WO2009131239A1 - 安定な多価抗体 - Google Patents
安定な多価抗体 Download PDFInfo
- Publication number
- WO2009131239A1 WO2009131239A1 PCT/JP2009/058249 JP2009058249W WO2009131239A1 WO 2009131239 A1 WO2009131239 A1 WO 2009131239A1 JP 2009058249 W JP2009058249 W JP 2009058249W WO 2009131239 A1 WO2009131239 A1 WO 2009131239A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- antibody
- seq
- heavy chain
- sequence
- amino acid
- Prior art date
Links
Images

Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
- C07K16/468—Immunoglobulins having two or more different antigen binding sites, e.g. multifunctional antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39591—Stabilisation, fragmentation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2818—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against CD28 or CD152
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2878—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the NGF-receptor/TNF-receptor superfamily, e.g. CD27, CD30, CD40, CD95
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/51—Complete heavy chain or Fd fragment, i.e. VH + CH1
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/624—Disulfide-stabilized antibody (dsFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/626—Diabody or triabody
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/64—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising a combination of variable region and constant region components
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
Definitions
- the present invention relates to a multivalent antibody in which a plurality of antibody heavy chain variable regions (hereinafter referred to as VH) are bound via an immunoglobulin domain or a fragment thereof, a DNA encoding the amino acid sequence of the multivalent antibody, the DNA And a method for producing a multivalent antibody using the transformant.
- VH antibody heavy chain variable regions
- Immunoglobulin is a glycoprotein present in the serum and tissue fluid of all mammals and has a function of recognizing a foreign antigen (Non-patent Document 1). Antibodies activate the complement system and effector functions such as cell phagocytosis, antibody-dependent cellular cytotoxicity, mediator release, and antigen presentation through the receptor (FcR) present on the cell surface. Is involved in biological defense. There are five different classes of human immunoglobulins, IgG, IgA, IgM, IgD, and IgE. IgG can be further classified into IgG1, IgG2, IgG3, and IgG4 subclasses, and IgA can be classified into IgA1 and IgA2 subclasses.
- the basic structure of an immunoglobulin is composed of two homologous light chains (L chain) and two homologous heavy chains (H chain).
- the class and subclass of immunoglobulins are determined by the heavy chain.
- Each class and subclass of immunoglobulin is known to have different functions.
- complement binding ability is strong in the order of IgM> IgG3> IgG1> IgG2.
- the affinity for the Fc receptor increases in the order of IgG3> IgG1> IgG4> IgG2.
- IgG1, IgG2, and IgG4 can bind to protein A.
- the antigen to which an antibody binds is determined by a combination of a heavy chain and a light chain. In the case of IgG, one molecule is composed of two pairs of heavy chain and light chain, and possesses two antigen binding sites per antibody molecule.
- Non-patent Document 2 the mouse anti-CD3 antibody, muromonab-CD3, was approved by the FDA.
- a chimeric antibody abciximab in which the constant region of the antibody was converted from a mouse type to a human type was approved.
- humanization technology was developed to reduce antigenicity.
- the anti-CD20 humanized antibody dacizumab, which humanized the variable region was approved.
- a fully human anti-TNF antibody, adalimumab was approved.
- a multivalent antibody having a plurality of different polypeptide chains recognizing different antigens as a heavy chain or a light chain is produced by a hybrid hybridoma.
- this method since two different types of heavy and light chains are expressed in one cell, about 10 combinations of antibody heavy and light chains are possible.
- the productivity of the polyvalent antibody having the correct combination of heavy chain and light chain is reduced as a result, and it is difficult to isolate and purify the target multivalent antibody (Non-patent Document 3).
- Non-patent Document 4 an antibody containing scFv in which heavy and light chain antigen recognition sites are linked by one polypeptide.
- the two antigen recognition sites were linked using the H chain constant region CH1 domain of the antibody IgG1 antibody or a partial fragment of the domain, the L chain constant region, or a flexible linker (Gly-Gly-Gly-Gly-Ser).
- Antibodies Non-patent Document 5, Patent Document 1, Patent Document 2 and the like have been reported.
- a multivalent antibody having a plurality of antigen recognition sites and having excellent stability and productivity has been conventionally demanded.
- the present inventors have found that a multivalent antibody having a plurality of antigen recognition sites in one heavy chain polypeptide, It was found that the stability is high and the productivity is good.
- the present inventors have found that such multivalent antibodies are excellent in stability and productivity, and thus are useful as various pharmaceuticals and research reagents, and have completed the present invention based on these findings. .
- the present invention includes the following features.
- a multivalent antibody characterized in that a plurality of antibody heavy chain variable regions (hereinafter referred to as VH) are linked through a linker having an amino acid sequence of an immunoglobulin domain or a fragment thereof.
- CH1 fragment is the first to 14th amino acid sequence from the N-terminus of the amino acid sequence of CH1 selected from IgD, ⁇ ⁇ ⁇ IgM, IgG, IgA and IgE antibody subclasses.
- the transformant according to (11) is cultured in a medium, and the multivalent antibody according to any one of (1) to (8) is produced and accumulated in the culture, and the antibody or the The method for producing a multivalent antibody according to any one of (1) to (8), wherein an antibody fragment is collected.
- the multivalent antibody according to the present invention is excellent in stability and productivity.
- the multivalent antibody according to the present invention can also be used as a therapeutic or diagnostic agent for various diseases.
- the multivalent antibody according to the present invention can also be used as a stable research reagent.
- Antibody refers to a gene encoding all or part of the variable region of the heavy chain and the constant region of the heavy chain, and the variable region of the light chain and the constant region of the light chain (“antibody gene”). Are collectively called).
- the antibodies of the present invention include antibodies having any immunoglobulin class and subclass.
- Human antibody means an antibody having the sequence of a human-derived antibody gene, such as a human B cell hybridoma, a humanized SCID mouse, a human antibody gene-expressing mouse, a human antibody gene library, Phage Display, Yeast Display, etc. It can be obtained by the technique.
- a humanized antibody refers to an antibody obtained by substituting a part of an antibody sequence obtained from a non-human animal with a human antibody sequence (Emmanuelle Laffy et. Al., Human Antibodies 14, 33-55, 2005).
- Heavy chain refers to a polypeptide having a larger molecular weight among the two types of polypeptides (H chain and L chain) constituting the immunoglobulin molecule. Determine antibody class and subclass. IgG1, IgG2, IgG4, IgA1, IgA2, IgM, IgD, and IgE each have a different amino acid sequence as a heavy chain constant region.
- Light chain refers to a polypeptide having a smaller molecular weight among two types of polypeptides (H chain and L chain) constituting an immunoglobulin molecule. There are two types of human antibodies: kappa and lambda.
- V region refers to a region rich in diversity of amino acid sequences usually located on the N-terminal side of immunoglobulins. The other parts have a less diversified structure and are called “constant regions” (also called C regions).
- the variable regions of the heavy and light chains form a complex that determines the properties of the antibody to antigen.
- the first to 117th variable regions in the EU index Kabat et. Al., EquSequences of proteins of immunological interest, 1991 Fifth edition) of Kabat et al. Begins.
- the first to 107th positions in the EU index of Kabat et al. are the variable regions, and the constant region begins at the 108th amino acid.
- the heavy chain variable region or the light chain variable region is abbreviated as VH or VL.
- the “antigen recognition site” is a site that recognizes an antigen, and indicates a site that forms a three-dimensional structure complementary to an antigenic determinant (epitope). Antigen recognition sites can cause strong intermolecular interactions with antigenic determinants. Examples of the antigen recognition site include a heavy chain variable region (VH) or a light chain variable region (VL) including at least three complementarity determining regions (complementary determining region: CDR). For human antibodies, the heavy and light chain variable regions each have three complementarity determining regions (CDRs) and contain an antigen recognition site. These CDRs are called CDR1, CDR2, and CDR3 in order from the N-terminal side.
- Multivalent antibody refers to an antibody having at least two antigen recognition sites in the heavy chain and / or light chain. Each antigen recognition site may recognize the same antigenic determinant or different antigenic determinants.
- the multivalent antibody of the present invention is a multivalent antibody in which a plurality of antibody heavy chain variable regions are bound via an immunoglobulin domain or a fragment thereof.
- one heavy chain polypeptide includes a plurality of (for example, 2 to 5) different antigen recognition sites, and the antigen recognition sites are not spaced apart from each other.
- the antigen recognition site is linked in tandem (tandem) via a polypeptide linker of 10 amino acids or more, preferably 50 amino acids or more, more preferably 50 to 500 amino acids, specifically, antigen recognition
- the sites are linked using, for example, a linker having the amino acid sequence of all or part of an immunoglobulin domain, and
- the light chain antigen recognition site forms a complex with the corresponding heavy chain antigen recognition site.
- the constant region of the heavy chain is, for example, all of the constant regions of the natural antibody heavy chain or It consists of a part (for example, CH1 fragment, CH1, CH2, CH3, CH1-hinge, CH1-hinge-CH2, CH1-hinge-CH2-CH3, etc.).
- FIG. 1 shows a linker structure together with a structural example of a multivalent antibody.
- immunoglobulin domain refers to a peptide consisting of about 100 amino acid residues having an amino acid sequence similar to that of an immunoglobulin and having at least two cysteine residues.
- immunoglobulin domain include immunoglobulin heavy chain VH, CH1, CH2 and CH3, and immunoglobulin light chain VL and CL.
- Immunoglobulin domains are also present in non-immunoglobulin proteins and are included in proteins belonging to the immunoglobulin superfamily such as major histocompatibility antigens (MHC), CD1, B7, and T cell receptors (TCR).
- MHC major histocompatibility antigens
- CD1, B7 CD1, B7
- TCR T cell receptors
- An immunoglobulin domain As the immunoglobulin domain used in the multivalent antibody of the present invention, any immunoglobulin domain can be used.
- An antibody that recognizes a single antigen is called a monoclonal antibody.
- a monoclonal antibody is an antibody that is secreted by an antibody-producing cell of a single clone, recognizes only one epitope (also referred to as an antigenic determinant), and has a uniform amino acid sequence (primary structure) constituting the monoclonal antibody. .
- Epitopes include a single amino acid sequence that is recognized and bound by a monoclonal antibody, a three-dimensional structure composed of amino acid sequences, an amino acid sequence linked with sugar chains, and a three-dimensional structure composed of amino acid sequences combined with sugar chains.
- CH1 represents a region having the amino acid sequence from 118th to 215th EU index.
- the hinge region is a region having the amino acid sequence from EU index 216 to 230
- CH2 is the EU index 231 to 340
- CH3 is the region having EU index 341 to 446.
- CL indicates the constant region of the light chain.
- Linker refers to a chemical structure that connects two antigen recognition sites. Preferably it means a polypeptide.
- the linker used in the multivalent antibody of the present invention is preferably a linker having an amino acid sequence of all or part of an immunoglobulin domain, or a linker having an amino acid sequence of all or part of a linker consisting of a plurality of immunoglobulin domains. .
- the amino acid sequence selected from the immunoglobulin domain may be intermittent or continuous, but is preferably a continuous amino acid sequence.
- the linker to be desired is a polypeptide having a length of 10 amino acids or more, preferably 14 amino acids or more, more desirably 50 amino acids or more, for example, a polypeptide having a length of 50 amino acids or more and 500 amino acids or less. .
- linker all or part of fragments of the amino acid sequence consisting of CH1, hinge, CH2 and CH3 of an antibody can be used in appropriate combination. Moreover, those amino acid sequences can be partially deleted, or the order can be changed.
- the immunoglobulin domain and fragments thereof used in the multivalent antibody of the present invention include, but are not limited to, an immunoglobulin domain consisting of CH1-hinge-CH2-CH3 (in the direction from N-terminal to C-terminal), CH1- Immunoglobulin domain consisting of hinge-CH2, immunoglobulin domain consisting of CH1-hinge, immunoglobulin domain consisting of CH1, CH1 N-terminal fragment, CH1 consisting of 14 amino acid residues in which the 14th amino acid of CH1 is Cys Examples include fragments, CH1 fragments consisting of 14 amino acid residues from the N-terminal side of CH1, and those obtained by modifying one or more amino acid residues in the amino acid sequences of these immunoglobulin domain fragments.
- the immunoglobulin domain and fragments thereof may be derived from any of the immunoglobulin subclasses IgD, IgM, IgG1, IgG2, IgG3, IgG4, IgA1, IgA1 and IgE, and preferably IgG and IgM.
- the immunoglobulin domain and the fragment thereof are more specifically represented by the immunoglobulin domain consisting of CH1, hinge, CH2 and CH3 represented by SEQ ID NO: 99, and amino acid sequences 1 to 219 of SEQ ID NO: 99.
- An immunoglobulin domain composed of CH1, hinge and CH2 an immunoglobulin domain composed of CH1 and hinge represented by amino acid sequences 1 to 94 of SEQ ID NO: 99, and an immunoglobulin domain composed of CH1 represented by SEQ ID NO: 77 it can.
- the CH1 fragment As the CH1 fragment, the CH1 fragment shown in SEQ ID NOs: 362 to 375, the CH1 fragment consisting of 14 amino acid residues in which the 14th amino acid of CH1 is Cys, or the 14 amino acid residues on the N-terminal side of CH1 CH1 fragments consisting of: SEQ ID NO: 311 and SEQ ID NOs: 334 to 361 can be mentioned more specifically.
- Examples of the multivalent antibody of the present invention include multivalent antibodies having two or more heavy chain variable regions bound using the above-described immunoglobulin domains or fragments thereof. When combining three or more heavy chain variable regions, different immunoglobulin domains or fragments thereof may be used, or the same immunoglobulin domain or fragment thereof may be used. When two or more heavy chain variable regions are linked, the length and type of the immunoglobulin domain or a fragment thereof can be changed so that each VH can bind to a specific antigen.
- the light chain variable regions contained in the multivalent antibody may be the same light chain variable region or different light chain variable regions.
- the heavy chain variable region of a multivalent antibody capable of binding to two or more antigens having the same light chain variable region is a phage display or the like so that each antibody variable region can bind to a specific antigen.
- the method can be used to select an appropriate heavy chain variable region.
- the antigen to which a multivalent antibody binds is not limited to the following, but for example, antigens associated with abnormal cell proliferation such as cancer, autoimmune diseases, allergic diseases, organ regeneration and tissue regeneration
- the multivalent antibodies of the present invention are capable of binding to two or more different antigens or epitopes. That is, the multivalent antibody of the present invention can bind to two different antigens, or can bind to two different epitopes present on one antigen.
- an antigen suitable for the target disease can be selected. Examples of antigens that can be targets of the multivalent antibody of the present invention are shown below, but are not limited thereto.
- Antigens that induce apoptosis by antibody binding include Cluster of differentiation (hereinafter referred to as CD) 19, CD20, CD21, CD22, CD23, CD24, CD37, CD53, CD72, CD73, CD74, CDw75, CDw76, CD77, CDw78, CD79a, CD79b, CD80 (B7.1), CD81, CD82, CD83, CDw84, CD85, CD86 (B7.2), human leukocyte antigen (HLA) -Class II, or Epidermal Growth Factor Receptor (EGFR) Etc.
- CD Cluster of differentiation
- CD20 CD21, CD22, CD23, CD24, CD37, CD53, CD72, CD73, CD74, CDw75, CDw76, CD77, CDw78, CD79a, CD79b, CD80
- CD81, CD82, CD83, CDw84, CD85, CD86 B7.2
- HLA human leukocyte antigen
- EGFR Epidermal Growth Factor Receptor
- Antigens involved in tumor pathogenesis or antibodies that regulate immune function include CD40, CD40 ligand, B7 family molecules (CD80, CD86, CD274, B7-DC, B7-H2, B7-H3, or B7-H4 ), B7 family molecule ligand (CD28, CTLA-4, ICOS, PD-1, or BTLA), OX-40, OX-40 ligand, CD137, tumor necrosis factor (TNF) receptor family molecule (DR4, DR5, TNFR1, or TNFR2), TNF-related apoptosis-inducing ligand receptor (TRAIL) family molecule, TRAIL family molecule receptor family (TRAIL-R1, TRAIL-R2, TRAIL-R3, or TRAIL-R4), receptor activator factor kappa B ligand (RANK), RANK ligand, CD25, folate receptor 4, cytokine [IL-1 ⁇ , IL-1 ⁇ , IL-4, IL-5, IL-6, IL-10,
- VEGF vascular endothelial growth factor
- FGF fibroblast growth factor
- EGF platelet-derived growth factor
- IGF insulin-like growth factor
- HGF hepatocyte growth factor
- EPO erythropoietin
- TGF ⁇ IL-8, Ephilin, SDF-1, or a receptor thereof.
- Antigens involved in angiogenesis of abnormal tissues or antigens involved in organ regeneration and tissue regeneration include VEGF, Angiopoietin, FGF, EGF, PDGF, IGF, HGF, EPO, TGF ⁇ , IL-8, Ephilin, SDF-1 Or a receptor thereof.
- the effector activity of the multivalent antibody can be controlled as follows.
- the multivalent antibody of the present invention can control effector activity by any method.
- Effector activity refers to antibody-dependent activity induced through the Fc region of an antibody.
- Antibody-dependent cytotoxic activity (ADCC activity), complement-dependent cytotoxic activity (CDC activity), macrophages and dendritic cells
- Antibody-dependent phagocytosis (ADP activity) by phagocytic cells such as is known.
- the antibody is expressed using a host cell into which the ⁇ 1,6-fucose transferase gene has been introduced. By doing so, a multivalent antibody to which fucose is bound can be obtained. Multivalent antibodies to which fucose is bound have a lower ADCC activity than antibodies to which fucose is not bound.
- ADCC activity and CDC activity can be increased or decreased by modifying amino acid residues in the Fc region of the multivalent antibody.
- the CDC activity of a multivalent antibody can be increased by using the amino acid sequence of the Fc region described in US2007 / 0148165.
- ADCC activity or CDC activity can be increased or decreased by performing amino acid modification described in US6,737,056, US7,297,775, or US7,317,091.
- a multivalent antibody in which the effector activity of the multivalent antibody is controlled can be obtained by combining the above-described methods and using it for one multivalent antibody.
- the stability of the multivalent antibody of the present invention can be evaluated by measuring the amount of aggregate (oligomer) formed in a sample stored under a purification process or under certain conditions. That is, when the aggregate amount is reduced under the same conditions, it is assumed that the stability of the antibody is improved.
- the amount of the aggregate can be measured by separating the aggregated antibody and the non-aggregated antibody using an appropriate chromatography including gel filtration chromatography. A method for measuring the amount of aggregates is illustrated in Example 18.
- the productivity of the multivalent antibody of the present invention can be evaluated by measuring the amount of antibody produced in the culture solution from antibody-producing cells. More specifically, it can be evaluated by measuring the amount of antibody contained in the culture supernatant obtained by removing the production cells from the culture solution by an appropriate method such as HPLC method or ELISA method. A method for measuring productivity is illustrated in Example 17.
- variable region can be derived from, for example, human or mouse
- constant region can be derived from human
- linker can be derived from human
- animal usually refers to mammals including humans, monkeys, chimpanzees, mice, rats, cows, pigs, goats, sheep, camels, birds and the like.
- the antibody of the present invention includes derivatives of the antibody.
- Derivatives include, for example, 1 to about 30, preferably 1 or several (eg, 1 to 10, preferably 1 to 5, more preferably 1 to 3) amino acid substitutions, deletions, additions, and And / or insertion.
- amino acid substitution is a conservative amino acid substitution, which means a substitution between amino acids that are similar in charge, polarity (or hydrophobicity) or side chain structure, such as a basic amino acid (Lys, Arg, His), acidic amino acids (Asp, Glu), uncharged polar amino acids (Gly, Asn, Gln, Ser, Thr, Tyr, Cys), nonpolar amino acids (Ala, Val, Leu, Ile, Pro), aromatic amino acids ( Phe, Trp, Tyr, His).
- the antibody of the present invention may be chemically modified. Such modifications include pegylation, acetylation, amidation, phosphorylation, glycosylation, etc., and generally modifications can be made through functional groups such as amino groups, carboxyl groups, hydroxyl groups, etc. .
- the antibody of the present invention may be conjugated with a pharmaceutical or diagnostic substance.
- the pharmaceutical or diagnostic substance is not particularly limited, and includes, for example, peptides, polypeptides, nucleic acids, small molecules, inorganic elements, inorganic molecules, organic molecules and the like.
- a pharmaceutical substance is a substance that can exert a therapeutic effect at a target site in a living body, and examples thereof include an anticancer agent and an antiviral agent.
- the diagnostic substance includes, for example, a radioisotope.
- a covalent bond, non-covalent bond, biotin / avidin (or streptavidin) system and the like can be used.
- the antibody of the present invention may be immobilized on a solid phase (eg, resin, plastic, paper, metal, etc.), such as a plate, bead, test strip, array, or the like.
- a method for producing a monoclonal antibody will be described in detail according to the above steps, but the method for producing the antibody is not limited thereto, and for example, antibody-producing cells other than spleen cells and myeloma can also be used. It is also possible to use an antibody derived from animal serum.
- the antigen protein may be used as it is, or may be used as a fusion protein in which the antigen protein is fused with another appropriate polypeptide.
- a fusion protein of the extracellular region of the antigen protein and the Fc region of human IgG or glutathione S-transferase (GST) can be used.
- a DNA encoding a fusion protein of an extracellular region of an antigen and a human IgG constant region or GST is incorporated into an expression vector for animal cells, the expression vector is introduced into animal cells, and the culture supernatant of the obtained transformant It can obtain by refine
- what purified the antigen itself which exists on the cell membrane of a human cell strain can also be used as an antigen.
- (1-2) Preparation step of antibody-producing cells
- the antigen obtained in (1-1) is mixed with Freund's complete or incomplete adjuvant, or an auxiliary agent such as potash alum, and used as an immunogen for experimental animals.
- Immunize For example, a mouse can be used as the experimental animal.
- Transgenic mice having the ability to produce antibodies derived from humans are most preferably used, but such mice are described by Tomizuka et al. (Tomizuka. Et al., Proc Natl Acad Sci USA., 2000 Vol 97: 722). It is described in.
- the immunogen administration method for mouse immunization may be subcutaneous injection, intraperitoneal injection, intravenous injection, intradermal injection, intramuscular injection, footpad injection, etc., but intraperitoneal injection, footpad injection or intravenous injection Is preferred.
- Immunization can be performed once or repeatedly at an appropriate interval (preferably at intervals of 3 days to 1 week). Thereafter, the antibody titer against the antigen in the serum of the immunized animal is measured, and if the animal having a sufficiently high antibody titer is used as a source of antibody-producing cells, the effect of subsequent operations can be enhanced. In general, it is preferable to use animal-derived antibody-producing cells 3 to 5 days after the final immunization for subsequent cell fusion.
- the antibody titers used here include radioisotope immunoassay (hereinafter referred to as “RIA method”), solid-phase enzyme immunoassay (hereinafter referred to as “ELISA method”), fluorescent antibody method, passive hemagglutination reaction.
- RIA method radioisotope immunoassay
- ELISA method solid-phase enzyme immunoassay
- fluorescent antibody method passive hemagglutination reaction.
- Various known techniques such as a method can be used.
- the measurement of the antibody titer in the present invention can be performed according to the procedure described below, for example, according to the ELISA method.
- a solid phase surface such as a 96-well plate for ELISA
- the solid surface on which no antigen is adsorbed is a protein unrelated to the antigen, such as bovine serum albumin (hereinafter referred to as “BSA”).
- BSA bovine serum albumin
- the surface is washed, the surface is contacted with a serially diluted sample (eg, mouse serum) as a primary antibody, and the antibody in the sample is bound to the antigen.
- an antibody against a human antibody labeled with an enzyme as a secondary antibody is added and bound to the human antibody.
- the substrate of the enzyme is added, and the change in absorbance due to color development based on the decomposition of the substrate is measured. calculate.
- (1-3) Process for preparing myeloma cells having no autoantibody-producing ability derived from mammals such as mice, rats, guinea pigs, hamsters, rabbits or humans can be used.
- Cell lines generally obtained from mice, such as 8-azaguanine resistant mice (derived from BALB / c) myeloma strain P3X63Ag8U.1 (P3-U1) (Yelton, DE et al. Current Topics in Microbiology and Immunology, 81 , 1-7 (1978)), P3 / NSI / 1-Ag4-1 (NS-1) (Kohler, G. et al. European J.
- These cell lines are prepared by using an appropriate medium such as 8-azaguanine medium [RPMI-1640 medium supplemented with glutamine, 2-mercaptoethanol, gentamicin and fetal calf serum (hereinafter referred to as “FCS”) with 8-azaguanine. ] Subculture in Iscove's Modified Dulbecco's Medium (hereinafter referred to as “IMDM”) or Dulbecco's Modified Eagle Medium (hereinafter referred to as “DMEM”), but 3 to 4 days before cell fusion And subculture in a normal medium (for example, DMEM medium containing 10% FCS), and secure a cell number of 2 ⁇ 10 7 or more on the day of fusion.
- IMDM Iscove's Modified Dulbecco's Medium
- DMEM Dulbecco's Modified Eagle Medium
- Cell fusion Antibody-producing cells are plasma cells and their precursor cells, lymphocytes, which may be obtained from any part of the individual, and are generally spleen, lymph nodes, bone marrow, tonsils, although it can be obtained from peripheral blood or a combination of these appropriately, spleen cells are most commonly used.
- a site where antibody-producing cells are present such as the spleen
- an experimental animal for example, mouse
- spleen cells that are antibody-producing cells are prepared.
- the most commonly used method for fusing the spleen cells with the myeloma obtained in step (3) is a method using polyethylene glycol, which has a relatively low cytotoxicity and a simple fusion procedure. This method includes, for example, the following procedure.
- Spleen cells and myeloma are thoroughly washed with serum-free medium (eg, DMEM) or phosphate buffered saline (hereinafter referred to as “phosphate buffer”), and the ratio of the number of spleen cells to myeloma is 5: 1 to Mix to about 10: 1 and centrifuge. After removing the supernatant and loosening the precipitated cells, a serum-free medium containing 1 ml of 50% (w / v) polyethylene glycol (molecular weight 1000-4000) is added dropwise with stirring. Thereafter, 10 ml of serum-free medium is slowly added and then centrifuged.
- serum-free medium eg, DMEM
- phosphate buffer phosphate buffere buffer
- HAT normal medium
- HAT hypoxanthine / aminopterin / thymidine
- IL-2 human interleukin-2
- the medium is replaced with a medium obtained by removing aminopterin from the HAT medium (hereinafter referred to as “HT medium”). Thereafter, a part of the culture supernatant is collected, and the antibody titer is measured, for example, by ELISA.
- HT medium a medium obtained by removing aminopterin from the HAT medium
- a multivalent antibody is obtained by cloning a plurality of monoclonal antibody genes for different epitopes expressed from, for example, the hybridoma obtained as described above, and defining an antigen recognition site thereof. It can be prepared by designing and designing a gene of a multivalent antibody containing the obtained antigen recognition site. More specifically, a multivalent antibody DNA obtained by appropriately combining the obtained antigen recognition site and a linker is synthesized and incorporated into an expression plasmid.
- the linker is used to link an antigen recognition site and another antigen recognition site, and is usually composed of a polypeptide of 10 amino acids or more, preferably 50 amino acids or more, more preferably 50 amino acids to 500 amino acids.
- a more preferred linker is a linker consisting of CH1 of the human antibody heavy chain constant region or a linker containing CH1, for example, a linker consisting of CH1-hinge-CH2-CH3, as shown in FIG. .
- the former linker has the amino acid sequence shown in SEQ ID NO: 77
- the latter linker has the amino acid sequence shown in SEQ ID NO: 99.
- expression plasmids examples include pTracer-CMV / Bsd, pTracer-EF / Bsd, pTracer-SV40 (Invitrogen) and the like.
- the expression plasmid can be introduced into applicable production cells (for example, animal cells such as CHO cells), and the resulting transformed cells can be cultured as polyvalent antibody-producing cells, and the polyvalent antibody can be purified from the culture solution.
- applicable production cells for example, animal cells such as CHO cells
- the resulting transformed cells can be cultured as polyvalent antibody-producing cells, and the polyvalent antibody can be purified from the culture solution.
- the method for producing a multivalent antibody is described in detail below, but the method for producing a multivalent antibody is not limited to the following description. For example, a method for expressing an expression plasmid in an animal and expressing it in animal serum or milk, a method for producing a polyvalent antibody by chemically synthesizing a polypeptide, and the like are considered as other methods for producing a multivalent antibody. .
- Hybridoma Cloning Hybridomas that have been found to produce specific antibodies by measuring antibody titers in the same manner as described in (1-2) are transferred to another plate for cloning.
- This cloning method includes a limiting dilution method of diluting and culturing so that one hybridoma is contained in one well of the plate, a soft agar method of collecting colonies by culturing in a soft agar medium, and one by one using a micromanipulator. And the like, and a “sorter clone” in which one cell is separated by a cell sorter.
- the limiting dilution method is simple and often used.
- cloning by limiting dilution is repeated 2 to 4 times, and those with stable antibody titers are selected as monoclonal antibody-producing hybridoma strains.
- the prepared DNA sequence encoding a multivalent antibody heavy chain and a DNA sequence encoding a single light chain are inserted into an appropriate protein expression vector to prepare a multivalent antibody expression vector.
- a DNA sequence encoding a plurality of antibody heavy chain variable regions is used as the immunoglobulin domain or fragment thereof used in the multivalent antibody of the present invention.
- Ligating with a linker sequence creates a DNA sequence encoding a multivalent antibody heavy chain.
- the DNAs encoding the heavy and light chains of the multivalent antibody may be inserted into a single expression vector to form a tandem multivalent antibody expression vector, or may be inserted into separate expression vectors and separated into multiple types.
- a titer antibody expression vector may be used.
- the produced multivalent antibody expression vector is introduced into a host (for example, mammalian cell, E. coli, yeast cell, insect cell, plant cell, etc.), and a recombinant antibody produced using gene recombination technology is prepared.
- a host for example, mammalian cell, E. coli, yeast cell, insect cell, plant cell, etc.
- a recombinant antibody produced using gene recombination technology is prepared.
- a phage or plasmid, virus, artificial chromosome or the like that can autonomously grow in the host is used.
- plasmid DNA include plasmids derived from Escherichia coli, Bacillus subtilis, or yeast.
- phage DNA include ⁇ phage, T7 phage, and M13 phage.
- viral vectors include adenovirus, adeno-associated virus, retrovirus, lentivirus and the like.
- artificial chromosomes include mammalian artificial chromosomes (MAC) including human artificial chromosomes (HAC), yeast artificial chromosomes (YAC), and bacterial artificial chromosomes (BAC, PAC).
- the host used for transformation is not particularly limited as long as it can express the target gene. Examples include bacteria (E. coli, Bacillus subtilis, etc.), yeast, animal cells (COS cells, CHO cells, etc.), insect cells, and the like.
- bacteria E. coli, Bacillus subtilis, etc.
- yeast yeast
- animal cells COS cells, CHO cells, etc.
- insect cells and the like.
- Methods for introducing a gene into a host are known, and any method (for example, a method using calcium ions, an electroporation method, a spheroplast method, a lithium acetate method, a calcium phosphate method, a lipofection method, etc.) can be mentioned.
- Methods for introducing genes into animals include microcell methods, microinjection methods, electroporation methods, lipofection methods for differentiated pluripotent cells such as embryonic stem (ES) cells and induced pluripotent stem (iPS) cells. Examples thereof include a method for introducing a gene using a method such as a method, and a nuclear transfer method. In this case, it is possible to produce a transgenic animal by introducing a pluripotent cell into a blastocyst and transplanting it into the uterus of a foster parent.
- ES embryonic stem
- iPS induced pluripotent stem
- the transformant containing the gene encoding the multivalent antibody of the present invention includes not only cells but also animals.
- a gene encoding a multivalent antibody in which a plurality of antigen recognition sites and linkers are appropriately combined can be synthesized, and the gene can be incorporated into an appropriate expression plasmid.
- an appropriate antigen-recognition site can be determined, isolated, and acquired by techniques such as Yeast display. (Emmanuelle Laffy et. Al., Human Antibodies 14, 33-55, 2005).
- a multivalent antibody can be obtained by culturing a transformant and collecting it from the culture.
- “Culture” means any of (a) culture supernatant, (b) cultured cells or cultured cells or disrupted products thereof, and (c) secretions of transformants.
- a stationary culture method, a culture method using a roller bottle, or the like is employed using a medium suitable for the host to be used.
- the antibody After culturing, when the target protein is produced in cells or cells, the antibody is collected by disrupting the cells or cells. When the target antibody is produced outside the cells or cells, the culture solution is used as it is, or the cells or cells are removed by centrifugation or the like. Thereafter, the target antibody can be isolated and purified from the culture by using general biochemical methods using various chromatographies used for protein isolation and purification alone or in appropriate combination. .
- the recognition epitope of a monoclonal antibody can be identified as follows. First, various partial structures of molecules recognized by monoclonal antibodies are prepared. In preparing the partial structure, a method for preparing various partial peptides of the molecule using a known oligopeptide synthesis technique, or a DNA sequence encoding the target partial peptide using a gene recombination technique as a suitable expression plasmid. There are methods for integration and production inside and outside the host such as Escherichia coli, but for the above purpose, it is common to use both in combination.
- the corresponding oligopeptides of the corresponding portion or variants of the peptides are synthesized in various ways using oligopeptide synthesis techniques well known to those skilled in the art, and the preventive or therapeutic agent of the present invention is contained as an active ingredient.
- the epitopes are limited by examining the binding properties of the monoclonal antibodies to those peptides, or by examining the competitive inhibitory activity of the peptides on the binding of the monoclonal antibody to the antigen.
- commercially available kits for example, SPOTs kit (Genosis Biotechnology), a series of multi-pin peptide synthesis kits using multi-pin synthesis method, etc.can also be used.
- the antibody binding experiment to the antigen includes not only the measurement by ELISA using the soluble antigen described in Example 19, but also analysis by flow cytometry using antigen-expressing cells, It is measured by a detection method using surface plasmon resonance using an antigen.
- Example 1 Acquisition of first antigen recognition site
- the anti-CD40 antibody described in WO02 / 088186 was used.
- the light chain and heavy chain of an antibody (hereinafter abbreviated as 341-1-19) produced by hybridoma KM341-1-19 (deposit number BP-7759) were used.
- Hybridoma KM341-1-19 is deposited at the National Institute of Advanced Industrial Science and Technology, Patent Biological Deposit Center (Chuo 1-1-1, Higashi 1-1-1, Tsukuba, Ibaraki, Japan, postal code 305-8566).
- the 341-1-19 antibody heavy chain full-length DNA sequence (SEQ ID NO: 1), amino acid sequence (SEQ ID NO: 2), DNA sequence encoding the light chain variable region (SEQ ID NO: 3) and amino acid sequence (SEQ ID NO: 4), respectively Shown in the sequence listing.
- the translation start point of the heavy chain DNA is an ATG codon starting from the 50th adenine (A) from the 5 ′ end of SEQ ID NO: 1, and the stop codon is TGA starting from the 1472th thymine (T).
- the boundary between the antibody variable region and the constant region is located between the 493rd adenine (A) and the 494th guanine (G) from the 5 ′ end.
- the heavy chain variable region is from the N-terminus of SEQ ID NO: 2 to the 148th serine (S) residue, and the 149th alanine (A) and subsequent are the constant regions.
- the signal sequence of the H chain was predicted from the N-terminus of SEQ ID NO: 2 to the 20th serine (S) by the gene sequence prediction software (Signal P ver.2).
- the N-terminus of the mature body is considered to be the 21st glutamine (Q) of SEQ ID NO: 2.
- the translation start point of the light chain DNA is the ATG codon starting from the 29th A from the 5 ′ end of SEQ ID NO: 3, and the variable region is from the 5 ′ end to the 400th adenine (A).
- the variable region is from the N-terminus of SEQ ID NO: 4 to the 124th lysine (K).
- the signal sequence of the L chain is from the N terminus of SEQ ID NO: 4 to the 20th glycine (G), and the mature N terminus is the 21st glutamic acid of SEQ ID NO: 4. It became clear that (E).
- Example 2 Immunization for obtaining the second antigen recognition site To obtain the second antigen recognition site, an anti-human CD28 antibody was obtained.
- Immunization for obtaining the anti-CD28 antibody was performed in accordance with the above-mentioned method WO02 / 088186 which obtained the anti-CD40 antibody.
- Recombinant Human CD28 / Fc Chimera R & D SYSTEM
- MPL + TDM EMULSION RiBi, Sigma
- Immunization was performed 3 times every 14 days. Furthermore, the same antigen was immunized 3 days before obtaining the spleen.
- Example 3 Preparation of scFV library of anti-CD28 antibody having light chain common to anti-CD40 antibody light chain
- the spleen of the mouse immunized with CD28 prepared in Example 2 was used to bind the heavy chain variable region gene fragment and the light chain variable region gene fragment of the anti-CD28 antibody.
- a library of chain antibody fragment (scFV) genes was prepared.
- This gene fragment was digested with SfiI and NotI, and inserted into a pCANTAB-5E vector vector (manufactured by GE Healthcare Bioscience) previously cleaved with SfiI and NotI.
- the obtained plasmid was designated as pCANTAB5E / 341-1-19.
- this plasmid was cleaved with SfiI and AscI (coding the VH of 341-1-19) in order to obtain an antibody with human CD28 as an antigen having the same amino acid sequence as the light chain of 341-1-19.
- the vector gene dephosphorylated with Alkaline Phosphatase (BAP, manufactured by Takara Bio Inc.) was used as a vector for library preparation.
- a heavy chain variable region gene fragment for preparing a phage antibody library was obtained using cDNA derived from the spleen of an immunized mouse as a template.
- a first step using a cDNA as a template, using a primer specific to the signal region of human heavy chain (SEQ ID NO: 11-35) and a primer specific to IgG constant region (SEQ ID NO: 36), DNA polymerase ( The reaction at 95 ° C. for 30 seconds, 58 ° C. for 30 seconds, and 68 ° C. for 30 seconds was performed for 30 cycles using KOD-Plus, manufactured by Toyobo Co., Ltd.
- a primer specific to the variable region of human heavy chain SEQ ID NO: 37-56
- a primer specific to the junction region SEQ ID NO: 57-61
- DNA polymerase KOD-Plus, manufactured by Toyobo Co., Ltd.
- 35 cycles of reactions at 95 ° C. for 30 seconds, 58 ° C. for 30 seconds, and 68 ° C. for 30 seconds were performed.
- the primer specific to the variable region was selected by the primer specific to the variable region used in the first-stage PCR reaction, and 5 types of primers specific to the junction region were used.
- a SfiI cleavage recognition site is located at the 5 ′ end of SEQ ID NOs: 37-56 and SEQ ID NOs: 57-61.
- An AscI cleavage recognition site and a linker sequence were inserted at the 5 ′ end.
- VH gene fragments amplified by PCR reaction are mixed and digested with SfiI and AscI. Then, DNA Ligation Kit (manufactured by Takara Bio Inc.) is used as a vector for library preparation, and the reaction is performed overnight at 16 ° C. Inserted. This ligated solution was introduced into TG1 Electroporation Competent Cells (manufactured by STRATAGENE) by electroporation. The transformed Escherichia coli was adjusted to 1 L with 2 ⁇ YTAG medium (17 g Bacto-tryptone, 10 g Bact-yeast extract, 5 g NaCl with distilled water. After autoclaving, 100 ⁇ g / ml ampicilin and 2% glucose were added.
- a SOBAG medium plate (20 g Bacto-tryptone, 5 g Bact-yeast extract, 15 g Bacto-agar, prepared using a standard dish (150 ⁇ 15 mm, manufactured by BD), 0.5g NaCl, 900ml distilled water was added and autoclaved.After cooling to 50-60 ° C, 10ml sterile 1M MgCl 2 , 55.6ml sterilized 2M glucose, Ampicilin was added.) And incubated at 30 ° C overnight . A colony group formed on the medium was recovered (colony was recovered with 3 mL of 2 ⁇ YTAG medium per plate) to obtain an scFv antibody library. In this example, a library was prepared by collecting about 5 ⁇ 10 5 colonies.
- the scFv antibody library (100 ⁇ L) was cultured with shaking in 2 ⁇ YTAG medium (50 mL) at 30 ° C. until the absorbance at 600 nm reached 0.3 to 0.5. After infecting this culture with M13KO helper phage at a MOI of 10-20 (shaking culture at 30 ° C for 1 hour), the medium was mixed with 2 x YTAK (17g Bacto-tryptone, 10g Bact-yeast extract, 5g NaCl with distilled water. After autoclaving, the mixture was switched to 100 ⁇ g / ml ampicilin and ⁇ 50 ⁇ g / ml kanamycin) and cultured with shaking at 30 ° C. overnight.
- This culture supernatant was used as an antibody phage library.
- the antibody phage library was precipitated by PEG (200 g of Polyethylene glycol 8000 and 146.1 g of NaCl in distilled water and dissolved in 1 L and autoclaved), and replaced with 3 mL of PBS ( ⁇ ).
- DNA polymerase KOD-Plus, manufactured by Toyobo Co., Ltd.
- DNA polymerase KOD-Plus, manufactured by Toyobo Co., Ltd.
- the gene fragment amplified by this PCR reaction was digested with KpnI and XbaI, and inserted into a pTracer-CMV / Zeo (Invitrogen) vector in which the Fc region of human IgG had been inserted in advance.
- the obtained plasmid was designated as pTracer / hECD28-Fc.
- the prepared expression vector gene is prepared with Nucleobomd PC2000EF (manufactured by Macherey-NAGEL), introduced into floating 293 cells using FreeStyle TM 293 Expression System (manufactured by Invitrogen), and each antibody is transiently expressed. A culture supernatant containing was obtained. The culture supernatant was collected 7 days after the introduction of the vector and filtered through a membrane filter (manufactured by MILLIPORE) having a pore size of 0.22 ⁇ m.
- This culture supernatant was charged to HiTrap rProtein A FF (column volume 1 ml) (GE Healthcare Bioscience), an affinity column for antibody purification, washed with PBS (-), 20 mM sodium citrate, 50 mM NaCl. It was eluted with a buffer solution (pH 2.7) and collected in a tube containing 200 mM sodium phosphate buffer solution (pH 7.0).
- HiTrap rProtein A FF column volume 1 ml
- PBS -
- 20 mM sodium citrate 50 mM NaCl
- Example 5 Concentration of phage displaying scFv antibody recognizing human CD28 Human CD28-Fc fusion protein prepared at 10 ⁇ g / mL in coating buffer (50 mM carbonate buffer, pH 9) was treated with a maxisorp immunotube (star tube type). , Manufactured by NUNC) and incubated at 4 ° C. overnight to immobilize. Blocking was performed by adding 500 mL of a blocking reagent (SuperBlock (registered trademark) Blocking Buffer, manufactured by PIERCE) and incubating at room temperature for 1 hour.
- a blocking reagent SuperBlock (registered trademark) Blocking Buffer, manufactured by PIERCE
- Example 6 Selection of antibody-displayed phage that recognizes human CD28 and preparation of anti-CD28 antibodies (341VL34 and 341VL36) Each single colony was inoculated into 200 ⁇ L of 2 ⁇ YTAG medium from an antibody library subjected to panning, and the mixture was subjected to 30 ° C. And cultured with shaking for 4 to 5 hours. After adding 200 ⁇ L of 1 ⁇ 10 10 pfu / mL M13KO helper phage to this culture solution and infecting (shaking culture at 30 ° C. for 1 hour), the medium was switched to 2 ⁇ YTAK and cultured at 30 ° C. overnight. . Using this culture supernatant as a phage solution, binding to an antigen was confirmed according to the following procedure (ELISA).
- scFv antibodies Two types of scFv antibodies whose binding to the antigen was confirmed by ELISA were named 341VL34 scFv and 341VL36 scFv.
- scFv antibody In order to convert the obtained scFv antibody into a normal type antibody, cloning of an antibody gene and preparation of an expression vector were performed.
- pCANTAB / 341VL34 and pCANTAB / 341VL36 were used as templates, and 5'-AAAGGTGTCCAGTGTGAGGTGCAGCTGGTGGAGTC-3 '(SEQ ID NO: 68) and 5'-TGAGGAGACGGTGACCGTGG-3' (SEQ ID NO: 69) were used as primers.
- DNA polymerase KOD-Plus, manufactured by Sakai Toyobo Co., Ltd.
- the reaction at 95 ° C. for 30 seconds, 58 ° C. for 30 seconds, and 68 ° C. for 30 seconds was performed for 30 cycles.
- PCR reaction was carried out to add a SalI sequence, a Kozac sequence and a signal encoding sequence to the 5 'end, and an NheI sequence to the 3' end.
- 5'-GGGGTCGACACCATGGAGTTTGGGCTGAGCTGGGTTTTCCTTGTTGCTATTTTAAAAGGTGTCCAGTGT-3 '(SEQ ID NO: 70) and 5'-GGGGCTAGCTGAGGAGACGGTGACC-3' (SEQ ID NO: 71) as primers DNA polymerase (KOD-Plus, manufactured by Sakai Toyobo Co., Ltd.)
- the PCR reaction was performed 35 cycles at 95 ° C for 30 seconds, 58 ° C for 30 seconds, and 68 ° C for 30 seconds.
- the heavy chain variable region of the 341-1-19 expression vector (using N5KG2Ser described in Japanese Patent Application 2003-431408) is SalI.
- 341VL34scFv and 341VL36scFV-derived heavy chain gene fragments digested with NheI and digested with SalI and NheI were inserted.
- An antibody composed of a 341-1-19 light chain (SEQ ID NO: 2) and a heavy chain derived from 341VL34scFv consists of a light chain derived from 341VL34, 341-1-19 (SEQ ID NO: 2) and a heavy chain derived from 341VL36scFV This antibody was named 341VL36.
- 341VL34 heavy chain nucleic acid sequence (SEQ ID NO: 72), 341VL34 heavy chain amino acid sequence (SEQ ID NO: 73), 341VL36 heavy chain nucleic acid sequence (SEQ ID NO: 74), and 341VL36 heavy chain amino acid sequence (SEQ ID NO: 75) are shown in the Sequence Listing.
- the translation start point of the heavy chain nucleic acid of the 341VL34 antibody is the ATG codon starting from the first adenine (A) from the 5 ′ end of SEQ ID NO: 72, and the stop codon is TGA starting from the 1417th thymine (T).
- the boundary between the antibody variable region and the constant region is located between the 438th adenine (A) and the 439th guanine (G) from the 5 ′ end.
- the heavy chain variable region is from the N-terminus of SEQ ID NO: 73 to the 146th serine (S) residue, and the 147th alanine (A) and subsequent are constant regions. It is considered that the signal sequence of the heavy chain extends from the N-terminus of SEQ ID NO: 73 to the 19th cysteine (C), and the mature N-terminus is the 20th glutamic acid (E).
- the translation start point of the heavy chain nucleic acid of the 341VL36 antibody is the ATG codon starting from the first adenine (A) from the 5 ′ end of SEQ ID NO: 74, and the stop codon is TGA starting from the 1417th thymine (T).
- the boundary between the antibody variable region and the constant region is located between the 438th adenine (A) and the 439th guanine (G) from the 5 ′ end.
- the heavy chain variable region extends from the N-terminus of SEQ ID NO: 75 to the 146th serine (S) residue, and the 147th alanine (A) and later are constant regions. It is considered that the signal sequence of the heavy chain extends from the N-terminus of SEQ ID NO: 75 to the 19th cysteine (C), and the mature N-terminus is the 20th glutamic acid (E).
- FIG. 1 shows the structural features of the multivalent antibody produced in the present invention.
- the variable regions derived from two types of antibodies are linked by a linker.
- one type of antibody (341-1-19) as an anti-CD40 antibody and two types (341VL34 and 341VL36) as anti-CD28 antibodies the antibodies were tested with different combinations of linker structures and positions. Carried out.
- the linker of SEQ ID NO: 77 containing the CH1 region of the IgG2 subclass derived from 341-1-19 or the linker of SEQ ID NO: 99 containing the CH1, hinge, CH2, and CH3 regions is inserted as the multivalent antibody linker in the Examples.
- the linker used in the present invention is not limited to these linkers.
- Table 2 summarizes the structures of the produced multivalent antibodies.
- Multivalent antibody having an antigen recognition site for CD28 (derived from 341VL34) on the N-terminal side and an antigen recognition site for CD40 (derived from 341-1-19) on the C-terminal side, and comprising a linker of SEQ ID NO: 77
- the heavy chain of anti-CD28 antibody 341VL34 was prepared in order to prepare a multivalent antibody in which the recognition site for CD28 and the recognition site for CD40 were aligned from the heavy chain N-terminal side.
- the chain variable region was tandemly linked to the heavy chain variable region of anti-CD40 antibody 341-1-19 via a linker (SEQ ID NO: 77). Since the same light chain as that of 341-1-19 is used for the anti-CD28 antibody, the expression vector retains one type of light chain sequence.
- This multivalent antibody was named 341VL34-CH1-341.
- the gene sequence encoding the heavy chain of 341VL34-CH1-341 was prepared by the following procedure.
- the obtained two gene fragments were ligated by Over-Extension-PCR to produce a linker--341-1-19 heavy chain gene fragment.
- This gene fragment was digested with NheI, cleaved with NheI, and then inserted into a 341VL4 expression vector dephosphorylated with AlkalineAlPhosphatase (BAP, manufactured by Takara Bio Inc.).
- 341VL34-CH1-341 heavy chain nucleic acid sequence (SEQ ID NO: 82) and 341VL34-CH1-341 heavy chain amino acid sequence (SEQ ID NO: 83) are shown in the sequence listing, respectively.
- Example 9 An antigen recognition site for CD40 (derived from 341-1-19) on the N-terminal side, an antigen recognition site for CD28 (derived from 341VL34) on the C-terminal side, and a polyvalent containing the linker of SEQ ID NO: 77
- Preparation of antibody (341-CH1-341VL34) expression vector The heavy chain variable of 341-1-19 was prepared in order to produce a polyvalent antibody in which the antigen recognition site for CD40 and the antigen recognition site for CD28 were arranged from the heavy chain N-terminal side. The region was tandemly linked to the heavy chain variable region of 341VL34 via the linker of SEQ ID NO: 77. The same light chain as that of 341-1-19 uses an anti-CD28 antibody.
- the gene sequence encoding the heavy chain of 341-CH1-341VL was prepared by the following procedure.
- 341VL-34 heavy chain sequence as template 5'-GTGGACAAGACAGTTGGATCCGAGGTGCAGCTGGTGGAGTC-3 '(SEQ ID NO: 84) and 5'-CTTGGTGCTAGCTGAGGAGACGGTGAC-3' (SEQ ID NO: 81) as primers, DNA polymerase (KOD-Plus, manufactured by Sakai Toyobo Co., Ltd.) ), A linker gene (21 bases at the 3 'end) at the 5' end and an NheI sequence at the 3 'end by performing 30 cycles of reactions at 95 ° C for 30 seconds, 55 ° C for 30 seconds, and 68 ° C for 30 seconds. The heavy chain gene fragment of 341-1-19 added with was amplified.
- the obtained two gene fragments were ligated by Over-Extension-PCR to prepare a linker--341VL34 heavy chain gene fragment.
- This gene fragment was digested with NheI, cleaved with NheI, and then inserted into the 341-1-19 expression vector dephosphorylated with AlkalineAlPhosphatase (BAP, manufactured by Takara Bio Inc.).
- 341-CH1-341VL34 heavy chain nucleic acid sequence (SEQ ID NO: 85) and 341-CH1-341VL34 heavy chain amino acid sequence (SEQ ID NO: 86) are shown in the sequence listing, respectively.
- An antigen recognition site for CD28 (derived from 341VL34) is located on the N-terminal side and an antigen recognition site for CD40 (derived from 341-1-19) is located on the C-terminal side.
- Preparation of expression vector for multivalent antibody (DVD341VL34-341) linked with recognition sites
- DVD341VL34-341 A multivalent antibody linked by a linker (SEQ ID NO: 87, 88) consisting of an amino acid sequence (6 amino acids) was prepared.
- DVD-IgG was prepared based on anti-CD40 antibody 341-1-19 and anti-CD28 antibody 341VL34. From the N-terminal side, DVDIgG having antigen recognition sites in the order of CD28 and CD40 was named DVD341VL34-341. The 341VL34 variable region was tandemly linked to the N-terminal side of the heavy chain variable region of 341-1-19.
- the 341VL34 light chain variable region was tandemly linked to the N-terminal side of the light chain variable region of 341-1-19.
- a partial sequence of the light chain kappa constant region (SEQ ID NO: 89, 90: 108th to 113th Kabat EU index) is inserted between the variable regions as a linker.
- the gene sequence encoding the heavy chain of DVD341VL34-341 was prepared by the following procedure.
- 341-1-19 heavy chain sequence as template 5'-GTCTCCTCAGCTAGCACCAAGGGCCCACAGGTCCAACTGCAGCAGTC -3 '(SEQ ID NO: 91) and 5'-CTTGGTGCTAGCTGAGGAGACGGTGAC-3' (SEQ ID NO: 81) as primers, DNA polymerase (KOD-Plus, Sakai Toyobo Using, for example, 35 cycles of reaction at 95 ° C. for 30 seconds, 55 ° C. for 30 seconds, and 68 ° C. for 30 seconds, the linker gene sequence (NheI sequence at the 5 ′ end of the linker) The heavy chain gene fragment of 341-1-19 with an NheI sequence added to the 3 ′ end was amplified.
- This gene fragment was digested with NheI, cleaved with NheI, and then inserted into the 341VL34 expression vector dephosphorylated with AlkalineAlPhosphatase (BAP, manufactured by Takara Bio Inc.). Furthermore, the light chain produced by the following method was inserted into this vector.
- the gene sequence encoding the light chain of DVD341VL34-341 was prepared by the following procedure.
- DVD341VL34-341 heavy chain nucleic acid sequence (SEQ ID NO: 94), DVD341VL34-341 heavy chain amino acid sequence (SEQ ID NO: 95), DVD341VL34-341 light chain nucleic acid sequence (SEQ ID NO: 96), DVD341VL34-341 light chain nucleic acid sequence (SEQ ID NO: 97) ) Is shown in the sequence listing.
- Example 11 An antigen recognition site for CD28 (derived from 341VL34) on the N-terminal side, an antigen recognition site for CD40 (derived from 341-1-19) on the C-terminal side and containing a linker of SEQ ID NO: 99
- Preparation of antibody (341VL34-CH1-H-CH2-CH3-341-CH1) expression vector CD28 and CD40 recognition sites are present in this order from the heavy chain N-terminal, and long linkers of SEQ ID NOs: 98 and 99 (CH1, hinge) , CH2, CH3: Kabat EU index 118th to 447th) were prepared.
- variable region of 341VL34 was linked to the variable region of 341-1-19 via the linkers of SEQ ID NOs: 98 and 99.
- a stop codon TGA was added to the 3 ′ end.
- the same light chain as that of 341-1-19 uses an anti-CD28 antibody. This antibody was named 341VL34-CH1-H-CH2-CH3-341-CH1.
- the gene sequence encoding the heavy chain of 341VL34-CH1-H-1CH2-CH3-341-CH1 was prepared by the following procedure.
- the obtained gene fragment was digested with NheI and BamHI, cleaved with NheI and BamHI, and inserted into the 341VL34 expression vector excluding the gene region encoding the heavy chain constant region.
- 5′-GATATCAAAGGATCCCAGGTCCAACTGCAGCAGTC-3 ′ (SEQ ID NO: 102) and 5′-GGGGGATCCTCAAACTGTCTTGTCCACCTTGG-3 ′ (SEQ ID NO: 103) as primers, Using DNA polymerase (KOD-Plus, Sakai Toyobo Co., Ltd.), by performing 35 cycles of reactions at 95 ° C for 30 seconds, 55 ° C for 30 seconds, 68 ° C for 30 seconds, the BamHI sequence at the 5 'end and the 3' end The BamHI heavy chain variable region and CH1 region of BamHI (from the 3 'end) added with the gene sequence encoding the
- 341VL34-CH1-H- CH2-CH3-341-CH1 heavy chain nucleic acid sequence SEQ ID NO: 104
- 341VL34-CH1-H- CH2-CH3-341-CH1 heavy chain amino acid sequence SEQ ID NO: 105
- Multivalent antibody having an antigen recognition site for CD28 (derived from 341VL36) on the N-terminal side and an antigen recognition site for CD40 (derived from 341-1-19) on the C-terminal side, and comprising a linker of SEQ ID NO: 77
- 341VL36-CH1-341 Preparation of (341VL36-CH1-341) expression vector
- a polyvalent antibody containing CD28 and CD40 recognition sites was prepared, and the 341VL36 heavy chain variable region was passed through the linker of SEQ ID NO: 77. Bound to the heavy chain variable region of 341-1-19 in tandem. Since the same light chain as that of 341-1-19 is used for the anti-CD28 antibody, the expression vector retains one type of light chain sequence.
- This multivalent antibody was named 341VL36-CH1-341.
- the gene sequence encoding the heavy chain of 341VL34-CH1-341 was prepared by the following procedure.
- DNA polymerase KOD-Plus, Sakai Toyobo
- the linker gene fragment added with the NheI sequence at the 5 ′ end was amplified by carrying out 30 cycles of reactions at 95 ° C. for 30 seconds, 55 ° C. for 30 seconds, and 68 ° C. for 30 seconds.
- the obtained two gene fragments were ligated by Over-Extension-PCR to produce a linker--341-1-19 heavy chain gene fragment.
- This gene fragment was digested with NheI, cleaved with NheI, and then inserted into the 341VL36 expression vector dephosphorylated with AlkalineAlPhosphatase (BAP, manufactured by Takara Bio Inc.).
- the 341VL36-CH1-341 heavy chain nucleic acid sequence (SEQ ID NO: 106) and the 341VL36-CH1-341 heavy chain amino acid sequence (SEQ ID NO: 107) are shown in the sequence listing, respectively.
- Example 13 An antigen recognition site for CD40 (derived from 341-1-19) on the N-terminal side, an antigen recognition site for CD28 (derived from 341VL36) on the C-terminal side, and containing a linker of SEQ ID NO: 77
- Preparation of antibody (341-CH1-341VL36) expression vector In order from the heavy chain N-terminal side, in order to create a multivalent antibody with CD40 and CD28 recognition sites, the 341-1-19 heavy chain variable region is SEQ ID NO: It was tandemly linked to the heavy chain variable region of 341VL36 via 77 linkers. The same light chain as that of 341-1-19 uses an anti-CD28 antibody.
- the gene sequence encoding the heavy chain of 341-CH1-341VL36 was prepared by the following procedure.
- DNA polymerase KOD-Plus, Sakai Toyobo
- the Linker gene fragment added with the NheI sequence at the 5 ′ end was amplified by performing 30 cycles of reaction at 95 ° C. for 30 seconds, 55 ° C. for 30 seconds, and 68 ° C. for 30 seconds.
- the obtained two gene fragments were ligated by Over-Extension-PCR to produce a linker--341 VL36 heavy chain gene fragment.
- This gene fragment was digested with NheI, cleaved with NheI, and then inserted into the 341-1-19 expression vector dephosphorylated with Alkaline-Phosphatase (BAP, manufactured by Takara Bio Inc.).
- sequences of the 341-CH1-341VL36 heavy chain nucleic acid sequence (SEQ ID NO: 108) and the 341-CH1-341VL36 heavy chain amino acid sequence (SEQ ID NO: 109) are shown in the sequence listing, respectively.
- An antigen recognition site (derived from 341VL36) for CD28 has an antigen recognition site (derived from 341-1-19) for CD40 on the C-terminal side at the N-terminal side, and two antigens with a short linker of SEQ ID NO: 88
- Preparation of expression vector of multivalent antibody (DVD341VL36-341) linked to recognition sites In order to compare the stability of multivalent antibody, according to the report of Wu et al. DVD-IgG was prepared based on the 341VL36 antibody. From the N-terminal side, DVDIgG having the recognition sites in the order of CD28 and CD40 was named DVD341VL36-341.
- the 341VL34 variable region was tandemly linked to the N-terminal side of the heavy chain variable region of 341-1-19.
- a linker of SEQ ID NO: 87,88 consisting of 6 amino acids is inserted between the variable regions.
- the 341VL36 light chain variable region was tandemly linked to the N-terminal side of the light chain variable region of 341-1-19. Between the variable regions, a partial sequence of the light chain kappa constant region (SEQ ID NO: 89, 90: positions 108 to 113 of the Kabat EU index) is inserted as a linker.
- the gene sequence encoding the heavy chain of DVD341VL36-341 was prepared by the following procedure.
- DNA polymerase KOD-Plus, Sakai Toyobo
- 341-1-19 heavy chain sequence 5'-GTCTCCTCAGCTAGCACCAAGGGCCCACAGGTCCAACTGCAGCAGTC -3 '(SEQ ID NO: 91) and 5'-CTTGGTGCTAGCTGAGGAGACGGTGAC-3' (SEQ ID NO: 84)
- a linker gene sequence was added to the 5 ′ end and an NheI sequence was added to the 3 ′ end by performing 35 cycles of reactions at 95 ° C. for 30 seconds, 55 ° C. for 30 seconds, and 68 ° C. for 30 seconds.
- the heavy chain gene fragment of -1-19 was amplified.
- This gene fragment was digested with NheI, cleaved with NheI, and then inserted into the 341VL36 expression vector dephosphorylated with AlkalineAlPhosphatase (BAP, manufactured by Takara Bio Inc.). Furthermore, the light chain produced by the following method was inserted into this vector.
- the gene sequence encoding the light chain of DVD341VL36-341 was prepared by the following procedure.
- DNA polymerase KOD-Plus, Sakai Toyobo
- the light chain gene fragment of 341-1-19 was amplified.
- This gene fragment was digested with BsiWI, cleaved with BsiWI, and then dephosphorylated with Alkaline Phosphatase (BAP, manufactured by Takara Bio Inc.) and inserted into the above-described expression vector holding the heavy chain of DVD341VL36-341.
- BAP Alkaline Phosphatase
- DVD341VL36-341 heavy chain nucleic acid sequence (SEQ ID NO: 110), DVD341VL36-341 heavy chain amino acid sequence (SEQ ID NO: 111), DVD341VL36-341 ⁇ light chain nucleic acid sequence (SEQ ID NO: 112), DVD341VL36-341 light chain nucleic acid sequence (SEQ ID NO: 113) ) are shown in the sequence listing.
- Example 15 An antigen recognition site for CD28 (derived from 341VL34) on the N-terminal side, an antigen recognition site for CD40 (derived from 341-1-19) on the C-terminal side, and a polyvalent containing the linker of SEQ ID NO: 99
- Preparation of expression vector for antibody (341VL36-CH1-H-CH2-CH3-341-CH1)
- Multivalent antibody that has CD28 and CD40 recognition sites in order from the N-terminal side of heavy chain and retains the long linker of SEQ ID NO: 99 was made.
- the heavy chain variable region of 341-1-19 was tandemly linked to the 341VL36 heavy chain variable region via the linkers of SEQ ID NOs: 98 and 99.
- a stop codon TGA was added to the 3 ′ end.
- the same light chain as that of 341-1-19 uses an anti-CD28 antibody.
- This antibody was named 341VL36-CH1-H-CH2-CH3-341-CH1.
- the gene sequence encoding the heavy chain of 341VL36-CH1-H- CH2-CH3-341-CH1 was prepared by the following procedure.
- the 341-1-19 heavy chain sequence as a template 5′-GATATCAAAGGATCCCAGGTCCAACTGCAGCAGTC-3 ′ (SEQ ID NO: 102) and 5′-GGGGGATCCTCAAACTGTCTTGTCCACCTTGG-3 ′ (SEQ ID NO: 103) as primers, Using DNA polymerase (KOD-Plus, Sakai Toyobo Co., Ltd.), by performing 35 cycles of reactions at 95 ° C for 30 seconds, 55 ° C for 30 seconds, 68 ° C for 30 seconds, the BamHI sequence at the 5 'end and the 3' end.
- the BamHI heavy chain variable region and the CH1 region were added to the BamHI sequence (from the 3 ′ end), added with a BamHI sequence, a stop codon and a gene sequence encoding the CH1 region (118th threonine to 215th valine).
- 341VL36-CH1-H- CH2-CH3-341-CH1 heavy chain nucleic acid sequence SEQ ID NO: 114
- 341VL36-CH1-H- CH2-CH3-341-CH1 heavy chain amino acid sequence SEQ ID NO: 115
- Example 16 Expression and purification of multivalent antibody
- the prepared expression vector gene was prepared with the QIAGEN Plasmid Maxi Kit (Qiagen), and the free floating 293 cells were prepared using FreeStyle TM 293 Expression System (Invitrogen).
- the culture supernatant containing each antibody was obtained by transient expression.
- the culture supernatant was collected 7 days after the introduction of the vector and filtered through a membrane filter (manufactured by MILLIPORE) having a pore size of 0.22 ⁇ m. From this culture supernatant, affinity purification was performed using Protein A resin (MabSelect, manufactured by GE Healthcare Bioscience).
- a phosphate buffer solution was used as a washing solution, and 20 mM sodium citrate, 50 mM NaCl buffer (pH 2.7) was used as an elution buffer.
- the elution fraction was adjusted to around pH 6.0 by adding 200 mM sodium phosphate buffer (pH 7.0).
- the prepared antibody solution is replaced with phosphate buffer using a dialysis membrane (10000 cut, manufactured by Spectrum Laboratories), purified by filtration through a 0.22 ⁇ m membrane filter (Millex-GV, manufactured by MILLIPORE), and purified. Antibody was obtained.
- the concentration of the purified antibody was determined by measuring the absorbance at 280 nm, and 1 mg / mL was calculated as the antibody concentration of 1.40 Optimal density.
- Example 17 Measurement of antibody productivity As antibody productivity, the antibody content in each culture supernatant was measured. The antibody content was measured using a high performance liquid chromatograph (Hitachi) and POROS 50 A (Applid Biosystem, cat. 4319037) and 20 mM Phosphate, 300 mM NaCl pH 7.0 as the solvent. . The antibody content is calculated by comparing the peak area obtained by injecting each culture supernatant with the peak area obtained by injecting 1, 2, 5, 10 ⁇ g of purified human antibody (IgG1) did.
- Hitachi high performance liquid chromatograph
- POROS 50 A Applid Biosystem, cat. 4319037
- Example 18 Evaluation of antibody stability Aggregate content of the antibody solution was determined using a high performance liquid chromatograph (Shimadzu) and a TSK-G3000 SW column (Tosoh), 20 mM sodium phosphate as a solvent, Analysis was performed using 500 mM NaCl, pH 7.0. By injecting 40ug of each antibody and comparing the elution position with the molecular weight marker for gel filtration HPLC (Catalog No. 40403701 manufactured by Oriental Yeast Co., Ltd.), the antibody protein monomer and higher aggregate peaks were identified. From the respective peak areas, the aggregate content was calculated.
- Example 20 Acquisition of first antigen recognition site An anti-CD40 antibody 281 was established using a new anti-CD40 antibody in the same manner as in Example 1.
- Example 21 Preparation of scFV library of anti-CD28 antibody having light chain common to light chain of anti-CD40 antibody Screening for anti-CD28 antibody having light chain common to light chain of anti-CD40 antibody of Example 20 In order to achieve this, the spleen of the mouse immunized with CD28 prepared in Example 2 was used to bind the heavy chain variable region gene fragment and the light chain variable region gene fragment of the anti-CD28 antibody ( scFV) gene library was prepared.
- 281 heavy chain (SEQ ID NO: 116) as a template, 5'-GCAACTGCGGCCCAGCCGGCCATGGCCCAGGTGCAGCTGCAGGAG-3 '(SEQ ID NO: 120) and 5'-CCGAGGCGCCCACCGCTGCCACCGCCTCCTGAGGAGACGGTGACCAG-3' (SEQ ID NO: 121) as a primer, SfiI sequence, 3 ′ 5′-CGGTGGGCGCGCCTCGGGCGGAGGTGGTTCAGAAATTGTGTTGACGCAG-3 ′ (SEQ ID NO: 122) and 5′ ⁇ using the 281 light chain (SEQ ID NO: 118) as a template as a template GAGTCATTCTCGACTTGCGGCCGCACGTTTGATCTCCAGTCGTGTCCC-3 '(SEQ ID NO: 123) as a primer, 281 light chain variable region gene fragments with a glycine-rich sequence added at the 5' end and a NotI sequence added at the 3 'end were respectively DNA polymerase (
- VH and VL gene fragments were ligated by Over Extension PCR in the same manner as in Example 3 to prepare a 281 scFv gene fragment.
- This gene fragment was digested with SfiI and NotI, and inserted into a pCANTAB-5E vector vector (manufactured by GE Healthcare Bioscience) previously cleaved with SfiI and NotI.
- the resulting plasmid was named pCANTAB5E / 281.
- this plasmid was cleaved with SfiI and AscI (the gene region coding for the VH of 341-1-19 was cloned) for the purpose of obtaining an antibody using human CD28 having an amino acid sequence common to 281 light chains as an antigen.
- the vector gene dephosphorylated with AlkalineAlPhosphatase (BAP, manufactured by Takara Bio Inc.) was used as a vector for library preparation.
- a heavy chain variable region gene fragment for preparing a phage antibody library was obtained.
- a DNA polymerase (KOD-Plus) using a primer specific to the variable region of human heavy chain (SEQ ID NO: 124-131) and a primer specific to the junction region (SEQ ID NO: 132-135). a DNA polymerase using a primer specific to the variable region of human heavy chain (SEQ ID NO: 124-131) and a primer specific to the junction region (SEQ ID NO: 132-135).
- a DNA polymerase KOD-Plus
- 35 reactions at 95 ° C. for 30 seconds, 58 ° C. for 30 seconds, and 68 ° C. for 30 seconds were performed.
- 5 types of primers specific to the junction region were used.
- SfiI cleavage recognition site was inserted at the 5 'end of SEQ ID NOs: 124-131, and an AscI cleavage recognition site and a linker sequence were inserted at the 5' ends of SEQ ID NOs: 132-135.
- VH gene fragments amplified by these PCR reactions were inserted into a vector prepared using pCANTAB5E / 281 according to the procedure of Example 3 to prepare an scFv antibody library.
- a library was prepared by collecting about 5 ⁇ 10 5 colonies.
- An antibody phage library was prepared from this scFv antibody library.
- Example 22 Concentration of phage displaying scFv antibody recognizing human CD28 The antibody phage library prepared in Example 21 was concentrated according to the procedure of Example 5.
- Example 23 Selection of antibody-displayed phage that recognizes human CD28 and preparation of anti-CD28 antibody (281VL4) Antibody-displayed phage was selected according to the procedure of Example 6.
- the scFv antibody whose binding to the antigen was confirmed by ELISA was named 281VL4 scFv.
- cloning of an antibody gene and preparation of an expression vector were performed.
- PCR reaction was carried out to add a SalI sequence, a Kozac sequence and a signal encoding sequence to the 5 'end, and an NheI sequence to the 3' end.
- the PCR reaction was performed for 35 cycles of 95 ° C. for 30 seconds, 58 ° C.
- 281VL4 scFv Since the light chain of 281VL4 scFv has a common amino acid sequence with 281, the heavy chain variable region of the 281 expression vector (using N5KG4PE described in WO2002 / 088186) was excised with SalI and NheI and digested with SalI and NheI The derived heavy chain gene fragment was inserted.
- An antibody composed of 281 light chains (SEQ ID NO: 118, 119) and a heavy chain derived from 281VL4 scFv was named 281VL4.
- 281VL4 heavy chain nucleic acid sequence (SEQ ID NO: 140) and 281VL4 heavy chain amino acid sequence (SEQ ID NO: 141) are shown in the sequence listing, respectively.
- the translation start point of the 281VL4 antibody heavy chain nucleic acid is the ATG codon starting from the first adenine (A) from the 5 ′ end of SEQ ID NO: 140, and the stop codon is TGA starting from the 1417th thymine (T).
- the boundary between the antibody variable region and the constant region is located between the 435th adenine (A) and the 436th guanine (G) from the 5 ′ end.
- the heavy chain variable region is from the N-terminus of SEQ ID NO: 141 to the 145th serine (S) residue, and the 146th alanine (A) and subsequent are the constant regions.
- the heavy chain signal sequence extends from the N-terminus of SEQ ID NO: 141 to the 19th serine (S), and the mature N-terminus is considered to be the 20th glutamic acid (E).
- the expression vector retains one type of light chain sequence.
- These multivalent antibodies were named 281VL4-CH1-281, 281VL4-CH1 (118-131) -281, 281VL4-CH1 (118-130) -281.
- 281VL4-CH1-281 has an IgG4 CH1 sequence (Kabat EU index # 118 to 215) between the heavy chains (281'4 heavy chain 3 'end, 281 heavy chain 5' end).
- a sequence with a BamHI sequence (GGATCC) added to the 3 ′ end is inserted as a linker.
- the gene sequence encoding the heavy chain of 281VL4-CH1-281 was prepared by the following procedure.
- DNA polymerase KOD-Plus, manufactured by Sakai Toyobo Co., Ltd.
- the linker gene fragment added with the NheI sequence at the 5 ′ end was amplified by performing 30 cycles of reaction at 95 ° C. for 30 seconds, 55 ° C. for 30 seconds, and 68 ° C. for 30 seconds.
- the obtained two gene fragments were ligated by Over-Extension-PCR to produce a linker--281 heavy chain gene fragment.
- This gene fragment was digested with NheI, cleaved with NheI, and then inserted into an 281VL4 expression vector dephosphorylated with AlkalineAlPhosphatase (BAP, manufactured by Takara Bio Inc.).
- BAP AlkalineAlPhosphatase
- the heavy chain variable region of the anti-CD28 antibody 281VL4 is linked to the linker (SEQ ID NO: 151).
- the linker SEQ ID NO: 1531
- the expression vector retains one type of light chain sequence.
- This multivalent antibody was named 281VL4-CH1 (118-131) -281.
- 281VL4-CH1 (118-131) -281 is an IgG4 CH1 sequence (Kabat EU index from 118 to 131) between heavy chains (3 ′ end of 281VL4 heavy chain, 5 ′ end of 281 heavy chain) ) As a linker.
- the gene sequence encoding the heavy chain of 281VL4-CH1 (118-131) -281 was prepared by the following procedure.
- DNA polymerase KOD-Plus, manufactured by Sakai Toyobo Co., Ltd.
- the reaction was carried out for 30 cycles of 95 ° C. for 30 seconds, 55 ° C. for 30 seconds, and 68 ° C. for 30 seconds.
- 5'-GGGGCTAGCACCAAGGGGCCATCCGTCTTCCCCCTGGCGCCC-3 '(SEQ ID NO: 151) and 5'-GGGGCTAGCTGAGGAGACGGTGACCA-3' (SEQ ID NO: 147) were used as primers, and DNA polymerase (KOD-Plus, manufactured by Sakai Toyobo Co., Ltd.) was used. Then, 35 cycles of reactions at 95 ° C. for 30 seconds, 55 ° C. for 30 seconds, and 68 ° C. for 30 seconds were performed, so that the linker gene (the 5 ′ end of the linker sequence is an NheI sequence) was added to the 5 ′ end.
- 281 heavy chain gene fragments with NheI sequence added to the ends were amplified.
- the obtained gene fragment was digested with NheI, cleaved with NheI, and inserted into an 281VL4 expression vector that had been dephosphorylated with Alkaline Phosphatase (BAP, manufactured by Takara Bio Inc.).
- BAP Alkaline Phosphatase
- the 281VL4-CH1 (118-131) -281 heavy chain nucleic acid sequence (SEQ ID NO: 152) and 281VL4-CH1 (118-131) -281 heavy chain amino acid sequence (SEQ ID NO: 153) are shown in the Sequence Listing, respectively.
- 281VL4-CH1 (118-130) -281 is an IgG4 CH1 sequence (Kabat EU index from 118 to 130) between the heavy chains (3 ′ end of 281VL4 heavy chain, 5 ′ end of 281 heavy chain) ) As a linker.
- the gene sequence encoding the heavy chain of 281VL4-CH1 (118-130) -281 was prepared by the following procedure.
- DNA polymerase KOD-Plus, manufactured by Sakai Toyobo Co., Ltd.
- the reaction was carried out for 30 cycles of 95 ° C. for 30 seconds, 55 ° C. for 30 seconds, and 68 ° C. for 30 seconds.
- 5'-GGGGCTAGCACCAAGGGGCCATCCGTCTTCCCCCTGGCGCCC-3 '(SEQ ID NO: 151) and 5'-GGGGCTAGCTGAGGAGACGGTGACCA-3' (SEQ ID NO: 147) were used as primers, and DNA polymerase (KOD-Plus, manufactured by Sakai Toyobo Co., Ltd.) was used. Then, 35 cycles of reactions at 95 ° C. for 30 seconds, 55 ° C. for 30 seconds, and 68 ° C. for 30 seconds were performed, so that the linker gene (the 5 ′ end of the linker sequence is an NheI sequence) was added to the 5 ′ end.
- 281 heavy chain gene fragments with NheI sequence added to the ends were amplified.
- the obtained gene fragment was digested with NheI, cleaved with NheI, and inserted into an 281VL4 expression vector that had been dephosphorylated with Alkaline Phosphatase (BAP, manufactured by Takara Bio Inc.).
- the 281VL4-CH1 (118-130) -281 heavy chain nucleic acid sequence (SEQ ID NO: 155) and 281VL4-CH1 (118-130) -281 heavy chain amino acid sequence (SEQ ID NO: 156) are shown in the sequence listing, respectively.
- Example 25 Expression and purification of multivalent antibody
- the prepared expression vector gene was prepared with the QIAGEN Plasmid Maxi Kit (Qiagen), and the suspension was prepared into free-floating 293 cells using the FreeStyle TM 293 Expression System (Invitrogen).
- the culture supernatant containing each antibody was obtained by transient expression.
- Purified antibody was obtained from this culture supernatant according to the procedure of Example 16.
- the concentration of the purified antibody was determined by measuring the absorbance at 280 nm, and 1 mg / mL was calculated as the antibody concentration of 1.40 Optimal density.
- Example 26 Measurement of antibody productivity As antibody productivity, the antibody content in each culture supernatant was measured. The antibody content was measured according to the procedure of Example 17. The results are shown in Table 7.
- Example 27 Evaluation of antibody stability The aggregate content of the antibody solution was measured according to the procedure of Example 18. The results are shown in Table 8.
- Example 28 Evaluation of antigen-binding property of antibody Binding of each of the prepared antibodies (CD40 and CD28) to each antigen was confirmed according to the procedure of Example 19. As a result, 281VL4-CH1-281, 281VL4-CH1 (118-131) -281, 281VL4-CH1 (118-130) -281 can bind to human CD40-Fc fusion protein and human CD28-Fc fusion protein. confirmed.
- Example 29 Preparation of an expression vector for a multivalent antibody having an antigen recognition site for CD28 (from 281VL4) on the N-terminal side and an antigen recognition site for CD40 (from 281) on the C-terminal side, and containing the linker shown in Table 9
- the recognition site for CD28 and the recognition site for CD40 are aligned from the N-terminal side of the heavy chain, from the N-terminal side, the heavy chain variable region of the anti-CD28 antibody 281VL4 is linked to the linker shown in Table 9.
- the expression vector retains one type of light chain sequence.
- This multivalent antibody was named 281VL4-CH1 (118-131 / C131S) -281.
- 281VL4-CH1 (118-131 / C131S) -281 has IgG1 CH1 sequence (from Kabat EU index 118) between heavy chains (3 ′ end of 281VL4 heavy chain, 5 ′ end of 281 heavy chain) 131) is inserted as a linker.
- the gene sequences encoding the heavy chains of these antibodies were prepared with reference to the genetic procedure used in Example 24.
- the 281VL4-CH1 (118-131 / C131S) -281 heavy chain nucleic acid sequence (SEQ ID NO: 157) and 281VL4-CH1 (118-131 / C131S) -281 heavy chain amino acid sequence (SEQ ID NO: 158) are shown in the Sequence Listing, respectively.
- Example 30 Preparation of an expression vector for a multivalent antibody having an antigen recognition site for CD28 (derived from 281VL4) on the N-terminal side and an antigen recognition site for CD40 (281-derived) on the C-terminal side, and comprising the linker shown in Table 10
- the recognition site for CD28 and the recognition site for CD40 are aligned from the N-terminal side of the heavy chain, from the N-terminal side, the heavy chain variable region of the anti-CD28 antibody 281VL4 is linked to the linker shown in Table 10.
- the heavy chain variable region of anti-CD40 antibody 281 via tandem.
- the expression vector retains one type of light chain sequence.
- These multivalent antibodies were 281VL4-CH1 (118-119 + C) -281, 281VL4-CH1 (118-120 + C) -281, 281VL4-CH1 (118-121 + C) -281, 281VL4-CH1 (118 -122 + C) -281, 281VL4-CH1 (118-123 + C) -281, 281VL4-CH1 (118-124 + C) -281, 281VL4-CH1 (118-125 + C) -281, 281VL4-CH1 Named (118-126 + C) -281, 281VL4-CH1 (118-127 + C) -281, 281VL4-CH1 (118-128 + C) -281, 281VL4-CH1 (118-129 + C) -281 It was.
- 281VL4-CH1 (118-119 + C) -281, 281VL4-CH1 (118-120 + C) -281, 281VL4-CH1 (118-121 + C) -281, 281VL4-CH1 (118-122 + C)- 281, 281VL4-CH1 (118-123 + C) -281, 281VL4-CH1 (118-124 + C) -281, 281VL4-CH1 (118-125 + C) -281, 281VL4-CH1 (118-126 + C ) -281, 281VL4-CH1 (118-127 + C) -281, 281VL4-CH1 (118-128 + C) -281, 281VL4-CH1 (118-129 + C) -281 IgG4 CH1 sequence (Kabat EU index No.
- a sequence added with a nucleic acid sequence encoding cysteine is inserted as a linker.
- the gene sequences encoding the heavy chains of these antibodies were prepared with reference to the genetic procedure used in Example 24.
- the respective heavy chain nucleic acid sequences and heavy chain amino acid sequences are shown in the Sequence Listing (SEQ ID NOs: 159-180).
- Example 31 Preparation of an expression vector for a multivalent antibody having an antigen recognition site for CD28 (from 281VL4) at the N-terminal side and an antigen recognition site for CD40 (from 281) at the C-terminal side, and containing the linkers shown in Table 11
- the recognition site for CD28 and the recognition site for CD40 are aligned from the N-terminal side of the heavy chain, from the N-terminal side, the heavy chain variable region of the anti-CD28 antibody 281VL4 is linked to the linker shown in Table 11.
- the heavy chain variable region of anti-CD40 antibody 281 via tandem.
- the expression vector retains one type of light chain sequence.
- These multivalent antibodies were 281VL4-CH1 (118-131 / A118S) -281, 281VL4-CH1 (118-131 / S119A) -281, 281VL4-CH1 (118-131 / T120A) -281, 281VL4-CH1 (118 -131 / K121A) -281, 281VL4-CH1 (118-131 / G122A) -281, 281VL4-CH1 (118-131 / P123A) -281, 281VL4-CH1 (118-131 / S124A) -281, 281VL4-CH1 (118-131 / V125A) -281, 281VL4-CH1 (118-131 / F126A) -281, 281VL4-CH1 (118-131 / P127A
- 281VL4-CH1 (118-131 / A118S) -281, 281VL4-CH1 (118-131 / S119A) -281, 281VL4-CH1 (118-131 / T120A) -281, 281VL4-CH1 (118-131 / K121A)- 281, 281VL4-CH1 (118-131 / G122A) -281, 281VL4-CH1 (118-131 / P123A) -281, 281VL4-CH1 (118-131 / S124A) -281, 281VL4-CH1 (118-131 / V125A ) -281, 281VL4-C29H1 (118-131 / F126A) -281, 281VL4-CH1 (118-131 / P127A) -281, 281VL4-CH1 (118-131 / L128A) -281, 281VL4-CH1 (
- EU index Nos. 118 to 131) is inserted as a linker.
- the mutation added to each linker is one amino acid, and the amino acid of the CH1 sequence of IgG4 is substituted with alanine.
- alanine is replaced with cysteine.
- the gene sequences encoding the heavy chains of these antibodies were prepared with reference to the genetic procedure used in Example 24.
- the respective heavy chain nucleic acid sequences and heavy chain amino acid sequences are shown in the Sequence Listing (SEQ ID NOs: 181 to 206).
- Example 32 Preparation of an expression vector for a multivalent antibody having an antigen recognition site for CD28 (derived from 281VL4) on the N-terminal side and an antigen recognition site for CD40 (281-derived) on the C-terminal side and containing the linker shown in Table 12
- the heavy chain variable region of the anti-CD28 antibody 281VL4 is linked from the N-terminal side with the linker shown in Table 12.
- the expression vector retains one type of light chain sequence.
- These multivalent antibodies were 281VL4-CH1 (IGHA) -281, 281VL4-CH1 (IGHD (14))-281, 281VL4-CH1 (IGHD (15))-281, 281VL4-CH1 (IGHE) -281, 281VL4- They were named CH1 (IGHGP) -281 and 281VL4-CH1 (IGHM) -281.
- 281VL4-CH1 (IGHA) -281, 281VL4-CH1 (IGHD (14))-281, 281VL4-CH1 (IGHE) -281, 281VL4-CH1 (IGHGP) -281, 281VL4-CH1 (IGHM) -281
- the CH1 sequence of each subclass (Kabat EU index 118 to 131) is inserted as a linker.
- IGHD IGHD (15)-281, the CH1 sequence of IGHD (from 118 to 132) is inserted between the heavy chains as a linker.
- the gene sequences encoding the heavy chains of these antibodies were prepared with reference to the genetic procedure used in Example 24.
- the respective heavy chain nucleic acid sequences and heavy chain amino acid sequences are shown in the Sequence Listing (SEQ ID NOs: 207-218).
- Example 33 Preparation of an expression vector for a multivalent antibody having an antigen recognition site for CD28 (derived from 281VL4) on the N-terminal side and an antigen recognition site for CD40 (281-derived) on the C-terminal side, and containing the linkers shown in Table 13
- the recognition site for CD28 and the recognition site for CD40 are aligned from the N-terminal side of the heavy chain
- the heavy chain variable region of the anti-CD28 antibody 281VL4 is linked from the N-terminal side with the linker shown in Table 13.
- the expression vector retains one type of light chain sequence.
- These multivalent antibodies were 281VL4-CH1 (118-131 / A118G) -281, 281VL4-CH1 (118-131 / S119T) -281, 281VL4-CH1 (118-131 / P123F) -281, 281VL4-CH1 (118 -131 / V125L) -281, 281VL4-CH1 (118-131 / V125I) -281, 281VL4-CH1 (118-131 / F126L) -281, 281VL4-CH1 (118-131 / F126Y) -281, 281VL4-CH1 (118-131 / P127G) -281, 281VL4-CH1 (118-131 / L128V) -281, 281VL4-CH1 (118-131 / L128V) -281, 281VL4-CH1 (118-131
- 281VL4-CH1 (118-131 / A118G) -281, 281VL4-CH1 (118-131 / S119T) -281, 281VL4-CH1 (118-131 / P123F) -281, 281VL4-CH1 (118-131 / V125L)- 281, 281VL4-CH1 (118-131 / V125I) -281, 281VL4-CH1 (118-131 / F126L) -281, 281VL4-CH1 (118-131 / F126Y) -281, 281VL4-CH1 (118-131 / P127G ) -281, 281VL4-CH1 (118-131 / L128V) -281, 281VL4-CH1 (118-131 / L128I) -281, 281VL4-CH1 (118-131 / A129I) -281, 281VL4-CH1 (118
- Example 34 Expression and purification of multivalent antibody
- the expression vector gene prepared in Examples 29-33 was prepared with QIAGEN Plasmid Maxi Kit (Qiagen) and FreeStyle TM 293 Expression System (Invitrogen) was used. And introduced into suspension 293 cells to obtain culture supernatants containing each antibody by transient expression. Purified antibody was obtained from this culture supernatant according to the procedure of Example 16. The concentration of the purified antibody was determined by measuring the absorbance at 280 nm, and 1 mg / mL was calculated as the antibody concentration of 1.40 Optimal density.
- Example 35 Evaluation of antibody stability The aggregate content of the antibody solution was measured according to the procedure of Example 18. The results are shown in Table 14.
- Example 36 An antigen recognition site for CD28 (derived from 281VL4) at the N-terminal side and an antigen recognition site for CD40 (from 281) at the C-terminal side, and multiple sequences using human Ig subclass CH1 region sequences as linkers
- Table 1 The structure of the heavy chain variable region of the anti-CD28 antibody 281VL4 from the N-terminal side is shown in Table 1 in order to produce a multivalent antibody in which the recognition site for CD28 and the recognition site for CD40 are aligned from the N-terminal side of the heavy chain. It was tandemly bound to the heavy chain variable region of anti-CD40 antibody 281 via the indicated linker.
- a linker in which a sequence in the CH1 region of each human Ig subclass and a BamHI sequence GS (GGATCC) are added to the 3 ′ end thereof is inserted.
- GGATCC BamHI sequence GS
- Each of these multivalent antibodies 281VL4-A1 (118-143) GS-281, 281VL4-A2 (118-143) GS-281, 281VL4-E (118-143) GS-281, 281VL4-G1 (118-143) GS-281, 281VL4-G2 (118-143) GS-281, 281VL4-G3 (118-143) GS-281, 281VL4-HGP (118-143) GS-281, 281VL4-D (118-143) GS-281, 281VL4-M (118-143) GS-281 I named it.
- Table 15 summarizes the structures of the produced multivalent antibodies.
- Example 37 Preparation of multivalent antibody expression vector having an antigen recognition site for CD28 (from 281VL4) at the N-terminal side and an antigen recognition site for CD40 (from 281) at the C-terminal side, and comprising the linkers of SEQ ID NOs: 244,246,250,252,254,256,258
- the heavy chain variable region of anti-CD28 antibody 281VL4 is linked from the N-terminal side with a linker (SEQ ID NO: 244,246,250,252,254,256,258).
- the expression vector retains one type of light chain sequence.
- Multivalent antibody expression vector having an antigen recognition site for CD28 (derived from 281VL4) on the N-terminal side and an antigen recognition site for CD40 (derived from 281) on the C-terminal side, and comprising the linkers of SEQ ID NOs: 248 and 260
- the heavy chain variable region of anti-CD28 antibody 281VL4 is linked from the N-terminal side to a linker (SEQ ID NO: 248). 260) to the heavy chain variable region of anti-CD40 antibody 281 via tandem. Since the light chain uses a common light chain for both the anti-281 antibody and the anti-CD28 antibody, the expression vector retains one type of light chain sequence.
- the gene sequence encoding the heavy chain of 281VL4-linker (SEQ ID NO: 248, 260) -281 was prepared by the following procedure.
- KOD-Plus manufactured by Toyobo Co., Ltd.
- NheI CD40 Hc L 5′-CTAGCTAGCTGAGGAGACGGTGACCAGGGTTCCCTGGCCCCAGGGGTGG-3 ′ (SEQ ID NO: 275) as U primer, IgD CH1-2U 5′-CATATCAGGGTGCAGACACCCAAAGGATAACAGCCCTGTGGTCCTGGCA-3 ′ (SEQ ID NO: 2781) -2 U 5'-CTCGTCTCCTGTGAGAATTCCCCGTCGGATACGAGCAGCGTGGCCGTTG -3 '(SEQ ID NO: 279), DNA polymerase (KOD-Plus, manufactured by Toyobo Co., Ltd.), 30 cycles at 95 ° C for 30 seconds, 55 ° C for 30 seconds, 68 ° C for 30 seconds Carried out.
- 281VL4 heavy chain sequence as template and U primer as 5'-GGGGTCGACACCATGAAGCACCTGTGGTTCTTCCTCCTGCTGGTGGCGG-3 '(SEQ ID NO: 138) , CD28-IgD L 5'-CATCCGGAGCCTTGGTGGGTGCTGAGGAGACGGTGACCATTGTCCCTTG-3 '(SEQ ID NO: 282), CD28-IgM L 5'-GGGTTGGGGCGGATGCACTCCCTGAGGAGACGGTGACCATTGTCCCTTG-3' (SEQ ID NO: 283) as the L primer ), 30 cycles of reaction at 95 ° C. for 30 seconds, 55 ° C. for 30 seconds, and 68 ° C.
- SalI-281VL4-linker gene fragment having a SalI sequence at the 5 ′ end.
- the SalI-281VL4-linker gene fragment and the linker-281 heavy chain-NheI gene fragment were ligated by Over Extension PCR, and 5'-GGGGTCGACACCATGAAGCACCTGTGGTTCTTCCTCCTGCTGGTGGCGG-3 '(SEQ ID NO: 138) and NheI CD40 Hc L 5'-CTAGCTAGCTGAGGAGGTGGGGACCACCGGGCTGG Using 3 ′ (SEQ ID NO: 275), DNA polymerase (KOD-Plus, manufactured by Toyobo Co., Ltd.), performing 30 cycles of 95 ° C.
- a gene fragment of SalI-281VL4-linker-281-NheI having a SalI sequence and an NheI sequence at the 3 ′ end was prepared. This gene fragment was digested with SalI and NheI and inserted into an 281VL4 expression vector cleaved with SalI and NheI.
- 281VL4-D (118-144) GS-281 heavy chain nucleic acid sequence (SEQ ID NO: 284), 281VL4-D (118-143) GS-281 heavy chain amino acid sequence (SEQ ID NO: 285), 281VL4-M (118-143)
- the GS-281 heavy chain nucleic acid sequence (SEQ ID NO: 286) and 281VL4-M (118-143) GS-281 heavy chain amino acid sequence (SEQ ID NO: 287) are shown in the sequence listing, respectively.
- Example 39 Expression of a multivalent antibody having an antigen recognition site for CD28 (derived from 281VL4) on the N-terminal side and an antigen recognition site for CD40 (derived from 281) on the C-terminal side and containing the linkers of SEQ ID NOs: 244 to 260 And purification
- the prepared expression vector gene is prepared with QIAGEN Plasmid Maxi Kit (Qiagen), introduced into suspension 293 cells using FreeStyle TM 293 Expression System (Invitrogen), and each expression by transient expression. A culture supernatant containing the antibody was obtained. Purified antibody was obtained from this culture supernatant according to the procedure of Example 16. The concentration of the purified antibody was determined by measuring the absorbance at 280 nm, and 1 mg / mL was calculated as the antibody concentration of 1.40 Optimal density.
- Example 40 Production of a multivalent antibody having an antigen recognition site for CD28 (derived from 281VL4) on the N-terminal side and an antigen recognition site for CD40 (derived from 281) on the C-terminal side and containing the linkers of SEQ ID NOs: 244 to 260 The antibody content in each culture supernatant was measured as antibody productivity. The antibody content was measured according to the procedure of Example 17. The results are shown in Table 16.
- Example 41 Stabilization of a multivalent antibody having an antigen recognition site (derived from 281VL4) for CD28 on the N-terminal side and an antigen recognition site (derived from 281) for CD40 on the C-terminal side and containing the linkers of SEQ ID NOs: 244 to 260 Evaluation of Sex The aggregate content of the antibody solution was measured according to the procedure of Example 18. The results are shown in Table 17.
- An antigen recognition site (derived from 281VL4) for CD28 has an antigen recognition site (derived from 281) for CD40 on the N-terminal side and a sequence of IgG2CH1 region (SEQ ID NOs: 254, 289,291,293,295,297, 299,301,303,305,307,309,311) Structure of the multivalent antibody used as a linker From the N-terminal side, the heavy chain variable region of the anti-CD28 antibody 281VL4 is used to produce a multivalent antibody in which the recognition site for CD28 and the recognition site for CD40 are aligned from the N-terminal side of the heavy chain.
- 281VL4-G2 (118-143) GS-281 is shown in Example 36. Further, 281VL4-CH1 (118-131) -281 shown in Example 24 was used as a linker using Kabat EU index No. 118 to No. 131 as a linker.
- Table 18 summarizes the structures of the produced multivalent antibodies.
- Multivalent antibody expression vector having an antigen recognition site (derived from 281VL4) for CD28 on the N-terminal side and an antigen recognition site (derived from 281) for CD40 on the C-terminal side, and containing a linker of SEQ ID NOs: 289,291,293,295,297,299,301,303,305,307,309
- the heavy chain variable region of anti-CD28 antibody 281VL4 is linked from the N-terminal side to a linker (SEQ ID NOs: 289,291,293,295,297 , 299, 301, 303, 305, 307, 309) to the heavy chain variable region of anti-CD40 antibody 281 in tandem. Since the light chain uses a common light chain for both the anti-281 antibody and the anti-CD28 antibody, the expression vector retains one type of light chain
- Example 44 Expression and purification of multivalent antibody
- the prepared expression vector gene was prepared with the QIAGEN Plasmid Maxi Kit (Qiagen), and free floating 293 cells using FreeStyle TM 293 Expression System (Invitrogen).
- the culture supernatant containing each antibody was obtained by transient expression.
- Purified antibody was obtained from this culture supernatant according to the procedure of Example 16.
- the concentration of the purified antibody was determined by measuring the absorbance at 280 nm, and 1 mg / mL was calculated as the antibody concentration of 1.40 Optimal density.
- Example 45 Measurement of antibody productivity As antibody productivity, the antibody content in each culture supernatant was measured. The antibody content was measured according to the procedure of Example 17. The results are shown in Table 19.
- Example 46 Evaluation of antibody stability The aggregate content of the antibody solution was measured according to the procedure of Example 18. The results are shown in Table 20.
- the antibody of the present invention is characterized by being highly stable and capable of being produced with high productivity, and has utility as a pharmaceutical or diagnostic antibody.
Abstract
この発明は、複数の抗体重鎖可変領域をイムノグロブリンドメインまたは該断片のアミノ酸配列を有するリンカーを介して結合していることを特徴とする安定な多価抗体に関する。
Description
本発明は、複数の抗体重鎖可変領域(以下、VHと記す)がイムノグロブリンドメインまたはその断片を介して結合している多価抗体、該多価抗体のアミノ酸配列をコードするDNA、該DNAを含むベクター、多価抗体を発現する形質転換体および該形質転換体を用いて多価抗体を製造する方法に関する。
イムノグロブリンは、すべての哺乳動物の血清や組織体液中に存在する糖蛋白質で、外来抗原を認識する働きをもっている(非特許文献1)。抗体は、補体系の活性化や、細胞表面に存在するレセプター(FcR)を介し、細胞の食作用、抗体依存性細胞障害作用、メディエーターの遊離作用、抗原提示作用などのエフェクター機能の活性化を介して、生体防御にかかわっている。ヒトのイムノグロブリンには、5つの異なったクラス、IgG, IgA, IgM, IgD, IgEが存在する。IgGはさらにIgG1,IgG2,IgG3,IgG4のサブクラスに、IgAは、IgA1,IgA2のサブクラスに分類することが出来る。イムノグロブリンの基本構造は、2本の相同な軽鎖(L鎖)と、2本の相同な重鎖(H鎖)から成り立っている。イムノグロブリンのクラスとサブクラスはH鎖によって決定される。それぞれのクラス、サブクラスのイムノグロブリンは異なった機能をもつことが解っている。たとえば、補体結合能は、IgM>IgG3>IgG1>IgG2の順で強い。また、Fcレセプターへの親和性は、IgG3>IgG1>IgG4>IgG2の順で高くなっている。プロテインAへは、IgG1,IgG2,IgG4が結合することができる。抗体は重鎖と軽鎖の組み合わせによって、結合する抗原が決定する。IgGの場合、1分子が2組の重鎖と軽鎖から構成され、抗体1分子当り2つの抗原結合部位を保有する。
近年数多くのモノクローナル抗体に関して臨床試験が実施されており、上市されているモノクローナル抗体も数多くある(非特許文献2)。1986年にマウス抗CD3抗体、muromonab-CD3がFDAから承認された。1994年には、抗原性を低減するために、抗体の定常領域をマウス型からヒト型に変換したキメラ抗体abciximabが承認を受けた。さらに抗原性を低減するためにヒト化技術が開発され、1997年には、可変領域をヒト化した、抗CD20ヒト化抗体、dacizumabが承認を受けた。2002年には、完全ヒト抗TNF抗体、adalimumabが承認された。
抗体の活性を変化させることを目的として、様々な抗体の変異体を作る試みが行われてきた。例えば、異なる抗原を認識する複数の異なるポリペプチド鎖を重鎖や軽鎖として有する多価抗体が、ハイブリッドハイブリドーマにより作製されている。しかし、この方法を用いた場合、2種類の異なる重鎖、軽鎖を一つの細胞で発現することから、抗体の重鎖と軽鎖の組み合わせが10通り程度できる。このことから、結果として求める重鎖と軽鎖の組み合わせを正しく有する多価抗体の生産性が低下し、目的の多価抗体を単離精製することが難しい(非特許文献3)。
この問題点を克服するために、1つのポリペプチド鎖の中に複数の抗原認識部位を連結することにより、サブユニット間の組み合わせのバリエーションを減らし、正しいポリペプチドの組み合わせを有する抗体を生産する試みが報告されている。例えば、重鎖と軽鎖の抗原認識部位を1つのポリペプチドで連結したscFvを含有した抗体(非特許文献4)が知られている。さらに、抗体IgG1抗体のH鎖定常領域CH1ドメインあるいは該ドメインの部分断片、L鎖定常領域またはフレキシブルリンカー(Gly-Gly-Gly-Gly-Ser)を用いて、二つの抗原認識部位を連結させた抗体(非特許文献5、特許文献1、特許文献2)などが報告されている。
しかしながら、このような従来の多価抗体は、抗体タンパク質が凝集し易く、安定性や生産性が低いという欠点があった。
Charles A. Janeway et. al. Immunobiology, 1997, Current Biology Ltd/Garland Publishing Inc.
Emmanuelle Laffy et. al., Human Antibodies 14, 33-55, 2005
Suresh et. al., Methods Enzymol. 121, 210-228, 1986
Gruber et. Al., J. Immunol. 152, 5369, 1994
Wu et. Al., Nat. Biothech. 25, 1290-1297, 2007
Kabat et. al., Sequences of proteins of immunological interest, 1991 Fifth edition
Tomizuka. et al., Proc Natl Acad Sci USA., 2000 Vol 97:722
Yelton, D.E. et al. Current Topics in Microbiology and Immunology, 81, 1-7(1978)
Kohler, G. et al. European J. Immunology, 6, 511-519 (1976)
Shulman, M. et al. Nature, 276, 269-270 (1978)
Kearney, J. F. et al. J. Immunology, 123, 1548-1550(1979)
Horibata, K. and Harris, A. W. Nature, 256, 495-497 (1975)
P.J.Delves., ANTIBODY PRODUCTION ESSENTIAL TECHNIQUES., 1997 WILEY
P.Shepherd and C.Dean. Monoclonal Antibodies., 2000 OXFORD UNIVERSITY PRESS,
J.W.Goding. Monoclonal Antibodies:principles and practice., 1993 ACADEMIC PRESS
複数の抗原認識部位を有する多価抗体であって、安定性および生産性に優れた多価抗体が従来から求められてきた。
本発明者らは、上記課題を解決すべく鋭意検討した結果、1つの重鎖ポリペプチド中に複数の抗原認識部位を有する多価抗体において、抗原認識部位が互いに近接していない多価抗体の安定性が高く、かつ、生産性も良いことを見出した。
本発明者らは、このような多価抗体が安定性や生産性に優れ、よって種々の医薬品や研究用試薬として有用であることを見出し、これらの知見に基づき本発明を完成させるに至った。
すなわち、本発明は、要約すると、以下の特徴を含む。
(1) 複数の抗体重鎖可変領域(以下、VHと記す)がイムノグロブリンドメインまたはその断片のアミノ酸配列を有するリンカーを介して結合していることを特徴とする多価抗体。
(2) イムノグロブリンドメインが、CH1、ヒンジ、CH2、および/またはCH3からなるイムノグロブリンドメインである、(1)記載の多価抗体。
(3) イムノグロブリンドメインが、CH1またはCH1断片である、(2)記載の多価抗体。
(4) CH1断片が、14番目がシステイン(Cys)である14アミノ酸からなるCH1断片である、(3)記載の多価抗体。
(5) CH1断片が、IgD, IgM, IgG, IgAおよびIgEの抗体サブクラスから選ばれるCH1のアミノ酸配列のN末端から1番目~14番目のアミノ酸配列である、(4)記載の多価抗体。
(6) CH1断片のアミノ酸配列が、配列番号311および配列番号334~配列番号361から選ばれるいずれか1つのアミノ酸配列である、(5)記載の多価抗体。
(7) CH1断片のアミノ酸配列が、配列番号362~配列番号375から選ばれるいずれか1つのアミノ酸配列である、(3)記載の多価抗体。
(8) 同一の軽鎖を含む、(1)~(7)のいずれかに記載の多価抗体。
(9) (1)~(8)のいずれかに記載の多価抗体のアミノ酸配列をコードするDNA。
(10) (9)記載のDNAを含む組換えベクター。
(11) (10)に記載の組換えベクターが導入された形質転換体。
(12) (11)に記載の形質転換体を培地に培養し、培養物中に(1)~(8)のいずれかに記載の多価抗体を生成蓄積させ、培養物から該抗体または該抗体断片を採取することを特徴とする(1)~(8)のいずれかに記載の多価抗体の製造方法。
本発明に係る多価抗体は、安定性に優れ、生産性が良い。本発明に係る多価抗体はまた、種々の疾患に対する治療薬や診断薬として使用できる。さらに本発明に係る多価抗体は安定な研究用試薬としても使用できる。
本明細書は本願の優先権の基礎である日本国特許出願2008-115463号の明細書および/または図面に記載される内容を包含する。
本明細書中で使用される用語は、以下の定義を含むものとする。
「抗体」とは、イムノグロブリンを構成する重鎖の可変領域及び重鎖の定常領域、並びに軽鎖の可変領域及び軽鎖の定常領域、の全部または一部をコードする遺伝子(「抗体遺伝子」と総称する)に由来するものである。本発明の抗体には、いずれのイムノグロブリンクラス及びサブクラスを有する抗体をも包含する。
「ヒト抗体」とは、ヒト由来の抗体遺伝子の配列を有する抗体を意味し、例えばヒトB細胞ハイブリドーマ、ヒト化SCIDマウス、ヒト抗体遺伝子発現マウス、ヒト抗体遺伝子ライブラリーからPhage Display、Yeast Display等の技術により取得することができる。ヒト化抗体とは、ヒト以外の動物から取得された抗体の配列の一部をヒト抗体の配列に置換した抗体を示す(Emmanuelle Laffy et. al., Human Antibodies 14, 33-55, 2005)。
「重鎖」とは、イムノグロブリン分子を構成する2種類のポリペプチド(H鎖、L鎖)のうち、分子量が大きいほうのポリペプチドのことを示す。抗体のクラスとサブクラスを決定する。IgG1,IgG2,IgG4, IgA1,IgA2, IgM, IgD, IgEはそれぞれ、重鎖の定常領域として異なったアミノ酸配列を有する。
「軽鎖」とは、イムノグロブリン分子を構成する2種類のポリペプチド(H鎖、L鎖)のうち、分子量が小さいほうのポリペプチドのことを示す。ヒトの抗体の場合カッパとラムダの2種類が存在する。
「可変領域」(variable region:V領域とも呼ばれる。)とは、通常イムノグロブリンのN末側にあるアミノ酸配列の多様性に富んだ領域を示す。それ以外の部分は多様性の少ない構造をしているので「定常領域」(constant region:C領域とも呼ばれる。)と呼ばれる。重鎖と軽鎖の可変領域は複合体を形成し、抗体の抗原への特性を決定する。ヒトの抗体の重鎖ではKabatらのEUインデックス(Kabat et. al., Sequences of proteins of immunological interest, 1991 Fifth edition)における1番目から117番目までが可変領域であり、118番目のアミノ酸から定常領域が始まる。ヒトの抗体の軽鎖ではKabatらのEUインデックスにおける1番目から107番目までが可変領域であり、108番目のアミノ酸から定常領域が始まる。また、以下において、重鎖可変領域または軽鎖可変領域を、VHまたはVLと略記する。
「抗原認識部位」とは、抗原を認識する部位であり、抗原決定基(エピトープ)と相補的な立体構造を形成する部位を示す。抗原認識部位は抗原決定基と強い分子間相互作用を起こすことができる。抗原認識部位は少なくとも3つの相補性決定領域(complementary determining region: CDR略す。)を含む重鎖可変領域(VH)または軽鎖可変領域(VL)があげられる。ヒトの抗体の場合、重鎖および軽鎖の可変領域はそれぞれ3つの相補性決定領域(CDR)を有し、抗原認識部位を含む。これらのCDRは、それぞれN末側から順番にCDR1、CDR2、CDR3と呼ばれる。
「多価抗体」とは、重鎖および/または軽鎖に抗原認識部位を少なくとも2つ以上有する抗体を示す。それぞれの抗原認識部位は同一の抗原決定基を認識してもいいし、異なる抗原決定基を認識してもいい。
本発明の多価抗体は、複数の抗体重鎖可変領域がイムノグロブリンドメイン又はその断片を介して結合している多価抗体である。
本発明の多価抗体として具体的には、(a)1つの重鎖ポリペプチドに複数(例えば2~5個)の異なる抗原認識部位を含み、抗原認識部位は互いに離間して近接していないこと、(b)抗原認識部位は10アミノ酸以上、好ましくは50アミノ酸以上、より好ましくは50~500アミノ酸のポリペプチドリンカーを介してタンデム(縦列)に連結されていること、具体的には、抗原認識部位は、例えばイムノグロブリンドメインの全部又は一部のアミノ酸配列を有するリンカーを用いて連結されていること、(c)軽鎖の抗原認識部位が対応する重鎖の抗原認識部位と複合体を形成していること、(d)図1に示されるように2本の重鎖ポリペプチドと少なくとも4本の軽鎖ポリペプチドからなる抗体構造を有すること、並びに、2本の重鎖ポリペプチド間は、ヒンジ領域でジスルフィド結合で連結され、軽鎖ポリペプチドと重鎖ポリペプチド間もジスルフィド結合で連結されていること、或いは、(e)重鎖の定常領域は、例えば天然型抗体重鎖の定常領域の全部又は一部(例えば,CH1断片, CH1, CH2, CH3, CH1-ヒンジ, CH1-ヒンジ-CH2, CH1-ヒンジ-CH2-CH3など)からなること、などを含む。
さらに具体的には、図1に多価抗体の構造例とともに、リンカー構造が示されている。
「イムノグロブリンドメイン」とは、イムノグロブリンと類似のアミノ酸配列を持ち、少なくとも2個のシステイン残基が存在する約100個のアミノ酸残基からなるペプチドを示す。イムノグロブリンドメインとしては、イムノグロブリン重鎖のVH, CH1, CH2およびCH3や、イムノグロブリン軽鎖のVLおよびCLなどがあげられる。また、イムノグロブリンドメインはイムノグロブリン以外のタンパク質にも存在し、例えば主要組織適合抗原(MHC)、CD1、B7、T細胞受容体(TCR)などのイムノグロブリンスーパーファミリーに属するタンパク質に含まれているイムノグロブリンドメインがあげられる。本発明の多価抗体に用いられるイムノグロブリンドメインとしては、いずれのイムノグロブリンドメインも使用可能である。
単一の抗原を認識する抗体をモノクローナル抗体という。
モノクローナル抗体とは、単一クローンの抗体産生細胞が分泌する抗体であり、ただ一つのエピトープ(抗原決定基ともいう)を認識し、モノクローナル抗体を構成するアミノ酸配列(1次構造)が均一である。
エピトープとは、モノクローナル抗体が認識し、結合する単一のアミノ酸配列、アミノ酸配列からなる立体構造、糖鎖が結合したアミノ酸配列および糖鎖が結合したアミノ酸配列からなる立体構造などがあげられる。
CH1とCH2の間には「ヒンジ(蝶番)領域」と呼ばれる柔軟性に富んだアミノ酸領域が存在する。
ヒトの抗体の場合、CH1はEUインデックス118番目から215番目のアミノ酸配列を有する領域を示す。同様にヒンジ領域はEUインデックス216番目から230番目、CH2はEUインデックス231番目から340番目、CH3はEUインデックス341番目から446番目のアミノ酸配列を有する領域を示す。
「CL」は軽鎖の定常領域を示す。ヒトの抗体のカッパ鎖の場合、KabatらのEUインデックス108番目から214番目、ラムダ鎖の場合、108番目から215番目のアミノ酸配列を有する領域を示す。
「リンカー」とは、2つの抗原認識部位をつなぐ化学構造を示す。望ましくはポリペプチドを意味する。
本発明の多価抗体に用いられるリンカーとしては、イムノグロブリンドメインの全部又は一部のアミノ酸配列を有するリンカーや、複数のイムノグロブリンドメインからなるリンカーの全部又は一部のアミノ酸配列を有するリンカーが望ましい。
イムノグロブリンドメインから選ばれるアミノ酸配列は断続的でも連続的でも良いが、好ましくは連続するアミノ酸配列が良い。本発明において、望むべきリンカーとしては、10アミノ酸以上の長さを有したポリペプチド、好ましくは14アミノ酸以上、さらに望ましくは50アミノ酸以上、例えば50アミノ酸以上500アミノ酸以下の長さのポリペプチドを示す。
本発明において、リンカーの1つの例として抗体のCH1、ヒンジ、CH2およびCH3からなるアミノ酸配列の、全部又は一部の断片を適宜組み合わせて用いることができる。また、それらのアミノ酸配列を部分的に欠損させたり、順番を入れ替えて使用することもできる。
本発明の多価抗体に用いられるイムノグロブリンドメインおよびその断片としては、(N末端からC末端への向きで)、非限定的に、CH1-ヒンジ-CH2-CH3からなるイムノグロブリンドメイン、CH1-ヒンジ-CH2からなるイムノグロブリンドメイン、CH1-ヒンジからなるイムノグロブリンドメイン、CH1からなるイムノグロブリンドメイン、CH1のN末端側の断片、CH1の14番目のアミノ酸がCysである14アミノ酸残基からなるCH1断片、CH1のN末端側から14アミノ酸残基からなるCH1断片、およびこれらイムノグロブリンドメイン断片のアミノ酸配列において、1つ以上のアミノ酸残基が改変されたものをあげることができる。
イムノグロブリンドメインおよびその断片は、イムノグロブリンサブクラスIgD、IgM、IgG1、IgG2、IgG3、IgG4、IgA1、IgA1およびIgEのいずれのサブクラス由来のものでもよく、好ましくは、IgG、IgM由来があげられる。
本発明において、イムノグロブリンドメインおよび該断片としてより具体的には、配列番号99に示されるCH1、ヒンジ、CH2およびCH3からなるイムノグロブリンドメイン、配列番号99の1~219番目のアミノ酸配列で示されるCH1、ヒンジおよびCH2からなるイムノグロブリンドメイン、配列番号99の1~94番目のアミノ酸配列で示されるCH1およびヒンジからなるイムノグロブリンドメインおよび配列番号77に示されるCH1からなるイムノグロブリンドメインをあげることができる。
また、本発明において、CH1断片としては、配列番号362~375に示されるCH1断片、CH1の14番目のアミノ酸がCysである14アミノ酸残基からなるCH1断片またはCH1のN末端側14アミノ酸残基からなるCH1断片をあげることができ、より具体的には、配列番号311および配列番号334~361をあげることができる。
本発明の多価抗体としては、上述のイムノグロブリンドメインまたはその断片を用いて結合させた2つ以上の重鎖可変領域を有する多価抗体があげられる。3つ以上の重鎖可変領域を結合させる場合には、異なるイムノグロブリンドメインまたはその断片を用いても良い、同じイムノグロブリンドメインまたはその断片を用いることもできる。また、2つ以上の重鎖可変領域を連結させる場合には、各VHが特異的抗原に結合可能なようにイムノグロブリンドメインまたはその断片の長さや種類を変えることができる。
本発明において、多価抗体に含まれる軽鎖可変領域は、同一の軽鎖可変領域であっても、異なる軽鎖可変領域であってもいずれでもよい。同一の軽鎖可変領域を有する2つ以上の抗原に結合することができる多価抗体の重鎖可変領域は、各抗体可変領域がそれぞれ特異的な抗原に結合できるように、ファージディプレイなどの方法を用いて適切な重鎖可変領域を選択することができる。
本発明において多価抗体が結合する抗原としては、以下のものに限定されないが、例えば、癌、自己免疫疾患、アレルギー疾患等の異常な細胞増殖を伴う疾患に関連した抗原、臓器再生や組織再生に関与する抗原などの抗原が挙げられ、本発明の多価抗体は、それら2つ以上の異なる抗原またはエピトープに結合することができる。すなわち、本発明の多価抗体は、異なる2つの抗原に結合することもできるし、1つの抗原上に存在する異なる2つのエピトープに結合することもできる。また、本発明の多価抗体は、抗原に結合して該抗原を活性化することも、不活性化することもできることから、標的とする疾患に合わせた抗原を選択することができる。以下に、本発明の多価抗体の標的となり得る抗原を例示するが、これに限定されない。
抗体の結合によりアポトーシスが誘導される抗原としては、Cluster of differentiation(以下、CDと記載する)19、CD20、CD21、CD22、CD23、CD24、CD37、CD53、CD72、CD73、CD74、CDw75、CDw76、CD77、CDw78、CD79a、CD79b、CD80(B7.1)、CD81、CD82、CD83、CDw84、CD85、CD86(B7.2)、human leukocyte antigen(HLA)-Class II、またはEpidermal Growth Factor Receptor(EGFR)などがあげられる。
腫瘍の病態形成に関わる抗原または免疫機能を調節する抗体の抗原としては、CD40、CD40リガンド、B7ファミリー分子(CD80、CD86、CD274、B7-DC、B7-H2、B7-H3、またはB7-H4)、B7ファミリー分子のリガンド(CD28、CTLA-4、ICOS、PD-1、またはBTLA)、OX-40、OX-40リガンド、CD137、tumor necrosis factor(TNF)受容体ファミリー分子(DR4、DR5、TNFR1、またはTNFR2)、TNF-related apoptosis-inducing ligand receptor(TRAIL)ファミリー分子、TRAILファミリー分子の受容体ファミリー(TRAIL-R1、TRAIL-R2、TRAIL-R3、またはTRAIL-R4)、receptor activator of nuclear factor kappa B ligand(RANK)、RANKリガンド、CD25、葉酸受容体4、サイトカイン[IL-1α、IL-1β、IL-4、IL-5、IL-6、IL-10、IL-13、transforming growth factor(TGF)β、またはTNFαなど]、これらのサイトカインの受容体、ケモカイン(SLC、ELC、I-309、TARC、MDC、またはCTACKなど)、またはこれらのケモカインの受容体、およびvascular endothelial growth factor(VEGF)、Angiopoietin、fibroblast growth factor(FGF)、EGF、platelet-derived growth factor(PDGF)、insulin-like growth factor(IGF)、hepatocyte growth factor(HGF)、erythropoietin(EPO)、TGFβ、IL-8、Ephilin、SDF-1、またはこれらの受容体があげられる。
異常組織の血管新生に関与する抗原、または臓器再生および組織再生に関与する抗原としては、VEGF、Angiopoietin、FGF、EGF、PDGF、IGF、HGF、EPO、TGFβ、IL-8、Ephilin、SDF-1、またはこれらの受容体などがあげられる。
本発明において、多価抗体のエフェクター活性は、以下のようにして制御することができる。
抗体のFc領域(CH2およびCH3ドメインからなる定常領域)の297番目のアスパラギン(Asn)に結合するN結合複合型糖鎖の還元末端に存在するN-アセチルグルコサミン(GlcNAc)にα-1,6結合するフコース(コアフコースともいう)の量を制御する方法(WO2005/035586、WO2002/31140、WO00/61739)や、抗体のFc領域のアミノ酸残基を改変することで制御する方法などが知られている。本発明の多価抗体はいずれの方法を用いても、エフェクター活性を制御することができる。
エフェクター活性とは、抗体のFc領域を介して引き起こされる抗体依存性の活性をいい、抗体依存性細胞傷害活性(ADCC活性)、補体依存性傷害活性(CDC活性)や、マクロファージや樹状細胞などの食細胞による抗体依存性ファゴサイトーシス(Antibody-dependent phagocytosis,ADP活性)などが知られている。
多価抗体のFcのN結合複合型糖鎖のコアフコースの含量を制御することで、多価抗体のエフェクター活性を増加または低下させることができる。抗体のFcに結合しているN結合複合型糖鎖に結合するフコースの含量を低下させる方法としては、α1,6-フコース転移酵素遺伝子が欠損したCHO細胞を用いて多価抗体を発現することで、フコースが結合していない多価抗体を取得することができる。フコースが結合していない多価抗体は高いADCC活性を有する。一方、多価抗体のFcに結合しているN結合複合型糖鎖に結合するフコースの含量を増加させる方法としては、α1,6-フコース転移酵素遺伝子を導入した宿主細胞を用いて抗体を発現させることで、フコースが結合している多価抗体を取得できる。フコースが結合している多価抗体は、フコースが結合していない抗体よりも低いADCC活性を有する。
また、多価抗体のFc領域のアミノ酸残基を改変することでADCC活性やCDC活性を増加または低下させることができる。例えば、US2007/0148165に記載のFc領域のアミノ酸配列を用いることで、多価抗体のCDC活性を増加させることができる。また、US6,737,056、US7,297,775、やUS7,317,091に記載のアミノ酸改変を行うことで、ADCC活性またはCDC活性を、増加させることも低下させることもできる。
更に、上述の方法を組み合わせて、一つの多価抗体に使用することにより、多価抗体のエフェクター活性が制御された多価抗体を取得することができる。
本発明に多価抗体をコードするDNA配列において、重鎖可変領域とリンカーの間に制限酵素部位を導入することによって、重鎖可変領域とリンカーの配列を様々に変更することが容易になる。
本発明の多価抗体の安定性は、精製過程や一定条件下で保存されたサンプルにおいて形成される凝集体(オリゴマー)量を測定することによって評価できる。すなわち、同一条件で凝集体量が低減する場合、抗体の安定性が向上したとする。凝集体量は、ゲルろ過クロマトグラフィーを含む適当なクロマトグラフィーを用いて凝集した抗体と凝集していない抗体を分離することによって測定することができる。凝集体量を測定する方法は、実施例18に例示されている。
本発明の多価抗体の生産性は、抗体産生細胞から培養液中に産生される抗体量を測定することによって評価できる。より具体的には、培養液から産生細胞を除いた培養上清に含まれる抗体の量をHPLC法やELISA法などの適当な方法で測定することによって評価できる。生産性を測定する方法は、実施例17に例示されている。
本発明の抗体については、使用する対象動物や目的に応じて、重鎖及び軽鎖の可変領域及び定常領域としていかなる動物に由来するものを使用するかを決定することができる。例えば、対象動物がヒトの場合には、可変領域は、例えばヒト又はマウス由来とし、定常領域をヒト由来とし、及びリンカーはヒト由来とすることができる。
本明細書において「動物」は、通常、ヒト、サル、チンパンジー、マウス、ラット、ウシ、ブタ、ヤギ、ヒツジ、ラクダ、トリ等を含む哺乳動物を指す。
本発明の抗体の具体例が後述の実施例に記載されるが、本発明の抗体には、抗体の誘導体も包含される。誘導体には、例えば1~約30個、好ましくは1もしくは数個(例えば、1~10個、好ましくは1~5個、さらに好ましくは1~3個)のアミノ酸の置換、欠失、付加及び/又は挿入が含まれる。アミノ酸置換の例は、保存的アミノ酸置換であり、この置換は、電荷、極性(もしくは疎水性)又は側鎖の構造が類似したアミノ酸間の置換を意味し、例えば塩基性アミノ酸(Lys, Arg, His)、酸性アミノ酸(Asp, Glu)、無電荷極性アミノ酸(Gly, Asn, Gln, Ser, Thr, Tyr, Cys)、無極性アミノ酸(Ala, Val, Leu, Ile, Pro)、芳香族アミノ酸(Phe, Trp, Tyr, His)などに分けることができる。
さらに、本発明の抗体は、化学修飾されていてもよい。このような修飾には、ペグ化、アセチル化、アミド化、リン酸化、グリコシル化などが含まれ、一般に、修飾は、アミノ基、カルボキシル基、ヒドロキシル基などの官能基を介して行うことができる。或いは、本発明の抗体は、医薬又は診断用物質とコンジュゲートしてもよい。医薬又は診断用物質は、特に限定されず、例えばペプチド、ポリペプチド、核酸、小分子、無機元素、無機分子、有機分子などを含む。医薬物質は、生体内の標的部位で治療効能を発揮しうる物質であり、例えば抗癌剤、抗ウイルス剤などが挙げられる。診断用物質は、例えば放射性同位元素を含む。コンジュゲーションには、共有結合、非共有結合、ビオチン/アビジン(又はストレプトアビジン)系などを利用することができる。或いは、本発明の抗体は、固相(例えば樹脂、プラスチック、紙、金属など)、例えばプレート、ビーズ、テストストリップ、アレイなどに固定されていてもよい。
以下、多価抗体の作製法を詳述するが、該抗体の作製法はこれに限定されない。
(1)モノクローナル抗体の作製方法
本発明において、抗体の製造にあたっては、下記の作業工程を包含する。
本発明において、抗体の製造にあたっては、下記の作業工程を包含する。
すなわち、(1)免疫原として使用する抗原の精製及び/又は抗原を細胞表面に過剰に発現している細胞の作製、(2)抗原を動物に免疫した後、血液を採取しその抗体価を検定して脾臓等の摘出の時期を決定し、抗体産生細胞を調製する工程、(3)骨髄腫細胞(以下「ミエローマ」という)の調製、(4)抗体産生細胞とミエローマとの細胞融合によるハイブリドーマの作製、(5)目的とする抗体を産生するハイブリドーマ群の選別、(6)単一細胞クローンへの分割(クローニング)、等である。
以下、モノクローナル抗体の作製法を上記工程に沿って詳述するが、該抗体の作製法はこれに制限されず、例えば脾細胞以外の抗体産生細胞及びミエローマを使用することもできる。また動物血清由来の抗体を用いることも可能である。
(1-1) 抗原の精製
タンパク質の抗原としては、抗原タンパク質をそのまま利用してもいいし、抗原タンパク質を適当な他のポリペプチドと融合した融合タンパク質として利用してもいい。例えば、抗原タンパク質の細胞外領域とヒトIgGのFc領域、もしくはグルタチオンS-トランスフェラーゼ(GST)との融合タンパク質を用いることができる。抗原の細胞外領域とヒトIgGの定常領域、もしくはGSTとの融合タンパク質をコードするDNAを動物細胞用発現ベクターに組み込み、該発現ベクターを動物細胞に導入し、取得した形質転換株の培養上清から精製することにより取得できる。また、ヒト細胞株の細胞膜上に存在する抗原そのものを精製したものも、抗原として使用することができる。
タンパク質の抗原としては、抗原タンパク質をそのまま利用してもいいし、抗原タンパク質を適当な他のポリペプチドと融合した融合タンパク質として利用してもいい。例えば、抗原タンパク質の細胞外領域とヒトIgGのFc領域、もしくはグルタチオンS-トランスフェラーゼ(GST)との融合タンパク質を用いることができる。抗原の細胞外領域とヒトIgGの定常領域、もしくはGSTとの融合タンパク質をコードするDNAを動物細胞用発現ベクターに組み込み、該発現ベクターを動物細胞に導入し、取得した形質転換株の培養上清から精製することにより取得できる。また、ヒト細胞株の細胞膜上に存在する抗原そのものを精製したものも、抗原として使用することができる。
(1-2)抗体産生細胞の調製工程
(1-1)で得られた抗原と、フロインドの完全若しくは不完全アジュバント、又はカリミョウバンのような助剤とを混合し、免疫原として実験動物に免疫する。実験動物としては例えばマウスを使用できる。ヒト由来の抗体を産生する能力を有するトランスジェニックマウスが最も好適に用いられるが、そのようなマウスは富塚らの文献(Tomizuka. et al., Proc Natl Acad Sci USA., 2000 Vol 97:722)に記載されている。
(1-1)で得られた抗原と、フロインドの完全若しくは不完全アジュバント、又はカリミョウバンのような助剤とを混合し、免疫原として実験動物に免疫する。実験動物としては例えばマウスを使用できる。ヒト由来の抗体を産生する能力を有するトランスジェニックマウスが最も好適に用いられるが、そのようなマウスは富塚らの文献(Tomizuka. et al., Proc Natl Acad Sci USA., 2000 Vol 97:722)に記載されている。
マウス免疫の際の免疫原投与法は、皮下注射、腹腔内注射、静脈内注射、皮内注射、筋肉内注射、足蹠注射などいずれでもよいが、腹腔内注射、足蹠注射又は静脈内注射が好ましい。
免疫は、一回、又は、適当な間隔で(好ましくは3日間から1週間間隔で)複数回繰返し行なうことができる。その後、免疫した動物の血清中の抗原に対する抗体価を測定し、抗体価が十分高くなった動物を抗体産生細胞の供給原として用いれば、以後の操作の効果を高めることができる。一般的には、最終免疫後3~5日後の動物由来の抗体産生細胞を、後の細胞融合に用いることが好ましい。
ここで用いられる抗体価の測定法としては、放射性同位元素免疫定量法(以下「RIA法」という)、固相酵素免疫定量法(以下「ELISA法」という)、蛍光抗体法、受身血球凝集反応法など種々の公知技術が利用できる。
本発明における抗体価の測定は、例えばELISA法によれば、以下に記載するような手順により行うことができる。まず、精製又は部分精製した抗原をELISA用96穴プレート等の固相表面に吸着させ、さらに抗原が吸着していない固相表面を抗原と無関係なタンパク質、例えばウシ血清アルブミン(以下「BSA」という)により覆い、該表面を洗浄後、一次抗体として段階希釈した試料(例えばマウス血清)に接触させ、上記抗原に試料中の抗体を結合させる。さらに二次抗体として酵素標識されたヒト抗体に対する抗体を加えてヒト抗体に結合させ、洗浄後該酵素の基質を加え、基質分解に基づく発色による吸光度の変化等を測定することにより、抗体価を算出する。
(1-3)ミエローマの調製工程
ミエローマとしては、マウス、ラット、モルモット、ハムスター、ウサギ又はヒト等の哺乳動物に由来する自己抗体産生能のない細胞を用いることが出来る。一般的にはマウスから得られた株化細胞、例えば8-アザグアニン耐性マウス(BALB/c由来)ミエローマ株P3X63Ag8U.1(P3-U1)(Yelton, D.E. et al. Current Topics in Microbiology and Immunology, 81, 1-7(1978))、P3/NSI/1-Ag4-1(NS-1) (Kohler, G. et al. European J. Immunology, 6, 511-519 (1976))、Sp2/O-Ag14(SP-2)(Shulman, M. et al. Nature, 276, 269-270 (1978))、P3X63Ag8.653(653)(Kearney, J. F. et al. J. Immunology, 123, 1548-1550(1979))、P3X63Ag8(X63)(Horibata, K. and Harris, A. W. Nature, 256, 495-497 (1975))などを用いることが好ましい。これらの細胞株は、適当な培地、例えば8-アザグアニン培地[グルタミン、2-メルカプトエタノール、ゲンタマイシン及びウシ胎児血清(以下「FCS」という)を加えたRPMI-1640培地に8-アザグアニンを加えた培地] 、イスコフ改変ダルベッコ培地(Iscove's Modified Dulbecco's Medium;以下「IMDM」という)、又はダルベッコ改変イーグル培地(Dulbecco's Modified Eagle Medium;以下「DMEM」という)で継代培養するが、細胞融合の3~4日前に正常培地(例えば、10% FCSを含むDMEM培地)で継代培養し、融合当日に2×107以上の細胞数を確保しておく。
ミエローマとしては、マウス、ラット、モルモット、ハムスター、ウサギ又はヒト等の哺乳動物に由来する自己抗体産生能のない細胞を用いることが出来る。一般的にはマウスから得られた株化細胞、例えば8-アザグアニン耐性マウス(BALB/c由来)ミエローマ株P3X63Ag8U.1(P3-U1)(Yelton, D.E. et al. Current Topics in Microbiology and Immunology, 81, 1-7(1978))、P3/NSI/1-Ag4-1(NS-1) (Kohler, G. et al. European J. Immunology, 6, 511-519 (1976))、Sp2/O-Ag14(SP-2)(Shulman, M. et al. Nature, 276, 269-270 (1978))、P3X63Ag8.653(653)(Kearney, J. F. et al. J. Immunology, 123, 1548-1550(1979))、P3X63Ag8(X63)(Horibata, K. and Harris, A. W. Nature, 256, 495-497 (1975))などを用いることが好ましい。これらの細胞株は、適当な培地、例えば8-アザグアニン培地[グルタミン、2-メルカプトエタノール、ゲンタマイシン及びウシ胎児血清(以下「FCS」という)を加えたRPMI-1640培地に8-アザグアニンを加えた培地] 、イスコフ改変ダルベッコ培地(Iscove's Modified Dulbecco's Medium;以下「IMDM」という)、又はダルベッコ改変イーグル培地(Dulbecco's Modified Eagle Medium;以下「DMEM」という)で継代培養するが、細胞融合の3~4日前に正常培地(例えば、10% FCSを含むDMEM培地)で継代培養し、融合当日に2×107以上の細胞数を確保しておく。
(1-4)細胞融合
抗体産生細胞は、形質細胞、及びその前駆細胞であるリンパ球であり、これは個体のいずれの部位から得てもよく、一般には脾、リンパ節、骨髄、扁桃、末梢血、又はこれらを適宜組み合わせたもの等から得ることができるが、脾細胞が最も一般的に用いられる。
抗体産生細胞は、形質細胞、及びその前駆細胞であるリンパ球であり、これは個体のいずれの部位から得てもよく、一般には脾、リンパ節、骨髄、扁桃、末梢血、又はこれらを適宜組み合わせたもの等から得ることができるが、脾細胞が最も一般的に用いられる。
最終免疫後、所定の抗体価が得られた実験動物(例えばマウス)から抗体産生細胞が存在する部位、例えば脾臓を摘出し、抗体産生細胞である脾細胞を調製する。この脾細胞と工程(3)で得られたミエローマを融合させる手段として現在最も一般的に行われているのは、細胞毒性が比較的少なく融合操作も簡単な、ポリエチレングリコールを用いる方法である。この方法は、例えば以下の手順よりなる。
脾細胞とミエローマとを無血清培地(例えばDMEM)、又はリン酸緩衝生理食塩液(以下「リン酸緩衝液」という)でよく洗浄し、脾細胞とミエローマの細胞数の比が5:1~10:1程度になるように混合し、遠心分離する。上清を除去し、沈澱した細胞群をよくほぐした後、撹拌しながら1mlの50%(w/v)ポリエチレングリコール(分子量1000~4000)を含む無血清培地を滴下する。その後、10mlの無血清培地をゆっくりと加えた後遠心分離する。再び上清を捨て、沈澱した細胞を適量のヒポキサンチン・アミノプテリン・チミジン(以下「HAT」という)液及びヒトインターロイキン-2(以下「IL-2」という)を含む正常培地(以下「HAT培地」という)中に懸濁して培養用プレート(以下「プレート」という)の各ウェルに分注し、5%炭酸ガス存在下、37℃で2週間程度培養する。途中適宜HAT培地を補う。
(1-5)ハイブリドーマ群の選択
上記ミエローマ細胞が、8-アザグアニン耐性株である場合、すなわち、ヒポキサンチン・グアニン・ホスホリボシルトランスフェラーゼ(HGPRT)欠損株である場合、融合しなかった該ミエローマ細胞、及びミエローマ細胞どうしの融合細胞は、HAT含有培地中では生存できない。従って、HAT含有培地中での培養を続けることによって、ハイブリドーマを選択することができる。
上記ミエローマ細胞が、8-アザグアニン耐性株である場合、すなわち、ヒポキサンチン・グアニン・ホスホリボシルトランスフェラーゼ(HGPRT)欠損株である場合、融合しなかった該ミエローマ細胞、及びミエローマ細胞どうしの融合細胞は、HAT含有培地中では生存できない。従って、HAT含有培地中での培養を続けることによって、ハイブリドーマを選択することができる。
コロニー状に生育してきたハイブリドーマについて、HAT培地からアミノプテリンを除いた培地(以下「HT培地」という)への培地交換を行う。以後、培養上清の一部を採取し、例えば、ELISA法により抗体価を測定する。
以上、8-アザグアニン耐性の細胞株を用いる方法を例示したが、その他の細胞株もハイブリドーマの選択方法に応じて使用することができる。
(2)多価抗体の作製方法
本発明において、多価抗体は例えば上記のようにして得られたハイブリドーマから発現される、異なるエピトープに対する複数のモノクローナル抗体の遺伝子をクローニングし、その抗原認識部位を決定し、得られた抗原認識部位を含む多価抗体の遺伝子を設計することによって作製することができる。より具体的には、得られた抗原認識部位とリンカーを適宜組み合わせた多価抗体のDNAを合成し、発現プラスミドに組み込む。
本発明において、多価抗体は例えば上記のようにして得られたハイブリドーマから発現される、異なるエピトープに対する複数のモノクローナル抗体の遺伝子をクローニングし、その抗原認識部位を決定し、得られた抗原認識部位を含む多価抗体の遺伝子を設計することによって作製することができる。より具体的には、得られた抗原認識部位とリンカーを適宜組み合わせた多価抗体のDNAを合成し、発現プラスミドに組み込む。
ここで、リンカーは、抗原認識部位と別の抗原認識部位との間を連結するものであり、通常、10アミノ酸以上のポリペプチドからなり、好ましくは50アミノ酸以上、より好ましくは50アミノ酸~500アミノ酸を有する。本発明の実施形態において、より好ましいリンカーは、図1に示されるような、ヒト抗体重鎖定常領域のCH1からなるリンカー又はCH1を含むリンカー、例えばCH1-ヒンジ-CH2-CH3からなるリンカーである。具体的には、前者のリンカーは配列番号77、後者のリンカーは配列番号99に示されるアミノ酸配列を有する。
また、発現プラスミドの例は、pTracer-CMV/Bsd, pTracer-EF/Bsd, pTracer-SV40(Invitrogen社)等があげられる。
発現プラスミドを適用な産生細胞(例えばCHO細胞などの動物細胞)に導入し、得られた形質転換細胞を多価抗体産生細胞として培養し、その培養液から多価抗体を精製することができる。以下に多価抗体の作製方法を詳述するが、多価抗体の作製法は以下の記述に限定されるものではない。例えば、発現プラスミドを動物中で発現させて動物の血清やミルク中に発現する方法や、ポリペプチドを化学合成して多価抗体を作製する方法などがその他の多価抗体の作製法として考えられる。
(2-1)ハイブリドーマのクローニング
(1-2)の記載と同様の方法で抗体価を測定することにより、特異的抗体を産生することが判明したハイブリドーマを、別のプレートに移しクローニングを行う。このクローニング法としては、プレートの1ウェルに1個のハイブリドーマが含まれるように希釈して培養する限界希釈法、軟寒天培地中で培養しコロニーを回収する軟寒天法、マイクロマニュピレーターによって1個ずつの細胞を取り出し培養する方法、セルソーターによって1個の細胞を分離する「ソータクローン」などが挙げられるが、限界希釈法が簡便であり、よく用いられる。
(1-2)の記載と同様の方法で抗体価を測定することにより、特異的抗体を産生することが判明したハイブリドーマを、別のプレートに移しクローニングを行う。このクローニング法としては、プレートの1ウェルに1個のハイブリドーマが含まれるように希釈して培養する限界希釈法、軟寒天培地中で培養しコロニーを回収する軟寒天法、マイクロマニュピレーターによって1個ずつの細胞を取り出し培養する方法、セルソーターによって1個の細胞を分離する「ソータクローン」などが挙げられるが、限界希釈法が簡便であり、よく用いられる。
抗体価の認められたウェルについて、例えば限界希釈法によるクローニングを2~4回繰返し、安定して抗体価が認められたものをモノクローナル抗体産生ハイブリドーマ株として選択する。
(2-2) 抗体産生細胞の作製
各抗原に対する抗体を産生するハイブリドーマ等の抗体産生細胞から抗体の重鎖および軽鎖をコードする遺伝子をクローニングする。単一の軽鎖を使用して多価抗体を作製する場合には、多価抗体に含まれる抗体可変領域が特異的抗原に反応するように、ファージディスプレイ法等のスクリーニングを行い、単一の軽鎖に最適化した抗体重鎖を選択する。選択した重鎖の可変領域をコードするDNA配列を、本発明の多価抗体に用いられているイムノグロブリンドメインまたは該断片のリンカー配列と連結させて、多価抗体重鎖をコードするDNA配列を作製する。作製した多価抗体重鎖をコードするDNA配列と単一の軽鎖をコードするDNA配列を、適当なタンパク質発現ベクターに挿入して、多価抗体発現ベクターを作製する。一方、各抗原ごとに異なる複数の軽鎖を利用する場合には、複数の抗体重鎖可変領域をコードするDNA配列を、本発明の多価抗体に用いられているイムノグロブリンドメインまたは該断片のリンカー配列と連結させて、多価抗体重鎖をコードするDNA配列を作製する。多価抗体の重鎖および軽鎖をコードするDNAは、単一の発現ベクターに挿入してタンデム型の多価抗体発現ベクターとしてもよいし、別々の発現ベクターに挿入して、セパレイト型の多価抗体発現ベクターとしてもよい。次に作製した多価抗体発現ベクターを、宿主(例えば哺乳類細胞、大腸菌、酵母細胞、昆虫細胞、植物細胞など)に導入し、遺伝子組換え技術を用いて産生させた組換え型抗体を調製することができる(P.J.Delves., ANTIBODY PRODUCTION ESSENTIAL TECHNIQUES., 1997 WILEY; P.Shepherd and C.Dean. Monoclonal Antibodies., 2000 OXFORD UNIVERSITY PRESS; J.W.Goding. Monoclonal Antibodies:principles and practice., 1993 ACADEMIC PRESS)。
各抗原に対する抗体を産生するハイブリドーマ等の抗体産生細胞から抗体の重鎖および軽鎖をコードする遺伝子をクローニングする。単一の軽鎖を使用して多価抗体を作製する場合には、多価抗体に含まれる抗体可変領域が特異的抗原に反応するように、ファージディスプレイ法等のスクリーニングを行い、単一の軽鎖に最適化した抗体重鎖を選択する。選択した重鎖の可変領域をコードするDNA配列を、本発明の多価抗体に用いられているイムノグロブリンドメインまたは該断片のリンカー配列と連結させて、多価抗体重鎖をコードするDNA配列を作製する。作製した多価抗体重鎖をコードするDNA配列と単一の軽鎖をコードするDNA配列を、適当なタンパク質発現ベクターに挿入して、多価抗体発現ベクターを作製する。一方、各抗原ごとに異なる複数の軽鎖を利用する場合には、複数の抗体重鎖可変領域をコードするDNA配列を、本発明の多価抗体に用いられているイムノグロブリンドメインまたは該断片のリンカー配列と連結させて、多価抗体重鎖をコードするDNA配列を作製する。多価抗体の重鎖および軽鎖をコードするDNAは、単一の発現ベクターに挿入してタンデム型の多価抗体発現ベクターとしてもよいし、別々の発現ベクターに挿入して、セパレイト型の多価抗体発現ベクターとしてもよい。次に作製した多価抗体発現ベクターを、宿主(例えば哺乳類細胞、大腸菌、酵母細胞、昆虫細胞、植物細胞など)に導入し、遺伝子組換え技術を用いて産生させた組換え型抗体を調製することができる(P.J.Delves., ANTIBODY PRODUCTION ESSENTIAL TECHNIQUES., 1997 WILEY; P.Shepherd and C.Dean. Monoclonal Antibodies., 2000 OXFORD UNIVERSITY PRESS; J.W.Goding. Monoclonal Antibodies:principles and practice., 1993 ACADEMIC PRESS)。
ベクターには、宿主で自律的に増殖し得るファージ又はプラスミド、ウイルス、人工染色体などが使用される。プラスミドDNAとしては、例えば大腸菌、枯草菌又は酵母由来のプラスミドなどが挙げられ、ファージDNAとしては、例えばλファージ、T7ファージ、M13ファージなどが挙げられる。ウイルスベクターとしては、例えばアデノウイルス、アデノ随伴ウイルス、レトロウイルス、レンチウイルスなどが挙げられる。人工染色体としては、例えばヒト人工染色体(HAC)を含む哺乳類人工染色体(MAC)、酵母人工染色体(YAC)、細菌人工染色体(BAC, PAC)などが挙げられる。
形質転換に使用する宿主としては、目的の遺伝子を発現できるものであれば特に限定されるものではない。例えば、細菌(大腸菌、枯草菌等)、酵母、動物細胞(COS細胞、CHO細胞等)、昆虫細胞などが挙げられる。
宿主への遺伝子の導入方法は公知であり、任意の方法(例えばカルシウムイオンを用いる方法、エレクトロポレーション法、スフェロプラスト法、酢酸リチウム法、リン酸カルシウム法、リポフェクション法等)が挙げられる。また、動物に遺伝子を導入する方法としては、胚性幹(ES)細胞、人工多能性幹(iPS)細胞などの分化多能性細胞にミクロセル法、マイクロインジェクション法、エレクトロポレーション法、リポフェクション法などの手法を使用して遺伝子を導入する方法、核移植法などが挙げられる。この場合、分化多能性細胞を胚盤胞に導入し、仮親の子宮に移植することによってトランスジェニック動物を作出することが可能である。
それゆえ、本発明の多価抗体をコードする遺伝子を含む形質転換体は、細胞だけでなく動物も包含する。
多価抗体の作製の場合は、複数の抗原認識部位とリンカーを適宜組み合わせた多価抗体をコードする遺伝子を合成し、その遺伝子を適当な発現プラスミドに組み込むことができる。抗原認識部位の取得のためには、上述のハイブリドーマを用いた方法のほかに、Phage Display法のほか、Yeast display等の技術により適当な抗原認識部位を決定、単離して、取得することが出来る(Emmanuelle Laffy et. al., Human Antibodies 14, 33-55, 2005)。
(2-3) 多価抗体の発現と精製
本発明において、多価抗体は、形質転換体を培養し、その培養物から採取することにより得ることができる。「培養物」とは、(a)培養上清、(b)培養細胞若しくは培養菌体又はその破砕物、(c)形質転換体の分泌物のいずれをも意味するものである。形質転換体を培養するには、使用する宿主に適した培地を用い、静置培養法、ローラーボトルによる培養法などが採用される。
本発明において、多価抗体は、形質転換体を培養し、その培養物から採取することにより得ることができる。「培養物」とは、(a)培養上清、(b)培養細胞若しくは培養菌体又はその破砕物、(c)形質転換体の分泌物のいずれをも意味するものである。形質転換体を培養するには、使用する宿主に適した培地を用い、静置培養法、ローラーボトルによる培養法などが採用される。
培養後、目的タンパク質が菌体内又は細胞内に生産される場合には、菌体又は細胞を破砕することにより抗体を採取する。また、目的抗体が菌体外又は細胞外に生産される場合には、培養液をそのまま使用するか、遠心分離等により菌体又は細胞を除去する。その後、タンパク質の単離精製に用いられる各種クロマトグラフィーを用いた一般的な生化学的方法を単独で又は適宜組み合わせて用いることにより、前記培養物中から目的の抗体を単離精製することができる。
(3) 抗原認識部位の決定方法
モノクローナル抗体の認識エピトープの同定は以下のようにして行なうことができる。まず、モノクローナル抗体の認識する分子の様々な部分構造を作製する。部分構造の作製にあたっては、公知のオリゴペプチド合成技術を用いてその分子の様々な部分ペプチドを作成する方法、遺伝子組換え技術を用いて目的の部分ペプチドをコードするDNA配列を好適な発現プラスミドに組み込み、大腸菌等の宿主内外で生産する方法等があるが、上記目的のためには両者を組み合わせて用いるのが一般的である。例えば、抗原タンパク質のC末端又はN末端から適当な長さで順次短くした一連のポリペプチドを当業者に周知の遺伝子組換え技術を用いて作製した後、それらに対するモノクローナル抗体の反応性を検討し、大まかな認識部位を決定する。
モノクローナル抗体の認識エピトープの同定は以下のようにして行なうことができる。まず、モノクローナル抗体の認識する分子の様々な部分構造を作製する。部分構造の作製にあたっては、公知のオリゴペプチド合成技術を用いてその分子の様々な部分ペプチドを作成する方法、遺伝子組換え技術を用いて目的の部分ペプチドをコードするDNA配列を好適な発現プラスミドに組み込み、大腸菌等の宿主内外で生産する方法等があるが、上記目的のためには両者を組み合わせて用いるのが一般的である。例えば、抗原タンパク質のC末端又はN末端から適当な長さで順次短くした一連のポリペプチドを当業者に周知の遺伝子組換え技術を用いて作製した後、それらに対するモノクローナル抗体の反応性を検討し、大まかな認識部位を決定する。
その後、さらに細かく、その対応部分のオリゴペプチド、又は該ペプチドの変異体等を、当業者に周知のオリゴペプチド合成技術を用いて種々合成し、本発明の予防又は治療剤が有効成分として含有するモノクローナル抗体のそれらペプチドに対する結合性を調べるか、又は該モノクローナル抗体と抗原との結合に対するペプチドの競合阻害活性を調べることによりエピトープを限定する。多種のオリゴペプチドを得るための簡便な方法として、市販のキット(例えば、SPOTsキット(ジェノシス・バイオテクノロジーズ社製)、マルチピン合成法を用いた一連のマルチピン・ペプチド合成キット(カイロン社製)等)を利用することもできる。
(4) 抗原結合実験方法
本発明において、抗原への抗体の結合実験は、実施例19に記載の可溶性抗原を用いたELISAによる測定の他,抗原発現細胞を用いたフローサイトメトリーによる解析、可溶性抗原を用いた表面プラズモン共鳴を利用した検出法により測定する。
本発明において、抗原への抗体の結合実験は、実施例19に記載の可溶性抗原を用いたELISAによる測定の他,抗原発現細胞を用いたフローサイトメトリーによる解析、可溶性抗原を用いた表面プラズモン共鳴を利用した検出法により測定する。
以下に多価抗体の実施例を挙げて本発明を詳細に説明するが、本発明がこれらの実施例に限定されるものでないことは言うまでもない。
また、ヒト、マウスを含む動物の抗体及びその遺伝子の配列は、例えばGenBankなどの遺伝子バンクに登録されたものを利用することができる。
[実施例1]第1の抗原認識部位の取得
第1の抗原認識部位を取得するために、WO02/088186に記載の抗CD40抗体を用いた。具体的にはハイブリドーマKM341-1-19(寄託番号BP-7759)が産生する抗体(以下341-1-19と略す)の軽鎖および重鎖を用いた。ハイブリドーマKM341-1-19は、独立行政法人産業技術総合研究所特許生物寄託センター(日本国茨城県つくば市東1-1-1中央第6、郵便番号305-8566)に寄託されている。
第1の抗原認識部位を取得するために、WO02/088186に記載の抗CD40抗体を用いた。具体的にはハイブリドーマKM341-1-19(寄託番号BP-7759)が産生する抗体(以下341-1-19と略す)の軽鎖および重鎖を用いた。ハイブリドーマKM341-1-19は、独立行政法人産業技術総合研究所特許生物寄託センター(日本国茨城県つくば市東1-1-1中央第6、郵便番号305-8566)に寄託されている。
341-1-19抗体の重鎖全長DNA配列(配列番号1)、アミノ酸配列(配列番号2)及び軽鎖可変領域をコードするDNA配列(配列番号3)およびアミノ酸配列(配列番号4)をそれぞれ配列表に示す。
重鎖DNAの翻訳開始点は、配列番号1の5'末端から50番目のアデニン(A)からはじまるATGコドンであり、終止コドンは1472番目のチミン(T)からはじまるTGAである。抗体可変領域と定常領域の境界は5'末端から493番目のアデニン(A)と494番目のグアニン(G)間に位置する。重鎖アミノ酸配列において、H鎖可変領域は配列番号2のN末端から148番目のセリン(S)残基までであり、149番目のアラニン(A)以降が定常領域である。遺伝子配列予測ソフトウェア(Signal P ver.2)により、H鎖のシグナル配列は配列番号2のN末端より20番目のセリン(S)までと予測された。成熟体のN末端は配列番号2の21番目のグルタミン(Q)であるものと考えられる。
軽鎖DNAの翻訳開始点は、配列番号3の5'末端から29番目のAからはじまるATGコドンであり、可変領域は5'末端から400番目のアデニン(A)までである。アミノ酸配列において、可変領域は配列番号4のN末端から124番目のリジン(K)までである。精製されたL鎖蛋白質のN末端分析により、L鎖のシグナル配列は配列番号4のN末端より20番目のグリシン(G)までであり、成熟体のN末端は配列番号4の21番目のグルタミン酸(E)であることが明らかとなった。
[実施例2]第2の抗原認識部位の取得のための免疫
第2の抗原認識部位を取得するために抗ヒトCD28抗体の取得を行った。
第2の抗原認識部位を取得するために抗ヒトCD28抗体の取得を行った。
抗CD28 抗体の取得のための免疫は、上述の抗CD40抗体を取得した方法WO02/088186に順じて行った。マウスにRecombinant Human CD28 / Fc Chimera(R&D SYSTEM社製)を、MPL+TDM EMULSION(RiBi, シグマ社製)と1:1で混合し、40μg/匹で右腹腔内に免疫した。免疫は、14日間毎に3回行った。さらに脾臓を取得する3日前に同抗原を免疫した。
[実施例3]抗CD40抗体の軽鎖と共通の軽鎖を有する抗CD28抗体のscFVライブラリーの作製
実施例1の抗CD40抗体341-1-19の軽鎖と共通の軽鎖を有する抗CD28抗体をスクリーニングするために、実施例2で作製されたCD28で免疫されたマウスの脾臓を用いて、抗CD28抗体の重鎖可変領域遺伝子断片と軽鎖可変領域遺伝子断片を結合させた1本鎖抗体断片(scFV)遺伝子のライブラリーを作製した。
実施例1の抗CD40抗体341-1-19の軽鎖と共通の軽鎖を有する抗CD28抗体をスクリーニングするために、実施例2で作製されたCD28で免疫されたマウスの脾臓を用いて、抗CD28抗体の重鎖可変領域遺伝子断片と軽鎖可変領域遺伝子断片を結合させた1本鎖抗体断片(scFV)遺伝子のライブラリーを作製した。
免疫されたマウスから脾臓を外科的に取得し、3mLのTRIzol Reagent(Invitrogen社製)を加えた後、ポリトロンにて組織を破砕した。添付説明書に従い、破砕液よりTotal RNAを抽出した。このTotal RNAよりoligotex-dT30 (super) mRNA purification kit (タカラバイオ社製)を用いて精製したmRNAを鋳型とし、Super Script III First-Stand Synthesis System (Invitrogen社製)を用いてcDNAを合成した。尚、cDNA合成の際には、同キットに含まれていたRandom Hexamersをプライマーとして使用した。
341-1-19の重鎖(配列番号1)を鋳型とし、5’-GCAACTGCGGCCCAGCCGGCCATGGCCCAGGTGCAGCTGCAGGAG-3’(配列番号5)及び、5’-CCGAGGCGCGCCCACCGCTGCCACCGCCTCCTGAGGAGACGGTGACCGT-3’ (配列番号6)をプライマーとして5’末端にSfiI配列、3’末端煮をグリシンリッチ配列が付加された341-1-19の重鎖可変領域遺伝子断片を、また341-1-19の軽鎖(配列番号3)を鋳型とし5’-CGGTGGGCGCGCCTCGGGCGGAGGTGGTTCAGAAATTGTGTTGACACAG-3’(配列番号7)及び、5’-CATTCTCGAGTTGCGGCCGCACGTTTGATATCCACTTTGGTC-3’ (配列番号8)をプライマーとして5’末端にグリシンリッチ配列、3’末端にNotI配列が付加された341-1-19の軽鎖可変領域遺伝子断片を、それぞれDNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、58℃ 30秒、68℃1分の反応を35サイクル実施することで増幅した。ここで使用したグリシンリッチ配列を配列番号9,10に示す。このグリシンリッチ配列にはAscIの切断認識部位を挿入した。この得られたVH, VL遺伝子断片を、PCRにて付加したグリシンリッチ配列を用いて、Over Extension PCRによって連結し、341-1-19 scFv遺伝子断片を作製した。この遺伝子断片をSfiIとNotIで消化し、あらかじめSfiIとNotIで開裂したpCANTAB 5Eベクター (GEヘルスケアバイオサイエンス社製)に挿入した。得られたプラスミドをpCANTAB5E/341-1-19と命名した。本件では341-1-19の軽鎖と共通のアミノ酸配列を有するヒトCD28を抗原とする抗体の取得を目的とするため、このプラスミドをSfiI、AscIで開裂(341-1-19のVHをコードする遺伝子領域を除いた)後、Alkaline Phosphatase(BAP, タカラバイオ社製)で脱リン酸化処理したベクター遺伝子を、ライブラリー作製用のベクターとした。
免疫したマウス脾臓由来のcDNAを鋳型とし、ファージ抗体ライブラリー作製のための重鎖可変領域遺伝子断片を取得した。第一段階として、cDNAを鋳型とし、ヒト重鎖のシグナル領域に特異的なプライマー(配列番号11-35)及び、IgG定常領域に特異的なプライマー(配列番号36)を用いて、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、58℃30秒、68℃30秒の反応を30サイクル実施した。第二段階として、これらPCR産物を鋳型として、ヒト重鎖の可変領域に特異的なプライマー(配列番号37-56)及び、Junction領域に特異的なプライマー(配列番号57-61)を用いて、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、58℃30秒、68℃30秒の反応を35サイクル実施した。尚、可変領域に特異的なプライマーは第一段階のPCR反応の際に使用した可変領域に特異的なプライマーによって選択し、Junction領域に特異的なプライマーは5種を混合して使用した。(第一段階のPCR産物と可変領域に特異的なプライマーの組み合わせを表1に示す。)また、配列番号37-56の5’末端にはSfiIの切断認識部位を、配列番号57-61の5’末端にはAscIの切断認識部位及びリンカー配列を挿入した。

PCR反応にて増幅したVH遺伝子断片を混合し、SfiI、AscIで消化した後、ライブラリー作製用のベクターにDNA Ligation Kit(タカラバイオ社製)を用いて、16℃一晩の反応を実施して挿入した。このライゲート液をエレクトロポレーションによって、TG1 Electroporation Competent Cells(STRATAGENE社製)に導入した。この形質転換した大腸菌を2×YTAG培地(17gのBacto-tryptone, 10gのBact-yeast extract, 5gのNaClを蒸留水で1L に調整した。オートクレーブ後、100μg/ml ampicilin ,2% glucoseを添加した)にて30℃で1時間振とう培養した後、スタンダードディッシュ(150×15mm, BD社製)を用いて作製したSOBAG培地プレート(20g Bacto-tryptone, 5g Bact-yeast extract, 15g Bacto-agar ,0.5g NaCl, 蒸留水900mlを加えオートクレーブした。50-60℃に冷却後、10mlのsterile 1M MgCl2, 55.6mlの滅菌 2M glucose, Ampicilinを添加した。)に播き、30℃で1晩インキュベートした。培地上にできたコロニー群を回収(1プレート当たり3mLの2×YTAG培地でコロニーを回収)し、scFv抗体ライブラリーとした。なお、本実施例では約5×105個のコロニーを集めてライブラリーを作製した。
scFv抗体ライブラリー(100μL)を2×YTAG培地(50mL)にて30℃で600nmの吸光度が0.3から0.5になるまで振とう培養した。この培養液にM13KOヘルパーファージを10~20のMOIで感染(30℃ 1時間で振とう培養)後、培地を2×YTAK(17g Bacto-tryptone, 10g Bact-yeast extract, 5g NaClを蒸留水で1Lに調整した。オートクレーブ後、100μg/ml ampicilin , 50μg/ml kanamycinを添加した)に切り換え、30℃で1晩振とう培養した。この培養上清を抗体ファージライブラリーとした。抗体ファージライブラリーはPEG(200gの Polyethylene glycol 8000と146.1gのNaClに蒸留水を加え1Lに溶かしオートクレーブした)による沈殿を行い、PBS(-)3mLに置換した。
[実施例4]ヒトCD28抗原の作製
ヒトCD28(配列番号62)は、Human Spleen Marathon Ready cDNA(Clontech社製)を鋳型とし、5’-ATGCTCAGGCTGCTCTTGGCTCTCAACTTATTC-3’(配列番号63)及び、5’-TCAGGAGCGATAGGCTGCGAAGTCGCG-3’(配列番号64)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃1分の反応を35サイクル実施することにより増幅した。この遺伝子断片を鋳型として使用し、ヒトCD28の細胞外ドメイン(配列番号65)とIgGのFc融合タンパク質(CD28-FC)の発現ベクターを作製した。ヒトCD28の細胞外領域の遺伝子断片を取得し、5’末端にKpnI配列を、3’末端にXbaI配列を付加するためのPCR反応を実施した。実際には、このヒトCD28cDNAを鋳型とし、5’-GGGGGTACCATGCTCAGGCTGCTCTTGGCTC-3’(配列番号66)及び5’-GGGTCTAGACCAAAAGGGCTTAGAAGGTCCG-3’(配列番号67)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒を35サイクルのPCR反応を行った。このPCR反応にて増幅した遺伝子断片を、KpnI、XbaIで消化し、あらかじめヒトIgGのFc領域が挿入されていたpTracer-CMV/Zeo(Invitrogen社製)ベクターに挿入した。得られたプラスミドをpTracer/hECD28-Fcと命名した。
ヒトCD28(配列番号62)は、Human Spleen Marathon Ready cDNA(Clontech社製)を鋳型とし、5’-ATGCTCAGGCTGCTCTTGGCTCTCAACTTATTC-3’(配列番号63)及び、5’-TCAGGAGCGATAGGCTGCGAAGTCGCG-3’(配列番号64)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃1分の反応を35サイクル実施することにより増幅した。この遺伝子断片を鋳型として使用し、ヒトCD28の細胞外ドメイン(配列番号65)とIgGのFc融合タンパク質(CD28-FC)の発現ベクターを作製した。ヒトCD28の細胞外領域の遺伝子断片を取得し、5’末端にKpnI配列を、3’末端にXbaI配列を付加するためのPCR反応を実施した。実際には、このヒトCD28cDNAを鋳型とし、5’-GGGGGTACCATGCTCAGGCTGCTCTTGGCTC-3’(配列番号66)及び5’-GGGTCTAGACCAAAAGGGCTTAGAAGGTCCG-3’(配列番号67)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒を35サイクルのPCR反応を行った。このPCR反応にて増幅した遺伝子断片を、KpnI、XbaIで消化し、あらかじめヒトIgGのFc領域が挿入されていたpTracer-CMV/Zeo(Invitrogen社製)ベクターに挿入した。得られたプラスミドをpTracer/hECD28-Fcと命名した。
作製した発現ベクター遺伝子をNucleobomd PC2000EF (Macherey-NAGEL社製)にて調製し、FreeStyleTM 293 Expression System (Invitrogen社製)を用いて浮遊性293細胞に導入して、一過性発現により各抗体を含む培養上清を得た。培養上清はベクター導入7日後に回収し、孔径0.22μmのメンブランフィルター(MILLIPORE社製)で濾過した。この培養上清を抗体精製用アフニティーカラムであるHiTrap rProtein A FF(カラム体積1ml)(GEヘルスケアバイオサイエンス社製)にチャージし、PBS (-)で洗浄後、20mMクエン酸ナトリウム, 50mM NaCl緩衝液(pH2.7)により溶出し、200mMリン酸ナトリウム緩衝液(pH7.0)を含むチューブに回収した。次に、Q-Sepharose(Hitrap Q HP, GEヘルスケアバイオサイエンス社製)と、SP-Sepharose(HiTrap SP FF, GEヘルスケアバイオサイエンス社製)を連結したカラムにチャージして吸着し、20mMリン酸ナトリウム緩衝液(pH5.0)にて洗浄後、1×PBSバッファーにて溶出した。この溶出液を孔径0.22μmのメンブランフィルター (Millex-GV, MILLIPORE社製)でろ過滅菌し、組み換え型Fc融合タンパクを得た。精製ヒトCD28-Fc融合タンパク質の濃度は280nmの吸光度を測定した。
[実施例5]ヒトCD28を認識するscFv抗体を提示するファージの濃縮
Coating buffer(50mM carbonate buffer, pH9)にて10μg/mLに調製したヒトCD28-Fc融合タンパク質をマキシソープイムノチューブ(スターチューブ型, NUNC社製)に加え、4℃で1晩インキュベートし、固相化した。ブロッキング試薬(SuperBlock(登録商標) Blocking Buffer, PIERCE社製)を500mL加え、室温で1時間インキュベートし、ブロッキングを実施した。Washing buffer(0.1% Tween20-PBS)にて3回洗浄した後、あらかじめBlock Ace(大日本住友製薬社製)を 2mL加えて室温で2時間インキュベートした抗体ファージライブラリーを加え、室温で2時間インキュベートした。Washing bufferにて10回洗浄した後、0.1M Glycine-HCl溶液(pH2.2)にて溶出し、2M Tris-base溶液を加え中和した。この溶出したファージを再びTG1に感染させ、2×YTAG培地プレートに播き、30℃で1晩インキュベートした。培地上にできたコロニー群を再び回収して上記手法にてパニングを行い、計3回実施した。
Coating buffer(50mM carbonate buffer, pH9)にて10μg/mLに調製したヒトCD28-Fc融合タンパク質をマキシソープイムノチューブ(スターチューブ型, NUNC社製)に加え、4℃で1晩インキュベートし、固相化した。ブロッキング試薬(SuperBlock(登録商標) Blocking Buffer, PIERCE社製)を500mL加え、室温で1時間インキュベートし、ブロッキングを実施した。Washing buffer(0.1% Tween20-PBS)にて3回洗浄した後、あらかじめBlock Ace(大日本住友製薬社製)を 2mL加えて室温で2時間インキュベートした抗体ファージライブラリーを加え、室温で2時間インキュベートした。Washing bufferにて10回洗浄した後、0.1M Glycine-HCl溶液(pH2.2)にて溶出し、2M Tris-base溶液を加え中和した。この溶出したファージを再びTG1に感染させ、2×YTAG培地プレートに播き、30℃で1晩インキュベートした。培地上にできたコロニー群を再び回収して上記手法にてパニングを行い、計3回実施した。
[実施例6]ヒトCD28を認識する抗体提示ファージの選定および抗CD28抗体(341VL34および341VL36)の作製
パニングを実施した抗体ライブラリーより、各単コロニーを2×YTAG培地200μLに接種し、30℃で4から5時間振とう培養した。この培養液に1×1010pfu/mLのM13KOヘルパーファージを200μL加えて感染(30℃ 1時間で振とう培養)した後、培地を2×YTAKに切り換え、30℃で1晩振とう培養した。この培養上清をファージ液として用いて、以下の手順(ELISA)に従い、抗原への結合性を確認した。
パニングを実施した抗体ライブラリーより、各単コロニーを2×YTAG培地200μLに接種し、30℃で4から5時間振とう培養した。この培養液に1×1010pfu/mLのM13KOヘルパーファージを200μL加えて感染(30℃ 1時間で振とう培養)した後、培地を2×YTAKに切り換え、30℃で1晩振とう培養した。この培養上清をファージ液として用いて、以下の手順(ELISA)に従い、抗原への結合性を確認した。
Coating buffer(50mM carbonate buffer, pH9)にて2μg/mLに調整したヒトCD28-Fc融合タンパク質を50μL/wellでマキシソープPlate(NUNC社製)に播き、4℃で1晩インキュベートし、固相化した。ブロッキング試薬(SuperBlock(登録商標)Blocking Buffer, PIERCE社製)を200μL/well加え、室温で30分間インキュベートし、ブロッキングを実施した。そこに、各ファージ液を50 μL/well加え、室温で1時間インキュベートした。Washing buffer(0.1% Tween20-TBS)にて3回洗浄した後、assay diluent (大日本住友製薬社製Block Aceを10%含む0.1%Tween20-TBS)で希釈したHRP/Anti-E Tag conjugate (GEヘルスケアバイオサイエンス社製)を各ウェルに50μL加え、更に室温にて1時間反応させた。Washing bufferにて3回洗浄後、TMB (DAKO社製)発色基質液を各ウェルに50μL加え、暗所にて室温でインキュベートし、発色させた後、0.5M硫酸(50 μL/well)を加え、反応を停止した。波長450nmでの吸光度をマイクロプレートリーダー(SPECTRAMAX190, Molecular Devices社製)で測定した。
ELISAにて抗原への結合が確認された2種のscFv抗体を341VL34 scFv, 341VL36 scFvと命名した。取得したscFv抗体を通常型の抗体に変換するため、抗体遺伝子のクローニング及び発現ベクターの作製を行った。
重鎖遺伝子断片を増幅するため、pCANTAB/341VL34及び、pCANTAB/341VL36を鋳型とし、5’-AAAGGTGTCCAGTGTGAGGTGCAGCTGGTGGAGTC-3’(配列番号68)及び、5’-TGAGGAGACGGTGACCGTGG-3’(配列番号69)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、58℃30秒、68℃30秒の反応を30サイクル実施した。この遺伝子断片を鋳型として使用し、その5’末端にSalI配列、Kozac配列及び、シグナルをコードする配列を、その3’末端にNheI配列を付加するためのPCR反応を実施した。各重鎖遺伝子断片を鋳型とし、5’-GGGGTCGACACCATGGAGTTTGGGCTGAGCTGGGTTTTCCTTGTTGCTATTTTAAAAGGTGTCCAGTGT-3’(配列番号70)及び5’-GGGGCTAGCTGAGGAGACGGTGACC-3’(配列番号71)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、58℃30秒、68℃30秒を35サイクルのPCR反応を行った。341VL34 scFv及び341VL36 scFvの軽鎖は341-1-19と共通のアミノ酸配列であるため、341-1-19発現ベクター(特願2003-431408に記載のN5KG2Serを使用)の重鎖可変領域をSalI、NheIで切り出し、SalI、NheIで消化した341VL34scFv、341VL36scFV由来の重鎖遺伝子断片を挿入した。341-1-19の軽鎖(配列番号2)と341VL34scFv由来の重鎖から構成される抗体を、341VL34, 341-1-19の軽鎖(配列番号2)と 341VL36scFV由来の重鎖から構成される抗体を341VL36と名付けた。
341VL34 重鎖核酸配列(配列番号72)、341VL34重鎖アミノ酸配列(配列番号73)341VL36 重鎖核酸配列(配列番号74)、341VL36重鎖アミノ酸配列(配列番号75)はそれぞれ配列表に示す。
341VL34抗体重鎖核酸の翻訳開始点は、配列番号72の5'末端から1番目のアデニン(A)からはじまるATGコドンであり、終止コドンは1417番目のチミン(T)からはじまるTGAである。抗体可変領域と定常領域の境界は5'末端から438番目のアデニン(A)と439番目のグアニン(G)間に位置する。アミノ酸配列において、重鎖可変領域は配列番号73のN末端から146番目のセリン(S)残基までであり、147番目のアラニン(A)以降が定常領域である。重鎖のシグナル配列は配列番号73のN末端より19番目のシステイン(C)までであり、成熟体のN末端は20番目のグルタミン酸(E)であるものと考える。
341VL36抗体重鎖核酸の翻訳開始点は、配列番号74の5'末端から1番目のアデニン(A)からはじまるATGコドンであり、終止コドンは1417番目のチミン(T)からはじまるTGAである。抗体可変領域と定常領域の境界は5'末端から438番目のアデニン(A)と439番目のグアニン(G)間に位置する。アミノ酸配列において、重鎖可変領域は配列番号75のN末端から146番目のセリン(S)残基までであり、147番目のアラニン(A)以降が定常領域である。重鎖のシグナル配列は配列番号75のN末端より19番目のシステイン(C)までであり、成熟体のN末端は20番目のグルタミン酸(E)であるものと考える。
[実施例7]作製した多価抗体の構造
本発明で作製した多価抗体の構造的特徴を図1に示す。2種類の抗体由来の可変領域をリンカーで結合している。抗体は、抗CD40抗体として1種類(341-1-19)、抗CD28抗体として2種類(341VL34, 341VL36)を使用し、それぞれリンカーの構造と位置の組み合わせを変えたものを作製して試験を実施した。実施例における多価抗体のリンカーとしては、341-1-19由来のIgG2サブクラスのCH1領域を含む配列番号77のリンカー、もしくは、CH1、ヒンジ、CH2、CH3領域を含む配列番号99のリンカーが挿入されている。しかしながら、本発明で用いられるリンカーはこれらのリンカーに限定されるものではない。
本発明で作製した多価抗体の構造的特徴を図1に示す。2種類の抗体由来の可変領域をリンカーで結合している。抗体は、抗CD40抗体として1種類(341-1-19)、抗CD28抗体として2種類(341VL34, 341VL36)を使用し、それぞれリンカーの構造と位置の組み合わせを変えたものを作製して試験を実施した。実施例における多価抗体のリンカーとしては、341-1-19由来のIgG2サブクラスのCH1領域を含む配列番号77のリンカー、もしくは、CH1、ヒンジ、CH2、CH3領域を含む配列番号99のリンカーが挿入されている。しかしながら、本発明で用いられるリンカーはこれらのリンカーに限定されるものではない。
表2に、作製した多価抗体の構造をまとめた。

[実施例8]CD28に対する抗原認識部位(341VL34由来)をN末側にCD40に対する抗原認識部位(341-1-19由来)をC末側に有し、配列番号77のリンカーを含む多価抗体(341VL34-CH1-341)の発現ベクターの作製
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体341VL34の重鎖可変領域を、リンカー(配列番号77)を介して抗CD40抗体341-1-19の重鎖可変領域にタンデムに結合した。軽鎖は、341-1-19と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。この多価抗体を、341VL34-CH1-341と名づけた。
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体341VL34の重鎖可変領域を、リンカー(配列番号77)を介して抗CD40抗体341-1-19の重鎖可変領域にタンデムに結合した。軽鎖は、341-1-19と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。この多価抗体を、341VL34-CH1-341と名づけた。
重鎖の間(341VL34の重鎖の3’末端、341-1-19の重鎖の5’末端)にはCH1配列(Kabat EUインデックス118番から215番)とさらに、その3’末端にBamHI配列(GGATCC)を付加した配列(配列番号76, 77)をリンカーとして挿入している。
341VL34-CH1-341 の重鎖をコードする遺伝子配列は以下の手順で作製した。
341-1-19重鎖配列を鋳型とし、5’-GGGGCTAGCACCAAGGGCCCATC-3’(配列番号78)及び、5’-GGATCCAACTGTCTTGTCCACCTTGG-3’(配列番号79)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施することで、5’末端にNheI配列を付加したリンカー遺伝子断片を増幅した。341-1-19重鎖配列を鋳型とし、5’-GTGGACAAGACAGTTGGATCCCAGGTCCAACTGCAGCAGTC-3’(配列番号80)及び、5’-CTTGGTGCTAGCTGAGGAGACGGTGAC-3’ (配列番号81)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施することで、5’末端にリンカー遺伝子(3’末端側から21塩基)を、3’末端にNheI配列を付加した341-1-19の重鎖遺伝子断片を増幅した。この得られた2つの遺伝子断片を、Over Extension PCRによって連結し、リンカー - 341-1-19重鎖の遺伝子断片を作製した。この遺伝子断片をNheIで消化し、NheIで開裂した後Alkaline Phosphatase(BAP, タカラバイオ社製)で脱リン酸化処理した341VL4発現ベクターに挿入した。
341VL34-CH1-341 重鎖核酸配列(配列番号82)、341VL34-CH1-341 重鎖アミノ酸配列(配列番号83)はそれぞれ配列表に示す。
[実施例9]CD40に対する抗原認識部位(341-1-19由来)をN末側に、CD28に対する抗原認識部位(341VL34由来)をC末側に有し、配列番号77のリンカーを含む多価抗体(341-CH1-341VL34)の発現ベクターの作製
重鎖N末側からCD40に対する抗原認識部位とCD28に対する抗原認識部位が並んだ多価抗体を作製するため、341-1-19の重鎖可変領域を配列番号77のリンカーを介して341VL34の重鎖可変領域にタンデムに結合した。軽鎖は、341-1-19と共通のものを抗CD28抗体も使用する。重鎖の間(341VL34の重鎖の3’末端、341-1-19の重鎖の5’末端)にはCH1配列(Kabat EUインデックス118番から215番)とさらに、その3’末端にBamHI配列(GGATCC)を付加した配列(配列番号76, 77)をリンカーとして挿入している。この抗体を341-CH1-341VL34と名づけた。
重鎖N末側からCD40に対する抗原認識部位とCD28に対する抗原認識部位が並んだ多価抗体を作製するため、341-1-19の重鎖可変領域を配列番号77のリンカーを介して341VL34の重鎖可変領域にタンデムに結合した。軽鎖は、341-1-19と共通のものを抗CD28抗体も使用する。重鎖の間(341VL34の重鎖の3’末端、341-1-19の重鎖の5’末端)にはCH1配列(Kabat EUインデックス118番から215番)とさらに、その3’末端にBamHI配列(GGATCC)を付加した配列(配列番号76, 77)をリンカーとして挿入している。この抗体を341-CH1-341VL34と名づけた。
341-CH1-341VL の重鎖をコードする遺伝子配列は以下の手順で作製した。
341-1-19重鎖配列を鋳型とし、5’-GGGGCTAGCACCAAGGGCCCATC-3’(配列番号78)及び、5’-GGATCCAACTGTCTTGTCCACCTTGG-3’ (配列番号79)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施することで、5’末端にNheI配列を付加したリンカー遺伝子断片を増幅した。341VL-34重鎖配列を鋳型とし、5’-GTGGACAAGACAGTTGGATCCGAGGTGCAGCTGGTGGAGTC-3’(配列番号84)及び、5’-CTTGGTGCTAGCTGAGGAGACGGTGAC-3’(配列番号81)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施することで、5’末端にリンカー遺伝子(3’末端21塩基)を、3’末端にNheI配列を付加した341-1-19の重鎖遺伝子断片を増幅した。この得られた2つの遺伝子断片を、Over Extension PCRによって連結し、リンカー - 341VL34重鎖の遺伝子断片を作製した。この遺伝子断片をNheIで消化し、NheIで開裂した後Alkaline Phosphatase(BAP, タカラバイオ社製)で脱リン酸化処理した341-1-19発現ベクターに挿入した。
341-CH1-341VL34 重鎖核酸配列(配列番号85)、341-CH1-341VL34 重鎖アミノ酸配列(配列番号86)はそれぞれ配列表に示した。
[実施例10]CD28に対する抗原認識部位(341VL34由来)をN末側にCD40に対する抗原認識部位(341-1-19由来)をC末側に有し、配列番号88の短いリンカーで2つの抗原認識部位を連結した多価抗体(DVD341VL34-341)の発現ベクターの作製
多価抗体の安定性を比較するために、Wuらの報告(非特許文献5)にしたがって、複数の抗原認識部位が短いアミノ酸配列(6アミノ酸)からなるリンカー(配列番号87、88)で連結された多価抗体を作製した。Wuらの報告による、短いリンカーを用いた多価抗体をDVDIgGと呼ぶ。具体的には、抗CD40抗体341-1-19と抗CD28抗体341VL34をもとにDVD-IgGを作製した。N末側から、CD28、CD40の順で抗原認識部位が存在するDVDIgGをDVD341VL34-341と名づけた。341-1-19の重鎖可変領域のN末端側に341VL34可変領域をタンデムに結合した。
多価抗体の安定性を比較するために、Wuらの報告(非特許文献5)にしたがって、複数の抗原認識部位が短いアミノ酸配列(6アミノ酸)からなるリンカー(配列番号87、88)で連結された多価抗体を作製した。Wuらの報告による、短いリンカーを用いた多価抗体をDVDIgGと呼ぶ。具体的には、抗CD40抗体341-1-19と抗CD28抗体341VL34をもとにDVD-IgGを作製した。N末側から、CD28、CD40の順で抗原認識部位が存在するDVDIgGをDVD341VL34-341と名づけた。341-1-19の重鎖可変領域のN末端側に341VL34可変領域をタンデムに結合した。
軽鎖については341-1-19の軽鎖可変領域のN末端側に341VL34軽鎖可変領域をタンデムに結合した。可変領域の間には、軽鎖kappa定常領域の部分配列(配列番号89、90:Kabat EUインデックスの108番目から113番目まで)をリンカーとして挿入している。
DVD341VL34-341の重鎖をコードする遺伝子配列は以下の手順で作製した。
341-1-19重鎖配列を鋳型とし、5’-GTCTCCTCAGCTAGCACCAAGGGCCCACAGGTCCAACTGCAGCAGTC -3’(配列番号91)及び、5’-CTTGGTGCTAGCTGAGGAGACGGTGAC-3’(配列番号81)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を35サイクル実施することで、5’末端にリンカー遺伝子配列(リンカーの5’末端はNheI配列)を、3’末端にNheI配列を付加した341-1-19の重鎖遺伝子断片を増幅した。この遺伝子断片をNheIで消化し、NheIで開裂した後Alkaline Phosphatase(BAP, タカラバイオ社製)で脱リン酸化処理した341VL34発現ベクターに挿入した。さらにこのベクターに下記の方法で作製した軽鎖を挿入した。
DVD341VL34-341の軽鎖をコードする遺伝子配列は以下の手順で作製した。
341-1-19軽鎖を鋳型とし、5’-GGGCGTACGGTGGCTGCACCAGAAATTGTGTTGACACAGTC-3’(配列番号92)及び、5’-GGGCGTACGTTTGATATCCACTTTGGTCC-3’(配列番号93)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を35サイクル実施することで、5’末端にリンカー遺伝子配列(リンカーの5’末端はBsiWI配列)を、3’末端にBsiWI配列を付加した付加した341-1-19の軽鎖遺伝子断片を増幅した。この遺伝子断片をBsiWIで消化し、BsiWIで開裂した後Alkaline Phosphatase(BAP, タカラバイオ社製)で脱リン酸化処理した、上述のDVD341VL34-341-1-19を保持する発現ベクターに挿入した。
DVD341VL34-341重鎖核酸配列(配列番号94)、DVD341VL34-341 重鎖アミノ酸配列(配列番号95)、DVD341VL34-341軽鎖核酸配列(配列番号96)、DVD341VL34-341軽鎖核酸配列(配列番号97)は配列表に記載した。
[実施例11]CD28に対する抗原認識部位(341VL34由来)をN末側に、CD40に対する抗原認識部位(341-1-19由来)をC末側に有し、配列番号99のリンカーを含む多価抗体(341VL34-CH1-H- CH2-CH3-341-CH1)の発現ベクターの作製
重鎖N末側から順に、CD28、CD40認識部位が存在し、長い配列番号98、99のリンカー(CH1,ヒンジ, CH2, CH3:Kabat EUインデックス118番目から447番目)を保持する多価抗体を作製した。具体的には341-1-19の可変領域に配列番号98、99のリンカーを介して341VL34の可変領域を連結した。3’末端には終止コドンであるTGAを付加した。軽鎖は、341-1-19と共通のものを抗CD28抗体も使用する。この抗体を341VL34-CH1-H- CH2-CH3-341-CH1と名づけた。
重鎖N末側から順に、CD28、CD40認識部位が存在し、長い配列番号98、99のリンカー(CH1,ヒンジ, CH2, CH3:Kabat EUインデックス118番目から447番目)を保持する多価抗体を作製した。具体的には341-1-19の可変領域に配列番号98、99のリンカーを介して341VL34の可変領域を連結した。3’末端には終止コドンであるTGAを付加した。軽鎖は、341-1-19と共通のものを抗CD28抗体も使用する。この抗体を341VL34-CH1-H- CH2-CH3-341-CH1と名づけた。
341VL34-CH1-H- CH2-CH3-341-CH1の重鎖をコードする遺伝子配列は以下の手順で作製した。
341-1-19重鎖配列を鋳型とし、5’-GTCTCCTCAGCTAGCACCAAGGGCCCA-3’(配列番号100)及び、5’- GGGGGATCCTTTACCCGGAGACAGGGAGAG-3’(配列番号101)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を35サイクル実施することで、3’末端にBamHI配列を付加したリンカー遺伝子断片(Linkerの5’末端はNheI配列)を増幅した。この得られた遺伝子断片をNheI, BamIで消化し、NheI, BamHIで開裂し、重鎖定常領域をコードする遺伝子領域を除いた、341VL34発現ベクターに挿入した。この発現ベクターの3’側に、341-1-19重鎖を鋳型とし、5’-GATATCAAAGGATCCCAGGTCCAACTGCAGCAGTC-3’(配列番号102)及び、5’-GGGGGATCCTCAAACTGTCTTGTCCACCTTGG-3’(配列番号103)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を35サイクル実施することで、5’末端にBamHI配列を、3’末端に(3’末端から)BamHI配列、終止コドン及びCH1領域(118番目のアデニンから215番目のバリン)をコードする遺伝子配列を付加した341-1-19の重鎖可変領域とCH1領域を、BamHIで消化し挿入した。
341VL34-CH1-H- CH2-CH3-341-CH1 重鎖核酸配列(配列番号104)、341VL34-CH1-H- CH2-CH3-341-CH1 重鎖アミノ酸配列(配列番号105)はそれぞれ配列表に記載した。
[実施例12]CD28に対する抗原認識部位(341VL36由来)をN末側にCD40に対する抗原認識部位(341-1-19由来)をC末側に有し、配列番号77のリンカーを含む多価抗体(341VL36-CH1-341)の発現ベクターの作製
重鎖N末側から順番に、CD28、CD40認識部位が存在する多価抗体を作製するため、341VL36重鎖可変領域を配列番号77のリンカーを介して341-1-19の重鎖可変領域にタンデムに結合した。軽鎖は、341-1-19と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。この多価抗体を、341VL36-CH1-341と名づけた。
重鎖N末側から順番に、CD28、CD40認識部位が存在する多価抗体を作製するため、341VL36重鎖可変領域を配列番号77のリンカーを介して341-1-19の重鎖可変領域にタンデムに結合した。軽鎖は、341-1-19と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。この多価抗体を、341VL36-CH1-341と名づけた。
重鎖の間(341VL-34の重鎖の3’末端、341-1-19の重鎖の5’末端)にはCH1配列(Kabat EUインデックス118番から215番)とさらに、その3’末端にBamHI配列(GGATCC)を付加した配列(配列番号76, 77)をリンカーとして用いた。
341VL34-CH1-341 の重鎖をコードする遺伝子配列は以下の手順で作製した。
341-1-19重鎖配列を鋳型とし、5’-GGGGCTAGCACCAAGGGCCCATC-3’(配列番号78)及び、5’-GGATCCAACTGTCTTGTCCACCTTGG-3’(配列番号79)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施することで、5’末端にNheI配列を付加したリンカー遺伝子断片を増幅した。341-1-19重鎖配列を鋳型とし、5’-GTGGACAAGACAGTTGGATCCCAGGTCCAACTGCAGCAGTC-3’(配列番号80)及び、5’-CTTGGTGCTAGCTGAGGAGACGGTGAC-3’ (配列番号81)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施することで、5’末端にリンカー配列(3’末端側から21塩基)を、3’末端にNheI配列を付加した341-1-19の重鎖遺伝子断片を増幅した。この得られた2つの遺伝子断片を、Over Extension PCRによって連結し、リンカー - 341-1-19重鎖の遺伝子断片を作製した。この遺伝子断片をNheIで消化し、NheIで開裂した後Alkaline Phosphatase(BAP, タカラバイオ社製)で脱リン酸化処理した341VL36発現ベクターに挿入した。
341VL36-CH1-341 重鎖核酸配列(配列番号106)、341VL36-CH1-341 重鎖アミノ酸配列(配列番号107)は、それぞれ配列表に記載した。
[実施例13]CD40に対する抗原認識部位(341-1-19由来)をN末側に、CD28に対する抗原認識部位(341VL36由来)をC末側に有し、配列番号77のリンカーを含む多価抗体(341-CH1-341VL36)の発現ベクターの作製
重鎖N末側から順番に、CD40、CD28認識部位が存在する多価抗体を作製するため、341-1-19重鎖可変領域を配列番号77のリンカーを介して341VL36の重鎖可変領域にタンデムに結合した。軽鎖は、341-1-19と共通のものを抗CD28抗体も使用する。重鎖の間(341VL36の重鎖の3’末端、341-1-19の重鎖の5’末端)にはCH1配列(Kabat EUインデックス118番から215番)とさらに、その3’末端にBamHI配列(GGATCC)を付加した配列(配列番号76, 77)をリンカーとして挿入した。この抗体を341-CH1-341VL36と名づけた。
重鎖N末側から順番に、CD40、CD28認識部位が存在する多価抗体を作製するため、341-1-19重鎖可変領域を配列番号77のリンカーを介して341VL36の重鎖可変領域にタンデムに結合した。軽鎖は、341-1-19と共通のものを抗CD28抗体も使用する。重鎖の間(341VL36の重鎖の3’末端、341-1-19の重鎖の5’末端)にはCH1配列(Kabat EUインデックス118番から215番)とさらに、その3’末端にBamHI配列(GGATCC)を付加した配列(配列番号76, 77)をリンカーとして挿入した。この抗体を341-CH1-341VL36と名づけた。
341-CH1-341VL36の重鎖をコードする遺伝子配列は以下の手順で作製した。
341-1-19重鎖配列を鋳型とし、5’-GGGGCTAGCACCAAGGGCCCATC-3’(配列番号78)及び、5’-GGATCCAACTGTCTTGTCCACCTTGG-3’(配列番号79)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施することで、5’末端にNheI配列を付加したLinker遺伝子断片を増幅した。341VL36を鋳型とし、5’-GTGGACAAGACAGTTGGATCCGAGGTGCAGCTGGTGGAGTC-3’(配列番号84)及び、5’-CTTGGTGCTAGCTGAGGAGACGGTGAC-3’(配列番号81)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施することで、5’末端にLinker遺伝子(3’末端21塩基)を、3’末端にNheI配列を付加した341-1-19の重鎖遺伝子断片を増幅した。この得られた2つの遺伝子断片を、Over Extension PCRによって連結し、リンカー - 341VL36重鎖の遺伝子断片を作製した。この遺伝子断片をNheIで消化し、NheIで開裂した後Alkaline Phosphatase(BAP, タカラバイオ社製)で脱リン酸化処理した341-1-19発現ベクターに挿入した。
341-CH1-341VL36重鎖核酸配列(配列番号108)、341-CH1-341VL36 重鎖アミノ酸配列(配列番号109)の配列はそれぞれ配列表に記載した。
[実施例14]CD28に対する抗原認識部位(341VL36由来)をN末側にCD40に対する抗原認識部位(341-1-19由来)をC末側に有し、短い配列番号88 のリンカーで2つの抗原認識部位を連結した多価抗体(DVD341VL36-341)の発現ベクターの作製
多価抗体の安定性を比較するために、Wuらの報告(非特許文献5.)にしたがって、341-1-19, 341VL36抗体をもとに、DVD-IgGを作製した。N末側から、CD28、CD40の順で認識部位が存在するDVDIgGをDVD341VL36-341と名づけた。341-1-19の重鎖可変領域のN末端側に341VL34可変領域をタンデムに結合した。可変領域の間には、6アミノ酸からなる配列番号87,88のリンカーを挿入している。
多価抗体の安定性を比較するために、Wuらの報告(非特許文献5.)にしたがって、341-1-19, 341VL36抗体をもとに、DVD-IgGを作製した。N末側から、CD28、CD40の順で認識部位が存在するDVDIgGをDVD341VL36-341と名づけた。341-1-19の重鎖可変領域のN末端側に341VL34可変領域をタンデムに結合した。可変領域の間には、6アミノ酸からなる配列番号87,88のリンカーを挿入している。
軽鎖については341-1-19の軽鎖可変領域のN末端側に341VL36軽鎖可変領域をタンデムに結合した。可変領域の間には、軽鎖kappa定常領域の部分配列(配列番号89,90:Kabat EUインデックスの108番目から113番目まで)をリンカーとして挿入している。
DVD341VL36-341の重鎖をコードする遺伝子配列は以下の手順で作製した。
341-1-19重鎖配列を鋳型とし、5’-GTCTCCTCAGCTAGCACCAAGGGCCCACAGGTCCAACTGCAGCAGTC -3’(配列番号91)及び、5’-CTTGGTGCTAGCTGAGGAGACGGTGAC-3’(配列番号84)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を35サイクル実施することで、5’末端にリンカー遺伝子配列を、3’末端にNheI配列を付加した341-1-19の重鎖遺伝子断片を増幅した。この遺伝子断片をNheIで消化し、NheIで開裂した後Alkaline Phosphatase(BAP, タカラバイオ社製)で脱リン酸化処理した341VL36発現ベクターに挿入した。さらにこのベクターに下記の方法で作製した軽鎖を挿入した。
DVD341VL36-341の軽鎖をコードする遺伝子配列は以下の手順で作製した。
341-1-19軽鎖配列を鋳型とし、5’-GGGCGTACGGTGGCTGCACCAGAAATTGTGTTGACACAGTC-3’(配列番号92)及び、5’-GGGCGTACGTTTGATATCCACTTTGGTCC-3’(配列番号93)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を35サイクル実施することで、5’末端にリンカー配列を、3’末端にBsiWI配列を付加した付加した341-1-19の軽鎖遺伝子断片を増幅した。この遺伝子断片をBsiWIで消化し、BsiWIで開裂した後Alkaline Phosphatase(BAP, タカラバイオ社製)で脱リン酸化処理した、上述の、DVD341VL36-341の重鎖を保持する発現ベクターに挿入した。
DVD341VL36-341重鎖核酸配列(配列番号110), DVD341VL36-341重鎖アミノ酸配列(配列番号111),DVD341VL36-341 軽鎖核酸配列(配列番号112), DVD341VL36-341 軽鎖核酸配列(配列番号113)はそれぞれ配列表に記載した。
[実施例15]CD28に対する抗原認識部位(341VL34由来)をN末側に、CD40に対する抗原認識部位(341-1-19由来)をC末側に有し、配列番号99のリンカーを含む多価抗体(341VL36-CH1-H- CH2-CH3-341-CH1)の発現ベクターの作製
重鎖N末側から順に、CD28、CD40認識部位が存在し、長い配列番号99のリンカーを保持する多価抗体を作製した。341-1-19の重鎖可変領域を配列番号98, 99のリンカーを介して341VL36重鎖可変領域にタンデムに結合した。3’末端には終止コドンであるTGAを付加した。軽鎖は、341-1-19と共通のものを抗CD28抗体も使用する。この抗体を341VL36-CH1-H- CH2-CH3-341-CH1と名づけた。
重鎖N末側から順に、CD28、CD40認識部位が存在し、長い配列番号99のリンカーを保持する多価抗体を作製した。341-1-19の重鎖可変領域を配列番号98, 99のリンカーを介して341VL36重鎖可変領域にタンデムに結合した。3’末端には終止コドンであるTGAを付加した。軽鎖は、341-1-19と共通のものを抗CD28抗体も使用する。この抗体を341VL36-CH1-H- CH2-CH3-341-CH1と名づけた。
341VL36-CH1-H- CH2-CH3-341-CH1の重鎖をコードする遺伝子配列は以下の手順で作製した。
341-1-19重鎖配列を鋳型とし、5’-GTCTCCTCAGCTAGCACCAAGGGCCCA-3’(配列番号100)及び、5’- GGGGGATCCTTTACCCGGAGACAGGGAGAG-3’(配列番号101)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を35サイクル実施することで、3’末端にBamHI配列を付加したリンカー遺伝子断片を増幅した。この得られた遺伝子断片をNheI, BamHIで消化し、NheI, BamHIで開裂した341VL36発現ベクターに挿入した。このベクターの3’側に、341-1-19重鎖配列を鋳型とし、5’-GATATCAAAGGATCCCAGGTCCAACTGCAGCAGTC-3’(配列番号102)及び、5’-GGGGGATCCTCAAACTGTCTTGTCCACCTTGG-3’(配列番号103)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を35サイクル実施することで、5’末端にBamHI配列を、3’末端に(3’末端から)BamHI配列、終止コドン及びCH1領域(118番目のスレオニンから215番目のバリン)をコードする遺伝子配列を付加した341-1-19の重鎖可変領域とCH1領域を、BamHIで消化し挿入した。341VL36-CH1-H- CH2-CH3-341-CH1 重鎖核酸配列(配列番号114)、341VL36-CH1-H- CH2-CH3-341-CH1 重鎖アミノ酸配列(配列番号115)は配列表に記載した。
[実施例16]多価抗体の発現と精製
作製した発現ベクター遺伝子をQIAGEN Plasmid Maxi Kit(キアゲン社製)にて調製し、FreeStyleTM 293 Expression System (Invitrogen社製)を用いて浮遊性293細胞に導入して、一過性発現により各抗体を含む培養上清を得た。培養上清はベクター導入7日後に回収し、孔径0.22μm のメンブランフィルター(MILLIPORE 製)で濾過した。この培養上清から、ProteinA樹脂(MabSelect, GEヘルスケアバイオサイエンス社製)を用いてアフィニティー精製した。洗浄液としてリン酸緩衝液、溶出緩衝液として20mMクエン酸ナトリウム, 50mM NaCl緩衝液(pH2.7)を用いた。溶出画分は200mMリン酸ナトリウム緩衝液(pH7.0)を添加してpH6.0付近に調整した。調製された抗体溶液は、透析膜(10000カット、Spectrum Laboratories社製)を用いてリン酸緩衝液に置換し、孔径0.22μmのメンブランフィルター (Millex-GV, MILLIPORE社製)でろ過滅菌し、精製抗体を得た。精製抗体の濃度は280nmの吸光度を測定し、1mg/mLを抗体の濃度は1.40 Optimal densityとして算出した。
作製した発現ベクター遺伝子をQIAGEN Plasmid Maxi Kit(キアゲン社製)にて調製し、FreeStyleTM 293 Expression System (Invitrogen社製)を用いて浮遊性293細胞に導入して、一過性発現により各抗体を含む培養上清を得た。培養上清はベクター導入7日後に回収し、孔径0.22μm のメンブランフィルター(MILLIPORE 製)で濾過した。この培養上清から、ProteinA樹脂(MabSelect, GEヘルスケアバイオサイエンス社製)を用いてアフィニティー精製した。洗浄液としてリン酸緩衝液、溶出緩衝液として20mMクエン酸ナトリウム, 50mM NaCl緩衝液(pH2.7)を用いた。溶出画分は200mMリン酸ナトリウム緩衝液(pH7.0)を添加してpH6.0付近に調整した。調製された抗体溶液は、透析膜(10000カット、Spectrum Laboratories社製)を用いてリン酸緩衝液に置換し、孔径0.22μmのメンブランフィルター (Millex-GV, MILLIPORE社製)でろ過滅菌し、精製抗体を得た。精製抗体の濃度は280nmの吸光度を測定し、1mg/mLを抗体の濃度は1.40 Optimal densityとして算出した。
[実施例17]抗体の生産性の測定
抗体の生産性として、各培養上清中の抗体含有量を測定した。抗体含有量の測定は、高速液体クロマトグラフ装置(日立社製)及びPOROS 50 A (Applid Biosystem社製, cat. 4319037)と、溶媒として20mM Phosphate, 300mM NaCl pH7.0を用いて分析を行った。抗体の含有量は各培養上清を注入して得られたピーク面積と、1, 2, 5, 10μgの精製ヒト抗体(IgG1)を注入して得られたピーク面積とを比較することで算出した。
抗体の生産性として、各培養上清中の抗体含有量を測定した。抗体含有量の測定は、高速液体クロマトグラフ装置(日立社製)及びPOROS 50 A (Applid Biosystem社製, cat. 4319037)と、溶媒として20mM Phosphate, 300mM NaCl pH7.0を用いて分析を行った。抗体の含有量は各培養上清を注入して得られたピーク面積と、1, 2, 5, 10μgの精製ヒト抗体(IgG1)を注入して得られたピーク面積とを比較することで算出した。
その結果を表3に示す。表3より短いリンカーを介した多価抗体は生産性が低いことがわかった。
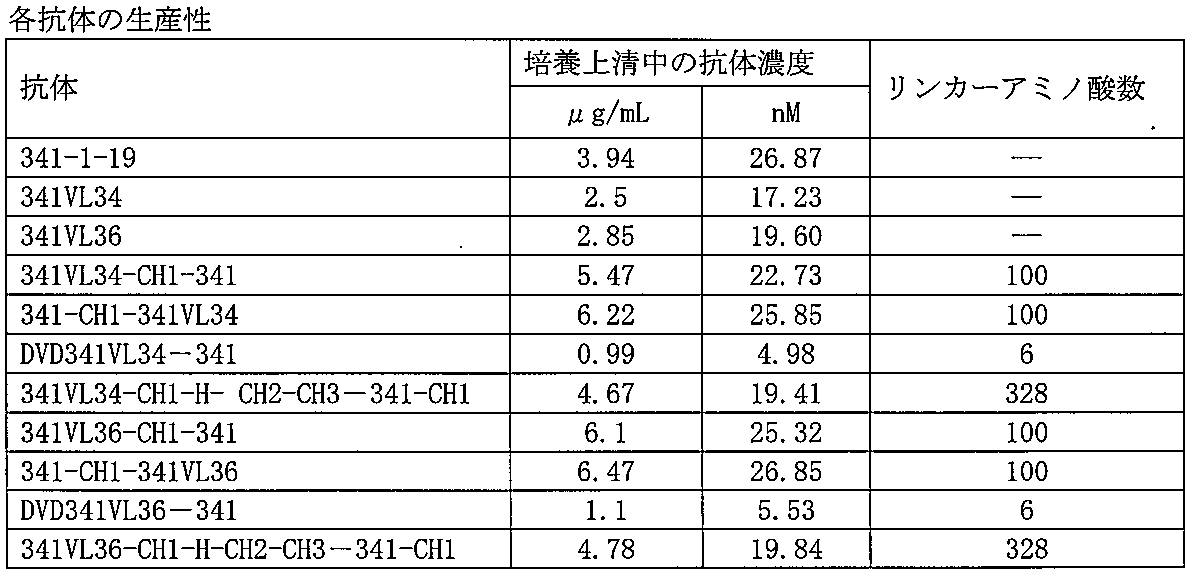
[実施例18]抗体の安定性の評価
抗体溶液の凝集体含有率は、高速液体クロマトグラフ装置(島津社製)及びTSK-G3000 SWカラム(東ソー社製)と、溶媒として20mMリン酸ナトリウム, 500mM NaCl, pH7.0を用いて分析を行った。各抗体を40ug注入し、溶出位置をゲルろ過HPLC用分子量マーカー(オリエンタル酵母社製Cat No. 40403701)と比較することで、抗体蛋白の単量体とそれ以上の凝集体のピークを同定して、それぞれのピーク面積から凝集体の含有率を算出した。
抗体溶液の凝集体含有率は、高速液体クロマトグラフ装置(島津社製)及びTSK-G3000 SWカラム(東ソー社製)と、溶媒として20mMリン酸ナトリウム, 500mM NaCl, pH7.0を用いて分析を行った。各抗体を40ug注入し、溶出位置をゲルろ過HPLC用分子量マーカー(オリエンタル酵母社製Cat No. 40403701)と比較することで、抗体蛋白の単量体とそれ以上の凝集体のピークを同定して、それぞれのピーク面積から凝集体の含有率を算出した。
その結果を表4に示す。表4より短いリンカーでは精製過程で多くの凝集体が発生し、多価抗体の水溶液中における安定性が悪いことがわかった。
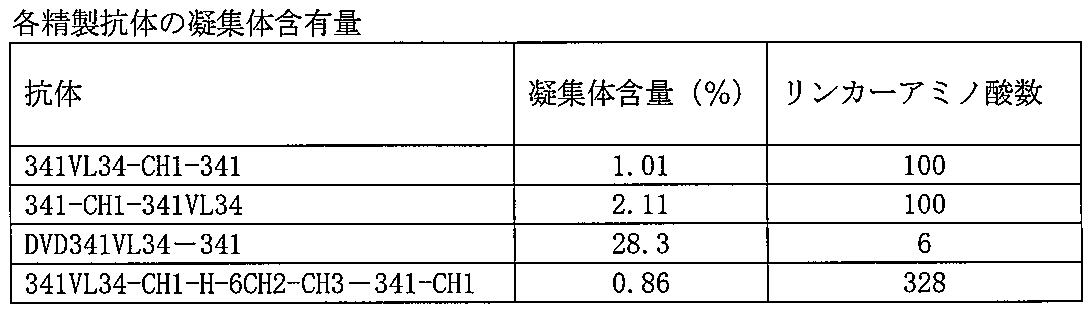
[実施例19]抗体の抗原結合性の評価
作製した2つ(CD40及びCD28)の認識部位を有する抗体の各抗原への結合を以下の手順に従い確認した。
作製した2つ(CD40及びCD28)の認識部位を有する抗体の各抗原への結合を以下の手順に従い確認した。
Coating buffer(50 mM carbonate buffer, pH9)にて1μg/mLに調製したヒトCD40-Fc融合タンパク質及び、ヒトCD28-Fc融合タンパク質を50μL/wellでマキシソープPlate(NUNC社製)に播き、4℃で1晩インキュベートし、固相化した。ブロッキング試薬(SuperBlock(登録商標)Blocking Buffer, PIERCE社製)を200μL/well加え、室温で30分間インキュベートし、ブロッキングを実施した。そこに、上記実施例で得た各抗体を含んだ培養上清を50μL/well加え、室温で1時間インキュベートした。Washing buffer(0.1% Tween20-TBS)にて3回洗浄した後、assay diluent (大日本住友製薬社製Block Aceを10%含む0.1%Tween20-TBS)で希釈したAffinity Isolated Antibody HRP Conjugated Goat F(ab)2 anti-Human kappa(EY Lab.社製)を各ウェルに50 μL加え、更に室温にて1時間反応させた。Washing bufferにて3回洗浄後、TMB (DAKO社製)発色基質液を各ウェルに50μL加え、暗所にて室温でインキュベートし、発色させた後、0.5M硫酸(50μL/well)を加え、反応を停止した。波長450nmでの吸光度をマイクロプレートリーダー(SPECTRAMAX190, Molecular Devices社製)で測定した。

[実施例20]第1の抗原認識部位の取得
新たな抗CD40抗体を、実施例1と同様にしてして抗CD40抗体281を確立した。
新たな抗CD40抗体を、実施例1と同様にしてして抗CD40抗体281を確立した。
[実施例21]抗CD40抗体の軽鎖と共通の軽鎖を有する抗CD28抗体のscFVライブラリーの作製
実施例20の抗CD40抗体281の軽鎖と共通の軽鎖を有する抗CD28抗体をスクリーニングするために、実施例2で作製されたCD28で免疫されたマウスの脾臓を用いて、抗CD28抗体の重鎖可変領域遺伝子断片と軽鎖可変領域遺伝子断片を結合させた1本鎖抗体断片(scFV)遺伝子のライブラリーを作製した。
実施例20の抗CD40抗体281の軽鎖と共通の軽鎖を有する抗CD28抗体をスクリーニングするために、実施例2で作製されたCD28で免疫されたマウスの脾臓を用いて、抗CD28抗体の重鎖可変領域遺伝子断片と軽鎖可変領域遺伝子断片を結合させた1本鎖抗体断片(scFV)遺伝子のライブラリーを作製した。
281の重鎖(配列番号116)を鋳型とし、5’-GCAACTGCGGCCCAGCCGGCCATGGCCCAGGTGCAGCTGCAGGAG-3’(配列番号120)及び、5’-CCGAGGCGCGCCCACCGCTGCCACCGCCTCCTGAGGAGACGGTGACCAG-3’(配列番号121)をプライマーとして5’末端にSfiI配列、3’末端にグリシンリッチ配列が付加された281の重鎖可変領域遺伝子断片を、また281の軽鎖(配列番号118)を鋳型とし5’-CGGTGGGCGCGCCTCGGGCGGAGGTGGTTCAGAAATTGTGTTGACGCAG-3’(配列番号122)及び、5’-GAGTCATTCTCGACTTGCGGCCGCACGTTTGATCTCCAGTCGTGTCCC-3’ (配列番号123)をプライマーとして5’末端にグリシンリッチ配列、3’末端にNotI配列が付加された281の軽鎖可変領域遺伝子断片を、それぞれDNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、58℃ 30秒、68℃1分の反応を35サイクル実施することで増幅した。この得られたVH, VL遺伝子断片を、実施例3と同様にOver Extension PCRによって連結し、281 scFv遺伝子断片を作製した。この遺伝子断片をSfiIとNotIで消化し、あらかじめSfiIとNotIで開裂したpCANTAB 5Eベクター (GEヘルスケアバイオサイエンス社製)に挿入した。得られたプラスミドをpCANTAB5E/281と命名した。本件では281の軽鎖と共通のアミノ酸配列を有するヒトCD28を抗原とする抗体の取得を目的とするため、このプラスミドをSfiI、AscIで開裂(341-1-19のVHをコードする遺伝子領域を除いた)後、Alkaline Phosphatase(BAP, タカラバイオ社製)で脱リン酸化処理したベクター遺伝子を、ライブラリー作製用のベクターとした。
実施例3で合成したcDNAを鋳型とし、ファージ抗体ライブラリー作製のための重鎖可変領域遺伝子断片を取得した。このcDNAを鋳型とし、ヒト重鎖の可変領域に特異的なプライマー(配列番号124-131)及び、Junction領域に特異的なプライマー(配列番号132-135)を用いて、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、58℃30秒、68℃30秒の反応を35サイクル実施した。尚、Junction領域に特異的なプライマーは5種を混合して使用した。また、配列番号124-131の5’末端にはSfiIの切断認識部位を、配列番号132-135の5’末端にはAscIの切断認識部位及びリンカー配列を挿入した。
これらPCR反応にて増幅したVH遺伝子断片を、実施例3の手順に従いpCANTAB5E/281を用いて作製したベクターに挿入し、scFv抗体ライブラリーを作製した。尚、本実施例では約5×105個のコロニーを集めてライブラリーを作製した。このscFv抗体ライブラリーより抗体ファージライブラリーを調整した。
[実施例22]ヒトCD28を認識するscFv抗体を提示するファージの濃縮
実施例21にて作製した抗体ファージライブラリーの濃縮を実施例5の手順に従い実施した。
実施例21にて作製した抗体ファージライブラリーの濃縮を実施例5の手順に従い実施した。
[実施例23]ヒトCD28を認識する抗体提示ファージの選定および抗CD28抗体(281VL4)の作製
実施例6の手順に従い抗体提示ファージの選定を行った。
実施例6の手順に従い抗体提示ファージの選定を行った。
ELISAにて抗原への結合が確認されたscFv抗体を281VL4 scFvと命名した。取得したscFv抗体を通常型の抗体に変換するため、抗体遺伝子のクローニング及び発現ベクターの作製を行った。
重鎖遺伝子断片を増幅するため、pCANTAB/281VL4を鋳型とし、5’-CTGCTGGTGGCGGCTCCCAGATGGGTCCTGTCCGAGGTCCAGCTGGTG-3’(配列番号136)及び、5’-TGAGGAGACGGTGACCA-3’(配列番号137)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、58℃30秒、68℃30秒の反応を30サイクル実施した。この遺伝子断片を鋳型として使用し、その5’末端にSalI配列、Kozac配列及び、シグナルをコードする配列を、その3’末端にNheI配列を付加するためのPCR反応を実施した。各重鎖遺伝子断片を鋳型とし、5’-GGGGTCGACACCATGAAGCACCTGTGGTTCTTCCTCCTGCTGGTGGCGG-3’(配列番号138)及び5’- GGGGCTAGCTGAGGAGACGGTGACCA-3’(配列番号139)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、58℃30秒、68℃30秒を35サイクルのPCR反応を行った。281VL4 scFvの軽鎖は281と共通のアミノ酸配列であるため、281発現ベクター(WO2002/088186に記載のN5KG4PEを使用)の重鎖可変領域をSalI、NheIで切り出し、SalI、NheIで消化した281VL4 scFv由来の重鎖遺伝子断片を挿入した。281の軽鎖(配列番号118, 119)と281VL4 scFv由来の重鎖から構成される抗体を、281VL4と名づけた。
281VL4 重鎖核酸配列(配列番号140)、281VL4重鎖アミノ酸配列(配列番号141)はそれぞれ配列表に示す。
281VL4抗体重鎖核酸の翻訳開始点は、配列番号140の5'末端から1番目のアデニン(A)からはじまるATGコドンであり、終止コドンは1417番目のチミン(T)からはじまるTGAである。抗体可変領域と定常領域の境界は5'末端から435番目のアデニン(A)と436番目のグアニン(G)間に位置する。アミノ酸配列において、重鎖可変領域は配列番号141のN末端から145番目のセリン(S)残基までであり、146番目のアラニン(A)以降が定常領域である。重鎖のシグナル配列は配列番号141のN末端より19番目のセリン(S)までであり、成熟体のN末端は20番目のグルタミン酸(E)であるものと考える。
[実施例24]CD28に対する抗原認識部位(281VL4由来)をN末側にCD40に対する抗原認識部位(281由来)をC末側に有し、表6のリンカーを含む多価抗体(281VL4-CH1-281、281VL4-CH1(118-131)-281、281VL4-CH1(118-130)-281)の発現ベクターの作製
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表6に示したリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、281と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。これら多価抗体を、281VL4-CH1-281、281VL4-CH1(118-131)-281、281VL4-CH1(118-130)-281と名づけた。

重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表6に示したリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、281と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。これら多価抗体を、281VL4-CH1-281、281VL4-CH1(118-131)-281、281VL4-CH1(118-130)-281と名づけた。
281VL4-CH1-281は、重鎖の間(281VL4の重鎖の3’末端、281の重鎖の5’末端)にはIgG4のCH1配列(Kabat EUインデックス118番から215番)とさらに、その3’末端にBamHI配列(GGATCC)を付加した配列をリンカーとして挿入している。
281VL4-CH1-281 の重鎖をコードする遺伝子配列は以下の手順で作製した。
281重鎖配列を鋳型とし、5’-GGGGCTAGCACCAAGGGGCCA-3’(配列番号144)及び、5’-GGATCCAACTCTCTTGTCCACCTT-3’(配列番号145)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施することで、5’末端にNheI配列を付加したリンカー遺伝子断片を増幅した。281重鎖配列を鋳型とし、5’-AAGAGAGTTGGATCCCAGGTGCAGCTGCAG-3’(配列番号146)及び、5’-GGGGCTAGCTGAGGAGACGGTGACCA-3’(配列番号147)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施することで、5’末端にリンカー遺伝子(3’末端側から15塩基)を、3’末端にNheI配列を付加した281の重鎖遺伝子断片を増幅した。この得られた2つの遺伝子断片を、Over Extension PCRによって連結し、リンカー - 281重鎖の遺伝子断片を作製した。この遺伝子断片をNheIで消化し、NheIで開裂した後Alkaline Phosphatase(BAP, タカラバイオ社製)で脱リン酸化処理した281VL4発現ベクターに挿入した。281VL4-CH1-281 重鎖核酸配列(配列番号148)、281VL4-CH1-281 重鎖アミノ酸配列(配列番号149)はそれぞれ配列表に示す。
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、リンカー(配列番号151)を介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、281と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。この多価抗体を、281VL4-CH1(118-131)-281と名づけた。
281VL4-CH1(118-131)-281は、重鎖の間(281VL4の重鎖の3’末端、281の重鎖の5’末端)にはIgG4のCH1配列(Kabat EUインデックス118番から131番)をリンカーとして挿入している。
281VL4-CH1(118-131)-281 の重鎖をコードする遺伝子配列は以下の手順で作製した。
281重鎖配列を鋳型とし、5’-GTCTTCCCCCTGGCGCCCTGCCAGGTGCAGCTGCAGGAGTC-3’(配列番号150)及び、5’-GGGGCTAGCTGAGGAGACGGTGACCA-3’(配列番号147)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施した。このPCR産物を鋳型とし、5’-GGGGCTAGCACCAAGGGGCCATCCGTCTTCCCCCTGGCGCCC-3’(配列番号151)及び、5’-GGGGCTAGCTGAGGAGACGGTGACCA-3’(配列番号147)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を35サイクル実施することで、5’末端にリンカー遺伝子(リンカー配列の5’末端はNheI配列である。)を、3’末端にNheI配列を付加した281の重鎖遺伝子断片を増幅した。この得られた遺伝子断片をNheIで消化し、NheIで開裂した後Alkaline Phosphatase(BAP, タカラバイオ社製)で脱リン酸化処理した281VL4発現ベクターに挿入した。281VL4-CH1(118-131)-281 重鎖核酸配列(配列番号152)、281VL4-CH1(118-131)-281 重鎖アミノ酸配列(配列番号153)はそれぞれ配列表に示す。
281VL4-CH1(118-130)-281は、重鎖の間(281VL4の重鎖の3’末端、281の重鎖の5’末端)にはIgG4のCH1配列(Kabat EUインデックス118番から130番)をリンカーとして挿入している。
281VL4-CH1(118-130)-281 の重鎖をコードする遺伝子配列は以下の手順で作製した。
281重鎖配列を鋳型とし、5’-GTCTTCCCCCTGGCGCCCCAGGTGCAGCTGCAGGAGTC-3’(配列番号154)及び、5’-GGGGCTAGCTGAGGAGACGGTGACCA-3’(配列番号147)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施した。このPCR産物を鋳型とし、5’-GGGGCTAGCACCAAGGGGCCATCCGTCTTCCCCCTGGCGCCC-3’(配列番号151)及び、5’-GGGGCTAGCTGAGGAGACGGTGACCA-3’(配列番号147)をプライマーとして、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)を用いて、95℃30秒、55℃30秒、68℃30秒の反応を35サイクル実施することで、5’末端にリンカー遺伝子(リンカー配列の5’末端はNheI配列である。)を、3’末端にNheI配列を付加した281の重鎖遺伝子断片を増幅した。この得られた遺伝子断片をNheIで消化し、NheIで開裂した後Alkaline Phosphatase(BAP, タカラバイオ社製)で脱リン酸化処理した281VL4発現ベクターに挿入した。281VL4-CH1(118-130)-281 重鎖核酸配列(配列番号155)、281VL4-CH1(118-130)-281 重鎖アミノ酸配列(配列番号156)はそれぞれ配列表に示す。
[実施例25]多価抗体の発現と精製
作製した発現ベクター遺伝子をQIAGEN Plasmid Maxi Kit(キアゲン社製)にて調製し、FreeStyleTM 293 Expression System (Invitrogen社製)を用いて浮遊性293細胞に導入して、一過性発現により各抗体を含む培養上清を得た。実施例16の手順に従い、この培養上清から精製抗体を得た。精製抗体の濃度は280nmの吸光度を測定し、1mg/mLを抗体の濃度は1.40 Optimal densityとして算出した。
作製した発現ベクター遺伝子をQIAGEN Plasmid Maxi Kit(キアゲン社製)にて調製し、FreeStyleTM 293 Expression System (Invitrogen社製)を用いて浮遊性293細胞に導入して、一過性発現により各抗体を含む培養上清を得た。実施例16の手順に従い、この培養上清から精製抗体を得た。精製抗体の濃度は280nmの吸光度を測定し、1mg/mLを抗体の濃度は1.40 Optimal densityとして算出した。
[実施例26]抗体の生産性の測定
抗体の生産性として、各培養上清中の抗体含有量を測定した。抗体含有量の測定は、実施例17の手順に従い行った。その結果を表7に示す。

抗体の生産性として、各培養上清中の抗体含有量を測定した。抗体含有量の測定は、実施例17の手順に従い行った。その結果を表7に示す。
[実施例27]抗体の安定性の評価
抗体溶液の凝集体含有率は、実施例18の手順に従い測定した。その結果を表8に示す。

抗体溶液の凝集体含有率は、実施例18の手順に従い測定した。その結果を表8に示す。
[実施例28]抗体の抗原結合性の評価
作製した2つ(CD40及びCD28)の認識部位を有する抗体の各抗原への結合を実施例19の手順に従い確認した。その結果、281VL4-CH1-281、281VL4-CH1(118-131)-281、281VL4-CH1(118-130)-281共にヒトCD40-Fc融合タンパク質及び、ヒトCD28-Fc融合タンパク質に結合することが確認された。
作製した2つ(CD40及びCD28)の認識部位を有する抗体の各抗原への結合を実施例19の手順に従い確認した。その結果、281VL4-CH1-281、281VL4-CH1(118-131)-281、281VL4-CH1(118-130)-281共にヒトCD40-Fc融合タンパク質及び、ヒトCD28-Fc融合タンパク質に結合することが確認された。
[実施例29]CD28に対する抗原認識部位(281VL4由来)をN末側にCD40に対する抗原認識部位(281由来)をC末側に有し、表9のリンカーを含む多価抗体の発現ベクターの作製
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表9に示したリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、281と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。この多価抗体を、281VL4-CH1(118-131/C131S)-281と名づけた。

重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表9に示したリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、281と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。この多価抗体を、281VL4-CH1(118-131/C131S)-281と名づけた。
281VL4-CH1(118-131/C131S)-281は、重鎖の間(281VL4の重鎖の3’末端、281の重鎖の5’末端)にはIgG1のCH1配列(Kabat EUインデックス118番から131番)をリンカーとして挿入している。
これら抗体の重鎖をコードする遺伝子配列は実施例24で用いた遺伝学的手法の手順を参考にして作製した。281VL4-CH1(118-131/C131S)-281 重鎖核酸配列(配列番号157)、281VL4-CH1(118-131/C131S)-281 重鎖アミノ酸配列(配列番号158)はそれぞれ配列表に示す。
[実施例30]CD28に対する抗原認識部位(281VL4由来)をN末側にCD40に対する抗原認識部位(281由来)をC末側に有し、表10のリンカーを含む多価抗体の発現ベクターの作製
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表10に示したリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、281と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。これら多価抗体を、281VL4-CH1(118-119+C)-281、281VL4-CH1(118-120+C)-281、281VL4-CH1(118-121+C)-281、281VL4-CH1(118-122+C)-281、281VL4-CH1(118-123+C)-281、281VL4-CH1(118-124+C)-281、281VL4-CH1(118-125+C)-281、281VL4-CH1(118-126+C)-281、281VL4-CH1(118-127+C)-281、281VL4-CH1(118-128+C)-281、281VL4-CH1(118-129+C)-281と名づけた。

重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表10に示したリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、281と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。これら多価抗体を、281VL4-CH1(118-119+C)-281、281VL4-CH1(118-120+C)-281、281VL4-CH1(118-121+C)-281、281VL4-CH1(118-122+C)-281、281VL4-CH1(118-123+C)-281、281VL4-CH1(118-124+C)-281、281VL4-CH1(118-125+C)-281、281VL4-CH1(118-126+C)-281、281VL4-CH1(118-127+C)-281、281VL4-CH1(118-128+C)-281、281VL4-CH1(118-129+C)-281と名づけた。
281VL4-CH1(118-119+C)-281、281VL4-CH1(118-120+C)-281、281VL4-CH1(118-121+C)-281、281VL4-CH1(118-122+C)-281、281VL4-CH1(118-123+C)-281、281VL4-CH1(118-124+C)-281、281VL4-CH1(118-125+C)-281、281VL4-CH1(118-126+C)-281、281VL4-CH1(118-127+C)-281、281VL4-CH1(118-128+C)-281、281VL4-CH1(118-129+C)-281は、重鎖の間(281VL4の重鎖の3’末端、281の重鎖の5’末端)にはIgG4のCH1配列(Kabat EUインデックス118番から119番 - 129番)とさらに、その3’末端にTGC(アミノ酸に変換した場合システインをコードする核酸配列)を付加した配列をリンカーとして挿入している。
これら抗体の重鎖をコードする遺伝子配列は実施例24で用いた遺伝学的手法の手順を参考にして作製した。それぞれの重鎖核酸配列、重鎖アミノ酸配列は配列表(配列番号159-180)に示す。
[実施例31]CD28に対する抗原認識部位(281VL4由来)をN末側にCD40に対する抗原認識部位(281由来)をC末側に有し、表11のリンカーを含む多価抗体の発現ベクターの作製
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表11に示したリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、281と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。これら多価抗体を、281VL4-CH1(118-131/A118S)-281、281VL4-CH1(118-131/S119A)-281、281VL4-CH1(118-131/T120A)-281、281VL4-CH1(118-131/K121A)-281、281VL4-CH1(118-131/G122A)-281、281VL4-CH1(118-131/P123A)-281、281VL4-CH1(118-131/S124A)-281、281VL4-CH1(118-131/V125A)-281、281VL4-CH1(118-131/F126A)-281、281VL4-CH1(118-131/P127A)-281、281VL4-CH1(118-131/L128A)-281、281VL4-CH1(118-131/A129S)-281、 281VL4-CH1(118-131/P130A)-281と名づけた。

重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表11に示したリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、281と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。これら多価抗体を、281VL4-CH1(118-131/A118S)-281、281VL4-CH1(118-131/S119A)-281、281VL4-CH1(118-131/T120A)-281、281VL4-CH1(118-131/K121A)-281、281VL4-CH1(118-131/G122A)-281、281VL4-CH1(118-131/P123A)-281、281VL4-CH1(118-131/S124A)-281、281VL4-CH1(118-131/V125A)-281、281VL4-CH1(118-131/F126A)-281、281VL4-CH1(118-131/P127A)-281、281VL4-CH1(118-131/L128A)-281、281VL4-CH1(118-131/A129S)-281、 281VL4-CH1(118-131/P130A)-281と名づけた。
281VL4-CH1(118-131/A118S)-281、281VL4-CH1(118-131/S119A)-281、281VL4-CH1(118-131/T120A)-281、281VL4-CH1(118-131/K121A)-281、281VL4-CH1(118-131/G122A)-281、281VL4-CH1(118-131/P123A)-281、281VL4-CH1(118-131/S124A)-281、281VL4-CH1(118-131/V125A)-281、281VL4-C29H1(118-131/F126A)-281、281VL4-CH1(118-131/P127A)-281、281VL4-CH1(118-131/L128A)-281、281VL4-CH1(118-131/A129S)-281、281VL4-CH1(118-131/P130A)-281は、重鎖の間(281VL4の重鎖の3’末端、281の重鎖の5’末端)にはIgG4のCH1(Kabat EUインデックス118番から131番)に変異を加えた配列をリンカーとして挿入している。各々のリンカーに加えた変異は1アミノ酸ずつであり、IgG4のCH1配列のアミノ酸をアラニンに置換している。なお、本来の配列がアラニンの箇所に変異を加える場合は、アラニンをシステインに置換している。
これら抗体の重鎖をコードする遺伝子配列は実施例24で用いた遺伝学的手法の手順を参考にして作製した。それぞれの重鎖核酸配列、重鎖アミノ酸配列は配列表(配列番号181-206)に示す。
[実施例32]CD28に対する抗原認識部位(281VL4由来)をN末側にCD40に対する抗原認識部位(281由来)をC末側に有し、表12のリンカーを含む多価抗体の発現ベクターの作製
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表12に示したリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、281と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。これら多価抗体を、281VL4-CH1(IGHA)-281、281VL4-CH1(IGHD(14))-281、281VL4-CH1(IGHD(15))-281、281VL4-CH1(IGHE)-281、281VL4-CH1(IGHGP)-281、281VL4-CH1(IGHM)-281と名づけた。

重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表12に示したリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、281と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。これら多価抗体を、281VL4-CH1(IGHA)-281、281VL4-CH1(IGHD(14))-281、281VL4-CH1(IGHD(15))-281、281VL4-CH1(IGHE)-281、281VL4-CH1(IGHGP)-281、281VL4-CH1(IGHM)-281と名づけた。
281VL4-CH1(IGHA)-281、281VL4-CH1(IGHD(14))-281、281VL4-CH1(IGHE)-281、281VL4-CH1(IGHGP)-281、281VL4-CH1(IGHM)-281は、重鎖の間(281VL4の重鎖の3’末端、281の重鎖の5’末端)には各サブクラスのCH1配列(Kabat EUインデックス118番から131番)をリンカーとして挿入している。131番目のアミノ酸がシステインではないサブクラスIGHDは131番のアミノ酸をグリシンからシステインに置換し、IGHGPは131番目のアミノ酸をセリンからシステインに置換している。なお、281VL4-CH1(IGHD(15))-281は、重鎖の間にIGHDのCH1配列(118番から132番)をリンカーとして挿入している。
これら抗体の重鎖をコードする遺伝子配列は実施例24で用いた遺伝学的手法の手順を参考にして作製した。それぞれの重鎖核酸配列、重鎖アミノ酸配列は配列表(配列番号207-218)に示す。
[実施例33]CD28に対する抗原認識部位(281VL4由来)をN末側にCD40に対する抗原認識部位(281由来)をC末側に有し、表13のリンカーを含む多価抗体の発現ベクターの作製
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表13に示したリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、281と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。これら多価抗体を、281VL4-CH1(118-131/A118G)-281、281VL4-CH1(118-131/S119T)-281、281VL4-CH1(118-131/P123F)-281、281VL4-CH1(118-131/V125L)-281、281VL4-CH1(118-131/V125I)-281、281VL4-CH1(118-131/F126L)-281、281VL4-CH1(118-131/F126Y)-281、281VL4-CH1(118-131/P127G)-281、281VL4-CH1(118-131/L128V)-281、281VL4-CH1(118-131/L128I)-281、281VL4-CH1(118-131/A129I)-281、281VL4-CH1(118-131/P130F)-281と名づけた。

重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表13に示したリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、281と共通のものを抗CD28抗体も使用するため、発現ベクターは1種類の軽鎖配列を保持する。これら多価抗体を、281VL4-CH1(118-131/A118G)-281、281VL4-CH1(118-131/S119T)-281、281VL4-CH1(118-131/P123F)-281、281VL4-CH1(118-131/V125L)-281、281VL4-CH1(118-131/V125I)-281、281VL4-CH1(118-131/F126L)-281、281VL4-CH1(118-131/F126Y)-281、281VL4-CH1(118-131/P127G)-281、281VL4-CH1(118-131/L128V)-281、281VL4-CH1(118-131/L128I)-281、281VL4-CH1(118-131/A129I)-281、281VL4-CH1(118-131/P130F)-281と名づけた。
281VL4-CH1(118-131/A118G)-281、281VL4-CH1(118-131/S119T)-281、281VL4-CH1(118-131/P123F)-281、281VL4-CH1(118-131/V125L)-281、281VL4-CH1(118-131/V125I)-281、281VL4-CH1(118-131/F126L)-281、281VL4-CH1(118-131/F126Y)-281、281VL4-CH1(118-131/P127G)-281、281VL4-CH1(118-131/L128V)-281、281VL4-CH1(118-131/L128I)-281、281VL4-CH1(118-131/A129I)-281、281VL4-CH1(118-131/P130F)-281は、重鎖の間(281VL4の重鎖の3’末端、281の重鎖の5’末端)にはIgG4のCH1(Kabat EUインデックス118番から131番)に変異を加えた配列をリンカーとして挿入している。各々のリンカーに加えた変異は1アミノ酸ずつであり、IgG4のCH1配列のアミノ酸をランダムに他のアミノ酸に置換している。
これら抗体の重鎖をコードする遺伝子配列は実施例24で用いた遺伝学的手法の手順を参考にして作製した。それぞれの重鎖核酸配列、重鎖アミノ酸配列は配列表(配列番号219-242)に示す。
[実施例34]多価抗体の発現と精製
実施例29~33で作製した発現ベクター遺伝子をQIAGEN Plasmid Maxi Kit(キアゲン社製)にて調製し、FreeStyleTM 293 Expression System (Invitrogen社製)を用いて浮遊性293細胞に導入して、一過性発現により各抗体を含む培養上清を得た。実施例16の手順に従い、この培養上清から精製抗体を得た。精製抗体の濃度は280nmの吸光度を測定し、1mg/mLを抗体の濃度は1.40 Optimal densityとして算出した。
実施例29~33で作製した発現ベクター遺伝子をQIAGEN Plasmid Maxi Kit(キアゲン社製)にて調製し、FreeStyleTM 293 Expression System (Invitrogen社製)を用いて浮遊性293細胞に導入して、一過性発現により各抗体を含む培養上清を得た。実施例16の手順に従い、この培養上清から精製抗体を得た。精製抗体の濃度は280nmの吸光度を測定し、1mg/mLを抗体の濃度は1.40 Optimal densityとして算出した。
[実施例35]抗体の安定性の評価
抗体溶液の凝集体含有率は、実施例18の手順に従い測定した。その結果を表14に示す。

抗体溶液の凝集体含有率は、実施例18の手順に従い測定した。その結果を表14に示す。

[実施例36]CD28に対する抗原認識部位(281VL4由来)をN末側にCD40に対する抗原認識部位(281由来)をC末側に有し、ヒトIg各サブクラスCH1領域内配列をリンカーとして用いた多価抗体の構造
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表1に示したリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。実施例における多価抗体のリンカーとしては、ヒトIg各サブクラスのCH1領域内配列と、その3’末端にBamHI配列であるGS(GGATCC)を加えたリンカーが挿入されている。これら多価抗体をそれぞれ
281VL4-A1(118~143)GS-281、281VL4-A2(118~143)GS-281、281VL4-E(118~143)GS-281、
281VL4-G1(118~143)GS-281、281VL4-G2(118~143)GS-281、281VL4-G3(118~143)GS-281、
281VL4-HGP(118~143)GS-281、281VL4-D(118~143)GS-281、281VL4-M(118~143)GS-281
と名付けた。
表15に、作製した多価抗体の構造をまとめた。

重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表1に示したリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。実施例における多価抗体のリンカーとしては、ヒトIg各サブクラスのCH1領域内配列と、その3’末端にBamHI配列であるGS(GGATCC)を加えたリンカーが挿入されている。これら多価抗体をそれぞれ
281VL4-A1(118~143)GS-281、281VL4-A2(118~143)GS-281、281VL4-E(118~143)GS-281、
281VL4-G1(118~143)GS-281、281VL4-G2(118~143)GS-281、281VL4-G3(118~143)GS-281、
281VL4-HGP(118~143)GS-281、281VL4-D(118~143)GS-281、281VL4-M(118~143)GS-281
と名付けた。
表15に、作製した多価抗体の構造をまとめた。

[実施例37]CD28に対する抗原認識部位(281VL4由来)をN末側にCD40に対する抗原認識部位(281由来)をC末側に有し、配列番号244,246,250,252,254,256,258のリンカーを含む多価抗体発現ベクターの作製
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、リンカー(配列番号244,246,250,252,254,256,258)を介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、抗281抗体、抗CD28抗体共に共通の軽鎖を使用するため、発現ベクターは1種類の軽鎖配列を保持する。
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、リンカー(配列番号244,246,250,252,254,256,258)を介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、抗281抗体、抗CD28抗体共に共通の軽鎖を使用するため、発現ベクターは1種類の軽鎖配列を保持する。
これら抗体の重鎖をコードする遺伝子配列は実施例24で用いた遺伝学的手法の手順を参考にして作製した。
281VL4-A1(118~143)GS-281 重鎖核酸配列(配列番号261)、
281VL4-A1(118~143)GS-281 重鎖アミノ酸配列(配列番号262)、
281VL4-A2(118~143)GS-281 重鎖核酸配列(配列番号263)、
281VL4-A2(118~143)GS-281 重鎖アミノ酸配列(配列番号264)、
281VL4-E(118~143)GS-281 重鎖核酸配列(配列番号265)、
281VL4-E(118~143)GS-281 重鎖アミノ酸配列(配列番号266)、
281VL4-G1(118~143)GS-281 重鎖核酸配列(配列番号267)、
281VL4-G1(118~143)GS-281 重鎖アミノ酸配列(配列番号268)、
281VL4-G2(118~143)GS-281 重鎖核酸配列(配列番号269)、
281VL4-G2(118~143)GS-281 重鎖アミノ酸配列(配列番号270)、
281VL4-G3(118~143)GS-281 重鎖核酸配列(配列番号271)、
281VL4-G3(118~143)GS-281 重鎖アミノ酸配列(配列番号272)、
281VL4-HGP(118~143)GS-281 重鎖核酸配列(配列番号273)、
281VL4-HGP(118~143)GS-281 重鎖アミノ酸配列(配列番号274)はそれぞれ配列表に示す。
281VL4-A1(118~143)GS-281 重鎖アミノ酸配列(配列番号262)、
281VL4-A2(118~143)GS-281 重鎖核酸配列(配列番号263)、
281VL4-A2(118~143)GS-281 重鎖アミノ酸配列(配列番号264)、
281VL4-E(118~143)GS-281 重鎖核酸配列(配列番号265)、
281VL4-E(118~143)GS-281 重鎖アミノ酸配列(配列番号266)、
281VL4-G1(118~143)GS-281 重鎖核酸配列(配列番号267)、
281VL4-G1(118~143)GS-281 重鎖アミノ酸配列(配列番号268)、
281VL4-G2(118~143)GS-281 重鎖核酸配列(配列番号269)、
281VL4-G2(118~143)GS-281 重鎖アミノ酸配列(配列番号270)、
281VL4-G3(118~143)GS-281 重鎖核酸配列(配列番号271)、
281VL4-G3(118~143)GS-281 重鎖アミノ酸配列(配列番号272)、
281VL4-HGP(118~143)GS-281 重鎖核酸配列(配列番号273)、
281VL4-HGP(118~143)GS-281 重鎖アミノ酸配列(配列番号274)はそれぞれ配列表に示す。
[実施例38]CD28に対する抗原認識部位(281VL4由来)をN末側にCD40に対する抗原認識部位(281由来)をC末側に有し、配列番号248、260のリンカーを含む多価抗体発現ベクターの作製
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、リンカー(配列番号248、260)を介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、抗281抗体、抗CD28抗体共に共通の軽鎖を使用するため、発現ベクターは1種類の軽鎖配列を保持する。
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、リンカー(配列番号248、260)を介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、抗281抗体、抗CD28抗体共に共通の軽鎖を使用するため、発現ベクターは1種類の軽鎖配列を保持する。
281VL4-リンカー(配列番号248、260)-281 の重鎖をコードする遺伝子配列は以下の手順で作製した。
281重鎖配列を鋳型とし、L primerとしてNheI CD40 Hc L 5’-CTAGCTAGCTGAGGAGACGGTGACCAGGGTTCCCTGGCCCCAGGGGTGG-3’(配列番号275)を、U primerとしてIgD-CH1-CD40 U 5’-GCCCTGTGGTCCTGGCAggatccCAGGTGCAGCTGCAGGAGTCGGGCCC-3’(配列番号276)IgM-CH1-CD40 U 5’-ACGAGCAGCGTGGCCGTTGGCggatccCAGGTGCAGCTGCAGGAGTCG-3’(配列番号277)を用いて、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)により、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施した。更にこのPCR productを鋳型としL primerとしてNheI CD40 Hc L 5’-CTAGCTAGCTGAGGAGACGGTGACCAGGGTTCCCTGGCCCCAGGGGTGG-3’(配列番号275)を、U primerとしてIgD CH1-2U 5’-CATATCAGGGTGCAGACACCCAAAGGATAACAGCCCTGTGGTCCTGGCA-3’(配列番号278)IgM-CH1-2 U 5’-CTCGTCTCCTGTGAGAATTCCCCGTCGGATACGAGCAGCGTGGCCGTTG -3’(配列番号279)を用い、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)により、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施した。更にこのPCR productを鋳型としL primerとしてNheI CD40 Hc L 5’-CTAGCTAGCTGAGGAGACGGTGACCAGGGTTCCCTGGCCCCAGGGGTGG-3’(配列番号275)を、U primerとしてIgD CH1 U 5’-GCACCCACCAAGGCTCCGGATGTGTTCCCCATCATATCAGGGTGCAGAC -3’(配列番号280)IgM CH1 U 5’-GGGAGTGCATCCGCCCCAACCCTTTTCCCCCTCGTCTCCTGTGAGAATT -3’(配列番号281)を用い、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)により、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施することにより、3’末端にNheI配列を有する、リンカー - 281重鎖-NheIの遺伝子断片を作製した。一方、281VL4重鎖配列を鋳型とし、U primerとして5’-GGGGTCGACACCATGAAGCACCTGTGGTTCTTCCTCCTGCTGGTGGCGG-3’(配列番号138)
、L primerとしてCD28-IgD L 5’-CATCCGGAGCCTTGGTGGGTGCTGAGGAGACGGTGACCATTGTCCCTTG-3’ (配列番号282)、CD28-IgM L 5’-GGGTTGGGGCGGATGCACTCCCTGAGGAGACGGTGACCATTGTCCCTTG-3’ (配列番号283)を用い、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)により、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施し、5’末端にSalI配列を有する、SalI- 281VL4-リンカーの遺伝子断片を作製した。SalI- 281VL4-リンカーの遺伝子断片とリンカー - 281重鎖-NheIの遺伝子断片を、Over Extension PCRによって連結し、5’-GGGGTCGACACCATGAAGCACCTGTGGTTCTTCCTCCTGCTGGTGGCGG-3’(配列番号138)とNheI CD40 Hc L 5’-CTAGCTAGCTGAGGAGACGGTGACCAGGGTTCCCTGGCCCCAGGGGTGG-3’(配列番号275)を用い、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)により、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施することにより、5’末端にSalI配列を、3’末端にNheI配列を有する、SalI- 281VL4-リンカー-281-NheIの遺伝子断片を作製した。この遺伝子断片をSalI及びNheIで消化し、SalI及びNheIで開裂した281VL4発現ベクターに挿入した。281VL4-D(118~144)GS-281重鎖核酸配列(配列番号284)、281VL4-D(118~143)GS-281重鎖アミノ酸配列(配列番号285)、281VL4-M(118~143)GS-281重鎖核酸配列(配列番号286)、281VL4-M(118~143)GS-281重鎖アミノ酸配列(配列番号287)はそれぞれ配列表に示す。
、L primerとしてCD28-IgD L 5’-CATCCGGAGCCTTGGTGGGTGCTGAGGAGACGGTGACCATTGTCCCTTG-3’ (配列番号282)、CD28-IgM L 5’-GGGTTGGGGCGGATGCACTCCCTGAGGAGACGGTGACCATTGTCCCTTG-3’ (配列番号283)を用い、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)により、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施し、5’末端にSalI配列を有する、SalI- 281VL4-リンカーの遺伝子断片を作製した。SalI- 281VL4-リンカーの遺伝子断片とリンカー - 281重鎖-NheIの遺伝子断片を、Over Extension PCRによって連結し、5’-GGGGTCGACACCATGAAGCACCTGTGGTTCTTCCTCCTGCTGGTGGCGG-3’(配列番号138)とNheI CD40 Hc L 5’-CTAGCTAGCTGAGGAGACGGTGACCAGGGTTCCCTGGCCCCAGGGGTGG-3’(配列番号275)を用い、DNAポリメラーゼ(KOD-Plus, 東洋紡社製)により、95℃30秒、55℃30秒、68℃30秒の反応を30サイクル実施することにより、5’末端にSalI配列を、3’末端にNheI配列を有する、SalI- 281VL4-リンカー-281-NheIの遺伝子断片を作製した。この遺伝子断片をSalI及びNheIで消化し、SalI及びNheIで開裂した281VL4発現ベクターに挿入した。281VL4-D(118~144)GS-281重鎖核酸配列(配列番号284)、281VL4-D(118~143)GS-281重鎖アミノ酸配列(配列番号285)、281VL4-M(118~143)GS-281重鎖核酸配列(配列番号286)、281VL4-M(118~143)GS-281重鎖アミノ酸配列(配列番号287)はそれぞれ配列表に示す。
[実施例39]CD28に対する抗原認識部位(281VL4由来)をN末側にCD40に対する抗原認識部位(281由来)をC末側に有し、配列番号244~260のリンカーを含む多価抗体の発現と精製
作製した発現ベクター遺伝子をQIAGEN Plasmid Maxi Kit(キアゲン社製)にて調製し、FreeStyleTM 293 Expression System (Invitrogen社製)を用いて浮遊性293細胞に導入して、一過性発現により各抗体を含む培養上清を得た。実施例16の手順に従い、この培養上清から精製抗体を得た。精製抗体の濃度は280nmの吸光度を測定し、1mg/mLを抗体の濃度は1.40 Optimal densityとして算出した。
作製した発現ベクター遺伝子をQIAGEN Plasmid Maxi Kit(キアゲン社製)にて調製し、FreeStyleTM 293 Expression System (Invitrogen社製)を用いて浮遊性293細胞に導入して、一過性発現により各抗体を含む培養上清を得た。実施例16の手順に従い、この培養上清から精製抗体を得た。精製抗体の濃度は280nmの吸光度を測定し、1mg/mLを抗体の濃度は1.40 Optimal densityとして算出した。
[実施例40]CD28に対する抗原認識部位(281VL4由来)をN末側にCD40に対する抗原認識部位(281由来)をC末側に有し、配列番号244~260のリンカーを含む多価抗体の生産性の測定
抗体の生産性として、各培養上清中の抗体含有量を測定した。抗体含有量の測定は、実施例17の手順に従い行った。その結果を表16に示す。

抗体の生産性として、各培養上清中の抗体含有量を測定した。抗体含有量の測定は、実施例17の手順に従い行った。その結果を表16に示す。
[実施例41]CD28に対する抗原認識部位(281VL4由来)をN末側にCD40に対する抗原認識部位(281由来)をC末側に有し、配列番号244~260のリンカーを含む多価抗体の安定性の評価
抗体溶液の凝集体含有率は、実施例18の手順に従い測定した。その結果を表17に示す。

抗体溶液の凝集体含有率は、実施例18の手順に従い測定した。その結果を表17に示す。
[実施例42]CD28に対する抗原認識部位(281VL4由来)をN末側にCD40に対する抗原認識部位(281由来)をC末側に有し、IgG2CH1領域の配列(配列番号254、289,291,293,295,297,299,301,303,305,307,309,311)をリンカーとして用いた多価抗体の構造
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表6に示したヒトIgG2のCH1配列(Kabat EUインデックス118番から143番)からN末に向かって1アミノ酸ずつ欠損させ(Kabat EUインデックス118番から131番)、その3’末端にBamHI配列であるGS(GGATCC)を加えた配列番号254、289,291,293,295,297,299,301,303,305,307,309,311のリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。これら多価抗体をそれぞれ、
281VL4-G2(118~143)GS-281、281VL4-G2(118~142)GS-281、281VL4-G2(118~141)GS-281、
281VL4-G2(118~140)GS-281、281VL4-G2(118~139)GS-281、281VL4-G2(118~138)GS-281、
281VL4-G2(118~137)GS-281、281VL4-G2(118~136)GS-281、281VL4-G2(118~135)GS-281、
281VL4-G2(118~134)GS-281、281VL4-G2(118~133)GS-281、281VL4-G2(118~132)GS-281 、
281VL4-CH1(118-131)-281と名付けた。なお、281VL4-G2(118~143)GS-281は実施例36に示した。また、Kabat EUインデックス118番から131番をリンカーとしたものは、実施例24に示した281VL4-CH1(118-131)-281を用いた。
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、表6に示したヒトIgG2のCH1配列(Kabat EUインデックス118番から143番)からN末に向かって1アミノ酸ずつ欠損させ(Kabat EUインデックス118番から131番)、その3’末端にBamHI配列であるGS(GGATCC)を加えた配列番号254、289,291,293,295,297,299,301,303,305,307,309,311のリンカーを介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。これら多価抗体をそれぞれ、
281VL4-G2(118~143)GS-281、281VL4-G2(118~142)GS-281、281VL4-G2(118~141)GS-281、
281VL4-G2(118~140)GS-281、281VL4-G2(118~139)GS-281、281VL4-G2(118~138)GS-281、
281VL4-G2(118~137)GS-281、281VL4-G2(118~136)GS-281、281VL4-G2(118~135)GS-281、
281VL4-G2(118~134)GS-281、281VL4-G2(118~133)GS-281、281VL4-G2(118~132)GS-281 、
281VL4-CH1(118-131)-281と名付けた。なお、281VL4-G2(118~143)GS-281は実施例36に示した。また、Kabat EUインデックス118番から131番をリンカーとしたものは、実施例24に示した281VL4-CH1(118-131)-281を用いた。
表18に、作製した多価抗体の構造をまとめた。


[実施例43]CD28に対する抗原認識部位(281VL4由来)をN末側にCD40に対する抗原認識部位(281由来)をC末側に有し、配列番号289,291,293,295,297,299,301,303,305,307,309のリンカーを含む多価抗体発現ベクターの作製
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、リンカー(配列番号289,291,293,295,297,299,301,303,305,307,309)を介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、抗281抗体、抗CD28抗体共に共通の軽鎖を使用するため、発現ベクターは1種類の軽鎖配列を保持する。これら抗体の重鎖をコードする遺伝子配列は実施例24で用いた遺伝学的手法の手順を参考にして作製した。
重鎖N末側からCD28に対する認識部位とCD40に対する認識部位が並んだ多価抗体を作製するために、N末端側から、抗CD28抗体281VL4の重鎖可変領域を、リンカー(配列番号289,291,293,295,297,299,301,303,305,307,309)を介して抗CD40抗体281の重鎖可変領域にタンデムに結合した。軽鎖は、抗281抗体、抗CD28抗体共に共通の軽鎖を使用するため、発現ベクターは1種類の軽鎖配列を保持する。これら抗体の重鎖をコードする遺伝子配列は実施例24で用いた遺伝学的手法の手順を参考にして作製した。
281VL4-G2(118~142)GS-281重鎖核酸配列(配列番号312)、
281VL4-G2(118~142)GS-281重鎖アミノ酸配列(配列番号313)、
281VL4-G2(118~141)GS-281重鎖核酸配列(配列番号314)、
281VL4-G2(118~141)GS-281重鎖アミノ酸配列(配列番号315)、
281VL4-G2(118~140)GS-281重鎖核酸配列(配列番号316)、
281VL4-G2(118~140)GS-281重鎖アミノ酸配列(配列番号317)、
281VL4-G2(118~139)GS-281重鎖核酸配列(配列番号318)、
281VL4-G2(118~139)GS-281重鎖アミノ酸配列(配列番号319)、
281VL4-G2(118~138)GS-281重鎖核酸配列(配列番号320)、
281VL4-G2(118~138)GS-281重鎖アミノ酸配列(配列番号321)、
281VL4-G2(118~137)GS-281重鎖核酸配列(配列番号322)、
281VL4-G2(118~137)GS-281重鎖アミノ酸配列(配列番号323)、
281VL4-G2(118~136)GS-281重鎖核酸配列(配列番号324)、
281VL4-G2(118~136)GS-281重鎖アミノ酸配列(配列番号325)、
281VL4-G2(118~135)GS-281重鎖核酸配列(配列番号326)、
281VL4-G2(118~135)GS-281重鎖アミノ酸配列(配列番号327)、
281VL4-G2(118~134)GS-281重鎖核酸配列(配列番号328)、
281VL4-G2(118~134)GS-281重鎖アミノ酸配列(配列番号329)、
281VL4-G2(118~133)GS-281重鎖核酸配列(配列番号330)、
281VL4-G2(118~133)GS-281重鎖アミノ酸配列(配列番号331)、
281VL4-G2(118~132)GS-281重鎖核酸配列(配列番号332)、
281VL4-G2(118~132)GS-281重鎖アミノ酸配列(配列番号333)はそれぞれ配列表に示す。
281VL4-G2(118~142)GS-281重鎖アミノ酸配列(配列番号313)、
281VL4-G2(118~141)GS-281重鎖核酸配列(配列番号314)、
281VL4-G2(118~141)GS-281重鎖アミノ酸配列(配列番号315)、
281VL4-G2(118~140)GS-281重鎖核酸配列(配列番号316)、
281VL4-G2(118~140)GS-281重鎖アミノ酸配列(配列番号317)、
281VL4-G2(118~139)GS-281重鎖核酸配列(配列番号318)、
281VL4-G2(118~139)GS-281重鎖アミノ酸配列(配列番号319)、
281VL4-G2(118~138)GS-281重鎖核酸配列(配列番号320)、
281VL4-G2(118~138)GS-281重鎖アミノ酸配列(配列番号321)、
281VL4-G2(118~137)GS-281重鎖核酸配列(配列番号322)、
281VL4-G2(118~137)GS-281重鎖アミノ酸配列(配列番号323)、
281VL4-G2(118~136)GS-281重鎖核酸配列(配列番号324)、
281VL4-G2(118~136)GS-281重鎖アミノ酸配列(配列番号325)、
281VL4-G2(118~135)GS-281重鎖核酸配列(配列番号326)、
281VL4-G2(118~135)GS-281重鎖アミノ酸配列(配列番号327)、
281VL4-G2(118~134)GS-281重鎖核酸配列(配列番号328)、
281VL4-G2(118~134)GS-281重鎖アミノ酸配列(配列番号329)、
281VL4-G2(118~133)GS-281重鎖核酸配列(配列番号330)、
281VL4-G2(118~133)GS-281重鎖アミノ酸配列(配列番号331)、
281VL4-G2(118~132)GS-281重鎖核酸配列(配列番号332)、
281VL4-G2(118~132)GS-281重鎖アミノ酸配列(配列番号333)はそれぞれ配列表に示す。
[実施例44]多価抗体の発現と精製
作製した発現ベクター遺伝子をQIAGEN Plasmid Maxi Kit(キアゲン社製)にて調製し、FreeStyleTM 293 Expression System (Invitrogen社製)を用いて浮遊性293細胞に導入して、一過性発現により各抗体を含む培養上清を得た。実施例16の手順に従い、この培養上清から精製抗体を得た。精製抗体の濃度は280nmの吸光度を測定し、1mg/mLを抗体の濃度は1.40 Optimal densityとして算出した。
作製した発現ベクター遺伝子をQIAGEN Plasmid Maxi Kit(キアゲン社製)にて調製し、FreeStyleTM 293 Expression System (Invitrogen社製)を用いて浮遊性293細胞に導入して、一過性発現により各抗体を含む培養上清を得た。実施例16の手順に従い、この培養上清から精製抗体を得た。精製抗体の濃度は280nmの吸光度を測定し、1mg/mLを抗体の濃度は1.40 Optimal densityとして算出した。
[実施例45]抗体の生産性の測定
抗体の生産性として、各培養上清中の抗体含有量を測定した。抗体含有量の測定は、実施例17の手順に従い行った。その結果を表19に示す。

抗体の生産性として、各培養上清中の抗体含有量を測定した。抗体含有量の測定は、実施例17の手順に従い行った。その結果を表19に示す。
[実施例46]抗体の安定性の評価
抗体溶液の凝集体含有率は、実施例18の手順に従い測定した。その結果を表20に示す。
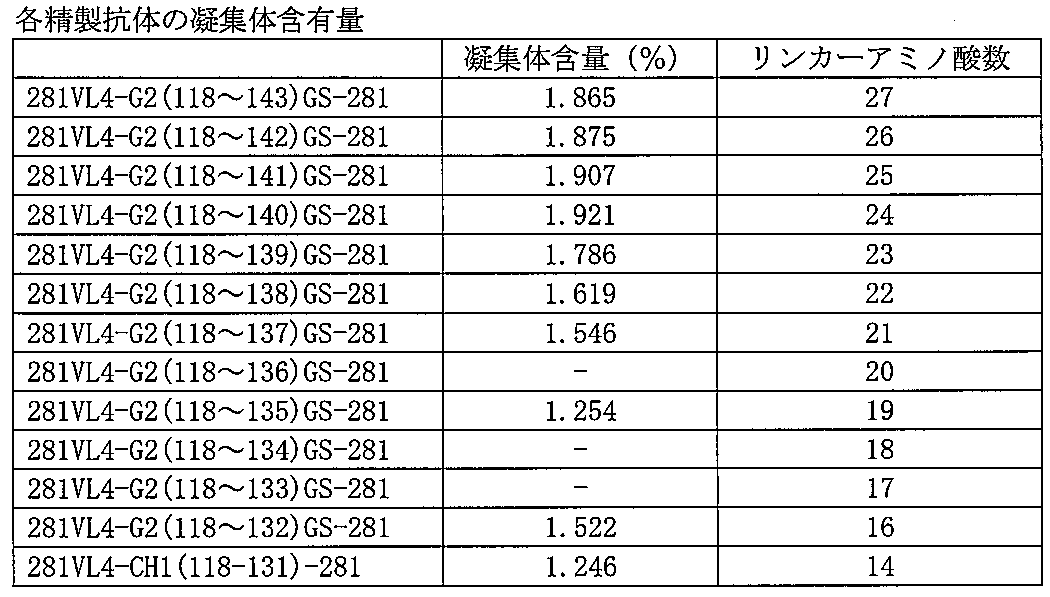
抗体溶液の凝集体含有率は、実施例18の手順に従い測定した。その結果を表20に示す。
本発明の抗体は、安定性が高い上に、生産性よく作製可能であるという特徴を有しており、医薬や診断用の抗体としての利用性を有している。
本明細書で引用した全ての刊行物、特許および特許出願をそのまま参考として本明細書にとり入れるものとする。
Claims (12)
- 複数の抗体重鎖可変領域がイムノグロブリンドメインまたはその断片のアミノ酸配列を有するリンカーを介して結合していることを特徴とする多価抗体。
- イムノグロブリンドメインが、CH1、ヒンジ、CH2、および/またはCH3からなるイムノグロブリンドメインである、請求項1記載の多価抗体。
- イムノグロブリンドメインが、CH1またはCH1断片である、請求項2記載の多価抗体。
- CH1断片が、14番目がシステイン(Cys)である14アミノ酸からなるCH1断片である、請求項3記載の多価抗体。
- CH1断片が、IgD, IgM, IgG, IgAおよびIgEの抗体サブクラスから選ばれるCH1のアミノ酸配列のN末端から1番目~14番目のアミノ酸配列である、請求項4記載の多価抗体。
- CH1断片のアミノ酸配列が、配列番号311および配列番号334~配列番号361から選ばれるいずれか1つのアミノ酸配列である、請求項5記載の多価抗体。
- CH1断片のアミノ酸配列が、配列番号362~配列番号375から選ばれるいずれか1つのアミノ酸配列である、請求項3記載の多価抗体。
- 同一の軽鎖を含む、請求項1~7のいずれか1項に記載の多価抗体。
- 請求項1~8のいずれか1項に記載の多価抗体のアミノ酸配列をコードするDNA。
- 請求項9記載のDNAを含む組換えベクター。
- 請求項10に記載の組換えベクターが導入された形質転換体。
- 請求項11に記載の形質転換体を培地に培養し、培養物中に請求項1~8のいずれか1項に記載の多価抗体を生成蓄積させ、培養物から該抗体または該抗体断片を採取することを特徴とする、請求項1~8のいずれか1項に記載の多価抗体の製造方法。
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP09734826.2A EP2281845B1 (en) | 2008-04-25 | 2009-04-27 | Stable polyvalent antibody |
| ES09734826T ES2828627T3 (es) | 2008-04-25 | 2009-04-27 | Anticuerpo multivalente estable |
| JP2010509254A JP5522405B2 (ja) | 2008-04-25 | 2009-04-27 | 安定な多価抗体 |
| US12/989,600 US9758594B2 (en) | 2008-04-25 | 2009-04-27 | Stable multivalent antibody |
| US15/670,177 US20170335016A1 (en) | 2008-04-25 | 2017-08-07 | Stable multivalent antibody |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008115463 | 2008-04-25 | ||
| JP2008-115463 | 2008-04-25 |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US12/989,600 A-371-Of-International US9758594B2 (en) | 2008-04-25 | 2009-04-27 | Stable multivalent antibody |
| US15/670,177 Division US20170335016A1 (en) | 2008-04-25 | 2017-08-07 | Stable multivalent antibody |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2009131239A1 true WO2009131239A1 (ja) | 2009-10-29 |
Family
ID=41216962
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2009/058249 WO2009131239A1 (ja) | 2008-04-25 | 2009-04-27 | 安定な多価抗体 |
Country Status (5)
| Country | Link |
|---|---|
| US (2) | US9758594B2 (ja) |
| EP (1) | EP2281845B1 (ja) |
| JP (1) | JP5522405B2 (ja) |
| ES (1) | ES2828627T3 (ja) |
| WO (1) | WO2009131239A1 (ja) |
Cited By (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2011143562A3 (en) * | 2010-05-14 | 2012-03-01 | Abbott Laboratories | Il-1 binding proteins |
| WO2012081628A1 (ja) | 2010-12-15 | 2012-06-21 | 大学共同利用機関法人情報・システム研究機構 | タンパク質の生産方法 |
| WO2012176779A1 (ja) | 2011-06-20 | 2012-12-27 | 協和発酵キリン株式会社 | 抗erbB3抗体 |
| CN106687478A (zh) * | 2014-07-15 | 2017-05-17 | 安斯泰来制药株式会社 | 新的抗人Tie‑2抗体 |
| US9670276B2 (en) | 2012-07-12 | 2017-06-06 | Abbvie Inc. | IL-1 binding proteins |
| WO2017117179A1 (en) * | 2015-12-28 | 2017-07-06 | Massachusetts Institute Of Technology | Bispecific antibodies having constant region mutations and uses therefor |
| WO2019093342A1 (ja) | 2017-11-08 | 2019-05-16 | 協和発酵キリン株式会社 | CD40とEpCAMに結合するバイスペシフィック抗体 |
| WO2019117208A1 (ja) | 2017-12-12 | 2019-06-20 | 協和発酵キリン株式会社 | 抗bmp10抗体及び該抗体を有効成分とする、高血圧および高血圧性疾患に対する治療剤 |
| WO2020004490A1 (ja) | 2018-06-26 | 2020-01-02 | 協和キリン株式会社 | コンドロイチン硫酸プロテオグリカン-5に結合する抗体 |
| WO2020004492A1 (ja) | 2018-06-26 | 2020-01-02 | 協和キリン株式会社 | Cell Adhesion Molecule3に結合する抗体 |
| WO2020138487A1 (ja) | 2018-12-28 | 2020-07-02 | 協和キリン株式会社 | TfRに結合するバイスペシフィック抗体 |
| WO2020230901A1 (ja) | 2019-05-15 | 2020-11-19 | 協和キリン株式会社 | Cd40とgpc3に結合するバイスペシフィック抗体 |
| WO2020230899A1 (ja) | 2019-05-15 | 2020-11-19 | 協和キリン株式会社 | Cd40とfapに結合するバイスペシフィック抗体 |
| JP2022540319A (ja) * | 2020-04-29 | 2022-09-15 | 三生国健薬業(上海)股▲ふん▼有限公司 | 四価二重特異性抗体、その製造方法および用途 |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6323718B2 (ja) | 2011-05-17 | 2018-05-16 | ザ ロックフェラー ユニバーシティー | ヒト免疫不全ウイルスを無毒化する抗体、およびその使用方法。 |
| WO2013012733A1 (en) * | 2011-07-15 | 2013-01-24 | Biogen Idec Ma Inc. | Heterodimeric fc regions, binding molecules comprising same, and methods relating thereto |
| GB2502127A (en) * | 2012-05-17 | 2013-11-20 | Kymab Ltd | Multivalent antibodies and in vivo methods for their production |
| SI2852615T1 (sl) | 2012-05-22 | 2019-02-28 | Bristol-Myers Squibb Company | IL-17A/F IL-23 bispecifična protitelesa in njihova uporaba |
| KR20150082367A (ko) * | 2012-11-06 | 2015-07-15 | 메디뮨 엘엘씨 | 항슈도모나스 psl 및 pcrv 결합 분자를 이용한 병용 요법 |
| CA2891280C (en) | 2012-11-24 | 2018-03-20 | Hangzhou Dac Biotech Co., Ltd. | Hydrophilic linkers and their uses for conjugation of drugs to cell binding molecules |
| EP2970485A1 (en) * | 2013-03-15 | 2016-01-20 | Merck Patent GmbH | Tetravalent bispecific antibodies |
| ES2960619T3 (es) | 2014-02-28 | 2024-03-05 | Hangzhou Dac Biotech Co Ltd | Enlazadores cargados y sus usos para la conjugación |
| MA41044A (fr) | 2014-10-08 | 2017-08-15 | Novartis Ag | Compositions et procédés d'utilisation pour une réponse immunitaire accrue et traitement contre le cancer |
| MX2018003183A (es) | 2015-09-15 | 2018-08-23 | Amgen Inc | Proteinas de enlace de antigeno biespecifico y tetraespecifico tetravalentes y usos de las mismas. |
| CR20180365A (es) | 2015-12-16 | 2018-09-28 | Amgen Inc | PROTEÍNAS DE UNIÓN AL ANTÍGENO BISPECÍFICO DE ANTI-TL1A/ANTI-TNF-a Y SUS USOS |
| FR3080621B1 (fr) * | 2018-04-26 | 2022-12-09 | Univ Limoges | Nouvelle classe d'immunoglobuline recombinante de type g : igg5, codee par le pseudo-gene gamma humain de chaine lourde |
| CA3192204A1 (en) | 2020-08-19 | 2022-02-24 | Xencor, Inc. | Anti-cd28 and/or anti-b7h3 compositions |
| WO2024040195A1 (en) | 2022-08-17 | 2024-02-22 | Capstan Therapeutics, Inc. | Conditioning for in vivo immune cell engineering |
Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2000061739A1 (en) | 1999-04-09 | 2000-10-19 | Kyowa Hakko Kogyo Co., Ltd. | Method for controlling the activity of immunologically functional molecule |
| WO2001077342A1 (en) | 2000-04-11 | 2001-10-18 | Genentech, Inc. | Multivalent antibodies and uses therefor |
| WO2002031140A1 (fr) | 2000-10-06 | 2002-04-18 | Kyowa Hakko Kogyo Co., Ltd. | Cellules produisant des compositions d'anticorps |
| WO2002088186A1 (en) | 2001-04-27 | 2002-11-07 | Kirin Beer Kabushiki Kaisha | Anti-cd40 monoclonal antibody |
| US6737056B1 (en) | 1999-01-15 | 2004-05-18 | Genentech, Inc. | Polypeptide variants with altered effector function |
| WO2005035586A1 (ja) | 2003-10-08 | 2005-04-21 | Kyowa Hakko Kogyo Co., Ltd. | 融合蛋白質組成物 |
| WO2007024715A2 (en) * | 2005-08-19 | 2007-03-01 | Abbott Laboratories | Dual variable domain immunoglobin and uses thereof |
| US20070071675A1 (en) | 2005-08-19 | 2007-03-29 | Chengbin Wu | Dual variable domain immunoglobulin and uses thereof |
| US20070148165A1 (en) | 2005-07-22 | 2007-06-28 | Kyowa Hakko Kogyo Co., Ltd. | Recombinant antibody composition |
| US7297775B2 (en) | 1998-04-02 | 2007-11-20 | Genentech, Inc. | Polypeptide variants |
| US7317091B2 (en) | 2002-03-01 | 2008-01-08 | Xencor, Inc. | Optimized Fc variants |
| JP2008115463A (ja) | 2006-10-10 | 2008-05-22 | Showa Denko Kk | Iii族窒化物半導体の積層構造及びその製造方法と半導体発光素子とランプ |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5196193A (en) * | 1989-10-31 | 1993-03-23 | Ophidian Pharmaceuticals, Inc. | Antivenoms and methods for making antivenoms |
| WO1995009917A1 (en) * | 1993-10-07 | 1995-04-13 | The Regents Of The University Of California | Genetically engineered bispecific tetravalent antibodies |
| US7381794B2 (en) * | 2004-03-08 | 2008-06-03 | Zymogenetics, Inc. | Dimeric fusion proteins and materials and methods for producing them |
| US20100047171A1 (en) * | 2006-01-24 | 2010-02-25 | Roland Beckmann | Fusion Proteins That Contain Natural Junctions |
-
2009
- 2009-04-27 JP JP2010509254A patent/JP5522405B2/ja active Active
- 2009-04-27 WO PCT/JP2009/058249 patent/WO2009131239A1/ja active Application Filing
- 2009-04-27 US US12/989,600 patent/US9758594B2/en active Active
- 2009-04-27 EP EP09734826.2A patent/EP2281845B1/en active Active
- 2009-04-27 ES ES09734826T patent/ES2828627T3/es active Active
-
2017
- 2017-08-07 US US15/670,177 patent/US20170335016A1/en not_active Abandoned
Patent Citations (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7297775B2 (en) | 1998-04-02 | 2007-11-20 | Genentech, Inc. | Polypeptide variants |
| US6737056B1 (en) | 1999-01-15 | 2004-05-18 | Genentech, Inc. | Polypeptide variants with altered effector function |
| WO2000061739A1 (en) | 1999-04-09 | 2000-10-19 | Kyowa Hakko Kogyo Co., Ltd. | Method for controlling the activity of immunologically functional molecule |
| WO2001077342A1 (en) | 2000-04-11 | 2001-10-18 | Genentech, Inc. | Multivalent antibodies and uses therefor |
| JP2003531588A (ja) * | 2000-04-11 | 2003-10-28 | ジェネンテック・インコーポレーテッド | 多価抗体とその用途 |
| WO2002031140A1 (fr) | 2000-10-06 | 2002-04-18 | Kyowa Hakko Kogyo Co., Ltd. | Cellules produisant des compositions d'anticorps |
| WO2002088186A1 (en) | 2001-04-27 | 2002-11-07 | Kirin Beer Kabushiki Kaisha | Anti-cd40 monoclonal antibody |
| US7317091B2 (en) | 2002-03-01 | 2008-01-08 | Xencor, Inc. | Optimized Fc variants |
| WO2005035586A1 (ja) | 2003-10-08 | 2005-04-21 | Kyowa Hakko Kogyo Co., Ltd. | 融合蛋白質組成物 |
| US20070148165A1 (en) | 2005-07-22 | 2007-06-28 | Kyowa Hakko Kogyo Co., Ltd. | Recombinant antibody composition |
| US20070071675A1 (en) | 2005-08-19 | 2007-03-29 | Chengbin Wu | Dual variable domain immunoglobulin and uses thereof |
| WO2007024715A2 (en) * | 2005-08-19 | 2007-03-01 | Abbott Laboratories | Dual variable domain immunoglobin and uses thereof |
| JP2008115463A (ja) | 2006-10-10 | 2008-05-22 | Showa Denko Kk | Iii族窒化物半導体の積層構造及びその製造方法と半導体発光素子とランプ |
Non-Patent Citations (26)
| Title |
|---|
| CHARLES A.; JANEWAY ET AL.: "Immunobiology", 1997, CURRENT BIOLOGY LTD/GARLAND PUBLISHING INC. |
| EMMANUELLE LAFFY ET AL., HUMAN ANTIBODIES, vol. 14, 2005, pages 33 - 55 |
| GRUBER ET AL., J IMMUNOL., vol. 152, 1994, pages 5369 |
| HORIBATA K.; HARRIS A.W ET AL., NATURE, vol. 256, 1975, pages 495 - 497 |
| HORIBATA, K.; HARRIS, A. W., NATURE, vol. 256, 1975, pages 495 - 497 |
| J.W.GODING.: "Monoclonal Antibodies:principles and practice", 1993, ACADEMIC PRESS |
| J.W.GODING: "Monoclonal Antibodies: principles and practice.", 1993, ACADEMIC PRESS |
| KABAT ET AL.: "Sequences of proteins of immunological interest", 1991 |
| KABAT ET AL.: "Sequences ofproteins of immunological interest", 1991 |
| KEARNEY J.F. ET AL., J IMMUNOLOGY, vol. 123, 1979, pages 1548 - 1550 |
| KEARNEY; J. F. ET AL., J IMMUNOLOGY, vol. 123, 1979, pages 1548 - 1550 |
| KOHLER G. ET AL., EUROPEAN J. IMMUNOLOGY, vol. 6, 1976, pages 511 - 519 |
| KOHLER, G. ET AL., EUROPEAN J IMMUNOLOGY, vol. 6, 1976, pages 511 - 519 |
| MORRISON S.: "Two heads are better than one.", NATURE BIOTECHNOLOGY, vol. 25, no. 11, 2007, pages 1233 - 1234, XP002470803 * |
| P. SHEPHERD; C. DEAN.: "Monoclonal Antibodies.", 2000, OXFORD UNIVERSITY PRESS |
| P.J. DEIVES.: "ANTIBODY PRODUCTION ESSENTIAL TECHNIQUES.", 1997, WILEY |
| P.J.DELVES.: "ANTIBODYPRODUCTION ESSENTIAL TECHNIQUES", 1997, WILEY |
| P.SHEPHERD; C.DEAN.: "Monoclonal Antibodies.", 2000, OXFORD UNIVERSITY PRESS |
| SHULMAN M. ET AL., NATURE, vol. 276, 1978, pages 269 - 270 |
| SHULMAN, M. ET AL., NATURE, vol. 276, 1978, pages 269 - 270 |
| SURESH ET AL., METHODS ENZYMOL., vol. 121, 1986, pages 210 - 228 |
| TOMIZUKA. ET AL., PROC NATL ACAD SCI USA., vol. 97, 2000, pages 722 |
| WU C. ET AL.: "Simultaneous targeting of multiple disease mediators by a dual-variable- domain immunoglobulin.", NATURE BIOTECHNOLOGY, vol. 25, no. 11, 2007, pages 1290 - 1297, XP002542446 * |
| WU ET AL., NAT. BIOTHECH., vol. 25, 2007, pages 1290 - 1297 |
| YELTON D.E. ET AL., CURRENT TOPICS IN MICROBIOLOGY AND IMMUNOLOGY, vol. 1, 1978, pages 7 |
| YELTON; D.E. ET AL., CURRENT TOPICS IN MICROBIOLOGY AND IMMUNOLOGY, vol. 81, 1978, pages 1 - 7 |
Cited By (37)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2011143562A3 (en) * | 2010-05-14 | 2012-03-01 | Abbott Laboratories | Il-1 binding proteins |
| US9447184B2 (en) | 2010-05-14 | 2016-09-20 | Abbvie Inc. | IL-1 binding proteins |
| US9409986B2 (en) | 2010-05-14 | 2016-08-09 | Abbvie Inc. | IL-1 binding proteins |
| CN103025758A (zh) * | 2010-05-14 | 2013-04-03 | Abbvie公司 | Il-1结合蛋白 |
| US8664367B2 (en) | 2010-05-14 | 2014-03-04 | Abbvie, Inc. | IL-I binding proteins |
| US8841417B2 (en) | 2010-05-14 | 2014-09-23 | Abbvie Inc. | IL-1 binding proteins |
| US9303085B2 (en) | 2010-05-14 | 2016-04-05 | Abbvie Inc. | IL-1 binding proteins |
| CN103025758B (zh) * | 2010-05-14 | 2017-01-18 | Abbvie 公司 | Il‑1结合蛋白 |
| US9441038B2 (en) | 2010-05-14 | 2016-09-13 | Abbvie Inc. | IL-1 binding proteins |
| US9447183B2 (en) | 2010-05-14 | 2016-09-20 | Abbvie Inc. | IL-1 binding proteins |
| WO2012081628A1 (ja) | 2010-12-15 | 2012-06-21 | 大学共同利用機関法人情報・システム研究機構 | タンパク質の生産方法 |
| WO2012176779A1 (ja) | 2011-06-20 | 2012-12-27 | 協和発酵キリン株式会社 | 抗erbB3抗体 |
| US9670276B2 (en) | 2012-07-12 | 2017-06-06 | Abbvie Inc. | IL-1 binding proteins |
| CN106687478B (zh) * | 2014-07-15 | 2020-08-28 | 安斯泰来制药株式会社 | 新的抗人Tie-2抗体 |
| CN106687478A (zh) * | 2014-07-15 | 2017-05-17 | 安斯泰来制药株式会社 | 新的抗人Tie‑2抗体 |
| WO2017117179A1 (en) * | 2015-12-28 | 2017-07-06 | Massachusetts Institute Of Technology | Bispecific antibodies having constant region mutations and uses therefor |
| US11459405B2 (en) | 2015-12-28 | 2022-10-04 | Massachusetts Institute Of Technology | Bispecific antibodies having constant region mutations and uses therefor |
| US11773180B2 (en) | 2017-11-08 | 2023-10-03 | Kyowa Kirin Co., Ltd. | Bispecific antibody which binds to CD40 and EpCAM |
| JPWO2019093342A1 (ja) * | 2017-11-08 | 2020-11-26 | 協和キリン株式会社 | CD40とEpCAMに結合するバイスペシフィック抗体 |
| CN111344307A (zh) * | 2017-11-08 | 2020-06-26 | 协和麒麟株式会社 | 与CD40和EpCAM结合的双特异性抗体 |
| KR20200078527A (ko) | 2017-11-08 | 2020-07-01 | 쿄와 기린 가부시키가이샤 | CD40과 EpCAM에 결합하는 이중특이적 항체 |
| TWI811260B (zh) * | 2017-11-08 | 2023-08-11 | 日商協和麒麟股份有限公司 | 與CD40及EpCAM結合之雙專一性抗體 |
| WO2019093342A1 (ja) | 2017-11-08 | 2019-05-16 | 協和発酵キリン株式会社 | CD40とEpCAMに結合するバイスペシフィック抗体 |
| JP7311425B2 (ja) | 2017-11-08 | 2023-07-19 | 協和キリン株式会社 | CD40とEpCAMに結合するバイスペシフィック抗体 |
| WO2019117208A1 (ja) | 2017-12-12 | 2019-06-20 | 協和発酵キリン株式会社 | 抗bmp10抗体及び該抗体を有効成分とする、高血圧および高血圧性疾患に対する治療剤 |
| WO2020004492A1 (ja) | 2018-06-26 | 2020-01-02 | 協和キリン株式会社 | Cell Adhesion Molecule3に結合する抗体 |
| WO2020004490A1 (ja) | 2018-06-26 | 2020-01-02 | 協和キリン株式会社 | コンドロイチン硫酸プロテオグリカン-5に結合する抗体 |
| CN113226371A (zh) * | 2018-12-28 | 2021-08-06 | 协和麒麟株式会社 | 与TfR结合的双特异性抗体 |
| KR20210108961A (ko) | 2018-12-28 | 2021-09-03 | 쿄와 기린 가부시키가이샤 | TfR에 결합하는 이중 특이적 항체 |
| WO2020138487A1 (ja) | 2018-12-28 | 2020-07-02 | 協和キリン株式会社 | TfRに結合するバイスペシフィック抗体 |
| KR20220008820A (ko) | 2019-05-15 | 2022-01-21 | 쿄와 기린 가부시키가이샤 | Cd40과 fap에 결합하는 이중 특이적 항체 |
| WO2020230899A1 (ja) | 2019-05-15 | 2020-11-19 | 協和キリン株式会社 | Cd40とfapに結合するバイスペシフィック抗体 |
| WO2020230901A1 (ja) | 2019-05-15 | 2020-11-19 | 協和キリン株式会社 | Cd40とgpc3に結合するバイスペシフィック抗体 |
| JP2022540319A (ja) * | 2020-04-29 | 2022-09-15 | 三生国健薬業(上海)股▲ふん▼有限公司 | 四価二重特異性抗体、その製造方法および用途 |
| JP2022145555A (ja) * | 2020-04-29 | 2022-10-04 | 丹生医薬技術(上海)有限公司 | Pd-1とlag-3を標的とした四価二重特異性抗体、その製造方法および用途 |
| JP2022153280A (ja) * | 2020-04-29 | 2022-10-12 | 丹生医薬技術(上海)有限公司 | Pd-1とvegfを標的とした四価二重特異性抗体、その製造方法および用途 |
| JP2022153281A (ja) * | 2020-04-29 | 2022-10-12 | 丹生医薬技術(上海)有限公司 | PD-1とTGF-betaを標的とした四価二重特異性抗体、その製造方法および用途 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20170335016A1 (en) | 2017-11-23 |
| JPWO2009131239A1 (ja) | 2011-08-25 |
| EP2281845A1 (en) | 2011-02-09 |
| JP5522405B2 (ja) | 2014-06-18 |
| ES2828627T3 (es) | 2021-05-27 |
| US20110076722A1 (en) | 2011-03-31 |
| EP2281845B1 (en) | 2020-09-02 |
| EP2281845A4 (en) | 2015-11-04 |
| US9758594B2 (en) | 2017-09-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5522405B2 (ja) | 安定な多価抗体 | |
| US11365260B2 (en) | Agonistic 4-1BB monoclonal antibody | |
| JP2022024054A (ja) | 細胞傷害性tリンパ球関連タンパク質4(ctla-4)に対する新規モノクローナル抗体 | |
| KR20200139189A (ko) | 다가 항체 | |
| CN114349865B (zh) | 一种pd-1/lag-3四价双特异性抗体、其制备方法和用途 | |
| TWI830151B (zh) | 抗GPRC5DxBCMAxCD3三特異性抗體及其用途 | |
| CN107108734B (zh) | 单克隆抗gpc-1抗体和其用途 | |
| WO2021143914A1 (zh) | 一种激活型抗ox40抗体、生产方法及应用 | |
| CN116554323B (zh) | 人源化抗il21抗体的开发和应用 | |
| TWI770619B (zh) | 對lif具有專一性的結合分子及其用途 | |
| WO2022253154A1 (en) | Monoclonal antibodies against cldn18.2 and fc-engineered versions thereof | |
| CN117247453A (zh) | 抗CD19 scFv FMC63序列的单克隆抗体及其制备和应用 | |
| CN117677637A (zh) | 抗犬cd20抗体 | |
| JP2022547135A (ja) | 増強されたプロテインl捕捉動的結合容量を有する二重特異性抗原結合ポリペプチドの精製方法 | |
| CN114249827A (zh) | 抗tigit抗体及双抗体和它们的应用 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 09734826 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2010509254 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 12989600 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2009734826 Country of ref document: EP |