WO2024048236A1 - ポリヌクレオチド、キット、及び、診断方法 - Google Patents
ポリヌクレオチド、キット、及び、診断方法 Download PDFInfo
- Publication number
- WO2024048236A1 WO2024048236A1 PCT/JP2023/029165 JP2023029165W WO2024048236A1 WO 2024048236 A1 WO2024048236 A1 WO 2024048236A1 JP 2023029165 W JP2023029165 W JP 2023029165W WO 2024048236 A1 WO2024048236 A1 WO 2024048236A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- seq
- base
- base sequence
- group
- nos
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/005—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from viruses
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/195—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from bacteria
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/02—Preparation of hybrid cells by fusion of two or more cells, e.g. protoplast fusion
- C12N15/03—Bacteria
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6806—Preparing nucleic acids for analysis, e.g. for polymerase chain reaction [PCR] assay
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6813—Hybridisation assays
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6888—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for detection or identification of organisms
- C12Q1/689—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for detection or identification of organisms for bacteria
Definitions
- the present disclosure relates to polynucleotides, kits, and diagnostic methods.
- Patent Document 1 states, ⁇ A step of using a sample containing two or more cells or cell-like structures, and encapsulating the cells or cell-like structures one cell or structure at a time in a droplet; gelling to produce a gel capsule; and lysing the cell or cell-like structure by immersing the gel capsule in one or more lysis reagents, wherein the polynucleotide in the cell is dissolved in the gel.
- a method for amplifying a polynucleotide in a cell or cell-like structure comprising the steps of:
- Genome analysis technology is particularly useful for infectious diseases caused by difficult-to-cultivate bacteria and viruses.
- One of the objectives of the present disclosure is to provide polynucleotides that may be used as markers for in vitro diagnosis of infectious diseases. Moreover, one of the problems of the present disclosure is to provide a primer set and a diagnostic method.
- polynucleotide disclosed herein is selected from the group consisting of: A polynucleotide consisting of at least one type of base sequence. (a) at least one base sequence selected from the group consisting of SEQ ID NOS: 1 to 4; (b) a base sequence having 80% or more homology to at least one base sequence selected from the group consisting of SEQ ID NOs: 1 to 4; (c) A base sequence of a polynucleotide that hybridizes under stringent conditions to a nucleic acid consisting of a base sequence complementary to at least one base sequence selected from the group consisting of SEQ ID NOs: 1 to 4.
- kit disclosed herein that includes a primer set and/or a probe includes a primer set designed from a base sequence selected from the group consisting of SEQ ID NOs: 1 to 4, and/or Alternatively, it is a kit containing the probe.
- kits comprising the primer set and/or probe disclosed herein is the following (e) to (n) [(e) to (n) are e, f, g , h, k, m, n] is a kit containing a primer set and/or probe designed from at least one region selected from the group consisting of: (e) region from base 641 to base 768 of SEQ ID NO: 3 (SEQ ID NO: 5), (f) Region from base 992 to base 1129 of SEQ ID NO: 2 (SEQ ID NO: 6) (g) Region from base 1223 to base 1338 of SEQ ID NO: 2 (SEQ ID NO: 7) (h) Region from base 695 to base 793 of SEQ ID NO: 2 (SEQ ID NO: 8) (k) Region from base 3938 to base 4030 of SEQ ID NO: 4 (SEQ ID NO: 9) (m) Region from base 2377 to base 2484 of SEQ ID NO: 4 (SEQ ID NO: 10) (n) Region from base 27
- polynucleotide disclosed herein is selected from the group consisting of: A polynucleotide consisting of at least one type of base sequence.
- At least one base sequence selected from the group consisting of SEQ ID NOs: 5 to 11 At least 80% of the base sequence selected from the group consisting of SEQ ID NOS: 5 to 11
- polynucleotides are provided that may be used as markers for in vitro diagnosis of infectious diseases. Further, according to the present disclosure, a primer set and a diagnostic method are provided.
- FIG. 2 is a diagram showing a procedure for determining a region (biomarker sequence) that is specifically detected in periodontal disease patients.
- FIG. 2 is a diagram showing a procedure for determining a region (biomarker sequence) that is specifically detected in periodontal disease patients.
- a numerical range expressed using " ⁇ ” means a range that includes the numerical values written before and after " ⁇ " as the lower limit and upper limit.
- a first embodiment of the polynucleotide disclosed herein is a polynucleotide consisting of at least one base sequence selected from the group consisting of (a) to (c) below.
- a sequence analysis method that is quantitative at the level of a single membrane vesicle is required.
- nucleotide sequence unique to a specific membrane vesicle is identified, there is another problem in applying this nucleotide sequence to PCR (polymerase chain reaction), etc. to detect diseases. . Selection is necessary to reduce the risk of false positive rate (events in which the desired signal is detected even in healthy individuals). This selection method had not been previously established.
- the base sequences of SEQ ID NOs: 1 to 4 are marker sequences that were selected and obtained by a method that was previously unknown, and are novel. In addition, if selected using an appropriate method, it can function as a marker with a low false positive rate in the diagnosis of infectious diseases, especially periodontal disease (diagnosis of the presence or absence of disease and the degree of progression). It has an effect.
- the polynucleotides consisting of the base sequences of SEQ ID NOs: 1 to 4 were generally acquired by the following novel procedure.
- membrane vesicles were extracted from saliva collected from healthy subjects and patients with periodontal disease.
- the base sequence of the DNA contained in the extracted membrane vesicles was analyzed for each membrane vesicle using single cell/particle analysis technology.
- the host (bacteria or virus) of each membrane vesicle was then identified based on the sequences derived from each membrane vesicle.
- hosts were identified that were more abundant in saliva samples from patients with periodontal disease compared to healthy individuals.
- sequence reads derived from membrane vesicles were mapped against the entire genome sequence of the host, and genomic regions obtained from a large number of membrane vesicles were identified (quantitatively).
- genomic regions parts with low homology to other bacteria and viruses were determined to be biomarker sequence candidates.
- biomarker candidate sequences those with low alignment scores were selected in comparison with saliva samples from healthy individuals.
- sequence reads for bacteria (or viruses) of the same taxon were excluded. In this way, sequences 1 to 3 derived from bacteria and sequence 4 derived from virus were identified.
- the polynucleotide of Example 1 derived from Sequences 1 to 4 selected and obtained through the above procedure can reduce the risk of false positives when used as a marker for diagnosing infectious diseases, particularly periodontal disease.
- This polynucleotide can also be the basis for the design of primer sets and probes.
- polynucleotide refers to a polymer form of nucleotides of any length. This term refers only to the primary structure of the molecule.
- the nucleotide sequence (b) preferably has 85% or more homology, and preferably 90% or more homology to at least one nucleotide sequence selected from the group consisting of SEQ ID NOS: 1 to 4. is more preferable, it is still more preferable to have a homology of 95% or more, and it is particularly preferable to have a homology of 98% or more. Note that the above also applies to the base sequence (r) described below.
- a polynucleotide that hybridizes under stringent conditions refers to, for example, using a polynucleotide as a probe using a colony hybridization method, a plaque hybridization method, a Southern blot hybridization method, or the like. It can be obtained by Note that the above also applies to (t) described later.
- polynucleotides that hybridize under stringent conditions can also be obtained according to the instructions included with common hybridization kits.
- hybridization kits include the Random Primed DNA Labeling Kit (manufactured by Roche Diagnostics), which prepares probes by a random prime method and performs hybridization under stringent conditions.
- SSC after hybridization is performed at 65°C in the presence of 0.7 to 1.0 M NaCl using a polynucleotide-immobilized filter, SSC at a concentration of 0.1 to 2 times It can also be obtained by washing the filter at 65°C using a (saline-sodium citrate) solution (the composition of a 1x SSC solution is 150mM sodium chloride and 15mM sodium citrate).
- a (saline-sodium citrate) solution the composition of a 1x SSC solution is 150mM sodium chloride and 15mM sodium citrate.
- Stringent conditions include, for example, combining a polynucleotide-immobilized filter and a polynucleotide probe in 50% formamide, 5x SSC (750mM sodium chloride, 75mM sodium citrate), and 50mM sodium phosphate (pH 7). .6), after incubation overnight at 42°C in a solution containing 5x Denhardt's solution, 10% dextran sulfate, and 20 ⁇ g/L denatured salmon sperm DNA, e.g. Conditions include washing the filter in 2 ⁇ SSC solution.
- the above conditions can also be set by adding and/or changing a blocking reagent used to suppress hybridization background. Addition of blocking reagents may involve altering hybridization conditions to adapt the conditions.
- a second embodiment of the polynucleotide disclosed herein is a marker for detecting an infectious disease from the base sequence of a membrane vesicle extracted from a biological sample in the first embodiment. , a polynucleotide.
- the polynucleotide of the first embodiment has a membrane vesicle-derived sequence that is specifically expressed in infectious disease patients and is obtained by selection using a novel technique. Therefore, if membrane vesicles extracted from biological samples are used as specimens, they can function as highly accurate diagnostic markers for detecting infectious diseases (particularly periodontal disease).
- the biological sample refers to a sample obtained from a human or a non-human animal, and may be subjected to predetermined pretreatment.
- a sample may be, for example, saliva, feces, saliva, sputum, surgical cleaning fluid, blood, skin/body mucous membrane swab, swab, or other collected samples, and saliva is particularly preferred.
- the sample may also be subjected to pretreatment, and preferably undergoes treatment to extract membrane vesicles.
- Membrane vesicles are contained in the above-mentioned biological sample together with host cells (or virus-infected host cells), etc., and membrane vesicles are separated from the host cells, Preferably, it is obtained.
- the method for separating host cells and membrane vesicles in a biological sample is not particularly limited, and any known method may be used.
- membrane vesicles can be obtained in the supernatant by centrifugation.
- a membrane filter eg, pore size 0.1 to 0.9 ⁇ m
- host cells remaining in the centrifugal supernatant can be easily separated.
- the centrifuged supernatant may contain contaminants such as proteins in addition to host cells, for example, it may be concentrated using a 100-200 kDa cutoff filter and then precipitated by ultracentrifugation to precipitate membrane vesicles. Methods of recovery may also be used.
- the precipitate obtained in this way may contain structures (e.g., flagella, flagella, etc.) derived from host cells (e.g., bacteria), and in order to remove these,
- host cells e.g., bacteria
- a method for further purification using density gradient centrifugation using sucrose or the like may be used.
- a biological sample is placed in a centrifuge tube with a volume of 1 to 100 mL (eg, 50 mL), and heated at 3,000 to 9,000 rpm (eg, 7,000 rpm) at 1 to 20°C (eg, 4°C) for 1 to 30 minutes (eg, 10 centrifuged for 1 minute).
- a centrifuge tube with a volume of 1 to 100 mL (eg, 50 mL), and heated at 3,000 to 9,000 rpm (eg, 7,000 rpm) at 1 to 20°C (eg, 4°C) for 1 to 30 minutes (eg, 10 centrifuged for 1 minute).
- the precipitate contains host cells, etc., and the supernatant is passed through a 0.1 to 0.9 ⁇ m (for example, 0.22 ⁇ m) filter. and stored in a separate centrifuge tube at 1-10°C (eg, 4°C).
- the supernatant is then placed in an ultracentrifuge tube, e.g. Ultracentrifuge for ⁇ 3 hours (eg, 2 hours). After ultracentrifugation, the supernatant is discarded and the precipitated membrane vesicles (OMVs) are resuspended in a buffer (e.g., PBS buffer, pH 7.4) and stored at 1-10°C (e.g., 4°C). Ru. Furthermore, this ultracentrifugation step may be repeated multiple times.
- a buffer e.g., PBS buffer, pH 7.4
- the obtained liquid may be diluted in order to adjust the number (concentration) of membrane vesicles contained per unit amount. This dilution process facilitates the separation and acquisition of individual membrane vesicles in the single cell/particle analysis described below.
- the dilution method is not particularly limited, but includes, for example, a method of diluting to an appropriate concentration based on the concentration of membrane vesicles in the liquid observed by dynamic light scattering or the like.
- the method for observing the concentration of membrane vesicles is to irradiate the particles with a laser, track the Brownian motion of each particle from the scattered light (tracking method), and calculate the particle diameter and diameter based on the Stokes-Einstein formula from the diffusion rate.
- a method of calculating the number of objects is preferable.
- Single cell/particle analysis can be used to isolate membrane vesicles and obtain their base sequences.
- single cell/particle analysis is synonymous with “single particle analysis”, and is based on the analysis of membrane vesicles from a specimen (sample) containing multiple types and/or multiple cells. This refers to a method of separating each individual and performing genome analysis.
- Single cell/particle analysis is, for example, a method in which membrane vesicles are collected one by one in each of a large number of microwells arranged on a plane, and genome analysis is performed on each membrane vesicle.
- the device described in Patent Document 1 the device described in International Publication No. 2017/094101, the device described in International Publication No. 2016/038670, etc. Examples include those using known devices and/or methods.
- membrane vesicles include outer membrane vesicles produced by bacteria, etc., “exosomes” produced and released by animal cells through the endocytic pathway, and “apoptosis” caused by apoptosis. “Corpuscles” are also included. Among these, membrane vesicles produced from cells infected with periodontal disease bacteria or periodontal disease-related viruses are preferred.
- Membrane vesicles produced by bacteria are produced in such a way that part of the bacterial cell membrane is stretched outside the bacterial body.
- examples include "outer membrane vesicles (OMVs),” which are microvesicles such as microvesicles, and “outer-inner membrane vesicles,” which are produced when bacteria rupture and lyse.
- OMVs outer membrane vesicles
- its size is not particularly limited, it is often 10 to 1000 nm, for Gram-negative bacteria it is often 10 to 300 nm, and for Gram-positive bacteria it is often 50 to 150 nm.
- membrane vesicles may be detected in membrane vesicles, and the term "membrane vesicle” as used herein does not include virus-derived DNA. You can leave it there.
- a third embodiment of the polynucleotide disclosed herein is a polynucleotide in which the infectious disease in the second embodiment is periodontal disease.
- polynucleotides consisting of the base sequences of SEQ ID NOs: 1 to 4 were determined from DNA base sequences derived from membrane vesicles extracted from the saliva of healthy individuals and patients with periodontal disease.
- the polynucleotide of the third embodiment is based on a sequence that is specifically expressed in this periodontal disease patient and whose eligibility as a marker is ensured, and is derived from a sample containing saliva (or saliva itself). as a marker for the detection of periodontal disease, the risk of false positives is reduced to a greater extent.
- the first embodiment of the kit disclosed herein is a kit that includes a primer set and/or probe designed from a base sequence selected from the group consisting of SEQ ID NOs: 1 to 4.
- the base sequence selected from the group consisting of SEQ ID NOs: 1 to 4 is a marker sequence selected from the DNA base sequence of membrane vesicles that are specifically expressed in periodontal disease patients. Primer sets and probes designed based on this are suitable for amplifying the above markers by real-time qPCR or the like.
- a second embodiment of the kit disclosed herein includes a primer set and/or probe designed from at least one region selected from the group consisting of (e) to (n) below.
- SEQ ID NOs. 5 to 11 are predetermined regions selected from SEQ ID NOs. 1 to 4, respectively. That is, it is part of the base sequences of SEQ ID NOS: 1 to 4. These sequences (regions) were particularly selected as sequences of about 100 bp suitable for detection by qPCR. In other words, a kit containing a primer set and/or probe based on the above sequence (region) can be used to accurately detect infectious diseases (particularly periodontal disease).
- a third embodiment of the kit disclosed herein is a polynucleotide consisting of at least one base sequence selected from the group consisting of (p) to (t) below.
- At least one base sequence selected from the group consisting of SEQ ID NOs: 5 to 11 At least 80% of the base sequence selected from the group consisting of SEQ ID NOS: 5 to 11 A polynucleotide that hybridizes under stringent conditions to a nucleic acid consisting of a base sequence complementary to at least one base sequence selected from the group consisting of homologous base sequences (t) SEQ ID NOs: 5 to 11. base sequence of
- SEQ ID NOs: 5 to 11 are part of the base sequences of SEQ ID NOs: 1 to 4, and were particularly selected as sequences of about 100 bp suitable for detection by qPCR method.
- the kit of the third embodiment based on the above base sequence can be used to accurately detect infectious diseases (particularly periodontal disease).
- the nucleotide sequence (r) preferably has 85% or more homology to at least one nucleotide sequence selected from the group consisting of SEQ ID NOS: 5 to 11, and 90% or more homology. It is more preferable to have a homology of 95% or more, and it is particularly preferable to have a homology of 98% or more.
- the first embodiment of the diagnostic method disclosed herein analyzes the base sequence of membrane vesicles extracted from a biological sample, and the following (a) to (c) [a, b, c ], and (p) to (t) confirming the presence or absence of a polynucleotide consisting of at least one base sequence selected from the group consisting of [p, r, t], or a part thereof. It is a diagnostic method, including.
- Base sequence At least one base sequence selected from the group consisting of SEQ ID NOS: 5 to 11 (r) At least one base sequence selected from the group consisting of SEQ ID NOS: 5 to 11, 80 Hybridize under stringent conditions to a nucleic acid consisting of a base sequence complementary to at least one base sequence selected from the group consisting of SEQ ID NOs: 5 to 11 (t) having a homology of % or more.
- the above-mentioned polynucleotide is a marker for diagnosing infectious diseases (particularly periodontal disease). This is a method to obtain information for diagnosing whether a donor (subject) is suffering from an infectious disease (typically periodontal disease) or the progress of the disease.
- confirmation of the presence or absence may be quantitative or non-quantitative.
- Non-quantitative confirmation of presence or absence includes, for example, measuring whether the marker is present in the base sequence of membrane vesicles isolated from a biological sample, and comparing it with a control sample.
- quantitative confirmation of the presence or absence may include a method of measuring the concentration and/or amount of the marker.
- other compounds that bind to the above-mentioned marker or its derivative compound can also be used to confirm the presence or absence.
- the method (detection method) used to confirm the presence or absence is not particularly limited, but includes, for example, real-time PCR, qPCR, real-time qPCR, Northern blotting, microarray, immunoassay, SAGE method, CAGE method, mass spectrometry, molecular Interaction analysis, next generation sequencer, etc. are mentioned, and among them, real-time PCR or real-time qPCR is preferable.
- Real-time PCR and real-time qPCR are methods for monitoring nucleic acids amplified by PCR in real time. For example, it can be carried out using a commercially available kit such as LightCycler480SYBRGreenIMaster (Roche).
- Examples of the monitoring method include an intercalation method, a hybridization method, and a LUX (LightUponeXtension) method.
- a typical intercalation method is to measure the amount of nucleic acid by utilizing the property that a fluorescent substance such as SYBRRG Green I enters double-stranded nucleic acid and emits light upon irradiation with excitation light. Since the intensity of fluorescence increases in proportion to the amount of nucleic acid, the amount of amplified nucleic acid can be determined by measuring the fluorescence intensity.
- quantitative methods using real-time PCR can be roughly divided into two quantitative methods: absolute quantitative method and relative quantitative method, and these methods can be used as appropriate.
- a substance capable of binding to the marker (or a part thereof) or a derivative derived from the marker is labeled with a labeling substance and used for real-time PCR, Northern blotting, etc. Can be done.
- This labeling can be performed by a known method.
- labeling substance it is possible to use labeling substances known to those skilled in the art such as fluorescent dyes, enzymes, coenzymes, chemiluminescent substances, and radioactive substances.
- specific examples include radioisotopes, fluorescein, Examples include rhodamine, dansyl chloride, umbelliferone, luciferase, peroxidase, alkaline phosphatase, ⁇ -galactosidase, ⁇ -glucosidase, horseradish peroxidase, glucoamylase, lysozyme, saccharide oxidase, microperoxidase, and biotin.
- biotin when used as a labeling substance, avidin bound to an enzyme such as alkaline phosphatase may be further added after adding the biotin-labeled antibody.
- a primer set refers to a set of primers consisting of a forward primer and a reverse primer.
- Primers are typically for real-time (q) PCR, and methods for designing such primers and probes are known.
- Probes and primers for real-time PCR can be designed using, for example, PRIMER EXPRESS® software (Applied Biosystems, Foster City, CA), Primer Quest software (Integrated DNA Technologies), etc. This can be done using the software.
- a second embodiment of the diagnostic method disclosed herein is a diagnostic method in the first embodiment, which further includes collecting the biological sample from the subject.
- the biological sample collected from the subject is not particularly limited, but is preferably saliva itself or a sample containing saliva.
- a third embodiment of the diagnostic method disclosed herein is a diagnostic method in the first or second embodiment of the diagnostic method, wherein the infectious disease is periodontal disease.
- SEQ ID NOS: 1 to 4 are marker sequences selected based on samples collected from healthy individuals and patients with periodontal disease, and SEQ ID NOs: 5 to 11 are partial regions thereof. In diagnostic methods based on these, when the infectious disease is periodontal disease, more accurate results with reduced risk of false positives can be obtained.
- a fourth embodiment of the diagnostic method disclosed herein is a method for diagnosing an infectious disease, in which the base sequence of membrane vesicles extracted from a biological sample is analyzed. This is a diagnostic method in which information for diagnosing the presence or absence of infection is obtained by detecting amplification of a target nucleic acid region using the kit of the second embodiment.
- a fifth embodiment of the diagnostic method disclosed in this specification is the diagnostic method of the fourth embodiment, further comprising collecting the biological sample from the subject, and wherein the infectious disease is periodontal disease. This is a diagnostic method.
- the biological sample used in the diagnostic methods of the fourth and fifth embodiments is not particularly limited, it is preferably saliva itself or a sample containing saliva.
- Saliva was obtained from three healthy subjects and six patients with periodontal disease. Regarding patients with periodontal disease, patients classified as stage III/grade C (classification of periodontal disease by the American Academy of Periodontology and the European Federation of Periodontology) were targeted. These patients had not received any antibiotics for 3 months, were non-smokers, and had no diabetes or other systemic diseases. Saliva collection was performed using the Saliva Collection Aid (Salimetrics LLC. Carlsbad, CA). A mixture of samples from three healthy individuals was used as a healthy individual sample, and samples from six periodontal disease patients were mixed together as periodontal disease patient sample 1 and periodontal disease patient sample 2. , used for subsequent analyses. In addition, below, a healthy person sample, periodontal disease patient sample 1, and periodontal disease patient sample 2 may be collectively referred to as a "saliva sample.”
- the separated membrane vesicle sample was treated with deoxyribonuclease (DNase) to degrade nucleic acid components outside the membrane vesicle. Specifically, 2 ⁇ L of DNase (13 units (U)/ ⁇ L) was added to 100 ⁇ L of purified membrane vesicle sample, and the mixture was treated at 37° C. for 30 minutes and at 80° C. for 10 minutes.
- DNase deoxyribonuclease
- the membrane vesicle sample was diluted and the membrane vesicle concentration was adjusted to a concentration of 40,000 particles/ ⁇ L.
- the particles are irradiated with a laser, the Brownian motion of each particle is tracked from the scattered light (tracking method), and the diffusion rate of the particles is determined based on the Stokes-Einstein equation.
- a method was used to calculate the diameter and number of pieces. Zetaview (DKSH, Germany) was used for measurements and calculations.
- the membrane vesicles after encapsulation were dissolved by adding the following reagents. 50U/ ⁇ L Ready-lyse Lysozyme Solution (Epicentre), 2U/mL Zymolyase (Zymo research), 22U/mL lysostaphin (MERCK), 250U/mL mutanolysin (MERCK), This treatment was carried out overnight at 37° C. in DPBS (Dulbecco's Phosphate-Buffered Saline).
- DPBS Dynabecco's Phosphate-Buffered Saline
- the DNA in the gel beads after dissolution was amplified using REPLI-g Single Cell Kit (QIAGEN). After DNA amplification, the gel bead DNA molecules were stained with a nucleic acid staining reagent (1x SYBR Green), and gel beads with a certain level of fluorescence observed were placed in a 96-well plate using a cell sorter (FACSMelody cell sorter (BD Bioscience)). One gel bead at a time was separated and collected.
- a nucleic acid staining reagent (1x SYBR Green
- FACSMelody cell sorter BD Bioscience
- SPAdes Bankevik et al., SPAdes: A New Genome Assembly Algorithm and Its Applications to Single-C These short read sequences were combined ( A long base sequence called a contig of several kbp to several tens of kbp was created.
- the protein coding region is determined by prokka (Seemann, Prokka: rapid prokaryotic genome annotation. Bioinformatics, 30, 14, 201 4) to predict and detect one of those CDS. For one, we performed a homology search using NCBI's complete protein sequence nr database and GTDB database as references, and determined that the bacterium that has the most CDS regions with the highest degree of matching in its genome is the host bacterium for that particle. .
- the host bacterial profile of membrane vesicles obtained as a result of the analysis of all particles was compared between healthy samples and patient samples, and the phylum Patescibacteria was found as the bacterial taxonomic group with the highest abundance ratio in the patient samples.
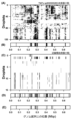
- FIG. 1 is a comparison of the base sequence profiles of membrane vesicles in samples from healthy individuals and samples from patients with periodontal disease. Based on the information on the detected base sequences, we identified the bacterial taxon from which the base sequences inside each membrane vesicle were derived.
- FIG. 1 is a heat map showing the detected base sequence lengths as frequencies when each bacterial strain is divided into phylum level (phylum) and genus level (genus). It was found that nucleotide sequences derived from TM7x, which belongs to the phylum Patescibacteria, are frequently detected in periodontal disease patient samples.
- bacterial strain A (Patescibacteria TM7x sp900555265), which was detected the most, was designated as a membranous vesicle host bacterial strain unique to periodontal disease patients.
- Figure 2 shows the results, showing the length of the region of virus-derived base sequences detected in each membrane vesicle for each species.
- virus species B Podviridae ctUiB3
- virus species B which was detected the most in periodontal disease patients compared to healthy individuals, was designated as a virus specific to periodontal disease patients.
- a homology search was performed using the frequently occurring region as a query sequence and the biological protein sequence (nr) spanning all domains registered with NCBI as a reference sequence (diamond). Alignment score (Max Score) of the top 20 protein coding sequences from the hit protein coding sequences in the database, excluding sequences of taxonomic groups to which the same strains or species belong (phylum in the case of bacteria, family in the case of viruses) The sum of these values was calculated, and only the sequence with the minimum value was selected as a biomarker candidate sequence.
- membrane vesicle-derived sequence reads whose hosts are bacterial strains belonging to the same taxonomic group (phylum level) as the bacterial strain A mentioned above were added to the membrane vesicle host bacteria of bacterial strain A. mapped against the genome.
- the final biomarker sequences (SEQ ID NOs: 1 to 3) for detecting periodontal disease were selected by excluding the regions detected in the sequence reads of these membrane vesicles from healthy subjects from the above biomarker candidate sequences. .
- FIG. 3 is a diagram showing a procedure for determining a region (biomarker sequence) that is specifically detected in periodontal disease patients.
- Figure 3 (A) shows the results of mapping the internal nucleotide sequence of membrane vesicles determined to be derived from TM7x sp900555265, among membrane vesicles derived from periodontal disease patient samples, to the reference sequence (genome sequence of TM7x sp900555265). It is a figure showing an example.
- the vertical axis of FIG. 3(A) represents individual membrane vesicles, and the horizontal axis represents the position on the genome sequence.
- the heat map in FIG. 3(B) represents the genome regions that are frequently detected in FIG. 3(A).
- the horizontal axis represents the position on the genome sequence.
- Figure 3 (C) shows that among membrane vesicles derived from healthy subjects, membrane vesicles determined to be derived from the phylum Patescibacteria and containing TM7x sp900555265 were mapped to the reference sequence (genome sequence of TM7x sp900555265). It is something.
- the vertical axis and the horizontal axis are the same as in FIG. 3(A).
- the heat map in FIG. 3(D) represents the genomic regions that are frequently detected in FIG. 3(C).
- the horizontal axis represents the position on the genome sequence.
- FIG. 3(E) is a map of the genomic regions specifically detected in periodontal disease patients from a comparison of FIG. 3(B) and FIG. 3(D) above. Each of these becomes a biomarker sequence.
- biomarker candidate sequence obtained above was used as the biomarker sequence (SEQ ID NO: 4). Among these sequences, continuous DNA regions of 1000 bp or more were targeted.
- FIG. 4 is a diagram showing a procedure for determining a region (biomarker sequence) that is specifically detected in periodontal disease patients.
- Figure 4 (B) shows the nucleotide sequence inside a membrane vesicle containing a CDS region determined to be derived from Podviridae ctUiB3, which was determined to be derived from a periodontal disease patient sample, to the reference sequence (genome sequence of ctUiB3).
- FIG. 3 is a diagram showing an example of the results.
- the vertical axis of FIG. 4(B) represents individual membrane vesicles, and the horizontal axis represents the position on the genome sequence.
- FIG. 4(A) shows the detection frequency for each region
- the heat map in FIG. 4(C) shows the genome regions detected with high frequency in FIG. 4(A). In both cases, the horizontal axis represents the position on the genome sequence. This genomic region becomes a biomarker sequence.
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Analytical Chemistry (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- Biomedical Technology (AREA)
- Immunology (AREA)
- Gastroenterology & Hepatology (AREA)
- Medicinal Chemistry (AREA)
- Plant Pathology (AREA)
- Virology (AREA)
- Cell Biology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024544088A JPWO2024048236A1 (https=) | 2022-09-01 | 2023-08-09 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022139056 | 2022-09-01 | ||
| JP2022-139056 | 2022-09-01 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024048236A1 true WO2024048236A1 (ja) | 2024-03-07 |
Family
ID=90099274
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2023/029165 Ceased WO2024048236A1 (ja) | 2022-09-01 | 2023-08-09 | ポリヌクレオチド、キット、及び、診断方法 |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2024048236A1 (https=) |
| WO (1) | WO2024048236A1 (https=) |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022102246A1 (ja) * | 2020-11-11 | 2022-05-19 | 国立研究開発法人物質・材料研究機構 | 細胞で産生された膜小胞に由来する塩基配列を解析する方法、その装置、及び、そのプログラム |
-
2023
- 2023-08-09 JP JP2024544088A patent/JPWO2024048236A1/ja active Pending
- 2023-08-09 WO PCT/JP2023/029165 patent/WO2024048236A1/ja not_active Ceased
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022102246A1 (ja) * | 2020-11-11 | 2022-05-19 | 国立研究開発法人物質・材料研究機構 | 細胞で産生された膜小胞に由来する塩基配列を解析する方法、その装置、及び、そのプログラム |
Non-Patent Citations (3)
| Title |
|---|
| BOR B., BEDREE J.K., SHI W., MCLEAN J.S., HE X.: "Saccharibacteria (TM7) in the Human Oral Microbiome", JOURNAL OF DENTAL RESEARCH, INTERNATIONAL ASSOCIATION FOR DENTAL RESEARCH, US, vol. 98, no. 5, 1 May 2019 (2019-05-01), US , pages 500 - 509, XP093143894, ISSN: 0022-0345, DOI: 10.1177/0022034519831671 * |
| DATABASE NUCLEOTIDE ANONYMOUS : "MAG TPA_asm: Caudoviricetes sp. isolate ctUiB3, partial genome", XP093143897, retrieved from NCBI * |
| HAN PINGPING, BARTOLD PETER MARK, SALOMON CARLOS, IVANOVSKI SASO: "Salivary Small Extracellular Vesicles Associated miRNAs in Periodontal Status—A Pilot Study", INTERNATIONAL JOURNAL OF MOLECULAR SCIENCES, MOLECULAR DIVERSITY PRESERVATION INTERNATIONAL (MDPI), BASEL, CH, vol. 21, no. 8, Basel, CH , pages 2809, XP093143899, ISSN: 1422-0067, DOI: 10.3390/ijms21082809 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2024048236A1 (https=) | 2024-03-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110541022B (zh) | 基于CRISPR-Cas12a系统的结核分枝杆菌复合群检测试剂盒 | |
| US10889868B2 (en) | Exosomal biomarkers diagnostic of tuberculosis | |
| Sanjuan-Jimenez et al. | Lessons learned with molecular methods targeting the BCSP-31 membrane protein for diagnosis of human brucellosis | |
| US20240200151A1 (en) | Metagenomic next-generation sequencing of microbial cell-free nucleic acids in subjects with lyme disease | |
| CN107513575A (zh) | 一种检测布鲁菌感染的方法及其应用 | |
| WO2021216985A2 (en) | Methods for detecting tissue damage, graft versus host disease, and infections using cell-free dna profiling | |
| US7381547B2 (en) | Methods and compositions to detect bacteria using multiplex PCR | |
| CN103937884A (zh) | 一种用于结核分枝杆菌检测的环介导等温扩增试剂盒及其使用方法 | |
| CN101942511A (zh) | 原位荧光环介导恒温核酸扩增技术检测结核分枝杆菌的方法及试剂盒 | |
| CN111733227B (zh) | 特发性视神经炎诊断分子标记物circRNA、试剂盒及应用 | |
| WO2021179469A1 (zh) | 检测病原体的组合物、试剂盒及方法 | |
| CN120249562A (zh) | RT-RPA-CRISPR/Cas12a一步法快速检测乙型流感病毒的技术及其应用 | |
| WO2024048236A1 (ja) | ポリヌクレオチド、キット、及び、診断方法 | |
| CN119410802A (zh) | 一种基于RPA和CRISPR-Cas12a的无乳链球菌快速检测试剂盒及其应用 | |
| CN115852004B (zh) | 一种表皮葡萄球菌的病原体特异性核酸基因及检测方法 | |
| CN114107454A (zh) | 基于宏基因/宏转录组测序的呼吸道感染病原检测方法 | |
| US20250188511A1 (en) | Contamination-free metagenomic dna sequencing | |
| CN112410343B (zh) | 基于crispr的试剂盒及其应用 | |
| CN116179570A (zh) | 一种奇异变形杆菌的病原体特异性核酸基因及检验方法 | |
| CN114196767A (zh) | 特异性分子靶标及其检测金黄色葡萄球菌st型的方法 | |
| CN105316350B (zh) | 结核分枝杆菌EmbB突变基因及其用途 | |
| CN113584190A (zh) | 一种诊断草酸钙结石的肠道菌群标志物及其应用 | |
| CN120099162B (zh) | 一组用于诊断结核病的生物标志物组合物 | |
| CN116064768B (zh) | 视神经脊髓炎谱系疾病相关性视神经炎诊断分子标记物circRNA试剂盒及应用 | |
| CN114561393B (zh) | 一种特异性识别鸟-胞内分枝杆菌复合群的dna适配子及其筛选方法和应用 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 23860002 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2024544088 Country of ref document: JP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 23860002 Country of ref document: EP Kind code of ref document: A1 |