JP2008506191A - 可変サイズの高速直交変換を実施する方法および機器 - Google Patents
可変サイズの高速直交変換を実施する方法および機器 Download PDFInfo
- Publication number
- JP2008506191A JP2008506191A JP2007520491A JP2007520491A JP2008506191A JP 2008506191 A JP2008506191 A JP 2008506191A JP 2007520491 A JP2007520491 A JP 2007520491A JP 2007520491 A JP2007520491 A JP 2007520491A JP 2008506191 A JP2008506191 A JP 2008506191A
- Authority
- JP
- Japan
- Prior art keywords
- architecture
- butterfly
- stage
- unit
- reconfigurable
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images

















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/14—Fourier, Walsh or analogous domain transformations, e.g. Laplace, Hilbert, Karhunen-Loeve, transforms
- G06F17/141—Discrete Fourier transforms
- G06F17/142—Fast Fourier transforms, e.g. using a Cooley-Tukey type algorithm
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/14—Fourier, Walsh or analogous domain transformations, e.g. Laplace, Hilbert, Karhunen-Loeve, transforms
Abstract
Description
2004年7月8日に出願した「Low−Power Reconfigurable Architecture for Simultaneous Implementation of Distinct Communication Standards」という名称の米国特許仮出願第60/586,390号(整理番号66940−016)、
2004年7月8日に出願した「Method and Architecture for Implementation of Reconfigurable Matrix−Vector Computations」という名称の米国特許仮出願第60/586,391号(整理番号66940−017)、
2004年7月8日に出願した「Method and Architecture for Implementation of Reconfigurable Orthogonal Transformations」という名称の米国特許仮出願第60/586,389号(整理番号66940−018)、
2004年7月8日に出願した「Method and Architecture for Implementation of Reconfigurable Trellis−Type Coding」という名称の米国特許仮出願第60/586,353号(整理番号66940−019)、
2004年8月25日に出願した「A Method And Device For On−line Reconfigurable Vitter Decoding Of Recursive And Non−recursive Systematic Convolution Codes With Varying Parameters」という名称の米国特許仮出願第60/604,258号(整理番号66940−020)、ならびに
2005年3月3日に出願した「Low−Power Reconfigurable Architecture For Simultaneous Implementation Of Distinct Communication Standards」という名称の米国特許出願第11/071,340号(整理番号66940−021)。
NポイントDFT(離散フーリエ変換)(たとえば、A.V.Oppenheim及びR.W.Schaferの「Discrete−Time Signal Processing」(Prentice Hill、New Jersey、1989)を参照されたい)のデジタル計算は、

であり、上式で、複素指数係数は、
である。
一般的に使われる他の2つのFFTアルゴリズムは、周波数分割(DIF)および時間分割(DIT)アルゴリズムであり、この2つは、性質が似ている。DIFアルゴリズムは、FFT中間結果が、
および同様に、
を有する偶部および奇部に分割されるアーキテクチャの実装を示すのに用いられる。
標準的な従来技術の手法において、関数特有の再構成可能性を実現するためには、計算構造を分析することが第1に必要である。FFTは、バタフライ・ブロックからなる、シャッフル交換相互連結ネットワークと見なすことができ、このネットワークは、FFTのサイズと共に変化し、したがって、最もエネルギー効率がよい完全並列実装の柔軟性のサポートを困難にする。完全並列実装において、シグナル・フロー・グラフは、ハードウェア上に直接マップすることができる。たとえば、16ポイントFFTの場合、合計で32個のバタフライ・ユニットがあり、こうしたユニットは、図2のトレリスで示すように相互連結される。概して、NポイントFFTは、(N/2)log2N個のバタフライ・ユニットを必要とする。この最大並列アーキテクチャには、高性能および低電力消費の可能性があるが、特に大きいFFTサイズに対しては、コストが高い、大きいシリコン域をもっている。
X[10]=X[10102]=Y[01012]=Y[5]
となる。
列ベースのFFTアーキテクチャにおいて、計算は、相互連結が、図3のトレリスで示されるすべての段階において同一に保たれるように再構成される。バタフライへの入力は、出力が演算されるともはや必要とされないので、出力は、同じバタフライの入力に経路指定することができ、同じバタフライはしたがって、反復方式で次および後続の段階用に再利用される(インプレース計算)。その結果、ただ一列のバタフライが必要とされ、この列は、異なる計算段階によって再利用される(時分割される)。ただし、FFT係数は、段階ごとに変更される必要がある。概して、NポイントFFTは、N/2個のバタフライ・ユニットを必要とし、たとえば8個のバタフライが、16ポイントFFT用に必要とされる。その電力消費は、完全並列アーキテクチャに非常に近いが、より小さい区域を必要とする。再構成可能な設計にさらに変換することは、単純な反復構造が特定のサイズ向けに最適化されるので、複雑なタスクである。並列から列ベースの実装への転換は、FFTフレームを処理するより多くのクロックを必要とする。実際、並列手法は、1クロック・サイクルでのフルFFTフレームの処理を可能にするが、列手法は、反復時分割構造により、log2N個(radix−2ベースのバタフライ・アーキテクチャを用いるとき)のクロック周期を必要とする。
FFTアルゴリズムを稼動するために正規のパイプライン型アーキテクチャを選ぶことによって、FFT変換の計算量の標準下方境界によって提供されるものと比較してもエネルギー・オーバーヘッドが非常に低い、再構成可能な設計を実装することが可能である。
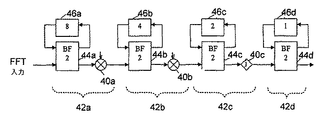
正規のパイプライン型アーキテクチャでは、ただ1つのバタフライ・ユニットが各段階ごとに使われ、完全並列手法での(N/2)log2Nおよび列ベースの手法でのN/2と比較して、合計でlog2Nの計算量となる。16ポイントFFTの長さに対するパイプライン手法の例を、図4に示してある。各段階42a、42bおよび42cの乗算器40は、ハードウェア要件同士を区別するために、バタフライ・ユニット44a、44bおよび44cとは区別される。バタフライ・ユニット44a、44b、44cおよび44dはそれぞれ、各段階ごとのN/2回のバタフライ演算の中で時分割される。バタフライ・ユニット44cを含む段階の場合、乗算器40cは「j」である。最後のバタフライ・ユニット44dの外には、乗算器は必要ない。パイプライン型ベースの実装は、列ベースの手法よりも、FFTフレームごとに、より多くのクロック周期を必要とする。というのは、パイプライン型ベースの手法は、N(radix−2ベースのバタフライ・アーキテクチャを用いるとき)クロック周期中にフルFFTフレームを実装することができ、列手法は、反復時分割構造により、log2N(radix−2ベースのバタフライ・アーキテクチャを用いるとき)クロック周期を必要とするからである。全段階のハードウェア実装において、FFTフレームを処理するクロック数は、障害とはならない。というのは、データは、直列に1フレームずつ挿入され、フレームごとのクロック周期数は、スループットが高いまま、一定の初期遅延に変換されるからである。
ハイブリッド手法は、列およびフィードバック手法の利益を兼ね備える。この手法は、フィードバック手法の要素を使ってメモリを保存し、列段階は、より優れたハードウェア使用に使われる。4ビット幅の列段階バタフライ・ユニットの使用は、より広いBUS幅および適正な再構成可能乗算器の利用と組み合わせることができる。このアーキテクチャは、高い空間使用率およびアルゴリズム効率のために必要な、正確なBUS幅をもつものにコンバートすることもできる。
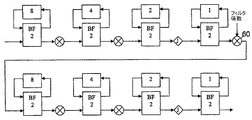
図6に示すような再構成可能な反復方式を用いると、効率が高いどの種類のフィルタも相関関数も実装することができる。この実装は、図6の60を見ると最もよく分かる、IFFTがその後に続く、フィルタ係数での乗算(時間領域乗算)用の、FFT変換の最終段階の乗算器を使うことによって遂行される。この実装は、FFT/IFFT、たとえば離散コサイン/サイン変換(DCTおよびDST)のどのサブプロダクト、ならびに(等化、予測、補間および相関の計算にも用いることができる)カスケード式FFTおよびIFFTアルゴリズムを用いるフィルタリングのような、上述したアルゴリズムの組合せであるどのアルゴリズムの実装においても効率的である。
radix−22アルゴリズムは、特に関心をもたれている。このアルゴリズムは、radix−4およびsplit−radixアルゴリズムそれぞれと乗算計算量が同じであり、同時に規則的なradix−2バタフライ構造を保持する。この空間的規則性は、VLSI実装用の他のアルゴリズムに勝る、構造上の大きな利点をもたらす。radix−22アルゴリズムの背景にある基本的な考え方は、正規のDIF FFTアルゴリズムの2段階をとり、実数/虚数スワップおよび符号反転のみを伴うW(N/4) N=Jによる自明な乗算の回数を最大にすることにある。言い換えると、FFT係数は再構成され、非自明な乗算は、すべての2段階においてただ1つの複素乗算器が必要とされるように一段階にまとめられる(全体的論理区域を削減する)。図7は、このような係数再構成を表すトレリスを(並列形で)示す。すなわち、どの2つのバタフライ係数、Wi NおよびW(i+(N/4)) Nに対しても、Wi Nが除かれ、次の段階に転送され、この段階は、係数1および
を、対応する位置に残す。この係数再構成を、係数ペアすべてに対して実施した後、一段階が、非自明な乗算なしで残される。
この10年間、いくつかのパイプライン型FFTアーキテクチャが提案されている。シグナル・フロー・グラフの空間規則性は、パイプライン型アーキテクチャにおいて保たれるので、高度にモジュール式であり拡張が容易である。シャッフル・ネットワーク80は、図8Aに示される単一パス遅延フィードバックを介して実装され、ここで、データは、単一パス中の段階82の間で処理され、フィードバックFIFOレジスタ84は、新たな入力および中間結果を格納するのに用いられる。この方式の背景にある基本的な考え方は、データを格納し、次の段階がデータを正しい順序で受け取ることができるようにスクランブルすることである。FIFOレジスタ84が、入力の前半部分で一杯になると、直前の結果の後半部分が、次の段階へシフトアウトされる。この間、演算要素は迂回される。入力の前半部分は、FIFOレジスタからシフトアウトされると、到着した入力の後半と共に処理要素に供給される。この間、演算要素は、2つの出力を操作し生成しており、1つは次の段階82に直接供給され、もう1つは、対応するFIFOレジスタにシフトインされる。乗算器(図示せず)は、必要な場合、radix−22またはradix−2アルゴリズムいずれかに従って、段階の間に挿入される。このような実装において使用するためのトレリスおよびデータ・パケットを、それぞれ図8B、8Cに示してある。
行列演算としてのradix−4変換に関する上記の考察から、アーキテクチャは、ウォルシュ拡散/逆拡散関数など、他の直交信号方式を処理するように容易に変えることができることがすぐにに分かる。後者は、乗算係数を、±1の自明なもので単に代用することによって、既存のアーキテクチャを用いて容易に実装することができる。さらに検討すると、非自明な係数および−jで乗算される係数のみが、変更される必要があることが分かる。さらに、非自明な乗算係数は、ウォルシュ拡散/逆拡散関数に必要とされる自明な乗算器の実装に必要なものをすべて、すなわちFFT←→IFFTと、−jでの乗算との間で変化するための能力を、既にもっている。ハードウェアに対する唯一の特別な要件は、コントローラ148を管理することにある。
2つの行列表現を比較することによって、2つの変換の間の関係を理解することができる。
radix−4変換は複素演算なので、実数ベクトルに対する2つの独立ウォルシュ拡散/逆拡散プロセスを取得する。というのは、±1での自明な乗数は、IとQ信号の間を入れ替わらないからである。したがって、この特徴は、たとえば、新しいWCDMA標準でのように、2finger RAKE受信機、または複素ウォルシュ拡散/逆拡散関数の実装用に用いることができる。また、第2の独立ウォルシュ拡散/逆拡散関数を、特別段階として使うことも、あるいは、適正な場所で、用意されたIおよびQによって、より大きいウォルシュ拡散/逆拡散用に使うこともできる(この可能性は、図9〜14に示す再構成可能なRadix22アーキテクチャにおいて既に実現されている)。
かっkお
回転乗数を使ってradix−2ベースのFFTを実施すると、乗数は、「1」にのみ変えることができる。図16は、16ポイントの、ウォルシュ拡散/逆拡散シーケンスの並列Radix−2(N=16)に基づく実装のトレリスの例、すなわち、変調/復調中の一連の16チップのウォルシュ拡散/逆拡散シーケンスの例を示す。
図17に示すように、4ビット幅の小さいradix22バタフライ・ユニットの「バンク」を組み合わせて、より広いBUS radix22を形成することができ、小さいRadixはそれぞれ、組合せ/分裂することができる、RAMの再構成可能な制御された「バンク」に接続される。BUS分裂用の再構成可能な乗算器は、上記方法に基づいて、非常に高い使用率および低電力消費である、任意の長さのIFFT/FFT/フィルタ/相関器およびウォルシュ/アダマール変換またはその任意の下位プロダクト、たとえば、CDMA DSSSコアもしくはDDS周波数フィルタも有する、再構成可能な「処理」コアを用いて実装することもでき、様々な並列/パイプライン/反復アルゴリズム・アーキテクチャ方式を含むいくつかのアルゴリズムがどの構成中でも稼動することができるとき、任意のBUS幅が必要になる。シリコンでのコアの実装は、最大クロック・レートを有するので、必要性による再構成は、任意の数の並列/パイプライン/反復アルゴリズム・アーキテクチャ方式をもたらし、各々が、いつでもアルゴリズムおよびシリコン実装資源用に、かつモデム実装のどの標準に対しても最適化され、したがって、高い使用性能を有する非常に小型の再構成アーキテクチャをもたらす。図17は、FFT/IFFTベクトルを処理する再構成可能なME−Iコアの例を示す。
最後に、一般直交変換を実装する再構成可能な装置の全体アーキテクチャを、Radix2i/xバタフライ変換の場合の図18に簡単に示す。計算ユニットは、Radix2、Radix22、Radix23、Radix4、Radix8などのバタフライ・ユニットを使用して実装することができる。この装置は好ましくは、再構成可能なRAMクラスタおよび再構成可能なBUSマルチプレクサ・ブロック180、1つまたは複数のバタフライ・ユニットを備える計算ユニット182、再構成可能な乗算器ブロック184、制御および記憶ユニット186ならびに検出装置188を備える。変換の各段階で、ユニット186は、2のバタフライ・ユニット内の乗算器の係数を、変換に従って修正する(対応する係数は、値{−1,1,j,−j}をとり得る)。ユニット182による演算の結果は、ユニット180(やはりユニット186によって制御される)のレジスタに格納される。レジスタのサイズは、段階ごとに変更される。格納されたデータの一部は、再構成可能な乗算器ブロック184に挿入され、データは、段階およびアルゴリズムに従って、制御および記憶ユニット186によって確立された係数で乗算される。乗算の結果は、ブロック180に格納される。ブロック180のマルチプレクサは、格納されたデータの多重化に使われる。各段階ごとにわずか1つのバタフライ・ユニットおよび1つのマルチプレクサを使えばよく、この1つのバタフライ・ユニットおよび乗算器は、ハードウェアを単に再構成することによって、各段階向けに再利用することができることが明らかであろう。
Claims (30)
- ベクトルの高速直交変換を多段階で実施する、再構成可能なアーキテクチャであって、ベクトルのサイズがNであり、Nは変化してよく、段階の数がNの関数であり、
1つまたは複数のバタフライ・ユニットを含むように構成され配置された計算ユニットと、
前記計算ユニットの出力に結合され、前記変換の少なくとも1つの段階向けの前記バタフライ演算をすべて実施するように構成され配置された1つまたは複数の乗算器を含むブロックと、
各バタフライ演算を実施する前記計算ユニットによる使用のために、前記バタフライ演算の中間結果および所定の係数を格納するように構成され配置された記憶ユニットであって、メモリおよび多重化アーキテクチャを含む前記記憶ユニットと、前記変換の前記バタフライ演算すべてを、前記段階用にただ1つの計算ユニットが必要とされるように前記一段階向けの前記計算ユニットを使って時分割するように構成され配置されたマルチプレクサ・ユニットと、
前記計算ユニットに係数を与え、前記記憶ユニット内のメモリのサイズおよび多重化アーキテクチャを制御するように構成され配置されたコントローラとを備え、
各段階用の、前記乗算器の係数、前記計算ユニットの前記係数、メモリのサイズ、および多重化アーキテクチャが、Nの値に応じて修正される、再構成可能なアーキテクチャ。 - 前記バタフライ・ユニットが、Radix2、Radix22、Radix23、Radix4、またはRadix8のアーキテクチャの1つで構成される、請求項1に記載の再構成可能なアーキテクチャ。
- 前記メモリ・レジスタがFIFOシフト・レジスタである、請求項1に記載の再構成可能なアーキテクチャ。
- 前記メモリ・レジスタの長さが、前記変換の前記段階の関数である、請求項1に記載の再構成可能なアーキテクチャ。
- 前記メモリ・レジスタの長さが、各後続段階と共に減少する、請求項1に記載の再構成可能なアーキテクチャ。
- 前記メモリ・レジスタの長さが、Nの値に応じて各段階ごとに調整される、請求項5に記載の再構成可能なアーキテクチャ。
- 前記マルチプレクサ・ユニットが、前記計算ユニットへの入力/出力ブロックを含む、請求項6に記載の再構成可能なアーキテクチャ。
- Nが、事前定義された範囲内で変化し、事前定義された範囲全体に入力サンプル・レートでのクロッキング周波数を提供するように構成され配置されたクロック・ユニットをさらに含む、請求項1に記載の再構成可能なアーキテクチャ。
- 前記アーキテクチャが、前記事前定義された範囲M全体が、ハードウェアに対する事前定義された範囲の前記変換をマップし、前記変換がM未満のときは不必要な計算ユニットを無効にすることによって調節されるように、前記ハードウェアとして配置された多数の計算ユニットを含む、請求項8に記載の再構成可能なアーキテクチャ。
- 前記アーキテクチャが、前記事前定義された範囲M全体より小さい「m」が調節されるように、ハードウェアとして配置された多数の計算ユニットを含み、前記段階が、「m」より大きい変換用の、少なくとも部分的に共有されたハードウェアである、請求項8に記載の再構成可能なアーキテクチャ。
- 各段階が、N/2回の計算を必要とする、請求項1に記載の再構成可能なアーキテクチャ。
- 複数の計算ユニットをさらに含み、1つが前記段階それぞれ用であり、前記計算ユニットが、パイプライン型アーキテクチャを提供するように実装される、請求項1に記載の再構成可能なアーキテクチャ。
- 複数の計算ユニットをさらに含み、1つが前記段階それぞれ用であり、前記計算ユニットが、パイプライン型、反復および並列のタイプの1つまたは複数で構成されたアーキテクチャを提供するように実装される、請求項1に記載の再構成可能なアーキテクチャ。
- 前記変換のフル・フレームが、Nクロック周期中で実装される、請求項1に記載の再構成可能なアーキテクチャ。
- 前記バタフライ・ユニットが、Radix2アーキテクチャを含む、請求項1に記載の再構成可能なアーキテクチャ。
- 前記バタフライ・ユニットが、Radix4アーキテクチャを含む、請求項1に記載の再構成可能なアーキテクチャ。
- 前記変換のフル・フレームが、N/2クロック周期中で実施される、請求項16に記載の再構成可能なアーキテクチャ。
- 変換アクセラレータをさらに含み、前記アクセラレータが、前記計算ユニット、記憶ユニット、およびマルチプレクサ・ユニットを含み、前記アクセラレータが、前記段階すべてに対する各バタフライ演算を、反復プロセスで実施するように構成され配置された、請求項1に記載の再構成可能なアーキテクチャ。
- 前記記憶ユニットが、フィルタ係数を含むように構成され配置され、前記変換の最終段階の前記計算ユニットの前記乗算器が、最終段階の出力を、フィルタリングされた出力を生じるように前記フィルタ係数の1つまたは複数で乗算するように適合される、請求項1に記載の再構成可能なアーキテクチャ。
- 前記フィルタリングされた出力が、直交変換の逆である変換の多段階の入力に加えられ、前記段階がそれぞれ、計算ユニットを含み、前記ユニットが、パイプライン型アーキテクチャを形成する、請求項19に記載の再構成可能なアーキテクチャ。
- 前記変換が高速フーリエ変換である、請求項1に記載の再構成可能なアーキテクチャ。
- 前記高速フーリエ変換が、異なるradixを含む、請求項21に記載の再構成可能なアーキテクチャ。
- 前記ベクトルが、実数ベクトルおよび複素ベクトル両方を含む、請求項1に記載の再構成可能なアーキテクチャ。
- 前記変換がウォルシュ直交変換を含む、請求項1に記載の再構成可能なアーキテクチャ。
- ベクトルの高速直交変換を多段階で実施する、再構成可能なアーキテクチャを備える集積チップであって、ベクトルのサイズがNであり、Nは変化してよく、段階の数がNの関数であり、前記アーキテクチャが、
1つまたは複数のバタフライ・ユニットを含むように構成され配置された計算ユニットと、
前記計算ユニットの出力に結合され、前記変換の少なくとも1つの段階向けの前記バタフライ演算をすべて実施するように構成され配置された1つまたは複数の乗算器を含むブロックと、
各バタフライ演算を実施する前記計算ユニットによる使用のために、前記バタフライ演算の中間結果および所定の係数を格納するように構成され配置された記憶ユニットであって、メモリおよび多重化アーキテクチャを含む前記記憶ユニットと、
メモリおよび多重化アーキテクチャを含む前記記憶ユニットと、
前記変換の前記バタフライ演算すべてを、前記段階用にただ1つの計算ユニットが必要とされるように前記一段階向けの前記計算ユニットを使って時分割するように構成され配置されたマルチプレクサ・ユニットと、
前記計算ユニットに係数を与え、前記記憶ユニット内のメモリのサイズおよび多重化アーキテクチャを制御するように構成され配置されたコントローラとを備え、
各段階用の、前記乗算器の係数、前記計算ユニットの前記係数、メモリのサイズ、および多重化アーキテクチャが、Nの値に応じて修正される集積チップ。 - 請求項25に記載の集積チップを含む通信システム。
- 前記ベクトルのサイズを判定する検出装置をさらに備える、請求項26に記載の通信システム。
- ベクトルの高速直交変換を多段階で実施する方法であって、ベクトルのサイズがNであり、Nは変化してよく、段階の数がNの関数であり、
計算ユニットを、1つまたは複数のバタフライ・ユニットを含むように、ブロックを、前記計算ユニットの出力に結合された1つまたは複数の乗算器を含むように構成し配列し、前記1つまたは複数のバタフライ・ユニットおよび1つまたは複数の乗算器を、前記変換の少なくとも1つの段階向けの前記バタフライ演算をすべて実施するように構成し配列すること、
各バタフライ演算を実施する前記計算ユニットによる使用のために、前記バタフライ演算の中間結果および所定の係数を記憶ユニットに格納することであって、前記記憶ユニットは、メモリおよび多重化アーキテクチャを含むこと、
前記変換の前記バタフライ演算すべてを、前記段階用にただ1つの計算ユニットが必要とされるように前記一段階向けの前記計算ユニットを使って時分割すること、ならびに
前記計算ユニットに係数を与え、前記記憶ユニット内のメモリのサイズおよび多重化アーキテクチャを制御することを含み、
各段階用の、前記乗算器の係数、前記計算ユニットの前記係数、メモリのサイズ、および多重化アーキテクチャが、Nの値に応じて修正される方法。 - ベクトルの高速直交変換を多段階で実施する方法であって、ベクトルのサイズがNであり、Nは変化してよく、段階の数がNの関数であり、
前記計算ユニットが、前記変換の少なくとも1つの段階向けの前記バタフライ演算すべてを実施することができるように、少なくとも1つの計算ユニットを、少なくとも1つのバタフライ・ユニットおよび前記バタフライ・ユニットの出力に結合された乗算器を含むように構成し配列することができるように構成され配置された、再構成可能な一群のバタフライ・ユニットおよび再構成可能な1組の乗算器、ならびに前記バタフライ演算の中間結果および各バタフライ演算の実施において使用するための所定の係数を格納するように前記計算ユニットに結合された再構成可能なメモリを使用することを含み、
各段階用の係数およびメモリのサイズが、Nの値に応じて修正される方法。 - ベクトルの高速直交変換を多段階で実施するシステムであって、ベクトルのサイズがNであり、Nは変化してよく、段階の数がNの関数であり、
前記計算ユニットが、前記変換の少なくとも1つの段階向けの前記バタフライ演算すべてを実施することができるように、少なくとも1つの計算ユニットを、少なくとも1つのバタフライ・ユニットおよび前記バタフライ・ユニットの出力に結合された乗算器を含むように構成し配列することができるように構成され配置された、再構成可能な一群のバタフライ・ユニットおよび再構成可能な1組の乗算器、ならびに前記バタフライ演算の中間結果および各バタフライ演算の実施において使用するための所定の係数を格納するように前記計算ユニットに結合された再構成可能なメモリを使用することを含み、
各段階用の係数およびメモリのサイズが、Nの値に応じて修正されるシステム。
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US58639104P | 2004-07-08 | 2004-07-08 | |
| US58639004P | 2004-07-08 | 2004-07-08 | |
| US58635304P | 2004-07-08 | 2004-07-08 | |
| US58638904P | 2004-07-08 | 2004-07-08 | |
| US60425804P | 2004-08-25 | 2004-08-25 | |
| US11/071,340 US7568059B2 (en) | 2004-07-08 | 2005-03-03 | Low-power reconfigurable architecture for simultaneous implementation of distinct communication standards |
| PCT/US2005/024063 WO2006014528A1 (en) | 2004-07-08 | 2005-07-08 | A method of and apparatus for implementing fast orthogonal transforms of variable size |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2008506191A true JP2008506191A (ja) | 2008-02-28 |
| JP2008506191A5 JP2008506191A5 (ja) | 2008-08-21 |
Family
ID=35787416
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007520491A Pending JP2008506191A (ja) | 2004-07-08 | 2005-07-08 | 可変サイズの高速直交変換を実施する方法および機器 |
Country Status (6)
| Country | Link |
|---|---|
| EP (1) | EP1769391A1 (ja) |
| JP (1) | JP2008506191A (ja) |
| KR (1) | KR101162649B1 (ja) |
| AU (1) | AU2005269896A1 (ja) |
| CA (1) | CA2563450A1 (ja) |
| WO (1) | WO2006014528A1 (ja) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009110022A1 (ja) * | 2008-03-03 | 2009-09-11 | 富士通株式会社 | 無線通信装置 |
| WO2013042249A1 (ja) * | 2011-09-22 | 2013-03-28 | 富士通株式会社 | 高速フーリエ変換回路 |
| WO2014013726A1 (ja) * | 2012-07-18 | 2014-01-23 | 日本電気株式会社 | Fft回路 |
| JPWO2013042249A1 (ja) * | 2011-09-22 | 2015-03-26 | 富士通株式会社 | 高速フーリエ変換回路 |
| US9880975B2 (en) | 2013-12-13 | 2018-01-30 | Nec Corporation | Digital filter device, digital filter processing method, and storage medium having digital filter program stored thereon |
| US9934199B2 (en) | 2013-07-23 | 2018-04-03 | Nec Corporation | Digital filter device, digital filtering method, and storage medium having digital filter program stored thereon |
| JP2019511056A (ja) * | 2016-04-01 | 2019-04-18 | エイアールエム リミテッド | 複素数乗算命令 |
| WO2021157172A1 (ja) * | 2020-02-06 | 2021-08-12 | 三菱電機株式会社 | 複素乗算回路 |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR2935819B1 (fr) * | 2008-09-05 | 2010-09-10 | Commissariat Energie Atomique | Dispositif de traitement numerique pour transformee de fourier et filtrage a reponse impulsionnelle finie |
| CN102737007B (zh) * | 2011-04-07 | 2015-01-28 | 中兴通讯股份有限公司 | 一种支持多个数据单元任意置换的方法和装置 |
| KR101275087B1 (ko) | 2011-10-28 | 2013-06-17 | (주)에프씨아이 | 오에프디엠 수신기 |
| KR102155770B1 (ko) * | 2018-11-27 | 2020-09-14 | 한국항공대학교산학협력단 | 레이다 응용을 위한 이중 완전 셔플 네트워크 기반 가변 푸리에 변환 장치 및 방법 |
| CN113111300B (zh) * | 2020-01-13 | 2022-06-03 | 上海大学 | 具有优化资源消耗的定点fft实现系统 |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH02504682A (ja) * | 1987-08-21 | 1990-12-27 | コモンウエルス・サイエンティフィック・アンド・インダストリアル・リサーチ・オーガニゼイション | 変換処理回路 |
| US5293330A (en) * | 1991-11-08 | 1994-03-08 | Communications Satellite Corporation | Pipeline processor for mixed-size FFTs |
| WO1997019412A1 (en) * | 1995-11-17 | 1997-05-29 | Teracom Svensk Rundradio | Improvements in or relating to real-time pipeline fast fourier transform processors |
| JP2001514771A (ja) * | 1997-01-06 | 2001-09-11 | ジョンソン、ロバート・ダブリュ | 無次元高速フーリエ変換法及び装置 |
| JP2002501253A (ja) * | 1998-01-21 | 2002-01-15 | テレフオンアクチーボラゲット エル エム エリクソン(パブル) | パイプライン高速フリーエ変換プロセッサ |
| JP2002215605A (ja) * | 2001-01-19 | 2002-08-02 | Sony Corp | 演算システム |
| JP2004153800A (ja) * | 2002-10-07 | 2004-05-27 | Matsushita Electric Ind Co Ltd | 通信装置及び通信装置再構築方法 |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11143860A (ja) * | 1997-11-07 | 1999-05-28 | Matsushita Electric Ind Co Ltd | 直交変換装置 |
| JP2001156644A (ja) * | 1999-11-29 | 2001-06-08 | Fujitsu Ltd | 直交変換装置 |
| US20030055861A1 (en) * | 2001-09-18 | 2003-03-20 | Lai Gary N. | Multipler unit in reconfigurable chip |
-
2005
- 2005-07-08 JP JP2007520491A patent/JP2008506191A/ja active Pending
- 2005-07-08 AU AU2005269896A patent/AU2005269896A1/en not_active Abandoned
- 2005-07-08 KR KR1020077003027A patent/KR101162649B1/ko not_active IP Right Cessation
- 2005-07-08 CA CA002563450A patent/CA2563450A1/en not_active Abandoned
- 2005-07-08 WO PCT/US2005/024063 patent/WO2006014528A1/en active Application Filing
- 2005-07-08 EP EP05768342A patent/EP1769391A1/en not_active Withdrawn
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH02504682A (ja) * | 1987-08-21 | 1990-12-27 | コモンウエルス・サイエンティフィック・アンド・インダストリアル・リサーチ・オーガニゼイション | 変換処理回路 |
| US5293330A (en) * | 1991-11-08 | 1994-03-08 | Communications Satellite Corporation | Pipeline processor for mixed-size FFTs |
| WO1997019412A1 (en) * | 1995-11-17 | 1997-05-29 | Teracom Svensk Rundradio | Improvements in or relating to real-time pipeline fast fourier transform processors |
| JP2001514771A (ja) * | 1997-01-06 | 2001-09-11 | ジョンソン、ロバート・ダブリュ | 無次元高速フーリエ変換法及び装置 |
| JP2002501253A (ja) * | 1998-01-21 | 2002-01-15 | テレフオンアクチーボラゲット エル エム エリクソン(パブル) | パイプライン高速フリーエ変換プロセッサ |
| JP2002215605A (ja) * | 2001-01-19 | 2002-08-02 | Sony Corp | 演算システム |
| JP2004153800A (ja) * | 2002-10-07 | 2004-05-27 | Matsushita Electric Ind Co Ltd | 通信装置及び通信装置再構築方法 |
Cited By (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009110022A1 (ja) * | 2008-03-03 | 2009-09-11 | 富士通株式会社 | 無線通信装置 |
| WO2013042249A1 (ja) * | 2011-09-22 | 2013-03-28 | 富士通株式会社 | 高速フーリエ変換回路 |
| JPWO2013042249A1 (ja) * | 2011-09-22 | 2015-03-26 | 富士通株式会社 | 高速フーリエ変換回路 |
| WO2014013726A1 (ja) * | 2012-07-18 | 2014-01-23 | 日本電気株式会社 | Fft回路 |
| JPWO2014013726A1 (ja) * | 2012-07-18 | 2016-06-30 | 日本電気株式会社 | Fft回路 |
| US9525579B2 (en) | 2012-07-18 | 2016-12-20 | Nec Corporation | FFT circuit |
| US9934199B2 (en) | 2013-07-23 | 2018-04-03 | Nec Corporation | Digital filter device, digital filtering method, and storage medium having digital filter program stored thereon |
| US9880975B2 (en) | 2013-12-13 | 2018-01-30 | Nec Corporation | Digital filter device, digital filter processing method, and storage medium having digital filter program stored thereon |
| JP2019511056A (ja) * | 2016-04-01 | 2019-04-18 | エイアールエム リミテッド | 複素数乗算命令 |
| WO2021157172A1 (ja) * | 2020-02-06 | 2021-08-12 | 三菱電機株式会社 | 複素乗算回路 |
| JP7317151B2 (ja) | 2020-02-06 | 2023-07-28 | 三菱電機株式会社 | 複素乗算回路 |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2005269896A1 (en) | 2006-02-09 |
| WO2006014528A1 (en) | 2006-02-09 |
| CA2563450A1 (en) | 2006-02-09 |
| KR101162649B1 (ko) | 2012-07-06 |
| EP1769391A1 (en) | 2007-04-04 |
| KR20070060074A (ko) | 2007-06-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7870176B2 (en) | Method of and apparatus for implementing fast orthogonal transforms of variable size | |
| JP2008506191A (ja) | 可変サイズの高速直交変換を実施する方法および機器 | |
| KR101842061B1 (ko) | 필터 벡터 프로세싱 연산들을 위해 탭핑-지연 라인을 이용하는 벡터 프로세싱 엔진, 및 관련된 벡터 프로세서 시스템들 및 방법들 | |
| KR101781057B1 (ko) | 실행 유닛들과 벡터 데이터 메모리 사이에 병합 회로를 갖는 벡터 프로세싱 엔진, 및 관련된 방법 | |
| US9977676B2 (en) | Vector processing engines (VPEs) employing reordering circuitry in data flow paths between execution units and vector data memory to provide in-flight reordering of output vector data stored to vector data memory, and related vector processor systems and methods | |
| US9880845B2 (en) | Vector processing engines (VPEs) employing format conversion circuitry in data flow paths between vector data memory and execution units to provide in-flight format-converting of input vector data to execution units for vector processing operations, and related vector processor systems and methods | |
| US7720897B2 (en) | Optimized discrete fourier transform method and apparatus using prime factor algorithm | |
| US9619227B2 (en) | Vector processing engines (VPEs) employing tapped-delay line(s) for providing precision correlation / covariance vector processing operations with reduced sample re-fetching and power consumption, and related vector processor systems and methods | |
| EP0329023A2 (en) | Apparatus for performing digital signal processing including fast fourier transform radix-4 butterfly computations | |
| US20150143076A1 (en) | VECTOR PROCESSING ENGINES (VPEs) EMPLOYING DESPREADING CIRCUITRY IN DATA FLOW PATHS BETWEEN EXECUTION UNITS AND VECTOR DATA MEMORY TO PROVIDE IN-FLIGHT DESPREADING OF SPREAD-SPECTRUM SEQUENCES, AND RELATED VECTOR PROCESSING INSTRUCTIONS, SYSTEMS, AND METHODS | |
| EP1546863B1 (en) | Computationally efficient mathematical engine | |
| Revanna et al. | A scalable FFT processor architecture for OFDM based communication systems | |
| CN100547580C (zh) | 用于实现可变大小的快速正交变换的方法和装置 | |
| Vergara et al. | A 195K FFT/s (256-points) high performance FFT/IFFT processor for OFDM applications | |
| EP0942379A1 (en) | Pipelined fast fourier transform processor | |
| KR100416641B1 (ko) | 프로그래머블 프로세서에서 고속 에프에프티 연산을 위한에프에프티 연산방법 및 그 연산을 실행하기 위한에프에프티 연산회로 | |
| Sakthivel et al. | Design of dynamically reconfigurable fully optimized low power FFT architecture for MC-CDMA receiver |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080703 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20080703 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20110223 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110228 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20110531 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20110607 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110831 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120206 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20120502 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20120511 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120806 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120828 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20121128 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20121205 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20130423 |