WO2013145156A1 - 音声信号処理装置及び音声信号処理プログラム - Google Patents
音声信号処理装置及び音声信号処理プログラム Download PDFInfo
- Publication number
- WO2013145156A1 WO2013145156A1 PCT/JP2012/058140 JP2012058140W WO2013145156A1 WO 2013145156 A1 WO2013145156 A1 WO 2013145156A1 JP 2012058140 W JP2012058140 W JP 2012058140W WO 2013145156 A1 WO2013145156 A1 WO 2013145156A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- audio signal
- voice component
- signal
- voice
- channel
- Prior art date
Links
- 230000005236 sound signal Effects 0.000 title claims abstract description 191
- 230000000694 effects Effects 0.000 claims abstract description 96
- 238000000926 separation method Methods 0.000 claims description 74
- 238000000034 method Methods 0.000 abstract description 29
- 230000008569 process Effects 0.000 abstract description 22
- 230000008859 change Effects 0.000 description 15
- 238000001514 detection method Methods 0.000 description 8
- 230000001755 vocal effect Effects 0.000 description 6
- 230000002411 adverse Effects 0.000 description 5
- 230000007423 decrease Effects 0.000 description 5
- 238000010586 diagram Methods 0.000 description 3
- 230000009931 harmful effect Effects 0.000 description 3
- 101100228946 Streptomyces fradiae neoB gene Proteins 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 230000002542 deteriorative effect Effects 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 238000004880 explosion Methods 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 230000007480 spreading Effects 0.000 description 1
- 230000002311 subsequent effect Effects 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
Images





Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0216—Noise filtering characterised by the method used for estimating noise
- G10L21/0232—Processing in the frequency domain
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/008—Multichannel audio signal coding or decoding using interchannel correlation to reduce redundancy, e.g. joint-stereo, intensity-coding or matrixing
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L2021/02087—Noise filtering the noise being separate speech, e.g. cocktail party
Definitions
- the present invention relates to a technique for effect processing on an audio signal including a voice component.
- Patent Document 1 discloses a circuit that cancels a vocal signal from left and right two-channel audio signals including a vocal signal and an accompaniment signal. Specifically, a low-frequency signal and a high-frequency signal are extracted from the left and right audio signals, respectively, and a mid-range signal in which the vocal signal is canceled is generated by generating a difference signal between the left and right audio signals. And the accompaniment signal which canceled the vocal signal is output by mixing those audio
- Dolby Pro Logic “dts neo6”, “dts neoX”, etc. are known as processes having the ability to separate lines from front channel signals.
- the middle signal of the L channel is (LR) and the R channel is (RL) for the middle region
- the middle band is the band that the listener is most sensitive to in terms of hearing. If the signal in the middle band is in an opposite phase relationship, the listener feels uncomfortable.
- both channels are set to either (LR) or (RL) in order to avoid reverse phase, a monaural signal is generated, and the mid-range stereo feeling is lost. End up.
- An object of the present invention is to provide a technique for separating voice components and performing effect processing on components other than the voice components without deteriorating the auditory quality.
- the invention according to claim 1 is an audio signal processing device, which receives a 2-channel audio signal including a voice component and separates the voice component from the audio signal of each channel; and the voice component An effect processing unit that performs effect processing on the audio signal of each channel after separation, and outputs the audio component separated by the voice component separation unit to the audio signal of each channel after the effect processing And an output unit.
- the invention according to claim 9 is an audio signal processing program executed by an audio signal processing apparatus including a computer, which receives a two-channel audio signal including a voice component, and extracts the voice component from the audio signal of each channel.
- the computer is caused to function as output means for adding and outputting the separated voice components.
- the audio signal processing apparatus receives a two-channel audio signal including a voice component, and separates the voice component from the audio signal of each channel, and the voice component is separated.
- An effect processing unit that performs effect processing on the audio signal of each channel after being processed, and an output that adds the voice component separated by the voice component separation unit to the audio signal of each channel after the effect processing A section.
- the above-mentioned audio signal processing device receives two left and right channel audio signals including voice components such as speech and separates the voice components. Predetermined effect processing is performed on the audio signal of each channel after the voice component is separated.
- the effect processing can be, for example, reflected sound addition processing, reverberation addition processing, processing for mixing a front signal with a surround signal, or the like. Then, the voice component separated earlier is added to the audio signal of each channel after the effect processing is performed, and is output.
- the effect processing as described above is performed on voice components such as speech, it may be harmful because the speech is difficult to hear.
- the effect processing is performed on the audio signals of the left and right channels from which the voice components are separated, so that such an adverse effect can be prevented.
- the voice component separated earlier is added to the left and right channel signals after effect processing and output, even if an error occurs in the voice component separation processing, the voice components are returned to the left and right channel signals. Thus, the error is canceled. Therefore, even if the voice component separation performance is not sufficiently high, it does not directly adversely affect the signal that is finally output.
- the voice component separation unit separates the voice component from the mid-high frequency component, a band division unit that divides the audio signal of each channel into a low-frequency component and a mid-high frequency component And a separation processing unit for outputting and an addition unit for adding the low frequency component to the middle and high frequency component after the voice component is separated and outputting the result.
- the audio signal of each channel is band-divided into a low-frequency component and a mid-high frequency component, and the voice component is separated from the mid-high frequency component.
- voice components such as speech are included in the left and right channels as in-phase components, so that the voice components can be separated by separating the in-phase signals.
- low frequency components of audio signals often include bass sounds and bass drum sounds as in-phase components, and separating in-phase components at low frequencies also separates bass sounds and bass drum sounds. The effect processing will not be performed. Therefore, by separating the in-phase voice component from only the middle and high frequency components, it is possible to prevent the inconvenience that the bass sound and bass drum sound are separated from the low frequency components.
- the voice component separation unit includes a voice component presence / absence determination unit that determines whether or not the audio signal of each channel includes a voice component, and the voice component. And a separation unit that outputs 1 ⁇ 2 of the sum of the audio signals of the two channels as the voice component when it is determined, and subtracts and outputs the voice component from the audio signal of each channel.
- the voice component presence / absence determination unit calculates the sum and difference of the audio signals of the two channels, and compares the obtained sum and difference to determine whether or not there is a voice component. Determine. Normally, voice components such as speech are included in the left and right channel signals in phase, so the presence or absence of a voice component can be determined by comparing the sum and difference signals of the left and right channel signals.
- the voice component presence / absence determination unit includes a coefficient value output unit that outputs a coefficient value of 0 or 1 based on the comparison result of the sum and difference, and the coefficient value.
- a time constant circuit for converting the signal into a continuous value between 0 and 1 and the separation unit outputs a product of the coefficient value and 1 ⁇ 2 of the sum of the audio signals of the two channels as the voice component.
- the voice component is subtracted from the audio signal of each channel and output.
- a steep change in the signal indicating the presence or absence of the voice component can be changed to a gradual change, and an audio signal can be output without a sense of incongruity.
- the voice component presence / absence determining unit determines that there is a voice component when the sum is greater than a predetermined multiple of the difference, and the sum is the predetermined multiple of the difference. When not larger, it is determined that there is no voice component. Thereby, the presence or absence of a voice component can be determined with a simple configuration.
- the predetermined multiple is five times.
- the voice component presence / absence determining unit further includes a circuit that doubles the coefficient value output from the time constant circuit and limits the coefficient value to a limit value of 1. As a result, voice components such as speech can be more reliably separated.
- an audio signal processing program executed by an audio signal processing apparatus including a computer receives a 2-channel audio signal including a voice component, and extracts the voice component from the audio signal of each channel.
- Voice component separation means for separating, effect processing means for effecting the sound signal of each channel after the voice component is separated, and separation of the voice component into the sound signal of each channel after the effect processing The computer is caused to function as output means for adding and outputting the separated voice components.
- the present embodiment provides a technique for performing various effect processing for 3D video on audio signals of left and right channels including voice components.
- effect processing such as 3D sound field processing is intended for background sounds and sound effects, and there are many cases where it is not desired to perform the same effect processing on lines. If the same effect processing is performed on the dialogue, the dialogue becomes difficult to hear or an excessive effect sound is felt, which is adversely affected.
- the in-phase component of the front two-channel signal may include speech.
- the target effect processing is not performed on the speech.
- the resultant signal does not become monaural as in the above-mentioned prior art document 1, and stereo can be maintained.
- the audio signal processing apparatus of the present embodiment first separates the voice component from the left and right channel audio signals, and then performs various effect processing on the audio signal after the voice component is separated. Then, the left and right channel audio signals are output by synthesizing the previously separated voice component with the audio signal after the effect processing.
- the audio signal processing apparatus according to the present embodiment is particularly suitable for an apparatus that includes a video monitor and reproduces video content.
- FIG. 1 shows a basic configuration of an audio signal processing apparatus according to an embodiment.
- the audio signal processing device 1 includes a voice component separation unit 10, an effect processing unit 100, and adders 5 and 6.
- the voice component separation unit 10 receives the left channel audio signal Li and the right channel audio signal Ri.
- channel is described as “ch”, “left channel” as “Lch”, and “right channel” as “Rch”.
- the voice component separation unit 10 separates voice components from the Lch audio signal Li and the Rch audio signal Ri. Then, the voice component separation unit 10 outputs the separated voice component as the voice component signal C to the adders 5 and 6, and the effect processing unit outputs the Lch audio signal L4 and the Rch audio signal R4 after the voice component is separated. Output to 100.
- the effect processing unit 100 performs various effect processes for 3D video on the Lch audio signal L4 and the Rch audio signal R4 after the voice components are separated. Then, the effect processing unit 100 outputs the Lch audio signal L5 after the effect processing to the adder 5, and outputs the Rch audio signal R5 after the effect processing to the adder 6.
- the adder 5 adds the voice component signal C to the Lch audio signal L5 after effect processing, and outputs an Lch audio signal Lo.
- the adder 6 adds the voice component signal C to the Rch audio signal R5 after effect processing, and outputs the Rch audio signal Ro.
- the adders 5 and 6 correspond to the output unit of the present invention.
- the effect processing unit 100 performs the effect processing on the Lch audio signal L4 and the Rch audio signal R4 after the voice components are separated, and the effect processing is not performed on the voice component signal C. . Therefore, there is no inconvenience such as difficulty in hearing lines due to the effect processing. In addition, the effect processing unit 100 can perform sufficient effect processing on the audio signal after the voice component is separated.
- the audio signal processing apparatus of the present embodiment is characterized in that the voice component signal C separated by the voice component separation unit 10 is added to the audio signals L5 and R5 after effect processing by the adders 5 and 6. .
- the voice component separation performance has a great influence on the final output performance in the apparatus / method mainly intended to separate speech and vocals.
- this embodiment mainly aims to remove the voice component from the target of the effect processing, not to separate and output the voice component, and synthesizes the voice component to the voice signal after the effect processing. .
- the temporarily separated voice component is returned to the audio signal after effect processing. Therefore, if the separation performance of the voice component separation unit 10 is low and an error occurs between the actually existing voice component and the separated voice component, the voice component is finally returned to the original voice signal. Thus, the error is canceled. Therefore, the separation performance of the voice component separation unit 10 does not directly affect the quality of the audio signals Lo and Ro that are final outputs.
- FIG. 2 shows the configuration of the voice component separation unit 10.
- the voice component separation unit 10 includes a crossover filter unit CF, a separation processing unit 20, and adders 14 and 15.
- the crossover filter unit CF includes four high-pass filters (HPF) 11 and four low-pass filters (LPF) 12.
- the crossover filter portion CF of this example is a so-called link Witz-Riley type filter.
- two HPFs 11 and two LPFs 12 are cascade-connected to the audio signals Li and Ri.
- the HPF 11 and the LPF 12 each have a characteristic of attenuation by 3 dB at the cutoff frequency.
- middle and high frequency components are extracted by the two-stage HPF 11 and sent to the separation processing unit 20 as the audio signal L1.
- the middle and high frequency components are extracted by the two-stage HPF 11 and sent to the separation processing unit 20 as the audio signal R1.
- the separation processing unit 20 generates a voice component signal C by separating the voice components from the voice signals L1 and R1, and outputs the voice component signal C.
- the separation processing unit 20 sends the audio signal L3 from which the voice component has been removed from the audio signal L1 to the adder 14 and sends the audio signal R3 from which the voice component has been removed from the audio signal R1 to the adder 15. Details of the separation processing unit 20 will be described later.
- a low frequency component is extracted from the audio signal Li by the two-stage LPF 12 and sent to the adder 14 as the audio signal L2.
- a low-frequency component is extracted from the audio signal Ri by the two-stage LPF 12 and sent to the adder 15 as the audio signal R2.
- the adder 14 adds the low-frequency Lch audio signal L2 to the mid- and high-frequency Lch audio signal L3 from which the voice component has been removed, and generates and outputs an Lch audio signal L4 for the entire band from which the voice component has been removed.
- the adder 15 adds the low-frequency Rch audio signal R2 to the mid- and high-frequency Rch signal R3 from which the voice component has been removed, and generates and outputs an Rch signal R4 for the entire band from which the voice component has been removed.
- the crossover filter unit CF divides the bands of the Lch audio signal Li and the Rch audio signal Ri into the low frequency band and the mid-high frequency band, and the separation processing unit targets only the mid-high frequency signal. 20 separates the voice component.
- the voice component such as speech is the in-phase component of the Lch audio signal and the Rch audio signal
- the separation processing of the voice component by the separation processing unit 20 separates the in-phase component of the Lch audio signal and the Rch audio signal as described later. It becomes processing to do.
- the low frequency signal often includes, for example, bass sound and bass drum sound as in-phase components, and when the voice component separation processing by the separation processing unit 20 is similarly performed on the low frequency signal, Bass sounds, bass drum sounds, and the like are separated as voice components, and are excluded from the effect processing in the subsequent stage. Therefore, in this embodiment, after the crossover filter unit CF divides the input audio signal into a low-frequency signal and a mid-high frequency signal, and performs voice component separation processing on the mid-high frequency signal to separate the voice component, The mid-high frequency signal and the low-frequency signal are synthesized again to obtain audio signals L4 and R4.
- the adder 14 and 15 add the low-frequency signal and the mid-high frequency signal to generate the signal of the entire band. It is preferable that the frequency characteristics become flat when the low-frequency and middle-high frequency signals are synthesized again. Further, if such characteristics can be obtained, the configuration of the crossover filter portion CF is not limited to that shown in FIG.
- the separation processing unit 20 is roughly divided into a separation unit and a voice component presence / absence determination unit.
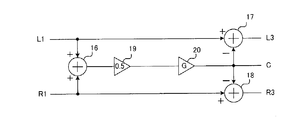
- the configuration of the separation unit is shown in FIG.
- the separation unit receives the Lch audio signal L1 and the Rch audio signal R1, and outputs a voice component signal C, an Lch audio signal L3 from which the voice component is separated, and an Rch audio signal R3 from which the voice component is separated.
- the separation unit includes adders 16 to 18 and amplifiers 19 and 20.
- the Lch audio signal L1 is supplied to the adders 16 and 17.
- the Rch audio signal R1 is supplied to the adders 16 and 18.
- the adder 16 adds the Lch audio signal L1 and the Rch audio signal R1 and sends the result to the amplifier 19.
- the amplifier 19 outputs 1 ⁇ 2 of the sum of the Lch audio signal L1 and the Rch audio signal R1, that is, the signal “(R1 + L1) / 2”. Further, the amplifier 20 multiplies the signal “(R1 + L1) / 2” by the coefficient G, outputs the signal “G (L1 + R1) / 2” as the voice component signal C, and outputs it to the adders 17 and 18. Supply.
- the coefficient “G” is a coefficient indicating the presence or absence of a voice component in the audio signal, and takes a value of 0.0 to 1.0. When the coefficient G is “0.0”, it indicates that no voice component is included in the audio signal, and when the coefficient G is “1.0”, it indicates that the voice component is included in the audio signal.
- the coefficient G is calculated by a voice component presence / absence determining unit described later.
- the output signal “(R1 + L1) / 2” of the amplifier 19 is 1 ⁇ 2 of the sum of the Lch audio signal L1 and the Rch audio signal R1.
- the coefficient G becomes a value close to “1.0”
- the signal “G (L1 + R1) / 2” is subtracted from the signal L1 and the Rch audio signal R1, respectively.
- L1 R1
- the voice component is removed from the Lch audio signal and the Rch audio signal.
- the coefficient G becomes a value close to “0.0”, and the Lch audio signal L1 and the Rch audio signal R1.
- the signal “G (L1 + R1) / 2” is hardly subtracted from the Lch audio signal L1 and the Rch audio signal R1, and the Lch audio signal L3 and the Rch audio signal R3 are output as they are.
- FIG. 4A shows a circuit that generates a sum signal and a difference signal of the Lch audio signal L1 and the Rch audio signal R1.
- the adder 24 subtracts the Rch audio signal R1 from the Lch audio signal L1 to generate a difference signal
- the absolute value circuit 25 performs an absolute value calculation of the difference signal and outputs a difference signal level A.
- the adder 26 adds the Lch audio signal L1 and the Rch audio signal R1 to generate a sum signal
- the amplifiers 27 and 28 multiply the sum signals by “0.5” and “0.4”, respectively. .
- the absolute value circuit 29 calculates the absolute value of the sum signal and outputs a sum signal level B.
- the voice component presence / absence determination unit compares the difference signal level A thus obtained with the sum signal level B.
- the comparison between the difference signal level A and the sum signal level B by the values multiplied by the amplifiers 27 and 28 means a comparison between the audio signal (L1 + R1) and five times the audio signal (L1-R1). That is, in this embodiment, when the sum of the voice signals L1 and R1 is five times or more larger than the difference between the voice signals L1 and R1 (that is, A ⁇ B), the voice component presence / absence determining unit determines the voice signals L1 and R1. Is determined to have a voice component.
- the voice component presence / absence determining unit determines that the audio signals L1 and R1 have no voice component. judge.
- the output of the switch 30 is multiplied by the experience value by the amplifier 31 and supplied to the time constant circuit 32.
- the time constant circuit 32 has a role of making a gradual change from a sharp rise / fall of a signal waveform caused by switching of the switch 30.
- the output of the time constant circuit 32 is multiplied by an empirical value “2” by the amplifier 33, is limited to a value of “0.0 to 1.0” by the limit circuit 34, and is output as a coefficient G.
- the coefficient G becomes a coefficient indicating the presence or absence of a voice component in the audio signals L1 and R1. That is, the coefficient G maintains the value “1.0” when the voice signals L1 and R1 have a voice component, and maintains the value “0.0” when there is no voice component.
- it will change with a smooth curve.
- the voice component presence / absence determination unit determines the presence / absence of a voice component in the audio signals L1 and R1, and the signal “(L1 + R1) only when the voice component is dominantly present. / 2 "is regarded as an in-phase component (that is, a voice component), and is subtracted from the audio signals L1 and R1, so that the voice component can be separated with high certainty. Further, unlike the prior art 1, it is possible to separate voice components while maintaining a stereo signal. Further, when there is no voice component such as speech, the signal can be sent to the effect processing unit at the subsequent stage as it is as the original signal, so that it is possible to perform effect processing without any harmful effect.
- the amplifier 33 and the limit circuit 34 that double the output of the time constant circuit 32, the effect of more reliably removing the voice component can be obtained.
- it has the effect of extending the voice component separation operation in time at the end of the speech. This can be paraphrased as simplification of the time constant circuit.
- the amplifier 33 and the limit circuit 34 can be omitted, and a similar effect can be obtained by adjusting the time constant of the time constant circuit 32.
- the separation processing unit 20 of this embodiment has a small processing amount and can suppress the hardware scale at the time of mounting, it can be realized at low cost.
- the effect processing executed by the effect processing unit 100 may be basically any type.
- a process of adding reflected sound, a process of adding reverberation (reverberation sound), and the like are known. These may be performed.
- a process of adding a reflected sound or a reverberation sound to a voice component such as a speech included in an audio signal
- effect processing for 3D video there is effect processing for combining a front ch signal with a surround ch signal (hereinafter referred to as “front channel signal mixing processing”). . This will be described in detail below.
- FIG. 5 shows a configuration of an effect processing unit 100 that performs front channel signal mixing processing.
- the effect processing unit 100 detects a steep rise of the front ch signal, specifically, a level increase of a predetermined ratio or more, and mixes (adds) the front ch signal to the surround ch signal when the steep rise is detected. To do.
- the front channel signal mixing process improves the force and presence by spreading a steep change in the input signal level to the rear of the sound field. This will be described in detail below.
- FIG. 5 is a block diagram showing a configuration of the effect processing unit 100. As shown in FIG. As described above, the effect processing unit 100 performs a process of adding the front ch signals FL and FR to the surround ch signals SL and SR, and the front ch signals FL, FR, and LFE signals are input. Since the signal is output as it is, the configuration of that portion is not shown.
- the effect processing unit 100 includes a level detection unit 110, a level control unit 120, adders 131, 132, 133, and an amplifier 140.
- the surround ch signal SL is input to the adder 132, and the surround ch signal SR is input to the adder 133.
- the amplifier 140 amplifies the front ch signal F based on the addition coefficient ⁇ supplied from the level control unit 120 to generate a signal ⁇ (FL + FR), and supplies the signal ⁇ to the adders 132 and 133.
- the addition coefficient ⁇ indicates the level of the front ch signal added to the surround ch signal (referred to as “addition level”). As the addition coefficient ⁇ increases, the level of the front ch signal added to the surround ch signal increases.
- the adder 132 adds the signal ⁇ (FL + FR) to the front ch signal SL and outputs it as a surround ch signal SLx.
- the adder 133 adds the signal ⁇ (FL + FR) to the front ch signal SR and outputs it as a surround ch signal SRx.
- the level detection unit 110 and the level control unit 120 have a role of controlling the addition coefficient ⁇ based on the level of the front ch signal F.
- the level detection unit 110 includes a past level holding unit 111, a current level detection unit 112, and a level ratio calculation unit 113.
- the level control unit 120 includes an addition coefficient determination unit 121 and a coefficient reduction unit 122.
- the current level detection unit 112 detects the level of the front ch signal F and holds it as the current level Lc.
- the past level holding unit 111 holds the level of the front ch signal F in a predetermined period immediately before the current time. That is, the past level holding unit 111 always holds the level of the front ch signal F detected by the current level detecting unit 112 for a predetermined period.
- the “predetermined period” is set to several seconds (for example, about 5 to 8 seconds).
- the past level holding unit 111 determines a past level Lp that represents the level of the front ch signal F during a predetermined period.
- the past level Lp can be, for example, the average value of the front ch signal F in a predetermined period, or the average value of the absolute value of the front ch signal at each time point or the maximum value of the absolute values.
- the level ratio R indicates the level change of the front ch signal F, and the level increase of the front ch signal F increases as the value of the level ratio R increases.
- the addition coefficient determination unit 121 of the level control unit 120 determines the addition coefficient ⁇ based on the level ratio R supplied from the level detection unit 110.
- FIG. 6 shows an example of the relationship between the level ratio R and the addition coefficient ⁇ .
- a threshold Rth of the level ratio R is prepared.
- This example is intended to add the front ch signal F to the surround ch signal when the level increase of the front ch signal is steep.
- the threshold value Rth indicates a predetermined ratio at which the level change of the front ch signal F is determined to be steep.
- the addition coefficient determination unit 121 determines that the level increase of the front ch signal F is not steep, and sets the addition coefficient ⁇ to “0”. Thereby, the front ch signal F is not added to the surround signal.
- the addition coefficient determination unit 121 determines that the level increase of the front ch signal F is steep, and sets the addition coefficient ⁇ to a value greater than “0”. As a result, the front ch signal F is added to the surround ch signal at a rate corresponding to the addition coefficient ⁇ .
- the threshold value Rth can be determined by experiments using various audio signal sources, and can be set to about “2 to 3”, for example. When the threshold value Rth is set to “2”, it is determined that the level increase is steep when the level of the front ch signal F is doubled.
- the addition coefficient ⁇ increases in proportion to the level ratio R. That is, as the level change of the front ch signal F becomes steeper, the level of the front ch signal F added to the surround ch signal, that is, the addition level increases.
- the level control unit 120 transmits the change greatly to the surround ch, and when the level change is small, the level change of the surround ch is set to an appropriate level. Thereby, the effect of a continuous and wide dynamic range can be acquired.
- a maximum value ⁇ max is set for the addition coefficient ⁇ .
- the maximum value ⁇ max of the addition coefficient is set to “0.5”, 1/2 or more of the front channel signal is not mixed with the surround ch. That is, even when the level change of the front ch signal F is large, the front ch signal F is not mixed with the surround ch signal without limitation. In this way, it is possible to prevent an uncomfortable feeling in the sound field due to excessive mixing processing.
- the coefficient reduction unit 122 has a role of limiting the time for mixing the front ch signal F to the surround ch signal to a certain time. Specifically, the coefficient reducing unit 122 has a predetermined time “ ⁇ ”. When the level ratio R becomes equal to or greater than the threshold value Rth, the addition coefficient determination unit 121 sets the addition coefficient ⁇ to a value larger than “0”, and the coefficient decreases when the front ch signal F is added to the surround ch signal by the amplifier 140. The unit 22 linearly decreases the addition coefficient ⁇ to “0” within a predetermined time ⁇ from the time when the front ch signal F starts to be added to the surround ch signal.
- the front ch signal F is added to the surround ch signal at a rate corresponding to the addition coefficient ⁇ , but thereafter the level of the front ch signal F that is gradually added. Decrease.
- the front ch signal F is not added to the surround ch signal.
- the effect of adding the front ch signal when the steep level increase of the front ch signal F occurs next is secured. Further, the effect can be reduced without a sense of incongruity by gradually reducing the ratio of adding the front ch signal F over a certain period of time.
- This fixed time “ ⁇ ” is set to about 1 to 1.5 seconds, for example.
- the predetermined time ⁇ is shorter than a predetermined time (7 to 8 seconds in the above example) that the past level holding unit 11 of the level detecting unit 10 holds the past level.
- the time of the past level holding unit 11 is a fixed time. About 5 to 6 times ⁇ is preferable.
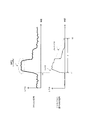
- FIG. 7 shows an example of the waveform of the front ch signal and the signal mixed with the surround ch signal by the above processing.
- the front ch signal is mixed with the surround ch signal at a rate corresponding to the addition coefficient ⁇ .
- the addition coefficient ⁇ gradually decreases, and the signal mixed with the surround ch signal gradually fades out.
- the addition coefficient ⁇ becomes “0”, and mixing of the front ch signal into the surround ch signal is stopped.
- the effect processing unit 100 performs the same processing. That is, the level control unit 120 determines the addition coefficient ⁇ based on the level ratio R at that time, and mixes the front ch signal with the surround ch signal for a certain time ⁇ .
- FIG. 8 shows a flowchart of the front ch signal mixing process. This processing is realized by a computer constituting the effect processing unit 100 executing a program prepared in advance and operating as each component shown in FIG.
- the level detection unit 110 detects the level of the front ch signal (step S11) and determines whether or not there is a steep increase in level (step S12). When there is no steep level increase (step S12; No), the process returns to step S11. When there is a steep level increase (step S12; Yes), the level control unit 120 determines the addition coefficient ⁇ based on the level ratio R at that time (step S13). Then, the level control unit 120 supplies the addition coefficient ⁇ to the amplifier 140, thereby mixing the front ch signal with the surround ch signal (step S14).
- the level control unit 120 determines whether or not a certain period ⁇ has elapsed since the start of mixing of the front ch signals (step S15).
- the level control unit 120 gradually decreases the addition coefficient ⁇ (step S16), and continues to mix the front ch signals (step S14).
- the process ends.
- the dynamic change of the volume occurring in the sound field on the front side of the listening room can be converted into the dynamic change of the front and rear sound fields of the entire listening room,
- the movement before and after the sound field can be made more dynamic.
- the front ch signal includes a sound effect such as an explosion sound, it can also be output from a surround speaker. In this way, it is possible to improve the force and sense of presence, improve the sense of movement of sound and the connection of sounds, and integrate the entire sound field.
- this process is very consistent with 3D video in terms of the connection between the front and rear sound fields and the sense of movement, and it is possible to give the viewer a higher level of realism.
- the above front channel signal mixing process is performed on the front ch signal including the voice component, the lines are also reproduced from the surround speakers, which causes a sense of incongruity.
- the above-described front channel signal mixing process is performed on the audio signal after the voice component separation unit 10 in the preceding stage of the effect processing unit 100 has separated the voice component, the speech is transmitted from the surround speaker. There is no problem of output.
- the crossover filter unit CF of the voice component separation unit 10 divides the audio signal band into a low frequency range and a mid-high frequency range. , It may be divided into three high frequency bands.
- the separation processing unit 20 performs a voice component separation process on the mid-range audio signal.
- the low-frequency and high-frequency signals are added to the mid-frequency signal after the voice component is separated by the separation processing unit 20 and supplied to the effect processing unit 100 as a full-band audio signal.
- the voice component separation unit 10 is provided with the crossover filter unit CF. However, this may be omitted to simplify the hardware configuration.
- a Link Witz-Riley filter is used as the crossover filter unit CF. However, when the characteristics may be sacrificed to some extent, a filter with a simpler configuration is used instead. It may be used.
- the above voice component separation unit 10 can be used alone for canceling karaoke singing. In the case of karaoke, since the low frequency is generally recorded in the same phase in Lch and Rch, the above method is effective.
- the present invention can be used for AV receivers, TVs, BD players and the like that reproduce audio signals together with video.
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Quality & Reliability (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Stereophonic System (AREA)
Abstract
音声信号処理装置は、セリフなどの声成分を含む左右2チャンネルの音声信号を受け取り、声成分を分離する。声成分が分離された後の各チャンネルの信号に対して、所定のエフェクト処理が施される。そして、エフェクト処理がなされた後の各チャンネルの音声信号に、先に分離された声成分が加算され、出力される。これにより、セリフなどの声成分にエフェクト処理が施されることによる弊害が防止される。
Description
本発明は、声の成分を含む音声信号にエフェクト処理を施す手法に関する。
特許文献1は、ボーカル信号と伴奏信号とを含む左右の2チャンネル音声信号からボーカル信号をキャンセルする回路を開示している。具体的には、左右の音声信号からそれぞれ低域信号、高域信号を抽出するとともに、左右の音声信号の差信号を生成することによりボーカル信号をキャンセルした中域信号を生成する。そして、それらの音声信号をミックスすることにより、ボーカル信号をキャンセルした伴奏信号を出力する。
また、「ドルビープロロジック」、「dts neo6」、「dts neoX」などは、フロントチャンネル信号からセリフを分離する能力を有する処理として知られている。
特許文献1の方法では、中域について、Lチャンネルが(L-R)、Rチャンネルが(R-L)の差信号を生成しているので、LチャンネルとRチャンネルの中域の信号が逆相関係となってしまう。中域は聴感上聴取者が最も敏感な帯域であり、その中域の信号が逆相関係になると、聴取者に違和感を与えてしまう。また、仮に逆相となるのを避けるために両チャンネルを(L-R)又は(R-L)のいずれか一方にした場合には、モノラル信号となってしまい、中域のステレオ感が無くなってしまう。
一方、「ドルビープロロジック」、「dts neo6」、「dts neoX」などの処理は、DSPなどでリアルタイム処理を行うにはかなりの処理量となり、ある程度大きなハードウェアの規模を必要とする。また、これらの処理は、セリフやボーカルを分離することが主たる目的であるので、セリフなどの分離性能が最終的な出力の性能に直接的に影響する。
本発明が解決しようとする課題としては、上記のものが一例として挙げられる。本発明は、聴感上の品質を低下させることなく声成分を分離して声成分以外の成分にエフェクト処理を施す手法を提供することを目的とする。
請求項1に記載の発明は、音声信号処理装置であって、声成分を含む2チャンネルの音声信号を受け取り、各チャンネルの音声信号から前記声成分を分離する声成分分離部と、前記声成分が分離された後の各チャンネルの音声信号に対してエフェクト処理を行うエフェクト処理部と、前記エフェクト処理後の各チャンネルの音声信号に、前記声成分分離部が分離した声成分を加算して出力する出力部と、を備えることを特徴とする。
請求項9に記載の発明は、コンピュータを備える音声信号処理装置により実行される音声信号処理プログラムであって、声成分を含む2チャンネルの音声信号を受け取り、各チャンネルの音声信号から前記声成分を分離する声成分分離手段と、前記声成分が分離された後の各チャンネルの音声信号に対してエフェクト処理を行うエフェクト処理手段と、前記エフェクト処理後の各チャンネルの音声信号に、前記声成分分離手段が分離した声成分を加算して出力する出力手段、として前記コンピュータを機能させることを特徴とする。
本発明の好適な実施形態では、音声信号処理装置は、声成分を含む2チャンネルの音声信号を受け取り、各チャンネルの音声信号から前記声成分を分離する声成分分離部と、前記声成分が分離された後の各チャンネルの音声信号に対してエフェクト処理を行うエフェクト処理部と、前記エフェクト処理後の各チャンネルの音声信号に、前記声成分分離部が分離した声成分を加算して出力する出力部と、を備える。
上記の音声信号処理装置は、セリフなどの声成分を含む左右2チャンネルの音声信号を受け取り、声成分を分離する。声成分が分離された後の各チャンネルの音声信号に対して、所定のエフェクト処理が施される。エフェクト処理は、例えば反射音付加処理、残響付加処理、フロント信号をサラウンド信号に混合する処理などとすることができる。そして、エフェクト処理がなされた後の各チャンネルの音声信号に、先に分離された声成分が加算され、出力される。
上記のようなエフェクト処理は、セリフなどの声成分に対して行われると、セリフが聞き取りにくいなどの理由で弊害となりうる。上記の音声信号処理装置では、声成分を分離した左右チャンネルの音声信号に対してエフェクト処理を行うので、そのような弊害を防止することができる。また、エフェクト処理後の左右チャンネル信号に、先に分離された声成分が加算されて出力されるので、声成分の分離処理に誤差が発生しても、その声成分が左右チャンネル信号に戻されることにより誤差がキャンセルされる構成となっている。よって、仮に声成分の分離性能が十分に高くない場合でも、それが最終的に出力される信号に直接的に悪影響を及ぼすことが無い。
上記の音声信号処理装置の一態様では、前記声成分分離部は、各チャンネルの音声信号を低域成分と中高域成分とに分割する帯域分割部と、前記中高域成分から前記声成分を分離して出力する分離処理部と、前記声成分が分離された後の中高域成分に前記低域成分を加算して出力する加算部と、を備える。
この態様では、各チャンネルの音声信号が低域成分と中高域成分とに帯域分割され、中高域成分から声成分が分離される。通常、セリフなどの声成分は左右のチャンネルに同相成分として含まれているので、同相信号を分離することにより声成分を分離することができる。しかし、音声信号の低域成分には、ベース音、バスドラム音などが同相成分として含まれている場合が多く、低域においても同相成分を分離すると、ベース音、バスドラム音などが分離されてしまい、エフェクト処理が施されなくなってしまう。そこで、中高域成分のみから同相成分である声成分を分離することにより、低域成分からベース音やバスドラム音などが分離されてしまうという不具合を防止することができる。
上記の音声信号処理装置の他の一態様では、前記声成分分離部は、前記各チャンネルの音声信号に声成分があるか否かを判定する声成分有無判定部と、前記声成分があると判定されたときに、前記2チャンネルの音声信号の和の1/2を前記声成分として出力するとともに、前記各チャンネルの音声信号から前記声成分を減算して出力する分離部と、を備える。これにより、簡易な構成で、ステレオ信号を維持したまま、セリフなどの声成分を分離することが可能となる。また、声成分が無いときには、元の音声信号がそのまま後段のエフェクト処理に供されるので、弊害の無いエフェクト処理が可能となる。
上記の音声信号処理装置の他の一態様では、前記声成分有無判定部は、前記2チャンネルの音声信号の和と差を算出し、得られた和と差を比較することにより声成分の有無を判定する。通常、セリフなどの声成分は左右チャンネル信号に同相で含まれているので、左右チャンネル信号の和信号と差信号を比較することにより、声成分の有無を判定することができる。
上記の音声信号処理装置の他の一態様では、前記声成分有無判定部は、前記和と差の比較結果に基づいて0又は1の係数値を出力する係数値出力部と、前記係数値を0~1の間の連続値に変換する時定数回路と、を備え、前記分離部は、前記係数値と前記2チャンネルの音声信号の和の1/2との積を前記声成分として出力するとともに、前記各チャンネルの音声信号から前記声成分を減算して出力する。この態様では、時定数回路を設けることにより、声成分の有無を示す信号の急峻な変化を緩やかな変化に変えることができ、違和感のない音声信号出力が可能となる。
上記の音声信号処理装置の他の一態様では、前記声成分有無判定部は、前記和が前記差の所定倍より大きい場合に声成分があると判定し、前記和が前記差の前記所定倍より大きくないときに声成分が無いと判定する。これにより簡易な構成で声成分の有無が判定できる。好適な例では所定倍は5倍である。
上記の音声信号処理装置の他の一態様では、前記声成分有無判定部は、前記時定数回路が出力する係数値を2倍し、制限値1でリミットする回路をさらに備える。これにより、セリフなどの声成分をより確実に分離することが可能となる。
本発明の他の好適な実施形態では、コンピュータを備える音声信号処理装置により実行される音声信号処理プログラムは、声成分を含む2チャンネルの音声信号を受け取り、各チャンネルの音声信号から前記声成分を分離する声成分分離手段と、前記声成分が分離された後の各チャンネルの音声信号に対してエフェクト処理を行うエフェクト処理手段と、前記エフェクト処理後の各チャンネルの音声信号に、前記声成分分離手段が分離した声成分を加算して出力する出力手段、として前記コンピュータを機能させる。この音声信号処理プログラムをコンピュータにより実行することで、声成分を除去して適切なエフェクト処理を行うことができる。
以下、図面を参照して本発明の好適な実施例について説明する。
[基本原理]
本実施例は、声成分を含む左右チャンネルの音声信号に対して3D映像用の各種のエフェクト処理を施す手法を提供する。一般に、3D音場用処理などのエフェクト処理は、背景音や効果音を対象とするものであり、セリフに対しては同じエフェクト処理を施したくない場合が多い。仮にセリフに対して同じエフェクト処理を行ってしまうと、セリフが聞き取りにくくなったり、過剰なエフェクト音を感じてしまったりして、逆に弊害となってしまう。
本実施例は、声成分を含む左右チャンネルの音声信号に対して3D映像用の各種のエフェクト処理を施す手法を提供する。一般に、3D音場用処理などのエフェクト処理は、背景音や効果音を対象とするものであり、セリフに対しては同じエフェクト処理を施したくない場合が多い。仮にセリフに対して同じエフェクト処理を行ってしまうと、セリフが聞き取りにくくなったり、過剰なエフェクト音を感じてしまったりして、逆に弊害となってしまう。
映画コンテンツの場合、チャンネル構成がフロント2チャンネルの構成となっているコンテンツでは、ほとんどのセリフが同相成分に含まれている。また、センターチャンネルをもっているような5.1chなどのコンテンツの場合でも、まれにフロント2チャンネル信号の同相成分にセリフが含まれていることがある。本実施例では、センターチャンネルの有無に関わらず、フロント2チャンネル信号の同相成分にセリフが含まれていた場合、目的のエフェクト処理がセリフに施されないようにする。また、セリフに限らず、音楽コンテンツであれば歌唱についてもエフェクトをかけないようにすることができる。しかもその際、前述の先行文献1のように結果の信号がモノラルになることはなく、ステレオを維持することができる。
具体的には、本実施例の音声信号処理装置は、まず左右チャンネルの音声信号から声成分を分離し、次に声成分を分離した後の音声信号に対して各種のエフェクト処理を施す。そして、先に分離した声成分を、エフェクト処理後の音声信号に合成することにより左右チャンネルの音声信号を出力する。これにより、セリフなどの声成分にエフェクトをかけずに、それ以外の背景音のみに奥行き感、立体感、臨場感等を演出するためのエフェクトをかけることが可能となり、自然なエフェクト効果を得ることができる。この点で、本実施例の音声信号処理装置は、映像用モニタを備え、映像コンテンツを再生するための装置に特に好適である。
[全体構成]
図1は、実施例に係る音声信号処理装置の基本構成を示す。図示のように、音声信号処理装置1は、声成分分離部10と、エフェクト処理部100と、加算器5、6とを備える。
図1は、実施例に係る音声信号処理装置の基本構成を示す。図示のように、音声信号処理装置1は、声成分分離部10と、エフェクト処理部100と、加算器5、6とを備える。
声成分分離部10は、左チャンネルの音声信号Liと右チャンネルの音声信号Riとが入力される。以下、「チャンネル」を「ch」、「左チャンネル」を「Lch」、「右チャンネル」を「Rch」と記述する。声成分分離部10は、Lch音声信号LiとRch音声信号Riから声成分を分離する。そして、声成分分離部10は、分離した声成分を声成分信号Cとして加算器5、6に出力するとともに、声成分が分離された後のLch音声信号L4及びRch音声信号R4をエフェクト処理部100へ出力する。
エフェクト処理部100は、声成分が分離された後のLch音声信号L4及びRch音声信号R4に対して、3D映像用の各種のエフェクト処理を施す。そして、エフェクト処理部100は、エフェクト処理後のLch音声信号L5を加算器5に出力し、エフェクト処理後のRch音声信号R5を加算器6へ出力する。
加算器5は、エフェクト処理後のLch音声信号L5に声成分信号Cを加算し、Lch音声信号Loを出力する。加算器6は、エフェクト処理後のRch音声信号R5に声成分信号Cを加算し、Rch音声信号Roを出力する。なお、加算器5、6は本発明の出力部に相当する。
以上の構成により、エフェクト処理部100は声成分が分離された後のLch音声信号L4及びRch音声信号R4に対してエフェクト処理を施すことになり、声成分信号Cに対してエフェクト処理は施されない。よって、エフェクト処理によりセリフなどが聞き取りにくくなるなどの不具合は生じない。また、エフェクト処理部100は、声成分が分離された後の音声信号を対象として、十分なエフェクト処理を行うことができる。
また、本実施例の音声信号処理装置では、声成分分離部10が分離した声成分信号Cを、加算器5、6により、エフェクト処理後の音声信号L5、R5に加算する点に特徴を有する。音声信号から声成分を分離する手法はいくつか知られているが、完全に声成分を分離することは現実的には難しい。前述の従来技術などのように、セリフやボーカルを分離することを主たる目的とする装置・手法では、声成分の分離性能が最終的な出力の性能に大きな影響を及ぼす。これに対し、本実施例は声成分を分離して出力することではなく、エフェクト処理の対象から声成分を除くことを主目的としており、エフェクト処理後の音声信号に声成分を合成している。即ち、一時的に分離した声成分を、エフェクト処理後の音声信号に戻している。よって、仮に声成分分離部10による分離性能が低く、実際に存在する声成分と分離された声成分との間に誤差が生じたとしても、最終的に声成分が元の音声信号に戻されることによりその誤差がキャンセルされる構成となっている。よって、声成分分離部10の分離性能が、最終出力である音声信号Lo、Roの品質に直接大きな影響を及ぼすことはない。
[声成分分離部]
次に、声成分分離部10について詳しく説明する。図2は、声成分分離部10の構成を示す。声成分分離部10は、クロスオーバーフィルタ部CFと、分離処理部20と、加算器14、15とを備える。
次に、声成分分離部10について詳しく説明する。図2は、声成分分離部10の構成を示す。声成分分離部10は、クロスオーバーフィルタ部CFと、分離処理部20と、加算器14、15とを備える。
クロスオーバーフィルタ部CFは、4つのハイパスフィルタ(HPF)11と、4つのローパスフィルタ(LPF)12とを備える。本例のクロスオーバーフィルタ部CFは、いわゆるリンクウィッツライリー型のフィルタである。具体的に、各音声信号Li、Riに対して、2つのHPF11と2つのLPF12とが従属接続されている。HPF11とLPF12は、それぞれカットオフ周波数において3dB減衰する特性を有する。
音声信号Liからは、2段のHPF11で中高域成分が抽出され、音声信号L1として分離処理部20へ送られる。音声信号Riからは、2段のHPF11で中高域成分が抽出され、音声信号R1として分離処理部20へ送られる。
分離処理部20は、音声信号L1、R1から声成分を分離して声成分信号Cを生成し、出力する。また、分離処理部20は、音声信号L1から声成分を除去した音声信号L3を加算器14へ送るとともに、音声信号R1から声成分を除去した音声信号R3を加算器15へ送る。なお、分離処理部20の詳細については後述する。
また、音声信号Liからは、2段のLPF12により低域成分が抽出され、音声信号L2として加算器14へ送られる。音声信号Riからは、2段のLPF12により低域成分が抽出され、音声信号R2として加算器15へ送られる。
加算器14は、声成分が除去された中高域のLch音声信号L3に、低域のLch音声信号L2を加算し、声成分が除去された全帯域のLch音声信号L4を生成して出力する。加算器15は、声成分が除去された中高域のRch信号R3に、低域のRch音声信号R2を加算し、声成分が除去された全帯域のRch信号R4を生成して出力する。
このように、声成分分離部10では、クロスオーバーフィルタ部CFでLch音声信号Li及びRch音声信号Riの帯域を低域と中高域とに分割し、中高域の信号のみを対象として分離処理部20による声成分の分離処理を行う。前述のようにセリフなどの声成分はLch音声信号とRch音声信号の同相成分であり、後述するように分離処理部20による声成分の分離処理はLch音声信号とRch音声信号の同相成分を分離する処理となる。一方で、低域信号には例えばベース音、バスドラム音が同相成分としてが含まれていることが多く、低域信号に対して同様に分離処理部20による声成分の分離処理を行うと、ベース音、バスドラム音などが声成分として分離されてしまい、後段のエフェクト処理の対象外となってしまう。そこで、本実施例では、クロスオーバーフィルタ部CFが入力音声信号を低域信号と中高域信号とに分割し、中高域信号に対して声成分の分離処理を行って声成分を分離した後、その中高域信号と低域信号と再度合成して音声信号L4、R4としている。
このように、本実施例では、加算器14、15により低域信号と中高域信号とを加算して全帯域の信号を生成する構成となっているので、クロスオーバーフィルタ部CFは、帯域分割した低域、中高域信号を再度合成した際に周波数特性がフラットとなる特性を有することが好ましい。また、そのような特性を得ることができれば、クロスオーバーフィルタ部CFの構成は図2に示すものには限定されない。
[分離処理部]
次に、分離処理部20について詳しく説明する。分離処理部20は、大別して分離部と、声成分有無判定部とにより構成される。
次に、分離処理部20について詳しく説明する。分離処理部20は、大別して分離部と、声成分有無判定部とにより構成される。
分離部の構成を図3に示す。分離部は、Lch音声信号L1及びRch音声信号R1を受け取り、声成分信号Cと、声成分が分離されたLch音声信号L3と、声成分が分離されたRch音声信号R3とを出力する。具体的に、分離部は、加算器16~18と、増幅器19、20とを備える。
Lch音声信号L1は加算器16、17に供給される。Rch音声信号R1は、加算器16、18に供給される。加算器16は、Lch音声信号L1とRch音声信号R1とを加算して増幅器19に送る。増幅器19は、Lch音声信号L1とRch音声信号R1との和の1/2、即ち、信号「(R1+L1)/2」を出力する。さらに、増幅器20は、信号「(R1+L1)/2」に対して係数Gを乗算し、信号「G(L1+R1)/2」を声成分信号Cとして出力するとともに、それを加算器17、18に供給する。
ここで、係数「G」は、音声信号中における声成分の有無を示す係数であり、0.0~1.0の値をとる。係数Gは、「0.0」のときは音声信号中に声成分が含まれていないことを示し、「1.0」のときは音声信号中に声成分が含まれていることを示す。係数Gは、後述の声成分有無判定部により算出される。
増幅器19の出力信号「(R1+L1)/2」は、Lch音声信号L1とRch音声信号R1の和の1/2である。声成分がLch音声信号及びRch音声信号に支配的に存在する場合(即ち、Lch音声信号とRch音声信号の同相成分が大きい場合)、係数Gは「1.0」に近い値となり、Lch音声信号L1とRch音声信号R1からそれぞれ信号「G(L1+R1)/2」が減算される。ここで、同相成分が大きいときは、ほぼL1=R1と考えられるので、それを減算することにより、Lch音声信号及びRch音声信号から声成分が除去される。逆に、声成分がほとんど存在しない場合(即ち、Lch音声信号とRch音声信号の同相成分が小さい場合)、係数Gは「0.0」に近い値となり、Lch音声信号L1とRch音声信号R1から信号「G(L1+R1)/2」はほとんど減算されず、Lch音声信号L1、Rch音声信号R1はほぼそのままLch音声信号L3、Rch音声信号R3として出力される。
次に、声成分有無判定部について説明する。声成分有無判定部の構成を図4(a)、4(b)に示す。図4(a)は、Lch音声信号L1とRch音声信号R1の和信号と差信号を生成する回路である。具体的に、加算器24はLch音声信号L1からRch音声信号R1を減算して差信号を生成し、絶対値回路25はその差信号の絶対値演算を行い差信号レベルAを出力する。一方、加算器26はLch音声信号L1とRch音声信号R1とを加算して和信号を生成し、増幅器27、28はその和信号にそれぞれ「0.5」、「0.4」を乗算する。ここで、増幅器27が乗算する「0.5」は和信号を1/2にするためのものであり、増幅器28が乗算する「0.4」は経験により得られた値である。そして、絶対値回路29はこの和信号の絶対値演算を行い、和信号レベルBを出力する。
次に、声成分有無判定部は、こうして得た差信号レベルAと和信号レベルBとを比較する。上記の増幅器27、28が乗算する値により、差信号レベルAと和信号レベルBとの比較は、音声信号(L1+R1)と、音声信号(L1-R1)の5倍との比較を意味する。即ち、本実施例では、声信号L1、R1の和が、音声信号のL1、R1の差より5倍以上大きい場合(即ち、A<B)は、声成分有無判定部は音声信号L1、R1に声成分があると判断する。一方、音声信号L1、R1の和が、音声信号L1、R1の差より5倍以上大きくない場合(即ち、A≧B)、声成分有無判定部は音声信号L1、R1に声成分が無いと判定する。
具体的に、図4(b)において、A<Bである場合、声成分があると判定され、スイッチ30は値「1.0」を選択する。一方、A≧Bである場合、声成分は無いと判定され、スイッチ30は値「0.0」を選択する。なお、スイッチ30は本発明の係数出力部に相当する。
スイッチ30の出力は、増幅器31で経験値が乗算され、時定数回路32に供給される。時定数回路32は、スイッチ30の切り替えによる信号波形の急峻な立ち上がり/立ち下がりを緩やかな変化にする役割を有する。時定数回路32の出力は、増幅器33で経験値である「2」が乗算され、リミット回路34により「0.0~1.0」の値に制限されて係数Gとして出力される。これにより、係数Gは、音声信号L1、R1における声成分の有無を示す係数となる。即ち、係数Gは、音声信号L1、R1に声成分があるときは値「1.0」の値を維持し、声成分が無いときは値「0.0」を維持し、それらの間の過渡期は滑らかな曲線で変化することになる。
以上のように、本実施例の分離処理部20は、声成分有無判定部が音声信号L1、R1における声成分の有無を判定し、声成分が支配的に存在するときのみ信号「(L1+R1)/2」を同相成分(即ち声成分)とみなして、それを音声信号L1、R1からを減算するので、高い確実性で声成分を分離することができる。また、先行技術1と異なり、ステレオ信号を維持したまま声成分を分離することができる。また、セリフなどの声成分が無いときには、元の信号のまま後段のエフェクト処理部に信号を送ることができるので、弊害の無いエフェクト処理が可能となる。
また、時定数回路32の出力を2倍する増幅器33とリミット回路34とを設けたことにより、声成分の除去をより確実に行える効果が得られる。特に、セリフの末尾で声成分の分離動作を時間的に引き伸ばす効果がある。これは、時定数回路の簡素化とも言い換えることが出来る。同様の効果を得るには、アタック、リリースの時定数を変えるなどの工夫が必要になり回路が複雑になるが、それを回避することができる。但し、この増幅器33とリミット回路34を省略し、時定数回路32の時定数を調整することに同様の効果を得ることも可能である。
さらに、本実施例の分離処理部20は、処理量が少なく、実装時のハードウェア規模を抑えることができるので、低コストで実現することが可能である。
[エフェクト処理部]
次に、エフェクト処理部100について説明する。本発明では、エフェクト処理部100が実行するエフェクト処理は基本的にどのようなものであってもよい。一般的に、3D映像とともに再生される音声信号に対して行われるエフェクト処理としては、反射音を付加する処理、リバーブ(残響音)を付加する処理などが知られており、エフェクト処理部100はこれらを行うこととしてもよい。この場合、音声信号に含まれるセリフなどの声成分に対して反射音を付加したり残響音を付加したりする処理を行うと、前述のようにセリフが聞き取りづらくなるなどの弊害がある。よって、本実施例のように、声成分分離部10により声成分を分離した後の音声信号に対してエフェクト処理を行えば、そのような弊害を防止することができる。
次に、エフェクト処理部100について説明する。本発明では、エフェクト処理部100が実行するエフェクト処理は基本的にどのようなものであってもよい。一般的に、3D映像とともに再生される音声信号に対して行われるエフェクト処理としては、反射音を付加する処理、リバーブ(残響音)を付加する処理などが知られており、エフェクト処理部100はこれらを行うこととしてもよい。この場合、音声信号に含まれるセリフなどの声成分に対して反射音を付加したり残響音を付加したりする処理を行うと、前述のようにセリフが聞き取りづらくなるなどの弊害がある。よって、本実施例のように、声成分分離部10により声成分を分離した後の音声信号に対してエフェクト処理を行えば、そのような弊害を防止することができる。
また、本発明において好適に使用されうる3D映像向けのエフェクト処理の他の一例として、フロントch信号をサラウンドch信号に合成するエフェクト処理(以下、「フロントチャンネル信号混合処理」と呼ぶ。)がある。これについて以下に詳しく説明する。
(フロントチャンネル信号混合処理)
図5は、フロントチャンネル信号混合処理を行うエフェクト処理部100の構成を示す。この例では、入力音声信号として、少なくとも左右のフロントch信号FL、FR及び左右のサラウンドch信号Sl、SRがあるものとする。エフェクト処理部100は、フロントch信号の急峻な立ち上がり、具体的には所定割合以上のレベル増加を検出し、急峻な立ち上がりが検出されたときに、フロントch信号をサラウンドch信号に混合(加算)する。フロントチャンネル信号混合処理は、入力信号レベルの急峻な変化を音場の後方に広げることにより、迫力、臨場感などを向上させる。以下、詳しく説明する。
図5は、フロントチャンネル信号混合処理を行うエフェクト処理部100の構成を示す。この例では、入力音声信号として、少なくとも左右のフロントch信号FL、FR及び左右のサラウンドch信号Sl、SRがあるものとする。エフェクト処理部100は、フロントch信号の急峻な立ち上がり、具体的には所定割合以上のレベル増加を検出し、急峻な立ち上がりが検出されたときに、フロントch信号をサラウンドch信号に混合(加算)する。フロントチャンネル信号混合処理は、入力信号レベルの急峻な変化を音場の後方に広げることにより、迫力、臨場感などを向上させる。以下、詳しく説明する。
図5は、エフェクト処理部100の構成を示すブロック図である。なお、前述のように、エフェクト処理部100は、フロントch信号FL、FRをサラウンドch信号SL、SRに加える処理を行うものであり、フロントch信号FL及びFR、LFE信号などについては入力された信号をそのまま出力するので、その部分の構成は図示を省略している。
図5に示すように、エフェクト処理部100は、レベル検出部110と、レベル制御部120と、加算器131、132、133と、増幅器140とを備える。サラウンドch信号SLは加算器132に入力され、サラウンドch信号SRは加算器133に入力される。
フロントch信号FL及びFRは加算器131により加算され、得られたフロントch信号F(=FL+FR)はレベル検出部110及び増幅器140へ供給される。増幅器140は、レベル制御部120から供給される加算係数αに基づいてフロントch信号Fを増幅して信号α(FL+FR)を生成し、加算器132、133へ供給する。加算係数αは、サラウンドch信号に加算されるフロントch信号のレベル(「加算レベル」という。)を示すものである。加算係数αが大きいほど、サラウンドch信号に加算されるフロントch信号のレベルが大きくなる。
加算器132はフロントch信号SLに信号α(FL+FR)を加算し、サラウンドch信号SLxとして出力する。同様に、加算器133は、フロントch信号SRに信号α(FL+FR)を加算し、サラウンドch信号SRxとして出力する。
レベル検出部110及びレベル制御部120は、フロントch信号Fのレベルに基づいて、加算係数αを制御する役割を有する。レベル検出部110は、過去レベル保持部111と、現在レベル検出部112と、レベル比算出部113とを備える。レベル制御部120は、加算係数決定部121と、係数減少部122とを備える。
現在レベル検出部112は、フロントch信号Fのレベルを検出し、現在レベルLcとして保持する。過去レベル保持部111は、現在を基準とした直前の所定期間における、フロントch信号Fのレベルを保持する。即ち、過去レベル保持部111は、現在レベル検出部112が検出したフロントch信号Fのレベルを、常に所定期間分保持する。ここで、「所定期間」は、数秒(例えば5~8秒程度)とする。そして、過去レベル保持部111は、所定期間のフロントch信号Fのレベルを代表する過去レベルLpを決定する。過去レベルLpは、例えば所定期間におけるフロントch信号Fの平均値、もしくは、各時点におけるフロントch信号の絶対値の平均値又は絶対値のうちの最大値などとすることができる。
レベル比算出部113は、現在レベルLcと過去レベルLpとの比であるレベル比R(=Lc/Lp)を算出し、レベル制御部120へ出力する。レベル比Rは、フロントch信号Fのレベル変化を示し、レベル比Rの値が大きいほど、フロントch信号Fのレベル増加は大きい。
レベル制御部120の加算係数決定部121は、レベル検出部110から供給されたレベル比Rに基づいて、加算係数αを決定する。図6は、レベル比Rと加算係数αとの関係の一例を示す。
図6に示すように、レベル比Rの閾値Rthが用意される。本例は、フロントch信号のレベル増加が急峻であるときに、サラウンドch信号にフロントch信号Fを加算することを意図している。閾値Rthは、フロントch信号Fのレベル変化が急峻であると判定される所定割合を示す。レベル比Rが閾値Rthより小さい場合、加算係数決定部121は、フロントch信号Fのレベル増加は急峻ではないと判定し、加算係数αを「0」とする。これにより、フロントch信号Fはサラウンド信号に加算されない。一方、レベル比Rが閾値Rth以上である場合、加算係数決定部121はフロントch信号Fのレベル増加が急峻であると判定し、加算係数αを「0」より大きい値に設定する。これにより、フロントch信号Fは、加算係数αに応じた割合でサラウンドch信号に加算される。
閾値Rthは、各種の音声信号ソースを用いた実験などにより決定することができ、例えば「2~3」程度に設定することができる。閾値Rthが「2」に設定された場合、フロントch信号Fのレベルが2倍となったときに、レベル増加が急峻であると判断される。
図6に示すように、レベル比Rが閾値Rth以上となった場合、加算係数αはレベル比Rに比例して増加する。つまり、フロントch信号Fのレベル変化が急峻であるほど、サラウンドch信号に加算されるフロントch信号Fのレベル、即ち加算レベルが増加する。こうして、レベル制御部120は、フロントch信号Fのレベル変化が大きいときにはその変化をサラウンドchにも大きく伝え、レベル変化が小さいときにはサラウンドchの変化もそれなりのレベルに設定する。これにより、連続的かつダイナミックレンジの広い効果を得ることができる。
また、図6に示すように、加算係数αには最大値αmaxが設定される。例えば、加算係数の最大値αmaxが「0.5」に設定されている場合、フロントチャンネル信号の1/2以上がサラウンドchに混合されることはない。つまり、フロントch信号Fのレベル変化が大きい場合でも、無制限にフロントch信号Fがサラウンドch信号に混合されることはない。こうして、過剰な混合処理がなされて音場に違和感が生じることを防止している。
係数減少部122は、フロントch信号Fをサラウンドch信号に混合する時間を一定時間に制限する役割を有する。具体的には、係数減少部122は予め決められた一定時間「τ」を有する。レベル比Rが閾値Rth以上となったとして加算係数決定部121が加算係数αを「0」より大きい値に設定し、増幅器140によりフロントch信号Fがサラウンドch信号に加算されると、係数減少部22はフロントch信号Fがサラウンドch信号に加算され始めた時点から一定時間τ内に加算係数αを直線的に「0」まで減少させる。よって、フロントch信号Fに急峻なレベル増加があると、加算係数αに応じた割合でフロントch信号Fがサラウンドch信号に加算されるが、その後は徐々に加算されるフロントch信号Fのレベルが減少する。そして、フロントch信号Fがサラウンドch信号に加算され始めてから一定時間τが経過したときには、フロントch信号Fはサラウンドch信号に加算されなくなる。これにより、次にフロントch信号Fの急峻なレベル増加が発生したときに、フロントch信号を加算することによる効果を確保する。また、フロントch信号Fを加算する割合をある程度の時間をかけて徐々に減少させることにより、違和感なく、効果を減少させていくことができる。
なお、この一定時間「τ」は、例えば1~1.5秒程度に設定される。また、この一定時間τは、レベル検出部10の過去レベル保持部11が過去レベルを保持する所定時間(上記の例では7~8秒)より小さく、例えば過去レベル保持部11の時間は一定時間τの5~6倍程度が好ましい。
図7は、フロントch信号、及び、上記の処理によりサラウンドch信号に混合される信号の波形の例を示す。図7に示すように、ある時刻t1でフロントch信号のレベルが急峻に増加すると、フロントch信号が加算係数αに応じた割合でサラウンドch信号へ混合される。その後、加算係数αは徐々に減少していき、サラウンドch信号に混合される信号は徐々にフェードアウトする。一定時間τが経過する時刻t2において加算係数αは「0」となり、フロントch信号のサラウンドch信号への混合が停止される。
なお、図7において、時刻t1~t2の間に再度フロントch信号の急峻なレベル増加が検出された場合には、エフェクト処理部100は同じ処理を行う。つまり、レベル制御部120はそのときのレベル比Rに基づいて加算係数αを決定し、一定時間τにわたりフロントch信号をサラウンドch信号に混合する。
図8は、フロントch信号混合処理のフローチャートを示す。この処理は、エフェクト処理部100を構成するコンピュータが、予め用意されたプログラムを実行し、図5に示す各構成要素として動作することにより実現される。
まず、レベル検出部110は、フロントch信号のレベルを検出し(ステップS11)、急峻なレベル増加があったか否かを判定する(ステップS12)。急峻なレベル増加が無い場合(ステップS12;No)、処理はステップS11へ戻る。急峻なレベル増加があった場合(ステップS12;Yes)、レベル制御部120はそのときのレベル比Rに基づいて加算係数αを決定する(ステップS13)。そして、レベル制御部120は増幅器140へ加算係数αを供給することにより、サラウンドch信号にフロントch信号を混合する(ステップS14)。
次に、レベル制御部120は、フロントch信号の混合を開始してから一定期間τが経過したか否かを判定する(ステップS15)。一定時間τが経過していない場合(ステップS15;No)、レベル制御部120は加算係数αを徐々に減少させ(ステップS16)、フロントch信号の混合を継続する(ステップS14)。一方、一定時間τが経過した場合(ステップS15;Yes)、処理は終了する。
以上説明したように、上記のフロントチャンネル信号混合処理によれば、リスニングルームのフロント側の音場で起きている音量のダイナミックな変化をリスニングルーム全体の前後音場のダイナミックな変化に変換でき、音場の前後の動きをよりダイナミックにすることができる。例えば、映画などのコンテンツにおいて、フロントch信号に爆発音などの効果音が含まれている場合には、それをサラウンドスピーカからも出力することができる。こうして、迫力、臨場感を向上させ、音の移動感、音のつながりを良くし、音場全体を一体化させることができる。また、本処理は、前後の音場のつながり、移動感という意味で3D映像と非常に整合がよく、視聴者により高いレベルの臨場感を与えることが可能となる。
ここで、上記のフロントチャンネル信号混合処理を、声成分を含むフロントch信号に対して行うと、セリフがサラウンドスピーカからも再生されることになり、違和感を生じる。この点、本実施例では、エフェクト処理部100の前段の声成分分離部10が声成分を分離した後の音声信号に対して上記のフロントチャンネル信号混合処理が行われるので、セリフがサラウンドスピーカから出力されるような不具合は生じない。
[変形例]
上記の実施例では、声成分分離部10のクロスオーバーフィルタ部CFは、音声信号の帯域を低域と中高域に分割しているが、その代わりに、音声信号の帯域を低域、中域、高域の3帯域に分割してもよい。その場合、分離処理部20は中域の音声信号に対して声成分の分離処理を実行する。低域及び高域の信号は、分離処理部20により声成分が分離された後の中域信号に加算され、全帯域の音声信号としてエフェクト処理部100へ供給される。
上記の実施例では、声成分分離部10のクロスオーバーフィルタ部CFは、音声信号の帯域を低域と中高域に分割しているが、その代わりに、音声信号の帯域を低域、中域、高域の3帯域に分割してもよい。その場合、分離処理部20は中域の音声信号に対して声成分の分離処理を実行する。低域及び高域の信号は、分離処理部20により声成分が分離された後の中域信号に加算され、全帯域の音声信号としてエフェクト処理部100へ供給される。
上記の実施例では、声成分分離部10にクロスオーバーフィルタ部CFを設けているが、これを省略してハードウェア構成を簡略化してもよい。また、上記の実施例では、クロスオーバーフィルタ部CFとしてリンクウィッツライリー型のフィルタを使用しているが、ある程度特性を犠牲にしてもよい場合には、その代わりに、より単純な構成のフィルタを用いてもよい。
上記の声成分分離部10は、単独でカラオケの歌唱キャンセルにも用いることが可能である。カラオケの場合、一般的に低域がLchとRchに同相で記録されている可能性が高いので、上記の手法は有効である。
本発明は、映像とともに音声信号を再生するAVレシーバー、TV、BDプレイヤーなどに利用することができる。
1 音声信号処理装置
10 音声分離部
5、6、14、15~18、24、26 加算器
11 ハイパスフィルタ(HPF)
12 ローパスフィルタ(LPF)
20 分離処理部
19、20、27、28、31、33 増幅器
32 時定数回路
34 リミット回路
100 エフェクト処理部
10 音声分離部
5、6、14、15~18、24、26 加算器
11 ハイパスフィルタ(HPF)
12 ローパスフィルタ(LPF)
20 分離処理部
19、20、27、28、31、33 増幅器
32 時定数回路
34 リミット回路
100 エフェクト処理部
Claims (9)
- 声成分を含む2チャンネルの音声信号を受け取り、各チャンネルの音声信号から前記声成分を分離する声成分分離部と、
前記声成分が分離された後の各チャンネルの音声信号に対してエフェクト処理を行うエフェクト処理部と、
前記エフェクト処理後の各チャンネルの音声信号に、前記声成分分離部が分離した声成分を加算して出力する出力部と、
を備えることを特徴とする音声信号処理装置。 - 前記声成分分離部は、
各チャンネルの音声信号を低域成分と中高域成分とに分割する帯域分割部と、
前記中高域成分から前記声成分を分離して出力する分離処理部と、
前記声成分が分離された後の中高域成分に前記低域成分を加算して出力する加算部と、
を備えることを特徴とする請求項1に記載の音声信号処理装置。 - 前記声成分分離部は、
前記各チャンネルの音声信号に声成分があるか否かを判定する声成分有無判定部と、
前記声成分があると判定されたときに、前記2チャンネルの音声信号の和の1/2を前記声成分として出力するとともに、前記各チャンネルの音声信号から前記声成分を減算して出力する分離部と、
を備えることを特徴とする請求項1に記載の音声信号処理装置。 - 前記声成分有無判定部は、前記2チャンネルの音声信号の和と差を算出し、得られた和と差を比較することにより声成分の有無を判定することを特徴とする請求項3に記載の音声信号処理装置。
- 前記声成分有無判定部は、
前記和と差の比較結果に基づいて0又は1の係数値を出力する係数値出力部と、
前記係数値を0~1の間の連続値に変換する時定数回路と、を備え、
前記分離部は、前記係数値と前記2チャンネルの音声信号の和の1/2との積を前記声成分として出力するとともに、前記各チャンネルの音声信号から前記声成分を減算して出力することを特徴とする請求項3又は4に記載の音声信号処理装置。 - 前記声成分有無判定部は、前記和が前記差の所定倍より大きい場合に声成分があると判定し、前記和が前記差の前記所定倍より大きくないときに声成分が無いと判定することを特徴とする請求項4に記載の音声信号処理装置。
- 前記所定倍は5倍であることを特徴とする請求項6に記載の音声信号処理装置。
- 前記声成分有無判定部は、前記時定数回路が出力する係数値を2倍し、制限値1でリミットする回路をさらに備えることを特徴とする請求項5に記載の音声信号処理装置。
- コンピュータを備える音声信号処理装置により実行される音声信号処理プログラムであって、
声成分を含む2チャンネルの音声信号を受け取り、各チャンネルの音声信号から前記声成分を分離する声成分分離手段と、
前記声成分が分離された後の各チャンネルの音声信号に対してエフェクト処理を行うエフェクト処理手段と、
前記エフェクト処理後の各チャンネルの音声信号に、前記声成分分離手段が分離した声成分を加算して出力する出力手段、として前記コンピュータを機能させることを特徴とする音声信号処理プログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2012/058140 WO2013145156A1 (ja) | 2012-03-28 | 2012-03-28 | 音声信号処理装置及び音声信号処理プログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2012/058140 WO2013145156A1 (ja) | 2012-03-28 | 2012-03-28 | 音声信号処理装置及び音声信号処理プログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2013145156A1 true WO2013145156A1 (ja) | 2013-10-03 |
Family
ID=49258523
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2012/058140 WO2013145156A1 (ja) | 2012-03-28 | 2012-03-28 | 音声信号処理装置及び音声信号処理プログラム |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2013145156A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3603107B1 (de) * | 2017-03-21 | 2023-07-12 | ASK Industries GmbH | Verfahren zur ausgabe eines audiosignals in einen innenraum über eine einen linken und einen rechten ausgabekanal umfassende ausgabeeinrichtung |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS61234607A (ja) * | 1985-04-10 | 1986-10-18 | Matsushita Electric Ind Co Ltd | ボ−カル信号除去装置 |
| JPH0560100U (ja) * | 1992-01-27 | 1993-08-06 | クラリオン株式会社 | 音響再生装置 |
| JPH0654400U (ja) * | 1991-12-12 | 1994-07-22 | 日本コロムビア株式会社 | ボーカルチェンジ装置 |
| JPH07212893A (ja) * | 1994-01-21 | 1995-08-11 | Matsushita Electric Ind Co Ltd | 音響再生装置 |
| JPH07319488A (ja) * | 1994-05-19 | 1995-12-08 | Sanyo Electric Co Ltd | ステレオ信号処理回路 |
| WO2006126473A1 (ja) * | 2005-05-23 | 2006-11-30 | Matsushita Electric Industrial Co., Ltd. | 音像定位装置 |
-
2012
- 2012-03-28 WO PCT/JP2012/058140 patent/WO2013145156A1/ja active Application Filing
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS61234607A (ja) * | 1985-04-10 | 1986-10-18 | Matsushita Electric Ind Co Ltd | ボ−カル信号除去装置 |
| JPH0654400U (ja) * | 1991-12-12 | 1994-07-22 | 日本コロムビア株式会社 | ボーカルチェンジ装置 |
| JPH0560100U (ja) * | 1992-01-27 | 1993-08-06 | クラリオン株式会社 | 音響再生装置 |
| JPH07212893A (ja) * | 1994-01-21 | 1995-08-11 | Matsushita Electric Ind Co Ltd | 音響再生装置 |
| JPH07319488A (ja) * | 1994-05-19 | 1995-12-08 | Sanyo Electric Co Ltd | ステレオ信号処理回路 |
| WO2006126473A1 (ja) * | 2005-05-23 | 2006-11-30 | Matsushita Electric Industrial Co., Ltd. | 音像定位装置 |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3603107B1 (de) * | 2017-03-21 | 2023-07-12 | ASK Industries GmbH | Verfahren zur ausgabe eines audiosignals in einen innenraum über eine einen linken und einen rechten ausgabekanal umfassende ausgabeeinrichtung |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4732807B2 (ja) | オーディオ信号処理 | |
| US20140185812A1 (en) | Method for Generating a Surround Audio Signal From a Mono/Stereo Audio Signal | |
| EP2252083B1 (en) | Signal processing apparatus | |
| JP2012151767A (ja) | オーディオ信号処理装置およびオーディオアンプ | |
| US20120020481A1 (en) | Sound reproduction system and method | |
| US9008318B2 (en) | Audio signal processing device | |
| AU2012257865B2 (en) | Apparatus and method and computer program for generating a stereo output signal for providing additional output channels | |
| JP2008301427A (ja) | マルチチャンネル音声再生装置 | |
| US9998844B2 (en) | Signal processing device and signal processing method | |
| US20090122994A1 (en) | Localization control device, localization control method, localization control program, and computer-readable recording medium | |
| WO2009113147A1 (ja) | 信号処理装置及び信号処理方法 | |
| JP4791613B2 (ja) | 音声調整装置 | |
| WO2013145156A1 (ja) | 音声信号処理装置及び音声信号処理プログラム | |
| WO2012035612A1 (ja) | サラウンド信号生成装置、サラウンド信号生成方法、及びサラウンド信号生成プログラム | |
| JP6124143B2 (ja) | サラウンド成分生成装置 | |
| KR101745019B1 (ko) | 오디오 시스템 및 그 제어방법 | |
| JP2009159020A (ja) | 信号処理装置、信号処理方法、プログラム | |
| WO2007129517A1 (ja) | オーディオ信号処理装置及びサラウンド信号生成方法等 | |
| US20120288122A1 (en) | Method and a system for an acoustic curtain that reveals and closes a sound scene | |
| JP4804597B1 (ja) | 音声信号処理装置及び音声信号処理プログラム | |
| WO2008050412A1 (fr) | Appareil de traitement de localisation d'images sonores et autres | |
| JP2011205687A (ja) | 音声調整装置 | |
| KR20060004529A (ko) | 입체 음향을 생성하는 장치 및 방법 | |
| JP2012213127A (ja) | 信号再生装置及び信号再生プログラム | |
| JP2006319801A (ja) | バーチャルサラウンドデコーダ装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 12872322 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 12872322 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: JP |