag 25020
gtggtcctcc cgatgtccct gtgccccatg gtgtcaagct gggttactat ggcccttcgt 25080
gacccagtgc agcagggatg tgggaaccag tgggtgtgaa gctgtgacgg gtcacaagag 25140
ggctgggacg tctcacagct tttacttata gcctagagcc tggggaaggg ttgccactct 25200
agtgatgaga gaggcgtgtg tgtgtgtgtg tgtatgcgtc tgtatgtatg tgtgcatttg 25260
catgtatata tgtgtgactg tatgtatgtg cacatctgtg agtatatgaa tgtgtgtgga 25320
agtgtgtata ggtgtttatg tgacagtttg tgtgtaaatg tgggtgtatg tgtgggtgtg 25380
tttatgcatg tacatctgtg ggtgtgtatg catagtgtgt atgtgtgagt ttgtgtgtgt 25440
gtgtgcattt gcatctctgt gtatatatgc atgtgtgtta ggggcaggca cacaggcctg 25500
ttggtaaatg agacacaaaa tacctacaaa atacaaaatg tgagacagga aatacaagcc 25560
ccagttactc atttttcagt gcaacagaca taagattacc atgtgaaatt gctatgaaag 25620
tttccgaaag cttcctgtca attcgtagtg agcagctagc agaggagtgc gggtccctgg 25680
agcctgcttg tgcaacgctg agctagtcca agggggaaga atggggtgca tggctctcag 25740
ctgcagacca gcctggaacc tctccagcct gctttagcag agacttgtta agaggtagca 25800
gcaggtggca agattaggag ccggagtagt aggctaaggc tgcacttcca gggacacact 25860
gcctctgcca ccacccgtgc cacgaaaatg ggagcccagg accctgaatc tctagcagtc 25920
cgtttctgaa tcagttacct tgggtatgtg cctctggttg atggaaacta acttgtagcc 25980
ctgctgggtg agagcctcac atcgggacat gtgacagctt tgttgaaagt agctttggaa 26040
acgcccacca cgtggggcca ctcactgtaa tataaacggt catgcatcac tgagcaacag 26100
ggatacgttc tgagaaatgc gtcgttaggc gatttcatca ctgtgggaat gttacagagt 26160
gtgcctacgc aaacctagat ggcagagccc actccacacc taggccagat ggcagagcct 26220
gttgtttcta ggatgcacgc ccgtacagta ggttactgta ctgaatactg taggcagttg 26280
taacaatggt gagtatttgt gtattcaaac atagaaaagg tatagtaaaa acaatggtgt 26340
tatggtccgc ggctggctga aacgttatgt ggtgcatgac tgtaggtata aagcattaca 26400
gttgtttgat ttttctcttt ttctcaccca cagtcttaag gcacctctta tgccttttgt 26460
ctgggatgtc ccgggcaggg ttggaacgtg tggttaaggc atggcggaaa ctgctttggg 26520
gacagacgat ggcctcagct tgccttgggg tgtcagtggg aaagatagga gctgcccctt 26580
tgccttcgtg tttcttcgta ataatctcag atgtacccgt ctggtgggcc tctcctagaa 26640
aaagccccgg tgctctttgc tcctgcggtg tttctcagga gggttgttgc ttctttgtaa 26700
tggtggggac tcagggaagg gacgcaggca gagggtgatg ccacatcaaa aagggaccct 26760
tggctgggtg tggtggctta cgcctgtaat cctagcactt tgggaggccg aggcaggtgg 26820
atcacctgag gtcaggagtt cgagaccagc ctggccaacg tggtgaaacc cggtccctag 26880
taaaaataca aaaatacaaa ggtggtgggt gcctgtaatc ccagttactc agtaggctga 26940
ggcagaagaa tcgcttgaac cggagaggtg gaggttgtga tgagccaaga ttgcgccatt 27000
gcactccagc ctgggtgaca gagtgcgact ccatctaaaa ataaactgaa aaaaaacaaa 27060
aaacaaactt gggccatcag cttcttggaa aggctggtgt gaggttgaag catttgctgg 27120
tgcctctgct caacgttttt gtggtgaacc tgagcaaaga ggttatcatt agtggatttt 27180
actgccttac ctgggtgggc actcccttgg gaggtggatg gacatttgca gctgagccca 27240
ggtgggggaa ttgcgctcac tccgccttca gaattccaaa ggctgggcat gcatcttggc 27300
ttcctctaac ccatgtcttt ctctaggtgg ccacagcaga gtgtcattaa gtatctattc 27360
tttgcttttg ttctcagggc aggaagatcc caacagtttg cgccataaat ataactttat 27420
cgcggacgtg gtggagaaga tcgcccctgc cgtggttcat atcgaattgt ttcgcaagta 27480
aagagagcct tcctttttcc tataacctcc gaagctttca ccgccactag caaaacatga 27540
gagctatttt tgagatacat taaagtgtca aagtgtcact gaatatcttc ctacttaaga 27600
taagtgtgtc tcccttagaa cattttccct attcgactat ataaatctac attcttgacc 27660
cttctgaatg tttaaagaac ctcgggctct gaagagattc tctaagaata ttttgtaagt 27720
ggaagttttt gatgcatgca aaaaattggc aggatgttta gtgtttaaat gctaagcccg 27780
atatataaag gagcgatggc taggtgtgtg tggctgttgc acaacccatt aatcaatgcg 27840
ttgaagcgtt cattttaagg tgctacaggc ttaagtgtgt actcctttgg attttaggct 27900
tccgttttct aaacgagagg tgccggtggc tagtgggtct gggtttattg tgtcggaaga 27960
tggactgatc gtgacaaatg cccacgtggt gaccaacaag caccgggtca aagttgagct 28020
gaagaacggt gccacttacg aagccaaaat caaggatgtg gatgagaaag cagacatcgc 28080
actcatcaaa attgaccacc aggtaagggt gttctcgcct gcagaggtga gttctcagat 28140
gccccggaac acccttggca aaggcaccag agctctctga ttgcagctga ttctcggggg 28200
gcactgaagc cagtctgagc cagtcacagg agggccttga ggagatgctg agtatggcct 28260
gggggtgtgg gagaggaagg ggctcaggaa aacttctgta aggagccaga taaaagtttt 28320
taaaataatg ttttaaatgt ttgtcaaaga aagcaataga tttgtaaaga aattagtagg 28380
taagtagtga aaattgattc tccttcccat tcccaatcct gtggcaactc ttgttacaga 28440
ttttatttat cctccacaga tacatcatgc gttcacaatg aacatagaat ttactgggtt 28500
ttagactgag ccatccttaa cttgtcaaca gttactttga aaacaaacca gctctcccaa 28560
attggggttt tgcggggtta tgagatgtgt ttcaaaagaa tgtttcgtac tttaaacatc 28620
ttggaaaact tgaattaaaa cagagctaat ggatttcttc tttccagacc ttctcagagc 28680
ttttagtatg ctagtgtgca cgtggcttgc ctacaaaagg gtgttgactg aactatttgc 28740
ccaaattata atcatttgag tatacagctt tttgtggggg caggcagaac tgagacatac 28800
caaaatcagt ttgggaaatg ctgtatttga aaatgctttc tatttaaata ttctctttgc 28860
aatcattttt gctctgttga tttgcttagc aaagtcttca tgtctgggac aatatccatt 28920
tcttactgac tcatcaaaaa cccccactcg acacgtcgat gagagaggtt ttgtttgctg 28980
tgtggcatgt tcagtgaaag cgtggtttcc agtttcttca catccttata attttctaga 29040
cttcagatgg agggaacaat cagaggaggc tggaatcctg cctctgacca aggaaaagac 29100
cagaggctga gccaggtggg gtctcttgtc cagccctctg cttgcctcgc tttacctggg 29160
tgtgggctga gtaattccag acaagcgtgg aattaatctg gctgtttgtg ctgttcagtg 29220
gcacgctggt tacacctcct tctggaaaca actctgcgtg tgctgtttgg gtggtaggat 29280
tccgggtctc cttctccgtc tttttataac atcaagttgc tgcccagctc aggctccttt 29340
acggccagtc ttcagaaaac caccagctaa cacatttact accctccttc cccgatgttc 29400
ctgtagcttc tctatggctg ggtggccagg catggccgaa gaggctctgg gtagatatag 29460
gctctgtgcc cggtgtgtgt aactggcctt gagtgaggct gcagttgtgt gttatttcta 29520
ttaggtcact gtggaatttc tagcgacaac taatctttca aagtgtgttt attggtcaca 29580
ggattattgg gccagcctct gccttcattc tttttcacct aatctgcata atagctgtgt 29640
tatccccatt ttagagaaga agaaacaggg gctcagagaa gtctagtaac ctgtgtgagg 29700
ccacacagca aacacctcat gaccctgccc tcctaaggca gcccatggct actgctggag 29760
ggatagaggc cggccccgtg gtttgatggg acagcttgac cttaaacagc ccatgggaag 29820
gcgggtgcat ctggtttagg aacaggctgc tagaaaggta tccaggatgt ggtagtctca 29880
ccggaaggag ccagtcagaa tagcacagcc tgtggccacg cgtgggacct gttcagcctc 29940
atggagcttt gggaggcagc cagcagcagg gcatgggctg tgtgcaggcg aggcgctggc 30000
ctggacgccg cccccactgc gtaacttcgt gtttggaatg cgtgggcaca taccgtgcgg 30060
ctgcttctgg ccgggggata ttcttttcca attttgagcc aaggtggaga ctgtctcctc 30120
gtgccatccc tggcatgtcc tggcaagacg tgaacgatct caatagacga gctttgcaga 30180
gtgtgtctga cctgactcct gctgtcttgg gagtttagct cttcagccag cagcatgctg 30240
tttgacatgt gtttcaagcc ccccaagaaa gggtgcttga aatttaaaat tgaactgatg 30300
tggcttttca aaatggaatt ggaaatgaaa ggatattaaa ttgcagacac ccacacaaaa 30360
gactggtttc cactgactaa actgcttttt tttgctgata gtagttgaaa gtagggagag 30420
taacagcatc tcttccagct ttttctcttt tgttcccttg ttttgatgat gggttatttc 30480
gggggaagct ctggctggcc ttgctttgtg tcatcttagg gataacaaag aggatgaaag 30540
agatcaggaa aaccgagaag gcagaacaga accagcagaa actgtgcttg aggaatgaaa 30600
atcacctaca cggctccttg tcatatgaga ctgtggccca gcctcctgca aagccattta 30660
agagtaaccc agtgaagctg gtgagactgc ctgccgcgtc cgtgggccca gtgactaact 30720
cggtggctta tcatctgggc ccagctcctc ccctggcatc ctgatttcac ttggaggggc 30780
ccccgttgtc cttcataaac atgtttattt cattttattt ttatgttttg agacagagtt 30840
ttactgttgc ccaggctgga gtgcagtggc gccatctccg ctcactgcaa cctccacctc 30900
caggactcaa gtgattctcc tgcctcagcc tcctgagtgg ctgggactac aggcgtgcac 30960
caccatgcct ggctactttt tgtattttta gtagagaccg ggttttgcca tgttggccag 31020
gctggtctca aactcctgac ctcaggtgat ccacctgcct cagcctccca aagtgctggg 31080
attacaggtg tgagccattg cgcgtggctg taaacgtgat attcttgaga ctttcagtga 31140
aataagaatt gccacggaca tctgtggtca ttgtccactt gccactcacc tacccccttt 31200
tctggcagca acagccggca tttcacatgt ccatcatcgg acagcgtagg tgggaccatc 31260
agtcatggtg tcctaccctc tgtggccaag gagtggacac aggacccagt tagggcaagc 31320
agaggctccc cttggaatcg caaagtgaag ctggatgcca cccacagaga ctaacatggt 31380
gaagctgctg tagcccctgc tgttgagccc ccagcactgc ctgagttctt gcactttgtg 31440
agtccagttt aatatctgct tttcctccca ttcttggagc tcccctcaca tctccagtgg 31500
cttgaagttg ccagagatgt ttctgggctt gtgaccaaat gactcctttt ctgcttctca 31560
ctgctgagca gacacatgtg cgctcacttt gcctgctgag tcttgggacc cggaagagct 31620
tttgggagac aatcacggac cagccccctc ttgcctgccc tgctgtctcc ctccaagcag 31680
gaggtgagaa ggtgtccacc tgcagccccg gccaggcatc cctttctgtg cttctgccca 31740
aatctgaaat tcccctctcc ttgggaccca cgactggggc cagcctgcct ggggagggaa 31800
tcccagctgc agaaagtcgg gacagtgtgc gtgtaaacat gttaatagaa agcagctttg 31860
agggcagact agttcagctt cagttacaaa ctctttccaa atgcgtttaa catgagccac 31920
tggctgtgcg cagcatatgt caagctttca tccaatggtg gcattttgtc cctgcggggt 31980
ttttttttcc tgagcagttt ggggcagggg tggggacagg gagagagaaa agtaaaaaga 32040
gagcagtttg gtttcttcag gctggagtac aaggcagagg taatgggatg tattgaagaa 32100
ggtaggaggg aaagttactt tagctacagc tatttgtcca gctgtgctga ttaagaaact 32160
tggagaaaag catctttgga atcatgtcct tcccatctta tatacagcct ttgcagattt 32220
cctgctgttc tgagagagat ctgaactcct taccaggacc ttgagggccc cacctgattg 32280
ggcacccctc actctctctg cccctcctcc ccttcccctc ctcccctcct ttctccaccc 32340
ccacctgctc tgctcagaca ccccttcctt ggttgcttcc cacaggccag ggctgtcccc 32400
tggggccttg gctgttcccc tcccaggagc gcccctctcc agctcctcat gcagccaacc 32460
ttcctgtcct tcaggcctct gattaaattc tgccttagac atctctcccc accccgctgt 32520
gtgaggtagc gccccatgcc ccagtcccct caactccact gcctcacttt ggggacacat 32580
caccccaggg acaactgcat tccactcttg gtttttccct cctcgtctat ttatcacaat 32640
ttagagtcgc ctcactcatt tgtcaaatga agttcatctc tgcagctgga ctgcggggtt 32700
gggggcacat ccggctgtcg gtcctcaggt aggaggtgct tggcaacctt gttcagagta 32760
ggacgttcac agctgtctgc cccggaggaa gcaagggcac ccgccacatg gatggaattg 32820
aggggaaggc acccggggct cctgcatcga gcttccctcc tatattcaat gaggaaatga 32880
ccctgcagaa ggctggctgc agatgcccct gcctcccggc tttgcctgct tggagtttga 32940
tggacacgtg gtcctgtcag ggctacagca ggtctatggt ctttggtaac ggaaagcgct 33000
ggtgaaacag tgagctttcc cgtgggtgct tttccctgac gccaacaacc aggtaaatat 33060
ttggaaacgg ccttgttgag gcttgtgagg tggttttcct ccctcccctg taggcctgcg 33120
ccaccccccc aaccccacgg ccacctttgg gccagatggc acccacagac ctgtttgaag 33180
tggccacaga gggagccctc tgggcgctgg ggccgctgtg tttgcagagg gtcctcttac 33240
tgctgagctg gctggtgcag tgagaaggaa ggccgacacc cctgatcctc atcaagttca 33300
gacgggggtc actgcgggtg aggggcctgg ggccttttac atgtcccggg agctgctgag 33360
caggccactc ttctccaggc caccagaact tggccctgcg catggtgaat cttccctgag 33420
tcagctgagt gagggggttc aggcagcccc ccgggacatg gcagtggcgg ggagtggact 33480
ggggtggtgc ttgccatgac tcacgccggt tctcctcagg caaccggatg gtcagatgcg 33540
ctgactcagt ggcctgagct cgtccaaaag cgaatcagag aacacagggc ctgggctcac 33600
ccgctgccct cttctggagt catctgtcac tcatcctcat gaaggaagcg cctgggagcc 33660
tggaatgcac atcgcactgc cccagctccc ctcttgtttc tgtgtttttc cattttggat 33720
tctttccccc aacgccttct gtactgggca ttttgtggtc tcttcttttt ctccgagaac 33780
tctgagggct accattgcat ttgctaatga tgccacagac ggtgttgacg ttatgaggct 33840
tctattactg tattgatttt taccattttt agggggacgg gaatcaatat ttcatgaggg 33900
aatgtgaagc cagacagtga agtagaagct ggcttttatt ttgtgccagg ctttgtccag 33960
aggcgggtgg ggacgtggct cctaagctct tgattgcagc tccttctggc ttgggaaacg 34020
tttcagttcc ccaaactctc agaactggat cccctgtgtg ttctctggcc cggattcaag 34080
aacttagttg attgtcaagg aaattctttg gctatatttt tctcttaata tggtaatgcc 34140
ttttttcact ctggcactct cttttcaggg aattggatta agactattat ttatgggtct 34200
gacaaagcag ttcccaagtt gttgggactg gatttgttta ggaatgtctc ctgtcctctt 34260
cattgagggg ggaatacaaa ttgcttccat ttgacagttt atcaagtgtg tgacagagta 34320
tcagagtcca gggttggcca actacagcca gtagtccaaa gctggccctc tgttgttgta 34380
aataaagttt tattgggaca tggtcatgct cacttattta ggtagagtgt atggctgcat 34440
tcagtctaca ccagcagagt taaatagttg tgatgaagac cacgtggccc gtgaagccaa 34500
aaatatttgc ttcctggccc tttacaggaa aaaaattccc agccccagtg gcaggcaatt 34560
aacaccttgt cctcgaggag ctgaaagtgg ctggaggcag gaatgcttat aagaaccaag 34620
cgaggtgaag cactaggtgg ccgcggcgag caggaagaga agctgatttt gtttgccctt 34680
tcgtttgcca gagattgtgg gttctttttt tttttttttt tttttttttt tttttgcaga 34740
gatgaagctt tgatcttgtc acaatagcag agggaggcct tatttttgtc tatttctctg 34800
tgacattggt agaaaggact ttgtcagaat tccaagctat ttggcaatta tccaattttg 34860
agatcctaat ggatctttcg aggtctagtt tgttcattct tttagtgatt ccttgttaat 34920
tccctgattt tataaatgtg tgttgaacat ctgtcttggc caaatacttc ttaggtgctg 34980
aggatgcagc aatagtgggc aaagccatgg ggcttaagat ctagtgtggg aaatgggtga 35040
tgtaaagtaa atatggcgat aagtacagtg cacgaagcaa acaagtgaag gggtagaagg 35100
tatcaggctg caaagacagc agatagtgta ggcagggaat cttatctgag ggggtgacat 35160
ctaagctgag atggaaagga cagtgagagc cagccaagga aacaagttgg gtgacaagag 35220
ttgcaggtgg agttgcttaa tttcccactt ctgctcagcc tgcagatcct ggatcttgga 35280
ctaattgcaa actgtcattt cctcgtgagt ttattagaac cctccagaac aagtttctgg 35340
ttagctagtt tctctgtgtg ttgtctcatt tcttgttggt tctggttctt tggggttcct 35400
actcatactc tggaaagctc cagtgtctta agtagtcagt ctcccaagag tctgaaagca 35460
caaagattca caatgatacg atcacctctc aatcatagca gcattgatgc agttccgtag 35520
ctggtttcct aaagccatcc agatctcttt ctgtggcaag agagaaataa gaccttctgg 35580
tgaattgagg actaattatc ctaataaaca tgcgaattaa cagttccttt ggttaaacaa 35640
agcaccagaa tctgataatg ggaacatgtg actcatggta tttccttctt tgctttatct 35700
accaggcagc tcacagaaac cactggcctt ccctgtgttc ccattttatg tcataaatat 35760
atatttaatt aacttattat aaaaggccct ttgttcattg accatatcaa attattctta 35820
tatagaagag gttatacatg ttttaaacat tttaaaataa atctgaaaag aatgctacat 35880
cctgggcaac ttccctgcat ttggggctca aagaagctct atgtggttat gggtaatgag 35940
gagccagagt gccttcaggg cagttcagca gatgctgaaa ggctgctgtg tgctgttcgc 36000
tgggcccacc aaatagagta ggactgagcc cctgtccacc atgacagccg ggagatacaa 36060
gctgttccct ttgcctccct gagccctgag ctttatagcc tatagacagc tgaaaagcag 36120
gctgcatccg ttacccagtc agttacccag acccaaatgc caggccttgg ctaaccccag 36180
ttattaccta attttaatat cccaatggat gttttaagac ctggctggtt cattctttca 36240
tttatttact tattcattga ttttgtaaat atttctggag catctgccat ggccacatgc 36300
tgttgtagca gcatcagcca ctctgaagtt ggtggatgaa aggggatgca tcaaaggcgc 36360
tgatgtatgg aggagacgca agttagactt gaccaagaca atattattcc tcctctggat 36420
gccccgaata tatacagtca ttagctgtcg ggcccccatg tggcactgtt gacattttgt 36480
ggtttaaaca ctgaagagta agggaatatt ggaaatggca aacatctgat atagtgtaaa 36540
ggagactaaa tattttgatg gtgttcataa acaccgagga ggaaagtctt ttcatttttt 36600
tcatttgtgt gctctctctt tctctgtttt tgcacactgt cctctgttct ccttctcctt 36660
ctctttttcc ttttttctcc cttcatctcc ccatttatct gatctctccc acctgaaccc 36720
cttctaccct gctgccctcc tgtccattct accttctcta ctcccctccc tagacagtag 36780
taatcacatg tcagttggag aaacatgatg gcaacttggt cacaccgttc ttctcagtct 36840
gtatatgtcg gtgatctcag tgcccatctg gcagatcctt cctgccctgg ctcttctgct 36900
cactgcgacc acccttgact ttgtgatcac tgataacctt caccttctct aatctaaatc 36960
ccaagcttct cactcttggt ccaccacctc ccagccttgt ccgttctgaa ccctgaacgg 37020
aagctgaatg gaaccctgaa cggaagggtt ctgaagctgt tcagaaccct gaatggaagc 37080
tgaaatatca atgggccatt gcttttcaca gtcctctgtg aaagattact ggccaagcca 37140
gcatctggag aattcctggt ccaccacctc cctgtctgga gaagctggaa cagccagctg 37200
catgagcatg tgacccgtgt actcacaggc cctgtgccct gagctcgctg ttttaatttt 37260
atctttgaat ttgtattttt gtgaataaag ccctatgagc taatggagca tgctcaggga 37320
acttggggct ttagctcagg ctggattcct cctgctgcct ccccagtccc tggtcccctg 37380
agaactccag ccccatctga ccttcccttc cctgtctcta tgcaggggtc attgctaccc 37440
tctatccctg gaaaggatgt aggcacaggg cagttctagg ttccagcttg ggcaccgctt 37500
aacatcttgg tggtgcaggg atcaggctga tgataccgtg gttgttctgt gggctactgg 37560
gcagggtcaa gccactccca ccctgatcca ggtacctaat gcacccgaca cagaagcggc 37620
agtgtccttg gggtcatcca ttatccatgt gttggaggag tgggacccta gggaagatgc 37680
ttggctcgac ttccccaccc ctagccaggg cacaatcaga ggtccagggg ctggtgggca 37740
caatgccaag tcgtgaggcc tccagtgtct gcgctcactg tcccataaat aaccacagta 37800
ataactagca aatcaaaaac attgtgatag gtcgagagag acagcatgtg gaagaaagga 37860
aaaagctttc tattttagta cctttaacag tgctttctgt atgctttatg aacaaggagc 37920
ctgcattttt attttgcact gggctctgct aattttgtag ctggtcctgc cccctagtag 37980
ctcaagtcag caaatctttg gttcatctga gtccacagtc cgctgacccg ccctttttca 38040
cagttcctcc cctgcccatg tgctcacttc cctccttacc cagcttggcg cactccctca 38100
agcaagtctt tggatgctga catcccccgt aaacaaccct tctgcggcct ggtttgattt 38160
tccttaggag acatgcaagt tctatagcac tgtttcttgc tgggtatgga ggatgtgcta 38220
ttttgtccat tgcatatttt ttaaagaaaa tgaaaggtta gcataactgt ttccagaagg 38280
cacattgaat cactcagttg agtcccagcc agttgctgca atgttagcct ttgaagcaaa 38340
cttgaaccaa cacaggacca gcctagaagt cccagcctcc agaaatgatg cagtggattc 38400
tgcagattca gcaacaacaa tatttttgta actcaagagc acttagtaat tttcaaagga 38460
gagaaagaag taattgactt ggcttattag gttgaaaaag agttgccaac tttttctttg 38520
gttttgatgt tattggtttt tttttatttt tcttttctcc aagcttcagg gaatgagatt 38580
gaatgagcac tcaagtgcta ctaggcagaa ccctgaatgg aaggaagctg aaataccgat 38640
gggtcattgc ttttcacagt cctctatgaa agattactgg ccaagccagc atctggagaa 38700
ttctaggaac gccccctcct cttgcagcag tataagtttg cggggatcat ctgaccccat 38760
tggggagttg tatgaaaaag gggatttatt ggggaccctg ttgcctgttt ggatcttact 38820
tacatttaac tattgtctgc taatggattt tttggaaagc aaccaggttt tccgtaaaga 38880
atagctaatt gtcagagctg agatgaccat tggagatcac tgggctcaac tccctaattt 38940
tagaggtgct aaaaccgcaa tccagagaag ctaatcaagt ggttcaaggt tgtagactga 39000
gttcatatag gaccaagacc cagcccagat gtcctactgt ctgggacagt gttctctcag 39060
catacgtgga gcctgagggg gtaatgtgtg tgcgtgtgtg tgcatgtatg catatacaca 39120
taggtgtttt gcctaagttt tcacttctgc cccaccttgg ttgatcttgg agaatgagcc 39180
tgaggcgcgc tgtcaacctg ggggcctcat tcagcacagg cccaactttt ctgccctggg 39240
ggagttccag cagttatggt tcatctgtgg ttcagttatg gaactcacac cacacatagt 39300
gcccccaaaa ccgaggctgc gtgcacagac ctcccctccc ttcccgtggt gggcccctgc 39360
ttgggttctt cctaaacttc ccctttgccc tgctctgtgt tataccctct ctggtcccct 39420
gtccctgtgg agtgatccgg ggcacaaggg cagctgtttc cccgctgacc tctgtgtgcc 39480
ctgagcatct gggaggtggg gagcaggctg gtgagaagaa cacctggagt ggaggttggg 39540
gtcagggagg gtcccagtcc cggtaccacc cccacctgct gtgggacctg cagtcccctc 39600
atcagcagaa cggctatgaa gccatcctgc ccatccacag ggtggtgggt cgtgaaggct 39660
gcatacctgg cagagcggga gaagctctgg gaagatgccg gacacgcgcc gtgggagtga 39720
tttccctgcc ttgcccagat tctgctccca tcacctgaac ctgcctgtca ccaccatgga 39780
actgctgtga ccattgcttt ccttttaagc agattagcag acatctcctg ctccaccctg 39840
ccaaacaaac aaacaaacaa gcaaacaaac aaacaaaaat gtgcatgagg gagtatggac 39900
ttgtagagtc ttttctaaac attgttaggt gcttgtattg ggatcctctc ttaaaatgaa 39960
ccatattccc caggctttgg atgacactca tggttgccca ccctccaact tccttccctg 40020
ctggcagagc cctgggtttg ttttagttcc aaccctgacc ccaccgcatt cctgactcag 40080
gcaaattcgc agggtccaat gcagtcaggg gagccacgtt ccctcctcca acgagtgctg 40140
aggtcgctgc ttgattggat actgccgatg acctacgagg aggagggtgc cagggcgctt 40200
ttgggacttt gcttttctgg agagatgctt ccacagcatg gtcatggaca cagtcacgtc 40260
ttgatgtgat gtctggaatg gtggtggccg tcttgtggct gtgagaacag gctgaggttg 40320
attggatgga gggaaggaag gagccttgtt cttgatgctg tctgtgagcc tttgagttat 40380
cagcctggta ccacccagcc cttggacaga tatctactct acatactcca tttggagttt 40440
tttttttttt tttttttttt tttttttttt gtcacttgca gttgaaaaca ccctaattga 40500
tacacacaaa ctatttttag tgctggtctg tgtttggccc ttatggaaga ctctgggctg 40560
agctgcccat ggtgagggag gtggactttg tgttttctta ctgctctgtg tcctggtggc 40620
ttgtttgtgt ctctgcccat gagacaaaag ccgagagggc aagggcagat tttcttaatc 40680
atatgttccc tgcaccaagc tcataggaga cactcactga atggttgttg agagagttct 40740
ctttcacgga ggcaatgttt tgtgaaacga tgctgcttgt tgttgtctgt tggttgtaat 40800
atgcatgaac actaagagcc atctttaatc atgctgtggg ccgcctcttc caaggtgtta 40860
gcattactcc cactacctgg tcagcatcct gcctatggct aggactttgc aatttacata 40920
gatatggtgg ggagacctgg agcccatggc caggactctg acaccctcac tggatctgtt 40980
tctacatcta cctggatggc cgtctaggac attagaggat ttgtgtcttc ctaaagtccc 41040
tctgttgaga gacttctggc tctgttaaga ggacactatt tagcattgtg agtccctgca 41100
ggctgggggc cagtgggcgt ttttcttcta gatgccccct ctcttcttct ggcctcccag 41160
gcttcctgct cctgagattg tgagaactgg cctgtgctgg gctcactgca gaaagactgt 41220
cgtccccaaa ggttttgcac caaacttgag ctacaagatc ttttaggggg acctgagatc 41280
tccgcctggg ctctatgaga gcaggcatgg gttgtttttg ccccgtcact gcagtcatgc 41340
ccacacttgc attttctttt ccccccagca gtgtgaggat ctggcatgag gagtgggact 41400
cgcgtgccct ctttcttctc ctcttccctc tggccttttc atccgtcagt gggggacaga 41460
tgtttgccct gtttacttct aggcttactg tggggctcca gggagatggt gaagtggcca 41520
aggagaggag ctgccacctt caagacggcc tgtggccggt gccgctttaa agggagactc 41580
agaggtgctt tgctgtgggt ggcgcgggaa ccagcctggg gacagcagtg cagaggcctt 41640
ggactcagag tgcgtgggcc ccgcggggct tcacggcgcc tgtggctgtg cacttccagc 41700
catatctgtg ctgcatctct tccacattcc cccatggagc tgatgtctag acagctatgg 41760
aattaaatgc tcaattaccg agtaggaatt tggccagcag aggtatagct gctgagtaga 41820
cagactcgag gtgaggctca cggctgagaa caggccccat ctggctttgg aatgagctga 41880
ggtgcccgat gctcctgcag ccagtggctc ctgtggggag ctggggccgt gacccccaaa 41940
aggcagcttg acctcatgga ccaccataaa tctggcctgg tcaacatctc tgccagacat 42000
cattcccttg caaagatttc tgcctgtgat tggaattctg gatgaacatg tactgggcgt 42060
gtgggtctga cagctgggaa gcttgttctc ttgtttagcc aggctgccca tcatctgtaa 42120
gcctcagtat ccacatcttt aaaatggggg gaaaatatag ctcaactcct aatggtgcca 42180
tgagaatact ttgtcacctg ccaggcaaaa gcttattcct ttcacagaaa tccagggttt 42240
acaatgtgag acccctcccc actccgccgc atgtgtctgc ttgctttttt ctgtcttagg 42300
gttgcccttc atgagctagg aaatgtctga gtggatgaaa acctaaacga gatgatcact 42360
ggtggtgccc attggtgcag cctttgccta aatggctact tacgtagcca catttcctcg 42420
tctgtgttca ggtgaggact ggttcctggg cagactgcct gggtttgcat cacgggtgtc 42480
catcttgtcg aagcccatgt ggtcacccaa gtgtgactga gccaggcttg cccacggggt 42540
gctctgggcc ccattttcgg cagcaggcag cgtcccctgg aggcctggcc ctccccggga 42600
gcatggggag tagcgcctat gggcaagcag cctgcagcct ccatccctgc ctgggggctc 42660
ccccgcccca gcctcacagc ttctccaaaa gtgtttgtct ccttgccgca tcctctaggc 42720
ctgagctcag acggtggaaa agaagagctg gaaggagagt tgcctttcag tctctctgcc 42780
ttctgaggtc tcctgagaca tagagcctgg gcctgcctcc ctttctagga ggcgccaagg 42840
ggtggtaaga ataggggatg agtgagatgt gaattaggat ccccacagca agccctgcct 42900
cgtaactttc tgatgggttt tcaatgtgtg gtgaagcaga cgcctgctgg gcccccttcc 42960
tgagttgagt ttgacctcct gcctcctgtc tatctccttg ggcagccagg ccaccccgct 43020
ccattaacct gtgccacccc atccctttac ctgtcgcaag cccagccctg aaggcctcaa 43080
aggcctggtc ttccagccag tccagggcct gaagggatgg cagtgtccct ggtggacctc 43140
ccctggtgtg gcctagtgca catcccagcc ctgcctcctg ccccgcctgc acgccatgag 43200
tgctgaagtc atgcctggca ggggctgctg gcccaggccc agagtaaaca cactgcgctg 43260
agctcgctgg tgtgctgctg gatgctgatg agcttgagga gtgtgggaag tgagcatggg 43320
gctgagtaga gatgcggcag gcctgcacct ccccgcagct gccctgcatg ctccagcctc 43380
aggcagccac acagggaaag ggtcacccac tgtcagggca gacctttacc atggctgggt 43440
gacacgggct ggctgtggaa aggtgtttgg tggttcccgc tgttggattt gcacaggccc 43500
agatgctcac agcaaaacca acacctagat ggtgcttaca ggagccagcg ggtattcaaa 43560
gagctgttca gatcttaagt tgcttcattc tcacagtgga ccattgaggt agctgtacgt 43620
tagtcccatt ttccagatga gaaaactgag gacctgagtg gtcataagct caggccctca 43680
tctaaatcac gcagcctggc cccaggtgtg tgctcttgac catggacagt gctctcctgg 43740
tcctcttggt atctgtgatc tgagggacct tcctcctcct cagtctcgta tagtcagttt 43800
taggtcttgg actctgtctt catatccctt tctcccttcg tgagctttct cacccagcac 43860
cttccttatt tggtgtgtgt tgggggatat ttgtggtgtg gcgtggcact gtgtagtgga 43920
tgagagagtc tgtttttccg atcccagtcc caggtttcaa accctgctct gtctcgagtc 43980
acccagaatc ttggaccctc agtttcctca tctgttaaat gggcatggtg gtcaccccac 44040
ctcatcagct agtgtctgct ccatccctgg tggaggagat gactcaagta acccctgggt 44100
tccacctgcc ccaccccact ggtcccctgg ctctttcttt gttgagatag acgaatgtga 44160
ggctctggag ttgcagttcc cacgagggct ggggtggctg tctgatttct gggcctggtc 44220
catgttgttc agggcagctg ctcgttctaa gtgaataaag gctgaaggaa ctcgggaggt 44280
ctgctcggct ccgaggaagg cagagaggga aagggccccg atgccttccc tgatagagct 44340
agggaggccc ttctgtggtt ccccccagct ccttggcctg ggtgaccctg gagctggctt 44400
ctgttccatt ttgttgtgca gagttgtttg agactcctgg ctttgcctgg cctttgtggg 44460
acgctggaga tcagggcttc tggagttggc caattagcct gcccagacca ggaagcacag 44520
gtggctgaca gagggccgtt tcaggagagg agagacagcc tacctattcg gtcttgctgt 44580
ccccatgctc catccctgcc cctgaccagt gtggccctgt actcagcata ggcgtgcacc 44640
tgagtcagta cagttccctg cccgcagagc accccaaata ttccaggcct caggacggat 44700
gtgcacatga tgagtcgggg caggtttcac tgcctgtagc ttgggatcct tccctggggc 44760
ttggttctct agggccatcc ccagcagtct caccccaaac cctaaattca tgttgtcttc 44820
ctctgtctct tggcctcaag gtttcagagt gagtctgtgc tgatagcttc aagatgtgat 44880
gagaccccga cttggcctcc agttacctcc ccacggtttc cttggtgtgt gtgtggcttc 44940
agtgttcact ggctcccgca cggcttgcaa tgtgtggatt acgggtggga gggaaatcca 45000
gtcctgcccg cagcaaaggg atgttagttg tgagctcagt tccccaccgg gcctggtgtt 45060
tccaaatagc ccgtcactgt ccctgcttgg ttttccatga tatctgtgcc tttacctatt 45120
tggttaaatt aaaccaactc agcaacgcca gccattgtgg tttcagggca agctgcctgt 45180
cctgctgctt ggccgctcct cagagctgcg gccgggagag ttcgtggtcg ccatcggaag 45240
cccgttttcc cttcaaaaca cagtcaccac cgggatcgtg agcaccaccc agcgaggcgg 45300
caaagagctg gggctccgca actcagacat ggactacatc cagaccgacg ccatcatcaa 45360
cgtgagcctc tgtccctctg cgggtgggga ttggggcaga gttttgccag ggggagagga 45420
gtcagcatag gtcttagccc ctgactttgt tgtagtctgc gtgaagggat ggaactagac 45480
caagccatgt ggattctagt gccagcagca tggcaggggt cacatggcgg ggacggtgac 45540
accggagcag gtggacagcc agcctcctcc caggaggaag aagttgtatt gggtgcttta 45600
gggtgattgc agttggcttc tgggcttcag agagaaaatc tccctgttta cggcacctct 45660
aaaactttct gaaaattgtt aaggtcattt ttttccggca aaatattagg ttaatgggaa 45720
tgaatctcag agaagaatcg tgccccccac tctaggcacc gtgctcagga aacgaccagg 45780
cagggacata gattgaacca tgttatgaca cgatttgtaa ccttttcatt tctgtttaat 45840
tgcagtatgg aaactcggga ggcccgttag taaacctggt aaggtctttt aaacctatgt 45900
taggtcattt gtttttatct atgtatacgc tgttttttgt ttgtttgttt gttgtttgtt 45960
tgtttttgag gcagggggtc ttttcaaaca taaggttgcc aaagtgtatt ataaattcct 46020
ttaaaatggc tctgtaaatg tactgcgtgc ttgcaaatga ccctacggat cttttctgga 46080
aagagtaagg caggccggag gtgagggttg gaaatgttat gccagagaac acacttgtgt 46140
ctcagagtta caggtaaaca ccgtgaaatt cagggccaat gcaggagtaa ggtgaaggtc 46200
actaaaaatg ctggccagtc accgaaagca cctcctccaa attaaatctc ctgggctgct 46260
gaaggagctg gctgggctca tacacatttt ctcttggcca ggaatcctcc cttaaggcct 46320
ggctggaatg aggaggagtt acccacccac aaagatatca cttaagtctt cccttaaata 46380
cttgagcaga aaaagtgaag ccttagaaca cagaccagca gagctagagg gcagctctgg 46440
ggccatttat agagggcagc tctggggcca tttatagagg gcagctctgg ggccatttat 46500
aggggctgtc tttagcaagg cccagtgtga tggcacctcc tagatggtgc cttggcatca 46560
ggtactgaca tctcagcact cctgggaagt gtgcacttgg cagctttctc ttcccagcag 46620
aggggcagct gtgctcccag ctctgtcctc tgcctccccg cgcagcactt ggggatggag 46680
tggagatggc tttgctggta atgaagcatg acagccctaa gctctagggt tgtttccccc 46740
tgaagtcagc agagtcatct taagatcatt agacatggga gaagcaggaa ggtgtgggca 46800
gccacctaaa ggagtttgag cctttggaaa cgtattcctt gtgaaacagg agcaaatcat 46860
atcgtgcatt ttgaaactat ctgtgcttac cgtgaggtga gcacccagtg ccgacctgga 46920
gtatgtgcga ttcttccaca gctgcgcgtg gctcgcgctg cctgggtgtc ctgatgcctc 46980
tctccctgct gccacgggga tcccctcctt gcatctcccc acttcgatct ctgaaatagc 47040
tcagggactt ctttcaggca tattctctct gggtgtgtac ctgccggtaa agcttcacga 47100
ttcagtaagc cgtgtccttc ttgcttttca ggacggtgaa gtgattggaa ttaacacttt 47160
gaaagtgaca gctggaatct cctttgcaat cccatctgat aagattaaaa agttcctcac 47220
ggagtcccat gaccgacagg ccaaaggtag gcaaggccca cacagccctg gggactccgg 47280
agatggggcc tgaagctcag ctgccctttg ggacttgggg aagggaaaag cggcagcccc 47340
taggactagc caagccgtct ctgatccaga agtgaacggg aatgcacatt actaaatccc 47400
tcgcagaagg tcacagacat ttcaccattt ttgtcctctg atcatggcaa tgtcacttga 47460
gtcagtctaa tatgtaccag gcatgatcct aggtgacttg tgtacattat ttcactttct 47520
ttatgtatgt cacttaattc ttttgcccta tcagttagga attactagtc ccattttgct 47580
gatgagaaaa cggttcaggg agatcattct gcaaacgttt attgccccat ctgctctaag 47640
tcaagcaggg agcttggcag tggacagctc aactggggcc tggggctcaa caggggcctt 47700
tgccggtgtg acttttatgt tctgttgggg gatgggaagg ctgacagtaa ataatcaaac 47760
acataagata ctattagtgc tcccaagaaa acggatcagg gtggccgtca agggagcgac 47820
tggaggggca gctggtggag atggtgtggc caggaaatgc cttccaagct gaggtctgag 47880
tgaggaggaa ccagcgggca gggatgtggg gggaacactc cagaaggaaa gacagaggac 47940
tcagcatagt tgagtgagca caaggcccct gaagtggcct gagggccgga gcacagtgac 48000
agcatggagt tccccggggt ggaaagaggc caaggccggg cgagcaggct cacagcaggc 48060
cgtggtgagg gacctgggtt gcatcctaac gacatttaag aacagggaag tttatgatct 48120
gattgatgtc actgaaagga cactctgatg gctgcgggga gtctgctgga ggggttgctg 48180
gaagttgggg accggttaag gggctctccc agccatctgg atgagacatg ctggggtctc 48240
agacaagggt ggtggcagtg gaggtgggac agaggggtca cattccagat atatatgggg 48300
ggtagagcaa gcttggggaa gggccagctg tcaggatgag gccatgagga attaagggtc 48360
atgcccaggt acctgaccat taattgaaac aatgggactt tcccaaggtc ccccagaggg 48420
gaggggtcca gaccaggatt tgagccgcaa cctcagtgta cccttctgtg gcccttcctg 48480
caacctgggg gattgggccc ccggcccctg gtgtccccag cacccccacc aactgggctg 48540
accttctgct gtccctttgt tgtctcacca ggaaaagcca tcaccaagaa gaagtatatt 48600
ggtatccgaa tgatgtcact cacgtccagg tgggtaaaca ggatgcgtgt ctgtgtctta 48660
aattttaata aacctgaact tcagaaggtg ctcacgggca cccctgaaag agaaacctta 48720
tgctgcctta agacgtctca gtttctgctt ataatgaagt agcatcggga aagaggacag 48780
gtcattagcc ttggcccctt tgtttggttt taacctgtgt ttttgcattc tgagctggtt 48840
ttcttcactg gcagcaggcc ctccggtgta gaaggttctg ccctcctctt tgaaggcagg 48900
cctgaacagt gtgtgcgtgg tggggctgtt gattcactct ggctcacgtc ttccttaccc 48960
cacattctgt tgaaacccac attccaggag ggccccaagc ccctcccgca gctctaggca 49020
ctctgctttc gttgctctgc agctcgtggg ccgcggctcc aggaatgcca gggcaggtcc 49080
agcgcaggga agtgaatgac tgatgtgctt gttttccccg agctggtgga attgcggcct 49140
gtggttggca ggctcatggc atcctggtgt tctaaactgg atgaaaaatt ctggtgtaat 49200
ctcatgagtc ctggtagtag actcacctgg catggctaaa actgtcagag gtaaagtagg 49260
taaagactag aatatagtaa cagatagatt aatgtgttca ttactatgat gaattaatga 49320
ttcactcact gtgaaagtat taatatattt tgatacatgt tatgaatggt ggtccctttc 49380
ttagcactcc agaagatgga gccatttgtc aaggttaaag tgtcccctca gttgtttgcc 49440
tttggaacta cgaggtgtag ggaaagatgg taagcccttg gtgcccagct tcctgggttc 49500
ctgtccctgc tctgatatgt cctgccttgt gaccttggga acgatatgac ccctgagtgc 49560
ctcagtttcc tcctcttcag gatagggatg acagcgcagg tgcttctgat gtgtggccag 49620
gctcagatca gggagtggtg gcaggggtca ccagccacag tgatgccagc cactatgtat 49680
cacacgtact gggccaggtg ccttactggg atgatctcat ctgatcctca caactcatgt 49740
tgtagggtac tgttattatc cccattttgc aggtgaggaa atgaaggcac agagaagtta 49800
agcaactgtc cgaggtcaca cagctagcaa atggccgagc tagggctgca aaccaggcca 49860
accactgtac tttactgact ccttagtaat agctactatt aattaagaaa taataacaat 49920
gatgatggct gggtgcggtg gctcacatct gtaatcccag cactttggga ggccaaggcg 49980
ggcagatcac ttgaggccag gagttcgaga ccagcctggc caatttgtga aaccctgttt 50040
ctactaaaaa tataaaaaat tagccgggct tggtggcagg cacctgtaat cccagctact 50100
cgggtggctg aggcaggaga attgcttgaa cccgggatat gtaggttgca gtgaactgag 50160
atcgtaccac tgcactccag cctgggcgac agagcaagac tctgtctcaa aaaaaaaaaa 50220
ataaataaaa aaaataaata aataataaag cactttcctt gctgttacca agtaaatctt 50280
tgactctggt agacaggcaa ttttaatttt aaaataggat cagaattcct ggaggaattt 50340
taccttagac ctaaggagaa gacgggaact ggtgagagct gagttttgcg tgaggaaggc 50400
ctggtgtttc ttcacactaa cacgggtgct ttttctctgg agcagcaaag ccaaagagct 50460
gaaggaccgg caccgggact tcccagacgt gatctcagga gcgtatataa ttgaagtaat 50520
tcctgatacc ccagcagaag cgtgagttgg agtcgttttc tcttttccca atattcttgt 50580
tgttcctgtg ggggtagcag gaagagggag cgctgttcct tttctactgg ctcagatgat 50640
tatgttgatc cttgacagac gtggtcggac gttgcttgtc attcctgctg gccaggcctt 50700
ccgacctggc tcggctcggg actcatccat aggagggtgc cttctgtctt caaaagtcct 50760
tgctccacga ggaccctcca gatggacaga gcaatagcag actcgtaatg agtctctgag 50820
atggcccggc tggccagaga gagggtttca ggaacagtgt ccccaagccc tcacttggtg 50880
gtccttttct aggcttcagg acccttctct tcctggagtc ttccagaatg tctctgacaa 50940
ttaggcccat acctgtcaac acctccagaa aaataaccca agtgatatca aagtaacatg 51000
acaagaagta gctcaaccat ccatcagggt ttgttacctg tattggcgga atatccagag 51060
aaaagtgcga gaccagggac cagcaaatgt gccttggggg ctggatctgg cccactgcct 51120
gcttttatat ggagctgtgg gctaagaata gtttttgcat tttattttta tttttactta 51180
ttttttattt tcataggttt ttgggggaac aggtggtatt tggttacatg agtaagttct 51240
ttggtggtga tttgtgaggt tttggtgcac ccatcaccca agcagtgtac actgaaccca 51300
atttgtagtc ttttatccct catccctgtc ccagcctttc cccttgagtc cccagagtcc 51360
attgtatcat tcttatgcct ttgtgtcctc gtagcttagt tcccacttat gagaacattt 51420
aaatggttga aaaaatcctg aaataagaat agtattttgt gacatgttaa atttgtatga 51480
aattcaaatt tcagtgtcca ctgtaatttg gtttatgaca tctatggtgg cttttgtgct 51540
ggaacagcag agttgagtag cttcaacaga gaccatatgt actgcaaagc ctaaaatatt 51600
tcctatggag ccctttacag aaaaagtttg cagacccttg tgctagccca tgaaggacca 51660
tgacagcgtt ttgacgctga gctatataag agctacagtt atagtggcaa ccacacaaag 51720
gaagtgcctc ttaacagaaa cattccgccc acccctatag gaactgcatt ctgagttgca 51780
atacccatta taagcaagtt ggccagatag tggccaacta tctggcagat atctggccaa 51840
ctacgtggca gatagtacct ggtacatcct tccccacttt ggggtcaatc ttgacctttg 51900
atctccttgg ggtcataaag ccacacaagt gttagtaggc atttctacag tggacacaat 51960
ggatgattta gcctaaaaat ctcaaaagga gcccagcatc ctggcacatg catgtaatcc 52020
cagctactca ggaggctgaa gcagaaggat cccttgagcc caggagttcg agactagctt 52080
gggcaacaat tgagacccca tctcaaaaaa aaaaaaaaaa aaaaaaaaag agtggggaaa 52140
aaagaacatt attaaaaaaa aaaaccttaa aaagtaatcc aatctaccga tggtttattt 52200
tttattttat tttatttttt ttgagatgga atcccactct gtcacccagg ctggagtgca 52260
gtggcacaat cttggctcac tgcaacctcc acctcctggg ttcaagtgaa tctcttgcct 52320
cagcctctga gtagctggga ttacaggtgc ccaccaccaa acctggctct tttttttttt 52380
ttttttgtaa ttttagtaga gacggggctt caccatgttg gccaggctgg tcttgaactc 52440
ctgacctcag gtgatccacc tgcctcagcc tcccaaagtg ctgggattac aggcatgagc 52500
caccgtgcct gacccactga tggtttgaat tattctaagt tcgccaccgt ccaatcctgt 52560
ttgctctggg cttttaggtt ctaagctgtg cctctgtcca tgtaaagtca gaccaggagg 52620
aatggaaaca cgaaacattg ccattgtgtt tccctttgtg ttgcagtggt ggtctcaagg 52680
aaaacgacgt cataatcagc atcaatggac agtccgtggt ctccgccaat gatgtcagcg 52740
acgtcattaa aagggaaagc accctgaaca tggtggtccg caggggtaat gaagatatca 52800
tgatcacagt gattcccgaa gaaattgacc cataggcaga ggcatgagct ggacttcatg 52860
tttccctcaa agactctccc gtggatgacg gatgaggact ctgggctgct ggaataggac 52920
actcaagact tttgactgcc attttgtttg ttcagtggag actccctggc caacagaatc 52980
cttcttgata gtttgcaggc aaaacaaatg taatgttgca gatccgcagg cagaagctct 53040
gcccttctgt atcctatgta tgcagtgtgc tttttcttgc cagcttgggc cattcttgct 53100
tagacagtca gcatttgtct cctcctttaa ctgagtcatc atcttagtcc aactaatgca 53160
gtcgatacaa tgcgtagata gaagaagccc cacgggagcc aggatgggac tggtcgtgtt 53220
tgtgcttttc tccaagtcag cacccaaagg tcaatgcaca gagaccccgg gtgggtgagc 53280
gctggcttct caaacggccg aagttgcctc ttttaggaat ctctttggaa ttgggagcac 53340
gatgactctg agtttgagct attaaagtac ttcttacaca ttgc 53384
<210> 11
<211> 18
<212> DNA
<213> artificial
<220>
<223> Oligonucleotide sequence motif
<400> 11
caaatattta cctggttg 18
<210> 12
<211> 16
<212> DNA
<213> artificial
<220>
<223> Oligonucleotide sequence motif
<400> 12
tttacctggt tgttgg 16
<210> 13
<211> 18
<212> DNA
<213> artificial
<220>
<223> Oligonucleotide sequence motif
<400> 13
ccaaatattt acctggtt 18
<210> 14
<211> 20
<212> DNA
<213> artificial
<220>
<223> Oligonucleotide sequence motif
<400> 14
ccaaatattt acctggttgt 20
<210> 15
<211> 18
<212> DNA
<213> artificial
<220>
<223> Oligonucleotide sequence motif
<400> 15
atatttacct ggttgttg 18
<210> 16
<211> 16
<212> DNA
<213> artificial
<220>
<223> Oligonucleotide sequence motif
<400> 16
tatttacctg gttgtt 16
<210> 17
<211> 16
<212> DNA
<213> artificial
<220>
<223> Oligonucleotide sequence motif
<400> 17
atatttacct ggttgt 16
<210> 18
<211> 17
<212> DNA
<213> artificial
<220>
<223> Oligonucleotide sequence motif
<400> 18
atatttacct ggttgtt 17
<210> 19
<211> 11
<212> DNA
<213> artificial
<220>
<223> Oligonucleotide sequence motif
<400> 19
tttacctggt t 11
Claims (20)
- 화학식 (II) 의 화합물:

[식 중,
X 는 산소, 황, -CRaRb-, -C(Ra)=C(Rb)-, -C(=CRaRb)-, -C(Ra)=N-, -Si(Ra)2-, -SO2-, -NRa-; -O-NRa-, -NRa-O-, -C(=J)-, Se, -O-NRa-, -NRa-CRaRb-, -N(Ra)-O- 또는 -O-CRaRb- 이고;
Y 는 산소, 황, -(CRaRb)n-, -CRaRb-O-CRaRb-, -C(Ra)=C(Rb)-, -C(Ra)=N-, -Si(Ra)2-, -SO2-, -NRa-, -C(=J)-, Se, -O-NRa-, -NRa-CRaRb-, -N(Ra)-O- 또는 -O-CRaRb- 이고;
단, -X-Y- 는 -O-O-, Si(Ra)2-Si(Ra)2-, -SO2-SO2-, -C(Ra)=C(Rb)-C(Ra)=C(Rb), -C(Ra)=N-C(Ra)=N-, -C(Ra)=N-C(Ra)=C(Rb), -C(Ra)=C(Rb)-C(Ra)=N- 또는 -Se-Se- 가 아니고;
J 는 산소, 황, =CH2 또는 =N(Ra) 이고;
Ra 및 Rb 는 수소, 할로겐, 하이드록실, 시아노, 티오하이드록실, 알킬, 치환된 알킬, 알케닐, 치환된 알케닐, 알키닐, 치환된 알키닐, 알콕시, 치환된 알콕시, 알콕시알킬, 알케닐옥시, 카르복실, 알콕시카르보닐, 알킬카르보닐, 포르밀, 아릴, 헤테로시클릴, 아미노, 알킬아미노, 카르바모일, 알킬아미노카르보닐, 아미노알킬아미노카르보닐, 알킬아미노알킬아미노카르보닐, 알킬카르보닐아미노, 카르바미도, 알카노일옥시, 설포닐, 알킬설포닐옥시, 니트로, 아지도, 티오하이드록실설파이드알킬설파닐, 아릴옥시카르보닐, 아릴옥시, 아릴카르보닐, 헤테로아릴, 헤테로아릴옥시카르보닐, 헤테로아릴옥시, 헤테로아릴카르보닐, -OC(=Xa)Rc, -OC(=Xa)NRcRd 및 -NReC(=Xa)NRcRd 로부터 독립적으로 선택되거나;
또는 2 개의 제미날(geminal) Ra 및 Rb 는 함께 임의 치환된 메틸렌을 형성하거나;
또는 2 개의 제미날 Ra 및 Rb 는, 이들이 부착된 탄소 원자와 함께, -X-Y- 의 오직 하나의 탄소 원자와 시클로알킬 또는 할로시클로알킬을 형성하고;
치환된 알킬, 치환된 알케닐, 치환된 알키닐, 치환된 알콕시 및 치환된 메틸렌은 할로겐, 하이드록실, 알킬, 알케닐, 알키닐, 알콕시, 알콕시알킬, 알케닐옥시, 카르복실, 알콕시카르보닐, 알킬카르보닐, 포르밀, 헤테로시클릴, 아릴 및 헤테로아릴로부터 독립적으로 선택된 1 내지 3 개의 치환기로 치환된 알킬, 알케닐, 알키닐 및 메틸렌이고;
Xa 는 산소, 황 또는 -NRc 이고;
Rc, Rd 및 Re 는 수소 및 알킬로부터 독립적으로 선택되고;
n 은 1, 2 또는 3 이고;
R5 는 하이드록실 보호기이고;
Rx 는 페닐, 니트로페닐, 페닐알킬, 할로페닐알킬, 시아노알킬, 페닐카르보닐설파닐알킬, 할로페닐카르보닐설파닐알킬 알킬카르보닐설파닐알킬 또는 알킬카르보닐카르보닐설파닐알킬이고;
Ry 는 디알킬아미노 또는 피롤리디닐이고;
Nu 는 핵염기 또는 보호된 핵염기임]. - 제 1 항에 있어서, -X-Y- 가 -CH2-O-, -CH(CH3)-O- 또는 -CH2CH2-O- 인 화합물.
- 제 1 항 또는 제 2 항에 있어서, 화학식 (III) 또는 (IV) 의 화합물인 화합물:

[식 중, R5, Rx, Ry 및 Nu 는 제 1 항에 정의된 바와 같음]. - 화학식 (IIb) 의 화합물:

[식 중, R5 는 하이드록실 보호기이고,
Rx 는 페닐, 니트로페닐, 페닐알킬, 할로페닐알킬, 시아노알킬, 페닐카르보닐설파닐알킬, 할로페닐카르보닐설파닐알킬 알킬카르보닐설파닐알킬 또는 알킬카르보닐카르보닐설파닐알킬이고;
Ry 는 디알킬아미노 또는 피롤리디닐이고;
Nu 는 핵염기 또는 보호된 핵염기임]. - 제 1 항 내지 제 4 항 중 어느 한 항에 있어서, Rx 가 페닐, 니트로페닐, 페닐메틸, 디클로로페닐메틸, 시아노에틸, 메틸카르보닐설파닐에틸, 에틸카르보닐설파닐에틸, 이소프로필카르보닐설파닐에틸, tert.-부틸카르보닐설파닐에틸, 메틸카르보닐카르보닐설파닐에틸 또는 디플루오로페닐카르보닐설파닐에틸인 화합물.
- 제 1 항 내지 제 5 항 중 어느 한 항에 있어서, Rx 가 페닐카르보닐설파닐알킬인 화합물.
- 제 1 항 내지 제 6 항 중 어느 한 항에 있어서, Rx 가 페닐카르보닐설파닐에틸인 화합물.
- 제 1 항 내지 제 7 항 중 어느 한 항에 있어서, Ry 가 디이소프로필아미노 또는 피롤리디닐인 화합물.
- 제 1 항 내지 제 8 항 중 어느 한 항에 있어서, Ry 가 피롤리디닐인 화합물.
- 제 1 항 내지 제 9 항 중 어느 한 항에 있어서, 화학식 (V) 의 화합물인 화합물:

[식 중, R5 및 Nu 는 제 1 항에 정의된 바와 같음]. - 제 4 항 내지 제 9 항 중 어느 한 항에 있어서, 화학식 (Vb) 의 화합물인 화합물:

[식 중, R5 및 Nu 는 제 4 항에 정의된 바와 같음]. - 제 1 항 내지 제 11 항 중 어느 한 항에 있어서, Nu 가 티민, 보호된 티민, 아데노신, 보호된 아데노신, 시토신, 보호된 시토신, 5-메틸시토신, 보호된 5-메틸시토신, 구아닌, 보호된 구아닌, 우라실 또는 보호된 우라실인 화합물.
- 제 1 항 내지 제 12 항 중 어느 한 항에 있어서, 하기로부터 선택되는 화합물:


- 제 1 항 내지 제 12 항 중 어느 한 항에 있어서, 하기로부터 선택되는 화합물:


- 산성 커플링제 및 실릴화제의 존재하의 5'-보호된 LNA 또는 MOE 뉴클레오시드와 포스핀 및 단일-보호된 디티올의 반응을 포함하는, 제 1 항 내지 제 14 항 중 어느 한 항에 따른 화학식 (II) 또는 (IIb) 의 화합물의 제조 방법.
- 제 15 항에 있어서, 산성 커플링제 및 실릴화제의 존재하의 화학식 (C) 또는 (Cb) 의 화합물과 화학식 P(Ry)3 의 화합물 및 화학식 HSRx 의 화합물의 반응을 포함하는, 화합물의 제조 방법:

[식 중, X, Y, R5, Nu, Rx 및 Ry 는 제 1 항 내지 제 12 항 중 어느 한 항에 정의된 바와 같음]. - 제 15 항 또는 제 16 항에 있어서, 산성 커플링제 및 실릴화제의 존재하의 화학식 (C1) 의 화합물과 화학식 P(Ry)3 의 화합물 및 화학식 HSRx 의 화합물의 반응을 포함하는 화합물의 제조 방법:

[식 중, R5, Nu, Rx 및 Ry 는 제 1 항 내지 제 12 항 중 어느 한 항에 정의된 바와 같음]. - 제 15 항 내지 제 17 항 중 어느 한 항에 있어서, 화학식 (II) 또는 (IIb) 의 미정제 화합물이 분취용 HPLC 에 의해 정제되는 화합물의 제조 방법.
- 제 18 항에 있어서, 화학식 (II) 또는 (IIb) 의 미정제 화합물이 아세토니트릴 대 물 중 암모늄 하이드록사이드의 구배로 용리되는 화합물의 제조 방법.
- 올리고뉴클레오티드의 제조에서의 제 1 항 내지 제 14 항 중 어느 한 항에 따른 화합물의 용도.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CNPCT/CN2017/118043 | 2017-12-22 | ||
| CN2017118043 | 2017-12-22 | ||
| EP18198487.3 | 2018-10-03 | ||
| EP18198487 | 2018-10-03 | ||
| PCT/EP2018/086457 WO2019122277A1 (en) | 2017-12-22 | 2018-12-21 | Novel thiophosphoramidites |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20200104302A true KR20200104302A (ko) | 2020-09-03 |
Family
ID=65003376
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020207017875A KR20200104302A (ko) | 2017-12-22 | 2018-12-21 | 신규 티오포스포르아미다이트 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US11597926B2 (ko) |
| EP (2) | EP3728590A1 (ko) |
| JP (2) | JP2021508327A (ko) |
| KR (1) | KR20200104302A (ko) |
| CN (1) | CN111448316A (ko) |
| WO (1) | WO2019122277A1 (ko) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019168687A1 (en) * | 2018-03-02 | 2019-09-06 | Dicerna Pharmaceuticals, Inc. | Compositions and methods for inhibiting gys2 expression |
| TW202028222A (zh) * | 2018-11-14 | 2020-08-01 | 美商Ionis製藥公司 | Foxp3表現之調節劑 |
| JPWO2021256297A1 (ko) * | 2020-06-15 | 2021-12-23 | ||
| JPWO2022065413A1 (ko) * | 2020-09-25 | 2022-03-31 |
Family Cites Families (54)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5602244A (en) * | 1988-05-26 | 1997-02-11 | Competitive Technologies, Inc. | Polynucleotide phosphorodithioate compounds |
| EP0463712A3 (en) | 1990-06-27 | 1992-04-08 | University Patents, Inc. | Polynucleotide phosphorodithioates as therapeutic agents for retroviral infections |
| EP1331011A3 (en) | 1991-10-24 | 2003-12-17 | Isis Pharmaceuticals, Inc. | Derivatized oligonucleotides having improved uptake and other properties |
| JP3756313B2 (ja) | 1997-03-07 | 2006-03-15 | 武 今西 | 新規ビシクロヌクレオシド及びオリゴヌクレオチド類縁体 |
| EP1557424A1 (en) | 1997-09-12 | 2005-07-27 | Exiqon A/S | Bi-cyclic nucleoside, nucleotide and oligonucleoide analogues |
| US6020475A (en) * | 1998-02-10 | 2000-02-01 | Isis Pharmeuticals, Inc. | Process for the synthesis of oligomeric compounds |
| US6867294B1 (en) * | 1998-07-14 | 2005-03-15 | Isis Pharmaceuticals, Inc. | Gapped oligomers having site specific chiral phosphorothioate internucleoside linkages |
| ID30093A (id) | 1999-02-12 | 2001-11-01 | Sankyo Co | Analog-analog nukleosida dan oligonukleotida baru |
| ES2283298T3 (es) | 1999-05-04 | 2007-11-01 | Santaris Pharma A/S | Analogos de l-ribo-lna. |
| US6617442B1 (en) | 1999-09-30 | 2003-09-09 | Isis Pharmaceuticals, Inc. | Human Rnase H1 and oligonucleotide compositions thereof |
| US6693187B1 (en) * | 2000-10-17 | 2004-02-17 | Lievre Cornu Llc | Phosphinoamidite carboxlates and analogs thereof in the synthesis of oligonucleotides having reduced internucleotide charge |
| DK2284269T3 (en) | 2002-11-18 | 2017-10-23 | Roche Innovation Ct Copenhagen As | Antisense design |
| CA2629323A1 (en) | 2005-11-10 | 2007-05-24 | The University Of North Carolina At Chapel Hill | Splice switching oligomers for tnf superfamily receptors and their use in treatment of disease |
| AU2007211080B9 (en) | 2006-01-27 | 2012-05-03 | Isis Pharmaceuticals, Inc. | 6-modified bicyclic nucleic acid analogs |
| KR101407707B1 (ko) | 2006-04-03 | 2014-06-19 | 산타리스 팔마 에이/에스 | Anti-mirna 안티센스 올리고뉴클레오타이드를 함유하는 약학적 조성물 |
| AU2007257094B2 (en) | 2006-05-05 | 2012-10-25 | Isis Pharmaceuticals, Inc. | Compounds and methods for modulating expression of SGLT2 |
| US7547684B2 (en) | 2006-05-11 | 2009-06-16 | Isis Pharmaceuticals, Inc. | 5′-modified bicyclic nucleic acid analogs |
| US7666854B2 (en) | 2006-05-11 | 2010-02-23 | Isis Pharmaceuticals, Inc. | Bis-modified bicyclic nucleic acid analogs |
| DK2092065T4 (da) | 2006-10-18 | 2019-10-21 | Ionis Pharmaceuticals Inc | Antisense-forbindelser |
| WO2008113832A2 (en) | 2007-03-22 | 2008-09-25 | Santaris Pharma A/S | SHORT RNA ANTAGONIST COMPOUNDS FOR THE MODULATION OF TARGET mRNA |
| KR101738655B1 (ko) | 2007-05-01 | 2017-05-22 | 로슈 이노베이션 센터 코펜하겐 에이/에스 | Tnf 슈퍼패밀리 수용체에 대한 스플라이스 스위칭 올리고머 및 질병 치료에 있어서의 그의 용도 |
| CA2688321A1 (en) | 2007-05-30 | 2008-12-11 | Isis Pharmaceuticals, Inc. | N-substituted-aminomethylene bridged bicyclic nucleic acid analogs |
| DK2173760T4 (en) | 2007-06-08 | 2016-02-08 | Isis Pharmaceuticals Inc | Carbocyclic bicyclic nukleinsyreanaloge |
| ES2376507T5 (es) | 2007-07-05 | 2015-08-31 | Isis Pharmaceuticals, Inc. | Análogos de ácidos nucleicos bicíclicos 6-disustituidos |
| CN101821391B (zh) | 2007-10-04 | 2016-04-27 | 桑塔里斯制药公司 | 微小聚体 |
| US8546556B2 (en) | 2007-11-21 | 2013-10-01 | Isis Pharmaceuticals, Inc | Carbocyclic alpha-L-bicyclic nucleic acid analogs |
| WO2009090182A1 (en) | 2008-01-14 | 2009-07-23 | Santaris Pharma A/S | C4'-substituted - dna nucleotide gapmer oligonucleotides |
| EP2356129B1 (en) | 2008-09-24 | 2013-04-03 | Isis Pharmaceuticals, Inc. | Substituted alpha-l-bicyclic nucleosides |
| WO2011017521A2 (en) | 2009-08-06 | 2011-02-10 | Isis Pharmaceuticals, Inc. | Bicyclic cyclohexose nucleic acid analogs |
| WO2011156202A1 (en) | 2010-06-08 | 2011-12-15 | Isis Pharmaceuticals, Inc. | Substituted 2 '-amino and 2 '-thio-bicyclic nucleosides and oligomeric compounds prepared therefrom |
| EP3702460A1 (en) | 2010-11-12 | 2020-09-02 | The General Hospital Corporation | Polycomb-associated non-coding rnas |
| EP3067421B1 (en) | 2011-02-08 | 2018-10-10 | Ionis Pharmaceuticals, Inc. | Oligomeric compounds comprising bicyclic nucleotides and uses thereof |
| WO2013022966A1 (en) | 2011-08-11 | 2013-02-14 | Isis Pharmaceuticals, Inc. | Linkage modified gapped oligomeric compounds and uses thereof |
| DK2751270T3 (en) | 2011-08-29 | 2018-10-29 | Ionis Pharmaceuticals Inc | OLIGOMER-CONJUGATE COMPLEXES AND THEIR USE |
| US9751909B2 (en) | 2011-09-07 | 2017-09-05 | Marina Biotech, Inc. | Synthesis and uses of nucleic acid compounds with conformationally restricted monomers |
| WO2013154798A1 (en) | 2012-04-09 | 2013-10-17 | Isis Pharmaceuticals, Inc. | Tricyclic nucleic acid analogs |
| EP2920304B1 (en) | 2012-11-15 | 2019-03-06 | Roche Innovation Center Copenhagen A/S | Oligonucleotide conjugates |
| SG11201508433TA (en) | 2013-04-12 | 2015-11-27 | Andaloussi Samir El | Therapeutic delivery vesicles |
| EP2992098B1 (en) | 2013-05-01 | 2019-03-27 | Ionis Pharmaceuticals, Inc. | Compositions and methods for modulating hbv and ttr expression |
| SG10201908122XA (en) | 2013-06-27 | 2019-10-30 | Roche Innovation Ct Copenhagen As | Antisense oligomers and conjugates targeting pcsk9 |
| JP2017505623A (ja) | 2014-01-30 | 2017-02-23 | エフ.ホフマン−ラ ロシュ アーゲーF. Hoffmann−La Roche Aktiengesellschaft | 生物切断性コンジュゲートを有するポリオリゴマー化合物 |
| EP3020813A1 (en) * | 2014-11-16 | 2016-05-18 | Neurovision Pharma GmbH | Antisense-oligonucleotides as inhibitors of TGF-R signaling |
| WO2016079181A1 (en) * | 2014-11-19 | 2016-05-26 | Roche Innovation Center Copenhagen A/S | Lna gapmer oligonucleotides comprising chiral phosphorothioate linkages |
| WO2016127002A1 (en) | 2015-02-04 | 2016-08-11 | Bristol-Myers Squibb Company | Lna oligonucleotides with alternating flanks |
| CN107636159B (zh) | 2015-02-04 | 2022-06-14 | 百时美施贵宝公司 | 选择治疗性分子的方法 |
| WO2016172598A1 (en) | 2015-04-22 | 2016-10-27 | The Broad Institute Inc. | Exosomes and uses thereof |
| EP3394258B1 (en) | 2015-10-22 | 2021-09-22 | Roche Innovation Center Copenhagen A/S | In vitro toxicity screening assay |
| WO2017173034A1 (en) | 2016-03-30 | 2017-10-05 | The University Of North Carolina At Chapel Hill | Biological agent-exosome compositions and uses thereof |
| US10882884B2 (en) * | 2016-05-18 | 2021-01-05 | Eth Zurich | Stereoselective synthesis of phosphorothioate oligoribonucleotides |
| US11105794B2 (en) | 2016-06-17 | 2021-08-31 | Hoffmann-La Roche Inc. | In vitro nephrotoxicity screening assay |
| CN109415732B (zh) | 2016-07-01 | 2024-01-02 | 豪夫迈·罗氏有限公司 | 用于调节htra1表达的反义寡核苷酸 |
| EP3491002A2 (en) | 2016-07-27 | 2019-06-05 | Roche Innovation Center Copenhagen A/S | Synthesis of oligonucleotides comprising achiral 3'-s- or 5'-s-phosphorothiolate internucleoside linkage |
| JP2019535839A (ja) | 2016-11-29 | 2019-12-12 | ピュアテック ヘルス エルエルシー | 治療剤の送達のためのエクソソーム |
| EP3620519A1 (en) | 2018-09-04 | 2020-03-11 | F. Hoffmann-La Roche AG | Use of isolated milk extracellular vesicles for delivering oligonucleotides orally |
-
2018
- 2018-12-21 EP EP18830479.4A patent/EP3728590A1/en active Pending
- 2018-12-21 EP EP21215936.2A patent/EP4092118A1/en active Pending
- 2018-12-21 KR KR1020207017875A patent/KR20200104302A/ko not_active Application Discontinuation
- 2018-12-21 JP JP2020534517A patent/JP2021508327A/ja active Pending
- 2018-12-21 CN CN201880079212.XA patent/CN111448316A/zh active Pending
- 2018-12-21 US US15/733,302 patent/US11597926B2/en active Active
- 2018-12-21 WO PCT/EP2018/086457 patent/WO2019122277A1/en active Search and Examination
-
2023
- 2023-07-28 JP JP2023122967A patent/JP2023139252A/ja active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| CN111448316A (zh) | 2020-07-24 |
| WO2019122277A1 (en) | 2019-06-27 |
| US20210115438A1 (en) | 2021-04-22 |
| JP2023139252A (ja) | 2023-10-03 |
| EP4092118A1 (en) | 2022-11-23 |
| JP2021508327A (ja) | 2021-03-04 |
| EP3728590A1 (en) | 2020-10-28 |
| US11597926B2 (en) | 2023-03-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2024041845A (ja) | ホスホロジチオアートヌクレオシド間結合を含むギャップマーオリゴヌクレオチド | |
| EP2612917B1 (en) | Antisense nucleic acid | |
| JP2023139252A (ja) | 新規のチオホスホラミダイト | |
| JP2022106785A (ja) | Htra1の発現を調節するためのアンチセンスオリゴヌクレオチド | |
| TW202219273A (zh) | 靶向rna結合蛋白位點之寡核苷酸 | |
| JP2024041886A (ja) | ホスホロジチオアートヌクレオシド間結合を含むオリゴヌクレオチド | |
| JP2021511029A (ja) | Srebp1を標的とするアンチセンスオリゴヌクレオチド | |
| KR20200108315A (ko) | Tmem106b의 발현을 조절하기 위한 올리고뉴클레오티드 | |
| KR20200015608A (ko) | Htra1 발현을 조절하기 위한 안티센스 올리고뉴클레오티드 | |
| TW202102676A (zh) | 調節atxn2表現之寡核苷酸 | |
| KR20200104339A (ko) | Htra1 rna 길항제에 대한 동반 진단제 | |
| TW202246500A (zh) | 用於抑制 rtel1 表現之增強型寡核苷酸 | |
| JP2021510295A (ja) | Gsk3b発現を調節するためのオリゴヌクレオチド | |
| WO2019038228A1 (en) | OLIGONUCLEOTIDES FOR MODULATION OF TOM1 EXPRESSION | |
| WO2020007889A1 (en) | Antisense oligonucleotides targeting stat1 | |
| WO2019145386A1 (en) | Oligonucleotides for modulating csnk1d expression | |
| WO2019115417A2 (en) | Oligonucleotides for modulating rb1 expression |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal | ||
| E601 | Decision to refuse application |