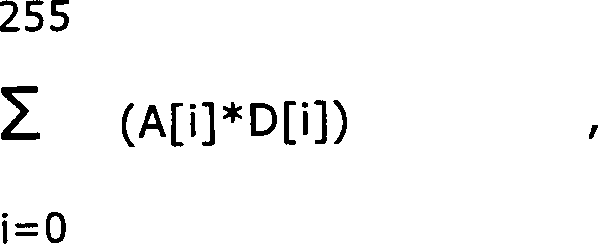-
HINTERGRUND
DER ERFINDUNG
-
Gebiet der Erfindung
-
Die vorliegende Erfindung bezieht
sich auf einen Datenprozessor für
die digitale Signalverarbeitung mit hoher Geschwindigkeit sowie
auf ein Verfahren zum Verarbeiten von Daten für eine digitale Signalverarbeitung
mit hoher Geschwindigkeit.
-
Beschreibung
des einschlägigen
Standes der Technik
-
Digitale Signalprozessoren (DSPs)
mit einer Architektur, die für
die Signalverarbeitung geeignet ist, sind bereits als Datenprozessoren
in Verwendung, die speziell für
eine digitale Signalverarbeitung mit hoher Geschwindigkeit ausgebildet
sind. Diese DSPs führen
Verarbeitungen aus, wie sie bei der Signalverarbeitung häufig zur
Anwendung kommen, wie zum Beispiel Multiplikations-Additions-Operationen
mit hoher Geschwindigkeit. Ein Beispiel für die DSPs ist der Motorola
DSP56000. Der DSP56000 weist zwei Adressenzeiger, zwei Datenspeicher
und eine Multiplikations-Additions-Operationseinheit auf.
-
Die parallele Ausführung der
Ladung von Daten (z. B. der Ladung von Koeffizienten und Daten) aus
zwei 1-Wort-Speichern, die jeweils von den Adressenzeigern bezeichnet
werden, die Aktualisierung der beiden Adressenzeiger sowie die Multiplikations-Additions-Operation
ermöglichen
die Ausführung
der Multiplikations-Additions-Operation mit hohem Durchsatz (DSP56000
Digital Signal Processor Family Manual 1992). Auf diese Weise hat
der DSP normalerweise zwei Speicher. Daten werden auf beide der
Speicher verteilt. Manche DSPs verwenden einen RAM mit zwei Anschlußstellen
für eine
effiziente Datenübertragung.
-
Ein Beispiel von Mikroprozessoren,
in die die DSP-Funktion integriert ist, beinhaltet die Motorola-CPU16.
Die CPU16 kann die Multiplikations-Additions-Operation und das 2-Wort-Laden ansprechend auf
einen einzigen RMAC-Befehl wiederholt ausführen. Die CPU16, bei der eine
Multiplikations-Addition zwölf
Zyklen benötigt,
hat jedoch Schwierigkeiten, ein Leistungsvermögen zu erzielen, das mit den DSPs
konkurrieren kann (CPU16 Reference Manual 1992).
-
In den letzten Jahren sind einige
Mikroprozessoren bei gesteigerter Betriebsfrequenz für die Ausführung der
Signalverarbeitung mittels Software vorgesehen worden. Zum Verbessern
der Rechenleistung sehen einige der Mikroprozessoren außerdem Multiplikations-Additions-Operationsbefehle
vor und führen
die kompliziertesten, parallelen Verarbeitungstechniken, wie zum
Beispiel Superpipeline- und superskalare Techniken, zum Erzielen
eines Leistungsvermögens
auf DSP-Niveau aus. Zum Beispiel kann der PowerPC603 (Motorola und
IBM) eine Gleitkomma-Multiplikations-Additions-Operation mit einfacher
Genauigkeit mit einem Durchsatz in einem einzigen Taktzyklus unter
Verwendung einer 3-Stufen-Pipelineverarbeitung
ausführen.
-
Dies macht viel Hardware und eine äußerst komplizierte
Steuerung erforderlich. Zur Ausführung einer
einzigen Multiplikations-Additions-Operation für jeden Taktzyklus benötigt ein
einziger Taktzyklus 2-Wort-Daten. Der PowerPC603 kann maximal ein Wort
für jeden
Taktzyklus laden, was zu einem unzulänglichen Vorrat an Operanden
führt (Proceedings of
COMPCON 1994: "The PowerPC603 Microprocessor: A High Performance,
Low Power, Superscalar RISC Microprocessor", PowerPC603 RISC Microprocessor
User's Manual 1994).
-
Die DSPs, die zwei Speicher beinhalten müssen, weisen
eine komplizierte Speicherkonstruktion auf und benötigen ein
sehr mühsames
Datenmanagement für
die Verteilung von Daten zwischen den beiden Speichern. Die Verwendung
eines RAM mit zwei Anschlußstellen
erhöht
die Fläche
bzw. Größe und Kosten
des Datenprozessors. Ferner handelt es sich bei dem DSP im allgemeinen
um eine Akkumulatormaschine, und er kann eine komplizierte Datenverarbeitung
nur mit Schwierigkeiten ausführen.
-
Die Mikroprozessoren, die einen einzigen Speicher
benötigen,
weisen eine relativ einfache Speicherkonstruktion auf. Die Mikroprozessoren
sind in der Signalverarbeitung jedoch nicht effizient, und zwar
im Gegensatz zu den DSPs, bei denen die Hardware direkt den Fluß der Signalverarbeitung darstellt.
Zur Erzielung eines Leistungsvermögens auf DSP-Niveau benötigen die
Mikroprozessoren des Standes der Technik ein größeres Ausmaß an Hardware, so daß die Kosten
des Datenprozessors weiter steigen. Ferner besteht bei den Mikroprozessoren die
Schwierigkeit, den Stromverbrauch zu reduzieren, da sie bei hohen
Frequenzen arbeiten müssen.
-
NAKAJIMA M. et al.: 'Ohmega: a VLSI
superscalar processor architecture for numerical applications' COMPUTER
ARCHITECTURE NEWS, Band 19, Nr. 3, Mai 1991, USA, Seiten 160–168, offenbaren
einen Datenprozessor mit einem Befehlsspeicher zum Speichern von
Befehlen, die einen ersten Operationscode und einen zweiten Operationscode
beinhalten, einen Datenspeicher, eine Befehlsdecodiereinheit zum
Decodieren des ersten und des zweiten Befehlscodes parallel miteinander,
eine Registerdatei, mehrere Operationseinheiten zum Ausführen einer
Rechenoperation sowie eine Operandenzugriffseinheit, die parallel
mit der Operationseinheit betrieben wird.
-
KURZBESCHREIBUNG
DER ERFINDUNG
-
Gemäß der vorliegenden Erfindung,
wie sie in Anspruch 1 definiert ist, weist ein Datenprozessor Folgendes
auf: einen ersten Speicherbereich zum Speichern eines Befehls, der
einen ersten Operationscode und einen zweiten Operationscode aufweist;
einen zweiten Speicherbereich zum Speichern von Daten; eine Befehlsdecodiereinheit
zum Empfangen des in dem ersten Speicherbereich gespeicherten Befehls,
wobei die Befehlsdecodiereinheit einen ersten und einen zweiten
Decodieren zum Decodieren des ersten bzw. zweiten Operationscodes
parallel miteinander aufweist; einen Registerdateibereich, der eine
Vielzahl von Registern zum Speichern von Daten aufweist, um Daten
aus dem zweiten Speicherbereich sowie in den zweiten Speicherbereich
zu übertragen;
eine Operationseinheit zum Empfangen von ersten Daten, die in einem
ersten Register des Registerdateibereichs gespeichert sind, um unter
Verwendung der ersten Daten eine Rechen operation in Abhängigkeit
von einem Steuersignal auszuführen,
wobei es sich bei dem Steuersignal um den von dem ersten Decodieren
der Befehlsdecodiereinheit decodierten ersten Operationscode handelt;
sowie eine Operandenzugriffseinheit, die parallel mit der Operationseinheit
betrieben wird, um die parallele Übertragung von in dem zweiten
Speicherbereich gespeicherten zweiten und dritten Daten sowie die
Speicherung derselben in einem zweiten bzw. dritten Register des
Registerdateibereichs in Abhängigkeit
von einem Steuersignal zu veranlassen, wobei es sich bei dem Steuersignal
um den von dem zweiten Decodieren der Befehlsdecodiereinheit decodierten,
zweiten Operationscode handelt.
-
Gemäß der vorliegenden Erfindung
handelt es sich bei den zweiten und dritten Daten jeweils um Daten
mit einer Länge
von n Bits (wobei n eine natürliche
Zahl ist), wobei die zweiten und die dritten Daten zu 2n-Bit-Daten
kombiniert werden, wenn die zweiten und dritten Daten in den Registerdateibereich übertragen
werden.
-
Gemäß der vorliegenden Erfindung
beinhaltet die Operationseinheit einen Multiplizierer zum miteinander
Multiplizieren der ersten Daten und der vierten Daten, die in einem
vierten Register des Registerdateibereichs gespeichert sind, sowie
einen Addieren, um mindestens zwei Daten zusammen zu addieren, wobei
der Addierer das Resultat der Multiplikation des Multiplizierers
sowie die in einem Register des Registerdateibereichs gespeicherten
Daten zusammen addiert, so daß ein
Register des Registerdateibereichs das Ergebnis der Addition speichert.
-
Ein Ziel der vorliegenden Erfindung
besteht somit in der Angabe eines kostengünstigen Hochleistungs-Datenprozessors
vom Mikroprozessor-Typ, bei dem sich bei einer relativ einfachen
Steuerung der Stromverbrauch einfach reduzieren läßt.
-
Ein weiteres Ziel der vorliegenden
Erfindung besteht in der Angabe eines Datenprozessors, der ein Leistungsvermögen der
digitalen Signalverarbeitung auf DSP-Niveau aufweist.
-
Noch ein weiteres Ziel der vorliegenden
Erfindung besteht in der Angabe eines Verfahrens zum Verarbeiten
von Daten, mit dem sich eine Hochleistungs-Datenverarbeitungssteuerung erzielen
läßt.
-
Diese sowie weitere Ziele, Merkmale,
Gesichtspunkte und Vorteile der vorliegenden Erfindung werden aus
der nachfolgenden ausführlichen
Beschreibung der vorliegenden Erfindung in Verbindung mit den Begleitzeichnungen
noch deutlicher.
-
KURZBESCHREIBUNG
DER ZEICHNUNGEN
-
Es zeigen:
-
1 eine
Darstellung eines Satzes von Registern für einen Datenprozessor gemäß einem
ersten bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
2 eine
Darstellung eines Prozessor-Statusworts für den Datenprozessor gemäß dem ersten bevorzugten
Ausführungsbeispiel
der vorliegenden Erfindung;
-
3 eine
Darstellung eines Befehlsformats für den Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
4 eine
Darstellung eines kurzen Formats eines 2-Operanden-Befehls für den Datenprozessor
gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
5 eine
Darstellung eines kurzen Formats eines Verzweigungsbefehls für den Datenprozessor
gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
6 eine
Darstellung eines langen Formats eines 3-Operanden-Befehls oder eines
Lade-/Speicherbefehls für
den Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
7 eine
Darstellung eines Formats eines Befehls, der einen Befehlscode in
seinem linken Behälter
aufweist, für
den Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
8 ein
Funktionsblockdiagramm des Datenprozessors gemäß dem ersten bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
9 ein
detailliertes Blockdiagramm einer ersten Operationseinheit für den Datenprozessor
gemäß dem ersten
bevorzugten Ausführungsbeispiel gemäß der vorliegenden
Erfindung;
-
10 ein
detailliertes Blockdiagramm einer PC-Einheit für den Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
11 ein
detailliertes Blockdiagramm einer zweiten Operationseinheit für den Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel der
vorliegenden Erfindung;
-
12 eine
Darstellung einer Pipeline-Verarbeitung für den Datenprozessor gemäß dem ersten bevorzugten
Ausführungsbeispiel
der vorliegenden Erfindung;
-
13 eine
Darstellung eines Pipeline-Zustands beim Auftreten einer Ladeoperanden-Störung in
dem Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
14 eine
Darstellung eines Pipeline-Zustands beim Auftreten einer Störung bei
der Rechen-Hardware in dem Datenprozessor gemäß dem ersten bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
15 eine
Darstellung eines Programms eines FIR-Filters mit 256 Abgriffen
für den
Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
16 eine
Darstellung eines Bit-Musters bei paralleler Ausführung eines
2-Wort-Ladebefehls und eines Multiplikations-Additions-Operationsbefehls
in dem Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
17 eine
Darstellung des Inhalts eines internen Befehlsspeichers, der einem
Schleifenteil des Programms des FIR-Filters entspricht, für den Datenprozessor
gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
18 eine
Abbildung eines internen Datenspeichers in Relation zu Koeffizienten
und Daten in dem Programm des FIR-Filters für den Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
19 eine
Darstellung der jeweiligen Positionen der 19A bis 19C;
-
19A–19C Darstellungen eines Ablaufs der Verarbeitung
in einer Schleife des Programms des FIR-Filters für den Datenprozessor
gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
20 eine
Darstellung von Signalleitungen eines Sekundär-Direktform-Typ-II-IIR-Filters
mit n Stufen;
-
21 eine
Darstellung eines Programms des IIR-Filters für den Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
22 eine
Darstellung des Inhalts des internen Befehlsspeichers, der einem
Schleifenteil des Programms des IIR-Filters entspricht, für den Datenprozessor
gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
23 eine
Abbildung des internen Datenspeichers in Relation zu Koeffizienten
und Daten in dem Programm des IIR-Filters für den Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
24 Darstellungen
der jeweiligen Positionen der 24A–24C;
-
24A–24C Darstellungen eines Flusses der Verarbeitung
in einer Schleife des Programms des IIR-Filters für den Datenprozessor
gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
25 eine
Darstellung eines Schleifenteils eines Programms eines IFFT für den Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel der
vorliegenden Erfindung;
-
26 eine
Darstellung eines Schleifenteils eines Programms einer Subtraktions-Absolutadditions-Operation
für den
Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
27 eine
Darstellung der jeweiligen Positionen der 27A–27C;
-
27A–27C Darstellungen eines Flusses der Verarbeitung
in der Schleife des Programms der Subtraktions-Absolutadditions-Operation
für den
Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
28 ein
detailliertes Blockdiagramm der zweiten Operationseinheit für den Datenprozessor gemäß einem
zweiten bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
29 eine
Darstellung eines Programms einer Subtraktions-Quadratadditions-Operation
für den
Datenprozessor gemäß dem zweiten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
30 eine
Darstellung des Inhalts des internen Befehlsspeichers, der einem
Schleifenteil des Programms der Subtraktions-Quadratadditions-Operation
entspricht, für
den Datenprozessor gemäß dem zweiten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
31 eine
Abbildung des internen Datenspeichers in Relation zu Daten in dem
Programm der Subtraktions-Quadratadditions-Operation für den Datenprozessor
gemäß dem zweiten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
32 eine
Darstellung der jeweiligen Positionen der 32A–32C;
-
32A–32C Darstellungen eines Flusses der Verarbeitung
in der Schleife des Programms der Subtraktions-Quadratadditions-Operation
für den Datenprozessor
gemäß dem zweiten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
33 eine
Darstellung des Inhalts des inneren Befehlsspeichers, der dem Schleifenteil
des Programms der Subtraktions-Absolutadditions-Operation entspricht,
für den
Datenprozessor gemäß dem zweiten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
34 eine
Darstellung der jeweiligen Positionen der 34A–34C;
-
34A–34C Darstellungen eines Flusses der Verarbeitung
in der Schleife des Programms der Subtraktions-Absolutadditions-Operation
für den
Datenprozessor gemäß dem zweiten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
35 ein
Funktionsblockdiagramm des Datenprozessors gemäß einem dritten bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
36 eine
Darstellung eines Befehlsformats für den Datenprozessor gemäß dem dritten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
37 ein
Blockdiagramm der zweiten Operationseinheit für den Datenprozessor gemäß einem vierten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
38 eine
Darstellung eines Befehlsformats für den Datenprozessor gemäß dem vierten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung;
-
39 eine
Darstellung eines grundlegenden Formats von Behältern eines Befehls für den Datenprozessor
gemäß einem
vierten bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung; und
-
40 eine
Darstellung eines Schleifenteils des Programms des FIR-Filters für den Datenprozessor
gemäß dem vierten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung.
-
BESCHREIBUNG
DER BEVORZUGTEN AUSFÜHRUNGSBEISPIELE
-
Erstes bevorzugtes
Ausführungsbeispiel
-
Im folgenden wird ein Datenprozessor
gemäß einem
ersten bevorzugten Ausführungsbeispiel der
vorliegenden Erfindung beschrieben. Bei dem Datenprozessor des ersten
bevorzugten Ausführungsbeispiels
handelt es sich um einen 16-Bit-Prozessor, dessen Adressen und Daten
eine Länge
von 16 Bit aufweisen.
-
1 zeigt
einen Satz von Registern für
den Datenprozessor dieses bevorzugten Ausführungsbeispiels. Der Datenprozessor
verwendet eine mit dem dicken Ende anfangende Bit- und Byte-Ordnung,
bei der das höchstwertige
Bit das Bit 0 ist.
-
16 Mehrzweckregister R0 bis R15 sind
zum Speichern von Daten und Adressenwerten vorgesehen. Die Mehrzweckregister
R0 bis R14 sind in 1 jeweils
mit den Bezugszeichen 1 bis 15 bezeichnet. Das
Mehrzweckregister R13 (das in 1 mit
14 bezeichnet ist) ist als Verbindungsgliedregister (VERBINDUNGSGLIED)
zum Speichern einer Rücksprungadresse
für einen
Unterprogrammsprung zugeteilt.
-
Bei dem Mehrzweckregister R15 handelt
es sich um ein Register für
einen Stapelzeiger (SP), der einen Unterbrechungs-Stapelzeiger (SPI) 16 und
einen Benutzer-Stapelzeiger (SPU) 17 aufweist. Ein später noch
zu beschreibendes Funktionszustandswort bzw. Prozessorstatuswort
(PSW) schaltet zwischen dem Unterbrechungs-Stapelzeiger (SPI) 16 und
dem Benutzer-Stapelzeiger (SPU) 17 um. Der SPI 16 und
der SPU 17 werden im folgenden allgemein als SP bezeichnet.
-
Die Anzahl von jedem der Register
ist in einem 4-Bit-Register-Spezifikationsfeld spezifiziert, falls
nichts anderes angegeben ist. Der Datenprozessor dieses bevorzugten
Ausführungsbeispiels
beinhaltet einen Befehl zum Abarbeiten eines Paares von Registern,
z. B. R0 und R1. In diesem Fall wird das Paar der Register derart
bezeichnet, daß ein
geradzahliges Register bezeichnet wird, um dadurch indirekt das
entsprechende Register mit der ungeraden Zahl zu spezifizieren,
das der geraden Zahl plus eins entspricht.
-
Die Bezugszeichen 21 bis 29 bezeichnen 16-Bit-Steuerregister.
Die Anzahl eines jeden der Steuerregister ist durch vier Bits dargestellt,
und zwar ähnlich
denen der Mehrzweckregister. Das mit dem Bezugszeichen 21 bezeichnete
Steuerregister CR0 ist ein Register für das Funktionszustandswort (PSW),
das ein Bit zum Spezifizieren des Betriebsmodus des Datenprozessors
sowie ein Flag beinhaltet, das das Ergebnis von Operationen anzeigt. 2 veranschaulicht die Konstruktion
des PSW 21.
-
Das Bezugszeichen 41 bezeichnet
ein SM-Bit (Bit 0), das einen Stapelmoduls zum Spezifizieren der
entsprechenden Beziehung anzeigt, wenn das Mehrzweckregister R15
in der vorstehend beschriebenen Weise spezifiziert wird. Das SM-Bit 41 zeigt
einen Unterbrechungsmodus an, wenn es "0" beträgt. Der SPI wird dann als Mehrzweckregister R15
verwendet. Das SM-Bit 41 zeigt einen Benutzermodus an,
wenn es "1" beträgt.
In diesem Fall wird der SPU als Mehrzweckregister R15 verwendet.
-
Das Bezugszeichen 42 bezeichnet
ein IE-Bit (Bit 5) zum Spezifizieren eines Unterbrechungs-Aktivierungszustands.
Wenn das IE-Bit "0" ist, wird die Unterbrechung deaktiviert (ignoriert,
wenn sich dies herausstellt). Wenn das IE-Bit "1" ist, wird die
Unterbrechung akzeptiert. In dem Datenprozessor dieses bevorzugten
Ausführungsbeispiels
wird eine Wiederholfunktion zum Erzielen einer Nullaufwand-Schleifenverarbeitung
ausgeführt.
-
Das Bezugszeichen 43 bezeichnet
ein RP-Bit (Bit 6), das einen Wiederholungszustand anzeigt. Das
RP-Bit zeigt an, daß keine
Wiederholung durchgeführt
wird, wenn es "0" ist. Das RP-Bit zeigt an, daß eine Wiederholung durchgeführt wird,
wenn es "1" ist. In dem Datenprozessor dieses bevorzugten Ausführungsbeispiels
wird eine Modulo-Adressierungsfunktion ausgeführt, bei der es sich um eine Adressierung
zum Zugreifen auf einen Ringpuffer handelt.
-
Das Bezugszeichen 44 bezeichnet
ein MD-Bit (Bit 7) zum Spezifizieren eines Modulo-Aktivierungszustands.
Wenn das MD-Bit "0" ist, wird die Modulo-Adressierung deaktiviert. Ist das MD-Bit
"1" wird die Modulo-Adressierung aktiviert. Das Bezugszeichen 45 bezeichnet
ein Ausführungssteuerflag (Bit 12),
an dem das Resultat eines Vergleichsbefehls oder dergleichen gesetzt
wird. Das Bezugszeichen 46 bezeichnet ein Übertrags-Flag
(Bit 15), an dem ein Übertrag
gesetzt wird, wenn Additions- und Subtraktionsbefehle ausgeführt werden.
-
Bei dem in 1 mit 23 bezeichneten Steuerregister
CR2 handelt es sich um ein Register für einen Programmzähler (PC),
der die ausgeführte
Befehlsadresse angibt. Die Länge
des von dem Datenprozessor dieses bevorzugten Ausführungsbeispiels verarbeiteten
Befehls ist im allgemeinen auf 32 Bits festgelegt. Der Programmzähler 23 enthält eine Wortadresse,
bei der 32 Bits ein Wort bilden.
-
Bei dem in 1 mit dem Bezugszeichen 22 bezeichneten
Steuerregister CR1 handelt es sich um ein Register für ein Sicherungs-Funktionszustandswort
bzw. Sicherungs-Prozessorstatuswort (BPSW), und bei dem in 1 mit dem Bezugszeichen 24 bezeichneten
Steuerregister CR3 handelt es sich um ein Register für einen
Sicherungsprogrammzähler (BPC).
Die Steuerregister CR1 und CR3 sind Register zum Sichern und Halten
der Werte des ausgeführten
PSW 21 und PC 23, wenn eine Ausnahme bzw. eine Unterbrechung
festgestellt wird.
-
Die Steuerregister 25 bis 27 sind
der Wiederholung zugeordnete Register, die einem Benutzer ein Lesen
und Schreiben der Werte derselben ermöglichen, so daß eine Unterbrechung
während
einer Wiederholung akzeptiert wird. Bei dem in 1 mit dem Bezugzeichen 25 bezeichneten
Steuerregister CR7 handelt es sich um ein Register für einen
Wiederholungszähler
(RPT_C) zum Halten des Zählwerts,
der den anschließenden
Wiederholungszählwert
angibt.
-
Bei dem in 1 mit dem Bezugszeichen 26 bezeichneten
Steuerregister CR8 handelt es sich um ein Register für eine Wiederholungs-Startadresse (RPT_S)
zum Halten der ersten Befehlsadresse in dem zu wiederholenden Block.
Bei dem in 1 mit 27
bezeichneten Steuerregister CR9 handelt es sich um ein Register für eine Wiederholungs-Endadresse (RPT_E)
zum Halten der letzten Befehlsadresse in dem zu wiederholenden Block.
-
Die Steuerregister 28 und 29 sind
für die Ausführung einer
Modulo-Adressierung vorgesehen. Das in 1 mit 28 bezeichnete Steuerregister CR10
hält eine
Modulo-Startadresse (MOD_S), und das in 1 mit 29 bezeichnete Steuerregister CR11 hält eine
Modulo-Endadresse (MOD_E). Beide der Steuerregister CR10 und CR11
halten die ersten und letzten Wortadressen (mit 16 Bits).
-
Wenn die Modulo-Adressierung während eines
Inkrements verwendet wird, dann wird die niedrigere Adresse auf
die Adresse MOD_S 28 gesetzt und die höhere Adresse wird auf die Adresse
MOD_E 29 gesetzt. Wenn der in dem zu inkrementierenden Register
gehaltene ursprüngliche
Wert mit der Adresse übereinstimmt,
die in der MOD_E 29 enthalten ist, wird der in der Adresse
MOD_S 28 enthaltene Wert als inkrementiertes Resultat auf
das Register zurückgeschrieben.
-
Die Bezugszeichen 31 und 32 bezeichnen 40-Bit-Akkumulatoren
A0 und A1 zum Halten des Resultats einer Multiplikations-Additions-Operation
in einem Ganzzahlformat. Die in 1 mit
31 und 32 bezeichneten Akkumulatoren A0 und A1 weisen Bereiche AOH
(31b) und A1H (32b) zum Halten der höherwertigen
16 Bits des Ergebnisses der Multiplikations-Additions-Operation,
Bereiche A0L (31c) und A1L (32c) zum Halten der
niederwertigen 16 Bits des Ergebnisses der Multiplikations-Additions-Operation sowie
der 8 Schutzbitbereiche A0G (31a) und A1G (32a)
zum Halten von Bits auf, die jeweils aus den höherwertigen Bits des Ergebnisses
der Multipliaktions-Additions-Operation übergelaufen sind.
-
Der Datenprozessor des ersten bevorzugten Ausführungsbeispiels
verarbeitet einen 2-Weg-VLIW-Befehlssatz (VLIW = Very Long Instruction
Word bzw. sehr langes Befehlswort). 3 veranschaulicht
ein Befehlsformat für
den Datenprozessor des ersten bevorzugten Ausführungsbeispiels. Die Länge des
Befehls ist im allgemeinen auf 32 Bits festgelegt, und der Befehl
ist in 4-Byte-(32-Bit-)Grenzen
ausgerichtet. Jeder 32-Bit-Befehlscode besitzt zwei Formatspezifikationsbits
(FM-Bits) 51, die das Format des Befehls angeben, einen
linken 15-Bit-Behälter 52 und
einen rechten 15-Bit-Behälter
53.
-
In jedem der Behälter 52 und 53 kann
ein 15-Bit-Kurzformat-Unterbefehl gespeichert werden. Ferner können die
Behälter 52 und 53 zusammen
einen 30-Bit-Langformat-Unterbefehl speichern. Aus Gründen der
Vereinfachung werden der Kurzformat-Unterbefehl und der Langformat-Unterbefehl
im folgenden als kurzer Befehl bzw. langer Befehl bezeichnet.
-
Die FM-Bits 51 können das
Format des Befehls sowie die Reihenfolge der beiden auszuführenden
kurzen Befehle spezifizieren. Wenn die FM-Bits 51"11" sind,
zeigen die FM-Bits 51 an, daß die Behälter 52 und 53' den
langen Befehl halten. Wenn sie nicht "11" sind, zeigen die FM-Bits 51 an,
daß jeder der
Behälter 52 und 53 den
kurzen Befehl hält.
Ist die Anzeige derart, daß zwei
kurze Befehle gehalten werden, geben die FM-Bits 51 die
Reihenfolge der Ausführung
an.
-
Wenn die FM-Bits 51 "00"
sind, zeigen die FM-Bits 51 an, daß die beiden kurzen Befehle
parallel ausgeführt
werden. Sind sie "01", zeigen die FM-Bits 51 an, daß der in
dem rechten Behälter 53 enthaltene
kurze Befehl ausgeführt
wird, nachdem der in dem linken Behälter 52 enthaltene
kurze Befehl ausgeführt
ist. Sind sie "10", zeigen die FM-Bits 51 an, daß der in
dem linken Behälter 52 enthaltene
kurze Befehl ausgeführt
wird, nachdem der in dem rechten Behälter 53 enthaltene
kurze Befehl ausgeführt worden
ist.
-
Auf diese Weise ermöglicht das
erste bevorzugte Ausführungsbeispiel
eine Codierung in Form eines 32-Bit-Befehls, der zwei kurze Befehle
beinhaltet, die nacheinander auszuführen sind, so daß die Codiereffizienz
verbessert wird.
-
Die 4 bis 7 veranschaulichen eine typische
Befehlscodierung; dabei zeigt 4 die
Befehlscodierung eines kurzen Befehls mit zwei Operanden. Felder 61 und 62 sind
Operationscodefelder. Das Feld 64 bezeichnet in manchen
Fällen
eine Akkumulatornummer. Felder 62 und 63 bezeichnen
die von dem Operandenwert zu haltenden Positionen unter Verwendung
einer Registernummer oder einer Akkumulatornummer. Das Feld 63 bezeichnet
in manchen Fällen
einen 4 Bits kurzen unmittelbaren Wert.
-
5 veranschaulicht
die Befehlscodierung eines Kurzformat-Verzweigungsbefehls, der ein
Operationscodefeld 71 und ein 8-Bit-Verzweigungsabstandsfeld
72 aufweist. Der Verzweigungsabstand ist durch den Offset eines
Wort-Offets (32 Bits) spezifiziert, wie dies auch für den PC-Wert
gilt.
-
6 zeigt
ein Format eines 3-Operanden-Befehls mit einem 16-Bit-Abstand oder
einem unmittelbaren Wert oder einem Lade-/Speicherbefehl, der ein
Operationscodefeld 81, Felder 82 und 83 zum
Spezifizieren einer Registernummer, wie des Kurzformats, sowie ein
erweitertes Datenfeld 84 zum Spezifizieren des 16-Bit-Abstands
oder des unmittelbaren Werts aufweist.
-
7 zeigt
ein Format eines Befehls mit einem Operationscode in seinem rechten
Behälter 53, wobei
ein 2-Bit-Feld 91 "01" angibt. Die Bezugszeichen 93 und 96 bezeichnen
Operationscodefelder, und die Bezugszeichen 94 und 95 bezeichnen
Felder zum Spezifizieren einer Registernummer oder dergleichen.
Das Bezugszeichen 92 bezeichnet reservierte Bits, die nach
Bedarf für
den Operationscode oder die Registernummer verwendet werden.
-
Ferner sind einige Operationen vorgesehen, die
eine spezielle Befehlscodierung aufweisen, wie zum Beispiel ein
Befehl, bei dem alle 15 Bits einen Operationscode darstellen, wie
zum Beispiel einen NOP-(Nulloperations-)Befehl, sowie einen 1-Operandenbefehl.
-
Bei Unterbefehlen für den Datenprozessor dieses
bevorzugten Ausführungsbeispiels
handelt es sich um einen Befehlssatz nach RISC-Art. Nur der Lade/Speicherbefehl
weist an, daß auf
die Speicherdaten zugegriffen wird, und der Operationsbefehl weist
an, daß eine
Rechenoperation an einem Operanden in dem Register/Akkumulator oder
einem unmittelbaren Operanden durchgeführt wird.
-
Es gibt fünf Operandendaten-Adressiermoden:
einen register-indirekten Modus, einen register-indirekten Modus
mit Nachinkrementierung, einen registerindirekten Modus mit Nachdekrementierung, einen
Druckmodus sowie einen register-relativen indirekten Modus, deren
Mnemotechnik "@Rsrc", "@Rsrc+", "@Rsrc-", "@-SP" bzw. "@(disp16,
Rsrc)" sind, wobei Rsrc eine Registernummer zum Spezifizieren einer
Basisadresse ist und displ6 der 16-Bit-Verschiebewert bzw. Abstandswert
ist. Die Adresse des Operanden wird durch eine Byte-Adresse spezifiziert.
-
Sämtliche
Moden mit Ausnahme des register-relativen indirekten Modus haben
das in 4 gezeigte Befehlsformat.
Das Feld 63 gibt eine Basisregisternummer an, und das Feld 62 gibt
die Nummer eines Registers an, in das ein aus dem Speicher geladener
Wert eingeschrieben wird, oder die Nummer eines Registers zum Halten
des zu speichernden Werts. In dem register-indirekten Modus dient
der Wert des als Basisregister spezifizierten Registers als Operandenadresse.
-
In dem register-indirekten Modus
mit Nachdekrementierung dient der Wert des als Basisregister spezifizierten
Registers als Operandenadresse, und der Wert in dem Basisregister
wird durch die Größe (die
Anzahl von Bytes) des Operanden nachinkrementiert und zurückgeschrieben.
-
In dem register-indirekten Modus
mit Nachdekrementierung dient der Wert des als Basisregister spezifizierten
Registers als Operandenadresse, und der Wert in dem Basisregister
wird durch die Größe (die
Anzahl von Bytes) des Operanden nach-dekrementiert und zurückgeschrieben.
-
Der Druckmodus ist nur dann verwendbar, wenn
der Speicherbefehl vorliegt und das Basisregister das Register R15
ist. In dem Druckmodus dient der Wert des Stapelzeigers (SP), der
durch die Größe (die
Anzahl von Bytes) des Operanden vor-dekrementiert wurde, als Operandenadresse,
und der dekrementierte Wert wird in den SP zurückgeschrieben.
-
Der register-relative indirekte Modus
weist das in 6 gezeigte
Befehlsformat auf. Das Feld 83 gibt eine Basisregisternummer
an, und das Feld 82 gibt die Nummer eines Registers an,
in das der aus dem Speicher geladene Wert eingeschrieben wird, oder
die Nummer eines Registers zum Halten des zu speichernden Werts.
-
Das Feld 84 spezifiziert
den Wert der Verlagerung der Position, an der der Operand von der
Basisadresse gespeichert wird. In dem register-relativen indirekten
Modus gilt der 16-Bit-Abstandswert, der zu dem Wert in dem als Basisregister
spezifizierten Register hinzuaddiert ist, als Operandenadresse.
-
Der register-indirekte Modus vom
Typ mit Nachinkrementierung und der register-indirekte Modus vom Typ mit Nachdekrementierung
können
einen Modulo-Adressiermodus
verwenden, indem das MD-Bit 44 in dem PSW 21 auf
"1" gesetzt wird.
-
Eine Sprungzieladressierung eines
Sprungbefehls beinhaltet eine registerindirekte Adressierung zum
Spezifizieren der Sprungzieladresse unter Verwendung eines Registerwerts
sowie eine PC-relative indirekte Adressierung zum Spezifizieren
der Sprungzieladresse unter Verwendung einer Verzweigungsdistanz
des Sprungbefehls von dem Programmzähler PC.
-
Die PC-relative indirekte Adressierung
beinhaltet eine Kurzformat-Adressierung zum Spezifizieren der Verzweigungsdistanz
unter Verwendung von 8 Bits sowie eine Langformat-Adressierung zum
Spezifizieren der Verzweigungsdistanz unter Verwendung von 16 Bits.
Ferner weist der Datenprozessor einen Wiederholungsbefehl zum Starten
der Wiederholungsfunktion auf, so daß eine Schleifenverarbeitung
ohne Zusatzaufwand bzw. Programmverwaltungsaufwand erzielt wird.
-
8 zeigt
ein Funktionsblockdiagramm eines Datenprozessors 100 gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung. Der Datenprozessor 100 besitzt
einen MPU-Kern 101, eine Befehlsabrufeinheit 102 zum Zugreifen
auf Befehlsdaten in Abhängigkeit
von einer Aufforderung von dem MPU-Kern 101, einen internen Befehlsspeicher 103,
eine Operanden-Zugriffseinheit 104 zum Zugreifen auf Operandendaten
in Abhängigkeit
von einer Aufforderung von dem MPU-Kern 101, einen internen
Datenspeicher 105 sowie eine externe Bus-Schnittstelleneinheit 106 zum
Entscheiden von Aufforderungen von der Befehlsabrufeinheit 102 und
der Operanden-Zugriffseinheit 104, um auf einen extern
von dem Datenprozessor 100 vorgesehenen Speicher zuzugreifen.
-
Der MPU-Kern 101 weist eine
Befehlswarteschlange 111, eine Steuereinheit 112,
eine Registerdatei 115, eine erste Operationseinheit 116,
eine zweite Operationseinheit 117 sowie eine PC-Einheit 118 auf.
-
Die Befehlswarteschlange 111 enthält zwei Einträge eines
32-Bit-Befehlscodes und eines gültigen
Bits. Die Warteschlange wird in einer FIFO-(First-In First-Out-)Reihenfolge gesteuert.
Die Befehlswarteschlange 111 hält vorübergehend Befehlsdaten, die
von der Befehlsabrufeinheit 102 abgerufen werden, um die
Befehlsdaten zu der Steuereinheit 112 zu übertragen.
-
Die Steuereinheit 112 führt die
Gesamtsteuerung an dem MPU-Kern 101 aus, wie zum Beispiel die
Steuerung der Befehlswarteschlange 111, die Pipeline-Steuerung, die Ausführung von
Befehlen sowie die Schnittstellenbildung mit der Befehlsabrufeinheit 102 und
der Operandenzugriffseinheit 104. Die Steuereinheit 112 weist
eine Befehlsdecodiereinheit 119 auf, um einen von der Befehlswarteschlange 111 übertragenen
Befehlscode zu decodieren. Die Befehlsdecodiereinheit 119 weist
zwei Decodierer auf, d. h. einen ersten und einen zweiten Decodierer 113 und 114.
-
Der erste Decodierer 113 decodiert
den in der ersten Operationseinheit 116 auszuführenden Befehl,
und der zweite Decodierer 114 decodiert den in der zweiten
Operationseinheit 117 auszuführenden Befehl. In einem ersten
Zyklus der Decodierung eines 32-Bit-Befehls analysiert der erste
Decodierer 113 einen Befehlscode in dem linken Behälter 52, und
der zweite Decodierer 114 analysiert einen Befehlscode
in dem rechten Behälter 53.
-
Die Daten in dem FM-Bit 51 sowie
das Bit 0 und das Bit 1 des linken Behälters 52 werden sowohl von
dem ersten als auch von dem zweiten Decodierer 113 und
114 analysiert. Die Daten in dem rechten Behälter 53 werden zu
dem ersten Decodierer 113 geschickt, um die erweiterten
Daten zu extrahieren, die nicht analysiert sind. Somit muß der auszuführende Befehl
zuerst an einer Stelle vorgesehen werden, die einer Operationseinheit
zum Ausführen
des Befehls entspricht.
-
Wenn zwei kurze Befehle nacheinander
ausgeführt
werden, wird der später
auszuführende
Befehl sowohl zu dem ersten als auch zu dem zweiten Decodieren 113 und 114 übertragen,
und es wird ein ausführbares
Decodierergebnis gültig.
Wenn ein Befehl sowohl von dem ersten als auch von dem zweiten Decodieren 113 und 114 ausführbar ist,
wird nur das decodierte Ergebnis in dem ersten Decodieren 113 gültig gemacht,
und das decodierte Ergebnis in dem zweiten Decodieren 114 wird
ungültig
gemacht bzw. annulliert.
-
Die Registerdatei 115 beinhaltet
die Register 1 bis 17 und ist durch eine Vielzahl
von Busleitungen mit der ersten Operationseinheit 116,
der zweiten Operationseinheit 117 und der PC-Einheit 118 verbunden.
-
9 zeigt
ein detailliertes Blockdiagramm der ersten Operationseinheit 116.
Die erste Operationseinheit 116 ist mit der Registerdatei 115 durch
einen S1-Bus 301, einen S2-Bus 302 und einen S3-Bus 303 verbunden,
um Daten durch die drei Busse 301, 302 und 303 aus
den Registern auszulesen. Der S2-Bus 302 ist nur mit ungeradzahligen
Registern verbunden, und der S1-Bus 301 und der S2-Bus 302 können gemeinsam
2-Wort-Daten von dem Registerpaar parallel übertragen.
-
Die erste Operationseinheit 116 ist
ferner über
einen D1-Bus 311, einen W1-Bus 314 und einen W2-Bus 315 mit
der Registerdatei 115 verbunden, um Daten durch die drei
Busse 311, 314 und 315 in die Register
einzuschreiben. Der W1-Bus 314 ist nur mit den geradzahligen
Registern verbunden, und der W2-Bus 315 ist nur mit den
ungeradzahligen Registern verbunden. Der W1-Bus 314 und
der W2-Bus 315 können
gemeinsam 2-Wort-Daten parallel zu dem Registerpaar übertragen.
-
Ein AA-Zwischenspeicher 151 und
ein AB-Zwischenspeicher 152 bilden Eingangs-Zwischenspeicher
für eine
arithmetisch-logische Einheit bzw. ALU 153. Der AA-Zwischenspeicher 151 erhält einen
durch den S1-Bus 301 oder den S3-Bus 303 gelesenen Registerwert
und besitzt eine Nullauslösefunktion.
Der AB-Zwischenspeicher 152 erhält einen durch den S3-Bus 303 gelesenen
Registerwert oder einen durch Decodieren in dem ersten Decodierer 113 erzeugten
unmittelbaren 16-Bit-Wert und hat eine Nullauslösefunktion.
-
Die ALU 153 führt in erster
Linie eine Übertragung,
einen Vergleich, eine arithmetische und logische Operation, eine
Berechnung/Übertragung
von Operandenadressen, eine Inkrementierung/Dekrementierung der
Basisadressenwerte der Operandenadressen sowie eine Berechnung/Übertragung
der Sprungzieladressen durch. Die Resultate der Operation und der
Adressenmodifikation werden durch einen Selektor 155 und
den D1-Bus 311 in das durch den Befehl bezeichnete Register
in der Registerdatei 115 zurückgeschrieben.
-
Ein AO-Zwischenspeicher 154 bildet
einen Zwischenspeicher zum Halten von Operandenadressen, der das
Resultat der Adressenberechnung in der ALU 153 oder den
in dem AA-Zwischenspeicher 151 gehaltenen Basisadressenwert
selektiv hält
und durch einen OA-Bus 321 an die Operandenzugriffseinheit 104 abgibt.
Für die
Berechnung oder Übertragung
der Sprungzieladresse wird das Ausgangssignal von der ALU 153 durch
einen JA-Bus 323 zu der PC-Einheit 118 übertragen.
-
Bei einem MOD_S 156 und einem MOD_E 157 handelt
es sich um Steuerregister, die den Steuerregistern CR10 (28)
bzw. CR11 (29) der 1 entsprechen.
Ein Komparator 158 vergleicht den Wert in dem MOD_E 157 mit
dem Basisadressenwert auf dem S3-Bus 303. Bei der Modulo-Adressierung,
die in dem registerindirekten Modus mit Nach-Inkrementierung/Dekrementierung
aktiviert wird, wird der in dem Zwischenspeicher 159 gehaltene
Wert in dem MOD_S 156 durch den Selektor 155 und
den D1-Bus 311 in das Basisadressenregister in der Registerdatei 115 zurückgeschrieben.
-
Ein Speicherdaten-(SD-)Register 116 beinhaltet
zwei 16-Bit-Register und hält
vorübergehend Speicherdaten,
die an den S1-Bus 301 oder sowohl an den S1-Bus 301 als
auch den S2-Bus 302 ausgegeben werden. In dem SD-Register 160 gehaltene Daten
werden durch einen Zwischenspeicher 161 an eine Ausrichtschaltung 162 übertragen.
Die Ausrichtschaltung 162 richtet die Daten entsprechend
der Operandenadresse in 32-Bit-Form aus, um die Daten durch einen
Zwischenspeicher 163 und einen OD-Bus 322 an die
Operandenzugriffseinheit 104 abzugeben.
-
Die von der Operandenzugriffseinheit 104 geladenen
Daten werden durch den OD-Bus 322 einem Ladedaten-(LD-)Register 164 zugeführt, das zwei
16-Bit-Register beinhaltet. Der Wert in dem LD-Register 164 wird
durch einen Zwischenspeicher 165 zu einer Ausrichtschaltung 166 übertragen.
Die Ausrichtschaltung 166 richtet die Daten aus, um an die
geradzahligen Register zu übertragende
Daten auf den W1-Bus 314 abzugeben und auf die ungeradzahligen
Register zu übertragende
Daten an den W2-Bus 315 abzugeben.
-
Wenn 1-Wort-Daten geladen werden,
werden die Ladedaten an einen von dem W1-Bus 314 und dem
W2-Bus 315 abgegeben. Wenn 2-Wort-Daten geladen werden,
werden die Ladedaten sowohl an den W1-Bus 314 als auch
den W2-Bus 315 abgegeben. Die abgegebenen Daten werden
in das bezeichnete Register in der Registerdatei 115 geschrieben.
-
Bei einem PSW 171 in der
Steuereinheit 112 handelt es sich um ein Register zum Halten
des Werts in dem Steuerregister CR0 (21) der 1. Eine PSW-Aktualisierungseinheit 172 mit
einem Zwischenspeicher aktualisiert den Wert in dem PSW 171 in
Abhängigkeit
von dem Ergebnis einer Operation oder die Ausführung eines Befehls. Zum Übertragen eines
Werts zu dem PSW 171 werden nur zugewiesene Bits von dem
AB-Zwischenspeicher 152 zu der Steuereinheit 112 übertragen.
-
Zum Lesen eines Werts aus dem PSW 171 wird
der Wert von der PSW-Aktualisierungseinheit 172 an den
D1-Bus 311 abgegeben und in die Registerdatei 115 geschrieben.
Bei einem BPSW 167 handelt es sich um ein Register, das
dem Steuerregister CR1 (22) der 1 entspricht. Während einer Ausnahmeverarbeitung
wird der an den W1-Bus 311 abgegebene Wert in dem PSW 21 in
den BPSW 167 geschrieben. Der Wert in dem BPSW 167 wird
in den S3-Bus 303 eingelesen und zu dem PSW 171 oder der
Registerdatei 115 übertragen.
-
10 zeigt
ein detailliertes Blockdiagramm der PC-Einheit 118. Ein
Befehlsadressen-(IA-)Register 181 hält die Adresse des als nächsten abzurufenden
Befehls und gibt die Adresse des abzurufenden Befehls an die Befehlsabrufeinheit 102 ab.
Wenn der nachfolgende Befehl abgerufen werden soll, wird der von
dem IA-Register 181 durch einen Zwischenspeicher 182 übertragene
Adressenwert in einen Inkrementierer 183 um 1 inkrementiert
und dann in das IA-Register 181 zurückgeschrieben. Wenn die Sequenz
durch einen Sprung oder eine Wiederholung verändert wird, erhält das IA-Register 181 die
von dem JA-Bus 323 übertragene
Sprungbefehladresse.
-
Bei einem RPT_S 184, einem RPT_E 186 und
einem RPT_C 188 handelt es sich um Wiederholungssteuerregister,
die den Steuerregistern CR8 (26), CR9 (27) bzw.
CR7 (25) in dem Registersatz der 1 entsprechen. Das RPT_E 186 hält die Adresse des
letzten Befehls in dem zu wiederholenden Block. Die letzte Adresse
wird in der ersten Operationseinheit 116 während einer
Wiederholungsbefehlbearbeitung berechnet und durch den JA-Bus 323 dem RPT_E 186 zugeführt. Ein
Komparator 187 vergleicht den Wert der in dem RPT_E 186 gehaltenen
Endadresse in dem Wiederholungsblock mit dem Wert einer in dem IA-Register 181 gehaltenen
Abrufadresse.
-
Wenn der Wert in dem RPT_C 188 zum
Halten eines Wiederholungszählwerts
während
einer Wiederholungsbearbeitung nicht "1" ist, und die beiden Adressen
miteinander übereinstimmen,
wird eine in dem RPT_S 184 gehaltene Startadresse des zu wiederholenden
Blocks durch einen Zwischenspeicher 185 und den JA-Bus 323 zu
dem IA-Register 181 übertragen.
Bei jeder Ausführung
des Befehls an der letzten Adresse des zu wiederholenden Blocks
wird der Wert in dem RPT_C 188 über
einen Zwischenspeicher 189 durch einen Dekrementierer 190 um
1 dekrementiert.
-
Wenn das Ergebnis der Dekrementierung gleich
Null ist, wird das RP-Bit 43 in dem PSW 21 gelöscht, und
die Wiederholungsbearbeitung wird abgeschlossen. Das RPT_S 184,
das RPT_E 186 und das RPT_C 188 weisen eine Eingangsschnittstelle von
dem D1-Bus 311 sowie eine Ausgangsschnittstelle zu dem S3-Bus 303 auf.
Unter Verwendung dieser Busse werden eine durch Wiederholungsbefehlverarbeitung
veranlaßte
Initialisierung sowie Sicherungs- und
Rückkehroperationen
durchgeführt.
-
Eine Ausführungsstufe PC(EPC) 194 enthält den PC-Wert
des ausgeführten
Befehls und ein PC für
den nächsten
Befehl (NPC) 191 berechnet den PC-Wert des als nächsten auszuführenden
Befehls. Wenn während
der Ausführung
ein Sprung auftritt, erhält
der NPC 191 den Wert auf dem JA-Bus 323, auf den
die Sprungzieladresse übertragen
wird. Wenn während
einer Wiederholung eine Verzweigung stattfindet, erhält der NPC 191 die
erste Adresse in dem zu wiederholenden Block von dem Zwischenspeicher 185.
In anderen Fällen
wird der durch einen Zwischenspeicher 192 übertragene
Wert in dem NPC 191 durch einen Inkrementierer 193 inkrementiert
und dann in den NPC 191 zurückgeschrieben.
-
Im Fall eines Unterprogramm-Sprungbefehls wird
der Wert in dem Zwischenspeicher 192 als Rückkehradresse
an den D1-Bus 311 abgegeben und dann in das Register R13
zurückgeschrieben, das
in der Registerdatei 115 als Verbindungsgliedregister definiert
ist. Wenn der nächste
Befehl zur Ausführung
gebracht werden soll, wird der Wert in dem Zwischenspeicher 192 zu
dem EPC 194 übertragen. Wenn
auf den PC-Wert des ausgeführten
Befehls zurückgegriffen
werden soll, wird der Wert in dem EPC 194 an den S3-Bus 303 abgegeben
und zu der ersten Operationseinheit 116 übertragen.
-
Ein BPC 196 entspricht dem
Steuerregister CR3 (23) in dem Registersatz der 1. Wenn eine Ausnahme oder
eine Unterbrechung festgestellt wird, wird der Wert in dem EPC 194 durch
einen Zwischenspeicher 195 zu dem BPC 196 übertragen.
Der BPC 196 weist eine Eingangsanschlußstelle von dem D1-Bus 311 und
eine Ausgangsanschlußstelle
zu dem S3-Bus 303 auf, und es folgt eine Übertragung zu
sowie von der Registerdatei 115.
-
11 zeigt
ein detailliertes Blockdiagramm der zweiten Operationseinheit 117.
Die zweite Operationseinheit 117 ist mit der Registerdatei 115 durch einen
S4-Bus 304 und einen S5-Bus 305 verbunden, um Daten durch die beiden Busse 304 und 305 aus den
Registern auszulesen. Der S4-Bus 304 und der S5-Bus 305 können gemeinsam
2-Wort-Daten aus dem Registerpaar parallel übertragen.
-
Die zweite Operationseinheit 117 ist
ferner durch einen D2-Bus 312 und einen D3-Bus 313 mit der
Registerdatei 115 verbunden, um Daten durch die beiden
Busse 312 und 313 in die Register einzuschreiben.
Der D2-Bus 312 ist mit allen Registern verbunden, während der
D3-Bus 313 nur mit den ungeradzahligen Registern verbunden
ist. Der D2-Bus 312 und der D3-Bus 313 können gemeinsam 2-Wort-Daten
parallel zu dem Registerpaar übertragen.
-
Akkumulatoren 208 entsprechen
den beiden 40-Bit-Akkumulatoren A0 und A1, die in 1 mit 31 und 32 bezeichnet sind.
-
Das Bezugszeichen 201 bezeichnet
eine 40-Bit-ALU, die einen Schutzbitaddierer für den Akkumulator mit einer
Länge von
8 Bits (Bit 0 bis Bit 7), eine arithmetisch-logische Einheit 16 mit
einer Länge von
16 Bits (Bit 8 bis Bit 23) sowie einen Addieren zum Addieren der
16 Bits niedriger Ordnung des Akkumulators mit einer Länge von
16 Bits (Bit 24 bis Bit 39) aufweist. Die ALU 201 führt Additions-
und Subtraktionsoperationen von bis zu 40 Bits sowie eine Logikoperation
von 16 Bits aus.
-
Bei einem A-Zwischenspeicher 202 und
einem B-Zwischenspeicher 203 handelt es sich um Eingangszwischenspeicher
für die
ALU 201. Der A-Zwischenspeicher 202 erhält die Daten
auf dem S4-Bus 304 an den Positionen von Bit 8 bis Bit
23, erhält
den Wert in dem Akkumulator 208 durch einen Shifter 204 in
intakter Form oder erhält
den Wert in dem Akkumulator 208 durch den Shifter 204 arithmetisch
um 16 Bits nach rechts verschoben.
-
Ein Shifter 205 erhält den Wert
in dem Akkumulator 8 durch eine Zwischenverbindungsleitung 206 (8
Schutzbits), den S4-Bus 304 (16 höchstwertige Bits) und den S5-Bus 305'(16
niedrigstwertige Bits) oder erhält
den Wert in dem Register, der einer Vorzeichenerweiterung in 40
Bits unterzogen wird, nur durch den S5-Bus 305 oder durch die S4-
und S5-Busse 304 und 305. Der Shifter 205 erhält dann den
Wert, der um einen beliebigen Betrag im Bereich von 3 Bits nach
links bis 1 Bit nach rechts arithmetisch verschoben ist.
-
Der B-Zwischenspeicher 203 erhält die Daten
auf dem S5-Bus 305 an den Positionen von Bit 8 bis Bit
23 oder erhält
den Ausgang von einem Multiplizieren 211 durch den P-Zwischenspeicher 214 oder den
Ausgang von dem Shifter 205. Der A-Zwischenspeicher 202 und
der B-Zwischenspeicher 203 haben eine Funktion zum Löschen der
darin befindlichen Daten auf Null und zum Setzen der darin befindlichen
Daten auf einen konstanten Wert.
-
Wenn ein Bestimmungsoperand den Akkumulator 208 angibt,
wird der Ausgangswert von der ALU 201 durch einen Selektor 207 in
den Akkumulator 208 eingeschrieben. Wenn der Bestimmungsoperand
das Register angibt, wird der Ausgangswert von der ALU 201 durch
den Selektor 207 und entweder nur den D2-Bus 312 (1-Wort-Daten)
oder sowohl den D2-Bus 312 als auch den D3-Bus 313 (2-Wort-Daten) in
die Registerdatei 115 eingeschrieben.
-
Eine Sättigungsschaltung 209 erhält den Ausgangswert
von der ALU 201 und hat die Funktion zum Begrenzen seines
Ausgangswerts auf einen maximalen oder minimalen Wert, der sich
in Bezug auf die Schutzbits in Form von 16 Bits oder 32 Bits ausdrücken läßt, um Ausgangsdaten
abzugeben, die 16 höchstwertige
Bits oder sowohl 32 höchstwertige und
niedrigstwertige Bits enthalten.
-
Der Ausgangswert von der Sättigungsschaltung 209 kann
nur durch den D2-Bus 312 (1-Wort-Daten) oder sowohl durch
den D2-Bus 312 als auch den D3-Bus 313 (2-Wort-Daten)
in die Registerdatei 115 eingeschrieben werden. Zur Berechnung
von Absolutwerten und die Ausführung
von Maximalwert- und Minimalwert-Setzbefehlen sind die Ausgänge des
A-Zwischenspeichers 202 und des B-Zwischenspeichers 203 mit
dem Eingang des Selektors 207 verbunden.
-
Ein Prioritätscodierer (PENC) 210 erhält den Wert
in dem B-Zwischenspeicher 203. Der PENC erzeugt den Shift-Zählwert,
der zum Normalisieren der Eingangsdaten in einem Festkommaformat
erforderlich ist, und gibt das Ergebnis durch den D2-Bus 312 an
die Registerdatei 115 ab.
-
Ein X-Zwischenspeicher 212 und
ein Y-Zwischenspeicher 213 erhalten die 16-Bit-Werte auf
dem S4-Bus 304 bzw. dem S5-Bus 305 und haben die Funktion
einer Nullerweiterung oder Vorzeichenerweiterung der 16-Bit-Werte
auf 17 Bits.
-
Bei dem Multiplizieren 211 handelt
es sich um einen 17-Bit × 17-Bit-Multiplizieren
zum Multiplizieren des in dem X-Zwischenspeicher 212 gespeicherten
Werts mit dem in dem Y-Zwischenspeicher 213 gespeicherten
Wert. Wenn der Multiplizieren 211 einen Multiplikations-Additions-Befehl
oder einen Multiplikations-Subtraktions-Befehl
erhält,
wird das Ergebnis der Multiplikation einem P-Zwischenspeicher 214 zugeführt und
zu dem B-Zwischenspeicher 203 übertragen. Wenn der Multiplizieren 211 einen Multiplikationsbefehl
erhält
und der Bestimmungsoperand den Akkumulator 208 angibt,
wird das Ergebnis der Multiplikation durch den Selektor 207 in
den Akkumulator 208 eingeschrieben.
-
Ein Trommel-Shifter 215 kann
eine arithmetische/logische Verschiebung an 40-Bit- oder 16-Bit-Daten
von bis zu 16 Bits nach links und nach rechts durchführen. Ein
Verschiebedaten-(SD-)Zwischenspeicher 217 erhält als Verschiebedaten
den Wert in dem Akkumulator 208 oder den Wert in dem Register
durch Zufuhr über
den S4-Bus 304. Ein Verschiebezähl-(SC-)Zwischenspeicher 216 erhält als Verschiebezählwert den
unmittelbaren Wert oder den Registerwert durch den S5-Bus 305.
Der Trommel-Shifter 215 führt eine Verschiebung durch,
die durch den Operationscode auf den Daten in dem SB-Zwischenspeicher 217 bezeichnet
sind, und zwar durch den Verschiebezählwert, der durch den SC-Zwischenspeicher 216 spezifiziert
wird.
-
Das Ergebnis der Verschiebung wird
in den Akkumulator 208 oder durch den D2-Bus 312 in
die Registerdatei zurückgeschrieben.
Der Shifter 215 weist eine 2-Wort-Übertragungsfunktion auf. Genauer
gesagt gibt der Shifter 215 die durch den S4-Bus 304 und
den 55-Bus 305 empfangenen 2-Wort-Daten durch den SB-Zwischenspeicher
217 und den Shifter 215 an den D2-Bus 312 und
den D3-Bus 313 ab, um die 2-Wort-Daten in die Registerdatei 115 zurückzuschreiben.
Der Shifter 215 kann eine 1-Wort-Übertragung ausführen.
-
Ein Zwischenspeicher 218 für den unmittelbaren
Wert erweitert einen von dem zweiten Decodierer 114 erzeugten
unmittelbaren 6-Bit-Wert in einen 16-Bit-Wert und hält dann
den 16-Bit-Wert, um den 16-Bit-Wert durch den S5-Bus 305 in
eine Recheneinheit zu übertragen.
-
Im folgenden wird eine Pipeline-
bzw. Fließband-Verarbeitung
in dem Datenprozessor gemäß dem ersten
bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung beschrieben. 12 veranschaulicht diese Fließband-Verarbeitung.
Der Datenprozessor des ersten bevorzugten Ausführungsbeispiels führt eine
5-Stufen-Fließband-Verarbeitung unter
Verwendung einer Befehlsabruf-(IF-)Stufe 401 zum Abrufen
von Befehlsdaten, einer Befehlsdecodier-(D-)Stufe 402 zum
Analysieren von Befehlen, einer Befehlsausführungsstufe (E) 403 zum
Ausführen von
Operationen, einer Speicherzugriffs-(M-)Stufe 404 zum Zugreifen
auf einen Datenspeicher sowie einer Zurückschreib-(W-)Stufe 405 zum
Schreiben von aus einem Speicher geladenen Operanden in ein Register
durch.
-
Für
Multiplikations-Additions-/Multiplikations-Subtraktions-Operationen
wird ein weiteres 2-Stufen-Fließband,
das Multiplikation und Addition beinhaltet, zum Ausführen von
Befehlen verwendet. Die Verarbeitung in letzterer Stufe wird als
Befehlsausführungs-Doppelstufe
(E2) 406 bezeichnet.
-
In der IF-Stufe 401 erfolgen
in erster Linie ein Abruf von Befehlen, ein Management der Befehlswarteschlange 111 sowie
eine Wiederholungssteuerung. Die IF-Stufe 401 steuert die
Operationen der Befehlsabrufeinheit 102, des internen Befehlsspeichers 103,
der externen Bus-Schnittstelleneinheit 106, der Befehlswarteschlange 111,
des IA-Registers 181, des Zwischenspeichers 182,
des Inkrementierers 182 und des Komparators 187 in
der PC-Einheit 118 sowie Einheiten zum Ausführen der
Stufensteuerung, der Befehlsabrufsteuerung, der Steuerung der PC-Einheit 118 sowie
der Steuerung der Befehlswarteschlange 111 in der Steuereinheit 113.
Die IF-Stufe 401 wird durch einen Sprung an der E-Stufe 403 initialisiert.
-
Die Abrufadresse ist in dem IA-Register 181 gehalten.
Wenn ein Sprung an der E-Stufe 403 stattfindet, erhält das LA-Register 181 die
Sprungzieladresse durch den )A-Bus 323, zum Ausführen einer Initialisierung.
Wenn die Befehlsdaten nacheinander abgerufen werden, inkrementiert
der Inkrementierer 182 die Adresse. Die Sequenzumschaltsteuerung wird
durchgeführt,
wenn der Komparator 187 eine Übereinstimmung zwischen dem
Wert in dem IA-Register 181 und dem Wert in dem RPT_E 186 während der
Wiederholungsbearbeitung feststellt und der Wert in dem RPT C 188
nicht "1" ist. Der in dem RPT S 184 gehaltene Wert wird dann durch
den Zwischenspeicher 185 aus dem JA-Bus 323 in
das IA-Register 181 übertragen.
-
Der Wert in dem IA-Register 181 wird
zu der Befehlsabrufeinheit 102 geschickt, die wiederum
die Befehlsdaten abruft. Wenn die entsprechenden Befehlsdaten in
dem internen Befehlsspeicher 103 gespeichert sind, wird
ein Befehlscode aus dem internen Befehlsspeicher 103 ausgelesen.
In diesem Fall wird der Befehlsabruf innerhalb eines einzigen Taktzyklus
abgeschlossen. Wenn die entsprechenden Befehlsdaten nicht in dem
internen Befehlsspeicher 103 gespeichert sind, wird eine
Befehlsabrufaufforderung zu der externen Bus-Schnittstelleneinheit 106 geschickt.
-
Die externe Bus-Schnittstelleneinheit 106 entscheidet
zwischen der Befehlsabrufaufforderung und einer Aufforderung von
der Operandenzugriffseinheit 104. Wenn die externe Bus-Schnittstelleneinheit 106 die
Befehlsabrufaufforderung von der Befehlsabrufeinheit 102 akzeptiert,
liest die externe Bus-Schnittstelleneinheit 106 die Befehlsdaten
von einem externen Speicher aus und überträgt den abgerufenen Befehl zu
der Befehlsabrufeinheit 102.
-
Die externe Bus-Schnittstelleneinheit 106 benötigt minimal
2 Taktzyklen zum Zugreifen auf den externen Speicher. Die Befehlsabrufeinheit überträgt den erhaltenen
Befehl zu der Befehlswarteschlange 111. Bei der Befehlswarteschlange 111 handelt
es sich um eine 2-Eintrag-Warteschlange, die dem unter FIFO-Steuerung
erhaltenen Befehlscode an die Befehlsdecodierer 113 und
114 abgibt.
-
In der D-Stufe 402 analysiert
die Befehlsdecodiereinheit 119 den Operationscode und erzeugt Ausführungssteuersignale
zum Steuern der ersten Operationseinheit 116, der zweiten
Operationseinheit 117 und der PC-Einheit 188 zum
Ausführen
von Befehlen. Die D-Stufe 402 wird durch einen Sprung an der
E-Stufe 403 initialisiert. Wenn der von der Befehlswarteschlange 111 geschickte
Befehlscode ungültig
ist, wird die D-Stufe 402 in einen Ruhezyklus versetzt,
und sie wartet auf den Erhalt eines gültigen Befehlscodes.
-
Wenn die E-Stufe 403 die
nächste
Verarbeitung nicht starten darf, werden die Ausführungssteuersignale ungültig gemacht,
und die D-Stufe 403 wartet auf die Beendigung der Verarbeitung
des vorausgehenden Befehls an der E-Stufe 403. Eine solche Bedingung
tritt zum Beispiel dann auf, wenn es sich an der E-Stufe 403 ausgeführten Befehl
um einen Speicherzugriffsbefehl handelt und der vorausgehende Speicherzugriff
an der M-Stufe 404 nicht abgeschlossen ist.
-
Die D-Stufe 402 führt auch
eine Teilung von zwei nacheinander auszuführenden Befehlen, eine Sequenzsteuerung
eines 2-Zyklus-Ausführungsbefehls,
eine Konfliktprüfung
an einem Lastoperanden unter Verwendung eines Auswerteregisters
(nicht gezeigt) sowie eine Konfliktprüfung an einer Operationseinheit
in der zweiten Operationseinheit 117 durch. Wenn diese
Konflikte festgestellt werden, wird die Abgabe des Steuersignals
unterbunden, bis der Konflikt behoben ist.
-
13 veranschaulicht
ein Beispiel des Ladeoperandenkonflikts. Wenn unmittelbar nach einem Ladebefehl
ein Multiplikations-Additions-Operationsbefehl auf einen durch den
Ladebefehl zu ladenden Operanden Bezug nimmt, wird der Start der
Ausführung
des Multiplikations-Additions-Operationsbefehls unterbunden, bis
das Laden in das Register abgeschlossen ist. In diesem Fall tritt
eine 2-Taktzyklen-Verzögerung
auf, wenn der Speicherzugriff innerhalb eines einzigen Taktzyklus
abgeschlossen ist. 14 veranschaulicht
ein Beispiel eines Hardwarebetriebsmittelkonflikts bei der zweiten
Operation.
-
Wenn ein Rundungsbefehl, der von
einem Addierer Gebrauch macht, unmittelbar nach einem Multiplikations-Additions-Operationsbefehl
erfolgt, wird der Beginn der Ausführung des Rundungsbefehls unterbunden,
bis die Operation des vorangehenden Befehls abgeschlossen ist. In
diesem Fall tritt eine Verzögerung
von einem Taktzyklus auf. Es finden keine Verzögerungen statt, wenn die Multiplikations-Additions-Operationsbefehle
nacheinander ausgeführt
werden.
-
Der erste Decodieren 113 erzeugt
in erster Linie Operationssteuersignale für die Gesamtsteuerung der ersten
Operationseinheit 116, die Steuerung von Teilen der PC-Einheit 118,
die nicht von der TF-Stufe 404 gesteuert sind, die Lesesteuerung
der Registerdatei 115 auf den S1-Bus 301, den
S2-Bus 302 und den S3-Bus 303 sowie die Schreibsteuerung derselben
von dem B1-Bus 311. Der erste Decodieren 113 erzeugt
auch die befehlsabhängige
Steuerinformation zur Verwendung in der M-Stufe 404 und der
W-Stufe 405, so daß diese
Information durch die Pipeline geschickt wird. Der zweite Decodieren 114 erzeugt
in erster Linie Ausführungssteuersignale
in der zweiten Operationseinheit 117.
-
Die E-Einheit 403 führt eine
Verarbeitung von nahezu allen Befehlsausführungen mit Ausnahme des Speicherzugriffs
und der Addition der Multiplikations-Additions-/Multiplikations-Subtraktions-Operationsbefehle
durch, wie zum Beispiel eine Rechenoperation, einen Vergleich, eine
Datenübertragung zwischen
Registern einschließlich
Steuerregistern, eine Operanden-Adressenberechnung der Lade/Steuerbefehle,
eine Berechnung der Sprungzieladresse des Sprungbefehls, eine Sprungverarbeitung,
eine EIT (Ausnahme-, Unterbrechungs-, Fallen)Detektion sowie einen
Sprung zu einer EIT-Vektortabelle durch.
-
Bei aktivierter Unterbrechung wird
die Unterbrechung an dem Ende eines 32-Bit-Befehls ohne Ausfall
detektiert. Zwischen zwei kurzen Befehlen, die nacheinander in dem
32-Bit-Befehl ausgeführt werden
sollen, wird keine Unterbrechung akzeptiert.
-
Die Beendigung der Ausführung in
der E-Stufe 403 muß in
einem Wartezustand vorliegen, wenn der in der E-Stufe 403 verarbeitete
Befehl ein Operandenzugriffsbefehl ist und der vorangehende Speicherzugriff
in der M-Stufe 404 nicht abgeschlossen ist. Die Stufensteuerung
wird in der Steuereinheit 112 durchgeführt.
-
In der E-Stufe 403 führt die
erste Operationseinheit 116 arithmetische und logische
Operationen, einen Vergleich sowie eine Übertragung aus. Die ALU 153 berechnet
die Adresse des Speicheroperanden, der eine Modulosteuerung beinhaltet,
sowie eine Verzweigungszieladresse. Der Wert in dem Register, der
durch einen Befehl als Operand bezeichnet ist, wird zu der ersten
Operationseinheit 116 übertragen.
Erweiterte Daten, wie ein unmittelbarer Wert und ein Verlagerungswert
werden ebenfalls von dem ersten Decodieren übertragen, falls dies erforderlich ist.
-
In der ALU 153 wird eine
arithmetisch-logische Operation durchgeführt, und das Ergebnis wird durch
den D1-Bus 311 in die Registerdatei 115 zurückgeschrieben.
Wenn der Lade/Speicherbefehl vorliegt, wird das Ergebnis der Rechenoperation durch
den AO-Zwischenspeicher 154 und den OA-Bus 321 zu
der Operandenzugriffseinheit 104 übertragen. Wenn der Sprungbefehl
vorliegt, wird die Sprungzieladresse durch den JA-Bus 323 zu
den jeweiligen Einheiten übertragen.
-
Die Speicherdaten werden durch den S1-Bus 301 und
den S2-Bus 302 aus der Registerdatei 115 ausgelesen
sowie gehalten und ausgerichtet. Die Speicherdaten werden dann durch
den OD-Bus 322 zu der Operandenzugriffseinheit 104 übertragen. Die
PC-Einheit 118 verwaltet den PC-Wert des ausgeführten Befehls
und berechnet die nächste
Befehlsadresse. Die Datenübertragung
zwischen dem Steuerregister (mit Ausnahme des Akkumulators) und
der Registerdatei 115 wird sowohl durch die erste Operationseinheit 116 als
auch die PC-Einheit 118 durchgeführt.
-
In der E-Stufe 403 führt die
zweite Operationseinheit 116 alle Operationen mit Ausnahme
der Addition der Multiplikations-Additions-Operation durch, wie
zum Beispiel arithmetische und logische Operationen, Vergleich, Übertragung
und Verschiebung. Der Wert eines Operanden wird von der Registerdatei 115,
dem Register 218 für
den unmittelbaren Wert sowie dem Akkumulator 208 durch
den S4-Bus 304, den S5-Bus 305 sowie andere ausschließliche Wege
zu den jeweiligen Operationseinheiten übertragen und einer bezeichneten
Operation unterzogen. Das Ergebnis der Operation wird in den Akkumulator 208 oder
durch den D2-Bus 312 und den D3-Bus 313 in die
Registerdatei 115 zurückgeschrieben.
-
Das in dem zweiten Decodieren 114 erzeugte
Steuersignal für
die Ausführung
der Addition und Subtraktion der Multiplikations-Additions-/Multiplikations-Subtraktions-Operation
wird unter der Steuerung der E-Stufe 403 gehalten.
-
In der M-Stufe 404 erfolgt
ein Operandenspeicherzugriff in Abhängigkeit von der von der ersten
Operationseinheit 116 geschickten Adresse. Die Operandenzugriffseinheit 104 führt ein
Auslesen/Einschreiben von Daten aus/in dem internen Datenspeicher 105 oder
einer chipintegrierten Eingabe-/Ausgabeeinrichtung
(nicht gezeigt) in einem einzigen Taktzyklus aus, wenn sich der
Operand in dem internen Datenspeicher 105 oder der chipintegrierten
Eingabe-/Ausgabeeinrichtung befindet.
-
Die Operandenzugriffseinheit 104 gibt
eine Datenzugriffsaufforderung an die externe Bus-Schnittstelleneinheit 106 ab,
wenn sich der Operand nicht in dem internen Datenspeicher 105 oder der
chipintegrierten Eingabe/Ausgabeeinrichtung (nicht gezeigt) befindet.
Die externe Bus-Schnittstelleneinheit 106 greift auf Daten
in dem externen Speicher zu und überträgt die ausgelesenen
Daten zu der Operandenzugriffseinheit 104, wenn der Ladebefehl vorliegt.
-
Die externe Bus-Schnittstelleneinheit 106 benötigt minimal
zwei Taktzyklen zum Zugreifen auf den externen Speicher. Wenn der
Ladebefehl vorliegt, überträgt die Operandenzugriffseinheit 104 die gelesenen
Daten durch den OD-Bus 322 zu dem LD-Register 164.
Die Steuerung der M-Stufe 404 erfolgt in der Steuereinheit 112.
-
In der W-Stufe erfolgen ein Ausrichten
von geladenen Operanden, eine Null-Vorzeichen-Erweiterung von Byte-Daten
sowie ein Einschreiben in die Registerdatei 115.
-
In der E2-Stufe 406 führt die
ALU 201 die Addition und Subtraktion der Multiplikations-Additions-/Multiplikations-Subtraktions-Operation
durch.
-
Der Datenprozessor dieses bevorzugten Ausführungsbeispiels
verwendet ein durch Multiplizieren eines Eingangstakts mit Vier
erzeugtes Taktsignal zum Erzielen des internen Taktsignals. Jede
der Fließbandstufen
benötigt
ein Minimum von einem internen Taktzyklus zum Beenden ihrer Verarbeitung. Die
Details der Taktsteuerung haben keinen direkten Bezug zu der vorliegenden
Erfindung und werden deshalb nicht beschrieben.
-
Ein Beispiel für die Verarbeitung der jeweiligen
Unterbefehle wird nachfolgend erläutert. Die Verarbeitung von
Operationsbefehlen, wie Addition, Subtraktion, Logikoperation und
Vergleich, sowie von Register-zu-Register-Übertragungsbefehlen wird in drei
Stufen abgeschlossen: der IF-Stufe 401, der D-Stufe 402 und
der E-Stufe 403. Die Operationen und die Datenübertragung
werden in der E-Stufe 403 ausgeführt.
-
Der Multiplikations-Additions-/Multiplikations-Subtraktions-Befehl
benötigt
zwei Taktzyklen zur Ausführung
der Multiplikation in der E-Stufe 403 sowie der Addition
und Subtraktion in der E2-Stufe 406, d. h. es handelt sich
im wesentlichen um eine 4-Stufen-Verarbeitung.
-
Der Ladebefehl benötigt fünf Stufen:
die IF-Stufe 402, die D-Stufe 402, die E-Stufe 403,
die M-Stufe 404 sowie die W-Stufe 405 zum Abschließen der
Verarbeitung. Der Speicherbefehl benötigt vier Stufen: die IF-Stufe 401,
die D-Stufe 402, die E-Stufe 403 und die M-Stufe 404 zum
Abschließen
der Verarbeitung.
-
Ein Befehl, der zwei Zyklen für die Ausführung benötigt, gibt
die Anweisung, daß der
erste und der zweite Befehlsdecodierer 113 und 114 die
Bearbeitung in zwei Zyklen ausführen.
Der erste und der zweite Befehlsdecodierer 113 und 114 geben
jeweils ein Befehlssteuersignal für jeden Zyklus ab und führen die
Operation in zwei Zyklen durch.
-
Die vorstehend beschriebene Verarbeitung wird
mit einem einzigen langen Befehl ausgeführt. Zwei parallel auszuführende Befehle
führen
die vorstehend beschriebene Verarbeitung in Abhängigkeit von dem Befehl aus,
der eine größere Anzahl
von Taktzyklen für
die Befehlsausführung
in der E-Stufe 403 benötigt.
-
Zum Beispiel benötigt eine Kombination des in
zwei Zyklen auszuführenden
Befehls sowie des in einem einzigen Zyklus auszuführenden
Befehls zwei Zyklen.
-
Zwei kurze Befehle, die nacheinander
auszuführen
sind, werden nacheinander in der D-Stufe 402 decodiert
und nacheinander in der E-Stufe 403 ausgeführt. Zum
Beispiel werden zwei an der E-Stufe 403 abzuschließende Additionsbefehle
in der D-Stufe 402 in jeweilige Befehlsprozesse geteilt
und in der E-Stufe 403 über
zwei Zyklen ausgeführt.
-
Ein Beispiel der Verarbeitung wird
nun auf der Basis einiger Programme beschrieben.
-
15 veranschaulicht
ein erläuterndes Programm
eines FIR-(Finite Impulse Response) Filters (Rahmenverarbeitung)
mit 256 Abgriffen des Datenprozessors gemäß dem ersten bevorzugten Ausführungsbeispiel.
Das Symbol "||" in
15 zeigt
an, daß zwei
kurze Befehle parallel ausgeführt
werden. Das FIR-Filter führt
folgende Berechnung durch:
wobei A[i] ein Koeffizientenfeld
ist und D[i] ein Datenfeld ist. Diese Berechnung beinhaltet 256
Multiplikations-Additions-Operationen. Die Koeffizienten und die
Daten weisen jeweils eine Länge
von 16 Bits auf.
-
In 15 ist
die Initialisierung mit 501, die Schleifenverarbeitung mit 502 und
die Nachverarbeitung mit 503 bezeichnet. Die Schleifenverarbeitung ohne
Zusatzaufwand wird durch einen Wiederholungsbefehl (repi) implementiert.
Ein Block aus sechs Befehlen zwischen dem repi-Befehl und dem mit
der Bezeichnung "loopend" benachbarten Befehl wird 42 Mal ausgeführt.
-
Bei dem repi-Befehl handelt es sich
um einen langen Befehl, der einen Operationscode, eine 16-Bit-Verschiebung
zum Spezifizieren der letzten Adresse des Wiederholungsblocks in
dem PC-relativen Modus sowie einen unmittelbaren 8-Bit-Wert zum
Spezifizieren des Wiederholungszählwerts
beinhaltet und zwei Taktzyklen für
die Ausführung
benötigt.
In dem ersten Zyklus wird die dem repi-Befehl unmittelbar benachbarte
Adresse unmittelbar von dem Zwischenspeicher 192 durch
den D1-Bus 311 zu dem RPT_S 184 und dem Zwischenspeicher 185 übertragen.
-
Die Adresse des repi-Befehls wird
von dem EPC 194 durch den S3-Bus 303 zu dem AA-Zwischenspeicher 151 übertragen,
und der durch den Befehl bezeichnete Verschiebewert wird von dem ersten
Decodieren 113 dem AB-Zwischenspeicher 152 zugeführt. Die
ALU 153 addiert die Daten in dem AA-Zwischenspeicher 151 und
dem AB-Zwischenspeicher 152 zusammen, um das Ergebnis der
Addition, bei der es sich um die letzte Befehlsadresse des zu wiederholenden
Blocks handelt, durch den JA-Bus 323 zu dem RPT_E 186 zu übertragen.
-
In dem zweiten Zyklus wird der unmittelbare 8-Bit-Wert,
der in 16 Bits nullerweitert ist, von dem ersten Decodieren 113 dem
A-Zwischenspeicher 152 zugeführt und sodann durch die ALU 153 und
den D1-Bus 311 zu dem RPT_C 188 übertragen.
Das RP-Bit 43 in dem PSW 21 wird auf "1" gesetzt.
Auf diese Weise wird die für
die Wiederholungsverarbeitung erforderliche Initialisierung abgeschlossen.
Die Register R0 bis R5 werden als Puffer für Daten verwendet; die Register
R6 bis R11 werden als Puffer für Koeffizienten
verwendet; das Register R12 wird als Datenzeiger verwendet; und
das Register R14 wird als Zeiger für Koeffizienten verwendet.
-
Die Verarbeitung in der Schleife
wird im folgenden ausführlich
beschrieben. Jeder Befehl beinhaltet den Ladebefehl und den Multiplikations-Additions-Operationsbefehl,
und die beiden kurzen Befehle werden parallel ausgeführt. In 15 bedeutet "LD2W Rdest,
@Rsrc+", daß 2-Wort-(32-Bit)Daten unter
Verwendung des Inhalts des von Rsrc als Operandenadresse bezeichneten
Registers abgerufen werden, und der abgerufene Operandenwert wird
in ein Paar Register eingeschrieben, die durch Rdest (zum Beispiel
ein Register R0 und R1, wenn Rdest R0 bezeichnet) bezeichnet werden.
-
Der Wert von Rsrc plus 4 (Bytegröße des Operanden)
wird zurückgeschrieben.
"MAC Adest, Rsrc1, Rsrc2" bezeichnet den Multiplikations-Additions-Operationsbefehl.
Der Wert in dem durch Rsrc1 bezeichneten Register und der Wert in
dem durch Rsrc2 bezeichneten Register werden als Vorzeichenwerte
miteinander multipliziert, und das Ergebnis der Multiplikation wird
zu dem Wert in dem durch Adest bezeichneten Akkumulator hinzuaddiert.
Das Ergebnis der Addition wird in den Akkumulator zurückgeschrieben.
-
16 veranschaulicht
ein Bitmuster, wenn diese beiden Befehle parallel ausgeführt werden. Diese
Befehle werden als Befehle zugeordnet, die der Bitzuordnung des
kurzen Befehls mit zwei Operanden gemäß 4 entsprechen.
-
Das Bezugszeichen 521 bezeichnet
FM-Bits, die "00" sind, da zwei Befehle parallel ausgeführt werden.
Die Bezugszeichen 522 und 525 bezeichnen Operationscodes
eines LD2W-Befehls mit Nach-Inkrementierung, und das Bezugszeichen 526 bezeichnet
einen Operationscode eines MAC-Befehls.
-
Die Bezugszeichen 523, 524, 527 und 528 bezeichnen
Bereiche zum Spezifizieren der Registernummern von Rdest, Rsrc,
Rsrc1 bzw. Rsrc2 zum Halten von Operanden. Rdest kann nur geradzahlige Register
bezeichnen. Das Bezugszeichen 529 bezeichnet einen Bereich
Ad zum Bezeichnen der Akkumulatornummer von Adest. 17 veranschaulicht den Inhalt des internen
Befehlsspeichers, der dem Schleifenteil entspricht.
-
Aus Gründen der Vereinfachung ist
der Inhalt des Speichers in Form der Mnemotechnik dargestellt. Die
32-Bit-Befehle sind mit I1 (511), I2 (512) und
dergleichen bezeichnet, und die kurzen Befehle sind mit I1a (512(a)),
I1b (512(b)) und dergleichen bezeichnet. Die sechs Befehle
I1 (501) bis I6 (516) werden 42 Mal wiederholt
in der Schleife ausgeführt.
-
18 veranschaulicht
eine Abbildung des internen Datenspeichers in Bezug auf die Koeffizienten
A[i] und die Daten D[i]. Jeder Bereich des internen Datenspeichers
hält 256
Daten. Für
die Koeffizienten A[i] werden 16-Bit-Daten in 256-Wort-(512-Byte-)Bereichen
an den Adressen 2000 bis 21ff in Hexadezimalform
gehalten. Für
die Daten D[i] werden 16-Bit-Daten in 256-Wort-(512-Byte-)Bereichen
an den Adressen 2400 bis 25ff in Hexadezimalform
gehalten.
-
19 (19A bis 19C)
veranschaulichen einen Ablauf der Verarbeitung in der Schleife,
wobei die Fließbandstufen
entlang der Abzisse und die Zeit entlang der Ordinate dargestellt
sind. Alle Befehle sind in dem internen Befehlsspeicher 103 gespeichert,
und alle Operandendaten sind in dem internen Datenspeicher 105 gespeichert.
Es ist ein Taktzyklus zum Abschließen der Verarbeitung in einer
Stufe erforderlich. Während
der fortgesetzten Wiederholungsverarbeitung folgt T1 auf T6.
-
Es erfolgt nun eine Beschreibung
auf der Basis der Verarbeitung von I1 (511). In der IF-Stufe 401 wird
I1 (511) während
der T1-Periode (531) abgerufen. Der Inhalt des IA-Registers 181 wird
zu der Befehlsabrufeinheit 102 übertragen. Der Komparator 187 vergleicht
den Wert in dem IA-Register 181 mit dem Wert in dem RPT_E
186. Da eine Ungleichheit vorliegt, wird der Wert in dem IA-Register 181 durch den
Inkrementierer 182 inkrementiert und zurückgeschrieben.
-
Die Befehlsabrufeinheit 102 greift
auf den internen Befehlsspeicher 103 zu, um die gelesenen 32-Bit-Befehlsdaten
zu der Befehlswarteschlange 111 zu übertragen. Die Befehlswarteschlange 111 schickt
die zu ihr übertragenen
Befehlsdaten während
des gleichen Zyklus zu dem ersten Decodieren 113 und dem
zweiten Decodieren 114.
-
In der D-Stufe 402 wird
I1 (511) während
der T2-Periode (537) decodiert. Der erste Decodierer 113 decodiert
den LD2W-Befehl von I1a (511(a)), um das Steuersignal zu
erzeugen, und der zweite Decodierer 114 decodiert den MAC-Befehl
von I1b (511(b)), um das Steuersignal zu erzeugen. Die
Steuersignale von dem ersten und dem zweiten Decodierer 113 und 114 werden
zu der ersten Operationseinheit 116 bzw. der zweiten Operationseinheit 117 abgegeben.
Der unmittelbare Wert, der "4" beträgt, wird zu der ersten Operationseinheit 116 geschickt.
-
In der D-Stufe 401 erfolgt
eine Konfliktprüfung
an den Operanden und den Recheneinheiten, jedoch tritt keine Störung auf.
Der Wert des Leseoperanden des MAC-Befehls ist bereits geladen worden. Der
MAC-Befehl von I1b (511(b)) wird während der T3-Periode (543)
ausgeführt.
Das Einschreiben eines Werts in das Register R0 ist während der
T1-Periode (535) abgeschlossen worden, und das Einschreiben
eines Werts in das Register R6 ist während der T2-Periode 540 abgeschlossen
worden.
-
In der E-Stufe 403 wird
I1 (511) während
der T3-Periode (543) ausgeführt. Die erste Operationseinheit 116 erzeugt
die Operandenadresse des LD2W-Befehls von I1a (511(a))
und aktualisiert den Wert des Adressenzeigers. Der Wert in dem Register R12
der Registerdatei 115, bei dem es sich um die Operandenadresse
handelt, wird durch den S3-Bus 303 zu dem AA-Zwischenspeicher 151 übertragen.
-
Der Wert in dem AA-Zwischenspeicher 151 wird
durch den AO-Zwischenspeicher 154 und den OA-Bus 321 intakt
an die Operandenzugriffseinheit 104 abgegeben. Der von
dem ersten Decodieren 113 abgebene, unmittelbare Wert wird
zu dem AB-Zwischenspeicher 152 übertragen. Die ALU 153 führt eine
Addition durch, um das Ergebnis der Addition in das Register R12
der Registerdatei 115 durch den Selektor 155 und
den D1-Bus 311 zurückzuschreiben.
-
Die zweite Operationseinheit 117 führt eine Multiplikation
des MAC-Befehls von Ilb (511(b)) durch. Der Wert in dem
Register R0 der Registerdatei 115 wird durch den S4-Bus 304 dem
X-Register 212 zugeführt,
und der Wert in dem Register R6 der Registerdatei 115 wird
durch den S5-Bus 305 dem Y-Register 213 zugeführt. Beide
dieser Werte werden als Vorzeichenwerte behandelt und miteinander
multipliziert. Das Ergebnis der Multiplikation wird dem P-Register 214 zugeführt.
-
In der M-Stufe und der E2-Stufe 404 und 406 wird
I1 (511) während
der T4-Periode (549) einem Speicherzugriff bzw. einer Addition
unterzogen. Die Operandenzugriffseinheit 104 lädt die 4-Byte-Daten aus
dem internen Datenspeicher 105 an der von der ersten Operationseinheit 116 übermittelten
Adresse, um den abgerufenen Wert durch den OD-Bus 322 in das
LD-Register 164 zu übertragen.
Die zweite Operationseinheit 117 führt eine Addition des MAC-Befehls
von I1b (511(b)) durch.
-
Der Wert in dem Akkumulator 208 (A0)
wird durch den Shifter 204 nicht verschoben, sondern dem
A-Zwischenspeicher 202 zugeführt. Der Wert in dem P-Register 214 wird
einer Vorzeichenerweiterung in 40 Bits unterzogen und dem B-Zwischenspeicher 203 zugeführt. Die
ALU 201 addiert die Werte in dem A- und dem B-Zwischenspeicher 202 und 203 zusammen,
um das Ergebnis der Addition in den Akkumulator 208 (A0)
zurückzuschreiben.
-
In der W-Stufe 405 erfolgt
das Zurückschreiben
in das Register während
der T5-Periode (555). Die erste Operationseinheit 116 gibt
die in dem LD-Register 164 gehaltenen Daten durch den Zwischenspeicher 161 und
die Ausrichtschaltung 166 an den W1-Bus 314 und
den W2-Bus 315 ab. Da der Operand in 4 Bytes ausgerichtet
ist, werden die beiden höchstwertigen
Bytes an den W1-Bus 314 abgegeben, und die beiden niedrigstwertigen
Bytes werden an den W2-Bus 315 abgegeben. Die Daten auf dem
W1-Bus 314 werden in das Register R4 der Registerdatei 115 eingeschrieben
und die Daten auf dem W2-Bus 315 werden in das Register
R5 der Registerdatei 115 eingeschrieben.
-
Die Fließband-Verarbeitung von einem 32-Bit-Befehl
für jeden
Taktzyklus erzielt eine Multiplikations-Additions-Operation für jeden
Taktzyklus. Auf diese Weise wird der geladene Datenwert während der
T1-Periode 535 in der W-Stufe 405 jedes zweite
Wort in die Register R0 und R1 der Registerdatei geschrieben, und
der geladene Koeffizientenwert wird während der T2-Periode 540 in
der W-Stufe 405 jedes zweite Wort in die Register R6 und
R7 der Registerdatei 115 eingeschrieben.
-
Der Wert in dem Register R0 der Registerdatei 115 zum
Halten der Daten und der Wert in dem Register R6 der Registerdatei 115 zum
Halten des entsprechenden Koeffizienten werden aufgegriffen und
während
der T3-Periode 543 in der E-Stufe 403 miteinander
multipliziert. Der Wert in dem Register R1 der Registerdatei 115 zum
Halten der Daten und der Wert in dem Register R7 der Registerdatei 115 zum
Halten des entsprechenden Koeffizienten werden aufgegriffen und
während
der T4-Periode 548 in der E-Stufe 403 miteinander
multipliziert. Eine solche Fließband-Verarbeitung
mittels Software ohne Operanden-Störung verbessert die Effizienz.
-
Die Wiederholungsverarbeitung ist
in 19 nicht ausführlich dargestellt,
wird jedoch nachfolgend kurz erläutert.
In der IF-Stufe 401 wird eine Abrufadresse mit der letzten
Adresse des Wiederholungsblocks verglichen. Eine Übereinstimmung
tritt während
der T6-Periode 556 in der IF-Stufe 401 auf. Der Zählwert von
RPT_C 188, der nicht "1" beträgt,
zeigt eine weitere Wiederholung der Verarbeitung an, und die Verarbeitungsabfolge
wird verändert.
-
Der Wert in dem Zwischenspeicher 185,
bei dem es sich um die Startadresse des zu wiederholenden Blocks
handelt, wird durch den JA-Bus 323 zu dem IA-Register 181 übertragen.
Der Befehl an der Startadresse des zu wiederholenden Blocks wird während der
T7-Periode (nicht gezeigt) abgerufen, die der T1-Periode 531 in
der IF-Stufe 401 entspricht. Das letzte Befehlsadressenübereinstimmungs-Detektionsergebnis
des Wiederholungsblocks wird durch die Pipeline übertragen.
-
Während
der T2-Periode 538 in der E-Stufe 403, in der
I6 ausgeführt
wird, dekrementiert der Dekrementierer 190 den Wert in
dem Wiederholungszähler
RPT_C 188 um 1 unabhängig
von dem auszuführenden
Befehl. Wenn der Wert in dem RPT_C 188 vor der Dekrementierung "1"
beträgt,
wird das RP-Bit in dem PSW auf Null gelöscht und die Wiederholung wird
deaktiviert.
-
Im folgenden wird ein IIR- (Infinite
Impuls Response) Filter des Direktform-Typs II zweiter Ordnung mit
n-Stufen (n biquad) beschrieben. 20 veranschaulicht
eine grafische Darstellung des Signalflusses des Filters. In 20 stellt 601 die
Multiplikation von Koeffizienten dar, 602 stellt die Addition von
Eingangsdaten dar, und 603 stellt eine Einheitsverzögerung dar.
In der Schleife werden fünf
Multiplikations-Additions-Operationen ausgeführt. In diesem Fall ist es
notwendig, die Daten der beiden letzten Operationen während der
Schleifen periode in den Speicher einzuschreiben. Die Daten und die
Koeffizienten weisen jeweils eine Länge von 16 Bits auf.
-
21 veranschaulicht
ein Beispiel eines Programms des IIR-Filters für den Datenprozessor des ersten
bevorzugten Ausführungsbeispiels.
Eine Initialisierung erfolgt bei dem Bezugszeichen 606,
die Schleifenverarbeitung erfolgt bei 607 und die Nachbearbeitung
bei 608. Die Schleifenverarbeitung ohne Zusatzaufwand wird
durch den Wiederholungsbefehl implementiert.
-
Im folgenden wird die Verarbeitung
in der Schleife ausführlich
beschrieben. 22 zeigt
den Inhalt des internen Befehlsspeichers, der dem Schleifenteil
entspricht. Sechs Befehle I1 (611) bis I7 (617)
werden 42 Mal wiederholt in der Schleife ausgeführt. Ein ST2W-Befehl bei 611(a)
gibt die Anweisung, daß der
Speicher die Werte in den beiden Registern R0 und R1 speichert.
-
Der Wert in dem Register R12, der
als Basisadresse dient, wird nachinkrementiert. In MULX-Befehl bei 611(b)
gibt die Anweisung, daß die
Werte in den beiden Registern R0 und R6 als Vorzeichenwerte miteinander
multipliziert werden und das Ergebnis der Multiplikation in den
Akkumulator zurückgeschrieben
wird. Das Ergebnis der Multiplikation wird innerhalb des gleichen
Zyklus durch den Selektor 207 in den Akkumulator 208 zurückgeschrieben.
-
Ein ADD-Befehl bei 612(a)
gibt die Anweisung, daß die
ALU 201 dem Inhalt des Registers R12 4 hinzuaddiert.
Ein MV-Befehl bei 613(b) gibt die Anweisung, daß der Wert
von r4 auf r1 kopiert wird. Ein MV2W-Befehl bei 616(b) überträgt zwei
Worte, d. h. überträgt die Werte
in den Registern R4 und R5 auf die Register R2 bzw. R3. Da die Daten
in diesem Fall durch den Trommel-Shifter 215 übertragen
werden, verursacht ein Hardware-Betriebsmittel keine Störung hinsichtlich
des unmittelbar vorausgehenden Multiplikations-Additions-Operationsbefehls.
-
Ein RACHI-Befehl bei 617(b)
gibt die Anweisung, daß der
Wert in dem Akkumulator A0 um 1 Bit nach links verschoben wird,
auf die 16 oberen Bits gerundet wird, auf der Basis des Werts der
Schutzbits auf einen Maximalwert h'7fff, der sich in 16 Bits ausdrücken läßt, begrenzt
wird, wenn ein Überlauf auftritt,
sowie auf einen Minimalwert h'8000, der sich Form von 16s Bit ausdrücken läßt, begrenzt
wird, wenn ein Unterlauf auftritt, sowie in das Register R0 zurückgeschrieben
wird. Diese Operation wird unter Verwendung der ALU 201 und
der Sättigungsschaltung 209 ausgeführt.
-
Das Register R0 hält Eingangsdaten für die nächste Stufe.
Das Register R1 wird als Aktualisierungsdatenregister Di1 (wobei
i eine ganze Zahl ist, die nicht mehr als n beträgt) verwendet. Die Register R2
bis R5 werden als Puffer zum Halten der Daten verwendet. Die Register
R6 und R8 bis R11 werden als Puffer für Koeffizienten verwendet.
Das Register R12 wird als Datenzeiger verwendet. Das Register R14
wird als Zeiger für
Koeffizienten verwendet. Das Register R7 hält ungültige Daten, um eine 32-Bit-Ausrichtung
der Koeffizientendaten aufrechtzuerhalten.
-
23 zeigt
eine Abbildung des internen Datenspeichers in Bezug auf die Koeffizienten
und Daten. Die jeweiligen Daten haben eine Länge von 16 Bits. In der Anordnung
der 20 sind fünf Koeffizienten
pro Stufe sowie zwei Daten pro Stufe vorgesehen. Ein Koeffizient
Ai (621) ist mit einem Eingangswert zu multiplizieren.
Die Bezugszeichen 622 und 626 bezeichnen Leerbereiche
für einen
effizienten Zugriff auf die Koeffizienten.
-
24 (24A bis 24C)
veranschaulichen einen Ablauf der Verarbeitung in der Schleife,
bei der die Pipeline- bzw. Fließbandstufen
entlang der Abszisse dargestellt sind und die Zeit entlang der Ordinate
aufgetragen ist. Alle Befehle sind in dem internen Befehlsspeicher 103 gespeichert,
und alle Operandendaten sind in dem internen Datenspeicher 105 gespeichert.
Zum Abschließen
der Verarbeitung in einer Stufe ist ein Taktzyklus erforderlich.
Während
der fortgesetzten Wiederholungsverarbeitung folgt T1 auf T7.
-
Wie bei dem vorstehend beschriebenen FIR-Filter
werden die abgerufenen Daten mindestens zwei Zyklen später aufgegriffen.
Der Befehl bei 611 gibt die Anweisung, daß eine Multiplikation
gleichzeitig ausgeführt
wird, wenn zwei Worte für
eine Datenaktualisierung gespeichert werden. Der MV2W-Befehl gibt
die Anweisung, daß der
Inhalt der Daten zu einem Zeitpunkt (bei 643) jedes zweite
Wort übertragen
wird, so daß die
gleiche Registernummer bei jeder Wiederholung der Schleife verwendet
wird.
-
Der Wert in dem Register R4, der
bei 659 während
der T4-Periode geladen wird, und der Wert in dem Register R10, der
bei 655 während
der T3-Periode geladen wird, werden während der T6-Periode bei 666 miteinander
multipliziert, und der Wert in dem Register R5, der während der
T4-Periode bei 659 geladen wird, sowie der Wert in dem
Register R11, der während
der T3-Periode bei 655 geladen wird, werden während der
T7-Periode bei 670 miteinander multipliziert. Eine solche
Verarbeitung ermöglicht, daß sieben
Zyklen für
die Ausführung
der Verarbeitung des IIR-Filters vom Direktform-Typ II zweiter Ordnung
in einer einzigen Stufe erforderlich sind.
-
Im folgenden wird ein Beispiel einer
IFFT (einer umgekehrten schnellen Fourier-Transformation) beschrieben. Die Einzelverarbeitung
ist wie folgt: tmp_r = (b_r*c_r) – (b_i*c_i); tmp_i = (b_r*c_i)*(b_i*c_r); A_r = a_r – tmp_r; A_i = a_i – tmp_i; B_r = a_r + tmp_r; B_i
= a_i + tmp_i; wobei a und b komplexe Variable von Eingangsdaten
sind, A und B komplexe Variable von Ausgangsdaten (Aktualisierungsdaten)
sind, tmp eine vorübergehende
komplexe Variable ist, c eine komplexe Konstante ist, "_r" ein Realteil
und "_i" ein Imaginärteil
ist.
-
25 veranschaulicht
ein Beispiel eines Programms in einem Schleifenteil, wenn zwei Einzelverarbeitungen
der IFFT eine einzige Schleife bilden. Die Register R0, R1, sowie
R2, R3 halten a und A. Die Register R4 und R5 halten b. Die Register
R6 und R7 halten tmp. Die Register R8 und R9 halten a und B. Die
Register R10 und R11 halten c. Die geradzahligen Register halten
den Realteil, und die ungeradzahligen Register halten den Imaginärteil. Das Register
R12 hält
die Adresse von a. Das Register R14 hält die Adresse von 6.
-
Das Symbol "msu" gibt den Multiplikations-Subtraktions-Befehl
an, der die Anweisung gibt, daß das
Ergebnis der Multiplikation von dem Akkumulator subtrahiert wird.
Dies ist dadurch bedingt, daß das
Quadrat von i (komplexe Zahl) gleich –1 beträgt.
-
In diesem Fall sind 15 Zyklen erforderlich, um
zwei Einzelverarbeitungen in Bezug auf die beiden Paare komplexer
Zahlen auszuführen.
Die dreißig
Unterbefehle beinhalten vier 2-Wort-Ladebefehle, vier 2-Wort-Speicherbefehle,
vier Additionen, vier Subtraktionen, vier Multiplikationen, zwei
Multiplikations-Additions-Operationen,
zwei Multiplikations-Subtraktions-Operationen, vier Rundungsbefehle
sowie zwei 2-Wort-Übertragungsbefehle,
so daß eine
sehr hohe Effizienz der Operationen geschaffen wird.
-
26 veranschaulicht
ein Beispiel eines Programms in einem Schleifenteil einer Subtraktions-Absolutadditions-Operation.
Ein Befehl absadd gibt die Anweisung, daß der spezifizierte Registerwert
aus der Registerdatei 115 durch den S5-Bus 305 den
niedrigstwertigen Positionen des Shifters 205 zugeführt wird.
Der Shifter 205 führt
eine Vorzeichenerweiterung an dem Wert in 40 Bits aus, verschiebt
jedoch den Wert nicht, um den Wert dem B-Zwischenspeicher 203 zuzuführen.
-
Der Wert wird der Operation mit dem
von der ALU 201 spezifizierten Wert in dem Akkumulator 208 unterzogen,
und das Ergebnis der Operation wird in den Akkumulator 208 zurückgeschrieben.
Die ALU 201 führt
eine Addition durch, wenn der Wert in dem B-Zwischenspeicher 203 positiv
ist, und führt
eine Subtraktion durch, wenn der Wert negativ ist. Die Subtraktion
wird ausgeführt
durch Invertieren der Daten und Vorsehen eines Übertrags zu dem niedrigstwertigen
Bit. Auf diese Weise ist ein Taktzyklus zum Ausführen der Absolutadditions-Operation
erforderlich.
-
27 (27A bis 27C)
veranschaulichen einen Ablauf der Verarbeitung in der Schleife.
Der 2-Wort-Ladebefehl wird parallel mit dem Absolutadditionsbefehl
des Ergebnisses der Subtraktion ausgeführt. Während des T3-Zyklus werden
Daten in Abhängigkeit
von dem LD2W-Befehl von I5a in die Register R6 und R7 geladen (813).
Während
des T4-Zyklus werden dann Daten in Abhängigkeit von dem LD2W-Befehl
von I6a in die Register R2 und R3 geladen (817).
-
Während
des T6-Zyklus wird der Wert in dem Register R7 in Abhängigkeit
von dem durch I4a dargestellten Befehl von dem Wert in dem Register
R3 subtrahiert, und das Ergebnis der Subtraktion wird in das Register
R3 zurückgeschrieben.
Ferner wird der Wert in dem Register R6 in Abhängigkeit von dem durch I4b
dargestellten Befehl von dem Wert in dem Register R2 parallel subtrahiert,
und das Ergebnis der Subtraktion wird in das Register R2 zurückgeschrieben
(824). Auf diese Weise werden vier Subtraktions-Absolutadditions-Operationen in sechs
Zyklen ausgeführt.
-
Zweites bevorzugtes
Ausführungsbeispiel
-
28 zeigt
ein Blockdiagramm einer zweiten Operationseinheit 120 für den Datenprozessor gemäß einem
zweiten bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung, die der zweiten Operationseinheit 117 des
ersten bevorzugten Ausführungsbeispiels
entspricht. Die übrigen
Einheiten des Datenprozessors des zweiten bevorzugten Ausführungsbeispiels
weisen eine ähnliche
Konstruktion wie die des ersten bevorzugten Ausführungsbeispiels auf.
-
Die zweite Operationseinheit 120 unterscheidet
sich von der zweiten Operationseinheit 117 des ersten bevorzugten
Ausführungsbeispiels
darin, daß sie
eine ALU 221 aufweist, die unabhängig von einem Addieren 231 zum
Ausführen
der Multiplikations-Additions-Operation betreibbar ist. Dies ermöglicht die
Ausführung
der Addition und Subtraktion der Multiplikations-Additions-/Multiplikations-Subtraktions-Befehle
sowie weiterer arithmetischer und logischer Operationen ohne Störungen von
Hardware.
-
Die ALU 221 führt eine
arithmetische und logische 16-Bit-Operation durch. Ein mit dem S4-Bus 304 verbundener
A2-Zwischenspeicher 222 und ein mit dem S5-Bus 305 verbundener
B2-Zwischenspeicher 223 bilden Eingangszwischenspeicher
für die ALU 221.
Ein ALUO-Zwischenspeicher 225 ist ein Ausgangs-Zwischenspeicher
für die
ALU221.
-
Ein Selektor 224 wählt den
Ausgang von der ALU 221, den Wert in dem A2-Zwischenspeicher 222 oder
den Wert in dem B2-Zwischenspeicher 223 aus, um den ausgewählten Wert
durch den D2-Bus 312 in die Registerdatei 115 zurückzuschreiben.
Der Ausgang von dem ALUO-Zwischenspeicher 225 kann auf
die niedrigstwertigen Positionen gesetzt werden und einer Vorzeichenerweiterung
durch einen Shifter 235 unterzogen werden.
-
Ein B-Zwischenspeicher 233 erhält selektiv den
Ausgangswert von dem Shifer 235 oder den Wert in dem P-Zwischenspeicher 214,
der als Ausgangs-Zwischenspeicher des Multiplizierers 211 dient.
Ein A-Zwischenspeicher 232 empfängt Daten von dem Akkumulator 208 durch
den Shifter 204. Die übrigen
Elemente der zweiten Operationseinheit 120 sind mit denen
der zweiten Operationseinheit 117 des ersten bevorzugten
Ausführungsbeispiels
im wesentlichen identisch.
-
Im folgenden wird ein Verarbeitungsbeispiel beschrieben. 29 veranschaulicht ein exemplarisches
Programm einer Subtraktions-Quadratadditions-Operation. Die Initialisierung
erfolgt bei 701, die Schleifenverarbeitung bei 702 und
die Nachverarbeitung bei 703. 30 veranschaulicht den Inhalt des internen
Befehlsspeichers, der dem Schleifenteil entspricht. Es wird die
Subtraktions-Quadratakkumulierungs-Operation
von D1[i] und D2[i] durchgeführt.
-
Das Register R12 hält die Adresse
von D1[i], und das Register R14 hält die Adresse von D2[i]. Die Register
R0 bis R3 halten die Daten D1[i], und die Register R4 bis R7 halten
die Daten D2[i]. Alle Befehle werden parallel ausgeführt. Es
sind sechs Zyklen erforderlich, um die Verarbeitung vier Mal auszuführen. 31 veranschaulicht eine
Abbildung des internen Datenspeichers in Bezug auf die Daten. Die jeweiligen
Daten besitzen eine Länge
von 16 Bits. Die Daten D1[i] und D2[i] sind in verschiedenen Bereichen
gespeichert.
-
32 (32A bis 32C)
veranschaulicht einen Ablauf der Verarbeitung in der Schleife. Zum Beispiel
führen
der Addieren 231 und die ALU 221 die Addition
(746) der Multiplikations-Additions-Operation sowie die
Subtraktion (745) zum Bestimmen der Differenz parallel
während
der T6-Periode aus.
-
Der Datenprozessor des zweiten bevorzugten
Ausführungsbeispiels
kann die in dem ersten bevorzugten Ausführungsbeispiel beschriebene
Subtraktions-Absolutadditions-Operation
in effizienterer Weise durchführen. 33 veranschaulicht den Inhalt
des internen Befehlsspeichers, der dem Schleifenteil entspricht.
Das Register R12 hält
die Adresse eines ersten Datenfeldes, und die Register R0 bis R5 halten
die Daten desselben. Das Register R14 hält die Adresse eines zweiten
Datenfeldes, und die Register R6 bis R11 halten die Daten desselben.
-
Bei einem Befehl daadd handelt es
sich um einen Befehl zum Bestimmen der Subtraktions-Absolutadditions-Operation,
wobei das Ergebnis der Operation in dem Akkumulator gehalten wird.
Dieser Befehl gibt, wie auch der Multiplikations-Additions-Operationsbefehl, die Anweisung,
daß eine
Zweistufen-Fließband-Verarbeitung ausgeführt wird.
-
34 (34A bis 34C)
veranschaulicht einen Ablauf der Verarbeitung in der Schleife. Die Verarbeitungsbedingungen
in 34 sind im wesentlichen
denen im Fall des bei dem ersten bevorzugten Ausführungsbeispiel
beschriebenen FIR-Filters ähnlich.
In 34 wird anstelle
der Multiplikations-Additions-Operation
die Subtraktions-Absolutadditions-Operation ausgeführt. Das
heißt,
die Multiplikation wird durch eine Subtraktion ersetzt, und die Addition
wird durch die Absolutadditions-Operation ersetzt. Auf diese Weise
ist der Durchsatz bei der Verarbeitung derart, daß eine Subtraktions-Absolutadditions-Operation
pro Zyklus ausgeführt
wird.
-
Drittes bevorzugtes
Ausführungsbeispiel
-
35 zeigt
ein Funktionsblockdiagramm des Datenprozessors gemäß einem
dritten bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung. Bei einer MPU 850 handelt es
sich um einen MPU-Kern. Eine Befehlsabrufeinheit 863 und
eine Operandenzugriffseinheit 864 sind der Befehlsabrufeinheit 102 und
der Operandenzugriffseinheit 104 des Datenprozessors des
ersten bevorzugten Ausführungsbeispiels
im wesentlichen ähnlich.
Die Befehlsdaten, die eine Länge
von 64 Bits aufweisen, werden der Befehlsabrufeinheit 863 zugeführt. Die Bus-Schnittstelleneinheit
und dergleichen sind in 35 nicht
dargestellt.
-
Der MPU-Kern 850 weist eine
Befehlswarteschlange 851, eine Steuereinheit 852,
eine Registerdatei 860, eine erste Operationseinheit 858,
eine zweite Operationseinheit 859, eine dritte Operationseinheit 861 sowie
eine vierte Operationseinheit 862 auf. Bei der Befehlswarteschlange 851 handelt
es sich um einen FIFO-gesteuerten Befehlspuffer zum Halten von maximal
zwei 64-Bit-Befehlen. Die erste Operationseinheit 858 beinhaltet
einen Inkrementierer, einen Dekrementierer sowie einen Addierer
und führt
eine Verwaltung des PC-Wertes, eine Berechnung der Verzweigungszieladresse
sowie eine Wiederholungssteuerung aus.
-
Die zweite Operationseinheit 859 beinhaltet eine
ALU und eine Ausrichtschaltung und führt eine Operanden-Adressen-Erzeugung,
eine Aktualisierung des Zeigers, arithmetisch-logische Operationen, eine Übertragung,
einen Vergleich, ein Halten und ein Ausrichten von geladenen Daten
sowie ein Halten und Ausrichten von zu speichernden Daten aus. Die dritte
Operationseinheit 861 beinhaltet eine ALU und einen Shifter
und führt
eine Operationsverarbeitung, wie arithmetisch-logische Operationen, eine Übertragung,
einen Vergleich und eine Verschiebung aus.
-
Die vierte Operationseinheit 862 beinhaltet eine
Multiplikations-Additions-Operationseinheit,
einen Shifter und einen Akkumulator und führt in erster Linie die Multiplikations-Additions-
und Multiplikations-Subtraktions-Operationen sowie eine Akkumulator-Verschiebung
aus. Auf diese Weise weist der MPU-Kern 850 die vier unabhängigen Recheneinheiten
in mit der Registerdatei verbundener Weise auf.
-
Die Steuereinheit 852 beinhaltet
eine Befehlsdecodiereinheit 853. Die Befehlsdecodiereinheit 853 weist
vier Decodieren auf. 36 veranschaulicht
ein Befehlsformat, das durch den Datenprozessor des dritten bevorzugten
Ausführungsbeispiels verarbeitet
wird. FM-Bits 871 mit einem 4-Bit-Format sind in zwei Mal
2 Bits unterteilt, um die Formate der Kombination des ersten und
des zweiten Behälters 872 und 873 sowie
der Kombination des dritten und des vierten Behälters 874 und 875 in
der gleichen Weise wie bei dem Datenprozessor des ersten bevorzugten
Ausführungsbeispiels
zu bezeichnen. Jeder des ersten bis vierten Behälters 872 bis 875 wird in
Form von 15 Bits ausgedrückt.
-
Der erste Decodierer 854 decodiert
in erster Linie den Operationscode des ersten Behälters 872, um
Steuersignale für
die Registerdatei 860 und die erste Operationseinheit 858 zu
erzeugen. Der Verzweigungsbefehl wird in erster Linie in dem Feld
des ersten Behälters 872 spezifiziert.
Der zweite Decodieren 855 decodiert in erster Linie den
Operationscode des zweiten Behälters 873,
um Steuersignale für
die Registerdatei 860 und die zweite Operationseinheit 859 zu
erzeugen.
-
Der Lade/Speicherbefehl, der arithmetisch-logische
Operationsbefehl, der Übertragungsbefehl
und der Vergleichsbefehl werden in erster Linie in dem Feld des
zweiten Behälters 873 angegeben.
Der dritte Decodieren 856 decodiert in erster Linie den
Operationscode des dritten Behälters 874, um
Steuersignale für
die Registerdatei 860 und die dritte Operationseinheit 861 zu
erzeugen.
-
Der arithmetisch-logische Operationsbefehl, der Übertragungsbefehl,
der Vergleichsbefehl und der Verschiebebefehl werden in erster Linie
in dem Feld des dritten Behälters 874 angegeben.
Der vierte Decodieren 857 decodiert in erster Linie den
Operationscode des vierten Behälters 875,
um Steuersignale für
die Registerdatei 860 und die vierte Operationseinheit 862 zu
erzeugen. Der Multiplikations-Additions-Operationsbefehl wird in
erster Linie in dem Feld des vierten Behälters 875 spezifiziert.
-
Eine derartige Anordnung erlaubt
eine sehr ausgefeilte parallele Verarbeitung. Die vorliegende Erfindung
ist auch bei einem solchen Fall anwendbar. Zum Beispiel können zur
Ausführung
der Subtraktions-Quadratadditions-Operation die zweite, dritte und
vierte Operationseinheit 859, 861, 862 die
Lade-, Subtraktions- und
Absolutadditions-Operation parallel ausführen, um für einen derartigen Durchsatz
der Verarbeitung zu sorgen, daß eine
Subtraktions-Quadratadditions-Operation
pro Zyklus ausgeführt
wird. In ähnlicher
Weise wird auch die IFFT-Verarbeitung mit hohen Geschwindigkeiten
ausgeführt.
-
Gemäß der vorliegenden Erfindung
ist die Anzahl der Recheneinheiten nicht begrenzt, sondern kann
auf der Basis einer Abwägung
zwischen der erforderlichen Leistungsfähigkeit und den Kosten bestimmt
werden. Wenn der Durchsatz der Datenübertragung unzulänglich ist,
sollten vier Worte parallel übertragen
werden. Wenn die Anzahl der Register unzulänglich ist, sollte die Anzahl
der Register erhöht werden,
wobei dies eine Erhöhung
der Bitlänge
erforderlich macht.
-
Für
die Verbesserung des Durchsatzes der Multiplikations-Additions-Operation
sollte eine Vielzahl von Operationseinheiten Multiplikations-Additions-Operationseinheiten
aufweisen, um die Anzahl der zu übertragenden
Operanden zu erhöhen.
Die vorliegende Erfindung ist auch in diesem Fall anwendbar.
-
Viertes bevorzugtes
Ausführungsbeispiel
-
37 zeigt
ein Blockdiagramm der zweiten Operationseinheit 120 des
Datenprozessors gemäß einem
vierten bevorzugten Ausführungsbeispiel
der vorliegenden Erfindung, die der zweiten Operationseinheit 117 des
Datenprozessors des ersten bevorzugten Ausführungsbeispiels entspricht.
Die übrigen Einheiten
des Datenprozessors des vierten bevorzugten Ausführungsbeispiels sind in ihrer
Konstruktion mit denen des ersten bevorzugten Ausführungsbeispiels
im wesentlichen identisch.
-
Bei dem vierten bevorzugten Ausführungsbeispiel
wird das Ergebnis der Multiplikations-Additions-Operation für jede Operation
in dem Register gespeichert, und es sind keine Schutzbits vorgesehen. Zusätzliche
Schutzbits können
vorgesehen werden, falls dies im Hinblick auf die Operationsgenauigkeit erforderlich
ist.
-
38 veranschaulicht
ein Befehlsformat für den
Datenprozessor des vierten bevorzugten Ausführungsbeispiels, wobei der
Befehl eine Länge
von 64 Bits aufweist. Der Befehl weist zwei FM-Bits 941, einen
linken 31-Bit-Behälter 942 und
einen rechten 31-Bit-Behälter 943 auf. 39 veranschaulicht ein Grundformat
jedes Behälters,
bei dem es sich im Großen
und Ganzen um ein 3-Operanden-Format mit
drei Feldern handelt: zwei Quellenregisternummer-Spezifikationsfelder 946 und 947 sowie
ein Zielregisternummer-Spezifikationsfeld 945. Es sind
64 Register vorgesehen, und die Registernummer ist in einem 6-Bit-Feld
spezifiziert.
-
Die grundlegende Fließband-Verarbeitung des
vierten bevorzugten Ausführungsbeispiels
ist der des ersten bevorzugten Ausführungsbeispiels ähnlich,
so daß auf
eine Beschreibung derselben verzichtet wird. Ein S4-Bus 913,
ein S5-Bus 914, ein D2-Bus 915 und ein D3-Bus 916 arbeiten
in der E-Stufe 403. Diese Busse übertragen in erster Linie Operandenwerte
eines normalen ganzzahligen Operationsbefehls und dergleichen.
-
Ein S6-Bus 911, ein S7-Bus 912,
ein D4-Bus 917 und ein D5-Bus 918 arbeiten in
der E2-Stufe 406. Diese Busse übertragen in erster Linie einen
akkumulierten Wert. Ein Addieren 934 sowie dessen Eingangs-
und Ausgangseinheit arbeiten in der E-Stufe 403 und der
E2-Stufe 406, während
weitere Recheneinheiten und Zwischenspeicher in der E-Stufe 403 arbeiten.
-
Bei einem Befehl "mac" für eine Multiplikations-Additions-Operation
handelt es sich um einen 3-Operanden-Befehl. Die Verarbeitungsspezifikationen
von "mac Rdest, Rsrc1, Rsrc2" sind derart, daß der durch Rsrc1 spezifizierte
Registerwert und der durch Rsrc2 spezifizierte Registerwert miteinander mulitpliziert
werden und das Ergebnis der Multiplikation zu dem Wert in dem Paar
von Registern hinzu addiert wird, das durch Rdest spezifiziert ist.
-
Die Hardwareverarbeitung wird ausführlich beschrieben.
Zuerst werden in der E-Stufe 403 die durch Rsrc1 und Rsrc2
spezifizierten Registerwerte von einer Registerdatei 903 durch
den S4-Bus 913 und den S5-Bus 914 zu einem X-Zwischenspeicher 938 bzw.
einem Y-Zwischenspeicher 939 übertragen.
-
Ein Multiplizierer 940 führt eine
Multiplikation durch, und das P-Register 941 hält des Ergebnis
der Multiplikation. In der E2-Stufe 406 werden dann die durch
Rdest spezifizierten Werte in dem Paar von Registern von der Registerdatei 903 durch
den S6-Bus 911, den S7-Bus 912 und den Shifter 913 einem
A-Zwischenspeicher 931 zugeführt.
-
Der Wert in dem P-Register 941 wird
einem B-Zwischenspeicher 933 zugeführt. Der Addieren 934 addiert
die Werte in dem A-Zwischenspeicher 931 und dem B-Zwischenspeicher 933 zusammen. Das
Ergebnis der Addition wird durch eine Sättigungsschaltung 937 an
den D4-Bus 917 und den D5-Bus 918 abgegeben und
in das durch Rdest spezifizierte Paar von Registern in der Registerdatei 903 zurückgeschrieben.
-
40 veranschaulicht
ein Beispiel des Programms in dem Schleifenteil des FIR-Filters.
Der 2-Wort-Ladebefehl und der Multiplikations-Additions-Operationsbefehl
werden parallel decodiert und parallel ausgeführt. Dadurch wird eine Multiplikations-Additions-Operation
pro Zyklus erzielt, und zwar in der gleichen Weise wie bei dem Datenprozessor des
ersten bevorzugten Ausführungsbeispiels,
mit der Ausnahme, daß das
Ergebnis der Multiplikations-Additions-Operation
für jede
Operation in die Registerdatei zurückgeschrieben wird.
-
Auf diese Weise ist die Technik der
vorliegenden Erfindung auch dann wirksam, wenn das kumulative Ergebnis
der Multiplikations-Additions-Operationen in dem Register gehalten
wird. Die Operanden werden vorliegend nicht umgangen, jedoch kann ein
Umgehungsweg bei Bedarf vorgesehen werden.
-
Fünftes bevorzugtes
Ausführungsbeispiel
-
Bei dem Datenprozessor der vorstehend
beschriebenen bevorzugten Ausführungsbeispiels
wird angenommen, daß ein
Wort eine Länge
von 16 Bits aufweist. Ein Wort kann jedoch eine Länge mit
einer beliebigen Anzahl von Bits aufweisen. Zum Beispiel ist bei
einer Audioverarbeitung eine Länge
von etwa 24 Bits erforderlich, und ein Wort kann eine Länge von
24 Bits aufweisen.
-
Ein Wort kann auch eine Länge von
32 Bits hinsichtlich der Ausrichtung mit einem Prozessor aufweisen.
In diesem Fall muß der
Multiplizieren nicht notwendigerweise eine Form von 1 Wort × 1 Wort sein,
sondern es sollte ein Multiplizierer mit einer hinsichtlich der
Genauigkeit der zu verarbeitenden Anwendung essentiellen Größe ausgewählt und
implementiert werden.
-
Sechstes bevorzugtes
Ausführungsbeispiel
-
Bei dem Datenprozessor der vorstehend
beschriebenen bevorzugten Ausführungsbeispiele
wird die Multiplikations-Additions-Operation einer zweistufigen
Fließband-Verarbeitung
unterzogen. Die letzte Additionsstufe des Multiplizierers sowie
der Addieren für
die Addition können
jedoch zusammengelegt werden, um die Multiplikations-Additions-Operation
in einem Zyklus auszuführen.
-
Zusätzlich dazu kann für eine Operation
mit hoher Geschwindigkeit die Multiplikation durch eine Zweistufen-Pipeline
durchgeführt
werden, so daß die Multiplikations-Additions-Operation
durch eine Dreistufen-Pipeline durchgeführt werden kann. Andere Pipelines
lassen sich frei wählen.
Zum Beispiel können
die E-Stufe 403 und die M-Stufe 404 für die Verarbeitung
zu einer einzigen Pipeline-Stufe
zusammengeführt
werden.
-
Zum Verbessern der Arbeitsfrequenz
kann ferner die Zurückschreib-Operation
in das Register in einer anderen Pipeline-Stufe als der E-Stufe
ausgeführt
werden. Außerdem
können
Daten von dem Schreibweg zu dem Register umgangen werden, wobei
dies für
eine Verarbeitung mit hoher Geschwindigkeit effektiv ist.
-
Siebtes Bevorzugtes
Ausführungsbeispiel
-
Bei den vorstehend beschriebenen
bevorzugten Ausführungsbeispielen
der vorliegenden Erfindung ist der Mikroprozessor mit einer VLIW-Architektur
als Beispiel dargestellt. Die Technik der vorstehenden Erfindung
ist jedoch auch bei einem superskalaren RISC-Prozessor und dergleichen
Programmierung anwendbar, wenn die Dateils der Hardware berücksichtigt
werden und die Bedingungen für
eine parallele Verarbeitung ergriffen werden.
-
Der Unterschied besteht darin, daß die parallele
Ausführung
in dem Programm codiert ist oder die Hardware bestimmt, ob die parallele
Ausführung
zulässig
ist oder nicht. Die FM-Bits können
in der VLIW-Architektur fehlen. Die Befehle können stets parallel ausgeführt werden.
In diesem Fall sollte die Operation, die nicht parallel ausgeführt wird,
auf eine Nulloperation gesetzt werden.
-
Die Erfindung ist zwar ausführlich beschrieben
worden, jedoch ist die vorstehende Beschreibung in allen Aspekten
als erläuternd
und nicht als einschränkend
zu verstehen. Es versteht sich, daß zahlreiche weitere Modifikationen
und Variationen im Umfang der Erfindung, wie sie durch die beigefügten Ansprüche definiert
ist, vorgenommen werden können.