KR20230053602A - 항-ror1 항체 및 관련된 이중특이적 결합 단백질 - Google Patents
항-ror1 항체 및 관련된 이중특이적 결합 단백질 Download PDFInfo
- Publication number
- KR20230053602A KR20230053602A KR1020237005603A KR20237005603A KR20230053602A KR 20230053602 A KR20230053602 A KR 20230053602A KR 1020237005603 A KR1020237005603 A KR 1020237005603A KR 20237005603 A KR20237005603 A KR 20237005603A KR 20230053602 A KR20230053602 A KR 20230053602A
- Authority
- KR
- South Korea
- Prior art keywords
- ser
- ror1
- thr
- val
- antibody
- Prior art date
Links
- 108091008324 binding proteins Proteins 0.000 title claims abstract description 225
- 102000014914 Carrier Proteins Human genes 0.000 title abstract description 213
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 39
- 230000027455 binding Effects 0.000 claims description 251
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 claims description 212
- 210000004027 cell Anatomy 0.000 claims description 206
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 173
- 229920001184 polypeptide Polymers 0.000 claims description 170
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 170
- 239000000427 antigen Substances 0.000 claims description 158
- 102000036639 antigens Human genes 0.000 claims description 158
- 108091007433 antigens Proteins 0.000 claims description 158
- 239000012634 fragment Substances 0.000 claims description 113
- 108090000623 proteins and genes Proteins 0.000 claims description 70
- 238000000034 method Methods 0.000 claims description 59
- 102000004169 proteins and genes Human genes 0.000 claims description 57
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 claims description 56
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 claims description 55
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 49
- 230000035772 mutation Effects 0.000 claims description 39
- 108060003951 Immunoglobulin Proteins 0.000 claims description 36
- 102000018358 immunoglobulin Human genes 0.000 claims description 36
- 101001103039 Homo sapiens Inactive tyrosine-protein kinase transmembrane receptor ROR1 Proteins 0.000 claims description 35
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 35
- 239000013598 vector Substances 0.000 claims description 30
- 150000007523 nucleic acids Chemical class 0.000 claims description 23
- 101710098119 Chaperonin GroEL 2 Proteins 0.000 claims description 22
- 101000588258 Taenia solium Paramyosin Proteins 0.000 claims description 22
- 102000039446 nucleic acids Human genes 0.000 claims description 22
- 108020004707 nucleic acids Proteins 0.000 claims description 22
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 claims description 20
- 102000049583 human ROR1 Human genes 0.000 claims description 19
- 101001103036 Homo sapiens Nuclear receptor ROR-alpha Proteins 0.000 claims description 18
- 230000000694 effects Effects 0.000 claims description 18
- 239000008194 pharmaceutical composition Substances 0.000 claims description 15
- 125000000539 amino acid group Chemical group 0.000 claims description 13
- 238000011534 incubation Methods 0.000 claims description 12
- 206010035226 Plasma cell myeloma Diseases 0.000 claims description 10
- 201000000050 myeloid neoplasm Diseases 0.000 claims description 10
- 238000005734 heterodimerization reaction Methods 0.000 claims description 9
- 238000004519 manufacturing process Methods 0.000 claims description 9
- 201000011510 cancer Diseases 0.000 claims description 8
- 238000000423 cell based assay Methods 0.000 claims description 8
- 230000001627 detrimental effect Effects 0.000 claims description 8
- 238000000684 flow cytometry Methods 0.000 claims description 7
- 206010006187 Breast cancer Diseases 0.000 claims description 6
- 230000000259 anti-tumor effect Effects 0.000 claims description 6
- 239000012472 biological sample Substances 0.000 claims description 6
- 230000004927 fusion Effects 0.000 claims description 6
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 claims description 5
- 208000026310 Breast neoplasm Diseases 0.000 claims description 5
- 238000012258 culturing Methods 0.000 claims description 5
- 230000012010 growth Effects 0.000 claims description 5
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 4
- 208000003721 Triple Negative Breast Neoplasms Diseases 0.000 claims description 3
- 208000022679 triple-negative breast carcinoma Diseases 0.000 claims description 3
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 2
- 230000010261 cell growth Effects 0.000 claims description 2
- 102100039614 Nuclear receptor ROR-alpha Human genes 0.000 claims 16
- 102000023732 binding proteins Human genes 0.000 claims 12
- 230000002489 hematologic effect Effects 0.000 claims 1
- 201000005202 lung cancer Diseases 0.000 claims 1
- 208000020816 lung neoplasm Diseases 0.000 claims 1
- 238000011282 treatment Methods 0.000 abstract description 25
- 201000005787 hematologic cancer Diseases 0.000 abstract description 3
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 abstract description 3
- 102000005435 Receptor Tyrosine Kinase-like Orphan Receptors Human genes 0.000 abstract description 2
- 108010006700 Receptor Tyrosine Kinase-like Orphan Receptors Proteins 0.000 abstract description 2
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 55
- 235000018102 proteins Nutrition 0.000 description 54
- 238000010494 dissociation reaction Methods 0.000 description 35
- 230000005593 dissociations Effects 0.000 description 35
- 210000001744 T-lymphocyte Anatomy 0.000 description 30
- 230000014509 gene expression Effects 0.000 description 29
- 208000035475 disorder Diseases 0.000 description 27
- 241000880493 Leptailurus serval Species 0.000 description 26
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 26
- 239000000203 mixture Substances 0.000 description 24
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 22
- 108010031719 prolyl-serine Proteins 0.000 description 21
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 20
- 108010092854 aspartyllysine Proteins 0.000 description 19
- 108010073969 valyllysine Proteins 0.000 description 19
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 18
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 18
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 17
- HNDMFDBQXYZSRM-IHRRRGAJSA-N Ser-Val-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HNDMFDBQXYZSRM-IHRRRGAJSA-N 0.000 description 17
- 108010015792 glycyllysine Proteins 0.000 description 17
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 16
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 16
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 16
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 16
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 16
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 16
- 108010044292 tryptophyltyrosine Proteins 0.000 description 16
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 15
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 15
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 15
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 15
- 108010008355 arginyl-glutamine Proteins 0.000 description 15
- 238000006467 substitution reaction Methods 0.000 description 15
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 14
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 14
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 14
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 14
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 14
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 14
- 108010087924 alanylproline Proteins 0.000 description 14
- 108010068265 aspartyltyrosine Proteins 0.000 description 14
- 239000013604 expression vector Substances 0.000 description 14
- 230000006870 function Effects 0.000 description 14
- 108010077112 prolyl-proline Proteins 0.000 description 14
- 210000004881 tumor cell Anatomy 0.000 description 14
- OHLLDUNVMPPUMD-DCAQKATOSA-N Cys-Leu-Val Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N OHLLDUNVMPPUMD-DCAQKATOSA-N 0.000 description 13
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 13
- 241000699666 Mus <mouse, genus> Species 0.000 description 13
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 13
- NADLKBTYNKUJEP-KATARQTJSA-N Ser-Thr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NADLKBTYNKUJEP-KATARQTJSA-N 0.000 description 13
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 13
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 13
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 13
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 13
- 108010003137 tyrosyltyrosine Proteins 0.000 description 13
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 12
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 12
- UGCIQUYEJIEHKX-GVXVVHGQSA-N Lys-Val-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O UGCIQUYEJIEHKX-GVXVVHGQSA-N 0.000 description 12
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 12
- RHAPJNVNWDBFQI-BQBZGAKWSA-N Ser-Pro-Gly Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O RHAPJNVNWDBFQI-BQBZGAKWSA-N 0.000 description 12
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 12
- 230000004913 activation Effects 0.000 description 12
- 108010038850 arginyl-isoleucyl-tyrosine Proteins 0.000 description 12
- 239000000872 buffer Substances 0.000 description 12
- 238000013461 design Methods 0.000 description 12
- 239000012636 effector Substances 0.000 description 12
- 108010050848 glycylleucine Proteins 0.000 description 12
- 108010017391 lysylvaline Proteins 0.000 description 12
- 239000002953 phosphate buffered saline Substances 0.000 description 12
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 12
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 11
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 11
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 11
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 11
- QLFAPXUXEBAWEK-NHCYSSNCSA-N Lys-Val-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QLFAPXUXEBAWEK-NHCYSSNCSA-N 0.000 description 11
- SJDQOYTYNGZZJX-SRVKXCTJSA-N Met-Glu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SJDQOYTYNGZZJX-SRVKXCTJSA-N 0.000 description 11
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 11
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 11
- JQTYTBPCSOAZHI-FXQIFTODSA-N Val-Ser-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N JQTYTBPCSOAZHI-FXQIFTODSA-N 0.000 description 11
- 235000001014 amino acid Nutrition 0.000 description 11
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 11
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 11
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 11
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 11
- JEPNLGMEZMCFEX-QSFUFRPTSA-N Ala-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C)N JEPNLGMEZMCFEX-QSFUFRPTSA-N 0.000 description 10
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 10
- OCQUNKSFDYDXBG-QXEWZRGKSA-N Gly-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N OCQUNKSFDYDXBG-QXEWZRGKSA-N 0.000 description 10
- FFJQAEYLAQMGDL-MGHWNKPDSA-N Ile-Lys-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FFJQAEYLAQMGDL-MGHWNKPDSA-N 0.000 description 10
- QLQHWWCSCLZUMA-KKUMJFAQSA-N Leu-Asp-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QLQHWWCSCLZUMA-KKUMJFAQSA-N 0.000 description 10
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 10
- MIFFFXHMAHFACR-KATARQTJSA-N Lys-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN MIFFFXHMAHFACR-KATARQTJSA-N 0.000 description 10
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 10
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 10
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 10
- RCMHSGRBJCMFLR-BPUTZDHNSA-N Trp-Met-Asn Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(O)=O)=CNC2=C1 RCMHSGRBJCMFLR-BPUTZDHNSA-N 0.000 description 10
- SZEIFUXUTBBQFQ-STQMWFEESA-N Tyr-Pro-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O SZEIFUXUTBBQFQ-STQMWFEESA-N 0.000 description 10
- MWUYSCVVPVITMW-IGNZVWTISA-N Tyr-Tyr-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 MWUYSCVVPVITMW-IGNZVWTISA-N 0.000 description 10
- OJCISMMNNUNNJA-BZSNNMDCSA-N Tyr-Tyr-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 OJCISMMNNUNNJA-BZSNNMDCSA-N 0.000 description 10
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 10
- 150000001413 amino acids Chemical class 0.000 description 10
- 238000012512 characterization method Methods 0.000 description 10
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 10
- 230000003013 cytotoxicity Effects 0.000 description 10
- 231100000135 cytotoxicity Toxicity 0.000 description 10
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 10
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 10
- 108010049041 glutamylalanine Proteins 0.000 description 10
- 108010010147 glycylglutamine Proteins 0.000 description 10
- 239000001963 growth medium Substances 0.000 description 10
- 108010070643 prolylglutamic acid Proteins 0.000 description 10
- 238000001542 size-exclusion chromatography Methods 0.000 description 10
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 9
- LRCIOEVFVGXZKB-BZSNNMDCSA-N Asn-Tyr-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LRCIOEVFVGXZKB-BZSNNMDCSA-N 0.000 description 9
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 9
- OZHXXYOHPLLLMI-CIUDSAMLSA-N Cys-Lys-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OZHXXYOHPLLLMI-CIUDSAMLSA-N 0.000 description 9
- 108020004414 DNA Proteins 0.000 description 9
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 9
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 9
- OACQOWPRWGNKTP-AVGNSLFASA-N Gln-Tyr-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O OACQOWPRWGNKTP-AVGNSLFASA-N 0.000 description 9
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 9
- IESFZVCAVACGPH-PEFMBERDSA-N Glu-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O IESFZVCAVACGPH-PEFMBERDSA-N 0.000 description 9
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 9
- FJWYJQRCVNGEAQ-ZPFDUUQYSA-N Ile-Asn-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N FJWYJQRCVNGEAQ-ZPFDUUQYSA-N 0.000 description 9
- KWHFUMYCSPJCFQ-NGTWOADLSA-N Ile-Thr-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N KWHFUMYCSPJCFQ-NGTWOADLSA-N 0.000 description 9
- VUBIPAHVHMZHCM-KKUMJFAQSA-N Leu-Tyr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CC=C(O)C=C1 VUBIPAHVHMZHCM-KKUMJFAQSA-N 0.000 description 9
- RFQATBGBLDAKGI-VHSXEESVSA-N Lys-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCCCN)N)C(=O)O RFQATBGBLDAKGI-VHSXEESVSA-N 0.000 description 9
- 241000699670 Mus sp. Species 0.000 description 9
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 9
- WEDZFLRYSIDIRX-IHRRRGAJSA-N Phe-Ser-Arg Chemical compound NC(=N)NCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 WEDZFLRYSIDIRX-IHRRRGAJSA-N 0.000 description 9
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 9
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 9
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 9
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 9
- YLRLHDFMMWDYTK-KKUMJFAQSA-N Tyr-Cys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 YLRLHDFMMWDYTK-KKUMJFAQSA-N 0.000 description 9
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 9
- 229940024606 amino acid Drugs 0.000 description 9
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 9
- 239000003814 drug Substances 0.000 description 9
- 230000001404 mediated effect Effects 0.000 description 9
- 230000004048 modification Effects 0.000 description 9
- 238000012986 modification Methods 0.000 description 9
- 239000000523 sample Substances 0.000 description 9
- 108010071635 tyrosyl-prolyl-arginine Proteins 0.000 description 9
- 108010077037 tyrosyl-tyrosyl-phenylalanine Proteins 0.000 description 9
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 8
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 8
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 8
- 238000002965 ELISA Methods 0.000 description 8
- GJBUAAAIZSRCDC-GVXVVHGQSA-N Glu-Leu-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O GJBUAAAIZSRCDC-GVXVVHGQSA-N 0.000 description 8
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 8
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 8
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 8
- IXHKPDJKKCUKHS-GARJFASQSA-N Lys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IXHKPDJKKCUKHS-GARJFASQSA-N 0.000 description 8
- NTBFKPBULZGXQL-KKUMJFAQSA-N Lys-Asp-Tyr Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NTBFKPBULZGXQL-KKUMJFAQSA-N 0.000 description 8
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 8
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 8
- SJRQWEDYTKYHHL-SLFFLAALSA-N Phe-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O SJRQWEDYTKYHHL-SLFFLAALSA-N 0.000 description 8
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 8
- MHHQQZIFLWFZGR-DCAQKATOSA-N Pro-Lys-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O MHHQQZIFLWFZGR-DCAQKATOSA-N 0.000 description 8
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 8
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 8
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 8
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 8
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 8
- LDKDSFQSEUOCOO-RPTUDFQQSA-N Tyr-Thr-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LDKDSFQSEUOCOO-RPTUDFQQSA-N 0.000 description 8
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 8
- BMGOFDMKDVVGJG-NHCYSSNCSA-N Val-Asp-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BMGOFDMKDVVGJG-NHCYSSNCSA-N 0.000 description 8
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 8
- JVGDAEKKZKKZFO-RCWTZXSCSA-N Val-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N)O JVGDAEKKZKKZFO-RCWTZXSCSA-N 0.000 description 8
- 108010047857 aspartylglycine Proteins 0.000 description 8
- 238000003556 assay Methods 0.000 description 8
- 238000012575 bio-layer interferometry Methods 0.000 description 8
- 230000000295 complement effect Effects 0.000 description 8
- 230000009089 cytolysis Effects 0.000 description 8
- 239000003937 drug carrier Substances 0.000 description 8
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 8
- 108010078144 glutaminyl-glycine Proteins 0.000 description 8
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 8
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 8
- 238000001727 in vivo Methods 0.000 description 8
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 8
- 238000003259 recombinant expression Methods 0.000 description 8
- 230000001105 regulatory effect Effects 0.000 description 8
- 241000894007 species Species 0.000 description 8
- 230000001225 therapeutic effect Effects 0.000 description 8
- ADPACBMPYWJJCE-FXQIFTODSA-N Arg-Ser-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O ADPACBMPYWJJCE-FXQIFTODSA-N 0.000 description 7
- MJIJBEYEHBKTIM-BYULHYEWSA-N Asn-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N MJIJBEYEHBKTIM-BYULHYEWSA-N 0.000 description 7
- RUFHOVYUYSNDNY-ACZMJKKPSA-N Glu-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O RUFHOVYUYSNDNY-ACZMJKKPSA-N 0.000 description 7
- SYOJVRNQCXYEOV-XVKPBYJWSA-N Gly-Val-Glu Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SYOJVRNQCXYEOV-XVKPBYJWSA-N 0.000 description 7
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 7
- PELXPRPDQRFBGQ-KKUMJFAQSA-N Lys-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N)O PELXPRPDQRFBGQ-KKUMJFAQSA-N 0.000 description 7
- GILLQRYAWOMHED-DCAQKATOSA-N Lys-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN GILLQRYAWOMHED-DCAQKATOSA-N 0.000 description 7
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 7
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 7
- OHKLFYXEOGGGCK-ZLUOBGJFSA-N Ser-Asp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OHKLFYXEOGGGCK-ZLUOBGJFSA-N 0.000 description 7
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 7
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 7
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 7
- UIPXCLNLUUAMJU-JBDRJPRFSA-N Ser-Ile-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UIPXCLNLUUAMJU-JBDRJPRFSA-N 0.000 description 7
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 7
- JMBRNXUOLJFURW-BEAPCOKYSA-N Thr-Phe-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N)O JMBRNXUOLJFURW-BEAPCOKYSA-N 0.000 description 7
- 239000004480 active ingredient Substances 0.000 description 7
- 239000003795 chemical substances by application Substances 0.000 description 7
- 230000000875 corresponding effect Effects 0.000 description 7
- 108010089804 glycyl-threonine Proteins 0.000 description 7
- 108010057952 lysyl-phenylalanyl-lysine Proteins 0.000 description 7
- 108010064235 lysylglycine Proteins 0.000 description 7
- 239000000463 material Substances 0.000 description 7
- 239000013642 negative control Substances 0.000 description 7
- 108010051242 phenylalanylserine Proteins 0.000 description 7
- BQVCCPGCDUSGOE-UHFFFAOYSA-N phenylarsine oxide Chemical compound O=[As]C1=CC=CC=C1 BQVCCPGCDUSGOE-UHFFFAOYSA-N 0.000 description 7
- 239000013612 plasmid Substances 0.000 description 7
- 230000008685 targeting Effects 0.000 description 7
- 229940124597 therapeutic agent Drugs 0.000 description 7
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 7
- 108010051110 tyrosyl-lysine Proteins 0.000 description 7
- 108010052774 valyl-lysyl-glycyl-phenylalanyl-tyrosine Proteins 0.000 description 7
- 238000005406 washing Methods 0.000 description 7
- SSSROGPPPVTHLX-FXQIFTODSA-N Ala-Arg-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSROGPPPVTHLX-FXQIFTODSA-N 0.000 description 6
- DPNZTBKGAUAZQU-DLOVCJGASA-N Ala-Leu-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DPNZTBKGAUAZQU-DLOVCJGASA-N 0.000 description 6
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 6
- OINVDEKBKBCPLX-JXUBOQSCSA-N Ala-Lys-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OINVDEKBKBCPLX-JXUBOQSCSA-N 0.000 description 6
- BVLIJXXSXBUGEC-SRVKXCTJSA-N Asn-Asn-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BVLIJXXSXBUGEC-SRVKXCTJSA-N 0.000 description 6
- SRUUBQBAVNQZGJ-LAEOZQHASA-N Asn-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N SRUUBQBAVNQZGJ-LAEOZQHASA-N 0.000 description 6
- WQLJRNRLHWJIRW-KKUMJFAQSA-N Asn-His-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)N)N)O WQLJRNRLHWJIRW-KKUMJFAQSA-N 0.000 description 6
- RCFGLXMZDYNRSC-CIUDSAMLSA-N Asn-Lys-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O RCFGLXMZDYNRSC-CIUDSAMLSA-N 0.000 description 6
- HPBNLFLSSQDFQW-WHFBIAKZSA-N Asn-Ser-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O HPBNLFLSSQDFQW-WHFBIAKZSA-N 0.000 description 6
- HNXWVVHIGTZTBO-LKXGYXEUSA-N Asn-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O HNXWVVHIGTZTBO-LKXGYXEUSA-N 0.000 description 6
- KBQOUDLMWYWXNP-YDHLFZDLSA-N Asn-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KBQOUDLMWYWXNP-YDHLFZDLSA-N 0.000 description 6
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 6
- JSNWZMFSLIWAHS-HJGDQZAQSA-N Asp-Thr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O JSNWZMFSLIWAHS-HJGDQZAQSA-N 0.000 description 6
- AWPWHMVCSISSQK-QWRGUYRKSA-N Asp-Tyr-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O AWPWHMVCSISSQK-QWRGUYRKSA-N 0.000 description 6
- YMBAVNPKBWHDAW-CIUDSAMLSA-N Cys-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N YMBAVNPKBWHDAW-CIUDSAMLSA-N 0.000 description 6
- SMEYEQDCCBHTEF-FXQIFTODSA-N Cys-Pro-Ala Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O SMEYEQDCCBHTEF-FXQIFTODSA-N 0.000 description 6
- KSMSFCBQBQPFAD-GUBZILKMSA-N Cys-Pro-Pro Chemical compound SC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 KSMSFCBQBQPFAD-GUBZILKMSA-N 0.000 description 6
- NDNZRWUDUMTITL-FXQIFTODSA-N Cys-Ser-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NDNZRWUDUMTITL-FXQIFTODSA-N 0.000 description 6
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 6
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 6
- HUFCEIHAFNVSNR-IHRRRGAJSA-N Glu-Gln-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUFCEIHAFNVSNR-IHRRRGAJSA-N 0.000 description 6
- YHOJJFFTSMWVGR-HJGDQZAQSA-N Glu-Met-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YHOJJFFTSMWVGR-HJGDQZAQSA-N 0.000 description 6
- AAJHGGDRKHYSDH-GUBZILKMSA-N Glu-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O AAJHGGDRKHYSDH-GUBZILKMSA-N 0.000 description 6
- BPCLDCNZBUYGOD-BPUTZDHNSA-N Glu-Trp-Glu Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 BPCLDCNZBUYGOD-BPUTZDHNSA-N 0.000 description 6
- WGYHAAXZWPEBDQ-IFFSRLJSSA-N Glu-Val-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGYHAAXZWPEBDQ-IFFSRLJSSA-N 0.000 description 6
- BUEFQXUHTUZXHR-LURJTMIESA-N Gly-Gly-Pro zwitterion Chemical compound NCC(=O)NCC(=O)N1CCC[C@H]1C(O)=O BUEFQXUHTUZXHR-LURJTMIESA-N 0.000 description 6
- GMTXWRIDLGTVFC-IUCAKERBSA-N Gly-Lys-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMTXWRIDLGTVFC-IUCAKERBSA-N 0.000 description 6
- JSLVAHYTAJJEQH-QWRGUYRKSA-N Gly-Ser-Phe Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JSLVAHYTAJJEQH-QWRGUYRKSA-N 0.000 description 6
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 6
- WTUSRDZLLWGYAT-KCTSRDHCSA-N Gly-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)CN WTUSRDZLLWGYAT-KCTSRDHCSA-N 0.000 description 6
- FULZDMOZUZKGQU-ONGXEEELSA-N Gly-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN FULZDMOZUZKGQU-ONGXEEELSA-N 0.000 description 6
- TTYKEFZRLKQTHH-MELADBBJSA-N His-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O TTYKEFZRLKQTHH-MELADBBJSA-N 0.000 description 6
- MKWSZEHGHSLNPF-NAKRPEOUSA-N Ile-Ala-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O)N MKWSZEHGHSLNPF-NAKRPEOUSA-N 0.000 description 6
- DFJJAVZIHDFOGQ-MNXVOIDGSA-N Ile-Glu-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N DFJJAVZIHDFOGQ-MNXVOIDGSA-N 0.000 description 6
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 6
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 6
- 108010065920 Insulin Lispro Proteins 0.000 description 6
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 6
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 6
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 6
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 6
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 6
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 6
- WSXTWLJHTLRFLW-SRVKXCTJSA-N Lys-Ala-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O WSXTWLJHTLRFLW-SRVKXCTJSA-N 0.000 description 6
- NKKFVJRLCCUJNA-QWRGUYRKSA-N Lys-Gly-Lys Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN NKKFVJRLCCUJNA-QWRGUYRKSA-N 0.000 description 6
- OIQSIMFSVLLWBX-VOAKCMCISA-N Lys-Leu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OIQSIMFSVLLWBX-VOAKCMCISA-N 0.000 description 6
- DIBZLYZXTSVGLN-CIUDSAMLSA-N Lys-Ser-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O DIBZLYZXTSVGLN-CIUDSAMLSA-N 0.000 description 6
- RKIIYGUHIQJCBW-SRVKXCTJSA-N Met-His-Glu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O RKIIYGUHIQJCBW-SRVKXCTJSA-N 0.000 description 6
- 241001529936 Murinae Species 0.000 description 6
- BPCLGWHVPVTTFM-QWRGUYRKSA-N Phe-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O BPCLGWHVPVTTFM-QWRGUYRKSA-N 0.000 description 6
- FMLRRBDLBJLJIK-DCAQKATOSA-N Pro-Leu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FMLRRBDLBJLJIK-DCAQKATOSA-N 0.000 description 6
- ULWBBFKQBDNGOY-RWMBFGLXSA-N Pro-Lys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@@H]2C(=O)O ULWBBFKQBDNGOY-RWMBFGLXSA-N 0.000 description 6
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 6
- KHRLUIPIMIQFGT-AVGNSLFASA-N Pro-Val-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KHRLUIPIMIQFGT-AVGNSLFASA-N 0.000 description 6
- UEJYSALTSUZXFV-SRVKXCTJSA-N Rigin Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O UEJYSALTSUZXFV-SRVKXCTJSA-N 0.000 description 6
- HZWAHWQZPSXNCB-BPUTZDHNSA-N Ser-Arg-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HZWAHWQZPSXNCB-BPUTZDHNSA-N 0.000 description 6
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 6
- UGJRQLURDVGULT-LKXGYXEUSA-N Ser-Asn-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UGJRQLURDVGULT-LKXGYXEUSA-N 0.000 description 6
- FTVRVZNYIYWJGB-ACZMJKKPSA-N Ser-Asp-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FTVRVZNYIYWJGB-ACZMJKKPSA-N 0.000 description 6
- LAFLAXHTDVNVEL-WDCWCFNPSA-N Thr-Gln-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O LAFLAXHTDVNVEL-WDCWCFNPSA-N 0.000 description 6
- SXAGUVRFGJSFKC-ZEILLAHLSA-N Thr-His-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SXAGUVRFGJSFKC-ZEILLAHLSA-N 0.000 description 6
- ZESGVALRVJIVLZ-VFCFLDTKSA-N Thr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O ZESGVALRVJIVLZ-VFCFLDTKSA-N 0.000 description 6
- XGFGVFMXDXALEV-XIRDDKMYSA-N Trp-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N XGFGVFMXDXALEV-XIRDDKMYSA-N 0.000 description 6
- SNWIAPVRCNYFNI-SZMVWBNQSA-N Trp-Met-Arg Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N SNWIAPVRCNYFNI-SZMVWBNQSA-N 0.000 description 6
- SSSDKJMQMZTMJP-BVSLBCMMSA-N Trp-Tyr-Val Chemical compound C([C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CC=C(O)C=C1 SSSDKJMQMZTMJP-BVSLBCMMSA-N 0.000 description 6
- UOXPLPBMEPLZBW-WDSOQIARSA-N Trp-Val-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 UOXPLPBMEPLZBW-WDSOQIARSA-N 0.000 description 6
- QYSBJAUCUKHSLU-JYJNAYRXSA-N Tyr-Arg-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O QYSBJAUCUKHSLU-JYJNAYRXSA-N 0.000 description 6
- GZUIDWDVMWZSMI-KKUMJFAQSA-N Tyr-Lys-Cys Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CS)C(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GZUIDWDVMWZSMI-KKUMJFAQSA-N 0.000 description 6
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 6
- KSGKJSFPWSMJHK-JNPHEJMOSA-N Tyr-Tyr-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KSGKJSFPWSMJHK-JNPHEJMOSA-N 0.000 description 6
- NXPDPYYCIRDUHO-ULQDDVLXSA-N Tyr-Val-His Chemical compound C([C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CC=C(O)C=C1 NXPDPYYCIRDUHO-ULQDDVLXSA-N 0.000 description 6
- OACSGBOREVRSME-NHCYSSNCSA-N Val-His-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](CC(N)=O)C(O)=O OACSGBOREVRSME-NHCYSSNCSA-N 0.000 description 6
- SDHZOOIGIUEPDY-JYJNAYRXSA-N Val-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 SDHZOOIGIUEPDY-JYJNAYRXSA-N 0.000 description 6
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 6
- GVNLOVJNNDZUHS-RHYQMDGZSA-N Val-Thr-Lys Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O GVNLOVJNNDZUHS-RHYQMDGZSA-N 0.000 description 6
- 210000004899 c-terminal region Anatomy 0.000 description 6
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 6
- 238000012217 deletion Methods 0.000 description 6
- 230000037430 deletion Effects 0.000 description 6
- 230000001419 dependent effect Effects 0.000 description 6
- 201000010099 disease Diseases 0.000 description 6
- 108010037850 glycylvaline Proteins 0.000 description 6
- 210000004408 hybridoma Anatomy 0.000 description 6
- 230000001900 immune effect Effects 0.000 description 6
- 238000000338 in vitro Methods 0.000 description 6
- 108010000761 leucylarginine Proteins 0.000 description 6
- 108010091871 leucylmethionine Proteins 0.000 description 6
- 230000003211 malignant effect Effects 0.000 description 6
- 108010073101 phenylalanylleucine Proteins 0.000 description 6
- 238000003998 size exclusion chromatography high performance liquid chromatography Methods 0.000 description 6
- 239000000243 solution Substances 0.000 description 6
- 239000006228 supernatant Substances 0.000 description 6
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 6
- 210000001519 tissue Anatomy 0.000 description 6
- 230000009258 tissue cross reactivity Effects 0.000 description 6
- 238000001890 transfection Methods 0.000 description 6
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 5
- KUDREHRZRIVKHS-UWJYBYFXSA-N Ala-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KUDREHRZRIVKHS-UWJYBYFXSA-N 0.000 description 5
- WCBVQNZTOKJWJS-ACZMJKKPSA-N Ala-Cys-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O WCBVQNZTOKJWJS-ACZMJKKPSA-N 0.000 description 5
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 5
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 5
- ZDILXFDENZVOTL-BPNCWPANSA-N Ala-Val-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDILXFDENZVOTL-BPNCWPANSA-N 0.000 description 5
- ISJWBVIYRBAXEB-CIUDSAMLSA-N Arg-Ser-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISJWBVIYRBAXEB-CIUDSAMLSA-N 0.000 description 5
- AIFHRTPABBBHKU-RCWTZXSCSA-N Arg-Thr-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O AIFHRTPABBBHKU-RCWTZXSCSA-N 0.000 description 5
- ZJBUILVYSXQNSW-YTWAJWBKSA-N Arg-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ZJBUILVYSXQNSW-YTWAJWBKSA-N 0.000 description 5
- XYOVHPDDWCEUDY-CIUDSAMLSA-N Asn-Ala-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O XYOVHPDDWCEUDY-CIUDSAMLSA-N 0.000 description 5
- WMLFFCRUSPNENW-ZLUOBGJFSA-N Asp-Ser-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O WMLFFCRUSPNENW-ZLUOBGJFSA-N 0.000 description 5
- QOJJMJKTMKNFEF-ZKWXMUAHSA-N Asp-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O QOJJMJKTMKNFEF-ZKWXMUAHSA-N 0.000 description 5
- ALTQTAKGRFLRLR-GUBZILKMSA-N Cys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N ALTQTAKGRFLRLR-GUBZILKMSA-N 0.000 description 5
- XOKGKOQWADCLFQ-GARJFASQSA-N Gln-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XOKGKOQWADCLFQ-GARJFASQSA-N 0.000 description 5
- IULKWYSYZSURJK-AVGNSLFASA-N Gln-Leu-Lys Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O IULKWYSYZSURJK-AVGNSLFASA-N 0.000 description 5
- CLROYXHHUZELFX-FXQIFTODSA-N Glu-Gln-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O CLROYXHHUZELFX-FXQIFTODSA-N 0.000 description 5
- OCJRHJZKGGSPRW-IUCAKERBSA-N Glu-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O OCJRHJZKGGSPRW-IUCAKERBSA-N 0.000 description 5
- MFNUFCFRAZPJFW-JYJNAYRXSA-N Glu-Lys-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFNUFCFRAZPJFW-JYJNAYRXSA-N 0.000 description 5
- RFTVTKBHDXCEEX-WDSKDSINSA-N Glu-Ser-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RFTVTKBHDXCEEX-WDSKDSINSA-N 0.000 description 5
- GGAPHLIUUTVYMX-QWRGUYRKSA-N Gly-Phe-Ser Chemical compound OC[C@@H](C([O-])=O)NC(=O)[C@@H](NC(=O)C[NH3+])CC1=CC=CC=C1 GGAPHLIUUTVYMX-QWRGUYRKSA-N 0.000 description 5
- CQMFNTVQVLQRLT-JHEQGTHGSA-N Gly-Thr-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O CQMFNTVQVLQRLT-JHEQGTHGSA-N 0.000 description 5
- XHVONGZZVUUORG-WEDXCCLWSA-N Gly-Thr-Lys Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN XHVONGZZVUUORG-WEDXCCLWSA-N 0.000 description 5
- FFALDIDGPLUDKV-ZDLURKLDSA-N Gly-Thr-Ser Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O FFALDIDGPLUDKV-ZDLURKLDSA-N 0.000 description 5
- UIQGJYUEQDOODF-KWQFWETISA-N Gly-Tyr-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 UIQGJYUEQDOODF-KWQFWETISA-N 0.000 description 5
- GBYYQVBXFVDJPJ-WLTAIBSBSA-N Gly-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)CN)O GBYYQVBXFVDJPJ-WLTAIBSBSA-N 0.000 description 5
- SDTPKSOWFXBACN-GUBZILKMSA-N His-Glu-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O SDTPKSOWFXBACN-GUBZILKMSA-N 0.000 description 5
- QQFSKBMCAKWHLG-UHFFFAOYSA-N Ile-Phe-Pro-Pro Chemical compound C1CCC(C(=O)N2C(CCC2)C(O)=O)N1C(=O)C(NC(=O)C(N)C(C)CC)CC1=CC=CC=C1 QQFSKBMCAKWHLG-UHFFFAOYSA-N 0.000 description 5
- FBGXMKUWQFPHFB-JBDRJPRFSA-N Ile-Ser-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N FBGXMKUWQFPHFB-JBDRJPRFSA-N 0.000 description 5
- DBVWMYGBVFCRBE-CIUDSAMLSA-N Leu-Asn-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O DBVWMYGBVFCRBE-CIUDSAMLSA-N 0.000 description 5
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 5
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 5
- AMSSKPUHBUQBOQ-SRVKXCTJSA-N Leu-Ser-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N AMSSKPUHBUQBOQ-SRVKXCTJSA-N 0.000 description 5
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 5
- PXHCFKXNSBJSTQ-KKUMJFAQSA-N Lys-Asn-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N)O PXHCFKXNSBJSTQ-KKUMJFAQSA-N 0.000 description 5
- QQPSCXKFDSORFT-IHRRRGAJSA-N Lys-Lys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN QQPSCXKFDSORFT-IHRRRGAJSA-N 0.000 description 5
- ODTZHNZPINULEU-KKUMJFAQSA-N Lys-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N ODTZHNZPINULEU-KKUMJFAQSA-N 0.000 description 5
- VOOINLQYUZOREH-SRVKXCTJSA-N Met-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCSC)N VOOINLQYUZOREH-SRVKXCTJSA-N 0.000 description 5
- FWAHLGXNBLWIKB-NAKRPEOUSA-N Met-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCSC FWAHLGXNBLWIKB-NAKRPEOUSA-N 0.000 description 5
- JDMKQHSHKJHAHR-UHFFFAOYSA-N Phe-Phe-Leu-Tyr Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)CC1=CC=CC=C1 JDMKQHSHKJHAHR-UHFFFAOYSA-N 0.000 description 5
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 5
- 229920001213 Polysorbate 20 Polymers 0.000 description 5
- PPNPDKGQRFSCAC-CIUDSAMLSA-N Ser-Lys-Asp Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPNPDKGQRFSCAC-CIUDSAMLSA-N 0.000 description 5
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 5
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 5
- XHWCDRUPDNSDAZ-XKBZYTNZSA-N Thr-Ser-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O XHWCDRUPDNSDAZ-XKBZYTNZSA-N 0.000 description 5
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 5
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 5
- JJNXZIPLIXIGBX-HJPIBITLSA-N Tyr-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JJNXZIPLIXIGBX-HJPIBITLSA-N 0.000 description 5
- LHADRQBREKTRLR-DCAQKATOSA-N Val-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N LHADRQBREKTRLR-DCAQKATOSA-N 0.000 description 5
- OXVPMZVGCAPFIG-BQFCYCMXSA-N Val-Gln-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N OXVPMZVGCAPFIG-BQFCYCMXSA-N 0.000 description 5
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 5
- TVGWMCTYUFBXAP-QTKMDUPCSA-N Val-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N)O TVGWMCTYUFBXAP-QTKMDUPCSA-N 0.000 description 5
- PGBMPFKFKXYROZ-UFYCRDLUSA-N Val-Tyr-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N PGBMPFKFKXYROZ-UFYCRDLUSA-N 0.000 description 5
- BGTDGENDNWGMDQ-KJEVXHAQSA-N Val-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N)O BGTDGENDNWGMDQ-KJEVXHAQSA-N 0.000 description 5
- 239000000611 antibody drug conjugate Substances 0.000 description 5
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 5
- 229940049595 antibody-drug conjugate Drugs 0.000 description 5
- 108010018691 arginyl-threonyl-arginine Proteins 0.000 description 5
- 238000011190 asparagine deamidation Methods 0.000 description 5
- 210000003719 b-lymphocyte Anatomy 0.000 description 5
- 230000015861 cell surface binding Effects 0.000 description 5
- 238000005119 centrifugation Methods 0.000 description 5
- 230000001472 cytotoxic effect Effects 0.000 description 5
- 210000003527 eukaryotic cell Anatomy 0.000 description 5
- 108010079413 glycyl-prolyl-glutamic acid Proteins 0.000 description 5
- 230000036541 health Effects 0.000 description 5
- 230000002401 inhibitory effect Effects 0.000 description 5
- 230000005764 inhibitory process Effects 0.000 description 5
- 238000002347 injection Methods 0.000 description 5
- 239000007924 injection Substances 0.000 description 5
- 238000003780 insertion Methods 0.000 description 5
- 230000037431 insertion Effects 0.000 description 5
- 239000003446 ligand Substances 0.000 description 5
- 230000036210 malignancy Effects 0.000 description 5
- 210000004962 mammalian cell Anatomy 0.000 description 5
- 239000012528 membrane Substances 0.000 description 5
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 5
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 5
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 5
- 230000000069 prophylactic effect Effects 0.000 description 5
- 108010048818 seryl-histidine Proteins 0.000 description 5
- 230000011664 signaling Effects 0.000 description 5
- 208000024891 symptom Diseases 0.000 description 5
- 230000009466 transformation Effects 0.000 description 5
- 108010009962 valyltyrosine Proteins 0.000 description 5
- 239000003981 vehicle Substances 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- MDNAVFBZPROEHO-UHFFFAOYSA-N Ala-Lys-Val Natural products CC(C)C(C(O)=O)NC(=O)C(NC(=O)C(C)N)CCCCN MDNAVFBZPROEHO-UHFFFAOYSA-N 0.000 description 4
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 4
- VNFSAYFQLXPHPY-CIQUZCHMSA-N Ala-Thr-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNFSAYFQLXPHPY-CIQUZCHMSA-N 0.000 description 4
- XRNXPIGJPQHCPC-RCWTZXSCSA-N Arg-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCCNC(N)=N)[C@@H](C)O)C(O)=O XRNXPIGJPQHCPC-RCWTZXSCSA-N 0.000 description 4
- SWLOHUMCUDRTCL-ZLUOBGJFSA-N Asn-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N SWLOHUMCUDRTCL-ZLUOBGJFSA-N 0.000 description 4
- RZVVKNIACROXRM-ZLUOBGJFSA-N Asn-Ala-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N RZVVKNIACROXRM-ZLUOBGJFSA-N 0.000 description 4
- GXMSVVBIAMWMKO-BQBZGAKWSA-N Asn-Arg-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N GXMSVVBIAMWMKO-BQBZGAKWSA-N 0.000 description 4
- DXVMJJNAOVECBA-WHFBIAKZSA-N Asn-Gly-Asn Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O DXVMJJNAOVECBA-WHFBIAKZSA-N 0.000 description 4
- IICZCLFBILYRCU-WHFBIAKZSA-N Asn-Gly-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O IICZCLFBILYRCU-WHFBIAKZSA-N 0.000 description 4
- RBOBTTLFPRSXKZ-BZSNNMDCSA-N Asn-Phe-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RBOBTTLFPRSXKZ-BZSNNMDCSA-N 0.000 description 4
- YNQIDCRRTWGHJD-ZLUOBGJFSA-N Asp-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(O)=O YNQIDCRRTWGHJD-ZLUOBGJFSA-N 0.000 description 4
- HSWYMWGDMPLTTH-FXQIFTODSA-N Asp-Glu-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HSWYMWGDMPLTTH-FXQIFTODSA-N 0.000 description 4
- KYQNAIMCTRZLNP-QSFUFRPTSA-N Asp-Ile-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O KYQNAIMCTRZLNP-QSFUFRPTSA-N 0.000 description 4
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 4
- YIDFBWRHIYOYAA-LKXGYXEUSA-N Asp-Ser-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YIDFBWRHIYOYAA-LKXGYXEUSA-N 0.000 description 4
- HTSSXFASOUSJQG-IHPCNDPISA-N Asp-Tyr-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HTSSXFASOUSJQG-IHPCNDPISA-N 0.000 description 4
- 101100512078 Caenorhabditis elegans lys-1 gene Proteins 0.000 description 4
- 108091026890 Coding region Proteins 0.000 description 4
- NIXHTNJAGGFBAW-CIUDSAMLSA-N Cys-Lys-Ser Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N NIXHTNJAGGFBAW-CIUDSAMLSA-N 0.000 description 4
- JJKKWYQVHRUSDG-GUBZILKMSA-N Glu-Ala-Lys Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O JJKKWYQVHRUSDG-GUBZILKMSA-N 0.000 description 4
- AVZHGSCDKIQZPQ-CIUDSAMLSA-N Glu-Arg-Ala Chemical compound C[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AVZHGSCDKIQZPQ-CIUDSAMLSA-N 0.000 description 4
- WATXSTJXNBOHKD-LAEOZQHASA-N Glu-Asp-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O WATXSTJXNBOHKD-LAEOZQHASA-N 0.000 description 4
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 4
- CLODWIOAKCSBAN-BQBZGAKWSA-N Gly-Arg-Asp Chemical compound NC(N)=NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(O)=O)C(O)=O CLODWIOAKCSBAN-BQBZGAKWSA-N 0.000 description 4
- XCLCVBYNGXEVDU-WHFBIAKZSA-N Gly-Asn-Ser Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O XCLCVBYNGXEVDU-WHFBIAKZSA-N 0.000 description 4
- BIRKKBCSAIHDDF-WDSKDSINSA-N Gly-Glu-Cys Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(O)=O BIRKKBCSAIHDDF-WDSKDSINSA-N 0.000 description 4
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 4
- TVMNTHXFRSXZGR-IHRRRGAJSA-N His-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O TVMNTHXFRSXZGR-IHRRRGAJSA-N 0.000 description 4
- CSTDQOOBZBAJKE-BWAGICSOSA-N His-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC2=CN=CN2)N)O CSTDQOOBZBAJKE-BWAGICSOSA-N 0.000 description 4
- NZGTYCMLUGYMCV-XUXIUFHCSA-N Ile-Lys-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N NZGTYCMLUGYMCV-XUXIUFHCSA-N 0.000 description 4
- RKQAYOWLSFLJEE-SVSWQMSJSA-N Ile-Thr-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)O)N RKQAYOWLSFLJEE-SVSWQMSJSA-N 0.000 description 4
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 4
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 4
- HXWALXSAVBLTPK-NUTKFTJISA-N Leu-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(C)C)N HXWALXSAVBLTPK-NUTKFTJISA-N 0.000 description 4
- STAVRDQLZOTNKJ-RHYQMDGZSA-N Leu-Arg-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O STAVRDQLZOTNKJ-RHYQMDGZSA-N 0.000 description 4
- VQPPIMUZCZCOIL-GUBZILKMSA-N Leu-Gln-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O VQPPIMUZCZCOIL-GUBZILKMSA-N 0.000 description 4
- FAELBUXXFQLUAX-AJNGGQMLSA-N Leu-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C FAELBUXXFQLUAX-AJNGGQMLSA-N 0.000 description 4
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 4
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 4
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 4
- MPGHETGWWWUHPY-CIUDSAMLSA-N Lys-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN MPGHETGWWWUHPY-CIUDSAMLSA-N 0.000 description 4
- XABXVVSWUVCZST-GVXVVHGQSA-N Lys-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN XABXVVSWUVCZST-GVXVVHGQSA-N 0.000 description 4
- HXSUFWQYLPKEHF-IHRRRGAJSA-N Phe-Asn-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HXSUFWQYLPKEHF-IHRRRGAJSA-N 0.000 description 4
- NAXPHWZXEXNDIW-JTQLQIEISA-N Phe-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 NAXPHWZXEXNDIW-JTQLQIEISA-N 0.000 description 4
- BWTKUQPNOMMKMA-FIRPJDEBSA-N Phe-Ile-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BWTKUQPNOMMKMA-FIRPJDEBSA-N 0.000 description 4
- GLJZDMZJHFXJQG-BZSNNMDCSA-N Phe-Ser-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O GLJZDMZJHFXJQG-BZSNNMDCSA-N 0.000 description 4
- JARJPEMLQAWNBR-GUBZILKMSA-N Pro-Asp-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JARJPEMLQAWNBR-GUBZILKMSA-N 0.000 description 4
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 4
- PCWLNNZTBJTZRN-AVGNSLFASA-N Pro-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 PCWLNNZTBJTZRN-AVGNSLFASA-N 0.000 description 4
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 4
- YUSRGTQIPCJNHQ-CIUDSAMLSA-N Ser-Arg-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O YUSRGTQIPCJNHQ-CIUDSAMLSA-N 0.000 description 4
- ZOHGLPQGEHSLPD-FXQIFTODSA-N Ser-Gln-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZOHGLPQGEHSLPD-FXQIFTODSA-N 0.000 description 4
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 4
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 4
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 4
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 4
- PJIQEIFXZPCWOJ-FXQIFTODSA-N Ser-Pro-Asp Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O PJIQEIFXZPCWOJ-FXQIFTODSA-N 0.000 description 4
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 4
- RXUOAOOZIWABBW-XGEHTFHBSA-N Ser-Thr-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RXUOAOOZIWABBW-XGEHTFHBSA-N 0.000 description 4
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 4
- UBTNVMGPMYDYIU-HJPIBITLSA-N Ser-Tyr-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O UBTNVMGPMYDYIU-HJPIBITLSA-N 0.000 description 4
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 4
- DGDCHPCRMWEOJR-FQPOAREZSA-N Thr-Ala-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 DGDCHPCRMWEOJR-FQPOAREZSA-N 0.000 description 4
- XSLXHSYIVPGEER-KZVJFYERSA-N Thr-Ala-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O XSLXHSYIVPGEER-KZVJFYERSA-N 0.000 description 4
- GLQFKOVWXPPFTP-VEVYYDQMSA-N Thr-Arg-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O GLQFKOVWXPPFTP-VEVYYDQMSA-N 0.000 description 4
- JVTHIXKSVYEWNI-JRQIVUDYSA-N Thr-Asn-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JVTHIXKSVYEWNI-JRQIVUDYSA-N 0.000 description 4
- GKWNLDNXMMLRMC-GLLZPBPUSA-N Thr-Glu-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O GKWNLDNXMMLRMC-GLLZPBPUSA-N 0.000 description 4
- PAXANSWUSVPFNK-IUKAMOBKSA-N Thr-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N PAXANSWUSVPFNK-IUKAMOBKSA-N 0.000 description 4
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 4
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 4
- RPECVQBNONKZAT-WZLNRYEVSA-N Thr-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H]([C@@H](C)O)N RPECVQBNONKZAT-WZLNRYEVSA-N 0.000 description 4
- CYCGARJWIQWPQM-YJRXYDGGSA-N Thr-Tyr-Ser Chemical compound C[C@@H](O)[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CO)C([O-])=O)CC1=CC=C(O)C=C1 CYCGARJWIQWPQM-YJRXYDGGSA-N 0.000 description 4
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 4
- NLWCSMOXNKBRLC-WDSOQIARSA-N Trp-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLWCSMOXNKBRLC-WDSOQIARSA-N 0.000 description 4
- FFCRCJZJARTYCG-KKUMJFAQSA-N Tyr-Cys-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N)O FFCRCJZJARTYCG-KKUMJFAQSA-N 0.000 description 4
- SLCSPPCQWUHPPO-JYJNAYRXSA-N Tyr-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SLCSPPCQWUHPPO-JYJNAYRXSA-N 0.000 description 4
- AUZADXNWQMBZOO-JYJNAYRXSA-N Tyr-Pro-Arg Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)C1=CC=C(O)C=C1 AUZADXNWQMBZOO-JYJNAYRXSA-N 0.000 description 4
- ZYVAAYAOTVJBSS-GMVOTWDCSA-N Tyr-Trp-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O ZYVAAYAOTVJBSS-GMVOTWDCSA-N 0.000 description 4
- YMTOEGGOCHVGEH-IHRRRGAJSA-N Val-Lys-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O YMTOEGGOCHVGEH-IHRRRGAJSA-N 0.000 description 4
- ZHWZDZFWBXWPDW-GUBZILKMSA-N Val-Val-Cys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O ZHWZDZFWBXWPDW-GUBZILKMSA-N 0.000 description 4
- 108010081404 acein-2 Proteins 0.000 description 4
- 238000001042 affinity chromatography Methods 0.000 description 4
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 4
- 108010013835 arginine glutamate Proteins 0.000 description 4
- 108010059459 arginyl-threonyl-phenylalanine Proteins 0.000 description 4
- 238000004113 cell culture Methods 0.000 description 4
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 4
- 238000002784 cytotoxicity assay Methods 0.000 description 4
- 231100000263 cytotoxicity test Toxicity 0.000 description 4
- 238000011161 development Methods 0.000 description 4
- 230000018109 developmental process Effects 0.000 description 4
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 4
- 230000002538 fungal effect Effects 0.000 description 4
- 108010027338 isoleucylcysteine Proteins 0.000 description 4
- 239000002245 particle Substances 0.000 description 4
- 102000040430 polynucleotide Human genes 0.000 description 4
- 108091033319 polynucleotide Proteins 0.000 description 4
- 239000002157 polynucleotide Substances 0.000 description 4
- 238000012545 processing Methods 0.000 description 4
- 230000009467 reduction Effects 0.000 description 4
- 230000002829 reductive effect Effects 0.000 description 4
- 238000003571 reporter gene assay Methods 0.000 description 4
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 4
- 108010026333 seryl-proline Proteins 0.000 description 4
- 239000000126 substance Substances 0.000 description 4
- 108010038745 tryptophylglycine Proteins 0.000 description 4
- 230000004614 tumor growth Effects 0.000 description 4
- 108010035534 tyrosyl-leucyl-alanine Proteins 0.000 description 4
- GJLXVWOMRRWCIB-MERZOTPQSA-N (2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-acetamido-5-(diaminomethylideneamino)pentanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]-3-(1H-indol-3-yl)propanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanamide Chemical compound C([C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=C(O)C=C1 GJLXVWOMRRWCIB-MERZOTPQSA-N 0.000 description 3
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 3
- HOVPGJUNRLMIOZ-CIUDSAMLSA-N Ala-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N HOVPGJUNRLMIOZ-CIUDSAMLSA-N 0.000 description 3
- OLGCWMNDJTWQAG-GUBZILKMSA-N Asn-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(N)=O OLGCWMNDJTWQAG-GUBZILKMSA-N 0.000 description 3
- 241000283707 Capra Species 0.000 description 3
- VIRYODQIWJNWNU-NRPADANISA-N Cys-Glu-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N VIRYODQIWJNWNU-NRPADANISA-N 0.000 description 3
- 101150074155 DHFR gene Proteins 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 108091029865 Exogenous DNA Proteins 0.000 description 3
- XKBASPWPBXNVLQ-WDSKDSINSA-N Gln-Gly-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O XKBASPWPBXNVLQ-WDSKDSINSA-N 0.000 description 3
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 3
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 3
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 3
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 3
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- 208000002250 Hematologic Neoplasms Diseases 0.000 description 3
- CNMOKANDJMLAIF-CIQUZCHMSA-N Ile-Thr-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O CNMOKANDJMLAIF-CIQUZCHMSA-N 0.000 description 3
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 3
- 102000003855 L-lactate dehydrogenase Human genes 0.000 description 3
- 108700023483 L-lactate dehydrogenases Proteins 0.000 description 3
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 3
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 3
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 3
- FGMHXLULNHTPID-KKUMJFAQSA-N Lys-His-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CN=CN1 FGMHXLULNHTPID-KKUMJFAQSA-N 0.000 description 3
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 3
- CTJUSALVKAWFFU-CIUDSAMLSA-N Lys-Ser-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N CTJUSALVKAWFFU-CIUDSAMLSA-N 0.000 description 3
- SQXZLVXQXWILKW-KKUMJFAQSA-N Lys-Ser-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQXZLVXQXWILKW-KKUMJFAQSA-N 0.000 description 3
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 3
- 108010079364 N-glycylalanine Proteins 0.000 description 3
- CUMXHKAOHNWRFQ-BZSNNMDCSA-N Phe-Asp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 CUMXHKAOHNWRFQ-BZSNNMDCSA-N 0.000 description 3
- JLLJTMHNXQTMCK-UBHSHLNASA-N Phe-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 JLLJTMHNXQTMCK-UBHSHLNASA-N 0.000 description 3
- JHSRGEODDALISP-XVSYOHENSA-N Phe-Thr-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O JHSRGEODDALISP-XVSYOHENSA-N 0.000 description 3
- 108020004511 Recombinant DNA Proteins 0.000 description 3
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 3
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 3
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 3
- AXKJPUBALUNJEO-UBHSHLNASA-N Ser-Trp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O AXKJPUBALUNJEO-UBHSHLNASA-N 0.000 description 3
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 3
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 3
- KGKWKSSSQGGYAU-SUSMZKCASA-N Thr-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KGKWKSSSQGGYAU-SUSMZKCASA-N 0.000 description 3
- CYVQBKQYQGEELV-NKIYYHGXSA-N Thr-His-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O CYVQBKQYQGEELV-NKIYYHGXSA-N 0.000 description 3
- KKPOGALELPLJTL-MEYUZBJRSA-N Thr-Lys-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KKPOGALELPLJTL-MEYUZBJRSA-N 0.000 description 3
- NQQMWWVVGIXUOX-SVSWQMSJSA-N Thr-Ser-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O NQQMWWVVGIXUOX-SVSWQMSJSA-N 0.000 description 3
- COYHRQWNJDJCNA-NUJDXYNKSA-N Thr-Thr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O COYHRQWNJDJCNA-NUJDXYNKSA-N 0.000 description 3
- UKINEYBQXPMOJO-UBHSHLNASA-N Trp-Asn-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N UKINEYBQXPMOJO-UBHSHLNASA-N 0.000 description 3
- SMLCYZYQFRTLCO-UWJYBYFXSA-N Tyr-Cys-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O SMLCYZYQFRTLCO-UWJYBYFXSA-N 0.000 description 3
- YYLHVUCSTXXKBS-IHRRRGAJSA-N Tyr-Pro-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YYLHVUCSTXXKBS-IHRRRGAJSA-N 0.000 description 3
- NUQZCPSZHGIYTA-HKUYNNGSSA-N Tyr-Trp-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N NUQZCPSZHGIYTA-HKUYNNGSSA-N 0.000 description 3
- 101150117115 V gene Proteins 0.000 description 3
- ZLFHAAGHGQBQQN-GUBZILKMSA-N Val-Ala-Pro Natural products CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O ZLFHAAGHGQBQQN-GUBZILKMSA-N 0.000 description 3
- GNWUWQAVVJQREM-NHCYSSNCSA-N Val-Asn-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N GNWUWQAVVJQREM-NHCYSSNCSA-N 0.000 description 3
- VCAWFLIWYNMHQP-UKJIMTQDSA-N Val-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N VCAWFLIWYNMHQP-UKJIMTQDSA-N 0.000 description 3
- VCIYTVOBLZHFSC-XHSDSOJGSA-N Val-Phe-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N VCIYTVOBLZHFSC-XHSDSOJGSA-N 0.000 description 3
- DEGUERSKQBRZMZ-FXQIFTODSA-N Val-Ser-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DEGUERSKQBRZMZ-FXQIFTODSA-N 0.000 description 3
- WUFHZIRMAZZWRS-OSUNSFLBSA-N Val-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C(C)C)N WUFHZIRMAZZWRS-OSUNSFLBSA-N 0.000 description 3
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 3
- USXYVSTVPHELAF-RCWTZXSCSA-N Val-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](C(C)C)N)O USXYVSTVPHELAF-RCWTZXSCSA-N 0.000 description 3
- 101150109862 WNT-5A gene Proteins 0.000 description 3
- 102000043366 Wnt-5a Human genes 0.000 description 3
- 108700020483 Wnt-5a Proteins 0.000 description 3
- 238000004458 analytical method Methods 0.000 description 3
- 210000004102 animal cell Anatomy 0.000 description 3
- 230000000890 antigenic effect Effects 0.000 description 3
- 108010038633 aspartylglutamate Proteins 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 3
- 238000010367 cloning Methods 0.000 description 3
- 238000004132 cross linking Methods 0.000 description 3
- 238000006471 dimerization reaction Methods 0.000 description 3
- BFMYDTVEBKDAKJ-UHFFFAOYSA-L disodium;(2',7'-dibromo-3',6'-dioxido-3-oxospiro[2-benzofuran-1,9'-xanthene]-4'-yl)mercury;hydrate Chemical group O.[Na+].[Na+].O1C(=O)C2=CC=CC=C2C21C1=CC(Br)=C([O-])C([Hg])=C1OC1=C2C=C(Br)C([O-])=C1 BFMYDTVEBKDAKJ-UHFFFAOYSA-L 0.000 description 3
- 238000004520 electroporation Methods 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- 238000009472 formulation Methods 0.000 description 3
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 3
- 230000009033 hematopoietic malignancy Effects 0.000 description 3
- 230000001976 improved effect Effects 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- 230000000670 limiting effect Effects 0.000 description 3
- 108010003700 lysyl aspartic acid Proteins 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 239000002609 medium Substances 0.000 description 3
- 210000001236 prokaryotic cell Anatomy 0.000 description 3
- 108010004914 prolylarginine Proteins 0.000 description 3
- 108010090894 prolylleucine Proteins 0.000 description 3
- 230000005180 public health Effects 0.000 description 3
- 230000010076 replication Effects 0.000 description 3
- 238000011160 research Methods 0.000 description 3
- 238000010561 standard procedure Methods 0.000 description 3
- 239000011534 wash buffer Substances 0.000 description 3
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 3
- YRNWIFYIFSBPAU-UHFFFAOYSA-N 4-[4-(dimethylamino)phenyl]-n,n-dimethylaniline Chemical compound C1=CC(N(C)C)=CC=C1C1=CC=C(N(C)C)C=C1 YRNWIFYIFSBPAU-UHFFFAOYSA-N 0.000 description 2
- LGQPPBQRUBVTIF-JBDRJPRFSA-N Ala-Ala-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LGQPPBQRUBVTIF-JBDRJPRFSA-N 0.000 description 2
- WXERCAHAIKMTKX-ZLUOBGJFSA-N Ala-Asp-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O WXERCAHAIKMTKX-ZLUOBGJFSA-N 0.000 description 2
- LTTLSZVJTDSACD-OWLDWWDNSA-N Ala-Thr-Trp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O LTTLSZVJTDSACD-OWLDWWDNSA-N 0.000 description 2
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 2
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 description 2
- FNXCAFKDGBROCU-STECZYCISA-N Arg-Ile-Tyr Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FNXCAFKDGBROCU-STECZYCISA-N 0.000 description 2
- CGWVCWFQGXOUSJ-ULQDDVLXSA-N Arg-Tyr-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O CGWVCWFQGXOUSJ-ULQDDVLXSA-N 0.000 description 2
- PDQBXRSOSCTGKY-ACZMJKKPSA-N Asn-Ala-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N PDQBXRSOSCTGKY-ACZMJKKPSA-N 0.000 description 2
- KLKHFFMNGWULBN-VKHMYHEASA-N Asn-Gly Chemical compound NC(=O)C[C@H](N)C(=O)NCC(O)=O KLKHFFMNGWULBN-VKHMYHEASA-N 0.000 description 2
- DDPXDCKYWDGZAL-BQBZGAKWSA-N Asn-Gly-Arg Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N DDPXDCKYWDGZAL-BQBZGAKWSA-N 0.000 description 2
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 2
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 2
- PUUPMDXIHCOPJU-HJGDQZAQSA-N Asn-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O PUUPMDXIHCOPJU-HJGDQZAQSA-N 0.000 description 2
- BCADFFUQHIMQAA-KKHAAJSZSA-N Asn-Thr-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O BCADFFUQHIMQAA-KKHAAJSZSA-N 0.000 description 2
- RTFXPCYMDYBZNQ-SRVKXCTJSA-N Asn-Tyr-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O RTFXPCYMDYBZNQ-SRVKXCTJSA-N 0.000 description 2
- QNNBHTFDFFFHGC-KKUMJFAQSA-N Asn-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QNNBHTFDFFFHGC-KKUMJFAQSA-N 0.000 description 2
- DXHINQUXBZNUCF-MELADBBJSA-N Asn-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC(=O)N)N)C(=O)O DXHINQUXBZNUCF-MELADBBJSA-N 0.000 description 2
- OERMIMJQPQUIPK-FXQIFTODSA-N Asp-Arg-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O OERMIMJQPQUIPK-FXQIFTODSA-N 0.000 description 2
- ILJQISGMGXRZQQ-IHRRRGAJSA-N Asp-Arg-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ILJQISGMGXRZQQ-IHRRRGAJSA-N 0.000 description 2
- XACXDSRQIXRMNS-OLHMAJIHSA-N Asp-Asn-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N)O XACXDSRQIXRMNS-OLHMAJIHSA-N 0.000 description 2
- VZNOVQKGJQJOCS-SRVKXCTJSA-N Asp-Asp-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VZNOVQKGJQJOCS-SRVKXCTJSA-N 0.000 description 2
- DTNUIAJCPRMNBT-WHFBIAKZSA-N Asp-Gly-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O DTNUIAJCPRMNBT-WHFBIAKZSA-N 0.000 description 2
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 2
- NVFSJIXJZCDICF-SRVKXCTJSA-N Asp-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N NVFSJIXJZCDICF-SRVKXCTJSA-N 0.000 description 2
- SQIARYGNVQWOSB-BZSNNMDCSA-N Asp-Tyr-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQIARYGNVQWOSB-BZSNNMDCSA-N 0.000 description 2
- 102100038080 B-cell receptor CD22 Human genes 0.000 description 2
- 108020004635 Complementary DNA Proteins 0.000 description 2
- 108091035707 Consensus sequence Proteins 0.000 description 2
- CLDCTNHPILWQCW-CIUDSAMLSA-N Cys-Arg-Glu Chemical compound C(C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CS)N)CN=C(N)N CLDCTNHPILWQCW-CIUDSAMLSA-N 0.000 description 2
- CMYVIUWVYHOLRD-ZLUOBGJFSA-N Cys-Ser-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O CMYVIUWVYHOLRD-ZLUOBGJFSA-N 0.000 description 2
- 108090000695 Cytokines Proteins 0.000 description 2
- 102000004127 Cytokines Human genes 0.000 description 2
- 241000196324 Embryophyta Species 0.000 description 2
- 102000004190 Enzymes Human genes 0.000 description 2
- 108090000790 Enzymes Proteins 0.000 description 2
- 241000588724 Escherichia coli Species 0.000 description 2
- NKCZYEDZTKOFBG-GUBZILKMSA-N Gln-Gln-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NKCZYEDZTKOFBG-GUBZILKMSA-N 0.000 description 2
- QFJPFPCSXOXMKI-BPUTZDHNSA-N Gln-Gln-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N QFJPFPCSXOXMKI-BPUTZDHNSA-N 0.000 description 2
- NSNUZSPSADIMJQ-WDSKDSINSA-N Gln-Gly-Asp Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NSNUZSPSADIMJQ-WDSKDSINSA-N 0.000 description 2
- IOFDDSNZJDIGPB-GVXVVHGQSA-N Gln-Leu-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IOFDDSNZJDIGPB-GVXVVHGQSA-N 0.000 description 2
- ZEEPYMXTJWIMSN-GUBZILKMSA-N Gln-Lys-Ser Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CO)C(O)=O)NC(=O)[C@@H](N)CCC(N)=O ZEEPYMXTJWIMSN-GUBZILKMSA-N 0.000 description 2
- QKWBEMCLYTYBNI-GVXVVHGQSA-N Gln-Lys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(N)=O QKWBEMCLYTYBNI-GVXVVHGQSA-N 0.000 description 2
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 2
- XKPACHRGOWQHFH-IRIUXVKKSA-N Gln-Thr-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XKPACHRGOWQHFH-IRIUXVKKSA-N 0.000 description 2
- VEYGCDYMOXHJLS-GVXVVHGQSA-N Gln-Val-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VEYGCDYMOXHJLS-GVXVVHGQSA-N 0.000 description 2
- WZZSKAJIHTUUSG-ACZMJKKPSA-N Glu-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O WZZSKAJIHTUUSG-ACZMJKKPSA-N 0.000 description 2
- IRDASPPCLZIERZ-XHNCKOQMSA-N Glu-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N IRDASPPCLZIERZ-XHNCKOQMSA-N 0.000 description 2
- CKOFNWCLWRYUHK-XHNCKOQMSA-N Glu-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CKOFNWCLWRYUHK-XHNCKOQMSA-N 0.000 description 2
- HNVFSTLPVJWIDV-CIUDSAMLSA-N Glu-Glu-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HNVFSTLPVJWIDV-CIUDSAMLSA-N 0.000 description 2
- ZHNHJYYFCGUZNQ-KBIXCLLPSA-N Glu-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O ZHNHJYYFCGUZNQ-KBIXCLLPSA-N 0.000 description 2
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 2
- FBEJIDRSQCGFJI-GUBZILKMSA-N Glu-Leu-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FBEJIDRSQCGFJI-GUBZILKMSA-N 0.000 description 2
- QDMVXRNLOPTPIE-WDCWCFNPSA-N Glu-Lys-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QDMVXRNLOPTPIE-WDCWCFNPSA-N 0.000 description 2
- JVZLZVJTIXVIHK-SXNHZJKMSA-N Glu-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N JVZLZVJTIXVIHK-SXNHZJKMSA-N 0.000 description 2
- ZSIDREAPEPAPKL-XIRDDKMYSA-N Glu-Trp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N ZSIDREAPEPAPKL-XIRDDKMYSA-N 0.000 description 2
- RLFSBAPJTYKSLG-WHFBIAKZSA-N Gly-Ala-Asp Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O RLFSBAPJTYKSLG-WHFBIAKZSA-N 0.000 description 2
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 2
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 2
- GAFKBWKVXNERFA-QWRGUYRKSA-N Gly-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 GAFKBWKVXNERFA-QWRGUYRKSA-N 0.000 description 2
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 2
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 2
- WCORRBXVISTKQL-WHFBIAKZSA-N Gly-Ser-Ser Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WCORRBXVISTKQL-WHFBIAKZSA-N 0.000 description 2
- ZVXMEWXHFBYJPI-LSJOCFKGSA-N Gly-Val-Ile Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZVXMEWXHFBYJPI-LSJOCFKGSA-N 0.000 description 2
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 2
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 2
- 241000238631 Hexapoda Species 0.000 description 2
- FOCSWPCHUDVNLP-PMVMPFDFSA-N His-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC4=CN=CN4)N FOCSWPCHUDVNLP-PMVMPFDFSA-N 0.000 description 2
- 101000690301 Homo sapiens Aldo-keto reductase family 1 member C4 Proteins 0.000 description 2
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 description 2
- 101001116548 Homo sapiens Protein CBFA2T1 Proteins 0.000 description 2
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 2
- 101001103033 Homo sapiens Tyrosine-protein kinase transmembrane receptor ROR2 Proteins 0.000 description 2
- REJKOQYVFDEZHA-SLBDDTMCSA-N Ile-Asp-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N REJKOQYVFDEZHA-SLBDDTMCSA-N 0.000 description 2
- FADXGVVLSPPEQY-GHCJXIJMSA-N Ile-Cys-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)N)C(=O)O)N FADXGVVLSPPEQY-GHCJXIJMSA-N 0.000 description 2
- CDGLBYSAZFIIJO-RCOVLWMOSA-N Ile-Gly-Gly Chemical compound CC[C@H](C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O CDGLBYSAZFIIJO-RCOVLWMOSA-N 0.000 description 2
- CAHCWMVNBZJVAW-NAKRPEOUSA-N Ile-Pro-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)O)N CAHCWMVNBZJVAW-NAKRPEOUSA-N 0.000 description 2
- WKSHBPRUIRGWRZ-KCTSRDHCSA-N Ile-Trp-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)NCC(=O)O)N WKSHBPRUIRGWRZ-KCTSRDHCSA-N 0.000 description 2
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 description 2
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 description 2
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 2
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 2
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 2
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 2
- WSGXUIQTEZDVHJ-GARJFASQSA-N Leu-Ala-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O WSGXUIQTEZDVHJ-GARJFASQSA-N 0.000 description 2
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 2
- DPWGZWUMUUJQDT-IUCAKERBSA-N Leu-Gln-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O DPWGZWUMUUJQDT-IUCAKERBSA-N 0.000 description 2
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 2
- HPBCTWSUJOGJSH-MNXVOIDGSA-N Leu-Glu-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HPBCTWSUJOGJSH-MNXVOIDGSA-N 0.000 description 2
- QJUWBDPGGYVRHY-YUMQZZPRSA-N Leu-Gly-Cys Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N QJUWBDPGGYVRHY-YUMQZZPRSA-N 0.000 description 2
- SEMUSFOBZGKBGW-YTFOTSKYSA-N Leu-Ile-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SEMUSFOBZGKBGW-YTFOTSKYSA-N 0.000 description 2
- LIINDKYIGYTDLG-PPCPHDFISA-N Leu-Ile-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LIINDKYIGYTDLG-PPCPHDFISA-N 0.000 description 2
- HVHRPWQEQHIQJF-AVGNSLFASA-N Leu-Lys-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O HVHRPWQEQHIQJF-AVGNSLFASA-N 0.000 description 2
- BIZNDKMFQHDOIE-KKUMJFAQSA-N Leu-Phe-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(N)=O)C(O)=O)CC1=CC=CC=C1 BIZNDKMFQHDOIE-KKUMJFAQSA-N 0.000 description 2
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 2
- AKVBOOKXVAMKSS-GUBZILKMSA-N Leu-Ser-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O AKVBOOKXVAMKSS-GUBZILKMSA-N 0.000 description 2
- KCXUCYYZNZFGLL-SRVKXCTJSA-N Lys-Ala-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O KCXUCYYZNZFGLL-SRVKXCTJSA-N 0.000 description 2
- FUKDBQGFSJUXGX-RWMBFGLXSA-N Lys-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)N)C(=O)O FUKDBQGFSJUXGX-RWMBFGLXSA-N 0.000 description 2
- KPJJOZUXFOLGMQ-CIUDSAMLSA-N Lys-Asp-Asn Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N KPJJOZUXFOLGMQ-CIUDSAMLSA-N 0.000 description 2
- MYZMQWHPDAYKIE-SRVKXCTJSA-N Lys-Leu-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O MYZMQWHPDAYKIE-SRVKXCTJSA-N 0.000 description 2
- IPSDPDAOSAEWCN-RHYQMDGZSA-N Lys-Met-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IPSDPDAOSAEWCN-RHYQMDGZSA-N 0.000 description 2
- LUTDBHBIHHREDC-IHRRRGAJSA-N Lys-Pro-Lys Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O LUTDBHBIHHREDC-IHRRRGAJSA-N 0.000 description 2
- GIKFNMZSGYAPEJ-HJGDQZAQSA-N Lys-Thr-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O GIKFNMZSGYAPEJ-HJGDQZAQSA-N 0.000 description 2
- 108010052285 Membrane Proteins Proteins 0.000 description 2
- UYAKZHGIPRCGPF-CIUDSAMLSA-N Met-Glu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCSC)N UYAKZHGIPRCGPF-CIUDSAMLSA-N 0.000 description 2
- IHRFZLQEQVHXFA-RHYQMDGZSA-N Met-Thr-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCCN IHRFZLQEQVHXFA-RHYQMDGZSA-N 0.000 description 2
- 206010027476 Metastases Diseases 0.000 description 2
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 2
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 2
- 108010047562 NGR peptide Proteins 0.000 description 2
- 101100068676 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gln-1 gene Proteins 0.000 description 2
- JOXIIFVCSATTDH-IHPCNDPISA-N Phe-Asn-Trp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N JOXIIFVCSATTDH-IHPCNDPISA-N 0.000 description 2
- BIYWZVCPZIFGPY-QWRGUYRKSA-N Phe-Gly-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](CO)C(O)=O BIYWZVCPZIFGPY-QWRGUYRKSA-N 0.000 description 2
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 2
- AFNJAQVMTIQTCB-DLOVCJGASA-N Phe-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 AFNJAQVMTIQTCB-DLOVCJGASA-N 0.000 description 2
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 2
- FYQSMXKJYTZYRP-DCAQKATOSA-N Pro-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 FYQSMXKJYTZYRP-DCAQKATOSA-N 0.000 description 2
- LGSANCBHSMDFDY-GARJFASQSA-N Pro-Glu-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O LGSANCBHSMDFDY-GARJFASQSA-N 0.000 description 2
- UUHXBJHVTVGSKM-BQBZGAKWSA-N Pro-Gly-Asn Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O UUHXBJHVTVGSKM-BQBZGAKWSA-N 0.000 description 2
- DXTOOBDIIAJZBJ-BQBZGAKWSA-N Pro-Gly-Ser Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CO)C(O)=O DXTOOBDIIAJZBJ-BQBZGAKWSA-N 0.000 description 2
- AFXCXDQNRXTSBD-FJXKBIBVSA-N Pro-Gly-Thr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O AFXCXDQNRXTSBD-FJXKBIBVSA-N 0.000 description 2
- OWQXAJQZLWHPBH-FXQIFTODSA-N Pro-Ser-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O OWQXAJQZLWHPBH-FXQIFTODSA-N 0.000 description 2
- WWXNZNWZNZPDIF-SRVKXCTJSA-N Pro-Val-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 WWXNZNWZNZPDIF-SRVKXCTJSA-N 0.000 description 2
- -1 ROR1 Proteins 0.000 description 2
- 239000012980 RPMI-1640 medium Substances 0.000 description 2
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 2
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 2
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 2
- DWUIECHTAMYEFL-XVYDVKMFSA-N Ser-Ala-His Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 DWUIECHTAMYEFL-XVYDVKMFSA-N 0.000 description 2
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 2
- OYEDZGNMSBZCIM-XGEHTFHBSA-N Ser-Arg-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OYEDZGNMSBZCIM-XGEHTFHBSA-N 0.000 description 2
- BNFVPSRLHHPQKS-WHFBIAKZSA-N Ser-Asp-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O BNFVPSRLHHPQKS-WHFBIAKZSA-N 0.000 description 2
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 2
- WSTIOCFMWXNOCX-YUMQZZPRSA-N Ser-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N WSTIOCFMWXNOCX-YUMQZZPRSA-N 0.000 description 2
- GVIGVIOEYBOTCB-XIRDDKMYSA-N Ser-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CC(C)C)C(O)=O)=CNC2=C1 GVIGVIOEYBOTCB-XIRDDKMYSA-N 0.000 description 2
- KJKQUQXDEKMPDK-FXQIFTODSA-N Ser-Met-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O KJKQUQXDEKMPDK-FXQIFTODSA-N 0.000 description 2
- ADJDNJCSPNFFPI-FXQIFTODSA-N Ser-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO ADJDNJCSPNFFPI-FXQIFTODSA-N 0.000 description 2
- WLJPJRGQRNCIQS-ZLUOBGJFSA-N Ser-Ser-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O WLJPJRGQRNCIQS-ZLUOBGJFSA-N 0.000 description 2
- PPCZVWHJWJFTFN-ZLUOBGJFSA-N Ser-Ser-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPCZVWHJWJFTFN-ZLUOBGJFSA-N 0.000 description 2
- OZPDGESCTGGNAD-CIUDSAMLSA-N Ser-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CO OZPDGESCTGGNAD-CIUDSAMLSA-N 0.000 description 2
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 2
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 2
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 2
- ZKOKTQPHFMRSJP-YJRXYDGGSA-N Ser-Thr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKOKTQPHFMRSJP-YJRXYDGGSA-N 0.000 description 2
- OQSQCUWQOIHECT-YJRXYDGGSA-N Ser-Tyr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OQSQCUWQOIHECT-YJRXYDGGSA-N 0.000 description 2
- LLSLRQOEAFCZLW-NRPADANISA-N Ser-Val-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LLSLRQOEAFCZLW-NRPADANISA-N 0.000 description 2
- 230000006044 T cell activation Effects 0.000 description 2
- GFDUZZACIWNMPE-KZVJFYERSA-N Thr-Ala-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O GFDUZZACIWNMPE-KZVJFYERSA-N 0.000 description 2
- YOSLMIPKOUAHKI-OLHMAJIHSA-N Thr-Asp-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O YOSLMIPKOUAHKI-OLHMAJIHSA-N 0.000 description 2
- RKDFEMGVMMYYNG-WDCWCFNPSA-N Thr-Gln-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O RKDFEMGVMMYYNG-WDCWCFNPSA-N 0.000 description 2
- HUPLKEHTTQBXSC-YJRXYDGGSA-N Thr-Ser-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUPLKEHTTQBXSC-YJRXYDGGSA-N 0.000 description 2
- XVHAUVJXBFGUPC-RPTUDFQQSA-N Thr-Tyr-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XVHAUVJXBFGUPC-RPTUDFQQSA-N 0.000 description 2
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 2
- CXUFDWZBHKUGKK-CABZTGNLSA-N Trp-Ala-Gly Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O)=CNC2=C1 CXUFDWZBHKUGKK-CABZTGNLSA-N 0.000 description 2
- SAKLWFSRZTZQAJ-GQGQLFGLSA-N Trp-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N SAKLWFSRZTZQAJ-GQGQLFGLSA-N 0.000 description 2
- BURPTJBFWIOHEY-UWJYBYFXSA-N Tyr-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 BURPTJBFWIOHEY-UWJYBYFXSA-N 0.000 description 2
- SCCKSNREWHMKOJ-SRVKXCTJSA-N Tyr-Asn-Ser Chemical compound N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O SCCKSNREWHMKOJ-SRVKXCTJSA-N 0.000 description 2
- OGPKMBOPMDTEDM-IHRRRGAJSA-N Tyr-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N OGPKMBOPMDTEDM-IHRRRGAJSA-N 0.000 description 2
- SQUMHUZLJDUROQ-YDHLFZDLSA-N Tyr-Val-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O SQUMHUZLJDUROQ-YDHLFZDLSA-N 0.000 description 2
- NVJCMGGZHOJNBU-UFYCRDLUSA-N Tyr-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N NVJCMGGZHOJNBU-UFYCRDLUSA-N 0.000 description 2
- 102100039616 Tyrosine-protein kinase transmembrane receptor ROR2 Human genes 0.000 description 2
- WDIGUPHXPBMODF-UMNHJUIQSA-N Val-Glu-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N WDIGUPHXPBMODF-UMNHJUIQSA-N 0.000 description 2
- ZIGZPYJXIWLQFC-QTKMDUPCSA-N Val-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C(C)C)N)O ZIGZPYJXIWLQFC-QTKMDUPCSA-N 0.000 description 2
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 2
- HPANGHISDXDUQY-ULQDDVLXSA-N Val-Lys-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N HPANGHISDXDUQY-ULQDDVLXSA-N 0.000 description 2
- KISFXYYRKKNLOP-IHRRRGAJSA-N Val-Phe-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N KISFXYYRKKNLOP-IHRRRGAJSA-N 0.000 description 2
- KRAHMIJVUPUOTQ-DCAQKATOSA-N Val-Ser-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KRAHMIJVUPUOTQ-DCAQKATOSA-N 0.000 description 2
- HWNYVQMOLCYHEA-IHRRRGAJSA-N Val-Ser-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N HWNYVQMOLCYHEA-IHRRRGAJSA-N 0.000 description 2
- QPJSIBAOZBVELU-BPNCWPANSA-N Val-Tyr-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N QPJSIBAOZBVELU-BPNCWPANSA-N 0.000 description 2
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 2
- 241000700605 Viruses Species 0.000 description 2
- 238000002835 absorbance Methods 0.000 description 2
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 230000003110 anti-inflammatory effect Effects 0.000 description 2
- 229940125644 antibody drug Drugs 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 238000003705 background correction Methods 0.000 description 2
- 230000001580 bacterial effect Effects 0.000 description 2
- 230000008827 biological function Effects 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 229960002685 biotin Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 239000011616 biotin Substances 0.000 description 2
- 230000000903 blocking effect Effects 0.000 description 2
- 239000001506 calcium phosphate Substances 0.000 description 2
- 229960001714 calcium phosphate Drugs 0.000 description 2
- 229910000389 calcium phosphate Inorganic materials 0.000 description 2
- 235000011010 calcium phosphates Nutrition 0.000 description 2
- 230000022534 cell killing Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 238000000576 coating method Methods 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 150000001875 compounds Chemical class 0.000 description 2
- 239000000562 conjugate Substances 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 108010016616 cysteinylglycine Proteins 0.000 description 2
- 108010060199 cysteinylproline Proteins 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- 239000000539 dimer Substances 0.000 description 2
- 210000003162 effector t lymphocyte Anatomy 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 229940088598 enzyme Drugs 0.000 description 2
- 108020001507 fusion proteins Proteins 0.000 description 2
- 102000037865 fusion proteins Human genes 0.000 description 2
- 239000000499 gel Substances 0.000 description 2
- 210000004602 germ cell Anatomy 0.000 description 2
- 150000004676 glycans Chemical class 0.000 description 2
- 108010062266 glycyl-glycyl-argininal Proteins 0.000 description 2
- 108010010096 glycyl-glycyl-tyrosine Proteins 0.000 description 2
- 238000004128 high performance liquid chromatography Methods 0.000 description 2
- 102000054751 human RUNX1T1 Human genes 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- 238000004191 hydrophobic interaction chromatography Methods 0.000 description 2
- 230000003053 immunization Effects 0.000 description 2
- 230000005847 immunogenicity Effects 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 239000003112 inhibitor Substances 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- 238000012004 kinetic exclusion assay Methods 0.000 description 2
- 108010034529 leucyl-lysine Proteins 0.000 description 2
- 108010057821 leucylproline Proteins 0.000 description 2
- 238000001638 lipofection Methods 0.000 description 2
- 210000004185 liver Anatomy 0.000 description 2
- 108010038320 lysylphenylalanine Proteins 0.000 description 2
- 230000009401 metastasis Effects 0.000 description 2
- 108010005942 methionylglycine Proteins 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 230000035515 penetration Effects 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 2
- 230000004481 post-translational protein modification Effects 0.000 description 2
- 230000003389 potentiating effect Effects 0.000 description 2
- 239000003755 preservative agent Substances 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 239000000047 product Substances 0.000 description 2
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 2
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 2
- 108010053725 prolylvaline Proteins 0.000 description 2
- 238000001742 protein purification Methods 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 239000012857 radioactive material Substances 0.000 description 2
- 238000003127 radioimmunoassay Methods 0.000 description 2
- 102000005962 receptors Human genes 0.000 description 2
- 108020003175 receptors Proteins 0.000 description 2
- 230000003362 replicative effect Effects 0.000 description 2
- 102200050406 rs121918361 Human genes 0.000 description 2
- 102200082880 rs35890959 Human genes 0.000 description 2
- 239000012146 running buffer Substances 0.000 description 2
- 230000028327 secretion Effects 0.000 description 2
- 230000035945 sensitivity Effects 0.000 description 2
- 108010071207 serylmethionine Proteins 0.000 description 2
- 230000007781 signaling event Effects 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 210000004988 splenocyte Anatomy 0.000 description 2
- 230000004083 survival effect Effects 0.000 description 2
- 239000000725 suspension Substances 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 108010061238 threonyl-glycine Proteins 0.000 description 2
- 230000005030 transcription termination Effects 0.000 description 2
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 2
- 108010079202 tyrosyl-alanyl-cysteine Proteins 0.000 description 2
- 238000000825 ultraviolet detection Methods 0.000 description 2
- 239000013603 viral vector Substances 0.000 description 2
- IESDGNYHXIOKRW-YXMSTPNBSA-N (2s)-2-[[(2s)-1-[(2s)-6-amino-2-[[(2s,3r)-2-amino-3-hydroxybutanoyl]amino]hexanoyl]pyrrolidine-2-carbonyl]amino]-5-(diaminomethylideneamino)pentanoic acid Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IESDGNYHXIOKRW-YXMSTPNBSA-N 0.000 description 1
- NWUYHJFMYQTDRP-UHFFFAOYSA-N 1,2-bis(ethenyl)benzene;1-ethenyl-2-ethylbenzene;styrene Chemical compound C=CC1=CC=CC=C1.CCC1=CC=CC=C1C=C.C=CC1=CC=CC=C1C=C NWUYHJFMYQTDRP-UHFFFAOYSA-N 0.000 description 1
- CJIJXIFQYOPWTF-UHFFFAOYSA-N 7-hydroxycoumarin Natural products O1C(=O)C=CC2=CC(O)=CC=C21 CJIJXIFQYOPWTF-UHFFFAOYSA-N 0.000 description 1
- 102000012440 Acetylcholinesterase Human genes 0.000 description 1
- 108010022752 Acetylcholinesterase Proteins 0.000 description 1
- 208000010507 Adenocarcinoma of Lung Diseases 0.000 description 1
- 206010052747 Adenocarcinoma pancreas Diseases 0.000 description 1
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 1
- TTXMOJWKNRJWQJ-FXQIFTODSA-N Ala-Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N TTXMOJWKNRJWQJ-FXQIFTODSA-N 0.000 description 1
- SHYYAQLDNVHPFT-DLOVCJGASA-N Ala-Asn-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SHYYAQLDNVHPFT-DLOVCJGASA-N 0.000 description 1
- GWFSQQNGMPGBEF-GHCJXIJMSA-N Ala-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N GWFSQQNGMPGBEF-GHCJXIJMSA-N 0.000 description 1
- DECCMEWNXSNSDO-ZLUOBGJFSA-N Ala-Cys-Ala Chemical compound C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O DECCMEWNXSNSDO-ZLUOBGJFSA-N 0.000 description 1
- VGPWRRFOPXVGOH-BYPYZUCNSA-N Ala-Gly-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)NCC(O)=O VGPWRRFOPXVGOH-BYPYZUCNSA-N 0.000 description 1
- LBYMZCVBOKYZNS-CIUDSAMLSA-N Ala-Leu-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O LBYMZCVBOKYZNS-CIUDSAMLSA-N 0.000 description 1
- SUHLZMHFRALVSY-YUMQZZPRSA-N Ala-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O SUHLZMHFRALVSY-YUMQZZPRSA-N 0.000 description 1
- OSRZOHXQCUFIQG-FPMFFAJLSA-N Ala-Phe-Pro Chemical compound C([C@H](NC(=O)[C@@H]([NH3+])C)C(=O)N1[C@H](CCC1)C([O-])=O)C1=CC=CC=C1 OSRZOHXQCUFIQG-FPMFFAJLSA-N 0.000 description 1
- WQLDNOCHHRISMS-NAKRPEOUSA-N Ala-Pro-Ile Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WQLDNOCHHRISMS-NAKRPEOUSA-N 0.000 description 1
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 1
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 1
- XKXAZPSREVUCRT-BPNCWPANSA-N Ala-Tyr-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=C(O)C=C1 XKXAZPSREVUCRT-BPNCWPANSA-N 0.000 description 1
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 1
- 239000012099 Alexa Fluor family Substances 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 241000024188 Andala Species 0.000 description 1
- BVBKBQRPOJFCQM-DCAQKATOSA-N Arg-Asn-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BVBKBQRPOJFCQM-DCAQKATOSA-N 0.000 description 1
- GHNDBBVSWOWYII-LPEHRKFASA-N Arg-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O GHNDBBVSWOWYII-LPEHRKFASA-N 0.000 description 1
- NTAZNGWBXRVEDJ-FXQIFTODSA-N Arg-Asp-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NTAZNGWBXRVEDJ-FXQIFTODSA-N 0.000 description 1
- YSUVMPICYVWRBX-VEVYYDQMSA-N Arg-Asp-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YSUVMPICYVWRBX-VEVYYDQMSA-N 0.000 description 1
- HPKSHFSEXICTLI-CIUDSAMLSA-N Arg-Glu-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HPKSHFSEXICTLI-CIUDSAMLSA-N 0.000 description 1
- PNQWAUXQDBIJDY-GUBZILKMSA-N Arg-Glu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNQWAUXQDBIJDY-GUBZILKMSA-N 0.000 description 1
- HPSVTWMFWCHKFN-GARJFASQSA-N Arg-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O HPSVTWMFWCHKFN-GARJFASQSA-N 0.000 description 1
- AUFHLLPVPSMEOG-YUMQZZPRSA-N Arg-Gly-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AUFHLLPVPSMEOG-YUMQZZPRSA-N 0.000 description 1
- RFXXUWGNVRJTNQ-QXEWZRGKSA-N Arg-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCCN=C(N)N)N RFXXUWGNVRJTNQ-QXEWZRGKSA-N 0.000 description 1
- UAOSDDXCTBIPCA-QXEWZRGKSA-N Arg-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UAOSDDXCTBIPCA-QXEWZRGKSA-N 0.000 description 1
- LVMUGODRNHFGRA-AVGNSLFASA-N Arg-Leu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O LVMUGODRNHFGRA-AVGNSLFASA-N 0.000 description 1
- UZGFHWIJWPUPOH-IHRRRGAJSA-N Arg-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UZGFHWIJWPUPOH-IHRRRGAJSA-N 0.000 description 1
- COXMUHNBYCVVRG-DCAQKATOSA-N Arg-Leu-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O COXMUHNBYCVVRG-DCAQKATOSA-N 0.000 description 1
- NIELFHOLFTUZME-HJWJTTGWSA-N Arg-Phe-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O NIELFHOLFTUZME-HJWJTTGWSA-N 0.000 description 1
- LXMKTIZAGIBQRX-HRCADAONSA-N Arg-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O LXMKTIZAGIBQRX-HRCADAONSA-N 0.000 description 1
- QHVRVUNEAIFTEK-SZMVWBNQSA-N Arg-Pro-Trp Chemical compound N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O QHVRVUNEAIFTEK-SZMVWBNQSA-N 0.000 description 1
- FBXMCPLCVYUWBO-BPUTZDHNSA-N Arg-Ser-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N FBXMCPLCVYUWBO-BPUTZDHNSA-N 0.000 description 1
- ZUVMUOOHJYNJPP-XIRDDKMYSA-N Arg-Trp-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZUVMUOOHJYNJPP-XIRDDKMYSA-N 0.000 description 1
- LOVIQNMIPQVIGT-BVSLBCMMSA-N Arg-Trp-Phe Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CCCN=C(N)N)N)C(O)=O)C1=CC=CC=C1 LOVIQNMIPQVIGT-BVSLBCMMSA-N 0.000 description 1
- QLSRIZIDQXDQHK-RCWTZXSCSA-N Arg-Val-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QLSRIZIDQXDQHK-RCWTZXSCSA-N 0.000 description 1
- SLKLLQWZQHXYSV-CIUDSAMLSA-N Asn-Ala-Lys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O SLKLLQWZQHXYSV-CIUDSAMLSA-N 0.000 description 1
- IOTKDTZEEBZNCM-UGYAYLCHSA-N Asn-Asn-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOTKDTZEEBZNCM-UGYAYLCHSA-N 0.000 description 1
- KXEGPPNPXOKKHK-ZLUOBGJFSA-N Asn-Asp-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O KXEGPPNPXOKKHK-ZLUOBGJFSA-N 0.000 description 1
- ZMWDUIIACVLIHK-GHCJXIJMSA-N Asn-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)N)N ZMWDUIIACVLIHK-GHCJXIJMSA-N 0.000 description 1
- WONGRTVAMHFGBE-WDSKDSINSA-N Asn-Gly-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N WONGRTVAMHFGBE-WDSKDSINSA-N 0.000 description 1
- QUAWOKPCAKCHQL-SRVKXCTJSA-N Asn-His-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N QUAWOKPCAKCHQL-SRVKXCTJSA-N 0.000 description 1
- HDHZCEDPLTVHFZ-GUBZILKMSA-N Asn-Leu-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O HDHZCEDPLTVHFZ-GUBZILKMSA-N 0.000 description 1
- KHCNTVRVAYCPQE-CIUDSAMLSA-N Asn-Lys-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O KHCNTVRVAYCPQE-CIUDSAMLSA-N 0.000 description 1
- NTWOPSIUJBMNRI-KKUMJFAQSA-N Asn-Lys-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NTWOPSIUJBMNRI-KKUMJFAQSA-N 0.000 description 1
- UWFOMGUWGPRVBW-GUBZILKMSA-N Asn-Pro-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC(=O)N)N UWFOMGUWGPRVBW-GUBZILKMSA-N 0.000 description 1
- VCJCPARXDBEGNE-GUBZILKMSA-N Asn-Pro-Pro Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 VCJCPARXDBEGNE-GUBZILKMSA-N 0.000 description 1
- JWQWPRCDYWNVNM-ACZMJKKPSA-N Asn-Ser-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N JWQWPRCDYWNVNM-ACZMJKKPSA-N 0.000 description 1
- CBHVAFXKOYAHOY-NHCYSSNCSA-N Asn-Val-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O CBHVAFXKOYAHOY-NHCYSSNCSA-N 0.000 description 1
- XJQRWGXKUSDEFI-ACZMJKKPSA-N Asp-Glu-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O XJQRWGXKUSDEFI-ACZMJKKPSA-N 0.000 description 1
- RATOMFTUDRYMKX-ACZMJKKPSA-N Asp-Glu-Cys Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)O)N RATOMFTUDRYMKX-ACZMJKKPSA-N 0.000 description 1
- KHGPWGKPYHPOIK-QWRGUYRKSA-N Asp-Gly-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O KHGPWGKPYHPOIK-QWRGUYRKSA-N 0.000 description 1
- WSGVTKZFVJSJOG-RCOVLWMOSA-N Asp-Gly-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O WSGVTKZFVJSJOG-RCOVLWMOSA-N 0.000 description 1
- KTTCQQNRRLCIBC-GHCJXIJMSA-N Asp-Ile-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O KTTCQQNRRLCIBC-GHCJXIJMSA-N 0.000 description 1
- DPNWSMBUYCLEDG-CIUDSAMLSA-N Asp-Lys-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O DPNWSMBUYCLEDG-CIUDSAMLSA-N 0.000 description 1
- DONWIPDSZZJHHK-HJGDQZAQSA-N Asp-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)O DONWIPDSZZJHHK-HJGDQZAQSA-N 0.000 description 1
- NONWUQAWAANERO-BZSNNMDCSA-N Asp-Phe-Tyr Chemical compound C([C@H](NC(=O)[C@H](CC(O)=O)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 NONWUQAWAANERO-BZSNNMDCSA-N 0.000 description 1
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 1
- MVRGBQGZSDJBSM-GMOBBJLQSA-N Asp-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC(=O)O)N MVRGBQGZSDJBSM-GMOBBJLQSA-N 0.000 description 1
- QSFHZPQUAAQHAQ-CIUDSAMLSA-N Asp-Ser-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O QSFHZPQUAAQHAQ-CIUDSAMLSA-N 0.000 description 1
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 1
- XYPJXLLXNSAWHZ-SRVKXCTJSA-N Asp-Ser-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XYPJXLLXNSAWHZ-SRVKXCTJSA-N 0.000 description 1
- RSMZEHCMIOKNMW-GSSVUCPTSA-N Asp-Thr-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RSMZEHCMIOKNMW-GSSVUCPTSA-N 0.000 description 1
- YUELDQUPTAYEGM-XIRDDKMYSA-N Asp-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)O)N YUELDQUPTAYEGM-XIRDDKMYSA-N 0.000 description 1
- 241000271566 Aves Species 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 102000014447 Complement C1q Human genes 0.000 description 1
- 108010078043 Complement C1q Proteins 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- AMRLSQGGERHDHJ-FXQIFTODSA-N Cys-Ala-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMRLSQGGERHDHJ-FXQIFTODSA-N 0.000 description 1
- RRIJEABIXPKSGP-FXQIFTODSA-N Cys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CS RRIJEABIXPKSGP-FXQIFTODSA-N 0.000 description 1
- NDUSUIGBMZCOIL-ZKWXMUAHSA-N Cys-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CS)N NDUSUIGBMZCOIL-ZKWXMUAHSA-N 0.000 description 1
- YZFCGHIBLBDZDA-ZLUOBGJFSA-N Cys-Asp-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YZFCGHIBLBDZDA-ZLUOBGJFSA-N 0.000 description 1
- PORWNQWEEIOIRH-XHNCKOQMSA-N Cys-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CS)N)C(=O)O PORWNQWEEIOIRH-XHNCKOQMSA-N 0.000 description 1
- RUZAUSCMOVLBRI-QAETUUGQSA-N Cys-Gln-Pro-Tyr Chemical compound N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccc(O)cc1)C(O)=O RUZAUSCMOVLBRI-QAETUUGQSA-N 0.000 description 1
- UCMIKRLLIOVDRJ-XKBZYTNZSA-N Cys-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CS)N)O UCMIKRLLIOVDRJ-XKBZYTNZSA-N 0.000 description 1
- SFRQEQGPRTVDPO-NRPADANISA-N Cys-Gln-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O SFRQEQGPRTVDPO-NRPADANISA-N 0.000 description 1
- VBPGTULCFGKGTF-ACZMJKKPSA-N Cys-Glu-Asp Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O VBPGTULCFGKGTF-ACZMJKKPSA-N 0.000 description 1
- DIUBVGXMXONJCF-KKUMJFAQSA-N Cys-His-Tyr Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O DIUBVGXMXONJCF-KKUMJFAQSA-N 0.000 description 1
- ZXCAQANTQWBICD-DCAQKATOSA-N Cys-Lys-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CS)N ZXCAQANTQWBICD-DCAQKATOSA-N 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 101100264065 Danio rerio wnt5b gene Proteins 0.000 description 1
- XPDXVDYUQZHFPV-UHFFFAOYSA-N Dansyl Chloride Chemical compound C1=CC=C2C(N(C)C)=CC=CC2=C1S(Cl)(=O)=O XPDXVDYUQZHFPV-UHFFFAOYSA-N 0.000 description 1
- 241000702421 Dependoparvovirus Species 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 102100024746 Dihydrofolate reductase Human genes 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- 238000001061 Dunnett's test Methods 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 108050007261 Frizzled domains Proteins 0.000 description 1
- 102000018152 Frizzled domains Human genes 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- WUAYFMZULZDSLB-ACZMJKKPSA-N Gln-Ala-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O WUAYFMZULZDSLB-ACZMJKKPSA-N 0.000 description 1
- DTMLKCYOQKZXKZ-HJGDQZAQSA-N Gln-Arg-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DTMLKCYOQKZXKZ-HJGDQZAQSA-N 0.000 description 1
- CRRFJBGUGNNOCS-PEFMBERDSA-N Gln-Asp-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CRRFJBGUGNNOCS-PEFMBERDSA-N 0.000 description 1
- DHNWZLGBTPUTQQ-QEJZJMRPSA-N Gln-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N DHNWZLGBTPUTQQ-QEJZJMRPSA-N 0.000 description 1
- OWOFCNWTMWOOJJ-WDSKDSINSA-N Gln-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(O)=O OWOFCNWTMWOOJJ-WDSKDSINSA-N 0.000 description 1
- ZQPOVSJFBBETHQ-CIUDSAMLSA-N Gln-Glu-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZQPOVSJFBBETHQ-CIUDSAMLSA-N 0.000 description 1
- VOLVNCMGXWDDQY-LPEHRKFASA-N Gln-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O VOLVNCMGXWDDQY-LPEHRKFASA-N 0.000 description 1
- DRDSQGHKTLSNEA-GLLZPBPUSA-N Gln-Glu-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DRDSQGHKTLSNEA-GLLZPBPUSA-N 0.000 description 1
- NJMYZEJORPYOTO-BQBZGAKWSA-N Gln-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(O)=O NJMYZEJORPYOTO-BQBZGAKWSA-N 0.000 description 1
- OKARHJKJTKFQBM-ACZMJKKPSA-N Gln-Ser-Asn Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OKARHJKJTKFQBM-ACZMJKKPSA-N 0.000 description 1
- OSCLNNWLKKIQJM-WDSKDSINSA-N Gln-Ser-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O OSCLNNWLKKIQJM-WDSKDSINSA-N 0.000 description 1
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 1
- JTWZNMUVQWWGOX-SOUVJXGZSA-N Gln-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O JTWZNMUVQWWGOX-SOUVJXGZSA-N 0.000 description 1
- FITIQFSXXBKFFM-NRPADANISA-N Gln-Val-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FITIQFSXXBKFFM-NRPADANISA-N 0.000 description 1
- CSMHMEATMDCQNY-DZKIICNBSA-N Gln-Val-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CSMHMEATMDCQNY-DZKIICNBSA-N 0.000 description 1
- 102000006395 Globulins Human genes 0.000 description 1
- 108010044091 Globulins Proteins 0.000 description 1
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 1
- MLCPTRRNICEKIS-FXQIFTODSA-N Glu-Asn-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MLCPTRRNICEKIS-FXQIFTODSA-N 0.000 description 1
- PKYAVRMYTBBRLS-FXQIFTODSA-N Glu-Cys-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O PKYAVRMYTBBRLS-FXQIFTODSA-N 0.000 description 1
- MIQCYAJSDGNCNK-BPUTZDHNSA-N Glu-Gln-Trp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O MIQCYAJSDGNCNK-BPUTZDHNSA-N 0.000 description 1
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 1
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 1
- VMKCPNBBPGGQBJ-GUBZILKMSA-N Glu-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N VMKCPNBBPGGQBJ-GUBZILKMSA-N 0.000 description 1
- SWRVAQHFBRZVNX-GUBZILKMSA-N Glu-Lys-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O SWRVAQHFBRZVNX-GUBZILKMSA-N 0.000 description 1
- YGLCLCMAYUYZSG-AVGNSLFASA-N Glu-Lys-His Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 YGLCLCMAYUYZSG-AVGNSLFASA-N 0.000 description 1
- BFEZQZKEPRKKHV-SRVKXCTJSA-N Glu-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O BFEZQZKEPRKKHV-SRVKXCTJSA-N 0.000 description 1
- ZKONLKQGTNVAPR-DCAQKATOSA-N Glu-Pro-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)O)N ZKONLKQGTNVAPR-DCAQKATOSA-N 0.000 description 1
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 1
- ALMBZBOCGSVSAI-ACZMJKKPSA-N Glu-Ser-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ALMBZBOCGSVSAI-ACZMJKKPSA-N 0.000 description 1
- IDEODOAVGCMUQV-GUBZILKMSA-N Glu-Ser-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IDEODOAVGCMUQV-GUBZILKMSA-N 0.000 description 1
- HMJULNMJWOZNFI-XHNCKOQMSA-N Glu-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N)C(=O)O HMJULNMJWOZNFI-XHNCKOQMSA-N 0.000 description 1
- HJTSRYLPAYGEEC-SIUGBPQLSA-N Glu-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCC(=O)O)N HJTSRYLPAYGEEC-SIUGBPQLSA-N 0.000 description 1
- MFYLRRCYBBJYPI-JYJNAYRXSA-N Glu-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O MFYLRRCYBBJYPI-JYJNAYRXSA-N 0.000 description 1
- ZALGPUWUVHOGAE-GVXVVHGQSA-N Glu-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZALGPUWUVHOGAE-GVXVVHGQSA-N 0.000 description 1
- SOYWRINXUSUWEQ-DLOVCJGASA-N Glu-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O SOYWRINXUSUWEQ-DLOVCJGASA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- MFVQGXGQRIXBPK-WDSKDSINSA-N Gly-Ala-Glu Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O MFVQGXGQRIXBPK-WDSKDSINSA-N 0.000 description 1
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 1
- JRDYDYXZKFNNRQ-XPUUQOCRSA-N Gly-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN JRDYDYXZKFNNRQ-XPUUQOCRSA-N 0.000 description 1
- OVSKVOOUFAKODB-UWVGGRQHSA-N Gly-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N OVSKVOOUFAKODB-UWVGGRQHSA-N 0.000 description 1
- WKJKBELXHCTHIJ-WPRPVWTQSA-N Gly-Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N WKJKBELXHCTHIJ-WPRPVWTQSA-N 0.000 description 1
- DWUKOTKSTDWGAE-BQBZGAKWSA-N Gly-Asn-Arg Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DWUKOTKSTDWGAE-BQBZGAKWSA-N 0.000 description 1
- WJZLEENECIOOSA-WDSKDSINSA-N Gly-Asn-Gln Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)O WJZLEENECIOOSA-WDSKDSINSA-N 0.000 description 1
- JVACNFOPSUPDTK-QWRGUYRKSA-N Gly-Asn-Phe Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JVACNFOPSUPDTK-QWRGUYRKSA-N 0.000 description 1
- LURCIJSJAKFCRO-QWRGUYRKSA-N Gly-Asn-Tyr Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LURCIJSJAKFCRO-QWRGUYRKSA-N 0.000 description 1
- XBWMTPAIUQIWKA-BYULHYEWSA-N Gly-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CN XBWMTPAIUQIWKA-BYULHYEWSA-N 0.000 description 1
- STVHDEHTKFXBJQ-LAEOZQHASA-N Gly-Glu-Ile Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O STVHDEHTKFXBJQ-LAEOZQHASA-N 0.000 description 1
- PDAWDNVHMUKWJR-ZETCQYMHSA-N Gly-Gly-His Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC1=CNC=N1 PDAWDNVHMUKWJR-ZETCQYMHSA-N 0.000 description 1
- SWQALSGKVLYKDT-UHFFFAOYSA-N Gly-Ile-Ala Natural products NCC(=O)NC(C(C)CC)C(=O)NC(C)C(O)=O SWQALSGKVLYKDT-UHFFFAOYSA-N 0.000 description 1
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 1
- OQQKUTVULYLCDG-ONGXEEELSA-N Gly-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)CN)C(O)=O OQQKUTVULYLCDG-ONGXEEELSA-N 0.000 description 1
- OOCFXNOVSLSHAB-IUCAKERBSA-N Gly-Pro-Pro Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OOCFXNOVSLSHAB-IUCAKERBSA-N 0.000 description 1
- YOBGUCWZPXJHTN-BQBZGAKWSA-N Gly-Ser-Arg Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YOBGUCWZPXJHTN-BQBZGAKWSA-N 0.000 description 1
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 1
- DNVDEMWIYLVIQU-RCOVLWMOSA-N Gly-Val-Asp Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O DNVDEMWIYLVIQU-RCOVLWMOSA-N 0.000 description 1
- MAABHGXCIBEYQR-XVYDVKMFSA-N His-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N MAABHGXCIBEYQR-XVYDVKMFSA-N 0.000 description 1
- WMKXFMUJRCEGRP-SRVKXCTJSA-N His-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N WMKXFMUJRCEGRP-SRVKXCTJSA-N 0.000 description 1
- QSLKWWDKIXMWJV-SRVKXCTJSA-N His-Cys-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N QSLKWWDKIXMWJV-SRVKXCTJSA-N 0.000 description 1
- FYVHHKMHFPMBBG-GUBZILKMSA-N His-Gln-Asp Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N FYVHHKMHFPMBBG-GUBZILKMSA-N 0.000 description 1
- HVCRQRQPIIRNLY-IUCAKERBSA-N His-Gln-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)NCC(=O)O)N HVCRQRQPIIRNLY-IUCAKERBSA-N 0.000 description 1
- HIAHVKLTHNOENC-HGNGGELXSA-N His-Glu-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HIAHVKLTHNOENC-HGNGGELXSA-N 0.000 description 1
- LYDKQVYYCMYNMC-SRVKXCTJSA-N His-Lys-Cys Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CS)C(O)=O)NC(=O)[C@@H](N)CC1=CN=CN1 LYDKQVYYCMYNMC-SRVKXCTJSA-N 0.000 description 1
- NKRWVZQTPXPNRZ-SRVKXCTJSA-N His-Met-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC1=CN=CN1 NKRWVZQTPXPNRZ-SRVKXCTJSA-N 0.000 description 1
- HZWWOGWOBQBETJ-CUJWVEQBSA-N His-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O HZWWOGWOBQBETJ-CUJWVEQBSA-N 0.000 description 1
- IXQGOKWTQPCIQM-YJRXYDGGSA-N His-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N)O IXQGOKWTQPCIQM-YJRXYDGGSA-N 0.000 description 1
- ALPXXNRQBMRCPZ-MEYUZBJRSA-N His-Thr-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ALPXXNRQBMRCPZ-MEYUZBJRSA-N 0.000 description 1
- SWTSERYNZQMPBI-WDSOQIARSA-N His-Trp-Met Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCSC)C(O)=O)C1=CN=CN1 SWTSERYNZQMPBI-WDSOQIARSA-N 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 108700039609 IRW peptide Proteins 0.000 description 1
- DFFTXLCCDFYRKD-MBLNEYKQSA-N Ile-Gly-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N DFFTXLCCDFYRKD-MBLNEYKQSA-N 0.000 description 1
- HUORUFRRJHELPD-MNXVOIDGSA-N Ile-Leu-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N HUORUFRRJHELPD-MNXVOIDGSA-N 0.000 description 1
- FCWFBHMAJZGWRY-XUXIUFHCSA-N Ile-Leu-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)O)N FCWFBHMAJZGWRY-XUXIUFHCSA-N 0.000 description 1
- PWUMCBLVWPCKNO-MGHWNKPDSA-N Ile-Leu-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PWUMCBLVWPCKNO-MGHWNKPDSA-N 0.000 description 1
- IITVUURPOYGCTD-NAKRPEOUSA-N Ile-Pro-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IITVUURPOYGCTD-NAKRPEOUSA-N 0.000 description 1
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 1
- VGSPNSSCMOHRRR-BJDJZHNGSA-N Ile-Ser-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N VGSPNSSCMOHRRR-BJDJZHNGSA-N 0.000 description 1
- JNLSTRPWUXOORL-MMWGEVLESA-N Ile-Ser-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N JNLSTRPWUXOORL-MMWGEVLESA-N 0.000 description 1
- RQJUKVXWAKJDBW-SVSWQMSJSA-N Ile-Ser-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N RQJUKVXWAKJDBW-SVSWQMSJSA-N 0.000 description 1
- NXRNRBOKDBIVKQ-CXTHYWKRSA-N Ile-Tyr-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N NXRNRBOKDBIVKQ-CXTHYWKRSA-N 0.000 description 1
- 102000009786 Immunoglobulin Constant Regions Human genes 0.000 description 1
- 108010009817 Immunoglobulin Constant Regions Proteins 0.000 description 1
- 108090001005 Interleukin-6 Proteins 0.000 description 1
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- UILIPCLTHRPCRB-XUXIUFHCSA-N Leu-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(C)C)N UILIPCLTHRPCRB-XUXIUFHCSA-N 0.000 description 1
- WUFYAPWIHCUMLL-CIUDSAMLSA-N Leu-Asn-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O WUFYAPWIHCUMLL-CIUDSAMLSA-N 0.000 description 1
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 1
- POJPZSMTTMLSTG-SRVKXCTJSA-N Leu-Asn-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N POJPZSMTTMLSTG-SRVKXCTJSA-N 0.000 description 1
- NFHJQETXTSDZSI-DCAQKATOSA-N Leu-Cys-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NFHJQETXTSDZSI-DCAQKATOSA-N 0.000 description 1
- RRSLQOLASISYTB-CIUDSAMLSA-N Leu-Cys-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O RRSLQOLASISYTB-CIUDSAMLSA-N 0.000 description 1
- KUEVMUXNILMJTK-JYJNAYRXSA-N Leu-Gln-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KUEVMUXNILMJTK-JYJNAYRXSA-N 0.000 description 1
- FIYMBBHGYNQFOP-IUCAKERBSA-N Leu-Gly-Gln Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N FIYMBBHGYNQFOP-IUCAKERBSA-N 0.000 description 1
- BTNXKBVLWJBTNR-SRVKXCTJSA-N Leu-His-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O BTNXKBVLWJBTNR-SRVKXCTJSA-N 0.000 description 1
- HRTRLSRYZZKPCO-BJDJZHNGSA-N Leu-Ile-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HRTRLSRYZZKPCO-BJDJZHNGSA-N 0.000 description 1
- AUNMOHYWTAPQLA-XUXIUFHCSA-N Leu-Met-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AUNMOHYWTAPQLA-XUXIUFHCSA-N 0.000 description 1
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 1
- RRVCZCNFXIFGRA-DCAQKATOSA-N Leu-Pro-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O RRVCZCNFXIFGRA-DCAQKATOSA-N 0.000 description 1
- IDGZVZJLYFTXSL-DCAQKATOSA-N Leu-Ser-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IDGZVZJLYFTXSL-DCAQKATOSA-N 0.000 description 1
- IZPVWNSAVUQBGP-CIUDSAMLSA-N Leu-Ser-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O IZPVWNSAVUQBGP-CIUDSAMLSA-N 0.000 description 1
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 1
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 1
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 1
- KLSUAWUZBMAZCL-RHYQMDGZSA-N Leu-Thr-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(O)=O KLSUAWUZBMAZCL-RHYQMDGZSA-N 0.000 description 1
- SUYRAPCRSCCPAK-VFAJRCTISA-N Leu-Trp-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SUYRAPCRSCCPAK-VFAJRCTISA-N 0.000 description 1
- TUIOUEWKFFVNLH-DCAQKATOSA-N Leu-Val-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O TUIOUEWKFFVNLH-DCAQKATOSA-N 0.000 description 1
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 description 1
- 208000028018 Lymphocytic leukaemia Diseases 0.000 description 1
- FZIJIFCXUCZHOL-CIUDSAMLSA-N Lys-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN FZIJIFCXUCZHOL-CIUDSAMLSA-N 0.000 description 1
- KNKHAVVBVXKOGX-JXUBOQSCSA-N Lys-Ala-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KNKHAVVBVXKOGX-JXUBOQSCSA-N 0.000 description 1
- YKIRNDPUWONXQN-GUBZILKMSA-N Lys-Asn-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YKIRNDPUWONXQN-GUBZILKMSA-N 0.000 description 1
- NRQRKMYZONPCTM-CIUDSAMLSA-N Lys-Asp-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O NRQRKMYZONPCTM-CIUDSAMLSA-N 0.000 description 1
- KWUKZRFFKPLUPE-HJGDQZAQSA-N Lys-Asp-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWUKZRFFKPLUPE-HJGDQZAQSA-N 0.000 description 1
- MWVUEPNEPWMFBD-SRVKXCTJSA-N Lys-Cys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCCCN MWVUEPNEPWMFBD-SRVKXCTJSA-N 0.000 description 1
- BYEBKXRNDLTGFW-CIUDSAMLSA-N Lys-Cys-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O BYEBKXRNDLTGFW-CIUDSAMLSA-N 0.000 description 1
- NNCDAORZCMPZPX-GUBZILKMSA-N Lys-Gln-Ser Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N NNCDAORZCMPZPX-GUBZILKMSA-N 0.000 description 1
- GJJQCBVRWDGLMQ-GUBZILKMSA-N Lys-Glu-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O GJJQCBVRWDGLMQ-GUBZILKMSA-N 0.000 description 1
- ODUQLUADRKMHOZ-JYJNAYRXSA-N Lys-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)O ODUQLUADRKMHOZ-JYJNAYRXSA-N 0.000 description 1
- SPCHLZUWJTYZFC-IHRRRGAJSA-N Lys-His-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(O)=O SPCHLZUWJTYZFC-IHRRRGAJSA-N 0.000 description 1
- SKRGVGLIRUGANF-AVGNSLFASA-N Lys-Leu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SKRGVGLIRUGANF-AVGNSLFASA-N 0.000 description 1
- YXPJCVNIDDKGOE-MELADBBJSA-N Lys-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)N)C(=O)O YXPJCVNIDDKGOE-MELADBBJSA-N 0.000 description 1
- ZCWWVXAXWUAEPZ-SRVKXCTJSA-N Lys-Met-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZCWWVXAXWUAEPZ-SRVKXCTJSA-N 0.000 description 1
- AZOFEHCPMBRNFD-BZSNNMDCSA-N Lys-Phe-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CC=CC=C1 AZOFEHCPMBRNFD-BZSNNMDCSA-N 0.000 description 1
- WQDKIVRHTQYJSN-DCAQKATOSA-N Lys-Ser-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N WQDKIVRHTQYJSN-DCAQKATOSA-N 0.000 description 1
- MGKFCQFVPKOWOL-CIUDSAMLSA-N Lys-Ser-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N MGKFCQFVPKOWOL-CIUDSAMLSA-N 0.000 description 1
- IEVXCWPVBYCJRZ-IXOXFDKPSA-N Lys-Thr-His Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 IEVXCWPVBYCJRZ-IXOXFDKPSA-N 0.000 description 1
- DLCAXBGXGOVUCD-PPCPHDFISA-N Lys-Thr-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DLCAXBGXGOVUCD-PPCPHDFISA-N 0.000 description 1
- YKBSXQFZWFXFIB-VOAKCMCISA-N Lys-Thr-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCCN)C(O)=O YKBSXQFZWFXFIB-VOAKCMCISA-N 0.000 description 1
- CAVRAQIDHUPECU-UVOCVTCTSA-N Lys-Thr-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAVRAQIDHUPECU-UVOCVTCTSA-N 0.000 description 1
- SUZVLFWOCKHWET-CQDKDKBSSA-N Lys-Tyr-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O SUZVLFWOCKHWET-CQDKDKBSSA-N 0.000 description 1
- HMZPYMSEAALNAE-ULQDDVLXSA-N Lys-Val-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O HMZPYMSEAALNAE-ULQDDVLXSA-N 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- IIPHCNKHEZYSNE-DCAQKATOSA-N Met-Arg-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O IIPHCNKHEZYSNE-DCAQKATOSA-N 0.000 description 1
- MHQXIBRPDKXDGZ-ZFWWWQNUSA-N Met-Gly-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)CNC(=O)[C@@H](N)CCSC)C(O)=O)=CNC2=C1 MHQXIBRPDKXDGZ-ZFWWWQNUSA-N 0.000 description 1
- UEZVMMHDMIWARA-UHFFFAOYSA-N Metaphosphoric acid Chemical compound OP(=O)=O UEZVMMHDMIWARA-UHFFFAOYSA-N 0.000 description 1
- 241001465754 Metazoa Species 0.000 description 1
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 1
- XZFYRXDAULDNFX-UHFFFAOYSA-N N-L-cysteinyl-L-phenylalanine Natural products SCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XZFYRXDAULDNFX-UHFFFAOYSA-N 0.000 description 1
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 1
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 1
- 108091028043 Nucleic acid sequence Proteins 0.000 description 1
- 206010033128 Ovarian cancer Diseases 0.000 description 1
- 206010061535 Ovarian neoplasm Diseases 0.000 description 1
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 1
- 108090000526 Papain Proteins 0.000 description 1
- 206010057249 Phagocytosis Diseases 0.000 description 1
- DFEVBOYEUQJGER-JURCDPSOSA-N Phe-Ala-Ile Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O DFEVBOYEUQJGER-JURCDPSOSA-N 0.000 description 1
- JEGFCFLCRSJCMA-IHRRRGAJSA-N Phe-Arg-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)O)N JEGFCFLCRSJCMA-IHRRRGAJSA-N 0.000 description 1
- ZFVWWUILVLLVFA-AVGNSLFASA-N Phe-Gln-Cys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N ZFVWWUILVLLVFA-AVGNSLFASA-N 0.000 description 1
- MSHZERMPZKCODG-ACRUOGEOSA-N Phe-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MSHZERMPZKCODG-ACRUOGEOSA-N 0.000 description 1
- KNYPNEYICHHLQL-ACRUOGEOSA-N Phe-Leu-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 KNYPNEYICHHLQL-ACRUOGEOSA-N 0.000 description 1
- INHMISZWLJZQGH-ULQDDVLXSA-N Phe-Leu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 INHMISZWLJZQGH-ULQDDVLXSA-N 0.000 description 1
- AUJWXNGCAQWLEI-KBPBESRZSA-N Phe-Lys-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O AUJWXNGCAQWLEI-KBPBESRZSA-N 0.000 description 1
- ZJPGOXWRFNKIQL-JYJNAYRXSA-N Phe-Pro-Pro Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=CC=C1 ZJPGOXWRFNKIQL-JYJNAYRXSA-N 0.000 description 1
- OLZVAVSJEUAOHI-UNQGMJICSA-N Phe-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N)O OLZVAVSJEUAOHI-UNQGMJICSA-N 0.000 description 1
- 108010004729 Phycoerythrin Proteins 0.000 description 1
- OOLOTUZJUBOMAX-GUBZILKMSA-N Pro-Ala-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O OOLOTUZJUBOMAX-GUBZILKMSA-N 0.000 description 1
- SSSFPISOZOLQNP-GUBZILKMSA-N Pro-Arg-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSFPISOZOLQNP-GUBZILKMSA-N 0.000 description 1
- SKICPQLTOXGWGO-GARJFASQSA-N Pro-Gln-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O SKICPQLTOXGWGO-GARJFASQSA-N 0.000 description 1
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 1
- LHALYDBUDCWMDY-CIUDSAMLSA-N Pro-Glu-Ala Chemical compound C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1)C(O)=O LHALYDBUDCWMDY-CIUDSAMLSA-N 0.000 description 1
- KIPIKSXPPLABPN-CIUDSAMLSA-N Pro-Glu-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 KIPIKSXPPLABPN-CIUDSAMLSA-N 0.000 description 1
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 1
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 1
- QEWBZBLXDKIQPS-STQMWFEESA-N Pro-Gly-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QEWBZBLXDKIQPS-STQMWFEESA-N 0.000 description 1
- KWMUAKQOVYCQJQ-ZPFDUUQYSA-N Pro-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@@H]1CCCN1 KWMUAKQOVYCQJQ-ZPFDUUQYSA-N 0.000 description 1
- HBBBLSVBQGZKOZ-GUBZILKMSA-N Pro-Met-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O HBBBLSVBQGZKOZ-GUBZILKMSA-N 0.000 description 1
- HWLKHNDRXWTFTN-GUBZILKMSA-N Pro-Pro-Cys Chemical compound C1C[C@H](NC1)C(=O)N2CCC[C@H]2C(=O)N[C@@H](CS)C(=O)O HWLKHNDRXWTFTN-GUBZILKMSA-N 0.000 description 1
- KBUAPZAZPWNYSW-SRVKXCTJSA-N Pro-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KBUAPZAZPWNYSW-SRVKXCTJSA-N 0.000 description 1
- GOMUXSCOIWIJFP-GUBZILKMSA-N Pro-Ser-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GOMUXSCOIWIJFP-GUBZILKMSA-N 0.000 description 1
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 1
- LNICFEXCAHIJOR-DCAQKATOSA-N Pro-Ser-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LNICFEXCAHIJOR-DCAQKATOSA-N 0.000 description 1
- SXJOPONICMGFCR-DCAQKATOSA-N Pro-Ser-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O SXJOPONICMGFCR-DCAQKATOSA-N 0.000 description 1
- KIDXAAQVMNLJFQ-KZVJFYERSA-N Pro-Thr-Ala Chemical compound C[C@@H](O)[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](C)C(O)=O KIDXAAQVMNLJFQ-KZVJFYERSA-N 0.000 description 1
- CHYAYDLYYIJCKY-OSUNSFLBSA-N Pro-Thr-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CHYAYDLYYIJCKY-OSUNSFLBSA-N 0.000 description 1
- RMJZWERKFFNNNS-XGEHTFHBSA-N Pro-Thr-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O RMJZWERKFFNNNS-XGEHTFHBSA-N 0.000 description 1
- VVEQUISRWJDGMX-VKOGCVSHSA-N Pro-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@@H]3CCCN3 VVEQUISRWJDGMX-VKOGCVSHSA-N 0.000 description 1
- FHJQROWZEJFZPO-SRVKXCTJSA-N Pro-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 FHJQROWZEJFZPO-SRVKXCTJSA-N 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000004022 Protein-Tyrosine Kinases Human genes 0.000 description 1
- 108090000412 Protein-Tyrosine Kinases Proteins 0.000 description 1
- 238000002123 RNA extraction Methods 0.000 description 1
- 108091082331 ROR family Proteins 0.000 description 1
- 102000042839 ROR family Human genes 0.000 description 1
- 108010017324 STAT3 Transcription Factor Proteins 0.000 description 1
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 1
- MESDJCNHLZBMEP-ZLUOBGJFSA-N Ser-Asp-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MESDJCNHLZBMEP-ZLUOBGJFSA-N 0.000 description 1
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 1
- KNCJWSPMTFFJII-ZLUOBGJFSA-N Ser-Cys-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O KNCJWSPMTFFJII-ZLUOBGJFSA-N 0.000 description 1
- KMWFXJCGRXBQAC-CIUDSAMLSA-N Ser-Cys-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N KMWFXJCGRXBQAC-CIUDSAMLSA-N 0.000 description 1
- MOVJSUIKUNCVMG-ZLUOBGJFSA-N Ser-Cys-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N)O MOVJSUIKUNCVMG-ZLUOBGJFSA-N 0.000 description 1
- OHKFXGKHSJKKAL-NRPADANISA-N Ser-Glu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OHKFXGKHSJKKAL-NRPADANISA-N 0.000 description 1
- AEGUWTFAQQWVLC-BQBZGAKWSA-N Ser-Gly-Arg Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O AEGUWTFAQQWVLC-BQBZGAKWSA-N 0.000 description 1
- QBUWQRKEHJXTOP-DCAQKATOSA-N Ser-His-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QBUWQRKEHJXTOP-DCAQKATOSA-N 0.000 description 1
- HMRAQFJFTOLDKW-GUBZILKMSA-N Ser-His-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O HMRAQFJFTOLDKW-GUBZILKMSA-N 0.000 description 1
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 1
- XUDRHBPSPAPDJP-SRVKXCTJSA-N Ser-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO XUDRHBPSPAPDJP-SRVKXCTJSA-N 0.000 description 1
- GDUZTEQRAOXYJS-SRVKXCTJSA-N Ser-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GDUZTEQRAOXYJS-SRVKXCTJSA-N 0.000 description 1
- FBLNYDYPCLFTSP-IXOXFDKPSA-N Ser-Phe-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FBLNYDYPCLFTSP-IXOXFDKPSA-N 0.000 description 1
- NUEHQDHDLDXCRU-GUBZILKMSA-N Ser-Pro-Arg Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NUEHQDHDLDXCRU-GUBZILKMSA-N 0.000 description 1
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 1
- GYDFRTRSSXOZCR-ACZMJKKPSA-N Ser-Ser-Glu Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O GYDFRTRSSXOZCR-ACZMJKKPSA-N 0.000 description 1
- NVNPWELENFJOHH-CIUDSAMLSA-N Ser-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CO)N NVNPWELENFJOHH-CIUDSAMLSA-N 0.000 description 1
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 1
- PURRNJBBXDDWLX-ZDLURKLDSA-N Ser-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CO)N)O PURRNJBBXDDWLX-ZDLURKLDSA-N 0.000 description 1
- PCJLFYBAQZQOFE-KATARQTJSA-N Ser-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N)O PCJLFYBAQZQOFE-KATARQTJSA-N 0.000 description 1
- PZHJLTWGMYERRJ-SRVKXCTJSA-N Ser-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N)O PZHJLTWGMYERRJ-SRVKXCTJSA-N 0.000 description 1
- VVKVHAOOUGNDPJ-SRVKXCTJSA-N Ser-Tyr-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VVKVHAOOUGNDPJ-SRVKXCTJSA-N 0.000 description 1
- RCOUFINCYASMDN-GUBZILKMSA-N Ser-Val-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O RCOUFINCYASMDN-GUBZILKMSA-N 0.000 description 1
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 1
- 102100024040 Signal transducer and activator of transcription 3 Human genes 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- FQPQPTHMHZKGFM-XQXXSGGOSA-N Thr-Ala-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O FQPQPTHMHZKGFM-XQXXSGGOSA-N 0.000 description 1
- UKBSDLHIKIXJKH-HJGDQZAQSA-N Thr-Arg-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O UKBSDLHIKIXJKH-HJGDQZAQSA-N 0.000 description 1
- ASJDFGOPDCVXTG-KATARQTJSA-N Thr-Cys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O ASJDFGOPDCVXTG-KATARQTJSA-N 0.000 description 1
- KWQBJOUOSNJDRR-XAVMHZPKSA-N Thr-Cys-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N)O KWQBJOUOSNJDRR-XAVMHZPKSA-N 0.000 description 1
- DSLHSTIUAPKERR-XGEHTFHBSA-N Thr-Cys-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O DSLHSTIUAPKERR-XGEHTFHBSA-N 0.000 description 1
- VOHWDZNIESHTFW-XKBZYTNZSA-N Thr-Glu-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N)O VOHWDZNIESHTFW-XKBZYTNZSA-N 0.000 description 1
- JQAWYCUUFIMTHE-WLTAIBSBSA-N Thr-Gly-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JQAWYCUUFIMTHE-WLTAIBSBSA-N 0.000 description 1
- WPSDXXQRIVKBAY-NKIYYHGXSA-N Thr-His-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O WPSDXXQRIVKBAY-NKIYYHGXSA-N 0.000 description 1
- IHAPJUHCZXBPHR-WZLNRYEVSA-N Thr-Ile-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N IHAPJUHCZXBPHR-WZLNRYEVSA-N 0.000 description 1
- HOVLHEKTGVIKAP-WDCWCFNPSA-N Thr-Leu-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HOVLHEKTGVIKAP-WDCWCFNPSA-N 0.000 description 1
- FIFDDJFLNVAVMS-RHYQMDGZSA-N Thr-Leu-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O FIFDDJFLNVAVMS-RHYQMDGZSA-N 0.000 description 1
- PRNGXSILMXSWQQ-OEAJRASXSA-N Thr-Leu-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PRNGXSILMXSWQQ-OEAJRASXSA-N 0.000 description 1
- NCXVJIQMWSGRHY-KXNHARMFSA-N Thr-Leu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O NCXVJIQMWSGRHY-KXNHARMFSA-N 0.000 description 1
- JLNMFGCJODTXDH-WEDXCCLWSA-N Thr-Lys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O JLNMFGCJODTXDH-WEDXCCLWSA-N 0.000 description 1
- XSEPSRUDSPHMPX-KATARQTJSA-N Thr-Lys-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O XSEPSRUDSPHMPX-KATARQTJSA-N 0.000 description 1
- KPNSNVTUVKSBFL-ZJDVBMNYSA-N Thr-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KPNSNVTUVKSBFL-ZJDVBMNYSA-N 0.000 description 1
- MXNAOGFNFNKUPD-JHYOHUSXSA-N Thr-Phe-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MXNAOGFNFNKUPD-JHYOHUSXSA-N 0.000 description 1
- XKWABWFMQXMUMT-HJGDQZAQSA-N Thr-Pro-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XKWABWFMQXMUMT-HJGDQZAQSA-N 0.000 description 1
- MROIJTGJGIDEEJ-RCWTZXSCSA-N Thr-Pro-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 MROIJTGJGIDEEJ-RCWTZXSCSA-N 0.000 description 1
- WPSKTVVMQCXPRO-BWBBJGPYSA-N Thr-Ser-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WPSKTVVMQCXPRO-BWBBJGPYSA-N 0.000 description 1
- ZMYCLHFLHRVOEA-HEIBUPTGSA-N Thr-Thr-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ZMYCLHFLHRVOEA-HEIBUPTGSA-N 0.000 description 1
- BEZTUFWTPVOROW-KJEVXHAQSA-N Thr-Tyr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O BEZTUFWTPVOROW-KJEVXHAQSA-N 0.000 description 1
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 1
- QNXZCKMXHPULME-ZNSHCXBVSA-N Thr-Val-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O QNXZCKMXHPULME-ZNSHCXBVSA-N 0.000 description 1
- BPGDJSUFQKWUBK-KJEVXHAQSA-N Thr-Val-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BPGDJSUFQKWUBK-KJEVXHAQSA-N 0.000 description 1
- 101710120037 Toxin CcdB Proteins 0.000 description 1
- AVYVKJMBNLPWRX-WFBYXXMGSA-N Trp-Ala-Ser Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 AVYVKJMBNLPWRX-WFBYXXMGSA-N 0.000 description 1
- LAIUAVGWZYTBKN-VHWLVUOQSA-N Trp-Asn-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(O)=O LAIUAVGWZYTBKN-VHWLVUOQSA-N 0.000 description 1
- DQDXHYIEITXNJY-BPUTZDHNSA-N Trp-Gln-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N DQDXHYIEITXNJY-BPUTZDHNSA-N 0.000 description 1
- UDCHKDYNMRJYMI-QEJZJMRPSA-N Trp-Glu-Ser Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O UDCHKDYNMRJYMI-QEJZJMRPSA-N 0.000 description 1
- NLLARHRWSFNEMH-NUTKFTJISA-N Trp-Lys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N NLLARHRWSFNEMH-NUTKFTJISA-N 0.000 description 1
- RERRMBXDSFMBQE-ZFWWWQNUSA-N Trp-Met-Gly Chemical compound CSCC[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N RERRMBXDSFMBQE-ZFWWWQNUSA-N 0.000 description 1
- QJBWZNTWJSZUOY-UWJYBYFXSA-N Tyr-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QJBWZNTWJSZUOY-UWJYBYFXSA-N 0.000 description 1
- AKXBNSZMYAOGLS-STQMWFEESA-N Tyr-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AKXBNSZMYAOGLS-STQMWFEESA-N 0.000 description 1
- PEVVXUGSAKEPEN-AVGNSLFASA-N Tyr-Asn-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PEVVXUGSAKEPEN-AVGNSLFASA-N 0.000 description 1
- XKDOQXAXKFQWQJ-SRVKXCTJSA-N Tyr-Cys-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O XKDOQXAXKFQWQJ-SRVKXCTJSA-N 0.000 description 1
- RIJPHPUJRLEOAK-JYJNAYRXSA-N Tyr-Gln-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O RIJPHPUJRLEOAK-JYJNAYRXSA-N 0.000 description 1
- WVRUKYLYMFGKAN-IHRRRGAJSA-N Tyr-Glu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 WVRUKYLYMFGKAN-IHRRRGAJSA-N 0.000 description 1
- CDHQEOXPWBDFPL-QWRGUYRKSA-N Tyr-Gly-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 CDHQEOXPWBDFPL-QWRGUYRKSA-N 0.000 description 1
- HVPPEXXUDXAPOM-MGHWNKPDSA-N Tyr-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 HVPPEXXUDXAPOM-MGHWNKPDSA-N 0.000 description 1
- NSGZILIDHCIZAM-KKUMJFAQSA-N Tyr-Leu-Ser Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N NSGZILIDHCIZAM-KKUMJFAQSA-N 0.000 description 1
- XDGPTBVOSHKDFT-KKUMJFAQSA-N Tyr-Met-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O XDGPTBVOSHKDFT-KKUMJFAQSA-N 0.000 description 1
- LMKKMCGTDANZTR-BZSNNMDCSA-N Tyr-Phe-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 LMKKMCGTDANZTR-BZSNNMDCSA-N 0.000 description 1
- WURLIFOWSMBUAR-SLFFLAALSA-N Tyr-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)C(=O)O WURLIFOWSMBUAR-SLFFLAALSA-N 0.000 description 1
- NHOVZGFNTGMYMI-KKUMJFAQSA-N Tyr-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NHOVZGFNTGMYMI-KKUMJFAQSA-N 0.000 description 1
- HRHYJNLMIJWGLF-BZSNNMDCSA-N Tyr-Ser-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 HRHYJNLMIJWGLF-BZSNNMDCSA-N 0.000 description 1
- PWKMJDQXKCENMF-MEYUZBJRSA-N Tyr-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O PWKMJDQXKCENMF-MEYUZBJRSA-N 0.000 description 1
- WQOHKVRQDLNDIL-YJRXYDGGSA-N Tyr-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O WQOHKVRQDLNDIL-YJRXYDGGSA-N 0.000 description 1
- TYGHOWWWMTWVKM-HJOGWXRNSA-N Tyr-Tyr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 TYGHOWWWMTWVKM-HJOGWXRNSA-N 0.000 description 1
- UUJHRSTVQCFDPA-UFYCRDLUSA-N Tyr-Tyr-Val Chemical compound C([C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 UUJHRSTVQCFDPA-UFYCRDLUSA-N 0.000 description 1
- ZLFHAAGHGQBQQN-AEJSXWLSSA-N Val-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZLFHAAGHGQBQQN-AEJSXWLSSA-N 0.000 description 1
- SLLKXDSRVAOREO-KZVJFYERSA-N Val-Ala-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N)O SLLKXDSRVAOREO-KZVJFYERSA-N 0.000 description 1
- SCBITHMBEJNRHC-LSJOCFKGSA-N Val-Asp-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N SCBITHMBEJNRHC-LSJOCFKGSA-N 0.000 description 1
- IRLYZKKNBFPQBW-XGEHTFHBSA-N Val-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N)O IRLYZKKNBFPQBW-XGEHTFHBSA-N 0.000 description 1
- VFOHXOLPLACADK-GVXVVHGQSA-N Val-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N VFOHXOLPLACADK-GVXVVHGQSA-N 0.000 description 1
- PWRITNSESKQTPW-NRPADANISA-N Val-Gln-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N PWRITNSESKQTPW-NRPADANISA-N 0.000 description 1
- RKIGNDAHUOOIMJ-BQFCYCMXSA-N Val-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 RKIGNDAHUOOIMJ-BQFCYCMXSA-N 0.000 description 1
- UEHRGZCNLSWGHK-DLOVCJGASA-N Val-Glu-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UEHRGZCNLSWGHK-DLOVCJGASA-N 0.000 description 1
- MJXNDRCLGDSBBE-FHWLQOOXSA-N Val-His-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N MJXNDRCLGDSBBE-FHWLQOOXSA-N 0.000 description 1
- XTDDIVQWDXMRJL-IHRRRGAJSA-N Val-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N XTDDIVQWDXMRJL-IHRRRGAJSA-N 0.000 description 1
- ZZGPVSZDZQRJQY-ULQDDVLXSA-N Val-Leu-Phe Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](Cc1ccccc1)C(O)=O ZZGPVSZDZQRJQY-ULQDDVLXSA-N 0.000 description 1
- RWOGENDAOGMHLX-DCAQKATOSA-N Val-Lys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C(C)C)N RWOGENDAOGMHLX-DCAQKATOSA-N 0.000 description 1
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 1
- VPGCVZRRBYOGCD-AVGNSLFASA-N Val-Lys-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O VPGCVZRRBYOGCD-AVGNSLFASA-N 0.000 description 1
- SBJCTAZFSZXWSR-AVGNSLFASA-N Val-Met-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SBJCTAZFSZXWSR-AVGNSLFASA-N 0.000 description 1
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 1
- BGXVHVMJZCSOCA-AVGNSLFASA-N Val-Pro-Lys Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)O)N BGXVHVMJZCSOCA-AVGNSLFASA-N 0.000 description 1
- KSFXWENSJABBFI-ZKWXMUAHSA-N Val-Ser-Asn Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O KSFXWENSJABBFI-ZKWXMUAHSA-N 0.000 description 1
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 1
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 1
- BZDGLJPROOOUOZ-XGEHTFHBSA-N Val-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C(C)C)N)O BZDGLJPROOOUOZ-XGEHTFHBSA-N 0.000 description 1
- DVLWZWNAQUBZBC-ZNSHCXBVSA-N Val-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N)O DVLWZWNAQUBZBC-ZNSHCXBVSA-N 0.000 description 1
- ZLNYBMWGPOKSLW-LSJOCFKGSA-N Val-Val-Asp Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLNYBMWGPOKSLW-LSJOCFKGSA-N 0.000 description 1
- 208000036142 Viral infection Diseases 0.000 description 1
- IEDXPSOJFSVCKU-HOKPPMCLSA-N [4-[[(2S)-5-(carbamoylamino)-2-[[(2S)-2-[6-(2,5-dioxopyrrolidin-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl N-[(2S)-1-[[(2S)-1-[[(3R,4S,5S)-1-[(2S)-2-[(1R,2R)-3-[[(1S,2R)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]-N-methylcarbamate Chemical compound CC[C@H](C)[C@@H]([C@@H](CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)c1ccccc1)OC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCc1ccc(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN2C(=O)CCC2=O)C(C)C)cc1)C(C)C IEDXPSOJFSVCKU-HOKPPMCLSA-N 0.000 description 1
- 239000003070 absorption delaying agent Substances 0.000 description 1
- 229940022698 acetylcholinesterase Drugs 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 238000007792 addition Methods 0.000 description 1
- 239000011543 agarose gel Substances 0.000 description 1
- 108010066875 alanyl-prolyl-tryptophyl-cysteine Proteins 0.000 description 1
- 108010005233 alanylglutamic acid Proteins 0.000 description 1
- 108010047495 alanylglycine Proteins 0.000 description 1
- 108010070783 alanyltyrosine Proteins 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 239000003429 antifungal agent Substances 0.000 description 1
- 239000002246 antineoplastic agent Substances 0.000 description 1
- 229940041181 antineoplastic drug Drugs 0.000 description 1
- 239000008135 aqueous vehicle Substances 0.000 description 1
- 108010060035 arginylproline Proteins 0.000 description 1
- 239000012911 assay medium Substances 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- 230000003305 autocrine Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- 229940126587 biotherapeutics Drugs 0.000 description 1
- 229960003008 blinatumomab Drugs 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 201000008274 breast adenocarcinoma Diseases 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 230000005907 cancer growth Effects 0.000 description 1
- 238000002619 cancer immunotherapy Methods 0.000 description 1
- 239000006143 cell culture medium Substances 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000005754 cellular signaling Effects 0.000 description 1
- 238000010382 chemical cross-linking Methods 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 238000004040 coloring Methods 0.000 description 1
- 238000010668 complexation reaction Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 108010069495 cysteinyltyrosine Proteins 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 239000002254 cytotoxic agent Substances 0.000 description 1
- 229940127089 cytotoxic agent Drugs 0.000 description 1
- 231100000599 cytotoxic agent Toxicity 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 239000003405 delayed action preparation Substances 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 238000011026 diafiltration Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 108010009297 diglycyl-histidine Proteins 0.000 description 1
- 108020001096 dihydrofolate reductase Proteins 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 239000002270 dispersing agent Substances 0.000 description 1
- 239000002612 dispersion medium Substances 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 230000009881 electrostatic interaction Effects 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 230000012202 endocytosis Effects 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 1
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000005713 exacerbation Effects 0.000 description 1
- 230000008175 fetal development Effects 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 238000011223 gene expression profiling Methods 0.000 description 1
- 238000012252 genetic analysis Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 1
- JYPCXBJRLBHWME-UHFFFAOYSA-N glycyl-L-prolyl-L-arginine Natural products NCC(=O)N1CCCC1C(=O)NC(CCCN=C(N)N)C(O)=O JYPCXBJRLBHWME-UHFFFAOYSA-N 0.000 description 1
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 1
- 108010025801 glycyl-prolyl-arginine Proteins 0.000 description 1
- 108010081551 glycylphenylalanine Proteins 0.000 description 1
- 208000024908 graft versus host disease Diseases 0.000 description 1
- 230000003394 haemopoietic effect Effects 0.000 description 1
- 210000002216 heart Anatomy 0.000 description 1
- 230000006801 homologous recombination Effects 0.000 description 1
- 238000002744 homologous recombination Methods 0.000 description 1
- 238000007654 immersion Methods 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 238000002649 immunization Methods 0.000 description 1
- 238000003018 immunoassay Methods 0.000 description 1
- 229940127121 immunoconjugate Drugs 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 238000003364 immunohistochemistry Methods 0.000 description 1
- 238000002513 implantation Methods 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 238000011081 inoculation Methods 0.000 description 1
- 238000012482 interaction analysis Methods 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000010255 intramuscular injection Methods 0.000 description 1
- 239000007927 intramuscular injection Substances 0.000 description 1
- 230000002601 intratumoral effect Effects 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- 239000003456 ion exchange resin Substances 0.000 description 1
- 229920003303 ion-exchange polymer Polymers 0.000 description 1
- 210000004153 islets of langerhan Anatomy 0.000 description 1
- 239000007951 isotonicity adjuster Substances 0.000 description 1
- 230000002147 killing effect Effects 0.000 description 1
- 108010053037 kyotorphin Proteins 0.000 description 1
- 108010030617 leucyl-phenylalanyl-valine Proteins 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- 238000007422 luminescence assay Methods 0.000 description 1
- 238000004020 luminiscence type Methods 0.000 description 1
- HWYHZTIRURJOHG-UHFFFAOYSA-N luminol Chemical compound O=C1NNC(=O)C2=C1C(N)=CC=C2 HWYHZTIRURJOHG-UHFFFAOYSA-N 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 201000005296 lung carcinoma Diseases 0.000 description 1
- 208000003747 lymphoid leukemia Diseases 0.000 description 1
- 239000012139 lysis buffer Substances 0.000 description 1
- 108010025153 lysyl-alanyl-alanine Proteins 0.000 description 1
- 108010026228 mRNA guanylyltransferase Proteins 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 230000013011 mating Effects 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 108010056582 methionylglutamic acid Proteins 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 239000003607 modifier Substances 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 238000010172 mouse model Methods 0.000 description 1
- ZTLGJPIZUOVDMT-UHFFFAOYSA-N n,n-dichlorotriazin-4-amine Chemical compound ClN(Cl)C1=CC=NN=N1 ZTLGJPIZUOVDMT-UHFFFAOYSA-N 0.000 description 1
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 1
- 238000001728 nano-filtration Methods 0.000 description 1
- 210000000822 natural killer cell Anatomy 0.000 description 1
- 210000005170 neoplastic cell Anatomy 0.000 description 1
- 230000003472 neutralizing effect Effects 0.000 description 1
- 208000002154 non-small cell lung carcinoma Diseases 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 238000002515 oligonucleotide synthesis Methods 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 230000014207 opsonization Effects 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 201000002094 pancreatic adenocarcinoma Diseases 0.000 description 1
- 201000002528 pancreatic cancer Diseases 0.000 description 1
- 229940055729 papain Drugs 0.000 description 1
- 235000019834 papain Nutrition 0.000 description 1
- 210000002990 parathyroid gland Anatomy 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 230000007310 pathophysiology Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 230000008782 phagocytosis Effects 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 230000034190 positive regulation of NF-kappaB transcription factor activity Effects 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000002335 preservative effect Effects 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 108010079317 prolyl-tyrosine Proteins 0.000 description 1
- 108010029020 prolylglycine Proteins 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 230000007115 recruitment Effects 0.000 description 1
- 239000011347 resin Substances 0.000 description 1
- 229920005989 resin Polymers 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 108010091078 rigin Proteins 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 238000009738 saturating Methods 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 239000006152 selective media Substances 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- 230000009450 sialylation Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 210000000130 stem cell Anatomy 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 150000005846 sugar alcohols Polymers 0.000 description 1
- 230000008093 supporting effect Effects 0.000 description 1
- 239000000375 suspending agent Substances 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 229940104230 thymidine Drugs 0.000 description 1
- 238000004448 titration Methods 0.000 description 1
- 239000012929 tonicity agent Substances 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 230000005026 transcription initiation Effects 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 238000011277 treatment modality Methods 0.000 description 1
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 description 1
- 238000007492 two-way ANOVA Methods 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 238000000108 ultra-filtration Methods 0.000 description 1
- ORHBXUUXSCNDEV-UHFFFAOYSA-N umbelliferone Chemical compound C1=CC(=O)OC2=CC(O)=CC=C21 ORHBXUUXSCNDEV-UHFFFAOYSA-N 0.000 description 1
- HFTAFOQKODTIJY-UHFFFAOYSA-N umbelliferone Natural products Cc1cc2C=CC(=O)Oc2cc1OCC=CC(C)(C)O HFTAFOQKODTIJY-UHFFFAOYSA-N 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 238000009736 wetting Methods 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 108010027345 wheylin-1 peptide Proteins 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
Images
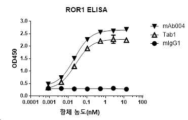




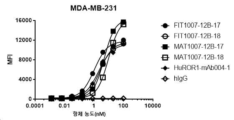








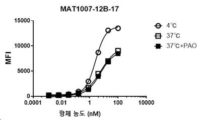


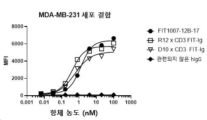
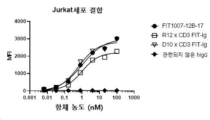

Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
- C07K16/468—Immunoglobulins having two or more different antigen binding sites, e.g. multifunctional antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- A61P35/02—Antineoplastic agents specific for leukemia
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/577—Immunoassay; Biospecific binding assay; Materials therefor involving monoclonal antibodies binding reaction mechanisms characterised by the use of monoclonal antibodies; monoclonal antibodies per se are classified with their corresponding antigens
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6872—Intracellular protein regulatory factors and their receptors, e.g. including ion channels
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/522—CH1 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/71—Decreased effector function due to an Fc-modification
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/77—Internalization into the cell
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/705—Assays involving receptors, cell surface antigens or cell surface determinants
- G01N2333/70503—Immunoglobulin superfamily, e.g. VCAMs, PECAM, LFA-3
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Engineering & Computer Science (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Biomedical Technology (AREA)
- Hematology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Veterinary Medicine (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Public Health (AREA)
- Biotechnology (AREA)
- Urology & Nephrology (AREA)
- Microbiology (AREA)
- Physics & Mathematics (AREA)
- Cell Biology (AREA)
- General Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Oncology (AREA)
- Pathology (AREA)
- General Physics & Mathematics (AREA)
- Analytical Chemistry (AREA)
- Food Science & Technology (AREA)
- Plant Pathology (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
본원은 수용체 티로신 키나제-유사 희귀수용체 1(ROR1)을 인식하는 항체, 이중특이적 ROR1/CD3 결합 단백질, 예를 들어 FIT-Ig 및 MAT-Fab 결합 단백질, 및 조혈성 암 및 고형 종양의 치료를 위한 상기 항체 및 이중특이적 결합 단백질의 용도를 제공한다.
Description
본 개시내용은 수용체 티로신 키나제-유사 희귀수용체 1(ROR1)을 인식할 수 있는 항체, 및 관련된 이중특이적 결합 단백질(bispecific binding protein), 예를 들어 이중특이적 ROR1/CD3 결합 단백질(예를 들어, FIT-Ig 및 MAT-Fab 결합 단백질)에 관한 것이다. 본원에 개시된 항체 및 이중특이적 결합 단백질은 조혈성 암(hematopoietic cancer) 및 고형 종양(solid tumor)과 같은 질병의 치료에 유용할 수 있다.
수용체 티로신 키나제-유사 희귀수용체 1(ROR1)은 ROR 서브패밀리(subfamily)에 속하는 진화적으로 보존된 I형 막 단백질이다. 이것은 ROR 패밀리의 유일한 다른 구성원인 ROR2와 58% 아미노산(aa) 서열 동일성(identity)을 공유한다. ROR1 및 ROR2는, 하나의 면역글로불린 유사(Ig-유사) 도메인(domain)을 갖는 구별되는 세포외 영역, 하나의 프리즐드(Fz) 도메인 및 하나의 크링글(Kr) 도메인에 이어서 막관통 영역, 및 티로신 키나제 도메인을 함유하는 세포내 영역으로 구성된다(Baskar, S., et al, (2008) Clinical Cancer Research, 14(2), 396-404).
ROR1의 발현은 발생적으로 조절되며 태아 발생 동안 약화된다. B-세포 악성종양 및 정상 B 림프구의 유전자 발현 프로파일링은 ROR1의 발견 및 림프구성 백혈병 세포에서의 이의 독특한 발현으로 이어졌다(상기 문헌[Baskar et al., 2008]을 참조하시오). 고감도 뮤린(murine) 항-인간 ROR1 mAb 6D4의 사용에 의해, ROR1이 난소암(ovarian cancer), 삼중 음성 유방암(triple negative breast cancer), 폐 선암종(lung adenocarcinomas) 및 췌장 선암종(pancreatic adenocarcinomas)을 포함한 특정 유형의 고형 종양에서 전형적으로 막성(membranous)이고 균일하게 발현되는 것으로서 특성화되었다. 또한, ROR1의 세포 표면 발현은 특정 정상 조직(예를 들어, 부갑상선, 췌장 섬 및 인간 장의 여러 영역)에서 관찰되었지만 다른 조직(예를 들어, 뇌, 심장, 폐 및 간)에서는 관찰되지 않았다(Berger et al., 2016, Clinical Cancer Research, 23(12), 3061-3071).
ROR1은 암 치료의 표적으로서 제안되었다. 예를 들어, WO2005100605, WO2007051077, WO2008103849 및 WO2012097313은 ROR1에 대한 항체, 및 유방암과 같은 고형 종양 및 만성 림프구성 백혈병(CLL)과 같은 혈액 종양을 포함한 종양을 표적화하기 위한 치료제로서의 이의 용도를 기재하였다. WO2012097313의 항-ROR1 항체 D10에 의해 결합된 에피토프(epitope)의 맵핑에 의해 생성된 시름투주맙은 만성 림프구성 백혈병(CLL)을 포함한 다양한 암에 대한 임상 시험에서 인간화된 단클론 항체(monoclonal antibody)이다. 시름투주맙은 ROR1이 이의 리간드 Wnt5a에 결합하는 것을 차단하며, 이는 NF-κB 활성화의 Wnt5a 유도된 자극을 억제하고 이에 의해 CLL에서 자가분비 IL-6-의존적인 STAT3 활성화를 억제할 수 있다(Chen et al., 2019, Blood, 134(13), 1084-1094). 시름투주맙은 세포내에 내재화될 수 있으며 항-ROR1 항체 약물 접합체(ADC)에서 표적화 모이어티(moiety)로서의 사용이 평가되었다. 시름투주맙-기반, MMAE-함유 ADC인 VLS-101이 ROR1-양성 악성종양 환자의 치료를 위해 개발되었다.
ROR1 및 제2 항원에 대한 이중특이적 항체, 예를 들어 이중특이적 T 세포 인게이저(BiTEs)가 또 다른 치료학적 양상으로서 개발되었다. WO2014/167022는 하나의 가지로 서 서서히 내재화된 항-ROR1 항체, R12, 및 또 다른 가지로서 항-CD3ε 항체를 갖는 이중특이적 항체를 개시하고 있다. 문헌[Gohil et al., 2017 Onco Immunology, 6(7), 1-11]은 ROR1의 프리즐드 도메인을 표적화하는 단쇄 가변 단편(scFv)을 사용하여 BiTE를 생성시켰으며, 이는 뮤린 모델에서 췌장 종양 이종이식편의 생착(engraftment)을 방지하였다. 문헌[Qi et al., 2018 Proceedings of the National Academy of Sciences of the United States of America, 115(24), E5467-E5476]은 막-근위 에피토프, R11을 갖는 ROR1-표적화 scFv를 개시하며, 이는 이종이량체성 및 아글리코실화된 Fc 도메인을 기반으로 하는 ROR1 x CD3 이중특이적 항체를 사용하여 scFv-Fc 포맷으로 구성될 때 효능있고 선택성인 항종양 활성을 나타내었다.
BiTE는 T-세포/CD3 복합체의 불변-성분과 종양-연관 항원(TAA)에 대한 이중특이적 항체이다. 이러한 이중특이적 항체는 T-세포의 세포독성 활성을 비-MHC 제한된 방식으로 다시 악성 세포를 향하게 하는 것과 같은 특정한 장점을 갖는다. 최근 몇 년 동안 블리나투모맙에 대해 관찰된 임상적 성공으로, 암 면역요법을 위한 CD3-표적화 BiTE에 대한 관심이 높아져 왔다. 그러나, 이러한 치료 양식의 효능 및 독성/안전성과 관련된 문제가 대두되었다.
예를 들어, 엄격히 종양-특이적인 항원의 경우, 친화도가 증가된 항체를 갖는 것이 바람직할 수 있다. 그러나, 종양에서 과발현되지만 정상 조직에서도 발현되는 종양-연관 항원의 경우, 종양과 정상 조직에서의 항원 발현을 구별하는 항체의 능력이 유리할 수 있다. 항체의 내재화 특성은 또한 치료학적 적용에 영향을 미칠 수 있다. 예를 들어, 항체 결합 시 강한 내재화는 항체 접합체(conjugate)가, 접합된 독소를 표적 세포로 효율적으로 전달하는 데 바람직할 수 있다. 그러나 내재화가 BiTE를 세포 표면에 유지시키는 것이 T 세포의 관여에 의한 세포독성 활성을 유도하는 데 바람직할 수 있다는 점에서, T 세포 인게이저에게는 바람직하지 않을 수 있다. 또한 항체 약물(drug)의 고형 종양 침투 및 효능은 항체의 친화도 및 항원 내재화에 의해 영향을 받을 수도 있음이 밝혀졌다. 문헌[Rudnick et al, 2011, Cancer Res; 71(6); 2250-9]에 따르면, 높은 친화도 및 빠른 내재화가 항체의 종양 내로의 침투를 제한할 수 있는 반면, 상대적으로 낮은 친화도와 낮은 내재화는 고형 종양에 더 효과적으로 침투할 수 있게 한다.
당해 분야에서 BiTE의 생체내(in vivo) 효능 및 종양 선택성에 영향을 미치는 많은 인자가 언급되었다. 그리고 종종, 표적/에피토프의 특성에 따라, T 세포 인게이저에 대해 다른 속성을 채택하는 것이 바람직 할 수 있다.
예를 들어, 문헌[James et al., Antigen sensitivity of CD22-specific chimeric TCR is modulated by target epitope distance from the cell membrane, J.Immunol. 180 (10) (2008) 7028-7038]은 BiTE의 효능 및/또는 종양 선택성을 향상시키기 위해서 막까지의 에피토프 거리를 조절함을 기재하였다. 제임스 등은 CAR-T 세포가 있는 막까지 다양한 거리로 CD22의 에피토프를 표적화함으로써, 중간 도메인의 표적화는 표적 B 세포주(cell line)의 효율적인 용해로 이어졌지만 정상 B 세포의 용해는 검출할 수 없음을 발견하였다. 유사하게, 쿠이(Qi) 등은 ROR1상의 에피토프 위치가 scFv-Fc 포맷의 ROR1 x CD3 이중특이적 항체의 활성에 영향을 미칠 수 있음을 발견하였다(상기 문헌[Qi et al., 2018]을 참조하시오). ROR1상의 상이한 에피토프로 mAb의 패널을 스크리닝함으로써, 쿠이 등의 데이터는 R11에 의해 표적화된 ROR1의 Kr 도메인 중의 막-근위 에피토프가 이중특이적 항체에 의한 T 세포 관여에 적합한 부위일 수 있는 반면, R12에 의해 표적화된 Fz 및 Kr 도메인의 접합부에서의 막-원위 에피토프는 그렇지 않을 수 있음을 제시한다. 항체 R12 가지(arm)를 갖는 이중특이적 항체는 종양에 대해 단지 약한 생체내 활성만을 드러내었다.
크기, 원자가(valency) 및 기하학을 포함하여, 항체 포맷을 조작함으로써 종양 세포의 우선적 관여를 증가시키는 다양한 접근법이 기재되었다. 문헌[Slaga et al., Avidity-based binding to HER2 results inselective killing of HER2-overexpressing cells by anti-HER2/CD3, Sci. Transl. Med.10 (463) (2018)]은 다가 항체 포맷으로 결합활성-기반 전략을 탐구하였고, 저밀도 또는 고밀도로 HER2를 발현하는 세포간의 구별을 증가시키기 위해 선택된 친화도를 갖는 이중특이적 항체를 개발하였다. 문헌[G.L. Moore, et al., A robust heterodimeric Fc platform engineered for efficient development of bispecific antibodies of multiple formats, Methods (2018)]은 유사한 전략을 보고하였다.
더욱이, 이중특이적 항체의 개발에서 고려해야 할 사항은 제조 적합성이다. 낮은 생산 수율 및 상당한 응집체 형성은 항체 약물을 전-임상(pre-clinical) 및 임상 병기 평가 수행에 비실용적이게 하는 특성이다.
상기에 비추어, 그리고 ROR1이 암 치료에서 유망한 표적이라는 점을 감안할 때, 상이한 결합 효능 및/또는 결합 부위 또는 내재화 특성을 갖는 다양한 항-ROR1 분자를 개발하고, 다양한 항체 포맷을 개발하고, 치료학적 유용성 및 제조 적합성을 확대 및/또는 개선시킬 필요가 당업계에 여전히 남아 있다.
본 개시내용은 신규의 항-ROR1 항체, 항-CD3 항체, 및 ROR1 및 CD3 모두에 결합하는 조작된 이중특이적 단백질을 제공함으로써 상기 필요성을 해결한다.
특히, 일부 구현예에서, 본 발명은 항-ROR1 항체, 예를 들어 ROR1-발현 세포에 대한 높은 결합 효능 및 낮은 내재화율을 갖는 항체를 제공한다. 일부 구현예에서, 본 개시내용은 또한 CD3에 결합하는 항체, 예를 들어 높은 친화도로 CD3에 결합하는 항체를 제공한다. 일부 구현예에서, 본 개시내용은 또한 Fabs-in-Tandem 면역글로불린(FIT-Ig) 포맷 또는 1가 비대칭 탠덤(tandem) Fab 이중특이적 항체(MAT-Fab) 포맷의 ROR1/CD3 이중특이적 결합 단백질(이들은 ROR1 및 CD3 모두와 반응성이다)을 제공한다. 일부 구현예에서, 본 개시내용의 항체는 인간 ROR1 또는 인간 CD3를 검출하고, ROR1 신호전달을 억제하고/하거나, 인간 ROR1-매개된 종양 성장 또는 전이를 억제하는 데(이들 모두 시험관 내 또는 생체 내에서) 유용하다. 추가로, 일부 구현예에서, 본원에 기재된 이중특이적 다가 결합 단백질은 ROR1-전향된 T 세포 세포독성 및/또는 ROR1-발현 악성 세포에 대한 생체내 효능있는 항-종양 활성을 유도하는 데 유용하다.
일부 구현예에서, 본 개시내용은 또한 본원에 기재된 항-ROR1 및 항-CD3 항체 및 ROR1/CD3 이중특이적 결합 단백질을 제조 및 사용하는 방법을 제공한다. 다양한 조성물, 예를 들어 샘플에서 ROR1 및/또는 CD3을 검출하는 방법, 및/또는 ROR1 및/또는 CD3 활성과 연관된 개인에서 장애를 치료 또는 예방하는 방법에 사용될 수 있는 조성물을 또한 개시한다.
도 1은 단클론 항체의 ROR1-ECD 단백질 결합 활성을 도시한다. 관련되지 않은 mIgG1이 음성 대조군으로서 사용되었다.
도 2A-B는 ROR1-발현 세포에 대한 항-ROR1 단클론 항체의 결합 활성을 예시한다. 관련되지 않은 mIgG1이 음성 대조군으로서 사용되었다.
도 3은 상응하는 모 항-CD3 단클론 항체와 비교된 ROR1 x CD3 이중특이적 항체의 CD3 결합 효능을 도시한다. 관련되지 않은 hIgG가 음성 대조군으로서 사용되었다.
도 4A-D는 ROR1-발현 종양 세포, (A) NCI-H1975, (B) MDA- MB-231, (C) A549 및 (D) RPMI-8226에 대한 ROR1 x CD3 이중특이적 항체 및 이들의 공유된 모 항-ROR1 단클론 IgG1 항체(HuROR1-mAb004-1)의 ROR1 결합 효능을 예시한다.
도 5는 단일특이적 항-CD3 IgG(HuEM1006-01-24 및 HuEM1006-01-27) 및 관련되지 않은 FIT-Ig(EMB01)와 비교된, ROR1 x CD3 이중특이적 FIT-Ig 및 MAT-Fab 항체에 의해 전향된 CD3 활성화를 측정하는 공-배양된 리포터 유전자 분석의 결과를 도시한다.
도 6은 단일특이적 항-CD3 IgG(HuEM1006-01-24 및 HuEM1006-01-27) 및 관련되지 않은 FIT-Ig(EMB01)와 비교된, 인간화된 ROR1 x CD3 이중특이적 항체 노출에 의한 비-표적 전향된 CD3 활성화를 시험하는 Jurkat-NFAT-luc 기반 리포터 유전자 분석의 결과를 도시한다.
도 7은 다양한 ROR1 x CD3 이중특이적 항체를 조사하는 전향된 T 세포 세포독성 분석의 결과를 도시한다. 관련되지 않은 FIT-Ig(EMB01)가 음성 대조군으로 사용되었다.
도 8은 ROR1 x CD3 이중특이적 항체 또는 비히클(vehicle) 대조군으로 처리된 인간 PBMC 생착된 M-NSG 마우스에서 MDA-MB-231 종양 부피의 프로파일을 도시한다.
도 9A-C는 인간화된 항-ROR1 항체 및 이중특이적 항체, (A) HuROR-mAb004-1, (B) FIT1007-12B-17 및 (C) MAT1007-12B-17을 사용하는 내재화 분석의 결과를 도시한다.
도 10A는 포맷 LH 및 포맷 HL에서 FIT-Ig 이중특이적 항체의 도메인 구조의도식적 도해를 제공한다. 도 10B는 포맷 LH 및 포맷 HL에서 MAT-Fab 이중특이적 항체의 도메인 구조의 도식적 도해를 제공한다.
도 11A는 ROR1 발현 MDA-MB-231 세포에 대한 FIT-Ig 분자의 세포 결합 활성을 도시한다. 도 11B는 CD3 발현 Jurkat 세포에 대한 FIT-Ig 분자의 세포 결합 활성을 도시한다. 도 11C는 FIT1007-12B-17을 2개의 참조 FIT-Ig 분자와 비교하는 전향된 T 세포 세포독성 분석의 결과를 도시한다.
도 2A-B는 ROR1-발현 세포에 대한 항-ROR1 단클론 항체의 결합 활성을 예시한다. 관련되지 않은 mIgG1이 음성 대조군으로서 사용되었다.
도 3은 상응하는 모 항-CD3 단클론 항체와 비교된 ROR1 x CD3 이중특이적 항체의 CD3 결합 효능을 도시한다. 관련되지 않은 hIgG가 음성 대조군으로서 사용되었다.
도 4A-D는 ROR1-발현 종양 세포, (A) NCI-H1975, (B) MDA- MB-231, (C) A549 및 (D) RPMI-8226에 대한 ROR1 x CD3 이중특이적 항체 및 이들의 공유된 모 항-ROR1 단클론 IgG1 항체(HuROR1-mAb004-1)의 ROR1 결합 효능을 예시한다.
도 5는 단일특이적 항-CD3 IgG(HuEM1006-01-24 및 HuEM1006-01-27) 및 관련되지 않은 FIT-Ig(EMB01)와 비교된, ROR1 x CD3 이중특이적 FIT-Ig 및 MAT-Fab 항체에 의해 전향된 CD3 활성화를 측정하는 공-배양된 리포터 유전자 분석의 결과를 도시한다.
도 6은 단일특이적 항-CD3 IgG(HuEM1006-01-24 및 HuEM1006-01-27) 및 관련되지 않은 FIT-Ig(EMB01)와 비교된, 인간화된 ROR1 x CD3 이중특이적 항체 노출에 의한 비-표적 전향된 CD3 활성화를 시험하는 Jurkat-NFAT-luc 기반 리포터 유전자 분석의 결과를 도시한다.
도 7은 다양한 ROR1 x CD3 이중특이적 항체를 조사하는 전향된 T 세포 세포독성 분석의 결과를 도시한다. 관련되지 않은 FIT-Ig(EMB01)가 음성 대조군으로 사용되었다.
도 8은 ROR1 x CD3 이중특이적 항체 또는 비히클(vehicle) 대조군으로 처리된 인간 PBMC 생착된 M-NSG 마우스에서 MDA-MB-231 종양 부피의 프로파일을 도시한다.
도 9A-C는 인간화된 항-ROR1 항체 및 이중특이적 항체, (A) HuROR-mAb004-1, (B) FIT1007-12B-17 및 (C) MAT1007-12B-17을 사용하는 내재화 분석의 결과를 도시한다.
도 10A는 포맷 LH 및 포맷 HL에서 FIT-Ig 이중특이적 항체의 도메인 구조의도식적 도해를 제공한다. 도 10B는 포맷 LH 및 포맷 HL에서 MAT-Fab 이중특이적 항체의 도메인 구조의 도식적 도해를 제공한다.
도 11A는 ROR1 발현 MDA-MB-231 세포에 대한 FIT-Ig 분자의 세포 결합 활성을 도시한다. 도 11B는 CD3 발현 Jurkat 세포에 대한 FIT-Ig 분자의 세포 결합 활성을 도시한다. 도 11C는 FIT1007-12B-17을 2개의 참조 FIT-Ig 분자와 비교하는 전향된 T 세포 세포독성 분석의 결과를 도시한다.
본 개시내용은 항-ROR1 항체, 항-CD3 항체, 이의 항원-결합 부분, 및 ROR1 및 CD3 모두에 결합하는 FIT-Ig 또는 MAT-Fab와 같은 다가의 이중특이적 결합 단백질에 관한 것이다. 본 개시내용의 다양한 양태는 항-ROR1 및 항-CD3 항체 및 항체 단편, 인간 ROR1 및 인간 CD3에 결합하는 FIT-Ig 및 MAT-Fab 결합 단백질, 및 이의 약제학적 조성물 뿐만 아니라 이러한 항체, 기능성 항체 단편 및 결합 단백질을 제조하기 위한 핵산, 재조합 발현 벡터(vector) 및 숙주 세포에 관한 것이다. 인간 ROR1, 인간 CD3, 또는 이 둘 모두를 검출하고; 인간 ROR1 및/또는 인간 CD3 활성을 시험관내에서 또는 생체내에서 조절하고; ROR1 및 CD3의 이들 각각의 리간드에의 결합에 의해 매개되는 질병, 특히 암을 치료하기 위해 본 개시내용의 항체, 기능성 항체 단편, 및 이중특이적 결합 단백질을 사용하는 방법이 또한 본 개시내용에 의해 포함된다.
정의
본원에서 달리 정의되지 않는 한, 본 발명과 관련하여 사용되는 과학 및 기술 용어는 당업자에 의해 일반적으로 이해되는 의미를 가질 것이다. 잠재된 모호성이 있는 경우 여기에 제공된 정의가 임의의 사전 또는 외부 정의보다 우선한다. 또한, 문맥상 달리 요구되지 않는 한, 단수 용어는 복수를 포함하고 복수 용어는 단수를 포함한다. 본원에서 "또는"("or")의 사용은 달리 언급하지 않는 한 "및/또는"("and/or")을 의미한다. 또한, "포함하는"("including")이라는 용어뿐만 아니라 "포함한다"("include") 및 "포함된"("included")과 같은 다른 형태의 사용은 제한되지 않는다. 또한, "요소"("element") 또는 "성분"("component")과 같은 용어는 달리 구체적으로 언급하지 않는 한 하나의 단위를 포함하는 요소 및 성분과 하나 이상의 하위 단위를 포함하는 요소 및 성분을 모두 포함한다.
본원에 사용된 바와 같이, 중쇄 및 경쇄의 모든 불변 영역 및 도메인의 아미노산 위치는 문헌[Kabat, et al., Sequences of Proteins of Immunological Interest, 5th ed., Public Health Service, National Institutes of Health, Bethesda, MD (1991)]에 기재된 카밧 넘버링(Kabat numbering) 시스템에 따라 넘버링되며, 본원에서 "Kabat에 따른 넘버링"으로서 지칭된다. 특히, 문헌[Kabat, et al., Sequences of Proteins of Immunological Interest, 5th ed., Public Health Service, National Institutes of Health, Bethesda, MD (1991)]의 카밧 넘버링 시스템(페이지 647-660 참조)은 카파 및 람다 동형(isotype)의 경쇄 불변 도메인 CL에 사용되고, Kabat EU 인덱스 넘버링 시스템(페이지 661-723 참조)은 불변 중쇄 도메인(CH1, 힌지, CH2 및 CH3, 이 경우에 이들은 본원에서 "Kabat EU 인덱스에 따른 넘버링"으로 지칭함으로써 더욱 명확해진다)에 사용된다.
인간 면역글로불린 경쇄 및 중쇄의 서열에 관한 일반 정보는 문헌[Kabat, E.A., et al., Sequences of Proteins of Immunological Interest, 5th ed., Public Health Service, National Institutes of Health, Bethesda, MD (1991)]에 제공되어 있다.
"단리된 단백질" 또는 "단리된 폴리펩티드"라는 용어는 이의 기원 또는 유래된 공급원으로 인해 천연 상태에서 동반되는 자연적으로 관련된 구성요소와 연관되지 않고, 동일한 종의 다른 단백질이 실질적으로 없으며, 상이한 종으로부터의 세포에 의해 발현되거나, 또는 자연에서 발생하지 않는 단백질 또는 폴리펩티드이다. 화학적으로 합성되거나 자연에서 기원하는 세포와 상이한 세포 시스템에서 합성되는 폴리펩티드는 자연적으로 연관된 성분으로부터 "단리"될 수 있다. 단백질은 또한 당업계에 주지된 단백질 정제 기술을 사용하여 단리에 의해, 자연적으로 연관된 성분이 실질적으로 없게 할 수 있다.
항체, 결합 단백질 또는 펩티드와 제2 화학종과의 상호작용과 관련하여 "특이적 결합" 또는 "특이적으로 결합하는"이라는 용어는 상기 상호작용이 상기 제2 화학종 상의 특정 구조(예를 들어, 항원성 결정인자 또는 에피토프)의 존재에 의존함을 의미한다. 예를 들어, 항체는 일반적인 단백질보다는 특정한 단백질 구조를 인식하고 이에 결합한다. 일반적으로, 항체가 에피토프 "A"에 특이적이라면, 표지된 "A"와 항체를 함유하는 반응에서 에피토프 A(또는 표지되지 않은 유리 A)를 함유하는 분자의 존재는 상기 항체에 결합된 표지된 A의 양을 감소시킬 것이다.
"항체"라는 용어는 광범위하게 4개의 폴리펩티드 쇄, 2개의 중(H)쇄 및 2개의 경(L)쇄로 구성된 임의의 면역글로불린(Ig) 분자, 또는 Ig 분자의 필수적인 에피토프 결합 특징을 유지하는 이의 임의의 기능적 단편, 돌연변이체, 변이체 또는 유도체를 지칭한다. 이러한 돌연변이체, 변이체, 또는 유도체 항체 포맷은 당업계에 공지되어 있고 비-제한적인 구현예가 하기에서 논의된다.
완전길이 항체(full-length antibody)에서, 각 중쇄는 중쇄 가변 영역(본원에서는 VH로 약칭함) 및 중쇄 불변 영역으로 구성된다. 중쇄 불변 영역은 CH1, CH2 및 CH3의 3개 도메인으로 구성된다. 각 경쇄는 경쇄 가변 영역(본원에서는 VL로 약칭함) 및 경쇄 불변 영역으로 구성된다. 경쇄 불변 영역은 하나의 도메인 CL로 구성된다. VH 및 VL 영역은 상보성 결정 영역(CDR)이라고 하는 고가변 영역으로 추가 세분될 수 있으며, 프레임워크 영역(FR)이라고 하는 보다 보존된 영역이 산재되어 있다. 각각의 VH 및 VL은 아미노 말단으로부터 카복시 말단까지 FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4의 순서로 배열된 3개의 CDR과 4개의 FR로 구성된다. VH 도메인의 첫 번째, 두 번째 및 세 번째 CDR은 일반적으로 CDR-H1, CDR-H2 및 CDR-H3으로 열거되며; 마찬가지로 VL 도메인의 첫 번째, 두 번째 및 세 번째 CDR은 일반적으로 CDR-L1, CDR-L2 및 CDR-L3으로 열거된다. 면역글로불린 분자는 임의의 유형(예를 들어, IgG, IgE, IgM, IgD, IgA 및 IgY), 부류(예를 들어, IgG1, IgG2, IgG3, IgG4, IgA1 및 IgA2) 또는 하위부류의 것일 수 있다.
"Fc 영역"이라는 용어는 온전한 항체의 파파인 절단(papain digestion)에 의해 생성될 수 있는 면역글로불린 중쇄의 C-말단 영역을 정의하는 데 사용된다. Fc 영역은 고유 서열 Fc 영역 또는 변이 Fc 영역일 수 있다. 면역글로불린의 Fc 영역은 일반적으로 2개의 불변 도메인, 즉 CH2 도메인 및 CH3 도메인을 포함하고, 예를 들어 IgM 및 IgE 항체의 Fc 영역의 경우에서와 같이 임의로 CH4 도메인을 포함한다. IgG, IgA 및 IgD 항체의 Fc 영역은 힌지 영역(hinge region), CH2 도메인 및 CH3 도메인을 포함한다. 대조적으로, IgM 및 IgE 항체의 Fc 영역은 힌지 영역이 없지만 CH2 도메인, CH3 도메인 및 CH4 도메인을 포함한다. 항체 효과기 기능을 변경시키기 위해 Fc 부분에서 아미노산 잔기의 대체를 갖는 변이 Fc 영역은 당업계에 공지되어 있다(예를 들어, Winter et al., 미국특허 제5,648,260호 및 제5,624,821호를 참조하시오). 항체의 Fc 부분은 하나 이상의 효과기 기능, 예를 들어 사이토카인 유도, ADCC, 식균작용, 보체 의존적인 세포독성(CDC) 및/또는 항체 및 항원-항체 복합체의 반감기/제거율을 매개할 수 있다. 일부의 경우, 이러한 효과기 기능이 치료용 항체에 바람직하지만 다른 경우에는 치료 목적에 따라 불필요하거나 심지어 해로울 수 있다. 특정의 인간 IgG 동형, 특히 IgG1 및 IgG3은 각각 FcγR 및 보체 C1q에의 결합을 통해 ADCC 및 CDC를 매개한다. 더욱 또 다른 구현예에서 적어도 하나의 아미노산 잔기는 항체의 효과기 기능이 변경되도록 항체의 불변 영역, 예를 들어 항체의 Fc 영역에서 대체된다. 면역글로불린의 2개의 동일한 중쇄의 이량체화는 CH3 도메인의 이량체화에 의해 매개되고 CH1 불변 도메인을 Fc 불변 도메인(예를 들어, CH2 및 CH3)에 연결하는 힌지 영역 내의 디설파이드 결합에 의해 안정화된다. IgG의 소염 활성은 IgG Fc 단편의 N-결합 글리칸의 시알화에 의존한다. 소염 활성을 위한 정확한 글리칸 요건이 결정되었으며, 따라서 적합한 IgG1 Fc 단편이 생성될 수 있고, 이에 의해 효능이 크게 향상된 완전한 재조합 시알화된 IgG1 Fc를 생성시킬 수 있다(문헌[Anthony et al., Science, 320:373-376 (2008)]을 참조하시오).
항체의 "항원-결합 부분" 및 "항원-결합 단편" 또는 "기능적 단편"이라는 용어는 호환가능하게 사용되며 항원, 즉 일부 또는 단편이 유래되는 완전길이 항체와 동일한 항원(예를 들어, ROR1, CD3)에 특이적으로 결합하는 능력을 유지하는 항체의 하나 이상의 단편을 지칭한다. 항체의 항원 결합 기능은 완전길이 항체의 단편에 의해 수행될 수 있음이 밝혀졌다. 이러한 항체 구현예는 또한 이중특이적, 이중 특이적(dual specific) 또는 다중-특이적 포맷일 수 있으며; 2개 이상의 상이한 항원(예를 들어, ROR1, 및 CD3과 같은 상이한 항원)에 특이적으로 결합한다. 항체의 "항원-결합 부분"이라는 용어 내에 포함되는 결합 단편의 예는 (i) VL, VH, CL 및 CH1 도메인으로 이루어지는 1가 단편인 Fab 단편; (ii) 힌지 영역에서 디설파이드 브릿지(disulfide bridge)에 의해 연결된 2개의 Fab 단편을 포함하는 2가 단편인 F(ab')2 단편; (iii) VH 및 CH1 도메인으로 이루어지는 Fd 단편; (iv) 항체의 단일 가지의 VL 및 VH 도메인으로 이루어지는 Fv 단편, (v) 단일 가변 도메인을 포함하는 dAb 단편(Ward et al., Nature, 341: 544-546 (1989); PCT 공개 번호 WO 90/05144); 및 (vi) 단리된 상보성 결정 영역(CDR)을 포함한다. 또한, Fv 단편의 두 도메인인 VL과 VH는 별도의 유전자에 의해 암호화되지만, 이들은 재조합 방법을 사용하여, 상기 VL 및 VH 영역이 쌍을 이루어 1가 분자(단쇄 Fv(scFv)로서 공지됨; 예를 들어 문헌[Bird et al., Science, 242: 423-426 (1988)]; 및 문헌[Huston et al., Proc. Natl. Acad. Sci. USA, 85: 5879-5883 (1988)]을 참조하시오)를 형성하는 단일 단백질 쇄로서 제조될 수 있게 하는 합성 링커(linker)에 의해 결합될 수 있다. 이러한 단쇄 항체는 또한 항체의 "항원-결합 부분"이라는 용어 및 상기 제공된 균등한 용어 내에 포함되는 것으로 의도된다. 디아바디와 같은 단쇄 항체의 다른 형태도 포함된다. 디아바디는, VH 및 VL 도메인이 단일 폴리펩티드 쇄에서, 그러나 동일한 쇄 상에서 상기 두 도메인 간에 쌍을 이루기에는 너무 짧아 상기 도메인이 또 다른 쇄의 상보성 도메인과 강제로 쌍을 이루어 2개의 항원 결합 부위를 생성시키는 링커를 사용하여 발현되는 2가의 이중특이적 항체이다(예를 들어 문헌[Holliger et al., Proc. Natl. Acad. Sci. USA, 90: 6444-6448 (1993)]을 참조하시오). 이와 같은 항체 결합 부분은 당업계에 공지되어 있다(Kontermann and D bel eds., Antibody Engineering (Springer-Verlag, New York, 2001), p. 790 (ISBN 3-540-41354-5)). 또한, 단쇄 항체는 상보적인 경쇄 폴리펩티드와 함께 한 쌍의 항원 결합 영역을 형성하는 한 쌍의 탠덤 Fv 분절(VH-CH1-VH-CH1)을 포함하는 "선형 항체"를 포함한다(Zapata et al., Protein Eng., 8(10): 1057-1062(1995); 및 미국특허 제5,641,870호).
bel eds., Antibody Engineering (Springer-Verlag, New York, 2001), p. 790 (ISBN 3-540-41354-5)). 또한, 단쇄 항체는 상보적인 경쇄 폴리펩티드와 함께 한 쌍의 항원 결합 영역을 형성하는 한 쌍의 탠덤 Fv 분절(VH-CH1-VH-CH1)을 포함하는 "선형 항체"를 포함한다(Zapata et al., Protein Eng., 8(10): 1057-1062(1995); 및 미국특허 제5,641,870호).
면역글로불린 불변(C) 도메인은 중쇄(CH) 또는 경쇄(CL) 불변 도메인을 지칭한다. 뮤린 및 인간 IgG 중쇄 및 경쇄 불변 도메인 아미노산 서열은 당업계에 공지되어 있다.
"단클론 항체" 또는 "mAb"라는 용어는 실질적으로 동종인 항체 집단으로부터 수득된 항체를 지칭한다, 즉 집단을 구성하는 개별 항체는 소량으로 존재할 수 있는 가능한 자연 발생 돌연변이를 제외하고는 동일하다. 단클론 항체는 단일 항원 결정인자(에피토프)에 대한 것으로, 고도로 특이적이다. 또한, 전형적으로 상이한 결정인자(에피토프)에 대해 지시된 상이한 항체를 포함하는 다클론 항체 제제와 대조적으로, 각 mAb는 항원상의 단일 결정인자에 대해 지시된다. 수식어 "단클론"은 임의의 특정 방법에 의한 항체 생성을 필요로 하는 것으로 해석되지 않는다.
본원에 따른 항체 또는 결합 단백질의 경쇄 불변 도메인 CL, 중쇄 불변 도메인 CH 및 Fc 영역과 관련하여 "인간 서열"이라는 용어는 서열이 인간 면역글로불린 서열의, 또는 인간 면역글로불린 서열로부터 유래함을 의미한다. 본 개시내용의 인간 서열은 고유 인간 서열, 또는 하나 이상(예를 들어, 최대 20, 15, 10)의 아미노산 잔기 변화를 포함하는 이의 변이체일 수 있다.
"키메라 항체(chimeric antibody)"라는 용어는 하나의 종으로부터의 중쇄 및 경쇄 가변 영역 서열 및 또 다른 종으로부터의 불변 영역 서열을 포함하는 항체, 예를 들어 인간 불변 영역에 연결된 뮤린 중쇄 및 경쇄 가변 영역을 갖는 항체를 지칭한다.
"CDR-접목된 항체"라는 용어는, 하나의 종의 중쇄 및 경쇄 가변 영역 서열을 포함하지만 VH 및/또는 VL의 CDR 영역 중 하나 이상의 서열이 또 다른 종의 CDR 서열로 대체된 항체, 예를 들어 인간 CDR 중 하나 이상이 뮤린 CDR 서열로 대체된 인간 중쇄 및 경쇄 가변 영역을 갖는 항체를 지칭한다.
"인간화된 항체"라는 용어는, 비-인간 종(예를 들어, 마우스)으로부터의 중쇄 및 경쇄 가변 영역 서열을 포함하지만 VH 및/또는 VL 서열의 적어도 일부가 보다 "인간-유사"하도록, 즉 인간 생식세포계열 가변 서열과 보다 유사하도록 변경된 항체를 지칭한다. 인간화된 항체의 한 유형은 비-인간 종(예를 들어, 마우스)의 CDR 서열이 인간 VH 및 VL 프레임워크 서열에 도입된 CDR-접목된 항체이다. 인간화된 항체는 목적 항원에 면역특이적으로 결합하고 실질적으로 인간 항체의 아미노산 서열을 갖는 프레임워크 영역 및 불변 영역이지만, 실질적으로 비-인간 항체의 아미노산 서열을 갖는 상보성 결정 영역(CDR)을 포함하는 항체 또는 이의 변이체, 유도체, 유사체 또는 단편이다. 본원에 사용된 바와 같이 CDR의 맥락에서 "실질적으로"라는 용어는 비-인간 CDR의 아미노산 서열에 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 일치하는 아미노산 서열을 갖는 CDR을 지칭한다. 인간화된 항체는 적어도 하나, 및 전형적으로 2개의 가변 도메인(Fab, Fab', F(ab')2, Fv)을 실질적으로 전부 포함하며, 여기서 CDR 영역의 전부 또는 실질적으로 전부는 비-인간 면역글로불린(즉, 공여자 항체)의 영역에 상응하고 프레임워크 영역의 전부 또는 실질적으로 전부는 인간 면역글로불린 공통 서열의 영역이다. 하나의 구현예에서, 인간화된 항체는 또한 면역글로불린 불변 영역(Fc)의 적어도 일부, 전형적으로는 인간 면역글로불린의 부분을 포함한다. 일부 구현예에서, 인간화된 항체는 경쇄뿐만 아니라 적어도 중쇄의 가변 도메인을 모두 함유한다. 항체는 또한 중쇄의 CH1, 힌지, CH2, CH3 및 CH4 영역을 포함할 수 있다. 일부 구현예에서, 인간화된 항체는 인간화된 경쇄만을 함유한다. 일부 구현예에서, 인간화된 항체는 인간화된 중쇄만을 함유한다. 특정 구현예에서, 인간화된 항체는 경쇄 및/또는 인간화된 중쇄의 인간화된 가변 도메인만을 함유한다.
인간화된 항체는 IgM, IgG, IgD, IgA 및 IgE를 포함하는 면역글로불린의 임의 부류, 및 비제한적으로 IgG1, IgG2, IgG3 및 IgG4를 포함하는 임의의 동형 중에서 선택될 수 있다. 인간화된 항체는 하나 이상의 부류 또는 동형으로부터의 서열을 포함할 수 있고, 특정 불변 도메인을 선택하여 당업계에 주지된 기법을 사용하여 목적하는 효과기 기능을 최적화할 수 있다.
인간화된 항체의 프레임워크 및 CDR 영역은 모 서열(parental sequence)과 정확히 일치할 필요는 없다, 예를 들어 공여자 항체 CDR 또는 수용자 프레임워크는 적어도 하나의 아미노산 잔기의 치환, 삽입 및/또는 결실에 의해 돌연변이될 수 있으므로 해당 부위의 CDR 또는 프레임워크 잔기가 공여자 항체 또는 공통 프레임워크(consensus framework)에 해당하지 않는다. 그러나 예시적인 구현예에서, 이러한 돌연변이는 광범위하지 않을 것이다. 일반적으로, 인간화된 항체 잔기의 적어도 80%, 적어도 85%, 적어도 90%, 또는 적어도 95%는 모 FR 및 CDR 서열의 잔기에 상응할 것이다. 공여자 항체의 해당 위치에 나타나는 동일한 아미노산을 복원하기 위한 특정 프레임워크 위치에서의 역돌연변이는 종종, 특정 루프 구조를 보존하거나 표적 항원과의 접촉을 위해 CDR 서열을 올바르게 배향시키기 위해 이용된다.
"CDR"이라는 용어는 항체 가변 도메인 서열 내의 상보성 결정 영역을 의미한다. 중쇄 및 경쇄의 각 가변 영역에는 CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3으로 지정된 3개의 CDR이 있다. 본원에 사용된 바와 같은 "CDR 세트"라는 용어는 항원에 결합할 수 있는 단일 가변 영역에서 발생하는 3개의 CDR의 그룹을 지칭한다. 이러한 CDR의 정확한 경계는 다른 시스템에 따라 다르게 정의되었다. 문헌[Kabat et al., Sequences of Proteins of Immunological Interest (National Institutes of Health, Bethesda, Maryland (1987) and (1991)]에 기재된 시스템은 항체의 임의의 가변 영역에 적용 가능한 명확한 잔기 넘버링 시스템을 제공할 뿐만 아니라, 3개의 CDR을 정의하는 정확한 잔기 경계를 제공한다.
당업계에서 인식되는 항체의 중쇄 및 경쇄 CDR과 관련하여 "카밧 넘버링"이라는 용어는 항체 또는 이의 항원 결합 부분의 중쇄 및 경쇄 가변 영역에서 다른 아미노산 잔기보다 더 가변적인(즉, 고가변성) 아미노산 잔기의 넘버링 시스템을 지칭한다. 문헌[Kabat et al., Ann. NY Acad. Sci., 190: 382-391 (1971)]; 및 문헌[Kabat et al., Sequences of Proteins of Immunological Interest, Fifth Edition, U.S. Department of Health and Human Services, NIH Publication No. 91-3242 (1991)]을 참조하시오.
지난 20년 동안 가변 중쇄 및 경쇄 영역의 아미노산 서열에 대한 광범위한 공개 데이터베이스의 성장 및 분석은 프레임워크 영역(FR)과 가변 영역 서열 내의 CDR 서열 사이의 전형적인 경계에 대한 이해를 가져왔고 숙련가로 하여금 CDR을 카밧 넘버링, Chothia 넘버링, 또는 다른 시스템에 따라 정확하게 결정할 수 있게 하였다. 예를 들어 문헌[Martin, "Protein Sequence and Structure Analysis of Antibody Variable Domains," In Kontermann and D bel, eds., Antibody Engineering (Springer-Verlag, Berlin, 2001), chapter 31, pages 432-433]을 참조하시오.
bel, eds., Antibody Engineering (Springer-Verlag, Berlin, 2001), chapter 31, pages 432-433]을 참조하시오.
"다가 결합 단백질"이라는 용어는 2개 이상의 항원 결합 부위를 포함하는 결합 단백질을 나타낸다. 다가 결합 단백질은 특정 경우에 3개 이상의 항원 결합 부위를 갖도록 조작되며 일반적으로 자연 발생 항체가 아니다. "이중특이적 결합 단백질"(달리 언급되지 않는 한, "이중특이적 항체"라는 용어와 호환가능하게 사용될 수 있다)이라는 용어는 특이성이 다른 두 표적에 결합할 수 있는 결합 단백질을 의미한다. 본 개시내용의 FIT-Ig 결합 단백질은 4개의 항원 결합 부위를 포함하며 전형적으로 4가 결합 단백질이다. 본 개시내용의 MAT-Fab 결합 단백질은 2개의 항원 결합 부위를 포함하고 전형적으로 2가 결합 단백질이다. 본 개시내용에 따른 FIT-Ig 또는 MAT-Fab는 ROR1 및 CD3 모두에 결합하고 이중특이적이다.
2개의 긴(중쇄) V-C-V-C-Fc 폴리펩티드 및 4개의 짧은(경쇄) V-C 폴리펩티드를 포함하는 FIT-Ig 결합 단백질은 4개의 Fab 항원 결합 부위(VL-CL과 쌍을 이루는 VH-CH1, 때때로 VH-CH1::VL-CL로 표시됨)를 나타내는 육량체(hexamer)를 형성한다. FIT-Ig의 각 절반은 중쇄 폴리펩티드 및 2개의 경쇄 폴리펩티드를 포함하고, 상기 3개의 쇄의 VH-CH1 및 VL-CL 요소의 상보적인 면역글로불린 쌍은 직렬로 배열된 2개의 Fab-구조화된 항원 결합 부위를 생성시킨다. 본 개시내용에서 Fab 요소를 포함하는 면역글로불린 도메인은 도메인간 링커를 사용하지 않고 중쇄 폴리펩티드에 직접 융합되는 것이 바람직하다. 즉, 긴(중쇄) 폴리펩티드 쇄의 N-말단 V-C 요소는 이의 C-말단에서 또 다른 V-C 요소의 N-말단에 직접 융합되며, 이는 차례로 C-말단 Fc 영역에 연결된다. 이중특이적 FIT-Ig 결합 단백질에서, 탠덤 Fab 요소는 상이한 항원과 반응할 수 있다. 각 Fab 항원 결합 부위는 항원 결합 부위당 총 6개의 CDR이 있는 중쇄 가변 도메인과 경쇄 가변 도메인을 포함한다.
FIT-Ig 분자의 설계, 발현 및 특성화에 대한 설명은 PCT 공개 WO 2015/103072에서 제공된다. 이러한 FIT-Ig 분자의 예는 중쇄 및 2개의 상이한 경쇄를 포함한다. 중쇄는 구조식 VLA-CL-VHB-CH1-Fc(여기서 CL은 VHB에 직접 융합된다)(즉 "포맷 LH") 또는 VHA-CH1-VLB-CL-Fc(여기서 CH1은 VLB에 직접 융합된다(즉 "포맷 HL")를 포함하고, FIT-Ig의 2개의 경쇄 폴리펩티드는 상응하게 각각 화학식 VHA-CH1 및 VLB-CL("포맷 LH"의 경우) 또는 VLA-CL 및 VHB-CH1("포맷 HL"의 경우)을 가지며; 여기서 VLA는 항원 A에 결합하는 모 항체로부터의 가변 경쇄 도메인이고, VLB는 항원 B에 결합하는 모 항체로부터의 가변 경쇄 도메인이고, VHA는 항원 A에 결합하는 모 항체로부터의 가변 중쇄 도메인이고, VHB는 항원 B에 결합하는 모 항체로부터의 가변 중쇄 도메인이고, CL은 경쇄 불변 도메인이고, CH1은 중쇄 불변 도메인이고, Fc는 면역글로불린 Fc 영역(예를 들어, IgG1 항체의 중쇄의 C-말단 힌지-CH2-CH3 부분)이다. 이중특이적 FIT-Ig 구현예에서, 항원 A 및 항원 B는 상이한 항원이거나 동일한 항원의 상이한 에피토프이다. 본 개시내용에서 A 및 B 중 하나는 ROR1이고 다른 하나는 CD3이며, 예를 들어 A는 ROR1이고 B는 CD3이다.
1개의 긴(중쇄)V-C-V-C-Fc 폴리펩티드, 2개의 짧은(경쇄) V-C 폴리펩티드, 및 1개의 면역학적 Fc 쇄 폴리펩티드를 포함하는 MAT-Fab 결합 단백질은 일렬로 배열된 2개의 Fab 항원 결합 부위를 나타내는 사량체(VH-CH1은 VL-CL과 쌍을 이루고, 때때로 VH-CH1::VL-CL로 표시됨), 및 하나의 Fc:Fc 이량체를 형성한다. 종종 MAT-Fab 중쇄의 Fc 영역의 CH3 도메인(CH3m1 도메인으로 약칭) 및 또한 MAT-Fab Fc 폴리펩티드 쇄의 CH3 도메인(CH3m2 도메인으로 약칭)에 변형이 도입되어 상기 2개의 CH3 도메인의 이종이량체화(heterodimerization)를 촉진한다. 상기 변형은 "구멍에 손잡이"(Knob-in-hole; KIH) 돌연변이일 수 있다, 예를 들어 상보적인 구조적 구멍을 포함하는 Fc 쇄의 CH3m2 도메인과 쌍을 이루기 위해 중쇄의 CH3m1 도메인에 구조적 손잡이를 형성하도록 돌연변이가 만들어진다. 그러나 도메인 염 가교 또는 정전기적 상호작용에 도입되는 것들과 같은 다른 변형도 또한 유용하다. 불변 영역은 또한 다른 변형, 예를 들어 MAT-Fab 분자를 안정시키기 위한 Cys 잔기, 및/또는 Fc 효과기 기능을 방지하거나 손상시키기 위한 돌연변이일 수 있다. 바람직하게는, 본원에 기재된 MAT-Fab 이중특이적 항체 구조의 특징은 모든 인접한 면역글로불린 중쇄 및 경쇄 가변 및 불변 도메인이 개재 합성 아미노산 또는 펩티드 링커 없이 서로 직접 연결된다는 것이다.
MAT-Fab 분자의 설계, 발현 및 특성화에 대한 설명은 PCT 공개 WO2018/035084에서 제공된다. 이러한 MAT-Fab 분자의 일례는 Fc 영역에 "손잡이"가 있는 중쇄, 2개의 상이한 경쇄, 및 "구멍"이 있는 하나의 Fc 폴리펩티드 쇄를 포함한다. 일부 구현예에서, 중쇄는 구조식 VLA-CL-VHB-CH1-힌지-CH2-CH3m1(여기서 CL은 VHB에 직접 융합된다)(즉 "포맷 LH") 또는 VHA-CH1-VLB-CL-Fc(여기서 CH1은 VLB에 직접 융합된다(즉 "포맷 HL")를 포함하고, MAT-Fab의 2개의 경쇄 폴리펩티드 쇄는 상응하게 각각 화학식 VHA-CH1 및 VLB-CL("포맷 LH"의 경우) 또는 VLA-CL 및 VHB-CH1("포맷 HL"의 경우)을 가지며; 여기서 VLA는 항원 A에 결합하는 모 항체로부터의 가변 경쇄 도메인이고, VLB는 항원 B에 결합하는 모 항체로부터의 가변 경쇄 도메인이고, VHA는 항원 A에 결합하는 모 항체로부터의 가변 중쇄 도메인이고, VHB는 항원 B에 결합하는 모 항체로부터의 가변 중쇄 도메인이고, CL은 경쇄 불변 도메인이고, CH1은 중쇄 불변 도메인 1이고, CH3m1은 S354C 및 T366W와 같은 손잡이 돌연변이를 갖는 중쇄 불변 도메인 3이다. Fc 폴리펩티드 쇄는 CH3m2 중에 T366S, L368A, 및 Y407V와 같은 손잡이 돌연변이에 상보성인 구멍 돌연변이를 갖는, 면역글로불린(예를 들어 IgG 항체)의 중쇄의 C-말단 힌지-CH2-CH3 부분일 수 있다. 이중특이적 MAT-Fab 구현예에서, 항원 A 및 항원 B는 상이한 항원이거나 동일한 항원의 상이한 에피토프이다. 본 개시내용에서 A 및 B 중 하나는 ROR1이고 다른 하나는 CD3이며, 예를 들어 A는 ROR1이고 B는 CD3이다.
본원에 사용된 바와 같은 "kon"(또한 "Kon", "kon")이라는 용어는 당업계에 공지된 바와 같이 결합 복합체, 예를 들어 항체/항원 복합체를 형성하는, 항원에 대한 결합 단백질(예를 들어, 항체)의 결합에 대한 결합속도 상수를 지칭한다. "kon"은 또한 본원에서 호환가능하게 사용되는 바와 같은 "결합속도 상수" 또는 "ka"라는 용어로도 공지되어 있다. 이 값은 항체가 이의 표적 항원에 결합하는 속도 또는 항체와 항원 간의 복합체 형성 속도를 나타내며 하기의 식으로 나타낸다:
항체("Ab") + 항원("Ag") → Ab-Ag.
본원에 사용된 바와 같은 "koff"(또한 "Koff", "koff")라는 용어는 당업계에 공지된 바와 같이 결합 복합체(예를 들어, 항체/항원 복합체)로부터의 결합 단백질(예를 들어, 항체)의 해리를 위한 해리속도 상수, 또는 "해리 속도 상수"를 지칭하고자 한다. 이 값은 항체가 이의 표적 항원으로부터 해리되는 속도 또는 시간에 따른 Ab-Ag 복합체의 유리 항체와 항원으로의 분리를 가리키며 하기의 식으로 나타낸다:
Ab + Ag ← Ab-Ag.
본원에 사용되는 바와 같이 "KD"(또한 "Kd")라는 용어는 "평형 해리 상수"를 지칭하고자 하며, 평형 상태에서 적정 측정에서 얻은 값, 또는 해리속도 상수(koff)를 결합속도 상수(kon)로 나누어 얻은 값을 지칭한다. 결합속도 상수(kon), 해리속도 상수(koff), 및 평형 해리 상수(KD)는 항원에 대한 항체의 결합 친화도를 나타내는 데 사용된다. 결합 및 해리속도 상수를 측정하는 방법은 당업계에 주지되어 있다. 형광-기반 기법의 사용은 고감도 및 평형시 생리 완충제 중에서 샘플을 검사할 수 있는 능력을 제공한다. 다른 실험 접근법 및 장비, 예를 들어 BIAcore®(생물분자 상호작용 분석) 분석을 사용할 수 있다(예를 들어 BIAcore International AB, a GE Healthcare company, Uppsala, Sweden으로부터 입수할 수 있는 장비). 예를 들어 Octet® RED96 시스템(Pall Fort Bio LLC)을 사용하는 생물층 간섭계(BLI)가 또 다른 친화도 분석 기법이다. 추가로, Sapidyne Instruments(Boise, Idaho)로부터 입수할 수 있는 KinExA®(Kinetic Exclusion Assay) 분석을 또한 사용할 수 있다.
Bio LLC)을 사용하는 생물층 간섭계(BLI)가 또 다른 친화도 분석 기법이다. 추가로, Sapidyne Instruments(Boise, Idaho)로부터 입수할 수 있는 KinExA®(Kinetic Exclusion Assay) 분석을 또한 사용할 수 있다.
"단리된 핵산"이란 용어는 인간의 개입에 의해, 상기가 자연에서 발견되는 폴리뉴클레오티드의 전부 또는 일부와 연관되지 않거나; 상기가 자연에서는 연결되지 않는 폴리뉴클레오티드에 작동가능하게 연결되거나; 또는 더 큰 서열의 일부로서 자연에서는 존재하지 않는 폴리뉴클레오티드(예를 들어, 게놈, cDNA 또는 합성 기원, 또는 이들의 일부 조합의)를 의미한다.
본원에 사용된 바와 같은 "벡터"라는 용어는 상기가 연결된 또 다른 핵산을 수송할 수 있는 핵산 분자를 지칭하고자 한다. 한 가지 유형의 벡터는 "플라스미드"이며, 이는 추가적인 DNA 분절이 결찰될 수 있는 원형 이중 가닥 DNA 루프를 지칭한다. 또 다른 유형의 벡터는 바이러스 벡터이며, 여기서 추가적인 DNA 분절이 바이러스 게놈에 결찰될 수 있다. 특정 벡터는 상기가 도입되는 숙주 세포에서 자가 복제가 가능하다(예를 들어, 세균 복제 기원을 갖는 세균 벡터 및 에피솜 포유동물 벡터). 다른 벡터(예를 들어, 비-에피솜 포유동물 벡터)는 숙주 세포내로 도입시 상기 숙주 세포의 게놈으로 통합될 수 있고, 이로써 숙주 게놈과 함께 복제된다. 또한, 특정 벡터는 작동적으로 연결된 유전자의 발현을 지시할 수 있다. 이러한 벡터는 본원에서 "재조합 발현 벡터"(또는 간단히 "발현 벡터")로 지칭된다. 일반적으로, 재조합 DNA 기법에 유용한 발현 벡터는 종종 플라스미드 형태이다. 본 명세서에서 "플라스미드"와 "벡터"는, 플라스미드가 가장 일반적으로 사용되는 벡터 형태이므로, 호환가능하게 사용될 수 있다. 그러나, 본 개시내용은 동등한 기능을 제공하는 바이러스 벡터(예를 들어, 복제 결함 레트로바이러스, 아데노바이러스 및 아데노-관련 바이러스)와 같은 다른 형태의 발현 벡터를 포함하고자 한다.
"작동가능하게 연결된"이라는 용어는 기재된 성분이 의도된 방식으로 기능하도록 허용하는 관계에 있는 병치를 지칭한다. 암호화 서열(coding sequence)에 "작동적으로 연결된" 조절 서열은 암호화 서열의 발현이 상기 조절 서열과 호환되는 조건 하에서 달성되는 방식으로 결찰된다. "작동적으로 연결된" 서열은, 목적 유전자와 인접한 발현 조절 서열 및 목적 유전자를 조절하기 위해 트랜스로 또는 멀리 떨어져서 작용하는 발현 조절 서열을 모두 포함한다. 본원에 사용된 바와 같은 "발현 조절 서열"이라는 용어는 상기가 연결된 암호화 서열의 발현 및 처리에 영향을 미치는 데 필요한 폴리뉴클레오티드 서열을 지칭한다. 발현 조절 서열은 적합한 전사 개시, 종결, 프로모터(promoter) 및 인핸서 서열을 포함하고; 스플라이싱 및 폴리아데닐화 신호와 같은 효율적인 RNA 가공 신호; 세포질 mRNA를 안정화시키는 서열; 번역 효율을 향상시키는 서열(즉, Kozak 공통 서열); 단백질 안정성을 향상시키는 서열; 및 목적하는 경우 단백질 분비를 향상시키는 서열을 포함한다. 이러한 조절 서열의 특성은 숙주 유기체에 따라 다르며; 원핵생물에서, 이러한 조절 서열은 일반적으로 프로모터, 리보솜 결합 부위 및 전사 종결 서열을 포함하고; 진핵생물에서, 일반적으로 이러한 조절 서열은 프로모터 및 전사 종결 서열을 포함한다. "조절 서열"이라는 용어는 그 존재가 발현 및 처리에 필수적인 성분을 포함하고자 하며, 예를 들어 리더 서열 및 융합 상대 서열과 같이 그 존재가 유리한 추가적인 성분을 포함할 수도 있다.
본원에 정의된 바와 같은 "형질전환"은 외인성 DNA가 숙주 세포에 들어가는 임의의 과정을 지칭한다. 형질전환은 당업계에 주지된 다양한 방법을 사용하여 자연적으로, 또는 인공적인 조건 하에서 일어날 수 있다. 형질전환은 외래 핵산 서열을 원핵 또는 진핵 숙주 세포에 삽입하기 위한 임의의 공지된 방법에 의존할 수 있다. 상기 방법은 형질전환되는 숙주 세포에 기초하여 선택되며 형질감염, 바이러스 감염, 일렉트로포레이션(electroporation), 리포펙션(lipofection) 및 입자 충격을 포함할 수 있지만 이에 제한되지 않는다. 이러한 "형질전환된" 세포는 삽입된 DNA가 자가 복제 플라스미드로서 또는 숙주 염색체의 일부로서 복제할 수 있는 안정적으로 형질전환된 세포를 포함한다. 상기는 또한 제한된 시간 동안 삽입된 DNA 또는 RNA를 일시적으로 발현하는 세포를 포함한다.
"재조합 숙주 세포"(또는 간단히 "숙주 세포")라는 용어는 외인성 DNA가 도입된 세포를 지칭하고자 한다. 하나의 구현예에서, 숙주 세포는 예를 들어 미국특허 제7,262,028호에 기재된 숙주 세포와 같이, 항체를 암호화(encoding)하는 2개 이상(예를 들어, 다수)의 핵산을 포함한다. 이러한 용어는 특정한 피실험 세포뿐만 아니라 이러한 세포의 자손도 지칭하고자 한다. 돌연변이 또는 환경적 영향으로 인해 다음 세대에서 특정 변형이 발생할 수 있기 때문에 이러한 자손은 실제로 부모 세포와 동일하지 않을 수 있지만 여전히 본원에서 사용되는 "숙주 세포"라는 용어의 범위 내에 포함된다. 하나의 구현예에서, 숙주 세포는 임의의 생명의 왕국으로부터 선택된 원핵 및 진핵 세포를 포함한다. 다른 구현예에서, 진핵 세포는 원생생물, 진균, 식물 및 동물 세포를 포함한다. 또 다른 구현예에서, 숙주 세포는 원핵 세포주 에스케리키아 콜라이(Escherichia coli); 포유동물 세포주 CHO, HEK 293, COS, NS0, SP2 및 PER.C6; 곤충 세포주 Sf9; 및 진균 세포 사카로마이세스 세레비지아에(Saccharomyces cerevisiae)를 포함하지만 이에 제한되지 않는다.
본원에 사용된 바와 같이, "유효량"이라는 용어는 장애 또는 이의 하나 이상의 증상의 중증도(severity) 및/또는 지속 기간을 감소시키거나 완화시키고; 장애의 진행을 방지하고; 장애의 퇴행을 유발하고; 장애와 관련된 하나 이상의 증상의 재발, 발달 또는 진행을 방지하고; 장애를 검출하거나; 또는 또 다른 요법(예를 들어, 예방제 또는 치료제)의 예방학적 또는 치료학적 효과(들)를 향상시키거나 또는 개선시키기에 충분한 요법의 양을 지칭한다.
본 개시내용에 따른 항체, 이의 기능적 단편 및 결합 단백질은 상기 항체 및 결합 단백질을 정제하기 위해 당업계에서 이용가능한 하나 이상의 다양한 방법 및 물질을 사용하여 (의도된 용도를 위해) 정제될 수 있다. 이러한 방법 및 물질은 비제한적으로, 의도된 용도에 적합한 순도를 얻기 위한 친화성 크로마토그래피(예를 들어, 단백질 A, 단백질 G, 단백질 L 또는 항체의 특정 리간드, 이의 기능적 단편 또는 결합 단백질에 접합된 수지, 입자 또는 멤브레인(membrane)을 사용함), 이온 교환 크로마토그래피(예를 들어, 이온 교환 입자 또는 멤브레인을 사용함), 소수성 상호작용 크로마토그래피("HIC"; 예를 들어, 소수성 입자 또는 멤브레인을 사용함), 한외여과, 나노여과, 정용여과, 크기 배제 크로마토그래피("SEC"), 낮은 pH 처리(오염 바이러스 비활성화) 및 이들의 조합을 포함한다. 오염 바이러스를 불활성화하기 위한 낮은 pH 처리의 비제한적 예는 본 개시내용의 항체, 이의 기능적 단편 또는 결합 단백질을 포함하는 용액 또는 현탁액의 pH를 18℃ 내지 25℃에서 60 내지 70분 동안 0.5 M 인산을 사용하여 pH 3.5로 감소시키는 것을 포함한다.
표준 기법을 재조합 DNA, 올리고뉴클레오티드 합성, 및 조직 배양 및 형질전환에 사용할 수 있다(예를 들어 일렉트로포레이션, 리포펙션). 효소 반응 및 정제 기법은 제조사의 사양에 따라 또는 당업계에서 일반적으로 달성되거나 본원에 기재된 바와 같이 수행될 수 있다. 상기 기법 및 과정은 일반적으로 당업계에 주지된 통상적인 방법에 따라서, 및 본 명세서 전체에 걸쳐 인용되고 논의되는 다양한 일반적이고 더 구체적인 참고문헌에 기재된 바와 같이 수행될 수 있다. 예를 들어, 문헌[Sambrook et al., Molecular Cloning: A Laboratory Manual, 2nd ed. (Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., 1989)]을 참조하시오.
항-ROR1 및 항-CD3 단일특이적 항체
본 개시내용의 항-ROR1 및 항-CD3 항체는 당업계에 공지된 다수의 기법 중 어느 하나에 의해 생성될 수 있다. 예를 들어, 숙주 세포로부터의 발현이 있으며, 여기서 중쇄 및 경쇄를 암호화하는 발현 벡터(들)를 표준 기법에 의해 숙주 세포에 형질감염시킨다. "형질감염"이라는 용어의 다양한 형태는 외인성 DNA를 원핵 또는 진핵 숙주 세포로 도입하기 위해 통상적으로 사용되는 광범위하게 다양한 기법, 예를 들어 일렉트로포레이션, 칼슘-포스페이트 침전, DEAE-덱스트란 형질감염 등을 포함하고자 한다. 원핵 또는 진핵 숙주 세포에서 본 개시내용의 항체를 발현시키는 것이 가능하지만, 진핵 세포, 예를 들어 포유동물 숙주 세포에서의 항체의 발현이 특히 고려되는데, 이는 이러한 진핵 세포(및 특히 포유동물 세포)가 원핵 세포보다 적합하게 폴딩되고 면역학적으로 활성인 항체를 조립 및 분비할 가능성이 더 높기 때문이다.
일부 구현예에서, 본 개시내용의 재조합 항체의 발현을 위한 포유동물 숙주 세포는 중국 햄스터 난소(CHO 세포)(dhfr- CHO 세포 포함, 문헌[Urlaub and Chasin, Proc. Natl. Acad. Sci. USA, 77: 4216-4220 (1980)]에 기재되어 있으며, 예를 들어 문헌[Kaufman and Sharp, J. Mol. Biol., 159: 601-621 (1982)]에 기재된 바와 같이 DHFR 선택성 마커와 함께 사용됨), NS0 골수종 세포, COS 세포 및 SP2 세포이다. 항체 유전자를 암호화하는 재조합 발현 벡터가 포유동물 숙주 세포에 도입될 때, 항체는 숙주 세포에서 항체의 발현, 또는 숙주 세포가 증식하는 배양 배지내로의 항체의 추가 분비를 허용하기에 충분한 시간 동안 숙주 세포를 배양함으로써 생성된다. 항체는 표준 단백질 정제 방법을 사용하여 배양 배지에서 회수될 수 있다.
숙주 세포는 또한 Fab 단편 또는 scFv 분자와 같은 기능성 항체 단편을 생산하는 데 사용될 수 있다. 상기 과정에 대한 변형이 본 개시내용의 범위 내에 있다는 것이 이해될 것이다. 예를 들어, 본 개시내용의 항체의 경쇄 및/또는 중쇄의 기능적 단편을 암호화하는 DNA로 숙주 세포를 형질감염시키는 것이 바람직할 수 있다. 재조합 DNA 기술은, 목적 항원에의 결합이 필요하지 않은 경쇄 및 중쇄 중 하나 또는 둘 모두를 암호화하는 DNA의 일부 또는 전부를 제거하는 데에도 사용될 수 있다. 이러한 절두된(truncated) DNA 분자로부터 발현된 분자도 또한 본 개시내용의 항체에 포함된다. 또한, 하나의 중쇄 및 하나의 경쇄가 본 개시내용의 항체이고 다른 중쇄 및 경쇄는 목적 항원 이외의 항원에 대해 특이적인 이기능성 항체를, 표준 화학 가교결합 방법에 의해 본 개시내용의 항체를 제2 항체에 가교결합시킴으로써 생성시킬 수 있다.
본 개시내용의 항체 또는 이의 항원 결합 부분의 재조합 발현을 위한 예시적인 시스템에서, 항체 중쇄 및 항체 경쇄를 둘 다 암호화하는 재조합 발현 벡터는 칼슘 포스페이트-매개된 형질감염에 의해 dhfr- CHO 세포에 도입된다. 재조합 발현 벡터 내에서 항체 중쇄 및 경쇄 유전자는 각각 CMV 인핸서/AdMLP 프로모터 조절 요소에 작동적으로 연결되어 높은 수준의 유전자 전사를 유도한다. 재조합 발현 벡터는 또한 메토트렉세이트 선택/증폭을 사용하여 벡터로 형질감염된 CHO 세포의 선택을 허용하는 DHFR 유전자를 운반한다. 선택된 형질감염된 숙주 세포를 배양하여 항체 중쇄 및 경쇄의 발현을 허용하고 온전한 항체를 배양 배지로부터 회수한다. 표준 분자 생물학 기법을 사용하여 재조합 발현 벡터를 제조하고, 숙주 세포를 형질감염시키고, 형질감염체를 선택하고, 숙주 세포를 배양하고, 배양 배지로부터 항체를 회수한다. 더욱 또한 본 개시내용은 본 개시내용의 재조합 항체가 생산될 때까지 적합한 배양 배지에서 본 개시내용의 형질감염된 숙주 세포를 배양함으로써 재조합 항-ROR1 또는 항-CD3 항체를 제조하는 방법을 제공한다. 상기 방법은 배양 배지로부터 재조합 항체를 단리하는 것을 추가로 포함할 수 있다.
항-ROR1 항체
일부 구현예에서, 본 개시내용은 ROR1 Ig-유사 도메인의 C-말단에서 ROR1에 결합하는 항체를 제공한다. 본원에 개시된 항체는 일부 구현예에서 높은 세포 결합 효능을 갖고/갖거나, 예를 들어 세포-기반 분석에서 측정된 바와 같은 낮은 내재화 율을 특징으로 한다.
일부 구현예에서, 본 개시내용은 ROR1에 특이적으로 결합하는 단리된 항-ROR1 항체 또는 이의 항원 결합 단편을 개시한다. 추가 구현예에서, 항-ROR1 항체 또는 이의 항원-결합 단편은 6개의 CDR, CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3의 세트를 포함하며, 여기서:
- CDR-H1은 RSWMN(서열번호 1)의 서열을 포함하고;
- CDR-H2는 RIYPGNGDIKYNGNFKG(서열번호 2) 또는 RIYPGNADIKYNANFKG(서열번호 4)의 서열을 포함하고;
- CDR-H3은 IYYDFYYALDY(서열번호 3)의 서열을 포함하고;
- CDR-L1은 KASQDINKYIT(서열번호 5)의 서열을 포함하고;
- CDR-L2는 YTSTLQP(서열번호 6)의 서열을 포함하고;
- CDR-L3은 LQYDSLLWT(서열번호 7)의 서열을 포함하고,
여기서 CDR은 카밧 넘버링에 따라 정의된다.
일부 구현예에서, 항-ROR1 항체 또는 이의 항원-결합 단편은 카밧 넘버링에 따른 위치 H31-H35, H50-H65 및 H95-H102에서, (i) 서열번호 1, 2, 3; 또는 (ii) 서열번호 1, 4, 3으로 이루어지는 그룹 중에서 선택된 CDR-H1, CDR-H2 및 CDR-H3의 아미노산 서열을 포함한다.
하나의 구현예에서, 항-ROR1 항체 또는 이의 항원-결합 단편은 카밧 넘버링에 따른 위치 L24-34, L50-56 및 L89-97에서, 각각 CDR-L1, CDR-L2 및 CDR-L3에 대한 서열번호 5, 6, 및 7의 아미노산 서열을 포함한다.
특정 구현예에서, 항-ROR1 항체 또는 이의 항원-결합 단편은 카밧 넘버링에 따른 VH 도메인 중의 G55A 및 G61A 돌연변이를 포함한다. 일부 구현예에서, 상기 돌연변이는 항-ROR1 항체 또는 이의 항원 결합 단편에서 아스파라긴 탈아미드화 성향을 감소시킨다. 일부 구현예에서, 상기 돌연변이가 있는 항-ROR1 항체 또는 이의 항원 결합 단편은 돌연변이가 없는 모 항체에 비해 증가된 안정성을 갖는다.
일부 구현예에서, 항-ROR1 항체 또는 이의 항원-결합 단편은 서열번호 1-3 및 5-7의 CDR 서열에서 적어도 1, 2, 3, 4, 그러나 5개 이하의 잔기 변형을 포함한다. 일부 구현예에서, 항-ROR1 항체 또는 이의 항원-결합 단편은 서열번호 1, 4, 3 및 5-7의 CDR 서열에서 적어도 1, 2, 3, 4, 그러나 5개 이하의 잔기 변형을 포함한다. 상기 아미노산 변형은 아미노산 치환, 결실 및/또는 추가, 예를 들어 보존적 치환일 수 있다.
하나의 구현예에서, 본 개시내용에 따른 항-ROR1 항체 또는 이의 항원-결합 단편은 하기의 VH/VL 서열쌍: 서열번호 8/9, 17/9, 10/13, 10/14, 10/15, 10/16, 11/13, 11/14, 11/15, 11/16, 12/13, 12/14, 12/15, 12/16, 및 21/13으로 이루어지는 그룹 중에서 선택된, 중쇄 가변 도메인 VH 및 경쇄 가변 도메인 VL의 CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3을 포함한다. CDR은 가장 넓은 CDR 정의 체계, 예를 들어 Kabat, Chothia 또는 IMGT 정의를 사용하여 당업자에 의해 결정될 수 있다.
하나의 구현예에서, 본 개시내용에 따른 항-ROR1 항체 또는 이의 항원-결합 단편은 중쇄 가변 도메인 VH 및 경쇄 가변 도메인 VL을 포함하며, 여기서:
-VH 도메인은 서열번호 8 또는 17의 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하고/하거나
-VL 도메인은 서열번호 9의 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함한다.
또 다른 구현예에서, 본 개시내용에 따른 항-ROR1 항체 또는 이의 항원-결합 단편은 중쇄 가변 도메인 VH 및 경쇄 가변 도메인 VL을 포함하며, 여기서:
-VH 도메인은 서열번호 10-12 및 21 중에서 선택된 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하고/하거나
-VL 도메인은 서열번호 13-16 중에서 선택된 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함한다.
일부 구현예에서, 항-ROR1 항체는, 참조 서열에 비해 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖고 치환(예를 들어 보존적 치환), 삽입, 또는 결실을 함유하는 반면, 동일하거나 개선된 결합 특성, 예를 들어 해리속도 및/또는 내재화율과 함께 ROR1에 결합하는 능력은 유지하는 VH 서열을 포함한다. 일부 구현예에서, 총 1 내지 10개의 아미노산이 서열번호 8, 17, 또는 서열번호 10-12 또는 21에서 치환, 삽입 및/또는 결실되었다. 특정 구현예에서, 치환, 삽입 또는 결실은 CDR 외부 영역(즉, FR)에서 발생한다. 임의로, 항-ROR1 항체는 서열 번호 8, 17, 또는 서열 번호 10-12 또는 21의 VH 서열(해당 서열의 번역후 변형 포함)을 포함한다. 특정 구현예에서, VH는 (a) 서열번호 1의 아미노산 서열을 포함하는 CDR-H1, (b) 서열번호 2/4의 아미노산 서열을 포함하는 CDR-H2, 및 (c) 서열번호 3의 아미노산 서열을 포함하는 CDR-H3 중에서 선택된 1, 2 또는 3개의 CDR을 포함한다. 일부 구현예에서, VH 서열은 인간화된 VH 서열이다.
일부 구현예에서, 항-ROR1 항체는, 참조 서열에 비해 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖고 치환(예를 들어 보존적 치환), 삽입, 또는 결실을 함유하는 반면, 동일하거나 개선된 결합 특성, 예를 들어 해리속도 및/또는 내재화율과 함께 ROR1에 결합하는 능력은 유지하는 VL 서열을 포함한다. 일부 구현예에서, 총 1 내지 10개의 아미노산이 서열번호 13에서 치환, 삽입 및/또는 결실되었다. 특정 구현예에서, 치환, 삽입 또는 결실은 CDR 외부 영역(즉, FR)에서 발생한다. 임의로, 항-ROR1 항체는 서열번호 13의 VL 서열(해당 서열의 번역후 변형 포함)을 포함한다. 특정 구현예에서, VL 서열은 (a) 서열번호 5의 아미노산 서열을 포함하는 CDR-L1, (b) 서열번호 6의 아미노산 서열을 포함하는 CDR-L2, 및 (c) 서열번호 7의 아미노산 서열을 포함하는 CDR-L3 중에서 선택된 1, 2 또는 3개의 CDR을 포함한다. 일부 구현예에서, VL 서열은 인간화된 VL 서열이다.
하나의 구현예에서, 본 개시내용에 따른 항-ROR1 항체 또는 이의 항원-결합 단편은 서열번호 21을 포함하거나 이로 이루어지는 중쇄 가변 도메인 VH, 및 서열번호 13을 포함하거나 이로 이루어지는 경쇄 가변 도메인 VL을 포함한다.
하나의 구현예에서, 본 개시내용에 따른 단리된 항-ROR1 항체 또는 항원-결합 단편은 키메라 항체 또는 인간화된 항체이다. 일부 구현예에서, 항-ROR1 항체 또는 항원-결합 단편은 인간화된 항체이다.
일부 구현예에서, 본 개시내용에 따른 인간화된 단리된 항-ROR1 항체 또는 항원-결합 단편은 결합 특성을 개선하기 위해 프레임워크 영역의 위치에서 하나 이상의 역돌연변이(back mutation)를 포함한다. 일부 구현예에서, 본 개시내용에 따른 인간화된 항-ROR1 항체 또는 항원-결합 단편의 VH 도메인은 인간으로부터 하기 잔기로의 역돌연변이를 포함한다: 카밧 넘버링에 따라, 위치 1에서 Glu(1E), 위치 27에서 Tyr(27Y), 위치 94에서 His(94H), 및 임의로 위치 38에서 Lys(38K), 위치 48에서 Ile(48I), 위치에서 Lys(66K), 및 위치 67에서 Ala(67A) 중 하나 이상. 하나의 구현예에서, 본 개시내용에 따른 인간화된 항-ROR1 항체 또는 항원-결합 단편의 VL 도메인은 인간으로부터 하기 잔기로의 역돌연변이를 포함한다: 카밧 넘버링에 따라, 위치 71에서 Tyr(71Y), 및 임의로 위치 4에서 Leu(4L), 위치 69에서 Arg(69R), 위치 49에서 His(49H), 위치 58에서 Ile(58I) 중 하나 이상.
하나의 구현예에서, 본 개시내용에 따른 단리된 항-ROR1 항체 또는 항원-결합 단편은 (i) 1E, 27Y, 및 94H, (ii) 1E, 27Y, 48I, 67A, 및 94H, (iii) 1E, 27Y, 38K, 48I, 67A, 66K, 및 94H(모두 카밧 넘버링에 따름)로 이루어지는 그룹 중에서 선택된 VH 도메인에서 역-돌연변이된 아미노산 잔기; 및/또는 (i) 71Y; (ii) 49H, 69R, 및 71Y, (iii) 4L, 69R, 및 71Y, 및 (iv) 4L, 49H, 58I, 69R, 및 71Y(모두 카밧 넘버링에 따름)로 이루어지는 그룹 중에서 선택된 VL 도메인에서 역-돌연변이된 아미노산 잔기를 포함하는 인간화된 항체이다.
하나의 구현예에서, 본 개시내용에 따른 단리된 항-ROR1 항체 또는 항원-결합 단편은 카밧 넘버링에 따른 VH 도메인의 아미노산 잔기 1E, 27Y 및 94H 및 VL 도메인의 아미노산 잔기 71Y를 포함하는 인간화된 항체이다. 추가의 구현예에서, 본 개시내용에 따른 단리된 항-ROR1 항체 또는 항원-결합 단편은 카밧 넘버링에 따른 VH 도메인에서 G55A 및 G61A 돌연변이를 추가로 포함한다.
일부 구현예에서, 본 개시내용에 따른 단리된 항-ROR1 항체 또는 항원-결합 단편은 하기로 이루어지는 그룹 중에서 선택된 VH 및 VL 서열의 조합을 포함한다:

일부 구현예에서, 항체는 서열번호 21의 서열을 포함하거나 이로 이루어지는 VH 도메인, 및 서열번호 13의 서열을 포함하거나 이로 이루어지는 VL 도메인을 포함한다.
본 개시내용에 따른 항-ROR1 항체 또는 항원-결합 단편의 일부 구현예에서, 항체 또는 항원-결합 단편은 고유 또는 변이 Fc 영역일 수 있는 Fc 영역을 포함한다. 특정 구현예에서, Fc 영역은 IgG1, IgG2, IgG3, IgG4, IgA, IgM, IgE 또는 IgD 로부터의 인간 Fc 영역이다. 항체의 유용성에 따라, 적어도 하나의 효과기 기능, 예를 들어 ADCC 및/또는 CDC를 변화(예를 들어, 감소 또는 제거)시키기 위해 변이 Fc 영역을 사용하는 것이 바람직할 수 있다. 일부 구현예에서, 본 개시내용은 적어도 하나의 효과기 기능을 변화시키는 하나 이상의 돌연변이, 예를 들어 L234A 및 L235A를 갖는 Fc 영역을 포함하는 항-ROR1 항체 또는 항원-결합 단편을 제공한다.
일부 구현예에서, 본 개시내용에 따른 항-ROR1 항체의 항원-결합 단편은 예를 들어, Fv, Fab, Fab', Fab'-SH, F(ab')2; 디아바디(diabody); 선형 항체; 또는 단쇄 항체 분자(예를 들어 scFv)일 수 있다.
하나의 구현예에서, 본원에 기재된 항-ROR1 항체 또는 이의 항원-결합 단편은 ROR1 세포외 도메인 또는 이의 일부에 결합한다. 일부 구현예에서, ROR1 세포외 도메인은 UniProt 식별자 Q01973-1 하의 인간 ROR1 단백질의 아미노산 서열 Q30-Y406, 또는 서열번호 41의 아미노산 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함한다.
하나의 구현예에서, 본원에 기재된 항-ROR1 항체 또는 이의 항원-결합 단편은 ROR1 Ig-유사 도메인의 C-말단에서 ROR1에 결합한다. 하나의 구현예에서, 항체는 서열 8 및 9의 VH/VL 서열쌍을 갖는 항체와 동일한 에피토프에서 ROR1에 결합한다(예를 들어, ROR1-mAb004). 하나의 구현예에서, 항체는 ROR1에 결합하기 위해 서열 42 및 43의 VH/VL 서열쌍을 갖는 항체(예를 들어, WO2012097313의 D10 항체)와 경쟁한다.
하나의 구현예에서, 본원에 기재된 항-ROR1 항체 또는 이의 항원-결합 단편은 생물층 간섭계 또는 표면 플라스몬(plasmon) 공명에 의해 측정시, 인간 ROR1에 대해 적어도 1 Х 104 M-1s-1, 적어도 3 Х 104 M-1s-1, 적어도 5 Х 104 M-1s-1, 적어도 7 Х 104 M-1s-1, 적어도 9 Х 104 M-1s-1, 적어도 1 Х 105 M-1s-1의 결합속도 상수(kon)를 갖는다.
또 다른 구현예에서, 본원에 기재된 항-ROR1 항체 또는 이의 항원-결합 단편은 표면 플라스몬 공명 또는 생물층 간섭계에 의해 측정시, 인간 ROR1에 대해 5 Х 10-3 s-1 미만, 3 Х 10-3s-1 미만, 2 Х 10-3s-1 미만, 1 Х 10-3 s-1 미만의 해리속도 상수(koff)를 갖는다. 추가의 구현예에서, 본원에 기재된 항-ROR1 항체 또는 이의 항원-결합 단편은 인간화된 항체이고, 동일한 항체 포맷으로 서열번호 8 및 9의 VH/VL 서열쌍을 갖는 항체의 인간 ROR1에 대한 koff 값의 약 1-100%, 예를 들어 약 3-50%인 인간 ROR1에 대한 koff를 갖는다. 해리속도는 항체의 이의 항원에의 결합 지속기간을 특성화하는 데 사용될 수 있다. 일반적으로, 긴 해리속도는 형성된 복합체의 느린 해리와 상관되는 반면, 짧은 해리속도는 빠른 해리와 상관된다. 하나의 구현예에서, 본원에 기재된 항-ROR1 항체 또는 이의 항원-결합 단편은 WO2012097313에 기재된 바와 같이 D10에 대해 관찰된 것보다 더 느린 해리속도를 가지며, 표적 ROR1에 더 오래 결합된 상태를 유지하고, 이는 ROR1-발현("ROR1+") 종양 세포에 대한 효과기 분자의 향상된 모집을 촉진할 수 있다.
하나의 구현예에서, 본원에 기재된 항-ROR1 항체 또는 이의 항원-결합 단편 은 나노몰(10-7 내지 10-9) 범위, 예를 들어 8 Х 10-7 M 미만, 5 Х 10-7 M 미만, 3 Х 10-7 M 미만, 1 Х 10-7 M 미만, 8 Х 10-8M 미만,5 Х 10-8M 미만,3 Х 10-8 M 미만, 2 Х 10-8 M 미만, 1 Х 10-8M 미만, 8 Х 10-9M 미만, 6 Х 10-9M 미만, 4 Х 10-9M 미만, 2 Х 10-9 M, 또는 1 Х 10-9 M 미만의 ROR1에 대한 해리 상수(KD)를 갖는다.
하나의 구현예에서, 본원에 기재된 항-ROR1 항체 또는 이의 항원-결합 단편은 ROR1을 발현하는 CHO 세포주 또는 골수종 세포주와 같은 ROR1+ 표적 세포 상에 표시된 ROR1에 특이적으로 결합한다. 세포-기반 분석에서 유세포 분석에 의해 측정시, 항-ROR1 항체는 WO2012097313에 기재된 바와 같이 D10에 대해 관찰된 것보다 더 강한 ROR1+ 세포에 대한 강한 결합 효능을 나타낸다. 일부 구현예에서, 세포 결합 효능은 항체의 포화 농도 또는 약 100 nM의 항체 농도에서 검출된 MFI에 의해 반영된다. 일부 구현예에서, 본원에 기재된 항-ROR1 항체 또는 항원-결합 단편은 서열번호 44 및 45의 VH/VL 서열쌍을 갖는 항체(예를 들어 WO 2014167022의 항체 R12), 또는 ROR1의 Ig 및 Fz 도메인의 접합부에서 R12와 동일한 에피토프에 결합하는 항체와 비교하여 표적 세포 상에 나타난 ROR1에 대해 더 높은 결합 효능을 나타낸다. 하나의 구현예에서, ROR1-발현 세포에 대한 항체의 결합 효능을 실시예 1.3에 기재된 바와 같은 세포-기반 분석에서 측정한다.
일부 구현예에서, 예상된 바와 같이, 나노몰 범위에서 ROR1에 대해 상대적으로 낮은 친화도를 갖지만 강한 세포 표면 결합 효능을 갖는 본원에 기재된 항-ROR1 항체는 종양내로의 분포에 유리하고/하거나, 더 높은 밀도의 표적을 발현하는 종양 세포의 보다 선택적인 표적화를 유도할 수 있었다.
하나의 구현예에서, 본원에 기재된 항-ROR1 항체 또는 이의 항원-결합 단편은 ROR1-발현 세포의 세포 표면에 결합시 최소 내재화를 나타낸다. 하나의 구현예에서, 내재화율은 세포-기반 분석에서 측정 시, 내재화되지 않은 항체의 20%, 15%, 14%, 13%, 12%, 11% 또는 10% 이하이다. 내재화율은 2시간 동안 4℃에서 유지된 대조군에 비해, 같은 기간 동안 37℃에서 배양 후 ROR1-발현 세포의 표면에 결합하는 항체의 유세포 분석에 의해 검출된 평균 형광 강도(MFI)의 감소 백분율에 의해 반영될 수 있다. 하나의 구현예에서, 항-ROR1 항체의 내재화는 ROR1-발현 골수종 세포주를 사용하여 특성화된다. 하나의 구현예에서, MFI가 검출되기 전에, 시험 항체를 ROR1-발현 세포와 배양하는 것을, 항체가 세포의 세포 표면상의 ROR1에 결합되게 하는 기간 동안, 예를 들어 4℃에서 30분 동안 수행하고, 이어서 세포를 내재화가 허용되도록 37℃에서 2시간 동안 배양하거나, 또는 대조군으로서 작용하도록 같은 기간 동안 4℃에서 유지시킨다. 하나의 구현예에서, 내재화율을 페닐아르신 옥사이드(PAO)와 같은 내재화 억제제의 존재 하에 37℃ 배양에서 측정된 내재화율과 비교하여 보정한다. 하나의 구현예에서, 내재화 정도를 실시예 8에 기재된 바와 같은 세포-기반 분석에서 측정한다.
하나의 구현예에서, 항체는 ROR1이 ROR-발현 세포의 세포 표면 상에서 이의 리간드 Wnt5a에 결합하는 것을 차단할 수 있다. 또 다른 구현예에서, 항체는 ROR1/wnt5 신호전달을 억제하기 위해 사용될 수 있다. 추가 구현예에서, 항체는 ROR1/wnt5A 경로와 관련된 암 성장 및 전이를 억제하기 위해 사용될 수 있다.
항-CD3 항체
본 개시내용은 또한 인간 CD3에 결합할 수 있는 항체를 제공한다.
일부 구현예에서, 본 개시내용에 따른 항-CD3 항체는 6개의 CDR, CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3의 세트를 포함하며, 여기서:
- CDR-H1은 NYYVH(서열번호 25)의 서열을 포함하고;
- CDR-H2는 WISPGSDNTKYNEKFKG(서열번호 26)의 서열을 포함하고;
- CDR-H3은 DDYGNYYFDY(서열번호 27)의 서열을 포함하고;
- CDR-L1은 KSSQSLLNARTRKNYLA(서열번호 28)의 서열을 포함하고;
- CDR-L2는 WASTRES(서열번호 29)의 서열을 포함하고;
- CDR-L3은 KQSYILRT(서열번호 30)의 서열을 포함하고,
여기서 CDR은 카밧 넘버링에 따라 정의된다.
일부 구현예에서, 본원에 따른 항-CD3 항체 또는 이의 항원-결합 단편은 하기를 포함한다:
- 서열번호 22 또는 23의 서열, 또는 이와 적어도 80%-90%, 또는 95%-99% 동일성을 갖는 서열을 포함하는 VH 도메인, 및/또는
- 서열번호 24의 서열, 또는 이와 적어도 80%-90%, 또는 95%-99% 동일성을 갖는 서열을 포함하는 VL 도메인.
일부 구현예에서, 항-CD3 항체 또는 이의 항원 결합 단편은 서열번호 22의 서열을 포함하는 VH 도메인 및 서열번호 24의 서열을 포함하는 VL 도메인을 포함한다. 다른 구현예에서, 항-CD3 항체 또는 이의 항원 결합 단편은 서열번호 23의 서열을 포함하는 VH 도메인 및 서열번호 24의 서열을 포함하는 VL 도메인을 포함한다.
일부 구현예에서, 본 개시내용에 따른 항-ROR1 항체 또는 본 개시내용에 따른 항-CD3 항체는 당업계에서 잘 확립된 기법에 의해 동일한 표적 항원을 인식하는 유도체 결합 단백질을 만드는 데 사용될 수 있다. 이러한 유도체는 예를 들어 단쇄 항체(scFv), Fab 단편(Fab), Fab' 단편, F(ab')2, Fv, 및 디설파이드 연결된 Fv일 수 있다. 이러한 유도체는 예를 들어, 본 개시내용에 따른 항-ROR1 항체 또는 본 개시내용에 따른 항-CD3 항체를 포함하는 융합 단백질(fusion protein) 또는 접합체일 수 있다. 융합 단백질은 다중-특이적 항체 또는 CAR 분자일 수 있다. 접합체는 항체-약물 접합체(ADC) 또는 방사성 동위원소와 같은 검출 물질과 접합된 항체일 수 있다.
ROR1xCD3 이중특이적 결합 단백질
또 다른 양태에서, 본 개시내용은 ROR1 및 CD3 모두에 결합할 수 있는 ROR1/CD3 이중특이적 결합 단백질, 특히 Fabs-in-Tandem 면역글로불린(FIT-Ig) 및 1가 비대칭 탠덤 Fab 이중특이적 항체(MAT-Fab)를 제공한다. FIT-Ig 또는 MAT-Fab의 각 가변 도메인(VH 또는 VL)을 표적 항원 중 하나, 즉 ROR1 또는 CD3에 결합하는 하나 이상의 "모(parental)" 단클론 항체로부터 수득할 수 있다. FIT-Ig 또는 MAT-Fab 결합 단백질을 본원에 개시된 항-ROR1 및 항-CD3 단클론 항체의 가변 도메인 서열을 사용하여 생성시킬 수 있다. 예를 들어, 모 항체는 인간화된 항체이다.
본 개시내용의 하나의 양태는 FIT-Ig 또는 MAT-Fab 분자에서 목적하는 적어도 하나 이상의 특성을 갖는 모 항체를 선택하는 것에 관한 것이다. 하나의 구현예에서, 항체 특성은 항원 특이성(antigen specificity), 항원에 대한 친화도, 해리속도, 세포 결합 효능, 내재화율, 생물학적 기능, 에피토프 인식, 안정성, 용해도, 생산 효율, 면역원성, 약동학, 생체이용률, 조직 교차 반응성 및 자기유래 항원 결합으로 이루어지는 그룹 중에서 선택된다.
일부 구현예에서, 본 개시내용에 따른 이중특이적 FIT-Ig 및 MAT-Fab 단백질은 임의의 도메인간 펩티드 링커 없이 구성된다. 탠덤 결합 부위를 갖는 다가(multivalent) 조작된 면역글로불린 포맷에서, 결합 부위를 공간적으로 분리하기 위해 가요성 링커가 사용되지 않는 한, 인접한 결합 부위가 서로 간섭할 것이라는 것이 당업계에서 일반적으로 이해되었다. 그러나, 본 개시내용의 ROR1/CD3 FIT-Ig 및 MAT-Fab에 대해, 본원에 개시된 쇄 공식에 따른 면역글로불린 도메인의 배열이, 형질감염된 포유동물 세포에서 잘 발현되고, 적절하게 조립되며, 표적 항원 ROR1 및 CD3에 결합하는 이중특이적의 다가 면역글로불린-유사 결합 단백질로서 분비되는 폴리펩티드 쇄를 생성시킨다는 것이 발견되었다. 하기 실시예를 참조하시오. 더욱이, 결합 단백질로부터 합성 링커 서열의 생략은 포유동물 면역계에 의해 인식될 수 있는 항원 부위의 생성을 피할 수 있고, 이러한 방식으로 링커의 제거는 FIT-Ig 및 MAT-Fab의 가능한 면역원성을 감소시킨다, 즉 FIT-Ig 및 MAT-Fab는 면역 옵소닌화(opsonization) 및 간에서의 포획을 통해 빠르게 제거되지 않는다.
일부 구현예에서, 본원에 따른 ROR1 x CD3 이중특이적 결합 단백질은 하기를 포함한다:
a) ROR1에 특이적으로 결합하는 제1 항원 결합 부위; 및
b) CD3에 특이적으로 결합하는 제2 항원 결합 부위.
하나의 구현예에서, 본원에 기재된 바와 같은 이중특이적 결합 단백질은 이중특이적 결합 단백질의 ROR1 결합 부위를 형성하기 위해 본원에 기재되고 본원에 따른 임의의 항-ROR1 항체 또는 이의 항원-결합 단편으로부터 유래된 6개의 CDR, CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3의 세트를 포함한다. 일부 추가 구현예에서, 본원에 기재된 바와 같은 이중특이적 결합 단백질은 이중특이적 결합 단백질의 ROR1 결합 부위를 형성하기 위해 본원에 기재되고 본원에 따른 임의의 항-ROR1 항체 또는 이의 항원-결합 단편으로부터 유래된 VH/VL 쌍을 포함한다.
하나의 구현예에서, 본원에 기재된 바와 같은 이중특이적 결합 단백질은 이중특이적 결합 단백질의 CD3 결합 부위를 형성하기 위해 본원에 기재되고 본원에 따른 임의의 항-CD3 항체 또는 이의 항원-결합 단편으로부터 유래된 6개의 CDR, CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3의 세트를 추가로 포함한다. 일부 추가 구현예에서, 본원에 기재된 바와 같은 이중특이적 결합 단백질은 이중특이적 결합 단백질의 CD3 결합 부위를 형성하기 위해 본원에 기재되고 본원에 따른 임의의 항-CD3 항체 또는 이의 항원-결합 단편으로부터 유래된 VH/VL 쌍을 포함한다.
하나의 구현예에서, 본원에 따른 이중특이적 ROR1/CD3 결합 단백질의 ROR1 결합 부위 및 CD3 결합 부위는 각각 인간화된 VH/VL 서열을 포함하여, 인간화된다.
이중특이적 FIT-Ig 결합 단백질
하나의 구현예에서, 본원에 따른 ROR1 x CD3 이중특이적 결합 단백질은 ROR1 및 CD3에 결합할 수 있는 이중특이적 FIT-Ig 결합 단백질이다. Fabs-in-Tandem 면역글로불린(FIT-Ig) 결합 단백질은 6개의 폴리펩티드 쇄를 포함하고 2개의 외부 Fab 결합 영역과 2개의 내부 Fab 결합 영역이 있는 4개의 기능적 Fab 결합 영역을 갖는 단량체성(monomeric), 이중특이적 4가 결합 단백질이다. 도 10A에 도시된 바와 같이, 결합 단백질은 (외부 Fab-내부 Fab-Fc)x2 포맷을 채택하고, 항원 A 및 항원 B 모두에 결합한다. 하나의 양태에서, 본원에 따른 ROR1 x CD3 이중특이적 결합 단백질은 이중특이적 FIT-Ig 결합 단백질이며; 여기서 FIT-Ig 단백질의 2개의 Fab 도메인은 ROR1에 특이적으로 결합하는 제1 항원 결합 부위를 형성하고; FIT-Ig 단백질의 다른 두 Fab 도메인은 CD3에 특이적으로 결합하는 제2 항원 결합 부위를 형성한다. 일부 구현예에서, 본 개시내용에 따른 FIT-Ig 결합 단백질은 면역글로불린 도메인 사이에 링커를 사용하지 않는다.
추가 구현예에서, 본 개시내용은 제1 폴리펩티드 쇄, 제2 폴리펩티드 쇄 및 제3 폴리펩티드 쇄를 포함하는 이중특이적 Fabs-in-Tandem 면역글로불린(FIT-Ig) 결합 단백질을 제공하며, 여기서
(i) 포맷 LH에서, 제1 폴리펩티드 쇄는 아미노 말단으로부터 카복실 말단까지 VLA-CL-VHB-CH1-Fc를 포함하며, 여기서 CL은 VHB에 직접 융합되고; 제2 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VHA-CH1을 포함하고; 제3 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VLB-CL을 포함하거나; 또는
(ii) 포맷 HL에서, 제1 폴리펩티드 쇄는 아미노 말단으로부터 카복실 말단까지 VHA-CH1-VLB-CL-Fc를 포함하며, 여기서 CH1은 VLB에 직접 융합되고; 제2 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VLA-CL을 포함하고; 제3 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VHB-CH1을 포함하며;
여기서 VL은 경쇄 가변 도메인이고, CL은 경쇄 불변 도메인이고, VH는 중쇄 가변 도메인이고, CH1은 중쇄 불변 도메인이고, Fc는 면역글로불린 Fc 영역, 예를 들어 IgG1의 Fc(예를 들어, 아미노 말단으로부터 카복실 말단까지 힌지-CH2-CH3를 포함하는 Fc)이고,
여기서 VLA-CL은 VHA-CH1과 쌍을 이루어 제1 항원 A에 특이적으로 결합하는 제1 Fab를 형성하고, VLB-CL은 VHB-CH1과 쌍을 이루어 제2 항원 B에 특이적으로 결합하는 제2 Fab를 형성하며,
여기서 제1 항원 A는 ROR1이고 제2 항원 B는 CD3이거나, 또는 제1 항원 A는 CD3이고 제2 항원 B는 ROR1이며,
여기서 제1 폴리펩티드 쇄 중 2개, 제2 폴리펩티드 쇄 중 2개, 및 제3 폴리펩티드 쇄 중 2개가 결합되어 FIT-Ig 결합 단백질을 형성한다.
본원에 따른 이중특이적 FIT-Ig 결합 단백질의 일부 구현예에서, 제1 폴리펩티드 쇄는 아미노 말단으로부터 카복실 말단까지 VLA-CL-VHB-CH1-Fc를 포함하며, 여기서 항원 A는 ROR1이고 항원 B는 CD3이거나, 또는 항원 A는 CD3이고 항원 B는 ROR1이다.
일부 구현예에서, FIT-Ig 결합 단백질에서 VL-CL이 VH-CH1과 쌍을 이루는 것에 의해 형성된(예를 들어, A가 ROR1인 경우, VLA-CL 및 VHA-CH1에 의해 형성된; 또는 B가 ROR1인 경우, VLB-CL 및 VHB-CH1에 의해 형성된) ROR1에 결합하는 Fab는 이중특이적 결합 단백질의 ROR1 결합 부위를 형성하기 위해 본원에 기재되고 본원에 따른 임의의 항-ROR1 항체 또는 이의 항원-결합 단편으로부터 유래된 6개의 CDR, CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3의 세트를 포함한다. 일부 추가 구현예에서, CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3은 각각 서열번호 1, 2, 3 및 5, 6, 7의 서열; 또는 서열번호 1, 4, 3 및 5, 6, 7의 서열을 포함한다.
일부 구현예에서, FIT-Ig 결합 단백질에서 ROR1에 결합하는 Fab는 본원에 기재되고 본원에 따른 임의의 항-ROR1 항체 또는 이의 항원-결합 단편으로부터 유래된 VH/VL 쌍을 포함한다. 일부 추가 구현예에서, VH/VL 쌍은 하기 VH/VL 서열쌍으로 이루어지는 그룹 중에서 선택된 서열을 포함한다: 서열번호 8/9, 17/9, 10/13, 10/14, 10/15, 10/16, 11/13, 11/14, 11/15, 11/16, 12/13, 12/14, 12/15, 12/16, 및 21/13, 또는 이와 적어도 80%, 85%, 90%, 95% 또는 99% 동일성을 갖는 서열. 일부 구현예에서, FIT-Ig 결합 단백질에서 ROR1에 결합하는 Fab는 서열번호 21의 VH 서열 및 서열번호 13의 VL 서열을 포함한다.
일부 구현예에서, FIT-Ig 결합 단백질에서 VL-CL이 VH-CH1과 쌍을 이루는 것에 의해 형성된(예를 들어, A가 CD3인 경우, VLA-CL 및 VHA-CH1에 의해 형성된; 또는 B가 CD3인 경우, VLB-CL 및 VHB-CH1에 의해 형성된) CD3에 결합하는 Fab는 이중특이적 결합 단백질의 CD3 결합 부위를 형성하기 위해 본원에 기재되고 본원에 따른 임의의 항-CD3 항체 또는 이의 항원-결합 단편으로부터 유래된 6개의 CDR, CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3의 세트를 포함한다. 일부 구현예에서, FIT-Ig 결합 단백질에서 VL-CL이 VH-CH1과 쌍을 이루는 것에 의해 형성된 CD3에 결합하는 Fab는 6개의 CDR 세트를 포함하며, 여기서 CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3은 각각 서열번호 25, 26, 27 및 28, 29, 30의 서열을 포함한다. 일부 추가 구현예에서, CD3에 결합하는 Fab는 서열번호 22 및 24의 서열, 또는 이와 적어도 80%, 85%, 90%, 95% 또는 99% 동일성을 갖는 서열; 또는 서열번호 23 및 24의 서열, 또는 이와 적어도 80%, 85%, 90%, 95% 또는 99% 동일성을 갖는 서열을 포함하는 VH/VL 쌍을 포함한다.
추가 구현예에서, 본 개시내용은 제1, 제2 및 제3 폴리펩티드 쇄를 포함하는 이중특이적 Fabs-in-Tandem 면역글로불린(FIT-Ig) 결합 단백질을 제공하며, 여기서
(i) 포맷 LH에서, 제1 폴리펩티드 쇄는 아미노 말단으로부터 카복실 말단까지 VLA-CL-VHB-CH1-Fc를 포함하며, 여기서 CL은 VHB에 직접 융합되고; 제2 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VHA-CH1을 포함하고; 제3 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VLB-CL을 포함하거나; 또는
(ii) 포맷 HL에서, 제1 폴리펩티드 쇄는 아미노 말단으로부터 카복실 말단까지 VHA-CH1-VLB-CL-Fc를 포함하며, 여기서 CH1은 VLB에 직접 융합되고; 제2 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VLA-CL을 포함하고; 제3 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VHB-CH1을 포함하며;
여기서 VL은 경쇄 가변 도메인이고, CL은 경쇄 불변 도메인이고, VH는 중쇄 가변 도메인이고, CH1은 중쇄 불변 도메인이고, Fc는 면역글로불린 Fc 영역이고, A는 ROR1의 에피토프이고 B는 CD3의 에피토프이거나, 또는 A는 CD3의 에피토프이고 B는 ROR1의 에피토프이다. 본 개시내용에 따르면, 이러한 FIT-Ig 결합 단백질은 ROR1 및 CD3 모두에 결합한다.
일부 구현예에서, 이러한 FIT-Ig 결합 단백질의 Fab 단편은 항원 ROR1 및 CD3 중 하나에 결합하는 모 항체로부터의 VLA-CL 및 VHA-CH1 도메인을 포함하고, 항원 ROR1 및 CD3 중 다른 것에 결합하는 상이한 모 항체로부터의 VLB-CL 및 VHB-CH1 도메인을 포함한다. 일부 구현예에서, VH-CH1::VL-CL 짝짓기는 ROR1 및 CD3를 둘 다 인식하는 탠덤 Fab 모이어티를 생성시킨다.
본 개시내용에 따르면, ROR1/CD3 FIT-Ig 결합 단백질은 제1, 제2 및 제3 폴리펩티드 쇄를 포함하고, 여기서 제1 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VLROR1-CL-VHCD3-CH1-힌지-CH2-CH3를 포함하며, 여기서 CL은 VHCD3에 직접 융합되고, 여기서 제2 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VHROR1-CH1을 포함하고; 여기서 제3 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VLCD3-CL을 포함한다. 대안적 구현예에서, ROR1/CD3 FIT-Ig 결합 단백질은 제1, 제2 및 제3 폴리펩티드 쇄를 포함하고, 여기서 제1 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VHROR1-CH1-VLCD3-CL-힌지-CH2-CH3을 포함하고, 여기서 CH1은 VLCD3에 직접 융합되며, 여기서 제2 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VLROR1-CL을 포함하고; 여기서 제3 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VHCD3-CH1을 포함한다. 일부 구현예에서, VLROR1은 항-ROR1 항체의 경쇄 가변 도메인이고, CL은 경쇄 불변 도메인이고, VHROR1은 항-ROR1 항체의 중쇄 가변 도메인이고, CH1은 중쇄 불변 도메인이고, VLCD3은 항-CD3 항체의 경쇄 가변 도메인이고, VHCD3은 항-CD3 항체의 중쇄 가변 도메인이고; 임의로, 도메인 VLCD3-CL은 항-CD3 모 항체의 경쇄와 동일하고, 도메인 VHCD3-CH1은 항-CD3 모 항체의 중쇄 가변 및 중쇄 불변 도메인과 동일하고, 도메인 VLROR1-CL은 항-ROR1 모 항체의 경쇄와 동일하고, 도메인 VHROR1-CH1은 항-ROR1 모 항체의 중쇄 가변 및 중쇄 불변 도메인과 동일하다.
FIT-Ig 결합 단백질에 대한 상기 화학식에서, Fc 영역은 고유 또는 변이 Fc 영역일 수 있다. 특정 구현예에서, Fc 영역은 IgG1, IgG2, IgG3, IgG4, IgA, IgM, IgE 또는 IgD로부터의 인간 Fc 영역이다. 특정 구현예에서, Fc는 IgG1으로부터의 인간 Fc, 또는 적어도 하나의 Fc 효과기 기능, 예를 들어 Fc의 FcγR에의 결합, ADCC 및/또는 CDC를 감소시키거나 제거하기 위한 하나 이상의 돌연변이를 포함하는 변형된 인간 Fc이다. 돌연변이는 예를 들어 L234A/L235A(Kabat EU 인덱스에 따른 넘버링)일 수 있다. 하나의 구현예에서, Fc 영역은 하기 표 8에 기재된 바와 같은 돌연변이 L234A 및 L235A(서열번호 31의 aa104 내지 aa227)를 갖는 인간 IgG1의 것이다. 하나의 구현예에서, Fc 영역은 서열번호 31의 aa104 내지 aa 227의 서열, 또는 이와 적어도 90%, 95%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함한다.
본 개시내용에 따른 FIT-Ig 결합 단백질의 일부 구현예에서, CH1, CL 및 Fc 도메인은 인간 서열의 것이거나 또는 인간 서열로부터 유래한다. 본 개시내용에 따른 FIT-Ig 결합 단백질의 일부 구현예에서, CH1은 예를 들어 서열번호 33의 서열, 또는 이와 적어도 90%, 95%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 갖는 인간 IgG1 불변 CH1 도메인이다. FIT-Ig 결합 단백질에 대한 상기 화학식에서, CL은 예를 들어 서열번호 32의 서열, 또는 이와 적어도 90%, 95%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 갖는 인간 불변 카파 CL 도메인이다.
하나의 구현예에서, 본 개시내용의 FIT-Ig 결합 단백질은 모 항체의 하나 이상의 특성을 보유한다. 일부 구현예에서, FIT-Ig는 모 항체의 경우에 필적하는 표적 항원(즉, CD3 및 ROR1)에 대한 결합 친화도를 유지하며, 이는 ROR1 및 CD3 항원 표적에 대한 FIT-Ig 결합 단백질의 결합 친화도가 표면 플라스몬 공명 또는 생물층 간섭계에 의해 측정된 바와 같이 각각의 표적 항원에 대한 모 항체의 결합 친화도와 비교하여 10배 이상 변하지 않음을 의미한다.
하나의 구현예에서, 본 개시내용의 FIT-Ig 결합 단백질은 ROR1 및 CD3에 결합하고, 제1 폴리펩티드 쇄, 제2 폴리펩티드 쇄 및 제3 폴리펩티드 쇄로 구성되며, 여기서:
- 제1 폴리펩티드 쇄는 서열번호 34 또는 37의 아미노산 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하고,
- 제2 폴리펩티드 쇄는 서열번호 35의 아미노산 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하고,
- 제3 폴리펩티드 쇄는 서열번호 36의 아미노산 서열, 또는 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함한다.
하나의 구현예에서, 본 개시내용의 FIT-Ig 결합 단백질은 ROR1 및 CD3에 결합하고, 서열번호 34 또는 37의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 제1 폴리펩티드 쇄; 서열번호 35의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 제2 폴리펩티드 쇄; 및 서열번호 36의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 제3 폴리펩티드 쇄로 구성된다.
이중특이적 MAT-Fab 결합 단백질
하나의 구현예에서, 본원에 따른 ROR1 x CD3 이중특이적 결합 단백질은 ROR1 및 CD3에 결합할 수 있는 이중특이적 MAT-Fab 결합 단백질이다. 1가 비대칭 탠덤 Fab(MAT-Fab) 이중특이적 결합 단백질은 4개의 폴리펩티드 쇄를 포함하고 2개의 기능적 Fab 결합 영역을 직렬로 갖는 단량체성, 이중특이적 2가 결합 단백질이다. 도 10B에 도시된 바와 같이, 결합 단백질은 외부 Fab-내부 Fab-Fc:Fc 이량체 포맷을 채택하고, 항원 A 및 항원 B 모두에 결합한다. 일부 구현예에서, 본원에 따른 ROR1 x CD3 이중특이적 결합 단백질은 이중특이적 MAT-Fab 결합 단백질이며, 여기서 MAT-Fab 단백질의 하나의 Fab 도메인은 ROR1에 특이적으로 결합하는 제1 항원 결합 부위를 형성하고; MAT-Fab 단백질의 다른 Fab 도메인은 CD3에 특이적으로 결합하는 제2 항원 결합 부위를 형성한다.
추가의 구현예에서, 본 개시내용은 제1 폴리펩티드 쇄, 제2 폴리펩티드 쇄, 제3 폴리펩티드 쇄 및 제4 폴리펩티드 쇄를 포함하는 이중특이적 1가 비대칭 탠덤 Fab(MAT-Fab) 결합 단백질을 제공하며, 여기서
(i) 포맷 LH에서, 제1 폴리펩티드 쇄는 아미노 말단으로부터 카복실 말단까지 VLA-CL-VHB-CH1-Fc를 포함하며, 여기서 CL은 VHB에 직접 융합되고; 제2 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VHA-CH1을 포함하고; 제3 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VLB-CL을 포함하고; 제4 폴리펩티드 쇄는 Fc를 포함하거나; 또는
(ii) 포맷 HL에서, 제1 폴리펩티드 쇄는 아미노 말단으로부터 카복실 말단까지 VHA-CH1-VLB-CL-Fc를 포함하며, 여기서 CH1은 VLB에 직접 융합되고; 제2 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VLA-CL을 포함하고; 제3 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VHB-CH1을 포함하고; 제4 폴리펩티드 쇄는 Fc를 포함하며;
여기서 VL은 경쇄 가변 도메인이고, CL은 경쇄 불변 도메인이고, VH는 중쇄 가변 도메인이고, CH1은 중쇄 불변 도메인이고, Fc는 면역글로불린 Fc 영역, 예를 들어 IgG1의 Fc(예를 들어, 아미노 말단으로부터 카복실 말단까지 힌지-CH2-CH3를 포함하는 Fc)이고,
여기서 VLA-CL은 VHA-CH1과 쌍을 이루어 제1 항원 A에 특이적으로 결합하는 제1 Fab를 형성하고, VLB-CL은 VHB-CH1과 쌍을 이루어 제2 항원 B에 특이적으로 결합하는 제2 Fab를 형성하며,
여기서 제1 항원 A는 ROR1이고 제2 항원 B는 CD3이거나, 또는 제1 항원 A는 CD3이고 제2 항원 B는 ROR1이며,
여기서 제1 폴리펩티드 쇄, 제2 폴리펩티드, 제3 폴리펩티드 쇄 및 제4 폴리펩티드 쇄는 결합되어 MAT-Fab 결합 단백질을 형성한다.
본 개시내용에 따른 MAT-Fab 결합 단백질의 일부 구현예에서, Fc는 아미노 말단에서 카복실 말단까지 힌지-CH2-CH3을 포함하는 면역글로불린 Fc 영역이고, 여기서 힌지-CH2는 면역글로불린 중쇄의 힌지-CH2 영역이고, 힌지-CH2는 CH3에 직접 융합되고, 제1 폴리펩티드 쇄의 Fc 영역은 제1 CH3 도메인(CH3m1 도메인)을 포함하고, 제4 폴리펩티드 쇄의 Fc 영역은 제2 CH3 도메인(CH3m2 도메인)을 포함한다. 추가 구현예에서, 제1 및 제4 폴리펩티드 쇄의 Fc 영역, 특히 이의 CH3 도메인은 이종이량체화 변형을 포함하며, 이는 2개의 Fc 영역의 동종이량체화(homodimerization)보다 이종이량체화를 촉진한다. 일부 구현예에서, 구멍에 손잡이 이종이량체화 기술은 쇄의 이종이량체화를 촉진하기 위해 사용된다. 임의로, MAT-Fab 결합 단백질은 2개의 CH3 도메인 짝짓기에서 디설파이드 결합 형성을 촉진하는 시스테인 잔기를 도입하기 위해 제1 CH3 도메인(CH3m1 도메인) 및 제2 CH3 도메인(CH3m2 도메인)에 돌연변이를 추가로 포함한다.
일부 구현예에서, 하나 이상의 구멍에 손잡이(KiH) 돌연변이를 제1 쇄의 제1 CH3 도메인(CH3m1 도메인) 및 제4 쇄의 제2 CH3 도메인(CH3m2 도메인)에 도입한다. 추가의 구현예에서, 제1 쇄의 제1 CH3 도메인(CH3m1 도메인)이 구조화된 손잡이를 형성하도록 돌연변이되었을 때, 제4 쇄의 제2 CH3 도메인(CH3m2 도메인)이 돌연변이되어 상보적인 구조적 구멍을 형성하여 제1 CH3 도메인과 제2 CH3 도메인의 짝짓기를 촉진하거나; 또는 제1 쇄의 제1 CH3 도메인(CH3m1 도메인)이 구조적 구멍을 형성하도록 돌연변이되었을 때, 제4 쇄의 제2 CH3 도메인(CH3m2 도메인)이 돌연변이되어 상보적인 구조적 손잡이를 형성하여 제1 CH3 도메인과 제2 CH3 도메인의 짝짓기를 촉진하였다. 일부 구현예에서, "손잡이" 돌연변이는 T366W 치환이고, 상보적인 "구멍" 돌연변이는 T366S, L368A 및 Y407V 치환이다.
일부 구현예에서, 본 개시내용에 따른 이중특이적 결합 단백질은 제1 CH3 도메인에서 전형적인 손잡이(T366W) 치환 및 제2 CH3 도메인에서 상응하는 구멍 치환(T366S, L368A 및 Y407V)을 갖고, 임의로 2개의 추가 도입된 시스테인 잔기 S354C/Y349C(각각의 상응하는 CH3 서열에 함유됨)를 갖는 MAT-Fab 단백질이다. 예를 들어, 제1 CH3 도메인(CH3m1 도메인)은 손잡이 치환 T366W 및 도입된 시스테인 잔기 S354C를 포함할 수 있고, 제2 CH3 도메인(CH3m2 도메인)은 구멍 치환으로서 T366S, L368A 및 Y407V 및 도입된 시스테인 잔기 Y349C를 포함한다.
구멍에 손잡이 이량체화 모듈 및 항체 조작에서의 이의 용도는 당업계에 주지되어 있으며, 예를 들어 문헌[Ridgway et al., 1996, Protein Engineering 9(7) 617-621]에 기재되어 있다. CH3 도메인에 추가적인 디설파이드 브릿지의 도입은 예를 들어 문헌[Merchant, A.M., et al., Nat. Biotechnol. 16 (1998) 677-681]에 보고되어 있다.
본원에 따른 이중특이적 MAT-Fab 결합 단백질의 일부 구현예에서, 제1 폴리펩티드 쇄는 아미노 말단으로부터 카복실 말단까지 VLA-CL-VHB-CH1-Fc를 포함하며, 여기서 항원 A는 ROR1이고, 항원 B는 CD3이거나, 또는 항원 A는 CD3이고 항원 B는 ROR1이다.
일부 구현예에서, MAT-Fab 결합 단백질에서 VL-CL이 VH-CH1과 쌍을 이루는 것에 의해 형성된(예를 들어, A가 ROR1인 경우, VLA-CL 및 VHA-CH1에 의해 형성된) ROR1에 결합하는 Fab는 이중특이적 결합 단백질의 ROR1 결합 부위를 형성하기 위해 본원에 기재되고 본원에 따른 임의의 항-ROR1 항체 또는 이의 항원-결합 단편으로부터 유래된 6개의 CDR 세트, 즉 CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3을 포함한다. 일부 구현예에서, CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3은 각각 서열번호 1, 2, 3 및 5, 6, 7의 서열; 또는 서열번호 1, 4, 3 및 5, 6, 7의 서열을 포함한다. 일부 구현예에서, MAT-Fab 결합 단백질에서 ROR1에 결합하는 Fab는 이중특이적 결합 단백질의 ROR1 결합 부위를 형성하기 위해 본원에 기재되고 본원에 따른 임의의 항-ROR1 항체 또는 이의 항원-결합 단편으로부터 유래된 VH/VL 쌍을 포함한다. 일부 추가 구현예에서, VH/VL 쌍은 하기 VH/VL 서열쌍으로 이루어지는 그룹 중에서 선택된 서열을 포함한다: 서열번호 8/9, 17/9, 10/13, 10/14, 10/15, 10/16, 11/13, 11/14, 11/15, 11/16, 12/13, 12/14, 12/15, 12/16, 및 21/13, 또는 이와 적어도 80%, 85%, 90%, 95% 또는 99% 동일성을 갖는 서열. 일부 구현예에서, MAT-Fab 결합 단백질에서 ROR1에 결합하는 Fab는 서열번호 21의 VH 서열 및 서열번호 13의 VL 서열을 포함한다.
일부 구현예에서, MAT-Fab 결합 단백질에서 VL-CL이 VH-CH1과 쌍을 이루는 것에 의해 형성된(예를 들어, B가 CD3인 경우, VLB-CL 및 VHB-CH1에 의해 형성된) CD3에 결합하는 Fab는 이중특이적 결합 단백질의 CD3 결합 부위를 형성하기 위해 본원에 기재되고 본원에 따른 임의의 항-CD3 항체 또는 이의 항원-결합 단편으로부터 유래된 6개의 CDR, CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3의 세트를 포함한다. 일부 구현예에서, MAT-Fab 결합 단백질에서 VL-CL이 VH-CH1과 쌍을 이루는 것에 의해 형성된 CD3에 결합하는 Fab는 6개의 CDR 세트를 포함하며, 여기서 CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3은 각각 서열번호 25, 26, 27 및 28, 29, 30의 서열을 포함한다. 일부 추가 구현예에서, CD3에 결합하는 Fab는 서열번호 22 및 24, 또는 이와 적어도 80%, 85%, 90%, 95% 또는 99% 동일성을 갖는 서열; 또는 서열번호 23 및 24, 또는 이와 적어도 80%, 85%, 90%, 95% 또는 99% 동일성을 갖는 서열을 포함하는 VH/VL 쌍을 포함한다.
추가 구현예에서, 본 개시내용은 제1, 제2 및 제3 폴리펩티드 쇄를 포함하는 이중특이적 1가 비대칭 탠덤 Fab(MAT-Fab) 결합 단백질을 제공하며, 여기서
(i) 포맷 LH에서, 제1 폴리펩티드 쇄는 아미노 말단으로부터 카복실 말단까지 VLA-CL-VHB-CH1-Fc를 포함하며, 여기서 CL은 VHB에 직접 융합되고; 제2 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VHA-CH1을 포함하고; 제3 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VL B -CL을 포함하고 제4 폴리펩티드 쇄는 Fc를 포함하거나; 또는
(ii) 포맷 HL에서, 제1 폴리펩티드 쇄는 아미노 말단으로부터 카복실 말단까지 VH A -CH1-VL B -CL-Fc를 포함하며, 여기서 CH1은 VL B 에 직접 융합되고; 제2 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VL A -CL을 포함하고; 제3 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VH B -CH1을 포함하고; 제4 폴리펩티드는 Fc를 포함하며;
여기서 VL은 경쇄 가변 도메인이고, CL은 경쇄 불변 도메인이고, VH는 중쇄 가변 도메인이고, CH1은 중쇄 불변 도메인이고, Fc는 아미노 말단으로부터 카복실 말단까지 힌지-CH2-CH3을 포함하는 면역글로불린 Fc 영역이고, A는 ROR1의 에피토프이고 B는 CD3의 에피토프이거나, 또는 A는 CD3의 에피토프이고 B는 ROR1의 에피토프이다. 본 개시내용에 따르면, 이러한 MAT-Fab 결합 단백질은 ROR1 및 CD3 모두에 결합한다.
일부 구현예에서, 이러한 MAT-Fab 결합 단백질의 Fab 단편은 항원 ROR1 및 CD3(예를 들어 본원에 기재된 항-ROR1 또는 항-CD3) 중 하나에 결합하는 모 항체로부터의 VLA-CL 및 VHA-CH1 도메인을 포함하고, 항원 ROR1 및 CD3(예를 들어 본원에 기재된 항-ROR1 또는 항-CD3) 중 다른 것에 결합하는 상이한 모 항체로부터의 VLB-CL 및 VHB-CH1 도메인을 포함한다. 일부 구현예에서, VH-CH1::VL-CL 짝짓기는 ROR1 및 CD3를 둘 다 인식하는 탠덤 Fab 모이어티를 생성시킨다.
본 개시내용에 따르면, ROR1/CD3 MAT-Fab 결합 단백질은 제1, 제2, 제3 및 제4 폴리펩티드 쇄를 포함하고, 여기서 제1 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VLROR1-CL-VHCD3-CH1-힌지-CH2-CH3ml를 포함하며, 여기서 CL은 VHCD3에 직접 융합되고; 여기서 제2 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VHROR1-CH1을 포함하고; 여기서 제3 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VLCD3-CL을 포함하고; 여기서 제4 폴리펩티드 쇄는 힌지-CH2-CH3m2를 포함하는 Fc 폴리펩티드 쇄이다. 대안적 구현예에서, ROR1/CD3 MAT-Fab 결합 단백질은 제1, 제2, 제3 및 제4 폴리펩티드 쇄를 포함하고, 여기서 제1 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VHROR1-CH1-VLCD3-CL-힌지-CH2-CH3m1을 포함하고, 여기서 CH1은 VLCD3에 직접 융합되며; 여기서 제2 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VLROR1-CL을 포함하고; 여기서 제3 폴리펩티드 쇄는 아미노으로부터 카복실 말단까지 VHCD3-CH1을 포함하고; 여기서 제4 폴리펩티드는 힌지-CH2-CH3m2를 포함하는 Fc 폴리펩티드 쇄이다. 일부 구현예에서, VLROR1은 항-ROR1 항체의 경쇄 가변 도메인이고, CL은 경쇄 불변 도메인이고, VHROR1은 항-ROR1 항체의 중쇄 가변 도메인이고, CH1은 중쇄 불변 도메인이고, VLCD3은 항-CD3 항체의 경쇄 가변 도메인이고, VHCD3은 항-CD3 항체의 중쇄 가변 도메인이고; 하나 이상의 "구멍에 손잡이" 돌연변이가 CH3m1 및 CH3m2 도메인의 이종이량체화를 촉진하기 위해 CH3m1 및 CH3m2 도메인에 도입되고; 도메인 VLCD3-CL은 항-CD3 모 항체의 경쇄와 동일하고, 도메인 VHCD3-CH1은 항-CD3 모 항체의 중쇄 가변 및 중쇄 불변 도메인과 동일하고, 도메인 VLROR1-CL은 항-ROR1 모 항체의 경쇄와 동일하고, 도메인 VHROR1-CH1은 항-ROR1 모 항체의 중쇄 가변 및 중쇄 불변 도메인과 동일하다.
MAT-Fab 결합 단백질의 제1 폴리펩티드 쇄에 대한 상기 화학식에서, Fc 영역은 고유 또는 변이 Fc 영역일 수 있다. 특정 구현예에서, Fc 영역은 IgG1, IgG2, IgG3, IgG4, IgA, IgM, IgE 또는 IgD로부터의 인간 Fc 영역이다. 특정 구현예에서, Fc는 IgG로부터의 인간 Fc, 또는 이의 변이체이다. 일부 구현예에서, Fc 영역은 상기 Fc 영역의 적어도 하나의 Fc 효과기 기능, 예를 들어 Fc의 FcγR에의 결합, ADCC 및/또는 CDC를 감소시키거나 제거하기 위한 돌연변이를 포함하는 변이 Fc 영역이다. 돌연변이는 예를 들어 L234A 및 L235A(Kabat EU 인덱스에 따른 넘버링)일 수 있다. 하나의 구현예에서, Fc 영역은 돌연변이 L234A 및 L235A를 갖는 인간 IgG1의 것이다.
본 개시내용에 따른 MAT-Fab 결합 단백질의 일부 구현예에서, CH1, CL 및 Fc 도메인은 인간 서열의 것이거나 또는 인간 서열로부터 유래된다. 본 개시내용에 따른 MAT-Fab 결합 단백질의 일부 구현예에서, CH1은 예를 들어 서열번호 33, 또는 이와 적어도 90%, 95%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 갖는 인간 IgG1 불변 CH1 도메인이다. MAT-Fab 결합 단백질에 대한 상기 화학식에서, CL은 경쇄 불변 도메인, 예를 들어 서열번호 32의 서열, 또는 이와 적어도 90%, 95%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 갖는 인간 불변 카파 CL 도메인이다.
하나의 구현예에서, 본 개시내용의 MAT-Fab 결합 단백질은 면역글로불린 도메인간에 링커를 사용하지 않는다.
하나의 구현예에서, 본 개시내용의 MAT-Fab 결합 단백질은 모 항체의 하나 이상의 특성을 보유한다. 일부 구현예에서, MAT-Fab는 모 항체의 경우에 필적하는 표적 항원(즉, CD3 및 ROR1)에 대한 결합 친화도를 유지하며, 이는 ROR1 및 CD3 항원 표적에 대한 MAT-Fab 결합 단백질의 결합 친화도가 표면 플라스몬 공명 또는 생물층 간섭계에 의해 측정된 바와 같이 각각의 표적 항원에 대한 모 항체의 결합 친화도와 비교하여 10배 이상 변하지 않음을 의미한다.
하나의 구현예에서, 본 개시내용의 MAT-Fab 결합 단백질은 ROR1 및 CD3에 결합하고, 제1 폴리펩티드 쇄, 제2 폴리펩티드 쇄, 및 제3 폴리펩티드 쇄 및 제4 폴리펩티드로 구성되며, 여기서:
- 제1 폴리펩티드 쇄는 서열번호 38 또는 40의 아미노산 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하고,
- 제2 폴리펩티드 쇄는 서열번호 35의 아미노산 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하고,
- 제3 폴리펩티드 쇄는 서열번호 36의 아미노산 서열, 또는 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하고,
- 제4 폴리펩티드 쇄는 서열번호 39의 아미노산 서열, 또는 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함한다.
하나의 구현예에서, 본 개시내용의 MAT-Fab 결합 단백질은 ROR1 및 CD3에 결합하고, 서열번호 38 또는 40의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 제1 폴리펩티드 쇄; 서열번호 35의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 제2 폴리펩티드 쇄; 서열번호 36의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 제3 폴리펩티드 쇄; 및 서열번호 39의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 제4 폴리펩티드 쇄로 구성된다.
이중특이적 결합 단백질의 특성
하나의 구현예에서, 본원에 기재된 바와 같은 CD3 및 ROR1 모두에 결합할 수 있는 이중특이적 ROR1/CD3 FIT-Ig 또는 MAT-Fab 결합 단백질은 인간화된 ROR 결합 부위, 또는 키메라 ROR1 결합 부위, 예를 들어 인간화된 ROR 결합 부위를 포함한다. 하나의 구현예에서, FIT-Ig 또는 MAT-Fab 단백질 포맷의 인간화된 ROR1 결합 부위는 동일한 FIT-Ig 또는 MAT-Fab 포맷(서열 번호 8 및 9의 VH 및 VL 쌍으로 이루어진다)의 키메라 ROR1 결합 부위에 비해 ROR1 결합에 대한 해리속도가 더 느리다. 추가의 구현예에서, 키메라 ROR1 결합 부위에 비해 인간화된 ROR1 결합 부위의 해리속도 비는 표면 플라스몬 공명 또는 생물층 간섭계로 측정시, 90%, 80%, 70%, 60%, 50%, 40%, 30%, 20%, 15%, 10%, 5% 미만이다. 하나의 구현예에서, ROR1에 대해 본원에 기재된 FIT-Ig 결합 단백질의 해리속도는 표면 플라스몬 공명 또는 생물층 간섭계로 측정시, 2 Х 10-3 s-1, 1 Х 10-3 s-1, 8 Х 10-4 s-1, 6 Х 10-4 s-1, 5 Х 10-4 s-1, 4 Х 10-4 s-1, 3 Х 10-4 s-1, 2 Х 10-4 s-1, 1Х 10-4 s-1, 8 Х 10-5 s-1, 6Х 10-5 s-1 미만이다. 하나의 구현예에서, 본원에 기재된 FIT-Ig 결합 단백질 항체 또는 이의 항원-결합 단편은 10-8 내지 10-10 범위, 예를 들어 8 Х 10-8 M 미만, 5 Х 10-8 M 미만, 3 Х 10-8 M 미만, 2 Х 10-8 M 미만, 1 Х 10-8 M 미만, 8 Х 10-9 M 미만, 6 Х 10-9 M 미만, 4 Х 10-9 M 미만, 2 Х 10-9 M, 또는 1 Х 10-9 M 미만, 8 Х 10-10 M 미만, 6 Х 10-10 M 미만, 4 Х 10-10 M 미만, 2 Х 10-10 M, 또는 1 Х 10-10 M 미만의 ROR1에 대한 해리상수(KD)를 갖는다. 하나의 구현예에서, 본원에 기재된 FIT-Ig 결합 단백질 항체 또는 이의 항원-결합 단편은 ROR1 결합에 관하여 1Х 10-3 s-1 내지 1Х 10-4 s-1, 예를 들어 2Х 10-4 s-1 미만 범위의 해리속도, 및 1 x 10-9 s-1 내지 1 x 10-10 s-1, 예를 들어 6 x 10-10 s-1 미만 범위의 KD를 갖는다.
하나의 구현예에서, 본원에 기재된 바와 같은 CD3 및 ROR1에 결합할 수 있는 이중특이적 ROR1/CD3 FIT-Ig 결합 단백질 또는 MAT-Fab 결합 단백질은 CHO 세포 또는 HEK293 세포와 같은 형질감염된 포유동물 숙주 세포의 배양물에서 세포 배양물 리터당 ROR1/CD3 FIT-Ig 또는 MAT-Fab 결합 단백질 10 ㎎ 초과(>10 ㎎/L) 수준으로 발현될 수 있다. 하나의 구현예에서, FIT-Ig 또는 MAT-Fab 결합 단백질의 발현 수준은 15 ㎎/L 초과, 예를 들어 15 ㎎/L 내지 100 ㎎/L, 또는 그 이상이다. 또 다른 구현예에서, FIT-Ig 또는 MAT-Fab 결합 단백질의 발현 수준은 20 ㎎/L 초과이다.
하나의 구현예에서, 본원에 기재된 바와 같은 CD3 및 ROR1에 결합할 수 있는 이중특이적 ROR1/CD3 FIT-Ig 결합 단백질 또는 MAT-Fab 결합 단백질은 단백질 A 친화성 크로마토그래피를 사용하여 세포 배양 배지로부터 1-단계 정제 후에, SEC-HPLC에 의해 검출시 90% 이상의 순도를 갖는다. 하나의 구현예에서, 1-단계 정제된 결합 단백질은 SEC-HPLC에 의해 검출시 91%, 92%, 93%, 95%, 97%, 99% 이상의 순도를 갖는다.
하나의 구현예에서, 본원에 기재된 바와 같은 이중특이적 ROR1/CD3 FIT-Ig 결합 단백질 또는 MAT-Fab 결합 단백질은 ROR1-발현 세포의 세포 표면에 결합시 세포에 의한 최소 내재화를 나타낸다. 하나의 구현예에서, 내재화율은 세포-기반 분석에 따라 20%, 15%, 14%, 13%, 12%, 11%, 10% 이하이거나, 또는 결합 단백질이 내재화되지 않는다.
하나의 구현예에서, 본원에 기재된 바와 같은 이중특이적 ROR1/CD3 FIT-Ig 결합 단백질 또는 MAT-Fab 결합 단백질은 CD3-발현 세포 및 ROR1-발현 세포 모두에 결합할 수 있다. 하나의 구현예에서, CD3-발현 세포는 인간 TCR/CD3 복합체 형질감염된 CHO 세포주 또는 인간 T 세포이다. 하나의 구현예에서, ROR1-발현 세포는 ROR1-발현 종양 세포, 예를 들어 인간 비-소세포 폐암 세포, 인간 유방암 세포, 폐 암종 세포 또는 골수종 세포이다.
하나의 구현예에서, 세포-기반 분석에서 유세포 분석에 의해 측정된 바와 같이, ROR1-발현 세포에 대한 이중특이적 FIT-Ig 결합 단백질의 결합 효능은 상기 이중특이적 FIT-Ig 단백질과 동일한 ROR1 결합에 대한 VH/VL 서열쌍을 포함하는 상응하는 모 항-ROR1 단클론 IgG 항체와 동등하거나 이에 필적한다. 하나의 구현예에서, CD3-발현 세포에 대한 이중특이적 FIT-Ig 결합 단백질의 결합 효능은 유세포 분석에 의해 측정시, 예를 들어 실시예 4에 기재된 분석에서와 같이, 상기 이중특이적 FIT-Ig 단백질과 동일한 CD3 결합에 대한 VH/VL 서열쌍을 포함하는 상응하는 모 항-CD3 단클론 IgG 항체와 동등하거나 또는 이보다 비교적 더 낮다(그러나, 10배 이하의 차이, 예를 들어, 2배, 1배 이하, 또는 50% 감소).
하나의 구현예에서, 본원에 기재된 이중특이적 결합 단백질은 ROR1, CD3 또는 이들 둘 다의 생물학적 기능을 조절할 수 있다. 하나의 구현예에서, 본원에 기재된 바와 같은 이중특이적 ROR1/CD3 FIT-Ig 결합 단백질 또는 MAT-Fab 결합 단백질은 ROR1-의존성에 관하여 CD3 신호전달을 활성화할 수 있다. 하나의 구현예에서, 본 개시내용의 이중특이적 결합 단백질은 T 세포의 ROR1-의존적 활성화를 나타낸다. 하나의 구현예에서, 본원에 기재된 바와 같은 이중특이적 ROR1/CD3 FIT-Ig 결합 단백질 또는 MAT-Fab 결합 단백질은 ROR1-전향된 T 세포 세포독성을 나타낸다. 하나의 구현예에서, 본 개시내용의 이중특이적 결합 단백질은 비-MHC 제한 방식으로 ROR1 발현 세포를 향한 T-세포의 세포독성 활성을 전향시키기 위해 사용된다.
하나의 구현예에서, 본원에 기재된 바와 같은 이중특이적 ROR1/CD3 FIT-Ig 결합 단백질 또는 MAT-Fab 결합 단백질은 ROR1-의존성 CD3 활성화를 나타낸다. 하나의 구현예에서, ROR1-발현 세포에 결합시, 이중특이적 ROR1/CD3 항체는 T 세포 상에서 CD3/TCR 복합체의 가교결합 및 CD3 신호전달의 활성화를 유도한다. 하나의 구현예에서, 표적 ROR1-발현 세포 대 효과기 T 세포의 비는 약 1:1이다. 추가 구현예에서, 이중특이적 ROR1/CD3 결합 단백질은, 예를 들어 약 1:1 표적 세포 대 효과기 T 세포의 비로 측정시, 상기 이중특이적 FIT-Ig 또는 MAT-Fab 단백질과 동일한 CD3 결합에 대한 VH/VL 서열 쌍을 포함하는 상응하는 모 항-CD3 단클론 IgG 항체와 비교하여, ROR1-발현 표적 세포의 존재 하에서 증가된 T 세포 활성화를 나타내고, ROR1-발현 표적 세포의 부재 하에서 훨씬 적은 비-표적 전향된 CD3 활성화를 나타낸다.
하나의 구현예에서, 본원에 기재된 바와 같은 이중특이적 ROR1/CD3 FIT-Ig 결합 단백질 또는 MAT-Fab 결합 단백질은 T 세포 세포독성을 ROR1-발현 종양 세포로 전향시킨다. 또 다른 구현예에서, 본원에 기재된 바와 같은 이중특이적 ROR1/CD3 FIT-Ig 결합 단백질 또는 MAT-Fab 결합 단백질은 종양 크기 감소, 종양 성장 억제 또는 신생물 세포 확대 억제와 같은 항종양 활성을 나타낸다.
약제학적 조성물
본 개시내용은 또한 본 개시내용의 항체, 또는 이의 항원-결합 부분, 또는 이중특이적 다가 결합 단백질(즉, 1차 활성 성분) 및 약제학적으로 허용되는 담체(carrier)를 포함하는 약제학적 조성물을 제공한다. 특정 구현예에서, 조성물은 본 개시내용의 하나 이상의 항체 또는 결합 단백질을 포함한다. 본 개시내용은 또한 본원에 기재된 바와 같은 항-ROR1 및 항-CD3 항체의 조합, 또는 이의 항원-결합 단편(들), 및 약제학적으로 허용되는 담체를 포함하는 약제학적 조성물을 제공한다. 특히, 본 개시내용은 ROR1 및 CD3에 결합할 수 있는 적어도 하나의 FIT-Ig 결합 단백질 및 약제학적으로 허용되는 담체를 포함하는 약제학적 조성물을 제공한다. 특히, 본 개시내용은 ROR1 및 CD3에 결합할 수 있는 적어도 하나의 MAT-Fab 결합 단백질 및 약제학적으로 허용되는 담체를 포함하는 약제학적 조성물을 제공한다. 본 발명의 약제학적 조성물은 적어도 하나의 추가적인 활성 성분을 추가로 포함할 수 있다. 일부 구현예에서, 이러한 추가적인 성분은 비제한적으로, 예방제 및/또는 치료제, 검출제, 예를 들어 항종양 약물, 세포독성제, 상이한 특이성의 항체 또는 이의 기능적 단편, 검출가능한 표지 또는 리포터를 포함한다. 하나의 구현예에서, 약제학적 조성물은 ROR1 활성이 유해한 장애를 치료하기 위한 하나 이상의 추가적인 예방제 또는 치료제, 즉 본 개시내용의 항체 또는 결합 단백질 이외의 제제를 포함한다. 하나의 구현예에서, 추가적인 예방제 또는 치료제는 장애 또는 이의 하나 이상의 증상의 예방, 치료, 관리 또는 개선에 유용한 것으로 공지되어 있거나, 사용되었거나, 또는 현재 사용되고 있다.
본 발명의 단백질을 포함하는 약제학적 조성물은 장애를 진단, 검출 또는 모니터링; 장애 또는 이의 하나 이상의 증상을 치료, 관리 또는 개선; 및/또는 연구하는데 사용하기 위한 것이지만, 이에 제한되지는 않는다. 일부 구현예에서, 조성물은 담체, 희석제 또는 부형제(excipient)를 추가로 포함할 수 있다. 부형제는 일반적으로 1차 활성 성분 이외에(즉, 본 개시내용의 항체, 이의 기능적 부분 또는 결합 단백질 이외에) 조성물에 목적하는 특징을 제공하는 임의의 화합물 또는 화합물의 조합이다.
핵산, 벡터 및 숙주 세포
추가의 양태에서, 본 개시내용은 본 개시내용의 항-ROR1 항체 또는 이의 항원-결합 단편의 하나 이상의 아미노산 서열을 암호화하는 단리된 핵산을 제공하고; 본 발명의 항-CD3 항체 또는 이의 항원-결합 단편의 하나 이상의 아미노산 서열을 암호화하는 단리된 핵산; 및 ROR1 및 CD3 모두에 결합할 수 있는, Fabs-in-Tandem 면역글로불린(FIT-Ig) 및 MAT-Fab 결합 단백질을 포함하는 이중특이적 결합 단백질의 하나 이상의 아미노산 서열을 암호화하는 단리된 핵산을 제공한다. 이러한 핵산은 다양한 유전자 분석을 수행하거나 본원에 기재된 항체 또는 결합 단백질의 하나 이상의 특성을 발현, 특성화, 또는 개선시키기 위해 벡터에 삽입될 수 있다. 벡터는 본원에 기재된 항체 또는 결합 단백질의 하나 이상의 아미노산 서열을 암호화하는 하나 이상의 핵산 분자를 포함할 수 있으며, 여기서 하나 이상의 핵산 분자는 상기 벡터를 운반하는 특정 숙주 세포 중의 항체 또는 결합 단백질의 발현을 허용하기에 적합한 전사 및/또는 번역 서열에 작동적으로 연결된다. 본원에 기재된 결합 단백질의 아미노산 서열을 암호화하는 핵산을 클로닝 또는 발현하기 위한 벡터의 예는 pcDNA, pTT, pTT3, pEFBOS, pBV, pJV, 및 pBJ, 및 이들의 유도체를 포함하지만 이에 제한되지 않는다.
본 개시내용은 또한 본원에 기재된 항체 또는 결합 단백질의 하나 이상의 아미노산 서열을 암호화하는 핵산을 포함하는 벡터를 발현하거나 발현할 수 있는 숙주 세포를 제공한다. 본 발명에 유용한 숙주 세포는 원핵생물 또는 진핵생물일 수 있다. 예시적인 원핵 숙주 세포는 에스케리키아 콜라이(Escherichia coli)이다. 본 개시내용에서 숙주 세포로서 유용한 진핵 세포는 원생생물 세포, 동물 세포, 식물 세포 및 진균 세포를 포함한다. 예시적인 진균 세포는 사카로마이세스 세레비지아에(Saccharomyces cerevisiae)를 포함한 효모 세포이다. 본 발명에 따른 숙주 세포로서 유용한 예시적인 동물세포는 포유동물 세포, 조류 세포 및 곤충 세포를 포함하나 이에 제한되지 않는다. 예시적인 포유동물 세포는 CHO 세포, HEK 세포 및 COS 세포를 포함하지만 이에 제한되지 않는다.
생성 방법
또 다른 양태에서, 본 개시내용은 항체 또는 기능적 단편을 암호화하는 발현 벡터를 포함하는 숙주 세포를 배양 배지에서 상기 숙주 세포가 ROR1에 결합할 수 있는 항체 또는 단편을 발현시키기에 충분한 조건 하에서 배양하는 것을 포함하는, 항-ROR1 항체 또는 이의 기능적 단편의 생성 방법을 제공한다.
또 다른 양태에서, 본 개시내용은 항체 또는 기능적 단편을 암호화하는 발현 벡터를 포함하는 숙주 세포를 배양 배지에서 상기 숙주 세포가 CD3에 결합할 수 있는 항체 또는 단편을 발현시키기에 충분한 조건 하에 배양하는 것을 포함하는, 항-CD3 항체 또는 이의 기능적 단편의 생성 방법을 제공한다.
또 다른 양태에서, 본 개시내용은 FIT-Ig 또는 MAT-Fab 결합 단백질을 암호화하는 발현 벡터를 포함하는 숙주 세포를 배양 배지에서 상기 숙주 세포가 ROR1 및 CD3에 결합할 수 있는 상기 결합 단백질을 발현시키기에 충분한 조건 하에 배양하는 것을 포함하는, ROR1 및 CD3에 결합할 수 있는 이중특이적의 다가 결합 단백질, 구체적으로 FIT-Ig 또는 MAT-Fab 결합 단백질의 생성 방법을 제공한다. 본원에 개시된 방법에 의해 생성된 단백질을 단리하여 본원에 기재된 다양한 조성물 및 방법에 사용할 수 있다.
항체 및 결합 단백질의 용도
인간 ROR1 및/또는 CD3에 결합하는 능력을 고려할 때, 본원에 기재된 항체, 이의 기능적 단편, 및 본원에 기재된 이중특이적 다가 결합 단백질을, ROR1 또는 CD3, 또는 이 둘 모두, 예를 들어 이들 표적 항원 중 하나 또는 둘 모두를 발현하는 세포를 함유하는 생물학적 샘플에서 이들을 검출하는 데 사용할 수 있다. 본 개시내용의 항체, 기능적 단편 및 결합 단백질은 효소 결합된 면역흡수 분석(ELISA), 방사성면역분석(RIA) 또는 조직 면역조직화학과 같은 통상적인 면역분석에 사용될 수 있다. 본 개시내용은 생물학적 샘플을 본 개시내용의 항체, 이의 항원 결합 부분 또는 결합 단백질과 접촉시키고 표적 항원에 대한 결합이 발생하는지 여부를 검출함으로써 상기 생물학적 샘플에서 상기 표적의 존재 또는 부재를 검출함을 포함하는, 상기 생물학적 샘플에서 ROR1 또는 CD3를 검출하는 방법을 제공한다. 항체, 기능적 단편 또는 결합 단백질을, 결합된 또는 결합되지 않은 항체/단편/결합 단백질의 검출을 용이하게 하기 위해 검출가능한 물질로 직접 또는 간접적으로 표지할 수 있다. 적합한 검출가능한 물질은 다양한 효소, 보결분자단, 형광 물질, 발광 물질 및 방사성 물질을 포함한다. 적합한 효소의 예는 양고추냉이 퍼옥시다제, 알칼리 포스파타제, β-갈락토시다제 또는 아세틸콜린에스테라제를 포함한다. 적합한 보결분자단 복합체의 예는 스트렙트아비딘/비오틴 및 아비딘/비오틴을 포함하고; 적합한 형광 물질의 예는 움벨리페론, 플루오레세인, 플루오레세인 이소티오시아네이트, 로다민, 디클로로트리아지닐아민 플루오레세인, 단실 클로라이드 또는 피코에리트린을 포함하고; 발광 물질의 예는 루미놀을 포함하고; 적합한 방사성 물질의 예는 3H, 14C, 35S, 90Y, 99Tc, 111In, 125I, 131I, 177Lu, 166Ho, 또는 153Sm을 포함한다.
일부 구현예에서, 본 개시내용의 항체, 이의 기능적 단편은 시험관내 및 생체내 모두에서 인간 ROR1 활성을 중화시킬 수 있다. 따라서, 본 개시내용의 항체, 이의 기능적 단편을, 인간 ROR1 활성을 억제하는데, 예를 들어 ROR1-발현 세포를 함유하는 세포 배양물에서, 인간 대상체(subject)에서, 또는 본 개시내용의 항체, 이의 기능적 단편 또는 결합 단백질이 교차 반응하는 ROR1을 갖는 다른 포유동물 대상체에서 ROR1에 의해 매개된 세포 신호전달을 억제하는 데 사용할 수 있다.
또 다른 구현예에서, 본 개시내용은 ROR1 활성이 유해한 질병 또는 장애를 앓고 있는 대상체를 치료하는데 사용하기 위한 본 개시내용의 항체 또는 이중특이적 결합 단백질을 제공하며, 여기서 상기 항체 또는 결합 단백질은 대상체에게 투여되어 상기 대상체에서 ROR1에 의해 매개되는 활성이 감소된다. 본원에 사용된 바와 같이, "ROR1 활성이 유해한 장애"라는 용어는 장애를 앓고 있는 대상체에서 ROR1과 이의 리간드(Wnt-5A)와의 상호작용이 상기 장애의 병태생리학의 원인이거나 또는 상기 장애의 악화에 기여하는 인자인 질병 및 다른 장애를 포함하고자 한다. 따라서, ROR1 활성이 유해한 장애는 ROR1 활성의 억제가 상기 장애의 증상 및/또는 진행을 완화시킬 것으로 예상되는 장애이다. 하나의 구현예에서, 본 개시내용의 항-ROR1 항체, 이의 기능적 단편은 악성 세포의 성장 또는 생존을 억제하거나 종양 크기를 감소시키는 방법에 사용된다.
일부 구현예에서, 본 개시내용의 이중특이적 결합 단백질(FIT-Ig 또는 MAT-Fab)은 시험관내 및 생체내 모두에서 T 세포 세포독성을 ROR-발현 세포를 향해 전향될 수 있다. 따라서, 본 개시내용의 이중특이적 결합 단백질은 항체, 이의 기능적 단편 또는 이중특이적 결합 단백질과 교차-반응하는 ROR1을 갖는 인간 대상체 또는 다른 포유동물 대상체에서 ROR1-발현 악성 세포의 성장 또는 확대를 억제하는데 사용될 수 있다.
다른 구현예에서, 본 개시내용은 대상체에서 ROR1-발현 악성종양을 치료하는데 사용하기 위한 CD3/ROR1 이중특이적(FIT-Ig 또는 MAT-Fab) 결합 단백질을 제공하며, 여기서 결합 단백질은 대상체에게 투여된다. 일부 구현예에서, 악성 종양은 고형 종양 또는 조혈성 악성종양이다.
본 개시내용의 항체(이의 기능적 단편 포함) 및 결합 단백질은 대상체에게 투여하기에 적합한 약제학적 조성물에 혼입될 수 있다. 전형적으로, 약제학적 조성물은 본 발명의 항체 또는 결합 단백질 및 약제학적으로 허용되는 담체를 포함한다. 본원에 사용된 바와 같이, "약제학적으로 허용되는 담체"는 생리학적으로 적합한 모든 용매, 분산 매질, 코팅제, 항균제 및 항진균제, 등장화제 및 흡수 지연제 등을 포함한다. 약제학적으로 허용되는 담체의 예는 하나 이상의 물, 식염수, 포스페이트 완충된 염수, 덱스트로스, 글리세롤, 에탄올 등 뿐만 아니라 이들의 조합을 포함한다. 많은 경우에, 등장화제, 예를 들어 당, 폴리알콜(예를 들어, 만니톨 또는 소르비톨) 또는 염화나트륨을 조성물에 포함시키는 것이 바람직할 것이다. 약제학적으로 허용되는 담체는 조성물에 존재하는 항체 또는 결합 단백질의 저장 수명 또는 유효성을 향상시키는 습윤제 또는 유화제, 보존제 또는 완충제와 같은 소량의 보조 물질을 추가로 포함할 수 있다. 본 개시내용의 약제학적 조성물은 의도된 투여 경로에 적합하도록 제형화된다.
본 개시내용의 방법은 주사에 의한(예를 들어, 일시 주사 또는 연속 주입에 의한) 비경구 투여용으로 제형화된 조성물의 투여를 포함할 수 있다. 주사용 제형은 보존제가 첨가된 단위 투여형(예를 들어, 앰플 또는 다중-용량 용기)로 제공될 수 있다. 조성물은 유성 또는 수성 비히클 중의 현탁액, 용액 또는 유화액과 같은 형태를 취할 수 있고, 현탁제, 안정화제 및/또는 분산제와 같은 제형 보조제를 함유할 수 있다. 대안적으로, 1차 활성 성분은 사용 전에 적합한 비히클(예를 들어, 멸균된 발열원이 없는 물)로 구성하기 위한 분말 형태일 수 있다.
본 개시내용의 용도는 데포(depot) 제제로서 제형화된 조성물의 투여를 포함할 수 있다. 이러한 장기간 작용 제형은 이식(예를 들어, 피하 또는 근육내) 또는 근육내 주사에 의해 투여될 수 있다. 예를 들어, 조성물을 적합한 중합체 또는 소수성 물질(예를 들어, 허용 가능한 오일 중의 유화액으로서) 또는 이온 교환 수지, 또는 난용성 유도체(예를 들어, 난용성 염으로서)로 제형화할 수 있다.
본 개시내용의 항체, 이의 기능적 단편 또는 결합 단백질은 또한 다양한 질병의 치료에 유용한 하나 이상의 추가적인 치료제와 함께 투여할 수 있다. 본원에 기재된 항체, 이의 기능적 단편 및 결합 단백질은 단독으로 또는 추가적인 작용제, 예를 들어 추가적인 치료제와 조합하여 사용될 수 있으며, 추가적인 작용제는 이의 의도된 목적을 위해 당업자에 의해 선택된다. 예를 들어, 추가적인 작용제는 본 개시내용의 항체 또는 결합 단백질에 의해 치료되는 질병 또는 상태를 치료하는 데 유용한 것으로 당해 분야에서 인식된 치료제일 수 있다. 추가적인 작용제는 또한 치료학적 조성물에 유익한 속성을 부여하는 작용제, 예를 들어 조성물의 점도에 영향을 미치는 작용제일 수 있다.
치료 방법 및 의학적 용도
하나의 구현예에서, 본 개시내용은 ROR1-매개된 신호전달 활성이 연관되거나 유해한 장애(예를 들어, ROR+ 고형 종양 또는 조혈성 악성종양)의 치료를 필요로 하는 대상체에서 상기 장애를 치료하는 방법을 제공하며, 상기 방법은 상기 대상체에게 본원에 기재된 바와 같은 항-ROR1 항체 또는 이의 ROR1-결합 단편을 투여함을 포함하고, 여기서 상기 항체 또는 결합 단편은 ROR1에 결합할 수 있고 ROR1을 발현하는 세포에서 ROR1-매개된 신호전달을 억제할 수 있다. 또 다른 구현예에서, 본 개시내용은 이러한 장애의 치료에서 유효량의 본원에 기재된 항-ROR1 항체 또는 이의 항원-결합 단편의 용도를 제공한다. 또 다른 구현예에서, 본 개시내용은 이러한 장애의 치료를 위한 조성물의 제조에서 본원에 기재된 항-ROR1 항체 또는 이의 항원-결합 단편의 용도를 제공한다. 또 다른 구현예에서, 본 개시내용은 이러한 장애의 치료에 사용하기 위한 본원에 기재된 항-ROR1 항체 또는 이의 항원-결합 단편을 제공한다.
본원에 기재된 방법 또는 용도의 추가 구현예에서, 본 개시내용의 항-ROR1 항체 또는 항원 결합 단편은 ROR1에 결합하고, 서열번호 10 또는 21의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 VH 도메인, 및 서열번호 13의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 VL 도메인을 포함한다.
또 다른 구현예에서, 본 개시내용은 ROR1-매개된 신호전달 활성이 연관되거나 유해한 장애(예를 들어, ROR+ 고형 종양 또는 조혈 악성종양)의 치료를 필요로 하는 대상체에서 상기 장애를 치료하는 방법을 제공하며, 상기 방법은 상기 대상체에게 본원에 기재된 바와 같은 CD3 및 ROR1에 결합할 수 있는 이중특이적 FIT-Ig 또는 MAT-Fab 결합 단백질을 투여함을 포함하고, 여기서 상기 결합 단백질은 ROR1 및 CD3에 결합하고, ROR1-발현 종양 세포에 전향된 T-세포 세포독성을 유도할 수 있다. 또 다른 구현예에서, 본 개시내용은 이러한 장애의 치료에서 유효량의 본원에 기재된 이중특이적 FIT-Ig 또는 MAT-Fab 결합 단백질의 용도를 제공한다. 또 다른 구현예에서, 본 개시내용은 이러한 장애의 치료를 위한 조성물의 제조에서 본원에 기재된 이중특이적 FIT-Ig 또는 MAT-Fab 결합 단백질의 용도를 제공한다. 또 다른 구현예에서, 본 개시내용은 이러한 장애의 치료에 사용하기 위한 본원에 기재된 이중특이적 FIT-Ig 또는 MAT-Fab 결합 단백질을 제공한다.
본원에 기재된 방법 또는 용도의 추가 구현예에서, 본 개시내용의 FIT-Ig 결합 단백질은 ROR1 및 CD3에 결합하고, 서열번호 34 또는 37의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 제1 폴리펩티드 쇄; 서열번호 35의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 제2 폴리펩티드 쇄; 및 서열번호 36의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 제3 폴리펩티드 쇄로 구성된다. 추가의 구현예에서, 본 개시내용의 MAT-Fab 결합 단백질은 ROR1 및 CD3에 결합하고, 서열번호 38 또는 40의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 제1 폴리펩티드 쇄; 서열번호 35의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 제2 폴리펩티드 쇄; 서열번호 36의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 제3 폴리펩티드 쇄; 및 서열번호 39의 서열을 포함하거나, 이로 필수적으로 이루어지거나, 또는 이루어지는 제4 폴리펩티드 쇄로 구성된다.
일부 구현예에서, 본 개시내용에 따른 항체 또는 결합 단백질로 치료될 수 있는 장애는 악성 세포의 세포 표면상에서 ROR1을 발현하는 다양한 조혈성 및 고형 악성종양을 포함한다. 또 다른 구현예에서, 상기 항체 또는 결합 단백질은 악성 세포의 성장 또는 생존을 억제한다. 또 다른 구현예에서, 상기 항체 또는 결합 단백질은 종양 크기를 감소시킨다. 또 다른 구현예에서, 암은 삼중 음성 유방 선암종과 같은 유방암, 또는 만성 림프구성 백혈병(CLL)과 같은 백혈병이다.
본원에 기재된 치료 방법은 의도된 치료 목적을 위해 본 항체 또는 결합 단백질과 함께 적합하게 존재하는 추가 활성 성분, 예를 들어 항-종양(anti-tumor) 활성을 갖는 또 다른 약물을 이를 필요로 하는 대상체에게 투여하는 것을 추가로 포함할 수 있다. 본 개시내용의 치료 방법에서, 추가 활성 성분은 본 개시내용의 항체 또는 결합 단백질을 포함하는 조성물 및 치료를 필요로 하는 대상체에게 투여되는 조성물에 혼입될 수 있다. 또 다른 구현예에서, 본 개시내용의 치료 방법은 치료를 필요로 하는 대상체에게 본원에 기재된 항체 또는 결합 단백질을 투여하는 단계 및 상기 대상체에게 본 개시내용의 항체 또는 결합 단백질을 투여하는 단계 전에, 상기 단계와 동시에, 또는 상기 단계 후에 상기 추가 활성 성분을 투여하는 별도의 단계를 포함할 수 있다.
이제 본 개시내용을 상세히 기술하였지만, 이는 하기 실시예를 참조하여 보다 명확하게 이해될 것이며, 이들 실시예는 단지 예시의 목적으로 포함되고 본 개시내용을 제한하려는 의도가 아니다.
실시예
개선된 특성을 가진 ROR1 표적 단클론 항체를 수득하기 위해 통상적인 하이브리도마 기술을 사용하여 항-ROR1 항체를 생성시켰다. 이어서 ROR1 Ig-유사 도메인의 C-말단에서 ROR1에 결합하는 항체 ROR1-mAb004를 선택하고 특성화하였다. ROR1-mAb004 서열을 통상적인 CDR 접목 방법에 의해 추가로 인간화하였다. 인간화된 서열을 설계하였다. 이들 서열 중 일부를 재조합 FIT-Ig로서 발현하였고 그들의 결합 친화도에 대해 특성화하였다.
FIT-Ig 단백질 FIT1007-12B-17을 구성하였고, 이의 MAT-Fab 대응물인 MAT1007-12B-17뿐만 아니라, 이의 CD3 친화도 비교물인 FIT1007-12B-18도 또한 생성시켰다. 일반적으로, 동일한 Ig 가변 서열을 가질 때 FIT-Ig 포맷은 MAT-Fab보다 우수한 시험관내 종양 세포 사멸 효능 및 더 높은 사이토카인 방출을 보였다. 감소된 CD3 친화도는 또한 감소된 전향된 T 세포 세포독성(RTCC) 효능으로 이어졌다.
FIT-Ig 및 MAT-Fab는 모두 공배양된 리포트 유전자 분석에서 T 세포의 ROR1 표적 의존적 활성화를 나타내었다. 이것은 표적 ROR1이 존재하지 않을 때 T 세포가 효율적으로 활성화되지 않을 수 있음을 시사한다. 이러한 현상은 FIT-Ig와 이의 모 CD3 단클론 항체 간의 CD3 결합 활성 차이와 일치한다.
FIT-Ig 및 MAT-Fab는 삼중 음성 유방암 이종이식 모델에서 강한 생체 내 효능을 나타내었다.
실시예 1. 항-ROR1 항체의 생성
Balb/c 또는 SJL 마우스를 재조합 인간 ROR1 세포외 도메인(UniProt 식별자: Q01973-1)인, 인간 ROR1의 Q30-Y406으로 면역화하여 항-ROR1 항체를 수득하였다:

마우스를 2주 간격으로 면역화하고 두 번째 주사 후 일주일에 한 번 혈청 역가를 모니터링하였다. 4 내지 6회 면역화 후, 비장 세포를 수확하고 마우스 골수종 세포와 융합시켜 하이브리도마 세포주를 형성시켰다. 융합 생성물을, 96-웰 플레이트에서 하이포잔틴-아미노프테린-티미딘(HAT)을 함유하는 선택 배지에 웰당 1×105 비장 세포의 밀도로 도말하였다. 융합 7 내지 10일 후, 거시적인 하이브리도마 콜로니가 관찰되었다. 이어서 하이브리도마 세포의 상등액을 스크리닝하고 선택하여 ROR1-특이적 마우스 항체를 생성하는 세포주를 확인하였다. 예비 특성화 시, 하나의 항-ROR1 항체, ROR1-mAb004를 선택하고 서열분석하였다.
실시예 1.1 중쇄 및 경쇄 가변 영역 서열
중쇄 및 경쇄 가변 영역을 증폭시키기 위해서, TRIzol™ RNA 추출 시약(Invitrogen, Cat. #15596018)을 사용하여 각 하이브리도마 클론의 전체 RNA를 5×106 이상의 세포로부터 단리하였다. cDNA를 제조사의 설명에 따라 Invitrogen™ SuperScript ™ III 제1-가닥 합성 SuperMix 키트(ThermoFisher Scientific Cat. #18080)를 사용하여 합성하고, 마우스 면역글로불린 경쇄 및 중쇄에 대한 가변 영역을 암호화하는 cDNA를 MilliporeSigma™ Novagen™ 마우스 Ig-프라이머 세트(Fisher Scientific Cat. #698313)를 사용하여 증폭시켰다. PCR 산물을, SYBR™ Safe DNA 젤 착색제(ThermoFisher Cat. #S33102)를 사용하여 1.2% 아가로스 젤에서 전기영동에 의해 분석하였다. 올바른 크기의 DNA 단편을 제조사의 설명에 따라 NucleoSpin® 젤 및 PCR 클린업 키트(Macherey-Nagel, Cat. #740609)를 사용하여 정제하고 pMD18-T 벡터에 개별적으로 서브클로닝하였다. 각각의 형질전환으로부터 15개의 콜로니를 선택하고 삽입 단편의 서열을 DNA 서열분석에 의해 분석하였다. 뮤린 mAb 가변 영역의 단백질 서열을 서열 상동성 정렬에 의해 분석하였다.
상기 선택된 항-ROR1 항체에 대한 가변 도메인 서열을 하기 표에 제시한다. 상보성 결정 영역(CDR)을 카밧 넘버링에 기초하여 밑줄 표시한다.
| 항체 | 도메인 | 서열번호 | 아미노산 서열 |
| ROR1-mAb004 | VH | 8 | QVQLQQSGPELVKPGASVKISCKASGYAFSRSWMNWVKQRPEKGLEWIGRIYPGNGDIKYNGNFKGKATLTADKSSSTAYMQLSSLTSEDSAVYFCAHIYYDFYYALDYWGQGTSVTVSS |
| VL | 9 | DIQLTQSPSSLSASLGGKVTITCKASQDINKYITWYQHKPGKGPRLLIHYTSTLQPGIPSRFSGSGSGRDYSFSISNLEPEDIATYYCLQYDSLLWTFGGGTKLEIK |
실시예 1.2 항-ROR1 항체의 결합 동역학
항-ROR1 항체의 결합 친화도 및 동역학 상수를 표준 과정에 따라 Octet®RED96 생물층 간섭계(Pall ForteBio LLC)를 사용하여 25℃에서 측정하였다. 간략하게, 항-마우스 IgG Fc 포획(AMC) 바이오센서를 사용하여, 정제된 항-ROR1 항체를 포획하였다. 이어서 센서를 재조합 인간 ROR1-ECD 단백질이 함유된 용액에 침지하여 포획된 항체에 결합하는 표적 단백질을 검출하였다. 동역학 상수를, Fortebio 분석 소프트웨어를 사용하여 데이터를 처리하고 이를 1:1 결합 모델에 피팅하여 결정하였다. 하기 표 2는 ROR1-mAb004에 대해, 이전에 기재된 2개의 항-ROR1 단클론 항체와 비교하여 획득된 결과이며, ROR1-Tab1은 WO2014167022에 기재된 바와 같은 클론 R12이고, ROR1-Tab2는 WO2012097313에 기재된 바와 같은 클론 D10이다.
| 샘플 ID | KD (M) | kon(1/Ms) | kdis(1/s) |
| ROR1-mAb004 | 1.85E-08 | 9.25E+04 | 1.71E-03 |
| ROR1-Tab1 | 1.28E-09 | 5.17E+05 | 6.60E-04 |
| ROR1-Tab2 | 9.88E-08 | 3.25E+05 | 3.21E-02 |
실시예 1.3 항-ROR1 클론 항체의 세포 표면 결합 특성화
항-ROR1 항체의 결합 특이성 및 효능을 단백질 ELISA 및 세포 표면 결합의 유세포 분석 분석에 의해 특성화하였다. 결합 EC50을 계산하여 하기 표 3에 나타내었다. 간략하게, 항-ROR1 항체의 결합 특성을 ELISA로 하기와 같이 측정하였다: 재조합 ROR1-ECD 단백질을 4℃에서 밤새 96-웰 플레이트 상에 1 ㎍/㎖로 코팅하였다. 플레이트를 세척 완충제(0.05% 트윈 20을 함유하는 PBS)로 1회 세척하고 ELISA 차단 완충제(0.05% 트윈 20을 함유하는 PBS 중 1% BSA)로 실온에서 2시간 동안 차단하였다. 이어서 항-ROR1 항체를 첨가하고 37℃에서 1시간 동안 배양하였다. 플레이트를 세척 완충제로 3회 세척하였다. HRP 표지된 항-마우스 IgG 2차 항체(Sigma, Cat. #A0168)를 첨가하고 플레이트를 37℃에서 30분 동안 배양한 후 세척 완충제로 5회 세척하였다. 100 ㎕의 테트라메틸벤지딘(TMB) 발색 용액을 각 웰에 첨가하였다. 발색 후, 1 노르말 HCl로 반응을 중단시키고 Varioskan™ LUX 마이크로플레이트 판독기(ThermoFisher Scientific)에서 450 ㎚에서 흡광도를 측정하였다. GraphPad Prism 6.0 소프트웨어를 사용하여 항체 농도에 대해 결합 신호를 플롯팅하고 이에 따라 EC50을 계산하였다. 결과를 도 1에 나타낸다. 도 1은 단클론 항체 ROR1-mAb004 및 ROR1-Tab1의 ROR1-ECD 단백질 결합 활성을 도시하며, 음성 대조군으로서, 관련되지 않은 mIgG1을 사용하였다.
항-ROR1 항체의 세포 결합 활성을 인간 ROR1 형질감염된 CHO 세포주(CHO-ROR1) 및 ROR1-발현 골수종 세포주(RPMI8226)로 측정하였다. 간략하게, 5×105 세포를 96-웰 플레이트의 각 웰에 시딩하였다. 세포를 400 g에서 5분 동안 원심분리하고 상등액은 버렸다. 이어서 각 웰에 연속적으로 희석된 항체 100 ㎕를 첨가하고 세포와 혼합하였다. 4℃에서 40분간 배양한 후, 플레이트를 여러 번 세척하여 과잉 항체를 제거하였다. 이어서 2차 형광색소-접합된 염소 항-마우스 IgG 항체를 첨가하고 실온에서 20분 동안 세포와 함께 배양하였다. 또 다른 라운드의 원심분리 및 세척 단계 후, 세포를 CytoFLEX 유식 세포분석기(Beckman Coulter)에서 판독하기 위해 FACS 완충제에 재현탁하였다. 중간 형광 강도(MFI) 판독값을 항체 농도에 대해 플롯팅하고 GraphPad Prism 6.0 소프트웨어로 분석하였다. 도 2A-B에 나타낸 결과는 ROR1 발현 세포에 대한 항-ROR1 단클론 항체 ROR1-mAb004 및 ROR1-Tab1의 결합 활성을 예시한다. 관련되지 않은 mIgG1을 음성 대조군으로서 사용하였다.
| 샘플 ID | EC50 (nM) | ||
| ROR1-ECD | CHOK1-ROR1 | RPMI-8226 | |
| ROR1-mAb004 | 0.022 | 2.306 | 0.983 |
| ROR1-Tab1 | 0.025 | 0.774 | 0.128 |
실시예 1.4 항-ROR1 항체의 내재화 특성화
항-ROR1 항체의 결합 내재화를 ROR1-발현 골수종 세포주 RPMI8226으로 특성화하였다. 세포를 수확하고 FACS 완충액에 300만/㎖의 밀도로 재현탁하였다. 희석된 항체를 튜브에 첨가하고 4℃에서 30분 동안 배양하였다. 첫 번째 배양 후, 세포를 저온 PBS로 3회 세척하여 결합되지 않은 항체를 제거하였다. 이어서 각 항체 처리의 세포를 "대조군"과 "내재화"를 위해 각각 두 그룹으로 나누었다. "내재화" 그룹의 세포를 예열된 배지에 재현탁하고 내재화를 허용하기 위해 37℃에서 2시간 동안 배양한 반면, "대조군" 그룹의 세포는 동일한 기간 동안 4℃에서 유지시켰다. 2차 배양 후, 세포를 저온 PBS로 1회 세척하고 4℃에서 30분 동안 플루오레세인 표지된 2차 항체와 함께 배양하였다. 또 다른 라운드의 원심분리 및 세척 단계 후, 세포를 CytoFLEX 유식 세포분석기(Beckman Coulter)에서 판독하기 위해 FACS 완충제에 재현탁하였다. 관련되지 않은 마우스 IgG 대조군(MFI배경)을 배경 보정에 사용하였다. "대조군"의 MFI 판독값과 "내재화"의 상기 값과의 차이(ΔMFI)는 ROR1 항체의 내재화를 반영하며, "대조군"의 보정된 MFI에 대한 이러한 차이는 항체 내재화의 백분율을 반영하고, 이는 하기와 같이 계산되며 이를 하기 표 4에 요약한다.
내재화 백분율(ΔMFI) = [1- (MFI내재화) - MFI배경)/(MFI대조군 - MFI배경)] x 100%
| 샘플 ID | 내재화의 백분율 |
| ROR1-mAb004 | 11.58% |
| ROR1-Tab1 | -3.23% |
| ROR1-Tab2 | 29.94% |
실시예 1.5 항-ROR1 항체의 에피토프 비닝
경쟁 ELISA로 ROR1 항체의 결합 에피토프를 확인하였다. 요약하면, 96웰 플레이트를 1 ug/㎖의 정제된 항체로 코팅하고 4℃에서 밤새 배양하였다. 0.05% Tween 20을 함유하는 PBS로 세척한 후, 플레이트를 차단 완충제(0.05% Tween 20 및 2% BSA를 함유하는 PBS)로 37℃에서 2시간 동안 차단하였다. ROR1 항체(샘플) 또는 관련되지 않은 마우스 IgG(기준선)와 사전-혼합된 비오틴화된 인간 ROR1-ECD 단백질을 플레이트 웰에 첨가하고 37℃에서 1시간 동안 배양한 후 3회 세척하였다. 이어서 스트렙트아비딘-HRP(1:5000 희석)를 각 웰에 첨가하고 37℃에서 1시간 동안 배양한 후 다시 3회 세척하였다. 테트라메틸벤지딘(TMB) 발색 용액을 첨가하여 5분간 발색시킨 후 1 M HCl로 반응을 정지시켰다. 450 ㎚에서의 흡광도(OD450)를 마이크로플레이트 판독기에서 측정하였다. OD450기준선은 경쟁이 없을 때 ROR1 항체에 결합하는 인간 ROR1-ECD의 수준을 나타내는 반면, OD450기준선과 OD450샘플 간의 차이는 플레이트에 코팅된 ROR1 항체와 용액 내 항체 간의 경쟁을 반영한다. 억제 백분율을 하기 식으로 계산하였다:
억제 % = (1 - OD450샘플/OD450기준선) x 100%
하기 표 5는 억제율에 관한 경쟁 ELISA의 결과를 나타내며, 이는 ROR1-mAb004가 ROR1-Tab2와 경쟁하지만 ROR1-Tab1과는 경쟁하지 않음을 가리킨다.
| 코팅 경쟁 |
ROR1-Tab1 | ROR1-mAb004 | ROR1-Tab2 |
| ROR1-Tab1 | 95% | -54% | -84% |
| ROR1-mAb004 | -22% | 93% | 92% |
| ROR1-Tab2 | -21% | 56% | 92% |
실시예 2. ROR1-mAb004의 인간화된 설계
ROR1-mAb004 가변 영역 유전자를 인간화 설계에 사용하였다. 이 과정의 첫 번째 단계에서, ROR1-mAb004의 VH 및 VL 도메인의 아미노산 서열을, 전체적으로 가장 일치하는 인간 생식세포계열 Ig V-유전자 서열을 찾기 위해 인간 Ig V-유전자 서열의 입수가능한 데이터베이스와 비교하였다. 추가로, VH 또는 VL의 프레임워크 4 분절을 J-영역 데이터베이스와 비교하여 각각 뮤린 VH 및 VL 영역에 가장 높은 상동성을 갖는 인간 프레임워크를 발견하였다. 경쇄의 경우 가장 가까운 인간 V-유전자 일치는 O18 유전자였고; 중쇄의 경우 인간과 가장 근접한 일치는 VH1-69 유전자였다. 이어서, ROR1-mAb004 경쇄의 VL 도메인의 CDR-L1, CDR-L2 및 CDR-L3이 각각 CDR-L3 뒤의 JK4 프레임워크 4 서열을 갖는 O18 유전자의 프레임워크 서열 상에 접목되고; ROR1-mAb004 중쇄의 VH 도메인의 CDR-H1, CDR-H2 및 CDR-H3이 CDR-H3 뒤의 JH6 프레임워크 4 서열이 있는 VH1-69의 프레임워크 서열상에 접목된 인간화된 가변 도메인 서열을 설계하였다. 이어서 ROR1-mAb004의 3차원 Fv 모델을 생성시켜, 마우스 아미노산이 루프 구조 또는 VH/VL 인터페이스를 지원하는 데 관련된 임의의 프레임워크 위치가 존재하는 지를 결정하였다. 인간화된 서열 중의 이들 잔기를, 친화도/활성을 유지시키기 위해 동일한 위치에서 마우스 잔기로 역돌연변이시킬 수 있었다. 하기 표 6에 나타낸 바와 같이, ROR1-mAb004 VH 및 VL에 대해 여러 바람직한 역 돌연변이가 확인되었고, 대안적인 VH 및 VL 설계를 구성하였다.
또한, 상이한 점 돌연변이를 갖는 4개의 마우스 VH 서열을 또한 설계하고 표 6의 마지막 4개의 VH 서열에 나타내어, ROR1-mAb004의 CDR-H2에서 2개의 "NG"(Asn-Gly) 아미노산에 의해 도입된 잠재적인 아스파라긴 탈아미드화를 방지하였다. 항체의 CDR-H2에서 "NG"(Asn-Gly) 아미노산에 의해 유도된 아스파라긴 탈아미드화 및 항체의 안정성에 미치는 영향에 대해서, 예를 들어 문헌[Qingrong Yan et al., (2018) Structure Based Prediction of Asparagine Deamidation Propensity in Monoclonal Antibodies, mAbs, 10:6, 901-912]을 참조하시오.
| 인간화된 ROR1-mAb004 VH / VL 식별자 | 서열번호 | 아미노산 서열 |
| ROR1-mAb004VH.1a | 10 | EVQLVQSGAEVKKPGSSVKVSCKASGYTFSRSWMNWVRQAPGQGLEWMGRIYPGNGDIKYNGNFKGRVTITADKSTSTAYMELSSLRSEDTAVYYCAHIYYDFYYALDYWGQGTTVTVSS |
| ROR1-mAb004VH.1b | 11 | EVQLVQSGAEVKKPGSSVKVSCKASGYTFSRSWMNWVRQAPGQGLEWIGRIYPGNGDIKYNGNFKGRATITADKSTSTAYMELSSLRSEDTAVYYCAHIYYDFYYALDYWGQGTTVTVSS |
| ROR1-mAb004VH.1c | 12 | EVQLVQSGAEVKKPGSSVKVSCKASGYTFSRSWMNWVKQAPGQGLEWIGRIYPGNGDIKYNGNFKGKATITADKSTSTAYMELSSLRSEDTAVYYCAHIYYDFYYALDYWGQGTTVTVSS |
| ROR1-mAb004VK.1a | 13 | DIQMTQSPSSLSASVGDRVTITCKASQDINKYITWYQQKPGKAPKLLIYYTSTLQPGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCLQYDSLLWTFGGGTKVEIK |
| ROR1-mAb004VK.1b | 14 | DIQMTQSPSSLSASVGDRVTITCKASQDINKYITWYQQKPGKAPKLLIHYTSTLQPGVPSRFSGSGSGRDYTFTISSLQPEDIATYYCLQYDSLLWTFGGGTKVEIK |
| ROR1-mAb004VK.1c | 15 | DIQLTQSPSSLSASVGDRVTITCKASQDINKYITWYQQKPGKAPKLLIYYTSTLQPGVPSRFSGSGSGRDYTFTISSLQPEDIATYYCLQYDSLLWTFGGGTKVEIK |
| ROR1-mAb004VK.1d | 16 | DIQLTQSPSSLSASVGDRVTITCKASQDINKYITWYQQKPGKAPKLLIHYTSTLQPGIPSRFSGSGSGRDYTFTISSLQPEDIATYYCLQYDSLLWTFGGGTKVEIK |
| ROR1-mAb004 VH 식별자, CDR-H2에서 점 돌연변이 존재 | 서열번호 | 아미노산 서열 |
| ROR1-mAb004VH(AA) | 17 | QVQLQQSGPELVKPGASVKISCKASGYAFSRSWMNWVKQRPEKGLEWIGRIYPGNADIKYNANFKGKATLTADKSSSTAYMQLSSLTSEDSAVYFCAHIYYDFYYALDYWGQGTSVTVSS |
| ROR1-mAb004VH(QQ) | 18 | QVQLQQSGPELVKPGASVKISCKASGYAFSRSWMNWVKQRPEKGLEWIGRIYPGQGDIKYQGNFKGKATLTADKSSSTAYMQLSSLTSEDSAVYFCAHIYYDFYYALDYWGQGTSVTVSS |
| ROR1-mAb004VH(AQ) | 19 | QVQLQQSGPELVKPGASVKISCKASGYAFSRSWMNWVKQRPEKGLEWIGRIYPGNADIKYQGNFKGKATLTADKSSSTAYMQLSSLTSEDSAVYFCAHIYYDFYYALDYWGQGTSVTVSS |
| ROR1-mAb004VH(QA) | 20 | QVQLQQSGPELVKPGASVKISCKASGYAFSRSWMNWVKQRPEKGLEWIGRIYPGQGDIKYNANFKGKATLTADKSSSTAYMQLSSLTSEDSAVYFCAHIYYDFYYALDYWGQGTSVTVSS |
주: 인간화된 항체의 역돌연변이된 프레임워크 아미노산 잔기 및 키메라 항체의 CDR-H2 점 돌연변이는  로 표시된다.
로 표시된다.
실시예 3. 인간화된 항-CD3 항체의 생성 및 특성화
통상적인 하이브리도마 기술을 사용하여 하이브리도마-생성된 항-CD3 단클론 항체 mAbCD3-001을 생성시키고 선택한 다음, 통상적인 CDR 접목 방법에 의해 인간화하였다. 이어서 역돌연변이를 인간화된 VH 서열에 도입하고, 아스파라긴 탈아미드화 불안정성을 제거하기 위해 인간화된 카파 쇄에서 NA를 대체하는 NS 돌연변이를 생성시켰다(상세한 설명은 내용 전체가 본원에 참고로 포함된 PCT/CN/120991에 제공되었다). 생성된 인간화된 VH 및 VL 구성물을 표 7(아래)에 나타낸다.
| 항-CD3 VH/VL 식별자 | 서열번호 | 아미노산 서열 |
| EM0006-01vh.1h | 22 | EVQLVQSGAEVKKPGASVKVSCKASGFSFTNYYVHWMRQAPGQGLEWMGWISPGSDNTKYNEKFKGRVTMTRDTSISTAYMELSRLRSDDTAVYYCARDDYGNYYFDYWGQGTTVTVSS |
| EM0006-01vh.1g | 23 | EVQLVQSGAEVKKPGASVKVSCKASGFSFTNYYVHWMRQAPGQGLEWIGWISPGSDNTKYNEKFKGRVTLTADTSISTAYMELSRLRSDDTAVYYCARDDYGNYYFDYWGQGTTVTVSS |
| EM0006-01vK.1(s32aa) | 24 | DIVMTQSPDSLAVSLGERATINCKSSQSLLNARTRKNYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSYILRTFGGGTKVEIK |
인간 VH 및 인간 VK 서열의 짝짓기는 HuEM0006-01-24(서열번호 22 및 24의 VH/VL 쌍을 갖는다) 및 HuEM0006-01-27(서열번호 23 및 24의 VH/VL 쌍을 갖는다)로 지정된, 2개의 인간화된 항체를 생성시켰다(표 7). 재조합 인간화된 mAb를 HEK293 세포에서 일시적으로 발현시키고 단백질 A 크로마토그래피로 정제하였다.
인간화된 항-CD3 항체의 결합 활성을, 인간 CD3-발현 Jurkat T 세포주를 사용하여 유세포 분석을 통해 시험하였다. FACS 완충제 중의 5×105 Jurkat 세포를 96-웰 플레이트의 각 웰에 시딩하였다. 세포를 400 g에서 5분 동안 원심분리하고 상등액을 버렸다. 각 웰에 연속적으로 희석된 항체 100 ㎕를 첨가하고 세포와 혼합하였다. 4℃에서 40분간 배양한 후, 플레이트를 여러 번 세척하여 과잉 항체를 제거하였다. 이어서 2차 형광색소-접합된 항체(Alexa Fluor® 647 염소 항-인간 IgG1 H&L; Jackson ImmunoResearch, Cat. #109-606-170)를 첨가하고 실온에서 20분 동안 세포와 함께 배양하였다. 또 다른 라운드의 원심분리 및 세척 단계 후, 세포를 CytoFLEX 유식 세포분석기(Beckman Coulter)에서 판독하기 위해 FACS 완충제에 재현탁하였다. 중간 형광 강도(MFI) 판독값을 항체 농도에 대해 플롯팅하고 GraphPad Prism 5.0 소프트웨어로 분석하였다. 항체 HuEM0006-01-24는 항체 HuEM0006-01-27보다 더 높은 CD3 결합 친화도를 나타내었다.
실시예 4. ROR1/CD3 FIT-Ig의 생성
항-ROR1 모이어티로서 표 6의 VH/VL 서열, 항-CD3 모이어티로서 표 7의 VH/VL 서열, 및 표 8의 인간 불변 영역 서열을 사용하여 인간 ROR1 및 인간 CD3 모두를 인식하는 FIT-Ig 단백질 그룹을 구성하였다.
| 불변 영역 | 서열번호 | 아미노산 서열 |
| CH1-힌지-CH2-CH3 (L234A/L235A 돌연변이를 갖는 인간 불변 IgG1) |
31 | ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK |
| CL(인간 불변 카파) | 32 | RTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC |
| CH1 | 33 | ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSC |
FIT-Ig 분자를 PCT 공개 WO 2015/103072에 기재된 일반 과정에 따라 구성하였다. 각 FIT-Ig는 하기의 구조를 갖는 3개의 폴리펩티드 쇄로 이루어졌다:
쇄 #1(장쇄): VLA-CL-VHB-CH1-힌지-CH2-CH3;
쇄 #2(제1 단쇄): VHA-CH1;
쇄 #3(제2 단쇄): VLB-CL;
여기서 A는 ROR1을 나타내고 B는 CD3을 나타내며, VLROR1은 ROR1을 인식하는 인간화된 단클론 항체의 경쇄 가변 도메인이고, VHCD3은 CD3을 인식하는 인간화된 단클론 항체의 중쇄 가변 도메인이고, VLCD3은 CD3를 인식하는 인간화된 단클론 항체의 경쇄 가변 도메인이고, VHROR1은 ROR1을 인식하는 인간화된 단클론 항체의 중쇄 가변 도메인이고, 각 CL은 경쇄 불변 도메인(서열번호 32)이며, 각 CH1은 제1 중쇄 불변 도메인(서열번호 33)이고, CH1-힌지-CH2-CH3은 CH1에서부터 Fc 영역의 말단을 통한 C-말단 중쇄 불변 영역(서열번호 31)이다.
장쇄 벡터를 구성하기 위해, VLROR1-CL-VHCD3 분절을 암호화하는 cDNA를 드노보(de novo) 합성하여 인간 CH1-힌지-CH2-CH3에 대한 암호화 서열을 포함하는 벡터의 다중 클로닝 부위(MCS)에 삽입하였다. 생성된 벡터에서, 상동성 재조합 동안 MCS 서열을 제거하여 모든 도메인 단편이 올바른 판독 프레임에 있도록 하였다. 유사하게, 제1 및 제2 단쇄를 구성하기 위해서, VHROR1 및 VLCD3 구조 유전자를 드노보 합성하고 각각 인간 CH1 및 CL 도메인에 대한 암호화 분절을 포함하는 적합한 벡터의 MCS에 삽입하였다.
인간화된 VH 및 인간화된 VL의 짝짓기는 하기 표 9에 나열된 인간화된 ROR1/CD3 FIT-Ig 결합 단백질을 생성시켰다. ROR1-mAb004의 모 마우스 VH/VL 및 인간 불변 서열을 갖는 키메라 항체(FIT1007-12B)를 또한, 인간화된 결합 단백질 순위를 위한 양성 대조군으로서 생성시켰다.
| FIT-Ig 식별자 | VH ROR1 | VL ROR1 | VH CD3 | VL CD3 |
| FIT1007-12B-1 | ROR1-mAb004VH.1a | ROR1-mAb004VK.1a | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-2 | ROR1-mAb004VH.1b | ROR1-mAb004VK.1a | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-3 | ROR1-mAb004VH.1c | ROR1-mAb004VK.1a | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-4 | ROR1-mAb004VH.1a | ROR1-mAb004VK.1b | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-5 | ROR1-mAb004VH.1b | ROR1-mAb004VK.1b | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-6 | ROR1-mAb004VH.1c | ROR1-mAb004VK.1b | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-7 | ROR1-mAb004VH.1a | ROR1-mAb004VK.1c | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-8 | ROR1-mAb004VH.1b | ROR1-mAb004VK.1c | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-9 | ROR1-mAb004VH.1c | ROR1-mAb004VK.1c | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-10 | ROR1-mAb004VH.1a | ROR1-mAb004VK.1d | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-11 | ROR1-mAb004VH.1b | ROR1-mAb004VK.1d | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-12 | ROR1-mAb004VH.1c | ROR1-mAb004VK.1d | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-13 | ROR1-mAb004VH(AA) | ROR1-mAb004VK | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-14 | ROR1-mAb004VH(QQ) | ROR1-mAb004VK | EM0006-01vh.1g | EM0006-01vk.1(s31aa) |
| FIT1007-12B-15 | ROR1-mAb004VH(AQ) | ROR1-mAb004VK | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-16 | ROR1-mAb004VH(QA) | ROR1-mAb004VK | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B | ROR1-mAb004VH | ROR1-mAb004VK | EM0006-01vh.1h | EM0006-01vk.1(s31aa) |
| FIT1007-12B-18 | ROR1-mAb004VH.1a(AA) | ROR1-mAb004VK.1a | EM0006-01vh.1g | EM0006-01vk.1(s31aa) |
표 10에 나열된 재조합 FIT-Ig 단백질을 본원에 기재된 바와 같이 일시적으로 발현시키고 정제하였다. 각각의 FIT-Ig 구성물에 대해, 각각 3개의 폴리펩티드 쇄에 대한 3개의 플라스미드를 HEK 293F 세포에 동시-형질감염시켰다. 형질감염-후 세포 배양 약 6일 후에, 상등액을 수확하고 단백질 A 친화성 크로마토그래피를 수행하였다. 정제된 항체의 조성 및 순도를 크기 배제 크로마토그래피(SEC)로 분석하였다. PBS에서 정제된 항체를 TSKgel SuperSW3000, 300 x 4.6 ㎜, SEC 컬럼(TOSOH)에 적용하였다. DIONEX™ UltiMate 3000 HPLC 장비(Thermo Scientific)를 280 ㎚ 및 214 ㎚에서 UV 검출을 사용하는 SEC에 사용하였다. 발현 및 SEC-HPLC 결과를 하기 표 10에 나타낸다.
ROR1/CD3 FIT-Ig 단백질을 Octet® RED96 생물층 간섭계(Pall ForteBio LLC)를 사용하여 해리속도 상수(koff, "해리속도")에 대해 분석하고 순위를 매겼다. 항-hIgG Fc 포획(AHC) 바이오센서(Pall)를 먼저 항체 포획을 위해 30초 동안 100 nM의 농도로 항체에 노출시킨 다음, 실행 완충제(1X pH 7.2 PBS, 0.05% Tween 20, 0.1% BSA)에 60초 동안 침지시켜 기준선을 확인하였다. 항체가 포획된 센서를 10 ug/㎖의 재조합 인간 ROR1 ECD 단백질에 5분 동안 침지시켜 결합을 측정한 다음, 실행 완충제에 1200초 동안 침지시켜 해리를 측정하였다. 결합 및 해리 곡선을 ForteBio 데이터 분석 소프트웨어(Pall)를 사용하여 1:1 Langmuir 결합 모델에 피팅하였다. 결과를 하기 표 10에 나타낸다. 해리속도 비를 FIT1007-12B에 대한 항체의 해리속도에 의해 계산하였다. 보다 낮은 비는 모 키메라 항체 FIT1007-12B와 비교하여 항체의 보다 느린 해리를 가리킨다.
| FIT-Ig 식별자 | 발현 역가 |
순도%
(SEC-HPLC) |
해리속도 비 |
| FIT1007-12B-1 | 27.16 ㎎/L | 97.38 | 5.25% |
| FIT1007-12B-2 | 100.58 ㎎/L | 95.4 | 7.87% |
| FIT1007-12B-3 | 65.75 ㎎/L | 90.66 | 11.91% |
| FIT1007-12B-4 | 20.13 ㎎/L | 97.63 | 35.89% |
| FIT1007-12B-5 | 80.55 ㎎/L | 93.65 | 28.53% |
| FIT1007-12B-6 | 76.92 ㎎/L | 93.35 | 25.81% |
| FIT1007-12B-7 | 27.23 ㎎/L | 97.28 | 13.55% |
| FIT1007-12B-8 | 85.72 ㎎/L | 94.29 | 15.37% |
| FIT1007-12B-9 | 69.35 ㎎/L | 96.54 | 11.99% |
| FIT1007-12B-10 | 28.43 ㎎/L | 97.28 | 36.73% |
| FIT1007-12B-11 | 64.12 ㎎/L | 91.24 | 28.91% |
| FIT1007-12B-12 | 54.82 ㎎/L | 92.82 | 25.16% |
| FIT1007-12B-13 | 14.56 ㎎/L | 90.03 | 89.13% |
| FIT1007-12B-14 | 발현 없음 | N/A | N/A |
| FIT1007-12B-15 | 1.66 ㎎/L | 84.77 | 결합 활성 없음 |
| FIT1007-12B-16 | 14.23 ㎎/L | 91.51 | 139.13% |
| FIT1007-12B | 66.75 ㎎/L | 97.13 | 100% |
가장 높은 결합 활성을 위해 FIT1007-12B-1의 VH/VL 인간화된 설계를 선택하였다. 또한, FIT1007-12B-13의 CDR-H2 점 돌연변이 설계는 다른 설계에 비해 더 높은 발현 역가와 결합 활성을 보였다. 후보 분자를 생성시키기 위해 "ROR1-mAb004VH.1a"(서열번호 10)의 VH 인간화된 설계와의 조합을 위해 "ROR1-mAb004VH(AA)"(서열번호 17)의 돌연변이 설계를 선택하였다. 인간화된 VH 서열, 즉 ROR1-mAb004VH.1a(AA)를 하기와 같이 나타낸다:
>ROR1-mAb004VH.1a(AA)(서열번호 21)

실시예 5. ROR1/CD3 FIT-Ig 및 MAT-Fab의 구성 및 발현
FIT-Ig의 구성은 실시예 4에 나타낸 것과 동일한 방법을 사용하였다. 면역글로불린 도메인 사이에 링커를 사용하지 않았다. FIT-Ig 결합 단백질에 대한 완전한 서열을 표 11의 서열 정보에 제공한다.
| 폴리펩티드 | 서열번호 | 아미노산 서열 |
| FIT1007-12B-17 쇄 #1 | 34 | DIQMTQSPSSLSASVGDRVTITCKASQDINKYITWYQQKPGKAPKLLIYYTSTLQPGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCLQYDSLLWTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECEVQLVQSGAEVKKPGASVKVSCKASGFSFTNYYVHWMRQAPGQGLEWMGWISPGSDNTKYNEKFKGRVTMTRDTSISTAYMELSRLRSDDTAVYYCARDDYGNYYFDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK |
| FIT1007-12B-17 쇄 #2 | 35 | EVQLVQSGAEVKKPGSSVKVSCKASGYTFSRSWMNWVRQAPGQGLEWMGRIYPGNADIKYNANFKGRVTITADKSTSTAYMELSSLRSEDTAVYYCAHIYYDFYYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSC |
| FIT1007-12B-17 쇄 #3 | 36 | DIVMTQSPDSLAVSLGERATINCKSSQSLLNARTRKNYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSYILRTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC |
| FIT1007-12B-18 쇄 #1 | 37 | DIQMTQSPSSLSASVGDRVTITCKASQDINKYITWYQQKPGKAPKLLIYYTSTLQPGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCLQYDSLLWTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECEVQLVQSGAEVKKPGASVKVSCKASGFSFTNYYVHWMRQAPGQGLEWIGWISPGSDNTKYNEKFKGRVTLTADTSISTAYMELSRLRSDDTAVYYCARDDYGNYYFDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK |
| FIT1007-12B-18 쇄 #2 | 35 | EVQLVQSGAEVKKPGSSVKVSCKASGYTFSRSWMNWVRQAPGQGLEWMGRIYPGNADIKYNANFKGRVTITADKSTSTAYMELSSLRSEDTAVYYCAHIYYDFYYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSC |
| FIT1007-12B-18 쇄 #3 | 36 | DIVMTQSPDSLAVSLGERATINCKSSQSLLNARTRKNYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSYILRTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC |
WO2018/035084에 기재된 과정에 따라 VH/VL 서열의 동일한 조합으로 ROR1/CD3 MAT-Fab 단백질 그룹을 또한 구성하였다. 각 MAT-Fab는 하기의 구조를 갖는 4개의 폴리펩티드 쇄로 이루어졌다:
쇄 #1("손잡이"가 있는 장쇄): VLA-CL-VHB-CH1-힌지-CH2-CH3;
쇄 #2(제1 단쇄): VHA-CH1;
쇄 #3(제2 단쇄): VLB-CL;
쇄 #4(Fc "구멍"): 힌지-CH2-CH3;
여기서, 쇄 #1은 "손잡이"로서 돌연변이 S354C, T366W를 갖는 돌연변이 인간 불변 IgG1을 갖고, 쇄 #4는 "구멍"으로서 돌연변이 Y349C, T366S, L368A, Y407V를 갖는 Fc의 쇄이고, 여기서 A는 ROR1을 나타낸다 B는 CD3을 나타낸다.
FIT-Ig에 대해 이전에 나타낸 것과 유사한 클로닝 방법에 따라, MAT-Fab 폴리펩티드 쇄의 VH/VL 유전자를 합성적으로 생성시킨 다음 각각의 불변 도메인을 포함하는 벡터에 각각 클로닝하였다. MAT-Fab 단백질의 전체 서열을 표 12의 서열 정보에 제공한다.
| 폴리펩티드 | 서열번호 | 아미노산 서열 |
| MAT1007-12B-17 쇄 #1 (VK-hck-VH-hIgG1) |
38 | DIQMTQSPSSLSASVGDRVTITCKASQDINKYITWYQQKPGKAPKLLIYYTSTLQPGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCLQYDSLLWTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECEVQLVQSGAEVKKPGASVKVSCKASGFSFTNYYVHWMRQAPGQGLEWMGWISPGSDNTKYNEKFKGRVTMTRDTSISTAYMELSRLRSDDTAVYYCARDDYGNYYFDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK |
| MAT1007-12B-17 쇄 #2(VH-CH1) | 35 | EVQLVQSGAEVKKPGSSVKVSCKASGYTFSRSWMNWVRQAPGQGLEWMGRIYPGNADIKYNANFKGRVTITADKSTSTAYMELSSLRSEDTAVYYCAHIYYDFYYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSC |
| MAT1007-12B-17 쇄 #3(VK-hck) | 36 | DIVMTQSPDSLAVSLGERATINCKSSQSLLNARTRKNYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSYILRTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC |
| MAT1007-12B-17 쇄 #4(FC) | 39 | PKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSREEMTKNQVSLSCAVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK |
| MAT1007-12B-18 쇄 #1(VK-hck-VH-hIgG1) | 40 | DIQMTQSPSSLSASVGDRVTITCKASQDINKYITWYQQKPGKAPKLLIYYTSTLQPGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCLQYDSLLWTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECEVQLVQSGAEVKKPGASVKVSCKASGFSFTNYYVHWMRQAPGQGLEWIGWISPGSDNTKYNEKFKGRVTLTADTSISTAYMELSRLRSDDTAVYYCARDDYGNYYFDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK |
| MAT1007-12B-18 쇄 #2(VH-CH1) | 35 | EVQLVQSGAEVKKPGSSVKVSCKASGYTFSRSWMNWVRQAPGQGLEWMGRIYPGNADIKYNANFKGRVTITADKSTSTAYMELSSLRSEDTAVYYCAHIYYDFYYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSC |
| MAT1007-12B-18 쇄 #3(VK-hck) | 36 | DIVMTQSPDSLAVSLGERATINCKSSQSLLNARTRKNYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSYILRTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC |
| MAT1007-12B-18 쇄 #4(FC) | 39 | PKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSREEMTKNQVSLSCAVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK |
재조합 FIT-Ig 및 MAT-Fab 단백질을 본원에 기재된 바와 같이 일시적으로 발현시키고 정제하였다. 각각의 FIT-Ig 또는 MAT-Fab에 대해, 각각 상응하는 폴리펩티드 쇄를 암호화하는 3개 또는 4개의 플라스미드를 HEK 293F 세포에 동시-형질감염시켰다. 형질감염-후 세포 배양 약 6일 후에, 상등액을 수확하고 단백질 A 친화성 크로마토그래피를 수행하였다. 정제된 항체의 조성 및 순도를 크기 배제 크로마토그래피(SEC)로 분석하였다. PBS에서 정제된 항체를 TSKgel SuperSW3000, 300 x 4.6 ㎜, SEC 컬럼(TOSOH)에 적용하였다. DIONEX™ UltiMate 3000 HPLC 장비(Thermo Scientific)를 280 ㎚ 및 214 ㎚에서 UV 검출을 사용하는 SEC에 사용하였다. 발현 및 SEC-HPLC 결과를 하기 표 13에 나타낸다.
| FIT-Ig 식별자 | 발현 역가 | 순도% (SEC-HPLC) |
| FIT1007-12B-17 | 14.12 ㎎/L | 100 |
| FIT1007-12B-18 | 12.52 ㎎/L | 99.89 |
| MAT1007-12B-17 | 23.15 ㎎/L | 98.52 |
| MAT1007-12B-18 | 29.32 ㎎/L | 95.64 |
인간화된 후보 FIT1007-12B-17 및 이의 모 키메라 FIT-Ig FIT1007-12B의 ROR1 결합 친화도/동역학을 실시예 3에 기재된 방법과 동일한 방법을 사용하여 측정하였다. 각각의 항체에 대해, 측정치를 6개의 항원 농도에 의해 적정하였다, 즉 500 nM에서 3배 희석하였다. 결합 동역학 및 친화도를 하기 표 14에 나타낸다. FIT1007-12B-18, MAT1007-12B-17 및 MAT1007-12B-18의 결합 동역학은 FIT1007-12B-17과 유사하다. 이들 후보는 동일한 ROR1 결합 Fab를 공유한다.
| 샘플 ID | KD (M) | kon(1/Ms) | kdis(1/s) |
| FIT1007-12B | 5.67E-09 | 1.82E+05 | 1.03E-03 |
| FIT1007-12B-17 | 5.25E-10 | 2.24E+05 | 1.17E-04 |
실시예 6. 인간화된 FIT-Ig 및 MAT-Fab의 결합 특성화
ROR1 x CD3 항체의 세포 결합 활성을 인간 TCR/CD3 복합체 형질감염된 CHO 세포주(CHO-CD3-TCR) 및 ROR1-발현 종양 세포주(NCI-H1975, MDA-MB-231, A549 및 RPMI8226)로 측정하였다. 간략하게, 5×105 세포를 96-웰 플레이트의 각 웰에 시딩하였다. 세포를 400 g에서 5분 동안 원심분리하고 상등액을 버렸다. 각 웰에 연속적으로 희석된 항체 100 ㎕를 첨가하고 세포와 혼합하였다. 4℃에서 40분간 배양한 후, 플레이트를 여러 번 세척하여 과잉 항체를 제거하였다. 2차 형광색소-접합된 염소 항-인간 IgG 항체를 첨가하고 실온에서 20분 동안 세포와 함께 배양하였다. 또 다른 원심분리 및 세척 단계 후, 세포를 CytoFLEX 유식 세포분석기(Beckman Coulter)에서 판독하기 위해 FACS 완충제에 재현탁하였다. 중간 형광 강도(MFI) 판독값을 항체 농도에 대해 플롯팅하고 GraphPad Prism 6.0 소프트웨어로 분석하였다.
도 3에 도시된 바와 같이, CHO-CD3-TCR 결합 효능은 각 분자의 CD3 결합 친화도 및 원자가와 상관있었다. FIT-Ig를 이의 모 항-CD3 단클론성 IgG1 항체와 비교함으로써, 즉 FIT1007-12B-17 대 HuEM0006-01-24(VH/VL 서열: 서열번호 22 및 24, 표 7), 또는 FIT1007-12B-18 대 HuEM0006-01-27(VH/VL 서열: 서열번호 23 및 24,표 7)을 비교함으로써, FIT-Ig는 상대적으로 낮은 결합도를 나타냈으며, 이는 입체 장애 때문일 수 있다.
도 4A-D에 도시된 바와 같이, ROR1-발현 종양 세포에 대한 결합 효능은 FIT-Ig와 이들의 공유된 모 항-ROR1 단클론 항체(HuROR1-mAb004-1, ROR1-mAb004VH.1a(AA) 및 ROR1-mAb004VK.1a, 서열번호 21 및 13의 서열을 가짐) 간에 비교적 유사하다. MAT-Fab의 결합 곡선은 FIT-Ig 및 이의 모 항-ROR1 단클론 항체와 상이하게 나타나며, 이는 다른 표적 결합 원자가 때문일 수 있다.
실시예 7. 인간화된 FIT-Ig 및 MAT-Fab의 전향된 CD3 활성화
ROR1 x CD3 이중특이적 FIT-Ig 및 MAT-Fab 항체에 의한 전향된 CD3 활성화를 측정하기 위해서, 공-배양된 리포터 유전자 분석을 사용하였다. 이 분석에서 Jurkat-NFAT-luc 세포는 세포 표면 CD3가 활성화될 때 하류 루시퍼라제 신호를 촉발한다. RPMI8226 세포가, ROR1 결합 시 이중특이적 ROR1 x CD3 항체를 통해 T 세포 상의 CD3/TCR 복합체를 가교결합시킬 수 있는 ROR1-발현 표적 세포로서 사용되었다. Jurkat-NFAT-luc 및 RPMI8226 세포를 세척하고 별도로 분석 배지(RPMI1640 및 10% FBS)에 재현탁시켰다. 두 세포 유형 모두 96-웰 플레이트(Costar #3903)에 1:1의 비로 웰당 1×105 세포로 시딩하였다. FIT-Ig 또는 MAT-Fab 항체를 첨가하고 세포와 혼합하고 37℃에서 4시간 동안 배양하였다. 배양의 끝에서, ONE-Glo™ 발광 분석 키트(Promega, Cat. #E6130) 시약을 제조하고 이를 제조사의 설명에 따라 웰에 첨가하였다. Varioskan™ LUX 마이크로플레이트 판독기(ThermoFisher Scientific)를 사용하여 플레이트를 발광 신호에 대해 판독하였다. 결과를 도 5에 나타낸다.
1개의 관련되지 않은 음성 대조군 FIT-Ig, 항-EGFR x cMET 이중특이적 분자(EMB01) 및 2개의 항-CD3 단클론 항체, 즉 HuEM0006-01-24 및 HuEM0006-01-27을 또한 시험하였다. 모든 이중특이적 ROR1 x CD3 결합 단백질은, ROR1 결합 활성이 없는 단일특이적 항-CD3 결합 단백질과 비교하여, ROR1-발현 표적 세포의 존재 하에 T 세포 활성화를 증가시켰다.
표적 세포의 부재하에서 Jurkat-NFAT-luc 기반 리포터 유전자 분석을 사용하여 비-표적 전향된 CD3 활성화를 시험하였다. 결과를 도 6에 나타낸다. 이 분석을, 이중특이적 결합 단백질, 이 경우 ROR1에 대한 공동-표적을 발현하는 세포의 부재하에서 수행하였다. 이중특이적 ROR1 x CD3 항체는 ROR1-발현 표적 세포의 부재 하에 항-CD3 항체 단독보다 더 적은 비-표적 전향된 활성화를 나타내었다.
실시예 8. 인간화된 FIT-Ig 및 MAT-Fab의 전향된 T 세포 세포독성
ROR1 x CD3 이중특이적 결합 단백질의 종양 세포 사멸 효능을, 인간 유방암 세포주 MDA-MB-231을 표적 세포로 사용하고 인간 T 세포를 효과기 세포로 사용하여 전향된 T 세포 세포독성 분석에서 측정하였다. 간략하게, 세포를 수확하고, 세척하고, 분석 배지(10% FBS를 함유한 RPMI1640)로 재현탁하였다. MDA-MB-231 세포를 편평 바닥 96-웰 플레이트(Corning, Cat. #3599)에 웰당 5×104 세포로 시딩하였다. 상업적인 PBMC 단리 키트(EasySep™, Stemcell Technologies, Cat. #17951)를 사용하여 인간 PBMC로부터 T 세포를 정제하고 웰당 2×105 세포로 웰에 첨가하였다. 시험 항체를 첨가하고 세포 혼합물과 함께 37℃에서 48시간 동안 배양하였다. 락테이트 데하이드로게나제(LDH) 방출을 CytoTox 96® 세포독성 분석 키트(Promega, Cat. #G1780)로 측정하였다. 제조사의 설명에 따라 OD490 판독값을 획득하였다. 최대 및 최소 용해를 또한 CytoTox 키트(Promega, #G1780) 설명에 따라 생성시켰다. 최대 용해는 종양 세포만 있는 샘플에 용해 완충제를 첨가하여 생성되었다. 최소 용해는 배양 배지 배경으로부터 생성되었다. 모든 샘플의 판독값에서 최소 용해를 감한다. 표적 세포 MDA-MB-231 최대 용해(100%) - 최소 용해(0%)를 정규화 분모로서 제시하였다. LDH 방출의 백분율을 이중특이적 항체의 농도에 대해 플롯팅하였다. 도 7에 도시된 바와 같이, ROR1 x CD3 이중특이적 결합 단백질은 MDA-MB-231 종양 세포에 대해 전향된 T 세포 세포독성을 입증한 반면, EGFR x cMET 이중특이적 결합 FIT-Ig EMB01은 낮은 세포독성 활성을 나타내었다.
실시예 9. ROR1 x CD3 이중특이적 항체로 처리된 인간 PBMC 생착된 M-NSG 마우스에서의 MDA-MB-231 종양 부피
T 세포, B 세포 및 자연 살해 세포가 결여된 면역결핍 균주인 M-NSG 마우스에서 항종양 효능을 평가하였다. MDA-MB-231 세포(5 x 106)를 우측 등 옆구리에 피하 주사하였다. 종양 세포 접종 5일 후, 마우스에게 3.5 x 106 인간 PBMC의 단일 복강내 투여를 제공하였다. 15일째에 동물을 종양 크기(~150-300 ㎣)에 기초하여 무작위 분류하고 다음날에 처리를 시작하였다. 종양 성장을 캘리퍼스 측정에 의해 모니터링하였다. 첫 번째 투여 후 16일째에 연구를 종료하고, GVHD 징후가 나타나면 마우스를 안락사시켰다. 마우스를 1 ㎎/㎏의 FIT1007-12B-17, FIT1007-12B-18, MAT1007-12B-17 또는 비히클로 복강내(i.p.) 주사에 의해 3주 동안 주 1회(QW x 3) 처리하였다. 도 8에 도시된 바와 같이, FIT-Ig 및 MAT-Fab 처리 그룹 마우스는 비히클 그룹과 비교하여, 상당한 종양 성장 억제를 나타내었다(****P<0.0001; 비히클 그룹과 비교하여, Dunnett 검정과 조합된 양방향 ANOVA).
실시예 10. 인간화된 항-ROR1 항체의 내재화 특성화
인간화된 항-ROR1 항체의 결합 내재화를 앞서 실시예 1.4에 기재된 것과 유사한 방법으로 ROR1-발현 골수종 세포주 RPMI8226으로 특성화하였다. 간략하게, 세포를 수확하고 ㎖당 300만의 밀도로 FACS 완충제에 재현탁시켰다. 희석된 항체를 튜브에 첨가하고 4℃에서 30분 동안 배양하였다. 첫 번째 배양 후, 결합되지 않은 항체를 제거하기 위해 세포를 저온 PBS로 3회 세척하였다. 이어서, 각 항체 처리 세포를 각각 4℃, 37℃ 및 37℃ + PAO의 세 그룹으로 나누었다. 37℃ "내재화" 그룹의 세포를 예열된 배지에 재현탁하고 내재화를 허용하기 위해 37℃에서 2시간 동안 배양한 반면, 4℃ "대조용" 그룹의 세포는 동일한 기간 동안 4℃에서 유지시켰다. "37℃ + PAO" 그룹의 세포를 예열된 배지에 재현탁하고 3 μM 페닐아르신 옥사이드(막 단백질의 내재화를 방지하기 위한 엔도사이토시스 억제제)의 존재하에 37℃에서 2시간 동안 배양하였다. 37℃+PAO 처리 그룹은 항체 해리 효과를 보정하는 목적을 수행하였다. 2차 배양 후, 세포를 저온 PBS로 1회 세척하고 4℃에서 30분 동안 플루오레세인 표지된 2차 항체와 함께 배양하였다. 또 다른 라운드의 원심분리 및 세척 단계 후, 세포를 CytoFLEX 유식 세포분석기(Beckman Coulter)에서 판독하기 위해 FACS 완충액에 재현탁하였다. 관련되지 않은 마우스 IgG 대조군(MFI배경)을 계산하고 배경 보정에 사용하였다. "대조군"의 MFI 판독값과 "내재화"의 판독값의 차이(ΔMFI)는 ROR1 항체의 내재화를 반영하며, "대조군"의 보정된 MFI에 대한 이러한 차이는 항체 내재화의 백분율을 반영하고, 이는 하기와 같이 계산되며 이를 하기 표 15에 요약한다. 도 9에 나타낸 바와 같이, 100 nM 항체 농도에서 HuROR1-mAb004-1 및 이의 각각의 FIT-Ig/MAT-Fab는 제한된 내재화를 나타내었다. HuROR-mAb004-1 및 FIT1007-12B-17의 계산된 항체 내재화 백분율은 실시예 1.4, 표 4에 제시된 결과와 일치하였다.
MAT-Fab는 37℃에서 감소된 결합을 나타내었으며, 이는 37℃에서 이의 보다 낮은 결합가와 보다 높은 결합 해리속도에 기인할 수 있다. MAT-Fab 내재화 계산의 경우, 결합 곡선은 100 nM에서 결합 평탄역에 도달하지 않았다.
내재화 백분율(ΔMFI) = [1-(MFI내재화 - MFI배경)/(MFI대조군 - MFI배경)] x 100%.
| 샘플 ID | MFI 감소(보정 후 내재화 백분율*) |
| HuROR1-mAb004-1 | 13% (13%) |
| FIT1007-12B-17 | 15% (15%) |
| MAT1007-12B-17 | 33% (-4%) |
*괄호 안의 숫자는 PAO 처리 그룹의 수로 보정되었다
실시예 11. Ref FIT-Ig 생성 및 FIT1007-12B-17과의 시험관내 활성 비교
표 7에 나타낸 항-CD3 항체 서열을 사용하여 2개의 참조 항-ROR1 항체, ROR1-Tab1(클론 R12) 및 ROR1-Tab2(클론 D10) 중 하나의 VH/VL 서열을 갖는 FIT-Ig를 생성시켰다. 참조 FIT-Ig의 구성 및 생성을 실시예 3에 기재된 바와 같이 수행하였다. 면역글로불린 도메인 사이에 링커를 사용하지 않았다. FIT-Ig 결합 단백질에 대한 완전한 서열은 표 16 및 17의 서열 정보에 제공된다. 참조 FIT-Ig의 세포 표면 결합 활성을 실시예 1.3에 기재된 방법을 사용하여 평가하고, 전향된 세포독성 활성을 실시예 6에 기재된 바와 같은 방법을 사용하여 평가하였다.
본 실시예에서 사용된 2개의 참조 항-ROR1 항체, ROR1-Tab1(클론 R12) 및 ROR1-Tab2(클론 D10) 중 하나의 VH/VL 서열은 하기와 같다:
항체 D10의 VH 서열(서열번호 42)

항체 D10의 VL 서열(서열번호 43)

항체 R12의 VH 서열(서열번호 44)

항체 R12의 VL 서열(서열번호 45)

| 폴리펩티드 | 서열번호 | 아미노산 서열 |
| D10 x CD3 FIT-Ig 쇄 #1 | 46 | EIVLSQSPAITAASLGQKVTITCSASSNVSYIHWYQQRSGTSPRPWIYEISKLASGVPVRFSGSGSGTSYSLTISSMEAEDAAIYYCQQWNYPLITFGSGTKLEIQRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECEVQLVQSGAEVKKPGASVKVSCKASGFSFTNYYVHWMRQAPGQGLEWMGWISPGSDNTKYNEKFKGRVTMTRDTSISTAYMELSRLRSDDTAVYYCARDDYGNYYFDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK |
| D10 x CD3 FIT-Ig 쇄 #2 | 47 | QVQLKESGPGLVAPSQTLSITCTVSGFSLTSYGVHWVRQPPGKGLEWLGVIWAGGFTNYNSALKSRLSISKDNSKSQVLLKMTSLQTDDTAMYYCARRGSSYSMDYWGQGTSVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSC |
| D10 x CD3 FIT-Ig 쇄 #3 | 48 | DIVMTQSPDSLAVSLGERATINCKSSQSLLNARTRKNYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSYILRTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC |
| R12 x CD3 FIT-Ig 쇄 #1 | 49 | ELVLTQSPSVSAALGSPAKITCTLSSAHKTDTIDWYQQLQGEAPRYLMQVQSDGSYTKRPGVPDRFSGSSSGADRYLIIPSVQADDEADYYCGADYIGGYVFGGGTQLTVTGGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKADSSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGSTVEKTVAPTECSEVQLVQSGAEVKKPGASVKVSCKASGFSFTNYYVHWMRQAPGQGLEWMGWISPGSDNTKYNEKFKGRVTMTRDTSISTAYMELSRLRSDDTAVYYCARDDYGNYYFDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK |
| R12 x CD3 FIT-Ig 쇄 #2 | 50 | QEQLVESGGRLVTPGGSLTLSCKASGFDFSAYYMSWVRQAPGKGLEWIATIYPSSGKTYYATWVNGRFTISSDNAQNTVDLQMNSLTAADRATYFCARDSYADDGALFNIWGPGTLVTISSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSC |
| R12 x CD3 FIT-Ig 쇄 #3 | 51 | DIVMTQSPDSLAVSLGERATINCKSSQSLLNARTRKNYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSYILRTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC |
도 11은 표 16에 제공된 참조 FIT-Ig 분자에 대한 FIT1007-12B-17의 비교를 입증한다. 도 11A 및 11B는 FIT1007-12B-17 및 참조 FIT-Ig가 ROR1 발현 MDA-MB-231 및 CD3 발현 Jurkat 세포 모두에 대해 유사한 세포 표면 결합을 나타내었음을 입증한다. 그러나, MDA-MB-231 세포에 대해 전향된 T 세포 세포독성에 대해 도 11C에 도시된 바와 같이, FIT1007-12B-17은 참조 FIT-Ig 분자보다 더 강한 세포독성을 달성하였다.
SEQUENCE LISTING
<110> EpimAb Biotherapeutics (HK) Limited
<120> ANTI-ROR1 ANTIBODIES AND RELATED BISPECIFIC BINDING PROTEINS
<130> PF 210390PCT
<160> 51
<170> PatentIn version 3.3
<210> 1
<211> 5
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 1
Arg Ser Trp Met Asn
1 5
<210> 2
<211> 17
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 2
Arg Ile Tyr Pro Gly Asn Gly Asp Ile Lys Tyr Asn Gly Asn Phe Lys
1 5 10 15
Gly
<210> 3
<211> 11
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 3
Ile Tyr Tyr Asp Phe Tyr Tyr Ala Leu Asp Tyr
1 5 10
<210> 4
<211> 17
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 4
Arg Ile Tyr Pro Gly Asn Ala Asp Ile Lys Tyr Asn Ala Asn Phe Lys
1 5 10 15
Gly
<210> 5
<211> 11
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 5
Lys Ala Ser Gln Asp Ile Asn Lys Tyr Ile Thr
1 5 10
<210> 6
<211> 7
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 6
Tyr Thr Ser Thr Leu Gln Pro
1 5
<210> 7
<211> 9
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 7
Leu Gln Tyr Asp Ser Leu Leu Trp Thr
1 5
<210> 8
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 8
Gln Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ala Phe Ser Arg Ser
20 25 30
Trp Met Asn Trp Val Lys Gln Arg Pro Glu Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Tyr Pro Gly Asn Gly Asp Ile Lys Tyr Asn Gly Asn Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala His Ile Tyr Tyr Asp Phe Tyr Tyr Ala Leu Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 9
<211> 107
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 9
Asp Ile Gln Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Gly Lys Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Lys Tyr
20 25 30
Ile Thr Trp Tyr Gln His Lys Pro Gly Lys Gly Pro Arg Leu Leu Ile
35 40 45
His Tyr Thr Ser Thr Leu Gln Pro Gly Ile Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Arg Asp Tyr Ser Phe Ser Ile Ser Asn Leu Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Ser Leu Leu Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 10
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 10
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Ser Arg Ser
20 25 30
Trp Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Tyr Pro Gly Asn Gly Asp Ile Lys Tyr Asn Gly Asn Phe
50 55 60
Lys Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala His Ile Tyr Tyr Asp Phe Tyr Tyr Ala Leu Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 11
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 11
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Ser Arg Ser
20 25 30
Trp Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Tyr Pro Gly Asn Gly Asp Ile Lys Tyr Asn Gly Asn Phe
50 55 60
Lys Gly Arg Ala Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala His Ile Tyr Tyr Asp Phe Tyr Tyr Ala Leu Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 12
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 12
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Ser Arg Ser
20 25 30
Trp Met Asn Trp Val Lys Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Tyr Pro Gly Asn Gly Asp Ile Lys Tyr Asn Gly Asn Phe
50 55 60
Lys Gly Lys Ala Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala His Ile Tyr Tyr Asp Phe Tyr Tyr Ala Leu Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 13
<211> 107
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 13
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Lys Tyr
20 25 30
Ile Thr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Thr Leu Gln Pro Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Phe Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Ser Leu Leu Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 14
<211> 107
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 14
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Lys Tyr
20 25 30
Ile Thr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
His Tyr Thr Ser Thr Leu Gln Pro Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Arg Asp Tyr Thr Phe Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Ser Leu Leu Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 15
<211> 107
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 15
Asp Ile Gln Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Lys Tyr
20 25 30
Ile Thr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Thr Leu Gln Pro Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Arg Asp Tyr Thr Phe Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Ser Leu Leu Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 16
<211> 107
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 16
Asp Ile Gln Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Lys Tyr
20 25 30
Ile Thr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
His Tyr Thr Ser Thr Leu Gln Pro Gly Ile Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Arg Asp Tyr Thr Phe Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Ser Leu Leu Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 17
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 17
Gln Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ala Phe Ser Arg Ser
20 25 30
Trp Met Asn Trp Val Lys Gln Arg Pro Glu Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Tyr Pro Gly Asn Ala Asp Ile Lys Tyr Asn Ala Asn Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala His Ile Tyr Tyr Asp Phe Tyr Tyr Ala Leu Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 18
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 18
Gln Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ala Phe Ser Arg Ser
20 25 30
Trp Met Asn Trp Val Lys Gln Arg Pro Glu Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Tyr Pro Gly Gln Gly Asp Ile Lys Tyr Gln Gly Asn Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala His Ile Tyr Tyr Asp Phe Tyr Tyr Ala Leu Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 19
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 19
Gln Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ala Phe Ser Arg Ser
20 25 30
Trp Met Asn Trp Val Lys Gln Arg Pro Glu Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Tyr Pro Gly Asn Ala Asp Ile Lys Tyr Gln Gly Asn Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala His Ile Tyr Tyr Asp Phe Tyr Tyr Ala Leu Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 20
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 20
Gln Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ala Phe Ser Arg Ser
20 25 30
Trp Met Asn Trp Val Lys Gln Arg Pro Glu Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Tyr Pro Gly Gln Gly Asp Ile Lys Tyr Asn Ala Asn Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala His Ile Tyr Tyr Asp Phe Tyr Tyr Ala Leu Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 21
<211> 120
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 21
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Ser Arg Ser
20 25 30
Trp Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Tyr Pro Gly Asn Ala Asp Ile Lys Tyr Asn Ala Asn Phe
50 55 60
Lys Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala His Ile Tyr Tyr Asp Phe Tyr Tyr Ala Leu Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 22
<211> 119
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 22
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Ser Phe Thr Asn Tyr
20 25 30
Tyr Val His Trp Met Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Pro Gly Ser Asp Asn Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Asp Tyr Gly Asn Tyr Tyr Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser
115
<210> 23
<211> 119
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 23
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Ser Phe Thr Asn Tyr
20 25 30
Tyr Val His Trp Met Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Trp Ile Ser Pro Gly Ser Asp Asn Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Leu Thr Ala Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Asp Tyr Gly Asn Tyr Tyr Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser
115
<210> 24
<211> 112
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 24
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Leu Leu Asn Ala
20 25 30
Arg Thr Arg Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Lys Gln
85 90 95
Ser Tyr Ile Leu Arg Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 25
<211> 5
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 25
Asn Tyr Tyr Val His
1 5
<210> 26
<211> 17
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 26
Trp Ile Ser Pro Gly Ser Asp Asn Thr Lys Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 27
<211> 10
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 27
Asp Asp Tyr Gly Asn Tyr Tyr Phe Asp Tyr
1 5 10
<210> 28
<211> 17
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 28
Lys Ser Ser Gln Ser Leu Leu Asn Ala Arg Thr Arg Lys Asn Tyr Leu
1 5 10 15
Ala
<210> 29
<211> 7
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 29
Trp Ala Ser Thr Arg Glu Ser
1 5
<210> 30
<211> 8
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 30
Lys Gln Ser Tyr Ile Leu Arg Thr
1 5
<210> 31
<211> 330
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 31
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
225 230 235 240
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 32
<211> 107
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 32
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 33
<211> 103
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 33
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys
100
<210> 34
<211> 663
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 34
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Lys Tyr
20 25 30
Ile Thr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Thr Leu Gln Pro Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Phe Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Ser Leu Leu Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Val Gln Ser Gly Ala Glu
210 215 220
Val Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly
225 230 235 240
Phe Ser Phe Thr Asn Tyr Tyr Val His Trp Met Arg Gln Ala Pro Gly
245 250 255
Gln Gly Leu Glu Trp Met Gly Trp Ile Ser Pro Gly Ser Asp Asn Thr
260 265 270
Lys Tyr Asn Glu Lys Phe Lys Gly Arg Val Thr Met Thr Arg Asp Thr
275 280 285
Ser Ile Ser Thr Ala Tyr Met Glu Leu Ser Arg Leu Arg Ser Asp Asp
290 295 300
Thr Ala Val Tyr Tyr Cys Ala Arg Asp Asp Tyr Gly Asn Tyr Tyr Phe
305 310 315 320
Asp Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr
325 330 335
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
340 345 350
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
355 360 365
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
370 375 380
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
385 390 395 400
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
405 410 415
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
420 425 430
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
435 440 445
Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
450 455 460
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
465 470 475 480
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
485 490 495
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
500 505 510
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
515 520 525
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
530 535 540
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
545 550 555 560
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys
565 570 575
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
580 585 590
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
595 600 605
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
610 615 620
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
625 630 635 640
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
645 650 655
Leu Ser Leu Ser Pro Gly Lys
660
<210> 35
<211> 223
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 35
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Ser Arg Ser
20 25 30
Trp Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Tyr Pro Gly Asn Ala Asp Ile Lys Tyr Asn Ala Asn Phe
50 55 60
Lys Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala His Ile Tyr Tyr Asp Phe Tyr Tyr Ala Leu Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
<210> 36
<211> 219
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 36
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Leu Leu Asn Ala
20 25 30
Arg Thr Arg Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Lys Gln
85 90 95
Ser Tyr Ile Leu Arg Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 37
<211> 663
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 37
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Lys Tyr
20 25 30
Ile Thr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Thr Leu Gln Pro Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Phe Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Ser Leu Leu Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Val Gln Ser Gly Ala Glu
210 215 220
Val Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly
225 230 235 240
Phe Ser Phe Thr Asn Tyr Tyr Val His Trp Met Arg Gln Ala Pro Gly
245 250 255
Gln Gly Leu Glu Trp Ile Gly Trp Ile Ser Pro Gly Ser Asp Asn Thr
260 265 270
Lys Tyr Asn Glu Lys Phe Lys Gly Arg Val Thr Leu Thr Ala Asp Thr
275 280 285
Ser Ile Ser Thr Ala Tyr Met Glu Leu Ser Arg Leu Arg Ser Asp Asp
290 295 300
Thr Ala Val Tyr Tyr Cys Ala Arg Asp Asp Tyr Gly Asn Tyr Tyr Phe
305 310 315 320
Asp Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr
325 330 335
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
340 345 350
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
355 360 365
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
370 375 380
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
385 390 395 400
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
405 410 415
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
420 425 430
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
435 440 445
Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
450 455 460
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
465 470 475 480
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
485 490 495
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
500 505 510
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
515 520 525
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
530 535 540
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
545 550 555 560
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys
565 570 575
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
580 585 590
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
595 600 605
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
610 615 620
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
625 630 635 640
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
645 650 655
Leu Ser Leu Ser Pro Gly Lys
660
<210> 38
<211> 663
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 38
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Lys Tyr
20 25 30
Ile Thr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Thr Leu Gln Pro Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Phe Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Ser Leu Leu Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Val Gln Ser Gly Ala Glu
210 215 220
Val Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly
225 230 235 240
Phe Ser Phe Thr Asn Tyr Tyr Val His Trp Met Arg Gln Ala Pro Gly
245 250 255
Gln Gly Leu Glu Trp Met Gly Trp Ile Ser Pro Gly Ser Asp Asn Thr
260 265 270
Lys Tyr Asn Glu Lys Phe Lys Gly Arg Val Thr Met Thr Arg Asp Thr
275 280 285
Ser Ile Ser Thr Ala Tyr Met Glu Leu Ser Arg Leu Arg Ser Asp Asp
290 295 300
Thr Ala Val Tyr Tyr Cys Ala Arg Asp Asp Tyr Gly Asn Tyr Tyr Phe
305 310 315 320
Asp Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr
325 330 335
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
340 345 350
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
355 360 365
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
370 375 380
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
385 390 395 400
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
405 410 415
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
420 425 430
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
435 440 445
Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
450 455 460
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
465 470 475 480
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
485 490 495
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
500 505 510
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
515 520 525
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
530 535 540
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
545 550 555 560
Glu Pro Gln Val Tyr Thr Leu Pro Pro Cys Arg Glu Glu Met Thr Lys
565 570 575
Asn Gln Val Ser Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
580 585 590
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
595 600 605
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
610 615 620
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
625 630 635 640
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
645 650 655
Leu Ser Leu Ser Pro Gly Lys
660
<210> 39
<211> 231
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 39
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
1 5 10 15
Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
20 25 30
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
35 40 45
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
50 55 60
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
65 70 75 80
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
85 90 95
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
100 105 110
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
115 120 125
Glu Pro Gln Val Cys Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys
130 135 140
Asn Gln Val Ser Leu Ser Cys Ala Val Lys Gly Phe Tyr Pro Ser Asp
145 150 155 160
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
165 170 175
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Val Ser
180 185 190
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
195 200 205
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
210 215 220
Leu Ser Leu Ser Pro Gly Lys
225 230
<210> 40
<211> 663
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 40
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Lys Tyr
20 25 30
Ile Thr Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Thr Leu Gln Pro Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Phe Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Ser Leu Leu Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Val Gln Ser Gly Ala Glu
210 215 220
Val Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly
225 230 235 240
Phe Ser Phe Thr Asn Tyr Tyr Val His Trp Met Arg Gln Ala Pro Gly
245 250 255
Gln Gly Leu Glu Trp Ile Gly Trp Ile Ser Pro Gly Ser Asp Asn Thr
260 265 270
Lys Tyr Asn Glu Lys Phe Lys Gly Arg Val Thr Leu Thr Ala Asp Thr
275 280 285
Ser Ile Ser Thr Ala Tyr Met Glu Leu Ser Arg Leu Arg Ser Asp Asp
290 295 300
Thr Ala Val Tyr Tyr Cys Ala Arg Asp Asp Tyr Gly Asn Tyr Tyr Phe
305 310 315 320
Asp Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr
325 330 335
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
340 345 350
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
355 360 365
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
370 375 380
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
385 390 395 400
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
405 410 415
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
420 425 430
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
435 440 445
Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
450 455 460
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
465 470 475 480
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
485 490 495
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
500 505 510
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
515 520 525
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
530 535 540
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
545 550 555 560
Glu Pro Gln Val Tyr Thr Leu Pro Pro Cys Arg Glu Glu Met Thr Lys
565 570 575
Asn Gln Val Ser Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
580 585 590
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
595 600 605
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
610 615 620
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
625 630 635 640
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
645 650 655
Leu Ser Leu Ser Pro Gly Lys
660
<210> 41
<211> 377
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 41
Gln Glu Thr Glu Leu Ser Val Ser Ala Glu Leu Val Pro Thr Ser Ser
1 5 10 15
Trp Asn Ile Ser Ser Glu Leu Asn Lys Asp Ser Tyr Leu Thr Leu Asp
20 25 30
Glu Pro Met Asn Asn Ile Thr Thr Ser Leu Gly Gln Thr Ala Glu Leu
35 40 45
His Cys Lys Val Ser Gly Asn Pro Pro Pro Thr Ile Arg Trp Phe Lys
50 55 60
Asn Asp Ala Pro Val Val Gln Glu Pro Arg Arg Leu Ser Phe Arg Ser
65 70 75 80
Thr Ile Tyr Gly Ser Arg Leu Arg Ile Arg Asn Leu Asp Thr Thr Asp
85 90 95
Thr Gly Tyr Phe Gln Cys Val Ala Thr Asn Gly Lys Glu Val Val Ser
100 105 110
Ser Thr Gly Val Leu Phe Val Lys Phe Gly Pro Pro Pro Thr Ala Ser
115 120 125
Pro Gly Tyr Ser Asp Glu Tyr Glu Glu Asp Gly Phe Cys Gln Pro Tyr
130 135 140
Arg Gly Ile Ala Cys Ala Arg Phe Ile Gly Asn Arg Thr Val Tyr Met
145 150 155 160
Glu Ser Leu His Met Gln Gly Glu Ile Glu Asn Gln Ile Thr Ala Ala
165 170 175
Phe Thr Met Ile Gly Thr Ser Ser His Leu Ser Asp Lys Cys Ser Gln
180 185 190
Phe Ala Ile Pro Ser Leu Cys His Tyr Ala Phe Pro Tyr Cys Asp Glu
195 200 205
Thr Ser Ser Val Pro Lys Pro Arg Asp Leu Cys Arg Asp Glu Cys Glu
210 215 220
Ile Leu Glu Asn Val Leu Cys Gln Thr Glu Tyr Ile Phe Ala Arg Ser
225 230 235 240
Asn Pro Met Ile Leu Met Arg Leu Lys Leu Pro Asn Cys Glu Asp Leu
245 250 255
Pro Gln Pro Glu Ser Pro Glu Ala Ala Asn Cys Ile Arg Ile Gly Ile
260 265 270
Pro Met Ala Asp Pro Ile Asn Lys Asn His Lys Cys Tyr Asn Ser Thr
275 280 285
Gly Val Asp Tyr Arg Gly Thr Val Ser Val Thr Lys Ser Gly Arg Gln
290 295 300
Cys Gln Pro Trp Asn Ser Gln Tyr Pro His Thr His Thr Phe Thr Ala
305 310 315 320
Leu Arg Phe Pro Glu Leu Asn Gly Gly His Ser Tyr Cys Arg Asn Pro
325 330 335
Gly Asn Gln Lys Glu Ala Pro Trp Cys Phe Thr Leu Asp Glu Asn Phe
340 345 350
Lys Ser Asp Leu Cys Asp Ile Pro Ala Cys Asp Ser Lys Asp Ser Lys
355 360 365
Glu Lys Asn Lys Met Glu Ile Leu Tyr
370 375
<210> 42
<211> 117
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 42
Gln Val Gln Leu Lys Glu Ser Gly Pro Gly Leu Val Ala Pro Ser Gln
1 5 10 15
Thr Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Ser Tyr
20 25 30
Gly Val His Trp Val Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ala Gly Gly Phe Thr Asn Tyr Asn Ser Ala Leu Lys
50 55 60
Ser Arg Leu Ser Ile Ser Lys Asp Asn Ser Lys Ser Gln Val Leu Leu
65 70 75 80
Lys Met Thr Ser Leu Gln Thr Asp Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Arg Arg Gly Ser Ser Tyr Ser Met Asp Tyr Trp Gly Gln Gly Thr Ser
100 105 110
Val Thr Val Ser Ser
115
<210> 43
<211> 106
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 43
Glu Ile Val Leu Ser Gln Ser Pro Ala Ile Thr Ala Ala Ser Leu Gly
1 5 10 15
Gln Lys Val Thr Ile Thr Cys Ser Ala Ser Ser Asn Val Ser Tyr Ile
20 25 30
His Trp Tyr Gln Gln Arg Ser Gly Thr Ser Pro Arg Pro Trp Ile Tyr
35 40 45
Glu Ile Ser Lys Leu Ala Ser Gly Val Pro Val Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Ile Tyr Tyr Cys Gln Gln Trp Asn Tyr Pro Leu Ile Thr
85 90 95
Phe Gly Ser Gly Thr Lys Leu Glu Ile Gln
100 105
<210> 44
<211> 121
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 44
Gln Glu Gln Leu Val Glu Ser Gly Gly Arg Leu Val Thr Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Lys Ala Ser Gly Phe Asp Phe Ser Ala Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Ala Thr Ile Tyr Pro Ser Ser Gly Lys Thr Tyr Tyr Ala Thr Trp Val
50 55 60
Asn Gly Arg Phe Thr Ile Ser Ser Asp Asn Ala Gln Asn Thr Val Asp
65 70 75 80
Leu Gln Met Asn Ser Leu Thr Ala Ala Asp Arg Ala Thr Tyr Phe Cys
85 90 95
Ala Arg Asp Ser Tyr Ala Asp Asp Gly Ala Leu Phe Asn Ile Trp Gly
100 105 110
Pro Gly Thr Leu Val Thr Ile Ser Ser
115 120
<210> 45
<211> 112
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 45
Glu Leu Val Leu Thr Gln Ser Pro Ser Val Ser Ala Ala Leu Gly Ser
1 5 10 15
Pro Ala Lys Ile Thr Cys Thr Leu Ser Ser Ala His Lys Thr Asp Thr
20 25 30
Ile Asp Trp Tyr Gln Gln Leu Gln Gly Glu Ala Pro Arg Tyr Leu Met
35 40 45
Gln Val Gln Ser Asp Gly Ser Tyr Thr Lys Arg Pro Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Ser Ser Gly Ala Asp Arg Tyr Leu Ile Ile Pro
65 70 75 80
Ser Val Gln Ala Asp Asp Glu Ala Asp Tyr Tyr Cys Gly Ala Asp Tyr
85 90 95
Ile Gly Gly Tyr Val Phe Gly Gly Gly Thr Gln Leu Thr Val Thr Gly
100 105 110
<210> 46
<211> 662
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 46
Glu Ile Val Leu Ser Gln Ser Pro Ala Ile Thr Ala Ala Ser Leu Gly
1 5 10 15
Gln Lys Val Thr Ile Thr Cys Ser Ala Ser Ser Asn Val Ser Tyr Ile
20 25 30
His Trp Tyr Gln Gln Arg Ser Gly Thr Ser Pro Arg Pro Trp Ile Tyr
35 40 45
Glu Ile Ser Lys Leu Ala Ser Gly Val Pro Val Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Ile Tyr Tyr Cys Gln Gln Trp Asn Tyr Pro Leu Ile Thr
85 90 95
Phe Gly Ser Gly Thr Lys Leu Glu Ile Gln Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val
210 215 220
Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe
225 230 235 240
Ser Phe Thr Asn Tyr Tyr Val His Trp Met Arg Gln Ala Pro Gly Gln
245 250 255
Gly Leu Glu Trp Met Gly Trp Ile Ser Pro Gly Ser Asp Asn Thr Lys
260 265 270
Tyr Asn Glu Lys Phe Lys Gly Arg Val Thr Met Thr Arg Asp Thr Ser
275 280 285
Ile Ser Thr Ala Tyr Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr
290 295 300
Ala Val Tyr Tyr Cys Ala Arg Asp Asp Tyr Gly Asn Tyr Tyr Phe Asp
305 310 315 320
Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys
325 330 335
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
340 345 350
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
355 360 365
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
370 375 380
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
385 390 395 400
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
405 410 415
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
420 425 430
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
435 440 445
Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
450 455 460
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
465 470 475 480
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
485 490 495
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
500 505 510
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
515 520 525
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
530 535 540
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
545 550 555 560
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn
565 570 575
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
580 585 590
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
595 600 605
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
610 615 620
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
625 630 635 640
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
645 650 655
Ser Leu Ser Pro Gly Lys
660
<210> 47
<211> 220
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 47
Gln Val Gln Leu Lys Glu Ser Gly Pro Gly Leu Val Ala Pro Ser Gln
1 5 10 15
Thr Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Ser Tyr
20 25 30
Gly Val His Trp Val Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ala Gly Gly Phe Thr Asn Tyr Asn Ser Ala Leu Lys
50 55 60
Ser Arg Leu Ser Ile Ser Lys Asp Asn Ser Lys Ser Gln Val Leu Leu
65 70 75 80
Lys Met Thr Ser Leu Gln Thr Asp Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Arg Arg Gly Ser Ser Tyr Ser Met Asp Tyr Trp Gly Gln Gly Thr Ser
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
<210> 48
<211> 219
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 48
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Leu Leu Asn Ala
20 25 30
Arg Thr Arg Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Lys Gln
85 90 95
Ser Tyr Ile Leu Arg Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 49
<211> 667
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 49
Glu Leu Val Leu Thr Gln Ser Pro Ser Val Ser Ala Ala Leu Gly Ser
1 5 10 15
Pro Ala Lys Ile Thr Cys Thr Leu Ser Ser Ala His Lys Thr Asp Thr
20 25 30
Ile Asp Trp Tyr Gln Gln Leu Gln Gly Glu Ala Pro Arg Tyr Leu Met
35 40 45
Gln Val Gln Ser Asp Gly Ser Tyr Thr Lys Arg Pro Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Ser Ser Gly Ala Asp Arg Tyr Leu Ile Ile Pro
65 70 75 80
Ser Val Gln Ala Asp Asp Glu Ala Asp Tyr Tyr Cys Gly Ala Asp Tyr
85 90 95
Ile Gly Gly Tyr Val Phe Gly Gly Gly Thr Gln Leu Thr Val Thr Gly
100 105 110
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
115 120 125
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
130 135 140
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
145 150 155 160
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
165 170 175
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
180 185 190
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
195 200 205
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser Glu Val Gln Leu Val Gln
210 215 220
Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys
225 230 235 240
Lys Ala Ser Gly Phe Ser Phe Thr Asn Tyr Tyr Val His Trp Met Arg
245 250 255
Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly Trp Ile Ser Pro Gly
260 265 270
Ser Asp Asn Thr Lys Tyr Asn Glu Lys Phe Lys Gly Arg Val Thr Met
275 280 285
Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr Met Glu Leu Ser Arg Leu
290 295 300
Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys Ala Arg Asp Asp Tyr Gly
305 310 315 320
Asn Tyr Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser
325 330 335
Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser
340 345 350
Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
355 360 365
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
370 375 380
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr
385 390 395 400
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln
405 410 415
Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp
420 425 430
Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
435 440 445
Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro
450 455 460
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
465 470 475 480
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
485 490 495
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
500 505 510
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val
515 520 525
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
530 535 540
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
545 550 555 560
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu
565 570 575
Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
580 585 590
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
595 600 605
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
610 615 620
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
625 630 635 640
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
645 650 655
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 50
<211> 224
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 50
Gln Glu Gln Leu Val Glu Ser Gly Gly Arg Leu Val Thr Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Lys Ala Ser Gly Phe Asp Phe Ser Ala Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Ala Thr Ile Tyr Pro Ser Ser Gly Lys Thr Tyr Tyr Ala Thr Trp Val
50 55 60
Asn Gly Arg Phe Thr Ile Ser Ser Asp Asn Ala Gln Asn Thr Val Asp
65 70 75 80
Leu Gln Met Asn Ser Leu Thr Ala Ala Asp Arg Ala Thr Tyr Phe Cys
85 90 95
Ala Arg Asp Ser Tyr Ala Asp Asp Gly Ala Leu Phe Asn Ile Trp Gly
100 105 110
Pro Gly Thr Leu Val Thr Ile Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
<210> 51
<211> 219
<212> PRT
<213> artificial sequence
<220>
<223> artificial construct
<400> 51
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Leu Leu Asn Ala
20 25 30
Arg Thr Arg Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Lys Gln
85 90 95
Ser Tyr Ile Leu Arg Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
Claims (25)
- 6개의 CDR, CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3의 세트를 포함하는, ROR1에 특이적으로 결합하는 단리된 항체(isolated antibody) 또는 이의 항원-결합 단편으로서, 여기서
CDR-H1이 RSWMN(서열번호 1)의 서열을 포함하고;
CDR-H2가 RIYPGNGDIKYNGNFKG(서열번호 2) 또는 RIYPGNADIKYNANFKG(서열번호 4)의 서열을 포함하고;
CDR-H3이 IYYDFYYALDY(서열번호 3)의 서열을 포함하고;
CDR-L1이 KASQDINKYIT(서열번호 5)의 서열을 포함하고;
CDR-L2가 YTSTLQP(서열번호 6)의 서열을 포함하고;
CDR-L3이 LQYDSLLWT(서열번호 7)의 서열을 포함하고,
임의로, 여기서 CDR이 카밧 넘버링(Kabat numbering)에 따라 정의되는
단리된 항체 또는 항원-결합 단편. - 제1항에 있어서,
항체가 중쇄 가변 도메인 VH 및 경쇄 가변 도메인 VL을 포함하며, 여기서:
상기 VH 도메인이 서열번호 8 또는 17의 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성(identity)을 갖는 서열을 포함하고/하거나,
상기 VL 도메인이 서열번호 9의 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하거나; 또는
상기 VH 도메인이 서열번호 10-12 및 21 중 어느 하나 중에서 선택된 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하고/하거나
상기 VL 도메인이 서열번호 13-16 중 어느 하나 중에서 선택된 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하는,
단리된 항체 또는 항원-결합 단편. - 제1항에 있어서,
항체가 키메라 또는 인간화된 항체이고, 임의로 상기 항체가 인간화된 항체이며,
또한 임의로, 상기 항체의 VH 도메인이 카밧 넘버링에 따른, 아미노산 잔기 1E, 27Y 및 94H, 및 38K, 48I, 66K 및 67A 중에서 선택된 0 내지 4개의 잔기를 포함하고; VL 도메인이 카밧 넘버링에 따른, 아미노산 잔기 71Y, 및 4L, 49H, 58I 및 69R 중에서 선택된 0 내지 4개의 잔기를 포함하는, 단리된 항체 또는 항원-결합 단편. - 제1항에 있어서,
항체가 하기로 이루어지는 그룹 중에서 선택된 VH 및 VL 서열의 조합을 포함하고:

임의로, 상기 항체가 서열번호 21의 서열을 포함하는 VH 도메인, 및 서열번호 13의 서열을 포함하는 VL 도메인을 포함하는, 단리된 항체 또는 항원-결합 단편. - 제1항 내지 제4항 중 어느 한 항에 있어서,
항체가 하기의 특징 중 하나 이상을 갖는, 단리된 항체 또는 항원-결합 단편:
(i) ROR1-발현 세포(예를 들어, ROR1-발현 골수종 세포주)의 세포 표면에 결합하는 경우, 항체가 세포 기반 분석에서 측정 시 20% 이하, 임의로 15% 이하, 또는 14%, 13%, 12%, 11% 내재화되며, 여기서 상기 내재화는 2시간 배양(two-hour incubation) 동안 4℃에서 유지된 대조군에 비해, 37℃에서 2시간 배양 후 ROR1-발현 세포(예를 들어, ROR1-발현 골수종 세포주)의 표면에 결합하는 항체의 유세포 분석(flow cytometry)에 의해 검출된 바와 같은, 중간 형광 강도(MFI)의 감소 백분율에 의해 반영될 수 있음;
(ii) 항체가 ROR1의 Ig-유사 도메인의 C-말단에서 인간 ROR1에 결합하고, 임의로 ROR1에 대한 결합에 대해 서열번호 42 및 43의 VH/VL 서열 쌍을 갖는 항체와 경쟁함;
(iii) ROR1에 대한 항체의 결합이 항-종양 활성을 유도하며, 예를 들어 종양 크기/성장/세포 확대를 감소시킴. - 제1항 내지 제5항 중 어느 한 항의 단리된 항체 또는 항원-결합 단편을 포함하는 융합체(fusion) 또는 접합체(conjugate).
- 제1항 내지 제5항 중 어느 한 항의 단리된 항체 또는 항원-결합 단편을 암호화하는 핵산 분자.
- 제7항의 핵산 분자를 포함하는 벡터(vector).
- 제1항 내지 제5항 중 어느 한 항의 단리된 항체 또는 항원-결합 단편을 암호화(encoding)하는 핵산 분자를 발현하는 숙주 세포.
- 제1항 내지 제5항 중 어느 한 항의 단리된 항체 또는 항원-결합 단편, 제6항의 융합체 또는 접합체, 제7항의 핵산 분자, 제8항의 벡터, 또는 제9항의 숙주 세포를 포함하는 약제학적 조성물.
- 생물학적 샘플을 제1항 내지 제5항 중 어느 한 항의 단리된 항체 또는 항원-결합 단편, 또는 제6항의 융합체 또는 접합체와 접촉시킴을 포함하는, 상기 생물학적 샘플에서 ROR1을 검출하는 방법.
- ROR1 및 CD3에 특이적으로 결합하는 이중특이적 결합 단백질(bispecific binding protein)로서,
a) ROR1에 특이적으로 결합하는 제1 항원-결합 부위; 및
b) CD3에 특이적으로 결합하는 제2 항원-결합 부위
를 포함하고, 여기서 상기 제1 항원-결합 부위가 6개의 CDR, CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3의 세트를 포함하고, 여기서
CDR-H1이 RSWMN(서열번호 1)의 서열을 포함하고;
CDR-H2가 RIYPGNGDIKYNGNFKG(서열번호 2) 또는 RIYPGNADIKYNANFKG(서열번호 4)의 서열을 포함하고;
CDR-H3이 IYYDFYYALDY(서열번호 3)의 서열을 포함하고;
CDR-L1이 KASQDINKYIT(서열번호 5)의 서열을 포함하고;
CDR-L2가 YTSTLQP(서열번호 6)의 서열을 포함하고;
CDR-L3이 LQYDSLLWT(서열번호 7)의 서열을 포함하고,
여기서 CDR이 카밧 넘버링에 따라 정의되며,
임의로, 상기 제1 항원-결합 부위가 제2항 내지 제4항 중 어느 한 항에 정의된 바와 같은 VH 도메인 및 VL 도메인을 포함하는, 이중특이적 결합 단백질. - 제12항에 있어서,
제2 항원-결합 부위가 6개의 CDR, CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 및 CDR-L3의 세트를 포함하며, 여기서:
CDR-H1이 NYYVH(서열번호 25)의 서열을 포함하고;
CDR-H2가 WISPGSDNTKYNEKFKG(서열번호 26)의 서열을 포함하고;
CDR-H3이 DDYGNYYFDY(서열번호 27)의 서열을 포함하고;
CDR-L1이 KSSQSLLNARTRKNYLA(서열번호 28)의 서열을 포함하고;
CDR-L2가 WASTRES(서열번호 29)의 서열을 포함하고;
CDR-L3이 KQSYILRT(서열번호 30)의 서열을 포함하고,
여기서 CDR이 카밧 넘버링에 따라 정의되며,
임의로, 상기 제2 항원-결합 부위가
서열번호 22 또는 23의 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하는 VH 도메인, 및/또는
서열번호 24의 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하는 VL 도메인
을 포함하는, 이중특이적 결합 단백질. - 제12항 또는 제13항에 있어서,
제1 폴리펩티드 쇄, 제2 폴리펩티드 쇄 및 제3 폴리펩티드 쇄를 포함하고, 여기서
(i) 상기 제1 폴리펩티드 쇄가 아미노 말단으로부터 카복실 말단까지 VLA-CL-VHB-CH1-Fc를 포함하며, 여기서 CL이 VHB에 직접 융합되고; 상기 제2 폴리펩티드 쇄가 아미노으로부터 카복실 말단까지 VHA-CH1을 포함하고; 상기 제3 폴리펩티드 쇄가 아미노으로부터 카복실 말단까지 VLB-CL을 포함하거나; 또는
(ii) 상기 제1 폴리펩티드 쇄가 아미노 말단으로부터 카복실 말단까지 VHA-CH1-VLB-CL-Fc를 포함하며, 여기서 CH1이 VLB에 직접 융합되고; 상기 제2 폴리펩티드 쇄가 아미노으로부터 카복실 말단까지 VLA-CL을 포함하고; 상기 제3 폴리펩티드 쇄가 아미노으로부터 카복실 말단까지 VHB-CH1을 포함하며;
여기서 VL이 경쇄 가변 도메인이고, CL이 경쇄 불변 도메인이고, VH가 중쇄 가변 도메인이고, CH1이 중쇄 불변 도메인이고, Fc가 면역글로불린 Fc 영역, 예를 들어 IgG1의 Fc(임의로, 아미노 말단으로부터 카복실 말단까지 힌지-CH2-CH3을 포함함)이고,
여기서 VLA-CL이 VHA-CH1과 쌍을 이루어 제1 항원 A에 특이적으로 결합하는 제1 Fab를 형성하고, VLB-CL이 VHB-CH1과 쌍을 이루어 제2 항원 B에 특이적으로 결합하는 제2 Fab를 형성하며,
여기서 제1 항원 A가 ROR1이고 제2 항원 B가 CD3이고,
여기서 상기 제1 폴리펩티드 쇄 중 2개, 상기 제2 폴리펩티드 쇄 중 2개, 및 상기 제3 폴리펩티드 쇄 중 2개가 결합되어 FIT-Ig 결합 단백질을 형성하는
이중특이적 결합 단백질. - 제14항에 있어서,
제1 폴리펩티드 쇄가 서열번호 34 또는 37의 아미노산 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하고,
제2 폴리펩티드 쇄가 서열번호 35의 아미노산 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하고,
제3 폴리펩티드 쇄가 서열번호 36의 아미노산 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하는
이중특이적 결합 단백질. - 제12항 또는 제13항에 있어서,
제1 폴리펩티드 쇄, 제2 폴리펩티드 쇄, 제3 폴리펩티드 쇄, 및 제4 폴리펩티드 쇄를 포함하고, 여기서
(i) 상기 제1 폴리펩티드 쇄가 아미노 말단으로부터 카복실 말단까지 VLA-CL-VHB-CH1-Fc를 포함하며, 여기서 CL이 VHB에 직접 융합되고; 상기 제2 폴리펩티드 쇄가 아미노으로부터 카복실 말단까지 VHA-CH1을 포함하고; 상기 제3 폴리펩티드 쇄가 아미노으로부터 카복실 말단까지 VLB-CL을 포함하고; 상기 제4 폴리펩티드 쇄가 Fc를 포함하거나; 또는
(ii) 상기 제1 폴리펩티드 쇄가 아미노 말단으로부터 카복실 말단까지 VHA-CH1-VLB-CL-Fc를 포함하며, 여기서 CH1이 VLB에 직접 융합되고; 상기 제2 폴리펩티드 쇄가 아미노으로부터 카복실 말단까지 VLA-CL을 포함하고; 상기 제3 폴리펩티드 쇄가 아미노으로부터 카복실 말단까지 VHB-CH1을 포함하고; 상기 제4 폴리펩티드 쇄가 Fc를 포함하며;
여기서 VL이 경쇄 가변 도메인이고, CL이 경쇄 불변 도메인이고, VH가 중쇄 가변 도메인이고, CH1이 중쇄 불변 도메인이고, Fc가 면역글로불린 Fc 영역(임의로, 아미노 말단으로부터 카복실 말단까지 힌지-CH2-CH3을 포함함)이고,
여기서 VLA-CL이 VHA-CH1과 쌍을 이루어 제1 항원 A에 특이적으로 결합하는 제1 Fab를 형성하고, VLB-CL이 VHB-CH1과 쌍을 이루어 제2 항원 B에 특이적으로 결합하는 제2 Fab를 형성하며,
여기서 제1 항원 A가 ROR1이고 제2 항원 B가 CD3이고,
여기서 상기 제1 폴리펩티드 쇄, 상기 제2 폴리펩티드, 상기 제3 폴리펩티드 쇄 및 상기 제4 폴리펩티드 쇄가 결합되어 MAT-Fab 단백질을 형성하고,
임의로, 여기서 상기 제1 폴리펩티드 쇄의 Fc 및 상기 제4 폴리펩티드 쇄의 Fc가, 특히 CH3 도메인에서, 상기 두 쇄의 동종이량체화(homodimerization)보다 이종이량체화(heterodimerization)를 촉진(favoring)하는 이종이량체화 변형을 포함하며,
또한 임의로, 상기 제1 폴리펩티드 쇄가 "손잡이(knob)"로서 돌연변이 T366W가 있는 인간 IgG1 Fc 영역을 갖고, 상기 제4 폴리펩티드 쇄가 "구멍(hole)"으로서 돌연변이 T366S, L368A 및 Y407V가 있는 인간 IgG1 Fc 영역을 갖고/갖거나; 상기 제1 폴리펩티드 쇄가 S354C가 있는 인간 IgG1 Fc 영역을 갖고, 상기 제4 폴리펩티드 쇄가 돌연변이 Y349C가 있는 인간 IgG1 Fc 영역을 가져서 CH3 도메인에 추가적인 디설파이드 브릿지(disulfide bridge)를 형성하는
이중특이적 결합 단백질. - 제16항에 있어서,
제1 폴리펩티드 쇄가 서열번호 38 또는 40의 아미노산 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하고,
제2 폴리펩티드 쇄가 서열번호 35의 아미노산 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하고,
제3 폴리펩티드 쇄가 서열번호 36의 아미노산 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하고,
제4 폴리펩티드 쇄가 서열번호 39의 아미노산 서열, 또는 이와 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상의 동일성을 갖는 서열을 포함하는
이중특이적 결합 단백질. - 제12항 내지 제17항 중 어느 한 항의 이중특이적 결합 단백질을 암호화하는 핵산 분자.
- 제18항의 핵산 분자를 포함하는 벡터.
- 제18항의 핵산 분자 또는 제19항의 벡터를 포함하는 숙주 세포.
- 제1항 내지 제5항 중 어느 한 항의 단리된 항체 또는 항원-결합 단편, 또는 제12항 내지 제17항 중 어느 한 항의 이중특이적 결합 단백질을 제조하는 방법으로서,
제9항 또는 제20항의 숙주 세포를, 상기 항체, 항원-결합 단편, 또는 이중특이적 결합 단백질의 생산을 허용하는 조건 하에서 배양하는 단계; 및
상기 배양물로부터 상기 항체, 항원-결합 단편, 또는 이중특이적 결합 단백질을 회수하는 단계
를 포함하는 방법. - 제12항 내지 제19항 중 어느 한 항의 이중특이적 결합 단백질, 제20항의 핵산, 제19항의 벡터, 또는 제20항의 숙주 세포를 포함하는, 약제학적 조성물.
- ROR1 활성이 유해한 장애를 치료하는 방법으로서, 이의 치료를 필요로 하는 대상체(subject)에게 치료 유효량의 제10항 또는 제22항의 약제학적 조성물을 투여하는 단계를 포함하는 방법.
- 제23항에 있어서,
대상체가 인간인, 방법 - 제23항에 있어서,
장애가 암, 예를 들어 ROR1-양성 혈액암, 예를 들어 만성 림프구성 백혈병(CLL), 또는 ROR1-양성 고형 종양, 예를 들어 폐암, 및 유방암(3중-음성 유방암 포함)인, 방법.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2020110841 | 2020-08-24 | ||
| CNPCT/CN2020/110841 | 2020-08-24 | ||
| CNPCT/CN2020/141398 | 2020-12-30 | ||
| CN2020141398 | 2020-12-30 | ||
| PCT/CN2021/114088 WO2022042488A1 (en) | 2020-08-24 | 2021-08-23 | Anti-ror1 antibodies and related bispecific binding proteins |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230053602A true KR20230053602A (ko) | 2023-04-21 |
Family
ID=77946069
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237005603A KR20230053602A (ko) | 2020-08-24 | 2021-08-23 | 항-ror1 항체 및 관련된 이중특이적 결합 단백질 |
Country Status (12)
| Country | Link |
|---|---|
| US (1) | US20240010753A1 (ko) |
| EP (1) | EP4200336A1 (ko) |
| JP (1) | JP2023538945A (ko) |
| KR (1) | KR20230053602A (ko) |
| CN (2) | CN114085288A (ko) |
| AU (1) | AU2021334677A1 (ko) |
| BR (1) | BR112023002895A2 (ko) |
| CA (1) | CA3190117A1 (ko) |
| IL (1) | IL300760A (ko) |
| MX (1) | MX2023002181A (ko) |
| TW (1) | TW202227491A (ko) |
| WO (1) | WO2022042488A1 (ko) |
Families Citing this family (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102056963B1 (ko) * | 2013-12-30 | 2019-12-17 | 에피맙 바이오테라퓨틱스 인코포레이티드 | Fabs-인-탠덤 면역글로불린 및 이의 용도 |
| TWI672317B (zh) * | 2016-08-16 | 2019-09-21 | 英屬開曼群島商岸邁生物科技有限公司 | 單價不對稱串聯Fab雙特異性抗體 |
| CN114539411B (zh) * | 2022-04-29 | 2022-11-11 | 山东博安生物技术股份有限公司 | 一种ror1抗体或其抗原结合片段 |
| CA3234822A1 (en) | 2021-10-28 | 2023-05-04 | Suman Kumar VODNALA | Methods for culturing cells expressing ror1-binding protein |
| WO2023186100A1 (zh) * | 2022-04-02 | 2023-10-05 | 山东先声生物制药有限公司 | 抗ror1的抗体及其用途 |
| WO2024014930A1 (ko) * | 2022-07-15 | 2024-01-18 | 에이비엘바이오 주식회사 | 항-ror1 항체, 이를 포함하는 이중특이성 항체, 및 이들의 용도 |
| WO2024064958A1 (en) | 2022-09-23 | 2024-03-28 | Lyell Immunopharma, Inc. | Methods for culturing nr4a-deficient cells |
| WO2024064952A1 (en) | 2022-09-23 | 2024-03-28 | Lyell Immunopharma, Inc. | Methods for culturing nr4a-deficient cells overexpressing c-jun |
| WO2024077174A1 (en) | 2022-10-05 | 2024-04-11 | Lyell Immunopharma, Inc. | Methods for culturing nr4a-deficient cells |
| WO2024094151A1 (en) * | 2022-11-03 | 2024-05-10 | Hansoh Bio Llc | Multi-specific antibody and medical use thereof |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9242014B2 (en) * | 2010-06-15 | 2016-01-26 | The Regents Of The University Of California | Receptor tyrosine kinase-like orphan receptor 1 (ROR1) single chain Fv antibody fragment conjugates and methods of use thereof |
| EP2789630A1 (en) * | 2013-04-09 | 2014-10-15 | EngMab AG | Bispecific antibodies against CD3e and ROR1 |
| CN107847596B (zh) * | 2015-05-18 | 2022-05-31 | 优瑞科生物技术公司 | 抗ror1抗体 |
| WO2017053469A2 (en) * | 2015-09-21 | 2017-03-30 | Aptevo Research And Development Llc | Cd3 binding polypeptides |
| KR20180069067A (ko) * | 2015-10-30 | 2018-06-22 | 엔비이-테라퓨틱스 아게 | 안티-ror1 항체 |
| MA43658A (fr) * | 2016-01-22 | 2018-11-28 | Janssen Biotech Inc | Anticorps anti-ror1, anticorps bispécifiques ror1 x cd3, et leurs procédés d'utilisation |
| TWI672317B (zh) * | 2016-08-16 | 2019-09-21 | 英屬開曼群島商岸邁生物科技有限公司 | 單價不對稱串聯Fab雙特異性抗體 |
| GB201710835D0 (en) * | 2017-07-05 | 2017-08-16 | Ucl Business Plc | ROR1 Antibodies |
| GB201710838D0 (en) * | 2017-07-05 | 2017-08-16 | Ucl Business Plc | Bispecific antibodies |
| GB201710836D0 (en) * | 2017-07-05 | 2017-08-16 | Ucl Business Plc | ROR1 Car T-Cells |
| WO2020160050A1 (en) * | 2019-01-29 | 2020-08-06 | Juno Therapeutics, Inc. | Antibodies and chimeric antigen receptors specific for receptor tyrosine kinase like orphan receptor 1 (ror1) |
| CN111286512A (zh) * | 2019-06-05 | 2020-06-16 | 南京艾德免疫治疗研究院有限公司 | 靶向人源化酪氨酸激酶孤儿受体1的嵌合抗原受体及其用途 |
| EP3973000A4 (en) * | 2019-06-07 | 2023-09-06 | Adimab, LLC | HIGH AFFINITY ANTI-CD3 ANTIBODIES AND METHODS OF GENERATION AND USE THEREOF |
| EP4065164A4 (en) * | 2019-11-26 | 2024-03-27 | Shanghai Epimab Biotherapeutics Co Ltd | ANTIBODIES AGAINST CD3 AND BCMA AND BISPECIFIC BINDING PROTEINS PRODUCED THEREOF |
-
2021
- 2021-08-23 WO PCT/CN2021/114088 patent/WO2022042488A1/en active Application Filing
- 2021-08-23 EP EP21860323.1A patent/EP4200336A1/en active Pending
- 2021-08-23 US US18/042,762 patent/US20240010753A1/en active Pending
- 2021-08-23 KR KR1020237005603A patent/KR20230053602A/ko unknown
- 2021-08-23 AU AU2021334677A patent/AU2021334677A1/en active Pending
- 2021-08-23 BR BR112023002895A patent/BR112023002895A2/pt unknown
- 2021-08-23 CA CA3190117A patent/CA3190117A1/en active Pending
- 2021-08-23 JP JP2023513532A patent/JP2023538945A/ja active Pending
- 2021-08-23 IL IL300760A patent/IL300760A/en unknown
- 2021-08-23 CN CN202110968072.5A patent/CN114085288A/zh active Pending
- 2021-08-23 MX MX2023002181A patent/MX2023002181A/es unknown
- 2021-08-23 TW TW110131088A patent/TW202227491A/zh unknown
- 2021-08-23 CN CN202110969266.7A patent/CN113480656B/zh active Active
Also Published As
| Publication number | Publication date |
|---|---|
| WO2022042488A1 (en) | 2022-03-03 |
| CN113480656B (zh) | 2022-06-03 |
| BR112023002895A2 (pt) | 2023-03-21 |
| CN113480656A (zh) | 2021-10-08 |
| JP2023538945A (ja) | 2023-09-12 |
| US20240010753A1 (en) | 2024-01-11 |
| MX2023002181A (es) | 2023-03-02 |
| CA3190117A1 (en) | 2022-03-03 |
| AU2021334677A1 (en) | 2023-03-02 |
| TW202227491A (zh) | 2022-07-16 |
| IL300760A (en) | 2023-04-01 |
| CN114085288A (zh) | 2022-02-25 |
| EP4200336A1 (en) | 2023-06-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20240010753A1 (en) | Anti-ror1 antibodies and related bispecific binding proteins | |
| US20230002489A1 (en) | Antibodies to cd3 and bcma, and bispecific binding proteins made therefrom | |
| TWI784190B (zh) | 針對lag-3之工程化抗體及自其製備之雙特異性pd-1/lag-3結合蛋白 | |
| US20230312722A1 (en) | Anti-b7h4 antibody, and bispecific antibody and use thereof | |
| KR20160131061A (ko) | 항-mcam 항체 및 관련된 사용 방법 | |
| CA3128104A1 (en) | Anti-pd-1 antibody, antigen-binding fragment thereof and pharmaceutical use thereof | |
| CA3101304A1 (en) | Monospecific and multispecific anti-tmeff2 antibodies and their uses | |
| WO2023078113A1 (en) | Anti-cd122 antibodies, anti-cd132 antibodies, and related bispecific binding proteins | |
| TW202136301A (zh) | TGFβ/PD—L1雙特異性結合蛋白 | |
| US20230357398A1 (en) | Novel human antibodies binding to human cd3 epsilon | |
| WO2022258015A1 (en) | Antibodies and bispecific binding proteins that bind ox40 and/or pd-l1 | |
| US20230134183A1 (en) | Cldn18.2-targeting antibody, bispecific antibody and use thereof | |
| WO2023078386A1 (zh) | 抗cldn18.2抗体及其用途 | |
| KR20240046557A (ko) | 항-b7-h4 항체 및 이의 제조 방법과 용도 | |
| TW202214705A (zh) | 抗tigit抗體及雙抗體和它們的應用 |