WO2021049606A1 - DcR3改変体 - Google Patents
DcR3改変体 Download PDFInfo
- Publication number
- WO2021049606A1 WO2021049606A1 PCT/JP2020/034444 JP2020034444W WO2021049606A1 WO 2021049606 A1 WO2021049606 A1 WO 2021049606A1 JP 2020034444 W JP2020034444 W JP 2020034444W WO 2021049606 A1 WO2021049606 A1 WO 2021049606A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- dcr3
- amino acid
- acid sequence
- variant
- seq
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images





























































Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/715—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons
- C07K14/7151—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons for tumor necrosis factor [TNF], for lymphotoxin [LT]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/06—Immunosuppressants, e.g. drugs for graft rejection
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/08—Antiallergic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70575—NGF/TNF-superfamily, e.g. CD70, CD95L, CD153, CD154
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70578—NGF-receptor/TNF-receptor superfamily, e.g. CD27, CD30, CD40, CD95
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/32—Fusion polypeptide fusions with soluble part of a cell surface receptor, "decoy receptors"
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/10—Plasmid DNA
- C12N2800/106—Plasmid DNA for vertebrates
- C12N2800/107—Plasmid DNA for vertebrates for mammalian
Definitions
- the present invention relates to a DcR3 variant, which is a variant of wild-type DcR3. More specifically, the present invention has a ligand-binding activity (preferably neutralizing activity) of DcR3, and when a mammalian-derived cell is used as a host, the amount of aggregates produced is reduced as compared with wild-type DcR3. And / or related to DcR3 variants showing improved pharmacokinetics.
- TNFSF Tumor necrosis factor
- TNFRSF TNF receptor superfamily
- DcR decoy receptors
- OPG is a soluble decoy receptor for RANKL and TRAIL, which inhibits signal transduction by competing for binding of RANKL and TRAIL receptors to ligands.
- DcR1 and DcR2 have a ligand for TRAIL
- DcR3 has a ligand for three molecules, LIGHT, TL1A, and FasL, by competitively inhibiting the binding to the signal-transmitting receptor. It is a decoy receptor to be harmonized (Non-Patent Document 2).
- DcR3 is a soluble molecule consisting of 300 amino acid residues. A signal peptide on the N-terminal side, followed by four cysteine-rich domains (CRDs) characteristic of TNFRSF (CRD1, CRD2, CRD3 and CRD4), and a basic amino acid containing a heparan sulfate-binding motif on the C-terminal side. It has a rich heparan sulfate binding region (HBD). LIGHT, TL1A and FasL are all bound via CRD2 and CRD3 of DcR3 (Non-Patent Documents 3, 4, 5).
- DcR3 has a function as an immunomodulatory molecule based on the activity of HBD in addition to the function as a decoy receptor by ligand neutralization. For example, it binds directly to glycosaminoglycans (GAG) such as heparan sulfate on the cell membrane of monocytes, macrophages, or dendritic cells via HBD, and leads to Th2 by differentiation of dendritic cells, M2 macrophages. It has been reported to induce various immunosuppressive and immunostimulatory effects such as induction of monocytes, enhancement of monocyte adhesion, osteoclast differentiation, or decreased expression of MHC class II molecules. (Non-Patent Documents 6 and 12).
- GAG glycosaminoglycans
- DcR3 ligands have been reported to be involved in autoimmune diseases, inflammatory diseases, allergies, cancers, infectious diseases, or various other inflammatory reactions.
- LIGHT, TL1A and FasL are all included in the susceptibility locus in inflammatory bowel disease (IBD), and in particular, TL1A is known to have multiple genetic polymorphisms associated with the pathology.
- IBD inflammatory bowel disease
- TL1A is known to have multiple genetic polymorphisms associated with the pathology.
- DcR3 in normal human tissues is extremely low, but its expression is induced by infection or tissue damage.
- elevated blood levels of DcR3 can be seen in various autoimmune or inflammatory diseases such as IBD, systemic lupus erythematosus (SLE), atopic dermatitis (AD), or rheumatoid arthritis (RA). I know.
- Non-Patent Documents 6 and 10 Although the DcR3 homologue has not been identified in mice, in mouse pathological models such as type I diabetes model, multiple sclerosis model, or nephritis model, improvement of pathological condition in human DcR3 transgenic mice and plasmid or The efficacy of recombinant DcR3 administration has been confirmed (Non-Patent Documents 6 and 10).
- Eli Lilly has obtained FLINT, a protease-resistant DcR3 mutant, by a 1-amino acid mutation (R218Q) of wild-type DcR3, and reported that pharmacokinetics are improved in mice and monkeys compared to wild-type DcR3. ..
- wild-type DcR3 and FLINT are administered to cynomolgus monkeys by intravenous injection of 0.5 mg / kg, the half-life in blood is extremely short, 9 hours and 12.3 hours, respectively (Patent Documents 2, 3 and Non-Patent). Document 11).
- FLINT which is an amino acid variant of wild-type DcR3
- FLINT has extremely poor pharmacokinetics and requires frequent administration as a recombinant preparation having a ligand-neutralizing mechanism of action, which is not desirable as a pharmaceutical product. Therefore, a DcR3 variant that can secure a certain period of administration interval by improving pharmacokinetics is expected to be useful as a pharmaceutical product.
- the present invention has a binding activity (preferably neutralizing activity) to a ligand of DcR3, and when producing a DcR3 protein using a mammalian-derived cell as a host, the amount of aggregates produced is reduced as compared with the wild-type DcR3.
- DcR3 variant showing improved pharmacokinetics, DNA encoding the DcR3 variant, vector containing the DNA, transformant obtained by introducing the vector, modification using the transformant
- An object of the present invention is to provide a method for producing a body, a pharmaceutical composition containing the variant as an active ingredient, and a prophylactic or therapeutic agent for autoimmune diseases, inflammatory diseases or allergies.
- a DcR3 variant that is a variant of wild-type Decoy Receptor 3 (hereinafter abbreviated as DcR3) and exhibits improved pharmacokinetics compared to the wild-type DcR3.
- DcR3 variant according to [1] which has one or more N-glycosidic bond complex sugar chains.
- the DcR3 variant according to [1] or [2] which has neutralizing activity against at least one of LIGHT, TL1A and FasL.
- a DcR3 variant comprising a second chimeric cysteine rich region consisting of an amino acid sequence.
- the DcR3 variant according to [7] which has one or more N-glycosidic bond complex sugar chains.
- At least a portion of the cysteine-rich domain of wild-type DcR3 is selected from all or part of CRD1, all or part of CRD2, all or part of CRD3, and all or part of CRD4.
- At least a portion of the cysteine-rich domain of the TNF receptor superfamily molecule is selected from all or part of CRD1, all or part of CRD2, all or part of CRD3, and all or part of CRD4. , [7] to [13].
- the DcR3 variant according to any one of [7] to [13].
- the first chimeric cysteine-rich region is Substitution of a portion of the CRD1 of the wild-type DcR3 with a portion of the CRD1 of the TNF receptor superfamily molecule corresponding to a portion of the CRD1 of the wild-type DcR3. Substitution of all of CRD1 of the wild-type DcR3 with all of CRD1 of the TNF receptor superfamily molecule, Substitution of a portion of the CRD2 of the wild-type DcR3 with a portion of the CRD2 of the TNF receptor superfamily molecule corresponding to a portion of the CRD2 of the wild-type DcR3.
- the first chimeric cysteine rich region contains the following amino acid sequences (a), (b), (c) or (d), and the second chimeric cysteine rich region is as follows.
- Amino acid sequence in which CRD4 is substituted with CRD4 of OPG (d)
- the 103rd to 123rd portions from the N-terminal are the cysteine-rich domains of OPG.
- Amino acid sequence substituted with the corresponding portion of the amino acid sequence (e) In the amino acid sequence of (a), (b), (c) or (d), 1 to 30 amino acids are deleted, substituted or inserted.
- the added amino acid sequence [19]
- the amino acid sequence of (a) above is an amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence of SEQ ID NO: 26 or 50.
- the amino acid sequence of (b) is an amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence set forth in SEQ ID NO: 28 or 52.
- the amino acid sequence of (c) is an amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence set forth in SEQ ID NO: 30 or 54.
- the DcR3 variant according to [18], wherein the amino acid sequence of (d) is an amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence set forth in SEQ ID NO: 32 or 56.
- the amino acid sequence of (e) is from the 57th Glu, the 58th Arg and the 60th Arg of the amino acid sequence of (a), (b), (c) or (d) from the N-terminal.
- the amino acid sequence of (e) is changed to another amino acid of Glu at position 57 and Arg at position 58 from the N-terminal of the amino acid sequence of (a), (b), (c) or (d).
- the DcR3 variant according to any one of [18] to [20], which has the substitution of.
- the amino acid sequence of (e) is the 57th Glu Lys, Leu, Arg, Val, Ala, from the N-terminal of the amino acid sequence of (a), (b), (c) or (d).
- the DcR3 variant according to any one of [18] to [21], which has a substitution.
- the amino acid sequence of (e) is the 57th Glu Lys, Leu, Arg, Val, Ala, from the N-terminal of the amino acid sequence of (a), (b), (c) or (d).
- the amino acid sequence of (e) above is the amino acid sequence of SEQ ID NO: 58, 60, 62, 64, 66, 68, 70, 180, 182, 184, 186, 188, 270, 272, 274, 276, 278,
- the DcR3 variant according to any one of [18] to [25], which is an amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequences described in 280, 282, 284 or 286.
- the DcR3 variant is (I) The amino acid sequence set forth in SEQ ID NO: 26, 28, 30, 32, 34, 36, 38, 40, 42, 44 or 46, or 1 to 30 amino acids are deleted or substituted in the amino acid sequence.
- the DcR3 variant is an Fc region derived from a human IgG1, IgG2 or IgG4 antibody, or an amino acid sequence in which one or several amino acids are deleted, substituted, inserted or added in the amino acid sequence of the Fc region.
- the Fc region or the mutant Fc region is bound to the C-terminal side of the first or second chimeric cysteine rich region via another region or a linker, according to [29].
- the mutant Fc region is the substitution of Leu at position 234 with Ala and the substitution of Leu at position 235 with Ala, which are indicated by the EU index, and position 237.
- the DcR3 variant according to [31] which comprises the substitution of Gly with Ala.
- the mutant Fc region is the substitution of Met at position 252 with Tyr, and the substitution of Ser at position 254 with Thr, and position 256.
- the mutant Fc region is the substitution of Ser at position 228 with Pro and the substitution of Leu at position 235 with Glu at position 409 of the EU index.
- the DcR3 variant comprises a mutant Fc region consisting of the amino acid sequence set forth in SEQ ID NO: 72, 74, 156, 158, 160, 162, 164, 166, 311, 312 or 313, [29] or The DcR3 variant according to [30].
- the DcR3 variant contains SEQ ID NOs: 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 150, 168, 170, 172, 174, 176, 178, 190.
- a DcR3 variant composition comprising the DcR3 variant according to any one of [1] to [37].
- [42] A transformant obtained by introducing the genetically modified vector according to [41] into a host cell. [43] The transformant according to [42], wherein the host cell is a cell derived from a mammal. [44] The transformant according to [43], wherein the mammalian-derived cell is a CHO cell. [45] The transformant according to any one of [42] to [44] is cultured in a medium to generate the DcR3 variant according to any one of [1] to [37].
- a method for producing a DcR3 variant or a DcR3 variant composition which comprises accumulating and purifying the DcR3 variant from the obtained culture medium.
- the pharmaceutical composition according to [47] which is a prophylactic or therapeutic agent for an autoimmune disease, an inflammatory disease or an allergic disease.
- Autoimmune disease, inflammatory comprising administering the pharmaceutical composition according to [47] or [48] to a patient in need of prevention or treatment of an autoimmune disease, inflammatory disease or allergic disease. How to prevent or treat a disease or allergic disease.
- the amount of aggregates produced is higher than that of wild-type DcR3 when producing a DcR3 protein using a mammalian-derived cell as a host and having a binding activity (preferably neutralizing activity) to a ligand of DcR3.
- a DcR3 variant showing reduced and / or improved pharmacokinetics, a DNA encoding the DcR3 variant, a vector containing the DNA, a transformant obtained by introducing the vector, and the transformant are used.
- Provided are a method for producing a variant, a pharmaceutical composition containing the variant as an active ingredient, and a prophylactic or therapeutic agent for autoimmune diseases, inflammatory diseases or allergies.
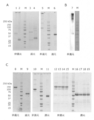
- FIG. 1A shows the results of SDS-PAGE of various wild-type DcR3 controls made from mammalian cells. Lanes 1 and 3 were electrophoresed on DcR3 FL-Fc, lanes 2 and 4 were electrophoresed on DcR3 FL-FLAG, and lanes 5 and 6 were electrophoresed on S195-Fc (g1S) under non-reducing or reducing conditions.
- FIG. 1B commercially available human DcR3-Fc (lane 7) prepared from HEK293 cells was electrophoresed under non-reducing conditions and detected by immunoblot with an anti-human IgG antibody.
- FIG. 1A shows the results of SDS-PAGE of various wild-type DcR3 controls made from mammalian cells. Lanes 1 and 3 were electrophoresed on DcR3 FL-Fc, lanes 2 and 4 were electrophoresed on DcR3 FL-FLAG, and lanes 5 and 6 were electrophoresed on S195-Fc (g1S) under non
- FIG. 1C shows commercially available DcR3 FL-Fc (lanes 8, 9), S195-Fc (g1S) (lanes 10, 11), DcR3 FL-Fc (g1S) (lanes 14, 15, 18, 19) prepared from insect cells. ) And R218Q-Fc (g1S) (lanes 12, 13, 16, 17) were electrophoresed under non-reducing or reducing conditions, respectively. M indicates a molecular weight marker (Bio-Rad Laboratories, Inc.).
- FIG. 2 shows the cysteine rich domains as CRD1, CRD2, CRD3, and CRD4 in the alignment of the immature amino acid sequences of human DcR3 and human OPG, respectively.
- FIG. 3 schematically shows the domain structures of various wild-type DcR3 controls, various DcR3 variants, and human OPG produced.
- the vertical lines of CRD4 of E and F indicate that there are two or three substitutions of N-type sugar chain addition residues, respectively, and the DD of I indicates Death domine.
- Lanes 1 and 4 were chimeric A-Fc (IEGRMD g1S) prepared with Expi293 cells, lanes 2 and 5 were chimeric A-Fc (IEGRMD g1S) prepared with CHO-S cells, and lanes 3 and 6 were prepared with Expi293 cells.
- Chimeric B-Fc (g1S), lanes 7 and 8, were electrophoresed on chimeric C-Fc (IEGRMD g1S) prepared from Expi293 cells under non-reducing or reducing conditions.
- M indicates a molecular weight marker (Bio-Rad Laboratories, Inc.).
- FIG. 5 shows melting curves by the DSF method for R218Q-Fc, S195-Fc and chimeric A-Fc (IEGRMD g1S).
- FIG. 6 shows the binding of various wild-type DcR3 controls and various DcR3 variants to human primary cells and CHO cells. Each cell was reacted with each DcR3 variant of 10 ⁇ g / mL, subsequently stained with 0.1 ⁇ g / mL PE-labeled anti-human antibody, and the fluorescence intensity of PE was measured by flow cytometry.
- the vertical axis of the graph shows the geometric mean (Geo. Mean) of PE.
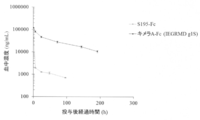
- FIG. 7 shows 10 mg / kg i.S. of S195-Fc and chimeric A-Fc (IEGRMD g1S) in BALB / c mice. v. The transition of blood concentration at the time of administration is shown. The vertical axis shows the blood concentration (ng / mL), and the horizontal axis shows the elapsed time (hr) after administration.
- FIG. 8A shows the binding of various wild-type DcR3 controls and various DcR3 variants to RANKL (OPG ligand) and FIG. 8B shows TRAIL (OPG ligand).
- RANKL or TRAIL diluted to each concentration was added to evaluate the binding.
- biotinylated anti-RANKL antibody or biotinylated anti-TRAIL antibody and streptavidin-HRP were used.
- the horizontal axis shows the concentration of RANKL or TRAIL (pg / mL), and the vertical axis shows the absorbance (the value obtained by subtracting the absorbance at 570 nm from the absorbance at 450 nm).
- FIG. 9 shows the neutralizing activity of various wild-type DcR3 controls and various DcR3 variants with respect to LIGHT.
- FIG. 10 shows the neutralizing activity of various wild-type DcR3 controls and various DcR3 variants with respect to TL1A.
- FIG. 11 shows the neutralizing activity of various wild-type DcR3 and various DcR3 variant controls against FasL.
- FIG. 12A shows the binding of chimeric A-Fc (g4PEK) and FasL-reducing variant (g4PEK) to each DcR3 ligand.
- FIG. 12B shows the binding of the FasL binding reduced variant (g4PEK) to each DcR3 ligand.
- FIG. 12C shows the binding of the FasL binding reduced variant (g4PEK) to each DcR3 ligand.
- the sensorgram when each FasL binding-reducing variant was captured by a sensor chip on which an anti-human antibody was immobilized and DcR3 ligand (human FasL, human LIGHT, human TL1A) was flowed as an analyzer is shown.
- the vertical axis represents the amount of binding (RU), and the horizontal axis represents time (Sec).
- FIG. 12C shows the binding of the FasL binding reduced variant (g4PEK) to each DcR3 ligand.
- the sensorgram when each FasL binding-reducing variant was captured by a sensor chip on which an anti-human antibody was immobilized and DcR3 ligand (human FasL, human LIGHT, human TL1A) was flowed as an analyzer is shown.
- FIG. 13 shows the results of SDS-PAGE of wild-type DcR3 control produced in various mammalian cells.
- SDS-PAGE was performed by electrophoresis of commercially available human DcR3-Fc prepared from various mammalian cells under reducing or non-reducing conditions.
- HEK293 cells As mammalian cells, HEK293 cells (Abcam) were used in lanes 1 and 4, CHO cells (AdipoGen) were used in lanes 2 and 5, and HEK293 cells (Enzo) were used in lanes 3 and 6.
- M indicates a molecular weight marker (Bio-Rad Laboratories, Inc.).
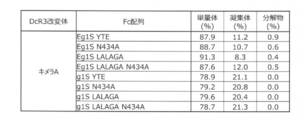
- FIG. 14A shows the percentage of monomer, aggregate and degradation product content calculated from the peak area of SEC-HPLC or SEC-UPLC of the Protein A-purified FasL-reduced variant.
- FIG. 14A shows the results of all FasL binding reduced variants (g4PEK) prepared.
- FIG. 14B shows the percentage of monomer, aggregate and degradation product content calculated from the peak area of SEC-HPLC or SEC-UPLC of the Protein A-purified FasL-reduced variant.
- FIG. 14B shows the results of various mutant Fc fusions of selected FasL-impaired variants.
- FIG. 14C shows the percentage (%) of the content of monomers, aggregates and decomposition products calculated from the peak area of SEC-HPLC or SEC-UPLC of various Chimeric A-mutant Fc fusions purified by Protein A.
- FIG. 15A shows the results of measuring the binding activity of various DcR3 variants to each DcR3 ligand by BIAcore.
- kd shows the K D).
- FIG. 15A shows the results of various chimeric A-Fc with different Fc sequences.
- FIG. 15B shows the results of measuring the binding activity of various DcR3 variants to each DcR3 ligand by BIAcore.
- kd, KD is shown.
- FIG. 15B shows the results of the FasL binding reduced variant.
- FIG. 16A shows the results of comparing the kinetic constants (KD values) for each DcR3 ligand calculated by BIAcore at the time of selection of the modified FasL-binding variant with the chimeric A-Fc (g4PEK).
- FIG. 16A shows the results of the 1 amino acid substitution product.
- FIG. 16B shows the results of comparing the kinetic constants (KD values) for each DcR3 ligand calculated by BIAcore at the time of selection of the modified FasL-binding variant with the chimeric A-Fc (g4PEK).
- FIG. 16B shows the results of the diamino acid substitution.
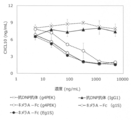
- FIG. 17A shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble LIGHT.
- FIG. 17A shows the inhibitory activity of various chimeric A-Fc with different Fc sequences on LIGHT-dependent-CXCL10 production from IFN- ⁇ -stimulated intestinal myofibroblasts.
- the vertical axis shows the CXCL10 concentration (ng / mL), and the horizontal axis shows the added DcR3 variant concentration (ng / mL).
- FIG. 17B shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble LIGHT.
- FIG. 17B shows the inhibitory activity of chimeric A-Fc with different mutagenesis Fc sequences on LIGHT-dependent CXCL10 production from IFN- ⁇ stimulated intestinal myofibroblasts.
- FIG. 17C shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble LIGHT.
- FIG. 17C shows the inhibitory activity of a 1-amino acid-substituted FasL-reducing variant on LIGHT-dependent IL-8 production from HT-29 cells.
- the vertical axis shows the IL-8 concentration (ng / mL), and the horizontal axis shows the added DcR3 variant concentration (ng / mL).
- FIG. 17D shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble LIGHT.
- FIG. 17D shows the inhibitory activity of the 2-amino acid-substituted FasL-reducing variant on LIGHT-dependent CXCL10 production from IFN- ⁇ -stimulated intestinal myofibroblasts.
- the vertical axis shows the CXCL10 concentration (ng / mL), and the horizontal axis shows the added DcR3 variant concentration (ng / mL).
- FIG. 18A shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble TL1A.
- FIG. 18A shows the inhibitory activity of various chimeric A-Fc with different Fc sequences on TL1A-dependent IFN- ⁇ production from IL-12 and IL-18 stimulated human T cells.
- FIG. 18B shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble TL1A.
- FIG. 18B shows the inhibitory activity of chimeric A-Fc with different mutagenesis Fc sequences on TL1A-dependent IFN- ⁇ production from IL-12 and IL-18 stimulated human T cells.
- the vertical axis shows the IFN- ⁇ concentration (pg / mL), and the horizontal axis shows the added DcR3 variant concentration (ng / mL).
- FIG. 18C shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble TL1A.
- FIG. 18C shows the inhibitory activity of a 1-amino acid-substituted FasL-reducing variant on TL1A-dependent IFN- ⁇ production from IL-12 and IL-18-stimulated human T cells.
- the vertical axis shows the IFN- ⁇ concentration (pg / mL), and the horizontal axis shows the added DcR3 variant concentration (ng / mL).
- FIG. 18D shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble TL1A.
- FIG. 18D shows the inhibitory activity of the diamino acid-substituted FasL-reducing variant on TL1A-dependent IFN- ⁇ production from IL-12 and IL-18-stimulated human T cells.
- the vertical axis shows the IFN- ⁇ concentration (pg / mL), and the horizontal axis shows the added DcR3 variant concentration (ng / mL).
- FIG. 19A shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble FasL.
- FIG. 19A shows the inhibitory activity of A3 cells against cell death by various chimeric A-Fc having different Fc sequences.
- FIG. 19B shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble FasL.
- FIG. 19B shows the inhibitory activity of Jurkat cells against cell death by chimeric A-Fc having different mutagenesis Fc sequences.
- FIG. 19C shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble FasL.
- FIG. 19C shows the inhibitory activity of Jurkat cells against cell death by a 1-amino acid-substituted FasL-reducing variant.
- FIG. 19D shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble FasL.
- FIG. 19D shows the inhibitory activity of Jurkat cells against cell death by a 2-amino acid-substituted FasL-reducing variant.
- FIG. 20A shows the results of evaluation of the binding activity of various chimeric A-Fc having different S195-Fc and Fc sequences against the membrane-type LIGHT forced expression strain. Each cell was reacted with various DcR3 variants, stained with a PE-labeled anti-human antibody, and the fluorescence intensity of PE was measured by flow cytometry. The vertical axis of the graph shows the geometric mean (Geo. Mean) of PE.
- FIG. 20B shows the results of evaluation of the binding activity of various chimeric A-Fc having different S195-Fc and Fc sequences against membrane-type TL1A and membrane-type FasL forced expression strains.
- Each cell was reacted with various DcR3 variants, stained with a PE-labeled anti-human antibody, and the fluorescence intensity of PE was measured by flow cytometry.
- the vertical axis of the graph shows the geometric mean (Geo. Mean) of PE.
- FIG. 21A shows the results of evaluation of the binding activity of S195-Fc, various chimeric A-Fc, and FasL-reduced binding variants to the membrane-type LIGHT forced expression strain.
- FIG. 21B shows the results of evaluation of the binding activity of S195-Fc, various chimeric A-Fc, and FasL binding-reducing variants with respect to the membrane-type TL1A forced expression strain.
- Each cell was reacted with various DcR3 variants, stained with a PE-labeled anti-human antibody, and the fluorescence intensity of PE was measured by flow cytometry.
- the vertical axis of the graph shows the geometric mean (Geo. Mean) of PE.
- FIG. 21C shows the results of evaluation of the binding activity of chimeric A-Fc and FasL-reduced binding variant (g4PEK) with respect to the membrane-type FasL forced expression strain.
- Each cell was reacted with various DcR3 variants, stained with a PE-labeled anti-human antibody, and the fluorescence intensity of PE was measured by flow cytometry.
- the vertical axis of the graph shows the geometric mean (Geo. Mean) of PE.
- FIG. 22 shows the results of evaluation of the binding activity of chimeric A-Fc to the membrane-type LIGHT of primary cells.
- FIG. 22A shows the results of measuring the expression of membrane-type LIGHT on activated human T cells with a PE-labeled anti-LIGHT antibody.
- FIG. 22B shows the geometric mean (Geo. Mean) calculated by measuring the binding of Alexa Fluor 488-labeled chimera A-Fc to membrane-type LIGHT on activated human T cells by flow cytometry.
- the vertical axis represents the geometric mean (Geo. Mean) of the fluorescence intensity.
- FIG. 23 shows the results of evaluation of the binding activity of chimeric A-Fc to membrane type TL1A of primary cells. The binding of Alexa Fluor 647-labeled chimera A-Fc to membrane-type TL1A on HUVEC cells in the presence or absence of a competing protein was measured by flow cytometry, and the calculated geometric mean (Geo. Mean) is shown.
- FIG. 24 shows the results of measuring the binding activity of chimeric A-Fc to FasL derived from primary cells by sandwich ELISA to soluble FasL in the culture supernatant of AICD-induced human T cells.
- FIG. 24A shows the value of absorbance at 450 nm when the culture supernatant was added to a plate on which Chimera A-Fc was captured and FIG. 24B was captured with FasL antibody and detected with an anti-FasL antibody.
- FIG. 25 shows the results of elution time (minutes) in hydrophobic interaction chromatography (HIC) of various chimeric A-Fc and FasL binding reduced variants with different Fc sequences.
- HIC hydrophobic interaction chromatography
- FIG. 26 shows the results of Tm values (° C.) calculated by the Differential Scanning Fluorometery (DSF) method for various chimeric A-Fc and FasL binding-reducing variants having different Fc sequences.
- FIG. 27 shows 10 mg / kg i.I. of chimeric A-Fc (Eg1S) and FasL-impaired variants with different Fc sequences in BALB / c mice.
- v. The values of the elimination phase blood half-life (h) after administration and the area under the blood concentration-time curve AUC0- ⁇ ( ⁇ g * h ⁇ mL) up to infinite time are shown.
- FIG. 28A shows an index of macroscopic pathological condition score in a drug efficacy test of chimeric A-Fc using a mouse acute interspecific GVHD model.
- FIG. 28B shows the average pathological score for each individual in each group and for each group. The vertical axis shows the pathological condition score, and the horizontal axis shows each treatment group.
- FIG. 29 shows the number of cells per spleen for each of human CD45-positive, human CD3 and CD4-positive, and human CD3 and CD8-positive cells in the efficacy test of chimeric A-Fc using a mouse acute interspecific GVHD model. It is shown by the average value for each individual and each group.
- Group 1 shows a DNP antibody-administered group without human cell transfer
- 2 groups show a DNP antibody-administered group with human cell transfer
- group 3 shows a chimeric A-Fc-administered group with human cell transfer.
- the vertical axis shows the number of cells positive for each surface marker
- the horizontal axis shows each treatment group.
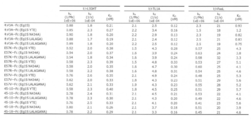
- FIG. 30A shows the results of measuring the binding activity of various DcR3 variants to human DcR3 ligand by BIAcore.
- human DcR3 ligand shows human FasL, human LIGHT, or human TL1A trimer various kinetic constants when using (ka, kd, K D) a.
- FIG. 30B shows the results of measuring the binding activity of various DcR3 variants to the cynomolgus monkey DcR3 ligand by BIAcore. Shown as cynomolgus DcR3 ligand, cynomolgus FasL, cynomolgus LIGHT, or various kinetic constants when using the trimer of cynomolgus TL1A (ka, kd, K D ) a.
- FIG. 31 shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble LIGHT.
- FIG. 31 shows the inhibitory activity of chimeric A-Fc and FasL-reduced binding variants with various mutant Fc on LIGHT-dependent CXCL10 production of intestinal myofibroblasts.
- the vertical axis shows the CXCL10 concentration (ng / mL), and the horizontal axis shows the added DcR3 variant concentration (ng / mL).
- FIG. 32 shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble TL1A.
- FIG. 32 shows the inhibitory activity of chimeric A-Fc and FasL-reducing variants with various mutant Fc on TL1A-dependent IFN- ⁇ production of human T cells.
- FIG. 33 shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to soluble FasL.
- FIG. 33 shows the inhibitory activity of Jurkat cells against cell death by chimeric A-Fc having various mutant Fc and FasL binding-reducing variant.
- RLU ⁇ 10 6 ATP-dependent chemiluminescence
- FIG. 34A shows the results of flow cytometry evaluation of the binding activity of various DcR3 variants to the membrane-type LIGHT forced expression strain.
- the vertical axis of the graph shows the geometric mean (Geo. Mean) of PE.
- FIG. 34B shows the results of evaluation of the binding activity of various DcR3 variants to the membrane-type TL1A forced expression strain by flow cytometry.
- the vertical axis of the graph shows the geometric mean (Geo. Mean) of PE.
- FIG. 34C shows the results of evaluation of the binding activity of various DcR3 variants to the membrane-type FasL forced expression strain by flow cytometry.
- the vertical axis of the graph shows the geometric mean (Geo. Mean) of PE.
- FIG. 35 shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to the membrane-type LIGHT.
- FIG. 35 shows the inhibitory activity of chimeric A-Fc and FasL-reduced binding variants having various mutant Fc on membrane-type LIGHT-dependent CXCL10 production of intestinal myofibroblasts.
- the vertical axis shows the CXCL10 concentration (ng / mL), and the horizontal axis shows the added DcR3 variant concentration (ng / mL).
- FIG. 36 shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to the membrane type TL1A.
- FIG. 36 shows the inhibitory activity of chimeric A-Fc and FasL-reducing variants with various mutant Fcs on membrane-type TL1A-dependent IFN- ⁇ production of human CD4-positive T cells.
- the vertical axis shows the IFN- ⁇ concentration (pg / mL), and the horizontal axis shows the added DcR3 variant concentration (ng / mL).
- FIG. 37 shows the results of evaluation of the neutralization activity of various DcR3 variants with respect to membrane-type FasL.
- FIG. 37 shows the inhibitory activity of Jurkat cells against membrane-type FasL-dependent cell death by chimeric A-Fc having various mutant Fc and FasL binding-reducing variants.
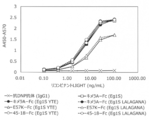
- FIG. 38A shows the results of measuring the binding activity of various DcR3 variants to recombinant human LIGHT by sandwich ELISA.
- the vertical axis shows the value obtained by subtracting the absorbance at 570 nm from the absorbance at 450 nm, and the horizontal axis shows the concentration (ng / mL) of the added recombinant human LIGHT.
- FIG. 38A shows the results of measuring the binding activity of various DcR3 variants to recombinant human LIGHT by sandwich ELISA.
- the vertical axis shows the value obtained by subtracting the absorbance at 570 nm from the absorbance at 450 nm, and the horizontal axis shows the concentration (ng / mL) of the added recombinant human LIGHT.
- FIG. 38A shows the results of measuring the binding activity of various DcR3 variants to recombinant human LIGHT by sandwich ELISA.
- the vertical axis shows the value obtained by subtracting the absorbance at
- FIG. 38B shows the results of measuring the binding activity of various DcR3 variants to LIGHT derived from human primary cells by sandwich ELISA to soluble LIGHT in the culture supernatant of human T cells.
- the white bar shows the result of using the culture supernatant when the human T cells were cultured without stimulation, and the black bar shows the result of using the culture supernatant of the human T cells stimulated with the anti-CD3 antibody and the anti-CD28 antibody.
- the vertical axis shows the value obtained by subtracting the absorbance at 570 nm from the absorbance at 450 nm.
- FIG. 38C shows the results of measuring the binding activity of various DcR3 variants to recombinant human TL1A by sandwich ELISA.
- FIG. 38D shows the results of measuring the binding activity of various DcR3 variants to TL1A derived from human primary cells by sandwich ELISA to soluble TL1A in the culture supernatant of human PBMC.
- the white bar shows the result of using the culture supernatant when human PBMC was cultured without stimulation, and the black bar shows the result of using the culture supernatant of human PBMC stimulated with the immune complex.
- FIG. 38E shows the results of measuring the binding activity of various DcR3 variants to recombinant human FasL by sandwich ELISA.
- the vertical axis represents the value obtained by subtracting the absorbance at 570 nm from the absorbance at 450 nm, and the horizontal axis represents the human FasL concentration (ng / mL).
- FIG. 38F shows the results of measuring the binding activity of various DcR3 variants to FasL derived from human primary cells by sandwich ELISA for soluble FasL in the culture supernatant of AICD-induced human T cells.
- the white bar shows the result of using the culture supernatant of non-AICD-induced human T cells
- the black bar shows the result of using the culture supernatant of AICD-induced human T cells.
- the vertical axis shows the value obtained by subtracting the absorbance at 570 nm from the absorbance at 450 nm.
- FIG. 39 shows various DCR3 variants applied to BALB / c mice at 10 mg / kg i. v.
- the values of the elimination phase blood half-life (h) after administration and the area under the blood concentration-time curve AUC0- ⁇ ( ⁇ g * h ⁇ mL) up to infinite time are shown.
- Lanes 1 and 5 are 30-fold concentrates of the culture supernatant expressing S195-His6, lanes 2 and 6 are 6-fold dilutions of the culture supernatant expressing chimeric A-His6, and lanes 3 and 7 are E57K-.
- a 6-fold dilution of the culture supernatant expressing His6 and a 6-fold dilution of the culture supernatant expressing 45-18-His6 in lanes 4 and 8 were electrophoresed under non-reducing or reducing conditions, respectively. It was detected by electrophoresis with an anti-6x-His tag antibody.
- the present invention relates to a DcR3 variant, which is a variant of wild-type DcR3.
- the present invention has DcR3 ligand-binding activity (or neutralizing activity) and is better than wild-type DcR3 in terms of pharmacokinetics and / or production in mammalian cells than wild-type DcR3. It relates to a DcR3 variant showing reduced aggregation and a DcR3 variant containing a cysteine-rich domain in which a mutation has been introduced into one or more amino acids in the cysteine-rich domain of wild-type DcR3.
- DcR3 is also commonly referred to as Decoy Receptor 3, DCR3, TNFSF6B (Tumor necrosis factory receptor 6B), TR6 or M68.
- DcR3 is a soluble decoy receptor that does not have a transmembrane domain and belongs to the TNF receptor superfamily. By binding to three ligands, LIGHT, TL1A, or FasL, each ligand and receptor can be combined. Competitively inhibits binding and neutralizes the ligand.
- glycosaminoglycans such as heparan sulfate on the cell membrane of monocytes, macrophages, or dendritic cells via the heparan sulfate binding region (HBD). It has been reported that it directly binds to each other and induces various immunosuppressive and immunostimulatory effects [Biochemical. Pharmacology, 2011, 81: p. 838-847, J. Mol. Immunol. , 2006, 176: p. 173-180].
- GAG glycosaminoglycans
- the naturally occurring DcR3 has CRD1, CRD2, CRD3, CRD4 and HBD in order from the N-terminal side.
- the naturally occurring DcR3 exists between CRD1 and CRD2, between CRD2 and CRD3, between CRD3 and CRD4, and between CRD4 and HBD. It has an additional area to do.
- the naturally occurring cysteine-rich region of DcR3 is the region from the N-terminus of CRD1 to the C-terminus of CRD4, which includes CRD1, CRD2, CRD3 and CRD4 and exists between CRD1 and CRD2. It includes a region existing between CRD3 and a region existing between CRD3 and CRD4.
- a “wild-type DcR3” is a molecule containing a cysteine-rich region and HBD in which the cysteine-rich region and HBD are wild-type (ie, the cysteine-rich region and HBD are naturally occurring DcR3 cysteine-rich regions and HBD. Means a molecule (same as). Therefore, in addition to naturally occurring DcR3, naturally occurring mutants of DcR3 such as gene polymorphisms and isoforms are also included in "wild type DcR3" as long as they contain a cysteine-rich region of naturally occurring DcR3 and HBD. Will be done. In addition, immature DcR3 and mature DcR3 are also included in "wild type DcR3".
- Immature DcR3 means DcR3 having a signal peptide
- mature DcR3 means DcR3 in which the signal peptide is cleaved.
- the signal peptide may be any of a naturally occurring sequence derived from DcR3, an artificial sequence, a sequence derived from an expression vector, and a sequence derived from another protein suitable for a host cell expressing naturally occurring DcR3.
- a sequence in which the mature N-terminal amino acid differs is also included in "wild type DcR3".
- wild-type CRD The naturally occurring CRD of DcR3 and the CRD of wild-type DcR3 are also referred to as "wild-type CRD", and the naturally occurring cysteine-rich region of DcR3 and the cysteine-rich region of wild-type DcR3 are also referred to as "wild-type cysteine-rich region”.
- the origin of the wild-type DcR3 in the present invention is not limited, but examples thereof include DcR3 derived from various eukaryotes.
- amphibians such as frogs, birds such as chickens, or mammals, such as primates including humans, or DcR3 derived from cloven-hoofed animals such as pigs and cows.
- DcR3 variant of the present invention is used for humans, it is preferable to use human-derived DcR3 as the wild-type DcR3.
- the human-derived DcR3 cDNA sequence is represented by SEQ ID NO: 1, and the corresponding mRNA sequence is registered in GenBank (US NCBI) as accession number: NM_003823.3.
- GenBank accession number: NM_003823.3.
- the amino acid sequence of human-derived DcR3 is represented by SEQ ID NO: 2 and is registered in GenBank (National Center for Biotechnology Information) as Accession No. NP_003814.1.
- the immature human DcR3 has a signal peptide at the N-terminus, followed by four CRDs (CRD1, CRD2, CRD3, CRD4) characteristic of the TNF receptor superfamily, and an HBD rich in basic amino acids at the C-terminus. Has.
- the mature human DcR3 is an immature type in which the signal peptide is cleaved, and the amino acid sequence of the mature human DcR3 is represented by, for example, SEQ ID NO: 4, and encodes the amino acid sequence of the mature human DcR3.
- the base sequence of the DNA to be used is represented by, for example, SEQ ID NO: 3.
- the amino acid sequences of human DcR3 SEQ ID NO: 2
- the 30th to 70th regions from the N-terminal are CRD1 (SEQ ID NO: 6)
- the 73rd to 113th regions are CRD2 (SEQ ID NO: 8), 115.
- the 150th region is defined as CRD3 (SEQ ID NO: 10), the 153rd to 193rd region is defined as CRD4 (SEQ ID NO: 12), and the 196th to 300th region is defined as HBD (SEQ ID NO: 48) (FIG. 2).
- the base sequences of the DNAs encoding the amino acid sequences of CRD1, CRD2, CRD3, CRD4 and HBD of human DcR3 are represented by, for example, SEQ ID NOs: 5, 7, 9, 11 and 47, respectively.
- the amino acid sequence of CRD has a plurality of definitions other than those described above, but any definition of the amino acid sequence of CRD can be used for the DcR3 variant of the present invention by utilizing known information. [UniProt O95407, GenBank NP_003814.1, Structure, 2011, 19: p. 162-171].
- LIGHT, TL1A and FasL all of which belong to TNFSF, can be mentioned.
- LIGHT (lymphotoxin-like, exhibits inducible expression, and competes with herpes simplex virus (HSV) glycoprotein D (gD) for HVEM, a receptor expressed by T lymphocytes) are generally, TNFSF14 (Tumor necrosis factor superfamily member 14), LTg , HVEM-L or CD258.
- HSV herpes simplex virus
- gD glycoprotein D
- the human LIGHT mRNA sequence and its corresponding cDNA sequence are registered with accession number: NM_003807.4, and the amino acid sequence is registered with accession number: NP_003798.2 in GenBank (USA NCBI).
- Soluble LIGHT is produced by expressing the extracellular LIGHT as a membrane LIGHT on the cell membrane and then shedding the extracellular space with a protease.
- the cleavage site in the membrane-type LIGHT is between the 82nd and 83rd amino acids of NP_003798.2. Both the soluble type and the
- TL1A Tumor necrosis factor (TNF) -like cytokine 1A
- TNFSF15 TNF superfamily member 15
- TL1A mRNA sequence and its corresponding cDNA sequence are registered with accession number: NM_005118.3, and the amino acid sequence is registered with accession number: NP_005109.2 in GenBank (NCBI, USA).
- Soluble TL1A is produced by expressing on the cell membrane as membrane TL1A and then shedding the extracellular region with a protease.
- the cleavage site in the membrane type TL1A is between the 71st and 72nd amino acids of NP_005109.2, and both the soluble type and the membrane type are functional.
- FasL (Fas ligand) is also commonly referred to as FASLG, TNFSF6 (Tumor necrosis factoror superior family 6), CD178 or APT1LG1.
- the human FasL mRNA sequence and its corresponding cDNA sequence are registered with Accession No. NM_000639.2, and the amino acid sequence is registered with GenBank (USA NCBI) as Accession No. NP_000630.1.
- Soluble FasL is produced by expression on the cell membrane as membrane FasL and then shedding the extracellular region with protease.
- the cleavage site in membrane FasL is between the 81st and 82nd amino acids of NP_000630.1, or between the 129th and 130th amino acids.
- Membrane-type FasL has been reported to be a predominantly functional ligand in vivo.
- gene polymorphisms or isoforms are often found in genes encoding eukaryotic proteins.
- a gene whose base sequence or amino acid sequence is mutated due to such a polymorphism in the gene used in the present invention is also included in the gene encoding LIGHT, TL1A, or FasL in the present invention.
- DcR3 variant contains a chimeric cysteine-rich region.
- the chimeric cysteine rich region of the present invention consists of an amino acid sequence in which mutations are introduced into one or more amino acids in the amino acid sequence of the cysteine rich region of wild-type DcR3.
- a mutation was introduced into a certain amino acid sequence / base sequence means that one or more amino acids / bases were substituted, deleted, inserted or added in the sequence.
- Substitution, deletion, insertion or addition also includes a combination of two or more mutations selected from substitution, deletion, insertion and addition. Mutations are introduced into at least one or more CRDs selected from CRD1, CRD2, CRD3 and CRD4 in the cysteine-rich region of wild-type DcR3.
- mutations are introduced in the region existing between CRD1 and CRD2, the region existing between CRD2 and CRD3, and the region existing between CRD3 and CRD4. It may or may not be introduced. Mutations are introduced into one or more regions selected from the region between CRD1 and CRD2, the region between CRD2 and CRD3, and the region between CRD3 and CRD4.
- the number of amino acids constituting each region after the introduction of the mutation is usually 1 to 10, preferably 1 to 7, more preferably 1 to 5, still more preferably 1 to 3, and even more preferably.
- the amino acid sequence of each region after the introduction of the mutation is not particularly limited.
- the chimeric cysteine rich region in the present invention includes, for example, a chimeric cysteine rich consisting of an amino acid sequence in which one or more amino acids are substituted, deleted, inserted or added in the amino acid sequence of the cysteine rich region of wild-type DcR3. Regions are mentioned, and examples of such chimeric cysteine-rich regions include first and second chimeric cysteine-rich regions described later.
- first chimeric cysteine rich region In the first chimeric cysteine rich region, at least a part of the CRD of wild type DcR3 was replaced with another peptide or protein in the amino acid sequence of the cysteine rich region of wild type DcR3. It consists of an amino acid sequence. That is, the first chimeric cysteine-rich region contains an amino acid sequence derived from the cysteine-rich region of wild-type DcR3 and an amino acid sequence derived from another peptide or protein.
- the portion of the cysteine-rich region of wild-type DcR3 that is replaced by another peptide or protein is preferably at least a part of at least one CRD selected from CRD1, CRD2, CRD3 and CRD4. Therefore, in the cysteine-rich region of wild-type DcR3, the portion substituted with another peptide or protein is all or part of CRD1, all or part of CRD2, all or part of CRD3, and all of CRD4. Or you can choose from some.
- the amino acid sequence of the first chimeric cysteine-rich region in the amino acid sequence of the cysteine-rich region of wild-type DcR3, in addition to at least a part of the CRD of wild-type DcR3, a portion other than the wild-type CRD is another peptide or Amino acid sequences substituted with proteins are also included.
- the part other than CRD that is replaced with another peptide or protein is from the region existing between CRD1 and CRD2, the region existing between CRD2 and CRD3, and the region existing between CRD3 and CRD4. You can choose.
- the part other than CRD that is replaced with another peptide or protein may be one part or two or more parts.
- the sequence is also included in the amino acid sequence of the first chimeric cysteine rich region.
- the portion substituted with another peptide or protein may be one portion or two or more portions.
- the substituted portion may be all or part of one CRD or all or part of a plurality of CRDs. All or part of CRD2 of wild-type DcR3 involved in binding to LIGHT, TL1A and FasL and / or all or part of CRD3 region is retained and all or part of other CRDs are other peptides. Alternatively, it is more preferably substituted with a protein.
- the other peptide or protein to be substituted may be either a natural or artificial peptide or protein, and examples thereof include at least a part of CRD derived from a protein other than DcR3.
- the other peptide or protein to be substituted is at least part of the CRD of a TNF receptor superfamily (TNFRSF) molecule other than DcR3.
- TNFRSF TNF receptor superfamily
- the first chimeric cysteine-rich region has at least a portion of the wild-type DcR3 cysteine-rich domain in the amino acid sequence of the wild-type DcR3 cysteine-rich region, which is a cysteine-rich molecule of a TNFRSF molecule other than DcR3.
- the first chimeric cysteine-rich region replaces a part of CRD1 of wild-type DcR3 with a part of CRD1 of TNFRSF molecule corresponding to a part of CRD1 of wild-type DcR3, CRD1 of wild-type DcR3.
- the first chimeric cysteine rich region for example, a chimeric cysteine rich region having a substitution of CRD1 of wild DcR3 with CRD1 of a TNFRSF molecule (in the chimeric cysteine rich region, preferably wild DcR3). Other CRDs are retained), a chimeric cysteine-rich region in which the CRD4 of wild-type DcR3 has a substitution of the TNFRSF molecule for CRD4 (in the chimeric cysteine-rich region, preferably the other CRD of wild-type DcR3).
- CRD1 of wild-type DcR3 is replaced with CRD1 of TNFRSF molecule
- CRD4 of wild-type DcR3 is replaced with CRD4 of TNFRSF molecule in a chimeric cysteine-rich region (the chimera).
- the type cysteine rich region preferably, other CRDs of wild type DcR3 are retained) and the like.
- a portion of CRD2 of wild-type DcR3 is replaced with a portion of CRD2 of the TNFRSF molecule corresponding to that portion, and / or a portion of CRD3 of wild-type DcR3.
- a chimeric cysteine-rich region having a further substitution of the TNFRSF molecule corresponding to that portion with a portion of CRD3 is also included in the first chimeric cysteine-rich region.
- each receptor belongs to human TNFRSF, and each receptor has a CRD in the extracellular domain of the N-terminal, and 6 Cys residues form 3 disulfide bonds per CRD. Typically, each receptor has one to four CRDs [Trends Biochem Sci, 2002.27: p-19-26. ].
- Human TNFRSF includes, for example, DcR1 (TNFRSF10C, TRAIL-R3, LIT, TRID, CD263), DcR2 (TNFRSF10D, TRAIL-R4, TRUNDD, CD264), TNFR type I (TNFRSF1A, TNF-R, CD120).
- DcR1 TNFRSF10C, TRAIL-R3, LIT, TRID, CD263
- DcR2 TNFRSF10D, TRAIL-R4, TRUNDD, CD264
- TNFR type I TNFRSF1A, TNF-R, CD120.
- TNFR type II TNFRSF1B, TNFBR, CD120b, TNFR80, p75, TNF-R75
- LTBR Lymphotoxin beta receptor
- CD40 TNFRSF5, Bp50, p50
- Fas Fas cell surface depth receptor, TNFSF6, CD95, APO-1, APT1, FAS1), CD27 (TNFRSF7) (TNFRSF8, Ki-1), 4-1BB (TNFRSF9, CD137, ILA), DR4 (TNFRSF10A, Apo2, TRAILR-1, CD261), DR5 (TNFRSF10B, TRAIL-R2, KILLER, TRICK2A, TRICKB, CD262), RANK (TNFRSF11A, CD265, FEO), FN14 (TNFRSF12A, TweekR, CD266), RANK (TNFRSF11A, CD265, FEO), FN14 (TNFRSF12A, TweekR, CD266), RANK (TNFRSF11A
- the other peptide or protein that replaces at least a part of wild-type DcR3 in the first chimeric cysteine-rich region is not limited, but OPG is particularly preferable among TNFRSF.
- the OPG is not limited to its origin, but includes various eukaryotic OPGs.
- the cDNA sequence of human-derived OPG is represented by SEQ ID NO: 13, and the corresponding mRNA sequence is registered in GenBank (NCBI, USA) as accession number: NM_002546.3.
- the amino acid sequence of human-derived OPG is represented by SEQ ID NO: 14, and is registered in GenBank (NCBI, USA) as accession number: NP_0025373.3.
- the immature human OPG (SEQ ID NO: 14) has a signal peptide at the N-terminus.
- the mature human OPG is an immature type in which the signal peptide is cleaved, and the amino acid sequence of the mature human OPG is represented by, for example, SEQ ID NO: 16, and the amino acid sequence of the mature human OPG is used.
- the base sequence of the encoding DNA is represented by, for example, SEQ ID NO: 15.
- the 22nd to 62nd regions from the N-terminal are CRD1 (SEQ ID NO: 18), and the 65th to 105th regions are CRD2 (SEQ ID NO: 20).
- the 107th to 142nd regions are defined as CRD3 (SEQ ID NO: 22), and the 145th to 185th regions are defined as CRD4 (SEQ ID NO: 24).
- the base sequences of the DNAs encoding the amino acid sequences of CRD1, CRD2, CRD3 and CRD4 of human OPG are represented by, for example, SEQ ID NOs: 17, 19, 21 and 23, respectively.
- any of the definitions of the CRD amino acid sequence can be used for the DcR3 variant of the present invention by utilizing known information. [UniProt O00300, GenBank NP_0025373.].
- gene polymorphisms and isoforms are often found in genes encoding eukaryotic proteins.
- a gene whose base sequence or amino acid sequence is mutated due to such a polymorphism in the gene used in the present invention is also included in the gene encoding the OPG of the present invention.
- OPG binds to RANKL and suppresses bone destruction by osteoclasts by neutralizing its activity [J. Immunol. , 2012, 189: p. 245-252]. OPG also binds to TRAIL and neutralizes its activity, thereby inhibiting TRAIL-mediated apoptosis [Am. J. Cancer. Res. , 2012, 2: p. 45-64]. Since neutralization of any ligand may cause undesired activity or the like, it is desirable that the DcR3 variant of the present invention does not have neutralizing activity against either RANKL or TRAIL.
- the first chimeric cysteine-rich region comprises or consists of the following amino acid sequences (a), (b), (c) or (d).
- (B) In the amino acid sequence of the cysteine-rich region of wild-type DcR3, the CRD4 of wild-type DcR3 is replaced with the CRD4 of OPG (in the amino acid sequence, preferably other CRDs of wild-type DcR3 are retained.
- amino acid sequence of (d) for example, in the amino acid sequence of (a), (b) or (c), the 103rd to 123rd portions from the N-terminal correspond to the amino acid sequence of CRD of OPG.
- Amino acid sequences substituted with moieties include.
- the amino acid sequence containing the 18th to 36th parts of CRD3 of wild-type DcR3 and the two amino acid residues following the C-terminal side of the amino acid sequence of CRD3 is a part of the OPG corresponding to the amino acid sequence. It has been replaced.
- amino acid sequence of (a) above include an amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequences of SEQ ID NO: 26 or 50, and the amino acid sequence of (b) above.
- amino acid sequence of (b) above include an amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequences set forth in SEQ ID NO: 28 or 52, and specific examples of the amino acid sequence of (c) above include SEQ ID NO: 30.
- amino acid sequences shown in 54 an amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal can be mentioned, and specific examples of the amino acid sequence of (d) above include the amino acid sequence of SEQ ID NO: 32 or 56. Among them, an amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal can be mentioned.
- SEQ ID NO: 26 is the amino acid sequence of chimeric B-HBD (DcR3 variant in which CRD1 is replaced with CRD1 of OPG in wild type DcR3 (SEQ ID NO: 4)), and SEQ ID NO: 28 is chimeric C-HBD (wild type).
- DcR3 SEQ ID NO: 4
- the amino acid sequence of DcR3 variant in which CRD4 was replaced with CRD4 of OPG SEQ ID NO: 30, respectively, in chimeric A-HBD (wild type DcR3 (SEQ ID NO: 4), CDR1 and CDR4 were OPG.
- the amino acid sequence of the DcR3 variant substituted with CDR1 and CDR4, SEQ ID NO: 32 is 103-123OPG-HBD (in the chimeric A-HBD, the 18th to 36th portions of CRD3 and the two amino acids on the C-terminal side thereof).
- the amino acid sequence of the DcR3 variant in which the amino acid sequence containing the above is replaced with human OPG, SEQ ID NO: 50, is the chimera B (wild-type DcR3 (SEQ ID NO: 4) in which CRD1 is replaced with CRD1 of OPG and the heparan sulfate binding region.
- SEQ ID NO: 52 is a chimera C (DcR3 variant in which CRD4 was replaced with CRD4 of OPG and the heparan sulfate binding region was deleted in wild-type DcR3 (SEQ ID NO: 4)).
- the amino acid sequence of SEQ ID NO: 54 is the amino acid of chimeric A (a DcR3 variant in which CDR1 and CDR4 were replaced with CDR1 and CDR4 of OPG, respectively, and the heparan sulfate binding region was deleted in wild-type DcR3 (SEQ ID NO: 4)).
- SEQ ID NO: 56 is the amino acid sequence of 103-123 OPG (DcR3 variant in which the amino acid sequence containing the 18th to 36th portions of CRD3 and the 2 amino acids on the C-terminal side thereof in chimera A is replaced with human OPG). Represents.
- the DcR3 variants containing the first chimeric cysteine-rich region include DcR3 variants, LIGHT, TL1A and FasL that have binding activity to at least one of LIGHT, TL1A and FasL.
- DcR3 variant that has binding activity for all a DcR3 variant that does not have binding activity for FasL and has binding activity for any one of LIGHT and TL1A, or FasL. Examples thereof include DcR3 variants that do not have binding activity and have binding activity to LIGHT and TL1A.
- "having binding activity to a ligand” means that the binding activity of a DcR3 variant containing the first chimeric cysteine-rich region to the ligand is compared with the binding activity of wild-type DcR3 to the ligand. It is used in the sense that it is equivalent and not significantly decreased, and that it is significantly enhanced as compared with the binding activity of wild-type DcR3 to the ligand. For example, when determined by surface plasmon resonance (SPR method), if less than 3 times dissociation constant (K D) values of DcR3 variants as compared to wild-type DcR3, determines that has binding activity for the ligand be able to.
- SPR method surface plasmon resonance
- the expression "the DcR3 variant has no binding activity to the ligand” means that the binding activity of the DcR3 variant containing the first chimeric cysteine-rich region to the ligand is not detected, and that the binding activity of the DcR3 variant to the ligand is not detected. , It is used in the sense that it is significantly reduced as compared with the binding activity of wild-type DcR3 to the ligand. For example, when measured by the SPR method, when the KD value of the DcR3 variant is greater than 3 times that of the wild-type DcR3, or when the Rmax of the DcR3 variant is less than 5, the binding activity to the ligand is significantly reduced. It can be defined that the DcR3 variant has no binding activity to the ligand.
- examples of the DcR3 variant containing the first chimeric cysteine-rich region include a DcR3 variant having reduced binding to FasL.
- a "FasL-reducing variant” is a DcR variant comprising a chimeric cysteine-rich region that has no binding activity to FasL and has binding activity to any one or more of LIGHT and TL1A.
- it means a DcR3 variant containing a chimeric cysteine-rich region that has no binding activity to FasL and has binding activity to LIGHT and TL1A.
- the DcR3 variants of the invention are neutralizing activity against all of the DcR3 variants, LIGHT, TL1A and FasL, which have neutralizing activity against at least one of LIGHT, TL1A and FasL.
- DcR3 variant having no neutralizing activity against FasL and having neutralizing activity against any one of LIGHT and TL1A, or DcR3 variant having neutralizing activity against FasL It is a DcR3 variant that does not have and has neutralizing activity against LIGHT and TL1A.
- the expression "neutralizing activity for a ligand” means that the ligand binds to a DcR3 variant to inhibit the binding of the ligand to a receptor on the cell membrane surface, and that the ligand binds to a receptor.
- the expression that the DcR3 variant has "neutralizing activity” means that the neutralizing activity of the DcR3 variant against the ligand is significantly different from the neutralizing activity of the wild-type DcR3 against the ligand. It is used in the sense that it is absent and that it is significantly enhanced as compared with the neutralizing activity of wild-type DcR3 against the ligand.
- the expression "the DcR3 variant has no neutralizing activity” means that the neutralizing activity of the DcR3 variant against the ligand is significantly higher than the neutralizing activity of the wild-type DcR3 against the ligand. It is used in the sense that it is decreasing.
- the DcR3 variant in the present invention is a DcR3 variant with reduced binding to FasL.
- the "FasL binding-reducing variant” has no neutralizing activity against FasL and has a neutralizing activity against any one or more of LIGHT and TL1A, or a DcR3 variant or FasL. It means a DcR3 variant having no neutralizing activity and having a neutralizing activity against LIGHT and TL1A.
- the second chimeric cysteine rich region is the amino acid sequence of the first chimeric cysteine rich region in which 1 to 30 amino acids have been deleted, substituted, inserted or added. is there.
- a site-specific mutagenesis method As a method for obtaining a polypeptide having an amino acid sequence in which one or more amino acids are deleted, substituted, inserted or added in the amino acid sequence of the first chimeric cysteine-rich region, a site-specific mutagenesis method [Molecular Cloning, A Laboratory Manual, Second Edition, Cold Spring Harbor Laboratory Press (1989), Mutation Protocols amino acid Molecular Biology, John Willy & Son Natl. Acad. Sci. USA. , 79, 6409, (1982), Gene, 34, 315 (1985), Proc. Natl. Acad. Sci. USA. , 82,488 (1985)].
- Mutations (modifications) made to the first chimeric cysteine-rich region include both natural mutations and artificial amino acid substitutions, deletions, insertions or additions, and the second chimeric cysteine.
- the amino acid sequence of the rich region is one or two or more, preferably 1 to 30, more preferably 1 to 10, and even more preferably 1 to 5 in the amino acid sequence of the first chimeric cysteine rich region. 80% or more, preferably 85% or more, with the amino acid sequence of 1, 3 more preferably 1 to 3 amino acid substitutions, deletions, insertions or additions, or the amino acid sequence of the first chimeric cysteine rich region.
- amino acid sequences having 90% or more, for example 93% or more, 95% or more, 97% or more, 98% or more, or 99% or more identity can be mentioned.
- As a method for describing the amino acid substitute for example, when Asn at the 131st position from the N-terminal of the amino acid sequence to be replaced with an amino acid is replaced with Ser, it can be expressed as N131S.
- the second chimeric cysteine-rich region comprises or consists of the amino acid sequence of (e) below.
- Examples of the mutation (modification) added to the first chimeric cysteine-rich region include addition or deletion of a glycosylated site.
- the biological activity or characteristics of the DcR3 variant of the present invention thermodynamics such as blood half-life, or physics such as protein stability.
- the chemical properties can be controlled.
- Sugar chain addition generally means that a sugar chain binds to an asparagine residue of a peptide or protein with an N-glycosidic bond, and / and that a sugar chain binds to a serine or threonine residue with an O-glycosidic bond.
- O-type sugar chain added to the DcR3 variant include core 1, core 2, etc.
- examples of the N-type sugar chain include high mannose type, hybrid type, or complex type sugar chain, and the complex type sugar is preferable. It is a chain.
- At least one amino acid in the amino acid sequence of the first chimeric cysteine rich region is subjected to N-glycosidic bond or O-. Substitution with an amino acid to which a sugar chain can be added by glycosidic bond to add a sugar chain, and it is particularly preferable to add an N-glycoside-linked sugar chain.
- amino acid sequence of the chimeric cysteine rich region at least one amino acid, preferably two or more amino acids involved in the N-glycosidic bond may be replaced with another amino acid to remove the sugar chain.
- amino acid sequence of the chimeric cysteine rich region at least one amino acid, preferably two or more amino acids involved in the N-glycosidic bond may be replaced with another amino acid to remove the sugar chain.
- the sequence of Asn-X-Thr / Ser where X is an arbitrary amino acid residue other than Pro
- the N-glycosidic bond type sugar chain can be removed by substituting Asn, Ser or Thr of the Asn-X-Thr / Ser sequence present in the DcR3 variant with another amino acid.
- the amino acid sequence of the first chimeric cysteine rich region for example, 1 from the N-terminal of SEQ ID NO: 30.
- a chimeric cysteine-rich region having a sugar chain that binds N-glycosid to Asn at the 157th position from the N-terminal of (amino acid sequence consisting of the 164th amino acid) is preferable.
- the amino acid sequence of the second chimeric cysteine-rich region from which the glycosylation site has been removed is (F) The amino acid sequence of (b), (c) or (d) above (for example, the amino acid sequence shown by SEQ ID NO: 28, 30, 32, 52, 54 or 56, which is the 1st to 164th amino acid sequence from the N-terminal.
- amino acid sequence consisting of amino acids amino acid sequence consisting of amino acids
- G Of the amino acid sequences of (b), (c) or (d) above (for example, the amino acid sequences shown by SEQ ID NOs: 28, 30, 32, 52, 54 or 56, the 1st to 164th amino acids from the N-terminal).
- Substitution of Thr (amino acid sequence consisting of amino acids) from the N-terminal to other amino acids at Thr 133 and Ser at 146, and (I) Of the amino acid sequences of (b), (c) or (d) above (for example, the amino acid sequences shown by SEQ ID NOs: 28, 30, 32, 52, 54 or 56, the 1st to 164th amino acids from the N-terminal). It has a substitution selected from substitutions with other amino acids at the 133rd Thr, 146th Ser and 159th Thr from the N-terminus of the amino acid sequence consisting of amino acids).
- the amino acid sequence from which the glycosylation site has been removed is (F') Of the amino acid sequences of (b), (c) or (d) above (for example, the amino acid sequences shown by SEQ ID NOs: 28, 30, 32, 52, 54 or 56, 1st to 164th from the N-terminal). Substitution of Asn at positions 131 and 144 from the N-terminus to Ser, (G') Of the amino acid sequences of (b), (c) or (d) above (for example, the amino acid sequences shown by SEQ ID NOs: 28, 30, 32, 52, 54 or 56, 1st to 164th from the N-terminal).
- amino acid sequence having the substitution of (f') for example, in the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal among the amino acid sequences shown in SEQ ID NO: 30 or SEQ ID NO: 54, 131 from the N-terminal.
- Amino acid sequence in which the Asn at the th and 144th positions are replaced with Ser (N131S / N144S) amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal among the amino acid sequences shown in SEQ ID NO: 34 or SEQ ID NO: 58
- SEQ ID NO: 34 is the amino acid sequence of N131S / N144S-HBD (a DcR3 variant in which Asn at positions 131 and 144 from the N-terminus is replaced with Ser in chimeric A-HBD), and SEQ ID NO: 58 is N131S / N144S. (In chimera A, a DcR3 variant in which Asn at positions 131 and 144 from the N-terminal is replaced with Ser) is represented.
- amino acid sequence having the substitution of (h') for example, in the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal among the amino acid sequences shown in SEQ ID NO: 30 or SEQ ID NO: 54, 133 from the N-terminal.
- Amino acid sequence in which the th Thr and the 146th Ser are replaced with Ala (T133A / S146A) (Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequences shown in SEQ ID NO: 36 or SEQ ID NO: 60).
- Etc. can be mentioned.
- SEQ ID NO: 36 is the amino acid sequence of T133A / S146A-HBD (in chimeric A-HBD, the 133rd Thr and 146th Ser are replaced with Ala in the chimeric A-HBD), and SEQ ID NO: 60 is T133A.
- S146A in chimera A, a DcR3 variant in which Thr at the 133rd position from the N-terminal and Ser at the 146th position are replaced with Ala
- the amino acid sequence having the substitution of (g') is, for example, the 131st amino acid sequence from the N-terminal in the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence set forth in SEQ ID NO: 30 or SEQ ID NO: 54.
- the amino acid sequence in which Asn at positions 144 and 157 is replaced with Ser (N131S / N144S / N157S) (consisting of the amino acids 1 to 164 from the N-terminal of the amino acid sequence shown in SEQ ID NO: 38 or SEQ ID NO: 62). Amino acid sequence) and the like.
- SEQ ID NO: 38 is the amino acid sequence of N131S / N144S / N157S-HBD (DcR3 variant in which Asn at 131st, 144th and 157th from the N-terminal is replaced with Ser in chimeric A-HBD), SEQ ID NO: 62. Represents the amino acid sequence of N131S / N144S / N157S (in chimera A, a DcR3 variant in which Asn at positions 131, 144 and 157 from the N-terminal is replaced with Ser).
- amino acid sequence having the substitution of (i') for example, in the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal among the amino acid sequences shown in SEQ ID NO: 30 or SEQ ID NO: 54, 133 from the N-terminal.
- Amino acid sequence in which the thr, the 146th Ser, and the 159th Thr are replaced with Ala (T133A / S146A / T159A) (Amino acid sequence shown in SEQ ID NO: 40 or SEQ ID NO: 64, 1 to 164 from the N-terminal).
- Amino acid sequence consisting of the second amino acid and the like.
- the amino acid sequence of SEQ ID NO: 40 is the amino acid sequence of T133A / S146A / T159A-HBD (in the chimeric A-HBD, the 133rd Thr from the N-terminal and the 146th Ser and the 159th Thr substituted with Ala).
- SEQ ID NO: 64 represents the amino acid sequence of T133A / S146A / T159A (in chimera A, a DcR3 variant in which Thr at the 133rd position from the N-terminus and Ser at the 146th position and Thr at the 159th position are replaced with Ala).
- the mutation is inserted into CRD2 and CRD3 of the first chimeric cysteine-rich region involved in binding to LIGHT, TL1A and FasL.
- the DcR3 variant comprising the second chimeric cysteine rich region is a DcR3 variant comprising a chimeric cysteine rich region having binding activity to at least one of LIGHT, TL1A and FasL.
- DcR3 variant containing a chimeric cysteine-rich region having binding activity to all of LIGHT, TL1A and FasL, not binding to FasL and to any one of LIGHT and TL1A A DcR3 variant containing a chimeric cysteine-rich region having binding activity, or a DcR3 variant containing a chimeric cysteine-rich region that does not have binding activity to FasL and has binding activity to LIGHT and TL1A. And so on.
- the meanings of the expressions that the DcR3 variant of the present invention "has binding activity to a ligand" and "has no binding activity to a ligand" are as described above.
- examples of the DcR3 variant containing the second chimeric cysteine-rich region include a DcR3 variant having reduced binding to FasL.
- a "FasL-reducing variant” is a DcR3 variant comprising a chimeric cysteine-rich region that has no binding activity to FasL and has binding activity to any one or more of LIGHT and TL1A.
- it means a DcR3 variant containing a chimeric cysteine-rich region that has no binding activity to FasL and has binding activity to LIGHT and TL1A.
- the DcR3 variant comprising a second chimeric cysteine rich region includes a DcR3 variant comprising a chimeric cysteine rich region having neutralizing activity for at least one of LIGHT, TL1A and FasL.
- Examples thereof include a DcR3 variant containing a region.
- the meanings of the expressions that the DcR3 variant of the present invention has "neutralizing activity against a ligand" and "does not have a neutralizing activity against a ligand" are as described above.
- examples of the DcR3 variant containing the second chimeric cysteine-rich region include a DcR3 variant having reduced neutralizing activity against FasL.
- the "FasL binding-reducing variant” is a DcR3 modification containing a chimeric cysteine-rich region that does not have neutralizing activity against FasL and has neutralizing activity against any one or more of LIGHT and TL1A. It means a DcR3 variant containing a chimeric cysteine-rich region that does not have neutralizing activity against FasL and has neutralizing activity against LIGHT and TL1A.
- the binding site of the DcR3 or DcR3 variant with each ligand which is inferred from crystal structure analysis or the like, is replaced with Ala or another amino acid. It can be obtained by preparing the modified product having been prepared and measuring the binding activity and neutralizing activity to LIGHT, TL1A or FasL ligand.
- a gene library in which the ligand binding site of DcR3 or DcR3 variant is randomly converted to other amino acids is prepared and displayed on phage, yeast, mammalian cells, etc., and the binding activity to LIGHT, TL1A or FasL ligand and the medium It can also be obtained by screening using the sum activity as an index.
- Amino acid sequences having substitutions of one or more amino acids selected from the group consisting of Glu at the 57th position, Arg at the 58th position, and Arg at the 60th position from the N-terminal of the amino acid sequence with other amino acids are listed. Be done.
- the other amino acids substituted with the 57th Glu are not particularly limited, and 20 kinds of amino acids (Glu, Ala, Asp, Lys, Leu, Cys, Ph, Gly, His, Ile, Met, Asn, Pro, Gln) are not particularly limited. , Arg, Ser, Thr, Val, Trp, Tyr), which can be appropriately selected from 19 kinds of amino acids excluding Glu, but selected from Lys, Leu, Arg, Val, Ala, Ph, His, Ile and Met. It is more preferable to select from Lys, Leu, Arg and Val, even more preferably to select from Lys, Arg and Val, and even more preferably to select from Lys and Arg.
- the other amino acid substituted with Arg at position 58 is not particularly limited and can be appropriately selected from 19 types of amino acids excluding Arg among 20 types of amino acids, but can be selected from Asp, Glu and Thr. It is preferable to select from Asp and Glu.
- the other amino acid substituted with the 60th Arg is not particularly limited and can be appropriately selected from 19 types of amino acids excluding Arg among the 20 types of amino acids, but Lys is preferable.
- one or more amino acids selected from the group consisting of 57th Glu, 58th Arg and 60th Arg is one amino acid consisting of 57th Glu.
- one or more amino acids selected from the group consisting of 57th Glu, 58th Arg and 60th Arg is 2 consisting of 57th Glu and 58th Arg. It is an amino acid.
- the second chimeric cysteine-rich region may have substitutions of one or more amino acids other than the 57th Glu, the 58th Arg and the 60th Arg with other amino acids.
- amino acids other than the 57th Glu, the 58th Arg and the 60th Arg include the Trp at the 53rd position from the N-terminal of the amino acid sequences (a), (b), (c) or (d) above. Examples include the 54th Asn, the 55th Tyr, and the 56th Leu.
- the other amino acid substituted with the 53rd Trp is not particularly limited and can be appropriately selected from 19 types of amino acids excluding Trp among 20 types of amino acids, but it is preferably selected from Asp and Asn. Substitution with another amino acid of Trp at position 53 can be combined with, for example, substitution with another amino acid of Glu at position 57.
- the other amino acid substituted with Asn at position 54 is not particularly limited and can be appropriately selected from 19 types of amino acids excluding Asn among 20 types of amino acids, but Asp is preferable. Substitutions with other amino acids at position 54 Asn can be combined, for example, with substitutions with other amino acids at position 57 Glu.
- the other amino acid substituted with the 55th Tyr is not particularly limited and can be appropriately selected from 19 kinds of amino acids excluding Tyr out of 20 kinds of amino acids, but is selected from Thr, Asp, Gln and Glu. Is preferable. Substitutions with other amino acids of Tyr at position 55 can be combined, for example, with substitutions with other amino acids at position 57 Glu.
- the other amino acid substituted with Leu at position 56 is not particularly limited and can be appropriately selected from 19 types of amino acids excluding Leu among 20 types of amino acids, but Asp, Gln, Thr, Glu, Gly, It is preferable to select from Asn and Pro. Substitutions with other amino acids of Leu at position 56 can be combined, for example, with substitutions with other amino acids of Glu at position 57.
- an amino acid sequence having a substitution of one amino acid with another amino acid specifically, In the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Lys (the amino acid sequence shown in SEQ ID NO: 42).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal In the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in SEQ ID NO: 54, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Lys (the amino acid sequence shown in SEQ ID NO: 66).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal In the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Leu (the amino acid sequence shown in SEQ ID NO: 44).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal Among the amino acid sequences shown in SEQ ID NO: 54, in the amino acid sequence consisting of the amino acids 1 to 164 from the N-terminal, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Leu (the amino acid sequence shown in SEQ ID NO: 68).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal Among the amino acid sequences shown in SEQ ID NO: 30, in the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal, the Arg at the 60th position from the N-terminal is replaced with Lys (the amino acid sequence shown in SEQ ID NO: 46).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal Among the amino acid sequences shown in SEQ ID NO: 54, in the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal, the Arg at the 60th position from the N-terminal is replaced with Lys (the amino acid sequence shown in SEQ ID NO: 70).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal In the amino acid sequence consisting of the amino acids 1 to 164 from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Arg, Among the amino acid sequences shown in SEQ ID NO: 54, in the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal, the Glu at the 57th position from the N-terminal is replaced with Arg (the amino acid sequence shown in SEQ ID NO: 180).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal In the amino acid sequence consisting of the amino acids 1 to 164 from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Val, Among the amino acid sequences shown in SEQ ID NO: 54, in the amino acid sequence consisting of the amino acids 1 to 164 from the N-terminal, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Val (of the amino acid sequence shown in SEQ ID NO: 182).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal In the amino acid sequence consisting of the amino acids 1 to 164 from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Ala, In the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in SEQ ID NO: 54, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Ala (of the amino acid sequence shown in SEQ ID NO: 270).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal In the amino acid sequence consisting of the amino acids 1 to 164 from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Ph.
- the amino acid sequences shown in SEQ ID NO: 54 in the amino acid sequence consisting of the amino acids 1 to 164 from the N-terminal, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Phe (of the amino acid sequence shown in SEQ ID NO: 272).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal In the amino acid sequence consisting of the amino acids 1 to 164 from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with His, Among the amino acid sequences shown in SEQ ID NO: 54, in the amino acid sequence consisting of the amino acids 1 to 164 from the N-terminal, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with His (the amino acid sequence shown in SEQ ID NO: 274).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal In the amino acid sequence consisting of the amino acids 1 to 164 from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Ile, Among the amino acid sequences shown in SEQ ID NO: 54, in the amino acid sequence consisting of the amino acids 1 to 164 from the N-terminal, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Ile (the amino acid sequence shown in SEQ ID NO: 276).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal In the amino acid sequence consisting of the amino acids 1 to 164 from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Met, Among the amino acid sequences shown in SEQ ID NO: 54, in the amino acid sequence consisting of the amino acids 1 to 164 from the N-terminal, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Met (the amino acid sequence shown in SEQ ID NO: 278).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal In the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the 57th Glu from the N-terminal is replaced with Lys and the 58th Arg is replaced with Asp. In the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in SEQ ID NO: 54, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Lys and Arg at the 58th position is replaced with Asp (sequence).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in No. 184 In the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the 57th Glu from the N-terminal is replaced with Lys and the 58th Arg is replaced with Glu. In the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in SEQ ID NO: 54, the 57th Glu from the N-terminal is replaced with Lys and the 58th Arg is replaced with Glu (sequence).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in No. 186) In the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the 57th Glu from the N-terminal is replaced with Arg, and the 58th Arg is replaced with Asp.
- the amino acid sequences shown in SEQ ID NO: 54 in the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal, the 57th Glu from the N-terminal is replaced with Arg and the 58th Arg is replaced with Asp (sequence).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in No. 188) In the amino acid sequence consisting of the amino acids 1 to 164 from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Lys and Arg at the 58th position is replaced with Thr.
- amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in SEQ ID NO: 54 the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Lys and Arg at the 58th position is replaced with Thr (sequence).
- the 57th Glu from the N-terminal is replaced with Leu and the 58th Arg is replaced with Glu.
- amino acid sequences shown in SEQ ID NO: 54 in the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal, the 57th Glu from the N-terminal is replaced with Leu and the 58th Arg is replaced with Glu (sequence).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in No. 282) In the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the 57th Glu from the N-terminal is replaced with Val and the 58th Arg is replaced with Thr.
- amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in SEQ ID NO: 54 the amino acid sequence in which Glu at the 57th position from the N-terminal is replaced with Val and Arg at the 58th position is replaced with Thr (sequence).
- Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in No. 284) In the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in SEQ ID NO: 30, the 57th Glu from the N-terminal is replaced with Val and the 58th Arg is replaced with TGlu.
- amino acid sequences shown in SEQ ID NO: 54 in the amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal, the 57th Glu from the N-terminal is replaced with Val and the 58th Arg is replaced with Glu (sequence). Amino acid sequence consisting of the 1st to 164th amino acids from the N-terminal of the amino acid sequence shown in No. 286) And so on.
- SEQ ID NO: 42 is the amino acid sequence of chimeric A-E57K-HBD (in chimeric A-HBD, the 57th Glu from the N-terminal is replaced with Lys), and SEQ ID NO: 44 is the amino acid sequence of chimeric A-E57L-.
- the amino acid sequence of HBD (DcR3 variant in which the 57th Glu from the N-terminal is replaced with Leu in the chimeric A-HBD),
- SEQ ID NO: 46 is the chimeric A-R60K-HBD (in the chimeric A-HBD, 60 from the N-terminal).
- SEQ ID NO: 66 is the amino acid sequence of the chimera A-E57K (the DcR3 variant in which the 57th Glu from the N-terminal is replaced with Lys in the chimera A).
- SEQ ID NO: 68 is the amino acid sequence of chimeric A-E57L (in chimera A, a DcR3 variant in which the 57th Glu from the N-terminal is replaced with Leu), and SEQ ID NO: 70 is chimera A-R60K (in chimera A, N-terminal).
- SEQ ID NO: 180 is the amino acid sequence of chimeric A-E57R (DcR3 variant in which Glu at position 57 from the N end is replaced with Arg in chimera A).
- SEQ ID NO: 182 is the amino acid sequence of chimeric A-E57V (in chimera A, a DcR3 variant in which the 57th Glu from the N-terminal is replaced with Val)
- SEQ ID NO: 184 is chimera A-E57K_R58D (in chimera A, N.
- SEQ ID NO: 186 is the chimera A-E57K_R58E (in the chimera A, the 57th Glu from the N end is Lys.
- SEQ ID NO: 188 is obtained by chimera A-E57R_R58D (in chimera A, the 57th Glu from the N-terminal is Arg and the 58th Arg is Asp.
- SEQ ID NO: 270 is the amino acid sequence of chimeric A-E57A (DcR3 variant in which Glu at the 57th position from the N-terminal is replaced with Ala in chimera A)
- SEQ ID NO: 272 is The amino acid sequence of chimeric A-E57F (DcR3 variant in which the 57th Glu from the N-terminal is replaced with Ph in chimera A)
- SEQ ID NO: 274 is the Glu at the 57th N-terminal in the chimera A-E57H.
- SEQ ID NO: 276 is the amino acid sequence of chimeric A-E57I (in chimera A, a DcR3 variant in which the 57th Glu from the N-terminus is replaced with Ile), and SEQ ID NO: 278 is chimera A-E57M (in chimera A, in chimera A).
- SEQ ID NO: 280 is the chimeric A-E57K_R58T (in the chimera A, the 57th Glu from the N-terminal is Lys and the 58th Arg is.
- the amino acid sequence of the DcR3 variant substituted with Thr), SEQ ID NO: 282, is the chimeric A-E57K_R58T (in the chimera A, the DcR3 variant in which the 57th Glu from the N-terminal is replaced with Lys and the 58th Arg is replaced with Thr).
- the amino acid sequence of SEQ ID NO: 284 is the amino acid sequence of chimeric A-E57V_R58T (in chimeric A, the 57th Glu from the N-terminal is replaced with Val and the 58th Arg is replaced with Thr).
- Chimera A-E57V_R58E in chimera A, a DcR3 variant in which Glu at the 57th position from the N-terminal is replaced with Val and Arg at the 58th position is replaced with Glu).
- the DcR3 variant of the present invention may or may not contain one or more other regions bound to the C-terminal side of the first or second chimeric cysteine-rich region. ..
- Other regions include, for example, some or all of the region existing between CRD4 and HBD in wild-type DcR3, following the C-terminus of the amino acid sequence of CRD4 in TNF receptor superfamily (TNFRSF) molecules other than DcR3.
- TNFRSF TNF receptor superfamily
- the DcR3 variant of the present invention is a region existing between CRD4 and HBD in wild-type DcR3 as another region bound to the C-terminal side of the first or second chimeric cysteine-rich region. Including some or all.
- the other region is preferably directly attached to the C-terminus of the first or second chimeric cysteine-rich region.
- the DcR3 variants of the invention are CRD4 in a TNF receptor superfamily (TNFRSF) molecule other than DcR3 as the other region bound to the C-terminus of the first or second chimeric cysteine-rich region.
- TNFRSF TNF receptor superfamily
- the other region is preferably directly attached to the C-terminus of the first or second chimeric cysteine-rich region.
- TNFRSF is preferably OPG.
- the CRD4 of wild DcR3 is replaced with the CRD4 of OPG.
- the DcR3 variant of the present invention preferably contains a plurality of amino acid residues following the C-terminus of the amino acid sequence of CRD4 of OPG as the other region bound to the C-terminus of the chimeric cysteine-rich region.
- a plurality of amino acid residues following the C-terminal of the amino acid sequence of CRD4 of wild-type DcR3 are also a plurality of amino acid residues following the C-terminal of the amino acid sequence of CRD4 of OPG. It is preferably replaced with an amino acid residue.
- the 186th to 194th amino acid residues of the amino acid sequence of OPG are preferable, but CRD4 of wild type DcR3
- the number of amino acid residues to be replaced with a plurality of amino acid residues following the C-terminal of the above can be appropriately adjusted.
- the number of multiple amino acid residues following the C-terminus of the CRD4 amino acid sequence of OPG is usually 1 to 12, preferably 1 to 10, more preferably 1 to 9, 1 to 6, or 1 to 3. It is an individual.
- CRD4 is derived from wild-type DcR3 in the first or second chimeric cysteine-rich region (for example, the first chimeric cysteine-rich region consisting of the amino acid sequences of (a) and (d) above)
- the amino acid sequence following the C-terminal of the CRD4 amino acid sequence of wild-type DcR3 is bound to the C-terminal of the amino acid sequence of CRD4 in the first chimeric cysteine-rich region.
- Examples of such an amino acid sequence include the 194th to 195th amino acids of SEQ ID NO: 2, but the number of amino acid residues constituting the amino acid sequence following the C-terminal of the CRD4 amino acid sequence of wild-type DcR3 is It can be adjusted as appropriate.
- the number of amino acid residues constituting the amino acid sequence following the C-terminal of CRD4 of wild-type DcR3 is usually 1 to 10, preferably 1 to 5, more preferably 1 to 3, and even more preferably 1 to 2. It is an individual.
- the DcR3 variant of the invention comprises some or all of the wild-type DcR3 HBD as the other region bound to the C-terminus of the first or second chimeric cysteine-rich region.
- the other region may be directly attached to the C-terminus of the first or second chimeric cysteine-rich region, or wild at the C-terminus of the first or second chimeric cysteine rich region. Binding through some or all of the region existing between CRD4 and HBD in type DcR3, or through some or all of the region following the C-terminus of the amino acid sequence of CRD4 in TNFRSF molecules other than DcR3. You may be doing it.
- the DcR3 variant of the present invention does not contain HBD as another region bound to the C-terminal side of the first or second chimeric cysteine-rich region, and contains the 186th to 186th amino acid sequences of OPG (SEQ ID NO: 14). It preferably contains the 194th amino acid residue.
- the DcR3 variant of the present invention also includes a DcR3 variant containing at least one sugar chain.
- the present invention also includes a DcR3 variant containing any sugar chain as long as at least one sugar chain is bound to the cysteine-rich region contained in the above-mentioned DcR3 variant or other amino acid residues.
- Glycoprotein has one or more sugar chains.
- the glycoprotein may have one type of sugar chain or two or more types of sugar chains.
- sugar chains contained in glycoproteins include sugar chains that N-glycosidically bind to amino acid residues of peptides or proteins (eg, asparagin residues, etc.), amino acid residues of peptides or proteins (eg, serine residues, threonins, etc.).
- Residues, etc.) include sugar chains that bind to O-glycosids.
- the O-type sugar chain include core 1, core 2, and the like, and examples of the N-type sugar chain include high mannose type, hybrid type, and complex type sugar chain, and the complex type sugar is preferable. It is a chain.
- the DcR3 variant of the present invention includes the same or heterologous peptide on the N-terminal side or C-terminal side of the chimeric cysteine-rich region (or the chimeric type containing other regions is the cysteine-rich region). Also included are proteins to which the polypeptide or protein is attached or fused directly or, if necessary, via a suitable peptide linker. The number of amino acids constituting the peptide linker is not particularly limited, and examples thereof include 4, 5, 6, and 15 amino acids.
- polypeptide or protein that binds to or fuses with the chimeric cysteine-rich region examples include a constant region or Fc region of immunoglobulin, a peptide that binds to FcRn (neontal Fc acceptor), albumin, protein A, protein G, and ⁇ -galactosidase. , Glutathion-S-transferase (GST), maltose-binding protein, polyhistidine, FLAG peptide and other polypeptides or proteins, preferably the Fc region of immunoglobulin or a variant thereof (variant Fc region), and further.
- it is an Fc region of a mammalian-derived immunoglobulin or a variant thereof (variant Fc region).
- the Fc region of immunoglobulin (also referred to as antibody), the Fc region of human immunoglobulin is preferable in the case of use in humans.
- Immunoglobulin classes and subclasses include, but are not limited to, IgG, IgD, IgE, IgM, IgA, IgG1, IgG2, IgG2a, IgG2b, IgG2c, IgG3, IgG4, IgA1 and the like. If used, it is preferred to use human immunoglobulin classes and subclasses.
- the Fc region of immunoglobulin is used as the polypeptide or protein to be bound or fused to the chimeric cysteine rich region
- the Fc region of immunoglobulin is preferably bound or fused to the C-terminal side of the chimeric cysteine rich region.
- Immunoglobulin is composed of heavy chain and light chain polypeptides, and the constant region of the heavy chain of human IgG is composed of CH1 domain, hinge domain, CH2 domain, and CH3 domain in order from the N-terminal.
- the Fc region of IgG in the present invention also includes a region in which the CH2 domain and the CH3 domain are combined, and a region in which a part or all of the hinge domain and the CH2 domain and the CH3 domain are combined.
- Each domain contained in the Fc region of IgG in the present invention can be identified by the number of the EU index. Specifically, the hinge domain is specified by the EU index 216th to 230th, the CH2 domain is specified by the EU index 231st to 340th, and CH3 is specified by the EU index 341th to 447th.
- polypeptide or protein that binds to or fuses with the chimeric cysteine-rich region includes the biological activity or characteristics of the DcR3 variant, pharmacokinetics such as blood half-life, or physical or chemical such as protein stability. Also included are modified polypeptides or proteins in which one or more amino acids have been substituted, deleted, inserted or added due to changes in properties. Modifications of a polypeptide or protein that bind or fuse to a chimeric cysteine-rich region include either natural mutations and artificial amino acid substitutions, deletions, insertions or additions.
- Modified polypeptides or proteins include, for example, a mutant Fc region consisting of an amino acid sequence in which one or several amino acids are deleted, substituted, inserted or added in the amino acid sequence of the Fc region of immunoglobulin. ..
- As the amino acid sequence of the mutant Fc region for example, in the amino acid sequence of the Fc region of immunoglobulin, one or more, preferably 2 to 30, more preferably 2 to 10, and particularly preferably 2 to 5 are used.
- Amino acid having 80% or more, preferably 85% or more, more preferably 90% or more identity with the amino acid sequence in which the amino acid of the above is substituted, deleted, inserted or added, or the amino acid sequence of the Fc region of immunoglobulin.
- An array can be mentioned.
- glycosylation site is also included in the modification of the polypeptide or protein that binds to or fuses with the chimeric cysteine-rich region.
- a glycosylation site can be added by adding or inserting a polypeptide containing an N-type glycosylation site.
- Specific polypeptide sequences include GGNGT or YGNGT consisting of 5 amino acids [International Publication No. 2014/153111].
- Substitutions for human IgG1 that reduce or eliminate complement-dependent cytotoxicity (CDC) activity include the 234th Leu (L234), 235th Leu (L235), and 265th Asp (D265) indicated by the EU index. , 270th Asp (D265), 322nd Lys (K322), 329th Pro (P329), 331st Pro (P331), etc., with one or more amino acids selected from other amino acids.
- Substitutions and the like can be mentioned, specifically, substitution of one or more amino acids selected from L234, L235, D270, K322, P329, P331 and the like indicated by the EU index with Ala, Ser or Gly of P331, and the like. For example, replacement with [J. Immunol. , 2000, 164: p. 4178-4184, Cell. Immunol. , 2000, 200: p. 16-26].
- N297 replaced with Ala N297A
- N297 replaced with Gln N297Q
- N297 replaced with Gly N297G
- L234 replaced with Ala L234A
- / L235 substitution with Ala L235A
- G237 substitution with Ala G237A
- the mutant Fc region has a substitution of Cys at position 220 in the amino acid sequence of the heavy chain of an antibody belonging to the human IgG1 subclass with Ser.
- the mutant Fc region according to this form is, for example, an Fc region (SEQ ID NO: 153) obtained by removing the 216th Glu indicated by the EU index contained in the CH1 domain and the hinge domain from the constant region (SEQ ID NO: 153) of the heavy chain of human IgG1.
- the Fc region of immunoglobulin having an amino acid sequence in which Cys at position 220 indicated by the EU index involved in binding to the light chain is replaced with Ser (C220S) (hereinafter referred to as Fc region).
- g1S Described as g1S, SEQ ID NO: 72), in the Fc region (EU index 216th to 447th) excluding the CH1 domain from the constant region (SEQ ID NO: 153) of the heavy chain of human IgG1, the 220th Cys was replaced with Ser.
- Examples thereof include the Fc region of immunoglobulin having the amino acid sequence (C220S) (hereinafter referred to as Eg1S, SEQ ID NO: 156).
- the first chimeric cysteine-rich region is preferred, in which the CRD4 of the wild-type DcR3 is replaced with the CRD4 of the OPG.
- the DcR3 variant of the present invention contains a mutant Fc region according to this form
- the second chimeric cysteine-rich region contained in the DcR3 variant of the present invention is at the 57th Glu other amino acid. It is preferable to have a substitution or a substitution with another amino acid of Glu at position 57 and a substitution with another amino acid of Arg at position 58.
- the other amino acid to be replaced with Glu at position 57 is preferably selected from Lys, Leu, Arg, Val, Ala, Phe, His, Ile and Met, and further selected from Lys, Leu, Arg and Val. preferable.
- the other amino acid to be replaced with Arg at position 58 is preferably selected from Asp, Glu and Thr, and more preferably selected from Asp and Glu.
- the variant Fc region is the substitution of Ser at position 228 of the EU index with Pro, at position 235 of the EU index, in the amino acid sequence of the heavy chain of an antibody belonging to the human IgG4 subclass. It has a substitution of Leu with Glu and a substitution of Arg at position 409 with Lys as indicated by the EU index.
- the mutant Fc region according to this form for example, the CH1 domain is excluded from the constant region (SEQ ID NO: 154) of the heavy chain of human IgG4, and the Ser of position 228 shown by the EU index described in International Patent Publication 2006/33386.
- g4PEK Fc of immunoglobulin having an amino acid sequence in which Arg at position 409 is replaced with Lys
- g4PEK Fc of immunoglobulin having an amino acid sequence in which Arg at position 409 is replaced with Lys
- the second chimeric cysteine-rich region contained in the DcR3 variant of the present invention is at the 57th Glu other amino acid. It is preferable to have a substitution or a substitution with another amino acid of Glu at position 57 and a substitution with another amino acid of Arg at position 58.
- the other amino acid to be replaced with Glu at position 57 is preferably selected from Lys, Leu, Arg, Val, Ala, Phe, His, Ile and Met, and further selected from Lys, Leu, Arg and Val. preferable.
- the other amino acid to be replaced with Arg at position 58 is preferably selected from Asp, Glu and Thr, and more preferably selected from Asp and Glu.
- substitution with another amino acid of the 57th Glu and the substitution with another amino acid of the 58th Arg Lys, Leu, Arg, Val, Ala, Phe, His, Ile or It is preferable to combine the substitution with Met and the substitution with Asp, Glu or Thr of the 58th Arg, the substitution with Lys, Leu, Arg or Val of the 57th Glu and the Asp or Asp of the 58th Arg. It is even more preferable to combine the substitution with Glu, and it is even more preferable to combine the substitution of Lys or Arg of the 57th Glu with the substitution of Asp or Glu of the 58th Arg.
- the variant Fc region is the substitution of Leu at position 234 with Ala, indicated by EU index, in the amino acid sequence of the heavy chain of antibodies belonging to the human IgG1 subclass, position 235, indicated by EU index.
- the mutant Fc region according to this form for example, in the Fc region of g1S shown by SEQ ID NO: 72 or Eg1S shown by SEQ ID NO: 156, the 234th Leu is Ala and the 235th Leu is Ala.
- Fc region of immunoglycine having an amino acid sequence in which Gly at position 237 is replaced with Ala hereinafter referred to as g1S LALAGA or Eg1S LALAGA, SEQ ID NO: 162, 164
- g1S LALAGA or Eg1S LALAGA, SEQ ID NO: 162, 164 Fc region of immunoglycine having an amino acid sequence in which Gly at position 237 is replaced with Ala
- the DcR3 variant of the present invention contains a mutant Fc region according to this form
- the CRD1 of the wild-type DcR3 is replaced with the CRD1 of OPG as the first chimeric cysteine-rich region contained in the DcR3 variant of the present invention.
- the first chimeric cysteine-rich region is preferred, in which the CRD4 of the wild-type DcR3 is replaced with the CRD4 of the OPG.
- the second chimeric cysteine-rich region contained in the DcR3 variant of the present invention is at the 57th Glu other amino acid. It is preferable to have a substitution or a substitution with another amino acid of Glu at position 57 and a substitution with another amino acid of Arg at position 58.
- the other amino acid to be replaced with Glu at position 57 is preferably selected from Lys, Leu, Arg, Val, Ala, Phe, His, Ile and Met, and further selected from Lys, Leu, Arg and Val. preferable.
- the other amino acid to be replaced with Arg at position 58 is preferably selected from Asp, Glu and Thr, and more preferably selected from Asp and Glu.
- substitution with another amino acid of the 57th Glu and the substitution with another amino acid of the 58th Arg Lys, Leu, Arg, Val, Ala, Phe, His, Ile or It is preferable to combine the substitution with Met and the substitution with Asp, Glu or Thr of the 58th Arg, the substitution with Lys, Leu, Arg or Val of the 57th Glu and the Asp or Asp of the 58th Arg. It is even more preferable to combine the substitution with Glu, and it is even more preferable to combine the substitution of Lys or Arg of the 57th Glu with the substitution of Asp or Glu of the 58th Arg.
- the mutant Fc region has a substitution of Asn at position 434 in the amino acid sequence of the heavy chain of an antibody belonging to the human IgG1 subclass with Ala.
- the mutant Fc region according to this form has, for example, an amino acid sequence in which Asn at position 434 of the Fc region of g1S represented by SEQ ID NO: 72 or Eg1S represented by SEQ ID NO: 156 is replaced with Ala.
- Fc region of immunogroglin (hereinafter referred to as g1S N434A or Eg1S N434A, SEQ ID NO: 312, 160), g1S LALAGA represented by SEQ ID NO: 162, or Fc region of Eg1S LALAGA represented by SEQ ID NO: 164 at the 434th position.
- Fc region of immunogroglin having an amino acid sequence in which Asn is replaced with Ala (hereinafter referred to as g1S LALAGANA or Eg1S LALAGANA, SEQ ID NO: 313, 166) and the like can be mentioned.
- the DcR3 variant of the present invention contains a mutant Fc region according to this form
- the CRD1 of the wild-type DcR3 is replaced with the CRD1 of OPG as the first chimeric cysteine-rich region contained in the DcR3 variant of the present invention.
- the first chimeric cysteine-rich region is preferred, in which the CRD4 of the wild-type DcR3 is replaced with the CRD4 of the OPG.
- the second chimeric cysteine-rich region contained in the DcR3 variant of the present invention is at the 57th Glu other amino acid.
- the other amino acid to be replaced with Glu at position 57 is preferably selected from Lys, Leu, Arg, Val, Ala, Phe, His, Ile and Met, and further selected from Lys, Leu, Arg and Val. preferable.
- the other amino acid to be replaced with Arg at position 58 is preferably selected from Asp, Glu and Thr, and more preferably selected from Asp and Glu.
- the variant Fc region is the substitution of the 252nd Met represented by the EU index on the Tyr of the heavy chain amino acid sequence of an antibody belonging to the human IgG1 subclass, the 254th represented by the EU index. It has a substitution of Ser with Thr and a substitution of Thr at position 256 with Glu indicated by the EU index.
- the mutant Fc region according to this form for example, in the Fc region of g1S shown by SEQ ID NO: 72 or Eg1S shown by SEQ ID NO: 156, the 252nd Met is Tyr and the 254th Ser is Thr.
- Fc region of immunogroglin having an amino acid sequence in which Thr at position 256 is substituted with Glu hereinafter referred to as g1S YTE or Eg1S YTE, SEQ ID NO: 311, 158, and the like.
- g1S YTE or Eg1S YTE, SEQ ID NO: 311, 158 Fc region of immunogroglin having an amino acid sequence in which Thr at position 256 is substituted with Glu
- the second chimeric cysteine-rich region contained in the DcR3 variant of the present invention is at the 57th Glu other amino acid. It is preferable to have a substitution or a substitution with another amino acid of Glu at position 57 and a substitution with another amino acid of Arg at position 58.
- the other amino acid to be replaced with Glu at position 57 is preferably selected from Lys, Leu, Arg, Val, Ala, Phe, His, Ile and Met, and further selected from Lys, Leu, Arg and Val. preferable.
- the other amino acid to be replaced with Arg at position 58 is preferably selected from Asp, Glu and Thr, and more preferably selected from Asp and Glu.
- substitution with another amino acid of the 57th Glu and the substitution with another amino acid of the 58th Arg Lys, Leu, Arg, Val, Ala, Phe, His, Ile or It is preferable to combine the substitution with Met and the substitution with Asp, Glu or Thr of the 58th Arg, the substitution with Lys, Leu, Arg or Val of the 57th Glu and the Asp or Asp of the 58th Arg. It is even more preferable to combine the substitution with Glu, and it is even more preferable to combine the substitution of Lys or Arg of the 57th Glu with the substitution of Asp or Glu of the 58th Arg.
- the mutant Fc region includes, but is not limited to, the amino acid sequence set forth in SEQ ID NO: 72, 74, 156, 158, 160, 162, 164, 166, 311, 312 or 313, for example.
- a mutant Fc region consisting of the amino acid sequence can be mentioned.
- the peptide linker added to link the same or different peptides, polypeptides or proteins to the N-terminal or C-terminal side of the chimeric cysteine-rich region is not limited, but is limited to, for example, IEGRMD linker or Examples thereof include peptide linkers such as GS linkers and chemical linkers.
- the DcR3 variant of the present invention is most preferably a DcR3 variant containing a first or second chimeric cysteine-rich region and an Fc region or a mutant Fc region.
- the amino acid sequence contained in the DcR3 variant of the present invention includes, for example, the amino acid sequence set forth in SEQ ID NO: 26, 28, 30, 32, 34, 36, 38, 40, 42, 44 or 46, or , Amino acid sequences in which 1 to 30 amino acids are deleted, substituted, inserted or added in the amino acid sequence.
- the DcR3 variant of the present invention may consist of the above amino acid sequence or may contain the above amino acid sequence, but is preferably composed of the above amino acid sequence.
- the amino acid sequence includes HBD.
- the amino acid sequence contained in the DcR3 variant of the present invention includes, for example, SEQ ID NO: 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 180, 182, 184. , 186, 188, 270, 272, 274, 276, 278, 280, 282, 284 or 286, or in the amino acid sequence, 1 to 30 amino acids are deleted, substituted, inserted or added.
- the amino acid sequence given is mentioned.
- the DcR3 variant of the present invention may consist of the above amino acid sequence or may contain the above amino acid sequence, but is preferably composed of the above amino acid sequence.
- the amino acid sequence does not include HBD.
- the amino acid sequence contained in the DcR3 variant of the present invention includes, for example, SEQ ID NOs: 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 180, 182, 184. , 186, 188, 270, 272, 274, 276, 278, 280, 282, 284 or 286, or in the amino acid sequence, 1 to 30 amino acids are deleted, substituted, inserted or added.
- the modified Fc region include an amino acid sequence including the amino acid sequence set forth in SEQ ID NO: 72, 74, 156, 158, 160, 162, 164, 166, 311, 312 or 313.
- the amino acid sequence contained in the DcR3 variant of the present invention includes, for example, SEQ ID NOs: 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 150, 168, 170, 172, 174, 176, 178, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 288, 290, 292, 294, 296, 298, 300, 302, 304, 314, 315, 316, 317, 318, 319, 320, 321, 322, 323, 324, 325, 326, 327, 328, 329, 330, 33
- the DcR3 variant of the present invention may consist of the above amino acid sequence or may contain the above amino acid sequence, but is preferably composed of the above amino acid sequence.
- the amino acid sequence includes an Fc region or a variant thereof (mutant Fc region).
- SEQ ID NO: 76 is the amino acid sequence of chimeric B-Fc (IEGRMD g1S) (DcR3 variant in which chimeric B, IEGRMD linker, and Fc (g1S) are fused), and SEQ ID NO: 78 is chimeric C-Fc.
- the amino acid sequence of (IEGRMD g1S) (DcR3 variant in which chimera C, IEGRMD linker and Fc (g1S) are fused)
- SEQ ID NO: 80 is the chimeric A-Fc (IEGRMD g1S) (chimera A and IEGRMD linker).
- SEQ ID NO: 82 of chimeric A-Fc (g4PEK) (DcR3 variant fused chimeric A and Fc (g4PEK)).
- the amino acid sequence, SEQ ID NO: 84 is the amino acid sequence of 103-123OPG-Fc (g4PEK) (DcR3 variant obtained by fusing 103-123OPG and Fc (g4PEK)), and SEQ ID NO: 86 is N131S / N144S-Fc ( The amino acid sequence of g4PEK) (DcR3 variant obtained by fusing N131S / N144S and Fc (g4PEK)), SEQ ID NO: 88 is T133A / S146A-Fc (g4PEK) (T133A / S146A and Fc (g4PEK).
- the amino acid sequence of the fused DcR3 variant is the amino acid sequence of N131S / N144S / N157S-Fc (g4PEK) (DcR3 variant in which N131S / N144S / N157S and Fc (g4PEK) are fused).
- SEQ ID NO: 92 is the amino acid sequence of T133A / S146A / T159A-Fc (g4PEK) (DcR3 variant in which T133A / S146A / T159A and Fc (g4PEK) are fused
- SEQ ID NO: 94 is chimeric A-E57K.
- the amino acid sequence of -Fc (g4PEK) (DcR3 variant obtained by fusing chimeric A-E57K and Fc (g4PEK)), SEQ ID NO: 96 is the chimeric A-E57L-Fc (g4PEK) (chimera A-E57L and Chimera A-E57L).
- the amino acid sequence of DcR3 variant fused with Fc (g4PEK), SEQ ID NO: 98 is the DcR3 variant fused with chimeric A-R60K-Fc (g4PEK) (chimera A-R60K and Fc (g4PEK)).
- SEQ ID NO: 150 is the amino acid sequence of chimeric A-Fc (g1S) (DcR3 variant in which chimeric A and Fc (g1S) are fused), and SEQ ID NO: 168 is chimeric A-Fc (Eg1S). ) (Fusion of chimera A and Fc (Eg1S)
- the amino acid sequence and SEQ ID NO: 170 of the combined DcR3 variant) are the amino acid sequences and SEQ ID NOs of chimeric A-Fc (Eg1S-YTE) (DcR3 variant in which chimeric A and Fc (Eg1S YTE) are fused).
- 172 is the amino acid sequence of chimeric A-Fc (Eg1S-N434A) (DcR3 variant in which chimeric A and Fc (Eg1S-N434A) are fused), and SEQ ID NO: 174 is chimeric A-Fc (g1S-LALAGA). (DcR3 variant in which chimera A and Fc (g1S-LALAGA) are fused), SEQ ID NO: 176 is the chimeric A-Fc (Eg1S-LALAGA) (chimera A and Fc (Eg1S-LALAGA)).
- the amino acid sequence of (DcR3 variant) fused with, SEQ ID NO: 178 is the amino acid sequence of chimeric A-Fc (Eg1S-LALGANA) (DcR3 variant fused with chimeric A and Fc (Eg1S-LALGANA)).
- SEQ ID NO: 190 is the amino acid sequence of chimeric A-E57R-Fc (g4PEK) (DcR3 variant in which chimeric A-E57R and Fc (g4PEK) are fused)
- SEQ ID NO: 192 is chimeric A-E57V-Fc ( The amino acid sequence of g4PEK) (DcR3 variant in which chimeric A-E57V and Fc (g4PEK) are fused)
- SEQ ID NO: 194 is the chimeric A-E57K_R58D-Fc (g4PEK) (chimera A-E57K_R58D) and Fc (g4PEK).
- SEQ ID NO: 196 is the amino acid of chimeric A-E57K_R58E-Fc (g4PEK) (DcR3 variant fused Chimera A-E57K_R58E and Fc (g4PEK)).
- SEQ ID NO: 198 is the amino acid sequence of chimeric A-E57R_R58D-Fc (g4PEK) (DcR3 variant obtained by fusing chimeric A-E57R_R58D and Fc (g4PEK)), and SEQ ID NO: 200 is chimeric A-E57K-.
- SEQ ID NO: 202 is the chimeric A-E57L-Fc (Eg1S) (chimera A-E57L and Fc).
- SEQ ID NO: 204 is the chimeric A-E57R-Fc (Eg1S) (DcR3 variant fused with chimeric A-E57R and Fc (Eg1S)).
- the amino acid sequence of, SEQ ID NO: 206 is chimera A-E5.
- SEQ ID NO: 208 is the chimeric A-E57K_R58D-Fc (Eg1S) (chimera A-E57K_R58D).
- SEQ ID NO: 210 is the DcR3 variant fused with chimeric A-E57K_R58E-Fc (Eg1S) (chimera A-E57K_R58E and Fc (Eg1S)).
- SEQ ID NO: 212 is the amino acid sequence of chimeric A-E57R_R58D-Fc (Eg1S) (DcR3 variant obtained by fusing chimeric A-E57R_R58D and Fc (Eg1S)), and SEQ ID NO: 214 is chimeric.
- A-E57K-Fc (DcR3 variant in which chimeric A-E57K and Fc (Eg1S YTE) are fused)
- SEQ ID NO: 216 is the chimeric A-E57L-Fc (Eg1SYTE)
- SEQ ID NO: 218 is the chimeric A-E57R-Fc (Eg1S YTE) (chimera A-E57R and Fc (Eg1S YTE).
- SEQ ID NO: 220 is the chimeric A-E57V-Fc (Eg1S YTE) (DcR3 variant fused with chimeric A-E57V and Fc (Eg1S YTE)).
- Amino acid sequence, SEQ ID NO: 222 is the amino acid sequence of chimeric A-E57K_R58D-Fc (Eg1SYTE) (DcR3 variant obtained by fusing chimeric A-E57K_R58D and Fc (Eg1S YTE)), and SEQ ID NO: 224 is chimeric.
- A-E57K_R58E-Fc (Eg1S YTE) (DcR3 variant in which chimeric A-E57K_R58E and Fc (Eg1S YTE) are fused)
- SEQ ID NO: 226 is the chimeric A-E57R_R58D-Fc (Eg1S YTE)
- SEQ ID NO: 228 is the chimeric A-E57K-Fc (Eg1S N434A) (chimera A-E57K and Fc (Eg1S N434A).
- the amino acid sequence of (DcR3 variant) fused with), SEQ ID NO: 230, is the chimeric A-E57L-Fc (Eg1S N434A) (chimera A-E57L) and Fc (
- the amino acid sequence of DcR3 variant (DcR3 variant fused with Eg1S N434A), SEQ ID NO: 232 is a DcR3 variant fused with chimeric A-E57R-Fc (Eg1S N434A) (chimera A-E57R and Fc (Eg1S N434A)).
- SEQ ID NO: 234 is the amino acid sequence of chimeric A-E57V-Fc (Eg1S N434A) (DcR3 variant obtained by fusing chimeric A-E57V and Fc (Eg1S N434A)), and SEQ ID NO: 236 is , Chimera A-E57K_R58D-Fc (Eg1S N434A) (DcR3 variant in which chimera A-E57K_R58D and Fc (Eg1S N434A) are fused), SEQ ID NO: 238 is the amino acid sequence of chimeric A-E57K_R58E-Fc (Eg1S N434A).
- SEQ ID NO: 240 is the chimeric A-E57R_R58D-Fc (Eg1S N434A) (chimera A-E57R_R58D) and Fc ( The amino acid sequence of DcR3 variant (DcR3 variant fused with Eg1S N434A), SEQ ID NO: 242 is a DcR3 variant fused with chimeric A-E57K-Fc (Eg1S LALAGA) (chimera A-E57K) and Fc (Eg1S LALAGA).
- SEQ ID NO: 244 is the amino acid sequence of chimeric A-E57L-Fc (Eg1S LALAGA) (DcR3 variant obtained by fusing chimeric A-E57L and Fc (Eg1S LALAGA)), and SEQ ID NO: 246 is , Chimera A-E57R-Fc (Eg1S LALAGA) (DcR3 variant in which chimera A-E57R and Fc (Eg1S LALAGA) are fused), SEQ ID NO: 248 is the chimeric A-E57V-Fc (Eg1S LALAGA).
- SEQ ID NO: 250 is the chimeric A-E57K_R58D-Fc (Eg1S LALAGA) (chimera A-E57K_R58D) and Fc
- SEQ ID NO: 252 is a DcR3 variant fused with chimeric A-E57K_R58E-Fc (Eg1S LALAGA) (chimera A-E57K_R58E) and Fc (Eg1S LALAGA).
- Body amino acid sequence, sequence No.
- SEQ ID NO: 254 is the amino acid sequence of chimeric A-E57R_R58D-Fc (Eg1S LALAGA) (a DcR3 variant in which chimeric A-E57R_R58D and Fc (Eg1S LALAGA) are fused), and SEQ ID NO: 256 is the chimeric A-E57K-Fc.
- the amino acid sequence of (Eg1S LALAGANA) DcR3 variant in which chimeric A-E57K and Fc (Eg1S LALAGANA) are fused
- SEQ ID NO: 258 is the chimeric A-E57L-Fc (Eg1S LALAGANA) (chimera A-E57L).
- Fc (DcR3 variant fused with Eg1S LALAGANA), SEQ ID NO: 260, is a fusion of chimeric A-E57R-Fc (Eg1S LALAGANA) (chimera A-E57R) and Fc (Eg1S LALAGANA).
- DcR3 variant) amino acid sequence SEQ ID NO: 262 is the amino acid sequence and sequence of chimeric A-E57V-Fc (Eg1S LALAGANA) (DcR3 variant in which chimeric A-E57V and Fc (Eg1S LALAGANA) are fused).
- SEQ ID NO: 266 is chimeric A-E57K_R58E-Fc.
- amino acid sequence and SEQ ID NO: 268 of (Eg1S LALAGANA) are the chimeric A-E57R_R58D-Fc (Eg1S LALAGANA) (chimera A-E57R_R58D).
- Fc DcR3 variant fused with Eg1S LALAGANA
- SEQ ID NO: 288 is DcR3 fused with chimeric A-E57A-Fc (g4PEK) (chimera A-E57A and Fc (g4PEK)).
- SEQ ID NO: 290 is the amino acid sequence of chimeric A-E57F-Fc (g4PEK) (DcR3 variant obtained by fusing chimeric A-E57F and Fc (g4PEK))
- SEQ ID NO: 292 is The amino acid sequence of the chimeric A-E57H-Fc (g4PEK) (DcR3 variant obtained by fusing the chimeric A-E57H and Fc (g4PEK)
- SEQ ID NO: 294 is the chimeric A-E57I-Fc (g4PEK) (chimera A).
- DcR3 variant (EK) fused with SEQ ID NO: 296 is that of chimera A-E57M-Fc (g4PEK) (DcR3 variant fused with chimera A-E57M and Fc (g4PEK)).
- the amino acid sequence, SEQ ID NO: 298, is chimeric A-E57K_R58.
- T-Fc (DcR3 variant obtained by fusing chimeric A-E57K_R58T and Fc (g4PEK)
- SEQ ID NO: 300 is the chimera A-E57L_R58E-Fc (g4PEK) (chimera A-E57L_R58E).
- SEQ ID NO: 302 is the DcR3 variant fused with chimeric A-E57V_R58T-Fc (g4PEK) (chimera A-E57V_R58T and Fc (g4PEK)).
- SEQ ID NO: 304 is the amino acid sequence of chimeric A-E57V_R58E-Fc (g4PEK) (DcR3 variant obtained by fusing chimeric A-E57V_R58E and Fc (g4PEK)), and SEQ ID NO: 314 is chimeric.
- the amino acid sequence of A-Fc (g1S YTE) (DcR3 variant in which chimera A and Fc (g1S YTE) are fused)
- SEQ ID NO: 315 is the chimeric A-Fc (g1S N434A) (chimera A and Fc (chimera A and Fc).
- SEQ ID NO: 316 is the amino acid of chimeric A-Fc (g1S LALAGANA) (DcR3 variant fused with chimeric A and Fc (g1S LALAGANA)).
- SEQ ID NO: 317 is the amino acid sequence of chimeric A-E57K-Fc (g1SYTE) (DcR3 variant in which chimeric A-E57K and Fc (g1SYTE) are fused), and SEQ ID NO: 318 is chimeric A-.
- E57L-Fc (g1S YTE) (DcR3 variant obtained by fusing chimeric A-E57L and Fc (g1S YTE)), SEQ ID NO: 319 is the chimeric A-E57R-Fc (g1S YTE) (chimera A).
- SEQ ID NO: 320 is a combination of chimeric A-E57V-Fc (g1S YTE) (chimera A-E57V and Fc (g1S YTE)).
- SEQ ID NO: 321 is the amino acid of the chimeric A-E57K_R58D-Fc (g1SYTE) (DcR3 variant obtained by fusing the chimeric A-E57K_R58D and Fc (g1S YTE)).
- SEQ ID NO: 322 is the amino acid sequence of chimeric A-E57K_R58E-Fc (g1SYTE) (DcR3 variant obtained by fusing chimeric A-E57K_R58E and Fc (g1S YTE)), SEQ ID NO: 32.
- SEQ ID NO: 3 is the amino acid sequence of chimeric A-E57R_R58D-Fc (g1SYTE) (DcR3 variant obtained by fusing chimeric A-E57R_R58D and Fc (g1S YTE)), and SEQ ID NO: 324 is chimeric A-E57K-Fc ( The amino acid sequence of g1S N434A) (DcR3 variant in which chimeric A-E57K and Fc (g1S N434A) are fused), SEQ ID NO: 325 is the chimeric A-E57L-Fc (g1S N434A) (chimera A-E57L).
- the amino acid sequence of DcR3 variant fused with Fc (g1S N434A), SEQ ID NO: 326, is a fusion of chimeric A-E57R-Fc (g1S N434A) (chimera A-E57R) and Fc (g1S N434A).
- the amino acid sequence of DcR3 variant), SEQ ID NO: 327 is the amino acid sequence and SEQ ID NO: of chimeric A-E57V-Fc (g1S N434A) (DcR3 variant in which chimeric A-E57V and Fc (g1S N434A) are fused).
- SEQ ID NO: 329 is chimeric A-E57K_R58E-Fc ( The amino acid sequence of g1S N434A) (DcR3 variant in which chimeric A-E57K_R58E and Fc (g1S N434A) are fused), SEQ ID NO: 330 is the chimeric A-E57R_R58D-Fc (g1S N434A) (chimera A-E57R_R58D).
- DcR3 variant fused with Fc (g1S N434A)
- SEQ ID NO: 331 is a fusion of chimeric A-E57K-Fc (g1S LALAGANA) (chimera A-E57K) and Fc (g1S LALAGANA).
- DcR3 variant) amino acid sequence SEQ ID NO: 332 is the amino acid sequence, SEQ ID NO: of chimeric A-E57L-Fc (g1S LALAGANA) (DcR3 variant in which chimeric A-E57L and Fc (g1S LALAGANA) are fused).
- 333 is the amino acid sequence of chimeric A-E57R-Fc (g1S LALAGANA) (DcR3 variant in which chimeric A-E57R and Fc (g1S LALAGANA) are fused), and SEQ ID NO: 334 is chimeric A-E57V-Fc ( Dc in which g1S LALAGANA) (chimera A-E57V and Fc (g1S LALAGANA) are fused.
- the amino acid sequence and SEQ ID NO: 335 of the R3 variant are the amino acid sequence and SEQ ID NO of the chimeric A-E57K_R58D-Fc (g1S LALAGANA) (DcR3 variant obtained by fusing the chimeric A-E57K_R58D and Fc (g1S LALAGANA)).
- 336 is the amino acid sequence of chimeric A-E57K_R58E-Fc (g1S LALAGANA) (DcR3 variant obtained by fusing chimeric A-E57K_R58E and Fc (g1S LALAGANA)), and SEQ ID NO: 337 is chimeric A-E57R_R58D-Fc ( Represents the amino acid sequence of g1S LALAGANA) (DcR3 variant in which chimeric A-E57R_R58D and Fc (g1S LALAGANA) are fused).
- the mutation (modification) added to the amino acid sequence includes any of natural mutation and artificial amino acid substitution, deletion, insertion or addition.
- the sequence in which 1 to 30 amino acids are deleted, substituted, inserted or added in the above amino acid sequence is 1 or 2 or more, preferably 2 to 30.
- Amino acid sequences having an identity of% or more, for example 93% or more, 95% or more, 97% or more, 98% or more, or 99% or more can be mentioned.
- DcR3 variant of the present invention is further chemically modified for the purpose of changing biological activity or its properties, thermodynamics such as blood half-life, or physical or chemical properties such as protein stability. Good.
- Examples of the chemical modification include polyethylene glycol (PEG) formation, acetylation, amidation, phosphorylation, and the like, and PEGylation is particularly preferable.
- PEGification for example, one or more PEG molecules are added to an amino acid residue having a functional group such as an N-terminal amino group of a protein or a functional group such as a ⁇ -amino group, a carboxyl group, a thiol group or a hydroxyl group of Lys in a side chain. To combine.
- the average molecular weight of the PEG molecule is not limited to the following, but can be used in the range of about 3000 to about 50,000.
- an active group such as a carboxyl group, a formyl (aldehyde) group, an N-hydroxysuccinimide ester group, an amino group, a thiol group or a maleimide group is introduced into the PEG terminal portion.
- a method of reacting with a functional group such as an amino group, a carboxyl group, a thiol group or a hydroxyl group contained in the side chain of the DcR3 variant can be mentioned.
- the signal peptide is not limited, but when the N-terminal CRD domain contained in the DcR3 variant is derived from human DcR3, the signal of human DcR3 consisting of the amino acid sequences 1 to 29 of SEQ ID NO: 2 Peptides can be mentioned.
- the N-terminal CRD domain contained in the DcR3 variant is derived from human OPG, a signal peptide derived from human OPG consisting of the 1st to 21st amino acid sequences of SEQ ID NO: 14 can be mentioned.
- the signal peptide of the present invention includes artificial sequences, sequences derived from expression vectors, and sequences derived from other proteins suitable for host cells expressing DcR3 variants.
- the DcR3 variant containing the signal peptide is an immature polypeptide, and in one embodiment the signal peptide is cleaved during maturation.
- the DcR3 variants of the present invention also include those having different N-terminals in which the signal peptide was cleaved at a position different from the predicted site.
- DcR3 variant of the present invention can be prepared by using the method described in Molecular Cloning: A Laboratory Manual, 3rd edition, Cold Spring Harbor Laboratory Press (2001), etc.
- the DNA encoding the variant can be expressed and produced in a host cell.
- the signal peptide is not limited, but when the N-terminal CRD domain contained in the DcR3 variant is derived from human DcR3, the signal of human DcR3 consisting of the amino acid sequences 1 to 29 of SEQ ID NO: 2 Peptides can be mentioned.
- the N-terminal CRD domain contained in the DcR3 variant is derived from human OPG, a signal peptide derived from human OPG consisting of the 1st to 21st amino acid sequences of SEQ ID NO: 14 can be mentioned.
- any of the artificial sequence, the sequence derived from the expression vector, and the sequence derived from another protein suitable for the host cell expressing the DcR3 variant can be used for producing the DcR3 variant of the present invention.
- the DcR3 variants of the present invention also include those having different N-terminals in which the signal peptide was cleaved at a position different from the predicted site.
- the DcR3 variant of the present invention is artificially designed based on the amino acid sequence of the cysteine-rich region of wild-type DcR3 before amino acid substitution, the amino acid sequence of the cysteine-rich region of the DcR3 variant, or the amino acid sequence of the DcR3 variant. It can be obtained or it can be obtained by analyzing the mutant.
- As the mutation introduction method a site-specific mutagenesis method using a PCR method using a primer is preferable (Kunkel et al., Proc. Natl. Acad. Sci. USA, 1985, 82: 488-492).
- a method of totally synthesizing the mutated gene or a primer containing the mutation is used to perform PCR separately for the part before the mutation site and the part after the mutation site, and the two fragments are used for the region containing the mutation.
- Examples thereof include a method of linking by overlapping and inserting into a vector by an In-fusion cloning method (Clontech) or the like.
- a library into which the mutation is randomly introduced is prepared, displayed on phage, yeast, etc., and screened by binding activity to obtain a mutant having the desired binding mode.
- the method can be mentioned.
- a method of producing a vector into which a DNA mutation for substituting a specific amino acid with a different amino acid has been introduced by expressing it in a host cell to obtain a mutant having a desired binding mode can be mentioned.
- the DNA encoding the DcR3 variant of the present invention can be synthesized by a DNA synthesizer by designing a base sequence encoding this from the amino acid sequence of the DcR3 variant of the present invention. It can also be isolated by PCR using cDNA of human or the like as a template.
- a recombinant vector is prepared by inserting the DNA encoding the DcR3 variant of the present invention obtained above downstream of the promoter of an appropriate expression vector, and the recombinant vector is used as a host suitable for the expression vector. Introduce into cells.
- the base sequence of the DNA encoding the DcR3 variant can be substituted so as to be the optimum codon for expression in the host, thereby improving the production rate of the target DcR3 variant. it can.
- a DNA encoding the signal peptide of the secretory protein is added to the 5'end thereof, and the DNA is used for recombination in the same manner as described above.
- the peptide can be secreted into a medium for production.
- the signal peptide include sequences derived from DcR3 or OPG, artificial sequences, sequences derived from expression vectors, sequences derived from other proteins suitable for host cells, and the like.
- the base sequence of the DNA encoding the amino acid sequence of the DcR3 variant is, for example, the base sequence set forth in SEQ ID NO: 25, 27, 29, 31, 33, 35, 37, 39, 41, 43 and 45. Can be mentioned.
- the base sequence of the DNA encoding the amino acid sequence of the DcR3 variant includes, for example, SEQ ID NOs: 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 179, 181. , 183, 185, 187, 269, 271, 273, 275, 277, 279, 281, 283 and 285.
- the base sequence of the DNA encoding the amino acid sequence of the DcR3 variant includes, for example, SEQ ID NOs: 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 149, 167, 169, 171, 173, 175, 177, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 287, 289, 291.
- the base sequences described in 293, 295, 297, 299, 301 and 303 can be mentioned.
- any one that can autonomously replicate in the host cell to be used or integrate into the chromosome and contains an appropriate promoter at a position where the DNA encoding the polypeptide can be transcribed should be used. Can be done.
- any one that can express a gene encoding a DcR3 variant such as yeast, insect cell, and animal cell
- Preferred include yeast, animal cells, or insect cells capable of glycosylating the protein.
- Saccharomyces Saccharomyces (Saccharomyces) genus Schizosaccharomyces (Schizosaccharomyces) genus Kluyveromyces (Kluyveromyces) genus Trichosporon (Trichosporon) genus Schwanniomyces (Schwanniomyces) genus Pichia (Pichia) sp., Candida ( Candida) microorganism belonging to the genus or the like, for example, Saccharomyces cerevisiae, Schizosaccharomyces pombe, Kluyveromyces lactis, Trichosporon pullulans, Schwanniomyces alluvius, or Candida utilis and the like.
- insect cells examples include Sf9 and Sf21 [Baculovirus Expression Vectors, A Laboratory Manual, W. H. Freeman and Company, New York (1992)], High 5 (manufactured by Invitrogen), which is an ovarian cell of Trichoplusia ni, or S2 (Schneider 2) cell derived from the terminal embryo of Drosophila melanogaster.
- animal cells examples include human cells, Namalwa cells, monkey cells, COS cells, and Chinese hamster cells, CHO cells [Journal of Experimental Medicine, 108, 945 (1958); Proc. Natl. Acad. Sci. USA, 60, 1275 (1968); Genetics, 55, 513 (1968); Chromosome, 41, 129 (1973); Methods in Cell Science, 18, 115 (1996); Radiation Research, 148, 260 (1997); Proc. .. Natl. Acad. Sci. USA, 77, 4216 (1980); Proc. Natl. Acad. Sci.
- 293 cells which are human cells (ATCC number:: CRL-1573), Freestyle 293F cells, Expi293 cells (Thermo Scientific), DUkXB11 (ATCC number: CCL-9906), Pro-5 (ATCC number: CCL-1781), CHO-S (Life Technologies), C , Pro-3, rat myeloma cells YB2 / 3HL. P2.
- G11.16Ag. 20 also referred to as YB2 / 0
- mouse myeloma cell NSO mouse myeloma cell SP2 / 0-Ag14
- Syrian hamster cell BHK, HBT5637 Japanese Patent Laid-Open No. 63-299
- yeast When yeast is used as a host cell, examples of the expression vector include YEP13 (ATCC number: 37115), YEp24 (ATCC37051), YCp50 (ATCC37419), pHS19, pHS15 and the like.
- any promoter that can be expressed in the yeast strain may be used.
- a promoter of a glycolytic gene such as hexsource kinase, a PHO5 promoter, a PGK promoter, a GAP promoter, an ADH promoter, or gal. 1 promoter, gal 10 promoter, heat shock polypeptide promoter, MF ⁇ 1 promoter, CUP 1 promoter and the like can be mentioned.
- any method for introducing DNA into yeast can be used.
- an electroporation method [Methods Enzymol. , 194,182 (1990)]
- spheroplast method Proc. Natl. Acad. Sci. USA, 75, 1929 (1978)]
- Lithium acetate method [J. Bacteriology, 153,163 (1983)]
- Proc. Natl. Acad. Sci. The method described in USA, 75, 1929 (1978) and the like can be mentioned.
- the recombinant virus is further infected with the insect cells to express the peptide. Can be made to.
- Examples of the gene transfer vector used in this method include pVL1392, pVL1393 (manufactured by Becton Dickinson), pBlueBac4.5 (manufactured by Invitrogen), and the like.
- Augurafa califormica nuclear polyhedrosis virus which is a virus that infects Noctuidae insects, can be used.
- Examples of the method for co-introducing the recombinant gene transfer vector into insect cells and the baculovirus for preparing a recombinant virus include the calcium phosphate method (Japanese Patent Laid-Open No. 2-227075) or the lipofection method [Proc. Natl. Acad. Sci. USA, 84, 7413 (1987)] and the like.
- Thermo Scientific When using S2 (Schneider 2) cells (Thermo Scientific) derived from the terminal embryo of the insect cell Drosophila melanogaster as a host, for example, Mol. Biotechnol. , 2015, 10: p.
- the peptide can be expressed by introducing a gene transfer vector such as pMTBiPV5-HisA (Thermo Scientific) into a host cell by the calcium phosphate method according to the method described in 914-922 or the like.
- expression vectors for example, pCI mammalian expression vector (Promega), pcDNA3.1 (+) (Invitrogen), pcDNA I / Amp, pcDNA I, pcDM8 (manufactured by Funakoshi) ), PAGE107 [Japanese Patent Laid-Open No. 3-22979, Cytotechnology, 3,133 (1990)], pAS3-3 (Japanese Patent Laid-Open No. 2-227075), pCDM8 [Nature, 329,840 (1987)], pREP4 (Invitrogen). (Manufactured by the company), pAGE103 [J. Biochem. , 101, 1307 (1987)], pAGE210, pME18SFL3, or pKANTEX93 (International Publication No. 97/10354) and the like.
- any promoter that functions in animal cells can be used.
- a promoter of the IE (immediate early) gene of cytomegalovirus (CMV) an early promoter of SV40, a promoter of retrovirus, and a metallothioneine. Promoters, heat shock promoters, SR ⁇ promoters and the like can be mentioned.
- an enhancer of the IE gene of human CMV may be used together with a promoter.
- any method for introducing DNA into an animal cell can be used.
- an electroporation method [Cytotechnology, 3,133 (1990)]
- a calcium phosphate method Japanese Unexamined Patent Publication No. 2-227075
- Lipofection method [Proc. Natl. Acad. Sci. USA, 84,7413 (1987)]
- the method described in Virology, 52,456 (1973) can be used.
- the expression vector of the DcR3 variant of the present invention obtained by the above-mentioned method, or an expression vector modified thereto can be used for transient expression of the DcR3 variant.
- any host cell capable of expressing the DcR3 variant can be used.
- COS-7 cells ATCC number: CRL1651
- CRL1651 Method of expressing the DcR3 variant
- the DEAE-dextran method Method of Nucleic Acids Res. .. , CRC Press, (1991)
- lipofection method Method of Nucleic Acids Res. USA, 84, 7413 (1987)
- a transformant that stably expresses the DcR3 variant can be obtained by using the expression vector of the DcR3 variant of the present invention obtained by the above-mentioned method or an expression vector modified thereof. After the introduction of the expression vector, a transformant that stably expresses the recombinant antibody is selected by culturing in a medium for culturing animal cells containing a drug such as G418 sulfate (Japanese Patent Laid-Open No. 2-257891). ).
- the transformant is a transformant obtained by using a eukaryotic organism such as yeast as a host, a carbon source, a nitrogen source, and / or a carbon source, a nitrogen source, and / or which can be assimilated by the transformant as a medium for culturing the transformant.
- a eukaryotic organism such as yeast
- a carbon source such as a nitrogen source, and / or a carbon source, a nitrogen source, and / or which can be assimilated by the transformant as a medium for culturing the transformant.
- a natural medium or a synthetic medium may be used as long as it is a medium containing inorganic salts and the like and capable of efficiently culturing the transformant.
- the carbon source may be any assimilated by the transformant, for example, glucose, fructose, sucrose, carbohydrates containing these such as sugar, starch or starch hydrolysate, and organic acids such as acetic acid and propionic acid. , Ethanol, alcohols such as propanol, and the like can be used.
- Nitrogen sources include, for example, ammonium salts of inorganic or organic acids such as ammonia, ammonium chloride, ammonium sulfate, ammonium acetate, and / or ammonium phosphate, other nitrogen-containing compounds, and peptone, meat extract, yeast extract, corns. Chipliker, casein hydrolyzate, soybean meal and soybean meal hydrolyzate, various fermented bacterial cells and their digests can be used.
- inorganic salt for example, primary potassium phosphate, secondary potassium phosphate, magnesium phosphate, magnesium sulfate, sodium chloride, ferrous sulfate, manganese sulfate, copper sulfate, and / or calcium carbonate can be used. ..
- the culture is preferably carried out under aerobic conditions such as shaking culture or deep aeration stirring culture.
- the culturing temperature is preferably 15 to 40 ° C., and the culturing time is usually preferably 16 hours to 7 days.
- the pH during culturing is preferably maintained at 3.0-9.0.
- the pH can be adjusted using an inorganic or organic acid, an alkaline solution, urea, calcium carbonate, ammonia or the like.
- antibiotics such as ampicillin or tetracycline may be added to the medium as needed during culturing.
- a medium for culturing a transformant obtained by using an insect cell as a host As a medium for culturing a transformant obtained by using an insect cell as a host, a commonly used TNM-FH medium (manufactured by Becton Dickinson), Sf-900 II SFM medium (manufactured by Invitrogen), ExCell400, ExCell405 (All manufactured by JRH Biosciences), Grace's insect medium [Nature, 195,788 (1962)], Schneider's Medium (Thermo Fisher), or the like can be used.
- TNM-FH medium manufactured by Becton Dickinson
- Sf-900 II SFM medium manufactured by Invitrogen
- ExCell400 ExCell405
- ExCell405 All manufactured by JRH Biosciences
- Grace's insect medium [Nature, 195,788 (1962)]
- Schneider's Medium Thermo Fisher
- the culture of the transformant obtained by using insect cells as a host is usually preferably performed at a pH of 6 to 7 and a temperature of 25 to 30 ° C. for 1 to 5 days.
- antibiotics such as gentamicin may be added to the medium as needed during culturing.
- Animal cell culture medium includes RPMI1640 medium (Invitrogen), GIT medium (Nippon Pharmaceutical Co., Ltd.), EX-CELL301 medium (JRH), EX-CELL325 PF CHO serum-Free medium (Sigma Aldrich). ), IMDM Medium (manufactured by Invitrogen), Hybridoma-SFM Medium (manufactured by Invigen), Eagle's Minimal Essential Medium (MEM) [Science, 122,501 (1952)], Darbeco Modified Eagle Medium [Virology, 8,396 (1959)], 199 medium [Proceeding of the Society for the Biological Medicine, 73, 1 (1950)] or a medium obtained by adding various additives such as FBS to these media is used.
- the culture of animal cells is usually preferably carried out in the presence of 5% CO 2 , the pH is preferably 6 to 8, the temperature is preferably 30 to 40 ° C., and it is preferably carried out for 1 to 7 days.
- antibiotics such as kanamycin or penicillin may be added to the medium as needed during culturing.
- the DcR3 variant or the DcR3 variant is expressed and accumulated in the culture supernatant.
- the transformant can increase the expression level of the DcR3 variant or the DcR3 variant by using a DHFR amplification system (Japanese Patent Laid-Open No. 2-257891) or the like.
- the DcR3 variant according to the present invention can be produced by producing and accumulating the DcR3 variant according to the present invention in the culture as described above and collecting the DcR3 variant according to the present invention from the culture.
- the DcR3 variant of the present invention when secreted extracellularly, the DcR3 variant can be recovered from the culture supernatant. That is, a culture supernatant is obtained by treating the culture by a method such as centrifugation, and a normal protein isolation and purification method, that is, a solvent extraction method, a salting out method using sulfuric acid, etc., is used from the culture supernatant.
- a culture supernatant is obtained by treating the culture by a method such as centrifugation, and a normal protein isolation and purification method, that is, a solvent extraction method, a salting out method using sulfuric acid, etc.
- a method such as an electrophoresis method such as isoelectric point electrophoresis alone or in combination.
- the DcR3 variant of the present invention has Fc of an immunoglobulin capable of binding to protein G or protein A
- a protein G chromatography method or protein in which protein G or protein A is bound to a carrier as an affinity ligand is used.
- a chromatography method can be used as an affinity chromatography method.
- a DcR3 variant in which a peptide, a sugar chain, PEG or the like is chemically modified can also be obtained by using a conventional chemical modification method. ..
- the DcR3 variant of the present invention is preferably a DcR3 variant having neutralizing activity against at least one of LIGHT, TL1A, and FasL, LIGHT. , DcR3 variant having neutralizing activity against all of TL1A and FasL, DcR3 variant having no neutralizing activity against FasL and having neutralizing activity against any one of LIGHT and TL1A Examples thereof include DcR3 variants having no neutralizing activity against body and FasL and having neutralizing activity against LIGHT and TL1A.
- the DcR3 variant of the present invention can measure biological activity such as neutralization activity, physical properties and pharmacokinetics by using the following method.
- LIGHT, TL1A and FasL used in the present invention are not limited, and examples thereof include eukaryotic-derived LIGHT, TL1A and FasL.
- Eukaryotic-derived LIGHT, TL1A and FasL include, for example, yeast, insects or mammals.
- Preferred examples include LIGHT, TL1A and FasL derived from primates including humans or rodents including mice.
- a cell expressing LIGHT, TL1A or FasL or its ligand can use an expression vector containing a cDNA encoding the full length or partial length of LIGHT, TL1A or FasL as a suitable host such as Escherichia coli, yeast, insect cells, or animal cells. It can be obtained by introducing it into cells. It can also be obtained by purifying the ligand from various cultured human cells or human tissues expressing a large amount of LIGHT, TL1A or FasL. Further, the cultured cells or the tissues can be used as they are as a ligand. Furthermore, a synthetic peptide having a partial sequence of LIGHT, TL1A or FasL can be prepared by a chemical synthesis method such as the Fmoc method or the tBoc method.
- LIGHT, TL1A and FasL are prepared by using the method described in Molecular Cloning, A Laboratory Manual, Second Edition, Cold Spring Harbor Laboratory Press (1989), etc. DNA can be introduced into a host cell, expressed, and produced.
- Soluble LIGHT, TL1A and FasL are produced by being expressed on the cell membrane as membrane-type LIGHT, membrane-type TL1A and membrane-type FasL, respectively, and then shedding the extracellular region with a protease.
- the cleavage site has been identified for each ligand, any sequence in the vicinity of the cleavage site can be included when preparing a recombinant of the soluble ligand.
- the soluble LIGHT recombinant can be prepared from the 66-240th region, the 74-240th region, the 83-240th region, etc. from the N-terminal in the amino acid sequence of the membrane-type LIGHT.
- the soluble TL1A recombinant can be prepared from the 72nd to 251st region from the N-terminal in the amino acid sequence of the membrane TL1A.
- Soluble FasL can be prepared from the 130-281th region from the N-terminal, the 134th-281st region, etc. in the amino acid sequence of membrane-type FasL.
- a recombinant of the soluble ligand can be prepared by adding a His tag, a FLAG tag, or the like to the N-terminal of the above region, and obtained by affinity purification.
- Examples of the amino acid sequence of the soluble recombinant of LIGHT, TL1A and FasL include the amino acid sequences set forth in SEQ ID NOs: 114, 116, 118, 120, 122, 124, 126, 128, 130 and 306.
- Examples of the base sequence of the DNA encoding the amino acid sequence of the soluble recombinant of LIGHT, TL1A and FasL are described in SEQ ID NOs: 113, 115, 117, 119, 121, 123, 125, 127, 129 and 305. A base sequence can be mentioned.
- Functional LIGHT, TL1A or FasL can form a homotrimer.
- Soluble LIGHT, TL1A or FasL prepared by any of the methods described above can be analyzed by SEC-MALS to determine the molecular weight.
- SEC-MALS is the maximum scattering intensity detected by a multi-angle light scattering detector (Multi Angle Light Scattering; MALS) for each peak detected by SEC (Size Exclusion Chromatography) -HPLC at a wavelength of 215 nm. This is an analysis method for calculating the molecular weight using a value.
- MALS Multi Angle Light Scattering
- SEC Size Exclusion Chromatography
- HPLC system include Prominence manufactured by Shimadzu Corporation, TSKgel manufactured by Tosoh Corporation as an SEC column, and miniDAWN TREOS manufactured by Waitt Technology Co., Ltd.
- SEC purification for example, an AKTA purifier manufactured by GE Healthcare Co., Ltd. is used as an HPLC system, and Superdex 200 Increase 10/300 GL manufactured by GE Healthcare Co., Ltd. is used as an SEC column, and a crude product is prepared according to the molecular weight size. Examples thereof include a method of fractionating and recovering only the molecular weight fraction of the homotrimer.
- a method for measuring the binding activity of DcR3 variant to soluble LIGHT, soluble TL1A or soluble FasL for example, an enzyme immunoassay method ( Binding assay by ELISA) and kinetics analysis by Biacore and the like can be mentioned.
- the ligand a gene-introduced cell or recombinant protein obtained by introducing an expression vector containing a DNA sequence encoding the extracellular domain of each ligand of LIGHT, TL1A or FasL into Escherichia coli, yeast, insect cells, animal cells and the like. , And serum, plasma, culture supernatant, etc. containing a ligand obtained from human tissue or human cells are used.
- an anti-human IgG antibody is immobilized on a plate such as 96 wells, a DcR3 variant is reacted, and then each ligand is dispensed and bound. After washing, an unlabeled anti-ligand antibody or a receptor-Fc fusion of each ligand is reacted, and then an anti-Fc antibody labeled with biotin, an enzyme, a chemical luminescent substance, or the like is reacted or labeled.
- An anti-ligand antibody or a receptor-Fc fusion of each ligand can be reacted, detection can be performed according to the labeling substance, and binding of the DcR3 variant to the ligand can be measured.
- Biacore T100 or Biacore T200 is used to measure kinetics in the binding between each ligand and the DcR3 variant, and the result is analyzed by the analysis software attached to the device. Specifically, after immobilizing an anti-human IgG antibody on the sensor chip CM5 by an amine coupling method, a DcR3 variant is flowed to bind it in an appropriate amount on the sensor chip, and a plurality of ligands having known concentrations are further flowed. To measure binding and dissociation. The obtained data is analyzed by kinetics using a 1: 1 binding model using the software attached to the device, and various parameters are acquired.
- binding and dissociation are measured by flowing a plurality of DcR3 variants having known concentrations. Kinetics analysis is performed on the obtained data using the software attached to the device using a viable binding model, and various parameters are acquired.
- a DcR3 variant is flowed through the sensor chip Protein A in which the MabSelectSure ligand, which is an IgG-binding domain variant protein of Protein A, is immobilized on the sensor chip, and an appropriate amount is bound onto the sensor chip, and a plurality of ligands having known concentrations are further added. By flowing, binding and dissociation are measured. The obtained data is analyzed by kinetics using a 1: 1 binding model using the software attached to the device, and various parameters are acquired.
- the binding activity of the DcR3 variant to membrane-type LIGHT, membrane-type TL1A or membrane-type FasL can be obtained, for example, by introducing an expression vector containing a DNA sequence encoding the full length of each ligand of LIGHT, TL1A and FasL into animal cells or the like.
- Mitogen stimulation such as PHA-L, PMA, or Ionomycin, or anti-CD3 antibody and anti-CD28 antibody stimulation, cytokine, IgG, immune complex stimulation, etc.
- cytokine IgG, immune complex stimulation, etc.
- a DcR3 variant is reacted with a cell expressing a membrane-type ligand and a fluorescently labeled anti-Fc antibody or the like is reacted, or a DcR3 variant labeled with biotin or a fluorescent dye or the like is reacted. After washing, it can be measured by detecting the fluorescence intensity according to the labeling substance using a flow cytometer.
- the DcR3 variants of the present invention measured by the above method include, for example, all of DcR3 variants, LIGHT, TL1A and FasL having binding activity to at least one of LIGHT, TL1A and FasL.
- DcR3 variant that has binding activity to FasL DcR3 variant that does not have binding activity to FasL and has binding activity to any one of LIGHT and TL1A, or binding to FasL Examples thereof include DcR3 variants having no activity and binding activity to LIGHT and TL1A.
- the inhibitory activity on the binding of human LIGHT to the corresponding receptor can be measured by the following method, for example, using the method described in US patent US8,974,787 B2.
- HVEM or LT ⁇ R labeled with biotin, fluorescent dye, etc. was reacted with cells expressing the membrane-type LIGHT, washed, and then fluorescent according to the labeled substance using a flow cytometer. Measure by detecting the intensity.
- LIGHT labeled with biotin, a fluorescent dye, or the like is reacted with cells expressing HVEM or LT ⁇ R, washed, and then fluorescent according to the labeled substance using a flow cytometer. Measure by detecting the intensity.
- the inhibitory activity of the DcR3 variant on the binding of LIGHT to the corresponding receptor is confirmed by the decrease in fluorescence intensity as compared with the case where the DcR3 variant was not added.
- the inhibitory activity on binding of TL1A or FasL to the corresponding receptor can also be measured.
- the DcR3 variants of the present invention include DcR3 variants, LIGHT, TL1A and FasL, which have inhibitory activity against at least one of the bindings of LIGHT, TL1A and FasL to the corresponding receptors. Any one of a DcR3 variant having an inhibitory activity on all of the binding to and a binding of FasL to the corresponding receptor and not having an inhibitory activity on the binding of FasL to the corresponding receptor and LIGHT and TL1A to the corresponding receptor.
- the expression "has no inhibitory activity on the binding of a certain ligand to the corresponding receptor" is used to include that the inhibitory activity is significantly lower than that of wild-type DcR3. ..
- the inhibitory activity on cell function induced by the addition of LIGHT can be measured as follows, for example, by using the method described in US Pat. No. US8,974,787 B2.
- chemokine production such as CCL20 is measured by the ELISA method using the culture supernatant, alphaLISA (Perkin Elmer), CBA assay (BD bioscience), or the like.
- soluble or membrane-type LIGHT-dependent chemokine production such as CXCL-10 is also measured using the same method. ..
- soluble or membrane-type LIGHT instead of soluble or membrane-type LIGHT, anti-CD3 antibody and anti-CD28 antibody, or LIGHT whose expression is induced from PBMC or T cells stimulated with PMA, Ionomycin, etc. can be used for measurement in the same manner. ..
- the inhibitory activity of the DcR3 variant on the cell function evoked by the addition of the soluble or membrane-type LIGHT is confirmed by the decrease in the amount of the chemokine produced in comparison with the case where the DcR3 variant is not added.
- IL-12 using blood derived from primates such as humans or rodents such as mice, PBMC, pan T cells, CD4 positive T cells, memory CD4 positive T cells, etc. in a medium supplemented with a DcR3 variant. , IL-18, and TL1A, or TL1A-dependent IFN- ⁇ , IL-6, GM-CSF by stimulating the cells with IL-12, IL-18, IL-15, and TL1A cytokine cocktails.
- TNF- ⁇ , IL-5, IL-13, IL-17 or IL-22, etc. are measured by the ELISA method using the culture supernatant, alphaLISA, CBA assay and the like.
- Immunoty, 2002, 16 p.
- Cells and the like are stimulated with anti-CD3 antibody and anti-CD28 antibody, and TL1A-dependent IFN- ⁇ and IL-2 production is measured by the same method as described above.
- TNBS (2,4,6-trinivobenzensulphonic acid) -induced colitis model described in 172-185, or Mucosal Immunology, 2014, 7: p.
- DSS extran body sulfate
- improvement in survival, body weight, pathology, pathology, etc. by administration of a DCR3 variant can be evaluated.
- the inhibitory activity on cell function induced by the addition of FasL is described by, for example, J. Rheumator. , 2013, 40: p.
- the measurement can be performed as follows by using the method described in 1316-1326 or the like. Annexin V / Propium Iodide staining or live cells for soluble FasL or antibody-bridged soluble FasL-dependent apoptosis using Jurkat cells (DSMZ number: ACC 282) in a medium supplemented with a DcR3 variant. It is measured by the BrdU uptake and the amount of ATP. Alternatively, it can be measured by the same method using a membrane-type FasL forced expression strain instead of soluble-type FasL.
- FasL derived from stimulated PBMC or T cells.
- the inhibitory activity of the DcR3 variant on the cellular function evoked by the addition of FasL is confirmed by the reduction of the apoptosis as compared with the case where the DcR3 variant was not added.
- Examples of the DcR3 variant of the present invention measured by the method described above include DcR3 variant, LIGHT, which have inhibitory activity on at least one or more of the cell functions induced by the addition of LIGHT, TL1A and FasL.
- DcR3 variant having inhibitory activity on all of the cellular functions evoked by the addition of TL1A and FasL, which does not have an inhibitory activity on the cellular functions evoked by the addition of FasL and is evoked by the addition of LIGHT and TL1A.
- Examples thereof include a DcR3 variant having an inhibitory activity on.
- the expression "does not have inhibitory activity on cell function induced by the addition of a certain ligand" is used to include that the inhibitory activity is significantly lower than that of wild-type DcR3.
- the DcR3 variant of the present invention has a sequence derived from OPG in any or all of CRD1, CRD4, and CRD3 that are not involved in ligand binding. It is one of the features.
- the fact that the DcR3 variant does not have binding activity to the OPG ligands RANKL and TRAIL can be evaluated by, for example, the same method as the above-mentioned method for measuring binding activity to LIGHT, TL1A and FasL. it can.
- DcR3 variant of the present invention does not have neutralizing activity against RANKL and TRAIL.
- the neutralizing activity of the DcR3 variant against RANKL is described by, for example, J. Immunol. , 2012, 189: p. It can be evaluated by using TRAP (startrate-resistant acid phosphatase) activity measurement, which is a differentiation assay of osteoclast precursor cells stimulated by RANKL, described in 245-252.
- TRAP startrate-resistant acid phosphatase
- the neutralizing activity of the DcR3 variant against TRAIL is such that in a human cancer cell line expressing DR4 or DR5, the induction of apoptosis by soluble TRAIL or crosslinked soluble TRAIL is neutralized against FasL described above. It can be evaluated by the same method as the method for measuring the activity.
- the DcR3 variant of the present invention is preferably a DcR3 variant in which the binding to heparan sulfate contained in heparan sulfate proteoglycan (HSPG) on the cell membrane is reduced or eliminated, and heparan sulfate is preferable. Those without a binding domain (HBD) are more preferred.
- HSPG heparan sulfate proteoglycan
- Whether or not there is a bond to heparan sulfate on the cell membrane via HBD is determined by, for example, J. Immunol., 2006,176: p. It can be measured as follows by using the method described in 173-180. Either a wild-type DcR3 or a DcR3 variant is reacted with an arbitrary cell, for example, a CHO cell, a human cell line, a vascular endothelial cell, a hepatocyte, or a blood cell, and a fluorescently labeled detection antibody or the like is reacted.
- an arbitrary cell for example, a CHO cell, a human cell line, a vascular endothelial cell, a hepatocyte, or a blood cell, and a fluorescently labeled detection antibody or the like is reacted.
- GAG such as heparin or heparan sulfate is added as an inhibitor during the reaction of wild-type DcR3 or DcR3 variant, or cells are preliminarily treated with an enzyme such as heparinase or trypsin. Examples thereof include a method of reacting with wild-type DcR3 or a DcR3 variant by treating with or the like.
- DcR3 variant of the present invention is that the pharmacokinetics is improved as compared with the wild-type DcR3 because the disappearance via heparan sulfate is reduced in vivo.
- improved pharmacokinetics means that the half-life in blood is longer than that of wild-type DcR3, or the area under the blood concentration-time curve up to infinite time (area under the contact-time curve; AUC). ) It means that the value is high.
- DcR3 FL-Fc amino acid sequence: SEQ ID NO: 100, DNA base sequence: SEQ ID NO: 99
- DcR3 FL-FLAG amino acid sequence: SEQ ID NO: 104, DNA base sequence: SEQ ID NO: 103
- wild S195-Fc amino acid sequence: SEQ ID NO: 102, DNA base sequence: SEQ ID NO: 101
- full-length DcR3 amino acid sequence: SEQ ID NO: 112, having one amino acid mutation in HBD
- R128Q-Fc [US patent US6,835,814 B1, US6,965,01 B1] in which Fc is fused to the C-terminal of DNA base sequence: SEQ ID NO: 111).
- DcR3 variants For changes in blood concentration of DcR3 variants in rodents such as mice and non-human primates such as cynomolgus monkeys, an arbitrary dose is intravenously or subcutaneously administered, blood is collected at an arbitrary time, and a detection system for DcR3 or human Fc is obtained. Can be measured using. Dynamic parameters such as blood half-life and AUC include, for example, pharmacokinetics, 1999, 14: p. It can be calculated from the transition of blood concentration by using a method such as moment analysis by using the method described in 286-293.
- the DcR3 variant of the present invention having an N-type sugar chain also preferably has a large number of sialic acids added.
- the number of sialic acids added per protein molecule shall be compared with the standard curve of sialic acid by separating labeled sialic acid using, for example, a reagent kit for sialic acid fluorescence labeling (Takara Co., Ltd.) by reverse phase HPLC. Can be calculated by
- the DcR3 variant of the present invention is characterized in that the content of aggregates is lower than that of wild-type DcR3 when expressed, isolated or purified using mammalian cells. is there.
- Whether or not aggregates are generated during protein expression and secretion is determined by, for example, collecting host cells and / or culture sperm into which a recombinant vector carrying a DcR3 variant has been introduced, and anti-DcR3 antibody or Fc fusion.
- a body or a tagged adduct such as His or FLAG
- a method of calculating the molecular weight of a protein from an amino acid sequence can be mentioned. Further, when a more accurate molecular weight is to be obtained, an analysis method by SEC-MALS can be mentioned. For each peak detected at a wavelength of 215 nm separated by SEC (Size Exclusion Chromatography) -HPLC, the molecular weight is determined using the maximum value of the scattering intensity detected by a multi-angle light scattering detector (MALS). Can be calculated.
- MALS multi-angle light scattering detector
- Examples of the HPLC system include Prominence manufactured by Shimadzu Corporation, TSKgel manufactured by Tosoh Corporation as an SEC column, and miniDAWN TREOS manufactured by Waitt Technology Co., Ltd. as a detector of MALS.
- the isolated or purified protein is aggregated can be detected by SDS-PAGE of the protein under non-reducing conditions and CBB staining or the like, or by immunoblotting in the same manner as described above.
- the ratio of each peak can be calculated from the area of each peak detected at a wavelength of 215 nm separated by gel filtration chromatography (SEC) using HPLC.
- SEC column examples include TSKgel G3000SW manufactured by Tosoh Corporation, ACQUITY UPLC Protein BEH SEC manufactured by Waters Corp., and the like.
- the preferable agglomerate content is 0 to 60%, the more preferable agglomerate content is 0 to 40%, and the more preferable agglomerate content is 0 to 30%.
- the more preferred aggregate content is 0-20%, and the most preferred aggregate content is 0-10%.
- the DcR3 variant of the present invention is characterized by having a lower hydrophobicity than the wild-type DcR3.
- the hydrophobicity of a protein can be measured using a hydrophobic chromatography (HIC) column that interacts with a hydrophobic region present on the surface of the protein.
- HIC hydrophobic chromatography
- examples of the HIC column include TSKgel Butyl-NPR manufactured by Tosoh Corporation.
- the DcR3 variant of the present invention is characterized in that the thermal stability is improved as compared with the wild-type DcR3.
- a calorimetric measurement method such as DSC (Differential scanning calorimetry), or spectroscopy for obtaining a self-fluorescence spectrum or a circular dichroism (CD) spectrum at the time of thermal denaturation or chemical denaturation.
- Methods, DSF (Denaturation spectroscopy), etc. in which the exposure of the hydrophobic region existing inside the protein due to an increase in temperature is detected by a fluorescent dye (Cypro Orange, etc.), and the like can be mentioned [J Am Chem Soc, 2009, 131: p. 3794-3795].
- DSFs for evaluating the thermal stability of proteins include, for example, J. et al. Pharm. Sci. , 2013, 102: p.
- the amount of fluorescence at each temperature can be measured by using the method described in 2471-2483 or the like. Further, using software such as CFX manager of BioRad, a melting curve can be drawn and a Tm (thermal unfolding transition midpoints) value can be calculated.
- DSCs for assessing the thermal stability of proteins include, for example, J. et al. Pharm. Sci. , 2012, 101: p.
- the heat capacity and Tm value at each temperature can be calculated by using the method described in 955-964 or the like.
- the DcR3 modified composition of the present invention includes a composition composed of a DcR3 modified molecule.
- the DcR3 modified composition of the present invention has the same primary amino acid sequence constituting the DcR3 modified molecule, and is subjected to post-translational modification such as oxidation / reduction reaction, glycosylation addition reaction, sulfate addition reaction, etc. in the amino acid sequence. Examples include compositions containing a plurality of possible DcR3 variants.
- the DcR3 variant of the present invention may include, for example, a DcR3 variant having one or more N-glycoside-linked complex sugar chains and a DcR3 variant having no N-glycosidic complex sugar chain.
- the proportion of the DcR3 variant having one or more N-glycoside-linked complex sugar chains is, for example, preferably 70 to 100%, more preferably 90 to 99%, based on the total number of DcR3 variants of the present invention. It is particularly preferably 95 to 98%.
- compositions Containing DcR3 Variants One embodiment of the present invention is a composition comprising an effective amount of the DcR3 variants of the present invention.
- the composition containing the DcR3 variant of the present invention can be used as an active ingredient of a prophylactic or therapeutic agent for autoimmune diseases, inflammatory diseases, or allergic diseases, including mucosal diseases. That is, by administering a pharmaceutical composition containing the DcR3 variant of the present invention to a patient in need of prevention or treatment of an autoimmune disease, an inflammatory disease or an allergic disease, the autoimmune disease, the inflammatory disease or the allergic disease The disease can be prevented or treated.
- Pathological conditions or diseases in which the compositions of the present invention are used include, but are not limited to, for example, inflammatory bowel disease (IBD), systemic erythematosus, psoriasis, chronic implant-to-host disease, acute implant-to-host.
- IBD inflammatory bowel disease
- systemic erythematosus systemic erythematosus
- psoriasis chronic implant-to-host disease
- acute implant-to-host acute implant-to-host.
- the pharmaceutical composition containing the DcR3 variant of the present invention can contain the DcR3 variant as an active ingredient, or a mixture with any other active ingredient for treatment.
- these pharmaceutical formulations are produced by mixing the active ingredient with one or more pharmaceutically acceptable carriers and using any method well known in the technical field of pharmaceutics.
- the content of the DcR3 variant of the present invention in the pharmaceutical composition varies depending on the dosage form, the pharmacologically acceptable dose of the DcR3 variant of the present invention, etc., but is, for example, about 0.01 to 100% by weight. ..
- the content of the pharmacologically acceptable carrier in the pharmaceutical preparation varies depending on the dosage form, the pharmacologically acceptable dose of the DcR3 variant of the present invention, and the like, and is, for example, 0 to 99.9 weight. %.
- oral administration or parenteral administration such as intravenous, subcutaneous, oral, respiratory, rectal, intramuscular, or intraperitoneal. Administration is mentioned.
- the administration form includes tablets, powders, granules, syrups, injections and the like.
- Suitable formulations for oral administration include, for example, liquid preparations such as syrups, sugars such as water, sucrose, sorbitol, or fructose, glycols such as polyethylene glycol or propylene glycol, sesame oil, olive oil, or large. It can be produced by using oils such as soybean oil, preservatives such as p-hydroxybenzoic acid esters, strawberry flavors, flavors such as peppermint, and the like.
- tablets, powders, granules, etc. are excipients such as lactose, glucose, glycerin, or mannit, starch, disintegrants such as sodium alginate, lubricants such as magnesium stearate, or talc, and polyvinyl. It can be produced by using a binder such as alcohol, hydroxypropyl cellulose or gelatin, a surfactant such as a fatty acid ester, a plasticizer such as glycerin, or the like.
- a suitable preparation for parenteral administration preferably consists of a sterile aqueous agent containing an active compound that is isotonic with the blood of the recipient.
- a solution for injection is prepared using a salt solution, a glucose solution, or a carrier composed of a mixture of salt water and a glucose solution.
- parenteral agents are also selected from the diluents, preservatives, flavors, excipients, disintegrants, lubricants, binders, surfactants, plasticizers and the like exemplified for the oral agents1 Seeds or more auxiliary ingredients can also be added.
- the medicament containing the DcR3 variant of the present invention can be safely administered to mammals (eg, humans, mice, rats, rabbits, dogs, cats, cows, horses, pigs, monkeys, etc.). ..
- the dose and frequency of administration of the DcR3 variant of the present invention vary depending on the dosage form, the age, body weight, disease of the patient, the nature or severity of the symptom to be treated, but usually 0.01 mg per adult in the case of oral administration.
- parenteral administration such as intravenous administration, 0.001 to 100 mg, preferably 0.01 to 10 mg, is administered once or several times a day per adult.
- these doses and the number of administrations vary depending on the various conditions described above.
- Example 1 Evaluation of aggregation of wild-type DcR3 in mammalian cells Wild-type DcR3 (also referred to as full-length DcR3) (SEQ ID NO: 4), linker sequence IEGRMD (SEQ ID NO: 106), and human IgG1 Fc region (g1S) ( Fusion protein with SEQ ID NO: 72) (DcR3 FL-Fc) (FIG. 3A, SEQ ID NO: 100), human DcR3 (SEQ ID NO: 108) lacking the HBD region, linker sequence IEGRMD (SEQ ID NO: 106), and human IgG1 Fc. Fusion protein (S195-Fc) with region (SEQ ID NO: 72) (FIG.
- SEQ ID NO: 104 protein with FLAG tag added to full-length DcR3 (SEQ ID NO: 4) (DcR3 FL-FLAG).
- SEQ ID NO: 104 was prepared as follows.
- DcR3 FL-Fc DNA fragment of signal peptide sequence, DNA fragment of human DcR3 (SEQ ID NO: 3), DNA fragment of linker sequence IEGRMD (SEQ ID NO: 105), DNA fragment of Fc (g1S) (SEQ ID NO: 71) Using In-Fusion HD Cloning Kit (Clontech) for pCIpuro vector (partially modified Promega pCI) that was artificially synthesized (GENEWIZ or Sigma) and digested with restriction enzymes NheI and SalI (New England Biolabs).
- Escherichia coli DH5 ⁇ competent cell (TOYOBO) was transformed to obtain a transformant into which a DcR3 FL-Fc DNA fragment (SEQ ID NO: 99) was inserted.
- a DNA fragment of the signal peptide sequence a DNA fragment of human DcR3 excluding HBD (SEQ ID NO: 107), a DNA fragment of the linker sequence IEGRMD (SEQ ID NO: 105), and a DNA fragment of Fc (g1S) (SEQ ID NO: 105).
- SEQ ID NO: 71) was artificially synthesized to obtain a transformant into which the S195-Fc DNA fragment (SEQ ID NO: 101) was inserted.
- DcR3 FL-FLAG a DNA fragment of a signal peptide sequence, a DNA fragment of human DcR3 (SEQ ID NO: 3), and a DNA fragment of FLAG tag (SEQ ID NO: 109) were artificially synthesized, and a DcR3 FL-FLAG DNA fragment (SEQ ID NO: 103) was artificially synthesized. ) was inserted to obtain a transformant.
- Each plasmid obtained from each transformant was introduced into one of the host cells of Freestyle CHO-S cell, Freestyle 293F cell, and Expi293 cell (all by Thermo Scientific), and the protein was transiently introduced. It was expressed.
- Freestyle MAX Reagent, 293Fectin Transfection Reagent, and ExpiFectamine 293 was used.
- the culture supernatant of DcR3 FL-FLAG is also charged to the resin in the same manner, washed with PBS, eluted with elution buffer (100 mM glycine-HCl, pH 3.5), and immediately neutralized buffer (1M Tris-). Neutralized with HCl, pH 8.0).
- the absorbance (A 280 ) of each elution fraction at 280 nm was measured, and continuous fractions with high measured values were recovered.
- the buffer solution of the collected fraction was replaced with PBS using a NAP column (GE Healthcare), and the protein passed through a 0.22 ⁇ m filter was used as a purified protein.
- the concentrations of DcR3 FL-Fc, S195-Fc and DcR3 FL-FLAG at 280 nm were calculated as 1.03, 1.17 and 0.77, respectively, and SDS under non-reducing and 100 mM DTT reducing conditions. -After PAGE, the gel was stained with Kumashi (Nacalai Tesque) to confirm the molecular weight.
- the estimated molecular weights predicted from the amino acid sequences of DcR3 FL-Fc, S195-Fc and DcR3 FL-FLAG are about 56.4 kDa, 44.7 kDa and 31.0 kDa for the monomer, respectively.
- the Fc fusions DcR3 FL-Fc and S195-Fc exist as dimers, so that the estimated molecular weights are about 112.8 kDa and 89.4 kDa, respectively.
- US patents US685814B1, US6965012B1, SEQ ID NO: 340), and HBD-deficient S195-Fc (SEQ ID NO: 102) were prepared and evaluated for aggregation.
- DNA fragment (SEQ ID NO: 105) and Fc (g1S) DNA fragment (SEQ ID NO: 71) were artificially synthesized, and pMTBiPV5-HisA (Thermo Scientific) and Drosophila Expression System (Thermo Scientific) were used to obtain DC3.
- pMTBiPV5-HisA Thermo Scientific
- Drosophila Expression System Thermo Scientific
- R218Q-Fc and S195-Fc were obtained in an S2 cell line that stably expresses them. From the culture supernatant of the stable expression strain, affinity purification by MabSelect SuRe was carried out in the same manner as described above.
- Example 2 Preparation of a DcR3 variant that does not aggregate in a mammalian cell expression system A human DcR3 variant that does not aggregate in a mammalian cell expression system has not been known so far. Therefore, an attempt was made to prepare a DcR3 variant in which the amount of aggregates produced was reduced while maintaining the activity of DcR3.
- DcR3 is a soluble molecule consisting of 300 residues, and has a signal peptide on the N-terminal side, and then four Cysteine rich aminos (CRD1, CRD2, CRD3, CRD4) characteristic of the TNF receptor superfamily (TNFRSF).
- the C-terminal side consists of Heparan Sulfate Binding Domine (HBD) rich in basic amino acids containing a heparan sulfate binding motif (FIGS. 2 and 3A).
- HFD Heparan Sulfate Binding Domine
- TL1A and FasL all bind via CRD2 and CRD3 of DcR3. Therefore, while retaining the region containing CRD2 and CRD3 of DcR3, CRD1 and / or CRD4 of DcR3 was replaced with a soluble decoy receptor Osteoprotegerin (OPG), which is a related TNFRSF molecule, to prepare a DcR3 variant.
- OPG soluble decoy receptor Osteoprotegerin
- CRD1 and CRD4 are used as human OPG amino acid sequences
- CRD2 and CRD3 are used as human DcR3 amino acid sequences
- chimeric A (SEQ ID NO: 54) from which the HBD amino acid sequence has been removed and the Fc sequence (IEGRMD g1S (SEQ ID NO:)). 339), or g4PEK (SEQ ID NO: 74) in which Ser at position 228 of the heavy chain of human IgG4 indicated by EU index is replaced with Pro, Leu at position 235 is replaced with Glu, and Arg at position 409 is replaced with Lys.
- chimeric A-Fc FIG.
- human DcR3, CRD1 is the human OPG amino acid sequence
- CRD2, CRD3 and CRD4 are the human DcR3 amino acid sequences
- HBD HBD
- CRD1, CRD2 and CRD3 are human Chimera C-Fc (FIG. 3H, FIG.
- 3D, SEQ ID NO: 84) fused with g4PEK were prepared by the following method.
- the DcR3 variant in which CRD4 is derived from DcR3 has a TS sequence at the C-terminal of CRD4, which is the 194th to 195th amino acid sequence of DcR3 (SEQ ID NO: 2), and the DcR3 variant in which CRD4 is derived from OPG has CRD4.
- the SGNSESTQK sequence which is the 186th to 194th amino acid sequence of OPG (SEQ ID NO: 14), is added to the C-terminal.
- a DNA fragment encoding a DNA fragment of a signal peptide sequence, chimera A, chimera B, chimera C or 103-123OPG, from which the HBD sequence has been removed (chimera A: SEQ ID NO: 53, chimera B: SEQ ID NO: 49, chimera C: SEQ ID NO: 51, 103-123OPG: SEQ ID NO: 55) is artificially synthesized and linked to a DNA fragment (SEQ ID NO: 338, 73) encoding the Fc sequence (IEGRMD g1S or g4PEK), and pCIpuro is used in the same manner as in Example 1.
- DNA fragments that are inserted into the vector and encode various DcR3 variants (chimera A-Fc: SEQ ID NO: 79 or 81, chimera B-Fc: SEQ ID NO: 75, chimera C-Fc: SEQ ID NO: 77, 103-123OPG-Fc: A plasmid in which SEQ ID NO: 83) was inserted was obtained.
- the obtained plasmid was introduced into any of the host cells of Freestyle CHO-S cells, Freestyle 293F cells, and Expi293 cells in the same manner as in Example 1, the protein was transiently expressed, and the affinity with MabSelectSuRe was obtained from the culture supernatant. Purification was performed.
- the molecular weights of the dimers predicted from the amino acid sequences of chimeric A-Fc (IEGRMD g1S or g4PEK) and 103-123OPG-Fc are 92.0 kDa, 90.1 kDa, and 90.5 kDa, respectively. It was confirmed that the DcR3 variant also exists as a dimer.
- Example 3 Analysis of N-type sugar chain addition rate of chimeric A-Fc (g4PEK) and evaluation of its effect on aggregation.
- N-type sugar predicted from the amino acid sequence in chimeric A-Fc (g4PEK) (SEQ ID NO: 82).
- Asns predicted to be chain-added in CRD4 derived from OPG N131, N144, N157
- one in the Fc region N260. Therefore, the presence or absence of N-type glycosylation of chimeric A-Fc (g4PEK) was evaluated by the following method.
- the N-type sugar chain of the reduced and alkylated chimeric A-Fc (g4PEK) was cleaved by PNGaseF treatment, and then the protein was digested with each protease of trypsin, endoproteinase Asp-N, and chymotrypsin.
- the resulting peptide mixture was dissolved in 5% (v / v) acetonitrile / 0.1% formic acid and analyzed by liquid chromatography-electrospray ionization-mass spectrometer (LC-ESI-MS).
- MAGIC2000 HPLC (Michrom Bioraces) equipped with a C18 reverse phase column (0.2 mm x 150 mm) (GL Sciences) and LTQ Orbitrap XL ion trap-Orbitrap hybrid mass spectrometer (Thermo Scientific)
- 5- Analysis was performed by gradient elution of% (v / v) acetonitrile / 0.1% formic acid.
- the obtained peptide fragment was identified by performing MASCOT analysis (Matrix Science) on the amino acid sequence of chimeric A-Fc (g4PEK).
- N-type sugar chain-added Asn was converted to Asp by PNGaseF treatment and the mass increased by 0.984 Da, and the peptide whose peak in the MS spectrum was shifted and the sugar chain addition site contained in the peptide were identified.
- N-type sugar chain was added to any Asn residue of N131, N144, N157 and N260.
- N157 and N260 had sugar chains added to almost all peptide fragments, but for N131 and N144, both sugar chain-added fragments and non-glycosylated fragments were detected.
- the two sugar chain removers include N131S / N144S-Fc (g4PEK) (SEQ ID NO: 86) in which N131 and N144 are replaced with Ser, respectively, or T133A / S146A-Fc (g4PEK) (g4PEK) in which T133 and S146 are replaced with Ala, respectively.
- SEQ ID NO: 88 was prepared.
- N131S / N144S / N157S-Fc (SEQ ID NO: 90) in which N131, N144 and N157 were substituted with Ser, respectively, or T133A / S146A in which T133, S146 and T159 were substituted with Ala, respectively.
- T159A-Fc (SEQ ID NO: 92) was prepared.
- a DNA fragment of the signal peptide sequence and a DNA fragment (SEQ ID NO: 85, 87, 89, 91) encoding each sugar chain remover were artificially synthesized, inserted into the pCIpuro vector in the same manner as in Example 1, and Expi293 cells. Introduced in.
- the aggregate content of the two-site sugar chain remover was slightly increased in all the amino acid substitutions as compared with the chimeric A-Fc (Table 2), and the three-site sugar chain remover had any amino acid substitution. A further increase in aggregates was also observed in the body. From this, among the three N-type sugar chains (N131, N144, N157) added to CRD4 derived from OPG, the sugar chain added to N157 reduces the aggregates of chimera A. It was shown to be contributing. On the other hand, even if all three N-type sugar chains were removed, the proportion of aggregates was lower than that of DcR3 FL-Fc and S195-Fc (Table 1). Therefore, it was shown that the sequences of the N-type sugar chain and the OPG each have an effect of reducing the aggregates of the wild-type DcR3, and the combination of both has the effect of further reducing the aggregates.
- Example 4 Evaluation of physical properties of various DcR3 variants
- Hydrophobic interaction chromatography is an analytical method in which the higher the hydrophobicity of the protein surface, the longer the elution time from the column.
- Buffer A (2 mmol / L ammonium sulfate, 20 mmol / L Tris buffer, pH 7.0
- Buffer B (20 mmol / L Tris) using a hydrophobic chromatography column (TSKgel Butyl-NPR 4.6 mm x 35 mm) (Tosoh).
- Table 5 shows the elution time (minutes) detected at a wavelength of 215 nm after separating an 8 ⁇ g sample at a flow rate of 0.5 mL / min using a gradient of buffer solution, pH 7.0) as a mobile phase.
- S2-derived S195-Fc mammalian cell-derived chimera A-Fc (IEGRMD g1S, g4PEK), 103-123OPG-Fc (g4PEK), as compared to the full-length DcR3 1-amino acid variant R218Q-Fc prepared in insect cell S2. It is considered that the dissolution time of each of the two sugar chain removers was shortened, the physical properties were improved due to the decrease in hydrophobicity, and the aggregates were reduced.
- the chimera C and the three-site sugar chain remover which had a slightly attenuated aggregate reducing effect, were hydrophobic at the same level as or higher than R218Q-Fc, and there was a correlation between the proportion of aggregates and the hydrophobicity of the protein. Shown.
- DSF differential scanning fluorometery
- a 96-well white microplate BioRad
- 9.5 ⁇ g of various DcR3 variants and 1 ⁇ L of SYPRO Orange Protein Gel Stein (Invitrogen) diluted 50-fold with water were mixed in a 20 ⁇ L system, and a C1000 thermal cycler (BioRad) was mixed.
- the temperature was raised from 20 ° C. to 95 ° C. by 0.5 ° C. for 10 seconds. Fluorescence at each temperature was detected on the FRET channel, and the melting curve (FIG. 5) and melting temperature (Tm value) (° C.) (Table 6) were calculated using CFX Manager software (BioRad).
- the Tm value was significantly increased and the thermal stability was improved in the S2-derived S195-Fc, so that the HBD region became thermally unstable. It was suggested that it contributed.
- the Tm value of the mammalian cell-derived chimeric A-Fc (IEGRMD g1S) was higher than that of S195-Fc, the DcR3 modification in which a part of the CRD of DcR3 was replaced with a part of the CRD of OPG. It was revealed that the body not only decreased the cohesiveness but also improved the thermal stability of the protein (Tables 6 and 5).
- Example 5 Evaluation of reactivity of DcR3 variant from which heparan sulfate-binding domain (HBD) has been removed to normal human cells and CHO cells The pharmacokinetics of wild-type DcR3 and its mutant FLINT (R218Q mutation) in mice and cynomolgus monkeys It has been reported to be extremely bad (Drug Metabolism and Disposition, 2003, 31: p.502-507).
- One of the factors is thought to be that DcR3 binds directly to heparan sulfate proteoglycan on the cell membrane due to the heparan sulfate binding domain (HBD) present in wild-type DcR3 (J. Immunol., 2006, 2006). 176: 173-180).
- K194-Fc (amino acid sequence: SEQ ID NO: 152, DNA base sequence: SEQ ID NO: 151) contains the IEGRMD linker (SEQ ID NO: 106) and the IEGRMD linker (SEQ ID NO: 106) in the amino acid sequence of Lys at positions 1 to 194 of OPG (SEQ ID NO: 14). It is a protein in which the amino acid sequence of Fc (g1S) (SEQ ID NO: 72) is fused, and is transiently expressed using Expi293 cells by the method described in Example 1 to generate Mabselect SuRe (GE Healthcare). Purified from the culture supernatant using. The anti-DNP antibody (g4PEK) is described in Clin. Cancer Res.
- variable region of the anti-2,4-dinitrophenol (DNP) antibody described in 3126-3135 was inserted into a vector encoding an Fc sequence (g4PEK), introduced into CHO cells for expression, and an antibody purified from Protein A from the culture supernatant.
- g4PEK an Fc sequence
- Human primary cells HUVEC (Lonza) and Male Human Hepatocytes (Bioreclamation IVT) were used. Human primary cells were cultured using a collagen-coated adhesive plate (IWAKI) using a designated medium for each cell according to the package insert.
- CHO cells were suspended-cultured using EX-CELL 325 PF CHO Serum-Free Medium (Sigma-Aldrich).
- HUVEC and Hepatocyte were stripped using a 0.02% EDTA solution and a cell scraper, and passed through a cell strainer (40 ⁇ m).
- CHO cells separated from the exfoliated HUVEC, hepatocytes and suspension culture solution were washed with FCM buffer (1% BSA, 1 mmol / L EDTA, PBS containing 0.05% NaN 3 ) and then with FCM buffer. Suspended.
- DcR3 FL-Fc IgG1 (R & D) is remarkable for all of HUVEC, Hepatocyte and CHO cells. Shown a bond. On the other hand, none of the DcR3 variants from which HBD had been removed bound (Fig. 6).
- each DcR3 variant was prepared by stable expression of CHO cells by the method shown below.
- a set prepared by artificially synthesizing a DNA fragment of a signal peptide sequence and a DNA fragment (SEQ ID NOs: 81 and 83) encoding each DcR3 variant, and prepared by the method described in International Publication No. 2012/081628 in the same manner as in Example 1. It was inserted into a recombinant vector and the vector was introduced into CHO cells by electroporation.
- a single dose of S195-Fc and 10 mg / kg of each DcR3 variant to 5-6 week old BALB / c mice ( ⁇ ) i. v. After administration (n 2 or 3), blood was collected from the tail vein at any time after administration, and the concentrations of S195-Fc and each DcR3 variant in the blood were measured by the following method. Streptavidin-immobilized beads were reacted with biotinylated-labeled monkey anti-human IgG polyclonal antibody, and S195-Fc and each DcR3 variant in the bound serum were detected by Alexa Fluor 647-labeled monkey anti-human IgG polyclonal antibody.
- CD-1 mice were given wild-type DcR3 and FLINT (R218Q mutation) at a single dose of 0.5 mg / kg i. v.
- the half-life in blood after administration was reported to be 1.2 hours and 3.1 hours, respectively, and the AUC0- ⁇ ( ⁇ g * h / mL) was reported to be 0.48 and 0.36, respectively (Drug). Metabolism and Disposition, 2003.31: p.502-507.). Comparing the concentration transitions multiplied by the dose ratio assuming linearity, the DcR3 variant showed high exposure to wild-type DcR3 and FLINT.
- Example 7 Evaluation of binding activity to DcR3 ligand (1) Preparation of DcR3 ligand A soluble recombinant of human, crab monkey, or mouse DcR3 ligand (LIGHT, TL1A, FasL) was prepared (amino acid sequence: sequence). Numbers 114, 116, 118, 120, 122, 124, 126, 128, 130, DNA base sequences: SEQ ID NOs: 113, 115, 117, 119, 121, 123, 125, 127, 129).
- Soluble recombinant LIGHT of human, cynomolgus monkey, or mouse has a His tag (His10) and a GS linker (GGGSGGGGSGGGSIEGR) added to the N-terminus, and the extracellular region of LIGHT (human LIGHT: Asp74-Val240 (sequence)) downstream thereof.
- His10 His tag
- GGGSGGGGSGGGSIEGR GS linker
- Soluble recombinant TL1A from humans, cynomolgus monkeys, or mice has a His tag (His6) and a GS linker (GGGSGGGGSGGS) added to the N-terminal, and the extracellular region of TL1A (human TL1A: Leu72-Leu251 (sequence)) downstream thereof.
- His6 His tag
- GGGSGGGGSGGS GS linker
- Soluble recombinant FasL of human, crab monkey, or mouse has a His tag (His6) attached to its N-terminal, downstream of which is the extracellular region of FasL (human FasL: Pro134-Leu281 (SEQ ID NO: 144), crab quiz FasL). : Pro133-Leu280 (SEQ ID NO: 146) and mouse FasL: Pro132-Leu279 (SEQ ID NO: 148) were linked.
- the DNA sequence of the soluble DcR3 ligand to which the DNA fragment of the signal peptide sequence and the tag were added was artificially synthesized (GENEWIZ), and the pCI-Hygro2.01 vector (Promega) was used using In-Fusion HD Cloning Kit (Promega).
- the company pCI was partially modified) and inserted downstream of the CMV promoter to transform Escherichia coli DH5 ⁇ competent cells (TOYOBO).
- the obtained plasmid was introduced into Expi293 cells (Thermo Scientific) to transiently express the protein.
- the plasmid was introduced using ExpiFectamine 293 (Thermo Scientific), and after culturing for 3 days, the culture supernatant was collected.
- Human FasL and cynomolgus monkey FasL were introduced into host cells of Freestyle CHO-S cells (Thermo Scientific) to transiently express the protein.
- the plasmid was introduced using Freestyle MAX Reagent (Thermo Scientific), and after culturing for 3 days, the culture supernatant was collected.
- Protein purification from the culture supernatant of Expi293 cells was performed using Ni Sepharose Fast Flow resin and His Buffer Kit (both from GE Healthcare).
- the culture supernatant is passed through a column filled with resin, washed with a washing buffer (60 mmol / L imidazole, 20 mmol / L sodium phosphate, 0.5 mol / L NaCl, pH 7.4), and then eluted. It was eluted with a solution (250 mmol / L imidazole, 20 mmol / L sodium phosphate, 0.5 mol / L NaCl, pH 7.4).
- Protein purification from the culture supernatant of Freestyle CHO-S cells was performed using Complete His-Tag Purification Resin (Roche) and His Buffeter Kit (GE Healthcare).
- the culture supernatant is passed through a column filled with resin, washed with a washing buffer (2 mmol / L imidazole, 20 mmol / L sodium phosphate, 0.5 mol / L NaCl, pH 7.4), and then eluted. It was eluted with a solution (250 mmol / L imidazole, 20 mmol / L sodium phosphate, 0.5 mol / L NaCl, pH 7.4).
- each DcR3 ligand is used as a monomer (human LIGHT monomer: 20.8 kDa, human TL1A monomer: 22.1 kDa, human FasL monomer: 17.7 kDa, crab quiz LIGHT monomer: 20.8 kDa, crab quiz TL1A monomer: 22.0 kDa, crab quiz fasL monomer: 17.7 kDa, mouse LIGHT monomer: 20.9 kDa, mouse TL1A monomer: 21.5 kDa, mouse FasL monomer: 17.7kDa), each kinetic constants (k a, k d, were calculated K D) (Table 10-12).
- Example 8 Evaluation of binding activity to OPG ligands (RANKL, TRAIL) It is known that RANKL binds to RANK for bone resorption and TRAIL binds to the TRAIL receptor and is involved in cell death. Using various human DcR3 recombinants prepared, the binding activity to RANKL and TRAIL was analyzed by ELISA. As positive controls that bind to the OPG ligand, the C-terminal region defect K194-Fc, RANK-Fc (Enzo Life Science), and TRAIL R1-Fc (R & D systems) of OPG prepared in Example 5 were used. As a negative control, anti-DNP antibody (IgG1) [Clin. Cancer Res.
- IgG1 anti-DNP antibody
- variable region of the anti-2,4-dinitrophenol (DNP) antibody described in 3126-3135 was inserted into a vector encoding Fc of IgG1 and introduced into CHO cells for expression, and a Protein A-purified antibody was used.
- Anti-human IgG1 (American Qualex) prepared at 10 ⁇ g / mL with PBS was dispensed into a 96-well plate (MAXISORP NUNC-IMMUNO PLATE, Thermo Scientific) at a rate of 50 ⁇ L / well and allowed to stand overnight at 4 ° C. And adsorbed. After removing the immobilization solution, 100 ⁇ L / well of 1% Block Ace prepared by dissolving 1 g of Block Ace powder (DS Pharma Biomedical) in 100 mL of water was dispensed and allowed to stand at room temperature for 1 hour. Then, it was blocked and washed 3 times with PBS containing 0.1% Tween (hereinafter referred to as PBST). Next, the plate No.
- PBST PBS containing 0.1% Tween
- 1 contains various human DcR3 recombinants or various DcR3 variants diluted to 1 ⁇ g / mL with 1% BSA-PBS and RANK-Fc.
- various wild-type DcR3 or various DcR3 variants diluted with 1% BSA-PBS to 1 ⁇ g / mL and TRAIL R1-Fc were dispensed at 50 ⁇ L / well and allowed to stand at room temperature for 1 hour.
- RANKL (Peprotech) diluted to 0.64-50000 pg / mL with 1% BSA-PBS was added to Plate No. 1.
- TRAIL (Peprotech) diluted to 0.64-50000 pg / mL with 1% BSA-PBS was dispensed at 50 ⁇ L / well and allowed to stand at room temperature for 1 hour.
- TMB + Substrate Chromogen Dako
- a 0.5 mol / L sulfuric acid solution was dispensed at 50 ⁇ L / well to stop the color development reaction, and the absorbance at a sample wavelength of 450 nm and a reference wavelength of 570 nm was measured using a plate reader.
- a DcR3 variant prepared by substituting a part of the CRD of DcR3 with a part of the CRD of OPG together with the result of Example 7 shows the same binding activity as the wild-type DcR3 for the ligand of DcR3. It was confirmed that it does not bind to the ligand of OPG.
- Example 9 Measurement of DcR3 ligand neutralization activity The neutralization activity of various wild-type DcR3 controls and DcR3 variants against LIGHT, TL1A, and FasL was measured by the methods shown below.
- the DNP antibody was prepared by the method described in Examples 5 and 8.
- various wild-type DcR3s or various types have a final concentration of 0.1, 1, or 10 ⁇ g / mL.
- a DcR3 variant was added.
- human LIGHT (Gly66-Val240) (described in JP2013153749) with a FLAG tag (DYKDDDDDK) added to the N-terminal is added so that the final concentration becomes 0.1 ⁇ g / mL, and the total amount of the culture solution becomes 200 ⁇ L / well.
- PBMC Frozen healthy PBMC (AllCells) was thawed in a water bath at 37 ° C. and suspended in a medium containing DNaseI (STEMCELL) warmed to 37 ° C. After shaking at 37 ° C. for 2 hours at low speed, T cells were isolated using EasySep Human T cell Enrichment Kit (STEMCELL). After seeding the isolated T cells on a 96-well suspension culture plate (Sumitomo Bakelite) at 1x10 5 cells / well, various wild-type DcR3 controls or various types have a final concentration of 0.1, 1, 10 ⁇ g / mL. A DcR3 variant was added.
- Example 6 the recombinant His10 human TL1A prepared in Example 6 was added so that the final concentration was 0.1 ⁇ g / mL.
- Human IL-12 (Miltenyi Biotec) having a final concentration of 2 ng / mL and Recombinant Human IL-18 (MBL) having a final concentration of 50 ng / mL were added to prepare the culture solution so that the total volume of the culture solution was 200 ⁇ L / well. After culturing at 37 ° C. for 3 days in a 5% CO 2 incubator, the culture supernatant was collected, and the IFN- ⁇ concentration in the culture supernatant was collected using AlphaLISA IFN- ⁇ Immunoassay Research Kit (PerkinElmer). Was measured.
- the Jurkat cell line was seeded on a 96-well suspension culture plate at 5x10 4 cells / well, and then various wild-type DcR3 or DcR3 variants were applied to final concentrations of 0.01, 0.1, and 1 ⁇ g / mL. Added. Then, recombinant human His6 Fas Land (CST Japan) was added so that the final concentration was 0.1 ⁇ g / mL, and the total amount of the culture solution was adjusted to 100 ⁇ L / well. After culturing overnight at 37 ° C.
- CellTiter-Glo Promega was added to the Jurkat culture plate at 100 ⁇ L / well, and ATP was used using a luminometer (Veritas, Promega). The number of viable cells was measured using the production amount as an index.
- Example 10 Ligand-neutralizing activity and binding activity of FasL binding-reducing variant Based on chimeric A-Fc (g4PEK), among DcR3 ligands, it has binding and neutralizing activity to TL1A and LIGHT, but to FasL. Preparation and evaluation of a 1-amino acid substituent with reduced binding and neutralizing activity were performed. A variant in which any amino acid of CRD2 and CRD3 shown in Table 13 was replaced with Ala or an amino acid other than Ala was prepared, and the neutralizing activity against the DcR3 ligand was measured by the same method as in Example 9.
- Example 11 Evaluation of Aggregation of Commercially Available Wild DcR3 in Mammalian Cells
- commercially available full-length DcR3-Fc (Abcam) and CHO cells prepared using HEK293 cells as host cells were used.
- Full length DcR3-Fc (AdipoGen) of a commercially available product prepared as a host cell Fc fusion of a DcR3 molecule (Enzo) in which about half of the C-terminal side of a commercially available HBD prepared using HEK293 cells as a host cell is deleted.
- the molecular weight of the monomer expected from the migration under reducing conditions was about 50 kDa to 60 kDa, but the migration under non-reducing conditions was significantly larger than the expected dimer molecular weight, and any commercially available product. Most of the products also existed as aggregates (Fig. 13).
- chimeric A-Fc A one-amino acid substituent (E57X; X is any amino acid other than Glu) was prepared by substituting Glu (E57) at the 57th position from the N-terminal of g4PEK) (SEQ ID NO: 82) with an amino acid other than Glu.
- E57K, E57L, E57R, and E57V in which E57 is replaced with any of Lys, Leu, Arg, and Val 53 from the N-terminal of chimeric A-Fc (g4PEK) (SEQ ID NO: 82), which is a nearby amino acid.
- Any of the trp (W53), the 54th Asn (N54), the 55th Tyrosine (Y55), the 56th Leu (L56), and the 58th Arg (R58) is further added to the specific amino acid Z (Z).
- Is a two-amino acid substitution product (E57X_W53Z, E57X_N54Z, E57X_Y55Z, E57X_L56Z, E57X_R58Z) substituted with Asp, Glu, Asn, Gln, Pro, Thr, or Gly.
- a fusion of Fc (g4PEK) and Fc (g4PEK) was prepared.
- chimeric A-E57K (amino acid sequence: SEQ ID NO: 66, DNA base sequence: SEQ ID NO: 65), chimera A-E57R (amino acid sequence: SEQ ID NO: 180, DNA base sequence: SEQ ID NO: 179), chimera A -E57V (Amino acid sequence: SEQ ID NO: 182, DNA base sequence: SEQ ID NO: 181), Chimera A-E57K_R58D (Modified number: 45-10, Amino acid sequence: SEQ ID NO: 184, DNA base sequence: SEQ ID NO: 183), Chimera A-E57K_R58E (modified number: 45-18, amino acid sequence: SEQ ID NO: 186, DNA base sequence: SEQ ID NO: 185) and chimera A are fused with some of the various mutation-introduced Fc sequences shown in Table 14.
- Nucleotide sequence SEQ ID NO: 213, 217, 219, 221, 223, 227, 231, 233, 235, 237, 255, 259, 261, 263, 265, 149, 167, 169, 171 and 173, 175, 177, Amino Acid Sequence: SEQ ID NO: 214, 218, 220, 222, 224, 228, 232, 234, 236, 238, 256, 260, 262, 264, 266, 317, 319, 320, 321, 322, 324 , 326, 327, 328, 329, 331, 333, 334, 335, 336, 150, 168, 170, 172, 174, 176, 178).
- E216 indicates Glu at position 216 of the human IgG1 heavy chain as indicated by the EU index.
- the mutation introduction sites C220S, M252Y, S254T, T256E, N434A, L234A, L235A, and G237A each have the 220th Cys of the human IgG1 heavy chain indicated by the EU index as Ser, the 252nd Met as Tyr, and the 254th.
- Ser was replaced with Thr
- Thr at 256th was replaced with Glu
- Asn at 434th was replaced with Ala
- Leu at 234th was replaced with Ala
- Leu at 235th was replaced with Ala
- Gly at 237th was replaced with Ala. ..
- the chimeric A-Fc (g1S) (base sequence: SEQ ID NO: 149, amino acid sequence: SEQ ID NO: 150) is a chimeric A-Fc (IEGRMD g1S) containing the linker sequence IEGRMD (SEQ ID NO: 106) prepared in Example 2.
- the IEGRMD sequence deleted from SEQ ID NO: 80) was prepared by the method described in Example 6 by stable expression of CHO cells.
- Chimera A-Fc (Eg1S) (base sequence: SEQ ID NO: 167, amino acid sequence: SEQ ID NO: 168) is a CHO cell in which a sequence in which chimera A (SEQ ID NO: 54) and Eg1S are linked is expressed by the method described in Example 6. It was prepared by stable expression of.
- Chimera A-Fc (Eg1S YTE, Eg1S N434A, Eg1S LALAGA, Eg1S LALAGANA) (base sequence: SEQ ID NO: 169, 171, 175, 177, amino acid sequence: SEQ ID NO: 170, 172, 176, 178) is a chimera A (sequence).
- a sequence in which each Fc was fused to the C-terminal of No. 54) was obtained by transient expression of CHO-S cells.
- Chimera A-Fc (g1S YTE, g1S N434A, g1S LALAGA, g1S LALAGANA) (amino acid sequence: SEQ ID NO: 314, 315, 174, 316) is obtained by fusing each Fc to the C-terminal of chimera A (SEQ ID NO: 54). The sequence was obtained by transient expression of Expi293 cells.
- the plasmid expressing the fusion of each amino acid substitution product and Fc uses the DNA sequence of either chimeric A-Fc (g4PEK) or E57X-Fc (g4PEK; X is K, R or V) as a template.
- each amino acid substitution product with each Fc of Eg1S YTE, Eg1S N434A, or Eg1S LALAGANA is designed to include a mutation site using the DNA sequence of any of the chimeric A-Fc having each mutant Fc sequence as a template.
- Chimera A-various mutant Fc using the PCR primers obtained by PCR amplification of two regions from the EcoRI site to the site where the amino acid substitution was introduced and from the site where the amino acid substitution was introduced to the Bsu36I site.
- a plasmid was prepared by inserting into the EcoRI and Bsu36I sites of the vector.
- each amino acid substitution product with each Fc of g1S YTE, g1S N434A, or g1S LALAGANA is a PCR primer designed to exclude E216 using the DNA sequence of any of the above amino acid substitution products-Fc as a template.
- each amino acid substituent-Fc vector EcoRI and Bsu36I site was used as a template. The plasmid was prepared by inserting into.
- Each plasmid was introduced into Expi293 cells and transiently expressed, and affinity purification with MabSelect SuRe was performed from the culture supernatant.
- the content of each of the prepared chimeric A-Fc, 1 or 2 amino acid substitution product-Fc monomer, aggregate, and decomposition product was determined by the same method as in Example 2 of SEC-UPLC (ACQUITY UPLC Protein BEH SEC 4). It was calculated from the peak area analyzed by .6 mm ⁇ 150 mm) (Waters) or SEC-HPLC (TSKgel SuperSW3000 4.0 ⁇ m, 4.6 mm ⁇ 300 mm) (Tosoh).
- Example 13 Evaluation of binding activity to DcR3-soluble trimer ligand DcR3-Fc, S195-Fc, various chimeric A-Fc having different Fc sequences, and various FasL binding-reducing variants prepared in Example 12 , A soluble human LIGHT trimer, a soluble human TL1A trimer, and a soluble human FasL trimer were evaluated for their binding activity by partially modifying the method described in Example 7.
- the human soluble recombinant TL1A is a sequence in which a His tag (His6) and a GS linker (GGGSGGGSGGGS) are added to the N-terminal, and the extracellular region of TL1A (Leu72-Leu251) (SEQ ID NO: 138) is linked downstream thereof.
- His6-TL1A was used (base sequence: SEQ ID NO: 115, amino acid sequence: SEQ ID NO: 116).
- Each plasmid was prepared in the same manner as in Example 7 and transiently expressed by Expi293 cells.
- FLAG-LIGHT was purified using ANTI-FLAG M2 Infinity Gel (Sigma).
- the culture supernatant is passed through a column filled with resin, washed with a washing buffer (50 mM Tris HCl, 150 mM NaCl, pH 7.4), and then the eluate (0.1 M glycine hydrochloride, pH 3.5). Eluted with.
- His6-TL1A was purified by the following method.
- the culture supernatant is passed through a column filled with Complete His-Tag Purification Resin (Roche), washed with a washing buffer (50 mM NaH2PO4 pH 8.0, 300 mM NaCl), and then washed with an eluate (50 mM NaH2PO4 pH 8.0). , 300 mM NaCl, 250 mM Imidazole).
- the eluate replaced with PBS using a NAP column (GE Healthcare) is passed through a column filled with Ni Sepharose Fast Flow resin (GE Healthcare), and His Buffer Kit (GE Healthcare) is used.
- washing buffer 60 mM imidazole, 20 mM sodium phosphate, 0.5 M NaCl, pH 7.4
- elution buffer 250 mM imidazole, 20 mM sodium phosphate, 0.5 M NaCl, pH 7.4.
- the eluted fractions of FLAG-LIGHT and His6-TL1A were replaced with PBS using a NAP column (GE Healthcare), and sterilized through a 0.22 ⁇ m filter.
- the obtained purified protein was fractionated into a trimer fraction by gel filtration chromatography (SEC) (TSKgel G3000 SWXL 7.8 mm x 300 mm) (Tosoh Corporation) using HPLC (Shimadzu Corporation).
- FasL In human soluble recombinant FasL, a His tag (His6) is added to the N-terminal, and the extracellular region of FasL (Pro134-Leu281) (SEQ ID NO: 144) is linked downstream thereof.
- Human His6 FasLigand / TNFSF6 Cell Signaling TECHNOLOGY was used. SEC-MALS was carried out in the same manner as in Example 2, and it was confirmed that it was a trimer.
- the binding activity to the human DcR3 trimer ligand was analyzed by the SPR method.
- BIAcore T-100 (GE Healthcare) is used to measure binding activity to human LIGHT and human TL1A
- BIAcore T-100 GE Healthcare
- BIAcore T-200 GE Healthcare
- HBS-EP + Buffer was used as the buffer solution.
- BIAcore T-100 evaluation software 1: 1 Binding model or BIAcore T-200 evaluation software, 1: 1 Binding model was used to measure the binding activity to human FasL, and the ligand was used as a monomer (human FasL monomer: 19). .8kDa), each kinetic constants (k a, k d, it was calculated K D).
- FasL binding reduced variants prepared in Example 12, one amino acid substitution chimeric A-E57K-Fc (g4PEK) (amino acid sequence: SEQ ID NO: 94, DNA base sequence: SEQ ID NO: 93) (hereinafter It may be referred to as "E57K-Fc"), chimeric A-E57L-Fc (g4PEK) (amino acid sequence: SEQ ID NO: 96, DNA base sequence: SEQ ID NO: 95) (hereinafter, may be referred to as "E57L-Fc”.
- E57K-Fc, E57L-Fc, E57R-Fc, E57V-Fc, 45-10-Fc, 45-18-Fc, and 82-5Fc are SEC-HPLC (column; TSKgel G3000 SWXL 7.8 mm x 300 mm, Tosoh Corporation, HPLC; Shimadzu Corporation) purified the monomer to 95% or more, and each kinetic constant when subjected to BIAcore measurement is shown in FIG. 15B.
- Example 14 Evaluation of neutralization activity of DcR3 soluble ligand The evaluation of neutralization activity of various DcR3 variants against soluble human LIGHT, soluble human TL1A, and soluble human FasL is described in Example 9. The method was partially changed and implemented.
- chimera A-Fc having different Fc sequences
- chimera A-Fc those prepared in Example 12 were used.
- the final concentration of IFN- ⁇ was 10 ng / mL
- the final concentration of the trimeric FLAG-LIGHT prepared in Example 13 was 20 ng / mL
- each final concentration of various DcR3 variants is 19.5, 78.1, 313, 1250, 5000, 20000 ng / mL, or 4.88, 19.5, 78.1, 313, 1250, 5000 ng
- Each was added to / mL and cultured for 3 days.
- the culture supernatant was collected, and the CXCL10 concentration in the culture supernatant was measured using a CXCL10 / IP-10 (human) AlphaLisa Detection Kit (Perkin Elmer).
- CXCL10 / IP-10 human
- AlphaLisa Detection Kit Perkin Elmer
- IFN- ⁇ -stimulated intestinal myofibroblasts similar to chimeric A-Fc.
- the inhibitory activity against LIGHT dependent CXCL10 production from intestinal myofibroblasts cell number per well 2x10 4 each final concentration of the test substance 19.5,78.1,313,1250,5000,20000ng / mL It was evaluated under the condition of. As a result, it was confirmed that all the variants inhibited CXCL10 production in a concentration-dependent manner and had neutralizing activity against soluble LIGHT (Fig. 17D).
- FasL binding-reducing variants E57K-Fc, E57L-Fc, E57R-Fc, E57V-Fc, 45-10-Fc, 45-18-Fc, 82-5Fc (all Fc is g4PEK) Similarly, it was confirmed that it has a neutralizing activity against soluble TL1A (FIGS. 18C and D).
- Example 15 Evaluation of binding activity to DcR3 membrane-type ligand A flow using a forced expression strain of membrane-type ligand for the binding activity of various DcR3 variants to membrane-type human LIGHT, membrane-type human TL1A, and membrane-type human FasL. Evaluated by cytometry.
- As the membrane-type human LIGHT forced expression HEK293 cells those described in US8974787 were used.
- Membrane-type TL1A and membrane-type FasL are PCR-amplified by adding a Met residue and FLAG tag (DYKDDDDK) to the N-terminal using each commercially available ORF clone (Origene) as a template (base sequence: SEQ ID NOs: 307 and 309).
- the obtained plasmid was introduced into CHO-K1 cells (ECACC) using Nucleofector and Cell Line Nucleofector Kit T (both from Lonza), and 10 ⁇ g / mL Puromycin (Thermo Fisher Scientific).
- the obtained drug-resistant cells were stained with DyLight488-labeled anti-human TL1A antibody (Novus Biopharmacy) or APC-labeled anti-human FasL antibody (BD Harmingen), and the highly expressed fraction was sorted using a cell sorter (Sony). ..
- the cells were stained with PE-labeled anti-human TL1A antibody (Novus Biologics) or PE-labeled anti-human FasL antibody (BioLegend), and then sorted again to obtain a membrane-type human TL1A or membrane-type human FasL-expressing cell line. ..
- the binding activity of various DcR3 variants to the membrane ligand forced expression strain and the host cell was evaluated by the same method as in Example 5 under the following conditions.
- the HEK293 and membrane-type LIGHT forced expression strains were reacted with 1 ⁇ g / mL of each protein and 10 ng / mL of the secondary antibody Goat F (ab') 2 Anti-Human IgG R-phycoerythrin Conjugate (Southern Biotech).
- Goat F (ab') 2 Anti-Human IgG R-phycoerythrin Conjugate Southern Biotech.
- each protein was reacted under the conditions of 1 or 10 ⁇ g / mL
- the secondary antibody was reacted under the conditions of 0.1 or 1 ⁇ g / mL, respectively.
- Example 16 Evaluation of binding activity to DcR3 primary ligand The binding activity of various DcR3 variants to each DcR3 ligand derived from the primary cell was evaluated by the following method.
- the induced-stimulated PBMC was reacted with Human FcR Blocking Reagent (Miltenyi Biotech), followed by BV510-labeled CD3 antibody (BioLegend), 7-AAD Staining Sol. BD Pharmingen) and PE-labeled LIGHT antibody (LSBio) or PE-labeled mouse IgG1 ⁇ isotype control antibody (BioLegend) were added, washed after reaction, and in CD3-positive T cells of the live cell fraction with a flow cytometer. The fluorescence intensity of PE in was analyzed.
- the TL1A antibody 1D1 1.31 has the amino acid sequences of VL and VH described in US2015 / 0132311 linked to the constant region of human IgG1 and transiently expressed using Expi293 cells by the method described in Example 1. , Purified from the culture supernatant using Mabselect SuRe (GE Healthcare) was used. The anti-DNP antibody (IgG1) described in Example 8 was used as a negative control.
- Primary FasL Binding Activity The binding of chimeric A-Fc (IEGRMD g1S) to primary soluble FasL produced from human T cells inducing activation-induced cell death (AICD) was evaluated by the following method.
- Primary soluble FasL was prepared by the following method. That is, human T cells isolated from frozen healthy human PBMCs were seeded on a 96-well U-bottom plate (BD) at 2x10 4 cells / well in the same manner as in Example 9, and PHA-L having a final concentration of 1 ⁇ g / mL was inoculated.
- IL-2 Peptrotech
- IL-2 Peptrotech
- a final concentration of 1 ⁇ g / mL was added and cultured for 5 days.
- cells were collected, seeded on a 96-well U-bottom plate immobilized with 5 ⁇ g / mL anti-CD3 antibody OKT3 (BioLegend), AICD was induced, and the cells were cultured overnight, and then the culture supernatant was collected.
- Amicon Ultra-15 Millipore
- the solution volume was concentrated to 1/10.
- a 96-well immunoplate (Thermo Scientific) immobilized with a 10 ⁇ g / mL anti-human IgG antibody (American Quarex) was blocked with 1% Block Ace (DS Pharma Biomedical), and then 20 ⁇ g / mL chimeric A- Fc (IEGRMD g1S) or Fas-Fc (R & D) was captured. After washing, recombinant FasL (abcam) used as a standard or 10-fold concentrated AICD culture supernatant was reacted, and after washing, biotinylated anti-FasL antibody (abcam) was reacted.
- FasL abcam
- FIG. 24A The result of the plate on which the chimera A-Fc (IEGRMD g1S) was captured is shown in FIG. 24A, and the result of the plate on which the Fas-Fc was captured is shown in FIG. 24B.
- CD3 refers to the use of culture supernatants of AICD-induced T cells under anti-CD3 antibody OKT3 stimulation conditions, and none refers to the use of culture supernatants of T cells not induced to AICD.
- FasL was detected only in the culture supernatant of AICD-induced T cells on plates that captured either chimeric A-Fc or Fas-Fc. From this, it was confirmed that the chimeric A-Fc binds to soluble FasL produced from AICD-induced T cells (FIGS. 24A, B).
- Example 17 Evaluation of physical properties of DcR3 variant Various chimeric A-Fc (g1S, Eg1S, Eg1S YTE, Eg1S N434A, Eg1S LALAGANA, Eg1S LALAGA, g4PEK) and FasL binding-reducing variant E57K-Fc, E57L-Fc Hydrophobic interaction chromatography (HIC) for E57R-Fc, E57V-Fc, 45-10-Fc, 45-18-Fc, 82-5Fc (all g4PEK) in the same manner as in Example 4.
- the elution time (minutes) was calculated according to the above method, and the Tm value (° C.) was calculated by the Differential Scanning Fluidity (DSF) method.
- DSF Differential Scanning Fluidity
- the effect of introducing the YTE mutation on the thermal stability was observed. Since the Tm values of the FasL-reduced variants were not significantly different from those of chimeric Ag4PEK, it was found that the introduction of 1 or 2 amino acid substitutions into the CRD portion of DcR3 had no effect on thermal stability. It was confirmed (Fig. 26).
- Example 18 Evaluation of mouse pharmacokinetics of DcR3 variant Chimeric A-Fc (Eg1S) and FasL binding-reducing variant E57K-Fc, E57L-Fc, E57R-Fc, E57V-Fc, 45-10-Fc, For 45-18-Fc and 82-5-Fc (both Fc is g4PEK), the pharmacokinetics in mice was evaluated in the same manner as described in Example 6.
- Chimera A-Fc (Eg1S) was prepared by stable expression of CHO-K1 cells, and each FasL binding-reducing variant was prepared by transient expression of CHO-S cells, and SEC (GE Healthcare) was used. Those purified to 95% or more of the monomer by Superdex 200 Expression 10/300 GL) (GE Healthcare) were used.
- the half-life (h) in the blood of the disappearing phase after a single administration at the time of administration (n 2 or 3) and the area under the blood concentration-time curve (area under the conjunction-time curve) up to infinite time.
- AUC0- ⁇ ( ⁇ g * h / mL) was calculated (FIG. 27).
- each DcR3 variant prepared by transient expression of Expi293 cells was used.
- Example 19 Evaluation of in vivo efficacy of DcR3 variant In vivo efficacy evaluation of chimeric A-Fc (g4PEK) was performed using a mouse acute heterologous graft-versus-host disease (GVHD) model. ..
- mice were irradiated with a lethal dose of 1.7 Gy or less using a CellRad type X-ray irradiation device (Faxiron).
- axiron CellRad type X-ray irradiation device
- PBMCs On day 0, 3x10 6 human PBMCs (AllCells) were intraperitoneally injected, followed by intraperitoneal injection of 300 ⁇ g of chimeric A-Fc or DNP antibody (both g4PEK) prepared with 100 ⁇ L PBS. ..
- 300 ⁇ g of chimeric A-Fc was additionally administered on the 4th and 8th days. Twelve days later, the gross pathological condition score by the GVHD reaction was determined, and the spleen was collected from the sacrificed mice to evaluate the number of human cells in the spleen.
- Count Bright Absolute Counting Beads for flow cytometry (Thermo Fisher Scientific) was used to measure the cell number, and the fluorescent bead count detected by flow cytometry and the abundance ratio of the number of each cell subset were corrected by the known amount of added beads. , The total number of cells in the spleen was calculated.
- Example 20 Evaluation of binding activity to soluble DcR3 ligand trimer Regarding the chimeric A-Fc having various mutant Fc and the FasL binding-reducing variant prepared in Example 12, the soluble human LIGHT trimer , Evaluation of binding activity to soluble crab monkey LIGHT trimer, soluble human TL1A trimer, soluble crab monkey TL1A trimer, soluble human FasL trimer, or soluble crab monkey FasL trimer
- the method described in Example 7 and Example 13 was partially modified and carried out as follows.
- TL1A His6-cynoTL1A
- cynomolgus monkey soluble FasL His6-cynoFasL
- LIGHT and TL1A were transiently expressed by Expi293
- FasL was transiently expressed by CHO-S.
- His6-cynoFasL is a washing buffer solution (60 mM) prepared by passing the culture supernatant through a column filled with Ni Sepharose Fast Flow resin (GE Healthcare) and using His Buffer Kit (GE Healthcare). After washing with imidazole, 20 mM sodium phosphate, 0.5 M NaCl, pH 7.4), elute with an elution buffer (250 mM imidazole, 20 mM sodium phosphate, 0.5 M NaCl, pH 7.4) and replace the buffer with PBS. did.
- Purified FLAG-cynoLIGHT and His6-cynoTL1A are trimeric fractionated by gel filtration chromatography (SEC) (Superdex 200 Increase 10/300 GL) (GE Healthcare) using AKTA purifier (GE Healthcare). Sorted. Purified His6-cynoFasL was analyzed by SEC-UP HPLC (equipment: Nexera X2 (Shimadzu), column: ACQUITY UPLC Protein BEH SEC 200 ⁇ , 1.7 ⁇ m, 4.6 ⁇ 150 mm (Waters)), and 85% or more was 3 It was confirmed that it was a protein.
- the binding activity to human or cynomolgus monkey DcR3 ligand trimer was analyzed by the SPR method.
- BIAcore T-100 GE Healthcare
- BIAcore T-200 GE Healthcare
- HBS-EP + Buffer was used as the buffer solution.
- Human FasL trimer was run at 30 ⁇ L / min for 1 minute to monitor binding, followed by buffer running for 3 minutes to monitor dissociation. Then, 3 mol / L magnesium chloride was flowed at 30 ⁇ L / min for 1 minute to carry out a regeneration reaction.
- each DcR3 ligand is used as a trimer (human LIGHT trimer: 62.4 kDa, crab quizal LIGHT trimer: 57.9 kDa, human TL1A trimer: 66.2 kDa, crab quizal TL1A trimer. : 66.1kDa, human FasL trimer: 53.1kDa, cynomolgus FasL trimer: 53.1kDa), each kinetic constants (k a, k d, were calculated K D).
- the chimeric A-Fc (Eg1S, Eg1S YTE, Eg1S N434A, Eg1S LALAGA, Eg1S LALAGANA) (each amino acid sequence: SEQ ID NO: 168, 170, 172, 176, 178) having various mutant Fc was human and It was confirmed that it binds to each DcR3 trimer ligand of cynomolgus monkey (Fig. 30A, B).
- FasL-binding reduced variants E57K-Fc, E57R-Fc, E57V-Fc, 45-10-Fc, 45-18-Fc (all Fc are Eg1S YTE, Eg1S N434A or Eg1S LALAGANA) having various mutant Fc. both were no notable differences in K D values for the compared to the chimeric a-Eg1S human LIGHT trimers and human TL1A trimer. However, in these FasL binding decreases variants, both has increased significantly compared K D values for human FasL trimer chimeric A-Eg1S, human FasL selectively binding is decreased It was confirmed that it was present (Fig. 30A).
- Example 21 Evaluation of neutralization activity of DcR3 soluble ligand The neutralization activity of FasL-reducing variants having various mutant Fc against soluble human LIGHT, soluble human TL1A, and soluble human FasL. was carried out in the same manner as in Example 9 or Example 14.
- Examples of various DcR3 variants include the chimeric A-Fc prepared in Example 12, the FasL binding-reducing variant E57K-Fc prepared by transient expression of CHO-S cells, and 45-18-Fc (all).
- Fc is a single dose of Eg1S YTE or Eg1S LALAGANA) by the method described in Example 14 (1) or by SEC (HiLoad 16/600 Superdex 200 pg) using AKTA purifier (GE Healthcare). Those purified to 95% or more of the body were used.
- the solid line and X are anti-DNP antibodies that are negative controls
- the solid line and black circle (- ⁇ -) are chimeric A-Fc (Eg1S YTE), solid line and white triangle (-].
- ⁇ -) is E57K-Fc (Eg1S YTE)
- solid line and white circle (- ⁇ -) are 45-18-Fc (Eg1S YTE)
- dotted line and black circle (- ⁇ -) are chimeric A-Fc (Eg1S LALAGANA).
- the dotted line and the white triangle (- ⁇ -) represent E57K-Fc (Eg1S LALAGANA)
- the dotted line and the white circle (- ⁇ -) represent 45-18-Fc (Eg1S LALAGANA).
- Example 22 Evaluation of binding activity to DcR3 membrane-type ligand For chimeric A and FasL-reduced binding variants having various mutant Fc, evaluation of binding activity to membrane-type human LIGHT, membrane-type human TL1A, and membrane-type human FasL was performed. , The same method as in Example 15 was carried out.
- the chimeric A-Fc (Eg1S) was prepared from a stable expression strain of CHO cells and purified to 95% or more of the monomer by SEC.
- Chimeric A-Fc (Eg1S YTE, Eg1S N434A, Eg1S LALAGA, Eg1S LALAGANA) were all prepared by transient expression of CHO-S cells, and those purified to 95% or more of monomers by SEC were used.
- a cell line (also referred to as LIGHT / HEK293, TL1A / CHO, or FasL / CHO, respectively) that forcibly expresses a membrane-type molecule of human LIGHT, human TL1A, or human FasL described in Example 15, and a host cell thereof.
- HEK293, CHO-K1 cells with the above sample at a final concentration of 10 ⁇ g / mL, secondary antibody Goat F (ab') 2 Anti-Human IgG R-phycoerythrin Conjugate (Southern Biotech) at a final concentration of 100 ng / mL. After the reaction, the fluorescence intensity of PE was analyzed by a flow cytometer. The results are shown in FIGS.
- the black bar in FIG. 34A represents the reactivity to LIGHT / HEK293, and the white bar represents the reactivity to HEK293 cells.
- the black bar in FIG. 34B represents the reactivity to TL1A / CHO, and the white bar represents the reactivity to CHO-K1 cells.
- the black bar in FIG. 34C represents the reactivity to FasL / CHO, and the white bar represents the reactivity to CHO-K1 cells.
- the chimeric A-Fc (Eg1S, Eg1S YTE, Eg1S N434A, Eg1S LALAGA, Eg1S LALAGANA), E57K-Fc, It was confirmed that E57R-Fc, E57V-Fc, 45-10-Fc and 45-18-Fc (all Fc is Eg1S YTE or Eg1S LALAGANA) bind to each other.
- FIG. 34C it was confirmed that for membrane-type FasL, the binding activity of all FasL binding-reducing variants was significantly reduced as compared with chimera A having various mutant Fc. It was.
- Example 23 Evaluation of neutralization activity of DcR3 membrane-type ligand Membrane-type human LIGHT, membrane-type human TL1A, and membrane-type human of chimeric A and FasL-reduced binding variants having various mutant Fc by the methods shown below.
- the neutralizing activity against FasL was evaluated.
- Chimeras A-Fc, E57K-Fc, and 45-18-Fc (all Fc are Eg1SYTE or Eg1S LALAGANA) were prepared by transient expression of CHO-S, and were produced by transient expression of CHO-S, and a single amount was prepared by SEC as in Example 21. Those purified to 95% or more of the body were used.
- Membrane-type human LIGHT neutralization activity Using human intestinal myofibroblasts (Lonza), CXCL10 production by co-culture with the membrane-type LIGHT forced expression HEK293 cell line (LIGHT / HEK293) used in Example 22 was produced. As indicators, the membrane-type human LIGHT neutralization activity of chimeric A-Fc, E57K-Fc, and 45-18-Fc (all of which are Eg1SYTE or Eg1S LALAGANA) was evaluated.
- Human intestinal myofibroblasts were seeded on Collagen Icoat 96 well plates (Corning) at 1 ⁇ 10 4 cells / well and cultured overnight at 37 ° C.
- LIGHT / HEK293 washed with PBS and medium after fixing with Fixation Buffer (BD Bioscience) at 1 ⁇ 10 4 cells / well, recombinant human IFN- ⁇ (Fujifilm Wako Pure Chemical Industries, Ltd.) at final concentration of 10 ng / mL, chimera A-Fc, E57K-Fc, 45-18-Fc (Fc is Eg1SYTE or Eg1S LALAGANA) to a final concentration of 4.88, 19.5, 78.1, 313, 1250, or 5000 ng / mL.
- the total amount of the culture solution was adjusted to 200 ⁇ L / well.
- the culture supernatant after culturing for 4 days was collected, and the CXCL10 concentration in the culture supernatant was measured using CXCL10 / IP-10 (human) AlphaLISA Detection Kit (Perkin Elmer).
- the results are shown in FIG. In FIG. 35, the solid line and X (- ⁇ -) are anti-DNP antibodies that are negative controls, the solid line and black circle (- ⁇ -) are chimeric A-Fc (Eg1SYTE), and the solid line and white triangle (- ⁇ -) are E57K.
- any of the chimeric A-Fc, E57K-Fc, and 45-18-Fc inhibits the production of CXCL10 by membrane-type LIGHT in a concentration-dependent manner. It was confirmed that both Chimera A and FasL-reducing variants E57K-Fc and 45-18-Fc had membrane-type LIGHT neutralizing activity.
- CD4 positive T cells were isolated from frozen healthy PBMC (AllCells) using EasySep Human CD4 + T cell Isolation Kit (STEMCELL Technologies). The isolated CD4-positive T cells were seeded on a 96-well suspension culture plate at 2 ⁇ 10 5 cells / well, and then Human IL-12 (Miltenyi Biotec) was added to a final concentration of 2 ng / mL, Recombinant Human IL-18 (MBL). The final concentration was 50 ng / mL, and Human IL-15 (Miltenyi Biotec) was added to a final concentration of 25 ng / mL, and the cells were fixed with Fixation Buffer (BD Bioscience).
- membrane-type TL1A-expressing CHO-K1 cells washed with PBS and medium were subjected to 3 ⁇ 10 4 cells / well, chimeric A-Fc, E57K-Fc, 45-18-Fc (Fc is Eg1S YTE or Eg1S LALAGANA).
- Fc is Eg1S YTE or Eg1S LALAGANA
- the culture supernatant after culturing for 2 days was collected, and the IFN- ⁇ concentration in the culture supernatant was measured using AlphaLISA IFN- ⁇ Immunoassay Research Kit (Perkin Elmer). The results are shown in FIG.
- the solid line and X are anti-DNP antibodies that are negative controls
- the solid line and black circle (- ⁇ -) are chimeric A-Fc (Eg1SYTE)
- the solid line and white triangle (- ⁇ -) are E57K.
- solid line and white circle (- ⁇ -) are 45-18-Fc (Eg1S YTE)
- dotted line and black circle (- ⁇ -) are chimera A-Fc (Eg1S LALAGANA)
- dotted line and white triangle are chimera A-Fc (Eg1S LALAGANA), dotted line and white triangle.
- (- ⁇ -) Represents E57K-Fc (Eg1S LALAGANA), and dotted lines and white circles (- ⁇ -) represent 45-18-Fc (Eg1S LALAGANA).
- Membrane-type human FasL neutralization activity The neutralization activity of chimeric A-Fc, E57K-Fc, and 45-18-Fc (all Fc is Eg1SYTE or Eg1S LALAGANA) with respect to membrane-type human FasL is defined as a soluble type.
- Apoptosis of Jurkat cells by co-culture with a forced expression strain of membrane-type FasL into which a non-cleavable modification was introduced was used as an index.
- a FLAG tag (DYKDDDDK) was added to the N-terminal, and the FasL cleavage site (Glu128-Ile131) (Nat. Med., 1998, 4 (1), p.31-36) and the proline-rich region (Pro8-) of the intracellular region were added. Pro69) (Nat. Med., 1996, 2 (3), p.317-322) is removed to express a membrane-type human FasL variant sequence (base sequence: SEQ ID NO: 343, amino acid sequence: SEQ ID NO: 344).
- the plasmid was prepared by the following method.
- Example 15 Using the membrane-type FasL expression plasmid described in Example 15 as a template and using primers designed to delete the target sequence, three regions from the PstI site to Tyr7, from Pro70 to Leu127, and from Gly132 to NotI site, respectively.
- the PCR-amplified product was inserted under the CMV promoter of the pCIpuro vector in the same manner as in Example 1.
- the obtained plasmid was introduced into CHO-K1 cells in the same manner as in Example 15, and membrane-type human FasL variants highly expressed CHO-K1 cells were subjected to cell sorting of a PE-labeled anti-human FasL antibody (BioLegend) positive fraction.
- the strain (FasLdel / CHO) was acquired.
- FasLdel / CHO was seeded on a 96-well adhesive culture plate (Sumitomo Bakelite) at 5 ⁇ 10 3 cells / well, cultured overnight at 37 ° C. in a 5% CO 2 incubator, and then the cells were washed once. ..
- Jurkat cells were seeded therein at 5x10 4 cells / well and chimeric A-Fc, E57K-Fc, 45-18 to a final concentration of 24.4, 97.7, 391, 1563, 6250, or 25000 ng / mL.
- -Fc Fc is Eg1S YTE or Eg1S LALAGANA
- the total volume of the culture solution was adjusted to 100 ⁇ L / well, and after culturing in a 5% CO 2 incubator at 37 ° C. for 4 hours, only Jurkat cells were recovered.
- the collected Jurkat cells were seeded on a 96-well U-bottom plate (Falcon) and stained with PE annexin V apoptosis detection kit (BD Bioscience) for 15 minutes at room temperature. After washing the cells with a buffer for FCM, the fluorescence intensity was analyzed by a flow cytometer FACS Fortessa (BD Bioscience), and Annexin V-positive cells were detected as a dead cell fraction. The results are shown in FIG. In FIG.
- the solid line and X are anti-DNP antibodies that are negative controls
- the solid line and black circle (- ⁇ -) are chimeric A-Fc (Eg1SYTE)
- the solid line and white triangle (- ⁇ -) are E57K.
- solid line and white circle (- ⁇ -) are 45-18-Fc
- dotted line and black circle (- ⁇ -) are chimera A-Fc (Eg1S LALAGANA)
- dotted line and white triangle Represents E57K-Fc (Eg1S LALAGANA)
- dotted lines and white circles (- ⁇ -) represent 45-18-Fc (Eg1S LALAGANA).
- chimeric A-Fc (Eg1S YTE, Eg1S LALAGANA) inhibits cell death of Jurkat cells in a concentration-dependent manner and has neutralizing activity against membrane-type FasL.
- E57K-Fc and 45-18-Fc both of Fc are Eg1S YTE or Eg1S LALAGANA
- E57K-Fc and 45-18-Fc both of Fc are Eg1S YTE or Eg1S LALAGANA
- Example 24 Evaluation of binding activity to soluble DcR3 ligand derived from human primary cells Various soluble forms of chimeric A-Fc, E57K-Fc, and 45-18-Fc (all Fc are Eg1S YTE or Eg1S LALAGANA). The binding activity to the DcR ligand was evaluated using a soluble DcR3 ligand derived from human primary cells. All of the test substances were prepared by transient expression of CHO-S, and those purified to 95% or more of monomers by SEC as in Example 21 were used.
- the cells were seeded at 6 cells / well, an anti-CD28 antibody (BioLegend) having a final concentration of 1 ⁇ g / mL was added, and the cells were cultured in a 5% CO 2 incubator for 3 days, and then the culture supernatant was collected.
- the primary soluble LIGHT concentration in the collected culture supernatant was measured using Human LIGHT / TNFSF14 Quantikine ELISA Kit (R & D), and 14 pg / mL in the culture supernatant of unstimulated human T cells, anti-CD3. It was confirmed that 5.6 ng / mL soluble ELISA was present in the culture supernatant of human T cells stimulated with the antibody and anti-CD28 antibody.
- the supernatant was reacted.
- the soluble recombinant FLAG-LIGHT trimer prepared in Example 13 was used. After washing the plate, a biotinylated anti-LIGHT antibody (R & D) was reacted. After washing the plate, streptavidin-HRP (PIERCE) was reacted, and after washing again, TMB solution (Dako) was added to develop color, the color reaction was stopped with 2N sulfuric acid solution, and 450 nm (reference). The absorbance at a wavelength of 570 nm) was measured.
- FIG. 38A The results of the soluble recombinant FLAG-LIGHT trimer are shown in FIG. 38A, and the results of the culture supernatant of LIGHT-induced human T cells are shown in FIG. 38B.
- the solid line and X are anti-DNP antibodies that are negative controls
- the solid line and black circle (- ⁇ -) are chimeric A-Fc (Eg1S YTE)
- the solid line and white square (- ⁇ -) are chimeras.
- A-Fc (Eg1S), solid line and white triangle (- ⁇ -) are E57K-Fc (Eg1S YTE), solid line and white circle (- ⁇ -) are 45-18-Fc (Eg1S YTE), dotted line and black circle (---) ⁇ -) Is chimera
- dotted line and white triangle (- ⁇ -) is E57K-Fc (Eg1S LALAGANA)
- dotted line and white circle (- ⁇ -) are 45-18-Fc.
- Represents (Eg1S LALAGANA).
- “6 ⁇ sup.CD3 / 28” indicated by a black bar uses a culture supernatant 6 times concentrated in human T cells inducing LIGHT expression under anti-CD3 antibody OKT3 and anti-CD28 antibody stimulation conditions. “6 ⁇ sup. None” indicated by a white bar indicates that a culture supernatant 6 times concentrated from unstimulated human T cells was used.
- LIGHT expression was induced in wells that captured any of the chimeric A-Fc, E57K-Fc, and 45-18-Fc (all of which were Eg1S, Eg1S YTE, or Eg1S LALAGANA). LIGHT was detected only in the culture supernatant of human T cells. From this, chimeric A-Fc, E57K-Fc, and 45-18-Fc (all Fc are Eg1S, Eg1S YTE, or Eg1S LALAGANA) are produced from human T cells stimulated with anti-CD3 antibody and anti-CD28 antibody. It was confirmed that it binds to the soluble LIGHT.
- the binding of chimeric A-Fc, E57K-Fc, and 45-18-Fc (all Fc is Eg1S YTE or Eg1S LALAGANA) to the activated human PBMC-derived primary soluble TL1A was evaluated. ..
- the primary soluble TL1A was prepared by the following method. A 250 ⁇ g / mL human IgG antibody (Jackson ImmunoResearch) was immobilized on a 6-well adhesive culture plate (Sumitomo Bakelite), and an anti-human ⁇ light chain antibody (Bethyl Laboratories) and an anti-human ⁇ light chain antibody (Bethyl Laboratories) were further immobilized.
- PBMC AllCells
- Sandwich ELISA was carried out in the same manner as in (1).
- Chimeric A-Fc, E57K-Fc, 45-18-Fc (all Fc are Eg1S YTE or Eg1S LALAGANA), or the anti-human TL1A antibody prepared in Example 16 were captured on a 96-well immunoplate.
- the plate was reacted with a 4-fold concentrated culture supernatant of PBMC in which TL1A production was induced, or the soluble recombinant His6-TL1A trimer prepared in Example 13 as a standard, and biotinylated anti-TL1A antibody ( Detected by R & D).
- FIG. 38C The results of the soluble recombinant His6-TL1A trimer are shown in FIG. 38C, and the results of the culture supernatant of PBMC inducing TL1A production are shown in FIG. 38D.
- the solid line and X are anti-DNP antibodies that are negative controls
- the solid line and black circle (- ⁇ -) are chimeric A-Fc (Eg1S YTE)
- the solid white square (- ⁇ -) is chimeric.
- A-Fc (Eg1S), solid line and white triangle (- ⁇ -) are E57K-Fc (Eg1S YTE), solid line and white circle (- ⁇ -) are 45-18-Fc (Eg1S YTE), dotted line and black circle (---) ⁇ -) Is chimera
- dotted line and white triangle (- ⁇ -) is E57K-Fc (Eg1S LALAGANA)
- dotted line and white circle (- ⁇ -) are 45-18-Fc.
- the solid black triangle (- ⁇ -) represents an anti-TL1A antibody.
- the black bar “4 ⁇ supIC” indicates that the culture supernatant of PBMC that induced TL1A expression under immune complex stimulation conditions was used, which is indicated by the white bar.
- “4 ⁇ sup.none” indicates that an unstimulated PBMC culture supernatant was used.
- TL1A expression was induced in wells that captured any of the chimeric A-Fc, E57K-Fc, and 45-18-Fc (all of which were Eg1S, Eg1S YTE, or Eg1S LALAGANA). TL1A was detected only in the culture supernatant of PBMC.
- chimeric A-Fc, E57K-Fc, and 45-18-Fc are converted into soluble TL1A produced from PBMC stimulated by an immune complex. It was confirmed that they would combine.
- Sandwich ELISA was carried out in the same manner as in (1).
- a human in which chimeric A-Fc, E57K-Fc, 45-18-Fc (all Fc are Eg1S YTE or Eg1S LALAGANA) or Fas-Fc (R & D) were captured on a 96-well immunoplate and then AICD was induced.
- a 6-fold concentrated culture supernatant of T cells, or human His6 Fas Land / TNFSF6 (Cell Signaling TECHNOLOGY) was reacted as a standard, and detection was performed with a biotinylated anti-FasL antibody attached to Human Fas Land ELISA Kit (Abcam).
- FIG. 38E The result of soluble recombinant His6-FasL is shown in FIG. 38E, and the result of the culture supernatant of AICD-induced human T cells is shown in FIG. 38F.
- the solid line and X are anti-DNP antibodies that are negative controls
- the solid line and black circle (- ⁇ -) are chimeric A-Fc (Eg1S YTE)
- the solid line and white square (- ⁇ -) are chimeras.
- A-Fc (Eg1S), solid line and white triangle (- ⁇ -) are E57K-Fc (Eg1S YTE), solid line and white circle "- ⁇ -" are 45-18-Fc (Eg1S YTE), dotted line and black circle (- ⁇ -) Is chimera A-Fc (Eg1S LALAGANA), dotted line and white triangle (- ⁇ -) is E57K-Fc (Eg1S LALAGANA), dotted line and white circle (- ⁇ -) are 45-18-Fc. (Eg1S LALAGANA), solid line and black triangle (- ⁇ -) represent Fas-Fc.
- the black bar “6 ⁇ sup.CD3” indicates that the culture supernatant of AICD-induced human T cells was used under the anti-CD3 antibody OKT3 stimulation condition, which is indicated by the white bar “6”.
- “Xsup.none” indicates that the culture supernatant of human T cells in which AICD was not induced was used.
- FasL was detected only in the culture supernatant of AICD-induced human T cells.
- FasL detected in the culture supernatant of AICD-induced human T cells was significantly reduced. It was confirmed that these variants had attenuated binding activity to soluble FasL derived from human T cells.
- Example 25 Evaluation of physical properties of DcR3 variant E57K-Fc, 45-18-Fc (E57K-Fc, 45-18-Fc) prepared by transient expression of CHO-S and purified to 95% or more of monomers by SEC in the same manner as in Example 21.
- Fc is Eg1S YTE or Eg1S LALAGANA
- the elution time is calculated by hydrophobic interaction chromatography (HIC) and the Tm value (DSF) by the differential scanning fluorometry (DSF) method in the same manner as in Example 4. °C) was calculated.
- Example 26 Evaluation of mouse pharmacokinetics of DcR3 variant Chimera A-Fc, E57K-, which was prepared by transient expression of CHO-S and purified to 95% or more of monomers by SEC in the same manner as in Example 21.
- Fc and 45-18-Fc both Fc are Eg1SYTE or Eg1S LALAGANA
- the pharmacokinetics in mice was evaluated by the same method as described in Example 6. The results are shown in FIG.
- the AUC of each DcR3 variant was significantly improved as compared with the AUC value 354 of S195-Fc (IEGRMD g1S), which is the wild-type DcR3 described in Example 6.
- Example 27 Evaluation of Aggregation of DcR3 Variant Not Fused with Fc Protein (S195-His6) (base sequence: SEQ ID NO: 345) in which a His6 tag is added to the C-terminal of human wild-type DcR3 (S195) lacking the HBD region.
- a DNA fragment of a signal peptide sequence was added to the N-terminal of a human DcR3 DNA fragment (SEQ ID NO: 107) excluding HBD, and a sequence in which a His6 tag sequence was added to the C-terminal was artificially synthesized (Fasmac).
- Chimera A-His6, chimera A-E57K-His6, and 45-18-His6 are DNA fragments of chimera A (SEQ ID NO: 353), DNA fragments of chimera A-E57K (SEQ ID NO: 354), or DNA of 45-18, respectively.
- a DNA fragment of a signal peptide sequence was artificially synthesized at the N-terminal of the fragment (SEQ ID NO: 355), and a sequence in which a His6 tag sequence was added at the C-terminal was artificially synthesized.
- Each artificial synthetic fragment was introduced into the pCIpuro vector by the method described in Example 1 and transiently expressed by Expi293 cells.
- Amicon Ultra-0.5 (Millipore) with a fractionated molecular weight of 3 kDa prerinsed with sterilized water, the culture supernatant expressing S195-His6 was concentrated 30-fold, and Chimera A-His6 and Chimera A-E57K were concentrated.
- the culture supernatants expressing -His6 and 45-18-His6 were each diluted 6-fold.
- DcR3 variant of the present invention had a significantly reduced aggregate content as compared with the wild-type DcR3. That is, by substituting CRD1 and CRD4 of DcR3 with CRD1 and CRD4 derived from OPG, respectively, there is an effect of reducing the aggregation observed in wild-type DcR3, and this effect depends on whether or not the binding property to FasL is reduced. It was shown to be exerted regardless.
- SEQ ID NO: 1 Nucleotide sequence of human DcR3 cDNA (accession number: NM_003823.3)
- SEQ ID NO: 2 Amino acid sequence of human DcR3 (accession number: NP_003814.1)
- SEQ ID NO: 3 Nucleotide sequence of human DcR3 (without signal peptide)
- SEQ ID NO: 4 Amino acid sequence of human DcR3 (without signal peptide)
- SEQ ID NO: 6 Amino acid sequence of CRD1 of human DcR3
- SEQ ID NO: 7 Nucleotide sequence of CRD2 of human DcR3
- SEQ ID NO: 8 Amino acid sequence of CRD2 of human DcR3
- SEQ ID NO: 9 Nucleotide sequence of CRD3 of human DcR3 SEQ ID NO: 10: Amino acid sequence of CRD
- Nucleotide sequence of chimeric A-R60K-HBD Nucleotide sequence of HBD of wild type DcR3 SEQ ID NO: 48: Nucleotide sequence of HBD of wild type DcR3 SEQ ID NO: 49: Nucleotide sequence of chimera B SEQ ID NO: 50: Nucleotide sequence of chimeric B SEQ ID NO: 51: Nucleotide sequence of chimera C SEQ ID NO: 52: Nucleotide sequence of chimera C 53: Nucleotide sequence of chimera A SEQ ID NO: 54: Nucleotide sequence of chimera A SEQ ID NO: 55: Nucleotide sequence of OPG SEQ ID NO: 56: 103-123 OPG Nucleotide Sequence Sequence No.
- T133A / S146A SEQ ID NO: 61 Nucleotide sequence of N131S / N144S / N157S SEQ ID NO: 62: Nucleotide sequence of N131S / N144S / N157S SEQ ID NO: 63: Nucleotide sequence of T133A / S146A / T159A 65: Nucleotide sequence of chimeric A-E57K SEQ ID NO: 66: Nucleotide sequence of chimeric A-E57K SEQ ID NO: 67: Nucleotide sequence of chimeric A-E57L SEQ ID NO: 68: Nucleotide sequence of chimera A-E57L SEQ ID NO: 69: Chimera A-R60K Nucleotide Sequence No.
- Nucleotide sequence of chimeric A-Fc (IEGRMD g1S) 81: Nucleotide sequence of chimeric A-Fc (g4PEK) SEQ ID NO: 82: Nucleotide sequence of chimeric A-Fc (g4PEK) SEQ ID NO: 83: 103-123 OPG-Fc (g4PEK) Nucleotide sequence SEQ ID NO: 84: 103-123OPG-Fc (G4PEK) Nucleotide Sequence No. 85: N131S / N144S-Fc (g4PEK) Nucleotide Sequence No.
- Nucleotide sequence of crab monkey LIGHT (Asp74-Val240) Nucleotide Sequence No. 135: Nucleotide Sequence No. 136 of the extracellular region of mouse LIGHT (Asp72-Val239): Nucleotide sequence No. 137 of the extracellular region of mouse LIGHT (Asp72-Val239): Human TL1A Nucleotide sequence number 138 of the extracellular region (Leu72-Leu251): Nucleotide sequence number 139 of the extracellular region (Leu72-Leu251) of human TL1A: Nucleotide sequence number of the extracellular region (Leu72-Leu251) of the crab monkey TL1A.
- Fc (Eg1S-LALAGANA) : Nucleotide sequence of chimeric A-Fc (Eg1S) SEQ ID NO: 168: Nucleotide sequence of chimeric A-Fc (Eg1S) SEQ ID NO: 169: Nucleotide sequence of chimeric A-Fc (Eg1S-YTE) SEQ ID NO: 170: Chimera A-Fc ( Nucleotide Sequence No. 171 of Eg1S-YTE) Nucleotide Sequence No. 172 of Chimera A-Fc (Eg1S-N434A): Nucleotide Sequence No.
- Nucleotide Sequence No. 188 of Chimera A-E57R_R58D Nucleotide Sequence No. 189 of Chimera A-E57R_R58D: Nucleotide Sequence No. 190: Chimera A-E57R -Fc (g4PEK)
- Nucleotide Sequence No. 191 Nucleotide Sequence No. 192 of Chimera A-E57V-Fc (g4PEK): Nucleotide Sequence No.
- Amino Acid SEQ ID NO: 251 Chimera A-E57K_R58E-Fc (Eg1S LALAGA) Base Sequence No. 252: Chimera A-E57K_R58E-Fc (Eg1S LALAGA) Eg1S LALAGA) Amino Acid SEQ ID NO: 253: Chimera A-E57R_R58D-Fc (Eg1S LALAGA) Base Sequence No. 254: Chimera A-E57R_R58D-Fc (Eg1S LALAGA) Amino Acid SEQ ID NO: 255: Chimera A-E57K-Fc (Eg1S LALAGANA) Base Sequence No.
- SEQ ID NO: 345 Human Amino acid sequence of amino acid SEQ ID NO: 345: S195-His6 in which the cleavage site and intracellular proline-rich region were deleted from the DcR3 ligand FasL and the FLAG tag was inserted at the N-terminal. No.
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Immunology (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Gastroenterology & Hepatology (AREA)
- Toxicology (AREA)
- Cell Biology (AREA)
- Pulmonology (AREA)
- Pain & Pain Management (AREA)
- Rheumatology (AREA)
- Transplantation (AREA)
- Wood Science & Technology (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Epidemiology (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Priority Applications (11)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| BR112022004590A BR112022004590A2 (pt) | 2019-09-13 | 2020-09-11 | Variante dcr3 |
| KR1020227007739A KR20220061967A (ko) | 2019-09-13 | 2020-09-11 | DcR3 개변체 |
| CA3154191A CA3154191A1 (en) | 2019-09-13 | 2020-09-11 | Dcr3 variant |
| CN202511771538.7A CN121930331A (zh) | 2019-09-13 | 2020-09-11 | DcR3变体 |
| AU2020346580A AU2020346580A1 (en) | 2019-09-13 | 2020-09-11 | DcR3 variant |
| JP2021545613A JP7679300B2 (ja) | 2019-09-13 | 2020-09-11 | DcR3改変体 |
| EP20864177.9A EP4056232B1 (en) | 2019-09-13 | 2020-09-11 | Dcr3 variant |
| CN202080064092.3A CN114450301B (zh) | 2019-09-13 | 2020-09-11 | DcR3变体 |
| CN202511751554.XA CN121949515A (zh) | 2019-09-13 | 2020-09-11 | DcR3变体 |
| US17/642,485 US20220340642A1 (en) | 2019-09-13 | 2020-09-11 | Dcr3 variant |
| JP2025077324A JP2025121978A (ja) | 2019-09-13 | 2025-05-07 | DcR3改変体 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019167728 | 2019-09-13 | ||
| JP2019-167728 | 2019-09-13 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021049606A1 true WO2021049606A1 (ja) | 2021-03-18 |
Family
ID=74865719
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/034444 Ceased WO2021049606A1 (ja) | 2019-09-13 | 2020-09-11 | DcR3改変体 |
Country Status (10)
| Country | Link |
|---|---|
| US (1) | US20220340642A1 (https=) |
| EP (1) | EP4056232B1 (https=) |
| JP (2) | JP7679300B2 (https=) |
| KR (1) | KR20220061967A (https=) |
| CN (3) | CN121930331A (https=) |
| AU (1) | AU2020346580A1 (https=) |
| BR (1) | BR112022004590A2 (https=) |
| CA (1) | CA3154191A1 (https=) |
| TW (1) | TW202124425A (https=) |
| WO (1) | WO2021049606A1 (https=) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11274140B2 (en) | 2020-05-08 | 2022-03-15 | Alpine Immune Sciences, Inc. | APRIL and BAFF inhibitory immunomodulatory proteins and methods of use thereof |
| WO2023288182A1 (en) * | 2021-07-12 | 2023-01-19 | Genentech, Inc. | Structures for reducing antibody-lipase binding |
| JP2023530046A (ja) * | 2020-04-02 | 2023-07-13 | ラ ホヤ インスティテュート フォー イムノロジー | Tnfファミリーのメンバーの二重標的化のための方法および組合せ |
| WO2025160334A1 (en) * | 2024-01-26 | 2025-07-31 | Flagship Pioneering Innovations Vii, Llc | Immunoreceptor inhibitory proteins and related methods |
| US12612446B2 (en) | 2017-10-10 | 2026-04-28 | Alpine Immune Sciences, Inc. | CTLA-4 variant immunomodulatory proteins and uses thereof |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN121843714A (zh) | 2023-08-11 | 2026-04-10 | 派拉冈医疗公司 | Tl1a结合抗体及使用方法 |
Citations (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS529625B1 (https=) | 1970-04-29 | 1977-03-17 | ||
| JPS63299A (ja) | 1986-04-22 | 1988-01-05 | イミユネツクス・コ−ポレ−シヨン | ヒトg−csfタンパク質の発現 |
| JPH02227075A (ja) | 1988-09-29 | 1990-09-10 | Kyowa Hakko Kogyo Co Ltd | 新規ポリペプチド |
| JPH02257891A (ja) | 1989-03-31 | 1990-10-18 | Kyowa Hakko Kogyo Co Ltd | 組換え動物細胞による蛋白質の製造 |
| JPH0322979A (ja) | 1989-06-19 | 1991-01-31 | Kyowa Hakko Kogyo Co Ltd | 新規プラスミノーゲン活性化因子 |
| WO1997010354A1 (fr) | 1995-09-11 | 1997-03-20 | Kyowa Hakko Kogyo Co., Ltd. | Anticorps de la chaine alpha du recepteur de l'interleukine 5 humaine |
| JP2001516581A (ja) * | 1997-09-18 | 2001-10-02 | ジェネンテク・インコーポレイテッド | DcR3ポリペプチドというTNFR相同体 |
| WO2002031140A1 (en) | 2000-10-06 | 2002-04-18 | Kyowa Hakko Kogyo Co., Ltd. | Cells producing antibody compositions |
| US6835814B1 (en) | 1999-03-30 | 2004-12-28 | Eli Lilly And Company | Protease resistant flint analogs |
| WO2005035586A1 (ja) | 2003-10-08 | 2005-04-21 | Kyowa Hakko Kogyo Co., Ltd. | 融合蛋白質組成物 |
| US6965012B1 (en) | 1999-03-30 | 2005-11-15 | Eli Lilly And Company | Flint polypeptide analogs |
| WO2006033386A1 (ja) | 2004-09-22 | 2006-03-30 | Kirin Beer Kabushiki Kaisha | 安定化されたヒトIgG4抗体 |
| WO2012081628A1 (ja) | 2010-12-15 | 2012-06-21 | 大学共同利用機関法人情報・システム研究機構 | タンパク質の生産方法 |
| JP2013153749A (ja) | 2006-08-28 | 2013-08-15 | Kyowa Hakko Kirin Co Ltd | アンタゴニストのヒトlight特異的ヒトモノクローナル抗体 |
| WO2014153111A2 (en) | 2013-03-14 | 2014-09-25 | Amgen Inc. | Interleukin-2 muteins for the expansion of t-regulatory cells |
| US20150132311A1 (en) | 2013-11-13 | 2015-05-14 | Pfizer Inc. | Tumor necrosis factor-like ligand 1a specific antibodies and compositions and uses thereof |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20040231011A1 (en) * | 2001-06-28 | 2004-11-18 | Genentech, Inc. | DcR3 polypeptide, a TNFR homolog |
| BRPI0519008A2 (pt) * | 2004-12-13 | 2008-12-23 | Evogenix Ltd | proteÍnas variantes de osteoprotegerina |
| US20140193410A1 (en) * | 2013-01-09 | 2014-07-10 | University Of Miami | Compositions and Methods for the Regulation of T Regulatory Cells Using TL1A-Ig Fusion Protein |
| ES2894963T3 (es) * | 2013-05-17 | 2022-02-16 | Cedars Sinai Medical Center | Variantes de TNFSF15 y DcR3 asociadas con la enfermedad de Crohn |
| EP3730188B1 (en) * | 2015-08-21 | 2024-07-31 | The Children's Hospital of Philadelphia | Compositions and methods for use in combination for the treatment and diagnosis of autoimmune diseases |
-
2020
- 2020-09-11 CN CN202511771538.7A patent/CN121930331A/zh active Pending
- 2020-09-11 EP EP20864177.9A patent/EP4056232B1/en active Active
- 2020-09-11 JP JP2021545613A patent/JP7679300B2/ja active Active
- 2020-09-11 AU AU2020346580A patent/AU2020346580A1/en active Pending
- 2020-09-11 US US17/642,485 patent/US20220340642A1/en active Pending
- 2020-09-11 CN CN202511751554.XA patent/CN121949515A/zh active Pending
- 2020-09-11 CA CA3154191A patent/CA3154191A1/en active Pending
- 2020-09-11 CN CN202080064092.3A patent/CN114450301B/zh active Active
- 2020-09-11 WO PCT/JP2020/034444 patent/WO2021049606A1/ja not_active Ceased
- 2020-09-11 BR BR112022004590A patent/BR112022004590A2/pt unknown
- 2020-09-11 KR KR1020227007739A patent/KR20220061967A/ko active Pending
- 2020-09-11 TW TW109131285A patent/TW202124425A/zh unknown
-
2025
- 2025-05-07 JP JP2025077324A patent/JP2025121978A/ja active Pending
Patent Citations (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS529625B1 (https=) | 1970-04-29 | 1977-03-17 | ||
| JPS63299A (ja) | 1986-04-22 | 1988-01-05 | イミユネツクス・コ−ポレ−シヨン | ヒトg−csfタンパク質の発現 |
| JPH02227075A (ja) | 1988-09-29 | 1990-09-10 | Kyowa Hakko Kogyo Co Ltd | 新規ポリペプチド |
| JPH02257891A (ja) | 1989-03-31 | 1990-10-18 | Kyowa Hakko Kogyo Co Ltd | 組換え動物細胞による蛋白質の製造 |
| JPH0322979A (ja) | 1989-06-19 | 1991-01-31 | Kyowa Hakko Kogyo Co Ltd | 新規プラスミノーゲン活性化因子 |
| WO1997010354A1 (fr) | 1995-09-11 | 1997-03-20 | Kyowa Hakko Kogyo Co., Ltd. | Anticorps de la chaine alpha du recepteur de l'interleukine 5 humaine |
| JP4303883B2 (ja) | 1997-09-18 | 2009-07-29 | ジェネンテック・インコーポレーテッド | DcR3ポリペプチドというTNFR相同体 |
| JP2001516581A (ja) * | 1997-09-18 | 2001-10-02 | ジェネンテク・インコーポレイテッド | DcR3ポリペプチドというTNFR相同体 |
| US6835814B1 (en) | 1999-03-30 | 2004-12-28 | Eli Lilly And Company | Protease resistant flint analogs |
| US6965012B1 (en) | 1999-03-30 | 2005-11-15 | Eli Lilly And Company | Flint polypeptide analogs |
| WO2002031140A1 (en) | 2000-10-06 | 2002-04-18 | Kyowa Hakko Kogyo Co., Ltd. | Cells producing antibody compositions |
| WO2005035586A1 (ja) | 2003-10-08 | 2005-04-21 | Kyowa Hakko Kogyo Co., Ltd. | 融合蛋白質組成物 |
| WO2006033386A1 (ja) | 2004-09-22 | 2006-03-30 | Kirin Beer Kabushiki Kaisha | 安定化されたヒトIgG4抗体 |
| JP2013153749A (ja) | 2006-08-28 | 2013-08-15 | Kyowa Hakko Kirin Co Ltd | アンタゴニストのヒトlight特異的ヒトモノクローナル抗体 |
| US8974787B2 (en) | 2006-08-28 | 2015-03-10 | Kyowa Hakko Kirin Co., Limited | Antagonistic human light-specific human monoclonal antibodies |
| WO2012081628A1 (ja) | 2010-12-15 | 2012-06-21 | 大学共同利用機関法人情報・システム研究機構 | タンパク質の生産方法 |
| WO2014153111A2 (en) | 2013-03-14 | 2014-09-25 | Amgen Inc. | Interleukin-2 muteins for the expansion of t-regulatory cells |
| US20150132311A1 (en) | 2013-11-13 | 2015-05-14 | Pfizer Inc. | Tumor necrosis factor-like ligand 1a specific antibodies and compositions and uses thereof |
Non-Patent Citations (68)
| Title |
|---|
| "Antibodies-A Laboratory Manual", 1988, COLD SPRING HARBOR LABORATORY |
| "GenBank", Database accession no. NP_002537.3 |
| "Methods in Nucleic Acids Res.", vol. 283, 1991, CRC PRESS |
| "Molecular Cloning, A Laboratory Manual", 1989, COLD SPRING HARBOR LABORATORY PRESS |
| "Molecular Cloning: A Laboratory Manual", 2001, COLD SPRING HARBOR LABORATORY PRESS |
| "UniProt", Database accession no. 000300 |
| ACAD. SCI. USA., vol. 82, 1985, pages 488 |
| AM. J. CANCER. RES., vol. 2, 2012, pages 45 - 64 |
| AM. J. PHYSIOL. GASTROINTEST. LIVER PHYSIOL., vol. 285, 2003, pages G754 - G760 |
| BIOCHEMICAL PHARMACOLOGY, vol. 81, 2011, pages 838 - 847 |
| BIOCHEMICAL. PHARMACOLOGY, vol. 81, 2011, pages 838 - 847 |
| CELL, vol. 6, 1975, pages 121 |
| CELL. IMMUNOL., vol. 200, 2000, pages 16 - 26 |
| CHROMOSOMA, vol. 41, 1973, pages 129 |
| CLIN. CANCER RES., vol. 11, no. 8, 2005, pages 3126 - 3135 |
| CURR. OPIN. CELL. BIOL., vol. 20, 2009, pages 685 - 691 |
| CYTOTECHNOLOGY, vol. 3, 1990, pages 133 |
| DRUG METABOLISM AND DISPOSITION, vol. 31, 2003, pages 502 - 507 |
| GENE, vol. 34, 1985, pages 315 |
| GENETICS, vol. 55, 1968, pages 513 |
| IMMUNITY, vol. 16, 2002, pages 479 - 492 |
| IMMUNOLOGY, vol. 128, 2009, pages 451 - 458 |
| J AM CHEM SOC, vol. 131, 2009, pages 3794 - 3795 |
| J. BACTERIOLOGY, vol. 153, 1983, pages 163 |
| J. BIOCHEM., vol. 101, 1987, pages 1307 |
| J. IMMUNOL., vol. 164, 2000, pages 4178 - 4184 |
| J. IMMUNOL., vol. 176, 2006, pages 173 - 180 |
| J. IMMUNOL., vol. 182, 2009, pages 7663 - 7671 |
| J. IMMUNOL., vol. 189, 2012, pages 245 - 252 |
| J. PHARM. SCI., vol. 101, 2012, pages 955 - 964 |
| J. PHARM. SCI., vol. 102, 2013, pages 2471 - 2483 |
| J. PHARM. SCI., vol. 104, 2015, pages 1866 - 1884 |
| J. RHEUMATOL., vol. 40, 2013, pages 1316 - 1326 |
| JOURNAL OF BIOMEDICAL SCIENCE, vol. 24, 2017, pages 39 |
| JOURNAL OF EXPERIMENTAL MEDICINE, vol. 108, 1958, pages 945 |
| KUNKEL ET AL., PROC. NATL. ACAD. SCI. USA, vol. 82, 1985, pages 488 - 492 |
| MABS, vol. 9, 2017, pages 844 - 853 |
| METHODS ENZYMOL., vol. 194, 1990, pages 182 |
| METHODS IN CELL SCIENCE, vol. 18, 1996, pages 115 |
| MOL. BIOTECHNOL., vol. 10, 2015, pages 914 - 922 |
| MOLECULAR CELLGENETICS, pages 883 - 900 |
| MUCOSAL IMMUNOLOGY, vol. 4, 2011, pages 172 - 185 |
| MUCOSAL IMMUNOLOGY, vol. 7, 2014, pages 1492 - 1503 |
| MUCOSAL IMMUNOLOGY, vol. 8, 2015, pages 545 - 558 |
| NAT. MED., vol. 2, no. 3, 1996, pages 317 - 322 |
| NAT. MED., vol. 4, no. 1, 1998, pages 31 - 36 |
| NATURE REVIEWS CANCER, vol. 2, 2002, pages 420 - 430 |
| NATURE REVIEWS DRUG DISCOVERY, vol. 12, 2013, pages 147 - 168 |
| NATURE, vol. 195, 1962, pages 788 |
| NATURE, vol. 329, 1987, pages 840 |
| NUCLEIC ACIDS RESEARCH, vol. 10, 1982, pages 6487 |
| P.N.A.S., vol. 103, 2006, pages 8441 - 8446 |
| PROC. NATL. ACAD. SCI. USA, vol. 60, 1968, pages 1275 |
| PROC. NATL. ACAD. SCI. USA, vol. 75, 1978, pages 1929 |
| PROC. NATL. ACAD. SCI. USA, vol. 77, 1980, pages 4216 |
| PROC. NATL. ACAD. SCI. USA, vol. 84, 1987, pages 7413 |
| PROC. NATL. ACAD. SCI. USA., vol. 79, 1982, pages 6409 |
| RADIATION RESEARCH, vol. 148, 1997, pages 260 |
| SCIENCE, vol. 122, 1952, pages 501 |
| See also references of EP4056232A4 |
| STRUCTURE, vol. 19, 2011, pages 162 - 171 |
| STRUCTURE, vol. 22, 2014, pages 1252 - 1262 |
| STRUCTURE, vol. 24, 2016, pages 2016 - 2023 |
| THE JOURNAL OF IMMUNOLOGY, vol. 173, 2004, pages 502 - 507 |
| TRENDS BIOCHEM SCI, vol. 27, 2002, pages 19 - 26 |
| VIROLOGY, vol. 52, 1973, pages 456 |
| VIROLOGY, vol. 8, 1959, pages 396 |
| XENOBIOTIC METABOLISM AND DISPOSITION, vol. 14, 1999, pages 286 - 293 |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12612446B2 (en) | 2017-10-10 | 2026-04-28 | Alpine Immune Sciences, Inc. | CTLA-4 variant immunomodulatory proteins and uses thereof |
| JP2023530046A (ja) * | 2020-04-02 | 2023-07-13 | ラ ホヤ インスティテュート フォー イムノロジー | Tnfファミリーのメンバーの二重標的化のための方法および組合せ |
| US11274140B2 (en) | 2020-05-08 | 2022-03-15 | Alpine Immune Sciences, Inc. | APRIL and BAFF inhibitory immunomodulatory proteins and methods of use thereof |
| US12202882B2 (en) | 2020-05-08 | 2025-01-21 | Alpine Immune Sciences, Inc. | APRIL and BAFF inhibitory immunomodulatory proteins and methods of use thereof |
| US12304943B2 (en) | 2020-05-08 | 2025-05-20 | Alpine Immune Sciences, Inc. | April and BAFF inhibitory immunomodulatory proteins and methods of use thereof |
| US12612447B2 (en) | 2020-05-08 | 2026-04-28 | Alpine Immune Sciences, Inc. | April and BAFF inhibitory immunomodulatory proteins and methods of use thereof |
| WO2023288182A1 (en) * | 2021-07-12 | 2023-01-19 | Genentech, Inc. | Structures for reducing antibody-lipase binding |
| WO2025160334A1 (en) * | 2024-01-26 | 2025-07-31 | Flagship Pioneering Innovations Vii, Llc | Immunoreceptor inhibitory proteins and related methods |
Also Published As
| Publication number | Publication date |
|---|---|
| TW202124425A (zh) | 2021-07-01 |
| BR112022004590A2 (pt) | 2022-06-14 |
| CN114450301A (zh) | 2022-05-06 |
| CN114450301B (zh) | 2025-12-05 |
| KR20220061967A (ko) | 2022-05-13 |
| JP7679300B2 (ja) | 2025-05-19 |
| US20220340642A1 (en) | 2022-10-27 |
| AU2020346580A1 (en) | 2022-03-31 |
| EP4056232A4 (en) | 2023-09-13 |
| JPWO2021049606A1 (https=) | 2021-03-18 |
| EP4056232B1 (en) | 2026-05-06 |
| EP4056232A1 (en) | 2022-09-14 |
| CN121930331A (zh) | 2026-04-28 |
| JP2025121978A (ja) | 2025-08-20 |
| CA3154191A1 (en) | 2021-03-18 |
| CN121949515A (zh) | 2026-05-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7679300B2 (ja) | DcR3改変体 | |
| KR102884523B1 (ko) | IL-12 이종이량체 Fc-융합 단백질 | |
| CN111138542B (zh) | 双特异性抗体及其用途 | |
| JP7662516B2 (ja) | Pd-1標的化il-15/il-15rアルファfc融合タンパク質およびその組み合わせ療法での使用 | |
| US20230227584A1 (en) | Bispecific antibodies comprising a modified c-terminal crossfab fragment | |
| JP7746258B2 (ja) | 特性が改善されたpd-1標的化il-15/il-15rαfc融合タンパク質 | |
| AU2012317418B2 (en) | Antigen-binding molecule for promoting elimination of antigens | |
| RU2722829C9 (ru) | Антигенсвязывающая молекула, индуцирующая иммунный ответ на антиген-мишень | |
| KR20190014525A (ko) | 면역 조절 단백질과 종양 항원을 결합하는 이중특이적 결합 단백질 | |
| RS60664B1 (sr) | Anti-ox40 antitela i njihove upotrebe | |
| BR112015024587B1 (pt) | Variante de região fc de igg1 humana, polipeptídeo compreendendo a mesma, seu método de produção e composição farmacêutica | |
| KR20140130707A (ko) | FcγRIIB를 매개로 항원의 소실을 촉진하는 항원 결합 분자 | |
| KR20140015501A (ko) | 항원 결합 분자의 혈장 체류성과 면역원성을 개변하는 방법 | |
| JP7529568B2 (ja) | 抗体組成物 | |
| KR20220121822A (ko) | FcγRIIB 친화력이 강화된 항체 Fc 영역 | |
| WO2021201236A1 (ja) | 抗体組成物 | |
| CN121532432A (zh) | 免疫治疗蛋白 | |
| JP7833531B2 (ja) | Cd40を特異的に認識する抗体およびその使用 | |
| HK40067776A (en) | Dcr3 variant | |
| CA3150762A1 (en) | 4-1 bb and ox40 binding proteins and related compositions and methods, antibodies against 4-1 bb, antibodies against ox40 | |
| RU2799423C1 (ru) | Способ изменения удержания в плазме и иммуногенности антигенсвязывающей молекулы |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20864177 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 3154191 Country of ref document: CA |
|
| ENP | Entry into the national phase |
Ref document number: 2021545613 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01A Ref document number: 112022004590 Country of ref document: BR |
|
| ENP | Entry into the national phase |
Ref document number: 2020346580 Country of ref document: AU Date of ref document: 20200911 Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2020864177 Country of ref document: EP Effective date: 20220413 |
|
| ENP | Entry into the national phase |
Ref document number: 112022004590 Country of ref document: BR Kind code of ref document: A2 Effective date: 20220311 |
|
| WWD | Wipo information: divisional of initial pct application |
Ref document number: 824478 Country of ref document: NZ |