WO2024053123A1 - 再生システム、再生方法、および、プログラム - Google Patents
再生システム、再生方法、および、プログラム Download PDFInfo
- Publication number
- WO2024053123A1 WO2024053123A1 PCT/JP2022/044501 JP2022044501W WO2024053123A1 WO 2024053123 A1 WO2024053123 A1 WO 2024053123A1 JP 2022044501 W JP2022044501 W JP 2022044501W WO 2024053123 A1 WO2024053123 A1 WO 2024053123A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- content
- amplification factor
- emotion
- reproduction
- inaudible sound
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/011—Arrangements for interaction with the human body, e.g. for user immersion in virtual reality
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B60—VEHICLES IN GENERAL
- B60K—ARRANGEMENT OR MOUNTING OF PROPULSION UNITS OR OF TRANSMISSIONS IN VEHICLES; ARRANGEMENT OR MOUNTING OF PLURAL DIVERSE PRIME-MOVERS IN VEHICLES; AUXILIARY DRIVES FOR VEHICLES; INSTRUMENTATION OR DASHBOARDS FOR VEHICLES; ARRANGEMENTS IN CONNECTION WITH COOLING, AIR INTAKE, GAS EXHAUST OR FUEL SUPPLY OF PROPULSION UNITS IN VEHICLES
- B60K35/00—Instruments specially adapted for vehicles; Arrangement of instruments in or on vehicles
- B60K35/20—Output arrangements, i.e. from vehicle to user, associated with vehicle functions or specially adapted therefor
- B60K35/26—Output arrangements, i.e. from vehicle to user, associated with vehicle functions or specially adapted therefor using acoustic output
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H1/00—Details of electrophonic musical instruments
- G10H1/46—Volume control
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10K—SOUND-PRODUCING DEVICES; METHODS OR DEVICES FOR PROTECTING AGAINST, OR FOR DAMPING, NOISE OR OTHER ACOUSTIC WAVES IN GENERAL; ACOUSTICS NOT OTHERWISE PROVIDED FOR
- G10K15/00—Acoustics not otherwise provided for
- G10K15/02—Synthesis of acoustic waves
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10K—SOUND-PRODUCING DEVICES; METHODS OR DEVICES FOR PROTECTING AGAINST, OR FOR DAMPING, NOISE OR OTHER ACOUSTIC WAVES IN GENERAL; ACOUSTICS NOT OTHERWISE PROVIDED FOR
- G10K15/00—Acoustics not otherwise provided for
- G10K15/04—Sound-producing devices
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03G—CONTROL OF AMPLIFICATION
- H03G3/00—Gain control in amplifiers or frequency changers
- H03G3/20—Automatic control
- H03G3/30—Automatic control in amplifiers having semiconductor devices
- H03G3/3089—Control of digital or coded signals
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B60—VEHICLES IN GENERAL
- B60W—CONJOINT CONTROL OF VEHICLE SUB-UNITS OF DIFFERENT TYPE OR DIFFERENT FUNCTION; CONTROL SYSTEMS SPECIALLY ADAPTED FOR HYBRID VEHICLES; ROAD VEHICLE DRIVE CONTROL SYSTEMS FOR PURPOSES NOT RELATED TO THE CONTROL OF A PARTICULAR SUB-UNIT
- B60W2540/00—Input parameters relating to occupants
- B60W2540/22—Psychological state; Stress level or workload
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2203/00—Indexing scheme relating to G06F3/00 - G06F3/048
- G06F2203/01—Indexing scheme relating to G06F3/01
- G06F2203/011—Emotion or mood input determined on the basis of sensed human body parameters such as pulse, heart rate or beat, temperature of skin, facial expressions, iris, voice pitch, brain activity patterns
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2220/00—Input/output interfacing specifically adapted for electrophonic musical tools or instruments
- G10H2220/155—User input interfaces for electrophonic musical instruments
- G10H2220/371—Vital parameter control, i.e. musical instrument control based on body signals, e.g. brainwaves, pulsation, temperature or perspiration; Biometric information
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2220/00—Input/output interfacing specifically adapted for electrophonic musical tools or instruments
- G10H2220/155—User input interfaces for electrophonic musical instruments
- G10H2220/405—Beam sensing or control, i.e. input interfaces involving substantially immaterial beams, radiation, or fields of any nature, used, e.g. as a switch as in a light barrier, or as a control device, e.g. using the theremin electric field sensing principle
- G10H2220/435—Ultrasound, i.e. input or control device involving inaudible pressure waves, e.g. focused as a beam
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2240/00—Data organisation or data communication aspects, specifically adapted for electrophonic musical tools or instruments
- G10H2240/075—Musical metadata derived from musical analysis or for use in electrophonic musical instruments
- G10H2240/085—Mood, i.e. generation, detection or selection of a particular emotional content or atmosphere in a musical piece
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2250/00—Aspects of algorithms or signal processing methods without intrinsic musical character, yet specifically adapted for or used in electrophonic musical processing
- G10H2250/025—Envelope processing of music signals in, e.g. time domain, transform domain or cepstrum domain
- G10H2250/035—Crossfade, i.e. time domain amplitude envelope control of the transition between musical sounds or melodies, obtained for musical purposes, e.g. for ADSR tone generation, articulations, medley, remix
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R2499/00—Aspects covered by H04R or H04S not otherwise provided for in their subgroups
- H04R2499/10—General applications
- H04R2499/13—Acoustic transducers and sound field adaptation in vehicles
Definitions
- the present disclosure relates to a playback system, a playback method, and a program.
- the present disclosure provides a playback system, a playback method, and a program that appropriately induce a user's emotions using playback of inaudible sounds.
- a playback system in the present disclosure is a content playback system that guides a user's emotion from a first emotion to a second emotion, and includes a first content corresponding to the first emotion and a second content corresponding to the second emotion.
- the second amplification factor of the second inaudible sound being played is gradually increased during playback of the second content.
- the playback system according to the present disclosure can appropriately induce the user's emotions using playback of inaudible sounds.
- FIG. 2 is an explanatory diagram showing human emotions and emotion induction.
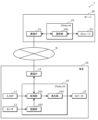
- FIG. 1 is a block diagram showing the configuration of a playback system in an embodiment.
- FIG. 2 is a block diagram showing the configuration of a playback section in an embodiment.
- FIG. 3 is an explanatory diagram showing reproduction of content by a reproduction unit in the embodiment.
- FIG. 3 is an explanatory diagram showing a first example of the transition of the amplification factor in the embodiment.
- FIG. 7 is an explanatory diagram showing a second example of the transition of the amplification factor in the embodiment.
- FIG. 7 is an explanatory diagram showing a third example of the transition of the amplification factor in the embodiment.
- FIG. 3 is a flow diagram showing a first example of processing of the playback system in the embodiment.
- FIG. 1 is a block diagram showing the configuration of a playback system in an embodiment.
- FIG. 2 is a block diagram showing the configuration of a playback section in an embodiment.
- FIG. 3 is an ex
- FIG. 7 is an explanatory diagram showing a fourth example of the change in amplification factor in the embodiment.
- FIG. 7 is an explanatory diagram showing a fifth example of the change in amplification factor in the embodiment. It is a flowchart which shows the second example of the process of the reproduction
- FIG. 7 is an explanatory diagram showing an example of emotion transition in a modification of the embodiment.
- FIG. 7 is an explanatory diagram showing an example of the transition of the amplification factor in a modification of the embodiment.
- the above technology is based on the premise that the audio sound of the content includes audible sounds and inaudible sounds. Then, by switching between applying or not applying a filter that removes inaudible sounds from audio sounds, it is possible to switch between outputting audible sounds and inaudible sounds, or outputting only audible sounds. It is known that inaudible sounds have the effect of activating the brains of people who perceive them.
- the driver when the driver should concentrate on driving the vehicle, the driver is made to perceive audible sounds and inaudible sounds, which contributes to making the driver concentrate on driving. Furthermore, when there is no need to concentrate on driving, the driver can only perceive audible sounds, contributing to relaxing and enjoying the audio. In this way, the above technology induces the driver's emotions.
- the inventor of the present application when inducing a person's emotions, the inventor of the present application first listens to music that corresponds to the person's current (that is, before induction) emotion, and then plays music that corresponds to the target emotion that the person wants to induce. The idea was that by asking people to listen to them, it might be possible to induce their emotions more appropriately. In addition, when inducing emotions, by playing non-audible sounds and appropriately controlling the intensity of the sound pressure of the non-audible sounds being played, it is possible to control the intensity of a person's emotions, and the intensity of the person's emotions can be controlled. The idea was that it might be possible to more appropriately guide people's emotions.
- a content playback system that guides a user's emotion from a first emotion to a second emotion, which includes a first content corresponding to the first emotion and a second content corresponding to the second emotion.
- the playback system causes the user to perceive the first content that gives the same impression as the user's emotion (first emotion) before induction, together with the inaudible sound, and then the second content that gives the same impression as the target emotion.
- first emotion the user's emotion
- second content the user's emotions are guided to the target emotion based on the principle of homogeneity.
- the amplification factor of the inaudible sound is gradually lowered to weaken the intensity of the user's emotions before the induction, and then the amplification factor of the inaudible sound is gradually reduced while the second content is played back. This contributes to increasing the intensity of the user's target emotion.
- the playback system can appropriately induce the user's emotions using the playback of inaudible sounds.
- the playback unit sets the first amplification factor to 0 at the end of playback of the first content, and sets the second amplification factor to 0 at the start of playback of the second content;
- the playback system sets the amplification factor of the inaudible sound to 0 at the timing of switching the content to be played back, so the playback system switches the content at the timing when the intensity of the user's emotion before guidance is the weakest, and then It contributes to gradually strengthening the target emotion. Therefore, the playback system can more appropriately induce the user's emotions using the playback of inaudible sounds.
- the reproduction unit is configured to: The first amplification factor of the inaudible sound is maintained at a first value, and the first amplification factor of the first inaudible sound being reproduced is changed from the first value in a section after the first section.
- the second inaudible sound is gradually lowered and is being played during the playback of the second content in a second section from the start of the chorus part included in the second content to the end of the second content.
- the second amplification factor of the second inaudible sound being played is maintained at a second value, and the second amplification factor of the second inaudible sound being reproduced is gradually increased toward the second value in a section before the second section.
- the regeneration system according to (1) or (2), wherein the regeneration system is increased to
- the playback system further increases the intensity of the user's emotion before the guidance when the user perceives the chorus part of the first content, and further increases the intensity of the user's emotion before the guidance when the user perceives the chorus part of the second content.
- the intensity of the user's target emotion can be further increased. Therefore, the playback system can induce the user's emotions more appropriately.
- the playback section reduces the first amplification factor linearly with respect to time, and during playback of the second content,
- the reproduction system according to any one of (1) to (3), wherein when gradually increasing the second amplification factor, the second amplification factor is increased linearly with respect to time.
- the reproduction system can reduce or increase the amplification factor of the inaudible sound through a relatively simple process of decreasing or increasing the amplification factor of the inaudible sound linearly with respect to time. . Therefore, the playback system can appropriately induce the user's emotions using the playback of inaudible sounds through relatively simple processing.
- the reproduction unit decreases the first amplification factor exponentially with respect to time
- the reproduction system according to any one of (1) to (3), wherein when gradually increasing the second amplification factor during reproduction, the second amplification factor is increased exponentially with respect to time.
- the playback system exponentially decreases or increases the amplification factor of the non-audible sound with respect to time, so that the user can enjoy the non-audible sound that is similar to the sense of strength of sound perceived by humans.
- the playback system can appropriately induce the user's emotions using the playback of the inaudible sound by using appropriate intensities of the inaudible sound.
- the playback system further includes a recognition unit that recognizes the user's emotion when the playback unit is playing the first content or the second content; when the emotion recognized by the unit deviates from a predetermined transition, the first amplification of the first inaudible sound being played so as to bring the user's emotion closer to the predetermined transition;
- the reproduction system according to any one of (1) to (5), which adjusts the rate.
- the playback system when the user's emotions while playing the content change differently from the predetermined change, the playback system can cause the user's emotions to change close to the predetermined change. can. Therefore, the playback system can more appropriately induce the user's emotions using the playback of inaudible sounds.
- the playback system further includes a recognition unit that recognizes the user's emotion when the playback unit is playing the first content or the second content, and the playback unit According to any one of (1) to (5), the amplification factor of the first inaudible sound being reproduced is set to 0 when the emotion recognized by the section deviates from a predetermined trend. playback system.
- the playback system has a negative effect on the user by stopping the playback of the inaudible sound when the user's emotions change differently from a predetermined change during playback of the content. Contributes to restraining giving. Therefore, the playback system can more appropriately induce the user's emotions using the playback of inaudible sounds.
- the playback system easily induces the user's emotions by continuously playing the first content and the second content.
- the playback system can more easily induce the user's emotions appropriately by using the playback of inaudible sounds.
- the playback system guides the user's emotion from the first emotion to the second emotion via one or more third emotions
- the acquisition unit guides the user's emotion from the first emotion to the second emotion via one or more third emotions.
- One or more third contents corresponding to the respective third contents are acquired, and the reproduction unit sequentially reproduces each of the one or more third contents after the reproduction of the first content is finished.
- the third content is played back along with a corresponding third inaudible sound, and when the playback of the one or more third contents is finished, the playback of the second content is started, and the playback of each of the one or more third contents is started.
- the reproduction system according to any one of (1) to (8), wherein during reproduction, the third amplification factor of the third inaudible sound being reproduced is gradually increased and then gradually decreased.
- the playback system easily induces the user's emotions by continuously playing the first content, third content, and second content in this order.
- the playback system can more easily induce the user's emotions appropriately by using the playback of inaudible sounds.
- the playback system sets the amplification factor of the inaudible sound to 0 at the timing of switching the content to be played back, so the playback system switches the content at the timing when the intensity of the user's emotion before guidance is the weakest, and then It contributes to gradually strengthening the target emotion. Therefore, the playback system can more appropriately induce the user's emotions using the playback of inaudible sounds.
- the reproduction section is configured to reproduce the third inaudible sound being reproduced in a third section including from the start to the end of the chorus of the third content.
- the third amplification factor is maintained at a third value, and in the section before the third section, the third amplification factor of the third inaudible sound being reproduced is gradually moved toward the third value. as described in (9) or (10), wherein the third amplification factor of the third inaudible sound being reproduced is gradually decreased from the third value in a section after the third section. playback system.
- the playback system can further increase the intensity of the user's intermediate emotion when the user is perceiving the chorus part of the third content. Therefore, the playback system can more appropriately guide the user's emotions via intermediate emotions.
- the playback system further includes a selection unit that selects the first content corresponding to the first emotion and the second content corresponding to the second emotion from among the plurality of contents. , the reproduction system according to any one of (1) to (11), wherein the acquisition unit acquires the first content and the second content selected by the selection unit.
- the playback system appropriately selects the first content and second content corresponding to the user's emotion before induction and the target emotion, and combines the selected first content and second content with each other. can be used to induce the user's emotions. Therefore, the reproduction system can appropriately induce the user's emotions by using appropriate content and reproduction of inaudible sounds according to the content.
- a reproduction method executed by one or more computers included in a content reproduction system which guides a user's emotion from a first emotion to a second emotion, the first content corresponding to the first emotion; (a) A first inaudible sound corresponding to the first content, the basic signal of the first inaudible sound is transmitted by a speaker at a first amplification rate; (b) a second amplification of the basic signal of the second inaudible sound, which is a second inaudible sound corresponding to the second content; reproducing the second content together with a second inaudible sound amplified by a factor of 1, and gradually decreasing the first amplification factor of the first inaudible sound being reproduced while the first content is being played; A reproduction method that gradually increases the second amplification factor of the second inaudible sound being reproduced while the second content is being reproduced.
- FIG. 1 is an explanatory diagram showing human emotions and changes (also referred to as transitions) in human emotions.
- FIG. 1 a diagram is shown in which a plurality of human emotions (for example, tension, joy, relaxation, etc.) are arranged in a ring.
- FIG. 1 is also generally referred to as Russell's circle of emotions model.
- human emotions are known to be arranged on a two-dimensional plane consisting of a pleasure and displeasure axis (horizontal axis) and an arousal and sleepiness axis (vertical axis). ing.
- the emotion may include concepts such as feeling, mood, psychological state, or emotion.
- the transition of a person's emotions is expressed in Figure 1 as a movement from a position corresponding to one emotion to a position corresponding to another emotion. Changing a person's emotions is also called inducing emotions.
- Paths from tension to relaxation include, for example, paths P and Q.
- Path P is a path that transitions from tension to relaxation directly (that is, without going through other emotions).
- Path Q is a path that transitions from tension to relaxation via the emotion of joy, which is an example of another emotion. If the distance between the person's emotions before being induced and the emotions of the person after being induced is relatively large, it may be appropriate to induce the emotion via another emotion.
- the playback system 1 contributes to appropriately guiding the user's emotions to a target emotion through an arbitrary route.
- FIG. 2 is a block diagram showing the configuration of the playback system 1 in this embodiment.
- the reproduction system 1 guides the user's emotion from an emotion before being induced (also referred to as a pre-induction emotion or a first emotion) to a target emotion (also referred to as a target emotion or a second emotion). It is an information processing system that
- the playback system 1 includes a terminal 10 and a server 20.
- the terminal 10 and the server 20 are connected via a network N.
- Network N may consist of any communication line or network, and may include, for example, the Internet, a mobile phone carrier network, an Internet provider's access network, or a public access network.
- the terminal 10 is an information processing terminal that outputs sound related to content and makes it perceptible to the user.
- Terminal 10 may be, for example, a smartphone, a tablet, a personal computer, or the like.
- the terminal 10 includes an input IF 11, a sensor 12, a communication IF 13, a processor 14, and a speaker 15.
- the input IF 11 receives information input from the user.
- the information received by the input IF 11 includes a target emotion (for example, relaxation).
- the information received by the input IF 11 may include emotions (also referred to as intermediate emotions) to be passed through in order to guide the emotion from the emotion before induction to the target emotion.
- the playback system 1 guides the user's emotion from the pre-guidance emotion to the target emotion via an intermediate emotion
- the information received by the input IF 11 needs to include the intermediate emotion (for example, joy). Note that there may be one intermediate emotion, or there may be two or more intermediate emotions.
- the input IF 11 is, for example, a touch interface, a keyboard, a mouse, or a microphone.
- the input IF 11 receives information through key operations, clicks, taps, and the like.
- the input IF 11 includes a microphone, the input IF 11 receives the input of the information using voice recognition processing for the user's voice received by the microphone.
- the sensor 12 senses physical quantities related to the user's living body and generates information about the living body (also referred to as biometric information).
- the sensor 12 provides the generated biological information to the processor 14 (more specifically, the recognition unit 102).
- the sensor 12 is, for example, a camera, a body temperature sensor, a heartbeat sensor, or a blood pressure sensor.
- the camera captures an image of the user's face (also referred to as a face image) by photographing the user's face, and provides the image to the processor 14 as biometric information.
- the sensor 12 may be provided in a device external to the terminal 10. In that case, the device and the terminal 10 are communicably connected, and the sensor 12 transmits biological information to the terminal 10 via communication.
- the device may be, for example, a wristband type device worn on the user's wrist.
- the communication IF 13 is a communication interface that can communicate with the server 20 through the network N.
- the communication IF 13 may be a wireless LAN (Local Area Network) interface such as Wi-Fi (registered trademark), or a wired LAN interface such as Ethernet (registered trademark).
- Wi-Fi registered trademark
- Ethernet registered trademark
- the processor 14 implements the software functions of the terminal 10 by executing a predetermined program using a memory (not shown).
- the software functions realized by the processor 14 will be explained later.
- the speaker 15 outputs sound.
- the sounds output by the speaker 15 include not only audible sounds but also inaudible sounds.
- Audible sound is sound in a frequency band that can be perceived by humans, and generally falls within the range of 20 Hz to 20 kHz.
- Inaudible sounds are sounds in a frequency range that humans cannot perceive, and are sounds included in a range other than the frequency range of audible sounds.
- a sound having a frequency higher than the audible sound frequency range high-frequency inaudible sound
- inaudible sound a sound having a frequency higher than the audible sound frequency range (high-frequency inaudible sound) is referred to as inaudible sound.
- the speaker 15 outputs sound based on sound pressure amplitude waveform data (also simply referred to as waveform data) provided from the processor 14 (more specifically, the reproduction unit 103).
- sound pressure amplitude waveform data also simply referred to as waveform data
- the terminal 10 may include an output IF instead of the speaker 15.
- the output IF is connected to an external speaker, and outputs sound by outputting waveform data to the external speaker.
- the acquisition unit 101, the recognition unit 102, and the playback unit 103 which are functional units realized by the processor 14 executing a predetermined program using a memory (not shown), will be described.
- the recognition unit 102 recognizes the user's emotions.
- the recognition unit 102 recognizes the user's emotions using the user's biometric information provided from the sensor 12 .
- the recognition unit 102 recognizes the user's emotions before being guided (in other words, before playing the content). Furthermore, the recognition unit 102 may recognize the user's emotions even during guidance (in other words, while playing content).
- the recognition unit 102 recognizes the user's emotion by analyzing the user's facial expression from the user's facial image acquired by the camera, which is the sensor 12.
- Well-known emotion recognition techniques may be used to recognize the user's emotions.
- the recognition unit 102 recognizes the user's emotion from the body temperature measured by the body temperature sensor that is the sensor 12. At this time, the recognition unit 102 can recognize the user's emotions from the measured body temperature using the well-known correspondence between human emotions and body temperature.
- a well-known correspondence between human emotions and body temperature for example, a relatively high body temperature is associated with a feeling of happiness or anger, and a relatively low body temperature is associated with a feeling of sadness or depression. There is a correspondence.
- the recognition unit 102 recognizes the user's emotion from heart rate fluctuations measured by the heart rate sensor, which is the sensor 12. At this time, the recognition unit 102 can recognize the user's emotions from the measured heart rate fluctuations using the well-known correspondence between human emotions and heart rate fluctuations.
- the well-known correspondence between human emotions and heart rate variability is shown in, for example, Non-Patent Document 1. For example, it is known that people who are feeling emotions such as joy, worry, surprise, sadness, or anger have characteristic heart rate fluctuations that correspond to each emotion they are feeling.
- the recognition unit 102 recognizes the user's emotion from the blood pressure measured by the blood pressure sensor, which is the sensor 12. At this time, the recognition unit 102 can recognize the user's emotion from the measured blood pressure using the well-known correspondence between human emotion and blood pressure.
- the well-known correspondence between human emotions and blood pressure is shown in Non-Patent Document 2, for example. For example, an increase in blood pressure corresponds to a feeling of anger, and a decrease in blood pressure corresponds to a feeling of relaxation.
- the acquisition unit 101 acquires content used to guide the user's emotions.
- the content acquired by the acquisition unit 101 is content that includes at least sound, and is, for example, music content, and this case will be described as an example.
- the content acquired by the acquisition unit 101 may be content that includes video as well as sound.
- the acquisition unit 101 acquires the first content corresponding to the emotion before induction and the second content corresponding to the target emotion from the server 20 via the communication IFs 13 and 21 and the network N.
- the acquisition unit 101 converts the acquired first content and second content into waveform data (also referred to as sound source waveform data), and provides the data to the reproduction unit 103.
- the acquisition unit 101 provides the user's pre-guidance emotion and target emotion to the server 20 via the communication IFs 13 and 21 and the network N in order to acquire the first content and the second content from the server 20.
- the first content and the second content acquired by the acquisition unit 101 are contents selected by the server 20 (more specifically, the selection unit 201 described below) as content corresponding to the emotion before induction and the target emotion, respectively. It is.
- the emotion before guidance is the user's emotion obtained by the sensor 12 and the recognition unit 102 before the reproduction unit 103 reproduces the first content.
- the target emotion is a target emotion input into the input IF 11.
- the acquisition unit 101 acquires the first content and the second content as described above.
- the acquisition unit 101 supports the intermediate emotion in addition to the first content and the second content. Get the third content.
- the intermediate emotion may be provided to the server 20.
- the intermediate emotion may be generated by the terminal 10 using, for example, the emotion before induction and the target emotion.
- the reproduction unit 103 sequentially reproduces the first content and the second content provided from the acquisition unit 101 using the speaker 15.
- the reproduction unit 103 first reproduces the first content together with an inaudible sound (also referred to as a first inaudible sound) according to the first content, and then reproduces an inaudible sound (also referred to as a second inaudible sound) according to the second content. ), and the second content is played back.
- the first inaudible sound is an inaudible sound obtained by amplifying the basic signal of the first inaudible sound
- the second inaudible sound is an inaudible sound obtained by amplifying the basic signal of the second inaudible sound.
- the amplification factor for the first inaudible sound is also referred to as a first amplification factor
- the amplification factor for the second inaudible sound is also referred to as a second amplification factor.
- the reproducing unit 103 gradually lowers the first amplification factor of the first inaudible sound being reproduced while reproducing the first content, and also increases the first amplification factor of the second inaudible sound being reproduced while reproducing the second content. Gradually increase the second amplification factor of the audible sound.
- the basic signal will be explained in detail later.
- the reproduction unit 103 may include a period in which the first amplification factor of the first inaudible sound being reproduced is maintained. Moreover, the reproduction unit 103 may include a period during reproduction of the second content in which the second amplification factor of the second inaudible sound being reproduced is maintained.
- the reproduction unit 103 sets the first amplification factor of the first inaudible sound being reproduced at the end of reproduction of the first content and the first amplification factor of the first inaudible sound being reproduced at the time of starting reproduction of the second content.
- the second amplification factor of the second inaudible sound may be the same value. The same value as above is, for example, 0.
- the reproduction unit 103 may maintain the first amplification factor of the first inaudible sound being reproduced at the same value during a certain period including the end of reproduction of the first content.
- the reproduction unit 103 may maintain the second amplification factor of the second inaudible sound being reproduced at the same value during a certain period including the start time of reproduction of the second content.
- the playback unit 103 adds and updates a code (also referred to as a time code) indicating the playback position of the content being played back, and plays the content while referring to the time code.
- a code also referred to as a time code
- the server 20 includes a communication IF 21, a processor 22, and a storage 23.
- the communication IF 21 is a communication interface that can communicate with the terminal 10 through the network N.
- the communication IF 21 may be a wireless LAN interface such as Wi-Fi, or may be a wired LAN interface such as Ethernet.
- the processor 22 implements the software functions of the server 20 by executing a predetermined program using a memory (not shown).
- the software functions realized by the processor 22 will be explained later.
- the storage 23 stores multiple contents.
- the plurality of contents stored in the storage 23 are the plurality of contents that may be played back on the terminal 10.
- the plurality of contents stored in the storage 23 are read out by the processor 22 (more specifically, the selection unit 201).
- the storage 23 may be realized by a memory, an HDD (Hard Disk Drive), or the like.
- the selection unit 201 which is realized by the processor 22 executing a predetermined program using a memory (not shown), will be described.
- the selection unit 201 selects content. Specifically, the selection unit 201 provides the terminal 10 with the first content corresponding to the emotion before induction and the second content corresponding to the target emotion via the communication IFs 13 and 21 and the network N.
- the selection unit 201 acquires the user's pre-guidance emotion from the acquisition unit 101 via the communication IF 21, the communication IF 13, and the network N, and selects the content corresponding to the acquired pre-guidance emotion as the first content. select.
- the selection unit 201 stores in advance a correspondence relationship in which emotions are associated with each of a plurality of contents stored in the storage 23, and refers to the correspondence relationship to select the first content corresponding to the emotion before induction. select.
- the selection unit 201 acquires the target emotion from the acquisition unit 101 via the communication IFs 21 and 13 and the network N, and selects the content corresponding to the acquired target emotion as the second content.
- the selection unit 201 selects the second content corresponding to the target emotion by referring to the correspondence relationship.
- the selection unit 201 selects the content corresponding to the intermediate emotion as the third content. .
- the selection unit 201 selects the third content corresponding to the intermediate emotion by referring to the correspondence relationship.
- the intermediate emotion may be acquired from the terminal 10, or may be generated by the selection unit 201 using the emotion before guidance and the target emotion.
- FIG. 3 is a block diagram showing the configuration of the playback section 103 in this embodiment.
- the reproduction section 103 includes a generation section 111, a determination section 112, an adjustment section 113, and an addition section 114.
- the generation unit 111 generates a basic signal of inaudible sound according to the content.
- the generation unit 111 generates waveform data of the basic signal of the inaudible sound based on the waveform data of the sound source provided from the acquisition unit 101. More specifically, the generation unit 111 generates a basic signal of an inaudible sound corresponding to the first content and an inaudible sound corresponding to the second content, respectively, based on the waveform data of the first content and the second content. Generates the basic signal of hearing. Furthermore, when the third content is used, the generation unit 111 generates a basic signal of an inaudible sound (third inaudible sound) corresponding to the third content based on the waveform data of the third content. The generation unit 111 provides the adjustment unit 113 with waveform data of the generated basic signal of the inaudible sound.
- generating the waveform data of the basic signal of the inaudible sound based on the waveform data of the audible sound means, for example, performing clip processing on the waveform data obtained by amplifying the waveform data of the sound source (that is, the waveform data of the audible sound). This can be achieved by removing audible sound components from waveform data containing inaudible sounds generated by
- the determining unit 112 determines the amplification factor of the basic signal of the inaudible sound generated by the generating unit 111 (also simply referred to as the amplification factor of the inaudible sound). Specifically, the determining unit 112 determines the amplification factor of the inaudible sound based on the time code updated by the reproducing unit 103.
- the amplification factor determined by the determining unit 112 includes a first amplification factor and a second amplification factor, and when the third content is used, includes a third amplification factor that is the amplification factor of the third inaudible sound.
- the determining unit 112 stores, for example, the transition of the amplification factor of the inaudible sound determined for the time code, and refers to the transition of the amplification factor to determine whether the acquisition unit 101 or the generating unit 111 Determine the amplification factor of the inaudible sound to be added to the waveform data provided.
- the transition of the amplification factor of inaudible sounds will be explained later.
- the adjustment unit 113 adjusts the sound pressure of the reproduced inaudible sound by multiplying the amplitude of the waveform data of the inaudible sound generated by the generation unit 111 by the amplification factor determined by the determination unit 112.
- the adjustment unit 113 provides the adjusted inaudible sound waveform data to the addition unit 114.
- the adding unit 114 generates waveform data to be reproduced by the speaker 15 by adding the waveform data of the inaudible sound provided from the adjustment unit 113 to the waveform data of the sound source provided from the acquisition unit 101.
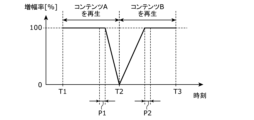
- FIG. 4 is an explanatory diagram showing reproduction of content by the reproduction unit 103 in this embodiment.
- the reproduction unit 103 reproduces two contents.
- the above two contents correspond to contents A and B in FIG. 4.
- the playback unit 103 starts playing content A at time T1.
- reproducing unit 103 reproduces inaudible sound generated according to content A.
- the reproduction unit 103 reproduces content A to the end.
- the time at which the reproducing unit 103 finishes reproducing content A is defined as time T2.
- the playback unit 103 starts playing content B at time T2.
- the reproducing unit 103 reproduces inaudible sound generated according to content B.
- the reproduction unit 103 reproduces content B to the end.
- the time at which the playback unit 103 finishes playing content B is time T3.
- time T2 is determined according to the reproduction time length of content A.
- time T3 is determined according to the playback time lengths of contents A and B. Therefore, the time length from time T1 to time T2 and the time length from time T2 to time T3 are independent; in other words, they may be the same or different.
- content A corresponds to the first content
- content B corresponds to the second content
- the reproducing unit 103 reproduces three contents.
- the above three contents correspond to contents A, B, and C in FIG. 4.
- the reproducing unit 103 reproduces content C after reproducing contents A and B in the same way as when reproducing the above two contents.
- the reproducing unit 103 starts reproducing content C at time T3.
- reproducing unit 103 reproduces inaudible sound generated according to content C.
- the reproduction unit 103 reproduces the content C to the end.
- the time at which the playback unit 103 finishes playing the content C is defined as time T4.
- time T4 is determined according to the playback time lengths of contents A, B, and C. Therefore, the time length from time T3 to time T4 is independent of the time length from time T1 to time T2 or the time length from time T2 to time T3. In other words, they may be the same or different. be.
- content A corresponds to the first content
- content C corresponds to the second content
- content B corresponds to the third content.
- a plurality of contents B may be used when the above three contents are used.
- the reproducing unit 103 determines the transition of this amplification factor, and also determines the amplification factor of the inaudible sound at each time.
- FIG. 5 is an explanatory diagram showing a first example of the transition of the amplification factor in this embodiment.
- the reproducing unit 103 decreases the amplification factor from 100% to 0% linearly with respect to time in the period from time T1 to time T2. Furthermore, the reproduction unit 103 increases the amplification factor linearly with respect to time from 0% to 100% during the period from time T2 to time T3. In this way, the processing in which the reproducing unit 103 generates the transition of the amplification factor that decreases or increases linearly with respect to time can be realized by relatively simple processing.
- the playback system 1 can induce the user's emotions while adjusting the amplification factor of the inaudible sound through relatively simple processing.
- FIG. 6 is an explanatory diagram showing a second example of the transition of the amplification factor in this embodiment.
- the transition of the amplification factor shown in FIG. 6 is a transition determined based on the position of the chorus part of the content.
- the chorus is a relatively exciting part of the content, or in other words, a part that gives a relatively strong impression to the user who is perceiving the part.
- the process of detecting a hook part in the content can be realized by, for example, a process of extracting a part of the content where the sound pressure is relatively high, and can be executed by the playback unit 103.
- the chorus portion P1 shown in FIG. 6 is the chorus portion of content A, and the chorus portion P2 is the chorus portion of content B.
- the reproduction unit 103 maintains the amplification factor at 100% from time T1 to the end of the chorus P1, and from the end of the chorus P1 to time T2. During the period, the amplification factor is decreased from 100% to 0% linearly with respect to time.
- the reproduction unit 103 increases the amplification factor from 0% to 100% linearly with respect to time during the period from time T2 to the start of the chorus P2, and increases the amplification factor linearly with respect to time from the start of the chorus P2 to the time T3. During this period, the amplification factor is maintained at 100%.
- the section from the start of content A to the end of chorus portion P1 is also referred to as a first section
- the section from the start of chorus portion P2 to the end of content B is also referred to as a second section.
- the amplification factor in the first section is also referred to as a first value, and the first value may be selected from a relatively high amplification factor range (for example, 70% to 100%).
- the amplification factor in the second section is also referred to as a second value, and the second value may be selected from a relatively high amplification factor range (for example, 70% to 100%).
- the processing in which the reproducing unit 103 generates the transition of the amplification factor that linearly decreases or increases with respect to time can be realized by a relatively simple process.
- any one of the plurality of chorus parts may be set as the chorus part P1.
- any one of the plurality of chorus parts may be set as the chorus part P2.
- the last chorus part of the plurality of chorus parts may be set as the chorus part P1.
- the first chorus part of the plurality of chorus parts may be the chorus part P2.
- the playback system 1 adjusts the amplification factor of the inaudible sound through relatively simple processing, thereby improving the user's emotions when the playback unit 103 is playing the chorus of each content. It is possible to more appropriately induce the user's emotions while increasing the intensity.
- FIG. 7 is an explanatory diagram showing a third example of the transition of the amplification factor in this embodiment.
- the transition of the amplification factor shown in FIG. 7 is a transition determined non-linearly with respect to time.
- the reproduction unit 103 decreases the amplification factor from 100% to 0% exponentially with respect to time in the period from time T1 to time T2. Furthermore, the reproduction unit 103 increases the amplification factor from 0% to 100% exponentially with respect to time during the period from time T2 to time T3.
- the transition of the amplification factor shown in FIG. 7 is generally also called an A curve.
- the transition of the amplification factor shown in FIG. 5 is generally also called a B curve.
- the intensity of sound whose amplification factor is adjusted according to the A curve is relatively close to the sense of intensity of sound perceived by humans. Therefore, by using an amplification factor that changes according to the A curve, it is possible to naturally guide the intensity of the user's emotions.
- the playback system 1 can more naturally guide the intensity of the user's emotions.
- the transition of the amplification factor shown in FIG. 7 is generated by replacing the linear change part in the transition of the amplification factor shown in FIG. 5 with an exponential change.
- the linear change part in the amplification factor transition shown in FIG. 6 can be replaced with an exponential change.
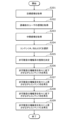
- FIG. 8 is a block diagram showing a first example of processing of the playback system 1 in this embodiment.
- the components that are the main bodies that execute the processes shown below are examples, and the main bodies that execute the processes are other components. It may be.
- step S101 the acquisition unit 101 uses the input IF 11 to acquire the target emotion.
- step S102 the acquisition unit 101 uses the sensor 12 and the recognition unit 102 to acquire the user's emotion before guidance.
- step S103 the acquisition unit 101 transmits the user's pre-guidance emotion and target emotion to the server 20, and requests content to be played by the terminal 10.
- the selection unit 201 acquires the user's pre-guidance emotion and target emotion transmitted by the acquisition unit 101, and selects content corresponding to the acquired user's pre-guidance emotion and target emotion, that is, content that should be played by the terminal 10. The content is selected and the selected content is provided to the acquisition unit 101.
- the content to be played by the terminal 10 includes content A and content B.
- Content A is content that is associated with the user's pre-guidance emotion
- content B is content that is associated with the target emotion.
- the acquisition unit 101 acquires content provided from the selection unit 201.
- step S104 the reproduction unit 103 determines the transition of the amplification factor of the inaudible sound.
- the determined amplification factor transition is, for example, the amplification factor transition shown in FIG. 5, FIG. 6, or FIG. 7.
- step S105 the reproduction unit 103 reproduces the content A while gradually decreasing the amplification factor of the inaudible sound.
- the playback unit 103 generates inaudible sound waveform data from the content A waveform data (sound source waveform data) acquired by the acquisition unit 101 in step S103, and combines the generated inaudible sound waveform data with the waveform data of the generated inaudible sound.
- the reproducing unit 103 gradually lowers the amplification factor of the inaudible sound being reproduced according to the transition determined in step S104.
- step S106 the reproduction unit 103 reproduces content B while gradually increasing the amplification factor of the inaudible sound.
- the playback unit 103 generates inaudible sound waveform data from the waveform data of content B (sound source waveform data) acquired by the acquisition unit 101 in step S103, and combines the generated inaudible sound waveform data with the waveform data of the generated inaudible sound.
- the reproducing unit 103 gradually increases the amplification factor of the inaudible sound being reproduced according to the transition determined in step S104.
- the playback unit 103 plays back content B to the end, it ends the series of processing shown in FIG. 8 .
- the reproduction system 1 can appropriately induce the user's emotions by using two contents and reproduction of inaudible sounds according to the two contents.
- the amplification factor of the inaudible sounds (the first inaudible sound, the second inaudible sound, and the third inaudible sound) when the playback system 1 induces the user's emotions by playing three contents will be explained.
- the reproducing unit 103 (more specifically, the determining unit 112) determines the transition of this amplification factor, and also determines the amplification factor of the inaudible sound at each time.
- the reproduction unit 103 During reproduction of one or more contents B, the reproduction unit 103 gradually increases the amplification factor of the third inaudible sound being reproduced, and then gradually decreases the amplification factor.
- the reproduction unit 103 may set the amplification factor of the third inaudible sound being reproduced to 0 at the start and end of reproduction of one or more contents B.
- FIG. 9 is an explanatory diagram showing a fourth example of the transition of the amplification factor in this embodiment.
- the reproducing unit 103 decreases the amplification factor from 100% to 0% linearly with respect to time in the period from time T1 to time T2.
- the reproducing unit 103 increases the amplification factor from 0% to 100% linearly with respect to time in the period from time T2 to time T2A, and then increases the amplification factor in the period from time T2A to time T3. decreases linearly with time from 100% to 0%.
- Time T2A is any time between time T2 and time T3, and may be, for example, an intermediate time between time T2 and time T3.
- the reproduction unit 103 increases the amplification factor from 0% to 100% linearly with respect to time in the period from time T3 to time T3.
- the processing in which the reproducing unit 103 generates the transition of the amplification factor that linearly decreases or increases with respect to time can be realized by a relatively simple process.
- the playback system 1 can induce the user's emotions while adjusting the amplification factor of the inaudible sound through relatively simple processing.
- FIG. 10 is an explanatory diagram showing a fifth example of the transition of the amplification factor in this embodiment.
- the transition of the amplification factor shown in FIG. 10 is a transition determined based on the position of the chorus part of the content.
- a chorus portion P1 shown in FIG. 10 is a chorus portion of content A
- a chorus portion P2 is a chorus portion of content B
- a chorus portion P3 is a chorus portion of content C.
- the transition of the amplification factor in the period from time T1 to time T2 is the same as that in FIG. 6.
- the reproduction unit 103 increases the amplification factor from 0% to 100% linearly with respect to time during the period from time T2 to the start of the chorus P2, and increases the amplification factor from the start of the chorus P2 to the end of the chorus P2. During this period, the amplification factor is maintained at 100%. Furthermore, the reproduction unit 103 decreases the amplification factor from 100% to 0% linearly with respect to time during the period from the end of the chorus portion P2 to time T3.
- the reproduction unit 103 increases the amplification factor from 0% to 100% linearly with respect to time during the period from time T3 to the start of the chorus P3, and increases the amplification factor linearly with respect to time from the start of the chorus P3 to the time T4. During this period, the amplification factor is maintained at 100%.
- section from the start of content A to the end of chorus portion P1 corresponds to the first section
- section from the start of chorus section P3 to the end of content C corresponds to the second section.
- the section from the start to the end of the chorus P2 is also referred to as a third section.
- the amplification factor in the third section is also referred to as a third value, and the third value may be selected from a relatively high amplification factor range (for example, 70% to 100%).
- the processing in which the reproducing unit 103 generates the transition of the amplification factor that linearly decreases or increases with respect to time can be realized by a relatively simple process.
- any one of the plurality of chorus parts may be set as the chorus part P1.
- any one of the plurality of chorus parts may be set as the chorus part P2.
- any one of the plurality of chorus parts may be set as the chorus part P3.
- the content A may be the last chorus part P1 of the multiple chorus parts.
- the period from the start of the first chorus part to the end of the last chorus part among the plurality of chorus parts may be defined as the chorus part P2.
- the last chorus part of the plurality of chorus parts may be the chorus part P3.
- the playback system 1 adjusts the amplification factor of the inaudible sound through relatively simple processing, thereby improving the user's emotions when the playback unit 103 is playing the chorus of each content. It is possible to more appropriately induce the user's emotions while increasing the intensity.
- the linear change portion in the transition of the amplification factor shown in FIG. 9 or FIG. 10 can also be replaced with an exponential change.
- the playback system 1 can more appropriately guide the user's emotions while increasing the intensity of the user's emotions when the playback unit 103 is playing the chorus of each content.
- FIG. 11 is a block diagram showing a second example of processing of the playback system 1 in this embodiment.
- step S201 the acquisition unit 101 uses the input IF 11 to acquire the target emotion.
- step S202 the acquisition unit 101 uses the sensor 12 and the recognition unit 102 to acquire the user's emotion before guidance.
- step S203 the acquisition unit 101 acquires an emotion (also referred to as an intermediate emotion) that is used to guide the target emotion from the emotion before induction.
- the intermediate emotion may be obtained by inputting it into the input IF 11 from the user, or may be determined by the obtaining unit 101 based on the emotion before induction and the target emotion.
- step S204 the acquisition unit 101 transmits the user's pre-guidance emotion, intermediate emotion, and target emotion to the server 20, and requests the content to be reproduced by the terminal 10.
- the selection unit 201 acquires the user's pre-guidance emotion, intermediate emotion, and target emotion transmitted by the acquisition unit 101, and selects content corresponding to the acquired user's pre-guidance emotion, intermediate emotion, and target emotion, that is, Content to be reproduced is selected by the terminal 10 and the selected content is provided to the acquisition unit 101.
- the content to be played by the terminal 10 includes content A, B, and C.
- Content A is content associated with a user's pre-guidance emotion
- content B is content associated with an intermediate emotion
- content C is content associated with a target emotion.
- the acquisition unit 101 acquires content provided from the selection unit 201.
- step S205 the reproduction unit 103 determines the transition of the amplification factor of the inaudible sound.
- the determined amplification factor transition is, for example, the amplification factor transition shown in FIG. 9 or FIG. 10.
- step S206 the reproduction unit 103 reproduces the content A while gradually decreasing the amplification factor of the inaudible sound.
- the process of reproducing content A while gradually decreasing the amplification factor of the inaudible sound is performed in the same manner as step S105 (FIG. 8) according to the transition determined in step S205.
- the reproduction unit 103 reproduces content A to the end the process proceeds to step S207.
- step S207 the reproduction unit 103 reproduces content B while gradually increasing the amplification factor of the inaudible sound.
- the reproduction unit 103 proceeds to step S208 at a timing before the content B is reproduced to the end (time T2A in FIG. 9 or a time included in the chorus portion P2 in FIG. 10).
- the process of reproducing content B continues in step S208.
- the process of reproducing content B while gradually increasing the amplification factor of the inaudible sound is performed in the same manner as step S106 (FIG. 8) according to the transition determined in step S205.
- step S208 the reproduction unit 103 reproduces content B while gradually decreasing the amplification factor of the inaudible sound.
- Reproduction of content B continues from step S207.
- the process of reproducing content B while gradually decreasing the amplification factor of the inaudible sound is performed in the same manner as step S105 (FIG. 8) according to the transition determined in step S205.
- the reproduction unit 103 reproduces content B to the end the process advances to step S209.
- step S209 the reproduction unit 103 reproduces the content C while gradually increasing the amplification factor of the inaudible sound.
- the process of reproducing content C while gradually increasing the amplification factor of the inaudible sound is performed in the same manner as step S106 (FIG. 8) according to the transition determined in step S205.
- step S106 FIG. 8
- the playback unit 103 ends the series of processing shown in FIG. 11 .
- the process in step S203 may be executed by the selection unit 201 instead of being executed by the acquisition unit 101. That is, the selection unit 201 may acquire the intermediate emotion.
- the intermediate emotion may be determined by the selection unit 201 based on the emotion before induction and the target emotion.
- the selection unit 201 determines an intermediate emotion
- the emotion before induction and the target emotion necessary for determining the intermediate emotion are those acquired by the acquisition unit 101 in steps S201 and S202, and are transmitted to the server 20 after acquisition. It can be something that has been done.
- the selection unit 201 may transmit the intermediate emotion to the acquisition unit 101 in step S203.
- step S204 the selection unit 201 selects contents A, B, and C using the pre-guidance emotion and target emotion acquired in step S203, and the intermediate emotion acquired in step S204.
- the playback system 1 can appropriately induce the user's emotions using the three contents and the playback of inaudible sounds according to the three contents.
- the playback system 1 in this modified example guides the user's emotions by playing back content, senses the guided user's emotions, and responds to the user's emotions. to control the amplification factor of inaudible sounds.
- the reproduction unit 103 holds a target transition indicating a predetermined transition of the emotions of the user whose emotions are to be induced.
- the goal transition is information indicating the type of emotion of the user whose emotions are being induced and the intensity of the emotion.
- the reproduction unit 103 adjusts the amplification factor of the first inaudible sound being reproduced so as to bring the user's emotion closer to the target transition. do.
- the reproduction unit 103 may set the amplification factor of the first inaudible sound being reproduced to 0 when the emotion recognized by the recognition unit 102 deviates from the target transition.
- the fact that the user's emotion deviates from the target transition can be determined by determining whether the difference between the user's emotion and the emotion in the target transition is greater than or equal to a predetermined value.
- FIG. 12 is an explanatory diagram showing the target transition in this modification.
- the target transition with respect to time (corresponding to time code) is shown.
- the target transition shown in FIG. 12 shows the target transition in the case where the emotion before induction is excitement, the target emotion is relaxation, and two contents are used to induce the user's emotion.
- the intensity of emotion is shown as an example in the range of 0% to 100%, but it is not limited to this.
- the type of emotion is excitement, and the emotion intensity gradually decreases from 100% to 0%.
- the type of emotion is relaxing, and the emotion intensity gradually increases from 0% to 100%.
- FIG. 13 is a flow diagram showing the processing of the playback system 1 in this modification.
- the playback system 1 simultaneously executes the process shown in FIG. 13 while the playback unit 103 is playing back the content (for example, steps S105 and S106 in FIG. 8).
- steps S105 and S106 in FIG. 8 As an example of the transition of the amplification factor of the inaudible sound, the transition of the amplification factor shown in FIG. 5 will be described as determined (step S104).
- step S301 the acquisition unit 101 acquires the time code at the time of reproduction of the content being reproduced by the reproduction unit 103.
- the time code indicates which temporal position in the content being played back is being played back by the playback unit 103.
- step S302 the acquisition unit 101 acquires the emotion at the time of reproduction in the target transition.
- the emotion at the time of reproduction includes the type of emotion and the intensity of the emotion.
- step S303 the acquisition unit 101 acquires the user's current emotion (that is, at the time when this process is executed).
- step S304 the acquisition unit 101 determines whether the difference between the emotion at the playback position in the target transition acquired in step S302 and the user's current emotion acquired in step S303 is greater than or equal to a predetermined value. For example, if the type of emotion at the playback position in the target transition is the same as the type of the user's current emotion, and the intensity of the emotion at the playback position in the goal transition is If the intensity is higher or lower by 10 points or more, it may be determined that the difference is greater than or equal to a predetermined value. Further, for example, when the type of emotion at the playback position in the target transition is different from the type of emotion of the user at the current time, the acquisition unit 101 may determine that the difference is greater than or equal to a predetermined value. If it is determined that the difference is greater than or equal to a predetermined value (Yes in step S304), the process proceeds to step S305, and if not, step S301 is executed again.
- step S305 the acquisition unit 101 adjusts the amplification factor. For example, if the type of emotion at the playback position in the target transition is the same as the type of the user's current emotion, and the intensity of the emotion at the playback position in the goal transition is If the intensity is 10 points or more higher, the current amplification factor in the amplification factor transition determined in step S104 is adjusted to a lower value. At this time, if the amplification factor after the current point in the transition of the amplification factor determined in step S104 is on a decreasing trend, the acquisition unit 101 reduces the amplification factor after the current point to less than or equal to the adjusted amplification factor at the current point. You may adjust it accordingly.
- the acquisition unit 101 may determine whether the type of emotion at the playback position in the goal transition is the same as the type of emotion at the user's current moment, and the intensity of the emotion at the playback position in the goal transition is If the intensity of the emotion is lower by 10 points or more, the current amplification factor in the amplification factor transition determined in step S104 is adjusted to a higher value. At this time, if the amplification factor after the current point in the transition of the amplification factor determined in step S104 is on an increasing trend, the acquisition unit 101 sets the amplification factor after the current point to be higher than the adjusted amplification factor at the current point. You may adjust it accordingly.
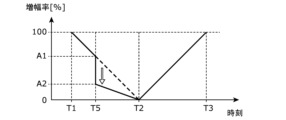
- FIG. 14 is an explanatory diagram showing an example of emotion transition in this modification.
- FIG. 15 is an explanatory diagram showing an example of the transition of the amplification factor in this modification.
- FIG. 14 shows the transition of the user's actual emotions, whose emotions are induced by the playback system 1, as well as the transition of the goal.
- the user's actual emotion transition is a temporal transition of the user's emotion obtained by the sensor 12 and recognition unit 102.
- the actual emotion of the user shown in FIG. 14 is an emotion of excitement whose intensity is 100% at time T1, and is decreasing from 100% after time T1.
- the acquisition unit 101 determines that the difference d between the emotional intensity of the user at the current moment and the emotional intensity at the playback position in the target transition is 10 points or more higher.
- the reproducing unit 103 adjusts the amplification factor at time T5 to decrease from the value A1 before adjustment to the value A2. Further, the transition of the amplification factor after time T5 is adjusted so as to gradually decrease from the adjusted value A2 (see FIG. 15). By doing so, the playback system 1 enhances the effect of reducing the intensity of the user's excitement, and contributes to inducing the user's emotions with a transition close to the target transition.
- the reproducing unit 103 may set the amplification factor to 0 after time T5.
- the reason why the reproduction unit 103 sets the amplification factor to 0 after time T5 is, for example, in step S304, when the acquisition unit 101 determines that the type of emotion at the reproduction position in the target transition is different from the type of emotion of the user at the current time. This is the case when it is determined.
- the playback system 1 can stop playing the inaudible sound (that is, stop inducing the user's emotions). If the user is not in a state suitable for having their emotions induced, inducing the user's emotions may have a negative impact on the user (for example, causing a psychological burden), and this should be suppressed. Contribute to things.
- the present disclosure can be used in a system that induces a user's emotions.
- Playback system 10 Terminal 11 Input IF 12 Sensor 13, 21 Communication IF 14, 22 Processor 15 Speaker 20 Server 23 Storage 101 Acquisition unit 102 Recognition unit 103 Reproduction unit 111 Generation unit 112 Determination unit 113 Adjustment unit 114 Addition unit 201 Selection unit N Network P, Q Route
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- General Physics & Mathematics (AREA)
- Human Computer Interaction (AREA)
- Chemical & Material Sciences (AREA)
- Mechanical Engineering (AREA)
- Transportation (AREA)
- Combustion & Propulsion (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- Circuit For Audible Band Transducer (AREA)
- Reverberation, Karaoke And Other Acoustics (AREA)
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024545425A JPWO2024053123A1 (https=) | 2022-09-05 | 2022-12-02 | |
| CN202280099564.8A CN119817115A (zh) | 2022-09-05 | 2022-12-02 | 再现系统、再现方法及程序 |
| EP22958201.0A EP4586641A4 (en) | 2022-09-05 | 2022-12-02 | READING SYSTEM, READING METHOD AND PROGRAM |
| US19/062,472 US20250192743A1 (en) | 2022-09-05 | 2025-02-25 | Reproduction system, reproduction method, and recording medium |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022-141032 | 2022-09-05 | ||
| JP2022141032 | 2022-09-05 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US19/062,472 Continuation US20250192743A1 (en) | 2022-09-05 | 2025-02-25 | Reproduction system, reproduction method, and recording medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024053123A1 true WO2024053123A1 (ja) | 2024-03-14 |
Family
ID=90192214
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/044501 Ceased WO2024053123A1 (ja) | 2022-09-05 | 2022-12-02 | 再生システム、再生方法、および、プログラム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20250192743A1 (https=) |
| EP (1) | EP4586641A4 (https=) |
| JP (1) | JPWO2024053123A1 (https=) |
| CN (1) | CN119817115A (https=) |
| WO (1) | WO2024053123A1 (https=) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010266748A (ja) * | 2009-05-15 | 2010-11-25 | Panasonic Electric Works Co Ltd | 音響振動再生装置並びに音響振動再生方法 |
| JP2014226361A (ja) * | 2013-05-23 | 2014-12-08 | ヤマハ株式会社 | 音源装置およびプログラム |
| JP2017050597A (ja) * | 2015-08-31 | 2017-03-09 | 株式会社竹中工務店 | 音源処理装置、音響装置及び部屋 |
| JP2019006191A (ja) | 2017-06-22 | 2019-01-17 | マツダ株式会社 | 車両用サウンドシステム |
| WO2021192072A1 (ja) * | 2020-03-25 | 2021-09-30 | ヤマハ株式会社 | 室内用音環境生成装置、音源装置、室内用音環境生成方法および音源装置の制御方法 |
-
2022
- 2022-12-02 WO PCT/JP2022/044501 patent/WO2024053123A1/ja not_active Ceased
- 2022-12-02 EP EP22958201.0A patent/EP4586641A4/en active Pending
- 2022-12-02 CN CN202280099564.8A patent/CN119817115A/zh active Pending
- 2022-12-02 JP JP2024545425A patent/JPWO2024053123A1/ja active Pending
-
2025
- 2025-02-25 US US19/062,472 patent/US20250192743A1/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010266748A (ja) * | 2009-05-15 | 2010-11-25 | Panasonic Electric Works Co Ltd | 音響振動再生装置並びに音響振動再生方法 |
| JP2014226361A (ja) * | 2013-05-23 | 2014-12-08 | ヤマハ株式会社 | 音源装置およびプログラム |
| JP2017050597A (ja) * | 2015-08-31 | 2017-03-09 | 株式会社竹中工務店 | 音源処理装置、音響装置及び部屋 |
| JP2019006191A (ja) | 2017-06-22 | 2019-01-17 | マツダ株式会社 | 車両用サウンドシステム |
| WO2021192072A1 (ja) * | 2020-03-25 | 2021-09-30 | ヤマハ株式会社 | 室内用音環境生成装置、音源装置、室内用音環境生成方法および音源装置の制御方法 |
Non-Patent Citations (2)
| Title |
|---|
| JUNICHIRO HAYANO: "Health and Medical New Technology Presentation Meetings", 3 October 2017, JAPAN SCIENCE AND TECHNOLOGY AGENCY, article "Estimation of Emotion Spectra from Biosignals" |
| KAORI TAKEDA: "Bulletin of Nayoro City University", vol. 5, 31 March 2011, article "Effect of Negative Emotions (Anger, Depression, Anxiety) on Blood Pressure" |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2024053123A1 (https=) | 2024-03-14 |
| EP4586641A1 (en) | 2025-07-16 |
| CN119817115A (zh) | 2025-04-11 |
| EP4586641A4 (en) | 2025-12-10 |
| US20250192743A1 (en) | 2025-06-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101590046B1 (ko) | 바이노럴 비트를 이용한 뇌파 유도 오디오 장치 및 방법 | |
| US9191764B2 (en) | Binaural audio signal-based applications | |
| WO2007081051A1 (ja) | コンテンツ再生装置および再生方法 | |
| WO2016063879A1 (ja) | 音声合成装置および方法 | |
| WO2018038235A1 (ja) | 聴覚トレーニング装置、聴覚トレーニング方法、およびプログラム | |
| JP6266427B2 (ja) | ユーザのストレス度に応じて音楽を選択する装置、プログラム及び方法 | |
| JP6477298B2 (ja) | 音源装置 | |
| JP2023025013A (ja) | 音楽療法のための歌唱補助装置 | |
| JP2010259457A (ja) | 放音制御装置 | |
| WO2024053123A1 (ja) | 再生システム、再生方法、および、プログラム | |
| JP2005064744A (ja) | 聴覚補助装置 | |
| JP6539547B2 (ja) | 音源処理装置、音響装置及び部屋 | |
| JP5997369B2 (ja) | リハビリテーション支援装置及びその制御方法 | |
| JP5790021B2 (ja) | 音声出力システム | |
| US8163991B2 (en) | Headphone metronome | |
| JP2017138506A (ja) | 環境音生成装置及びそれを用いた環境音生成システム、環境音生成プログラム、音環境形成方法及び記録媒体 | |
| JP2016188920A (ja) | 端末装置、サーバ、歌唱データ生成方法、及び、プログラム | |
| WO2019150442A1 (ja) | プログラム、コンピュータ読み取り可能な記録媒体、携帯端末、および運動支援システム | |
| JP2016157084A (ja) | 再生装置、再生方法、及び、プログラム | |
| JP2021099535A (ja) | 再生装置、再生方法、及び、プログラム | |
| JP2016157082A (ja) | 再生装置、再生方法、及び、プログラム | |
| JP2016157088A (ja) | 楽曲再生システム、端末装置、楽曲データ提供方法、及び、プログラム | |
| JP2019219675A (ja) | 音声信号出力装置、音声信号出力方法、及び、プログラム | |
| JP3106929U (ja) | 催眠効果を有する音声データを記憶するための情報記憶媒体 | |
| JP2016157087A (ja) | 楽曲再生システム、サーバ、楽曲データ提供方法、及び、プログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22958201 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2024545425 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202280099564.8 Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2022958201 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWP | Wipo information: published in national office |
Ref document number: 202280099564.8 Country of ref document: CN |
|
| ENP | Entry into the national phase |
Ref document number: 2022958201 Country of ref document: EP Effective date: 20250407 |
|
| WWP | Wipo information: published in national office |
Ref document number: 2022958201 Country of ref document: EP |