WO2024053123A1 - 再生システム、再生方法、および、プログラム - Google Patents
再生システム、再生方法、および、プログラム Download PDFInfo
- Publication number
- WO2024053123A1 WO2024053123A1 PCT/JP2022/044501 JP2022044501W WO2024053123A1 WO 2024053123 A1 WO2024053123 A1 WO 2024053123A1 JP 2022044501 W JP2022044501 W JP 2022044501W WO 2024053123 A1 WO2024053123 A1 WO 2024053123A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- content
- amplification factor
- emotion
- reproduction
- inaudible sound
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims description 36
- 230000008451 emotion Effects 0.000 claims abstract description 346
- 230000003321 amplification Effects 0.000 claims abstract description 215
- 238000003199 nucleic acid amplification method Methods 0.000 claims abstract description 215
- 230000007704 transition Effects 0.000 claims description 99
- HAORKNGNJCEJBX-UHFFFAOYSA-N cyprodinil Chemical group N=1C(C)=CC(C2CC2)=NC=1NC1=CC=CC=C1 HAORKNGNJCEJBX-UHFFFAOYSA-N 0.000 claims description 75
- 230000001965 increasing effect Effects 0.000 claims description 29
- 230000003247 decreasing effect Effects 0.000 claims description 19
- 241001342895 Chorus Species 0.000 description 31
- 238000010586 diagram Methods 0.000 description 28
- 230000008569 process Effects 0.000 description 25
- 238000004891 communication Methods 0.000 description 17
- 230000006698 induction Effects 0.000 description 17
- 230000007423 decrease Effects 0.000 description 16
- 230000008859 change Effects 0.000 description 15
- 230000004048 modification Effects 0.000 description 10
- 238000012986 modification Methods 0.000 description 10
- 230000036772 blood pressure Effects 0.000 description 9
- 230000036760 body temperature Effects 0.000 description 8
- 238000005516 engineering process Methods 0.000 description 8
- 230000001939 inductive effect Effects 0.000 description 8
- 230000000694 effects Effects 0.000 description 6
- 241000282412 Homo Species 0.000 description 5
- 238000007792 addition Methods 0.000 description 4
- 239000012141 concentrate Substances 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 230000008929 regeneration Effects 0.000 description 4
- 238000011069 regeneration method Methods 0.000 description 4
- 206010016352 Feeling of relaxation Diseases 0.000 description 3
- 230000002996 emotional effect Effects 0.000 description 3
- 230000010365 information processing Effects 0.000 description 2
- 230000002040 relaxant effect Effects 0.000 description 2
- 238000005728 strengthening Methods 0.000 description 2
- 230000002123 temporal effect Effects 0.000 description 2
- 208000019901 Anxiety disease Diseases 0.000 description 1
- 208000032140 Sleepiness Diseases 0.000 description 1
- 206010041349 Somnolence Diseases 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 230000036506 anxiety Effects 0.000 description 1
- 230000037007 arousal Effects 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 230000008909 emotion recognition Effects 0.000 description 1
- 230000001815 facial effect Effects 0.000 description 1
- 230000008921 facial expression Effects 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 230000036651 mood Effects 0.000 description 1
- 230000000452 restraining effect Effects 0.000 description 1
- 230000037321 sleepiness Effects 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 210000000707 wrist Anatomy 0.000 description 1
Images











Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61M—DEVICES FOR INTRODUCING MEDIA INTO, OR ONTO, THE BODY; DEVICES FOR TRANSDUCING BODY MEDIA OR FOR TAKING MEDIA FROM THE BODY; DEVICES FOR PRODUCING OR ENDING SLEEP OR STUPOR
- A61M21/00—Other devices or methods to cause a change in the state of consciousness; Devices for producing or ending sleep by mechanical, optical, or acoustical means, e.g. for hypnosis
- A61M21/02—Other devices or methods to cause a change in the state of consciousness; Devices for producing or ending sleep by mechanical, optical, or acoustical means, e.g. for hypnosis for inducing sleep or relaxation, e.g. by direct nerve stimulation, hypnosis, analgesia
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10K—SOUND-PRODUCING DEVICES; METHODS OR DEVICES FOR PROTECTING AGAINST, OR FOR DAMPING, NOISE OR OTHER ACOUSTIC WAVES IN GENERAL; ACOUSTICS NOT OTHERWISE PROVIDED FOR
- G10K15/00—Acoustics not otherwise provided for
- G10K15/02—Synthesis of acoustic waves
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10K—SOUND-PRODUCING DEVICES; METHODS OR DEVICES FOR PROTECTING AGAINST, OR FOR DAMPING, NOISE OR OTHER ACOUSTIC WAVES IN GENERAL; ACOUSTICS NOT OTHERWISE PROVIDED FOR
- G10K15/00—Acoustics not otherwise provided for
- G10K15/04—Sound-producing devices
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R3/00—Circuits for transducers, loudspeakers or microphones
Definitions
- the present disclosure relates to a playback system, a playback method, and a program.
- the present disclosure provides a playback system, a playback method, and a program that appropriately induce a user's emotions using playback of inaudible sounds.
- a playback system in the present disclosure is a content playback system that guides a user's emotion from a first emotion to a second emotion, and includes a first content corresponding to the first emotion and a second content corresponding to the second emotion.
- the second amplification factor of the second inaudible sound being played is gradually increased during playback of the second content.
- the playback system according to the present disclosure can appropriately induce the user's emotions using playback of inaudible sounds.
- FIG. 2 is an explanatory diagram showing human emotions and emotion induction.
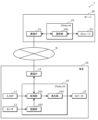
- FIG. 1 is a block diagram showing the configuration of a playback system in an embodiment.
- FIG. 2 is a block diagram showing the configuration of a playback section in an embodiment.
- FIG. 3 is an explanatory diagram showing reproduction of content by a reproduction unit in the embodiment.
- FIG. 3 is an explanatory diagram showing a first example of the transition of the amplification factor in the embodiment.
- FIG. 7 is an explanatory diagram showing a second example of the transition of the amplification factor in the embodiment.
- FIG. 7 is an explanatory diagram showing a third example of the transition of the amplification factor in the embodiment.
- FIG. 3 is a flow diagram showing a first example of processing of the playback system in the embodiment.
- FIG. 1 is a block diagram showing the configuration of a playback system in an embodiment.
- FIG. 2 is a block diagram showing the configuration of a playback section in an embodiment.
- FIG. 3 is an ex
- FIG. 7 is an explanatory diagram showing a fourth example of the change in amplification factor in the embodiment.
- FIG. 7 is an explanatory diagram showing a fifth example of the change in amplification factor in the embodiment. It is a flowchart which shows the second example of the process of the reproduction
- FIG. 7 is an explanatory diagram showing an example of emotion transition in a modification of the embodiment.
- FIG. 7 is an explanatory diagram showing an example of the transition of the amplification factor in a modification of the embodiment.
- the above technology is based on the premise that the audio sound of the content includes audible sounds and inaudible sounds. Then, by switching between applying or not applying a filter that removes inaudible sounds from audio sounds, it is possible to switch between outputting audible sounds and inaudible sounds, or outputting only audible sounds. It is known that inaudible sounds have the effect of activating the brains of people who perceive them.
- the driver when the driver should concentrate on driving the vehicle, the driver is made to perceive audible sounds and inaudible sounds, which contributes to making the driver concentrate on driving. Furthermore, when there is no need to concentrate on driving, the driver can only perceive audible sounds, contributing to relaxing and enjoying the audio. In this way, the above technology induces the driver's emotions.
- the inventor of the present application when inducing a person's emotions, the inventor of the present application first listens to music that corresponds to the person's current (that is, before induction) emotion, and then plays music that corresponds to the target emotion that the person wants to induce. The idea was that by asking people to listen to them, it might be possible to induce their emotions more appropriately. In addition, when inducing emotions, by playing non-audible sounds and appropriately controlling the intensity of the sound pressure of the non-audible sounds being played, it is possible to control the intensity of a person's emotions, and the intensity of the person's emotions can be controlled. The idea was that it might be possible to more appropriately guide people's emotions.
- a content playback system that guides a user's emotion from a first emotion to a second emotion, which includes a first content corresponding to the first emotion and a second content corresponding to the second emotion.
- the playback system causes the user to perceive the first content that gives the same impression as the user's emotion (first emotion) before induction, together with the inaudible sound, and then the second content that gives the same impression as the target emotion.
- first emotion the user's emotion
- second content the user's emotions are guided to the target emotion based on the principle of homogeneity.
- the amplification factor of the inaudible sound is gradually lowered to weaken the intensity of the user's emotions before the induction, and then the amplification factor of the inaudible sound is gradually reduced while the second content is played back. This contributes to increasing the intensity of the user's target emotion.
- the playback system can appropriately induce the user's emotions using the playback of inaudible sounds.
- the playback unit sets the first amplification factor to 0 at the end of playback of the first content, and sets the second amplification factor to 0 at the start of playback of the second content;
- the playback system sets the amplification factor of the inaudible sound to 0 at the timing of switching the content to be played back, so the playback system switches the content at the timing when the intensity of the user's emotion before guidance is the weakest, and then It contributes to gradually strengthening the target emotion. Therefore, the playback system can more appropriately induce the user's emotions using the playback of inaudible sounds.
- the reproduction unit is configured to: The first amplification factor of the inaudible sound is maintained at a first value, and the first amplification factor of the first inaudible sound being reproduced is changed from the first value in a section after the first section.
- the second inaudible sound is gradually lowered and is being played during the playback of the second content in a second section from the start of the chorus part included in the second content to the end of the second content.
- the second amplification factor of the second inaudible sound being played is maintained at a second value, and the second amplification factor of the second inaudible sound being reproduced is gradually increased toward the second value in a section before the second section.
- the regeneration system according to (1) or (2), wherein the regeneration system is increased to
- the playback system further increases the intensity of the user's emotion before the guidance when the user perceives the chorus part of the first content, and further increases the intensity of the user's emotion before the guidance when the user perceives the chorus part of the second content.
- the intensity of the user's target emotion can be further increased. Therefore, the playback system can induce the user's emotions more appropriately.
- the playback section reduces the first amplification factor linearly with respect to time, and during playback of the second content,
- the reproduction system according to any one of (1) to (3), wherein when gradually increasing the second amplification factor, the second amplification factor is increased linearly with respect to time.
- the reproduction system can reduce or increase the amplification factor of the inaudible sound through a relatively simple process of decreasing or increasing the amplification factor of the inaudible sound linearly with respect to time. . Therefore, the playback system can appropriately induce the user's emotions using the playback of inaudible sounds through relatively simple processing.
- the reproduction unit decreases the first amplification factor exponentially with respect to time
- the reproduction system according to any one of (1) to (3), wherein when gradually increasing the second amplification factor during reproduction, the second amplification factor is increased exponentially with respect to time.
- the playback system exponentially decreases or increases the amplification factor of the non-audible sound with respect to time, so that the user can enjoy the non-audible sound that is similar to the sense of strength of sound perceived by humans.
- the playback system can appropriately induce the user's emotions using the playback of the inaudible sound by using appropriate intensities of the inaudible sound.
- the playback system further includes a recognition unit that recognizes the user's emotion when the playback unit is playing the first content or the second content; when the emotion recognized by the unit deviates from a predetermined transition, the first amplification of the first inaudible sound being played so as to bring the user's emotion closer to the predetermined transition;
- the reproduction system according to any one of (1) to (5), which adjusts the rate.
- the playback system when the user's emotions while playing the content change differently from the predetermined change, the playback system can cause the user's emotions to change close to the predetermined change. can. Therefore, the playback system can more appropriately induce the user's emotions using the playback of inaudible sounds.
- the playback system further includes a recognition unit that recognizes the user's emotion when the playback unit is playing the first content or the second content, and the playback unit According to any one of (1) to (5), the amplification factor of the first inaudible sound being reproduced is set to 0 when the emotion recognized by the section deviates from a predetermined trend. playback system.
- the playback system has a negative effect on the user by stopping the playback of the inaudible sound when the user's emotions change differently from a predetermined change during playback of the content. Contributes to restraining giving. Therefore, the playback system can more appropriately induce the user's emotions using the playback of inaudible sounds.
- the playback system easily induces the user's emotions by continuously playing the first content and the second content.
- the playback system can more easily induce the user's emotions appropriately by using the playback of inaudible sounds.
- the playback system guides the user's emotion from the first emotion to the second emotion via one or more third emotions
- the acquisition unit guides the user's emotion from the first emotion to the second emotion via one or more third emotions.
- One or more third contents corresponding to the respective third contents are acquired, and the reproduction unit sequentially reproduces each of the one or more third contents after the reproduction of the first content is finished.
- the third content is played back along with a corresponding third inaudible sound, and when the playback of the one or more third contents is finished, the playback of the second content is started, and the playback of each of the one or more third contents is started.
- the reproduction system according to any one of (1) to (8), wherein during reproduction, the third amplification factor of the third inaudible sound being reproduced is gradually increased and then gradually decreased.
- the playback system easily induces the user's emotions by continuously playing the first content, third content, and second content in this order.
- the playback system can more easily induce the user's emotions appropriately by using the playback of inaudible sounds.
- the playback system sets the amplification factor of the inaudible sound to 0 at the timing of switching the content to be played back, so the playback system switches the content at the timing when the intensity of the user's emotion before guidance is the weakest, and then It contributes to gradually strengthening the target emotion. Therefore, the playback system can more appropriately induce the user's emotions using the playback of inaudible sounds.
- the reproduction section is configured to reproduce the third inaudible sound being reproduced in a third section including from the start to the end of the chorus of the third content.
- the third amplification factor is maintained at a third value, and in the section before the third section, the third amplification factor of the third inaudible sound being reproduced is gradually moved toward the third value. as described in (9) or (10), wherein the third amplification factor of the third inaudible sound being reproduced is gradually decreased from the third value in a section after the third section. playback system.
- the playback system can further increase the intensity of the user's intermediate emotion when the user is perceiving the chorus part of the third content. Therefore, the playback system can more appropriately guide the user's emotions via intermediate emotions.
- the playback system further includes a selection unit that selects the first content corresponding to the first emotion and the second content corresponding to the second emotion from among the plurality of contents. , the reproduction system according to any one of (1) to (11), wherein the acquisition unit acquires the first content and the second content selected by the selection unit.
- the playback system appropriately selects the first content and second content corresponding to the user's emotion before induction and the target emotion, and combines the selected first content and second content with each other. can be used to induce the user's emotions. Therefore, the reproduction system can appropriately induce the user's emotions by using appropriate content and reproduction of inaudible sounds according to the content.
- a reproduction method executed by one or more computers included in a content reproduction system which guides a user's emotion from a first emotion to a second emotion, the first content corresponding to the first emotion; (a) A first inaudible sound corresponding to the first content, the basic signal of the first inaudible sound is transmitted by a speaker at a first amplification rate; (b) a second amplification of the basic signal of the second inaudible sound, which is a second inaudible sound corresponding to the second content; reproducing the second content together with a second inaudible sound amplified by a factor of 1, and gradually decreasing the first amplification factor of the first inaudible sound being reproduced while the first content is being played; A reproduction method that gradually increases the second amplification factor of the second inaudible sound being reproduced while the second content is being reproduced.
- FIG. 1 is an explanatory diagram showing human emotions and changes (also referred to as transitions) in human emotions.
- FIG. 1 a diagram is shown in which a plurality of human emotions (for example, tension, joy, relaxation, etc.) are arranged in a ring.
- FIG. 1 is also generally referred to as Russell's circle of emotions model.
- human emotions are known to be arranged on a two-dimensional plane consisting of a pleasure and displeasure axis (horizontal axis) and an arousal and sleepiness axis (vertical axis). ing.
- the emotion may include concepts such as feeling, mood, psychological state, or emotion.
- the transition of a person's emotions is expressed in Figure 1 as a movement from a position corresponding to one emotion to a position corresponding to another emotion. Changing a person's emotions is also called inducing emotions.
- Paths from tension to relaxation include, for example, paths P and Q.
- Path P is a path that transitions from tension to relaxation directly (that is, without going through other emotions).
- Path Q is a path that transitions from tension to relaxation via the emotion of joy, which is an example of another emotion. If the distance between the person's emotions before being induced and the emotions of the person after being induced is relatively large, it may be appropriate to induce the emotion via another emotion.
- the playback system 1 contributes to appropriately guiding the user's emotions to a target emotion through an arbitrary route.
- FIG. 2 is a block diagram showing the configuration of the playback system 1 in this embodiment.
- the reproduction system 1 guides the user's emotion from an emotion before being induced (also referred to as a pre-induction emotion or a first emotion) to a target emotion (also referred to as a target emotion or a second emotion). It is an information processing system that
- the playback system 1 includes a terminal 10 and a server 20.
- the terminal 10 and the server 20 are connected via a network N.
- Network N may consist of any communication line or network, and may include, for example, the Internet, a mobile phone carrier network, an Internet provider's access network, or a public access network.
- the terminal 10 is an information processing terminal that outputs sound related to content and makes it perceptible to the user.
- Terminal 10 may be, for example, a smartphone, a tablet, a personal computer, or the like.
- the terminal 10 includes an input IF 11, a sensor 12, a communication IF 13, a processor 14, and a speaker 15.
- the input IF 11 receives information input from the user.
- the information received by the input IF 11 includes a target emotion (for example, relaxation).
- the information received by the input IF 11 may include emotions (also referred to as intermediate emotions) to be passed through in order to guide the emotion from the emotion before induction to the target emotion.
- the playback system 1 guides the user's emotion from the pre-guidance emotion to the target emotion via an intermediate emotion
- the information received by the input IF 11 needs to include the intermediate emotion (for example, joy). Note that there may be one intermediate emotion, or there may be two or more intermediate emotions.
- the input IF 11 is, for example, a touch interface, a keyboard, a mouse, or a microphone.
- the input IF 11 receives information through key operations, clicks, taps, and the like.
- the input IF 11 includes a microphone, the input IF 11 receives the input of the information using voice recognition processing for the user's voice received by the microphone.
- the sensor 12 senses physical quantities related to the user's living body and generates information about the living body (also referred to as biometric information).
- the sensor 12 provides the generated biological information to the processor 14 (more specifically, the recognition unit 102).
- the sensor 12 is, for example, a camera, a body temperature sensor, a heartbeat sensor, or a blood pressure sensor.
- the camera captures an image of the user's face (also referred to as a face image) by photographing the user's face, and provides the image to the processor 14 as biometric information.
- the sensor 12 may be provided in a device external to the terminal 10. In that case, the device and the terminal 10 are communicably connected, and the sensor 12 transmits biological information to the terminal 10 via communication.
- the device may be, for example, a wristband type device worn on the user's wrist.
- the communication IF 13 is a communication interface that can communicate with the server 20 through the network N.
- the communication IF 13 may be a wireless LAN (Local Area Network) interface such as Wi-Fi (registered trademark), or a wired LAN interface such as Ethernet (registered trademark).
- Wi-Fi registered trademark
- Ethernet registered trademark
- the processor 14 implements the software functions of the terminal 10 by executing a predetermined program using a memory (not shown).
- the software functions realized by the processor 14 will be explained later.
- the speaker 15 outputs sound.
- the sounds output by the speaker 15 include not only audible sounds but also inaudible sounds.
- Audible sound is sound in a frequency band that can be perceived by humans, and generally falls within the range of 20 Hz to 20 kHz.
- Inaudible sounds are sounds in a frequency range that humans cannot perceive, and are sounds included in a range other than the frequency range of audible sounds.
- a sound having a frequency higher than the audible sound frequency range high-frequency inaudible sound
- inaudible sound a sound having a frequency higher than the audible sound frequency range (high-frequency inaudible sound) is referred to as inaudible sound.
- the speaker 15 outputs sound based on sound pressure amplitude waveform data (also simply referred to as waveform data) provided from the processor 14 (more specifically, the reproduction unit 103).
- sound pressure amplitude waveform data also simply referred to as waveform data
- the terminal 10 may include an output IF instead of the speaker 15.
- the output IF is connected to an external speaker, and outputs sound by outputting waveform data to the external speaker.
- the acquisition unit 101, the recognition unit 102, and the playback unit 103 which are functional units realized by the processor 14 executing a predetermined program using a memory (not shown), will be described.
- the recognition unit 102 recognizes the user's emotions.
- the recognition unit 102 recognizes the user's emotions using the user's biometric information provided from the sensor 12 .
- the recognition unit 102 recognizes the user's emotions before being guided (in other words, before playing the content). Furthermore, the recognition unit 102 may recognize the user's emotions even during guidance (in other words, while playing content).
- the recognition unit 102 recognizes the user's emotion by analyzing the user's facial expression from the user's facial image acquired by the camera, which is the sensor 12.
- Well-known emotion recognition techniques may be used to recognize the user's emotions.
- the recognition unit 102 recognizes the user's emotion from the body temperature measured by the body temperature sensor that is the sensor 12. At this time, the recognition unit 102 can recognize the user's emotions from the measured body temperature using the well-known correspondence between human emotions and body temperature.
- a well-known correspondence between human emotions and body temperature for example, a relatively high body temperature is associated with a feeling of happiness or anger, and a relatively low body temperature is associated with a feeling of sadness or depression. There is a correspondence.
- the recognition unit 102 recognizes the user's emotion from heart rate fluctuations measured by the heart rate sensor, which is the sensor 12. At this time, the recognition unit 102 can recognize the user's emotions from the measured heart rate fluctuations using the well-known correspondence between human emotions and heart rate fluctuations.
- the well-known correspondence between human emotions and heart rate variability is shown in, for example, Non-Patent Document 1. For example, it is known that people who are feeling emotions such as joy, worry, surprise, sadness, or anger have characteristic heart rate fluctuations that correspond to each emotion they are feeling.
- the recognition unit 102 recognizes the user's emotion from the blood pressure measured by the blood pressure sensor, which is the sensor 12. At this time, the recognition unit 102 can recognize the user's emotion from the measured blood pressure using the well-known correspondence between human emotion and blood pressure.
- the well-known correspondence between human emotions and blood pressure is shown in Non-Patent Document 2, for example. For example, an increase in blood pressure corresponds to a feeling of anger, and a decrease in blood pressure corresponds to a feeling of relaxation.
- the acquisition unit 101 acquires content used to guide the user's emotions.
- the content acquired by the acquisition unit 101 is content that includes at least sound, and is, for example, music content, and this case will be described as an example.
- the content acquired by the acquisition unit 101 may be content that includes video as well as sound.
- the acquisition unit 101 acquires the first content corresponding to the emotion before induction and the second content corresponding to the target emotion from the server 20 via the communication IFs 13 and 21 and the network N.
- the acquisition unit 101 converts the acquired first content and second content into waveform data (also referred to as sound source waveform data), and provides the data to the reproduction unit 103.
- the acquisition unit 101 provides the user's pre-guidance emotion and target emotion to the server 20 via the communication IFs 13 and 21 and the network N in order to acquire the first content and the second content from the server 20.
- the first content and the second content acquired by the acquisition unit 101 are contents selected by the server 20 (more specifically, the selection unit 201 described below) as content corresponding to the emotion before induction and the target emotion, respectively. It is.
- the emotion before guidance is the user's emotion obtained by the sensor 12 and the recognition unit 102 before the reproduction unit 103 reproduces the first content.
- the target emotion is a target emotion input into the input IF 11.
- the acquisition unit 101 acquires the first content and the second content as described above.
- the acquisition unit 101 supports the intermediate emotion in addition to the first content and the second content. Get the third content.
- the intermediate emotion may be provided to the server 20.
- the intermediate emotion may be generated by the terminal 10 using, for example, the emotion before induction and the target emotion.
- the reproduction unit 103 sequentially reproduces the first content and the second content provided from the acquisition unit 101 using the speaker 15.
- the reproduction unit 103 first reproduces the first content together with an inaudible sound (also referred to as a first inaudible sound) according to the first content, and then reproduces an inaudible sound (also referred to as a second inaudible sound) according to the second content. ), and the second content is played back.
- the first inaudible sound is an inaudible sound obtained by amplifying the basic signal of the first inaudible sound
- the second inaudible sound is an inaudible sound obtained by amplifying the basic signal of the second inaudible sound.
- the amplification factor for the first inaudible sound is also referred to as a first amplification factor
- the amplification factor for the second inaudible sound is also referred to as a second amplification factor.
- the reproducing unit 103 gradually lowers the first amplification factor of the first inaudible sound being reproduced while reproducing the first content, and also increases the first amplification factor of the second inaudible sound being reproduced while reproducing the second content. Gradually increase the second amplification factor of the audible sound.
- the basic signal will be explained in detail later.
- the reproduction unit 103 may include a period in which the first amplification factor of the first inaudible sound being reproduced is maintained. Moreover, the reproduction unit 103 may include a period during reproduction of the second content in which the second amplification factor of the second inaudible sound being reproduced is maintained.
- the reproduction unit 103 sets the first amplification factor of the first inaudible sound being reproduced at the end of reproduction of the first content and the first amplification factor of the first inaudible sound being reproduced at the time of starting reproduction of the second content.
- the second amplification factor of the second inaudible sound may be the same value. The same value as above is, for example, 0.
- the reproduction unit 103 may maintain the first amplification factor of the first inaudible sound being reproduced at the same value during a certain period including the end of reproduction of the first content.
- the reproduction unit 103 may maintain the second amplification factor of the second inaudible sound being reproduced at the same value during a certain period including the start time of reproduction of the second content.
- the playback unit 103 adds and updates a code (also referred to as a time code) indicating the playback position of the content being played back, and plays the content while referring to the time code.
- a code also referred to as a time code
- the server 20 includes a communication IF 21, a processor 22, and a storage 23.
- the communication IF 21 is a communication interface that can communicate with the terminal 10 through the network N.
- the communication IF 21 may be a wireless LAN interface such as Wi-Fi, or may be a wired LAN interface such as Ethernet.
- the processor 22 implements the software functions of the server 20 by executing a predetermined program using a memory (not shown).
- the software functions realized by the processor 22 will be explained later.
- the storage 23 stores multiple contents.
- the plurality of contents stored in the storage 23 are the plurality of contents that may be played back on the terminal 10.
- the plurality of contents stored in the storage 23 are read out by the processor 22 (more specifically, the selection unit 201).
- the storage 23 may be realized by a memory, an HDD (Hard Disk Drive), or the like.
- the selection unit 201 which is realized by the processor 22 executing a predetermined program using a memory (not shown), will be described.
- the selection unit 201 selects content. Specifically, the selection unit 201 provides the terminal 10 with the first content corresponding to the emotion before induction and the second content corresponding to the target emotion via the communication IFs 13 and 21 and the network N.
- the selection unit 201 acquires the user's pre-guidance emotion from the acquisition unit 101 via the communication IF 21, the communication IF 13, and the network N, and selects the content corresponding to the acquired pre-guidance emotion as the first content. select.
- the selection unit 201 stores in advance a correspondence relationship in which emotions are associated with each of a plurality of contents stored in the storage 23, and refers to the correspondence relationship to select the first content corresponding to the emotion before induction. select.
- the selection unit 201 acquires the target emotion from the acquisition unit 101 via the communication IFs 21 and 13 and the network N, and selects the content corresponding to the acquired target emotion as the second content.
- the selection unit 201 selects the second content corresponding to the target emotion by referring to the correspondence relationship.
- the selection unit 201 selects the content corresponding to the intermediate emotion as the third content. .
- the selection unit 201 selects the third content corresponding to the intermediate emotion by referring to the correspondence relationship.
- the intermediate emotion may be acquired from the terminal 10, or may be generated by the selection unit 201 using the emotion before guidance and the target emotion.
- FIG. 3 is a block diagram showing the configuration of the playback section 103 in this embodiment.
- the reproduction section 103 includes a generation section 111, a determination section 112, an adjustment section 113, and an addition section 114.
- the generation unit 111 generates a basic signal of inaudible sound according to the content.
- the generation unit 111 generates waveform data of the basic signal of the inaudible sound based on the waveform data of the sound source provided from the acquisition unit 101. More specifically, the generation unit 111 generates a basic signal of an inaudible sound corresponding to the first content and an inaudible sound corresponding to the second content, respectively, based on the waveform data of the first content and the second content. Generates the basic signal of hearing. Furthermore, when the third content is used, the generation unit 111 generates a basic signal of an inaudible sound (third inaudible sound) corresponding to the third content based on the waveform data of the third content. The generation unit 111 provides the adjustment unit 113 with waveform data of the generated basic signal of the inaudible sound.
- generating the waveform data of the basic signal of the inaudible sound based on the waveform data of the audible sound means, for example, performing clip processing on the waveform data obtained by amplifying the waveform data of the sound source (that is, the waveform data of the audible sound). This can be achieved by removing audible sound components from waveform data containing inaudible sounds generated by
- the determining unit 112 determines the amplification factor of the basic signal of the inaudible sound generated by the generating unit 111 (also simply referred to as the amplification factor of the inaudible sound). Specifically, the determining unit 112 determines the amplification factor of the inaudible sound based on the time code updated by the reproducing unit 103.
- the amplification factor determined by the determining unit 112 includes a first amplification factor and a second amplification factor, and when the third content is used, includes a third amplification factor that is the amplification factor of the third inaudible sound.
- the determining unit 112 stores, for example, the transition of the amplification factor of the inaudible sound determined for the time code, and refers to the transition of the amplification factor to determine whether the acquisition unit 101 or the generating unit 111 Determine the amplification factor of the inaudible sound to be added to the waveform data provided.
- the transition of the amplification factor of inaudible sounds will be explained later.
- the adjustment unit 113 adjusts the sound pressure of the reproduced inaudible sound by multiplying the amplitude of the waveform data of the inaudible sound generated by the generation unit 111 by the amplification factor determined by the determination unit 112.
- the adjustment unit 113 provides the adjusted inaudible sound waveform data to the addition unit 114.
- the adding unit 114 generates waveform data to be reproduced by the speaker 15 by adding the waveform data of the inaudible sound provided from the adjustment unit 113 to the waveform data of the sound source provided from the acquisition unit 101.
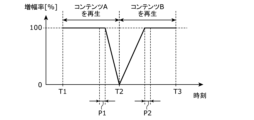
- FIG. 4 is an explanatory diagram showing reproduction of content by the reproduction unit 103 in this embodiment.
- the reproduction unit 103 reproduces two contents.
- the above two contents correspond to contents A and B in FIG. 4.
- the playback unit 103 starts playing content A at time T1.
- reproducing unit 103 reproduces inaudible sound generated according to content A.
- the reproduction unit 103 reproduces content A to the end.
- the time at which the reproducing unit 103 finishes reproducing content A is defined as time T2.
- the playback unit 103 starts playing content B at time T2.
- the reproducing unit 103 reproduces inaudible sound generated according to content B.
- the reproduction unit 103 reproduces content B to the end.
- the time at which the playback unit 103 finishes playing content B is time T3.
- time T2 is determined according to the reproduction time length of content A.
- time T3 is determined according to the playback time lengths of contents A and B. Therefore, the time length from time T1 to time T2 and the time length from time T2 to time T3 are independent; in other words, they may be the same or different.
- content A corresponds to the first content
- content B corresponds to the second content
- the reproducing unit 103 reproduces three contents.
- the above three contents correspond to contents A, B, and C in FIG. 4.
- the reproducing unit 103 reproduces content C after reproducing contents A and B in the same way as when reproducing the above two contents.
- the reproducing unit 103 starts reproducing content C at time T3.
- reproducing unit 103 reproduces inaudible sound generated according to content C.
- the reproduction unit 103 reproduces the content C to the end.
- the time at which the playback unit 103 finishes playing the content C is defined as time T4.
- time T4 is determined according to the playback time lengths of contents A, B, and C. Therefore, the time length from time T3 to time T4 is independent of the time length from time T1 to time T2 or the time length from time T2 to time T3. In other words, they may be the same or different. be.
- content A corresponds to the first content
- content C corresponds to the second content
- content B corresponds to the third content.
- a plurality of contents B may be used when the above three contents are used.
- the reproducing unit 103 determines the transition of this amplification factor, and also determines the amplification factor of the inaudible sound at each time.
- FIG. 5 is an explanatory diagram showing a first example of the transition of the amplification factor in this embodiment.
- the reproducing unit 103 decreases the amplification factor from 100% to 0% linearly with respect to time in the period from time T1 to time T2. Furthermore, the reproduction unit 103 increases the amplification factor linearly with respect to time from 0% to 100% during the period from time T2 to time T3. In this way, the processing in which the reproducing unit 103 generates the transition of the amplification factor that decreases or increases linearly with respect to time can be realized by relatively simple processing.
- the playback system 1 can induce the user's emotions while adjusting the amplification factor of the inaudible sound through relatively simple processing.
- FIG. 6 is an explanatory diagram showing a second example of the transition of the amplification factor in this embodiment.
- the transition of the amplification factor shown in FIG. 6 is a transition determined based on the position of the chorus part of the content.
- the chorus is a relatively exciting part of the content, or in other words, a part that gives a relatively strong impression to the user who is perceiving the part.
- the process of detecting a hook part in the content can be realized by, for example, a process of extracting a part of the content where the sound pressure is relatively high, and can be executed by the playback unit 103.
- the chorus portion P1 shown in FIG. 6 is the chorus portion of content A, and the chorus portion P2 is the chorus portion of content B.
- the reproduction unit 103 maintains the amplification factor at 100% from time T1 to the end of the chorus P1, and from the end of the chorus P1 to time T2. During the period, the amplification factor is decreased from 100% to 0% linearly with respect to time.
- the reproduction unit 103 increases the amplification factor from 0% to 100% linearly with respect to time during the period from time T2 to the start of the chorus P2, and increases the amplification factor linearly with respect to time from the start of the chorus P2 to the time T3. During this period, the amplification factor is maintained at 100%.
- the section from the start of content A to the end of chorus portion P1 is also referred to as a first section
- the section from the start of chorus portion P2 to the end of content B is also referred to as a second section.
- the amplification factor in the first section is also referred to as a first value, and the first value may be selected from a relatively high amplification factor range (for example, 70% to 100%).
- the amplification factor in the second section is also referred to as a second value, and the second value may be selected from a relatively high amplification factor range (for example, 70% to 100%).
- the processing in which the reproducing unit 103 generates the transition of the amplification factor that linearly decreases or increases with respect to time can be realized by a relatively simple process.
- any one of the plurality of chorus parts may be set as the chorus part P1.
- any one of the plurality of chorus parts may be set as the chorus part P2.
- the last chorus part of the plurality of chorus parts may be set as the chorus part P1.
- the first chorus part of the plurality of chorus parts may be the chorus part P2.
- the playback system 1 adjusts the amplification factor of the inaudible sound through relatively simple processing, thereby improving the user's emotions when the playback unit 103 is playing the chorus of each content. It is possible to more appropriately induce the user's emotions while increasing the intensity.
- FIG. 7 is an explanatory diagram showing a third example of the transition of the amplification factor in this embodiment.
- the transition of the amplification factor shown in FIG. 7 is a transition determined non-linearly with respect to time.
- the reproduction unit 103 decreases the amplification factor from 100% to 0% exponentially with respect to time in the period from time T1 to time T2. Furthermore, the reproduction unit 103 increases the amplification factor from 0% to 100% exponentially with respect to time during the period from time T2 to time T3.
- the transition of the amplification factor shown in FIG. 7 is generally also called an A curve.
- the transition of the amplification factor shown in FIG. 5 is generally also called a B curve.
- the intensity of sound whose amplification factor is adjusted according to the A curve is relatively close to the sense of intensity of sound perceived by humans. Therefore, by using an amplification factor that changes according to the A curve, it is possible to naturally guide the intensity of the user's emotions.
- the playback system 1 can more naturally guide the intensity of the user's emotions.
- the transition of the amplification factor shown in FIG. 7 is generated by replacing the linear change part in the transition of the amplification factor shown in FIG. 5 with an exponential change.
- the linear change part in the amplification factor transition shown in FIG. 6 can be replaced with an exponential change.
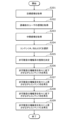
- FIG. 8 is a block diagram showing a first example of processing of the playback system 1 in this embodiment.
- the components that are the main bodies that execute the processes shown below are examples, and the main bodies that execute the processes are other components. It may be.
- step S101 the acquisition unit 101 uses the input IF 11 to acquire the target emotion.
- step S102 the acquisition unit 101 uses the sensor 12 and the recognition unit 102 to acquire the user's emotion before guidance.
- step S103 the acquisition unit 101 transmits the user's pre-guidance emotion and target emotion to the server 20, and requests content to be played by the terminal 10.
- the selection unit 201 acquires the user's pre-guidance emotion and target emotion transmitted by the acquisition unit 101, and selects content corresponding to the acquired user's pre-guidance emotion and target emotion, that is, content that should be played by the terminal 10. The content is selected and the selected content is provided to the acquisition unit 101.
- the content to be played by the terminal 10 includes content A and content B.
- Content A is content that is associated with the user's pre-guidance emotion
- content B is content that is associated with the target emotion.
- the acquisition unit 101 acquires content provided from the selection unit 201.
- step S104 the reproduction unit 103 determines the transition of the amplification factor of the inaudible sound.
- the determined amplification factor transition is, for example, the amplification factor transition shown in FIG. 5, FIG. 6, or FIG. 7.
- step S105 the reproduction unit 103 reproduces the content A while gradually decreasing the amplification factor of the inaudible sound.
- the playback unit 103 generates inaudible sound waveform data from the content A waveform data (sound source waveform data) acquired by the acquisition unit 101 in step S103, and combines the generated inaudible sound waveform data with the waveform data of the generated inaudible sound.
- the reproducing unit 103 gradually lowers the amplification factor of the inaudible sound being reproduced according to the transition determined in step S104.
- step S106 the reproduction unit 103 reproduces content B while gradually increasing the amplification factor of the inaudible sound.
- the playback unit 103 generates inaudible sound waveform data from the waveform data of content B (sound source waveform data) acquired by the acquisition unit 101 in step S103, and combines the generated inaudible sound waveform data with the waveform data of the generated inaudible sound.
- the reproducing unit 103 gradually increases the amplification factor of the inaudible sound being reproduced according to the transition determined in step S104.
- the playback unit 103 plays back content B to the end, it ends the series of processing shown in FIG. 8 .
- the reproduction system 1 can appropriately induce the user's emotions by using two contents and reproduction of inaudible sounds according to the two contents.
- the amplification factor of the inaudible sounds (the first inaudible sound, the second inaudible sound, and the third inaudible sound) when the playback system 1 induces the user's emotions by playing three contents will be explained.
- the reproducing unit 103 (more specifically, the determining unit 112) determines the transition of this amplification factor, and also determines the amplification factor of the inaudible sound at each time.
- the reproduction unit 103 During reproduction of one or more contents B, the reproduction unit 103 gradually increases the amplification factor of the third inaudible sound being reproduced, and then gradually decreases the amplification factor.
- the reproduction unit 103 may set the amplification factor of the third inaudible sound being reproduced to 0 at the start and end of reproduction of one or more contents B.
- FIG. 9 is an explanatory diagram showing a fourth example of the transition of the amplification factor in this embodiment.
- the reproducing unit 103 decreases the amplification factor from 100% to 0% linearly with respect to time in the period from time T1 to time T2.
- the reproducing unit 103 increases the amplification factor from 0% to 100% linearly with respect to time in the period from time T2 to time T2A, and then increases the amplification factor in the period from time T2A to time T3. decreases linearly with time from 100% to 0%.
- Time T2A is any time between time T2 and time T3, and may be, for example, an intermediate time between time T2 and time T3.
- the reproduction unit 103 increases the amplification factor from 0% to 100% linearly with respect to time in the period from time T3 to time T3.
- the processing in which the reproducing unit 103 generates the transition of the amplification factor that linearly decreases or increases with respect to time can be realized by a relatively simple process.
- the playback system 1 can induce the user's emotions while adjusting the amplification factor of the inaudible sound through relatively simple processing.
- FIG. 10 is an explanatory diagram showing a fifth example of the transition of the amplification factor in this embodiment.
- the transition of the amplification factor shown in FIG. 10 is a transition determined based on the position of the chorus part of the content.
- a chorus portion P1 shown in FIG. 10 is a chorus portion of content A
- a chorus portion P2 is a chorus portion of content B
- a chorus portion P3 is a chorus portion of content C.
- the transition of the amplification factor in the period from time T1 to time T2 is the same as that in FIG. 6.
- the reproduction unit 103 increases the amplification factor from 0% to 100% linearly with respect to time during the period from time T2 to the start of the chorus P2, and increases the amplification factor from the start of the chorus P2 to the end of the chorus P2. During this period, the amplification factor is maintained at 100%. Furthermore, the reproduction unit 103 decreases the amplification factor from 100% to 0% linearly with respect to time during the period from the end of the chorus portion P2 to time T3.
- the reproduction unit 103 increases the amplification factor from 0% to 100% linearly with respect to time during the period from time T3 to the start of the chorus P3, and increases the amplification factor linearly with respect to time from the start of the chorus P3 to the time T4. During this period, the amplification factor is maintained at 100%.
- section from the start of content A to the end of chorus portion P1 corresponds to the first section
- section from the start of chorus section P3 to the end of content C corresponds to the second section.
- the section from the start to the end of the chorus P2 is also referred to as a third section.
- the amplification factor in the third section is also referred to as a third value, and the third value may be selected from a relatively high amplification factor range (for example, 70% to 100%).
- the processing in which the reproducing unit 103 generates the transition of the amplification factor that linearly decreases or increases with respect to time can be realized by a relatively simple process.
- any one of the plurality of chorus parts may be set as the chorus part P1.
- any one of the plurality of chorus parts may be set as the chorus part P2.
- any one of the plurality of chorus parts may be set as the chorus part P3.
- the content A may be the last chorus part P1 of the multiple chorus parts.
- the period from the start of the first chorus part to the end of the last chorus part among the plurality of chorus parts may be defined as the chorus part P2.
- the last chorus part of the plurality of chorus parts may be the chorus part P3.
- the playback system 1 adjusts the amplification factor of the inaudible sound through relatively simple processing, thereby improving the user's emotions when the playback unit 103 is playing the chorus of each content. It is possible to more appropriately induce the user's emotions while increasing the intensity.
- the linear change portion in the transition of the amplification factor shown in FIG. 9 or FIG. 10 can also be replaced with an exponential change.
- the playback system 1 can more appropriately guide the user's emotions while increasing the intensity of the user's emotions when the playback unit 103 is playing the chorus of each content.
- FIG. 11 is a block diagram showing a second example of processing of the playback system 1 in this embodiment.
- step S201 the acquisition unit 101 uses the input IF 11 to acquire the target emotion.
- step S202 the acquisition unit 101 uses the sensor 12 and the recognition unit 102 to acquire the user's emotion before guidance.
- step S203 the acquisition unit 101 acquires an emotion (also referred to as an intermediate emotion) that is used to guide the target emotion from the emotion before induction.
- the intermediate emotion may be obtained by inputting it into the input IF 11 from the user, or may be determined by the obtaining unit 101 based on the emotion before induction and the target emotion.
- step S204 the acquisition unit 101 transmits the user's pre-guidance emotion, intermediate emotion, and target emotion to the server 20, and requests the content to be reproduced by the terminal 10.
- the selection unit 201 acquires the user's pre-guidance emotion, intermediate emotion, and target emotion transmitted by the acquisition unit 101, and selects content corresponding to the acquired user's pre-guidance emotion, intermediate emotion, and target emotion, that is, Content to be reproduced is selected by the terminal 10 and the selected content is provided to the acquisition unit 101.
- the content to be played by the terminal 10 includes content A, B, and C.
- Content A is content associated with a user's pre-guidance emotion
- content B is content associated with an intermediate emotion
- content C is content associated with a target emotion.
- the acquisition unit 101 acquires content provided from the selection unit 201.
- step S205 the reproduction unit 103 determines the transition of the amplification factor of the inaudible sound.
- the determined amplification factor transition is, for example, the amplification factor transition shown in FIG. 9 or FIG. 10.
- step S206 the reproduction unit 103 reproduces the content A while gradually decreasing the amplification factor of the inaudible sound.
- the process of reproducing content A while gradually decreasing the amplification factor of the inaudible sound is performed in the same manner as step S105 (FIG. 8) according to the transition determined in step S205.
- the reproduction unit 103 reproduces content A to the end the process proceeds to step S207.
- step S207 the reproduction unit 103 reproduces content B while gradually increasing the amplification factor of the inaudible sound.
- the reproduction unit 103 proceeds to step S208 at a timing before the content B is reproduced to the end (time T2A in FIG. 9 or a time included in the chorus portion P2 in FIG. 10).
- the process of reproducing content B continues in step S208.
- the process of reproducing content B while gradually increasing the amplification factor of the inaudible sound is performed in the same manner as step S106 (FIG. 8) according to the transition determined in step S205.
- step S208 the reproduction unit 103 reproduces content B while gradually decreasing the amplification factor of the inaudible sound.
- Reproduction of content B continues from step S207.
- the process of reproducing content B while gradually decreasing the amplification factor of the inaudible sound is performed in the same manner as step S105 (FIG. 8) according to the transition determined in step S205.
- the reproduction unit 103 reproduces content B to the end the process advances to step S209.
- step S209 the reproduction unit 103 reproduces the content C while gradually increasing the amplification factor of the inaudible sound.
- the process of reproducing content C while gradually increasing the amplification factor of the inaudible sound is performed in the same manner as step S106 (FIG. 8) according to the transition determined in step S205.
- step S106 FIG. 8
- the playback unit 103 ends the series of processing shown in FIG. 11 .
- the process in step S203 may be executed by the selection unit 201 instead of being executed by the acquisition unit 101. That is, the selection unit 201 may acquire the intermediate emotion.
- the intermediate emotion may be determined by the selection unit 201 based on the emotion before induction and the target emotion.
- the selection unit 201 determines an intermediate emotion
- the emotion before induction and the target emotion necessary for determining the intermediate emotion are those acquired by the acquisition unit 101 in steps S201 and S202, and are transmitted to the server 20 after acquisition. It can be something that has been done.
- the selection unit 201 may transmit the intermediate emotion to the acquisition unit 101 in step S203.
- step S204 the selection unit 201 selects contents A, B, and C using the pre-guidance emotion and target emotion acquired in step S203, and the intermediate emotion acquired in step S204.
- the playback system 1 can appropriately induce the user's emotions using the three contents and the playback of inaudible sounds according to the three contents.
- the playback system 1 in this modified example guides the user's emotions by playing back content, senses the guided user's emotions, and responds to the user's emotions. to control the amplification factor of inaudible sounds.
- the reproduction unit 103 holds a target transition indicating a predetermined transition of the emotions of the user whose emotions are to be induced.
- the goal transition is information indicating the type of emotion of the user whose emotions are being induced and the intensity of the emotion.
- the reproduction unit 103 adjusts the amplification factor of the first inaudible sound being reproduced so as to bring the user's emotion closer to the target transition. do.
- the reproduction unit 103 may set the amplification factor of the first inaudible sound being reproduced to 0 when the emotion recognized by the recognition unit 102 deviates from the target transition.
- the fact that the user's emotion deviates from the target transition can be determined by determining whether the difference between the user's emotion and the emotion in the target transition is greater than or equal to a predetermined value.
- FIG. 12 is an explanatory diagram showing the target transition in this modification.
- the target transition with respect to time (corresponding to time code) is shown.
- the target transition shown in FIG. 12 shows the target transition in the case where the emotion before induction is excitement, the target emotion is relaxation, and two contents are used to induce the user's emotion.
- the intensity of emotion is shown as an example in the range of 0% to 100%, but it is not limited to this.
- the type of emotion is excitement, and the emotion intensity gradually decreases from 100% to 0%.
- the type of emotion is relaxing, and the emotion intensity gradually increases from 0% to 100%.
- FIG. 13 is a flow diagram showing the processing of the playback system 1 in this modification.
- the playback system 1 simultaneously executes the process shown in FIG. 13 while the playback unit 103 is playing back the content (for example, steps S105 and S106 in FIG. 8).
- steps S105 and S106 in FIG. 8 As an example of the transition of the amplification factor of the inaudible sound, the transition of the amplification factor shown in FIG. 5 will be described as determined (step S104).
- step S301 the acquisition unit 101 acquires the time code at the time of reproduction of the content being reproduced by the reproduction unit 103.
- the time code indicates which temporal position in the content being played back is being played back by the playback unit 103.
- step S302 the acquisition unit 101 acquires the emotion at the time of reproduction in the target transition.
- the emotion at the time of reproduction includes the type of emotion and the intensity of the emotion.
- step S303 the acquisition unit 101 acquires the user's current emotion (that is, at the time when this process is executed).
- step S304 the acquisition unit 101 determines whether the difference between the emotion at the playback position in the target transition acquired in step S302 and the user's current emotion acquired in step S303 is greater than or equal to a predetermined value. For example, if the type of emotion at the playback position in the target transition is the same as the type of the user's current emotion, and the intensity of the emotion at the playback position in the goal transition is If the intensity is higher or lower by 10 points or more, it may be determined that the difference is greater than or equal to a predetermined value. Further, for example, when the type of emotion at the playback position in the target transition is different from the type of emotion of the user at the current time, the acquisition unit 101 may determine that the difference is greater than or equal to a predetermined value. If it is determined that the difference is greater than or equal to a predetermined value (Yes in step S304), the process proceeds to step S305, and if not, step S301 is executed again.
- step S305 the acquisition unit 101 adjusts the amplification factor. For example, if the type of emotion at the playback position in the target transition is the same as the type of the user's current emotion, and the intensity of the emotion at the playback position in the goal transition is If the intensity is 10 points or more higher, the current amplification factor in the amplification factor transition determined in step S104 is adjusted to a lower value. At this time, if the amplification factor after the current point in the transition of the amplification factor determined in step S104 is on a decreasing trend, the acquisition unit 101 reduces the amplification factor after the current point to less than or equal to the adjusted amplification factor at the current point. You may adjust it accordingly.
- the acquisition unit 101 may determine whether the type of emotion at the playback position in the goal transition is the same as the type of emotion at the user's current moment, and the intensity of the emotion at the playback position in the goal transition is If the intensity of the emotion is lower by 10 points or more, the current amplification factor in the amplification factor transition determined in step S104 is adjusted to a higher value. At this time, if the amplification factor after the current point in the transition of the amplification factor determined in step S104 is on an increasing trend, the acquisition unit 101 sets the amplification factor after the current point to be higher than the adjusted amplification factor at the current point. You may adjust it accordingly.
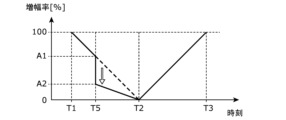
- FIG. 14 is an explanatory diagram showing an example of emotion transition in this modification.
- FIG. 15 is an explanatory diagram showing an example of the transition of the amplification factor in this modification.
- FIG. 14 shows the transition of the user's actual emotions, whose emotions are induced by the playback system 1, as well as the transition of the goal.
- the user's actual emotion transition is a temporal transition of the user's emotion obtained by the sensor 12 and recognition unit 102.
- the actual emotion of the user shown in FIG. 14 is an emotion of excitement whose intensity is 100% at time T1, and is decreasing from 100% after time T1.
- the acquisition unit 101 determines that the difference d between the emotional intensity of the user at the current moment and the emotional intensity at the playback position in the target transition is 10 points or more higher.
- the reproducing unit 103 adjusts the amplification factor at time T5 to decrease from the value A1 before adjustment to the value A2. Further, the transition of the amplification factor after time T5 is adjusted so as to gradually decrease from the adjusted value A2 (see FIG. 15). By doing so, the playback system 1 enhances the effect of reducing the intensity of the user's excitement, and contributes to inducing the user's emotions with a transition close to the target transition.
- the reproducing unit 103 may set the amplification factor to 0 after time T5.
- the reason why the reproduction unit 103 sets the amplification factor to 0 after time T5 is, for example, in step S304, when the acquisition unit 101 determines that the type of emotion at the reproduction position in the target transition is different from the type of emotion of the user at the current time. This is the case when it is determined.
- the playback system 1 can stop playing the inaudible sound (that is, stop inducing the user's emotions). If the user is not in a state suitable for having their emotions induced, inducing the user's emotions may have a negative impact on the user (for example, causing a psychological burden), and this should be suppressed. Contribute to things.
- the present disclosure can be used in a system that induces a user's emotions.
- Playback system 10 Terminal 11 Input IF 12 Sensor 13, 21 Communication IF 14, 22 Processor 15 Speaker 20 Server 23 Storage 101 Acquisition unit 102 Recognition unit 103 Reproduction unit 111 Generation unit 112 Determination unit 113 Adjustment unit 114 Addition unit 201 Selection unit N Network P, Q Route
Landscapes
- Health & Medical Sciences (AREA)
- Acoustics & Sound (AREA)
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Anesthesiology (AREA)
- Multimedia (AREA)
- Animal Behavior & Ethology (AREA)
- Heart & Thoracic Surgery (AREA)
- Hematology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Psychology (AREA)
- Biomedical Technology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Pain & Pain Management (AREA)
- Signal Processing (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Reverberation, Karaoke And Other Acoustics (AREA)
Abstract
ユーザの感情を第一感情から第二感情に誘導する、コンテンツの再生システム(1)は、第一感情に対応する第一コンテンツと、第二感情に対応する第二コンテンツとを取得する取得部(101)と、スピーカ(15)により、第一コンテンツに応じた第一非可聴音であって、第一非可聴音の基礎信号を第一増幅率で増幅した第一非可聴音とともに第一コンテンツを再生した後に、第二コンテンツに応じた第二非可聴音であって、第二非可聴音の基礎信号を第二増幅率で増幅した第二非可聴音とともに第二コンテンツを再生する再生部(103)とを備え、再生部(103)は、第一コンテンツの再生中に、再生している第一非可聴音の第一増幅率を徐々に低下させ、第二コンテンツの再生中に、再生している第二非可聴音の第二増幅率を徐々に上昇させる。
Description
本開示は、再生システム、再生方法、および、プログラムに関する。
運転者が車両の運転に集中する必要があるか否かに応じて、オーディオ音に含まれる非可聴音の再生を制御する技術がある(例えば特許文献1参照)。
早野 順一郎、"生体信号による情動スペクトルの推定"、[online]、平成29年10月3日、健康・医療 新技術説明会、科学技術振興機構、[令和4年8月29日検索]、インターネット、<URL:https://shingi.jst.go.jp/list/list_2017/2017_3chubu.html#20171003X-008>
武田かおり、"負感情(怒り・うつ傾向・不安)傾向が血圧に及ぼす影響"、[online]、平成23年3月31日、名寄市立大学紀要(2007.3+)第5巻、[令和4年8月29日検索]、インターネット、<URL:http://id.nii.ac.jp/1088/00000025/>
本開示は、非可聴音の再生を用いてユーザの感情を適切に誘導する再生システム、再生方法、および、プログラムを提供する。
本開示における再生システムは、ユーザの感情を第一感情から第二感情に誘導する、コンテンツの再生システムであって、前記第一感情に対応する第一コンテンツと、前記第二感情に対応する第二コンテンツとを取得する取得部と、スピーカにより、(a)前記第一コンテンツに応じた第一非可聴音であって、前記第一非可聴音の基礎信号を第一増幅率で増幅した第一非可聴音とともに前記第一コンテンツを再生した後に、(b)前記第二コンテンツに応じた第二非可聴音であって、前記第二非可聴音の基礎信号を第二増幅率で増幅した第二非可聴音とともに前記第二コンテンツを再生する、再生部とを備え、前記再生部は、前記第一コンテンツの再生中に、再生している前記第一非可聴音の前記第一増幅率を徐々に低下させ、前記第二コンテンツの再生中に、再生している前記第二非可聴音の前記第二増幅率を徐々に上昇させる再生システムである。
本開示における再生システムは、非可聴音の再生を用いてユーザの感情を適切に誘導することができる。
(本開示の基礎となった知見)
本発明者は、「背景技術」の欄において記載した、非可聴音の再生に関する技術に関し、以下の問題が生じることを見出した。
本発明者は、「背景技術」の欄において記載した、非可聴音の再生に関する技術に関し、以下の問題が生じることを見出した。
上記技術では、コンテンツのオーディオ音に可聴音および非可聴音が含まれていることを前提としている。そして、オーディオ音の非可聴音を除去するフィルタを適用するか、または、適用しないかを切り替えることで、可聴音および非可聴音を出力するか、または、可聴音のみを出力するかを切り替える。非可聴音は、非可聴音を知覚した人の脳を活性化させる効果があることが知られている。
これにより、運転者が車両の運転に集中すべきときには、運転者に可聴音および非可聴音を知覚させることで、運転に集中させることに寄与する。また、運転に集中する必要がないときには、運転者に可聴音のみを知覚させることで、リラックスしてオーディオを楽しませることに寄与する。このように、上記技術では、運転者の感情を誘導する。
一方、人の感情を誘導することに関して、「同質の原理」と呼ばれる原理がある。同質の原理によれば、人は、その感情に対応した音楽を聴くことによって、その感情をより一層強めることができる。「感情に対応した音楽」は、その感情と同じ印象を与える音楽を意味する。
例えば、人がリラックスしているときには、リラックスの感情に対応した音楽を聴くことで、リラックスの感情を強めることができる。人が興奮状態にあるときには、興奮の感情に対応した音楽を聴くことで、興奮の感情を強めることができる。
そこで、本願発明者は、人の感情を誘導する際には、まず、その人の現在(つまり誘導前)の感情に対応した音楽を聞かせ、その後に、誘導したい目標の感情に対応した音楽を聞かせることで、より適切にその人の感情を誘導することができる可能性があることに着想した。また、感情の誘導の際に、非可聴音を再生し、再生している非可聴音の音圧の強弱を適切に制御することで、人の感情の強弱を制御することができ、その人の感情の誘導をより適切に行うことができる可能性があることに着想した。
以下、本明細書の開示内容から得られる発明を例示し、その発明から得られる効果等を説明する。
(1)ユーザの感情を第一感情から第二感情に誘導する、コンテンツの再生システムであって、前記第一感情に対応する第一コンテンツと、前記第二感情に対応する第二コンテンツとを取得する取得部と、スピーカにより、(a)前記第一コンテンツに応じた第一非可聴音であって、前記第一非可聴音の基礎信号を第一増幅率で増幅した第一非可聴音とともに前記第一コンテンツを再生した後に、(b)前記第二コンテンツに応じた第二非可聴音であって、前記第二非可聴音の基礎信号を第二増幅率で増幅した第二非可聴音とともに前記第二コンテンツを再生する、再生部とを備え、前記再生部は、前記第一コンテンツの再生中に、再生している前記第一非可聴音の前記第一増幅率を徐々に低下させ、前記第二コンテンツの再生中に、再生している前記第二非可聴音の前記第二増幅率を徐々に上昇させる再生システム。
上記態様によれば、再生システムは、誘導前のユーザの感情(第一感情)と同じ印象を与える第一コンテンツを非可聴音とともにユーザに知覚させた後に、目標感情と同じ印象を与える第二コンテンツを非可聴音とともにユーザに知覚させることで、同質の原理に基づいてユーザの感情を目標感情に誘導する。そして、第一コンテンツの再生中に非可聴音の増幅率を徐々に低下させることで誘導前のユーザの感情の強度を弱めた後に、第二コンテンツの再生中に非可聴音の増幅率を徐々に上昇させることでユーザの目標感情の強度を強めることに寄与する。このように、再生システムは、非可聴音の再生を用いてユーザの感情を適切に誘導することができる。
(2)前記再生部は、前記第一コンテンツの再生の終了時点では、前記第一増幅率を0とし、前記第二コンテンツの再生の開始時点では、前記第二増幅率を0とする、(1)に記載の再生システム。
上記態様によれば、再生システムは、再生するコンテンツを切り替えるタイミングにおいて、非可聴音の増幅率を0とするので、誘導前のユーザの感情の強度を最も弱めたタイミングでコンテンツを切り替え、その後に徐々に目標感情を強くしていくことに寄与する。よって、再生システムは、非可聴音の再生を用いてユーザの感情をより適切に誘導することができる。
(3)前記再生部は、前記第一コンテンツの再生中に、 前記第一コンテンツの開始から、前記第一コンテンツに含まれるサビ部分の終了までの第一区間において、再生している前記第一非可聴音の前記第一増幅率を第一値に維持し、上記第一区間より後の区間において、再生している前記第一非可聴音の前記第一増幅率を、前記第一値から徐々に低下させ、前記第二コンテンツの再生中に、前記第二コンテンツに含まれるサビ部分の開始から、前記第二コンテンツの終了までの第二区間において、再生している前記第二非可聴音の前記第二増幅率を第二値に維持し、上記第二区間より前の区間において、再生している前記第二非可聴音の前記第二増幅率を、前記第二値に向けて徐々に上昇させる、(1)または(2)に記載の再生システム。
上記態様によれば、再生システムは、第一コンテンツのサビ部分をユーザが知覚しているときには誘導前のユーザの感情の強度をより一層高め、また、第二コンテンツのサビ部分をユーザが知覚しているときには、ユーザの目標感情の強度をより一層高めることができる。よって、再生システムは、より適切にユーザの感情を誘導することができる。
(4)前記再生部は、前記第一コンテンツの再生中に前記第一増幅率を徐々に低下させるときには、前記第一増幅率を時刻に対して線形に低下させ、前記第二コンテンツの再生中に前記第二増幅率を徐々に上昇させるときには、前記第二増幅率を時刻に対して線形に上昇させる、(1)~(3)のいずれかに記載の再生システム。
上記態様によれば、再生システムは、非可聴音の増幅率を時刻に対して線形に低下または上昇させるという、比較的簡易な処理によって、非可聴音の増幅率を低下または上昇させることができる。よって、再生システムは、比較的簡易な処理によって、非可聴音の再生を用いてユーザの感情を適切に誘導することができる。
(5)前記再生部は、前記第一コンテンツの再生中に前記第一増幅率を徐々に低下させるときには、前記第一増幅率を時刻に対して指数関数的に低下させ、前記第二コンテンツの再生中に前記第二増幅率を徐々に上昇させるときには、前記第二増幅率を時刻に対して指数関数的に上昇させる、(1)~(3)のいずれかに記載の再生システム。
上記態様によれば、再生システムは、非可聴音の増幅率を時刻に対して指数関数的に低下または上昇させることで、ユーザは、人間が感知する音の強弱の感覚に近い、非可聴音の強弱を感じることができ、言い換えれば、人にとって自然な強弱を有する非可聴音を感じることができる。よって、再生システムは、適切な非可聴音の強弱を用いて、非可聴音の再生を用いてユーザの感情を適切に誘導することができる。
(6)前記再生システムは、さらに、前記再生部が前記第一コンテンツまたは前記第二コンテンツを再生しているときに、前記ユーザの感情を認識する認識部を備え、前記再生部は、前記認識部が認識した前記感情が予め定められた推移から逸脱しているときには、前記ユーザの感情を前記予め定められた推移に近づけるように、再生している前記第一非可聴音の前記第一増幅率を調整する、(1)~(5)のいずれかに記載の再生システム。
上記態様によれば、再生システムは、コンテンツの再生中におけるユーザの感情が、予め定められた推移と異なる推移をしている場合に、予め定められた推移に近い推移をするようにすることができる。よって、再生システムは、非可聴音の再生を用いてユーザの感情をより適切に誘導することができる。
(7)前記再生システムは、さらに、前記再生部が前記第一コンテンツまたは前記第二コンテンツを再生しているときに、前記ユーザの感情を認識する認識部を備え、前記再生部は、前記認識部が認識した前記感情が予め定められた推移から逸脱しているときには、再生している前記第一非可聴音の増幅率を0とする、(1)~(5)のいずれかに記載の再生システム。
上記態様によれば、再生システムは、コンテンツの再生中におけるユーザの感情が、予め定められた推移と異なる推移をしている場合に、非可聴音の再生を停止することで、ユーザに悪影響を与えることを抑制することに寄与する。よって、再生システムは、非可聴音の再生を用いてユーザの感情をより適切に誘導することができる。
(8)前記再生部は、前記第一コンテンツの再生を終了した時点で、前記第二コンテンツの再生を開始する、(1)~(7)のいずれかに記載の再生システム。
上記態様によれば、再生システムは、第一コンテンツと第二コンテンツとを連続して再生することで、容易に、ユーザの感情を誘導する。再生システムは、非可聴音の再生を用いてより容易にユーザの感情を適切に誘導することができる。
(9)前記再生システムは、前記ユーザの感情を、前記第一感情から、1以上の第三感情を経由して前記第二感情に誘導し、前記取得部は、前記1以上の第三感情それぞれに対応する第三コンテンツである、1以上の第三コンテンツを取得し、前記再生部は、前記第一コンテンツの再生を終了した時点以降に、順次に、前記1以上の第三コンテンツそれぞれに応じた第三非可聴音とともに当該第三コンテンツを再生し、前記1以上の第三コンテンツの再生を終了した時点で、前記第二コンテンツの再生を開始し、前記1以上の第三コンテンツそれぞれの再生中に、再生している前記第三非可聴音の第三増幅率を徐々に上昇させた後に、徐々に低下させる、(1)~(8)のいずれかに記載の再生システム。
上記態様によれば、再生システムは、第一コンテンツ、第三コンテンツおよび第二コンテンツをこの順で連続して再生することで、容易に、ユーザの感情を誘導する。再生システムは、非可聴音の再生を用いてより容易にユーザの感情を適切に誘導することができる。
(10)前記再生部は、前記1以上の第三コンテンツの再生の開始時点および終了時点では、第三増幅率を0とする、(9)に記載の再生システム。
上記態様によれば、再生システムは、再生するコンテンツを切り替えるタイミングにおいて、非可聴音の増幅率を0とするので、誘導前のユーザの感情の強度を最も弱めたタイミングでコンテンツを切り替え、その後に徐々に目標感情を強くしていくことに寄与する。よって、再生システムは、非可聴音の再生を用いてユーザの感情をより適切に誘導することができる。
(11)前記再生部は、前記1以上の第三コンテンツそれぞれの再生中に、当該第三コンテンツのサビ部分の開始から終了を含む第三区間において、再生している前記第三非可聴音の前記第三増幅率を第三値に維持し、上記第三区間より前の区間において、再生している前記第三非可聴音の前記第三増幅率を、前記第三値に向けて徐々に上昇させ、上記第三区間より後の区間において、再生している前記第三非可聴音の前記第三増幅率を、前記第三値から徐々に低下させる、(9)または(10)に記載の再生システム。
上記態様によれば、再生システムは、第三コンテンツのサビ部分をユーザが知覚しているときにはユーザの中間感情の強度をより一層高めることができる。よって、再生システムは、より適切に、ユーザの感情を中間感情を経由して誘導することができる。
(12)前記再生システムは、さらに、複数のコンテンツのうちから、前記第一感情に対応する前記第一コンテンツと、前記第二感情に対応する前記第二コンテンツとを選択する選択部とを備え、前記取得部は、前記選択部が選択した前記第一コンテンツと前記第二コンテンツとを取得する、(1)~(11)のいずれかに記載の再生システム。
上記態様によれば、再生システムは、誘導前のユーザの感情と、目標感情とのそれぞれに対応する第一コンテンツと第二コンテンツとを適切に選択し、選択した第一コンテンツと第二コンテンツとを用いてユーザの感情を誘導することができる。よって、再生システムは、適切なコンテンツとそのコンテンツに応じた非可聴音の再生とを用いてユーザの感情を適切に誘導することができる。
(13)ユーザの感情を第一感情から第二感情に誘導する、コンテンツの再生システムが備える1以上のコンピュータが実行する再生方法であって、前記第一感情に対応する第一コンテンツと、前記第二感情に対応する第二コンテンツとを取得し、スピーカにより、(a)前記第一コンテンツに応じた第一非可聴音であって、前記第一非可聴音の基礎信号を第一増幅率で増幅した第一非可聴音とともに前記第一コンテンツを再生した後に、(b)前記第二コンテンツに応じた第二非可聴音であって、前記第二非可聴音の基礎信号を第二増幅率で増幅した第二非可聴音とともに前記第二コンテンツを再生し、前記第一コンテンツの再生中に、再生している前記第一非可聴音の前記第一増幅率を徐々に低下させ、前記第二コンテンツの再生中に、再生している前記第二非可聴音の前記第二増幅率を徐々に上昇させる、再生方法。
上記態様によれば、上記再生システムと同様の効果を奏する。
(14)(13)に記載の再生方法をコンピュータに実行させるプログラム。
上記態様によれば、上記再生システムと同様の効果を奏する。
以下、適宜図面を参照しながら、実施の形態を詳細に説明する。但し、必要以上に詳細な説明は省略する場合がある。例えば、既によく知られた事項の詳細説明や実質的に同一の構成に対する重複説明を省略する場合がある。これは、以下の説明が不必要に冗長になるのを避け、当業者の理解を容易にするためである。
なお、発明者(ら)は、当業者が本開示を十分に理解するために添付図面および以下の説明を提供するのであって、これらによって請求の範囲に記載の主題を限定することを意図するものではない。
(実施の形態)
本実施の形態において、非可聴音の再生を用いてユーザの感情を適切に誘導する再生システムについて説明する。
本実施の形態において、非可聴音の再生を用いてユーザの感情を適切に誘導する再生システムについて説明する。
まず、人の感情について図1を参照しながら説明する。
図1は、人の感情と、人の感情の変化(遷移ともいう)とを示す説明図である。
図1において、人の複数の感情(例えば、緊張、喜びおよびリラックスなど)が円環状に配置された図が示されている。図1は、一般に、ラッセルの感情円環モデルとも呼ばれる。
図1に示されるように、人の感情は、快および不快の軸(横軸)と、覚醒および眠気の軸(縦軸)とで構成される二次元平面上に配置されることが知られている。なお、感情とは、気持ち、気分、心理状態または情動などの概念を含んでもよい。
人の感情の遷移は、図1において一の感情に対応する位置から、別の感情に対応する位置への移動として表現される。人の感情を遷移させることを、感情を誘導する、ともいう。
例えば、人の感情を緊張からリラックスに誘導する場合、複数の経路のうちのいずれかをとることができる。緊張からリラックスに向かう経路には、例えば経路PおよびQがある。経路Pは、直接に(つまり、他の感情を経由することなく)緊張からリラックスへ遷移する経路である。経路Qは、他の感情の一例である喜びの感情を経由して、緊張からリラックスへ遷移する経路である。誘導される前の人の感情と、誘導された後の人の感情との離間距離が比較的大きい場合、他の感情を経由して感情を誘導するのが適切であることがある。
本実施の形態に係る再生システム1は、任意の経路でユーザの感情を、目標とする感情へ適切に誘導することに寄与する。
[1.構成]
図2は、本実施の形態における再生システム1の構成を示すブロック図である。
図2は、本実施の形態における再生システム1の構成を示すブロック図である。
再生システム1は、ユーザの感情を、誘導される前の感情(誘導前の感情、または、第一感情ともいう)から、目標とする感情(目標感情、または、第二感情ともいう)に誘導する情報処理システムである。
図2に示されるように、再生システム1は、端末10と、サーバ20とを備える。端末10とサーバ20とは、ネットワークNを介して接続されている。ネットワークNは、どのような通信回線またはネットワークから構成されてもよく、例えば、インターネット、携帯電話のキャリアネットワーク、インターネットプロバイダのアクセスネットワーク、または公衆アクセスネットワークなどを含み得る。
端末10は、コンテンツに係る音を出力し、ユーザに知覚させる情報処理端末である。端末10は、例えば、スマートフォン、タブレット、パーソナルコンピュータなどであり得る。
図2に示されるように、端末10は、入力IF11と、センサ12と、通信IF13と、プロセッサ14と、スピーカ15とを備える。
入力IF11は、ユーザからの情報の入力を受け付ける。入力IF11が受け付ける情報は、目標感情(例えばリラックス)を含む。入力IF11が受け付ける情報は、誘導前の感情から目標感情に誘導するために経由する感情(中間感情ともいう)を含んでもよい。再生システム1がユーザの感情を、誘導前の感情から中間感情を経由して目標感情に誘導する場合には、入力IF11が受け付ける情報に中間感情(例えば喜び)が含まれている必要がある。なお、中間感情は、1つであってもよいし、2つ以上であってもよい。
入力IF11は、例えば、タッチインタフェース、キーボード、マウスまたはマイクなどである。入力IF11がタッチインタフェース、キーボードまたはマウスを含む場合、入力IF11は、キー操作、クリック、タップ等によって情報を受け付ける。入力IF11がマイクを含む場合、入力IF11は、マイクが受け付けたユーザの音声に対する音声認識処理を用いて、上記情報の入力を受け付ける。
センサ12は、ユーザの生体に関する物理量を感知し、生体に関する情報(生体情報ともいう)を生成する。センサ12は生成した生体情報をプロセッサ14(より具体的には認識部102)に提供する。
センサ12は、例えば、カメラ、体温センサ、心拍センサまたは血圧センサなどである。カメラは、ユーザの顔を撮影することで、ユーザの顔が映っている画像(顔画像ともいう)を取得し、生体情報としてプロセッサ14に提供する。
センサ12は、端末10の外部のデバイスに備えられてもよい。その場合、上記デバイスと端末10とが通信可能に接続されており、センサ12が通信を介して生体情報を端末10に送信する。上記デバイスは、例えば、ユーザの手首に装着されるリストバンド型デバイスであってもよい。
通信IF13は、サーバ20とネットワークNを通じて通信し得る通信インタフェースである。通信IF13は、Wi-Fi(登録商標)などの無線LAN(Local Area Network)インタフェースであってもよいし、Ethernet(登録商標)などの有線LANインタフェースであってもよい。
プロセッサ14は、メモリ(不図示)を用いて所定のプログラムを実行することで端末10のソフトウェア機能を実現する。プロセッサ14が実現するソフトウェア機能については後で説明する。
スピーカ15は、音を出力する。スピーカ15が出力する音は、可聴音だけではなく、非可聴音をも含む。可聴音は、人が知覚することができる周波数帯の音であり、一般に20Hzから20kHzの範囲に含まれる音である。非可聴音は、人が知覚できない周波数帯の音であり、可聴音の周波数範囲を除く範囲に含まれる音である。ここでは、可聴音の周波数範囲より高い周波数を有する音(高周波非可聴音)を非可聴音という。
スピーカ15は、プロセッサ14(より具体的には再生部103)から提供される、音圧の振幅の波形データ(単に波形データともいう)に基づいて音を出力する。
なお、端末10は、スピーカ15に代えて、出力IFを備えてもよい。この場合、出力IFは、外部のスピーカに接続されており、外部のスピーカに波形データを出力することで音を出力させる。
プロセッサ14がメモリ(不図示)を用いて所定のプログラムを実行することで実現される機能部である取得部101と、認識部102と、再生部103とについて説明する。
認識部102は、ユーザの感情を認識する。認識部102は、センサ12から提供されたユーザの生体情報を用いてユーザの感情を認識する。認識部102は、誘導前(言い換えれば、コンテンツを再生する前)のユーザの感情を認識する。また、認識部102は、誘導中(言い換えれば、コンテンツを再生しているとき)にも、ユーザの感情を認識してもよい。
例えば、認識部102は、センサ12であるカメラが取得したユーザの顔画像から、ユーザの表情を分析することでユーザの感情を認識する。ユーザの感情の認識には、周知の感情認識技術が用いられ得る。
また、例えば、認識部102は、センサ12である体温センサにより計測された体温から、ユーザの感情を認識する。このとき、認識部102は、人の感情と体温との周知の対応関係を用いて、計測された体温からユーザの感情を認識することができる。人の感情と体温との周知の対応関係として、例えば、幸福または怒りの感情に対して比較的高い体温が対応付けられ、悲しみまたは落ち込みの感情に対して比較的低い体温が対応付けられる、という対応関係がある。
また、例えば、認識部102は、センサ12である心拍センサにより計測された心拍変動から、ユーザの感情を認識する。このとき、認識部102は、人の感情と心拍変動との周知の対応関係を用いて、計測された心拍変動からユーザの感情を認識することができる。人の感情と心拍変動との周知の対応関係は、例えば、非特許文献1に示されている。例えば、喜び、心配、驚き、悲しみ、または、怒りなどの感情を抱いている人に、その抱いている感情それぞれに対応する特徴的な心拍変動が見られることが知られている。
また、例えば、認識部102は、センサ12である血圧センサにより計測された血圧から、ユーザの感情を認識する。このとき、認識部102は、人の感情と血圧との周知の対応関係を用いて、計測された血圧からユーザの感情を認識することができる。人の感情と血圧との周知の対応関係は、例えば、非特許文献2に示されている。例えば、怒りの感情に対して血圧の上昇が対応しており、また、リラックスの感情に関して血圧の降下が対応している。
取得部101は、ユーザの感情の誘導に用いるコンテンツを取得する。取得部101が取得するコンテンツは、少なくとも音を含むコンテンツであり、例えば楽曲のコンテンツであり、この場合を例として説明する。なお、取得部101が取得するコンテンツは、音とともに映像を含むコンテンツであってもよい。
取得部101は、具体的には、誘導前の感情に対応する第一コンテンツと、目標感情に対応する第二コンテンツとを、通信IF13ならびに21およびネットワークNを介してサーバ20から取得する。取得部101は、取得した第一コンテンツと第二コンテンツとを、それぞれ波形データ(音源の波形データともいう)に変換し、再生部103に提供する。
取得部101は、第一コンテンツおよび第二コンテンツをサーバ20から取得するために、ユーザの誘導前の感情と目標感情とを、通信IF13ならびに21およびネットワークNを介してサーバ20に提供する。取得部101が取得する第一コンテンツおよび第二コンテンツは、それぞれ、誘導前の感情と目標感情とに対応するコンテンツとしてサーバ20(より具体的には、後述する選択部201)により選択されたコンテンツである。誘導前の感情は、再生部103が第一コンテンツを再生する前にセンサ12および認識部102により得たユーザの感情である。目標感情は、入力IF11に入力された目標感情である。
なお、再生システム1がユーザの感情を、誘導前の感情から目標感情に直接に誘導する場合には、取得部101は、上記のとおり第一コンテンツと第二コンテンツとを取得する。再生システム1がユーザの感情を、誘導前の感情から中間感情を経由して目標感情に誘導する場合には、取得部101は、第一コンテンツと第二コンテンツとに加えて、中間感情に対応する第三コンテンツを取得する。取得部101が第三コンテンツをサーバ20から取得するために、中間感情をサーバ20に提供してもよい。中間感情は、例えば、誘導前の感情と目標感情とを用いて端末10が生成したものであってよい。
再生部103は、取得部101から提供された第一コンテンツと第二コンテンツとを順次に、スピーカ15により再生する。再生部103は、まず、第一コンテンツに応じた非可聴音(第一非可聴音ともいう)とともに第一コンテンツを再生し、その後、第二コンテンツに応じた非可聴音(第二非可聴音ともいう)とともに第二コンテンツを再生する。第一非可聴音は、第一非可聴音の基礎信号を増幅した非可聴音であり、第二非可聴音は、第二非可聴音の基礎信号を増幅した非可聴音である。第一非可聴音の増幅率を第一増幅率ともいい、第二非可聴音の増幅率を第二増幅率ともいう。再生部103は、第一コンテンツの再生中に、再生している第一非可聴音の第一増幅率を徐々に低下させ、また、第二コンテンツの再生中に、再生している第二非可聴音の第二増幅率を徐々に上昇させる。基礎信号については後で詳しく説明する。
なお、再生部103は、第一コンテンツの再生中に、再生している第一非可聴音の第一増幅率を維持する期間を含んでもよい。また、再生部103は、第二コンテンツの再生中に、再生している第二非可聴音の第二増幅率を維持する期間を含んでもよい。
ここで、再生部103は、第一コンテンツの再生の終了時点での、再生している第一非可聴音の第一増幅率と、第二コンテンツの再生の開始時点での、再生している第二非可聴音の第二増幅率とを同じ値にしてもよい。上記同じ値は、例えば0である。なお、再生部103は、第一コンテンツの再生の終了時点を含む一定期間に、再生している第一非可聴音の第一増幅率を同じ値に維持してもよい。また、再生部103は、第二コンテンツの再生の開始時点を含む一定期間に、再生している第二非可聴音の第二増幅率を同じ値に維持してもよい。
また、再生部103は、再生しているコンテンツの再生位置を示すコード(タイムコードともいう)を、加算しながら更新しており、タイムコードを参照しながら上記コンテンツを再生する。再生部103の構成の詳細は、後で説明する。
また、図2に示されるように、サーバ20は、通信IF21と、プロセッサ22と、ストレージ23とを備える。
通信IF21は、端末10とネットワークNを通じて通信し得る通信インタフェースである。通信IF21は、Wi-Fiなどの無線LANインタフェースであってもよいし、Ethernetなどの有線LANインタフェースであってもよい。
プロセッサ22は、メモリ(不図示)を用いて所定のプログラムを実行することでサーバ20のソフトウェア機能を実現する。プロセッサ22が実現するソフトウェア機能については後で説明する。
ストレージ23は、複数のコンテンツを記憶している。ストレージ23が記憶している複数のコンテンツは、端末10で再生することになる可能性がある複数のコンテンツである。ストレージ23が記憶している複数のコンテンツは、プロセッサ22(より具体的には選択部201)により読み出される。ストレージ23は、メモリまたはHDD(Hard Disk Drive)などで実現され得る。
プロセッサ22がメモリ(不図示)を用いて所定のプログラムを実行することで実現される選択部201について説明する。
選択部201は、コンテンツを選択する。具体的には、選択部201は、誘導前の感情に対応する第一コンテンツと、目標感情に対応する第二コンテンツとを、通信IF13ならびに21およびネットワークNを介して端末10に提供する。
具体的には、選択部201は、通信IF21ならびに通信IF13およびネットワークNを介して取得部101からユーザの誘導前の感情を取得し、取得した誘導前の感情に対応するコンテンツを第一コンテンツとして選択する。選択部201は、ストレージ23が記憶している複数のコンテンツそれぞれについて感情を対応付けた対応関係を予め保有しており、その対応関係を参照して、誘導前の感情に対応する第一コンテンツを選択する。
また、選択部201は、通信IF21ならびに13およびネットワークNを介して取得部101から目標感情を取得し、取得した目標感情に対応するコンテンツを第二コンテンツとして選択する。選択部201は、上記対応関係を参照して目標感情に対応する第二コンテンツを選択する。
なお、再生システム1がユーザの感情を、誘導前の感情から中間感情を経由して目標感情に誘導する場合には、選択部201は、中間感情に対応するコンテンツを、第三コンテンツとして選択する。選択部201は、上記対応関係を参照して中間感情に対応する第三コンテンツを選択する。中間感情は、端末10から取得したものであってもよいし、誘導前の感情と目標感情とを用いて選択部201によって生成されたものであってもよい。
図3は、本実施の形態における再生部103の構成を示すブロック図である。
図3に示されるように、再生部103は、生成部111と、決定部112と、調整部113と、加算部114とを備える。
生成部111は、コンテンツに応じた非可聴音の基礎信号を生成する。生成部111は、取得部101から提供された音源の波形データに基づいて、非可聴音の基礎信号の波形データを生成する。より具体的には、生成部111は、第一コンテンツおよび第二コンテンツの波形データに基づいて、それぞれ、第一コンテンツに応じた非可聴音の基礎信号、および、第二コンテンツに応じた非可聴音の基礎信号を生成する。また、生成部111は、第三コンテンツが用いられる場合には、第三コンテンツの波形データに基づいて、第三コンテンツに応じた非可聴音(第三非可聴音)の基礎信号を生成する。生成部111は、生成した非可聴音の基礎信号の波形データを調整部113に提供する。
なお、可聴音の波形データに基づいて非可聴音の基礎信号の波形データを生成することは、例えば、音源の波形データ(つまり可聴音の波形データ)を増幅した波形データにクリップ処理を施すことで生成される、非可聴音を含む波形データから、可聴音の成分を除去することにより実現され得る。
決定部112は、生成部111が生成した非可聴音の基礎信号の増幅率(単に、非可聴音の増幅率ともいう)を決定する。具体的には、決定部112は、再生部103が更新しているタイムコードに基づいて、非可聴音の増幅率を決定する。決定部112が決定する増幅率は、第一増幅率および第二増幅率を含み、第三コンテンツが用いられる場合には、第三非可聴音の増幅率である第三増幅率を含む。決定部112は、例えば、タイムコードに対して定められた非可聴音の増幅率の推移を保有しており、その増幅率の推移を参照して、時刻ごとに、取得部101から生成部111に提供された波形データに付加する非可聴音の増幅率を決定する。非可聴音の増幅率の推移については、後で説明する。
調整部113は、生成部111が生成した非可聴音の波形データの振幅に、決定部112が決定した増幅率を乗ずることで、再生される非可聴音の音圧を調整する。調整部113は、調整後の非可聴音の波形データを加算部114に提供する。
加算部114は、取得部101から提供された音源の波形データに、調整部113から提供された非可聴音の波形データを加算することで、スピーカ15により再生される波形データを生成する。
以降において、再生部103によるコンテンツの再生について説明する。
図4は、本実施の形態における再生部103によるコンテンツの再生を示す説明図である。
再生システム1が誘導前の感情から直接に目標感情に誘導する場合には、再生部103は、2つのコンテンツを再生する。上記2つのコンテンツは、図4のコンテンツAおよびBに相当する。
具体的には、再生部103は、時刻T1にコンテンツAの再生を開始する。再生部103は、コンテンツAを再生するときに、コンテンツAに応じて生成した非可聴音を再生する。再生部103は、コンテンツAを末尾まで再生する。再生部103がコンテンツAの再生を終える時刻を、時刻T2とする。
次に、再生部103は、時刻T2にコンテンツBの再生を開始する。再生部103は、コンテンツBを再生するときに、コンテンツBに応じて生成した非可聴音を再生する。再生部103は、コンテンツBを末尾まで再生する。再生部103がコンテンツBの再生を終える時刻を、時刻T3とする。
なお、上記の通り、時刻T2は、コンテンツAの再生時間長に応じて定められる。また、上記の通り、時刻T3は、コンテンツAおよびBの再生時間長に応じて定められる。よって、時刻T1から時刻T2までの時間長と、時刻T2から時刻T3までの時間長とは、独立であり、言い換えれば、同じ場合もあれば異なる場合もある。
再生部103は、コンテンツBの再生を終えると、一連のコンテンツの再生を終える。この場合、コンテンツAが第一コンテンツに相当し、コンテンツBが第二コンテンツに相当する。
また、再生システム1が誘導前の感情から1つの中間感情を経由して目標感情に誘導する場合には、再生部103は、3つのコンテンツを再生する。上記3つのコンテンツは、図4のコンテンツA、BおよびCに相当する。
具体的には、再生部103は、上記2つのコンテンツを再生する場合と同様にコンテンツAおよびBを再生した後に、コンテンツCを再生する。コンテンツCを再生する際には、再生部103は、時刻T3にコンテンツCの再生を開始する。再生部103は、コンテンツCを再生するときに、コンテンツCに応じて生成した非可聴音を再生する。再生部103は、コンテンツCを末尾まで再生する。再生部103がコンテンツCの再生を終える時刻を、時刻T4とする。
なお、上記の通り、時刻T4は、コンテンツA、BおよびCの再生時間長に応じて定められる。よって、時刻T3から時刻T4までの時間長は、時刻T1から時刻T2までの時間長、または、時刻T2から時刻T3までの時間長と独立であり、言い換えれば、同じ場合もあれば異なる場合もある。
再生部103は、コンテンツCの再生を終えると、一連のコンテンツの再生を終える。この場合、コンテンツAが第一コンテンツに相当し、コンテンツCが第二コンテンツに相当し、コンテンツBが第三コンテンツに相当する。
なお、再生システム1が誘導前の感情から複数の中間感情を経由して目標感情に誘導する場合には、上記3つのコンテンツを用いる場合におけるコンテンツBを複数とすればよい。
以降において、非可聴音の増幅率の推移について説明する。ここでは、再生システム1が2つのコンテンツを用いてユーザの感情を誘導する場合と、再生システム1が3つのコンテンツを用いてユーザの感情を誘導する場合とのそれぞれについて説明する。
[2.非可聴音の増幅率の推移(2つのコンテンツを用いる場合)]
以降において、再生システム1が2つのコンテンツを再生することでユーザの感情を誘導する場合における、非可聴音(第一非可聴音および第二非可聴音)の増幅率の推移について、複数の例を説明する。再生部103(より具体的には決定部112)は、この増幅率の推移を決定し、また、時刻ごとの非可聴音の増幅率を決定する。
以降において、再生システム1が2つのコンテンツを再生することでユーザの感情を誘導する場合における、非可聴音(第一非可聴音および第二非可聴音)の増幅率の推移について、複数の例を説明する。再生部103(より具体的には決定部112)は、この増幅率の推移を決定し、また、時刻ごとの非可聴音の増幅率を決定する。
図5は、本実施の形態における増幅率の推移の第一例を示す説明図である。
図5に示される増幅率の推移において、再生部103は、時刻T1から時刻T2までの期間において、増幅率を100%から0%に、時刻に対して線形に低下させる。また、再生部103は、時刻T2から時刻T3までの期間において、増幅率を0%から100%に、時刻に対して線形に上昇させる。このように、再生部103が時刻に対して線形に低下または上昇する増幅率の推移を生成する処理は、比較的簡易な処理により実現可能である。
このようにすることで、再生システム1は、比較的簡易な処理により非可聴音の増幅率を調整しながら、ユーザの感情を誘導することができる。
図6は、本実施の形態における増幅率の推移の第二例を示す説明図である。
図6に示される増幅率の推移は、コンテンツのサビ部分の位置に基づいて定められる推移である。ここで、サビ部分とは、コンテンツにおいて比較的盛り上がる部分であり、言い換えれば、当該部分を知覚しているユーザに与える印象が比較的強い部分である。コンテンツにおけるサビ部分を検出する処理は、例えば、コンテンツにおいて音圧が比較的高い部分を抽出する処理により実現可能であり、再生部103により実行可能である。
図6に示されるサビ部分P1は、コンテンツAのサビ部分であり、サビ部分P2は、コンテンツBのサビ部分である。
図6に示される増幅率の推移において、再生部103は、時刻T1から、サビ部分P1の終了時点までの期間において、増幅率を100%に維持し、サビ部分P1の終了時点から時刻T2までの期間において増幅率を100%から0%に、時刻に対して線形に低下させる。
また、再生部103は、時刻T2から、サビ部分P2の開始時点までの期間において、増幅率を0%から100%に、時刻に対して線形に上昇させ、サビ部分P2の開始時点から時刻T3までの期間において、増幅率を100%に維持する。なお、コンテンツAの開始からサビ部分P1の終了までの区間を第一区間ともいい、サビ部分P2の開始から、コンテンツBの終了までの区間を第二区間ともいう。第一区間における増幅率を第一値ともいい、第一値は、比較的高い増幅率の範囲(例えば70%~100%)から選択されてよい。第二区間における増幅率を第二値ともいい、第二値は、比較的高い増幅率の範囲(例えば70%~100%)から選択されてよい。
このように、再生部103が時刻に対して線形に低下または上昇する増幅率の推移を生成する処理は、比較的簡易な処理により実現可能である。
なお、コンテンツAが複数のサビ部分を有する場合、複数のサビ部分のうちのいずれかをサビ部分P1としてよい。また、コンテンツBが複数のサビ部分を有する場合、複数のサビ部分のいずれかをサビ部分P2としてよい。
また、コンテンツAが複数のサビ部分を有する場合、複数のサビ部分のうちの最後のサビ部分をサビ部分P1としてもよい。また、コンテンツBが複数のサビ部分を有する場合、複数のサビ部分のうちの最初のサビ部分をサビ部分P2としてもよい。
このようにすることで、再生システム1は、比較的簡易な処理により非可聴音の増幅率を調整することで、再生部103が各コンテンツのサビ部分を再生しているときのユーザの感情の強度を高めながら、より適切にユーザの感情を誘導することができる。
図7は、本実施の形態における増幅率の推移の第三例を示す説明図である。
図7に示される増幅率の推移は、時刻に対して非線形に定められる推移である。
図7に示される増幅率の推移において、再生部103は、時刻T1から時刻T2までの期間において、増幅率を100%から0%に、時刻に対して指数関数的に低下させる。また、再生部103は、時刻T2から時刻T3までの期間において、増幅率を0%から100%に、時刻に対して指数関数的に上昇させる。
なお、図7に示される増幅率の推移は、一般にAカーブとも呼ばれる。これに対して、図5に示される増幅率の推移は、一般にBカーブとも呼ばれる。一般に、Aカーブに従って増幅率が調整された音の強弱は、人間が感知する音の強弱の感覚に比較的近いと言われている。そのため、Aカーブに従って推移する増幅率を用いることで、ユーザの感情の強度を自然に誘導することができる。
このようにすることで、再生システム1は、ユーザの感情の強度を、より一層、自然に誘導することができる。
なお、図7に示される増幅率の推移は、図5に示される増幅率の推移における線形変化の部分を、指数関数的な変化に置き換えることで生成される。これと同様に、図6に示される増幅率の推移における線形変化の部分を指数関数的な変化に置き換えることもできる。このようにすることで、再生システム1は、再生部103が各コンテンツのサビ部分を再生しているときのユーザの感情の強度を高めながら、より適切にユーザの感情を誘導することができる。
[3.再生システム1の処理(2つのコンテンツを用いる場合)]
図8は、本実施の形態における再生システム1の処理の第一例を示すブロック図である。なお、以降に示される処理を実行する主体である構成要素(端末10およびサーバ20、ならびに、端末10およびサーバ20が備える構成要素)は一例であり、処理を実行する主体は、他の構成要素であってもよい。
図8は、本実施の形態における再生システム1の処理の第一例を示すブロック図である。なお、以降に示される処理を実行する主体である構成要素(端末10およびサーバ20、ならびに、端末10およびサーバ20が備える構成要素)は一例であり、処理を実行する主体は、他の構成要素であってもよい。
ステップS101において、取得部101は、入力IF11を用いて、目標感情を取得する。
ステップS102において、取得部101は、センサ12および認識部102を用いて、誘導前のユーザの感情を取得する。
ステップS103において、取得部101は、ユーザの誘導前の感情と目標感情とをサーバ20に送信し、端末10によって再生すべきコンテンツを要求する。選択部201は、取得部101が送信したユーザの誘導前の感情と目標感情とを取得し、取得したユーザの誘導前の感情と目標感情とに対応するコンテンツ、つまり、端末10によって再生すべきコンテンツを選択し、選択したコンテンツを取得部101に提供する。端末10によって再生すべきコンテンツは、コンテンツAおよびBを含む。コンテンツAは、ユーザの誘導前の感情に対応付けられたコンテンツであり、コンテンツBは、目標感情に対応付けられたコンテンツである。取得部101は、選択部201から提供されたコンテンツを取得する。
ステップS104において、再生部103は、非可聴音の増幅率の推移を決定する。決定される増幅率の推移は、例えば、図5、図6または図7に示される増幅率の推移である。
ステップS105において、再生部103は、非可聴音の増幅率を徐々に低下させながらコンテンツAを再生する。具体的には、再生部103は、ステップS103で取得部101が取得したコンテンツAの波形データ(音源の波形データ)から非可聴音の波形データを生成し、生成した非可聴音の波形データとコンテンツAの波形データとを加算してスピーカ15に提供することで、非可聴音とともにコンテンツAを再生する。そして、再生部103は、非可聴音とともにコンテンツAを再生しながら、再生している非可聴音の増幅率をステップS104で決定した推移に従って徐々に低下させる。再生部103は、コンテンツAを、その末尾まで再生すると、ステップS106に進む。
ステップS106において、再生部103は、非可聴音の増幅率を徐々に上昇させながらコンテンツBを再生する。具体的には、再生部103は、ステップS103で取得部101が取得したコンテンツBの波形データ(音源の波形データ)から非可聴音の波形データを生成し、生成した非可聴音の波形データとコンテンツBの波形データとを加算してスピーカ15に提供することで、非可聴音とともにコンテンツBを再生する。そして、再生部103は、非可聴音とともにコンテンツBを再生しながら、再生している非可聴音の増幅率をステップS104で決定した推移に従って徐々に上昇させる。再生部103は、コンテンツBを、その末尾まで再生すると、図8に示される一連の処理を終了する。
図8に示される一連の処理により、再生システム1は、2つのコンテンツと、上記2つのコンテンツに応じた非可聴音の再生を用いてユーザの感情を適切に誘導することができる。
[4.非可聴音の増幅率の推移(3つのコンテンツを用いる場合)]
以降において、再生システム1が3つのコンテンツを再生することでユーザの感情を誘導する場合における、非可聴音(第一非可聴音、第二非可聴音および第三非可聴音)の増幅率の推移について、複数の例を説明する。再生部103(より具体的には決定部112)は、この増幅率の推移を決定し、また、時刻ごとの非可聴音の増幅率を決定する。
以降において、再生システム1が3つのコンテンツを再生することでユーザの感情を誘導する場合における、非可聴音(第一非可聴音、第二非可聴音および第三非可聴音)の増幅率の推移について、複数の例を説明する。再生部103(より具体的には決定部112)は、この増幅率の推移を決定し、また、時刻ごとの非可聴音の増幅率を決定する。
再生部103は、1以上のコンテンツBの再生中に、再生している第三非可聴音の増幅率を徐々に上昇させた後に、徐々に低下させる。再生部103は、1以上のコンテンツBの再生の開始時点および終了時点では、再生している第三非可聴音の増幅率を0としてもよい。
図9は、本実施の形態における増幅率の推移の第四例を示す説明図である。
図9に示される増幅率の推移において、再生部103は、時刻T1から時刻T2までの期間において、増幅率を100%から0%に、時刻に対して線形に低下させる。
また、再生部103は、時刻T2から時刻T2Aまでの期間において、増幅率を0%から100%に、時刻に対して線形に上昇させ、その後、時刻T2Aから時刻T3までの期間において、増幅率を100%から0%に、時刻に対して線形に低下させる。時刻T2Aは、時刻T2から時刻T3までの間の任意の時刻であり、例えば、時刻T2と時刻T3との中間の時刻であり得る。
また、再生部103は、時刻T3から時刻T3までの期間において、増幅率を0%から100%に、時刻に対して線形に上昇させる。
このように、再生部103が時刻に対して線形に低下または上昇する増幅率の推移を生成する処理は、比較的簡易な処理により実現可能である。
このようにすることで、再生システム1は、比較的簡易な処理により非可聴音の増幅率を調整しながら、ユーザの感情を誘導することができる。
図10は、本実施の形態における増幅率の推移の第五例を示す説明図である。
図10に示される増幅率の推移は、コンテンツのサビ部分の位置に基づいて定められる推移である。
図10に示されるサビ部分P1は、コンテンツAのサビ部分であり、サビ部分P2は、コンテンツBのサビ部分であり、サビ部分P3は、コンテンツCのサビ部分である。
図10に示される増幅率の推移において、時刻T1から時刻T2までの期間における増幅率の推移は、図6と同様である。
また、再生部103は、時刻T2から、サビ部分P2の開始時点までの期間において、増幅率を0%から100%に、時刻に対して線形に上昇させ、サビ部分P2の開始時点から終了時点までの期間において、増幅率を100%に維持する。また、再生部103は、サビ部分P2の終了時点から時刻T3までの期間において、増幅率を100%から0%に、時刻に対して線形に低下させる。
また、再生部103は、時刻T3から、サビ部分P3の開始時点までの期間において、増幅率を0%から100%に、時刻に対して線形に上昇させ、サビ部分P3の開始時点から時刻T4までの期間において、増幅率を100%に維持する。
なお、コンテンツAの開始からサビ部分P1の終了までの区間が第一区間に相当し、サビ部分P3の開始から、コンテンツCの終了までの区間が第二区間に相当する。サビ部分P2の開始から終了までの区間を第三区間ともいう。第三区間における増幅率を第三値ともいい、第三値は、比較的高い増幅率の範囲(例えば70%~100%)から選択されてよい。
このように、再生部103が時刻に対して線形に低下または上昇する増幅率の推移を生成する処理は、比較的簡易な処理により実現可能である。
なお、コンテンツAが複数のサビ部分を有する場合、複数のサビ部分のうちのいずれかをサビ部分P1としてよい。また、コンテンツBが複数のサビ部分を有する場合、複数のサビ部分のいずれかをサビ部分P2としてよい。また、コンテンツCが複数のサビ部分を有する場合、複数のサビ部分のいずれかをサビ部分P3としてよい。
また、コンテンツAが複数のサビ部分を有する場合、複数のサビ部分のうちの最後のサビ部分P1としてもよい。また、コンテンツBが複数のサビ部分を有する場合、複数のサビ部分のうちの最初のサビ部分の開始時点から、最後のサビ部分の終了時点までの期間を、サビ部分P2としてもよい。また、コンテンツCが複数のサビ部分を有する場合、複数のサビ部分の最後のサビ部分をサビ部分P3としてもよい。
このようにすることで、再生システム1は、比較的簡易な処理により非可聴音の増幅率を調整することで、再生部103が各コンテンツのサビ部分を再生しているときのユーザの感情の強度を高めながら、より適切にユーザの感情を誘導することができる。
なお、図9または図10に示される増幅率の推移における線形変化の部分を指数関数的な変化に置き換えることもできる。このようにすることで、再生システム1は、再生部103が各コンテンツのサビ部分を再生しているときのユーザの感情の強度を高めながら、より適切にユーザの感情を誘導することができる。
[5.再生システム1の処理(3つのコンテンツを用いる場合)]
図11は、本実施の形態における再生システム1の処理の第二例を示すブロック図である。
図11は、本実施の形態における再生システム1の処理の第二例を示すブロック図である。
ステップS201において、取得部101は、入力IF11を用いて、目標感情を取得する。
ステップS202において、取得部101は、センサ12および認識部102を用いて、誘導前のユーザの感情を取得する。
ステップS203において、取得部101は、誘導前の感情から目標感情に誘導するために経由する感情(中間感情ともいう)を取得する。中間感情の取得は、ユーザから入力IF11に入力されたものであってもよいし、誘導前の感情と目標感情とに基づいて、取得部101が決定したものであってもよい。
ステップS204において、取得部101は、ユーザの誘導前の感情と中間感情と目標感情とをサーバ20に送信し、端末10によって再生すべきコンテンツを要求する。選択部201は、取得部101が送信したユーザの誘導前の感情と中間感情と目標感情とを取得し、取得したユーザの誘導前の感情と中間感情と目標感情とに対応するコンテンツ、つまり、端末10によって再生すべきコンテンツを選択し、選択したコンテンツを取得部101に提供する。端末10によって再生すべきコンテンツは、コンテンツA、BおよびCを含む。コンテンツAは、ユーザの誘導前の感情に対応付けられたコンテンツであり、コンテンツBは、中間感情に対応付けられたコンテンツであり、コンテンツCは、目標感情に対応付けられたコンテンツである。取得部101は、選択部201から提供されたコンテンツを取得する。
ステップS205において、再生部103は、非可聴音の増幅率の推移を決定する。決定される増幅率の推移は、例えば、図9または図10に示される増幅率の推移である。
ステップS206において、再生部103は、非可聴音の増幅率を徐々に低下させながらコンテンツAを再生する。非可聴音の増幅率を徐々に低下させながらコンテンツAを再生する処理は、ステップS205で決定した推移に従って、ステップS105(図8)と同様になされる。再生部103は、コンテンツAを、その末尾まで再生すると、ステップS207に進む。
ステップS207において、再生部103は、非可聴音の増幅率を徐々に上昇させながらコンテンツBを再生する。再生部103は、コンテンツBを末尾まで再生する前のタイミング(図9における時刻T2A、または、図10におけるサビ部分P2に含まれる時点)で、ステップS208へ進む。コンテンツBを再生する処理は、引き続き、ステップS208で行われる。非可聴音の増幅率を徐々に上昇させながらコンテンツBを再生する処理は、ステップS205で決定した推移に従って、ステップS106(図8)と同様になされる。
ステップS208において、再生部103は、非可聴音の増幅率を徐々に低下させながらコンテンツBを再生する。コンテンツBの再生は、ステップS207から継続して行われている。非可聴音の増幅率を徐々に低下させながらコンテンツBを再生する処理は、ステップS205で決定した推移に従って、ステップS105(図8)と同様になされる。再生部103は、コンテンツBを、その末尾まで再生すると、ステップS209に進む。
ステップS209において、再生部103は、非可聴音の増幅率を徐々に上昇させながらコンテンツCを再生する。非可聴音の増幅率を徐々に上昇させながらコンテンツCを再生する処理は、ステップS205で決定した推移に従って、ステップS106(図8)と同様になされる。再生部103は、コンテンツCを、その末尾まで再生すると、図11に示される一連の処理を終了する。
なお、ステップS203の処理は、取得部101により実行される代わりに、選択部201により実行されてもよい。つまり、選択部201が、中間感情を取得してもよい。中間感情の取得は、誘導前の感情と目標感情とに基づいて、選択部201が決定したものであり得る。選択部201が中間感情を決定する場合、中間感情の決定に必要な誘導前の感情と目標感情とは、ステップS201およびS202で取得部101が取得したものであり、その取得後にサーバ20に送信されたものであり得る。なお、ステップS203の処理が選択部201により実行された場合、ステップS203において、選択部201は、中間感情を取得部101に送信してもよい。また、この場合、ステップS204で選択部201は、ステップS203で取得した誘導前の感情および目標感情と、ステップS204で取得した中間感情とを用いて、コンテンツA、BおよびCを選択する。
図11に示される一連の処理により、再生システム1は、3つのコンテンツと、上記3つのコンテンツに応じた非可聴音の再生とを用いてユーザの感情を適切に誘導することができる。
(実施の形態の変形例)
本変形例において、非可聴音の再生を用いてユーザの感情を適切に誘導する再生システムについて説明する。本変形例における再生システムは、誘導されているユーザの感情に応じて非可聴音の強弱を制御することで、より適切にユーザの感情を誘導する。
本変形例において、非可聴音の再生を用いてユーザの感情を適切に誘導する再生システムについて説明する。本変形例における再生システムは、誘導されているユーザの感情に応じて非可聴音の強弱を制御することで、より適切にユーザの感情を誘導する。
本変形例における再生システム1は、上記実施の形態の再生システム1と同様にコンテンツを再生することでユーザの感情を誘導しながら、誘導されているユーザの感情を感知し、ユーザの感情に応じて非可聴音の増幅率を制御する。
再生部103は、感情を誘導されるユーザの感情の予め定められた推移を示す目標推移を保有している。目標推移は、感情を誘導されている途中のユーザの感情の種別と、その感情の強度とを示す情報である。再生部103は、認識部102が認識したユーザの感情が、目標推移から逸脱しているときには、ユーザの感情を目標推移に近づけるように、再生している第一非可聴音の増幅率を調整する。なお、再生部103は、認識部102が認識した感情が、目標推移から逸脱しているときには、再生している第一非可聴音の増幅率を0としてもよい。ユーザの感情が目標推移から逸脱していることは、ユーザの感情と、目標推移における感情との差異が所定以上であるか否かを判定することでなされ得る。
図12は、本変形例における目標推移を示す説明図である。
図12において、時刻(タイムコードに対応)に対する目標推移が示されている。図12に示される目標推移は、誘導前の感情が興奮であり、目標感情がリラックスであり、2つのコンテンツを用いてユーザの感情を誘導する場合における目標推移を示している。ここでは、感情の強度を例として0%から100%の範囲で示しているが、これに限られない。
時刻T1から時刻T2までの期間では、感情の種別は興奮であり、その感情強度が100%から0%に向かって徐々に低下する。時刻T2から時刻T3までの期間には、感情の種別はリラックスであり、その感情強度が0%から100%に向かって徐々に上昇する。
図13は、本変形例における再生システム1の処理を示すフロー図である。
再生システム1は、再生部103によりコンテンツを再生しているとき(例えば図8のステップS105およびS106)に、同時並行的に、図13に示される処理を実行する。非可聴音の増幅率の推移として、一例として図5に示される増幅率の推移が決定されている(ステップS104)として説明する。
ステップS301において、取得部101は、再生部103が再生しているコンテンツの再生時点のタイムコードを取得する。タイムコードは、再生しているコンテンツにおける、どの時間的位置を再生部103が再生しているかを示している。
ステップS302において、取得部101は、目標推移における再生時点での感情を取得する。再生時点での感情は、感情の種別と、感情の強度とを含む。
ステップS303において、取得部101は、ユーザの現時点(つまり、本処理を実行している時点)の感情を取得する。
ステップS304において、取得部101は、ステップS302で取得した目標推移における再生位置での感情と、ステップS303で取得したユーザの現時点の感情との差異が所定以上であるか否かを判定する。例えば、取得部101は、目標推移における再生位置での感情の種別と、ユーザの現時点の感情の種別とが同じであって、目標推移における再生位置での感情の強度より、ユーザの現時点の感情の強度が10ポイント以上高いまたは低い場合に、上記差異が所定以上であると判定してもよい。また、例えば、取得部101は、目標推移における再生位置での感情の種別と、ユーザの現時点の感情の種別とが異なる場合に、上記差異が所定以上であると判定してもよい。上記差異が所定以上であると判定した場合(ステップS304でYes)にはステップS305に進み、そうでない場合には、ステップS301を再び実行する。
ステップS305において、取得部101は、増幅率を調整する。例えば、取得部101は、目標推移における再生位置での感情の種別と、ユーザの現時点の感情の種別とが同じであって、目標推移における再生位置での感情の強度より、ユーザの現時点の感情の強度が10ポイント以上高い場合に、ステップS104で決定されている増幅率の推移における現時点の増幅率を、より低い値に調整する。このとき、取得部101は、ステップS104で決定されている増幅率の推移における現時点以降の増幅率が減少傾向にある場合には、現時点以降の増幅率を、現時点の調整後の増幅率以下になるように調整してもよい。
また、例えば、取得部101は、目標推移における再生位置での感情の種別と、ユーザの現時点の感情の種別とが同じであって、目標推移における再生位置での感情の強度より、ユーザの現時点の感情の強度が10ポイント以上低い場合に、ステップS104で決定されている増幅率の推移における現時点の増幅率を、より高い値に調整する。このとき、取得部101は、ステップS104で決定されている増幅率の推移における現時点以降の増幅率が増加傾向にある場合には、現時点以降の増幅率を、現時点の調整後の増幅率以上になるように調整してもよい。
図14は、本変形例における感情の推移の例を示す説明図である。図15は、本変形例における増幅率の推移の例を示す説明図である。
図14には、目標推移とともに、再生システム1によって感情を誘導されるユーザの実際の感情の推移が示されている。ユーザの実際の感情の推移は、センサ12および認識部102によって得られたユーザの感情を、時間的な推移として示したものである。
図14に示されるユーザの実際の感情は、時刻T1において、強度が100%である興奮の感情であり、時刻T1より後において100%から低下しつつある。
時刻T5において、取得部101が目標推移における再生位置での感情強度に対する、ユーザの現時点の感情強度の差分dが、10ポイント以上高いと判定したとする。
その場合、再生部103は、時刻T5における増幅率を、調整前の値A1から値A2に低下させるように調整する。また、時刻T5より後の増幅率の推移を、調整後の値A2から徐々に低下するように調整する(図15参照)。このようにすることで、再生システム1は、ユーザの興奮の強度を低下させる効果を高め、目標推移に近い推移でユーザの感情を誘導することに寄与する。
なお、再生部103は、時刻T5以降の増幅率を0としてもよい。再生部103が時刻T5以降の増幅率を0とするのは、例えば、ステップS304で、目標推移における再生位置での感情の種別と、ユーザの現時点の感情の種別とが異なると取得部101が判定した場合である。このようにすることで、再生システム1は、非可聴音の再生を停止(つまり、ユーザの感情の誘導を停止)することができる。ユーザが、その感情を誘導されることに適さない状態である場合には、ユーザの感情を誘導することがユーザに悪影響を与える(例えば心理的負担となる等)ことがあり、それを抑制することに寄与する。
以上のように、本開示における技術の例示として、実施の形態を説明した。そのために、添付図面および詳細な説明を提供した。
したがって、添付図面および詳細な説明に記載された構成要素の中には、課題解決のために必須な構成要素だけでなく、上記実装を例示するために、課題解決のためには必須でない構成要素も含まれ得る。そのため、それらの必須ではない構成要素が添付図面や詳細な説明に記載されていることをもって、直ちに、それらの必須ではない構成要素が必須であるとの認定をするべきではない。
また、上述の実施の形態は、本開示における技術を例示するためのものであるから、請求の範囲またはその均等の範囲において種々の変更、置き換え、付加、省略などを行うことができる。
本開示は、ユーザの感情を誘導するシステムに利用可能である。
1 再生システム
10 端末
11 入力IF
12 センサ
13、21 通信IF
14、22 プロセッサ
15 スピーカ
20 サーバ
23 ストレージ
101 取得部
102 認識部
103 再生部
111 生成部
112 決定部
113 調整部
114 加算部
201 選択部
N ネットワーク
P、Q 経路
10 端末
11 入力IF
12 センサ
13、21 通信IF
14、22 プロセッサ
15 スピーカ
20 サーバ
23 ストレージ
101 取得部
102 認識部
103 再生部
111 生成部
112 決定部
113 調整部
114 加算部
201 選択部
N ネットワーク
P、Q 経路
Claims (14)
- ユーザの感情を第一感情から第二感情に誘導する、コンテンツの再生システムであって、
前記第一感情に対応する第一コンテンツと、前記第二感情に対応する第二コンテンツとを取得する取得部と、
スピーカにより、(a)前記第一コンテンツに応じた第一非可聴音であって、前記第一非可聴音の基礎信号を第一増幅率で増幅した第一非可聴音とともに前記第一コンテンツを再生した後に、(b)前記第二コンテンツに応じた第二非可聴音であって、前記第二非可聴音の基礎信号を第二増幅率で増幅した第二非可聴音とともに前記第二コンテンツを再生する、再生部とを備え、
前記再生部は、
前記第一コンテンツの再生中に、再生している前記第一非可聴音の前記第一増幅率を徐々に低下させ、
前記第二コンテンツの再生中に、再生している前記第二非可聴音の前記第二増幅率を徐々に上昇させる
再生システム。 - 前記再生部は、
前記第一コンテンツの再生の終了時点では、前記第一増幅率を0とし、
前記第二コンテンツの再生の開始時点では、前記第二増幅率を0とする
請求項1に記載の再生システム。 - 前記再生部は、
前記第一コンテンツの再生中に、
前記第一コンテンツの開始から、前記第一コンテンツに含まれるサビ部分の終了までの第一区間において、再生している前記第一非可聴音の前記第一増幅率を第一値に維持し、
上記第一区間より後の区間において、再生している前記第一非可聴音の前記第一増幅率を、前記第一値から徐々に低下させ、
前記第二コンテンツの再生中に、
前記第二コンテンツに含まれるサビ部分の開始から、前記第二コンテンツの終了までの第二区間において、再生している前記第二非可聴音の前記第二増幅率を第二値に維持し、
上記第二区間より前の区間において、再生している前記第二非可聴音の前記第二増幅率を、前記第二値に向けて徐々に上昇させる
請求項1または2に記載の再生システム。 - 前記再生部は、
前記第一コンテンツの再生中に前記第一増幅率を徐々に低下させるときには、前記第一増幅率を時刻に対して線形に低下させ、
前記第二コンテンツの再生中に前記第二増幅率を徐々に上昇させるときには、前記第二増幅率を時刻に対して線形に上昇させる
請求項1に記載の再生システム。 - 前記再生部は、
前記第一コンテンツの再生中に前記第一増幅率を徐々に低下させるときには、前記第一増幅率を時刻に対して指数関数的に低下させ、
前記第二コンテンツの再生中に前記第二増幅率を徐々に上昇させるときには、前記第二増幅率を時刻に対して指数関数的に上昇させる
請求項1に記載の再生システム。 - 前記再生システムは、さらに、
前記再生部が前記第一コンテンツまたは前記第二コンテンツを再生しているときに、前記ユーザの感情を認識する認識部を備え、
前記再生部は、
前記認識部が認識した前記感情が予め定められた推移から逸脱しているときには、前記ユーザの感情を前記予め定められた推移に近づけるように、再生している前記第一非可聴音の前記第一増幅率を調整する
請求項1に記載の再生システム。 - 前記再生システムは、さらに、
前記再生部が前記第一コンテンツまたは前記第二コンテンツを再生しているときに、前記ユーザの感情を認識する認識部を備え、
前記再生部は、
前記認識部が認識した前記感情が予め定められた推移から逸脱しているときには、再生している前記第一非可聴音の増幅率を0とする
請求項1に記載の再生システム。 - 前記再生部は、
前記第一コンテンツの再生を終了した時点で、前記第二コンテンツの再生を開始する
請求項1に記載の再生システム。 - 前記再生システムは、前記ユーザの感情を、前記第一感情から、1以上の第三感情を経由して前記第二感情に誘導し、
前記取得部は、前記1以上の第三感情それぞれに対応する第三コンテンツである、1以上の第三コンテンツを取得し、
前記再生部は、
前記第一コンテンツの再生を終了した時点以降に、順次に、前記1以上の第三コンテンツそれぞれに応じた第三非可聴音とともに当該第三コンテンツを再生し、
前記1以上の第三コンテンツの再生を終了した時点で、前記第二コンテンツの再生を開始し、
前記1以上の第三コンテンツそれぞれの再生中に、再生している前記第三非可聴音の第三増幅率を徐々に上昇させた後に、徐々に低下させる
請求項1に記載の再生システム。 - 前記再生部は、
前記1以上の第三コンテンツの再生の開始時点および終了時点では、第三増幅率を0とする
請求項9に記載の再生システム。 - 前記再生部は、
前記1以上の第三コンテンツそれぞれの再生中に、
当該第三コンテンツのサビ部分の開始から終了を含む第三区間において、再生している前記第三非可聴音の前記第三増幅率を第三値に維持し、
上記第三区間より前の区間において、再生している前記第三非可聴音の前記第三増幅率を、前記第三値に向けて徐々に上昇させ、
上記第三区間より後の区間において、再生している前記第三非可聴音の前記第三増幅率を、前記第三値から徐々に低下させる
請求項9に記載の再生システム。 - 前記再生システムは、さらに、
複数のコンテンツのうちから、前記第一感情に対応する前記第一コンテンツと、前記第二感情に対応する前記第二コンテンツとを選択する選択部とを備え、
前記取得部は、前記選択部が選択した前記第一コンテンツと前記第二コンテンツとを取得する
請求項1に記載の再生システム。 - ユーザの感情を第一感情から第二感情に誘導する、コンテンツの再生システムが備える1以上のコンピュータが実行する再生方法であって、
前記第一感情に対応する第一コンテンツと、前記第二感情に対応する第二コンテンツとを取得し、
スピーカにより、(a)前記第一コンテンツに応じた第一非可聴音であって、前記第一非可聴音の基礎信号を第一増幅率で増幅した第一非可聴音とともに前記第一コンテンツを再生した後に、(b)前記第二コンテンツに応じた第二非可聴音であって、前記第二非可聴音の基礎信号を第二増幅率で増幅した第二非可聴音とともに前記第二コンテンツを再生し、
前記第一コンテンツの再生中に、再生している前記第一非可聴音の前記第一増幅率を徐々に低下させ、
前記第二コンテンツの再生中に、再生している前記第二非可聴音の前記第二増幅率を徐々に上昇させる
再生方法。 - 請求項13に記載の再生方法をコンピュータに実行させるプログラム。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022141032 | 2022-09-05 | ||
| JP2022-141032 | 2022-09-05 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024053123A1 true WO2024053123A1 (ja) | 2024-03-14 |
Family
ID=90192214
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/044501 WO2024053123A1 (ja) | 2022-09-05 | 2022-12-02 | 再生システム、再生方法、および、プログラム |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2024053123A1 (ja) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010266748A (ja) * | 2009-05-15 | 2010-11-25 | Panasonic Electric Works Co Ltd | 音響振動再生装置並びに音響振動再生方法 |
| JP2014226361A (ja) * | 2013-05-23 | 2014-12-08 | ヤマハ株式会社 | 音源装置およびプログラム |
| JP2017050597A (ja) * | 2015-08-31 | 2017-03-09 | 株式会社竹中工務店 | 音源処理装置、音響装置及び部屋 |
| WO2021192072A1 (ja) * | 2020-03-25 | 2021-09-30 | ヤマハ株式会社 | 室内用音環境生成装置、音源装置、室内用音環境生成方法および音源装置の制御方法 |
-
2022
- 2022-12-02 WO PCT/JP2022/044501 patent/WO2024053123A1/ja unknown
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010266748A (ja) * | 2009-05-15 | 2010-11-25 | Panasonic Electric Works Co Ltd | 音響振動再生装置並びに音響振動再生方法 |
| JP2014226361A (ja) * | 2013-05-23 | 2014-12-08 | ヤマハ株式会社 | 音源装置およびプログラム |
| JP2017050597A (ja) * | 2015-08-31 | 2017-03-09 | 株式会社竹中工務店 | 音源処理装置、音響装置及び部屋 |
| WO2021192072A1 (ja) * | 2020-03-25 | 2021-09-30 | ヤマハ株式会社 | 室内用音環境生成装置、音源装置、室内用音環境生成方法および音源装置の制御方法 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101590046B1 (ko) | 바이노럴 비트를 이용한 뇌파 유도 오디오 장치 및 방법 | |
| US9191764B2 (en) | Binaural audio signal-based applications | |
| WO2016063879A1 (ja) | 音声合成装置および方法 | |
| WO2007081051A1 (ja) | コンテンツ再生装置および再生方法 | |
| JP6266427B2 (ja) | ユーザのストレス度に応じて音楽を選択する装置、プログラム及び方法 | |
| Zelechowska et al. | Headphones or speakers? An exploratory study of their effects on spontaneous body movement to rhythmic music | |
| WO2018038235A1 (ja) | 聴覚トレーニング装置、聴覚トレーニング方法、およびプログラム | |
| JP2023025013A (ja) | 音楽療法のための歌唱補助装置 | |
| WO2024053123A1 (ja) | 再生システム、再生方法、および、プログラム | |
| JP2010259457A (ja) | 放音制御装置 | |
| JP6477298B2 (ja) | 音源装置 | |
| JP6691737B2 (ja) | 歌詞音声出力装置、歌詞音声出力方法、及び、プログラム | |
| JP6539547B2 (ja) | 音源処理装置、音響装置及び部屋 | |
| JP5790021B2 (ja) | 音声出力システム | |
| US8163991B2 (en) | Headphone metronome | |
| WO2019150442A1 (ja) | プログラム、コンピュータ読み取り可能な記録媒体、携帯端末、および運動支援システム | |
| JP6810773B2 (ja) | 再生装置、再生方法、及び、プログラム | |
| JP4134844B2 (ja) | 聴覚補助装置 | |
| JP2016157084A (ja) | 再生装置、再生方法、及び、プログラム | |
| JP2021099535A (ja) | 再生装置、再生方法、及び、プログラム | |
| JP2016157082A (ja) | 再生装置、再生方法、及び、プログラム | |
| JP2016157088A (ja) | 楽曲再生システム、端末装置、楽曲データ提供方法、及び、プログラム | |
| JP2019219675A (ja) | 音声信号出力装置、音声信号出力方法、及び、プログラム | |
| JP2016157087A (ja) | 楽曲再生システム、サーバ、楽曲データ提供方法、及び、プログラム | |
| JP3106929U (ja) | 催眠効果を有する音声データを記憶するための情報記憶媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22958201 Country of ref document: EP Kind code of ref document: A1 |