CN108350449B - 工程化的CRISPR-Cas9核酸酶 - Google Patents
工程化的CRISPR-Cas9核酸酶 Download PDFInfo
- Publication number
- CN108350449B CN108350449B CN201680063266.8A CN201680063266A CN108350449B CN 108350449 B CN108350449 B CN 108350449B CN 201680063266 A CN201680063266 A CN 201680063266A CN 108350449 B CN108350449 B CN 108350449B
- Authority
- CN
- China
- Prior art keywords
- artificial sequence
- dna
- gene
- spcas9
- lys
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images




















































Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases RNAses, DNAses
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/102—Mutagenizing nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPRs]
Abstract
披露了具有改进的特异性的工程化CRISPR‑Cas9核酸酶及其在基因组工程、表观基因组工程、基因组靶向、和基因组编辑中的用途。
Description
优先权声明
本申请于35 USC§119(e)下要求以下美国专利申请序列号的优先权:62/211,553,2015年8月28日提交;62/216,033,2015年9月9日提交;62/258,280,2015年11月20日提交;62/271,938,2015年12月28日提交;以及15/015,947,2016年2月4日提交。以上文献的全部内容通过引用结合在此。
序列表
本申请包含一份已经以ASCII格式电子递交的序列表并且该序列表通过引用以其全文结合在此。创建于2016年8月26日的所述ASCII副本名称为SEQUENCE LISTING.txt并且大小是129,955字节。
联邦资助的研究或开发
本发明是根据由国立卫生研究院(National Institutes of Health)授予的授权号DP1GM105378和R01GM088040在政府支持下完成的。美国政府享有本发明的一定的权利。
技术领域
本发明至少部分地涉及具有改变和改进的靶特异性的工程化规律间隔成簇短回文重复序列(CRISPR)/CRISPR相关蛋白9(Cas9)核酸酶及其在基因组工程、表观基因组工程、基因组靶向、基因组编辑、以及体外诊断中的用途。
背景技术
CRISPR-Cas9核酸酶使得在多种多样的生物体和细胞类型中进行有效的基因组编辑成为可能(Sander&Joung,Nat Biotechnol[自然生物技术]32,347-355(2014);Hsu等人,Cell[细胞]157,1262-1278(2014);Doudna&Charpentier,Science[科学]346,1258096(2014);Barrangou&May,Expert Opin Biol Ther[生物疗法的专家意见]15,311-314(2015))。Cas9的靶位点识别是由编码与靶原型间隔子互补的序列的嵌合单指导RNA(sgRNA)编程(Jinek等人,Science[科学]337,816-821(2012)),而且需要进行短的邻近PAM的识别(Mojica等人,Microbiology[微生物学]155,733-740(2009);Shah等人,RNA Biol[RNA生物学]10,891-899(2013);Jiang等人,Nat Biotechnol[自然生物技术]31,233-239(2013);Jinek等人,Science[科学]337,816-821(2012);Sternberg等人,Nature[自然]507,62-67(2014))。
发明内容
如本文所述,理论上可以通过减小Cas9对DNA的结合亲和力,将Cas9蛋白工程化以显示增加的特异性。因此,本文描述了与野生型蛋白相比,具有增加的特异性(即在不完全匹配的或错配的DNA位点,诱导显著更少的脱靶效应)的多个Cas9变体,连同使用它们的方法。
在第一方面,本发明提供了分离的酿脓链球菌Cas9(SpCas9)蛋白,该蛋白具有在以下位置中的一个、两个、三个、四个、五个、六个、或全部七个处的突变:L169A、Y450、N497、R661、Q695、Q926、和/或D1135E,例如包含与SEQ ID NO:1的氨基酸序列至少80%一致的序列,所述序列具有在以下位置中的一个、两个、三个、四个、五个、六个、或七个处的突变:L169、Y450、N497、R661、Q695、Q926、D1135E,以及任选地核定位序列、细胞穿透肽序列、和/或亲和标签中的一种或多种。突变将氨基酸改变为不同于天然氨基酸的氨基酸(例如497是除了N之外的任何氨基酸)。在优选的实施例中,突变将氨基酸改变为不同于天然氨基酸(精氨酸或赖氨酸)的任何氨基酸;在一些实施例中,氨基酸是丙氨酸。
在一些实施例中,变体SpCas9蛋白包含在以下位置中的一个、两个、三个、或全部四个处的突变:N497、R661、Q695、和Q926,例如以下突变中的一个、两个、三个、或全部四个:N497A、R661A、Q695A、和Q926A。
在一些实施中,变体SpCas9蛋白包含在Q695和/或Q926处的突变,以及任选地L169、Y450、N497、R661和D1135E中的一个、两个、三个、四个或全部五个,例如包含但不限于:Y450A/Q695A、L169A/Q695A、Q695A/Q926A、Q695A/D1135E、Q926A/D1135E、Y450A/D1135E、L169A/Y450A/Q695A、L169A/Q695A/Q926A、Y450A/Q695A/Q926A、R661A/Q695A/Q926A、N497A/Q695A/Q926A、Y450A/Q695A/D1135E、Y450A/Q926A/D1135E、Q695A/Q926A/D1135E、L169A/Y450A/Q695A/Q926A、L169A/R661A/Q695A/Q926A、Y450A/R661A/Q695A/Q926A、N497A/Q695A/Q926A/D1135E、R661A/Q695A/Q926A/D1135E、和Y450A/Q695A/Q926A/D1135E。
在一些实施例中,变体SpCas9蛋白包含在以下处的突变:N14;S15;S55;R63;R78;H160;K163;R165;L169;R403;N407;Y450;M495;N497;K510;Y515;W659;R661;M694;Q695;H698;A728;S730;K775;S777;R778;R780;K782;R783;K789;K797;Q805;N808;K810;R832;Q844;S845;K848;S851;K855;R859;K862;K890;Q920;Q926;K961;S964;K968;K974;R976;N980;H982;K1003;K1014;S1040;N1041;N1044;K1047;K1059;R1060;K1107;E1108;S1109;K1113;R1114;S1116;K1118;D1135;S1136;K1153;K1155;K1158;K1200;Q1221;H1241;Q1254;Q1256;K1289;K1296;K1297;R1298;K1300;H1311;K1325;K1334;T1337和/或S1216。
在一些实施例中,变体SpCas9蛋白还包含以下突变中的一个或多个:N14A;S15A;S55A;R63A;R78A;R165A;R403A;N407A;N497A;Y450A;K510A;Y515A;R661A;Q695A;S730A;K775A;S777A;R778A;R780A;K782A;R783A;K789A;K797A;Q805A;N808A;K810A;R832A;Q844A;S845A;K848A;S851A;K855A;R859A;K862A;K890A;Q920A;Q926A;K961A;S964A;K968A;K974A;R976A;N980A;H982A;K1003A;K1014A;S1040A;N1041A;N1044A;K1047A;K1059A;R1060A;K1107A;E1108A;S1109A;K1113A;R1114A;S1116A;K1118A;D1135A;S1136A;K1153A;K1155A;K1158A;K1200A;Q1221A;H1241A;Q1254A;Q1256A;K1289A;K1296A;K1297A;R1298A;K1300A;H1311A;K1325A;K1334A;T1337A和/或S1216A。在一些实施例中,变体蛋白包含HF1(N497A/R661A/Q695A/Q926A)+K810A、HF1+K848A、HF1+K855A、HF1+H982A、HF1+K848A/K1003A、HF1+K848A/R1060A、HF1+K855A/K1003A、HF1+K855A/R1060A、HF1+H982A/K1003A、HF1+H982A/R1060A、HF1+K1003A/R1060A、HF1+K810A/K1003A/R1060A、HF1+K848A/K1003A/R1060A。在一些实施例中,变体蛋白包含HF1+K848A/K1003A、HF1+K848A/R1060A、HF1+K855A/K1003A、HF1+K855A/R1060A、HF1+K1003A/R1060A、HF1+K848A/K1003A/R1060A。在一些实施例中,变体蛋白包含Q695A/Q926A/R780A、Q695A/Q926A/R976A、Q695A/Q926A/H982A、Q695A/Q926A/K855A、Q695A/Q926A/K848A/K1003A、Q695A/Q926A/K848A/K855A、Q695A/Q926A/K848A/H982A、Q695A/Q926A/K1003A/R1060A、Q695A/Q926A/K848A/R1060A、Q695A/Q926A/K855A/H982A、Q695A/Q926A/K855A/K1003A、Q695A/Q926A/K855A/R1060A、Q695A/Q926A/H982A/K1003A、Q695A/Q926A/H982A/R1060A、Q695A/Q926A/K1003A/R1060A、Q695A/Q926A/K810A/K1003A/R1060A、Q695A/Q926A/K848A/K1003A/R1060A。在一些实施例中,变体包含N497A/R661A/Q695A/Q926A/K810A、N497A/R661A/Q695A/Q926A/K848A、N497A/R661A/Q695A/Q926A/K855A、N497A/R661A/Q695A/Q926A/R780A、N497A/R661A/Q695A/Q926A/K968A、N497A/R661A/Q695A/Q926A/H982A、N497A/R661A/Q695A/Q926A/K1003A、N497A/R661A/Q695A/Q926A/K1014A、N497A/R661A/Q695A/Q926A/K1047A、N497A/R661A/Q695A/Q926A/R1060A、N497A/R661A/Q695A/Q926A/K810A/K968A、N497A/R661A/Q695A/Q926A/K810A/K848A、N497A/R661A/Q695A/Q926A/K810A/K1003A、N497A/R661A/Q695A/Q926A/K810A/R1060A、N497A/R661A/Q695A/Q926A/K848A/K1003A、N497A/R661A/Q695A/Q926A/K848A/R1060A、N497A/R661A/Q695A/Q926A/K855A/K1003A、N497A/R661A/Q695A/Q926A/K855A/R1060A、N497A/R661A/Q695A/Q926A/K968A/K1003A、N497A/R661A/Q695A/Q926A/H982A/K1003A、N497A/R661A/Q695A/Q926A/H982A/R1060A、N497A/R661A/Q695A/Q926A/K1003A/R1060A、N497A/R661A/Q695A/Q926A/K810A/K1003A/R1060A、N497A/R661A/Q695A/Q926A/K848A/K1003A/R1060A、Q695A/Q926A/R780A、Q695A/Q926A/K810A、Q695A/Q926A/R832A、Q695A/Q926A/K848A、Q695A/Q926A/K855A、Q695A/Q926A/K968A、Q695A/Q926A/R976A、Q695A/Q926A/H982A、Q695A/Q926A/K1003A、Q695A/Q926A/K1014A、Q695A/Q926A/K1047A、Q695A/Q926A/R1060A、Q695A/Q926A/K848A/K968A、Q695A/Q926A/R976A、Q695A/Q926A/H982A、Q695A/Q926A/K855A、Q695A/Q926A/K848A/K1003A、Q695A/Q926A/K848A/K855A、Q695A/Q926A/K848A/H982A、Q695A/Q926A/K1003A/R1060A、Q695A/Q926A/R832A/R1060A、Q695A/Q926A/K968A/K1003A、Q695A/Q926A/K968A/R1060A、Q695A/Q926A/K848A/R1060A、Q695A/Q926A/K855A/H982A、Q695A/Q926A/K855A/K1003A、Q695A/Q926A/K855A/R1060A、Q695A/Q926A/H982A/K1003A、Q695A/Q926A/H982A/R1060A、Q695A/Q926A/K1003A/R1060A、Q695A/Q926A/K810A/K1003A/R1060A、Q695A/Q926A/K1003A/K1047A/R1060A、Q695A/Q926A/K968A/K1003A/R1060A、Q695A/Q926A/R832A/K1003A/R1060A、或Q695A/Q926A/K848A/K1003A/R1060A。
还包含除了丙氨酸之外的氨基酸的突变,并且可以在本发明的方法和组合物中制造和应用。
在一些实施例中,变体SpCas9蛋白包含以下另外的突变中的一个或多个:R63A、R66A、R69A、R70A、R71A、Y72A、R74A、R75A、K76A、N77A、R78A、R115A、H160A、K163A、R165A、L169A、R403A、T404A、F405A、N407A、R447A、N497A、I448A、Y450A、S460A、M495A、K510A、Y515A、R661A、M694A、Q695A、H698A、Y1013A、V1015A、R1122A、K1123A、K1124A、K1158A、K1185A、K1200A、S1216A、Q1221A、K1289A、R1298A、K1300A、K1325A、R1333A、K1334A、R1335A、和T1337A。
在一些实施例中,变体SpCas9蛋白包含多重取代突变:N497/R661/Q695/Q926(四重变体突变体);Q695/Q926(二重突变体);R661/Q695/Q926和N497/Q695/Q926(三重突变体)。在一些实施例中,可以将在L169、Y450和/或D1135处的另外的取代突变添加至这些二重、三重、和四重突变体上,或添加至携带Q695或Q926处的突变的单重突变体上。在一些实施例中,突变体具有代替野生型氨基酸的丙氨酸。在一些实施例中,突变体具有除了精氨酸或赖氨酸(或天然氨基酸)之外的任何氨基酸。
在一些实施例中,变体SpCas9蛋白还包含降低核酸酶活性的选自下组的一个或多个突变,该组由以下组成:在D10、E762、D839、H983、或D986处的突变;以及在H840或N863处的突变。在一些实施例中,突变是:(i)D10A或D10N以及(ii)H840A、H840N、或H840Y。
在一些实施例中,SpCas9变体还可以包含以下突变组中的一个:D1135V/R1335Q/T1337R(VQR变体);D1135E/R1335Q/T1337R(EQR变体);D1135V/G1218R/R1335Q/T1337R(VRQR变体);或D1135V/G1218R/R1335E/T1337R(VRER变体)。
本文还提供了分离的金黄色葡萄球菌Cas9(SaCas9)蛋白,该蛋白具有在以下位置中的一个、两个、三个、四个、五个、六个、或更多个位置处的突变:Y211、Y212、W229、Y230、R245、T392、N419、Y651、或R654,例如包含与SEQ ID NO:1的氨基酸序列至少80%一致的序列,所述序列具有在以下位置中的一个、两个、三个、四个、五个、或六个位置处的突变:Y211、Y212、W229、Y230、R245、T392、N419、Y651、或R654,并且任选地包含核定位序列、细胞穿透肽序列、和/或亲和标签中的一种或多种。在一些实施例中,本文描述的SaCas9变体包括SEQ ID NO:2的氨基酸序列,所述序列具有在以下位置中的一个、两个、三个、四个、五个、六个、或更多个位置处的突变:Y211、Y212、W229、Y230、R245、T392、N419、Y651和/或R654。在一些实施例中,变体包括以下突变中的一个或多个:Y211A、Y212A、W229、Y230A、R245A、T392A、N419A、Y651、和/或R654A。
在一些实施例中,变体SaCas9蛋白包含在N419和/或R654处的突变,以及任选地以下另外的突变中的一个、两个、三个、四个或更多个:Y211、Y212、W229、Y230、R245和T392,优选N419A/R654A、Y211A/R654A、Y211A/Y212A、Y211A/Y230A、Y211A/R245A、Y212A/Y230A、Y212A/R245A、Y230A/R245A、W229A/R654A、Y211A/Y212A/Y230A、Y211A/Y212A/R245A、Y211A/Y212A/Y651A、Y211A/Y230A/R245A、Y211A/Y230A/Y651A、Y211A/R245A/Y651A、Y211A/R245A/R654A、Y211A/R245A/N419A、Y211A/N419A/R654A、Y212A/Y230A/R245A、Y212A/Y230A/Y651A、Y212A/R245A/Y651A、Y230A/R245A/Y651A、R245A/N419A/R654A、T392A/N419A/R654A、R245A/T392A/N419A/R654A、Y211A/R245A/N419A/R654A、W229A/R245A/N419A/R654A、Y211A/R245A/T392A/N419A/R654A、或Y211A/W229A/R245A/N419A/R654A。
在一些实施例中,变体SaCas9蛋白包含在以下处的突变:Y211;Y212;W229;Y230;R245;T392;N419;L446;Q488;N492;Q495;R497;N498;R499;Q500;K518;K523;K525;H557;R561;K572;R634;Y651;R654;G655;N658;S662;N667;R686;K692;R694;H700;K751;D786;T787;Y789;T882;K886;N888;889;L909;N985;N986;R991;R1015;N44;R45;R51;R55;R59;R60;R116;R165;N169;R208;R209;Y211;T238;Y239;K248;Y256;R314;N394;Q414;K57;R61;H111;K114;V164;R165;L788;S790;R792;N804;Y868;K870;K878;K879;K881;Y897;R901;和/或K906。
在一些实施例中,变体SaCas9蛋白包含以下突变中的一个或多个:Y211A;Y212A;W229A;Y230A;R245A;T392A;N419A;L446A;Q488A;N492A;Q495A;R497A;N498A;R499A;Q500A;K518A;K523A;K525A;H557A;R561A;K572A;R634A;Y651A;R654A;G655A;N658A;S662A;N667A;R686A;K692A;R694A;H700A;K751A;D786A;T787A;Y789A;T882A;K886A;N888A;A889A;L909A;N985A;N986A;R991A;R1015A;N44A;R45A;R51A;R55A;R59A;R60A;R116A;R165A;N169A;R208A;R209A;T238A;Y239A;K248A;Y256A;R314A;N394A;Q414A;K57A;R61A;H111A;K114A;V164A;R165A;L788A;S790A;R792A;N804A;Y868A;K870A;K878A;K879A;K881A;Y897A;R901A;K906A。
在一些实施例中,变体SaCas9蛋白包含以下另外的突变中的一个或多个:Y211A、W229A、Y230A、R245A、T392A、N419A、L446A、Y651A、R654A、D786A、T787A、Y789A、T882A、K886A、N888A、A889A、L909A、N985A、N986A、R991A、R1015A、N44A、R45A、R51A、R55A、R59A、R60A、R116A、R165A、N169A、R208A、R209A、T238A、Y239A、K248A、Y256A、R314A、N394A、Q414A、K57A、R61A、H111A、K114A、V164A、R165A、L788A、S790A、R792A、N804A、Y868A、K870A、K878A、K879A、K881A、Y897A、R901A、K906A。
在一些实施例中,变体SaCas9蛋白包含多重取代突变:R245/T392/N419/R654和Y221/R245/N419/R654(四重变体突变体);N419/R654,R245/R654,Y221/R654,和Y221/N419(二重突变体);R245/N419/R654,Y211/N419/R654,和T392/N419/R654(三重突变体)。在一些实施例中,突变体包含代替野生型氨基酸的丙氨酸。
在一些实施例中,变体SaCas9蛋白还包含降低核酸酶活性的选自下组的一个或多个突变,该组由以下组成:在D10、E477、D556、H701、或D704处的突变;和在H557或N580处的突变。在一些实施例中,突变是:(i)D10A或D10N,(ii)H557A、H557N、或H557Y,(iii)N580A,和/或(iv)D556A。
在一些实施例中,变体SaCas9蛋白包含以下突变中的一个或多个:E782K、K929R、N968K、或R1015H。特别是E782K/N968K/R1015H(KKH变体);E782K/K929R/R1015H(KRH变体);或E782K/K929R/N968K/R1015H(KRKH变体)。
在一些实施例中,变体Cas9蛋白包含针对以下区域中的一个或多个的突变,以增加特异性:


本文还提供了融合蛋白,其包含使用任选的介入接头(intervening linker)与异源功能结构域融合的、本文所述的分离的变体Cas9蛋白,其中该接头不干扰该融合蛋白的活性。在一些实施例中,异源功能结构域直接作用于DNA或蛋白,例如作用于染色质。在一些实施例中,异源功能结构域是转录激活结构域。在一些实施例中,转录激活结构域来自VP64或NF-κB p65。在一些实施例中,异源功能结构域是转录沉默子或转录阻遏结构域。在一些实施例中,转录阻遏结构域是克鲁贝尔相关盒(Kruppel-associated box,KRAB)结构域、ERF阻遏因子域(ERD)或mSin3A相互作用结构域(SID)。在一些实施例中,转录沉默子是异染色质蛋白1(HP1),例如HP1α或HP1β。在一些实施例中,异源功能结构域是修饰DNA的甲基化状态的酶。在一些实施例中,修饰DNA的甲基化状态的酶是DNA甲基转移酶(DNMT)或TET蛋白的全部或双加氧酶结构域,例如包含富半胱氨酸延伸和由7个高度保守的外显子编码的2OGFeDO结构域的催化模块,例如包含氨基酸1580-2052的Tet1催化结构域,包含氨基酸1290-1905的Tet2,和包含氨基酸966-1678的Tet3。在一些实施例中,TET蛋白或TET源双加氧酶结构域来自TET1。在一些实施例中,异源功能结构域是修饰组蛋白亚基的酶。在一些实施例中,修饰组蛋白亚基的酶是组蛋白乙酰转移酶(HAT)、组蛋白脱乙酰酶(HDAC)、组蛋白甲基转移酶(HMT)或组蛋白脱甲基酶。在一些实施例中,异源功能结构域是生物系链。在一些实施例中,生物系链是MS2、Csy4或λN蛋白。在一些实施例中,异源功能结构域是FokI。
本文还提供了编码本文描述的变体Cas9蛋白的核酸、分离的核酸,连同载体,这些载体包含任选地有效地连接到一个或多个调节结构域的该分离的核酸,以用于表达本文描述的变体Cas9蛋白。本文还提供了宿主细胞,例如细菌的、酵母的、昆虫的、或哺乳动物的宿主细胞或转基因动物(例如小鼠),其包含本文描述的核酸,并且任选地表达本文描述的变体Cas9蛋白。
本文还提供了编码Cas9变体的分离的核酸,连同载体(这些载体包含任选地有效地连接到一个或多个调节结构域的该分离的核酸,以用于表达这些变体),以及包含核酸并任选表达这些变体蛋白的宿主细胞(例如,哺乳动物宿主细胞)。
本文还提供了通过在细胞中表达如本文描述的变体Cas9蛋白或融合蛋白,以及具有与在基因组靶位点具有最佳核苷酸间距的细胞的基因组的所选部分互补的区域的至少一个指导RNA,或使该细胞与所述变体Cas9蛋白或融合蛋白以及所述指导RNA接触,来改变该细胞的基因组或表观基因组的方法。这些方法可以包括使细胞与编码Cas9蛋白和指导RNA的核酸(例如,在单个载体中)接触;使细胞与编码Cas9蛋白的核酸和编码指导RNA的核酸(例如在多重载体中)接触;并且尤其是使细胞与纯化的Cas9蛋白、和合成的或纯化的gRNA的复合物接触。在一些实施例中,细胞稳定地表达gRNA或变体蛋白/融合蛋白中的一者或二者,并且将其他元件转染进或引入细胞。例如,细胞可以稳定地表达如本文描述的变体蛋白或融合蛋白,并且这些方法可以包括使细胞与合成gRNA、纯化的重组产生的gRNA、或编码gRNA的核酸接触。在一些实施例中,变体蛋白或融合蛋白包含核定位序列、细胞穿透肽序列、和/或亲和标签中的一种或多种。
本文还提供了用于在体外通过使分离的dsDNA与如本文描述的纯化的变体蛋白变体或融合蛋白,以及具有与该dsDNA分子的所选部分互补的区域的指导RNA接触,来改变(例如,选择性地改变)该dsDNA分子的方法。
除非另外定义,否则所有在此使用的技术和科学术语具有与本发明所属领域的普通技术人员通常所理解的相同的意思。本文描述了用于本发明的方法和材料;还可使用本领域已知的其他合适的方法和材料。这些材料、方法、以及实例仅是说明性的,并且不旨在进行限制。此处提及的所有出版物、专利申请、专利、序列、数据库条目和其他参考文献通过引用以其整体结合。在有矛盾的情况下,将以本说明书(包括定义)为准。
本发明的其他特征和优点将从下列详述和附图以及从权利要求中显而易见。
附图说明
图1A-E|携带形成非特异性DNA接触的残基的突变的SpCas9变体的鉴定和表征。A,描绘基于PDB 4OOG和4UN3(分别改编自参考序列31和32),靶DNA:sgRNA双链体的野生型SpCas9识别的示意图。B,在与DNA主链形成氢键的位置包含丙氨酸取代的SpCas9变体的表征。当用完全匹配的sgRNA或编码与靶位点的错配的四种其他sgRNA进行编程时,使用人类细胞EGFP破坏测定对野生型SpCas9和变体进行评估。对于n=3,误差条表示平均数标准误差(s.e.m.);用红色虚线表示背景EGFP损失的平均水平(对于此,小图和小图C)。C和D,通过EGFP破坏测定来评估横跨24个位点的野生型SpCas9和SpCas9-HF1的中靶活性(小图C),并且通过T7E1测定来评估13个内源位点的中靶活性(小图D)。对于n=3,误差条表示平均数标准误差。E,SpCas9-HF1与野生型SpCas9的中靶活性的比率(来自小图C和D)。
图2A-C|针对标准靶位点,具有sgRNA的野生型SpCas9和SpCas9-HF1的全基因组特异性。A,具有八个靶向内源人类基因的sgRNA的野生型SpCas9和SpCas9-HF1的脱靶位点,如通过GUIDE-seq确定。读数计数表示在给定位点的切割频率的度量;在间隔子或PAM内的错配位置以颜色进行突出显示。B,通过GUIDE-seq,针对来自小图A中使用的八个sgRNA的野生型SpCas9和SpCas9-HF1鉴定的全基因组脱靶位点总数的总结。C,针对八个sgRNA,鉴定野生型SpCas9和SpCas9-HF1的脱靶位点,相对于中靶位点,根据错配(在原型间隔子和PAM内)的总数进行分级。
图3A-C|通过由GUIDE-seq鉴定的脱靶位点的靶向深度测序进行的SpCas9-HF1特异性改进的验证。A,针对具有来自图2的六个sgRNA的野生型SpCas9和SpCas9-HF1,通过深度测序确定平均中靶百分比修饰。对于n=3,误差条表示平均数标准误差。B,包含indel突变的深度测序的中靶位点和GUIDE-seq检测的脱靶位点的百分率。针对野生型SpCas9、SpCas9-HF1、和对照条件,绘制一式三份的实验的图。x轴之下的实心圆圈表示多个重复,针对其未观察到插入或缺失突变。在具有星号的红色文本中显示不能通过PCR扩增的脱靶位点。仅在EMX1-1脱靶1和FANCF-3脱靶1,针对SpCas9-HF1和对照条件之间的比较,使用具有汇集的读数计数的单侧Fisher精确检验的假设检验发现显著差异(在使用Benjamini-Hochberg方法调节多重比较后,p<0.05)。还发现在所有脱靶位点,野生型SpCas9和SpCas9-HF1之间存在显著差异,并且在所有脱靶位点(除了RUNX1-1脱靶2外),野生型SpCas9和对照条件之间存在显著差异。C,在具有野生型SpCas9的中靶和脱靶切割位点,GUIDE-seq读数计数(来自图2A)和通过深度测序确定的平均百分比修饰之间的相关性的散点图。
图4A-C|具有sgRNA的野生型SpCas9和SpCas9-HF1的、非标准重复位点的全基因组特异性。A,使用已知用来切割大量脱靶位点的两种sgRNA,野生型SpCas9和SpCas9-HF1的GUIDE-seq特异性图(Fu等人,Nat Biotechnol[自然生物技术]31,822-826(2013);Tsai等人,Nat Biotechnol[自然生物技术]33,187-197(2015))。GUIDE-seq读数计数表示在给定位点的切割频率的度量;在间隔子或PAM内的错配位置以颜色进行突出显示;红圈指示在sgRNA-DNA界面,位点可能具有指示的凸起(Lin等人,Nucleic Acids Res[核酸研究]42,7473-7485(2014));蓝圈指示相对于显示的空位比对可以具有替代性空位比对的位点(参见图8)。B,针对来自小图A中使用的两个sgRNA的野生型SpCas9和SpCas9-HF1,通过GUIDE-seq鉴定的全基因组脱靶位点的总数的总结。C,针对VEGFA位点2和3,使用野生型SpCas9或SpCas9-HF1对脱靶位点进行鉴定,相对于中靶位点根据错配(在原型间隔子和PAM内)的总数进行分级。在小图A中标记有红圈的脱靶位点并不包括在这些计数中;用非空位比对中的错配的数目,计数小图A中标记有蓝圈的位点。
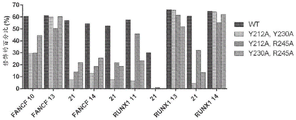
图5A-D|携带另外的取代的SpCas9-HF1衍生物的活性。A,具有八个sgRNA的野生型SpCas9、SpCas9-HF1、和SpCas9-HF1衍生物变体的人类细胞EGFP破坏活性。SpCas9-HF1具有N497A、R661A、Q695、和Q926A突变;HF2=HF1+D1135E;HF3=HF1+L169A;HF4=HF1+Y450A。对于n=3,误差条表示平均数标准误差;用红色虚线表示背景EGFP损失的平均水平。B,与具有来自小图a的八个sgRNA的野生型SpCas9相比,当使用SpCas9-HF变体时,中靶活性的总结。显示了中位数和四分位数间距;将显示>70%的野生型活性的间隔用绿色突出显示。C,在对SpCas9-HF1的作用具有抗性的来自图2A和4A的FANCF位点2和VEGFA位点3中靶位点、连同脱靶位点,SpCas9和HF变体的平均百分比修饰。通过T7E1测定确定百分比修饰;针对所有实验,减去背景indel百分率。对于n=3,误差条表示平均数标准误差。D,具有FANCF位点2或VEGFA位点3 sgRNA的野生型SpCas9和HF变体的特异性比率,绘制为中靶与脱靶活性的比率(来自小图C)。
图5E-F|具有sgRNA的SpCas9-HF1、-HF2、和-HF4的全基因组特异性,这些sgRNA具有对SpCas9-HF1的作用具有抗性的脱靶位点。E,对于小图F中的GUIDE-seq实验,在预期中靶位点处的平均GUIDE-seq标签整合。SpCas9-HF1=N497A/R661A/Q695A/Q926A;HF2=HF1+D1135E;HF4=HF1+Y450A。对于n=3,误差条表示平均数标准误差。F,具有FANCF位点2或VEGFA位点3 sgRNA的SpCas9-HF1、-HF2、或-HF4的GUIDE-seq鉴定的脱靶位点。读数计数表示在给定位点的切割频率的度量;在间隔子或PAM内的错配位置以颜色进行突出显示。在SpCas9-HF变体之间的比较之前,通过将SpCas9-HF变体的脱靶读数计数归一化为在中靶位点的读数计数,计算脱靶辨别的倍数改进。
图6A-B|SpCas9与sgRNA和靶DNA的相互作用。A,说明SpCas9:sgRNA复合物的示意图,其中sgRNA和靶DNA之间进行碱基配对。B,SpCas9:sgRNA复合物结合来自PDB:4UN3(ref.32)的靶DNA的结构示意图。与靶链DNA主链形成氢键接触的四个残基用蓝色突出显示;出于可视化目的,隐藏HNH结构域。
图7A-D|具有用于GUIDE-seq实验的不同sgRNA的野生型和SpCas9-HF1的中靶活性比较。A和C,通过限制性片段长度多态性测定量化,针对图2A和4A(分别是小图7A和7C)显示的GUIDE-seq实验,在预期中靶位点的平均GUIDE-seq标签整合。对于n=3,误差条表示平均数标准误差。b和d,通过T7E1测定检测,针对图2A和4A(分别是小图7B和7D)显示的GUIDE-seq实验,在预期中靶位点的平均百分比修饰。对于n=3,误差条表示平均数标准误差。
图8|针对VEGFA位点2脱靶位点的潜在替代性比对。使用Geneious(Kearse等人,Bioinformatics[生物信息学]28,1647-1649(2012))版本8.1.6进行比对,用会潜在地被识别为包含单核苷酸空位(Lin等人,Nucleic Acids Res[核酸研究]42,7473-7485(2014)))(右))的脱靶位点的GUIDE-seq(左)鉴定的十个VEGFA位点2脱靶位点。
图9|具有截短的sgRNAs14的野生型SpCas9和SpCas9-HF1的活性。使用靶向EGFP中的四个位点的全长或截短的sgRNA,野生型SpCas9和SpCas9-HF1的EGFP破坏。对于n=3,误差条表示平均数标准误差(s.e.m.);用红色虚线表示对照试验中背景EGFP损失的平均水平。
图10|具有携带5’错配的鸟嘌呤碱基的sgRNA的野生型SpCas9和SpCas9-HF1活性。具有靶向四个不同位点的sgRNA的野生型SpCas9和SpCas9-HF1的EGFP破坏活性。对于每个靶位点,sgRNA包含匹配的非鸟嘌呤5'-碱基或有意错配的5'-鸟嘌呤。
图11|滴定野生型SpCas9和SpCas9-HF1表达质粒的量。用不同量的野生型和SpCas9-HF1表达质粒转染的人类细胞EGFP破坏活性。对于所有转染,将含sgRNA质粒的量固定在250ng。使用靶向单独位点的两个sgRNA;对于n=3,误差条表示平均数标准误差(s.e.m.);用红色虚线表示阴性对照中背景EGFP损失的平均水平。
图12A-D|改变SpCas9-HF1的PAM识别特异性。A,用T7E1测定量化,使用8个sgRNA,通过SpCas9-VQR(ref.15)和改进的SpCas9-VRQR进行的中靶内源人类位点的平均百分比修饰的比较。将两种变体都工程化以识别NGAN PAM。对于n=2或3,误差条表示平均数标准误差。B,与使用八个sgRNA的SpCas9-HF1对应物相比,SpCas9-VQR和SpCas9-VRQR的中靶EGFP破坏活性。对于n=3,误差条表示平均数标准误差(s.e.m.);用红色虚线表示阴性对照中背景EGFP损失的平均水平。C,用T7E1测定量化,在八个内源人类基因位点,与SpCas9-HF1变体相比,通过SpCas9-VQR和SpCas9-VRQR进行的平均中靶百分比修饰的比较。对于n=3,误差条表示平均数标准误差(s.e.m.);ND,未检测到。D,与相应的SpCas9-HF1变体(来自小图B和C)相比,当使用SpCas9-VQR或SpCas9-VRQR时,中靶活性的倍数改变的总结。显示了中位数和四分位数间距;将显示>70%的野生型活性的间隔用绿色突出显示。
图13A-B|野生型SpCas9、SpCas9-HF1、和在可能潜在接触非靶DNA链的位置携带一个或多个丙氨酸取代的野生型SpCas9衍生物的活性。A和B,采用与EGFP基因中的位点完全匹配的sgRNA,连同有意在位置11和12(小图A)或位置9和10(小图B)错配的sgRNA,使用EGFP破坏测定,评估核酸酶。用为PAM最远端位置的位置20,对错配的位置进行编号;红色虚线表示EGFP破坏的背景水平;HF1=具有N497A/R661A/Q695A/Q926A取代的SpCas9。
图14A-B|野生型SpCas9、SpCas9-HF1、和在可能潜在接触非靶DNA链的位置携带一个或多个丙氨酸取代的SpCas9-HF1衍生物的活性。A和B,采用与EGFP基因中的位点完全匹配的sgRNA,连同有意在位置11和12(小图A)或位置9和10(小图B)错配的sgRNA,使用EGFP破坏测定,评估核酸酶。用为PAM最远端位置的位置20,对错配的位置进行编号;红色虚线表示EGFP破坏的背景水平;HF1=具有N497A/R661A/Q695A/Q926A取代的SpCas9。
图15|野生型SpCas9、SpCas9-HF1、和在可能潜在接触非靶DNA链的位置携带一个或多个丙氨酸取代的SpCas9(Q695A/Q926A)衍生物的活性。采用与EGFP基因中的位点完全匹配的sgRNA,连同有意在位置11和12错配的sgRNA,使用EGFP破坏测定,评估核酸酶。用为PAM最远端位置的位置20,对错配的位置进行编号;红色虚线表示EGFP破坏的背景水平;HF1=具有N497A/R661A/Q695A/Q926A取代的SpCas9;Dbl=具有Q695A/Q926A取代的SpCas9。
图16|使用匹配的sgRNA和在间隔子中的每个位置处具有单错配的sgRNA,野生型SpCas9、SpCas9-HF1、和eSpCas9-1.1的活性。采用与EGFP基因中的位点完全匹配的sgRNA(“匹配的”),连同有意在指示的位置错配的sgRNA,使用EGFP破坏测定,评估核酸酶。用为PAM最远端位置的位置20,对错配的位置进行编号。SpCas9-HF1=N497A/R661A/Q695A/Q926A,并且eSP1.1=K848A/K1003A/R1060A。
图17A-B|使用匹配的sgRNA和在间隔子中的不同位置处具有单错配的sgRNA,野生型SpCas9和变体的活性。(A)采用与EGFP基因中的位点完全匹配的sgRNA(“匹配的”),连同有意在指示的间隔子位置错配的sgRNA,使用EGFP破坏测定,评估包含丙氨酸取代(针对可能潜在接触靶或非靶DNA链的位置)的组合的SpCas9核酸酶的活性。(B)使用针对匹配的中靶位点的所有可能的单错配sgRNA的剩余者,测试来自(a)的这些核酸酶的子集。用为PAM最远端位置的位置20,对错配的位置进行编号。mm=错配,WT=野生型,Db=Q695A/Q926A,HF1=N497A/R661A/Q695A/Q926A,1.0=K810A/K1003A/R1060A,并且1.1=K848A/K1003A/R1060A。
图18|使用匹配的sgRNA和在间隔子中的不同单个位置处具有错配的sgRNA,野生型SpCas9和变体的活性。采用与EGFP基因中的位点完全匹配的sgRNA(“匹配的”),连同有意在指示的位置错配的sgRNA,使用EGFP破坏测定,评估包含丙氨酸取代(针对可能潜在接触靶或非靶DNA链的位置)的组合的SpCas9核酸酶的活性。Db=Q695A/Q926A,HF1=N497A/R661A/Q695A/Q926A。
图19A-B|使用匹配的sgRNA和在间隔子中的不同单个位置处具有错配的sgRNA,野生型SpCas9和变体的活性。(A)采用与EGFP基因中的位点完全匹配的两个sgRNA,使用EGFP破坏测定,评估包含丙氨酸取代(针对可能潜在接触靶或非靶DNA链的位置)的组合的SpCas9核酸酶的中靶活性。(B)采用在其间隔子序列中包含(sgRNA“位点1”的)位置12、14、16、或18的错配的sgRNA,测试来自(a)的这些核酸酶的子集,以确定是否对这些取代赋予的错配不耐受。Db=Q695A/Q926A,HF1=N497A/R661A/Q695A/Q926A。
图20|SpCas9(顶图)和SaCas9(底图)的结构比较,例示了四重突变体构建体(以黄色球形表示显示)中突变的位置之间的相似性。而且,以粉色球形表示显示的是接触DNA主链的其他残基。
图21A-B|携带一个或多个丙氨酸取代的野生SaCas9和SaCas9衍生物的活性。A和B,SaCas9取代针对可能潜在接触靶DNA链的位置(小图A),或先前已经显示影响PAM特异性的位置(小图B)。采用与EGFP基因中的位点完全匹配的sgRNA,连同有意在位置11和12错配的sgRNA,使用EGFP破坏测定,评估核酸酶。用为PAM最远端位置的位置20,对错配的位置进行编号;红色虚线表示EGFP破坏的背景水平。
图22A-B|野生型(WT)SaCas9和在可能潜在接触靶DNA链的残基处携带一个或多个丙氨酸取代的SaCas9衍生物的活性。A和B,采用与EGFP基因中的位点完全匹配的sgRNA(“匹配的”),连同有意在位置19和20错配的sgRNA,使用EGFP破坏测定,评估核酸酶。用为PAM最远端位置的位置20,对错配的位置进行编号。
图23|野生型(WT)SaCas9和在可能潜在接触靶DNA链的残基处携带丙氨酸取代的三重组合的SaCas9变体的活性。使用EGFP破坏测定评估核酸酶。使用四个不同的sgRNA(匹配的#1-4),其中还用已知由野生型SaCas9有效使用的错配的sgRNA,对四个靶位点中的每一个进行测试。针对每个位点的错配的sgRNA显示在每个匹配的sgRNA的右侧(例如,针对匹配位点3的唯一错配的sgRNA是mm 11&12)。用为PAM最远端位置的位置21,对错配的位置进行编号;mm,错配。
图24A-B|野生型(WT)SaCas9和在可能潜在接触靶DNA链的残基处携带一个或多个丙氨酸取代的SaCas9衍生物的活性。A和B,使用T7E1测定,针对匹配的和单错配的内源人类基因靶位点,对携带二重(A)或三重(B)组合取代的SaCas9变体进行评估。匹配的“中靶”位点根据其基因靶位点sgRNA数进行命名,根据Kleinstiver等人,Nature Biotechnology[自然生物技术]2015进行。采用发生在位置21(PAM最远端位置)的错配,对错配的sgRNA进行编号;错配的sgRNA源自在错配的sgRNA的左侧列出的匹配的中靶位点。
具体实施方案
CRISPR-Cas9核酸酶的限制是其在不完全匹配靶位点处,诱导不希望的“脱靶”突变的潜能(参见例如Tsai等人,Nat Biotechnol.[自然生物技术]2015),在一些情况下,其频率比得上在预期中靶位点处观察到的那些(Fu等人,Nat Biotechnol.[自然生物技术]2013)。用CRISPR-Cas9核酸酶进行的先前工作已经提示,减少指导RNA(gRNA)和靶位点的间隔子区域之间的序列特异性相互作用的数目可以在人类细胞中减少切割的脱靶位点处的诱变效应(Fu等人,Nat Biotechnol.[自然生物技术]2014)。
这早先是通过在其5’末端将gRNA截短2或3nt来实现,并且假设增加的特异性的机制是gRNA/Cas9复合物的相互作用能的降低,这样使得它达到平衡,具有刚好足够的能量来切割中靶位点,使它更不可能具有足够的能量来切割脱靶位点,在脱靶位点,由于靶DNA位点的错配,将可能存在能量惩罚(WO 2015/099850)。
假设可能通过减少与靶DNA位点的非特异性相互作用,将SpCas9的脱靶效应(在是与针对指导RNA的预期靶位点不完全匹配或错配的DNA位点处)最小化。SpCas9-sgRNA复合物切割由以下组成的靶位点:NGG PAM序列(由SpCas9识别)(Deltcheva,E.等人,Nature[自然]471,602-607(2011);Jinek,M.等人,Science[科学]337,816-821(2012);Jiang,W.等人,Nat Biotechnol[自然生物技术]31,233-239(2013);(Sternberg,S.H.等人,Nature[自然]507,62-67(2014))以及相邻的20bp原型间隔子序列(它与sgRNA的5’末端互补)(Jinek,M.等人,Science[科学]337,816-821(2012);Jinek,M.等人,Elife 2,e00471(2013);Mali,P.等人,Science[科学]339,823-826(2013);Cong,L.等人,Science[科学]339,819-823(2013))。先前建立理论:SpCas9-sgRNA复合物可以拥有比识别其预期靶DNA位点所需更多的能量,由此使得能够切割错配的脱靶位点(Fu,Y.,等人,Nat Biotechnol[自然生物技术]32,279-284(2014))。人们可以预想,对于Cas9在适应性细菌免疫中的预期作用,这一特性可能是有利的,赋予细菌切割可能会突变的外源序列的能力。先前研究也支持这一过剩能量模型,这些先前研究展示,通过以下,可以减小脱靶效应(但是未消除):通过减小SpCas9浓度(Hsu,P.D.等人,Nat Biotechnol[自然生物技术]31,827-832(2013);Pattanayak,V.等人,Nat Biotechnol[自然生物技术]31,839-843(2013)),或通过减小sgRNA的互补性长度(Fu,Y.,等人,Nat Biotechnol[自然生物技术]32,279-284(2014),尽管也已经提出了针对此效应的其他解释(Josephs,E.A.等人,Nucleic Acids Res[核酸研究]43,8924-8941(2015);(Sternberg,S.H.等人,Nature[自然]527,110-113(2015);(Kiani,S.等人,NatMethods[自然方法]12,1051-1054(2015))))。结构数据提示,可以通过若干SpCas9介导的DNA接触,来稳定SpCas9-sgRNA-靶DNA复合物,这些DNA接触包括由四个SpCas9残基(N497、R661、Q695、Q926)与靶DNA链的磷酸主链形成的直接氢键(Nishimasu,H.等人,Cell[细胞]156,935-949(2014);Anders,C.,等人,Nature[自然]513,569-573(2014))(图1a和图6a以及6b)。本发明的诸位发明人预想,这些接触中的一个或多个的破坏可能能量上将SpCas9-sgRNA复合物平衡在刚好足以保留稳健的中靶活性,但是对于切割错配的脱靶位点,具有降低的活性。
如此处所述,理论上可以通过减小Cas9对DNA的结合亲和力,将Cas9蛋白工程化以显示增加的特异性。通过使用结构信息、基于细菌选择的定向进化、和组合设计,将单个丙氨酸取代引入预期可能与DNA主链上的磷酸相互作用的SpCas9中的不同残基,将广泛使用的酿脓链球菌Cas9(SpCas9)的若干变体工程化。可以使用稳健的基于大肠杆菌的筛选测定,进一步测试变体的细胞活性,以便评估这些变体的细胞活性;在此细菌系统中,细胞存活取决于包含针对毒性旋转酶毒物ccdB的基因和gRNA与SpCas9靶向的23个碱基对的序列的选择质粒的切割和随后的破坏,并且导致与保留地或损失的活性相关的残基的鉴定。此外,鉴定并且表征在人类细胞中表现出改进的靶特性的另一种SpCas9变体。
此外,如在基于细菌细胞的系统中评估SpCas9的单丙氨酸取代突变体的活性,指示在50%-100%之间的存活百分率通常指示稳健的切割,而0%存活指示酶已经在功能上被损害。然后在细菌中测定SpCas9的另外的突变,包括:R63A、R66A、R69A、R70A、R71A、Y72A、R74A、R75A、K76A、N77A、R78A、R115A、H160A、K163A、R165A、L169A、R403A,T404A、F405A、N407A、R447A、N497A、I448A、Y450A、S460A、M495A、K510A、Y515A、R661A、M694A、Q695A、H698A、Y1013A、V1015A、R1122A、K1123A、K1124A、K1158A、K1185A、K1200A、S1216A、Q1221A、K1289A、R1298A、K1300A、K1325A、R1333A、K1334A、R1335A、和T1337A。除了在细菌中具有<5%存活的2个突变体(R69A和F405A),所有这些另外的单突变似乎对SpCas9的中靶活性没有影响(在细菌筛选中>70%存活)。
为了进一步确定在细菌筛选中鉴定的Cas9的变体在人类细胞中是否能有效发挥功能,使用基于人类U2OS细胞的EGFP破坏测定,测试不同丙氨酸取代Cas9突变体。在此测定中,在单个整合的、组成型地表达的EGFP基因的编码序列中的靶位点的成功切割导致indel突变的诱导和EGFP活性的破坏,这是通过流式细胞术定量评估的(参见例如Reyon等人,NatBiotechnol.[自然生物技术]2012年5月;30(5):460-5)。
这些实验显示,在基于细菌细胞的测定中获得的结果与人类细胞中的核酸酶活性很好地关联,提示这些工程化策略可以延伸至来自其他物种和不同细胞的Cas9。因此,这些发现提供了对SpCas9和SaCas9变体的支持,它们在此统称为“变体”或“这些变体”。
本文描述的所有变体可以快速地并入现有的和广泛使用的载体中,例如通过简单的定点诱变,并且由于它们仅需要少量突变,所以这些变体应当还可以与对以下的其他先前描述的改进一起起作用:SpCas9平台(例如,截短的sgRNA(Tsai等人,Nat Biotechnol[自然生物技术]33,187-197(2015);Fu等人,Nat Biotechnol[自然生物技术]32,279-284(2014)),切口酶突变(Mali等人,Nat Biotechnol[自然生物技术]31,833-838(2013);Ran等人,Cell[细胞]154,1380-1389(2013)),FokI-dCas9融合(Guilinger等人,NatBiotechnol[自然生物技术]32,577-582(2014);Tsai等人,Nat Biotechnol[自然生物技术]32,569-576(2014);WO 2014144288);以及具有改变的PAM特异性的工程化的CRISPR-Cas9核酸酶(Kleinstiver等人,Nature[自然].2015年7月,23;523(7561):481-5)。
因此,此处提供的是Cas9变体,包括SpCas9变体。SpCas9野生型序列如下:


本文描述的SpCas9变体可以包括SEQ ID NO:1的氨基酸序列,所述氨基酸序列在以下位置中的一个或多个处具有突变(即用不同氨基酸,例如丙氨酸、甘氨酸、或丝氨酸替换天然氨基酸):N497,R661,Q695,Q926(或在与其类似的位置处)。在一些实施例中,SpCas9变体与SEQ ID NO:1的氨基酸序列是至少80%,例如至少85%、90%或95%一致的,例如,在被替换的SEQ ID NO:1的残基的高达5%、10%、15%或20%处具有差异,例如除了本文描述的突变,具有保守突变。在优选的实施例中,该变体保留亲本的所希望活性,例如核酸酶活性(亲本是切口酶或死Cas9除外),和/或与指导RNA和靶DNA相互作用的能力。
为了测定两个核酸序列的百分比一致性,出于最佳比对的目的将序列比对(例如,在一个第一和第二氨基酸或核酸序列的一个或两个中引入空位以用于最佳比对,并且出于比较目的,非同源序列可以忽略)。为了比较目的,出于比较目的而比对的参考序列的长度是参考序列的长度的至少80%,并且在一些实施例中为至少90%或100%。然后比较相应的氨基酸位置或核苷酸位置处的核苷酸。当第一序列中的位置被与第二个序列中的对应位置相同的核苷酸占据时,那么分子在该位置是一致的(如此处所使用,核酸“一致性”等同于核酸“同源性”)。两个序列之间的百分比一致性是这些序列共享的多个一致性位置的一个函数,考虑了空位数目以及每个空位的长度,需要引入它以用于两个序列的最佳比对。两种多肽或核酸序列之间的百分比一致性以本领域技术范围内的各种方式确定,例如使用公开可获得的计算机软件,例如Smith Waterman Alignment(Smith,T.F.和M.S.Waterman(1981)JMol Biol[分子生物学杂志]147:195-7);“BestFit”(Smith和Waterman,Advances inApplied Mathematics[应用数学进展],482-489(1981)),如结合于GeneMatcher PlusTM,Schwarz和Dayhof(1979)Atlas of Protein Sequence and Structure[蛋白序列和结构图谱],Dayhof,M.O.编辑,第353-358页;BLAST程序(基本局部比对搜索工具;(Altschul,S.F.,W.Gish,等人(1990)J Mol Biol[分子生物学杂志]215:403-10)、BLAST-2、BLAST-P、BLAST-N、BLAST-X、WU-BLAST-2、ALIGN、ALIGN-2、CLUSTAL、或Megalign(DNASTAR)软件。另外,本领域技术人员可以确定用于测量比对的适当参数,包括为了在被比较的序列的长度上实现最大比对所需要的任何算法。通常,对于蛋白或核酸,比较长度可以是任何长度,直到并包括全长(例如5%、10%、20%、30%、40%、50%、60%、70%、80%、90%、95%或100%)。为了本发明的组合物和方法的目的,对序列的全长的至少80%进行比对。
为了本发明的目的,序列的比较和两个序列之间的百分比一致性的确定可以使用具有12的空位罚分、4的空位延伸罚分和5的移码空位罚分的Blossum 62评分矩阵来完成。
保守取代典型地包括在以下组内的取代:甘氨酸,丙氨酸;缬氨酸,异亮氨酸,亮氨酸;天冬氨酸,谷氨酸,天冬酰胺,谷氨酰胺;丝氨酸,苏氨酸;赖氨酸,精氨酸;以及苯丙氨酸,酪氨酸。
在一些实施例中,SpCas9变体包括以下组的突变中的一个:N497A/R661A/Q695/Q926A(四重丙氨酸突变体);Q695A/Q926A(二重丙氨酸突变体);R661A/Q695A/Q926A和N497A/Q695A/Q926A(三重丙氨酸突变体)。在一些实施例中,可以将在L169和/或Y450处的另外的取代突变添加至这些二重、三重、和四重突变体,或添加至在Q695或Q926处携带突变的单重突变体。在一些实施例中,突变体具有代替野生型氨基酸的丙氨酸。在一些实施例中,突变体具有除了精氨酸或赖氨酸(或天然氨基酸)之外的任何氨基酸。
在一些实施例中,SpCas9变体还包括以下突变之一,所述突变降低或破坏Cas9的核酸酶活性:D10、E762、D839、H983或D986和H840或N863,例如D10A/D10N和H840A/H840N/H840Y,以使蛋白的核酸酶部分无催化活性;在这些位置处的取代可以是丙氨酸(如在Nishimasu等人,Cell[细胞]156,935-949(2014)中的)或其他残基,例如谷氨酰胺、天冬酰胺、酪氨酸、丝氨酸或天冬氨酸,例如E762Q、H983N、H983Y、D986N、N863D、N863S、或N863H(参见WO 2014/152432)。在一些实施例中,该变体包括D10A或H840A处的突变(其产生单链切口酶)或D10A和H840A处的突变(其消除核酸酶活性;这种突变体称为死Cas9或dCas9)。
SpCas9N497A/R661A/Q695A/R926A突变具有金黄色葡萄球菌Cas9(SaCas9)中的类似残基;参见图20。如我们对SpCas9已经观察到的那样,预期与DNA或RNA主链接触的残基的突变增加SaCas9的特异性。因此,本文还提供了SaCas9变体。
SaCas9野生型序列如下:


本文描述的SaCas9变体包括SEQ ID NO:2的氨基酸序列,所述氨基酸序列具有在以下位置中的一个、两个、三个、四个、五个、或全部六个位置处的突变:Y211、W229、R245、T392、N419、和/或R654,例如包含与SEQ ID NO:2的氨基酸序列至少80%一致的序列,所述序列具有在以下位置中的一个、两个、三个、四个、五个或六个位置处的突变:Y211、W229、R245、T392、N419、和/或R654。
在一些实施例中,变体SaCas9蛋白还包含以下突变中的一个或多个:Y211A;W229A;Y230A;R245A;T392A;N419A;L446A;Y651A;R654A;D786A;T787A;Y789A;T882A;K886A;N888A;A889A;L909A;N985A;N986A;R991A;R1015A;N44A;R45A;R51A;R55A;R59A;R60A;R116A;R165A;N169A;R208A;R209A;Y211A;T238A;Y239A;K248A;Y256A;R314A;N394A;Q414A;K57A;R61A;H111A;K114A;V164A;R165A;L788A;S790A;R792A;N804A;Y868A;K870A;K878A;K879A;K881A;Y897A;R901A;K906A。
在一些实施例中,变体SaCas9蛋白包含以下另外的突变中的一个或多个:Y211A、W229A、Y230A、R245A、T392A、N419A、L446A、Y651A、R654A、D786A、T787A、Y789A、T882A、K886A、N888A、A889A、L909A、N985A、N986A、R991A、R1015A、N44A、R45A、R51A、R55A、R59A、R60A、R116A、R165A、N169A、R208A、R209A、Y211A、T238A、Y239A、K248A、Y256A、R314A、N394A、Q414A、K57A、R61A、H111A、K114A、V164A、R165A、L788A、S790A、R792A、N804A、Y868A、K870A、K878A、K879A、K881A、Y897A、R901A、K906A。
在一些实施例中,变体SaCas9蛋白包含多重取代突变:R245/T392/N419/R654和Y221/R245/N419/R654(四重变体突变体);N419/R654,R245/R654,Y221/R654,和Y221/N419(二重突变体);R245/N419/R654,Y211/N419/R654,和T392/N419/R654(三重突变体)。在一些实施例中,突变体包含代替野生型氨基酸的丙氨酸。
在一些实施例中,变体SaCas9蛋白还包含在E782K、K929R、N968K、和/或R1015H处的突变。例如,KKH变体(E782K/N968K/R1015H)、KRH变体(E782K/K929R/R1015H)、或KRKH变体(E782K/K929R/N968K/R1015H)]。
在一些实施例中,变体SaCas9蛋白还包含降低核酸酶活性的选自下组的一个或多个突变,该组由以下组成:在D10、E477、D556、H701、或D704处的突变;和在H557或N580处的突变。
在一些实施例中,突变是:(i)D10A或D10N,(ii)H557A、H557N、或H557Y,(iii)N580A,和/或(iv)D556A。
本文还提供了编码Cas9变体的分离的核酸,包含任选地有效地连接到一个或多个调节结构域的该分离的核酸的用于表达这些变体蛋白的载体,以及包含核酸并任选表达这些变体蛋白的宿主细胞(例如,哺乳动物宿主细胞)。
本文描述的变体可用于改变细胞的基因组;方法通常包括在细胞中表达这些变体蛋白,以及具有与细胞基因组的所选部分互补的区域的指导RNA。选择性地改变细胞基因组的方法在本领域中是已知的,参见例如,US 8,993,233;US 20140186958;US 9,023,649;WO/2014/099744;WO 2014/089290;WO 2014/144592;WO 144288;WO 2014/204578;WO2014/152432;WO 2115/099850;US 8,697,359;US 20160024529;US 20160024524;US20160024523;US 20160024510;US 20160017366;US 20160017301;US 20150376652;US20150356239;US 20150315576;US 20150291965;US 20150252358;US 20150247150;US20150232883;US 20150232882;US 20150203872;US 20150191744;US 20150184139;US20150176064;US 20150167000;US 20150166969;US 20150159175;US 20150159174;US20150093473;US 20150079681;US 20150067922;US 20150056629;US 20150044772;US20150024500;US 20150024499;US 20150020223;US 20140356867;US 20140295557;US20140273235;U S20140273226;US 20140273037;US 20140189896;US 20140113376;US20140093941;US 20130330778;US 20130288251;US 20120088676;US 20110300538;US20110236530;US 20110217739;US 20110002889;US 20100076057;US 20110189776;US20110223638;US 20130130248;US 20150050699;US 20150071899;US 20150050699;US20150045546;US 20150031134;US 20150024500;US 20140377868;US 20140357530;US20140349400;US 20140335620;US 20140335063;US 20140315985;US 20140310830;US20140310828;US 20140309487;US 20140304853;US 20140298547;US 20140295556;US20140294773;US 20140287938;US 20140273234;US 20140273232;US 20140273231;US20140273230;US 20140271987;US 20140256046;US 20140248702;US 20140242702;US20140242700;US 20140242699;US 20140242664;US 20140234972;US 20140227787;US20140212869;US 20140201857;US 20140199767;US 20140189896;US 20140186958;US20140186919;US 20140186843;US 20140179770;US 20140179006;US 20140170753;WO/2008/108989;WO/2010/054108;WO/2012/164565;WO/2013/098244;WO/2013/176772;US20150071899;Makarova等人,“Evolution and classification of the CRISPR-Cassystem[CRISPR-Cas系统的进化与分类]”9(6)Nature Reviews Microbiology[自然微生物学评论]467-477(1-23)(2011年6月);Wiedenheft等人,“RNA-guided genetic silencingsystems in bacteria and archaea[在细菌和古生菌中RNA指导的基因沉默系统]”482Nature[自然]331-338(2012年2月16日);Gasiunas等人,“Cas9-crRNA ribonucleoproteincomplex mediates specific DNA cleavage for adaptive immunity in bacteria[Cas9-crRNA核糖核蛋白复合体介导细菌中适应免疫的特异性DNA切割]”109(39)Proceedings of the National Academy of Sciences USA[美国国家科学院院刊]E2579-E2586(2012年9月4日);Jinek等人,“A Programmable Dual-RNA-Guided DNAEndonuclease in Adaptive Bacterial Immunity[适应性细菌免疫中的一种可编程的双RNA指导DNA内切核酸酶]”337Science[科学]816-821(2012年8月17日);Carroll,“ACRISPR Approach to Gene Targeting[基因靶向的CRISPR途径]”20(9)MolecularTherapy[分子治疗]1658-1660(2012年9月);在2012年5月25日提交的美国申请号61/652,086;Al-Attar等人,Clustered Regularly Interspaced Short Palindromic Repeats(CRISPRs):The Hallmark of an Ingenious Antiviral Defense Mechanism inProkaryotes[规律间隔成簇短回文重复序列(CRISPR):原核生物中独特的抗病毒防御机制的特点],Biol Chem.[生物化学](2011)第392卷,第4期,第277-289页;Hale等人,Essential Features and Rational Design of CRISPR RNAs That Function With theCas RAMP Module Complex to Cleave RNAs[利用Cas RAMP模块复合物来切割RNA的CRISPR RNA的基本特征和合理设计],Molecular Cell[分子细胞],(2012)第45卷,第3期,292-302。
本文描述的变体蛋白可以用于代替以上参考文献中描述的Cas9蛋白中的任一种,或除了以上参考文献中描述的Cas9蛋白中的任一种,可以使用本文描述的变体蛋白,或可以将本文描述的变体蛋白与本文描述的突变组合使用。此外,本文描述的变体可以用于融合蛋白,代替本领域已知的野生型Cas9或其他Cas9突变(例如上述的dCas9或Cas9切口酶),例如具有异源功能结构域的融合蛋白,如以下文献中所述的:US 8,993,233;US20140186958;US 9,023,649;WO/2014/099744;WO 2014/089290;WO 2014/144592;WO144288;WO 2014/204578;WO 2014/152432;WO 2115/099850;US 8,697,359;US 2010/0076057;US 2011/0189776;US 2011/0223638;US 2013/0130248;WO/2008/108989;WO/2010/054108;WO/2012/164565;WO/2013/098244;WO/2013/176772;US 20150050699;US20150071899和WO 2014/124284。例如,优选包含一个或多个核酸酶减少、改变、或杀死突变的变体可以在Cas9的N或C末端融合到转录激活结构域或其他异源功能结构域(例如,转录阻遏因子(例如KRAB、ERD、SID等,例如ets2阻遏因子(ERF)阻遏因子结构域(ERD)的氨基酸473-530,KOX1的KRAB结构域的氨基酸1-97或Mad mSIN3相互作用结构域(SID)的氨基酸1-36;参见Beerli等人,PNAS USA[美国国家科学院院刊]95:14628-14633(1998))或沉默子如异染色质蛋白1(HP1,也称为swi6),例如,HP1α或HP1β;也可以使用本领域中已知的可以募集与固定的RNA结合序列(例如由MS2外壳蛋白、内切核糖核酸酶Csy4或λN蛋白结合的那些)融合的长的非编码RNA(lncRNA)的蛋白或肽;修饰DNA的甲基化状态的酶(例如DNA甲基转移酶(DNMT)或TET蛋白));或修饰组蛋白亚基的酶(例如组蛋白乙酰转移酶(HAT)、组蛋白脱乙酰酶(HDAC)、组蛋白甲基转移酶(例如,用于赖氨酸或精氨酸残基的甲基化)或组蛋白脱甲基酶(例如,用于赖氨酸或精氨酸残基的脱甲基化))。此类结构域的多个序列是本领域已知的,例如催化DNA中甲基化胞嘧啶的羟基化作用的结构域。示例性蛋白包括十-十一易位(TET)1-3家族,这是在DNA中转化5-甲基胞嘧啶(5-mC)为5-羟甲基胞嘧啶(5-hmC)的酶。
人类TET1-3的序列是本领域中已知的,并且在下表中示出:

*变体(1)表示较长转录物并且编码较长同种型(a)。与变体1相比,变体(2)差别在于5'UTR且在于3'UTR以及编码序列。与同种型a相比,所得同种型(b)更短并且具有不同C末端。
在一些实施例中,可以包括催化结构域的全长序列的全部或一部分,例如包含富半胱氨酸延伸和由7个高度保守的外显子编码的2OGFeDO结构域的催化模块,例如包含氨基酸1580-2052的Tet1催化结构域,包含氨基酸1290-1905的Tet2,和包含氨基酸966-1678的Tet3。参见例如,Iyer等人,Cell Cycle[细胞周期].2009年6月1日;8(11):1698-710的图1。电子出版物2009年6月27日针对例示了所有三种Tet蛋白中的关键催化残基的比对,及其针对全长序列的补充材料(在ftp站点ftp.ncbi.nih.gov/pub/aravind/DONS/supplementary_material_DONS.html可得)(参见例如seq 2c);在一些实施例中,该序列包括Tet1的氨基酸1418-2136或Tet2/3中的相应区域。
其他催化模块可以来自Iyer等人,2009鉴定的蛋白。
在一些实施例中,异源功能结构域是生物系链,并且包含MS2外壳蛋白、内切核糖核酸酶Csy4或λN蛋白(例如,DNA结合结构域)的全部或部分。这些蛋白可用于将包含特定茎环结构的RNA分子募集到由dCas9gRNA靶向序列指定的位置。例如,与MS2外壳蛋白、内切核糖核酸酶Csy4或λN融合的dCas9变体可用于募集长的非编码RNA(lncRNA)如XIST或HOTAIR;参见例如,Keryer-Bibens等人,Biol.Cell[生物细胞]100:125-138(2008),其与Csy4、MS2或λN结合序列连接。可替代地,Csy4、MS2或λN蛋白结合序列可以连接到另一种蛋白,例如,如Keryer-Bibens等人,同上所述的,并且可以使用本文描述的方法和组合物将蛋白靶向dCas9变体结合位点。在一些实施例中,Csy4是无催化活性的。在一些实施例中,Cas9变体(优选dCas9变体)与FokI融合,如以下文献中所述:US 8,993,233;US 20140186958;US 9,023,649;WO/2014/099744;WO 2014/089290;WO 2014/144592;WO 144288;WO 2014/204578;WO 2014/152432;WO 2115/099850;US 8,697,359;US 2010/0076057;US 2011/0189776;US 2011/0223638;US 2013/0130248;WO/2008/108989;WO/2010/054108;WO/2012/164565;WO/2013/098244;WO/2013/176772;US 20150050699;US 20150071899和WO2014/204578。
在一些实施例中,融合蛋白包括dCas9变体和异源功能域之间的接头。可以用于这些融合蛋白(或在连接的结构中的融合蛋白之间)的接头可以包括并不干扰融合蛋白的功能的任何序列。在优选的实施例中,该接头是短的,例如2-20个氨基酸,并且典型地是柔性的(即包含具有高自由度的氨基酸,例如甘氨酸、丙氨酸、和丝氨酸)。在一些实施例中,该接头包含由GGGS(SEQ ID NO:3)或GGGGS(SEQ ID NO:4)组成的一个或多个单元,例如GGGS(SEQ ID NO:5)或GGGGS(SEQ ID NO:6)单元的两个、三个、四个、或更多个重复。也可以使用其他的接头序列。
在一些实施例中,变体蛋白包括协助递送至细胞内空间的细胞穿透肽,例如HIV源的TAT肽、穿膜肽、转运肽、或hCT源的细胞穿透肽,参见例如Caron等人,(2001)Mol Ther.[分子治疗]3(3):310-8;Langel,Cell-Penetrating Peptides:Processes andApplications[细胞穿透肽:过程和应用](CRC出版社(CRC Press),博卡拉顿市(BocaRaton)FL 2002);El-Andaloussi等人,(2005),Curr Pharm Des.[当前药物设计]11(28):3597-611;以及Deshayes等人,(2005)Cell Mol Life Sci.[细胞分子生命科学]62(16):1839-49。
细胞穿透肽(CPP)是协助广泛范围的生物分子横跨细胞膜移动进入细胞质或其他细胞器,例如线粒体和细胞核的短肽。可以由CPP递送的分子的实例包括治疗药物、质粒DNA、寡核苷酸、siRNA、肽核酸(PNA)、蛋白、肽、纳米颗粒、和脂质体。CPP一般是30个氨基酸或更小,天然地起源或是非天然存在的蛋白或嵌合序列,并且包含高相对丰度的正电荷氨基酸,例如赖氨酸或精氨酸,抑或交替模式的极性和非极性氨基酸。通常用于本领域的CPP包括Tat(Frankel等人,(1988)Cell.[细胞]55:1189-1193,Vives等人,(1997)J.Biol.Chem.[生物化学杂志]272:16010-16017)、穿膜肽(Derossi等人,(1994)J.Biol.Chem.[生物化学杂志]269:10444-10450)、聚精氨酸肽序列(Wender等人,(2000)Proc.Natl.Acad.Sci.USA[美国国家科学院院刊]97:13003-13008,Futaki等人,(2001)J.Biol.Chem.[生物化学杂志]276:5836-5840)、以及转运素(transportan)(Pooga等人,(1998)Nat.Biotechnol.[自然生物技术]16:857-861)。
通过共价的或非共价的策略,CPP可以连接有其货物。用于共价接合CPP及其货物的方法是本领域已知的,例如化学交联(Stetsenko等人,(2000)J.Org.Chem.[生物化学杂志]65:4900-4909,Gait等人,(2003)Cell.Mol.Life.Sci.[细胞与分子生命科学]60:844-853)或克隆融合蛋白(Nagahara等人,(1998)Nat.Med.[自然医学]4:1449-1453)。通过电的和疏水的相互作用,建立货物和包含极性的和非极性的结构域的短两亲CPP之间的非共价连接。
本领域已经利用CPP来潜在地递送治疗性生物分子到细胞中。实例包括用于免疫抑制的连接至聚精氨酸的环孢霉素(Rothbard等人,(2000)Nature Medicine[自然医学]6(11):1253-1257),用于抑制肿瘤发生的、针对连接至称为MPG的CPP的细胞周期蛋白B1的siRNA(Crombez等人,(2007)Biochem Soc.Trans.[生物化学学会汇报]35:44-46),用来减少癌细胞生长的、连接至CPP的肿瘤抑制基因p53肽(Takenobu等人,(2002)Mol.CancerTher.[分子癌症治疗学]1(12):1043-1049,Snyder等人,(2004)PLoS Biol.[公共科学图书馆生物学]2:E36),和用来治疗哮喘的、Ras或融合至Tat的磷酸肌醇3激酶(PI3K)的显性负效形式(Myou等人,(2003)J.Immunol.[免疫学杂志]171:4399-4405)。
本领域已经利用CPP来运输造影剂到细胞中,用于成像和生物传感应用。例如,附接至Tat的绿色荧光蛋白(GFP)已经用于标记癌细胞(Shokolenko等人,(2005)DNA Repair[DNA修复]4(4):511-518)。缀合至量子点的Tat已经被用于成功横跨血脑屏障以便将大鼠大脑可视化(Santra等人,(2005)Chem.Commun.[化学通讯]3144-3146)。CPP也已经结合磁共振成像技术用于细胞成像(Liu等人,(2006)Biochem.and Biophys.Res.Comm.[生物化学和生物物理研究通讯]347(1):133-140)。还参见Ramsey和Flynn,Pharmacol Ther.[药理学和治疗学]2015年7月22日.pii:S0163-7258(15)00141-2。
可替代地,或此外,变体蛋白可以包括核定位序列,例如SV40大T抗原NLS(PKKKRRV(SEQ ID NO:7))和核质蛋白NLS(KRPAATKKAGQAKKKK(SEQ ID NO:8))。其他NLS是本领域已知的;参见例如Cokol等人,EMBO Rep.[欧洲分子生物学组织报告]2000年11月15日;1(5):411-415;Freitas和Cunha,Curr Genomics.[现代基因组学]2009年12月;10(8):550-557。
在一些实施例中,变体包括对于配体,例如GST、FLAG或六组氨酸序列具有高亲和力的部分。此类亲和标签可以协助纯化重组变体蛋白。
对于其中将变体蛋白递送至细胞的方法,可以使用本领域已知的任何方法产生蛋白,例如通过体外翻译,或在适合的宿主细胞中,自编码变体蛋白的核酸的表达;本领域已知用于产生蛋白的多种方法。例如,可以在以下中产生蛋白并且然后纯化:酵母、大肠杆菌、昆虫细胞系、植物、转基因动物、或培养的哺乳动物细胞;参见例如Palomares等人,“Production of Recombinant Proteins:Challenges and Solutions[重组蛋白的产生:挑战和解决方案],”Methods Mol Biol.[分子生物学方法]2004;267:15-52。此外,可以将变体蛋白连接至协助转移进细胞的部分,例如脂质纳米颗粒,任选地使用一旦蛋白进入细胞,被切割掉的接头。参见例如LaFountaine等人,Int J Pharm.[国际药物杂志]2015年8月13日;494(1):180-194。
表达系统
为了使用本文描述的Cas9变体,可能希望从编码它们的核酸表达它们。这可以按多种方式进行。例如,可以将编码Cas9变体的核酸克隆进中间载体,用于转化进原核细胞或真核细胞,以便复制和/或表达。中间载体典型地是原核生物载体,例如质粒,或穿梭载体,或昆虫载体,用于编码Cas9变体的核酸的储存或操纵或用于生产Cas9变体。还可以将编码Cas9变体的核酸克隆进表达载体,用于给予至植物细胞、动物细胞,优选是哺乳动物细胞或人类细胞,真菌细胞,细菌细胞,或原生动物细胞。
为了获得表达,典型地将编码Cas9变体的序列亚克隆进包含用来指导转录的启动子的表达载体中。适合的细菌和真核启动子是本领域熟知的,并且例如在Sambrook等人,Molecular Cloning,A Laboratory Manual[分子克隆实验指南](第3版,2001);Kriegler,Gene Transfer and Expression:A Laboratory Manual[基因转移和表达:实验室手册](1990);和Current Protocols in Molecular Biology[分子生物学现代方法](Ausubel等人编辑,2010)中描述。用于表达工程蛋白的细菌表达系统是可得的,例如在大肠杆菌、芽孢杆菌属物种、和沙门氏菌属中(Palva等人,1983,Gene[基因]22:229-235)。用于此类表达系统的试剂盒是可商购的。用于哺乳动物细胞、酵母、和昆虫细胞的真核生物表达系统是本领域熟知的,并且也是可商购的。
用于指导核酸的表达的启动子取决于具体应用。例如,典型地,强组成型启动子用于融合蛋白的表达和纯化。相比之下,当体内给予Cas9变体用于基因调节时,可以使用组成型启动子或诱导型启动子,取决于Cas9变体的具体用途。此外,用于给予Cas9变体的优选启动子可以是弱启动子,例如HSV TK,或具有类似活性的启动子。该启动子还可以包括响应转录激活的元件,例如缺氧应答元件、Gal4应答元件、lac阻遏因子应答元件、和小分子控制系统,例如四环素调节系统和RU-486系统(参见例如,Gossen&Bujard,1992,Proc.Natl.Acad.Sci.USA[美国国家科学院院刊],89:5547;Oligino等人,1998,GeneTher.[基因治疗],5:491-496;Wang等人,1997,Gene Ther.[基因治疗],4:432-441;Neering等人,1996,Blood[血液],88:1147-55;和Rendahl等人,1998,Nat.Biotechnol.[自然生物技术],16:757-761)。
除了启动子,表达载体典型地包含转录单位或表达盒,该转录单位或表达盒包含在宿主细胞(原核的或真核的)中表达核酸所需的所有另外的元件。因此,典型的表达盒包含有效地连接到,例如编码Cas9变体,和例如转录物的有效聚腺苷酸化、转录终止、核糖体结合位点、或翻译终止所需的任何信号的核酸序列上的启动子。盒的另外的元件可以包括,例如增强子,和异源剪接固有信号。
关于Cas9变体的预期用途,选择用于运输遗传信息进入细胞的具体表达载体,预期用途例如是在植物、动物、细菌、真菌、原生动物等中表达。标准细菌表达载体包括质粒,例如基于pBR322的质粒,pSKF、pET23D、和可商购的标签融合表达系统,例如GST和LacZ。
包含来自真核病毒的调节元件的表达载体通常用于真核表达载体,例如SV40载体、乳头瘤病毒载体、和源自埃-巴二氏病毒的载体。其他示例性真核载体包括pMSG、pAV009/A+、pMTO10/A+、pMAMneo-5、杆状病毒pDSVE以及允许在以下启动子的指导下表达蛋白的任何其他载体:SV40早期启动子、SV40晚期启动子、金属硫蛋白启动子、鼠类乳腺肿瘤病毒启动子、劳斯肉瘤病毒启动子、多角体蛋白启动子,或示出对在真核细胞中的表达有效的其他启动子。
用于表达Cas9变体的载体可以包括RNA Pol III启动子,以驱动指导RNA的表达,例如H1、U6或7SK启动子。这些人类启动子允许在质粒转染后,在哺乳动物细胞中,表达Cas9变体。
一些表达系统具有用于选择稳定转染细胞系的标记,例如胸苷激酶、潮霉素B磷酸转移酶、和二氢叶酸还原酶。高产率表达系统也是适合的,例如在昆虫细胞中使用杆状病毒载体,具有在多角体蛋白启动子或其他强杆状病毒启动子的指导下的gRNA编码序列。
典型地包含在表达载体中的元件还包括在大肠杆菌中发挥功能的复制子、编码用来允许选择容纳重组质粒的细菌的抗生素抗性的基因、和用来允许重组序列的插入的在质粒的非必需区中的独特限制酶切位点。
使用标准转染方法来产生表达大量蛋白的细菌的、哺乳动物的、酵母的或昆虫的细胞系,然后使用标准技术纯化这些蛋白(参见例如Colley等人,1989,J.Biol.Chem.[生物化学杂志],264:17619-22;对蛋白纯化的引导[Guide to Protein Purification],Methods in Enzymology[酶学方法],第182卷(Deutscher编辑,1990))。根据标准技术,进行真核细胞和原核细胞的转化(参见例如,Morrison,1977,J.Bacteriol.[细菌学杂志]132:349-351;Clark-Curtiss&Curtiss,Methods in Enzymology[酶学方法]101:347-362(Wu等人编辑,1983)。
用于将外源核苷酸序列引入宿主细胞的任何已知程序都是可以使用的。这些包括使用磷酸钙转染、凝聚胺(polybrene)、原生质体融合、电穿孔、核转染、脂质体、微注射、裸DNA、质粒载体、病毒载体,附加型和整合型二者,和用于将克隆的基因组DNA、cDNA、合成DNA、或其他外源基因材料引入宿主细胞的任何其他熟知方法(参见例如Sambrook等人,同上)。只需要使用能够成功地将至少一个基因引入能够表达Cas9变体的宿主细胞中的具体遗传工程化程序。
本发明的方法还可以包括通过将纯化的Cas9蛋白与gRNA一起引入细胞作为核糖核蛋白(RNP)复合物,连同引入gRNA加上编码Cas9的mRNA,来修饰gDNA。gRNA可以是合成的gRNA或编码指导RNA的核酸(例如在表达载体中)。
本发明还包括载体和包含载体的细胞。
实施例
本发明在以下实例中进一步说明,这些实例不得限制权利要求书中所描述的本发明的范围。
方法
用于进化SpCas9变体的基于细菌的阳性选择测定
用Cas9/sgRNA编码质粒转化包含阳性选择质粒(具有嵌入靶位点)的感受态大肠杆菌BW25141(γDE3)23。在SOB培养基中恢复60分钟后,将转化体铺板在包含氯霉素(非选择性)或氯霉素+10mM阿拉伯糖(选择性)的LB板上。
为了鉴定对全基因组靶特异性可能至关重要的另外的位置,我们调整了先前用于研究归巢内切核酸酶性质的细菌选择系统(以下称为阳性选择)(Chen&Zhao,NucleicAcids Res[核酸研究]33,e154(2005);Doyon等人,J Am Chem Soc[美国化学会志]128,2477-2484(2006))。
在对该系统的本调整中,Cas9介导的编码诱导型毒性基因的阳性选择质粒的切割使得细胞能够存活,这归因于线性化质粒的随后降解和损失。在确定SpCas9可以在阳性选择系统中起作用之后,测试了野生型和变体切割含选择自已知人类基因组的靶位点的选择质粒的能力。将这些变体用包含靶位点的阳性选择质粒引入细菌中并铺板在选择性培养基上。通过计算存活频率:选择性板上的菌落/非选择性板上的菌落,来估计阳性选择质粒的切割(参见图1,5-6)。
在此研究中使用的质粒的子集(序列显示如下)

人类细胞培养和转染
在37℃,5%CO2下,将含组成型地表达的EGFP-PEST报道基因15的单一整合拷贝的U2OS.EGFP细胞在补充有10%FBS、2mM GlutaMax(生命技术公司(Life Technologies))、青霉素/链霉素和400μg/ml的G418的高级DMEM培养基(生命技术公司)中进行培养。根据制造商的方案,用Lonza4D-核转染仪的DN-100程序,将细胞与750ng的Cas9质粒和250ng的sgRNA质粒(除非另有注解)共转染。将与空U6启动子质粒一起转染的Cas9质粒用作所有人类细胞实验的阴性对照。(参见图2,7-10)。
人类细胞EGFP破坏测定
如先前所述16进行EGFP破坏实验。使用Fortessa流式细胞仪(BD生物科学公司(BDBiosciences)),转染后约52小时分析转染细胞的EGFP表达。所有实验的背景EGFP损失门控为大约2.5%(参见图2,7)。
T7E1测定、靶向深度测序和GUIDE-seq来定量核酸酶诱导的突变率
如先前针对人类细胞所述进行T7E1测定(Kleinstiver,B.P.等人,Nature[自然]523,481-485(2015))。对于U2OS.EGFP人类细胞,在转染后约72小时,使用AgencourtDNAdvance基因组DNA分离试剂盒(贝克曼库尔特基因组学公司),从转染的细胞中提取基因组DNA。将大约200ng纯化的PCR产物变性、退火并用T7E1(新英格兰生物实验室)消化。使用Qiaxcel毛细管电泳仪(凯杰公司(QIagen))定量诱变频率,如先前针对人类细胞所述(Kleinstiver等人,Nature[自然]523,481-485(2015);Reyon等人,Nat Biotechnol[自然生物技术]30,460-465(2012))。
如先前所述进行GUIDE-seq实验(Tsai等人,Nat Biotechnol[自然生物技术]33,187-197(2015))。简言之,如上所述,将磷酸化的硫代磷酸酯修饰的双链寡脱氧核苷酸(dsODN)与Cas9核酸酶连同Cas9和sgRNA表达质粒一起转染入U2OS细胞。进行dsODN特异性扩增、高通量测序和作图,以鉴定含有DSB活性的基因组区间。对于野生型与二重或四重突变体变体实验,脱靶读数计数被归一化为中靶读数计数,以校正样本之间的测序深度差异。然后比较野生型和变体SpCas9的归一化比率,以计算脱靶位点处活性的倍数变化。为了确定GUIDE-seq的野生型和SpCas9变体样本在预期的靶位点是否具有相似的寡核苷酸标签整合率,通过用Phusion Hot-Start Flex从100ng基因组DNA(如上所述分离)扩增预期靶座位来进行限制性片段长度多态性(RFLP)测定。在使用Agencourt Ampure XP试剂盒进行清理之前,在37℃,将大约150ng PCR产物用20U NdeI(新英格兰生物实验室)消化3小时。使用Qiaxcel毛细管电泳仪(凯杰公司)对RFLP结果进行定量,以粗略估计寡核苷酸标签整合率。如上所述,为了类似目的进行T7E1测定。
实施例1
用来解决CRISPR-Cas9RNA指导基因编辑的靶向特异性的一个潜在解决方案将是用新颖的突变将Cas9变体工程化。
基于这些更早的结果,得出假设(不希望受理论束缚):通过降低Cas9对DNA的非特异性结合亲和力(由结合至DNA上的磷酸基团或与DNA堆积相互作用的疏水碱基介导),能显著降低CRISPR-Cas9核酸酶的特异性。这一方法将具有以下优点:如在先前所述的截短的gRNA方法中,不减小由gRNA/Cas9复合物识别的靶位点的长度。推断可能通过将与靶DNA上的磷酸基团接触的氨基酸残基突变,来减小Cas9对DNA的非特异性结合亲和力。
已经使用类似方法来产生非Cas9核酸酶(例如TALEN)的变体(参见例如Guilinger等人,Nat.Methods.[自然方法]11:429(2014))。
在该假设的初始测试中,本发明的诸位发明人尝试通过将单个丙氨酸取代引入可能预期与DNA主链上的磷酸相互作用的SpCas9中的不同残基,来将广泛使用的酿脓链球菌Cas9(SpCas9)的减小亲和力变体工程化。使用基于大肠杆菌的筛选测定,来评估这些变体的活性(Kleinstiver等人,Nature[自然].2015年7月23日;523(7561):481-5)。在此细菌系统中,细胞存活取决于包含针对毒性旋转酶毒物ccdB的基因和gRNA与SpCas9靶向的23个碱基对的序列的选择质粒的切割(和随后的破坏)。此实验鉴定的保留或损失活性的残基的结果(表1)。
表1:Cas9的单丙氨酸取代突变体的活性
如在图1中显示的基于细菌细胞的系统中评估的。
| 突变 | %存活 | 突变 | %存活 | 突变 | %存活 | ||
| R63A | 84.2 | Q926A | 53.3 | K1158A | 46.5 | ||
| R66A | 0 | K1107A | 47.4 | K1185A | 19.3 | ||
| R70A | 0 | E1108A | 40.0 | K1200A | 24.5 | ||
| R74A | 0 | S1109A | 96.6 | S1216A | 100.4 | ||
| R78A | 56.4 | K1113A | 51.8 | Q1221A | 98.8 | ||
| R165A | 68.9 | R1114A | 47.3 | K1289A | 55.2 | ||
| R403A | 85.2 | S1116A | 73.8 | R1298A | 28.6 | ||
| N407A | 97.2 | K1118A | 48.7 | K1300A | 59.8 | ||
| N497A | 72.6 | D1135A | 67.2 | K1325A | 52.3 | ||
| K510A | 79.0 | S1136A | 69.2 | R1333A | 0 | ||
| Y515A | 34.1 | K1151A | 0 | K1334A | 87.5 | ||
| R661A | 75.0 | K1153A | 76.6 | R1335A | 0 | ||
| Q695A | 69.8 | K1155A | 44.6 | T1337A | 64.6 |
在50%-100%之间的存活百分率通常指示稳健的切割,而0%存活指示酶已经在功能上被损害。在细菌中测定的另外的突变(但是未在上表中显示)包括:R69A、R71A、Y72A、R75A、K76A、N77A、R115A、H160A、K163A、L169A、T404A、F405A、R447A、I448A、Y450A、S460A、M495A、M694A、H698A、Y1013A、V1015A、R1122A、K1123A、和K1124A。除了R69A和F405A(在细菌中具有<5%存活),所有这些另外的单突变似乎对SpCas9的中靶活性没有影响(在细菌筛选中>70%存活)。
构建携带N497A、R661A、Q695A、和Q926A突变的所有可能的单重、二重、三重和四重组合的15种不同的SpCas9变体,以便测试由这些残基造成的接触是否可能对于中靶活性而言是无效的(图1b)。对于这些实验而言,使用先前所述的基于人类细胞的测定,其中通过单一整合的EGFP报道基因内的非同源末端接合(NHEJ)介导的修复的插入或缺失突变(indel)的切割和诱导导致细胞荧光的损失(Reyon,D.等人,Nat Biotechnol.[自然生物技术]30,460-465,2012)。当与野生型SpCas9配对时,使用先前在人类细胞中显示有效破坏EGFP表达的EGFP靶向的sgRNA(Fu,Y.等人,Nat Biotechnol[自然生物技术]31,822-826(2013)),所有15种SpCas9变体拥有与野生型SpCas9可比较的EGFP破坏活性(图1b,灰色条)。因此,这些残基中的一个或所有的取代并不减小具有此EGFP靶向的sgRNA的SpCas9的中靶切割效率。
接下来,进行实验来评估所有15种SpCas9变体在错配的靶位点处的相对活性。为做到这一点,使用在位置13和14、15和16、17和18、以及18和19处包含取代的碱基对的、在先前实验中使用的EGFP靶向的sgRNA的衍生物,重复EGFP破坏测定(如下进行编号,对于PAM最近端的碱基,用1开始,并且对于PAM最远端的碱基,用20结束;图1b)。这些分析揭示,三重突变体(R661A/Q695A/Q926A)和四重突变体(N497A/R661A/Q695A/Q926A)之一都显示等价于使用所有四种错配的sgRNA的背景的EGFP破坏的水平(图1b,有颜色条)。值得注意地,在15种变体中,拥有与错配的sgRNA的最低活性的那些都含Q695A和Q926A突变。基于这些结果和来自使用针对另一EGFP靶位点的sgRNA的实验的类似数据,选择四重突变体(N497A/R661A/Q695A/Q926A)用于另外的分析并且将其指定为SpCas9-HF1(用于高保真性变体#1)。
SpCas9-HF1的中靶活性
为了确定在更大数量的中靶位点处,SpCas9-HF1能够多稳健地起作用,使用另外的sgRNA,在此变体和野生型SpCas9之间进行直接比较。总计,测试了37种不同的sgRNA:24种靶向至EGFP(用EGFP破坏测定进行测定),并且13种靶向内源人类基因靶(使用T7内切核酸酶I(T7EI)错配测定进行测定)。用EGFP破坏测定测试的24种sgRNA中的20种(图1c)和在内源人类基因位点上测试的13种sgRNA中的12种(图1d)显示SpCas9-HF1的活性,这些活性为野生型SpCas9与相同sgRNA之间的活性的至少70%(图1e)。事实上,SpCas9-HF1显示与野生型SpCas9相比,与绝大部分sgRNA之间的高度可比较的活性(90-140%)(图1e)。测试的37种sgRNA中的三种显示与SpCas9-HF1之间基本上没有活性,并且这些靶位点的检查并不提示,与观察到高活性的那些相比,这些序列的特征中的任何明显差异(表3)。总体而言,对于测试的86%(32/37)的sgRNA,SpCas9-HF1拥有可比较的活性(大于70%的野生型SpCas9活性)。
表3:sgRNA靶的清单
酿脓链球菌sgRNA




内源基因









*1,NGA EMX1位点4,来自Kleinstiver等人,Nature[自然]2015
*2,NGA FANCF位点1,来自Kleinstiver等人,Nature[自然]2015
*3,NGA FANCF位点3,来自Kleinstiver等人,Nature[自然]2015
*4,NGA FANCF位点4,来自Kleinstiver等人,Nature[自然]2015
*5,NGA RUNX1位点1,来自Kleinstiver等人,Nature[自然]2015
*6,NGA RUNX1位点3,来自Kleinstiver等人,Nature[自然]2015
*7,NGA VEGFA位点1,来自Kleinstiver等人,Nature[自然]2015
*8,NGA ZNF629位点,来自Kleinstiver等人,Nature[自然]2015
SpCas9-HF1的全基因组特异性
为了测试在人类细胞中,SpCas9-HF1是否表现出减小的脱靶效应,使用通过测序(GUIDE-seq)方法实现的双链断裂的全基因组无偏鉴定。GUIDE-seq使用进入双链断裂的短双链寡脱氧核苷酸(dsODN)标签的整合,以便实现相邻基因组序列的扩增和测序,其中在任何给定位点的标签整合的数目提供切割效率的定量测量(Tsai,S.Q.等人,Nat Biotechnol[自然生物技术]33,187-197(2015))。采用靶向内源人类EMX1、FANCF、RUNX1、和ZSCAN2基因中的不同位点的八种不同的sgRNA,使用GUIDE-seq来比较由野生型SpCas9和SpCas9-HF1诱导的脱靶效应的图谱。由这些sgRNA靶向的序列是独特的,并且在参比人类基因组中具有可变数量的预测的错配位点(表2)。对于八种sgRNA,中靶dsODN标签整合(通过限制性片段长度多态性(RFLP)测定)和indel形成(通过T7EI测定)的评估揭示与野生型SpCas9和SpCas9-HF1的可比较的中靶活性(分别为图7a和7b)。GUIDE-seq实验显示,八种sgRNA中的七种诱导使用野生型SpCas9在多个全基因组脱靶位点(每个sgRNA范围为从2至25)处的切割,而第八种sgRNA(对于FANCF位点4)并不产生任何可检测的脱靶位点(图2a和2b)。然而,诱导与野生型SpCas9的indel的七种sgRNA中的六种显示与SpCas9-HF1的GUIDE-seq可检测脱靶事件的引人注目的完全不存在(图2a和2b);并且剩余的第七种sgRNA(对于FANCF位点2)诱导在含原型间隔子种子序列内的一个错配的位点处的唯一一个单个可检测全基因组脱靶切割事件(图2a)。总而言之,当使用SpCas9-HF1时未检测到的脱靶位点含原型间隔子和/或PAM序列中的一至六个错配(图2c)。当使用SpCas9-HF1进行测试时,如与野生型SpCas9一起,第八种sgRNA(对于FANCF位点4)并未产生可检测的脱靶切割事件(图2a)。
为了确认GUIDE-seq发现,将靶向扩增子测序用于更直接地测量由野生型SpCas9和SpCas9-HF1诱导的NHEJ介导的indel突变的频率。对于这些实验,仅用sgRNA-和Cas9编码质粒(即,无GUIDE-seq标签)转染人类细胞。然后将下一代测序用于检查对于GUIDE-seq实验中的六种sgRNA,已经用野生型SpCas9鉴定的40个脱靶位点中的36个(40个位点中的四个不能检查,因为它们不能从基因组DNA中特异性地扩增)。这些深度测序实验显示:(1)在六个sgRNA中靶位点中的每一个处,野生型SpCas9和SpCas9-HF1诱导可比较频率的indel(图3a和3b);(2)如预期,野生型SpCas9显示,在36个脱靶位点中的35个处,indel突变的统计上显著的证据(图3b),其频率与对于这些相同位点的GUIDE-seq读数计数很好地关联(图3c);以及(3)在36个脱靶位点中的34个处,由SpCas9-HF1诱导的indel的频率与在来自对照转染的样品中观察到的indel的背景水平不可区分(图3b)。对于相对于阴性对照,使用SpCas9-HF1似乎具有统计上显著的突变频率的两个脱靶位点,indel的平均频率为0.049%和0.037%,在这个水平难以确定这些是否是由于测序/PCR错误或是真实的核酸酶诱导的indel导致的。基于这些结果,结论是SpCas9-HF1可以完全地或接近完全地减少横跨使用野生型SpCas9的一系列不同频率发生的脱靶脱变至不可检测的水平。
接下来,评估了SpCas9-HF1减少靶向非典型均聚的或重复的序列的sgRNA的全基因组脱靶效应的能力。尽管很多人现在试图避免具有这些特征的中靶位点由于其相对缺乏与基因组的正交性,仍希望探索SpCas9-HF1是否可能减少脱靶indel(甚至对于这些挑战性的靶)。因此,使用先前表征的sgRNA(Fu,Y.等人,Nat Biotechnol[自然生物技术]31,Tsai,S.Q.等人,Nat Biotechnol[自然生物技术]33,187-197(2015)),它们靶向在人类VEGFA基因中的富含胞嘧啶的均聚序列抑或包含多个TG重复的序列(分别是VEGFA位点2和VEGFA位点3)(表2)。在对照实验中,使用野生型SpCas9和SpCas9-HF1二者,这些sgRNA中的每一个诱导可比较水平的GUIDE-seq ds ODN标签合并(图7c)和indel突变(图7d),展示在与这些sgRNA中的任一者的中靶活性方面,SpCas9-HF1并未受损。重要的是,GUIDE-seq实验揭示,在减少这些sgRNA的脱靶位点方面,SpCas9-HF1高度有效,其中对于VEGFA位点2,123/144个位点未检测到,对于VEGFA位点3,31/32个位点未检测到(图4a和4b)。用SpCas9-HF1未检测到的这些脱靶位点的检查显示,它们各自在其原型间隔子和PAM序列内拥有一系列的总错配:对于VEGFA位点2 sgRNA,是2至7个错配,并且对于VEGFA位点3 sgRNA,是1至4个错配(图4c);而且,对于VEGFA位点2的这些脱靶位点中的九个可以在sgRNA-DNA界面具有潜在的凸起碱基(Lin,Y.等人,.Nucleic Acids Res[核酸研究]42,7473-7485(2014))(图4a和图8)。用SpCas9-HF1未检测到的位点拥有针对VEGFA位点2 sgRNA的2至6个错配,和在针对VEGFA位点3 sgRNA的单个位点中的2个错配(图4c),其中针对VEGFA位点2 sgRNA的三个脱靶位点再次具有潜在的凸起(图8)。总而言之,这些结果展示SpCas9-HF1在减小靶向至简单重复序列的sgRNA的脱靶效应方面,可以是高度有效的,并且还可以具有对靶向至均聚序列的sgRNA的实质性影响。
表2|针对由GUIDE-seq检查的十种sgRNA,在参比人类基因组中的潜在错配位点的总结

*使用Cas-OFFinder确定(Bae等人,Bioinformatics[生物信息学]30,1473-1475(2014))
表4:研究中使用的寡核苷酸







将SpCas9-HF1的特异性细化
先前所述的方法,例如截短的gRNA(Fu,Y.等人,Nat Biotechnol[自然生物技术]32,279-284(2014))和SpCas9-D1135E变体(Kleinstiver,B.P.等人,Nature[自然]523,481-485(2015))可以部分减小SpCas9脱靶效应,并且本发明的诸位发明人想知道这些是否可能与SpCas9-HF1组合,从而进一步改进其全基因组特异性。用在基于人类细胞的EGFP破坏测定中靶向四个位点的错配的全长的和截短的sgRNA测试SpCas9-HF1,揭示缩短sgRNA互补性长度实质上损害了中靶活性(图9)。相比之下,具有另外的D1135E突变的SpCas9-HF1(在此称为SpCas9-HF2的变体)保留了使用基于人类细胞的EGFP破坏测定测试的具有八个sgRNA中的六个的野生型SpCas9的70%的或更高的活性(图5a和5b)。还产生分别含L169A或Y450A突变的SpCas9-HF3和SpCas9-HF4变体,突变位置是在其侧链介导与靶DNA在其PAM近端的疏水非特异性相互作用处(Nishimasu,H.等人,Cell[细胞]156,935-949(2014);Jiang,F.等人,Science[科学]348,1477-1481(2015))。SpCas9-HF3和SpCas9-HF4保留了用具有八个EGFP靶向的sgRNA中的相同六个的野生型SpCas9观察到的70%的或更高的活性(图5a和5b)。
为了确定SpCas9-HF2、-HF3、和-HF4是否可以减小在对SpCas9-HF1有抗性的两个脱靶位点的indel频率(对于FANCF位点2和VEGFA位点3sgRNA),进行了进一步的实验。对于FANCF位点2脱靶,其携带在原型间隔子的种子序列中的单错配,如通过T7EI测定判断,SpCas9-HF4将indel突变频率降低至接近背景水平,同时还有益地增加了中靶活性(图5c),导致在这三个变体中的特异性方面的最大增加(图5d)。对于VEGFA位点3脱靶位点,其携带两个原型间隔子错配(一个在种子序列中,并且一个在PAM序列的最远端的核苷酸处),SpCas9-HF2显示在indel形成方面的最大减少,同时显示对中靶突变效率的仅适度的影响(图5c),导致在测试的三个变体中,特异性方面的最大增加(图5d)。总之,这些结果展示,通过在介导非特异性DNA接触或可以改变PAM识别的其他残基处引入另外的突变,减少了对SpCas9-HF1有抗性的脱靶效应的潜能。
为了分别对上述显示SpCas9-HF4和SpCas9-HF2具有针对FANCF位点2和VEGFA位点3 sgRNA的脱靶的相对SpCas9-HF1的改进的辨别的T7E1测定发现进行概括,使用GUIDE-seq检查这些变体的全基因组特异性。使用RFLP测定,确定SpCas9-HF4和SpCas9-HF2具有如通过GUIDE-seq标签整合率测定,与SpCas9-HF1类似的中靶活性(图5E)。当分析GUIDE-seq数据时,对于SpCas9-HF2或SpCas9-HF4,没有鉴定到新的脱靶位点(图5F)。与SpCas9-HF1相比,在所有位点的脱靶活性都是通过GUIDE-seq不可检测抑或实质上降低的。相对于SpCas9-HF1,SpCas9-HF4具有针对单FANCF位点2脱靶位点(该位点保留了对SpCas9-HF1的特异性改进的不服从)的接近26倍更好的特异性(图5F)。对于高频率VEGFA位点3脱靶,相对于SpCas9-HF1,SpCas9-HF2具有接近4倍改进的特异性,同时还显著降低(>38倍)或消除了在其他低频率脱靶位点处的GUIDE-seq可检测的事件。值得注意的是,针对SpCas9-HF1鉴定的这些低频率位点中的3个的基因组位置邻近先前表征的背景U2OS细胞断点热点。总而言之,这些结果提示,SpCas9-HF2和SpCas9-HF4变体可以改进SpCas9-HF1的全基因组特异性。
当使用针对标准非重复靶序列设计的sgRNA时,SpCas9-HF1稳健并且一致地减少了脱靶突变。对SpCas9-HF1最具有抗性的两个脱靶位点具有原型间隔子中的唯一一个和两个错配。总之,这些观察结果提示,可能通过使用SpCas9-HF1,并且靶向并不具有携带基因组中其他位置处的一个或两个错配的紧密相关位点的非重复序列(其可以使用现有公开可得的软件程序实现),将脱靶突变最小化至不可检测的水平(Bae,S.等人,Bioinformatics[生物信息学]30,1473-1475(2014))。使用者应考虑到的一个参数是SpCas9-HF1可能是不与普通实践(使用与原型间隔子序列错配的gRNA的5’末端处的G)兼容的。携带与其靶位点错配的5’G的四个sgRNA的测试显示,与野生型SpCas9相比,四个中的三个具有与SpCas9-HF1之间的降低的活性(图10),可能反映了SpCas9-HF1更好地辨别了部分地错配的位点的能力。
进一步的生物化学工作可以确认或阐明SpCas9-HF1借以实现其高的全基因组特异性的精确机制。引入的四个突变看起来并未改变SpCas9在细胞中的稳定性或稳态表达水平,因为降低浓度的表达质粒的滴定实验提示,野生型SpCas9和SpCas9-HF1表现为与其浓度降低是可比较的(图11)。替代地,最简单的机械解释是,这些突变减少了Cas9-sgRNA和靶DNA之间的相互作用的能量学,其中复合物的能量在刚好足以保留中靶活性的水平,而且将其充分降低,使得脱靶位点切割无效或不存在。这一机制符合结构数据中在突变的残基和靶DNA磷酸主链之间观察到的非特异性相互作用(Nishimasu,H.等人,Cell[细胞]156,935-949(2014),Anders,C等人,Nature[自然]513,569-573(2014))。已经提出在某种程度上类似的机制来解释携带在正电荷残基处的取代的类转录激活因子效应物核酸酶的增加的特异性(Guilinger,J.P.等人,Nat Methods[自然方法]11,429-435(2014))。
可能是SpCas9-HF1也可能与已经显示改变Cas9功能的其他突变组合。例如,携带三个氨基酸取代的SpCas9突变体(D1135V/R1335Q/T1337R,也称为SpCas9-VQR变体)识别具有NGAN PAM的位点(具有以下相对效率,NGAG>NGAT=NGAA>NGAC)(Kleinstiver,B.P.等人,Nature[自然]523,481-485(2015)),并且最近鉴定的四重SpCas9突变体(D1135V/G1218R/R1335Q/T1337R,称为SpCas9-VRQR变体)相对于VQR,针对具有NGAH(H=A、C、或T)PAM的位点,具有改进的活性(图12a)。分别将来自SpCas9-HF1的四个突变(N497A/R661A/Q695A/Q926A)引入SpCas9-VQR和SpCas9-VRQR,产生SpCas9-VQR-HF1和SpCas9-VRQR-HF1。这些核酸酶的两种HF版本显示出与其具有靶向EGFP报道基因的八个sgRNA中的五个的,以及具有靶向内源人类基因位点的八个sgRNA中的七个的非HF对应物的可比较的(即70%或更多)中靶活性(图12b-12d)。
更广泛地,这些结果说明了用于CRISPR相关核酸酶的另外的高保真性变体的工程化的一般策略。在非特异性DNA接触残基处添加另外的突变进一步减少了SpCas9-HF1具有的、一些非常少量的残余脱靶位点。因此,取决于脱靶序列的性质,可以按自定义的方式利用变体,例如SpCas9-HF2、SpCas9-HF3、SpCas9-HF4等。此外,将SpCas9的高保真性变体工程化的成功提示,使非特异性DNA接触突变的方法可以扩展至其他天然存在的并且工程化的Cas9直系同源物(Ran,F.A.等人,Nature[自然]520,186-191(2015),Esvelt,K.M.等人,NatMethods[自然方法]10,1116-1121(2013);Hou,Z.等人;Proc Natl Acad Sci U S A[美国国家科学院院刊](2013);Fonfara,I.等人;Nucleic Acids Res[核酸研究]42,2577-2590(2014);Kleinstiver,B.P.等人;Nat Biotechnol[自然生物技术](2015)),连同正以增加的频率被发现和表征的较新的CRISPR相关核酸酶(Zetsche,B.等人,Cell[细胞]163,759-771(2015);Shmakov,S等人,Molecular Cell[分子细胞]60,385-397)。
实施例2
在此描述的是在接触靶链DNA的残基中具有丙氨酸取代的SpCas9变体,包括N497A、Q695A、R661A、和Q926A。除了这些残基,本发明的诸位发明人试图确定是否可能通过在以下似乎与非靶DNA链接触的正电荷SpCas9残基中添加取代,进一步改进这些变体,例如SpCas9-HF1变体(N497A/R661A/Q695A/Q926A)的特异性:R780、K810、R832、K848、K855、K968、R976、H982、K1003、K1014、K1047、和/或R1060(参见Slaymaker等人,Science[科学].2016年1月1日;351(6268):84-8)。
最初用设计为EGFP基因中的位点的完全匹配的sgRNA(以便评估中靶活性),以及携带在位置11和12(其中位置1是PAM最近端的碱基)处的有意错配的相同sgRNA(以便评估在错配位点处的活性,如将在脱靶位点处发现),使用EGFP破坏测定,测试携带在这些位置处的单丙氨酸取代的野生型SpCas9衍生物及其组合的活性(图13A)。(注意,携带三重取代K810A/K1003A/R1060A或K848A/K1003A/R1060A的衍生物与分别称为eSpCas9(1.0)和eSpCas9(1.1)的最近描述的变体是相同的;参见ref.1)。如预期,野生型SpCas9具有稳健的中靶和错配靶的活性。作为对照,在此实验中,我们还测试了SpCas9-HF1,并且发现,如预期,它维持了中靶活性,同时减少了错配靶活性(图13A)。携带在可能潜在接触非靶DNA链的位置处的一个或多个丙氨酸取代的所有野生型SpCas9衍生物显示出与野生型SpCas9可比较的中靶活性(图13A)。有趣的是,这些衍生物中的一些还显示出相对于用野生型SpCas9观察到的活性,错配的11/12 sgRNA的切割减少了,提示在这些衍生物中的取代的子集赋予相对于野生型SpCas9,针对这一错配位点的增强的特异性(图13A)。然而,这些单取代或取代的组合中没有一个足以完全消除用11/12错配的sgRNA观察到的活性。当我们使用携带在位置9和10处的错配的另外的sgRNA测试野生型SpCas9、SpCas9-HF1、和这些相同的野生型SpCas9衍生物时(图13B),对于多数衍生物,仅观察到错配靶活性方面的最小改变。这再一次展示了,在这些潜在非靶链接触残基处的单重、二重、或甚至三重取代(等价于先前所述的eSpCas9(1.0)和(1.1)变体)不足以消除在不完全匹配DNA位点处的活性。总而言之,这些数据展示了,野生型SpCas9变体保留了与匹配的sgRNA的中靶活性,并且包含在这些衍生物中的取代靠它们自身(在野生型SpCas9的背景下)不足以消除针对两种不同错配的DNA位点的核酸酶活性(图13A和13B)。
鉴于这些结果,假设携带在可能接触非靶DNA链的残基处的一个或多个另外的氨基酸取代的SpCas9-HF1衍生物相对于亲本SpCas9-HF1蛋白可能进一步改进了特异性。因此,在基于人类细胞的EGFP破坏测定中,使用完全匹配的sgRNA(以测试中靶活性),和携带在位置11和12处的错配的相同sgRNA(以评估在错配的靶位点处的活性,如将针对脱靶位点发现),测试携带单重、二重、或三重丙氨酸取代的组合的不同SpCas9-HF1衍生物。这些sgRNA是用于图13A-B的相同sgRNA。此实验揭示,我们测试的多数SpCas9-HF1衍生物变体显示了与用野生型SpCas9和SpCas9-HF1二者观察到的可比较的中靶活性(图14A)。用11/12错配的sgRNA,测试的SpCas9-HF1衍生物(例如SpCas9-HF1+R832A和SpCas9-HF1+K1014A)中的一些在用错配的sgRNA切割方面并未显示可感知的改变。然而,重要的是,与用SpCas9-HF1、eSpCas9(1.0)、或eSpCas9(1.1)观察到的相比,多数SpCas9-HF1衍生物具有与11/12错配的sgRNA的基本上更低的活性,提示这些新变体的某些组合已经减小了错配靶活性并且因此改进了特异性(图14A)。在将与11/12错配的sgRNA的错配靶活性减小至接近背景水平的16种SpCas9-HF1衍生物中,9种似乎对中靶活性具有仅最小的影响(使用完全匹配的sgRNA评估;图14A)。在EGFP破坏测定中,使用有意在位置9和10错配的sgRNA(图14B),这些SpCas9-HF1衍生物的子集的另外的测试也揭示,与用SpCas9-HF1(图14b),用eSpCas9(1.1)(图13A),抑或用添加至野生型SpCas9核酸酶的相同取代(图13B)观察到的相比,具有这一错配的sgRNA的这些变体拥有更低的活性。重要的是,在用9/10错配的sgRNA的此测定中,五种变体显示背景水平的脱靶活性。
接下来,测试非靶链的这些丙氨酸取代是否可以与仅包含来自我们的SpCas9-HF1变体的Q695A和Q926A取代的SpCas9变体(在此为“二重”变体)组合。因为以上测试的很多HF1衍生物显示中靶活性方面的可观察到的(并且不希望的)减少,假设将来自SpCas9-HF1的仅有的两种最重要的取代(Q695A和Q926A;参见图1B)与接触取代的一个或多个非靶链结合可以拯救中靶活性,但是仍维持当这些取代被添加至SpCas9-HF1变体时观察到的特异性方面的增加。因此,使用用于图13A-B的靶向上述EGFP的相同完全匹配的sgRNA(以测试中靶活性)和携带在位置11和12处的错配的相同sgRNA(以评估在错配的靶位点处的活性,如将针对脱靶位点发现),在基于人类细胞的EGFP破坏测定中,测试携带在潜在非靶DNA链相互作用位置处的单重、二重、或三重丙氨酸取代的组合的不同SpCas9(Q695A/Q926A)衍生物。此实验揭示,多数测试的SpCas9(Q695A/Q926A)衍生物变体显示与用野生型SpCas9和SpCas9-HF1二者观察到的那些中靶活性可比较的中靶活性(图15)。重要的是,与用SpCas9-HF1、eSpCas9(1.0)或eSpCas9(1.1)观察到的相比,很多SpCas9-HF1衍生物具有与11/12错配的sgRNA的实质上更低的活性,提示这些新变体的某些组合具有减小的错配靶活性,并且因此具有改进的特异性(图15)。在将与11/12错配的sgRNA的错配靶活性减小至接近背景水平的13种SpCas9(Q695A/Q926A)衍生物中,仅1种似乎对中靶活性具有实质的影响(使用完全匹配的sgRNA评估;图15)。
总体而言,这些数据展示了,在可能接触非靶DNA链的位置处,添加一个、两个、或三个丙氨酸取代至SpCas9-HF1或SpCas9(Q695A/Q926A)可以导致具有改进的能力的新变体,以排斥错配的脱靶位点(相对于其亲本克隆或最近描述的eSpCas9(1.0)或(1.1))。重要的是,在野生型SpCas9的背景下,这些相同取代似乎并不提供任何实质的特异性益处。
为了更好地限定和比较SpCas9-HF1和eSpCas9-1.1对在sgRNA-靶DNA互补性界面处的错配的耐受性,使用包含在间隔子互补性区域中的所有可能位置处的单错配的sgRNA,检查其活性。当与野生型SpCas9比较时,SpCas9-HF1和eSPCas9-1.1变体二者具有对多数单错配的sgRNA的类似活性,有少量例外,其中SpCas9-HF1性能超过了eSpCas9-1.1(图16)。
接下来,我们测试了一些变体的单核苷酸错配耐受性,所述变体包含来自在接触靶链DNA或潜在接触非靶链DNA的残基中具有另外的丙氨酸取代的二重突变体(Db=Q695A/Q926A)、SpCas9-HF1(N497A/R661A/Q695A/Q926A)、eSpCas9-1.0(1.0=K810A/K1003A/R1060A),抑或eSpCas9-1.1(1.1=K848A/K1003A/R1060A)的氨基酸取代的组合(图17A-B)。使用完全匹配的sgRNA评估中靶活性,同时使用在间隔子序列中携带在位置4、8、12、或16处的此类错配的sgRNA,评估单核苷酸错配耐受性(图17A)。多个这样的变体维持了中靶活性,在用错配的sgRNA观察到的活性方面,具有实质的减小。用剩余单错配sgRNA(包含在位置1-3、5-7、9-11、13-15、和17-20处的错配)进一步测试了这些变体(Q695A/K848A/Q926A/K1003A/R1060A、N497A/R661A/Q695A/K855A/Q926A/R1060A、和N497A/R661A/Q695A/Q926A/H982A/R1060A)中的三个。这些变体展示了,与eSpCas9-1.1相比,对sgRNA中的单核苷酸取代的更稳健的不耐受,这展示了这些新变体的改进的特异性谱(图17B)。使用在间隔子中包含在位置5、7、和9处的错配的sgRNA(因为更早的变体似乎耐受在这些位置处的错配,使用这些具体错配的sgRNA),测试包含氨基酸取代的替代性组合的另外的变体核酸酶(图18)。多个这样的核酸酶具有针对错配位点的改进的特异性,具有中靶活性方面的仅微小的减小(图18)。
为了进一步确定突变的另外的组合是否可以传达特异性改进,测试了一个极大扩展的组的具有两种另外的匹配的sgRNA的核酸酶变体,以在EGFP破坏活性方面检查中靶活性(图19A)。多个这样的变体维持了稳健的中靶活性,提示它们可以用于产生对特异性的进一步改进(图19B)。用包含在位置12、14、16、或18处的单取代的sgRNA测试多个这样的变体,以确定是否可以观察到并且发现表现出对在这些位置处的单核苷酸错配的更大的不耐受的特异性改进(图19B)。
实施例3
采用金黄色葡萄球菌Cas9(SaCas9),如我们已经用SpCas9进行的那样类似的策略进行实验,以通过将丙氨酸取代引入已知接触靶DNA链的残基中(图20和图21A),引入可以接触非靶DNA的残基中(正在进行的实验),以及我们已经先前显示可以影响PAM特异性的残基中(图21B),改进SaCas9的特异性。可以接触靶链DNA主链的残基包括:Y211,Y212,W229,Y230,R245,T392,N419,L446,Y651,和R654;可以接触非靶链DNA的残基包括:Q848,N492,Q495,R497,N498,R499,Q500,K518,K523,K525,H557,R561,K572,R634,R654,G655,N658,S662,N668,R686,K692,R694,H700,K751;并且接触PAM的残基包括:E782,D786,T787,Y789,T882,K886,N888,A889,L909,K929,N985,N986,R991,和R1015。在一个预实验中,在靶链DNA接触残基抑或PAM接触残基(分别是图21A和B)中,单丙氨酸取代(或其一些组合)具有对中靶EGFP破坏活性的可变影响(使用完全匹配的sgRNA),并且不能消除脱靶切割(当使用在位置11和12处错配的sgRNA时)。有趣的是,在HF1中的SpCas9突变不能完全消除用类似错配的靶/sgRNA对的脱靶活性,提示包含靶链/非靶链取代的组合的变体对于改进在此类位点处的特异性而言是必需的(如我们用SpCas9观察到的)。
为了进一步评估使潜在靶链DNA接触突变以改进SaCas9特异性的策略,检查了突变的单重、二重、三重、和四重组合耐受在sgRNA中的位置19和20处的错配的潜能(图22A和B)。这些组合揭示了,如通过更好地排斥错配位点的能力判断的那样,当与其他取代组合时,在Y230和R245处的丙氨酸取代可以增加特异性。
接下来,在EGFP中的4个中靶位点处,检查了这些三重丙氨酸取代变体(Y211A/Y230A/R245A和Y212A/Y230A/R245A)中的两个的中靶基因破坏活性(匹配位点#1-4;图23)。对于匹配位点1和2,这些变体维持了稳健的中靶活性,但是用匹配位点3和4,显示了中靶活性的大约60%-70%的损失。如通过使用携带在靶位点1-4的间隔子中的不同位置处的二重错配的sgRNA判断的那样,相对于野生型SaCas9,这些三重丙氨酸取代变体中的两者显著改进了特异性(图23)。
使用包含在位置21(预期PAM最远端位置对于排斥错配而言将是挑战)处的单错配的sgRNA,针对六个内源位点,测试了携带这些丙氨酸取代的二重和三重组合的SaCas9变体(分别是图24A和B)的中靶活性和评估的特异性方面的改进。在一些情况下,用变体维持了匹配的sgRNA的中靶活性,同时消除了在位置21处错配的sgRNA的“脱靶”活性(图24A和B)。在其他情况下,用匹配的sgRNA观察到活性的微小至完全的损失。
参考文献
1.Sander,J.D.&Joung,J.K.CRISPR-Cas systems for editing,regulating andtargeting genomes.Nat Biotechnol 32,347-355(2014).
2.Hsu,P.D.,Lander,E.S.&Zhang,F.Development and applications ofCRISPR-Cas9for genome engineering.Cell 157,1262-1278(2014).
3.Doudna,J.A.&Charpentier,E.Genome editing.The new frontier of genomeengineering with CRISPR-Cas9.Science 346,1258096(2014).
4.Barrangou,R.&May,A.P.Unraveling the potential of CRISPR-Cas9 forgene therapy.Expert Opin Biol Ther 15,311-314(2015).
5.Jinek,M.et al.A programmable dual-RNA-guided DNA endonuclease inadaptive bacterial immunity.Science 337,816-821(2012).
6.Sternberg,S.H.,Redding,S.,Jinek,M.,Greene,E.C.&Doudna,J.A.DNAinterrogation by the CRISPR RNA-guided endonuclease Cas9.Nature 507,62-67(2014).
7.Hsu,P.D.et al.DNA targeting specificity of RNA-guided Cas9nucleases.Nat Biotechnol 31,827-832(2013).
8.Tsai,S.Q.et al.GUIDE-seq enables genome-wide profiling of off-target cleavage by CRISPR-Cas nucleases.Nat Biotechnol 33,187-197(2015).
9.Hou,Z.et al.Efficient genome engineering in human pluripotent stemcells using Cas9 from Neisseria meningitidis.Proc Natl Acad Sci U S A(2013).
10.Fonfara,I.et al.Phylogeny of Cas9 determines functionalexchangeability of dual-RNA and Cas9 among orthologous type II CRISPR-Cassystems.Nucleic Acids Res 42,2577-2590(2014).
11.Esvelt,K.M.et al.Orthogonal Cas9 proteins for RNA-guided generegulation and editing.Nat Methods 10,1116-1121(2013).
12.Cong,L.et al.Multiplex genome engineering using CRISPR/Cassystems.Science 339,819-823(2013).
13.Horvath,P.et al.Diversity,activity,and evolution of CRISPR loci inStreptococcus thermophilus.J Bacteriol 190,1401-1412(2008).
14.Anders,C.,Niewoehner,O.,Duerst,A.&Jinek,M.Structural basis of PAM-dependent target DNA recognition by the Cas9 endonuclease.Nature 513,569-573(2014).
15.Reyon,D.et al.FLASH assembly of TALENs for high-throughput genomeediting.Nat Biotechnol 30,460-465(2012).
16.Fu,Y.et al.High-frequency off-target mutagenesis induced byCRISPR-Cas nucleases in human cells.Nat Biotechnol 31,822-826(2013).
17.Chen,Z.&Zhao,H.A highly sensitive selection method for directedevolution of homing endonucleases.Nucleic Acids Res 33,e154(2005).
18.Doyon,J.B.,Pattanayak,V.,Meyer,C.B.&Liu,D.R.Directed evolution andsubstrate specificity profile of homing endonuclease I-SceI.J Am Chem Soc128,2477-2484(2006).
19.Jiang,W.,Bikard,D.,Cox,D.,Zhang,F.&Marraffini,L.A.RNA-guidedediting of bacterial genomes using CRISPR-Cas systems.Nat Biotechnol 31,233-239(2013).
20.Mali,P.et al.RNA-guided human genome engineering via Cas9.Science339,823-826(2013).
21.Hwang,W.Y.et al.Efficient genome editing in zebrafish using aCRISPR-Cas system.Nat Biotechnol 31,227-229(2013).
22.Chylinski,K.,Le Rhun,A.&Charpentier,E.The tracrRNA and Cas9families of type II CRISPR-Cas immunity systems.RNA Biol 10,726-737(2013).
23.Kleinstiver,B.P.,Fernandes,A.D.,Gloor,G.B.&Edgell,D.R.A unifiedgenetic,computational and experimental framework identifies functionallyrelevant residues of the homing endonuclease I-BmoI.Nucleic Acids Res 38,2411-2427(2010).
24.Gagnon,J.A.et al.Efficient mutagenesis by Cas9protein-mediatedoligonucleotide insertion and large-scale assessment of single-guideRNAs.PLoS One 9,e98186(2014).
序列
SEQ ID NO:271-JDS246:CMV-T7-人类SpCas9-NLS-3xFLAG
人类密码子优化的酿脓链球菌Cas9以常规字体显示,NLS
 3xFLAG标签以粗体显示:
3xFLAG标签以粗体显示:




SEQ ID NO:272-VP12:CMV-T7-人类SpCas9-HF1(N497A,R661A,Q695A,Q926A)-NLS-3xFLAG
人类密码子优化的酿脓链球菌Cas9以常规字体显示,修饰的密码子以小写字母显示,NLS 3xFLAG标签以粗体显示:
3xFLAG标签以粗体显示:




SEQ ID NO:273-MSP2135:CMV-T7-人类SpCas9-HF2(N497A,R661A,Q695A,Q926A,D1135E)-NLS-3xFLAG
人类密码子优化的酿脓链球菌Cas9以常规字体显示,修饰的密码子以小写字母显示,NLS 3xFLAG标签以粗体显示:
3xFLAG标签以粗体显示:




SEQ ID NO:274-MSP2133:CMV-T7-人类SpCas9-HF4(Y450A,N497A,R661A,Q695A,Q926A)-NLS-3xFLAG
人类密码子优化的酿脓链球菌Cas9以常规字体显示,修饰的密码子以小写字母显示,NLS 3xFLAG标签以粗体显示:
3xFLAG标签以粗体显示:




SEQ ID NO:275-MSP469:CMV-T7-人类SpCas9-VQR(D1135V,R1335Q,T1337R)-NLS-3xFLAG
人类密码子优化的酿脓链球菌Cas9以常规字体显示,修饰的密码子以小写字母显示,NLS 3xFLAG标签以粗体显示:
3xFLAG标签以粗体显示:




SEQ ID NO:276-MSP2440:CMV-T7-人类SpCas9-VQR-HF1(N497A,R661A,Q695A,Q926A,D1135V,R1335Q,T1337R)-NLS-3xFLAG
人类密码子优化的酿脓链球菌Cas9以常规字体显示,修饰的密码子以小写字母显示,NLS 3xFLAG标签以粗体显示:
3xFLAG标签以粗体显示:




SEQ ID NO:277-BPK2797:CMV-T7-人类SpCas9-VRQR(D1135V,G1218R,R1335Q,T1337R)-NLS-3xFLAG
人类密码子优化的酿脓链球菌Cas9以常规字体显示,修饰的密码子以小写字母显示,NLS 3xFLAG标签以粗体显示:
3xFLAG标签以粗体显示:




SEQ ID NO:278-MSP2443:CMV-T7-人类SpCas9-VRQR-HF1(N497A,R661A,Q695A,Q926A,D1135V,G1218R,R1335Q,T1337R)-NLS-3xFLAG
人类密码子优化的酿脓链球菌Cas9以常规字体显示,修饰的密码子以小写字母显示,NLS 3xFLAG标签以粗体显示:
3xFLAG标签以粗体显示:




SEQ ID NO:279-BPK1520:U6-BsmBI盒-Sp-sgRNA
U6启动子以常规字体显示,BsmBI位点以斜体显示,酿脓链球菌sgRNA以小写字母显示,U6终止子

其他实施方案
应理解,虽然已经结合详细描述对本发明进行了描述,但前面的描述旨在说明而非限制本发明的范围,本发明的范围由所附的权利要求书的范围限定。其他方面、优点以及修饰都在以下权利要求书的范围之内。
序列表
<110> 通用医疗公司(THE GENERAL HOSPITAL CORPORATION)
<120> 工程化的CRISPR-Cas9核酸酶
<130> 29539-0189WO1
<150> US 15/015,947
<151> 2016-02-04
<150> US 62/258,280
<151> 2015-11-20
<150> US 62/216,033
<151> 2015-09-09
<150> US 62/211,553
<151> 2015-08-28
<150> US 62/271,938
<151> 2015-12-28
<160> 279
<170> SIPOSequenceListing 1.0
<210> 1
<211> 1368
<212> PRT
<213> 酿脓链球菌(Streptococcus pyogenes)
<400> 1
Met Asp Lys Lys Tyr Ser Ile Gly Leu Asp Ile Gly Thr Asn Ser Val
1 5 10 15
Gly Trp Ala Val Ile Thr Asp Glu Tyr Lys Val Pro Ser Lys Lys Phe
20 25 30
Lys Val Leu Gly Asn Thr Asp Arg His Ser Ile Lys Lys Asn Leu Ile
35 40 45
Gly Ala Leu Leu Phe Asp Ser Gly Glu Thr Ala Glu Ala Thr Arg Leu
50 55 60
Lys Arg Thr Ala Arg Arg Arg Tyr Thr Arg Arg Lys Asn Arg Ile Cys
65 70 75 80
Tyr Leu Gln Glu Ile Phe Ser Asn Glu Met Ala Lys Val Asp Asp Ser
85 90 95
Phe Phe His Arg Leu Glu Glu Ser Phe Leu Val Glu Glu Asp Lys Lys
100 105 110
His Glu Arg His Pro Ile Phe Gly Asn Ile Val Asp Glu Val Ala Tyr
115 120 125
His Glu Lys Tyr Pro Thr Ile Tyr His Leu Arg Lys Lys Leu Val Asp
130 135 140
Ser Thr Asp Lys Ala Asp Leu Arg Leu Ile Tyr Leu Ala Leu Ala His
145 150 155 160
Met Ile Lys Phe Arg Gly His Phe Leu Ile Glu Gly Asp Leu Asn Pro
165 170 175
Asp Asn Ser Asp Val Asp Lys Leu Phe Ile Gln Leu Val Gln Thr Tyr
180 185 190
Asn Gln Leu Phe Glu Glu Asn Pro Ile Asn Ala Ser Gly Val Asp Ala
195 200 205
Lys Ala Ile Leu Ser Ala Arg Leu Ser Lys Ser Arg Arg Leu Glu Asn
210 215 220
Leu Ile Ala Gln Leu Pro Gly Glu Lys Lys Asn Gly Leu Phe Gly Asn
225 230 235 240
Leu Ile Ala Leu Ser Leu Gly Leu Thr Pro Asn Phe Lys Ser Asn Phe
245 250 255
Asp Leu Ala Glu Asp Ala Lys Leu Gln Leu Ser Lys Asp Thr Tyr Asp
260 265 270
Asp Asp Leu Asp Asn Leu Leu Ala Gln Ile Gly Asp Gln Tyr Ala Asp
275 280 285
Leu Phe Leu Ala Ala Lys Asn Leu Ser Asp Ala Ile Leu Leu Ser Asp
290 295 300
Ile Leu Arg Val Asn Thr Glu Ile Thr Lys Ala Pro Leu Ser Ala Ser
305 310 315 320
Met Ile Lys Arg Tyr Asp Glu His His Gln Asp Leu Thr Leu Leu Lys
325 330 335
Ala Leu Val Arg Gln Gln Leu Pro Glu Lys Tyr Lys Glu Ile Phe Phe
340 345 350
Asp Gln Ser Lys Asn Gly Tyr Ala Gly Tyr Ile Asp Gly Gly Ala Ser
355 360 365
Gln Glu Glu Phe Tyr Lys Phe Ile Lys Pro Ile Leu Glu Lys Met Asp
370 375 380
Gly Thr Glu Glu Leu Leu Val Lys Leu Asn Arg Glu Asp Leu Leu Arg
385 390 395 400
Lys Gln Arg Thr Phe Asp Asn Gly Ser Ile Pro His Gln Ile His Leu
405 410 415
Gly Glu Leu His Ala Ile Leu Arg Arg Gln Glu Asp Phe Tyr Pro Phe
420 425 430
Leu Lys Asp Asn Arg Glu Lys Ile Glu Lys Ile Leu Thr Phe Arg Ile
435 440 445
Pro Tyr Tyr Val Gly Pro Leu Ala Arg Gly Asn Ser Arg Phe Ala Trp
450 455 460
Met Thr Arg Lys Ser Glu Glu Thr Ile Thr Pro Trp Asn Phe Glu Glu
465 470 475 480
Val Val Asp Lys Gly Ala Ser Ala Gln Ser Phe Ile Glu Arg Met Thr
485 490 495
Asn Phe Asp Lys Asn Leu Pro Asn Glu Lys Val Leu Pro Lys His Ser
500 505 510
Leu Leu Tyr Glu Tyr Phe Thr Val Tyr Asn Glu Leu Thr Lys Val Lys
515 520 525
Tyr Val Thr Glu Gly Met Arg Lys Pro Ala Phe Leu Ser Gly Glu Gln
530 535 540
Lys Lys Ala Ile Val Asp Leu Leu Phe Lys Thr Asn Arg Lys Val Thr
545 550 555 560
Val Lys Gln Leu Lys Glu Asp Tyr Phe Lys Lys Ile Glu Cys Phe Asp
565 570 575
Ser Val Glu Ile Ser Gly Val Glu Asp Arg Phe Asn Ala Ser Leu Gly
580 585 590
Thr Tyr His Asp Leu Leu Lys Ile Ile Lys Asp Lys Asp Phe Leu Asp
595 600 605
Asn Glu Glu Asn Glu Asp Ile Leu Glu Asp Ile Val Leu Thr Leu Thr
610 615 620
Leu Phe Glu Asp Arg Glu Met Ile Glu Glu Arg Leu Lys Thr Tyr Ala
625 630 635 640
His Leu Phe Asp Asp Lys Val Met Lys Gln Leu Lys Arg Arg Arg Tyr
645 650 655
Thr Gly Trp Gly Arg Leu Ser Arg Lys Leu Ile Asn Gly Ile Arg Asp
660 665 670
Lys Gln Ser Gly Lys Thr Ile Leu Asp Phe Leu Lys Ser Asp Gly Phe
675 680 685
Ala Asn Arg Asn Phe Met Gln Leu Ile His Asp Asp Ser Leu Thr Phe
690 695 700
Lys Glu Asp Ile Gln Lys Ala Gln Val Ser Gly Gln Gly Asp Ser Leu
705 710 715 720
His Glu His Ile Ala Asn Leu Ala Gly Ser Pro Ala Ile Lys Lys Gly
725 730 735
Ile Leu Gln Thr Val Lys Val Val Asp Glu Leu Val Lys Val Met Gly
740 745 750
Arg His Lys Pro Glu Asn Ile Val Ile Glu Met Ala Arg Glu Asn Gln
755 760 765
Thr Thr Gln Lys Gly Gln Lys Asn Ser Arg Glu Arg Met Lys Arg Ile
770 775 780
Glu Glu Gly Ile Lys Glu Leu Gly Ser Gln Ile Leu Lys Glu His Pro
785 790 795 800
Val Glu Asn Thr Gln Leu Gln Asn Glu Lys Leu Tyr Leu Tyr Tyr Leu
805 810 815
Gln Asn Gly Arg Asp Met Tyr Val Asp Gln Glu Leu Asp Ile Asn Arg
820 825 830
Leu Ser Asp Tyr Asp Val Asp His Ile Val Pro Gln Ser Phe Leu Lys
835 840 845
Asp Asp Ser Ile Asp Asn Lys Val Leu Thr Arg Ser Asp Lys Asn Arg
850 855 860
Gly Lys Ser Asp Asn Val Pro Ser Glu Glu Val Val Lys Lys Met Lys
865 870 875 880
Asn Tyr Trp Arg Gln Leu Leu Asn Ala Lys Leu Ile Thr Gln Arg Lys
885 890 895
Phe Asp Asn Leu Thr Lys Ala Glu Arg Gly Gly Leu Ser Glu Leu Asp
900 905 910
Lys Ala Gly Phe Ile Lys Arg Gln Leu Val Glu Thr Arg Gln Ile Thr
915 920 925
Lys His Val Ala Gln Ile Leu Asp Ser Arg Met Asn Thr Lys Tyr Asp
930 935 940
Glu Asn Asp Lys Leu Ile Arg Glu Val Lys Val Ile Thr Leu Lys Ser
945 950 955 960
Lys Leu Val Ser Asp Phe Arg Lys Asp Phe Gln Phe Tyr Lys Val Arg
965 970 975
Glu Ile Asn Asn Tyr His His Ala His Asp Ala Tyr Leu Asn Ala Val
980 985 990
Val Gly Thr Ala Leu Ile Lys Lys Tyr Pro Lys Leu Glu Ser Glu Phe
995 1000 1005
Val Tyr Gly Asp Tyr Lys Val Tyr Asp Val Arg Lys Met Ile Ala Lys
1010 1015 1020
Ser Glu Gln Glu Ile Gly Lys Ala Thr Ala Lys Tyr Phe Phe Tyr Ser
1025 1030 1035 1040
Asn Ile Met Asn Phe Phe Lys Thr Glu Ile Thr Leu Ala Asn Gly Glu
1045 1050 1055
Ile Arg Lys Arg Pro Leu Ile Glu Thr Asn Gly Glu Thr Gly Glu Ile
1060 1065 1070
Val Trp Asp Lys Gly Arg Asp Phe Ala Thr Val Arg Lys Val Leu Ser
1075 1080 1085
Met Pro Gln Val Asn Ile Val Lys Lys Thr Glu Val Gln Thr Gly Gly
1090 1095 1100
Phe Ser Lys Glu Ser Ile Leu Pro Lys Arg Asn Ser Asp Lys Leu Ile
1105 1110 1115 1120
Ala Arg Lys Lys Asp Trp Asp Pro Lys Lys Tyr Gly Gly Phe Asp Ser
1125 1130 1135
Pro Thr Val Ala Tyr Ser Val Leu Val Val Ala Lys Val Glu Lys Gly
1140 1145 1150
Lys Ser Lys Lys Leu Lys Ser Val Lys Glu Leu Leu Gly Ile Thr Ile
1155 1160 1165
Met Glu Arg Ser Ser Phe Glu Lys Asn Pro Ile Asp Phe Leu Glu Ala
1170 1175 1180
Lys Gly Tyr Lys Glu Val Lys Lys Asp Leu Ile Ile Lys Leu Pro Lys
1185 1190 1195 1200
Tyr Ser Leu Phe Glu Leu Glu Asn Gly Arg Lys Arg Met Leu Ala Ser
1205 1210 1215
Ala Gly Glu Leu Gln Lys Gly Asn Glu Leu Ala Leu Pro Ser Lys Tyr
1220 1225 1230
Val Asn Phe Leu Tyr Leu Ala Ser His Tyr Glu Lys Leu Lys Gly Ser
1235 1240 1245
Pro Glu Asp Asn Glu Gln Lys Gln Leu Phe Val Glu Gln His Lys His
1250 1255 1260
Tyr Leu Asp Glu Ile Ile Glu Gln Ile Ser Glu Phe Ser Lys Arg Val
1265 1270 1275 1280
Ile Leu Ala Asp Ala Asn Leu Asp Lys Val Leu Ser Ala Tyr Asn Lys
1285 1290 1295
His Arg Asp Lys Pro Ile Arg Glu Gln Ala Glu Asn Ile Ile His Leu
1300 1305 1310
Phe Thr Leu Thr Asn Leu Gly Ala Pro Ala Ala Phe Lys Tyr Phe Asp
1315 1320 1325
Thr Thr Ile Asp Arg Lys Arg Tyr Thr Ser Thr Lys Glu Val Leu Asp
1330 1335 1340
Ala Thr Leu Ile His Gln Ser Ile Thr Gly Leu Tyr Glu Thr Arg Ile
1345 1350 1355 1360
Asp Leu Ser Gln Leu Gly Gly Asp
1365
<210> 2
<211> 1053
<212> PRT
<213> 金黄色葡萄球菌(Staphylococcus aureus)
<400> 2
Met Lys Arg Asn Tyr Ile Leu Gly Leu Asp Ile Gly Ile Thr Ser Val
1 5 10 15
Gly Tyr Gly Ile Ile Asp Tyr Glu Thr Arg Asp Val Ile Asp Ala Gly
20 25 30
Val Arg Leu Phe Lys Glu Ala Asn Val Glu Asn Asn Glu Gly Arg Arg
35 40 45
Ser Lys Arg Gly Ala Arg Arg Leu Lys Arg Arg Arg Arg His Arg Ile
50 55 60
Gln Arg Val Lys Lys Leu Leu Phe Asp Tyr Asn Leu Leu Thr Asp His
65 70 75 80
Ser Glu Leu Ser Gly Ile Asn Pro Tyr Glu Ala Arg Val Lys Gly Leu
85 90 95
Ser Gln Lys Leu Ser Glu Glu Glu Phe Ser Ala Ala Leu Leu His Leu
100 105 110
Ala Lys Arg Arg Gly Val His Asn Val Asn Glu Val Glu Glu Asp Thr
115 120 125
Gly Asn Glu Leu Ser Thr Lys Glu Gln Ile Ser Arg Asn Ser Lys Ala
130 135 140
Leu Glu Glu Lys Tyr Val Ala Glu Leu Gln Leu Glu Arg Leu Lys Lys
145 150 155 160
Asp Gly Glu Val Arg Gly Ser Ile Asn Arg Phe Lys Thr Ser Asp Tyr
165 170 175
Val Lys Glu Ala Lys Gln Leu Leu Lys Val Gln Lys Ala Tyr His Gln
180 185 190
Leu Asp Gln Ser Phe Ile Asp Thr Tyr Ile Asp Leu Leu Glu Thr Arg
195 200 205
Arg Thr Tyr Tyr Glu Gly Pro Gly Glu Gly Ser Pro Phe Gly Trp Lys
210 215 220
Asp Ile Lys Glu Trp Tyr Glu Met Leu Met Gly His Cys Thr Tyr Phe
225 230 235 240
Pro Glu Glu Leu Arg Ser Val Lys Tyr Ala Tyr Asn Ala Asp Leu Tyr
245 250 255
Asn Ala Leu Asn Asp Leu Asn Asn Leu Val Ile Thr Arg Asp Glu Asn
260 265 270
Glu Lys Leu Glu Tyr Tyr Glu Lys Phe Gln Ile Ile Glu Asn Val Phe
275 280 285
Lys Gln Lys Lys Lys Pro Thr Leu Lys Gln Ile Ala Lys Glu Ile Leu
290 295 300
Val Asn Glu Glu Asp Ile Lys Gly Tyr Arg Val Thr Ser Thr Gly Lys
305 310 315 320
Pro Glu Phe Thr Asn Leu Lys Val Tyr His Asp Ile Lys Asp Ile Thr
325 330 335
Ala Arg Lys Glu Ile Ile Glu Asn Ala Glu Leu Leu Asp Gln Ile Ala
340 345 350
Lys Ile Leu Thr Ile Tyr Gln Ser Ser Glu Asp Ile Gln Glu Glu Leu
355 360 365
Thr Asn Leu Asn Ser Glu Leu Thr Gln Glu Glu Ile Glu Gln Ile Ser
370 375 380
Asn Leu Lys Gly Tyr Thr Gly Thr His Asn Leu Ser Leu Lys Ala Ile
385 390 395 400
Asn Leu Ile Leu Asp Glu Leu Trp His Thr Asn Asp Asn Gln Ile Ala
405 410 415
Ile Phe Asn Arg Leu Lys Leu Val Pro Lys Lys Val Asp Leu Ser Gln
420 425 430
Gln Lys Glu Ile Pro Thr Thr Leu Val Asp Asp Phe Ile Leu Ser Pro
435 440 445
Val Val Lys Arg Ser Phe Ile Gln Ser Ile Lys Val Ile Asn Ala Ile
450 455 460
Ile Lys Lys Tyr Gly Leu Pro Asn Asp Ile Ile Ile Glu Leu Ala Arg
465 470 475 480
Glu Lys Asn Ser Lys Asp Ala Gln Lys Met Ile Asn Glu Met Gln Lys
485 490 495
Arg Asn Arg Gln Thr Asn Glu Arg Ile Glu Glu Ile Ile Arg Thr Thr
500 505 510
Gly Lys Glu Asn Ala Lys Tyr Leu Ile Glu Lys Ile Lys Leu His Asp
515 520 525
Met Gln Glu Gly Lys Cys Leu Tyr Ser Leu Glu Ala Ile Pro Leu Glu
530 535 540
Asp Leu Leu Asn Asn Pro Phe Asn Tyr Glu Val Asp His Ile Ile Pro
545 550 555 560
Arg Ser Val Ser Phe Asp Asn Ser Phe Asn Asn Lys Val Leu Val Lys
565 570 575
Gln Glu Glu Asn Ser Lys Lys Gly Asn Arg Thr Pro Phe Gln Tyr Leu
580 585 590
Ser Ser Ser Asp Ser Lys Ile Ser Tyr Glu Thr Phe Lys Lys His Ile
595 600 605
Leu Asn Leu Ala Lys Gly Lys Gly Arg Ile Ser Lys Thr Lys Lys Glu
610 615 620
Tyr Leu Leu Glu Glu Arg Asp Ile Asn Arg Phe Ser Val Gln Lys Asp
625 630 635 640
Phe Ile Asn Arg Asn Leu Val Asp Thr Arg Tyr Ala Thr Arg Gly Leu
645 650 655
Met Asn Leu Leu Arg Ser Tyr Phe Arg Val Asn Asn Leu Asp Val Lys
660 665 670
Val Lys Ser Ile Asn Gly Gly Phe Thr Ser Phe Leu Arg Arg Lys Trp
675 680 685
Lys Phe Lys Lys Glu Arg Asn Lys Gly Tyr Lys His His Ala Glu Asp
690 695 700
Ala Leu Ile Ile Ala Asn Ala Asp Phe Ile Phe Lys Glu Trp Lys Lys
705 710 715 720
Leu Asp Lys Ala Lys Lys Val Met Glu Asn Gln Met Phe Glu Glu Lys
725 730 735
Gln Ala Glu Ser Met Pro Glu Ile Glu Thr Glu Gln Glu Tyr Lys Glu
740 745 750
Ile Phe Ile Thr Pro His Gln Ile Lys His Ile Lys Asp Phe Lys Asp
755 760 765
Tyr Lys Tyr Ser His Arg Val Asp Lys Lys Pro Asn Arg Glu Leu Ile
770 775 780
Asn Asp Thr Leu Tyr Ser Thr Arg Lys Asp Asp Lys Gly Asn Thr Leu
785 790 795 800
Ile Val Asn Asn Leu Asn Gly Leu Tyr Asp Lys Asp Asn Asp Lys Leu
805 810 815
Lys Lys Leu Ile Asn Lys Ser Pro Glu Lys Leu Leu Met Tyr His His
820 825 830
Asp Pro Gln Thr Tyr Gln Lys Leu Lys Leu Ile Met Glu Gln Tyr Gly
835 840 845
Asp Glu Lys Asn Pro Leu Tyr Lys Tyr Tyr Glu Glu Thr Gly Asn Tyr
850 855 860
Leu Thr Lys Tyr Ser Lys Lys Asp Asn Gly Pro Val Ile Lys Lys Ile
865 870 875 880
Lys Tyr Tyr Gly Asn Lys Leu Asn Ala His Leu Asp Ile Thr Asp Asp
885 890 895
Tyr Pro Asn Ser Arg Asn Lys Val Val Lys Leu Ser Leu Lys Pro Tyr
900 905 910
Arg Phe Asp Val Tyr Leu Asp Asn Gly Val Tyr Lys Phe Val Thr Val
915 920 925
Lys Asn Leu Asp Val Ile Lys Lys Glu Asn Tyr Tyr Glu Val Asn Ser
930 935 940
Lys Cys Tyr Glu Glu Ala Lys Lys Leu Lys Lys Ile Ser Asn Gln Ala
945 950 955 960
Glu Phe Ile Ala Ser Phe Tyr Asn Asn Asp Leu Ile Lys Ile Asn Gly
965 970 975
Glu Leu Tyr Arg Val Ile Gly Val Asn Asn Asp Leu Leu Asn Arg Ile
980 985 990
Glu Val Asn Met Ile Asp Ile Thr Tyr Arg Glu Tyr Leu Glu Asn Met
995 1000 1005
Asn Asp Lys Arg Pro Pro Arg Ile Ile Lys Thr Ile Ala Ser Lys Thr
1010 1015 1020
Gln Ser Ile Lys Lys Tyr Ser Thr Asp Ile Leu Gly Asn Leu Tyr Glu
1025 1030 1035 1040
Val Lys Ser Lys Lys His Pro Gln Ile Ile Lys Lys Gly
1045 1050
<210> 3
<211> 4
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<221> PEPTIDE
<222> (1)..(4)
<223> 人工序列的说明: 合成 肽
<400> 3
Gly Gly Gly Ser
1
<210> 4
<211> 5
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<221> PEPTIDE
<222> (1)..(5)
<223> 人工序列的说明: 合成 肽
<400> 4
Gly Gly Gly Gly Ser
1 5
<210> 5
<211> 4
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<221> PEPTIDE
<222> (1)..(4)
<223> 人工序列的说明: 合成 肽
<400> 5
Gly Gly Gly Ser
1
<210> 6
<211> 5
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<221> PEPTIDE
<222> (1)..(5)
<223> 人工序列的说明: 合成 肽
<400> 6
Gly Gly Gly Gly Ser
1 5
<210> 7
<211> 7
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<221> PEPTIDE
<222> (1)..(7)
<223> 人工序列的说明: 合成 肽
<400> 7
Pro Lys Lys Lys Arg Arg Val
1 5
<210> 8
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<221> PEPTIDE
<222> (1)..(16)
<223> 人工序列的说明: 合成 肽
<400> 8
Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1 5 10 15
<210> 9
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 9
gggcacgggc agcttgccgg 20
<210> 10
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 10
gggcacgggc agcttgccgg tggt 24
<210> 11
<211> 18
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(18)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 11
gcacgggcag cttgccgg 18
<210> 12
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 12
gcacgggcag cttgccggtg gt 22
<210> 13
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 13
gggcacccgc agcttgccgg 20
<210> 14
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 14
gggcacccgc agcttgccgg tggt 24
<210> 15
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 15
gggctggggc agcttgccgg 20
<210> 16
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 16
gggctggggc agcttgccgg tggt 24
<210> 17
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 17
ggcgacgggc agcttgccgg 20
<210> 18
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 18
ggcgacgggc agcttgccgg tggt 24
<210> 19
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 19
gcccacgggc agcttgccgg 20
<210> 20
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 20
gcccacgggc agcttgccgg tggt 24
<210> 21
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 21
gtcgccctcg aacttcacct 20
<210> 22
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 22
gtcgccctcg aacttcacct cggc 24
<210> 23
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 23
gtaggtcagg gtggtcacga 20
<210> 24
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 24
gtaggtcagg gtggtcacga gggt 24
<210> 25
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 25
ggcgagggcg atgccaccta 20
<210> 26
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 26
ggcgagggcg atgccaccta cggc 24
<210> 27
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 27
ggtcgccacc atggtgagca 20
<210> 28
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 28
ggtcgccacc atggtgagca aggg 24
<210> 29
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 29
ggtcagggtg gtcacgaggg 20
<210> 30
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 30
ggtcagggtg gtcacgaggg tggg 24
<210> 31
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 31
ggtggtgcag atgaacttca 20
<210> 32
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 32
ggtggtgcag atgaacttca gggt 24
<210> 33
<211> 17
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(17)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 33
ggtgcagatg aacttca 17
<210> 34
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(21)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 34
ggtgcagatg aacttcaggg t 21
<210> 35
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 35
gttggggtct ttgctcaggg 20
<210> 36
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 36
gttggggtct ttgctcaggg cgga 24
<210> 37
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 37
ggtggtcacg agggtgggcc 20
<210> 38
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 38
ggtggtcacg agggtgggcc aggg 24
<210> 39
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 39
gatgccgttc ttctgcttgt 20
<210> 40
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 40
gatgccgttc ttctgcttgt cggc 24
<210> 41
<211> 17
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(17)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 41
gccgttcttc tgcttgt 17
<210> 42
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(21)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 42
gccgttcttc tgcttgtcgg c 21
<210> 43
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 43
gtcgccacca tggtgagcaa 20
<210> 44
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 44
gtcgccacca tggtgagcaa gggc 24
<210> 45
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 45
gcactgcacg ccgtaggtca 20
<210> 46
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 46
gcactgcacg ccgtaggtca gggt 24
<210> 47
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 47
gtgaaccgca tcgagctgaa 20
<210> 48
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 48
gtgaaccgca tcgagctgaa gggc 24
<210> 49
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 49
gaagggcatc gacttcaagg 20
<210> 50
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 50
gaagggcatc gacttcaagg agga 24
<210> 51
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 51
gcttcatgtg gtcggggtag 20
<210> 52
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 52
gcttcatgtg gtcggggtag cggc 24
<210> 53
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 53
gctgaagcac tgcacgccgt 20
<210> 54
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 54
gctgaagcac tgcacgccgt aggt 24
<210> 55
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 55
gccgtcgtcc ttgaagaaga 20
<210> 56
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 56
gccgtcgtcc ttgaagaaga tggt 24
<210> 57
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 57
gaccaggatg ggcaccaccc 20
<210> 58
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 58
gaccaggatg ggcaccaccc cggt 24
<210> 59
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 59
gacgtagcct tcgggcatgg 20
<210> 60
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 60
gacgtagcct tcgggcatgg cgga 24
<210> 61
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 61
gaagttcgag ggcgacaccc 20
<210> 62
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 62
gaagttcgag ggcgacaccc tggt 24
<210> 63
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 63
gagctggacg gcgacgtaaa 20
<210> 64
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 64
gagctggacg gcgacgtaaa cggc 24
<210> 65
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 65
ggcatcgccc tcgccctcgc 20
<210> 66
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 66
ggcatcgccc tcgccctcgc cgga 24
<210> 67
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 67
ggccacaagt tcagcgtgtc 20
<210> 68
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> GC_signal
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 68
ggccacaagt tcagcgtgtc cggc 24
<210> 69
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 69
gggcgaggag ctgttcaccg 20
<210> 70
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 70
gggcgaggag ctgttcaccg gggt 24
<210> 71
<211> 18
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(18)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 71
gcgaggagct gttcaccg 18
<210> 72
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 72
gcgaggagct gttcaccggg gt 22
<210> 73
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 73
cctcgaactt cacctcggcg 20
<210> 74
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 74
cctcgaactt cacctcggcg cggg 24
<210> 75
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 75
gctcgaactt cacctcggcg 20
<210> 76
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 76
gctcgaactt cacctcggcg cggg 24
<210> 77
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 77
caactacaag acccgcgccg 20
<210> 78
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 78
caactacaag acccgcgccg aggt 24
<210> 79
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 79
gaactacaag acccgcgccg 20
<210> 80
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 80
gaactacaag acccgcgccg aggt 24
<210> 81
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 81
cgctcctgga cgtagccttc 20
<210> 82
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 82
cgctcctgga cgtagccttc gggc 24
<210> 83
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 83
ggctcctgga cgtagccttc 20
<210> 84
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 84
cgctcctgga cgtagccttc gggc 24
<210> 85
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 85
agggcgagga gctgttcacc 20
<210> 86
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 86
agggcgagga gctgttcacc gggg 24
<210> 87
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 87
ggggcgagga gctgttcacc 20
<210> 88
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 88
ggggcgagga gctgttcacc gggg 24
<210> 89
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 89
gttcgagggc gacaccctgg 20
<210> 90
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 90
gttcgagggc gacaccctgg tgaa 24
<210> 91
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 91
gttcaccagg gtgtcgccct 20
<210> 92
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 92
gttcaccagg gtgtcgccct cgaa 24
<210> 93
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 93
gcccaccctc gtgaccaccc 20
<210> 94
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 94
gcccaccctc gtgaccaccc tgac 24
<210> 95
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 95
gcccttgctc accatggtgg 20
<210> 96
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 96
gcccttgctc accatggtgg cgac 24
<210> 97
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 97
gtcgccgtcc agctcgacca 20
<210> 98
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 98
gtcgccgtcc agctcgacca ggat 24
<210> 99
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 99
gtgtccggcg agggcgaggg 20
<210> 100
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 100
gtgtccggcg agggcgaggg cgat 24
<210> 101
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 101
ggggtggtgc ccatcctggt 20
<210> 102
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 102
ggggtggtgc ccatcctggt cgag 24
<210> 103
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 103
gccaccatgg tgagcaaggg 20
<210> 104
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 104
gccaccatgg tgagcaaggg cgag 24
<210> 105
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 105
gagtccgagc agaagaagaa 20
<210> 106
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 106
gagtccgagc agaagaagaa gggc 24
<210> 107
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 107
gtcacctcca atgactaggg 20
<210> 108
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 108
gtcacctcca atgactaggg tggg 24
<210> 109
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 109
gggaagactg aggctacata 20
<210> 110
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 110
gggaagactg aggctacata gggt 24
<210> 111
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 111
gccacgaagc aggccaatgg 20
<210> 112
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 112
gccacgaagc aggccaatgg ggag 24
<210> 113
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 113
ggaatccctt ctgcagcacc 20
<210> 114
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 114
ggaatccctt ctgcagcacc tgga 24
<210> 115
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 115
gctgcagaag ggattccatg 20
<210> 116
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 116
gctgcagaag ggattccatg aggt 24
<210> 117
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 117
ggcggctgca caaccagtgg 20
<210> 118
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 118
ggcggctgca caaccagtgg aggc 24
<210> 119
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 119
gctccagagc cgtgcgaatg 20
<210> 120
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 120
gctccagagc cgtgcgaatg gggc 24
<210> 121
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 121
gaatcccttc tgcagcacct 20
<210> 122
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 122
gaatcccttc tgcagcacct ggat 24
<210> 123
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 123
gcggcggctg cacaaccagt 20
<210> 124
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 124
gcggcggctg cacaaccagt ggag 24
<210> 125
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 125
ggttgtgcag ccgccgctcc 20
<210> 126
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 126
ggttgtgcag ccgccgctcc agag 24
<210> 127
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 127
gcattttcag gaggaagcga 20
<210> 128
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 128
gcattttcag gaggaagcga tggc 24
<210> 129
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 129
gggagaagaa agagagatgt 20
<210> 130
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 130
gggagaagaa agagagatgt aggg 24
<210> 131
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 131
ggtgcatttt caggaggaag 20
<210> 132
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 132
ggtgcatttt caggaggaag cgat 24
<210> 133
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 133
gagatgtagg gctagagggg 20
<210> 134
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 134
gagatgtagg gctagagggg tgag 24
<210> 135
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 135
ggtatccagc agaggggaga 20
<210> 136
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 136
ggtatccagc agaggggaga agaa 24
<210> 137
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 137
gaggcatctc tgcaccgagg 20
<210> 138
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 138
gaggcatctc tgcaccgagg tgaa 24
<210> 139
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 139
gaggggtgag gctgaaacag 20
<210> 140
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 140
gaggggtgag gctgaaacag tgac 24
<210> 141
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 141
gagcaaaagt agatattaca 20
<210> 142
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 142
gagcaaaagt agatattaca agac 24
<210> 143
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 143
ggaattcaaa ctgaggcata 20
<210> 144
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 144
ggaattcaaa ctgaggcata tgat 24
<210> 145
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 145
gcagagggga gaagaaagag 20
<210> 146
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 146
gcagagggga gaagaaagag agat 24
<210> 147
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 147
gcaccgaggc atctctgcac 20
<210> 148
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 148
gcaccgaggc atctctgcac cgag 24
<210> 149
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 149
gagatgtagg gctagagggg 20
<210> 150
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 150
gagatgtagg gctagagggg tgag 24
<210> 151
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 151
gtgcggcaag agcttcagcc 20
<210> 152
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 152
gtgcggcaag agcttcagcc gggg 24
<210> 153
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 153
gggtgggggg agtttgctcc 20
<210> 154
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 154
gggtgggggg agtttgctcc tgga 24
<210> 155
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 155
gaccccctcc accccgcctc 20
<210> 156
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 156
gaccccctcc accccgcctc cggg 24
<210> 157
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 157
ggtgagtgag tgtgtgcgtg 20
<210> 158
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 158
ggtgagtgag tgtgtgcgtg tggg 24
<210> 159
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 159
gcgagcagcg tcttcgagag 20
<210> 160
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 160
gcgagcagcg tcttcgagag tgag 24
<210> 161
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 161
gtgcggcaag agcttcagcc 20
<210> 162
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 162
gtgcggcaag agcttcagcc agag 24
<210> 163
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 163
gagtccgagc agaagaagaa ggg 23
<210> 164
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 164
gtcacctcca atgactaggg tgg 23
<210> 165
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 165
ggaatccctt ctgcagcacc tgg 23
<210> 166
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 166
gctgcagaag ggattccatg agg 23
<210> 167
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 167
ggcggctgca caaccagtgg agg 23
<210> 168
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 168
gctccagagc cgtgcgaatg ggg 23
<210> 169
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 169
gcattttcag gaggaagcga tgg 23
<210> 170
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 170
gtgcggcaag agcttcagcc ggg 23
<210> 171
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 171
gaccccctcc accccgcctc cgg 23
<210> 172
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 寡核苷酸
<400> 172
ggtgagtgag tgtgtgcgtg tgg 23
<210> 173
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 引物
<400> 173
ggagcagctg gtcagagggg 20
<210> 174
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 174
ccatagggaa gggggacact gg 22
<210> 175
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 引物
<400> 175
gggccgggaa agagttgctg 20
<210> 176
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 176
gccctacatc tgctctccct cc 22
<210> 177
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 177
ccagcacaac ttactcgcac ttgac 25
<210> 178
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 178
catcaccaac ccacagccaa gg 22
<210> 179
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 引物
<400> 179
tccagatggc acattgtcag 20
<210> 180
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 引物
<400> 180
agggagcagg aaagtgaggt 20
<210> 181
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 181
cgaggaagag agagacgggg tc 22
<210> 182
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 182
ctccaatgca cccaagacag cag 23
<210> 183
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 引物
<400> 183
agtgtggggt gtgtgggaag 20
<210> 184
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 引物
<400> 184
gcaaggggaa gactctggca 20
<210> 185
<211> 19
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(19)
<223> 人工序列的说明: 合成 引物
<400> 185
tacgagtgcc tagagtgcg 19
<210> 186
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 186
gcagatgtag gtcttggagg ac 22
<210> 187
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(20)
<223> 人工序列的说明: 合成 引物
<400> 187
ggagcagctg gtcagagggg 20
<210> 188
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 188
cgatgtcctc cccattggcc tg 22
<210> 189
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 189
gtggggagat ttgcatctgt ggagg 25
<210> 190
<211> 26
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(26)
<223> 人工序列的说明: 合成 引物
<400> 190
gcttttatac catcttgggg ttacag 26
<210> 191
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 引物
<400> 191
caatgtgctt caacccatca cggc 24
<210> 192
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(27)
<223> 人工序列的说明: 合成 引物
<400> 192
ccatgaattt gtgatggatg cagtctg 27
<210> 193
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 引物
<400> 193
gagaaggagg tgcaggagct agac 24
<210> 194
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 引物
<400> 194
catcccgacc ttcatccctc ctgg 24
<210> 195
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 195
gtagttctga cattcctcct gaggg 25
<210> 196
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 196
tcaaacaagg tgcagataca gca 23
<210> 197
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 197
cagggtcgct cagtctgtgt gg 22
<210> 198
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 引物
<400> 198
ccagcgcacc attcactcca cctg 24
<210> 199
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 199
ggctgaagag gaagaccaga ctcag 25
<210> 200
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 200
ggcccctctg aattcaattc tctgc 25
<210> 201
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(21)
<223> 人工序列的说明: 合成 引物
<400> 201
ccacagcgag gagtgacagc c 21
<210> 202
<211> 26
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(26)
<223> 人工序列的说明: 合成 引物
<400> 202
ccaagtcttt cctaactcga ccttgg 26
<210> 203
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 203
ccctaggccc acaccagcaa tg 22
<210> 204
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 引物
<400> 204
gggatgggaa tgggaatgtg aggc 24
<210> 205
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 205
gcccaggtga aggtgtggtt cc 22
<210> 206
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(21)
<223> 人工序列的说明: 合成 引物
<400> 206
ccaaagcctg gccagggagt g 21
<210> 207
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 207
aggcaaagat ctaggacctg gatgg 25
<210> 208
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 引物
<400> 208
ccatctgagt cagccagcct tgtc 24
<210> 209
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(21)
<223> 人工序列的说明: 合成 引物
<400> 209
ggttccctcc cttctgagcc c 21
<210> 210
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 210
ggataggaat gaagaccccc tctcc 25
<210> 211
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 211
ggactggctg gctgtgtgtt ttgag 25
<210> 212
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 引物
<400> 212
cttatccagg gctacctcat tgcc 24
<210> 213
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 213
gctgctgctg ctttgatcac tcctg 25
<210> 214
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 引物
<400> 214
ctccttaaac cctcagaagc tggc 24
<210> 215
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 215
gcactgtcag ctgatcctac agg 23
<210> 216
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 引物
<400> 216
acgttggaac agtcgagctg tagc 24
<210> 217
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 217
tgtgcataac tcatgttggc aaact 25
<210> 218
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 218
tccacaacta ccctcagctg gag 23
<210> 219
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 219
ccactgacaa ttcactcaac cctgc 25
<210> 220
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 引物
<400> 220
aggcagacca gttatttggc agtc 24
<210> 221
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 221
acaggcgcag ttcactgaga ag 22
<210> 222
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 222
gggtaggctg actttgggct cc 22
<210> 223
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 223
gccctcttgc ctccactggt tg 22
<210> 224
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 224
cgcggatgtt ccaatcagta cgc 23
<210> 225
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 225
gcgggcagtg gcgtcttagt cg 22
<210> 226
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 226
ccctgggttt ggttggctgc tc 22
<210> 227
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(21)
<223> 人工序列的说明: 合成 引物
<400> 227
ctccttgccg cccagccggt c 21
<210> 228
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 228
cactggggaa gaggcgagga cac 23
<210> 229
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 229
ccagtgtttc ccatccccaa cac 23
<210> 230
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 230
gaatggatcc ccccctagag ctc 23
<210> 231
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 231
caggcccaca ggtccttctg ga 22
<210> 232
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(21)
<223> 人工序列的说明: 合成 引物
<400> 232
ccacacggaa ggctgaccac g 21
<210> 233
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(21)
<223> 人工序列的说明: 合成 引物
<400> 233
gcgcagagag agcaggacgt c 21
<210> 234
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 234
gcacctcatg gaatcccttc tgc 23
<210> 235
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 235
caagtgatgc gacttccaac ctc 23
<210> 236
<211> 26
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(26)
<223> 人工序列的说明: 合成 引物
<400> 236
ccctcagagt tcagcttaaa aagacc 26
<210> 237
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 237
tgcttctcat ccactctaga ctgct 25
<210> 238
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 238
caccaaccag ccatgtgcca tg 22
<210> 239
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 239
ctgcctgtgc tcctcgatgg tg 22
<210> 240
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 240
gggttcaaag ctcatctgcc cc 22
<210> 241
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 241
gcatgtgcct tgagattgcc tgg 23
<210> 242
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 242
gacattcaga gaagcgacca tgtgg 25
<210> 243
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 243
ccatcttccc ctttggccca cag 23
<210> 244
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 244
ccccaaaagt ggccaagagc ctgag 25
<210> 245
<211> 26
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(26)
<223> 人工序列的说明: 合成 引物
<400> 245
gttctccaaa ggaagagagg ggaatg 26
<210> 246
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 246
ggtgctgtgt cctcatgcat cc 22
<210> 247
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 247
cggcttgcct agggtcgttg ag 22
<210> 248
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 248
ccttcagggg ctcttccagg tc 22
<210> 249
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(21)
<223> 人工序列的说明: 合成 引物
<400> 249
gggaactggc aggcaccgag g 21
<210> 250
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 250
gggtgaggct gaaacagtga cc 22
<210> 251
<211> 26
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(26)
<223> 人工序列的说明: 合成 引物
<400> 251
gggaggatgt tggttttagg gaactg 26
<210> 252
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(27)
<223> 人工序列的说明: 合成 引物
<400> 252
tccaatcact acatgccatt ttgaaga 27
<210> 253
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> GC_signal
<222> (1)..(24)
<223> 人工序列的说明: 合成 引物
<400> 253
ccaccctctt cctttgatcc tccc 24
<210> 254
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 254
tcctccctac tccttcaccc agg 23
<210> 255
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 255
gagtgcctga catgtgggga gag 23
<210> 256
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 256
tccagctaaa gcctttccca cac 23
<210> 257
<211> 26
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(26)
<223> 人工序列的说明: 合成 引物
<400> 257
gaactctctg atgcacctga aggctg 26
<210> 258
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 258
accgtatcag tgtgatgcat gtggt 25
<210> 259
<211> 28
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(28)
<223> 人工序列的说明: 合成 引物
<400> 259
tgggtttaat catgtgttct gcactatg 28
<210> 260
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 引物
<400> 260
cccatcttcc attctgccct ccac 24
<210> 261
<211> 28
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(28)
<223> 人工序列的说明: 合成 引物
<400> 261
cagctagtcc atttgttctc agactgtg 28
<210> 262
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 262
ggccaacatt gtgaaaccct gtctc 25
<210> 263
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(22)
<223> 人工序列的说明: 合成 引物
<400> 263
ccagggacct gtgcttgggt tc 22
<210> 264
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 264
caccccatga cctggcacaa gtg 23
<210> 265
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(24)
<223> 人工序列的说明: 合成 引物
<400> 265
aagtgttcct cagaatgcca gccc 24
<210> 266
<211> 23
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(23)
<223> 人工序列的说明: 合成 引物
<400> 266
caggagtgca gttgtgttgg gag 23
<210> 267
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 267
ctgatgaagc accagagaac ccacc 25
<210> 268
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(21)
<223> 人工序列的说明: 合成 引物
<400> 268
cacacctggc acccatatgg c 21
<210> 269
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(25)
<223> 人工序列的说明: 合成 引物
<400> 269
gatccacact ggtgagaagc cttac 25
<210> 270
<211> 26
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(26)
<223> 人工序列的说明: 合成 引物
<400> 270
cttcccacac tcacagcaga tgtagg 26
<210> 271
<211> 4206
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(4206)
<223> 人工序列的说明: 合成 多核苷酸
<400> 271
atggataaaa agtattctat tggtttagac atcggcacta attccgttgg atgggctgtc 60
ataaccgatg aatacaaagt accttcaaag aaatttaagg tgttggggaa cacagaccgt 120
cattcgatta aaaagaatct tatcggtgcc ctcctattcg atagtggcga aacggcagag 180
gcgactcgcc tgaaacgaac cgctcggaga aggtatacac gtcgcaagaa ccgaatatgt 240
tacttacaag aaatttttag caatgagatg gccaaagttg acgattcttt ctttcaccgt 300
ttggaagagt ccttccttgt cgaagaggac aagaaacatg aacggcaccc catctttgga 360
aacatagtag atgaggtggc atatcatgaa aagtacccaa cgatttatca cctcagaaaa 420
aagctagttg actcaactga taaagcggac ctgaggttaa tctacttggc tcttgcccat 480
atgataaagt tccgtgggca ctttctcatt gagggtgatc taaatccgga caactcggat 540
gtcgacaaac tgttcatcca gttagtacaa acctataatc agttgtttga agagaaccct 600
ataaatgcaa gtggcgtgga tgcgaaggct attcttagcg cccgcctctc taaatcccga 660
cggctagaaa acctgatcgc acaattaccc ggagagaaga aaaatgggtt gttcggtaac 720
cttatagcgc tctcactagg cctgacacca aattttaagt cgaacttcga cttagctgaa 780
gatgccaaat tgcagcttag taaggacacg tacgatgacg atctcgacaa tctactggca 840
caaattggag atcagtatgc ggacttattt ttggctgcca aaaaccttag cgatgcaatc 900
ctcctatctg acatactgag agttaatact gagattacca aggcgccgtt atccgcttca 960
atgatcaaaa ggtacgatga acatcaccaa gacttgacac ttctcaaggc cctagtccgt 1020
cagcaactgc ctgagaaata taaggaaata ttctttgatc agtcgaaaaa cgggtacgca 1080
ggttatattg acggcggagc gagtcaagag gaattctaca agtttatcaa acccatatta 1140
gagaagatgg atgggacgga agagttgctt gtaaaactca atcgcgaaga tctactgcga 1200
aagcagcgga ctttcgacaa cggtagcatt ccacatcaaa tccacttagg cgaattgcat 1260
gctatactta gaaggcagga ggatttttat ccgttcctca aagacaatcg tgaaaagatt 1320
gagaaaatcc taacctttcg cataccttac tatgtgggac ccctggcccg agggaactct 1380
cggttcgcat ggatgacaag aaagtccgaa gaaacgatta ctccatggaa ttttgaggaa 1440
gttgtcgata aaggtgcgtc agctcaatcg ttcatcgaga ggatgaccaa ctttgacaag 1500
aatttaccga acgaaaaagt attgcctaag cacagtttac tttacgagta tttcacagtg 1560
tacaatgaac tcacgaaagt taagtatgtc actgagggca tgcgtaaacc cgcctttcta 1620
agcggagaac agaagaaagc aatagtagat ctgttattca agaccaaccg caaagtgaca 1680
gttaagcaat tgaaagagga ctactttaag aaaattgaat gcttcgattc tgtcgagatc 1740
tccggggtag aagatcgatt taatgcgtca cttggtacgt atcatgacct cctaaagata 1800
attaaagata aggacttcct ggataacgaa gagaatgaag atatcttaga agatatagtg 1860
ttgactctta ccctctttga agatcgggaa atgattgagg aaagactaaa aacatacgct 1920
cacctgttcg acgataaggt tatgaaacag ttaaagaggc gtcgctatac gggctgggga 1980
cgattgtcgc ggaaacttat caacgggata agagacaagc aaagtggtaa aactattctc 2040
gattttctaa agagcgacgg cttcgccaat aggaacttta tgcagctgat ccatgatgac 2100
tctttaacct tcaaagagga tatacaaaag gcacaggttt ccggacaagg ggactcattg 2160
cacgaacata ttgcgaatct tgctggttcg ccagccatca aaaagggcat actccagaca 2220
gtcaaagtag tggatgagct agttaaggtc atgggacgtc acaaaccgga aaacattgta 2280
atcgagatgg cacgcgaaaa tcaaacgact cagaaggggc aaaaaaacag tcgagagcgg 2340
atgaagagaa tagaagaggg tattaaagaa ctgggcagcc agatcttaaa ggagcatcct 2400
gtggaaaata cccaattgca gaacgagaaa ctttacctct attacctaca aaatggaagg 2460
gacatgtatg ttgatcagga actggacata aaccgtttat ctgattacga cgtcgatcac 2520
attgtacccc aatccttttt gaaggacgat tcaatcgaca ataaagtgct tacacgctcg 2580
gataagaacc gagggaaaag tgacaatgtt ccaagcgagg aagtcgtaaa gaaaatgaag 2640
aactattggc ggcagctcct aaatgcgaaa ctgataacgc aaagaaagtt cgataactta 2700
actaaagctg agaggggtgg cttgtctgaa cttgacaagg ccggatttat taaacgtcag 2760
ctcgtggaaa cccgccaaat cacaaagcat gttgcacaga tactagattc ccgaatgaat 2820
acgaaatacg acgagaacga taagctgatt cgggaagtca aagtaatcac tttaaagtca 2880
aaattggtgt cggacttcag aaaggatttt caattctata aagttaggga gataaataac 2940
taccaccatg cgcacgacgc ttatcttaat gccgtcgtag ggaccgcact cattaagaaa 3000
tacccgaagc tagaaagtga gtttgtgtat ggtgattaca aagtttatga cgtccgtaag 3060
atgatcgcga aaagcgaaca ggagataggc aaggctacag ccaaatactt cttttattct 3120
aacattatga atttctttaa gacggaaatc actctggcaa acggagagat acgcaaacga 3180
cctttaattg aaaccaatgg ggagacaggt gaaatcgtat gggataaggg ccgggacttc 3240
gcgacggtga gaaaagtttt gtccatgccc caagtcaaca tagtaaagaa aactgaggtg 3300
cagaccggag ggttttcaaa ggaatcgatt cttccaaaaa ggaatagtga taagctcatc 3360
gctcgtaaaa aggactggga cccgaaaaag tacggtggct tcgatagccc tacagttgcc 3420
tattctgtcc tagtagtggc aaaagttgag aagggaaaat ccaagaaact gaagtcagtc 3480
aaagaattat tggggataac gattatggag cgctcgtctt ttgaaaagaa ccccatcgac 3540
ttccttgagg cgaaaggtta caaggaagta aaaaaggatc tcataattaa actaccaaag 3600
tatagtctgt ttgagttaga aaatggccga aaacggatgt tggctagcgc cggagagctt 3660
caaaagggga acgaactcgc actaccgtct aaatacgtga atttcctgta tttagcgtcc 3720
cattacgaga agttgaaagg ttcacctgaa gataacgaac agaagcaact ttttgttgag 3780
cagcacaaac attatctcga cgaaatcata gagcaaattt cggaattcag taagagagtc 3840
atcctagctg atgccaatct ggacaaagta ttaagcgcat acaacaagca cagggataaa 3900
cccatacgtg agcaggcgga aaatattatc catttgttta ctcttaccaa cctcggcgct 3960
ccagccgcat tcaagtattt tgacacaacg atagatcgca aacgatacac ttctaccaag 4020
gaggtgctag acgcgacact gattcaccaa tccatcacgg gattatatga aactcggata 4080
gatttgtcac agcttggggg tgacggatcc cccaagaaga agaggaaagt ctcgagcgac 4140
tacaaagacc atgacggtga ttataaagat catgacatcg attacaagga tgacgatgac 4200
aagtga 4206
<210> 272
<211> 4206
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(4206)
<223> 人工序列的说明: 合成 多核苷酸
<400> 272
atggataaaa agtattctat tggtttagac atcggcacta attccgttgg atgggctgtc 60
ataaccgatg aatacaaagt accttcaaag aaatttaagg tgttggggaa cacagaccgt 120
cattcgatta aaaagaatct tatcggtgcc ctcctattcg atagtggcga aacggcagag 180
gcgactcgcc tgaaacgaac cgctcggaga aggtatacac gtcgcaagaa ccgaatatgt 240
tacttacaag aaatttttag caatgagatg gccaaagttg acgattcttt ctttcaccgt 300
ttggaagagt ccttccttgt cgaagaggac aagaaacatg aacggcaccc catctttgga 360
aacatagtag atgaggtggc atatcatgaa aagtacccaa cgatttatca cctcagaaaa 420
aagctagttg actcaactga taaagcggac ctgaggttaa tctacttggc tcttgcccat 480
atgataaagt tccgtgggca ctttctcatt gagggtgatc taaatccgga caactcggat 540
gtcgacaaac tgttcatcca gttagtacaa acctataatc agttgtttga agagaaccct 600
ataaatgcaa gtggcgtgga tgcgaaggct attcttagcg cccgcctctc taaatcccga 660
cggctagaaa acctgatcgc acaattaccc ggagagaaga aaaatgggtt gttcggtaac 720
cttatagcgc tctcactagg cctgacacca aattttaagt cgaacttcga cttagctgaa 780
gatgccaaat tgcagcttag taaggacacg tacgatgacg atctcgacaa tctactggca 840
caaattggag atcagtatgc ggacttattt ttggctgcca aaaaccttag cgatgcaatc 900
ctcctatctg acatactgag agttaatact gagattacca aggcgccgtt atccgcttca 960
atgatcaaaa ggtacgatga acatcaccaa gacttgacac ttctcaaggc cctagtccgt 1020
cagcaactgc ctgagaaata taaggaaata ttctttgatc agtcgaaaaa cgggtacgca 1080
ggttatattg acggcggagc gagtcaagag gaattctaca agtttatcaa acccatatta 1140
gagaagatgg atgggacgga agagttgctt gtaaaactca atcgcgaaga tctactgcga 1200
aagcagcgga ctttcgacaa cggtagcatt ccacatcaaa tccacttagg cgaattgcat 1260
gctatactta gaaggcagga ggatttttat ccgttcctca aagacaatcg tgaaaagatt 1320
gagaaaatcc taacctttcg cataccttac tatgtgggac ccctggcccg agggaactct 1380
cggttcgcat ggatgacaag aaagtccgaa gaaacgatta ctccctggaa ttttgaggaa 1440
gttgtcgata aaggtgcgtc agctcaatcg ttcatcgaga ggatgaccgc ctttgacaag 1500
aatttaccga acgaaaaagt attgcctaag cacagtttac tttacgagta tttcacagtg 1560
tacaatgaac tcacgaaagt taagtatgtc actgagggca tgcgtaaacc cgcctttcta 1620
agcggagaac agaagaaagc aatagtagat ctgttattca agaccaaccg caaagtgaca 1680
gttaagcaat tgaaagagga ctactttaag aaaattgaat gcttcgattc tgtcgagatc 1740
tccggggtag aagatcgatt taatgcgtca cttggtacgt atcatgacct cctaaagata 1800
attaaagata aggacttcct ggataacgaa gagaatgaag atatcttaga agatatagtg 1860
ttgactctta ccctctttga agatcgggaa atgattgagg aaagactaaa aacatacgct 1920
cacctgttcg acgataaggt tatgaaacag ttaaagaggc gtcgctatac gggctgggga 1980
gccttgtcgc ggaaacttat caacgggata agagacaagc aaagtggtaa aactattctc 2040
gattttctaa agagcgacgg cttcgccaat aggaacttta tggccctgat ccatgatgac 2100
tctttaacct tcaaagagga tatacaaaag gcacaggttt ccggacaagg ggactcattg 2160
cacgaacata ttgcgaatct tgctggttcg ccagccatca aaaagggcat actccagaca 2220
gtcaaagtag tggatgagct agttaaggtc atgggacgtc acaaaccgga aaacattgta 2280
atcgagatgg cacgcgaaaa tcaaacgact cagaaggggc aaaaaaacag tcgagagcgg 2340
atgaagagaa tagaagaggg tattaaagaa ctgggcagcc agatcttaaa ggagcatcct 2400
gtggaaaata cccaattgca gaacgagaaa ctttacctct attacctaca aaatggaagg 2460
gacatgtatg ttgatcagga actggacata aaccgtttat ctgattacga cgtcgatcac 2520
attgtacccc aatccttttt gaaggacgat tcaatcgaca ataaagtgct tacacgctcg 2580
gataagaacc gagggaaaag tgacaatgtt ccaagcgagg aagtcgtaaa gaaaatgaag 2640
aactattggc ggcagctcct aaatgcgaaa ctgataacgc aaagaaagtt cgataactta 2700
actaaagctg agaggggtgg cttgtctgaa cttgacaagg ccggatttat taaacgtcag 2760
ctcgtggaaa cccgcgccat cacaaagcat gttgcgcaga tactagattc ccgaatgaat 2820
acgaaatacg acgagaacga taagctgatt cgggaagtca aagtaatcac tttaaagtca 2880
aaattggtgt cggacttcag aaaggatttt caattctata aagttaggga gataaataac 2940
taccaccatg cgcacgacgc ttatcttaat gccgtcgtag ggaccgcact cattaagaaa 3000
tacccgaagc tagaaagtga gtttgtgtat ggtgattaca aagtttatga cgtccgtaag 3060
atgatcgcga aaagcgaaca ggagataggc aaggctacag ccaaatactt cttttattct 3120
aacattatga atttctttaa gacggaaatc actctggcaa acggagagat acgcaaacga 3180
cctttaattg aaaccaatgg ggagacaggt gaaatcgtat gggataaggg ccgggacttc 3240
gcgacggtga gaaaagtttt gtccatgccc caagtcaaca tagtaaagaa aactgaggtg 3300
cagaccggag ggttttcaaa ggaatcgatt cttccaaaaa ggaatagtga taagctcatc 3360
gctcgtaaaa aggactggga cccgaaaaag tacggtggct tcgatagccc tacagttgcc 3420
tattctgtcc tagtagtggc aaaagttgag aagggaaaat ccaagaaact gaagtcagtc 3480
aaagaattat tggggataac gattatggag cgctcgtctt ttgaaaagaa ccccatcgac 3540
ttccttgagg cgaaaggtta caaggaagta aaaaaggatc tcataattaa actaccaaag 3600
tatagtctgt ttgagttaga aaatggccga aaacggatgt tggctagcgc cggagagctt 3660
caaaagggga acgaactcgc actaccgtct aaatacgtga atttcctgta tttagcgtcc 3720
cattacgaga agttgaaagg ttcacctgaa gataacgaac agaagcaact ttttgttgag 3780
cagcacaaac attatctcga cgaaatcata gagcaaattt cggaattcag taagagagtc 3840
atcctagctg atgccaatct ggacaaagta ttaagcgcat acaacaagca cagggataaa 3900
cccatacgtg agcaggcgga aaatattatc catttgttta ctcttaccaa cctcggcgct 3960
ccagccgcat tcaagtattt tgacacaacg atagatcgca aacgatacac ttctaccaag 4020
gaggtgctag acgcgacact gattcaccaa tccatcacgg gattatatga aactcggata 4080
gatttgtcac agcttggggg tgacggatcc cccaagaaga agaggaaagt ctcgagcgac 4140
tacaaagacc atgacggtga ttataaagat catgacatcg attacaagga tgacgatgac 4200
aagtga 4206
<210> 273
<211> 4206
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(4206)
<223> 人工序列的说明: 合成 多核苷酸
<400> 273
atggataaaa agtattctat tggtttagac atcggcacta attccgttgg atgggctgtc 60
ataaccgatg aatacaaagt accttcaaag aaatttaagg tgttggggaa cacagaccgt 120
cattcgatta aaaagaatct tatcggtgcc ctcctattcg atagtggcga aacggcagag 180
gcgactcgcc tgaaacgaac cgctcggaga aggtatacac gtcgcaagaa ccgaatatgt 240
tacttacaag aaatttttag caatgagatg gccaaagttg acgattcttt ctttcaccgt 300
ttggaagagt ccttccttgt cgaagaggac aagaaacatg aacggcaccc catctttgga 360
aacatagtag atgaggtggc atatcatgaa aagtacccaa cgatttatca cctcagaaaa 420
aagctagttg actcaactga taaagcggac ctgaggttaa tctacttggc tcttgcccat 480
atgataaagt tccgtgggca ctttctcatt gagggtgatc taaatccgga caactcggat 540
gtcgacaaac tgttcatcca gttagtacaa acctataatc agttgtttga agagaaccct 600
ataaatgcaa gtggcgtgga tgcgaaggct attcttagcg cccgcctctc taaatcccga 660
cggctagaaa acctgatcgc acaattaccc ggagagaaga aaaatgggtt gttcggtaac 720
cttatagcgc tctcactagg cctgacacca aattttaagt cgaacttcga cttagctgaa 780
gatgccaaat tgcagcttag taaggacacg tacgatgacg atctcgacaa tctactggca 840
caaattggag atcagtatgc ggacttattt ttggctgcca aaaaccttag cgatgcaatc 900
ctcctatctg acatactgag agttaatact gagattacca aggcgccgtt atccgcttca 960
atgatcaaaa ggtacgatga acatcaccaa gacttgacac ttctcaaggc cctagtccgt 1020
cagcaactgc ctgagaaata taaggaaata ttctttgatc agtcgaaaaa cgggtacgca 1080
ggttatattg acggcggagc gagtcaagag gaattctaca agtttatcaa acccatatta 1140
gagaagatgg atgggacgga agagttgctt gtaaaactca atcgcgaaga tctactgcga 1200
aagcagcgga ctttcgacaa cggtagcatt ccacatcaaa tccacttagg cgaattgcat 1260
gctatactta gaaggcagga ggatttttat ccgttcctca aagacaatcg tgaaaagatt 1320
gagaaaatcc taacctttcg cataccttac tatgtgggac ccctggcccg agggaactct 1380
cggttcgcat ggatgacaag aaagtccgaa gaaacgatta ctccctggaa ttttgaggaa 1440
gttgtcgata aaggtgcgtc agctcaatcg ttcatcgaga ggatgaccgc ctttgacaag 1500
aatttaccga acgaaaaagt attgcctaag cacagtttac tttacgagta tttcacagtg 1560
tacaatgaac tcacgaaagt taagtatgtc actgagggca tgcgtaaacc cgcctttcta 1620
agcggagaac agaagaaagc aatagtagat ctgttattca agaccaaccg caaagtgaca 1680
gttaagcaat tgaaagagga ctactttaag aaaattgaat gcttcgattc tgtcgagatc 1740
tccggggtag aagatcgatt taatgcgtca cttggtacgt atcatgacct cctaaagata 1800
attaaagata aggacttcct ggataacgaa gagaatgaag atatcttaga agatatagtg 1860
ttgactctta ccctctttga agatcgggaa atgattgagg aaagactaaa aacatacgct 1920
cacctgttcg acgataaggt tatgaaacag ttaaagaggc gtcgctatac gggctgggga 1980
gccttgtcgc ggaaacttat caacgggata agagacaagc aaagtggtaa aactattctc 2040
gattttctaa agagcgacgg cttcgccaat aggaacttta tggccctgat ccatgatgac 2100
tctttaacct tcaaagagga tatacaaaag gcacaggttt ccggacaagg ggactcattg 2160
cacgaacata ttgcgaatct tgctggttcg ccagccatca aaaagggcat actccagaca 2220
gtcaaagtag tggatgagct agttaaggtc atgggacgtc acaaaccgga aaacattgta 2280
atcgagatgg cacgcgaaaa tcaaacgact cagaaggggc aaaaaaacag tcgagagcgg 2340
atgaagagaa tagaagaggg tattaaagaa ctgggcagcc agatcttaaa ggagcatcct 2400
gtggaaaata cccaattgca gaacgagaaa ctttacctct attacctaca aaatggaagg 2460
gacatgtatg ttgatcagga actggacata aaccgtttat ctgattacga cgtcgatcac 2520
attgtacccc aatccttttt gaaggacgat tcaatcgaca ataaagtgct tacacgctcg 2580
gataagaacc gagggaaaag tgacaatgtt ccaagcgagg aagtcgtaaa gaaaatgaag 2640
aactattggc ggcagctcct aaatgcgaaa ctgataacgc aaagaaagtt cgataactta 2700
actaaagctg agaggggtgg cttgtctgaa cttgacaagg ccggatttat taaacgtcag 2760
ctcgtggaaa cccgcgccat cacaaagcat gttgcgcaga tactagattc ccgaatgaat 2820
acgaaatacg acgagaacga taagctgatt cgggaagtca aagtaatcac tttaaagtca 2880
aaattggtgt cggacttcag aaaggatttt caattctata aagttaggga gataaataac 2940
taccaccatg cgcacgacgc ttatcttaat gccgtcgtag ggaccgcact cattaagaaa 3000
tacccgaagc tagaaagtga gtttgtgtat ggtgattaca aagtttatga cgtccgtaag 3060
atgatcgcga aaagcgaaca ggagataggc aaggctacag ccaaatactt cttttattct 3120
aacattatga atttctttaa gacggaaatc actctggcaa acggagagat acgcaaacga 3180
cctttaattg aaaccaatgg ggagacaggt gaaatcgtat gggataaggg ccgggacttc 3240
gcgacggtga gaaaagtttt gtccatgccc caagtcaaca tagtaaagaa aactgaggtg 3300
cagaccggag ggttttcaaa ggaatcgatt cttccaaaaa ggaatagtga taagctcatc 3360
gctcgtaaaa aggactggga cccgaaaaag tacggtggct tcgagagccc tacagttgcc 3420
tattctgtcc tagtagtggc aaaagttgag aagggaaaat ccaagaaact gaagtcagtc 3480
aaagaattat tggggataac gattatggag cgctcgtctt ttgaaaagaa ccccatcgac 3540
ttccttgagg cgaaaggtta caaggaagta aaaaaggatc tcataattaa actaccaaag 3600
tatagtctgt ttgagttaga aaatggccga aaacggatgt tggctagcgc cggagagctt 3660
caaaagggga acgaactcgc actaccgtct aaatacgtga atttcctgta tttagcgtcc 3720
cattacgaga agttgaaagg ttcacctgaa gataacgaac agaagcaact ttttgttgag 3780
cagcacaaac attatctcga cgaaatcata gagcaaattt cggaattcag taagagagtc 3840
atcctagctg atgccaatct ggacaaagta ttaagcgcat acaacaagca cagggataaa 3900
cccatacgtg agcaggcgga aaatattatc catttgttta ctcttaccaa cctcggcgct 3960
ccagccgcat tcaagtattt tgacacaacg atagatcgca aacgatacac ttctaccaag 4020
gaggtgctag acgcgacact gattcaccaa tccatcacgg gattatatga aactcggata 4080
gatttgtcac agcttggggg tgacggatcc cccaagaaga agaggaaagt ctcgagcgac 4140
tacaaagacc atgacggtga ttataaagat catgacatcg attacaagga tgacgatgac 4200
aagtga 4206
<210> 274
<211> 4206
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(4206)
<223> 人工序列的说明: 合成 多核苷酸
<400> 274
atggataaaa agtattctat tggtttagac atcggcacta attccgttgg atgggctgtc 60
ataaccgatg aatacaaagt accttcaaag aaatttaagg tgttggggaa cacagaccgt 120
cattcgatta aaaagaatct tatcggtgcc ctcctattcg atagtggcga aacggcagag 180
gcgactcgcc tgaaacgaac cgctcggaga aggtatacac gtcgcaagaa ccgaatatgt 240
tacttacaag aaatttttag caatgagatg gccaaagttg acgattcttt ctttcaccgt 300
ttggaagagt ccttccttgt cgaagaggac aagaaacatg aacggcaccc catctttgga 360
aacatagtag atgaggtggc atatcatgaa aagtacccaa cgatttatca cctcagaaaa 420
aagctagttg actcaactga taaagcggac ctgaggttaa tctacttggc tcttgcccat 480
atgataaagt tccgtgggca ctttctcatt gagggtgatc taaatccgga caactcggat 540
gtcgacaaac tgttcatcca gttagtacaa acctataatc agttgtttga agagaaccct 600
ataaatgcaa gtggcgtgga tgcgaaggct attcttagcg cccgcctctc taaatcccga 660
cggctagaaa acctgatcgc acaattaccc ggagagaaga aaaatgggtt gttcggtaac 720
cttatagcgc tctcactagg cctgacacca aattttaagt cgaacttcga cttagctgaa 780
gatgccaaat tgcagcttag taaggacacg tacgatgacg atctcgacaa tctactggca 840
caaattggag atcagtatgc ggacttattt ttggctgcca aaaaccttag cgatgcaatc 900
ctcctatctg acatactgag agttaatact gagattacca aggcgccgtt atccgcttca 960
atgatcaaaa ggtacgatga acatcaccaa gacttgacac ttctcaaggc cctagtccgt 1020
cagcaactgc ctgagaaata taaggaaata ttctttgatc agtcgaaaaa cgggtacgca 1080
ggttatattg acggcggagc gagtcaagag gaattctaca agtttatcaa acccatatta 1140
gagaagatgg atgggacgga agagttgctt gtaaaactca atcgcgaaga tctactgcga 1200
aagcagcgga ctttcgacaa cggtagcatt ccacatcaaa tccacttagg cgaattgcat 1260
gctatactta gaaggcagga ggatttttat ccgttcctca aagacaatcg tgaaaagatt 1320
gagaaaatcc taacctttcg catacctgcc tatgtgggac ccctggcccg agggaactct 1380
cggttcgcat ggatgacaag aaagtccgaa gaaacgatta ctccctggaa ttttgaggaa 1440
gttgtcgata aaggtgcgtc agctcaatcg ttcatcgaga ggatgaccgc ctttgacaag 1500
aatttaccga acgaaaaagt attgcctaag cacagtttac tttacgagta tttcacagtg 1560
tacaatgaac tcacgaaagt taagtatgtc actgagggca tgcgtaaacc cgcctttcta 1620
agcggagaac agaagaaagc aatagtagat ctgttattca agaccaaccg caaagtgaca 1680
gttaagcaat tgaaagagga ctactttaag aaaattgaat gcttcgattc tgtcgagatc 1740
tccggggtag aagatcgatt taatgcgtca cttggtacgt atcatgacct cctaaagata 1800
attaaagata aggacttcct ggataacgaa gagaatgaag atatcttaga agatatagtg 1860
ttgactctta ccctctttga agatcgggaa atgattgagg aaagactaaa aacatacgct 1920
cacctgttcg acgataaggt tatgaaacag ttaaagaggc gtcgctatac gggctgggga 1980
gccttgtcgc ggaaacttat caacgggata agagacaagc aaagtggtaa aactattctc 2040
gattttctaa agagcgacgg cttcgccaat aggaacttta tggccctgat ccatgatgac 2100
tctttaacct tcaaagagga tatacaaaag gcacaggttt ccggacaagg ggactcattg 2160
cacgaacata ttgcgaatct tgctggttcg ccagccatca aaaagggcat actccagaca 2220
gtcaaagtag tggatgagct agttaaggtc atgggacgtc acaaaccgga aaacattgta 2280
atcgagatgg cacgcgaaaa tcaaacgact cagaaggggc aaaaaaacag tcgagagcgg 2340
atgaagagaa tagaagaggg tattaaagaa ctgggcagcc agatcttaaa ggagcatcct 2400
gtggaaaata cccaattgca gaacgagaaa ctttacctct attacctaca aaatggaagg 2460
gacatgtatg ttgatcagga actggacata aaccgtttat ctgattacga cgtcgatcac 2520
attgtacccc aatccttttt gaaggacgat tcaatcgaca ataaagtgct tacacgctcg 2580
gataagaacc gagggaaaag tgacaatgtt ccaagcgagg aagtcgtaaa gaaaatgaag 2640
aactattggc ggcagctcct aaatgcgaaa ctgataacgc aaagaaagtt cgataactta 2700
actaaagctg agaggggtgg cttgtctgaa cttgacaagg ccggatttat taaacgtcag 2760
ctcgtggaaa cccgcgccat cacaaagcat gttgcgcaga tactagattc ccgaatgaat 2820
acgaaatacg acgagaacga taagctgatt cgggaagtca aagtaatcac tttaaagtca 2880
aaattggtgt cggacttcag aaaggatttt caattctata aagttaggga gataaataac 2940
taccaccatg cgcacgacgc ttatcttaat gccgtcgtag ggaccgcact cattaagaaa 3000
tacccgaagc tagaaagtga gtttgtgtat ggtgattaca aagtttatga cgtccgtaag 3060
atgatcgcga aaagcgaaca ggagataggc aaggctacag ccaaatactt cttttattct 3120
aacattatga atttctttaa gacggaaatc actctggcaa acggagagat acgcaaacga 3180
cctttaattg aaaccaatgg ggagacaggt gaaatcgtat gggataaggg ccgggacttc 3240
gcgacggtga gaaaagtttt gtccatgccc caagtcaaca tagtaaagaa aactgaggtg 3300
cagaccggag ggttttcaaa ggaatcgatt cttccaaaaa ggaatagtga taagctcatc 3360
gctcgtaaaa aggactggga cccgaaaaag tacggtggct tcgatagccc tacagttgcc 3420
tattctgtcc tagtagtggc aaaagttgag aagggaaaat ccaagaaact gaagtcagtc 3480
aaagaattat tggggataac gattatggag cgctcgtctt ttgaaaagaa ccccatcgac 3540
ttccttgagg cgaaaggtta caaggaagta aaaaaggatc tcataattaa actaccaaag 3600
tatagtctgt ttgagttaga aaatggccga aaacggatgt tggctagcgc cggagagctt 3660
caaaagggga acgaactcgc actaccgtct aaatacgtga atttcctgta tttagcgtcc 3720
cattacgaga agttgaaagg ttcacctgaa gataacgaac agaagcaact ttttgttgag 3780
cagcacaaac attatctcga cgaaatcata gagcaaattt cggaattcag taagagagtc 3840
atcctagctg atgccaatct ggacaaagta ttaagcgcat acaacaagca cagggataaa 3900
cccatacgtg agcaggcgga aaatattatc catttgttta ctcttaccaa cctcggcgct 3960
ccagccgcat tcaagtattt tgacacaacg atagatcgca aacgatacac ttctaccaag 4020
gaggtgctag acgcgacact gattcaccaa tccatcacgg gattatatga aactcggata 4080
gatttgtcac agcttggggg tgacggatcc cccaagaaga agaggaaagt ctcgagcgac 4140
tacaaagacc atgacggtga ttataaagat catgacatcg attacaagga tgacgatgac 4200
aagtga 4206
<210> 275
<211> 4206
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(4206)
<223> 人工序列的说明: 合成 多核苷酸
<400> 275
atggataaaa agtattctat tggtttagac atcggcacta attccgttgg atgggctgtc 60
ataaccgatg aatacaaagt accttcaaag aaatttaagg tgttggggaa cacagaccgt 120
cattcgatta aaaagaatct tatcggtgcc ctcctattcg atagtggcga aacggcagag 180
gcgactcgcc tgaaacgaac cgctcggaga aggtatacac gtcgcaagaa ccgaatatgt 240
tacttacaag aaatttttag caatgagatg gccaaagttg acgattcttt ctttcaccgt 300
ttggaagagt ccttccttgt cgaagaggac aagaaacatg aacggcaccc catctttgga 360
aacatagtag atgaggtggc atatcatgaa aagtacccaa cgatttatca cctcagaaaa 420
aagctagttg actcaactga taaagcggac ctgaggttaa tctacttggc tcttgcccat 480
atgataaagt tccgtgggca ctttctcatt gagggtgatc taaatccgga caactcggat 540
gtcgacaaac tgttcatcca gttagtacaa acctataatc agttgtttga agagaaccct 600
ataaatgcaa gtggcgtgga tgcgaaggct attcttagcg cccgcctctc taaatcccga 660
cggctagaaa acctgatcgc acaattaccc ggagagaaga aaaatgggtt gttcggtaac 720
cttatagcgc tctcactagg cctgacacca aattttaagt cgaacttcga cttagctgaa 780
gatgccaaat tgcagcttag taaggacacg tacgatgacg atctcgacaa tctactggca 840
caaattggag atcagtatgc ggacttattt ttggctgcca aaaaccttag cgatgcaatc 900
ctcctatctg acatactgag agttaatact gagattacca aggcgccgtt atccgcttca 960
atgatcaaaa ggtacgatga acatcaccaa gacttgacac ttctcaaggc cctagtccgt 1020
cagcaactgc ctgagaaata taaggaaata ttctttgatc agtcgaaaaa cgggtacgca 1080
ggttatattg acggcggagc gagtcaagag gaattctaca agtttatcaa acccatatta 1140
gagaagatgg atgggacgga agagttgctt gtaaaactca atcgcgaaga tctactgcga 1200
aagcagcgga ctttcgacaa cggtagcatt ccacatcaaa tccacttagg cgaattgcat 1260
gctatactta gaaggcagga ggatttttat ccgttcctca aagacaatcg tgaaaagatt 1320
gagaaaatcc taacctttcg cataccttac tatgtgggac ccctggcccg agggaactct 1380
cggttcgcat ggatgacaag aaagtccgaa gaaacgatta ctccatggaa ttttgaggaa 1440
gttgtcgata aaggtgcgtc agctcaatcg ttcatcgaga ggatgaccaa ctttgacaag 1500
aatttaccga acgaaaaagt attgcctaag cacagtttac tttacgagta tttcacagtg 1560
tacaatgaac tcacgaaagt taagtatgtc actgagggca tgcgtaaacc cgcctttcta 1620
agcggagaac agaagaaagc aatagtagat ctgttattca agaccaaccg caaagtgaca 1680
gttaagcaat tgaaagagga ctactttaag aaaattgaat gcttcgattc tgtcgagatc 1740
tccggggtag aagatcgatt taatgcgtca cttggtacgt atcatgacct cctaaagata 1800
attaaagata aggacttcct ggataacgaa gagaatgaag atatcttaga agatatagtg 1860
ttgactctta ccctctttga agatcgggaa atgattgagg aaagactaaa aacatacgct 1920
cacctgttcg acgataaggt tatgaaacag ttaaagaggc gtcgctatac gggctgggga 1980
cgattgtcgc ggaaacttat caacgggata agagacaagc aaagtggtaa aactattctc 2040
gattttctaa agagcgacgg cttcgccaat aggaacttta tgcagctgat ccatgatgac 2100
tctttaacct tcaaagagga tatacaaaag gcacaggttt ccggacaagg ggactcattg 2160
cacgaacata ttgcgaatct tgctggttcg ccagccatca aaaagggcat actccagaca 2220
gtcaaagtag tggatgagct agttaaggtc atgggacgtc acaaaccgga aaacattgta 2280
atcgagatgg cacgcgaaaa tcaaacgact cagaaggggc aaaaaaacag tcgagagcgg 2340
atgaagagaa tagaagaggg tattaaagaa ctgggcagcc agatcttaaa ggagcatcct 2400
gtggaaaata cccaattgca gaacgagaaa ctttacctct attacctaca aaatggaagg 2460
gacatgtatg ttgatcagga actggacata aaccgtttat ctgattacga cgtcgatcac 2520
attgtacccc aatccttttt gaaggacgat tcaatcgaca ataaagtgct tacacgctcg 2580
gataagaacc gagggaaaag tgacaatgtt ccaagcgagg aagtcgtaaa gaaaatgaag 2640
aactattggc ggcagctcct aaatgcgaaa ctgataacgc aaagaaagtt cgataactta 2700
actaaagctg agaggggtgg cttgtctgaa cttgacaagg ccggatttat taaacgtcag 2760
ctcgtggaaa cccgccaaat cacaaagcat gttgcacaga tactagattc ccgaatgaat 2820
acgaaatacg acgagaacga taagctgatt cgggaagtca aagtaatcac tttaaagtca 2880
aaattggtgt cggacttcag aaaggatttt caattctata aagttaggga gataaataac 2940
taccaccatg cgcacgacgc ttatcttaat gccgtcgtag ggaccgcact cattaagaaa 3000
tacccgaagc tagaaagtga gtttgtgtat ggtgattaca aagtttatga cgtccgtaag 3060
atgatcgcga aaagcgaaca ggagataggc aaggctacag ccaaatactt cttttattct 3120
aacattatga atttctttaa gacggaaatc actctggcaa acggagagat acgcaaacga 3180
cctttaattg aaaccaatgg ggagacaggt gaaatcgtat gggataaggg ccgggacttc 3240
gcgacggtga gaaaagtttt gtccatgccc caagtcaaca tagtaaagaa aactgaggtg 3300
cagaccggag ggttttcaaa ggaatcgatt cttccaaaaa ggaatagtga taagctcatc 3360
gctcgtaaaa aggactggga cccgaaaaag tacggtggct tcgtgagccc tacagttgcc 3420
tattctgtcc tagtagtggc aaaagttgag aagggaaaat ccaagaaact gaagtcagtc 3480
aaagaattat tggggataac gattatggag cgctcgtctt ttgaaaagaa ccccatcgac 3540
ttccttgagg cgaaaggtta caaggaagta aaaaaggatc tcataattaa actaccaaag 3600
tatagtctgt ttgagttaga aaatggccga aaacggatgt tggctagcgc cggagagctt 3660
caaaagggga acgaactcgc actaccgtct aaatacgtga atttcctgta tttagcgtcc 3720
cattacgaga agttgaaagg ttcacctgaa gataacgaac agaagcaact ttttgttgag 3780
cagcacaaac attatctcga cgaaatcata gagcaaattt cggaattcag taagagagtc 3840
atcctagctg atgccaatct ggacaaagta ttaagcgcat acaacaagca cagggataaa 3900
cccatacgtg agcaggcgga aaatattatc catttgttta ctcttaccaa cctcggcgct 3960
ccagccgcat tcaagtattt tgacacaacg atagatcgca aacagtacag atctaccaag 4020
gaggtgctag acgcgacact gattcaccaa tccatcacgg gattatatga aactcggata 4080
gatttgtcac agcttggggg tgacggatcc cccaagaaga agaggaaagt ctcgagcgac 4140
tacaaagacc atgacggtga ttataaagat catgacatcg attacaagga tgacgatgac 4200
aagtga 4206
<210> 276
<211> 4206
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(4206)
<223> 人工序列的说明: 合成 多核苷酸
<400> 276
atggataaaa agtattctat tggtttagac atcggcacta attccgttgg atgggctgtc 60
ataaccgatg aatacaaagt accttcaaag aaatttaagg tgttggggaa cacagaccgt 120
cattcgatta aaaagaatct tatcggtgcc ctcctattcg atagtggcga aacggcagag 180
gcgactcgcc tgaaacgaac cgctcggaga aggtatacac gtcgcaagaa ccgaatatgt 240
tacttacaag aaatttttag caatgagatg gccaaagttg acgattcttt ctttcaccgt 300
ttggaagagt ccttccttgt cgaagaggac aagaaacatg aacggcaccc catctttgga 360
aacatagtag atgaggtggc atatcatgaa aagtacccaa cgatttatca cctcagaaaa 420
aagctagttg actcaactga taaagcggac ctgaggttaa tctacttggc tcttgcccat 480
atgataaagt tccgtgggca ctttctcatt gagggtgatc taaatccgga caactcggat 540
gtcgacaaac tgttcatcca gttagtacaa acctataatc agttgtttga agagaaccct 600
ataaatgcaa gtggcgtgga tgcgaaggct attcttagcg cccgcctctc taaatcccga 660
cggctagaaa acctgatcgc acaattaccc ggagagaaga aaaatgggtt gttcggtaac 720
cttatagcgc tctcactagg cctgacacca aattttaagt cgaacttcga cttagctgaa 780
gatgccaaat tgcagcttag taaggacacg tacgatgacg atctcgacaa tctactggca 840
caaattggag atcagtatgc ggacttattt ttggctgcca aaaaccttag cgatgcaatc 900
ctcctatctg acatactgag agttaatact gagattacca aggcgccgtt atccgcttca 960
atgatcaaaa ggtacgatga acatcaccaa gacttgacac ttctcaaggc cctagtccgt 1020
cagcaactgc ctgagaaata taaggaaata ttctttgatc agtcgaaaaa cgggtacgca 1080
ggttatattg acggcggagc gagtcaagag gaattctaca agtttatcaa acccatatta 1140
gagaagatgg atgggacgga agagttgctt gtaaaactca atcgcgaaga tctactgcga 1200
aagcagcgga ctttcgacaa cggtagcatt ccacatcaaa tccacttagg cgaattgcat 1260
gctatactta gaaggcagga ggatttttat ccgttcctca aagacaatcg tgaaaagatt 1320
gagaaaatcc taacctttcg cataccttac tatgtgggac ccctggcccg agggaactct 1380
cggttcgcat ggatgacaag aaagtccgaa gaaacgatta ctccctggaa ttttgaggaa 1440
gttgtcgata aaggtgcgtc agctcaatcg ttcatcgaga ggatgaccgc ctttgacaag 1500
aatttaccga acgaaaaagt attgcctaag cacagtttac tttacgagta tttcacagtg 1560
tacaatgaac tcacgaaagt taagtatgtc actgagggca tgcgtaaacc cgcctttcta 1620
agcggagaac agaagaaagc aatagtagat ctgttattca agaccaaccg caaagtgaca 1680
gttaagcaat tgaaagagga ctactttaag aaaattgaat gcttcgattc tgtcgagatc 1740
tccggggtag aagatcgatt taatgcgtca cttggtacgt atcatgacct cctaaagata 1800
attaaagata aggacttcct ggataacgaa gagaatgaag atatcttaga agatatagtg 1860
ttgactctta ccctctttga agatcgggaa atgattgagg aaagactaaa aacatacgct 1920
cacctgttcg acgataaggt tatgaaacag ttaaagaggc gtcgctatac gggctgggga 1980
gccttgtcgc ggaaacttat caacgggata agagacaagc aaagtggtaa aactattctc 2040
gattttctaa agagcgacgg cttcgccaat aggaacttta tggccctgat ccatgatgac 2100
tctttaacct tcaaagagga tatacaaaag gcacaggttt ccggacaagg ggactcattg 2160
cacgaacata ttgcgaatct tgctggttcg ccagccatca aaaagggcat actccagaca 2220
gtcaaagtag tggatgagct agttaaggtc atgggacgtc acaaaccgga aaacattgta 2280
atcgagatgg cacgcgaaaa tcaaacgact cagaaggggc aaaaaaacag tcgagagcgg 2340
atgaagagaa tagaagaggg tattaaagaa ctgggcagcc agatcttaaa ggagcatcct 2400
gtggaaaata cccaattgca gaacgagaaa ctttacctct attacctaca aaatggaagg 2460
gacatgtatg ttgatcagga actggacata aaccgtttat ctgattacga cgtcgatcac 2520
attgtacccc aatccttttt gaaggacgat tcaatcgaca ataaagtgct tacacgctcg 2580
gataagaacc gagggaaaag tgacaatgtt ccaagcgagg aagtcgtaaa gaaaatgaag 2640
aactattggc ggcagctcct aaatgcgaaa ctgataacgc aaagaaagtt cgataactta 2700
actaaagctg agaggggtgg cttgtctgaa cttgacaagg ccggatttat taaacgtcag 2760
ctcgtggaaa cccgcgccat cacaaagcat gttgcgcaga tactagattc ccgaatgaat 2820
acgaaatacg acgagaacga taagctgatt cgggaagtca aagtaatcac tttaaagtca 2880
aaattggtgt cggacttcag aaaggatttt caattctata aagttaggga gataaataac 2940
taccaccatg cgcacgacgc ttatcttaat gccgtcgtag ggaccgcact cattaagaaa 3000
tacccgaagc tagaaagtga gtttgtgtat ggtgattaca aagtttatga cgtccgtaag 3060
atgatcgcga aaagcgaaca ggagataggc aaggctacag ccaaatactt cttttattct 3120
aacattatga atttctttaa gacggaaatc actctggcaa acggagagat acgcaaacga 3180
cctttaattg aaaccaatgg ggagacaggt gaaatcgtat gggataaggg ccgggacttc 3240
gcgacggtga gaaaagtttt gtccatgccc caagtcaaca tagtaaagaa aactgaggtg 3300
cagaccggag ggttttcaaa ggaatcgatt cttccaaaaa ggaatagtga taagctcatc 3360
gctcgtaaaa aggactggga cccgaaaaag tacggtggct tcgtgagccc tacagttgcc 3420
tattctgtcc tagtagtggc aaaagttgag aagggaaaat ccaagaaact gaagtcagtc 3480
aaagaattat tggggataac gattatggag cgctcgtctt ttgaaaagaa ccccatcgac 3540
ttccttgagg cgaaaggtta caaggaagta aaaaaggatc tcataattaa actaccaaag 3600
tatagtctgt ttgagttaga aaatggccga aaacggatgt tggctagcgc cggagagctt 3660
caaaagggga acgaactcgc actaccgtct aaatacgtga atttcctgta tttagcgtcc 3720
cattacgaga agttgaaagg ttcacctgaa gataacgaac agaagcaact ttttgttgag 3780
cagcacaaac attatctcga cgaaatcata gagcaaattt cggaattcag taagagagtc 3840
atcctagctg atgccaatct ggacaaagta ttaagcgcat acaacaagca cagggataaa 3900
cccatacgtg agcaggcgga aaatattatc catttgttta ctcttaccaa cctcggcgct 3960
ccagccgcat tcaagtattt tgacacaacg atagatcgca aacagtacag atctaccaag 4020
gaggtgctag acgcgacact gattcaccaa tccatcacgg gattatatga aactcggata 4080
gatttgtcac agcttggggg tgacggatcc cccaagaaga agaggaaagt ctcgagcgac 4140
tacaaagacc atgacggtga ttataaagat catgacatcg attacaagga tgacgatgac 4200
aagtga 4206
<210> 277
<211> 4206
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(4206)
<223> 人工序列的说明: 合成 多核苷酸
<400> 277
atggataaaa agtattctat tggtttagac atcggcacta attccgttgg atgggctgtc 60
ataaccgatg aatacaaagt accttcaaag aaatttaagg tgttggggaa cacagaccgt 120
cattcgatta aaaagaatct tatcggtgcc ctcctattcg atagtggcga aacggcagag 180
gcgactcgcc tgaaacgaac cgctcggaga aggtatacac gtcgcaagaa ccgaatatgt 240
tacttacaag aaatttttag caatgagatg gccaaagttg acgattcttt ctttcaccgt 300
ttggaagagt ccttccttgt cgaagaggac aagaaacatg aacggcaccc catctttgga 360
aacatagtag atgaggtggc atatcatgaa aagtacccaa cgatttatca cctcagaaaa 420
aagctagttg actcaactga taaagcggac ctgaggttaa tctacttggc tcttgcccat 480
atgataaagt tccgtgggca ctttctcatt gagggtgatc taaatccgga caactcggat 540
gtcgacaaac tgttcatcca gttagtacaa acctataatc agttgtttga agagaaccct 600
ataaatgcaa gtggcgtgga tgcgaaggct attcttagcg cccgcctctc taaatcccga 660
cggctagaaa acctgatcgc acaattaccc ggagagaaga aaaatgggtt gttcggtaac 720
cttatagcgc tctcactagg cctgacacca aattttaagt cgaacttcga cttagctgaa 780
gatgccaaat tgcagcttag taaggacacg tacgatgacg atctcgacaa tctactggca 840
caaattggag atcagtatgc ggacttattt ttggctgcca aaaaccttag cgatgcaatc 900
ctcctatctg acatactgag agttaatact gagattacca aggcgccgtt atccgcttca 960
atgatcaaaa ggtacgatga acatcaccaa gacttgacac ttctcaaggc cctagtccgt 1020
cagcaactgc ctgagaaata taaggaaata ttctttgatc agtcgaaaaa cgggtacgca 1080
ggttatattg acggcggagc gagtcaagag gaattctaca agtttatcaa acccatatta 1140
gagaagatgg atgggacgga agagttgctt gtaaaactca atcgcgaaga tctactgcga 1200
aagcagcgga ctttcgacaa cggtagcatt ccacatcaaa tccacttagg cgaattgcat 1260
gctatactta gaaggcagga ggatttttat ccgttcctca aagacaatcg tgaaaagatt 1320
gagaaaatcc taacctttcg cataccttac tatgtgggac ccctggcccg agggaactct 1380
cggttcgcat ggatgacaag aaagtccgaa gaaacgatta ctccatggaa ttttgaggaa 1440
gttgtcgata aaggtgcgtc agctcaatcg ttcatcgaga ggatgaccaa ctttgacaag 1500
aatttaccga acgaaaaagt attgcctaag cacagtttac tttacgagta tttcacagtg 1560
tacaatgaac tcacgaaagt taagtatgtc actgagggca tgcgtaaacc cgcctttcta 1620
agcggagaac agaagaaagc aatagtagat ctgttattca agaccaaccg caaagtgaca 1680
gttaagcaat tgaaagagga ctactttaag aaaattgaat gcttcgattc tgtcgagatc 1740
tccggggtag aagatcgatt taatgcgtca cttggtacgt atcatgacct cctaaagata 1800
attaaagata aggacttcct ggataacgaa gagaatgaag atatcttaga agatatagtg 1860
ttgactctta ccctctttga agatcgggaa atgattgagg aaagactaaa aacatacgct 1920
cacctgttcg acgataaggt tatgaaacag ttaaagaggc gtcgctatac gggctgggga 1980
cgattgtcgc ggaaacttat caacgggata agagacaagc aaagtggtaa aactattctc 2040
gattttctaa agagcgacgg cttcgccaat aggaacttta tgcagctgat ccatgatgac 2100
tctttaacct tcaaagagga tatacaaaag gcacaggttt ccggacaagg ggactcattg 2160
cacgaacata ttgcgaatct tgctggttcg ccagccatca aaaagggcat actccagaca 2220
gtcaaagtag tggatgagct agttaaggtc atgggacgtc acaaaccgga aaacattgta 2280
atcgagatgg cacgcgaaaa tcaaacgact cagaaggggc aaaaaaacag tcgagagcgg 2340
atgaagagaa tagaagaggg tattaaagaa ctgggcagcc agatcttaaa ggagcatcct 2400
gtggaaaata cccaattgca gaacgagaaa ctttacctct attacctaca aaatggaagg 2460
gacatgtatg ttgatcagga actggacata aaccgtttat ctgattacga cgtcgatcac 2520
attgtacccc aatccttttt gaaggacgat tcaatcgaca ataaagtgct tacacgctcg 2580
gataagaacc gagggaaaag tgacaatgtt ccaagcgagg aagtcgtaaa gaaaatgaag 2640
aactattggc ggcagctcct aaatgcgaaa ctgataacgc aaagaaagtt cgataactta 2700
actaaagctg agaggggtgg cttgtctgaa cttgacaagg ccggatttat taaacgtcag 2760
ctcgtggaaa cccgccaaat cacaaagcat gttgcacaga tactagattc ccgaatgaat 2820
acgaaatacg acgagaacga taagctgatt cgggaagtca aagtaatcac tttaaagtca 2880
aaattggtgt cggacttcag aaaggatttt caattctata aagttaggga gataaataac 2940
taccaccatg cgcacgacgc ttatcttaat gccgtcgtag ggaccgcact cattaagaaa 3000
tacccgaagc tagaaagtga gtttgtgtat ggtgattaca aagtttatga cgtccgtaag 3060
atgatcgcga aaagcgaaca ggagataggc aaggctacag ccaaatactt cttttattct 3120
aacattatga atttctttaa gacggaaatc actctggcaa acggagagat acgcaaacga 3180
cctttaattg aaaccaatgg ggagacaggt gaaatcgtat gggataaggg ccgggacttc 3240
gcgacggtga gaaaagtttt gtccatgccc caagtcaaca tagtaaagaa aactgaggtg 3300
cagaccggag ggttttcaaa ggaatcgatt cttccaaaaa ggaatagtga taagctcatc 3360
gctcgtaaaa aggactggga cccgaaaaag tacggtggct tcgtgagccc tacagttgcc 3420
tattctgtcc tagtagtggc aaaagttgag aagggaaaat ccaagaaact gaagtcagtc 3480
aaagaattat tggggataac gattatggag cgctcgtctt ttgaaaagaa ccccatcgac 3540
ttccttgagg cgaaaggtta caaggaagta aaaaaggatc tcataattaa actaccaaag 3600
tatagtctgt ttgagttaga aaatggccga aaacggatgt tggctagcgc cagagagctt 3660
caaaagggga acgaactcgc actaccgtct aaatacgtga atttcctgta tttagcgtcc 3720
cattacgaga agttgaaagg ttcacctgaa gataacgaac agaagcaact ttttgttgag 3780
cagcacaaac attatctcga cgaaatcata gagcaaattt cggaattcag taagagagtc 3840
atcctagctg atgccaatct ggacaaagta ttaagcgcat acaacaagca cagggataaa 3900
cccatacgtg agcaggcgga aaatattatc catttgttta ctcttaccaa cctcggcgct 3960
ccagccgcat tcaagtattt tgacacaacg atagatcgca aacagtacag atctaccaag 4020
gaggtgctag acgcgacact gattcaccaa tccatcacgg gattatatga aactcggata 4080
gatttgtcac agcttggggg tgacggatcc cccaagaaga agaggaaagt ctcgagcgac 4140
tacaaagacc atgacggtga ttataaagat catgacatcg attacaagga tgacgatgac 4200
aagtga 4206
<210> 278
<211> 4206
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(4206)
<223> 人工序列的说明: 合成 多核苷酸
<400> 278
atggataaaa agtattctat tggtttagac atcggcacta attccgttgg atgggctgtc 60
ataaccgatg aatacaaagt accttcaaag aaatttaagg tgttggggaa cacagaccgt 120
cattcgatta aaaagaatct tatcggtgcc ctcctattcg atagtggcga aacggcagag 180
gcgactcgcc tgaaacgaac cgctcggaga aggtatacac gtcgcaagaa ccgaatatgt 240
tacttacaag aaatttttag caatgagatg gccaaagttg acgattcttt ctttcaccgt 300
ttggaagagt ccttccttgt cgaagaggac aagaaacatg aacggcaccc catctttgga 360
aacatagtag atgaggtggc atatcatgaa aagtacccaa cgatttatca cctcagaaaa 420
aagctagttg actcaactga taaagcggac ctgaggttaa tctacttggc tcttgcccat 480
atgataaagt tccgtgggca ctttctcatt gagggtgatc taaatccgga caactcggat 540
gtcgacaaac tgttcatcca gttagtacaa acctataatc agttgtttga agagaaccct 600
ataaatgcaa gtggcgtgga tgcgaaggct attcttagcg cccgcctctc taaatcccga 660
cggctagaaa acctgatcgc acaattaccc ggagagaaga aaaatgggtt gttcggtaac 720
cttatagcgc tctcactagg cctgacacca aattttaagt cgaacttcga cttagctgaa 780
gatgccaaat tgcagcttag taaggacacg tacgatgacg atctcgacaa tctactggca 840
caaattggag atcagtatgc ggacttattt ttggctgcca aaaaccttag cgatgcaatc 900
ctcctatctg acatactgag agttaatact gagattacca aggcgccgtt atccgcttca 960
atgatcaaaa ggtacgatga acatcaccaa gacttgacac ttctcaaggc cctagtccgt 1020
cagcaactgc ctgagaaata taaggaaata ttctttgatc agtcgaaaaa cgggtacgca 1080
ggttatattg acggcggagc gagtcaagag gaattctaca agtttatcaa acccatatta 1140
gagaagatgg atgggacgga agagttgctt gtaaaactca atcgcgaaga tctactgcga 1200
aagcagcgga ctttcgacaa cggtagcatt ccacatcaaa tccacttagg cgaattgcat 1260
gctatactta gaaggcagga ggatttttat ccgttcctca aagacaatcg tgaaaagatt 1320
gagaaaatcc taacctttcg cataccttac tatgtgggac ccctggcccg agggaactct 1380
cggttcgcat ggatgacaag aaagtccgaa gaaacgatta ctccctggaa ttttgaggaa 1440
gttgtcgata aaggtgcgtc agctcaatcg ttcatcgaga ggatgaccgc ctttgacaag 1500
aatttaccga acgaaaaagt attgcctaag cacagtttac tttacgagta tttcacagtg 1560
tacaatgaac tcacgaaagt taagtatgtc actgagggca tgcgtaaacc cgcctttcta 1620
agcggagaac agaagaaagc aatagtagat ctgttattca agaccaaccg caaagtgaca 1680
gttaagcaat tgaaagagga ctactttaag aaaattgaat gcttcgattc tgtcgagatc 1740
tccggggtag aagatcgatt taatgcgtca cttggtacgt atcatgacct cctaaagata 1800
attaaagata aggacttcct ggataacgaa gagaatgaag atatcttaga agatatagtg 1860
ttgactctta ccctctttga agatcgggaa atgattgagg aaagactaaa aacatacgct 1920
cacctgttcg acgataaggt tatgaaacag ttaaagaggc gtcgctatac gggctgggga 1980
gccttgtcgc ggaaacttat caacgggata agagacaagc aaagtggtaa aactattctc 2040
gattttctaa agagcgacgg cttcgccaat aggaacttta tggccctgat ccatgatgac 2100
tctttaacct tcaaagagga tatacaaaag gcacaggttt ccggacaagg ggactcattg 2160
cacgaacata ttgcgaatct tgctggttcg ccagccatca aaaagggcat actccagaca 2220
gtcaaagtag tggatgagct agttaaggtc atgggacgtc acaaaccgga aaacattgta 2280
atcgagatgg cacgcgaaaa tcaaacgact cagaaggggc aaaaaaacag tcgagagcgg 2340
atgaagagaa tagaagaggg tattaaagaa ctgggcagcc agatcttaaa ggagcatcct 2400
gtggaaaata cccaattgca gaacgagaaa ctttacctct attacctaca aaatggaagg 2460
gacatgtatg ttgatcagga actggacata aaccgtttat ctgattacga cgtcgatcac 2520
attgtacccc aatccttttt gaaggacgat tcaatcgaca ataaagtgct tacacgctcg 2580
gataagaacc gagggaaaag tgacaatgtt ccaagcgagg aagtcgtaaa gaaaatgaag 2640
aactattggc ggcagctcct aaatgcgaaa ctgataacgc aaagaaagtt cgataactta 2700
actaaagctg agaggggtgg cttgtctgaa cttgacaagg ccggatttat taaacgtcag 2760
ctcgtggaaa cccgcgccat cacaaagcat gttgcgcaga tactagattc ccgaatgaat 2820
acgaaatacg acgagaacga taagctgatt cgggaagtca aagtaatcac tttaaagtca 2880
aaattggtgt cggacttcag aaaggatttt caattctata aagttaggga gataaataac 2940
taccaccatg cgcacgacgc ttatcttaat gccgtcgtag ggaccgcact cattaagaaa 3000
tacccgaagc tagaaagtga gtttgtgtat ggtgattaca aagtttatga cgtccgtaag 3060
atgatcgcga aaagcgaaca ggagataggc aaggctacag ccaaatactt cttttattct 3120
aacattatga atttctttaa gacggaaatc actctggcaa acggagagat acgcaaacga 3180
cctttaattg aaaccaatgg ggagacaggt gaaatcgtat gggataaggg ccgggacttc 3240
gcgacggtga gaaaagtttt gtccatgccc caagtcaaca tagtaaagaa aactgaggtg 3300
cagaccggag ggttttcaaa ggaatcgatt cttccaaaaa ggaatagtga taagctcatc 3360
gctcgtaaaa aggactggga cccgaaaaag tacggtggct tcgtgagccc tacagttgcc 3420
tattctgtcc tagtagtggc aaaagttgag aagggaaaat ccaagaaact gaagtcagtc 3480
aaagaattat tggggataac gattatggag cgctcgtctt ttgaaaagaa ccccatcgac 3540
ttccttgagg cgaaaggtta caaggaagta aaaaaggatc tcataattaa actaccaaag 3600
tatagtctgt ttgagttaga aaatggccga aaacggatgt tggctagcgc cagagagctt 3660
caaaagggga acgaactcgc actaccgtct aaatacgtga atttcctgta tttagcgtcc 3720
cattacgaga agttgaaagg ttcacctgaa gataacgaac agaagcaact ttttgttgag 3780
cagcacaaac attatctcga cgaaatcata gagcaaattt cggaattcag taagagagtc 3840
atcctagctg atgccaatct ggacaaagta ttaagcgcat acaacaagca cagggataaa 3900
cccatacgtg agcaggcgga aaatattatc catttgttta ctcttaccaa cctcggcgct 3960
ccagccgcat tcaagtattt tgacacaacg atagatcgca aacagtacag atctaccaag 4020
gaggtgctag acgcgacact gattcaccaa tccatcacgg gattatatga aactcggata 4080
gatttgtcac agcttggggg tgacggatcc cccaagaaga agaggaaagt ctcgagcgac 4140
tacaaagacc atgacggtga ttataaagat catgacatcg attacaagga tgacgatgac 4200
aagtga 4206
<210> 279
<211> 422
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221> gene
<222> (1)..(422)
<223> 人工序列的说明: 合成 多核苷酸
<400> 279
tgtacaaaaa agcaggcttt aaaggaacca attcagtcga ctggatccgg taccaaggtc 60
gggcaggaag agggcctatt tcccatgatt ccttcatatt tgcatatacg atacaaggct 120
gttagagaga taattagaat taatttgact gtaaacacaa agatattagt acaaaatacg 180
tgacgtagaa agtaataatt tcttgggtag tttgcagttt taaaattatg ttttaaaatg 240
gactatcata tgcttaccgt aacttgaaag tatttcgatt tcttggcttt atatatcttg 300
tggaaaggac gaaacaccgg agacgattaa tgcgtctccg ttttagagct agaaatagca 360
agttaaaata aggctagtcc gttatcaact tgaaaaagtg gcaccgagtc ggtgcttttt 420
tt 422
Claims (33)
1.一种分离的酿脓链球菌Cas9(SpCas9)蛋白,该蛋白的氨基酸序列为在SEQ ID NO:1所示的氨基酸序列中具有Q695A和Q926A两个突变,并且该蛋白任选地包含核定位序列、细胞穿透肽序列、和/或亲和标签中的一种或多种。
2.如权利要求1所述的分离的蛋白,其包含以下全部四个位置处的突变:N497A、R661A、Q695A、和Q926A。
3.如权利要求2所述的分离的蛋白,其进一步包含在L169A、Y450A和D1135A位置处的一个、两个或全部三个位置处的突变。
4.如权利要求1所述的分离的蛋白,其进一步包含在L169A、Y450A、N497A、R661A和D1135A位置处的一个、两个、三个、四个或全部五个位置处的突变。
5.如权利要求1所述的分离的蛋白,其进一步包含以下突变中的一个或多个:D1135E;D1135V;D1135V/R1335Q/T1337R;D1135E/R1335Q/T1337R;D1135V/G1218R/R1335Q/T1337R;或
D1135V/G1218R/R1335E/T1337R。
6.如权利要求1所述的分离的蛋白,其还包含降低核酸酶活性的选自下组的一个或多个突变,该组由以下组成:在D10A/D10N、E762Q、H983N/H983Y或D986N处的突变;和在H840A/H840N/H840Y或N863D/N863S/N863H处的突变。
7.如权利要求6所述的分离的蛋白,其中这些降低核酸酶活性的突变是:
(i)D10A或D10N,和
(ii)H840A、H840N、或H840Y。
8.一种融合蛋白,其包含使用任选的介入接头与异源功能结构域融合的、如权利要求1-7任一项中所述的分离的蛋白,其中该接头不干扰该融合蛋白的活性。
9.如权利要求8所述的融合蛋白,其中该异源功能结构域是转录激活结构域。
10.如权利要求9所述的融合蛋白,其中该转录激活结构域来自VP64或NF-κB p65。
11.如权利要求8所述的融合蛋白,其中该异源功能结构域是转录沉默子或转录阻遏结构域。
12.如权利要求11所述的融合蛋白,其中该转录阻遏结构域是克鲁贝尔相关盒(KRAB)结构域、ERF阻遏因子结构域(ERD)或mSin3A相互作用结构域(SID)。
13.如权利要求11所述的融合蛋白,其中该转录沉默子是异染色质蛋白1(HP1)。
14.如权利要求13所述的融合蛋白,其中该转录沉默子是HP1α或HP1β。
15.如权利要求8所述的融合蛋白,其中该异源功能结构域是修饰DNA的甲基化状态的酶。
16.如权利要求15所述的融合蛋白,其中该修饰DNA的甲基化状态的酶是DNA甲基转移酶(DNMT)或TET蛋白。
17.如权利要求16所述的融合蛋白,其中该TET蛋白是TET1。
18.如权利要求8所述的融合蛋白,其中该异源功能结构域是修饰组蛋白亚基的酶。
19.如权利要求18所述的融合蛋白,其中该修饰组蛋白亚基的酶是组蛋白乙酰转移酶(HAT)、组蛋白脱乙酰酶(HDAC)、组蛋白甲基转移酶(HMT)或组蛋白脱甲基酶。
20.如权利要求8所述的融合蛋白,其中该异源功能结构域是生物系链。
21.如权利要求20所述的融合蛋白,其中该生物系链是MS2、Csy4或λN蛋白。
22.如权利要求8所述的融合蛋白,其中该异源功能结构域是FokI。
23.一种编码如权利要求1-7任一项所述的蛋白的分离的核酸。
24.一种包含如权利要求23所述的分离的核酸的载体,该分离的核酸任选地连接到一个或多个调节结构域,以表达如权利要求1-7任一项所述的蛋白。
25.一种宿主细胞,该宿主细胞包含如权利要求23所述的核酸。
26.如权利要求25所述的宿主细胞,其中所述细胞是哺乳动物宿主细胞。
27.如权利要求25所述的宿主细胞,其中所述细胞表达如权利要求1-7任一项所述的蛋白。
28.一种改变细胞的基因组或表观基因组的体外或离体方法,该方法包括在该细胞中表达如权利要求1-7任一项所述的分离的蛋白或者如权利要求8-22任一项所述的融合蛋白以及具有与该细胞的基因组的所选部分互补的区域的指导RNA,或使该细胞与所述分离的蛋白或所述融合蛋白以及所述指导RNA接触。
29.如权利要求28所述的方法,其中该分离的蛋白或融合蛋白包含核定位序列、细胞穿透肽序列和/或亲和标签中的一种或多种。
30.如权利要求28所述的方法,其中该细胞是干细胞。
31.如权利要求30所述的方法,其中所述干细胞是间充质干细胞或诱导多能干细胞。
32.一种改变双链DNA(dsDNA)分子的体外或离体方法,该方法包括使该dsDNA分子与如权利要求1-7任一项所述的分离的蛋白或者如权利要求8-22任一项所述的融合蛋白以及具有与该dsDNA分子的所选部分互补的区域的指导RNA接触。
33.如权利要求1-7任一项所述的分离的蛋白或者如权利要求8-22任一项所述的融合蛋白,其用于改变双链DNA(dsDNA)分子的方法中,所述方法包括使该dsDNA分子与所述分离的蛋白或者所述融合蛋白以及具有与该dsDNA分子的所选部分互补的区域的指导RNA接触。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210550934.7A CN114875012A (zh) | 2015-08-28 | 2016-08-26 | 工程化的CRISPR-Cas9核酸酶 |
Applications Claiming Priority (11)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201562211553P | 2015-08-28 | 2015-08-28 | |
| US62/211,553 | 2015-08-28 | ||
| US201562216033P | 2015-09-09 | 2015-09-09 | |
| US62/216,033 | 2015-09-09 | ||
| US201562258280P | 2015-11-20 | 2015-11-20 | |
| US62/258,280 | 2015-11-20 | ||
| US201562271938P | 2015-12-28 | 2015-12-28 | |
| US62/271,938 | 2015-12-28 | ||
| US15/015,947 US9512446B1 (en) | 2015-08-28 | 2016-02-04 | Engineered CRISPR-Cas9 nucleases |
| US15/015,947 | 2016-02-04 | ||
| PCT/US2016/049147 WO2017040348A1 (en) | 2015-08-28 | 2016-08-26 | Engineered crispr-cas9 nucleases |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210550934.7A Division CN114875012A (zh) | 2015-08-28 | 2016-08-26 | 工程化的CRISPR-Cas9核酸酶 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108350449A CN108350449A (zh) | 2018-07-31 |
| CN108350449B true CN108350449B (zh) | 2022-05-31 |
Family
ID=58188120
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201680063266.8A Active CN108350449B (zh) | 2015-08-28 | 2016-08-26 | 工程化的CRISPR-Cas9核酸酶 |
| CN202210550934.7A Pending CN114875012A (zh) | 2015-08-28 | 2016-08-26 | 工程化的CRISPR-Cas9核酸酶 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210550934.7A Pending CN114875012A (zh) | 2015-08-28 | 2016-08-26 | 工程化的CRISPR-Cas9核酸酶 |
Country Status (8)
| Country | Link |
|---|---|
| EP (2) | EP4036236A1 (zh) |
| JP (6) | JP6799586B2 (zh) |
| KR (1) | KR20180042394A (zh) |
| CN (2) | CN108350449B (zh) |
| AU (2) | AU2016316845B2 (zh) |
| CA (1) | CA2996888A1 (zh) |
| HK (1) | HK1257676A1 (zh) |
| WO (1) | WO2017040348A1 (zh) |
Families Citing this family (67)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6261500B2 (ja) | 2011-07-22 | 2018-01-17 | プレジデント アンド フェローズ オブ ハーバード カレッジ | ヌクレアーゼ切断特異性の評価および改善 |
| US20150044192A1 (en) | 2013-08-09 | 2015-02-12 | President And Fellows Of Harvard College | Methods for identifying a target site of a cas9 nuclease |
| US9359599B2 (en) | 2013-08-22 | 2016-06-07 | President And Fellows Of Harvard College | Engineered transcription activator-like effector (TALE) domains and uses thereof |
| US9340799B2 (en) | 2013-09-06 | 2016-05-17 | President And Fellows Of Harvard College | MRNA-sensing switchable gRNAs |
| US9388430B2 (en) | 2013-09-06 | 2016-07-12 | President And Fellows Of Harvard College | Cas9-recombinase fusion proteins and uses thereof |
| US9526784B2 (en) | 2013-09-06 | 2016-12-27 | President And Fellows Of Harvard College | Delivery system for functional nucleases |
| US9840699B2 (en) | 2013-12-12 | 2017-12-12 | President And Fellows Of Harvard College | Methods for nucleic acid editing |
| ES2888976T3 (es) | 2014-06-23 | 2022-01-10 | Massachusetts Gen Hospital | Identificación no sesgada pangenómica de DSBs evaluada por secuenciación (GUIDE-Seq.) |
| WO2016022363A2 (en) | 2014-07-30 | 2016-02-11 | President And Fellows Of Harvard College | Cas9 proteins including ligand-dependent inteins |
| CA2963820A1 (en) | 2014-11-07 | 2016-05-12 | Editas Medicine, Inc. | Methods for improving crispr/cas-mediated genome-editing |
| AU2016226077B2 (en) | 2015-03-03 | 2021-12-23 | The General Hospital Corporation | Engineered CRISPR-Cas9 nucleases with altered PAM specificity |
| EP3294896A1 (en) | 2015-05-11 | 2018-03-21 | Editas Medicine, Inc. | Optimized crispr/cas9 systems and methods for gene editing in stem cells |
| WO2016201047A1 (en) | 2015-06-09 | 2016-12-15 | Editas Medicine, Inc. | Crispr/cas-related methods and compositions for improving transplantation |
| AU2016316845B2 (en) * | 2015-08-28 | 2022-03-10 | The General Hospital Corporation | Engineered CRISPR-Cas9 nucleases |
| CA3000816A1 (en) | 2015-09-11 | 2017-03-16 | The General Hospital Corporation | Full interrogation of nuclease dsbs and sequencing (find-seq) |
| WO2017053879A1 (en) | 2015-09-24 | 2017-03-30 | Editas Medicine, Inc. | Use of exonucleases to improve crispr/cas-mediated genome editing |
| CA3000762A1 (en) | 2015-09-30 | 2017-04-06 | The General Hospital Corporation | Comprehensive in vitro reporting of cleavage events by sequencing (circle-seq) |
| US20190225955A1 (en) | 2015-10-23 | 2019-07-25 | President And Fellows Of Harvard College | Evolved cas9 proteins for gene editing |
| EP3433363A1 (en) | 2016-03-25 | 2019-01-30 | Editas Medicine, Inc. | Genome editing systems comprising repair-modulating enzyme molecules and methods of their use |
| EP3443086B1 (en) | 2016-04-13 | 2021-11-24 | Editas Medicine, Inc. | Cas9 fusion molecules, gene editing systems, and methods of use thereof |
| KR102547316B1 (ko) | 2016-08-03 | 2023-06-23 | 프레지던트 앤드 펠로우즈 오브 하바드 칼리지 | 아데노신 핵염기 편집제 및 그의 용도 |
| AU2017308889B2 (en) | 2016-08-09 | 2023-11-09 | President And Fellows Of Harvard College | Programmable Cas9-recombinase fusion proteins and uses thereof |
| US11542509B2 (en) | 2016-08-24 | 2023-01-03 | President And Fellows Of Harvard College | Incorporation of unnatural amino acids into proteins using base editing |
| CA3039409A1 (en) * | 2016-10-07 | 2018-04-12 | Integrated Dna Technologies, Inc. | S. pyogenes cas9 mutant genes and polypeptides encoded by same |
| KR20240007715A (ko) | 2016-10-14 | 2024-01-16 | 프레지던트 앤드 펠로우즈 오브 하바드 칼리지 | 핵염기 에디터의 aav 전달 |
| US10745677B2 (en) | 2016-12-23 | 2020-08-18 | President And Fellows Of Harvard College | Editing of CCR5 receptor gene to protect against HIV infection |
| US11898179B2 (en) | 2017-03-09 | 2024-02-13 | President And Fellows Of Harvard College | Suppression of pain by gene editing |
| EP3592777A1 (en) | 2017-03-10 | 2020-01-15 | President and Fellows of Harvard College | Cytosine to guanine base editor |
| US11268082B2 (en) | 2017-03-23 | 2022-03-08 | President And Fellows Of Harvard College | Nucleobase editors comprising nucleic acid programmable DNA binding proteins |
| US11591589B2 (en) | 2017-04-21 | 2023-02-28 | The General Hospital Corporation | Variants of Cpf1 (Cas12a) with altered PAM specificity |
| CN108795989A (zh) * | 2017-04-26 | 2018-11-13 | 哈尔滨工业大学 | SpyCas9的基因编辑活性抑制位点及其抑制剂 |
| EP3615672A1 (en) | 2017-04-28 | 2020-03-04 | Editas Medicine, Inc. | Methods and systems for analyzing guide rna molecules |
| US11560566B2 (en) | 2017-05-12 | 2023-01-24 | President And Fellows Of Harvard College | Aptazyme-embedded guide RNAs for use with CRISPR-Cas9 in genome editing and transcriptional activation |
| AU2018273968A1 (en) | 2017-05-25 | 2019-11-28 | The General Hospital Corporation | Using split deaminases to limit unwanted off-target base editor deamination |
| MX2019014640A (es) | 2017-06-09 | 2020-10-05 | Editas Medicine Inc | Nucleasas de repeticiones palíndromicas agrupadas y regularmente interespaciadas de proteina asociada 9 (cas9) genomanipuladas. |
| BR112020000310A2 (pt) * | 2017-07-07 | 2020-07-14 | Toolgen Incorporated | variantes de crispr alvo específicas |
| WO2019014564A1 (en) | 2017-07-14 | 2019-01-17 | Editas Medicine, Inc. | SYSTEMS AND METHODS OF TARGETED INTEGRATION AND GENOME EDITING AND DETECTION THEREOF WITH INTEGRATED PRIMING SITES |
| WO2019023680A1 (en) | 2017-07-28 | 2019-01-31 | President And Fellows Of Harvard College | METHODS AND COMPOSITIONS FOR EVOLUTION OF BASIC EDITORS USING PHAGE-ASSISTED CONTINUOUS EVOLUTION (PACE) |
| JP2020532967A (ja) | 2017-08-23 | 2020-11-19 | ザ ジェネラル ホスピタル コーポレイション | 変更されたPAM特異性を有する遺伝子操作されたCRISPR−Cas9ヌクレアーゼ |
| WO2019139645A2 (en) | 2017-08-30 | 2019-07-18 | President And Fellows Of Harvard College | High efficiency base editors comprising gam |
| US11530396B2 (en) | 2017-09-05 | 2022-12-20 | The University Of Tokyo | Modified CAS9 protein, and use thereof |
| WO2019060469A2 (en) * | 2017-09-19 | 2019-03-28 | Massachusetts Institute Of Technology | CAS9 STREPTOCOCCUS CANIS AS A GENOMIC ENGINEERING PLATFORM WITH NEW PAM SPECIFICITY |
| EP3694993A4 (en) | 2017-10-11 | 2021-10-13 | The General Hospital Corporation | METHOD OF DETECTING A SITE-SPECIFIC AND UNDESIRED GENOMIC DESAMINATION INDUCED BY BASE EDITING TECHNOLOGIES |
| US11795443B2 (en) | 2017-10-16 | 2023-10-24 | The Broad Institute, Inc. | Uses of adenosine base editors |
| EP3749764A1 (en) | 2018-02-08 | 2020-12-16 | Zymergen, Inc. | Genome editing using crispr in corynebacterium |
| CN109306361B (zh) * | 2018-02-11 | 2022-06-28 | 华东师范大学 | 一种新的a/t到g/c碱基定点转换的基因编辑系统 |
| EP3781585A4 (en) | 2018-04-17 | 2022-01-26 | The General Hospital Corporation | SENSITIVE IN VITRO TESTS FOR SUBSTRATE PREFERENCES AND SITE FOR NUCLEIC ACID BINDERS, MODIFIERS AND CLEAVAGE AGENTS |
| JP2021524272A (ja) | 2018-07-10 | 2021-09-13 | エーエルアイエー セラピューティクス エス. アール. エル. | ガイドrna分子および/またはガイドrna分子/rna誘導型ヌクレアーゼ複合体の無痕跡送達のための小胞およびその産生方法 |
| EP3853363A4 (en) * | 2018-09-19 | 2022-12-14 | The University of Hong Kong | ENHANCED HIGH THROUGHPUT COMBINATORY GENE MODIFICATION SYSTEM AND OPTIMIZED CAS9 ENZYME VARIANTS |
| CN109265562B (zh) * | 2018-09-26 | 2021-03-30 | 北京市农林科学院 | 一种切刻酶及其在基因组碱基替换中的应用 |
| EP3921417A4 (en) | 2019-02-04 | 2022-11-09 | The General Hospital Corporation | ADENINE DNA BASE EDITOR VARIANTS WITH REDUCED OFF-TARGET RNA EDITING |
| MA55297A (fr) * | 2019-03-12 | 2022-01-19 | Bayer Healthcare Llc | Nouveaux systèmes d'endonucléase à arn programmable haute fidélité et leurs utilisations |
| CA3130488A1 (en) | 2019-03-19 | 2020-09-24 | David R. Liu | Methods and compositions for editing nucleotide sequences |
| EP3960853A4 (en) * | 2019-04-26 | 2023-03-15 | Toolgen Incorporated | TARGET-SPECIFIC CRISPR MUTANT |
| CN110272881B (zh) * | 2019-06-29 | 2021-04-30 | 复旦大学 | 核酸内切酶SpCas9高特异性截短变异体TSpCas9-V1/V2及其应用 |
| CN110577969B (zh) * | 2019-08-08 | 2022-07-22 | 复旦大学 | CRISPR/Sa-SlugCas9基因编辑系统及其应用 |
| CA3157131A1 (en) * | 2019-12-10 | 2021-06-17 | Inscripta, Inc. | Novel mad nucleases |
| CN112979822B (zh) * | 2019-12-18 | 2022-11-15 | 华东师范大学 | 一种疾病动物模型的构建方法及融合蛋白 |
| JP2023507034A (ja) * | 2019-12-18 | 2023-02-20 | イースト チャイナ ノーマル ユニバーシティ | ゲノム編集効率を向上させる融合タンパク質及びその使用 |
| GB2614813A (en) | 2020-05-08 | 2023-07-19 | Harvard College | Methods and compositions for simultaneous editing of both strands of a target double-stranded nucleotide sequence |
| CN116457024A (zh) * | 2020-07-26 | 2023-07-18 | Asc 治疗公司 | Cas核酸酶的变体 |
| GB202019908D0 (en) * | 2020-12-16 | 2021-01-27 | Oxford Genetics Ltd | Cripr polypeptides |
| CN112680430B (zh) * | 2020-12-28 | 2023-06-06 | 南方医科大学 | 一种CRISPR SpCas9突变体及其应用 |
| CN112538471B (zh) * | 2020-12-28 | 2023-12-12 | 南方医科大学 | 一种CRISPR SpCas9(K510A)突变体及其应用 |
| EP4326864A1 (en) * | 2021-04-22 | 2024-02-28 | Emendobio Inc. | Novel omni 117, 140, 150-158, 160-165, 167-177, 180-188, 191-198, 200, 201, 203, 205-209, 211-217, 219, 220, 222, 223, 226, 227, 229, 231-236, 238-245, 247, 250, 254, 256, 257, 260 and 262 crispr nucleases |
| US20230279442A1 (en) * | 2021-12-15 | 2023-09-07 | Versitech Limited | Engineered cas9-nucleases and method of use thereof |
| WO2023159136A2 (en) | 2022-02-18 | 2023-08-24 | Dana-Farber Cancer Institute, Inc. | Epitope engineering of cell-surface receptors |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2015089364A1 (en) * | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Crystal structure of a crispr-cas system, and uses thereof |
| CN104854241A (zh) * | 2012-05-25 | 2015-08-19 | 埃玛纽埃尔·沙尔庞捷 | 用于rna定向的靶dna修饰和用于rna定向的转录调节的方法和组合物 |
Family Cites Families (68)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| NZ597299A (en) | 2005-08-26 | 2013-03-28 | Dupont Nutrition Biosci Aps | Use of a cas gene in combination with CRISPR repeats for modulating resistance in a cell |
| CN104531672B (zh) | 2007-03-02 | 2020-01-10 | 杜邦营养生物科学有限公司 | 具有改善的噬菌体抗性的培养物 |
| FR2925918A1 (fr) | 2007-12-28 | 2009-07-03 | Pasteur Institut | Typage et sous-typage moleculaire de salmonella par identification des sequences nucleotidiques variables des loci crispr |
| US8546553B2 (en) | 2008-07-25 | 2013-10-01 | University Of Georgia Research Foundation, Inc. | Prokaryotic RNAi-like system and methods of use |
| US20100076057A1 (en) | 2008-09-23 | 2010-03-25 | Northwestern University | TARGET DNA INTERFERENCE WITH crRNA |
| WO2010054108A2 (en) | 2008-11-06 | 2010-05-14 | University Of Georgia Research Foundation, Inc. | Cas6 polypeptides and methods of use |
| WO2010054154A2 (en) | 2008-11-07 | 2010-05-14 | Danisco A/S | Bifidobacteria crispr sequences |
| DK2367938T3 (da) | 2008-12-12 | 2014-08-25 | Dupont Nutrition Biosci Aps | Genetisk cluster af stammer af streptococcus thermophilus med unikke rheologiske egenskaber til mælkefermentering |
| US10087431B2 (en) | 2010-03-10 | 2018-10-02 | The Regents Of The University Of California | Methods of generating nucleic acid fragments |
| CN103038338B (zh) | 2010-05-10 | 2017-03-08 | 加利福尼亚大学董事会 | 核糖核酸内切酶组合物及其使用方法 |
| WO2012054726A1 (en) | 2010-10-20 | 2012-04-26 | Danisco A/S | Lactococcus crispr-cas sequences |
| WO2012164565A1 (en) | 2011-06-01 | 2012-12-06 | Yeda Research And Development Co. Ltd. | Compositions and methods for downregulating prokaryotic genes |
| GB201122458D0 (en) | 2011-12-30 | 2012-02-08 | Univ Wageningen | Modified cascade ribonucleoproteins and uses thereof |
| KR101833589B1 (ko) | 2012-02-24 | 2018-03-02 | 프레드 헛친슨 켄서 리서치 센터 | 이상혈색소증 치료를 위한 조성물 및 방법 |
| US9637739B2 (en) | 2012-03-20 | 2017-05-02 | Vilnius University | RNA-directed DNA cleavage by the Cas9-crRNA complex |
| US9102936B2 (en) | 2012-06-11 | 2015-08-11 | Agilent Technologies, Inc. | Method of adaptor-dimer subtraction using a CRISPR CAS6 protein |
| EP2674501A1 (en) | 2012-06-14 | 2013-12-18 | Agence nationale de sécurité sanitaire de l'alimentation,de l'environnement et du travail | Method for detecting and identifying enterohemorrhagic Escherichia coli |
| US9258704B2 (en) | 2012-06-27 | 2016-02-09 | Advanced Messaging Technologies, Inc. | Facilitating network login |
| WO2014071235A1 (en) | 2012-11-01 | 2014-05-08 | Massachusetts Institute Of Technology | Genetic device for the controlled destruction of dna |
| KR102145760B1 (ko) | 2012-12-06 | 2020-08-19 | 시그마-알드리치 컴퍼니., 엘엘씨 | Crispr-기초된 유전체 변형과 조절 |
| CN114634950A (zh) | 2012-12-12 | 2022-06-17 | 布罗德研究所有限公司 | 用于序列操纵的crispr-cas组分系统、方法以及组合物 |
| EP2931898B1 (en) | 2012-12-12 | 2016-03-09 | The Broad Institute, Inc. | Engineering and optimization of systems, methods and compositions for sequence manipulation with functional domains |
| EP3045537A1 (en) | 2012-12-12 | 2016-07-20 | The Broad Institute, Inc. | Engineering and optimization of systems, methods and compositions for sequence manipulation with functional domains |
| EP4299741A3 (en) | 2012-12-12 | 2024-02-28 | The Broad Institute, Inc. | Delivery, engineering and optimization of systems, methods and compositions for sequence manipulation and therapeutic applications |
| EP2931899A1 (en) | 2012-12-12 | 2015-10-21 | The Broad Institute, Inc. | Functional genomics using crispr-cas systems, compositions, methods, knock out libraries and applications thereof |
| ES2701749T3 (es) | 2012-12-12 | 2019-02-25 | Broad Inst Inc | Métodos, modelos, sistemas y aparatos para identificar secuencias diana para enzimas Cas o sistemas CRISPR-Cas para secuencias diana y transmitir resultados de los mismos |
| US8697359B1 (en) | 2012-12-12 | 2014-04-15 | The Broad Institute, Inc. | CRISPR-Cas systems and methods for altering expression of gene products |
| WO2014093694A1 (en) | 2012-12-12 | 2014-06-19 | The Broad Institute, Inc. | Crispr-cas nickase systems, methods and compositions for sequence manipulation in eukaryotes |
| WO2014093635A1 (en) | 2012-12-12 | 2014-06-19 | The Broad Institute, Inc. | Engineering and optimization of improved systems, methods and enzyme compositions for sequence manipulation |
| CN113528577A (zh) | 2012-12-12 | 2021-10-22 | 布罗德研究所有限公司 | 用于序列操纵的系统、方法和优化的指导组合物的工程化 |
| JP6473419B2 (ja) | 2012-12-13 | 2019-02-20 | ダウ アグロサイエンシィズ エルエルシー | 部位特異的ヌクレアーゼ活性のdna検出方法 |
| KR20150095861A (ko) | 2012-12-17 | 2015-08-21 | 프레지던트 앤드 펠로우즈 오브 하바드 칼리지 | Rna-가이드된 인간 게놈 조작 |
| CN105142396A (zh) | 2013-01-14 | 2015-12-09 | 重组股份有限公司 | 缺角家畜 |
| US20140212869A1 (en) | 2013-01-25 | 2014-07-31 | Agilent Technologies, Inc. | Nucleic Acid Proximity Assay Involving the Formation of a Three-way junction |
| AU2014214719B2 (en) | 2013-02-07 | 2020-02-13 | The General Hospital Corporation | Tale transcriptional activators |
| US10660943B2 (en) | 2013-02-07 | 2020-05-26 | The Rockefeller University | Sequence specific antimicrobials |
| JP6491113B2 (ja) | 2013-02-25 | 2019-03-27 | サンガモ セラピューティクス, インコーポレイテッド | ヌクレアーゼ媒介性遺伝子破壊を増強するための方法および組成物 |
| JP2016507244A (ja) | 2013-02-27 | 2016-03-10 | ヘルムホルツ・ツェントルム・ミュンヒェン・ドイチェス・フォルシュンクスツェントルム・フューア・ゲズントハイト・ウント・ウムベルト(ゲーエムベーハー)Helmholtz Zentrum MuenchenDeutsches Forschungszentrum fuer Gesundheit und Umwelt (GmbH) | Cas9ヌクレアーゼによる卵母細胞における遺伝子編集 |
| US10612043B2 (en) | 2013-03-09 | 2020-04-07 | Agilent Technologies, Inc. | Methods of in vivo engineering of large sequences using multiple CRISPR/cas selections of recombineering events |
| DK3620534T3 (da) | 2013-03-14 | 2021-12-06 | Caribou Biosciences Inc | Crispr-cas sammensætninger af nucleinsyre-targeting nucleinsyrer |
| EP2970997A1 (en) | 2013-03-15 | 2016-01-20 | Regents of the University of Minnesota | Engineering plant genomes using crispr/cas systems |
| WO2014204578A1 (en) | 2013-06-21 | 2014-12-24 | The General Hospital Corporation | Using rna-guided foki nucleases (rfns) to increase specificity for rna-guided genome editing |
| US9234213B2 (en) | 2013-03-15 | 2016-01-12 | System Biosciences, Llc | Compositions and methods directed to CRISPR/Cas genomic engineering systems |
| US10760064B2 (en) | 2013-03-15 | 2020-09-01 | The General Hospital Corporation | RNA-guided targeting of genetic and epigenomic regulatory proteins to specific genomic loci |
| EP3741868A1 (en) | 2013-03-15 | 2020-11-25 | The General Hospital Corporation | Rna-guided targeting of genetic and epigenomic regulatory proteins to specific genomic loci |
| US20140273230A1 (en) | 2013-03-15 | 2014-09-18 | Sigma-Aldrich Co., Llc | Crispr-based genome modification and regulation |
| US11332719B2 (en) | 2013-03-15 | 2022-05-17 | The Broad Institute, Inc. | Recombinant virus and preparations thereof |
| US20140349400A1 (en) | 2013-03-15 | 2014-11-27 | Massachusetts Institute Of Technology | Programmable Modification of DNA |
| RU2723130C2 (ru) | 2013-04-05 | 2020-06-08 | ДАУ АГРОСАЙЕНСИЗ ЭлЭлСи | Способы и композиции для встраивания экзогенной последовательности в геном растений |
| US20150056629A1 (en) | 2013-04-14 | 2015-02-26 | Katriona Guthrie-Honea | Compositions, systems, and methods for detecting a DNA sequence |
| SG11201508028QA (en) | 2013-04-16 | 2015-10-29 | Regeneron Pharma | Targeted modification of rat genome |
| US10604771B2 (en) | 2013-05-10 | 2020-03-31 | Sangamo Therapeutics, Inc. | Delivery methods and compositions for nuclease-mediated genome engineering |
| US9873907B2 (en) | 2013-05-29 | 2018-01-23 | Agilent Technologies, Inc. | Method for fragmenting genomic DNA using CAS9 |
| WO2014194190A1 (en) | 2013-05-30 | 2014-12-04 | The Penn State Research Foundation | Gene targeting and genetic modification of plants via rna-guided genome editing |
| CN105392885B (zh) | 2013-07-19 | 2020-11-03 | 赖瑞克斯生物科技公司 | 用于产生双等位基因敲除的方法和组合物 |
| WO2015021426A1 (en) | 2013-08-09 | 2015-02-12 | Sage Labs, Inc. | A crispr/cas system-based novel fusion protein and its application in genome editing |
| WO2015031775A1 (en) | 2013-08-29 | 2015-03-05 | Temple University Of The Commonwealth System Of Higher Education | Methods and compositions for rna-guided treatment of hiv infection |
| US9388430B2 (en) | 2013-09-06 | 2016-07-12 | President And Fellows Of Harvard College | Cas9-recombinase fusion proteins and uses thereof |
| JP6174811B2 (ja) | 2013-12-11 | 2017-08-02 | リジェネロン・ファーマシューティカルズ・インコーポレイテッドRegeneron Pharmaceuticals, Inc. | ゲノムの標的改変のための方法及び組成物 |
| JP2017501149A (ja) | 2013-12-12 | 2017-01-12 | ザ・ブロード・インスティテュート・インコーポレイテッド | 粒子送達構成成分を用いた障害及び疾患の標的化のためのcrispr−cas系及び組成物の送達、使用及び治療適用 |
| JP6793547B2 (ja) * | 2013-12-12 | 2020-12-02 | ザ・ブロード・インスティテュート・インコーポレイテッド | 最適化機能CRISPR−Cas系による配列操作のための系、方法および組成物 |
| US20150191744A1 (en) | 2013-12-17 | 2015-07-09 | University Of Massachusetts | Cas9 effector-mediated regulation of transcription, differentiation and gene editing/labeling |
| JP6721508B2 (ja) | 2013-12-26 | 2020-07-15 | ザ ジェネラル ホスピタル コーポレイション | 多重ガイドrna |
| EP3553176A1 (en) | 2014-03-10 | 2019-10-16 | Editas Medicine, Inc. | Crispr/cas-related methods and compositions for treating leber's congenital amaurosis 10 (lca10) |
| MA41349A (fr) * | 2015-01-14 | 2017-11-21 | Univ Temple | Éradication de l'herpès simplex de type i et d'autres virus de l'herpès associés guidée par arn |
| RU2752834C2 (ru) * | 2015-06-18 | 2021-08-09 | Те Брод Инститьют, Инк. | Мутации фермента crispr, уменьшающие нецелевые эффекты |
| AU2016316845B2 (en) * | 2015-08-28 | 2022-03-10 | The General Hospital Corporation | Engineered CRISPR-Cas9 nucleases |
| WO2017081288A1 (en) * | 2015-11-11 | 2017-05-18 | Lonza Ltd | Crispr-associated (cas) proteins with reduced immunogenicity |
-
2016
- 2016-08-26 AU AU2016316845A patent/AU2016316845B2/en active Active
- 2016-08-26 CA CA2996888A patent/CA2996888A1/en active Pending
- 2016-08-26 JP JP2018510914A patent/JP6799586B2/ja active Active
- 2016-08-26 KR KR1020187008311A patent/KR20180042394A/ko active IP Right Grant
- 2016-08-26 CN CN201680063266.8A patent/CN108350449B/zh active Active
- 2016-08-26 WO PCT/US2016/049147 patent/WO2017040348A1/en active Application Filing
- 2016-08-26 EP EP22156340.6A patent/EP4036236A1/en active Pending
- 2016-08-26 CN CN202210550934.7A patent/CN114875012A/zh active Pending
- 2016-08-26 EP EP16842722.7A patent/EP3341477B1/en active Active
-
2019
- 2019-01-02 HK HK19100040.9A patent/HK1257676A1/zh unknown
- 2019-08-26 JP JP2019153881A patent/JP6745391B2/ja active Active
-
2020
- 2020-08-03 JP JP2020131422A patent/JP6942848B2/ja active Active
- 2020-11-20 JP JP2020193171A patent/JP7074827B2/ja active Active
-
2021
- 2021-09-08 JP JP2021145911A patent/JP7326391B2/ja active Active
-
2022
- 2022-05-11 AU AU2022203146A patent/AU2022203146A1/en active Pending
-
2023
- 2023-08-02 JP JP2023125901A patent/JP2023145657A/ja active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104854241A (zh) * | 2012-05-25 | 2015-08-19 | 埃玛纽埃尔·沙尔庞捷 | 用于rna定向的靶dna修饰和用于rna定向的转录调节的方法和组合物 |
| WO2015089364A1 (en) * | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Crystal structure of a crispr-cas system, and uses thereof |
Non-Patent Citations (2)
| Title |
|---|
| AKS40380.1;Nodvig等;《GenBank》;20150802;全文 * |
| Engineered CRISPR-Cas9 nucleases with altered PAM specificities;Kleinstiver等;《NATURE》;20150723;第523卷;摘要,第483页右栏第1段,图3 * |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4036236A1 (en) | 2022-08-03 |
| EP3341477A1 (en) | 2018-07-04 |
| CA2996888A1 (en) | 2017-03-09 |
| JP2023145657A (ja) | 2023-10-11 |
| CN114875012A (zh) | 2022-08-09 |
| EP3341477A4 (en) | 2019-07-10 |
| AU2016316845A1 (en) | 2018-03-22 |
| WO2017040348A1 (en) | 2017-03-09 |
| JP6745391B2 (ja) | 2020-08-26 |
| JP7326391B2 (ja) | 2023-08-15 |
| AU2016316845B2 (en) | 2022-03-10 |
| JP2020010695A (ja) | 2020-01-23 |
| HK1257676A1 (zh) | 2019-10-25 |
| JP2021040644A (ja) | 2021-03-18 |
| JP7074827B2 (ja) | 2022-05-24 |
| JP2018525019A (ja) | 2018-09-06 |
| KR20180042394A (ko) | 2018-04-25 |
| AU2022203146A1 (en) | 2022-06-02 |
| JP2021003110A (ja) | 2021-01-14 |
| JP6799586B2 (ja) | 2020-12-16 |
| EP3341477B1 (en) | 2022-03-23 |
| JP6942848B2 (ja) | 2021-09-29 |
| CN108350449A (zh) | 2018-07-31 |
| JP2022023028A (ja) | 2022-02-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108350449B (zh) | 工程化的CRISPR-Cas9核酸酶 | |
| US11060078B2 (en) | Engineered CRISPR-Cas9 nucleases | |
| US10633642B2 (en) | Engineered CRISPR-Cas9 nucleases | |
| AU2018254619B2 (en) | Variants of Cpf1 (CAS12a) with altered PAM specificity | |
| AU2016226077B2 (en) | Engineered CRISPR-Cas9 nucleases with altered PAM specificity | |
| CN111278450B (zh) | 具有改变的PAM特异性的工程化的CRISPR-Cas9核酸酶 | |
| CN114144519A (zh) | 单碱基置换蛋白以及包含其的组合物 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |