WO2020125744A1 - 双特异性蛋白 - Google Patents
双特异性蛋白 Download PDFInfo
- Publication number
- WO2020125744A1 WO2020125744A1 PCT/CN2019/126903 CN2019126903W WO2020125744A1 WO 2020125744 A1 WO2020125744 A1 WO 2020125744A1 CN 2019126903 W CN2019126903 W CN 2019126903W WO 2020125744 A1 WO2020125744 A1 WO 2020125744A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- seq
- variable region
- chain variable
- antibody
- heavy chain
- Prior art date
Links
Images




Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2869—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against hormone receptors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/22—Hormones
- A61K38/26—Glucagons
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
- A61P3/10—Drugs for disorders of the metabolism for glucose homeostasis for hyperglycaemia, e.g. antidiabetics
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/575—Hormones
- C07K14/605—Glucagons
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/524—CH2 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/626—Diabody or triabody
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/71—Decreased effector function due to an Fc-modification
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/94—Stability, e.g. half-life, pH, temperature or enzyme-resistance
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/70—Fusion polypeptide containing domain for protein-protein interaction
- C07K2319/74—Fusion polypeptide containing domain for protein-protein interaction containing a fusion for binding to a cell surface receptor
- C07K2319/75—Fusion polypeptide containing domain for protein-protein interaction containing a fusion for binding to a cell surface receptor containing a fusion for activation of a cell surface receptor, e.g. thrombopoeitin, NPY and other peptide hormones
Definitions
- the present disclosure relates to human GCGR antibody, GLP-1 peptide and mutants thereof, as well as bispecific protein formed by fusion of GCGR antibody and GLP-1 peptide, and preparation method and application thereof.
- Diabetes is a metabolic disease characterized by defects in insulin secretion and/or dysfunction of insulin, characterized by hyperglycemia, and its onset is mainly the result of the joint action of insulin and glucagon.
- GLP-1 is one of the most important hormones that affect the secretion of insulin, together with glucagon (Glucagon) is derived from proinsulin.
- Proproinsulin is composed of about 158 amino acids and is cleaved into different peptide chains at different sites.
- the biologically active GLP-1 in the human body mainly includes GLP-1 (7-36) amide and GLP-1 (7-37) two forms.
- GLP-1 is secreted by L cells in the small intestine, mainly promotes insulin secretion in a glucose concentration-dependent manner, protects islet ⁇ cells, and inhibits glucagon secretion to reduce the body's blood glucose level.
- GLP-1 also suppresses gastric emptying and reduces appetite. It can be used clinically to treat type 2 diabetes and obesity.
- the half-life of natural active GLP-1 in the body is very short (less than 2 minutes), it is easily degraded by DPPIV enzyme in the body, and has no clinical value.
- GLP-1 GLP-1 proliferative protein
- Glucagon has the opposite effect of insulin and mainly plays a role in raising the body's blood sugar.
- Glucagon is a 29-amino acid peptide secreted by pancreatic islet alpha cells. After binding to the GCGR receptor on the hepatocyte membrane, it mainly accelerates glycogenolysis, lipolysis and gluconeogenesis by activating downstream cAMP/PKA pathways to make blood glucose Rise.
- GCGR knockout mice exhibited a series of phenotypes such as increased GLP-1, decreased glycogen output, increased lipid metabolism, and decreased appetite.
- GCGR is one of the most popular targets for diabetes treatment, but the development of antagonist drugs for GCGR is slow.
- REMD-477 of REMD Biotherapeutics is currently the most advanced GCGR monoclonal antibody drug and is in clinical phase two.
- GCGR antibodies in patents such as CN101589062A, CN101983208A, CN102482350A, CN103314011A, CN105189560A, CN107614695A, US20180273629A1, WO2013059531A1, etc., but still needs to provide new and efficient GCGR antibodies and diabetes treatment methods.
- the present disclosure provides an anti-GCGR monoclonal antibody or antigen-binding fragment thereof.
- the antibody or antigen-binding fragment thereof has the ability to bind to human GCGR (or the epitope contained therein).
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof comprises a combination of a heavy chain variable region and a light chain variable region selected from the following a) or b):
- the heavy chain variable region contains HCDR1, HCDR2, and HCDR3 regions as shown in SEQ ID NO: 48, 49, and 50, and the light chain variable region contains SEQ ID NO: 51, 52, and 50, respectively.
- the heavy chain variable region contains HCDR1, HCDR2 and HCDR3 regions as shown in SEQ ID NO: 38, 39 and 54 respectively, and the light chain variable region contains as SEQ ID NO: 55, 56 and 57 shows the LCDR1, LCDR2, and LCDR3 areas.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof comprises any combination of a heavy chain variable region and a light chain variable region selected from the following i) to vi):
- the heavy chain variable region contains HCDR1, HCDR2 and HCDR3 regions as shown in SEQ ID NO: 14, 15 and 16, respectively, and the light chain variable region contains SEQ ID NO: 17, 18 and LCDR1, LCDR2 and LCDR3 areas shown in 19;
- the heavy chain variable region contains HCDR1, HCDR2 and HCDR3 regions as shown in SEQ ID NO: 20, 21 and 22, and the light chain variable region contains SEQ ID NO: 23, 24 and LCDR1, LCDR2 and LCDR3 areas shown in 25;
- the heavy chain variable region contains the HCDR1, HCDR2, and HCDR3 regions shown in SEQ ID NOs: 26, 27, and 28, and the light chain variable region contains the SEQ ID NOs: 29, 30, and 28, respectively.
- the heavy chain variable region comprises HCDR1, HCDR2 and HCDR3 regions as shown in SEQ ID NO: 32, 33 and 34, and the light chain variable region comprises SEQ ID NO: 35, 36 and LCDR1, LCDR2 and LCDR3 areas shown in 37;
- the heavy chain variable region contains HCDR1, HCDR2 and HCDR3 regions as shown in SEQ ID NO: 38, 39 and 40, and the light chain variable region contains SEQ ID NO: 41, 42 and LCDR1, LCDR2 and LCDR3 areas shown in 43; or
- the heavy chain variable region contains HCDR1, HCDR2 and HCDR3 regions as shown in SEQ ID NO: 38, 39 and 44, respectively, and the light chain variable region contains SEQ ID NO: 45, 46 and 47 shows the LCDR1, LCDR2 and LCDR3 areas.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof is a murine antibody, chimeric antibody or humanized antibody or antigen-binding fragment thereof.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof comprises a framework region derived from a human antibody or a framework region variant thereof, the framework region variant is in human There are at most 10 back mutations on the light chain framework region of the antibody, and/or, the framework region variant has at most 10, at most 9, at most 8, at most 7, based on the heavy chain framework region of the human antibody , At most 6, at most 5, at most 4, at most 3, at most 2, at most 1 amino acid back mutation.
- the framework region variant comprises a member selected from:
- the light chain variable region contains one or more amino acid back mutations in 42G, 44V, 71Y and 87F, and/or the heavy chain variable region contains 38K, 48I, 67A, 69F, 71A, 73P, 78A and One or more amino acids in 93S are back-mutated; or
- the light chain variable region contains one or more amino acid back mutations in 38L, 44V, 59S, 70E and 71Y, and/or the heavy chain variable region contains 38K, 48I, 66K, 67A, 69L, 73R, One or more amino acids in 78M and 94S are back-mutated. Further, the position of the back mutation site is determined according to the Kabat numbering rule.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof comprises a sequence as shown in any one of SEQ ID NO: 2, 61, 62, 63, and 64 or is identical to SEQ ID NO: 2, 61 , 62, 63, and 64 show variable heavy chains with at least 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity District; and/or
- sequence is as shown in any of SEQ ID NO: 3, 58, 59 and 60 or has at least 90%, 91%, 92%, 93%, 94% as shown in any of SEQ ID NO: 3, 58, 59 and 60 , 95%, 96%, 97%, 98%, or 99% light chain variable regions with sequence identity.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof comprises a heavy chain variable region having a sequence as described in SEQ ID NO: 63 and a light chain having a sequence as shown in SEQ ID NO: 58 Variable area.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof comprises the sequence shown in SEQ ID NO: 4 or has at least 90%, 91%, 92% as shown in SEQ ID NO: 4 , 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity heavy chain variable regions and/or sequences are shown in SEQ ID NO: 5 or with SEQ ID NO: 5
- the light chain variable regions shown have at least 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof comprises the sequence shown in SEQ ID NO: 6 or at least 90%, 91%, 92% as shown in SEQ ID NO: 6 , 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity heavy chain variable regions and/or sequences are shown in SEQ ID NO: 7 or with SEQ ID NO: 7
- the light chain variable regions shown have at least 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof comprises the sequence shown in any of SEQ ID NO: 8, 68, 69, 70, and 71 or is in accordance with SEQ ID NO: 8, 68 , 69, 70, and 71 show heavy chain variable with at least 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity
- the regions and/or sequences are shown in any of SEQ ID NO: 9, 65, 66 and 67 or have at least 90%, 91%, 92%, 93 as shown in SEQ ID NO: 9, 65, 66 and 67 %, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity light chain variable regions.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof comprises a heavy chain variable region whose sequence is as described in SEQ ID NO: 71 and a light chain whose sequence is as shown in SEQ ID NO: 67 Variable area.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof comprises a sequence shown in SEQ ID NO: 10 or at least 90%, 91%, 92% as shown in SEQ ID NO: 10 , 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity heavy chain variable regions and/or sequences are shown in SEQ ID NO: 11 or with SEQ ID NO: 11
- the light chain variable regions shown have at least 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof comprises a sequence shown in SEQ ID NO: 12 or at least 90%, 91%, 92% as shown in SEQ ID NO: 12 , 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity heavy chain variable regions and/or sequences are shown in SEQ ID NO: 13 or with SEQ ID NO: 13
- the light chain variable regions shown have at least 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof wherein the antibody is a full-length antibody, further including an antibody constant region, specifically, the heavy chain constant region of the antibody constant region is selected from Human IgG1, IgG2, IgG3 and IgG4 constant regions and their conventional variants, the light chain constant regions of the antibody constant regions are selected from human antibody ⁇ and ⁇ chain constant regions and their conventional variants, more preferably comprising SEQ ID NO: 72 The human antibody heavy chain constant region shown and the human light chain constant region shown in SEQ ID NO: 73 are shown.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof includes a heavy chain and a light chain, wherein:
- the heavy chain is shown in SEQ ID NO: 74, 76 or 78 or has at least 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity
- the light chain is shown in SEQ ID NO: 75 or has at least 85%, 86%, 87%, 88%, 89 %, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof includes a heavy chain and a light chain, wherein:
- the heavy chain is shown in SEQ ID NO: 74, 76 or 78 or has at least 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity
- the light chain is shown in SEQ ID NO: 77 or has at least 85%, 86%, 87%, 88%, 89 %, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof includes a heavy chain and a light chain, wherein:
- the heavy chain is shown in SEQ ID NO: 74, 76 or 78 or has at least 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity
- the light chain is shown in SEQ ID NO: 79 or has at least 85%, 86%, 87%, 88%, 89 %, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof includes a heavy chain and a light chain, wherein:
- the heavy chain is shown in SEQ ID NO: 80 or has at least 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96 %, 97%, 98%, or 99% sequence identity
- the light chain is shown in SEQ ID NO: 81 or has at least 85%, 86%, 87%, 88%, 89%, 90% , 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof includes a heavy chain and a light chain, wherein:
- the heavy chain is shown in SEQ ID NO: 82 or has at least 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96 %, 97%, 98%, or 99% sequence identity
- the light chain is shown in SEQ ID NO: 83 or has at least 85%, 86%, 87%, 88%, 89%, 90% , 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof includes a heavy chain and a light chain, wherein:
- the heavy chain is shown in SEQ ID NO: 84 or has at least 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96 %, 97%, 98%, or 99% sequence identity
- the light chain is shown in SEQ ID NO:85 or has at least 85%, 86%, 87%, 88%, 89%, 90% , 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof includes a heavy chain and a light chain, wherein:
- the heavy chain is shown in SEQ ID NO: 86 or has at least 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96 %, 97%, 98%, or 99% sequence identity
- the light chain is shown in SEQ ID NO: 87 or has at least 85%, 86%, 87%, 88%, 89%, 90% , 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof includes a heavy chain and a light chain, wherein:
- the heavy chain is shown in SEQ ID NO: 88 or has at least 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96 %, 97%, 98%, or 99% sequence identity
- the light chain is shown in SEQ ID NO: 89 or has at least 85%, 86%, 87%, 88%, 89%, 90% , 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof comprises a heavy chain as shown in SEQ ID NO: 78 and a light chain as shown in SEQ ID NO: 79.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof comprises a heavy chain as shown in SEQ ID NO: 84 and a light chain as shown in SEQ ID NO: 85.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof comprises any combination of a heavy chain variable region and a light chain variable region selected from the following ac) to ah):
- the heavy chain variable region contains the HCDR1, HCDR2 and HCDR3 regions having the same sequence as the heavy chain variable region shown in SEQ ID NO: 2, and the light chain variable region contains the SEQ ID NO: 3
- the light chain variable region has the same sequence of LCDR1, LCDR2 and LCDR3 regions;
- the heavy chain variable region contains HCDR1, HCDR2, and HCDR3 regions having the same sequence as the heavy chain variable region shown in SEQ ID NO: 4, and the light chain variable region contains the same as SEQ ID NO: 5.
- the light chain variable region has the same sequence of LCDR1, LCDR2 and LCDR3 regions;
- the heavy chain variable region comprises the HCDR1, HCDR2 and HCDR3 regions having the same sequence as the heavy chain variable region shown in SEQ ID NO: 6, and the light chain variable region comprises the SEQ ID NO: 7
- the light chain variable region has the same sequence of LCDR1, LCDR2 and LCDR3 regions;
- the heavy chain variable region contains HCDR1, HCDR2 and HCDR3 regions having the same sequence as the heavy chain variable region shown in SEQ ID NO: 8, and the light chain variable region contains the same as SEQ ID NO: 9.
- the light chain variable region has the same sequence of LCDR1, LCDR2 and LCDR3 regions;
- the heavy chain variable region contains HCDR1, HCDR2, and HCDR3 regions having the same sequence as the heavy chain variable region shown in SEQ ID NO: 10, and the light chain variable region contains SEQ ID NO: 11
- the light chain variable region has the same sequence of LCDR1, LCDR2, and LCDR3 regions; or
- the heavy chain variable region contains the HCDR1, HCDR2, and HCDR3 regions having the same sequence as the heavy chain variable region shown in SEQ ID NO: 12, and the light chain variable region contains the SEQ ID NO: 13
- the light chain variable region has the same sequence of LCDR1, LCDR2, and LCDR3 regions.
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof wherein the antigen-binding fragment is selected from the group consisting of Fab, Fab', F(ab') 2, single-chain antibody, and dimerized V Region (diabodies) and disulfide-stabilized V region (dsFv).
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof is characterized by competing with the aforementioned monoclonal antibody or antigen-binding fragment thereof for binding to human GCGR (or its epitope).
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof has at least one of the following characteristics:
- the anti-GCGR monoclonal antibody or antigen-binding fragment thereof wherein the monoclonal antibody or antigen-binding fragment thereof binds to the same antigen table as the monoclonal antibody or antigen-binding fragment thereof as described above Bit.
- the present disclosure provides a bispecific protein.
- a bispecific protein comprising a GLP-1 peptide and a GCGR antibody, the GLP-1 peptide and the polypeptide chain of the GCGR antibody by a peptide bond Or the connector is covalently connected.
- the bispecific protein wherein the carboxy terminus of the GLP-1 peptide is connected to the amino terminus of the heavy chain variable region of the GCGR antibody by a peptide bond or linker, or the GLP-1 peptide
- the carboxyl terminus of the GCGR antibody is connected to the amino terminus of the light chain variable region of the GCGR antibody by a peptide bond or linker.
- the bispecific protein wherein the carboxy terminus of the GLP-1 peptide and the amino terminus of the heavy chain variable region of the GCGR antibody are connected by a peptide bond or linker.
- the bispecific protein wherein the carboxy terminus of the GLP-1 peptide and the amino terminus of the light chain variable region of the GCGR antibody are connected by a peptide bond or linker.
- the bispecific protein wherein the carboxy terminus of the GLP-1 peptide is connected to the amino terminus of the heavy chain of the GCGR full-length antibody by a peptide bond or linker.
- the bispecific protein wherein the carboxy terminus of the GLP-1 peptide and the light chain amino terminus of the full-length GCGR antibody are connected by a peptide bond or linker.
- the GCGR antibody is selected from the anti-GCGR monoclonal antibody or antigen-binding fragment thereof as described above.
- the bispecific protein, the GLP-1 peptide is GLP-1A as shown in SEQ ID NO: 91, or the GLP-1 peptide has Q17E, GLP-1A peptide variants with one or more amino acid substitutions in I23V, K28R and G30R.
- the bispecific protein, the GLP-1 peptide is GLP-1A as shown in SEQ ID NO: 91, or the GLP-1 peptide has Q17E based on GLP-1A GLP-1A peptide variants.
- the bispecific protein, the GLP-1 peptide is GLP-1A shown in SEQ ID NO: 91, or the GLP-1 peptide has a Q17E substitution based on GLP-1A , And also has one or more amino acids in I23V, K28R and G30R instead of GLP-1A peptide variants.
- the bispecific protein, the GLP-1 peptide is GLP-1A shown in SEQ ID NO: 91, or the GLP-1 peptide has Q17E or GLP-1A on the basis of GLP-1A GLP-1A peptide variant with Q17E and I23V.
- the bispecific protein, the GLP-1A peptide variant comprises the sequence shown in SEQ ID NO: 92, 93, 94, 95, 96, 97, 98 or 99 or by composition.
- the bispecific protein, the GCGR antibody is selected from the anti-GCGR monoclonal antibody or antigen-binding fragment thereof as described in any one of the preceding items and the GLP-1A peptide as described in any one of the preceding items Or GLP-1A peptide variants.
- the bispecific protein has a first polypeptide chain and a second polypeptide chain, wherein: the first polypeptide chain is selected from SEQ ID NO: 100 , 101, 102, 103, 104, 105, 106, 107, and 108, and the second polypeptide chain is selected from the polypeptides shown in SEQ ID NO: 79.
- the bispecific protein has a first polypeptide chain comprising a GCGR antibody heavy chain and a second polypeptide chain comprising a GCGR antibody light chain, wherein: the first A polypeptide chain is selected from the polypeptide shown in SEQ ID NO: 109, and the second polypeptide chain is selected from the polypeptide shown in SEQ ID NO: 81;
- the bispecific protein has a first polypeptide chain comprising a GCGR antibody heavy chain and a second polypeptide chain comprising a GCGR antibody light chain, wherein: the first One polypeptide chain is selected from the polypeptide shown in SEQ ID NO: 110, and the second polypeptide chain is selected from the polypeptide shown in SEQ ID NO: 83;
- the bispecific protein has a first polypeptide chain comprising a GCGR antibody heavy chain and a second polypeptide chain comprising a GCGR antibody light chain, wherein: the first One polypeptide chain is selected from the polypeptide shown in SEQ ID NO: 111, and the second polypeptide chain is selected from the polypeptide shown in SEQ ID NO: 85;
- the bispecific protein has a first polypeptide chain comprising a GCGR antibody heavy chain and a second polypeptide chain comprising a GCGR antibody light chain, wherein: the first A polypeptide chain is selected from the polypeptide shown in SEQ ID NO: 112, and the second polypeptide chain is selected from the polypeptide shown in SEQ ID NO: 87; or
- the bispecific protein has a first polypeptide chain comprising a GCGR antibody heavy chain and a second polypeptide chain comprising a GCGR antibody light chain, wherein: the first A polypeptide chain is selected from the polypeptide shown in SEQ ID NO: 113, and the second polypeptide chain is selected from the polypeptide shown in SEQ ID NO: 89.
- the present disclosure also provides a GLP-1 peptide variant.
- the GLP-1 peptide variant is a mutant having one or more amino acid mutations in Q17E, I23V, K28R, and G30R based on GLP-1A shown in SEQ ID NO: 91.
- the GLP-1 peptide is GLP-1A as shown in SEQ ID NO: 91, or the GLP-1 peptide has Q17E or GLP-1A with Q17E and I23V based on GLP-1A Peptide variants.
- the GLP-1 peptide variant has the sequence shown in SEQ ID NO: 92, 93, 94, 95, 96, 97, 98 or 99.
- the present disclosure also provides a pharmaceutical composition containing a therapeutically effective amount of the anti-GCGR monoclonal antibody or antigen-binding fragment thereof as described above, or the bispecific protein as described above, or as described above GLP-1 peptide variants, and one or more pharmaceutically acceptable carriers, diluents, buffers or excipients.
- the present disclosure also provides an isolated nucleic acid molecule encoding the anti-GCGR monoclonal antibody or antigen-binding fragment thereof as described above, or the bispecific protein as described above, or the GLP-1 as described above Peptide variants.
- the present disclosure provides a recombinant vector comprising the isolated nucleic acid molecule as described above.
- the present disclosure provides a host cell transformed with the recombinant vector as described above, the host cell being selected from prokaryotic cells and eukaryotic cells, preferably eukaryotic cells, more preferably mammalian cells or insect cells.
- the present disclosure provides methods for producing anti-GCGR monoclonal antibodies or antigen-binding fragments thereof as previously described, or bispecific proteins as previously described, or GLP-1 peptide variants as previously described,
- the method includes culturing the host cell as described above in a medium to form and accumulate the anti-GCGR monoclonal antibody or antigen-binding fragment thereof as described above, or the bispecific protein as described above, or GLP-1 peptide variants as previously described, and recovering the monoclonal antibody or antigen-binding fragment or bispecific protein or GLP-1 peptide variant from the culture.
- the present disclosure provides a method for in vitro detection or determination of human GCGR, which method includes the use of a monoclonal antibody or antigen-binding fragment thereof as previously described.
- a kit for detecting human GCGR which contains the monoclonal antibody or antigen-binding fragment thereof as described above.
- kits eg kits, arrays, test papers, multi-well plates, magnetic beads, coated microparticles
- a kit includes a multi-well plate coated with the aforementioned anti-GCGR monoclonal antibody or antigen-binding fragment thereof.
- the present disclosure provides the use of the aforementioned monoclonal antibody or antigen-binding fragment thereof in the preparation of reagents for detecting or measuring human GCGR.
- the present disclosure provides a method of reducing the blood glucose concentration of a subject, the method comprising administering to the subject a therapeutically effective amount of an anti-GCGR monoclonal antibody or antigen-binding fragment thereof as described above, or as previously described Bispecific protein, or the GLP-1 peptide variant as described above, or the pharmaceutical composition as described above.
- the therapeutically effective amount is a unit dose of the composition containing 0.1-3000 mg of the anti-GCGR monoclonal antibody or antigen-binding fragment thereof as described above, or the bispecific protein as described above, or according to GLP-1 peptide variants as previously described.
- the present disclosure provides a method of treating a metabolic disorder, the method comprising administering to the subject an anti-GCGR monoclonal antibody or antigen-binding fragment thereof, or a bispecific protein as described above, or as The aforementioned GLP-1 peptide variant, or the pharmaceutical composition as described above; preferably, the metabolic disorder is metabolic syndrome, obesity, impaired glucose tolerance, diabetes, diabetic ketoacidosis, high Glucose, hyperglycemic hyperosmolar syndrome, perioperative hyperglycemia, hyperinsulinemia, insulin resistance syndrome, impaired fasting blood glucose, dyslipidemia, atherosclerosis, or prediabetes.
- the metabolic disorder is metabolic syndrome, obesity, impaired glucose tolerance, diabetes, diabetic ketoacidosis, high Glucose, hyperglycemic hyperosmolar syndrome, perioperative hyperglycemia, hyperinsulinemia, insulin resistance syndrome, impaired fasting blood glucose, dyslipidemia, atherosclerosis, or prediabetes.
- the present disclosure also provides anti-GCGR monoclonal antibodies or antigen-binding fragments thereof as described above, or bispecific proteins as described above, or GLP-1 peptide variants as described above, or as previously described Use of the pharmaceutical composition described in the preparation of a medicament for treating metabolic disorders or reducing the blood glucose concentration of a subject
- the metabolic disorder is metabolic syndrome, obesity, impaired glucose tolerance, diabetes, diabetic ketoacidosis, hyperglycemia, hyperglycemic hyperosmolar syndrome, perioperative hyperglycemia, hyperinsulinemia , Insulin resistance syndrome, impaired fasting blood glucose, dyslipidemia, atherosclerosis, or prediabetes.
- the present disclosure also provides the use of anti-GCGR monoclonal antibodies or antigen-binding fragments thereof as described above, or bispecific proteins as described above, or GLP-1 peptide variants as described above, or as previously described
- the pharmaceutical composition described above is used as a medicine, preferably as a medicine for treating metabolic disorders or lowering the blood glucose concentration of a subject.
- the metabolic disorder is metabolic syndrome, obesity, impaired glucose tolerance, diabetes, diabetic ketoacidosis, hyperglycemia, hyperglycemic hyperosmolar syndrome, perioperative hyperglycemia, hyperinsulinemia Syndrome, insulin resistance syndrome, impaired fasting blood glucose, dyslipidemia, atherosclerosis, or prediabetes.
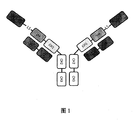
- FIG. 1 Schematic diagram of the bispecific protein (GLP-1/GCGR anti) of the present disclosure.
- Figure 2 Antagonistic activity of bispecific protein and GCGR antibody against GCGR.
- Figure 3 Activating activity of GLP-1R by bispecific protein and duraglutide.
- Figure 4 Effect of long-term medication on random blood glucose in ob/ob mice.
- Vehicle empty carrier
- PBS phosphate buffered saline
- hu1803-9D-3mpk hu1803-9-2.84mpk
- dora Glycopeptide-1.16mpk is the amount concentration of the same substance.
- Figure 5 Effect of long-term medication on hungry blood glucose in ob/ob mice. All experimental groups can significantly reduce the fasting blood glucose concentration of mice, of which hu1803-9D-3mpk and hu1803-9-2.84mpk have the strongest hypoglycemic concentration ability, and hu1803-9D-3mpk has better hypoglycemic activity than hu1803-9- 2.84mpk.
- bispecific protein refers to a protein molecule capable of binding two target proteins or target antigens.
- the bispecific protein refers to a protein that can bind GCGR and GLP-1R (GLP-1 receptor) and is formed by fusion of the polypeptide chain of the GLP-1 peptide and the GCGR antibody (or antigen-binding fragment thereof).
- GLP-1 peptide refers to a peptide that can bind to and activate the GLP-1 receptor.
- Prior art peptides are described in patent applications WO2008/071972, WO2008/101017, WO2009/155258, WO2010/096052, WO2010/096142, WO2011/075393, WO2008/152403, WO2010/070251, WO2010/070252, WO2010/070253, WO2010 /070255, WO2011/160630, WO2011/006497, WO2011/117415, WO2011/117416, WO2006/134340, WO1997046584, WO2007124461, WO2017100107, WO2007039140, CN1935261A, CN1935846A, WO2006036834, WO2005058958, WO2002046227, WO1999043705, WO1999043708, WO1999043341, WO1999043341 ,
- GLP-1 Including GLP-1, GLP-1 analogs and GLP-1 receptor peptide agonists, some specific GLP-1 peptides such as: Lixisenatide/AVE0010/ZP10/Lyxumia, Exenatide /Exendin-4/Byetta/Bydureon/ITCA650/AC-2993, Liraglutide/Victoza, Somalutide (Semaglutide), Taspoglutide, Syncria/Abilutide ( Albiglutide), Dulaglutide, rExendin-4, CJC-1134-PC, PB-1023, TTP-054, Langlenatide/HM-11260C, CM-3, GLP-1Eligen, ORMD-0901, NN-9924 , NN-9926, NN-9927, Nodexen, Viador-GLP-1, CVX-096, ZYOG-1, ZYD-1, GSK-2374697, DA-3091, MAR-701, MAR709
- GPCR G protein-coupled Receptor
- GPCR G protein-coupled receptor
- GPCR consists of more than 800 members and is currently the largest family of membrane proteins in the mammalian genome. In the human body, GPCR proteins are widely distributed in the central nervous system, immune system, cardiovascular, retina and other organs and tissues, and participate in the development of the body and normal functioning.
- the main body of the GPCR protein is composed of 7-segment ⁇ -helix structures across the plasma membrane.
- the N-terminus and three loops are located outside the cell and are involved in the interaction between the protein and its receptor; the C-terminus and 3 loops are located inside the cell, where the C-terminus and the third loop are mediated by the interaction between the GPCR protein and the downstream G protein It plays an important role in the intracellular signaling process.
- GCGR is a glucagon (Glucagon) receptor and is one of the members of the GPCR family. After combining glucagon with GCGR, it mainly accelerates glycogenolysis, lipolysis and/or gluconeogenesis by activating downstream pathways, Increase blood sugar.
- antibody (Ab) includes at least one antigen-binding molecule (or molecule that specifically binds to or interacts with (eg recognizes and/or binds to) a specific antigen (or its epitope) (eg GCGR) (eg, recognition and/or binding) Complex).
- a specific antigen or its epitope
- eg GCGR eg, recognition and/or binding
- antibody includes: immunoglobulin molecules including four polypeptide chains interconnected by disulfide bonds, two heavy (H) chains and two light (L) chains, and multimers thereof (eg, IgM).
- Each heavy chain includes a heavy chain variable region (abbreviated herein as HCVR or VH) and a heavy chain constant region (CH).
- This heavy chain constant region contains three regions (domains), CH1, CH2 and CH3.
- Each light chain includes a light chain variable region (abbreviated herein as LCVR or VL) and a light chain constant region (CL).
- VH and VL regions can be further subdivided into hypervariable regions, called complementarity-determining regions (CDR), with more conservative regions interspersed between them, called framework regions (FR, also known as framework regions, framework regions).
- CDR complementarity-determining regions
- FR framework regions
- Each VH and VL is composed of three CDRs and four FRs, arranged from the amino end to the carboxy end in the following order: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4.
- the FR of the anti-GCGR antibody may be the same as the human germline sequence, or may be modified naturally or artificially.
- the antibodies may be antibodies of different subclasses, for example, IgG (eg, IgG1, IgG2, IgG3, or IgG4 subclass), IgA1, IgA2, IgD, IgE, or IgM antibodies.
- antibody also includes antigen-binding fragments of complete antibody molecules.
- antigen-binding portion include any naturally occurring, enzymatically produced, synthetic or genetically engineered complex that specifically binds to an antigen to form a complex Polypeptide or glycoprotein.
- Antigen-binding fragments of antibodies can be derived from, for example, whole antibody molecules using any suitable standard techniques, such as proteolytic digestion or recombinant genetic engineering techniques involving DNA manipulation and expression of variable regions and (optionally) constant regions of antibodies. This DNA is known and/or can be easily obtained from, for example, commercially available sources, DNA databases (including, for example, phage-antibody databases) or can be synthesized.
- This DNA can be sequenced and manipulated chemically or through the use of molecular biotechnology, such as arranging one or more variable and/or constant regions into a suitable configuration, or introducing codons to produce cysteine residues, modifications , Add or delete amino acids, etc.
- Non-limiting examples of antigen-binding fragments include: (i) Fab fragments; (ii) F(ab′) 2 fragments; (iii) Fd fragments; (iv) Fv fragments; (v) single-chain Fv (scFv) molecules; vi) dAb fragment.
- Other engineered molecules such as region-specific antibodies, single-domain antibodies, region-deleting antibodies, chimeric antibodies, diabodies, triabodies, tetrabodies, minibodies, nanobodies (such as monovalent Nanobodies, bivalent Nanobodies, etc.), Small module immunopharmaceutical (SMIP) and shark variable IgNAR region are also covered by the term "antigen-binding fragment" used in the text.
- the antigen-binding fragment will typically contain at least one variable region.
- the variable region may be a region of any size or amino acid composition and will generally contain CDRs adjacent to or within one or more framework sequences.
- the antigen-binding fragment of the antibody is in any configuration of a variable region and a constant region, the variable region and the constant region may be directly connected to each other or may be connected by a complete or partial hinge or linker region .
- the hinge region may be composed of at least 2 (e.g. 5, 10, 15, 20, 40, 60 or more) amino acids, so that flexibility is created between adjacent variable and/or constant regions in a single polypeptide molecule And semi-flexible connection.
- the "murine antibody” in this disclosure is a monoclonal antibody derived from a mouse or a rat prepared according to the knowledge and skills in the art. When preparing, inject the test subjects with antigen, and then isolate the hybridoma expressing the antibody with the desired sequence or functional characteristics. When the injected test subject is a mouse, the antibody produced is a mouse-derived antibody. When the injected test subject is In the case of rats, the antibodies produced are those derived from rats.
- a “chimeric antibody” is an antibody obtained by fusing a variable region of an antibody of a first species (such as a mouse) with a constant region of an antibody of a second species (such as a human).
- a first species such as a mouse
- a second species such as a human
- To create a chimeric antibody first create a hybridoma that secretes monoclonal antibodies of the first species (such as a mouse), then clone the variable region genes from the hybridoma cells, and then clone the constant region genes of the second species (such as human) antibodies as needed
- the gene of the variable region of the first species and the gene of the constant region of the second species are connected into a chimeric gene and inserted into an expression vector, and finally the chimeric antibody molecule is expressed in a eukaryotic or prokaryotic system.
- the antibody light chain of the chimeric antibody further comprises a light chain constant region of human ⁇ , ⁇ chain or a variant thereof.
- the antibody heavy chain of the chimeric antibody further comprises a heavy chain constant region of human IgG1, IgG2, IgG3, IgG4 or a variant thereof, preferably a human heavy chain constant region of IgG1, IgG2 or IgG4, or amino acid mutation ( IgG1, IgG2 or IgG4 heavy chain constant region variants such as YTE mutation or back mutation, L234A and/or L235A mutation, or S228P mutation).
- humanized antibody includes CDR-grafted antibodies, which refers to the grafting of the CDR sequences of animal-derived antibodies, such as murine antibodies, into the framework region (or framework of human antibody variable regions) Region, framework) region.
- Humanized antibodies can overcome the heterogeneous reactions induced by chimeric antibodies due to the large number of heterologous protein components.
- the sequences of such framework regions can be obtained from public DNA databases or published references that include germline antibody gene sequences.
- the germline DNA sequences of human heavy chain and light chain variable region genes can be found in the "VBase" human germline sequence database (available on the Internet at http://www.vbase2.org/), and in Kabat, EA, etc. 1991 Sequences of Proteins of Immunological Interest, found in 5th edition.
- the framework sequence of the variable region of the human antibody may be subjected to minimal reverse mutation or back mutation to maintain activity.
- the humanized antibodies of the present disclosure also include humanized antibodies after further affinity affinity maturation of CDRs by phage display.
- the grafting of the CDR may result in the reduced affinity of the produced antibody or antigen-binding fragment thereof for the antigen due to the framework residues in contact with the antigen. Such interactions may be the result of somatic cell mutations. Therefore, it may still be necessary to graft amino acids of such donor frameworks to the framework of humanized antibodies.
- Amino acid residues from non-human antibodies or antigen-binding fragments involved in antigen binding can be identified by examining the sequence and structure of the variable regions of animal monoclonal antibodies. Each residue in the CDR donor framework that is different from the germline can be considered to be related.
- the sequence can be compared to the consensus sequence of a subclass consensus sequence or animal antibody sequence with a high percentage of similarity. Rare framework residues are thought to be the result of highly somatic mutations, and thus play an important role in binding.
- the antibody or antigen-binding fragment thereof may further comprise a light chain constant region of human or murine ⁇ , ⁇ chain or a variant thereof, or further comprise human or murine IgG1 , IgG2, IgG3, IgG4 or its heavy chain constant region.
- “Conventional variants" of human antibody heavy chain constant regions and human antibody light chain constant regions refer to human-derived heavy chain constant regions or light chain constant regions derived from humans that do not change the structure and function of antibody variable regions Variants
- exemplary variants include IgG1, IgG2, IgG3, or IgG4 heavy chain constant region variants that undergo site-directed modification and amino acid replacement of the heavy chain constant region, specifically replacing YTE mutations known in the prior art, L234A and/ Or L235A mutation, or S228P mutation, or mutations that obtain knob-into-hole structure (making the antibody heavy chain have a combination of knob-Fc and hole-Fc), these mutations have been proven to make the antibody have new properties, but do not change the antibody Variable area function.
- Human antibody and “human antibody” are used interchangeably, and can be an antibody derived from human or an antibody obtained from a transgenic organism that has been "modified” to produce in response to antigen stimulation
- Specific human antibodies can be produced by any method known in the art. In some techniques, elements of human heavy and light chain loci are introduced into cell lines of organisms derived from embryonic stem cell lines, and endogenous heavy and light chain loci in these cell lines are targeted damage. Transgenic organisms can synthesize human antibodies specific for human antigens, and the organisms can be used to produce human antibody-secreting hybridomas.
- the human antibody may also be an antibody in which the heavy and light chains are encoded by nucleotide sequences derived from one or more human DNA sources. Fully human antibodies can also be constructed by gene or chromosome transfection methods and phage display technology, or by B cells activated in vitro, all of which are known in the art.
- “Monoclonal antibody” refers to an antibody obtained from a population of substantially homogeneous antibodies, that is, except for possible variant antibodies (eg, containing naturally occurring mutations or mutations that were produced during the manufacture of monoclonal antibody preparations, these variants are usually Except in small amounts), the individual antibodies that make up the population recognize the same and/or bind the same epitope. Unlike polyclonal antibody preparations that usually contain different antibodies against different determinants (epitopes), each monoclonal antibody of a monoclonal antibody preparation (preparation) is directed against a single determinant on the antigen.
- monoclonal indicates the characteristics of antibodies as obtained from a substantially homogeneous population of antibodies, and should not be interpreted as requiring the production of antibodies by any particular method.
- monoclonal antibodies used in accordance with the present disclosure can be prepared by various techniques including, but not limited to, hybridoma methods, recombinant DNA methods, phage display methods, and the use of transgenic animals containing all or part of human immunoglobulin loci Methods, such methods, and other exemplary methods for preparing monoclonal antibodies are described herein.
- the term "monoclonal antibody or antigen-binding fragment thereof" refers to a full-length antibody.
- full-length antibody intact antibody
- complete antibody completely antibody
- whole antibody in which the heavy chain sequentially includes the VH region, CH1 region, hinge region, and Fc region from the amino terminal to the carboxy terminal
- the light chain sequentially includes the VL region and CL region from the amino terminal to the carboxy terminal.
- single-chain Fv single-chain Fv
- scFv single-chain Fv
- Such single chain antibodies are also intended to be included in the term "antigen-binding fragment" of an antibody.
- Such antibody fragments are obtained using conventional techniques known to those skilled in the art, and the fragments are screened for utility in the same manner as for intact antibodies.
- the antigen-binding portion can be produced by recombinant DNA technology or by enzymatic or chemical fragmentation of intact immunoglobulins.
- Antigen-binding fragments can also be incorporated into single-chain molecules containing a pair of tandem Fv fragments (VH-CH1-VH-CH1), which together with complementary light chain polypeptides form a pair of antigen-binding regions (Zapata et al. , 1995 Protein Eng. 8 (10): 1057-1062; and US Patent US5641870).
- Fab is an antibody fragment having a molecular weight of about 50,000 Da obtained by treating an IgG antibody molecule with papain (cutting the amino acid residue at position 224 of the H chain), which has antigen-binding activity, in which about half of the N-terminal side of the H chain and The entire L chain is joined together by disulfide bonds.
- F(ab')2 is an antibody fragment with a molecular weight of about 100,000 Da obtained by digesting the lower part of the two disulfide bonds in the hinge region of IgG with pepsin, and has antigen-binding activity and contains two connected at the hinge position Fab area.
- Fab' is an antibody fragment having a molecular weight of about 50,000 Da and having antigen-binding activity obtained by cleaving the disulfide bond of the hinge region of F(ab') 2 described above.
- Fab' can be produced by treating F(ab')2 that specifically recognizes and binds an antigen with a reducing agent such as dithiothreitol.
- the Fab' can be produced by inserting DNA encoding the Fab' fragment of the antibody into a prokaryotic expression vector or a eukaryotic expression vector and introducing the vector into a prokaryotic or eukaryotic organism to express the Fab'.
- single-chain antibody single-chain Fv
- scFv single-chain Fv
- Such scFv molecules may have a general structure: NH 2 -VL-linker-VH-COOH or NH 2 -VH-linker-VL-COOH.
- Suitable prior art linkers consist of repeating GGGGS amino acid sequences or variants thereof, for example using 1-4 (including 1, 2, 3 or 4) repeating variants (Holliger et al. (1993), Proc Natl Acad Sci USA. 90:6444-6448).
- linkers that can be used in the present disclosure are Alfthan et al. (1995), Protein Eng. 8:725-731, Choi et al. (2001), Eur J Immuno. 31:94-106, Hu et al. (1996), Cancer Res .56:3055-3061, described by Kipriyanov et al. (1999), J Mol Biol. 293:41-56 and Roovers et al. (2001), Cancer Immunol Immunother. 50:51-59.
- Linker or “linker” or “linker” refers to a connecting polypeptide sequence used to connect protein domains, and usually has a certain flexibility. The use of linkers will not cause the original function of the protein domain to be lost.
- Diabody refers to an antibody fragment in which scFv is dimerized, and is an antibody fragment having bivalent antigen binding activity. In the bivalent antigen binding activity, the two antigens may be the same or different.
- dsFv is obtained by connecting a polypeptide in which one amino acid residue in each VH and VL is replaced by a cysteine residue via a disulfide bond between the cysteine residues.
- Amino acid residues substituted with cysteine residues can be selected according to a known method (Protein Engineering. 7:697 (1994)) based on the prediction of the three-dimensional structure of the antibody.
- the antigen-binding fragment can be produced by obtaining the coding cDNA of the VH and/or VL of the monoclonal antibody of the present disclosure that specifically recognizes and binds the antigen and other required domains, and constructs the coding antigen Binding fragment DNA, inserting the DNA into a prokaryote expression vector or eukaryote expression vector, and then introducing the expression vector into a prokaryote or eukaryote to express the antigen-binding fragment.
- the "Fc region” may be a native sequence Fc region or a variant Fc region. Although the boundaries of the Fc region of the immunoglobulin heavy chain may vary, the human IgG heavy chain Fc region is generally defined as extending from the amino acid residue at position Cys226 or from Pro230 to its carboxyl terminus. The numbering of the residues in the Fc region is the numbering of the EU index as in Kabat. Kabat et al., Sequences of Proteins of Immunological Interest, 5th Edition Public Health Service, National Institutes of Health, Bethesda, Md., 1991. The Fc region of immunoglobulins usually has two constant region domains CH2 and CH3.
- Knob-Fc refers to a point mutation containing T366W in the Fc region of an antibody to form a spatial structure similar to a knob.
- hole-Fc refers to a point mutation containing T366S, L368A, and Y407V in the Fc region of an antibody to form a hole-like spatial structure.
- Knob-Fc and hole-Fc are more likely to form heterodimers due to steric hindrance.
- point mutations of S354C and Y349C can also be introduced in knock-Fc and hole-Fc, respectively, to further promote the formation of heterodimers through disulfide bonds.
- knob-Fc or hole-Fc can be used either as the Fc region of the first polypeptide chain or as the Fc region of the second polypeptide chain.
- the first polypeptide The Fc region of the chain and the second polypeptide chain are not knob-Fc or hole-Fc at the same time.
- amino acid difference or “amino acid mutation” means that the variant protein or polypeptide has an amino acid change or mutation compared to the original protein or polypeptide, including the insertion of one or several amino acids on the basis of the original protein or polypeptide, Missing or replacing.
- variable region of an antibody refers to the variable region (VL) of the antibody light chain or the variable region (VH) of the antibody heavy chain, alone or in combination.
- VL variable region
- VH variable region
- the variable regions of the heavy and light chains each consist of 4 framework regions (FR) connected by 3 complementarity determining regions (CDRs) (also called hypervariable regions).
- FR framework regions
- CDRs complementarity determining regions
- the CDRs in each chain are held tightly by the FR and together with the CDRs from the other chain contribute to the formation of the antigen-binding site of the antibody.
- There are at least 2 techniques for determining CDRs (1) Methods based on cross-species sequence variability (ie, Kabat et al.
- CDR may refer to a CDR determined by either method or a combination of both methods.
- antibody framework or "FR region” refers to a part of the variable domain VL or VH, which serves as a scaffold for the antigen binding loop (CDR) of the variable domain. Essentially, it is a variable domain without CDR.
- CDR complementarity determining region
- HCDR1, HCDR2, HCDR3 three CDRs in each heavy chain variable region and three CDRs (LCDR1, LCDR2, LCDR3) in each light chain variable region.
- Any of a variety of well-known schemes can be used to determine the amino acid sequence boundaries of the CDR, including "Kabat” numbering rules (see Kabat et al.
- the CDR amino acid residue numbers in the heavy chain variable domain (VH) are 31-35 (HCDR1), 50-65 (HCDR2) and 95-102 (HCDR3); light
- the CDR amino acid residues in the chain variable domain (VL) are numbered 24-34 (LCDR1), 50-56 (LCDR2) and 89-97 (LCDR3).
- the CDR amino acid numbers in VH are 26-32 (HCDR1), 52-56 (HCDR2) and 95-102 (HCDR3); and the amino acid residue numbers in VL are 26-32 (LCDR1), 50- 52 (LCDR2) and 91-96 (LCDR3).
- the CDR is composed of amino acid residues 26-35 (HCDR1), 50-65 (HCDR2) and 95-102 (HCDR3) in human VH and amino acid residues 24- in human VL 34 (LCDR1), 50-56 (LCDR2) and 89-97 (LCDR3).
- the CDR amino acid residue numbers in VH are approximately 26-35 (CDR1), 51-57 (CDR2) and 93-102 (CDR3)
- the CDR amino acid residue numbers in VL are approximately 27-32 (CDR1 ), 50-52 (CDR2) and 89-97 (CDR3).
- the CDR region of an antibody can be determined using the program IMGT/DomainGap Align.
- Any CDR variant thereof in “HCDR1, HCDR2, and HCDR3 regions or any CDR variants thereof” refers to a variant obtained by amino acid mutation of any one, or two, or three HCDRs in HCDR1, HCDR2, and HCDR3 regions body.
- Antibody constant region domains refer to the constant region domains derived from the light and heavy chains of antibodies, including CL and the CH1, CH2, CH3, and CH4 domains derived from different classes of antibodies.
- Epitope or “antigenic determinant” refers to a site on an antigen where immunoglobulins or antibodies specifically bind. Epitopes typically include at least 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, or 15 consecutive or non-contiguous amino acids in a unique spatial conformation. See, for example, Epitope Mapping Protocols Methods Molecular Biology, Volume 66, G.E. Morris, Ed. (1996).
- antibodies bind with an affinity (KD) of about less than 10 -8 M, such as about less than 10 -9 M, 10 -10 M, 10 -11 M or less.
- the term “competition” in the case of competition for antigen-binding proteins (eg, neutralizing antigen-binding proteins or neutralizing antibodies) of the same epitope, it means competition between antigen-binding proteins, which is determined by the following assay:
- the antigen-binding protein to be detected eg, antibody or antigen-binding fragment thereof
- prevents or inhibits eg, reduces
- the specific binding of the reference antigen-binding protein eg, ligand or reference antibody
- Many types of competitive binding assays can be used to determine whether one antigen-binding protein competes with another.
- These assays include, for example, solid-phase direct or indirect radioimmunoassay (RIA), solid-phase direct or indirect enzyme immunoassay (EIA), Sandwich competition assay (see, for example, Stahli et al., 1983, Methods in Enzymology 9: 242-253); solid phase direct biotin-avidin EIA (see for example Kirkland et al., 1986, J. Immunol. 137:3614-3619), solid Phase direct labeling assay, solid phase direct labeling sandwich assay (see for example Harlow and Lane, 1988, Antibodies, A Laboratory (Manual), Cold Spring Harbor Press); solid phase direct labeling with I-125 marker RIA (see for example Morel et al., 1988, Molec.
- RIA solid-phase direct or indirect radioimmunoassay
- EIA enzyme immunoassay
- Sandwich competition assay see, for example, Stahli et al., 1983, Methods in Enzymology 9: 242-253
- the assay involves the use of purified antigen (the antigen is on a solid surface or cell surface) that can bind to an unlabeled detection antigen binding protein and a labeled reference antigen binding protein. In the presence of the antigen-binding protein to be tested, the amount of label bound to the solid surface or cell is measured to measure competitive inhibition. Usually, the antigen-binding protein to be tested is present in excess.
- the antigen binding protein identified by the competitive assay includes: an antigen binding protein that binds to the same epitope as the reference antigen binding protein; and an antigen binding that binds to an adjacent epitope sufficiently close to the binding epitope of the reference antigen binding protein Protein, the two epitopes prevent each other from binding spatially. Additional details regarding methods for determining competitive binding are provided in the embodiments of the present disclosure. Usually when the antigen binding protein in competition is present in excess, it will inhibit (eg, reduce) at least 40-45%, 45-50%, 50-55%, 55-60%, 60-65%, 65-70%, 70 -75% or 75% or more of the specific binding of the reference antigen binding protein to the common antigen. In some cases, binding is inhibited by at least 80-85%, 85-90%, 90-95%, 95-97%, or 97% or more.
- affinity refers to the strength of the interaction between antibody and antigen at a single epitope. Within each antigenic site, the variable region of the "arm" of the antibody interacts with the antigen at multiple amino acid sites through weak non-covalent forces; the greater the interaction, the stronger the affinity.
- an antibody or antigen-binding fragment thereof e.g. Fab fragments
- the term “high affinity” generally refers to having a K D 1E -9 M in K D or less (e.g.
- KD refers to a particular antibody - antigen interaction dissociation equilibrium constant.
- antibodies bind antigen with a dissociation equilibrium constant (KD) of less than about 1E -8 M, such as less than about 1E -9 M, 1E -10 M, or 1E -11 M or less, for example, if using surface plasmon resonance (SPR) technology is measured in the BIACORE instrument.
- KD dissociation equilibrium constant
- SPR surface plasmon resonance
- nucleic acid molecule refers to DNA molecules and RNA molecules.
- the nucleic acid molecule may be single-stranded or double-stranded, but preferably is double-stranded DNA.
- a nucleic acid is "operably linked" when it is placed into a functional relationship with another nucleic acid sequence. For example, if a promoter or enhancer affects the transcription of a coding sequence, then the promoter or enhancer is effectively linked to the coding sequence.
- vector means a construct capable of delivering one or more genes or sequences of interest and preferably expressing it in a host cell.
- vectors include, but are not limited to, viral vectors, naked DNA or RNA expression vectors, plasmids, cosmids or phage vectors, DNA or RNA expression vectors associated with cationic coagulants, DNA encapsulated in liposomes or RNA expression vectors and certain eukaryotic cells such as producer cells.
- mice can be immunized with antigens or fragments thereof, the obtained antibodies can be renatured and purified, and amino acid sequencing can be performed by conventional methods.
- Antigen-binding fragments can also be prepared by conventional methods.
- the antibody or antigen-binding fragment described in the present disclosure is genetically engineered to add one or more human FR regions to a non-human CDR region.
- the human FR germline sequence can be obtained from the website http://www.imgt.org/ by aligning the IMGT human antibody variable region germline gene database and MOE software, or from the Journal of Immunoglobulin, 2001ISBN012441351.
- host cell refers to a cell into which an expression vector has been introduced.
- Host cells may include bacterial, microbial, plant or animal cells.
- Bacteria that are easily transformed include members of the Enterobacteriaceae family, such as strains of Escherichia coli or Salmonella; Bacillaceae such as Bacillus subtilis; Pneumococcus; Streptococcus and Haemophilus influenzae.
- Suitable microorganisms include Saccharomyces cerevisiae and Pichia pastoris.
- Suitable animal host cell lines include CHO (Chinese Hamster Ovary Cell Line), HEK293 cells (non-limiting examples such as HEK293E cells) and NS0 cells.
- Engineered antibodies or antigen-binding fragments can be prepared and purified by conventional methods. For example, cDNA sequences encoding heavy and light chains can be cloned and recombined into GS expression vectors. The recombinant immunoglobulin expression vector can stably transfect CHO cells. As an alternative prior art, mammalian expression systems can lead to glycosylation of antibodies, especially at the highly conserved N-terminal sites in the Fc region. Stable clones are obtained by expressing antibodies that specifically bind to the antigen. Positive clones were expanded in serum-free medium in the bioreactor to produce antibodies. The antibody-secreted culture fluid can be purified by conventional techniques.
- a protein A or protein G Sepharose FF column containing adjusted buffer is used for purification. Non-specifically bound components are washed away. Then, the bound antibody was eluted by pH gradient method, and antibody fragments were detected by SDS-PAGE and collected. Antibodies can be filtered and concentrated by conventional methods. Soluble mixtures and polymers can also be removed by conventional methods, such as molecular sieves and ion exchange. The resulting product should be frozen immediately, such as -70 °C, or lyophilized.
- administering when applied to animals, humans, experimental subjects, cells, tissues, organs or biological fluids, refers to the application of exogenous drugs, therapeutic agents, Diagnostic agents, compositions, or human operations (such as “euthanasia” in the examples) are provided to animals, humans, subjects, cells, tissues, organs, or biological fluids.
- administering and “treatment” may refer to, for example, treatment, pharmacokinetics, diagnosis, research, and experimental methods.
- the treatment of cells includes contact of reagents with cells and contact of reagents with fluids, wherein the fluids contact cells.
- administering and “treating” also mean in vitro and ex vivo treatment of, for example, cells by an agent, diagnosis, binding composition, or by another cell.
- Treatment when applied to human, veterinary or research subjects refers to therapeutic treatment, prophylactic or preventative measures, research and diagnostic applications.
- Treatment means administration of a therapeutic agent for internal or external use to a subject, such as a composition comprising any of the compounds of the embodiments of the present disclosure, the subject has (or is suspected of having, or is susceptible to) Or a variety of disease symptoms, and the therapeutic agent is known to have a therapeutic effect on these symptoms.
- the therapeutic agent is administered to the treated subject or population in an amount effective to relieve the symptoms of one or more diseases to induce the regression of such symptoms or inhibit the development of such symptoms to any clinically measurable extent.
- the amount of therapeutic agent effective to relieve the symptoms of any specific disease may vary according to various factors, such as the disease state, age, and weight of the subject, and the effect of the drug on the subject. ability.
- embodiments of the present disclosure may not be effective in relieving the symptoms of each target disease, according to any statistical test methods known in the art such as Student's test, chi-square test, according to Mann and Whitney's U test, Kruskal-Wallis test (H test), Jonckheere-Terpstra test, and Wilcoxon test determined that it should alleviate the target disease symptoms in a statistically significant number of subjects.
- Constant amino acid modification or “conservative amino acid substitution” refers to the substitution of amino acids in a protein or polypeptide by other amino acids with similar characteristics (such as charge, side chain size, hydrophobicity/hydrophilicity, backbone conformation, rigidity, etc.), thereby This allows frequent changes without changing the biological activity of the protein or polypeptide or other desired characteristics (such as antigen affinity and/or specificity).
- Those skilled in the art recognize that, in general, single amino acid substitutions in non-essential regions of polypeptides do not substantially change biological activity (see, for example, Watson et al. (1987) Molecular Biology of the Gene, The Benjamin/Cummings Pub. Co ., page 224 (4th edition)).
- substitution of structurally or functionally similar amino acids is unlikely to destroy biological activity.
- Exemplary conservative amino acid substitutions are as follows:
- Effective amount and “effective dose” refer to the amount of drug, compound or pharmaceutical composition necessary to obtain any one or more beneficial or desired therapeutic results.
- beneficial or desired results include elimination or reduction of risk, reduction of severity or delay of the onset of the disorder, including the disorder, its complications, and the biochemical, tissue, and intermediate pathological phenotypes exhibited during the development of the disorder Academic and/or behavioral symptoms.
- beneficial or desired results include clinical results, such as reducing the incidence or improving one or more symptoms of the various target antigen-related disorders of the present disclosure, reducing the dose of other agents required to treat the disorder , Enhance the efficacy of another agent, and/or delay the progression of the subject's target antigen-related disorders of the present disclosure.
- Exogenous refers to substances produced outside the body of organisms, cells or humans as the case may be.
- Endogenous refers to substances produced in cells, organisms, or humans according to circumstances.
- Homology and “identity” are interchangeable herein and refer to the sequence similarity between two polynucleotide sequences or between two polypeptides. When the positions in the two compared sequences are occupied by the same base or amino acid monomer subunit, for example, if each position of two DNA molecules is occupied by adenine, then the molecules are homologous at that position .
- the percentage of homology between two sequences is a function of the number of matching or homologous positions shared by the two sequences divided by the number of positions compared ⁇ 100.
- the two sequences are 60% homologous; if there are 95 matches at 100 positions in the two sequences Or homology, then the two sequences are 95% homologous.
- a comparison is made when aligning two sequences to give the maximum percentage of homology.
- the comparison can be performed by the BLAST algorithm, where the parameters of the algorithm are selected to give the maximum match between the individual sequences over the entire length of the individual reference sequences.
- BLAST ALGORITHMS Altschul, SF et al., (1990) J. Mol. Biol. 215:403-410; Gish, W. et al., (1993 ) Nature Genet. 3: 266-272; Madden, TL et al. (1996) Meth. Enzymol. 266: 131-141; Altschul, SF et al. (1997) Nucleic Acids Res. 25: 3389-3402; Zhang, J. et al. (1997) Genome Res. 7:649-656.
- Other conventional BLAST algorithms such as those provided by NCBI BLAST are also well known to those skilled in the art.
- isolated means changed to "depart from its original state of existence", and in this case means that the designated molecule is substantially free of other non-target biomolecules.
- isolated is not intended to refer to the complete absence of these materials or the absence of water, buffers, or salts unless they are present in amounts that significantly interfere with the experimental or therapeutic use of the compounds as described herein.
- “Pharmaceutical composition” means a mixture containing one or more compounds of the present disclosure or a physiological/pharmaceutically acceptable salt or prodrug thereof with other chemical components, such as physiological/pharmaceutically acceptable Carriers and excipients.
- the purpose of the pharmaceutical composition is to promote the administration to the living body, facilitate the absorption of the active ingredient and thereby exert the biological activity.
- pharmaceutically acceptable carrier refers to any inactive substance suitable for use in formulations for delivery of antibodies or antigen-binding fragments.
- Carriers can be anti-adherents, binders, coatings, disintegrating agents, fillers or diluents, preservatives (such as antioxidants, antibacterial or antifungal agents), sweeteners, absorption delaying agents, wetting agents Agent, emulsifier, buffer, etc.
- suitable pharmaceutically acceptable carriers include water, ethanol, polyol (e.g. glycerin, propylene glycol, polyethylene glycol, etc.) dextrose, vegetable oil (e.g. olive oil), saline, buffer, buffered saline and the like Osmotic agents such as sugar, polyols, sorbitol and sodium chloride.
- metabolic disorders are metabolic syndrome, obesity, impaired glucose tolerance, diabetes, diabetic ketoacidosis, hyperglycemia, hyperglycemic hyperosmolar syndrome, perioperative hyperglycemia, hyperinsulinemia Syndrome, insulin resistance syndrome, impaired fasting blood glucose, dyslipidemia, atherosclerosis, or prediabetes.
- another aspect of the present disclosure relates to a method for immunodetection or determination of a target antigen, a reagent for immunodetection or determination of a target antigen, a method for immunodetection or determination of cells expressing the target antigen, and a method for diagnosis and target antigen
- a diagnostic agent for a disease related to positive cells which contains a monoclonal antibody or antibody fragment of the present disclosure that specifically recognizes and binds a target antigen as an active ingredient.
- the method for detecting or measuring the amount of target antigen may be any known method.
- it includes immunodetection or assay methods.
- the immunodetection or measurement method is a method of detecting or measuring the amount of antibody or antigen using labeled antigen or antibody.
- immunodetection or measurement methods include radioactive substance-labeled immunoantibody method (RIA), enzyme immunoassay (EIA or ELISA), fluorescence immunoassay (FIA), luminescence immunoassay, Western blot, physical-chemical method Wait.
- the above-mentioned diseases related to target antigen-positive cells can be diagnosed by detecting or measuring cells expressing the target antigen with the monoclonal antibodies or antibody fragments of the present disclosure.
- the living sample used for detecting or measuring the target antigen there is no particular limitation on the living sample used for detecting or measuring the target antigen, as long as it has the possibility of including cells expressing the target antigen, such as tissue cells, blood, plasma, serum, pancreatic juice, urine, Feces, tissue fluid or culture fluid.
- cells expressing the target antigen such as tissue cells, blood, plasma, serum, pancreatic juice, urine, Feces, tissue fluid or culture fluid.
- the diagnostic agent containing the monoclonal antibody or antibody fragment of the present disclosure may also contain a reagent for performing an antigen-antibody reaction or a reagent for detecting the reaction.
- Reagents for performing antigen-antibody reactions include buffers, salts, and the like.
- the reagents used for detection include reagents commonly used in immunodetection or measurement methods, such as a labeled second antibody that recognizes the monoclonal antibody, its antibody fragment, or a conjugate thereof, a substrate corresponding to the label, and the like.
- Human GCGR cDNA encoding a glucagon receptor with a total length of 477 amino acids was subcloned into an expression vector (such as pcDNA3.1) and transfected into CHO-K1 cells. After screening and single-cell cloning, monoclonals were selected for antigen expression and receptor-based cell surface expression characterization studies. The following GCGR antigens refer to human GCGR unless otherwise specified.
- Full-length GCGR used to construct GCGR overexpressing cell lines, or used for immunization antigen and subsequent detection:
- ProteinG is preferred for affinity chromatography.
- the supernatant of the cultured hybridoma is centrifuged to take 10-15% volume of 1M Tris-HCl (pH8.0-8.5) according to the volume of the supernatant. Clear pH.
- the ProteinG column is washed 3-5 times the column volume with 6M guanidine hydrochloride, and then washed 3-5 times the column volume with pure water; use a buffer system such as 1 ⁇ PBS (pH7.4) as the equilibrium buffer to equilibrate the column 3-5 Double the column volume; combine the cell supernatant with a low flow rate and control the flow rate so that the retention time is about 1min or longer; wash the column 3-5 times the column volume with 1 ⁇ PBS (pH7.4) until the UV absorption drops to Baseline; use 0.1M acetic acid/sodium acetate (pH3.0) buffer for sample elution, collect elution peaks according to UV detection, and use 1M Tris-HCl (pH8.0) to quickly adjust pH to 5-6.
- a buffer system such as 1 ⁇ PBS (pH7.4) as the equilibrium buffer to equilibrate the column 3-5 Double the column volume; combine the cell supernatant with a low flow rate and control the flow
- the solution can be replaced by methods well known to those skilled in the art, such as ultrafiltration concentration using ultrafiltration tubes and solution replacement to the desired buffer system, or the use of molecular exclusion such as G-25 desalting to replace the desired Buffer system, or use high-resolution size exclusion columns such as Superdex 200 to remove polymer components in the eluted product to improve sample purity.
- methods well known to those skilled in the art such as ultrafiltration concentration using ultrafiltration tubes and solution replacement to the desired buffer system, or the use of molecular exclusion such as G-25 desalting to replace the desired Buffer system, or use high-resolution size exclusion columns such as Superdex 200 to remove polymer components in the eluted product to improve sample purity.
- the cell culture supernatant expressing Fc bispecific protein or antibody is subjected to high-speed centrifugation to collect the supernatant.
- the ProteinA affinity column was washed 3-5 times the column volume with 6M guanidine hydrochloride and then 3-5 times the column volume with pure water.
- the chromatographic column is equilibrated 3-5 times the column volume using a buffer system such as 1 ⁇ PBS (pH7.4) as the equilibration buffer.
- the supernatant of the cells was loaded with a low flow rate, and the flow rate was controlled so that the retention time was about 1 min or longer.
- the solution can be replaced by methods well known to those skilled in the art, such as ultrafiltration concentration using ultrafiltration tubes and solution replacement to the desired buffer system, or the use of molecular exclusion such as G-25 desalting to replace the desired Buffer system, or use high-resolution size exclusion columns such as Superdex 200 to remove polymer components in the eluted product to improve sample purity.
- Mouse immunity Anti-human GCGR monoclonal antibodies are produced by immunizing mice. Experimental SJL white mice, female, 6-8 weeks of age (Beijing Weitong Lihua Experimental Animal Technology Co., Ltd., animal production license number: SCXK (Beijing) 2012-0001). Feeding environment: SPF level. After the mice were purchased, they were kept in the laboratory environment for 1 week, adjusted for a 12/12 hour light/dark cycle, and the temperature was 20-25°C; The mice that have adapted to the environment are immunized according to the following protocol. The immune antigen is GCGRCHO-K1 stable cells.
- IP intraperitoneal
- GCGR CHO-K1 intraperitoneally
- the inoculation time is 0, 14, 28, 42, 56, 70, 84, 98, 112 days.
- Blood was collected on days 35, 63, and 91, and the antibody titer in the serum of mice was determined by ELISA.
- mice with high antibody titers in the serum and titers tending to the platform were selected for fusion of spleen cells.
- booster immunization was performed, and 1E7 cells/GCGC CHO-K1 cells were injected intraperitoneally (IP) to stabilize the cells.
- Rat immunization 6-8 week old SD rats were immunized with DNA (encoding full length hGCGR, see Genbank accession number: NM_000160), and the antibody titer in rat serum was determined by FACS method. After the 3-4th immunization, rats with high antibody titers in the serum and titers tending to plateau were selected for splenocyte fusion. Immunization was boosted 3 days before splenocyte fusion.
- hybridoma cells spleen lymphocytes and myeloma cells Sp2/0 cells ( CRL-8287 TM ) to obtain hybridoma cells.
- the fused hybridoma cells were resuspended in a complete medium (IMEM medium containing 20% FBS, 1 ⁇ HAT, 1 ⁇ OPI) at a density of 0.5-1E6/ml, and 100 ⁇ l/well was seeded in a 96-well plate at 37°C After incubating for 3-4 days with 5% CO 2 , supplement 100 ⁇ l/well of HAT complete medium and continue culturing for 3-4 days until colonies are formed.
- IMEM medium containing 20% FBS, 1 ⁇ HAT, 1 ⁇ OPI
- HT complete medium IMDM medium containing 20% FBS, 1 ⁇ HT and 1 ⁇ OPI
- ELISA test was performed after incubation at 37° C. and 5% CO 2 for 3 days.
- the hybridoma culture supernatant was detected by cell binding ELISA method.
- the well cells that tested positive were expanded, frozen, and subcloned two to three times in time until a single cell clone was obtained.
- Each subcloned cell also needs to be tested by GCGR cell combined with ELISA test.
- the hybridoma clones were obtained through experimental screening, and the antibody was further prepared by serum-free cell culture method, and the antibody was purified according to the purification example for use in the test example.
- the process of cloning sequences from positive hybridomas is as follows.
- the logarithmic growth phase hybridoma cells were collected, RNA was extracted using Trizol (Invitrogen, Cat No. 15596-018) according to the kit instructions, and reverse transcription was performed using PrimeScript TM Reverse Transcriptase kit (Takara, Cat No. 2680A).
- the cDNA obtained by reverse transcription was amplified by PCR using mouse Ig-Primer Set (Novagen, TB326 Rev. B 0503) and then sequenced.
- Screened positive clones were obtained from the obtained DNA sequence, antibodies were prepared by serum-free cell culture method, the antibodies were purified according to the purification example, and cell-based GCGR binding blocking experiments were used in the test examples after multiple rounds of screening to obtain Mouse hybridoma clones 1803, 1805, 1808 and 1810, and rat hybridoma clones 1817 and 1822.
- the light and heavy chain CDR sequences of the above mouse-derived antibodies m1803, m1805, m1808 and m1810 have high homology
- the light and heavy chain CDR sequences of the rat-derived antibodies rat1817 and rat1822 have high The homology, the consensus sequence is shown in the following table:
- IMGT human antibody heavy and light chain variable region germline gene databases were compared, and heavy chain and light chain variable region germline genes with high homology to murine antibodies were selected as templates.
- the CDRs of murine antibodies were transplanted into the corresponding human templates to form variable region sequences in the order of FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4. If necessary, part of the amino acids in the backbone sequence are back-mutated to the amino acids corresponding to the murine antibody to obtain the humanized anti-GCGR monoclonal antibody.
- the determination of amino acid residues in the CDR region is determined and annotated by the Kabat numbering system.
- the light and heavy chain variable regions of the mouse antibody and the light and heavy chain constant regions of the human antibody are connected to form a chimeric antibody.
- the chimeric antibody corresponding to clone 1803 is named ch1803, and other antibodies can be deduced by analogy.
- the humanized light chain templates of the murine antibody m1803 are IGKV1-39*01 and hjk4.1, and the humanized heavy chain templates are IGHV1-3*01 and hjh6.1.
- the sequence of the humanized variable region is as follows:
- the order is FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, the italic in the sequence is the FR sequence, and the underline is the CDR sequence.
- hybridoma clone 1803 The humanized template selection and back mutation design of hybridoma clone 1803 are as follows:
- P44V means to mutate Kabat number 44 P back to V according to Kabat numbering system.
- the grafting represents that the mouse antibody CDR is directly implanted into the human germline FR region sequence.
- the humanized antibody light chain variable region and heavy chain variable region sequence combinations of antibody derived from hybridoma clone 1803 are as follows:
- the antibody light and heavy chain variable regions indicated by the antibody names in the above table may be connected to the antibody light and heavy chain constant regions to form a full-length antibody.
- the light chain variable region is linked to the Kappa chain constant region shown in SEQ ID NO: 73 to form the antibody light chain
- the heavy chain variable region is linked to SEQ ID NO: 72
- the IgG4-AA shown are joined to form the antibody heavy chain.
- the humanized light chain templates of the murine antibody m1810 are IGKV1-39*01 and hJK4.1, and the humanized heavy chain templates are IGHV1-69*02 and hJH4.1.
- the sequence of the humanized variable region is as follows:
- Hu1810VH-CDR grafting (SEQ ID NO: 68)
- Hu1810VL-CDR grafting (SEQ ID NO: 65)
- the order is FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, the italic in the sequence is the FR sequence, and the underline is the CDR sequence.
- hybridoma clone 1810 The humanized template selection and back mutation design of hybridoma clone 1810 are as follows:
- P44V means to mutate Kabat number 44 P back to V according to Kabat numbering system.
- the grafting represents that the mouse antibody CDR is directly implanted into the human germline FR region sequence.
- the antibody light and heavy chain variable regions referred to by the antibody names in the above table can be connected to the antibody light and heavy chain constant regions respectively to form full-length antibodies.
- the light chain variable regions and The Kappa chain constant region shown in SEQ ID NO: 73 is connected to form an antibody light chain
- the heavy chain variable region is connected to the IgG4-AA shown in SEQ ID NO: 72 to form an antibody heavy chain.
- Example 4 Construction and expression of IgG4-AA form of GCGR chimera/humanized antibody
- IgG4-AA antibody form can be obtained by simple point mutation of the IgG4 antibody form, and IgG4-AA represents F234A, L235A and S228P mutations. Mutations of F234A and L235A can reduce the binding ability of IgG4-Fc and Fc ⁇ R, and further reduce ADCC/CDC.
- S228P represents the mutation of amino acid S at position 228 of the hinge region of wild-type IgG4 to P. This site mutation can avoid natural IgG4 antibody in Mismatches caused by Fab-exchanges occur in the body.
- ch1803, ch1805, ch1808, ch1810, ch1817, and ch1822 are chimeric antibodies formed by linking the light and heavy chain variable regions of animal origin shown in Table 1 to the human antibody kappa chain and the human antibody IgG4-AA heavy chain constant region, respectively.
- the sequence of the heavy chain constant region of IgG4-AA is as follows: (SEQ ID NO: 72)
- the sequence of the light chain (Kappa chain) constant region of the antibody is as follows: (SEQ ID NO: 73)
- hu1803-1 Antibody form IgG4AA
- hu1803-1 heavy chain sequence (SEQ ID NO: 76)
- ch1808 heavy chain sequence (SEQ ID NO: 82)
- hu1810-12 heavy chain sequence (SEQ ID NO: 84)
- Duramose peptide is a double-stranded form, the single-stranded is GLP-1/hIgG4Fc (SEQ ID NO: 90)
- the human GLP-1 peptide is used as the GLP-1 receptor agonist part in the bispecific protein, and the GCGR antibody is used as the GCGR antagonist part of the bispecific protein to form the GLP-1/GCGR antibody bispecific protein.
- GLP-1 amino acid mutations at specific positions of GLP-1 (such as Q17E, I23V, K28R or G30R)
- the new GLP-1/GCGR antibody bispecific protein formed was more stable in vitro, and the GLP-1A
- the Q mutation at position 17 is E
- the I mutation at position 23 is V form (GLP-1C), with the highest stability.
- Non-limiting example sequences of GLP-1 and its mutant forms of the present disclosure are as follows:
- the C-terminal amino acid of the GLP-1 peptide of the present disclosure is connected to the N-terminal amino acid of the GCGR antibody heavy chain through a peptide bond or linker.
- Regular expression through the 293 expression system yields the model structure of the bispecific protein shown in Table 9:
- the GLP-1 peptide can be attached to the amino terminus of the variable region of the GCGR antibody heavy chain or to the amino terminus of the variable region of the GCGR antibody light chain. It has been verified by experiments that the bispecific protein linked to the amino terminus of the heavy chain variable region of the GCGR antibody by the GLP-1 peptide is more stable than the amino terminus linked to the variable region of the light chain of the GCGR antibody.
- the structure of the bispecific protein in some embodiments of the GLP-1 peptide of the present disclosure linked to the variable region of the heavy chain of the GCGR full-length antibody is shown in FIG.
- the different GLP-1 peptides are connected to the heavy chain amino acids of different antibodies with a linker (eg (GGGGS) 3 ) to form the following proteins:
- the linker linker of the bispecific protein can be (GGGGS) 3 , and in other embodiments, it can also be a peptide bond or other linkers conventionally used for polypeptide connection.
- the use of (GGGGS) 3 is not a bispecific protein of the present disclosure. Restrictions on connectors.
- the nucleotide sequence encoding GLP-1, the nucleotide sequence encoding the GCGR antibody, and the nucleotide sequence of the linker protein fragment ((GGGGS) 3 ) are obtained by conventional technical means in the art.
- the C-terminal nucleotide of GLP-1 was connected to the N-terminal nucleotide of the GCGR antibody via a linker protein, and cloned into the Phr-BsmbI vector.
- the recombinant GLP-1/GCGR antibody bispecific protein was expressed in 293 cells and purified by the method of Example 6. The purified protein can be used in the following examples.
- the supernatant was collected after centrifugation of the cell culture fluid at high speed, and the first step of purification was performed by affinity chromatography.
- the chromatographic medium is Protein A that interacts with Fc or a derivative filler, such as GE's Mabselect.
- the equilibration buffer is 1 ⁇ PBS (137 mmol/L NaCl, 2.7 mmol/L KCl, 10 mmol/L Na 2 HPO 4 , 2 mmol/L KH 2 PO 4 , pH7.4), after equilibrating 5 times the column volume, place the cells on The combination of clearing and loading, the flow rate is controlled to the sample retention time on the column ⁇ 1min.
- the column was rinsed with 1 ⁇ PBS (pH 7.4) until the UV absorption of A280 dropped to the baseline.
- the column was then washed with 0.1 M glycine (pH 3.0) elution buffer, the elution peak was collected based on the A280 ultraviolet absorption peak, and the collected elution sample was neutralized with 1 M Tris (pH 8.5).
- the neutralized eluted sample was ultrafiltered and concentrated, and then subjected to size exclusion chromatography.
- the buffer solution was 1 ⁇ PBS
- the chromatography column was XK26/60Superdex200 (GE)
- the flow rate was controlled at 4 ml/min
- the sample loading volume was less than 5 ml.
- the collected protein was identified by SEC-HPLC with a purity of greater than 95%, and was identified as correct by LC-MS and then distributed. GLP-1/GCGR antibody bispecific protein was obtained.
- Test Example 1 ELISA experiment of GCGR chimeric antibody binding to GCGR of human, mouse and cynomolgus monkey
- the binding capacity of the anti-GCGR antibody was tested by the antibody binding experiment with CHO cells overexpressing GCGR. After transfection, the GCGR full-length plasmids of human, mouse and cynomolgus monkeys were transferred into CHO cells for two weeks under pressure and the expression of GCGR was detected. After the overexpression cells were fixed to the bottom of the 96-well plate, the strength of the signal after the addition of the antibody was used to determine the binding activity of the antibody and GCGR overexpressing CHO cells.
- the GCGR method is used as an example. The specific experimental methods are as follows:
- the cells were seeded in 96-well plates at a density of 0.9-1.0 ⁇ 10 6 /ml, 100 ⁇ l/well, and cultured overnight. After discarding the supernatant and washing it three times with PBS, 100 ⁇ l/well of cell immunofixation solution (Beyotime, Cat Wo. P0098) was added for fixation at room temperature for 1 hour, and PBS was washed four times. After discarding the liquid, 5% skimmed milk (BD skim milk, Cat Wo.232100) blocking solution diluted with PBS was added 200 ⁇ l/well, and incubated at 37° C. incubator for 3 hours for blocking.
- 5% skimmed milk BD skim milk, Cat Wo.232100
- the plate was washed 3 times with PBST buffer (pH7.4PBS containing 0.05% tweeeW-20), and 50 ⁇ l/well of different concentrations of the test antibody (hybridized antibody) diluted with the sample diluent were added , Chimeric antibody or humanized antibody), placed in an incubator at 37 °C for 2 hours. After the incubation, the plate was washed 3 times with PBST, and 50 ⁇ l/well of HRP-labeled goat anti-mouse secondary antibody (JacksoW ImmuWo Research, Cat Wo. 115-035-003) or goat anti-human secondary antibody (JacksoW) ImmuWo Research, Cat Wo.
- HRP-labeled goat anti-mouse secondary antibody JacksoW ImmuWo Research, Cat Wo. 115-035-003
- goat anti-human secondary antibody JacksoW
- Test Example 2 GCGR chimeric antibody blocks the binding of GCGR ligand to GCGR
- the antagonistic activity of GCGR chimeric antibodies was evaluated by the GCGR chimeric antibody blocking the binding of GCGR ligand glucagon to GCGR.
- the combination of cAMP and CRE can start the expression of the luciferase gene (luciferase) downstream of the CRE.
- the luciferase binds to its substrate and emits fluorescence, which reflects the inhibition efficiency through changes in the fluorescence signal.
- the CRE was cloned upstream of the luciferase gene, and the CHO-K1 cells were co-transfected with the plasmid containing the GCGR gene to select monoclonal cells that highly expressed both CRE and GCGR.
- the GLP-1/GCGR antibody bispecific protein and glucagon can competitively bind to GCGR, blocking the downstream signal transmission of GCGR, affecting the downstream cAMP expression, and evaluating the GLP-1/GCGR antibody by measuring the change in fluorescence signal Antagonistic activity of bispecific protein against GCGR.
- Test Example 3 Blocking test of GCGR ligand binding to GCGR by GCGR humanized antibody
- Test Example 4 Stability of GLP-1/GCGR antibody bispecific protein in PBS
- test antibody bispecific protein dissolved in 1ml 1 ⁇ PBS (pH7.4), store in a 37°C incubator; take samples on days 0 and 14, respectively, and use Agilent 6530Q-TOF for LC-MS to detect the complete heavy chain retention , The results are shown in Table 14 below.
- the bispecific proteins containing the modified GLP-1 peptides are much more stable than the bispecific proteins containing GLP-1A (SEQ ID NO: 91), and hu1803-9B, hu1803-9D and hu1803-9G show Better stability.
- Figure 2 and Table 15 show that both hu1803-9B and hu1803-9D can completely inhibit the antagonistic activity of GCGR, and have comparable efficacy and IC50 (concentration required to inhibit 50% of the maximum activity) with GCGR monoclonal antibody, indicating that hu1803-9B Both hu1803-9D and GCGR antibody retain partial biological activity.
- IC50 concentration required to inhibit 50% of the maximum activity
- the GLP-1/GCGR antibody bispecific protein GLP-1 portion was evaluated for GLP-1R activation activity.
- cAMP cyclopentase
- CRE cyclopentase binds to its substrate, it emits fluorescence, which reflects the inhibition efficiency through the change of fluorescence signal.
- CRE was cloned upstream of the luciferase gene, and CHO-K1 cells were co-transfected with the plasmid containing the GLP-1R gene to select monoclonal cells that simultaneously expressed CRE and GLP-1R.
- the GLP-1/GCGR antibody bispecific protein and the positive control Doxyl glycopeptide can bind to GLP-1R, activate downstream signal transmission of GLP-1R, stimulate downstream cAMP expression, and evaluate GLP-1/ by measuring changes in fluorescence signal Activating activity of GCGR antibody bispecific protein on GLP-1R.
- a Prepare a cell suspension with fresh cell culture medium, add 25000 cells/well to a 96-well cell culture plate of 90 ⁇ l culture system, and incubate at 37°C for 16 hours with 5% carbon dioxide.
- Figure 3 and Table 17 show that both hu1803-9B and hu1803-9D can fully activate GLP-1R, and have comparable efficacy and EC50 (concentration required to activate 50% of the maximum activity) with the positive control duraglutide, indicating hu1803 Both -9B and hu1803-9D retained the full biological activity of GLP-1.
- Table 18 shows that the ch1805-D, ch1808-D, and ch1817-D chimeric antibodies can fully activate GLP-1R by linking with GLP1 peptides, and they have comparable efficacy and EC50 (50% of the maximum activation activity) as the positive control degree of glycopyrrolate The desired concentration) indicates that the bispecific protein formed by linking different GCGR antibodies to the GLP1 peptide in the manner disclosed herein does not affect the biological activity of the GLP1 peptide.
- C57 mice Four C57 mice were used in the experiment, female, with light/dark adjustment for 12/12 hours, constant temperature of 24 ⁇ 3°C, humidity of 50-60%, and free access to drinking water. Purchased from Jie Jie Jie Experimental Animal Co., Ltd. On the day of the experiment, C57 mice were injected with equimolar hu1803-9D and the positive control drug dula glycopeptide into the tail vein, respectively, the dosage was 6 mg/kg and 2.35 mg/kg, and the injection volume was 10 ml/kg.
- the drug metabolism time in mice is shorter, and the selected blood sampling time point is: Day 0h, 1h, 24h (day 2), on day 3, blood was taken from the fundus vein of mice, each time 150 ⁇ l (before blood collection, 1.5 ⁇ l DPP-4 inhibitor was added to blood collection tube in advance); The collected blood samples were placed at 4°C for half an hour to agglomerate, and then centrifuged at 14000 ⁇ g for 5 minutes at 4°C. Collect the supernatant (approximately 80 ⁇ l) and store at -80°C immediately.
- the detection process is described as follows:
- the PK analysis result shows that the half-life of the bispecific protein molecule hu1803-9D of the present disclosure in mice is about 23.4h, which is twice that of the positive control drug.
- Test Example 8 In vivo drug efficacy experiment of ob/ob mice
- mice diabetic ob/ob mice and wild-type mice of the same age (Nanjing Institute of Model Animals, Nanjing University), the purpose is to observe the continuous multiple administration of GLP-1/GCGR antibody bispecific protein Therapeutic effect on diabetes-related indicators such as blood glucose, glycated hemoglobin, weight, and food intake of ob/ob mice.
- mice in the model group were divided into 6 groups according to the random and fasting body weight and random and fasting blood glucose on the day of the experiment, respectively:
- Model control group 2.84mg/kg, 1.42mg/kg GCGR monoclonal antibody group (hu1803-9), 1.16mg/kg positive control group (duratopeptide) and 3mg/kg, 1.5mg/kghu1803-9D
- model control Group mice were given subcutaneous injection (SC) with phosphate buffer solution, and mice in each group were given subcutaneous injection (9:00AM) once a week for a total of 4 times (Table 20).
- Group deal with dose Dosing frequency Mode of administration 1 ob/ob mouse model control group PBS Once a week x 4 weeks S.C. 2 GCGR monoclonal antibody low dose group 1.42mpk Once a week x 4 weeks S.C. 3 GCGR monoclonal antibody high-dose group 2.84mpk Once a week x 4 weeks S.C. 4 Positive control high-dose group 1.16mpk Once a week x 4 weeks S.C. 4 hu1803-9D low-dose group 1.5mpk Once a week x 4 weeks S.C. 5 hu1803-9D high-dose group 3mpk Once a week x 4 weeks S.C.
- Random blood glucose was measured before the first administration and on days 1, 2, 3, and 7 after the administration, and random blood glucose was measured once a week thereafter.
- the fasting blood glucose was measured at 6h before the first administration and on the 3rd and 7th days after the administration, and the fasting blood glucose was measured once a week thereafter.
- mice were euthanized after fasting for 6 hours (8:00-14:00). After the heart was drawn, the whole blood was divided into two parts, and a part of about 30 ⁇ l was injected into the centrifuge tube with the added anticoagulant and stored. It is used for measuring glycated hemoglobin in wet ice, and the other part is centrifuged and the serum is centrifuged to determine the levels of TG, FFA, CHOL, HDL and LDL.
- the data is analyzed by graphpad Prism 6 software, and Student-t test is used for statistical analysis of the data.
- the random blood glucose of ob/ob mice in the model control group was maintained at a high level throughout the test period.
- the random blood glucose of mice in each group had different degrees Decreased, showing a good dose effect and significantly lower than the model control group.
- 2.84mg/kg administration of hu1803-9 and 3mg/kg administration of hu1803-9D were significantly better than other test groups, while 3mg/kg administration of hu1803-9D administration on days 3, 6, 14 and 30 Random blood sugar is better.
- Test Example 9 Competitive ELISA experiment of GCGR antibody
- the biotinylated antibody competes with standard antibodies at different concentrations for binding to CHO cells overexpressing GCGR to detect and classify the epitope that GCGR antibody binds to GCGR.
- the preparation method of the cell plate is the same as that of Test Example 1.
- the specific experimental methods are as follows:
- the antibody was labeled according to the instructions of the biotin labeling kit (Dojindo Molecular Technologies, Inc. LK03).
- a biotin labeling kit (Dojindo Molecular Technologies, Inc. LK03).
- 50 ⁇ l/well of different concentrations of unbiotin-labeled test antibody diluted with the sample diluent were placed and incubated at 37°C for 2 hours. After incubation, wash the plate 3 times with PBST, add 50 ⁇ l/well of biotinylated antibody diluted with sample diluent to 0.1 ⁇ g/ml, wash the plate 3 times with PBST after incubating for 2 hours at 37°C, add HRP-labeled goat anti-human Secondary antibody (JacksoW ImmuWo Research, Cat Wo.
- IC% (test antibody highest OD 450nm - test antibody Minimum OD 450nm) / (tested up to OD 450nm - labeled antibody Minimum OD 450nm) calculated competition efficiency, 22 results in the table below.
Abstract
Description













| hu1803_VL.1 | hu1803_VL.1A | hu1803_VL.1B | |
| hu1803_VH.1 | hu1803-1 | hu1803-5 | hu1803-9 |
| hu1803_VH.1A | hu1803-2 | hu1803-6 | hu1803-10 |
| hu1803_VH.1B | hu1803-3 | hu1803-7 | hu1803-11 |
| hu1803_VH.1C | hu1803-4 | hu1803-8 | hu1803-12 |






| hu1810_VL.1 | hu1810_VL.1A | hu1810_VL.1B | |
| hu1810_VH.1 | hu1810-1 | hu1810-5 | hu1810-9 |
| hu1810_VH.1A | hu1810-2 | hu1810-6 | hu1810-10 |
| hu1810_VH.1B | hu1810-3 | hu1810-7 | hu1810-11 |
| hu1810_VH.1C | hu1810-4 | hu1810-8 | hu1810-12 |





























| 抗体EC50(nM) | ch1803 | ch1805 | ch1808 | ch1810 | ch1817 | ch1822 |
| 人GCGR | 0.1167 | 0.2969 | 0.6769 | 0.1168 | 0.1926 | 0.3834 |
| 小鼠GCGR | 0.7183 | 0.3428 | 1.019 | 0.4415 | 0.1638 | 0.5681 |
| 食蟹猴GCGR | 0.2128 | 0.3585 | 0.5356 | 0.2480 | 0.2968 | 0.4280 |



| 蛋白 | 第14天 |
| hu1803-9A | 70.12% |
| hu1803-9B | ≥97% |
| hu1803-9C | 93.98% |
| hu1803-9D | ≥97% |
| hu1803-9E | 94.15% |
| hu1803-9F | 94.65% |
| hu1803-9G | ≥97% |



| 蛋白 | EC50(nM) | Emax(%) |
| 度拉糖肽 | 0.21 | 100 |
| hu1803-9B | 0.22 | 100 |
| hu1803-9D | 0.32 | 100 |
| 样本 | EC50(nM) | Emax% |
| ch1805-D | 0.11 | 108 |
| ch1808-D | 0.14 | 107 |
| ch1817-D | 0.30 | 106 |
| 受试药物 | 给药方式 | T1/2(h) |
| hu1803-9D | IV(6mg/kg) | 23.4 |
| 度拉糖肽 | IV(2.35mg/kg) | 10 |
| 组别 | 处理 | 剂量 | 给药频率 | 给药方式 |
| 1 | ob/ob小鼠模型对照组 | PBS | 每周一次x 4周 | S.C. |
| 2 | GCGR单抗低剂量组 | 1.42mpk | 每周一次x 4周 | S.C. |
| 3 | GCGR单抗高剂量组 | 2.84mpk | 每周一次x 4周 | S.C. |
| 4 | 阳性对照高剂量组 | 1.16mpk | 每周一次x 4周 | S.C. |
| 4 | hu1803-9D低剂量组 | 1.5mpk | 每周一次x 4周 | S.C. |
| 5 | hu1803-9D高剂量组 | 3mpk | 每周一次x 4周 | S.C. |



Claims (25)
- 一种抗GCGR的单克隆抗体或其抗原结合片段,其包含选自如下所示的重链可变区和轻链可变区的组合:a)重链可变区,其包含分别如SEQ ID NO:48、49和50所示的HCDR1、HCDR2和HCDR3区,和轻链可变区,其包含分别如SEQ ID NO:51、52和53所示的LCDR1、LCDR2和LCDR3区;或b)重链可变区,其包含分别如SEQ ID NO:38、39和54所示的HCDR1、HCDR2和HCDR3区,和轻链可变区,其包含分别如SEQ ID NO:55、56和57所示的LCDR1、LCDR2和LCDR3区。
- 根据权利要求1所述的抗GCGR的单克隆抗体或其抗原结合片段,其包含选自如下所示的重链可变区和轻链可变区的组合:i)重链可变区,其包含分别如SEQ ID NO:14、15和16所示的HCDR1、HCDR2和HCDR3区,和轻链可变区,其包含分别如SEQ ID NO:17、18和19所示的LCDR1、LCDR2和LCDR3区;ii)重链可变区,其包含分别如SEQ ID NO:20、21和22所示的HCDR1、HCDR2和HCDR3区,和轻链可变区,其包含分别如SEQ ID NO:23、24和25所示的LCDR1、LCDR2和LCDR3区;iii)重链可变区,其包含分别如SEQ ID NO:26、27和28所示的HCDR1、HCDR2和HCDR3区,和轻链可变区,其包含分别如SEQ ID NO:29、30和31所示的LCDR1、LCDR2和LCDR3区;iv)重链可变区,其包含分别如SEQ ID NO:32、33和34所示的HCDR1、HCDR2和HCDR3区,和轻链可变区,其包含分别如SEQ ID NO:35、36和37所示的LCDR1、LCDR2和LCDR3区;v)重链可变区,其包含分别如SEQ ID NO:38、39和40所示的HCDR1、HCDR2和HCDR3区,和轻链可变区,其包含分别如SEQ ID NO:41、42和43所示的LCDR1、LCDR2和LCDR3区;和vi)重链可变区,其包含分别如SEQ ID NO:38、39和44所示的HCDR1、 HCDR2和HCDR3区,和轻链可变区,其包含分别如SEQ ID NO:45、46和47所示的LCDR1、LCDR2和LCDR3区。
- 根据权利要求1或2所述的抗GCGR的单克隆抗体或其抗原结合片段,其是鼠源抗体或其抗原结合片段、嵌合抗体或其抗原结合片段、或人源化抗体或其抗原结合片段。
- 根据权利要求3所述的抗GCGR的单克隆抗体或其抗原结合片段,所述人源化抗体包含源自人抗体的框架区或其框架区变体,其中:所述框架区变体在人抗体的轻链框架区和/或重链框架区上分别具有至多10个氨基酸的回复突变,优选地,所述氨基酸回复突变选自:aa)轻链可变区中包含42G、44V、71Y和87F中的一个或更多个回复突变,和/或重链可变区中包含38K、48I、67A、69F、71A、73P、78A和93S中的一个或更多个回复突变;或者ab)轻链可变区中包含38L、44V、59S、70E和71Y中的一个或更多个回复突变,和/或重链可变区中包含38K、48I、66K、67A、69L、73R、78M和94S中的一个或更多个回复突变。
- 根据权利要求3所述的抗GCGR的单克隆抗体或其抗原结合片段,其包含选自如下所示的轻链可变区和重链可变区组合:c)重链可变区,其序列如SEQ ID NO:2、61、62、63和64任一所示或与SEQ ID NO:2、61、62、63和64任一所示具有至少90%序列同一性;和轻链可变区,其序列如SEQ ID NO:3、58、59和60任一所示或与SEQ ID NO:3、58、59和60任一所示具有至少90%序列同一性;d)重链可变区,其序列如SEQ ID NO:4所示或与SEQ ID NO:4所示具有至少90%序列同一性;和轻链可变区,其序列如SEQ ID NO:5所示或与SEQ ID NO:5所示具有至少90%序列同一性;e)重链可变区,其序列如SEQ ID NO:6所示或与SEQ ID NO:6所示具有至少90%序列同一性;和轻链可变区,其序列如SEQ ID NO:7所示或与SEQ ID NO:7所示具有至少90%序列同一性;f)重链可变区,其序列如SEQ ID NO:8、68、69、70和71任一所示或与SEQ ID NO:8、68、69、70和71任一所示具有至少90%序列同一性;和轻链可变区,其序列如SEQ ID NO:9、65、66和67任一所示或与SEQ ID NO:9、65、66和67任一所示具有至少90%序列同一性;g)重链可变区,其序列如SEQ ID NO:10所示或与SEQ ID NO:10所示具有至少90%序列同一性;和轻链可变区,其序列如SEQ ID NO:11所示或与SEQ ID NO:11所示具有至少90%序列同一性;和h)重链可变区,其序列如SEQ ID NO:12所示或与SEQ ID NO:12所示具有至少90%序列同一性;和轻链可变区,其序列如SEQ ID NO:13所示或与SEQ ID NO:13所示具有至少90%序列同一性。
- 根据权利要求1至5任一项所述的抗GCGR的单克隆抗体或其抗原结合片段,其中所述抗体为全长抗体,进一步包括抗体恒定区,优选地,所述重链恒定区选自人IgG1、IgG2、IgG3和IgG4恒定区及其常规变体,所述轻链恒定区选自人抗体κ和λ链恒定区及其常规变体,更优选包含SEQ ID NO:72所示的人抗体重链恒定区和SEQ ID NO:73所示的人抗体轻链恒定区。
- 根据权利要求6所述的抗GCGR的单克隆抗体或其抗原结合片段,包括选自如下任一项所示的重链和轻链的组合:j)所述重链为SEQ ID NO:74、76或78所示或与其具有至少85%序列同一性,且所述轻链为SEQ ID NO:75、77或79所示或与其具有至少85%序列同一性;k)所述重链为SEQ ID NO:80所示或与其具有至少85%序列同一性,且所述轻链为SEQ ID NO:81所示或与其具有至少85%序列同一性;l)所述重链为SEQ ID NO:82所示或与其具有至少85%序列同一性,且所述轻链为SEQ ID NO:83所示或与其具有至少85%序列同一性;m)所述重链为SEQ ID NO:84所示或与其具有至少85%序列同一性,且所述轻链为SEQ ID NO:85所示或与其具有至少85%序列同一性;n)所述重链为SEQ ID NO:86所示或与其具有至少85%序列同一性,且所述轻链为SEQ ID NO:87所示或与其具有至少85%序列同一性;和o)所述重链为SEQ ID NO:88所示或与其具有至少85%序列同一性,且所述轻链为SEQ ID NO:89所示或与其具有至少85%序列同一性。
- 一种抗GCGR的单克隆抗体或其抗原结合片段,其中包含选自如下所示的重链可变区和轻链可变区组合:ac)重链可变区,其包含与SEQ ID NO:2所示重链可变区具有相同序列的HCDR1、HCDR2和HCDR3区,和轻链可变区,其包含与SEQ ID NO:3所示轻链可变区具有相同序列的LCDR1、LCDR2和LCDR3区;ad)重链可变区,其包含与SEQ ID NO:4所示重链可变区具有相同序列的HCDR1、HCDR2和HCDR3区,和轻链可变区,其包含与SEQ ID NO:5所示轻链可变区具有相同序列的LCDR1、LCDR2和LCDR3区;ae)重链可变区,其包含与SEQ ID NO:6所示重链可变区具有相同序列的HCDR1、HCDR2和HCDR3区,和轻链可变区,其包含与SEQ ID NO:7所示轻链可变区具有相同序列的LCDR1、LCDR2和LCDR3区;af)重链可变区,其包含与SEQ ID NO:8所示重链可变区具有相同序列的HCDR1、HCDR2和HCDR3区,和轻链可变区,其包含与SEQ ID NO:9所示轻链可变区具有相同序列的LCDR1、LCDR2和LCDR3区;ag)重链可变区,其包含与SEQ ID NO:10所示重链可变区具有相同序列的HCDR1、HCDR2和HCDR3区,和轻链可变区,其包含与SEQ ID NO:11所示轻链可变区具有相同序列的LCDR1、LCDR2和LCDR3区;和ah)重链可变区,其包含与SEQ ID NO:12所示重链可变区具有相同序列的HCDR1、HCDR2和HCDR3区,和轻链可变区,其包含与SEQ ID NO:13所示轻链可变区具有相同序列的LCDR1、LCDR2和LCDR3区。
- 根据权利要求1至8任一项所述的抗GCGR的单克隆抗体或其抗原结合片段,其中所述抗原结合片段选自Fab、Fab'、F(ab')2、单链抗体、二聚化的V区(双抗体)和二硫键稳定化的V区(dsFv)。
- 一种双特异性蛋白,其包含GLP-1肽和抗GCGR抗体或其抗原结合片段,所述GLP-1肽通过肽键或接头共价连接至所述的抗GCGR抗体或其抗原结合片段。
- 根据权利要求10所述的双特异性蛋白,其中:所述GLP-1肽的羧基端通过肽键或接头连接至所述抗GCGR的单克隆抗体或其抗原结合片段的重链可变区的氨基端;或者所述GLP-1肽的羧基端通过肽键或接头连接至所述抗GCGR抗体或其抗原结合片段的轻链可变区的氨基端。
- 根据权利要求11所述的双特异性蛋白,其中所述的抗GCGR抗体或其抗原结合片段是权利要求1至9任一项所述的抗GCGR的单克隆抗体或其抗原结合片段。
- 根据权利要求10至12任一项所述的双特异性蛋白,其中:所述GLP-1肽是SEQ ID NO:91所示的GLP-1肽或其变体,所述GLP-1肽变体为SEQ ID NO:91所示GLP-1肽中包含Q17E、I23V、K28R和G30R中一个或更多个氨基酸突变,优选地,所述GLP-1肽变体包含Q17E突变、或包含Q17E和I23V突变。
- 根据权利要求13所述的双特异性蛋白,其中所述GLP-1肽变体的序列如SEQ ID NO:92、93、94、95、96、97、98或99所示。
- 根据权利要求14所述的双特异性蛋白,所述双特异性蛋白包含第一多肽链和第二多肽链,所述第一多肽链包含权利要求1至9任一项所述抗GCGR的单克隆抗体的重链;所述第二多肽链包含权利要求1至9任一项所述抗GCGR的单克隆抗体的轻链;其中:(ai)所述第一多肽链包含:选自SEQ ID NO:100、101、102、103、104、105、106、107和108任一所示的多肽,和所述第二多肽链包含SEQ ID NO:79所示的多肽;(aj)所述第一多肽链包含SEQ ID NO:109所示的多肽,和所述第二多肽链包含SEQ ID NO:81所示的多肽;(ak)所述第一多肽链包含SEQ ID NO:110所示的多肽,和所述第二多肽链包含SEQ ID NO:83所示的多肽;(al)所述第一多肽链包含SEQ ID NO:111所示的多肽,和所述第二多肽链包含SEQ ID NO:85所示的多肽;(am)所述第一多肽链包含SEQ ID NO:112所示的多肽,和所述第二多肽链包含SEQ ID NO:87所示的多肽;或者(an)所述第一多肽链包含SEQ ID NO:113所示的多肽,和所述第二多肽链包含SEQ ID NO:89所示的多肽。
- 一种GLP-1肽变体,所述GLP-1肽变体是在SEQ ID NO:91所示的GLP-1 肽基础上包含Q17E、I23V、K28R和G30R中一个或更多个氨基酸突变,优选地,所述GLP-1肽变体包含Q17E突变、或包含Q17E和I23V突变。
- 根据权利要求16所述的GLP-1肽变体,所述GLP-1肽变体的序列如SEQ ID NO:92、93、94、95、96、97、98或99所示。
- 一种药物组合物,其含有:治疗有效量的根据权利要求1至9任一项所述抗GCGR的单克隆抗体或其抗原结合片段,或根据权利要求10至15任一项所述的双特异性蛋白,或根据权利要求16或17所述的GLP-1肽变体,以及一种或多种药学上可接受的载体、稀释剂、缓冲剂或赋形剂。
- 一种分离的核酸分子,其编码权利要求1至9任一项所述的抗GCGR的单克隆抗体或其抗原结合片段,或根据权利要求10至15任一项所述的双特异性蛋白,或根据权利要求16或17所述的GLP-1肽变体。
- 一种重组载体,其包含权利要求19所述的分离的核酸分子。
- 一种宿主细胞,其转化有权利要求20所述的重组载体,所述宿主细胞选自原核细胞和真核细胞,优选为真核细胞,更优选哺乳动物细胞或昆虫细胞。
- 一种制备权利要求1至9任一项所述的抗GCGR的单克隆抗体或其抗原结合片段,或权利要求10至15任一项所述的双特异性蛋白,或权利要求16或17所述的GLP-1肽变体的方法,所述方法包括:培养权利要求21所述的宿主细胞形成权利要求1至9任一项所述的抗GCGR的单克隆抗体或其抗原结合片段,或权利要求10至15任一项所述的双特异性蛋白,或权利要求16或17所述的GLP-1肽变体,以及从培养物回收所述单克隆抗体或其抗原结合片段、或双特异性蛋白、或GLP-1肽变体。
- 一种检测样本中人GCGR的试剂,其包含权利要求1至9任一项所述的抗GCGR的单克隆抗体或其抗原结合片段。
- 一种降低受试者血糖浓度的方法,所述方法包括:向受试者施用治疗有效量的权利要求1至9任一项所述的抗GCGR的单克隆抗体或其抗原结合片段,或权利要求10至15任一项所述的双特异性蛋白,或权利要求16或17所述的GLP-1肽变体,或权利要求18所述的药物组合物,优选地,所述治疗有效量为单位剂量中含有0.1至3000mg的权利要求1至9任一项所述的抗GCGR的单克隆抗体或其抗原结合片段,或权利要求10至15任一项所述的双特异性蛋白,或权利要求16或17所述的GLP-1肽变体。
- 一种治疗代谢障碍的方法,所述方法包括:向受试者施用治疗有效量的权利要求1至9任一项所述的抗GCGR的单克隆抗体或其抗原结合片段,或权利要求10至15任一项所述的双特异性蛋白,或权利要求16或17所述的GLP-1肽变体,或权利要求18所述的药物组合物;优选地,所述代谢障碍选自:代谢综合征、肥胖症、葡萄糖耐量受损、糖尿病、糖尿病酮症酸中毒、高血糖症、高血糖高渗综合征、围术期高血糖症、高胰岛素血症、胰岛素抵抗综合症、空腹血糖受损、血脂异常、动脉粥样硬化和糖尿病前期状态。
Priority Applications (9)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| MX2021007444A MX2021007444A (es) | 2018-12-21 | 2019-12-20 | Proteina biespecifica. |
| KR1020217021692A KR20210109552A (ko) | 2018-12-21 | 2019-12-20 | 이중특이적 단백질 |
| EP19898966.7A EP3901173A4 (en) | 2018-12-21 | 2019-12-20 | BISPECIFIC PROTEIN |
| AU2019410643A AU2019410643A1 (en) | 2018-12-21 | 2019-12-20 | Bispecific protein |
| JP2021535930A JP2022516439A (ja) | 2018-12-21 | 2019-12-20 | 二特異性タンパク質 |
| CA3123979A CA3123979A1 (en) | 2018-12-21 | 2019-12-20 | Bispecific protein |
| US17/416,237 US20220153853A1 (en) | 2018-12-21 | 2019-12-20 | Bispecific protein |
| CN202211312212.4A CN115947849A (zh) | 2018-12-21 | 2019-12-20 | 双特异性蛋白 |
| CN201980071999.XA CN112996811B (zh) | 2018-12-21 | 2019-12-20 | 双特异性蛋白 |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811573634.0 | 2018-12-21 | ||
| CN201811573634 | 2018-12-21 | ||
| CN201811606887.3 | 2018-12-27 | ||
| CN201811606887 | 2018-12-27 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020125744A1 true WO2020125744A1 (zh) | 2020-06-25 |
Family
ID=71102514
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2019/126903 WO2020125744A1 (zh) | 2018-12-21 | 2019-12-20 | 双特异性蛋白 |
Country Status (10)
| Country | Link |
|---|---|
| US (1) | US20220153853A1 (zh) |
| EP (1) | EP3901173A4 (zh) |
| JP (1) | JP2022516439A (zh) |
| KR (1) | KR20210109552A (zh) |
| CN (2) | CN115947849A (zh) |
| AU (1) | AU2019410643A1 (zh) |
| CA (1) | CA3123979A1 (zh) |
| MX (1) | MX2021007444A (zh) |
| TW (1) | TW202024134A (zh) |
| WO (1) | WO2020125744A1 (zh) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022083720A1 (zh) * | 2020-10-23 | 2022-04-28 | 江苏恒瑞医药股份有限公司 | Glp1-gcgr抗体融合蛋白变体及包含其的组合物 |
| WO2022143516A1 (zh) * | 2020-12-29 | 2022-07-07 | 苏州康宁杰瑞生物科技有限公司 | 一种人glp-1多肽变体及其应用 |
Citations (42)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5641870A (en) | 1995-04-20 | 1997-06-24 | Genentech, Inc. | Low pH hydrophobic interaction chromatography for antibody purification |
| WO1997046584A1 (de) | 1996-06-05 | 1997-12-11 | Boehringer Mannheim Gmbh | Exendin-analoga, verfahren zu deren herstellung und diese enthaltende arzneimittel |
| WO1999043341A1 (en) | 1998-02-27 | 1999-09-02 | Novo Nordisk A/S | Glp-1 derivatives with helix-content exceeding 25 %, forming partially structured micellar-like aggregates |
| WO1999043705A1 (en) | 1998-02-27 | 1999-09-02 | Novo Nordisk A/S | N-terminally truncated glp-1 derivatives |
| WO1999043708A1 (en) | 1998-02-27 | 1999-09-02 | Novo Nordisk A/S | Glp-1 derivatives of glp-1 and exendin with protracted profile of action |
| WO2002046227A2 (en) | 2000-12-07 | 2002-06-13 | Eli Lilly And Company | Glp-1 fusion proteins |
| WO2005058958A2 (en) | 2003-12-18 | 2005-06-30 | Novo Nordisk A/S | Novel glp-1 analogues linked to albumin-like agents |
| WO2006036834A2 (en) | 2004-09-24 | 2006-04-06 | Amgen Inc. | MODIFIED Fc MOLECULES |
| WO2006134340A2 (en) | 2005-06-13 | 2006-12-21 | Imperial Innovations Limited | Oxyntomodulin analogues and their effects on feeding behaviour |
| CN1935846A (zh) | 2005-09-14 | 2007-03-28 | 王庆华 | 一种用于治疗糖尿病的融合蛋白及其制备方法和应用 |
| CN1935261A (zh) | 2005-09-14 | 2007-03-28 | 王庆华 | 一种用于预防和治疗i型糖尿病的药物复合物及其应用 |
| WO2007039140A1 (en) | 2005-09-22 | 2007-04-12 | Biocompatibles Uk Ltd. | Glp-1 ( glucagon-like peptide-1 ) fusion polypeptides with increased peptidase resistance |
| WO2007124461A2 (en) | 2006-04-20 | 2007-11-01 | Amgen Inc. | Glp-1 compounds |
| WO2008071972A1 (en) | 2006-12-13 | 2008-06-19 | Imperial Innovations Limited | Novel compounds and their effects on feeding behaviour |
| WO2008101017A2 (en) | 2007-02-15 | 2008-08-21 | Indiana Unversity Research And Technology Corporation | Glucagon/glp-1 receptor co-agonists |
| WO2008152403A1 (en) | 2007-06-15 | 2008-12-18 | Zealand Pharma A/S | Glucagon analogues |
| CN101589062A (zh) | 2006-09-20 | 2009-11-25 | 安姆根有限公司 | 与胰高血糖素受体抗体相关的组合物和方法 |
| WO2009155258A2 (en) | 2008-06-17 | 2009-12-23 | Indiana University Research And Technology Corporation | Glucagon/glp-1 receptor co-agonists |
| WO2010070255A1 (en) | 2008-12-15 | 2010-06-24 | Zealand Pharma A/S | Glucagon analogues |
| WO2010070251A1 (en) | 2008-12-15 | 2010-06-24 | Zealand Pharma A/S | Glucagon analogues |
| WO2010070252A1 (en) | 2008-12-15 | 2010-06-24 | Zealand Pharma A/S | Glucagon analogues |
| WO2010070253A1 (en) | 2008-12-15 | 2010-06-24 | Zealand Pharma A/S | Glucagon analogues |
| WO2010096142A1 (en) | 2009-02-19 | 2010-08-26 | Merck Sharp & Dohme, Corp. | Oxyntomodulin analogs |
| WO2011006497A1 (en) | 2009-07-13 | 2011-01-20 | Zealand Pharma A/S | Acylated glucagon analogues |
| CN101983208A (zh) | 2008-03-27 | 2011-03-02 | 伊莱利利公司 | 胰高血糖素受体拮抗剂 |
| WO2011075393A2 (en) | 2009-12-18 | 2011-06-23 | Indiana University Research And Technology Corporation | Glucagon/glp-1 receptor co-agonists |
| WO2011117415A1 (en) | 2010-03-26 | 2011-09-29 | Novo Nordisk A/S | Novel glucagon analogues |
| WO2011160630A2 (en) | 2010-06-23 | 2011-12-29 | Zealand Pharma A/S | Glucagon analogues |
| CN102482350A (zh) | 2009-09-08 | 2012-05-30 | 株式会社新药 | 作用于胰高血糖素受体的抗体及其应用 |
| CN102949730A (zh) | 2011-09-16 | 2013-03-06 | 西藏海思科药业集团股份有限公司 | 特异结合glp-1受体的药物融合体 |
| WO2013059531A1 (en) | 2011-10-20 | 2013-04-25 | Genentech, Inc. | Anti-gcgr antibodies and uses thereof |
| CN103314011A (zh) | 2010-11-23 | 2013-09-18 | 瑞泽恩制药公司 | 胰高血糖素受体的人抗体 |
| WO2014096150A1 (en) | 2012-12-21 | 2014-06-26 | Sanofi | Dual glp1/gip or trigonal glp1/gip/glucagon agonists |
| CN104293834A (zh) | 2014-10-11 | 2015-01-21 | 上海兴迪金生物技术有限公司 | GLP-1或其类似物与抗体Fc片段融合蛋白的制备方法 |
| CN104327187A (zh) | 2014-10-11 | 2015-02-04 | 上海兴迪金生物技术有限公司 | 一种重组人GLP-1-Fc融合蛋白 |
| WO2015049651A1 (en) | 2013-10-01 | 2015-04-09 | Glaxosmithkline Intellectual Property Development Limited | Compounds for affinity chromatography and for extending the half-life of a therapeutic agent |
| WO2015067716A1 (en) | 2013-11-06 | 2015-05-14 | Zealand Pharma A/S | Glucagon-glp-1-gip triple agonist compounds |
| CN105189560A (zh) | 2013-05-07 | 2015-12-23 | 瑞纳神经科学公司 | 抗胰高血糖素受体抗体和其使用方法 |
| WO2017100107A2 (en) | 2015-12-09 | 2017-06-15 | Merck Sharp & Dohme Corp. | Co-agonists of the glucagon and glp-1 receptors |
| CN107614695A (zh) | 2015-04-02 | 2018-01-19 | 瑞美德生物医药科技有限公司 | 用胰高血糖素受体拮抗性抗体治疗肥胖症和非酒精性脂肪肝病或非酒精性脂肪性肝炎的方法 |
| CN108025060A (zh) * | 2014-06-08 | 2018-05-11 | 瑞美德生物医药科技有限公司 | 使用胰高血糖素受体拮抗性抗体治疗1型糖尿病的方法 |
| WO2018140729A1 (en) * | 2017-01-27 | 2018-08-02 | Ngm Biopharmaceuticals, Inc. | Glucagon receptor binding proteins and methods of use thereof |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8771696B2 (en) * | 2010-11-23 | 2014-07-08 | Regeneron Pharmaceuticals, Inc. | Method of reducing the severity of stress hyperglycemia with human antibodies to the glucagon receptor |
| EP2685257A4 (en) * | 2011-03-08 | 2014-10-01 | Sanwa Kagaku Kenkyusho Co | METHOD OF ANALYSIS |
| CN110357959B (zh) * | 2018-04-10 | 2023-02-28 | 鸿运华宁(杭州)生物医药有限公司 | Gcgr抗体及其与glp-1的融合蛋白质,以及其药物组合物和应用 |
-
2019
- 2019-12-20 AU AU2019410643A patent/AU2019410643A1/en not_active Abandoned
- 2019-12-20 CA CA3123979A patent/CA3123979A1/en active Pending
- 2019-12-20 JP JP2021535930A patent/JP2022516439A/ja active Pending
- 2019-12-20 KR KR1020217021692A patent/KR20210109552A/ko active Search and Examination
- 2019-12-20 TW TW108146977A patent/TW202024134A/zh unknown
- 2019-12-20 US US17/416,237 patent/US20220153853A1/en active Pending
- 2019-12-20 WO PCT/CN2019/126903 patent/WO2020125744A1/zh unknown
- 2019-12-20 CN CN202211312212.4A patent/CN115947849A/zh active Pending
- 2019-12-20 EP EP19898966.7A patent/EP3901173A4/en not_active Withdrawn
- 2019-12-20 CN CN201980071999.XA patent/CN112996811B/zh active Active
- 2019-12-20 MX MX2021007444A patent/MX2021007444A/es unknown
Patent Citations (48)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5641870A (en) | 1995-04-20 | 1997-06-24 | Genentech, Inc. | Low pH hydrophobic interaction chromatography for antibody purification |
| WO1997046584A1 (de) | 1996-06-05 | 1997-12-11 | Boehringer Mannheim Gmbh | Exendin-analoga, verfahren zu deren herstellung und diese enthaltende arzneimittel |
| WO1999043341A1 (en) | 1998-02-27 | 1999-09-02 | Novo Nordisk A/S | Glp-1 derivatives with helix-content exceeding 25 %, forming partially structured micellar-like aggregates |
| WO1999043705A1 (en) | 1998-02-27 | 1999-09-02 | Novo Nordisk A/S | N-terminally truncated glp-1 derivatives |
| WO1999043708A1 (en) | 1998-02-27 | 1999-09-02 | Novo Nordisk A/S | Glp-1 derivatives of glp-1 and exendin with protracted profile of action |
| WO2002046227A2 (en) | 2000-12-07 | 2002-06-13 | Eli Lilly And Company | Glp-1 fusion proteins |
| WO2005058958A2 (en) | 2003-12-18 | 2005-06-30 | Novo Nordisk A/S | Novel glp-1 analogues linked to albumin-like agents |
| WO2006036834A2 (en) | 2004-09-24 | 2006-04-06 | Amgen Inc. | MODIFIED Fc MOLECULES |
| WO2006134340A2 (en) | 2005-06-13 | 2006-12-21 | Imperial Innovations Limited | Oxyntomodulin analogues and their effects on feeding behaviour |
| CN1935846A (zh) | 2005-09-14 | 2007-03-28 | 王庆华 | 一种用于治疗糖尿病的融合蛋白及其制备方法和应用 |
| CN1935261A (zh) | 2005-09-14 | 2007-03-28 | 王庆华 | 一种用于预防和治疗i型糖尿病的药物复合物及其应用 |
| WO2007039140A1 (en) | 2005-09-22 | 2007-04-12 | Biocompatibles Uk Ltd. | Glp-1 ( glucagon-like peptide-1 ) fusion polypeptides with increased peptidase resistance |
| WO2007124461A2 (en) | 2006-04-20 | 2007-11-01 | Amgen Inc. | Glp-1 compounds |
| CN101589062A (zh) | 2006-09-20 | 2009-11-25 | 安姆根有限公司 | 与胰高血糖素受体抗体相关的组合物和方法 |
| WO2008071972A1 (en) | 2006-12-13 | 2008-06-19 | Imperial Innovations Limited | Novel compounds and their effects on feeding behaviour |
| WO2008101017A2 (en) | 2007-02-15 | 2008-08-21 | Indiana Unversity Research And Technology Corporation | Glucagon/glp-1 receptor co-agonists |
| WO2008152403A1 (en) | 2007-06-15 | 2008-12-18 | Zealand Pharma A/S | Glucagon analogues |
| CN101983208A (zh) | 2008-03-27 | 2011-03-02 | 伊莱利利公司 | 胰高血糖素受体拮抗剂 |
| WO2009155258A2 (en) | 2008-06-17 | 2009-12-23 | Indiana University Research And Technology Corporation | Glucagon/glp-1 receptor co-agonists |
| WO2010070255A1 (en) | 2008-12-15 | 2010-06-24 | Zealand Pharma A/S | Glucagon analogues |
| WO2010070251A1 (en) | 2008-12-15 | 2010-06-24 | Zealand Pharma A/S | Glucagon analogues |
| WO2010070252A1 (en) | 2008-12-15 | 2010-06-24 | Zealand Pharma A/S | Glucagon analogues |
| WO2010070253A1 (en) | 2008-12-15 | 2010-06-24 | Zealand Pharma A/S | Glucagon analogues |
| WO2010096142A1 (en) | 2009-02-19 | 2010-08-26 | Merck Sharp & Dohme, Corp. | Oxyntomodulin analogs |
| WO2010096052A1 (en) | 2009-02-19 | 2010-08-26 | Merck Sharp & Dohme Corp. | Oxyntomodulin analogs |
| WO2011006497A1 (en) | 2009-07-13 | 2011-01-20 | Zealand Pharma A/S | Acylated glucagon analogues |
| CN102482350A (zh) | 2009-09-08 | 2012-05-30 | 株式会社新药 | 作用于胰高血糖素受体的抗体及其应用 |
| WO2011075393A2 (en) | 2009-12-18 | 2011-06-23 | Indiana University Research And Technology Corporation | Glucagon/glp-1 receptor co-agonists |
| WO2011117415A1 (en) | 2010-03-26 | 2011-09-29 | Novo Nordisk A/S | Novel glucagon analogues |
| WO2011117416A1 (en) | 2010-03-26 | 2011-09-29 | Novo Nordisk A/S | Novel glucagon analogues |
| WO2011160630A2 (en) | 2010-06-23 | 2011-12-29 | Zealand Pharma A/S | Glucagon analogues |
| CN103314011A (zh) | 2010-11-23 | 2013-09-18 | 瑞泽恩制药公司 | 胰高血糖素受体的人抗体 |
| CN102949730A (zh) | 2011-09-16 | 2013-03-06 | 西藏海思科药业集团股份有限公司 | 特异结合glp-1受体的药物融合体 |
| WO2013059531A1 (en) | 2011-10-20 | 2013-04-25 | Genentech, Inc. | Anti-gcgr antibodies and uses thereof |
| WO2014096149A1 (en) | 2012-12-21 | 2014-06-26 | Sanofi | Exendin-4 Derivatives |
| WO2014096150A1 (en) | 2012-12-21 | 2014-06-26 | Sanofi | Dual glp1/gip or trigonal glp1/gip/glucagon agonists |
| WO2014096145A1 (en) | 2012-12-21 | 2014-06-26 | Sanofi | Exendin-4 derivatives as dual glp1/gip or trigonal glp1/gip/glucagon agonists |
| WO2014096148A1 (en) | 2012-12-21 | 2014-06-26 | Sanofi | Functionalized exendin-4 derivatives |
| CN105189560A (zh) | 2013-05-07 | 2015-12-23 | 瑞纳神经科学公司 | 抗胰高血糖素受体抗体和其使用方法 |
| WO2015049651A1 (en) | 2013-10-01 | 2015-04-09 | Glaxosmithkline Intellectual Property Development Limited | Compounds for affinity chromatography and for extending the half-life of a therapeutic agent |
| WO2015067716A1 (en) | 2013-11-06 | 2015-05-14 | Zealand Pharma A/S | Glucagon-glp-1-gip triple agonist compounds |
| CN108025060A (zh) * | 2014-06-08 | 2018-05-11 | 瑞美德生物医药科技有限公司 | 使用胰高血糖素受体拮抗性抗体治疗1型糖尿病的方法 |
| CN104293834A (zh) | 2014-10-11 | 2015-01-21 | 上海兴迪金生物技术有限公司 | GLP-1或其类似物与抗体Fc片段融合蛋白的制备方法 |
| CN104327187A (zh) | 2014-10-11 | 2015-02-04 | 上海兴迪金生物技术有限公司 | 一种重组人GLP-1-Fc融合蛋白 |
| CN107614695A (zh) | 2015-04-02 | 2018-01-19 | 瑞美德生物医药科技有限公司 | 用胰高血糖素受体拮抗性抗体治疗肥胖症和非酒精性脂肪肝病或非酒精性脂肪性肝炎的方法 |
| WO2017100107A2 (en) | 2015-12-09 | 2017-06-15 | Merck Sharp & Dohme Corp. | Co-agonists of the glucagon and glp-1 receptors |
| WO2018140729A1 (en) * | 2017-01-27 | 2018-08-02 | Ngm Biopharmaceuticals, Inc. | Glucagon receptor binding proteins and methods of use thereof |
| US20180273629A1 (en) | 2017-01-27 | 2018-09-27 | Ngm Biopharmaceuticals, Inc. | Glucagon receptor binding proteins and methods of use thereof |
Non-Patent Citations (28)
| Title |
|---|
| "Genbank", Database accession no. NM_000160 |
| ALFTHAN ET AL., PROTEIN ENG, vol. 8, no. 10, 1995, pages 1057 - 1062 |
| AL-LAZIKANI ET AL., J. MOLEC. BIOL., vol. 273, 1997, pages 927 - 948 |
| AL-LAZIKANI ET AL., JMB, vol. 273, 1997, pages 927 - 948 |
| ALTSCHUL, S.F. ET AL., NUCLEIC ACIDS RES, vol. 25, 1997, pages 3389 - 3402 |
| ALTSCHUL, SF ET AL., J. MOL. BIOL., vol. 215, 1990, pages 403 - 410 |
| BIRD ET AL., SCIENCE, 1988, pages 423 - 426 |
| CHEUNG ET AL., VIROLOGY, vol. 176, 1990, pages 546 - 552 |
| CHOI ET AL., EUR J IMMUNO, vol. 31, 2001, pages 94 - 106 |
| EPITOPE MAPPING PROTOCOLS IN METHODS IN MOLECULAR BIOLOGY, vol. 66, 1996 |
| GISH, W. ET AL., NATURE GENET, vol. 3, 1993, pages 266 - 272 |
| HOLLIGER ET AL., PROC NATL ACAD SCI USA., vol. 90, 1993, pages 6444 - 6448 |
| HU ET AL., CANCER RES, vol. 56, 1996, pages 3055 - 3061 |
| HUSTON ET AL., PROC. NATL. ACAD. SCI USA, vol. 85, 1988, pages 5879 - 5883 |
| KABAT ET AL.: "Sequences of Proteins of Immunological Interest", 1991, PUBLIC HEALTH SERVICE, NATIONAL INSTITUTES OF HEALTH |
| KABAT, E.A. ET AL., SEQUENCES OF PROTEINS OF IMMUNOLOGICAL INTEREST, 1991 |
| KIPRIYANOV ET AL., J MOL BIOL, vol. 293, 1999, pages 41 - 56 |
| KIRKLAND ET AL., J. IMMUNOL., vol. 137, 1986, pages 3614 - 3619 |
| LEFRANC MP, IMMUNOLOGIST, vol. 7, 1999, pages 132 - 136 |
| LEFRANC, MP, DEV. COMP. IMMUNOL., vol. 27, 2003, pages 55 - 77 |
| MADDEN, T.L. ET AL., METH. ENZYMOL., vol. 266, 1996, pages 131 - 141 |
| MOLDENHAUER ET AL., SCAND. J. IMMUNOL., vol. 32, 1990, pages 77 - 82 |
| MOREL ET AL., MOLEC. IMMUNOL., vol. 25, 1988, pages 7 - 15 |
| ROOVERS ET AL., CANCER IMMUNOL IMMUNOTHER, vol. 50, 2001, pages 51 - 59 |
| See also references of EP3901173A4 |
| STAHLI ET AL., METHODS IN ENZYMOLOGY, vol. 9, 1983, pages 242 - 253 |
| WATSON ET AL.: "A Laboratory Manual for Antibodies", 1987, COLD SPRING HARBOR LABORATORY PRESS, pages: 224 |
| ZHANG, J ET AL., GENOME RES, vol. 7, 1997, pages 649 - 656 |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022083720A1 (zh) * | 2020-10-23 | 2022-04-28 | 江苏恒瑞医药股份有限公司 | Glp1-gcgr抗体融合蛋白变体及包含其的组合物 |
| WO2022143516A1 (zh) * | 2020-12-29 | 2022-07-07 | 苏州康宁杰瑞生物科技有限公司 | 一种人glp-1多肽变体及其应用 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112996811B (zh) | 2022-11-22 |
| TW202024134A (zh) | 2020-07-01 |
| MX2021007444A (es) | 2021-08-05 |
| CN115947849A (zh) | 2023-04-11 |
| KR20210109552A (ko) | 2021-09-06 |
| US20220153853A1 (en) | 2022-05-19 |
| CA3123979A1 (en) | 2020-06-25 |
| EP3901173A4 (en) | 2022-11-23 |
| EP3901173A1 (en) | 2021-10-27 |
| AU2019410643A1 (en) | 2021-08-12 |
| CN112996811A (zh) | 2021-06-18 |
| JP2022516439A (ja) | 2022-02-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| TWI781108B (zh) | 抗gprc5d抗體、結合gprc5d與cd3之雙特異性抗原結合分子及其用途 | |
| US11680100B2 (en) | B7-H3 antibody, antigen-binding fragment thereof and medical use thereof | |
| WO2019062832A1 (zh) | Tigit抗体、其抗原结合片段及医药用途 | |
| TW202017945A (zh) | 抗cd73抗體、其抗原結合片段及應用 | |
| WO2020156509A1 (zh) | 抗pd-1抗体、其抗原结合片段及医药用途 | |
| US20220185875A1 (en) | Bispecific antibody specifically bound to vegf and ang2 | |
| US20230138315A1 (en) | Anti-angptl3 antibody and use thereof | |
| CN114746440A (zh) | 新型多肽复合物 | |
| CN110790839A (zh) | 抗pd-1抗体、其抗原结合片段及医药用途 | |
| WO2020125744A1 (zh) | 双特异性蛋白 | |
| CN113840836B (zh) | 抗结缔组织生长因子抗体及其应用 | |
| RU2784486C1 (ru) | Биспецифический белок | |
| RU2807484C2 (ru) | Антитело к pd-1, его антигенсвязывающий фрагмент и его фармацевтическое применение | |
| CN115956089A (zh) | 抑制性抗enpp1抗体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19898966 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 3123979 Country of ref document: CA |
|
| ENP | Entry into the national phase |
Ref document number: 2021535930 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01A Ref document number: 112021011595 Country of ref document: BR |
|
| ENP | Entry into the national phase |
Ref document number: 20217021692 Country of ref document: KR Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2019898966 Country of ref document: EP Effective date: 20210721 |
|
| ENP | Entry into the national phase |
Ref document number: 2019410643 Country of ref document: AU Date of ref document: 20191220 Kind code of ref document: A |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01E Ref document number: 112021011595 Country of ref document: BR Free format text: COM BASE NA PORTARIA 405 DE 21/12/2020, SOLICITA-SE QUE SEJA APRESENTADO, EM ATE 60 (SESSENTA) DIAS, NOVO CONTEUDO DE LISTAGEM DE SEQUENCIA POIS O CONTEUDO APRESENTADO NA PETICAO NO 870210053610 DE 15/06/2021 NAO POSSUI TODOS OS CAMPOS OBRIGATORIOS INFORMADOS, NAO CONSTANDO O CAMPO 150 / 151 . DEVERA SER INCLUIDO O CAMPO 140 / 141 UMA VEZ QUE O DEPOSITANTE JA POSSUI O NUMERO DO PEDIDO NO BRASIL. |
|
| ENP | Entry into the national phase |
Ref document number: 112021011595 Country of ref document: BR Kind code of ref document: A2 Effective date: 20210615 |